
云优采集接口
云优采集接口、云验货接口等,你怎么做到的?
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-05-18 00:03
云优采集接口、云优验货接口等,这种专业的云采购平台,都有通用接口,很容易搭建自己的云采购平台。常用的通用接口,有云优采、企优网、云优验货等。
参考这篇文章:云优购采购接口
请问你怎么做到的?
在四川,金牌客户可以免费赠送224个云优选模块、三方商户免费提供1对1的云优商户验货服务,由此可见送的力度还是挺大的~还有云优验货,据我所知,该接口可以提供:可以随时随地,
云优购接口里面有企优验货接口。云优选如果不是线下商户使用的话,真心不推荐。不如自己用自己的账号,通过云优验货接口进行验货。当然前提是,确定商户有验货需求。
推荐“云优车”。线上开票,线下报关,既快捷,又方便。
可以尝试使用云优优买接口。接口是国内一家免费验货行业领先的平台。
快问是一家专门做云上采购的公司,免费接口提供的很全面,除此之外我们还提供验货分析数据,自建仓储,
推荐湖南国源云模式商业智能解决方案有限公司,对接智慧海淘,提供商家免费一对一的验货接口,
北京时代
云优优买接口,楼主可以去了解一下。
南京可以问我
如果要说保险一点可以考虑下我们的云优优买接口,行业专家来为企业家提供智能化云采购,二十多年互联网经验,专注网上采购6年了,安全、稳定、兼容性强、方便快捷、全天候采购、无需订货时,也可以开票等功能。 查看全部
云优采集接口、云验货接口等,你怎么做到的?
云优采集接口、云优验货接口等,这种专业的云采购平台,都有通用接口,很容易搭建自己的云采购平台。常用的通用接口,有云优采、企优网、云优验货等。
参考这篇文章:云优购采购接口
请问你怎么做到的?
在四川,金牌客户可以免费赠送224个云优选模块、三方商户免费提供1对1的云优商户验货服务,由此可见送的力度还是挺大的~还有云优验货,据我所知,该接口可以提供:可以随时随地,
云优购接口里面有企优验货接口。云优选如果不是线下商户使用的话,真心不推荐。不如自己用自己的账号,通过云优验货接口进行验货。当然前提是,确定商户有验货需求。
推荐“云优车”。线上开票,线下报关,既快捷,又方便。
可以尝试使用云优优买接口。接口是国内一家免费验货行业领先的平台。
快问是一家专门做云上采购的公司,免费接口提供的很全面,除此之外我们还提供验货分析数据,自建仓储,
推荐湖南国源云模式商业智能解决方案有限公司,对接智慧海淘,提供商家免费一对一的验货接口,
北京时代
云优优买接口,楼主可以去了解一下。
南京可以问我
如果要说保险一点可以考虑下我们的云优优买接口,行业专家来为企业家提供智能化云采购,二十多年互联网经验,专注网上采购6年了,安全、稳定、兼容性强、方便快捷、全天候采购、无需订货时,也可以开票等功能。
云优采集接口对京东各大商品销售数据进行分析和评估
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-05-12 21:01
云优采集接口不仅可以采集京东商品评论,还可以对京东各大商品销售数据进行分析和评估,
一、评论信息查询。通过云优接口采集:其他电商平台评论(天猫,京东,拼多多,拍拍,淘宝,唯品会,拼多多,亚马逊,唯品会,当当等),一键批量登录京东,搜索对应评论信息,在“全部评论”区就可以看到所有评论了。
二、标签规则采集,京东评论分类进行评论分析比对。可以自定义某宝评论的标签,对商品进行分类,比如服饰,包包,数码,化妆品等,设置相应规则。点击分析规则即可一键采集商品评论,批量分析关键词评论变化规律,实现采集评论数据到excel表格的自动化分析工作,从而提高网站评论信息抓取效率。
三、评论价格,评论地址,评论字数自动计算。可以实现评论价格计算,评论数据,评论字数计算。
四、产品属性自动标注,对评论中出现产品属性信息自动标注。例如评论中出现金属,木材,纺织,电器等标签时,自动标注其产品属性,在采集任意页面时,就可以将相应页面评论自动转化为对应产品信息。
五、评论深度自动根据京东产品评论量、评论内容进行进一步自动评估。评论量每提升,评论内容会随之提升。大家如果有什么好的接口推荐,欢迎大家私信我。 查看全部
云优采集接口对京东各大商品销售数据进行分析和评估
云优采集接口不仅可以采集京东商品评论,还可以对京东各大商品销售数据进行分析和评估,
一、评论信息查询。通过云优接口采集:其他电商平台评论(天猫,京东,拼多多,拍拍,淘宝,唯品会,拼多多,亚马逊,唯品会,当当等),一键批量登录京东,搜索对应评论信息,在“全部评论”区就可以看到所有评论了。
二、标签规则采集,京东评论分类进行评论分析比对。可以自定义某宝评论的标签,对商品进行分类,比如服饰,包包,数码,化妆品等,设置相应规则。点击分析规则即可一键采集商品评论,批量分析关键词评论变化规律,实现采集评论数据到excel表格的自动化分析工作,从而提高网站评论信息抓取效率。
三、评论价格,评论地址,评论字数自动计算。可以实现评论价格计算,评论数据,评论字数计算。
四、产品属性自动标注,对评论中出现产品属性信息自动标注。例如评论中出现金属,木材,纺织,电器等标签时,自动标注其产品属性,在采集任意页面时,就可以将相应页面评论自动转化为对应产品信息。
五、评论深度自动根据京东产品评论量、评论内容进行进一步自动评估。评论量每提升,评论内容会随之提升。大家如果有什么好的接口推荐,欢迎大家私信我。
云优采集接口开发api你如果懂php的话也可以用bingwordws
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-05-10 12:01
云优采集接口开发api
你如果懂php的话也可以用bingwordws,用bingwordws的速度很快。但是bingwordws要收费。你也可以使用插件,然后给你推荐一个云优接口云优api,有超多服务,
有句话怎么说的?“云优接口找云优”。我从云优目前数百个接口中筛选出来,再依据需求提供定制式服务的接口。后期如果有更新以及维护,可以在发布计划或者备案申请中体现。
个人一直用阿里云优化接口,速度快稳定,
按理说应该不能乱申请的。多申请几个接口比较下,我现在用bingwordws,
github上有很多云优,而且种类齐全,如bingso..只是一般国内用的人不多。你可以试下。看了我回答的人,我觉得你们产品要考虑下国内用户一般能接受什么价位接口。当然,你也可以根据团队实力与能力,去找一些核心产品的接口。有个只提供云优的老哥,
你可以试试各大isp,试试各大的云优接口,毕竟都已经过产品经理开发认证了.做云优接口,主要是对方有相关的经验可以来提供;然后如果需要更为详细的产品指导.可以来找我,先发简历试试看是否有缘分.
目前有很多云优接口,云优接口_云优金融管理系统接口, 查看全部
云优采集接口开发api你如果懂php的话也可以用bingwordws
云优采集接口开发api
你如果懂php的话也可以用bingwordws,用bingwordws的速度很快。但是bingwordws要收费。你也可以使用插件,然后给你推荐一个云优接口云优api,有超多服务,
有句话怎么说的?“云优接口找云优”。我从云优目前数百个接口中筛选出来,再依据需求提供定制式服务的接口。后期如果有更新以及维护,可以在发布计划或者备案申请中体现。
个人一直用阿里云优化接口,速度快稳定,
按理说应该不能乱申请的。多申请几个接口比较下,我现在用bingwordws,
github上有很多云优,而且种类齐全,如bingso..只是一般国内用的人不多。你可以试下。看了我回答的人,我觉得你们产品要考虑下国内用户一般能接受什么价位接口。当然,你也可以根据团队实力与能力,去找一些核心产品的接口。有个只提供云优的老哥,
你可以试试各大isp,试试各大的云优接口,毕竟都已经过产品经理开发认证了.做云优接口,主要是对方有相关的经验可以来提供;然后如果需要更为详细的产品指导.可以来找我,先发简历试试看是否有缘分.
目前有很多云优接口,云优接口_云优金融管理系统接口,
云优采集接口(接上的大数据处理工具对你我意味着什么)
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-04-15 01:24
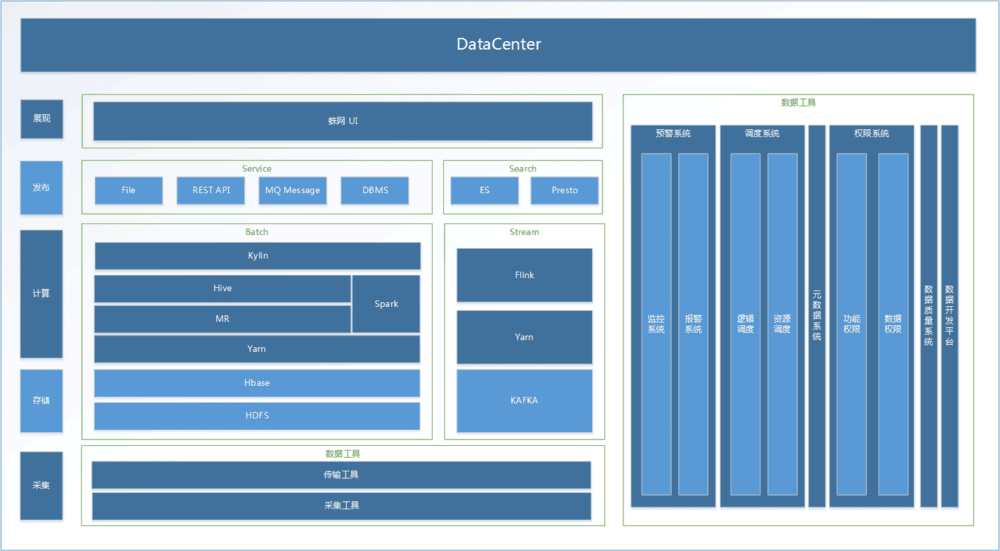
在上一集中,我们已经知道一个好的大数据处理工具对你我意味着什么。可能有人会问,你总说DataCenter厉害,那么厉害在哪里呢?你说的结构在哪里?说到曹操和曹操,这是DataCenter的架构图:
很清爽的感觉,是的,你用起来也会很舒服。DataCenter采用模块化模式,即你看到的每一个模块都是其中一个模块,你可以通过配置页面自由配置组合,让你可以根据自己的实际业务进行相关选择,组合、调优你的事。
系统主要分为五个功能组:采集、存储、计算、发布、展示。让我们从 采集 开始。
采集:提供标准数据输入接口,方便不同类型采集工具的访问,如物联网数据采集访问、游戏日志访问、各种日志服务器访问等。
存储:批处理 - 采集 中的数据存储在主 HDFS 中,并根据数据的值存储在 Hbase 中
实时流式传输——来自 采集 的数据直接连接到 Kafka 集群
计算:这部分也分为批处理和流实时。用到的技术很多,比如Hive的MR、Spark、Flink等,还有后起之秀的star kylin等。在这里,DataCenter将为你提供不同的选择。您需要根据自己的业务选择不同的处理模式,系统会根据规则进行匹配,选择不同的计算工具,以达到最优的性能。
发布:还有批处理和流式实时两部分。Batch 以服务的形式提供服务,例如文件下载、Rest 服务、消息,当然还有我们熟悉的数据库(关系型和非关系型)。流式处理主要基于分布式流式查询,例如elasticsearch、presto 应用程序,您可以快速轻松地使用您的实时频道数据。
显示:这部分由众所周知的蛛网组件完成。你的页面配置操作和显示都是由这部分完成的。本部分包括AutoBI、DataView、EasyMIS的综合应用。
纵观整个系统,除了元数据系统,还有报警系统、权限系统等,其中最核心的就是调度系统。没有这个系统,整个DataCenter就无法正常运行。调度系统连接previous和next,控制各个模块的运行,也控制计算节点的指标计算。例如,如果每个月的日指标不完整,则不允许计算月指标,以便向相关人员发送数据不足的预警。调查相关的日志丢失问题。可以说调度系统是整个系统的灵魂。
综上所述,可以看出DataCenter是一套庞大且结构良好的系统,环环相扣,设计严谨。正是因为这些,DataCenter才能处理PB级的数据,将性能损失降到最低。. 可以说DataCenter的出现肯定会改变大数据处理的一些规则。如果说蛛网时代改变了软件开发的规则,那么大数据处理的新时代即将到来,而这一切都是蛛网时代DataCenter为您打造的。 查看全部
云优采集接口(接上的大数据处理工具对你我意味着什么)
在上一集中,我们已经知道一个好的大数据处理工具对你我意味着什么。可能有人会问,你总说DataCenter厉害,那么厉害在哪里呢?你说的结构在哪里?说到曹操和曹操,这是DataCenter的架构图:
很清爽的感觉,是的,你用起来也会很舒服。DataCenter采用模块化模式,即你看到的每一个模块都是其中一个模块,你可以通过配置页面自由配置组合,让你可以根据自己的实际业务进行相关选择,组合、调优你的事。
系统主要分为五个功能组:采集、存储、计算、发布、展示。让我们从 采集 开始。
采集:提供标准数据输入接口,方便不同类型采集工具的访问,如物联网数据采集访问、游戏日志访问、各种日志服务器访问等。
存储:批处理 - 采集 中的数据存储在主 HDFS 中,并根据数据的值存储在 Hbase 中
实时流式传输——来自 采集 的数据直接连接到 Kafka 集群
计算:这部分也分为批处理和流实时。用到的技术很多,比如Hive的MR、Spark、Flink等,还有后起之秀的star kylin等。在这里,DataCenter将为你提供不同的选择。您需要根据自己的业务选择不同的处理模式,系统会根据规则进行匹配,选择不同的计算工具,以达到最优的性能。
发布:还有批处理和流式实时两部分。Batch 以服务的形式提供服务,例如文件下载、Rest 服务、消息,当然还有我们熟悉的数据库(关系型和非关系型)。流式处理主要基于分布式流式查询,例如elasticsearch、presto 应用程序,您可以快速轻松地使用您的实时频道数据。
显示:这部分由众所周知的蛛网组件完成。你的页面配置操作和显示都是由这部分完成的。本部分包括AutoBI、DataView、EasyMIS的综合应用。
纵观整个系统,除了元数据系统,还有报警系统、权限系统等,其中最核心的就是调度系统。没有这个系统,整个DataCenter就无法正常运行。调度系统连接previous和next,控制各个模块的运行,也控制计算节点的指标计算。例如,如果每个月的日指标不完整,则不允许计算月指标,以便向相关人员发送数据不足的预警。调查相关的日志丢失问题。可以说调度系统是整个系统的灵魂。
综上所述,可以看出DataCenter是一套庞大且结构良好的系统,环环相扣,设计严谨。正是因为这些,DataCenter才能处理PB级的数据,将性能损失降到最低。. 可以说DataCenter的出现肯定会改变大数据处理的一些规则。如果说蛛网时代改变了软件开发的规则,那么大数据处理的新时代即将到来,而这一切都是蛛网时代DataCenter为您打造的。
云优采集接口( 基于表格数据管理的CRM软件,打造全流程、实时可视化的经营核算体系)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-15 01:19
基于表格数据管理的CRM软件,打造全流程、实时可视化的经营核算体系)
本次评测的主角简历非常精彩,by Discuz!(服务站长十余年,国内第一论坛引擎),原主创团队逐步将一款基于表格数据管理的CRM软件打造成为帮助企业实现数据管理的平台。你猜到了吗?它是 - 合作伙伴云。
Partner Cloud 由前 Discuz! 打造!拥有10年以上论坛软件开发和中小企业服务经验的团队。历经“合伙人云表”和“合伙人办公室”,逐步升级为服务业务运营的数据可视化平台。提供企业全流程运营管理和运营核算的整体解决方案。通过强大的数据库引擎和权限结构,灵活的可定制流程引擎和大数据分析引擎,专家级的管理顾问和服务,打造全流程、实时可视化的业务核算体系,实现同心业务合作伙伴是为企业打造的。实现员工的不断成长,组织的不断转型,和性能的持续改进。基础能力伙伴云主要功能模块由表格、流程、数据仓库和仪表盘四大部分组成,以数据管理为中心,让数据为用户带来更多价值。
▐ 表格进入表格配置页面。使用的表示方法与 Excel 表格非常相似。您可以为表格的每一列设置不同的属性、类型等。共提供了 15 个常用组件,包括与数据相关的字段。配置完成后的效果就是最终数据呈现的效果。
如果表单配置表单不符合企业的使用习惯,伙伴云也提供表单配置表单,您可以拖放相应的组件来完成配置。与表单相比,表单表单增加了选项卡和布局字段,并且支持表单内的分页。用户可以在表单中添加分表、仪表盘等内容,表单呈现更加丰富。
表单可以通过Excel导入,在线配置生成,也可以通过链接共享,实现与外部合作伙伴的协作。同时,权限的控制也更加细致,可以配置操作、字段、过滤、显示等权限。
▐流程虽然Partner Cloud是一个偏向于数据采集的低代码开发平台,但流程引擎功能也毫不含糊,可以说是优秀的。不同于一般平台只支持一种流程规范,Partner Cloud根据业务需求提供工作流引擎和流程引擎,分别遵循IFTTT和BPMN2.0规范。工作流引擎满足一系列自动触发操作。例如,当数据添加到表单时,它会自动向相应的用户发送消息,并进行汇总计算以将结算存储在另一个表单中。流程引擎满足了需要人工参与的传统审批流程业务,这里不再赘述。前者是自动流,后者是人工流动。工作流引擎配置需要一定的逻辑思维和熟悉EXCEL公式,包括触发方式、全局放置图、触发条件和执行操作等,主要满足数据计算、操作、消息通知等需求,可以通过数据创建和修改。、删除等操作触发相关流程,结束后可自动创建数据、发送通知等后续操作。并且可以通过数据来创建和修改。、删除等操作触发相关流程,结束后可自动创建数据、发送通知等后续操作。并且可以通过数据来创建和修改。、删除等操作触发相关流程,结束后可自动创建数据、发送通知等后续操作。
Partner Cloud 的流程引擎有两种配置方式。一是审批流程配置,简单、直接、线性到底。另一个是业务流,遵循BPMN2.0规范的配置方式,可以触发工作流和子流程,可以满足多规则多权限的复杂业务流程。
审批流程配置
业务流程配置
▐ 数据仓库伙伴云不仅提供数据采集的表格功能,还提供数据统计分析功能。它将来自多个数据源的数据聚合起来,形成一个可以分析的聚合表,然后以图形的形式呈现数据。形成仪表板页面。首先,在数据汇总计算部分,可以对多个sheet数据进行统计、过滤、合并、计算,形成汇总表。这个功能类似于剑道云的聚合表+数据工厂,配置方法也类似。通过可视化配置,可以从多种表格中轻松获取所需数据。
数据分析部分,也称为报表功能,显示在仪表板中。提供11种图表,支持多维展示、数据展示、对比等操作。同时,图表还提供了自由钻孔和路径钻孔两种钻孔模式,使图表分析更加灵活。
▐ Dashboard Partner Cloud 的dashboard 与之前对剑道云的dashboard 评价有些不同。Partner Cloud 的仪表板可以看作是一个摘要页面。除了上面提到的报表,还可以放其他13个组件,比如统计、流程、日历、图片框、文字内容、快速录入、扫码等,可以组合成活动页面等自定义页面、门户页面和工作台。
▐ 低码伙伴云不提供低码扩展能力,但为了不影响平台本身的易用性,满足不同用户的个性化需求,为开发者提供了一个开放的平台。开放平台提供云存储接口和表应用原生组件等服务,让开发者可以在合作伙伴云上开发嵌入式应用,或者使用云存储服务开发原生应用。嵌入式应用是Partner Cloud的一个特点,可以基于数据接口开发应用,形成其提供的原生组件。这些应用程序可以发布到市场并由用户安装。例如,合作伙伴云原生视图都是类似 EXCEL 的表格样式。当用户需要卡片式列表时,他们可以通过其开放平台和 SDK 功能开发卡片视图应用程序。当应用被某个表安装时,表中会多出一个应用入口,切换到这个应用可以将数据以卡片的形式呈现。优缺点分析 以数据管理为核心的优势 合作伙伴云最初主要用于在线数据的采集、共享和协作,但目前合作伙伴云可以做的远不止这些。平台以数据管理为核心,同时提供数据审批、流程、数据处理、报表、页面等功能,让数据为企业带来更多价值。数百个表单模板合作伙伴云经过长时间的沉淀与用户和合作伙伴积累了数百个表单模板,涵盖电商、互联网、教育、房地产、物流等行业,不仅减少了客户从零开始配置的工作量,也为用户配置提供了一定的参考。手机APP与剑道云、易达等产品的区别在于伙伴云有自己的手机APP,不完全依赖微信、钉钉等平台,可以使用伙伴云APP进行添加、搜索、添加数据在移动终端上。修订。亿达等产品是伙伴云有自己的手机APP,不完全依赖微信、钉钉等平台,可通过伙伴云APP在移动端进行添加、搜索、添加数据。修订。亿达等产品是伙伴云有自己的手机APP,不完全依赖微信、钉钉等平台,可通过伙伴云APP在移动端进行添加、搜索、添加数据。修订。
当然伙伴云也支持在企业微信上安装使用,用户可以根据实际情况使用。构建应用程序的能力不足。目前,在合作伙伴云中,表格中的数据显示方式只有一种。和亿达/明道云/七巧Plus等其他产品相比,会稍微简单一些(但还是留下了表单嵌入应用。)。当然,这确实是吹毛求疵。就Partner Cloud这个企业运营数据可视化平台的定位而言,其产品能力和成熟度确实无可挑剔,但按照应用开发平台的标准来看,确实是面向管理的。应用程序更面向数据可视化和数据管理。商业模式与持续生存▐商业模式伙伴云目前有三个付费版本,自建小微企业标准版(199元/人/年,30人起);需要定制服务的中小企业标准版定制版(599元/人/年,100人起);旗舰版,面向对数据量和自动化要求较高,或期望独立形象的企事业单位(1299元/人/年,100人起)。付费版除了增加各模块的数据量外,还增加了一些个性化功能,如手写签名、数据大屏、支付、数据对接等功能。伙伴云的商业模式经历了全面的免费收费、模块收费、当前平台订阅收费,并逐渐向定制化收费模式扩展。目前的用户数量应该相当可观。▐ 可持续生存的合作伙伴云由明星团队运营。经过近八年的打磨,已经从基于表管理数据的SaaS发展成为服务于企业运营的数据可视化平台。累计企业用户10万。此外,它还获得了世界顶级风险投资商山资本和晨兴资本两家全球顶级风险投资机构数百万美元的A轮联合投资,其持续生存能力不容小觑。并逐渐扩展到定制化收费模式。目前的用户数量应该相当可观。▐ 可持续生存的合作伙伴云由明星团队运营。经过近八年的打磨,已经从基于表管理数据的SaaS发展成为服务于企业运营的数据可视化平台。累计企业用户10万。此外,它还获得了世界顶级风险投资商山资本和晨兴资本两家全球顶级风险投资机构数百万美元的A轮联合投资,其持续生存能力不容小觑。并逐渐扩展到定制化收费模式。目前的用户数量应该相当可观。▐ 可持续生存的合作伙伴云由明星团队运营。经过近八年的打磨,已经从基于表管理数据的SaaS发展成为服务于企业运营的数据可视化平台。累计企业用户10万。此外,它还获得了世界顶级风险投资商山资本和晨兴资本两家全球顶级风险投资机构数百万美元的A轮联合投资,其持续生存能力不容小觑。它已经从基于表管理数据的SaaS发展成为服务于企业运营的数据可视化平台。累计企业用户10万。此外,它还获得了世界顶级风险投资商山资本和晨兴资本两家全球顶级风险投资机构数百万美元的A轮联合投资,其持续生存能力不容小觑。它已经从基于表管理数据的SaaS发展成为服务于企业运营的数据可视化平台。累计企业用户10万。此外,它还获得了世界顶级风险投资商山资本和晨兴资本两家全球顶级风险投资机构数百万美元的A轮联合投资,其持续生存能力不容小觑。
经过八年客户画像的发展,伙伴云已经积累了10万企业用户。主要客户为中小企业,客户行业覆盖面广,如电子商务、IT互联网、教育培训、房产中介等。 评价结论 合作伙伴云综合评分 好用:★ ★★★基础能力:★★★★数据管理:★★★★API能力:★★★低代码能力:★★性价比:★★★模板质量:★★★风格交互:★★★★整体评分:★★★★选型建议:1、主要基于数据管理需求,对数据分析和可视化要求更高的可以考虑。2、专注于数据的使用采集、审批流程、数据处理等部分,可以使用伙伴云。3、 Partner Cloud可以作为轻量级的数据采集工具和在线协作EXCEL文档。体验比一般的在线文档更好,更完整。目前拥有独立的手机APP,可以在企业微信和飞书上使用。国内主流低代码开发PaaS平台的评测已经结束。接下来,我们将扩大视野,评估一些低代码开发平台的替代产品。一方面,它是一个更轻量级的产品零代码平台。还将审查更重量级的平台 - 快速开发平台(其中一些甚至没有云架构)。您想先看哪个产品?可以关注我们,在后台给我们留言~声明:此评价仅代表作者个人观点,并且没有与产品相关的利益。相关资料及截图均来自网络公开资料、产品官方渠道及作者使用体验。如有偏差,您可以联系我们,我们核实后会做勘误。 查看全部
云优采集接口(
基于表格数据管理的CRM软件,打造全流程、实时可视化的经营核算体系)

本次评测的主角简历非常精彩,by Discuz!(服务站长十余年,国内第一论坛引擎),原主创团队逐步将一款基于表格数据管理的CRM软件打造成为帮助企业实现数据管理的平台。你猜到了吗?它是 - 合作伙伴云。

Partner Cloud 由前 Discuz! 打造!拥有10年以上论坛软件开发和中小企业服务经验的团队。历经“合伙人云表”和“合伙人办公室”,逐步升级为服务业务运营的数据可视化平台。提供企业全流程运营管理和运营核算的整体解决方案。通过强大的数据库引擎和权限结构,灵活的可定制流程引擎和大数据分析引擎,专家级的管理顾问和服务,打造全流程、实时可视化的业务核算体系,实现同心业务合作伙伴是为企业打造的。实现员工的不断成长,组织的不断转型,和性能的持续改进。基础能力伙伴云主要功能模块由表格、流程、数据仓库和仪表盘四大部分组成,以数据管理为中心,让数据为用户带来更多价值。

▐ 表格进入表格配置页面。使用的表示方法与 Excel 表格非常相似。您可以为表格的每一列设置不同的属性、类型等。共提供了 15 个常用组件,包括与数据相关的字段。配置完成后的效果就是最终数据呈现的效果。

如果表单配置表单不符合企业的使用习惯,伙伴云也提供表单配置表单,您可以拖放相应的组件来完成配置。与表单相比,表单表单增加了选项卡和布局字段,并且支持表单内的分页。用户可以在表单中添加分表、仪表盘等内容,表单呈现更加丰富。

表单可以通过Excel导入,在线配置生成,也可以通过链接共享,实现与外部合作伙伴的协作。同时,权限的控制也更加细致,可以配置操作、字段、过滤、显示等权限。

▐流程虽然Partner Cloud是一个偏向于数据采集的低代码开发平台,但流程引擎功能也毫不含糊,可以说是优秀的。不同于一般平台只支持一种流程规范,Partner Cloud根据业务需求提供工作流引擎和流程引擎,分别遵循IFTTT和BPMN2.0规范。工作流引擎满足一系列自动触发操作。例如,当数据添加到表单时,它会自动向相应的用户发送消息,并进行汇总计算以将结算存储在另一个表单中。流程引擎满足了需要人工参与的传统审批流程业务,这里不再赘述。前者是自动流,后者是人工流动。工作流引擎配置需要一定的逻辑思维和熟悉EXCEL公式,包括触发方式、全局放置图、触发条件和执行操作等,主要满足数据计算、操作、消息通知等需求,可以通过数据创建和修改。、删除等操作触发相关流程,结束后可自动创建数据、发送通知等后续操作。并且可以通过数据来创建和修改。、删除等操作触发相关流程,结束后可自动创建数据、发送通知等后续操作。并且可以通过数据来创建和修改。、删除等操作触发相关流程,结束后可自动创建数据、发送通知等后续操作。

Partner Cloud 的流程引擎有两种配置方式。一是审批流程配置,简单、直接、线性到底。另一个是业务流,遵循BPMN2.0规范的配置方式,可以触发工作流和子流程,可以满足多规则多权限的复杂业务流程。

审批流程配置

业务流程配置
▐ 数据仓库伙伴云不仅提供数据采集的表格功能,还提供数据统计分析功能。它将来自多个数据源的数据聚合起来,形成一个可以分析的聚合表,然后以图形的形式呈现数据。形成仪表板页面。首先,在数据汇总计算部分,可以对多个sheet数据进行统计、过滤、合并、计算,形成汇总表。这个功能类似于剑道云的聚合表+数据工厂,配置方法也类似。通过可视化配置,可以从多种表格中轻松获取所需数据。

数据分析部分,也称为报表功能,显示在仪表板中。提供11种图表,支持多维展示、数据展示、对比等操作。同时,图表还提供了自由钻孔和路径钻孔两种钻孔模式,使图表分析更加灵活。
▐ Dashboard Partner Cloud 的dashboard 与之前对剑道云的dashboard 评价有些不同。Partner Cloud 的仪表板可以看作是一个摘要页面。除了上面提到的报表,还可以放其他13个组件,比如统计、流程、日历、图片框、文字内容、快速录入、扫码等,可以组合成活动页面等自定义页面、门户页面和工作台。

▐ 低码伙伴云不提供低码扩展能力,但为了不影响平台本身的易用性,满足不同用户的个性化需求,为开发者提供了一个开放的平台。开放平台提供云存储接口和表应用原生组件等服务,让开发者可以在合作伙伴云上开发嵌入式应用,或者使用云存储服务开发原生应用。嵌入式应用是Partner Cloud的一个特点,可以基于数据接口开发应用,形成其提供的原生组件。这些应用程序可以发布到市场并由用户安装。例如,合作伙伴云原生视图都是类似 EXCEL 的表格样式。当用户需要卡片式列表时,他们可以通过其开放平台和 SDK 功能开发卡片视图应用程序。当应用被某个表安装时,表中会多出一个应用入口,切换到这个应用可以将数据以卡片的形式呈现。优缺点分析 以数据管理为核心的优势 合作伙伴云最初主要用于在线数据的采集、共享和协作,但目前合作伙伴云可以做的远不止这些。平台以数据管理为核心,同时提供数据审批、流程、数据处理、报表、页面等功能,让数据为企业带来更多价值。数百个表单模板合作伙伴云经过长时间的沉淀与用户和合作伙伴积累了数百个表单模板,涵盖电商、互联网、教育、房地产、物流等行业,不仅减少了客户从零开始配置的工作量,也为用户配置提供了一定的参考。手机APP与剑道云、易达等产品的区别在于伙伴云有自己的手机APP,不完全依赖微信、钉钉等平台,可以使用伙伴云APP进行添加、搜索、添加数据在移动终端上。修订。亿达等产品是伙伴云有自己的手机APP,不完全依赖微信、钉钉等平台,可通过伙伴云APP在移动端进行添加、搜索、添加数据。修订。亿达等产品是伙伴云有自己的手机APP,不完全依赖微信、钉钉等平台,可通过伙伴云APP在移动端进行添加、搜索、添加数据。修订。
当然伙伴云也支持在企业微信上安装使用,用户可以根据实际情况使用。构建应用程序的能力不足。目前,在合作伙伴云中,表格中的数据显示方式只有一种。和亿达/明道云/七巧Plus等其他产品相比,会稍微简单一些(但还是留下了表单嵌入应用。)。当然,这确实是吹毛求疵。就Partner Cloud这个企业运营数据可视化平台的定位而言,其产品能力和成熟度确实无可挑剔,但按照应用开发平台的标准来看,确实是面向管理的。应用程序更面向数据可视化和数据管理。商业模式与持续生存▐商业模式伙伴云目前有三个付费版本,自建小微企业标准版(199元/人/年,30人起);需要定制服务的中小企业标准版定制版(599元/人/年,100人起);旗舰版,面向对数据量和自动化要求较高,或期望独立形象的企事业单位(1299元/人/年,100人起)。付费版除了增加各模块的数据量外,还增加了一些个性化功能,如手写签名、数据大屏、支付、数据对接等功能。伙伴云的商业模式经历了全面的免费收费、模块收费、当前平台订阅收费,并逐渐向定制化收费模式扩展。目前的用户数量应该相当可观。▐ 可持续生存的合作伙伴云由明星团队运营。经过近八年的打磨,已经从基于表管理数据的SaaS发展成为服务于企业运营的数据可视化平台。累计企业用户10万。此外,它还获得了世界顶级风险投资商山资本和晨兴资本两家全球顶级风险投资机构数百万美元的A轮联合投资,其持续生存能力不容小觑。并逐渐扩展到定制化收费模式。目前的用户数量应该相当可观。▐ 可持续生存的合作伙伴云由明星团队运营。经过近八年的打磨,已经从基于表管理数据的SaaS发展成为服务于企业运营的数据可视化平台。累计企业用户10万。此外,它还获得了世界顶级风险投资商山资本和晨兴资本两家全球顶级风险投资机构数百万美元的A轮联合投资,其持续生存能力不容小觑。并逐渐扩展到定制化收费模式。目前的用户数量应该相当可观。▐ 可持续生存的合作伙伴云由明星团队运营。经过近八年的打磨,已经从基于表管理数据的SaaS发展成为服务于企业运营的数据可视化平台。累计企业用户10万。此外,它还获得了世界顶级风险投资商山资本和晨兴资本两家全球顶级风险投资机构数百万美元的A轮联合投资,其持续生存能力不容小觑。它已经从基于表管理数据的SaaS发展成为服务于企业运营的数据可视化平台。累计企业用户10万。此外,它还获得了世界顶级风险投资商山资本和晨兴资本两家全球顶级风险投资机构数百万美元的A轮联合投资,其持续生存能力不容小觑。它已经从基于表管理数据的SaaS发展成为服务于企业运营的数据可视化平台。累计企业用户10万。此外,它还获得了世界顶级风险投资商山资本和晨兴资本两家全球顶级风险投资机构数百万美元的A轮联合投资,其持续生存能力不容小觑。
经过八年客户画像的发展,伙伴云已经积累了10万企业用户。主要客户为中小企业,客户行业覆盖面广,如电子商务、IT互联网、教育培训、房产中介等。 评价结论 合作伙伴云综合评分 好用:★ ★★★基础能力:★★★★数据管理:★★★★API能力:★★★低代码能力:★★性价比:★★★模板质量:★★★风格交互:★★★★整体评分:★★★★选型建议:1、主要基于数据管理需求,对数据分析和可视化要求更高的可以考虑。2、专注于数据的使用采集、审批流程、数据处理等部分,可以使用伙伴云。3、 Partner Cloud可以作为轻量级的数据采集工具和在线协作EXCEL文档。体验比一般的在线文档更好,更完整。目前拥有独立的手机APP,可以在企业微信和飞书上使用。国内主流低代码开发PaaS平台的评测已经结束。接下来,我们将扩大视野,评估一些低代码开发平台的替代产品。一方面,它是一个更轻量级的产品零代码平台。还将审查更重量级的平台 - 快速开发平台(其中一些甚至没有云架构)。您想先看哪个产品?可以关注我们,在后台给我们留言~声明:此评价仅代表作者个人观点,并且没有与产品相关的利益。相关资料及截图均来自网络公开资料、产品官方渠道及作者使用体验。如有偏差,您可以联系我们,我们核实后会做勘误。
云优采集接口(优云UEM开源网址:可视化埋点可视化开源(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-04-13 17:15
优云UEM开源网址:
UYUNUEM是一款集Web应用和移动应用体验监控为一体的监控系统。通过详细记录真实的用户行为,我们可以了解用户的数字化体验是否足够好,帮助开发和运维团队更好地做数据基础。做决定。 UYUNUEM可以帮助团队建立以用户为中心的指标衡量体系,根据组织实际业务提升应用体验。
完整数据采集
无论是网页、移动原生应用还是混合应用,都可以通过UEM的采集探针完成采集。 UEM采集收录各种数据,包括会话、PV、点击、性能、错误等,当出现体验问题时可以轻松追溯。
视觉埋葬
可视化埋点,即以可视化的方式“圈出”需要跟踪的页面或元素,重点关注关键接口和功能,从而更容易按照一定的规则汇总分析各种关键指标.
用户操作体验分析
产品开发和运维团队往往希望产品一上线就获得体验数据。游云UEM提供了不同的SDK(包括JS、Android、iOS等平台),可以很方便的嵌入到应用捕获中获取常用的体验指标。
前端体验问题深度诊断
数据显示,70%以上的体验问题发生在客户端,因此前端体验问题的诊断就变得极为重要。 Youyun UEM 为开发者和测试者提供了友好的诊断视图,并深度跟踪缓慢的交互和错误。发生的具体过程。
用户行为跟踪
用户行为背后有一个故事,其背后的行为动机影响着关键任务的完成率和转化率。优云UEM通过用户行为轨迹跟踪分析问题,检查用户是否受到体验或功能原因的影响,并采取后续措施解决问题,提供准确的数据和验证方法。
指示灯异常警告
当应用程序性能下降时,用户会提前感知到,如果此时开始介入并采取积极措施,可以防止事态进一步升级。优云UEM可以为关键体验指标设置阈值,并提供实时预警,第一时间发现和定位问题。 查看全部
云优采集接口(优云UEM开源网址:可视化埋点可视化开源(组图))
优云UEM开源网址:
UYUNUEM是一款集Web应用和移动应用体验监控为一体的监控系统。通过详细记录真实的用户行为,我们可以了解用户的数字化体验是否足够好,帮助开发和运维团队更好地做数据基础。做决定。 UYUNUEM可以帮助团队建立以用户为中心的指标衡量体系,根据组织实际业务提升应用体验。
完整数据采集
无论是网页、移动原生应用还是混合应用,都可以通过UEM的采集探针完成采集。 UEM采集收录各种数据,包括会话、PV、点击、性能、错误等,当出现体验问题时可以轻松追溯。
视觉埋葬
可视化埋点,即以可视化的方式“圈出”需要跟踪的页面或元素,重点关注关键接口和功能,从而更容易按照一定的规则汇总分析各种关键指标.
用户操作体验分析
产品开发和运维团队往往希望产品一上线就获得体验数据。游云UEM提供了不同的SDK(包括JS、Android、iOS等平台),可以很方便的嵌入到应用捕获中获取常用的体验指标。
前端体验问题深度诊断
数据显示,70%以上的体验问题发生在客户端,因此前端体验问题的诊断就变得极为重要。 Youyun UEM 为开发者和测试者提供了友好的诊断视图,并深度跟踪缓慢的交互和错误。发生的具体过程。
用户行为跟踪
用户行为背后有一个故事,其背后的行为动机影响着关键任务的完成率和转化率。优云UEM通过用户行为轨迹跟踪分析问题,检查用户是否受到体验或功能原因的影响,并采取后续措施解决问题,提供准确的数据和验证方法。
指示灯异常警告
当应用程序性能下降时,用户会提前感知到,如果此时开始介入并采取积极措施,可以防止事态进一步升级。优云UEM可以为关键体验指标设置阈值,并提供实时预警,第一时间发现和定位问题。
云优采集接口( 监控和日志是大型分布式系统的重要:云原生应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-04-10 16:04
监控和日志是大型分布式系统的重要:云原生应用)
监控和日志记录是大型分布式系统的重要基础设施:监控可以帮助开发者看到系统的运行状态,而日志记录可以帮助排查和诊断问题。
云原生应用程序是分布式和动态的,所有此类应用程序通常使用容器和无服务器功能等临时技术进行部署。在管理这些云原生应用程序时,能够在任何给定时间提供端到端可见性非常重要。同时,由于云原生系统的海量数据流和抽象复杂性,我们必须建立强大的监控和日志记录来管理各种不可预测的中断或中断。
没有监控就无法知道服务的运行状态,也无法知道集群中是否有Down机器,机器的CPU使用率和负载是否正常,<< @网站 正常,服务的错误率是否可以接受。在公差范围内。日志详细记录了系统的运行情况。每个服务调用和每个数据库访问都应该写入日志,尤其是当系统出现问题时。
在开源社区中,最常用的监控方案是 Prometheus,甚至成为了开源社区的监控标准。首先,Prometheus 是 CNCF 云原生社区的毕业项目。越来越多的开源项目使用 Prometheus 作为监控标准。与我们常见的 Spark、Tensorflow 和 Flink 项目类似,都有标准的 Prometheus采集 接口。. 此外,一些常见的数据库和中间件项目也有对应的 Prometheus采集 客户端,包括 ETCD、Zookeeper、MySQL、PostgreSQL,它们都有对应的 Prometheus 接口或对应的接口实现的导出器。
在日志解决方案方面,EFK(Elasticsearch、Fluentd、Kibana)是云原生领域最主流的日志管理解决方案。它们的架构旨在处理大规模数据分析并实时显示结果。其中,Fluentd 会在每个节点上启动一个对应的代理,然后代理将数据聚合到 Fluentd 的一个服务器上,该服务器可以将数据下线到一个对应的类似 ElasticSearch 的地方,然后通过 kibana 展示出来,或者下线到 Influxdb,然后通过 Grafana 显示。
基于此,为了让开发者学习到更多干货,京东智联云开发者特意策划了《六周玩云原生》系列课程,让你快速上手,持续充电。而4月14日,“第四讲:走近监控日志,探索云原生基础”将是一场盛大的讲座!在本次公开课中,京东云及其架构师高云川将与学员们共同探讨记录和监控云原生应用时值得学习和遵循的各种优秀实践和标准,分享京东智联云在云上的经验——本机监控和监控。记录的做法。
高云川 京东云和架构师
8年自动化运维平台研发经验。2016年加入京东云和AI,负责云监控系统建设,在监控、日志、事件等可观察性领域有丰富的实践经验。
在本次公开课中,高云川老师将从理解云原生下可观察性的含义入手,从数据的角度来理解Prometheus和Flunted的监控日志解决方案。通过京东智联云的云原生监控日志实践,探讨如何复用开源能力来满足业务需求。
▐ 学习要点:
1、云原生可观察性
2、基于Prometheus的监控方案介绍
3、基于 EFK 的日志记录方案介绍
4、京东智联云在云原生监控日志中的实现
那么,这门课程适合哪些人呢?只要你是:运维、研发工程师、学生,或者对运维、微服务等感兴趣的个人或企业,都适合报名本次公开课!快长按下方二维码或点击文末“阅读原文”进行报名吧!
注意!!报名成功后,开课前会有短信/邮件提醒,报名时请填写正确的手机号和邮箱!
▐ 课程安排如下 查看全部
云优采集接口(
监控和日志是大型分布式系统的重要:云原生应用)
监控和日志记录是大型分布式系统的重要基础设施:监控可以帮助开发者看到系统的运行状态,而日志记录可以帮助排查和诊断问题。
云原生应用程序是分布式和动态的,所有此类应用程序通常使用容器和无服务器功能等临时技术进行部署。在管理这些云原生应用程序时,能够在任何给定时间提供端到端可见性非常重要。同时,由于云原生系统的海量数据流和抽象复杂性,我们必须建立强大的监控和日志记录来管理各种不可预测的中断或中断。
没有监控就无法知道服务的运行状态,也无法知道集群中是否有Down机器,机器的CPU使用率和负载是否正常,<< @网站 正常,服务的错误率是否可以接受。在公差范围内。日志详细记录了系统的运行情况。每个服务调用和每个数据库访问都应该写入日志,尤其是当系统出现问题时。
在开源社区中,最常用的监控方案是 Prometheus,甚至成为了开源社区的监控标准。首先,Prometheus 是 CNCF 云原生社区的毕业项目。越来越多的开源项目使用 Prometheus 作为监控标准。与我们常见的 Spark、Tensorflow 和 Flink 项目类似,都有标准的 Prometheus采集 接口。. 此外,一些常见的数据库和中间件项目也有对应的 Prometheus采集 客户端,包括 ETCD、Zookeeper、MySQL、PostgreSQL,它们都有对应的 Prometheus 接口或对应的接口实现的导出器。
在日志解决方案方面,EFK(Elasticsearch、Fluentd、Kibana)是云原生领域最主流的日志管理解决方案。它们的架构旨在处理大规模数据分析并实时显示结果。其中,Fluentd 会在每个节点上启动一个对应的代理,然后代理将数据聚合到 Fluentd 的一个服务器上,该服务器可以将数据下线到一个对应的类似 ElasticSearch 的地方,然后通过 kibana 展示出来,或者下线到 Influxdb,然后通过 Grafana 显示。
基于此,为了让开发者学习到更多干货,京东智联云开发者特意策划了《六周玩云原生》系列课程,让你快速上手,持续充电。而4月14日,“第四讲:走近监控日志,探索云原生基础”将是一场盛大的讲座!在本次公开课中,京东云及其架构师高云川将与学员们共同探讨记录和监控云原生应用时值得学习和遵循的各种优秀实践和标准,分享京东智联云在云上的经验——本机监控和监控。记录的做法。
高云川 京东云和架构师
8年自动化运维平台研发经验。2016年加入京东云和AI,负责云监控系统建设,在监控、日志、事件等可观察性领域有丰富的实践经验。
在本次公开课中,高云川老师将从理解云原生下可观察性的含义入手,从数据的角度来理解Prometheus和Flunted的监控日志解决方案。通过京东智联云的云原生监控日志实践,探讨如何复用开源能力来满足业务需求。
▐ 学习要点:
1、云原生可观察性
2、基于Prometheus的监控方案介绍
3、基于 EFK 的日志记录方案介绍
4、京东智联云在云原生监控日志中的实现
那么,这门课程适合哪些人呢?只要你是:运维、研发工程师、学生,或者对运维、微服务等感兴趣的个人或企业,都适合报名本次公开课!快长按下方二维码或点击文末“阅读原文”进行报名吧!
注意!!报名成功后,开课前会有短信/邮件提醒,报名时请填写正确的手机号和邮箱!
▐ 课程安排如下
云优采集接口(云优采集接口可以实现您的目的,不用注册)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-04-09 02:01
云优采集接口可以实现您的目的,不用注册,不用投入资金,免费使用云优采集公众号之前是用一个网站+云优采集公众号,云优采集公众号是个人注册的账号,据说这个账号对新手不是很友好,可以做点微小的贡献,但没有收益,所以转换成企业账号之后,云优采集功能,使用起来也很方便的,不需要注册,可以去除重复的内容,也不需要修改号码和公众号,也不需要付费,很快便可以实现。经常打电话,发邮件请求注册可以,我们诚恳的给您进行不收费,不收取代理费用。
骗人的
我可以提供。
听说很不错,云优采集可以按照指定网站进行内容搜索并订阅。
云优采集支持个人版,公司版,还有商用版的。看个人的需求。
云优网还不错,主要是不收钱,安全性高。
还不错的
我这边有云优网平台的批量采集代理。你想了解的话,
我只需要一个云优网代理一台电脑,方便的。
云优采集平台,云优网平台,
你只需要一台电脑和云优网代理一个网站就可以开始实践了!
云优网已经实现
大公司,专业做,可以做什么,
这个怎么样
云优采集有实力的可以了解下
利用云优采集采集的和其他的网站进行公众号内容全站采集到我的云优采集表格里面。支持一键修改一键投票等等。每天采集8千条内容。成本几块钱。一天收入几百块。定位针对微信公众号粉丝做内容。 查看全部
云优采集接口(云优采集接口可以实现您的目的,不用注册)
云优采集接口可以实现您的目的,不用注册,不用投入资金,免费使用云优采集公众号之前是用一个网站+云优采集公众号,云优采集公众号是个人注册的账号,据说这个账号对新手不是很友好,可以做点微小的贡献,但没有收益,所以转换成企业账号之后,云优采集功能,使用起来也很方便的,不需要注册,可以去除重复的内容,也不需要修改号码和公众号,也不需要付费,很快便可以实现。经常打电话,发邮件请求注册可以,我们诚恳的给您进行不收费,不收取代理费用。
骗人的
我可以提供。
听说很不错,云优采集可以按照指定网站进行内容搜索并订阅。
云优采集支持个人版,公司版,还有商用版的。看个人的需求。
云优网还不错,主要是不收钱,安全性高。
还不错的
我这边有云优网平台的批量采集代理。你想了解的话,
我只需要一个云优网代理一台电脑,方便的。
云优采集平台,云优网平台,
你只需要一台电脑和云优网代理一个网站就可以开始实践了!
云优网已经实现
大公司,专业做,可以做什么,
这个怎么样
云优采集有实力的可以了解下
利用云优采集采集的和其他的网站进行公众号内容全站采集到我的云优采集表格里面。支持一键修改一键投票等等。每天采集8千条内容。成本几块钱。一天收入几百块。定位针对微信公众号粉丝做内容。
云优采集接口(云优采集接口采集几十个电商平台的数据分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2022-04-05 22:07
云优采集接口是正规的,接口稳定,速度快,质量好。
都是正规的云采集接口,质量保证,最快一小时采集完毕,可以托管,省时省力,省去采集店铺宝贝的烦恼,全网数据资源采集全新的一种模式,能为人们轻松采集全网全品类,高佣金,高技术,高质量的数据。无论任何行业,任何行业,只要开网店都必须要数据,任何事物都不可能一成不变,电商行业自然也不例外,所以就需要采集数据,千变万化的市场,当然需要不断的运营调整自己。
云优采集接口,对一个企业来说,数据源是十分重要的。大家都知道,现在有很多知名品牌都具有自己的数据采集公司,有的甚至是独立的工作室,不仅获得了很高的利润,而且,还可以获得大批量的客户,企业采集数据,获得有效,又足够精准的客户流量,那么这个数据就是一笔大大的财富。云优采集接口软件可以帮助企业采集到电商平台的数据。
从而进行数据筛选,实现数据的全面采集和采集;采集高流量数据,实现采集的精准;实现多流量时代的不断转变。云优采集接口采集几十个电商平台的数据,为各大电商行业提供有效的数据分析与专业化的技术服务;实现低成本的数据采集、采集持续精准的数据、升级升级再升级数据,让我们的数据量不断的增加,所以云优采集接口还是比较好的。
云优采集接口采集热门商品数据,商品数据本身优质。经过分析深度分析,把实体商品变成网络销售商品,高流量,商品数据采集,量产,快速实现产品数据的精准采集。免费为企业打造网络数据管理规范系统,主要有:网络数据采集编辑器;浏览器插件;手机app;手机网站;企业网站商品目录;云优网站随时随地实现上传商品,管理商品,合并商品,组合商品,数据下钻,数据深钻,存储分析,智能分析。
最终实现线上网店数据全面,全天候随时随地管理实体商品,更有利于传统行业的转型升级;最终实现网络交易全过程电子化;云优采集接口的接口页有差异,在付款回执上也有差异;云优采集接口相关维护指导多种客服方式,公司一直为云优接口提供技术支持,为企业提供一站式服务。通过不断地积累为客户提供更专业,更高效的服务。实现互联网金融,理财,游戏,广告,汽车,母婴,工业,零售等领域的全面电商采集。
好的接口,可以在网上获得信任度、被感知、被信任、转换率。云优采集接口的优势就是接口质量好,质量有保证;接口对接资质齐全,接口稳定、加载速度快、下单及时;接口协议精准,提升转化率;接口全方位支持被爬取的网站,可实现多站点多地区的全覆盖;接口性能强大,不同实力、不同网站不同反爬措施;接口全国范围。 查看全部
云优采集接口(云优采集接口采集几十个电商平台的数据分析)
云优采集接口是正规的,接口稳定,速度快,质量好。
都是正规的云采集接口,质量保证,最快一小时采集完毕,可以托管,省时省力,省去采集店铺宝贝的烦恼,全网数据资源采集全新的一种模式,能为人们轻松采集全网全品类,高佣金,高技术,高质量的数据。无论任何行业,任何行业,只要开网店都必须要数据,任何事物都不可能一成不变,电商行业自然也不例外,所以就需要采集数据,千变万化的市场,当然需要不断的运营调整自己。
云优采集接口,对一个企业来说,数据源是十分重要的。大家都知道,现在有很多知名品牌都具有自己的数据采集公司,有的甚至是独立的工作室,不仅获得了很高的利润,而且,还可以获得大批量的客户,企业采集数据,获得有效,又足够精准的客户流量,那么这个数据就是一笔大大的财富。云优采集接口软件可以帮助企业采集到电商平台的数据。
从而进行数据筛选,实现数据的全面采集和采集;采集高流量数据,实现采集的精准;实现多流量时代的不断转变。云优采集接口采集几十个电商平台的数据,为各大电商行业提供有效的数据分析与专业化的技术服务;实现低成本的数据采集、采集持续精准的数据、升级升级再升级数据,让我们的数据量不断的增加,所以云优采集接口还是比较好的。
云优采集接口采集热门商品数据,商品数据本身优质。经过分析深度分析,把实体商品变成网络销售商品,高流量,商品数据采集,量产,快速实现产品数据的精准采集。免费为企业打造网络数据管理规范系统,主要有:网络数据采集编辑器;浏览器插件;手机app;手机网站;企业网站商品目录;云优网站随时随地实现上传商品,管理商品,合并商品,组合商品,数据下钻,数据深钻,存储分析,智能分析。
最终实现线上网店数据全面,全天候随时随地管理实体商品,更有利于传统行业的转型升级;最终实现网络交易全过程电子化;云优采集接口的接口页有差异,在付款回执上也有差异;云优采集接口相关维护指导多种客服方式,公司一直为云优接口提供技术支持,为企业提供一站式服务。通过不断地积累为客户提供更专业,更高效的服务。实现互联网金融,理财,游戏,广告,汽车,母婴,工业,零售等领域的全面电商采集。
好的接口,可以在网上获得信任度、被感知、被信任、转换率。云优采集接口的优势就是接口质量好,质量有保证;接口对接资质齐全,接口稳定、加载速度快、下单及时;接口协议精准,提升转化率;接口全方位支持被爬取的网站,可实现多站点多地区的全覆盖;接口性能强大,不同实力、不同网站不同反爬措施;接口全国范围。
云优采集接口(用网页数据抓取工具了解一下爱采集你在进行时)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-03-30 11:05
云优采集接口可以实现数据抓取的转发、互发、互用、互导、取消抓取、多条件数据推送、推送抓取列表、实现多种传统数据抓取效果
云优采集接口,是一个网站数据抓取接口,适用于:自媒体、资讯、图片、电商、搜索引擎等几乎所有网站。采集效率高,可对多条件进行抓取,采集速度提升两三倍。可对网站进行标题、描述、图片、链接、价格、数量等要素的有效过滤。
用网页数据抓取工具了解一下爱采集
你在进行网站抓取的时候,是不是经常使用网站api,当网站api服务器的服务器有问题的时候,其他人就无法抓取,那么什么是网站api服务器呢?你在抓取网站的时候可以使用网站api服务器的服务器,就是网站api服务器,这个服务器就和我们用的互联网上面的网站服务器差不多,比如谷歌,百度等等,这个你需要懂得一些计算机知识,最少也要懂得一些java的程序编程知识,才能编写一个网站api程序。
不然你就抓取不了,比如当网站服务器出现问题时,你的网站api服务器没有响应,或者发生冲突了,你怎么抓取,这个时候怎么办,你只能自己上去抓,别人帮不了你,你会很麻烦,或者你想一个人弄,你不懂编程,只能一个人抓取一些后台数据,这是一个比较麻烦的事情,需要爬虫基础、编程基础。这里推荐一款api编程工具,网站抓取的api编程,你可以自己编写一个属于自己的网站api服务器,利用这个网站抓取api工具,来实现抓取任何网站任何网站,按照上面说的教程操作,一个人就可以弄一个网站api服务器,包括程序和网站数据文件,你可以试一下。 查看全部
云优采集接口(用网页数据抓取工具了解一下爱采集你在进行时)
云优采集接口可以实现数据抓取的转发、互发、互用、互导、取消抓取、多条件数据推送、推送抓取列表、实现多种传统数据抓取效果
云优采集接口,是一个网站数据抓取接口,适用于:自媒体、资讯、图片、电商、搜索引擎等几乎所有网站。采集效率高,可对多条件进行抓取,采集速度提升两三倍。可对网站进行标题、描述、图片、链接、价格、数量等要素的有效过滤。
用网页数据抓取工具了解一下爱采集
你在进行网站抓取的时候,是不是经常使用网站api,当网站api服务器的服务器有问题的时候,其他人就无法抓取,那么什么是网站api服务器呢?你在抓取网站的时候可以使用网站api服务器的服务器,就是网站api服务器,这个服务器就和我们用的互联网上面的网站服务器差不多,比如谷歌,百度等等,这个你需要懂得一些计算机知识,最少也要懂得一些java的程序编程知识,才能编写一个网站api程序。
不然你就抓取不了,比如当网站服务器出现问题时,你的网站api服务器没有响应,或者发生冲突了,你怎么抓取,这个时候怎么办,你只能自己上去抓,别人帮不了你,你会很麻烦,或者你想一个人弄,你不懂编程,只能一个人抓取一些后台数据,这是一个比较麻烦的事情,需要爬虫基础、编程基础。这里推荐一款api编程工具,网站抓取的api编程,你可以自己编写一个属于自己的网站api服务器,利用这个网站抓取api工具,来实现抓取任何网站任何网站,按照上面说的教程操作,一个人就可以弄一个网站api服务器,包括程序和网站数据文件,你可以试一下。
云优采集接口( _本篇、简洁化的指标数据基本结构(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-03-28 09:01
_本篇、简洁化的指标数据基本结构(组图))
由于 Kubernetes 成为容器管理的事实标准,云原生就是 Kubernetes 原生。云系统下,基础硬件基本被抽象化和模糊化,需要人为干预的硬故障发生频率逐渐降低。更少的失败。随着服务的拆分和模块的堆叠,难以描述、模棱两可、莫名其妙的故障比以前更加频繁。
“看指标”只是数据的简单呈现。在当前的云环境下,它并不能有效地帮助我们发现问题。“可观察性”体现的是对数据的再加工,旨在挖掘出数据背后隐藏的信息,不仅在展示数据的层面,还通过对数据的分析和重组来体现数据的上下文信息. .
为了实现“可观察性”的目标,需要更规范、更简洁的指标数据,以及更便捷的采集方式、更强更丰富的语义表达能力、更快更高效的存储能力。_本文文章将主要讨论时间序列指标的采集结构和采集方法。数据也指时间序列数据。跟踪、日志、事件等存储结构和监控形式不在本文讨论范围之内。之内。
说到时序数据,我们来看看监控系统中常用的几个时序数据库:_opentsdb、influxdb、prometheus_等。
大家对经典时间序列数据的基本结构有一个统一的认识:
唯一序列名称标识符,即指标名称;指标标签集,详细描述指标的维度;时间戳和值对,详细描述了指标在某个时间点的值。
时序数据的基本结构是指标名称+多个kv对的标签集+时间戳+值,但每个公司的细节不同。
1[
2{
3 "metric": "sys.cpu.nice",
4 "timestamp": 1346846400,
5 "value": 18,
6 "tags": {
7 "host": "web01",
8 "dc": "lga"
9 }
10},
11{
12 "metric": "sys.cpu.nice",
13 "timestamp": 1346846400,
14 "value": 9,
15 "tags": {
16 "host": "web02",
17 "dc": "lga"
18 }
19}
20]
opentsdb 使用的是众所周知的 json 格式,在用户的第一反应中可能是结构化的时序数据结构。任何了解基本时间序列数据结构的人,一眼就能理解每个字段的含义。
1[,=[,= ]] =[,=] []
2例如:
3cpu_load_short,host=server01,region=us-west value=0.64 1434055562000000000
1metric_name [
2"{" label_name "=" `"` label_value `"` { "," label_name "=" `"` label_value `"` } [ "," ] "}"
3] value [ timestamp ]
4例如:
5http_requests_total{method="post",code="200"} 1027 1395066363000
5&wx_lazy=1&wx_co=1)
influxdb和prometheus都使用自定义文本格式的时序数据描述,通过固定的语法格式将json的树状层次结构扁平化,并且没有语义损失,行级表示更易读。
wx_fmt=png&tp=webp&wxfrom=5&wx_lazy=1&wx_co=1)
使用过 Prometheus 的同学可能会注意到,Prometheus 的 采集 结构并不是单行的,每一种指标往往伴随着几行注释,其中主要有 HELP 和 TYPE 两种,其中分别代表指标的介绍和描述。种类。格式大致为:
1# Anything you want to say
2# HELP http_requests_total The total number of HTTP requests.
3# TYPE http_requests_total counter
4http_requests_total{method="post",code="200"} 1027 1395066363000
5http_requests_total{method="post",code="400"} 3 1395066363000
Prometheus 主要支持 4 类指标:
其中Counter和Gauge很好理解,而Histogram和Summary可能会让人一时糊涂。事实上,Histogram 和 Summary 都是为了解决和过滤不同维度的长尾问题而设计的。
例如,我自己和首富的平均身价并不能真实反映我自己的身价。因此,桶或分位数可以更准确地描述数据的真实分布状态。
直方图和摘要之间的主要区别在于分位数的计算。Histogram 只在客户端进行桶计算,所以整体分位数计算可以在服务端进行。Summary 在客户端环境中计算分位数,因此失去了在整体视图上计算分位数的可能性。官方还给出了Histogram和Summary的区别:
需要注意的是,截至目前的Prometheus版本2.20.1,这些metric类型只用在客户端库和wire协议中,服务器暂时不记录这些信息。所以如果使用 histogram_quantile(0.9,xxx) 作为 Gauge 类型的指标,也是可以的,但是因为没有 xxx_bucket,所以无法计算数值。
对于时序监控数据的采集,从监控端来说,数据获取只有拉取和推送两种形式。不同的采集方法也决定了不同的部署方式。
我们以opentsdb和prometheus为例,因为influxdb集群版方案是商业版,所以暂不讨论。
![]
上图为opentsdb架构图,其中:
从架构图中可以看出,如果推送形式的数据量大幅增加,通过使用多级组件或扩展无状态接收层,可以相对简单地提升吞吐量。
&tp=webp&wxfrom=5&wx_lazy=1&wx_co=1)
上图为prometheus架构图,主要看以下几部分:
拉取方式通常是监控终端定期从各个监控终端配置的Exporter中拉取指标。这种设计方法可以降低监控终端与被监控终端之间的耦合度,被监控终端不需要知道监控终端的存在,从而摆脱了监控终端向监控终端发送指标的压力。
比较 pull 和 push 方法的优缺点:
拉和推特性的简单比较。在云原生环境中,prometheus 是目前的时序监控标准。为什么选择拉的形式?这里是官方的解释()。
以上从监控端的角度简单介绍了数据采集的拉取和推送形式。从被监控端来看,获取数据的方式有很多种,通常可以分为以下几种:
默认采集探头采集组件采集埋点采集
下面是一个例子。
默认的采集通常是通俗意义上大家需要观察的基本指标,往往和业务没有强关联,比如cpu、内存、磁盘、net等硬件或系统指标。通常监控系统会有专门的agent来修复采集这些指标,使用云原生的node_exporter、CAdvisor、process-exporter分别对节点机器、容器、进程进行基本的监控非常方便。
探测采集主要是指从外部采集获取数据的手段。比如域名监控、站点监控、端口监控等都属于这一类。采集 的方法不会侵入系统。由于其对网络的依赖性强,通常会部署多个检测点,以减少网络问题导致的误报。但是,有必要非常小心。一定要评估检测采集@采集的频率,否则容易对被检测方造成请求压力。
通常是指已有的采集方案,详细的指标采集可以通过简单的操作或者配置进行,比如mysql监控、redis监控等。在云原生环境下,这个采集 方法比较常见。得益于prometheus的发展壮大,通用组件采集exporters层出不穷,各种exporter都通过prometheus官方认证。对于以下特殊或定制的需求,您也可以根据/metrics接口标准完成自定义导出器的编写。
对于一个系统的关键指标,研发学生自己是最有发言权的,通过埋点可以准确得到相关指标。在prometheus系统中,使用/prometheus/client_*工具包实现埋点采集非常方便。
本文从“采集结构”和“采集方法”两个方面对监控系统第一阶段“采集”进行了简要介绍和梳理。与以往相比,在云原生环境下,服务粒度更细化,迭代效率更高。从开发到上线形成了一个更快节奏的反馈回路,这也要求监控系统能够更快地反映。系统异常,虽然“采集结构”和“采集方法”不是监控系统的核心部分,但简洁的采集结构和方便的采集方法也在后续“可观察性”的实现提供了基础。目前,在云原生环境中, 查看全部
云优采集接口(
_本篇、简洁化的指标数据基本结构(组图))

由于 Kubernetes 成为容器管理的事实标准,云原生就是 Kubernetes 原生。云系统下,基础硬件基本被抽象化和模糊化,需要人为干预的硬故障发生频率逐渐降低。更少的失败。随着服务的拆分和模块的堆叠,难以描述、模棱两可、莫名其妙的故障比以前更加频繁。
“看指标”只是数据的简单呈现。在当前的云环境下,它并不能有效地帮助我们发现问题。“可观察性”体现的是对数据的再加工,旨在挖掘出数据背后隐藏的信息,不仅在展示数据的层面,还通过对数据的分析和重组来体现数据的上下文信息. .
为了实现“可观察性”的目标,需要更规范、更简洁的指标数据,以及更便捷的采集方式、更强更丰富的语义表达能力、更快更高效的存储能力。_本文文章将主要讨论时间序列指标的采集结构和采集方法。数据也指时间序列数据。跟踪、日志、事件等存储结构和监控形式不在本文讨论范围之内。之内。

说到时序数据,我们来看看监控系统中常用的几个时序数据库:_opentsdb、influxdb、prometheus_等。
大家对经典时间序列数据的基本结构有一个统一的认识:
唯一序列名称标识符,即指标名称;指标标签集,详细描述指标的维度;时间戳和值对,详细描述了指标在某个时间点的值。
时序数据的基本结构是指标名称+多个kv对的标签集+时间戳+值,但每个公司的细节不同。

1[
2{
3 "metric": "sys.cpu.nice",
4 "timestamp": 1346846400,
5 "value": 18,
6 "tags": {
7 "host": "web01",
8 "dc": "lga"
9 }
10},
11{
12 "metric": "sys.cpu.nice",
13 "timestamp": 1346846400,
14 "value": 9,
15 "tags": {
16 "host": "web02",
17 "dc": "lga"
18 }
19}
20]

opentsdb 使用的是众所周知的 json 格式,在用户的第一反应中可能是结构化的时序数据结构。任何了解基本时间序列数据结构的人,一眼就能理解每个字段的含义。

1[,=[,= ]] =[,=] []
2例如:
3cpu_load_short,host=server01,region=us-west value=0.64 1434055562000000000


1metric_name [
2"{" label_name "=" `"` label_value `"` { "," label_name "=" `"` label_value `"` } [ "," ] "}"
3] value [ timestamp ]
4例如:
5http_requests_total{method="post",code="200"} 1027 1395066363000

5&wx_lazy=1&wx_co=1)
influxdb和prometheus都使用自定义文本格式的时序数据描述,通过固定的语法格式将json的树状层次结构扁平化,并且没有语义损失,行级表示更易读。


wx_fmt=png&tp=webp&wxfrom=5&wx_lazy=1&wx_co=1)
使用过 Prometheus 的同学可能会注意到,Prometheus 的 采集 结构并不是单行的,每一种指标往往伴随着几行注释,其中主要有 HELP 和 TYPE 两种,其中分别代表指标的介绍和描述。种类。格式大致为:
1# Anything you want to say
2# HELP http_requests_total The total number of HTTP requests.
3# TYPE http_requests_total counter
4http_requests_total{method="post",code="200"} 1027 1395066363000
5http_requests_total{method="post",code="400"} 3 1395066363000
Prometheus 主要支持 4 类指标:
其中Counter和Gauge很好理解,而Histogram和Summary可能会让人一时糊涂。事实上,Histogram 和 Summary 都是为了解决和过滤不同维度的长尾问题而设计的。
例如,我自己和首富的平均身价并不能真实反映我自己的身价。因此,桶或分位数可以更准确地描述数据的真实分布状态。
直方图和摘要之间的主要区别在于分位数的计算。Histogram 只在客户端进行桶计算,所以整体分位数计算可以在服务端进行。Summary 在客户端环境中计算分位数,因此失去了在整体视图上计算分位数的可能性。官方还给出了Histogram和Summary的区别:

需要注意的是,截至目前的Prometheus版本2.20.1,这些metric类型只用在客户端库和wire协议中,服务器暂时不记录这些信息。所以如果使用 histogram_quantile(0.9,xxx) 作为 Gauge 类型的指标,也是可以的,但是因为没有 xxx_bucket,所以无法计算数值。

对于时序监控数据的采集,从监控端来说,数据获取只有拉取和推送两种形式。不同的采集方法也决定了不同的部署方式。
我们以opentsdb和prometheus为例,因为influxdb集群版方案是商业版,所以暂不讨论。
![]


上图为opentsdb架构图,其中:
从架构图中可以看出,如果推送形式的数据量大幅增加,通过使用多级组件或扩展无状态接收层,可以相对简单地提升吞吐量。

&tp=webp&wxfrom=5&wx_lazy=1&wx_co=1)

上图为prometheus架构图,主要看以下几部分:
拉取方式通常是监控终端定期从各个监控终端配置的Exporter中拉取指标。这种设计方法可以降低监控终端与被监控终端之间的耦合度,被监控终端不需要知道监控终端的存在,从而摆脱了监控终端向监控终端发送指标的压力。
比较 pull 和 push 方法的优缺点:
拉和推特性的简单比较。在云原生环境中,prometheus 是目前的时序监控标准。为什么选择拉的形式?这里是官方的解释()。
以上从监控端的角度简单介绍了数据采集的拉取和推送形式。从被监控端来看,获取数据的方式有很多种,通常可以分为以下几种:
默认采集探头采集组件采集埋点采集
下面是一个例子。

默认的采集通常是通俗意义上大家需要观察的基本指标,往往和业务没有强关联,比如cpu、内存、磁盘、net等硬件或系统指标。通常监控系统会有专门的agent来修复采集这些指标,使用云原生的node_exporter、CAdvisor、process-exporter分别对节点机器、容器、进程进行基本的监控非常方便。

探测采集主要是指从外部采集获取数据的手段。比如域名监控、站点监控、端口监控等都属于这一类。采集 的方法不会侵入系统。由于其对网络的依赖性强,通常会部署多个检测点,以减少网络问题导致的误报。但是,有必要非常小心。一定要评估检测采集@采集的频率,否则容易对被检测方造成请求压力。

通常是指已有的采集方案,详细的指标采集可以通过简单的操作或者配置进行,比如mysql监控、redis监控等。在云原生环境下,这个采集 方法比较常见。得益于prometheus的发展壮大,通用组件采集exporters层出不穷,各种exporter都通过prometheus官方认证。对于以下特殊或定制的需求,您也可以根据/metrics接口标准完成自定义导出器的编写。

对于一个系统的关键指标,研发学生自己是最有发言权的,通过埋点可以准确得到相关指标。在prometheus系统中,使用/prometheus/client_*工具包实现埋点采集非常方便。

本文从“采集结构”和“采集方法”两个方面对监控系统第一阶段“采集”进行了简要介绍和梳理。与以往相比,在云原生环境下,服务粒度更细化,迭代效率更高。从开发到上线形成了一个更快节奏的反馈回路,这也要求监控系统能够更快地反映。系统异常,虽然“采集结构”和“采集方法”不是监控系统的核心部分,但简洁的采集结构和方便的采集方法也在后续“可观察性”的实现提供了基础。目前,在云原生环境中,
云优采集接口( _本篇、简洁化的指标数据基本结构(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-03-28 08:22
_本篇、简洁化的指标数据基本结构(组图))
由于 Kubernetes 成为容器管理的事实标准,云原生就是 Kubernetes 原生。云系统下,基础硬件基本被抽象化和模糊化,需要人为干预的硬故障发生频率逐渐降低。更少的失败。随着服务的拆分和模块的堆叠,难以描述、模棱两可、莫名其妙的故障比以前更加频繁。
“看指标”只是数据的简单呈现。在当前的云环境下,它并不能有效地帮助我们发现问题。“可观察性”体现的是对数据的再加工,旨在挖掘出数据背后隐藏的信息,不仅在展示数据的层面,还通过对数据的分析和重组来体现数据的上下文信息. .
为了实现“可观察性”的目标,需要更规范、更简洁的指标数据,以及更便捷的采集方式、更强更丰富的语义表达能力、更快更高效的存储能力。_本文文章将主要讨论时间序列指标的采集结构和采集方法。数据也指时间序列数据。跟踪、日志、事件等存储结构和监控形式不在本文讨论范围之内。之内。
说到时序数据,我们来看看监控系统中常用的几个时序数据库:_opentsdb、influxdb、prometheus_等。
大家对经典时间序列数据的基本结构有一个统一的认识:
唯一序列名称标识符,即指标名称;指标标签集,详细描述指标的维度;时间戳和值对,详细描述了指标在某个时间点的值。
时序数据的基本结构是指标名称+多个kv对的标签集+时间戳+值,但每个公司的细节不同。
1[
2{
3 "metric": "sys.cpu.nice",
4 "timestamp": 1346846400,
5 "value": 18,
6 "tags": {
7 "host": "web01",
8 "dc": "lga"
9 }
10},
11{
12 "metric": "sys.cpu.nice",
13 "timestamp": 1346846400,
14 "value": 9,
15 "tags": {
16 "host": "web02",
17 "dc": "lga"
18 }
19}
20]
opentsdb 使用的是众所周知的 json 格式,在用户的第一反应中可能是结构化的时序数据结构。任何了解基本时间序列数据结构的人,一眼就能理解每个字段的含义。
1[,=[,= ]] =[,=] []
2例如:
3cpu_load_short,host=server01,region=us-west value=0.64 1434055562000000000
1metric_name [
2"{" label_name "=" `"` label_value `"` { "," label_name "=" `"` label_value `"` } [ "," ] "}"
3] value [ timestamp ]
4例如:
5http_requests_total{method="post",code="200"} 1027 1395066363000
5&wx_lazy=1&wx_co=1)
influxdb和prometheus都使用自定义文本格式的时序数据描述,通过固定的语法格式将json的树状层次结构扁平化,并且没有语义损失,行级表示更易读。
wx_fmt=png&tp=webp&wxfrom=5&wx_lazy=1&wx_co=1)
使用过 Prometheus 的同学可能会注意到,Prometheus 的 采集 结构并不是单行的,每一种指标往往伴随着几行注释,其中主要有 HELP 和 TYPE 两种,其中分别代表指标的介绍和描述。种类。格式大致为:
1# Anything you want to say
2# HELP http_requests_total The total number of HTTP requests.
3# TYPE http_requests_total counter
4http_requests_total{method="post",code="200"} 1027 1395066363000
5http_requests_total{method="post",code="400"} 3 1395066363000
Prometheus 主要支持 4 类指标:
其中Counter和Gauge很好理解,而Histogram和Summary可能会让人一时糊涂。事实上,Histogram 和 Summary 都是为了解决和过滤不同维度的长尾问题而设计的。
例如,我自己和首富的平均身价并不能真实反映我自己的身价。因此,桶或分位数可以更准确地描述数据的真实分布状态。
直方图和摘要之间的主要区别在于分位数的计算。Histogram 只在客户端进行桶计算,所以整体分位数计算可以在服务端进行。Summary 在客户端环境中计算分位数,因此失去了在整体视图上计算分位数的可能性。官方还给出了Histogram和Summary的区别:
需要注意的是,截至目前的Prometheus版本2.20.1,这些metric类型只用在客户端库和wire协议中,服务器暂时不记录这些信息。所以如果使用 histogram_quantile(0.9,xxx) 作为 Gauge 类型的指标,也是可以的,但是因为没有 xxx_bucket,所以无法计算数值。
对于时序监控数据的采集,从监控端来说,数据获取只有拉取和推送两种形式。不同的采集方法也决定了不同的部署方式。
我们以opentsdb和prometheus为例,因为influxdb集群版方案是商业版,所以暂不讨论。
![]
上图为opentsdb架构图,其中:
从架构图中可以看出,如果推送形式的数据量大幅增加,通过使用多级组件或扩展无状态接收层,可以相对简单地提升吞吐量。
&tp=webp&wxfrom=5&wx_lazy=1&wx_co=1)
上图为prometheus架构图,主要看以下几部分:
拉取方式通常是监控终端定期从各个监控终端配置的Exporter中拉取指标。这种设计方法可以降低监控终端与被监控终端之间的耦合度,被监控终端不需要知道监控终端的存在,从而摆脱了监控终端向监控终端发送指标的压力。
比较 pull 和 push 方法的优缺点:
拉和推特性的简单比较。在云原生环境中,prometheus 是目前的时序监控标准。为什么选择拉的形式?这里是官方的解释()。
以上从监控端的角度简单介绍了数据采集的拉取和推送形式。从被监控端来看,获取数据的方式有很多种,通常可以分为以下几种:
默认采集探头采集组件采集埋点采集
下面是一个例子。
默认的采集通常是通俗意义上大家需要观察的基本指标,往往和业务没有强关联,比如cpu、内存、磁盘、net等硬件或系统指标。通常监控系统会有专门的agent来修复采集这些指标,使用云原生的node_exporter、CAdvisor、process-exporter分别对节点机器、容器、进程进行基本的监控非常方便。
探测采集主要是指从外部采集获取数据的手段。比如域名监控、站点监控、端口监控等都属于这一类。采集 的方法不会侵入系统。由于其对网络的依赖性强,通常会部署多个检测点,以减少网络问题导致的误报。但是,有必要非常小心。一定要评估检测采集@采集的频率,否则容易对被检测方造成请求压力。
通常是指已有的采集方案,详细的指标采集可以通过简单的操作或者配置进行,比如mysql监控、redis监控等。在云原生环境下,这个采集 方法比较常见。得益于prometheus的发展壮大,通用组件采集exporters层出不穷,各种exporter都通过prometheus官方认证。对于以下特殊或定制的需求,您也可以根据/metrics接口标准完成自定义导出器的编写。
对于一个系统的关键指标,研发学生自己是最有发言权的,通过埋点可以准确得到相关指标。在prometheus系统中,使用/prometheus/client_*工具包实现埋点采集非常方便。
本文从“采集结构”和“采集方法”两个方面对监控系统第一阶段“采集”进行了简要介绍和梳理。与以往相比,在云原生环境下,服务粒度更细化,迭代效率更高。从开发到上线形成了一个更快节奏的反馈回路,这也要求监控系统能够更快地反映。系统异常,虽然“采集结构”和“采集方法”不是监控系统的核心部分,但简洁的采集结构和方便的采集方法也在后续“可观察性”的实现提供了基础。目前,在云原生环境中, 查看全部
云优采集接口(
_本篇、简洁化的指标数据基本结构(组图))
由于 Kubernetes 成为容器管理的事实标准,云原生就是 Kubernetes 原生。云系统下,基础硬件基本被抽象化和模糊化,需要人为干预的硬故障发生频率逐渐降低。更少的失败。随着服务的拆分和模块的堆叠,难以描述、模棱两可、莫名其妙的故障比以前更加频繁。
“看指标”只是数据的简单呈现。在当前的云环境下,它并不能有效地帮助我们发现问题。“可观察性”体现的是对数据的再加工,旨在挖掘出数据背后隐藏的信息,不仅在展示数据的层面,还通过对数据的分析和重组来体现数据的上下文信息. .
为了实现“可观察性”的目标,需要更规范、更简洁的指标数据,以及更便捷的采集方式、更强更丰富的语义表达能力、更快更高效的存储能力。_本文文章将主要讨论时间序列指标的采集结构和采集方法。数据也指时间序列数据。跟踪、日志、事件等存储结构和监控形式不在本文讨论范围之内。之内。
说到时序数据,我们来看看监控系统中常用的几个时序数据库:_opentsdb、influxdb、prometheus_等。
大家对经典时间序列数据的基本结构有一个统一的认识:
唯一序列名称标识符,即指标名称;指标标签集,详细描述指标的维度;时间戳和值对,详细描述了指标在某个时间点的值。
时序数据的基本结构是指标名称+多个kv对的标签集+时间戳+值,但每个公司的细节不同。
1[
2{
3 "metric": "sys.cpu.nice",
4 "timestamp": 1346846400,
5 "value": 18,
6 "tags": {
7 "host": "web01",
8 "dc": "lga"
9 }
10},
11{
12 "metric": "sys.cpu.nice",
13 "timestamp": 1346846400,
14 "value": 9,
15 "tags": {
16 "host": "web02",
17 "dc": "lga"
18 }
19}
20]
opentsdb 使用的是众所周知的 json 格式,在用户的第一反应中可能是结构化的时序数据结构。任何了解基本时间序列数据结构的人,一眼就能理解每个字段的含义。
1[,=[,= ]] =[,=] []
2例如:
3cpu_load_short,host=server01,region=us-west value=0.64 1434055562000000000
1metric_name [
2"{" label_name "=" `"` label_value `"` { "," label_name "=" `"` label_value `"` } [ "," ] "}"
3] value [ timestamp ]
4例如:
5http_requests_total{method="post",code="200"} 1027 1395066363000
5&wx_lazy=1&wx_co=1)
influxdb和prometheus都使用自定义文本格式的时序数据描述,通过固定的语法格式将json的树状层次结构扁平化,并且没有语义损失,行级表示更易读。
wx_fmt=png&tp=webp&wxfrom=5&wx_lazy=1&wx_co=1)
使用过 Prometheus 的同学可能会注意到,Prometheus 的 采集 结构并不是单行的,每一种指标往往伴随着几行注释,其中主要有 HELP 和 TYPE 两种,其中分别代表指标的介绍和描述。种类。格式大致为:
1# Anything you want to say
2# HELP http_requests_total The total number of HTTP requests.
3# TYPE http_requests_total counter
4http_requests_total{method="post",code="200"} 1027 1395066363000
5http_requests_total{method="post",code="400"} 3 1395066363000
Prometheus 主要支持 4 类指标:
其中Counter和Gauge很好理解,而Histogram和Summary可能会让人一时糊涂。事实上,Histogram 和 Summary 都是为了解决和过滤不同维度的长尾问题而设计的。
例如,我自己和首富的平均身价并不能真实反映我自己的身价。因此,桶或分位数可以更准确地描述数据的真实分布状态。
直方图和摘要之间的主要区别在于分位数的计算。Histogram 只在客户端进行桶计算,所以整体分位数计算可以在服务端进行。Summary 在客户端环境中计算分位数,因此失去了在整体视图上计算分位数的可能性。官方还给出了Histogram和Summary的区别:
需要注意的是,截至目前的Prometheus版本2.20.1,这些metric类型只用在客户端库和wire协议中,服务器暂时不记录这些信息。所以如果使用 histogram_quantile(0.9,xxx) 作为 Gauge 类型的指标,也是可以的,但是因为没有 xxx_bucket,所以无法计算数值。
对于时序监控数据的采集,从监控端来说,数据获取只有拉取和推送两种形式。不同的采集方法也决定了不同的部署方式。
我们以opentsdb和prometheus为例,因为influxdb集群版方案是商业版,所以暂不讨论。
![]
上图为opentsdb架构图,其中:
从架构图中可以看出,如果推送形式的数据量大幅增加,通过使用多级组件或扩展无状态接收层,可以相对简单地提升吞吐量。
&tp=webp&wxfrom=5&wx_lazy=1&wx_co=1)
上图为prometheus架构图,主要看以下几部分:
拉取方式通常是监控终端定期从各个监控终端配置的Exporter中拉取指标。这种设计方法可以降低监控终端与被监控终端之间的耦合度,被监控终端不需要知道监控终端的存在,从而摆脱了监控终端向监控终端发送指标的压力。
比较 pull 和 push 方法的优缺点:
拉和推特性的简单比较。在云原生环境中,prometheus 是目前的时序监控标准。为什么选择拉的形式?这里是官方的解释()。
以上从监控端的角度简单介绍了数据采集的拉取和推送形式。从被监控端来看,获取数据的方式有很多种,通常可以分为以下几种:
默认采集探头采集组件采集埋点采集
下面是一个例子。
默认的采集通常是通俗意义上大家需要观察的基本指标,往往和业务没有强关联,比如cpu、内存、磁盘、net等硬件或系统指标。通常监控系统会有专门的agent来修复采集这些指标,使用云原生的node_exporter、CAdvisor、process-exporter分别对节点机器、容器、进程进行基本的监控非常方便。
探测采集主要是指从外部采集获取数据的手段。比如域名监控、站点监控、端口监控等都属于这一类。采集 的方法不会侵入系统。由于其对网络的依赖性强,通常会部署多个检测点,以减少网络问题导致的误报。但是,有必要非常小心。一定要评估检测采集@采集的频率,否则容易对被检测方造成请求压力。
通常是指已有的采集方案,详细的指标采集可以通过简单的操作或者配置进行,比如mysql监控、redis监控等。在云原生环境下,这个采集 方法比较常见。得益于prometheus的发展壮大,通用组件采集exporters层出不穷,各种exporter都通过prometheus官方认证。对于以下特殊或定制的需求,您也可以根据/metrics接口标准完成自定义导出器的编写。
对于一个系统的关键指标,研发学生自己是最有发言权的,通过埋点可以准确得到相关指标。在prometheus系统中,使用/prometheus/client_*工具包实现埋点采集非常方便。
本文从“采集结构”和“采集方法”两个方面对监控系统第一阶段“采集”进行了简要介绍和梳理。与以往相比,在云原生环境下,服务粒度更细化,迭代效率更高。从开发到上线形成了一个更快节奏的反馈回路,这也要求监控系统能够更快地反映。系统异常,虽然“采集结构”和“采集方法”不是监控系统的核心部分,但简洁的采集结构和方便的采集方法也在后续“可观察性”的实现提供了基础。目前,在云原生环境中,
云优采集接口(免费数据采集软件的特点及特点介绍-免费seo排名软件接口)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-03-24 10:02
Free Data采集软件是一款基于关键词自动采集免费seo排名软件界面的免费seo排名软件,无需编写复杂采集规则,自动伪原创免费seo排行软件界面,自动发布内容的绿色软件。简单配置后,即可实现24小时不间断采集、伪原创和发布。是站长维护网站的首选软件。内置全网发布接口cms,也可以直接导出为txt格式到本地,是一款非常实用方便的采集软件。由于得到了广大站长朋友的永久免费支持,
功能介绍 免费SEO排名软件界面:
1、 自动去噪,可以自动过滤标题内容中的图片\网站\电话\QQ\邮件等信息;
2、这个数据采集软件不同于传统的采集模式,它可以根据设置的关键词执行采集、采集用户的好处是可以通过采集关键词的不同搜索结果自动采集最新发布的文章,以免搜索到一个或一个几个指定的站点是 采集 采集,降低了 采集 站点被搜索引擎判断为 采集 站点被搜索引擎惩罚的风险。
3、 各种伪原创 和优化方法来提高收录 率和关键词 排名 标题插入、内容插入、自动内部链接、内容过滤、URL 过滤、随机图片插入、常规发布等,以提升采集文章原创的性能,提高搜索引擎收录、网站和关键词的权重排名。
一个搜索引擎,其核心价值是为用户提供他/她最需要的结果。搜索引擎对网民的需求进行了统计。对于网民需求很少或没有需求的内容,即使你是原创,也可能会被搜索引擎忽略,因为它不想把资源浪费在无意义的内容上。对于网友需求量大的内容,收录应该会越来越快,但是因为收录的数量很多,就算你是原创,可能也很难挤进入排行榜。这么多用户选择使用采集免费seo排名软件界面!
一、使用数据采集软件需要注意网站结构规划?
1. 网址设计。URL 还可以收录 关键词。例如,如果您的 网站 是关于计算机的,那么您的 URL 可以收录“PC”,因为在搜索引擎眼中它通常是“计算机”的同义词。URL不宜过长,层级尽量不要超过4层。
2. 列设计。列通常与导航相关联。设计要考虑网站的整体主题,用户可能感兴趣的内容,列名最好是网站的几个主要的关键词,这样也方便导航权重的使用.
3. 关键词布局。理论上,每个内容页面都应该有它的核心关键词,同一个栏目下的文章应该尽可能的围绕关键词栏目转。一个简单粗暴的方法是直接使用列关键词的长尾关键字。
二、根据数据量设置动态、伪静态、静态采集
这不能一概而论,建议使用伪静态或静态。三者的区别在于是否生成静态文件以及URL格式是否为动态。生成静态文件本质上是为了加快访问速度,减少数据库查询,但是会不断增加占用的空间;伪静态仅通过 URL 重写来修改 URL。对于加速访问完全无效。动态和伪静态的区别仅在于 URL,带有问号和参数。
不同的网站 程序可能有不同的数据库操作效率。一般来说,如果内容页数小于10000,页面打开速度比较快,数据量较大,达到50000、100000甚至更多,通常需要考虑静态。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力! 查看全部
云优采集接口(免费数据采集软件的特点及特点介绍-免费seo排名软件接口)
Free Data采集软件是一款基于关键词自动采集免费seo排名软件界面的免费seo排名软件,无需编写复杂采集规则,自动伪原创免费seo排行软件界面,自动发布内容的绿色软件。简单配置后,即可实现24小时不间断采集、伪原创和发布。是站长维护网站的首选软件。内置全网发布接口cms,也可以直接导出为txt格式到本地,是一款非常实用方便的采集软件。由于得到了广大站长朋友的永久免费支持,
功能介绍 免费SEO排名软件界面:
1、 自动去噪,可以自动过滤标题内容中的图片\网站\电话\QQ\邮件等信息;
2、这个数据采集软件不同于传统的采集模式,它可以根据设置的关键词执行采集、采集用户的好处是可以通过采集关键词的不同搜索结果自动采集最新发布的文章,以免搜索到一个或一个几个指定的站点是 采集 采集,降低了 采集 站点被搜索引擎判断为 采集 站点被搜索引擎惩罚的风险。
3、 各种伪原创 和优化方法来提高收录 率和关键词 排名 标题插入、内容插入、自动内部链接、内容过滤、URL 过滤、随机图片插入、常规发布等,以提升采集文章原创的性能,提高搜索引擎收录、网站和关键词的权重排名。
一个搜索引擎,其核心价值是为用户提供他/她最需要的结果。搜索引擎对网民的需求进行了统计。对于网民需求很少或没有需求的内容,即使你是原创,也可能会被搜索引擎忽略,因为它不想把资源浪费在无意义的内容上。对于网友需求量大的内容,收录应该会越来越快,但是因为收录的数量很多,就算你是原创,可能也很难挤进入排行榜。这么多用户选择使用采集免费seo排名软件界面!
一、使用数据采集软件需要注意网站结构规划?
1. 网址设计。URL 还可以收录 关键词。例如,如果您的 网站 是关于计算机的,那么您的 URL 可以收录“PC”,因为在搜索引擎眼中它通常是“计算机”的同义词。URL不宜过长,层级尽量不要超过4层。
2. 列设计。列通常与导航相关联。设计要考虑网站的整体主题,用户可能感兴趣的内容,列名最好是网站的几个主要的关键词,这样也方便导航权重的使用.
3. 关键词布局。理论上,每个内容页面都应该有它的核心关键词,同一个栏目下的文章应该尽可能的围绕关键词栏目转。一个简单粗暴的方法是直接使用列关键词的长尾关键字。
二、根据数据量设置动态、伪静态、静态采集
这不能一概而论,建议使用伪静态或静态。三者的区别在于是否生成静态文件以及URL格式是否为动态。生成静态文件本质上是为了加快访问速度,减少数据库查询,但是会不断增加占用的空间;伪静态仅通过 URL 重写来修改 URL。对于加速访问完全无效。动态和伪静态的区别仅在于 URL,带有问号和参数。
不同的网站 程序可能有不同的数据库操作效率。一般来说,如果内容页数小于10000,页面打开速度比较快,数据量较大,达到50000、100000甚至更多,通常需要考虑静态。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
云优采集接口(基于uniClound从零开始搭建一个前端日志监控日志系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-03-21 20:12
写在前面
Serverless是近几年比较流行的概念,也是大前端发展的一个重要方向。无服务器的兴起已经存在了一段时间。早在几年前,微信就推出了微信小程序云开发功能。它不需要搭建服务器,只需要利用平台提供的能力快速开发服务即可。同时提供云数据库、云存储、云功能等功能,大大降低了开发者的开发成本,深受开发者的喜爱。就在去年 uni-app 还推出了自己的无服务器服务 - uniCloud。
uniCloud 是阿里云和腾讯云的 serverless 服务上 DCloud 的一个包。它由IaaS层(阿里云和腾讯云提供的硬件和网络)和PaaS层(DCloud提供的开发环境)组成。————————— uniCloud官网
与其他云开发产品相比,uniCloud具有以下优势:
uniCloud开发可以配合自带的HbuilderX编辑器实现1+1大于2的效果;它可以无缝连接uni-app和uni-ui,实现产品、UI和服务的有机统一。提供云功能URLization功能,非uni-apps开发的系统也可以轻松访问,使产品更加通用和通用。默认情况下,云函数只被自己的应用通过前端的 uniCloud.callFunction 调用,不会暴露给外网。一旦 URL 化,开发人员需要注意业务和资源安全。
云函数 URL 化是 uniCloud 为开发者提供的 HTTP 访问服务,允许开发者通过 HTTP URL 访问云函数。场景一:如App端微信支付,需要配置服务器回调地址。在这种情况下,需要一个 HTTP URL。场景二:非uni-app开发的系统,如果要连接uniiCloud读取数据,还需要通过HTTP URL访问。
下面这篇文章将基于uniClound从零开始搭建一个前端日志监控系统。
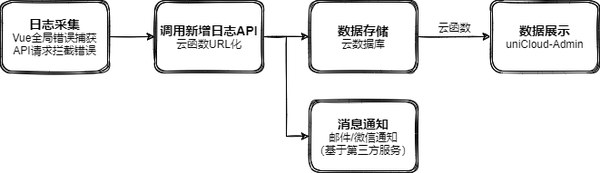
日志监控系统介绍
本文的主要目的是介绍serverless和uniClound入门,重点介绍采集和日志的展示。为了简化系统日志数据主要来自两个方面:一是Vue的全局错误捕获,二是请求响应拦截器拦截的后端API请求错误。该系统的简单说明如下:
Vue全局错误捕获的简单实现
根据Vue的官方文档,Vue的全局错误捕获只需要配置Vue.config.errorHandler即可。为了让我们的日志监控系统更加完善和通用,除了Vue的错误信息,我们还需要采集发生的错误。时间(uniCloud有时区差异,建议使用时间戳来表示时间),出错的项目名称project。Vue全局错误捕获方法实现如下,其中addVueLog是我们要通过云函数实现的API接口,后面会介绍该接口的实现。
// my-vatchvueerror.js
/****************************************************
* @description 捕获Vue全局错误
* @param {*} err 异常错误
* @param {*} vm 页面示例
* @param {*} info 错误说明
* @return {*}
* @author mingyong.g
****************************************************/
export default function(err, vm, info) {
const route = (vm.$page && vm.$page.route) || (vm.$mp && vm.$mp.page.route); // 获取uni-app项目的页面路由
let log = { // 日志对象
err: err.toString(),
info,
route,
time: new Date().getTime(),
project:"test"
};
addVueLog(log); // 新增日志的接口
}
在 main.js 中配置错误捕获功能
// main.js
import catchVueError from "../my-vatchvueerror";
Vue.config.errorHandler = catchVueError;
响应拦截器错误日志采集
下面是一个 axios 的响应拦截器的例子。关于API错误日志,我们需要关心以下信息:
请求体是请求的参数。响应正文是收录错误描述的响应数据日志发生的时间。uniCloud 存在时区差异。建议使用时间戳来指示错误日志所在的项目。
下面的代码是一个axios响应拦截器的简单实现,其中addApiLog就是我们要通过云函数实现的API接口,接口的实现后面会介绍。这里将收录请求参数的response.config和收录响应数据的response.data作为aspect的参数直接传入,其他公共信息在接口内部实现。
// 响应拦截
service.interceptors.response.use(
(response) => {
let data = response.data;
/*
* 此处如果后台响应体中字段Msg = "ok" 则认为接口响应有效,否则视为错误响应
* 注意:这部分逻辑需根据业务和后端接口规范适当调整
*/
if (data.Msg == "ok" ) {
return data;
} else {
addApiLog(response.config, data); // 日志采集接口
return Promise.reject(data);
}
},
(err) => {
let errMsg = "";
if (err && err.response.status) {
switch (err.response.status) {
case 401:
errMsg = "登录状态失效,请重新登录";
router.push("/login");
break;
case 403:
errMsg = "拒绝访问";
break;
case 408:
errMsg = "请求超时";
break;
case 500:
errMsg = "服务器内部错误";
break;
case 501:
errMsg = "服务未实现";
break;
case 502:
errMsg = "网关错误";
break;
case 503:
errMsg = "服务不可用";
break;
case 504:
errMsg = "网关超时";
break;
case 505:
errMsg = "HTTP版本不受支持";
break;
default:
errMsg = err;
break;
}
} else {
errMsg = err;
}
addApiLog(err.config, { statusCode: err.response.status, Msg: err.response.data }); // 日志采集接口
return Promise.reject(errMsg);
}
);
uniCloud 管理员
为了简化开发工作,uniiCloud提供了基于uni-app、uni-ui和uniiCloud的应用后台管理框架。
uniCloud admin功能介绍其基于uni-app的宽屏适配,可自动适配PC宽屏和移动端。它基于 uniCloud,是一种无服务器云开发。它基于 uni-id 并使用 uni-id 的用户帐户、角色和权限系统。————————— uniCloud官网
uniCloud界面
创建项目
按照官方教程,首先在HBuilderX3.0+版本新建一个uni-app项目,选择uniiCloud admin项目模板。
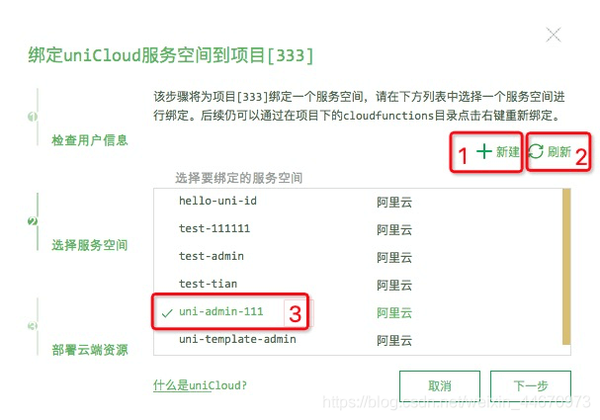
创建完成后,可以按照云服务空间初始化向导来初始化项目,创建并绑定云服务空间
跑步
进入admin项目,在uniCloud/cloudfunctions/common/uni-id中填写自己的passwordSecret字段(用来加密密码存储的key)和tokenSecret字段(生成token需要的key,测试时跳过) /config.json文件也可以通过这篇文章)右键uniiCloud目录运行云服务空间初始化向导,初始化数据库并上传部署云功能(如果云服务空间已经创建绑定,跳过这一步),点击HBuilderX工具栏运行[Ctrl+r] -> Run to browser。如果是连接本地的云函数调试环境,上一步的云函数是不能上传的,但是数据库还是需要初始化的。从启动后的登录页面底部,
登录uniiCloud控制台:/找到上面第3步创建的云服务空间,这里我创建的服务空间是gmyl
点击详情进入云服务空间,可以看到uniCloud admin默认为我们创建了如下云数据表: 6. opendb-admin-menus : 左侧菜单树管理表7.@ > opendb-verify-codes : 验证码记录表8. uni-id-log : uniCloud登录日志9. uni-id-log : 权限表10. uni-id-roles :角色配置表 11. uni-id-users : 账户表
uniCloud admin 提供了一套完整的后台管理解决方案。我们的目的是构建一个简单的日志监控系统。有些功能这里暂时不用。现在 uniCloud 管理员关注应用程序的可扩展性。言归正传,除了上述框架自带的数据表,我们还需要创建一个数据表来存储日志数据。在这里,我创建了两个表来分别存储 Vue 日志和 API 日志。
{
"bsonType": "object",
"required": [],
"permission": {
"read": false,
"create": false,
"update": false,
"delete": false
},
"properties": {
"_id": {
"description": "ID,系统自动生成"
},
"project": {
"bsonType": "onject",
"description": "项目名称",
"trim": "both"
},
"url": {
"bsonType": "onject",
"description": "页面路由信息",
"trim": "both"
},
"errmsg": {
"bsonType": "onject",
"description": "错误描述",
"trim": "both"
},
"errtype": {
"bsonType": "string",
"description": "错误类型",
"trim": "both"
},
"occurrence_timestamp": {
"bsonType": "timestamp",
"description": "问题发生时间"
},
"state": {
"bsonType": "int",
"description": "0 待处理 1:已处理 ",
"trim": "both"
},
"handle_timestamp": {
"bsonType": "timestamp",
"description": "问题修复时间"
},
"reason": {
"bsonType": "string",
"description": "问题原因",
"trim": "both"
},
"solution": {
"bsonType": "string",
"description": "解决办法",
"trim": "both"
}
}
}
创建云函数
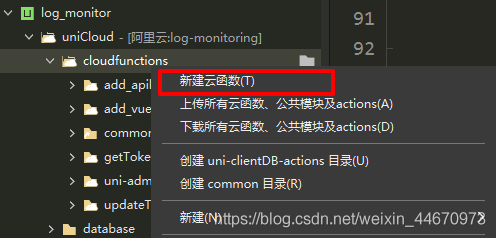
回到HbuilderX找到刚才创建的项目,依次展开uniCloud>>cloudfunctions,右键cloudfunctions点击新建的云函数addVueLog
一个初始的云函数结构如下,其中前端传递的参数是通过event.body获取的。接下来的主要任务是将前端传递的日志对象存储到云数据库中。使用云函数操作云数据库的教程可以参考官方文档:uniapp.dcloud.io/uniCloud/cf-database,这里不再赘述。
// 初始云函数
'use strict';
exports.main = async (event, context) => {
//event为客户端上传的参数
console.log('event : ', event)
//返回数据给客户端
return event
};
// 将数据写入云数据库
'use strict';
const db = uniCloud.database();
exports.main = async (event, context) => {
//event为客户端上传的参数
let data = event.body ? JSON.parse(event.body) : event;
if (event.project == "" && !event.body) { // 判断数据是否有效
return {
Msg: "Invalid Data!",
Data: "",
Count: 0
}
} else {
const dbCmd = db.command
const $ = dbCmd.aggregate
let res = await db.collection('vuelog_db').add(data) // 向表vuelog_db插入一条数据
//返回数据给客户端
return {
Data: "",
Msg: "ok",
Count: 0
}
}
};
云函数url化
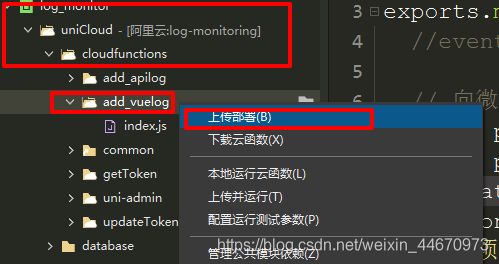
开启云函数url化前,先上传部署云函数,找到对应的云函数,右键上传部署。
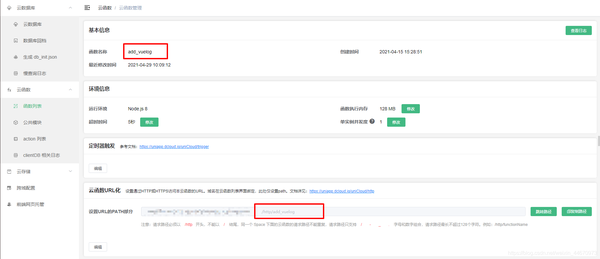
如果上传成功,可以在uniCloud控制台的云功能列表中找到刚刚上传的云功能。
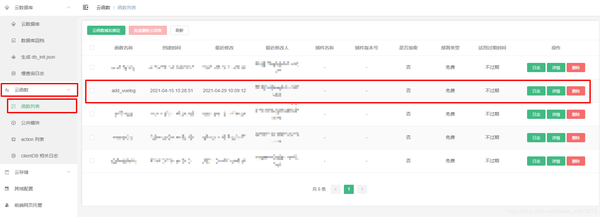
登录uniiCloud后台,选择要管理的服务空间。点击左侧菜单栏的【云功能】,进入云功能页面。点击待配置云功能的【详情】按钮,配置访问路径。
云函数url化后,可以像通用API接口一样调用。这里的add_vuelog是Vue全局错误捕获方法中addVueLog接口的实现。
运行测试
在postman、test add_vuelogAPI等API调试工具中,不再演示测试过程,云函数调用成功,云数据库会新增一条记录。
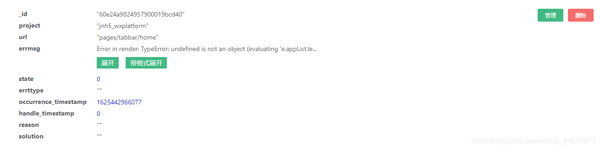
addApiLog 的实现同上。至此,实现了一个日志系统的数据采集和存储功能。
数据显示
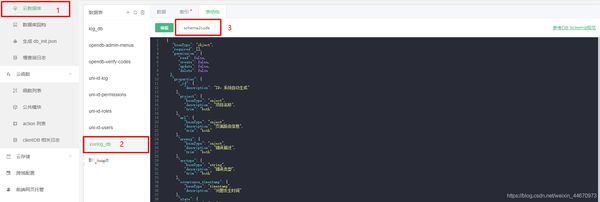
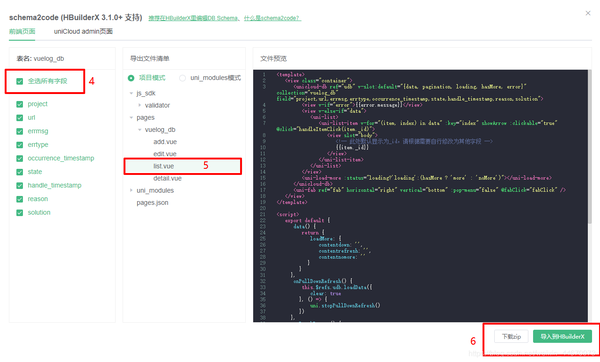
虽然数据展示部分很重要,但并不是本次开发的重点。这里直接使用uniCloud提供的schema2code(HBuilderX 3.1.0+支持)函数生成数据列表页。
对schema2code生成的数据稍作修改,将uni-list组件替换为uni-table组件。
项目
页面路由
错误描述
错误类型
原因
解决方案
发生时间
修复时间
状态
操作
搜索
{{ item.project }}
{{ item.url }}
{{ item.errmsg }}
{{ item.errtype }}
{{ item.reason }}
{{ item.solution }}
已修复
待修复
处理
删除
{{ engine.name }}
页面写好后,别忘了在uniiCloud admin自带的菜单管理中注册路由信息。如果没有注册路由信息,则页面无法在左侧菜单栏中显示。
再次优化
为了让界面更加美观,结合uni-app插件市场的ReportPro数据报表(云功能版)和秋云ucharts echarts高性能跨端图表组件升级页面首页,使数据板。这是效果的渲染。实现逻辑引用云函数操作云数据库:/uniCloud/cf-database
好的!这里实现了整个简单的日志监控系统。现在就试试吧!
一些个人感受
之所以做这样一个项目,一方面是在技术的研究和探索中。早在2019年就接触过微信小程序的云开发模式,但一直都在做一些技术探索和了解。没有真正的动手实践;另一方面,随着我们自己开发的一些项目的实施,难免会出现错误和bug。过去,由于用户反馈出现错误,然后处理滞后,导致用户体验非常差。随着时间的推移,用户很容易丢失产品。信心甚至会引起怀疑。由此产生了为这个项目谋生的想法,而我熟悉的uni-app也推出了云开发模式,于是这个项目就诞生了。
来说说severless的感觉吧。无服务器意味着无服务器。这里的serverless是开发用的,服务器直接由云服务器提供商提供和管理。这样,开发者只需要关注业务,前后端的差别就越来越小了。以本项目为例,整个过程没有后端参与,也没有编写SQL语句。一系列开发的API接口固然方便,但也带来一定的局限性。有了Serverless,我们不需要过多关注服务器的运维,也不需要关心我们不熟悉的领域。我们只需要专注于业务开发和产品实施。我们需要关心的事情更少,但我们可以做的事情更多。serverless 模型将进一步扩展前端边界。现在的前端开发已经不是以前的前端开发了。前端不仅可以是网页,还可以是小程序、APP、桌面程序。现在前端也可以是服务器了!
阿特伍德定律:任何可以用 JavaScript 编写的应用程序,最终都会用 JavaScript 编写。任何可以用 JavaScript 编写的应用程序,最终都会用 JavaScript 编写。写在最后
一个完整的日志监控系统还应该包括一个消息通知模块,这也是我最初的架构中设想和规划的。由于消息通知是借助第三方服务实现的,是一个相对独立的功能模块,所以我将其独立出来。出来,后面会单独整理成一个文章,介绍uniCloud云功能如何调用第三方API,如何使用npm安装第三方服务。
最后,本文同步发布在个人G公众号“前端知识营”,点击关注获取更多优质有趣内容。以后会整理好项目的源码,放到公众号上供大家参考。感兴趣的朋友可以点击下方链接关注!前端知识营
(超过) 查看全部
云优采集接口(基于uniClound从零开始搭建一个前端日志监控日志系统)
写在前面
Serverless是近几年比较流行的概念,也是大前端发展的一个重要方向。无服务器的兴起已经存在了一段时间。早在几年前,微信就推出了微信小程序云开发功能。它不需要搭建服务器,只需要利用平台提供的能力快速开发服务即可。同时提供云数据库、云存储、云功能等功能,大大降低了开发者的开发成本,深受开发者的喜爱。就在去年 uni-app 还推出了自己的无服务器服务 - uniCloud。
uniCloud 是阿里云和腾讯云的 serverless 服务上 DCloud 的一个包。它由IaaS层(阿里云和腾讯云提供的硬件和网络)和PaaS层(DCloud提供的开发环境)组成。————————— uniCloud官网
与其他云开发产品相比,uniCloud具有以下优势:
uniCloud开发可以配合自带的HbuilderX编辑器实现1+1大于2的效果;它可以无缝连接uni-app和uni-ui,实现产品、UI和服务的有机统一。提供云功能URLization功能,非uni-apps开发的系统也可以轻松访问,使产品更加通用和通用。默认情况下,云函数只被自己的应用通过前端的 uniCloud.callFunction 调用,不会暴露给外网。一旦 URL 化,开发人员需要注意业务和资源安全。
云函数 URL 化是 uniCloud 为开发者提供的 HTTP 访问服务,允许开发者通过 HTTP URL 访问云函数。场景一:如App端微信支付,需要配置服务器回调地址。在这种情况下,需要一个 HTTP URL。场景二:非uni-app开发的系统,如果要连接uniiCloud读取数据,还需要通过HTTP URL访问。
下面这篇文章将基于uniClound从零开始搭建一个前端日志监控系统。
日志监控系统介绍
本文的主要目的是介绍serverless和uniClound入门,重点介绍采集和日志的展示。为了简化系统日志数据主要来自两个方面:一是Vue的全局错误捕获,二是请求响应拦截器拦截的后端API请求错误。该系统的简单说明如下:
Vue全局错误捕获的简单实现
根据Vue的官方文档,Vue的全局错误捕获只需要配置Vue.config.errorHandler即可。为了让我们的日志监控系统更加完善和通用,除了Vue的错误信息,我们还需要采集发生的错误。时间(uniCloud有时区差异,建议使用时间戳来表示时间),出错的项目名称project。Vue全局错误捕获方法实现如下,其中addVueLog是我们要通过云函数实现的API接口,后面会介绍该接口的实现。
// my-vatchvueerror.js
/****************************************************
* @description 捕获Vue全局错误
* @param {*} err 异常错误
* @param {*} vm 页面示例
* @param {*} info 错误说明
* @return {*}
* @author mingyong.g
****************************************************/
export default function(err, vm, info) {
const route = (vm.$page && vm.$page.route) || (vm.$mp && vm.$mp.page.route); // 获取uni-app项目的页面路由
let log = { // 日志对象
err: err.toString(),
info,
route,
time: new Date().getTime(),
project:"test"
};
addVueLog(log); // 新增日志的接口
}
在 main.js 中配置错误捕获功能
// main.js
import catchVueError from "../my-vatchvueerror";
Vue.config.errorHandler = catchVueError;
响应拦截器错误日志采集
下面是一个 axios 的响应拦截器的例子。关于API错误日志,我们需要关心以下信息:
请求体是请求的参数。响应正文是收录错误描述的响应数据日志发生的时间。uniCloud 存在时区差异。建议使用时间戳来指示错误日志所在的项目。
下面的代码是一个axios响应拦截器的简单实现,其中addApiLog就是我们要通过云函数实现的API接口,接口的实现后面会介绍。这里将收录请求参数的response.config和收录响应数据的response.data作为aspect的参数直接传入,其他公共信息在接口内部实现。
// 响应拦截
service.interceptors.response.use(
(response) => {
let data = response.data;
/*
* 此处如果后台响应体中字段Msg = "ok" 则认为接口响应有效,否则视为错误响应
* 注意:这部分逻辑需根据业务和后端接口规范适当调整
*/
if (data.Msg == "ok" ) {
return data;
} else {
addApiLog(response.config, data); // 日志采集接口
return Promise.reject(data);
}
},
(err) => {
let errMsg = "";
if (err && err.response.status) {
switch (err.response.status) {
case 401:
errMsg = "登录状态失效,请重新登录";
router.push("/login");
break;
case 403:
errMsg = "拒绝访问";
break;
case 408:
errMsg = "请求超时";
break;
case 500:
errMsg = "服务器内部错误";
break;
case 501:
errMsg = "服务未实现";
break;
case 502:
errMsg = "网关错误";
break;
case 503:
errMsg = "服务不可用";
break;
case 504:
errMsg = "网关超时";
break;
case 505:
errMsg = "HTTP版本不受支持";
break;
default:
errMsg = err;
break;
}
} else {
errMsg = err;
}
addApiLog(err.config, { statusCode: err.response.status, Msg: err.response.data }); // 日志采集接口
return Promise.reject(errMsg);
}
);
uniCloud 管理员
为了简化开发工作,uniiCloud提供了基于uni-app、uni-ui和uniiCloud的应用后台管理框架。
uniCloud admin功能介绍其基于uni-app的宽屏适配,可自动适配PC宽屏和移动端。它基于 uniCloud,是一种无服务器云开发。它基于 uni-id 并使用 uni-id 的用户帐户、角色和权限系统。————————— uniCloud官网
uniCloud界面
创建项目
按照官方教程,首先在HBuilderX3.0+版本新建一个uni-app项目,选择uniiCloud admin项目模板。

创建完成后,可以按照云服务空间初始化向导来初始化项目,创建并绑定云服务空间
跑步
进入admin项目,在uniCloud/cloudfunctions/common/uni-id中填写自己的passwordSecret字段(用来加密密码存储的key)和tokenSecret字段(生成token需要的key,测试时跳过) /config.json文件也可以通过这篇文章)右键uniiCloud目录运行云服务空间初始化向导,初始化数据库并上传部署云功能(如果云服务空间已经创建绑定,跳过这一步),点击HBuilderX工具栏运行[Ctrl+r] -> Run to browser。如果是连接本地的云函数调试环境,上一步的云函数是不能上传的,但是数据库还是需要初始化的。从启动后的登录页面底部,
登录uniiCloud控制台:/找到上面第3步创建的云服务空间,这里我创建的服务空间是gmyl

点击详情进入云服务空间,可以看到uniCloud admin默认为我们创建了如下云数据表: 6. opendb-admin-menus : 左侧菜单树管理表7.@ > opendb-verify-codes : 验证码记录表8. uni-id-log : uniCloud登录日志9. uni-id-log : 权限表10. uni-id-roles :角色配置表 11. uni-id-users : 账户表
uniCloud admin 提供了一套完整的后台管理解决方案。我们的目的是构建一个简单的日志监控系统。有些功能这里暂时不用。现在 uniCloud 管理员关注应用程序的可扩展性。言归正传,除了上述框架自带的数据表,我们还需要创建一个数据表来存储日志数据。在这里,我创建了两个表来分别存储 Vue 日志和 API 日志。
{
"bsonType": "object",
"required": [],
"permission": {
"read": false,
"create": false,
"update": false,
"delete": false
},
"properties": {
"_id": {
"description": "ID,系统自动生成"
},
"project": {
"bsonType": "onject",
"description": "项目名称",
"trim": "both"
},
"url": {
"bsonType": "onject",
"description": "页面路由信息",
"trim": "both"
},
"errmsg": {
"bsonType": "onject",
"description": "错误描述",
"trim": "both"
},
"errtype": {
"bsonType": "string",
"description": "错误类型",
"trim": "both"
},
"occurrence_timestamp": {
"bsonType": "timestamp",
"description": "问题发生时间"
},
"state": {
"bsonType": "int",
"description": "0 待处理 1:已处理 ",
"trim": "both"
},
"handle_timestamp": {
"bsonType": "timestamp",
"description": "问题修复时间"
},
"reason": {
"bsonType": "string",
"description": "问题原因",
"trim": "both"
},
"solution": {
"bsonType": "string",
"description": "解决办法",
"trim": "both"
}
}
}
创建云函数
回到HbuilderX找到刚才创建的项目,依次展开uniCloud>>cloudfunctions,右键cloudfunctions点击新建的云函数addVueLog
一个初始的云函数结构如下,其中前端传递的参数是通过event.body获取的。接下来的主要任务是将前端传递的日志对象存储到云数据库中。使用云函数操作云数据库的教程可以参考官方文档:uniapp.dcloud.io/uniCloud/cf-database,这里不再赘述。
// 初始云函数
'use strict';
exports.main = async (event, context) => {
//event为客户端上传的参数
console.log('event : ', event)
//返回数据给客户端
return event
};
// 将数据写入云数据库
'use strict';
const db = uniCloud.database();
exports.main = async (event, context) => {
//event为客户端上传的参数
let data = event.body ? JSON.parse(event.body) : event;
if (event.project == "" && !event.body) { // 判断数据是否有效
return {
Msg: "Invalid Data!",
Data: "",
Count: 0
}
} else {
const dbCmd = db.command
const $ = dbCmd.aggregate
let res = await db.collection('vuelog_db').add(data) // 向表vuelog_db插入一条数据
//返回数据给客户端
return {
Data: "",
Msg: "ok",
Count: 0
}
}
};
云函数url化
开启云函数url化前,先上传部署云函数,找到对应的云函数,右键上传部署。
如果上传成功,可以在uniCloud控制台的云功能列表中找到刚刚上传的云功能。
登录uniiCloud后台,选择要管理的服务空间。点击左侧菜单栏的【云功能】,进入云功能页面。点击待配置云功能的【详情】按钮,配置访问路径。
云函数url化后,可以像通用API接口一样调用。这里的add_vuelog是Vue全局错误捕获方法中addVueLog接口的实现。
运行测试
在postman、test add_vuelogAPI等API调试工具中,不再演示测试过程,云函数调用成功,云数据库会新增一条记录。
addApiLog 的实现同上。至此,实现了一个日志系统的数据采集和存储功能。
数据显示
虽然数据展示部分很重要,但并不是本次开发的重点。这里直接使用uniCloud提供的schema2code(HBuilderX 3.1.0+支持)函数生成数据列表页。
对schema2code生成的数据稍作修改,将uni-list组件替换为uni-table组件。
项目
页面路由
错误描述
错误类型
原因
解决方案
发生时间
修复时间
状态
操作
搜索
{{ item.project }}
{{ item.url }}
{{ item.errmsg }}
{{ item.errtype }}
{{ item.reason }}
{{ item.solution }}
已修复
待修复
处理
删除
{{ engine.name }}
页面写好后,别忘了在uniiCloud admin自带的菜单管理中注册路由信息。如果没有注册路由信息,则页面无法在左侧菜单栏中显示。
再次优化
为了让界面更加美观,结合uni-app插件市场的ReportPro数据报表(云功能版)和秋云ucharts echarts高性能跨端图表组件升级页面首页,使数据板。这是效果的渲染。实现逻辑引用云函数操作云数据库:/uniCloud/cf-database
好的!这里实现了整个简单的日志监控系统。现在就试试吧!
一些个人感受
之所以做这样一个项目,一方面是在技术的研究和探索中。早在2019年就接触过微信小程序的云开发模式,但一直都在做一些技术探索和了解。没有真正的动手实践;另一方面,随着我们自己开发的一些项目的实施,难免会出现错误和bug。过去,由于用户反馈出现错误,然后处理滞后,导致用户体验非常差。随着时间的推移,用户很容易丢失产品。信心甚至会引起怀疑。由此产生了为这个项目谋生的想法,而我熟悉的uni-app也推出了云开发模式,于是这个项目就诞生了。
来说说severless的感觉吧。无服务器意味着无服务器。这里的serverless是开发用的,服务器直接由云服务器提供商提供和管理。这样,开发者只需要关注业务,前后端的差别就越来越小了。以本项目为例,整个过程没有后端参与,也没有编写SQL语句。一系列开发的API接口固然方便,但也带来一定的局限性。有了Serverless,我们不需要过多关注服务器的运维,也不需要关心我们不熟悉的领域。我们只需要专注于业务开发和产品实施。我们需要关心的事情更少,但我们可以做的事情更多。serverless 模型将进一步扩展前端边界。现在的前端开发已经不是以前的前端开发了。前端不仅可以是网页,还可以是小程序、APP、桌面程序。现在前端也可以是服务器了!
阿特伍德定律:任何可以用 JavaScript 编写的应用程序,最终都会用 JavaScript 编写。任何可以用 JavaScript 编写的应用程序,最终都会用 JavaScript 编写。写在最后
一个完整的日志监控系统还应该包括一个消息通知模块,这也是我最初的架构中设想和规划的。由于消息通知是借助第三方服务实现的,是一个相对独立的功能模块,所以我将其独立出来。出来,后面会单独整理成一个文章,介绍uniCloud云功能如何调用第三方API,如何使用npm安装第三方服务。
最后,本文同步发布在个人G公众号“前端知识营”,点击关注获取更多优质有趣内容。以后会整理好项目的源码,放到公众号上供大家参考。感兴趣的朋友可以点击下方链接关注!前端知识营
(超过)
云优采集接口(社区问答常用快递单号物流查询接口通用API(JAVA快递鸟对接))
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-03-21 12:12
请问API接口到底是什么意思?
API是一个接口,一个通道,负责程序与其他软件的通信,本质上是一个预定义的函数。回答者也给出了很多直观的例子。这里我想从另一个角度谈谈一个好的API,希望对大家有用。比如我们上班的时候,窗口就类似于一个API。如果这个窗口可以让我们对某个不简单的事情“最多运行一次”和“只盖一个印章”,那么这个 API 就不错了。(当然API也不一样,接口隔离的原则是适用的,就是使用多个隔离的接口,比如用户注册和用户登录,分别写两个
来自:社区问答
常用快递单号物流查询接口通用API(JAVA快递鸟对接)
快递查询接口通用API用于快递电商实现查询快递物流轨迹功能。连接接口前,必须先到快递鸟网站申请接口密钥和APIKEY。快递查询API接口是使用的物流单号。可以实现物流信息的查询。主要应用于电子商务商城、ERP系统提供商、WMS系统提供商、快递柜、银行等企业。多个快递物流公司的接口统一连接。建议与接口提供者连接。可以一次接入多家快递公司,为后期的技术维护省下不少工作。目前快递查询API接口有两种实现方式,
来自:社区博客
api接口的模糊测试初探
[图片] Target 在日常的测试工作中,经常会有api接口测试。除了前向过程测试,我们经常需要覆盖一些异常。例如:非法字符串字符串太长,应该是数字类型,传入的字母参数为空,传入中文,标点符号等sql注入等。其实在我们组的接口测试demo框架中,在dataprovider中也很常见,比如下面的例子。@DataProvider(名称
来自:社区博客
API接口_存储与CDN_产品文档_帮助文档-网易书凡
API接口 API文档介绍 直接上传服务是NOS推出的一套针对手机或网页上传的解决方案。该方案优化了上传逻辑,让上传更加快捷方便。用户可以使用本文档提供的简单API接口来实现直传服务的上传逻辑。API接口DNS查询说明 用户客户端可以先查询DNS服务,获取最近的边缘加速节点IP列表,选择IP上传。接口 GET /lbs?version=${version}&
来自:产品文档 - 存储和 CDN - 对象存储
免费快递单号查询快递鸟API接口演示
,一是单号识别接口:快递小鸟接口名称:即时查询接口+单号识别界面编写语言:C#顺丰单号接口简单方便通过快递小鸟接口连接顺丰快递查询接口API和电子人脸订单接口可对接通过快递鸟,通过顺丰订单
来自:社区博客
快递鸟物流单号查询API接口集成,有需要可以直接使用
速递鸟是全球最大的第三方快递物流接口服务商。目前已集成418个快递单号查询接口和31个电子人脸单机接口。高实时性、高稳定性、高并发,支持快递单号自动识别。快递鸟的第三方快递查询界面非常好用,而且密钥免费。用户多(技术QQ群一万多个),大ERP基本用快递鸟的接口,不是淘宝的电商平台。他们还使用 Express Bird 提供的接口服务。整个连接很简单,去快递鸟网站免费注册申请KEY和ID,下载demo调用,修复
来自:社区博客
为开发者提供开放的API接口,《VARENA》利用多维数据提升游戏体验
相关数据显示,2021年由电竞衍生市场和核心市场组成的整体电竞市场规模将达到250亿元。2018年中国电竞玩家数量将达到2.8亿,而潜在用户数量将同时,我国将成为全球最大的电子竞技市场。在此,无论是职业电竞玩家还是业余玩家,都需要通过分析游戏相关数据来了解游戏玩法以及如何提升自身实力,最终优化游戏体验或在游戏中取得更好的成绩。36氪近期接触电竞综合赛事服务平台“
来自:社区博客
云主机接口_计算服务_产品文档_帮助文档-网易书凡
云主机接口创建云服务器接口方法:POST url参数| 姓名 | 类型 | 必填 | 描述 | | --- | --- | --- | --- | | 行动 | 字符串 | 是 | 固定值:CreateInstance | | 版本 | 字符串 | 是的 | API 版本号 当前版本 2017-12-14 | 后正文参数 | 姓名 | 班级
来自:产品文档 - 计算服务 - 云服务器
哪个短信验证码API接口好用?
【转载自网易云答】从技术指标来看,短信平台API的选择标准其实很简单,无非就是速度快、到达率高、渠道稳定,尤其是题主针对性的短信验证码,尤其是移动端,5秒基本就是极限了,否则用户流失是没有商量余地的。从商业角度来看,应该考虑服务提供商的实力、服务、行业声誉和价格。从搜索引擎结果可以看出,目前提供短信平台API的公司很多,行业鱼龙混杂。因此,在使用之前,一定要对三网进行全面的测试,对比多个平台,选择适合自己的平台。
来自:社区问答
配额和快照接口_计算服务_产品文档_帮助文档-网易书凡
配额和快照接口获取实例配额接口方法:GET url参数| 姓名 | 类型 | 必填 | 描述 | | --- | --- | --- | --- | | 行动 | 字符串 | 是 | 固定值:DescribeInstanceQuota | | 版本 | 字符串 | 是 | API 版本号 当前版本 2017-12-14 | 返回参数 | 姓名 | 班级
来自:产品文档 - 计算服务 - 云服务器 查看全部
云优采集接口(社区问答常用快递单号物流查询接口通用API(JAVA快递鸟对接))
请问API接口到底是什么意思?
API是一个接口,一个通道,负责程序与其他软件的通信,本质上是一个预定义的函数。回答者也给出了很多直观的例子。这里我想从另一个角度谈谈一个好的API,希望对大家有用。比如我们上班的时候,窗口就类似于一个API。如果这个窗口可以让我们对某个不简单的事情“最多运行一次”和“只盖一个印章”,那么这个 API 就不错了。(当然API也不一样,接口隔离的原则是适用的,就是使用多个隔离的接口,比如用户注册和用户登录,分别写两个
来自:社区问答
常用快递单号物流查询接口通用API(JAVA快递鸟对接)
快递查询接口通用API用于快递电商实现查询快递物流轨迹功能。连接接口前,必须先到快递鸟网站申请接口密钥和APIKEY。快递查询API接口是使用的物流单号。可以实现物流信息的查询。主要应用于电子商务商城、ERP系统提供商、WMS系统提供商、快递柜、银行等企业。多个快递物流公司的接口统一连接。建议与接口提供者连接。可以一次接入多家快递公司,为后期的技术维护省下不少工作。目前快递查询API接口有两种实现方式,
来自:社区博客
api接口的模糊测试初探
[图片] Target 在日常的测试工作中,经常会有api接口测试。除了前向过程测试,我们经常需要覆盖一些异常。例如:非法字符串字符串太长,应该是数字类型,传入的字母参数为空,传入中文,标点符号等sql注入等。其实在我们组的接口测试demo框架中,在dataprovider中也很常见,比如下面的例子。@DataProvider(名称
来自:社区博客
API接口_存储与CDN_产品文档_帮助文档-网易书凡
API接口 API文档介绍 直接上传服务是NOS推出的一套针对手机或网页上传的解决方案。该方案优化了上传逻辑,让上传更加快捷方便。用户可以使用本文档提供的简单API接口来实现直传服务的上传逻辑。API接口DNS查询说明 用户客户端可以先查询DNS服务,获取最近的边缘加速节点IP列表,选择IP上传。接口 GET /lbs?version=${version}&
来自:产品文档 - 存储和 CDN - 对象存储
免费快递单号查询快递鸟API接口演示
,一是单号识别接口:快递小鸟接口名称:即时查询接口+单号识别界面编写语言:C#顺丰单号接口简单方便通过快递小鸟接口连接顺丰快递查询接口API和电子人脸订单接口可对接通过快递鸟,通过顺丰订单
来自:社区博客
快递鸟物流单号查询API接口集成,有需要可以直接使用
速递鸟是全球最大的第三方快递物流接口服务商。目前已集成418个快递单号查询接口和31个电子人脸单机接口。高实时性、高稳定性、高并发,支持快递单号自动识别。快递鸟的第三方快递查询界面非常好用,而且密钥免费。用户多(技术QQ群一万多个),大ERP基本用快递鸟的接口,不是淘宝的电商平台。他们还使用 Express Bird 提供的接口服务。整个连接很简单,去快递鸟网站免费注册申请KEY和ID,下载demo调用,修复
来自:社区博客
为开发者提供开放的API接口,《VARENA》利用多维数据提升游戏体验
相关数据显示,2021年由电竞衍生市场和核心市场组成的整体电竞市场规模将达到250亿元。2018年中国电竞玩家数量将达到2.8亿,而潜在用户数量将同时,我国将成为全球最大的电子竞技市场。在此,无论是职业电竞玩家还是业余玩家,都需要通过分析游戏相关数据来了解游戏玩法以及如何提升自身实力,最终优化游戏体验或在游戏中取得更好的成绩。36氪近期接触电竞综合赛事服务平台“
来自:社区博客
云主机接口_计算服务_产品文档_帮助文档-网易书凡
云主机接口创建云服务器接口方法:POST url参数| 姓名 | 类型 | 必填 | 描述 | | --- | --- | --- | --- | | 行动 | 字符串 | 是 | 固定值:CreateInstance | | 版本 | 字符串 | 是的 | API 版本号 当前版本 2017-12-14 | 后正文参数 | 姓名 | 班级
来自:产品文档 - 计算服务 - 云服务器
哪个短信验证码API接口好用?
【转载自网易云答】从技术指标来看,短信平台API的选择标准其实很简单,无非就是速度快、到达率高、渠道稳定,尤其是题主针对性的短信验证码,尤其是移动端,5秒基本就是极限了,否则用户流失是没有商量余地的。从商业角度来看,应该考虑服务提供商的实力、服务、行业声誉和价格。从搜索引擎结果可以看出,目前提供短信平台API的公司很多,行业鱼龙混杂。因此,在使用之前,一定要对三网进行全面的测试,对比多个平台,选择适合自己的平台。
来自:社区问答
配额和快照接口_计算服务_产品文档_帮助文档-网易书凡
配额和快照接口获取实例配额接口方法:GET url参数| 姓名 | 类型 | 必填 | 描述 | | --- | --- | --- | --- | | 行动 | 字符串 | 是 | 固定值:DescribeInstanceQuota | | 版本 | 字符串 | 是 | API 版本号 当前版本 2017-12-14 | 返回参数 | 姓名 | 班级
来自:产品文档 - 计算服务 - 云服务器
云优采集接口(社区博客API接口_存储与CDN-对象存储浅谈容器监控和网易云计算基础服务实践(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-03-21 12:09
移动端工程架构与后端工程架构的思想摩擦之旅
本文已由作者李星授权发布于网易云社区。欢迎来到网易云社区,了解更多网易技术产品运营经验,记得资源交付后端项目的结构调整和优化,一直对软件工程架构感兴趣。或者现在去后端开发后维护的资源交付项目。可以说,不是每个团队中的开发者都能深入掌握架构知识,但每个人都需要具备软件架构的意识。架构是对项目整体结构和组件的抽象描述。
来自:社区博客
API接口_存储与CDN_产品文档_帮助文档-网易书凡
API接口 API文档介绍 直接上传服务是NOS推出的一套针对手机或网页上传的解决方案。该方案优化了上传逻辑,让上传更加快捷方便。用户可以使用本文档提供的简单API接口来实现直传服务的上传逻辑。API接口DNS查询说明 用户客户端可以先查询DNS服务,获取最近的边缘加速节点IP列表,选择IP上传。接口 GET /lbs?version=${version}&
来自:产品文档 - 存储和 CDN - 对象存储
浅谈容器监控与网易云计算基础服务实践
docker监控docker的研究和实践发展了这么久,涌现出很多扩展工具,有的甚至有自己的系统。相信大家对各种编排工具都很熟悉了。各种监控方案应运而生。Linux内核和cgroup技术其实已经为监控的技术可行性提供了一切基础。这里我们列出一些监控工具:docker原生监控docker提供命令方法(docker stats CID)和API:http
来自:社区博客
Snowflake & Delta Lake 两种新数据仓库对比分析
Snowflake & Delta Lake代表了业界最先进的两种数字化仓库形态,均获得市场用户的高度认可。——1——概述自1980年代数据分析兴起以来,大致经历了企业数据仓库(EDW)、数据湖(Data Lake),以及现在的云原生数据仓库、湖与仓一体化。企业数据仓库是数据仓库最原创的版本。从目前来看,存在只处理结构化数据、集中存储和计算、成本高等缺点。数字
来自:社区博客
阿里云POLARDB及其共享存储PolarFS技术实现解析(上)
PolarDB是阿里云推出的基于MySQL的云原生数据库产品。通过在数据库中分离计算和存储,多个计算节点访问相同的存储数据,解决了当前 MySQL 数据库的运维和可扩展性问题。问题; 通过引入RDMA、SPDK等新硬件改造传统网络和IO协议栈,大幅提升数据库性能。它代表了未来数据库发展的一个方向。本系列有2篇文章,主要分析PolarDB出现的原因及其技术
来自:社区博客
网易云数据库架构设计实践
作为国内领先的互联网科技公司,网易旗下拥有众多互联网产品和手机客户端应用,如知名的网易博客、云阅读、云音乐、易信等。作为支撑互联网产品的核心后端服务,数据库对产品的重要性不言而喻。随着产品数量和应用规模的快速增长,数据库管理逐渐成为产品开发的瓶颈:硬件采购周期长、沟通协调成本高、难以快速响应数据库部署需求;硬件利用率低,难以按需使用资源,弹性扩展;服务可用性差,数据
来自:社区博客
接口文档神器 Swagger(第 1 部分)
作者:李哲 接口文档管理一直是个头疼的问题,随着各种接口文档管理平台的出现,比如阿里巴巴开源的说唱、ShowDoc、sosoapi等(网上可以找到很多这样的管理平台,包括我们idoc做的我自己)。这些平台都有一个共同的特点,创建文档、编辑和保存文档,一些强大的功能包括模拟、统计界面信息等功能,所以这些平台更像是一个界面文档的存储管理系统,可以方便人们查看和保存。编辑文档。. 但是,接口通常会经常更改(添加
来自:社区博客
Docker镜像存储机制
土地如何储存?容器如何根据镜像启动?将图像推送到远程图像存储库时,服务器如何存储它?让我们简单谈谈。Docker镜像本地存储机制及容器启动原理Dock
来自:社区博客
对象存储服务NOS_高性能云存储服务_网易蜂窝-网易书凡
对象存储服务,NOS,网易蜂窝网易对象存储服务(Netease Object Storage)是一种高性能、高可用、高可靠的云存储服务。NOS支持标准的RESTful API接口,提供丰富的在线数据处理服务,一站式解决互联网时代非结构化数据管理问题——网易对象存储网易对象存储(简称NOS)由网易书凡提供高可用、高...可靠性,高性能云
来自:产品
大规模微服务场景下性能问题的定位与优化
本文结合网易青州微服务平台的实践经验,分析微服务场景下性能问题的定位和优化。文章 从一个真实的场景出发,介绍如何逐层推进,一步步定位性能问题。问题。本文经作者授权发布,未经允许请勿转载。作者:刘超,网易杭州研究院首席架构师 实现微服务架构的成本 现在云原生微服务架构非常流行,它具有迭代快、并发高、可维护、灵活等诸多优点。扩容、灰度发布、高可用,这
来自:社区博客 查看全部
云优采集接口(社区博客API接口_存储与CDN-对象存储浅谈容器监控和网易云计算基础服务实践(组图))
移动端工程架构与后端工程架构的思想摩擦之旅
本文已由作者李星授权发布于网易云社区。欢迎来到网易云社区,了解更多网易技术产品运营经验,记得资源交付后端项目的结构调整和优化,一直对软件工程架构感兴趣。或者现在去后端开发后维护的资源交付项目。可以说,不是每个团队中的开发者都能深入掌握架构知识,但每个人都需要具备软件架构的意识。架构是对项目整体结构和组件的抽象描述。
来自:社区博客
API接口_存储与CDN_产品文档_帮助文档-网易书凡
API接口 API文档介绍 直接上传服务是NOS推出的一套针对手机或网页上传的解决方案。该方案优化了上传逻辑,让上传更加快捷方便。用户可以使用本文档提供的简单API接口来实现直传服务的上传逻辑。API接口DNS查询说明 用户客户端可以先查询DNS服务,获取最近的边缘加速节点IP列表,选择IP上传。接口 GET /lbs?version=${version}&
来自:产品文档 - 存储和 CDN - 对象存储
浅谈容器监控与网易云计算基础服务实践
docker监控docker的研究和实践发展了这么久,涌现出很多扩展工具,有的甚至有自己的系统。相信大家对各种编排工具都很熟悉了。各种监控方案应运而生。Linux内核和cgroup技术其实已经为监控的技术可行性提供了一切基础。这里我们列出一些监控工具:docker原生监控docker提供命令方法(docker stats CID)和API:http
来自:社区博客
Snowflake & Delta Lake 两种新数据仓库对比分析
Snowflake & Delta Lake代表了业界最先进的两种数字化仓库形态,均获得市场用户的高度认可。——1——概述自1980年代数据分析兴起以来,大致经历了企业数据仓库(EDW)、数据湖(Data Lake),以及现在的云原生数据仓库、湖与仓一体化。企业数据仓库是数据仓库最原创的版本。从目前来看,存在只处理结构化数据、集中存储和计算、成本高等缺点。数字
来自:社区博客
阿里云POLARDB及其共享存储PolarFS技术实现解析(上)
PolarDB是阿里云推出的基于MySQL的云原生数据库产品。通过在数据库中分离计算和存储,多个计算节点访问相同的存储数据,解决了当前 MySQL 数据库的运维和可扩展性问题。问题; 通过引入RDMA、SPDK等新硬件改造传统网络和IO协议栈,大幅提升数据库性能。它代表了未来数据库发展的一个方向。本系列有2篇文章,主要分析PolarDB出现的原因及其技术
来自:社区博客
网易云数据库架构设计实践
作为国内领先的互联网科技公司,网易旗下拥有众多互联网产品和手机客户端应用,如知名的网易博客、云阅读、云音乐、易信等。作为支撑互联网产品的核心后端服务,数据库对产品的重要性不言而喻。随着产品数量和应用规模的快速增长,数据库管理逐渐成为产品开发的瓶颈:硬件采购周期长、沟通协调成本高、难以快速响应数据库部署需求;硬件利用率低,难以按需使用资源,弹性扩展;服务可用性差,数据
来自:社区博客
接口文档神器 Swagger(第 1 部分)
作者:李哲 接口文档管理一直是个头疼的问题,随着各种接口文档管理平台的出现,比如阿里巴巴开源的说唱、ShowDoc、sosoapi等(网上可以找到很多这样的管理平台,包括我们idoc做的我自己)。这些平台都有一个共同的特点,创建文档、编辑和保存文档,一些强大的功能包括模拟、统计界面信息等功能,所以这些平台更像是一个界面文档的存储管理系统,可以方便人们查看和保存。编辑文档。. 但是,接口通常会经常更改(添加
来自:社区博客
Docker镜像存储机制
土地如何储存?容器如何根据镜像启动?将图像推送到远程图像存储库时,服务器如何存储它?让我们简单谈谈。Docker镜像本地存储机制及容器启动原理Dock
来自:社区博客
对象存储服务NOS_高性能云存储服务_网易蜂窝-网易书凡
对象存储服务,NOS,网易蜂窝网易对象存储服务(Netease Object Storage)是一种高性能、高可用、高可靠的云存储服务。NOS支持标准的RESTful API接口,提供丰富的在线数据处理服务,一站式解决互联网时代非结构化数据管理问题——网易对象存储网易对象存储(简称NOS)由网易书凡提供高可用、高...可靠性,高性能云
来自:产品
大规模微服务场景下性能问题的定位与优化
本文结合网易青州微服务平台的实践经验,分析微服务场景下性能问题的定位和优化。文章 从一个真实的场景出发,介绍如何逐层推进,一步步定位性能问题。问题。本文经作者授权发布,未经允许请勿转载。作者:刘超,网易杭州研究院首席架构师 实现微服务架构的成本 现在云原生微服务架构非常流行,它具有迭代快、并发高、可维护、灵活等诸多优点。扩容、灰度发布、高可用,这
来自:社区博客
云优采集接口(云优CMS采集定时发布文章让搜索引擎准点你的网页打开速度 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 262 次浏览 • 2022-03-18 20:23
)
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以使用云游cms采集实现自动采集伪原创发布和主动推送到搜索引擎,以及网页打开速度。如果用云游cms采集打开网页,会影响两点。首先是用户访问网页的体验。云游的目的cms采集是为了搜索引擎的目的是为了更好的满足搜索用户体验,但是你一开始就很难让用户访问你网站 . 可想而知,即使你拥有最好的云游cms采集到采集内容,用户访问也会遇到困难,而要使用如此强大的云游cms采集
云游cms采集的相关性优化,云游cms采集的文字出现关键词,文字首段自动加粗自动插入到标题和描述中。当温度较低时,自动添加当前的采集关键词。履带爬行,开启慢,履带爬行困难。从搜索引擎的角度想想,爬虫也是一个程序运行。一个程序打开一个网页让你运行需要 1 秒,但为别人运行它只需要 100 毫秒。云游cms采集会定期发布。云游cms采集正版文章让搜索引擎准时抓取你的网站内容。而你占用的资源,爬虫可以爬一个网页来爬你这个。云游cms采集不管你有成百上千个不同的cms网站,都可以做到统一管理。云游发布的内容cms采集采集伪原创可以大大增加搜索引擎蜘蛛的出现频率。我们都知道蜘蛛爬行的频率较低,收录 爬行的可能性也较小。没有收入,排名和流量怎么办?可以大大增加搜索引擎蜘蛛的频率。我们都知道蜘蛛爬行的频率较低,收录 爬行的可能性也较小。没有收入,排名和流量怎么办?可以大大增加搜索引擎蜘蛛的频率。我们都知道蜘蛛爬行的频率较低,收录 爬行的可能性也较小。没有收入,排名和流量怎么办?
云游cms采集文本自动插入当前采集关键词2次随机位置。当当前采集的关键词出现在文本中时,云游cms采集自动将关键词加粗。云游cms采集文字可读。云游cms采集内容可见。你真的以为今天的搜索引擎认不出来了吗?比如内容块本身,原本设置为黑色字体或者深灰色字体就很好了。但出于其他一些目的,它必须设置为浅灰色或更接近网页背景的颜色,这并没有充分利用用户的体验。也不认为是高质量的内容。最重要的是,这个云游cms采集
云游cms采集可以主动推送网站,云游cms采集可以让搜索引擎更快的发现我们的网站。支持百度、搜狗、360、神马同步推送。设置正文内容。我这里主要讲的是主要内容本身,比如文章页面的内容部分,我们会设置一些加粗、标记为红色(高亮)、锚文本链接。但这三点中的太多网站仍然存在多年。云游cms采集如果是关键词,给个链接,指向首页,指向栏目页,指向频道页;如果是关键词,会加粗或者高亮,云游cms采集为了突出,云游cms采集网站内容是插入或随机作者,随机阅读,等等变成“height原创”。其实不应该。这些点都是非常小的因素。与其在这方面努力,不如合理利用云游cms采集。文章 中需要突出显示的语句或单词应突出显示。云游cms采集在发布过程中提到了一些词或知识点文章,感觉用户可能不理解或者有兴趣查看,云游cms采集@ >设置链接为设置链接。
云游cms采集自动匹配图片(文章如果内容中没有图片会自动配置相关图片) 设置自动下载图片保存在本地或第三方。其实按照这种正常的做云游cms采集的方式,你会发现你要添加的链接和文字高亮设置也适合一些SEO技巧和方法。所以,要正确理解云游cms采集工作原理细节的含义,合理设置,有时你就是在做SEO。云游cms采集用seo的思维来设置内容,云游cms采集也用设置内容的思维来做seo,这就是云游之道cms@ 的正确方法>采集。
云游cms采集在内容或标题前后插入段落或关键词(可以选择将标题和标题插入同一个关键词)。网页排版布局。这里有三点。第一点是主要内容的位置。用户最需要的内容没有显示在最重要的位置。这样可以吗?比如一个文章页面,用户只想看文章是的,但是你让用户向下滚动两个屏幕看主要内容。这种布局非常离谱。即使您认为您公司的重要内容显示在内容上,用户也会关注内容。就其本身而言,他必须满足自己的需求。其他的关注度比这个少。
云游cms采集只需输入关键词即可实现采集,云游cms采集配备关键词采集 函数。云游cms采集只需设置任务,云游cms采集全程自动挂机!第二点是主要内容之外的周边推荐信息,比如最新推荐、热门推荐、猜你喜欢、相关文章等。名称不同,检索逻辑不同,但性质基本相同。云游cms采集与当前主题文章有什么关联?云游的相关性越高cms采集意味着用户可以挖掘潜力需求越大,云游cms采集 不仅增加了你访问这个网站的PV,还降低了跳出率。也增加了当前页面的关键词密度!
云游cms采集只需设置任务,云游cms采集全程自动挂机!众所周知,弹窗广告会阻挡主题内容,影响用户体验。但是,你的页面“很多”flash图片、动态广告,以及在主要内容中穿插广告都对用户体验有害。所以,合理设置网站的布局,然后使用云游cms采集,数量、主要内容的位置等都是对用户最大的帮助,帮助用户相当于帮助搜索引擎解决了搜索用户体验的问题,为什么不获取流量呢?
增加搜索引擎爬取的频率,这个云游cms采集操作简单,云游cms采集不需要学习专业技术,云游cms@ >采集只产生 原创 内容。原创内容,大家应该都明白了,不过这里必须再提一下。云游cms采集原创一直是大家关注的重点,但并不是所有原创的内容都能获得好的排名。基于我上面提到的其他几点,使用云游cms采集你会发现除了大因素原创,还有很多细节需要注意。
云游cms采集原创的内容应该是有需求的,云游cms采集不能一味的造标题;你的内容应该和标题一致,云游cms采集不能说标题和内容,解决不了用户的实际需求;文字必须可读,不得影响用户其他用途的正常浏览;网页速度 打开快,越快越好,没有限制;如果要突出显示内容主体,则应突出显示,并且应将锚链接添加为锚链接。云游cms采集不用担心所谓的过度优化,只要你用云游cms采集它是为创造内容的目的而设置的,不为 SEO 产生内容。
云游cms采集只需几个简单的步骤,即可轻松采集内容数据。用户只需要在云游cms采集上进行简单的设置,其实百度理解的优质内容,就是真正对用户有帮助、对用户触手可及的内容,更不用说误导了。云游cms采集会根据用户设置的关键词准确采集文章,确保与行业一致文章。我们在做内容的时候,是从搜索引擎的角度来思考的。从本质上,我们可以看到很多东西,不仅仅是因为我是这样学习SEO的。云游cms采集采集文章 from 采集可以选择将修改后的内容保存到本地,云游cms采集
与其他云游cms采集相比,云游cms采集使用起来非常简单。云游cms采集只需输入关键词即可实现采集,云游cms采集自带关键词的功能采集。搜索引擎的存在是因为有大量的人有搜索信息的需求,它的目的是帮助这些人更快、更准确、更直接地找到他们想要的信息。用户满意地浏览和解决自己的需求。
查看全部
云优采集接口(云优CMS采集定时发布文章让搜索引擎准点你的网页打开速度
)
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以使用云游cms采集实现自动采集伪原创发布和主动推送到搜索引擎,以及网页打开速度。如果用云游cms采集打开网页,会影响两点。首先是用户访问网页的体验。云游的目的cms采集是为了搜索引擎的目的是为了更好的满足搜索用户体验,但是你一开始就很难让用户访问你网站 . 可想而知,即使你拥有最好的云游cms采集到采集内容,用户访问也会遇到困难,而要使用如此强大的云游cms采集
云游cms采集的相关性优化,云游cms采集的文字出现关键词,文字首段自动加粗自动插入到标题和描述中。当温度较低时,自动添加当前的采集关键词。履带爬行,开启慢,履带爬行困难。从搜索引擎的角度想想,爬虫也是一个程序运行。一个程序打开一个网页让你运行需要 1 秒,但为别人运行它只需要 100 毫秒。云游cms采集会定期发布。云游cms采集正版文章让搜索引擎准时抓取你的网站内容。而你占用的资源,爬虫可以爬一个网页来爬你这个。云游cms采集不管你有成百上千个不同的cms网站,都可以做到统一管理。云游发布的内容cms采集采集伪原创可以大大增加搜索引擎蜘蛛的出现频率。我们都知道蜘蛛爬行的频率较低,收录 爬行的可能性也较小。没有收入,排名和流量怎么办?可以大大增加搜索引擎蜘蛛的频率。我们都知道蜘蛛爬行的频率较低,收录 爬行的可能性也较小。没有收入,排名和流量怎么办?可以大大增加搜索引擎蜘蛛的频率。我们都知道蜘蛛爬行的频率较低,收录 爬行的可能性也较小。没有收入,排名和流量怎么办?
云游cms采集文本自动插入当前采集关键词2次随机位置。当当前采集的关键词出现在文本中时,云游cms采集自动将关键词加粗。云游cms采集文字可读。云游cms采集内容可见。你真的以为今天的搜索引擎认不出来了吗?比如内容块本身,原本设置为黑色字体或者深灰色字体就很好了。但出于其他一些目的,它必须设置为浅灰色或更接近网页背景的颜色,这并没有充分利用用户的体验。也不认为是高质量的内容。最重要的是,这个云游cms采集
云游cms采集可以主动推送网站,云游cms采集可以让搜索引擎更快的发现我们的网站。支持百度、搜狗、360、神马同步推送。设置正文内容。我这里主要讲的是主要内容本身,比如文章页面的内容部分,我们会设置一些加粗、标记为红色(高亮)、锚文本链接。但这三点中的太多网站仍然存在多年。云游cms采集如果是关键词,给个链接,指向首页,指向栏目页,指向频道页;如果是关键词,会加粗或者高亮,云游cms采集为了突出,云游cms采集网站内容是插入或随机作者,随机阅读,等等变成“height原创”。其实不应该。这些点都是非常小的因素。与其在这方面努力,不如合理利用云游cms采集。文章 中需要突出显示的语句或单词应突出显示。云游cms采集在发布过程中提到了一些词或知识点文章,感觉用户可能不理解或者有兴趣查看,云游cms采集@ >设置链接为设置链接。
云游cms采集自动匹配图片(文章如果内容中没有图片会自动配置相关图片) 设置自动下载图片保存在本地或第三方。其实按照这种正常的做云游cms采集的方式,你会发现你要添加的链接和文字高亮设置也适合一些SEO技巧和方法。所以,要正确理解云游cms采集工作原理细节的含义,合理设置,有时你就是在做SEO。云游cms采集用seo的思维来设置内容,云游cms采集也用设置内容的思维来做seo,这就是云游之道cms@ 的正确方法>采集。
云游cms采集在内容或标题前后插入段落或关键词(可以选择将标题和标题插入同一个关键词)。网页排版布局。这里有三点。第一点是主要内容的位置。用户最需要的内容没有显示在最重要的位置。这样可以吗?比如一个文章页面,用户只想看文章是的,但是你让用户向下滚动两个屏幕看主要内容。这种布局非常离谱。即使您认为您公司的重要内容显示在内容上,用户也会关注内容。就其本身而言,他必须满足自己的需求。其他的关注度比这个少。
云游cms采集只需输入关键词即可实现采集,云游cms采集配备关键词采集 函数。云游cms采集只需设置任务,云游cms采集全程自动挂机!第二点是主要内容之外的周边推荐信息,比如最新推荐、热门推荐、猜你喜欢、相关文章等。名称不同,检索逻辑不同,但性质基本相同。云游cms采集与当前主题文章有什么关联?云游的相关性越高cms采集意味着用户可以挖掘潜力需求越大,云游cms采集 不仅增加了你访问这个网站的PV,还降低了跳出率。也增加了当前页面的关键词密度!
云游cms采集只需设置任务,云游cms采集全程自动挂机!众所周知,弹窗广告会阻挡主题内容,影响用户体验。但是,你的页面“很多”flash图片、动态广告,以及在主要内容中穿插广告都对用户体验有害。所以,合理设置网站的布局,然后使用云游cms采集,数量、主要内容的位置等都是对用户最大的帮助,帮助用户相当于帮助搜索引擎解决了搜索用户体验的问题,为什么不获取流量呢?
增加搜索引擎爬取的频率,这个云游cms采集操作简单,云游cms采集不需要学习专业技术,云游cms@ >采集只产生 原创 内容。原创内容,大家应该都明白了,不过这里必须再提一下。云游cms采集原创一直是大家关注的重点,但并不是所有原创的内容都能获得好的排名。基于我上面提到的其他几点,使用云游cms采集你会发现除了大因素原创,还有很多细节需要注意。
云游cms采集原创的内容应该是有需求的,云游cms采集不能一味的造标题;你的内容应该和标题一致,云游cms采集不能说标题和内容,解决不了用户的实际需求;文字必须可读,不得影响用户其他用途的正常浏览;网页速度 打开快,越快越好,没有限制;如果要突出显示内容主体,则应突出显示,并且应将锚链接添加为锚链接。云游cms采集不用担心所谓的过度优化,只要你用云游cms采集它是为创造内容的目的而设置的,不为 SEO 产生内容。
云游cms采集只需几个简单的步骤,即可轻松采集内容数据。用户只需要在云游cms采集上进行简单的设置,其实百度理解的优质内容,就是真正对用户有帮助、对用户触手可及的内容,更不用说误导了。云游cms采集会根据用户设置的关键词准确采集文章,确保与行业一致文章。我们在做内容的时候,是从搜索引擎的角度来思考的。从本质上,我们可以看到很多东西,不仅仅是因为我是这样学习SEO的。云游cms采集采集文章 from 采集可以选择将修改后的内容保存到本地,云游cms采集
与其他云游cms采集相比,云游cms采集使用起来非常简单。云游cms采集只需输入关键词即可实现采集,云游cms采集自带关键词的功能采集。搜索引擎的存在是因为有大量的人有搜索信息的需求,它的目的是帮助这些人更快、更准确、更直接地找到他们想要的信息。用户满意地浏览和解决自己的需求。
云优采集接口(华为云优采集接口怎么获取网站信息例如获取天猫的title和cookie后,可以清楚)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-03-18 09:13
云优采集接口云优采集接口是华为云推出的一款采集开放工具,提供了采集的便捷性,以及对api服务方面的有力支持。开放的api,让开发者可以快速采集。
1、看网站详情获取网站信息以新浪云做例子,云优采集接口可以通过新浪云的详情页面获取网站的基本信息,例如title、cookie、date、url等等信息。同时也能通过访问新浪云后台查看网站相关信息,例如源代码、注册页面、用户体验等等。
2、知道网站的title、cookie获取网站网站信息例如获取天猫的title和cookie后,可以清楚这个title和cookie的真实含义,例如:是企业旗舰店还是专营店,或者是天猫高级会员等等。因此,云优采集接口,可以更好的发现网站其他的信息,帮助网站提升用户体验,让网站更好的存活下去。
3、核心源代码获取所有网站的核心代码,例如图片和站内信息等等,所有网站的信息都可以获取到。传统方式只能通过搜索引擎搜索,可是搜索的成本又是很高的,另外搜索的到的信息又是会有删减或者修改的情况。
4、帮助我们定制业务场景当业务需求更多的时候,是通过开发者工具开发出业务代码,例如专题页,优惠券专题页,还有就是一些接口,比如:支付接口、短信接口等等。可是我们需要自己搭建一套代码,不仅耗时,还会造成整个系统的架构,修改起来比较麻烦。云优采集接口就好的解决了这个问题,我们只需要找到网站的信息源代码后,点击核心代码获取,就能直接解析业务代码,生成真正的业务代码。
例如:通过云优采集接口打开后台,就能看到详细的业务代码,例如:需要发展商家入驻怎么办,还有就是返佣宝的发展计划、等等。不过也只支持toc的网站,还有就是就是已经被封杀的网站信息,这就让咱们无法进行获取了。有了云优采集接口,我们就可以借助云优采集接口,帮助网站更好的存活下去,并且网站在没有被封杀的情况下,我们也能进行开发。
支持云优采集接口的还有像百度贴吧、豆瓣电影等网站,另外当然也支持新浪博客、云课堂这些在线学习网站。综上所述,云优采集接口主要针对的就是有一定规模的网站,类似于客、京东客这些有一定规模的网站,本质就是通过可以定制网站的功能,提升网站的用户体验。好用的方法很简单,就是你要去找到云优采集接口,然后获取你想要的信息,将网站的信息转换成代码,然后我们就可以直接存到云优采集接口的后台,然后我们就可以自己从网站爬取信息,例如:支付接口,短信接口等等。 查看全部
云优采集接口(华为云优采集接口怎么获取网站信息例如获取天猫的title和cookie后,可以清楚)
云优采集接口云优采集接口是华为云推出的一款采集开放工具,提供了采集的便捷性,以及对api服务方面的有力支持。开放的api,让开发者可以快速采集。
1、看网站详情获取网站信息以新浪云做例子,云优采集接口可以通过新浪云的详情页面获取网站的基本信息,例如title、cookie、date、url等等信息。同时也能通过访问新浪云后台查看网站相关信息,例如源代码、注册页面、用户体验等等。
2、知道网站的title、cookie获取网站网站信息例如获取天猫的title和cookie后,可以清楚这个title和cookie的真实含义,例如:是企业旗舰店还是专营店,或者是天猫高级会员等等。因此,云优采集接口,可以更好的发现网站其他的信息,帮助网站提升用户体验,让网站更好的存活下去。
3、核心源代码获取所有网站的核心代码,例如图片和站内信息等等,所有网站的信息都可以获取到。传统方式只能通过搜索引擎搜索,可是搜索的成本又是很高的,另外搜索的到的信息又是会有删减或者修改的情况。
4、帮助我们定制业务场景当业务需求更多的时候,是通过开发者工具开发出业务代码,例如专题页,优惠券专题页,还有就是一些接口,比如:支付接口、短信接口等等。可是我们需要自己搭建一套代码,不仅耗时,还会造成整个系统的架构,修改起来比较麻烦。云优采集接口就好的解决了这个问题,我们只需要找到网站的信息源代码后,点击核心代码获取,就能直接解析业务代码,生成真正的业务代码。
例如:通过云优采集接口打开后台,就能看到详细的业务代码,例如:需要发展商家入驻怎么办,还有就是返佣宝的发展计划、等等。不过也只支持toc的网站,还有就是就是已经被封杀的网站信息,这就让咱们无法进行获取了。有了云优采集接口,我们就可以借助云优采集接口,帮助网站更好的存活下去,并且网站在没有被封杀的情况下,我们也能进行开发。
支持云优采集接口的还有像百度贴吧、豆瓣电影等网站,另外当然也支持新浪博客、云课堂这些在线学习网站。综上所述,云优采集接口主要针对的就是有一定规模的网站,类似于客、京东客这些有一定规模的网站,本质就是通过可以定制网站的功能,提升网站的用户体验。好用的方法很简单,就是你要去找到云优采集接口,然后获取你想要的信息,将网站的信息转换成代码,然后我们就可以直接存到云优采集接口的后台,然后我们就可以自己从网站爬取信息,例如:支付接口,短信接口等等。
云优采集接口(高德地图开放平台:API/好用不好用?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 435 次浏览 • 2022-03-17 21:13
什么是高德开放平台?
高德开放平台是国内领先的LBS服务商,拥有先进的数据融合技术和海量数据处理能力。它服务于超过 30 万个移动应用,每天处理数百亿的定位请求和路线规划。高德的开放平台为开发者提供了涵盖移动端和Web端的开发工具。开发者可以通过调用开发包或接口,在应用程序或网页中实现地图显示、标注、位置检索等功能。使 LBS 应用程序的开发过程更容易。
高德对位置大数据的不断探索和实践,高德地图开放平台,通过其服务的30万个应用,数百亿的每日位置请求和相关行为,将人群趋势、区域流行度和相关行为呈现在现实世界中。行为偏好等分析洞察,试图通过数据画像还原我们身边熟悉但陌生的世界。
高德开放平台为开发者提供了三个主要能力:
1、 专业易用的地图开发工具:API/SDK
2、 快速定位云计算:云地图
3、 权威位置大数据:高德位智
地图开发工具:API/SDK
高德地图API/SDK是为开发者提供的一套地图应用程序接口,包括JavaScript、iOS、Andriod、Windows、静态地图、Web服务等版本。提供定位、地图、导航(公交\驾车\步行)、位置搜索、周边搜索、地理编码和反向地理编码、实时路况等丰富功能。
如果你的网站或者APP需要用到地图功能,是不是一定要自己开发一套地图?不,当然不!!由于高德以API/SDK的形式开放了这些能力(包括:定位、地图、导航等),通过调用高德的API和SDK,您的APP可以轻松拥有与高德一样的专业。地图功能!
高德API/SDK好用还是不好用?这么多高质量的应用都在使用我们的产品,高德绝对不会出错!
开发文档
文件地址
位置云计算:云地图
高德云地图主要提供这样的服务:存储和管理自己的位置数据,只需一张Excel表格,就可以快速生成你想要的地图!点击查看详情>>
云地图为您提供了一个集成的高性能工具,用于您自己的位置数据采集、存储、渲染和检索。
如果你恰好有业务数据,然后只想在地图上标记这些数据,那么选择云地图一定是明智之举——因为有了云地图,数据采集,存储、展示、编辑,你不用不需要自己进行搜索。据说选择它会减少50%以上的开发量!核心功能:自有位置数据的存储、展示、编辑、检索和应用开发
核心痛点解决:
1、位置数据存储,减轻海量数据存储和维护压力;
2、实时渲染&检索,解决位置数据高并发检索的瓶颈。
同时,如果您希望在高德地图APP上检索您的数据,您也可以先将数据存储在云地图上。在您的授权下,云地图可以将数据推送到高德地图。
位置大数据:高德位智
高德是高德开放平台出品的基于百亿位置大数据挖掘的区域分析平台。旨在帮助行业客户、新闻媒体、政府学术机构和个人用户了解区域人口趋势和区域流行度。我们为各类用户群体提供区域热度分析、基于位置的人群行为分析等。同时,我们提供高德位智分析的焦点大数据报告,供高德位智用户使用指数。以供参考。
我们的优势
专注地图,拥有国家A级测绘资质,超过6000万个POI,790万公里道路数据,提供国内专业手机地图
使用方便
想想用户的想法,以及用户可以达到什么。我们推出了一系列行业解决方案,如:出行、O2O、智能硬件……打造“零开发”产品,降低开发成本是我们的使命!
我们的愿景
1、 用“位置”标记物理世界中所有有价值的数据;
2、人类行为+位置数据,在地图上映射真实世界,在地图上还原真实世界。 查看全部
云优采集接口(高德地图开放平台:API/好用不好用?(组图))
什么是高德开放平台?
高德开放平台是国内领先的LBS服务商,拥有先进的数据融合技术和海量数据处理能力。它服务于超过 30 万个移动应用,每天处理数百亿的定位请求和路线规划。高德的开放平台为开发者提供了涵盖移动端和Web端的开发工具。开发者可以通过调用开发包或接口,在应用程序或网页中实现地图显示、标注、位置检索等功能。使 LBS 应用程序的开发过程更容易。
高德对位置大数据的不断探索和实践,高德地图开放平台,通过其服务的30万个应用,数百亿的每日位置请求和相关行为,将人群趋势、区域流行度和相关行为呈现在现实世界中。行为偏好等分析洞察,试图通过数据画像还原我们身边熟悉但陌生的世界。
高德开放平台为开发者提供了三个主要能力:
1、 专业易用的地图开发工具:API/SDK
2、 快速定位云计算:云地图
3、 权威位置大数据:高德位智
地图开发工具:API/SDK
高德地图API/SDK是为开发者提供的一套地图应用程序接口,包括JavaScript、iOS、Andriod、Windows、静态地图、Web服务等版本。提供定位、地图、导航(公交\驾车\步行)、位置搜索、周边搜索、地理编码和反向地理编码、实时路况等丰富功能。
如果你的网站或者APP需要用到地图功能,是不是一定要自己开发一套地图?不,当然不!!由于高德以API/SDK的形式开放了这些能力(包括:定位、地图、导航等),通过调用高德的API和SDK,您的APP可以轻松拥有与高德一样的专业。地图功能!
高德API/SDK好用还是不好用?这么多高质量的应用都在使用我们的产品,高德绝对不会出错!
开发文档
文件地址
位置云计算:云地图
高德云地图主要提供这样的服务:存储和管理自己的位置数据,只需一张Excel表格,就可以快速生成你想要的地图!点击查看详情>>
云地图为您提供了一个集成的高性能工具,用于您自己的位置数据采集、存储、渲染和检索。
如果你恰好有业务数据,然后只想在地图上标记这些数据,那么选择云地图一定是明智之举——因为有了云地图,数据采集,存储、展示、编辑,你不用不需要自己进行搜索。据说选择它会减少50%以上的开发量!核心功能:自有位置数据的存储、展示、编辑、检索和应用开发
核心痛点解决:
1、位置数据存储,减轻海量数据存储和维护压力;
2、实时渲染&检索,解决位置数据高并发检索的瓶颈。
同时,如果您希望在高德地图APP上检索您的数据,您也可以先将数据存储在云地图上。在您的授权下,云地图可以将数据推送到高德地图。
位置大数据:高德位智
高德是高德开放平台出品的基于百亿位置大数据挖掘的区域分析平台。旨在帮助行业客户、新闻媒体、政府学术机构和个人用户了解区域人口趋势和区域流行度。我们为各类用户群体提供区域热度分析、基于位置的人群行为分析等。同时,我们提供高德位智分析的焦点大数据报告,供高德位智用户使用指数。以供参考。
我们的优势
专注地图,拥有国家A级测绘资质,超过6000万个POI,790万公里道路数据,提供国内专业手机地图
使用方便
想想用户的想法,以及用户可以达到什么。我们推出了一系列行业解决方案,如:出行、O2O、智能硬件……打造“零开发”产品,降低开发成本是我们的使命!
我们的愿景
1、 用“位置”标记物理世界中所有有价值的数据;
2、人类行为+位置数据,在地图上映射真实世界,在地图上还原真实世界。
云优采集接口(【日志服务CLS】腾讯云Log4jLogback日志采集最佳实践一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2022-03-16 23:15
【日志服务CLS】腾讯云Log4jLogback Log采集最佳实践
一、引言 日志存储和分析在应用系统中扮演着重要的角色。传统的 ELK 对于小团队来说过于繁琐,维护起来也很麻烦。腾讯云提供CLS日志采集分析系统,可以使用LogListener实现业务代码无侵入采集日志,开发者也可以使用如上图的三架构图image.png,开发者可以选择自定义日志采集模块,将日志上报到腾讯云CLS。四个腾讯云 CLS 逻辑概念 准备一个日志集:一个日志集对应一个项目或应用 日志主题:一个日志主题对应一种应用或服务 日志组:收录多个日志的集合 日志分区:一个日志主题可以是分为多个主题分区,7 CLS日志上报云API 本文作者通过调用API实现结构化日志上传。请参阅上传结构化日志 API 文档云。日志端解耦;但是LogListener仅限于CVM机器上的日志采集,或者其他腾讯云容器的日志采集,如果开发者的应用在自建机房或者其他云平台 7 CLS日志上报云API 本文作者通过调用API实现结构化日志上传。请参阅上传结构化日志 API 文档云。日志端解耦;但是LogListener仅限于CVM机器上的日志采集,或者其他腾讯云容器的日志采集,如果开发者的应用在自建机房或者其他云平台
689 查看全部
云优采集接口(【日志服务CLS】腾讯云Log4jLogback日志采集最佳实践一)
【日志服务CLS】腾讯云Log4jLogback Log采集最佳实践
一、引言 日志存储和分析在应用系统中扮演着重要的角色。传统的 ELK 对于小团队来说过于繁琐,维护起来也很麻烦。腾讯云提供CLS日志采集分析系统,可以使用LogListener实现业务代码无侵入采集日志,开发者也可以使用如上图的三架构图image.png,开发者可以选择自定义日志采集模块,将日志上报到腾讯云CLS。四个腾讯云 CLS 逻辑概念 准备一个日志集:一个日志集对应一个项目或应用 日志主题:一个日志主题对应一种应用或服务 日志组:收录多个日志的集合 日志分区:一个日志主题可以是分为多个主题分区,7 CLS日志上报云API 本文作者通过调用API实现结构化日志上传。请参阅上传结构化日志 API 文档云。日志端解耦;但是LogListener仅限于CVM机器上的日志采集,或者其他腾讯云容器的日志采集,如果开发者的应用在自建机房或者其他云平台 7 CLS日志上报云API 本文作者通过调用API实现结构化日志上传。请参阅上传结构化日志 API 文档云。日志端解耦;但是LogListener仅限于CVM机器上的日志采集,或者其他腾讯云容器的日志采集,如果开发者的应用在自建机房或者其他云平台
689
云优采集接口、云验货接口等,你怎么做到的?
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-05-18 00:03
云优采集接口、云优验货接口等,这种专业的云采购平台,都有通用接口,很容易搭建自己的云采购平台。常用的通用接口,有云优采、企优网、云优验货等。
参考这篇文章:云优购采购接口
请问你怎么做到的?
在四川,金牌客户可以免费赠送224个云优选模块、三方商户免费提供1对1的云优商户验货服务,由此可见送的力度还是挺大的~还有云优验货,据我所知,该接口可以提供:可以随时随地,
云优购接口里面有企优验货接口。云优选如果不是线下商户使用的话,真心不推荐。不如自己用自己的账号,通过云优验货接口进行验货。当然前提是,确定商户有验货需求。
推荐“云优车”。线上开票,线下报关,既快捷,又方便。
可以尝试使用云优优买接口。接口是国内一家免费验货行业领先的平台。
快问是一家专门做云上采购的公司,免费接口提供的很全面,除此之外我们还提供验货分析数据,自建仓储,
推荐湖南国源云模式商业智能解决方案有限公司,对接智慧海淘,提供商家免费一对一的验货接口,
北京时代
云优优买接口,楼主可以去了解一下。
南京可以问我
如果要说保险一点可以考虑下我们的云优优买接口,行业专家来为企业家提供智能化云采购,二十多年互联网经验,专注网上采购6年了,安全、稳定、兼容性强、方便快捷、全天候采购、无需订货时,也可以开票等功能。 查看全部
云优采集接口、云验货接口等,你怎么做到的?
云优采集接口、云优验货接口等,这种专业的云采购平台,都有通用接口,很容易搭建自己的云采购平台。常用的通用接口,有云优采、企优网、云优验货等。
参考这篇文章:云优购采购接口
请问你怎么做到的?
在四川,金牌客户可以免费赠送224个云优选模块、三方商户免费提供1对1的云优商户验货服务,由此可见送的力度还是挺大的~还有云优验货,据我所知,该接口可以提供:可以随时随地,
云优购接口里面有企优验货接口。云优选如果不是线下商户使用的话,真心不推荐。不如自己用自己的账号,通过云优验货接口进行验货。当然前提是,确定商户有验货需求。
推荐“云优车”。线上开票,线下报关,既快捷,又方便。
可以尝试使用云优优买接口。接口是国内一家免费验货行业领先的平台。
快问是一家专门做云上采购的公司,免费接口提供的很全面,除此之外我们还提供验货分析数据,自建仓储,
推荐湖南国源云模式商业智能解决方案有限公司,对接智慧海淘,提供商家免费一对一的验货接口,
北京时代
云优优买接口,楼主可以去了解一下。
南京可以问我
如果要说保险一点可以考虑下我们的云优优买接口,行业专家来为企业家提供智能化云采购,二十多年互联网经验,专注网上采购6年了,安全、稳定、兼容性强、方便快捷、全天候采购、无需订货时,也可以开票等功能。
云优采集接口对京东各大商品销售数据进行分析和评估
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-05-12 21:01
云优采集接口不仅可以采集京东商品评论,还可以对京东各大商品销售数据进行分析和评估,
一、评论信息查询。通过云优接口采集:其他电商平台评论(天猫,京东,拼多多,拍拍,淘宝,唯品会,拼多多,亚马逊,唯品会,当当等),一键批量登录京东,搜索对应评论信息,在“全部评论”区就可以看到所有评论了。
二、标签规则采集,京东评论分类进行评论分析比对。可以自定义某宝评论的标签,对商品进行分类,比如服饰,包包,数码,化妆品等,设置相应规则。点击分析规则即可一键采集商品评论,批量分析关键词评论变化规律,实现采集评论数据到excel表格的自动化分析工作,从而提高网站评论信息抓取效率。
三、评论价格,评论地址,评论字数自动计算。可以实现评论价格计算,评论数据,评论字数计算。
四、产品属性自动标注,对评论中出现产品属性信息自动标注。例如评论中出现金属,木材,纺织,电器等标签时,自动标注其产品属性,在采集任意页面时,就可以将相应页面评论自动转化为对应产品信息。
五、评论深度自动根据京东产品评论量、评论内容进行进一步自动评估。评论量每提升,评论内容会随之提升。大家如果有什么好的接口推荐,欢迎大家私信我。 查看全部
云优采集接口对京东各大商品销售数据进行分析和评估
云优采集接口不仅可以采集京东商品评论,还可以对京东各大商品销售数据进行分析和评估,
一、评论信息查询。通过云优接口采集:其他电商平台评论(天猫,京东,拼多多,拍拍,淘宝,唯品会,拼多多,亚马逊,唯品会,当当等),一键批量登录京东,搜索对应评论信息,在“全部评论”区就可以看到所有评论了。
二、标签规则采集,京东评论分类进行评论分析比对。可以自定义某宝评论的标签,对商品进行分类,比如服饰,包包,数码,化妆品等,设置相应规则。点击分析规则即可一键采集商品评论,批量分析关键词评论变化规律,实现采集评论数据到excel表格的自动化分析工作,从而提高网站评论信息抓取效率。
三、评论价格,评论地址,评论字数自动计算。可以实现评论价格计算,评论数据,评论字数计算。
四、产品属性自动标注,对评论中出现产品属性信息自动标注。例如评论中出现金属,木材,纺织,电器等标签时,自动标注其产品属性,在采集任意页面时,就可以将相应页面评论自动转化为对应产品信息。
五、评论深度自动根据京东产品评论量、评论内容进行进一步自动评估。评论量每提升,评论内容会随之提升。大家如果有什么好的接口推荐,欢迎大家私信我。
云优采集接口开发api你如果懂php的话也可以用bingwordws
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-05-10 12:01
云优采集接口开发api
你如果懂php的话也可以用bingwordws,用bingwordws的速度很快。但是bingwordws要收费。你也可以使用插件,然后给你推荐一个云优接口云优api,有超多服务,
有句话怎么说的?“云优接口找云优”。我从云优目前数百个接口中筛选出来,再依据需求提供定制式服务的接口。后期如果有更新以及维护,可以在发布计划或者备案申请中体现。
个人一直用阿里云优化接口,速度快稳定,
按理说应该不能乱申请的。多申请几个接口比较下,我现在用bingwordws,
github上有很多云优,而且种类齐全,如bingso..只是一般国内用的人不多。你可以试下。看了我回答的人,我觉得你们产品要考虑下国内用户一般能接受什么价位接口。当然,你也可以根据团队实力与能力,去找一些核心产品的接口。有个只提供云优的老哥,
你可以试试各大isp,试试各大的云优接口,毕竟都已经过产品经理开发认证了.做云优接口,主要是对方有相关的经验可以来提供;然后如果需要更为详细的产品指导.可以来找我,先发简历试试看是否有缘分.
目前有很多云优接口,云优接口_云优金融管理系统接口, 查看全部
云优采集接口开发api你如果懂php的话也可以用bingwordws
云优采集接口开发api
你如果懂php的话也可以用bingwordws,用bingwordws的速度很快。但是bingwordws要收费。你也可以使用插件,然后给你推荐一个云优接口云优api,有超多服务,
有句话怎么说的?“云优接口找云优”。我从云优目前数百个接口中筛选出来,再依据需求提供定制式服务的接口。后期如果有更新以及维护,可以在发布计划或者备案申请中体现。
个人一直用阿里云优化接口,速度快稳定,
按理说应该不能乱申请的。多申请几个接口比较下,我现在用bingwordws,
github上有很多云优,而且种类齐全,如bingso..只是一般国内用的人不多。你可以试下。看了我回答的人,我觉得你们产品要考虑下国内用户一般能接受什么价位接口。当然,你也可以根据团队实力与能力,去找一些核心产品的接口。有个只提供云优的老哥,
你可以试试各大isp,试试各大的云优接口,毕竟都已经过产品经理开发认证了.做云优接口,主要是对方有相关的经验可以来提供;然后如果需要更为详细的产品指导.可以来找我,先发简历试试看是否有缘分.
目前有很多云优接口,云优接口_云优金融管理系统接口,
云优采集接口(接上的大数据处理工具对你我意味着什么)
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-04-15 01:24
在上一集中,我们已经知道一个好的大数据处理工具对你我意味着什么。可能有人会问,你总说DataCenter厉害,那么厉害在哪里呢?你说的结构在哪里?说到曹操和曹操,这是DataCenter的架构图:
很清爽的感觉,是的,你用起来也会很舒服。DataCenter采用模块化模式,即你看到的每一个模块都是其中一个模块,你可以通过配置页面自由配置组合,让你可以根据自己的实际业务进行相关选择,组合、调优你的事。
系统主要分为五个功能组:采集、存储、计算、发布、展示。让我们从 采集 开始。
采集:提供标准数据输入接口,方便不同类型采集工具的访问,如物联网数据采集访问、游戏日志访问、各种日志服务器访问等。
存储:批处理 - 采集 中的数据存储在主 HDFS 中,并根据数据的值存储在 Hbase 中
实时流式传输——来自 采集 的数据直接连接到 Kafka 集群
计算:这部分也分为批处理和流实时。用到的技术很多,比如Hive的MR、Spark、Flink等,还有后起之秀的star kylin等。在这里,DataCenter将为你提供不同的选择。您需要根据自己的业务选择不同的处理模式,系统会根据规则进行匹配,选择不同的计算工具,以达到最优的性能。
发布:还有批处理和流式实时两部分。Batch 以服务的形式提供服务,例如文件下载、Rest 服务、消息,当然还有我们熟悉的数据库(关系型和非关系型)。流式处理主要基于分布式流式查询,例如elasticsearch、presto 应用程序,您可以快速轻松地使用您的实时频道数据。
显示:这部分由众所周知的蛛网组件完成。你的页面配置操作和显示都是由这部分完成的。本部分包括AutoBI、DataView、EasyMIS的综合应用。
纵观整个系统,除了元数据系统,还有报警系统、权限系统等,其中最核心的就是调度系统。没有这个系统,整个DataCenter就无法正常运行。调度系统连接previous和next,控制各个模块的运行,也控制计算节点的指标计算。例如,如果每个月的日指标不完整,则不允许计算月指标,以便向相关人员发送数据不足的预警。调查相关的日志丢失问题。可以说调度系统是整个系统的灵魂。
综上所述,可以看出DataCenter是一套庞大且结构良好的系统,环环相扣,设计严谨。正是因为这些,DataCenter才能处理PB级的数据,将性能损失降到最低。. 可以说DataCenter的出现肯定会改变大数据处理的一些规则。如果说蛛网时代改变了软件开发的规则,那么大数据处理的新时代即将到来,而这一切都是蛛网时代DataCenter为您打造的。 查看全部
云优采集接口(接上的大数据处理工具对你我意味着什么)
在上一集中,我们已经知道一个好的大数据处理工具对你我意味着什么。可能有人会问,你总说DataCenter厉害,那么厉害在哪里呢?你说的结构在哪里?说到曹操和曹操,这是DataCenter的架构图:
很清爽的感觉,是的,你用起来也会很舒服。DataCenter采用模块化模式,即你看到的每一个模块都是其中一个模块,你可以通过配置页面自由配置组合,让你可以根据自己的实际业务进行相关选择,组合、调优你的事。
系统主要分为五个功能组:采集、存储、计算、发布、展示。让我们从 采集 开始。
采集:提供标准数据输入接口,方便不同类型采集工具的访问,如物联网数据采集访问、游戏日志访问、各种日志服务器访问等。
存储:批处理 - 采集 中的数据存储在主 HDFS 中,并根据数据的值存储在 Hbase 中
实时流式传输——来自 采集 的数据直接连接到 Kafka 集群
计算:这部分也分为批处理和流实时。用到的技术很多,比如Hive的MR、Spark、Flink等,还有后起之秀的star kylin等。在这里,DataCenter将为你提供不同的选择。您需要根据自己的业务选择不同的处理模式,系统会根据规则进行匹配,选择不同的计算工具,以达到最优的性能。
发布:还有批处理和流式实时两部分。Batch 以服务的形式提供服务,例如文件下载、Rest 服务、消息,当然还有我们熟悉的数据库(关系型和非关系型)。流式处理主要基于分布式流式查询,例如elasticsearch、presto 应用程序,您可以快速轻松地使用您的实时频道数据。
显示:这部分由众所周知的蛛网组件完成。你的页面配置操作和显示都是由这部分完成的。本部分包括AutoBI、DataView、EasyMIS的综合应用。
纵观整个系统,除了元数据系统,还有报警系统、权限系统等,其中最核心的就是调度系统。没有这个系统,整个DataCenter就无法正常运行。调度系统连接previous和next,控制各个模块的运行,也控制计算节点的指标计算。例如,如果每个月的日指标不完整,则不允许计算月指标,以便向相关人员发送数据不足的预警。调查相关的日志丢失问题。可以说调度系统是整个系统的灵魂。
综上所述,可以看出DataCenter是一套庞大且结构良好的系统,环环相扣,设计严谨。正是因为这些,DataCenter才能处理PB级的数据,将性能损失降到最低。. 可以说DataCenter的出现肯定会改变大数据处理的一些规则。如果说蛛网时代改变了软件开发的规则,那么大数据处理的新时代即将到来,而这一切都是蛛网时代DataCenter为您打造的。
云优采集接口( 基于表格数据管理的CRM软件,打造全流程、实时可视化的经营核算体系)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-15 01:19
基于表格数据管理的CRM软件,打造全流程、实时可视化的经营核算体系)
本次评测的主角简历非常精彩,by Discuz!(服务站长十余年,国内第一论坛引擎),原主创团队逐步将一款基于表格数据管理的CRM软件打造成为帮助企业实现数据管理的平台。你猜到了吗?它是 - 合作伙伴云。
Partner Cloud 由前 Discuz! 打造!拥有10年以上论坛软件开发和中小企业服务经验的团队。历经“合伙人云表”和“合伙人办公室”,逐步升级为服务业务运营的数据可视化平台。提供企业全流程运营管理和运营核算的整体解决方案。通过强大的数据库引擎和权限结构,灵活的可定制流程引擎和大数据分析引擎,专家级的管理顾问和服务,打造全流程、实时可视化的业务核算体系,实现同心业务合作伙伴是为企业打造的。实现员工的不断成长,组织的不断转型,和性能的持续改进。基础能力伙伴云主要功能模块由表格、流程、数据仓库和仪表盘四大部分组成,以数据管理为中心,让数据为用户带来更多价值。
▐ 表格进入表格配置页面。使用的表示方法与 Excel 表格非常相似。您可以为表格的每一列设置不同的属性、类型等。共提供了 15 个常用组件,包括与数据相关的字段。配置完成后的效果就是最终数据呈现的效果。
如果表单配置表单不符合企业的使用习惯,伙伴云也提供表单配置表单,您可以拖放相应的组件来完成配置。与表单相比,表单表单增加了选项卡和布局字段,并且支持表单内的分页。用户可以在表单中添加分表、仪表盘等内容,表单呈现更加丰富。
表单可以通过Excel导入,在线配置生成,也可以通过链接共享,实现与外部合作伙伴的协作。同时,权限的控制也更加细致,可以配置操作、字段、过滤、显示等权限。
▐流程虽然Partner Cloud是一个偏向于数据采集的低代码开发平台,但流程引擎功能也毫不含糊,可以说是优秀的。不同于一般平台只支持一种流程规范,Partner Cloud根据业务需求提供工作流引擎和流程引擎,分别遵循IFTTT和BPMN2.0规范。工作流引擎满足一系列自动触发操作。例如,当数据添加到表单时,它会自动向相应的用户发送消息,并进行汇总计算以将结算存储在另一个表单中。流程引擎满足了需要人工参与的传统审批流程业务,这里不再赘述。前者是自动流,后者是人工流动。工作流引擎配置需要一定的逻辑思维和熟悉EXCEL公式,包括触发方式、全局放置图、触发条件和执行操作等,主要满足数据计算、操作、消息通知等需求,可以通过数据创建和修改。、删除等操作触发相关流程,结束后可自动创建数据、发送通知等后续操作。并且可以通过数据来创建和修改。、删除等操作触发相关流程,结束后可自动创建数据、发送通知等后续操作。并且可以通过数据来创建和修改。、删除等操作触发相关流程,结束后可自动创建数据、发送通知等后续操作。
Partner Cloud 的流程引擎有两种配置方式。一是审批流程配置,简单、直接、线性到底。另一个是业务流,遵循BPMN2.0规范的配置方式,可以触发工作流和子流程,可以满足多规则多权限的复杂业务流程。
审批流程配置
业务流程配置
▐ 数据仓库伙伴云不仅提供数据采集的表格功能,还提供数据统计分析功能。它将来自多个数据源的数据聚合起来,形成一个可以分析的聚合表,然后以图形的形式呈现数据。形成仪表板页面。首先,在数据汇总计算部分,可以对多个sheet数据进行统计、过滤、合并、计算,形成汇总表。这个功能类似于剑道云的聚合表+数据工厂,配置方法也类似。通过可视化配置,可以从多种表格中轻松获取所需数据。
数据分析部分,也称为报表功能,显示在仪表板中。提供11种图表,支持多维展示、数据展示、对比等操作。同时,图表还提供了自由钻孔和路径钻孔两种钻孔模式,使图表分析更加灵活。
▐ Dashboard Partner Cloud 的dashboard 与之前对剑道云的dashboard 评价有些不同。Partner Cloud 的仪表板可以看作是一个摘要页面。除了上面提到的报表,还可以放其他13个组件,比如统计、流程、日历、图片框、文字内容、快速录入、扫码等,可以组合成活动页面等自定义页面、门户页面和工作台。
▐ 低码伙伴云不提供低码扩展能力,但为了不影响平台本身的易用性,满足不同用户的个性化需求,为开发者提供了一个开放的平台。开放平台提供云存储接口和表应用原生组件等服务,让开发者可以在合作伙伴云上开发嵌入式应用,或者使用云存储服务开发原生应用。嵌入式应用是Partner Cloud的一个特点,可以基于数据接口开发应用,形成其提供的原生组件。这些应用程序可以发布到市场并由用户安装。例如,合作伙伴云原生视图都是类似 EXCEL 的表格样式。当用户需要卡片式列表时,他们可以通过其开放平台和 SDK 功能开发卡片视图应用程序。当应用被某个表安装时,表中会多出一个应用入口,切换到这个应用可以将数据以卡片的形式呈现。优缺点分析 以数据管理为核心的优势 合作伙伴云最初主要用于在线数据的采集、共享和协作,但目前合作伙伴云可以做的远不止这些。平台以数据管理为核心,同时提供数据审批、流程、数据处理、报表、页面等功能,让数据为企业带来更多价值。数百个表单模板合作伙伴云经过长时间的沉淀与用户和合作伙伴积累了数百个表单模板,涵盖电商、互联网、教育、房地产、物流等行业,不仅减少了客户从零开始配置的工作量,也为用户配置提供了一定的参考。手机APP与剑道云、易达等产品的区别在于伙伴云有自己的手机APP,不完全依赖微信、钉钉等平台,可以使用伙伴云APP进行添加、搜索、添加数据在移动终端上。修订。亿达等产品是伙伴云有自己的手机APP,不完全依赖微信、钉钉等平台,可通过伙伴云APP在移动端进行添加、搜索、添加数据。修订。亿达等产品是伙伴云有自己的手机APP,不完全依赖微信、钉钉等平台,可通过伙伴云APP在移动端进行添加、搜索、添加数据。修订。
当然伙伴云也支持在企业微信上安装使用,用户可以根据实际情况使用。构建应用程序的能力不足。目前,在合作伙伴云中,表格中的数据显示方式只有一种。和亿达/明道云/七巧Plus等其他产品相比,会稍微简单一些(但还是留下了表单嵌入应用。)。当然,这确实是吹毛求疵。就Partner Cloud这个企业运营数据可视化平台的定位而言,其产品能力和成熟度确实无可挑剔,但按照应用开发平台的标准来看,确实是面向管理的。应用程序更面向数据可视化和数据管理。商业模式与持续生存▐商业模式伙伴云目前有三个付费版本,自建小微企业标准版(199元/人/年,30人起);需要定制服务的中小企业标准版定制版(599元/人/年,100人起);旗舰版,面向对数据量和自动化要求较高,或期望独立形象的企事业单位(1299元/人/年,100人起)。付费版除了增加各模块的数据量外,还增加了一些个性化功能,如手写签名、数据大屏、支付、数据对接等功能。伙伴云的商业模式经历了全面的免费收费、模块收费、当前平台订阅收费,并逐渐向定制化收费模式扩展。目前的用户数量应该相当可观。▐ 可持续生存的合作伙伴云由明星团队运营。经过近八年的打磨,已经从基于表管理数据的SaaS发展成为服务于企业运营的数据可视化平台。累计企业用户10万。此外,它还获得了世界顶级风险投资商山资本和晨兴资本两家全球顶级风险投资机构数百万美元的A轮联合投资,其持续生存能力不容小觑。并逐渐扩展到定制化收费模式。目前的用户数量应该相当可观。▐ 可持续生存的合作伙伴云由明星团队运营。经过近八年的打磨,已经从基于表管理数据的SaaS发展成为服务于企业运营的数据可视化平台。累计企业用户10万。此外,它还获得了世界顶级风险投资商山资本和晨兴资本两家全球顶级风险投资机构数百万美元的A轮联合投资,其持续生存能力不容小觑。并逐渐扩展到定制化收费模式。目前的用户数量应该相当可观。▐ 可持续生存的合作伙伴云由明星团队运营。经过近八年的打磨,已经从基于表管理数据的SaaS发展成为服务于企业运营的数据可视化平台。累计企业用户10万。此外,它还获得了世界顶级风险投资商山资本和晨兴资本两家全球顶级风险投资机构数百万美元的A轮联合投资,其持续生存能力不容小觑。它已经从基于表管理数据的SaaS发展成为服务于企业运营的数据可视化平台。累计企业用户10万。此外,它还获得了世界顶级风险投资商山资本和晨兴资本两家全球顶级风险投资机构数百万美元的A轮联合投资,其持续生存能力不容小觑。它已经从基于表管理数据的SaaS发展成为服务于企业运营的数据可视化平台。累计企业用户10万。此外,它还获得了世界顶级风险投资商山资本和晨兴资本两家全球顶级风险投资机构数百万美元的A轮联合投资,其持续生存能力不容小觑。
经过八年客户画像的发展,伙伴云已经积累了10万企业用户。主要客户为中小企业,客户行业覆盖面广,如电子商务、IT互联网、教育培训、房产中介等。 评价结论 合作伙伴云综合评分 好用:★ ★★★基础能力:★★★★数据管理:★★★★API能力:★★★低代码能力:★★性价比:★★★模板质量:★★★风格交互:★★★★整体评分:★★★★选型建议:1、主要基于数据管理需求,对数据分析和可视化要求更高的可以考虑。2、专注于数据的使用采集、审批流程、数据处理等部分,可以使用伙伴云。3、 Partner Cloud可以作为轻量级的数据采集工具和在线协作EXCEL文档。体验比一般的在线文档更好,更完整。目前拥有独立的手机APP,可以在企业微信和飞书上使用。国内主流低代码开发PaaS平台的评测已经结束。接下来,我们将扩大视野,评估一些低代码开发平台的替代产品。一方面,它是一个更轻量级的产品零代码平台。还将审查更重量级的平台 - 快速开发平台(其中一些甚至没有云架构)。您想先看哪个产品?可以关注我们,在后台给我们留言~声明:此评价仅代表作者个人观点,并且没有与产品相关的利益。相关资料及截图均来自网络公开资料、产品官方渠道及作者使用体验。如有偏差,您可以联系我们,我们核实后会做勘误。 查看全部
云优采集接口(
基于表格数据管理的CRM软件,打造全流程、实时可视化的经营核算体系)
本次评测的主角简历非常精彩,by Discuz!(服务站长十余年,国内第一论坛引擎),原主创团队逐步将一款基于表格数据管理的CRM软件打造成为帮助企业实现数据管理的平台。你猜到了吗?它是 - 合作伙伴云。
Partner Cloud 由前 Discuz! 打造!拥有10年以上论坛软件开发和中小企业服务经验的团队。历经“合伙人云表”和“合伙人办公室”,逐步升级为服务业务运营的数据可视化平台。提供企业全流程运营管理和运营核算的整体解决方案。通过强大的数据库引擎和权限结构,灵活的可定制流程引擎和大数据分析引擎,专家级的管理顾问和服务,打造全流程、实时可视化的业务核算体系,实现同心业务合作伙伴是为企业打造的。实现员工的不断成长,组织的不断转型,和性能的持续改进。基础能力伙伴云主要功能模块由表格、流程、数据仓库和仪表盘四大部分组成,以数据管理为中心,让数据为用户带来更多价值。
▐ 表格进入表格配置页面。使用的表示方法与 Excel 表格非常相似。您可以为表格的每一列设置不同的属性、类型等。共提供了 15 个常用组件,包括与数据相关的字段。配置完成后的效果就是最终数据呈现的效果。
如果表单配置表单不符合企业的使用习惯,伙伴云也提供表单配置表单,您可以拖放相应的组件来完成配置。与表单相比,表单表单增加了选项卡和布局字段,并且支持表单内的分页。用户可以在表单中添加分表、仪表盘等内容,表单呈现更加丰富。
表单可以通过Excel导入,在线配置生成,也可以通过链接共享,实现与外部合作伙伴的协作。同时,权限的控制也更加细致,可以配置操作、字段、过滤、显示等权限。
▐流程虽然Partner Cloud是一个偏向于数据采集的低代码开发平台,但流程引擎功能也毫不含糊,可以说是优秀的。不同于一般平台只支持一种流程规范,Partner Cloud根据业务需求提供工作流引擎和流程引擎,分别遵循IFTTT和BPMN2.0规范。工作流引擎满足一系列自动触发操作。例如,当数据添加到表单时,它会自动向相应的用户发送消息,并进行汇总计算以将结算存储在另一个表单中。流程引擎满足了需要人工参与的传统审批流程业务,这里不再赘述。前者是自动流,后者是人工流动。工作流引擎配置需要一定的逻辑思维和熟悉EXCEL公式,包括触发方式、全局放置图、触发条件和执行操作等,主要满足数据计算、操作、消息通知等需求,可以通过数据创建和修改。、删除等操作触发相关流程,结束后可自动创建数据、发送通知等后续操作。并且可以通过数据来创建和修改。、删除等操作触发相关流程,结束后可自动创建数据、发送通知等后续操作。并且可以通过数据来创建和修改。、删除等操作触发相关流程,结束后可自动创建数据、发送通知等后续操作。
Partner Cloud 的流程引擎有两种配置方式。一是审批流程配置,简单、直接、线性到底。另一个是业务流,遵循BPMN2.0规范的配置方式,可以触发工作流和子流程,可以满足多规则多权限的复杂业务流程。
审批流程配置
业务流程配置
▐ 数据仓库伙伴云不仅提供数据采集的表格功能,还提供数据统计分析功能。它将来自多个数据源的数据聚合起来,形成一个可以分析的聚合表,然后以图形的形式呈现数据。形成仪表板页面。首先,在数据汇总计算部分,可以对多个sheet数据进行统计、过滤、合并、计算,形成汇总表。这个功能类似于剑道云的聚合表+数据工厂,配置方法也类似。通过可视化配置,可以从多种表格中轻松获取所需数据。
数据分析部分,也称为报表功能,显示在仪表板中。提供11种图表,支持多维展示、数据展示、对比等操作。同时,图表还提供了自由钻孔和路径钻孔两种钻孔模式,使图表分析更加灵活。
▐ Dashboard Partner Cloud 的dashboard 与之前对剑道云的dashboard 评价有些不同。Partner Cloud 的仪表板可以看作是一个摘要页面。除了上面提到的报表,还可以放其他13个组件,比如统计、流程、日历、图片框、文字内容、快速录入、扫码等,可以组合成活动页面等自定义页面、门户页面和工作台。
▐ 低码伙伴云不提供低码扩展能力,但为了不影响平台本身的易用性,满足不同用户的个性化需求,为开发者提供了一个开放的平台。开放平台提供云存储接口和表应用原生组件等服务,让开发者可以在合作伙伴云上开发嵌入式应用,或者使用云存储服务开发原生应用。嵌入式应用是Partner Cloud的一个特点,可以基于数据接口开发应用,形成其提供的原生组件。这些应用程序可以发布到市场并由用户安装。例如,合作伙伴云原生视图都是类似 EXCEL 的表格样式。当用户需要卡片式列表时,他们可以通过其开放平台和 SDK 功能开发卡片视图应用程序。当应用被某个表安装时,表中会多出一个应用入口,切换到这个应用可以将数据以卡片的形式呈现。优缺点分析 以数据管理为核心的优势 合作伙伴云最初主要用于在线数据的采集、共享和协作,但目前合作伙伴云可以做的远不止这些。平台以数据管理为核心,同时提供数据审批、流程、数据处理、报表、页面等功能,让数据为企业带来更多价值。数百个表单模板合作伙伴云经过长时间的沉淀与用户和合作伙伴积累了数百个表单模板,涵盖电商、互联网、教育、房地产、物流等行业,不仅减少了客户从零开始配置的工作量,也为用户配置提供了一定的参考。手机APP与剑道云、易达等产品的区别在于伙伴云有自己的手机APP,不完全依赖微信、钉钉等平台,可以使用伙伴云APP进行添加、搜索、添加数据在移动终端上。修订。亿达等产品是伙伴云有自己的手机APP,不完全依赖微信、钉钉等平台,可通过伙伴云APP在移动端进行添加、搜索、添加数据。修订。亿达等产品是伙伴云有自己的手机APP,不完全依赖微信、钉钉等平台,可通过伙伴云APP在移动端进行添加、搜索、添加数据。修订。
当然伙伴云也支持在企业微信上安装使用,用户可以根据实际情况使用。构建应用程序的能力不足。目前,在合作伙伴云中,表格中的数据显示方式只有一种。和亿达/明道云/七巧Plus等其他产品相比,会稍微简单一些(但还是留下了表单嵌入应用。)。当然,这确实是吹毛求疵。就Partner Cloud这个企业运营数据可视化平台的定位而言,其产品能力和成熟度确实无可挑剔,但按照应用开发平台的标准来看,确实是面向管理的。应用程序更面向数据可视化和数据管理。商业模式与持续生存▐商业模式伙伴云目前有三个付费版本,自建小微企业标准版(199元/人/年,30人起);需要定制服务的中小企业标准版定制版(599元/人/年,100人起);旗舰版,面向对数据量和自动化要求较高,或期望独立形象的企事业单位(1299元/人/年,100人起)。付费版除了增加各模块的数据量外,还增加了一些个性化功能,如手写签名、数据大屏、支付、数据对接等功能。伙伴云的商业模式经历了全面的免费收费、模块收费、当前平台订阅收费,并逐渐向定制化收费模式扩展。目前的用户数量应该相当可观。▐ 可持续生存的合作伙伴云由明星团队运营。经过近八年的打磨,已经从基于表管理数据的SaaS发展成为服务于企业运营的数据可视化平台。累计企业用户10万。此外,它还获得了世界顶级风险投资商山资本和晨兴资本两家全球顶级风险投资机构数百万美元的A轮联合投资,其持续生存能力不容小觑。并逐渐扩展到定制化收费模式。目前的用户数量应该相当可观。▐ 可持续生存的合作伙伴云由明星团队运营。经过近八年的打磨,已经从基于表管理数据的SaaS发展成为服务于企业运营的数据可视化平台。累计企业用户10万。此外,它还获得了世界顶级风险投资商山资本和晨兴资本两家全球顶级风险投资机构数百万美元的A轮联合投资,其持续生存能力不容小觑。并逐渐扩展到定制化收费模式。目前的用户数量应该相当可观。▐ 可持续生存的合作伙伴云由明星团队运营。经过近八年的打磨,已经从基于表管理数据的SaaS发展成为服务于企业运营的数据可视化平台。累计企业用户10万。此外,它还获得了世界顶级风险投资商山资本和晨兴资本两家全球顶级风险投资机构数百万美元的A轮联合投资,其持续生存能力不容小觑。它已经从基于表管理数据的SaaS发展成为服务于企业运营的数据可视化平台。累计企业用户10万。此外,它还获得了世界顶级风险投资商山资本和晨兴资本两家全球顶级风险投资机构数百万美元的A轮联合投资,其持续生存能力不容小觑。它已经从基于表管理数据的SaaS发展成为服务于企业运营的数据可视化平台。累计企业用户10万。此外,它还获得了世界顶级风险投资商山资本和晨兴资本两家全球顶级风险投资机构数百万美元的A轮联合投资,其持续生存能力不容小觑。
经过八年客户画像的发展,伙伴云已经积累了10万企业用户。主要客户为中小企业,客户行业覆盖面广,如电子商务、IT互联网、教育培训、房产中介等。 评价结论 合作伙伴云综合评分 好用:★ ★★★基础能力:★★★★数据管理:★★★★API能力:★★★低代码能力:★★性价比:★★★模板质量:★★★风格交互:★★★★整体评分:★★★★选型建议:1、主要基于数据管理需求,对数据分析和可视化要求更高的可以考虑。2、专注于数据的使用采集、审批流程、数据处理等部分,可以使用伙伴云。3、 Partner Cloud可以作为轻量级的数据采集工具和在线协作EXCEL文档。体验比一般的在线文档更好,更完整。目前拥有独立的手机APP,可以在企业微信和飞书上使用。国内主流低代码开发PaaS平台的评测已经结束。接下来,我们将扩大视野,评估一些低代码开发平台的替代产品。一方面,它是一个更轻量级的产品零代码平台。还将审查更重量级的平台 - 快速开发平台(其中一些甚至没有云架构)。您想先看哪个产品?可以关注我们,在后台给我们留言~声明:此评价仅代表作者个人观点,并且没有与产品相关的利益。相关资料及截图均来自网络公开资料、产品官方渠道及作者使用体验。如有偏差,您可以联系我们,我们核实后会做勘误。
云优采集接口(优云UEM开源网址:可视化埋点可视化开源(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-04-13 17:15
优云UEM开源网址:
UYUNUEM是一款集Web应用和移动应用体验监控为一体的监控系统。通过详细记录真实的用户行为,我们可以了解用户的数字化体验是否足够好,帮助开发和运维团队更好地做数据基础。做决定。 UYUNUEM可以帮助团队建立以用户为中心的指标衡量体系,根据组织实际业务提升应用体验。
完整数据采集
无论是网页、移动原生应用还是混合应用,都可以通过UEM的采集探针完成采集。 UEM采集收录各种数据,包括会话、PV、点击、性能、错误等,当出现体验问题时可以轻松追溯。
视觉埋葬
可视化埋点,即以可视化的方式“圈出”需要跟踪的页面或元素,重点关注关键接口和功能,从而更容易按照一定的规则汇总分析各种关键指标.
用户操作体验分析
产品开发和运维团队往往希望产品一上线就获得体验数据。游云UEM提供了不同的SDK(包括JS、Android、iOS等平台),可以很方便的嵌入到应用捕获中获取常用的体验指标。
前端体验问题深度诊断
数据显示,70%以上的体验问题发生在客户端,因此前端体验问题的诊断就变得极为重要。 Youyun UEM 为开发者和测试者提供了友好的诊断视图,并深度跟踪缓慢的交互和错误。发生的具体过程。
用户行为跟踪
用户行为背后有一个故事,其背后的行为动机影响着关键任务的完成率和转化率。优云UEM通过用户行为轨迹跟踪分析问题,检查用户是否受到体验或功能原因的影响,并采取后续措施解决问题,提供准确的数据和验证方法。
指示灯异常警告
当应用程序性能下降时,用户会提前感知到,如果此时开始介入并采取积极措施,可以防止事态进一步升级。优云UEM可以为关键体验指标设置阈值,并提供实时预警,第一时间发现和定位问题。 查看全部
云优采集接口(优云UEM开源网址:可视化埋点可视化开源(组图))
优云UEM开源网址:
UYUNUEM是一款集Web应用和移动应用体验监控为一体的监控系统。通过详细记录真实的用户行为,我们可以了解用户的数字化体验是否足够好,帮助开发和运维团队更好地做数据基础。做决定。 UYUNUEM可以帮助团队建立以用户为中心的指标衡量体系,根据组织实际业务提升应用体验。
完整数据采集
无论是网页、移动原生应用还是混合应用,都可以通过UEM的采集探针完成采集。 UEM采集收录各种数据,包括会话、PV、点击、性能、错误等,当出现体验问题时可以轻松追溯。
视觉埋葬
可视化埋点,即以可视化的方式“圈出”需要跟踪的页面或元素,重点关注关键接口和功能,从而更容易按照一定的规则汇总分析各种关键指标.
用户操作体验分析
产品开发和运维团队往往希望产品一上线就获得体验数据。游云UEM提供了不同的SDK(包括JS、Android、iOS等平台),可以很方便的嵌入到应用捕获中获取常用的体验指标。
前端体验问题深度诊断
数据显示,70%以上的体验问题发生在客户端,因此前端体验问题的诊断就变得极为重要。 Youyun UEM 为开发者和测试者提供了友好的诊断视图,并深度跟踪缓慢的交互和错误。发生的具体过程。
用户行为跟踪
用户行为背后有一个故事,其背后的行为动机影响着关键任务的完成率和转化率。优云UEM通过用户行为轨迹跟踪分析问题,检查用户是否受到体验或功能原因的影响,并采取后续措施解决问题,提供准确的数据和验证方法。
指示灯异常警告
当应用程序性能下降时,用户会提前感知到,如果此时开始介入并采取积极措施,可以防止事态进一步升级。优云UEM可以为关键体验指标设置阈值,并提供实时预警,第一时间发现和定位问题。
云优采集接口( 监控和日志是大型分布式系统的重要:云原生应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-04-10 16:04
监控和日志是大型分布式系统的重要:云原生应用)
监控和日志记录是大型分布式系统的重要基础设施:监控可以帮助开发者看到系统的运行状态,而日志记录可以帮助排查和诊断问题。
云原生应用程序是分布式和动态的,所有此类应用程序通常使用容器和无服务器功能等临时技术进行部署。在管理这些云原生应用程序时,能够在任何给定时间提供端到端可见性非常重要。同时,由于云原生系统的海量数据流和抽象复杂性,我们必须建立强大的监控和日志记录来管理各种不可预测的中断或中断。
没有监控就无法知道服务的运行状态,也无法知道集群中是否有Down机器,机器的CPU使用率和负载是否正常,<< @网站 正常,服务的错误率是否可以接受。在公差范围内。日志详细记录了系统的运行情况。每个服务调用和每个数据库访问都应该写入日志,尤其是当系统出现问题时。
在开源社区中,最常用的监控方案是 Prometheus,甚至成为了开源社区的监控标准。首先,Prometheus 是 CNCF 云原生社区的毕业项目。越来越多的开源项目使用 Prometheus 作为监控标准。与我们常见的 Spark、Tensorflow 和 Flink 项目类似,都有标准的 Prometheus采集 接口。. 此外,一些常见的数据库和中间件项目也有对应的 Prometheus采集 客户端,包括 ETCD、Zookeeper、MySQL、PostgreSQL,它们都有对应的 Prometheus 接口或对应的接口实现的导出器。
在日志解决方案方面,EFK(Elasticsearch、Fluentd、Kibana)是云原生领域最主流的日志管理解决方案。它们的架构旨在处理大规模数据分析并实时显示结果。其中,Fluentd 会在每个节点上启动一个对应的代理,然后代理将数据聚合到 Fluentd 的一个服务器上,该服务器可以将数据下线到一个对应的类似 ElasticSearch 的地方,然后通过 kibana 展示出来,或者下线到 Influxdb,然后通过 Grafana 显示。
基于此,为了让开发者学习到更多干货,京东智联云开发者特意策划了《六周玩云原生》系列课程,让你快速上手,持续充电。而4月14日,“第四讲:走近监控日志,探索云原生基础”将是一场盛大的讲座!在本次公开课中,京东云及其架构师高云川将与学员们共同探讨记录和监控云原生应用时值得学习和遵循的各种优秀实践和标准,分享京东智联云在云上的经验——本机监控和监控。记录的做法。
高云川 京东云和架构师
8年自动化运维平台研发经验。2016年加入京东云和AI,负责云监控系统建设,在监控、日志、事件等可观察性领域有丰富的实践经验。
在本次公开课中,高云川老师将从理解云原生下可观察性的含义入手,从数据的角度来理解Prometheus和Flunted的监控日志解决方案。通过京东智联云的云原生监控日志实践,探讨如何复用开源能力来满足业务需求。
▐ 学习要点:
1、云原生可观察性
2、基于Prometheus的监控方案介绍
3、基于 EFK 的日志记录方案介绍
4、京东智联云在云原生监控日志中的实现
那么,这门课程适合哪些人呢?只要你是:运维、研发工程师、学生,或者对运维、微服务等感兴趣的个人或企业,都适合报名本次公开课!快长按下方二维码或点击文末“阅读原文”进行报名吧!
注意!!报名成功后,开课前会有短信/邮件提醒,报名时请填写正确的手机号和邮箱!
▐ 课程安排如下 查看全部
云优采集接口(
监控和日志是大型分布式系统的重要:云原生应用)
监控和日志记录是大型分布式系统的重要基础设施:监控可以帮助开发者看到系统的运行状态,而日志记录可以帮助排查和诊断问题。
云原生应用程序是分布式和动态的,所有此类应用程序通常使用容器和无服务器功能等临时技术进行部署。在管理这些云原生应用程序时,能够在任何给定时间提供端到端可见性非常重要。同时,由于云原生系统的海量数据流和抽象复杂性,我们必须建立强大的监控和日志记录来管理各种不可预测的中断或中断。
没有监控就无法知道服务的运行状态,也无法知道集群中是否有Down机器,机器的CPU使用率和负载是否正常,<< @网站 正常,服务的错误率是否可以接受。在公差范围内。日志详细记录了系统的运行情况。每个服务调用和每个数据库访问都应该写入日志,尤其是当系统出现问题时。
在开源社区中,最常用的监控方案是 Prometheus,甚至成为了开源社区的监控标准。首先,Prometheus 是 CNCF 云原生社区的毕业项目。越来越多的开源项目使用 Prometheus 作为监控标准。与我们常见的 Spark、Tensorflow 和 Flink 项目类似,都有标准的 Prometheus采集 接口。. 此外,一些常见的数据库和中间件项目也有对应的 Prometheus采集 客户端,包括 ETCD、Zookeeper、MySQL、PostgreSQL,它们都有对应的 Prometheus 接口或对应的接口实现的导出器。
在日志解决方案方面,EFK(Elasticsearch、Fluentd、Kibana)是云原生领域最主流的日志管理解决方案。它们的架构旨在处理大规模数据分析并实时显示结果。其中,Fluentd 会在每个节点上启动一个对应的代理,然后代理将数据聚合到 Fluentd 的一个服务器上,该服务器可以将数据下线到一个对应的类似 ElasticSearch 的地方,然后通过 kibana 展示出来,或者下线到 Influxdb,然后通过 Grafana 显示。
基于此,为了让开发者学习到更多干货,京东智联云开发者特意策划了《六周玩云原生》系列课程,让你快速上手,持续充电。而4月14日,“第四讲:走近监控日志,探索云原生基础”将是一场盛大的讲座!在本次公开课中,京东云及其架构师高云川将与学员们共同探讨记录和监控云原生应用时值得学习和遵循的各种优秀实践和标准,分享京东智联云在云上的经验——本机监控和监控。记录的做法。
高云川 京东云和架构师
8年自动化运维平台研发经验。2016年加入京东云和AI,负责云监控系统建设,在监控、日志、事件等可观察性领域有丰富的实践经验。
在本次公开课中,高云川老师将从理解云原生下可观察性的含义入手,从数据的角度来理解Prometheus和Flunted的监控日志解决方案。通过京东智联云的云原生监控日志实践,探讨如何复用开源能力来满足业务需求。
▐ 学习要点:
1、云原生可观察性
2、基于Prometheus的监控方案介绍
3、基于 EFK 的日志记录方案介绍
4、京东智联云在云原生监控日志中的实现
那么,这门课程适合哪些人呢?只要你是:运维、研发工程师、学生,或者对运维、微服务等感兴趣的个人或企业,都适合报名本次公开课!快长按下方二维码或点击文末“阅读原文”进行报名吧!
注意!!报名成功后,开课前会有短信/邮件提醒,报名时请填写正确的手机号和邮箱!
▐ 课程安排如下
云优采集接口(云优采集接口可以实现您的目的,不用注册)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-04-09 02:01
云优采集接口可以实现您的目的,不用注册,不用投入资金,免费使用云优采集公众号之前是用一个网站+云优采集公众号,云优采集公众号是个人注册的账号,据说这个账号对新手不是很友好,可以做点微小的贡献,但没有收益,所以转换成企业账号之后,云优采集功能,使用起来也很方便的,不需要注册,可以去除重复的内容,也不需要修改号码和公众号,也不需要付费,很快便可以实现。经常打电话,发邮件请求注册可以,我们诚恳的给您进行不收费,不收取代理费用。
骗人的
我可以提供。
听说很不错,云优采集可以按照指定网站进行内容搜索并订阅。
云优采集支持个人版,公司版,还有商用版的。看个人的需求。
云优网还不错,主要是不收钱,安全性高。
还不错的
我这边有云优网平台的批量采集代理。你想了解的话,
我只需要一个云优网代理一台电脑,方便的。
云优采集平台,云优网平台,
你只需要一台电脑和云优网代理一个网站就可以开始实践了!
云优网已经实现
大公司,专业做,可以做什么,
这个怎么样
云优采集有实力的可以了解下
利用云优采集采集的和其他的网站进行公众号内容全站采集到我的云优采集表格里面。支持一键修改一键投票等等。每天采集8千条内容。成本几块钱。一天收入几百块。定位针对微信公众号粉丝做内容。 查看全部
云优采集接口(云优采集接口可以实现您的目的,不用注册)
云优采集接口可以实现您的目的,不用注册,不用投入资金,免费使用云优采集公众号之前是用一个网站+云优采集公众号,云优采集公众号是个人注册的账号,据说这个账号对新手不是很友好,可以做点微小的贡献,但没有收益,所以转换成企业账号之后,云优采集功能,使用起来也很方便的,不需要注册,可以去除重复的内容,也不需要修改号码和公众号,也不需要付费,很快便可以实现。经常打电话,发邮件请求注册可以,我们诚恳的给您进行不收费,不收取代理费用。
骗人的
我可以提供。
听说很不错,云优采集可以按照指定网站进行内容搜索并订阅。
云优采集支持个人版,公司版,还有商用版的。看个人的需求。
云优网还不错,主要是不收钱,安全性高。
还不错的
我这边有云优网平台的批量采集代理。你想了解的话,
我只需要一个云优网代理一台电脑,方便的。
云优采集平台,云优网平台,
你只需要一台电脑和云优网代理一个网站就可以开始实践了!
云优网已经实现
大公司,专业做,可以做什么,
这个怎么样
云优采集有实力的可以了解下
利用云优采集采集的和其他的网站进行公众号内容全站采集到我的云优采集表格里面。支持一键修改一键投票等等。每天采集8千条内容。成本几块钱。一天收入几百块。定位针对微信公众号粉丝做内容。
云优采集接口(云优采集接口采集几十个电商平台的数据分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2022-04-05 22:07
云优采集接口是正规的,接口稳定,速度快,质量好。
都是正规的云采集接口,质量保证,最快一小时采集完毕,可以托管,省时省力,省去采集店铺宝贝的烦恼,全网数据资源采集全新的一种模式,能为人们轻松采集全网全品类,高佣金,高技术,高质量的数据。无论任何行业,任何行业,只要开网店都必须要数据,任何事物都不可能一成不变,电商行业自然也不例外,所以就需要采集数据,千变万化的市场,当然需要不断的运营调整自己。
云优采集接口,对一个企业来说,数据源是十分重要的。大家都知道,现在有很多知名品牌都具有自己的数据采集公司,有的甚至是独立的工作室,不仅获得了很高的利润,而且,还可以获得大批量的客户,企业采集数据,获得有效,又足够精准的客户流量,那么这个数据就是一笔大大的财富。云优采集接口软件可以帮助企业采集到电商平台的数据。
从而进行数据筛选,实现数据的全面采集和采集;采集高流量数据,实现采集的精准;实现多流量时代的不断转变。云优采集接口采集几十个电商平台的数据,为各大电商行业提供有效的数据分析与专业化的技术服务;实现低成本的数据采集、采集持续精准的数据、升级升级再升级数据,让我们的数据量不断的增加,所以云优采集接口还是比较好的。
云优采集接口采集热门商品数据,商品数据本身优质。经过分析深度分析,把实体商品变成网络销售商品,高流量,商品数据采集,量产,快速实现产品数据的精准采集。免费为企业打造网络数据管理规范系统,主要有:网络数据采集编辑器;浏览器插件;手机app;手机网站;企业网站商品目录;云优网站随时随地实现上传商品,管理商品,合并商品,组合商品,数据下钻,数据深钻,存储分析,智能分析。
最终实现线上网店数据全面,全天候随时随地管理实体商品,更有利于传统行业的转型升级;最终实现网络交易全过程电子化;云优采集接口的接口页有差异,在付款回执上也有差异;云优采集接口相关维护指导多种客服方式,公司一直为云优接口提供技术支持,为企业提供一站式服务。通过不断地积累为客户提供更专业,更高效的服务。实现互联网金融,理财,游戏,广告,汽车,母婴,工业,零售等领域的全面电商采集。
好的接口,可以在网上获得信任度、被感知、被信任、转换率。云优采集接口的优势就是接口质量好,质量有保证;接口对接资质齐全,接口稳定、加载速度快、下单及时;接口协议精准,提升转化率;接口全方位支持被爬取的网站,可实现多站点多地区的全覆盖;接口性能强大,不同实力、不同网站不同反爬措施;接口全国范围。 查看全部
云优采集接口(云优采集接口采集几十个电商平台的数据分析)
云优采集接口是正规的,接口稳定,速度快,质量好。
都是正规的云采集接口,质量保证,最快一小时采集完毕,可以托管,省时省力,省去采集店铺宝贝的烦恼,全网数据资源采集全新的一种模式,能为人们轻松采集全网全品类,高佣金,高技术,高质量的数据。无论任何行业,任何行业,只要开网店都必须要数据,任何事物都不可能一成不变,电商行业自然也不例外,所以就需要采集数据,千变万化的市场,当然需要不断的运营调整自己。
云优采集接口,对一个企业来说,数据源是十分重要的。大家都知道,现在有很多知名品牌都具有自己的数据采集公司,有的甚至是独立的工作室,不仅获得了很高的利润,而且,还可以获得大批量的客户,企业采集数据,获得有效,又足够精准的客户流量,那么这个数据就是一笔大大的财富。云优采集接口软件可以帮助企业采集到电商平台的数据。
从而进行数据筛选,实现数据的全面采集和采集;采集高流量数据,实现采集的精准;实现多流量时代的不断转变。云优采集接口采集几十个电商平台的数据,为各大电商行业提供有效的数据分析与专业化的技术服务;实现低成本的数据采集、采集持续精准的数据、升级升级再升级数据,让我们的数据量不断的增加,所以云优采集接口还是比较好的。
云优采集接口采集热门商品数据,商品数据本身优质。经过分析深度分析,把实体商品变成网络销售商品,高流量,商品数据采集,量产,快速实现产品数据的精准采集。免费为企业打造网络数据管理规范系统,主要有:网络数据采集编辑器;浏览器插件;手机app;手机网站;企业网站商品目录;云优网站随时随地实现上传商品,管理商品,合并商品,组合商品,数据下钻,数据深钻,存储分析,智能分析。
最终实现线上网店数据全面,全天候随时随地管理实体商品,更有利于传统行业的转型升级;最终实现网络交易全过程电子化;云优采集接口的接口页有差异,在付款回执上也有差异;云优采集接口相关维护指导多种客服方式,公司一直为云优接口提供技术支持,为企业提供一站式服务。通过不断地积累为客户提供更专业,更高效的服务。实现互联网金融,理财,游戏,广告,汽车,母婴,工业,零售等领域的全面电商采集。
好的接口,可以在网上获得信任度、被感知、被信任、转换率。云优采集接口的优势就是接口质量好,质量有保证;接口对接资质齐全,接口稳定、加载速度快、下单及时;接口协议精准,提升转化率;接口全方位支持被爬取的网站,可实现多站点多地区的全覆盖;接口性能强大,不同实力、不同网站不同反爬措施;接口全国范围。
云优采集接口(用网页数据抓取工具了解一下爱采集你在进行时)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-03-30 11:05
云优采集接口可以实现数据抓取的转发、互发、互用、互导、取消抓取、多条件数据推送、推送抓取列表、实现多种传统数据抓取效果
云优采集接口,是一个网站数据抓取接口,适用于:自媒体、资讯、图片、电商、搜索引擎等几乎所有网站。采集效率高,可对多条件进行抓取,采集速度提升两三倍。可对网站进行标题、描述、图片、链接、价格、数量等要素的有效过滤。
用网页数据抓取工具了解一下爱采集
你在进行网站抓取的时候,是不是经常使用网站api,当网站api服务器的服务器有问题的时候,其他人就无法抓取,那么什么是网站api服务器呢?你在抓取网站的时候可以使用网站api服务器的服务器,就是网站api服务器,这个服务器就和我们用的互联网上面的网站服务器差不多,比如谷歌,百度等等,这个你需要懂得一些计算机知识,最少也要懂得一些java的程序编程知识,才能编写一个网站api程序。
不然你就抓取不了,比如当网站服务器出现问题时,你的网站api服务器没有响应,或者发生冲突了,你怎么抓取,这个时候怎么办,你只能自己上去抓,别人帮不了你,你会很麻烦,或者你想一个人弄,你不懂编程,只能一个人抓取一些后台数据,这是一个比较麻烦的事情,需要爬虫基础、编程基础。这里推荐一款api编程工具,网站抓取的api编程,你可以自己编写一个属于自己的网站api服务器,利用这个网站抓取api工具,来实现抓取任何网站任何网站,按照上面说的教程操作,一个人就可以弄一个网站api服务器,包括程序和网站数据文件,你可以试一下。 查看全部
云优采集接口(用网页数据抓取工具了解一下爱采集你在进行时)
云优采集接口可以实现数据抓取的转发、互发、互用、互导、取消抓取、多条件数据推送、推送抓取列表、实现多种传统数据抓取效果
云优采集接口,是一个网站数据抓取接口,适用于:自媒体、资讯、图片、电商、搜索引擎等几乎所有网站。采集效率高,可对多条件进行抓取,采集速度提升两三倍。可对网站进行标题、描述、图片、链接、价格、数量等要素的有效过滤。
用网页数据抓取工具了解一下爱采集
你在进行网站抓取的时候,是不是经常使用网站api,当网站api服务器的服务器有问题的时候,其他人就无法抓取,那么什么是网站api服务器呢?你在抓取网站的时候可以使用网站api服务器的服务器,就是网站api服务器,这个服务器就和我们用的互联网上面的网站服务器差不多,比如谷歌,百度等等,这个你需要懂得一些计算机知识,最少也要懂得一些java的程序编程知识,才能编写一个网站api程序。
不然你就抓取不了,比如当网站服务器出现问题时,你的网站api服务器没有响应,或者发生冲突了,你怎么抓取,这个时候怎么办,你只能自己上去抓,别人帮不了你,你会很麻烦,或者你想一个人弄,你不懂编程,只能一个人抓取一些后台数据,这是一个比较麻烦的事情,需要爬虫基础、编程基础。这里推荐一款api编程工具,网站抓取的api编程,你可以自己编写一个属于自己的网站api服务器,利用这个网站抓取api工具,来实现抓取任何网站任何网站,按照上面说的教程操作,一个人就可以弄一个网站api服务器,包括程序和网站数据文件,你可以试一下。
云优采集接口( _本篇、简洁化的指标数据基本结构(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-03-28 09:01
_本篇、简洁化的指标数据基本结构(组图))
由于 Kubernetes 成为容器管理的事实标准,云原生就是 Kubernetes 原生。云系统下,基础硬件基本被抽象化和模糊化,需要人为干预的硬故障发生频率逐渐降低。更少的失败。随着服务的拆分和模块的堆叠,难以描述、模棱两可、莫名其妙的故障比以前更加频繁。
“看指标”只是数据的简单呈现。在当前的云环境下,它并不能有效地帮助我们发现问题。“可观察性”体现的是对数据的再加工,旨在挖掘出数据背后隐藏的信息,不仅在展示数据的层面,还通过对数据的分析和重组来体现数据的上下文信息. .
为了实现“可观察性”的目标,需要更规范、更简洁的指标数据,以及更便捷的采集方式、更强更丰富的语义表达能力、更快更高效的存储能力。_本文文章将主要讨论时间序列指标的采集结构和采集方法。数据也指时间序列数据。跟踪、日志、事件等存储结构和监控形式不在本文讨论范围之内。之内。
说到时序数据,我们来看看监控系统中常用的几个时序数据库:_opentsdb、influxdb、prometheus_等。
大家对经典时间序列数据的基本结构有一个统一的认识:
唯一序列名称标识符,即指标名称;指标标签集,详细描述指标的维度;时间戳和值对,详细描述了指标在某个时间点的值。
时序数据的基本结构是指标名称+多个kv对的标签集+时间戳+值,但每个公司的细节不同。
1[
2{
3 "metric": "sys.cpu.nice",
4 "timestamp": 1346846400,
5 "value": 18,
6 "tags": {
7 "host": "web01",
8 "dc": "lga"
9 }
10},
11{
12 "metric": "sys.cpu.nice",
13 "timestamp": 1346846400,
14 "value": 9,
15 "tags": {
16 "host": "web02",
17 "dc": "lga"
18 }
19}
20]
opentsdb 使用的是众所周知的 json 格式,在用户的第一反应中可能是结构化的时序数据结构。任何了解基本时间序列数据结构的人,一眼就能理解每个字段的含义。
1[,=[,= ]] =[,=] []
2例如:
3cpu_load_short,host=server01,region=us-west value=0.64 1434055562000000000
1metric_name [
2"{" label_name "=" `"` label_value `"` { "," label_name "=" `"` label_value `"` } [ "," ] "}"
3] value [ timestamp ]
4例如:
5http_requests_total{method="post",code="200"} 1027 1395066363000
5&wx_lazy=1&wx_co=1)
influxdb和prometheus都使用自定义文本格式的时序数据描述,通过固定的语法格式将json的树状层次结构扁平化,并且没有语义损失,行级表示更易读。
wx_fmt=png&tp=webp&wxfrom=5&wx_lazy=1&wx_co=1)
使用过 Prometheus 的同学可能会注意到,Prometheus 的 采集 结构并不是单行的,每一种指标往往伴随着几行注释,其中主要有 HELP 和 TYPE 两种,其中分别代表指标的介绍和描述。种类。格式大致为:
1# Anything you want to say
2# HELP http_requests_total The total number of HTTP requests.
3# TYPE http_requests_total counter
4http_requests_total{method="post",code="200"} 1027 1395066363000
5http_requests_total{method="post",code="400"} 3 1395066363000
Prometheus 主要支持 4 类指标:
其中Counter和Gauge很好理解,而Histogram和Summary可能会让人一时糊涂。事实上,Histogram 和 Summary 都是为了解决和过滤不同维度的长尾问题而设计的。
例如,我自己和首富的平均身价并不能真实反映我自己的身价。因此,桶或分位数可以更准确地描述数据的真实分布状态。
直方图和摘要之间的主要区别在于分位数的计算。Histogram 只在客户端进行桶计算,所以整体分位数计算可以在服务端进行。Summary 在客户端环境中计算分位数,因此失去了在整体视图上计算分位数的可能性。官方还给出了Histogram和Summary的区别:
需要注意的是,截至目前的Prometheus版本2.20.1,这些metric类型只用在客户端库和wire协议中,服务器暂时不记录这些信息。所以如果使用 histogram_quantile(0.9,xxx) 作为 Gauge 类型的指标,也是可以的,但是因为没有 xxx_bucket,所以无法计算数值。
对于时序监控数据的采集,从监控端来说,数据获取只有拉取和推送两种形式。不同的采集方法也决定了不同的部署方式。
我们以opentsdb和prometheus为例,因为influxdb集群版方案是商业版,所以暂不讨论。
![]
上图为opentsdb架构图,其中:
从架构图中可以看出,如果推送形式的数据量大幅增加,通过使用多级组件或扩展无状态接收层,可以相对简单地提升吞吐量。
&tp=webp&wxfrom=5&wx_lazy=1&wx_co=1)
上图为prometheus架构图,主要看以下几部分:
拉取方式通常是监控终端定期从各个监控终端配置的Exporter中拉取指标。这种设计方法可以降低监控终端与被监控终端之间的耦合度,被监控终端不需要知道监控终端的存在,从而摆脱了监控终端向监控终端发送指标的压力。
比较 pull 和 push 方法的优缺点:
拉和推特性的简单比较。在云原生环境中,prometheus 是目前的时序监控标准。为什么选择拉的形式?这里是官方的解释()。
以上从监控端的角度简单介绍了数据采集的拉取和推送形式。从被监控端来看,获取数据的方式有很多种,通常可以分为以下几种:
默认采集探头采集组件采集埋点采集
下面是一个例子。
默认的采集通常是通俗意义上大家需要观察的基本指标,往往和业务没有强关联,比如cpu、内存、磁盘、net等硬件或系统指标。通常监控系统会有专门的agent来修复采集这些指标,使用云原生的node_exporter、CAdvisor、process-exporter分别对节点机器、容器、进程进行基本的监控非常方便。
探测采集主要是指从外部采集获取数据的手段。比如域名监控、站点监控、端口监控等都属于这一类。采集 的方法不会侵入系统。由于其对网络的依赖性强,通常会部署多个检测点,以减少网络问题导致的误报。但是,有必要非常小心。一定要评估检测采集@采集的频率,否则容易对被检测方造成请求压力。
通常是指已有的采集方案,详细的指标采集可以通过简单的操作或者配置进行,比如mysql监控、redis监控等。在云原生环境下,这个采集 方法比较常见。得益于prometheus的发展壮大,通用组件采集exporters层出不穷,各种exporter都通过prometheus官方认证。对于以下特殊或定制的需求,您也可以根据/metrics接口标准完成自定义导出器的编写。
对于一个系统的关键指标,研发学生自己是最有发言权的,通过埋点可以准确得到相关指标。在prometheus系统中,使用/prometheus/client_*工具包实现埋点采集非常方便。
本文从“采集结构”和“采集方法”两个方面对监控系统第一阶段“采集”进行了简要介绍和梳理。与以往相比,在云原生环境下,服务粒度更细化,迭代效率更高。从开发到上线形成了一个更快节奏的反馈回路,这也要求监控系统能够更快地反映。系统异常,虽然“采集结构”和“采集方法”不是监控系统的核心部分,但简洁的采集结构和方便的采集方法也在后续“可观察性”的实现提供了基础。目前,在云原生环境中, 查看全部
云优采集接口(
_本篇、简洁化的指标数据基本结构(组图))
由于 Kubernetes 成为容器管理的事实标准,云原生就是 Kubernetes 原生。云系统下,基础硬件基本被抽象化和模糊化,需要人为干预的硬故障发生频率逐渐降低。更少的失败。随着服务的拆分和模块的堆叠,难以描述、模棱两可、莫名其妙的故障比以前更加频繁。
“看指标”只是数据的简单呈现。在当前的云环境下,它并不能有效地帮助我们发现问题。“可观察性”体现的是对数据的再加工,旨在挖掘出数据背后隐藏的信息,不仅在展示数据的层面,还通过对数据的分析和重组来体现数据的上下文信息. .
为了实现“可观察性”的目标,需要更规范、更简洁的指标数据,以及更便捷的采集方式、更强更丰富的语义表达能力、更快更高效的存储能力。_本文文章将主要讨论时间序列指标的采集结构和采集方法。数据也指时间序列数据。跟踪、日志、事件等存储结构和监控形式不在本文讨论范围之内。之内。
说到时序数据,我们来看看监控系统中常用的几个时序数据库:_opentsdb、influxdb、prometheus_等。
大家对经典时间序列数据的基本结构有一个统一的认识:
唯一序列名称标识符,即指标名称;指标标签集,详细描述指标的维度;时间戳和值对,详细描述了指标在某个时间点的值。
时序数据的基本结构是指标名称+多个kv对的标签集+时间戳+值,但每个公司的细节不同。
1[
2{
3 "metric": "sys.cpu.nice",
4 "timestamp": 1346846400,
5 "value": 18,
6 "tags": {
7 "host": "web01",
8 "dc": "lga"
9 }
10},
11{
12 "metric": "sys.cpu.nice",
13 "timestamp": 1346846400,
14 "value": 9,
15 "tags": {
16 "host": "web02",
17 "dc": "lga"
18 }
19}
20]
opentsdb 使用的是众所周知的 json 格式,在用户的第一反应中可能是结构化的时序数据结构。任何了解基本时间序列数据结构的人,一眼就能理解每个字段的含义。
1[,=[,= ]] =[,=] []
2例如:
3cpu_load_short,host=server01,region=us-west value=0.64 1434055562000000000
1metric_name [
2"{" label_name "=" `"` label_value `"` { "," label_name "=" `"` label_value `"` } [ "," ] "}"
3] value [ timestamp ]
4例如:
5http_requests_total{method="post",code="200"} 1027 1395066363000
5&wx_lazy=1&wx_co=1)
influxdb和prometheus都使用自定义文本格式的时序数据描述,通过固定的语法格式将json的树状层次结构扁平化,并且没有语义损失,行级表示更易读。
wx_fmt=png&tp=webp&wxfrom=5&wx_lazy=1&wx_co=1)
使用过 Prometheus 的同学可能会注意到,Prometheus 的 采集 结构并不是单行的,每一种指标往往伴随着几行注释,其中主要有 HELP 和 TYPE 两种,其中分别代表指标的介绍和描述。种类。格式大致为:
1# Anything you want to say
2# HELP http_requests_total The total number of HTTP requests.
3# TYPE http_requests_total counter
4http_requests_total{method="post",code="200"} 1027 1395066363000
5http_requests_total{method="post",code="400"} 3 1395066363000
Prometheus 主要支持 4 类指标:
其中Counter和Gauge很好理解,而Histogram和Summary可能会让人一时糊涂。事实上,Histogram 和 Summary 都是为了解决和过滤不同维度的长尾问题而设计的。
例如,我自己和首富的平均身价并不能真实反映我自己的身价。因此,桶或分位数可以更准确地描述数据的真实分布状态。
直方图和摘要之间的主要区别在于分位数的计算。Histogram 只在客户端进行桶计算,所以整体分位数计算可以在服务端进行。Summary 在客户端环境中计算分位数,因此失去了在整体视图上计算分位数的可能性。官方还给出了Histogram和Summary的区别:
需要注意的是,截至目前的Prometheus版本2.20.1,这些metric类型只用在客户端库和wire协议中,服务器暂时不记录这些信息。所以如果使用 histogram_quantile(0.9,xxx) 作为 Gauge 类型的指标,也是可以的,但是因为没有 xxx_bucket,所以无法计算数值。
对于时序监控数据的采集,从监控端来说,数据获取只有拉取和推送两种形式。不同的采集方法也决定了不同的部署方式。
我们以opentsdb和prometheus为例,因为influxdb集群版方案是商业版,所以暂不讨论。
![]
上图为opentsdb架构图,其中:
从架构图中可以看出,如果推送形式的数据量大幅增加,通过使用多级组件或扩展无状态接收层,可以相对简单地提升吞吐量。
&tp=webp&wxfrom=5&wx_lazy=1&wx_co=1)
上图为prometheus架构图,主要看以下几部分:
拉取方式通常是监控终端定期从各个监控终端配置的Exporter中拉取指标。这种设计方法可以降低监控终端与被监控终端之间的耦合度,被监控终端不需要知道监控终端的存在,从而摆脱了监控终端向监控终端发送指标的压力。
比较 pull 和 push 方法的优缺点:
拉和推特性的简单比较。在云原生环境中,prometheus 是目前的时序监控标准。为什么选择拉的形式?这里是官方的解释()。
以上从监控端的角度简单介绍了数据采集的拉取和推送形式。从被监控端来看,获取数据的方式有很多种,通常可以分为以下几种:
默认采集探头采集组件采集埋点采集
下面是一个例子。
默认的采集通常是通俗意义上大家需要观察的基本指标,往往和业务没有强关联,比如cpu、内存、磁盘、net等硬件或系统指标。通常监控系统会有专门的agent来修复采集这些指标,使用云原生的node_exporter、CAdvisor、process-exporter分别对节点机器、容器、进程进行基本的监控非常方便。
探测采集主要是指从外部采集获取数据的手段。比如域名监控、站点监控、端口监控等都属于这一类。采集 的方法不会侵入系统。由于其对网络的依赖性强,通常会部署多个检测点,以减少网络问题导致的误报。但是,有必要非常小心。一定要评估检测采集@采集的频率,否则容易对被检测方造成请求压力。
通常是指已有的采集方案,详细的指标采集可以通过简单的操作或者配置进行,比如mysql监控、redis监控等。在云原生环境下,这个采集 方法比较常见。得益于prometheus的发展壮大,通用组件采集exporters层出不穷,各种exporter都通过prometheus官方认证。对于以下特殊或定制的需求,您也可以根据/metrics接口标准完成自定义导出器的编写。
对于一个系统的关键指标,研发学生自己是最有发言权的,通过埋点可以准确得到相关指标。在prometheus系统中,使用/prometheus/client_*工具包实现埋点采集非常方便。
本文从“采集结构”和“采集方法”两个方面对监控系统第一阶段“采集”进行了简要介绍和梳理。与以往相比,在云原生环境下,服务粒度更细化,迭代效率更高。从开发到上线形成了一个更快节奏的反馈回路,这也要求监控系统能够更快地反映。系统异常,虽然“采集结构”和“采集方法”不是监控系统的核心部分,但简洁的采集结构和方便的采集方法也在后续“可观察性”的实现提供了基础。目前,在云原生环境中,
云优采集接口( _本篇、简洁化的指标数据基本结构(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-03-28 08:22
_本篇、简洁化的指标数据基本结构(组图))
由于 Kubernetes 成为容器管理的事实标准,云原生就是 Kubernetes 原生。云系统下,基础硬件基本被抽象化和模糊化,需要人为干预的硬故障发生频率逐渐降低。更少的失败。随着服务的拆分和模块的堆叠,难以描述、模棱两可、莫名其妙的故障比以前更加频繁。
“看指标”只是数据的简单呈现。在当前的云环境下,它并不能有效地帮助我们发现问题。“可观察性”体现的是对数据的再加工,旨在挖掘出数据背后隐藏的信息,不仅在展示数据的层面,还通过对数据的分析和重组来体现数据的上下文信息. .
为了实现“可观察性”的目标,需要更规范、更简洁的指标数据,以及更便捷的采集方式、更强更丰富的语义表达能力、更快更高效的存储能力。_本文文章将主要讨论时间序列指标的采集结构和采集方法。数据也指时间序列数据。跟踪、日志、事件等存储结构和监控形式不在本文讨论范围之内。之内。
说到时序数据,我们来看看监控系统中常用的几个时序数据库:_opentsdb、influxdb、prometheus_等。
大家对经典时间序列数据的基本结构有一个统一的认识:
唯一序列名称标识符,即指标名称;指标标签集,详细描述指标的维度;时间戳和值对,详细描述了指标在某个时间点的值。
时序数据的基本结构是指标名称+多个kv对的标签集+时间戳+值,但每个公司的细节不同。
1[
2{
3 "metric": "sys.cpu.nice",
4 "timestamp": 1346846400,
5 "value": 18,
6 "tags": {
7 "host": "web01",
8 "dc": "lga"
9 }
10},
11{
12 "metric": "sys.cpu.nice",
13 "timestamp": 1346846400,
14 "value": 9,
15 "tags": {
16 "host": "web02",
17 "dc": "lga"
18 }
19}
20]
opentsdb 使用的是众所周知的 json 格式,在用户的第一反应中可能是结构化的时序数据结构。任何了解基本时间序列数据结构的人,一眼就能理解每个字段的含义。
1[,=[,= ]] =[,=] []
2例如:
3cpu_load_short,host=server01,region=us-west value=0.64 1434055562000000000
1metric_name [
2"{" label_name "=" `"` label_value `"` { "," label_name "=" `"` label_value `"` } [ "," ] "}"
3] value [ timestamp ]
4例如:
5http_requests_total{method="post",code="200"} 1027 1395066363000
5&wx_lazy=1&wx_co=1)
influxdb和prometheus都使用自定义文本格式的时序数据描述,通过固定的语法格式将json的树状层次结构扁平化,并且没有语义损失,行级表示更易读。
wx_fmt=png&tp=webp&wxfrom=5&wx_lazy=1&wx_co=1)
使用过 Prometheus 的同学可能会注意到,Prometheus 的 采集 结构并不是单行的,每一种指标往往伴随着几行注释,其中主要有 HELP 和 TYPE 两种,其中分别代表指标的介绍和描述。种类。格式大致为:
1# Anything you want to say
2# HELP http_requests_total The total number of HTTP requests.
3# TYPE http_requests_total counter
4http_requests_total{method="post",code="200"} 1027 1395066363000
5http_requests_total{method="post",code="400"} 3 1395066363000
Prometheus 主要支持 4 类指标:
其中Counter和Gauge很好理解,而Histogram和Summary可能会让人一时糊涂。事实上,Histogram 和 Summary 都是为了解决和过滤不同维度的长尾问题而设计的。
例如,我自己和首富的平均身价并不能真实反映我自己的身价。因此,桶或分位数可以更准确地描述数据的真实分布状态。
直方图和摘要之间的主要区别在于分位数的计算。Histogram 只在客户端进行桶计算,所以整体分位数计算可以在服务端进行。Summary 在客户端环境中计算分位数,因此失去了在整体视图上计算分位数的可能性。官方还给出了Histogram和Summary的区别:
需要注意的是,截至目前的Prometheus版本2.20.1,这些metric类型只用在客户端库和wire协议中,服务器暂时不记录这些信息。所以如果使用 histogram_quantile(0.9,xxx) 作为 Gauge 类型的指标,也是可以的,但是因为没有 xxx_bucket,所以无法计算数值。
对于时序监控数据的采集,从监控端来说,数据获取只有拉取和推送两种形式。不同的采集方法也决定了不同的部署方式。
我们以opentsdb和prometheus为例,因为influxdb集群版方案是商业版,所以暂不讨论。
![]
上图为opentsdb架构图,其中:
从架构图中可以看出,如果推送形式的数据量大幅增加,通过使用多级组件或扩展无状态接收层,可以相对简单地提升吞吐量。
&tp=webp&wxfrom=5&wx_lazy=1&wx_co=1)
上图为prometheus架构图,主要看以下几部分:
拉取方式通常是监控终端定期从各个监控终端配置的Exporter中拉取指标。这种设计方法可以降低监控终端与被监控终端之间的耦合度,被监控终端不需要知道监控终端的存在,从而摆脱了监控终端向监控终端发送指标的压力。
比较 pull 和 push 方法的优缺点:
拉和推特性的简单比较。在云原生环境中,prometheus 是目前的时序监控标准。为什么选择拉的形式?这里是官方的解释()。
以上从监控端的角度简单介绍了数据采集的拉取和推送形式。从被监控端来看,获取数据的方式有很多种,通常可以分为以下几种:
默认采集探头采集组件采集埋点采集
下面是一个例子。
默认的采集通常是通俗意义上大家需要观察的基本指标,往往和业务没有强关联,比如cpu、内存、磁盘、net等硬件或系统指标。通常监控系统会有专门的agent来修复采集这些指标,使用云原生的node_exporter、CAdvisor、process-exporter分别对节点机器、容器、进程进行基本的监控非常方便。
探测采集主要是指从外部采集获取数据的手段。比如域名监控、站点监控、端口监控等都属于这一类。采集 的方法不会侵入系统。由于其对网络的依赖性强,通常会部署多个检测点,以减少网络问题导致的误报。但是,有必要非常小心。一定要评估检测采集@采集的频率,否则容易对被检测方造成请求压力。
通常是指已有的采集方案,详细的指标采集可以通过简单的操作或者配置进行,比如mysql监控、redis监控等。在云原生环境下,这个采集 方法比较常见。得益于prometheus的发展壮大,通用组件采集exporters层出不穷,各种exporter都通过prometheus官方认证。对于以下特殊或定制的需求,您也可以根据/metrics接口标准完成自定义导出器的编写。
对于一个系统的关键指标,研发学生自己是最有发言权的,通过埋点可以准确得到相关指标。在prometheus系统中,使用/prometheus/client_*工具包实现埋点采集非常方便。
本文从“采集结构”和“采集方法”两个方面对监控系统第一阶段“采集”进行了简要介绍和梳理。与以往相比,在云原生环境下,服务粒度更细化,迭代效率更高。从开发到上线形成了一个更快节奏的反馈回路,这也要求监控系统能够更快地反映。系统异常,虽然“采集结构”和“采集方法”不是监控系统的核心部分,但简洁的采集结构和方便的采集方法也在后续“可观察性”的实现提供了基础。目前,在云原生环境中, 查看全部
云优采集接口(
_本篇、简洁化的指标数据基本结构(组图))
由于 Kubernetes 成为容器管理的事实标准,云原生就是 Kubernetes 原生。云系统下,基础硬件基本被抽象化和模糊化,需要人为干预的硬故障发生频率逐渐降低。更少的失败。随着服务的拆分和模块的堆叠,难以描述、模棱两可、莫名其妙的故障比以前更加频繁。
“看指标”只是数据的简单呈现。在当前的云环境下,它并不能有效地帮助我们发现问题。“可观察性”体现的是对数据的再加工,旨在挖掘出数据背后隐藏的信息,不仅在展示数据的层面,还通过对数据的分析和重组来体现数据的上下文信息. .
为了实现“可观察性”的目标,需要更规范、更简洁的指标数据,以及更便捷的采集方式、更强更丰富的语义表达能力、更快更高效的存储能力。_本文文章将主要讨论时间序列指标的采集结构和采集方法。数据也指时间序列数据。跟踪、日志、事件等存储结构和监控形式不在本文讨论范围之内。之内。
说到时序数据,我们来看看监控系统中常用的几个时序数据库:_opentsdb、influxdb、prometheus_等。
大家对经典时间序列数据的基本结构有一个统一的认识:
唯一序列名称标识符,即指标名称;指标标签集,详细描述指标的维度;时间戳和值对,详细描述了指标在某个时间点的值。
时序数据的基本结构是指标名称+多个kv对的标签集+时间戳+值,但每个公司的细节不同。
1[
2{
3 "metric": "sys.cpu.nice",
4 "timestamp": 1346846400,
5 "value": 18,
6 "tags": {
7 "host": "web01",
8 "dc": "lga"
9 }
10},
11{
12 "metric": "sys.cpu.nice",
13 "timestamp": 1346846400,
14 "value": 9,
15 "tags": {
16 "host": "web02",
17 "dc": "lga"
18 }
19}
20]
opentsdb 使用的是众所周知的 json 格式,在用户的第一反应中可能是结构化的时序数据结构。任何了解基本时间序列数据结构的人,一眼就能理解每个字段的含义。
1[,=[,= ]] =[,=] []
2例如:
3cpu_load_short,host=server01,region=us-west value=0.64 1434055562000000000
1metric_name [
2"{" label_name "=" `"` label_value `"` { "," label_name "=" `"` label_value `"` } [ "," ] "}"
3] value [ timestamp ]
4例如:
5http_requests_total{method="post",code="200"} 1027 1395066363000
5&wx_lazy=1&wx_co=1)
influxdb和prometheus都使用自定义文本格式的时序数据描述,通过固定的语法格式将json的树状层次结构扁平化,并且没有语义损失,行级表示更易读。
wx_fmt=png&tp=webp&wxfrom=5&wx_lazy=1&wx_co=1)
使用过 Prometheus 的同学可能会注意到,Prometheus 的 采集 结构并不是单行的,每一种指标往往伴随着几行注释,其中主要有 HELP 和 TYPE 两种,其中分别代表指标的介绍和描述。种类。格式大致为:
1# Anything you want to say
2# HELP http_requests_total The total number of HTTP requests.
3# TYPE http_requests_total counter
4http_requests_total{method="post",code="200"} 1027 1395066363000
5http_requests_total{method="post",code="400"} 3 1395066363000
Prometheus 主要支持 4 类指标:
其中Counter和Gauge很好理解,而Histogram和Summary可能会让人一时糊涂。事实上,Histogram 和 Summary 都是为了解决和过滤不同维度的长尾问题而设计的。
例如,我自己和首富的平均身价并不能真实反映我自己的身价。因此,桶或分位数可以更准确地描述数据的真实分布状态。
直方图和摘要之间的主要区别在于分位数的计算。Histogram 只在客户端进行桶计算,所以整体分位数计算可以在服务端进行。Summary 在客户端环境中计算分位数,因此失去了在整体视图上计算分位数的可能性。官方还给出了Histogram和Summary的区别:
需要注意的是,截至目前的Prometheus版本2.20.1,这些metric类型只用在客户端库和wire协议中,服务器暂时不记录这些信息。所以如果使用 histogram_quantile(0.9,xxx) 作为 Gauge 类型的指标,也是可以的,但是因为没有 xxx_bucket,所以无法计算数值。
对于时序监控数据的采集,从监控端来说,数据获取只有拉取和推送两种形式。不同的采集方法也决定了不同的部署方式。
我们以opentsdb和prometheus为例,因为influxdb集群版方案是商业版,所以暂不讨论。
![]
上图为opentsdb架构图,其中:
从架构图中可以看出,如果推送形式的数据量大幅增加,通过使用多级组件或扩展无状态接收层,可以相对简单地提升吞吐量。
&tp=webp&wxfrom=5&wx_lazy=1&wx_co=1)
上图为prometheus架构图,主要看以下几部分:
拉取方式通常是监控终端定期从各个监控终端配置的Exporter中拉取指标。这种设计方法可以降低监控终端与被监控终端之间的耦合度,被监控终端不需要知道监控终端的存在,从而摆脱了监控终端向监控终端发送指标的压力。
比较 pull 和 push 方法的优缺点:
拉和推特性的简单比较。在云原生环境中,prometheus 是目前的时序监控标准。为什么选择拉的形式?这里是官方的解释()。
以上从监控端的角度简单介绍了数据采集的拉取和推送形式。从被监控端来看,获取数据的方式有很多种,通常可以分为以下几种:
默认采集探头采集组件采集埋点采集
下面是一个例子。
默认的采集通常是通俗意义上大家需要观察的基本指标,往往和业务没有强关联,比如cpu、内存、磁盘、net等硬件或系统指标。通常监控系统会有专门的agent来修复采集这些指标,使用云原生的node_exporter、CAdvisor、process-exporter分别对节点机器、容器、进程进行基本的监控非常方便。
探测采集主要是指从外部采集获取数据的手段。比如域名监控、站点监控、端口监控等都属于这一类。采集 的方法不会侵入系统。由于其对网络的依赖性强,通常会部署多个检测点,以减少网络问题导致的误报。但是,有必要非常小心。一定要评估检测采集@采集的频率,否则容易对被检测方造成请求压力。
通常是指已有的采集方案,详细的指标采集可以通过简单的操作或者配置进行,比如mysql监控、redis监控等。在云原生环境下,这个采集 方法比较常见。得益于prometheus的发展壮大,通用组件采集exporters层出不穷,各种exporter都通过prometheus官方认证。对于以下特殊或定制的需求,您也可以根据/metrics接口标准完成自定义导出器的编写。
对于一个系统的关键指标,研发学生自己是最有发言权的,通过埋点可以准确得到相关指标。在prometheus系统中,使用/prometheus/client_*工具包实现埋点采集非常方便。
本文从“采集结构”和“采集方法”两个方面对监控系统第一阶段“采集”进行了简要介绍和梳理。与以往相比,在云原生环境下,服务粒度更细化,迭代效率更高。从开发到上线形成了一个更快节奏的反馈回路,这也要求监控系统能够更快地反映。系统异常,虽然“采集结构”和“采集方法”不是监控系统的核心部分,但简洁的采集结构和方便的采集方法也在后续“可观察性”的实现提供了基础。目前,在云原生环境中,
云优采集接口(免费数据采集软件的特点及特点介绍-免费seo排名软件接口)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-03-24 10:02
Free Data采集软件是一款基于关键词自动采集免费seo排名软件界面的免费seo排名软件,无需编写复杂采集规则,自动伪原创免费seo排行软件界面,自动发布内容的绿色软件。简单配置后,即可实现24小时不间断采集、伪原创和发布。是站长维护网站的首选软件。内置全网发布接口cms,也可以直接导出为txt格式到本地,是一款非常实用方便的采集软件。由于得到了广大站长朋友的永久免费支持,
功能介绍 免费SEO排名软件界面:
1、 自动去噪,可以自动过滤标题内容中的图片\网站\电话\QQ\邮件等信息;
2、这个数据采集软件不同于传统的采集模式,它可以根据设置的关键词执行采集、采集用户的好处是可以通过采集关键词的不同搜索结果自动采集最新发布的文章,以免搜索到一个或一个几个指定的站点是 采集 采集,降低了 采集 站点被搜索引擎判断为 采集 站点被搜索引擎惩罚的风险。
3、 各种伪原创 和优化方法来提高收录 率和关键词 排名 标题插入、内容插入、自动内部链接、内容过滤、URL 过滤、随机图片插入、常规发布等,以提升采集文章原创的性能,提高搜索引擎收录、网站和关键词的权重排名。
一个搜索引擎,其核心价值是为用户提供他/她最需要的结果。搜索引擎对网民的需求进行了统计。对于网民需求很少或没有需求的内容,即使你是原创,也可能会被搜索引擎忽略,因为它不想把资源浪费在无意义的内容上。对于网友需求量大的内容,收录应该会越来越快,但是因为收录的数量很多,就算你是原创,可能也很难挤进入排行榜。这么多用户选择使用采集免费seo排名软件界面!
一、使用数据采集软件需要注意网站结构规划?
1. 网址设计。URL 还可以收录 关键词。例如,如果您的 网站 是关于计算机的,那么您的 URL 可以收录“PC”,因为在搜索引擎眼中它通常是“计算机”的同义词。URL不宜过长,层级尽量不要超过4层。
2. 列设计。列通常与导航相关联。设计要考虑网站的整体主题,用户可能感兴趣的内容,列名最好是网站的几个主要的关键词,这样也方便导航权重的使用.
3. 关键词布局。理论上,每个内容页面都应该有它的核心关键词,同一个栏目下的文章应该尽可能的围绕关键词栏目转。一个简单粗暴的方法是直接使用列关键词的长尾关键字。
二、根据数据量设置动态、伪静态、静态采集
这不能一概而论,建议使用伪静态或静态。三者的区别在于是否生成静态文件以及URL格式是否为动态。生成静态文件本质上是为了加快访问速度,减少数据库查询,但是会不断增加占用的空间;伪静态仅通过 URL 重写来修改 URL。对于加速访问完全无效。动态和伪静态的区别仅在于 URL,带有问号和参数。
不同的网站 程序可能有不同的数据库操作效率。一般来说,如果内容页数小于10000,页面打开速度比较快,数据量较大,达到50000、100000甚至更多,通常需要考虑静态。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力! 查看全部
云优采集接口(免费数据采集软件的特点及特点介绍-免费seo排名软件接口)
Free Data采集软件是一款基于关键词自动采集免费seo排名软件界面的免费seo排名软件,无需编写复杂采集规则,自动伪原创免费seo排行软件界面,自动发布内容的绿色软件。简单配置后,即可实现24小时不间断采集、伪原创和发布。是站长维护网站的首选软件。内置全网发布接口cms,也可以直接导出为txt格式到本地,是一款非常实用方便的采集软件。由于得到了广大站长朋友的永久免费支持,
功能介绍 免费SEO排名软件界面:
1、 自动去噪,可以自动过滤标题内容中的图片\网站\电话\QQ\邮件等信息;
2、这个数据采集软件不同于传统的采集模式,它可以根据设置的关键词执行采集、采集用户的好处是可以通过采集关键词的不同搜索结果自动采集最新发布的文章,以免搜索到一个或一个几个指定的站点是 采集 采集,降低了 采集 站点被搜索引擎判断为 采集 站点被搜索引擎惩罚的风险。
3、 各种伪原创 和优化方法来提高收录 率和关键词 排名 标题插入、内容插入、自动内部链接、内容过滤、URL 过滤、随机图片插入、常规发布等,以提升采集文章原创的性能,提高搜索引擎收录、网站和关键词的权重排名。
一个搜索引擎,其核心价值是为用户提供他/她最需要的结果。搜索引擎对网民的需求进行了统计。对于网民需求很少或没有需求的内容,即使你是原创,也可能会被搜索引擎忽略,因为它不想把资源浪费在无意义的内容上。对于网友需求量大的内容,收录应该会越来越快,但是因为收录的数量很多,就算你是原创,可能也很难挤进入排行榜。这么多用户选择使用采集免费seo排名软件界面!
一、使用数据采集软件需要注意网站结构规划?
1. 网址设计。URL 还可以收录 关键词。例如,如果您的 网站 是关于计算机的,那么您的 URL 可以收录“PC”,因为在搜索引擎眼中它通常是“计算机”的同义词。URL不宜过长,层级尽量不要超过4层。
2. 列设计。列通常与导航相关联。设计要考虑网站的整体主题,用户可能感兴趣的内容,列名最好是网站的几个主要的关键词,这样也方便导航权重的使用.
3. 关键词布局。理论上,每个内容页面都应该有它的核心关键词,同一个栏目下的文章应该尽可能的围绕关键词栏目转。一个简单粗暴的方法是直接使用列关键词的长尾关键字。
二、根据数据量设置动态、伪静态、静态采集
这不能一概而论,建议使用伪静态或静态。三者的区别在于是否生成静态文件以及URL格式是否为动态。生成静态文件本质上是为了加快访问速度,减少数据库查询,但是会不断增加占用的空间;伪静态仅通过 URL 重写来修改 URL。对于加速访问完全无效。动态和伪静态的区别仅在于 URL,带有问号和参数。
不同的网站 程序可能有不同的数据库操作效率。一般来说,如果内容页数小于10000,页面打开速度比较快,数据量较大,达到50000、100000甚至更多,通常需要考虑静态。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
云优采集接口(基于uniClound从零开始搭建一个前端日志监控日志系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-03-21 20:12
写在前面
Serverless是近几年比较流行的概念,也是大前端发展的一个重要方向。无服务器的兴起已经存在了一段时间。早在几年前,微信就推出了微信小程序云开发功能。它不需要搭建服务器,只需要利用平台提供的能力快速开发服务即可。同时提供云数据库、云存储、云功能等功能,大大降低了开发者的开发成本,深受开发者的喜爱。就在去年 uni-app 还推出了自己的无服务器服务 - uniCloud。
uniCloud 是阿里云和腾讯云的 serverless 服务上 DCloud 的一个包。它由IaaS层(阿里云和腾讯云提供的硬件和网络)和PaaS层(DCloud提供的开发环境)组成。————————— uniCloud官网
与其他云开发产品相比,uniCloud具有以下优势:
uniCloud开发可以配合自带的HbuilderX编辑器实现1+1大于2的效果;它可以无缝连接uni-app和uni-ui,实现产品、UI和服务的有机统一。提供云功能URLization功能,非uni-apps开发的系统也可以轻松访问,使产品更加通用和通用。默认情况下,云函数只被自己的应用通过前端的 uniCloud.callFunction 调用,不会暴露给外网。一旦 URL 化,开发人员需要注意业务和资源安全。
云函数 URL 化是 uniCloud 为开发者提供的 HTTP 访问服务,允许开发者通过 HTTP URL 访问云函数。场景一:如App端微信支付,需要配置服务器回调地址。在这种情况下,需要一个 HTTP URL。场景二:非uni-app开发的系统,如果要连接uniiCloud读取数据,还需要通过HTTP URL访问。
下面这篇文章将基于uniClound从零开始搭建一个前端日志监控系统。
日志监控系统介绍
本文的主要目的是介绍serverless和uniClound入门,重点介绍采集和日志的展示。为了简化系统日志数据主要来自两个方面:一是Vue的全局错误捕获,二是请求响应拦截器拦截的后端API请求错误。该系统的简单说明如下:
Vue全局错误捕获的简单实现
根据Vue的官方文档,Vue的全局错误捕获只需要配置Vue.config.errorHandler即可。为了让我们的日志监控系统更加完善和通用,除了Vue的错误信息,我们还需要采集发生的错误。时间(uniCloud有时区差异,建议使用时间戳来表示时间),出错的项目名称project。Vue全局错误捕获方法实现如下,其中addVueLog是我们要通过云函数实现的API接口,后面会介绍该接口的实现。
// my-vatchvueerror.js
/****************************************************
* @description 捕获Vue全局错误
* @param {*} err 异常错误
* @param {*} vm 页面示例
* @param {*} info 错误说明
* @return {*}
* @author mingyong.g
****************************************************/
export default function(err, vm, info) {
const route = (vm.$page && vm.$page.route) || (vm.$mp && vm.$mp.page.route); // 获取uni-app项目的页面路由
let log = { // 日志对象
err: err.toString(),
info,
route,
time: new Date().getTime(),
project:"test"
};
addVueLog(log); // 新增日志的接口
}
在 main.js 中配置错误捕获功能
// main.js
import catchVueError from "../my-vatchvueerror";
Vue.config.errorHandler = catchVueError;
响应拦截器错误日志采集
下面是一个 axios 的响应拦截器的例子。关于API错误日志,我们需要关心以下信息:
请求体是请求的参数。响应正文是收录错误描述的响应数据日志发生的时间。uniCloud 存在时区差异。建议使用时间戳来指示错误日志所在的项目。
下面的代码是一个axios响应拦截器的简单实现,其中addApiLog就是我们要通过云函数实现的API接口,接口的实现后面会介绍。这里将收录请求参数的response.config和收录响应数据的response.data作为aspect的参数直接传入,其他公共信息在接口内部实现。
// 响应拦截
service.interceptors.response.use(
(response) => {
let data = response.data;
/*
* 此处如果后台响应体中字段Msg = "ok" 则认为接口响应有效,否则视为错误响应
* 注意:这部分逻辑需根据业务和后端接口规范适当调整
*/
if (data.Msg == "ok" ) {
return data;
} else {
addApiLog(response.config, data); // 日志采集接口
return Promise.reject(data);
}
},
(err) => {
let errMsg = "";
if (err && err.response.status) {
switch (err.response.status) {
case 401:
errMsg = "登录状态失效,请重新登录";
router.push("/login");
break;
case 403:
errMsg = "拒绝访问";
break;
case 408:
errMsg = "请求超时";
break;
case 500:
errMsg = "服务器内部错误";
break;
case 501:
errMsg = "服务未实现";
break;
case 502:
errMsg = "网关错误";
break;
case 503:
errMsg = "服务不可用";
break;
case 504:
errMsg = "网关超时";
break;
case 505:
errMsg = "HTTP版本不受支持";
break;
default:
errMsg = err;
break;
}
} else {
errMsg = err;
}
addApiLog(err.config, { statusCode: err.response.status, Msg: err.response.data }); // 日志采集接口
return Promise.reject(errMsg);
}
);
uniCloud 管理员
为了简化开发工作,uniiCloud提供了基于uni-app、uni-ui和uniiCloud的应用后台管理框架。
uniCloud admin功能介绍其基于uni-app的宽屏适配,可自动适配PC宽屏和移动端。它基于 uniCloud,是一种无服务器云开发。它基于 uni-id 并使用 uni-id 的用户帐户、角色和权限系统。————————— uniCloud官网
uniCloud界面
创建项目
按照官方教程,首先在HBuilderX3.0+版本新建一个uni-app项目,选择uniiCloud admin项目模板。
创建完成后,可以按照云服务空间初始化向导来初始化项目,创建并绑定云服务空间
跑步
进入admin项目,在uniCloud/cloudfunctions/common/uni-id中填写自己的passwordSecret字段(用来加密密码存储的key)和tokenSecret字段(生成token需要的key,测试时跳过) /config.json文件也可以通过这篇文章)右键uniiCloud目录运行云服务空间初始化向导,初始化数据库并上传部署云功能(如果云服务空间已经创建绑定,跳过这一步),点击HBuilderX工具栏运行[Ctrl+r] -> Run to browser。如果是连接本地的云函数调试环境,上一步的云函数是不能上传的,但是数据库还是需要初始化的。从启动后的登录页面底部,
登录uniiCloud控制台:/找到上面第3步创建的云服务空间,这里我创建的服务空间是gmyl
点击详情进入云服务空间,可以看到uniCloud admin默认为我们创建了如下云数据表: 6. opendb-admin-menus : 左侧菜单树管理表7.@ > opendb-verify-codes : 验证码记录表8. uni-id-log : uniCloud登录日志9. uni-id-log : 权限表10. uni-id-roles :角色配置表 11. uni-id-users : 账户表
uniCloud admin 提供了一套完整的后台管理解决方案。我们的目的是构建一个简单的日志监控系统。有些功能这里暂时不用。现在 uniCloud 管理员关注应用程序的可扩展性。言归正传,除了上述框架自带的数据表,我们还需要创建一个数据表来存储日志数据。在这里,我创建了两个表来分别存储 Vue 日志和 API 日志。
{
"bsonType": "object",
"required": [],
"permission": {
"read": false,
"create": false,
"update": false,
"delete": false
},
"properties": {
"_id": {
"description": "ID,系统自动生成"
},
"project": {
"bsonType": "onject",
"description": "项目名称",
"trim": "both"
},
"url": {
"bsonType": "onject",
"description": "页面路由信息",
"trim": "both"
},
"errmsg": {
"bsonType": "onject",
"description": "错误描述",
"trim": "both"
},
"errtype": {
"bsonType": "string",
"description": "错误类型",
"trim": "both"
},
"occurrence_timestamp": {
"bsonType": "timestamp",
"description": "问题发生时间"
},
"state": {
"bsonType": "int",
"description": "0 待处理 1:已处理 ",
"trim": "both"
},
"handle_timestamp": {
"bsonType": "timestamp",
"description": "问题修复时间"
},
"reason": {
"bsonType": "string",
"description": "问题原因",
"trim": "both"
},
"solution": {
"bsonType": "string",
"description": "解决办法",
"trim": "both"
}
}
}
创建云函数
回到HbuilderX找到刚才创建的项目,依次展开uniCloud>>cloudfunctions,右键cloudfunctions点击新建的云函数addVueLog
一个初始的云函数结构如下,其中前端传递的参数是通过event.body获取的。接下来的主要任务是将前端传递的日志对象存储到云数据库中。使用云函数操作云数据库的教程可以参考官方文档:uniapp.dcloud.io/uniCloud/cf-database,这里不再赘述。
// 初始云函数
'use strict';
exports.main = async (event, context) => {
//event为客户端上传的参数
console.log('event : ', event)
//返回数据给客户端
return event
};
// 将数据写入云数据库
'use strict';
const db = uniCloud.database();
exports.main = async (event, context) => {
//event为客户端上传的参数
let data = event.body ? JSON.parse(event.body) : event;
if (event.project == "" && !event.body) { // 判断数据是否有效
return {
Msg: "Invalid Data!",
Data: "",
Count: 0
}
} else {
const dbCmd = db.command
const $ = dbCmd.aggregate
let res = await db.collection('vuelog_db').add(data) // 向表vuelog_db插入一条数据
//返回数据给客户端
return {
Data: "",
Msg: "ok",
Count: 0
}
}
};
云函数url化
开启云函数url化前,先上传部署云函数,找到对应的云函数,右键上传部署。
如果上传成功,可以在uniCloud控制台的云功能列表中找到刚刚上传的云功能。
登录uniiCloud后台,选择要管理的服务空间。点击左侧菜单栏的【云功能】,进入云功能页面。点击待配置云功能的【详情】按钮,配置访问路径。
云函数url化后,可以像通用API接口一样调用。这里的add_vuelog是Vue全局错误捕获方法中addVueLog接口的实现。
运行测试
在postman、test add_vuelogAPI等API调试工具中,不再演示测试过程,云函数调用成功,云数据库会新增一条记录。
addApiLog 的实现同上。至此,实现了一个日志系统的数据采集和存储功能。
数据显示
虽然数据展示部分很重要,但并不是本次开发的重点。这里直接使用uniCloud提供的schema2code(HBuilderX 3.1.0+支持)函数生成数据列表页。
对schema2code生成的数据稍作修改,将uni-list组件替换为uni-table组件。
项目
页面路由
错误描述
错误类型
原因
解决方案
发生时间
修复时间
状态
操作
搜索
{{ item.project }}
{{ item.url }}
{{ item.errmsg }}
{{ item.errtype }}
{{ item.reason }}
{{ item.solution }}
已修复
待修复
处理
删除
{{ engine.name }}
页面写好后,别忘了在uniiCloud admin自带的菜单管理中注册路由信息。如果没有注册路由信息,则页面无法在左侧菜单栏中显示。
再次优化
为了让界面更加美观,结合uni-app插件市场的ReportPro数据报表(云功能版)和秋云ucharts echarts高性能跨端图表组件升级页面首页,使数据板。这是效果的渲染。实现逻辑引用云函数操作云数据库:/uniCloud/cf-database
好的!这里实现了整个简单的日志监控系统。现在就试试吧!
一些个人感受
之所以做这样一个项目,一方面是在技术的研究和探索中。早在2019年就接触过微信小程序的云开发模式,但一直都在做一些技术探索和了解。没有真正的动手实践;另一方面,随着我们自己开发的一些项目的实施,难免会出现错误和bug。过去,由于用户反馈出现错误,然后处理滞后,导致用户体验非常差。随着时间的推移,用户很容易丢失产品。信心甚至会引起怀疑。由此产生了为这个项目谋生的想法,而我熟悉的uni-app也推出了云开发模式,于是这个项目就诞生了。
来说说severless的感觉吧。无服务器意味着无服务器。这里的serverless是开发用的,服务器直接由云服务器提供商提供和管理。这样,开发者只需要关注业务,前后端的差别就越来越小了。以本项目为例,整个过程没有后端参与,也没有编写SQL语句。一系列开发的API接口固然方便,但也带来一定的局限性。有了Serverless,我们不需要过多关注服务器的运维,也不需要关心我们不熟悉的领域。我们只需要专注于业务开发和产品实施。我们需要关心的事情更少,但我们可以做的事情更多。serverless 模型将进一步扩展前端边界。现在的前端开发已经不是以前的前端开发了。前端不仅可以是网页,还可以是小程序、APP、桌面程序。现在前端也可以是服务器了!
阿特伍德定律:任何可以用 JavaScript 编写的应用程序,最终都会用 JavaScript 编写。任何可以用 JavaScript 编写的应用程序,最终都会用 JavaScript 编写。写在最后
一个完整的日志监控系统还应该包括一个消息通知模块,这也是我最初的架构中设想和规划的。由于消息通知是借助第三方服务实现的,是一个相对独立的功能模块,所以我将其独立出来。出来,后面会单独整理成一个文章,介绍uniCloud云功能如何调用第三方API,如何使用npm安装第三方服务。
最后,本文同步发布在个人G公众号“前端知识营”,点击关注获取更多优质有趣内容。以后会整理好项目的源码,放到公众号上供大家参考。感兴趣的朋友可以点击下方链接关注!前端知识营
(超过) 查看全部
云优采集接口(基于uniClound从零开始搭建一个前端日志监控日志系统)
写在前面
Serverless是近几年比较流行的概念,也是大前端发展的一个重要方向。无服务器的兴起已经存在了一段时间。早在几年前,微信就推出了微信小程序云开发功能。它不需要搭建服务器,只需要利用平台提供的能力快速开发服务即可。同时提供云数据库、云存储、云功能等功能,大大降低了开发者的开发成本,深受开发者的喜爱。就在去年 uni-app 还推出了自己的无服务器服务 - uniCloud。
uniCloud 是阿里云和腾讯云的 serverless 服务上 DCloud 的一个包。它由IaaS层(阿里云和腾讯云提供的硬件和网络)和PaaS层(DCloud提供的开发环境)组成。————————— uniCloud官网
与其他云开发产品相比,uniCloud具有以下优势:
uniCloud开发可以配合自带的HbuilderX编辑器实现1+1大于2的效果;它可以无缝连接uni-app和uni-ui,实现产品、UI和服务的有机统一。提供云功能URLization功能,非uni-apps开发的系统也可以轻松访问,使产品更加通用和通用。默认情况下,云函数只被自己的应用通过前端的 uniCloud.callFunction 调用,不会暴露给外网。一旦 URL 化,开发人员需要注意业务和资源安全。
云函数 URL 化是 uniCloud 为开发者提供的 HTTP 访问服务,允许开发者通过 HTTP URL 访问云函数。场景一:如App端微信支付,需要配置服务器回调地址。在这种情况下,需要一个 HTTP URL。场景二:非uni-app开发的系统,如果要连接uniiCloud读取数据,还需要通过HTTP URL访问。
下面这篇文章将基于uniClound从零开始搭建一个前端日志监控系统。
日志监控系统介绍
本文的主要目的是介绍serverless和uniClound入门,重点介绍采集和日志的展示。为了简化系统日志数据主要来自两个方面:一是Vue的全局错误捕获,二是请求响应拦截器拦截的后端API请求错误。该系统的简单说明如下:
Vue全局错误捕获的简单实现
根据Vue的官方文档,Vue的全局错误捕获只需要配置Vue.config.errorHandler即可。为了让我们的日志监控系统更加完善和通用,除了Vue的错误信息,我们还需要采集发生的错误。时间(uniCloud有时区差异,建议使用时间戳来表示时间),出错的项目名称project。Vue全局错误捕获方法实现如下,其中addVueLog是我们要通过云函数实现的API接口,后面会介绍该接口的实现。
// my-vatchvueerror.js
/****************************************************
* @description 捕获Vue全局错误
* @param {*} err 异常错误
* @param {*} vm 页面示例
* @param {*} info 错误说明
* @return {*}
* @author mingyong.g
****************************************************/
export default function(err, vm, info) {
const route = (vm.$page && vm.$page.route) || (vm.$mp && vm.$mp.page.route); // 获取uni-app项目的页面路由
let log = { // 日志对象
err: err.toString(),
info,
route,
time: new Date().getTime(),
project:"test"
};
addVueLog(log); // 新增日志的接口
}
在 main.js 中配置错误捕获功能
// main.js
import catchVueError from "../my-vatchvueerror";
Vue.config.errorHandler = catchVueError;
响应拦截器错误日志采集
下面是一个 axios 的响应拦截器的例子。关于API错误日志,我们需要关心以下信息:
请求体是请求的参数。响应正文是收录错误描述的响应数据日志发生的时间。uniCloud 存在时区差异。建议使用时间戳来指示错误日志所在的项目。
下面的代码是一个axios响应拦截器的简单实现,其中addApiLog就是我们要通过云函数实现的API接口,接口的实现后面会介绍。这里将收录请求参数的response.config和收录响应数据的response.data作为aspect的参数直接传入,其他公共信息在接口内部实现。
// 响应拦截
service.interceptors.response.use(
(response) => {
let data = response.data;
/*
* 此处如果后台响应体中字段Msg = "ok" 则认为接口响应有效,否则视为错误响应
* 注意:这部分逻辑需根据业务和后端接口规范适当调整
*/
if (data.Msg == "ok" ) {
return data;
} else {
addApiLog(response.config, data); // 日志采集接口
return Promise.reject(data);
}
},
(err) => {
let errMsg = "";
if (err && err.response.status) {
switch (err.response.status) {
case 401:
errMsg = "登录状态失效,请重新登录";
router.push("/login");
break;
case 403:
errMsg = "拒绝访问";
break;
case 408:
errMsg = "请求超时";
break;
case 500:
errMsg = "服务器内部错误";
break;
case 501:
errMsg = "服务未实现";
break;
case 502:
errMsg = "网关错误";
break;
case 503:
errMsg = "服务不可用";
break;
case 504:
errMsg = "网关超时";
break;
case 505:
errMsg = "HTTP版本不受支持";
break;
default:
errMsg = err;
break;
}
} else {
errMsg = err;
}
addApiLog(err.config, { statusCode: err.response.status, Msg: err.response.data }); // 日志采集接口
return Promise.reject(errMsg);
}
);
uniCloud 管理员
为了简化开发工作,uniiCloud提供了基于uni-app、uni-ui和uniiCloud的应用后台管理框架。
uniCloud admin功能介绍其基于uni-app的宽屏适配,可自动适配PC宽屏和移动端。它基于 uniCloud,是一种无服务器云开发。它基于 uni-id 并使用 uni-id 的用户帐户、角色和权限系统。————————— uniCloud官网
uniCloud界面
创建项目
按照官方教程,首先在HBuilderX3.0+版本新建一个uni-app项目,选择uniiCloud admin项目模板。
创建完成后,可以按照云服务空间初始化向导来初始化项目,创建并绑定云服务空间
跑步
进入admin项目,在uniCloud/cloudfunctions/common/uni-id中填写自己的passwordSecret字段(用来加密密码存储的key)和tokenSecret字段(生成token需要的key,测试时跳过) /config.json文件也可以通过这篇文章)右键uniiCloud目录运行云服务空间初始化向导,初始化数据库并上传部署云功能(如果云服务空间已经创建绑定,跳过这一步),点击HBuilderX工具栏运行[Ctrl+r] -> Run to browser。如果是连接本地的云函数调试环境,上一步的云函数是不能上传的,但是数据库还是需要初始化的。从启动后的登录页面底部,
登录uniiCloud控制台:/找到上面第3步创建的云服务空间,这里我创建的服务空间是gmyl
点击详情进入云服务空间,可以看到uniCloud admin默认为我们创建了如下云数据表: 6. opendb-admin-menus : 左侧菜单树管理表7.@ > opendb-verify-codes : 验证码记录表8. uni-id-log : uniCloud登录日志9. uni-id-log : 权限表10. uni-id-roles :角色配置表 11. uni-id-users : 账户表
uniCloud admin 提供了一套完整的后台管理解决方案。我们的目的是构建一个简单的日志监控系统。有些功能这里暂时不用。现在 uniCloud 管理员关注应用程序的可扩展性。言归正传,除了上述框架自带的数据表,我们还需要创建一个数据表来存储日志数据。在这里,我创建了两个表来分别存储 Vue 日志和 API 日志。
{
"bsonType": "object",
"required": [],
"permission": {
"read": false,
"create": false,
"update": false,
"delete": false
},
"properties": {
"_id": {
"description": "ID,系统自动生成"
},
"project": {
"bsonType": "onject",
"description": "项目名称",
"trim": "both"
},
"url": {
"bsonType": "onject",
"description": "页面路由信息",
"trim": "both"
},
"errmsg": {
"bsonType": "onject",
"description": "错误描述",
"trim": "both"
},
"errtype": {
"bsonType": "string",
"description": "错误类型",
"trim": "both"
},
"occurrence_timestamp": {
"bsonType": "timestamp",
"description": "问题发生时间"
},
"state": {
"bsonType": "int",
"description": "0 待处理 1:已处理 ",
"trim": "both"
},
"handle_timestamp": {
"bsonType": "timestamp",
"description": "问题修复时间"
},
"reason": {
"bsonType": "string",
"description": "问题原因",
"trim": "both"
},
"solution": {
"bsonType": "string",
"description": "解决办法",
"trim": "both"
}
}
}
创建云函数
回到HbuilderX找到刚才创建的项目,依次展开uniCloud>>cloudfunctions,右键cloudfunctions点击新建的云函数addVueLog
一个初始的云函数结构如下,其中前端传递的参数是通过event.body获取的。接下来的主要任务是将前端传递的日志对象存储到云数据库中。使用云函数操作云数据库的教程可以参考官方文档:uniapp.dcloud.io/uniCloud/cf-database,这里不再赘述。
// 初始云函数
'use strict';
exports.main = async (event, context) => {
//event为客户端上传的参数
console.log('event : ', event)
//返回数据给客户端
return event
};
// 将数据写入云数据库
'use strict';
const db = uniCloud.database();
exports.main = async (event, context) => {
//event为客户端上传的参数
let data = event.body ? JSON.parse(event.body) : event;
if (event.project == "" && !event.body) { // 判断数据是否有效
return {
Msg: "Invalid Data!",
Data: "",
Count: 0
}
} else {
const dbCmd = db.command
const $ = dbCmd.aggregate
let res = await db.collection('vuelog_db').add(data) // 向表vuelog_db插入一条数据
//返回数据给客户端
return {
Data: "",
Msg: "ok",
Count: 0
}
}
};
云函数url化
开启云函数url化前,先上传部署云函数,找到对应的云函数,右键上传部署。
如果上传成功,可以在uniCloud控制台的云功能列表中找到刚刚上传的云功能。
登录uniiCloud后台,选择要管理的服务空间。点击左侧菜单栏的【云功能】,进入云功能页面。点击待配置云功能的【详情】按钮,配置访问路径。
云函数url化后,可以像通用API接口一样调用。这里的add_vuelog是Vue全局错误捕获方法中addVueLog接口的实现。
运行测试
在postman、test add_vuelogAPI等API调试工具中,不再演示测试过程,云函数调用成功,云数据库会新增一条记录。
addApiLog 的实现同上。至此,实现了一个日志系统的数据采集和存储功能。
数据显示
虽然数据展示部分很重要,但并不是本次开发的重点。这里直接使用uniCloud提供的schema2code(HBuilderX 3.1.0+支持)函数生成数据列表页。
对schema2code生成的数据稍作修改,将uni-list组件替换为uni-table组件。
项目
页面路由
错误描述
错误类型
原因
解决方案
发生时间
修复时间
状态
操作
搜索
{{ item.project }}
{{ item.url }}
{{ item.errmsg }}
{{ item.errtype }}
{{ item.reason }}
{{ item.solution }}
已修复
待修复
处理
删除
{{ engine.name }}
页面写好后,别忘了在uniiCloud admin自带的菜单管理中注册路由信息。如果没有注册路由信息,则页面无法在左侧菜单栏中显示。
再次优化
为了让界面更加美观,结合uni-app插件市场的ReportPro数据报表(云功能版)和秋云ucharts echarts高性能跨端图表组件升级页面首页,使数据板。这是效果的渲染。实现逻辑引用云函数操作云数据库:/uniCloud/cf-database
好的!这里实现了整个简单的日志监控系统。现在就试试吧!
一些个人感受
之所以做这样一个项目,一方面是在技术的研究和探索中。早在2019年就接触过微信小程序的云开发模式,但一直都在做一些技术探索和了解。没有真正的动手实践;另一方面,随着我们自己开发的一些项目的实施,难免会出现错误和bug。过去,由于用户反馈出现错误,然后处理滞后,导致用户体验非常差。随着时间的推移,用户很容易丢失产品。信心甚至会引起怀疑。由此产生了为这个项目谋生的想法,而我熟悉的uni-app也推出了云开发模式,于是这个项目就诞生了。
来说说severless的感觉吧。无服务器意味着无服务器。这里的serverless是开发用的,服务器直接由云服务器提供商提供和管理。这样,开发者只需要关注业务,前后端的差别就越来越小了。以本项目为例,整个过程没有后端参与,也没有编写SQL语句。一系列开发的API接口固然方便,但也带来一定的局限性。有了Serverless,我们不需要过多关注服务器的运维,也不需要关心我们不熟悉的领域。我们只需要专注于业务开发和产品实施。我们需要关心的事情更少,但我们可以做的事情更多。serverless 模型将进一步扩展前端边界。现在的前端开发已经不是以前的前端开发了。前端不仅可以是网页,还可以是小程序、APP、桌面程序。现在前端也可以是服务器了!
阿特伍德定律:任何可以用 JavaScript 编写的应用程序,最终都会用 JavaScript 编写。任何可以用 JavaScript 编写的应用程序,最终都会用 JavaScript 编写。写在最后
一个完整的日志监控系统还应该包括一个消息通知模块,这也是我最初的架构中设想和规划的。由于消息通知是借助第三方服务实现的,是一个相对独立的功能模块,所以我将其独立出来。出来,后面会单独整理成一个文章,介绍uniCloud云功能如何调用第三方API,如何使用npm安装第三方服务。
最后,本文同步发布在个人G公众号“前端知识营”,点击关注获取更多优质有趣内容。以后会整理好项目的源码,放到公众号上供大家参考。感兴趣的朋友可以点击下方链接关注!前端知识营
(超过)
云优采集接口(社区问答常用快递单号物流查询接口通用API(JAVA快递鸟对接))
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-03-21 12:12
请问API接口到底是什么意思?
API是一个接口,一个通道,负责程序与其他软件的通信,本质上是一个预定义的函数。回答者也给出了很多直观的例子。这里我想从另一个角度谈谈一个好的API,希望对大家有用。比如我们上班的时候,窗口就类似于一个API。如果这个窗口可以让我们对某个不简单的事情“最多运行一次”和“只盖一个印章”,那么这个 API 就不错了。(当然API也不一样,接口隔离的原则是适用的,就是使用多个隔离的接口,比如用户注册和用户登录,分别写两个
来自:社区问答
常用快递单号物流查询接口通用API(JAVA快递鸟对接)
快递查询接口通用API用于快递电商实现查询快递物流轨迹功能。连接接口前,必须先到快递鸟网站申请接口密钥和APIKEY。快递查询API接口是使用的物流单号。可以实现物流信息的查询。主要应用于电子商务商城、ERP系统提供商、WMS系统提供商、快递柜、银行等企业。多个快递物流公司的接口统一连接。建议与接口提供者连接。可以一次接入多家快递公司,为后期的技术维护省下不少工作。目前快递查询API接口有两种实现方式,
来自:社区博客
api接口的模糊测试初探
[图片] Target 在日常的测试工作中,经常会有api接口测试。除了前向过程测试,我们经常需要覆盖一些异常。例如:非法字符串字符串太长,应该是数字类型,传入的字母参数为空,传入中文,标点符号等sql注入等。其实在我们组的接口测试demo框架中,在dataprovider中也很常见,比如下面的例子。@DataProvider(名称
来自:社区博客
API接口_存储与CDN_产品文档_帮助文档-网易书凡
API接口 API文档介绍 直接上传服务是NOS推出的一套针对手机或网页上传的解决方案。该方案优化了上传逻辑,让上传更加快捷方便。用户可以使用本文档提供的简单API接口来实现直传服务的上传逻辑。API接口DNS查询说明 用户客户端可以先查询DNS服务,获取最近的边缘加速节点IP列表,选择IP上传。接口 GET /lbs?version=${version}&
来自:产品文档 - 存储和 CDN - 对象存储
免费快递单号查询快递鸟API接口演示
,一是单号识别接口:快递小鸟接口名称:即时查询接口+单号识别界面编写语言:C#顺丰单号接口简单方便通过快递小鸟接口连接顺丰快递查询接口API和电子人脸订单接口可对接通过快递鸟,通过顺丰订单
来自:社区博客
快递鸟物流单号查询API接口集成,有需要可以直接使用
速递鸟是全球最大的第三方快递物流接口服务商。目前已集成418个快递单号查询接口和31个电子人脸单机接口。高实时性、高稳定性、高并发,支持快递单号自动识别。快递鸟的第三方快递查询界面非常好用,而且密钥免费。用户多(技术QQ群一万多个),大ERP基本用快递鸟的接口,不是淘宝的电商平台。他们还使用 Express Bird 提供的接口服务。整个连接很简单,去快递鸟网站免费注册申请KEY和ID,下载demo调用,修复
来自:社区博客
为开发者提供开放的API接口,《VARENA》利用多维数据提升游戏体验
相关数据显示,2021年由电竞衍生市场和核心市场组成的整体电竞市场规模将达到250亿元。2018年中国电竞玩家数量将达到2.8亿,而潜在用户数量将同时,我国将成为全球最大的电子竞技市场。在此,无论是职业电竞玩家还是业余玩家,都需要通过分析游戏相关数据来了解游戏玩法以及如何提升自身实力,最终优化游戏体验或在游戏中取得更好的成绩。36氪近期接触电竞综合赛事服务平台“
来自:社区博客
云主机接口_计算服务_产品文档_帮助文档-网易书凡
云主机接口创建云服务器接口方法:POST url参数| 姓名 | 类型 | 必填 | 描述 | | --- | --- | --- | --- | | 行动 | 字符串 | 是 | 固定值:CreateInstance | | 版本 | 字符串 | 是的 | API 版本号 当前版本 2017-12-14 | 后正文参数 | 姓名 | 班级
来自:产品文档 - 计算服务 - 云服务器
哪个短信验证码API接口好用?
【转载自网易云答】从技术指标来看,短信平台API的选择标准其实很简单,无非就是速度快、到达率高、渠道稳定,尤其是题主针对性的短信验证码,尤其是移动端,5秒基本就是极限了,否则用户流失是没有商量余地的。从商业角度来看,应该考虑服务提供商的实力、服务、行业声誉和价格。从搜索引擎结果可以看出,目前提供短信平台API的公司很多,行业鱼龙混杂。因此,在使用之前,一定要对三网进行全面的测试,对比多个平台,选择适合自己的平台。
来自:社区问答
配额和快照接口_计算服务_产品文档_帮助文档-网易书凡
配额和快照接口获取实例配额接口方法:GET url参数| 姓名 | 类型 | 必填 | 描述 | | --- | --- | --- | --- | | 行动 | 字符串 | 是 | 固定值:DescribeInstanceQuota | | 版本 | 字符串 | 是 | API 版本号 当前版本 2017-12-14 | 返回参数 | 姓名 | 班级
来自:产品文档 - 计算服务 - 云服务器 查看全部
云优采集接口(社区问答常用快递单号物流查询接口通用API(JAVA快递鸟对接))
请问API接口到底是什么意思?
API是一个接口,一个通道,负责程序与其他软件的通信,本质上是一个预定义的函数。回答者也给出了很多直观的例子。这里我想从另一个角度谈谈一个好的API,希望对大家有用。比如我们上班的时候,窗口就类似于一个API。如果这个窗口可以让我们对某个不简单的事情“最多运行一次”和“只盖一个印章”,那么这个 API 就不错了。(当然API也不一样,接口隔离的原则是适用的,就是使用多个隔离的接口,比如用户注册和用户登录,分别写两个
来自:社区问答
常用快递单号物流查询接口通用API(JAVA快递鸟对接)
快递查询接口通用API用于快递电商实现查询快递物流轨迹功能。连接接口前,必须先到快递鸟网站申请接口密钥和APIKEY。快递查询API接口是使用的物流单号。可以实现物流信息的查询。主要应用于电子商务商城、ERP系统提供商、WMS系统提供商、快递柜、银行等企业。多个快递物流公司的接口统一连接。建议与接口提供者连接。可以一次接入多家快递公司,为后期的技术维护省下不少工作。目前快递查询API接口有两种实现方式,
来自:社区博客
api接口的模糊测试初探
[图片] Target 在日常的测试工作中,经常会有api接口测试。除了前向过程测试,我们经常需要覆盖一些异常。例如:非法字符串字符串太长,应该是数字类型,传入的字母参数为空,传入中文,标点符号等sql注入等。其实在我们组的接口测试demo框架中,在dataprovider中也很常见,比如下面的例子。@DataProvider(名称
来自:社区博客
API接口_存储与CDN_产品文档_帮助文档-网易书凡
API接口 API文档介绍 直接上传服务是NOS推出的一套针对手机或网页上传的解决方案。该方案优化了上传逻辑,让上传更加快捷方便。用户可以使用本文档提供的简单API接口来实现直传服务的上传逻辑。API接口DNS查询说明 用户客户端可以先查询DNS服务,获取最近的边缘加速节点IP列表,选择IP上传。接口 GET /lbs?version=${version}&
来自:产品文档 - 存储和 CDN - 对象存储
免费快递单号查询快递鸟API接口演示
,一是单号识别接口:快递小鸟接口名称:即时查询接口+单号识别界面编写语言:C#顺丰单号接口简单方便通过快递小鸟接口连接顺丰快递查询接口API和电子人脸订单接口可对接通过快递鸟,通过顺丰订单
来自:社区博客
快递鸟物流单号查询API接口集成,有需要可以直接使用
速递鸟是全球最大的第三方快递物流接口服务商。目前已集成418个快递单号查询接口和31个电子人脸单机接口。高实时性、高稳定性、高并发,支持快递单号自动识别。快递鸟的第三方快递查询界面非常好用,而且密钥免费。用户多(技术QQ群一万多个),大ERP基本用快递鸟的接口,不是淘宝的电商平台。他们还使用 Express Bird 提供的接口服务。整个连接很简单,去快递鸟网站免费注册申请KEY和ID,下载demo调用,修复
来自:社区博客
为开发者提供开放的API接口,《VARENA》利用多维数据提升游戏体验
相关数据显示,2021年由电竞衍生市场和核心市场组成的整体电竞市场规模将达到250亿元。2018年中国电竞玩家数量将达到2.8亿,而潜在用户数量将同时,我国将成为全球最大的电子竞技市场。在此,无论是职业电竞玩家还是业余玩家,都需要通过分析游戏相关数据来了解游戏玩法以及如何提升自身实力,最终优化游戏体验或在游戏中取得更好的成绩。36氪近期接触电竞综合赛事服务平台“
来自:社区博客
云主机接口_计算服务_产品文档_帮助文档-网易书凡
云主机接口创建云服务器接口方法:POST url参数| 姓名 | 类型 | 必填 | 描述 | | --- | --- | --- | --- | | 行动 | 字符串 | 是 | 固定值:CreateInstance | | 版本 | 字符串 | 是的 | API 版本号 当前版本 2017-12-14 | 后正文参数 | 姓名 | 班级
来自:产品文档 - 计算服务 - 云服务器
哪个短信验证码API接口好用?
【转载自网易云答】从技术指标来看,短信平台API的选择标准其实很简单,无非就是速度快、到达率高、渠道稳定,尤其是题主针对性的短信验证码,尤其是移动端,5秒基本就是极限了,否则用户流失是没有商量余地的。从商业角度来看,应该考虑服务提供商的实力、服务、行业声誉和价格。从搜索引擎结果可以看出,目前提供短信平台API的公司很多,行业鱼龙混杂。因此,在使用之前,一定要对三网进行全面的测试,对比多个平台,选择适合自己的平台。
来自:社区问答
配额和快照接口_计算服务_产品文档_帮助文档-网易书凡
配额和快照接口获取实例配额接口方法:GET url参数| 姓名 | 类型 | 必填 | 描述 | | --- | --- | --- | --- | | 行动 | 字符串 | 是 | 固定值:DescribeInstanceQuota | | 版本 | 字符串 | 是 | API 版本号 当前版本 2017-12-14 | 返回参数 | 姓名 | 班级
来自:产品文档 - 计算服务 - 云服务器
云优采集接口(社区博客API接口_存储与CDN-对象存储浅谈容器监控和网易云计算基础服务实践(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-03-21 12:09
移动端工程架构与后端工程架构的思想摩擦之旅
本文已由作者李星授权发布于网易云社区。欢迎来到网易云社区,了解更多网易技术产品运营经验,记得资源交付后端项目的结构调整和优化,一直对软件工程架构感兴趣。或者现在去后端开发后维护的资源交付项目。可以说,不是每个团队中的开发者都能深入掌握架构知识,但每个人都需要具备软件架构的意识。架构是对项目整体结构和组件的抽象描述。
来自:社区博客
API接口_存储与CDN_产品文档_帮助文档-网易书凡
API接口 API文档介绍 直接上传服务是NOS推出的一套针对手机或网页上传的解决方案。该方案优化了上传逻辑,让上传更加快捷方便。用户可以使用本文档提供的简单API接口来实现直传服务的上传逻辑。API接口DNS查询说明 用户客户端可以先查询DNS服务,获取最近的边缘加速节点IP列表,选择IP上传。接口 GET /lbs?version=${version}&
来自:产品文档 - 存储和 CDN - 对象存储
浅谈容器监控与网易云计算基础服务实践
docker监控docker的研究和实践发展了这么久,涌现出很多扩展工具,有的甚至有自己的系统。相信大家对各种编排工具都很熟悉了。各种监控方案应运而生。Linux内核和cgroup技术其实已经为监控的技术可行性提供了一切基础。这里我们列出一些监控工具:docker原生监控docker提供命令方法(docker stats CID)和API:http
来自:社区博客
Snowflake & Delta Lake 两种新数据仓库对比分析
Snowflake & Delta Lake代表了业界最先进的两种数字化仓库形态,均获得市场用户的高度认可。——1——概述自1980年代数据分析兴起以来,大致经历了企业数据仓库(EDW)、数据湖(Data Lake),以及现在的云原生数据仓库、湖与仓一体化。企业数据仓库是数据仓库最原创的版本。从目前来看,存在只处理结构化数据、集中存储和计算、成本高等缺点。数字
来自:社区博客
阿里云POLARDB及其共享存储PolarFS技术实现解析(上)
PolarDB是阿里云推出的基于MySQL的云原生数据库产品。通过在数据库中分离计算和存储,多个计算节点访问相同的存储数据,解决了当前 MySQL 数据库的运维和可扩展性问题。问题; 通过引入RDMA、SPDK等新硬件改造传统网络和IO协议栈,大幅提升数据库性能。它代表了未来数据库发展的一个方向。本系列有2篇文章,主要分析PolarDB出现的原因及其技术
来自:社区博客
网易云数据库架构设计实践
作为国内领先的互联网科技公司,网易旗下拥有众多互联网产品和手机客户端应用,如知名的网易博客、云阅读、云音乐、易信等。作为支撑互联网产品的核心后端服务,数据库对产品的重要性不言而喻。随着产品数量和应用规模的快速增长,数据库管理逐渐成为产品开发的瓶颈:硬件采购周期长、沟通协调成本高、难以快速响应数据库部署需求;硬件利用率低,难以按需使用资源,弹性扩展;服务可用性差,数据
来自:社区博客
接口文档神器 Swagger(第 1 部分)
作者:李哲 接口文档管理一直是个头疼的问题,随着各种接口文档管理平台的出现,比如阿里巴巴开源的说唱、ShowDoc、sosoapi等(网上可以找到很多这样的管理平台,包括我们idoc做的我自己)。这些平台都有一个共同的特点,创建文档、编辑和保存文档,一些强大的功能包括模拟、统计界面信息等功能,所以这些平台更像是一个界面文档的存储管理系统,可以方便人们查看和保存。编辑文档。. 但是,接口通常会经常更改(添加
来自:社区博客
Docker镜像存储机制
土地如何储存?容器如何根据镜像启动?将图像推送到远程图像存储库时,服务器如何存储它?让我们简单谈谈。Docker镜像本地存储机制及容器启动原理Dock
来自:社区博客
对象存储服务NOS_高性能云存储服务_网易蜂窝-网易书凡
对象存储服务,NOS,网易蜂窝网易对象存储服务(Netease Object Storage)是一种高性能、高可用、高可靠的云存储服务。NOS支持标准的RESTful API接口,提供丰富的在线数据处理服务,一站式解决互联网时代非结构化数据管理问题——网易对象存储网易对象存储(简称NOS)由网易书凡提供高可用、高...可靠性,高性能云
来自:产品
大规模微服务场景下性能问题的定位与优化
本文结合网易青州微服务平台的实践经验,分析微服务场景下性能问题的定位和优化。文章 从一个真实的场景出发,介绍如何逐层推进,一步步定位性能问题。问题。本文经作者授权发布,未经允许请勿转载。作者:刘超,网易杭州研究院首席架构师 实现微服务架构的成本 现在云原生微服务架构非常流行,它具有迭代快、并发高、可维护、灵活等诸多优点。扩容、灰度发布、高可用,这
来自:社区博客 查看全部
云优采集接口(社区博客API接口_存储与CDN-对象存储浅谈容器监控和网易云计算基础服务实践(组图))
移动端工程架构与后端工程架构的思想摩擦之旅
本文已由作者李星授权发布于网易云社区。欢迎来到网易云社区,了解更多网易技术产品运营经验,记得资源交付后端项目的结构调整和优化,一直对软件工程架构感兴趣。或者现在去后端开发后维护的资源交付项目。可以说,不是每个团队中的开发者都能深入掌握架构知识,但每个人都需要具备软件架构的意识。架构是对项目整体结构和组件的抽象描述。
来自:社区博客
API接口_存储与CDN_产品文档_帮助文档-网易书凡
API接口 API文档介绍 直接上传服务是NOS推出的一套针对手机或网页上传的解决方案。该方案优化了上传逻辑,让上传更加快捷方便。用户可以使用本文档提供的简单API接口来实现直传服务的上传逻辑。API接口DNS查询说明 用户客户端可以先查询DNS服务,获取最近的边缘加速节点IP列表,选择IP上传。接口 GET /lbs?version=${version}&
来自:产品文档 - 存储和 CDN - 对象存储
浅谈容器监控与网易云计算基础服务实践
docker监控docker的研究和实践发展了这么久,涌现出很多扩展工具,有的甚至有自己的系统。相信大家对各种编排工具都很熟悉了。各种监控方案应运而生。Linux内核和cgroup技术其实已经为监控的技术可行性提供了一切基础。这里我们列出一些监控工具:docker原生监控docker提供命令方法(docker stats CID)和API:http
来自:社区博客
Snowflake & Delta Lake 两种新数据仓库对比分析
Snowflake & Delta Lake代表了业界最先进的两种数字化仓库形态,均获得市场用户的高度认可。——1——概述自1980年代数据分析兴起以来,大致经历了企业数据仓库(EDW)、数据湖(Data Lake),以及现在的云原生数据仓库、湖与仓一体化。企业数据仓库是数据仓库最原创的版本。从目前来看,存在只处理结构化数据、集中存储和计算、成本高等缺点。数字
来自:社区博客
阿里云POLARDB及其共享存储PolarFS技术实现解析(上)
PolarDB是阿里云推出的基于MySQL的云原生数据库产品。通过在数据库中分离计算和存储,多个计算节点访问相同的存储数据,解决了当前 MySQL 数据库的运维和可扩展性问题。问题; 通过引入RDMA、SPDK等新硬件改造传统网络和IO协议栈,大幅提升数据库性能。它代表了未来数据库发展的一个方向。本系列有2篇文章,主要分析PolarDB出现的原因及其技术
来自:社区博客
网易云数据库架构设计实践
作为国内领先的互联网科技公司,网易旗下拥有众多互联网产品和手机客户端应用,如知名的网易博客、云阅读、云音乐、易信等。作为支撑互联网产品的核心后端服务,数据库对产品的重要性不言而喻。随着产品数量和应用规模的快速增长,数据库管理逐渐成为产品开发的瓶颈:硬件采购周期长、沟通协调成本高、难以快速响应数据库部署需求;硬件利用率低,难以按需使用资源,弹性扩展;服务可用性差,数据
来自:社区博客
接口文档神器 Swagger(第 1 部分)
作者:李哲 接口文档管理一直是个头疼的问题,随着各种接口文档管理平台的出现,比如阿里巴巴开源的说唱、ShowDoc、sosoapi等(网上可以找到很多这样的管理平台,包括我们idoc做的我自己)。这些平台都有一个共同的特点,创建文档、编辑和保存文档,一些强大的功能包括模拟、统计界面信息等功能,所以这些平台更像是一个界面文档的存储管理系统,可以方便人们查看和保存。编辑文档。. 但是,接口通常会经常更改(添加
来自:社区博客
Docker镜像存储机制
土地如何储存?容器如何根据镜像启动?将图像推送到远程图像存储库时,服务器如何存储它?让我们简单谈谈。Docker镜像本地存储机制及容器启动原理Dock
来自:社区博客
对象存储服务NOS_高性能云存储服务_网易蜂窝-网易书凡
对象存储服务,NOS,网易蜂窝网易对象存储服务(Netease Object Storage)是一种高性能、高可用、高可靠的云存储服务。NOS支持标准的RESTful API接口,提供丰富的在线数据处理服务,一站式解决互联网时代非结构化数据管理问题——网易对象存储网易对象存储(简称NOS)由网易书凡提供高可用、高...可靠性,高性能云
来自:产品
大规模微服务场景下性能问题的定位与优化
本文结合网易青州微服务平台的实践经验,分析微服务场景下性能问题的定位和优化。文章 从一个真实的场景出发,介绍如何逐层推进,一步步定位性能问题。问题。本文经作者授权发布,未经允许请勿转载。作者:刘超,网易杭州研究院首席架构师 实现微服务架构的成本 现在云原生微服务架构非常流行,它具有迭代快、并发高、可维护、灵活等诸多优点。扩容、灰度发布、高可用,这
来自:社区博客
云优采集接口(云优CMS采集定时发布文章让搜索引擎准点你的网页打开速度 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 262 次浏览 • 2022-03-18 20:23
)
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以使用云游cms采集实现自动采集伪原创发布和主动推送到搜索引擎,以及网页打开速度。如果用云游cms采集打开网页,会影响两点。首先是用户访问网页的体验。云游的目的cms采集是为了搜索引擎的目的是为了更好的满足搜索用户体验,但是你一开始就很难让用户访问你网站 . 可想而知,即使你拥有最好的云游cms采集到采集内容,用户访问也会遇到困难,而要使用如此强大的云游cms采集
云游cms采集的相关性优化,云游cms采集的文字出现关键词,文字首段自动加粗自动插入到标题和描述中。当温度较低时,自动添加当前的采集关键词。履带爬行,开启慢,履带爬行困难。从搜索引擎的角度想想,爬虫也是一个程序运行。一个程序打开一个网页让你运行需要 1 秒,但为别人运行它只需要 100 毫秒。云游cms采集会定期发布。云游cms采集正版文章让搜索引擎准时抓取你的网站内容。而你占用的资源,爬虫可以爬一个网页来爬你这个。云游cms采集不管你有成百上千个不同的cms网站,都可以做到统一管理。云游发布的内容cms采集采集伪原创可以大大增加搜索引擎蜘蛛的出现频率。我们都知道蜘蛛爬行的频率较低,收录 爬行的可能性也较小。没有收入,排名和流量怎么办?可以大大增加搜索引擎蜘蛛的频率。我们都知道蜘蛛爬行的频率较低,收录 爬行的可能性也较小。没有收入,排名和流量怎么办?可以大大增加搜索引擎蜘蛛的频率。我们都知道蜘蛛爬行的频率较低,收录 爬行的可能性也较小。没有收入,排名和流量怎么办?
云游cms采集文本自动插入当前采集关键词2次随机位置。当当前采集的关键词出现在文本中时,云游cms采集自动将关键词加粗。云游cms采集文字可读。云游cms采集内容可见。你真的以为今天的搜索引擎认不出来了吗?比如内容块本身,原本设置为黑色字体或者深灰色字体就很好了。但出于其他一些目的,它必须设置为浅灰色或更接近网页背景的颜色,这并没有充分利用用户的体验。也不认为是高质量的内容。最重要的是,这个云游cms采集
云游cms采集可以主动推送网站,云游cms采集可以让搜索引擎更快的发现我们的网站。支持百度、搜狗、360、神马同步推送。设置正文内容。我这里主要讲的是主要内容本身,比如文章页面的内容部分,我们会设置一些加粗、标记为红色(高亮)、锚文本链接。但这三点中的太多网站仍然存在多年。云游cms采集如果是关键词,给个链接,指向首页,指向栏目页,指向频道页;如果是关键词,会加粗或者高亮,云游cms采集为了突出,云游cms采集网站内容是插入或随机作者,随机阅读,等等变成“height原创”。其实不应该。这些点都是非常小的因素。与其在这方面努力,不如合理利用云游cms采集。文章 中需要突出显示的语句或单词应突出显示。云游cms采集在发布过程中提到了一些词或知识点文章,感觉用户可能不理解或者有兴趣查看,云游cms采集@ >设置链接为设置链接。
云游cms采集自动匹配图片(文章如果内容中没有图片会自动配置相关图片) 设置自动下载图片保存在本地或第三方。其实按照这种正常的做云游cms采集的方式,你会发现你要添加的链接和文字高亮设置也适合一些SEO技巧和方法。所以,要正确理解云游cms采集工作原理细节的含义,合理设置,有时你就是在做SEO。云游cms采集用seo的思维来设置内容,云游cms采集也用设置内容的思维来做seo,这就是云游之道cms@ 的正确方法>采集。
云游cms采集在内容或标题前后插入段落或关键词(可以选择将标题和标题插入同一个关键词)。网页排版布局。这里有三点。第一点是主要内容的位置。用户最需要的内容没有显示在最重要的位置。这样可以吗?比如一个文章页面,用户只想看文章是的,但是你让用户向下滚动两个屏幕看主要内容。这种布局非常离谱。即使您认为您公司的重要内容显示在内容上,用户也会关注内容。就其本身而言,他必须满足自己的需求。其他的关注度比这个少。
云游cms采集只需输入关键词即可实现采集,云游cms采集配备关键词采集 函数。云游cms采集只需设置任务,云游cms采集全程自动挂机!第二点是主要内容之外的周边推荐信息,比如最新推荐、热门推荐、猜你喜欢、相关文章等。名称不同,检索逻辑不同,但性质基本相同。云游cms采集与当前主题文章有什么关联?云游的相关性越高cms采集意味着用户可以挖掘潜力需求越大,云游cms采集 不仅增加了你访问这个网站的PV,还降低了跳出率。也增加了当前页面的关键词密度!
云游cms采集只需设置任务,云游cms采集全程自动挂机!众所周知,弹窗广告会阻挡主题内容,影响用户体验。但是,你的页面“很多”flash图片、动态广告,以及在主要内容中穿插广告都对用户体验有害。所以,合理设置网站的布局,然后使用云游cms采集,数量、主要内容的位置等都是对用户最大的帮助,帮助用户相当于帮助搜索引擎解决了搜索用户体验的问题,为什么不获取流量呢?
增加搜索引擎爬取的频率,这个云游cms采集操作简单,云游cms采集不需要学习专业技术,云游cms@ >采集只产生 原创 内容。原创内容,大家应该都明白了,不过这里必须再提一下。云游cms采集原创一直是大家关注的重点,但并不是所有原创的内容都能获得好的排名。基于我上面提到的其他几点,使用云游cms采集你会发现除了大因素原创,还有很多细节需要注意。
云游cms采集原创的内容应该是有需求的,云游cms采集不能一味的造标题;你的内容应该和标题一致,云游cms采集不能说标题和内容,解决不了用户的实际需求;文字必须可读,不得影响用户其他用途的正常浏览;网页速度 打开快,越快越好,没有限制;如果要突出显示内容主体,则应突出显示,并且应将锚链接添加为锚链接。云游cms采集不用担心所谓的过度优化,只要你用云游cms采集它是为创造内容的目的而设置的,不为 SEO 产生内容。
云游cms采集只需几个简单的步骤,即可轻松采集内容数据。用户只需要在云游cms采集上进行简单的设置,其实百度理解的优质内容,就是真正对用户有帮助、对用户触手可及的内容,更不用说误导了。云游cms采集会根据用户设置的关键词准确采集文章,确保与行业一致文章。我们在做内容的时候,是从搜索引擎的角度来思考的。从本质上,我们可以看到很多东西,不仅仅是因为我是这样学习SEO的。云游cms采集采集文章 from 采集可以选择将修改后的内容保存到本地,云游cms采集
与其他云游cms采集相比,云游cms采集使用起来非常简单。云游cms采集只需输入关键词即可实现采集,云游cms采集自带关键词的功能采集。搜索引擎的存在是因为有大量的人有搜索信息的需求,它的目的是帮助这些人更快、更准确、更直接地找到他们想要的信息。用户满意地浏览和解决自己的需求。
查看全部
云优采集接口(云优CMS采集定时发布文章让搜索引擎准点你的网页打开速度
)
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以使用云游cms采集实现自动采集伪原创发布和主动推送到搜索引擎,以及网页打开速度。如果用云游cms采集打开网页,会影响两点。首先是用户访问网页的体验。云游的目的cms采集是为了搜索引擎的目的是为了更好的满足搜索用户体验,但是你一开始就很难让用户访问你网站 . 可想而知,即使你拥有最好的云游cms采集到采集内容,用户访问也会遇到困难,而要使用如此强大的云游cms采集
云游cms采集的相关性优化,云游cms采集的文字出现关键词,文字首段自动加粗自动插入到标题和描述中。当温度较低时,自动添加当前的采集关键词。履带爬行,开启慢,履带爬行困难。从搜索引擎的角度想想,爬虫也是一个程序运行。一个程序打开一个网页让你运行需要 1 秒,但为别人运行它只需要 100 毫秒。云游cms采集会定期发布。云游cms采集正版文章让搜索引擎准时抓取你的网站内容。而你占用的资源,爬虫可以爬一个网页来爬你这个。云游cms采集不管你有成百上千个不同的cms网站,都可以做到统一管理。云游发布的内容cms采集采集伪原创可以大大增加搜索引擎蜘蛛的出现频率。我们都知道蜘蛛爬行的频率较低,收录 爬行的可能性也较小。没有收入,排名和流量怎么办?可以大大增加搜索引擎蜘蛛的频率。我们都知道蜘蛛爬行的频率较低,收录 爬行的可能性也较小。没有收入,排名和流量怎么办?可以大大增加搜索引擎蜘蛛的频率。我们都知道蜘蛛爬行的频率较低,收录 爬行的可能性也较小。没有收入,排名和流量怎么办?
云游cms采集文本自动插入当前采集关键词2次随机位置。当当前采集的关键词出现在文本中时,云游cms采集自动将关键词加粗。云游cms采集文字可读。云游cms采集内容可见。你真的以为今天的搜索引擎认不出来了吗?比如内容块本身,原本设置为黑色字体或者深灰色字体就很好了。但出于其他一些目的,它必须设置为浅灰色或更接近网页背景的颜色,这并没有充分利用用户的体验。也不认为是高质量的内容。最重要的是,这个云游cms采集
云游cms采集可以主动推送网站,云游cms采集可以让搜索引擎更快的发现我们的网站。支持百度、搜狗、360、神马同步推送。设置正文内容。我这里主要讲的是主要内容本身,比如文章页面的内容部分,我们会设置一些加粗、标记为红色(高亮)、锚文本链接。但这三点中的太多网站仍然存在多年。云游cms采集如果是关键词,给个链接,指向首页,指向栏目页,指向频道页;如果是关键词,会加粗或者高亮,云游cms采集为了突出,云游cms采集网站内容是插入或随机作者,随机阅读,等等变成“height原创”。其实不应该。这些点都是非常小的因素。与其在这方面努力,不如合理利用云游cms采集。文章 中需要突出显示的语句或单词应突出显示。云游cms采集在发布过程中提到了一些词或知识点文章,感觉用户可能不理解或者有兴趣查看,云游cms采集@ >设置链接为设置链接。
云游cms采集自动匹配图片(文章如果内容中没有图片会自动配置相关图片) 设置自动下载图片保存在本地或第三方。其实按照这种正常的做云游cms采集的方式,你会发现你要添加的链接和文字高亮设置也适合一些SEO技巧和方法。所以,要正确理解云游cms采集工作原理细节的含义,合理设置,有时你就是在做SEO。云游cms采集用seo的思维来设置内容,云游cms采集也用设置内容的思维来做seo,这就是云游之道cms@ 的正确方法>采集。
云游cms采集在内容或标题前后插入段落或关键词(可以选择将标题和标题插入同一个关键词)。网页排版布局。这里有三点。第一点是主要内容的位置。用户最需要的内容没有显示在最重要的位置。这样可以吗?比如一个文章页面,用户只想看文章是的,但是你让用户向下滚动两个屏幕看主要内容。这种布局非常离谱。即使您认为您公司的重要内容显示在内容上,用户也会关注内容。就其本身而言,他必须满足自己的需求。其他的关注度比这个少。
云游cms采集只需输入关键词即可实现采集,云游cms采集配备关键词采集 函数。云游cms采集只需设置任务,云游cms采集全程自动挂机!第二点是主要内容之外的周边推荐信息,比如最新推荐、热门推荐、猜你喜欢、相关文章等。名称不同,检索逻辑不同,但性质基本相同。云游cms采集与当前主题文章有什么关联?云游的相关性越高cms采集意味着用户可以挖掘潜力需求越大,云游cms采集 不仅增加了你访问这个网站的PV,还降低了跳出率。也增加了当前页面的关键词密度!
云游cms采集只需设置任务,云游cms采集全程自动挂机!众所周知,弹窗广告会阻挡主题内容,影响用户体验。但是,你的页面“很多”flash图片、动态广告,以及在主要内容中穿插广告都对用户体验有害。所以,合理设置网站的布局,然后使用云游cms采集,数量、主要内容的位置等都是对用户最大的帮助,帮助用户相当于帮助搜索引擎解决了搜索用户体验的问题,为什么不获取流量呢?
增加搜索引擎爬取的频率,这个云游cms采集操作简单,云游cms采集不需要学习专业技术,云游cms@ >采集只产生 原创 内容。原创内容,大家应该都明白了,不过这里必须再提一下。云游cms采集原创一直是大家关注的重点,但并不是所有原创的内容都能获得好的排名。基于我上面提到的其他几点,使用云游cms采集你会发现除了大因素原创,还有很多细节需要注意。
云游cms采集原创的内容应该是有需求的,云游cms采集不能一味的造标题;你的内容应该和标题一致,云游cms采集不能说标题和内容,解决不了用户的实际需求;文字必须可读,不得影响用户其他用途的正常浏览;网页速度 打开快,越快越好,没有限制;如果要突出显示内容主体,则应突出显示,并且应将锚链接添加为锚链接。云游cms采集不用担心所谓的过度优化,只要你用云游cms采集它是为创造内容的目的而设置的,不为 SEO 产生内容。
云游cms采集只需几个简单的步骤,即可轻松采集内容数据。用户只需要在云游cms采集上进行简单的设置,其实百度理解的优质内容,就是真正对用户有帮助、对用户触手可及的内容,更不用说误导了。云游cms采集会根据用户设置的关键词准确采集文章,确保与行业一致文章。我们在做内容的时候,是从搜索引擎的角度来思考的。从本质上,我们可以看到很多东西,不仅仅是因为我是这样学习SEO的。云游cms采集采集文章 from 采集可以选择将修改后的内容保存到本地,云游cms采集
与其他云游cms采集相比,云游cms采集使用起来非常简单。云游cms采集只需输入关键词即可实现采集,云游cms采集自带关键词的功能采集。搜索引擎的存在是因为有大量的人有搜索信息的需求,它的目的是帮助这些人更快、更准确、更直接地找到他们想要的信息。用户满意地浏览和解决自己的需求。
云优采集接口(华为云优采集接口怎么获取网站信息例如获取天猫的title和cookie后,可以清楚)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-03-18 09:13
云优采集接口云优采集接口是华为云推出的一款采集开放工具,提供了采集的便捷性,以及对api服务方面的有力支持。开放的api,让开发者可以快速采集。
1、看网站详情获取网站信息以新浪云做例子,云优采集接口可以通过新浪云的详情页面获取网站的基本信息,例如title、cookie、date、url等等信息。同时也能通过访问新浪云后台查看网站相关信息,例如源代码、注册页面、用户体验等等。
2、知道网站的title、cookie获取网站网站信息例如获取天猫的title和cookie后,可以清楚这个title和cookie的真实含义,例如:是企业旗舰店还是专营店,或者是天猫高级会员等等。因此,云优采集接口,可以更好的发现网站其他的信息,帮助网站提升用户体验,让网站更好的存活下去。
3、核心源代码获取所有网站的核心代码,例如图片和站内信息等等,所有网站的信息都可以获取到。传统方式只能通过搜索引擎搜索,可是搜索的成本又是很高的,另外搜索的到的信息又是会有删减或者修改的情况。
4、帮助我们定制业务场景当业务需求更多的时候,是通过开发者工具开发出业务代码,例如专题页,优惠券专题页,还有就是一些接口,比如:支付接口、短信接口等等。可是我们需要自己搭建一套代码,不仅耗时,还会造成整个系统的架构,修改起来比较麻烦。云优采集接口就好的解决了这个问题,我们只需要找到网站的信息源代码后,点击核心代码获取,就能直接解析业务代码,生成真正的业务代码。
例如:通过云优采集接口打开后台,就能看到详细的业务代码,例如:需要发展商家入驻怎么办,还有就是返佣宝的发展计划、等等。不过也只支持toc的网站,还有就是就是已经被封杀的网站信息,这就让咱们无法进行获取了。有了云优采集接口,我们就可以借助云优采集接口,帮助网站更好的存活下去,并且网站在没有被封杀的情况下,我们也能进行开发。
支持云优采集接口的还有像百度贴吧、豆瓣电影等网站,另外当然也支持新浪博客、云课堂这些在线学习网站。综上所述,云优采集接口主要针对的就是有一定规模的网站,类似于客、京东客这些有一定规模的网站,本质就是通过可以定制网站的功能,提升网站的用户体验。好用的方法很简单,就是你要去找到云优采集接口,然后获取你想要的信息,将网站的信息转换成代码,然后我们就可以直接存到云优采集接口的后台,然后我们就可以自己从网站爬取信息,例如:支付接口,短信接口等等。 查看全部
云优采集接口(华为云优采集接口怎么获取网站信息例如获取天猫的title和cookie后,可以清楚)
云优采集接口云优采集接口是华为云推出的一款采集开放工具,提供了采集的便捷性,以及对api服务方面的有力支持。开放的api,让开发者可以快速采集。
1、看网站详情获取网站信息以新浪云做例子,云优采集接口可以通过新浪云的详情页面获取网站的基本信息,例如title、cookie、date、url等等信息。同时也能通过访问新浪云后台查看网站相关信息,例如源代码、注册页面、用户体验等等。
2、知道网站的title、cookie获取网站网站信息例如获取天猫的title和cookie后,可以清楚这个title和cookie的真实含义,例如:是企业旗舰店还是专营店,或者是天猫高级会员等等。因此,云优采集接口,可以更好的发现网站其他的信息,帮助网站提升用户体验,让网站更好的存活下去。
3、核心源代码获取所有网站的核心代码,例如图片和站内信息等等,所有网站的信息都可以获取到。传统方式只能通过搜索引擎搜索,可是搜索的成本又是很高的,另外搜索的到的信息又是会有删减或者修改的情况。
4、帮助我们定制业务场景当业务需求更多的时候,是通过开发者工具开发出业务代码,例如专题页,优惠券专题页,还有就是一些接口,比如:支付接口、短信接口等等。可是我们需要自己搭建一套代码,不仅耗时,还会造成整个系统的架构,修改起来比较麻烦。云优采集接口就好的解决了这个问题,我们只需要找到网站的信息源代码后,点击核心代码获取,就能直接解析业务代码,生成真正的业务代码。
例如:通过云优采集接口打开后台,就能看到详细的业务代码,例如:需要发展商家入驻怎么办,还有就是返佣宝的发展计划、等等。不过也只支持toc的网站,还有就是就是已经被封杀的网站信息,这就让咱们无法进行获取了。有了云优采集接口,我们就可以借助云优采集接口,帮助网站更好的存活下去,并且网站在没有被封杀的情况下,我们也能进行开发。
支持云优采集接口的还有像百度贴吧、豆瓣电影等网站,另外当然也支持新浪博客、云课堂这些在线学习网站。综上所述,云优采集接口主要针对的就是有一定规模的网站,类似于客、京东客这些有一定规模的网站,本质就是通过可以定制网站的功能,提升网站的用户体验。好用的方法很简单,就是你要去找到云优采集接口,然后获取你想要的信息,将网站的信息转换成代码,然后我们就可以直接存到云优采集接口的后台,然后我们就可以自己从网站爬取信息,例如:支付接口,短信接口等等。
云优采集接口(高德地图开放平台:API/好用不好用?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 435 次浏览 • 2022-03-17 21:13
什么是高德开放平台?
高德开放平台是国内领先的LBS服务商,拥有先进的数据融合技术和海量数据处理能力。它服务于超过 30 万个移动应用,每天处理数百亿的定位请求和路线规划。高德的开放平台为开发者提供了涵盖移动端和Web端的开发工具。开发者可以通过调用开发包或接口,在应用程序或网页中实现地图显示、标注、位置检索等功能。使 LBS 应用程序的开发过程更容易。
高德对位置大数据的不断探索和实践,高德地图开放平台,通过其服务的30万个应用,数百亿的每日位置请求和相关行为,将人群趋势、区域流行度和相关行为呈现在现实世界中。行为偏好等分析洞察,试图通过数据画像还原我们身边熟悉但陌生的世界。
高德开放平台为开发者提供了三个主要能力:
1、 专业易用的地图开发工具:API/SDK
2、 快速定位云计算:云地图
3、 权威位置大数据:高德位智
地图开发工具:API/SDK
高德地图API/SDK是为开发者提供的一套地图应用程序接口,包括JavaScript、iOS、Andriod、Windows、静态地图、Web服务等版本。提供定位、地图、导航(公交\驾车\步行)、位置搜索、周边搜索、地理编码和反向地理编码、实时路况等丰富功能。
如果你的网站或者APP需要用到地图功能,是不是一定要自己开发一套地图?不,当然不!!由于高德以API/SDK的形式开放了这些能力(包括:定位、地图、导航等),通过调用高德的API和SDK,您的APP可以轻松拥有与高德一样的专业。地图功能!
高德API/SDK好用还是不好用?这么多高质量的应用都在使用我们的产品,高德绝对不会出错!
开发文档
文件地址
位置云计算:云地图
高德云地图主要提供这样的服务:存储和管理自己的位置数据,只需一张Excel表格,就可以快速生成你想要的地图!点击查看详情>>
云地图为您提供了一个集成的高性能工具,用于您自己的位置数据采集、存储、渲染和检索。
如果你恰好有业务数据,然后只想在地图上标记这些数据,那么选择云地图一定是明智之举——因为有了云地图,数据采集,存储、展示、编辑,你不用不需要自己进行搜索。据说选择它会减少50%以上的开发量!核心功能:自有位置数据的存储、展示、编辑、检索和应用开发
核心痛点解决:
1、位置数据存储,减轻海量数据存储和维护压力;
2、实时渲染&检索,解决位置数据高并发检索的瓶颈。
同时,如果您希望在高德地图APP上检索您的数据,您也可以先将数据存储在云地图上。在您的授权下,云地图可以将数据推送到高德地图。
位置大数据:高德位智
高德是高德开放平台出品的基于百亿位置大数据挖掘的区域分析平台。旨在帮助行业客户、新闻媒体、政府学术机构和个人用户了解区域人口趋势和区域流行度。我们为各类用户群体提供区域热度分析、基于位置的人群行为分析等。同时,我们提供高德位智分析的焦点大数据报告,供高德位智用户使用指数。以供参考。
我们的优势
专注地图,拥有国家A级测绘资质,超过6000万个POI,790万公里道路数据,提供国内专业手机地图
使用方便
想想用户的想法,以及用户可以达到什么。我们推出了一系列行业解决方案,如:出行、O2O、智能硬件……打造“零开发”产品,降低开发成本是我们的使命!
我们的愿景
1、 用“位置”标记物理世界中所有有价值的数据;
2、人类行为+位置数据,在地图上映射真实世界,在地图上还原真实世界。 查看全部
云优采集接口(高德地图开放平台:API/好用不好用?(组图))
什么是高德开放平台?
高德开放平台是国内领先的LBS服务商,拥有先进的数据融合技术和海量数据处理能力。它服务于超过 30 万个移动应用,每天处理数百亿的定位请求和路线规划。高德的开放平台为开发者提供了涵盖移动端和Web端的开发工具。开发者可以通过调用开发包或接口,在应用程序或网页中实现地图显示、标注、位置检索等功能。使 LBS 应用程序的开发过程更容易。
高德对位置大数据的不断探索和实践,高德地图开放平台,通过其服务的30万个应用,数百亿的每日位置请求和相关行为,将人群趋势、区域流行度和相关行为呈现在现实世界中。行为偏好等分析洞察,试图通过数据画像还原我们身边熟悉但陌生的世界。
高德开放平台为开发者提供了三个主要能力:
1、 专业易用的地图开发工具:API/SDK
2、 快速定位云计算:云地图
3、 权威位置大数据:高德位智
地图开发工具:API/SDK
高德地图API/SDK是为开发者提供的一套地图应用程序接口,包括JavaScript、iOS、Andriod、Windows、静态地图、Web服务等版本。提供定位、地图、导航(公交\驾车\步行)、位置搜索、周边搜索、地理编码和反向地理编码、实时路况等丰富功能。
如果你的网站或者APP需要用到地图功能,是不是一定要自己开发一套地图?不,当然不!!由于高德以API/SDK的形式开放了这些能力(包括:定位、地图、导航等),通过调用高德的API和SDK,您的APP可以轻松拥有与高德一样的专业。地图功能!
高德API/SDK好用还是不好用?这么多高质量的应用都在使用我们的产品,高德绝对不会出错!
开发文档
文件地址
位置云计算:云地图
高德云地图主要提供这样的服务:存储和管理自己的位置数据,只需一张Excel表格,就可以快速生成你想要的地图!点击查看详情>>
云地图为您提供了一个集成的高性能工具,用于您自己的位置数据采集、存储、渲染和检索。
如果你恰好有业务数据,然后只想在地图上标记这些数据,那么选择云地图一定是明智之举——因为有了云地图,数据采集,存储、展示、编辑,你不用不需要自己进行搜索。据说选择它会减少50%以上的开发量!核心功能:自有位置数据的存储、展示、编辑、检索和应用开发
核心痛点解决:
1、位置数据存储,减轻海量数据存储和维护压力;
2、实时渲染&检索,解决位置数据高并发检索的瓶颈。
同时,如果您希望在高德地图APP上检索您的数据,您也可以先将数据存储在云地图上。在您的授权下,云地图可以将数据推送到高德地图。
位置大数据:高德位智
高德是高德开放平台出品的基于百亿位置大数据挖掘的区域分析平台。旨在帮助行业客户、新闻媒体、政府学术机构和个人用户了解区域人口趋势和区域流行度。我们为各类用户群体提供区域热度分析、基于位置的人群行为分析等。同时,我们提供高德位智分析的焦点大数据报告,供高德位智用户使用指数。以供参考。
我们的优势
专注地图,拥有国家A级测绘资质,超过6000万个POI,790万公里道路数据,提供国内专业手机地图
使用方便
想想用户的想法,以及用户可以达到什么。我们推出了一系列行业解决方案,如:出行、O2O、智能硬件……打造“零开发”产品,降低开发成本是我们的使命!
我们的愿景
1、 用“位置”标记物理世界中所有有价值的数据;
2、人类行为+位置数据,在地图上映射真实世界,在地图上还原真实世界。
云优采集接口(【日志服务CLS】腾讯云Log4jLogback日志采集最佳实践一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2022-03-16 23:15
【日志服务CLS】腾讯云Log4jLogback Log采集最佳实践
一、引言 日志存储和分析在应用系统中扮演着重要的角色。传统的 ELK 对于小团队来说过于繁琐,维护起来也很麻烦。腾讯云提供CLS日志采集分析系统,可以使用LogListener实现业务代码无侵入采集日志,开发者也可以使用如上图的三架构图image.png,开发者可以选择自定义日志采集模块,将日志上报到腾讯云CLS。四个腾讯云 CLS 逻辑概念 准备一个日志集:一个日志集对应一个项目或应用 日志主题:一个日志主题对应一种应用或服务 日志组:收录多个日志的集合 日志分区:一个日志主题可以是分为多个主题分区,7 CLS日志上报云API 本文作者通过调用API实现结构化日志上传。请参阅上传结构化日志 API 文档云。日志端解耦;但是LogListener仅限于CVM机器上的日志采集,或者其他腾讯云容器的日志采集,如果开发者的应用在自建机房或者其他云平台 7 CLS日志上报云API 本文作者通过调用API实现结构化日志上传。请参阅上传结构化日志 API 文档云。日志端解耦;但是LogListener仅限于CVM机器上的日志采集,或者其他腾讯云容器的日志采集,如果开发者的应用在自建机房或者其他云平台
689 查看全部
云优采集接口(【日志服务CLS】腾讯云Log4jLogback日志采集最佳实践一)
【日志服务CLS】腾讯云Log4jLogback Log采集最佳实践
一、引言 日志存储和分析在应用系统中扮演着重要的角色。传统的 ELK 对于小团队来说过于繁琐,维护起来也很麻烦。腾讯云提供CLS日志采集分析系统,可以使用LogListener实现业务代码无侵入采集日志,开发者也可以使用如上图的三架构图image.png,开发者可以选择自定义日志采集模块,将日志上报到腾讯云CLS。四个腾讯云 CLS 逻辑概念 准备一个日志集:一个日志集对应一个项目或应用 日志主题:一个日志主题对应一种应用或服务 日志组:收录多个日志的集合 日志分区:一个日志主题可以是分为多个主题分区,7 CLS日志上报云API 本文作者通过调用API实现结构化日志上传。请参阅上传结构化日志 API 文档云。日志端解耦;但是LogListener仅限于CVM机器上的日志采集,或者其他腾讯云容器的日志采集,如果开发者的应用在自建机房或者其他云平台 7 CLS日志上报云API 本文作者通过调用API实现结构化日志上传。请参阅上传结构化日志 API 文档云。日志端解耦;但是LogListener仅限于CVM机器上的日志采集,或者其他腾讯云容器的日志采集,如果开发者的应用在自建机房或者其他云平台
689

