
内容采集系统
10种数据分析方法,助我们针对性解决问题!
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-03-21 04:10
内容采集系统可以为我们提供监测点击率、用户浏览路径、客户反馈等基础数据。这些数据是推广、竞价、微信运营人员必不可少的支撑数据。系统采集的数据特点分析,能帮助我们针对性解决问题。下面这10种数据分析方法,可以在根据采集的数据分析,找到我们的问题。
1、客户访问路径分析通过对客户访问路径的跟踪可以帮助我们做出精准推广预算和方案。一般主要路径采用爬虫抓取,比如:微信,google、等站点。比如:根据相关内容推广人群的行为走向分析,能让我们的运营更有目的性。做数据分析时一定要对新媒体推广提高重视,可以采用图表方式展示数据。
2、客户粘性分析通过对客户访问页面进行分析,我们可以了解客户的品牌购买意愿,留存率,预算分布,年龄分布,性别分布等等。其中,了解客户的购买行为是很有价值的一个参考因素。比如:通过点击采集数据,我们可以跟踪用户与产品的互动行为,也就是用户粘性,判断是否要做大规模的推广。
3、企业家分析这个分析方法其实很简单,我们只需要设置不同的思维维度。比如:粉丝精准性、群体基数、单个数、在多个上完成行为、在多个浏览器上完成行为、在多个操作系统上完成行为、在多个浏览器上完成行为等等。通过这个分析我们可以判断客户一定还会购买同一产品或服务的多个维度。这样我们就能做到以一打多,避免我们对多个产品进行时间和内容上的盲目性。
4、行为路径分析这里所说的行为路径是指用户浏览到落地页后的每一步行为。这里所说的路径分析主要考虑客户如何点击落地页,点击到页面各位置的转化率,行为路径重要性,路径中的关键内容等等。这一块需要重点考虑的路径有:客户点击落地页后的第一页,第一名客户点击落地页后的下一页,购买页,到支付页等等。
5、一点带多面这个也很好理解,我们是要做客户,就要尽可能去抓住用户。在抓住用户的同时,必须要去用好关键词。我们在抓住客户的同时,要去不断抓住他的行为,满足他。抓住用户的同时,要搞好用户关系,在满足他的基础上,尽可能用好关键词。比如:搜索产品推广关键词:假设客户当天来一次,他可能是1个步骤关注你,3个步骤转化,3个步骤购买,3个步骤复购,那我们就要弄清楚,如何在一点带多面。
6、转化漏斗分析与渠道多点分析、营销指标对比这三个方法同样也是针对运营推广的,但一点带多面、转化漏斗分析更侧重运营,网站数据的监测更多是用在bd的场景中。而渠道多点分析和营销指标对比在分析更偏向产品和用户数据方面。比如:6个步骤下来,我们的注册率是多少, 查看全部
10种数据分析方法,助我们针对性解决问题!
内容采集系统可以为我们提供监测点击率、用户浏览路径、客户反馈等基础数据。这些数据是推广、竞价、微信运营人员必不可少的支撑数据。系统采集的数据特点分析,能帮助我们针对性解决问题。下面这10种数据分析方法,可以在根据采集的数据分析,找到我们的问题。
1、客户访问路径分析通过对客户访问路径的跟踪可以帮助我们做出精准推广预算和方案。一般主要路径采用爬虫抓取,比如:微信,google、等站点。比如:根据相关内容推广人群的行为走向分析,能让我们的运营更有目的性。做数据分析时一定要对新媒体推广提高重视,可以采用图表方式展示数据。
2、客户粘性分析通过对客户访问页面进行分析,我们可以了解客户的品牌购买意愿,留存率,预算分布,年龄分布,性别分布等等。其中,了解客户的购买行为是很有价值的一个参考因素。比如:通过点击采集数据,我们可以跟踪用户与产品的互动行为,也就是用户粘性,判断是否要做大规模的推广。
3、企业家分析这个分析方法其实很简单,我们只需要设置不同的思维维度。比如:粉丝精准性、群体基数、单个数、在多个上完成行为、在多个浏览器上完成行为、在多个操作系统上完成行为、在多个浏览器上完成行为等等。通过这个分析我们可以判断客户一定还会购买同一产品或服务的多个维度。这样我们就能做到以一打多,避免我们对多个产品进行时间和内容上的盲目性。
4、行为路径分析这里所说的行为路径是指用户浏览到落地页后的每一步行为。这里所说的路径分析主要考虑客户如何点击落地页,点击到页面各位置的转化率,行为路径重要性,路径中的关键内容等等。这一块需要重点考虑的路径有:客户点击落地页后的第一页,第一名客户点击落地页后的下一页,购买页,到支付页等等。
5、一点带多面这个也很好理解,我们是要做客户,就要尽可能去抓住用户。在抓住用户的同时,必须要去用好关键词。我们在抓住客户的同时,要去不断抓住他的行为,满足他。抓住用户的同时,要搞好用户关系,在满足他的基础上,尽可能用好关键词。比如:搜索产品推广关键词:假设客户当天来一次,他可能是1个步骤关注你,3个步骤转化,3个步骤购买,3个步骤复购,那我们就要弄清楚,如何在一点带多面。
6、转化漏斗分析与渠道多点分析、营销指标对比这三个方法同样也是针对运营推广的,但一点带多面、转化漏斗分析更侧重运营,网站数据的监测更多是用在bd的场景中。而渠道多点分析和营销指标对比在分析更偏向产品和用户数据方面。比如:6个步骤下来,我们的注册率是多少,
天宇(CGSEEK)集成网页搜索、内容智能提取与过滤
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-01-27 10:28
该系统集成了Web搜索,智能内容提取和过滤,自动分类,自动重复数据删除和其他技术,以实现Internet信息采集的自动化和集成,过滤,提取和批量上传。
一、系统简介
新闻媒体,政府部门和大型企事业单位已经使用Internet技术来构建网络信息采集平台:新闻媒体需要在Internet上获取大量新闻材料以丰富新闻数据库;政府机构需要采集与自身业务有关的文件,提高办公和决策效率;大型企业和机构需要快速获取行业的宏观环境,政策动态和竞争对手的信息……
天宇智能互联网信息采集系统(CGSEEK)集成了Web搜索,智能内容提取和过滤,自动分类,自动重复数据删除等技术,实现了互联网信息采集的过滤,提取和批量上传自动化和整合。
二、系统结构
三、系统的主要功能
◆支持采集各种标准格式的信息资源,例如HTML页面,文本信息,表格,图片,声音,视频等。
◆实现网页和嵌入式图片采集的统一。
◆支持传统页面的采集(BIG5代码),并自动转换为标准的简化代码(GB代码),支持Unicode代码集。
◆采集支持程序自动生成的页面内容,例如JavaScript生成的页面。
◆它可以轻松捕获网站后端数据库(JSP,ASP,CGI)的内容,并捕获需要通过用户身份验证的网站内容。
◆支持批量下载单个网页和网站历史数据。
◆支持采集各种标准格式的信息资源,例如HTML页面,文本信息,表格,图片,声音,视频等。
◆实现网页和嵌入式图片采集的统一。
◆支持传统页面的采集(BIG5代码),并自动转换为标准的简化代码(GB代码),支持Unicode代码集。
◆采集支持程序自动生成的页面内容,例如JavaScript生成的页面。
◆它可以轻松捕获网站后端数据库(JSP,ASP,CGI)的内容,并捕获需要通过用户身份验证的网站内容。
◆支持批量下载单个网页和网站历史数据。
◆支持采集各种标准格式的信息资源,例如HTML页面,文本信息,表格,图片,声音,视频等。
◆实现网页和嵌入式图片采集的统一。
◆支持传统页面的采集(BIG5代码),并自动转换为标准的简化代码(GB代码),支持Unicode代码集。
◆采集支持程序自动生成的页面内容,例如JavaScript生成的页面。
◆它可以轻松捕获网站后端数据库(JSP,ASP,CGI)的内容,并捕获需要通过用户身份验证的网站内容。
◆支持批量下载单个网页和网站历史数据。
信息使用
◆您可以将采集中的网页信息放置在本地计算机指定的文件夹中以供使用。
◆该系统支持将采集的文本内容批量上传到天语CGRS全文数据库,天语采集分配系统和全文检索系统可用于信息采集,编辑,查看,发布和全文检索。
◆智能提取的文本内容可以上传到主流关系数据库(例如SQL Server)以丰富数据库,并且第三方应用程序系统也可以用于采集,发布和检索信息。
四、系统功能
◆网页采集具有全面的内容
<p>适应网站内容格式的可变性,可以完全获取需要采集的页面,几乎没有遗漏,并且网页采集的内容完整性高于99%。 查看全部
天宇(CGSEEK)集成网页搜索、内容智能提取与过滤
该系统集成了Web搜索,智能内容提取和过滤,自动分类,自动重复数据删除和其他技术,以实现Internet信息采集的自动化和集成,过滤,提取和批量上传。
一、系统简介
新闻媒体,政府部门和大型企事业单位已经使用Internet技术来构建网络信息采集平台:新闻媒体需要在Internet上获取大量新闻材料以丰富新闻数据库;政府机构需要采集与自身业务有关的文件,提高办公和决策效率;大型企业和机构需要快速获取行业的宏观环境,政策动态和竞争对手的信息……
天宇智能互联网信息采集系统(CGSEEK)集成了Web搜索,智能内容提取和过滤,自动分类,自动重复数据删除等技术,实现了互联网信息采集的过滤,提取和批量上传自动化和整合。
二、系统结构

三、系统的主要功能
◆支持采集各种标准格式的信息资源,例如HTML页面,文本信息,表格,图片,声音,视频等。
◆实现网页和嵌入式图片采集的统一。
◆支持传统页面的采集(BIG5代码),并自动转换为标准的简化代码(GB代码),支持Unicode代码集。
◆采集支持程序自动生成的页面内容,例如JavaScript生成的页面。
◆它可以轻松捕获网站后端数据库(JSP,ASP,CGI)的内容,并捕获需要通过用户身份验证的网站内容。
◆支持批量下载单个网页和网站历史数据。
◆支持采集各种标准格式的信息资源,例如HTML页面,文本信息,表格,图片,声音,视频等。
◆实现网页和嵌入式图片采集的统一。
◆支持传统页面的采集(BIG5代码),并自动转换为标准的简化代码(GB代码),支持Unicode代码集。
◆采集支持程序自动生成的页面内容,例如JavaScript生成的页面。
◆它可以轻松捕获网站后端数据库(JSP,ASP,CGI)的内容,并捕获需要通过用户身份验证的网站内容。
◆支持批量下载单个网页和网站历史数据。
◆支持采集各种标准格式的信息资源,例如HTML页面,文本信息,表格,图片,声音,视频等。
◆实现网页和嵌入式图片采集的统一。
◆支持传统页面的采集(BIG5代码),并自动转换为标准的简化代码(GB代码),支持Unicode代码集。
◆采集支持程序自动生成的页面内容,例如JavaScript生成的页面。
◆它可以轻松捕获网站后端数据库(JSP,ASP,CGI)的内容,并捕获需要通过用户身份验证的网站内容。
◆支持批量下载单个网页和网站历史数据。
信息使用
◆您可以将采集中的网页信息放置在本地计算机指定的文件夹中以供使用。
◆该系统支持将采集的文本内容批量上传到天语CGRS全文数据库,天语采集分配系统和全文检索系统可用于信息采集,编辑,查看,发布和全文检索。
◆智能提取的文本内容可以上传到主流关系数据库(例如SQL Server)以丰富数据库,并且第三方应用程序系统也可以用于采集,发布和检索信息。
四、系统功能
◆网页采集具有全面的内容
<p>适应网站内容格式的可变性,可以完全获取需要采集的页面,几乎没有遗漏,并且网页采集的内容完整性高于99%。
汇总:WEB数据采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 269 次浏览 • 2021-01-15 12:04
B WEB数据采集系统一.概述面对Internet上的大量信息,政府机构,企事业单位和研究机构都渴望获得与其工作有关的有价值的信息,以及如何获得这些信息。这些信息方便快捷地变得至关重要。如果使用原创的手动采集方法,则将很耗时,费力且效率低下。面对越来越多的信息资源,劳动强度和困难可想而知。因此,现代政府和企业迫切需要一种能够提供高质量,高效运行信息的解决方案采集。该系统针对不同行业用户的应用需求,旨在捕获Internet,并实现了在用户定义的规则下可以从Internet捕获指定信息。捕获的信息可以存储在数据库中或直接发送到指定的列,以实现网站信息的及时更新和数据量的增加,从而增加搜索引擎收录的数量并扩大公司信息的推广。二.典型应用1.政府机构实时跟踪,采集与业务相关的信息来源。 充分满足内部人员对全球互联网信息观察的需求。 及时解决政务外网和政务内网的信息源问题,实现动态发布。 快速解决地方政府领导网站的信息获取需求。 全面整合信息,实现跨区域,跨部门的信息资源共享和政府内部的有效沟通。 节省信息采集的人力,物力和时间,提高办公效率。2.企业实时,准确地监视和跟踪竞争对手的动态是企业获取竞争情报的有力工具。
<p>及时获取竞争对手的公共信息,以研究同一行业的发展和市场需求。 为企业决策部门和管理人员提供方便,多渠道的企业战略决策工具。 实质性提高企业获取和利用智能的效率,节省智能信息采集,存储和挖掘的相关费用,是提高企业核心竞争力的关键。 提升公司的整体分析研究能力,快速的市场响应能力,建立以知识管理为核心的“竞争情报数据仓库”,是提高公司核心竞争力的神经中心。3.新闻媒体快速准确地自动采集计数信息。 支持每天有效抓取上万条新闻。 支持智能提取和查看所需内容。 实现Internet信息内容采集,浏览,编辑,管理和发布的集成。三.。系统架构工作流程描述采集的目的是将另一方网站上的网页上的某些文本或图片下载到您的网站。此过程需要进行以下配置工作:下载网页配置,分析网页配置,修改结果配置和数据输出配置。如果数据符合您的要求,则可以省略校正结果的步骤。配置完成后,将配置形成一个任务(该任务以XML格式描述),采集系统根据该任务的描述开始工作,最后将采集的结果存储在网站服务器。工作流程图如下:数据处理逻辑图:四.系统功能根据用户预先配置的规则(网页下载规则,网页解析规则等),对数据进行处理采集。 查看全部
汇总:WEB数据采集系统
B WEB数据采集系统一.概述面对Internet上的大量信息,政府机构,企事业单位和研究机构都渴望获得与其工作有关的有价值的信息,以及如何获得这些信息。这些信息方便快捷地变得至关重要。如果使用原创的手动采集方法,则将很耗时,费力且效率低下。面对越来越多的信息资源,劳动强度和困难可想而知。因此,现代政府和企业迫切需要一种能够提供高质量,高效运行信息的解决方案采集。该系统针对不同行业用户的应用需求,旨在捕获Internet,并实现了在用户定义的规则下可以从Internet捕获指定信息。捕获的信息可以存储在数据库中或直接发送到指定的列,以实现网站信息的及时更新和数据量的增加,从而增加搜索引擎收录的数量并扩大公司信息的推广。二.典型应用1.政府机构实时跟踪,采集与业务相关的信息来源。 充分满足内部人员对全球互联网信息观察的需求。 及时解决政务外网和政务内网的信息源问题,实现动态发布。 快速解决地方政府领导网站的信息获取需求。 全面整合信息,实现跨区域,跨部门的信息资源共享和政府内部的有效沟通。 节省信息采集的人力,物力和时间,提高办公效率。2.企业实时,准确地监视和跟踪竞争对手的动态是企业获取竞争情报的有力工具。
<p>及时获取竞争对手的公共信息,以研究同一行业的发展和市场需求。 为企业决策部门和管理人员提供方便,多渠道的企业战略决策工具。 实质性提高企业获取和利用智能的效率,节省智能信息采集,存储和挖掘的相关费用,是提高企业核心竞争力的关键。 提升公司的整体分析研究能力,快速的市场响应能力,建立以知识管理为核心的“竞争情报数据仓库”,是提高公司核心竞争力的神经中心。3.新闻媒体快速准确地自动采集计数信息。 支持每天有效抓取上万条新闻。 支持智能提取和查看所需内容。 实现Internet信息内容采集,浏览,编辑,管理和发布的集成。三.。系统架构工作流程描述采集的目的是将另一方网站上的网页上的某些文本或图片下载到您的网站。此过程需要进行以下配置工作:下载网页配置,分析网页配置,修改结果配置和数据输出配置。如果数据符合您的要求,则可以省略校正结果的步骤。配置完成后,将配置形成一个任务(该任务以XML格式描述),采集系统根据该任务的描述开始工作,最后将采集的结果存储在网站服务器。工作流程图如下:数据处理逻辑图:四.系统功能根据用户预先配置的规则(网页下载规则,网页解析规则等),对数据进行处理采集。
最新信息:一套内容采集系统 解放编辑人员
采集交流 • 优采云 发表了文章 • 0 个评论 • 234 次浏览 • 2021-01-14 13:03
内容采集系统对于基于内容的网站是非常好的助手。除了原创的内容外,其他内容也需要由编辑者或采集系统采集,然后添加到自己的网站中。 Discuz DvBBScms和其他产品具有其自己的内容采集功能,以达到采集指定的相关内容。单客户端优采云采集器对于采集指定的内容也可能非常有用。这些工具都希望机器取代人类,从内容处理工作中解放编辑人员,并进行一些高端工作,例如采集对内容的结果进行微调,SEO优化,设置精确的采集规则,使采集的内容更符合网站的需求。
以下内容采集系统是根据此思想开发的,该采集系统由两部分组成:
1.编辑器使用的采集规则设置程序以及用于查看,微调和发布采集的结果的网站。
2.定时采集器和定时发送器已部署在服务器上。
首先,编辑器通过采集规则设置程序(NiceCollectoer.exe)将网站设置为采集,然后等待采集完成,然后编辑器将网站(PickWeb)传递给[审查,微调和优化k15的结果,然后自行发布网站。编辑者需要做的是设置采集的规则并优化采集的结果。工作的其他部分由机器完成。
NicePicker是一个HTML分析器,用于提取Url,NiceCollector和HostCollector都使用NicePicker分析Html,NiceCollectoer是采集规则设置程序,目标网站只需要设置一次:
用法类似于最早的优采云采集器,这里我们以博客园为目标采集网站,在采集本质上设置文章,采集规则为非常简单:成为编辑者设置采集规则后,这些规则将保存在Setting.mdb中与NiceCollector.exe相同的目录中。通常,设置采集规则后,基本上无需更改它。仅当目标网站的Html Dom结构更改时,才需要再次微调采集规则。 NiceCollector还用于设置和添加新目标采集网站的操作。
编辑器完成采集规则设置后,将Setting.mdb放在HostCollector.exe下,HostCollector将根据Setting.mdb的设置执行实际的采集,并将采集的结果存储在数据库。
在此步骤中,内容的采集工作完成,编辑器可以打开PickWeb,微调和优化采集的结果,然后批准并将其发送给他们的网站:
PickWeb并没有完成向自己网站发送采集结果的工作。编辑器完成内容审阅后,PostToForum.exe将读取数据库,并将通过审阅的采集结果发送给您自己的网站,当然您需要自己的网站。 ashx或其他方式来接收采集的结果,不建议PostToFormu.exe直接操作您自己的网站数据库,最好使用您自己的[k14上的API]来接收采集。
NiceCollectoer,HostCollector,PickWeb,PostToForum,这些程序的共同工作已基本完成采集,并且发送,HostCollector,PickWeb,PostToForum的工作已部署在服务器上,HostCollector需要定期调用,请访问采集目标网站生成的新内容,HostRunnerService.exe是Windows服务,用于定期调用HostCollector,使用管理员在控制台下运行installutil / i HostRunnerService.exe来安装此Windows服务:
HostRunnerService的配置也非常简单:
在RunTime.txt中多次设置每日时间采集:
当新内容为采集时,编辑者需要定期登录PickWeb以优化,微调和查看新内容,或设置默认查看。同样,还需要定期调用PostToForum来发送批准的新内容。 CallSenderService.exe与HostRunnerService.exe相似。这也是Windows服务,用于定期调用PostToFormu.exe。
至此,除了其他两件事之外,整个系统已基本完成:SelfChecker.exe和HealthChecker.exe。 SelfCheck.exe用于检查Setting.mdb中设置的规则是否为有效规则,例如,检查采集规则是否设置了内容采集项目。 HealthChecker.exe用于采集HostCollector.exe和PostToForum.exe生成的日志,然后将日志发送到指定的系统维护者。
此内容采集系统中仍有许多地方需要改进和优化。当前状态只能说是原型。例如,NicePick需要进一步抽象和重构,并提供更多接口,并分析Html插件的所有方面,从而允许用户在每个分析步骤中加载自己的分析器。在NiceCollector上,需要越来越全面的采集规则设置。可以在PickWeb上添加一些默认的SEO优化规则,例如标题内容的批量SEO优化以及其他方面。
可执行文件下载:
08_453455_if8l_NROutput.rar(链接已更新)
源代码下载:
08_234324_if8l_NiceCollector.rar(链接已更新) 查看全部
最新信息:一套内容采集系统 解放编辑人员
内容采集系统对于基于内容的网站是非常好的助手。除了原创的内容外,其他内容也需要由编辑者或采集系统采集,然后添加到自己的网站中。 Discuz DvBBScms和其他产品具有其自己的内容采集功能,以达到采集指定的相关内容。单客户端优采云采集器对于采集指定的内容也可能非常有用。这些工具都希望机器取代人类,从内容处理工作中解放编辑人员,并进行一些高端工作,例如采集对内容的结果进行微调,SEO优化,设置精确的采集规则,使采集的内容更符合网站的需求。
以下内容采集系统是根据此思想开发的,该采集系统由两部分组成:
1.编辑器使用的采集规则设置程序以及用于查看,微调和发布采集的结果的网站。
2.定时采集器和定时发送器已部署在服务器上。
首先,编辑器通过采集规则设置程序(NiceCollectoer.exe)将网站设置为采集,然后等待采集完成,然后编辑器将网站(PickWeb)传递给[审查,微调和优化k15的结果,然后自行发布网站。编辑者需要做的是设置采集的规则并优化采集的结果。工作的其他部分由机器完成。

NicePicker是一个HTML分析器,用于提取Url,NiceCollector和HostCollector都使用NicePicker分析Html,NiceCollectoer是采集规则设置程序,目标网站只需要设置一次:


用法类似于最早的优采云采集器,这里我们以博客园为目标采集网站,在采集本质上设置文章,采集规则为非常简单:成为编辑者设置采集规则后,这些规则将保存在Setting.mdb中与NiceCollector.exe相同的目录中。通常,设置采集规则后,基本上无需更改它。仅当目标网站的Html Dom结构更改时,才需要再次微调采集规则。 NiceCollector还用于设置和添加新目标采集网站的操作。
编辑器完成采集规则设置后,将Setting.mdb放在HostCollector.exe下,HostCollector将根据Setting.mdb的设置执行实际的采集,并将采集的结果存储在数据库。
在此步骤中,内容的采集工作完成,编辑器可以打开PickWeb,微调和优化采集的结果,然后批准并将其发送给他们的网站:


PickWeb并没有完成向自己网站发送采集结果的工作。编辑器完成内容审阅后,PostToForum.exe将读取数据库,并将通过审阅的采集结果发送给您自己的网站,当然您需要自己的网站。 ashx或其他方式来接收采集的结果,不建议PostToFormu.exe直接操作您自己的网站数据库,最好使用您自己的[k14上的API]来接收采集。
NiceCollectoer,HostCollector,PickWeb,PostToForum,这些程序的共同工作已基本完成采集,并且发送,HostCollector,PickWeb,PostToForum的工作已部署在服务器上,HostCollector需要定期调用,请访问采集目标网站生成的新内容,HostRunnerService.exe是Windows服务,用于定期调用HostCollector,使用管理员在控制台下运行installutil / i HostRunnerService.exe来安装此Windows服务:

HostRunnerService的配置也非常简单:

在RunTime.txt中多次设置每日时间采集:

当新内容为采集时,编辑者需要定期登录PickWeb以优化,微调和查看新内容,或设置默认查看。同样,还需要定期调用PostToForum来发送批准的新内容。 CallSenderService.exe与HostRunnerService.exe相似。这也是Windows服务,用于定期调用PostToFormu.exe。
至此,除了其他两件事之外,整个系统已基本完成:SelfChecker.exe和HealthChecker.exe。 SelfCheck.exe用于检查Setting.mdb中设置的规则是否为有效规则,例如,检查采集规则是否设置了内容采集项目。 HealthChecker.exe用于采集HostCollector.exe和PostToForum.exe生成的日志,然后将日志发送到指定的系统维护者。
此内容采集系统中仍有许多地方需要改进和优化。当前状态只能说是原型。例如,NicePick需要进一步抽象和重构,并提供更多接口,并分析Html插件的所有方面,从而允许用户在每个分析步骤中加载自己的分析器。在NiceCollector上,需要越来越全面的采集规则设置。可以在PickWeb上添加一些默认的SEO优化规则,例如标题内容的批量SEO优化以及其他方面。
可执行文件下载:
08_453455_if8l_NROutput.rar(链接已更新)
源代码下载:
08_234324_if8l_NiceCollector.rar(链接已更新)
汇总:一套内容采集系统源码
采集交流 • 优采云 发表了文章 • 0 个评论 • 237 次浏览 • 2020-12-18 11:18
一组内容采集系统源代码
一套内容采集系统解放了编辑人员。内容采集系统是基于内容网站的很好的助手。除了原创内容外,其他内容也需要编辑者或采集系统来采集和整理,然后添加到自己的网站中。 Discuz DvBBScms和其他产品具有其自己的内容采集功能,以达到采集指定的相关内容。单客户端优采云采集器对于采集指定的内容也可能非常有用。这些工具都希望机器取代人类,从内容处理工作中解放编辑人员,并进行一些高端工作,例如采集对内容的结果进行微调,SEO优化,设置精确的采集规则,使采集的内容更符合网站的需求。
以下内容采集系统是根据此思想开发的,该采集系统由两部分组成:
1.编辑器使用的采集规则设置程序以及用于查看,微调和发布采集的结果的网站。
2.定时采集器和定时发送器已部署在服务器上。
首先,编辑器通过采集规则设置程序(NiceCollectoer.exe)将网站设置为采集,然后等待采集完成,然后编辑器将网站(PickWeb)传递给[审查,微调和优化k15的结果,然后自行发布网站。编辑者需要做的是采集规则的设置和采集结果的优化。工作的其他部分由机器完成。
NicePicker是一个HTML分析器,用于提取Url,NiceCollector和HostCollector都使用NicePicker分析Html,NiceCollectoer是采集规则设置程序,目标网站只需要设置一次:
用法类似于最早的优采云采集器,这里我们以博客园为目标采集网站,在采集本质上设置文章,采集规则为非常简单:成为编辑者设置采集规则后,这些规则将保存在Setting.mdb中与NiceCollector.exe相同的目录中。通常,设置采集规则后,基本上无需更改它。仅当目标网站的Html Dom结构更改时,才需要再次微调采集规则。 NiceCollector还用于设置和添加新目标采集网站的操作。
编辑器完成采集规则设置后,将Setting.mdb放在HostCollector.exe下,HostCollector将根据Setting.mdb的设置执行实际的采集,并将采集的结果存储在数据库。
在此步骤中,内容的采集工作已完成。编辑者可以打开PickWeb,微调和优化采集的结果,然后批准并将其发送到他们的网站
PickWeb并没有完成向自己网站发送采集结果的工作。编辑者完成内容审阅后,PostToForum.exe将读取数据库并将通过审阅的采集结果发送给他们自己的网站,当然您需要一个网站。 ashx或其他方式来接收采集的结果,不建议PostToFormu.exe直接操作自己的网站数据库,最好使用自己的[k14上的API]来接收采集。
该数据库位于DB_51aspx文件夹(sql2005)中,只需附加它即可。
登录用户名和密码均为51aspx 查看全部
汇总:一套内容采集系统源码
一组内容采集系统源代码
一套内容采集系统解放了编辑人员。内容采集系统是基于内容网站的很好的助手。除了原创内容外,其他内容也需要编辑者或采集系统来采集和整理,然后添加到自己的网站中。 Discuz DvBBScms和其他产品具有其自己的内容采集功能,以达到采集指定的相关内容。单客户端优采云采集器对于采集指定的内容也可能非常有用。这些工具都希望机器取代人类,从内容处理工作中解放编辑人员,并进行一些高端工作,例如采集对内容的结果进行微调,SEO优化,设置精确的采集规则,使采集的内容更符合网站的需求。
以下内容采集系统是根据此思想开发的,该采集系统由两部分组成:
1.编辑器使用的采集规则设置程序以及用于查看,微调和发布采集的结果的网站。
2.定时采集器和定时发送器已部署在服务器上。
首先,编辑器通过采集规则设置程序(NiceCollectoer.exe)将网站设置为采集,然后等待采集完成,然后编辑器将网站(PickWeb)传递给[审查,微调和优化k15的结果,然后自行发布网站。编辑者需要做的是采集规则的设置和采集结果的优化。工作的其他部分由机器完成。
NicePicker是一个HTML分析器,用于提取Url,NiceCollector和HostCollector都使用NicePicker分析Html,NiceCollectoer是采集规则设置程序,目标网站只需要设置一次:
用法类似于最早的优采云采集器,这里我们以博客园为目标采集网站,在采集本质上设置文章,采集规则为非常简单:成为编辑者设置采集规则后,这些规则将保存在Setting.mdb中与NiceCollector.exe相同的目录中。通常,设置采集规则后,基本上无需更改它。仅当目标网站的Html Dom结构更改时,才需要再次微调采集规则。 NiceCollector还用于设置和添加新目标采集网站的操作。
编辑器完成采集规则设置后,将Setting.mdb放在HostCollector.exe下,HostCollector将根据Setting.mdb的设置执行实际的采集,并将采集的结果存储在数据库。
在此步骤中,内容的采集工作已完成。编辑者可以打开PickWeb,微调和优化采集的结果,然后批准并将其发送到他们的网站
PickWeb并没有完成向自己网站发送采集结果的工作。编辑者完成内容审阅后,PostToForum.exe将读取数据库并将通过审阅的采集结果发送给他们自己的网站,当然您需要一个网站。 ashx或其他方式来接收采集的结果,不建议PostToFormu.exe直接操作自己的网站数据库,最好使用自己的[k14上的API]来接收采集。
该数据库位于DB_51aspx文件夹(sql2005)中,只需附加它即可。
登录用户名和密码均为51aspx
操作方法:BeeCollector(小蜜蜂采集器)文章采集系统 v1.1027
采集交流 • 优采云 发表了文章 • 0 个评论 • 344 次浏览 • 2020-11-27 13:15
BeeCollector(Little Bee采集器)文章采集系统,改进了Flash 采集模块对目标字符集UTF8的支持。
功能介绍:
1、支持文章内容分页采集;
2、支持论坛采集;
3、支持将UTF-8转换为GB2312,并且采集内容字符格式可以作为UTF-8的目标;
4、支持在本地保存文章的内容;
5、支持站点+列管理,因此采集管理一目了然;
6、支持链接替换,页面链接替换,破解由JS /后端程序设置的一些反选功能;
7、支持采集器设置无限过滤功能;
8、支持在本地保存图片采集,自动替换文件名以避免重复;
9、支持将FLASH文件采集保存在本地,并自动替换文件名以避免重复;
10、支持限制PHP FOPEN和FSOCKET功能的虚拟主机;
1 1、支持采集手动过滤结果,并提供快速过滤和删除“空标题,空白内容”的功能;
1 2、支持Flash专业网站采集,专门开发采集 Flash游戏,可以完善采集缩略图和游戏介绍;
1 3、支持导入和导出站点范围的配置规则;
1 4、支持导入和导出列配置规则,并提供规则复制功能以简化设置;
1 5、提供数据库规则的导入和导出;
1 6、支持自定义采集间隔时间,以避免被误认为是DDOS攻击和拒绝响应。可以设置采集来防止DDOS攻击网站;
1 7、支持自定义的仓储间隔时间,避免了并发虚拟主机的限制;
1 8、支持自定义内容写入,用户可以设置任何内容(例如自己的链接,广告代码),并写入采集的内容:第一个,最后一个或随机写入;导入库时,它将自动带出需要编写的内容,而无需修改WEB系统的模板。
1 9、支持采集内容替换功能,用户可以设置替换规则以随意替换;
20、支持html标签过滤,允许采集仅保留必要的html标签,甚至保留纯文本,而没有任何html标签;
2 1、支持各种cms指南库软件包,包括PHP cms V2 / V 3、 Dede cms(织梦)V2 / V 3、 PHP168 cms,mephpcms,Mambo cms,Joomla cms系统指南库规则和操作说明;
2 2、支持PHPWIND,Discuz论坛指南库,该程序包收录2个论坛指南库规则和操作说明;
2 3、附带数据库优化工具,以减少频繁出现的采集过多数据碎片并降低数据库性能。
以下特殊功能仅适用于“小蜜蜂采集器”:
1、支持采集进程断点恢复功能,该功能不受浏览器意外关闭的影响,并且在重新启动采集之后将不再重复;
2、支持自动比较和过滤功能,不会重复采集和入库采集的链接系统;以上两个功能可以大大减少采集时间并减少系统负载。
3、支持系统每天自动创建图片存储目录,以便于管理;
4、支持采集 /制导间隔时间设置,以避免被目标电台识别为交通攻击并拒绝响应;
5、支持自定义内容编写,以实现简单的防摘功能;
6、支持html标签过滤,可以完美显示您想要的采集效果;
7、内容存储的完美解决方案,不受目标编程语言和数据库类别的限制。
上述许多强大功能免费供您使用,并且体验信息采集易于立即安装和有效使用。 查看全部
BeeCollector(Little Bee采集器)文章采集系统v1.1027
BeeCollector(Little Bee采集器)文章采集系统,改进了Flash 采集模块对目标字符集UTF8的支持。
功能介绍:
1、支持文章内容分页采集;
2、支持论坛采集;
3、支持将UTF-8转换为GB2312,并且采集内容字符格式可以作为UTF-8的目标;
4、支持在本地保存文章的内容;
5、支持站点+列管理,因此采集管理一目了然;
6、支持链接替换,页面链接替换,破解由JS /后端程序设置的一些反选功能;
7、支持采集器设置无限过滤功能;
8、支持在本地保存图片采集,自动替换文件名以避免重复;
9、支持将FLASH文件采集保存在本地,并自动替换文件名以避免重复;
10、支持限制PHP FOPEN和FSOCKET功能的虚拟主机;
1 1、支持采集手动过滤结果,并提供快速过滤和删除“空标题,空白内容”的功能;
1 2、支持Flash专业网站采集,专门开发采集 Flash游戏,可以完善采集缩略图和游戏介绍;
1 3、支持导入和导出站点范围的配置规则;
1 4、支持导入和导出列配置规则,并提供规则复制功能以简化设置;
1 5、提供数据库规则的导入和导出;
1 6、支持自定义采集间隔时间,以避免被误认为是DDOS攻击和拒绝响应。可以设置采集来防止DDOS攻击网站;
1 7、支持自定义的仓储间隔时间,避免了并发虚拟主机的限制;
1 8、支持自定义内容写入,用户可以设置任何内容(例如自己的链接,广告代码),并写入采集的内容:第一个,最后一个或随机写入;导入库时,它将自动带出需要编写的内容,而无需修改WEB系统的模板。
1 9、支持采集内容替换功能,用户可以设置替换规则以随意替换;
20、支持html标签过滤,允许采集仅保留必要的html标签,甚至保留纯文本,而没有任何html标签;
2 1、支持各种cms指南库软件包,包括PHP cms V2 / V 3、 Dede cms(织梦)V2 / V 3、 PHP168 cms,mephpcms,Mambo cms,Joomla cms系统指南库规则和操作说明;
2 2、支持PHPWIND,Discuz论坛指南库,该程序包收录2个论坛指南库规则和操作说明;
2 3、附带数据库优化工具,以减少频繁出现的采集过多数据碎片并降低数据库性能。
以下特殊功能仅适用于“小蜜蜂采集器”:
1、支持采集进程断点恢复功能,该功能不受浏览器意外关闭的影响,并且在重新启动采集之后将不再重复;
2、支持自动比较和过滤功能,不会重复采集和入库采集的链接系统;以上两个功能可以大大减少采集时间并减少系统负载。
3、支持系统每天自动创建图片存储目录,以便于管理;
4、支持采集 /制导间隔时间设置,以避免被目标电台识别为交通攻击并拒绝响应;
5、支持自定义内容编写,以实现简单的防摘功能;
6、支持html标签过滤,可以完美显示您想要的采集效果;
7、内容存储的完美解决方案,不受目标编程语言和数据库类别的限制。
上述许多强大功能免费供您使用,并且体验信息采集易于立即安装和有效使用。
即将发布:网页内容采集器Content Grabber Premium v2.48
采集交流 • 优采云 发表了文章 • 0 个评论 • 368 次浏览 • 2020-11-23 11:01
Content Grabber Premium破解版是用于Web爬网和Web自动化的Web内容采集工具。它可以按照您选择的格式从几乎所有网站中提取内容(包括Excel报告,XML,CSV和大多数数据库),并将其另存为结构化数据,欢迎有需要的朋友下载和使用。
基本介绍
Content Grabber Premium(Web内容采集器)一种由外国神灵制作的人工制品,可以从网页中获取内容(视频,图片,文本)并将其提取到Excel,XML,CSV和大多数基于Web的数据库中抓取和网络自动化。它是完全免费的,并且经常用于数据调查和测试目的。
功能介绍
价格比较门户/移动应用程序
-数据摘要
-合作列表(例如房屋止赎,工作委员会,旅游景点)
-新闻和内容汇总
-搜索引擎排名
市场情报和监控
-有竞争力的价格
-零售链监控
-社交媒体和品牌监控
-金融与市场研究
-欺诈识别
-知识产权保护
-合规与风险管理
政府解决方案
-及时获取来自世界各地的新闻,事件和意见
-减少数据采集和IT成本
-促进信息共享
-开源情报(OSINT)
内容集成
-内容迁移(即cms/ CRM)
-企业搜索
-传统应用程序集成
B2B集成/流程自动化
-合作伙伴/供应商/客户集成
可扩展性和可靠性
内容采集器针对的是对网络搜寻至关重要的公司,并专注于可伸缩性和可靠性。该网络收录大量数据,借助多线程,优化的Web浏览器和许多其他性能调整选项,Content Grabber将比任何其他软件更快,更可靠地提取。我们强大的测试和调试功能可以帮助您构建可靠的代理,可靠的错误处理和错误恢复将使代理在最困难的情况下运行。
建立数百种网页抓取代理
“ Content Crawler”代理编辑器的易用性和可视化使其适合于构建数百个Web爬网代理,比使用任何其他软件要快得多。
代理编辑器将自动检测和配置所需的命令。它会自动创建内容和链接列表,处理分页和Web表单,下载或上传文件,并配置您在网页上执行的任何其他操作。同时,您始终可以手动微调这些命令,因此“内容抓取器”为您提供了简单性和控制性。
有数百个Web爬网程序,您需要正确的工具来管理这些工具,并且爬网内容不会使您失望。您可以查看所有代理的状态和日志,也可以在集中位置运行和安排代理。
净刮除剂的使用费分配免费
构建免版税,自收录的Web爬网代理,该代理可以在没有“内容爬网程序”软件的情况下在任何地方运行。独立代理是一个简单的可执行文件,可以随时随地发送或复制,并具有丰富的配置选项。您可以自由出售或赠送独立代理商,也可以在代理商的用户界面中添加促销信息和广告。
使用脚本自定义所有内容
脚本是“内容获取器”不可或缺的一部分,可用于需要某些特殊功能才能完全根据您的需要完成所有操作的情况下使用。使用内置脚本编辑器,或使用Content Grabber和Visual Studio的集成来实现更强大的脚本编辑和调试功能。
使用API构建独特的解决方案
将Web抓取功能添加到您自己的桌面应用程序中,并免费分发应用程序的Content Grabber运行时。根据需要使用专用的内容采集器Web API来构建Web应用程序并直接从网站执行Web抓取代理。
系统要求
在安装内容采集器之前,请确保您满足这些要求。
Windows 7/8/10 / 2008R2 / 2012 / 2012R2
.NET v4.5(如果您的计算机尚未安装,则会自动安装。)
安装步骤
1、从本站点提供的百度网站下载该软件,并将其解压缩后,双击“ setup.exe”程序
2、如果计算机上未安装Microsoft .NET版本,安装程序将显示Microsoft .NET版本4.5许可协议,并将自动为您安装
3、接受许可协议并安装
4、按照提示在安装向导中进行安装 查看全部
Web内容采集器Content Grabber Premium v2.48
Content Grabber Premium破解版是用于Web爬网和Web自动化的Web内容采集工具。它可以按照您选择的格式从几乎所有网站中提取内容(包括Excel报告,XML,CSV和大多数数据库),并将其另存为结构化数据,欢迎有需要的朋友下载和使用。
基本介绍
Content Grabber Premium(Web内容采集器)一种由外国神灵制作的人工制品,可以从网页中获取内容(视频,图片,文本)并将其提取到Excel,XML,CSV和大多数基于Web的数据库中抓取和网络自动化。它是完全免费的,并且经常用于数据调查和测试目的。
功能介绍
价格比较门户/移动应用程序
-数据摘要
-合作列表(例如房屋止赎,工作委员会,旅游景点)
-新闻和内容汇总
-搜索引擎排名
市场情报和监控
-有竞争力的价格
-零售链监控
-社交媒体和品牌监控
-金融与市场研究
-欺诈识别
-知识产权保护
-合规与风险管理
政府解决方案
-及时获取来自世界各地的新闻,事件和意见
-减少数据采集和IT成本
-促进信息共享
-开源情报(OSINT)
内容集成
-内容迁移(即cms/ CRM)
-企业搜索
-传统应用程序集成
B2B集成/流程自动化
-合作伙伴/供应商/客户集成
可扩展性和可靠性
内容采集器针对的是对网络搜寻至关重要的公司,并专注于可伸缩性和可靠性。该网络收录大量数据,借助多线程,优化的Web浏览器和许多其他性能调整选项,Content Grabber将比任何其他软件更快,更可靠地提取。我们强大的测试和调试功能可以帮助您构建可靠的代理,可靠的错误处理和错误恢复将使代理在最困难的情况下运行。
建立数百种网页抓取代理
“ Content Crawler”代理编辑器的易用性和可视化使其适合于构建数百个Web爬网代理,比使用任何其他软件要快得多。
代理编辑器将自动检测和配置所需的命令。它会自动创建内容和链接列表,处理分页和Web表单,下载或上传文件,并配置您在网页上执行的任何其他操作。同时,您始终可以手动微调这些命令,因此“内容抓取器”为您提供了简单性和控制性。
有数百个Web爬网程序,您需要正确的工具来管理这些工具,并且爬网内容不会使您失望。您可以查看所有代理的状态和日志,也可以在集中位置运行和安排代理。
净刮除剂的使用费分配免费
构建免版税,自收录的Web爬网代理,该代理可以在没有“内容爬网程序”软件的情况下在任何地方运行。独立代理是一个简单的可执行文件,可以随时随地发送或复制,并具有丰富的配置选项。您可以自由出售或赠送独立代理商,也可以在代理商的用户界面中添加促销信息和广告。
使用脚本自定义所有内容
脚本是“内容获取器”不可或缺的一部分,可用于需要某些特殊功能才能完全根据您的需要完成所有操作的情况下使用。使用内置脚本编辑器,或使用Content Grabber和Visual Studio的集成来实现更强大的脚本编辑和调试功能。
使用API构建独特的解决方案
将Web抓取功能添加到您自己的桌面应用程序中,并免费分发应用程序的Content Grabber运行时。根据需要使用专用的内容采集器Web API来构建Web应用程序并直接从网站执行Web抓取代理。
系统要求
在安装内容采集器之前,请确保您满足这些要求。
Windows 7/8/10 / 2008R2 / 2012 / 2012R2
.NET v4.5(如果您的计算机尚未安装,则会自动安装。)
安装步骤
1、从本站点提供的百度网站下载该软件,并将其解压缩后,双击“ setup.exe”程序
2、如果计算机上未安装Microsoft .NET版本,安装程序将显示Microsoft .NET版本4.5许可协议,并将自动为您安装
3、接受许可协议并安装
4、按照提示在安装向导中进行安装
最新版本:WEB数据采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 267 次浏览 • 2020-11-12 08:01
B WEB数据采集系统一.概述面对Internet上的大量信息,政府机构,企事业单位和研究机构都渴望获得与其工作有关的有价值的信息,以及如何获得这些信息。这些信息方便快捷地变得至关重要。如果使用原创的手动采集方法,则将很耗时,费力且效率低下。面对越来越多的信息资源,劳动强度和困难可想而知。因此,现代政府和企业迫切需要一种能够提供高质量,高效运行信息的解决方案采集。该系统针对不同行业用户的应用需求,旨在捕获Internet,并实现了在用户定义的规则下可以从Internet捕获指定信息。捕获的信息可以存储在数据库中或直接发送到指定的列,以实现网站信息的及时更新和数据量的增加,从而增加搜索引擎收录的数量并扩大公司信息的推广。二.典型应用1.政府机构实时跟踪,采集与业务相关的信息来源。 充分满足内部人员对全球互联网信息观察的需求。 及时解决政务外网和政务内网的信息源问题,实现动态发布。 快速解决地方政府领导网站的信息获取需求。 全面整合信息,实现跨区域,跨部门的信息资源共享和政府内部的有效沟通。 节省人力,物力和信息时间采集,并提高办公效率。2.企业实时,准确地监视和跟踪竞争对手的动态是企业获取竞争情报的有力工具。
及时获取竞争对手的公共信息,以研究同一行业的发展和市场需求。 为企业决策部门和管理人员提供方便,多渠道的企业战略决策工具。 实质性提高企业获取和利用智能的效率,节省智能信息采集,存储和挖掘的相关费用,是提高企业核心竞争力的关键。 提升公司的整体分析研究能力,快速的市场反应能力,建立以知识管理为核心的“竞争情报数据仓库”,是提高公司核心竞争力的神经中心。3.新闻媒体快速准确地自动采集计数信息。 支持每天有效抓取上万条新闻。 支持智能提取和查看所需内容。 实现Internet信息内容采集,浏览,编辑,管理和发布的集成。三.。系统架构工作流程描述采集的目的是将另一方网站上的网页上的某些文本或图片下载到您的网站。此过程需要进行以下配置工作:下载网页配置,分析网页配置,修改结果配置和数据输出配置。如果数据符合您的要求,则可以省略校正结果的步骤。配置完成后,将配置形成一个任务(该任务以XML格式描述),采集系统根据该任务的描述开始工作,最后将采集的结果存储在网站服务器。工作流程图如下:数据处理逻辑图:四.系统功能根据用户预先配置的规则(网页下载规则,网页解析规则等),处理数据采集。当对方的网站数据被更新或添加了新数据时,系统将自动检测它,执行采集,然后更新为自己的数据... 查看全部
WEB数据采集系统
B WEB数据采集系统一.概述面对Internet上的大量信息,政府机构,企事业单位和研究机构都渴望获得与其工作有关的有价值的信息,以及如何获得这些信息。这些信息方便快捷地变得至关重要。如果使用原创的手动采集方法,则将很耗时,费力且效率低下。面对越来越多的信息资源,劳动强度和困难可想而知。因此,现代政府和企业迫切需要一种能够提供高质量,高效运行信息的解决方案采集。该系统针对不同行业用户的应用需求,旨在捕获Internet,并实现了在用户定义的规则下可以从Internet捕获指定信息。捕获的信息可以存储在数据库中或直接发送到指定的列,以实现网站信息的及时更新和数据量的增加,从而增加搜索引擎收录的数量并扩大公司信息的推广。二.典型应用1.政府机构实时跟踪,采集与业务相关的信息来源。 充分满足内部人员对全球互联网信息观察的需求。 及时解决政务外网和政务内网的信息源问题,实现动态发布。 快速解决地方政府领导网站的信息获取需求。 全面整合信息,实现跨区域,跨部门的信息资源共享和政府内部的有效沟通。 节省人力,物力和信息时间采集,并提高办公效率。2.企业实时,准确地监视和跟踪竞争对手的动态是企业获取竞争情报的有力工具。
及时获取竞争对手的公共信息,以研究同一行业的发展和市场需求。 为企业决策部门和管理人员提供方便,多渠道的企业战略决策工具。 实质性提高企业获取和利用智能的效率,节省智能信息采集,存储和挖掘的相关费用,是提高企业核心竞争力的关键。 提升公司的整体分析研究能力,快速的市场反应能力,建立以知识管理为核心的“竞争情报数据仓库”,是提高公司核心竞争力的神经中心。3.新闻媒体快速准确地自动采集计数信息。 支持每天有效抓取上万条新闻。 支持智能提取和查看所需内容。 实现Internet信息内容采集,浏览,编辑,管理和发布的集成。三.。系统架构工作流程描述采集的目的是将另一方网站上的网页上的某些文本或图片下载到您的网站。此过程需要进行以下配置工作:下载网页配置,分析网页配置,修改结果配置和数据输出配置。如果数据符合您的要求,则可以省略校正结果的步骤。配置完成后,将配置形成一个任务(该任务以XML格式描述),采集系统根据该任务的描述开始工作,最后将采集的结果存储在网站服务器。工作流程图如下:数据处理逻辑图:四.系统功能根据用户预先配置的规则(网页下载规则,网页解析规则等),处理数据采集。当对方的网站数据被更新或添加了新数据时,系统将自动检测它,执行采集,然后更新为自己的数据...
直观:数据采集系统有哪几种采集方式,各自有什么特点
采集交流 • 优采云 发表了文章 • 0 个评论 • 512 次浏览 • 2020-10-13 09:01
编辑器总结了几种常用数据采集技术供您参考,它们主要分为以下几类:一、CS软件数据采集技术。 C / S体系结构软件属于较旧的体系结构,并且能够支持采集这样的软件数据的产品很少。最常见的机器人是Bowei Xiaobang软件机器人,它基于“您所见即所得”采集界面上的数据,而无需软件供应商的合作。输出结果是结构化数据库或excel表。如果仅需要业务数据,或者制造商破产,并且数据库分析困难,则可以使用此工具来处理采集数据,尤其是明细页数据的采集功能。值得一提的是,使用该产品的门槛非常低,没有IT背景的商科学生也可以使用它,这极大地扩大了用户群体。二、Web数据采集 API。通过网络爬虫和平台提供的某些网站公共API(例如Twitter和Sina Wei)Web API)和其他方法从网站获取数据。这样,可以从网页中提取非结构化数据和半结构化数据的网页数据。互联网网页大数据采集的总体处理过程包括四个两个主要模块:Web采集器(Spider),数据处理(DataProcess),搜寻URL队列(URLQueue)和数据。三、数据库方法两个系统都有自己的数据库,对于相同类型的数据库更方便:[K24]如果两个数据库位于同一服务器上,只要正确设置用户名,它们就可以直接互相访问。您需要在from之后输入数据库名称和表的架构所有者。 select * fromDATABASE1.dbo.table12)如果两个系统的数据库不在同一服务器上,建议连接到服务器进行处理,或者使用openset和opendatasource。这需要外围服务器配置才能进行数据库访问。不同类型的数据库之间的连接更加麻烦,并且需要进行许多设置才能生效,因此在此不再赘述。开放数据库方法需要与各种软件供应商协调以打开数据库,这是非常困难的。如果平台必须连接许多软件制造商的数据库,并且要实时获取数据,这对于平台本身的性能也是一个巨大的挑战。 查看全部
data采集系统有多少种采集方法,它们的特点是什么?
编辑器总结了几种常用数据采集技术供您参考,它们主要分为以下几类:一、CS软件数据采集技术。 C / S体系结构软件属于较旧的体系结构,并且能够支持采集这样的软件数据的产品很少。最常见的机器人是Bowei Xiaobang软件机器人,它基于“您所见即所得”采集界面上的数据,而无需软件供应商的合作。输出结果是结构化数据库或excel表。如果仅需要业务数据,或者制造商破产,并且数据库分析困难,则可以使用此工具来处理采集数据,尤其是明细页数据的采集功能。值得一提的是,使用该产品的门槛非常低,没有IT背景的商科学生也可以使用它,这极大地扩大了用户群体。二、Web数据采集 API。通过网络爬虫和平台提供的某些网站公共API(例如Twitter和Sina Wei)Web API)和其他方法从网站获取数据。这样,可以从网页中提取非结构化数据和半结构化数据的网页数据。互联网网页大数据采集的总体处理过程包括四个两个主要模块:Web采集器(Spider),数据处理(DataProcess),搜寻URL队列(URLQueue)和数据。三、数据库方法两个系统都有自己的数据库,对于相同类型的数据库更方便:[K24]如果两个数据库位于同一服务器上,只要正确设置用户名,它们就可以直接互相访问。您需要在from之后输入数据库名称和表的架构所有者。 select * fromDATABASE1.dbo.table12)如果两个系统的数据库不在同一服务器上,建议连接到服务器进行处理,或者使用openset和opendatasource。这需要外围服务器配置才能进行数据库访问。不同类型的数据库之间的连接更加麻烦,并且需要进行许多设置才能生效,因此在此不再赘述。开放数据库方法需要与各种软件供应商协调以打开数据库,这是非常困难的。如果平台必须连接许多软件制造商的数据库,并且要实时获取数据,这对于平台本身的性能也是一个巨大的挑战。
完美:各大企业都在用的数据采集配置,轻松日采数据千亿条
采集交流 • 优采云 发表了文章 • 0 个评论 • 314 次浏览 • 2020-09-19 12:01
本文介绍了根据我多年的行业经验在巨人的肩膀上开发的data 采集应用程序,这就是我们通常所说的履带系统。说到系统,它不是一个单独的采集器脚本,而是一整套自动化的内容采集。因为我尝试了许多构建此系统的方法,所以这里是最简单,易于实现和共享的最佳内容。现在,每个主要的日常数据相关企业都基本采用了此数据采集技术,该技术简单,快速且实用。这是基于Python的产品设计和应用的简要说明。
编程语言:Python
使用框架:Scrapy,Gerapy
数据仓库:Mongodb
其他内容:IP池
简短地讨论一般业务流程。
安排数据爬网的目录并将其分类为文件。
根据文档编写Scrapy采集器脚本。
在Gerapy中部署Scrapy脚本并进行相关设置以实现24小时自动化采集。
对应中会有一些问题。
如何确定抓取的网站失败了?
如何使用IP池?
在部署过程中的任何时候都会遇到各种坑。
以后如何使用捕获的数据?
对于使用中的各种问题,请检查我的技术文章。这里我们仅介绍业务流程和功能使用。
靠近主题,开始就是内容
组织数据采集文档
如果您使用傻瓜式方式而不是穷举的方式进行采集,则此步骤是不可避免的。它是组织我们要爬网的目标页面。根据Scrapy捕获的格式要求进行组织。
例如,例如《新华网》和《人民日报在线》,此网站页实际上很多,并且由于该页的CSS不同,因此对其进行分类很令人讨厌,但您只能使用它完成一次之后。
Spider下与脚本名称相对应的py文件以记录形式组织。 查看全部
所有主要企业使用的数据采集配置,每天轻松采集数千亿个数据
本文介绍了根据我多年的行业经验在巨人的肩膀上开发的data 采集应用程序,这就是我们通常所说的履带系统。说到系统,它不是一个单独的采集器脚本,而是一整套自动化的内容采集。因为我尝试了许多构建此系统的方法,所以这里是最简单,易于实现和共享的最佳内容。现在,每个主要的日常数据相关企业都基本采用了此数据采集技术,该技术简单,快速且实用。这是基于Python的产品设计和应用的简要说明。
编程语言:Python
使用框架:Scrapy,Gerapy
数据仓库:Mongodb
其他内容:IP池
简短地讨论一般业务流程。
安排数据爬网的目录并将其分类为文件。
根据文档编写Scrapy采集器脚本。
在Gerapy中部署Scrapy脚本并进行相关设置以实现24小时自动化采集。
对应中会有一些问题。
如何确定抓取的网站失败了?
如何使用IP池?
在部署过程中的任何时候都会遇到各种坑。
以后如何使用捕获的数据?
对于使用中的各种问题,请检查我的技术文章。这里我们仅介绍业务流程和功能使用。
靠近主题,开始就是内容

组织数据采集文档
如果您使用傻瓜式方式而不是穷举的方式进行采集,则此步骤是不可避免的。它是组织我们要爬网的目标页面。根据Scrapy捕获的格式要求进行组织。
例如,例如《新华网》和《人民日报在线》,此网站页实际上很多,并且由于该页的CSS不同,因此对其进行分类很令人讨厌,但您只能使用它完成一次之后。

Spider下与脚本名称相对应的py文件以记录形式组织。
解读:如何设计一个内容推荐系统?
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2020-09-01 09:54
传输: 用户的兴趣采集越快越好,以便可以将特定用户的操作快速反馈到下一个建议,因此需要稳定的传输和更新日志,但是出于成本考虑,用户配置文件并非所有都可以实时更新. 有些可能会延迟1小时,有些可能每天更新一次,每周更新一次,甚至更长.
挖掘: 此过程是将用户数据计算并挖掘到我们想要的功能中(通常称为“用户个人资料”,在行业中通常称为用户个人资料). 用户挖掘通常需要与算法结合,而不是凭空挖掘特征. 没有算法应用程序就很棒的用户头像也不值钱.
存储: 用户的兴趣在一段时间内不会有太大变化,因此可以使用用户的长期行为来积累用户肖像,并且需要存储这些配置文件. 如果用户数量很大,那么所需的存储资源也很大,那么就需要一个可以以分布式方式存储大量数据的数据库,并且它必须可靠且便宜,例如hdfs(Hadoop Distributed文件系统),如果您想进行实时计算用户兴趣需要一个可以快速访问的数据库(例如Redis),因此对于微博和头条等公司来说,购买服务器也是一大笔开支.
当然,用户的兴趣不是一成不变的,因此用户的兴趣需要随着时间的流逝而“衰减”. 设置合理的衰减系数对于用户配置文件也非常重要.
此外,用户行为挖掘还存在另一个历史问题-用户冷启动. 我们需要在此主题文章上另开篇文章.
四种排序算法
在前三个步骤中收录内容和用户数据时,可以在第四步中使用该算法来匹配两者. 个性化推荐的本质是进行前N名排名,该排名通常包括两个模块: “召回”和“排名”. 例如,如果我有100,000条消息,但是用户每天只能看到10条消息,那么我应该向用户推荐10条消息?我可以将100,000个项目从10,000到100,000进行分类,因此,无论用户希望看到多少个项目,我都只需从已排序的10,000个项目中从前到后进行选择. 这个过程是“排序”;但是这种排序方法在实时索引上的计算量太大,可能带来高延迟,因此我们首先使用一种相对简单的方法从100,000个中选择相对可靠的1,000个,然后对1,000个进行排序,然后选择100,000个. 10,000个过程是“召回”.
算法中有很多方法. 您可以参考官方帐户上发布的文章,其中详细介绍了推荐系统中常用的最有效算法. 另外,无论哪种算法在内容推荐之后都需要使用“动态指标”(例如ctr),如何在推荐之前获得该动态指标?此处涉及的内容的冷启动将在以后另行讨论.
5. 推荐的搜索引擎
为什么有搜索引擎?是的,您没有记错. 实际上,个性化推荐和搜索是非常相似的领域. 两者都是信息筛选方法,并且都在做一种“相关性”等级,并且目标函数非常接近(点击率). 只是搜索更加关注用户当前搜索关键字的相关性,而推荐则更加关注内容和用户个人资料的相关性. 每次用户浏览时,这都是实时请求. 因此,有必要实时地计算出最能满足用户兴趣的内容. 此步骤由在线搜索引擎执行. 但是,由于性能要求,联机索引步骤不应太耗时. 通常,排序算法会计算初始结果,而在线引擎会进行算法调度和规范化排序. 此外,在线索引还将负责接收请求,输出数据并公开服务,例如单击删除通常负责对业务和产品要求进行次要排名(例如插入广告,分解相同类型的内容等). ).
VI. ABtest系统
尽管ABtest系统不是个性化推荐系统的必要模块,但是没有ABtest的推荐系统必须是伪造的推荐系统!推荐系统的优化实际上是y = f(x),y是目标函数. 首先,目标函数必须非常清晰且可量化的指标; f(x)是选择的算法,算法特征参数和算法调度实际上,业界一直采用如此多的有效算法,而算法原理却很少. 但是,如何结合您自己的产品方案选择功能和参数已成为个性化推荐准确性的关键因素. 如果有一个ABtest系统,那么我们可以尝试引入各种参数和功能,并且ABtest实验将获得最佳y,以便可以迭代和优化推荐系统.
当然,算法的优化并不像更改参数那样简单. 推荐者需要对数据非常敏感,并且能够将复杂的问题抽象为可量化的指标,然后结合ABtest实验来快速进行迭代. 我总结的算法优化过程是: “数据分析发现问题,合理的假设,设计实验,实现,数据分析,并得出结论或新的假设. ”更改参数只是“实现”步骤,也是最简单的步骤. 大多数人通常只关注“实现”,而很少关注分析和假设的过程. 这种优化的效果无法保证,某些产品和技术人员会陷入盲目的ABtest的误解,漫无目的地尝试,经常进行ABtest并发现AB组数据没有差异,甚至认为ABtest是效率低下. 这些分析思想打开了算法工程师之间的鸿沟.
摘要
通过这6个部分,已构建了完整的个性化推荐系统. 整个系统包括算法工程师,自然语言处理/图像处理工程师,服务器工程师/架构师,数据挖掘工程师以及数据分析师,产品经理还需要大量标签审阅者,内容操作人员以及前端和客户端技术支持. 因此,构建良好的个性化推荐系统相对昂贵,但有时我们不需要该系统. 一些简单的规则可能会实现相对个性化并提高用户效率(例如,将用户最近浏览的商品放在首位),因此提高效率的思想和方法最为重要,这是我们需要讨论的问题很久了. 查看全部
如何设计内容推荐系统?
传输: 用户的兴趣采集越快越好,以便可以将特定用户的操作快速反馈到下一个建议,因此需要稳定的传输和更新日志,但是出于成本考虑,用户配置文件并非所有都可以实时更新. 有些可能会延迟1小时,有些可能每天更新一次,每周更新一次,甚至更长.
挖掘: 此过程是将用户数据计算并挖掘到我们想要的功能中(通常称为“用户个人资料”,在行业中通常称为用户个人资料). 用户挖掘通常需要与算法结合,而不是凭空挖掘特征. 没有算法应用程序就很棒的用户头像也不值钱.
存储: 用户的兴趣在一段时间内不会有太大变化,因此可以使用用户的长期行为来积累用户肖像,并且需要存储这些配置文件. 如果用户数量很大,那么所需的存储资源也很大,那么就需要一个可以以分布式方式存储大量数据的数据库,并且它必须可靠且便宜,例如hdfs(Hadoop Distributed文件系统),如果您想进行实时计算用户兴趣需要一个可以快速访问的数据库(例如Redis),因此对于微博和头条等公司来说,购买服务器也是一大笔开支.
当然,用户的兴趣不是一成不变的,因此用户的兴趣需要随着时间的流逝而“衰减”. 设置合理的衰减系数对于用户配置文件也非常重要.
此外,用户行为挖掘还存在另一个历史问题-用户冷启动. 我们需要在此主题文章上另开篇文章.
四种排序算法
在前三个步骤中收录内容和用户数据时,可以在第四步中使用该算法来匹配两者. 个性化推荐的本质是进行前N名排名,该排名通常包括两个模块: “召回”和“排名”. 例如,如果我有100,000条消息,但是用户每天只能看到10条消息,那么我应该向用户推荐10条消息?我可以将100,000个项目从10,000到100,000进行分类,因此,无论用户希望看到多少个项目,我都只需从已排序的10,000个项目中从前到后进行选择. 这个过程是“排序”;但是这种排序方法在实时索引上的计算量太大,可能带来高延迟,因此我们首先使用一种相对简单的方法从100,000个中选择相对可靠的1,000个,然后对1,000个进行排序,然后选择100,000个. 10,000个过程是“召回”.
算法中有很多方法. 您可以参考官方帐户上发布的文章,其中详细介绍了推荐系统中常用的最有效算法. 另外,无论哪种算法在内容推荐之后都需要使用“动态指标”(例如ctr),如何在推荐之前获得该动态指标?此处涉及的内容的冷启动将在以后另行讨论.
5. 推荐的搜索引擎
为什么有搜索引擎?是的,您没有记错. 实际上,个性化推荐和搜索是非常相似的领域. 两者都是信息筛选方法,并且都在做一种“相关性”等级,并且目标函数非常接近(点击率). 只是搜索更加关注用户当前搜索关键字的相关性,而推荐则更加关注内容和用户个人资料的相关性. 每次用户浏览时,这都是实时请求. 因此,有必要实时地计算出最能满足用户兴趣的内容. 此步骤由在线搜索引擎执行. 但是,由于性能要求,联机索引步骤不应太耗时. 通常,排序算法会计算初始结果,而在线引擎会进行算法调度和规范化排序. 此外,在线索引还将负责接收请求,输出数据并公开服务,例如单击删除通常负责对业务和产品要求进行次要排名(例如插入广告,分解相同类型的内容等). ).
VI. ABtest系统
尽管ABtest系统不是个性化推荐系统的必要模块,但是没有ABtest的推荐系统必须是伪造的推荐系统!推荐系统的优化实际上是y = f(x),y是目标函数. 首先,目标函数必须非常清晰且可量化的指标; f(x)是选择的算法,算法特征参数和算法调度实际上,业界一直采用如此多的有效算法,而算法原理却很少. 但是,如何结合您自己的产品方案选择功能和参数已成为个性化推荐准确性的关键因素. 如果有一个ABtest系统,那么我们可以尝试引入各种参数和功能,并且ABtest实验将获得最佳y,以便可以迭代和优化推荐系统.
当然,算法的优化并不像更改参数那样简单. 推荐者需要对数据非常敏感,并且能够将复杂的问题抽象为可量化的指标,然后结合ABtest实验来快速进行迭代. 我总结的算法优化过程是: “数据分析发现问题,合理的假设,设计实验,实现,数据分析,并得出结论或新的假设. ”更改参数只是“实现”步骤,也是最简单的步骤. 大多数人通常只关注“实现”,而很少关注分析和假设的过程. 这种优化的效果无法保证,某些产品和技术人员会陷入盲目的ABtest的误解,漫无目的地尝试,经常进行ABtest并发现AB组数据没有差异,甚至认为ABtest是效率低下. 这些分析思想打开了算法工程师之间的鸿沟.
摘要
通过这6个部分,已构建了完整的个性化推荐系统. 整个系统包括算法工程师,自然语言处理/图像处理工程师,服务器工程师/架构师,数据挖掘工程师以及数据分析师,产品经理还需要大量标签审阅者,内容操作人员以及前端和客户端技术支持. 因此,构建良好的个性化推荐系统相对昂贵,但有时我们不需要该系统. 一些简单的规则可能会实现相对个性化并提高用户效率(例如,将用户最近浏览的商品放在首位),因此提高效率的思想和方法最为重要,这是我们需要讨论的问题很久了.
基于BBS内容安全监管的数据采集系统的设计与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 283 次浏览 • 2020-08-29 18:20
计算机科学20 0 6V 0 1. 33N _ o . 9 ( 专辑)基于B B S 内容安全监管的数据采集系统的设计与实现李艳玲戴冠中朱烨行( 西j也工业大学自动化学院南京7 10 0 7 2)摘襄针对不良信息对网路空间的侵袭, 给社会带来的害处, 本文提出了B B S 内容安全篮管系统结构模型, 对嚣申的数据采集系统进行了诺细设诗与实现, 并通过系统的实际运行证明, 该系统可以为B B S 的实时监控提供有效的数据支持。美键溺B 骼, 悫容安全监蟹, 数据采集1序言随着网路应角的普及, 阏络已成为信息转播的主要载体。 其中, B B S 等网路峰会成为网民参与讨论、 表达意见的主要场所。 网络空间本身具有的容量, 为信息的频繁、 大量发布与复制提供了可能, 某些别有用心的人很容易提升个别不良信息( 包括反共、 谣言、 暴力、 色情等信息)的报导频度和硬度, 弓l起人们对这种信息的关注, 给正常的社会秩序注入不稳定诱因, 某些憾况下, 甚至可熊弓l发突发事件。嚣此, 需要赜8蹒进行监控与管理, 及时掌援阏络虚拟世界中的热点话题, 为政府揣度民情和民声, 做出科学的决策, 采取糨应的播旖键进有益的趋势稻防止现实化学世界中可能出现的不良后果提供支持。
本文提出了B B S 内容安全监管系统结构模型,对其中的数据采集系统进行了详尽设计与实现。2 B B S 内容安全监管系统结构模型图1B B s内容安全监管系统结构模型9 1B B S 内容安全监管系统结构模型如图1所示。整个系统分为四个层次, 数据采集层负责采集监管须要的数据, 内容剖析层负责对内容的安全检查、 预测剖析等, 研讨层把人脑中的知识同系统中的有关信息结合上去, 扩展专家和计算机的能力, 从而提出对复杂问题的解决方案, 输出层是处理结果。人机接口{ }任务管理器j【主题I燃集器JLS蠡心№合山_ 一飞页面孥器}=跟踪数据整理器她lIl虚拟社联挖掘I内'攀库J鬯本!容b点掣掘f薪陋赢删黍图2数据采集系统构架3数据采集系统构架数据采集系统构架如图2所示, 主要包括五个功能模块: 任务管理器、 数据采集器、 页面处理器、 数据整理模块和主题跟踪器, 各模块通过任务管理器,在操作员的调度下, 完成内容安全剖析等须要数据的手动采集。 尽量做到数据的自动化处理, 即数据采集过程对用户是透明的, 但须要用户可以通过窗口对其监视, 或下达停止、 添加任务等命令。其中, 任务管理器主要负责工作任务的设置、 添加、 删除及运行状况的查看等, 工作任务包括数据采集的运行时间、 周期设置、 目标站点的设置、 目标主题的设置等, 由操作员通过人机插口下达; 数据采集器按照任务管理器下达的任务, 到指定的目标峰会采集数据, 生成待处理贴子的H T M I. 页面的U R I。队列, 送入文件集合。 页面处理器主要负责对采集到的页面进行剖析处理, 提取... 查看全部
基于BBS内容安全监管的数据采集系统的设计与实现
计算机科学20 0 6V 0 1. 33N _ o . 9 ( 专辑)基于B B S 内容安全监管的数据采集系统的设计与实现李艳玲戴冠中朱烨行( 西j也工业大学自动化学院南京7 10 0 7 2)摘襄针对不良信息对网路空间的侵袭, 给社会带来的害处, 本文提出了B B S 内容安全篮管系统结构模型, 对嚣申的数据采集系统进行了诺细设诗与实现, 并通过系统的实际运行证明, 该系统可以为B B S 的实时监控提供有效的数据支持。美键溺B 骼, 悫容安全监蟹, 数据采集1序言随着网路应角的普及, 阏络已成为信息转播的主要载体。 其中, B B S 等网路峰会成为网民参与讨论、 表达意见的主要场所。 网络空间本身具有的容量, 为信息的频繁、 大量发布与复制提供了可能, 某些别有用心的人很容易提升个别不良信息( 包括反共、 谣言、 暴力、 色情等信息)的报导频度和硬度, 弓l起人们对这种信息的关注, 给正常的社会秩序注入不稳定诱因, 某些憾况下, 甚至可熊弓l发突发事件。嚣此, 需要赜8蹒进行监控与管理, 及时掌援阏络虚拟世界中的热点话题, 为政府揣度民情和民声, 做出科学的决策, 采取糨应的播旖键进有益的趋势稻防止现实化学世界中可能出现的不良后果提供支持。
本文提出了B B S 内容安全监管系统结构模型,对其中的数据采集系统进行了详尽设计与实现。2 B B S 内容安全监管系统结构模型图1B B s内容安全监管系统结构模型9 1B B S 内容安全监管系统结构模型如图1所示。整个系统分为四个层次, 数据采集层负责采集监管须要的数据, 内容剖析层负责对内容的安全检查、 预测剖析等, 研讨层把人脑中的知识同系统中的有关信息结合上去, 扩展专家和计算机的能力, 从而提出对复杂问题的解决方案, 输出层是处理结果。人机接口{ }任务管理器j【主题I燃集器JLS蠡心№合山_ 一飞页面孥器}=跟踪数据整理器她lIl虚拟社联挖掘I内'攀库J鬯本!容b点掣掘f薪陋赢删黍图2数据采集系统构架3数据采集系统构架数据采集系统构架如图2所示, 主要包括五个功能模块: 任务管理器、 数据采集器、 页面处理器、 数据整理模块和主题跟踪器, 各模块通过任务管理器,在操作员的调度下, 完成内容安全剖析等须要数据的手动采集。 尽量做到数据的自动化处理, 即数据采集过程对用户是透明的, 但须要用户可以通过窗口对其监视, 或下达停止、 添加任务等命令。其中, 任务管理器主要负责工作任务的设置、 添加、 删除及运行状况的查看等, 工作任务包括数据采集的运行时间、 周期设置、 目标站点的设置、 目标主题的设置等, 由操作员通过人机插口下达; 数据采集器按照任务管理器下达的任务, 到指定的目标峰会采集数据, 生成待处理贴子的H T M I. 页面的U R I。队列, 送入文件集合。 页面处理器主要负责对采集到的页面进行剖析处理, 提取...
捷豹淘宝采集助手 v1.0官方版
采集交流 • 优采云 发表了文章 • 0 个评论 • 453 次浏览 • 2020-08-29 15:01
捷豹淘宝采集助手是一款专为电商用户的构建的采集软件,能够帮助用户快速采集闲鱼网上所有店面内商品的信息,信息资源更新快,系统24小时手动采集。内容精准详尽,多项店面信息。
基本简介
捷豹淘宝采集助手是一款就能帮助使用者快速采集闲鱼网上所有店面内商品的信息,让您更精准、更快速的找到理想中的数据!
功能介绍
1、操作简单,搜索速度快。(本软件使用云采集技术,10分钟即可采集实时更新数据1000条以上,最多比市面上其他软件快20倍!)
2、软件可以采集到店面名称、旺旺名、商品名,价格、销量、地区、旺旺注册时间等。
3、直接点击【开始采集】即可。
4、软件操作的界面人性化的选项开始、停止。
5、采集完成后可以选择不同格式,不同的数组导入想要的数据。
6、点击店面链接可以查看更详尽的店面信息。
7、信息资源更新快,系统24小时手动采集。
8、无人工干预,软件手动采集,让顾客更放心。
9、内容精准详尽,多项店面信息。
10、软件自行过滤重复数据。
常见问题
启动时报错
请先安装.net4.0再运行本程序 →→点击下载NET4.0 ←←
点读取数据没反应
一.在压缩包里运行可能会出现这样的问题,请先解压再运行
二.电脑的的时间不对,改成正确的时间
三.软件不支持 XP系统,请更换成win7及以上的操作系统 查看全部
捷豹淘宝采集助手 v1.0官方版
捷豹淘宝采集助手是一款专为电商用户的构建的采集软件,能够帮助用户快速采集闲鱼网上所有店面内商品的信息,信息资源更新快,系统24小时手动采集。内容精准详尽,多项店面信息。

基本简介
捷豹淘宝采集助手是一款就能帮助使用者快速采集闲鱼网上所有店面内商品的信息,让您更精准、更快速的找到理想中的数据!
功能介绍
1、操作简单,搜索速度快。(本软件使用云采集技术,10分钟即可采集实时更新数据1000条以上,最多比市面上其他软件快20倍!)
2、软件可以采集到店面名称、旺旺名、商品名,价格、销量、地区、旺旺注册时间等。
3、直接点击【开始采集】即可。
4、软件操作的界面人性化的选项开始、停止。
5、采集完成后可以选择不同格式,不同的数组导入想要的数据。
6、点击店面链接可以查看更详尽的店面信息。
7、信息资源更新快,系统24小时手动采集。
8、无人工干预,软件手动采集,让顾客更放心。
9、内容精准详尽,多项店面信息。
10、软件自行过滤重复数据。
常见问题
启动时报错

请先安装.net4.0再运行本程序 →→点击下载NET4.0 ←←
点读取数据没反应
一.在压缩包里运行可能会出现这样的问题,请先解压再运行
二.电脑的的时间不对,改成正确的时间
三.软件不支持 XP系统,请更换成win7及以上的操作系统
推荐系统之数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 579 次浏览 • 2020-08-28 05:56
对于做推荐系统或则是策略相关的产品朋友最难的是哪些?是没有数据的支撑。没有数据就没有办法建立用户画像、标签体系;没有办法进行数据统计、指标剖析、AB 实验疗效验证。那么问题来了,数据从哪儿来。这一篇文章就介绍推荐系统中容易使人忽略,又极为重要,又相当多坑的一个环节——数据采集。
信息流数据采集完整流程
在之家推荐、画像、标签相关的产品总监有数据需求的时侯就会先和数据产品沟通,当然若果公司职位没有分得那么细的话,往往推荐产品或是画像的产品总监要自己去走完这整个流程,这一个流程走出来,就会对数据的完整流转相当的熟悉,当然也是一个心筛的过程,各种坑等着你。接下来我就依照这个流程重点介绍数据采集的全流程,普通页面的数据采集知乎上好多文章介绍,无非就是根据标准的sdk或js进行采集 我们这儿的重点是推荐信息流的数据采集,是以信息流的产品形态为根本出发点。
数据需求梳理
数据需求来源比较广,可以说假如是中台部门,各种各样的数据需求就会提及这儿上去,如营销、画像、算法、推广、标签等等,那么在考虑到各个具体需求时,既要要建立灵活的数据埋点上报规范,又满足现有需求,为将来可能会出现的需求留出扩充的空间。
埋点规范制订
信息流的埋点一般遵守以下的原则:
以恳求爆光风波埋点为例说明
定义:当用户刷新时,客户端恳求推荐插口获取推荐内容。 事件id:recm_req_show 统一风波id的整体格式,各推荐位置以recm_id进行分辨 请求爆光内容格式:一次恳求上报一条日志,收录此次恳求的推荐位置id:recm_id;请求惟一标示:pvid;内容列表itemlist,各推荐位置须要统一上报的内容格式。
请求爆光风波上报数据示例
也许有的朋友可能不明白里面的参数是哪些意思,为什么如此设计,我在这里解释一下里面规范示例中各参数的意义和作用。但你们牢记各信息流产品形态的参数须要依照实际业务来进行调整和定义。
推荐位id分配
埋点施行注意事项
上面大约介大致介绍了一下该规范的内容,还有三点在埋点施行过程中要注意的:
1.必须明晰风波上报的条件
比如恳求爆光,就要求在恳求成功后立刻上报;可见爆光则要求在爆光页面逗留超过一定的时长,这个问题在之家最早的规范中没有明晰,每次就会有开发朋友问,什么时候上报。
2.必须明晰每一个数组参数从哪些地方取
刚才前面介绍的参数,对于埋点朋友比较郁闷的时侯,找不到这种数从哪里取,或者是害怕取错,埋点一旦弄错,后面的数据统计,画像、标签都是错的,所以这个地方产品总监一定得和埋点同事确认清楚每一个参数的正确取数位置。
3.必须明晰数据的格式
数据格式的确认,主要是为了数据上报后,数仓同事对日志进行处理时才能高效、便捷,如果出现各种各样的格式,这里多个冒号,那里多个空格,这些非标准格式她们都得去处理,耗费时间和精力。
埋点初验
埋点初验主要是三点:
验收是否要所有推荐位都有数据上报 上报的参数是否有所有遗漏 上报的数据格式是否和规范要求一致
数据应用
当埋点完备、上报的数据经过数仓处理后,接下来就是数据的各类应用了。
数据统计
数据统计是最重要最基础的应用,特别是对于推荐系统最重要的一个指标CTR,用点击/可见爆光来进行估算。如果没有点击风波和可见爆光风波的埋点,这个数据就不可能形成,那么推荐系统的疗效就很难从量化指标上进行评估。
用户画像
因为在每条物料透传下来的stra扩充参数中,会带有表征物料的特点,以用户主动发生的行为风波为纽带,将物料的特点传递到用户头上,这个特点就是用户画像中的某个偏好。
以之家为例——如果数据采集到某用户近日点击的物料中较高频度出现某车系,那么这个车系都会成为该用户画像中其短期兴趣车系,就可以根据此车系推荐相关的内容,并估算该车系的相像车系或是竞品车系推荐给用户,关于用户画像的详尽介绍可以看下边这篇文章:
龚旭东:推荐系统之用户画像
还有其他数据应用场景就不再这儿一一介绍了,有兴趣的你们可以单独沟通
总结
说一下埋点这个工作的实际情况。以我的真实经历,埋点不是个技术活,也不难,需要的是耐心,细心,这个工作再怎样做也不会非常的出彩,所以大部分产品都不乐意干这个活,总会推来推去,最后搞得稀里糊涂,但是假如埋点做不好,上层的应用就做不好。说得不好听的,现如今互联网产品假如数据都搞不对,可以说基本就是死,所以建议这块儿还是专人负责。 查看全部
推荐系统之数据采集
对于做推荐系统或则是策略相关的产品朋友最难的是哪些?是没有数据的支撑。没有数据就没有办法建立用户画像、标签体系;没有办法进行数据统计、指标剖析、AB 实验疗效验证。那么问题来了,数据从哪儿来。这一篇文章就介绍推荐系统中容易使人忽略,又极为重要,又相当多坑的一个环节——数据采集。
信息流数据采集完整流程
在之家推荐、画像、标签相关的产品总监有数据需求的时侯就会先和数据产品沟通,当然若果公司职位没有分得那么细的话,往往推荐产品或是画像的产品总监要自己去走完这整个流程,这一个流程走出来,就会对数据的完整流转相当的熟悉,当然也是一个心筛的过程,各种坑等着你。接下来我就依照这个流程重点介绍数据采集的全流程,普通页面的数据采集知乎上好多文章介绍,无非就是根据标准的sdk或js进行采集 我们这儿的重点是推荐信息流的数据采集,是以信息流的产品形态为根本出发点。
数据需求梳理
数据需求来源比较广,可以说假如是中台部门,各种各样的数据需求就会提及这儿上去,如营销、画像、算法、推广、标签等等,那么在考虑到各个具体需求时,既要要建立灵活的数据埋点上报规范,又满足现有需求,为将来可能会出现的需求留出扩充的空间。
埋点规范制订
信息流的埋点一般遵守以下的原则:
以恳求爆光风波埋点为例说明
定义:当用户刷新时,客户端恳求推荐插口获取推荐内容。 事件id:recm_req_show 统一风波id的整体格式,各推荐位置以recm_id进行分辨 请求爆光内容格式:一次恳求上报一条日志,收录此次恳求的推荐位置id:recm_id;请求惟一标示:pvid;内容列表itemlist,各推荐位置须要统一上报的内容格式。

请求爆光风波上报数据示例
也许有的朋友可能不明白里面的参数是哪些意思,为什么如此设计,我在这里解释一下里面规范示例中各参数的意义和作用。但你们牢记各信息流产品形态的参数须要依照实际业务来进行调整和定义。

推荐位id分配
埋点施行注意事项
上面大约介大致介绍了一下该规范的内容,还有三点在埋点施行过程中要注意的:
1.必须明晰风波上报的条件
比如恳求爆光,就要求在恳求成功后立刻上报;可见爆光则要求在爆光页面逗留超过一定的时长,这个问题在之家最早的规范中没有明晰,每次就会有开发朋友问,什么时候上报。
2.必须明晰每一个数组参数从哪些地方取
刚才前面介绍的参数,对于埋点朋友比较郁闷的时侯,找不到这种数从哪里取,或者是害怕取错,埋点一旦弄错,后面的数据统计,画像、标签都是错的,所以这个地方产品总监一定得和埋点同事确认清楚每一个参数的正确取数位置。
3.必须明晰数据的格式
数据格式的确认,主要是为了数据上报后,数仓同事对日志进行处理时才能高效、便捷,如果出现各种各样的格式,这里多个冒号,那里多个空格,这些非标准格式她们都得去处理,耗费时间和精力。
埋点初验
埋点初验主要是三点:
验收是否要所有推荐位都有数据上报 上报的参数是否有所有遗漏 上报的数据格式是否和规范要求一致
数据应用
当埋点完备、上报的数据经过数仓处理后,接下来就是数据的各类应用了。
数据统计
数据统计是最重要最基础的应用,特别是对于推荐系统最重要的一个指标CTR,用点击/可见爆光来进行估算。如果没有点击风波和可见爆光风波的埋点,这个数据就不可能形成,那么推荐系统的疗效就很难从量化指标上进行评估。
用户画像
因为在每条物料透传下来的stra扩充参数中,会带有表征物料的特点,以用户主动发生的行为风波为纽带,将物料的特点传递到用户头上,这个特点就是用户画像中的某个偏好。
以之家为例——如果数据采集到某用户近日点击的物料中较高频度出现某车系,那么这个车系都会成为该用户画像中其短期兴趣车系,就可以根据此车系推荐相关的内容,并估算该车系的相像车系或是竞品车系推荐给用户,关于用户画像的详尽介绍可以看下边这篇文章:
龚旭东:推荐系统之用户画像

还有其他数据应用场景就不再这儿一一介绍了,有兴趣的你们可以单独沟通
总结
说一下埋点这个工作的实际情况。以我的真实经历,埋点不是个技术活,也不难,需要的是耐心,细心,这个工作再怎样做也不会非常的出彩,所以大部分产品都不乐意干这个活,总会推来推去,最后搞得稀里糊涂,但是假如埋点做不好,上层的应用就做不好。说得不好听的,现如今互联网产品假如数据都搞不对,可以说基本就是死,所以建议这块儿还是专人负责。
YGBOOK小说采集系统 php版 v1.4 下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 276 次浏览 • 2020-08-26 01:27
YGBOOK小说内容管理系统(以下简称YGBOOK)提供一个轻量级小说网站解决方案,基于ThinkPHP+MySQL的技术开发。
YGBOOK是介于CMS和扒手网站之间的一款新型网站系统,批量采集目标网站数据,并进行数据入库。不仅URL完全不同,模板不同,数据也属于自己,完全为解放站长右手,只需搭建好网站,即可手动采集+自动更新。
本软件以SEO性能极好的笔趣阁模板为基础,进行了大量优化,呈送给你们一款SEO优秀,不失美观大方的小说网站系统。
YGBOOK免费版本提供了基础小说功能,包括:
1.全手动采集2345导航小说的数据,内置采集规则,无需自己设置管理
2.数据入库,不必担忧目标站改版或死掉
3.网站本身进提供小说简介和章节列表的展示,章节阅读采用跳转到原站模式,以规避版权问题
4.自带伪静态功能,但未能自由订制,无手机版本、无站内搜索、无sitemap、无结构化数据
YGBOOK基于ThinkPHP+MYSQL开发,可以在大部分常见的服务器上运行。
如windows服务器,IIS+PHP+MYSQL,
Linux服务器,Apache/Nginx+PHP+MYSQL
强烈推荐使用Linux服务器,可以发挥更大性能优势
软件方面,PHP要求5.3版本以上,低于5.3版本未能运行。
硬件方面,一般配置的虚拟主机即可正常运行本系统,如果有服务器会更好。
伪静态配置参见压缩包中txt文件,针对不同环境的有不同配置说明(自带.htacess文件重新优化了兼容性,解决了apache+nts模式下可能出现的“No input file specified.”问题)
安装步骤:
1.将文件解压后上传至相应目录等
2.网站必须配置好伪静态(参考上一步配置),才能正常进行安装和使用(初次访问首页会手动步入安装页面,或自动输入//www.域名.com/install)
3.同意使用合同步入下一步检查目录权限
4.检测通过后,填写常规数据库配置项,填写正确即可安装成功,安装成功后会手动步入后台页面//www.域名.com/admin,填写安装时输入的后台管理员和密码即可登入
5.在后台文章列表页面,可以进行自动采集文章,和批量采集文章数据。初次安装完毕建议采集一些数据填充网站内容。网站在运行过程中,会手动执行采集操作(需前台访问触发,蜘蛛亦可触发采集),无须人工干预。
YGBOOK小说采集系统 更新日志:
v1.4
增加了百度sitemap功能
安装1.4版本后,您的sitemap地址即为“//您的域名/home/sitemap/baidu.xml”
您将域名替换成自己的域名后,访问查看无误,即可递交到百度站长平台
利于百度蜘蛛的爬取 查看全部
YGBOOK小说采集系统 php版 v1.4 下载
YGBOOK小说内容管理系统(以下简称YGBOOK)提供一个轻量级小说网站解决方案,基于ThinkPHP+MySQL的技术开发。
YGBOOK是介于CMS和扒手网站之间的一款新型网站系统,批量采集目标网站数据,并进行数据入库。不仅URL完全不同,模板不同,数据也属于自己,完全为解放站长右手,只需搭建好网站,即可手动采集+自动更新。
本软件以SEO性能极好的笔趣阁模板为基础,进行了大量优化,呈送给你们一款SEO优秀,不失美观大方的小说网站系统。
YGBOOK免费版本提供了基础小说功能,包括:
1.全手动采集2345导航小说的数据,内置采集规则,无需自己设置管理
2.数据入库,不必担忧目标站改版或死掉
3.网站本身进提供小说简介和章节列表的展示,章节阅读采用跳转到原站模式,以规避版权问题
4.自带伪静态功能,但未能自由订制,无手机版本、无站内搜索、无sitemap、无结构化数据
YGBOOK基于ThinkPHP+MYSQL开发,可以在大部分常见的服务器上运行。
如windows服务器,IIS+PHP+MYSQL,
Linux服务器,Apache/Nginx+PHP+MYSQL
强烈推荐使用Linux服务器,可以发挥更大性能优势
软件方面,PHP要求5.3版本以上,低于5.3版本未能运行。
硬件方面,一般配置的虚拟主机即可正常运行本系统,如果有服务器会更好。
伪静态配置参见压缩包中txt文件,针对不同环境的有不同配置说明(自带.htacess文件重新优化了兼容性,解决了apache+nts模式下可能出现的“No input file specified.”问题)
安装步骤:
1.将文件解压后上传至相应目录等
2.网站必须配置好伪静态(参考上一步配置),才能正常进行安装和使用(初次访问首页会手动步入安装页面,或自动输入//www.域名.com/install)
3.同意使用合同步入下一步检查目录权限
4.检测通过后,填写常规数据库配置项,填写正确即可安装成功,安装成功后会手动步入后台页面//www.域名.com/admin,填写安装时输入的后台管理员和密码即可登入
5.在后台文章列表页面,可以进行自动采集文章,和批量采集文章数据。初次安装完毕建议采集一些数据填充网站内容。网站在运行过程中,会手动执行采集操作(需前台访问触发,蜘蛛亦可触发采集),无须人工干预。
YGBOOK小说采集系统 更新日志:
v1.4
增加了百度sitemap功能
安装1.4版本后,您的sitemap地址即为“//您的域名/home/sitemap/baidu.xml”
您将域名替换成自己的域名后,访问查看无误,即可递交到百度站长平台
利于百度蜘蛛的爬取
《PHP的数据采集》PPT课件.ppt
采集交流 • 优采云 发表了文章 • 0 个评论 • 324 次浏览 • 2020-08-23 01:10
《《PHP的数据采集》PPT课件.ppt》由会员分享,可在线阅读,更多相关《《PHP的数据采集》PPT课件.ppt(29页珍藏版)》请在人人文库网上搜索。
1、PHP动态网页设计教程,六、PHP的数据采集,黄迎久 内蒙古科技大学工程训练中心,主要内容,本讲主要内容 (1)浏览器端数据的递交方法; (2)绝对路径和相对路径的概念; (3)使用实现浏览器端的数据采集方法;,一、浏览器端数据的递交方法,浏览器向WEB服务器某PHP程序发送一个“请求”,该PHP程序接收到该“请求”后,接受所有“请求”数据,然后对这种“请求”数据进行处理,WEB服务器将处理结果作为“响应”返回给浏览器。 浏览器向WEB服务器递交数据的方法GET递交方法和POST递交方法。,一、浏览器端数据的递交方法,1、GET递交方法 GET递交方法是将“请求”数据以查询字符串(Query 。
2、String)的形式附在URL以后“提交”数据。 如 http//localhost/2/register.phpusernamejohnpassword1234 查询字符串中 “”表示查询字符串的开始,“”之后的字符串参数为查询字符串,可以收录多个查询字符串,每个参数以“参数名参数值”的格式定义。,一、浏览器端数据的递交方法,2、POST递交方法 POST数据递交方法通常通过表单实现,默认的情况下表单的数据递交方法为GET方法,因此,必须在表单的标签中加入”post”将数据递交方法更改为POST方法。,一、浏览器端数据的递交方法,3、GET和POST混和递交方法 使用表单可以实现GET和PO。
3、ST混和递交方法,向WEB服务器发出GET恳求的同时,还向该PHP程序发出“POST恳求”。, register.php 程序如下 ,一、浏览器端数据的递交方法,4、两种方法的比较 (1)POST递交方法比GET方法递交方法安全。在例如“注册”、“登录”等系统,不建议使用GET递交方法。 (2)POST递交方法可以递交更多的数据。如“新闻发布系统”中递交篇幅较长的新闻信息时,不建议使用GET递交方法;带有“文件上传功能”的表单必须使用POST递交方法。,二、相对路径与绝对路径,1、绝对路径 “绝对路径”是一个完整的URL,该URL是由以下两部份组成 (1)Scheme拿来描述找寻数据所采用的机。
4、制(协议),如http、ftp等。 (2)位置(location)用来描述到哪儿去找寻数据的资源。这部份使用“//”分隔,例如。 绝对路径无论出现在那里,都代表相同的内容,因此,绝对路径一般在访问系统外部资源时才使用,而访问内部资源时通常使用相对路径。,二、相对路径与绝对路径,2、相对路径 “相对路径”在不同的地方代表的内容是不同的。,例如一个完整的电话号码是“区位号”“电话号码”。以南京为例,0371-66666666是一个在中国境内的“绝对路径”。而到了成都后,只需拨通“66666666”即可,此时“66666666”就是一个“相对路径”。,例如当前目录“c/web/www/6/”中有in。
5、dex.html文件,使用超链接访问该目录下的register.php文件,只需在链接中指定到register.php文件的相对路径即可。 ,二、相对路径与绝对路径,3、相对路径其他概念 (1)同一文件夹下的资源访问 若文件1和文件2在同一目录中,这两个文件的互相访问直接使用文件名即可。 例如a.html和b.php两个文件在同一文件夹下,a.html页面的访问b.php文件时,a.html页面的表单可以这样写 . ,二、相对路径与绝对路径,3、相对路径其他概念 (2)如何表示当前目录 “.”表示文件的当前目录。若a.html和b.php文件在同一目录中,a.html页面的表单访问b.php文。
6、件时,a.html页面的表单写为 . ,二、相对路径与绝对路径,3、相对路径其他概念 (3)如何表示上级目录 “../”表示文件所在目录的上一级目录, “../../”表示文件所在目录的上上级目录。,(4)如何表示下级目录 若文件1访问下级目录中的文件2,直接指定该目录和文件2的文件名即可。 若a.html文件坐落cwwwweb”,b.php文件坐落cwwwwebtest”,则a.html页面的表单访问b.php页面时,a.html页面的表单写为 ,三、使用表单实现浏览器端的数据采集,表单由3部份构成 1表单标签 定义了表单处理程序及数据递交方法等信息; 2表单控件包括文本框、单选钮、复选框及。
7、文件上传等表单控件; 3表单按键包括递交、重置和通常按键;,三、使用表单实现浏览器端的数据采集,1、表单标签 表单标签常用的属性有action、、enctype、title、name等。 1 action设置当前表单数据“提交”的目的地址;当不设置action属性或属性值为空action“”时,表单数据递交给当前页面; 2设置表单数据的“提交”方式。属性值为GET或POST; 3title设置表单数据的提示信息。当用户的键盘表针在表单处逗留时,浏览器用一个红色的小鱼漂显示提示文本。 4enctype设置递交表单数据时的编码方法。属性值为multipart/-data,或 application。
8、/x-www--urlencoded。当一个表单存在文件上传框时,必须将enctype设置为multipart/for-data编码方法。,三、使用表单实现浏览器端的数据采集,2、表单控件 1 文本框 *单行文本框通常拿来输入单行的文字,如姓名、地址等; *密码框一般拿来输入密码,输入的文字会被“*”代替; *多行文本框拿来输入内容较多的文字,如留言、个人简历等; 示例,三、使用表单实现浏览器端的数据采集,2、表单控件 2 隐藏域 隐藏域用于保存一些特定信息,对于浏览器用户来说,隐藏是看不见。但在表单递交时,隐藏域的name属性和value组成的信息将被发送给WEB服务器。 ,三、使用表单实现。
9、浏览器端的数据采集,2、表单控件 3 复选框 用来为浏览器用户提供一系列选项进行选择。 * value定义复选框的值; *checked定义初始状态下该复选框被选中;,例如 音乐 游戏 电影,三、使用表单实现浏览器端的数据采集,2、表单控件 4 单选框 用来为浏览器用户提供一个选项进行选择。 * value定义单选钮的值; *checked定义初始状态下该单选钮被选中; 注一组单选钮中只能有一项被选中;不同的name为不同组别;,例如 音乐 游戏 电影,三、使用表单实现浏览器端的数据采集,2、表单控件 5 文件上传框 浏览器用户可以使用文件上传框来选择上传的文件;表单递交时,该上传的文件名将与。
10、其他表单数据一起递交。 * size定义文件上传框的长度; *maxlength定义文件上传框最多输入的字符数; 注每位上传框只能选择一个文件;使用上传框时,表单标签的enctype属性必须设置为multipart/-data,属性必须设置为“post”提交形式。,例如 ,三、使用表单实现浏览器端的数据采集,2、表单控件 6 下拉选择框 分为单选和多选。单选式容许用户在一系列下拉选项中选择一个选项;多选式容许用户在一系列下拉选项中选择多个选项。, * size定义下拉框的高度,默认为1; *multiple定义下拉框是多项式还是多选式;,三、使用表单实现浏览器端的数据采集,2、表单控件 6 下。
11、拉选择框。,三、使用表单实现浏览器端的数据采集,3、表单按键 表单按键分为“提交按键”、“图像递交按键”、“重置按键” 。 “提交按键”和“图像递交按键”用于递交表单数据; “重置按键”用于将表单数据恢复至初始状态;,1 提交按键 ,* name定义递交按键的名称; * value定义递交按键上的显示文字; 例如 ,三、使用表单实现浏览器端的数据采集,3、表单按键 2 图像递交按键 * src图象的路径;,例如 ,3重置按键 例如 ,三、使用表单实现浏览器端的数据采集,4、表单综合应用 创建比如右图的表单,三、使用表单实现浏览器端的数据采集,5、使用_GET和_POST“采集”表单数据 当浏览。
12、器以”GET”方式递交数据时,服务器端PHP程序应该使用预定义变量_GET“采集”提交数据; 当浏览器以”POST”方式递交数据时,服务器端PHP程序应该使用预定义变量_POST“采集”提交数据;,例如上例的register.php程序 ,三、使用表单实现浏览器端的数据采集,6、 WEB服务器端其他数据采集方法 1 预定义变量 _REQUEST 使用_REQUEST既可以采集GET方法递交的URL程序字符串中的参数信息,也可以采集表单POST方法递交的参数信息。 之前程序使用_POST或_G优采云采集器的参数信息都可以换成使用_REQUEST采集。,例如上例的register.php程序 ,三、使。
13、用表单实现浏览器端的数据采集,6、 WEB服务器端其他数据采集方法 2 预定义变量 _SERVER 使用_SERVER可以得到浏览器端和服务器端主机的一些信息。,* _SERVER“REMOTE_ADDR”定义了浏览器端主机的IP地址; * _SERVER“SERVER_ADDR”定义了服务器端主机的IP地址; * _SERVER“PHP_SELF”定义了当前执行程序的文件名; * _SERVER“QUERY_STRING”定义了URL的查询字符串; * _SERVER“DOCUMENT_ROOT”定义了WEB服务器主目录; * _SERVER“REQUEST_RUI”定义了除域名外的其余URL部份;,本讲总结,本讲总结 1 掌握GET与POST递交数据的方式; 2 掌握表单控件的使用方式; 3 掌握_GET与_POST“采集”数据的使用方式; 4 掌握_REQUEST“采集”数据的使用方式; 5 了解_SERVER的使用方式;,Thank You ,内蒙古科技大学 工程训练中心,*** 次数1357533 已用完,请联系开发者***。 查看全部
《PHP的数据采集》PPT课件.ppt
《《PHP的数据采集》PPT课件.ppt》由会员分享,可在线阅读,更多相关《《PHP的数据采集》PPT课件.ppt(29页珍藏版)》请在人人文库网上搜索。
1、PHP动态网页设计教程,六、PHP的数据采集,黄迎久 内蒙古科技大学工程训练中心,主要内容,本讲主要内容 (1)浏览器端数据的递交方法; (2)绝对路径和相对路径的概念; (3)使用实现浏览器端的数据采集方法;,一、浏览器端数据的递交方法,浏览器向WEB服务器某PHP程序发送一个“请求”,该PHP程序接收到该“请求”后,接受所有“请求”数据,然后对这种“请求”数据进行处理,WEB服务器将处理结果作为“响应”返回给浏览器。 浏览器向WEB服务器递交数据的方法GET递交方法和POST递交方法。,一、浏览器端数据的递交方法,1、GET递交方法 GET递交方法是将“请求”数据以查询字符串(Query 。
2、String)的形式附在URL以后“提交”数据。 如 http//localhost/2/register.phpusernamejohnpassword1234 查询字符串中 “”表示查询字符串的开始,“”之后的字符串参数为查询字符串,可以收录多个查询字符串,每个参数以“参数名参数值”的格式定义。,一、浏览器端数据的递交方法,2、POST递交方法 POST数据递交方法通常通过表单实现,默认的情况下表单的数据递交方法为GET方法,因此,必须在表单的标签中加入”post”将数据递交方法更改为POST方法。,一、浏览器端数据的递交方法,3、GET和POST混和递交方法 使用表单可以实现GET和PO。
3、ST混和递交方法,向WEB服务器发出GET恳求的同时,还向该PHP程序发出“POST恳求”。, register.php 程序如下 ,一、浏览器端数据的递交方法,4、两种方法的比较 (1)POST递交方法比GET方法递交方法安全。在例如“注册”、“登录”等系统,不建议使用GET递交方法。 (2)POST递交方法可以递交更多的数据。如“新闻发布系统”中递交篇幅较长的新闻信息时,不建议使用GET递交方法;带有“文件上传功能”的表单必须使用POST递交方法。,二、相对路径与绝对路径,1、绝对路径 “绝对路径”是一个完整的URL,该URL是由以下两部份组成 (1)Scheme拿来描述找寻数据所采用的机。
4、制(协议),如http、ftp等。 (2)位置(location)用来描述到哪儿去找寻数据的资源。这部份使用“//”分隔,例如。 绝对路径无论出现在那里,都代表相同的内容,因此,绝对路径一般在访问系统外部资源时才使用,而访问内部资源时通常使用相对路径。,二、相对路径与绝对路径,2、相对路径 “相对路径”在不同的地方代表的内容是不同的。,例如一个完整的电话号码是“区位号”“电话号码”。以南京为例,0371-66666666是一个在中国境内的“绝对路径”。而到了成都后,只需拨通“66666666”即可,此时“66666666”就是一个“相对路径”。,例如当前目录“c/web/www/6/”中有in。
5、dex.html文件,使用超链接访问该目录下的register.php文件,只需在链接中指定到register.php文件的相对路径即可。 ,二、相对路径与绝对路径,3、相对路径其他概念 (1)同一文件夹下的资源访问 若文件1和文件2在同一目录中,这两个文件的互相访问直接使用文件名即可。 例如a.html和b.php两个文件在同一文件夹下,a.html页面的访问b.php文件时,a.html页面的表单可以这样写 . ,二、相对路径与绝对路径,3、相对路径其他概念 (2)如何表示当前目录 “.”表示文件的当前目录。若a.html和b.php文件在同一目录中,a.html页面的表单访问b.php文。
6、件时,a.html页面的表单写为 . ,二、相对路径与绝对路径,3、相对路径其他概念 (3)如何表示上级目录 “../”表示文件所在目录的上一级目录, “../../”表示文件所在目录的上上级目录。,(4)如何表示下级目录 若文件1访问下级目录中的文件2,直接指定该目录和文件2的文件名即可。 若a.html文件坐落cwwwweb”,b.php文件坐落cwwwwebtest”,则a.html页面的表单访问b.php页面时,a.html页面的表单写为 ,三、使用表单实现浏览器端的数据采集,表单由3部份构成 1表单标签 定义了表单处理程序及数据递交方法等信息; 2表单控件包括文本框、单选钮、复选框及。
7、文件上传等表单控件; 3表单按键包括递交、重置和通常按键;,三、使用表单实现浏览器端的数据采集,1、表单标签 表单标签常用的属性有action、、enctype、title、name等。 1 action设置当前表单数据“提交”的目的地址;当不设置action属性或属性值为空action“”时,表单数据递交给当前页面; 2设置表单数据的“提交”方式。属性值为GET或POST; 3title设置表单数据的提示信息。当用户的键盘表针在表单处逗留时,浏览器用一个红色的小鱼漂显示提示文本。 4enctype设置递交表单数据时的编码方法。属性值为multipart/-data,或 application。
8、/x-www--urlencoded。当一个表单存在文件上传框时,必须将enctype设置为multipart/for-data编码方法。,三、使用表单实现浏览器端的数据采集,2、表单控件 1 文本框 *单行文本框通常拿来输入单行的文字,如姓名、地址等; *密码框一般拿来输入密码,输入的文字会被“*”代替; *多行文本框拿来输入内容较多的文字,如留言、个人简历等; 示例,三、使用表单实现浏览器端的数据采集,2、表单控件 2 隐藏域 隐藏域用于保存一些特定信息,对于浏览器用户来说,隐藏是看不见。但在表单递交时,隐藏域的name属性和value组成的信息将被发送给WEB服务器。 ,三、使用表单实现。
9、浏览器端的数据采集,2、表单控件 3 复选框 用来为浏览器用户提供一系列选项进行选择。 * value定义复选框的值; *checked定义初始状态下该复选框被选中;,例如 音乐 游戏 电影,三、使用表单实现浏览器端的数据采集,2、表单控件 4 单选框 用来为浏览器用户提供一个选项进行选择。 * value定义单选钮的值; *checked定义初始状态下该单选钮被选中; 注一组单选钮中只能有一项被选中;不同的name为不同组别;,例如 音乐 游戏 电影,三、使用表单实现浏览器端的数据采集,2、表单控件 5 文件上传框 浏览器用户可以使用文件上传框来选择上传的文件;表单递交时,该上传的文件名将与。
10、其他表单数据一起递交。 * size定义文件上传框的长度; *maxlength定义文件上传框最多输入的字符数; 注每位上传框只能选择一个文件;使用上传框时,表单标签的enctype属性必须设置为multipart/-data,属性必须设置为“post”提交形式。,例如 ,三、使用表单实现浏览器端的数据采集,2、表单控件 6 下拉选择框 分为单选和多选。单选式容许用户在一系列下拉选项中选择一个选项;多选式容许用户在一系列下拉选项中选择多个选项。, * size定义下拉框的高度,默认为1; *multiple定义下拉框是多项式还是多选式;,三、使用表单实现浏览器端的数据采集,2、表单控件 6 下。
11、拉选择框。,三、使用表单实现浏览器端的数据采集,3、表单按键 表单按键分为“提交按键”、“图像递交按键”、“重置按键” 。 “提交按键”和“图像递交按键”用于递交表单数据; “重置按键”用于将表单数据恢复至初始状态;,1 提交按键 ,* name定义递交按键的名称; * value定义递交按键上的显示文字; 例如 ,三、使用表单实现浏览器端的数据采集,3、表单按键 2 图像递交按键 * src图象的路径;,例如 ,3重置按键 例如 ,三、使用表单实现浏览器端的数据采集,4、表单综合应用 创建比如右图的表单,三、使用表单实现浏览器端的数据采集,5、使用_GET和_POST“采集”表单数据 当浏览。
12、器以”GET”方式递交数据时,服务器端PHP程序应该使用预定义变量_GET“采集”提交数据; 当浏览器以”POST”方式递交数据时,服务器端PHP程序应该使用预定义变量_POST“采集”提交数据;,例如上例的register.php程序 ,三、使用表单实现浏览器端的数据采集,6、 WEB服务器端其他数据采集方法 1 预定义变量 _REQUEST 使用_REQUEST既可以采集GET方法递交的URL程序字符串中的参数信息,也可以采集表单POST方法递交的参数信息。 之前程序使用_POST或_G优采云采集器的参数信息都可以换成使用_REQUEST采集。,例如上例的register.php程序 ,三、使。
13、用表单实现浏览器端的数据采集,6、 WEB服务器端其他数据采集方法 2 预定义变量 _SERVER 使用_SERVER可以得到浏览器端和服务器端主机的一些信息。,* _SERVER“REMOTE_ADDR”定义了浏览器端主机的IP地址; * _SERVER“SERVER_ADDR”定义了服务器端主机的IP地址; * _SERVER“PHP_SELF”定义了当前执行程序的文件名; * _SERVER“QUERY_STRING”定义了URL的查询字符串; * _SERVER“DOCUMENT_ROOT”定义了WEB服务器主目录; * _SERVER“REQUEST_RUI”定义了除域名外的其余URL部份;,本讲总结,本讲总结 1 掌握GET与POST递交数据的方式; 2 掌握表单控件的使用方式; 3 掌握_GET与_POST“采集”数据的使用方式; 4 掌握_REQUEST“采集”数据的使用方式; 5 了解_SERVER的使用方式;,Thank You ,内蒙古科技大学 工程训练中心,*** 次数1357533 已用完,请联系开发者***。
原创 【视频】用Excel来录入和管理研究数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2020-08-23 00:38
临床研究中,不少人习惯用Excel作为数据录入和管理软件。当然,Excel有着显著的优势,普及性好、可操作性强、培训成本低...但当采集的变量较多或研究较复杂时,Excel的弊病也突显下来:变量多时,Excel界面呈现太不友好;无法进行嵌套变量的设置;对数据的保护性较差,较易被修改;若对数据进行处理,难以追踪追溯...
下面这个视频中提及的问题,也许你在临床研究工作中也以前遇见过。
有没有更好的代替工具呢?准备举办临床研究的伙伴,尤其是举办多中心研究的研究者们,推荐你使用电子数据采集系统(EDC)。
医咖会经过几年的产品打磨,开发了适宜临床大夫使用且通过了国内外多项数据安全权威认证的“医维云”电子数据采集系统(EDC)。
EDC可以多人协作,同时录入数据并及时发觉和处理数据问题,最大可能追回缺位数据,修正错误数据。EDC系统的录入页面清晰明了、简洁高效,提供丰富多样的系统核查功能(比如必填校准、数据格式输入约束、数值范围校准、日期范围校准、变量间的逻辑校准、条件显示等)。
研究负责人可以实时查看项目进度,实时同步查看最新数据,及时介入管理进度。最重要的是,EDC可导入多种数据集结构和格式,满足不同剖析群体的需求。导出清晰的变量辞典,有助于统计剖析时更容易理解数据。
在使用该EDC系统的同时,医咖会伙伴们还可以给你的研究设计、CRF表设计提供建设性意见,也可以协助你做数据清除和统计剖析! 查看全部
原创 【视频】用Excel来录入和管理研究数据
临床研究中,不少人习惯用Excel作为数据录入和管理软件。当然,Excel有着显著的优势,普及性好、可操作性强、培训成本低...但当采集的变量较多或研究较复杂时,Excel的弊病也突显下来:变量多时,Excel界面呈现太不友好;无法进行嵌套变量的设置;对数据的保护性较差,较易被修改;若对数据进行处理,难以追踪追溯...
下面这个视频中提及的问题,也许你在临床研究工作中也以前遇见过。
有没有更好的代替工具呢?准备举办临床研究的伙伴,尤其是举办多中心研究的研究者们,推荐你使用电子数据采集系统(EDC)。
医咖会经过几年的产品打磨,开发了适宜临床大夫使用且通过了国内外多项数据安全权威认证的“医维云”电子数据采集系统(EDC)。
EDC可以多人协作,同时录入数据并及时发觉和处理数据问题,最大可能追回缺位数据,修正错误数据。EDC系统的录入页面清晰明了、简洁高效,提供丰富多样的系统核查功能(比如必填校准、数据格式输入约束、数值范围校准、日期范围校准、变量间的逻辑校准、条件显示等)。
研究负责人可以实时查看项目进度,实时同步查看最新数据,及时介入管理进度。最重要的是,EDC可导入多种数据集结构和格式,满足不同剖析群体的需求。导出清晰的变量辞典,有助于统计剖析时更容易理解数据。
在使用该EDC系统的同时,医咖会伙伴们还可以给你的研究设计、CRF表设计提供建设性意见,也可以协助你做数据清除和统计剖析!
爬取百万数据的采集系统从零到整的过程
采集交流 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2020-08-22 19:56
记录下在上家公司负责过的一个采集系统从零到整的过程,包括需求,分析,设计,实现,遇到的问题及系统的成效,系统最主要功能就是可以通过对每位网站进行不同的采集规则配置对每位网站爬取数据,目前系统运行稳定,已爬取的数据量大约在600-700万之间(算上一些历史数据,应该也有到千万级了),每天采集的数据增量在一万左右,配置采集的网站1200多个,这个系统似乎并不大,但是作为主要的coding人员(基本整个系统的百分之八十的编码都是我写的),大概记录一下系统的实现,捡主要的内容分享下,最后在提供一些简单的爬虫demo供你们学习下
数据采集系统:一个可以通过配置规则采集不同网站的系统
主要实现目标:
·针对不同的网站通过配置不同的采集规则实现网页数据的爬取
·针对整篇内容可以实现对特点数据的提取
·定时去爬取所有网站的数据
·采集配置规则可维护
·采集入库数据可维护
第一步其实要先剖析需求,所以在抽取一下系统的主要需求:
·针对不同的网站可以通过不同的采集规则实现数据的爬取
·针对整篇内容可以实现对特点数据的提取,特征数据就是指标题,作者,发布时间这些信息
·定时任务关联任务或则任务组去爬取网站的数据
再剖析一下网站的结构,无非就是两种;
基本所有爬取的网站都可以具象成这样。
针对剖析的结果设计实现:
·任务表
o 每个网站可以当作一个任务,去执行采集
·两张规则表
o 每个网站对应自己的采集规则,根据前面剖析的网站结构,采集规则又可以细分为两个表,一个是收录网站链接,获取详情页列表的列表采集规则表,一个针对是网站详情页的特点数据采集的规则表 详情采集规则表
·url表
o 负责记录采集目标网站详情页的url
·定时任务表
o 根据定时任务去定时执行个别任务 (可以采用定时任务和多个任务进行关联,也可以考虑新增一个任务组表,定时任务跟任务组关联,任务组跟任务关联)
·数据储存表
o 这个因为我们采集的数据主要是招标和中标两种数据,分别建了两张表进行数据储存,中标信息表,招标信息表
基础构架就是:ssm+redis+htmlunit+jsoup+es+mq+quartz
java中可以实现爬虫的框架有很多,htmlunit,WebMagic,jsoup等等还有好多优秀的开源框架,当然httpclient也可以实现。
为什么用htmlunit?
htmlunit 是一款开源的java 页面剖析工具,读取页面后,可以有效的使用htmlunit剖析页面上的内容。项目可以模拟浏览器运行,被誉为java浏览器的开源实现
简单说下我对htmlunit的理解:
·一个是htmlunit提供了通过xpath去定位页面元素的功能,利用xpath就可以实现对页面特点数据进行提取;
·第二个就在于对js的支持,支持js意味着你真的可以把它当作一个浏览器,你可以用它模拟点击,输入,登录等操作,而且对于采集而言,支持js就可以解决页面使用ajax获取数据的问题
·当然除此之外,htmlunit还支持代理ip,https,通过配置可以实现模拟微软,火狐等浏览器,Referer,user-agent,是否加载js,css,是否支持ajax等。
XPath句型即为XML路径语言(XML Path Language),它是一种拿来确定XML文档中某部份位置的语言。
为什么用jsoup?
jsoup相较于htmlunit,就在于它提供了一种类似于jquery选择器的定位页面元素的功能,两者可以互补使用。
采集数据逻辑分为两个部份:url采集器,详情页采集器
url采集器:
·只负责采集目标网站的详情页url
详情页采集器:
·根据url去采集目标url的详情页数据
·使用htmlunit的xpath,jsoup的select句型,和正则表达式进行特点数据的采集。
这样设计目的主要是将url采集和详情页的采集流程分开,后续假如须要分拆服务的话就可以将url采集和详情页的采集分成两个服务。
url采集器与详情页采集器之间使用mq进行交互,url采集器采集到url做完处理过后把消息冷到mq队列,详情页采集器去获取数据进行详情页数据的采集。
·在采集url的时侯进行去重
·同过url进行去重,通过在redis储存key为url,缓存时间为3天,这种方法是为了避免对同一个url进行重复采集。
·通过标题进行去重,通过在redis中储存key为采集到的标题 ,缓存时间为3天,这种方法就是为了避免一篇文章被不同网站发布,重复采集情况的发生。
一个简短爬虫的代码实现:
上面的代码就实现了采集一个列表页
·url就是目标网址
·xpath就要采集的数据的xpath了
请求这个url::9001/getData?url=*[@id=post_list]/div/div[2]/h3/a 查看全部
爬取百万数据的采集系统从零到整的过程
记录下在上家公司负责过的一个采集系统从零到整的过程,包括需求,分析,设计,实现,遇到的问题及系统的成效,系统最主要功能就是可以通过对每位网站进行不同的采集规则配置对每位网站爬取数据,目前系统运行稳定,已爬取的数据量大约在600-700万之间(算上一些历史数据,应该也有到千万级了),每天采集的数据增量在一万左右,配置采集的网站1200多个,这个系统似乎并不大,但是作为主要的coding人员(基本整个系统的百分之八十的编码都是我写的),大概记录一下系统的实现,捡主要的内容分享下,最后在提供一些简单的爬虫demo供你们学习下
数据采集系统:一个可以通过配置规则采集不同网站的系统
主要实现目标:
·针对不同的网站通过配置不同的采集规则实现网页数据的爬取
·针对整篇内容可以实现对特点数据的提取
·定时去爬取所有网站的数据
·采集配置规则可维护
·采集入库数据可维护
第一步其实要先剖析需求,所以在抽取一下系统的主要需求:
·针对不同的网站可以通过不同的采集规则实现数据的爬取
·针对整篇内容可以实现对特点数据的提取,特征数据就是指标题,作者,发布时间这些信息
·定时任务关联任务或则任务组去爬取网站的数据
再剖析一下网站的结构,无非就是两种;
基本所有爬取的网站都可以具象成这样。
针对剖析的结果设计实现:
·任务表
o 每个网站可以当作一个任务,去执行采集
·两张规则表
o 每个网站对应自己的采集规则,根据前面剖析的网站结构,采集规则又可以细分为两个表,一个是收录网站链接,获取详情页列表的列表采集规则表,一个针对是网站详情页的特点数据采集的规则表 详情采集规则表
·url表
o 负责记录采集目标网站详情页的url
·定时任务表
o 根据定时任务去定时执行个别任务 (可以采用定时任务和多个任务进行关联,也可以考虑新增一个任务组表,定时任务跟任务组关联,任务组跟任务关联)
·数据储存表
o 这个因为我们采集的数据主要是招标和中标两种数据,分别建了两张表进行数据储存,中标信息表,招标信息表
基础构架就是:ssm+redis+htmlunit+jsoup+es+mq+quartz
java中可以实现爬虫的框架有很多,htmlunit,WebMagic,jsoup等等还有好多优秀的开源框架,当然httpclient也可以实现。
为什么用htmlunit?
htmlunit 是一款开源的java 页面剖析工具,读取页面后,可以有效的使用htmlunit剖析页面上的内容。项目可以模拟浏览器运行,被誉为java浏览器的开源实现
简单说下我对htmlunit的理解:
·一个是htmlunit提供了通过xpath去定位页面元素的功能,利用xpath就可以实现对页面特点数据进行提取;
·第二个就在于对js的支持,支持js意味着你真的可以把它当作一个浏览器,你可以用它模拟点击,输入,登录等操作,而且对于采集而言,支持js就可以解决页面使用ajax获取数据的问题
·当然除此之外,htmlunit还支持代理ip,https,通过配置可以实现模拟微软,火狐等浏览器,Referer,user-agent,是否加载js,css,是否支持ajax等。
XPath句型即为XML路径语言(XML Path Language),它是一种拿来确定XML文档中某部份位置的语言。
为什么用jsoup?
jsoup相较于htmlunit,就在于它提供了一种类似于jquery选择器的定位页面元素的功能,两者可以互补使用。
采集数据逻辑分为两个部份:url采集器,详情页采集器
url采集器:
·只负责采集目标网站的详情页url
详情页采集器:
·根据url去采集目标url的详情页数据
·使用htmlunit的xpath,jsoup的select句型,和正则表达式进行特点数据的采集。
这样设计目的主要是将url采集和详情页的采集流程分开,后续假如须要分拆服务的话就可以将url采集和详情页的采集分成两个服务。
url采集器与详情页采集器之间使用mq进行交互,url采集器采集到url做完处理过后把消息冷到mq队列,详情页采集器去获取数据进行详情页数据的采集。
·在采集url的时侯进行去重
·同过url进行去重,通过在redis储存key为url,缓存时间为3天,这种方法是为了避免对同一个url进行重复采集。
·通过标题进行去重,通过在redis中储存key为采集到的标题 ,缓存时间为3天,这种方法就是为了避免一篇文章被不同网站发布,重复采集情况的发生。
一个简短爬虫的代码实现:
上面的代码就实现了采集一个列表页
·url就是目标网址
·xpath就要采集的数据的xpath了
请求这个url::9001/getData?url=*[@id=post_list]/div/div[2]/h3/a
海量数据挖掘之中联通流量营运系统
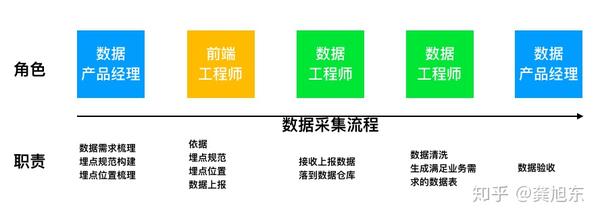
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2020-08-21 05:32
从联通运营商的核心网段中把须要的数据发送到ftp服务器上,然后我们那边都会提供ftp的客户端去采集ftp服务器的数据,然后处理以后过来进行剖析。
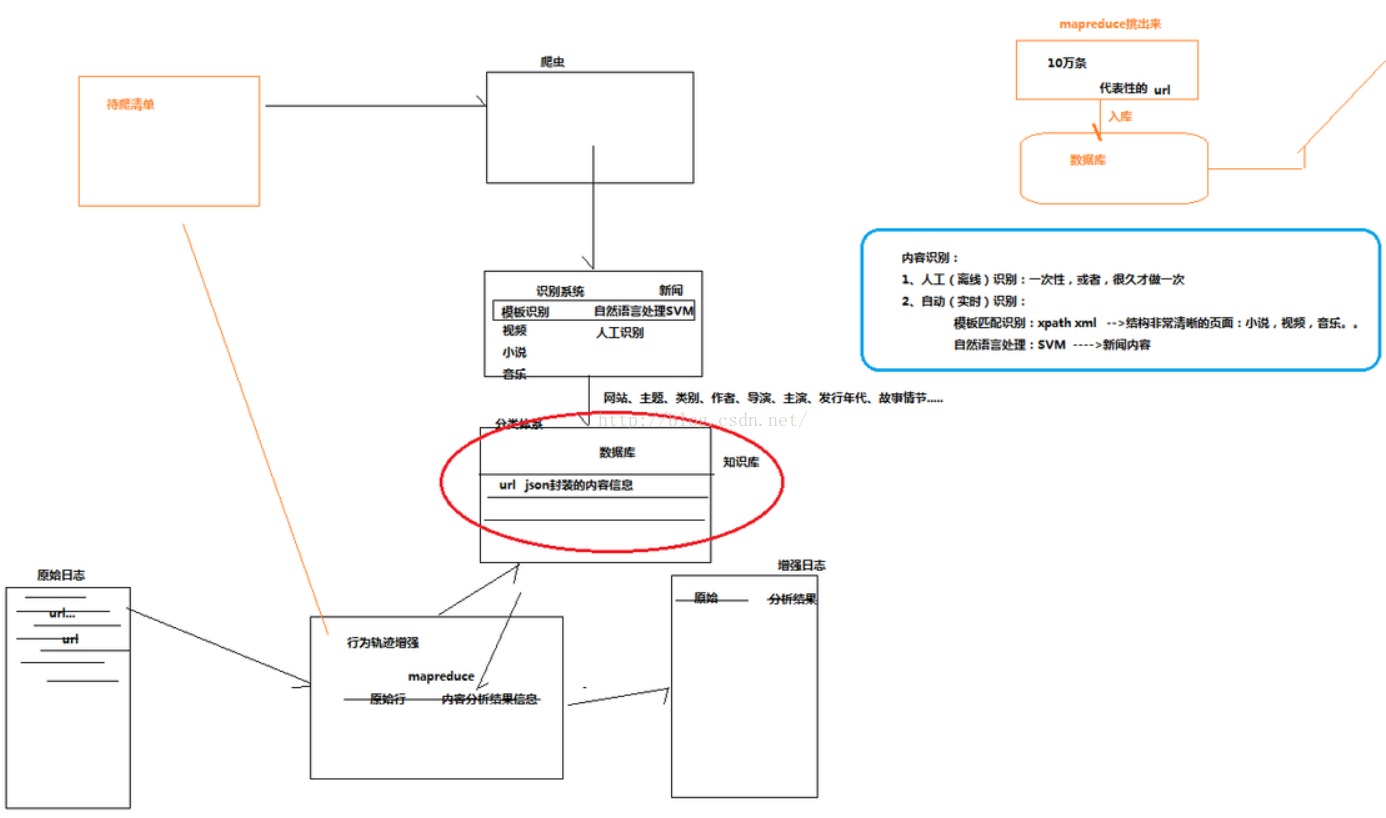
三、内容辨识模块
把url经过爬虫之后到辨识系统,分析出网站名,主题,类别,(作者)等
将分类体系导出到数据库中,url json封装的内容信息。
大量的日志不断的形成,然后通过行为轨迹提高,通过一个mapreduce,
如果这个数据匹配到了,则将原创行+内容剖析结果信息(从知识库来的数据)导出到提高日志。如果匹配不到的数据就输出到一个待爬清单中。
识别系统:自然语言处理SVM(实时辨识),人工辨识(人工一条条的去辨识),模板辨识(一个网页的内容的位置通常不会变,用xpath来定位到我们所须要查找的节点)
相信学过xml的应当就会使用xpath了,如果不会的话,可以查阅我这篇文章:
在这个项目中庸xpath来做这个模板匹配:例如
对于一个网页的html页面来说,我们可以这样来匹配其标题,例如我们打开搜狐的html,我们可以看见他的这个网页标题是的,所以我们对于这类网站就可以用xpath来定位这个title在那里,然后去获取这title节点中内容
souhu.com
movie_name
/path/.../
当然了,使用xpath和xml去做这些模板匹配有一定的局限性,适用于一个结构十分清晰的网页,例如视频、小说、音乐等,对于那个奇奇怪怪的网友就不适用了。
所以总的来说,对于内容辨识要采用多种方法去做,不要局限于一种,不同类型的网站最好有不同的解决方案。
我们使用自然语言处理来进行剖析的时侯还有问题就是,一个网页的内容太多了,svm剖析有时候不能完全的辨识到我们想要的内容,就像一条新闻,本来这个新闻的主标题才是中国网页的主要内容,而使用自然语言处理系统的话它可能会把新闻下边的广告读成了这个网页的主要内容了,所以这样的话都会有偏差了。当然咯,自然语言剖析还是很有用,那么为了更精确的辨识照料好网页的内容如何办呢。好吧,那当然是最传统的人工读取了,由帅气的实习生们把这种网页一条条的浏览,然后记录这个网页的主要内容!(好吧,不要震惊
,移动就是那么干的)。然后读取大约10万个网页,这样的话就产生了一个规则库,这个就比自然语言处理和模板匹配的结果愈发精确了。
四、知识库url选购
两个知识库,一个规则库(人工剖析的),还有一个实例库(自动剖析系统)。
先把url进行规则剖析,如果有则输出,没有没有则放在实例库,如果实例库也没有了,就放在待爬清单中。
先拿1T的样本数据,然后网址按流量汇总排序下来,总流量的前80%,总条数10万条。
因为只要选购下来就可以了,不需要实时在运行的,所以只要一个job就可以了。
这里我们主要领到一个url和总流量来进行剖析和处理,其他更为复杂的情况这儿就不分享了哦。
我们首先可以在eclipse总新建一个jav工程,导入各类hadoop/lib下边的jar包,或者直接新建一个mapRedecer工程也可以。
新建一个bean类:记得要承继一个Comparable插口。
package cn.tf.kpi;
public class FlowBean implements Comparable{
private String url;
private long upflow;
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public long getUpflow() {
return upflow;
}
public void setUpflow(long upflow) {
this.upflow = upflow;
}
public FlowBean(String url, long upflow) {
super();
this.url = url;
this.upflow = upflow;
}
public FlowBean() {
super();
}
@Override
public int compareTo(FlowBean o) {
return (int) (o.getUpflow() - this.upflow) ;
}
@Override
public String toString() {
return "FlowBean [url=" + url + ", upflow=" + upflow + "]";
}
}
然后写主方式:
其实这儿和我之前写的那种用户流量剖析系统有很多类似的地方。
<p>package cn.tf.kpi;
import java.io.IOException;
import java.util.TreeSet;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import cn.tf.kpi.TopURL.TopURLMapper.TopURlReducer;
public class TopURL {
public static class TopURLMapper extends
Mapper {
private Text k = new Text();
private LongWritable v = new LongWritable();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] fields = StringUtils.split(line, "\t");
try {
String url = fields[26];
long upFlow = Long.parseLong(fields[30]);
k.set(url);
v.set(upFlow);
context.write(k, v);
} catch (Exception e) {
e.printStackTrace();
}
}
public static class TopURlReducer extends
Reducer {
private Text k = new Text();
private LongWritable v = new LongWritable();
TreeSet urls = new TreeSet();
//全局流量和
long globalFlowSum =0;
@Override
protected void reduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException {
long count = 0;
for (LongWritable v : values) {
count += v.get();
}
globalFlowSum +=count;
FlowBean bean = new FlowBean(key.toString(), count);
urls.add(bean);
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
long tempSum=0;
for(FlowBean bean:urls){
//取前80%的
if(tempSum/globalFlowSum 查看全部
海量数据挖掘之中联通流量营运系统
从联通运营商的核心网段中把须要的数据发送到ftp服务器上,然后我们那边都会提供ftp的客户端去采集ftp服务器的数据,然后处理以后过来进行剖析。
三、内容辨识模块
把url经过爬虫之后到辨识系统,分析出网站名,主题,类别,(作者)等
将分类体系导出到数据库中,url json封装的内容信息。
大量的日志不断的形成,然后通过行为轨迹提高,通过一个mapreduce,
如果这个数据匹配到了,则将原创行+内容剖析结果信息(从知识库来的数据)导出到提高日志。如果匹配不到的数据就输出到一个待爬清单中。
识别系统:自然语言处理SVM(实时辨识),人工辨识(人工一条条的去辨识),模板辨识(一个网页的内容的位置通常不会变,用xpath来定位到我们所须要查找的节点)
相信学过xml的应当就会使用xpath了,如果不会的话,可以查阅我这篇文章:
在这个项目中庸xpath来做这个模板匹配:例如
对于一个网页的html页面来说,我们可以这样来匹配其标题,例如我们打开搜狐的html,我们可以看见他的这个网页标题是的,所以我们对于这类网站就可以用xpath来定位这个title在那里,然后去获取这title节点中内容
souhu.com
movie_name
/path/.../
当然了,使用xpath和xml去做这些模板匹配有一定的局限性,适用于一个结构十分清晰的网页,例如视频、小说、音乐等,对于那个奇奇怪怪的网友就不适用了。
所以总的来说,对于内容辨识要采用多种方法去做,不要局限于一种,不同类型的网站最好有不同的解决方案。
我们使用自然语言处理来进行剖析的时侯还有问题就是,一个网页的内容太多了,svm剖析有时候不能完全的辨识到我们想要的内容,就像一条新闻,本来这个新闻的主标题才是中国网页的主要内容,而使用自然语言处理系统的话它可能会把新闻下边的广告读成了这个网页的主要内容了,所以这样的话都会有偏差了。当然咯,自然语言剖析还是很有用,那么为了更精确的辨识照料好网页的内容如何办呢。好吧,那当然是最传统的人工读取了,由帅气的实习生们把这种网页一条条的浏览,然后记录这个网页的主要内容!(好吧,不要震惊

,移动就是那么干的)。然后读取大约10万个网页,这样的话就产生了一个规则库,这个就比自然语言处理和模板匹配的结果愈发精确了。
四、知识库url选购
两个知识库,一个规则库(人工剖析的),还有一个实例库(自动剖析系统)。
先把url进行规则剖析,如果有则输出,没有没有则放在实例库,如果实例库也没有了,就放在待爬清单中。
先拿1T的样本数据,然后网址按流量汇总排序下来,总流量的前80%,总条数10万条。
因为只要选购下来就可以了,不需要实时在运行的,所以只要一个job就可以了。
这里我们主要领到一个url和总流量来进行剖析和处理,其他更为复杂的情况这儿就不分享了哦。
我们首先可以在eclipse总新建一个jav工程,导入各类hadoop/lib下边的jar包,或者直接新建一个mapRedecer工程也可以。
新建一个bean类:记得要承继一个Comparable插口。
package cn.tf.kpi;
public class FlowBean implements Comparable{
private String url;
private long upflow;
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public long getUpflow() {
return upflow;
}
public void setUpflow(long upflow) {
this.upflow = upflow;
}
public FlowBean(String url, long upflow) {
super();
this.url = url;
this.upflow = upflow;
}
public FlowBean() {
super();
}
@Override
public int compareTo(FlowBean o) {
return (int) (o.getUpflow() - this.upflow) ;
}
@Override
public String toString() {
return "FlowBean [url=" + url + ", upflow=" + upflow + "]";
}
}
然后写主方式:
其实这儿和我之前写的那种用户流量剖析系统有很多类似的地方。
<p>package cn.tf.kpi;
import java.io.IOException;
import java.util.TreeSet;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import cn.tf.kpi.TopURL.TopURLMapper.TopURlReducer;
public class TopURL {
public static class TopURLMapper extends
Mapper {
private Text k = new Text();
private LongWritable v = new LongWritable();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] fields = StringUtils.split(line, "\t");
try {
String url = fields[26];
long upFlow = Long.parseLong(fields[30]);
k.set(url);
v.set(upFlow);
context.write(k, v);
} catch (Exception e) {
e.printStackTrace();
}
}
public static class TopURlReducer extends
Reducer {
private Text k = new Text();
private LongWritable v = new LongWritable();
TreeSet urls = new TreeSet();
//全局流量和
long globalFlowSum =0;
@Override
protected void reduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException {
long count = 0;
for (LongWritable v : values) {
count += v.get();
}
globalFlowSum +=count;
FlowBean bean = new FlowBean(key.toString(), count);
urls.add(bean);
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
long tempSum=0;
for(FlowBean bean:urls){
//取前80%的
if(tempSum/globalFlowSum
基于浏览器扩充的数据采集系统及技巧
采集交流 • 优采云 发表了文章 • 0 个评论 • 299 次浏览 • 2020-08-21 03:05
基于浏览器扩充的数据采集系统及技巧
【技术领域】
[0001]本发明涉及一种数据采集系统,特别涉及一种基于浏览器扩充的数据采集系统及借助该数据采集系统实现的基于浏览器扩充的数据采集方法。
【背景技术】
[0002 ]由于近1年多来,互联网协议并没有本质的变化,所有on I ine (互联网上)及h5 (指第5代HTML,所谓HTML是“超文本标记语言”的日文简写)等网站页面仍然遵守w3c(万维网联盟)标准,通讯一直借助http协议(超文本传输协议),因此负责网路数据采集的爬虫程序构架,在这段时期内,也没有实质性地提高。
[0003]但是随着JS(JavaScript,一种直译式脚本语言)及浏览器技术的发展,各种反爬手段层出不穷,其中尤以后端反爬为主,因为后端反爬是可以直接抵挡爬虫步入的第一道门槛。
[0004]目前现有的垂直爬虫也主要以前期配置抓取步骤及参数,然后据此进行连续抓取,此方式主要存在的一个不足之处就是:面临对方后端反爬策略的修改,无法第一时间主动适配,必然引起在开发人员介入之前的一段时间,无法正常抓取。
[0005]并且目前市面上好多第三方的(开源)浏览器控制引擎经过试用,被发觉都存在着众多功能方面的缺陷,并没有办法百分百模拟浏览器的行为特点,存在容易被对方探测到的风险。
[0006]因此,我们须要更为智能的爬虫系统,在面临对方后端反爬策略更改的第一时间,可以自适应而且持续正确抓取的动作。
【发明内容】
[0007]本发明要解决的技术问题是为了克服现有技术中目前通过垂直爬虫技术爬取网页信息存在在对方后端反爬策略修改时难以主动适配以及通过现有的浏览器未能完全模拟其行为特点的缺陷,提供一种基于浏览器扩充的数据采集系统及技巧。
[0008]本发明是通过下列技术方案来解决上述技术问题的:
[0009]本发明提供一种基于浏览器扩充的数据采集系统,其特征在于,其包括一浏览器、基于该浏览器的API(应用程序编程接口)说明建立的附加组件;
[0010]该附加组件用于主动协程一服务器,并从该服务器中获取一爬取目标;
[0011]该附加组件还用于控制该浏览器打开目标网页,并控制该浏览器对该目标网页进行访问,以及控制该浏览器从该目标网页中获取该爬取目标;
[0012]该附加组件还用于控制该浏览器对该目标网页中除该爬取目标外的其他页面内容进行访问;
[0013]该附加组件还用于控制该浏览器关掉该目标网页。
[0014]较佳地,该附加组件借助该浏览器的API施行控制操作以实现对该目标网页的访问。
[0015]较佳地,该控制操作包括点击操作、滚动操作和挥控操作。
[0016]本发明还提供一种基于浏览器扩充的数据采集方法,其特征在于,其借助上述的基于浏览器扩充的数据采集系统实现,该数据采集方法包括以下步骤:
[0017]S1、该附加组件主动协程一服务器,并从该服务器中获取一爬取目标;
[0018]&、该附加组件控制该浏览器打开目标网页;
[0019]&、该附加组件控制该浏览器对该目标网页进行访问;
[0020]S4、该附加组件控制该浏览器从该目标网页中获取该爬取目标;
[0021]&、该附加组件控制该浏览器对该目标网页中除该爬取目标外的其他页面内容进行访问;
[0022]S6、该附加组件控制该浏览器关掉该目标网页。
[0023]较佳地,该附加组件借助该浏览器的API施行控制操作以实现对该目标网页的访问。
[0024]较佳地,该控制操作包括点击操作、滚动操作和挥控操作。
[0025]在符合本领域常识的基础上,上述各优选条件,可任意组合,即得本发明各较佳实例。
[0026]本发明的积极进步疗效在于:
[0027]本发明可以更隐蔽地借助爬虫技术进行数据的抓取,并且因为直接采用浏览器,使得所有的访问恳求均真实有效,并且对方网页上所有的JS都被正常执行,所有的参数建立也通过浏览器手动执行,不需要人工干预,即使对方后端反爬有改动,浏览器也能手动适应,极大地降低了人工成本,并且最大限度确保抓取的成功率。而且,通过单次或少量的恳求,对方难以剖析判别出访问者是爬虫还是真实的用户,使得对方网站管理者不敢轻易封杀,确保了抓取行为的连续性。
【附图说明】
[0028]图1为本发明的较佳施行例的基于浏览器扩充的数据采集方法的流程图。
【具体施行方法】
[0029]下面通过施行例的方法进一步说明本发明,但并不因而将本发明限制在所述的施行例范围之中。
[0030]本施行例提供一种基于浏览器扩充的数据采集系统及方式,该数据采集系统包括一浏览器、基于该浏览器的API说明建立的附加组件。
[0031]其中,该附加组件具备的功能有:该附加组件用于操纵该浏览器进行特定网页的访问,控制该浏览器打开或关掉特定的网页,控制该浏览器页面的个别特定行为,例如点击、滚动以及挥控操作以及操纵该浏览器从该浏览器的网页中获取信息。
[0032]该附加组件用于主动协程一服务器,并从该服务器中获取一爬取目标;
[0033]该附加组件还用于控制该浏览器打开目标网页,并控制该浏览器对该目标网页进行访问,以及控制该浏览器从该目标网页中获取该爬取目标;
[0034]该附加组件还用于控制该浏览器对该目标网页中除该爬取目标外的其他页面内容进行访问;
[0035]该附加组件还用于控制该浏览器关掉该目标网页。
[0036]如图1所示,该数据采集方法借助上述的基于浏览器扩充的数据采集系统实现,该数据采集方法包括以下步骤:
[0037]步骤101、该附加组件主动协程一服务器,并从该服务器中获取一爬取目标;
[0038]步骤102、该附加组件控制该浏览器打开目标网页;
[0039]步骤103、该附加组件控制该浏览器对该目标网页进行访问,该附加组件借助该浏览器的API施行控制操作以实现对该目标网页的访问,其中该控制操作包括点击操作、滚动操作和挥控操作;
[0040]步骤104、该附加组件控制该浏览器从该目标网页中获取该爬取目标;
[0041]步骤105、该附加组件控制该浏览器对该目标网页中除该爬取目标外的其他页面内容进行访问;
[0042]步骤106、该附加组件控制该浏览器关掉该目标网页。
[0043]在本方式中,附加组件借助浏览器(如火狐浏览器)提供的API,直接滚动页面或模拟键盘、键盘点击页面。由于好多页面为了探测用户的行为,有很多预留的埋点,当用户键盘经过或页面滚动到特定高度,将会触发一次埋点的网路恳求,所以通过模拟滚动与点击的控制操作,可以真实模拟一个普通用户的浏览行为,使对方通过单次用户的行为数据剖析,无法判定出当前访问者是否是一个真实存在的用户。
[0044]通过附加组件模拟真实用户浏览页面,且附加组件在须要爬取的目标页面打开并完成数据提取以后,并不把页面立刻关闭,而是在页面上找寻个别特定的元素进行点击操作,这样可以更真实地模拟用户的行为。由于普通用户并不会长时间的访问某一单一种类的页面,其必然会浏览一些其他感兴趣的信息,比如网站推荐的信息或一些评论信息等,然后再将这一组页面关掉,进行下一次的抓取。使目标网站无法通过后期(旁路)的用户行为剖析模型,进行有效的爬虫访问判定。
[0045]由此,本发明可以更隐蔽地借助爬虫技术进行数据的抓取,并且因为直接采用浏览器,使得所有的访问恳求均真实有效,并且对方网页上所有的JS都被正常执行,所有的参数建立也通过浏览器手动执行,不需要人工干预,即使对方后端反爬有改动,浏览器也能手动适应,极大地降低了人工成本,并且最大限度确保抓取的成功率。而且,通过单次或少量的恳求,对方难以剖析判定出访问者是爬虫还是真实的用户,使得对方网站管理者不敢轻易封杀,确保了抓取行为的连续性。
[0046]虽然以上描述了本发明的【具体施行方法】,但是本领域的技术人员应该理解,这些仅是举例说明,本发明的保护范围是由所附权力要求书限定的。本领域的技术人员在不背离本发明的原理和实质的前提下,可以对那些施行方法作出多种变更或更改,但这种变更和更改均落入本发明的保护范围。
【主权项】
1.一种基于浏览器扩充的数据采集系统,其特点在于,其包括一浏览器、基于该浏览器的API说明建立的附加组件; 该附加组件用于主动协程一服务器,并从该服务器中获取一爬取目标; 该附加组件还用于控制该浏览器打开目标网页,并控制该浏览器对该目标网页进行访问,以及控制该浏览器从该目标网页中获取该爬取目标; 该附加组件还用于控制该浏览器对该目标网页中除该爬取目标外的其他页面内容进行访问; 该附加组件还用于控制该浏览器关掉该目标网页。2.如权力要求1所述的基于浏览器扩充的数据采集系统,其特点在于,该附加组件借助该浏览器的API施行控制操作以实现对该目标网页的访问。3.如权力要求2所述的基于浏览器扩充的数据采集系统,其特点在于,该控制操作包括点击操作、滚动操作和挥控操作。4.一种基于浏览器扩充的数据采集方法,其特点在于,其借助如权力要求1所述的基于浏览器扩充的数据采集系统实现,该数据采集方法包括以下步骤: 51、该附加组件主动协程一服务器,并从该服务器中获取一爬取目标; 52、该附加组件控制该浏览器打开目标网页; 53、该附加组件控制该浏览器对该目标网页进行访问; 54、该附加组件控制该浏览器从该目标网页中获取该爬取目标; &、该附加组件控制该浏览器对该目标网页中除该爬取目标外的其他页面内容进行访问; S6、该附加组件控制该浏览器关掉该目标网页。5.如权力要求4所述的基于浏览器扩充的数据采集方法,其特点在于,该附加组件借助该浏览器的API施行控制操作以实现对该目标网页的访问。6.如权力要求5所述的基于浏览器扩充的数据采集方法,其特点在于,该控制操作包括点击操作、滚动操作和挥控操作。
【专利摘要】本发明提供一种基于浏览器扩充的数据采集系统,其包括浏览器、基于浏览器的API说明建立的附加组件;附加组件用于主动协程服务器,从服务器中获取爬取目标;附加组件还用于控制浏览器打开目标网页,并控制浏览器对目标网页进行访问,以及控制浏览器从目标网页中获取爬取目标;附加组件还用于控制浏览器对目标网页中除爬取目标外的其他页面内容进行访问;附加组件还用于控制浏览器关掉目标网页。本发明可以更隐蔽地借助爬虫技术进行数据的抓取,并且因为直接采用浏览器,使得所有的访问恳求均真实有效,并且对方网页上所有的JS都被正常执行,即使对方后端反爬有改动,浏览器也能手动适应,减小了人工成本,最大限度确保抓取的成功率。
【IPC分类】G06F17/30
【公开号】CN105512193
【申请号】CN2
【发明人】吴凌峰, 吴鹏越
【申请人】上海携程商务有限公司
【公开日】2016年4月20日
【申请日】2015年11月26日 查看全部
基于浏览器扩充的数据采集系统及技巧
基于浏览器扩充的数据采集系统及技巧
【技术领域】
[0001]本发明涉及一种数据采集系统,特别涉及一种基于浏览器扩充的数据采集系统及借助该数据采集系统实现的基于浏览器扩充的数据采集方法。
【背景技术】
[0002 ]由于近1年多来,互联网协议并没有本质的变化,所有on I ine (互联网上)及h5 (指第5代HTML,所谓HTML是“超文本标记语言”的日文简写)等网站页面仍然遵守w3c(万维网联盟)标准,通讯一直借助http协议(超文本传输协议),因此负责网路数据采集的爬虫程序构架,在这段时期内,也没有实质性地提高。
[0003]但是随着JS(JavaScript,一种直译式脚本语言)及浏览器技术的发展,各种反爬手段层出不穷,其中尤以后端反爬为主,因为后端反爬是可以直接抵挡爬虫步入的第一道门槛。
[0004]目前现有的垂直爬虫也主要以前期配置抓取步骤及参数,然后据此进行连续抓取,此方式主要存在的一个不足之处就是:面临对方后端反爬策略的修改,无法第一时间主动适配,必然引起在开发人员介入之前的一段时间,无法正常抓取。
[0005]并且目前市面上好多第三方的(开源)浏览器控制引擎经过试用,被发觉都存在着众多功能方面的缺陷,并没有办法百分百模拟浏览器的行为特点,存在容易被对方探测到的风险。
[0006]因此,我们须要更为智能的爬虫系统,在面临对方后端反爬策略更改的第一时间,可以自适应而且持续正确抓取的动作。
【发明内容】
[0007]本发明要解决的技术问题是为了克服现有技术中目前通过垂直爬虫技术爬取网页信息存在在对方后端反爬策略修改时难以主动适配以及通过现有的浏览器未能完全模拟其行为特点的缺陷,提供一种基于浏览器扩充的数据采集系统及技巧。
[0008]本发明是通过下列技术方案来解决上述技术问题的:
[0009]本发明提供一种基于浏览器扩充的数据采集系统,其特征在于,其包括一浏览器、基于该浏览器的API(应用程序编程接口)说明建立的附加组件;
[0010]该附加组件用于主动协程一服务器,并从该服务器中获取一爬取目标;
[0011]该附加组件还用于控制该浏览器打开目标网页,并控制该浏览器对该目标网页进行访问,以及控制该浏览器从该目标网页中获取该爬取目标;
[0012]该附加组件还用于控制该浏览器对该目标网页中除该爬取目标外的其他页面内容进行访问;
[0013]该附加组件还用于控制该浏览器关掉该目标网页。
[0014]较佳地,该附加组件借助该浏览器的API施行控制操作以实现对该目标网页的访问。
[0015]较佳地,该控制操作包括点击操作、滚动操作和挥控操作。
[0016]本发明还提供一种基于浏览器扩充的数据采集方法,其特征在于,其借助上述的基于浏览器扩充的数据采集系统实现,该数据采集方法包括以下步骤:
[0017]S1、该附加组件主动协程一服务器,并从该服务器中获取一爬取目标;
[0018]&、该附加组件控制该浏览器打开目标网页;
[0019]&、该附加组件控制该浏览器对该目标网页进行访问;
[0020]S4、该附加组件控制该浏览器从该目标网页中获取该爬取目标;
[0021]&、该附加组件控制该浏览器对该目标网页中除该爬取目标外的其他页面内容进行访问;
[0022]S6、该附加组件控制该浏览器关掉该目标网页。
[0023]较佳地,该附加组件借助该浏览器的API施行控制操作以实现对该目标网页的访问。
[0024]较佳地,该控制操作包括点击操作、滚动操作和挥控操作。
[0025]在符合本领域常识的基础上,上述各优选条件,可任意组合,即得本发明各较佳实例。
[0026]本发明的积极进步疗效在于:
[0027]本发明可以更隐蔽地借助爬虫技术进行数据的抓取,并且因为直接采用浏览器,使得所有的访问恳求均真实有效,并且对方网页上所有的JS都被正常执行,所有的参数建立也通过浏览器手动执行,不需要人工干预,即使对方后端反爬有改动,浏览器也能手动适应,极大地降低了人工成本,并且最大限度确保抓取的成功率。而且,通过单次或少量的恳求,对方难以剖析判别出访问者是爬虫还是真实的用户,使得对方网站管理者不敢轻易封杀,确保了抓取行为的连续性。
【附图说明】
[0028]图1为本发明的较佳施行例的基于浏览器扩充的数据采集方法的流程图。
【具体施行方法】
[0029]下面通过施行例的方法进一步说明本发明,但并不因而将本发明限制在所述的施行例范围之中。
[0030]本施行例提供一种基于浏览器扩充的数据采集系统及方式,该数据采集系统包括一浏览器、基于该浏览器的API说明建立的附加组件。
[0031]其中,该附加组件具备的功能有:该附加组件用于操纵该浏览器进行特定网页的访问,控制该浏览器打开或关掉特定的网页,控制该浏览器页面的个别特定行为,例如点击、滚动以及挥控操作以及操纵该浏览器从该浏览器的网页中获取信息。
[0032]该附加组件用于主动协程一服务器,并从该服务器中获取一爬取目标;
[0033]该附加组件还用于控制该浏览器打开目标网页,并控制该浏览器对该目标网页进行访问,以及控制该浏览器从该目标网页中获取该爬取目标;
[0034]该附加组件还用于控制该浏览器对该目标网页中除该爬取目标外的其他页面内容进行访问;
[0035]该附加组件还用于控制该浏览器关掉该目标网页。
[0036]如图1所示,该数据采集方法借助上述的基于浏览器扩充的数据采集系统实现,该数据采集方法包括以下步骤:
[0037]步骤101、该附加组件主动协程一服务器,并从该服务器中获取一爬取目标;
[0038]步骤102、该附加组件控制该浏览器打开目标网页;
[0039]步骤103、该附加组件控制该浏览器对该目标网页进行访问,该附加组件借助该浏览器的API施行控制操作以实现对该目标网页的访问,其中该控制操作包括点击操作、滚动操作和挥控操作;
[0040]步骤104、该附加组件控制该浏览器从该目标网页中获取该爬取目标;
[0041]步骤105、该附加组件控制该浏览器对该目标网页中除该爬取目标外的其他页面内容进行访问;
[0042]步骤106、该附加组件控制该浏览器关掉该目标网页。
[0043]在本方式中,附加组件借助浏览器(如火狐浏览器)提供的API,直接滚动页面或模拟键盘、键盘点击页面。由于好多页面为了探测用户的行为,有很多预留的埋点,当用户键盘经过或页面滚动到特定高度,将会触发一次埋点的网路恳求,所以通过模拟滚动与点击的控制操作,可以真实模拟一个普通用户的浏览行为,使对方通过单次用户的行为数据剖析,无法判定出当前访问者是否是一个真实存在的用户。
[0044]通过附加组件模拟真实用户浏览页面,且附加组件在须要爬取的目标页面打开并完成数据提取以后,并不把页面立刻关闭,而是在页面上找寻个别特定的元素进行点击操作,这样可以更真实地模拟用户的行为。由于普通用户并不会长时间的访问某一单一种类的页面,其必然会浏览一些其他感兴趣的信息,比如网站推荐的信息或一些评论信息等,然后再将这一组页面关掉,进行下一次的抓取。使目标网站无法通过后期(旁路)的用户行为剖析模型,进行有效的爬虫访问判定。
[0045]由此,本发明可以更隐蔽地借助爬虫技术进行数据的抓取,并且因为直接采用浏览器,使得所有的访问恳求均真实有效,并且对方网页上所有的JS都被正常执行,所有的参数建立也通过浏览器手动执行,不需要人工干预,即使对方后端反爬有改动,浏览器也能手动适应,极大地降低了人工成本,并且最大限度确保抓取的成功率。而且,通过单次或少量的恳求,对方难以剖析判定出访问者是爬虫还是真实的用户,使得对方网站管理者不敢轻易封杀,确保了抓取行为的连续性。
[0046]虽然以上描述了本发明的【具体施行方法】,但是本领域的技术人员应该理解,这些仅是举例说明,本发明的保护范围是由所附权力要求书限定的。本领域的技术人员在不背离本发明的原理和实质的前提下,可以对那些施行方法作出多种变更或更改,但这种变更和更改均落入本发明的保护范围。
【主权项】
1.一种基于浏览器扩充的数据采集系统,其特点在于,其包括一浏览器、基于该浏览器的API说明建立的附加组件; 该附加组件用于主动协程一服务器,并从该服务器中获取一爬取目标; 该附加组件还用于控制该浏览器打开目标网页,并控制该浏览器对该目标网页进行访问,以及控制该浏览器从该目标网页中获取该爬取目标; 该附加组件还用于控制该浏览器对该目标网页中除该爬取目标外的其他页面内容进行访问; 该附加组件还用于控制该浏览器关掉该目标网页。2.如权力要求1所述的基于浏览器扩充的数据采集系统,其特点在于,该附加组件借助该浏览器的API施行控制操作以实现对该目标网页的访问。3.如权力要求2所述的基于浏览器扩充的数据采集系统,其特点在于,该控制操作包括点击操作、滚动操作和挥控操作。4.一种基于浏览器扩充的数据采集方法,其特点在于,其借助如权力要求1所述的基于浏览器扩充的数据采集系统实现,该数据采集方法包括以下步骤: 51、该附加组件主动协程一服务器,并从该服务器中获取一爬取目标; 52、该附加组件控制该浏览器打开目标网页; 53、该附加组件控制该浏览器对该目标网页进行访问; 54、该附加组件控制该浏览器从该目标网页中获取该爬取目标; &、该附加组件控制该浏览器对该目标网页中除该爬取目标外的其他页面内容进行访问; S6、该附加组件控制该浏览器关掉该目标网页。5.如权力要求4所述的基于浏览器扩充的数据采集方法,其特点在于,该附加组件借助该浏览器的API施行控制操作以实现对该目标网页的访问。6.如权力要求5所述的基于浏览器扩充的数据采集方法,其特点在于,该控制操作包括点击操作、滚动操作和挥控操作。
【专利摘要】本发明提供一种基于浏览器扩充的数据采集系统,其包括浏览器、基于浏览器的API说明建立的附加组件;附加组件用于主动协程服务器,从服务器中获取爬取目标;附加组件还用于控制浏览器打开目标网页,并控制浏览器对目标网页进行访问,以及控制浏览器从目标网页中获取爬取目标;附加组件还用于控制浏览器对目标网页中除爬取目标外的其他页面内容进行访问;附加组件还用于控制浏览器关掉目标网页。本发明可以更隐蔽地借助爬虫技术进行数据的抓取,并且因为直接采用浏览器,使得所有的访问恳求均真实有效,并且对方网页上所有的JS都被正常执行,即使对方后端反爬有改动,浏览器也能手动适应,减小了人工成本,最大限度确保抓取的成功率。
【IPC分类】G06F17/30
【公开号】CN105512193
【申请号】CN2
【发明人】吴凌峰, 吴鹏越
【申请人】上海携程商务有限公司
【公开日】2016年4月20日
【申请日】2015年11月26日
10种数据分析方法,助我们针对性解决问题!
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-03-21 04:10
内容采集系统可以为我们提供监测点击率、用户浏览路径、客户反馈等基础数据。这些数据是推广、竞价、微信运营人员必不可少的支撑数据。系统采集的数据特点分析,能帮助我们针对性解决问题。下面这10种数据分析方法,可以在根据采集的数据分析,找到我们的问题。
1、客户访问路径分析通过对客户访问路径的跟踪可以帮助我们做出精准推广预算和方案。一般主要路径采用爬虫抓取,比如:微信,google、等站点。比如:根据相关内容推广人群的行为走向分析,能让我们的运营更有目的性。做数据分析时一定要对新媒体推广提高重视,可以采用图表方式展示数据。
2、客户粘性分析通过对客户访问页面进行分析,我们可以了解客户的品牌购买意愿,留存率,预算分布,年龄分布,性别分布等等。其中,了解客户的购买行为是很有价值的一个参考因素。比如:通过点击采集数据,我们可以跟踪用户与产品的互动行为,也就是用户粘性,判断是否要做大规模的推广。
3、企业家分析这个分析方法其实很简单,我们只需要设置不同的思维维度。比如:粉丝精准性、群体基数、单个数、在多个上完成行为、在多个浏览器上完成行为、在多个操作系统上完成行为、在多个浏览器上完成行为等等。通过这个分析我们可以判断客户一定还会购买同一产品或服务的多个维度。这样我们就能做到以一打多,避免我们对多个产品进行时间和内容上的盲目性。
4、行为路径分析这里所说的行为路径是指用户浏览到落地页后的每一步行为。这里所说的路径分析主要考虑客户如何点击落地页,点击到页面各位置的转化率,行为路径重要性,路径中的关键内容等等。这一块需要重点考虑的路径有:客户点击落地页后的第一页,第一名客户点击落地页后的下一页,购买页,到支付页等等。
5、一点带多面这个也很好理解,我们是要做客户,就要尽可能去抓住用户。在抓住用户的同时,必须要去用好关键词。我们在抓住客户的同时,要去不断抓住他的行为,满足他。抓住用户的同时,要搞好用户关系,在满足他的基础上,尽可能用好关键词。比如:搜索产品推广关键词:假设客户当天来一次,他可能是1个步骤关注你,3个步骤转化,3个步骤购买,3个步骤复购,那我们就要弄清楚,如何在一点带多面。
6、转化漏斗分析与渠道多点分析、营销指标对比这三个方法同样也是针对运营推广的,但一点带多面、转化漏斗分析更侧重运营,网站数据的监测更多是用在bd的场景中。而渠道多点分析和营销指标对比在分析更偏向产品和用户数据方面。比如:6个步骤下来,我们的注册率是多少, 查看全部
10种数据分析方法,助我们针对性解决问题!
内容采集系统可以为我们提供监测点击率、用户浏览路径、客户反馈等基础数据。这些数据是推广、竞价、微信运营人员必不可少的支撑数据。系统采集的数据特点分析,能帮助我们针对性解决问题。下面这10种数据分析方法,可以在根据采集的数据分析,找到我们的问题。
1、客户访问路径分析通过对客户访问路径的跟踪可以帮助我们做出精准推广预算和方案。一般主要路径采用爬虫抓取,比如:微信,google、等站点。比如:根据相关内容推广人群的行为走向分析,能让我们的运营更有目的性。做数据分析时一定要对新媒体推广提高重视,可以采用图表方式展示数据。
2、客户粘性分析通过对客户访问页面进行分析,我们可以了解客户的品牌购买意愿,留存率,预算分布,年龄分布,性别分布等等。其中,了解客户的购买行为是很有价值的一个参考因素。比如:通过点击采集数据,我们可以跟踪用户与产品的互动行为,也就是用户粘性,判断是否要做大规模的推广。
3、企业家分析这个分析方法其实很简单,我们只需要设置不同的思维维度。比如:粉丝精准性、群体基数、单个数、在多个上完成行为、在多个浏览器上完成行为、在多个操作系统上完成行为、在多个浏览器上完成行为等等。通过这个分析我们可以判断客户一定还会购买同一产品或服务的多个维度。这样我们就能做到以一打多,避免我们对多个产品进行时间和内容上的盲目性。
4、行为路径分析这里所说的行为路径是指用户浏览到落地页后的每一步行为。这里所说的路径分析主要考虑客户如何点击落地页,点击到页面各位置的转化率,行为路径重要性,路径中的关键内容等等。这一块需要重点考虑的路径有:客户点击落地页后的第一页,第一名客户点击落地页后的下一页,购买页,到支付页等等。
5、一点带多面这个也很好理解,我们是要做客户,就要尽可能去抓住用户。在抓住用户的同时,必须要去用好关键词。我们在抓住客户的同时,要去不断抓住他的行为,满足他。抓住用户的同时,要搞好用户关系,在满足他的基础上,尽可能用好关键词。比如:搜索产品推广关键词:假设客户当天来一次,他可能是1个步骤关注你,3个步骤转化,3个步骤购买,3个步骤复购,那我们就要弄清楚,如何在一点带多面。
6、转化漏斗分析与渠道多点分析、营销指标对比这三个方法同样也是针对运营推广的,但一点带多面、转化漏斗分析更侧重运营,网站数据的监测更多是用在bd的场景中。而渠道多点分析和营销指标对比在分析更偏向产品和用户数据方面。比如:6个步骤下来,我们的注册率是多少,
天宇(CGSEEK)集成网页搜索、内容智能提取与过滤
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-01-27 10:28
该系统集成了Web搜索,智能内容提取和过滤,自动分类,自动重复数据删除和其他技术,以实现Internet信息采集的自动化和集成,过滤,提取和批量上传。
一、系统简介
新闻媒体,政府部门和大型企事业单位已经使用Internet技术来构建网络信息采集平台:新闻媒体需要在Internet上获取大量新闻材料以丰富新闻数据库;政府机构需要采集与自身业务有关的文件,提高办公和决策效率;大型企业和机构需要快速获取行业的宏观环境,政策动态和竞争对手的信息……
天宇智能互联网信息采集系统(CGSEEK)集成了Web搜索,智能内容提取和过滤,自动分类,自动重复数据删除等技术,实现了互联网信息采集的过滤,提取和批量上传自动化和整合。
二、系统结构
三、系统的主要功能
◆支持采集各种标准格式的信息资源,例如HTML页面,文本信息,表格,图片,声音,视频等。
◆实现网页和嵌入式图片采集的统一。
◆支持传统页面的采集(BIG5代码),并自动转换为标准的简化代码(GB代码),支持Unicode代码集。
◆采集支持程序自动生成的页面内容,例如JavaScript生成的页面。
◆它可以轻松捕获网站后端数据库(JSP,ASP,CGI)的内容,并捕获需要通过用户身份验证的网站内容。
◆支持批量下载单个网页和网站历史数据。
◆支持采集各种标准格式的信息资源,例如HTML页面,文本信息,表格,图片,声音,视频等。
◆实现网页和嵌入式图片采集的统一。
◆支持传统页面的采集(BIG5代码),并自动转换为标准的简化代码(GB代码),支持Unicode代码集。
◆采集支持程序自动生成的页面内容,例如JavaScript生成的页面。
◆它可以轻松捕获网站后端数据库(JSP,ASP,CGI)的内容,并捕获需要通过用户身份验证的网站内容。
◆支持批量下载单个网页和网站历史数据。
◆支持采集各种标准格式的信息资源,例如HTML页面,文本信息,表格,图片,声音,视频等。
◆实现网页和嵌入式图片采集的统一。
◆支持传统页面的采集(BIG5代码),并自动转换为标准的简化代码(GB代码),支持Unicode代码集。
◆采集支持程序自动生成的页面内容,例如JavaScript生成的页面。
◆它可以轻松捕获网站后端数据库(JSP,ASP,CGI)的内容,并捕获需要通过用户身份验证的网站内容。
◆支持批量下载单个网页和网站历史数据。
信息使用
◆您可以将采集中的网页信息放置在本地计算机指定的文件夹中以供使用。
◆该系统支持将采集的文本内容批量上传到天语CGRS全文数据库,天语采集分配系统和全文检索系统可用于信息采集,编辑,查看,发布和全文检索。
◆智能提取的文本内容可以上传到主流关系数据库(例如SQL Server)以丰富数据库,并且第三方应用程序系统也可以用于采集,发布和检索信息。
四、系统功能
◆网页采集具有全面的内容
<p>适应网站内容格式的可变性,可以完全获取需要采集的页面,几乎没有遗漏,并且网页采集的内容完整性高于99%。 查看全部
天宇(CGSEEK)集成网页搜索、内容智能提取与过滤
该系统集成了Web搜索,智能内容提取和过滤,自动分类,自动重复数据删除和其他技术,以实现Internet信息采集的自动化和集成,过滤,提取和批量上传。
一、系统简介
新闻媒体,政府部门和大型企事业单位已经使用Internet技术来构建网络信息采集平台:新闻媒体需要在Internet上获取大量新闻材料以丰富新闻数据库;政府机构需要采集与自身业务有关的文件,提高办公和决策效率;大型企业和机构需要快速获取行业的宏观环境,政策动态和竞争对手的信息……
天宇智能互联网信息采集系统(CGSEEK)集成了Web搜索,智能内容提取和过滤,自动分类,自动重复数据删除等技术,实现了互联网信息采集的过滤,提取和批量上传自动化和整合。
二、系统结构
三、系统的主要功能
◆支持采集各种标准格式的信息资源,例如HTML页面,文本信息,表格,图片,声音,视频等。
◆实现网页和嵌入式图片采集的统一。
◆支持传统页面的采集(BIG5代码),并自动转换为标准的简化代码(GB代码),支持Unicode代码集。
◆采集支持程序自动生成的页面内容,例如JavaScript生成的页面。
◆它可以轻松捕获网站后端数据库(JSP,ASP,CGI)的内容,并捕获需要通过用户身份验证的网站内容。
◆支持批量下载单个网页和网站历史数据。
◆支持采集各种标准格式的信息资源,例如HTML页面,文本信息,表格,图片,声音,视频等。
◆实现网页和嵌入式图片采集的统一。
◆支持传统页面的采集(BIG5代码),并自动转换为标准的简化代码(GB代码),支持Unicode代码集。
◆采集支持程序自动生成的页面内容,例如JavaScript生成的页面。
◆它可以轻松捕获网站后端数据库(JSP,ASP,CGI)的内容,并捕获需要通过用户身份验证的网站内容。
◆支持批量下载单个网页和网站历史数据。
◆支持采集各种标准格式的信息资源,例如HTML页面,文本信息,表格,图片,声音,视频等。
◆实现网页和嵌入式图片采集的统一。
◆支持传统页面的采集(BIG5代码),并自动转换为标准的简化代码(GB代码),支持Unicode代码集。
◆采集支持程序自动生成的页面内容,例如JavaScript生成的页面。
◆它可以轻松捕获网站后端数据库(JSP,ASP,CGI)的内容,并捕获需要通过用户身份验证的网站内容。
◆支持批量下载单个网页和网站历史数据。
信息使用
◆您可以将采集中的网页信息放置在本地计算机指定的文件夹中以供使用。
◆该系统支持将采集的文本内容批量上传到天语CGRS全文数据库,天语采集分配系统和全文检索系统可用于信息采集,编辑,查看,发布和全文检索。
◆智能提取的文本内容可以上传到主流关系数据库(例如SQL Server)以丰富数据库,并且第三方应用程序系统也可以用于采集,发布和检索信息。
四、系统功能
◆网页采集具有全面的内容
<p>适应网站内容格式的可变性,可以完全获取需要采集的页面,几乎没有遗漏,并且网页采集的内容完整性高于99%。
汇总:WEB数据采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 269 次浏览 • 2021-01-15 12:04
B WEB数据采集系统一.概述面对Internet上的大量信息,政府机构,企事业单位和研究机构都渴望获得与其工作有关的有价值的信息,以及如何获得这些信息。这些信息方便快捷地变得至关重要。如果使用原创的手动采集方法,则将很耗时,费力且效率低下。面对越来越多的信息资源,劳动强度和困难可想而知。因此,现代政府和企业迫切需要一种能够提供高质量,高效运行信息的解决方案采集。该系统针对不同行业用户的应用需求,旨在捕获Internet,并实现了在用户定义的规则下可以从Internet捕获指定信息。捕获的信息可以存储在数据库中或直接发送到指定的列,以实现网站信息的及时更新和数据量的增加,从而增加搜索引擎收录的数量并扩大公司信息的推广。二.典型应用1.政府机构实时跟踪,采集与业务相关的信息来源。 充分满足内部人员对全球互联网信息观察的需求。 及时解决政务外网和政务内网的信息源问题,实现动态发布。 快速解决地方政府领导网站的信息获取需求。 全面整合信息,实现跨区域,跨部门的信息资源共享和政府内部的有效沟通。 节省信息采集的人力,物力和时间,提高办公效率。2.企业实时,准确地监视和跟踪竞争对手的动态是企业获取竞争情报的有力工具。
<p>及时获取竞争对手的公共信息,以研究同一行业的发展和市场需求。 为企业决策部门和管理人员提供方便,多渠道的企业战略决策工具。 实质性提高企业获取和利用智能的效率,节省智能信息采集,存储和挖掘的相关费用,是提高企业核心竞争力的关键。 提升公司的整体分析研究能力,快速的市场响应能力,建立以知识管理为核心的“竞争情报数据仓库”,是提高公司核心竞争力的神经中心。3.新闻媒体快速准确地自动采集计数信息。 支持每天有效抓取上万条新闻。 支持智能提取和查看所需内容。 实现Internet信息内容采集,浏览,编辑,管理和发布的集成。三.。系统架构工作流程描述采集的目的是将另一方网站上的网页上的某些文本或图片下载到您的网站。此过程需要进行以下配置工作:下载网页配置,分析网页配置,修改结果配置和数据输出配置。如果数据符合您的要求,则可以省略校正结果的步骤。配置完成后,将配置形成一个任务(该任务以XML格式描述),采集系统根据该任务的描述开始工作,最后将采集的结果存储在网站服务器。工作流程图如下:数据处理逻辑图:四.系统功能根据用户预先配置的规则(网页下载规则,网页解析规则等),对数据进行处理采集。 查看全部
汇总:WEB数据采集系统
B WEB数据采集系统一.概述面对Internet上的大量信息,政府机构,企事业单位和研究机构都渴望获得与其工作有关的有价值的信息,以及如何获得这些信息。这些信息方便快捷地变得至关重要。如果使用原创的手动采集方法,则将很耗时,费力且效率低下。面对越来越多的信息资源,劳动强度和困难可想而知。因此,现代政府和企业迫切需要一种能够提供高质量,高效运行信息的解决方案采集。该系统针对不同行业用户的应用需求,旨在捕获Internet,并实现了在用户定义的规则下可以从Internet捕获指定信息。捕获的信息可以存储在数据库中或直接发送到指定的列,以实现网站信息的及时更新和数据量的增加,从而增加搜索引擎收录的数量并扩大公司信息的推广。二.典型应用1.政府机构实时跟踪,采集与业务相关的信息来源。 充分满足内部人员对全球互联网信息观察的需求。 及时解决政务外网和政务内网的信息源问题,实现动态发布。 快速解决地方政府领导网站的信息获取需求。 全面整合信息,实现跨区域,跨部门的信息资源共享和政府内部的有效沟通。 节省信息采集的人力,物力和时间,提高办公效率。2.企业实时,准确地监视和跟踪竞争对手的动态是企业获取竞争情报的有力工具。
<p>及时获取竞争对手的公共信息,以研究同一行业的发展和市场需求。 为企业决策部门和管理人员提供方便,多渠道的企业战略决策工具。 实质性提高企业获取和利用智能的效率,节省智能信息采集,存储和挖掘的相关费用,是提高企业核心竞争力的关键。 提升公司的整体分析研究能力,快速的市场响应能力,建立以知识管理为核心的“竞争情报数据仓库”,是提高公司核心竞争力的神经中心。3.新闻媒体快速准确地自动采集计数信息。 支持每天有效抓取上万条新闻。 支持智能提取和查看所需内容。 实现Internet信息内容采集,浏览,编辑,管理和发布的集成。三.。系统架构工作流程描述采集的目的是将另一方网站上的网页上的某些文本或图片下载到您的网站。此过程需要进行以下配置工作:下载网页配置,分析网页配置,修改结果配置和数据输出配置。如果数据符合您的要求,则可以省略校正结果的步骤。配置完成后,将配置形成一个任务(该任务以XML格式描述),采集系统根据该任务的描述开始工作,最后将采集的结果存储在网站服务器。工作流程图如下:数据处理逻辑图:四.系统功能根据用户预先配置的规则(网页下载规则,网页解析规则等),对数据进行处理采集。
最新信息:一套内容采集系统 解放编辑人员
采集交流 • 优采云 发表了文章 • 0 个评论 • 234 次浏览 • 2021-01-14 13:03
内容采集系统对于基于内容的网站是非常好的助手。除了原创的内容外,其他内容也需要由编辑者或采集系统采集,然后添加到自己的网站中。 Discuz DvBBScms和其他产品具有其自己的内容采集功能,以达到采集指定的相关内容。单客户端优采云采集器对于采集指定的内容也可能非常有用。这些工具都希望机器取代人类,从内容处理工作中解放编辑人员,并进行一些高端工作,例如采集对内容的结果进行微调,SEO优化,设置精确的采集规则,使采集的内容更符合网站的需求。
以下内容采集系统是根据此思想开发的,该采集系统由两部分组成:
1.编辑器使用的采集规则设置程序以及用于查看,微调和发布采集的结果的网站。
2.定时采集器和定时发送器已部署在服务器上。
首先,编辑器通过采集规则设置程序(NiceCollectoer.exe)将网站设置为采集,然后等待采集完成,然后编辑器将网站(PickWeb)传递给[审查,微调和优化k15的结果,然后自行发布网站。编辑者需要做的是设置采集的规则并优化采集的结果。工作的其他部分由机器完成。
NicePicker是一个HTML分析器,用于提取Url,NiceCollector和HostCollector都使用NicePicker分析Html,NiceCollectoer是采集规则设置程序,目标网站只需要设置一次:
用法类似于最早的优采云采集器,这里我们以博客园为目标采集网站,在采集本质上设置文章,采集规则为非常简单:成为编辑者设置采集规则后,这些规则将保存在Setting.mdb中与NiceCollector.exe相同的目录中。通常,设置采集规则后,基本上无需更改它。仅当目标网站的Html Dom结构更改时,才需要再次微调采集规则。 NiceCollector还用于设置和添加新目标采集网站的操作。
编辑器完成采集规则设置后,将Setting.mdb放在HostCollector.exe下,HostCollector将根据Setting.mdb的设置执行实际的采集,并将采集的结果存储在数据库。
在此步骤中,内容的采集工作完成,编辑器可以打开PickWeb,微调和优化采集的结果,然后批准并将其发送给他们的网站:
PickWeb并没有完成向自己网站发送采集结果的工作。编辑器完成内容审阅后,PostToForum.exe将读取数据库,并将通过审阅的采集结果发送给您自己的网站,当然您需要自己的网站。 ashx或其他方式来接收采集的结果,不建议PostToFormu.exe直接操作您自己的网站数据库,最好使用您自己的[k14上的API]来接收采集。
NiceCollectoer,HostCollector,PickWeb,PostToForum,这些程序的共同工作已基本完成采集,并且发送,HostCollector,PickWeb,PostToForum的工作已部署在服务器上,HostCollector需要定期调用,请访问采集目标网站生成的新内容,HostRunnerService.exe是Windows服务,用于定期调用HostCollector,使用管理员在控制台下运行installutil / i HostRunnerService.exe来安装此Windows服务:
HostRunnerService的配置也非常简单:
在RunTime.txt中多次设置每日时间采集:
当新内容为采集时,编辑者需要定期登录PickWeb以优化,微调和查看新内容,或设置默认查看。同样,还需要定期调用PostToForum来发送批准的新内容。 CallSenderService.exe与HostRunnerService.exe相似。这也是Windows服务,用于定期调用PostToFormu.exe。
至此,除了其他两件事之外,整个系统已基本完成:SelfChecker.exe和HealthChecker.exe。 SelfCheck.exe用于检查Setting.mdb中设置的规则是否为有效规则,例如,检查采集规则是否设置了内容采集项目。 HealthChecker.exe用于采集HostCollector.exe和PostToForum.exe生成的日志,然后将日志发送到指定的系统维护者。
此内容采集系统中仍有许多地方需要改进和优化。当前状态只能说是原型。例如,NicePick需要进一步抽象和重构,并提供更多接口,并分析Html插件的所有方面,从而允许用户在每个分析步骤中加载自己的分析器。在NiceCollector上,需要越来越全面的采集规则设置。可以在PickWeb上添加一些默认的SEO优化规则,例如标题内容的批量SEO优化以及其他方面。
可执行文件下载:
08_453455_if8l_NROutput.rar(链接已更新)
源代码下载:
08_234324_if8l_NiceCollector.rar(链接已更新) 查看全部
最新信息:一套内容采集系统 解放编辑人员
内容采集系统对于基于内容的网站是非常好的助手。除了原创的内容外,其他内容也需要由编辑者或采集系统采集,然后添加到自己的网站中。 Discuz DvBBScms和其他产品具有其自己的内容采集功能,以达到采集指定的相关内容。单客户端优采云采集器对于采集指定的内容也可能非常有用。这些工具都希望机器取代人类,从内容处理工作中解放编辑人员,并进行一些高端工作,例如采集对内容的结果进行微调,SEO优化,设置精确的采集规则,使采集的内容更符合网站的需求。
以下内容采集系统是根据此思想开发的,该采集系统由两部分组成:
1.编辑器使用的采集规则设置程序以及用于查看,微调和发布采集的结果的网站。
2.定时采集器和定时发送器已部署在服务器上。
首先,编辑器通过采集规则设置程序(NiceCollectoer.exe)将网站设置为采集,然后等待采集完成,然后编辑器将网站(PickWeb)传递给[审查,微调和优化k15的结果,然后自行发布网站。编辑者需要做的是设置采集的规则并优化采集的结果。工作的其他部分由机器完成。
NicePicker是一个HTML分析器,用于提取Url,NiceCollector和HostCollector都使用NicePicker分析Html,NiceCollectoer是采集规则设置程序,目标网站只需要设置一次:
用法类似于最早的优采云采集器,这里我们以博客园为目标采集网站,在采集本质上设置文章,采集规则为非常简单:成为编辑者设置采集规则后,这些规则将保存在Setting.mdb中与NiceCollector.exe相同的目录中。通常,设置采集规则后,基本上无需更改它。仅当目标网站的Html Dom结构更改时,才需要再次微调采集规则。 NiceCollector还用于设置和添加新目标采集网站的操作。
编辑器完成采集规则设置后,将Setting.mdb放在HostCollector.exe下,HostCollector将根据Setting.mdb的设置执行实际的采集,并将采集的结果存储在数据库。
在此步骤中,内容的采集工作完成,编辑器可以打开PickWeb,微调和优化采集的结果,然后批准并将其发送给他们的网站:
PickWeb并没有完成向自己网站发送采集结果的工作。编辑器完成内容审阅后,PostToForum.exe将读取数据库,并将通过审阅的采集结果发送给您自己的网站,当然您需要自己的网站。 ashx或其他方式来接收采集的结果,不建议PostToFormu.exe直接操作您自己的网站数据库,最好使用您自己的[k14上的API]来接收采集。
NiceCollectoer,HostCollector,PickWeb,PostToForum,这些程序的共同工作已基本完成采集,并且发送,HostCollector,PickWeb,PostToForum的工作已部署在服务器上,HostCollector需要定期调用,请访问采集目标网站生成的新内容,HostRunnerService.exe是Windows服务,用于定期调用HostCollector,使用管理员在控制台下运行installutil / i HostRunnerService.exe来安装此Windows服务:
HostRunnerService的配置也非常简单:
在RunTime.txt中多次设置每日时间采集:
当新内容为采集时,编辑者需要定期登录PickWeb以优化,微调和查看新内容,或设置默认查看。同样,还需要定期调用PostToForum来发送批准的新内容。 CallSenderService.exe与HostRunnerService.exe相似。这也是Windows服务,用于定期调用PostToFormu.exe。
至此,除了其他两件事之外,整个系统已基本完成:SelfChecker.exe和HealthChecker.exe。 SelfCheck.exe用于检查Setting.mdb中设置的规则是否为有效规则,例如,检查采集规则是否设置了内容采集项目。 HealthChecker.exe用于采集HostCollector.exe和PostToForum.exe生成的日志,然后将日志发送到指定的系统维护者。
此内容采集系统中仍有许多地方需要改进和优化。当前状态只能说是原型。例如,NicePick需要进一步抽象和重构,并提供更多接口,并分析Html插件的所有方面,从而允许用户在每个分析步骤中加载自己的分析器。在NiceCollector上,需要越来越全面的采集规则设置。可以在PickWeb上添加一些默认的SEO优化规则,例如标题内容的批量SEO优化以及其他方面。
可执行文件下载:
08_453455_if8l_NROutput.rar(链接已更新)
源代码下载:
08_234324_if8l_NiceCollector.rar(链接已更新)
汇总:一套内容采集系统源码
采集交流 • 优采云 发表了文章 • 0 个评论 • 237 次浏览 • 2020-12-18 11:18
一组内容采集系统源代码
一套内容采集系统解放了编辑人员。内容采集系统是基于内容网站的很好的助手。除了原创内容外,其他内容也需要编辑者或采集系统来采集和整理,然后添加到自己的网站中。 Discuz DvBBScms和其他产品具有其自己的内容采集功能,以达到采集指定的相关内容。单客户端优采云采集器对于采集指定的内容也可能非常有用。这些工具都希望机器取代人类,从内容处理工作中解放编辑人员,并进行一些高端工作,例如采集对内容的结果进行微调,SEO优化,设置精确的采集规则,使采集的内容更符合网站的需求。
以下内容采集系统是根据此思想开发的,该采集系统由两部分组成:
1.编辑器使用的采集规则设置程序以及用于查看,微调和发布采集的结果的网站。
2.定时采集器和定时发送器已部署在服务器上。
首先,编辑器通过采集规则设置程序(NiceCollectoer.exe)将网站设置为采集,然后等待采集完成,然后编辑器将网站(PickWeb)传递给[审查,微调和优化k15的结果,然后自行发布网站。编辑者需要做的是采集规则的设置和采集结果的优化。工作的其他部分由机器完成。
NicePicker是一个HTML分析器,用于提取Url,NiceCollector和HostCollector都使用NicePicker分析Html,NiceCollectoer是采集规则设置程序,目标网站只需要设置一次:
用法类似于最早的优采云采集器,这里我们以博客园为目标采集网站,在采集本质上设置文章,采集规则为非常简单:成为编辑者设置采集规则后,这些规则将保存在Setting.mdb中与NiceCollector.exe相同的目录中。通常,设置采集规则后,基本上无需更改它。仅当目标网站的Html Dom结构更改时,才需要再次微调采集规则。 NiceCollector还用于设置和添加新目标采集网站的操作。
编辑器完成采集规则设置后,将Setting.mdb放在HostCollector.exe下,HostCollector将根据Setting.mdb的设置执行实际的采集,并将采集的结果存储在数据库。
在此步骤中,内容的采集工作已完成。编辑者可以打开PickWeb,微调和优化采集的结果,然后批准并将其发送到他们的网站
PickWeb并没有完成向自己网站发送采集结果的工作。编辑者完成内容审阅后,PostToForum.exe将读取数据库并将通过审阅的采集结果发送给他们自己的网站,当然您需要一个网站。 ashx或其他方式来接收采集的结果,不建议PostToFormu.exe直接操作自己的网站数据库,最好使用自己的[k14上的API]来接收采集。
该数据库位于DB_51aspx文件夹(sql2005)中,只需附加它即可。
登录用户名和密码均为51aspx 查看全部
汇总:一套内容采集系统源码
一组内容采集系统源代码
一套内容采集系统解放了编辑人员。内容采集系统是基于内容网站的很好的助手。除了原创内容外,其他内容也需要编辑者或采集系统来采集和整理,然后添加到自己的网站中。 Discuz DvBBScms和其他产品具有其自己的内容采集功能,以达到采集指定的相关内容。单客户端优采云采集器对于采集指定的内容也可能非常有用。这些工具都希望机器取代人类,从内容处理工作中解放编辑人员,并进行一些高端工作,例如采集对内容的结果进行微调,SEO优化,设置精确的采集规则,使采集的内容更符合网站的需求。
以下内容采集系统是根据此思想开发的,该采集系统由两部分组成:
1.编辑器使用的采集规则设置程序以及用于查看,微调和发布采集的结果的网站。
2.定时采集器和定时发送器已部署在服务器上。
首先,编辑器通过采集规则设置程序(NiceCollectoer.exe)将网站设置为采集,然后等待采集完成,然后编辑器将网站(PickWeb)传递给[审查,微调和优化k15的结果,然后自行发布网站。编辑者需要做的是采集规则的设置和采集结果的优化。工作的其他部分由机器完成。
NicePicker是一个HTML分析器,用于提取Url,NiceCollector和HostCollector都使用NicePicker分析Html,NiceCollectoer是采集规则设置程序,目标网站只需要设置一次:
用法类似于最早的优采云采集器,这里我们以博客园为目标采集网站,在采集本质上设置文章,采集规则为非常简单:成为编辑者设置采集规则后,这些规则将保存在Setting.mdb中与NiceCollector.exe相同的目录中。通常,设置采集规则后,基本上无需更改它。仅当目标网站的Html Dom结构更改时,才需要再次微调采集规则。 NiceCollector还用于设置和添加新目标采集网站的操作。
编辑器完成采集规则设置后,将Setting.mdb放在HostCollector.exe下,HostCollector将根据Setting.mdb的设置执行实际的采集,并将采集的结果存储在数据库。
在此步骤中,内容的采集工作已完成。编辑者可以打开PickWeb,微调和优化采集的结果,然后批准并将其发送到他们的网站
PickWeb并没有完成向自己网站发送采集结果的工作。编辑者完成内容审阅后,PostToForum.exe将读取数据库并将通过审阅的采集结果发送给他们自己的网站,当然您需要一个网站。 ashx或其他方式来接收采集的结果,不建议PostToFormu.exe直接操作自己的网站数据库,最好使用自己的[k14上的API]来接收采集。
该数据库位于DB_51aspx文件夹(sql2005)中,只需附加它即可。
登录用户名和密码均为51aspx
操作方法:BeeCollector(小蜜蜂采集器)文章采集系统 v1.1027
采集交流 • 优采云 发表了文章 • 0 个评论 • 344 次浏览 • 2020-11-27 13:15
BeeCollector(Little Bee采集器)文章采集系统,改进了Flash 采集模块对目标字符集UTF8的支持。
功能介绍:
1、支持文章内容分页采集;
2、支持论坛采集;
3、支持将UTF-8转换为GB2312,并且采集内容字符格式可以作为UTF-8的目标;
4、支持在本地保存文章的内容;
5、支持站点+列管理,因此采集管理一目了然;
6、支持链接替换,页面链接替换,破解由JS /后端程序设置的一些反选功能;
7、支持采集器设置无限过滤功能;
8、支持在本地保存图片采集,自动替换文件名以避免重复;
9、支持将FLASH文件采集保存在本地,并自动替换文件名以避免重复;
10、支持限制PHP FOPEN和FSOCKET功能的虚拟主机;
1 1、支持采集手动过滤结果,并提供快速过滤和删除“空标题,空白内容”的功能;
1 2、支持Flash专业网站采集,专门开发采集 Flash游戏,可以完善采集缩略图和游戏介绍;
1 3、支持导入和导出站点范围的配置规则;
1 4、支持导入和导出列配置规则,并提供规则复制功能以简化设置;
1 5、提供数据库规则的导入和导出;
1 6、支持自定义采集间隔时间,以避免被误认为是DDOS攻击和拒绝响应。可以设置采集来防止DDOS攻击网站;
1 7、支持自定义的仓储间隔时间,避免了并发虚拟主机的限制;
1 8、支持自定义内容写入,用户可以设置任何内容(例如自己的链接,广告代码),并写入采集的内容:第一个,最后一个或随机写入;导入库时,它将自动带出需要编写的内容,而无需修改WEB系统的模板。
1 9、支持采集内容替换功能,用户可以设置替换规则以随意替换;
20、支持html标签过滤,允许采集仅保留必要的html标签,甚至保留纯文本,而没有任何html标签;
2 1、支持各种cms指南库软件包,包括PHP cms V2 / V 3、 Dede cms(织梦)V2 / V 3、 PHP168 cms,mephpcms,Mambo cms,Joomla cms系统指南库规则和操作说明;
2 2、支持PHPWIND,Discuz论坛指南库,该程序包收录2个论坛指南库规则和操作说明;
2 3、附带数据库优化工具,以减少频繁出现的采集过多数据碎片并降低数据库性能。
以下特殊功能仅适用于“小蜜蜂采集器”:
1、支持采集进程断点恢复功能,该功能不受浏览器意外关闭的影响,并且在重新启动采集之后将不再重复;
2、支持自动比较和过滤功能,不会重复采集和入库采集的链接系统;以上两个功能可以大大减少采集时间并减少系统负载。
3、支持系统每天自动创建图片存储目录,以便于管理;
4、支持采集 /制导间隔时间设置,以避免被目标电台识别为交通攻击并拒绝响应;
5、支持自定义内容编写,以实现简单的防摘功能;
6、支持html标签过滤,可以完美显示您想要的采集效果;
7、内容存储的完美解决方案,不受目标编程语言和数据库类别的限制。
上述许多强大功能免费供您使用,并且体验信息采集易于立即安装和有效使用。 查看全部
BeeCollector(Little Bee采集器)文章采集系统v1.1027
BeeCollector(Little Bee采集器)文章采集系统,改进了Flash 采集模块对目标字符集UTF8的支持。
功能介绍:
1、支持文章内容分页采集;
2、支持论坛采集;
3、支持将UTF-8转换为GB2312,并且采集内容字符格式可以作为UTF-8的目标;
4、支持在本地保存文章的内容;
5、支持站点+列管理,因此采集管理一目了然;
6、支持链接替换,页面链接替换,破解由JS /后端程序设置的一些反选功能;
7、支持采集器设置无限过滤功能;
8、支持在本地保存图片采集,自动替换文件名以避免重复;
9、支持将FLASH文件采集保存在本地,并自动替换文件名以避免重复;
10、支持限制PHP FOPEN和FSOCKET功能的虚拟主机;
1 1、支持采集手动过滤结果,并提供快速过滤和删除“空标题,空白内容”的功能;
1 2、支持Flash专业网站采集,专门开发采集 Flash游戏,可以完善采集缩略图和游戏介绍;
1 3、支持导入和导出站点范围的配置规则;
1 4、支持导入和导出列配置规则,并提供规则复制功能以简化设置;
1 5、提供数据库规则的导入和导出;
1 6、支持自定义采集间隔时间,以避免被误认为是DDOS攻击和拒绝响应。可以设置采集来防止DDOS攻击网站;
1 7、支持自定义的仓储间隔时间,避免了并发虚拟主机的限制;
1 8、支持自定义内容写入,用户可以设置任何内容(例如自己的链接,广告代码),并写入采集的内容:第一个,最后一个或随机写入;导入库时,它将自动带出需要编写的内容,而无需修改WEB系统的模板。
1 9、支持采集内容替换功能,用户可以设置替换规则以随意替换;
20、支持html标签过滤,允许采集仅保留必要的html标签,甚至保留纯文本,而没有任何html标签;
2 1、支持各种cms指南库软件包,包括PHP cms V2 / V 3、 Dede cms(织梦)V2 / V 3、 PHP168 cms,mephpcms,Mambo cms,Joomla cms系统指南库规则和操作说明;
2 2、支持PHPWIND,Discuz论坛指南库,该程序包收录2个论坛指南库规则和操作说明;
2 3、附带数据库优化工具,以减少频繁出现的采集过多数据碎片并降低数据库性能。
以下特殊功能仅适用于“小蜜蜂采集器”:
1、支持采集进程断点恢复功能,该功能不受浏览器意外关闭的影响,并且在重新启动采集之后将不再重复;
2、支持自动比较和过滤功能,不会重复采集和入库采集的链接系统;以上两个功能可以大大减少采集时间并减少系统负载。
3、支持系统每天自动创建图片存储目录,以便于管理;
4、支持采集 /制导间隔时间设置,以避免被目标电台识别为交通攻击并拒绝响应;
5、支持自定义内容编写,以实现简单的防摘功能;
6、支持html标签过滤,可以完美显示您想要的采集效果;
7、内容存储的完美解决方案,不受目标编程语言和数据库类别的限制。
上述许多强大功能免费供您使用,并且体验信息采集易于立即安装和有效使用。
即将发布:网页内容采集器Content Grabber Premium v2.48
采集交流 • 优采云 发表了文章 • 0 个评论 • 368 次浏览 • 2020-11-23 11:01
Content Grabber Premium破解版是用于Web爬网和Web自动化的Web内容采集工具。它可以按照您选择的格式从几乎所有网站中提取内容(包括Excel报告,XML,CSV和大多数数据库),并将其另存为结构化数据,欢迎有需要的朋友下载和使用。
基本介绍
Content Grabber Premium(Web内容采集器)一种由外国神灵制作的人工制品,可以从网页中获取内容(视频,图片,文本)并将其提取到Excel,XML,CSV和大多数基于Web的数据库中抓取和网络自动化。它是完全免费的,并且经常用于数据调查和测试目的。
功能介绍
价格比较门户/移动应用程序
-数据摘要
-合作列表(例如房屋止赎,工作委员会,旅游景点)
-新闻和内容汇总
-搜索引擎排名
市场情报和监控
-有竞争力的价格
-零售链监控
-社交媒体和品牌监控
-金融与市场研究
-欺诈识别
-知识产权保护
-合规与风险管理
政府解决方案
-及时获取来自世界各地的新闻,事件和意见
-减少数据采集和IT成本
-促进信息共享
-开源情报(OSINT)
内容集成
-内容迁移(即cms/ CRM)
-企业搜索
-传统应用程序集成
B2B集成/流程自动化
-合作伙伴/供应商/客户集成
可扩展性和可靠性
内容采集器针对的是对网络搜寻至关重要的公司,并专注于可伸缩性和可靠性。该网络收录大量数据,借助多线程,优化的Web浏览器和许多其他性能调整选项,Content Grabber将比任何其他软件更快,更可靠地提取。我们强大的测试和调试功能可以帮助您构建可靠的代理,可靠的错误处理和错误恢复将使代理在最困难的情况下运行。
建立数百种网页抓取代理
“ Content Crawler”代理编辑器的易用性和可视化使其适合于构建数百个Web爬网代理,比使用任何其他软件要快得多。
代理编辑器将自动检测和配置所需的命令。它会自动创建内容和链接列表,处理分页和Web表单,下载或上传文件,并配置您在网页上执行的任何其他操作。同时,您始终可以手动微调这些命令,因此“内容抓取器”为您提供了简单性和控制性。
有数百个Web爬网程序,您需要正确的工具来管理这些工具,并且爬网内容不会使您失望。您可以查看所有代理的状态和日志,也可以在集中位置运行和安排代理。
净刮除剂的使用费分配免费
构建免版税,自收录的Web爬网代理,该代理可以在没有“内容爬网程序”软件的情况下在任何地方运行。独立代理是一个简单的可执行文件,可以随时随地发送或复制,并具有丰富的配置选项。您可以自由出售或赠送独立代理商,也可以在代理商的用户界面中添加促销信息和广告。
使用脚本自定义所有内容
脚本是“内容获取器”不可或缺的一部分,可用于需要某些特殊功能才能完全根据您的需要完成所有操作的情况下使用。使用内置脚本编辑器,或使用Content Grabber和Visual Studio的集成来实现更强大的脚本编辑和调试功能。
使用API构建独特的解决方案
将Web抓取功能添加到您自己的桌面应用程序中,并免费分发应用程序的Content Grabber运行时。根据需要使用专用的内容采集器Web API来构建Web应用程序并直接从网站执行Web抓取代理。
系统要求
在安装内容采集器之前,请确保您满足这些要求。
Windows 7/8/10 / 2008R2 / 2012 / 2012R2
.NET v4.5(如果您的计算机尚未安装,则会自动安装。)
安装步骤
1、从本站点提供的百度网站下载该软件,并将其解压缩后,双击“ setup.exe”程序
2、如果计算机上未安装Microsoft .NET版本,安装程序将显示Microsoft .NET版本4.5许可协议,并将自动为您安装
3、接受许可协议并安装
4、按照提示在安装向导中进行安装 查看全部
Web内容采集器Content Grabber Premium v2.48
Content Grabber Premium破解版是用于Web爬网和Web自动化的Web内容采集工具。它可以按照您选择的格式从几乎所有网站中提取内容(包括Excel报告,XML,CSV和大多数数据库),并将其另存为结构化数据,欢迎有需要的朋友下载和使用。
基本介绍
Content Grabber Premium(Web内容采集器)一种由外国神灵制作的人工制品,可以从网页中获取内容(视频,图片,文本)并将其提取到Excel,XML,CSV和大多数基于Web的数据库中抓取和网络自动化。它是完全免费的,并且经常用于数据调查和测试目的。
功能介绍
价格比较门户/移动应用程序
-数据摘要
-合作列表(例如房屋止赎,工作委员会,旅游景点)
-新闻和内容汇总
-搜索引擎排名
市场情报和监控
-有竞争力的价格
-零售链监控
-社交媒体和品牌监控
-金融与市场研究
-欺诈识别
-知识产权保护
-合规与风险管理
政府解决方案
-及时获取来自世界各地的新闻,事件和意见
-减少数据采集和IT成本
-促进信息共享
-开源情报(OSINT)
内容集成
-内容迁移(即cms/ CRM)
-企业搜索
-传统应用程序集成
B2B集成/流程自动化
-合作伙伴/供应商/客户集成
可扩展性和可靠性
内容采集器针对的是对网络搜寻至关重要的公司,并专注于可伸缩性和可靠性。该网络收录大量数据,借助多线程,优化的Web浏览器和许多其他性能调整选项,Content Grabber将比任何其他软件更快,更可靠地提取。我们强大的测试和调试功能可以帮助您构建可靠的代理,可靠的错误处理和错误恢复将使代理在最困难的情况下运行。
建立数百种网页抓取代理
“ Content Crawler”代理编辑器的易用性和可视化使其适合于构建数百个Web爬网代理,比使用任何其他软件要快得多。
代理编辑器将自动检测和配置所需的命令。它会自动创建内容和链接列表,处理分页和Web表单,下载或上传文件,并配置您在网页上执行的任何其他操作。同时,您始终可以手动微调这些命令,因此“内容抓取器”为您提供了简单性和控制性。
有数百个Web爬网程序,您需要正确的工具来管理这些工具,并且爬网内容不会使您失望。您可以查看所有代理的状态和日志,也可以在集中位置运行和安排代理。
净刮除剂的使用费分配免费
构建免版税,自收录的Web爬网代理,该代理可以在没有“内容爬网程序”软件的情况下在任何地方运行。独立代理是一个简单的可执行文件,可以随时随地发送或复制,并具有丰富的配置选项。您可以自由出售或赠送独立代理商,也可以在代理商的用户界面中添加促销信息和广告。
使用脚本自定义所有内容
脚本是“内容获取器”不可或缺的一部分,可用于需要某些特殊功能才能完全根据您的需要完成所有操作的情况下使用。使用内置脚本编辑器,或使用Content Grabber和Visual Studio的集成来实现更强大的脚本编辑和调试功能。
使用API构建独特的解决方案
将Web抓取功能添加到您自己的桌面应用程序中,并免费分发应用程序的Content Grabber运行时。根据需要使用专用的内容采集器Web API来构建Web应用程序并直接从网站执行Web抓取代理。
系统要求
在安装内容采集器之前,请确保您满足这些要求。
Windows 7/8/10 / 2008R2 / 2012 / 2012R2
.NET v4.5(如果您的计算机尚未安装,则会自动安装。)
安装步骤
1、从本站点提供的百度网站下载该软件,并将其解压缩后,双击“ setup.exe”程序
2、如果计算机上未安装Microsoft .NET版本,安装程序将显示Microsoft .NET版本4.5许可协议,并将自动为您安装
3、接受许可协议并安装
4、按照提示在安装向导中进行安装
最新版本:WEB数据采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 267 次浏览 • 2020-11-12 08:01
B WEB数据采集系统一.概述面对Internet上的大量信息,政府机构,企事业单位和研究机构都渴望获得与其工作有关的有价值的信息,以及如何获得这些信息。这些信息方便快捷地变得至关重要。如果使用原创的手动采集方法,则将很耗时,费力且效率低下。面对越来越多的信息资源,劳动强度和困难可想而知。因此,现代政府和企业迫切需要一种能够提供高质量,高效运行信息的解决方案采集。该系统针对不同行业用户的应用需求,旨在捕获Internet,并实现了在用户定义的规则下可以从Internet捕获指定信息。捕获的信息可以存储在数据库中或直接发送到指定的列,以实现网站信息的及时更新和数据量的增加,从而增加搜索引擎收录的数量并扩大公司信息的推广。二.典型应用1.政府机构实时跟踪,采集与业务相关的信息来源。 充分满足内部人员对全球互联网信息观察的需求。 及时解决政务外网和政务内网的信息源问题,实现动态发布。 快速解决地方政府领导网站的信息获取需求。 全面整合信息,实现跨区域,跨部门的信息资源共享和政府内部的有效沟通。 节省人力,物力和信息时间采集,并提高办公效率。2.企业实时,准确地监视和跟踪竞争对手的动态是企业获取竞争情报的有力工具。
及时获取竞争对手的公共信息,以研究同一行业的发展和市场需求。 为企业决策部门和管理人员提供方便,多渠道的企业战略决策工具。 实质性提高企业获取和利用智能的效率,节省智能信息采集,存储和挖掘的相关费用,是提高企业核心竞争力的关键。 提升公司的整体分析研究能力,快速的市场反应能力,建立以知识管理为核心的“竞争情报数据仓库”,是提高公司核心竞争力的神经中心。3.新闻媒体快速准确地自动采集计数信息。 支持每天有效抓取上万条新闻。 支持智能提取和查看所需内容。 实现Internet信息内容采集,浏览,编辑,管理和发布的集成。三.。系统架构工作流程描述采集的目的是将另一方网站上的网页上的某些文本或图片下载到您的网站。此过程需要进行以下配置工作:下载网页配置,分析网页配置,修改结果配置和数据输出配置。如果数据符合您的要求,则可以省略校正结果的步骤。配置完成后,将配置形成一个任务(该任务以XML格式描述),采集系统根据该任务的描述开始工作,最后将采集的结果存储在网站服务器。工作流程图如下:数据处理逻辑图:四.系统功能根据用户预先配置的规则(网页下载规则,网页解析规则等),处理数据采集。当对方的网站数据被更新或添加了新数据时,系统将自动检测它,执行采集,然后更新为自己的数据... 查看全部
WEB数据采集系统
B WEB数据采集系统一.概述面对Internet上的大量信息,政府机构,企事业单位和研究机构都渴望获得与其工作有关的有价值的信息,以及如何获得这些信息。这些信息方便快捷地变得至关重要。如果使用原创的手动采集方法,则将很耗时,费力且效率低下。面对越来越多的信息资源,劳动强度和困难可想而知。因此,现代政府和企业迫切需要一种能够提供高质量,高效运行信息的解决方案采集。该系统针对不同行业用户的应用需求,旨在捕获Internet,并实现了在用户定义的规则下可以从Internet捕获指定信息。捕获的信息可以存储在数据库中或直接发送到指定的列,以实现网站信息的及时更新和数据量的增加,从而增加搜索引擎收录的数量并扩大公司信息的推广。二.典型应用1.政府机构实时跟踪,采集与业务相关的信息来源。 充分满足内部人员对全球互联网信息观察的需求。 及时解决政务外网和政务内网的信息源问题,实现动态发布。 快速解决地方政府领导网站的信息获取需求。 全面整合信息,实现跨区域,跨部门的信息资源共享和政府内部的有效沟通。 节省人力,物力和信息时间采集,并提高办公效率。2.企业实时,准确地监视和跟踪竞争对手的动态是企业获取竞争情报的有力工具。
及时获取竞争对手的公共信息,以研究同一行业的发展和市场需求。 为企业决策部门和管理人员提供方便,多渠道的企业战略决策工具。 实质性提高企业获取和利用智能的效率,节省智能信息采集,存储和挖掘的相关费用,是提高企业核心竞争力的关键。 提升公司的整体分析研究能力,快速的市场反应能力,建立以知识管理为核心的“竞争情报数据仓库”,是提高公司核心竞争力的神经中心。3.新闻媒体快速准确地自动采集计数信息。 支持每天有效抓取上万条新闻。 支持智能提取和查看所需内容。 实现Internet信息内容采集,浏览,编辑,管理和发布的集成。三.。系统架构工作流程描述采集的目的是将另一方网站上的网页上的某些文本或图片下载到您的网站。此过程需要进行以下配置工作:下载网页配置,分析网页配置,修改结果配置和数据输出配置。如果数据符合您的要求,则可以省略校正结果的步骤。配置完成后,将配置形成一个任务(该任务以XML格式描述),采集系统根据该任务的描述开始工作,最后将采集的结果存储在网站服务器。工作流程图如下:数据处理逻辑图:四.系统功能根据用户预先配置的规则(网页下载规则,网页解析规则等),处理数据采集。当对方的网站数据被更新或添加了新数据时,系统将自动检测它,执行采集,然后更新为自己的数据...
直观:数据采集系统有哪几种采集方式,各自有什么特点
采集交流 • 优采云 发表了文章 • 0 个评论 • 512 次浏览 • 2020-10-13 09:01
编辑器总结了几种常用数据采集技术供您参考,它们主要分为以下几类:一、CS软件数据采集技术。 C / S体系结构软件属于较旧的体系结构,并且能够支持采集这样的软件数据的产品很少。最常见的机器人是Bowei Xiaobang软件机器人,它基于“您所见即所得”采集界面上的数据,而无需软件供应商的合作。输出结果是结构化数据库或excel表。如果仅需要业务数据,或者制造商破产,并且数据库分析困难,则可以使用此工具来处理采集数据,尤其是明细页数据的采集功能。值得一提的是,使用该产品的门槛非常低,没有IT背景的商科学生也可以使用它,这极大地扩大了用户群体。二、Web数据采集 API。通过网络爬虫和平台提供的某些网站公共API(例如Twitter和Sina Wei)Web API)和其他方法从网站获取数据。这样,可以从网页中提取非结构化数据和半结构化数据的网页数据。互联网网页大数据采集的总体处理过程包括四个两个主要模块:Web采集器(Spider),数据处理(DataProcess),搜寻URL队列(URLQueue)和数据。三、数据库方法两个系统都有自己的数据库,对于相同类型的数据库更方便:[K24]如果两个数据库位于同一服务器上,只要正确设置用户名,它们就可以直接互相访问。您需要在from之后输入数据库名称和表的架构所有者。 select * fromDATABASE1.dbo.table12)如果两个系统的数据库不在同一服务器上,建议连接到服务器进行处理,或者使用openset和opendatasource。这需要外围服务器配置才能进行数据库访问。不同类型的数据库之间的连接更加麻烦,并且需要进行许多设置才能生效,因此在此不再赘述。开放数据库方法需要与各种软件供应商协调以打开数据库,这是非常困难的。如果平台必须连接许多软件制造商的数据库,并且要实时获取数据,这对于平台本身的性能也是一个巨大的挑战。 查看全部
data采集系统有多少种采集方法,它们的特点是什么?
编辑器总结了几种常用数据采集技术供您参考,它们主要分为以下几类:一、CS软件数据采集技术。 C / S体系结构软件属于较旧的体系结构,并且能够支持采集这样的软件数据的产品很少。最常见的机器人是Bowei Xiaobang软件机器人,它基于“您所见即所得”采集界面上的数据,而无需软件供应商的合作。输出结果是结构化数据库或excel表。如果仅需要业务数据,或者制造商破产,并且数据库分析困难,则可以使用此工具来处理采集数据,尤其是明细页数据的采集功能。值得一提的是,使用该产品的门槛非常低,没有IT背景的商科学生也可以使用它,这极大地扩大了用户群体。二、Web数据采集 API。通过网络爬虫和平台提供的某些网站公共API(例如Twitter和Sina Wei)Web API)和其他方法从网站获取数据。这样,可以从网页中提取非结构化数据和半结构化数据的网页数据。互联网网页大数据采集的总体处理过程包括四个两个主要模块:Web采集器(Spider),数据处理(DataProcess),搜寻URL队列(URLQueue)和数据。三、数据库方法两个系统都有自己的数据库,对于相同类型的数据库更方便:[K24]如果两个数据库位于同一服务器上,只要正确设置用户名,它们就可以直接互相访问。您需要在from之后输入数据库名称和表的架构所有者。 select * fromDATABASE1.dbo.table12)如果两个系统的数据库不在同一服务器上,建议连接到服务器进行处理,或者使用openset和opendatasource。这需要外围服务器配置才能进行数据库访问。不同类型的数据库之间的连接更加麻烦,并且需要进行许多设置才能生效,因此在此不再赘述。开放数据库方法需要与各种软件供应商协调以打开数据库,这是非常困难的。如果平台必须连接许多软件制造商的数据库,并且要实时获取数据,这对于平台本身的性能也是一个巨大的挑战。
完美:各大企业都在用的数据采集配置,轻松日采数据千亿条
采集交流 • 优采云 发表了文章 • 0 个评论 • 314 次浏览 • 2020-09-19 12:01
本文介绍了根据我多年的行业经验在巨人的肩膀上开发的data 采集应用程序,这就是我们通常所说的履带系统。说到系统,它不是一个单独的采集器脚本,而是一整套自动化的内容采集。因为我尝试了许多构建此系统的方法,所以这里是最简单,易于实现和共享的最佳内容。现在,每个主要的日常数据相关企业都基本采用了此数据采集技术,该技术简单,快速且实用。这是基于Python的产品设计和应用的简要说明。
编程语言:Python
使用框架:Scrapy,Gerapy
数据仓库:Mongodb
其他内容:IP池
简短地讨论一般业务流程。
安排数据爬网的目录并将其分类为文件。
根据文档编写Scrapy采集器脚本。
在Gerapy中部署Scrapy脚本并进行相关设置以实现24小时自动化采集。
对应中会有一些问题。
如何确定抓取的网站失败了?
如何使用IP池?
在部署过程中的任何时候都会遇到各种坑。
以后如何使用捕获的数据?
对于使用中的各种问题,请检查我的技术文章。这里我们仅介绍业务流程和功能使用。
靠近主题,开始就是内容
组织数据采集文档
如果您使用傻瓜式方式而不是穷举的方式进行采集,则此步骤是不可避免的。它是组织我们要爬网的目标页面。根据Scrapy捕获的格式要求进行组织。
例如,例如《新华网》和《人民日报在线》,此网站页实际上很多,并且由于该页的CSS不同,因此对其进行分类很令人讨厌,但您只能使用它完成一次之后。
Spider下与脚本名称相对应的py文件以记录形式组织。 查看全部
所有主要企业使用的数据采集配置,每天轻松采集数千亿个数据
本文介绍了根据我多年的行业经验在巨人的肩膀上开发的data 采集应用程序,这就是我们通常所说的履带系统。说到系统,它不是一个单独的采集器脚本,而是一整套自动化的内容采集。因为我尝试了许多构建此系统的方法,所以这里是最简单,易于实现和共享的最佳内容。现在,每个主要的日常数据相关企业都基本采用了此数据采集技术,该技术简单,快速且实用。这是基于Python的产品设计和应用的简要说明。
编程语言:Python
使用框架:Scrapy,Gerapy
数据仓库:Mongodb
其他内容:IP池
简短地讨论一般业务流程。
安排数据爬网的目录并将其分类为文件。
根据文档编写Scrapy采集器脚本。
在Gerapy中部署Scrapy脚本并进行相关设置以实现24小时自动化采集。
对应中会有一些问题。
如何确定抓取的网站失败了?
如何使用IP池?
在部署过程中的任何时候都会遇到各种坑。
以后如何使用捕获的数据?
对于使用中的各种问题,请检查我的技术文章。这里我们仅介绍业务流程和功能使用。
靠近主题,开始就是内容
组织数据采集文档
如果您使用傻瓜式方式而不是穷举的方式进行采集,则此步骤是不可避免的。它是组织我们要爬网的目标页面。根据Scrapy捕获的格式要求进行组织。
例如,例如《新华网》和《人民日报在线》,此网站页实际上很多,并且由于该页的CSS不同,因此对其进行分类很令人讨厌,但您只能使用它完成一次之后。
Spider下与脚本名称相对应的py文件以记录形式组织。
解读:如何设计一个内容推荐系统?
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2020-09-01 09:54
传输: 用户的兴趣采集越快越好,以便可以将特定用户的操作快速反馈到下一个建议,因此需要稳定的传输和更新日志,但是出于成本考虑,用户配置文件并非所有都可以实时更新. 有些可能会延迟1小时,有些可能每天更新一次,每周更新一次,甚至更长.
挖掘: 此过程是将用户数据计算并挖掘到我们想要的功能中(通常称为“用户个人资料”,在行业中通常称为用户个人资料). 用户挖掘通常需要与算法结合,而不是凭空挖掘特征. 没有算法应用程序就很棒的用户头像也不值钱.
存储: 用户的兴趣在一段时间内不会有太大变化,因此可以使用用户的长期行为来积累用户肖像,并且需要存储这些配置文件. 如果用户数量很大,那么所需的存储资源也很大,那么就需要一个可以以分布式方式存储大量数据的数据库,并且它必须可靠且便宜,例如hdfs(Hadoop Distributed文件系统),如果您想进行实时计算用户兴趣需要一个可以快速访问的数据库(例如Redis),因此对于微博和头条等公司来说,购买服务器也是一大笔开支.
当然,用户的兴趣不是一成不变的,因此用户的兴趣需要随着时间的流逝而“衰减”. 设置合理的衰减系数对于用户配置文件也非常重要.
此外,用户行为挖掘还存在另一个历史问题-用户冷启动. 我们需要在此主题文章上另开篇文章.
四种排序算法
在前三个步骤中收录内容和用户数据时,可以在第四步中使用该算法来匹配两者. 个性化推荐的本质是进行前N名排名,该排名通常包括两个模块: “召回”和“排名”. 例如,如果我有100,000条消息,但是用户每天只能看到10条消息,那么我应该向用户推荐10条消息?我可以将100,000个项目从10,000到100,000进行分类,因此,无论用户希望看到多少个项目,我都只需从已排序的10,000个项目中从前到后进行选择. 这个过程是“排序”;但是这种排序方法在实时索引上的计算量太大,可能带来高延迟,因此我们首先使用一种相对简单的方法从100,000个中选择相对可靠的1,000个,然后对1,000个进行排序,然后选择100,000个. 10,000个过程是“召回”.
算法中有很多方法. 您可以参考官方帐户上发布的文章,其中详细介绍了推荐系统中常用的最有效算法. 另外,无论哪种算法在内容推荐之后都需要使用“动态指标”(例如ctr),如何在推荐之前获得该动态指标?此处涉及的内容的冷启动将在以后另行讨论.
5. 推荐的搜索引擎
为什么有搜索引擎?是的,您没有记错. 实际上,个性化推荐和搜索是非常相似的领域. 两者都是信息筛选方法,并且都在做一种“相关性”等级,并且目标函数非常接近(点击率). 只是搜索更加关注用户当前搜索关键字的相关性,而推荐则更加关注内容和用户个人资料的相关性. 每次用户浏览时,这都是实时请求. 因此,有必要实时地计算出最能满足用户兴趣的内容. 此步骤由在线搜索引擎执行. 但是,由于性能要求,联机索引步骤不应太耗时. 通常,排序算法会计算初始结果,而在线引擎会进行算法调度和规范化排序. 此外,在线索引还将负责接收请求,输出数据并公开服务,例如单击删除通常负责对业务和产品要求进行次要排名(例如插入广告,分解相同类型的内容等). ).
VI. ABtest系统
尽管ABtest系统不是个性化推荐系统的必要模块,但是没有ABtest的推荐系统必须是伪造的推荐系统!推荐系统的优化实际上是y = f(x),y是目标函数. 首先,目标函数必须非常清晰且可量化的指标; f(x)是选择的算法,算法特征参数和算法调度实际上,业界一直采用如此多的有效算法,而算法原理却很少. 但是,如何结合您自己的产品方案选择功能和参数已成为个性化推荐准确性的关键因素. 如果有一个ABtest系统,那么我们可以尝试引入各种参数和功能,并且ABtest实验将获得最佳y,以便可以迭代和优化推荐系统.
当然,算法的优化并不像更改参数那样简单. 推荐者需要对数据非常敏感,并且能够将复杂的问题抽象为可量化的指标,然后结合ABtest实验来快速进行迭代. 我总结的算法优化过程是: “数据分析发现问题,合理的假设,设计实验,实现,数据分析,并得出结论或新的假设. ”更改参数只是“实现”步骤,也是最简单的步骤. 大多数人通常只关注“实现”,而很少关注分析和假设的过程. 这种优化的效果无法保证,某些产品和技术人员会陷入盲目的ABtest的误解,漫无目的地尝试,经常进行ABtest并发现AB组数据没有差异,甚至认为ABtest是效率低下. 这些分析思想打开了算法工程师之间的鸿沟.
摘要
通过这6个部分,已构建了完整的个性化推荐系统. 整个系统包括算法工程师,自然语言处理/图像处理工程师,服务器工程师/架构师,数据挖掘工程师以及数据分析师,产品经理还需要大量标签审阅者,内容操作人员以及前端和客户端技术支持. 因此,构建良好的个性化推荐系统相对昂贵,但有时我们不需要该系统. 一些简单的规则可能会实现相对个性化并提高用户效率(例如,将用户最近浏览的商品放在首位),因此提高效率的思想和方法最为重要,这是我们需要讨论的问题很久了. 查看全部
如何设计内容推荐系统?
传输: 用户的兴趣采集越快越好,以便可以将特定用户的操作快速反馈到下一个建议,因此需要稳定的传输和更新日志,但是出于成本考虑,用户配置文件并非所有都可以实时更新. 有些可能会延迟1小时,有些可能每天更新一次,每周更新一次,甚至更长.
挖掘: 此过程是将用户数据计算并挖掘到我们想要的功能中(通常称为“用户个人资料”,在行业中通常称为用户个人资料). 用户挖掘通常需要与算法结合,而不是凭空挖掘特征. 没有算法应用程序就很棒的用户头像也不值钱.
存储: 用户的兴趣在一段时间内不会有太大变化,因此可以使用用户的长期行为来积累用户肖像,并且需要存储这些配置文件. 如果用户数量很大,那么所需的存储资源也很大,那么就需要一个可以以分布式方式存储大量数据的数据库,并且它必须可靠且便宜,例如hdfs(Hadoop Distributed文件系统),如果您想进行实时计算用户兴趣需要一个可以快速访问的数据库(例如Redis),因此对于微博和头条等公司来说,购买服务器也是一大笔开支.
当然,用户的兴趣不是一成不变的,因此用户的兴趣需要随着时间的流逝而“衰减”. 设置合理的衰减系数对于用户配置文件也非常重要.
此外,用户行为挖掘还存在另一个历史问题-用户冷启动. 我们需要在此主题文章上另开篇文章.
四种排序算法
在前三个步骤中收录内容和用户数据时,可以在第四步中使用该算法来匹配两者. 个性化推荐的本质是进行前N名排名,该排名通常包括两个模块: “召回”和“排名”. 例如,如果我有100,000条消息,但是用户每天只能看到10条消息,那么我应该向用户推荐10条消息?我可以将100,000个项目从10,000到100,000进行分类,因此,无论用户希望看到多少个项目,我都只需从已排序的10,000个项目中从前到后进行选择. 这个过程是“排序”;但是这种排序方法在实时索引上的计算量太大,可能带来高延迟,因此我们首先使用一种相对简单的方法从100,000个中选择相对可靠的1,000个,然后对1,000个进行排序,然后选择100,000个. 10,000个过程是“召回”.
算法中有很多方法. 您可以参考官方帐户上发布的文章,其中详细介绍了推荐系统中常用的最有效算法. 另外,无论哪种算法在内容推荐之后都需要使用“动态指标”(例如ctr),如何在推荐之前获得该动态指标?此处涉及的内容的冷启动将在以后另行讨论.
5. 推荐的搜索引擎
为什么有搜索引擎?是的,您没有记错. 实际上,个性化推荐和搜索是非常相似的领域. 两者都是信息筛选方法,并且都在做一种“相关性”等级,并且目标函数非常接近(点击率). 只是搜索更加关注用户当前搜索关键字的相关性,而推荐则更加关注内容和用户个人资料的相关性. 每次用户浏览时,这都是实时请求. 因此,有必要实时地计算出最能满足用户兴趣的内容. 此步骤由在线搜索引擎执行. 但是,由于性能要求,联机索引步骤不应太耗时. 通常,排序算法会计算初始结果,而在线引擎会进行算法调度和规范化排序. 此外,在线索引还将负责接收请求,输出数据并公开服务,例如单击删除通常负责对业务和产品要求进行次要排名(例如插入广告,分解相同类型的内容等). ).
VI. ABtest系统
尽管ABtest系统不是个性化推荐系统的必要模块,但是没有ABtest的推荐系统必须是伪造的推荐系统!推荐系统的优化实际上是y = f(x),y是目标函数. 首先,目标函数必须非常清晰且可量化的指标; f(x)是选择的算法,算法特征参数和算法调度实际上,业界一直采用如此多的有效算法,而算法原理却很少. 但是,如何结合您自己的产品方案选择功能和参数已成为个性化推荐准确性的关键因素. 如果有一个ABtest系统,那么我们可以尝试引入各种参数和功能,并且ABtest实验将获得最佳y,以便可以迭代和优化推荐系统.
当然,算法的优化并不像更改参数那样简单. 推荐者需要对数据非常敏感,并且能够将复杂的问题抽象为可量化的指标,然后结合ABtest实验来快速进行迭代. 我总结的算法优化过程是: “数据分析发现问题,合理的假设,设计实验,实现,数据分析,并得出结论或新的假设. ”更改参数只是“实现”步骤,也是最简单的步骤. 大多数人通常只关注“实现”,而很少关注分析和假设的过程. 这种优化的效果无法保证,某些产品和技术人员会陷入盲目的ABtest的误解,漫无目的地尝试,经常进行ABtest并发现AB组数据没有差异,甚至认为ABtest是效率低下. 这些分析思想打开了算法工程师之间的鸿沟.
摘要
通过这6个部分,已构建了完整的个性化推荐系统. 整个系统包括算法工程师,自然语言处理/图像处理工程师,服务器工程师/架构师,数据挖掘工程师以及数据分析师,产品经理还需要大量标签审阅者,内容操作人员以及前端和客户端技术支持. 因此,构建良好的个性化推荐系统相对昂贵,但有时我们不需要该系统. 一些简单的规则可能会实现相对个性化并提高用户效率(例如,将用户最近浏览的商品放在首位),因此提高效率的思想和方法最为重要,这是我们需要讨论的问题很久了.
基于BBS内容安全监管的数据采集系统的设计与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 283 次浏览 • 2020-08-29 18:20
计算机科学20 0 6V 0 1. 33N _ o . 9 ( 专辑)基于B B S 内容安全监管的数据采集系统的设计与实现李艳玲戴冠中朱烨行( 西j也工业大学自动化学院南京7 10 0 7 2)摘襄针对不良信息对网路空间的侵袭, 给社会带来的害处, 本文提出了B B S 内容安全篮管系统结构模型, 对嚣申的数据采集系统进行了诺细设诗与实现, 并通过系统的实际运行证明, 该系统可以为B B S 的实时监控提供有效的数据支持。美键溺B 骼, 悫容安全监蟹, 数据采集1序言随着网路应角的普及, 阏络已成为信息转播的主要载体。 其中, B B S 等网路峰会成为网民参与讨论、 表达意见的主要场所。 网络空间本身具有的容量, 为信息的频繁、 大量发布与复制提供了可能, 某些别有用心的人很容易提升个别不良信息( 包括反共、 谣言、 暴力、 色情等信息)的报导频度和硬度, 弓l起人们对这种信息的关注, 给正常的社会秩序注入不稳定诱因, 某些憾况下, 甚至可熊弓l发突发事件。嚣此, 需要赜8蹒进行监控与管理, 及时掌援阏络虚拟世界中的热点话题, 为政府揣度民情和民声, 做出科学的决策, 采取糨应的播旖键进有益的趋势稻防止现实化学世界中可能出现的不良后果提供支持。
本文提出了B B S 内容安全监管系统结构模型,对其中的数据采集系统进行了详尽设计与实现。2 B B S 内容安全监管系统结构模型图1B B s内容安全监管系统结构模型9 1B B S 内容安全监管系统结构模型如图1所示。整个系统分为四个层次, 数据采集层负责采集监管须要的数据, 内容剖析层负责对内容的安全检查、 预测剖析等, 研讨层把人脑中的知识同系统中的有关信息结合上去, 扩展专家和计算机的能力, 从而提出对复杂问题的解决方案, 输出层是处理结果。人机接口{ }任务管理器j【主题I燃集器JLS蠡心№合山_ 一飞页面孥器}=跟踪数据整理器她lIl虚拟社联挖掘I内'攀库J鬯本!容b点掣掘f薪陋赢删黍图2数据采集系统构架3数据采集系统构架数据采集系统构架如图2所示, 主要包括五个功能模块: 任务管理器、 数据采集器、 页面处理器、 数据整理模块和主题跟踪器, 各模块通过任务管理器,在操作员的调度下, 完成内容安全剖析等须要数据的手动采集。 尽量做到数据的自动化处理, 即数据采集过程对用户是透明的, 但须要用户可以通过窗口对其监视, 或下达停止、 添加任务等命令。其中, 任务管理器主要负责工作任务的设置、 添加、 删除及运行状况的查看等, 工作任务包括数据采集的运行时间、 周期设置、 目标站点的设置、 目标主题的设置等, 由操作员通过人机插口下达; 数据采集器按照任务管理器下达的任务, 到指定的目标峰会采集数据, 生成待处理贴子的H T M I. 页面的U R I。队列, 送入文件集合。 页面处理器主要负责对采集到的页面进行剖析处理, 提取... 查看全部
基于BBS内容安全监管的数据采集系统的设计与实现
计算机科学20 0 6V 0 1. 33N _ o . 9 ( 专辑)基于B B S 内容安全监管的数据采集系统的设计与实现李艳玲戴冠中朱烨行( 西j也工业大学自动化学院南京7 10 0 7 2)摘襄针对不良信息对网路空间的侵袭, 给社会带来的害处, 本文提出了B B S 内容安全篮管系统结构模型, 对嚣申的数据采集系统进行了诺细设诗与实现, 并通过系统的实际运行证明, 该系统可以为B B S 的实时监控提供有效的数据支持。美键溺B 骼, 悫容安全监蟹, 数据采集1序言随着网路应角的普及, 阏络已成为信息转播的主要载体。 其中, B B S 等网路峰会成为网民参与讨论、 表达意见的主要场所。 网络空间本身具有的容量, 为信息的频繁、 大量发布与复制提供了可能, 某些别有用心的人很容易提升个别不良信息( 包括反共、 谣言、 暴力、 色情等信息)的报导频度和硬度, 弓l起人们对这种信息的关注, 给正常的社会秩序注入不稳定诱因, 某些憾况下, 甚至可熊弓l发突发事件。嚣此, 需要赜8蹒进行监控与管理, 及时掌援阏络虚拟世界中的热点话题, 为政府揣度民情和民声, 做出科学的决策, 采取糨应的播旖键进有益的趋势稻防止现实化学世界中可能出现的不良后果提供支持。
本文提出了B B S 内容安全监管系统结构模型,对其中的数据采集系统进行了详尽设计与实现。2 B B S 内容安全监管系统结构模型图1B B s内容安全监管系统结构模型9 1B B S 内容安全监管系统结构模型如图1所示。整个系统分为四个层次, 数据采集层负责采集监管须要的数据, 内容剖析层负责对内容的安全检查、 预测剖析等, 研讨层把人脑中的知识同系统中的有关信息结合上去, 扩展专家和计算机的能力, 从而提出对复杂问题的解决方案, 输出层是处理结果。人机接口{ }任务管理器j【主题I燃集器JLS蠡心№合山_ 一飞页面孥器}=跟踪数据整理器她lIl虚拟社联挖掘I内'攀库J鬯本!容b点掣掘f薪陋赢删黍图2数据采集系统构架3数据采集系统构架数据采集系统构架如图2所示, 主要包括五个功能模块: 任务管理器、 数据采集器、 页面处理器、 数据整理模块和主题跟踪器, 各模块通过任务管理器,在操作员的调度下, 完成内容安全剖析等须要数据的手动采集。 尽量做到数据的自动化处理, 即数据采集过程对用户是透明的, 但须要用户可以通过窗口对其监视, 或下达停止、 添加任务等命令。其中, 任务管理器主要负责工作任务的设置、 添加、 删除及运行状况的查看等, 工作任务包括数据采集的运行时间、 周期设置、 目标站点的设置、 目标主题的设置等, 由操作员通过人机插口下达; 数据采集器按照任务管理器下达的任务, 到指定的目标峰会采集数据, 生成待处理贴子的H T M I. 页面的U R I。队列, 送入文件集合。 页面处理器主要负责对采集到的页面进行剖析处理, 提取...
捷豹淘宝采集助手 v1.0官方版
采集交流 • 优采云 发表了文章 • 0 个评论 • 453 次浏览 • 2020-08-29 15:01
捷豹淘宝采集助手是一款专为电商用户的构建的采集软件,能够帮助用户快速采集闲鱼网上所有店面内商品的信息,信息资源更新快,系统24小时手动采集。内容精准详尽,多项店面信息。
基本简介
捷豹淘宝采集助手是一款就能帮助使用者快速采集闲鱼网上所有店面内商品的信息,让您更精准、更快速的找到理想中的数据!
功能介绍
1、操作简单,搜索速度快。(本软件使用云采集技术,10分钟即可采集实时更新数据1000条以上,最多比市面上其他软件快20倍!)
2、软件可以采集到店面名称、旺旺名、商品名,价格、销量、地区、旺旺注册时间等。
3、直接点击【开始采集】即可。
4、软件操作的界面人性化的选项开始、停止。
5、采集完成后可以选择不同格式,不同的数组导入想要的数据。
6、点击店面链接可以查看更详尽的店面信息。
7、信息资源更新快,系统24小时手动采集。
8、无人工干预,软件手动采集,让顾客更放心。
9、内容精准详尽,多项店面信息。
10、软件自行过滤重复数据。
常见问题
启动时报错
请先安装.net4.0再运行本程序 →→点击下载NET4.0 ←←
点读取数据没反应
一.在压缩包里运行可能会出现这样的问题,请先解压再运行
二.电脑的的时间不对,改成正确的时间
三.软件不支持 XP系统,请更换成win7及以上的操作系统 查看全部
捷豹淘宝采集助手 v1.0官方版
捷豹淘宝采集助手是一款专为电商用户的构建的采集软件,能够帮助用户快速采集闲鱼网上所有店面内商品的信息,信息资源更新快,系统24小时手动采集。内容精准详尽,多项店面信息。
基本简介
捷豹淘宝采集助手是一款就能帮助使用者快速采集闲鱼网上所有店面内商品的信息,让您更精准、更快速的找到理想中的数据!
功能介绍
1、操作简单,搜索速度快。(本软件使用云采集技术,10分钟即可采集实时更新数据1000条以上,最多比市面上其他软件快20倍!)
2、软件可以采集到店面名称、旺旺名、商品名,价格、销量、地区、旺旺注册时间等。
3、直接点击【开始采集】即可。
4、软件操作的界面人性化的选项开始、停止。
5、采集完成后可以选择不同格式,不同的数组导入想要的数据。
6、点击店面链接可以查看更详尽的店面信息。
7、信息资源更新快,系统24小时手动采集。
8、无人工干预,软件手动采集,让顾客更放心。
9、内容精准详尽,多项店面信息。
10、软件自行过滤重复数据。
常见问题
启动时报错
请先安装.net4.0再运行本程序 →→点击下载NET4.0 ←←
点读取数据没反应
一.在压缩包里运行可能会出现这样的问题,请先解压再运行
二.电脑的的时间不对,改成正确的时间
三.软件不支持 XP系统,请更换成win7及以上的操作系统
推荐系统之数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 579 次浏览 • 2020-08-28 05:56
对于做推荐系统或则是策略相关的产品朋友最难的是哪些?是没有数据的支撑。没有数据就没有办法建立用户画像、标签体系;没有办法进行数据统计、指标剖析、AB 实验疗效验证。那么问题来了,数据从哪儿来。这一篇文章就介绍推荐系统中容易使人忽略,又极为重要,又相当多坑的一个环节——数据采集。
信息流数据采集完整流程
在之家推荐、画像、标签相关的产品总监有数据需求的时侯就会先和数据产品沟通,当然若果公司职位没有分得那么细的话,往往推荐产品或是画像的产品总监要自己去走完这整个流程,这一个流程走出来,就会对数据的完整流转相当的熟悉,当然也是一个心筛的过程,各种坑等着你。接下来我就依照这个流程重点介绍数据采集的全流程,普通页面的数据采集知乎上好多文章介绍,无非就是根据标准的sdk或js进行采集 我们这儿的重点是推荐信息流的数据采集,是以信息流的产品形态为根本出发点。
数据需求梳理
数据需求来源比较广,可以说假如是中台部门,各种各样的数据需求就会提及这儿上去,如营销、画像、算法、推广、标签等等,那么在考虑到各个具体需求时,既要要建立灵活的数据埋点上报规范,又满足现有需求,为将来可能会出现的需求留出扩充的空间。
埋点规范制订
信息流的埋点一般遵守以下的原则:
以恳求爆光风波埋点为例说明
定义:当用户刷新时,客户端恳求推荐插口获取推荐内容。 事件id:recm_req_show 统一风波id的整体格式,各推荐位置以recm_id进行分辨 请求爆光内容格式:一次恳求上报一条日志,收录此次恳求的推荐位置id:recm_id;请求惟一标示:pvid;内容列表itemlist,各推荐位置须要统一上报的内容格式。
请求爆光风波上报数据示例
也许有的朋友可能不明白里面的参数是哪些意思,为什么如此设计,我在这里解释一下里面规范示例中各参数的意义和作用。但你们牢记各信息流产品形态的参数须要依照实际业务来进行调整和定义。
推荐位id分配
埋点施行注意事项
上面大约介大致介绍了一下该规范的内容,还有三点在埋点施行过程中要注意的:
1.必须明晰风波上报的条件
比如恳求爆光,就要求在恳求成功后立刻上报;可见爆光则要求在爆光页面逗留超过一定的时长,这个问题在之家最早的规范中没有明晰,每次就会有开发朋友问,什么时候上报。
2.必须明晰每一个数组参数从哪些地方取
刚才前面介绍的参数,对于埋点朋友比较郁闷的时侯,找不到这种数从哪里取,或者是害怕取错,埋点一旦弄错,后面的数据统计,画像、标签都是错的,所以这个地方产品总监一定得和埋点同事确认清楚每一个参数的正确取数位置。
3.必须明晰数据的格式
数据格式的确认,主要是为了数据上报后,数仓同事对日志进行处理时才能高效、便捷,如果出现各种各样的格式,这里多个冒号,那里多个空格,这些非标准格式她们都得去处理,耗费时间和精力。
埋点初验
埋点初验主要是三点:
验收是否要所有推荐位都有数据上报 上报的参数是否有所有遗漏 上报的数据格式是否和规范要求一致
数据应用
当埋点完备、上报的数据经过数仓处理后,接下来就是数据的各类应用了。
数据统计
数据统计是最重要最基础的应用,特别是对于推荐系统最重要的一个指标CTR,用点击/可见爆光来进行估算。如果没有点击风波和可见爆光风波的埋点,这个数据就不可能形成,那么推荐系统的疗效就很难从量化指标上进行评估。
用户画像
因为在每条物料透传下来的stra扩充参数中,会带有表征物料的特点,以用户主动发生的行为风波为纽带,将物料的特点传递到用户头上,这个特点就是用户画像中的某个偏好。
以之家为例——如果数据采集到某用户近日点击的物料中较高频度出现某车系,那么这个车系都会成为该用户画像中其短期兴趣车系,就可以根据此车系推荐相关的内容,并估算该车系的相像车系或是竞品车系推荐给用户,关于用户画像的详尽介绍可以看下边这篇文章:
龚旭东:推荐系统之用户画像
还有其他数据应用场景就不再这儿一一介绍了,有兴趣的你们可以单独沟通
总结
说一下埋点这个工作的实际情况。以我的真实经历,埋点不是个技术活,也不难,需要的是耐心,细心,这个工作再怎样做也不会非常的出彩,所以大部分产品都不乐意干这个活,总会推来推去,最后搞得稀里糊涂,但是假如埋点做不好,上层的应用就做不好。说得不好听的,现如今互联网产品假如数据都搞不对,可以说基本就是死,所以建议这块儿还是专人负责。 查看全部
推荐系统之数据采集
对于做推荐系统或则是策略相关的产品朋友最难的是哪些?是没有数据的支撑。没有数据就没有办法建立用户画像、标签体系;没有办法进行数据统计、指标剖析、AB 实验疗效验证。那么问题来了,数据从哪儿来。这一篇文章就介绍推荐系统中容易使人忽略,又极为重要,又相当多坑的一个环节——数据采集。
信息流数据采集完整流程
在之家推荐、画像、标签相关的产品总监有数据需求的时侯就会先和数据产品沟通,当然若果公司职位没有分得那么细的话,往往推荐产品或是画像的产品总监要自己去走完这整个流程,这一个流程走出来,就会对数据的完整流转相当的熟悉,当然也是一个心筛的过程,各种坑等着你。接下来我就依照这个流程重点介绍数据采集的全流程,普通页面的数据采集知乎上好多文章介绍,无非就是根据标准的sdk或js进行采集 我们这儿的重点是推荐信息流的数据采集,是以信息流的产品形态为根本出发点。
数据需求梳理
数据需求来源比较广,可以说假如是中台部门,各种各样的数据需求就会提及这儿上去,如营销、画像、算法、推广、标签等等,那么在考虑到各个具体需求时,既要要建立灵活的数据埋点上报规范,又满足现有需求,为将来可能会出现的需求留出扩充的空间。
埋点规范制订
信息流的埋点一般遵守以下的原则:
以恳求爆光风波埋点为例说明
定义:当用户刷新时,客户端恳求推荐插口获取推荐内容。 事件id:recm_req_show 统一风波id的整体格式,各推荐位置以recm_id进行分辨 请求爆光内容格式:一次恳求上报一条日志,收录此次恳求的推荐位置id:recm_id;请求惟一标示:pvid;内容列表itemlist,各推荐位置须要统一上报的内容格式。
请求爆光风波上报数据示例
也许有的朋友可能不明白里面的参数是哪些意思,为什么如此设计,我在这里解释一下里面规范示例中各参数的意义和作用。但你们牢记各信息流产品形态的参数须要依照实际业务来进行调整和定义。
推荐位id分配
埋点施行注意事项
上面大约介大致介绍了一下该规范的内容,还有三点在埋点施行过程中要注意的:
1.必须明晰风波上报的条件
比如恳求爆光,就要求在恳求成功后立刻上报;可见爆光则要求在爆光页面逗留超过一定的时长,这个问题在之家最早的规范中没有明晰,每次就会有开发朋友问,什么时候上报。
2.必须明晰每一个数组参数从哪些地方取
刚才前面介绍的参数,对于埋点朋友比较郁闷的时侯,找不到这种数从哪里取,或者是害怕取错,埋点一旦弄错,后面的数据统计,画像、标签都是错的,所以这个地方产品总监一定得和埋点同事确认清楚每一个参数的正确取数位置。
3.必须明晰数据的格式
数据格式的确认,主要是为了数据上报后,数仓同事对日志进行处理时才能高效、便捷,如果出现各种各样的格式,这里多个冒号,那里多个空格,这些非标准格式她们都得去处理,耗费时间和精力。
埋点初验
埋点初验主要是三点:
验收是否要所有推荐位都有数据上报 上报的参数是否有所有遗漏 上报的数据格式是否和规范要求一致
数据应用
当埋点完备、上报的数据经过数仓处理后,接下来就是数据的各类应用了。
数据统计
数据统计是最重要最基础的应用,特别是对于推荐系统最重要的一个指标CTR,用点击/可见爆光来进行估算。如果没有点击风波和可见爆光风波的埋点,这个数据就不可能形成,那么推荐系统的疗效就很难从量化指标上进行评估。
用户画像
因为在每条物料透传下来的stra扩充参数中,会带有表征物料的特点,以用户主动发生的行为风波为纽带,将物料的特点传递到用户头上,这个特点就是用户画像中的某个偏好。
以之家为例——如果数据采集到某用户近日点击的物料中较高频度出现某车系,那么这个车系都会成为该用户画像中其短期兴趣车系,就可以根据此车系推荐相关的内容,并估算该车系的相像车系或是竞品车系推荐给用户,关于用户画像的详尽介绍可以看下边这篇文章:
龚旭东:推荐系统之用户画像
还有其他数据应用场景就不再这儿一一介绍了,有兴趣的你们可以单独沟通
总结
说一下埋点这个工作的实际情况。以我的真实经历,埋点不是个技术活,也不难,需要的是耐心,细心,这个工作再怎样做也不会非常的出彩,所以大部分产品都不乐意干这个活,总会推来推去,最后搞得稀里糊涂,但是假如埋点做不好,上层的应用就做不好。说得不好听的,现如今互联网产品假如数据都搞不对,可以说基本就是死,所以建议这块儿还是专人负责。
YGBOOK小说采集系统 php版 v1.4 下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 276 次浏览 • 2020-08-26 01:27
YGBOOK小说内容管理系统(以下简称YGBOOK)提供一个轻量级小说网站解决方案,基于ThinkPHP+MySQL的技术开发。
YGBOOK是介于CMS和扒手网站之间的一款新型网站系统,批量采集目标网站数据,并进行数据入库。不仅URL完全不同,模板不同,数据也属于自己,完全为解放站长右手,只需搭建好网站,即可手动采集+自动更新。
本软件以SEO性能极好的笔趣阁模板为基础,进行了大量优化,呈送给你们一款SEO优秀,不失美观大方的小说网站系统。
YGBOOK免费版本提供了基础小说功能,包括:
1.全手动采集2345导航小说的数据,内置采集规则,无需自己设置管理
2.数据入库,不必担忧目标站改版或死掉
3.网站本身进提供小说简介和章节列表的展示,章节阅读采用跳转到原站模式,以规避版权问题
4.自带伪静态功能,但未能自由订制,无手机版本、无站内搜索、无sitemap、无结构化数据
YGBOOK基于ThinkPHP+MYSQL开发,可以在大部分常见的服务器上运行。
如windows服务器,IIS+PHP+MYSQL,
Linux服务器,Apache/Nginx+PHP+MYSQL
强烈推荐使用Linux服务器,可以发挥更大性能优势
软件方面,PHP要求5.3版本以上,低于5.3版本未能运行。
硬件方面,一般配置的虚拟主机即可正常运行本系统,如果有服务器会更好。
伪静态配置参见压缩包中txt文件,针对不同环境的有不同配置说明(自带.htacess文件重新优化了兼容性,解决了apache+nts模式下可能出现的“No input file specified.”问题)
安装步骤:
1.将文件解压后上传至相应目录等
2.网站必须配置好伪静态(参考上一步配置),才能正常进行安装和使用(初次访问首页会手动步入安装页面,或自动输入//www.域名.com/install)
3.同意使用合同步入下一步检查目录权限
4.检测通过后,填写常规数据库配置项,填写正确即可安装成功,安装成功后会手动步入后台页面//www.域名.com/admin,填写安装时输入的后台管理员和密码即可登入
5.在后台文章列表页面,可以进行自动采集文章,和批量采集文章数据。初次安装完毕建议采集一些数据填充网站内容。网站在运行过程中,会手动执行采集操作(需前台访问触发,蜘蛛亦可触发采集),无须人工干预。
YGBOOK小说采集系统 更新日志:
v1.4
增加了百度sitemap功能
安装1.4版本后,您的sitemap地址即为“//您的域名/home/sitemap/baidu.xml”
您将域名替换成自己的域名后,访问查看无误,即可递交到百度站长平台
利于百度蜘蛛的爬取 查看全部
YGBOOK小说采集系统 php版 v1.4 下载
YGBOOK小说内容管理系统(以下简称YGBOOK)提供一个轻量级小说网站解决方案,基于ThinkPHP+MySQL的技术开发。
YGBOOK是介于CMS和扒手网站之间的一款新型网站系统,批量采集目标网站数据,并进行数据入库。不仅URL完全不同,模板不同,数据也属于自己,完全为解放站长右手,只需搭建好网站,即可手动采集+自动更新。
本软件以SEO性能极好的笔趣阁模板为基础,进行了大量优化,呈送给你们一款SEO优秀,不失美观大方的小说网站系统。
YGBOOK免费版本提供了基础小说功能,包括:
1.全手动采集2345导航小说的数据,内置采集规则,无需自己设置管理
2.数据入库,不必担忧目标站改版或死掉
3.网站本身进提供小说简介和章节列表的展示,章节阅读采用跳转到原站模式,以规避版权问题
4.自带伪静态功能,但未能自由订制,无手机版本、无站内搜索、无sitemap、无结构化数据
YGBOOK基于ThinkPHP+MYSQL开发,可以在大部分常见的服务器上运行。
如windows服务器,IIS+PHP+MYSQL,
Linux服务器,Apache/Nginx+PHP+MYSQL
强烈推荐使用Linux服务器,可以发挥更大性能优势
软件方面,PHP要求5.3版本以上,低于5.3版本未能运行。
硬件方面,一般配置的虚拟主机即可正常运行本系统,如果有服务器会更好。
伪静态配置参见压缩包中txt文件,针对不同环境的有不同配置说明(自带.htacess文件重新优化了兼容性,解决了apache+nts模式下可能出现的“No input file specified.”问题)
安装步骤:
1.将文件解压后上传至相应目录等
2.网站必须配置好伪静态(参考上一步配置),才能正常进行安装和使用(初次访问首页会手动步入安装页面,或自动输入//www.域名.com/install)
3.同意使用合同步入下一步检查目录权限
4.检测通过后,填写常规数据库配置项,填写正确即可安装成功,安装成功后会手动步入后台页面//www.域名.com/admin,填写安装时输入的后台管理员和密码即可登入
5.在后台文章列表页面,可以进行自动采集文章,和批量采集文章数据。初次安装完毕建议采集一些数据填充网站内容。网站在运行过程中,会手动执行采集操作(需前台访问触发,蜘蛛亦可触发采集),无须人工干预。
YGBOOK小说采集系统 更新日志:
v1.4
增加了百度sitemap功能
安装1.4版本后,您的sitemap地址即为“//您的域名/home/sitemap/baidu.xml”
您将域名替换成自己的域名后,访问查看无误,即可递交到百度站长平台
利于百度蜘蛛的爬取
《PHP的数据采集》PPT课件.ppt
采集交流 • 优采云 发表了文章 • 0 个评论 • 324 次浏览 • 2020-08-23 01:10
《《PHP的数据采集》PPT课件.ppt》由会员分享,可在线阅读,更多相关《《PHP的数据采集》PPT课件.ppt(29页珍藏版)》请在人人文库网上搜索。
1、PHP动态网页设计教程,六、PHP的数据采集,黄迎久 内蒙古科技大学工程训练中心,主要内容,本讲主要内容 (1)浏览器端数据的递交方法; (2)绝对路径和相对路径的概念; (3)使用实现浏览器端的数据采集方法;,一、浏览器端数据的递交方法,浏览器向WEB服务器某PHP程序发送一个“请求”,该PHP程序接收到该“请求”后,接受所有“请求”数据,然后对这种“请求”数据进行处理,WEB服务器将处理结果作为“响应”返回给浏览器。 浏览器向WEB服务器递交数据的方法GET递交方法和POST递交方法。,一、浏览器端数据的递交方法,1、GET递交方法 GET递交方法是将“请求”数据以查询字符串(Query 。
2、String)的形式附在URL以后“提交”数据。 如 http//localhost/2/register.phpusernamejohnpassword1234 查询字符串中 “”表示查询字符串的开始,“”之后的字符串参数为查询字符串,可以收录多个查询字符串,每个参数以“参数名参数值”的格式定义。,一、浏览器端数据的递交方法,2、POST递交方法 POST数据递交方法通常通过表单实现,默认的情况下表单的数据递交方法为GET方法,因此,必须在表单的标签中加入”post”将数据递交方法更改为POST方法。,一、浏览器端数据的递交方法,3、GET和POST混和递交方法 使用表单可以实现GET和PO。
3、ST混和递交方法,向WEB服务器发出GET恳求的同时,还向该PHP程序发出“POST恳求”。, register.php 程序如下 ,一、浏览器端数据的递交方法,4、两种方法的比较 (1)POST递交方法比GET方法递交方法安全。在例如“注册”、“登录”等系统,不建议使用GET递交方法。 (2)POST递交方法可以递交更多的数据。如“新闻发布系统”中递交篇幅较长的新闻信息时,不建议使用GET递交方法;带有“文件上传功能”的表单必须使用POST递交方法。,二、相对路径与绝对路径,1、绝对路径 “绝对路径”是一个完整的URL,该URL是由以下两部份组成 (1)Scheme拿来描述找寻数据所采用的机。
4、制(协议),如http、ftp等。 (2)位置(location)用来描述到哪儿去找寻数据的资源。这部份使用“//”分隔,例如。 绝对路径无论出现在那里,都代表相同的内容,因此,绝对路径一般在访问系统外部资源时才使用,而访问内部资源时通常使用相对路径。,二、相对路径与绝对路径,2、相对路径 “相对路径”在不同的地方代表的内容是不同的。,例如一个完整的电话号码是“区位号”“电话号码”。以南京为例,0371-66666666是一个在中国境内的“绝对路径”。而到了成都后,只需拨通“66666666”即可,此时“66666666”就是一个“相对路径”。,例如当前目录“c/web/www/6/”中有in。
5、dex.html文件,使用超链接访问该目录下的register.php文件,只需在链接中指定到register.php文件的相对路径即可。 ,二、相对路径与绝对路径,3、相对路径其他概念 (1)同一文件夹下的资源访问 若文件1和文件2在同一目录中,这两个文件的互相访问直接使用文件名即可。 例如a.html和b.php两个文件在同一文件夹下,a.html页面的访问b.php文件时,a.html页面的表单可以这样写 . ,二、相对路径与绝对路径,3、相对路径其他概念 (2)如何表示当前目录 “.”表示文件的当前目录。若a.html和b.php文件在同一目录中,a.html页面的表单访问b.php文。
6、件时,a.html页面的表单写为 . ,二、相对路径与绝对路径,3、相对路径其他概念 (3)如何表示上级目录 “../”表示文件所在目录的上一级目录, “../../”表示文件所在目录的上上级目录。,(4)如何表示下级目录 若文件1访问下级目录中的文件2,直接指定该目录和文件2的文件名即可。 若a.html文件坐落cwwwweb”,b.php文件坐落cwwwwebtest”,则a.html页面的表单访问b.php页面时,a.html页面的表单写为 ,三、使用表单实现浏览器端的数据采集,表单由3部份构成 1表单标签 定义了表单处理程序及数据递交方法等信息; 2表单控件包括文本框、单选钮、复选框及。
7、文件上传等表单控件; 3表单按键包括递交、重置和通常按键;,三、使用表单实现浏览器端的数据采集,1、表单标签 表单标签常用的属性有action、、enctype、title、name等。 1 action设置当前表单数据“提交”的目的地址;当不设置action属性或属性值为空action“”时,表单数据递交给当前页面; 2设置表单数据的“提交”方式。属性值为GET或POST; 3title设置表单数据的提示信息。当用户的键盘表针在表单处逗留时,浏览器用一个红色的小鱼漂显示提示文本。 4enctype设置递交表单数据时的编码方法。属性值为multipart/-data,或 application。
8、/x-www--urlencoded。当一个表单存在文件上传框时,必须将enctype设置为multipart/for-data编码方法。,三、使用表单实现浏览器端的数据采集,2、表单控件 1 文本框 *单行文本框通常拿来输入单行的文字,如姓名、地址等; *密码框一般拿来输入密码,输入的文字会被“*”代替; *多行文本框拿来输入内容较多的文字,如留言、个人简历等; 示例,三、使用表单实现浏览器端的数据采集,2、表单控件 2 隐藏域 隐藏域用于保存一些特定信息,对于浏览器用户来说,隐藏是看不见。但在表单递交时,隐藏域的name属性和value组成的信息将被发送给WEB服务器。 ,三、使用表单实现。
9、浏览器端的数据采集,2、表单控件 3 复选框 用来为浏览器用户提供一系列选项进行选择。 * value定义复选框的值; *checked定义初始状态下该复选框被选中;,例如 音乐 游戏 电影,三、使用表单实现浏览器端的数据采集,2、表单控件 4 单选框 用来为浏览器用户提供一个选项进行选择。 * value定义单选钮的值; *checked定义初始状态下该单选钮被选中; 注一组单选钮中只能有一项被选中;不同的name为不同组别;,例如 音乐 游戏 电影,三、使用表单实现浏览器端的数据采集,2、表单控件 5 文件上传框 浏览器用户可以使用文件上传框来选择上传的文件;表单递交时,该上传的文件名将与。
10、其他表单数据一起递交。 * size定义文件上传框的长度; *maxlength定义文件上传框最多输入的字符数; 注每位上传框只能选择一个文件;使用上传框时,表单标签的enctype属性必须设置为multipart/-data,属性必须设置为“post”提交形式。,例如 ,三、使用表单实现浏览器端的数据采集,2、表单控件 6 下拉选择框 分为单选和多选。单选式容许用户在一系列下拉选项中选择一个选项;多选式容许用户在一系列下拉选项中选择多个选项。, * size定义下拉框的高度,默认为1; *multiple定义下拉框是多项式还是多选式;,三、使用表单实现浏览器端的数据采集,2、表单控件 6 下。
11、拉选择框。,三、使用表单实现浏览器端的数据采集,3、表单按键 表单按键分为“提交按键”、“图像递交按键”、“重置按键” 。 “提交按键”和“图像递交按键”用于递交表单数据; “重置按键”用于将表单数据恢复至初始状态;,1 提交按键 ,* name定义递交按键的名称; * value定义递交按键上的显示文字; 例如 ,三、使用表单实现浏览器端的数据采集,3、表单按键 2 图像递交按键 * src图象的路径;,例如 ,3重置按键 例如 ,三、使用表单实现浏览器端的数据采集,4、表单综合应用 创建比如右图的表单,三、使用表单实现浏览器端的数据采集,5、使用_GET和_POST“采集”表单数据 当浏览。
12、器以”GET”方式递交数据时,服务器端PHP程序应该使用预定义变量_GET“采集”提交数据; 当浏览器以”POST”方式递交数据时,服务器端PHP程序应该使用预定义变量_POST“采集”提交数据;,例如上例的register.php程序 ,三、使用表单实现浏览器端的数据采集,6、 WEB服务器端其他数据采集方法 1 预定义变量 _REQUEST 使用_REQUEST既可以采集GET方法递交的URL程序字符串中的参数信息,也可以采集表单POST方法递交的参数信息。 之前程序使用_POST或_G优采云采集器的参数信息都可以换成使用_REQUEST采集。,例如上例的register.php程序 ,三、使。
13、用表单实现浏览器端的数据采集,6、 WEB服务器端其他数据采集方法 2 预定义变量 _SERVER 使用_SERVER可以得到浏览器端和服务器端主机的一些信息。,* _SERVER“REMOTE_ADDR”定义了浏览器端主机的IP地址; * _SERVER“SERVER_ADDR”定义了服务器端主机的IP地址; * _SERVER“PHP_SELF”定义了当前执行程序的文件名; * _SERVER“QUERY_STRING”定义了URL的查询字符串; * _SERVER“DOCUMENT_ROOT”定义了WEB服务器主目录; * _SERVER“REQUEST_RUI”定义了除域名外的其余URL部份;,本讲总结,本讲总结 1 掌握GET与POST递交数据的方式; 2 掌握表单控件的使用方式; 3 掌握_GET与_POST“采集”数据的使用方式; 4 掌握_REQUEST“采集”数据的使用方式; 5 了解_SERVER的使用方式;,Thank You ,内蒙古科技大学 工程训练中心,*** 次数1357533 已用完,请联系开发者***。 查看全部
《PHP的数据采集》PPT课件.ppt
《《PHP的数据采集》PPT课件.ppt》由会员分享,可在线阅读,更多相关《《PHP的数据采集》PPT课件.ppt(29页珍藏版)》请在人人文库网上搜索。
1、PHP动态网页设计教程,六、PHP的数据采集,黄迎久 内蒙古科技大学工程训练中心,主要内容,本讲主要内容 (1)浏览器端数据的递交方法; (2)绝对路径和相对路径的概念; (3)使用实现浏览器端的数据采集方法;,一、浏览器端数据的递交方法,浏览器向WEB服务器某PHP程序发送一个“请求”,该PHP程序接收到该“请求”后,接受所有“请求”数据,然后对这种“请求”数据进行处理,WEB服务器将处理结果作为“响应”返回给浏览器。 浏览器向WEB服务器递交数据的方法GET递交方法和POST递交方法。,一、浏览器端数据的递交方法,1、GET递交方法 GET递交方法是将“请求”数据以查询字符串(Query 。
2、String)的形式附在URL以后“提交”数据。 如 http//localhost/2/register.phpusernamejohnpassword1234 查询字符串中 “”表示查询字符串的开始,“”之后的字符串参数为查询字符串,可以收录多个查询字符串,每个参数以“参数名参数值”的格式定义。,一、浏览器端数据的递交方法,2、POST递交方法 POST数据递交方法通常通过表单实现,默认的情况下表单的数据递交方法为GET方法,因此,必须在表单的标签中加入”post”将数据递交方法更改为POST方法。,一、浏览器端数据的递交方法,3、GET和POST混和递交方法 使用表单可以实现GET和PO。
3、ST混和递交方法,向WEB服务器发出GET恳求的同时,还向该PHP程序发出“POST恳求”。, register.php 程序如下 ,一、浏览器端数据的递交方法,4、两种方法的比较 (1)POST递交方法比GET方法递交方法安全。在例如“注册”、“登录”等系统,不建议使用GET递交方法。 (2)POST递交方法可以递交更多的数据。如“新闻发布系统”中递交篇幅较长的新闻信息时,不建议使用GET递交方法;带有“文件上传功能”的表单必须使用POST递交方法。,二、相对路径与绝对路径,1、绝对路径 “绝对路径”是一个完整的URL,该URL是由以下两部份组成 (1)Scheme拿来描述找寻数据所采用的机。
4、制(协议),如http、ftp等。 (2)位置(location)用来描述到哪儿去找寻数据的资源。这部份使用“//”分隔,例如。 绝对路径无论出现在那里,都代表相同的内容,因此,绝对路径一般在访问系统外部资源时才使用,而访问内部资源时通常使用相对路径。,二、相对路径与绝对路径,2、相对路径 “相对路径”在不同的地方代表的内容是不同的。,例如一个完整的电话号码是“区位号”“电话号码”。以南京为例,0371-66666666是一个在中国境内的“绝对路径”。而到了成都后,只需拨通“66666666”即可,此时“66666666”就是一个“相对路径”。,例如当前目录“c/web/www/6/”中有in。
5、dex.html文件,使用超链接访问该目录下的register.php文件,只需在链接中指定到register.php文件的相对路径即可。 ,二、相对路径与绝对路径,3、相对路径其他概念 (1)同一文件夹下的资源访问 若文件1和文件2在同一目录中,这两个文件的互相访问直接使用文件名即可。 例如a.html和b.php两个文件在同一文件夹下,a.html页面的访问b.php文件时,a.html页面的表单可以这样写 . ,二、相对路径与绝对路径,3、相对路径其他概念 (2)如何表示当前目录 “.”表示文件的当前目录。若a.html和b.php文件在同一目录中,a.html页面的表单访问b.php文。
6、件时,a.html页面的表单写为 . ,二、相对路径与绝对路径,3、相对路径其他概念 (3)如何表示上级目录 “../”表示文件所在目录的上一级目录, “../../”表示文件所在目录的上上级目录。,(4)如何表示下级目录 若文件1访问下级目录中的文件2,直接指定该目录和文件2的文件名即可。 若a.html文件坐落cwwwweb”,b.php文件坐落cwwwwebtest”,则a.html页面的表单访问b.php页面时,a.html页面的表单写为 ,三、使用表单实现浏览器端的数据采集,表单由3部份构成 1表单标签 定义了表单处理程序及数据递交方法等信息; 2表单控件包括文本框、单选钮、复选框及。
7、文件上传等表单控件; 3表单按键包括递交、重置和通常按键;,三、使用表单实现浏览器端的数据采集,1、表单标签 表单标签常用的属性有action、、enctype、title、name等。 1 action设置当前表单数据“提交”的目的地址;当不设置action属性或属性值为空action“”时,表单数据递交给当前页面; 2设置表单数据的“提交”方式。属性值为GET或POST; 3title设置表单数据的提示信息。当用户的键盘表针在表单处逗留时,浏览器用一个红色的小鱼漂显示提示文本。 4enctype设置递交表单数据时的编码方法。属性值为multipart/-data,或 application。
8、/x-www--urlencoded。当一个表单存在文件上传框时,必须将enctype设置为multipart/for-data编码方法。,三、使用表单实现浏览器端的数据采集,2、表单控件 1 文本框 *单行文本框通常拿来输入单行的文字,如姓名、地址等; *密码框一般拿来输入密码,输入的文字会被“*”代替; *多行文本框拿来输入内容较多的文字,如留言、个人简历等; 示例,三、使用表单实现浏览器端的数据采集,2、表单控件 2 隐藏域 隐藏域用于保存一些特定信息,对于浏览器用户来说,隐藏是看不见。但在表单递交时,隐藏域的name属性和value组成的信息将被发送给WEB服务器。 ,三、使用表单实现。
9、浏览器端的数据采集,2、表单控件 3 复选框 用来为浏览器用户提供一系列选项进行选择。 * value定义复选框的值; *checked定义初始状态下该复选框被选中;,例如 音乐 游戏 电影,三、使用表单实现浏览器端的数据采集,2、表单控件 4 单选框 用来为浏览器用户提供一个选项进行选择。 * value定义单选钮的值; *checked定义初始状态下该单选钮被选中; 注一组单选钮中只能有一项被选中;不同的name为不同组别;,例如 音乐 游戏 电影,三、使用表单实现浏览器端的数据采集,2、表单控件 5 文件上传框 浏览器用户可以使用文件上传框来选择上传的文件;表单递交时,该上传的文件名将与。
10、其他表单数据一起递交。 * size定义文件上传框的长度; *maxlength定义文件上传框最多输入的字符数; 注每位上传框只能选择一个文件;使用上传框时,表单标签的enctype属性必须设置为multipart/-data,属性必须设置为“post”提交形式。,例如 ,三、使用表单实现浏览器端的数据采集,2、表单控件 6 下拉选择框 分为单选和多选。单选式容许用户在一系列下拉选项中选择一个选项;多选式容许用户在一系列下拉选项中选择多个选项。, * size定义下拉框的高度,默认为1; *multiple定义下拉框是多项式还是多选式;,三、使用表单实现浏览器端的数据采集,2、表单控件 6 下。
11、拉选择框。,三、使用表单实现浏览器端的数据采集,3、表单按键 表单按键分为“提交按键”、“图像递交按键”、“重置按键” 。 “提交按键”和“图像递交按键”用于递交表单数据; “重置按键”用于将表单数据恢复至初始状态;,1 提交按键 ,* name定义递交按键的名称; * value定义递交按键上的显示文字; 例如 ,三、使用表单实现浏览器端的数据采集,3、表单按键 2 图像递交按键 * src图象的路径;,例如 ,3重置按键 例如 ,三、使用表单实现浏览器端的数据采集,4、表单综合应用 创建比如右图的表单,三、使用表单实现浏览器端的数据采集,5、使用_GET和_POST“采集”表单数据 当浏览。
12、器以”GET”方式递交数据时,服务器端PHP程序应该使用预定义变量_GET“采集”提交数据; 当浏览器以”POST”方式递交数据时,服务器端PHP程序应该使用预定义变量_POST“采集”提交数据;,例如上例的register.php程序 ,三、使用表单实现浏览器端的数据采集,6、 WEB服务器端其他数据采集方法 1 预定义变量 _REQUEST 使用_REQUEST既可以采集GET方法递交的URL程序字符串中的参数信息,也可以采集表单POST方法递交的参数信息。 之前程序使用_POST或_G优采云采集器的参数信息都可以换成使用_REQUEST采集。,例如上例的register.php程序 ,三、使。
13、用表单实现浏览器端的数据采集,6、 WEB服务器端其他数据采集方法 2 预定义变量 _SERVER 使用_SERVER可以得到浏览器端和服务器端主机的一些信息。,* _SERVER“REMOTE_ADDR”定义了浏览器端主机的IP地址; * _SERVER“SERVER_ADDR”定义了服务器端主机的IP地址; * _SERVER“PHP_SELF”定义了当前执行程序的文件名; * _SERVER“QUERY_STRING”定义了URL的查询字符串; * _SERVER“DOCUMENT_ROOT”定义了WEB服务器主目录; * _SERVER“REQUEST_RUI”定义了除域名外的其余URL部份;,本讲总结,本讲总结 1 掌握GET与POST递交数据的方式; 2 掌握表单控件的使用方式; 3 掌握_GET与_POST“采集”数据的使用方式; 4 掌握_REQUEST“采集”数据的使用方式; 5 了解_SERVER的使用方式;,Thank You ,内蒙古科技大学 工程训练中心,*** 次数1357533 已用完,请联系开发者***。
原创 【视频】用Excel来录入和管理研究数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2020-08-23 00:38
临床研究中,不少人习惯用Excel作为数据录入和管理软件。当然,Excel有着显著的优势,普及性好、可操作性强、培训成本低...但当采集的变量较多或研究较复杂时,Excel的弊病也突显下来:变量多时,Excel界面呈现太不友好;无法进行嵌套变量的设置;对数据的保护性较差,较易被修改;若对数据进行处理,难以追踪追溯...
下面这个视频中提及的问题,也许你在临床研究工作中也以前遇见过。
有没有更好的代替工具呢?准备举办临床研究的伙伴,尤其是举办多中心研究的研究者们,推荐你使用电子数据采集系统(EDC)。
医咖会经过几年的产品打磨,开发了适宜临床大夫使用且通过了国内外多项数据安全权威认证的“医维云”电子数据采集系统(EDC)。
EDC可以多人协作,同时录入数据并及时发觉和处理数据问题,最大可能追回缺位数据,修正错误数据。EDC系统的录入页面清晰明了、简洁高效,提供丰富多样的系统核查功能(比如必填校准、数据格式输入约束、数值范围校准、日期范围校准、变量间的逻辑校准、条件显示等)。
研究负责人可以实时查看项目进度,实时同步查看最新数据,及时介入管理进度。最重要的是,EDC可导入多种数据集结构和格式,满足不同剖析群体的需求。导出清晰的变量辞典,有助于统计剖析时更容易理解数据。
在使用该EDC系统的同时,医咖会伙伴们还可以给你的研究设计、CRF表设计提供建设性意见,也可以协助你做数据清除和统计剖析! 查看全部
原创 【视频】用Excel来录入和管理研究数据
临床研究中,不少人习惯用Excel作为数据录入和管理软件。当然,Excel有着显著的优势,普及性好、可操作性强、培训成本低...但当采集的变量较多或研究较复杂时,Excel的弊病也突显下来:变量多时,Excel界面呈现太不友好;无法进行嵌套变量的设置;对数据的保护性较差,较易被修改;若对数据进行处理,难以追踪追溯...
下面这个视频中提及的问题,也许你在临床研究工作中也以前遇见过。
有没有更好的代替工具呢?准备举办临床研究的伙伴,尤其是举办多中心研究的研究者们,推荐你使用电子数据采集系统(EDC)。
医咖会经过几年的产品打磨,开发了适宜临床大夫使用且通过了国内外多项数据安全权威认证的“医维云”电子数据采集系统(EDC)。
EDC可以多人协作,同时录入数据并及时发觉和处理数据问题,最大可能追回缺位数据,修正错误数据。EDC系统的录入页面清晰明了、简洁高效,提供丰富多样的系统核查功能(比如必填校准、数据格式输入约束、数值范围校准、日期范围校准、变量间的逻辑校准、条件显示等)。
研究负责人可以实时查看项目进度,实时同步查看最新数据,及时介入管理进度。最重要的是,EDC可导入多种数据集结构和格式,满足不同剖析群体的需求。导出清晰的变量辞典,有助于统计剖析时更容易理解数据。
在使用该EDC系统的同时,医咖会伙伴们还可以给你的研究设计、CRF表设计提供建设性意见,也可以协助你做数据清除和统计剖析!
爬取百万数据的采集系统从零到整的过程
采集交流 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2020-08-22 19:56
记录下在上家公司负责过的一个采集系统从零到整的过程,包括需求,分析,设计,实现,遇到的问题及系统的成效,系统最主要功能就是可以通过对每位网站进行不同的采集规则配置对每位网站爬取数据,目前系统运行稳定,已爬取的数据量大约在600-700万之间(算上一些历史数据,应该也有到千万级了),每天采集的数据增量在一万左右,配置采集的网站1200多个,这个系统似乎并不大,但是作为主要的coding人员(基本整个系统的百分之八十的编码都是我写的),大概记录一下系统的实现,捡主要的内容分享下,最后在提供一些简单的爬虫demo供你们学习下
数据采集系统:一个可以通过配置规则采集不同网站的系统
主要实现目标:
·针对不同的网站通过配置不同的采集规则实现网页数据的爬取
·针对整篇内容可以实现对特点数据的提取
·定时去爬取所有网站的数据
·采集配置规则可维护
·采集入库数据可维护
第一步其实要先剖析需求,所以在抽取一下系统的主要需求:
·针对不同的网站可以通过不同的采集规则实现数据的爬取
·针对整篇内容可以实现对特点数据的提取,特征数据就是指标题,作者,发布时间这些信息
·定时任务关联任务或则任务组去爬取网站的数据
再剖析一下网站的结构,无非就是两种;
基本所有爬取的网站都可以具象成这样。
针对剖析的结果设计实现:
·任务表
o 每个网站可以当作一个任务,去执行采集
·两张规则表
o 每个网站对应自己的采集规则,根据前面剖析的网站结构,采集规则又可以细分为两个表,一个是收录网站链接,获取详情页列表的列表采集规则表,一个针对是网站详情页的特点数据采集的规则表 详情采集规则表
·url表
o 负责记录采集目标网站详情页的url
·定时任务表
o 根据定时任务去定时执行个别任务 (可以采用定时任务和多个任务进行关联,也可以考虑新增一个任务组表,定时任务跟任务组关联,任务组跟任务关联)
·数据储存表
o 这个因为我们采集的数据主要是招标和中标两种数据,分别建了两张表进行数据储存,中标信息表,招标信息表
基础构架就是:ssm+redis+htmlunit+jsoup+es+mq+quartz
java中可以实现爬虫的框架有很多,htmlunit,WebMagic,jsoup等等还有好多优秀的开源框架,当然httpclient也可以实现。
为什么用htmlunit?
htmlunit 是一款开源的java 页面剖析工具,读取页面后,可以有效的使用htmlunit剖析页面上的内容。项目可以模拟浏览器运行,被誉为java浏览器的开源实现
简单说下我对htmlunit的理解:
·一个是htmlunit提供了通过xpath去定位页面元素的功能,利用xpath就可以实现对页面特点数据进行提取;
·第二个就在于对js的支持,支持js意味着你真的可以把它当作一个浏览器,你可以用它模拟点击,输入,登录等操作,而且对于采集而言,支持js就可以解决页面使用ajax获取数据的问题
·当然除此之外,htmlunit还支持代理ip,https,通过配置可以实现模拟微软,火狐等浏览器,Referer,user-agent,是否加载js,css,是否支持ajax等。
XPath句型即为XML路径语言(XML Path Language),它是一种拿来确定XML文档中某部份位置的语言。
为什么用jsoup?
jsoup相较于htmlunit,就在于它提供了一种类似于jquery选择器的定位页面元素的功能,两者可以互补使用。
采集数据逻辑分为两个部份:url采集器,详情页采集器
url采集器:
·只负责采集目标网站的详情页url
详情页采集器:
·根据url去采集目标url的详情页数据
·使用htmlunit的xpath,jsoup的select句型,和正则表达式进行特点数据的采集。
这样设计目的主要是将url采集和详情页的采集流程分开,后续假如须要分拆服务的话就可以将url采集和详情页的采集分成两个服务。
url采集器与详情页采集器之间使用mq进行交互,url采集器采集到url做完处理过后把消息冷到mq队列,详情页采集器去获取数据进行详情页数据的采集。
·在采集url的时侯进行去重
·同过url进行去重,通过在redis储存key为url,缓存时间为3天,这种方法是为了避免对同一个url进行重复采集。
·通过标题进行去重,通过在redis中储存key为采集到的标题 ,缓存时间为3天,这种方法就是为了避免一篇文章被不同网站发布,重复采集情况的发生。
一个简短爬虫的代码实现:
上面的代码就实现了采集一个列表页
·url就是目标网址
·xpath就要采集的数据的xpath了
请求这个url::9001/getData?url=*[@id=post_list]/div/div[2]/h3/a 查看全部
爬取百万数据的采集系统从零到整的过程
记录下在上家公司负责过的一个采集系统从零到整的过程,包括需求,分析,设计,实现,遇到的问题及系统的成效,系统最主要功能就是可以通过对每位网站进行不同的采集规则配置对每位网站爬取数据,目前系统运行稳定,已爬取的数据量大约在600-700万之间(算上一些历史数据,应该也有到千万级了),每天采集的数据增量在一万左右,配置采集的网站1200多个,这个系统似乎并不大,但是作为主要的coding人员(基本整个系统的百分之八十的编码都是我写的),大概记录一下系统的实现,捡主要的内容分享下,最后在提供一些简单的爬虫demo供你们学习下
数据采集系统:一个可以通过配置规则采集不同网站的系统
主要实现目标:
·针对不同的网站通过配置不同的采集规则实现网页数据的爬取
·针对整篇内容可以实现对特点数据的提取
·定时去爬取所有网站的数据
·采集配置规则可维护
·采集入库数据可维护
第一步其实要先剖析需求,所以在抽取一下系统的主要需求:
·针对不同的网站可以通过不同的采集规则实现数据的爬取
·针对整篇内容可以实现对特点数据的提取,特征数据就是指标题,作者,发布时间这些信息
·定时任务关联任务或则任务组去爬取网站的数据
再剖析一下网站的结构,无非就是两种;
基本所有爬取的网站都可以具象成这样。
针对剖析的结果设计实现:
·任务表
o 每个网站可以当作一个任务,去执行采集
·两张规则表
o 每个网站对应自己的采集规则,根据前面剖析的网站结构,采集规则又可以细分为两个表,一个是收录网站链接,获取详情页列表的列表采集规则表,一个针对是网站详情页的特点数据采集的规则表 详情采集规则表
·url表
o 负责记录采集目标网站详情页的url
·定时任务表
o 根据定时任务去定时执行个别任务 (可以采用定时任务和多个任务进行关联,也可以考虑新增一个任务组表,定时任务跟任务组关联,任务组跟任务关联)
·数据储存表
o 这个因为我们采集的数据主要是招标和中标两种数据,分别建了两张表进行数据储存,中标信息表,招标信息表
基础构架就是:ssm+redis+htmlunit+jsoup+es+mq+quartz
java中可以实现爬虫的框架有很多,htmlunit,WebMagic,jsoup等等还有好多优秀的开源框架,当然httpclient也可以实现。
为什么用htmlunit?
htmlunit 是一款开源的java 页面剖析工具,读取页面后,可以有效的使用htmlunit剖析页面上的内容。项目可以模拟浏览器运行,被誉为java浏览器的开源实现
简单说下我对htmlunit的理解:
·一个是htmlunit提供了通过xpath去定位页面元素的功能,利用xpath就可以实现对页面特点数据进行提取;
·第二个就在于对js的支持,支持js意味着你真的可以把它当作一个浏览器,你可以用它模拟点击,输入,登录等操作,而且对于采集而言,支持js就可以解决页面使用ajax获取数据的问题
·当然除此之外,htmlunit还支持代理ip,https,通过配置可以实现模拟微软,火狐等浏览器,Referer,user-agent,是否加载js,css,是否支持ajax等。
XPath句型即为XML路径语言(XML Path Language),它是一种拿来确定XML文档中某部份位置的语言。
为什么用jsoup?
jsoup相较于htmlunit,就在于它提供了一种类似于jquery选择器的定位页面元素的功能,两者可以互补使用。
采集数据逻辑分为两个部份:url采集器,详情页采集器
url采集器:
·只负责采集目标网站的详情页url
详情页采集器:
·根据url去采集目标url的详情页数据
·使用htmlunit的xpath,jsoup的select句型,和正则表达式进行特点数据的采集。
这样设计目的主要是将url采集和详情页的采集流程分开,后续假如须要分拆服务的话就可以将url采集和详情页的采集分成两个服务。
url采集器与详情页采集器之间使用mq进行交互,url采集器采集到url做完处理过后把消息冷到mq队列,详情页采集器去获取数据进行详情页数据的采集。
·在采集url的时侯进行去重
·同过url进行去重,通过在redis储存key为url,缓存时间为3天,这种方法是为了避免对同一个url进行重复采集。
·通过标题进行去重,通过在redis中储存key为采集到的标题 ,缓存时间为3天,这种方法就是为了避免一篇文章被不同网站发布,重复采集情况的发生。
一个简短爬虫的代码实现:
上面的代码就实现了采集一个列表页
·url就是目标网址
·xpath就要采集的数据的xpath了
请求这个url::9001/getData?url=*[@id=post_list]/div/div[2]/h3/a
海量数据挖掘之中联通流量营运系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2020-08-21 05:32
从联通运营商的核心网段中把须要的数据发送到ftp服务器上,然后我们那边都会提供ftp的客户端去采集ftp服务器的数据,然后处理以后过来进行剖析。
三、内容辨识模块
把url经过爬虫之后到辨识系统,分析出网站名,主题,类别,(作者)等
将分类体系导出到数据库中,url json封装的内容信息。
大量的日志不断的形成,然后通过行为轨迹提高,通过一个mapreduce,
如果这个数据匹配到了,则将原创行+内容剖析结果信息(从知识库来的数据)导出到提高日志。如果匹配不到的数据就输出到一个待爬清单中。
识别系统:自然语言处理SVM(实时辨识),人工辨识(人工一条条的去辨识),模板辨识(一个网页的内容的位置通常不会变,用xpath来定位到我们所须要查找的节点)
相信学过xml的应当就会使用xpath了,如果不会的话,可以查阅我这篇文章:
在这个项目中庸xpath来做这个模板匹配:例如
对于一个网页的html页面来说,我们可以这样来匹配其标题,例如我们打开搜狐的html,我们可以看见他的这个网页标题是的,所以我们对于这类网站就可以用xpath来定位这个title在那里,然后去获取这title节点中内容
souhu.com
movie_name
/path/.../
当然了,使用xpath和xml去做这些模板匹配有一定的局限性,适用于一个结构十分清晰的网页,例如视频、小说、音乐等,对于那个奇奇怪怪的网友就不适用了。
所以总的来说,对于内容辨识要采用多种方法去做,不要局限于一种,不同类型的网站最好有不同的解决方案。
我们使用自然语言处理来进行剖析的时侯还有问题就是,一个网页的内容太多了,svm剖析有时候不能完全的辨识到我们想要的内容,就像一条新闻,本来这个新闻的主标题才是中国网页的主要内容,而使用自然语言处理系统的话它可能会把新闻下边的广告读成了这个网页的主要内容了,所以这样的话都会有偏差了。当然咯,自然语言剖析还是很有用,那么为了更精确的辨识照料好网页的内容如何办呢。好吧,那当然是最传统的人工读取了,由帅气的实习生们把这种网页一条条的浏览,然后记录这个网页的主要内容!(好吧,不要震惊
,移动就是那么干的)。然后读取大约10万个网页,这样的话就产生了一个规则库,这个就比自然语言处理和模板匹配的结果愈发精确了。
四、知识库url选购
两个知识库,一个规则库(人工剖析的),还有一个实例库(自动剖析系统)。
先把url进行规则剖析,如果有则输出,没有没有则放在实例库,如果实例库也没有了,就放在待爬清单中。
先拿1T的样本数据,然后网址按流量汇总排序下来,总流量的前80%,总条数10万条。
因为只要选购下来就可以了,不需要实时在运行的,所以只要一个job就可以了。
这里我们主要领到一个url和总流量来进行剖析和处理,其他更为复杂的情况这儿就不分享了哦。
我们首先可以在eclipse总新建一个jav工程,导入各类hadoop/lib下边的jar包,或者直接新建一个mapRedecer工程也可以。
新建一个bean类:记得要承继一个Comparable插口。
package cn.tf.kpi;
public class FlowBean implements Comparable{
private String url;
private long upflow;
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public long getUpflow() {
return upflow;
}
public void setUpflow(long upflow) {
this.upflow = upflow;
}
public FlowBean(String url, long upflow) {
super();
this.url = url;
this.upflow = upflow;
}
public FlowBean() {
super();
}
@Override
public int compareTo(FlowBean o) {
return (int) (o.getUpflow() - this.upflow) ;
}
@Override
public String toString() {
return "FlowBean [url=" + url + ", upflow=" + upflow + "]";
}
}
然后写主方式:
其实这儿和我之前写的那种用户流量剖析系统有很多类似的地方。
<p>package cn.tf.kpi;
import java.io.IOException;
import java.util.TreeSet;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import cn.tf.kpi.TopURL.TopURLMapper.TopURlReducer;
public class TopURL {
public static class TopURLMapper extends
Mapper {
private Text k = new Text();
private LongWritable v = new LongWritable();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] fields = StringUtils.split(line, "\t");
try {
String url = fields[26];
long upFlow = Long.parseLong(fields[30]);
k.set(url);
v.set(upFlow);
context.write(k, v);
} catch (Exception e) {
e.printStackTrace();
}
}
public static class TopURlReducer extends
Reducer {
private Text k = new Text();
private LongWritable v = new LongWritable();
TreeSet urls = new TreeSet();
//全局流量和
long globalFlowSum =0;
@Override
protected void reduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException {
long count = 0;
for (LongWritable v : values) {
count += v.get();
}
globalFlowSum +=count;
FlowBean bean = new FlowBean(key.toString(), count);
urls.add(bean);
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
long tempSum=0;
for(FlowBean bean:urls){
//取前80%的
if(tempSum/globalFlowSum 查看全部
海量数据挖掘之中联通流量营运系统
从联通运营商的核心网段中把须要的数据发送到ftp服务器上,然后我们那边都会提供ftp的客户端去采集ftp服务器的数据,然后处理以后过来进行剖析。
三、内容辨识模块
把url经过爬虫之后到辨识系统,分析出网站名,主题,类别,(作者)等
将分类体系导出到数据库中,url json封装的内容信息。
大量的日志不断的形成,然后通过行为轨迹提高,通过一个mapreduce,
如果这个数据匹配到了,则将原创行+内容剖析结果信息(从知识库来的数据)导出到提高日志。如果匹配不到的数据就输出到一个待爬清单中。
识别系统:自然语言处理SVM(实时辨识),人工辨识(人工一条条的去辨识),模板辨识(一个网页的内容的位置通常不会变,用xpath来定位到我们所须要查找的节点)
相信学过xml的应当就会使用xpath了,如果不会的话,可以查阅我这篇文章:
在这个项目中庸xpath来做这个模板匹配:例如
对于一个网页的html页面来说,我们可以这样来匹配其标题,例如我们打开搜狐的html,我们可以看见他的这个网页标题是的,所以我们对于这类网站就可以用xpath来定位这个title在那里,然后去获取这title节点中内容
souhu.com
movie_name
/path/.../
当然了,使用xpath和xml去做这些模板匹配有一定的局限性,适用于一个结构十分清晰的网页,例如视频、小说、音乐等,对于那个奇奇怪怪的网友就不适用了。
所以总的来说,对于内容辨识要采用多种方法去做,不要局限于一种,不同类型的网站最好有不同的解决方案。
我们使用自然语言处理来进行剖析的时侯还有问题就是,一个网页的内容太多了,svm剖析有时候不能完全的辨识到我们想要的内容,就像一条新闻,本来这个新闻的主标题才是中国网页的主要内容,而使用自然语言处理系统的话它可能会把新闻下边的广告读成了这个网页的主要内容了,所以这样的话都会有偏差了。当然咯,自然语言剖析还是很有用,那么为了更精确的辨识照料好网页的内容如何办呢。好吧,那当然是最传统的人工读取了,由帅气的实习生们把这种网页一条条的浏览,然后记录这个网页的主要内容!(好吧,不要震惊
,移动就是那么干的)。然后读取大约10万个网页,这样的话就产生了一个规则库,这个就比自然语言处理和模板匹配的结果愈发精确了。
四、知识库url选购
两个知识库,一个规则库(人工剖析的),还有一个实例库(自动剖析系统)。
先把url进行规则剖析,如果有则输出,没有没有则放在实例库,如果实例库也没有了,就放在待爬清单中。
先拿1T的样本数据,然后网址按流量汇总排序下来,总流量的前80%,总条数10万条。
因为只要选购下来就可以了,不需要实时在运行的,所以只要一个job就可以了。
这里我们主要领到一个url和总流量来进行剖析和处理,其他更为复杂的情况这儿就不分享了哦。
我们首先可以在eclipse总新建一个jav工程,导入各类hadoop/lib下边的jar包,或者直接新建一个mapRedecer工程也可以。
新建一个bean类:记得要承继一个Comparable插口。
package cn.tf.kpi;
public class FlowBean implements Comparable{
private String url;
private long upflow;
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public long getUpflow() {
return upflow;
}
public void setUpflow(long upflow) {
this.upflow = upflow;
}
public FlowBean(String url, long upflow) {
super();
this.url = url;
this.upflow = upflow;
}
public FlowBean() {
super();
}
@Override
public int compareTo(FlowBean o) {
return (int) (o.getUpflow() - this.upflow) ;
}
@Override
public String toString() {
return "FlowBean [url=" + url + ", upflow=" + upflow + "]";
}
}
然后写主方式:
其实这儿和我之前写的那种用户流量剖析系统有很多类似的地方。
<p>package cn.tf.kpi;
import java.io.IOException;
import java.util.TreeSet;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import cn.tf.kpi.TopURL.TopURLMapper.TopURlReducer;
public class TopURL {
public static class TopURLMapper extends
Mapper {
private Text k = new Text();
private LongWritable v = new LongWritable();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] fields = StringUtils.split(line, "\t");
try {
String url = fields[26];
long upFlow = Long.parseLong(fields[30]);
k.set(url);
v.set(upFlow);
context.write(k, v);
} catch (Exception e) {
e.printStackTrace();
}
}
public static class TopURlReducer extends
Reducer {
private Text k = new Text();
private LongWritable v = new LongWritable();
TreeSet urls = new TreeSet();
//全局流量和
long globalFlowSum =0;
@Override
protected void reduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException {
long count = 0;
for (LongWritable v : values) {
count += v.get();
}
globalFlowSum +=count;
FlowBean bean = new FlowBean(key.toString(), count);
urls.add(bean);
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
long tempSum=0;
for(FlowBean bean:urls){
//取前80%的
if(tempSum/globalFlowSum
基于浏览器扩充的数据采集系统及技巧
采集交流 • 优采云 发表了文章 • 0 个评论 • 299 次浏览 • 2020-08-21 03:05
基于浏览器扩充的数据采集系统及技巧
【技术领域】
[0001]本发明涉及一种数据采集系统,特别涉及一种基于浏览器扩充的数据采集系统及借助该数据采集系统实现的基于浏览器扩充的数据采集方法。
【背景技术】
[0002 ]由于近1年多来,互联网协议并没有本质的变化,所有on I ine (互联网上)及h5 (指第5代HTML,所谓HTML是“超文本标记语言”的日文简写)等网站页面仍然遵守w3c(万维网联盟)标准,通讯一直借助http协议(超文本传输协议),因此负责网路数据采集的爬虫程序构架,在这段时期内,也没有实质性地提高。
[0003]但是随着JS(JavaScript,一种直译式脚本语言)及浏览器技术的发展,各种反爬手段层出不穷,其中尤以后端反爬为主,因为后端反爬是可以直接抵挡爬虫步入的第一道门槛。
[0004]目前现有的垂直爬虫也主要以前期配置抓取步骤及参数,然后据此进行连续抓取,此方式主要存在的一个不足之处就是:面临对方后端反爬策略的修改,无法第一时间主动适配,必然引起在开发人员介入之前的一段时间,无法正常抓取。
[0005]并且目前市面上好多第三方的(开源)浏览器控制引擎经过试用,被发觉都存在着众多功能方面的缺陷,并没有办法百分百模拟浏览器的行为特点,存在容易被对方探测到的风险。
[0006]因此,我们须要更为智能的爬虫系统,在面临对方后端反爬策略更改的第一时间,可以自适应而且持续正确抓取的动作。
【发明内容】
[0007]本发明要解决的技术问题是为了克服现有技术中目前通过垂直爬虫技术爬取网页信息存在在对方后端反爬策略修改时难以主动适配以及通过现有的浏览器未能完全模拟其行为特点的缺陷,提供一种基于浏览器扩充的数据采集系统及技巧。
[0008]本发明是通过下列技术方案来解决上述技术问题的:
[0009]本发明提供一种基于浏览器扩充的数据采集系统,其特征在于,其包括一浏览器、基于该浏览器的API(应用程序编程接口)说明建立的附加组件;
[0010]该附加组件用于主动协程一服务器,并从该服务器中获取一爬取目标;
[0011]该附加组件还用于控制该浏览器打开目标网页,并控制该浏览器对该目标网页进行访问,以及控制该浏览器从该目标网页中获取该爬取目标;
[0012]该附加组件还用于控制该浏览器对该目标网页中除该爬取目标外的其他页面内容进行访问;
[0013]该附加组件还用于控制该浏览器关掉该目标网页。
[0014]较佳地,该附加组件借助该浏览器的API施行控制操作以实现对该目标网页的访问。
[0015]较佳地,该控制操作包括点击操作、滚动操作和挥控操作。
[0016]本发明还提供一种基于浏览器扩充的数据采集方法,其特征在于,其借助上述的基于浏览器扩充的数据采集系统实现,该数据采集方法包括以下步骤:
[0017]S1、该附加组件主动协程一服务器,并从该服务器中获取一爬取目标;
[0018]&、该附加组件控制该浏览器打开目标网页;
[0019]&、该附加组件控制该浏览器对该目标网页进行访问;
[0020]S4、该附加组件控制该浏览器从该目标网页中获取该爬取目标;
[0021]&、该附加组件控制该浏览器对该目标网页中除该爬取目标外的其他页面内容进行访问;
[0022]S6、该附加组件控制该浏览器关掉该目标网页。
[0023]较佳地,该附加组件借助该浏览器的API施行控制操作以实现对该目标网页的访问。
[0024]较佳地,该控制操作包括点击操作、滚动操作和挥控操作。
[0025]在符合本领域常识的基础上,上述各优选条件,可任意组合,即得本发明各较佳实例。
[0026]本发明的积极进步疗效在于:
[0027]本发明可以更隐蔽地借助爬虫技术进行数据的抓取,并且因为直接采用浏览器,使得所有的访问恳求均真实有效,并且对方网页上所有的JS都被正常执行,所有的参数建立也通过浏览器手动执行,不需要人工干预,即使对方后端反爬有改动,浏览器也能手动适应,极大地降低了人工成本,并且最大限度确保抓取的成功率。而且,通过单次或少量的恳求,对方难以剖析判别出访问者是爬虫还是真实的用户,使得对方网站管理者不敢轻易封杀,确保了抓取行为的连续性。
【附图说明】
[0028]图1为本发明的较佳施行例的基于浏览器扩充的数据采集方法的流程图。
【具体施行方法】
[0029]下面通过施行例的方法进一步说明本发明,但并不因而将本发明限制在所述的施行例范围之中。
[0030]本施行例提供一种基于浏览器扩充的数据采集系统及方式,该数据采集系统包括一浏览器、基于该浏览器的API说明建立的附加组件。
[0031]其中,该附加组件具备的功能有:该附加组件用于操纵该浏览器进行特定网页的访问,控制该浏览器打开或关掉特定的网页,控制该浏览器页面的个别特定行为,例如点击、滚动以及挥控操作以及操纵该浏览器从该浏览器的网页中获取信息。
[0032]该附加组件用于主动协程一服务器,并从该服务器中获取一爬取目标;
[0033]该附加组件还用于控制该浏览器打开目标网页,并控制该浏览器对该目标网页进行访问,以及控制该浏览器从该目标网页中获取该爬取目标;
[0034]该附加组件还用于控制该浏览器对该目标网页中除该爬取目标外的其他页面内容进行访问;
[0035]该附加组件还用于控制该浏览器关掉该目标网页。
[0036]如图1所示,该数据采集方法借助上述的基于浏览器扩充的数据采集系统实现,该数据采集方法包括以下步骤:
[0037]步骤101、该附加组件主动协程一服务器,并从该服务器中获取一爬取目标;
[0038]步骤102、该附加组件控制该浏览器打开目标网页;
[0039]步骤103、该附加组件控制该浏览器对该目标网页进行访问,该附加组件借助该浏览器的API施行控制操作以实现对该目标网页的访问,其中该控制操作包括点击操作、滚动操作和挥控操作;
[0040]步骤104、该附加组件控制该浏览器从该目标网页中获取该爬取目标;
[0041]步骤105、该附加组件控制该浏览器对该目标网页中除该爬取目标外的其他页面内容进行访问;
[0042]步骤106、该附加组件控制该浏览器关掉该目标网页。
[0043]在本方式中,附加组件借助浏览器(如火狐浏览器)提供的API,直接滚动页面或模拟键盘、键盘点击页面。由于好多页面为了探测用户的行为,有很多预留的埋点,当用户键盘经过或页面滚动到特定高度,将会触发一次埋点的网路恳求,所以通过模拟滚动与点击的控制操作,可以真实模拟一个普通用户的浏览行为,使对方通过单次用户的行为数据剖析,无法判定出当前访问者是否是一个真实存在的用户。
[0044]通过附加组件模拟真实用户浏览页面,且附加组件在须要爬取的目标页面打开并完成数据提取以后,并不把页面立刻关闭,而是在页面上找寻个别特定的元素进行点击操作,这样可以更真实地模拟用户的行为。由于普通用户并不会长时间的访问某一单一种类的页面,其必然会浏览一些其他感兴趣的信息,比如网站推荐的信息或一些评论信息等,然后再将这一组页面关掉,进行下一次的抓取。使目标网站无法通过后期(旁路)的用户行为剖析模型,进行有效的爬虫访问判定。
[0045]由此,本发明可以更隐蔽地借助爬虫技术进行数据的抓取,并且因为直接采用浏览器,使得所有的访问恳求均真实有效,并且对方网页上所有的JS都被正常执行,所有的参数建立也通过浏览器手动执行,不需要人工干预,即使对方后端反爬有改动,浏览器也能手动适应,极大地降低了人工成本,并且最大限度确保抓取的成功率。而且,通过单次或少量的恳求,对方难以剖析判定出访问者是爬虫还是真实的用户,使得对方网站管理者不敢轻易封杀,确保了抓取行为的连续性。
[0046]虽然以上描述了本发明的【具体施行方法】,但是本领域的技术人员应该理解,这些仅是举例说明,本发明的保护范围是由所附权力要求书限定的。本领域的技术人员在不背离本发明的原理和实质的前提下,可以对那些施行方法作出多种变更或更改,但这种变更和更改均落入本发明的保护范围。
【主权项】
1.一种基于浏览器扩充的数据采集系统,其特点在于,其包括一浏览器、基于该浏览器的API说明建立的附加组件; 该附加组件用于主动协程一服务器,并从该服务器中获取一爬取目标; 该附加组件还用于控制该浏览器打开目标网页,并控制该浏览器对该目标网页进行访问,以及控制该浏览器从该目标网页中获取该爬取目标; 该附加组件还用于控制该浏览器对该目标网页中除该爬取目标外的其他页面内容进行访问; 该附加组件还用于控制该浏览器关掉该目标网页。2.如权力要求1所述的基于浏览器扩充的数据采集系统,其特点在于,该附加组件借助该浏览器的API施行控制操作以实现对该目标网页的访问。3.如权力要求2所述的基于浏览器扩充的数据采集系统,其特点在于,该控制操作包括点击操作、滚动操作和挥控操作。4.一种基于浏览器扩充的数据采集方法,其特点在于,其借助如权力要求1所述的基于浏览器扩充的数据采集系统实现,该数据采集方法包括以下步骤: 51、该附加组件主动协程一服务器,并从该服务器中获取一爬取目标; 52、该附加组件控制该浏览器打开目标网页; 53、该附加组件控制该浏览器对该目标网页进行访问; 54、该附加组件控制该浏览器从该目标网页中获取该爬取目标; &、该附加组件控制该浏览器对该目标网页中除该爬取目标外的其他页面内容进行访问; S6、该附加组件控制该浏览器关掉该目标网页。5.如权力要求4所述的基于浏览器扩充的数据采集方法,其特点在于,该附加组件借助该浏览器的API施行控制操作以实现对该目标网页的访问。6.如权力要求5所述的基于浏览器扩充的数据采集方法,其特点在于,该控制操作包括点击操作、滚动操作和挥控操作。
【专利摘要】本发明提供一种基于浏览器扩充的数据采集系统,其包括浏览器、基于浏览器的API说明建立的附加组件;附加组件用于主动协程服务器,从服务器中获取爬取目标;附加组件还用于控制浏览器打开目标网页,并控制浏览器对目标网页进行访问,以及控制浏览器从目标网页中获取爬取目标;附加组件还用于控制浏览器对目标网页中除爬取目标外的其他页面内容进行访问;附加组件还用于控制浏览器关掉目标网页。本发明可以更隐蔽地借助爬虫技术进行数据的抓取,并且因为直接采用浏览器,使得所有的访问恳求均真实有效,并且对方网页上所有的JS都被正常执行,即使对方后端反爬有改动,浏览器也能手动适应,减小了人工成本,最大限度确保抓取的成功率。
【IPC分类】G06F17/30
【公开号】CN105512193
【申请号】CN2
【发明人】吴凌峰, 吴鹏越
【申请人】上海携程商务有限公司
【公开日】2016年4月20日
【申请日】2015年11月26日 查看全部
基于浏览器扩充的数据采集系统及技巧
基于浏览器扩充的数据采集系统及技巧
【技术领域】
[0001]本发明涉及一种数据采集系统,特别涉及一种基于浏览器扩充的数据采集系统及借助该数据采集系统实现的基于浏览器扩充的数据采集方法。
【背景技术】
[0002 ]由于近1年多来,互联网协议并没有本质的变化,所有on I ine (互联网上)及h5 (指第5代HTML,所谓HTML是“超文本标记语言”的日文简写)等网站页面仍然遵守w3c(万维网联盟)标准,通讯一直借助http协议(超文本传输协议),因此负责网路数据采集的爬虫程序构架,在这段时期内,也没有实质性地提高。
[0003]但是随着JS(JavaScript,一种直译式脚本语言)及浏览器技术的发展,各种反爬手段层出不穷,其中尤以后端反爬为主,因为后端反爬是可以直接抵挡爬虫步入的第一道门槛。
[0004]目前现有的垂直爬虫也主要以前期配置抓取步骤及参数,然后据此进行连续抓取,此方式主要存在的一个不足之处就是:面临对方后端反爬策略的修改,无法第一时间主动适配,必然引起在开发人员介入之前的一段时间,无法正常抓取。
[0005]并且目前市面上好多第三方的(开源)浏览器控制引擎经过试用,被发觉都存在着众多功能方面的缺陷,并没有办法百分百模拟浏览器的行为特点,存在容易被对方探测到的风险。
[0006]因此,我们须要更为智能的爬虫系统,在面临对方后端反爬策略更改的第一时间,可以自适应而且持续正确抓取的动作。
【发明内容】
[0007]本发明要解决的技术问题是为了克服现有技术中目前通过垂直爬虫技术爬取网页信息存在在对方后端反爬策略修改时难以主动适配以及通过现有的浏览器未能完全模拟其行为特点的缺陷,提供一种基于浏览器扩充的数据采集系统及技巧。
[0008]本发明是通过下列技术方案来解决上述技术问题的:
[0009]本发明提供一种基于浏览器扩充的数据采集系统,其特征在于,其包括一浏览器、基于该浏览器的API(应用程序编程接口)说明建立的附加组件;
[0010]该附加组件用于主动协程一服务器,并从该服务器中获取一爬取目标;
[0011]该附加组件还用于控制该浏览器打开目标网页,并控制该浏览器对该目标网页进行访问,以及控制该浏览器从该目标网页中获取该爬取目标;
[0012]该附加组件还用于控制该浏览器对该目标网页中除该爬取目标外的其他页面内容进行访问;
[0013]该附加组件还用于控制该浏览器关掉该目标网页。
[0014]较佳地,该附加组件借助该浏览器的API施行控制操作以实现对该目标网页的访问。
[0015]较佳地,该控制操作包括点击操作、滚动操作和挥控操作。
[0016]本发明还提供一种基于浏览器扩充的数据采集方法,其特征在于,其借助上述的基于浏览器扩充的数据采集系统实现,该数据采集方法包括以下步骤:
[0017]S1、该附加组件主动协程一服务器,并从该服务器中获取一爬取目标;
[0018]&、该附加组件控制该浏览器打开目标网页;
[0019]&、该附加组件控制该浏览器对该目标网页进行访问;
[0020]S4、该附加组件控制该浏览器从该目标网页中获取该爬取目标;
[0021]&、该附加组件控制该浏览器对该目标网页中除该爬取目标外的其他页面内容进行访问;
[0022]S6、该附加组件控制该浏览器关掉该目标网页。
[0023]较佳地,该附加组件借助该浏览器的API施行控制操作以实现对该目标网页的访问。
[0024]较佳地,该控制操作包括点击操作、滚动操作和挥控操作。
[0025]在符合本领域常识的基础上,上述各优选条件,可任意组合,即得本发明各较佳实例。
[0026]本发明的积极进步疗效在于:
[0027]本发明可以更隐蔽地借助爬虫技术进行数据的抓取,并且因为直接采用浏览器,使得所有的访问恳求均真实有效,并且对方网页上所有的JS都被正常执行,所有的参数建立也通过浏览器手动执行,不需要人工干预,即使对方后端反爬有改动,浏览器也能手动适应,极大地降低了人工成本,并且最大限度确保抓取的成功率。而且,通过单次或少量的恳求,对方难以剖析判别出访问者是爬虫还是真实的用户,使得对方网站管理者不敢轻易封杀,确保了抓取行为的连续性。
【附图说明】
[0028]图1为本发明的较佳施行例的基于浏览器扩充的数据采集方法的流程图。
【具体施行方法】
[0029]下面通过施行例的方法进一步说明本发明,但并不因而将本发明限制在所述的施行例范围之中。
[0030]本施行例提供一种基于浏览器扩充的数据采集系统及方式,该数据采集系统包括一浏览器、基于该浏览器的API说明建立的附加组件。
[0031]其中,该附加组件具备的功能有:该附加组件用于操纵该浏览器进行特定网页的访问,控制该浏览器打开或关掉特定的网页,控制该浏览器页面的个别特定行为,例如点击、滚动以及挥控操作以及操纵该浏览器从该浏览器的网页中获取信息。
[0032]该附加组件用于主动协程一服务器,并从该服务器中获取一爬取目标;
[0033]该附加组件还用于控制该浏览器打开目标网页,并控制该浏览器对该目标网页进行访问,以及控制该浏览器从该目标网页中获取该爬取目标;
[0034]该附加组件还用于控制该浏览器对该目标网页中除该爬取目标外的其他页面内容进行访问;
[0035]该附加组件还用于控制该浏览器关掉该目标网页。
[0036]如图1所示,该数据采集方法借助上述的基于浏览器扩充的数据采集系统实现,该数据采集方法包括以下步骤:
[0037]步骤101、该附加组件主动协程一服务器,并从该服务器中获取一爬取目标;
[0038]步骤102、该附加组件控制该浏览器打开目标网页;
[0039]步骤103、该附加组件控制该浏览器对该目标网页进行访问,该附加组件借助该浏览器的API施行控制操作以实现对该目标网页的访问,其中该控制操作包括点击操作、滚动操作和挥控操作;
[0040]步骤104、该附加组件控制该浏览器从该目标网页中获取该爬取目标;
[0041]步骤105、该附加组件控制该浏览器对该目标网页中除该爬取目标外的其他页面内容进行访问;
[0042]步骤106、该附加组件控制该浏览器关掉该目标网页。
[0043]在本方式中,附加组件借助浏览器(如火狐浏览器)提供的API,直接滚动页面或模拟键盘、键盘点击页面。由于好多页面为了探测用户的行为,有很多预留的埋点,当用户键盘经过或页面滚动到特定高度,将会触发一次埋点的网路恳求,所以通过模拟滚动与点击的控制操作,可以真实模拟一个普通用户的浏览行为,使对方通过单次用户的行为数据剖析,无法判定出当前访问者是否是一个真实存在的用户。
[0044]通过附加组件模拟真实用户浏览页面,且附加组件在须要爬取的目标页面打开并完成数据提取以后,并不把页面立刻关闭,而是在页面上找寻个别特定的元素进行点击操作,这样可以更真实地模拟用户的行为。由于普通用户并不会长时间的访问某一单一种类的页面,其必然会浏览一些其他感兴趣的信息,比如网站推荐的信息或一些评论信息等,然后再将这一组页面关掉,进行下一次的抓取。使目标网站无法通过后期(旁路)的用户行为剖析模型,进行有效的爬虫访问判定。
[0045]由此,本发明可以更隐蔽地借助爬虫技术进行数据的抓取,并且因为直接采用浏览器,使得所有的访问恳求均真实有效,并且对方网页上所有的JS都被正常执行,所有的参数建立也通过浏览器手动执行,不需要人工干预,即使对方后端反爬有改动,浏览器也能手动适应,极大地降低了人工成本,并且最大限度确保抓取的成功率。而且,通过单次或少量的恳求,对方难以剖析判定出访问者是爬虫还是真实的用户,使得对方网站管理者不敢轻易封杀,确保了抓取行为的连续性。
[0046]虽然以上描述了本发明的【具体施行方法】,但是本领域的技术人员应该理解,这些仅是举例说明,本发明的保护范围是由所附权力要求书限定的。本领域的技术人员在不背离本发明的原理和实质的前提下,可以对那些施行方法作出多种变更或更改,但这种变更和更改均落入本发明的保护范围。
【主权项】
1.一种基于浏览器扩充的数据采集系统,其特点在于,其包括一浏览器、基于该浏览器的API说明建立的附加组件; 该附加组件用于主动协程一服务器,并从该服务器中获取一爬取目标; 该附加组件还用于控制该浏览器打开目标网页,并控制该浏览器对该目标网页进行访问,以及控制该浏览器从该目标网页中获取该爬取目标; 该附加组件还用于控制该浏览器对该目标网页中除该爬取目标外的其他页面内容进行访问; 该附加组件还用于控制该浏览器关掉该目标网页。2.如权力要求1所述的基于浏览器扩充的数据采集系统,其特点在于,该附加组件借助该浏览器的API施行控制操作以实现对该目标网页的访问。3.如权力要求2所述的基于浏览器扩充的数据采集系统,其特点在于,该控制操作包括点击操作、滚动操作和挥控操作。4.一种基于浏览器扩充的数据采集方法,其特点在于,其借助如权力要求1所述的基于浏览器扩充的数据采集系统实现,该数据采集方法包括以下步骤: 51、该附加组件主动协程一服务器,并从该服务器中获取一爬取目标; 52、该附加组件控制该浏览器打开目标网页; 53、该附加组件控制该浏览器对该目标网页进行访问; 54、该附加组件控制该浏览器从该目标网页中获取该爬取目标; &、该附加组件控制该浏览器对该目标网页中除该爬取目标外的其他页面内容进行访问; S6、该附加组件控制该浏览器关掉该目标网页。5.如权力要求4所述的基于浏览器扩充的数据采集方法,其特点在于,该附加组件借助该浏览器的API施行控制操作以实现对该目标网页的访问。6.如权力要求5所述的基于浏览器扩充的数据采集方法,其特点在于,该控制操作包括点击操作、滚动操作和挥控操作。
【专利摘要】本发明提供一种基于浏览器扩充的数据采集系统,其包括浏览器、基于浏览器的API说明建立的附加组件;附加组件用于主动协程服务器,从服务器中获取爬取目标;附加组件还用于控制浏览器打开目标网页,并控制浏览器对目标网页进行访问,以及控制浏览器从目标网页中获取爬取目标;附加组件还用于控制浏览器对目标网页中除爬取目标外的其他页面内容进行访问;附加组件还用于控制浏览器关掉目标网页。本发明可以更隐蔽地借助爬虫技术进行数据的抓取,并且因为直接采用浏览器,使得所有的访问恳求均真实有效,并且对方网页上所有的JS都被正常执行,即使对方后端反爬有改动,浏览器也能手动适应,减小了人工成本,最大限度确保抓取的成功率。
【IPC分类】G06F17/30
【公开号】CN105512193
【申请号】CN2
【发明人】吴凌峰, 吴鹏越
【申请人】上海携程商务有限公司
【公开日】2016年4月20日
【申请日】2015年11月26日

