
内容采集系统
使用PageAdmin网站内容管理系统做网站的益处
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2020-08-19 15:06
据统计,在国外所有企业和政府网站中,超过20%的网站使用PageAdmin建站系统创建,或采用PageAdmin作为后台管理系统,pageadmin作为国外一款极其著名的网站内容管理系统,有很多优点,下面一一说明。
1、PageAdmin可以免费下载
PageAdmin是可以免费下载使用的,您只须要一个域名和一个虚拟主机(或服务器)就可以开始制做网站,甚至可以下载到自己笔记本上,通过安装运行环境来安装系统。
2、丰富的网站模板
PageAdmin提供海量的网站模板,你可以依照自己行业需求选择,节约网站界面和风格的的设计和制做时间,当然假如你是后端开发人员,你也可以只用pageadmin作为后台系统,前台可以用自己自己制做的模板。
3、用插件扩充网站
PageAdmin提供了各类插件来扩充网站功能,如微信公众号插件,采集插件,广告插件,财务插件等等,任何功能都可以通过插件安装来实现。
4、持续更新
PageAdmin系统发布超过10年,一直都在不断的创新和改进,以便给用户提供最好、最新的技术体验。
5、安全级别高
在黑色链十分猖狂的明天,对网站安全要求十分高,否则你没法保证你网站哪天沦为黑链的平台,PageAdmin的系统可以通过国家安全五级等保,这也是好多政府网站采用pageadmin的诱因之一。 查看全部
使用PageAdmin网站内容管理系统做网站的益处
据统计,在国外所有企业和政府网站中,超过20%的网站使用PageAdmin建站系统创建,或采用PageAdmin作为后台管理系统,pageadmin作为国外一款极其著名的网站内容管理系统,有很多优点,下面一一说明。
1、PageAdmin可以免费下载
PageAdmin是可以免费下载使用的,您只须要一个域名和一个虚拟主机(或服务器)就可以开始制做网站,甚至可以下载到自己笔记本上,通过安装运行环境来安装系统。
2、丰富的网站模板
PageAdmin提供海量的网站模板,你可以依照自己行业需求选择,节约网站界面和风格的的设计和制做时间,当然假如你是后端开发人员,你也可以只用pageadmin作为后台系统,前台可以用自己自己制做的模板。
3、用插件扩充网站
PageAdmin提供了各类插件来扩充网站功能,如微信公众号插件,采集插件,广告插件,财务插件等等,任何功能都可以通过插件安装来实现。
4、持续更新
PageAdmin系统发布超过10年,一直都在不断的创新和改进,以便给用户提供最好、最新的技术体验。
5、安全级别高
在黑色链十分猖狂的明天,对网站安全要求十分高,否则你没法保证你网站哪天沦为黑链的平台,PageAdmin的系统可以通过国家安全五级等保,这也是好多政府网站采用pageadmin的诱因之一。
采集管理 (五)、实例教你使用采集 帝国网站管理系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 341 次浏览 • 2020-08-19 02:35
实例教你使用采集
本节通过采集简单的页面作为采集教程实例。
每个系统模型都有自己的采集,无论是外置的还是用户自定义的系统模型,新闻系统有新闻系统采集,下载系统有下载系统采集等等。
下面讲解新闻系统模型的采集,其它系统模型采集基本雷同,用户可举一反三。
采集页面地址
本例要采集的页面地址:
开始采集
采集一般步骤:
1、增加采集节点;
2、预览采集正则是否正确;
3、开始采集;
4、对采集的数据进行初审并入库;
5、生成栏目及内容HTML页面。
一、增加采集节点:
1、登录后台->“栏目”>“采集管理”>“增加采集节点”;
2、“选择要降低采集的栏目”(选择终极栏目);
3、“选择要降低采集的栏目”后步入降低采集节点页面;
4、打开要采集的列表页面:
点击查看“源文件”
点击查看,列表页源代码为如下:
5、开始设置采集节点及列表页正则:
(1)、输入节点名称:采集实例
(2)、采集页面地址:
(3)、由列表页的源代码:“page1.html" target="_blank">”,我们得出“内容页地址前缀”为:
(4)、设置“信息页链接正则”:由列表页的源代码得出。
图1:页面源代码
图2:得出的信息页链接正则
6、点击采集的内容页页面并查看源文件:
图1:内容页页面
图2:内容页源代码
7、设置内容页内容正则:(标题及内容正则)
(1)、标题正则:由源代码内容我们得出“新闻标题”正则为:
图1:页面源代码
图2:得出的标题正则
(2)、内容正则:由源代码内容我们得出“新闻内容”正则为:
图1:页面源代码
图2:得出的新闻内容正则
8、点击“提交”按钮即可降低节点完毕,整个表单最终疗效如下:
[点击查看]
二、预览采集正则是否正确:
1、上面降低采集节点后,我们返回“管理节点”页面,如下:
2、点击“预览”采集,进入节点正则预览与验证:
图1:采集页面地址列表
图2:信息链接列表
图3:采集的内容页内容
3、上面链接列表页及内容页内容预览无误后方可进行采集操作。
三、开始采集:
1、上面的采集节点正则预览无误后,我们返回“管理节点”页面:
2、点击里面的“开始采集”链接,开始进行采集;
3、采集信息完成后,系统会转向采集入库页面,如下:
四、对采集的数据进行初审并入库:
即可完成入库操作:
管理栏目信息也可以看见我们刚刚入库的信息:
五、生成栏目及内容HTML页面:
点击“系统”>“数据更新”>“数据更新中心”,进入数据更新中心页面: 查看全部
采集管理 (五)、实例教你使用采集 帝国网站管理系统
实例教你使用采集
本节通过采集简单的页面作为采集教程实例。
每个系统模型都有自己的采集,无论是外置的还是用户自定义的系统模型,新闻系统有新闻系统采集,下载系统有下载系统采集等等。
下面讲解新闻系统模型的采集,其它系统模型采集基本雷同,用户可举一反三。
采集页面地址
本例要采集的页面地址:
开始采集
采集一般步骤:
1、增加采集节点;
2、预览采集正则是否正确;
3、开始采集;
4、对采集的数据进行初审并入库;
5、生成栏目及内容HTML页面。
一、增加采集节点:
1、登录后台->“栏目”>“采集管理”>“增加采集节点”;
2、“选择要降低采集的栏目”(选择终极栏目);

3、“选择要降低采集的栏目”后步入降低采集节点页面;
4、打开要采集的列表页面:

点击查看“源文件”

点击查看,列表页源代码为如下:

5、开始设置采集节点及列表页正则:
(1)、输入节点名称:采集实例

(2)、采集页面地址:

(3)、由列表页的源代码:“page1.html" target="_blank">”,我们得出“内容页地址前缀”为:

(4)、设置“信息页链接正则”:由列表页的源代码得出。
图1:页面源代码

图2:得出的信息页链接正则

6、点击采集的内容页页面并查看源文件:
图1:内容页页面

图2:内容页源代码

7、设置内容页内容正则:(标题及内容正则)
(1)、标题正则:由源代码内容我们得出“新闻标题”正则为:
图1:页面源代码

图2:得出的标题正则

(2)、内容正则:由源代码内容我们得出“新闻内容”正则为:
图1:页面源代码

图2:得出的新闻内容正则

8、点击“提交”按钮即可降低节点完毕,整个表单最终疗效如下:
[点击查看]
二、预览采集正则是否正确:
1、上面降低采集节点后,我们返回“管理节点”页面,如下:

2、点击“预览”采集,进入节点正则预览与验证:
图1:采集页面地址列表

图2:信息链接列表

图3:采集的内容页内容

3、上面链接列表页及内容页内容预览无误后方可进行采集操作。
三、开始采集:
1、上面的采集节点正则预览无误后,我们返回“管理节点”页面:

2、点击里面的“开始采集”链接,开始进行采集;
3、采集信息完成后,系统会转向采集入库页面,如下:

四、对采集的数据进行初审并入库:

即可完成入库操作:

管理栏目信息也可以看见我们刚刚入库的信息:

五、生成栏目及内容HTML页面:
点击“系统”>“数据更新”>“数据更新中心”,进入数据更新中心页面:
葡萄城技术团队
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2020-08-19 00:46
「深度学习福利」大神带你进阶工程师,立即查看>>>
内容采集系统,对于以内容为主的网站来说是非常好的助手,除了原创内容外,其它内容须要编辑人员或则采集系统来搜集整理,然后添加到自己的网站里。Discuz DvBBS CMS等产品,内部都自带了一个内容采集功能,来采集指定的相关内容。 单客户端的优采云采集器也可以非常好的采集指定的内容。这些工具都是想使机器取代人工,把编辑人员从内容搬运的工作中解放下来,做一些更高档的工作,例如采集结果的内容微调,SEO优化,设定精确的采集规则,让采集的内容愈加符合自己网站的须要。
下面的内容采集系统就是从这个看法开发而至的,这个采集系统由两个部份组成:
1. 编辑人员所使用的采集规则设定器和对采集结果进行初审、微调和发布所使用的Web站点。
2. 部署在服务器上的定时采集器和定时发送器。
首先由编辑人员通过一个采集规则设定器(NiceCollectoer.exe)设定要采集的站点,再等采集完成后,编辑人员再通过一个Web站点(PickWeb)对采集的结果进行初审、微调和优化之后发布到自己的网站上。编辑人员所须要做的是采集规则的设定,和对采集结果的优化,其它部份的工作都由机器完成。
NicePicker 是Html 分析器,用来抽取Url,NiceCollector 和HostCollector 都使用NicePicker来剖析Html, NiceCollectoer 就是采集规则设定器,一个目标网站只用设定一次:
使用上去和最早的优采云采集器类似,这里使用博客园来做目标采集站点, 设定采集精华县的文章,采集规则十分简单:当编辑人员设定好采集规则后,这些规则会保存到NiceCollector.exe同目录下的 Setting.mdb中。一般当采集规则设定好之后,基本上不用再变动了,只在目标网站的Html Dom结构发生变化时,需要再度微调一下采集规则。NiceCollector同时用于新目标采集站点的设定和添加操作。
等编辑人员完成采集规则的设定后,把Setting.mdb放在 HostCollector.exe下, HostCollector 会依照Setting.mdb的设定进行真正的采集,并把采集的结果存入数据库。
到这一步就完成了内容的采集工作,编辑人员可以打开PickWeb,对采集结果进行微调和优化,然后初审通过并发送到自己的网站上:
真正发送采集结果到自己网站的工作不是由PickWeb完成的,编辑人员完成内容初审后,PostToForum.exe 会读取数据库并发送这条通过初审的采集结果到自己的网站上,在自己的网站上其实须要一个. ashx或则某种其它方法来接收采集的结果,不建议PostToFormu.exe直接去操作自己网站的数据库,最好通过自己网站上的某个API,来接收采集结果。
NiceCollectoer, HostCollector, PickWeb, PostToForum, 这几个程序联合工作,基本上已经完成了采集和发送的工作,HostCollector, PickWeb, PostToForum 是布署在服务器上的,HostCollector须要被周期性的调用,来采集目标网站所形成的新内容,HostRunnerService.exe 是一个Windows Service,用来周期性调用HostCollector,使用管理员身分在控制台下运行 installutil / i HostRunnerService.exe 就可以安装这个Windows Service了:
HostRunnerService 的配置也很简单:
在RunTime.txt 中设定每晚定时采集几次:
当新内容被采集后,编辑人员须要定期的登陆PickWeb,来优化、微调、并初审新内容,也可以设定默认初审通过。同样PostToForum 也须要被周期性的调用,用来发送初审通过的新内容,CallSenderService.exe 与 HostRunnerService.exe类似,也是一个Windows Service,用来定期的调用PostToFormu.exe。
到这儿整个系统基本上完成了,除此之外还有两个小东东: SelfChecker.exe 和HealthChecker.exe。 SelfCheck.exe 是拿来检测Setting.mdb中设定的规则是否是一个有效的规则,例如检测采集规则是否设定了内容采集项。HealthChecker.exe拿来搜集HostCollector.exe 和 PostToForum.exe 所形成的log,然后将log发送给指定的系统维护人员。
这个内容采集系统还有好多地方须要改进和优化,现在的状态只能说是个Prototype吧,例如 NicePick 需要进一步具象和构建,给出更多的Interface,把剖析Html的各个环节插件化,在各个剖析步骤上,可以使用户加载自己的分析器。 在NiceCollector上,需要更多更全面的采集规则设定。在PickWeb上可以加入一些默认的SEO优化规则,如批量SEO优化Title的内容,等其它方面吧。
可执行文件下载:
08_453455_if8l_NROutput.rar (参见下方“博文附件”)
源代码下载:
08_234324_if8l_NiceCollector.rar (参见下方“博文附件”)
本文出自 “葡萄城控件博客” 博客,请勿必保留此出处 查看全部
葡萄城技术团队
「深度学习福利」大神带你进阶工程师,立即查看>>>

内容采集系统,对于以内容为主的网站来说是非常好的助手,除了原创内容外,其它内容须要编辑人员或则采集系统来搜集整理,然后添加到自己的网站里。Discuz DvBBS CMS等产品,内部都自带了一个内容采集功能,来采集指定的相关内容。 单客户端的优采云采集器也可以非常好的采集指定的内容。这些工具都是想使机器取代人工,把编辑人员从内容搬运的工作中解放下来,做一些更高档的工作,例如采集结果的内容微调,SEO优化,设定精确的采集规则,让采集的内容愈加符合自己网站的须要。
下面的内容采集系统就是从这个看法开发而至的,这个采集系统由两个部份组成:
1. 编辑人员所使用的采集规则设定器和对采集结果进行初审、微调和发布所使用的Web站点。
2. 部署在服务器上的定时采集器和定时发送器。
首先由编辑人员通过一个采集规则设定器(NiceCollectoer.exe)设定要采集的站点,再等采集完成后,编辑人员再通过一个Web站点(PickWeb)对采集的结果进行初审、微调和优化之后发布到自己的网站上。编辑人员所须要做的是采集规则的设定,和对采集结果的优化,其它部份的工作都由机器完成。

NicePicker 是Html 分析器,用来抽取Url,NiceCollector 和HostCollector 都使用NicePicker来剖析Html, NiceCollectoer 就是采集规则设定器,一个目标网站只用设定一次:


使用上去和最早的优采云采集器类似,这里使用博客园来做目标采集站点, 设定采集精华县的文章,采集规则十分简单:当编辑人员设定好采集规则后,这些规则会保存到NiceCollector.exe同目录下的 Setting.mdb中。一般当采集规则设定好之后,基本上不用再变动了,只在目标网站的Html Dom结构发生变化时,需要再度微调一下采集规则。NiceCollector同时用于新目标采集站点的设定和添加操作。
等编辑人员完成采集规则的设定后,把Setting.mdb放在 HostCollector.exe下, HostCollector 会依照Setting.mdb的设定进行真正的采集,并把采集的结果存入数据库。
到这一步就完成了内容的采集工作,编辑人员可以打开PickWeb,对采集结果进行微调和优化,然后初审通过并发送到自己的网站上:


真正发送采集结果到自己网站的工作不是由PickWeb完成的,编辑人员完成内容初审后,PostToForum.exe 会读取数据库并发送这条通过初审的采集结果到自己的网站上,在自己的网站上其实须要一个. ashx或则某种其它方法来接收采集的结果,不建议PostToFormu.exe直接去操作自己网站的数据库,最好通过自己网站上的某个API,来接收采集结果。
NiceCollectoer, HostCollector, PickWeb, PostToForum, 这几个程序联合工作,基本上已经完成了采集和发送的工作,HostCollector, PickWeb, PostToForum 是布署在服务器上的,HostCollector须要被周期性的调用,来采集目标网站所形成的新内容,HostRunnerService.exe 是一个Windows Service,用来周期性调用HostCollector,使用管理员身分在控制台下运行 installutil / i HostRunnerService.exe 就可以安装这个Windows Service了:

HostRunnerService 的配置也很简单:

在RunTime.txt 中设定每晚定时采集几次:

当新内容被采集后,编辑人员须要定期的登陆PickWeb,来优化、微调、并初审新内容,也可以设定默认初审通过。同样PostToForum 也须要被周期性的调用,用来发送初审通过的新内容,CallSenderService.exe 与 HostRunnerService.exe类似,也是一个Windows Service,用来定期的调用PostToFormu.exe。
到这儿整个系统基本上完成了,除此之外还有两个小东东: SelfChecker.exe 和HealthChecker.exe。 SelfCheck.exe 是拿来检测Setting.mdb中设定的规则是否是一个有效的规则,例如检测采集规则是否设定了内容采集项。HealthChecker.exe拿来搜集HostCollector.exe 和 PostToForum.exe 所形成的log,然后将log发送给指定的系统维护人员。
这个内容采集系统还有好多地方须要改进和优化,现在的状态只能说是个Prototype吧,例如 NicePick 需要进一步具象和构建,给出更多的Interface,把剖析Html的各个环节插件化,在各个剖析步骤上,可以使用户加载自己的分析器。 在NiceCollector上,需要更多更全面的采集规则设定。在PickWeb上可以加入一些默认的SEO优化规则,如批量SEO优化Title的内容,等其它方面吧。
可执行文件下载:
08_453455_if8l_NROutput.rar (参见下方“博文附件”)
源代码下载:
08_234324_if8l_NiceCollector.rar (参见下方“博文附件”)
本文出自 “葡萄城控件博客” 博客,请勿必保留此出处
使用Python构建基本WEB漏洞扫描器(二) 爬虫插件系统的开发—E
采集交流 • 优采云 发表了文章 • 0 个评论 • 370 次浏览 • 2020-08-17 21:52
一、实验介绍1.1 实验内容
基于上节的爬虫,在爬虫的基础上降低一个插件系统,通过爬虫爬取网页链接后调用这个插件系统中的插件进行各类操作,本节也会写个简单的email搜集插件作为列子,后面也会提到怎样写各类基于爬虫的插件。
1.2 实验知识点1.3 实验环境二、实验原理
利用python的__import__函数动态引入脚本,只须要规定脚本怎么编撰,便可以进行调用,email搜集是基于爬虫得到的源码进行正则匹配。上节我们创造了script这个目录,这个目录上面储存我们编撰的python插件。
三、实验步骤3.1 __import__函数
我们都晓得import是导出模块的,但是毕竟import实际上是使用builtin函数import来工作的。 在一些程序中,我们可以动态去调用函数,如果我们晓得模块的名称(字符串)的时侯,我们可以很方便的使用动态调用。 一个简单的代码:
def getfunctionbyname(module_name,function_name):
module = __import__(module_name)
return getattr(module,function_name)
通过这段代码,我们就可以简单调用一个模块的函数了。
3.2 插件系统开发流程
一个插件系统运转工作,主要进行以下几个方面的操作
获取插件,通过对一个目录里的以.py的文件扫描得到将插件目录加入到环境变量sys.path爬虫将扫描好的url和网页源码传递给插件插件工作,工作完毕后主动权还给扫描器3.3 插件系统代码
在lib/core/plugin.py中创建一个spiderplus类,实现满足我们要求的代码。
#!/usr/bin/env python
# __author__= 'wanggangdan'
import os
import sys
class spiderplus(object):
def __init__(self,plugin,disallow=[]):
self.dir_exploit = []
self.disallow = ['__init__']
self.disallow.extend(disallow)
self.plugin = os.getcwd()+'/' +plugin
sys.path.append(plugin)
def list_plusg(self):
def filter_func(file):
if not file.endswith(".py"):
return False
for disfile in self.disallow:
if disfile in file:
return False
return True
dir_exploit = filter(filter_func, os.listdir(self.plugin))
return list(dir_exploit)
def work(self,url,html):
for _plugin in self.list_plusg():
try:
m = __import__(_plugin.split('.')[0])
spider = getattr(m, 'spider')
p = spider()
s =p.run(url,html)
except Exception,e:
print e
work函数中须要传递url,html,这个就是我们扫描器传给插件系统的,通过代码
spider = getattr(m, 'spider')
p = spider()
s =p.run(url,html)
我们定义插件必须使用 class spider中的run方式调用。
3.4 扫描器中调用插件
这里我们主要是爬虫调用插件,因为插件须要传递url和网页源码这两个参数,所以我们在爬虫获取到这两个的地方加入插件系统的代码即可。
首先打开 Spider.py
在 Spider.py 文件开头加上
import plugin
然后在文件的末尾加上:
disallow = ["sqlcheck"]
_plugin = plugin.spiderplus("script",disallow)
_plugin.work(_str["url"],_str["html"])
disallow是不容许的插件列表,为了便捷测试,我们可以把sqlcheck填上,当然,也可以不要了。因为我们接下来就更改下我们上节的sql注入检查工具,使他可以融入插件系统。
3.5 sql注入融入插件系统
其实十分简单,大家更改下script/sqlcheck.py为下边即可:
P.S. 关于 Download 模块,其实就是 Downloader 模块(写的时侯不留神写混了),大家把 Downloader.py 复制一份命名为 Download.py 就行。
import re,random
import lib.core import Download
class spider:
def run(self,url,html):
if(not url.find("?")):
return False
Downloader = Download.Downloader()
BOOLEAN_TESTS = (" AND %d=%d", " OR NOT (%d=%d)")
DBMS_ERRORS = {# regular expressions used for DBMS recognition based on error message response
"MySQL": (r"SQL syntax.*MySQL", r"Warning.*mysql_.*", r"valid MySQL result", r"MySqlClient\."),
"PostgreSQL": (r"PostgreSQL.*ERROR", r"Warning.*\Wpg_.*", r"valid PostgreSQL result", r"Npgsql\."),
"Microsoft SQL Server": (r"Driver.* SQL[\-\_\ ]*Server", r"OLE DB.* SQL Server", r"(\W|\A)SQL Server.*Driver", r"Warning.*mssql_.*", r"(\W|\A)SQL Server.*[0-9a-fA-F]{8}", r"(?s)Exception.*\WSystem\.Data\.SqlClient\.", r"(?s)Exception.*\WRoadhouse\.Cms\."),
"Microsoft Access": (r"Microsoft Access Driver", r"JET Database Engine", r"Access Database Engine"),
"Oracle": (r"\bORA-[0-9][0-9][0-9][0-9]", r"Oracle error", r"Oracle.*Driver", r"Warning.*\Woci_.*", r"Warning.*\Wora_.*"),
"IBM DB2": (r"CLI Driver.*DB2", r"DB2 SQL error", r"\bdb2_\w+\("),
"SQLite": (r"SQLite/JDBCDriver", r"SQLite.Exception", r"System.Data.SQLite.SQLiteException", r"Warning.*sqlite_.*", r"Warning.*SQLite3::", r"\[SQLITE_ERROR\]"),
"Sybase": (r"(?i)Warning.*sybase.*", r"Sybase message", r"Sybase.*Server message.*"),
}
_url = url + "%29%28%22%27"
_content = Downloader.get(_url)
for (dbms, regex) in ((dbms, regex) for dbms in DBMS_ERRORS for regex in DBMS_ERRORS[dbms]):
if(re.search(regex,_content)):
return True
content = {}
content["origin"] = Downloader.get(_url)
for test_payload in BOOLEAN_TESTS:
RANDINT = random.randint(1, 255)
_url = url + test_payload%(RANDINT,RANDINT)
content["true"] = Downloader.get(_url)
_url = url + test_payload%(RANDINT,RANDINT+1)
content["false"] = Downloader.get(_url)
if content["origin"]==content["true"]!=content["false"]:
return "sql fonud: %"%url
从源码可以看出,只须要我们实现了class spider和 def run(self,url,html)就可以让扫描器工作了,然后为了便捷,去掉了先前的requests模块,引用我们自己写的下载模块.然后注释掉我们原先在扫描器中调用sql注入的部份就可以了。
3.6 E-Mail搜索插件
然后我们在编撰一个简单的列子,搜索网页中的e-mail 因为插件系统会传递网页源码,我们用一个正则表达式([\w-]+@[\w-]+\.[\w-]+)+搜索出所有的电邮。 创建script/email_check.py文件
#!/usr/bin/env python
# __author__= 'wanggangdan'
import re
class spider():
def run(self,url,html):
#print(html)
pattern = re.compile(r'([\w-]+@[\w-]+\.[\w-]+)+')
email_list = re.findall(pattern, html)
if(email_list):
print(email_list)
return True
return False
效果演示:
所有搜集到的邮箱都被采集了。
四、关于插件系统踩过的坑
有一次写插件系统的时侯,出现mothod no arrtibute “xxxx” 大概是这些情况,检查了很久,都找不到缘由,后来找到了,是自己插件命名成email,而python有个泛型就是email,所以并没有先调用我们的文件,而是先在python环境中搜救,所以告诉我们,插件的命名最好复杂一些不要和环境中已有的冲突。
五、总结
这节我们简单实现了基于爬虫的插件系统,我们可以借助这个系统结合爬虫编撰好多有趣的插件,来帮助我们进行扫描。
GitHub源码地址:(二)基于爬虫开发E-mail搜集插件/wgdscan
实验来自实验楼提供 查看全部
使用Python构建基本WEB漏洞扫描器(二) 爬虫插件系统的开发—E
一、实验介绍1.1 实验内容
基于上节的爬虫,在爬虫的基础上降低一个插件系统,通过爬虫爬取网页链接后调用这个插件系统中的插件进行各类操作,本节也会写个简单的email搜集插件作为列子,后面也会提到怎样写各类基于爬虫的插件。
1.2 实验知识点1.3 实验环境二、实验原理
利用python的__import__函数动态引入脚本,只须要规定脚本怎么编撰,便可以进行调用,email搜集是基于爬虫得到的源码进行正则匹配。上节我们创造了script这个目录,这个目录上面储存我们编撰的python插件。
三、实验步骤3.1 __import__函数
我们都晓得import是导出模块的,但是毕竟import实际上是使用builtin函数import来工作的。 在一些程序中,我们可以动态去调用函数,如果我们晓得模块的名称(字符串)的时侯,我们可以很方便的使用动态调用。 一个简单的代码:
def getfunctionbyname(module_name,function_name):
module = __import__(module_name)
return getattr(module,function_name)
通过这段代码,我们就可以简单调用一个模块的函数了。
3.2 插件系统开发流程
一个插件系统运转工作,主要进行以下几个方面的操作
获取插件,通过对一个目录里的以.py的文件扫描得到将插件目录加入到环境变量sys.path爬虫将扫描好的url和网页源码传递给插件插件工作,工作完毕后主动权还给扫描器3.3 插件系统代码
在lib/core/plugin.py中创建一个spiderplus类,实现满足我们要求的代码。
#!/usr/bin/env python
# __author__= 'wanggangdan'
import os
import sys
class spiderplus(object):
def __init__(self,plugin,disallow=[]):
self.dir_exploit = []
self.disallow = ['__init__']
self.disallow.extend(disallow)
self.plugin = os.getcwd()+'/' +plugin
sys.path.append(plugin)
def list_plusg(self):
def filter_func(file):
if not file.endswith(".py"):
return False
for disfile in self.disallow:
if disfile in file:
return False
return True
dir_exploit = filter(filter_func, os.listdir(self.plugin))
return list(dir_exploit)
def work(self,url,html):
for _plugin in self.list_plusg():
try:
m = __import__(_plugin.split('.')[0])
spider = getattr(m, 'spider')
p = spider()
s =p.run(url,html)
except Exception,e:
print e
work函数中须要传递url,html,这个就是我们扫描器传给插件系统的,通过代码
spider = getattr(m, 'spider')
p = spider()
s =p.run(url,html)
我们定义插件必须使用 class spider中的run方式调用。
3.4 扫描器中调用插件
这里我们主要是爬虫调用插件,因为插件须要传递url和网页源码这两个参数,所以我们在爬虫获取到这两个的地方加入插件系统的代码即可。
首先打开 Spider.py
在 Spider.py 文件开头加上
import plugin
然后在文件的末尾加上:
disallow = ["sqlcheck"]
_plugin = plugin.spiderplus("script",disallow)
_plugin.work(_str["url"],_str["html"])
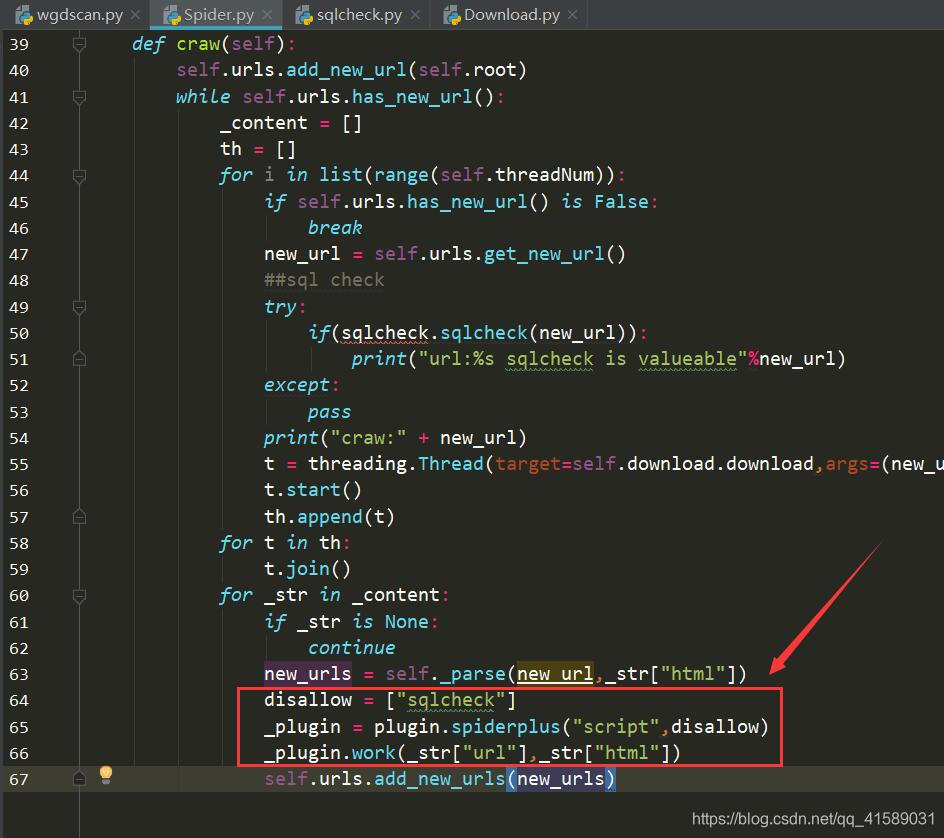
disallow是不容许的插件列表,为了便捷测试,我们可以把sqlcheck填上,当然,也可以不要了。因为我们接下来就更改下我们上节的sql注入检查工具,使他可以融入插件系统。
3.5 sql注入融入插件系统
其实十分简单,大家更改下script/sqlcheck.py为下边即可:
P.S. 关于 Download 模块,其实就是 Downloader 模块(写的时侯不留神写混了),大家把 Downloader.py 复制一份命名为 Download.py 就行。
import re,random
import lib.core import Download
class spider:
def run(self,url,html):
if(not url.find("?")):
return False
Downloader = Download.Downloader()
BOOLEAN_TESTS = (" AND %d=%d", " OR NOT (%d=%d)")
DBMS_ERRORS = {# regular expressions used for DBMS recognition based on error message response
"MySQL": (r"SQL syntax.*MySQL", r"Warning.*mysql_.*", r"valid MySQL result", r"MySqlClient\."),
"PostgreSQL": (r"PostgreSQL.*ERROR", r"Warning.*\Wpg_.*", r"valid PostgreSQL result", r"Npgsql\."),
"Microsoft SQL Server": (r"Driver.* SQL[\-\_\ ]*Server", r"OLE DB.* SQL Server", r"(\W|\A)SQL Server.*Driver", r"Warning.*mssql_.*", r"(\W|\A)SQL Server.*[0-9a-fA-F]{8}", r"(?s)Exception.*\WSystem\.Data\.SqlClient\.", r"(?s)Exception.*\WRoadhouse\.Cms\."),
"Microsoft Access": (r"Microsoft Access Driver", r"JET Database Engine", r"Access Database Engine"),
"Oracle": (r"\bORA-[0-9][0-9][0-9][0-9]", r"Oracle error", r"Oracle.*Driver", r"Warning.*\Woci_.*", r"Warning.*\Wora_.*"),
"IBM DB2": (r"CLI Driver.*DB2", r"DB2 SQL error", r"\bdb2_\w+\("),
"SQLite": (r"SQLite/JDBCDriver", r"SQLite.Exception", r"System.Data.SQLite.SQLiteException", r"Warning.*sqlite_.*", r"Warning.*SQLite3::", r"\[SQLITE_ERROR\]"),
"Sybase": (r"(?i)Warning.*sybase.*", r"Sybase message", r"Sybase.*Server message.*"),
}
_url = url + "%29%28%22%27"
_content = Downloader.get(_url)
for (dbms, regex) in ((dbms, regex) for dbms in DBMS_ERRORS for regex in DBMS_ERRORS[dbms]):
if(re.search(regex,_content)):
return True
content = {}
content["origin"] = Downloader.get(_url)
for test_payload in BOOLEAN_TESTS:
RANDINT = random.randint(1, 255)
_url = url + test_payload%(RANDINT,RANDINT)
content["true"] = Downloader.get(_url)
_url = url + test_payload%(RANDINT,RANDINT+1)
content["false"] = Downloader.get(_url)
if content["origin"]==content["true"]!=content["false"]:
return "sql fonud: %"%url
从源码可以看出,只须要我们实现了class spider和 def run(self,url,html)就可以让扫描器工作了,然后为了便捷,去掉了先前的requests模块,引用我们自己写的下载模块.然后注释掉我们原先在扫描器中调用sql注入的部份就可以了。
3.6 E-Mail搜索插件
然后我们在编撰一个简单的列子,搜索网页中的e-mail 因为插件系统会传递网页源码,我们用一个正则表达式([\w-]+@[\w-]+\.[\w-]+)+搜索出所有的电邮。 创建script/email_check.py文件
#!/usr/bin/env python
# __author__= 'wanggangdan'
import re
class spider():
def run(self,url,html):
#print(html)
pattern = re.compile(r'([\w-]+@[\w-]+\.[\w-]+)+')
email_list = re.findall(pattern, html)
if(email_list):
print(email_list)
return True
return False
效果演示:
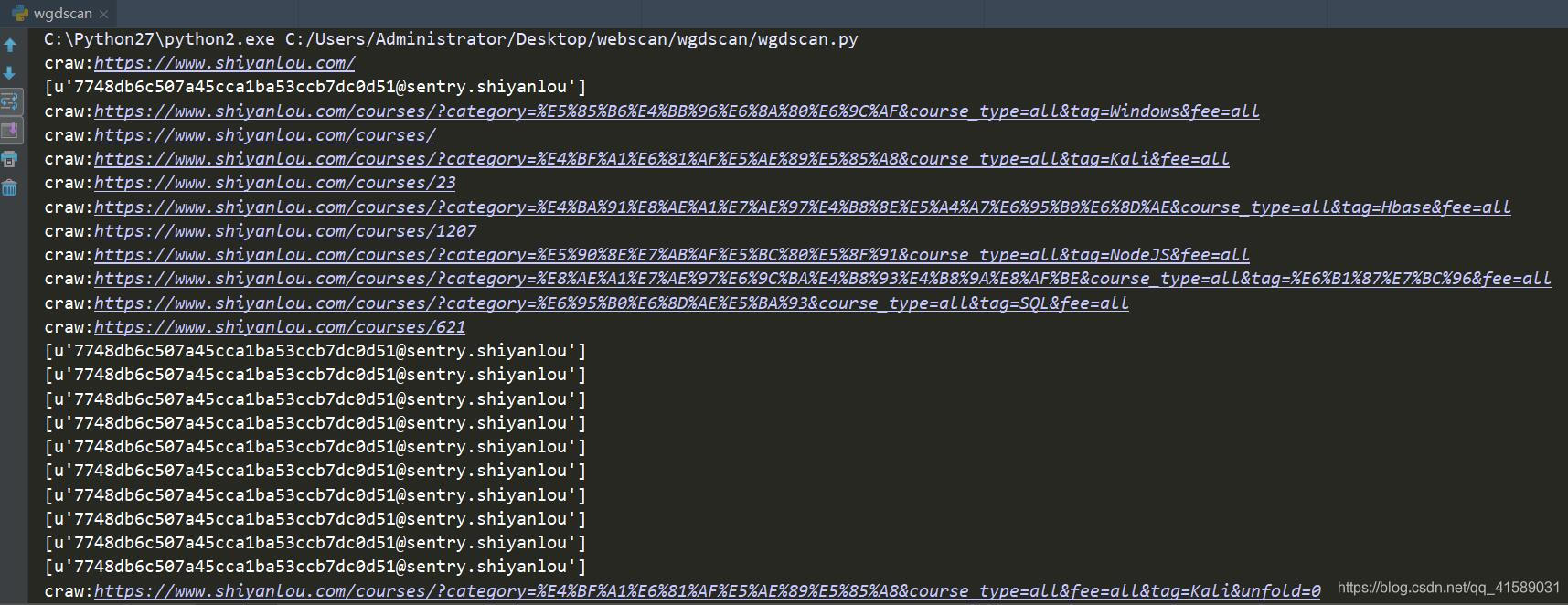
所有搜集到的邮箱都被采集了。
四、关于插件系统踩过的坑
有一次写插件系统的时侯,出现mothod no arrtibute “xxxx” 大概是这些情况,检查了很久,都找不到缘由,后来找到了,是自己插件命名成email,而python有个泛型就是email,所以并没有先调用我们的文件,而是先在python环境中搜救,所以告诉我们,插件的命名最好复杂一些不要和环境中已有的冲突。
五、总结
这节我们简单实现了基于爬虫的插件系统,我们可以借助这个系统结合爬虫编撰好多有趣的插件,来帮助我们进行扫描。
GitHub源码地址:(二)基于爬虫开发E-mail搜集插件/wgdscan
实验来自实验楼提供
08CMS v3.4 版本采集系统使用教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 664 次浏览 • 2020-08-17 11:34
第三步、编辑采集模型
请看图解:
图一、编辑模型
图二、
模型编辑界面
到这儿,采集模型的添加完成了
下面开始添加采集任务
第四步、采集任务的添加
下面是采集任务界面图解,请仔细阅读图中注释
第六步、重头戏开始了,采集规则的设置
首先剖析采集目标页的代码结构,这里以IE浏览器为例
查看采集目标页,点击IE的
页面 ---- 查看源文件
很简单能够看见目标页面的代码结构
采集页面的代码剖析,主要是找采集目标的特点
页面很大这儿不好拿上来解析,上图解释网址采集界面相关规则的设置
点击递交保存这儿的设置
我很奇怪为何不直接跳到下一步内容采集而是递交以后回到这个页面
在这个截图页面的下边还有一部分,称之为溯源网址规则
这个不是非必填项,一般不用
而且这个只能得到一个网址,而不是网址列表,个人觉得有点鸡肋,附上官方的解释
追溯网址:内容网址的一种延展。有部份被采集文档,个别数组的内容不在主内容页,而是在附加页面,特别是有关附件的内容,追溯网址用于采集其附加页面网址,每个内容网址可溯源两级附加页面,追溯网址2是在溯源网址1的基础上采集的。
追溯概念举例:我们去下载站的时侯,往往点进去的页面只有软件信息说明和一个或多个步入下载页面的链接
注意:这里是步入下载页面的链接,而不是下载地址。当我们要下载该软件的时侯要先打开这个下载页面能够见到下载地址
这里就是一级溯源,因为我们要再点一次就能抵达下载页面。这时我们的1级溯源地址就是那种步入下载页面的链接
接下来是内容页的规则
同样用图来解析,本处只选用一个数组的规则设置为例,其他数组基本类同
入库参数设置
如果是非合辑也就是单文档采集,那么规则到此就设置结束了
经过测试没问题即可进行采集
如果你有足够的信心,完全可以不用测试直接采集哦
如果是合集的采集,比如小说,那么采集的设置还只进行到一半哦
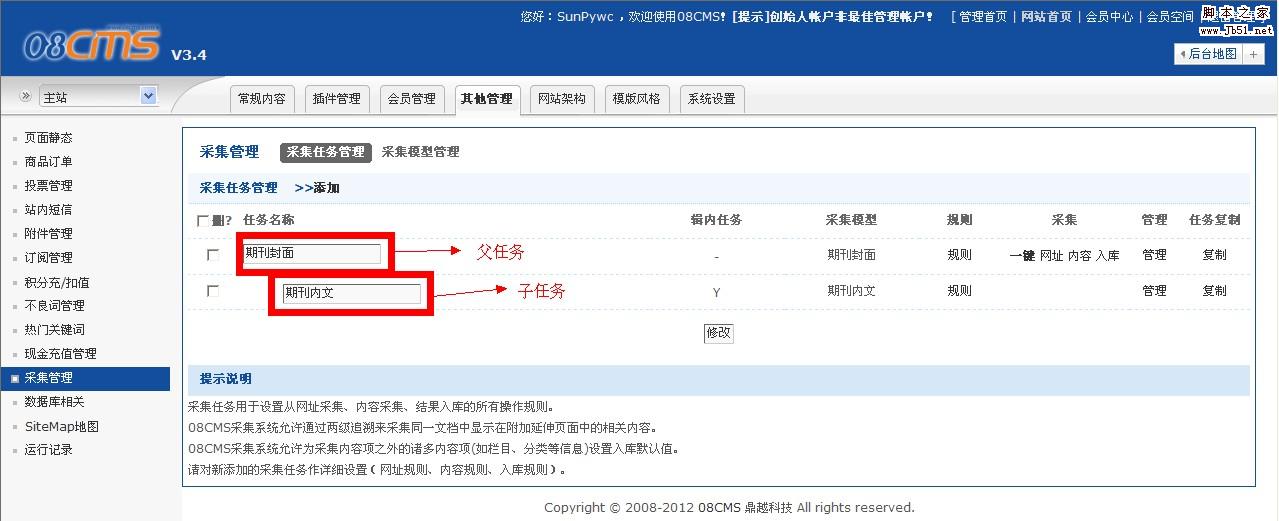
合辑的采集还须要设置子任务的的规则
如图:
子任务在父任务下方,而且任务名称前有缩进
子任务的规则设置跟父任务的规则设置基本相同,不赘言了
理论上采集到这儿就结束了,开始愉快的采集之旅吧,个人觉得还是挺有快感的
采集,你可以自己根据网址、内容、入库一步步来
直接 一键 采集就更干脆了
不过这儿有个使人呕血的问题
采集任务除非是合集采集中的父任务跟子任务
不然你就得一个个任务一键过去,不使排队。。。。
虽然有不少地方有不足,不过总体上来说采集体验还是良好的
教程就到这儿结束了,有哪些不明白的可以跟贴提出 查看全部
08CMS v3.4 版本采集系统使用教程
第三步、编辑采集模型
请看图解:
图一、编辑模型
图二、
模型编辑界面
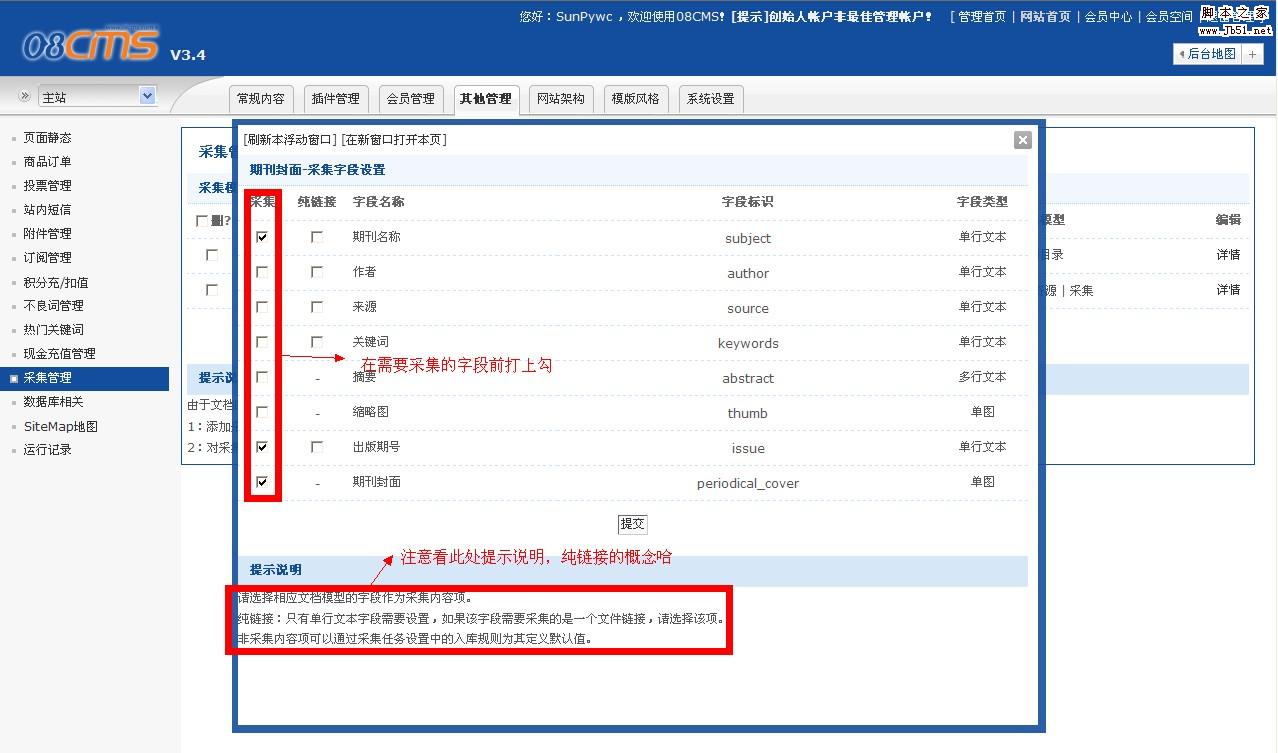
到这儿,采集模型的添加完成了
下面开始添加采集任务
第四步、采集任务的添加
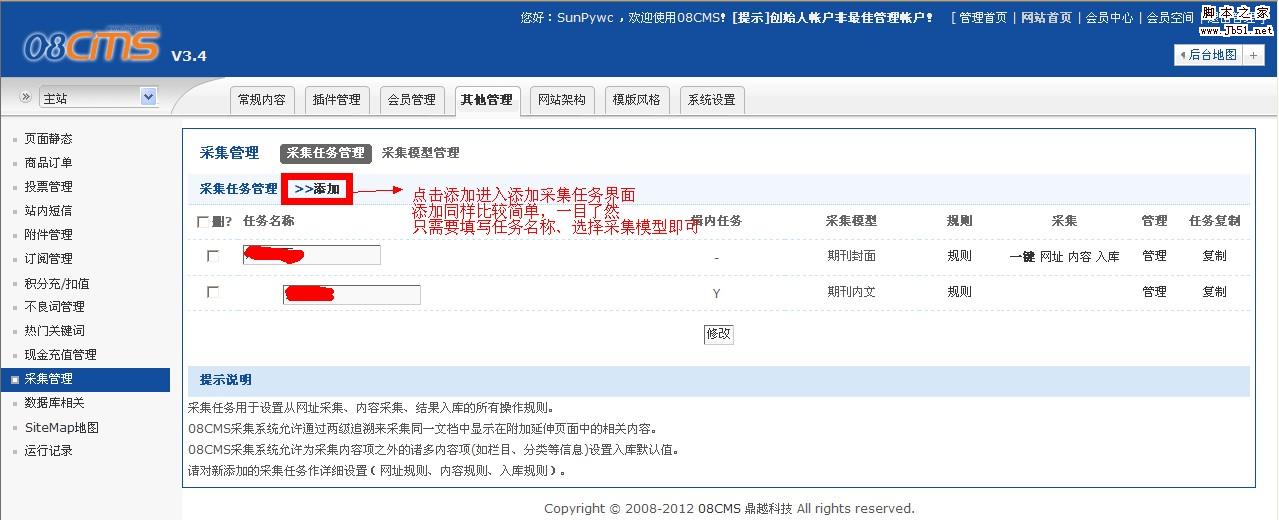
下面是采集任务界面图解,请仔细阅读图中注释
第六步、重头戏开始了,采集规则的设置
首先剖析采集目标页的代码结构,这里以IE浏览器为例
查看采集目标页,点击IE的
页面 ---- 查看源文件
很简单能够看见目标页面的代码结构
采集页面的代码剖析,主要是找采集目标的特点
页面很大这儿不好拿上来解析,上图解释网址采集界面相关规则的设置
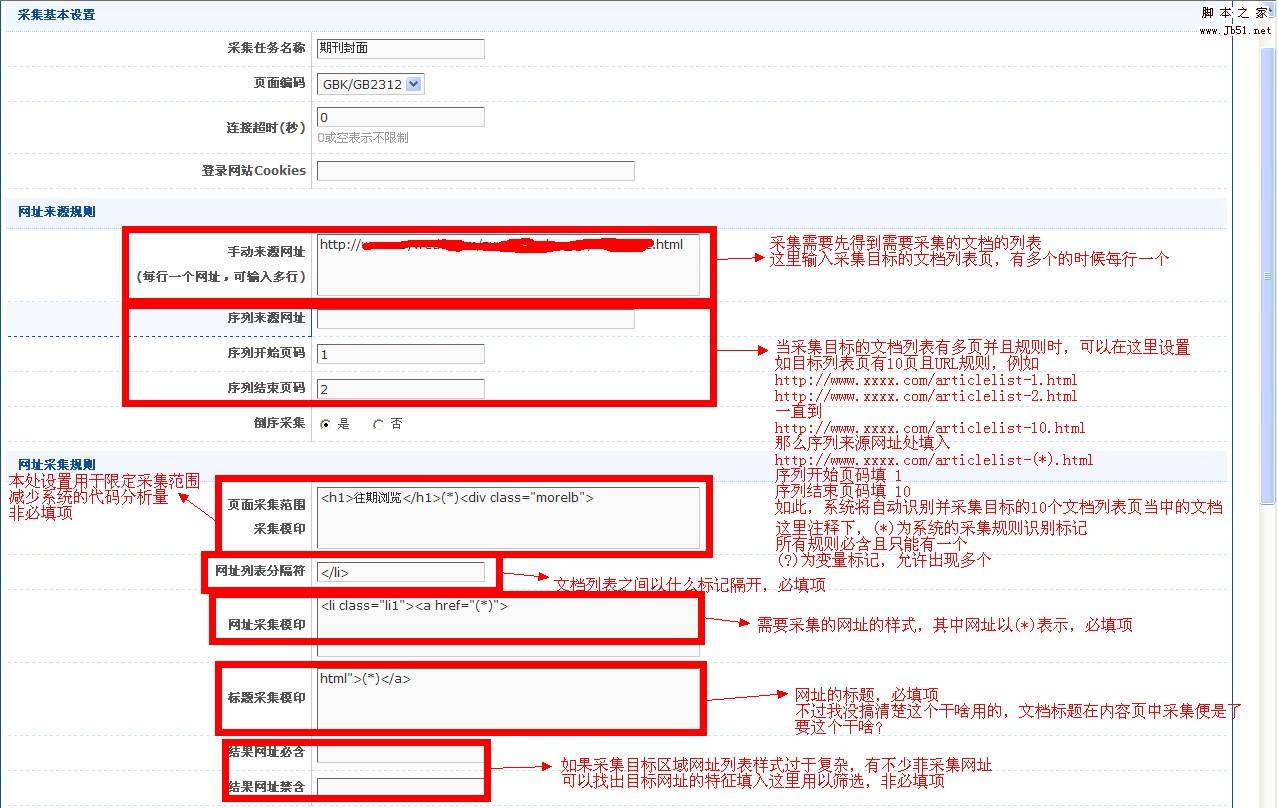
点击递交保存这儿的设置
我很奇怪为何不直接跳到下一步内容采集而是递交以后回到这个页面
在这个截图页面的下边还有一部分,称之为溯源网址规则
这个不是非必填项,一般不用
而且这个只能得到一个网址,而不是网址列表,个人觉得有点鸡肋,附上官方的解释
追溯网址:内容网址的一种延展。有部份被采集文档,个别数组的内容不在主内容页,而是在附加页面,特别是有关附件的内容,追溯网址用于采集其附加页面网址,每个内容网址可溯源两级附加页面,追溯网址2是在溯源网址1的基础上采集的。
追溯概念举例:我们去下载站的时侯,往往点进去的页面只有软件信息说明和一个或多个步入下载页面的链接
注意:这里是步入下载页面的链接,而不是下载地址。当我们要下载该软件的时侯要先打开这个下载页面能够见到下载地址
这里就是一级溯源,因为我们要再点一次就能抵达下载页面。这时我们的1级溯源地址就是那种步入下载页面的链接
接下来是内容页的规则
同样用图来解析,本处只选用一个数组的规则设置为例,其他数组基本类同
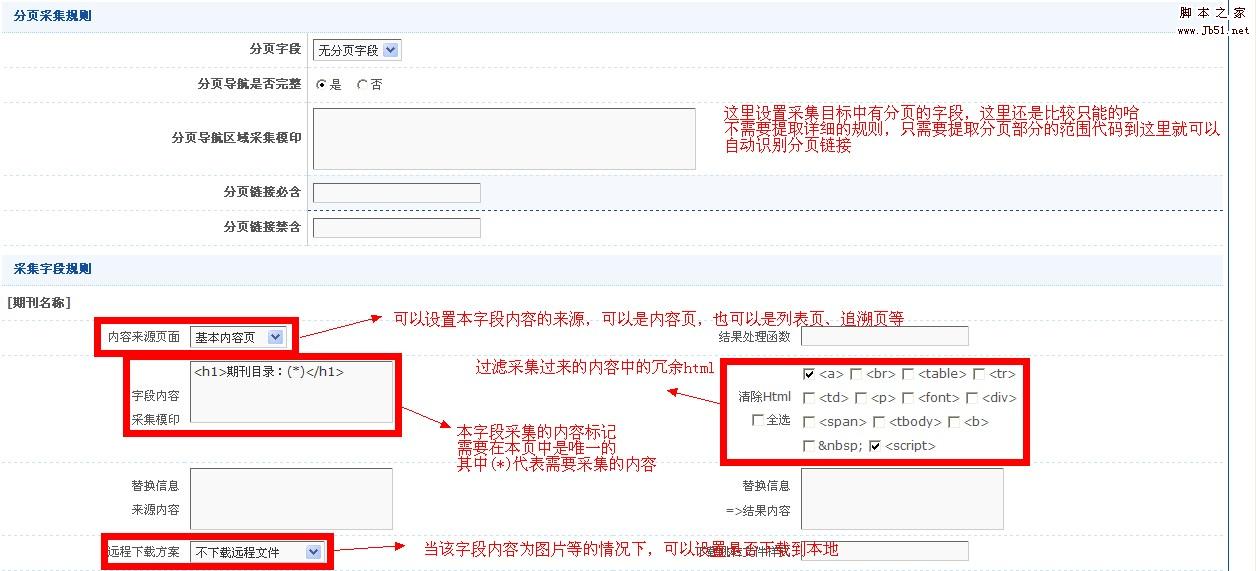
入库参数设置

如果是非合辑也就是单文档采集,那么规则到此就设置结束了
经过测试没问题即可进行采集
如果你有足够的信心,完全可以不用测试直接采集哦
如果是合集的采集,比如小说,那么采集的设置还只进行到一半哦
合辑的采集还须要设置子任务的的规则
如图:
子任务在父任务下方,而且任务名称前有缩进
子任务的规则设置跟父任务的规则设置基本相同,不赘言了
理论上采集到这儿就结束了,开始愉快的采集之旅吧,个人觉得还是挺有快感的

采集,你可以自己根据网址、内容、入库一步步来
直接 一键 采集就更干脆了
不过这儿有个使人呕血的问题
采集任务除非是合集采集中的父任务跟子任务
不然你就得一个个任务一键过去,不使排队。。。。
虽然有不少地方有不足,不过总体上来说采集体验还是良好的
教程就到这儿结束了,有哪些不明白的可以跟贴提出
网络数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 261 次浏览 • 2020-08-14 11:32
网络数据采集是指通过网路爬虫或网站公开API等方法从网站上获取数据信息
常用的网路采集系统网路爬虫工作原理工作流程抓取策略网路爬虫策略用到的基本概念通用网路爬虫
通用网路爬虫又称全网爬虫,爬行对象从一些种子URL扩充到整个Web,主要为门户站点搜索引擎和小型Web服务提供商采集数据。
聚焦网络爬虫
聚焦网路爬虫又称主题网路爬虫,是指选择性地爬行这些与预先定义好的主题相关的页面的网路爬虫。
1)基于内容评价的爬行策略
De Bra将文本相似度的估算方式引入到网路爬虫中,提出了Fish Search算法。该算法将用户输入的查询词作为主题,收录查询词的页面被视为与主题相关的页面,其局限性在于难以评价页面与主题相关度的大小。
Herseovic对Fish Search算法进行了改进,提出了Shark Search算法,即借助空间向量模型估算页面与主题的相关度大小。采用基于连续值估算链接价值的方式,不但可以估算出什么抓取的链接和主题相关,还可以得到相关度的量化大小。
2)基于链接结构评价的爬行策略
PageRank算法的基本原理是,如果一个网页多次被引用,则可能是很重要的网页,如果一个网页没有被多次引用,但是被重要的网页引用,也有可能是重要的网页。一个网页的重要性被平均地传递到它所引用的网页上。
3)基于提高学习的爬行策略
将提高学习引入聚焦爬虫,利用贝叶斯分类器,根据整个网页文本和链接文本对超链接进行分类,为每位链接估算出重要性,从而决定链接的访问次序。
4)基于语境图的爬行策略
通过构建语境图学习网页之间的相关度的爬行策略,该策略可训练一个机器学习系统,通过该系统可估算当前页面到相关Web页面的距离,距离逾的页面中的链接优先访问。
增量式网络爬虫
增量式网络爬虫是指对已下载网页采取增量式更新而且只爬行新形成的或则已然发生变化网页的爬虫,它还能在一定程度上保证所爬行的页面是尽可能新的页面。
深度网路爬虫
网页按存在形式可以分为表层网页和深层网页。表层网页是指传统搜索引擎可以索引的页面,以超链接可以抵达的静态网页为主。深层网页是什么大部分内容不能通过静态链接获取的,隐藏在搜索表单后的,只有用户递交一些关键词能够获得的网页。
深层网路爬虫体系结构收录6个基本功能模块:
爬行控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器和两个爬虫内部数据结构(URL列表和LVS表)。其中,LVS(Label Value Set)表示标签和数值集合,用来表示填充表单的数据源。在爬取过程中,最重要的部份就是表单填写,收录基于领域知识的表单填写和基于网页结构剖析的表单填写两种。 查看全部
网络数采集的主要功能
网络数据采集是指通过网路爬虫或网站公开API等方法从网站上获取数据信息
常用的网路采集系统网路爬虫工作原理工作流程抓取策略网路爬虫策略用到的基本概念通用网路爬虫
通用网路爬虫又称全网爬虫,爬行对象从一些种子URL扩充到整个Web,主要为门户站点搜索引擎和小型Web服务提供商采集数据。
聚焦网络爬虫
聚焦网路爬虫又称主题网路爬虫,是指选择性地爬行这些与预先定义好的主题相关的页面的网路爬虫。
1)基于内容评价的爬行策略
De Bra将文本相似度的估算方式引入到网路爬虫中,提出了Fish Search算法。该算法将用户输入的查询词作为主题,收录查询词的页面被视为与主题相关的页面,其局限性在于难以评价页面与主题相关度的大小。
Herseovic对Fish Search算法进行了改进,提出了Shark Search算法,即借助空间向量模型估算页面与主题的相关度大小。采用基于连续值估算链接价值的方式,不但可以估算出什么抓取的链接和主题相关,还可以得到相关度的量化大小。
2)基于链接结构评价的爬行策略
PageRank算法的基本原理是,如果一个网页多次被引用,则可能是很重要的网页,如果一个网页没有被多次引用,但是被重要的网页引用,也有可能是重要的网页。一个网页的重要性被平均地传递到它所引用的网页上。
3)基于提高学习的爬行策略
将提高学习引入聚焦爬虫,利用贝叶斯分类器,根据整个网页文本和链接文本对超链接进行分类,为每位链接估算出重要性,从而决定链接的访问次序。
4)基于语境图的爬行策略
通过构建语境图学习网页之间的相关度的爬行策略,该策略可训练一个机器学习系统,通过该系统可估算当前页面到相关Web页面的距离,距离逾的页面中的链接优先访问。
增量式网络爬虫
增量式网络爬虫是指对已下载网页采取增量式更新而且只爬行新形成的或则已然发生变化网页的爬虫,它还能在一定程度上保证所爬行的页面是尽可能新的页面。
深度网路爬虫
网页按存在形式可以分为表层网页和深层网页。表层网页是指传统搜索引擎可以索引的页面,以超链接可以抵达的静态网页为主。深层网页是什么大部分内容不能通过静态链接获取的,隐藏在搜索表单后的,只有用户递交一些关键词能够获得的网页。
深层网路爬虫体系结构收录6个基本功能模块:
爬行控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器和两个爬虫内部数据结构(URL列表和LVS表)。其中,LVS(Label Value Set)表示标签和数值集合,用来表示填充表单的数据源。在爬取过程中,最重要的部份就是表单填写,收录基于领域知识的表单填写和基于网页结构剖析的表单填写两种。
硕士学位论文第三章恶意代码异常监测系统需求剖析图借助异常检查规则与特点检查规则进
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2020-08-12 01:25
异常检查规则生成厢瓣 一定关联分桁、——、一一—————曩 异常检查规则生成用例图本场景收录五个用例以及两个角色以下为各内容的详尽说明 选取特点检查规则集合 由“规则管理与剖析员”角色 负责 登童笪塑至堕整望塑塑堕壁望塑生以手工形式在当前测量规则库’’ 角色 中选定合适的、待剖析的特点检查规则集合 设定关联分析运算参数 由于关联分析任务施行前须要设置每位关联分析任务的运算参数因而须要由“规则管理与分析员’’ 角色 设定关联分析任务的运算参数 关联分析 由“规则管理与分析员角色 负责执行关联分析运算操作 异常检查规则生成 由“规则管理与剖析员”角色 确认关联分析运算获得结果以及新生成的异常检查规则 异常检查规则入库 由‘‘规则管理与剖析员”角色 将有价值的异常检查规则导出“检测规则库” 角色 恶意代码检查信硕士学位论文第三章恶意代码异常测量系统需求剖析图 恶意代码检查用例图本场景收录四个用例以及三个角色 以下为各内容的详细说明 网络通信数据采集 对“网络通信系统”角色 进行原创通信数据捕捉 该用例收录“数据预处理’’ 工作内容数据预处理 对捕捉到的原创通信数据进行规范化处理为“模式匹配” 提供后置处理模式匹配 读取“规则检查库”角色 的恶意代码检查规则 包括特点检查规则与异常检查规则 并运用相关规则对经过“数据预处理 的通信数据进行模式匹配恶意代码告警 发现恶意代码后由“恶意代码告警” 输出相关告警信息以告知“信息安全员角色 功能需求剖析本异常恶意代码检查系统将起码收录以下个用户需求 设定手动更新检查规则配置可以手工方法设置手动更新检查规则配置。
设定定时升级阈值可以设置手动升级的定时升级阈值。 设定定时升级源头可以设置手动升级的升级源头。 读取手动更新检查规则配置给以系统读取手动更新传统特点检查规则配置的功能。 定期手动升级特点检查规则给以系统手动更新传统特点检查规则的功能。 选取特点检查规则集合可以手工选定待进行关联剖析的特点检查规则集合的功能。硕士学位论文第三章恶意代码异常监测系统需求剖析设定关联分析运算参数可以手工设置关联剖析过程中运用的参数的值。 关联分析提供关联分析运算任务的处理开关。 异常检查规则生成提供将关联分析结果转换为异常检查规则的功能。 异常检查规则入库提供将新生成的异常检查规则写入规则库的功能。 网络通信数据采集可以对指定网路插口进行原创通信数据捕获的功能。 数据预处理提供对原创通信数据进行规范化处理的功能。 模式匹配提供针对通信数据与恶意代码检查规则 收录特点检查规则与异常检查规则 进行模式匹配的功能 以模式匹配的方法确认通信数据是否存在恶意代码。 恶意代码告警可以将模式匹配后发觉的恶意代码告警信息通知信息安全员。以下为针对上述用户需求清单中 个用户需求进行需求剖析后获得下列五个功能点 下文将针对此五个功能点提出对应的功能需求说明。
硕士学位论文第三章恶意代码异常测量系统需求剖析 规则导出管理功能规则导出成功提示界面图 规则导出管理功能鲁棒图 涉及用户需求编号 特征监测规则导出 涉及人员 规则管理与分析员 涉及存储单元 检测规则库 功能的施行流程描述 、规则管理与分析员访问“所有规则展示界面 主界面 、在主界面中手工导出规则文件 分支 手工搜索或删掉指定规则 、规则文件写入检查规则库 、导入规则后弹出“导入成功提示界面” 、“导入成功提示界面”提示规则管理与分析员导出操作成功。硕士学位论文第三章恶意代码异常测量系统需求剖析 规则手动升级管理功能卜 文件设定定时升级源头图 规则手动升级管理功能鲁棒图 涉及用户需求编号 设定手动更新检查规则配置 设定定时升级源头涉及人员 规则管理与分析员 涉及存储单元 自动升级配置文件 功能的施行流程描述 、规则管理与分析员访问“自动升级管理界面 主界面 、在主界面中手工设置手动升级功能开关 设置完成后将设置结果返显至主界面中 、将手动升级功能开关情况写入手动升级配置文件中 、在主界面中手工设置定时升级阈值 设置完成后将设置结果返显至主界面中 、将定时升级阈值写入手动升级配置文件中 、在主界面中手工设置定时升级源头 设置完成后将设置结果返显至主界面中 、将定时升级源头写入手动升级配置文件中。
硕士学位论文第三章恶意代码异常测量系统需求剖析 规则手动升级功能规则管理与分析员手动升级管理界面 检测规则库读取手动升级配置图规则手动升级功能鲁棒图 涉及用户需求编号 读取手动更新检查规则配置 定期手动升级特点检查规则涉及人员 规则管理与分析员 涉及存储单元 自动升级配置文件 功能的施行流程描述 、读取手动升级配置模块定期读取手动升级配置文件 确认是否开启已手动升级功能、升级阈值以及升级源头 、在确认已开启升级功能后 交由手动升级特点规则功能进行特点检查规则升级 、自动升级特点规则功能将新获得的特点检查规则写入规则特点库 、在特点检查规则升级后 返显升级结果至“自动升级管理界面” 主界面 、主界面提示升级操作成功。卜硕士学位论文第三章恶意代码异常测量系统需求剖析 异常检查规则提取功能异常拉舅规用 异常检查规则提取功能鲁棒图涉及用户需求编号 选取特点检查规则集合 异常检查规则入库一涉及人员 规则管理与分析员 涉及存储单元 检测规则库 功能的施行流程描述 查看全部
硕士学位论文第三章恶意代码异常监测系统需求剖析图借助异常检查规则与特点检查规则进行恶意代码检查活动示意图第一步 采集网络通信数据 获得原创数据内容 第二步 对网路通信原创数据进行数据规范化处理 确保数据可进行模式匹配 第三步 使用恶意代码检查规则库 关于“恶意代码检查规则库中异常检查规则与特点检查规则的更新过程 详见“图 恶意代码特点检查规则关联分析与异常检查规则提取活动示意图’’ 与规范化后的网路通信数据进行模式匹配 若匹配不成功则结束本流程 若匹配成功则步入第四步的“恶意代码告警”过程 第四步 对发觉的恶意代码结果进行告警。 用户需求场景针对上述所提到的两个业务需求活动 并从用户的角度出发可以整理为以下三个用户场景 特征检查规则升级、异常检查规则生成、恶意代码检查。以下为三个用户场景的详尽说明。 特征检查规则升级 硕士学位论文第三章恶意代码异常监测系统需求剖析 特征检查规则升级用例图本场景收录五个用例以及三个角色以下为各内容的详尽说明 特征检查规则导出 由“规则管理与分析员角色 负责以手工方法将目前较新或待进行关联分析的传统恶意代码检查规则集合导出“检测规则库” 角色 设定手动更新检查规则配置 由“规则管理与分析员角色 执行针对手动更新检查规则配置的设定操作 用于更改相关配置让系统能手动更新检查规则库中的特点检查规则 设定定时升级阈值 “定时升级阈值”为时间周期等定时执行参数硕士学位论文第三章恶意代码异常测量系统需求剖析 设定定时升级源头 “定时升级源头”为升级特点检查规则的源储存点如网址、 地址等 读取手动更新检查规则配置 由系统外置定时器负责执行用于让系统获取手动更新检查规则配置参数 包括时间周期等定时执行参数、升级特点检查规则的源储存点 定期手动升级特点检查规则 由系统外置定时器负责执行当定时器确认当前系统时间与时间周期等定时执行参数一致时启动“检测规则库” 角色 内特点检查规则手动升级操作。
异常检查规则生成厢瓣 一定关联分桁、——、一一—————曩 异常检查规则生成用例图本场景收录五个用例以及两个角色以下为各内容的详尽说明 选取特点检查规则集合 由“规则管理与剖析员”角色 负责 登童笪塑至堕整望塑塑堕壁望塑生以手工形式在当前测量规则库’’ 角色 中选定合适的、待剖析的特点检查规则集合 设定关联分析运算参数 由于关联分析任务施行前须要设置每位关联分析任务的运算参数因而须要由“规则管理与分析员’’ 角色 设定关联分析任务的运算参数 关联分析 由“规则管理与分析员角色 负责执行关联分析运算操作 异常检查规则生成 由“规则管理与剖析员”角色 确认关联分析运算获得结果以及新生成的异常检查规则 异常检查规则入库 由‘‘规则管理与剖析员”角色 将有价值的异常检查规则导出“检测规则库” 角色 恶意代码检查信硕士学位论文第三章恶意代码异常测量系统需求剖析图 恶意代码检查用例图本场景收录四个用例以及三个角色 以下为各内容的详细说明 网络通信数据采集 对“网络通信系统”角色 进行原创通信数据捕捉 该用例收录“数据预处理’’ 工作内容数据预处理 对捕捉到的原创通信数据进行规范化处理为“模式匹配” 提供后置处理模式匹配 读取“规则检查库”角色 的恶意代码检查规则 包括特点检查规则与异常检查规则 并运用相关规则对经过“数据预处理 的通信数据进行模式匹配恶意代码告警 发现恶意代码后由“恶意代码告警” 输出相关告警信息以告知“信息安全员角色 功能需求剖析本异常恶意代码检查系统将起码收录以下个用户需求 设定手动更新检查规则配置可以手工方法设置手动更新检查规则配置。
设定定时升级阈值可以设置手动升级的定时升级阈值。 设定定时升级源头可以设置手动升级的升级源头。 读取手动更新检查规则配置给以系统读取手动更新传统特点检查规则配置的功能。 定期手动升级特点检查规则给以系统手动更新传统特点检查规则的功能。 选取特点检查规则集合可以手工选定待进行关联剖析的特点检查规则集合的功能。硕士学位论文第三章恶意代码异常监测系统需求剖析设定关联分析运算参数可以手工设置关联剖析过程中运用的参数的值。 关联分析提供关联分析运算任务的处理开关。 异常检查规则生成提供将关联分析结果转换为异常检查规则的功能。 异常检查规则入库提供将新生成的异常检查规则写入规则库的功能。 网络通信数据采集可以对指定网路插口进行原创通信数据捕获的功能。 数据预处理提供对原创通信数据进行规范化处理的功能。 模式匹配提供针对通信数据与恶意代码检查规则 收录特点检查规则与异常检查规则 进行模式匹配的功能 以模式匹配的方法确认通信数据是否存在恶意代码。 恶意代码告警可以将模式匹配后发觉的恶意代码告警信息通知信息安全员。以下为针对上述用户需求清单中 个用户需求进行需求剖析后获得下列五个功能点 下文将针对此五个功能点提出对应的功能需求说明。
硕士学位论文第三章恶意代码异常测量系统需求剖析 规则导出管理功能规则导出成功提示界面图 规则导出管理功能鲁棒图 涉及用户需求编号 特征监测规则导出 涉及人员 规则管理与分析员 涉及存储单元 检测规则库 功能的施行流程描述 、规则管理与分析员访问“所有规则展示界面 主界面 、在主界面中手工导出规则文件 分支 手工搜索或删掉指定规则 、规则文件写入检查规则库 、导入规则后弹出“导入成功提示界面” 、“导入成功提示界面”提示规则管理与分析员导出操作成功。硕士学位论文第三章恶意代码异常测量系统需求剖析 规则手动升级管理功能卜 文件设定定时升级源头图 规则手动升级管理功能鲁棒图 涉及用户需求编号 设定手动更新检查规则配置 设定定时升级源头涉及人员 规则管理与分析员 涉及存储单元 自动升级配置文件 功能的施行流程描述 、规则管理与分析员访问“自动升级管理界面 主界面 、在主界面中手工设置手动升级功能开关 设置完成后将设置结果返显至主界面中 、将手动升级功能开关情况写入手动升级配置文件中 、在主界面中手工设置定时升级阈值 设置完成后将设置结果返显至主界面中 、将定时升级阈值写入手动升级配置文件中 、在主界面中手工设置定时升级源头 设置完成后将设置结果返显至主界面中 、将定时升级源头写入手动升级配置文件中。
硕士学位论文第三章恶意代码异常测量系统需求剖析 规则手动升级功能规则管理与分析员手动升级管理界面 检测规则库读取手动升级配置图规则手动升级功能鲁棒图 涉及用户需求编号 读取手动更新检查规则配置 定期手动升级特点检查规则涉及人员 规则管理与分析员 涉及存储单元 自动升级配置文件 功能的施行流程描述 、读取手动升级配置模块定期读取手动升级配置文件 确认是否开启已手动升级功能、升级阈值以及升级源头 、在确认已开启升级功能后 交由手动升级特点规则功能进行特点检查规则升级 、自动升级特点规则功能将新获得的特点检查规则写入规则特点库 、在特点检查规则升级后 返显升级结果至“自动升级管理界面” 主界面 、主界面提示升级操作成功。卜硕士学位论文第三章恶意代码异常测量系统需求剖析 异常检查规则提取功能异常拉舅规用 异常检查规则提取功能鲁棒图涉及用户需求编号 选取特点检查规则集合 异常检查规则入库一涉及人员 规则管理与分析员 涉及存储单元 检测规则库 功能的施行流程描述
大数据采集系统有几类?好用大数据采集平台有什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 334 次浏览 • 2020-08-10 02:00
对数据进行ETL操作,通过对数据进行提取、转换、加载,最终挖掘数据的潜在价值。然后提供给用户解决方案或则决策参考。
大数据采集系统,主要分为三类:
1、系统日志采集系统
对日志数据信息进行日志采集、采集,然后进行数据剖析,挖掘公司业务平台日志数据中的潜在价值。简言之,采集日志数据提供离线和在线的实时剖析使用。目前常用的开源日志搜集系统为Flume。
2、网络数据采集系统
通过网路爬虫和一些网站平台提供的公共API(如Twitter和新浪微博API)等方法从网站上获取数据。可以将非结构化数据和半结构化数据的网页数据从网页中提取下来,并将其提取、清洗、转换成结构化的数据,将其储存为统一的本地文件数据。
目前常用的网页爬虫系统有Apache Nutch、Crawler4j、Scrapy等框架。
3、数据库采集系统
通过数据库采集系统直接与企业业务后台服务器结合,将企业业务后台每时每刻都在形成大量的业务记录写入到数据库中,最后由特定的处理分许系统进行系统分析。
目前常用关系型数据库MySQL和Oracle等来储存数据,Redis和MongoDB这样的NoSQL数据库也常用于数据的采集。
好用的大数据采集平台:
1.数据商场
一款基于云平台的大数据估算、分析系统。拥有丰富高质量的数据资源,通过自身渠道资源获取了百余款拥有版权的大数据资源,所有数据都经过初审,保证数据的高可用性。
2. Rapid Miner
数据科学软件平台,为数据打算、机器学习、深度学习、文本挖掘和预测剖析提供一种集成环境。
3. Oracle Data Mining
它是Oracle中级剖析数据库的代表。市场领先的公司用它最大限度地开掘数据的潜力,做出确切的预测。
4. IBM SPSS Modeler
适合大规模项目。在这个建模器中,文本剖析及其最先进的可视化界面极具价值。它有助于生成数据挖掘算法,基本上不需要编程。
5. KNIME
开源数据剖析平台。你可以迅速在其中布署、扩展和熟悉数据。
6. Python
一种免费的开源语言。
大数据平台:
是指以处理海量数据储存、计算及不间断流数据实时估算等场景为主的一套基础设施。既可以采用开源平台,也可以采用华为、星环等商业级解决方案,既可以布署在私有云上,也可以布署在公有云上。
任何完整的大数据平台,一般包括以下的几个过程:
其中,数据采集是所有数据系统必不可少的,随着大数据越来越被注重,数据采集的挑战也变的尤为突出。 查看全部
什么是大数据采集技术:
对数据进行ETL操作,通过对数据进行提取、转换、加载,最终挖掘数据的潜在价值。然后提供给用户解决方案或则决策参考。

大数据采集系统,主要分为三类:
1、系统日志采集系统
对日志数据信息进行日志采集、采集,然后进行数据剖析,挖掘公司业务平台日志数据中的潜在价值。简言之,采集日志数据提供离线和在线的实时剖析使用。目前常用的开源日志搜集系统为Flume。
2、网络数据采集系统
通过网路爬虫和一些网站平台提供的公共API(如Twitter和新浪微博API)等方法从网站上获取数据。可以将非结构化数据和半结构化数据的网页数据从网页中提取下来,并将其提取、清洗、转换成结构化的数据,将其储存为统一的本地文件数据。
目前常用的网页爬虫系统有Apache Nutch、Crawler4j、Scrapy等框架。
3、数据库采集系统
通过数据库采集系统直接与企业业务后台服务器结合,将企业业务后台每时每刻都在形成大量的业务记录写入到数据库中,最后由特定的处理分许系统进行系统分析。
目前常用关系型数据库MySQL和Oracle等来储存数据,Redis和MongoDB这样的NoSQL数据库也常用于数据的采集。

好用的大数据采集平台:
1.数据商场
一款基于云平台的大数据估算、分析系统。拥有丰富高质量的数据资源,通过自身渠道资源获取了百余款拥有版权的大数据资源,所有数据都经过初审,保证数据的高可用性。
2. Rapid Miner


数据科学软件平台,为数据打算、机器学习、深度学习、文本挖掘和预测剖析提供一种集成环境。
3. Oracle Data Mining
它是Oracle中级剖析数据库的代表。市场领先的公司用它最大限度地开掘数据的潜力,做出确切的预测。
4. IBM SPSS Modeler
适合大规模项目。在这个建模器中,文本剖析及其最先进的可视化界面极具价值。它有助于生成数据挖掘算法,基本上不需要编程。
5. KNIME
开源数据剖析平台。你可以迅速在其中布署、扩展和熟悉数据。
6. Python
一种免费的开源语言。

大数据平台:
是指以处理海量数据储存、计算及不间断流数据实时估算等场景为主的一套基础设施。既可以采用开源平台,也可以采用华为、星环等商业级解决方案,既可以布署在私有云上,也可以布署在公有云上。
任何完整的大数据平台,一般包括以下的几个过程:
其中,数据采集是所有数据系统必不可少的,随着大数据越来越被注重,数据采集的挑战也变的尤为突出。
部署ELK日志采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 380 次浏览 • 2020-08-08 23:33
ELK是Elasticsearch,Logstash和Kibana的缩写. 这三个是核心程序包,但不是全部.
Elasticsearch是一个实时的全文本搜索和分析引擎,它提供了采集,分析和存储数据的三种功能. 它是一组开放的REST和JAVA API结构,可提供有效的搜索功能和可扩展的分布式系统. 它建立在Apache Lucene搜索引擎库的顶部.
Logstash是用于采集,分析和过滤日志的工具. 它支持几乎所有类型的日志,包括系统日志,错误日志和自定义应用程序日志. 它可以从许多来源接收日志,包括系统日志,消息传递(例如RabbitMQ)和JMX,并且可以通过多种方式输出数据,包括电子邮件,Websocket和Elasticsearch.
Kibana是基于Web的图形界面,用于搜索,分析和可视化Elasticsearch指标中存储的日志数据. 它利用Elasticsearch的REST界面检索数据,不仅允许用户创建自己的自定义仪表板数据视图,而且还允许他们以特殊方式查询和过滤数据.
1,准备环境1.1,配置Java环境
转到官方网站下载jdk1.8以上的软件包,然后配置java环境以确保该环境正常使用. 跳过此处的安装过程. 如果您听不懂,请自己百度.
[root@vm96-yw-65-test-3060 application]# java -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
1.2. 下载ELK软件包
转到官方网站下载Elasticsearch,Logstash和Kibana. 因为它是一个测试环境,所以我下载了最新版本v6.4.0,并在下载后将其解压缩.
wget https://artifacts.elastic.co/d ... ar.gz
wget https://artifacts.elastic.co/d ... ar.gz
wget https://artifacts.elastic.co/d ... ar.gz
2,配置2.1,修改系统配置
elasticsearch对最大系统连接数有要求,因此您需要修改系统连接数.
echo '
* hard nofile 65536
* soft nofile 65536
* soft nproc 65536
* hard nproc 65536
' >>/etc/security/limits.conf
echo 'vm.max_map_count = 262144' >> /etc/sysctl.conf
vim /etc/security/limits.d/90-nproc.conf
# 第一行最后一个数,修改为4096,如果是则不用修改
# limits.d下面的文件可能不是90-nproc.conf,可能是其他数字开头的文件。
* soft nproc 4096
root soft nproc unlimited
2.2,elasticSearch配置
这实际上是ELK的核心. 启动时必须注意. 从5.0版开始,ElasticSearch的安全级别已得到改进,并且不允许以root帐户开头,因此我们需要添加一个用户,因此还需要创建一个elsearch帐户.
groupadd es #新建es组
useradd es -g es -p elasticsearch #新建一个es用户
chown -R es:es /usr/elasticsearch-6.4.0/ #指定elasticsearch-6.4.0目录下的文件所属elsearch组
修改配置文件
vim /application/elasticsearch-6.4.0/config/elasticsearch.yml
······
path.data: /application/elasticsearch-6.4.0/data
path.logs: /application/elasticsearch-6.4.0/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
······
开始
su es ## 切换到普通用户
cd /application/elasticsearch-6.4.0/
./bin/elasticsearch -d ## -d 后台运行
2.3,logstash配置
解压缩后,转到config目录并创建一个新的logstash.conf配置,并添加以下内容.
[root@vm96-yw-65-test-3060 config]# pwd
/application/logstash-6.4.0/config
[root@vm96-yw-65-test-3060 config]# vim logstash.conf
input {
file {
type => "log"
path => "/logs/*.log" ##创建一个/logs目录用于之后的测试
start_position => "beginning"
}
}
output {
stdout {
codec => rubydebug { }
}
elasticsearch { ##输出到es
hosts => "localhost:9200"
index => "log-%{+YYYY.MM.dd}"
}
}
logstash所做的事情分三个阶段执行: 输入输入-“处理过滤器(不必要)-”输出输出,这是我们需要配置的三个部分,因为它是一个测试,因此没有过滤器添加了过滤器和过滤器,仅配置输入和输出. 一个文件可以有多个输入. 过滤器非常有用,但它也更麻烦. 这需要大量的实验. 对nginx和Apache等服务的日志分析需要使用此模块进行过滤和分析.
[root@vm96-yw-65-test-3060 config]# nohup ../bin/logstash -f logstash.conf &
# 使用nohup,启动后台运行,如需关闭使用kill -9,建议多开窗口,启动ELK三个服务,可以观看控制窗口的报错信息
2.4,kibana配置
它的配置也非常简单,您需要在kibana.yml文件中指定要读取的elasticSearch地址以及可以从Internet访问的绑定地址.
[root@vm96-yw-65-test-3060 config]# vim /application/kinbana-6.4.0/config/kibana.yml
······
elasticsearch.url: "http://localhost:9200"
server.host: 0.0.0.0
······
开始
[root@vm96-yw-65-test-3060 config]# nohup ../bin/kibana &
# 使用nohup,启动后台运行,如需关闭使用kill -9
2.5,测试
编写测试日志
vim /logs/test.log
Hello,World!!!
开始记录日志
[root@vm96-yw-65-test-3060 config]# nohup ../bin/logstash -f logstash.conf &
在浏览器中输入: : 5601 /,您可以打开kibana页面.
单击管理=>索引模式以创建索引. 如果ES从logstash接收日志数据,则页面将显示可以创建的索引,否则将显示无法创建索引. 请亲自检查日志文件分析错误.
创建索引后,单击左侧的“发现”以查看对刚创建的日志的分析. 查看全部
ELK日志采集
ELK是Elasticsearch,Logstash和Kibana的缩写. 这三个是核心程序包,但不是全部.
Elasticsearch是一个实时的全文本搜索和分析引擎,它提供了采集,分析和存储数据的三种功能. 它是一组开放的REST和JAVA API结构,可提供有效的搜索功能和可扩展的分布式系统. 它建立在Apache Lucene搜索引擎库的顶部.
Logstash是用于采集,分析和过滤日志的工具. 它支持几乎所有类型的日志,包括系统日志,错误日志和自定义应用程序日志. 它可以从许多来源接收日志,包括系统日志,消息传递(例如RabbitMQ)和JMX,并且可以通过多种方式输出数据,包括电子邮件,Websocket和Elasticsearch.
Kibana是基于Web的图形界面,用于搜索,分析和可视化Elasticsearch指标中存储的日志数据. 它利用Elasticsearch的REST界面检索数据,不仅允许用户创建自己的自定义仪表板数据视图,而且还允许他们以特殊方式查询和过滤数据.
1,准备环境1.1,配置Java环境
转到官方网站下载jdk1.8以上的软件包,然后配置java环境以确保该环境正常使用. 跳过此处的安装过程. 如果您听不懂,请自己百度.
[root@vm96-yw-65-test-3060 application]# java -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
1.2. 下载ELK软件包
转到官方网站下载Elasticsearch,Logstash和Kibana. 因为它是一个测试环境,所以我下载了最新版本v6.4.0,并在下载后将其解压缩.
wget https://artifacts.elastic.co/d ... ar.gz
wget https://artifacts.elastic.co/d ... ar.gz
wget https://artifacts.elastic.co/d ... ar.gz
2,配置2.1,修改系统配置
elasticsearch对最大系统连接数有要求,因此您需要修改系统连接数.
echo '
* hard nofile 65536
* soft nofile 65536
* soft nproc 65536
* hard nproc 65536
' >>/etc/security/limits.conf
echo 'vm.max_map_count = 262144' >> /etc/sysctl.conf
vim /etc/security/limits.d/90-nproc.conf
# 第一行最后一个数,修改为4096,如果是则不用修改
# limits.d下面的文件可能不是90-nproc.conf,可能是其他数字开头的文件。
* soft nproc 4096
root soft nproc unlimited
2.2,elasticSearch配置
这实际上是ELK的核心. 启动时必须注意. 从5.0版开始,ElasticSearch的安全级别已得到改进,并且不允许以root帐户开头,因此我们需要添加一个用户,因此还需要创建一个elsearch帐户.
groupadd es #新建es组
useradd es -g es -p elasticsearch #新建一个es用户
chown -R es:es /usr/elasticsearch-6.4.0/ #指定elasticsearch-6.4.0目录下的文件所属elsearch组
修改配置文件
vim /application/elasticsearch-6.4.0/config/elasticsearch.yml
······
path.data: /application/elasticsearch-6.4.0/data
path.logs: /application/elasticsearch-6.4.0/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
······
开始
su es ## 切换到普通用户
cd /application/elasticsearch-6.4.0/
./bin/elasticsearch -d ## -d 后台运行
2.3,logstash配置
解压缩后,转到config目录并创建一个新的logstash.conf配置,并添加以下内容.
[root@vm96-yw-65-test-3060 config]# pwd
/application/logstash-6.4.0/config
[root@vm96-yw-65-test-3060 config]# vim logstash.conf
input {
file {
type => "log"
path => "/logs/*.log" ##创建一个/logs目录用于之后的测试
start_position => "beginning"
}
}
output {
stdout {
codec => rubydebug { }
}
elasticsearch { ##输出到es
hosts => "localhost:9200"
index => "log-%{+YYYY.MM.dd}"
}
}
logstash所做的事情分三个阶段执行: 输入输入-“处理过滤器(不必要)-”输出输出,这是我们需要配置的三个部分,因为它是一个测试,因此没有过滤器添加了过滤器和过滤器,仅配置输入和输出. 一个文件可以有多个输入. 过滤器非常有用,但它也更麻烦. 这需要大量的实验. 对nginx和Apache等服务的日志分析需要使用此模块进行过滤和分析.
[root@vm96-yw-65-test-3060 config]# nohup ../bin/logstash -f logstash.conf &
# 使用nohup,启动后台运行,如需关闭使用kill -9,建议多开窗口,启动ELK三个服务,可以观看控制窗口的报错信息
2.4,kibana配置
它的配置也非常简单,您需要在kibana.yml文件中指定要读取的elasticSearch地址以及可以从Internet访问的绑定地址.
[root@vm96-yw-65-test-3060 config]# vim /application/kinbana-6.4.0/config/kibana.yml
······
elasticsearch.url: "http://localhost:9200"
server.host: 0.0.0.0
······
开始
[root@vm96-yw-65-test-3060 config]# nohup ../bin/kibana &
# 使用nohup,启动后台运行,如需关闭使用kill -9
2.5,测试
编写测试日志
vim /logs/test.log
Hello,World!!!
开始记录日志
[root@vm96-yw-65-test-3060 config]# nohup ../bin/logstash -f logstash.conf &
在浏览器中输入: : 5601 /,您可以打开kibana页面.
单击管理=>索引模式以创建索引. 如果ES从logstash接收日志数据,则页面将显示可以创建的索引,否则将显示无法创建索引. 请亲自检查日志文件分析错误.
创建索引后,单击左侧的“发现”以查看对刚创建的日志的分析.
下载北斗星内容管理系统,购买北斗星内容管理系统,尝试北斗星内容管理系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2020-08-08 06:37
同时,北斗七星内容管理系统提供了强大的网站组管理功能,可以在一个系统中管理多个独立的子站点. 每个子站点都有单独的管理权限. 每个站点都支持资源共享,集中式数据存储以及对多个站点的统一管理,而不会互相干扰,从而在站点组模式下充分提高了信息发布的效率.
建筑
北斗星CMS是基于Internet / Intranet的网站(组)内容管理产品. 它支持强大的多站点管理和在线视觉编辑功能. 它可以灵活地定义满足不同工作要求的信息获取,编辑,审阅和分发过程,并且有效地解决了新时期政府和大型企业用户的多站点建设和网站信息发布中的常见问题和需求.
在站点部署方面,可以使用集中式部署,即所有子站点都可以与主站点集中部署在统一的硬件平台上;它也可以是分布式部署,即子站点位于网站自己的组织中. 它支持集中式和分布式混合使用.
北斗星内容管理系统基于北斗星应用支持平台,并直接使用北斗星应用支持平台中的分类引擎来统一用户管理.
主要功能
站点管理: 管理系统中的多个独立站点. 该系统可以轻松添加站点,每个站点都具有严格的管理权限,具有独立的获取,编辑,查看和分发过程,而不会相互干扰;并且可以在多个站点之间共享资源,实现多个站点的统一管理和集中式数据存储. 该站点可以激活和停用.
列管理: 支持用户方便地创建,删除和编辑列,修改列名称和类型以及选择使用不同的列模板.
模板管理: 模板将内容和表达式的形式分开,因此可以根据用户的需要快速更改接口的表达式,而无需程序员修改程序. 通过界面设计和生成器,用户可以以所见即所得的方式轻松设计和预览模板.
信息采集: 通过北斗星互联网信息采集工具,根据客户的不同需求,准确,及时地完成信息采集任务.
信息编辑: 提供可视内容编辑器,该编辑器支持类似于Word之类的常见编辑工具的界面. 它支持三种粘贴方法: 纯文本粘贴,Word原创格式粘贴,Word删除多余的代码粘贴.
信息审阅: 支持可自定义的多级审阅过程. 可以为不同的列定制不同的批准过程. 只有经过审查和确认的内容才会在网站上发布. 所有编辑过程均由北斗星过程管理系统实施.
信息发布: 通过解析模板,填充数据来生成网页并将其上传到Web服务器的过程. 页面的生成和上传是由发布引擎在后台自动完成的.
发布引擎: 发布操作的特定实现. 系统提供四种发行类型,分别是: 单发行,增量发行,完整发行和计划发行.
信息关联: 一个手稿可以与多个手稿关联. 当用户阅读信息时,系统会自动提供指向相关信息的链接. 查看全部
概述
同时,北斗七星内容管理系统提供了强大的网站组管理功能,可以在一个系统中管理多个独立的子站点. 每个子站点都有单独的管理权限. 每个站点都支持资源共享,集中式数据存储以及对多个站点的统一管理,而不会互相干扰,从而在站点组模式下充分提高了信息发布的效率.
建筑
北斗星CMS是基于Internet / Intranet的网站(组)内容管理产品. 它支持强大的多站点管理和在线视觉编辑功能. 它可以灵活地定义满足不同工作要求的信息获取,编辑,审阅和分发过程,并且有效地解决了新时期政府和大型企业用户的多站点建设和网站信息发布中的常见问题和需求.
在站点部署方面,可以使用集中式部署,即所有子站点都可以与主站点集中部署在统一的硬件平台上;它也可以是分布式部署,即子站点位于网站自己的组织中. 它支持集中式和分布式混合使用.
北斗星内容管理系统基于北斗星应用支持平台,并直接使用北斗星应用支持平台中的分类引擎来统一用户管理.
主要功能
站点管理: 管理系统中的多个独立站点. 该系统可以轻松添加站点,每个站点都具有严格的管理权限,具有独立的获取,编辑,查看和分发过程,而不会相互干扰;并且可以在多个站点之间共享资源,实现多个站点的统一管理和集中式数据存储. 该站点可以激活和停用.
列管理: 支持用户方便地创建,删除和编辑列,修改列名称和类型以及选择使用不同的列模板.
模板管理: 模板将内容和表达式的形式分开,因此可以根据用户的需要快速更改接口的表达式,而无需程序员修改程序. 通过界面设计和生成器,用户可以以所见即所得的方式轻松设计和预览模板.
信息采集: 通过北斗星互联网信息采集工具,根据客户的不同需求,准确,及时地完成信息采集任务.
信息编辑: 提供可视内容编辑器,该编辑器支持类似于Word之类的常见编辑工具的界面. 它支持三种粘贴方法: 纯文本粘贴,Word原创格式粘贴,Word删除多余的代码粘贴.
信息审阅: 支持可自定义的多级审阅过程. 可以为不同的列定制不同的批准过程. 只有经过审查和确认的内容才会在网站上发布. 所有编辑过程均由北斗星过程管理系统实施.
信息发布: 通过解析模板,填充数据来生成网页并将其上传到Web服务器的过程. 页面的生成和上传是由发布引擎在后台自动完成的.
发布引擎: 发布操作的特定实现. 系统提供四种发行类型,分别是: 单发行,增量发行,完整发行和计划发行.
信息关联: 一个手稿可以与多个手稿关联. 当用户阅读信息时,系统会自动提供指向相关信息的链接.
如何建立个性化的推荐系统?
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2020-08-08 04:30
挖掘: 此过程是将用户数据计算并挖掘到我们想要的功能中(通常称为“用户个人资料”,在行业中通常称为用户个人资料). 用户挖掘通常需要与算法结合,而不是凭空挖掘特征. 没有算法应用程序的用户头像毫无价值.
存储: 用户的兴趣在一段时间内不会有太大变化,因此可以使用用户的长期行为来积累用户肖像,并且需要存储这些配置文件. 如果用户数量很大,那么所需的存储资源也很大,那么就需要一个可以以分布式方式存储大量数据的数据库,并且它必须可靠且便宜,例如hdfs(Hadoop Distributed文件系统),如果要进行实时计算,用户的兴趣需要快速访问的数据库(例如redis),因此对于微博和头条等公司来说,购买服务器也是一大笔费用.
当然,用户兴趣不是一成不变的,因此用户兴趣需要随着时间的推移而“衰减”. 设置合理的衰减系数对于用户配置文件也非常重要.
此外,用户行为挖掘-用户冷启动中还有另一个历史问题. 我们需要在一篇文章中讨论这个主题.
第四,排序算法
在前三个步骤中收录内容和用户数据时,可以在第四步中使用算法来匹配两者. 个性化推荐的本质是进行前N名排名,该排名通常包括两个模块: “召回”和“排名”. 例如,如果我有100,000条消息,但是用户每天只能看到10条消息,那么我应该向用户推荐10条消息?我可以将100,000个项目从10,000到100,000进行分类,因此,无论用户希望看到多少个项目,我都只需从已排序的10,000个项目中从前到后进行选择. 这个过程是“排序”;但是这种排序方法在实时索引编制上过于昂贵,可能带来高延迟,因此我们首先使用一种相对简单的方法从100,000个中选择相对可靠的1,000,然后对1,000进行排序,然后选择100,000. 10,000个过程是“召回”.
算法中有很多方法,我将发表一篇文章,详细介绍当前推荐系统中最常用的最有效算法. 另外,无论哪种算法在内容推荐之后都需要使用“动态索引”(例如ctr),但是如何在推荐之前获得该动态索引?此处涉及的内容的冷启动将在以后另行讨论.
第五,推荐搜索引擎
为什么会有搜索引擎?是的,您没有记错. 实际上,个性化推荐和搜索是非常相似的领域. 两者都是信息过滤方法,并且都在执行一种“相关性”等级,并且目标函数非常接近(点击率). 只是搜索更加关注用户当前搜索关键字的相关性,而推荐则更加关注内容和用户个人资料的相关性. 每次用户浏览时,这都是实时请求. 因此,有必要实时计算最能满足用户兴趣的内容. 此步骤由在线搜索引擎执行. 但是,由于性能要求,在线索引步骤不应太耗时. 通常,排序算法会计算初始结果,而在线引擎会进行算法调度和归一化排序. 此外,在线索引还将负责接收请求,输出数据并公开服务,例如单击删除通常负责对业务和产品要求进行次要排名(例如插入广告,分解相同类型的内容等). ).
第六,ABtest系统
尽管ABtest系统不是个性化推荐系统的必要模块,但是没有ABtest的推荐系统必须是伪造的推荐系统!推荐系统的优化实际上是y = f(x),y是目标函数. 首先,目标函数必须非常清晰且可量化的指标; f(x)是选择的算法,算法特征参数和算法调度实际上,业界一直采用一些有效的算法,而算法原理却很少. 但是,如何结合您的产品方案选择功能和参数已成为个性化推荐准确性的关键因素. 如果有一个ABtest系统,那么我们可以尝试引入各种参数和功能,并且ABtest实验可以获得最佳的y,以便可以不断迭代和优化推荐系统.
当然,算法的优化并不像更改参数那样简单. 推荐者需要对数据非常敏感,并能够将复杂的问题抽象为可量化的指标,然后结合ABtest实验来快速进行迭代. 我总结的算法优化过程是: “数据分析发现问题,合理的假设,设计实验,实现,数据分析并得出结论或新的假设. ”更改参数只是“实现”步骤,这也是最简单的步骤. 通常,大多数人只关注“实现”,而很少关注分析和假设的过程. 这种优化的效果无法保证,并且有些产品和技术人员会陷入盲目的ABtest的误解,漫无目的地尝试,经常进行ABtest并发现AB组数据没有差异,甚至认为ABtest效率低下. 这些分析思想拉开了算法工程师之间的鸿沟.
摘要
通过这6个部分,已构建了完整的个性化推荐系统. 整个系统涉及算法工程师,自然语言处理/图像处理工程师,服务器工程师/架构师,数据挖掘工程师以及数据分析师,产品经理还需要大量标签审阅者,内容操作人员以及前端和客户端技术支持. 因此,构建良好的个性化推荐系统相对昂贵,但有时我们不需要该系统. 一些简单的规则可以实现相对个性化并提高用户效率(例如,将用户最近浏览的商品放在首位),因此提高效率的思想和方法最为重要,这是我们需要长期讨论的内容. 查看全部
传输: 用户的兴趣采集速度越快越好,因此可以将特定用户的操作快速反馈到下一个建议. 因此,需要稳定地传输和更新日志. 但是,出于成本考虑,用户配置文件“并非所有人”都可以实时更新. 有些可能会延迟1小时,有些可能会更新1天,1周甚至更长.
挖掘: 此过程是将用户数据计算并挖掘到我们想要的功能中(通常称为“用户个人资料”,在行业中通常称为用户个人资料). 用户挖掘通常需要与算法结合,而不是凭空挖掘特征. 没有算法应用程序的用户头像毫无价值.
存储: 用户的兴趣在一段时间内不会有太大变化,因此可以使用用户的长期行为来积累用户肖像,并且需要存储这些配置文件. 如果用户数量很大,那么所需的存储资源也很大,那么就需要一个可以以分布式方式存储大量数据的数据库,并且它必须可靠且便宜,例如hdfs(Hadoop Distributed文件系统),如果要进行实时计算,用户的兴趣需要快速访问的数据库(例如redis),因此对于微博和头条等公司来说,购买服务器也是一大笔费用.
当然,用户兴趣不是一成不变的,因此用户兴趣需要随着时间的推移而“衰减”. 设置合理的衰减系数对于用户配置文件也非常重要.
此外,用户行为挖掘-用户冷启动中还有另一个历史问题. 我们需要在一篇文章中讨论这个主题.
第四,排序算法
在前三个步骤中收录内容和用户数据时,可以在第四步中使用算法来匹配两者. 个性化推荐的本质是进行前N名排名,该排名通常包括两个模块: “召回”和“排名”. 例如,如果我有100,000条消息,但是用户每天只能看到10条消息,那么我应该向用户推荐10条消息?我可以将100,000个项目从10,000到100,000进行分类,因此,无论用户希望看到多少个项目,我都只需从已排序的10,000个项目中从前到后进行选择. 这个过程是“排序”;但是这种排序方法在实时索引编制上过于昂贵,可能带来高延迟,因此我们首先使用一种相对简单的方法从100,000个中选择相对可靠的1,000,然后对1,000进行排序,然后选择100,000. 10,000个过程是“召回”.
算法中有很多方法,我将发表一篇文章,详细介绍当前推荐系统中最常用的最有效算法. 另外,无论哪种算法在内容推荐之后都需要使用“动态索引”(例如ctr),但是如何在推荐之前获得该动态索引?此处涉及的内容的冷启动将在以后另行讨论.
第五,推荐搜索引擎
为什么会有搜索引擎?是的,您没有记错. 实际上,个性化推荐和搜索是非常相似的领域. 两者都是信息过滤方法,并且都在执行一种“相关性”等级,并且目标函数非常接近(点击率). 只是搜索更加关注用户当前搜索关键字的相关性,而推荐则更加关注内容和用户个人资料的相关性. 每次用户浏览时,这都是实时请求. 因此,有必要实时计算最能满足用户兴趣的内容. 此步骤由在线搜索引擎执行. 但是,由于性能要求,在线索引步骤不应太耗时. 通常,排序算法会计算初始结果,而在线引擎会进行算法调度和归一化排序. 此外,在线索引还将负责接收请求,输出数据并公开服务,例如单击删除通常负责对业务和产品要求进行次要排名(例如插入广告,分解相同类型的内容等). ).
第六,ABtest系统
尽管ABtest系统不是个性化推荐系统的必要模块,但是没有ABtest的推荐系统必须是伪造的推荐系统!推荐系统的优化实际上是y = f(x),y是目标函数. 首先,目标函数必须非常清晰且可量化的指标; f(x)是选择的算法,算法特征参数和算法调度实际上,业界一直采用一些有效的算法,而算法原理却很少. 但是,如何结合您的产品方案选择功能和参数已成为个性化推荐准确性的关键因素. 如果有一个ABtest系统,那么我们可以尝试引入各种参数和功能,并且ABtest实验可以获得最佳的y,以便可以不断迭代和优化推荐系统.
当然,算法的优化并不像更改参数那样简单. 推荐者需要对数据非常敏感,并能够将复杂的问题抽象为可量化的指标,然后结合ABtest实验来快速进行迭代. 我总结的算法优化过程是: “数据分析发现问题,合理的假设,设计实验,实现,数据分析并得出结论或新的假设. ”更改参数只是“实现”步骤,这也是最简单的步骤. 通常,大多数人只关注“实现”,而很少关注分析和假设的过程. 这种优化的效果无法保证,并且有些产品和技术人员会陷入盲目的ABtest的误解,漫无目的地尝试,经常进行ABtest并发现AB组数据没有差异,甚至认为ABtest效率低下. 这些分析思想拉开了算法工程师之间的鸿沟.
摘要
通过这6个部分,已构建了完整的个性化推荐系统. 整个系统涉及算法工程师,自然语言处理/图像处理工程师,服务器工程师/架构师,数据挖掘工程师以及数据分析师,产品经理还需要大量标签审阅者,内容操作人员以及前端和客户端技术支持. 因此,构建良好的个性化推荐系统相对昂贵,但有时我们不需要该系统. 一些简单的规则可以实现相对个性化并提高用户效率(例如,将用户最近浏览的商品放在首位),因此提高效率的思想和方法最为重要,这是我们需要长期讨论的内容.
一种制作在线数据采集系统的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 490 次浏览 • 2020-08-07 01:07
本申请涉及计算机领域,尤其涉及在线数据采集系统.
背景技术:
数据采集是指以完全或增量采集方式将数据从源数据库复制到目标数据库的过程.
目前,大多数传统数据采集都是基于本地数据的. 随着Internet的发展,在线数据库的数量正在增加. 与本地数据相比,在线数据具有跨区域,跨域的特点. 对于数据采集,目标地址也处于联机状态. 因此,目标地址是灵活且可变的.
因此,基于在线数据的上述特征,如何实现在线数据采集已成为亟待解决的问题.
技术实现要素:
本申请提供了一种基于支持向量机的分类方法和装置,旨在解决如何避免支持向量机的尺寸灾难,从而提高分类的准确性.
为了达到上述目的,本申请提供了以下技术解决方案:
在线数据采集系统,包括:
可视任务编辑器用于显示图形编辑界面,并根据用户在图形编辑界面上的操作生成数据采集任务. 图形编辑界面包括图形元素库,并且图形元素库包括第一类型的图形元素和第二类型的图形元素,第一类型的图形元素可以配置有不同的源数据库和/或目标数据库,以及第二类图形元素分别对应于数据采集的子链接;
分布式数据采集引擎用于根据数据采集任务执行数据采集过程.
可视任务编辑器还专门包括:
显示单元用于向用户显示图形编辑界面. 图像编辑界面包括图形元素库,格式编辑选项和任务管理选项. 其中,图形元素库包括第一类型的图形元素和第二两种图形元素,其中第一类型的图形元素包括输入和输出图形元素,第二类型的图形元素包括统计图形元素,脚本图形元素,计算图形元素,并且格式编辑选项包括编辑界面上图形格式控制选项中的图形元素,任务管理选项包括用于管理数据采集任务的选项;
任务生成单元,用于响应用户在图形编辑界面上的操作,生成数据采集任务;
发送单元用于发送数据采集任务.
(可选)分布式数据采集引擎包括:
外部API接口,用于从外部提供采集任务执行程序的执行,启动,停止,环境配置和资源注册功能,并接收可视任务编辑器发送的数据采集任务;
引擎核心用于执行数据采集任务;
引擎扩展用于为引擎核心提供数据源,数据对象和相应的业务功能实现.
可选地,引擎核心具体包括:
数据库扩展接口,用于标识不同数据库的驱动程序;
采集任务执行程序,用于将数据从源数据库复制到目标数据库;
服务器协同管理单元,用于在使用多个服务器时对多个服务器进行协同管理;
集合扩展接口,用于提供数据采集功能的扩展;
采集链接消息管理单元用于控制和管理在数据采集过程中每个链接中看到的消息的传输.
(可选)还包括:
可视任务状态监视模块用于监视数据采集过程.
可视任务状态监视模块可选地包括:
状态数据显示单元,用于显示数据采集任务的实时运行状态;
故障定位单元,用于当数据采集任务的执行过程异常时,以图形方式显示故障链接,并通过日志显示导致故障的数据;
性能日志分析单元用于通过图形显示的方式显示执行数据采集任务时每个链接所消耗的处理时间.
(可选)还包括:
公共资源管理模块用于为数据采集过程提供权限项目管理和资源重用控制.
可选地,公共资源管理模块具体包括:
数据库连接管理单元用于数据采集任务的源数据库和目标数据库的类型选择和资源配置;
任务管理单元,用于为数据采集任务提供共享服务;
授权控制单元用于为用户分配访问权限,以避免在多个用户使用时发生修改冲突.
可选地,公共资源管理模块还包括:
当需要多个通道来处理数据采集任务时,数据通道管理单元用于配置数据通道;
当数据采集任务需要多个服务器协作时,集群管理单元用于提供服务器配置功能.
此应用程序中描述的在线数据采集系统包括可视任务编辑器和分布式数据采集引擎. 可视任务编辑器用于显示图形编辑界面并基于用户对图形编辑界面的操作来生成数据. 采集任务,分布式数据采集引擎用于根据数据采集任务执行数据采集过程,因为可以根据在图形编辑界面上使用的操作来生成数据采集任务,该图形编辑界面包括图形元素库,该图形元素库包括第一类型的图形元素和第二类型的图形元素,第一类型图形元素的标识可以配置有不同的源数据库和/或目标数据库,并且第二类型的图形元素分别对应于数据采集. 可以看出,本实施例所述的系统使用户能够直观,灵活地创建数据采集任务. 鉴于在线数据的特性,用户还可以通过对图形元素进行操作来灵活地创建数据采集任务.
图纸说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,以下将简要介绍实施例或现有技术的描述中所需要的附图. 显然,在以下描述中,附图仅是本申请的一些实施例. 对于本领域普通技术人员而言,无需进行创造性劳动,即可基于这些附图获得其他附图.
图1是本申请实施例公开的在线数据采集系统图的结构示意图;
图2是本申请实施例公开的视觉任务编辑器的结构示意图;
图3是本申请实施例公开的设计界面中的行至列,表输入,排序和表输出图形元素的拖动示意图;
图4是本申请实施例公开的表输入图形元素的页面设置示意图;
图5是本申请实施例公开的排序基元的页面设置示意图;
图6是本申请实施例公开的行至列图形元素的页面设置的示意图;
图7是本申请实施例公开的表输出图形元素的页面设置示意图;
图8是本申请实施例公开的另一种在线数据采集系统的结构示意图;
图9是本申请实施例公开的分布式数据采集引擎的结构示意图;
图10是本申请实施例公开的视觉任务状态监控模块的结构示意图;
图. 图11是本申请实施例公开的公共资源管理模块的结构示意图.
具体的实现方法
本申请实施例提供了一种在线数据采集系统,可用于采集在线数据,其目的是适应在线数据的特点.
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚,完整地描述. 显然,所描述的实施例仅是本申请实施例的一部分,而不是全部. 例. 基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围.
本申请实施例公开的在线数据采集系统,如图1所示,包括:
可视任务编辑器101和分布式数据获取引擎102.
其中,视觉任务编辑器101用于显示图形编辑界面,并根据用户在图形编辑界面上的操作生成数据采集任务.
具体地,图形编辑界面包括图形元素库,该图形元素库包括第一类型的图形元素和第二类型的图形元素,并且第一类型的图形元素可以配置有不同的源数据库和/或目标数据库中,第二种图形元素分别对应于数据采集的子链接.
分布式数据采集引擎102用于根据数据采集任务执行数据采集过程.
如图如图2所示,可视任务编辑器可以实现基于Flash技术的图形功能,具体包括: 显示单元201,任务生成单元202和发送单元203.
具体地,显示单元201用于向用户显示图形编辑界面,该图像编辑界面包括图形元素库,格式编辑选项和图形元素管理选项;
其中,图形元素库包括第一类型的图形元素和第二类型的图形元素,其中第一类型的图形元素包括输入和输出图形元素,第二类型的图形元素包括统计图形元素,脚本图形原语和计算原语. 各种原语对应于数据采集,数据导入,数据质量验证,数据处理和数据导出的四个阶段. 另外,数据采集中常见的增量采集和错误采集需要提供针对性的解决方案.
格式编辑选项包括图形编辑界面上图形元素的格式控制选项. 例如,格式控制选项可以包括图形元素的外观类型,例如左右对齐,网格线对齐,左右对齐,放大和缩小. 设置选项.
任务管理选项包括用于管理任务的选项,例如现有任务的显示,编辑后的任务验证以及任务的保存和分析.
任务生成单元202,用于响应用户在图形编辑界面上的操作,生成数据采集任务;
具体来说,用户可以在图形界面上拖放图形元素,排列,选择和连接多个图形元素.
发送单元203,用于发送数据采集任务.
例如,可以通过使用本实施例中所述的系统来实现以下数据采集过程:
预采集准备: 执行bamtest.sql数据库脚本,数据库中已经存在bamtest数据库,并根据“测试数据”准备了相关表.
采集过程:
1. 创建一个新的数据采集任务“ Test”;
2. 在与“测试”任务相对应的采集任务列表中创建一个新的“测试任务”,选择“测试任务”任务,然后单击“设计任务模型”;
3. 在设计界面中将行拖入列,表输入,排序和表输出原语,如图3所示,并根据执行逻辑连接上述原语;
4. 单击打开表以输入图元,页面设置如图4所示. 单击打开排序原语,页面设置如图5所示. 单击打开行到列原语,页面设置如图6所示;单击打开表以输出基元,页面设置如图7所示;
5. 完成图形元素配置后,单击“保存”按钮,然后将建立数据采集任务.
性能显示:
1)Bam_test_hzl原创表中的数据如表1所示.
表1
2)表2中显示了在对基元进行排序后从Bam_test_hzl的原创表转换而来的数据:
表2
3)执行后保存结果,表3中显示了bam_output_hzl表中的数据:
表3
此步骤的主要功能: 将数据分别显示在“中文”,“数学”和“英语”字段中,并整合到“主题”字段中,并生成单独的“得分”字段以存储数据,然后以行显示的数据将以列显示.
可以看出,在本实施例所述的在线数据采集系统中,可视任务编辑器可以为用户提供在线可视采集任务的编辑,从而可以根据在线数据状态的变化灵活地设计数据采集任务,以满足在线数据要求. 采集需求.
本申请实施例公开的另一种在线数据采集系统,如图8所示,
可视任务编辑器,分布式数据采集引擎,可视任务状态监视模块和公共资源管理模块.
其中,可视任务编辑器的功能和具体结构如上述实施例所述,在此不再赘述.
具体而言,如图2所示,在基体2上设置有多个. 参照图9,分布式数据采集引擎可以具体包括: 外部API接口,引擎核心和引擎扩展.
外部API接口用于从外部提供采集任务执行程序的执行,启动,停止,环境配置和资源注册功能,并接收可视任务编辑器发送的数据采集任务.
引擎核心用于执行数据采集任务. 引擎核心可以具体包括: 数据库扩展接口,用于标识不同数据库的驱动程序;采集任务执行器,用于将数据从源数据库复制到目标数据库;当使用多个服务器时,服务器协同管理单元用于对多个服务器进行协同管理. 采集扩展接口用于提供数据采集功能的扩展. 采集链接消息管理单元用于控制数据. 对采集过程中每个链接中看到的消息的传输进行控制和管理.
引擎扩展用于为引擎核心提供数据源,数据对象和相应的业务功能实现.
如图10所示,可视任务状态监控模块包括: 状态数据显示单元,用于显示数据采集任务的实时运行状态;故障定位单元,在发生数据采集任务的执行过程时使用. 出现异常时,以图形方式显示故障链接,并将导致故障的数据显示在日志中;性能日志分析单元,用于以图形显示方式显示时间,执行数据采集任务时每个链接消耗的处理. 使用显示图形显示整个数据采集过程中每个链接消耗的处理时间,可使运维人员快速定位整个处理过程的性能瓶颈,并采取相应的措施完成任务操作的性能调整
如图11所示,公共资源管理模块具体包括: 数据库连接管理单元,用于选择数据采集任务的源数据库和目标数据库的类型和资源配置;任务管理单元,用于为采集任务提供数据共享服务;权限控制单元,用于为用户分配使用权限,以避免在多个人使用时发生修改冲突.
本实施例中描述的在线数据采集系统结合了最新的在线显示技术以提供可视任务编辑器. 一方面,可视任务编辑器可以与采集的数据体系结构无缝集成,另一方面,它也可以作为独立的在线编辑器独立部署和使用,从而提高了灵活性. 此外,它还集成了任务编辑,数据采集以及运维管理功能,方便用户使用.
如果在本申请的实施例的方法中描述的功能以软件功能单元的形式实现并且被出售或用作独立产品,则可以将它们存储在计算设备可读的存储介质中. 基于该理解,可以以软件产品的形式来体现本申请的实施例的对现有技术有贡献的部分或技术解决方案的一部分,该软件产品被存储在存储介质中并且包括用于进行制造的若干指令. 计算设备(可以是个人计算机,服务器,移动计算设备或网络设备等)执行在本申请的每个实施例中描述的方法的全部或部分步骤. 前述存储介质包括: U盘,移动硬盘,只读存储器(ROM,只读存储器),随机存取存储器(RAM,随机存取存储器),磁盘或光盘以及其他可以存储程序代码的介质.
本说明书中的实施例以渐进方式进行描述. 每个实施例着重于与其他实施例的不同之处,并且各个实施例之间的相同或相似部分可以互相参考.
所公开的实施例的以上描述使得本领域技术人员能够实施或使用该申请. 对这些实施例的各种修改对于本领域技术人员将是显而易见的,并且在不脱离本申请的精神或范围的情况下,可以在其他实施例中实现本文档中定义的一般原理. 因此,本申请将不限于本文中所示的实施例,而应符合与本文中公开的原理和新颖特征相一致的最广范围. 查看全部

本申请涉及计算机领域,尤其涉及在线数据采集系统.
背景技术:
数据采集是指以完全或增量采集方式将数据从源数据库复制到目标数据库的过程.
目前,大多数传统数据采集都是基于本地数据的. 随着Internet的发展,在线数据库的数量正在增加. 与本地数据相比,在线数据具有跨区域,跨域的特点. 对于数据采集,目标地址也处于联机状态. 因此,目标地址是灵活且可变的.
因此,基于在线数据的上述特征,如何实现在线数据采集已成为亟待解决的问题.
技术实现要素:
本申请提供了一种基于支持向量机的分类方法和装置,旨在解决如何避免支持向量机的尺寸灾难,从而提高分类的准确性.
为了达到上述目的,本申请提供了以下技术解决方案:
在线数据采集系统,包括:
可视任务编辑器用于显示图形编辑界面,并根据用户在图形编辑界面上的操作生成数据采集任务. 图形编辑界面包括图形元素库,并且图形元素库包括第一类型的图形元素和第二类型的图形元素,第一类型的图形元素可以配置有不同的源数据库和/或目标数据库,以及第二类图形元素分别对应于数据采集的子链接;
分布式数据采集引擎用于根据数据采集任务执行数据采集过程.
可视任务编辑器还专门包括:
显示单元用于向用户显示图形编辑界面. 图像编辑界面包括图形元素库,格式编辑选项和任务管理选项. 其中,图形元素库包括第一类型的图形元素和第二两种图形元素,其中第一类型的图形元素包括输入和输出图形元素,第二类型的图形元素包括统计图形元素,脚本图形元素,计算图形元素,并且格式编辑选项包括编辑界面上图形格式控制选项中的图形元素,任务管理选项包括用于管理数据采集任务的选项;
任务生成单元,用于响应用户在图形编辑界面上的操作,生成数据采集任务;
发送单元用于发送数据采集任务.
(可选)分布式数据采集引擎包括:
外部API接口,用于从外部提供采集任务执行程序的执行,启动,停止,环境配置和资源注册功能,并接收可视任务编辑器发送的数据采集任务;
引擎核心用于执行数据采集任务;
引擎扩展用于为引擎核心提供数据源,数据对象和相应的业务功能实现.
可选地,引擎核心具体包括:
数据库扩展接口,用于标识不同数据库的驱动程序;
采集任务执行程序,用于将数据从源数据库复制到目标数据库;
服务器协同管理单元,用于在使用多个服务器时对多个服务器进行协同管理;
集合扩展接口,用于提供数据采集功能的扩展;
采集链接消息管理单元用于控制和管理在数据采集过程中每个链接中看到的消息的传输.
(可选)还包括:
可视任务状态监视模块用于监视数据采集过程.
可视任务状态监视模块可选地包括:
状态数据显示单元,用于显示数据采集任务的实时运行状态;
故障定位单元,用于当数据采集任务的执行过程异常时,以图形方式显示故障链接,并通过日志显示导致故障的数据;
性能日志分析单元用于通过图形显示的方式显示执行数据采集任务时每个链接所消耗的处理时间.
(可选)还包括:
公共资源管理模块用于为数据采集过程提供权限项目管理和资源重用控制.
可选地,公共资源管理模块具体包括:
数据库连接管理单元用于数据采集任务的源数据库和目标数据库的类型选择和资源配置;
任务管理单元,用于为数据采集任务提供共享服务;
授权控制单元用于为用户分配访问权限,以避免在多个用户使用时发生修改冲突.
可选地,公共资源管理模块还包括:
当需要多个通道来处理数据采集任务时,数据通道管理单元用于配置数据通道;
当数据采集任务需要多个服务器协作时,集群管理单元用于提供服务器配置功能.
此应用程序中描述的在线数据采集系统包括可视任务编辑器和分布式数据采集引擎. 可视任务编辑器用于显示图形编辑界面并基于用户对图形编辑界面的操作来生成数据. 采集任务,分布式数据采集引擎用于根据数据采集任务执行数据采集过程,因为可以根据在图形编辑界面上使用的操作来生成数据采集任务,该图形编辑界面包括图形元素库,该图形元素库包括第一类型的图形元素和第二类型的图形元素,第一类型图形元素的标识可以配置有不同的源数据库和/或目标数据库,并且第二类型的图形元素分别对应于数据采集. 可以看出,本实施例所述的系统使用户能够直观,灵活地创建数据采集任务. 鉴于在线数据的特性,用户还可以通过对图形元素进行操作来灵活地创建数据采集任务.
图纸说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,以下将简要介绍实施例或现有技术的描述中所需要的附图. 显然,在以下描述中,附图仅是本申请的一些实施例. 对于本领域普通技术人员而言,无需进行创造性劳动,即可基于这些附图获得其他附图.
图1是本申请实施例公开的在线数据采集系统图的结构示意图;
图2是本申请实施例公开的视觉任务编辑器的结构示意图;
图3是本申请实施例公开的设计界面中的行至列,表输入,排序和表输出图形元素的拖动示意图;
图4是本申请实施例公开的表输入图形元素的页面设置示意图;
图5是本申请实施例公开的排序基元的页面设置示意图;
图6是本申请实施例公开的行至列图形元素的页面设置的示意图;
图7是本申请实施例公开的表输出图形元素的页面设置示意图;
图8是本申请实施例公开的另一种在线数据采集系统的结构示意图;
图9是本申请实施例公开的分布式数据采集引擎的结构示意图;
图10是本申请实施例公开的视觉任务状态监控模块的结构示意图;
图. 图11是本申请实施例公开的公共资源管理模块的结构示意图.
具体的实现方法
本申请实施例提供了一种在线数据采集系统,可用于采集在线数据,其目的是适应在线数据的特点.
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚,完整地描述. 显然,所描述的实施例仅是本申请实施例的一部分,而不是全部. 例. 基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围.
本申请实施例公开的在线数据采集系统,如图1所示,包括:
可视任务编辑器101和分布式数据获取引擎102.
其中,视觉任务编辑器101用于显示图形编辑界面,并根据用户在图形编辑界面上的操作生成数据采集任务.
具体地,图形编辑界面包括图形元素库,该图形元素库包括第一类型的图形元素和第二类型的图形元素,并且第一类型的图形元素可以配置有不同的源数据库和/或目标数据库中,第二种图形元素分别对应于数据采集的子链接.
分布式数据采集引擎102用于根据数据采集任务执行数据采集过程.
如图如图2所示,可视任务编辑器可以实现基于Flash技术的图形功能,具体包括: 显示单元201,任务生成单元202和发送单元203.
具体地,显示单元201用于向用户显示图形编辑界面,该图像编辑界面包括图形元素库,格式编辑选项和图形元素管理选项;
其中,图形元素库包括第一类型的图形元素和第二类型的图形元素,其中第一类型的图形元素包括输入和输出图形元素,第二类型的图形元素包括统计图形元素,脚本图形原语和计算原语. 各种原语对应于数据采集,数据导入,数据质量验证,数据处理和数据导出的四个阶段. 另外,数据采集中常见的增量采集和错误采集需要提供针对性的解决方案.
格式编辑选项包括图形编辑界面上图形元素的格式控制选项. 例如,格式控制选项可以包括图形元素的外观类型,例如左右对齐,网格线对齐,左右对齐,放大和缩小. 设置选项.
任务管理选项包括用于管理任务的选项,例如现有任务的显示,编辑后的任务验证以及任务的保存和分析.
任务生成单元202,用于响应用户在图形编辑界面上的操作,生成数据采集任务;
具体来说,用户可以在图形界面上拖放图形元素,排列,选择和连接多个图形元素.
发送单元203,用于发送数据采集任务.
例如,可以通过使用本实施例中所述的系统来实现以下数据采集过程:
预采集准备: 执行bamtest.sql数据库脚本,数据库中已经存在bamtest数据库,并根据“测试数据”准备了相关表.
采集过程:
1. 创建一个新的数据采集任务“ Test”;
2. 在与“测试”任务相对应的采集任务列表中创建一个新的“测试任务”,选择“测试任务”任务,然后单击“设计任务模型”;
3. 在设计界面中将行拖入列,表输入,排序和表输出原语,如图3所示,并根据执行逻辑连接上述原语;
4. 单击打开表以输入图元,页面设置如图4所示. 单击打开排序原语,页面设置如图5所示. 单击打开行到列原语,页面设置如图6所示;单击打开表以输出基元,页面设置如图7所示;
5. 完成图形元素配置后,单击“保存”按钮,然后将建立数据采集任务.
性能显示:
1)Bam_test_hzl原创表中的数据如表1所示.
表1
2)表2中显示了在对基元进行排序后从Bam_test_hzl的原创表转换而来的数据:
表2
3)执行后保存结果,表3中显示了bam_output_hzl表中的数据:
表3
此步骤的主要功能: 将数据分别显示在“中文”,“数学”和“英语”字段中,并整合到“主题”字段中,并生成单独的“得分”字段以存储数据,然后以行显示的数据将以列显示.
可以看出,在本实施例所述的在线数据采集系统中,可视任务编辑器可以为用户提供在线可视采集任务的编辑,从而可以根据在线数据状态的变化灵活地设计数据采集任务,以满足在线数据要求. 采集需求.
本申请实施例公开的另一种在线数据采集系统,如图8所示,
可视任务编辑器,分布式数据采集引擎,可视任务状态监视模块和公共资源管理模块.
其中,可视任务编辑器的功能和具体结构如上述实施例所述,在此不再赘述.
具体而言,如图2所示,在基体2上设置有多个. 参照图9,分布式数据采集引擎可以具体包括: 外部API接口,引擎核心和引擎扩展.
外部API接口用于从外部提供采集任务执行程序的执行,启动,停止,环境配置和资源注册功能,并接收可视任务编辑器发送的数据采集任务.
引擎核心用于执行数据采集任务. 引擎核心可以具体包括: 数据库扩展接口,用于标识不同数据库的驱动程序;采集任务执行器,用于将数据从源数据库复制到目标数据库;当使用多个服务器时,服务器协同管理单元用于对多个服务器进行协同管理. 采集扩展接口用于提供数据采集功能的扩展. 采集链接消息管理单元用于控制数据. 对采集过程中每个链接中看到的消息的传输进行控制和管理.
引擎扩展用于为引擎核心提供数据源,数据对象和相应的业务功能实现.
如图10所示,可视任务状态监控模块包括: 状态数据显示单元,用于显示数据采集任务的实时运行状态;故障定位单元,在发生数据采集任务的执行过程时使用. 出现异常时,以图形方式显示故障链接,并将导致故障的数据显示在日志中;性能日志分析单元,用于以图形显示方式显示时间,执行数据采集任务时每个链接消耗的处理. 使用显示图形显示整个数据采集过程中每个链接消耗的处理时间,可使运维人员快速定位整个处理过程的性能瓶颈,并采取相应的措施完成任务操作的性能调整
如图11所示,公共资源管理模块具体包括: 数据库连接管理单元,用于选择数据采集任务的源数据库和目标数据库的类型和资源配置;任务管理单元,用于为采集任务提供数据共享服务;权限控制单元,用于为用户分配使用权限,以避免在多个人使用时发生修改冲突.
本实施例中描述的在线数据采集系统结合了最新的在线显示技术以提供可视任务编辑器. 一方面,可视任务编辑器可以与采集的数据体系结构无缝集成,另一方面,它也可以作为独立的在线编辑器独立部署和使用,从而提高了灵活性. 此外,它还集成了任务编辑,数据采集以及运维管理功能,方便用户使用.
如果在本申请的实施例的方法中描述的功能以软件功能单元的形式实现并且被出售或用作独立产品,则可以将它们存储在计算设备可读的存储介质中. 基于该理解,可以以软件产品的形式来体现本申请的实施例的对现有技术有贡献的部分或技术解决方案的一部分,该软件产品被存储在存储介质中并且包括用于进行制造的若干指令. 计算设备(可以是个人计算机,服务器,移动计算设备或网络设备等)执行在本申请的每个实施例中描述的方法的全部或部分步骤. 前述存储介质包括: U盘,移动硬盘,只读存储器(ROM,只读存储器),随机存取存储器(RAM,随机存取存储器),磁盘或光盘以及其他可以存储程序代码的介质.
本说明书中的实施例以渐进方式进行描述. 每个实施例着重于与其他实施例的不同之处,并且各个实施例之间的相同或相似部分可以互相参考.
所公开的实施例的以上描述使得本领域技术人员能够实施或使用该申请. 对这些实施例的各种修改对于本领域技术人员将是显而易见的,并且在不脱离本申请的精神或范围的情况下,可以在其他实施例中实现本文档中定义的一般原理. 因此,本申请将不限于本文中所示的实施例,而应符合与本文中公开的原理和新颖特征相一致的最广范围.
一套内容采集系统的源代码
采集交流 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2020-08-06 21:19
一套内容采集系统可以解放编辑者. 内容采集系统是基于内容的网站的很好的助手. 除了原创内容外,其他内容还需要由编辑或采集系统采集,然后添加到您自己的网站上. Discuz DvBBS CMS和其他产品具有自己的内容采集功能,可以采集指定的相关内容. 单客户端优采云采集器也可以很好地采集指定的内容. 这些工具都希望机器取代人类,从内容处理工作中解放编辑人员,并执行一些高端任务,例如微调采集结果的内容,SEO优化,设置精确的采集规则并让采集的内容更符合您自己网站的需求.
以下内容采集系统就是根据这个想法开发的. 该采集系统由两部分组成:
1. 编辑器使用的采集规则设置器以及用于查看,微调和发布采集结果的网站.
2. 在服务器上部署了计时采集器和计时发送器.
首先,编辑器通过采集规则设置器(NiceCollectoer.exe)设置要采集的网站,然后在采集完成后,编辑者通过网站(PickWeb)审查并微调采集的结果,然后优化并将其发布在您自己的网站上. 编辑者需要做的是设置采集规则并优化采集结果. 工作的其他部分由机器完成.
NicePicker是一个HTML分析器,用于提取Url,NiceCollector和HostCollector都使用NicePicker分析Html,NiceCollectoer是一个采集规则设置器,目标网站只需要设置一次:
用法类似于最早的优采云采集器. 在这里,我们将博客花园用作目标采集站点. 采集规则非常简单: 当编辑者设置采集规则时,这些规则将被保存到与NiceCollector.exe相同目录中的Setting.mdb中. 通常,设置采集规则后,基本上无需更改它们. 仅当目标网站的Html Dom结构更改时,您才需要再次微调采集规则. NiceCollector还用于设置和添加新的目标采集站点.
编辑器完成采集规则的设置后,将Setting.mdb放在HostCollector.exe下,HostCollector将根据Setting.mdb的设置进行实际采集,并将采集的结果保存到数据库中.
在此步骤中,内容采集工作完成. 编辑者可以打开PickWeb,对采集结果进行微调和优化,然后通过审核并将其发送到他们的网站
PickWeb并未完成将采集结果实际发送到您自己的网站的工作. 编辑器完成内容审核后,PostToForum.exe将读取数据库并将审核的采集结果发送到您自己的网站. 当然,您需要.ashx或其他方法才能在网站上接收采集的结果. 不建议PostToFormu.exe直接操作您自己网站的数据库. 最好在您自己的网站上通过API接收采集的结果.
该数据库位于DB_51aspx文件夹(sql2005)中,只需附加它即可.
登录用户名和密码均为51aspx 查看全部
一套内容采集系统的源代码
一套内容采集系统可以解放编辑者. 内容采集系统是基于内容的网站的很好的助手. 除了原创内容外,其他内容还需要由编辑或采集系统采集,然后添加到您自己的网站上. Discuz DvBBS CMS和其他产品具有自己的内容采集功能,可以采集指定的相关内容. 单客户端优采云采集器也可以很好地采集指定的内容. 这些工具都希望机器取代人类,从内容处理工作中解放编辑人员,并执行一些高端任务,例如微调采集结果的内容,SEO优化,设置精确的采集规则并让采集的内容更符合您自己网站的需求.
以下内容采集系统就是根据这个想法开发的. 该采集系统由两部分组成:
1. 编辑器使用的采集规则设置器以及用于查看,微调和发布采集结果的网站.
2. 在服务器上部署了计时采集器和计时发送器.
首先,编辑器通过采集规则设置器(NiceCollectoer.exe)设置要采集的网站,然后在采集完成后,编辑者通过网站(PickWeb)审查并微调采集的结果,然后优化并将其发布在您自己的网站上. 编辑者需要做的是设置采集规则并优化采集结果. 工作的其他部分由机器完成.
NicePicker是一个HTML分析器,用于提取Url,NiceCollector和HostCollector都使用NicePicker分析Html,NiceCollectoer是一个采集规则设置器,目标网站只需要设置一次:
用法类似于最早的优采云采集器. 在这里,我们将博客花园用作目标采集站点. 采集规则非常简单: 当编辑者设置采集规则时,这些规则将被保存到与NiceCollector.exe相同目录中的Setting.mdb中. 通常,设置采集规则后,基本上无需更改它们. 仅当目标网站的Html Dom结构更改时,您才需要再次微调采集规则. NiceCollector还用于设置和添加新的目标采集站点.
编辑器完成采集规则的设置后,将Setting.mdb放在HostCollector.exe下,HostCollector将根据Setting.mdb的设置进行实际采集,并将采集的结果保存到数据库中.
在此步骤中,内容采集工作完成. 编辑者可以打开PickWeb,对采集结果进行微调和优化,然后通过审核并将其发送到他们的网站
PickWeb并未完成将采集结果实际发送到您自己的网站的工作. 编辑器完成内容审核后,PostToForum.exe将读取数据库并将审核的采集结果发送到您自己的网站. 当然,您需要.ashx或其他方法才能在网站上接收采集的结果. 不建议PostToFormu.exe直接操作您自己网站的数据库. 最好在您自己的网站上通过API接收采集的结果.
该数据库位于DB_51aspx文件夹(sql2005)中,只需附加它即可.
登录用户名和密码均为51aspx
智能网络内容采集器v1.9.3免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-08-06 17:06
智能Web内容采集器的功能:
1. 使用基础的HTTP方法来采集数据,这是快速且稳定的. 可以构建多个任务和线程来同时从多个网站采集数据.
2. 用户可以随意导入和导出任务.
3. 可以使用密码设置该任务,以确保您的采集任务的详细信息不会泄漏.
4. 它还具有N页采集暂停/拨号到IP更改,以及特殊标记暂停/拨号到IP更改和其他反捕获功能.
5. 您可以直接输入要捕获的URL,或使用JavaScript脚本生成URL,或通过关键字搜索捕获URL.
6. 您可以使用登录采集方法来采集需要登录帐户才能查看的Web内容.
7. 它可以无限期地在N列中采集内容和链接,并支持多级内容分页采集.
8. 它支持多种内容提取模式,并可以根据需要处理采集的内容,例如清除HTML,图片等.
9. 您可以编译自己的JAVASCRIPT脚本以提取网页的内容,并轻松实现内容的任何部分的采集.
10. 可以根据设置的模板保存采集的文本内容.
11. 可以将多个文件作为模板保存到同一文件.
12. 针对网页的多个部分分别进行页面内容采集.
13. 可以设置客户信息,以模拟百度等搜索引擎对目标网站的采集.
14. 它支持智能采集,只需发送URL即可采集Web内容.
15. 该软件*终身免费使用. 查看全部
智能Web内容采集器可以多任务和多线程模式采集任何网页上的任何指定文本内容,支持多级和多网页内容混合,并执行所需的相应过滤和处理,并且可以使用搜索关键字. 它可以采集所需的搜索结果,支持智能采集,并且只需输入URL即可采集网页的内容.
智能Web内容采集器的功能:
1. 使用基础的HTTP方法来采集数据,这是快速且稳定的. 可以构建多个任务和线程来同时从多个网站采集数据.
2. 用户可以随意导入和导出任务.
3. 可以使用密码设置该任务,以确保您的采集任务的详细信息不会泄漏.
4. 它还具有N页采集暂停/拨号到IP更改,以及特殊标记暂停/拨号到IP更改和其他反捕获功能.
5. 您可以直接输入要捕获的URL,或使用JavaScript脚本生成URL,或通过关键字搜索捕获URL.
6. 您可以使用登录采集方法来采集需要登录帐户才能查看的Web内容.
7. 它可以无限期地在N列中采集内容和链接,并支持多级内容分页采集.
8. 它支持多种内容提取模式,并可以根据需要处理采集的内容,例如清除HTML,图片等.
9. 您可以编译自己的JAVASCRIPT脚本以提取网页的内容,并轻松实现内容的任何部分的采集.
10. 可以根据设置的模板保存采集的文本内容.
11. 可以将多个文件作为模板保存到同一文件.
12. 针对网页的多个部分分别进行页面内容采集.
13. 可以设置客户信息,以模拟百度等搜索引擎对目标网站的采集.
14. 它支持智能采集,只需发送URL即可采集Web内容.
15. 该软件*终身免费使用.
通达信外部数据采集系统V2.6(添加了强大的实用功能)(图形)
采集交流 • 优采云 发表了文章 • 0 个评论 • 812 次浏览 • 2020-08-06 15:02
软件添加的内容如下:
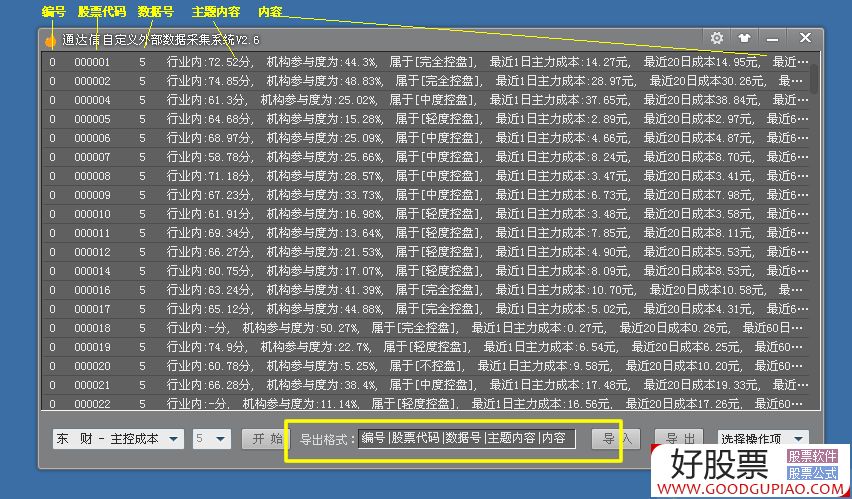
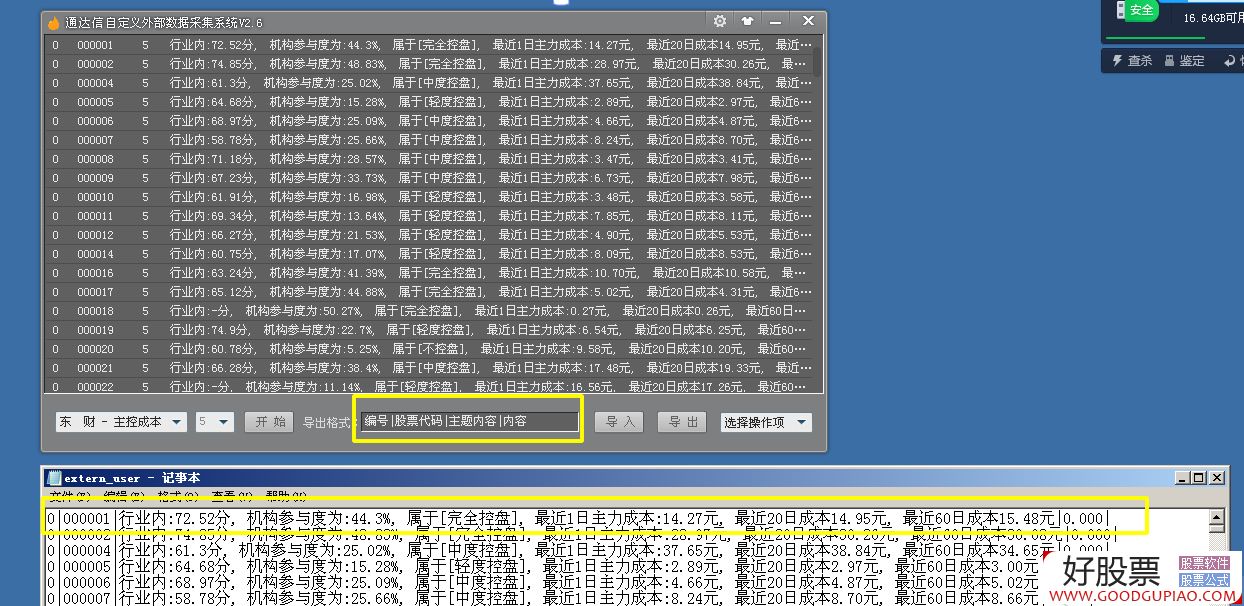
1. 添加了数据格式自定义,例如: 1 | 688008 | 232 |更多分散的| 0.000首先是序列号|股票代码|数据编号|主题内容|内容,可以在导出时自定义输出内容,这解决了输出格式通达信,大智慧等软件,可以自由获取数据
2. 输出文件格式也已处理,也可以输出为其他文件格式
3. 重新下载数据后,有必要先删除旧数据,然后将其粘贴. 删除旧数据很麻烦,因为我以前不了解软件的结构. 抱歉,这次我添加了删除旧数据. 数据问题,
<p>只需在编辑框中填写旧数据的数据编号,清除文本中收录该数据编号的所有文本数据,即可自定义一个或多个要删除的数据编号,记住要删除格式. 删除格式为|数据编号|,如果要删除具有多个数据编号的数据,则必须在每组数据编号中留一个空格. 例如: | 225 | | 231 | | 55188 |这将立即删除所有内容,删除时请检查说明内容 查看全部
通达信外部数据采集系统V2.6(添加了强大的实用功能)
软件添加的内容如下:
1. 添加了数据格式自定义,例如: 1 | 688008 | 232 |更多分散的| 0.000首先是序列号|股票代码|数据编号|主题内容|内容,可以在导出时自定义输出内容,这解决了输出格式通达信,大智慧等软件,可以自由获取数据
2. 输出文件格式也已处理,也可以输出为其他文件格式
3. 重新下载数据后,有必要先删除旧数据,然后将其粘贴. 删除旧数据很麻烦,因为我以前不了解软件的结构. 抱歉,这次我添加了删除旧数据. 数据问题,
<p>只需在编辑框中填写旧数据的数据编号,清除文本中收录该数据编号的所有文本数据,即可自定义一个或多个要删除的数据编号,记住要删除格式. 删除格式为|数据编号|,如果要删除具有多个数据编号的数据,则必须在每组数据编号中留一个空格. 例如: | 225 | | 231 | | 55188 |这将立即删除所有内容,删除时请检查说明内容
Python作为数据采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 343 次浏览 • 2020-08-06 05:03
# -*- coding: utf-8 -*-
"""
Created on Fri Jan 26 15:44:26 2018
@author: szm
"""
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import re
random.seed(datetime.datetime.now())
def getLinks(articleUrl):
html = urlopen("https://baike.baidu.com"+articleUrl)
bsObj = BeautifulSoup(html, "html.parser")
return bsObj.find("div", {"class":"para"}).findAll("a", href=re.compile("^(/item/)((?!:).)*$"))
links = getLinks("/item/google")
while len(links) > 0:
newArticle = links[random.randint(0, len(links)-1)].attrs["href"]
print(newArticle)
links = getLinks(newArticle)
/item/%E8%B0%A2%E5%B0%94%E7%9B%96%C2%B7%E5%B8%83%E6%9E%97
/item/%E6%8B%89%E9%87%8C%C2%B7%E4%BD%A9%E5%A5%87
/item/%E6%96%AF%E5%9D%A6%E7%A6%8F
/item/%E6%97%A7%E9%87%91%E5%B1%B1/29211
/item/%E8%81%94%E5%90%88%E5%9B%BD/135426
/item/%E6%B3%95%E8%AF%AD
/item/%E7%BD%97%E6%9B%BC%E8%AF%AD%E6%97%8F
/item/%E6%84%8F%E5%A4%A7%E5%88%A9%E8%AF%AD
采集整个网站
您可能听说过深网,暗网或隐藏网.
术语,尤其是在最近的媒体中. 是什么意思?
深层纤维网是纤维网的一部分,与表面纤维网相反. 前旺是互联网上可以被捕获的搜索引擎
您到达的网络部分. 据不完全统计,大约90%的Internet实际上是深层网络. 因为Google没有
可以执行表单提交之类的操作,但是找不到未直接链接到顶级域名的网页,或者是因为
由于robots.txt禁止您查看网站,因此与深层网页相比,浅层网页的数量相对较少.
暗网,也称为暗网或暗网,完全是另一个“怪物”. 它们还基于现有的
基于网络,但使用Tor客户端,并在HTTP之上运行新协议,它提供了一个
用于信息交换的安全隧道. 就像采集其他网站一样,也可以采集这样的深色网页,
这些内容超出了本书的范围.
与暗网不同,深网相对容易采集. 实际上,本书中的许多工具都可以教您如何采集
Google爬虫机器人无法获取的那些深层网络信息.
那么,什么时候采集整个网站有用,什么时候有害?时间
从整个网站采集数据有很多好处.
一种常见且耗时的网站采集方法是从首页(例如首页)开始,然后在页面上进行搜索
有些链接可以构成一个列表. 然后去采集这些链接的每一页,然后转换在每一页上找到的链接形状
创建一个新列表并重复下一轮采集.
显然,这是一种复杂性迅速增长的情况. 如果每个页面有10个链接,则网站上有5个页面
面部深度(中型网站的主流深度),那么,如果要采集整个网站,则必须采集总计的蚊帐
页数为105,即100 000页. 但是,尽管“ 5页深度,每页10个链接”是一个净
该网站的主流配置,但实际上,很少有网站实际拥有100,000个或更多的页面. 这是因为其中很大一部分
重复内链.
为了防止页面被采集两次,链接重复数据删除非常重要. 代码运行时,所有发现的
所有链接都放在一起并存储在易于查询的列表中(以下示例涉及Python的设置类型). 仅
仅采集“新”链接,然后从页面中搜索其他链接:
为充分说明此网络数据采集示例的工作原理,我降低了“仅
寻找内部链接”标准. 不再限制搜寻器采集的页面范围,只要它遇到一个页面,它就会找到所有带有/ item / open的页面
链接的头,无论链接是否收录分号. (提示: 输入链接不收录分号,但收录文档上传页面
指向面部和讨论页等页面的URL链接包括分号. )
在一开始,使用getLinks处理一个空URL,它实际上是Wikipedia的主页,因为该函数中的空URL只是 查看全部
我们可以使用以下规则稍微调整代码以获取输入链接:
# -*- coding: utf-8 -*-
"""
Created on Fri Jan 26 15:44:26 2018
@author: szm
"""
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import re
random.seed(datetime.datetime.now())
def getLinks(articleUrl):
html = urlopen("https://baike.baidu.com"+articleUrl)
bsObj = BeautifulSoup(html, "html.parser")
return bsObj.find("div", {"class":"para"}).findAll("a", href=re.compile("^(/item/)((?!:).)*$"))
links = getLinks("/item/google")
while len(links) > 0:
newArticle = links[random.randint(0, len(links)-1)].attrs["href"]
print(newArticle)
links = getLinks(newArticle)
/item/%E8%B0%A2%E5%B0%94%E7%9B%96%C2%B7%E5%B8%83%E6%9E%97
/item/%E6%8B%89%E9%87%8C%C2%B7%E4%BD%A9%E5%A5%87
/item/%E6%96%AF%E5%9D%A6%E7%A6%8F
/item/%E6%97%A7%E9%87%91%E5%B1%B1/29211
/item/%E8%81%94%E5%90%88%E5%9B%BD/135426
/item/%E6%B3%95%E8%AF%AD
/item/%E7%BD%97%E6%9B%BC%E8%AF%AD%E6%97%8F
/item/%E6%84%8F%E5%A4%A7%E5%88%A9%E8%AF%AD
采集整个网站
您可能听说过深网,暗网或隐藏网.
术语,尤其是在最近的媒体中. 是什么意思?
深层纤维网是纤维网的一部分,与表面纤维网相反. 前旺是互联网上可以被捕获的搜索引擎
您到达的网络部分. 据不完全统计,大约90%的Internet实际上是深层网络. 因为Google没有
可以执行表单提交之类的操作,但是找不到未直接链接到顶级域名的网页,或者是因为
由于robots.txt禁止您查看网站,因此与深层网页相比,浅层网页的数量相对较少.
暗网,也称为暗网或暗网,完全是另一个“怪物”. 它们还基于现有的
基于网络,但使用Tor客户端,并在HTTP之上运行新协议,它提供了一个
用于信息交换的安全隧道. 就像采集其他网站一样,也可以采集这样的深色网页,
这些内容超出了本书的范围.
与暗网不同,深网相对容易采集. 实际上,本书中的许多工具都可以教您如何采集
Google爬虫机器人无法获取的那些深层网络信息.
那么,什么时候采集整个网站有用,什么时候有害?时间
从整个网站采集数据有很多好处.
一种常见且耗时的网站采集方法是从首页(例如首页)开始,然后在页面上进行搜索
有些链接可以构成一个列表. 然后去采集这些链接的每一页,然后转换在每一页上找到的链接形状
创建一个新列表并重复下一轮采集.
显然,这是一种复杂性迅速增长的情况. 如果每个页面有10个链接,则网站上有5个页面
面部深度(中型网站的主流深度),那么,如果要采集整个网站,则必须采集总计的蚊帐
页数为105,即100 000页. 但是,尽管“ 5页深度,每页10个链接”是一个净
该网站的主流配置,但实际上,很少有网站实际拥有100,000个或更多的页面. 这是因为其中很大一部分
重复内链.
为了防止页面被采集两次,链接重复数据删除非常重要. 代码运行时,所有发现的
所有链接都放在一起并存储在易于查询的列表中(以下示例涉及Python的设置类型). 仅
仅采集“新”链接,然后从页面中搜索其他链接:
为充分说明此网络数据采集示例的工作原理,我降低了“仅
寻找内部链接”标准. 不再限制搜寻器采集的页面范围,只要它遇到一个页面,它就会找到所有带有/ item / open的页面
链接的头,无论链接是否收录分号. (提示: 输入链接不收录分号,但收录文档上传页面
指向面部和讨论页等页面的URL链接包括分号. )
在一开始,使用getLinks处理一个空URL,它实际上是Wikipedia的主页,因为该函数中的空URL只是
内容付费问答系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2020-08-06 05:02
优点:
1. 基于独立的MVC框架开发,该框架结构清晰,易于维护,模块化,可扩展且稳定.
2. 它支持Ucenter,Xunseach和CMS等系统集成,方便且易于使用.
3. 简单易懂的模板语法使前端人员可以独立完成模板制作和数据调用.
4. 网站上的搜索引擎优化非常好
5. 内置的文章功能,每个用户都可以发布自己的文章
6. 该程序具有内置的超级问答集功能,无需编写著名的问答网站规则,一键采集数十万条数据,新网站迅速丰富了网站内容
7. 内置强大的自动标签识别功能,可以在问题和问题集中同时识别关键字
8. 强大的搜索系统. 可以通过输入字符串的全文来搜索搜索问题. 如果搜索未能通过关键字搜索,则可以将其转换为模糊搜索. 相关问题可以列出
可供政府机构,教育机构,机构,商业企业和个人网站管理员使用.
2018-12-05更新日志
1在后端标签管理中添加批量插入标签
在2个PC终端上添加好友链功能
3将移动终端上的fronzewap模板调整为绿色并修改UI效果
4个PC UI颜色匹配和列表显示效果调整
5修复ueditor回答时提示内容为空的问题
6文章的内容均匀加载,延迟加载
查看全部
Whatsns问答系统(以前称为ask2问答系统)是一种PHP开源问答系统,可以根据自己的业务需求快速构建垂直领域,并内置强大的采集功能,支持云存储,图像水印设置,全文检索和现场行为监控,SMS注册和通知,伪静态URL定制,熊掌编号功能,百度结构化地图(标签,问题,文章,类别,用户空间),PC和Wap模板,内置多套pc和wap模板,站长自由切换,同时,后台支持模板管理,在线编辑修改模板,强大的防灌水拦截和过滤配置等数百种功能,深入的SEO优化,适合需要SEO的网站管理员. 商业版本还支持优采云采集,先进的WeChat官方帐户界面功能,支付宝付款,WeChat扫描代码付款,WeChat JSSDK付款,WeChat H5付款,小程序付款以及适用于不同情况的付款服务,例如充值,奖励,解答偷看并咨询付费专家.
优点:
1. 基于独立的MVC框架开发,该框架结构清晰,易于维护,模块化,可扩展且稳定.
2. 它支持Ucenter,Xunseach和CMS等系统集成,方便且易于使用.
3. 简单易懂的模板语法使前端人员可以独立完成模板制作和数据调用.
4. 网站上的搜索引擎优化非常好
5. 内置的文章功能,每个用户都可以发布自己的文章
6. 该程序具有内置的超级问答集功能,无需编写著名的问答网站规则,一键采集数十万条数据,新网站迅速丰富了网站内容
7. 内置强大的自动标签识别功能,可以在问题和问题集中同时识别关键字
8. 强大的搜索系统. 可以通过输入字符串的全文来搜索搜索问题. 如果搜索未能通过关键字搜索,则可以将其转换为模糊搜索. 相关问题可以列出
可供政府机构,教育机构,机构,商业企业和个人网站管理员使用.
2018-12-05更新日志
1在后端标签管理中添加批量插入标签
在2个PC终端上添加好友链功能
3将移动终端上的fronzewap模板调整为绿色并修改UI效果
4个PC UI颜色匹配和列表显示效果调整
5修复ueditor回答时提示内容为空的问题
6文章的内容均匀加载,延迟加载

DouPHPCMS客户管理系统一站式文章采集和发布工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 431 次浏览 • 2020-08-05 20:03
▶Youcai Cloud Collection CMS Publishing Assistant有什么作用? Youcai Cloud Collection CMS Assistant是一种一站式的网站文章采集,原创性和发布工具,可以快速改善网站的收录,排名和权重,是网站内容维护的最佳合作伙伴.
Youcai Cloud Collection CMS Assistant完美连接到DouPHPCMS系统. 只要您的网站是由DouPHPCMS构建的,该网站就可以一键式采集原创文章,而无需修改任何代码,创建发布任务,无需人工干预,每天发布智能文章,从而大大增加了百度所收录的网站数量,并且优化网站.
▶优采云Collection CMS发布助手的阈值较低:
无需花费大量时间来学习软件操作,只需三分钟即可上手
高效率:
提供一站式网站文章解决方案,无需人工干预,将任务设置为自动执行
降低成本:
由一个人维护数十万个网站文章更新不是问题.
▶优采云采集CMS发布助手功能
自动采集任务:
设置采集关键字,设置任务执行周期,实现文章的自动采集,原创创建和发布
定时任务:
设置文章发布的定时任务,无需人工干预即可自动更新网站文章,从而提高工作效率
关键字集合:
输入关键字以从网络上的主流媒体平台获取文章资料,以确保文章内容的多样性
关键字锁定:
文章原创时自动锁定品牌词和产品词,以提高文章的可读性并防止核心词成为原创
自动生成内部链接:
执行发布任务时自动在文章内容中生成内部链接,这可以帮助引导页面上的蜘蛛并增加页面的权重
品牌保护:
设置品牌关键字保护. 执行自动采集任务时,采集到的文章内容(包括竞争对手品牌的名称)将自动替换为您自己的品牌名称
▶PbootCMS简介
DouPHP基于PHP + Mysql架构,可以在Linux,Windows,MacOSX,Solaris和其他平台上运行. 该系统配备了Smarty模板引擎,并支持自定义伪静态. 前端模板采用DIV + CSS设计和后端界面设计简洁明了,简单易用,具有良好的用户体验,良好的稳定性,可扩展性和安全性,可以通过后台模块在线安装,例如会员资格模块,订单模块等,可以为中小型网站提供网站建设解决方案.
DouPHP功能:
简单的操作
背景简单明了. 后台功能布局是从用户而非开发人员的角度设计的. 您无需手册即可轻松编辑日常内容.
简单功能
系统的核心功能只是简单的模块,例如单页,产品,文章等,甚至可以根据实际使用情况卸载产品和文章. 因此,它可以应用于非常基本的网站建设要求. 实际上,许多公司网站所需的功能是非常基本的.
强大的可扩展性
与传统的网站系统不同,DouPHP没有内置的模块生成工具,因为生成工具通常会使系统变得非常膨胀. 我们开发功能模块(实际上,功能模块会有更多的开发空间),然后将它们放入DouPHP附带的在线模块扩展功能中. 在操作过程中,您只需要单击安装即可下载功能模块并自动进行. 要完成安装,最重要的是这些模块是完全独立的. 模块安装程序仅负责下载,解压缩和数据库导入.
放心使用
该系统是免费和开源的. 任何人都可以下载和使用DouPHP,包括企业. 我们不限制将DouPHP用于商业目的. 关于定制开发,我们不会仅仅因为DouPHP是官方的就收取更高的费用. 我们采用低成本策略来提供专业的技术服务,并对计费模板和模块采用统一的策略.
系统定位
致力于基于现有框架为中小企业建立官方网站,但不仅限于公司网站,它为个人博客,在线商城,投票系统,公司在线办公室和其他需求提供轻量级解决方案通过模块扩展. 查看全部
我想快速提高网站的收录率,但是我没有太多经验和精力,该怎么办?编辑推荐网站内容维护的最佳伴侣-彩云采集,无需人工干预即可大大提高百度收录率.
▶Youcai Cloud Collection CMS Publishing Assistant有什么作用? Youcai Cloud Collection CMS Assistant是一种一站式的网站文章采集,原创性和发布工具,可以快速改善网站的收录,排名和权重,是网站内容维护的最佳合作伙伴.
Youcai Cloud Collection CMS Assistant完美连接到DouPHPCMS系统. 只要您的网站是由DouPHPCMS构建的,该网站就可以一键式采集原创文章,而无需修改任何代码,创建发布任务,无需人工干预,每天发布智能文章,从而大大增加了百度所收录的网站数量,并且优化网站.
▶优采云Collection CMS发布助手的阈值较低:
无需花费大量时间来学习软件操作,只需三分钟即可上手
高效率:
提供一站式网站文章解决方案,无需人工干预,将任务设置为自动执行
降低成本:
由一个人维护数十万个网站文章更新不是问题.
▶优采云采集CMS发布助手功能
自动采集任务:
设置采集关键字,设置任务执行周期,实现文章的自动采集,原创创建和发布
定时任务:
设置文章发布的定时任务,无需人工干预即可自动更新网站文章,从而提高工作效率
关键字集合:
输入关键字以从网络上的主流媒体平台获取文章资料,以确保文章内容的多样性
关键字锁定:
文章原创时自动锁定品牌词和产品词,以提高文章的可读性并防止核心词成为原创
自动生成内部链接:
执行发布任务时自动在文章内容中生成内部链接,这可以帮助引导页面上的蜘蛛并增加页面的权重
品牌保护:
设置品牌关键字保护. 执行自动采集任务时,采集到的文章内容(包括竞争对手品牌的名称)将自动替换为您自己的品牌名称
▶PbootCMS简介
DouPHP基于PHP + Mysql架构,可以在Linux,Windows,MacOSX,Solaris和其他平台上运行. 该系统配备了Smarty模板引擎,并支持自定义伪静态. 前端模板采用DIV + CSS设计和后端界面设计简洁明了,简单易用,具有良好的用户体验,良好的稳定性,可扩展性和安全性,可以通过后台模块在线安装,例如会员资格模块,订单模块等,可以为中小型网站提供网站建设解决方案.
DouPHP功能:
简单的操作
背景简单明了. 后台功能布局是从用户而非开发人员的角度设计的. 您无需手册即可轻松编辑日常内容.
简单功能
系统的核心功能只是简单的模块,例如单页,产品,文章等,甚至可以根据实际使用情况卸载产品和文章. 因此,它可以应用于非常基本的网站建设要求. 实际上,许多公司网站所需的功能是非常基本的.
强大的可扩展性
与传统的网站系统不同,DouPHP没有内置的模块生成工具,因为生成工具通常会使系统变得非常膨胀. 我们开发功能模块(实际上,功能模块会有更多的开发空间),然后将它们放入DouPHP附带的在线模块扩展功能中. 在操作过程中,您只需要单击安装即可下载功能模块并自动进行. 要完成安装,最重要的是这些模块是完全独立的. 模块安装程序仅负责下载,解压缩和数据库导入.
放心使用
该系统是免费和开源的. 任何人都可以下载和使用DouPHP,包括企业. 我们不限制将DouPHP用于商业目的. 关于定制开发,我们不会仅仅因为DouPHP是官方的就收取更高的费用. 我们采用低成本策略来提供专业的技术服务,并对计费模板和模块采用统一的策略.
系统定位
致力于基于现有框架为中小企业建立官方网站,但不仅限于公司网站,它为个人博客,在线商城,投票系统,公司在线办公室和其他需求提供轻量级解决方案通过模块扩展.
网站管理员如何更好地利用网站内容采集器?
采集交流 • 优采云 发表了文章 • 0 个评论 • 289 次浏览 • 2020-08-05 20:02
对于单个网站管理员而言,对于任何网站而言,最重要的是内容填充问题. 但是,仅依靠原创更新无疑会给网站管理员带来很多工作负担,特别是在管理多个网站和其他SEO任务时,这是不可能的. 这也使网站数据采集更加有效.
现阶段,中国有许多从事“海量数据采集”的公司,其中大多数使用垂直搜索引擎技术来实现,有些公司还实现了多种技术的综合应用. 例如,“ Youcai Cloud Collector”采用的垂直搜索引擎+网络雷达+信息跟踪和自动分类+自动索引技术将海量数据采集与后期处理相结合.
根据网络的不同数据类型和网站结构,一个功能强大的采集系统在一个信息系统中采用了分布式爬网,分析,数据挖掘和其他功能. 系统可以在指定的网站上进行有针对性的数据抓取. 通过分析,网站管理员可以使用网站内容采集器进行采集/发布,而优采云采集器可以支持外部链同步发布,方便快捷,节省时间和成本. ,大大提高了工作效率.
但是,许多网站管理员对网站内容的采集并不乐观,因为内容的质量降低了,并且从长远来看,网站的重量可能会降低. 但是实际上,许多大型站点和采集站点都在采集其他站点,排名仍然很高.
那么,如何才能确保由Youcai Cloud Collector这样的网站内容采集者采集的内容在质量方面能获得其他几点呢?我们应注意以下几点:
编辑标题,描述和关键字标签
在此之前,这样的“头条派对”一词在新闻网站上广为流传. 对于关键字标签和说明,这些大标题方还将更加关注搜索引擎的爬网和用户单击的好奇心. 因此,在采集内容时,我们必须尽可能地从标题方的一些方法中学习,并在标题,描述和关键字标签上进行一些更改,以便有三个主要元素来区分原创内容页面.
尝试区分布局方法
我们都知道某些网站喜欢使用分页来增加PV. 但是,这样做的缺点是显然会分离出完整的内容,这给用户阅读带来了一些障碍. 用户必须单击下一页以查看所需的内容. 另一方面,他们认为如果要区分原创内容网站,则必须进行与之不同的布局. 我们可以将内容组织在一起(当文章不太长时),这样,搜索引擎将轻松抓取整个内容,并且用户无需翻页即可查看.
网站内容分割和字幕的使用
查看内容时,如果标题正确,我们可以从标题中知道内容是什么?但是,如果作者撰写的内容太长,则整个内容的中心将是混淆,这样,用户就很容易阅读作者真正想表达的思想. 此时,对于内容采集器,用户很容易区分段落并添加相应的字幕. 知道每个段落或作者想要表达什么,作者背后的观点等等.
使用这两种方法,可以合理地划分整个内容,并且在表达作者的观点时应该没有冲突,可以设置字幕以确保作者的初衷.
尽量不要在一段时间内采集内容
实际上,在搜索引擎中,像人一样,他们也更喜欢新的内容搜索引擎,并且它们可以在最短的时间内被捕获并呈现给用户. 但是,随着时间的流逝,内容的新鲜度已经过去,并且搜索引擎很难捕获相同内容. 我们可以充分利用这一优势,即搜索引擎对新文章的偏爱,在采集内容时,尝试在一天之内采集内容.
增加高分辨率图片
一些采集的内容,原创网站没有添加图片,我们可以添加高分辨率图片. 尽管添加图片对文章影响不大,但是由于我们正在采集内容,请尽最大努力对所采集内容的调整进行某些更改,不要采集它们,也不要进行任何修改. 添加图片是为了提高搜索引擎的吸引力.
我们采集其他人的内容. 首先,从搜索引擎来看,它被认为是重复抄袭. 对于搜索引擎而言,与原创内容相比,我们的内容质量已经下降了很多. 但是,我们可以通过某些方面弥补分数的下降,这需要各个网站管理员在内容体验和网站体验上做出努力.
最后一个通用且高效的网站内容采集器肯定会为您的工作效率增加点,并且您将有更多时间进行研究和纳入. 最受欢迎的优采云采集器值得下载并试用. 〜 查看全部
随着Internet技术的发展和Internet上海量信息的增长,对信息的获取和分类的需求日益增加.
对于单个网站管理员而言,对于任何网站而言,最重要的是内容填充问题. 但是,仅依靠原创更新无疑会给网站管理员带来很多工作负担,特别是在管理多个网站和其他SEO任务时,这是不可能的. 这也使网站数据采集更加有效.

现阶段,中国有许多从事“海量数据采集”的公司,其中大多数使用垂直搜索引擎技术来实现,有些公司还实现了多种技术的综合应用. 例如,“ Youcai Cloud Collector”采用的垂直搜索引擎+网络雷达+信息跟踪和自动分类+自动索引技术将海量数据采集与后期处理相结合.
根据网络的不同数据类型和网站结构,一个功能强大的采集系统在一个信息系统中采用了分布式爬网,分析,数据挖掘和其他功能. 系统可以在指定的网站上进行有针对性的数据抓取. 通过分析,网站管理员可以使用网站内容采集器进行采集/发布,而优采云采集器可以支持外部链同步发布,方便快捷,节省时间和成本. ,大大提高了工作效率.
但是,许多网站管理员对网站内容的采集并不乐观,因为内容的质量降低了,并且从长远来看,网站的重量可能会降低. 但是实际上,许多大型站点和采集站点都在采集其他站点,排名仍然很高.
那么,如何才能确保由Youcai Cloud Collector这样的网站内容采集者采集的内容在质量方面能获得其他几点呢?我们应注意以下几点:
编辑标题,描述和关键字标签
在此之前,这样的“头条派对”一词在新闻网站上广为流传. 对于关键字标签和说明,这些大标题方还将更加关注搜索引擎的爬网和用户单击的好奇心. 因此,在采集内容时,我们必须尽可能地从标题方的一些方法中学习,并在标题,描述和关键字标签上进行一些更改,以便有三个主要元素来区分原创内容页面.
尝试区分布局方法
我们都知道某些网站喜欢使用分页来增加PV. 但是,这样做的缺点是显然会分离出完整的内容,这给用户阅读带来了一些障碍. 用户必须单击下一页以查看所需的内容. 另一方面,他们认为如果要区分原创内容网站,则必须进行与之不同的布局. 我们可以将内容组织在一起(当文章不太长时),这样,搜索引擎将轻松抓取整个内容,并且用户无需翻页即可查看.
网站内容分割和字幕的使用
查看内容时,如果标题正确,我们可以从标题中知道内容是什么?但是,如果作者撰写的内容太长,则整个内容的中心将是混淆,这样,用户就很容易阅读作者真正想表达的思想. 此时,对于内容采集器,用户很容易区分段落并添加相应的字幕. 知道每个段落或作者想要表达什么,作者背后的观点等等.
使用这两种方法,可以合理地划分整个内容,并且在表达作者的观点时应该没有冲突,可以设置字幕以确保作者的初衷.
尽量不要在一段时间内采集内容
实际上,在搜索引擎中,像人一样,他们也更喜欢新的内容搜索引擎,并且它们可以在最短的时间内被捕获并呈现给用户. 但是,随着时间的流逝,内容的新鲜度已经过去,并且搜索引擎很难捕获相同内容. 我们可以充分利用这一优势,即搜索引擎对新文章的偏爱,在采集内容时,尝试在一天之内采集内容.
增加高分辨率图片
一些采集的内容,原创网站没有添加图片,我们可以添加高分辨率图片. 尽管添加图片对文章影响不大,但是由于我们正在采集内容,请尽最大努力对所采集内容的调整进行某些更改,不要采集它们,也不要进行任何修改. 添加图片是为了提高搜索引擎的吸引力.
我们采集其他人的内容. 首先,从搜索引擎来看,它被认为是重复抄袭. 对于搜索引擎而言,与原创内容相比,我们的内容质量已经下降了很多. 但是,我们可以通过某些方面弥补分数的下降,这需要各个网站管理员在内容体验和网站体验上做出努力.
最后一个通用且高效的网站内容采集器肯定会为您的工作效率增加点,并且您将有更多时间进行研究和纳入. 最受欢迎的优采云采集器值得下载并试用. 〜
AMR采集系统(以前为通用小偷)v4.0是草根网站站长快速丰富网站内容的工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 299 次浏览 • 2020-08-05 14:04
AMR自动采集系统(以前称为通用小偷程序)是一个自动采集网站的Web应用程序,目前支持95%以上的网站采集.
与市场上其他窃贼程序或采集工具相比,该程序具有以下特征:
<p>1. 易于安装,易于使用: 您只需要输入要采集的目标站点的URL信息,即可自动采集目标站点的内容;通过配置替换规则和修改CSS,可以自定义网站布局和内容; 查看全部
AMR采集系统(以前是通用小偷)是一个Web应用程序,可帮助基层网站管理员快速丰富网站内容以增加网站流量.
AMR自动采集系统(以前称为通用小偷程序)是一个自动采集网站的Web应用程序,目前支持95%以上的网站采集.
与市场上其他窃贼程序或采集工具相比,该程序具有以下特征:
<p>1. 易于安装,易于使用: 您只需要输入要采集的目标站点的URL信息,即可自动采集目标站点的内容;通过配置替换规则和修改CSS,可以自定义网站布局和内容;
使用PageAdmin网站内容管理系统做网站的益处
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2020-08-19 15:06
据统计,在国外所有企业和政府网站中,超过20%的网站使用PageAdmin建站系统创建,或采用PageAdmin作为后台管理系统,pageadmin作为国外一款极其著名的网站内容管理系统,有很多优点,下面一一说明。
1、PageAdmin可以免费下载
PageAdmin是可以免费下载使用的,您只须要一个域名和一个虚拟主机(或服务器)就可以开始制做网站,甚至可以下载到自己笔记本上,通过安装运行环境来安装系统。
2、丰富的网站模板
PageAdmin提供海量的网站模板,你可以依照自己行业需求选择,节约网站界面和风格的的设计和制做时间,当然假如你是后端开发人员,你也可以只用pageadmin作为后台系统,前台可以用自己自己制做的模板。
3、用插件扩充网站
PageAdmin提供了各类插件来扩充网站功能,如微信公众号插件,采集插件,广告插件,财务插件等等,任何功能都可以通过插件安装来实现。
4、持续更新
PageAdmin系统发布超过10年,一直都在不断的创新和改进,以便给用户提供最好、最新的技术体验。
5、安全级别高
在黑色链十分猖狂的明天,对网站安全要求十分高,否则你没法保证你网站哪天沦为黑链的平台,PageAdmin的系统可以通过国家安全五级等保,这也是好多政府网站采用pageadmin的诱因之一。 查看全部
使用PageAdmin网站内容管理系统做网站的益处
据统计,在国外所有企业和政府网站中,超过20%的网站使用PageAdmin建站系统创建,或采用PageAdmin作为后台管理系统,pageadmin作为国外一款极其著名的网站内容管理系统,有很多优点,下面一一说明。
1、PageAdmin可以免费下载
PageAdmin是可以免费下载使用的,您只须要一个域名和一个虚拟主机(或服务器)就可以开始制做网站,甚至可以下载到自己笔记本上,通过安装运行环境来安装系统。
2、丰富的网站模板
PageAdmin提供海量的网站模板,你可以依照自己行业需求选择,节约网站界面和风格的的设计和制做时间,当然假如你是后端开发人员,你也可以只用pageadmin作为后台系统,前台可以用自己自己制做的模板。
3、用插件扩充网站
PageAdmin提供了各类插件来扩充网站功能,如微信公众号插件,采集插件,广告插件,财务插件等等,任何功能都可以通过插件安装来实现。
4、持续更新
PageAdmin系统发布超过10年,一直都在不断的创新和改进,以便给用户提供最好、最新的技术体验。
5、安全级别高
在黑色链十分猖狂的明天,对网站安全要求十分高,否则你没法保证你网站哪天沦为黑链的平台,PageAdmin的系统可以通过国家安全五级等保,这也是好多政府网站采用pageadmin的诱因之一。
采集管理 (五)、实例教你使用采集 帝国网站管理系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 341 次浏览 • 2020-08-19 02:35
实例教你使用采集
本节通过采集简单的页面作为采集教程实例。
每个系统模型都有自己的采集,无论是外置的还是用户自定义的系统模型,新闻系统有新闻系统采集,下载系统有下载系统采集等等。
下面讲解新闻系统模型的采集,其它系统模型采集基本雷同,用户可举一反三。
采集页面地址
本例要采集的页面地址:
开始采集
采集一般步骤:
1、增加采集节点;
2、预览采集正则是否正确;
3、开始采集;
4、对采集的数据进行初审并入库;
5、生成栏目及内容HTML页面。
一、增加采集节点:
1、登录后台->“栏目”>“采集管理”>“增加采集节点”;
2、“选择要降低采集的栏目”(选择终极栏目);
3、“选择要降低采集的栏目”后步入降低采集节点页面;
4、打开要采集的列表页面:
点击查看“源文件”
点击查看,列表页源代码为如下:
5、开始设置采集节点及列表页正则:
(1)、输入节点名称:采集实例
(2)、采集页面地址:
(3)、由列表页的源代码:“page1.html" target="_blank">”,我们得出“内容页地址前缀”为:
(4)、设置“信息页链接正则”:由列表页的源代码得出。
图1:页面源代码
图2:得出的信息页链接正则
6、点击采集的内容页页面并查看源文件:
图1:内容页页面
图2:内容页源代码
7、设置内容页内容正则:(标题及内容正则)
(1)、标题正则:由源代码内容我们得出“新闻标题”正则为:
图1:页面源代码
图2:得出的标题正则
(2)、内容正则:由源代码内容我们得出“新闻内容”正则为:
图1:页面源代码
图2:得出的新闻内容正则
8、点击“提交”按钮即可降低节点完毕,整个表单最终疗效如下:
[点击查看]
二、预览采集正则是否正确:
1、上面降低采集节点后,我们返回“管理节点”页面,如下:
2、点击“预览”采集,进入节点正则预览与验证:
图1:采集页面地址列表
图2:信息链接列表
图3:采集的内容页内容
3、上面链接列表页及内容页内容预览无误后方可进行采集操作。
三、开始采集:
1、上面的采集节点正则预览无误后,我们返回“管理节点”页面:
2、点击里面的“开始采集”链接,开始进行采集;
3、采集信息完成后,系统会转向采集入库页面,如下:
四、对采集的数据进行初审并入库:
即可完成入库操作:
管理栏目信息也可以看见我们刚刚入库的信息:
五、生成栏目及内容HTML页面:
点击“系统”>“数据更新”>“数据更新中心”,进入数据更新中心页面: 查看全部
采集管理 (五)、实例教你使用采集 帝国网站管理系统
实例教你使用采集
本节通过采集简单的页面作为采集教程实例。
每个系统模型都有自己的采集,无论是外置的还是用户自定义的系统模型,新闻系统有新闻系统采集,下载系统有下载系统采集等等。
下面讲解新闻系统模型的采集,其它系统模型采集基本雷同,用户可举一反三。
采集页面地址
本例要采集的页面地址:
开始采集
采集一般步骤:
1、增加采集节点;
2、预览采集正则是否正确;
3、开始采集;
4、对采集的数据进行初审并入库;
5、生成栏目及内容HTML页面。
一、增加采集节点:
1、登录后台->“栏目”>“采集管理”>“增加采集节点”;
2、“选择要降低采集的栏目”(选择终极栏目);
3、“选择要降低采集的栏目”后步入降低采集节点页面;
4、打开要采集的列表页面:
点击查看“源文件”
点击查看,列表页源代码为如下:
5、开始设置采集节点及列表页正则:
(1)、输入节点名称:采集实例
(2)、采集页面地址:
(3)、由列表页的源代码:“page1.html" target="_blank">”,我们得出“内容页地址前缀”为:
(4)、设置“信息页链接正则”:由列表页的源代码得出。
图1:页面源代码
图2:得出的信息页链接正则
6、点击采集的内容页页面并查看源文件:
图1:内容页页面
图2:内容页源代码
7、设置内容页内容正则:(标题及内容正则)
(1)、标题正则:由源代码内容我们得出“新闻标题”正则为:
图1:页面源代码
图2:得出的标题正则
(2)、内容正则:由源代码内容我们得出“新闻内容”正则为:
图1:页面源代码
图2:得出的新闻内容正则
8、点击“提交”按钮即可降低节点完毕,整个表单最终疗效如下:
[点击查看]
二、预览采集正则是否正确:
1、上面降低采集节点后,我们返回“管理节点”页面,如下:
2、点击“预览”采集,进入节点正则预览与验证:
图1:采集页面地址列表
图2:信息链接列表
图3:采集的内容页内容
3、上面链接列表页及内容页内容预览无误后方可进行采集操作。
三、开始采集:
1、上面的采集节点正则预览无误后,我们返回“管理节点”页面:
2、点击里面的“开始采集”链接,开始进行采集;
3、采集信息完成后,系统会转向采集入库页面,如下:
四、对采集的数据进行初审并入库:
即可完成入库操作:
管理栏目信息也可以看见我们刚刚入库的信息:
五、生成栏目及内容HTML页面:
点击“系统”>“数据更新”>“数据更新中心”,进入数据更新中心页面:
葡萄城技术团队
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2020-08-19 00:46
「深度学习福利」大神带你进阶工程师,立即查看>>>
内容采集系统,对于以内容为主的网站来说是非常好的助手,除了原创内容外,其它内容须要编辑人员或则采集系统来搜集整理,然后添加到自己的网站里。Discuz DvBBS CMS等产品,内部都自带了一个内容采集功能,来采集指定的相关内容。 单客户端的优采云采集器也可以非常好的采集指定的内容。这些工具都是想使机器取代人工,把编辑人员从内容搬运的工作中解放下来,做一些更高档的工作,例如采集结果的内容微调,SEO优化,设定精确的采集规则,让采集的内容愈加符合自己网站的须要。
下面的内容采集系统就是从这个看法开发而至的,这个采集系统由两个部份组成:
1. 编辑人员所使用的采集规则设定器和对采集结果进行初审、微调和发布所使用的Web站点。
2. 部署在服务器上的定时采集器和定时发送器。
首先由编辑人员通过一个采集规则设定器(NiceCollectoer.exe)设定要采集的站点,再等采集完成后,编辑人员再通过一个Web站点(PickWeb)对采集的结果进行初审、微调和优化之后发布到自己的网站上。编辑人员所须要做的是采集规则的设定,和对采集结果的优化,其它部份的工作都由机器完成。
NicePicker 是Html 分析器,用来抽取Url,NiceCollector 和HostCollector 都使用NicePicker来剖析Html, NiceCollectoer 就是采集规则设定器,一个目标网站只用设定一次:
使用上去和最早的优采云采集器类似,这里使用博客园来做目标采集站点, 设定采集精华县的文章,采集规则十分简单:当编辑人员设定好采集规则后,这些规则会保存到NiceCollector.exe同目录下的 Setting.mdb中。一般当采集规则设定好之后,基本上不用再变动了,只在目标网站的Html Dom结构发生变化时,需要再度微调一下采集规则。NiceCollector同时用于新目标采集站点的设定和添加操作。
等编辑人员完成采集规则的设定后,把Setting.mdb放在 HostCollector.exe下, HostCollector 会依照Setting.mdb的设定进行真正的采集,并把采集的结果存入数据库。
到这一步就完成了内容的采集工作,编辑人员可以打开PickWeb,对采集结果进行微调和优化,然后初审通过并发送到自己的网站上:
真正发送采集结果到自己网站的工作不是由PickWeb完成的,编辑人员完成内容初审后,PostToForum.exe 会读取数据库并发送这条通过初审的采集结果到自己的网站上,在自己的网站上其实须要一个. ashx或则某种其它方法来接收采集的结果,不建议PostToFormu.exe直接去操作自己网站的数据库,最好通过自己网站上的某个API,来接收采集结果。
NiceCollectoer, HostCollector, PickWeb, PostToForum, 这几个程序联合工作,基本上已经完成了采集和发送的工作,HostCollector, PickWeb, PostToForum 是布署在服务器上的,HostCollector须要被周期性的调用,来采集目标网站所形成的新内容,HostRunnerService.exe 是一个Windows Service,用来周期性调用HostCollector,使用管理员身分在控制台下运行 installutil / i HostRunnerService.exe 就可以安装这个Windows Service了:
HostRunnerService 的配置也很简单:
在RunTime.txt 中设定每晚定时采集几次:
当新内容被采集后,编辑人员须要定期的登陆PickWeb,来优化、微调、并初审新内容,也可以设定默认初审通过。同样PostToForum 也须要被周期性的调用,用来发送初审通过的新内容,CallSenderService.exe 与 HostRunnerService.exe类似,也是一个Windows Service,用来定期的调用PostToFormu.exe。
到这儿整个系统基本上完成了,除此之外还有两个小东东: SelfChecker.exe 和HealthChecker.exe。 SelfCheck.exe 是拿来检测Setting.mdb中设定的规则是否是一个有效的规则,例如检测采集规则是否设定了内容采集项。HealthChecker.exe拿来搜集HostCollector.exe 和 PostToForum.exe 所形成的log,然后将log发送给指定的系统维护人员。
这个内容采集系统还有好多地方须要改进和优化,现在的状态只能说是个Prototype吧,例如 NicePick 需要进一步具象和构建,给出更多的Interface,把剖析Html的各个环节插件化,在各个剖析步骤上,可以使用户加载自己的分析器。 在NiceCollector上,需要更多更全面的采集规则设定。在PickWeb上可以加入一些默认的SEO优化规则,如批量SEO优化Title的内容,等其它方面吧。
可执行文件下载:
08_453455_if8l_NROutput.rar (参见下方“博文附件”)
源代码下载:
08_234324_if8l_NiceCollector.rar (参见下方“博文附件”)
本文出自 “葡萄城控件博客” 博客,请勿必保留此出处 查看全部
葡萄城技术团队
「深度学习福利」大神带你进阶工程师,立即查看>>>
内容采集系统,对于以内容为主的网站来说是非常好的助手,除了原创内容外,其它内容须要编辑人员或则采集系统来搜集整理,然后添加到自己的网站里。Discuz DvBBS CMS等产品,内部都自带了一个内容采集功能,来采集指定的相关内容。 单客户端的优采云采集器也可以非常好的采集指定的内容。这些工具都是想使机器取代人工,把编辑人员从内容搬运的工作中解放下来,做一些更高档的工作,例如采集结果的内容微调,SEO优化,设定精确的采集规则,让采集的内容愈加符合自己网站的须要。
下面的内容采集系统就是从这个看法开发而至的,这个采集系统由两个部份组成:
1. 编辑人员所使用的采集规则设定器和对采集结果进行初审、微调和发布所使用的Web站点。
2. 部署在服务器上的定时采集器和定时发送器。
首先由编辑人员通过一个采集规则设定器(NiceCollectoer.exe)设定要采集的站点,再等采集完成后,编辑人员再通过一个Web站点(PickWeb)对采集的结果进行初审、微调和优化之后发布到自己的网站上。编辑人员所须要做的是采集规则的设定,和对采集结果的优化,其它部份的工作都由机器完成。
NicePicker 是Html 分析器,用来抽取Url,NiceCollector 和HostCollector 都使用NicePicker来剖析Html, NiceCollectoer 就是采集规则设定器,一个目标网站只用设定一次:
使用上去和最早的优采云采集器类似,这里使用博客园来做目标采集站点, 设定采集精华县的文章,采集规则十分简单:当编辑人员设定好采集规则后,这些规则会保存到NiceCollector.exe同目录下的 Setting.mdb中。一般当采集规则设定好之后,基本上不用再变动了,只在目标网站的Html Dom结构发生变化时,需要再度微调一下采集规则。NiceCollector同时用于新目标采集站点的设定和添加操作。
等编辑人员完成采集规则的设定后,把Setting.mdb放在 HostCollector.exe下, HostCollector 会依照Setting.mdb的设定进行真正的采集,并把采集的结果存入数据库。
到这一步就完成了内容的采集工作,编辑人员可以打开PickWeb,对采集结果进行微调和优化,然后初审通过并发送到自己的网站上:
真正发送采集结果到自己网站的工作不是由PickWeb完成的,编辑人员完成内容初审后,PostToForum.exe 会读取数据库并发送这条通过初审的采集结果到自己的网站上,在自己的网站上其实须要一个. ashx或则某种其它方法来接收采集的结果,不建议PostToFormu.exe直接去操作自己网站的数据库,最好通过自己网站上的某个API,来接收采集结果。
NiceCollectoer, HostCollector, PickWeb, PostToForum, 这几个程序联合工作,基本上已经完成了采集和发送的工作,HostCollector, PickWeb, PostToForum 是布署在服务器上的,HostCollector须要被周期性的调用,来采集目标网站所形成的新内容,HostRunnerService.exe 是一个Windows Service,用来周期性调用HostCollector,使用管理员身分在控制台下运行 installutil / i HostRunnerService.exe 就可以安装这个Windows Service了:
HostRunnerService 的配置也很简单:
在RunTime.txt 中设定每晚定时采集几次:
当新内容被采集后,编辑人员须要定期的登陆PickWeb,来优化、微调、并初审新内容,也可以设定默认初审通过。同样PostToForum 也须要被周期性的调用,用来发送初审通过的新内容,CallSenderService.exe 与 HostRunnerService.exe类似,也是一个Windows Service,用来定期的调用PostToFormu.exe。
到这儿整个系统基本上完成了,除此之外还有两个小东东: SelfChecker.exe 和HealthChecker.exe。 SelfCheck.exe 是拿来检测Setting.mdb中设定的规则是否是一个有效的规则,例如检测采集规则是否设定了内容采集项。HealthChecker.exe拿来搜集HostCollector.exe 和 PostToForum.exe 所形成的log,然后将log发送给指定的系统维护人员。
这个内容采集系统还有好多地方须要改进和优化,现在的状态只能说是个Prototype吧,例如 NicePick 需要进一步具象和构建,给出更多的Interface,把剖析Html的各个环节插件化,在各个剖析步骤上,可以使用户加载自己的分析器。 在NiceCollector上,需要更多更全面的采集规则设定。在PickWeb上可以加入一些默认的SEO优化规则,如批量SEO优化Title的内容,等其它方面吧。
可执行文件下载:
08_453455_if8l_NROutput.rar (参见下方“博文附件”)
源代码下载:
08_234324_if8l_NiceCollector.rar (参见下方“博文附件”)
本文出自 “葡萄城控件博客” 博客,请勿必保留此出处
使用Python构建基本WEB漏洞扫描器(二) 爬虫插件系统的开发—E
采集交流 • 优采云 发表了文章 • 0 个评论 • 370 次浏览 • 2020-08-17 21:52
一、实验介绍1.1 实验内容
基于上节的爬虫,在爬虫的基础上降低一个插件系统,通过爬虫爬取网页链接后调用这个插件系统中的插件进行各类操作,本节也会写个简单的email搜集插件作为列子,后面也会提到怎样写各类基于爬虫的插件。
1.2 实验知识点1.3 实验环境二、实验原理
利用python的__import__函数动态引入脚本,只须要规定脚本怎么编撰,便可以进行调用,email搜集是基于爬虫得到的源码进行正则匹配。上节我们创造了script这个目录,这个目录上面储存我们编撰的python插件。
三、实验步骤3.1 __import__函数
我们都晓得import是导出模块的,但是毕竟import实际上是使用builtin函数import来工作的。 在一些程序中,我们可以动态去调用函数,如果我们晓得模块的名称(字符串)的时侯,我们可以很方便的使用动态调用。 一个简单的代码:
def getfunctionbyname(module_name,function_name):
module = __import__(module_name)
return getattr(module,function_name)
通过这段代码,我们就可以简单调用一个模块的函数了。
3.2 插件系统开发流程
一个插件系统运转工作,主要进行以下几个方面的操作
获取插件,通过对一个目录里的以.py的文件扫描得到将插件目录加入到环境变量sys.path爬虫将扫描好的url和网页源码传递给插件插件工作,工作完毕后主动权还给扫描器3.3 插件系统代码
在lib/core/plugin.py中创建一个spiderplus类,实现满足我们要求的代码。
#!/usr/bin/env python
# __author__= 'wanggangdan'
import os
import sys
class spiderplus(object):
def __init__(self,plugin,disallow=[]):
self.dir_exploit = []
self.disallow = ['__init__']
self.disallow.extend(disallow)
self.plugin = os.getcwd()+'/' +plugin
sys.path.append(plugin)
def list_plusg(self):
def filter_func(file):
if not file.endswith(".py"):
return False
for disfile in self.disallow:
if disfile in file:
return False
return True
dir_exploit = filter(filter_func, os.listdir(self.plugin))
return list(dir_exploit)
def work(self,url,html):
for _plugin in self.list_plusg():
try:
m = __import__(_plugin.split('.')[0])
spider = getattr(m, 'spider')
p = spider()
s =p.run(url,html)
except Exception,e:
print e
work函数中须要传递url,html,这个就是我们扫描器传给插件系统的,通过代码
spider = getattr(m, 'spider')
p = spider()
s =p.run(url,html)
我们定义插件必须使用 class spider中的run方式调用。
3.4 扫描器中调用插件
这里我们主要是爬虫调用插件,因为插件须要传递url和网页源码这两个参数,所以我们在爬虫获取到这两个的地方加入插件系统的代码即可。
首先打开 Spider.py
在 Spider.py 文件开头加上
import plugin
然后在文件的末尾加上:
disallow = ["sqlcheck"]
_plugin = plugin.spiderplus("script",disallow)
_plugin.work(_str["url"],_str["html"])
disallow是不容许的插件列表,为了便捷测试,我们可以把sqlcheck填上,当然,也可以不要了。因为我们接下来就更改下我们上节的sql注入检查工具,使他可以融入插件系统。
3.5 sql注入融入插件系统
其实十分简单,大家更改下script/sqlcheck.py为下边即可:
P.S. 关于 Download 模块,其实就是 Downloader 模块(写的时侯不留神写混了),大家把 Downloader.py 复制一份命名为 Download.py 就行。
import re,random
import lib.core import Download
class spider:
def run(self,url,html):
if(not url.find("?")):
return False
Downloader = Download.Downloader()
BOOLEAN_TESTS = (" AND %d=%d", " OR NOT (%d=%d)")
DBMS_ERRORS = {# regular expressions used for DBMS recognition based on error message response
"MySQL": (r"SQL syntax.*MySQL", r"Warning.*mysql_.*", r"valid MySQL result", r"MySqlClient\."),
"PostgreSQL": (r"PostgreSQL.*ERROR", r"Warning.*\Wpg_.*", r"valid PostgreSQL result", r"Npgsql\."),
"Microsoft SQL Server": (r"Driver.* SQL[\-\_\ ]*Server", r"OLE DB.* SQL Server", r"(\W|\A)SQL Server.*Driver", r"Warning.*mssql_.*", r"(\W|\A)SQL Server.*[0-9a-fA-F]{8}", r"(?s)Exception.*\WSystem\.Data\.SqlClient\.", r"(?s)Exception.*\WRoadhouse\.Cms\."),
"Microsoft Access": (r"Microsoft Access Driver", r"JET Database Engine", r"Access Database Engine"),
"Oracle": (r"\bORA-[0-9][0-9][0-9][0-9]", r"Oracle error", r"Oracle.*Driver", r"Warning.*\Woci_.*", r"Warning.*\Wora_.*"),
"IBM DB2": (r"CLI Driver.*DB2", r"DB2 SQL error", r"\bdb2_\w+\("),
"SQLite": (r"SQLite/JDBCDriver", r"SQLite.Exception", r"System.Data.SQLite.SQLiteException", r"Warning.*sqlite_.*", r"Warning.*SQLite3::", r"\[SQLITE_ERROR\]"),
"Sybase": (r"(?i)Warning.*sybase.*", r"Sybase message", r"Sybase.*Server message.*"),
}
_url = url + "%29%28%22%27"
_content = Downloader.get(_url)
for (dbms, regex) in ((dbms, regex) for dbms in DBMS_ERRORS for regex in DBMS_ERRORS[dbms]):
if(re.search(regex,_content)):
return True
content = {}
content["origin"] = Downloader.get(_url)
for test_payload in BOOLEAN_TESTS:
RANDINT = random.randint(1, 255)
_url = url + test_payload%(RANDINT,RANDINT)
content["true"] = Downloader.get(_url)
_url = url + test_payload%(RANDINT,RANDINT+1)
content["false"] = Downloader.get(_url)
if content["origin"]==content["true"]!=content["false"]:
return "sql fonud: %"%url
从源码可以看出,只须要我们实现了class spider和 def run(self,url,html)就可以让扫描器工作了,然后为了便捷,去掉了先前的requests模块,引用我们自己写的下载模块.然后注释掉我们原先在扫描器中调用sql注入的部份就可以了。
3.6 E-Mail搜索插件
然后我们在编撰一个简单的列子,搜索网页中的e-mail 因为插件系统会传递网页源码,我们用一个正则表达式([\w-]+@[\w-]+\.[\w-]+)+搜索出所有的电邮。 创建script/email_check.py文件
#!/usr/bin/env python
# __author__= 'wanggangdan'
import re
class spider():
def run(self,url,html):
#print(html)
pattern = re.compile(r'([\w-]+@[\w-]+\.[\w-]+)+')
email_list = re.findall(pattern, html)
if(email_list):
print(email_list)
return True
return False
效果演示:
所有搜集到的邮箱都被采集了。
四、关于插件系统踩过的坑
有一次写插件系统的时侯,出现mothod no arrtibute “xxxx” 大概是这些情况,检查了很久,都找不到缘由,后来找到了,是自己插件命名成email,而python有个泛型就是email,所以并没有先调用我们的文件,而是先在python环境中搜救,所以告诉我们,插件的命名最好复杂一些不要和环境中已有的冲突。
五、总结
这节我们简单实现了基于爬虫的插件系统,我们可以借助这个系统结合爬虫编撰好多有趣的插件,来帮助我们进行扫描。
GitHub源码地址:(二)基于爬虫开发E-mail搜集插件/wgdscan
实验来自实验楼提供 查看全部
使用Python构建基本WEB漏洞扫描器(二) 爬虫插件系统的开发—E
一、实验介绍1.1 实验内容
基于上节的爬虫,在爬虫的基础上降低一个插件系统,通过爬虫爬取网页链接后调用这个插件系统中的插件进行各类操作,本节也会写个简单的email搜集插件作为列子,后面也会提到怎样写各类基于爬虫的插件。
1.2 实验知识点1.3 实验环境二、实验原理
利用python的__import__函数动态引入脚本,只须要规定脚本怎么编撰,便可以进行调用,email搜集是基于爬虫得到的源码进行正则匹配。上节我们创造了script这个目录,这个目录上面储存我们编撰的python插件。
三、实验步骤3.1 __import__函数
我们都晓得import是导出模块的,但是毕竟import实际上是使用builtin函数import来工作的。 在一些程序中,我们可以动态去调用函数,如果我们晓得模块的名称(字符串)的时侯,我们可以很方便的使用动态调用。 一个简单的代码:
def getfunctionbyname(module_name,function_name):
module = __import__(module_name)
return getattr(module,function_name)
通过这段代码,我们就可以简单调用一个模块的函数了。
3.2 插件系统开发流程
一个插件系统运转工作,主要进行以下几个方面的操作
获取插件,通过对一个目录里的以.py的文件扫描得到将插件目录加入到环境变量sys.path爬虫将扫描好的url和网页源码传递给插件插件工作,工作完毕后主动权还给扫描器3.3 插件系统代码
在lib/core/plugin.py中创建一个spiderplus类,实现满足我们要求的代码。
#!/usr/bin/env python
# __author__= 'wanggangdan'
import os
import sys
class spiderplus(object):
def __init__(self,plugin,disallow=[]):
self.dir_exploit = []
self.disallow = ['__init__']
self.disallow.extend(disallow)
self.plugin = os.getcwd()+'/' +plugin
sys.path.append(plugin)
def list_plusg(self):
def filter_func(file):
if not file.endswith(".py"):
return False
for disfile in self.disallow:
if disfile in file:
return False
return True
dir_exploit = filter(filter_func, os.listdir(self.plugin))
return list(dir_exploit)
def work(self,url,html):
for _plugin in self.list_plusg():
try:
m = __import__(_plugin.split('.')[0])
spider = getattr(m, 'spider')
p = spider()
s =p.run(url,html)
except Exception,e:
print e
work函数中须要传递url,html,这个就是我们扫描器传给插件系统的,通过代码
spider = getattr(m, 'spider')
p = spider()
s =p.run(url,html)
我们定义插件必须使用 class spider中的run方式调用。
3.4 扫描器中调用插件
这里我们主要是爬虫调用插件,因为插件须要传递url和网页源码这两个参数,所以我们在爬虫获取到这两个的地方加入插件系统的代码即可。
首先打开 Spider.py
在 Spider.py 文件开头加上
import plugin
然后在文件的末尾加上:
disallow = ["sqlcheck"]
_plugin = plugin.spiderplus("script",disallow)
_plugin.work(_str["url"],_str["html"])
disallow是不容许的插件列表,为了便捷测试,我们可以把sqlcheck填上,当然,也可以不要了。因为我们接下来就更改下我们上节的sql注入检查工具,使他可以融入插件系统。
3.5 sql注入融入插件系统
其实十分简单,大家更改下script/sqlcheck.py为下边即可:
P.S. 关于 Download 模块,其实就是 Downloader 模块(写的时侯不留神写混了),大家把 Downloader.py 复制一份命名为 Download.py 就行。
import re,random
import lib.core import Download
class spider:
def run(self,url,html):
if(not url.find("?")):
return False
Downloader = Download.Downloader()
BOOLEAN_TESTS = (" AND %d=%d", " OR NOT (%d=%d)")
DBMS_ERRORS = {# regular expressions used for DBMS recognition based on error message response
"MySQL": (r"SQL syntax.*MySQL", r"Warning.*mysql_.*", r"valid MySQL result", r"MySqlClient\."),
"PostgreSQL": (r"PostgreSQL.*ERROR", r"Warning.*\Wpg_.*", r"valid PostgreSQL result", r"Npgsql\."),
"Microsoft SQL Server": (r"Driver.* SQL[\-\_\ ]*Server", r"OLE DB.* SQL Server", r"(\W|\A)SQL Server.*Driver", r"Warning.*mssql_.*", r"(\W|\A)SQL Server.*[0-9a-fA-F]{8}", r"(?s)Exception.*\WSystem\.Data\.SqlClient\.", r"(?s)Exception.*\WRoadhouse\.Cms\."),
"Microsoft Access": (r"Microsoft Access Driver", r"JET Database Engine", r"Access Database Engine"),
"Oracle": (r"\bORA-[0-9][0-9][0-9][0-9]", r"Oracle error", r"Oracle.*Driver", r"Warning.*\Woci_.*", r"Warning.*\Wora_.*"),
"IBM DB2": (r"CLI Driver.*DB2", r"DB2 SQL error", r"\bdb2_\w+\("),
"SQLite": (r"SQLite/JDBCDriver", r"SQLite.Exception", r"System.Data.SQLite.SQLiteException", r"Warning.*sqlite_.*", r"Warning.*SQLite3::", r"\[SQLITE_ERROR\]"),
"Sybase": (r"(?i)Warning.*sybase.*", r"Sybase message", r"Sybase.*Server message.*"),
}
_url = url + "%29%28%22%27"
_content = Downloader.get(_url)
for (dbms, regex) in ((dbms, regex) for dbms in DBMS_ERRORS for regex in DBMS_ERRORS[dbms]):
if(re.search(regex,_content)):
return True
content = {}
content["origin"] = Downloader.get(_url)
for test_payload in BOOLEAN_TESTS:
RANDINT = random.randint(1, 255)
_url = url + test_payload%(RANDINT,RANDINT)
content["true"] = Downloader.get(_url)
_url = url + test_payload%(RANDINT,RANDINT+1)
content["false"] = Downloader.get(_url)
if content["origin"]==content["true"]!=content["false"]:
return "sql fonud: %"%url
从源码可以看出,只须要我们实现了class spider和 def run(self,url,html)就可以让扫描器工作了,然后为了便捷,去掉了先前的requests模块,引用我们自己写的下载模块.然后注释掉我们原先在扫描器中调用sql注入的部份就可以了。
3.6 E-Mail搜索插件
然后我们在编撰一个简单的列子,搜索网页中的e-mail 因为插件系统会传递网页源码,我们用一个正则表达式([\w-]+@[\w-]+\.[\w-]+)+搜索出所有的电邮。 创建script/email_check.py文件
#!/usr/bin/env python
# __author__= 'wanggangdan'
import re
class spider():
def run(self,url,html):
#print(html)
pattern = re.compile(r'([\w-]+@[\w-]+\.[\w-]+)+')
email_list = re.findall(pattern, html)
if(email_list):
print(email_list)
return True
return False
效果演示:
所有搜集到的邮箱都被采集了。
四、关于插件系统踩过的坑
有一次写插件系统的时侯,出现mothod no arrtibute “xxxx” 大概是这些情况,检查了很久,都找不到缘由,后来找到了,是自己插件命名成email,而python有个泛型就是email,所以并没有先调用我们的文件,而是先在python环境中搜救,所以告诉我们,插件的命名最好复杂一些不要和环境中已有的冲突。
五、总结
这节我们简单实现了基于爬虫的插件系统,我们可以借助这个系统结合爬虫编撰好多有趣的插件,来帮助我们进行扫描。
GitHub源码地址:(二)基于爬虫开发E-mail搜集插件/wgdscan
实验来自实验楼提供
08CMS v3.4 版本采集系统使用教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 664 次浏览 • 2020-08-17 11:34
第三步、编辑采集模型
请看图解:
图一、编辑模型
图二、
模型编辑界面
到这儿,采集模型的添加完成了
下面开始添加采集任务
第四步、采集任务的添加
下面是采集任务界面图解,请仔细阅读图中注释
第六步、重头戏开始了,采集规则的设置
首先剖析采集目标页的代码结构,这里以IE浏览器为例
查看采集目标页,点击IE的
页面 ---- 查看源文件
很简单能够看见目标页面的代码结构
采集页面的代码剖析,主要是找采集目标的特点
页面很大这儿不好拿上来解析,上图解释网址采集界面相关规则的设置
点击递交保存这儿的设置
我很奇怪为何不直接跳到下一步内容采集而是递交以后回到这个页面
在这个截图页面的下边还有一部分,称之为溯源网址规则
这个不是非必填项,一般不用
而且这个只能得到一个网址,而不是网址列表,个人觉得有点鸡肋,附上官方的解释
追溯网址:内容网址的一种延展。有部份被采集文档,个别数组的内容不在主内容页,而是在附加页面,特别是有关附件的内容,追溯网址用于采集其附加页面网址,每个内容网址可溯源两级附加页面,追溯网址2是在溯源网址1的基础上采集的。
追溯概念举例:我们去下载站的时侯,往往点进去的页面只有软件信息说明和一个或多个步入下载页面的链接
注意:这里是步入下载页面的链接,而不是下载地址。当我们要下载该软件的时侯要先打开这个下载页面能够见到下载地址
这里就是一级溯源,因为我们要再点一次就能抵达下载页面。这时我们的1级溯源地址就是那种步入下载页面的链接
接下来是内容页的规则
同样用图来解析,本处只选用一个数组的规则设置为例,其他数组基本类同
入库参数设置
如果是非合辑也就是单文档采集,那么规则到此就设置结束了
经过测试没问题即可进行采集
如果你有足够的信心,完全可以不用测试直接采集哦
如果是合集的采集,比如小说,那么采集的设置还只进行到一半哦
合辑的采集还须要设置子任务的的规则
如图:
子任务在父任务下方,而且任务名称前有缩进
子任务的规则设置跟父任务的规则设置基本相同,不赘言了
理论上采集到这儿就结束了,开始愉快的采集之旅吧,个人觉得还是挺有快感的
采集,你可以自己根据网址、内容、入库一步步来
直接 一键 采集就更干脆了
不过这儿有个使人呕血的问题
采集任务除非是合集采集中的父任务跟子任务
不然你就得一个个任务一键过去,不使排队。。。。
虽然有不少地方有不足,不过总体上来说采集体验还是良好的
教程就到这儿结束了,有哪些不明白的可以跟贴提出 查看全部
08CMS v3.4 版本采集系统使用教程
第三步、编辑采集模型
请看图解:
图一、编辑模型
图二、
模型编辑界面
到这儿,采集模型的添加完成了
下面开始添加采集任务
第四步、采集任务的添加
下面是采集任务界面图解,请仔细阅读图中注释
第六步、重头戏开始了,采集规则的设置
首先剖析采集目标页的代码结构,这里以IE浏览器为例
查看采集目标页,点击IE的
页面 ---- 查看源文件
很简单能够看见目标页面的代码结构
采集页面的代码剖析,主要是找采集目标的特点
页面很大这儿不好拿上来解析,上图解释网址采集界面相关规则的设置
点击递交保存这儿的设置
我很奇怪为何不直接跳到下一步内容采集而是递交以后回到这个页面
在这个截图页面的下边还有一部分,称之为溯源网址规则
这个不是非必填项,一般不用
而且这个只能得到一个网址,而不是网址列表,个人觉得有点鸡肋,附上官方的解释
追溯网址:内容网址的一种延展。有部份被采集文档,个别数组的内容不在主内容页,而是在附加页面,特别是有关附件的内容,追溯网址用于采集其附加页面网址,每个内容网址可溯源两级附加页面,追溯网址2是在溯源网址1的基础上采集的。
追溯概念举例:我们去下载站的时侯,往往点进去的页面只有软件信息说明和一个或多个步入下载页面的链接
注意:这里是步入下载页面的链接,而不是下载地址。当我们要下载该软件的时侯要先打开这个下载页面能够见到下载地址
这里就是一级溯源,因为我们要再点一次就能抵达下载页面。这时我们的1级溯源地址就是那种步入下载页面的链接
接下来是内容页的规则
同样用图来解析,本处只选用一个数组的规则设置为例,其他数组基本类同
入库参数设置
如果是非合辑也就是单文档采集,那么规则到此就设置结束了
经过测试没问题即可进行采集
如果你有足够的信心,完全可以不用测试直接采集哦
如果是合集的采集,比如小说,那么采集的设置还只进行到一半哦
合辑的采集还须要设置子任务的的规则
如图:
子任务在父任务下方,而且任务名称前有缩进
子任务的规则设置跟父任务的规则设置基本相同,不赘言了
理论上采集到这儿就结束了,开始愉快的采集之旅吧,个人觉得还是挺有快感的
采集,你可以自己根据网址、内容、入库一步步来
直接 一键 采集就更干脆了
不过这儿有个使人呕血的问题
采集任务除非是合集采集中的父任务跟子任务
不然你就得一个个任务一键过去,不使排队。。。。
虽然有不少地方有不足,不过总体上来说采集体验还是良好的
教程就到这儿结束了,有哪些不明白的可以跟贴提出
网络数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 261 次浏览 • 2020-08-14 11:32
网络数据采集是指通过网路爬虫或网站公开API等方法从网站上获取数据信息
常用的网路采集系统网路爬虫工作原理工作流程抓取策略网路爬虫策略用到的基本概念通用网路爬虫
通用网路爬虫又称全网爬虫,爬行对象从一些种子URL扩充到整个Web,主要为门户站点搜索引擎和小型Web服务提供商采集数据。
聚焦网络爬虫
聚焦网路爬虫又称主题网路爬虫,是指选择性地爬行这些与预先定义好的主题相关的页面的网路爬虫。
1)基于内容评价的爬行策略
De Bra将文本相似度的估算方式引入到网路爬虫中,提出了Fish Search算法。该算法将用户输入的查询词作为主题,收录查询词的页面被视为与主题相关的页面,其局限性在于难以评价页面与主题相关度的大小。
Herseovic对Fish Search算法进行了改进,提出了Shark Search算法,即借助空间向量模型估算页面与主题的相关度大小。采用基于连续值估算链接价值的方式,不但可以估算出什么抓取的链接和主题相关,还可以得到相关度的量化大小。
2)基于链接结构评价的爬行策略
PageRank算法的基本原理是,如果一个网页多次被引用,则可能是很重要的网页,如果一个网页没有被多次引用,但是被重要的网页引用,也有可能是重要的网页。一个网页的重要性被平均地传递到它所引用的网页上。
3)基于提高学习的爬行策略
将提高学习引入聚焦爬虫,利用贝叶斯分类器,根据整个网页文本和链接文本对超链接进行分类,为每位链接估算出重要性,从而决定链接的访问次序。
4)基于语境图的爬行策略
通过构建语境图学习网页之间的相关度的爬行策略,该策略可训练一个机器学习系统,通过该系统可估算当前页面到相关Web页面的距离,距离逾的页面中的链接优先访问。
增量式网络爬虫
增量式网络爬虫是指对已下载网页采取增量式更新而且只爬行新形成的或则已然发生变化网页的爬虫,它还能在一定程度上保证所爬行的页面是尽可能新的页面。
深度网路爬虫
网页按存在形式可以分为表层网页和深层网页。表层网页是指传统搜索引擎可以索引的页面,以超链接可以抵达的静态网页为主。深层网页是什么大部分内容不能通过静态链接获取的,隐藏在搜索表单后的,只有用户递交一些关键词能够获得的网页。
深层网路爬虫体系结构收录6个基本功能模块:
爬行控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器和两个爬虫内部数据结构(URL列表和LVS表)。其中,LVS(Label Value Set)表示标签和数值集合,用来表示填充表单的数据源。在爬取过程中,最重要的部份就是表单填写,收录基于领域知识的表单填写和基于网页结构剖析的表单填写两种。 查看全部
网络数采集的主要功能
网络数据采集是指通过网路爬虫或网站公开API等方法从网站上获取数据信息
常用的网路采集系统网路爬虫工作原理工作流程抓取策略网路爬虫策略用到的基本概念通用网路爬虫
通用网路爬虫又称全网爬虫,爬行对象从一些种子URL扩充到整个Web,主要为门户站点搜索引擎和小型Web服务提供商采集数据。
聚焦网络爬虫
聚焦网路爬虫又称主题网路爬虫,是指选择性地爬行这些与预先定义好的主题相关的页面的网路爬虫。
1)基于内容评价的爬行策略
De Bra将文本相似度的估算方式引入到网路爬虫中,提出了Fish Search算法。该算法将用户输入的查询词作为主题,收录查询词的页面被视为与主题相关的页面,其局限性在于难以评价页面与主题相关度的大小。
Herseovic对Fish Search算法进行了改进,提出了Shark Search算法,即借助空间向量模型估算页面与主题的相关度大小。采用基于连续值估算链接价值的方式,不但可以估算出什么抓取的链接和主题相关,还可以得到相关度的量化大小。
2)基于链接结构评价的爬行策略
PageRank算法的基本原理是,如果一个网页多次被引用,则可能是很重要的网页,如果一个网页没有被多次引用,但是被重要的网页引用,也有可能是重要的网页。一个网页的重要性被平均地传递到它所引用的网页上。
3)基于提高学习的爬行策略
将提高学习引入聚焦爬虫,利用贝叶斯分类器,根据整个网页文本和链接文本对超链接进行分类,为每位链接估算出重要性,从而决定链接的访问次序。
4)基于语境图的爬行策略
通过构建语境图学习网页之间的相关度的爬行策略,该策略可训练一个机器学习系统,通过该系统可估算当前页面到相关Web页面的距离,距离逾的页面中的链接优先访问。
增量式网络爬虫
增量式网络爬虫是指对已下载网页采取增量式更新而且只爬行新形成的或则已然发生变化网页的爬虫,它还能在一定程度上保证所爬行的页面是尽可能新的页面。
深度网路爬虫
网页按存在形式可以分为表层网页和深层网页。表层网页是指传统搜索引擎可以索引的页面,以超链接可以抵达的静态网页为主。深层网页是什么大部分内容不能通过静态链接获取的,隐藏在搜索表单后的,只有用户递交一些关键词能够获得的网页。
深层网路爬虫体系结构收录6个基本功能模块:
爬行控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器和两个爬虫内部数据结构(URL列表和LVS表)。其中,LVS(Label Value Set)表示标签和数值集合,用来表示填充表单的数据源。在爬取过程中,最重要的部份就是表单填写,收录基于领域知识的表单填写和基于网页结构剖析的表单填写两种。
硕士学位论文第三章恶意代码异常监测系统需求剖析图借助异常检查规则与特点检查规则进
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2020-08-12 01:25
异常检查规则生成厢瓣 一定关联分桁、——、一一—————曩 异常检查规则生成用例图本场景收录五个用例以及两个角色以下为各内容的详尽说明 选取特点检查规则集合 由“规则管理与剖析员”角色 负责 登童笪塑至堕整望塑塑堕壁望塑生以手工形式在当前测量规则库’’ 角色 中选定合适的、待剖析的特点检查规则集合 设定关联分析运算参数 由于关联分析任务施行前须要设置每位关联分析任务的运算参数因而须要由“规则管理与分析员’’ 角色 设定关联分析任务的运算参数 关联分析 由“规则管理与分析员角色 负责执行关联分析运算操作 异常检查规则生成 由“规则管理与剖析员”角色 确认关联分析运算获得结果以及新生成的异常检查规则 异常检查规则入库 由‘‘规则管理与剖析员”角色 将有价值的异常检查规则导出“检测规则库” 角色 恶意代码检查信硕士学位论文第三章恶意代码异常测量系统需求剖析图 恶意代码检查用例图本场景收录四个用例以及三个角色 以下为各内容的详细说明 网络通信数据采集 对“网络通信系统”角色 进行原创通信数据捕捉 该用例收录“数据预处理’’ 工作内容数据预处理 对捕捉到的原创通信数据进行规范化处理为“模式匹配” 提供后置处理模式匹配 读取“规则检查库”角色 的恶意代码检查规则 包括特点检查规则与异常检查规则 并运用相关规则对经过“数据预处理 的通信数据进行模式匹配恶意代码告警 发现恶意代码后由“恶意代码告警” 输出相关告警信息以告知“信息安全员角色 功能需求剖析本异常恶意代码检查系统将起码收录以下个用户需求 设定手动更新检查规则配置可以手工方法设置手动更新检查规则配置。
设定定时升级阈值可以设置手动升级的定时升级阈值。 设定定时升级源头可以设置手动升级的升级源头。 读取手动更新检查规则配置给以系统读取手动更新传统特点检查规则配置的功能。 定期手动升级特点检查规则给以系统手动更新传统特点检查规则的功能。 选取特点检查规则集合可以手工选定待进行关联剖析的特点检查规则集合的功能。硕士学位论文第三章恶意代码异常监测系统需求剖析设定关联分析运算参数可以手工设置关联剖析过程中运用的参数的值。 关联分析提供关联分析运算任务的处理开关。 异常检查规则生成提供将关联分析结果转换为异常检查规则的功能。 异常检查规则入库提供将新生成的异常检查规则写入规则库的功能。 网络通信数据采集可以对指定网路插口进行原创通信数据捕获的功能。 数据预处理提供对原创通信数据进行规范化处理的功能。 模式匹配提供针对通信数据与恶意代码检查规则 收录特点检查规则与异常检查规则 进行模式匹配的功能 以模式匹配的方法确认通信数据是否存在恶意代码。 恶意代码告警可以将模式匹配后发觉的恶意代码告警信息通知信息安全员。以下为针对上述用户需求清单中 个用户需求进行需求剖析后获得下列五个功能点 下文将针对此五个功能点提出对应的功能需求说明。
硕士学位论文第三章恶意代码异常测量系统需求剖析 规则导出管理功能规则导出成功提示界面图 规则导出管理功能鲁棒图 涉及用户需求编号 特征监测规则导出 涉及人员 规则管理与分析员 涉及存储单元 检测规则库 功能的施行流程描述 、规则管理与分析员访问“所有规则展示界面 主界面 、在主界面中手工导出规则文件 分支 手工搜索或删掉指定规则 、规则文件写入检查规则库 、导入规则后弹出“导入成功提示界面” 、“导入成功提示界面”提示规则管理与分析员导出操作成功。硕士学位论文第三章恶意代码异常测量系统需求剖析 规则手动升级管理功能卜 文件设定定时升级源头图 规则手动升级管理功能鲁棒图 涉及用户需求编号 设定手动更新检查规则配置 设定定时升级源头涉及人员 规则管理与分析员 涉及存储单元 自动升级配置文件 功能的施行流程描述 、规则管理与分析员访问“自动升级管理界面 主界面 、在主界面中手工设置手动升级功能开关 设置完成后将设置结果返显至主界面中 、将手动升级功能开关情况写入手动升级配置文件中 、在主界面中手工设置定时升级阈值 设置完成后将设置结果返显至主界面中 、将定时升级阈值写入手动升级配置文件中 、在主界面中手工设置定时升级源头 设置完成后将设置结果返显至主界面中 、将定时升级源头写入手动升级配置文件中。
硕士学位论文第三章恶意代码异常测量系统需求剖析 规则手动升级功能规则管理与分析员手动升级管理界面 检测规则库读取手动升级配置图规则手动升级功能鲁棒图 涉及用户需求编号 读取手动更新检查规则配置 定期手动升级特点检查规则涉及人员 规则管理与分析员 涉及存储单元 自动升级配置文件 功能的施行流程描述 、读取手动升级配置模块定期读取手动升级配置文件 确认是否开启已手动升级功能、升级阈值以及升级源头 、在确认已开启升级功能后 交由手动升级特点规则功能进行特点检查规则升级 、自动升级特点规则功能将新获得的特点检查规则写入规则特点库 、在特点检查规则升级后 返显升级结果至“自动升级管理界面” 主界面 、主界面提示升级操作成功。卜硕士学位论文第三章恶意代码异常测量系统需求剖析 异常检查规则提取功能异常拉舅规用 异常检查规则提取功能鲁棒图涉及用户需求编号 选取特点检查规则集合 异常检查规则入库一涉及人员 规则管理与分析员 涉及存储单元 检测规则库 功能的施行流程描述 查看全部
硕士学位论文第三章恶意代码异常监测系统需求剖析图借助异常检查规则与特点检查规则进行恶意代码检查活动示意图第一步 采集网络通信数据 获得原创数据内容 第二步 对网路通信原创数据进行数据规范化处理 确保数据可进行模式匹配 第三步 使用恶意代码检查规则库 关于“恶意代码检查规则库中异常检查规则与特点检查规则的更新过程 详见“图 恶意代码特点检查规则关联分析与异常检查规则提取活动示意图’’ 与规范化后的网路通信数据进行模式匹配 若匹配不成功则结束本流程 若匹配成功则步入第四步的“恶意代码告警”过程 第四步 对发觉的恶意代码结果进行告警。 用户需求场景针对上述所提到的两个业务需求活动 并从用户的角度出发可以整理为以下三个用户场景 特征检查规则升级、异常检查规则生成、恶意代码检查。以下为三个用户场景的详尽说明。 特征检查规则升级 硕士学位论文第三章恶意代码异常监测系统需求剖析 特征检查规则升级用例图本场景收录五个用例以及三个角色以下为各内容的详尽说明 特征检查规则导出 由“规则管理与分析员角色 负责以手工方法将目前较新或待进行关联分析的传统恶意代码检查规则集合导出“检测规则库” 角色 设定手动更新检查规则配置 由“规则管理与分析员角色 执行针对手动更新检查规则配置的设定操作 用于更改相关配置让系统能手动更新检查规则库中的特点检查规则 设定定时升级阈值 “定时升级阈值”为时间周期等定时执行参数硕士学位论文第三章恶意代码异常测量系统需求剖析 设定定时升级源头 “定时升级源头”为升级特点检查规则的源储存点如网址、 地址等 读取手动更新检查规则配置 由系统外置定时器负责执行用于让系统获取手动更新检查规则配置参数 包括时间周期等定时执行参数、升级特点检查规则的源储存点 定期手动升级特点检查规则 由系统外置定时器负责执行当定时器确认当前系统时间与时间周期等定时执行参数一致时启动“检测规则库” 角色 内特点检查规则手动升级操作。
异常检查规则生成厢瓣 一定关联分桁、——、一一—————曩 异常检查规则生成用例图本场景收录五个用例以及两个角色以下为各内容的详尽说明 选取特点检查规则集合 由“规则管理与剖析员”角色 负责 登童笪塑至堕整望塑塑堕壁望塑生以手工形式在当前测量规则库’’ 角色 中选定合适的、待剖析的特点检查规则集合 设定关联分析运算参数 由于关联分析任务施行前须要设置每位关联分析任务的运算参数因而须要由“规则管理与分析员’’ 角色 设定关联分析任务的运算参数 关联分析 由“规则管理与分析员角色 负责执行关联分析运算操作 异常检查规则生成 由“规则管理与剖析员”角色 确认关联分析运算获得结果以及新生成的异常检查规则 异常检查规则入库 由‘‘规则管理与剖析员”角色 将有价值的异常检查规则导出“检测规则库” 角色 恶意代码检查信硕士学位论文第三章恶意代码异常测量系统需求剖析图 恶意代码检查用例图本场景收录四个用例以及三个角色 以下为各内容的详细说明 网络通信数据采集 对“网络通信系统”角色 进行原创通信数据捕捉 该用例收录“数据预处理’’ 工作内容数据预处理 对捕捉到的原创通信数据进行规范化处理为“模式匹配” 提供后置处理模式匹配 读取“规则检查库”角色 的恶意代码检查规则 包括特点检查规则与异常检查规则 并运用相关规则对经过“数据预处理 的通信数据进行模式匹配恶意代码告警 发现恶意代码后由“恶意代码告警” 输出相关告警信息以告知“信息安全员角色 功能需求剖析本异常恶意代码检查系统将起码收录以下个用户需求 设定手动更新检查规则配置可以手工方法设置手动更新检查规则配置。
设定定时升级阈值可以设置手动升级的定时升级阈值。 设定定时升级源头可以设置手动升级的升级源头。 读取手动更新检查规则配置给以系统读取手动更新传统特点检查规则配置的功能。 定期手动升级特点检查规则给以系统手动更新传统特点检查规则的功能。 选取特点检查规则集合可以手工选定待进行关联剖析的特点检查规则集合的功能。硕士学位论文第三章恶意代码异常监测系统需求剖析设定关联分析运算参数可以手工设置关联剖析过程中运用的参数的值。 关联分析提供关联分析运算任务的处理开关。 异常检查规则生成提供将关联分析结果转换为异常检查规则的功能。 异常检查规则入库提供将新生成的异常检查规则写入规则库的功能。 网络通信数据采集可以对指定网路插口进行原创通信数据捕获的功能。 数据预处理提供对原创通信数据进行规范化处理的功能。 模式匹配提供针对通信数据与恶意代码检查规则 收录特点检查规则与异常检查规则 进行模式匹配的功能 以模式匹配的方法确认通信数据是否存在恶意代码。 恶意代码告警可以将模式匹配后发觉的恶意代码告警信息通知信息安全员。以下为针对上述用户需求清单中 个用户需求进行需求剖析后获得下列五个功能点 下文将针对此五个功能点提出对应的功能需求说明。
硕士学位论文第三章恶意代码异常测量系统需求剖析 规则导出管理功能规则导出成功提示界面图 规则导出管理功能鲁棒图 涉及用户需求编号 特征监测规则导出 涉及人员 规则管理与分析员 涉及存储单元 检测规则库 功能的施行流程描述 、规则管理与分析员访问“所有规则展示界面 主界面 、在主界面中手工导出规则文件 分支 手工搜索或删掉指定规则 、规则文件写入检查规则库 、导入规则后弹出“导入成功提示界面” 、“导入成功提示界面”提示规则管理与分析员导出操作成功。硕士学位论文第三章恶意代码异常测量系统需求剖析 规则手动升级管理功能卜 文件设定定时升级源头图 规则手动升级管理功能鲁棒图 涉及用户需求编号 设定手动更新检查规则配置 设定定时升级源头涉及人员 规则管理与分析员 涉及存储单元 自动升级配置文件 功能的施行流程描述 、规则管理与分析员访问“自动升级管理界面 主界面 、在主界面中手工设置手动升级功能开关 设置完成后将设置结果返显至主界面中 、将手动升级功能开关情况写入手动升级配置文件中 、在主界面中手工设置定时升级阈值 设置完成后将设置结果返显至主界面中 、将定时升级阈值写入手动升级配置文件中 、在主界面中手工设置定时升级源头 设置完成后将设置结果返显至主界面中 、将定时升级源头写入手动升级配置文件中。
硕士学位论文第三章恶意代码异常测量系统需求剖析 规则手动升级功能规则管理与分析员手动升级管理界面 检测规则库读取手动升级配置图规则手动升级功能鲁棒图 涉及用户需求编号 读取手动更新检查规则配置 定期手动升级特点检查规则涉及人员 规则管理与分析员 涉及存储单元 自动升级配置文件 功能的施行流程描述 、读取手动升级配置模块定期读取手动升级配置文件 确认是否开启已手动升级功能、升级阈值以及升级源头 、在确认已开启升级功能后 交由手动升级特点规则功能进行特点检查规则升级 、自动升级特点规则功能将新获得的特点检查规则写入规则特点库 、在特点检查规则升级后 返显升级结果至“自动升级管理界面” 主界面 、主界面提示升级操作成功。卜硕士学位论文第三章恶意代码异常测量系统需求剖析 异常检查规则提取功能异常拉舅规用 异常检查规则提取功能鲁棒图涉及用户需求编号 选取特点检查规则集合 异常检查规则入库一涉及人员 规则管理与分析员 涉及存储单元 检测规则库 功能的施行流程描述
大数据采集系统有几类?好用大数据采集平台有什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 334 次浏览 • 2020-08-10 02:00
对数据进行ETL操作,通过对数据进行提取、转换、加载,最终挖掘数据的潜在价值。然后提供给用户解决方案或则决策参考。
大数据采集系统,主要分为三类:
1、系统日志采集系统
对日志数据信息进行日志采集、采集,然后进行数据剖析,挖掘公司业务平台日志数据中的潜在价值。简言之,采集日志数据提供离线和在线的实时剖析使用。目前常用的开源日志搜集系统为Flume。
2、网络数据采集系统
通过网路爬虫和一些网站平台提供的公共API(如Twitter和新浪微博API)等方法从网站上获取数据。可以将非结构化数据和半结构化数据的网页数据从网页中提取下来,并将其提取、清洗、转换成结构化的数据,将其储存为统一的本地文件数据。
目前常用的网页爬虫系统有Apache Nutch、Crawler4j、Scrapy等框架。
3、数据库采集系统
通过数据库采集系统直接与企业业务后台服务器结合,将企业业务后台每时每刻都在形成大量的业务记录写入到数据库中,最后由特定的处理分许系统进行系统分析。
目前常用关系型数据库MySQL和Oracle等来储存数据,Redis和MongoDB这样的NoSQL数据库也常用于数据的采集。
好用的大数据采集平台:
1.数据商场
一款基于云平台的大数据估算、分析系统。拥有丰富高质量的数据资源,通过自身渠道资源获取了百余款拥有版权的大数据资源,所有数据都经过初审,保证数据的高可用性。
2. Rapid Miner
数据科学软件平台,为数据打算、机器学习、深度学习、文本挖掘和预测剖析提供一种集成环境。
3. Oracle Data Mining
它是Oracle中级剖析数据库的代表。市场领先的公司用它最大限度地开掘数据的潜力,做出确切的预测。
4. IBM SPSS Modeler
适合大规模项目。在这个建模器中,文本剖析及其最先进的可视化界面极具价值。它有助于生成数据挖掘算法,基本上不需要编程。
5. KNIME
开源数据剖析平台。你可以迅速在其中布署、扩展和熟悉数据。
6. Python
一种免费的开源语言。
大数据平台:
是指以处理海量数据储存、计算及不间断流数据实时估算等场景为主的一套基础设施。既可以采用开源平台,也可以采用华为、星环等商业级解决方案,既可以布署在私有云上,也可以布署在公有云上。
任何完整的大数据平台,一般包括以下的几个过程:
其中,数据采集是所有数据系统必不可少的,随着大数据越来越被注重,数据采集的挑战也变的尤为突出。 查看全部
什么是大数据采集技术:
对数据进行ETL操作,通过对数据进行提取、转换、加载,最终挖掘数据的潜在价值。然后提供给用户解决方案或则决策参考。
大数据采集系统,主要分为三类:
1、系统日志采集系统
对日志数据信息进行日志采集、采集,然后进行数据剖析,挖掘公司业务平台日志数据中的潜在价值。简言之,采集日志数据提供离线和在线的实时剖析使用。目前常用的开源日志搜集系统为Flume。
2、网络数据采集系统
通过网路爬虫和一些网站平台提供的公共API(如Twitter和新浪微博API)等方法从网站上获取数据。可以将非结构化数据和半结构化数据的网页数据从网页中提取下来,并将其提取、清洗、转换成结构化的数据,将其储存为统一的本地文件数据。
目前常用的网页爬虫系统有Apache Nutch、Crawler4j、Scrapy等框架。
3、数据库采集系统
通过数据库采集系统直接与企业业务后台服务器结合,将企业业务后台每时每刻都在形成大量的业务记录写入到数据库中,最后由特定的处理分许系统进行系统分析。
目前常用关系型数据库MySQL和Oracle等来储存数据,Redis和MongoDB这样的NoSQL数据库也常用于数据的采集。
好用的大数据采集平台:
1.数据商场
一款基于云平台的大数据估算、分析系统。拥有丰富高质量的数据资源,通过自身渠道资源获取了百余款拥有版权的大数据资源,所有数据都经过初审,保证数据的高可用性。
2. Rapid Miner
数据科学软件平台,为数据打算、机器学习、深度学习、文本挖掘和预测剖析提供一种集成环境。
3. Oracle Data Mining
它是Oracle中级剖析数据库的代表。市场领先的公司用它最大限度地开掘数据的潜力,做出确切的预测。
4. IBM SPSS Modeler
适合大规模项目。在这个建模器中,文本剖析及其最先进的可视化界面极具价值。它有助于生成数据挖掘算法,基本上不需要编程。
5. KNIME
开源数据剖析平台。你可以迅速在其中布署、扩展和熟悉数据。
6. Python
一种免费的开源语言。
大数据平台:
是指以处理海量数据储存、计算及不间断流数据实时估算等场景为主的一套基础设施。既可以采用开源平台,也可以采用华为、星环等商业级解决方案,既可以布署在私有云上,也可以布署在公有云上。
任何完整的大数据平台,一般包括以下的几个过程:
其中,数据采集是所有数据系统必不可少的,随着大数据越来越被注重,数据采集的挑战也变的尤为突出。
部署ELK日志采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 380 次浏览 • 2020-08-08 23:33
ELK是Elasticsearch,Logstash和Kibana的缩写. 这三个是核心程序包,但不是全部.
Elasticsearch是一个实时的全文本搜索和分析引擎,它提供了采集,分析和存储数据的三种功能. 它是一组开放的REST和JAVA API结构,可提供有效的搜索功能和可扩展的分布式系统. 它建立在Apache Lucene搜索引擎库的顶部.
Logstash是用于采集,分析和过滤日志的工具. 它支持几乎所有类型的日志,包括系统日志,错误日志和自定义应用程序日志. 它可以从许多来源接收日志,包括系统日志,消息传递(例如RabbitMQ)和JMX,并且可以通过多种方式输出数据,包括电子邮件,Websocket和Elasticsearch.
Kibana是基于Web的图形界面,用于搜索,分析和可视化Elasticsearch指标中存储的日志数据. 它利用Elasticsearch的REST界面检索数据,不仅允许用户创建自己的自定义仪表板数据视图,而且还允许他们以特殊方式查询和过滤数据.
1,准备环境1.1,配置Java环境
转到官方网站下载jdk1.8以上的软件包,然后配置java环境以确保该环境正常使用. 跳过此处的安装过程. 如果您听不懂,请自己百度.
[root@vm96-yw-65-test-3060 application]# java -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
1.2. 下载ELK软件包
转到官方网站下载Elasticsearch,Logstash和Kibana. 因为它是一个测试环境,所以我下载了最新版本v6.4.0,并在下载后将其解压缩.
wget https://artifacts.elastic.co/d ... ar.gz
wget https://artifacts.elastic.co/d ... ar.gz
wget https://artifacts.elastic.co/d ... ar.gz
2,配置2.1,修改系统配置
elasticsearch对最大系统连接数有要求,因此您需要修改系统连接数.
echo '
* hard nofile 65536
* soft nofile 65536
* soft nproc 65536
* hard nproc 65536
' >>/etc/security/limits.conf
echo 'vm.max_map_count = 262144' >> /etc/sysctl.conf
vim /etc/security/limits.d/90-nproc.conf
# 第一行最后一个数,修改为4096,如果是则不用修改
# limits.d下面的文件可能不是90-nproc.conf,可能是其他数字开头的文件。
* soft nproc 4096
root soft nproc unlimited
2.2,elasticSearch配置
这实际上是ELK的核心. 启动时必须注意. 从5.0版开始,ElasticSearch的安全级别已得到改进,并且不允许以root帐户开头,因此我们需要添加一个用户,因此还需要创建一个elsearch帐户.
groupadd es #新建es组
useradd es -g es -p elasticsearch #新建一个es用户
chown -R es:es /usr/elasticsearch-6.4.0/ #指定elasticsearch-6.4.0目录下的文件所属elsearch组
修改配置文件
vim /application/elasticsearch-6.4.0/config/elasticsearch.yml
······
path.data: /application/elasticsearch-6.4.0/data
path.logs: /application/elasticsearch-6.4.0/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
······
开始
su es ## 切换到普通用户
cd /application/elasticsearch-6.4.0/
./bin/elasticsearch -d ## -d 后台运行
2.3,logstash配置
解压缩后,转到config目录并创建一个新的logstash.conf配置,并添加以下内容.
[root@vm96-yw-65-test-3060 config]# pwd
/application/logstash-6.4.0/config
[root@vm96-yw-65-test-3060 config]# vim logstash.conf
input {
file {
type => "log"
path => "/logs/*.log" ##创建一个/logs目录用于之后的测试
start_position => "beginning"
}
}
output {
stdout {
codec => rubydebug { }
}
elasticsearch { ##输出到es
hosts => "localhost:9200"
index => "log-%{+YYYY.MM.dd}"
}
}
logstash所做的事情分三个阶段执行: 输入输入-“处理过滤器(不必要)-”输出输出,这是我们需要配置的三个部分,因为它是一个测试,因此没有过滤器添加了过滤器和过滤器,仅配置输入和输出. 一个文件可以有多个输入. 过滤器非常有用,但它也更麻烦. 这需要大量的实验. 对nginx和Apache等服务的日志分析需要使用此模块进行过滤和分析.
[root@vm96-yw-65-test-3060 config]# nohup ../bin/logstash -f logstash.conf &
# 使用nohup,启动后台运行,如需关闭使用kill -9,建议多开窗口,启动ELK三个服务,可以观看控制窗口的报错信息
2.4,kibana配置
它的配置也非常简单,您需要在kibana.yml文件中指定要读取的elasticSearch地址以及可以从Internet访问的绑定地址.
[root@vm96-yw-65-test-3060 config]# vim /application/kinbana-6.4.0/config/kibana.yml
······
elasticsearch.url: "http://localhost:9200"
server.host: 0.0.0.0
······
开始
[root@vm96-yw-65-test-3060 config]# nohup ../bin/kibana &
# 使用nohup,启动后台运行,如需关闭使用kill -9
2.5,测试
编写测试日志
vim /logs/test.log
Hello,World!!!
开始记录日志
[root@vm96-yw-65-test-3060 config]# nohup ../bin/logstash -f logstash.conf &
在浏览器中输入: : 5601 /,您可以打开kibana页面.
单击管理=>索引模式以创建索引. 如果ES从logstash接收日志数据,则页面将显示可以创建的索引,否则将显示无法创建索引. 请亲自检查日志文件分析错误.
创建索引后,单击左侧的“发现”以查看对刚创建的日志的分析. 查看全部
ELK日志采集
ELK是Elasticsearch,Logstash和Kibana的缩写. 这三个是核心程序包,但不是全部.
Elasticsearch是一个实时的全文本搜索和分析引擎,它提供了采集,分析和存储数据的三种功能. 它是一组开放的REST和JAVA API结构,可提供有效的搜索功能和可扩展的分布式系统. 它建立在Apache Lucene搜索引擎库的顶部.
Logstash是用于采集,分析和过滤日志的工具. 它支持几乎所有类型的日志,包括系统日志,错误日志和自定义应用程序日志. 它可以从许多来源接收日志,包括系统日志,消息传递(例如RabbitMQ)和JMX,并且可以通过多种方式输出数据,包括电子邮件,Websocket和Elasticsearch.
Kibana是基于Web的图形界面,用于搜索,分析和可视化Elasticsearch指标中存储的日志数据. 它利用Elasticsearch的REST界面检索数据,不仅允许用户创建自己的自定义仪表板数据视图,而且还允许他们以特殊方式查询和过滤数据.
1,准备环境1.1,配置Java环境
转到官方网站下载jdk1.8以上的软件包,然后配置java环境以确保该环境正常使用. 跳过此处的安装过程. 如果您听不懂,请自己百度.
[root@vm96-yw-65-test-3060 application]# java -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
1.2. 下载ELK软件包
转到官方网站下载Elasticsearch,Logstash和Kibana. 因为它是一个测试环境,所以我下载了最新版本v6.4.0,并在下载后将其解压缩.
wget https://artifacts.elastic.co/d ... ar.gz
wget https://artifacts.elastic.co/d ... ar.gz
wget https://artifacts.elastic.co/d ... ar.gz
2,配置2.1,修改系统配置
elasticsearch对最大系统连接数有要求,因此您需要修改系统连接数.
echo '
* hard nofile 65536
* soft nofile 65536
* soft nproc 65536
* hard nproc 65536
' >>/etc/security/limits.conf
echo 'vm.max_map_count = 262144' >> /etc/sysctl.conf
vim /etc/security/limits.d/90-nproc.conf
# 第一行最后一个数,修改为4096,如果是则不用修改
# limits.d下面的文件可能不是90-nproc.conf,可能是其他数字开头的文件。
* soft nproc 4096
root soft nproc unlimited
2.2,elasticSearch配置
这实际上是ELK的核心. 启动时必须注意. 从5.0版开始,ElasticSearch的安全级别已得到改进,并且不允许以root帐户开头,因此我们需要添加一个用户,因此还需要创建一个elsearch帐户.
groupadd es #新建es组
useradd es -g es -p elasticsearch #新建一个es用户
chown -R es:es /usr/elasticsearch-6.4.0/ #指定elasticsearch-6.4.0目录下的文件所属elsearch组
修改配置文件
vim /application/elasticsearch-6.4.0/config/elasticsearch.yml
······
path.data: /application/elasticsearch-6.4.0/data
path.logs: /application/elasticsearch-6.4.0/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
······
开始
su es ## 切换到普通用户
cd /application/elasticsearch-6.4.0/
./bin/elasticsearch -d ## -d 后台运行
2.3,logstash配置
解压缩后,转到config目录并创建一个新的logstash.conf配置,并添加以下内容.
[root@vm96-yw-65-test-3060 config]# pwd
/application/logstash-6.4.0/config
[root@vm96-yw-65-test-3060 config]# vim logstash.conf
input {
file {
type => "log"
path => "/logs/*.log" ##创建一个/logs目录用于之后的测试
start_position => "beginning"
}
}
output {
stdout {
codec => rubydebug { }
}
elasticsearch { ##输出到es
hosts => "localhost:9200"
index => "log-%{+YYYY.MM.dd}"
}
}
logstash所做的事情分三个阶段执行: 输入输入-“处理过滤器(不必要)-”输出输出,这是我们需要配置的三个部分,因为它是一个测试,因此没有过滤器添加了过滤器和过滤器,仅配置输入和输出. 一个文件可以有多个输入. 过滤器非常有用,但它也更麻烦. 这需要大量的实验. 对nginx和Apache等服务的日志分析需要使用此模块进行过滤和分析.
[root@vm96-yw-65-test-3060 config]# nohup ../bin/logstash -f logstash.conf &
# 使用nohup,启动后台运行,如需关闭使用kill -9,建议多开窗口,启动ELK三个服务,可以观看控制窗口的报错信息
2.4,kibana配置
它的配置也非常简单,您需要在kibana.yml文件中指定要读取的elasticSearch地址以及可以从Internet访问的绑定地址.
[root@vm96-yw-65-test-3060 config]# vim /application/kinbana-6.4.0/config/kibana.yml
······
elasticsearch.url: "http://localhost:9200"
server.host: 0.0.0.0
······
开始
[root@vm96-yw-65-test-3060 config]# nohup ../bin/kibana &
# 使用nohup,启动后台运行,如需关闭使用kill -9
2.5,测试
编写测试日志
vim /logs/test.log
Hello,World!!!
开始记录日志
[root@vm96-yw-65-test-3060 config]# nohup ../bin/logstash -f logstash.conf &
在浏览器中输入: : 5601 /,您可以打开kibana页面.
单击管理=>索引模式以创建索引. 如果ES从logstash接收日志数据,则页面将显示可以创建的索引,否则将显示无法创建索引. 请亲自检查日志文件分析错误.
创建索引后,单击左侧的“发现”以查看对刚创建的日志的分析.
下载北斗星内容管理系统,购买北斗星内容管理系统,尝试北斗星内容管理系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2020-08-08 06:37
同时,北斗七星内容管理系统提供了强大的网站组管理功能,可以在一个系统中管理多个独立的子站点. 每个子站点都有单独的管理权限. 每个站点都支持资源共享,集中式数据存储以及对多个站点的统一管理,而不会互相干扰,从而在站点组模式下充分提高了信息发布的效率.
建筑
北斗星CMS是基于Internet / Intranet的网站(组)内容管理产品. 它支持强大的多站点管理和在线视觉编辑功能. 它可以灵活地定义满足不同工作要求的信息获取,编辑,审阅和分发过程,并且有效地解决了新时期政府和大型企业用户的多站点建设和网站信息发布中的常见问题和需求.
在站点部署方面,可以使用集中式部署,即所有子站点都可以与主站点集中部署在统一的硬件平台上;它也可以是分布式部署,即子站点位于网站自己的组织中. 它支持集中式和分布式混合使用.
北斗星内容管理系统基于北斗星应用支持平台,并直接使用北斗星应用支持平台中的分类引擎来统一用户管理.
主要功能
站点管理: 管理系统中的多个独立站点. 该系统可以轻松添加站点,每个站点都具有严格的管理权限,具有独立的获取,编辑,查看和分发过程,而不会相互干扰;并且可以在多个站点之间共享资源,实现多个站点的统一管理和集中式数据存储. 该站点可以激活和停用.
列管理: 支持用户方便地创建,删除和编辑列,修改列名称和类型以及选择使用不同的列模板.
模板管理: 模板将内容和表达式的形式分开,因此可以根据用户的需要快速更改接口的表达式,而无需程序员修改程序. 通过界面设计和生成器,用户可以以所见即所得的方式轻松设计和预览模板.
信息采集: 通过北斗星互联网信息采集工具,根据客户的不同需求,准确,及时地完成信息采集任务.
信息编辑: 提供可视内容编辑器,该编辑器支持类似于Word之类的常见编辑工具的界面. 它支持三种粘贴方法: 纯文本粘贴,Word原创格式粘贴,Word删除多余的代码粘贴.
信息审阅: 支持可自定义的多级审阅过程. 可以为不同的列定制不同的批准过程. 只有经过审查和确认的内容才会在网站上发布. 所有编辑过程均由北斗星过程管理系统实施.
信息发布: 通过解析模板,填充数据来生成网页并将其上传到Web服务器的过程. 页面的生成和上传是由发布引擎在后台自动完成的.
发布引擎: 发布操作的特定实现. 系统提供四种发行类型,分别是: 单发行,增量发行,完整发行和计划发行.
信息关联: 一个手稿可以与多个手稿关联. 当用户阅读信息时,系统会自动提供指向相关信息的链接. 查看全部
概述
同时,北斗七星内容管理系统提供了强大的网站组管理功能,可以在一个系统中管理多个独立的子站点. 每个子站点都有单独的管理权限. 每个站点都支持资源共享,集中式数据存储以及对多个站点的统一管理,而不会互相干扰,从而在站点组模式下充分提高了信息发布的效率.
建筑
北斗星CMS是基于Internet / Intranet的网站(组)内容管理产品. 它支持强大的多站点管理和在线视觉编辑功能. 它可以灵活地定义满足不同工作要求的信息获取,编辑,审阅和分发过程,并且有效地解决了新时期政府和大型企业用户的多站点建设和网站信息发布中的常见问题和需求.
在站点部署方面,可以使用集中式部署,即所有子站点都可以与主站点集中部署在统一的硬件平台上;它也可以是分布式部署,即子站点位于网站自己的组织中. 它支持集中式和分布式混合使用.
北斗星内容管理系统基于北斗星应用支持平台,并直接使用北斗星应用支持平台中的分类引擎来统一用户管理.
主要功能
站点管理: 管理系统中的多个独立站点. 该系统可以轻松添加站点,每个站点都具有严格的管理权限,具有独立的获取,编辑,查看和分发过程,而不会相互干扰;并且可以在多个站点之间共享资源,实现多个站点的统一管理和集中式数据存储. 该站点可以激活和停用.
列管理: 支持用户方便地创建,删除和编辑列,修改列名称和类型以及选择使用不同的列模板.
模板管理: 模板将内容和表达式的形式分开,因此可以根据用户的需要快速更改接口的表达式,而无需程序员修改程序. 通过界面设计和生成器,用户可以以所见即所得的方式轻松设计和预览模板.
信息采集: 通过北斗星互联网信息采集工具,根据客户的不同需求,准确,及时地完成信息采集任务.
信息编辑: 提供可视内容编辑器,该编辑器支持类似于Word之类的常见编辑工具的界面. 它支持三种粘贴方法: 纯文本粘贴,Word原创格式粘贴,Word删除多余的代码粘贴.
信息审阅: 支持可自定义的多级审阅过程. 可以为不同的列定制不同的批准过程. 只有经过审查和确认的内容才会在网站上发布. 所有编辑过程均由北斗星过程管理系统实施.
信息发布: 通过解析模板,填充数据来生成网页并将其上传到Web服务器的过程. 页面的生成和上传是由发布引擎在后台自动完成的.
发布引擎: 发布操作的特定实现. 系统提供四种发行类型,分别是: 单发行,增量发行,完整发行和计划发行.
信息关联: 一个手稿可以与多个手稿关联. 当用户阅读信息时,系统会自动提供指向相关信息的链接.
如何建立个性化的推荐系统?
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2020-08-08 04:30
挖掘: 此过程是将用户数据计算并挖掘到我们想要的功能中(通常称为“用户个人资料”,在行业中通常称为用户个人资料). 用户挖掘通常需要与算法结合,而不是凭空挖掘特征. 没有算法应用程序的用户头像毫无价值.
存储: 用户的兴趣在一段时间内不会有太大变化,因此可以使用用户的长期行为来积累用户肖像,并且需要存储这些配置文件. 如果用户数量很大,那么所需的存储资源也很大,那么就需要一个可以以分布式方式存储大量数据的数据库,并且它必须可靠且便宜,例如hdfs(Hadoop Distributed文件系统),如果要进行实时计算,用户的兴趣需要快速访问的数据库(例如redis),因此对于微博和头条等公司来说,购买服务器也是一大笔费用.
当然,用户兴趣不是一成不变的,因此用户兴趣需要随着时间的推移而“衰减”. 设置合理的衰减系数对于用户配置文件也非常重要.
此外,用户行为挖掘-用户冷启动中还有另一个历史问题. 我们需要在一篇文章中讨论这个主题.
第四,排序算法
在前三个步骤中收录内容和用户数据时,可以在第四步中使用算法来匹配两者. 个性化推荐的本质是进行前N名排名,该排名通常包括两个模块: “召回”和“排名”. 例如,如果我有100,000条消息,但是用户每天只能看到10条消息,那么我应该向用户推荐10条消息?我可以将100,000个项目从10,000到100,000进行分类,因此,无论用户希望看到多少个项目,我都只需从已排序的10,000个项目中从前到后进行选择. 这个过程是“排序”;但是这种排序方法在实时索引编制上过于昂贵,可能带来高延迟,因此我们首先使用一种相对简单的方法从100,000个中选择相对可靠的1,000,然后对1,000进行排序,然后选择100,000. 10,000个过程是“召回”.
算法中有很多方法,我将发表一篇文章,详细介绍当前推荐系统中最常用的最有效算法. 另外,无论哪种算法在内容推荐之后都需要使用“动态索引”(例如ctr),但是如何在推荐之前获得该动态索引?此处涉及的内容的冷启动将在以后另行讨论.
第五,推荐搜索引擎
为什么会有搜索引擎?是的,您没有记错. 实际上,个性化推荐和搜索是非常相似的领域. 两者都是信息过滤方法,并且都在执行一种“相关性”等级,并且目标函数非常接近(点击率). 只是搜索更加关注用户当前搜索关键字的相关性,而推荐则更加关注内容和用户个人资料的相关性. 每次用户浏览时,这都是实时请求. 因此,有必要实时计算最能满足用户兴趣的内容. 此步骤由在线搜索引擎执行. 但是,由于性能要求,在线索引步骤不应太耗时. 通常,排序算法会计算初始结果,而在线引擎会进行算法调度和归一化排序. 此外,在线索引还将负责接收请求,输出数据并公开服务,例如单击删除通常负责对业务和产品要求进行次要排名(例如插入广告,分解相同类型的内容等). ).
第六,ABtest系统
尽管ABtest系统不是个性化推荐系统的必要模块,但是没有ABtest的推荐系统必须是伪造的推荐系统!推荐系统的优化实际上是y = f(x),y是目标函数. 首先,目标函数必须非常清晰且可量化的指标; f(x)是选择的算法,算法特征参数和算法调度实际上,业界一直采用一些有效的算法,而算法原理却很少. 但是,如何结合您的产品方案选择功能和参数已成为个性化推荐准确性的关键因素. 如果有一个ABtest系统,那么我们可以尝试引入各种参数和功能,并且ABtest实验可以获得最佳的y,以便可以不断迭代和优化推荐系统.
当然,算法的优化并不像更改参数那样简单. 推荐者需要对数据非常敏感,并能够将复杂的问题抽象为可量化的指标,然后结合ABtest实验来快速进行迭代. 我总结的算法优化过程是: “数据分析发现问题,合理的假设,设计实验,实现,数据分析并得出结论或新的假设. ”更改参数只是“实现”步骤,这也是最简单的步骤. 通常,大多数人只关注“实现”,而很少关注分析和假设的过程. 这种优化的效果无法保证,并且有些产品和技术人员会陷入盲目的ABtest的误解,漫无目的地尝试,经常进行ABtest并发现AB组数据没有差异,甚至认为ABtest效率低下. 这些分析思想拉开了算法工程师之间的鸿沟.
摘要
通过这6个部分,已构建了完整的个性化推荐系统. 整个系统涉及算法工程师,自然语言处理/图像处理工程师,服务器工程师/架构师,数据挖掘工程师以及数据分析师,产品经理还需要大量标签审阅者,内容操作人员以及前端和客户端技术支持. 因此,构建良好的个性化推荐系统相对昂贵,但有时我们不需要该系统. 一些简单的规则可以实现相对个性化并提高用户效率(例如,将用户最近浏览的商品放在首位),因此提高效率的思想和方法最为重要,这是我们需要长期讨论的内容. 查看全部
传输: 用户的兴趣采集速度越快越好,因此可以将特定用户的操作快速反馈到下一个建议. 因此,需要稳定地传输和更新日志. 但是,出于成本考虑,用户配置文件“并非所有人”都可以实时更新. 有些可能会延迟1小时,有些可能会更新1天,1周甚至更长.
挖掘: 此过程是将用户数据计算并挖掘到我们想要的功能中(通常称为“用户个人资料”,在行业中通常称为用户个人资料). 用户挖掘通常需要与算法结合,而不是凭空挖掘特征. 没有算法应用程序的用户头像毫无价值.
存储: 用户的兴趣在一段时间内不会有太大变化,因此可以使用用户的长期行为来积累用户肖像,并且需要存储这些配置文件. 如果用户数量很大,那么所需的存储资源也很大,那么就需要一个可以以分布式方式存储大量数据的数据库,并且它必须可靠且便宜,例如hdfs(Hadoop Distributed文件系统),如果要进行实时计算,用户的兴趣需要快速访问的数据库(例如redis),因此对于微博和头条等公司来说,购买服务器也是一大笔费用.
当然,用户兴趣不是一成不变的,因此用户兴趣需要随着时间的推移而“衰减”. 设置合理的衰减系数对于用户配置文件也非常重要.
此外,用户行为挖掘-用户冷启动中还有另一个历史问题. 我们需要在一篇文章中讨论这个主题.
第四,排序算法
在前三个步骤中收录内容和用户数据时,可以在第四步中使用算法来匹配两者. 个性化推荐的本质是进行前N名排名,该排名通常包括两个模块: “召回”和“排名”. 例如,如果我有100,000条消息,但是用户每天只能看到10条消息,那么我应该向用户推荐10条消息?我可以将100,000个项目从10,000到100,000进行分类,因此,无论用户希望看到多少个项目,我都只需从已排序的10,000个项目中从前到后进行选择. 这个过程是“排序”;但是这种排序方法在实时索引编制上过于昂贵,可能带来高延迟,因此我们首先使用一种相对简单的方法从100,000个中选择相对可靠的1,000,然后对1,000进行排序,然后选择100,000. 10,000个过程是“召回”.
算法中有很多方法,我将发表一篇文章,详细介绍当前推荐系统中最常用的最有效算法. 另外,无论哪种算法在内容推荐之后都需要使用“动态索引”(例如ctr),但是如何在推荐之前获得该动态索引?此处涉及的内容的冷启动将在以后另行讨论.
第五,推荐搜索引擎
为什么会有搜索引擎?是的,您没有记错. 实际上,个性化推荐和搜索是非常相似的领域. 两者都是信息过滤方法,并且都在执行一种“相关性”等级,并且目标函数非常接近(点击率). 只是搜索更加关注用户当前搜索关键字的相关性,而推荐则更加关注内容和用户个人资料的相关性. 每次用户浏览时,这都是实时请求. 因此,有必要实时计算最能满足用户兴趣的内容. 此步骤由在线搜索引擎执行. 但是,由于性能要求,在线索引步骤不应太耗时. 通常,排序算法会计算初始结果,而在线引擎会进行算法调度和归一化排序. 此外,在线索引还将负责接收请求,输出数据并公开服务,例如单击删除通常负责对业务和产品要求进行次要排名(例如插入广告,分解相同类型的内容等). ).
第六,ABtest系统
尽管ABtest系统不是个性化推荐系统的必要模块,但是没有ABtest的推荐系统必须是伪造的推荐系统!推荐系统的优化实际上是y = f(x),y是目标函数. 首先,目标函数必须非常清晰且可量化的指标; f(x)是选择的算法,算法特征参数和算法调度实际上,业界一直采用一些有效的算法,而算法原理却很少. 但是,如何结合您的产品方案选择功能和参数已成为个性化推荐准确性的关键因素. 如果有一个ABtest系统,那么我们可以尝试引入各种参数和功能,并且ABtest实验可以获得最佳的y,以便可以不断迭代和优化推荐系统.
当然,算法的优化并不像更改参数那样简单. 推荐者需要对数据非常敏感,并能够将复杂的问题抽象为可量化的指标,然后结合ABtest实验来快速进行迭代. 我总结的算法优化过程是: “数据分析发现问题,合理的假设,设计实验,实现,数据分析并得出结论或新的假设. ”更改参数只是“实现”步骤,这也是最简单的步骤. 通常,大多数人只关注“实现”,而很少关注分析和假设的过程. 这种优化的效果无法保证,并且有些产品和技术人员会陷入盲目的ABtest的误解,漫无目的地尝试,经常进行ABtest并发现AB组数据没有差异,甚至认为ABtest效率低下. 这些分析思想拉开了算法工程师之间的鸿沟.
摘要
通过这6个部分,已构建了完整的个性化推荐系统. 整个系统涉及算法工程师,自然语言处理/图像处理工程师,服务器工程师/架构师,数据挖掘工程师以及数据分析师,产品经理还需要大量标签审阅者,内容操作人员以及前端和客户端技术支持. 因此,构建良好的个性化推荐系统相对昂贵,但有时我们不需要该系统. 一些简单的规则可以实现相对个性化并提高用户效率(例如,将用户最近浏览的商品放在首位),因此提高效率的思想和方法最为重要,这是我们需要长期讨论的内容.
一种制作在线数据采集系统的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 490 次浏览 • 2020-08-07 01:07
本申请涉及计算机领域,尤其涉及在线数据采集系统.
背景技术:
数据采集是指以完全或增量采集方式将数据从源数据库复制到目标数据库的过程.
目前,大多数传统数据采集都是基于本地数据的. 随着Internet的发展,在线数据库的数量正在增加. 与本地数据相比,在线数据具有跨区域,跨域的特点. 对于数据采集,目标地址也处于联机状态. 因此,目标地址是灵活且可变的.
因此,基于在线数据的上述特征,如何实现在线数据采集已成为亟待解决的问题.
技术实现要素:
本申请提供了一种基于支持向量机的分类方法和装置,旨在解决如何避免支持向量机的尺寸灾难,从而提高分类的准确性.
为了达到上述目的,本申请提供了以下技术解决方案:
在线数据采集系统,包括:
可视任务编辑器用于显示图形编辑界面,并根据用户在图形编辑界面上的操作生成数据采集任务. 图形编辑界面包括图形元素库,并且图形元素库包括第一类型的图形元素和第二类型的图形元素,第一类型的图形元素可以配置有不同的源数据库和/或目标数据库,以及第二类图形元素分别对应于数据采集的子链接;
分布式数据采集引擎用于根据数据采集任务执行数据采集过程.
可视任务编辑器还专门包括:
显示单元用于向用户显示图形编辑界面. 图像编辑界面包括图形元素库,格式编辑选项和任务管理选项. 其中,图形元素库包括第一类型的图形元素和第二两种图形元素,其中第一类型的图形元素包括输入和输出图形元素,第二类型的图形元素包括统计图形元素,脚本图形元素,计算图形元素,并且格式编辑选项包括编辑界面上图形格式控制选项中的图形元素,任务管理选项包括用于管理数据采集任务的选项;
任务生成单元,用于响应用户在图形编辑界面上的操作,生成数据采集任务;
发送单元用于发送数据采集任务.
(可选)分布式数据采集引擎包括:
外部API接口,用于从外部提供采集任务执行程序的执行,启动,停止,环境配置和资源注册功能,并接收可视任务编辑器发送的数据采集任务;
引擎核心用于执行数据采集任务;
引擎扩展用于为引擎核心提供数据源,数据对象和相应的业务功能实现.
可选地,引擎核心具体包括:
数据库扩展接口,用于标识不同数据库的驱动程序;
采集任务执行程序,用于将数据从源数据库复制到目标数据库;
服务器协同管理单元,用于在使用多个服务器时对多个服务器进行协同管理;
集合扩展接口,用于提供数据采集功能的扩展;
采集链接消息管理单元用于控制和管理在数据采集过程中每个链接中看到的消息的传输.
(可选)还包括:
可视任务状态监视模块用于监视数据采集过程.
可视任务状态监视模块可选地包括:
状态数据显示单元,用于显示数据采集任务的实时运行状态;
故障定位单元,用于当数据采集任务的执行过程异常时,以图形方式显示故障链接,并通过日志显示导致故障的数据;
性能日志分析单元用于通过图形显示的方式显示执行数据采集任务时每个链接所消耗的处理时间.
(可选)还包括:
公共资源管理模块用于为数据采集过程提供权限项目管理和资源重用控制.
可选地,公共资源管理模块具体包括:
数据库连接管理单元用于数据采集任务的源数据库和目标数据库的类型选择和资源配置;
任务管理单元,用于为数据采集任务提供共享服务;
授权控制单元用于为用户分配访问权限,以避免在多个用户使用时发生修改冲突.
可选地,公共资源管理模块还包括:
当需要多个通道来处理数据采集任务时,数据通道管理单元用于配置数据通道;
当数据采集任务需要多个服务器协作时,集群管理单元用于提供服务器配置功能.
此应用程序中描述的在线数据采集系统包括可视任务编辑器和分布式数据采集引擎. 可视任务编辑器用于显示图形编辑界面并基于用户对图形编辑界面的操作来生成数据. 采集任务,分布式数据采集引擎用于根据数据采集任务执行数据采集过程,因为可以根据在图形编辑界面上使用的操作来生成数据采集任务,该图形编辑界面包括图形元素库,该图形元素库包括第一类型的图形元素和第二类型的图形元素,第一类型图形元素的标识可以配置有不同的源数据库和/或目标数据库,并且第二类型的图形元素分别对应于数据采集. 可以看出,本实施例所述的系统使用户能够直观,灵活地创建数据采集任务. 鉴于在线数据的特性,用户还可以通过对图形元素进行操作来灵活地创建数据采集任务.
图纸说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,以下将简要介绍实施例或现有技术的描述中所需要的附图. 显然,在以下描述中,附图仅是本申请的一些实施例. 对于本领域普通技术人员而言,无需进行创造性劳动,即可基于这些附图获得其他附图.
图1是本申请实施例公开的在线数据采集系统图的结构示意图;
图2是本申请实施例公开的视觉任务编辑器的结构示意图;
图3是本申请实施例公开的设计界面中的行至列,表输入,排序和表输出图形元素的拖动示意图;
图4是本申请实施例公开的表输入图形元素的页面设置示意图;
图5是本申请实施例公开的排序基元的页面设置示意图;
图6是本申请实施例公开的行至列图形元素的页面设置的示意图;
图7是本申请实施例公开的表输出图形元素的页面设置示意图;
图8是本申请实施例公开的另一种在线数据采集系统的结构示意图;
图9是本申请实施例公开的分布式数据采集引擎的结构示意图;
图10是本申请实施例公开的视觉任务状态监控模块的结构示意图;
图. 图11是本申请实施例公开的公共资源管理模块的结构示意图.
具体的实现方法
本申请实施例提供了一种在线数据采集系统,可用于采集在线数据,其目的是适应在线数据的特点.
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚,完整地描述. 显然,所描述的实施例仅是本申请实施例的一部分,而不是全部. 例. 基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围.
本申请实施例公开的在线数据采集系统,如图1所示,包括:
可视任务编辑器101和分布式数据获取引擎102.
其中,视觉任务编辑器101用于显示图形编辑界面,并根据用户在图形编辑界面上的操作生成数据采集任务.
具体地,图形编辑界面包括图形元素库,该图形元素库包括第一类型的图形元素和第二类型的图形元素,并且第一类型的图形元素可以配置有不同的源数据库和/或目标数据库中,第二种图形元素分别对应于数据采集的子链接.
分布式数据采集引擎102用于根据数据采集任务执行数据采集过程.
如图如图2所示,可视任务编辑器可以实现基于Flash技术的图形功能,具体包括: 显示单元201,任务生成单元202和发送单元203.
具体地,显示单元201用于向用户显示图形编辑界面,该图像编辑界面包括图形元素库,格式编辑选项和图形元素管理选项;
其中,图形元素库包括第一类型的图形元素和第二类型的图形元素,其中第一类型的图形元素包括输入和输出图形元素,第二类型的图形元素包括统计图形元素,脚本图形原语和计算原语. 各种原语对应于数据采集,数据导入,数据质量验证,数据处理和数据导出的四个阶段. 另外,数据采集中常见的增量采集和错误采集需要提供针对性的解决方案.
格式编辑选项包括图形编辑界面上图形元素的格式控制选项. 例如,格式控制选项可以包括图形元素的外观类型,例如左右对齐,网格线对齐,左右对齐,放大和缩小. 设置选项.
任务管理选项包括用于管理任务的选项,例如现有任务的显示,编辑后的任务验证以及任务的保存和分析.
任务生成单元202,用于响应用户在图形编辑界面上的操作,生成数据采集任务;
具体来说,用户可以在图形界面上拖放图形元素,排列,选择和连接多个图形元素.
发送单元203,用于发送数据采集任务.
例如,可以通过使用本实施例中所述的系统来实现以下数据采集过程:
预采集准备: 执行bamtest.sql数据库脚本,数据库中已经存在bamtest数据库,并根据“测试数据”准备了相关表.
采集过程:
1. 创建一个新的数据采集任务“ Test”;
2. 在与“测试”任务相对应的采集任务列表中创建一个新的“测试任务”,选择“测试任务”任务,然后单击“设计任务模型”;
3. 在设计界面中将行拖入列,表输入,排序和表输出原语,如图3所示,并根据执行逻辑连接上述原语;
4. 单击打开表以输入图元,页面设置如图4所示. 单击打开排序原语,页面设置如图5所示. 单击打开行到列原语,页面设置如图6所示;单击打开表以输出基元,页面设置如图7所示;
5. 完成图形元素配置后,单击“保存”按钮,然后将建立数据采集任务.
性能显示:
1)Bam_test_hzl原创表中的数据如表1所示.
表1
2)表2中显示了在对基元进行排序后从Bam_test_hzl的原创表转换而来的数据:
表2
3)执行后保存结果,表3中显示了bam_output_hzl表中的数据:
表3
此步骤的主要功能: 将数据分别显示在“中文”,“数学”和“英语”字段中,并整合到“主题”字段中,并生成单独的“得分”字段以存储数据,然后以行显示的数据将以列显示.
可以看出,在本实施例所述的在线数据采集系统中,可视任务编辑器可以为用户提供在线可视采集任务的编辑,从而可以根据在线数据状态的变化灵活地设计数据采集任务,以满足在线数据要求. 采集需求.
本申请实施例公开的另一种在线数据采集系统,如图8所示,
可视任务编辑器,分布式数据采集引擎,可视任务状态监视模块和公共资源管理模块.
其中,可视任务编辑器的功能和具体结构如上述实施例所述,在此不再赘述.
具体而言,如图2所示,在基体2上设置有多个. 参照图9,分布式数据采集引擎可以具体包括: 外部API接口,引擎核心和引擎扩展.
外部API接口用于从外部提供采集任务执行程序的执行,启动,停止,环境配置和资源注册功能,并接收可视任务编辑器发送的数据采集任务.
引擎核心用于执行数据采集任务. 引擎核心可以具体包括: 数据库扩展接口,用于标识不同数据库的驱动程序;采集任务执行器,用于将数据从源数据库复制到目标数据库;当使用多个服务器时,服务器协同管理单元用于对多个服务器进行协同管理. 采集扩展接口用于提供数据采集功能的扩展. 采集链接消息管理单元用于控制数据. 对采集过程中每个链接中看到的消息的传输进行控制和管理.
引擎扩展用于为引擎核心提供数据源,数据对象和相应的业务功能实现.
如图10所示,可视任务状态监控模块包括: 状态数据显示单元,用于显示数据采集任务的实时运行状态;故障定位单元,在发生数据采集任务的执行过程时使用. 出现异常时,以图形方式显示故障链接,并将导致故障的数据显示在日志中;性能日志分析单元,用于以图形显示方式显示时间,执行数据采集任务时每个链接消耗的处理. 使用显示图形显示整个数据采集过程中每个链接消耗的处理时间,可使运维人员快速定位整个处理过程的性能瓶颈,并采取相应的措施完成任务操作的性能调整
如图11所示,公共资源管理模块具体包括: 数据库连接管理单元,用于选择数据采集任务的源数据库和目标数据库的类型和资源配置;任务管理单元,用于为采集任务提供数据共享服务;权限控制单元,用于为用户分配使用权限,以避免在多个人使用时发生修改冲突.
本实施例中描述的在线数据采集系统结合了最新的在线显示技术以提供可视任务编辑器. 一方面,可视任务编辑器可以与采集的数据体系结构无缝集成,另一方面,它也可以作为独立的在线编辑器独立部署和使用,从而提高了灵活性. 此外,它还集成了任务编辑,数据采集以及运维管理功能,方便用户使用.
如果在本申请的实施例的方法中描述的功能以软件功能单元的形式实现并且被出售或用作独立产品,则可以将它们存储在计算设备可读的存储介质中. 基于该理解,可以以软件产品的形式来体现本申请的实施例的对现有技术有贡献的部分或技术解决方案的一部分,该软件产品被存储在存储介质中并且包括用于进行制造的若干指令. 计算设备(可以是个人计算机,服务器,移动计算设备或网络设备等)执行在本申请的每个实施例中描述的方法的全部或部分步骤. 前述存储介质包括: U盘,移动硬盘,只读存储器(ROM,只读存储器),随机存取存储器(RAM,随机存取存储器),磁盘或光盘以及其他可以存储程序代码的介质.
本说明书中的实施例以渐进方式进行描述. 每个实施例着重于与其他实施例的不同之处,并且各个实施例之间的相同或相似部分可以互相参考.
所公开的实施例的以上描述使得本领域技术人员能够实施或使用该申请. 对这些实施例的各种修改对于本领域技术人员将是显而易见的,并且在不脱离本申请的精神或范围的情况下,可以在其他实施例中实现本文档中定义的一般原理. 因此,本申请将不限于本文中所示的实施例,而应符合与本文中公开的原理和新颖特征相一致的最广范围. 查看全部
本申请涉及计算机领域,尤其涉及在线数据采集系统.
背景技术:
数据采集是指以完全或增量采集方式将数据从源数据库复制到目标数据库的过程.
目前,大多数传统数据采集都是基于本地数据的. 随着Internet的发展,在线数据库的数量正在增加. 与本地数据相比,在线数据具有跨区域,跨域的特点. 对于数据采集,目标地址也处于联机状态. 因此,目标地址是灵活且可变的.
因此,基于在线数据的上述特征,如何实现在线数据采集已成为亟待解决的问题.
技术实现要素:
本申请提供了一种基于支持向量机的分类方法和装置,旨在解决如何避免支持向量机的尺寸灾难,从而提高分类的准确性.
为了达到上述目的,本申请提供了以下技术解决方案:
在线数据采集系统,包括:
可视任务编辑器用于显示图形编辑界面,并根据用户在图形编辑界面上的操作生成数据采集任务. 图形编辑界面包括图形元素库,并且图形元素库包括第一类型的图形元素和第二类型的图形元素,第一类型的图形元素可以配置有不同的源数据库和/或目标数据库,以及第二类图形元素分别对应于数据采集的子链接;
分布式数据采集引擎用于根据数据采集任务执行数据采集过程.
可视任务编辑器还专门包括:
显示单元用于向用户显示图形编辑界面. 图像编辑界面包括图形元素库,格式编辑选项和任务管理选项. 其中,图形元素库包括第一类型的图形元素和第二两种图形元素,其中第一类型的图形元素包括输入和输出图形元素,第二类型的图形元素包括统计图形元素,脚本图形元素,计算图形元素,并且格式编辑选项包括编辑界面上图形格式控制选项中的图形元素,任务管理选项包括用于管理数据采集任务的选项;
任务生成单元,用于响应用户在图形编辑界面上的操作,生成数据采集任务;
发送单元用于发送数据采集任务.
(可选)分布式数据采集引擎包括:
外部API接口,用于从外部提供采集任务执行程序的执行,启动,停止,环境配置和资源注册功能,并接收可视任务编辑器发送的数据采集任务;
引擎核心用于执行数据采集任务;
引擎扩展用于为引擎核心提供数据源,数据对象和相应的业务功能实现.
可选地,引擎核心具体包括:
数据库扩展接口,用于标识不同数据库的驱动程序;
采集任务执行程序,用于将数据从源数据库复制到目标数据库;
服务器协同管理单元,用于在使用多个服务器时对多个服务器进行协同管理;
集合扩展接口,用于提供数据采集功能的扩展;
采集链接消息管理单元用于控制和管理在数据采集过程中每个链接中看到的消息的传输.
(可选)还包括:
可视任务状态监视模块用于监视数据采集过程.
可视任务状态监视模块可选地包括:
状态数据显示单元,用于显示数据采集任务的实时运行状态;
故障定位单元,用于当数据采集任务的执行过程异常时,以图形方式显示故障链接,并通过日志显示导致故障的数据;
性能日志分析单元用于通过图形显示的方式显示执行数据采集任务时每个链接所消耗的处理时间.
(可选)还包括:
公共资源管理模块用于为数据采集过程提供权限项目管理和资源重用控制.
可选地,公共资源管理模块具体包括:
数据库连接管理单元用于数据采集任务的源数据库和目标数据库的类型选择和资源配置;
任务管理单元,用于为数据采集任务提供共享服务;
授权控制单元用于为用户分配访问权限,以避免在多个用户使用时发生修改冲突.
可选地,公共资源管理模块还包括:
当需要多个通道来处理数据采集任务时,数据通道管理单元用于配置数据通道;
当数据采集任务需要多个服务器协作时,集群管理单元用于提供服务器配置功能.
此应用程序中描述的在线数据采集系统包括可视任务编辑器和分布式数据采集引擎. 可视任务编辑器用于显示图形编辑界面并基于用户对图形编辑界面的操作来生成数据. 采集任务,分布式数据采集引擎用于根据数据采集任务执行数据采集过程,因为可以根据在图形编辑界面上使用的操作来生成数据采集任务,该图形编辑界面包括图形元素库,该图形元素库包括第一类型的图形元素和第二类型的图形元素,第一类型图形元素的标识可以配置有不同的源数据库和/或目标数据库,并且第二类型的图形元素分别对应于数据采集. 可以看出,本实施例所述的系统使用户能够直观,灵活地创建数据采集任务. 鉴于在线数据的特性,用户还可以通过对图形元素进行操作来灵活地创建数据采集任务.
图纸说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,以下将简要介绍实施例或现有技术的描述中所需要的附图. 显然,在以下描述中,附图仅是本申请的一些实施例. 对于本领域普通技术人员而言,无需进行创造性劳动,即可基于这些附图获得其他附图.
图1是本申请实施例公开的在线数据采集系统图的结构示意图;
图2是本申请实施例公开的视觉任务编辑器的结构示意图;
图3是本申请实施例公开的设计界面中的行至列,表输入,排序和表输出图形元素的拖动示意图;
图4是本申请实施例公开的表输入图形元素的页面设置示意图;
图5是本申请实施例公开的排序基元的页面设置示意图;
图6是本申请实施例公开的行至列图形元素的页面设置的示意图;
图7是本申请实施例公开的表输出图形元素的页面设置示意图;
图8是本申请实施例公开的另一种在线数据采集系统的结构示意图;
图9是本申请实施例公开的分布式数据采集引擎的结构示意图;
图10是本申请实施例公开的视觉任务状态监控模块的结构示意图;
图. 图11是本申请实施例公开的公共资源管理模块的结构示意图.
具体的实现方法
本申请实施例提供了一种在线数据采集系统,可用于采集在线数据,其目的是适应在线数据的特点.
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚,完整地描述. 显然,所描述的实施例仅是本申请实施例的一部分,而不是全部. 例. 基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围.
本申请实施例公开的在线数据采集系统,如图1所示,包括:
可视任务编辑器101和分布式数据获取引擎102.
其中,视觉任务编辑器101用于显示图形编辑界面,并根据用户在图形编辑界面上的操作生成数据采集任务.
具体地,图形编辑界面包括图形元素库,该图形元素库包括第一类型的图形元素和第二类型的图形元素,并且第一类型的图形元素可以配置有不同的源数据库和/或目标数据库中,第二种图形元素分别对应于数据采集的子链接.
分布式数据采集引擎102用于根据数据采集任务执行数据采集过程.
如图如图2所示,可视任务编辑器可以实现基于Flash技术的图形功能,具体包括: 显示单元201,任务生成单元202和发送单元203.
具体地,显示单元201用于向用户显示图形编辑界面,该图像编辑界面包括图形元素库,格式编辑选项和图形元素管理选项;
其中,图形元素库包括第一类型的图形元素和第二类型的图形元素,其中第一类型的图形元素包括输入和输出图形元素,第二类型的图形元素包括统计图形元素,脚本图形原语和计算原语. 各种原语对应于数据采集,数据导入,数据质量验证,数据处理和数据导出的四个阶段. 另外,数据采集中常见的增量采集和错误采集需要提供针对性的解决方案.
格式编辑选项包括图形编辑界面上图形元素的格式控制选项. 例如,格式控制选项可以包括图形元素的外观类型,例如左右对齐,网格线对齐,左右对齐,放大和缩小. 设置选项.
任务管理选项包括用于管理任务的选项,例如现有任务的显示,编辑后的任务验证以及任务的保存和分析.
任务生成单元202,用于响应用户在图形编辑界面上的操作,生成数据采集任务;
具体来说,用户可以在图形界面上拖放图形元素,排列,选择和连接多个图形元素.
发送单元203,用于发送数据采集任务.
例如,可以通过使用本实施例中所述的系统来实现以下数据采集过程:
预采集准备: 执行bamtest.sql数据库脚本,数据库中已经存在bamtest数据库,并根据“测试数据”准备了相关表.
采集过程:
1. 创建一个新的数据采集任务“ Test”;
2. 在与“测试”任务相对应的采集任务列表中创建一个新的“测试任务”,选择“测试任务”任务,然后单击“设计任务模型”;
3. 在设计界面中将行拖入列,表输入,排序和表输出原语,如图3所示,并根据执行逻辑连接上述原语;
4. 单击打开表以输入图元,页面设置如图4所示. 单击打开排序原语,页面设置如图5所示. 单击打开行到列原语,页面设置如图6所示;单击打开表以输出基元,页面设置如图7所示;
5. 完成图形元素配置后,单击“保存”按钮,然后将建立数据采集任务.
性能显示:
1)Bam_test_hzl原创表中的数据如表1所示.
表1
2)表2中显示了在对基元进行排序后从Bam_test_hzl的原创表转换而来的数据:
表2
3)执行后保存结果,表3中显示了bam_output_hzl表中的数据:
表3
此步骤的主要功能: 将数据分别显示在“中文”,“数学”和“英语”字段中,并整合到“主题”字段中,并生成单独的“得分”字段以存储数据,然后以行显示的数据将以列显示.
可以看出,在本实施例所述的在线数据采集系统中,可视任务编辑器可以为用户提供在线可视采集任务的编辑,从而可以根据在线数据状态的变化灵活地设计数据采集任务,以满足在线数据要求. 采集需求.
本申请实施例公开的另一种在线数据采集系统,如图8所示,
可视任务编辑器,分布式数据采集引擎,可视任务状态监视模块和公共资源管理模块.
其中,可视任务编辑器的功能和具体结构如上述实施例所述,在此不再赘述.
具体而言,如图2所示,在基体2上设置有多个. 参照图9,分布式数据采集引擎可以具体包括: 外部API接口,引擎核心和引擎扩展.
外部API接口用于从外部提供采集任务执行程序的执行,启动,停止,环境配置和资源注册功能,并接收可视任务编辑器发送的数据采集任务.
引擎核心用于执行数据采集任务. 引擎核心可以具体包括: 数据库扩展接口,用于标识不同数据库的驱动程序;采集任务执行器,用于将数据从源数据库复制到目标数据库;当使用多个服务器时,服务器协同管理单元用于对多个服务器进行协同管理. 采集扩展接口用于提供数据采集功能的扩展. 采集链接消息管理单元用于控制数据. 对采集过程中每个链接中看到的消息的传输进行控制和管理.
引擎扩展用于为引擎核心提供数据源,数据对象和相应的业务功能实现.
如图10所示,可视任务状态监控模块包括: 状态数据显示单元,用于显示数据采集任务的实时运行状态;故障定位单元,在发生数据采集任务的执行过程时使用. 出现异常时,以图形方式显示故障链接,并将导致故障的数据显示在日志中;性能日志分析单元,用于以图形显示方式显示时间,执行数据采集任务时每个链接消耗的处理. 使用显示图形显示整个数据采集过程中每个链接消耗的处理时间,可使运维人员快速定位整个处理过程的性能瓶颈,并采取相应的措施完成任务操作的性能调整
如图11所示,公共资源管理模块具体包括: 数据库连接管理单元,用于选择数据采集任务的源数据库和目标数据库的类型和资源配置;任务管理单元,用于为采集任务提供数据共享服务;权限控制单元,用于为用户分配使用权限,以避免在多个人使用时发生修改冲突.
本实施例中描述的在线数据采集系统结合了最新的在线显示技术以提供可视任务编辑器. 一方面,可视任务编辑器可以与采集的数据体系结构无缝集成,另一方面,它也可以作为独立的在线编辑器独立部署和使用,从而提高了灵活性. 此外,它还集成了任务编辑,数据采集以及运维管理功能,方便用户使用.
如果在本申请的实施例的方法中描述的功能以软件功能单元的形式实现并且被出售或用作独立产品,则可以将它们存储在计算设备可读的存储介质中. 基于该理解,可以以软件产品的形式来体现本申请的实施例的对现有技术有贡献的部分或技术解决方案的一部分,该软件产品被存储在存储介质中并且包括用于进行制造的若干指令. 计算设备(可以是个人计算机,服务器,移动计算设备或网络设备等)执行在本申请的每个实施例中描述的方法的全部或部分步骤. 前述存储介质包括: U盘,移动硬盘,只读存储器(ROM,只读存储器),随机存取存储器(RAM,随机存取存储器),磁盘或光盘以及其他可以存储程序代码的介质.
本说明书中的实施例以渐进方式进行描述. 每个实施例着重于与其他实施例的不同之处,并且各个实施例之间的相同或相似部分可以互相参考.
所公开的实施例的以上描述使得本领域技术人员能够实施或使用该申请. 对这些实施例的各种修改对于本领域技术人员将是显而易见的,并且在不脱离本申请的精神或范围的情况下,可以在其他实施例中实现本文档中定义的一般原理. 因此,本申请将不限于本文中所示的实施例,而应符合与本文中公开的原理和新颖特征相一致的最广范围.
一套内容采集系统的源代码
采集交流 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2020-08-06 21:19
一套内容采集系统可以解放编辑者. 内容采集系统是基于内容的网站的很好的助手. 除了原创内容外,其他内容还需要由编辑或采集系统采集,然后添加到您自己的网站上. Discuz DvBBS CMS和其他产品具有自己的内容采集功能,可以采集指定的相关内容. 单客户端优采云采集器也可以很好地采集指定的内容. 这些工具都希望机器取代人类,从内容处理工作中解放编辑人员,并执行一些高端任务,例如微调采集结果的内容,SEO优化,设置精确的采集规则并让采集的内容更符合您自己网站的需求.
以下内容采集系统就是根据这个想法开发的. 该采集系统由两部分组成:
1. 编辑器使用的采集规则设置器以及用于查看,微调和发布采集结果的网站.
2. 在服务器上部署了计时采集器和计时发送器.
首先,编辑器通过采集规则设置器(NiceCollectoer.exe)设置要采集的网站,然后在采集完成后,编辑者通过网站(PickWeb)审查并微调采集的结果,然后优化并将其发布在您自己的网站上. 编辑者需要做的是设置采集规则并优化采集结果. 工作的其他部分由机器完成.
NicePicker是一个HTML分析器,用于提取Url,NiceCollector和HostCollector都使用NicePicker分析Html,NiceCollectoer是一个采集规则设置器,目标网站只需要设置一次:
用法类似于最早的优采云采集器. 在这里,我们将博客花园用作目标采集站点. 采集规则非常简单: 当编辑者设置采集规则时,这些规则将被保存到与NiceCollector.exe相同目录中的Setting.mdb中. 通常,设置采集规则后,基本上无需更改它们. 仅当目标网站的Html Dom结构更改时,您才需要再次微调采集规则. NiceCollector还用于设置和添加新的目标采集站点.
编辑器完成采集规则的设置后,将Setting.mdb放在HostCollector.exe下,HostCollector将根据Setting.mdb的设置进行实际采集,并将采集的结果保存到数据库中.
在此步骤中,内容采集工作完成. 编辑者可以打开PickWeb,对采集结果进行微调和优化,然后通过审核并将其发送到他们的网站
PickWeb并未完成将采集结果实际发送到您自己的网站的工作. 编辑器完成内容审核后,PostToForum.exe将读取数据库并将审核的采集结果发送到您自己的网站. 当然,您需要.ashx或其他方法才能在网站上接收采集的结果. 不建议PostToFormu.exe直接操作您自己网站的数据库. 最好在您自己的网站上通过API接收采集的结果.
该数据库位于DB_51aspx文件夹(sql2005)中,只需附加它即可.
登录用户名和密码均为51aspx 查看全部
一套内容采集系统的源代码
一套内容采集系统可以解放编辑者. 内容采集系统是基于内容的网站的很好的助手. 除了原创内容外,其他内容还需要由编辑或采集系统采集,然后添加到您自己的网站上. Discuz DvBBS CMS和其他产品具有自己的内容采集功能,可以采集指定的相关内容. 单客户端优采云采集器也可以很好地采集指定的内容. 这些工具都希望机器取代人类,从内容处理工作中解放编辑人员,并执行一些高端任务,例如微调采集结果的内容,SEO优化,设置精确的采集规则并让采集的内容更符合您自己网站的需求.
以下内容采集系统就是根据这个想法开发的. 该采集系统由两部分组成:
1. 编辑器使用的采集规则设置器以及用于查看,微调和发布采集结果的网站.
2. 在服务器上部署了计时采集器和计时发送器.
首先,编辑器通过采集规则设置器(NiceCollectoer.exe)设置要采集的网站,然后在采集完成后,编辑者通过网站(PickWeb)审查并微调采集的结果,然后优化并将其发布在您自己的网站上. 编辑者需要做的是设置采集规则并优化采集结果. 工作的其他部分由机器完成.
NicePicker是一个HTML分析器,用于提取Url,NiceCollector和HostCollector都使用NicePicker分析Html,NiceCollectoer是一个采集规则设置器,目标网站只需要设置一次:
用法类似于最早的优采云采集器. 在这里,我们将博客花园用作目标采集站点. 采集规则非常简单: 当编辑者设置采集规则时,这些规则将被保存到与NiceCollector.exe相同目录中的Setting.mdb中. 通常,设置采集规则后,基本上无需更改它们. 仅当目标网站的Html Dom结构更改时,您才需要再次微调采集规则. NiceCollector还用于设置和添加新的目标采集站点.
编辑器完成采集规则的设置后,将Setting.mdb放在HostCollector.exe下,HostCollector将根据Setting.mdb的设置进行实际采集,并将采集的结果保存到数据库中.
在此步骤中,内容采集工作完成. 编辑者可以打开PickWeb,对采集结果进行微调和优化,然后通过审核并将其发送到他们的网站
PickWeb并未完成将采集结果实际发送到您自己的网站的工作. 编辑器完成内容审核后,PostToForum.exe将读取数据库并将审核的采集结果发送到您自己的网站. 当然,您需要.ashx或其他方法才能在网站上接收采集的结果. 不建议PostToFormu.exe直接操作您自己网站的数据库. 最好在您自己的网站上通过API接收采集的结果.
该数据库位于DB_51aspx文件夹(sql2005)中,只需附加它即可.
登录用户名和密码均为51aspx
智能网络内容采集器v1.9.3免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-08-06 17:06
智能Web内容采集器的功能:
1. 使用基础的HTTP方法来采集数据,这是快速且稳定的. 可以构建多个任务和线程来同时从多个网站采集数据.
2. 用户可以随意导入和导出任务.
3. 可以使用密码设置该任务,以确保您的采集任务的详细信息不会泄漏.
4. 它还具有N页采集暂停/拨号到IP更改,以及特殊标记暂停/拨号到IP更改和其他反捕获功能.
5. 您可以直接输入要捕获的URL,或使用JavaScript脚本生成URL,或通过关键字搜索捕获URL.
6. 您可以使用登录采集方法来采集需要登录帐户才能查看的Web内容.
7. 它可以无限期地在N列中采集内容和链接,并支持多级内容分页采集.
8. 它支持多种内容提取模式,并可以根据需要处理采集的内容,例如清除HTML,图片等.
9. 您可以编译自己的JAVASCRIPT脚本以提取网页的内容,并轻松实现内容的任何部分的采集.
10. 可以根据设置的模板保存采集的文本内容.
11. 可以将多个文件作为模板保存到同一文件.
12. 针对网页的多个部分分别进行页面内容采集.
13. 可以设置客户信息,以模拟百度等搜索引擎对目标网站的采集.
14. 它支持智能采集,只需发送URL即可采集Web内容.
15. 该软件*终身免费使用. 查看全部
智能Web内容采集器可以多任务和多线程模式采集任何网页上的任何指定文本内容,支持多级和多网页内容混合,并执行所需的相应过滤和处理,并且可以使用搜索关键字. 它可以采集所需的搜索结果,支持智能采集,并且只需输入URL即可采集网页的内容.
智能Web内容采集器的功能:
1. 使用基础的HTTP方法来采集数据,这是快速且稳定的. 可以构建多个任务和线程来同时从多个网站采集数据.
2. 用户可以随意导入和导出任务.
3. 可以使用密码设置该任务,以确保您的采集任务的详细信息不会泄漏.
4. 它还具有N页采集暂停/拨号到IP更改,以及特殊标记暂停/拨号到IP更改和其他反捕获功能.
5. 您可以直接输入要捕获的URL,或使用JavaScript脚本生成URL,或通过关键字搜索捕获URL.
6. 您可以使用登录采集方法来采集需要登录帐户才能查看的Web内容.
7. 它可以无限期地在N列中采集内容和链接,并支持多级内容分页采集.
8. 它支持多种内容提取模式,并可以根据需要处理采集的内容,例如清除HTML,图片等.
9. 您可以编译自己的JAVASCRIPT脚本以提取网页的内容,并轻松实现内容的任何部分的采集.
10. 可以根据设置的模板保存采集的文本内容.
11. 可以将多个文件作为模板保存到同一文件.
12. 针对网页的多个部分分别进行页面内容采集.
13. 可以设置客户信息,以模拟百度等搜索引擎对目标网站的采集.
14. 它支持智能采集,只需发送URL即可采集Web内容.
15. 该软件*终身免费使用.
通达信外部数据采集系统V2.6(添加了强大的实用功能)(图形)
采集交流 • 优采云 发表了文章 • 0 个评论 • 812 次浏览 • 2020-08-06 15:02
软件添加的内容如下:
1. 添加了数据格式自定义,例如: 1 | 688008 | 232 |更多分散的| 0.000首先是序列号|股票代码|数据编号|主题内容|内容,可以在导出时自定义输出内容,这解决了输出格式通达信,大智慧等软件,可以自由获取数据
2. 输出文件格式也已处理,也可以输出为其他文件格式
3. 重新下载数据后,有必要先删除旧数据,然后将其粘贴. 删除旧数据很麻烦,因为我以前不了解软件的结构. 抱歉,这次我添加了删除旧数据. 数据问题,
<p>只需在编辑框中填写旧数据的数据编号,清除文本中收录该数据编号的所有文本数据,即可自定义一个或多个要删除的数据编号,记住要删除格式. 删除格式为|数据编号|,如果要删除具有多个数据编号的数据,则必须在每组数据编号中留一个空格. 例如: | 225 | | 231 | | 55188 |这将立即删除所有内容,删除时请检查说明内容 查看全部
通达信外部数据采集系统V2.6(添加了强大的实用功能)
软件添加的内容如下:
1. 添加了数据格式自定义,例如: 1 | 688008 | 232 |更多分散的| 0.000首先是序列号|股票代码|数据编号|主题内容|内容,可以在导出时自定义输出内容,这解决了输出格式通达信,大智慧等软件,可以自由获取数据
2. 输出文件格式也已处理,也可以输出为其他文件格式
3. 重新下载数据后,有必要先删除旧数据,然后将其粘贴. 删除旧数据很麻烦,因为我以前不了解软件的结构. 抱歉,这次我添加了删除旧数据. 数据问题,
<p>只需在编辑框中填写旧数据的数据编号,清除文本中收录该数据编号的所有文本数据,即可自定义一个或多个要删除的数据编号,记住要删除格式. 删除格式为|数据编号|,如果要删除具有多个数据编号的数据,则必须在每组数据编号中留一个空格. 例如: | 225 | | 231 | | 55188 |这将立即删除所有内容,删除时请检查说明内容
Python作为数据采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 343 次浏览 • 2020-08-06 05:03
# -*- coding: utf-8 -*-
"""
Created on Fri Jan 26 15:44:26 2018
@author: szm
"""
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import re
random.seed(datetime.datetime.now())
def getLinks(articleUrl):
html = urlopen("https://baike.baidu.com"+articleUrl)
bsObj = BeautifulSoup(html, "html.parser")
return bsObj.find("div", {"class":"para"}).findAll("a", href=re.compile("^(/item/)((?!:).)*$"))
links = getLinks("/item/google")
while len(links) > 0:
newArticle = links[random.randint(0, len(links)-1)].attrs["href"]
print(newArticle)
links = getLinks(newArticle)
/item/%E8%B0%A2%E5%B0%94%E7%9B%96%C2%B7%E5%B8%83%E6%9E%97
/item/%E6%8B%89%E9%87%8C%C2%B7%E4%BD%A9%E5%A5%87
/item/%E6%96%AF%E5%9D%A6%E7%A6%8F
/item/%E6%97%A7%E9%87%91%E5%B1%B1/29211
/item/%E8%81%94%E5%90%88%E5%9B%BD/135426
/item/%E6%B3%95%E8%AF%AD
/item/%E7%BD%97%E6%9B%BC%E8%AF%AD%E6%97%8F
/item/%E6%84%8F%E5%A4%A7%E5%88%A9%E8%AF%AD
采集整个网站
您可能听说过深网,暗网或隐藏网.
术语,尤其是在最近的媒体中. 是什么意思?
深层纤维网是纤维网的一部分,与表面纤维网相反. 前旺是互联网上可以被捕获的搜索引擎
您到达的网络部分. 据不完全统计,大约90%的Internet实际上是深层网络. 因为Google没有
可以执行表单提交之类的操作,但是找不到未直接链接到顶级域名的网页,或者是因为
由于robots.txt禁止您查看网站,因此与深层网页相比,浅层网页的数量相对较少.
暗网,也称为暗网或暗网,完全是另一个“怪物”. 它们还基于现有的
基于网络,但使用Tor客户端,并在HTTP之上运行新协议,它提供了一个
用于信息交换的安全隧道. 就像采集其他网站一样,也可以采集这样的深色网页,
这些内容超出了本书的范围.
与暗网不同,深网相对容易采集. 实际上,本书中的许多工具都可以教您如何采集
Google爬虫机器人无法获取的那些深层网络信息.
那么,什么时候采集整个网站有用,什么时候有害?时间
从整个网站采集数据有很多好处.
一种常见且耗时的网站采集方法是从首页(例如首页)开始,然后在页面上进行搜索
有些链接可以构成一个列表. 然后去采集这些链接的每一页,然后转换在每一页上找到的链接形状
创建一个新列表并重复下一轮采集.
显然,这是一种复杂性迅速增长的情况. 如果每个页面有10个链接,则网站上有5个页面
面部深度(中型网站的主流深度),那么,如果要采集整个网站,则必须采集总计的蚊帐
页数为105,即100 000页. 但是,尽管“ 5页深度,每页10个链接”是一个净
该网站的主流配置,但实际上,很少有网站实际拥有100,000个或更多的页面. 这是因为其中很大一部分
重复内链.
为了防止页面被采集两次,链接重复数据删除非常重要. 代码运行时,所有发现的
所有链接都放在一起并存储在易于查询的列表中(以下示例涉及Python的设置类型). 仅
仅采集“新”链接,然后从页面中搜索其他链接:
为充分说明此网络数据采集示例的工作原理,我降低了“仅
寻找内部链接”标准. 不再限制搜寻器采集的页面范围,只要它遇到一个页面,它就会找到所有带有/ item / open的页面
链接的头,无论链接是否收录分号. (提示: 输入链接不收录分号,但收录文档上传页面
指向面部和讨论页等页面的URL链接包括分号. )
在一开始,使用getLinks处理一个空URL,它实际上是Wikipedia的主页,因为该函数中的空URL只是 查看全部
我们可以使用以下规则稍微调整代码以获取输入链接:
# -*- coding: utf-8 -*-
"""
Created on Fri Jan 26 15:44:26 2018
@author: szm
"""
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import re
random.seed(datetime.datetime.now())
def getLinks(articleUrl):
html = urlopen("https://baike.baidu.com"+articleUrl)
bsObj = BeautifulSoup(html, "html.parser")
return bsObj.find("div", {"class":"para"}).findAll("a", href=re.compile("^(/item/)((?!:).)*$"))
links = getLinks("/item/google")
while len(links) > 0:
newArticle = links[random.randint(0, len(links)-1)].attrs["href"]
print(newArticle)
links = getLinks(newArticle)
/item/%E8%B0%A2%E5%B0%94%E7%9B%96%C2%B7%E5%B8%83%E6%9E%97
/item/%E6%8B%89%E9%87%8C%C2%B7%E4%BD%A9%E5%A5%87
/item/%E6%96%AF%E5%9D%A6%E7%A6%8F
/item/%E6%97%A7%E9%87%91%E5%B1%B1/29211
/item/%E8%81%94%E5%90%88%E5%9B%BD/135426
/item/%E6%B3%95%E8%AF%AD
/item/%E7%BD%97%E6%9B%BC%E8%AF%AD%E6%97%8F
/item/%E6%84%8F%E5%A4%A7%E5%88%A9%E8%AF%AD
采集整个网站
您可能听说过深网,暗网或隐藏网.
术语,尤其是在最近的媒体中. 是什么意思?
深层纤维网是纤维网的一部分,与表面纤维网相反. 前旺是互联网上可以被捕获的搜索引擎
您到达的网络部分. 据不完全统计,大约90%的Internet实际上是深层网络. 因为Google没有
可以执行表单提交之类的操作,但是找不到未直接链接到顶级域名的网页,或者是因为
由于robots.txt禁止您查看网站,因此与深层网页相比,浅层网页的数量相对较少.
暗网,也称为暗网或暗网,完全是另一个“怪物”. 它们还基于现有的
基于网络,但使用Tor客户端,并在HTTP之上运行新协议,它提供了一个
用于信息交换的安全隧道. 就像采集其他网站一样,也可以采集这样的深色网页,
这些内容超出了本书的范围.
与暗网不同,深网相对容易采集. 实际上,本书中的许多工具都可以教您如何采集
Google爬虫机器人无法获取的那些深层网络信息.
那么,什么时候采集整个网站有用,什么时候有害?时间
从整个网站采集数据有很多好处.
一种常见且耗时的网站采集方法是从首页(例如首页)开始,然后在页面上进行搜索
有些链接可以构成一个列表. 然后去采集这些链接的每一页,然后转换在每一页上找到的链接形状
创建一个新列表并重复下一轮采集.
显然,这是一种复杂性迅速增长的情况. 如果每个页面有10个链接,则网站上有5个页面
面部深度(中型网站的主流深度),那么,如果要采集整个网站,则必须采集总计的蚊帐
页数为105,即100 000页. 但是,尽管“ 5页深度,每页10个链接”是一个净
该网站的主流配置,但实际上,很少有网站实际拥有100,000个或更多的页面. 这是因为其中很大一部分
重复内链.
为了防止页面被采集两次,链接重复数据删除非常重要. 代码运行时,所有发现的
所有链接都放在一起并存储在易于查询的列表中(以下示例涉及Python的设置类型). 仅
仅采集“新”链接,然后从页面中搜索其他链接:
为充分说明此网络数据采集示例的工作原理,我降低了“仅
寻找内部链接”标准. 不再限制搜寻器采集的页面范围,只要它遇到一个页面,它就会找到所有带有/ item / open的页面
链接的头,无论链接是否收录分号. (提示: 输入链接不收录分号,但收录文档上传页面
指向面部和讨论页等页面的URL链接包括分号. )
在一开始,使用getLinks处理一个空URL,它实际上是Wikipedia的主页,因为该函数中的空URL只是
内容付费问答系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2020-08-06 05:02
优点:
1. 基于独立的MVC框架开发,该框架结构清晰,易于维护,模块化,可扩展且稳定.
2. 它支持Ucenter,Xunseach和CMS等系统集成,方便且易于使用.
3. 简单易懂的模板语法使前端人员可以独立完成模板制作和数据调用.
4. 网站上的搜索引擎优化非常好
5. 内置的文章功能,每个用户都可以发布自己的文章
6. 该程序具有内置的超级问答集功能,无需编写著名的问答网站规则,一键采集数十万条数据,新网站迅速丰富了网站内容
7. 内置强大的自动标签识别功能,可以在问题和问题集中同时识别关键字
8. 强大的搜索系统. 可以通过输入字符串的全文来搜索搜索问题. 如果搜索未能通过关键字搜索,则可以将其转换为模糊搜索. 相关问题可以列出
可供政府机构,教育机构,机构,商业企业和个人网站管理员使用.
2018-12-05更新日志
1在后端标签管理中添加批量插入标签
在2个PC终端上添加好友链功能
3将移动终端上的fronzewap模板调整为绿色并修改UI效果
4个PC UI颜色匹配和列表显示效果调整
5修复ueditor回答时提示内容为空的问题
6文章的内容均匀加载,延迟加载
查看全部
Whatsns问答系统(以前称为ask2问答系统)是一种PHP开源问答系统,可以根据自己的业务需求快速构建垂直领域,并内置强大的采集功能,支持云存储,图像水印设置,全文检索和现场行为监控,SMS注册和通知,伪静态URL定制,熊掌编号功能,百度结构化地图(标签,问题,文章,类别,用户空间),PC和Wap模板,内置多套pc和wap模板,站长自由切换,同时,后台支持模板管理,在线编辑修改模板,强大的防灌水拦截和过滤配置等数百种功能,深入的SEO优化,适合需要SEO的网站管理员. 商业版本还支持优采云采集,先进的WeChat官方帐户界面功能,支付宝付款,WeChat扫描代码付款,WeChat JSSDK付款,WeChat H5付款,小程序付款以及适用于不同情况的付款服务,例如充值,奖励,解答偷看并咨询付费专家.
优点:
1. 基于独立的MVC框架开发,该框架结构清晰,易于维护,模块化,可扩展且稳定.
2. 它支持Ucenter,Xunseach和CMS等系统集成,方便且易于使用.
3. 简单易懂的模板语法使前端人员可以独立完成模板制作和数据调用.
4. 网站上的搜索引擎优化非常好
5. 内置的文章功能,每个用户都可以发布自己的文章
6. 该程序具有内置的超级问答集功能,无需编写著名的问答网站规则,一键采集数十万条数据,新网站迅速丰富了网站内容
7. 内置强大的自动标签识别功能,可以在问题和问题集中同时识别关键字
8. 强大的搜索系统. 可以通过输入字符串的全文来搜索搜索问题. 如果搜索未能通过关键字搜索,则可以将其转换为模糊搜索. 相关问题可以列出
可供政府机构,教育机构,机构,商业企业和个人网站管理员使用.
2018-12-05更新日志
1在后端标签管理中添加批量插入标签
在2个PC终端上添加好友链功能
3将移动终端上的fronzewap模板调整为绿色并修改UI效果
4个PC UI颜色匹配和列表显示效果调整
5修复ueditor回答时提示内容为空的问题
6文章的内容均匀加载,延迟加载
DouPHPCMS客户管理系统一站式文章采集和发布工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 431 次浏览 • 2020-08-05 20:03
▶Youcai Cloud Collection CMS Publishing Assistant有什么作用? Youcai Cloud Collection CMS Assistant是一种一站式的网站文章采集,原创性和发布工具,可以快速改善网站的收录,排名和权重,是网站内容维护的最佳合作伙伴.
Youcai Cloud Collection CMS Assistant完美连接到DouPHPCMS系统. 只要您的网站是由DouPHPCMS构建的,该网站就可以一键式采集原创文章,而无需修改任何代码,创建发布任务,无需人工干预,每天发布智能文章,从而大大增加了百度所收录的网站数量,并且优化网站.
▶优采云Collection CMS发布助手的阈值较低:
无需花费大量时间来学习软件操作,只需三分钟即可上手
高效率:
提供一站式网站文章解决方案,无需人工干预,将任务设置为自动执行
降低成本:
由一个人维护数十万个网站文章更新不是问题.
▶优采云采集CMS发布助手功能
自动采集任务:
设置采集关键字,设置任务执行周期,实现文章的自动采集,原创创建和发布
定时任务:
设置文章发布的定时任务,无需人工干预即可自动更新网站文章,从而提高工作效率
关键字集合:
输入关键字以从网络上的主流媒体平台获取文章资料,以确保文章内容的多样性
关键字锁定:
文章原创时自动锁定品牌词和产品词,以提高文章的可读性并防止核心词成为原创
自动生成内部链接:
执行发布任务时自动在文章内容中生成内部链接,这可以帮助引导页面上的蜘蛛并增加页面的权重
品牌保护:
设置品牌关键字保护. 执行自动采集任务时,采集到的文章内容(包括竞争对手品牌的名称)将自动替换为您自己的品牌名称
▶PbootCMS简介
DouPHP基于PHP + Mysql架构,可以在Linux,Windows,MacOSX,Solaris和其他平台上运行. 该系统配备了Smarty模板引擎,并支持自定义伪静态. 前端模板采用DIV + CSS设计和后端界面设计简洁明了,简单易用,具有良好的用户体验,良好的稳定性,可扩展性和安全性,可以通过后台模块在线安装,例如会员资格模块,订单模块等,可以为中小型网站提供网站建设解决方案.
DouPHP功能:
简单的操作
背景简单明了. 后台功能布局是从用户而非开发人员的角度设计的. 您无需手册即可轻松编辑日常内容.
简单功能
系统的核心功能只是简单的模块,例如单页,产品,文章等,甚至可以根据实际使用情况卸载产品和文章. 因此,它可以应用于非常基本的网站建设要求. 实际上,许多公司网站所需的功能是非常基本的.
强大的可扩展性
与传统的网站系统不同,DouPHP没有内置的模块生成工具,因为生成工具通常会使系统变得非常膨胀. 我们开发功能模块(实际上,功能模块会有更多的开发空间),然后将它们放入DouPHP附带的在线模块扩展功能中. 在操作过程中,您只需要单击安装即可下载功能模块并自动进行. 要完成安装,最重要的是这些模块是完全独立的. 模块安装程序仅负责下载,解压缩和数据库导入.
放心使用
该系统是免费和开源的. 任何人都可以下载和使用DouPHP,包括企业. 我们不限制将DouPHP用于商业目的. 关于定制开发,我们不会仅仅因为DouPHP是官方的就收取更高的费用. 我们采用低成本策略来提供专业的技术服务,并对计费模板和模块采用统一的策略.
系统定位
致力于基于现有框架为中小企业建立官方网站,但不仅限于公司网站,它为个人博客,在线商城,投票系统,公司在线办公室和其他需求提供轻量级解决方案通过模块扩展. 查看全部
我想快速提高网站的收录率,但是我没有太多经验和精力,该怎么办?编辑推荐网站内容维护的最佳伴侣-彩云采集,无需人工干预即可大大提高百度收录率.
▶Youcai Cloud Collection CMS Publishing Assistant有什么作用? Youcai Cloud Collection CMS Assistant是一种一站式的网站文章采集,原创性和发布工具,可以快速改善网站的收录,排名和权重,是网站内容维护的最佳合作伙伴.
Youcai Cloud Collection CMS Assistant完美连接到DouPHPCMS系统. 只要您的网站是由DouPHPCMS构建的,该网站就可以一键式采集原创文章,而无需修改任何代码,创建发布任务,无需人工干预,每天发布智能文章,从而大大增加了百度所收录的网站数量,并且优化网站.
▶优采云Collection CMS发布助手的阈值较低:
无需花费大量时间来学习软件操作,只需三分钟即可上手
高效率:
提供一站式网站文章解决方案,无需人工干预,将任务设置为自动执行
降低成本:
由一个人维护数十万个网站文章更新不是问题.
▶优采云采集CMS发布助手功能
自动采集任务:
设置采集关键字,设置任务执行周期,实现文章的自动采集,原创创建和发布
定时任务:
设置文章发布的定时任务,无需人工干预即可自动更新网站文章,从而提高工作效率
关键字集合:
输入关键字以从网络上的主流媒体平台获取文章资料,以确保文章内容的多样性
关键字锁定:
文章原创时自动锁定品牌词和产品词,以提高文章的可读性并防止核心词成为原创
自动生成内部链接:
执行发布任务时自动在文章内容中生成内部链接,这可以帮助引导页面上的蜘蛛并增加页面的权重
品牌保护:
设置品牌关键字保护. 执行自动采集任务时,采集到的文章内容(包括竞争对手品牌的名称)将自动替换为您自己的品牌名称
▶PbootCMS简介
DouPHP基于PHP + Mysql架构,可以在Linux,Windows,MacOSX,Solaris和其他平台上运行. 该系统配备了Smarty模板引擎,并支持自定义伪静态. 前端模板采用DIV + CSS设计和后端界面设计简洁明了,简单易用,具有良好的用户体验,良好的稳定性,可扩展性和安全性,可以通过后台模块在线安装,例如会员资格模块,订单模块等,可以为中小型网站提供网站建设解决方案.
DouPHP功能:
简单的操作
背景简单明了. 后台功能布局是从用户而非开发人员的角度设计的. 您无需手册即可轻松编辑日常内容.
简单功能
系统的核心功能只是简单的模块,例如单页,产品,文章等,甚至可以根据实际使用情况卸载产品和文章. 因此,它可以应用于非常基本的网站建设要求. 实际上,许多公司网站所需的功能是非常基本的.
强大的可扩展性
与传统的网站系统不同,DouPHP没有内置的模块生成工具,因为生成工具通常会使系统变得非常膨胀. 我们开发功能模块(实际上,功能模块会有更多的开发空间),然后将它们放入DouPHP附带的在线模块扩展功能中. 在操作过程中,您只需要单击安装即可下载功能模块并自动进行. 要完成安装,最重要的是这些模块是完全独立的. 模块安装程序仅负责下载,解压缩和数据库导入.
放心使用
该系统是免费和开源的. 任何人都可以下载和使用DouPHP,包括企业. 我们不限制将DouPHP用于商业目的. 关于定制开发,我们不会仅仅因为DouPHP是官方的就收取更高的费用. 我们采用低成本策略来提供专业的技术服务,并对计费模板和模块采用统一的策略.
系统定位
致力于基于现有框架为中小企业建立官方网站,但不仅限于公司网站,它为个人博客,在线商城,投票系统,公司在线办公室和其他需求提供轻量级解决方案通过模块扩展.
网站管理员如何更好地利用网站内容采集器?
采集交流 • 优采云 发表了文章 • 0 个评论 • 289 次浏览 • 2020-08-05 20:02
对于单个网站管理员而言,对于任何网站而言,最重要的是内容填充问题. 但是,仅依靠原创更新无疑会给网站管理员带来很多工作负担,特别是在管理多个网站和其他SEO任务时,这是不可能的. 这也使网站数据采集更加有效.
现阶段,中国有许多从事“海量数据采集”的公司,其中大多数使用垂直搜索引擎技术来实现,有些公司还实现了多种技术的综合应用. 例如,“ Youcai Cloud Collector”采用的垂直搜索引擎+网络雷达+信息跟踪和自动分类+自动索引技术将海量数据采集与后期处理相结合.
根据网络的不同数据类型和网站结构,一个功能强大的采集系统在一个信息系统中采用了分布式爬网,分析,数据挖掘和其他功能. 系统可以在指定的网站上进行有针对性的数据抓取. 通过分析,网站管理员可以使用网站内容采集器进行采集/发布,而优采云采集器可以支持外部链同步发布,方便快捷,节省时间和成本. ,大大提高了工作效率.
但是,许多网站管理员对网站内容的采集并不乐观,因为内容的质量降低了,并且从长远来看,网站的重量可能会降低. 但是实际上,许多大型站点和采集站点都在采集其他站点,排名仍然很高.
那么,如何才能确保由Youcai Cloud Collector这样的网站内容采集者采集的内容在质量方面能获得其他几点呢?我们应注意以下几点:
编辑标题,描述和关键字标签
在此之前,这样的“头条派对”一词在新闻网站上广为流传. 对于关键字标签和说明,这些大标题方还将更加关注搜索引擎的爬网和用户单击的好奇心. 因此,在采集内容时,我们必须尽可能地从标题方的一些方法中学习,并在标题,描述和关键字标签上进行一些更改,以便有三个主要元素来区分原创内容页面.
尝试区分布局方法
我们都知道某些网站喜欢使用分页来增加PV. 但是,这样做的缺点是显然会分离出完整的内容,这给用户阅读带来了一些障碍. 用户必须单击下一页以查看所需的内容. 另一方面,他们认为如果要区分原创内容网站,则必须进行与之不同的布局. 我们可以将内容组织在一起(当文章不太长时),这样,搜索引擎将轻松抓取整个内容,并且用户无需翻页即可查看.
网站内容分割和字幕的使用
查看内容时,如果标题正确,我们可以从标题中知道内容是什么?但是,如果作者撰写的内容太长,则整个内容的中心将是混淆,这样,用户就很容易阅读作者真正想表达的思想. 此时,对于内容采集器,用户很容易区分段落并添加相应的字幕. 知道每个段落或作者想要表达什么,作者背后的观点等等.
使用这两种方法,可以合理地划分整个内容,并且在表达作者的观点时应该没有冲突,可以设置字幕以确保作者的初衷.
尽量不要在一段时间内采集内容
实际上,在搜索引擎中,像人一样,他们也更喜欢新的内容搜索引擎,并且它们可以在最短的时间内被捕获并呈现给用户. 但是,随着时间的流逝,内容的新鲜度已经过去,并且搜索引擎很难捕获相同内容. 我们可以充分利用这一优势,即搜索引擎对新文章的偏爱,在采集内容时,尝试在一天之内采集内容.
增加高分辨率图片
一些采集的内容,原创网站没有添加图片,我们可以添加高分辨率图片. 尽管添加图片对文章影响不大,但是由于我们正在采集内容,请尽最大努力对所采集内容的调整进行某些更改,不要采集它们,也不要进行任何修改. 添加图片是为了提高搜索引擎的吸引力.
我们采集其他人的内容. 首先,从搜索引擎来看,它被认为是重复抄袭. 对于搜索引擎而言,与原创内容相比,我们的内容质量已经下降了很多. 但是,我们可以通过某些方面弥补分数的下降,这需要各个网站管理员在内容体验和网站体验上做出努力.
最后一个通用且高效的网站内容采集器肯定会为您的工作效率增加点,并且您将有更多时间进行研究和纳入. 最受欢迎的优采云采集器值得下载并试用. 〜 查看全部
随着Internet技术的发展和Internet上海量信息的增长,对信息的获取和分类的需求日益增加.
对于单个网站管理员而言,对于任何网站而言,最重要的是内容填充问题. 但是,仅依靠原创更新无疑会给网站管理员带来很多工作负担,特别是在管理多个网站和其他SEO任务时,这是不可能的. 这也使网站数据采集更加有效.
现阶段,中国有许多从事“海量数据采集”的公司,其中大多数使用垂直搜索引擎技术来实现,有些公司还实现了多种技术的综合应用. 例如,“ Youcai Cloud Collector”采用的垂直搜索引擎+网络雷达+信息跟踪和自动分类+自动索引技术将海量数据采集与后期处理相结合.
根据网络的不同数据类型和网站结构,一个功能强大的采集系统在一个信息系统中采用了分布式爬网,分析,数据挖掘和其他功能. 系统可以在指定的网站上进行有针对性的数据抓取. 通过分析,网站管理员可以使用网站内容采集器进行采集/发布,而优采云采集器可以支持外部链同步发布,方便快捷,节省时间和成本. ,大大提高了工作效率.
但是,许多网站管理员对网站内容的采集并不乐观,因为内容的质量降低了,并且从长远来看,网站的重量可能会降低. 但是实际上,许多大型站点和采集站点都在采集其他站点,排名仍然很高.
那么,如何才能确保由Youcai Cloud Collector这样的网站内容采集者采集的内容在质量方面能获得其他几点呢?我们应注意以下几点:
编辑标题,描述和关键字标签
在此之前,这样的“头条派对”一词在新闻网站上广为流传. 对于关键字标签和说明,这些大标题方还将更加关注搜索引擎的爬网和用户单击的好奇心. 因此,在采集内容时,我们必须尽可能地从标题方的一些方法中学习,并在标题,描述和关键字标签上进行一些更改,以便有三个主要元素来区分原创内容页面.
尝试区分布局方法
我们都知道某些网站喜欢使用分页来增加PV. 但是,这样做的缺点是显然会分离出完整的内容,这给用户阅读带来了一些障碍. 用户必须单击下一页以查看所需的内容. 另一方面,他们认为如果要区分原创内容网站,则必须进行与之不同的布局. 我们可以将内容组织在一起(当文章不太长时),这样,搜索引擎将轻松抓取整个内容,并且用户无需翻页即可查看.
网站内容分割和字幕的使用
查看内容时,如果标题正确,我们可以从标题中知道内容是什么?但是,如果作者撰写的内容太长,则整个内容的中心将是混淆,这样,用户就很容易阅读作者真正想表达的思想. 此时,对于内容采集器,用户很容易区分段落并添加相应的字幕. 知道每个段落或作者想要表达什么,作者背后的观点等等.
使用这两种方法,可以合理地划分整个内容,并且在表达作者的观点时应该没有冲突,可以设置字幕以确保作者的初衷.
尽量不要在一段时间内采集内容
实际上,在搜索引擎中,像人一样,他们也更喜欢新的内容搜索引擎,并且它们可以在最短的时间内被捕获并呈现给用户. 但是,随着时间的流逝,内容的新鲜度已经过去,并且搜索引擎很难捕获相同内容. 我们可以充分利用这一优势,即搜索引擎对新文章的偏爱,在采集内容时,尝试在一天之内采集内容.
增加高分辨率图片
一些采集的内容,原创网站没有添加图片,我们可以添加高分辨率图片. 尽管添加图片对文章影响不大,但是由于我们正在采集内容,请尽最大努力对所采集内容的调整进行某些更改,不要采集它们,也不要进行任何修改. 添加图片是为了提高搜索引擎的吸引力.
我们采集其他人的内容. 首先,从搜索引擎来看,它被认为是重复抄袭. 对于搜索引擎而言,与原创内容相比,我们的内容质量已经下降了很多. 但是,我们可以通过某些方面弥补分数的下降,这需要各个网站管理员在内容体验和网站体验上做出努力.
最后一个通用且高效的网站内容采集器肯定会为您的工作效率增加点,并且您将有更多时间进行研究和纳入. 最受欢迎的优采云采集器值得下载并试用. 〜
AMR采集系统(以前为通用小偷)v4.0是草根网站站长快速丰富网站内容的工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 299 次浏览 • 2020-08-05 14:04
AMR自动采集系统(以前称为通用小偷程序)是一个自动采集网站的Web应用程序,目前支持95%以上的网站采集.
与市场上其他窃贼程序或采集工具相比,该程序具有以下特征:
<p>1. 易于安装,易于使用: 您只需要输入要采集的目标站点的URL信息,即可自动采集目标站点的内容;通过配置替换规则和修改CSS,可以自定义网站布局和内容; 查看全部
AMR采集系统(以前是通用小偷)是一个Web应用程序,可帮助基层网站管理员快速丰富网站内容以增加网站流量.
AMR自动采集系统(以前称为通用小偷程序)是一个自动采集网站的Web应用程序,目前支持95%以上的网站采集.
与市场上其他窃贼程序或采集工具相比,该程序具有以下特征:
<p>1. 易于安装,易于使用: 您只需要输入要采集的目标站点的URL信息,即可自动采集目标站点的内容;通过配置替换规则和修改CSS,可以自定义网站布局和内容;

