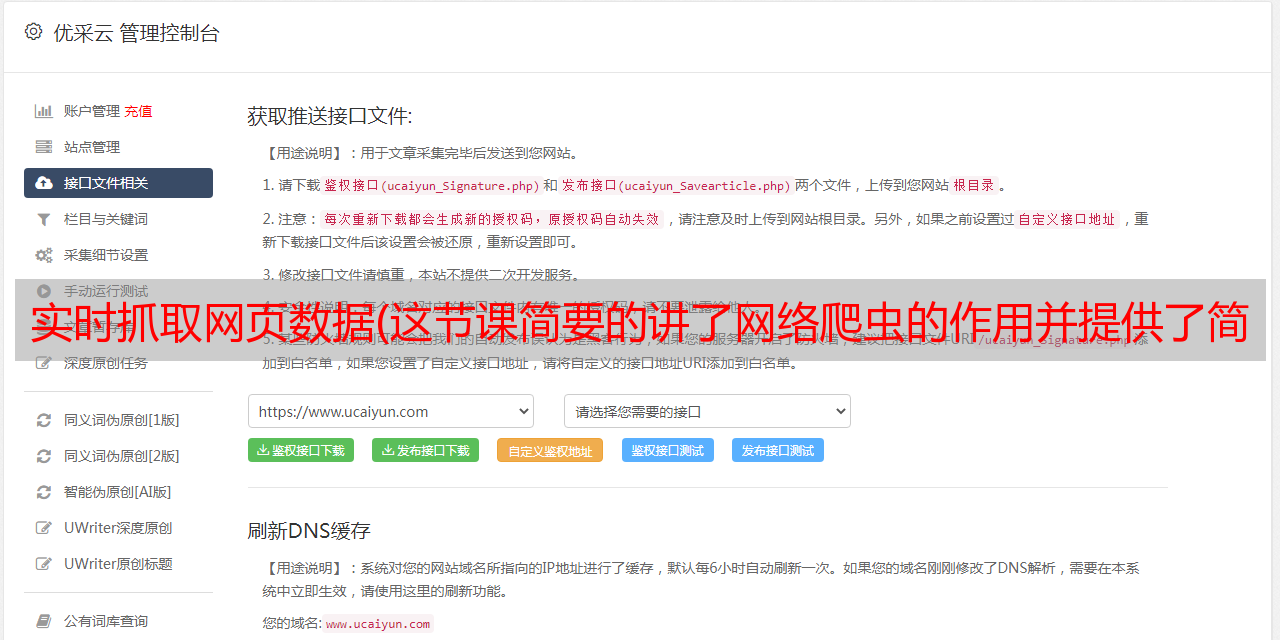
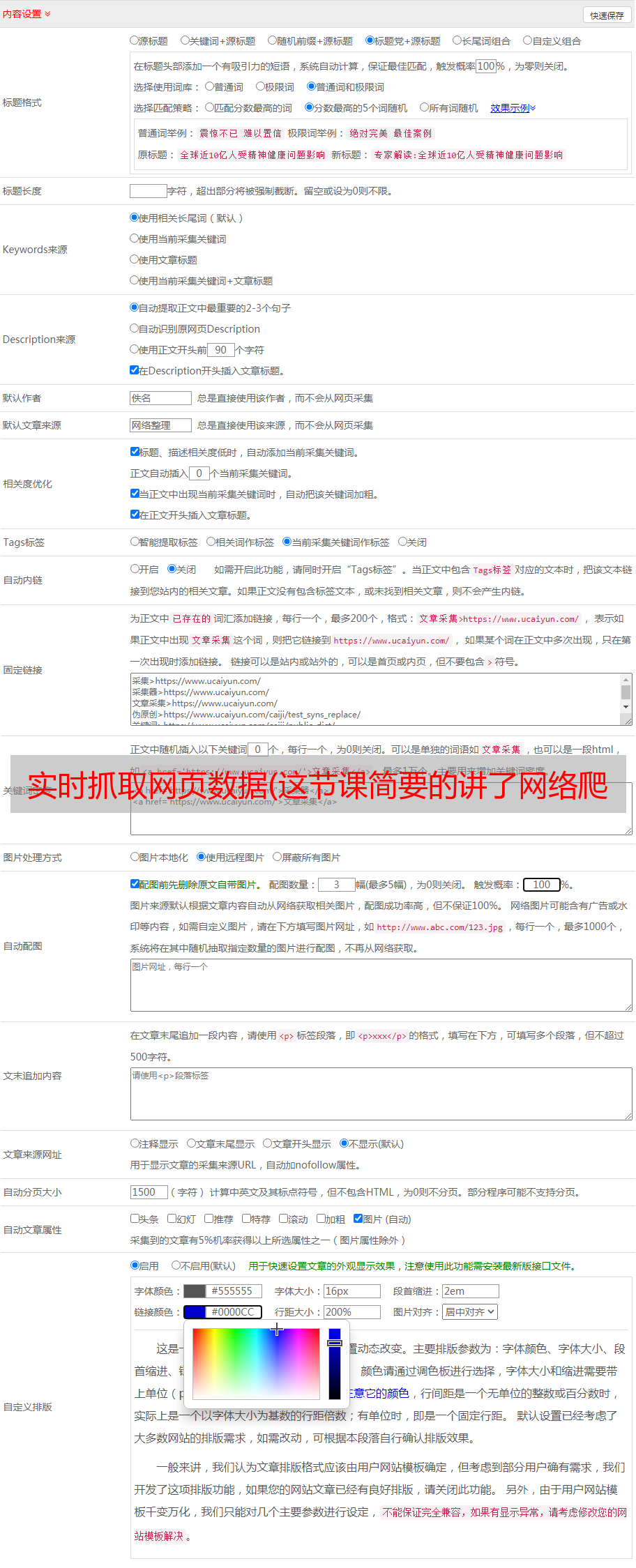
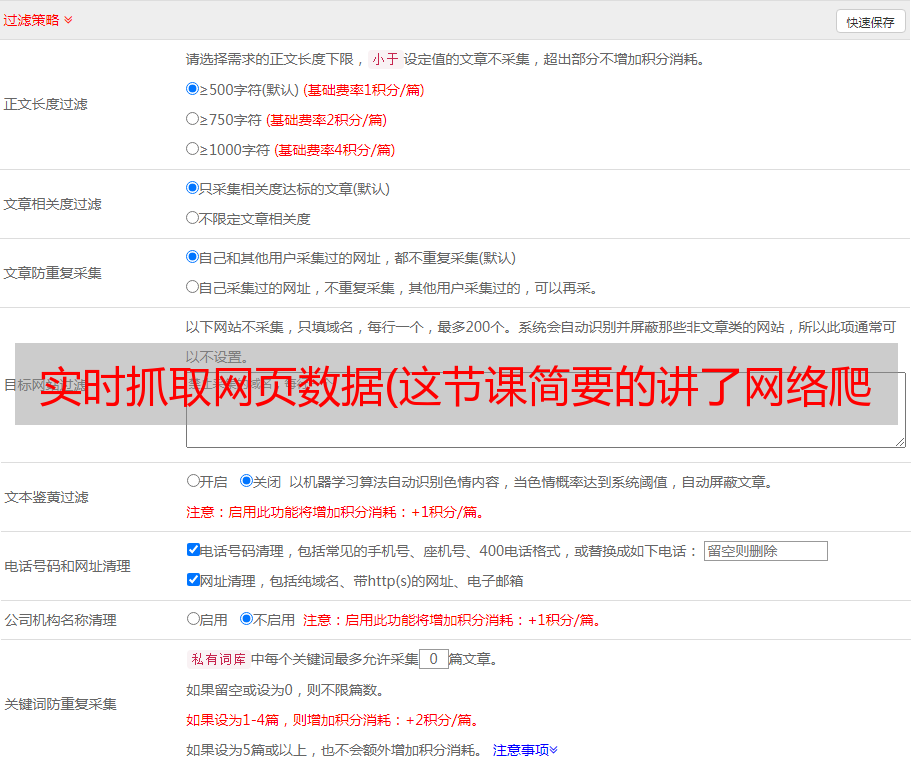
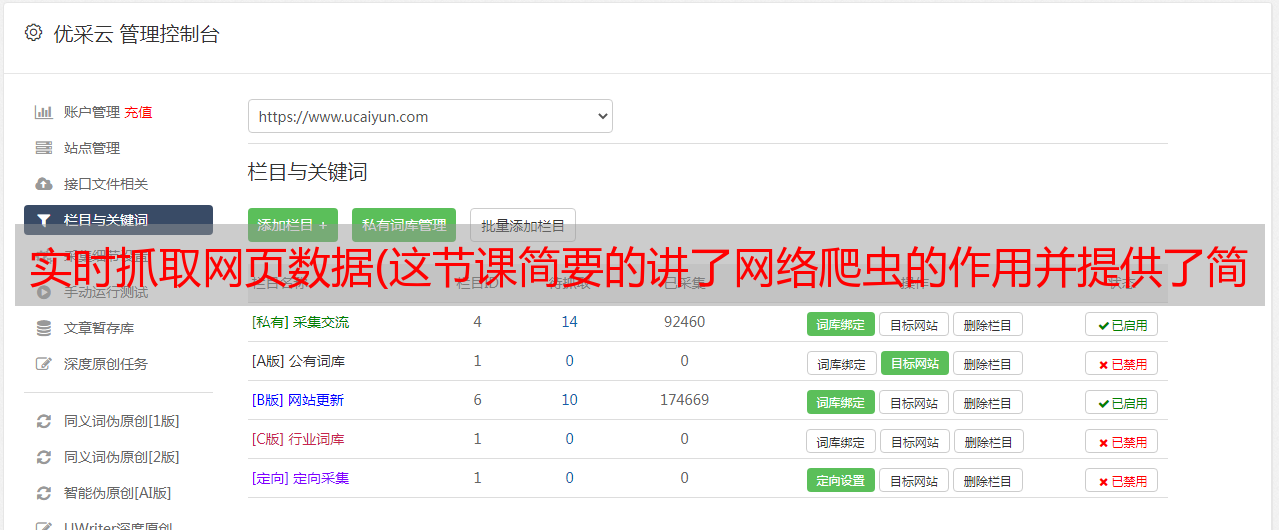
实时抓取网页数据(这节课简要的讲了网络爬虫的作用并提供了简单案例)
优采云 发布时间: 2022-04-18 08:04实时抓取网页数据(这节课简要的讲了网络爬虫的作用并提供了简单案例)
本课程简要讨论网络爬虫的作用,并提供突出法律风险的简单案例
由于网页越来越复杂,在实际操作中需要更多的细节。您可以查看网络爬虫的特别课程。
这部分的内容比较琐碎,但很重要,尤其是法律说明。
网页抓取和网页抓取的区别
这两个概念相似,但侧重点不同
网络爬虫从全网采集和索引数据,常用于搜索引擎
数据抓取往往针对特定站点中特定类型的数据,最后整理成数据表
数据抓取工具
网页数据抓取是为了和网站的管理者竞争。
curl 是最传统的直接下载特定网页的工具。但是很容易失败
selenium 等无头浏览器可以很好的模拟浏览器的操作。
因为他毕竟是一个没有用户界面的浏览器
如果您经常抓取数据,网站管理员可能会阻止 IP。
这时候就需要多开IP了。您可以从一些云服务提供商处购买它们。例如,AWS
一个实例
数据抓取:
首先,定位到web文件中的数据,
然后在代码中将数据的位置转换成模板,
最后运行代码批量抓取信息。
获取网页
使用无头浏览器下载html文件,需要使用一些软件来解析网页,
解析/操作网页
例如 Python 中的 beautifulsoup 用于解析网页和提取信息。
定位数据位置
使用浏览器的检查器 (F12) 来检查网页元素。这对于确定网页上数据的位置非常方便。
最后,提取结构化信息。
成本问题。
如果您使用云服务器,请优先考虑内存大小。
图像数据采集
抓取图片和抓取文字的步骤是一样的,但是要考虑图片的存储开销
网页抓取的法律风险
不违法,但不确定是否合法。(注意此声明)\
有些事情最好小心:

