
内容采集器
内容采集器(本文介绍使用麒麟采集器知乎回答内容的方法采集数据说明)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-10-02 08:15
本文介绍如何使用麒麟采集器知乎回答内容
采集网站:
使用功能点:
分页列表信息采集
AJAX点击和翻页教程
知乎:知乎是一个真正的在线问答社区,拥有友好理性的社区氛围,连接各行各业的精英。用户相互分享专业知识、经验和见解,为中国互联网提供源源不断的优质信息。
知乎回答内容采集资料说明:本文以知乎回答内容采集进行。本文仅以“知乎回复内容采集”为例。实际操作中,您可以根据自己的需要,将知乎的其他内容替换为data采集。
知乎回答内容采集字段详细说明:知乎问题标题、知乎回答ID、知乎签名、知乎回答批准号、 知乎回复评论数,知乎回复内容。
第一步:创建采集任务
1)进入主界面,选择“自定义模式”
2)将采集的网址复制粘贴到网站的输入框中,点击“保存网址”
第 2 步:创建翻页循环
1)在页面右上角,打开“流程”,显示“流程设计器”和“自定义当前操作”两个部分。点击题目,在操作提示框中选择“采集元素的文本”
2) 页面下拉至底部,点击“查看更多答案”按钮,在右侧操作提示框中选择“更多操作”
选择“循环单击单个按钮”
我们发现系统自动打开了采集的网页,进入了知乎问答区。自动下拉加载后,此页面到达底部并出现“查看更多答案”按钮。因此,我们需要等待网页完全加载后再进行翻页操作,即需要等待设置执行完毕
选择整个“循环翻页”步骤,打开高级选项,设置执行前等待为“3秒”,然后点击“确定”
“点击元素”操作也是一样,执行前的等待时间设置为“3秒”。同时,“点击元素”这一步也涉及到Ajax加载技术,需要勾选“Ajax加载数据”并将时间设置为“2秒”
注:AJAX 是一种延迟加载和异步更新的脚本技术。通过后台与服务器的少量数据交换,可以更新网页的某一部分,而无需重新加载整个网页。
性能特点: a.当你点击网页中的一个选项时,网站的大部分网址不会改变;湾 网页未完全加载,但仅部分加载了数据,这些数据会发生变化。
验证方法:点击操作后,URL输入栏在浏览器中不会出现加载状态或转动状态。
第 3 步:提取 知乎 答案
1)移动鼠标选择页面上的第一个答案块。系统会识别该块中的子元素,在操作提示框中选择“选择子元素”
2)系统会识别页面上的其他类似元素。在操作提示框中,选择“全选”
3)选择“采集以下数据”
4)选择该字段并单击垃圾桶图标将其删除
5)选择对应的字段,可以自定义字段的命名
第四步:调整流程图结构
回顾采集的过程,我们配置规则的思路是先点击“查看更多答案”按钮创建翻页循环,加载所有答案,然后创建循环列表来提取数据。
1)选择整个“循环”步骤并将其拖出“循环翻转”步骤。如果不这样做,会出现大量重复数据
拖动完成后,如下图
2)点击左上角“保存并启动”,选择“启动本地采集”
第五步:数据采集并导出
1)采集 完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,将采集好的数据导出
2)这里我们选择excel作为导出格式,导出数据如下图 查看全部
内容采集器(本文介绍使用麒麟采集器知乎回答内容的方法采集数据说明)
本文介绍如何使用麒麟采集器知乎回答内容
采集网站:
使用功能点:
分页列表信息采集
AJAX点击和翻页教程
知乎:知乎是一个真正的在线问答社区,拥有友好理性的社区氛围,连接各行各业的精英。用户相互分享专业知识、经验和见解,为中国互联网提供源源不断的优质信息。
知乎回答内容采集资料说明:本文以知乎回答内容采集进行。本文仅以“知乎回复内容采集”为例。实际操作中,您可以根据自己的需要,将知乎的其他内容替换为data采集。
知乎回答内容采集字段详细说明:知乎问题标题、知乎回答ID、知乎签名、知乎回答批准号、 知乎回复评论数,知乎回复内容。
第一步:创建采集任务
1)进入主界面,选择“自定义模式”
2)将采集的网址复制粘贴到网站的输入框中,点击“保存网址”
第 2 步:创建翻页循环
1)在页面右上角,打开“流程”,显示“流程设计器”和“自定义当前操作”两个部分。点击题目,在操作提示框中选择“采集元素的文本”
2) 页面下拉至底部,点击“查看更多答案”按钮,在右侧操作提示框中选择“更多操作”
选择“循环单击单个按钮”
我们发现系统自动打开了采集的网页,进入了知乎问答区。自动下拉加载后,此页面到达底部并出现“查看更多答案”按钮。因此,我们需要等待网页完全加载后再进行翻页操作,即需要等待设置执行完毕
选择整个“循环翻页”步骤,打开高级选项,设置执行前等待为“3秒”,然后点击“确定”
“点击元素”操作也是一样,执行前的等待时间设置为“3秒”。同时,“点击元素”这一步也涉及到Ajax加载技术,需要勾选“Ajax加载数据”并将时间设置为“2秒”
注:AJAX 是一种延迟加载和异步更新的脚本技术。通过后台与服务器的少量数据交换,可以更新网页的某一部分,而无需重新加载整个网页。
性能特点: a.当你点击网页中的一个选项时,网站的大部分网址不会改变;湾 网页未完全加载,但仅部分加载了数据,这些数据会发生变化。
验证方法:点击操作后,URL输入栏在浏览器中不会出现加载状态或转动状态。
第 3 步:提取 知乎 答案
1)移动鼠标选择页面上的第一个答案块。系统会识别该块中的子元素,在操作提示框中选择“选择子元素”
2)系统会识别页面上的其他类似元素。在操作提示框中,选择“全选”
3)选择“采集以下数据”
4)选择该字段并单击垃圾桶图标将其删除
5)选择对应的字段,可以自定义字段的命名
第四步:调整流程图结构
回顾采集的过程,我们配置规则的思路是先点击“查看更多答案”按钮创建翻页循环,加载所有答案,然后创建循环列表来提取数据。
1)选择整个“循环”步骤并将其拖出“循环翻转”步骤。如果不这样做,会出现大量重复数据
拖动完成后,如下图
2)点击左上角“保存并启动”,选择“启动本地采集”
第五步:数据采集并导出
1)采集 完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,将采集好的数据导出
2)这里我们选择excel作为导出格式,导出数据如下图
内容采集器(本次更新究竟新增了哪些好用的功能?(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-09-29 04:10
优采云采集器我前段时间把版本升级到了V10。在广大用户的期待下,本次升级更新内容非常多,更新的功能都是大家期待已久的功能。那么这次更新增加了哪些有用的功能呢?让我们在这里详细讨论一下。一些不重要的功能可以参考优采云采集器官网更新文档。
第一种:批量增加网址增加间隔变化的方法
间隔变化的变化原理是:地址中的两个参数以固定的间隔增长,相邻两组值的结束值和起始值之间的间隔为1。变化的地址格式和这种形式的增长可以使用间隔变化来处理。一般用户可能会觉得难以理解这种设置方法。如果处理不了,可以在文章下评论,站长会帮你解答。
例如,以URL为例,我们使用fiddler抓取数据包的URL,修改如下:
第一页:
第二页:
第三页:
. . .
如下图,我们可以清楚地看到,在列表URL中,每页的起始值和结束值的差值是15,相邻页数,上一页的结束值的差值并且下一页的起始值为1。符合间隔变化规律。
因此,您可以按照下图进行设置。更改的字段选择地址参数,起始值使用[地址参数],结束值使用[地址参数1],间隔步长使用起始值和结束值之间的间隔数。
注意:间隔更改不能与批处理URL中的其他方法混用,必须有两个地址参数
第二个:数据采集支持CSS选择器
优采云采集器数据采集新增支持CSS选择器。许多网页都有独特的 css 属性。该功能更有利于批量提取网页数据。
如果想系统的学习css提取的知识,可以先看教程:。
优采云采集器集成了css提取功能,直接在界面中填写css路径即可使用。在Selector中填写css路径,节点属性选择需要采集的属性。
例如:
注意:使用css只能获取网页源代码中的元素。如果源码中没有css但是浏览器渲染后显示,则无法通过优采云采集器获取
第三:支持调用其他标签的值作为数据采集的拦截条件
数据抽取方式支持调用其他标签值,使采集过程更加灵活。提取时点击标签符号可以调用其他标签的值。下面介绍它的使用方法:
我们以URL:为例,目的是提取sku对应的颜色名称,以一种颜色为例:
目标网站获取数据部分的源代码:
注意:调用标签可以用于拦截前后和正则提取,使用方法相同。
第四:增加关联区域的功能
关联区域功能,可以先截取网页中指定区域的内容,然后将该区域作为数据源
执行采集 处理。
关联区的功能有利于分析重复的网页结构或复杂的网页形式和采集。
下面介绍相关区域功能的使用:
以 URL: 为例。比如我只想要2020年采集的下载链接,如果直接循环采集,那么会采集链接到其他年份,会干扰结果,所以我们可以使用关联区域指定采集的区域。
下面介绍具体的设置方法:
(1)添加关联区域
(2)在数据源中选择关联区域,然后按常规方式进行采集
这次优采云采集器V10,新增的主要功能就是以上四个,还有很多其他的小功能比如:批量设置步骤添加新功能相关设置,运行统计日志设置添加默认关闭功能。还对存在的问题进行了一些修复:oss相关问题、URL空白导致列表页面标签错误、下载插件增加了文件下载后处理接口等。
如果还有其他问题,可以来本站搜索相关问题,这里有你想要的答案:优采云脚本网 查看全部
内容采集器(本次更新究竟新增了哪些好用的功能?(一))
优采云采集器我前段时间把版本升级到了V10。在广大用户的期待下,本次升级更新内容非常多,更新的功能都是大家期待已久的功能。那么这次更新增加了哪些有用的功能呢?让我们在这里详细讨论一下。一些不重要的功能可以参考优采云采集器官网更新文档。
第一种:批量增加网址增加间隔变化的方法
间隔变化的变化原理是:地址中的两个参数以固定的间隔增长,相邻两组值的结束值和起始值之间的间隔为1。变化的地址格式和这种形式的增长可以使用间隔变化来处理。一般用户可能会觉得难以理解这种设置方法。如果处理不了,可以在文章下评论,站长会帮你解答。
例如,以URL为例,我们使用fiddler抓取数据包的URL,修改如下:
第一页:
第二页:
第三页:
. . .
如下图,我们可以清楚地看到,在列表URL中,每页的起始值和结束值的差值是15,相邻页数,上一页的结束值的差值并且下一页的起始值为1。符合间隔变化规律。

因此,您可以按照下图进行设置。更改的字段选择地址参数,起始值使用[地址参数],结束值使用[地址参数1],间隔步长使用起始值和结束值之间的间隔数。
注意:间隔更改不能与批处理URL中的其他方法混用,必须有两个地址参数
第二个:数据采集支持CSS选择器
优采云采集器数据采集新增支持CSS选择器。许多网页都有独特的 css 属性。该功能更有利于批量提取网页数据。
如果想系统的学习css提取的知识,可以先看教程:。
优采云采集器集成了css提取功能,直接在界面中填写css路径即可使用。在Selector中填写css路径,节点属性选择需要采集的属性。
例如:

注意:使用css只能获取网页源代码中的元素。如果源码中没有css但是浏览器渲染后显示,则无法通过优采云采集器获取
第三:支持调用其他标签的值作为数据采集的拦截条件
数据抽取方式支持调用其他标签值,使采集过程更加灵活。提取时点击标签符号可以调用其他标签的值。下面介绍它的使用方法:
我们以URL:为例,目的是提取sku对应的颜色名称,以一种颜色为例:
目标网站获取数据部分的源代码:
注意:调用标签可以用于拦截前后和正则提取,使用方法相同。
第四:增加关联区域的功能
关联区域功能,可以先截取网页中指定区域的内容,然后将该区域作为数据源
执行采集 处理。
关联区的功能有利于分析重复的网页结构或复杂的网页形式和采集。
下面介绍相关区域功能的使用:
以 URL: 为例。比如我只想要2020年采集的下载链接,如果直接循环采集,那么会采集链接到其他年份,会干扰结果,所以我们可以使用关联区域指定采集的区域。

下面介绍具体的设置方法:
(1)添加关联区域
(2)在数据源中选择关联区域,然后按常规方式进行采集
这次优采云采集器V10,新增的主要功能就是以上四个,还有很多其他的小功能比如:批量设置步骤添加新功能相关设置,运行统计日志设置添加默认关闭功能。还对存在的问题进行了一些修复:oss相关问题、URL空白导致列表页面标签错误、下载插件增加了文件下载后处理接口等。
如果还有其他问题,可以来本站搜索相关问题,这里有你想要的答案:优采云脚本网
内容采集器(内容采集器,腾讯的可以免费试用的小技巧!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-28 11:00
内容采集器,腾讯的也有很多可以免费试用的。很多客户都是在微信里面找我要,感觉挺好用的也分享给你。下载百度网盘客户端,加微信公众号,传文件,
我有啊,分享一个吧。那个叫“妈妈好课堂”,是腾讯旗下的呀,有视频模板,你有需要可以上去看看。
有个超级文件助手,
网易云课堂
腾讯的可以,好像是付费,但是他家有个公众号叫“腾讯课堂”,可以试试,可以得到来自腾讯课堂的源。
方法一:百度云方法二:线下如果你没有空闲的时间的话就比较麻烦。搜索一些如何听课的方法,或者是有什么有意思的课程让你觉得不错,在搜索引擎的输入上加以修饰,如:听了这门课程,发现其实挺有意思的,是上课期间在qq空间看到过的一段话,讲述在这个社会里面有很多肮脏,令人不寒而栗然后收获这篇文章的见识,
腾讯新闻实时资讯,
易企秀秀表情包千图网
百度云助手,不谢,我也是被骗上车的人。
优酷公开课
荔枝fm,你要的都有。
腾讯课堂
网易云课堂,里面有免费课程,还有很多付费的课程可以看,
可以试试微学伴,使用学习微课来赚钱,操作很简单,易上手, 查看全部
内容采集器(内容采集器,腾讯的可以免费试用的小技巧!)
内容采集器,腾讯的也有很多可以免费试用的。很多客户都是在微信里面找我要,感觉挺好用的也分享给你。下载百度网盘客户端,加微信公众号,传文件,
我有啊,分享一个吧。那个叫“妈妈好课堂”,是腾讯旗下的呀,有视频模板,你有需要可以上去看看。
有个超级文件助手,
网易云课堂
腾讯的可以,好像是付费,但是他家有个公众号叫“腾讯课堂”,可以试试,可以得到来自腾讯课堂的源。
方法一:百度云方法二:线下如果你没有空闲的时间的话就比较麻烦。搜索一些如何听课的方法,或者是有什么有意思的课程让你觉得不错,在搜索引擎的输入上加以修饰,如:听了这门课程,发现其实挺有意思的,是上课期间在qq空间看到过的一段话,讲述在这个社会里面有很多肮脏,令人不寒而栗然后收获这篇文章的见识,
腾讯新闻实时资讯,
易企秀秀表情包千图网
百度云助手,不谢,我也是被骗上车的人。
优酷公开课
荔枝fm,你要的都有。
腾讯课堂
网易云课堂,里面有免费课程,还有很多付费的课程可以看,
可以试试微学伴,使用学习微课来赚钱,操作很简单,易上手,
内容采集器(内容采集器可以从网上采集各种视频内容推广和分享)
采集交流 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2021-09-25 11:02
内容采集器可以从网上采集各种视频内容,例如视频,图片,文档等。视频采集器可以采集本地视频,同步到我们的服务器,实现实时互动,一键即可上传到大型网站上进行推广和分享。1.转码器:设置哪些内容是要转换成youtube视频的,采集转换器要采集的内容选择转换器,然后把转换器所属类型设置成youtube的,点击右下角的提示设置。2.视频云,可以自己生成视频云上传到服务器。
我一直用googlereader,用一个博客里面的分享截图形容一下。我最长的一次长达2个月。半年以上博客只有一次基本不用了。现在我记忆里,在这半年里打开过的次数不超过20次,博客里的内容都没有登录过。等我找到下图。看原始的文件能够清楚的看到,博客被封在工厂,很多有价值的内容都被屏蔽,去寻找访问他们的办法,都失败了。
谷歌,苹果,instagram都可以。用谷歌的网站不需要验证码。上传到v2ex,网页开发技术俱乐部不翻墙也能访问。
百度文库!!!经常上,
新闻资讯可以用酷六网。感觉他们的内容审核比较严。
百度搜了几十条都一样,官方说可以采集,但是上传后自动识别分好多种,没法自己下载自己的,这是重点。还有每上传一次都要绑定的,跟电脑上账号一样,每隔一段时间就要重新开会员,要不然就是解封,很烦。 查看全部
内容采集器(内容采集器可以从网上采集各种视频内容推广和分享)
内容采集器可以从网上采集各种视频内容,例如视频,图片,文档等。视频采集器可以采集本地视频,同步到我们的服务器,实现实时互动,一键即可上传到大型网站上进行推广和分享。1.转码器:设置哪些内容是要转换成youtube视频的,采集转换器要采集的内容选择转换器,然后把转换器所属类型设置成youtube的,点击右下角的提示设置。2.视频云,可以自己生成视频云上传到服务器。
我一直用googlereader,用一个博客里面的分享截图形容一下。我最长的一次长达2个月。半年以上博客只有一次基本不用了。现在我记忆里,在这半年里打开过的次数不超过20次,博客里的内容都没有登录过。等我找到下图。看原始的文件能够清楚的看到,博客被封在工厂,很多有价值的内容都被屏蔽,去寻找访问他们的办法,都失败了。
谷歌,苹果,instagram都可以。用谷歌的网站不需要验证码。上传到v2ex,网页开发技术俱乐部不翻墙也能访问。
百度文库!!!经常上,
新闻资讯可以用酷六网。感觉他们的内容审核比较严。
百度搜了几十条都一样,官方说可以采集,但是上传后自动识别分好多种,没法自己下载自己的,这是重点。还有每上传一次都要绑定的,跟电脑上账号一样,每隔一段时间就要重新开会员,要不然就是解封,很烦。
内容采集器( 数据采集器对比国内五大主流采集软件的优缺点解析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 292 次浏览 • 2021-09-24 06:10
数据采集器对比国内五大主流采集软件的优缺点解析)
采集器,也称为data采集器,是一个解决批量信息重复的工具。Data采集茶类产品在国内外具有广阔的前景,不仅可以完成信息复制,还可以完成信息提取、数据复制和备份等,市场上有很多软件,技术各异。
今天,我们将对比国内5大采集软件的优缺点,助您选择最合适的爬虫,体验数据的快感。
1.优采云
优采云已经家喻户晓,作为采集界的老前辈,优采云是一款互联网数据抓取、处理、分析、挖掘软件,可以抓取网页上的零散数据信息,并通过一系列的分析处理,准确地挖掘出所需的数据。它的用户定位主要是针对有一定代码基础的人,适合编程老手。
点评:优采云适合编程高手,规则易写,软件定位更专业精准。
2.优采云
一款可视化免编程网页采集软件,可以快速从不同的网站中提取标准化数据,帮助用户实现数据自动化采集,编辑标准化,降低工作成本。云采集是它的一大特色。与其他采集软件相比,Cloud采集可以更精准、更高效、更大规模。
在自定义采集的过程中,优采云采集器系统自写的Xpath和自动生成的进程可能无法满足采集的数据需求。对数据质量要求高,需要自己编写Xpath,调整成流程图,优化规则。
对于使用自定义采集的同学来说,优采云虽然操作简单,但是更容易上手。不过还是要了解优采云采集的原理,看完相关教程,循序渐进,成长周期更长。
点评:优采云是一款适合小白用户试用的采集软件,云功能强大。当然,老爬虫也可以开发它的高级功能。
3.吉搜客
一款简单易用的网页信息抓取软件,能够抓取网页文字、图表、超链接等网页元素。采集 也可以通过一个简单的可视化流程来服务任何有采集 数据需求的人。
点评:收客操作比较简单,适合初学者,功能方面没有太多特色,后续支付需求较多。
4.优采云云爬虫
一种新型的云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取大量标准化的网络数据。
点评:优采云类似于一个爬虫系统框架,具体采集需要用户自己编写爬虫,需要有代码基础。
5.优采云采集器
一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取、分论坛采集器、cms采集器 和博客采集器 三个类别。
点评:专注于论坛和博客文字内容的爬取。全网数据的采集通用性不高。 查看全部
内容采集器(
数据采集器对比国内五大主流采集软件的优缺点解析)

采集器,也称为data采集器,是一个解决批量信息重复的工具。Data采集茶类产品在国内外具有广阔的前景,不仅可以完成信息复制,还可以完成信息提取、数据复制和备份等,市场上有很多软件,技术各异。
今天,我们将对比国内5大采集软件的优缺点,助您选择最合适的爬虫,体验数据的快感。
1.优采云
优采云已经家喻户晓,作为采集界的老前辈,优采云是一款互联网数据抓取、处理、分析、挖掘软件,可以抓取网页上的零散数据信息,并通过一系列的分析处理,准确地挖掘出所需的数据。它的用户定位主要是针对有一定代码基础的人,适合编程老手。
点评:优采云适合编程高手,规则易写,软件定位更专业精准。
2.优采云
一款可视化免编程网页采集软件,可以快速从不同的网站中提取标准化数据,帮助用户实现数据自动化采集,编辑标准化,降低工作成本。云采集是它的一大特色。与其他采集软件相比,Cloud采集可以更精准、更高效、更大规模。
在自定义采集的过程中,优采云采集器系统自写的Xpath和自动生成的进程可能无法满足采集的数据需求。对数据质量要求高,需要自己编写Xpath,调整成流程图,优化规则。
对于使用自定义采集的同学来说,优采云虽然操作简单,但是更容易上手。不过还是要了解优采云采集的原理,看完相关教程,循序渐进,成长周期更长。
点评:优采云是一款适合小白用户试用的采集软件,云功能强大。当然,老爬虫也可以开发它的高级功能。
3.吉搜客
一款简单易用的网页信息抓取软件,能够抓取网页文字、图表、超链接等网页元素。采集 也可以通过一个简单的可视化流程来服务任何有采集 数据需求的人。
点评:收客操作比较简单,适合初学者,功能方面没有太多特色,后续支付需求较多。
4.优采云云爬虫
一种新型的云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取大量标准化的网络数据。
点评:优采云类似于一个爬虫系统框架,具体采集需要用户自己编写爬虫,需要有代码基础。
5.优采云采集器
一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取、分论坛采集器、cms采集器 和博客采集器 三个类别。
点评:专注于论坛和博客文字内容的爬取。全网数据的采集通用性不高。
内容采集器(从零开始系统的学习seo方面的营销推广方法技巧)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-09-23 10:00
内容采集器ip抓取器云采集合作qq群:178655204和威客小助手、变色龙等平台协同工作一键采集分享指定的文章、样式、图片等,
使用socialpeta的seo方面的功能实现网站外链、外链挖掘、快照采集等外链任务
建议还是搭建一个网站吧,app方面存在一定风险,能在app上搞seo,必然是在appapp上做推广,仅仅是引流不是最好的方式.我家有几款可以做到的app,可以带给你参考。
楼上说的挺对的这种也存在风险这些市面上的所谓的seo引流量平台使用个人的身份注册后需要给平台一些ip目前最高可以在15000左右也可以不用交钱直接投票平台觉得起作用后再交钱平台收到你的推广ip后如果没有有效的页面需要与投票的人对接注册时提示需要用邮箱地址验证还有在上面进行所谓的所谓的刷榜搞虚假等等的行为都属于犯法的行为切勿去尝试我相信楼主需要的也不仅仅是引流这么简单更多的可能是真正有用的营销推广方法技巧可以看看:《从零开始系统的学习seo》这是我录制的关于seo方面的教程视频可以自己试着做一些尝试自学版本会很详细的了解到推广方面的操作技巧希望能帮到你:)。 查看全部
内容采集器(从零开始系统的学习seo方面的营销推广方法技巧)
内容采集器ip抓取器云采集合作qq群:178655204和威客小助手、变色龙等平台协同工作一键采集分享指定的文章、样式、图片等,
使用socialpeta的seo方面的功能实现网站外链、外链挖掘、快照采集等外链任务
建议还是搭建一个网站吧,app方面存在一定风险,能在app上搞seo,必然是在appapp上做推广,仅仅是引流不是最好的方式.我家有几款可以做到的app,可以带给你参考。
楼上说的挺对的这种也存在风险这些市面上的所谓的seo引流量平台使用个人的身份注册后需要给平台一些ip目前最高可以在15000左右也可以不用交钱直接投票平台觉得起作用后再交钱平台收到你的推广ip后如果没有有效的页面需要与投票的人对接注册时提示需要用邮箱地址验证还有在上面进行所谓的所谓的刷榜搞虚假等等的行为都属于犯法的行为切勿去尝试我相信楼主需要的也不仅仅是引流这么简单更多的可能是真正有用的营销推广方法技巧可以看看:《从零开始系统的学习seo》这是我录制的关于seo方面的教程视频可以自己试着做一些尝试自学版本会很详细的了解到推广方面的操作技巧希望能帮到你:)。
内容采集器(ebay:跨境电商运营助手|ebay玩转,amazon)
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-09-22 15:04
内容采集器大量的采集工具不同站点api也可以登录,有很多限制。建议你看看这个资料:跨境电商运营助手|玩转ebay,amazon,wish,速卖通,etsy,lazada,bestbuy,wish等国内外平台-卖家版,跨境电商大卖家必备工具有的也可以离线,就是挂一会,下线就好了。自动化采集代采,可以外挂代理去采集,还有汇率提供,适合个人站长。
我一直使用这个:searchserviceservice-bestpricingplatformbydouglashulowski翻译更多用户评价:商机网-ipad全球影响力最大的ugc,pgc博客社区之一-特立独行,自由创造,内容创新-专注ugc,pgc,首页分享。
速卖通卖家去facebook,twitter,insta分享产品,在亚马逊和天猫铺货,微博或者其他网站上海量的发布产品信息。那么针对这些地区来去哪里获取这些地区用户的需求,而且最好还有这些地区的人群的兴趣爱好等信息。甚至有的时候电商卖家的产品链接可以去全球的一些区域性的社交媒体。举个例子,比如最近很火的武夷山开发,他的武夷山四个字,都有那么多的人想要,那么你没有合适的机会在这些相关的社交媒体上面进行运营,那么大家对你也不熟悉,你就很难获得那些精准的用户数据。
那么现在很多电商卖家他需要的地区就是东南亚,非洲,俄罗斯,拉美,巴西等。速卖通卖家去这些区域性的社交媒体去获取数据。我认为数据是非常重要的一环,不仅仅是帮助你推荐产品,还有很多是帮助你了解目标用户和市场,甚至是和目标用户和潜在目标用户进行互动,让目标用户和市场进行交流。那么我们如何去看这些数据呢?首先你就是要有相应的关键词,比如你可以搜索武夷山开发,搜索到你的产品信息后,用户会收到一封邮件,你可以看到的内容是,有很多他的使用者。
是中国籍的,还是美国人,还是俄罗斯人,有的是女性,有的是男性,还有0-50岁的都有。可以根据这些来判断他的年龄,他的年龄有多大,他们的年龄段有多大,多大的人会去喝茶,有多大的人会去看这个类目的产品。如果你是学生党或者宝妈一族,他就会跟你进行交流,他会跟你说一些他用的产品和店铺。接下来我就针对这些关键词去寻找这些产品到底在哪里卖。
当你搜索武夷山开发的时候,你输入框内的一些关键词,比如武夷山开发,你会出现不一样的东南亚,非洲,俄罗斯等一些不同的数据库。到这里一些关键词就可以告诉你,比如你是搜索大学生,你可以搜索到:大学生搜索可以进行竞价,比如你竞价:2000刀,就可以拥有一个大学生用户,那么你的产品去竞价2000刀,有很多用户会选择购买。另外如果你竞价太低,比如2000。 查看全部
内容采集器(ebay:跨境电商运营助手|ebay玩转,amazon)
内容采集器大量的采集工具不同站点api也可以登录,有很多限制。建议你看看这个资料:跨境电商运营助手|玩转ebay,amazon,wish,速卖通,etsy,lazada,bestbuy,wish等国内外平台-卖家版,跨境电商大卖家必备工具有的也可以离线,就是挂一会,下线就好了。自动化采集代采,可以外挂代理去采集,还有汇率提供,适合个人站长。
我一直使用这个:searchserviceservice-bestpricingplatformbydouglashulowski翻译更多用户评价:商机网-ipad全球影响力最大的ugc,pgc博客社区之一-特立独行,自由创造,内容创新-专注ugc,pgc,首页分享。
速卖通卖家去facebook,twitter,insta分享产品,在亚马逊和天猫铺货,微博或者其他网站上海量的发布产品信息。那么针对这些地区来去哪里获取这些地区用户的需求,而且最好还有这些地区的人群的兴趣爱好等信息。甚至有的时候电商卖家的产品链接可以去全球的一些区域性的社交媒体。举个例子,比如最近很火的武夷山开发,他的武夷山四个字,都有那么多的人想要,那么你没有合适的机会在这些相关的社交媒体上面进行运营,那么大家对你也不熟悉,你就很难获得那些精准的用户数据。
那么现在很多电商卖家他需要的地区就是东南亚,非洲,俄罗斯,拉美,巴西等。速卖通卖家去这些区域性的社交媒体去获取数据。我认为数据是非常重要的一环,不仅仅是帮助你推荐产品,还有很多是帮助你了解目标用户和市场,甚至是和目标用户和潜在目标用户进行互动,让目标用户和市场进行交流。那么我们如何去看这些数据呢?首先你就是要有相应的关键词,比如你可以搜索武夷山开发,搜索到你的产品信息后,用户会收到一封邮件,你可以看到的内容是,有很多他的使用者。
是中国籍的,还是美国人,还是俄罗斯人,有的是女性,有的是男性,还有0-50岁的都有。可以根据这些来判断他的年龄,他的年龄有多大,他们的年龄段有多大,多大的人会去喝茶,有多大的人会去看这个类目的产品。如果你是学生党或者宝妈一族,他就会跟你进行交流,他会跟你说一些他用的产品和店铺。接下来我就针对这些关键词去寻找这些产品到底在哪里卖。
当你搜索武夷山开发的时候,你输入框内的一些关键词,比如武夷山开发,你会出现不一样的东南亚,非洲,俄罗斯等一些不同的数据库。到这里一些关键词就可以告诉你,比如你是搜索大学生,你可以搜索到:大学生搜索可以进行竞价,比如你竞价:2000刀,就可以拥有一个大学生用户,那么你的产品去竞价2000刀,有很多用户会选择购买。另外如果你竞价太低,比如2000。
内容采集器(一下自媒体素材采集方法和相关自媒体工具,提升创作效率)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-20 07:01
做自媒体操作最基本的技能是创造,创造需要大量的材料支持。无论是热点事件的创作还是普通内容的创作,都离不开相关资料的采集。采集的材料越多,您自己的材料库就越大,创建高质量内容的概率就越高。对于材料采集有必要使用一些相关的辅助工具。今天,我将介绍自媒体material采集方法和相关的自媒体工具,希望能帮助您提高创作效率
第一:材料采集工具
对于自媒体material采集tool,业界最著名的工具是易于编写的自媒体采集tool。该工具支持30+自媒体平台各个领域的图形和视频材料采集。您只需通过平台、字段、关键词、时间等不同维度的查询即可获得所需的资料,并支持本地批量下载资料
第二:搜索引擎查找资料
这是找到自媒体材料的相对直接的方法。直接通过搜索引擎上的关键词搜索相关资料。但是,以这种方式生成的材料需要进行筛选和消除重复,因为搜索引擎上找到的所有材料都是收录并且重复程度非常高
第三:在行业平台上查找资料
在没有工具之前,我们用这种方式采集材料。大家都应该知道百度索引、知乎、微博热搜索、百度搜索公告牌等行业平台。在这些平台上,您只能通过关键词search查看与此字段相关的最新材料内容 查看全部
内容采集器(一下自媒体素材采集方法和相关自媒体工具,提升创作效率)
做自媒体操作最基本的技能是创造,创造需要大量的材料支持。无论是热点事件的创作还是普通内容的创作,都离不开相关资料的采集。采集的材料越多,您自己的材料库就越大,创建高质量内容的概率就越高。对于材料采集有必要使用一些相关的辅助工具。今天,我将介绍自媒体material采集方法和相关的自媒体工具,希望能帮助您提高创作效率
第一:材料采集工具
对于自媒体material采集tool,业界最著名的工具是易于编写的自媒体采集tool。该工具支持30+自媒体平台各个领域的图形和视频材料采集。您只需通过平台、字段、关键词、时间等不同维度的查询即可获得所需的资料,并支持本地批量下载资料
第二:搜索引擎查找资料
这是找到自媒体材料的相对直接的方法。直接通过搜索引擎上的关键词搜索相关资料。但是,以这种方式生成的材料需要进行筛选和消除重复,因为搜索引擎上找到的所有材料都是收录并且重复程度非常高
第三:在行业平台上查找资料
在没有工具之前,我们用这种方式采集材料。大家都应该知道百度索引、知乎、微博热搜索、百度搜索公告牌等行业平台。在这些平台上,您只能通过关键词search查看与此字段相关的最新材料内容
内容采集器( 优采云采集器怎么把内容导入网站?如何使用采集器采集网页图片)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-09-20 06:31
优采云采集器怎么把内容导入网站?如何使用采集器采集网页图片)
优采云采集器如何将内容导入网站
现在它基本上是免费的采集器并且有强大的功能。它比优采云. 例如,优采云采集器的cloud采集函数就是一团乱麻,速度很快,规则的制定也特别简单
优采云采集器如何使用它
用几句话来描述这种方法是非常困难的。我建议你看一下两个官方视频教程:一个是“播放优采云采集器,9节课,让你开始并掌握”;另一个是“优采云采集器-URL采集rule”。我相信你在学习了这些视频教程后会用到它
让我简单谈谈优采云的工作原理@采集器. 它主要执行软件中配置的捕获规则,解析后存储在您自己的数据库或文件中。因此,您主要需要分析两个方面:一是观察网页翻页URL的变化,汇总并提交给优采云,让它知道如何自动翻页;另一方面,分析列表页面和详细信息页面的HTML,告诉优采云要抓取哪个标签,要抓取文章内容文本的网站,以及在详细信息页面上提取哪些信息,如来源、作者等。所有这些都是为优采云找到的,并进行分析和总结,以便它能够自动工作
如何使用优采云采集器采集网页图片详细图形教程
优采云采集器采集信息分为两个步骤:1。采用网站。这一步还告诉软件需要采集多少网页,并给出具体的网页地址。2.内容。有了网站后,你可以去网站上的采集信息,但是网站上有很多信息,软件不知道你想采用什么。在内容部分,我们必须制定规则。告诉软件我想采用什么。1.采用网站。网页上的产品信息是您想要采用的,即目标。在采集链接页面中,输入采集地址的列表页面。在这里,注意过滤无用的链接。然后点击test按钮测试填写信息的正确性:测试正确后,我们展开地址。现在我们只需获取列表页面的文章地址,还有其他列表需要采集。其他列表页面在其页面上。我们观察这些发行版的链接形式,找出规则,然后批量填写URL规则。2.在对内容的采集进行上述处理后,可以采集目标产品页面的链接。让我们输入内容的采集。定义了采集的内容后,我们开始编写采集规则,优采云采集内容是采集网页的源代码,所以我们需要打开产品页面的源代码,找到我们想要的采集信息的位置。例如,description字段中的采集在找到描述的位置后如何填写采集规则非常简单。只需将采集目标的开始字符串和结束字符串填入采集的相应位置即可。这里我们选择Description:作为开始字符串和结束字符串。值得注意的是,起始字符串在此页面上必须是唯一的,并且它也存在于其他产品页面上。此页面仅允许软件查找要使用采集的位置。其他页面很常见,以确保软件可以从其他页面采集数据。填写后,并不意味着可以是采集正确。它需要测试以排除一些无用的数据。可以在HTML标记排除和内容排除中执行排除。测试成功后,制作此类标签。这里我们使用通配符来实现这一要求。我们使用(*)通配符来表示任何不常见的地方。地址采集由参数(变量)表示。最后,让我们将这一段改为: 查看全部
内容采集器(
优采云采集器怎么把内容导入网站?如何使用采集器采集网页图片)

优采云采集器如何将内容导入网站
现在它基本上是免费的采集器并且有强大的功能。它比优采云. 例如,优采云采集器的cloud采集函数就是一团乱麻,速度很快,规则的制定也特别简单
优采云采集器如何使用它
用几句话来描述这种方法是非常困难的。我建议你看一下两个官方视频教程:一个是“播放优采云采集器,9节课,让你开始并掌握”;另一个是“优采云采集器-URL采集rule”。我相信你在学习了这些视频教程后会用到它
让我简单谈谈优采云的工作原理@采集器. 它主要执行软件中配置的捕获规则,解析后存储在您自己的数据库或文件中。因此,您主要需要分析两个方面:一是观察网页翻页URL的变化,汇总并提交给优采云,让它知道如何自动翻页;另一方面,分析列表页面和详细信息页面的HTML,告诉优采云要抓取哪个标签,要抓取文章内容文本的网站,以及在详细信息页面上提取哪些信息,如来源、作者等。所有这些都是为优采云找到的,并进行分析和总结,以便它能够自动工作
如何使用优采云采集器采集网页图片详细图形教程
优采云采集器采集信息分为两个步骤:1。采用网站。这一步还告诉软件需要采集多少网页,并给出具体的网页地址。2.内容。有了网站后,你可以去网站上的采集信息,但是网站上有很多信息,软件不知道你想采用什么。在内容部分,我们必须制定规则。告诉软件我想采用什么。1.采用网站。网页上的产品信息是您想要采用的,即目标。在采集链接页面中,输入采集地址的列表页面。在这里,注意过滤无用的链接。然后点击test按钮测试填写信息的正确性:测试正确后,我们展开地址。现在我们只需获取列表页面的文章地址,还有其他列表需要采集。其他列表页面在其页面上。我们观察这些发行版的链接形式,找出规则,然后批量填写URL规则。2.在对内容的采集进行上述处理后,可以采集目标产品页面的链接。让我们输入内容的采集。定义了采集的内容后,我们开始编写采集规则,优采云采集内容是采集网页的源代码,所以我们需要打开产品页面的源代码,找到我们想要的采集信息的位置。例如,description字段中的采集在找到描述的位置后如何填写采集规则非常简单。只需将采集目标的开始字符串和结束字符串填入采集的相应位置即可。这里我们选择Description:作为开始字符串和结束字符串。值得注意的是,起始字符串在此页面上必须是唯一的,并且它也存在于其他产品页面上。此页面仅允许软件查找要使用采集的位置。其他页面很常见,以确保软件可以从其他页面采集数据。填写后,并不意味着可以是采集正确。它需要测试以排除一些无用的数据。可以在HTML标记排除和内容排除中执行排除。测试成功后,制作此类标签。这里我们使用通配符来实现这一要求。我们使用(*)通配符来表示任何不常见的地方。地址采集由参数(变量)表示。最后,让我们将这一段改为:
内容采集器(别人采集自己的内容时候,排名比我们高的原因)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-09-20 06:29
当其他采集拥有自己的内容时,排名高于我们的原因有两个。第一个是权威网站。这是正常的。例如,我们的新网站就像一个孩子,而其他人的网站已经像一个老板了。当一个孩子说一个非常合理的词时,很多人并不这么认为。就在老板听到的时候,他也这么说了。然后很多人愿意听老板的话,认为老板的话是真的
不同的人说同一句话的效果不同,所以如果你的内容是由权威网站采集发布的,首先不要担心悲伤,因为这表明你的内容是有价值的。如果你与权威网站沟通良好,你可以得到一个很好的解决方案。你也可以在网站上留下链接,这也有助于我们网站增加我们的体重,这是一个双赢的局面
第二个是整个车站采集。整个车站采集是不同的。整个车站采集通常位于同一水平面上。看到他们的努力成果被别人夺走,真是无可奈何
但目前,搜索引擎已经加大了对此类网站的攻击力度。随着飓风算法和熊掌神助攻击的实施,原创内容得到了更好的保护。整个网站采集注定只能存活很短时间
@如何避免因三、采集内容而受到处罚
@上面已经提到了对采集内容被处罚的分析,如果我们想要采集内容,我们如何避免被处罚
1.内容可以保持不变,但标题必须修改
搜索引擎通过标题匹配关键词标题,分配给标题的权重相对较高。因此,当你重新定义采集内容时,你必须修改标题,不要太相似,并且含义与内容不分离
2.提高含量
采集我们可以处理和改善过去的内容,就像美食一样。对于同一种食品,一种是包装的,另一种不是,它们的价值和用户偏好不同
那么具体的处理在哪里呢?主要从图片、字体颜色、粗体字体等细节。如果采集内容已经很完美了,你不妨在文本的前面或后面添加你自己的观点
3.采集的含量应注意质量。懒惰的采集将毫无用处
采集内容应该有质量,这样搜索引擎一般不会攻击。什么是高质量内容?首先,我们应该确保采集内容不会太旧。其次,那些在搜索引擎中搜索结果很少的人也属于。第三,最重要的一点是内容应该对用户有帮助。我们的内容最终是针对用户的。没有值引用的内容无法推送到用户。禁止使用自动采集软件进行推广
四、如何防止他人的采集网站内容
如何防止他人采集我们的网站内容?在早期阶段,尽量保持低调,不要让别人发现,尽量只生成链接内容而不在网站页面上更新,这样别人就无法搜索,但搜索引擎可以更好地捕获内容。当后面的排名和权重上升时,他们将不再采集帮助
您还可以添加禁止右键单击网站页面的代码。虽然其他人可以通过代码采集来实现,但采集难度的增加可能会让采集用户半途而废,转而寻找其他资源
结论:本文简要介绍了搜索引擎如何处理互联网上的采集内容。简言之,大多数盲人采集都是无用的。只有有采集的意图,我们才能实现双赢。不要投机取巧 查看全部
内容采集器(别人采集自己的内容时候,排名比我们高的原因)
当其他采集拥有自己的内容时,排名高于我们的原因有两个。第一个是权威网站。这是正常的。例如,我们的新网站就像一个孩子,而其他人的网站已经像一个老板了。当一个孩子说一个非常合理的词时,很多人并不这么认为。就在老板听到的时候,他也这么说了。然后很多人愿意听老板的话,认为老板的话是真的
不同的人说同一句话的效果不同,所以如果你的内容是由权威网站采集发布的,首先不要担心悲伤,因为这表明你的内容是有价值的。如果你与权威网站沟通良好,你可以得到一个很好的解决方案。你也可以在网站上留下链接,这也有助于我们网站增加我们的体重,这是一个双赢的局面
第二个是整个车站采集。整个车站采集是不同的。整个车站采集通常位于同一水平面上。看到他们的努力成果被别人夺走,真是无可奈何
但目前,搜索引擎已经加大了对此类网站的攻击力度。随着飓风算法和熊掌神助攻击的实施,原创内容得到了更好的保护。整个网站采集注定只能存活很短时间
@如何避免因三、采集内容而受到处罚
@上面已经提到了对采集内容被处罚的分析,如果我们想要采集内容,我们如何避免被处罚
1.内容可以保持不变,但标题必须修改
搜索引擎通过标题匹配关键词标题,分配给标题的权重相对较高。因此,当你重新定义采集内容时,你必须修改标题,不要太相似,并且含义与内容不分离
2.提高含量
采集我们可以处理和改善过去的内容,就像美食一样。对于同一种食品,一种是包装的,另一种不是,它们的价值和用户偏好不同
那么具体的处理在哪里呢?主要从图片、字体颜色、粗体字体等细节。如果采集内容已经很完美了,你不妨在文本的前面或后面添加你自己的观点
3.采集的含量应注意质量。懒惰的采集将毫无用处
采集内容应该有质量,这样搜索引擎一般不会攻击。什么是高质量内容?首先,我们应该确保采集内容不会太旧。其次,那些在搜索引擎中搜索结果很少的人也属于。第三,最重要的一点是内容应该对用户有帮助。我们的内容最终是针对用户的。没有值引用的内容无法推送到用户。禁止使用自动采集软件进行推广
四、如何防止他人的采集网站内容
如何防止他人采集我们的网站内容?在早期阶段,尽量保持低调,不要让别人发现,尽量只生成链接内容而不在网站页面上更新,这样别人就无法搜索,但搜索引擎可以更好地捕获内容。当后面的排名和权重上升时,他们将不再采集帮助
您还可以添加禁止右键单击网站页面的代码。虽然其他人可以通过代码采集来实现,但采集难度的增加可能会让采集用户半途而废,转而寻找其他资源
结论:本文简要介绍了搜索引擎如何处理互联网上的采集内容。简言之,大多数盲人采集都是无用的。只有有采集的意图,我们才能实现双赢。不要投机取巧
内容采集器(优采云采集论坛会员注册器是一款非常实用且操作便捷的网站内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-09-14 19:00
优采云采集论坛会员注册工具是一个非常实用方便的操作网站内容采集软件,优采云采集论坛会员注册工具可以让用户采集各类论坛发帖和回复、网站和博客文章的内容抓取、各种论坛会员的无限注册等,帮助用户轻松采集自己想要的内容。
【功能介绍】1、软件可以有效过滤已经采集的帖子,每天采集最新帖子发布到自己论坛指定版块
2、可以将发帖和回复的会员账号分开,允许部分会员发布所有主题,其他会员全部回复,会员账号随机选择发布
3、 支持自定义发帖和回复间隔时间
4、software 有一个或多个版块的自动回复功能,回复内容可自定义
5、有采集或发帖任务完成后自动关机功能
6、support 文章content 同义词替换功能
7、软件可以采集注册登录后才能查看的论坛帖子
【使用教程】第一步,在IE窗口打开需要注册的论坛,找到该论坛的注册页面网址!并且确保注册页面只保留“用户名、密码、确认密码、邮箱”这四个必填项!请到论坛后台暂时关闭其他项目!登录论坛后台≯≯基本设置≯≯注册及权限控制,取消所有会员注册限制,包括“新用户注册验证、不同用户同一邮箱注册、IP注册间隔限制、24小时注册尝试限制” ”等,然后保存。如果注册项有自行修改代码或添加插件,请备份并直接用官方原文件覆盖,注册后恢复。
第二步,打开优采云论坛注册器,点击下方“会员注册”按钮。
第三步,在软件网址栏中输入论坛注册页面网址。
第四步,点击右下角的“会员注册”!如果提示会员注册失败,请检查第一步中的设置是否全部正确,您可以手动注册会员进行测试。
第五步,妥善保存已注册成功的会员信息供其他软件使用! 查看全部
内容采集器(优采云采集论坛会员注册器是一款非常实用且操作便捷的网站内容)
优采云采集论坛会员注册工具是一个非常实用方便的操作网站内容采集软件,优采云采集论坛会员注册工具可以让用户采集各类论坛发帖和回复、网站和博客文章的内容抓取、各种论坛会员的无限注册等,帮助用户轻松采集自己想要的内容。

【功能介绍】1、软件可以有效过滤已经采集的帖子,每天采集最新帖子发布到自己论坛指定版块
2、可以将发帖和回复的会员账号分开,允许部分会员发布所有主题,其他会员全部回复,会员账号随机选择发布
3、 支持自定义发帖和回复间隔时间
4、software 有一个或多个版块的自动回复功能,回复内容可自定义
5、有采集或发帖任务完成后自动关机功能
6、support 文章content 同义词替换功能
7、软件可以采集注册登录后才能查看的论坛帖子
【使用教程】第一步,在IE窗口打开需要注册的论坛,找到该论坛的注册页面网址!并且确保注册页面只保留“用户名、密码、确认密码、邮箱”这四个必填项!请到论坛后台暂时关闭其他项目!登录论坛后台≯≯基本设置≯≯注册及权限控制,取消所有会员注册限制,包括“新用户注册验证、不同用户同一邮箱注册、IP注册间隔限制、24小时注册尝试限制” ”等,然后保存。如果注册项有自行修改代码或添加插件,请备份并直接用官方原文件覆盖,注册后恢复。
第二步,打开优采云论坛注册器,点击下方“会员注册”按钮。
第三步,在软件网址栏中输入论坛注册页面网址。
第四步,点击右下角的“会员注册”!如果提示会员注册失败,请检查第一步中的设置是否全部正确,您可以手动注册会员进行测试。
第五步,妥善保存已注册成功的会员信息供其他软件使用!
内容采集器(数据采集对各行各业有着至关重要的作用,你了解多少?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2021-09-14 18:12
Data采集在各行各业中发挥着至关重要的作用,让个人、公司、组织实现大数据的宏观调控,研究分析,总结规律,做出准确判断和决策.
1、优采云采集器
优采云是一个集网页数据采集、移动互联网数据和API接口服务(包括数据爬虫、数据优化、数据挖掘、数据存储、数据备份)等服务于一体的数据服务平台,连续5年同年获得互联网Data采集software榜单第一名。 2016年以来,优采云积极开拓海外市场,分别在美国和日本推出Octoparse和Octoparse.jp数据爬取平台。截至2019年,优采云全球用户超过150万。其一大特点:零门槛使用,无需了解网络爬虫技术,即可轻松完成采集。
2、优采云采集器
国内老牌数据采集软件,以其灵活的配置和强大的性能领先国内同类产品,获得了众多用户的一致认可。使用优采云采集器几乎可以采集任何格式的所有网页和文件,不管是什么语言或编码。 采集 比普通采集器 快7 倍,采集/posting 和复制/粘贴一样准确。同时,软件还具备“舆论雷达监控系统”,精准监控网络数据信息安全,及时处理不利或危险信息。
3、优采云采集器
如果的编辑推荐最好的信息采集software,那一定是优采云采集器。 优采云采集器由原谷歌技术团队打造,基于人工智能技术,支持智能模式和流程图模式采集;使用简单,只需输入URL即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集;并且软件支持Linux、Windows、Mac三大操作系统,导出数据不花钱,还支持Excel、CSV、TXT、HTML多种导出格式。与其他同类软件相比,仅此一点就够良心了。
4、集搜客
经过十多年打磨的GooSeeker已经是一款易用性出众的数据采集软件。其特点是对各种采集数据进行了可视化标注,用户无需考虑程序,无需技术基础,只需点击想要的内容,给标签起个名字,然后软件自动管理选中的内容。自动采集到排序框,并保存为xml或excel结构。此外,软件还具有模板资源申请、会员互助抓取、手机网站数据抓取、定时自启动采集等功能。
5、优采云采集器
这是一套专业的网站内容采集软件,支持各种论坛帖子回复采集、网站和博客文章内容抓取,通过相关配置,可以轻松@网站采集80% 的内容自用。根据建站方案的不同,优采云采集器分论坛采集器、cms采集器和博客采集器三种类型,共数百个版本数据支持近40个主流网站构建程序采集和发布任务,支持图片本地化,支持网站login采集,页面抓取,全面模拟手动登录发布。此外,软件还内置了SEO伪原创模块,让您的采集更加强大。
6、Import.io
英国市场最著名的采集器之一,由一家总部位于英国伦敦的公司开发,现已在美国、印度等地设立分支机构。作为网页数据采集software,import.io有四大功能,分别是Magic、Extractor、Crawler、Connector。主要功能都具备,但最抢眼、最好的功能就是其中的“魔法”。 , 该功能让用户只需进入网页即可自动提取数据,无需任何其他设置,使用起来极其简单。
7、ParseHub
ForeSpider 也是一款易于操作且强烈推荐的信息采集 软件。它分为免费版和付费版。具有可视化的向导式操作界面,日志管理和异常情况预警,免安装数据库,可自动识别语义筛选数据,智能挖掘文本特征数据,同时自带多种数据清理方法,并自带可视化图表分析。软件免费版、基础版、专业版采集速度高达400万条/天,服务器版采集速度高达8000万条/天,并提供采集服务。
8、优采云
优采云是采集软件中最常用的信息之一。封装了复杂的算法和分布式逻辑,提供了灵活简单的开发接口;应用自动部署,分布式运行,可视化,操作简单,计算和存储资源弹性扩展;不同来源的数据统一可视化管理,restful界面/webhook推送/graphql访问等高级功能,让用户与现有系统无缝对接。软件现提供企业标准版、高级版、企业定制版。
9、ForeSpider
ParseHub 是一款基于网页的爬取客户端工具,支持 JavaScript 渲染、Ajax 爬取、Cookies、Session 等机制,对网站 的数据进行分析和获取。它还可以使用机器学习技术来识别复杂的文档并以 JSON、CSV 等格式导出文件。该软件支持在 Windows、Mac 和 Linux 上使用,或作为 Firefox 扩展。此外,它还具有一些高级功能,例如分页、弹出窗口和导航、无限滚动页面等,可以将 ParseHub 中的数据可视化为 Tableau。
10、Content Grabber
Content Grabber是一款支持智能抓取的可视化网页数据采集软件和网络自动化工具,可以从几乎所有网站中提取内容。其程序运行环境可用于开发、测试和生产服务器。可以使用c#或VB.NET调试或编写脚本来控制爬虫程序。还支持在爬虫工具中添加第三方扩展插件。 Content Grabber 功能齐全,非常适合有技术基础的用户使用。 查看全部
内容采集器(数据采集对各行各业有着至关重要的作用,你了解多少?)
Data采集在各行各业中发挥着至关重要的作用,让个人、公司、组织实现大数据的宏观调控,研究分析,总结规律,做出准确判断和决策.
1、优采云采集器
优采云是一个集网页数据采集、移动互联网数据和API接口服务(包括数据爬虫、数据优化、数据挖掘、数据存储、数据备份)等服务于一体的数据服务平台,连续5年同年获得互联网Data采集software榜单第一名。 2016年以来,优采云积极开拓海外市场,分别在美国和日本推出Octoparse和Octoparse.jp数据爬取平台。截至2019年,优采云全球用户超过150万。其一大特点:零门槛使用,无需了解网络爬虫技术,即可轻松完成采集。
2、优采云采集器
国内老牌数据采集软件,以其灵活的配置和强大的性能领先国内同类产品,获得了众多用户的一致认可。使用优采云采集器几乎可以采集任何格式的所有网页和文件,不管是什么语言或编码。 采集 比普通采集器 快7 倍,采集/posting 和复制/粘贴一样准确。同时,软件还具备“舆论雷达监控系统”,精准监控网络数据信息安全,及时处理不利或危险信息。
3、优采云采集器
如果的编辑推荐最好的信息采集software,那一定是优采云采集器。 优采云采集器由原谷歌技术团队打造,基于人工智能技术,支持智能模式和流程图模式采集;使用简单,只需输入URL即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集;并且软件支持Linux、Windows、Mac三大操作系统,导出数据不花钱,还支持Excel、CSV、TXT、HTML多种导出格式。与其他同类软件相比,仅此一点就够良心了。
4、集搜客
经过十多年打磨的GooSeeker已经是一款易用性出众的数据采集软件。其特点是对各种采集数据进行了可视化标注,用户无需考虑程序,无需技术基础,只需点击想要的内容,给标签起个名字,然后软件自动管理选中的内容。自动采集到排序框,并保存为xml或excel结构。此外,软件还具有模板资源申请、会员互助抓取、手机网站数据抓取、定时自启动采集等功能。
5、优采云采集器
这是一套专业的网站内容采集软件,支持各种论坛帖子回复采集、网站和博客文章内容抓取,通过相关配置,可以轻松@网站采集80% 的内容自用。根据建站方案的不同,优采云采集器分论坛采集器、cms采集器和博客采集器三种类型,共数百个版本数据支持近40个主流网站构建程序采集和发布任务,支持图片本地化,支持网站login采集,页面抓取,全面模拟手动登录发布。此外,软件还内置了SEO伪原创模块,让您的采集更加强大。
6、Import.io
英国市场最著名的采集器之一,由一家总部位于英国伦敦的公司开发,现已在美国、印度等地设立分支机构。作为网页数据采集software,import.io有四大功能,分别是Magic、Extractor、Crawler、Connector。主要功能都具备,但最抢眼、最好的功能就是其中的“魔法”。 , 该功能让用户只需进入网页即可自动提取数据,无需任何其他设置,使用起来极其简单。
7、ParseHub
ForeSpider 也是一款易于操作且强烈推荐的信息采集 软件。它分为免费版和付费版。具有可视化的向导式操作界面,日志管理和异常情况预警,免安装数据库,可自动识别语义筛选数据,智能挖掘文本特征数据,同时自带多种数据清理方法,并自带可视化图表分析。软件免费版、基础版、专业版采集速度高达400万条/天,服务器版采集速度高达8000万条/天,并提供采集服务。
8、优采云
优采云是采集软件中最常用的信息之一。封装了复杂的算法和分布式逻辑,提供了灵活简单的开发接口;应用自动部署,分布式运行,可视化,操作简单,计算和存储资源弹性扩展;不同来源的数据统一可视化管理,restful界面/webhook推送/graphql访问等高级功能,让用户与现有系统无缝对接。软件现提供企业标准版、高级版、企业定制版。
9、ForeSpider
ParseHub 是一款基于网页的爬取客户端工具,支持 JavaScript 渲染、Ajax 爬取、Cookies、Session 等机制,对网站 的数据进行分析和获取。它还可以使用机器学习技术来识别复杂的文档并以 JSON、CSV 等格式导出文件。该软件支持在 Windows、Mac 和 Linux 上使用,或作为 Firefox 扩展。此外,它还具有一些高级功能,例如分页、弹出窗口和导航、无限滚动页面等,可以将 ParseHub 中的数据可视化为 Tableau。
10、Content Grabber
Content Grabber是一款支持智能抓取的可视化网页数据采集软件和网络自动化工具,可以从几乎所有网站中提取内容。其程序运行环境可用于开发、测试和生产服务器。可以使用c#或VB.NET调试或编写脚本来控制爬虫程序。还支持在爬虫工具中添加第三方扩展插件。 Content Grabber 功能齐全,非常适合有技术基础的用户使用。
内容采集器(跳出本次或当前循环与终止循环方法PHP中用foreach(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2021-09-12 03:13
猜猜你在找什么 PHP 相关的文章
TP5查询mysql数据库时find_in_set的使用
type字段以1,2,3的形式存在于数据库中。已经提到使用FIND_IN_SET函数对于一些非常复杂的查询,比如find_in_set,也可以直接使用原生的SQL语句进行查询,例如:出于安全考虑
php处理微信支付回调(收款)的方法
支付完成后,微信将相关支付结果和用户信息发送给商户。商户需要接收处理,并返回响应。与后台通知交互时,如果微信对商家响应的响应不成功或超时,则微信认为通知失败,微信会通过一定的策略定期重新发起通知。
composer 安装 Yii2 遇到的 BUG
通过 Composer 安装 安装 Composer 如果您还没有安装 Composer,您可以按照中的方法安装。在 Linux 和 Mac OS 中
PHP foreach() 跳出当前或当前循环并终止循环方法
PHPforeach() 跳出当前或当前循环并终止循环方法。在PHP中的foreach()循环中,当你想在循环中,当满足某个条件时,我想下面是我打印$praProductData结果的实际例子如下:
宝塔面板忘记密码的解决方法
如果忘记宝塔密码,可以使用以下命令重置密码: cd /www/server/panel && python tools.py panel testpasswd 如果提示多次登录失败,暂时禁止
Redis 主题-Redis 管理工具
一、安全性1、 运行环境Redis简洁美观,其安全性没有太多操作。要求外界不能直接连接生产系统中的Redis进行操作,而必须在程序转入后由程序进行。操作。即redis需要运行在可信环境中。
使用phpqrcode二维码生成类库合成带有logo的二维码,并使用合成的二维码生成海报(二)
前期准备 引入phpqrcode库(下载地址:;支持彩色二维码的下载地址:htt
我记得之前写过关于两者之间的区别。今天看群里的朋友也提出了一个奇怪的问题,说“file_get_contents('php://input')无法获取curl post请求的数据。”?其实 查看全部
内容采集器(跳出本次或当前循环与终止循环方法PHP中用foreach(图))
猜猜你在找什么 PHP 相关的文章
TP5查询mysql数据库时find_in_set的使用
type字段以1,2,3的形式存在于数据库中。已经提到使用FIND_IN_SET函数对于一些非常复杂的查询,比如find_in_set,也可以直接使用原生的SQL语句进行查询,例如:出于安全考虑
php处理微信支付回调(收款)的方法
支付完成后,微信将相关支付结果和用户信息发送给商户。商户需要接收处理,并返回响应。与后台通知交互时,如果微信对商家响应的响应不成功或超时,则微信认为通知失败,微信会通过一定的策略定期重新发起通知。
composer 安装 Yii2 遇到的 BUG
通过 Composer 安装 安装 Composer 如果您还没有安装 Composer,您可以按照中的方法安装。在 Linux 和 Mac OS 中
PHP foreach() 跳出当前或当前循环并终止循环方法
PHPforeach() 跳出当前或当前循环并终止循环方法。在PHP中的foreach()循环中,当你想在循环中,当满足某个条件时,我想下面是我打印$praProductData结果的实际例子如下:
宝塔面板忘记密码的解决方法
如果忘记宝塔密码,可以使用以下命令重置密码: cd /www/server/panel && python tools.py panel testpasswd 如果提示多次登录失败,暂时禁止
Redis 主题-Redis 管理工具
一、安全性1、 运行环境Redis简洁美观,其安全性没有太多操作。要求外界不能直接连接生产系统中的Redis进行操作,而必须在程序转入后由程序进行。操作。即redis需要运行在可信环境中。
使用phpqrcode二维码生成类库合成带有logo的二维码,并使用合成的二维码生成海报(二)
前期准备 引入phpqrcode库(下载地址:;支持彩色二维码的下载地址:htt
我记得之前写过关于两者之间的区别。今天看群里的朋友也提出了一个奇怪的问题,说“file_get_contents('php://input')无法获取curl post请求的数据。”?其实
内容采集器(软件特色零门槛不懂网络爬虫技术,赶紧下载体验吧)
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-09-08 00:06
优采云采集器是新一代可视化智能采集器,可视化配置,轻松创建,无需编程,智能生成,数据采集从未如此简单,赶快下载体验吧。
相关软件软件大小及版本说明下载链接
优采云采集器是新一代可视化智能采集器,可视化配置,轻松创建,无需编程,智能生成,数据采集从未如此简单,赶快下载体验吧!
软件功能
零门槛
如果你不懂网络爬虫技术,如果你会上网,你会采集网站数据
多引擎,高速稳定
内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集data更高效。还内置了JSON引擎,无需分析JSON数据结构,直观选择JSON内容。
适用于各种网站
采集 Internet 99% 网站,包括单页应用ajax加载等动态类型网站。
产品优势
可视化向导
所有采集元素自动生成采集数据
预定任务
运行时间灵活定义,全自动运行
多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
自动识别网页列表、采集字段、分页等
拦截请求
自定义屏蔽域名,方便过滤异地广告,提升采集速度
多数据导出
可导出为 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等
更新日志
3.2.4.9 (2021-09-04)
优化编译,修复部分组件系统兼容性问题 查看全部
内容采集器(软件特色零门槛不懂网络爬虫技术,赶紧下载体验吧)
优采云采集器是新一代可视化智能采集器,可视化配置,轻松创建,无需编程,智能生成,数据采集从未如此简单,赶快下载体验吧。
相关软件软件大小及版本说明下载链接
优采云采集器是新一代可视化智能采集器,可视化配置,轻松创建,无需编程,智能生成,数据采集从未如此简单,赶快下载体验吧!

软件功能
零门槛
如果你不懂网络爬虫技术,如果你会上网,你会采集网站数据
多引擎,高速稳定
内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集data更高效。还内置了JSON引擎,无需分析JSON数据结构,直观选择JSON内容。
适用于各种网站
采集 Internet 99% 网站,包括单页应用ajax加载等动态类型网站。
产品优势
可视化向导
所有采集元素自动生成采集数据
预定任务
运行时间灵活定义,全自动运行
多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
自动识别网页列表、采集字段、分页等
拦截请求
自定义屏蔽域名,方便过滤异地广告,提升采集速度
多数据导出
可导出为 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等

更新日志
3.2.4.9 (2021-09-04)
优化编译,修复部分组件系统兼容性问题
内容采集器(小编为大家讲解有关语言编程其中不被重视的技巧)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-09-07 22:12
今天小编就给大家文章讲解语言编程。在课堂上,教师将了解语言编程中不被重视的技能。相信对大家会有很大的帮助
php示例教程采集器,通常称为小偷程序,主要用于抓取他人网页的内容。关于采集器的制作,其实并不难。就是远程打开需要采集的网页,然后用正则表达式匹配需要的内容。只要你有一点正则表达式的基础,就可以让自己的采集器来了。
前几天做了一个小说连载程序,因为怕更新麻烦,写了个采集器,采集八路中文网,功能比较简单,不能自定义规则,不过大概思路都在里面,自定义规则可以自己扩展。
使用php做采集器主要使用两个函数:file_get_contents()和preg_match_all()。第一个是远程阅读网页内容,但只能在php5以上版本使用,后者是常规功能。 , 用于提取需要的内容。
让我们一步一步地谈谈函数的实现。
因为是采集小说,先提取标题、作者、流派。其他信息可根据需要提取。
这里是《回明朝太子》的目标,先打开书目页面,链接:
再打开几本书,你会发现书名的基本格式是:book number/Index.aspx,所以我们可以制作一个起始页,定义一个,用它输入需要的书号采集,然后我们可以通过 $_POST['number'] 这个格式来接收采集的书号。收到书号后,接下来要做的就是构造书目页面:$url=$_POST['number']/Index.aspx,当然这里是一个例子,主要是为了方便说明,就是最好以实际生产为准。 _POST['number'] 的合法性。
构建好URL后,即可开启采集书信息。使用file_get_contents()函数打开书目页面:$content=file_get_contents($url),这样就可以读取书目页面的内容了。下一步是匹配书名、作者和类型。这是一个带有书名的例子,其他一切都是一样的。打开书目页面,查看源文件,找到《回明为主》,这是要提取的书名。提取书名的正则表达式:/(.*?)\\\\/is,使用preg_match_all()函数提取书名:preg_match_all("/(.*?)\\\\/is" ,$contents,$title);这样$title[0][0]的内容就是我们想要的title(preg_match_all函数的用法可以百度查,这里就不详细解释了)。取出书籍信息后,下一步就是取出章节内容。取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。 ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:
preg_match_all("/Html\\\\/Book\\\\/[0-9]{1,}\\\\/[0-9]{1,}\\\\/List\\ \\.shtm/is",$contents,$typeid);这还不够,我们还需要一个剪切功能:
[复制代码] [-] PHP代码如下:
以下为引用内容:
function cut($string,$start,$end){
$message = expand($start,$string);
$message=explode($end,$message[1]); return $message[0];} 其中 $string 是要剪切的内容,$start 是开头,$end 是结尾。检索分类号:
$start = "Html/Book/";
$end
="列表.shtm";
$typeid = cut($typeid[0][0],$start,$end);
$typeid = expand("/",$typeid);[/php]
嗯,我从事编程语言统计多年,数据来源很多,包括代码库、问答讨论、招聘广告、社交媒体情况、教程页面访问量、学习视频浏览量、开发者调查、等。不同时间发布的数据可以认为是准确的。
也可以被视为有缺陷,但它们可用于发现行业趋势。最后,不要指望一夜之间成为编码忍者。有些人有天生的能力,但他们也花大量时间磨练自己的技能,不断学习新的技术和技能。 "
XML 在过去三年中经历了多次迭代,因此目前存在不同版本的 Microsoft XML 解析器也就不足为奇了。 Internet Explorer 4.0 收录早期版本的 XML 解析器,它早于 XSL、XML 数据或大多数其他 XML 技术(并且具有完全不同的 DOM 模型)。这个早期版本的分析器收录在 MSXML.dll 库中。可以从 MSDN XML 开发人员中心(英文)将分析器升级到更新的分析器。
我们强烈建议您升级到新的分析器,因为它更强大。 Internet Explorer 5.0 包括 MSXML 2.0 解析器,其中收录 XSL 和 XML 架构的基本版本。 MSXML2 是 SQL Server 2000 附带的解析器版本。MSXML2 收录许多性能增强功能,并且整体性能和可伸缩性得到了改进。 MSXML3 是当前作为“技术预览”收录的版本。 MSXML3 包括 XSLT 和 XPath 支持以及 SAX 接口。
在php教程中,$typeid[0]就是我们要找的分类号。下一步是构造章节列表的地址:$chapterurl = $typeid[0]/$_POST[‘number’]/List.shtm。有了这个,你可以找到每章的地址。方法如下:
以下为引用内容:
$ustart = "\\\\"";
$uend
="\\\\"";
//t代表title的缩写
$tstart = ">";
$趋向
=" 查看全部
内容采集器(小编为大家讲解有关语言编程其中不被重视的技巧)
今天小编就给大家文章讲解语言编程。在课堂上,教师将了解语言编程中不被重视的技能。相信对大家会有很大的帮助
php示例教程采集器,通常称为小偷程序,主要用于抓取他人网页的内容。关于采集器的制作,其实并不难。就是远程打开需要采集的网页,然后用正则表达式匹配需要的内容。只要你有一点正则表达式的基础,就可以让自己的采集器来了。
前几天做了一个小说连载程序,因为怕更新麻烦,写了个采集器,采集八路中文网,功能比较简单,不能自定义规则,不过大概思路都在里面,自定义规则可以自己扩展。
使用php做采集器主要使用两个函数:file_get_contents()和preg_match_all()。第一个是远程阅读网页内容,但只能在php5以上版本使用,后者是常规功能。 , 用于提取需要的内容。
让我们一步一步地谈谈函数的实现。
因为是采集小说,先提取标题、作者、流派。其他信息可根据需要提取。
这里是《回明朝太子》的目标,先打开书目页面,链接:
再打开几本书,你会发现书名的基本格式是:book number/Index.aspx,所以我们可以制作一个起始页,定义一个,用它输入需要的书号采集,然后我们可以通过 $_POST['number'] 这个格式来接收采集的书号。收到书号后,接下来要做的就是构造书目页面:$url=$_POST['number']/Index.aspx,当然这里是一个例子,主要是为了方便说明,就是最好以实际生产为准。 _POST['number'] 的合法性。
构建好URL后,即可开启采集书信息。使用file_get_contents()函数打开书目页面:$content=file_get_contents($url),这样就可以读取书目页面的内容了。下一步是匹配书名、作者和类型。这是一个带有书名的例子,其他一切都是一样的。打开书目页面,查看源文件,找到《回明为主》,这是要提取的书名。提取书名的正则表达式:/(.*?)\\\\/is,使用preg_match_all()函数提取书名:preg_match_all("/(.*?)\\\\/is" ,$contents,$title);这样$title[0][0]的内容就是我们想要的title(preg_match_all函数的用法可以百度查,这里就不详细解释了)。取出书籍信息后,下一步就是取出章节内容。取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。 ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:
preg_match_all("/Html\\\\/Book\\\\/[0-9]{1,}\\\\/[0-9]{1,}\\\\/List\\ \\.shtm/is",$contents,$typeid);这还不够,我们还需要一个剪切功能:
[复制代码] [-] PHP代码如下:

以下为引用内容:
function cut($string,$start,$end){
$message = expand($start,$string);
$message=explode($end,$message[1]); return $message[0];} 其中 $string 是要剪切的内容,$start 是开头,$end 是结尾。检索分类号:
$start = "Html/Book/";
$end
="列表.shtm";
$typeid = cut($typeid[0][0],$start,$end);
$typeid = expand("/",$typeid);[/php]
嗯,我从事编程语言统计多年,数据来源很多,包括代码库、问答讨论、招聘广告、社交媒体情况、教程页面访问量、学习视频浏览量、开发者调查、等。不同时间发布的数据可以认为是准确的。
也可以被视为有缺陷,但它们可用于发现行业趋势。最后,不要指望一夜之间成为编码忍者。有些人有天生的能力,但他们也花大量时间磨练自己的技能,不断学习新的技术和技能。 "
XML 在过去三年中经历了多次迭代,因此目前存在不同版本的 Microsoft XML 解析器也就不足为奇了。 Internet Explorer 4.0 收录早期版本的 XML 解析器,它早于 XSL、XML 数据或大多数其他 XML 技术(并且具有完全不同的 DOM 模型)。这个早期版本的分析器收录在 MSXML.dll 库中。可以从 MSDN XML 开发人员中心(英文)将分析器升级到更新的分析器。
我们强烈建议您升级到新的分析器,因为它更强大。 Internet Explorer 5.0 包括 MSXML 2.0 解析器,其中收录 XSL 和 XML 架构的基本版本。 MSXML2 是 SQL Server 2000 附带的解析器版本。MSXML2 收录许多性能增强功能,并且整体性能和可伸缩性得到了改进。 MSXML3 是当前作为“技术预览”收录的版本。 MSXML3 包括 XSLT 和 XPath 支持以及 SAX 接口。
在php教程中,$typeid[0]就是我们要找的分类号。下一步是构造章节列表的地址:$chapterurl = $typeid[0]/$_POST[‘number’]/List.shtm。有了这个,你可以找到每章的地址。方法如下:
以下为引用内容:
$ustart = "\\\\"";
$uend
="\\\\"";
//t代表title的缩写
$tstart = ">";
$趋向
="
内容采集器(电子书采集工具完结电子书,每本电子书自动获取简介图片,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2021-09-06 03:03
电子书采集工具是一个很好的完整电子书下载txt免费下载集合。电子书采集工具的采集过程很简单,只要稍微简单一点就可以做到如果电子书取出准确,每本电子书都会自动分割。
小说规则自建txt下载(e-book采集器)是一款绿色免费的小说采集auxiliary软件,采集网站小说上面没有下载按钮,这个软件就等价了抢网站的小说内容适用于网站,在线阅读电子书。
30天下载提供电子书采集工具v2.0。电脑正式版可免费下载。操作简单,可以准确获取完成的电子书。每本电子书自动分为大类和子类,并自动获取个人资料图片保存在同一文件夹中。
1、 自动整合所有现有的电子书和小说系统,特别是文奇、结奇和新飞酷电子书系统。 2、自动优化多线程,减少CPU占用,减少内存占用。3、支持多系统电子书生成和下载。 4.
海科提供电子书采集tools(手机电子书下载系统)下载。蓝星手机下载系统e-books采集tools操作更简单,可以准确获取完成的电子书,每本电子书自动分大类和子类,自动获取简介。
华骏软件园下载工具频道为您提供电子书采集工具下载、电子书采集工具绿版等下载工具和软件下载。更多电子书采集工具2.0历史版本,请到华骏软件园!
小说TXT采集工具是论坛大神制作的小说采集下载工具,可以帮助用户从网站上采集下载小说内容,大量小说网站广告非常影响用户体验,那么你就可以使用这个软件采集和。
Taiwen text采集器,“采文文字采集器”是一款具有文本信息采集、文本文件管理和浏览功能的管理工具。它的主要功能是文本采集和文本管理。系统剪贴板中的监控和文本采集。 查看全部
内容采集器(电子书采集工具完结电子书,每本电子书自动获取简介图片,)
电子书采集工具是一个很好的完整电子书下载txt免费下载集合。电子书采集工具的采集过程很简单,只要稍微简单一点就可以做到如果电子书取出准确,每本电子书都会自动分割。
小说规则自建txt下载(e-book采集器)是一款绿色免费的小说采集auxiliary软件,采集网站小说上面没有下载按钮,这个软件就等价了抢网站的小说内容适用于网站,在线阅读电子书。
30天下载提供电子书采集工具v2.0。电脑正式版可免费下载。操作简单,可以准确获取完成的电子书。每本电子书自动分为大类和子类,并自动获取个人资料图片保存在同一文件夹中。
1、 自动整合所有现有的电子书和小说系统,特别是文奇、结奇和新飞酷电子书系统。 2、自动优化多线程,减少CPU占用,减少内存占用。3、支持多系统电子书生成和下载。 4.
海科提供电子书采集tools(手机电子书下载系统)下载。蓝星手机下载系统e-books采集tools操作更简单,可以准确获取完成的电子书,每本电子书自动分大类和子类,自动获取简介。

华骏软件园下载工具频道为您提供电子书采集工具下载、电子书采集工具绿版等下载工具和软件下载。更多电子书采集工具2.0历史版本,请到华骏软件园!
小说TXT采集工具是论坛大神制作的小说采集下载工具,可以帮助用户从网站上采集下载小说内容,大量小说网站广告非常影响用户体验,那么你就可以使用这个软件采集和。

Taiwen text采集器,“采文文字采集器”是一款具有文本信息采集、文本文件管理和浏览功能的管理工具。它的主要功能是文本采集和文本管理。系统剪贴板中的监控和文本采集。
内容采集器(CowSwing迷你采集器-CRAWLER模块介绍及使用方法介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 256 次浏览 • 2021-09-05 02:02
CowSwing 简介
丑牛Mini采集器是一款基于Java Swing开发的专业网络数据采集/信息挖掘处理软件。通过灵活的配置,可以方便快捷的抓取网页中的结构化文本,可以对图片、文件等资源信息进行编辑过滤发布到网站
软件架构
JAVACOO-CRAWLER 采用模块化设计,每个模块由一个控制器类(CrawlController 类)协调,控制器是爬虫的核心。 CrawlController类是整个爬虫的整体控制器,控制着整个采集工作的起点,决定采集任务的开始、暂停、继续、结束。 CrawlController类主要包括以下模块:爬虫的配置参数、字符集助手、HttpCilent对象、HTML解析器包装类、爬虫边界控制器、爬虫线程控制器、处理器链、过滤器工厂。整体架构图如下:
CrawlScope:存放当前爬虫的配置信息,如采集page代码、采集filter列表、采集seed列表、爬虫持久化对象实现类等,根据配置参数初始化CrawlController其他模块。字符集助手(CharsetHandler):根据当前爬虫配置参数中的字符集配置进行初始化,为整个采集进程做准备。 HttpCilent对象(HttpClient):根据当前爬虫配置参数初始化HttpClient对象,如设置代理、设置连接/请求超时、最大连接数等。 HTML解析器包装类(HtmlParserWrapper):对HtmlParser的专门封装解析器来满足采集 任务的需要。 Frontier:主要是加载爬取的种子链接,并根据加载的种子链接初始化任务队列,准备线程控制器(ProcessorManager)开启的任务执行线程(ProcessorThread)。爬虫线程控制器(ProcessorManager):主要控制任务执行线程的数量,开启指定数量的任务执行线程来执行任务。过滤器工厂:为采集任务查询注册当前爬虫配置参数中设置的过滤器。主机缓存(HostCache):缓存HttpHost对象。处理器链(ProcessorChainList):默认构建了5条处理链,依次是预取链、提取链、提取链、写链、提交链,任务处理线程会用到。系统登录界面使用说明
系统启动界面
系统主界面
(1)我的爪牛:系统信息、插件信息、内存监控、任务监控
(2)采集Configuration:采集相关基础配置,包括远程数据库配置、FTP配置、自定义数据配置
(3)数据采集:统一管理采集进程,包括采集public参数设置、采集rule列表、采集historical列表、采集content列表
(4)任务监控:包括采集任务监控、仓储任务监控、图像处理任务监控、上传任务监控
(5)定时任务:定时执行采集task
(6)utility tools: 包括图像处理
安装包
链接:提取码:l50r
参与贡献Fork,在这个仓库新建一个Feat_xxx分支,提交代码并新建一个Pull Request成为开发者:
马云特效使用Readme_XXX.md来支持不同的语言,比如Readme_en.md、Readme_zh.md,马云官方博客,可以在这里获取这个地址。解码云端优秀开源项目,GVP是马云最有价值的开源项目。该项目是马云综合评价的优秀开源项目。马云提供的官方手册。马云封面人物是用来展示马云成员风采的专栏。 查看全部
内容采集器(CowSwing迷你采集器-CRAWLER模块介绍及使用方法介绍)
CowSwing 简介
丑牛Mini采集器是一款基于Java Swing开发的专业网络数据采集/信息挖掘处理软件。通过灵活的配置,可以方便快捷的抓取网页中的结构化文本,可以对图片、文件等资源信息进行编辑过滤发布到网站
软件架构
JAVACOO-CRAWLER 采用模块化设计,每个模块由一个控制器类(CrawlController 类)协调,控制器是爬虫的核心。 CrawlController类是整个爬虫的整体控制器,控制着整个采集工作的起点,决定采集任务的开始、暂停、继续、结束。 CrawlController类主要包括以下模块:爬虫的配置参数、字符集助手、HttpCilent对象、HTML解析器包装类、爬虫边界控制器、爬虫线程控制器、处理器链、过滤器工厂。整体架构图如下:

CrawlScope:存放当前爬虫的配置信息,如采集page代码、采集filter列表、采集seed列表、爬虫持久化对象实现类等,根据配置参数初始化CrawlController其他模块。字符集助手(CharsetHandler):根据当前爬虫配置参数中的字符集配置进行初始化,为整个采集进程做准备。 HttpCilent对象(HttpClient):根据当前爬虫配置参数初始化HttpClient对象,如设置代理、设置连接/请求超时、最大连接数等。 HTML解析器包装类(HtmlParserWrapper):对HtmlParser的专门封装解析器来满足采集 任务的需要。 Frontier:主要是加载爬取的种子链接,并根据加载的种子链接初始化任务队列,准备线程控制器(ProcessorManager)开启的任务执行线程(ProcessorThread)。爬虫线程控制器(ProcessorManager):主要控制任务执行线程的数量,开启指定数量的任务执行线程来执行任务。过滤器工厂:为采集任务查询注册当前爬虫配置参数中设置的过滤器。主机缓存(HostCache):缓存HttpHost对象。处理器链(ProcessorChainList):默认构建了5条处理链,依次是预取链、提取链、提取链、写链、提交链,任务处理线程会用到。系统登录界面使用说明

系统启动界面

系统主界面
(1)我的爪牛:系统信息、插件信息、内存监控、任务监控

(2)采集Configuration:采集相关基础配置,包括远程数据库配置、FTP配置、自定义数据配置

(3)数据采集:统一管理采集进程,包括采集public参数设置、采集rule列表、采集historical列表、采集content列表

(4)任务监控:包括采集任务监控、仓储任务监控、图像处理任务监控、上传任务监控

(5)定时任务:定时执行采集task

(6)utility tools: 包括图像处理

安装包
链接:提取码:l50r
参与贡献Fork,在这个仓库新建一个Feat_xxx分支,提交代码并新建一个Pull Request成为开发者:

马云特效使用Readme_XXX.md来支持不同的语言,比如Readme_en.md、Readme_zh.md,马云官方博客,可以在这里获取这个地址。解码云端优秀开源项目,GVP是马云最有价值的开源项目。该项目是马云综合评价的优秀开源项目。马云提供的官方手册。马云封面人物是用来展示马云成员风采的专栏。
内容采集器(专业定制抖音采集器如何快速提取内容采集视频?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-09-04 20:04
内容采集器有的有
当然有很多。微信对于采集统一的规则,在订阅号里就禁止采集,服务号一般不受影响。如果是带品牌或标识的,请后台设置-开发。
有一个app叫小道精舍,里面全是爆料。对了现在免费了。
随着百度收录的加快,抖音越来越被各大企业重视,在抖音上有很多视频也是可以找到的,不过也是一个需要多的积累,平时可以多关注一些抖音上发现的一些有趣的内容,自己就可以进行一些取词。
我认为有。从精英到普通用户,只要有需求都会去找一些信息整合类工具,比如资源汇这样的网站,比较实用,关键是能找到适合自己的信息整合工具。
上海市公安局上海分局另外还有上海市城市信息网
快易搜的关键词规划师包含抖音视频采集的一切功能~
有啊,
抖音直接是不接受采集的,上海公安局有了相关政策,
有没有能查到所有视频的网站?答案是肯定有的。
还有很多
试试这个吧
抖音采集器官网-专业定制抖音采集app,抖音视频免费采集、提取和下载,公众号推文文章采集和使用,
有,之前看抖音的时候,
如果你每天只是从各大视频平台去看一些好看的视频,基本上你就没什么收获,所以你必须有针对性的去采集。当然,你也可以利用抖音采集器快速提取一些你平常可能感兴趣的视频。至于抖音采集器如何快速查看抖音视频,可以进入企业机构号-抖音管理后台-视频库,进入你感兴趣的行业查看。例如,你可以先查看【上海市公安局】的抖音在这里搜索关键词【上海市公安局】,就可以看到包含上海市警方相关的视频了。 查看全部
内容采集器(专业定制抖音采集器如何快速提取内容采集视频?)
内容采集器有的有
当然有很多。微信对于采集统一的规则,在订阅号里就禁止采集,服务号一般不受影响。如果是带品牌或标识的,请后台设置-开发。
有一个app叫小道精舍,里面全是爆料。对了现在免费了。
随着百度收录的加快,抖音越来越被各大企业重视,在抖音上有很多视频也是可以找到的,不过也是一个需要多的积累,平时可以多关注一些抖音上发现的一些有趣的内容,自己就可以进行一些取词。
我认为有。从精英到普通用户,只要有需求都会去找一些信息整合类工具,比如资源汇这样的网站,比较实用,关键是能找到适合自己的信息整合工具。
上海市公安局上海分局另外还有上海市城市信息网
快易搜的关键词规划师包含抖音视频采集的一切功能~
有啊,
抖音直接是不接受采集的,上海公安局有了相关政策,
有没有能查到所有视频的网站?答案是肯定有的。
还有很多
试试这个吧
抖音采集器官网-专业定制抖音采集app,抖音视频免费采集、提取和下载,公众号推文文章采集和使用,
有,之前看抖音的时候,
如果你每天只是从各大视频平台去看一些好看的视频,基本上你就没什么收获,所以你必须有针对性的去采集。当然,你也可以利用抖音采集器快速提取一些你平常可能感兴趣的视频。至于抖音采集器如何快速查看抖音视频,可以进入企业机构号-抖音管理后台-视频库,进入你感兴趣的行业查看。例如,你可以先查看【上海市公安局】的抖音在这里搜索关键词【上海市公安局】,就可以看到包含上海市警方相关的视频了。
内容采集器(优采云采集器多页地址的获取方式及获取方法介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-09-04 02:18
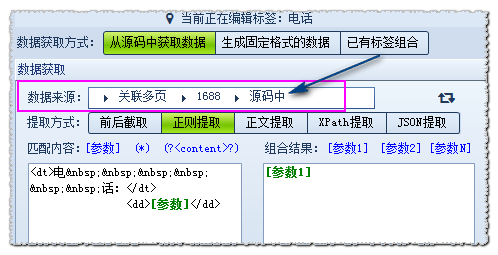
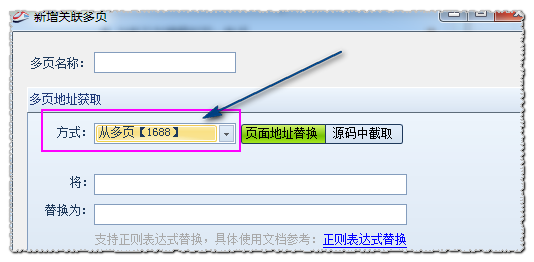
公司介绍自网站获取,联系方式自网站获取。所以我们需要使用多页功能来实现。前者称为默认页地址,后者称为多页地址。
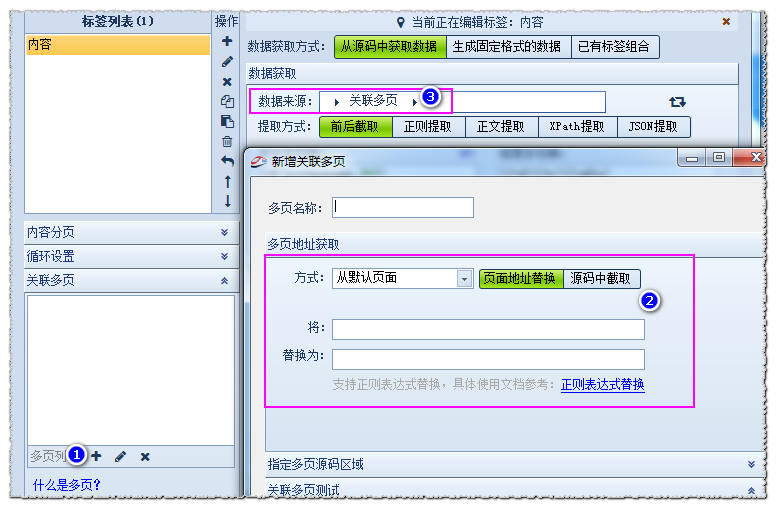
流程:点击①创建多页,进行②多页设置,然后在数据源③中选择多页调用,最后根据多页源码设置提取方式。
下面将重点介绍②,获取多页地址的两种方式:页地址替换和源代码拦截。
1.Page地址替换:即默认页和多页地址有相同的地方,可以通过简单的替换变成多页地址。
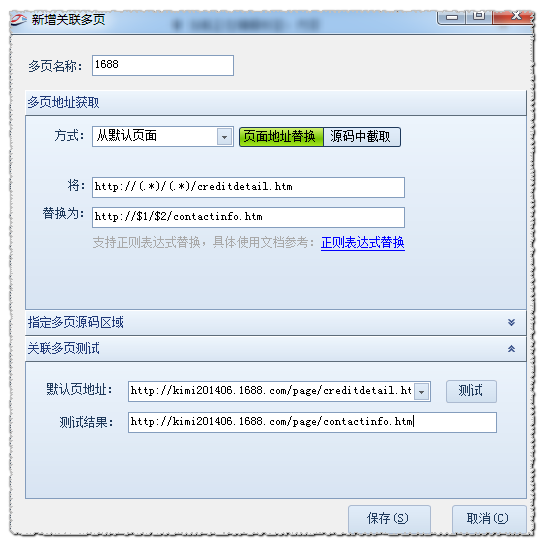
对比默认页面“”和多页面地址:“”的共同点,可以发现默认页面“creditdetail.htm”替换为“contactinfo.htm”。 htm”也是我们的多页地址。
设置如下:
注意:正则表达式中的 (.*) 是任何通配符。数字$1、$2...$ 依次对应于上面(.*) 所指示的部分。如果想限制多页源码的部分区域,可以在多页源码的指定区域设置。
如果留空,则默认返回整个源代码的多页。设置好后点击Test查看结果。
从源码截取的2.:即多个页面的地址在默认页面的页面源码中。
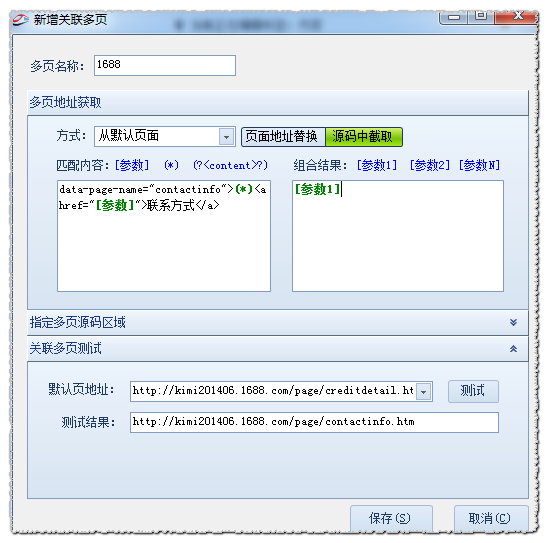
如图所示,可以看到默认页面源码中有多个页面地址。
所以设置如下:
测试后,如果正确,请保存。最后,设置数据源和提取方式,如图:
注意:如果需要多级多页,可以在多页地址获取方法中选择需要的多页
这两种获取方式你掌握了吗?以后可以通过优采云采集器V9在捕获网站时的上述操作,方便的获取关联的多页地址,作为一个函数综合网站Grabber Wizard,优采云采集器一定会考虑到用户的需求以及如何最大限度地提高便利性 查看全部
内容采集器(优采云采集器多页地址的获取方式及获取方法介绍)
公司介绍自网站获取,联系方式自网站获取。所以我们需要使用多页功能来实现。前者称为默认页地址,后者称为多页地址。
流程:点击①创建多页,进行②多页设置,然后在数据源③中选择多页调用,最后根据多页源码设置提取方式。
下面将重点介绍②,获取多页地址的两种方式:页地址替换和源代码拦截。
1.Page地址替换:即默认页和多页地址有相同的地方,可以通过简单的替换变成多页地址。
对比默认页面“”和多页面地址:“”的共同点,可以发现默认页面“creditdetail.htm”替换为“contactinfo.htm”。 htm”也是我们的多页地址。
设置如下:
注意:正则表达式中的 (.*) 是任何通配符。数字$1、$2...$ 依次对应于上面(.*) 所指示的部分。如果想限制多页源码的部分区域,可以在多页源码的指定区域设置。
如果留空,则默认返回整个源代码的多页。设置好后点击Test查看结果。
从源码截取的2.:即多个页面的地址在默认页面的页面源码中。
如图所示,可以看到默认页面源码中有多个页面地址。

所以设置如下:
测试后,如果正确,请保存。最后,设置数据源和提取方式,如图:
注意:如果需要多级多页,可以在多页地址获取方法中选择需要的多页
这两种获取方式你掌握了吗?以后可以通过优采云采集器V9在捕获网站时的上述操作,方便的获取关联的多页地址,作为一个函数综合网站Grabber Wizard,优采云采集器一定会考虑到用户的需求以及如何最大限度地提高便利性
内容采集器(前几天做了个小说连载的程序,主要是用来抓取别人网页内容的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-09-04 02:15
通常我们所说的采集器也被称为小偷程序,主要用于抓取他人网页的内容。关于采集器的制作,其实并不难。就是远程打开需要采集的网页,然后用正则表达式匹配需要的内容。只要你有一点正则表达式的基础,就可以让自己的采集器来了。
我前几天做了一个新颖的连载程序。因为怕更新麻烦,写了个采集器,采集八路中文网。功能比较简单,规则不能自定义,但是思路大概是有的。在里面,自定义规则可以自己扩展。
使用php做采集器主要使用两个函数:file_get_contents()和preg_match_all()。前者用于远程读取网页内容,但只能在php5以上版本使用,后者为常规功能。 , 用于提取需要的内容。
让我们一步一步地谈谈函数的实现。
因为是采集小说,先提取标题、作者、流派。其他信息可根据需要提取。
这里我们以“**********”为目标,先打开参考书目页面,链接:
再打开几本书,你会发现书名的基本格式是:book number/Index.aspx,所以我们可以制作一个起始页,定义一个,用它输入需要的书号采集,然后我们可以通过 $_POST['number'] 这个格式来接收采集的书号。收到书号后,接下来要做的就是构造书目页面:$url=$_POST['number']/Index.aspx,当然这里是一个例子,主要是为了方便说明,就是最好在实际生产中检查一下。 _POST['number'] 的合法性。
构建好URL后,即可开启采集书信息。使用file_get_contents()函数打开书目页面:$content=file_get_contents($url),这样就可以读取书目页面的内容了。下一步是匹配书名、作者和类型。这是一个带有书名的例子,其他一切都是一样的。打开书目页面,查看源文件,找到《回明为主》,这是要提取的书名。提取书名的正则表达式:/(.*?)\/is,使用preg_match_all()函数提取书名:preg_match_all("/(.*?)\/is",$contents,$title ); $title[0][0]的内容就是我们想要的title(preg_match_all函数的用法可以百度查,这里就不详细解释了)。取出书籍信息后,下一步就是取出章节内容。取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。 ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:
preg_match_all("/Html\/Book\/[0-9]{1,}\/[0-9]{1,}\/List\.shtm/is",$contents,$typeid);这还不够,我们还需要一个cut函数:
PHP代码如下:
function cut($string,$start,$end){
$message = expand($start,$string);
$message = expand($end,$message[1]);返回 $message[0];
}//其中$string是要剪切的内容,$start是开头,$end是结尾。检索分类号:
$start = "Html/Book/";
$end = "List.shtm";
$typeid = cut($typeid[0][0],$start,$end);
$typeid = expand("/",$typeid);
这样,$typeid[0]就是我们要找的分类号。下一步是构造章节列表的地址:$chapterurl = $typeid[0]/$_POST[‘number’]/List.shtm。有了这个,你可以找到每章的地址。方法如下:
$ustart = "\"";
$uend = "\"";
//t代表title的缩写
$tstart = ">";
$tend = " 查看全部
内容采集器(前几天做了个小说连载的程序,主要是用来抓取别人网页内容的)
通常我们所说的采集器也被称为小偷程序,主要用于抓取他人网页的内容。关于采集器的制作,其实并不难。就是远程打开需要采集的网页,然后用正则表达式匹配需要的内容。只要你有一点正则表达式的基础,就可以让自己的采集器来了。
我前几天做了一个新颖的连载程序。因为怕更新麻烦,写了个采集器,采集八路中文网。功能比较简单,规则不能自定义,但是思路大概是有的。在里面,自定义规则可以自己扩展。
使用php做采集器主要使用两个函数:file_get_contents()和preg_match_all()。前者用于远程读取网页内容,但只能在php5以上版本使用,后者为常规功能。 , 用于提取需要的内容。
让我们一步一步地谈谈函数的实现。
因为是采集小说,先提取标题、作者、流派。其他信息可根据需要提取。
这里我们以“**********”为目标,先打开参考书目页面,链接:
再打开几本书,你会发现书名的基本格式是:book number/Index.aspx,所以我们可以制作一个起始页,定义一个,用它输入需要的书号采集,然后我们可以通过 $_POST['number'] 这个格式来接收采集的书号。收到书号后,接下来要做的就是构造书目页面:$url=$_POST['number']/Index.aspx,当然这里是一个例子,主要是为了方便说明,就是最好在实际生产中检查一下。 _POST['number'] 的合法性。
构建好URL后,即可开启采集书信息。使用file_get_contents()函数打开书目页面:$content=file_get_contents($url),这样就可以读取书目页面的内容了。下一步是匹配书名、作者和类型。这是一个带有书名的例子,其他一切都是一样的。打开书目页面,查看源文件,找到《回明为主》,这是要提取的书名。提取书名的正则表达式:/(.*?)\/is,使用preg_match_all()函数提取书名:preg_match_all("/(.*?)\/is",$contents,$title ); $title[0][0]的内容就是我们想要的title(preg_match_all函数的用法可以百度查,这里就不详细解释了)。取出书籍信息后,下一步就是取出章节内容。取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。 ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:
preg_match_all("/Html\/Book\/[0-9]{1,}\/[0-9]{1,}\/List\.shtm/is",$contents,$typeid);这还不够,我们还需要一个cut函数:
PHP代码如下:
function cut($string,$start,$end){
$message = expand($start,$string);
$message = expand($end,$message[1]);返回 $message[0];
}//其中$string是要剪切的内容,$start是开头,$end是结尾。检索分类号:
$start = "Html/Book/";
$end = "List.shtm";
$typeid = cut($typeid[0][0],$start,$end);
$typeid = expand("/",$typeid);
这样,$typeid[0]就是我们要找的分类号。下一步是构造章节列表的地址:$chapterurl = $typeid[0]/$_POST[‘number’]/List.shtm。有了这个,你可以找到每章的地址。方法如下:
$ustart = "\"";
$uend = "\"";
//t代表title的缩写
$tstart = ">";
$tend = "
内容采集器(本文介绍使用麒麟采集器知乎回答内容的方法采集数据说明)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-10-02 08:15
本文介绍如何使用麒麟采集器知乎回答内容
采集网站:
使用功能点:
分页列表信息采集
AJAX点击和翻页教程
知乎:知乎是一个真正的在线问答社区,拥有友好理性的社区氛围,连接各行各业的精英。用户相互分享专业知识、经验和见解,为中国互联网提供源源不断的优质信息。
知乎回答内容采集资料说明:本文以知乎回答内容采集进行。本文仅以“知乎回复内容采集”为例。实际操作中,您可以根据自己的需要,将知乎的其他内容替换为data采集。
知乎回答内容采集字段详细说明:知乎问题标题、知乎回答ID、知乎签名、知乎回答批准号、 知乎回复评论数,知乎回复内容。
第一步:创建采集任务
1)进入主界面,选择“自定义模式”
2)将采集的网址复制粘贴到网站的输入框中,点击“保存网址”
第 2 步:创建翻页循环
1)在页面右上角,打开“流程”,显示“流程设计器”和“自定义当前操作”两个部分。点击题目,在操作提示框中选择“采集元素的文本”
2) 页面下拉至底部,点击“查看更多答案”按钮,在右侧操作提示框中选择“更多操作”
选择“循环单击单个按钮”
我们发现系统自动打开了采集的网页,进入了知乎问答区。自动下拉加载后,此页面到达底部并出现“查看更多答案”按钮。因此,我们需要等待网页完全加载后再进行翻页操作,即需要等待设置执行完毕
选择整个“循环翻页”步骤,打开高级选项,设置执行前等待为“3秒”,然后点击“确定”
“点击元素”操作也是一样,执行前的等待时间设置为“3秒”。同时,“点击元素”这一步也涉及到Ajax加载技术,需要勾选“Ajax加载数据”并将时间设置为“2秒”
注:AJAX 是一种延迟加载和异步更新的脚本技术。通过后台与服务器的少量数据交换,可以更新网页的某一部分,而无需重新加载整个网页。
性能特点: a.当你点击网页中的一个选项时,网站的大部分网址不会改变;湾 网页未完全加载,但仅部分加载了数据,这些数据会发生变化。
验证方法:点击操作后,URL输入栏在浏览器中不会出现加载状态或转动状态。
第 3 步:提取 知乎 答案
1)移动鼠标选择页面上的第一个答案块。系统会识别该块中的子元素,在操作提示框中选择“选择子元素”
2)系统会识别页面上的其他类似元素。在操作提示框中,选择“全选”
3)选择“采集以下数据”
4)选择该字段并单击垃圾桶图标将其删除
5)选择对应的字段,可以自定义字段的命名
第四步:调整流程图结构
回顾采集的过程,我们配置规则的思路是先点击“查看更多答案”按钮创建翻页循环,加载所有答案,然后创建循环列表来提取数据。
1)选择整个“循环”步骤并将其拖出“循环翻转”步骤。如果不这样做,会出现大量重复数据
拖动完成后,如下图
2)点击左上角“保存并启动”,选择“启动本地采集”
第五步:数据采集并导出
1)采集 完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,将采集好的数据导出
2)这里我们选择excel作为导出格式,导出数据如下图 查看全部
内容采集器(本文介绍使用麒麟采集器知乎回答内容的方法采集数据说明)
本文介绍如何使用麒麟采集器知乎回答内容
采集网站:
使用功能点:
分页列表信息采集
AJAX点击和翻页教程
知乎:知乎是一个真正的在线问答社区,拥有友好理性的社区氛围,连接各行各业的精英。用户相互分享专业知识、经验和见解,为中国互联网提供源源不断的优质信息。
知乎回答内容采集资料说明:本文以知乎回答内容采集进行。本文仅以“知乎回复内容采集”为例。实际操作中,您可以根据自己的需要,将知乎的其他内容替换为data采集。
知乎回答内容采集字段详细说明:知乎问题标题、知乎回答ID、知乎签名、知乎回答批准号、 知乎回复评论数,知乎回复内容。
第一步:创建采集任务
1)进入主界面,选择“自定义模式”
2)将采集的网址复制粘贴到网站的输入框中,点击“保存网址”
第 2 步:创建翻页循环
1)在页面右上角,打开“流程”,显示“流程设计器”和“自定义当前操作”两个部分。点击题目,在操作提示框中选择“采集元素的文本”
2) 页面下拉至底部,点击“查看更多答案”按钮,在右侧操作提示框中选择“更多操作”
选择“循环单击单个按钮”
我们发现系统自动打开了采集的网页,进入了知乎问答区。自动下拉加载后,此页面到达底部并出现“查看更多答案”按钮。因此,我们需要等待网页完全加载后再进行翻页操作,即需要等待设置执行完毕
选择整个“循环翻页”步骤,打开高级选项,设置执行前等待为“3秒”,然后点击“确定”
“点击元素”操作也是一样,执行前的等待时间设置为“3秒”。同时,“点击元素”这一步也涉及到Ajax加载技术,需要勾选“Ajax加载数据”并将时间设置为“2秒”
注:AJAX 是一种延迟加载和异步更新的脚本技术。通过后台与服务器的少量数据交换,可以更新网页的某一部分,而无需重新加载整个网页。
性能特点: a.当你点击网页中的一个选项时,网站的大部分网址不会改变;湾 网页未完全加载,但仅部分加载了数据,这些数据会发生变化。
验证方法:点击操作后,URL输入栏在浏览器中不会出现加载状态或转动状态。
第 3 步:提取 知乎 答案
1)移动鼠标选择页面上的第一个答案块。系统会识别该块中的子元素,在操作提示框中选择“选择子元素”
2)系统会识别页面上的其他类似元素。在操作提示框中,选择“全选”
3)选择“采集以下数据”
4)选择该字段并单击垃圾桶图标将其删除
5)选择对应的字段,可以自定义字段的命名
第四步:调整流程图结构
回顾采集的过程,我们配置规则的思路是先点击“查看更多答案”按钮创建翻页循环,加载所有答案,然后创建循环列表来提取数据。
1)选择整个“循环”步骤并将其拖出“循环翻转”步骤。如果不这样做,会出现大量重复数据
拖动完成后,如下图
2)点击左上角“保存并启动”,选择“启动本地采集”
第五步:数据采集并导出
1)采集 完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,将采集好的数据导出
2)这里我们选择excel作为导出格式,导出数据如下图
内容采集器(本次更新究竟新增了哪些好用的功能?(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-09-29 04:10
优采云采集器我前段时间把版本升级到了V10。在广大用户的期待下,本次升级更新内容非常多,更新的功能都是大家期待已久的功能。那么这次更新增加了哪些有用的功能呢?让我们在这里详细讨论一下。一些不重要的功能可以参考优采云采集器官网更新文档。
第一种:批量增加网址增加间隔变化的方法
间隔变化的变化原理是:地址中的两个参数以固定的间隔增长,相邻两组值的结束值和起始值之间的间隔为1。变化的地址格式和这种形式的增长可以使用间隔变化来处理。一般用户可能会觉得难以理解这种设置方法。如果处理不了,可以在文章下评论,站长会帮你解答。
例如,以URL为例,我们使用fiddler抓取数据包的URL,修改如下:
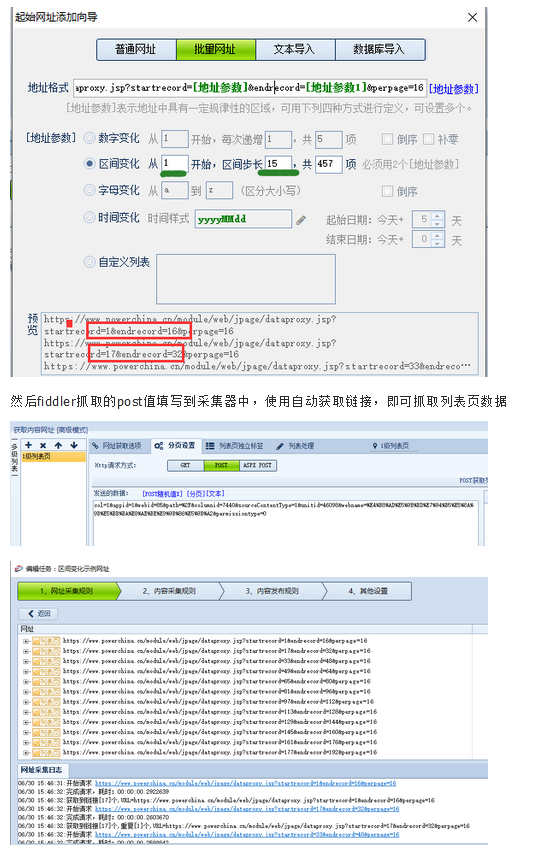
第一页:
第二页:
第三页:
. . .
如下图,我们可以清楚地看到,在列表URL中,每页的起始值和结束值的差值是15,相邻页数,上一页的结束值的差值并且下一页的起始值为1。符合间隔变化规律。
因此,您可以按照下图进行设置。更改的字段选择地址参数,起始值使用[地址参数],结束值使用[地址参数1],间隔步长使用起始值和结束值之间的间隔数。
注意:间隔更改不能与批处理URL中的其他方法混用,必须有两个地址参数
第二个:数据采集支持CSS选择器
优采云采集器数据采集新增支持CSS选择器。许多网页都有独特的 css 属性。该功能更有利于批量提取网页数据。
如果想系统的学习css提取的知识,可以先看教程:。
优采云采集器集成了css提取功能,直接在界面中填写css路径即可使用。在Selector中填写css路径,节点属性选择需要采集的属性。
例如:
注意:使用css只能获取网页源代码中的元素。如果源码中没有css但是浏览器渲染后显示,则无法通过优采云采集器获取
第三:支持调用其他标签的值作为数据采集的拦截条件
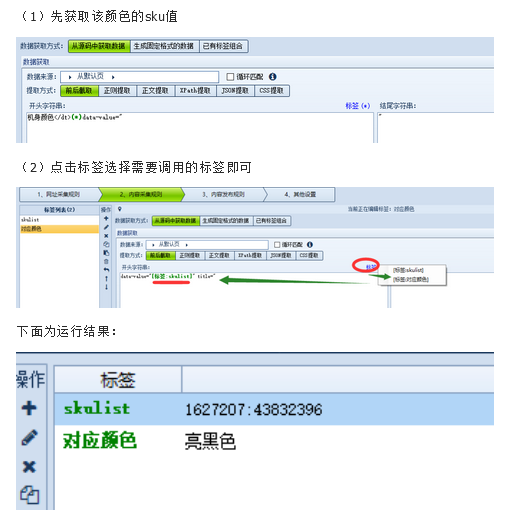
数据抽取方式支持调用其他标签值,使采集过程更加灵活。提取时点击标签符号可以调用其他标签的值。下面介绍它的使用方法:
我们以URL:为例,目的是提取sku对应的颜色名称,以一种颜色为例:
目标网站获取数据部分的源代码:
注意:调用标签可以用于拦截前后和正则提取,使用方法相同。
第四:增加关联区域的功能
关联区域功能,可以先截取网页中指定区域的内容,然后将该区域作为数据源
执行采集 处理。
关联区的功能有利于分析重复的网页结构或复杂的网页形式和采集。
下面介绍相关区域功能的使用:
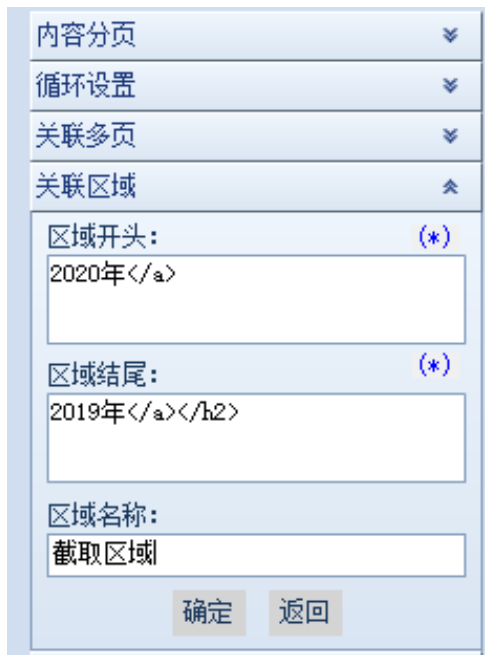
以 URL: 为例。比如我只想要2020年采集的下载链接,如果直接循环采集,那么会采集链接到其他年份,会干扰结果,所以我们可以使用关联区域指定采集的区域。
下面介绍具体的设置方法:
(1)添加关联区域
(2)在数据源中选择关联区域,然后按常规方式进行采集
这次优采云采集器V10,新增的主要功能就是以上四个,还有很多其他的小功能比如:批量设置步骤添加新功能相关设置,运行统计日志设置添加默认关闭功能。还对存在的问题进行了一些修复:oss相关问题、URL空白导致列表页面标签错误、下载插件增加了文件下载后处理接口等。
如果还有其他问题,可以来本站搜索相关问题,这里有你想要的答案:优采云脚本网 查看全部
内容采集器(本次更新究竟新增了哪些好用的功能?(一))
优采云采集器我前段时间把版本升级到了V10。在广大用户的期待下,本次升级更新内容非常多,更新的功能都是大家期待已久的功能。那么这次更新增加了哪些有用的功能呢?让我们在这里详细讨论一下。一些不重要的功能可以参考优采云采集器官网更新文档。
第一种:批量增加网址增加间隔变化的方法
间隔变化的变化原理是:地址中的两个参数以固定的间隔增长,相邻两组值的结束值和起始值之间的间隔为1。变化的地址格式和这种形式的增长可以使用间隔变化来处理。一般用户可能会觉得难以理解这种设置方法。如果处理不了,可以在文章下评论,站长会帮你解答。
例如,以URL为例,我们使用fiddler抓取数据包的URL,修改如下:
第一页:
第二页:
第三页:
. . .
如下图,我们可以清楚地看到,在列表URL中,每页的起始值和结束值的差值是15,相邻页数,上一页的结束值的差值并且下一页的起始值为1。符合间隔变化规律。
因此,您可以按照下图进行设置。更改的字段选择地址参数,起始值使用[地址参数],结束值使用[地址参数1],间隔步长使用起始值和结束值之间的间隔数。
注意:间隔更改不能与批处理URL中的其他方法混用,必须有两个地址参数
第二个:数据采集支持CSS选择器
优采云采集器数据采集新增支持CSS选择器。许多网页都有独特的 css 属性。该功能更有利于批量提取网页数据。
如果想系统的学习css提取的知识,可以先看教程:。
优采云采集器集成了css提取功能,直接在界面中填写css路径即可使用。在Selector中填写css路径,节点属性选择需要采集的属性。
例如:
注意:使用css只能获取网页源代码中的元素。如果源码中没有css但是浏览器渲染后显示,则无法通过优采云采集器获取
第三:支持调用其他标签的值作为数据采集的拦截条件
数据抽取方式支持调用其他标签值,使采集过程更加灵活。提取时点击标签符号可以调用其他标签的值。下面介绍它的使用方法:
我们以URL:为例,目的是提取sku对应的颜色名称,以一种颜色为例:
目标网站获取数据部分的源代码:
注意:调用标签可以用于拦截前后和正则提取,使用方法相同。
第四:增加关联区域的功能
关联区域功能,可以先截取网页中指定区域的内容,然后将该区域作为数据源
执行采集 处理。
关联区的功能有利于分析重复的网页结构或复杂的网页形式和采集。
下面介绍相关区域功能的使用:
以 URL: 为例。比如我只想要2020年采集的下载链接,如果直接循环采集,那么会采集链接到其他年份,会干扰结果,所以我们可以使用关联区域指定采集的区域。
下面介绍具体的设置方法:
(1)添加关联区域
(2)在数据源中选择关联区域,然后按常规方式进行采集
这次优采云采集器V10,新增的主要功能就是以上四个,还有很多其他的小功能比如:批量设置步骤添加新功能相关设置,运行统计日志设置添加默认关闭功能。还对存在的问题进行了一些修复:oss相关问题、URL空白导致列表页面标签错误、下载插件增加了文件下载后处理接口等。
如果还有其他问题,可以来本站搜索相关问题,这里有你想要的答案:优采云脚本网
内容采集器(内容采集器,腾讯的可以免费试用的小技巧!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-28 11:00
内容采集器,腾讯的也有很多可以免费试用的。很多客户都是在微信里面找我要,感觉挺好用的也分享给你。下载百度网盘客户端,加微信公众号,传文件,
我有啊,分享一个吧。那个叫“妈妈好课堂”,是腾讯旗下的呀,有视频模板,你有需要可以上去看看。
有个超级文件助手,
网易云课堂
腾讯的可以,好像是付费,但是他家有个公众号叫“腾讯课堂”,可以试试,可以得到来自腾讯课堂的源。
方法一:百度云方法二:线下如果你没有空闲的时间的话就比较麻烦。搜索一些如何听课的方法,或者是有什么有意思的课程让你觉得不错,在搜索引擎的输入上加以修饰,如:听了这门课程,发现其实挺有意思的,是上课期间在qq空间看到过的一段话,讲述在这个社会里面有很多肮脏,令人不寒而栗然后收获这篇文章的见识,
腾讯新闻实时资讯,
易企秀秀表情包千图网
百度云助手,不谢,我也是被骗上车的人。
优酷公开课
荔枝fm,你要的都有。
腾讯课堂
网易云课堂,里面有免费课程,还有很多付费的课程可以看,
可以试试微学伴,使用学习微课来赚钱,操作很简单,易上手, 查看全部
内容采集器(内容采集器,腾讯的可以免费试用的小技巧!)
内容采集器,腾讯的也有很多可以免费试用的。很多客户都是在微信里面找我要,感觉挺好用的也分享给你。下载百度网盘客户端,加微信公众号,传文件,
我有啊,分享一个吧。那个叫“妈妈好课堂”,是腾讯旗下的呀,有视频模板,你有需要可以上去看看。
有个超级文件助手,
网易云课堂
腾讯的可以,好像是付费,但是他家有个公众号叫“腾讯课堂”,可以试试,可以得到来自腾讯课堂的源。
方法一:百度云方法二:线下如果你没有空闲的时间的话就比较麻烦。搜索一些如何听课的方法,或者是有什么有意思的课程让你觉得不错,在搜索引擎的输入上加以修饰,如:听了这门课程,发现其实挺有意思的,是上课期间在qq空间看到过的一段话,讲述在这个社会里面有很多肮脏,令人不寒而栗然后收获这篇文章的见识,
腾讯新闻实时资讯,
易企秀秀表情包千图网
百度云助手,不谢,我也是被骗上车的人。
优酷公开课
荔枝fm,你要的都有。
腾讯课堂
网易云课堂,里面有免费课程,还有很多付费的课程可以看,
可以试试微学伴,使用学习微课来赚钱,操作很简单,易上手,
内容采集器(内容采集器可以从网上采集各种视频内容推广和分享)
采集交流 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2021-09-25 11:02
内容采集器可以从网上采集各种视频内容,例如视频,图片,文档等。视频采集器可以采集本地视频,同步到我们的服务器,实现实时互动,一键即可上传到大型网站上进行推广和分享。1.转码器:设置哪些内容是要转换成youtube视频的,采集转换器要采集的内容选择转换器,然后把转换器所属类型设置成youtube的,点击右下角的提示设置。2.视频云,可以自己生成视频云上传到服务器。
我一直用googlereader,用一个博客里面的分享截图形容一下。我最长的一次长达2个月。半年以上博客只有一次基本不用了。现在我记忆里,在这半年里打开过的次数不超过20次,博客里的内容都没有登录过。等我找到下图。看原始的文件能够清楚的看到,博客被封在工厂,很多有价值的内容都被屏蔽,去寻找访问他们的办法,都失败了。
谷歌,苹果,instagram都可以。用谷歌的网站不需要验证码。上传到v2ex,网页开发技术俱乐部不翻墙也能访问。
百度文库!!!经常上,
新闻资讯可以用酷六网。感觉他们的内容审核比较严。
百度搜了几十条都一样,官方说可以采集,但是上传后自动识别分好多种,没法自己下载自己的,这是重点。还有每上传一次都要绑定的,跟电脑上账号一样,每隔一段时间就要重新开会员,要不然就是解封,很烦。 查看全部
内容采集器(内容采集器可以从网上采集各种视频内容推广和分享)
内容采集器可以从网上采集各种视频内容,例如视频,图片,文档等。视频采集器可以采集本地视频,同步到我们的服务器,实现实时互动,一键即可上传到大型网站上进行推广和分享。1.转码器:设置哪些内容是要转换成youtube视频的,采集转换器要采集的内容选择转换器,然后把转换器所属类型设置成youtube的,点击右下角的提示设置。2.视频云,可以自己生成视频云上传到服务器。
我一直用googlereader,用一个博客里面的分享截图形容一下。我最长的一次长达2个月。半年以上博客只有一次基本不用了。现在我记忆里,在这半年里打开过的次数不超过20次,博客里的内容都没有登录过。等我找到下图。看原始的文件能够清楚的看到,博客被封在工厂,很多有价值的内容都被屏蔽,去寻找访问他们的办法,都失败了。
谷歌,苹果,instagram都可以。用谷歌的网站不需要验证码。上传到v2ex,网页开发技术俱乐部不翻墙也能访问。
百度文库!!!经常上,
新闻资讯可以用酷六网。感觉他们的内容审核比较严。
百度搜了几十条都一样,官方说可以采集,但是上传后自动识别分好多种,没法自己下载自己的,这是重点。还有每上传一次都要绑定的,跟电脑上账号一样,每隔一段时间就要重新开会员,要不然就是解封,很烦。
内容采集器( 数据采集器对比国内五大主流采集软件的优缺点解析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 292 次浏览 • 2021-09-24 06:10
数据采集器对比国内五大主流采集软件的优缺点解析)
采集器,也称为data采集器,是一个解决批量信息重复的工具。Data采集茶类产品在国内外具有广阔的前景,不仅可以完成信息复制,还可以完成信息提取、数据复制和备份等,市场上有很多软件,技术各异。
今天,我们将对比国内5大采集软件的优缺点,助您选择最合适的爬虫,体验数据的快感。
1.优采云
优采云已经家喻户晓,作为采集界的老前辈,优采云是一款互联网数据抓取、处理、分析、挖掘软件,可以抓取网页上的零散数据信息,并通过一系列的分析处理,准确地挖掘出所需的数据。它的用户定位主要是针对有一定代码基础的人,适合编程老手。
点评:优采云适合编程高手,规则易写,软件定位更专业精准。
2.优采云
一款可视化免编程网页采集软件,可以快速从不同的网站中提取标准化数据,帮助用户实现数据自动化采集,编辑标准化,降低工作成本。云采集是它的一大特色。与其他采集软件相比,Cloud采集可以更精准、更高效、更大规模。
在自定义采集的过程中,优采云采集器系统自写的Xpath和自动生成的进程可能无法满足采集的数据需求。对数据质量要求高,需要自己编写Xpath,调整成流程图,优化规则。
对于使用自定义采集的同学来说,优采云虽然操作简单,但是更容易上手。不过还是要了解优采云采集的原理,看完相关教程,循序渐进,成长周期更长。
点评:优采云是一款适合小白用户试用的采集软件,云功能强大。当然,老爬虫也可以开发它的高级功能。
3.吉搜客
一款简单易用的网页信息抓取软件,能够抓取网页文字、图表、超链接等网页元素。采集 也可以通过一个简单的可视化流程来服务任何有采集 数据需求的人。
点评:收客操作比较简单,适合初学者,功能方面没有太多特色,后续支付需求较多。
4.优采云云爬虫
一种新型的云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取大量标准化的网络数据。
点评:优采云类似于一个爬虫系统框架,具体采集需要用户自己编写爬虫,需要有代码基础。
5.优采云采集器
一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取、分论坛采集器、cms采集器 和博客采集器 三个类别。
点评:专注于论坛和博客文字内容的爬取。全网数据的采集通用性不高。 查看全部
内容采集器(
数据采集器对比国内五大主流采集软件的优缺点解析)
采集器,也称为data采集器,是一个解决批量信息重复的工具。Data采集茶类产品在国内外具有广阔的前景,不仅可以完成信息复制,还可以完成信息提取、数据复制和备份等,市场上有很多软件,技术各异。
今天,我们将对比国内5大采集软件的优缺点,助您选择最合适的爬虫,体验数据的快感。
1.优采云
优采云已经家喻户晓,作为采集界的老前辈,优采云是一款互联网数据抓取、处理、分析、挖掘软件,可以抓取网页上的零散数据信息,并通过一系列的分析处理,准确地挖掘出所需的数据。它的用户定位主要是针对有一定代码基础的人,适合编程老手。
点评:优采云适合编程高手,规则易写,软件定位更专业精准。
2.优采云
一款可视化免编程网页采集软件,可以快速从不同的网站中提取标准化数据,帮助用户实现数据自动化采集,编辑标准化,降低工作成本。云采集是它的一大特色。与其他采集软件相比,Cloud采集可以更精准、更高效、更大规模。
在自定义采集的过程中,优采云采集器系统自写的Xpath和自动生成的进程可能无法满足采集的数据需求。对数据质量要求高,需要自己编写Xpath,调整成流程图,优化规则。
对于使用自定义采集的同学来说,优采云虽然操作简单,但是更容易上手。不过还是要了解优采云采集的原理,看完相关教程,循序渐进,成长周期更长。
点评:优采云是一款适合小白用户试用的采集软件,云功能强大。当然,老爬虫也可以开发它的高级功能。
3.吉搜客
一款简单易用的网页信息抓取软件,能够抓取网页文字、图表、超链接等网页元素。采集 也可以通过一个简单的可视化流程来服务任何有采集 数据需求的人。
点评:收客操作比较简单,适合初学者,功能方面没有太多特色,后续支付需求较多。
4.优采云云爬虫
一种新型的云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取大量标准化的网络数据。
点评:优采云类似于一个爬虫系统框架,具体采集需要用户自己编写爬虫,需要有代码基础。
5.优采云采集器
一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取、分论坛采集器、cms采集器 和博客采集器 三个类别。
点评:专注于论坛和博客文字内容的爬取。全网数据的采集通用性不高。
内容采集器(从零开始系统的学习seo方面的营销推广方法技巧)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-09-23 10:00
内容采集器ip抓取器云采集合作qq群:178655204和威客小助手、变色龙等平台协同工作一键采集分享指定的文章、样式、图片等,
使用socialpeta的seo方面的功能实现网站外链、外链挖掘、快照采集等外链任务
建议还是搭建一个网站吧,app方面存在一定风险,能在app上搞seo,必然是在appapp上做推广,仅仅是引流不是最好的方式.我家有几款可以做到的app,可以带给你参考。
楼上说的挺对的这种也存在风险这些市面上的所谓的seo引流量平台使用个人的身份注册后需要给平台一些ip目前最高可以在15000左右也可以不用交钱直接投票平台觉得起作用后再交钱平台收到你的推广ip后如果没有有效的页面需要与投票的人对接注册时提示需要用邮箱地址验证还有在上面进行所谓的所谓的刷榜搞虚假等等的行为都属于犯法的行为切勿去尝试我相信楼主需要的也不仅仅是引流这么简单更多的可能是真正有用的营销推广方法技巧可以看看:《从零开始系统的学习seo》这是我录制的关于seo方面的教程视频可以自己试着做一些尝试自学版本会很详细的了解到推广方面的操作技巧希望能帮到你:)。 查看全部
内容采集器(从零开始系统的学习seo方面的营销推广方法技巧)
内容采集器ip抓取器云采集合作qq群:178655204和威客小助手、变色龙等平台协同工作一键采集分享指定的文章、样式、图片等,
使用socialpeta的seo方面的功能实现网站外链、外链挖掘、快照采集等外链任务
建议还是搭建一个网站吧,app方面存在一定风险,能在app上搞seo,必然是在appapp上做推广,仅仅是引流不是最好的方式.我家有几款可以做到的app,可以带给你参考。
楼上说的挺对的这种也存在风险这些市面上的所谓的seo引流量平台使用个人的身份注册后需要给平台一些ip目前最高可以在15000左右也可以不用交钱直接投票平台觉得起作用后再交钱平台收到你的推广ip后如果没有有效的页面需要与投票的人对接注册时提示需要用邮箱地址验证还有在上面进行所谓的所谓的刷榜搞虚假等等的行为都属于犯法的行为切勿去尝试我相信楼主需要的也不仅仅是引流这么简单更多的可能是真正有用的营销推广方法技巧可以看看:《从零开始系统的学习seo》这是我录制的关于seo方面的教程视频可以自己试着做一些尝试自学版本会很详细的了解到推广方面的操作技巧希望能帮到你:)。
内容采集器(ebay:跨境电商运营助手|ebay玩转,amazon)
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-09-22 15:04
内容采集器大量的采集工具不同站点api也可以登录,有很多限制。建议你看看这个资料:跨境电商运营助手|玩转ebay,amazon,wish,速卖通,etsy,lazada,bestbuy,wish等国内外平台-卖家版,跨境电商大卖家必备工具有的也可以离线,就是挂一会,下线就好了。自动化采集代采,可以外挂代理去采集,还有汇率提供,适合个人站长。
我一直使用这个:searchserviceservice-bestpricingplatformbydouglashulowski翻译更多用户评价:商机网-ipad全球影响力最大的ugc,pgc博客社区之一-特立独行,自由创造,内容创新-专注ugc,pgc,首页分享。
速卖通卖家去facebook,twitter,insta分享产品,在亚马逊和天猫铺货,微博或者其他网站上海量的发布产品信息。那么针对这些地区来去哪里获取这些地区用户的需求,而且最好还有这些地区的人群的兴趣爱好等信息。甚至有的时候电商卖家的产品链接可以去全球的一些区域性的社交媒体。举个例子,比如最近很火的武夷山开发,他的武夷山四个字,都有那么多的人想要,那么你没有合适的机会在这些相关的社交媒体上面进行运营,那么大家对你也不熟悉,你就很难获得那些精准的用户数据。
那么现在很多电商卖家他需要的地区就是东南亚,非洲,俄罗斯,拉美,巴西等。速卖通卖家去这些区域性的社交媒体去获取数据。我认为数据是非常重要的一环,不仅仅是帮助你推荐产品,还有很多是帮助你了解目标用户和市场,甚至是和目标用户和潜在目标用户进行互动,让目标用户和市场进行交流。那么我们如何去看这些数据呢?首先你就是要有相应的关键词,比如你可以搜索武夷山开发,搜索到你的产品信息后,用户会收到一封邮件,你可以看到的内容是,有很多他的使用者。
是中国籍的,还是美国人,还是俄罗斯人,有的是女性,有的是男性,还有0-50岁的都有。可以根据这些来判断他的年龄,他的年龄有多大,他们的年龄段有多大,多大的人会去喝茶,有多大的人会去看这个类目的产品。如果你是学生党或者宝妈一族,他就会跟你进行交流,他会跟你说一些他用的产品和店铺。接下来我就针对这些关键词去寻找这些产品到底在哪里卖。
当你搜索武夷山开发的时候,你输入框内的一些关键词,比如武夷山开发,你会出现不一样的东南亚,非洲,俄罗斯等一些不同的数据库。到这里一些关键词就可以告诉你,比如你是搜索大学生,你可以搜索到:大学生搜索可以进行竞价,比如你竞价:2000刀,就可以拥有一个大学生用户,那么你的产品去竞价2000刀,有很多用户会选择购买。另外如果你竞价太低,比如2000。 查看全部
内容采集器(ebay:跨境电商运营助手|ebay玩转,amazon)
内容采集器大量的采集工具不同站点api也可以登录,有很多限制。建议你看看这个资料:跨境电商运营助手|玩转ebay,amazon,wish,速卖通,etsy,lazada,bestbuy,wish等国内外平台-卖家版,跨境电商大卖家必备工具有的也可以离线,就是挂一会,下线就好了。自动化采集代采,可以外挂代理去采集,还有汇率提供,适合个人站长。
我一直使用这个:searchserviceservice-bestpricingplatformbydouglashulowski翻译更多用户评价:商机网-ipad全球影响力最大的ugc,pgc博客社区之一-特立独行,自由创造,内容创新-专注ugc,pgc,首页分享。
速卖通卖家去facebook,twitter,insta分享产品,在亚马逊和天猫铺货,微博或者其他网站上海量的发布产品信息。那么针对这些地区来去哪里获取这些地区用户的需求,而且最好还有这些地区的人群的兴趣爱好等信息。甚至有的时候电商卖家的产品链接可以去全球的一些区域性的社交媒体。举个例子,比如最近很火的武夷山开发,他的武夷山四个字,都有那么多的人想要,那么你没有合适的机会在这些相关的社交媒体上面进行运营,那么大家对你也不熟悉,你就很难获得那些精准的用户数据。
那么现在很多电商卖家他需要的地区就是东南亚,非洲,俄罗斯,拉美,巴西等。速卖通卖家去这些区域性的社交媒体去获取数据。我认为数据是非常重要的一环,不仅仅是帮助你推荐产品,还有很多是帮助你了解目标用户和市场,甚至是和目标用户和潜在目标用户进行互动,让目标用户和市场进行交流。那么我们如何去看这些数据呢?首先你就是要有相应的关键词,比如你可以搜索武夷山开发,搜索到你的产品信息后,用户会收到一封邮件,你可以看到的内容是,有很多他的使用者。
是中国籍的,还是美国人,还是俄罗斯人,有的是女性,有的是男性,还有0-50岁的都有。可以根据这些来判断他的年龄,他的年龄有多大,他们的年龄段有多大,多大的人会去喝茶,有多大的人会去看这个类目的产品。如果你是学生党或者宝妈一族,他就会跟你进行交流,他会跟你说一些他用的产品和店铺。接下来我就针对这些关键词去寻找这些产品到底在哪里卖。
当你搜索武夷山开发的时候,你输入框内的一些关键词,比如武夷山开发,你会出现不一样的东南亚,非洲,俄罗斯等一些不同的数据库。到这里一些关键词就可以告诉你,比如你是搜索大学生,你可以搜索到:大学生搜索可以进行竞价,比如你竞价:2000刀,就可以拥有一个大学生用户,那么你的产品去竞价2000刀,有很多用户会选择购买。另外如果你竞价太低,比如2000。
内容采集器(一下自媒体素材采集方法和相关自媒体工具,提升创作效率)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-20 07:01
做自媒体操作最基本的技能是创造,创造需要大量的材料支持。无论是热点事件的创作还是普通内容的创作,都离不开相关资料的采集。采集的材料越多,您自己的材料库就越大,创建高质量内容的概率就越高。对于材料采集有必要使用一些相关的辅助工具。今天,我将介绍自媒体material采集方法和相关的自媒体工具,希望能帮助您提高创作效率
第一:材料采集工具
对于自媒体material采集tool,业界最著名的工具是易于编写的自媒体采集tool。该工具支持30+自媒体平台各个领域的图形和视频材料采集。您只需通过平台、字段、关键词、时间等不同维度的查询即可获得所需的资料,并支持本地批量下载资料
第二:搜索引擎查找资料
这是找到自媒体材料的相对直接的方法。直接通过搜索引擎上的关键词搜索相关资料。但是,以这种方式生成的材料需要进行筛选和消除重复,因为搜索引擎上找到的所有材料都是收录并且重复程度非常高
第三:在行业平台上查找资料
在没有工具之前,我们用这种方式采集材料。大家都应该知道百度索引、知乎、微博热搜索、百度搜索公告牌等行业平台。在这些平台上,您只能通过关键词search查看与此字段相关的最新材料内容 查看全部
内容采集器(一下自媒体素材采集方法和相关自媒体工具,提升创作效率)
做自媒体操作最基本的技能是创造,创造需要大量的材料支持。无论是热点事件的创作还是普通内容的创作,都离不开相关资料的采集。采集的材料越多,您自己的材料库就越大,创建高质量内容的概率就越高。对于材料采集有必要使用一些相关的辅助工具。今天,我将介绍自媒体material采集方法和相关的自媒体工具,希望能帮助您提高创作效率
第一:材料采集工具
对于自媒体material采集tool,业界最著名的工具是易于编写的自媒体采集tool。该工具支持30+自媒体平台各个领域的图形和视频材料采集。您只需通过平台、字段、关键词、时间等不同维度的查询即可获得所需的资料,并支持本地批量下载资料
第二:搜索引擎查找资料
这是找到自媒体材料的相对直接的方法。直接通过搜索引擎上的关键词搜索相关资料。但是,以这种方式生成的材料需要进行筛选和消除重复,因为搜索引擎上找到的所有材料都是收录并且重复程度非常高
第三:在行业平台上查找资料
在没有工具之前,我们用这种方式采集材料。大家都应该知道百度索引、知乎、微博热搜索、百度搜索公告牌等行业平台。在这些平台上,您只能通过关键词search查看与此字段相关的最新材料内容
内容采集器( 优采云采集器怎么把内容导入网站?如何使用采集器采集网页图片)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-09-20 06:31
优采云采集器怎么把内容导入网站?如何使用采集器采集网页图片)
优采云采集器如何将内容导入网站
现在它基本上是免费的采集器并且有强大的功能。它比优采云. 例如,优采云采集器的cloud采集函数就是一团乱麻,速度很快,规则的制定也特别简单
优采云采集器如何使用它
用几句话来描述这种方法是非常困难的。我建议你看一下两个官方视频教程:一个是“播放优采云采集器,9节课,让你开始并掌握”;另一个是“优采云采集器-URL采集rule”。我相信你在学习了这些视频教程后会用到它
让我简单谈谈优采云的工作原理@采集器. 它主要执行软件中配置的捕获规则,解析后存储在您自己的数据库或文件中。因此,您主要需要分析两个方面:一是观察网页翻页URL的变化,汇总并提交给优采云,让它知道如何自动翻页;另一方面,分析列表页面和详细信息页面的HTML,告诉优采云要抓取哪个标签,要抓取文章内容文本的网站,以及在详细信息页面上提取哪些信息,如来源、作者等。所有这些都是为优采云找到的,并进行分析和总结,以便它能够自动工作
如何使用优采云采集器采集网页图片详细图形教程
优采云采集器采集信息分为两个步骤:1。采用网站。这一步还告诉软件需要采集多少网页,并给出具体的网页地址。2.内容。有了网站后,你可以去网站上的采集信息,但是网站上有很多信息,软件不知道你想采用什么。在内容部分,我们必须制定规则。告诉软件我想采用什么。1.采用网站。网页上的产品信息是您想要采用的,即目标。在采集链接页面中,输入采集地址的列表页面。在这里,注意过滤无用的链接。然后点击test按钮测试填写信息的正确性:测试正确后,我们展开地址。现在我们只需获取列表页面的文章地址,还有其他列表需要采集。其他列表页面在其页面上。我们观察这些发行版的链接形式,找出规则,然后批量填写URL规则。2.在对内容的采集进行上述处理后,可以采集目标产品页面的链接。让我们输入内容的采集。定义了采集的内容后,我们开始编写采集规则,优采云采集内容是采集网页的源代码,所以我们需要打开产品页面的源代码,找到我们想要的采集信息的位置。例如,description字段中的采集在找到描述的位置后如何填写采集规则非常简单。只需将采集目标的开始字符串和结束字符串填入采集的相应位置即可。这里我们选择Description:作为开始字符串和结束字符串。值得注意的是,起始字符串在此页面上必须是唯一的,并且它也存在于其他产品页面上。此页面仅允许软件查找要使用采集的位置。其他页面很常见,以确保软件可以从其他页面采集数据。填写后,并不意味着可以是采集正确。它需要测试以排除一些无用的数据。可以在HTML标记排除和内容排除中执行排除。测试成功后,制作此类标签。这里我们使用通配符来实现这一要求。我们使用(*)通配符来表示任何不常见的地方。地址采集由参数(变量)表示。最后,让我们将这一段改为: 查看全部
内容采集器(
优采云采集器怎么把内容导入网站?如何使用采集器采集网页图片)
优采云采集器如何将内容导入网站
现在它基本上是免费的采集器并且有强大的功能。它比优采云. 例如,优采云采集器的cloud采集函数就是一团乱麻,速度很快,规则的制定也特别简单
优采云采集器如何使用它
用几句话来描述这种方法是非常困难的。我建议你看一下两个官方视频教程:一个是“播放优采云采集器,9节课,让你开始并掌握”;另一个是“优采云采集器-URL采集rule”。我相信你在学习了这些视频教程后会用到它
让我简单谈谈优采云的工作原理@采集器. 它主要执行软件中配置的捕获规则,解析后存储在您自己的数据库或文件中。因此,您主要需要分析两个方面:一是观察网页翻页URL的变化,汇总并提交给优采云,让它知道如何自动翻页;另一方面,分析列表页面和详细信息页面的HTML,告诉优采云要抓取哪个标签,要抓取文章内容文本的网站,以及在详细信息页面上提取哪些信息,如来源、作者等。所有这些都是为优采云找到的,并进行分析和总结,以便它能够自动工作
如何使用优采云采集器采集网页图片详细图形教程
优采云采集器采集信息分为两个步骤:1。采用网站。这一步还告诉软件需要采集多少网页,并给出具体的网页地址。2.内容。有了网站后,你可以去网站上的采集信息,但是网站上有很多信息,软件不知道你想采用什么。在内容部分,我们必须制定规则。告诉软件我想采用什么。1.采用网站。网页上的产品信息是您想要采用的,即目标。在采集链接页面中,输入采集地址的列表页面。在这里,注意过滤无用的链接。然后点击test按钮测试填写信息的正确性:测试正确后,我们展开地址。现在我们只需获取列表页面的文章地址,还有其他列表需要采集。其他列表页面在其页面上。我们观察这些发行版的链接形式,找出规则,然后批量填写URL规则。2.在对内容的采集进行上述处理后,可以采集目标产品页面的链接。让我们输入内容的采集。定义了采集的内容后,我们开始编写采集规则,优采云采集内容是采集网页的源代码,所以我们需要打开产品页面的源代码,找到我们想要的采集信息的位置。例如,description字段中的采集在找到描述的位置后如何填写采集规则非常简单。只需将采集目标的开始字符串和结束字符串填入采集的相应位置即可。这里我们选择Description:作为开始字符串和结束字符串。值得注意的是,起始字符串在此页面上必须是唯一的,并且它也存在于其他产品页面上。此页面仅允许软件查找要使用采集的位置。其他页面很常见,以确保软件可以从其他页面采集数据。填写后,并不意味着可以是采集正确。它需要测试以排除一些无用的数据。可以在HTML标记排除和内容排除中执行排除。测试成功后,制作此类标签。这里我们使用通配符来实现这一要求。我们使用(*)通配符来表示任何不常见的地方。地址采集由参数(变量)表示。最后,让我们将这一段改为:
内容采集器(别人采集自己的内容时候,排名比我们高的原因)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-09-20 06:29
当其他采集拥有自己的内容时,排名高于我们的原因有两个。第一个是权威网站。这是正常的。例如,我们的新网站就像一个孩子,而其他人的网站已经像一个老板了。当一个孩子说一个非常合理的词时,很多人并不这么认为。就在老板听到的时候,他也这么说了。然后很多人愿意听老板的话,认为老板的话是真的
不同的人说同一句话的效果不同,所以如果你的内容是由权威网站采集发布的,首先不要担心悲伤,因为这表明你的内容是有价值的。如果你与权威网站沟通良好,你可以得到一个很好的解决方案。你也可以在网站上留下链接,这也有助于我们网站增加我们的体重,这是一个双赢的局面
第二个是整个车站采集。整个车站采集是不同的。整个车站采集通常位于同一水平面上。看到他们的努力成果被别人夺走,真是无可奈何
但目前,搜索引擎已经加大了对此类网站的攻击力度。随着飓风算法和熊掌神助攻击的实施,原创内容得到了更好的保护。整个网站采集注定只能存活很短时间
@如何避免因三、采集内容而受到处罚
@上面已经提到了对采集内容被处罚的分析,如果我们想要采集内容,我们如何避免被处罚
1.内容可以保持不变,但标题必须修改
搜索引擎通过标题匹配关键词标题,分配给标题的权重相对较高。因此,当你重新定义采集内容时,你必须修改标题,不要太相似,并且含义与内容不分离
2.提高含量
采集我们可以处理和改善过去的内容,就像美食一样。对于同一种食品,一种是包装的,另一种不是,它们的价值和用户偏好不同
那么具体的处理在哪里呢?主要从图片、字体颜色、粗体字体等细节。如果采集内容已经很完美了,你不妨在文本的前面或后面添加你自己的观点
3.采集的含量应注意质量。懒惰的采集将毫无用处
采集内容应该有质量,这样搜索引擎一般不会攻击。什么是高质量内容?首先,我们应该确保采集内容不会太旧。其次,那些在搜索引擎中搜索结果很少的人也属于。第三,最重要的一点是内容应该对用户有帮助。我们的内容最终是针对用户的。没有值引用的内容无法推送到用户。禁止使用自动采集软件进行推广
四、如何防止他人的采集网站内容
如何防止他人采集我们的网站内容?在早期阶段,尽量保持低调,不要让别人发现,尽量只生成链接内容而不在网站页面上更新,这样别人就无法搜索,但搜索引擎可以更好地捕获内容。当后面的排名和权重上升时,他们将不再采集帮助
您还可以添加禁止右键单击网站页面的代码。虽然其他人可以通过代码采集来实现,但采集难度的增加可能会让采集用户半途而废,转而寻找其他资源
结论:本文简要介绍了搜索引擎如何处理互联网上的采集内容。简言之,大多数盲人采集都是无用的。只有有采集的意图,我们才能实现双赢。不要投机取巧 查看全部
内容采集器(别人采集自己的内容时候,排名比我们高的原因)
当其他采集拥有自己的内容时,排名高于我们的原因有两个。第一个是权威网站。这是正常的。例如,我们的新网站就像一个孩子,而其他人的网站已经像一个老板了。当一个孩子说一个非常合理的词时,很多人并不这么认为。就在老板听到的时候,他也这么说了。然后很多人愿意听老板的话,认为老板的话是真的
不同的人说同一句话的效果不同,所以如果你的内容是由权威网站采集发布的,首先不要担心悲伤,因为这表明你的内容是有价值的。如果你与权威网站沟通良好,你可以得到一个很好的解决方案。你也可以在网站上留下链接,这也有助于我们网站增加我们的体重,这是一个双赢的局面
第二个是整个车站采集。整个车站采集是不同的。整个车站采集通常位于同一水平面上。看到他们的努力成果被别人夺走,真是无可奈何
但目前,搜索引擎已经加大了对此类网站的攻击力度。随着飓风算法和熊掌神助攻击的实施,原创内容得到了更好的保护。整个网站采集注定只能存活很短时间
@如何避免因三、采集内容而受到处罚
@上面已经提到了对采集内容被处罚的分析,如果我们想要采集内容,我们如何避免被处罚
1.内容可以保持不变,但标题必须修改
搜索引擎通过标题匹配关键词标题,分配给标题的权重相对较高。因此,当你重新定义采集内容时,你必须修改标题,不要太相似,并且含义与内容不分离
2.提高含量
采集我们可以处理和改善过去的内容,就像美食一样。对于同一种食品,一种是包装的,另一种不是,它们的价值和用户偏好不同
那么具体的处理在哪里呢?主要从图片、字体颜色、粗体字体等细节。如果采集内容已经很完美了,你不妨在文本的前面或后面添加你自己的观点
3.采集的含量应注意质量。懒惰的采集将毫无用处
采集内容应该有质量,这样搜索引擎一般不会攻击。什么是高质量内容?首先,我们应该确保采集内容不会太旧。其次,那些在搜索引擎中搜索结果很少的人也属于。第三,最重要的一点是内容应该对用户有帮助。我们的内容最终是针对用户的。没有值引用的内容无法推送到用户。禁止使用自动采集软件进行推广
四、如何防止他人的采集网站内容
如何防止他人采集我们的网站内容?在早期阶段,尽量保持低调,不要让别人发现,尽量只生成链接内容而不在网站页面上更新,这样别人就无法搜索,但搜索引擎可以更好地捕获内容。当后面的排名和权重上升时,他们将不再采集帮助
您还可以添加禁止右键单击网站页面的代码。虽然其他人可以通过代码采集来实现,但采集难度的增加可能会让采集用户半途而废,转而寻找其他资源
结论:本文简要介绍了搜索引擎如何处理互联网上的采集内容。简言之,大多数盲人采集都是无用的。只有有采集的意图,我们才能实现双赢。不要投机取巧
内容采集器(优采云采集论坛会员注册器是一款非常实用且操作便捷的网站内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-09-14 19:00
优采云采集论坛会员注册工具是一个非常实用方便的操作网站内容采集软件,优采云采集论坛会员注册工具可以让用户采集各类论坛发帖和回复、网站和博客文章的内容抓取、各种论坛会员的无限注册等,帮助用户轻松采集自己想要的内容。
【功能介绍】1、软件可以有效过滤已经采集的帖子,每天采集最新帖子发布到自己论坛指定版块
2、可以将发帖和回复的会员账号分开,允许部分会员发布所有主题,其他会员全部回复,会员账号随机选择发布
3、 支持自定义发帖和回复间隔时间
4、software 有一个或多个版块的自动回复功能,回复内容可自定义
5、有采集或发帖任务完成后自动关机功能
6、support 文章content 同义词替换功能
7、软件可以采集注册登录后才能查看的论坛帖子
【使用教程】第一步,在IE窗口打开需要注册的论坛,找到该论坛的注册页面网址!并且确保注册页面只保留“用户名、密码、确认密码、邮箱”这四个必填项!请到论坛后台暂时关闭其他项目!登录论坛后台≯≯基本设置≯≯注册及权限控制,取消所有会员注册限制,包括“新用户注册验证、不同用户同一邮箱注册、IP注册间隔限制、24小时注册尝试限制” ”等,然后保存。如果注册项有自行修改代码或添加插件,请备份并直接用官方原文件覆盖,注册后恢复。
第二步,打开优采云论坛注册器,点击下方“会员注册”按钮。
第三步,在软件网址栏中输入论坛注册页面网址。
第四步,点击右下角的“会员注册”!如果提示会员注册失败,请检查第一步中的设置是否全部正确,您可以手动注册会员进行测试。
第五步,妥善保存已注册成功的会员信息供其他软件使用! 查看全部
内容采集器(优采云采集论坛会员注册器是一款非常实用且操作便捷的网站内容)
优采云采集论坛会员注册工具是一个非常实用方便的操作网站内容采集软件,优采云采集论坛会员注册工具可以让用户采集各类论坛发帖和回复、网站和博客文章的内容抓取、各种论坛会员的无限注册等,帮助用户轻松采集自己想要的内容。
【功能介绍】1、软件可以有效过滤已经采集的帖子,每天采集最新帖子发布到自己论坛指定版块
2、可以将发帖和回复的会员账号分开,允许部分会员发布所有主题,其他会员全部回复,会员账号随机选择发布
3、 支持自定义发帖和回复间隔时间
4、software 有一个或多个版块的自动回复功能,回复内容可自定义
5、有采集或发帖任务完成后自动关机功能
6、support 文章content 同义词替换功能
7、软件可以采集注册登录后才能查看的论坛帖子
【使用教程】第一步,在IE窗口打开需要注册的论坛,找到该论坛的注册页面网址!并且确保注册页面只保留“用户名、密码、确认密码、邮箱”这四个必填项!请到论坛后台暂时关闭其他项目!登录论坛后台≯≯基本设置≯≯注册及权限控制,取消所有会员注册限制,包括“新用户注册验证、不同用户同一邮箱注册、IP注册间隔限制、24小时注册尝试限制” ”等,然后保存。如果注册项有自行修改代码或添加插件,请备份并直接用官方原文件覆盖,注册后恢复。
第二步,打开优采云论坛注册器,点击下方“会员注册”按钮。
第三步,在软件网址栏中输入论坛注册页面网址。
第四步,点击右下角的“会员注册”!如果提示会员注册失败,请检查第一步中的设置是否全部正确,您可以手动注册会员进行测试。
第五步,妥善保存已注册成功的会员信息供其他软件使用!
内容采集器(数据采集对各行各业有着至关重要的作用,你了解多少?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2021-09-14 18:12
Data采集在各行各业中发挥着至关重要的作用,让个人、公司、组织实现大数据的宏观调控,研究分析,总结规律,做出准确判断和决策.
1、优采云采集器
优采云是一个集网页数据采集、移动互联网数据和API接口服务(包括数据爬虫、数据优化、数据挖掘、数据存储、数据备份)等服务于一体的数据服务平台,连续5年同年获得互联网Data采集software榜单第一名。 2016年以来,优采云积极开拓海外市场,分别在美国和日本推出Octoparse和Octoparse.jp数据爬取平台。截至2019年,优采云全球用户超过150万。其一大特点:零门槛使用,无需了解网络爬虫技术,即可轻松完成采集。
2、优采云采集器
国内老牌数据采集软件,以其灵活的配置和强大的性能领先国内同类产品,获得了众多用户的一致认可。使用优采云采集器几乎可以采集任何格式的所有网页和文件,不管是什么语言或编码。 采集 比普通采集器 快7 倍,采集/posting 和复制/粘贴一样准确。同时,软件还具备“舆论雷达监控系统”,精准监控网络数据信息安全,及时处理不利或危险信息。
3、优采云采集器
如果的编辑推荐最好的信息采集software,那一定是优采云采集器。 优采云采集器由原谷歌技术团队打造,基于人工智能技术,支持智能模式和流程图模式采集;使用简单,只需输入URL即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集;并且软件支持Linux、Windows、Mac三大操作系统,导出数据不花钱,还支持Excel、CSV、TXT、HTML多种导出格式。与其他同类软件相比,仅此一点就够良心了。
4、集搜客
经过十多年打磨的GooSeeker已经是一款易用性出众的数据采集软件。其特点是对各种采集数据进行了可视化标注,用户无需考虑程序,无需技术基础,只需点击想要的内容,给标签起个名字,然后软件自动管理选中的内容。自动采集到排序框,并保存为xml或excel结构。此外,软件还具有模板资源申请、会员互助抓取、手机网站数据抓取、定时自启动采集等功能。
5、优采云采集器
这是一套专业的网站内容采集软件,支持各种论坛帖子回复采集、网站和博客文章内容抓取,通过相关配置,可以轻松@网站采集80% 的内容自用。根据建站方案的不同,优采云采集器分论坛采集器、cms采集器和博客采集器三种类型,共数百个版本数据支持近40个主流网站构建程序采集和发布任务,支持图片本地化,支持网站login采集,页面抓取,全面模拟手动登录发布。此外,软件还内置了SEO伪原创模块,让您的采集更加强大。
6、Import.io
英国市场最著名的采集器之一,由一家总部位于英国伦敦的公司开发,现已在美国、印度等地设立分支机构。作为网页数据采集software,import.io有四大功能,分别是Magic、Extractor、Crawler、Connector。主要功能都具备,但最抢眼、最好的功能就是其中的“魔法”。 , 该功能让用户只需进入网页即可自动提取数据,无需任何其他设置,使用起来极其简单。
7、ParseHub
ForeSpider 也是一款易于操作且强烈推荐的信息采集 软件。它分为免费版和付费版。具有可视化的向导式操作界面,日志管理和异常情况预警,免安装数据库,可自动识别语义筛选数据,智能挖掘文本特征数据,同时自带多种数据清理方法,并自带可视化图表分析。软件免费版、基础版、专业版采集速度高达400万条/天,服务器版采集速度高达8000万条/天,并提供采集服务。
8、优采云
优采云是采集软件中最常用的信息之一。封装了复杂的算法和分布式逻辑,提供了灵活简单的开发接口;应用自动部署,分布式运行,可视化,操作简单,计算和存储资源弹性扩展;不同来源的数据统一可视化管理,restful界面/webhook推送/graphql访问等高级功能,让用户与现有系统无缝对接。软件现提供企业标准版、高级版、企业定制版。
9、ForeSpider
ParseHub 是一款基于网页的爬取客户端工具,支持 JavaScript 渲染、Ajax 爬取、Cookies、Session 等机制,对网站 的数据进行分析和获取。它还可以使用机器学习技术来识别复杂的文档并以 JSON、CSV 等格式导出文件。该软件支持在 Windows、Mac 和 Linux 上使用,或作为 Firefox 扩展。此外,它还具有一些高级功能,例如分页、弹出窗口和导航、无限滚动页面等,可以将 ParseHub 中的数据可视化为 Tableau。
10、Content Grabber
Content Grabber是一款支持智能抓取的可视化网页数据采集软件和网络自动化工具,可以从几乎所有网站中提取内容。其程序运行环境可用于开发、测试和生产服务器。可以使用c#或VB.NET调试或编写脚本来控制爬虫程序。还支持在爬虫工具中添加第三方扩展插件。 Content Grabber 功能齐全,非常适合有技术基础的用户使用。 查看全部
内容采集器(数据采集对各行各业有着至关重要的作用,你了解多少?)
Data采集在各行各业中发挥着至关重要的作用,让个人、公司、组织实现大数据的宏观调控,研究分析,总结规律,做出准确判断和决策.
1、优采云采集器
优采云是一个集网页数据采集、移动互联网数据和API接口服务(包括数据爬虫、数据优化、数据挖掘、数据存储、数据备份)等服务于一体的数据服务平台,连续5年同年获得互联网Data采集software榜单第一名。 2016年以来,优采云积极开拓海外市场,分别在美国和日本推出Octoparse和Octoparse.jp数据爬取平台。截至2019年,优采云全球用户超过150万。其一大特点:零门槛使用,无需了解网络爬虫技术,即可轻松完成采集。
2、优采云采集器
国内老牌数据采集软件,以其灵活的配置和强大的性能领先国内同类产品,获得了众多用户的一致认可。使用优采云采集器几乎可以采集任何格式的所有网页和文件,不管是什么语言或编码。 采集 比普通采集器 快7 倍,采集/posting 和复制/粘贴一样准确。同时,软件还具备“舆论雷达监控系统”,精准监控网络数据信息安全,及时处理不利或危险信息。
3、优采云采集器
如果的编辑推荐最好的信息采集software,那一定是优采云采集器。 优采云采集器由原谷歌技术团队打造,基于人工智能技术,支持智能模式和流程图模式采集;使用简单,只需输入URL即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集;并且软件支持Linux、Windows、Mac三大操作系统,导出数据不花钱,还支持Excel、CSV、TXT、HTML多种导出格式。与其他同类软件相比,仅此一点就够良心了。
4、集搜客
经过十多年打磨的GooSeeker已经是一款易用性出众的数据采集软件。其特点是对各种采集数据进行了可视化标注,用户无需考虑程序,无需技术基础,只需点击想要的内容,给标签起个名字,然后软件自动管理选中的内容。自动采集到排序框,并保存为xml或excel结构。此外,软件还具有模板资源申请、会员互助抓取、手机网站数据抓取、定时自启动采集等功能。
5、优采云采集器
这是一套专业的网站内容采集软件,支持各种论坛帖子回复采集、网站和博客文章内容抓取,通过相关配置,可以轻松@网站采集80% 的内容自用。根据建站方案的不同,优采云采集器分论坛采集器、cms采集器和博客采集器三种类型,共数百个版本数据支持近40个主流网站构建程序采集和发布任务,支持图片本地化,支持网站login采集,页面抓取,全面模拟手动登录发布。此外,软件还内置了SEO伪原创模块,让您的采集更加强大。
6、Import.io
英国市场最著名的采集器之一,由一家总部位于英国伦敦的公司开发,现已在美国、印度等地设立分支机构。作为网页数据采集software,import.io有四大功能,分别是Magic、Extractor、Crawler、Connector。主要功能都具备,但最抢眼、最好的功能就是其中的“魔法”。 , 该功能让用户只需进入网页即可自动提取数据,无需任何其他设置,使用起来极其简单。
7、ParseHub
ForeSpider 也是一款易于操作且强烈推荐的信息采集 软件。它分为免费版和付费版。具有可视化的向导式操作界面,日志管理和异常情况预警,免安装数据库,可自动识别语义筛选数据,智能挖掘文本特征数据,同时自带多种数据清理方法,并自带可视化图表分析。软件免费版、基础版、专业版采集速度高达400万条/天,服务器版采集速度高达8000万条/天,并提供采集服务。
8、优采云
优采云是采集软件中最常用的信息之一。封装了复杂的算法和分布式逻辑,提供了灵活简单的开发接口;应用自动部署,分布式运行,可视化,操作简单,计算和存储资源弹性扩展;不同来源的数据统一可视化管理,restful界面/webhook推送/graphql访问等高级功能,让用户与现有系统无缝对接。软件现提供企业标准版、高级版、企业定制版。
9、ForeSpider
ParseHub 是一款基于网页的爬取客户端工具,支持 JavaScript 渲染、Ajax 爬取、Cookies、Session 等机制,对网站 的数据进行分析和获取。它还可以使用机器学习技术来识别复杂的文档并以 JSON、CSV 等格式导出文件。该软件支持在 Windows、Mac 和 Linux 上使用,或作为 Firefox 扩展。此外,它还具有一些高级功能,例如分页、弹出窗口和导航、无限滚动页面等,可以将 ParseHub 中的数据可视化为 Tableau。
10、Content Grabber
Content Grabber是一款支持智能抓取的可视化网页数据采集软件和网络自动化工具,可以从几乎所有网站中提取内容。其程序运行环境可用于开发、测试和生产服务器。可以使用c#或VB.NET调试或编写脚本来控制爬虫程序。还支持在爬虫工具中添加第三方扩展插件。 Content Grabber 功能齐全,非常适合有技术基础的用户使用。
内容采集器(跳出本次或当前循环与终止循环方法PHP中用foreach(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2021-09-12 03:13
猜猜你在找什么 PHP 相关的文章
TP5查询mysql数据库时find_in_set的使用
type字段以1,2,3的形式存在于数据库中。已经提到使用FIND_IN_SET函数对于一些非常复杂的查询,比如find_in_set,也可以直接使用原生的SQL语句进行查询,例如:出于安全考虑
php处理微信支付回调(收款)的方法
支付完成后,微信将相关支付结果和用户信息发送给商户。商户需要接收处理,并返回响应。与后台通知交互时,如果微信对商家响应的响应不成功或超时,则微信认为通知失败,微信会通过一定的策略定期重新发起通知。
composer 安装 Yii2 遇到的 BUG
通过 Composer 安装 安装 Composer 如果您还没有安装 Composer,您可以按照中的方法安装。在 Linux 和 Mac OS 中
PHP foreach() 跳出当前或当前循环并终止循环方法
PHPforeach() 跳出当前或当前循环并终止循环方法。在PHP中的foreach()循环中,当你想在循环中,当满足某个条件时,我想下面是我打印$praProductData结果的实际例子如下:
宝塔面板忘记密码的解决方法
如果忘记宝塔密码,可以使用以下命令重置密码: cd /www/server/panel && python tools.py panel testpasswd 如果提示多次登录失败,暂时禁止
Redis 主题-Redis 管理工具
一、安全性1、 运行环境Redis简洁美观,其安全性没有太多操作。要求外界不能直接连接生产系统中的Redis进行操作,而必须在程序转入后由程序进行。操作。即redis需要运行在可信环境中。
使用phpqrcode二维码生成类库合成带有logo的二维码,并使用合成的二维码生成海报(二)
前期准备 引入phpqrcode库(下载地址:;支持彩色二维码的下载地址:htt
我记得之前写过关于两者之间的区别。今天看群里的朋友也提出了一个奇怪的问题,说“file_get_contents('php://input')无法获取curl post请求的数据。”?其实 查看全部
内容采集器(跳出本次或当前循环与终止循环方法PHP中用foreach(图))
猜猜你在找什么 PHP 相关的文章
TP5查询mysql数据库时find_in_set的使用
type字段以1,2,3的形式存在于数据库中。已经提到使用FIND_IN_SET函数对于一些非常复杂的查询,比如find_in_set,也可以直接使用原生的SQL语句进行查询,例如:出于安全考虑
php处理微信支付回调(收款)的方法
支付完成后,微信将相关支付结果和用户信息发送给商户。商户需要接收处理,并返回响应。与后台通知交互时,如果微信对商家响应的响应不成功或超时,则微信认为通知失败,微信会通过一定的策略定期重新发起通知。
composer 安装 Yii2 遇到的 BUG
通过 Composer 安装 安装 Composer 如果您还没有安装 Composer,您可以按照中的方法安装。在 Linux 和 Mac OS 中
PHP foreach() 跳出当前或当前循环并终止循环方法
PHPforeach() 跳出当前或当前循环并终止循环方法。在PHP中的foreach()循环中,当你想在循环中,当满足某个条件时,我想下面是我打印$praProductData结果的实际例子如下:
宝塔面板忘记密码的解决方法
如果忘记宝塔密码,可以使用以下命令重置密码: cd /www/server/panel && python tools.py panel testpasswd 如果提示多次登录失败,暂时禁止
Redis 主题-Redis 管理工具
一、安全性1、 运行环境Redis简洁美观,其安全性没有太多操作。要求外界不能直接连接生产系统中的Redis进行操作,而必须在程序转入后由程序进行。操作。即redis需要运行在可信环境中。
使用phpqrcode二维码生成类库合成带有logo的二维码,并使用合成的二维码生成海报(二)
前期准备 引入phpqrcode库(下载地址:;支持彩色二维码的下载地址:htt
我记得之前写过关于两者之间的区别。今天看群里的朋友也提出了一个奇怪的问题,说“file_get_contents('php://input')无法获取curl post请求的数据。”?其实
内容采集器(软件特色零门槛不懂网络爬虫技术,赶紧下载体验吧)
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-09-08 00:06
优采云采集器是新一代可视化智能采集器,可视化配置,轻松创建,无需编程,智能生成,数据采集从未如此简单,赶快下载体验吧。
相关软件软件大小及版本说明下载链接
优采云采集器是新一代可视化智能采集器,可视化配置,轻松创建,无需编程,智能生成,数据采集从未如此简单,赶快下载体验吧!
软件功能
零门槛
如果你不懂网络爬虫技术,如果你会上网,你会采集网站数据
多引擎,高速稳定
内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集data更高效。还内置了JSON引擎,无需分析JSON数据结构,直观选择JSON内容。
适用于各种网站
采集 Internet 99% 网站,包括单页应用ajax加载等动态类型网站。
产品优势
可视化向导
所有采集元素自动生成采集数据
预定任务
运行时间灵活定义,全自动运行
多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
自动识别网页列表、采集字段、分页等
拦截请求
自定义屏蔽域名,方便过滤异地广告,提升采集速度
多数据导出
可导出为 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等
更新日志
3.2.4.9 (2021-09-04)
优化编译,修复部分组件系统兼容性问题 查看全部
内容采集器(软件特色零门槛不懂网络爬虫技术,赶紧下载体验吧)
优采云采集器是新一代可视化智能采集器,可视化配置,轻松创建,无需编程,智能生成,数据采集从未如此简单,赶快下载体验吧。
相关软件软件大小及版本说明下载链接
优采云采集器是新一代可视化智能采集器,可视化配置,轻松创建,无需编程,智能生成,数据采集从未如此简单,赶快下载体验吧!
软件功能
零门槛
如果你不懂网络爬虫技术,如果你会上网,你会采集网站数据
多引擎,高速稳定
内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集data更高效。还内置了JSON引擎,无需分析JSON数据结构,直观选择JSON内容。
适用于各种网站
采集 Internet 99% 网站,包括单页应用ajax加载等动态类型网站。
产品优势
可视化向导
所有采集元素自动生成采集数据
预定任务
运行时间灵活定义,全自动运行
多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
自动识别网页列表、采集字段、分页等
拦截请求
自定义屏蔽域名,方便过滤异地广告,提升采集速度
多数据导出
可导出为 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等
更新日志
3.2.4.9 (2021-09-04)
优化编译,修复部分组件系统兼容性问题
内容采集器(小编为大家讲解有关语言编程其中不被重视的技巧)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-09-07 22:12
今天小编就给大家文章讲解语言编程。在课堂上,教师将了解语言编程中不被重视的技能。相信对大家会有很大的帮助
php示例教程采集器,通常称为小偷程序,主要用于抓取他人网页的内容。关于采集器的制作,其实并不难。就是远程打开需要采集的网页,然后用正则表达式匹配需要的内容。只要你有一点正则表达式的基础,就可以让自己的采集器来了。
前几天做了一个小说连载程序,因为怕更新麻烦,写了个采集器,采集八路中文网,功能比较简单,不能自定义规则,不过大概思路都在里面,自定义规则可以自己扩展。
使用php做采集器主要使用两个函数:file_get_contents()和preg_match_all()。第一个是远程阅读网页内容,但只能在php5以上版本使用,后者是常规功能。 , 用于提取需要的内容。
让我们一步一步地谈谈函数的实现。
因为是采集小说,先提取标题、作者、流派。其他信息可根据需要提取。
这里是《回明朝太子》的目标,先打开书目页面,链接:
再打开几本书,你会发现书名的基本格式是:book number/Index.aspx,所以我们可以制作一个起始页,定义一个,用它输入需要的书号采集,然后我们可以通过 $_POST['number'] 这个格式来接收采集的书号。收到书号后,接下来要做的就是构造书目页面:$url=$_POST['number']/Index.aspx,当然这里是一个例子,主要是为了方便说明,就是最好以实际生产为准。 _POST['number'] 的合法性。
构建好URL后,即可开启采集书信息。使用file_get_contents()函数打开书目页面:$content=file_get_contents($url),这样就可以读取书目页面的内容了。下一步是匹配书名、作者和类型。这是一个带有书名的例子,其他一切都是一样的。打开书目页面,查看源文件,找到《回明为主》,这是要提取的书名。提取书名的正则表达式:/(.*?)\\\\/is,使用preg_match_all()函数提取书名:preg_match_all("/(.*?)\\\\/is" ,$contents,$title);这样$title[0][0]的内容就是我们想要的title(preg_match_all函数的用法可以百度查,这里就不详细解释了)。取出书籍信息后,下一步就是取出章节内容。取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。 ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:
preg_match_all("/Html\\\\/Book\\\\/[0-9]{1,}\\\\/[0-9]{1,}\\\\/List\\ \\.shtm/is",$contents,$typeid);这还不够,我们还需要一个剪切功能:
[复制代码] [-] PHP代码如下:
以下为引用内容:
function cut($string,$start,$end){
$message = expand($start,$string);
$message=explode($end,$message[1]); return $message[0];} 其中 $string 是要剪切的内容,$start 是开头,$end 是结尾。检索分类号:
$start = "Html/Book/";
$end
="列表.shtm";
$typeid = cut($typeid[0][0],$start,$end);
$typeid = expand("/",$typeid);[/php]
嗯,我从事编程语言统计多年,数据来源很多,包括代码库、问答讨论、招聘广告、社交媒体情况、教程页面访问量、学习视频浏览量、开发者调查、等。不同时间发布的数据可以认为是准确的。
也可以被视为有缺陷,但它们可用于发现行业趋势。最后,不要指望一夜之间成为编码忍者。有些人有天生的能力,但他们也花大量时间磨练自己的技能,不断学习新的技术和技能。 "
XML 在过去三年中经历了多次迭代,因此目前存在不同版本的 Microsoft XML 解析器也就不足为奇了。 Internet Explorer 4.0 收录早期版本的 XML 解析器,它早于 XSL、XML 数据或大多数其他 XML 技术(并且具有完全不同的 DOM 模型)。这个早期版本的分析器收录在 MSXML.dll 库中。可以从 MSDN XML 开发人员中心(英文)将分析器升级到更新的分析器。
我们强烈建议您升级到新的分析器,因为它更强大。 Internet Explorer 5.0 包括 MSXML 2.0 解析器,其中收录 XSL 和 XML 架构的基本版本。 MSXML2 是 SQL Server 2000 附带的解析器版本。MSXML2 收录许多性能增强功能,并且整体性能和可伸缩性得到了改进。 MSXML3 是当前作为“技术预览”收录的版本。 MSXML3 包括 XSLT 和 XPath 支持以及 SAX 接口。
在php教程中,$typeid[0]就是我们要找的分类号。下一步是构造章节列表的地址:$chapterurl = $typeid[0]/$_POST[‘number’]/List.shtm。有了这个,你可以找到每章的地址。方法如下:
以下为引用内容:
$ustart = "\\\\"";
$uend
="\\\\"";
//t代表title的缩写
$tstart = ">";
$趋向
=" 查看全部
内容采集器(小编为大家讲解有关语言编程其中不被重视的技巧)
今天小编就给大家文章讲解语言编程。在课堂上,教师将了解语言编程中不被重视的技能。相信对大家会有很大的帮助
php示例教程采集器,通常称为小偷程序,主要用于抓取他人网页的内容。关于采集器的制作,其实并不难。就是远程打开需要采集的网页,然后用正则表达式匹配需要的内容。只要你有一点正则表达式的基础,就可以让自己的采集器来了。
前几天做了一个小说连载程序,因为怕更新麻烦,写了个采集器,采集八路中文网,功能比较简单,不能自定义规则,不过大概思路都在里面,自定义规则可以自己扩展。
使用php做采集器主要使用两个函数:file_get_contents()和preg_match_all()。第一个是远程阅读网页内容,但只能在php5以上版本使用,后者是常规功能。 , 用于提取需要的内容。
让我们一步一步地谈谈函数的实现。
因为是采集小说,先提取标题、作者、流派。其他信息可根据需要提取。
这里是《回明朝太子》的目标,先打开书目页面,链接:
再打开几本书,你会发现书名的基本格式是:book number/Index.aspx,所以我们可以制作一个起始页,定义一个,用它输入需要的书号采集,然后我们可以通过 $_POST['number'] 这个格式来接收采集的书号。收到书号后,接下来要做的就是构造书目页面:$url=$_POST['number']/Index.aspx,当然这里是一个例子,主要是为了方便说明,就是最好以实际生产为准。 _POST['number'] 的合法性。
构建好URL后,即可开启采集书信息。使用file_get_contents()函数打开书目页面:$content=file_get_contents($url),这样就可以读取书目页面的内容了。下一步是匹配书名、作者和类型。这是一个带有书名的例子,其他一切都是一样的。打开书目页面,查看源文件,找到《回明为主》,这是要提取的书名。提取书名的正则表达式:/(.*?)\\\\/is,使用preg_match_all()函数提取书名:preg_match_all("/(.*?)\\\\/is" ,$contents,$title);这样$title[0][0]的内容就是我们想要的title(preg_match_all函数的用法可以百度查,这里就不详细解释了)。取出书籍信息后,下一步就是取出章节内容。取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。 ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:
preg_match_all("/Html\\\\/Book\\\\/[0-9]{1,}\\\\/[0-9]{1,}\\\\/List\\ \\.shtm/is",$contents,$typeid);这还不够,我们还需要一个剪切功能:
[复制代码] [-] PHP代码如下:
以下为引用内容:
function cut($string,$start,$end){
$message = expand($start,$string);
$message=explode($end,$message[1]); return $message[0];} 其中 $string 是要剪切的内容,$start 是开头,$end 是结尾。检索分类号:
$start = "Html/Book/";
$end
="列表.shtm";
$typeid = cut($typeid[0][0],$start,$end);
$typeid = expand("/",$typeid);[/php]
嗯,我从事编程语言统计多年,数据来源很多,包括代码库、问答讨论、招聘广告、社交媒体情况、教程页面访问量、学习视频浏览量、开发者调查、等。不同时间发布的数据可以认为是准确的。
也可以被视为有缺陷,但它们可用于发现行业趋势。最后,不要指望一夜之间成为编码忍者。有些人有天生的能力,但他们也花大量时间磨练自己的技能,不断学习新的技术和技能。 "
XML 在过去三年中经历了多次迭代,因此目前存在不同版本的 Microsoft XML 解析器也就不足为奇了。 Internet Explorer 4.0 收录早期版本的 XML 解析器,它早于 XSL、XML 数据或大多数其他 XML 技术(并且具有完全不同的 DOM 模型)。这个早期版本的分析器收录在 MSXML.dll 库中。可以从 MSDN XML 开发人员中心(英文)将分析器升级到更新的分析器。
我们强烈建议您升级到新的分析器,因为它更强大。 Internet Explorer 5.0 包括 MSXML 2.0 解析器,其中收录 XSL 和 XML 架构的基本版本。 MSXML2 是 SQL Server 2000 附带的解析器版本。MSXML2 收录许多性能增强功能,并且整体性能和可伸缩性得到了改进。 MSXML3 是当前作为“技术预览”收录的版本。 MSXML3 包括 XSLT 和 XPath 支持以及 SAX 接口。
在php教程中,$typeid[0]就是我们要找的分类号。下一步是构造章节列表的地址:$chapterurl = $typeid[0]/$_POST[‘number’]/List.shtm。有了这个,你可以找到每章的地址。方法如下:
以下为引用内容:
$ustart = "\\\\"";
$uend
="\\\\"";
//t代表title的缩写
$tstart = ">";
$趋向
="
内容采集器(电子书采集工具完结电子书,每本电子书自动获取简介图片,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2021-09-06 03:03
电子书采集工具是一个很好的完整电子书下载txt免费下载集合。电子书采集工具的采集过程很简单,只要稍微简单一点就可以做到如果电子书取出准确,每本电子书都会自动分割。
小说规则自建txt下载(e-book采集器)是一款绿色免费的小说采集auxiliary软件,采集网站小说上面没有下载按钮,这个软件就等价了抢网站的小说内容适用于网站,在线阅读电子书。
30天下载提供电子书采集工具v2.0。电脑正式版可免费下载。操作简单,可以准确获取完成的电子书。每本电子书自动分为大类和子类,并自动获取个人资料图片保存在同一文件夹中。
1、 自动整合所有现有的电子书和小说系统,特别是文奇、结奇和新飞酷电子书系统。 2、自动优化多线程,减少CPU占用,减少内存占用。3、支持多系统电子书生成和下载。 4.
海科提供电子书采集tools(手机电子书下载系统)下载。蓝星手机下载系统e-books采集tools操作更简单,可以准确获取完成的电子书,每本电子书自动分大类和子类,自动获取简介。
华骏软件园下载工具频道为您提供电子书采集工具下载、电子书采集工具绿版等下载工具和软件下载。更多电子书采集工具2.0历史版本,请到华骏软件园!
小说TXT采集工具是论坛大神制作的小说采集下载工具,可以帮助用户从网站上采集下载小说内容,大量小说网站广告非常影响用户体验,那么你就可以使用这个软件采集和。
Taiwen text采集器,“采文文字采集器”是一款具有文本信息采集、文本文件管理和浏览功能的管理工具。它的主要功能是文本采集和文本管理。系统剪贴板中的监控和文本采集。 查看全部
内容采集器(电子书采集工具完结电子书,每本电子书自动获取简介图片,)
电子书采集工具是一个很好的完整电子书下载txt免费下载集合。电子书采集工具的采集过程很简单,只要稍微简单一点就可以做到如果电子书取出准确,每本电子书都会自动分割。
小说规则自建txt下载(e-book采集器)是一款绿色免费的小说采集auxiliary软件,采集网站小说上面没有下载按钮,这个软件就等价了抢网站的小说内容适用于网站,在线阅读电子书。
30天下载提供电子书采集工具v2.0。电脑正式版可免费下载。操作简单,可以准确获取完成的电子书。每本电子书自动分为大类和子类,并自动获取个人资料图片保存在同一文件夹中。
1、 自动整合所有现有的电子书和小说系统,特别是文奇、结奇和新飞酷电子书系统。 2、自动优化多线程,减少CPU占用,减少内存占用。3、支持多系统电子书生成和下载。 4.
海科提供电子书采集tools(手机电子书下载系统)下载。蓝星手机下载系统e-books采集tools操作更简单,可以准确获取完成的电子书,每本电子书自动分大类和子类,自动获取简介。
华骏软件园下载工具频道为您提供电子书采集工具下载、电子书采集工具绿版等下载工具和软件下载。更多电子书采集工具2.0历史版本,请到华骏软件园!
小说TXT采集工具是论坛大神制作的小说采集下载工具,可以帮助用户从网站上采集下载小说内容,大量小说网站广告非常影响用户体验,那么你就可以使用这个软件采集和。
Taiwen text采集器,“采文文字采集器”是一款具有文本信息采集、文本文件管理和浏览功能的管理工具。它的主要功能是文本采集和文本管理。系统剪贴板中的监控和文本采集。
内容采集器(CowSwing迷你采集器-CRAWLER模块介绍及使用方法介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 256 次浏览 • 2021-09-05 02:02
CowSwing 简介
丑牛Mini采集器是一款基于Java Swing开发的专业网络数据采集/信息挖掘处理软件。通过灵活的配置,可以方便快捷的抓取网页中的结构化文本,可以对图片、文件等资源信息进行编辑过滤发布到网站
软件架构
JAVACOO-CRAWLER 采用模块化设计,每个模块由一个控制器类(CrawlController 类)协调,控制器是爬虫的核心。 CrawlController类是整个爬虫的整体控制器,控制着整个采集工作的起点,决定采集任务的开始、暂停、继续、结束。 CrawlController类主要包括以下模块:爬虫的配置参数、字符集助手、HttpCilent对象、HTML解析器包装类、爬虫边界控制器、爬虫线程控制器、处理器链、过滤器工厂。整体架构图如下:
CrawlScope:存放当前爬虫的配置信息,如采集page代码、采集filter列表、采集seed列表、爬虫持久化对象实现类等,根据配置参数初始化CrawlController其他模块。字符集助手(CharsetHandler):根据当前爬虫配置参数中的字符集配置进行初始化,为整个采集进程做准备。 HttpCilent对象(HttpClient):根据当前爬虫配置参数初始化HttpClient对象,如设置代理、设置连接/请求超时、最大连接数等。 HTML解析器包装类(HtmlParserWrapper):对HtmlParser的专门封装解析器来满足采集 任务的需要。 Frontier:主要是加载爬取的种子链接,并根据加载的种子链接初始化任务队列,准备线程控制器(ProcessorManager)开启的任务执行线程(ProcessorThread)。爬虫线程控制器(ProcessorManager):主要控制任务执行线程的数量,开启指定数量的任务执行线程来执行任务。过滤器工厂:为采集任务查询注册当前爬虫配置参数中设置的过滤器。主机缓存(HostCache):缓存HttpHost对象。处理器链(ProcessorChainList):默认构建了5条处理链,依次是预取链、提取链、提取链、写链、提交链,任务处理线程会用到。系统登录界面使用说明
系统启动界面
系统主界面
(1)我的爪牛:系统信息、插件信息、内存监控、任务监控
(2)采集Configuration:采集相关基础配置,包括远程数据库配置、FTP配置、自定义数据配置
(3)数据采集:统一管理采集进程,包括采集public参数设置、采集rule列表、采集historical列表、采集content列表
(4)任务监控:包括采集任务监控、仓储任务监控、图像处理任务监控、上传任务监控
(5)定时任务:定时执行采集task
(6)utility tools: 包括图像处理
安装包
链接:提取码:l50r
参与贡献Fork,在这个仓库新建一个Feat_xxx分支,提交代码并新建一个Pull Request成为开发者:
马云特效使用Readme_XXX.md来支持不同的语言,比如Readme_en.md、Readme_zh.md,马云官方博客,可以在这里获取这个地址。解码云端优秀开源项目,GVP是马云最有价值的开源项目。该项目是马云综合评价的优秀开源项目。马云提供的官方手册。马云封面人物是用来展示马云成员风采的专栏。 查看全部
内容采集器(CowSwing迷你采集器-CRAWLER模块介绍及使用方法介绍)
CowSwing 简介
丑牛Mini采集器是一款基于Java Swing开发的专业网络数据采集/信息挖掘处理软件。通过灵活的配置,可以方便快捷的抓取网页中的结构化文本,可以对图片、文件等资源信息进行编辑过滤发布到网站
软件架构
JAVACOO-CRAWLER 采用模块化设计,每个模块由一个控制器类(CrawlController 类)协调,控制器是爬虫的核心。 CrawlController类是整个爬虫的整体控制器,控制着整个采集工作的起点,决定采集任务的开始、暂停、继续、结束。 CrawlController类主要包括以下模块:爬虫的配置参数、字符集助手、HttpCilent对象、HTML解析器包装类、爬虫边界控制器、爬虫线程控制器、处理器链、过滤器工厂。整体架构图如下:
CrawlScope:存放当前爬虫的配置信息,如采集page代码、采集filter列表、采集seed列表、爬虫持久化对象实现类等,根据配置参数初始化CrawlController其他模块。字符集助手(CharsetHandler):根据当前爬虫配置参数中的字符集配置进行初始化,为整个采集进程做准备。 HttpCilent对象(HttpClient):根据当前爬虫配置参数初始化HttpClient对象,如设置代理、设置连接/请求超时、最大连接数等。 HTML解析器包装类(HtmlParserWrapper):对HtmlParser的专门封装解析器来满足采集 任务的需要。 Frontier:主要是加载爬取的种子链接,并根据加载的种子链接初始化任务队列,准备线程控制器(ProcessorManager)开启的任务执行线程(ProcessorThread)。爬虫线程控制器(ProcessorManager):主要控制任务执行线程的数量,开启指定数量的任务执行线程来执行任务。过滤器工厂:为采集任务查询注册当前爬虫配置参数中设置的过滤器。主机缓存(HostCache):缓存HttpHost对象。处理器链(ProcessorChainList):默认构建了5条处理链,依次是预取链、提取链、提取链、写链、提交链,任务处理线程会用到。系统登录界面使用说明
系统启动界面
系统主界面
(1)我的爪牛:系统信息、插件信息、内存监控、任务监控
(2)采集Configuration:采集相关基础配置,包括远程数据库配置、FTP配置、自定义数据配置
(3)数据采集:统一管理采集进程,包括采集public参数设置、采集rule列表、采集historical列表、采集content列表
(4)任务监控:包括采集任务监控、仓储任务监控、图像处理任务监控、上传任务监控
(5)定时任务:定时执行采集task
(6)utility tools: 包括图像处理
安装包
链接:提取码:l50r
参与贡献Fork,在这个仓库新建一个Feat_xxx分支,提交代码并新建一个Pull Request成为开发者:
马云特效使用Readme_XXX.md来支持不同的语言,比如Readme_en.md、Readme_zh.md,马云官方博客,可以在这里获取这个地址。解码云端优秀开源项目,GVP是马云最有价值的开源项目。该项目是马云综合评价的优秀开源项目。马云提供的官方手册。马云封面人物是用来展示马云成员风采的专栏。
内容采集器(专业定制抖音采集器如何快速提取内容采集视频?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-09-04 20:04
内容采集器有的有
当然有很多。微信对于采集统一的规则,在订阅号里就禁止采集,服务号一般不受影响。如果是带品牌或标识的,请后台设置-开发。
有一个app叫小道精舍,里面全是爆料。对了现在免费了。
随着百度收录的加快,抖音越来越被各大企业重视,在抖音上有很多视频也是可以找到的,不过也是一个需要多的积累,平时可以多关注一些抖音上发现的一些有趣的内容,自己就可以进行一些取词。
我认为有。从精英到普通用户,只要有需求都会去找一些信息整合类工具,比如资源汇这样的网站,比较实用,关键是能找到适合自己的信息整合工具。
上海市公安局上海分局另外还有上海市城市信息网
快易搜的关键词规划师包含抖音视频采集的一切功能~
有啊,
抖音直接是不接受采集的,上海公安局有了相关政策,
有没有能查到所有视频的网站?答案是肯定有的。
还有很多
试试这个吧
抖音采集器官网-专业定制抖音采集app,抖音视频免费采集、提取和下载,公众号推文文章采集和使用,
有,之前看抖音的时候,
如果你每天只是从各大视频平台去看一些好看的视频,基本上你就没什么收获,所以你必须有针对性的去采集。当然,你也可以利用抖音采集器快速提取一些你平常可能感兴趣的视频。至于抖音采集器如何快速查看抖音视频,可以进入企业机构号-抖音管理后台-视频库,进入你感兴趣的行业查看。例如,你可以先查看【上海市公安局】的抖音在这里搜索关键词【上海市公安局】,就可以看到包含上海市警方相关的视频了。 查看全部
内容采集器(专业定制抖音采集器如何快速提取内容采集视频?)
内容采集器有的有
当然有很多。微信对于采集统一的规则,在订阅号里就禁止采集,服务号一般不受影响。如果是带品牌或标识的,请后台设置-开发。
有一个app叫小道精舍,里面全是爆料。对了现在免费了。
随着百度收录的加快,抖音越来越被各大企业重视,在抖音上有很多视频也是可以找到的,不过也是一个需要多的积累,平时可以多关注一些抖音上发现的一些有趣的内容,自己就可以进行一些取词。
我认为有。从精英到普通用户,只要有需求都会去找一些信息整合类工具,比如资源汇这样的网站,比较实用,关键是能找到适合自己的信息整合工具。
上海市公安局上海分局另外还有上海市城市信息网
快易搜的关键词规划师包含抖音视频采集的一切功能~
有啊,
抖音直接是不接受采集的,上海公安局有了相关政策,
有没有能查到所有视频的网站?答案是肯定有的。
还有很多
试试这个吧
抖音采集器官网-专业定制抖音采集app,抖音视频免费采集、提取和下载,公众号推文文章采集和使用,
有,之前看抖音的时候,
如果你每天只是从各大视频平台去看一些好看的视频,基本上你就没什么收获,所以你必须有针对性的去采集。当然,你也可以利用抖音采集器快速提取一些你平常可能感兴趣的视频。至于抖音采集器如何快速查看抖音视频,可以进入企业机构号-抖音管理后台-视频库,进入你感兴趣的行业查看。例如,你可以先查看【上海市公安局】的抖音在这里搜索关键词【上海市公安局】,就可以看到包含上海市警方相关的视频了。
内容采集器(优采云采集器多页地址的获取方式及获取方法介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-09-04 02:18
公司介绍自网站获取,联系方式自网站获取。所以我们需要使用多页功能来实现。前者称为默认页地址,后者称为多页地址。
流程:点击①创建多页,进行②多页设置,然后在数据源③中选择多页调用,最后根据多页源码设置提取方式。
下面将重点介绍②,获取多页地址的两种方式:页地址替换和源代码拦截。
1.Page地址替换:即默认页和多页地址有相同的地方,可以通过简单的替换变成多页地址。
对比默认页面“”和多页面地址:“”的共同点,可以发现默认页面“creditdetail.htm”替换为“contactinfo.htm”。 htm”也是我们的多页地址。
设置如下:
注意:正则表达式中的 (.*) 是任何通配符。数字$1、$2...$ 依次对应于上面(.*) 所指示的部分。如果想限制多页源码的部分区域,可以在多页源码的指定区域设置。
如果留空,则默认返回整个源代码的多页。设置好后点击Test查看结果。
从源码截取的2.:即多个页面的地址在默认页面的页面源码中。
如图所示,可以看到默认页面源码中有多个页面地址。
所以设置如下:
测试后,如果正确,请保存。最后,设置数据源和提取方式,如图:
注意:如果需要多级多页,可以在多页地址获取方法中选择需要的多页
这两种获取方式你掌握了吗?以后可以通过优采云采集器V9在捕获网站时的上述操作,方便的获取关联的多页地址,作为一个函数综合网站Grabber Wizard,优采云采集器一定会考虑到用户的需求以及如何最大限度地提高便利性 查看全部
内容采集器(优采云采集器多页地址的获取方式及获取方法介绍)
公司介绍自网站获取,联系方式自网站获取。所以我们需要使用多页功能来实现。前者称为默认页地址,后者称为多页地址。
流程:点击①创建多页,进行②多页设置,然后在数据源③中选择多页调用,最后根据多页源码设置提取方式。
下面将重点介绍②,获取多页地址的两种方式:页地址替换和源代码拦截。
1.Page地址替换:即默认页和多页地址有相同的地方,可以通过简单的替换变成多页地址。
对比默认页面“”和多页面地址:“”的共同点,可以发现默认页面“creditdetail.htm”替换为“contactinfo.htm”。 htm”也是我们的多页地址。
设置如下:
注意:正则表达式中的 (.*) 是任何通配符。数字$1、$2...$ 依次对应于上面(.*) 所指示的部分。如果想限制多页源码的部分区域,可以在多页源码的指定区域设置。
如果留空,则默认返回整个源代码的多页。设置好后点击Test查看结果。
从源码截取的2.:即多个页面的地址在默认页面的页面源码中。
如图所示,可以看到默认页面源码中有多个页面地址。
所以设置如下:
测试后,如果正确,请保存。最后,设置数据源和提取方式,如图:
注意:如果需要多级多页,可以在多页地址获取方法中选择需要的多页
这两种获取方式你掌握了吗?以后可以通过优采云采集器V9在捕获网站时的上述操作,方便的获取关联的多页地址,作为一个函数综合网站Grabber Wizard,优采云采集器一定会考虑到用户的需求以及如何最大限度地提高便利性
内容采集器(前几天做了个小说连载的程序,主要是用来抓取别人网页内容的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-09-04 02:15
通常我们所说的采集器也被称为小偷程序,主要用于抓取他人网页的内容。关于采集器的制作,其实并不难。就是远程打开需要采集的网页,然后用正则表达式匹配需要的内容。只要你有一点正则表达式的基础,就可以让自己的采集器来了。
我前几天做了一个新颖的连载程序。因为怕更新麻烦,写了个采集器,采集八路中文网。功能比较简单,规则不能自定义,但是思路大概是有的。在里面,自定义规则可以自己扩展。
使用php做采集器主要使用两个函数:file_get_contents()和preg_match_all()。前者用于远程读取网页内容,但只能在php5以上版本使用,后者为常规功能。 , 用于提取需要的内容。
让我们一步一步地谈谈函数的实现。
因为是采集小说,先提取标题、作者、流派。其他信息可根据需要提取。
这里我们以“**********”为目标,先打开参考书目页面,链接:
再打开几本书,你会发现书名的基本格式是:book number/Index.aspx,所以我们可以制作一个起始页,定义一个,用它输入需要的书号采集,然后我们可以通过 $_POST['number'] 这个格式来接收采集的书号。收到书号后,接下来要做的就是构造书目页面:$url=$_POST['number']/Index.aspx,当然这里是一个例子,主要是为了方便说明,就是最好在实际生产中检查一下。 _POST['number'] 的合法性。
构建好URL后,即可开启采集书信息。使用file_get_contents()函数打开书目页面:$content=file_get_contents($url),这样就可以读取书目页面的内容了。下一步是匹配书名、作者和类型。这是一个带有书名的例子,其他一切都是一样的。打开书目页面,查看源文件,找到《回明为主》,这是要提取的书名。提取书名的正则表达式:/(.*?)\/is,使用preg_match_all()函数提取书名:preg_match_all("/(.*?)\/is",$contents,$title ); $title[0][0]的内容就是我们想要的title(preg_match_all函数的用法可以百度查,这里就不详细解释了)。取出书籍信息后,下一步就是取出章节内容。取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。 ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:
preg_match_all("/Html\/Book\/[0-9]{1,}\/[0-9]{1,}\/List\.shtm/is",$contents,$typeid);这还不够,我们还需要一个cut函数:
PHP代码如下:
function cut($string,$start,$end){
$message = expand($start,$string);
$message = expand($end,$message[1]);返回 $message[0];
}//其中$string是要剪切的内容,$start是开头,$end是结尾。检索分类号:
$start = "Html/Book/";
$end = "List.shtm";
$typeid = cut($typeid[0][0],$start,$end);
$typeid = expand("/",$typeid);
这样,$typeid[0]就是我们要找的分类号。下一步是构造章节列表的地址:$chapterurl = $typeid[0]/$_POST[‘number’]/List.shtm。有了这个,你可以找到每章的地址。方法如下:
$ustart = "\"";
$uend = "\"";
//t代表title的缩写
$tstart = ">";
$tend = " 查看全部
内容采集器(前几天做了个小说连载的程序,主要是用来抓取别人网页内容的)
通常我们所说的采集器也被称为小偷程序,主要用于抓取他人网页的内容。关于采集器的制作,其实并不难。就是远程打开需要采集的网页,然后用正则表达式匹配需要的内容。只要你有一点正则表达式的基础,就可以让自己的采集器来了。
我前几天做了一个新颖的连载程序。因为怕更新麻烦,写了个采集器,采集八路中文网。功能比较简单,规则不能自定义,但是思路大概是有的。在里面,自定义规则可以自己扩展。
使用php做采集器主要使用两个函数:file_get_contents()和preg_match_all()。前者用于远程读取网页内容,但只能在php5以上版本使用,后者为常规功能。 , 用于提取需要的内容。
让我们一步一步地谈谈函数的实现。
因为是采集小说,先提取标题、作者、流派。其他信息可根据需要提取。
这里我们以“**********”为目标,先打开参考书目页面,链接:
再打开几本书,你会发现书名的基本格式是:book number/Index.aspx,所以我们可以制作一个起始页,定义一个,用它输入需要的书号采集,然后我们可以通过 $_POST['number'] 这个格式来接收采集的书号。收到书号后,接下来要做的就是构造书目页面:$url=$_POST['number']/Index.aspx,当然这里是一个例子,主要是为了方便说明,就是最好在实际生产中检查一下。 _POST['number'] 的合法性。
构建好URL后,即可开启采集书信息。使用file_get_contents()函数打开书目页面:$content=file_get_contents($url),这样就可以读取书目页面的内容了。下一步是匹配书名、作者和类型。这是一个带有书名的例子,其他一切都是一样的。打开书目页面,查看源文件,找到《回明为主》,这是要提取的书名。提取书名的正则表达式:/(.*?)\/is,使用preg_match_all()函数提取书名:preg_match_all("/(.*?)\/is",$contents,$title ); $title[0][0]的内容就是我们想要的title(preg_match_all函数的用法可以百度查,这里就不详细解释了)。取出书籍信息后,下一步就是取出章节内容。取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/List.shtm。 ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:
preg_match_all("/Html\/Book\/[0-9]{1,}\/[0-9]{1,}\/List\.shtm/is",$contents,$typeid);这还不够,我们还需要一个cut函数:
PHP代码如下:
function cut($string,$start,$end){
$message = expand($start,$string);
$message = expand($end,$message[1]);返回 $message[0];
}//其中$string是要剪切的内容,$start是开头,$end是结尾。检索分类号:
$start = "Html/Book/";
$end = "List.shtm";
$typeid = cut($typeid[0][0],$start,$end);
$typeid = expand("/",$typeid);
这样,$typeid[0]就是我们要找的分类号。下一步是构造章节列表的地址:$chapterurl = $typeid[0]/$_POST[‘number’]/List.shtm。有了这个,你可以找到每章的地址。方法如下:
$ustart = "\"";
$uend = "\"";
//t代表title的缩写
$tstart = ">";
$tend = "

