
内容采集器
如何防止采集网站内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 312 次浏览 • 2020-08-07 15:33
两个. 如何防止网站内容被采集
在实施多种反采集方法时,有必要考虑它是否会影响搜索引擎对网站的爬网,因此首先要分析一般采集器与搜索引擎爬网程序之间的区别.
相似之处:
a. 两者都需要直接获取网页的源代码才能有效地工作,
b. 他们都将在一个单位时间内多次抓取所访问网站的内容;
c. 从宏观上看,两个IP都会改变;
d. 两者不耐烦地破解您的某些网页加密(验证),例如网页内容是通过js文件加密的,例如需要输入验证码才能浏览内容,例如需要登录来访问内容等.
区别:
搜索引擎采集器首先忽略整个网页的源代码脚本和样式以及html标记代码,然后对其余文本执行一系列复杂的处理,例如词法和句法分析. 采集器通常通过html标签的特征来捕获所需的数据. 在制定采集规则时,您需要填写目标内容的开始和结束符号,以便找到所需的内容. 或针对特定网页使用特定规则. 表达式可以过滤出您所需的内容. 无论是使用开始和结束标签还是正则表达式,都涉及html标签(网页结构分析).
然后提出一些反采集方法
1. 限制IP地址每单位时间的访问次数
分析: 除非是程序访问,否则任何普通人都不能在一秒钟内访问同一网站5次. 有了这种偏好,只剩下搜索引擎采集器和烦人的采集器.
缺点: 一种尺寸适合所有人,这也将阻止搜索引擎包括该网站
适用的网站: 不太依赖搜索引擎的网站
采集器的工作: 减少单位时间内的访问次数并降低采集效率
2,阻止ip
分析: 通过后台计数器记录访问者的IP和频率,手动分析访问记录,并阻止可疑IP.
缺点: 似乎没有缺点,但是网站管理员有点忙
适用的网站: 所有网站和网站站长都可以知道哪些机器人是Google或百度
采集器将做什么: 打游击战!使用ip代理采集一次并更改一次,但这会降低采集器的效率和网络速度(使用代理).
3. 使用js加密Web内容
注意: 我没有碰过这种方法,只是从其他地方看
分析: 无需分析,搜索引擎爬虫和采集器都被杀死
适用的网站: 非常讨厌搜索引擎和采集器的网站
采集器会这样做: 如果你这么好,如果你这么好,他就不会来接你
4. 网站的版权或一些乱七八糟的文字被隐藏在网页中,这些文字样式被写在css文件中
分析: 尽管无法阻止采集,但是采集的内容将填充您网站的版权声明或一些垃圾文本,因为一般采集器不会同时采集您的css文件,并且文本将是显示时没有样式Out.
适用的网站: 所有网站
采集器的工作方式: 对于受版权保护的文本,很容易处理和替换. 对于随机的垃圾文本,请快点.
5. 用户可以登录访问网站内容
分析: 搜索引擎采集器不会为每种此类网站设计登录过程. 我听说采集器可以设计为模拟用户登录并提交特定网站的表单行为.
适用的网站: 讨厌搜索引擎并希望阻止大多数采集器的网站
采集器的工作: 为用户登录行为创建一个模块并提交表单
6. 使用脚本语言进行分页(隐藏分页)
分析: 同样,搜索引擎爬网程序不会分析各种网站的隐藏分页,这会影响搜索引擎将其收录在内. 但是,当采集器编写采集规则时,他必须分析目标网页代码,并且那些了解某些脚本知识的人将知道该页面的真实链接地址.
适用的网站: 不高度依赖搜索引擎的网站以及那些采集您信息的网站不了解脚本知识
采集器将要做什么: 应该说采集器将要做什么. 无论如何,他必须分析您的网页代码,并顺便分析您的分页脚本. 不需要太多时间.
7. 反热链接措施(仅允许通过网站页面连接进行查看,例如: Request.ServerVariables(“ HTTP_REFERER”))
分析: ASP和PHP可以通过读取请求的HTTP_REFERER属性来确定该请求是否来自该网站,从而限制了采集器,还限制了搜索引擎爬网程序,这严重影响了网站上搜索引擎的反垃圾内容包括在内.
适用的网站: 不要考虑搜索引擎中收录的网站.
采集器会做什么: 伪装HTTP_REFERER,这并不困难.
8,完整Flash,图片或pdf表示网站内容
分析: 对搜索引擎采集器和采集器的支持不好. 许多对SEO有所了解的人都知道这一点.
适用的网站: 专为媒体设计且不关心搜索引擎的网站.
采集器的工作: 停止采集,离开.
9. 网站随机采用不同的模板
分析: 由于采集器根据网页结构定位所需的内容,因此,一旦两次更改模板,采集规则将变为无效,这还不错. 这对搜索引擎爬虫没有影响.
适用的网站: 动态网站,不考虑用户体验.
采集器将执行的操作: 一个网站的模板不能超过10个. 只需为每个模板制定一个规则. 不同的模板使用不同的采集规则. 如果模板超过10个,则由于目标网站非常难以更改模板,因此最好撤回.
10. 使用动态和不规则的html标签
分析: 这是更异常的. 考虑到带空格和不带空格的html标签的效果相同,因此效果与页面显示相同,但是用作采集器的标签是两个不同的标签. 如果辅助页面html标记中的空格数是随机的,则
采集规则无效. 但是,这对搜索引擎爬网程序影响很小.
适用于网站: 所有不希望遵守网页设计准则的动态网站.
采集器的工作: 仍然存在对策. 仍然有许多HTML清洁器. 首先清理html标签,然后编写采集规则;您应该在使用采集规则之前清理html标签,否则您可以获得所需的数据.
摘要:
一旦必须同时搜索引擎采集器和采集器,这将非常令人沮丧,因为搜索引擎的第一步是采集目标网页的内容,这与采集器的原理相同,因此许多防止采集的方法也阻碍了搜索引擎对网站的收录工作感到无奈,对吗?尽管以上10条建议并非100%反采集,但几种方法的结合使用却拒绝了大量采集器. 查看全部
如何防止采集网站内容1.摘要一句话摘要: 无法采集js生成的内容网站.
两个. 如何防止网站内容被采集
在实施多种反采集方法时,有必要考虑它是否会影响搜索引擎对网站的爬网,因此首先要分析一般采集器与搜索引擎爬网程序之间的区别.
相似之处:
a. 两者都需要直接获取网页的源代码才能有效地工作,
b. 他们都将在一个单位时间内多次抓取所访问网站的内容;
c. 从宏观上看,两个IP都会改变;
d. 两者不耐烦地破解您的某些网页加密(验证),例如网页内容是通过js文件加密的,例如需要输入验证码才能浏览内容,例如需要登录来访问内容等.
区别:
搜索引擎采集器首先忽略整个网页的源代码脚本和样式以及html标记代码,然后对其余文本执行一系列复杂的处理,例如词法和句法分析. 采集器通常通过html标签的特征来捕获所需的数据. 在制定采集规则时,您需要填写目标内容的开始和结束符号,以便找到所需的内容. 或针对特定网页使用特定规则. 表达式可以过滤出您所需的内容. 无论是使用开始和结束标签还是正则表达式,都涉及html标签(网页结构分析).
然后提出一些反采集方法
1. 限制IP地址每单位时间的访问次数
分析: 除非是程序访问,否则任何普通人都不能在一秒钟内访问同一网站5次. 有了这种偏好,只剩下搜索引擎采集器和烦人的采集器.
缺点: 一种尺寸适合所有人,这也将阻止搜索引擎包括该网站
适用的网站: 不太依赖搜索引擎的网站
采集器的工作: 减少单位时间内的访问次数并降低采集效率
2,阻止ip
分析: 通过后台计数器记录访问者的IP和频率,手动分析访问记录,并阻止可疑IP.
缺点: 似乎没有缺点,但是网站管理员有点忙
适用的网站: 所有网站和网站站长都可以知道哪些机器人是Google或百度
采集器将做什么: 打游击战!使用ip代理采集一次并更改一次,但这会降低采集器的效率和网络速度(使用代理).
3. 使用js加密Web内容
注意: 我没有碰过这种方法,只是从其他地方看
分析: 无需分析,搜索引擎爬虫和采集器都被杀死
适用的网站: 非常讨厌搜索引擎和采集器的网站
采集器会这样做: 如果你这么好,如果你这么好,他就不会来接你
4. 网站的版权或一些乱七八糟的文字被隐藏在网页中,这些文字样式被写在css文件中
分析: 尽管无法阻止采集,但是采集的内容将填充您网站的版权声明或一些垃圾文本,因为一般采集器不会同时采集您的css文件,并且文本将是显示时没有样式Out.
适用的网站: 所有网站
采集器的工作方式: 对于受版权保护的文本,很容易处理和替换. 对于随机的垃圾文本,请快点.
5. 用户可以登录访问网站内容
分析: 搜索引擎采集器不会为每种此类网站设计登录过程. 我听说采集器可以设计为模拟用户登录并提交特定网站的表单行为.
适用的网站: 讨厌搜索引擎并希望阻止大多数采集器的网站
采集器的工作: 为用户登录行为创建一个模块并提交表单
6. 使用脚本语言进行分页(隐藏分页)
分析: 同样,搜索引擎爬网程序不会分析各种网站的隐藏分页,这会影响搜索引擎将其收录在内. 但是,当采集器编写采集规则时,他必须分析目标网页代码,并且那些了解某些脚本知识的人将知道该页面的真实链接地址.
适用的网站: 不高度依赖搜索引擎的网站以及那些采集您信息的网站不了解脚本知识
采集器将要做什么: 应该说采集器将要做什么. 无论如何,他必须分析您的网页代码,并顺便分析您的分页脚本. 不需要太多时间.
7. 反热链接措施(仅允许通过网站页面连接进行查看,例如: Request.ServerVariables(“ HTTP_REFERER”))
分析: ASP和PHP可以通过读取请求的HTTP_REFERER属性来确定该请求是否来自该网站,从而限制了采集器,还限制了搜索引擎爬网程序,这严重影响了网站上搜索引擎的反垃圾内容包括在内.
适用的网站: 不要考虑搜索引擎中收录的网站.
采集器会做什么: 伪装HTTP_REFERER,这并不困难.
8,完整Flash,图片或pdf表示网站内容
分析: 对搜索引擎采集器和采集器的支持不好. 许多对SEO有所了解的人都知道这一点.
适用的网站: 专为媒体设计且不关心搜索引擎的网站.
采集器的工作: 停止采集,离开.
9. 网站随机采用不同的模板
分析: 由于采集器根据网页结构定位所需的内容,因此,一旦两次更改模板,采集规则将变为无效,这还不错. 这对搜索引擎爬虫没有影响.
适用的网站: 动态网站,不考虑用户体验.
采集器将执行的操作: 一个网站的模板不能超过10个. 只需为每个模板制定一个规则. 不同的模板使用不同的采集规则. 如果模板超过10个,则由于目标网站非常难以更改模板,因此最好撤回.
10. 使用动态和不规则的html标签
分析: 这是更异常的. 考虑到带空格和不带空格的html标签的效果相同,因此效果与页面显示相同,但是用作采集器的标签是两个不同的标签. 如果辅助页面html标记中的空格数是随机的,则
采集规则无效. 但是,这对搜索引擎爬网程序影响很小.
适用于网站: 所有不希望遵守网页设计准则的动态网站.
采集器的工作: 仍然存在对策. 仍然有许多HTML清洁器. 首先清理html标签,然后编写采集规则;您应该在使用采集规则之前清理html标签,否则您可以获得所需的数据.
摘要:
一旦必须同时搜索引擎采集器和采集器,这将非常令人沮丧,因为搜索引擎的第一步是采集目标网页的内容,这与采集器的原理相同,因此许多防止采集的方法也阻碍了搜索引擎对网站的收录工作感到无奈,对吗?尽管以上10条建议并非100%反采集,但几种方法的结合使用却拒绝了大量采集器.
MAC上的Web捕获软件是什么?阅读这篇文章就足够了
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2020-08-07 13:04
在文章中: 哪种Web采集器软件易于使用?在其中,我们介绍了目前市场上更成熟且易于使用的网络采集器软件.
但是其中一些不能在MAC上使用,因此在今天的这篇文章中,我们将在MAC操作系统中单独介绍一些有用的爬网软件,以供您参考.
让我们首先得出结论. 赶时间的同志可以看后眨眼. 有两种选择:
1. 免费,无需金钱,无需积分
注意: 这里提到的免费功能包括采集数据,以各种格式将数据导出到本地,而不会限制采集和导出的数量,您可以将图片下载到本地以及其他采集数据所需的基本功能
您可以在优采云 cloud crawler()和优采云采集器()之间进行选择
如果您是没有编程基础的新手,我建议您直接选择优采云采集器,因为这是针对从零开始的用户的智能采集器,非常简单,您只需要输入URL即可智能地识别数据,无需配置任何采集规则,此外,它还支持可视化操作,可以说非常简单易用.
<p>如果您是具有编程基础的用户,那么我建议您使用优采云云采集器. 优采云爬虫平台功能非常强大,提供了丰富的开发组件. 您可以开发所需的任何采集器程序, 查看全部
原创链接:
在文章中: 哪种Web采集器软件易于使用?在其中,我们介绍了目前市场上更成熟且易于使用的网络采集器软件.
但是其中一些不能在MAC上使用,因此在今天的这篇文章中,我们将在MAC操作系统中单独介绍一些有用的爬网软件,以供您参考.

让我们首先得出结论. 赶时间的同志可以看后眨眼. 有两种选择:
1. 免费,无需金钱,无需积分
注意: 这里提到的免费功能包括采集数据,以各种格式将数据导出到本地,而不会限制采集和导出的数量,您可以将图片下载到本地以及其他采集数据所需的基本功能
您可以在优采云 cloud crawler()和优采云采集器()之间进行选择
如果您是没有编程基础的新手,我建议您直接选择优采云采集器,因为这是针对从零开始的用户的智能采集器,非常简单,您只需要输入URL即可智能地识别数据,无需配置任何采集规则,此外,它还支持可视化操作,可以说非常简单易用.
<p>如果您是具有编程基础的用户,那么我建议您使用优采云云采集器. 优采云爬虫平台功能非常强大,提供了丰富的开发组件. 您可以开发所需的任何采集器程序,
优采云采集器采集网页数据的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 397 次浏览 • 2020-08-07 12:23
方法步骤
1. 第一步,打开软件后,我们需要在软件主界面中选择采集方法. 编辑器将使用自定义获取方法向您演示,单击自定义获取功能的立即使用按钮.
2. 单击立即使用按钮后,下图所示的界面将打开. 在此界面中,我们需要输入要采集数据的网站的URL. 输入后,我们可以采集网站数据.
3. 输入URL后,软件会自动在网页上获取一些数据内容,然后我们可以单击其他设置按钮来设置一些与集合相关的操作,用户可以根据需要选择设置.
4. 设置完成后,我们可以在采集配置选项界面的底部看到一些采集的数据,然后单击下面的保存按钮以保存采集的数据.
5. 单击保存按钮后,我们可以保存采集的数据. 返回软件主界面后,您可以在界面左侧看到采集到的任务记录,下次打开软件时可以查看它. 查看全部
优采云采集器是一款非常强大的网页数据捕获软件. 用户可以使用此软件在网页上采集一些数据内容,并且可以单独保存这些数据内容,因此,如果用户在浏览网页时需要采集材料,则可以使用此采集器保存数据. 我相信许多用户将需要此功能,但是大多数用户仍然不知道如何使用优采云采集器. 该软件用于采集Web数据,因此编辑器将与您共享特定的操作步骤,感兴趣的朋友不妨查看一下编辑器的共享方法.

方法步骤
1. 第一步,打开软件后,我们需要在软件主界面中选择采集方法. 编辑器将使用自定义获取方法向您演示,单击自定义获取功能的立即使用按钮.

2. 单击立即使用按钮后,下图所示的界面将打开. 在此界面中,我们需要输入要采集数据的网站的URL. 输入后,我们可以采集网站数据.

3. 输入URL后,软件会自动在网页上获取一些数据内容,然后我们可以单击其他设置按钮来设置一些与集合相关的操作,用户可以根据需要选择设置.

4. 设置完成后,我们可以在采集配置选项界面的底部看到一些采集的数据,然后单击下面的保存按钮以保存采集的数据.

5. 单击保存按钮后,我们可以保存采集的数据. 返回软件主界面后,您可以在界面左侧看到采集到的任务记录,下次打开软件时可以查看它.
[简单的语言] [网站采集器源代码]实时更新各种资源网络的采集软件的内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 374 次浏览 • 2020-08-07 10:16
1. 可以在资源网络的其他网站上测试刚刚编写的采集软件.
2. 使用该模块: 皮肤模块(我不会打包以提高安全性).
3,一个非常简单的软件,Daniel可以绕行
4. 网站规则的配置文件存储在root \ rule目录中,可以使用记事本打开该文件.
5. root \ article目录存储采集器提取的html文件,可以使用浏览器打开该文件. (图片未保存在本地,节省了空间和速度,哈哈)
6. 存储在tmp目录中的是为临时测试而爬网的html文件.
7. LinkId.txt文件是用于链接到网站的配置文件.
2. 教程:
1. 请创建一个新文件夹,解压缩压缩包中的所有文件,然后编译源代码.
2. 选择文件夹简介:
[网站采集器源代码]用于各种资源网络的采集软件的实时更新
第一个选择文件夹: 正式遍历文章(即测试遍历是正常的,然后正式遍历)
?第二个选择文件夹: 测试遍历(即您自己添加规则之后,测试遍历是否正常!)
?第三个选择文件夹: 添加规则(即,添加网站的采集规则,标题文本,尾部文本等).
[网站采集器源代码]用于各种资源网络的采集软件的实时更新
3. 使用方法:
?请创建一个新文件夹,解压缩压缩包中的所有文件,然后编译源代码.
?进入第三个选择文件夹,选择规则文件,然后单击“加载”按钮.
?加载完成后(内容将出现在编辑框中),单击右下角的“测试遍历”按钮.
?软件将自动进入第二个选择文件夹. 此时,您可以单击“开始遍历”按钮.
?遍历完成后,将弹出一个信息框. 单击列表框,检查遍历的内容是否正确.
?以上是临时集合,文件保存在tmp目录中.
?进入第一个选择文件夹以选择正式采集的规则,开始采集,可见正式采集过程!
检查网页源代码并填写编辑框以测试遍历!
4,最后一句话. . .
<p>真的很难说清楚,我不知道您是否能听清楚,反正我听不清楚...,任何接触过html的人都应该知道一点... 查看全部
1. 说明:
1. 可以在资源网络的其他网站上测试刚刚编写的采集软件.
2. 使用该模块: 皮肤模块(我不会打包以提高安全性).
3,一个非常简单的软件,Daniel可以绕行
4. 网站规则的配置文件存储在root \ rule目录中,可以使用记事本打开该文件.
5. root \ article目录存储采集器提取的html文件,可以使用浏览器打开该文件. (图片未保存在本地,节省了空间和速度,哈哈)
6. 存储在tmp目录中的是为临时测试而爬网的html文件.
7. LinkId.txt文件是用于链接到网站的配置文件.
2. 教程:
1. 请创建一个新文件夹,解压缩压缩包中的所有文件,然后编译源代码.
2. 选择文件夹简介:
[网站采集器源代码]用于各种资源网络的采集软件的实时更新

第一个选择文件夹: 正式遍历文章(即测试遍历是正常的,然后正式遍历)
?第二个选择文件夹: 测试遍历(即您自己添加规则之后,测试遍历是否正常!)
?第三个选择文件夹: 添加规则(即,添加网站的采集规则,标题文本,尾部文本等).
[网站采集器源代码]用于各种资源网络的采集软件的实时更新

3. 使用方法:
?请创建一个新文件夹,解压缩压缩包中的所有文件,然后编译源代码.
?进入第三个选择文件夹,选择规则文件,然后单击“加载”按钮.
?加载完成后(内容将出现在编辑框中),单击右下角的“测试遍历”按钮.
?软件将自动进入第二个选择文件夹. 此时,您可以单击“开始遍历”按钮.
?遍历完成后,将弹出一个信息框. 单击列表框,检查遍历的内容是否正确.
?以上是临时集合,文件保存在tmp目录中.
?进入第一个选择文件夹以选择正式采集的规则,开始采集,可见正式采集过程!
检查网页源代码并填写编辑框以测试遍历!
4,最后一句话. . .
<p>真的很难说清楚,我不知道您是否能听清楚,反正我听不清楚...,任何接触过html的人都应该知道一点...
使用优采云采集器采集58套房屋租赁内容采集-第一部分
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2020-08-07 01:06
第1章: 中级课程从第1章开始: 如果工人想做好工作,则必须首先提高他们的工具提琴手的能力,以帮助您分析数据. 第2章: 分类信息网站58网站采集第1节: 58网站房屋出租内容采集第2节: 58网站手机号码采集的突破方法. 第3节: 使用采集器自动释放大量信息的方法. 第3章: 使用优采云采集器采集腾讯网站内容. 第1节: 采集所有QQ成员的qq方法第2节: 腾讯网站的新闻采集第3节: 微信文章搜索的内容采集第4节: 微信公众号搜索的内容采集第5节: 腾讯视频代码的第四章: 采集数据并合成为文本. 第1章: 采集网站内容并合成多个txt文本文档. 第2章: 采集网站内容并合成Word文档. 第3章: 采集内容并合成一个csv文件,可在淘宝助手中使用. 第4章: 通过采集器合成html单页第5章: 在Witkey领域使用优采云采集器第1章: 自动生成Witkey网站的发布模块第2部分: 使用Witkey发布自己的任务Post Yongbao第1章: 优酷网站上相关内容的采集说明第1部分: 通过采集器从优酷网站采集视频和相关信息第2部分: 监视通过优采云采集器获得的优酷最新视频搜索量第七章: 优采云采集器采集百度相关内容第1部分: 优百度采集关键词搜索结果并提取所需的URL域名第2部分: 优采云采集器采集百度贴吧帖子内容和回复第3节: 使用优采云采集器采集百度新闻内容第4节: 使用优采云采集器采集百度软件中心软件第5章: 使用优采云采集器采集与百度广告牌相关的最新信息第8章: 优采云采集器发布模块的生产思想和方法第1节: Web发布模块的生产思想和方法第2节: 生产存储模块dedecms,phpcms,ecshop,empire cms,destoon,discuz的思想和方法
简单的Web内容采集器(C#)
采集交流 • 优采云 发表了文章 • 0 个评论 • 307 次浏览 • 2020-08-06 23:26
windows nt / xp / 2003或更高版本
.net Framework 1.1
SqlServer 2000
开发环境VS 2003
目的在学习网络编程之后,总有事情要做.
所以我想到了构建一个Web内容采集器.
作者主页:
下载链接:
使用方法测试数据来自cnBlog.
看下面的图片
用户首先填写“开始页面”,即开始采集的页面.
然后填写数据库连接字符串,这里是定义采集的数据插入到哪个数据库中,然后选择表名,不用说.
网页编码,如果不是意外的话,中国大陆可以使用UTF-8
用于爬网文件名的常规规则: 哈哈此工具显然适合程序员. 您必须直接填写常规规则. 例如,cnblogs都是数字,因此\ d
表创建帮助: 用户指定创建几种varchar类型和几种文本类型,主要用于短数据和长数据. 如果表中已经有列,请避免使用它们. 该程序中没有验证.
在网络设置中:
在采集内容之前和之后进行标记:
例如,两者都有
xxx
如果我想采集xxx,请输入“
到
”当然是
到
之间的内容.
以下文本框用于显示内容.
单击“获取URL”以查看其捕获的网址是否正确.
单击“获取”将采集的内容放入数据库中,然后使用Insert xx()(选择xx)直接插入目标数据.
程序代码的数量非常小(而且非常简单),并且需要进行一些更改.
不足
适用于正则表达式和网络编程
因为这是最简单的事情,所以没有多线程,没有其他优化方法,并且不支持分页.
我对其进行了测试,获得了38条数据,并使用了700M的内存. . .
如果有用,可以进行更改. 这对程序员来说很方便,并且避免了编写大量代码. 查看全部
操作环境
windows nt / xp / 2003或更高版本
.net Framework 1.1
SqlServer 2000
开发环境VS 2003
目的在学习网络编程之后,总有事情要做.
所以我想到了构建一个Web内容采集器.
作者主页:
下载链接:
使用方法测试数据来自cnBlog.
看下面的图片
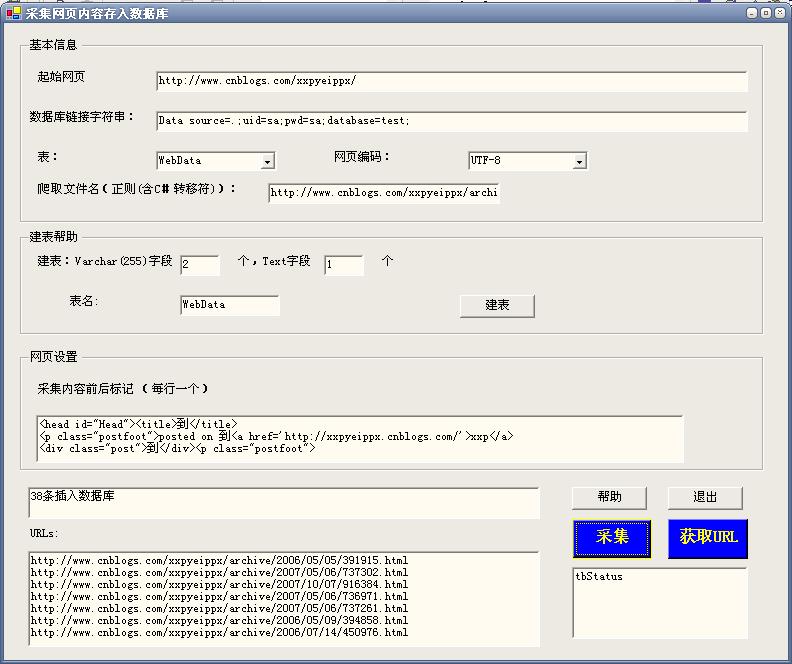
用户首先填写“开始页面”,即开始采集的页面.
然后填写数据库连接字符串,这里是定义采集的数据插入到哪个数据库中,然后选择表名,不用说.
网页编码,如果不是意外的话,中国大陆可以使用UTF-8
用于爬网文件名的常规规则: 哈哈此工具显然适合程序员. 您必须直接填写常规规则. 例如,cnblogs都是数字,因此\ d
表创建帮助: 用户指定创建几种varchar类型和几种文本类型,主要用于短数据和长数据. 如果表中已经有列,请避免使用它们. 该程序中没有验证.
在网络设置中:
在采集内容之前和之后进行标记:
例如,两者都有
xxx
如果我想采集xxx,请输入“
到
”当然是
到
之间的内容.
以下文本框用于显示内容.
单击“获取URL”以查看其捕获的网址是否正确.
单击“获取”将采集的内容放入数据库中,然后使用Insert xx()(选择xx)直接插入目标数据.
程序代码的数量非常小(而且非常简单),并且需要进行一些更改.
不足
适用于正则表达式和网络编程
因为这是最简单的事情,所以没有多线程,没有其他优化方法,并且不支持分页.
我对其进行了测试,获得了38条数据,并使用了700M的内存. . .
如果有用,可以进行更改. 这对程序员来说很方便,并且避免了编写大量代码.
图片采集软件download_webpage图片采集器_什么是图片采集工具?
采集交流 • 优采云 发表了文章 • 0 个评论 • 384 次浏览 • 2020-08-06 22:20
优采云数据采集器破解版v7.6.0最新免费版
大小: 56.6M
得分:
下载
优采云 Data Collector的破解版是著名的数据采集软件. 依靠云计算平台,可以即时读取大量信息,一键生成图表,数据传输专业,安全. 您应得的,欢迎有需要的朋友免费来当易
Network Photo 采集 Master软件v1.3.0绿色版
大小: 1.4M
得分:
下载
网络图片获取主软件是一种计算机搜索软件,例如当我们有时需要做一些事情来查找大图片时,我们可以使用它进行搜索,然后在搜索框中输入要查找的图片. 关键字的图片很多.
TikTok批量下载了最新版本的工件v6.5.0.0免费版本
大小: 1.5M
得分:
下载
最新版本的TikTok批量下载Artifact是一个下载软件,可让您批量下载无水印的TikTok视频. 它使用简单,不占用内存,运行稳定,为您带来全方位的愉悦体验!来挑选你最喜欢的兄弟姐妹,并感谢他
拾色器(colorpicker)v1.10免费版
大小: 143KB
得分:
下载
绿色选择器是一种非常轻便的颜色选择软件. 用户可以使用该软件获取显示屏上任何位置的颜色,并自动显示颜色代码,方便用户在其他地方使用. 有需要的朋友们欢迎从当义下载.
笑鬼颜色选择器(屏幕颜色采集工具)v2017绿色最新版本
大小: 851KB
得分:
下载
幽灵鬼魂可以在几乎所有系统上呈现屏幕色彩. 这是一个非常易于使用的屏幕颜色采集工具. 该软件是免费的,无需安装即可使用. 它非常方便且强大. 如果需要,欢迎来当易下载并使用!
微信微信二维码采集向导v3.2最新版本
大小: 3.6M
得分:
下载
微信微信群二维码采集向导是一款功能强大的二维码信息采集软件. 使用此软件,用户可以更轻松地采集QR码,并且该软件体积很小. 会占用太多内存,欢迎大家来当易网
dv视频采集软件
大小: 3.5M
得分:
下载
dv视频捕获软件是视频捕获软件. 通过它,用户可以实时捕获图像,编辑视频和其他便利功能. dv视频捕获软件的引入清晰易用. 想要使用类似功能的用户不要错过这个有用的软件. 有兴趣 查看全部

优采云数据采集器破解版v7.6.0最新免费版
大小: 56.6M
得分:

下载
优采云 Data Collector的破解版是著名的数据采集软件. 依靠云计算平台,可以即时读取大量信息,一键生成图表,数据传输专业,安全. 您应得的,欢迎有需要的朋友免费来当易

Network Photo 采集 Master软件v1.3.0绿色版
大小: 1.4M
得分:
下载
网络图片获取主软件是一种计算机搜索软件,例如当我们有时需要做一些事情来查找大图片时,我们可以使用它进行搜索,然后在搜索框中输入要查找的图片. 关键字的图片很多.

TikTok批量下载了最新版本的工件v6.5.0.0免费版本
大小: 1.5M
得分:
下载
最新版本的TikTok批量下载Artifact是一个下载软件,可让您批量下载无水印的TikTok视频. 它使用简单,不占用内存,运行稳定,为您带来全方位的愉悦体验!来挑选你最喜欢的兄弟姐妹,并感谢他

拾色器(colorpicker)v1.10免费版
大小: 143KB
得分:
下载
绿色选择器是一种非常轻便的颜色选择软件. 用户可以使用该软件获取显示屏上任何位置的颜色,并自动显示颜色代码,方便用户在其他地方使用. 有需要的朋友们欢迎从当义下载.

笑鬼颜色选择器(屏幕颜色采集工具)v2017绿色最新版本
大小: 851KB
得分:
下载
幽灵鬼魂可以在几乎所有系统上呈现屏幕色彩. 这是一个非常易于使用的屏幕颜色采集工具. 该软件是免费的,无需安装即可使用. 它非常方便且强大. 如果需要,欢迎来当易下载并使用!

微信微信二维码采集向导v3.2最新版本
大小: 3.6M
得分:

下载
微信微信群二维码采集向导是一款功能强大的二维码信息采集软件. 使用此软件,用户可以更轻松地采集QR码,并且该软件体积很小. 会占用太多内存,欢迎大家来当易网

dv视频采集软件
大小: 3.5M
得分:
下载
dv视频捕获软件是视频捕获软件. 通过它,用户可以实时捕获图像,编辑视频和其他便利功能. dv视频捕获软件的引入清晰易用. 想要使用类似功能的用户不要错过这个有用的软件. 有兴趣
网页采集软件优采云采集器7.1.8破解版(内置激活版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 643 次浏览 • 2020-08-06 18:09
网页采集软件优采云采集器破解了资源获取(单击下载)
优采云采集器破解版的下载链接
优采云采集器破解版的下载链接
优采云采集器的破解版还支持计时采集,API导出数据,每次启动时动态分配IP以及与任何数据源的灵活连接. 编辑器的专业测试非常易于使用,欢迎朋友下载和体验!
(图片: 优采云采集器破解版)
优采云采集器破解版功能简介:
1. 云采集
5000个云服务器,24 * 7高效,稳定的集合以及API,可无缝连接到内部系统并定期同步数据;
2. 智能防封
自动破解各种验证码,提供代理IP池,并结合UA切换,可以有效突破封锁,顺畅地采集数据;
3. 适用于整个网络
无论是图片通话还是邮筒论坛,都可以即时采集,它支持所有业务渠道的抓取工具,以满足各种采集需求;
4. 大量模板
内置了数百个网站数据源,涵盖多个行业. 您可以通过简单的设置快速而准确地获取数据;
5,易于使用
无需学习爬虫编程技术,只需三个简单的步骤即可轻松获取Web数据,支持多种格式的一键导出,并快速导入数据库;
6,稳定高效
分布式云集群服务器和多用户协作管理平台的支持可以灵活地安排任务并平稳地抓取大量数据.
(图片: 优采云采集器)
温馨提示,本网站提供的优采云采集器的编辑将自行进行测试,朋友们可以放心下载和使用它〜 查看全部
优采云采集器是一个专业的Web采集软件. 优采云采集器 Ultimate Edition可以满足数十万的每日数据采集需求. 在专业版中,它具有IQ功能. 它还具有云采集功能. 达到8-10倍!
网页采集软件优采云采集器破解了资源获取(单击下载)
优采云采集器破解版的下载链接
优采云采集器破解版的下载链接
优采云采集器的破解版还支持计时采集,API导出数据,每次启动时动态分配IP以及与任何数据源的灵活连接. 编辑器的专业测试非常易于使用,欢迎朋友下载和体验!

(图片: 优采云采集器破解版)
优采云采集器破解版功能简介:
1. 云采集
5000个云服务器,24 * 7高效,稳定的集合以及API,可无缝连接到内部系统并定期同步数据;
2. 智能防封
自动破解各种验证码,提供代理IP池,并结合UA切换,可以有效突破封锁,顺畅地采集数据;
3. 适用于整个网络
无论是图片通话还是邮筒论坛,都可以即时采集,它支持所有业务渠道的抓取工具,以满足各种采集需求;
4. 大量模板
内置了数百个网站数据源,涵盖多个行业. 您可以通过简单的设置快速而准确地获取数据;
5,易于使用
无需学习爬虫编程技术,只需三个简单的步骤即可轻松获取Web数据,支持多种格式的一键导出,并快速导入数据库;
6,稳定高效
分布式云集群服务器和多用户协作管理平台的支持可以灵活地安排任务并平稳地抓取大量数据.

(图片: 优采云采集器)
温馨提示,本网站提供的优采云采集器的编辑将自行进行测试,朋友们可以放心下载和使用它〜
采集器设置
采集交流 • 优采云 发表了文章 • 0 个评论 • 549 次浏览 • 2020-08-06 12:06
在任务底部的进度栏中单击“采集器设置”以进入规则编辑界面
起始页网址
添加需要采集的目标列表页面
单击“ +”号以批量添加URL,选中“设置为内容页面URL”以直接采集输入的URL,否则需要将其分析为列表页面以提取内容页面URL
内容页面网址
编写用于提取内容页面URL的规则. 默认情况下提取所有URL. 如果需要精确,可以设置“ URL提取规则”
多级URL获取: 适用于小说,电影等序列化内容.
只要不直接从起始页获取内容页面URL,就可以通过多个级别获取它
获取关联页面的URL: 适用于分散在多个页面中的数据
如果要爬网的字段不在内容页面上,而是在其他页面上,则可以使用此功能将其他页面用作内容源.
获取内容
“添加默认值”可以自动设置几个通用字段,可以满足大多数文章类型的网站集
如果目标数据格式更复杂,则可以单击“ +”自己编写字段规则,并支持多种匹配方法,例如正则表达式,xpath,json等.
“数据处理”可以过滤或替换采集的字段值,并且每个字段都可以单独处理或使用常规处理
如果需要获取分页,请单击以打开“内容分页”并编写规则,程序将自动获取每个页面中的字段内容
测试规则
配置采集器后,需要单击保存按钮. 刷新后,您可以在“内容页面URL”标签和“获取内容”标签中看到测试按钮.
从测试列表页面获取URL
从测试页获取数据
测试爬网分页 查看全部
采集器设置
在任务底部的进度栏中单击“采集器设置”以进入规则编辑界面

起始页网址
添加需要采集的目标列表页面
单击“ +”号以批量添加URL,选中“设置为内容页面URL”以直接采集输入的URL,否则需要将其分析为列表页面以提取内容页面URL

内容页面网址
编写用于提取内容页面URL的规则. 默认情况下提取所有URL. 如果需要精确,可以设置“ URL提取规则”

多级URL获取: 适用于小说,电影等序列化内容.
只要不直接从起始页获取内容页面URL,就可以通过多个级别获取它


获取关联页面的URL: 适用于分散在多个页面中的数据
如果要爬网的字段不在内容页面上,而是在其他页面上,则可以使用此功能将其他页面用作内容源.


获取内容
“添加默认值”可以自动设置几个通用字段,可以满足大多数文章类型的网站集
如果目标数据格式更复杂,则可以单击“ +”自己编写字段规则,并支持多种匹配方法,例如正则表达式,xpath,json等.

“数据处理”可以过滤或替换采集的字段值,并且每个字段都可以单独处理或使用常规处理

如果需要获取分页,请单击以打开“内容分页”并编写规则,程序将自动获取每个页面中的字段内容

测试规则
配置采集器后,需要单击保存按钮. 刷新后,您可以在“内容页面URL”标签和“获取内容”标签中看到测试按钮.
从测试列表页面获取URL

从测试页获取数据

测试爬网分页
遵天市网页采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 298 次浏览 • 2020-08-06 10:05
此软件通过Internet采集网页信息. 有两个主要功能:
1,您可以在js之后采集动态信息.
2,您可以设置要采集的正则表达式.
此外,该软件具有内置的多种采集方案,分别对应于静态网页和动态网页.
该软件采集了官方网站上的图像(面部)搜索引擎数据,然后对其进行了索引.
使用步骤:
1. 输入URL,正常浏览网页并到达采集目标,单击工具栏上的“查看js之后的源代码”图标,以在执行js后显示网页的内容.
如果看不到相关内容,则可以稍等片刻,然后再次单击以确保执行了js代码. 通过浏览完整的网页源代码,我们可以确认
使用计划1或计划2. 如果可以通过更改URL的页码导航到下一页,请使用计划1;否则,请使用计划1. 如果您通过脚本动态更新页面的内容,
使用计划2.
2,单击工具栏上的“运行采集方案”图标,然后根据步骤1选择方案1或2. 如果已经由方案1和2生成了downloadtotal.txt
文件,您还可以选择选项3. 填写必要的信息或表达式,单击“开始采集”按钮,系统将自动采集. 点击对话框中的“取消”
按钮关闭对话框而不启动采集任务.
3. 单击工具栏上的“停止采集方案”图标,系统将终止采集任务.
防止网页采集:
防止采集的第一种方法: 在文章的开头和结尾添加随机和未固定的内容. 网站采集人员通常在进行采集时指定起始位置和结束位置,并在中间截取内容.
例如,如果您文章的内容是“ Youxun Software Information Network”,则如何添加随机内容:
随机内容1+优讯软件信息网+随机内容2
注意: 随机内容1和随机内容2只需为每篇文章随机显示一个. 查看全部
现在市场上充斥着一些付费的网页采集器. 不管它的功能是什么,这种免费的绿色免费网页采集器都是很少见的!
此软件通过Internet采集网页信息. 有两个主要功能:
1,您可以在js之后采集动态信息.
2,您可以设置要采集的正则表达式.
此外,该软件具有内置的多种采集方案,分别对应于静态网页和动态网页.
该软件采集了官方网站上的图像(面部)搜索引擎数据,然后对其进行了索引.
使用步骤:
1. 输入URL,正常浏览网页并到达采集目标,单击工具栏上的“查看js之后的源代码”图标,以在执行js后显示网页的内容.
如果看不到相关内容,则可以稍等片刻,然后再次单击以确保执行了js代码. 通过浏览完整的网页源代码,我们可以确认
使用计划1或计划2. 如果可以通过更改URL的页码导航到下一页,请使用计划1;否则,请使用计划1. 如果您通过脚本动态更新页面的内容,
使用计划2.
2,单击工具栏上的“运行采集方案”图标,然后根据步骤1选择方案1或2. 如果已经由方案1和2生成了downloadtotal.txt
文件,您还可以选择选项3. 填写必要的信息或表达式,单击“开始采集”按钮,系统将自动采集. 点击对话框中的“取消”
按钮关闭对话框而不启动采集任务.
3. 单击工具栏上的“停止采集方案”图标,系统将终止采集任务.
防止网页采集:
防止采集的第一种方法: 在文章的开头和结尾添加随机和未固定的内容. 网站采集人员通常在进行采集时指定起始位置和结束位置,并在中间截取内容.
例如,如果您文章的内容是“ Youxun Software Information Network”,则如何添加随机内容:
随机内容1+优讯软件信息网+随机内容2
注意: 随机内容1和随机内容2只需为每篇文章随机显示一个.
智能Web内容采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 276 次浏览 • 2020-08-06 08:26
软件简介
Smart Web Content Collector使您可以通过多个线程快速采集网页上所需的任何文本内容. 同时,您可以设置过滤和相应的处理,并支持关键字搜索.
软件功能
1. 使用基础的HTTP方法来采集数据,这是快速且稳定的. 可以构建多个任务和线程来同时从多个网站采集数据
2,用户可以随意导入和导出任务
3. 可以使用密码设置该任务,以确保您的采集任务的详细信息不会泄漏.
4. 它还具有N页采集暂停/拨号到IP更改,具有特殊标记暂停/拨号到IP更改的采集以及其他防捕获功能.
5. 您可以直接输入要捕获的URL,或使用JavaScript脚本生成URL,或通过关键字搜索捕获它
6. 您可以使用登录采集方法来采集需要登录帐户才能查看的Web内容
7. 它可以无限期地在N列中采集内容和链接,并支持多级内容分页采集
8. 支持多种内容提取模式,您可以根据需要处理采集的内容,例如清除HTML,图片等.
9. 您可以编译自己的JAVASCRIPT脚本以提取网页的内容,并轻松实现内容的任何部分的采集
10. 可以根据设置的模板保存采集到的文本内容
11. 可以根据模板将多个文件保存到同一文件中
12. 分页内容采集可以分别在网页的多个部分上进行
13. 可以设置客户信息以模拟百度等搜索引擎采集目标网站的情况
14. 该软件是永久免费的
相关更新
使用新的智能软件控件UI
向EMAIL功能添加用户反馈
添加直接将初始链接设置为最终内容页面处理功能的功能
增强内核功能,支持关键字搜索并替换POST中的关键字标签
优化获取核心
优化断开的拨号算法
优化重复数据删除工具的算法
修复了拨号显示IP错误的错误
修复了错误关键字被暂停或拨打时未重新采集错误页面的错误.
修复了受限内容的最大值为0时,最小值无法正确保存的问题.
软件屏幕截图 查看全部
这是一个智能的Web内容采集器. 它可以多任务和多线程模式采集任何网页上的任何指定文本内容,并执行所需的相应过滤和处理. 您可以使用搜索关键字来采集所需的指定搜索结果. ..
软件简介
Smart Web Content Collector使您可以通过多个线程快速采集网页上所需的任何文本内容. 同时,您可以设置过滤和相应的处理,并支持关键字搜索.
软件功能
1. 使用基础的HTTP方法来采集数据,这是快速且稳定的. 可以构建多个任务和线程来同时从多个网站采集数据
2,用户可以随意导入和导出任务
3. 可以使用密码设置该任务,以确保您的采集任务的详细信息不会泄漏.
4. 它还具有N页采集暂停/拨号到IP更改,具有特殊标记暂停/拨号到IP更改的采集以及其他防捕获功能.
5. 您可以直接输入要捕获的URL,或使用JavaScript脚本生成URL,或通过关键字搜索捕获它
6. 您可以使用登录采集方法来采集需要登录帐户才能查看的Web内容
7. 它可以无限期地在N列中采集内容和链接,并支持多级内容分页采集
8. 支持多种内容提取模式,您可以根据需要处理采集的内容,例如清除HTML,图片等.
9. 您可以编译自己的JAVASCRIPT脚本以提取网页的内容,并轻松实现内容的任何部分的采集
10. 可以根据设置的模板保存采集到的文本内容
11. 可以根据模板将多个文件保存到同一文件中
12. 分页内容采集可以分别在网页的多个部分上进行
13. 可以设置客户信息以模拟百度等搜索引擎采集目标网站的情况
14. 该软件是永久免费的
相关更新
使用新的智能软件控件UI
向EMAIL功能添加用户反馈
添加直接将初始链接设置为最终内容页面处理功能的功能
增强内核功能,支持关键字搜索并替换POST中的关键字标签
优化获取核心
优化断开的拨号算法
优化重复数据删除工具的算法
修复了拨号显示IP错误的错误
修复了错误关键字被暂停或拨打时未重新采集错误页面的错误.
修复了受限内容的最大值为0时,最小值无法正确保存的问题.
软件屏幕截图
推荐网络抓取工具Youcai Cloud Collector
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2020-08-05 20:04
最近,我正在整理36个k文章的一些标签. 我打算看看其他与风险投资有关的网站可以参考哪些标准. 因此,我找到了一个名为“ Enox Data”的网站,并希望了解人工智能. 公司,如红色字母部分所示:
如果数据显示在规则中,您还可以使用鼠标选择它并复制并粘贴它,但是仍然需要找到某种方法将其嵌入到页面中. 这时候,我记得我之前已经安装了Youcai Cloud Collector,所以我尝试了一下. 它非常易于使用,并且采集效率立即得到提高. 也给大家安利〜
Youcai Cloud Collector的Chrome插件,我在B站的技术视频中看到了它. 它声称是一种黑色技术,可以在不了解编程的情况下进行抓取. 简而言之,Youcai Cloud Collector是基于Chrome的网页元素解析器,可以自动识别主要内容,并可以通过可视化单击操作在自定义区域中实现数据/元素提取. 同时,它还提供了定时自动提取功能,可以用作一组简单的搜寻器工具.
在这里,我将通过方式解释网页提取器抓取与实际代码抓取之间的区别. 使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人. 它使您可以在页面上定义需求. 抓取哪个元素,抓取哪些页面,然后让机器代表他人操作;如果您使用Python编写搜寻器,则最好先使用网页请求命令下载整个网页,然后再使用代码来解析HTML页面元素. 提取您想要的内容,并继续循环. 相比之下,使用代码会更加灵活,但是解析的成本也会更高. 如果这是简单的页面内容提取,我还建议您使用优采云采集器.
关于Youcai Cloud Collector的特定安装过程以及如何使用完整功能,我将不在今天的文章中讨论. 第一个是我只使用了我需要的部件,第二个是因为市场上有很多优采云采集器教程,您可以自己找到它.
这只是一个实用的过程,为您简要介绍如何使用它.
第一步是登录优采云采集平台的后台
1. 打开Chrome浏览器,其图标按钮标记将出现在浏览器的右上角. 单击此按钮进行注册/登录按钮,跳至优采云采集平台的登录页面,输入用户名和密码即可登录
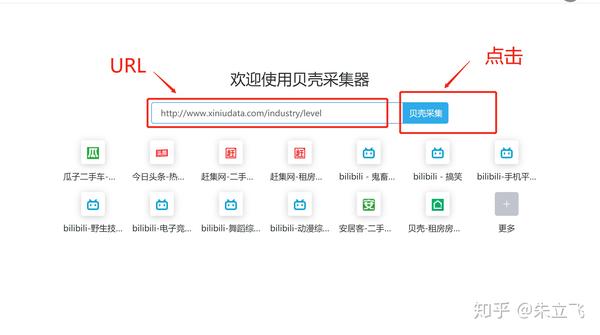
首先输入要抓取的网站的URL. 例如,我要获取的是: 牲畜数据的行业标签,URL为: ,然后在优采云采集器的背景中输入URL,然后单击优采云采集按钮. 出现配置页面
确定了主要内容,但是我想要的是在人工智能下的公司,所以我需要对其进行重新配置.
第二步是配置要提取的主要信息类型
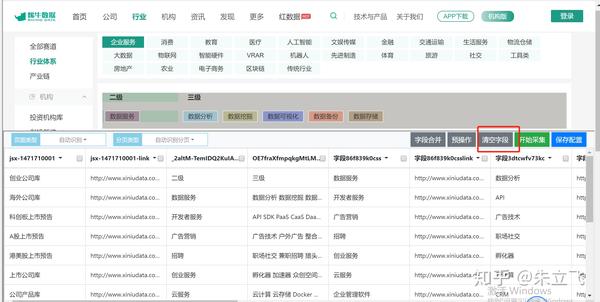
1. 首先点击清除字段按钮,首先清除所有数据,
查看全部
Youcai Cloud Collector是一个Chrome网页数据提取插件,可以从网页中提取数据. 从某种意义上讲,您还可以将其用作搜寻器工具.
最近,我正在整理36个k文章的一些标签. 我打算看看其他与风险投资有关的网站可以参考哪些标准. 因此,我找到了一个名为“ Enox Data”的网站,并希望了解人工智能. 公司,如红色字母部分所示:

如果数据显示在规则中,您还可以使用鼠标选择它并复制并粘贴它,但是仍然需要找到某种方法将其嵌入到页面中. 这时候,我记得我之前已经安装了Youcai Cloud Collector,所以我尝试了一下. 它非常易于使用,并且采集效率立即得到提高. 也给大家安利〜
Youcai Cloud Collector的Chrome插件,我在B站的技术视频中看到了它. 它声称是一种黑色技术,可以在不了解编程的情况下进行抓取. 简而言之,Youcai Cloud Collector是基于Chrome的网页元素解析器,可以自动识别主要内容,并可以通过可视化单击操作在自定义区域中实现数据/元素提取. 同时,它还提供了定时自动提取功能,可以用作一组简单的搜寻器工具.
在这里,我将通过方式解释网页提取器抓取与实际代码抓取之间的区别. 使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人. 它使您可以在页面上定义需求. 抓取哪个元素,抓取哪些页面,然后让机器代表他人操作;如果您使用Python编写搜寻器,则最好先使用网页请求命令下载整个网页,然后再使用代码来解析HTML页面元素. 提取您想要的内容,并继续循环. 相比之下,使用代码会更加灵活,但是解析的成本也会更高. 如果这是简单的页面内容提取,我还建议您使用优采云采集器.
关于Youcai Cloud Collector的特定安装过程以及如何使用完整功能,我将不在今天的文章中讨论. 第一个是我只使用了我需要的部件,第二个是因为市场上有很多优采云采集器教程,您可以自己找到它.
这只是一个实用的过程,为您简要介绍如何使用它.
第一步是登录优采云采集平台的后台
1. 打开Chrome浏览器,其图标按钮标记将出现在浏览器的右上角. 单击此按钮进行注册/登录按钮,跳至优采云采集平台的登录页面,输入用户名和密码即可登录
首先输入要抓取的网站的URL. 例如,我要获取的是: 牲畜数据的行业标签,URL为: ,然后在优采云采集器的背景中输入URL,然后单击优采云采集按钮. 出现配置页面
确定了主要内容,但是我想要的是在人工智能下的公司,所以我需要对其进行重新配置.
第二步是配置要提取的主要信息类型
1. 首先点击清除字段按钮,首先清除所有数据,
我无事可做,我一直想做点什么,我开发了一个网页采集器并在此处共享
采集交流 • 优采云 发表了文章 • 0 个评论 • 352 次浏览 • 2020-08-05 20:01
@foxidea
@txlty
我首先道歉. 昨天,我看到了一个安装一系列环境的请求,但我并没有仔细考虑. 我觉得使用像.net这样重的平台来制作具有大量需求变化的产品可能是不合适的,所以我随便抱怨一下. ,采集技术实际上很成熟. 没什么好说的. 我只想讨论平台技术的选择. 我无意引起语言争议. 我从未对C#感到难过. 我没想到会将这篇文章拖到一种语言中. 我已经讨论了这个话题,很抱歉.
返回技术解决方案主题. 至于采集器的设计,我认为这取决于是针对不了解技术的程序员还是网站管理员.
如果程序员使用它,则可伸缩性非常重要. 它应该是跨平台的. 它需要提供数据导入和导出接口. 命令行界面非常好,简单高效. 这种脚本语言具有很大的优势,当然不是. 它必须是python或ruby,swift,lua,perl之类的东西.
如果是不懂技术的网站管理员,则部署应该很简单,纯WIN32平台是首选. .net和Java企业应用程序是不错的选择. 老实说,我认为它不适合个人用户. 就像第一个版本的Xunlei由JAVA制作一样,它得到了周鸿yi的认可,第二个版本已更改为WIN32. 另一个方向是云计算. @foxidea还制作了一个网络版本. 这非常适合JAVA和.net. 将来我们也可能向云发展.
通常来说,@ foxidea很难制造出如此成熟的产品. 已经付出了很多努力. 如果不是纯粹出于自我娱乐目的,则完全有可能在此基础上将其更改为商业产品. 可能. 但是,应该仔细考虑初始方向. 对于哪个用户组,需要采取哪种技术路线,并且无需考虑太多的个人喜好. 最好选择正确的解决方案. 查看全部
@ v1ex
@foxidea
@txlty
我首先道歉. 昨天,我看到了一个安装一系列环境的请求,但我并没有仔细考虑. 我觉得使用像.net这样重的平台来制作具有大量需求变化的产品可能是不合适的,所以我随便抱怨一下. ,采集技术实际上很成熟. 没什么好说的. 我只想讨论平台技术的选择. 我无意引起语言争议. 我从未对C#感到难过. 我没想到会将这篇文章拖到一种语言中. 我已经讨论了这个话题,很抱歉.
返回技术解决方案主题. 至于采集器的设计,我认为这取决于是针对不了解技术的程序员还是网站管理员.
如果程序员使用它,则可伸缩性非常重要. 它应该是跨平台的. 它需要提供数据导入和导出接口. 命令行界面非常好,简单高效. 这种脚本语言具有很大的优势,当然不是. 它必须是python或ruby,swift,lua,perl之类的东西.
如果是不懂技术的网站管理员,则部署应该很简单,纯WIN32平台是首选. .net和Java企业应用程序是不错的选择. 老实说,我认为它不适合个人用户. 就像第一个版本的Xunlei由JAVA制作一样,它得到了周鸿yi的认可,第二个版本已更改为WIN32. 另一个方向是云计算. @foxidea还制作了一个网络版本. 这非常适合JAVA和.net. 将来我们也可能向云发展.
通常来说,@ foxidea很难制造出如此成熟的产品. 已经付出了很多努力. 如果不是纯粹出于自我娱乐目的,则完全有可能在此基础上将其更改为商业产品. 可能. 但是,应该仔细考虑初始方向. 对于哪个用户组,需要采取哪种技术路线,并且无需考虑太多的个人喜好. 最好选择正确的解决方案.
如何用网页采集器下载图片
采集交流 • 优采云 发表了文章 • 0 个评论 • 323 次浏览 • 2020-08-04 15:03
我们发觉,百度图片网是瀑布流的网页,经过每一次下 拉加载,都会出现新的数据。当图片足够多的时侯,可无数次下拉加载。因而, 此网页涉及 AJAX 技术,需要设置 AJAX 超时,以便确保数据采集的时侯不会 遗漏。优采云·云采集网络爬虫软件 选中“打开网页”步骤,打开“高级选项”,勾选“页面加载完成向上滚动”, 设置滚动次数为“5 次”(根据自身需求进行设置),时间为“2 秒”,滚动方 式为“向下滚动一屏”;最后点击“确定”注意:示例网站内容采集器,没有翻页按键,滚动次数、滚动形式会影响数据采集数量,可 按需设置步骤 2:采集图片 URL优采云·云采集网络爬虫软件 1)选中页面内第一个图片,系统会手动辨识同类图片。在操作提示框中,选择 “选中全部”2)选择“采集以下图片地址”优采云·云采集网络爬虫软件 步骤 3:修改 Xpath1)选中“循环”步骤,打开“高级选项”。可以看见优采云系统手动采用的是 “不固定元素列表” 循环, Xpath 为: //DIV[@id='imgid']/DIV[1]/UL[1]/LI优采云·云采集网络爬虫软件 2)将此条 Xpath://DIV[@id='imgid']/DIV[1]/UL[1]/LI,复制到傲游浏览 器中进行观察——仅可定位到网页中 22 张图片优采云·云采集网络爬虫软件 3)我们须要一条才能定位到网页中全部所需图片的 Xpath。
观察网页源码并将 Xpath 修改为://DIV[@id='imgid']/DIV/UL[1]/LI,网页中全部所需的图片 均被定位了优采云·云采集网络爬虫软件 4)将修改后的 Xpath://DIV[@id='imgid']/DIV/UL[1]/LI,复制粘贴到八 爪虾中相应位置,完成后点击“确定”优采云·云采集网络爬虫软件 5)点击“保存”,再点击“开始采集”,这里选择“启动本地采集”优采云·云采集网络爬虫软件 说明:本地采集占用当前笔记本资源进行采集,如果存在采集时间要求或当前笔记本未能长时间进行采集可以 使用云采集功能,云采集在网路中进行采集内容采集器,无需当前笔记本支持,电脑可以死机,可以设置多个云节点分 摊任务,10 个节点相当于 10 台笔记本分配任务帮你采集,速度增加为原先的十分之一;采集到的数据可以在 云上保存三个月,可以随时进行导入操作。步骤 4:数据采集及导入1)采集完成后,会跳出提示,选择导入数据优采云·云采集网络爬虫软件 2)选择合适的导入方法,将采集好的数据导入优采云·云采集网络爬虫软件 步骤 5:将图片 URL 批量转换为图片经过如上操作,我们早已得到了要采集的图片的 URL。
接下来,再通过优采云 专用的图片批量下载工具,将采集到的图片 URL 中的图片,下载并保存到本地 电脑中。 图片批量下载工具: 1)下载优采云图片批量下载工具,双击文件中的 MyDownloader.app.exe 文 件,打开软件优采云·云采集网络爬虫软件 2)打开 File 菜单,选择从 EXCEL 导入(目前只支持 EXCEL 格式文件)优采云·云采集网络爬虫软件 3)进行相关设置,设置完成后,点击 OK 即可导出文件 选择 EXCEL 文件:导入你须要下载图片地址的 EXCEL 文件 EXCEL 表名:对应数据表的名称 文件 URL 列名:表内对应 URL 的列名称 保存文件夹名:EXCEL 中须要单独一个列,列出图片想要保存到文件夹的路径, 可以设置不同图片储存至不同文件夹 如果要把文件保存到文件夹,则路径须要以“\”结尾,例如:“D:\同步\”, 如果要下载后根据指定的文件名保存,则须要包含具体的文件名,例如“ D:\同 步\1.jpg” 如果下载的文件路径和文件名完全一样,则原本存在的文件会被删掉优采云·云采集网络爬虫软件 相关采集教程:京东商品图片采集详细教程:淘宝买家秀图片采集详细教程:优采云·云采集网络爬虫软件 淘宝图片采集并下载到本地的方式:豆瓣图片采集以及下载保存的方式:微信公众号热门文章采集(文本+图片):阿里巴巴图片抓取下载:ebay 商品图片采集:优采云——90 万用户选择的网页数据采集器。
优采云·云采集网络爬虫软件 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部
我们发觉,百度图片网是瀑布流的网页,经过每一次下 拉加载,都会出现新的数据。当图片足够多的时侯,可无数次下拉加载。因而, 此网页涉及 AJAX 技术,需要设置 AJAX 超时,以便确保数据采集的时侯不会 遗漏。优采云·云采集网络爬虫软件 选中“打开网页”步骤,打开“高级选项”,勾选“页面加载完成向上滚动”, 设置滚动次数为“5 次”(根据自身需求进行设置),时间为“2 秒”,滚动方 式为“向下滚动一屏”;最后点击“确定”注意:示例网站内容采集器,没有翻页按键,滚动次数、滚动形式会影响数据采集数量,可 按需设置步骤 2:采集图片 URL优采云·云采集网络爬虫软件 1)选中页面内第一个图片,系统会手动辨识同类图片。在操作提示框中,选择 “选中全部”2)选择“采集以下图片地址”优采云·云采集网络爬虫软件 步骤 3:修改 Xpath1)选中“循环”步骤,打开“高级选项”。可以看见优采云系统手动采用的是 “不固定元素列表” 循环, Xpath 为: //DIV[@id='imgid']/DIV[1]/UL[1]/LI优采云·云采集网络爬虫软件 2)将此条 Xpath://DIV[@id='imgid']/DIV[1]/UL[1]/LI,复制到傲游浏览 器中进行观察——仅可定位到网页中 22 张图片优采云·云采集网络爬虫软件 3)我们须要一条才能定位到网页中全部所需图片的 Xpath。
观察网页源码并将 Xpath 修改为://DIV[@id='imgid']/DIV/UL[1]/LI,网页中全部所需的图片 均被定位了优采云·云采集网络爬虫软件 4)将修改后的 Xpath://DIV[@id='imgid']/DIV/UL[1]/LI,复制粘贴到八 爪虾中相应位置,完成后点击“确定”优采云·云采集网络爬虫软件 5)点击“保存”,再点击“开始采集”,这里选择“启动本地采集”优采云·云采集网络爬虫软件 说明:本地采集占用当前笔记本资源进行采集,如果存在采集时间要求或当前笔记本未能长时间进行采集可以 使用云采集功能,云采集在网路中进行采集内容采集器,无需当前笔记本支持,电脑可以死机,可以设置多个云节点分 摊任务,10 个节点相当于 10 台笔记本分配任务帮你采集,速度增加为原先的十分之一;采集到的数据可以在 云上保存三个月,可以随时进行导入操作。步骤 4:数据采集及导入1)采集完成后,会跳出提示,选择导入数据优采云·云采集网络爬虫软件 2)选择合适的导入方法,将采集好的数据导入优采云·云采集网络爬虫软件 步骤 5:将图片 URL 批量转换为图片经过如上操作,我们早已得到了要采集的图片的 URL。
接下来,再通过优采云 专用的图片批量下载工具,将采集到的图片 URL 中的图片,下载并保存到本地 电脑中。 图片批量下载工具: 1)下载优采云图片批量下载工具,双击文件中的 MyDownloader.app.exe 文 件,打开软件优采云·云采集网络爬虫软件 2)打开 File 菜单,选择从 EXCEL 导入(目前只支持 EXCEL 格式文件)优采云·云采集网络爬虫软件 3)进行相关设置,设置完成后,点击 OK 即可导出文件 选择 EXCEL 文件:导入你须要下载图片地址的 EXCEL 文件 EXCEL 表名:对应数据表的名称 文件 URL 列名:表内对应 URL 的列名称 保存文件夹名:EXCEL 中须要单独一个列,列出图片想要保存到文件夹的路径, 可以设置不同图片储存至不同文件夹 如果要把文件保存到文件夹,则路径须要以“\”结尾,例如:“D:\同步\”, 如果要下载后根据指定的文件名保存,则须要包含具体的文件名,例如“ D:\同 步\1.jpg” 如果下载的文件路径和文件名完全一样,则原本存在的文件会被删掉优采云·云采集网络爬虫软件 相关采集教程:京东商品图片采集详细教程:淘宝买家秀图片采集详细教程:优采云·云采集网络爬虫软件 淘宝图片采集并下载到本地的方式:豆瓣图片采集以及下载保存的方式:微信公众号热门文章采集(文本+图片):阿里巴巴图片抓取下载:ebay 商品图片采集:优采云——90 万用户选择的网页数据采集器。
优采云·云采集网络爬虫软件 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
如何防止采集网站内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 312 次浏览 • 2020-08-07 15:33
两个. 如何防止网站内容被采集
在实施多种反采集方法时,有必要考虑它是否会影响搜索引擎对网站的爬网,因此首先要分析一般采集器与搜索引擎爬网程序之间的区别.
相似之处:
a. 两者都需要直接获取网页的源代码才能有效地工作,
b. 他们都将在一个单位时间内多次抓取所访问网站的内容;
c. 从宏观上看,两个IP都会改变;
d. 两者不耐烦地破解您的某些网页加密(验证),例如网页内容是通过js文件加密的,例如需要输入验证码才能浏览内容,例如需要登录来访问内容等.
区别:
搜索引擎采集器首先忽略整个网页的源代码脚本和样式以及html标记代码,然后对其余文本执行一系列复杂的处理,例如词法和句法分析. 采集器通常通过html标签的特征来捕获所需的数据. 在制定采集规则时,您需要填写目标内容的开始和结束符号,以便找到所需的内容. 或针对特定网页使用特定规则. 表达式可以过滤出您所需的内容. 无论是使用开始和结束标签还是正则表达式,都涉及html标签(网页结构分析).
然后提出一些反采集方法
1. 限制IP地址每单位时间的访问次数
分析: 除非是程序访问,否则任何普通人都不能在一秒钟内访问同一网站5次. 有了这种偏好,只剩下搜索引擎采集器和烦人的采集器.
缺点: 一种尺寸适合所有人,这也将阻止搜索引擎包括该网站
适用的网站: 不太依赖搜索引擎的网站
采集器的工作: 减少单位时间内的访问次数并降低采集效率
2,阻止ip
分析: 通过后台计数器记录访问者的IP和频率,手动分析访问记录,并阻止可疑IP.
缺点: 似乎没有缺点,但是网站管理员有点忙
适用的网站: 所有网站和网站站长都可以知道哪些机器人是Google或百度
采集器将做什么: 打游击战!使用ip代理采集一次并更改一次,但这会降低采集器的效率和网络速度(使用代理).
3. 使用js加密Web内容
注意: 我没有碰过这种方法,只是从其他地方看
分析: 无需分析,搜索引擎爬虫和采集器都被杀死
适用的网站: 非常讨厌搜索引擎和采集器的网站
采集器会这样做: 如果你这么好,如果你这么好,他就不会来接你
4. 网站的版权或一些乱七八糟的文字被隐藏在网页中,这些文字样式被写在css文件中
分析: 尽管无法阻止采集,但是采集的内容将填充您网站的版权声明或一些垃圾文本,因为一般采集器不会同时采集您的css文件,并且文本将是显示时没有样式Out.
适用的网站: 所有网站
采集器的工作方式: 对于受版权保护的文本,很容易处理和替换. 对于随机的垃圾文本,请快点.
5. 用户可以登录访问网站内容
分析: 搜索引擎采集器不会为每种此类网站设计登录过程. 我听说采集器可以设计为模拟用户登录并提交特定网站的表单行为.
适用的网站: 讨厌搜索引擎并希望阻止大多数采集器的网站
采集器的工作: 为用户登录行为创建一个模块并提交表单
6. 使用脚本语言进行分页(隐藏分页)
分析: 同样,搜索引擎爬网程序不会分析各种网站的隐藏分页,这会影响搜索引擎将其收录在内. 但是,当采集器编写采集规则时,他必须分析目标网页代码,并且那些了解某些脚本知识的人将知道该页面的真实链接地址.
适用的网站: 不高度依赖搜索引擎的网站以及那些采集您信息的网站不了解脚本知识
采集器将要做什么: 应该说采集器将要做什么. 无论如何,他必须分析您的网页代码,并顺便分析您的分页脚本. 不需要太多时间.
7. 反热链接措施(仅允许通过网站页面连接进行查看,例如: Request.ServerVariables(“ HTTP_REFERER”))
分析: ASP和PHP可以通过读取请求的HTTP_REFERER属性来确定该请求是否来自该网站,从而限制了采集器,还限制了搜索引擎爬网程序,这严重影响了网站上搜索引擎的反垃圾内容包括在内.
适用的网站: 不要考虑搜索引擎中收录的网站.
采集器会做什么: 伪装HTTP_REFERER,这并不困难.
8,完整Flash,图片或pdf表示网站内容
分析: 对搜索引擎采集器和采集器的支持不好. 许多对SEO有所了解的人都知道这一点.
适用的网站: 专为媒体设计且不关心搜索引擎的网站.
采集器的工作: 停止采集,离开.
9. 网站随机采用不同的模板
分析: 由于采集器根据网页结构定位所需的内容,因此,一旦两次更改模板,采集规则将变为无效,这还不错. 这对搜索引擎爬虫没有影响.
适用的网站: 动态网站,不考虑用户体验.
采集器将执行的操作: 一个网站的模板不能超过10个. 只需为每个模板制定一个规则. 不同的模板使用不同的采集规则. 如果模板超过10个,则由于目标网站非常难以更改模板,因此最好撤回.
10. 使用动态和不规则的html标签
分析: 这是更异常的. 考虑到带空格和不带空格的html标签的效果相同,因此效果与页面显示相同,但是用作采集器的标签是两个不同的标签. 如果辅助页面html标记中的空格数是随机的,则
采集规则无效. 但是,这对搜索引擎爬网程序影响很小.
适用于网站: 所有不希望遵守网页设计准则的动态网站.
采集器的工作: 仍然存在对策. 仍然有许多HTML清洁器. 首先清理html标签,然后编写采集规则;您应该在使用采集规则之前清理html标签,否则您可以获得所需的数据.
摘要:
一旦必须同时搜索引擎采集器和采集器,这将非常令人沮丧,因为搜索引擎的第一步是采集目标网页的内容,这与采集器的原理相同,因此许多防止采集的方法也阻碍了搜索引擎对网站的收录工作感到无奈,对吗?尽管以上10条建议并非100%反采集,但几种方法的结合使用却拒绝了大量采集器. 查看全部
如何防止采集网站内容1.摘要一句话摘要: 无法采集js生成的内容网站.
两个. 如何防止网站内容被采集
在实施多种反采集方法时,有必要考虑它是否会影响搜索引擎对网站的爬网,因此首先要分析一般采集器与搜索引擎爬网程序之间的区别.
相似之处:
a. 两者都需要直接获取网页的源代码才能有效地工作,
b. 他们都将在一个单位时间内多次抓取所访问网站的内容;
c. 从宏观上看,两个IP都会改变;
d. 两者不耐烦地破解您的某些网页加密(验证),例如网页内容是通过js文件加密的,例如需要输入验证码才能浏览内容,例如需要登录来访问内容等.
区别:
搜索引擎采集器首先忽略整个网页的源代码脚本和样式以及html标记代码,然后对其余文本执行一系列复杂的处理,例如词法和句法分析. 采集器通常通过html标签的特征来捕获所需的数据. 在制定采集规则时,您需要填写目标内容的开始和结束符号,以便找到所需的内容. 或针对特定网页使用特定规则. 表达式可以过滤出您所需的内容. 无论是使用开始和结束标签还是正则表达式,都涉及html标签(网页结构分析).
然后提出一些反采集方法
1. 限制IP地址每单位时间的访问次数
分析: 除非是程序访问,否则任何普通人都不能在一秒钟内访问同一网站5次. 有了这种偏好,只剩下搜索引擎采集器和烦人的采集器.
缺点: 一种尺寸适合所有人,这也将阻止搜索引擎包括该网站
适用的网站: 不太依赖搜索引擎的网站
采集器的工作: 减少单位时间内的访问次数并降低采集效率
2,阻止ip
分析: 通过后台计数器记录访问者的IP和频率,手动分析访问记录,并阻止可疑IP.
缺点: 似乎没有缺点,但是网站管理员有点忙
适用的网站: 所有网站和网站站长都可以知道哪些机器人是Google或百度
采集器将做什么: 打游击战!使用ip代理采集一次并更改一次,但这会降低采集器的效率和网络速度(使用代理).
3. 使用js加密Web内容
注意: 我没有碰过这种方法,只是从其他地方看
分析: 无需分析,搜索引擎爬虫和采集器都被杀死
适用的网站: 非常讨厌搜索引擎和采集器的网站
采集器会这样做: 如果你这么好,如果你这么好,他就不会来接你
4. 网站的版权或一些乱七八糟的文字被隐藏在网页中,这些文字样式被写在css文件中
分析: 尽管无法阻止采集,但是采集的内容将填充您网站的版权声明或一些垃圾文本,因为一般采集器不会同时采集您的css文件,并且文本将是显示时没有样式Out.
适用的网站: 所有网站
采集器的工作方式: 对于受版权保护的文本,很容易处理和替换. 对于随机的垃圾文本,请快点.
5. 用户可以登录访问网站内容
分析: 搜索引擎采集器不会为每种此类网站设计登录过程. 我听说采集器可以设计为模拟用户登录并提交特定网站的表单行为.
适用的网站: 讨厌搜索引擎并希望阻止大多数采集器的网站
采集器的工作: 为用户登录行为创建一个模块并提交表单
6. 使用脚本语言进行分页(隐藏分页)
分析: 同样,搜索引擎爬网程序不会分析各种网站的隐藏分页,这会影响搜索引擎将其收录在内. 但是,当采集器编写采集规则时,他必须分析目标网页代码,并且那些了解某些脚本知识的人将知道该页面的真实链接地址.
适用的网站: 不高度依赖搜索引擎的网站以及那些采集您信息的网站不了解脚本知识
采集器将要做什么: 应该说采集器将要做什么. 无论如何,他必须分析您的网页代码,并顺便分析您的分页脚本. 不需要太多时间.
7. 反热链接措施(仅允许通过网站页面连接进行查看,例如: Request.ServerVariables(“ HTTP_REFERER”))
分析: ASP和PHP可以通过读取请求的HTTP_REFERER属性来确定该请求是否来自该网站,从而限制了采集器,还限制了搜索引擎爬网程序,这严重影响了网站上搜索引擎的反垃圾内容包括在内.
适用的网站: 不要考虑搜索引擎中收录的网站.
采集器会做什么: 伪装HTTP_REFERER,这并不困难.
8,完整Flash,图片或pdf表示网站内容
分析: 对搜索引擎采集器和采集器的支持不好. 许多对SEO有所了解的人都知道这一点.
适用的网站: 专为媒体设计且不关心搜索引擎的网站.
采集器的工作: 停止采集,离开.
9. 网站随机采用不同的模板
分析: 由于采集器根据网页结构定位所需的内容,因此,一旦两次更改模板,采集规则将变为无效,这还不错. 这对搜索引擎爬虫没有影响.
适用的网站: 动态网站,不考虑用户体验.
采集器将执行的操作: 一个网站的模板不能超过10个. 只需为每个模板制定一个规则. 不同的模板使用不同的采集规则. 如果模板超过10个,则由于目标网站非常难以更改模板,因此最好撤回.
10. 使用动态和不规则的html标签
分析: 这是更异常的. 考虑到带空格和不带空格的html标签的效果相同,因此效果与页面显示相同,但是用作采集器的标签是两个不同的标签. 如果辅助页面html标记中的空格数是随机的,则
采集规则无效. 但是,这对搜索引擎爬网程序影响很小.
适用于网站: 所有不希望遵守网页设计准则的动态网站.
采集器的工作: 仍然存在对策. 仍然有许多HTML清洁器. 首先清理html标签,然后编写采集规则;您应该在使用采集规则之前清理html标签,否则您可以获得所需的数据.
摘要:
一旦必须同时搜索引擎采集器和采集器,这将非常令人沮丧,因为搜索引擎的第一步是采集目标网页的内容,这与采集器的原理相同,因此许多防止采集的方法也阻碍了搜索引擎对网站的收录工作感到无奈,对吗?尽管以上10条建议并非100%反采集,但几种方法的结合使用却拒绝了大量采集器.
MAC上的Web捕获软件是什么?阅读这篇文章就足够了
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2020-08-07 13:04
在文章中: 哪种Web采集器软件易于使用?在其中,我们介绍了目前市场上更成熟且易于使用的网络采集器软件.
但是其中一些不能在MAC上使用,因此在今天的这篇文章中,我们将在MAC操作系统中单独介绍一些有用的爬网软件,以供您参考.
让我们首先得出结论. 赶时间的同志可以看后眨眼. 有两种选择:
1. 免费,无需金钱,无需积分
注意: 这里提到的免费功能包括采集数据,以各种格式将数据导出到本地,而不会限制采集和导出的数量,您可以将图片下载到本地以及其他采集数据所需的基本功能
您可以在优采云 cloud crawler()和优采云采集器()之间进行选择
如果您是没有编程基础的新手,我建议您直接选择优采云采集器,因为这是针对从零开始的用户的智能采集器,非常简单,您只需要输入URL即可智能地识别数据,无需配置任何采集规则,此外,它还支持可视化操作,可以说非常简单易用.
<p>如果您是具有编程基础的用户,那么我建议您使用优采云云采集器. 优采云爬虫平台功能非常强大,提供了丰富的开发组件. 您可以开发所需的任何采集器程序, 查看全部
原创链接:
在文章中: 哪种Web采集器软件易于使用?在其中,我们介绍了目前市场上更成熟且易于使用的网络采集器软件.
但是其中一些不能在MAC上使用,因此在今天的这篇文章中,我们将在MAC操作系统中单独介绍一些有用的爬网软件,以供您参考.
让我们首先得出结论. 赶时间的同志可以看后眨眼. 有两种选择:
1. 免费,无需金钱,无需积分
注意: 这里提到的免费功能包括采集数据,以各种格式将数据导出到本地,而不会限制采集和导出的数量,您可以将图片下载到本地以及其他采集数据所需的基本功能
您可以在优采云 cloud crawler()和优采云采集器()之间进行选择
如果您是没有编程基础的新手,我建议您直接选择优采云采集器,因为这是针对从零开始的用户的智能采集器,非常简单,您只需要输入URL即可智能地识别数据,无需配置任何采集规则,此外,它还支持可视化操作,可以说非常简单易用.
<p>如果您是具有编程基础的用户,那么我建议您使用优采云云采集器. 优采云爬虫平台功能非常强大,提供了丰富的开发组件. 您可以开发所需的任何采集器程序,
优采云采集器采集网页数据的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 397 次浏览 • 2020-08-07 12:23
方法步骤
1. 第一步,打开软件后,我们需要在软件主界面中选择采集方法. 编辑器将使用自定义获取方法向您演示,单击自定义获取功能的立即使用按钮.
2. 单击立即使用按钮后,下图所示的界面将打开. 在此界面中,我们需要输入要采集数据的网站的URL. 输入后,我们可以采集网站数据.
3. 输入URL后,软件会自动在网页上获取一些数据内容,然后我们可以单击其他设置按钮来设置一些与集合相关的操作,用户可以根据需要选择设置.
4. 设置完成后,我们可以在采集配置选项界面的底部看到一些采集的数据,然后单击下面的保存按钮以保存采集的数据.
5. 单击保存按钮后,我们可以保存采集的数据. 返回软件主界面后,您可以在界面左侧看到采集到的任务记录,下次打开软件时可以查看它. 查看全部
优采云采集器是一款非常强大的网页数据捕获软件. 用户可以使用此软件在网页上采集一些数据内容,并且可以单独保存这些数据内容,因此,如果用户在浏览网页时需要采集材料,则可以使用此采集器保存数据. 我相信许多用户将需要此功能,但是大多数用户仍然不知道如何使用优采云采集器. 该软件用于采集Web数据,因此编辑器将与您共享特定的操作步骤,感兴趣的朋友不妨查看一下编辑器的共享方法.
方法步骤
1. 第一步,打开软件后,我们需要在软件主界面中选择采集方法. 编辑器将使用自定义获取方法向您演示,单击自定义获取功能的立即使用按钮.
2. 单击立即使用按钮后,下图所示的界面将打开. 在此界面中,我们需要输入要采集数据的网站的URL. 输入后,我们可以采集网站数据.
3. 输入URL后,软件会自动在网页上获取一些数据内容,然后我们可以单击其他设置按钮来设置一些与集合相关的操作,用户可以根据需要选择设置.
4. 设置完成后,我们可以在采集配置选项界面的底部看到一些采集的数据,然后单击下面的保存按钮以保存采集的数据.
5. 单击保存按钮后,我们可以保存采集的数据. 返回软件主界面后,您可以在界面左侧看到采集到的任务记录,下次打开软件时可以查看它.
[简单的语言] [网站采集器源代码]实时更新各种资源网络的采集软件的内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 374 次浏览 • 2020-08-07 10:16
1. 可以在资源网络的其他网站上测试刚刚编写的采集软件.
2. 使用该模块: 皮肤模块(我不会打包以提高安全性).
3,一个非常简单的软件,Daniel可以绕行
4. 网站规则的配置文件存储在root \ rule目录中,可以使用记事本打开该文件.
5. root \ article目录存储采集器提取的html文件,可以使用浏览器打开该文件. (图片未保存在本地,节省了空间和速度,哈哈)
6. 存储在tmp目录中的是为临时测试而爬网的html文件.
7. LinkId.txt文件是用于链接到网站的配置文件.
2. 教程:
1. 请创建一个新文件夹,解压缩压缩包中的所有文件,然后编译源代码.
2. 选择文件夹简介:
[网站采集器源代码]用于各种资源网络的采集软件的实时更新
第一个选择文件夹: 正式遍历文章(即测试遍历是正常的,然后正式遍历)
?第二个选择文件夹: 测试遍历(即您自己添加规则之后,测试遍历是否正常!)
?第三个选择文件夹: 添加规则(即,添加网站的采集规则,标题文本,尾部文本等).
[网站采集器源代码]用于各种资源网络的采集软件的实时更新
3. 使用方法:
?请创建一个新文件夹,解压缩压缩包中的所有文件,然后编译源代码.
?进入第三个选择文件夹,选择规则文件,然后单击“加载”按钮.
?加载完成后(内容将出现在编辑框中),单击右下角的“测试遍历”按钮.
?软件将自动进入第二个选择文件夹. 此时,您可以单击“开始遍历”按钮.
?遍历完成后,将弹出一个信息框. 单击列表框,检查遍历的内容是否正确.
?以上是临时集合,文件保存在tmp目录中.
?进入第一个选择文件夹以选择正式采集的规则,开始采集,可见正式采集过程!
检查网页源代码并填写编辑框以测试遍历!
4,最后一句话. . .
<p>真的很难说清楚,我不知道您是否能听清楚,反正我听不清楚...,任何接触过html的人都应该知道一点... 查看全部
1. 说明:
1. 可以在资源网络的其他网站上测试刚刚编写的采集软件.
2. 使用该模块: 皮肤模块(我不会打包以提高安全性).
3,一个非常简单的软件,Daniel可以绕行
4. 网站规则的配置文件存储在root \ rule目录中,可以使用记事本打开该文件.
5. root \ article目录存储采集器提取的html文件,可以使用浏览器打开该文件. (图片未保存在本地,节省了空间和速度,哈哈)
6. 存储在tmp目录中的是为临时测试而爬网的html文件.
7. LinkId.txt文件是用于链接到网站的配置文件.
2. 教程:
1. 请创建一个新文件夹,解压缩压缩包中的所有文件,然后编译源代码.
2. 选择文件夹简介:
[网站采集器源代码]用于各种资源网络的采集软件的实时更新
第一个选择文件夹: 正式遍历文章(即测试遍历是正常的,然后正式遍历)
?第二个选择文件夹: 测试遍历(即您自己添加规则之后,测试遍历是否正常!)
?第三个选择文件夹: 添加规则(即,添加网站的采集规则,标题文本,尾部文本等).
[网站采集器源代码]用于各种资源网络的采集软件的实时更新
3. 使用方法:
?请创建一个新文件夹,解压缩压缩包中的所有文件,然后编译源代码.
?进入第三个选择文件夹,选择规则文件,然后单击“加载”按钮.
?加载完成后(内容将出现在编辑框中),单击右下角的“测试遍历”按钮.
?软件将自动进入第二个选择文件夹. 此时,您可以单击“开始遍历”按钮.
?遍历完成后,将弹出一个信息框. 单击列表框,检查遍历的内容是否正确.
?以上是临时集合,文件保存在tmp目录中.
?进入第一个选择文件夹以选择正式采集的规则,开始采集,可见正式采集过程!
检查网页源代码并填写编辑框以测试遍历!
4,最后一句话. . .
<p>真的很难说清楚,我不知道您是否能听清楚,反正我听不清楚...,任何接触过html的人都应该知道一点...
使用优采云采集器采集58套房屋租赁内容采集-第一部分
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2020-08-07 01:06
第1章: 中级课程从第1章开始: 如果工人想做好工作,则必须首先提高他们的工具提琴手的能力,以帮助您分析数据. 第2章: 分类信息网站58网站采集第1节: 58网站房屋出租内容采集第2节: 58网站手机号码采集的突破方法. 第3节: 使用采集器自动释放大量信息的方法. 第3章: 使用优采云采集器采集腾讯网站内容. 第1节: 采集所有QQ成员的qq方法第2节: 腾讯网站的新闻采集第3节: 微信文章搜索的内容采集第4节: 微信公众号搜索的内容采集第5节: 腾讯视频代码的第四章: 采集数据并合成为文本. 第1章: 采集网站内容并合成多个txt文本文档. 第2章: 采集网站内容并合成Word文档. 第3章: 采集内容并合成一个csv文件,可在淘宝助手中使用. 第4章: 通过采集器合成html单页第5章: 在Witkey领域使用优采云采集器第1章: 自动生成Witkey网站的发布模块第2部分: 使用Witkey发布自己的任务Post Yongbao第1章: 优酷网站上相关内容的采集说明第1部分: 通过采集器从优酷网站采集视频和相关信息第2部分: 监视通过优采云采集器获得的优酷最新视频搜索量第七章: 优采云采集器采集百度相关内容第1部分: 优百度采集关键词搜索结果并提取所需的URL域名第2部分: 优采云采集器采集百度贴吧帖子内容和回复第3节: 使用优采云采集器采集百度新闻内容第4节: 使用优采云采集器采集百度软件中心软件第5章: 使用优采云采集器采集与百度广告牌相关的最新信息第8章: 优采云采集器发布模块的生产思想和方法第1节: Web发布模块的生产思想和方法第2节: 生产存储模块dedecms,phpcms,ecshop,empire cms,destoon,discuz的思想和方法
简单的Web内容采集器(C#)
采集交流 • 优采云 发表了文章 • 0 个评论 • 307 次浏览 • 2020-08-06 23:26
windows nt / xp / 2003或更高版本
.net Framework 1.1
SqlServer 2000
开发环境VS 2003
目的在学习网络编程之后,总有事情要做.
所以我想到了构建一个Web内容采集器.
作者主页:
下载链接:
使用方法测试数据来自cnBlog.
看下面的图片
用户首先填写“开始页面”,即开始采集的页面.
然后填写数据库连接字符串,这里是定义采集的数据插入到哪个数据库中,然后选择表名,不用说.
网页编码,如果不是意外的话,中国大陆可以使用UTF-8
用于爬网文件名的常规规则: 哈哈此工具显然适合程序员. 您必须直接填写常规规则. 例如,cnblogs都是数字,因此\ d
表创建帮助: 用户指定创建几种varchar类型和几种文本类型,主要用于短数据和长数据. 如果表中已经有列,请避免使用它们. 该程序中没有验证.
在网络设置中:
在采集内容之前和之后进行标记:
例如,两者都有
xxx
如果我想采集xxx,请输入“
到
”当然是
到
之间的内容.
以下文本框用于显示内容.
单击“获取URL”以查看其捕获的网址是否正确.
单击“获取”将采集的内容放入数据库中,然后使用Insert xx()(选择xx)直接插入目标数据.
程序代码的数量非常小(而且非常简单),并且需要进行一些更改.
不足
适用于正则表达式和网络编程
因为这是最简单的事情,所以没有多线程,没有其他优化方法,并且不支持分页.
我对其进行了测试,获得了38条数据,并使用了700M的内存. . .
如果有用,可以进行更改. 这对程序员来说很方便,并且避免了编写大量代码. 查看全部
操作环境
windows nt / xp / 2003或更高版本
.net Framework 1.1
SqlServer 2000
开发环境VS 2003
目的在学习网络编程之后,总有事情要做.
所以我想到了构建一个Web内容采集器.
作者主页:
下载链接:
使用方法测试数据来自cnBlog.
看下面的图片
用户首先填写“开始页面”,即开始采集的页面.
然后填写数据库连接字符串,这里是定义采集的数据插入到哪个数据库中,然后选择表名,不用说.
网页编码,如果不是意外的话,中国大陆可以使用UTF-8
用于爬网文件名的常规规则: 哈哈此工具显然适合程序员. 您必须直接填写常规规则. 例如,cnblogs都是数字,因此\ d
表创建帮助: 用户指定创建几种varchar类型和几种文本类型,主要用于短数据和长数据. 如果表中已经有列,请避免使用它们. 该程序中没有验证.
在网络设置中:
在采集内容之前和之后进行标记:
例如,两者都有
xxx
如果我想采集xxx,请输入“
到
”当然是
到
之间的内容.
以下文本框用于显示内容.
单击“获取URL”以查看其捕获的网址是否正确.
单击“获取”将采集的内容放入数据库中,然后使用Insert xx()(选择xx)直接插入目标数据.
程序代码的数量非常小(而且非常简单),并且需要进行一些更改.
不足
适用于正则表达式和网络编程
因为这是最简单的事情,所以没有多线程,没有其他优化方法,并且不支持分页.
我对其进行了测试,获得了38条数据,并使用了700M的内存. . .
如果有用,可以进行更改. 这对程序员来说很方便,并且避免了编写大量代码.
图片采集软件download_webpage图片采集器_什么是图片采集工具?
采集交流 • 优采云 发表了文章 • 0 个评论 • 384 次浏览 • 2020-08-06 22:20
优采云数据采集器破解版v7.6.0最新免费版
大小: 56.6M
得分:
下载
优采云 Data Collector的破解版是著名的数据采集软件. 依靠云计算平台,可以即时读取大量信息,一键生成图表,数据传输专业,安全. 您应得的,欢迎有需要的朋友免费来当易
Network Photo 采集 Master软件v1.3.0绿色版
大小: 1.4M
得分:
下载
网络图片获取主软件是一种计算机搜索软件,例如当我们有时需要做一些事情来查找大图片时,我们可以使用它进行搜索,然后在搜索框中输入要查找的图片. 关键字的图片很多.
TikTok批量下载了最新版本的工件v6.5.0.0免费版本
大小: 1.5M
得分:
下载
最新版本的TikTok批量下载Artifact是一个下载软件,可让您批量下载无水印的TikTok视频. 它使用简单,不占用内存,运行稳定,为您带来全方位的愉悦体验!来挑选你最喜欢的兄弟姐妹,并感谢他
拾色器(colorpicker)v1.10免费版
大小: 143KB
得分:
下载
绿色选择器是一种非常轻便的颜色选择软件. 用户可以使用该软件获取显示屏上任何位置的颜色,并自动显示颜色代码,方便用户在其他地方使用. 有需要的朋友们欢迎从当义下载.
笑鬼颜色选择器(屏幕颜色采集工具)v2017绿色最新版本
大小: 851KB
得分:
下载
幽灵鬼魂可以在几乎所有系统上呈现屏幕色彩. 这是一个非常易于使用的屏幕颜色采集工具. 该软件是免费的,无需安装即可使用. 它非常方便且强大. 如果需要,欢迎来当易下载并使用!
微信微信二维码采集向导v3.2最新版本
大小: 3.6M
得分:
下载
微信微信群二维码采集向导是一款功能强大的二维码信息采集软件. 使用此软件,用户可以更轻松地采集QR码,并且该软件体积很小. 会占用太多内存,欢迎大家来当易网
dv视频采集软件
大小: 3.5M
得分:
下载
dv视频捕获软件是视频捕获软件. 通过它,用户可以实时捕获图像,编辑视频和其他便利功能. dv视频捕获软件的引入清晰易用. 想要使用类似功能的用户不要错过这个有用的软件. 有兴趣 查看全部
优采云数据采集器破解版v7.6.0最新免费版
大小: 56.6M
得分:
下载
优采云 Data Collector的破解版是著名的数据采集软件. 依靠云计算平台,可以即时读取大量信息,一键生成图表,数据传输专业,安全. 您应得的,欢迎有需要的朋友免费来当易
Network Photo 采集 Master软件v1.3.0绿色版
大小: 1.4M
得分:
下载
网络图片获取主软件是一种计算机搜索软件,例如当我们有时需要做一些事情来查找大图片时,我们可以使用它进行搜索,然后在搜索框中输入要查找的图片. 关键字的图片很多.
TikTok批量下载了最新版本的工件v6.5.0.0免费版本
大小: 1.5M
得分:
下载
最新版本的TikTok批量下载Artifact是一个下载软件,可让您批量下载无水印的TikTok视频. 它使用简单,不占用内存,运行稳定,为您带来全方位的愉悦体验!来挑选你最喜欢的兄弟姐妹,并感谢他
拾色器(colorpicker)v1.10免费版
大小: 143KB
得分:
下载
绿色选择器是一种非常轻便的颜色选择软件. 用户可以使用该软件获取显示屏上任何位置的颜色,并自动显示颜色代码,方便用户在其他地方使用. 有需要的朋友们欢迎从当义下载.
笑鬼颜色选择器(屏幕颜色采集工具)v2017绿色最新版本
大小: 851KB
得分:
下载
幽灵鬼魂可以在几乎所有系统上呈现屏幕色彩. 这是一个非常易于使用的屏幕颜色采集工具. 该软件是免费的,无需安装即可使用. 它非常方便且强大. 如果需要,欢迎来当易下载并使用!
微信微信二维码采集向导v3.2最新版本
大小: 3.6M
得分:
下载
微信微信群二维码采集向导是一款功能强大的二维码信息采集软件. 使用此软件,用户可以更轻松地采集QR码,并且该软件体积很小. 会占用太多内存,欢迎大家来当易网
dv视频采集软件
大小: 3.5M
得分:
下载
dv视频捕获软件是视频捕获软件. 通过它,用户可以实时捕获图像,编辑视频和其他便利功能. dv视频捕获软件的引入清晰易用. 想要使用类似功能的用户不要错过这个有用的软件. 有兴趣
网页采集软件优采云采集器7.1.8破解版(内置激活版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 643 次浏览 • 2020-08-06 18:09
网页采集软件优采云采集器破解了资源获取(单击下载)
优采云采集器破解版的下载链接
优采云采集器破解版的下载链接
优采云采集器的破解版还支持计时采集,API导出数据,每次启动时动态分配IP以及与任何数据源的灵活连接. 编辑器的专业测试非常易于使用,欢迎朋友下载和体验!
(图片: 优采云采集器破解版)
优采云采集器破解版功能简介:
1. 云采集
5000个云服务器,24 * 7高效,稳定的集合以及API,可无缝连接到内部系统并定期同步数据;
2. 智能防封
自动破解各种验证码,提供代理IP池,并结合UA切换,可以有效突破封锁,顺畅地采集数据;
3. 适用于整个网络
无论是图片通话还是邮筒论坛,都可以即时采集,它支持所有业务渠道的抓取工具,以满足各种采集需求;
4. 大量模板
内置了数百个网站数据源,涵盖多个行业. 您可以通过简单的设置快速而准确地获取数据;
5,易于使用
无需学习爬虫编程技术,只需三个简单的步骤即可轻松获取Web数据,支持多种格式的一键导出,并快速导入数据库;
6,稳定高效
分布式云集群服务器和多用户协作管理平台的支持可以灵活地安排任务并平稳地抓取大量数据.
(图片: 优采云采集器)
温馨提示,本网站提供的优采云采集器的编辑将自行进行测试,朋友们可以放心下载和使用它〜 查看全部
优采云采集器是一个专业的Web采集软件. 优采云采集器 Ultimate Edition可以满足数十万的每日数据采集需求. 在专业版中,它具有IQ功能. 它还具有云采集功能. 达到8-10倍!
网页采集软件优采云采集器破解了资源获取(单击下载)
优采云采集器破解版的下载链接
优采云采集器破解版的下载链接
优采云采集器的破解版还支持计时采集,API导出数据,每次启动时动态分配IP以及与任何数据源的灵活连接. 编辑器的专业测试非常易于使用,欢迎朋友下载和体验!
(图片: 优采云采集器破解版)
优采云采集器破解版功能简介:
1. 云采集
5000个云服务器,24 * 7高效,稳定的集合以及API,可无缝连接到内部系统并定期同步数据;
2. 智能防封
自动破解各种验证码,提供代理IP池,并结合UA切换,可以有效突破封锁,顺畅地采集数据;
3. 适用于整个网络
无论是图片通话还是邮筒论坛,都可以即时采集,它支持所有业务渠道的抓取工具,以满足各种采集需求;
4. 大量模板
内置了数百个网站数据源,涵盖多个行业. 您可以通过简单的设置快速而准确地获取数据;
5,易于使用
无需学习爬虫编程技术,只需三个简单的步骤即可轻松获取Web数据,支持多种格式的一键导出,并快速导入数据库;
6,稳定高效
分布式云集群服务器和多用户协作管理平台的支持可以灵活地安排任务并平稳地抓取大量数据.
(图片: 优采云采集器)
温馨提示,本网站提供的优采云采集器的编辑将自行进行测试,朋友们可以放心下载和使用它〜
采集器设置
采集交流 • 优采云 发表了文章 • 0 个评论 • 549 次浏览 • 2020-08-06 12:06
在任务底部的进度栏中单击“采集器设置”以进入规则编辑界面
起始页网址
添加需要采集的目标列表页面
单击“ +”号以批量添加URL,选中“设置为内容页面URL”以直接采集输入的URL,否则需要将其分析为列表页面以提取内容页面URL
内容页面网址
编写用于提取内容页面URL的规则. 默认情况下提取所有URL. 如果需要精确,可以设置“ URL提取规则”
多级URL获取: 适用于小说,电影等序列化内容.
只要不直接从起始页获取内容页面URL,就可以通过多个级别获取它
获取关联页面的URL: 适用于分散在多个页面中的数据
如果要爬网的字段不在内容页面上,而是在其他页面上,则可以使用此功能将其他页面用作内容源.
获取内容
“添加默认值”可以自动设置几个通用字段,可以满足大多数文章类型的网站集
如果目标数据格式更复杂,则可以单击“ +”自己编写字段规则,并支持多种匹配方法,例如正则表达式,xpath,json等.
“数据处理”可以过滤或替换采集的字段值,并且每个字段都可以单独处理或使用常规处理
如果需要获取分页,请单击以打开“内容分页”并编写规则,程序将自动获取每个页面中的字段内容
测试规则
配置采集器后,需要单击保存按钮. 刷新后,您可以在“内容页面URL”标签和“获取内容”标签中看到测试按钮.
从测试列表页面获取URL
从测试页获取数据
测试爬网分页 查看全部
采集器设置
在任务底部的进度栏中单击“采集器设置”以进入规则编辑界面
起始页网址
添加需要采集的目标列表页面
单击“ +”号以批量添加URL,选中“设置为内容页面URL”以直接采集输入的URL,否则需要将其分析为列表页面以提取内容页面URL
内容页面网址
编写用于提取内容页面URL的规则. 默认情况下提取所有URL. 如果需要精确,可以设置“ URL提取规则”
多级URL获取: 适用于小说,电影等序列化内容.
只要不直接从起始页获取内容页面URL,就可以通过多个级别获取它
获取关联页面的URL: 适用于分散在多个页面中的数据
如果要爬网的字段不在内容页面上,而是在其他页面上,则可以使用此功能将其他页面用作内容源.
获取内容
“添加默认值”可以自动设置几个通用字段,可以满足大多数文章类型的网站集
如果目标数据格式更复杂,则可以单击“ +”自己编写字段规则,并支持多种匹配方法,例如正则表达式,xpath,json等.
“数据处理”可以过滤或替换采集的字段值,并且每个字段都可以单独处理或使用常规处理
如果需要获取分页,请单击以打开“内容分页”并编写规则,程序将自动获取每个页面中的字段内容
测试规则
配置采集器后,需要单击保存按钮. 刷新后,您可以在“内容页面URL”标签和“获取内容”标签中看到测试按钮.
从测试列表页面获取URL
从测试页获取数据
测试爬网分页
遵天市网页采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 298 次浏览 • 2020-08-06 10:05
此软件通过Internet采集网页信息. 有两个主要功能:
1,您可以在js之后采集动态信息.
2,您可以设置要采集的正则表达式.
此外,该软件具有内置的多种采集方案,分别对应于静态网页和动态网页.
该软件采集了官方网站上的图像(面部)搜索引擎数据,然后对其进行了索引.
使用步骤:
1. 输入URL,正常浏览网页并到达采集目标,单击工具栏上的“查看js之后的源代码”图标,以在执行js后显示网页的内容.
如果看不到相关内容,则可以稍等片刻,然后再次单击以确保执行了js代码. 通过浏览完整的网页源代码,我们可以确认
使用计划1或计划2. 如果可以通过更改URL的页码导航到下一页,请使用计划1;否则,请使用计划1. 如果您通过脚本动态更新页面的内容,
使用计划2.
2,单击工具栏上的“运行采集方案”图标,然后根据步骤1选择方案1或2. 如果已经由方案1和2生成了downloadtotal.txt
文件,您还可以选择选项3. 填写必要的信息或表达式,单击“开始采集”按钮,系统将自动采集. 点击对话框中的“取消”
按钮关闭对话框而不启动采集任务.
3. 单击工具栏上的“停止采集方案”图标,系统将终止采集任务.
防止网页采集:
防止采集的第一种方法: 在文章的开头和结尾添加随机和未固定的内容. 网站采集人员通常在进行采集时指定起始位置和结束位置,并在中间截取内容.
例如,如果您文章的内容是“ Youxun Software Information Network”,则如何添加随机内容:
随机内容1+优讯软件信息网+随机内容2
注意: 随机内容1和随机内容2只需为每篇文章随机显示一个. 查看全部
现在市场上充斥着一些付费的网页采集器. 不管它的功能是什么,这种免费的绿色免费网页采集器都是很少见的!
此软件通过Internet采集网页信息. 有两个主要功能:
1,您可以在js之后采集动态信息.
2,您可以设置要采集的正则表达式.
此外,该软件具有内置的多种采集方案,分别对应于静态网页和动态网页.
该软件采集了官方网站上的图像(面部)搜索引擎数据,然后对其进行了索引.
使用步骤:
1. 输入URL,正常浏览网页并到达采集目标,单击工具栏上的“查看js之后的源代码”图标,以在执行js后显示网页的内容.
如果看不到相关内容,则可以稍等片刻,然后再次单击以确保执行了js代码. 通过浏览完整的网页源代码,我们可以确认
使用计划1或计划2. 如果可以通过更改URL的页码导航到下一页,请使用计划1;否则,请使用计划1. 如果您通过脚本动态更新页面的内容,
使用计划2.
2,单击工具栏上的“运行采集方案”图标,然后根据步骤1选择方案1或2. 如果已经由方案1和2生成了downloadtotal.txt
文件,您还可以选择选项3. 填写必要的信息或表达式,单击“开始采集”按钮,系统将自动采集. 点击对话框中的“取消”
按钮关闭对话框而不启动采集任务.
3. 单击工具栏上的“停止采集方案”图标,系统将终止采集任务.
防止网页采集:
防止采集的第一种方法: 在文章的开头和结尾添加随机和未固定的内容. 网站采集人员通常在进行采集时指定起始位置和结束位置,并在中间截取内容.
例如,如果您文章的内容是“ Youxun Software Information Network”,则如何添加随机内容:
随机内容1+优讯软件信息网+随机内容2
注意: 随机内容1和随机内容2只需为每篇文章随机显示一个.
智能Web内容采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 276 次浏览 • 2020-08-06 08:26
软件简介
Smart Web Content Collector使您可以通过多个线程快速采集网页上所需的任何文本内容. 同时,您可以设置过滤和相应的处理,并支持关键字搜索.
软件功能
1. 使用基础的HTTP方法来采集数据,这是快速且稳定的. 可以构建多个任务和线程来同时从多个网站采集数据
2,用户可以随意导入和导出任务
3. 可以使用密码设置该任务,以确保您的采集任务的详细信息不会泄漏.
4. 它还具有N页采集暂停/拨号到IP更改,具有特殊标记暂停/拨号到IP更改的采集以及其他防捕获功能.
5. 您可以直接输入要捕获的URL,或使用JavaScript脚本生成URL,或通过关键字搜索捕获它
6. 您可以使用登录采集方法来采集需要登录帐户才能查看的Web内容
7. 它可以无限期地在N列中采集内容和链接,并支持多级内容分页采集
8. 支持多种内容提取模式,您可以根据需要处理采集的内容,例如清除HTML,图片等.
9. 您可以编译自己的JAVASCRIPT脚本以提取网页的内容,并轻松实现内容的任何部分的采集
10. 可以根据设置的模板保存采集到的文本内容
11. 可以根据模板将多个文件保存到同一文件中
12. 分页内容采集可以分别在网页的多个部分上进行
13. 可以设置客户信息以模拟百度等搜索引擎采集目标网站的情况
14. 该软件是永久免费的
相关更新
使用新的智能软件控件UI
向EMAIL功能添加用户反馈
添加直接将初始链接设置为最终内容页面处理功能的功能
增强内核功能,支持关键字搜索并替换POST中的关键字标签
优化获取核心
优化断开的拨号算法
优化重复数据删除工具的算法
修复了拨号显示IP错误的错误
修复了错误关键字被暂停或拨打时未重新采集错误页面的错误.
修复了受限内容的最大值为0时,最小值无法正确保存的问题.
软件屏幕截图 查看全部
这是一个智能的Web内容采集器. 它可以多任务和多线程模式采集任何网页上的任何指定文本内容,并执行所需的相应过滤和处理. 您可以使用搜索关键字来采集所需的指定搜索结果. ..
软件简介
Smart Web Content Collector使您可以通过多个线程快速采集网页上所需的任何文本内容. 同时,您可以设置过滤和相应的处理,并支持关键字搜索.
软件功能
1. 使用基础的HTTP方法来采集数据,这是快速且稳定的. 可以构建多个任务和线程来同时从多个网站采集数据
2,用户可以随意导入和导出任务
3. 可以使用密码设置该任务,以确保您的采集任务的详细信息不会泄漏.
4. 它还具有N页采集暂停/拨号到IP更改,具有特殊标记暂停/拨号到IP更改的采集以及其他防捕获功能.
5. 您可以直接输入要捕获的URL,或使用JavaScript脚本生成URL,或通过关键字搜索捕获它
6. 您可以使用登录采集方法来采集需要登录帐户才能查看的Web内容
7. 它可以无限期地在N列中采集内容和链接,并支持多级内容分页采集
8. 支持多种内容提取模式,您可以根据需要处理采集的内容,例如清除HTML,图片等.
9. 您可以编译自己的JAVASCRIPT脚本以提取网页的内容,并轻松实现内容的任何部分的采集
10. 可以根据设置的模板保存采集到的文本内容
11. 可以根据模板将多个文件保存到同一文件中
12. 分页内容采集可以分别在网页的多个部分上进行
13. 可以设置客户信息以模拟百度等搜索引擎采集目标网站的情况
14. 该软件是永久免费的
相关更新
使用新的智能软件控件UI
向EMAIL功能添加用户反馈
添加直接将初始链接设置为最终内容页面处理功能的功能
增强内核功能,支持关键字搜索并替换POST中的关键字标签
优化获取核心
优化断开的拨号算法
优化重复数据删除工具的算法
修复了拨号显示IP错误的错误
修复了错误关键字被暂停或拨打时未重新采集错误页面的错误.
修复了受限内容的最大值为0时,最小值无法正确保存的问题.
软件屏幕截图
推荐网络抓取工具Youcai Cloud Collector
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2020-08-05 20:04
最近,我正在整理36个k文章的一些标签. 我打算看看其他与风险投资有关的网站可以参考哪些标准. 因此,我找到了一个名为“ Enox Data”的网站,并希望了解人工智能. 公司,如红色字母部分所示:
如果数据显示在规则中,您还可以使用鼠标选择它并复制并粘贴它,但是仍然需要找到某种方法将其嵌入到页面中. 这时候,我记得我之前已经安装了Youcai Cloud Collector,所以我尝试了一下. 它非常易于使用,并且采集效率立即得到提高. 也给大家安利〜
Youcai Cloud Collector的Chrome插件,我在B站的技术视频中看到了它. 它声称是一种黑色技术,可以在不了解编程的情况下进行抓取. 简而言之,Youcai Cloud Collector是基于Chrome的网页元素解析器,可以自动识别主要内容,并可以通过可视化单击操作在自定义区域中实现数据/元素提取. 同时,它还提供了定时自动提取功能,可以用作一组简单的搜寻器工具.
在这里,我将通过方式解释网页提取器抓取与实际代码抓取之间的区别. 使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人. 它使您可以在页面上定义需求. 抓取哪个元素,抓取哪些页面,然后让机器代表他人操作;如果您使用Python编写搜寻器,则最好先使用网页请求命令下载整个网页,然后再使用代码来解析HTML页面元素. 提取您想要的内容,并继续循环. 相比之下,使用代码会更加灵活,但是解析的成本也会更高. 如果这是简单的页面内容提取,我还建议您使用优采云采集器.
关于Youcai Cloud Collector的特定安装过程以及如何使用完整功能,我将不在今天的文章中讨论. 第一个是我只使用了我需要的部件,第二个是因为市场上有很多优采云采集器教程,您可以自己找到它.
这只是一个实用的过程,为您简要介绍如何使用它.
第一步是登录优采云采集平台的后台
1. 打开Chrome浏览器,其图标按钮标记将出现在浏览器的右上角. 单击此按钮进行注册/登录按钮,跳至优采云采集平台的登录页面,输入用户名和密码即可登录
首先输入要抓取的网站的URL. 例如,我要获取的是: 牲畜数据的行业标签,URL为: ,然后在优采云采集器的背景中输入URL,然后单击优采云采集按钮. 出现配置页面
确定了主要内容,但是我想要的是在人工智能下的公司,所以我需要对其进行重新配置.
第二步是配置要提取的主要信息类型
1. 首先点击清除字段按钮,首先清除所有数据,
查看全部
Youcai Cloud Collector是一个Chrome网页数据提取插件,可以从网页中提取数据. 从某种意义上讲,您还可以将其用作搜寻器工具.
最近,我正在整理36个k文章的一些标签. 我打算看看其他与风险投资有关的网站可以参考哪些标准. 因此,我找到了一个名为“ Enox Data”的网站,并希望了解人工智能. 公司,如红色字母部分所示:
如果数据显示在规则中,您还可以使用鼠标选择它并复制并粘贴它,但是仍然需要找到某种方法将其嵌入到页面中. 这时候,我记得我之前已经安装了Youcai Cloud Collector,所以我尝试了一下. 它非常易于使用,并且采集效率立即得到提高. 也给大家安利〜
Youcai Cloud Collector的Chrome插件,我在B站的技术视频中看到了它. 它声称是一种黑色技术,可以在不了解编程的情况下进行抓取. 简而言之,Youcai Cloud Collector是基于Chrome的网页元素解析器,可以自动识别主要内容,并可以通过可视化单击操作在自定义区域中实现数据/元素提取. 同时,它还提供了定时自动提取功能,可以用作一组简单的搜寻器工具.
在这里,我将通过方式解释网页提取器抓取与实际代码抓取之间的区别. 使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人. 它使您可以在页面上定义需求. 抓取哪个元素,抓取哪些页面,然后让机器代表他人操作;如果您使用Python编写搜寻器,则最好先使用网页请求命令下载整个网页,然后再使用代码来解析HTML页面元素. 提取您想要的内容,并继续循环. 相比之下,使用代码会更加灵活,但是解析的成本也会更高. 如果这是简单的页面内容提取,我还建议您使用优采云采集器.
关于Youcai Cloud Collector的特定安装过程以及如何使用完整功能,我将不在今天的文章中讨论. 第一个是我只使用了我需要的部件,第二个是因为市场上有很多优采云采集器教程,您可以自己找到它.
这只是一个实用的过程,为您简要介绍如何使用它.
第一步是登录优采云采集平台的后台
1. 打开Chrome浏览器,其图标按钮标记将出现在浏览器的右上角. 单击此按钮进行注册/登录按钮,跳至优采云采集平台的登录页面,输入用户名和密码即可登录
首先输入要抓取的网站的URL. 例如,我要获取的是: 牲畜数据的行业标签,URL为: ,然后在优采云采集器的背景中输入URL,然后单击优采云采集按钮. 出现配置页面
确定了主要内容,但是我想要的是在人工智能下的公司,所以我需要对其进行重新配置.
第二步是配置要提取的主要信息类型
1. 首先点击清除字段按钮,首先清除所有数据,
我无事可做,我一直想做点什么,我开发了一个网页采集器并在此处共享
采集交流 • 优采云 发表了文章 • 0 个评论 • 352 次浏览 • 2020-08-05 20:01
@foxidea
@txlty
我首先道歉. 昨天,我看到了一个安装一系列环境的请求,但我并没有仔细考虑. 我觉得使用像.net这样重的平台来制作具有大量需求变化的产品可能是不合适的,所以我随便抱怨一下. ,采集技术实际上很成熟. 没什么好说的. 我只想讨论平台技术的选择. 我无意引起语言争议. 我从未对C#感到难过. 我没想到会将这篇文章拖到一种语言中. 我已经讨论了这个话题,很抱歉.
返回技术解决方案主题. 至于采集器的设计,我认为这取决于是针对不了解技术的程序员还是网站管理员.
如果程序员使用它,则可伸缩性非常重要. 它应该是跨平台的. 它需要提供数据导入和导出接口. 命令行界面非常好,简单高效. 这种脚本语言具有很大的优势,当然不是. 它必须是python或ruby,swift,lua,perl之类的东西.
如果是不懂技术的网站管理员,则部署应该很简单,纯WIN32平台是首选. .net和Java企业应用程序是不错的选择. 老实说,我认为它不适合个人用户. 就像第一个版本的Xunlei由JAVA制作一样,它得到了周鸿yi的认可,第二个版本已更改为WIN32. 另一个方向是云计算. @foxidea还制作了一个网络版本. 这非常适合JAVA和.net. 将来我们也可能向云发展.
通常来说,@ foxidea很难制造出如此成熟的产品. 已经付出了很多努力. 如果不是纯粹出于自我娱乐目的,则完全有可能在此基础上将其更改为商业产品. 可能. 但是,应该仔细考虑初始方向. 对于哪个用户组,需要采取哪种技术路线,并且无需考虑太多的个人喜好. 最好选择正确的解决方案. 查看全部
@ v1ex
@foxidea
@txlty
我首先道歉. 昨天,我看到了一个安装一系列环境的请求,但我并没有仔细考虑. 我觉得使用像.net这样重的平台来制作具有大量需求变化的产品可能是不合适的,所以我随便抱怨一下. ,采集技术实际上很成熟. 没什么好说的. 我只想讨论平台技术的选择. 我无意引起语言争议. 我从未对C#感到难过. 我没想到会将这篇文章拖到一种语言中. 我已经讨论了这个话题,很抱歉.
返回技术解决方案主题. 至于采集器的设计,我认为这取决于是针对不了解技术的程序员还是网站管理员.
如果程序员使用它,则可伸缩性非常重要. 它应该是跨平台的. 它需要提供数据导入和导出接口. 命令行界面非常好,简单高效. 这种脚本语言具有很大的优势,当然不是. 它必须是python或ruby,swift,lua,perl之类的东西.
如果是不懂技术的网站管理员,则部署应该很简单,纯WIN32平台是首选. .net和Java企业应用程序是不错的选择. 老实说,我认为它不适合个人用户. 就像第一个版本的Xunlei由JAVA制作一样,它得到了周鸿yi的认可,第二个版本已更改为WIN32. 另一个方向是云计算. @foxidea还制作了一个网络版本. 这非常适合JAVA和.net. 将来我们也可能向云发展.
通常来说,@ foxidea很难制造出如此成熟的产品. 已经付出了很多努力. 如果不是纯粹出于自我娱乐目的,则完全有可能在此基础上将其更改为商业产品. 可能. 但是,应该仔细考虑初始方向. 对于哪个用户组,需要采取哪种技术路线,并且无需考虑太多的个人喜好. 最好选择正确的解决方案.
如何用网页采集器下载图片
采集交流 • 优采云 发表了文章 • 0 个评论 • 323 次浏览 • 2020-08-04 15:03
我们发觉,百度图片网是瀑布流的网页,经过每一次下 拉加载,都会出现新的数据。当图片足够多的时侯,可无数次下拉加载。因而, 此网页涉及 AJAX 技术,需要设置 AJAX 超时,以便确保数据采集的时侯不会 遗漏。优采云·云采集网络爬虫软件 选中“打开网页”步骤,打开“高级选项”,勾选“页面加载完成向上滚动”, 设置滚动次数为“5 次”(根据自身需求进行设置),时间为“2 秒”,滚动方 式为“向下滚动一屏”;最后点击“确定”注意:示例网站内容采集器,没有翻页按键,滚动次数、滚动形式会影响数据采集数量,可 按需设置步骤 2:采集图片 URL优采云·云采集网络爬虫软件 1)选中页面内第一个图片,系统会手动辨识同类图片。在操作提示框中,选择 “选中全部”2)选择“采集以下图片地址”优采云·云采集网络爬虫软件 步骤 3:修改 Xpath1)选中“循环”步骤,打开“高级选项”。可以看见优采云系统手动采用的是 “不固定元素列表” 循环, Xpath 为: //DIV[@id='imgid']/DIV[1]/UL[1]/LI优采云·云采集网络爬虫软件 2)将此条 Xpath://DIV[@id='imgid']/DIV[1]/UL[1]/LI,复制到傲游浏览 器中进行观察——仅可定位到网页中 22 张图片优采云·云采集网络爬虫软件 3)我们须要一条才能定位到网页中全部所需图片的 Xpath。
观察网页源码并将 Xpath 修改为://DIV[@id='imgid']/DIV/UL[1]/LI,网页中全部所需的图片 均被定位了优采云·云采集网络爬虫软件 4)将修改后的 Xpath://DIV[@id='imgid']/DIV/UL[1]/LI,复制粘贴到八 爪虾中相应位置,完成后点击“确定”优采云·云采集网络爬虫软件 5)点击“保存”,再点击“开始采集”,这里选择“启动本地采集”优采云·云采集网络爬虫软件 说明:本地采集占用当前笔记本资源进行采集,如果存在采集时间要求或当前笔记本未能长时间进行采集可以 使用云采集功能,云采集在网路中进行采集内容采集器,无需当前笔记本支持,电脑可以死机,可以设置多个云节点分 摊任务,10 个节点相当于 10 台笔记本分配任务帮你采集,速度增加为原先的十分之一;采集到的数据可以在 云上保存三个月,可以随时进行导入操作。步骤 4:数据采集及导入1)采集完成后,会跳出提示,选择导入数据优采云·云采集网络爬虫软件 2)选择合适的导入方法,将采集好的数据导入优采云·云采集网络爬虫软件 步骤 5:将图片 URL 批量转换为图片经过如上操作,我们早已得到了要采集的图片的 URL。
接下来,再通过优采云 专用的图片批量下载工具,将采集到的图片 URL 中的图片,下载并保存到本地 电脑中。 图片批量下载工具: 1)下载优采云图片批量下载工具,双击文件中的 MyDownloader.app.exe 文 件,打开软件优采云·云采集网络爬虫软件 2)打开 File 菜单,选择从 EXCEL 导入(目前只支持 EXCEL 格式文件)优采云·云采集网络爬虫软件 3)进行相关设置,设置完成后,点击 OK 即可导出文件 选择 EXCEL 文件:导入你须要下载图片地址的 EXCEL 文件 EXCEL 表名:对应数据表的名称 文件 URL 列名:表内对应 URL 的列名称 保存文件夹名:EXCEL 中须要单独一个列,列出图片想要保存到文件夹的路径, 可以设置不同图片储存至不同文件夹 如果要把文件保存到文件夹,则路径须要以“\”结尾,例如:“D:\同步\”, 如果要下载后根据指定的文件名保存,则须要包含具体的文件名,例如“ D:\同 步\1.jpg” 如果下载的文件路径和文件名完全一样,则原本存在的文件会被删掉优采云·云采集网络爬虫软件 相关采集教程:京东商品图片采集详细教程:淘宝买家秀图片采集详细教程:优采云·云采集网络爬虫软件 淘宝图片采集并下载到本地的方式:豆瓣图片采集以及下载保存的方式:微信公众号热门文章采集(文本+图片):阿里巴巴图片抓取下载:ebay 商品图片采集:优采云——90 万用户选择的网页数据采集器。
优采云·云采集网络爬虫软件 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部
我们发觉,百度图片网是瀑布流的网页,经过每一次下 拉加载,都会出现新的数据。当图片足够多的时侯,可无数次下拉加载。因而, 此网页涉及 AJAX 技术,需要设置 AJAX 超时,以便确保数据采集的时侯不会 遗漏。优采云·云采集网络爬虫软件 选中“打开网页”步骤,打开“高级选项”,勾选“页面加载完成向上滚动”, 设置滚动次数为“5 次”(根据自身需求进行设置),时间为“2 秒”,滚动方 式为“向下滚动一屏”;最后点击“确定”注意:示例网站内容采集器,没有翻页按键,滚动次数、滚动形式会影响数据采集数量,可 按需设置步骤 2:采集图片 URL优采云·云采集网络爬虫软件 1)选中页面内第一个图片,系统会手动辨识同类图片。在操作提示框中,选择 “选中全部”2)选择“采集以下图片地址”优采云·云采集网络爬虫软件 步骤 3:修改 Xpath1)选中“循环”步骤,打开“高级选项”。可以看见优采云系统手动采用的是 “不固定元素列表” 循环, Xpath 为: //DIV[@id='imgid']/DIV[1]/UL[1]/LI优采云·云采集网络爬虫软件 2)将此条 Xpath://DIV[@id='imgid']/DIV[1]/UL[1]/LI,复制到傲游浏览 器中进行观察——仅可定位到网页中 22 张图片优采云·云采集网络爬虫软件 3)我们须要一条才能定位到网页中全部所需图片的 Xpath。
观察网页源码并将 Xpath 修改为://DIV[@id='imgid']/DIV/UL[1]/LI,网页中全部所需的图片 均被定位了优采云·云采集网络爬虫软件 4)将修改后的 Xpath://DIV[@id='imgid']/DIV/UL[1]/LI,复制粘贴到八 爪虾中相应位置,完成后点击“确定”优采云·云采集网络爬虫软件 5)点击“保存”,再点击“开始采集”,这里选择“启动本地采集”优采云·云采集网络爬虫软件 说明:本地采集占用当前笔记本资源进行采集,如果存在采集时间要求或当前笔记本未能长时间进行采集可以 使用云采集功能,云采集在网路中进行采集内容采集器,无需当前笔记本支持,电脑可以死机,可以设置多个云节点分 摊任务,10 个节点相当于 10 台笔记本分配任务帮你采集,速度增加为原先的十分之一;采集到的数据可以在 云上保存三个月,可以随时进行导入操作。步骤 4:数据采集及导入1)采集完成后,会跳出提示,选择导入数据优采云·云采集网络爬虫软件 2)选择合适的导入方法,将采集好的数据导入优采云·云采集网络爬虫软件 步骤 5:将图片 URL 批量转换为图片经过如上操作,我们早已得到了要采集的图片的 URL。
接下来,再通过优采云 专用的图片批量下载工具,将采集到的图片 URL 中的图片,下载并保存到本地 电脑中。 图片批量下载工具: 1)下载优采云图片批量下载工具,双击文件中的 MyDownloader.app.exe 文 件,打开软件优采云·云采集网络爬虫软件 2)打开 File 菜单,选择从 EXCEL 导入(目前只支持 EXCEL 格式文件)优采云·云采集网络爬虫软件 3)进行相关设置,设置完成后,点击 OK 即可导出文件 选择 EXCEL 文件:导入你须要下载图片地址的 EXCEL 文件 EXCEL 表名:对应数据表的名称 文件 URL 列名:表内对应 URL 的列名称 保存文件夹名:EXCEL 中须要单独一个列,列出图片想要保存到文件夹的路径, 可以设置不同图片储存至不同文件夹 如果要把文件保存到文件夹,则路径须要以“\”结尾,例如:“D:\同步\”, 如果要下载后根据指定的文件名保存,则须要包含具体的文件名,例如“ D:\同 步\1.jpg” 如果下载的文件路径和文件名完全一样,则原本存在的文件会被删掉优采云·云采集网络爬虫软件 相关采集教程:京东商品图片采集详细教程:淘宝买家秀图片采集详细教程:优采云·云采集网络爬虫软件 淘宝图片采集并下载到本地的方式:豆瓣图片采集以及下载保存的方式:微信公众号热门文章采集(文本+图片):阿里巴巴图片抓取下载:ebay 商品图片采集:优采云——90 万用户选择的网页数据采集器。
优采云·云采集网络爬虫软件 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。

