
xpath
Python手动搜索关键词采集信息—以易迅为例!
采集交流 • 优采云 发表了文章 • 0 个评论 • 664 次浏览 • 2020-08-03 10:55
如果网页上有搜索框,但是搜索结果页面没有独立网址,想要采集搜索结果,直接做规则是采集不到的,要先做连续动作(输入+点击)来实现手动输入关键词并搜索,然后才会采集数据。下面用易迅搜索为例,演示手动搜索采集,操作步骤如下:
Python资源共享群:626017123
二、案例规则+操作步骤
注意:本案例易迅搜索是有独立网址的,对于具有独立网址的页面,最简单的方式就是构造出每位关键词的搜索网址,然后把线索网址导出到规则里,就可以批量采集,而不是设置连续动作
第一步:定义第一级规则
1.1打开集搜客网络爬虫,输入网址并Enter,加载出网页后再点击“定义规则”按钮,看到一个浮窗显示下来,称为工作台,在前面定义规则;
注意:这里的截图和文字说明都是集搜客网络爬虫版本,如果您安装的是傲游插件版,那么就没有“定义规则”按钮,而是应当运行MS谋数台
1.2在工作台北输入一级规则的主题名,再点击“查重”,提示“该名可以使用”或“该名已被占用,可编辑:是”,就可以使用这个主题名,否则请重命名。
1.3本级规则主要是设置连续动作,所以,整理箱可以随便抓取一个信息,用来给爬虫判定是否执行采集。双击网页上的信息,输入标签名,并打勾确认,再勾上关键内容,首次标明还要输入整理箱的名子,然后就完成标明映射了。
Tips:为了能确切定位网页信息,点击定义规则会把整个网页定格住,不能跳转网页链接,再次点击定义规则,才会恢复回普通的网页模式。
第二步:定义连续动作
点击工作台的“连续动作”页签,点击新建按键构建一个新动作,每个动作的设置方式都是一样,基本操作如下:
2.1 ,输入目标主题名
这里的目标主题名是填第二级主题名,点击“谁在用”查看目标主题名是否可用,如果早已被占用,换一个主题名就行
2.2, 创建第一个动作:输入
新建一个动作,并选择动作类型为输入。
2.2.1,填写定位表达式
首先键盘单击输入框,定位输入框的节点,然后点击“自动生成XPath”按钮,可以选择“偏好id”或者“偏好class”,就可以得到输入框的xpath表达式,再点击“搜索”按钮,检查一下这个xpath是否能惟一定位到输入框,没有问题就把xpath复制到定位表达式方框里。
注意:定位表达式里的xpath是要锁定动作对象的整个有效操作范围,具体就是指键盘就能点击或输入成功的网页模块,不要定位到最底层的text()节点。
2.2.2,输入关键词
输入关键词填写你想搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词要用双分号;;将每位关键词隔开,免费版只支持5个以内的关键词,旗舰版可以使用连发弹仓功能,支持1万以内的关键词
2.2.3,输入动作名称
告诉自己这一步动作是拿来干嘛的,方便之后更改。
2.3,创建第二个动作:点击
参考2.2的操作,创建第二个动作,选择类型为点击,定位到搜索按键,然后手动生成xpath,检验是否锁定到惟一节点,没问题的话填到定位表达式里就行了。
2.4,存规则
点击“存规则”按钮保存已完成的第一级规则
第三步:定义第二级规则
3.1,新建规则
创建第二级规则,点击“定义规则”恢复到普通网页模式,输入关键词搜索出结果后,再次点击“定义规则”切换到做规则模式,点击左上角“规则”菜单->“新建”,输入主题名,这里的主题名就是第一级规则的连续动作里填写的目标主题名。
3.2,标注想要采集的信息
3.2.1,标注网页上想要采集的信息,这里是对商品名称和价位做标明,因为标明只对文本信息有效,商品详情的链接是属性节点@href,所以,不能对链接做这样的直观标明,而要做内容映射,具体看下边的操作。
3.2.2,点击商品名称,下面的DOM节点定位到A标签,展开A标签下的attributes节点,就可以找到代表网址的@href节点,右击节点,选择“新建抓取内容“,输入一个名子,一般给这个抓取内容起一个和地址有关的名子,比如“下级网址“,或者”下级链接“等等。然后在工作台上,看到这个抓取内容有了。如果还要步入商品详情页采集,就要对着这个抓取内容勾选下级线索关键词自动采集,做层级抓取。
3.2.3,设置“关键内容”选项,这样爬虫就能判别出采集规则是否合适。在整理箱里选一个网页上必然能采到的标签关键词自动采集,勾上“关键内容”。这里选择的是“名称”做为“关键内容”。
3.2.4,前面只对一个商品做标明,也才能得到一个商品信息,如果想把一整页上每一个商品都采集下来,可以做样例复制,不懂的请参考基础教程《采集列表数据》
3.3,设置翻页路线
在爬虫路线设置翻页,这里用的是记号线索,不懂的请参考基础教程《设置翻页采集》
3.4,存规则
点击“测试”,检查信息完整性。不完整的话,重新标明就可以覆盖之前的内容。检查没问题后点击“存规则”。
第四步:抓数据
4.1,连续动作是连续执行的,所以只要运行第一级主题,第二级主题不用运行。打开DS打数机,搜索出第一级主题名,点击“单搜”或“集搜”,此时可以看见浏览器窗口里会手动输入关键词而且搜索,然后调用第二级主题手动采集搜索结果。
4.2,第一级主题没采到有意义的信息,所以,我们只看第二级主题的文件夹,就能看见采集的搜索结果数据,并且搜索的关键词是默认记录在xml文件的actionvalue数组中,这样才能一一对应上去。 查看全部
Python数据剖析之numpy字段全解析一、操作步骤
如果网页上有搜索框,但是搜索结果页面没有独立网址,想要采集搜索结果,直接做规则是采集不到的,要先做连续动作(输入+点击)来实现手动输入关键词并搜索,然后才会采集数据。下面用易迅搜索为例,演示手动搜索采集,操作步骤如下:
Python资源共享群:626017123
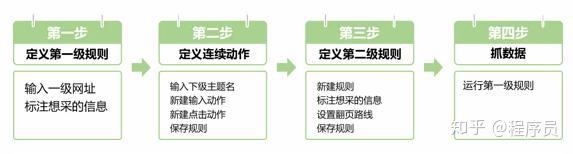
二、案例规则+操作步骤
注意:本案例易迅搜索是有独立网址的,对于具有独立网址的页面,最简单的方式就是构造出每位关键词的搜索网址,然后把线索网址导出到规则里,就可以批量采集,而不是设置连续动作
第一步:定义第一级规则
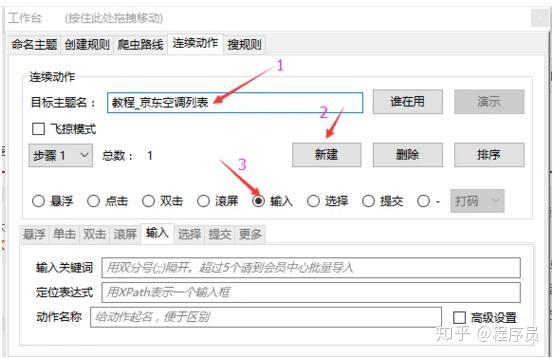
1.1打开集搜客网络爬虫,输入网址并Enter,加载出网页后再点击“定义规则”按钮,看到一个浮窗显示下来,称为工作台,在前面定义规则;
注意:这里的截图和文字说明都是集搜客网络爬虫版本,如果您安装的是傲游插件版,那么就没有“定义规则”按钮,而是应当运行MS谋数台
1.2在工作台北输入一级规则的主题名,再点击“查重”,提示“该名可以使用”或“该名已被占用,可编辑:是”,就可以使用这个主题名,否则请重命名。
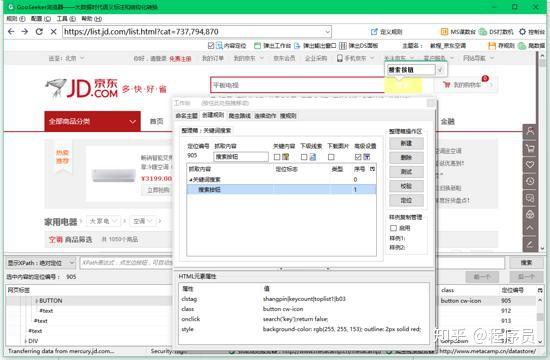
1.3本级规则主要是设置连续动作,所以,整理箱可以随便抓取一个信息,用来给爬虫判定是否执行采集。双击网页上的信息,输入标签名,并打勾确认,再勾上关键内容,首次标明还要输入整理箱的名子,然后就完成标明映射了。
Tips:为了能确切定位网页信息,点击定义规则会把整个网页定格住,不能跳转网页链接,再次点击定义规则,才会恢复回普通的网页模式。
第二步:定义连续动作
点击工作台的“连续动作”页签,点击新建按键构建一个新动作,每个动作的设置方式都是一样,基本操作如下:
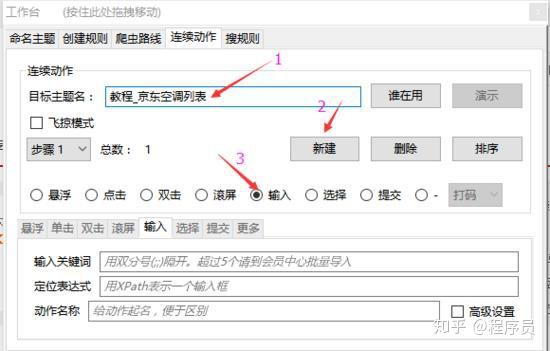
2.1 ,输入目标主题名
这里的目标主题名是填第二级主题名,点击“谁在用”查看目标主题名是否可用,如果早已被占用,换一个主题名就行
2.2, 创建第一个动作:输入
新建一个动作,并选择动作类型为输入。
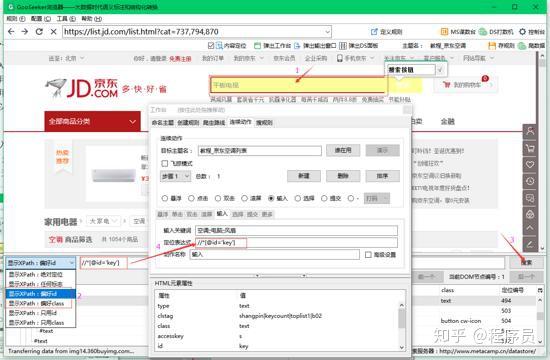
2.2.1,填写定位表达式
首先键盘单击输入框,定位输入框的节点,然后点击“自动生成XPath”按钮,可以选择“偏好id”或者“偏好class”,就可以得到输入框的xpath表达式,再点击“搜索”按钮,检查一下这个xpath是否能惟一定位到输入框,没有问题就把xpath复制到定位表达式方框里。
注意:定位表达式里的xpath是要锁定动作对象的整个有效操作范围,具体就是指键盘就能点击或输入成功的网页模块,不要定位到最底层的text()节点。
2.2.2,输入关键词
输入关键词填写你想搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词要用双分号;;将每位关键词隔开,免费版只支持5个以内的关键词,旗舰版可以使用连发弹仓功能,支持1万以内的关键词
2.2.3,输入动作名称
告诉自己这一步动作是拿来干嘛的,方便之后更改。
2.3,创建第二个动作:点击
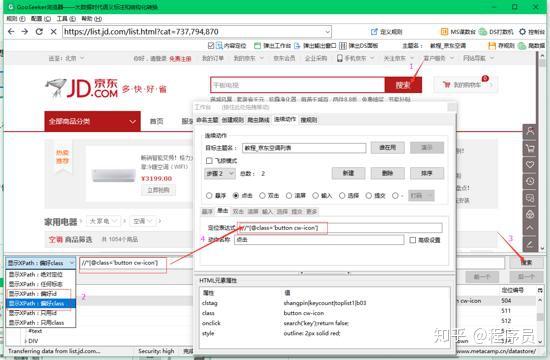
参考2.2的操作,创建第二个动作,选择类型为点击,定位到搜索按键,然后手动生成xpath,检验是否锁定到惟一节点,没问题的话填到定位表达式里就行了。
2.4,存规则
点击“存规则”按钮保存已完成的第一级规则
第三步:定义第二级规则
3.1,新建规则
创建第二级规则,点击“定义规则”恢复到普通网页模式,输入关键词搜索出结果后,再次点击“定义规则”切换到做规则模式,点击左上角“规则”菜单->“新建”,输入主题名,这里的主题名就是第一级规则的连续动作里填写的目标主题名。
3.2,标注想要采集的信息
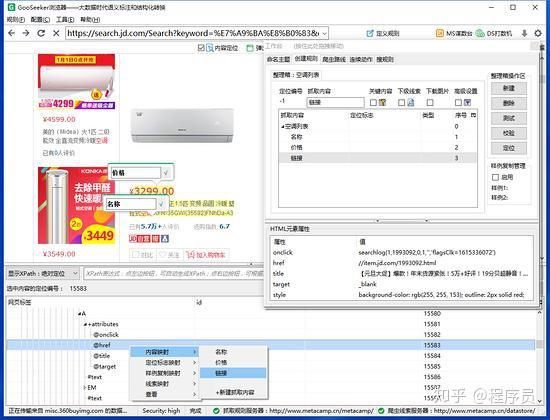
3.2.1,标注网页上想要采集的信息,这里是对商品名称和价位做标明,因为标明只对文本信息有效,商品详情的链接是属性节点@href,所以,不能对链接做这样的直观标明,而要做内容映射,具体看下边的操作。
3.2.2,点击商品名称,下面的DOM节点定位到A标签,展开A标签下的attributes节点,就可以找到代表网址的@href节点,右击节点,选择“新建抓取内容“,输入一个名子,一般给这个抓取内容起一个和地址有关的名子,比如“下级网址“,或者”下级链接“等等。然后在工作台上,看到这个抓取内容有了。如果还要步入商品详情页采集,就要对着这个抓取内容勾选下级线索关键词自动采集,做层级抓取。
3.2.3,设置“关键内容”选项,这样爬虫就能判别出采集规则是否合适。在整理箱里选一个网页上必然能采到的标签关键词自动采集,勾上“关键内容”。这里选择的是“名称”做为“关键内容”。
3.2.4,前面只对一个商品做标明,也才能得到一个商品信息,如果想把一整页上每一个商品都采集下来,可以做样例复制,不懂的请参考基础教程《采集列表数据》
3.3,设置翻页路线
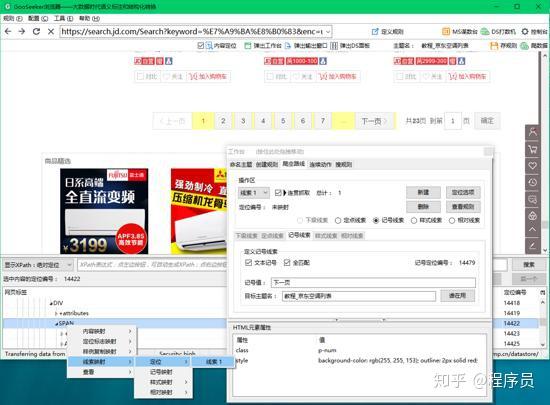
在爬虫路线设置翻页,这里用的是记号线索,不懂的请参考基础教程《设置翻页采集》
3.4,存规则
点击“测试”,检查信息完整性。不完整的话,重新标明就可以覆盖之前的内容。检查没问题后点击“存规则”。
第四步:抓数据
4.1,连续动作是连续执行的,所以只要运行第一级主题,第二级主题不用运行。打开DS打数机,搜索出第一级主题名,点击“单搜”或“集搜”,此时可以看见浏览器窗口里会手动输入关键词而且搜索,然后调用第二级主题手动采集搜索结果。
4.2,第一级主题没采到有意义的信息,所以,我们只看第二级主题的文件夹,就能看见采集的搜索结果数据,并且搜索的关键词是默认记录在xml文件的actionvalue数组中,这样才能一一对应上去。
R爬虫之上市公司公告批量下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 382 次浏览 • 2020-06-03 08:01
2017-4-13 17:46|发布者: 炼数成金_小数|查看: 22744|评论: 1|原作者: 黄耀鹏|来自: R语言英文社区
摘要: Selenium是一个用于测试网页应用的开源软件。它提供了浏览器中的点击,滚动,滑动,及文字输入等驱动程序。这样,利用Selenium即可以通过脚本程序来代替人工进行测试一个开发软件的各类功能。在处理爬虫任务中,经常 ...
tm
Python
测试
案例
开源软件
函数
selenium的安装及使用介绍
Selenium是一个用于测试网页应用的开源软件。它提供了浏览器中的点击r软件爬虫,滚动,滑动r软件爬虫,及文字输入等驱动程序。这样,利用Selenium即可以通过脚本程序来代替人工进行测试一个开发软件的各类功能。
在处理爬虫任务中,经常碰到须要输入文字,进行下拉菜单选择,以及滑鼠点击等情境。这个时侯,selenium就派上大用场了。
下面,我们先介绍一下Selenium的使用环境配置,接着介绍怎样通过R的拓展包Rwebdriver来使用Selenium,最后,展示一个爬虫案例应用。
安装配置
安装jre:
下载地址:#win
配置jre环境变量
下载selenium,并放至指定位置
下载地址:
启动selenium
打开命令提示符
进入selenium所在路径
启动selenium
cd "C:\Program Files (x86)\Rwebdriver"
java -jar selenium-server-standalone-2.49.0.jar
### selenium接口函数介绍
『Automated Data Collection with R』一书的作者开发了R包Rwebdriver,用于联接启用selenium。
该R包重要的函数如下:
更多细节请参考:
-『Automated Data Collection with R』第9章P253-P259
Selenium with Python
网页开发工具的使用介绍
(手动演示)
XML提取器相关函数的使用
xpathSApply(doc,path,fun = NULL)
可传入的fun如下:
案例演示——爬取上海证券交易所上市公司公告信息
#### packages we need ####
## ----------------------------------------------------------------------- ##
require(stringr)
require(XML)
require(RCurl)
library(Rwebdriver)
# set path
setwd("ListedCompanyAnnouncement")
# base url
BaseUrl<-"http://www.sse.com.cn/disclosu ... ot%3B
#start a session
quit_session()
start_session(root = "http://localhost:4444/wd/hub/",browser = "firefox")
# post Base Url
post.url(url = BaseUrl)
# get xpath
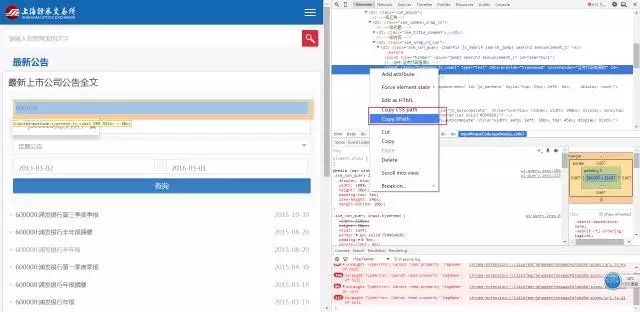
StockCodeField<-element_xpath_find(value = '//*[@id="inputCode"]')
ClassificationField<-element_xpath_find(value = '/html/body/div[7]/div[2]/div[2]/div[2]/div/div/div/div/div[2]/div[1]/div[3]/div/button')
StartDateField<-element_xpath_find(value = '//*[@id="start_date"]')
EndDateField<-element_xpath_find(value = '//*[@id="end_date"]')
SearchField<-element_xpath_find(value = '//*[@id="btnQuery"]')
# fill stock code
StockCode<-"600000"
element_click(StockCodeField)
keys(StockCode)
Sys.sleep(2)
#fill classification field
element_click(ClassificationField)
# get announcement xpath
RegularAnnouncement<-element_xpath_find(value = '/html/body/div[7]/div[2]/div[2]/div[2]/div/div/div/div/div[2]/div[1]/div[3]/div/div/ul/li[2]')
Sys.sleep(2)
element_click(RegularAnnouncement)
# #fill start and end date
# element_click(StartDateField)
# today's xpath
EndToday<-element_xpath_find(value = '/html/body/div[13]/div[3]/table/tfoot/tr/th')
Sys.sleep(2)
element_click(EndDateField)
Sys.sleep(2)
element_click(EndToday)
#click search
element_click(SearchField)
###################################
####获得所有文件的link ##
all_links<-character() 查看全部

2017-4-13 17:46|发布者: 炼数成金_小数|查看: 22744|评论: 1|原作者: 黄耀鹏|来自: R语言英文社区
摘要: Selenium是一个用于测试网页应用的开源软件。它提供了浏览器中的点击,滚动,滑动,及文字输入等驱动程序。这样,利用Selenium即可以通过脚本程序来代替人工进行测试一个开发软件的各类功能。在处理爬虫任务中,经常 ...
tm
Python
测试
案例
开源软件
函数
selenium的安装及使用介绍
Selenium是一个用于测试网页应用的开源软件。它提供了浏览器中的点击r软件爬虫,滚动,滑动r软件爬虫,及文字输入等驱动程序。这样,利用Selenium即可以通过脚本程序来代替人工进行测试一个开发软件的各类功能。
在处理爬虫任务中,经常碰到须要输入文字,进行下拉菜单选择,以及滑鼠点击等情境。这个时侯,selenium就派上大用场了。
下面,我们先介绍一下Selenium的使用环境配置,接着介绍怎样通过R的拓展包Rwebdriver来使用Selenium,最后,展示一个爬虫案例应用。
安装配置
安装jre:
下载地址:#win
配置jre环境变量
下载selenium,并放至指定位置
下载地址:
启动selenium
打开命令提示符
进入selenium所在路径
启动selenium
cd "C:\Program Files (x86)\Rwebdriver"
java -jar selenium-server-standalone-2.49.0.jar
### selenium接口函数介绍
『Automated Data Collection with R』一书的作者开发了R包Rwebdriver,用于联接启用selenium。
该R包重要的函数如下:
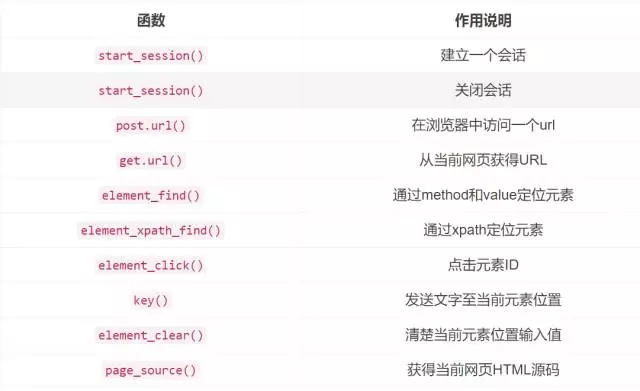
更多细节请参考:
-『Automated Data Collection with R』第9章P253-P259
Selenium with Python
网页开发工具的使用介绍
(手动演示)
XML提取器相关函数的使用
xpathSApply(doc,path,fun = NULL)
可传入的fun如下:

案例演示——爬取上海证券交易所上市公司公告信息
#### packages we need ####
## ----------------------------------------------------------------------- ##
require(stringr)
require(XML)
require(RCurl)
library(Rwebdriver)
# set path
setwd("ListedCompanyAnnouncement")
# base url
BaseUrl<-"http://www.sse.com.cn/disclosu ... ot%3B
#start a session
quit_session()
start_session(root = "http://localhost:4444/wd/hub/",browser = "firefox")
# post Base Url
post.url(url = BaseUrl)
# get xpath
StockCodeField<-element_xpath_find(value = '//*[@id="inputCode"]')
ClassificationField<-element_xpath_find(value = '/html/body/div[7]/div[2]/div[2]/div[2]/div/div/div/div/div[2]/div[1]/div[3]/div/button')
StartDateField<-element_xpath_find(value = '//*[@id="start_date"]')
EndDateField<-element_xpath_find(value = '//*[@id="end_date"]')
SearchField<-element_xpath_find(value = '//*[@id="btnQuery"]')
# fill stock code
StockCode<-"600000"
element_click(StockCodeField)
keys(StockCode)
Sys.sleep(2)
#fill classification field
element_click(ClassificationField)
# get announcement xpath
RegularAnnouncement<-element_xpath_find(value = '/html/body/div[7]/div[2]/div[2]/div[2]/div/div/div/div/div[2]/div[1]/div[3]/div/div/ul/li[2]')
Sys.sleep(2)
element_click(RegularAnnouncement)
# #fill start and end date
# element_click(StartDateField)
# today's xpath
EndToday<-element_xpath_find(value = '/html/body/div[13]/div[3]/table/tfoot/tr/th')
Sys.sleep(2)
element_click(EndDateField)
Sys.sleep(2)
element_click(EndToday)
#click search
element_click(SearchField)
###################################
####获得所有文件的link ##
all_links<-character()
百度搜索结果爬虫实现方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 351 次浏览 • 2020-05-12 08:03
八爪鱼·云采集服务平台 百度搜索结果爬虫实现方式做 SEO 做流量的朋友,很多百度搜索数据都须要自己去抓取,大家就会选择用 八爪鱼爬虫工具进行百度搜索结果的数据采集,大批量又高效。如何配置百度搜 索的采集任务呢,接下来本文将介绍使用八爪鱼采集百度搜索结果的方式。采集网站:使用功能点:? 分页列表信息采集 ? Xpath ? AJAX 点击和翻页步骤 1:创建采集任务1)进入主界面,选择“自定义模式”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 12)将要采集的网址复制粘贴到网站输入框中,点击“保存网址”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 2步骤 2:输入文本1)在页面右上角,打开“流程”,以突显出“流程设计器”和“定制当前操作” 两个蓝筹股。点击搜索框,在操作提示框中,选择“输入文字”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 32)输入要采集的文本,这里以输入“八爪鱼采集器”为例。完成后,点击“确 定”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 43)输入的文本手动填充到搜索框后,点击“百度一下”按钮。在操作提示框中, 选择“点击该按键”百度搜索结果爬虫方式图 5此步骤涉及 Ajax 技术。
打开“高级选项”,勾选“Ajax 加载数据”,设置时间 为“2 秒”。完成后,点击“确定”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 6步骤 3:创建翻页循环1)将页面下拉到顶部,点击“下一页”按钮,在两侧的操作提示框中,选择“循 环点击下一页”,以完善一个翻页循环八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 72)选中“循环翻页”步骤,打开“高级选项”,将单个元素中的这条 Xpath: //A[@class='n',复制粘贴到火狐浏览器中的相应位置八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 8可以看见,当在第 1 页的时侯,使用此条 Xpath,可以定位到“下一页”百度搜索结果爬虫方式图 9八爪鱼·云采集服务平台 当翻到第 2 页的时侯,使用此条 Xpath,既可定位到“上一页”,又可定位到 “下一页”百度搜索结果爬虫方式图 103)返回八爪鱼采集器,点击“自定义”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 114)勾选“元素文本=下一页>”百度爬虫,对应生成的 Xpath 为://A[@text()='下一 页']。完成后,点击“确定”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 125)将修改后的 Xpath://A[@text()='下一页'],再次复制粘贴到火狐浏览器 中。
可以看见,当翻到第 2 页的时侯,可正常定位到“下一页”,第 3、4、5、 6 等也可正常定位到“下一页”,翻页循环可正常运行八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 13步骤 4:创建列表循环并提取数据1)移动滑鼠,选中页面里第一条搜索结果的区块,再选中页面内另一条搜索结 果的区块。系统会手动辨识并选中,页面里其他搜索结果的区块,以完善一个列 表循环。在操作提示框中,选择“采集以下元素文本”。整个区块里的信息,作 为一个数组,被采集下来八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 142)选中“循环”步骤,打开“高级选项”,将不固定元素列表中的这条 Xpath: //DIV[@id='content_left']/DIV,复制粘贴到火狐浏览器中的相应位置八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 153)将八爪鱼中的 Xpath,复制到火狐浏览器中的相应位置。观察页面,我们不 需要采集的“相关搜索”和“广告”内容也被定位了八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 164 ) 观 察 网 页 源 码 , 我 们 要 采 集 的 区 块 , 具 有 相 同 的 tpl 属 性 , tpl="se_com_default"(如图红框中所示),通过 tpl 属性,可即将采集的县 块与不需要采集的广告、推荐内容分辨开来。
将 Xpath 修改为: //DIV[@id='content_left']/DIV[@tpl="se_com_default"]。再观察页面, 要采集的内容都被定位了,不需要采集的广告、推荐内容未被定位八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 175)将修改后的 Xpath: //DIV[@id='content_left']/DIV[@tpl="se_com_default"], 复制粘贴到八 爪虾采集器的相应位置。完成后,点击“确定”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 186)在这里,我们还想采集每条搜索结果的链接 URL。选中页面内一条搜索结果 的链接,在操作提示框中,选择“采集该链接地址”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 197)字段选择完成后,选中相应的数组,可以进行数组的自定义命名。完成后, 点击左上角的“保存并启动”,选择“启动本地采集”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 20步骤 5:数据采集及导入1)采集完成后,会跳出提示,选择“导出数据”。选择“合适的导入方法”, 将采集好的数据导入八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 212)这里我们选择 excel 作为导入为格式,数据导入后如下图百度搜索结果爬虫方式图 22八爪鱼·云采集服务平台 相关采集教程: 百度爬虫 百度地图店家采集工具 百度地图数据采集 百度搜索结果抓取和采集详细教程 使用八爪鱼 v7.0 简易模式采集百度百科内容 百度地图店家地址采集 百度文库数据采集方法,以列表页为例 百度贴吧内容采集 百度相关搜索关键词采集 百度知道问答采集八爪鱼·云采集服务平台 http://www.bazhuayu.com/tutorial/bdzhidaocj八爪鱼——百万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机百度爬虫,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部

八爪鱼·云采集服务平台 百度搜索结果爬虫实现方式做 SEO 做流量的朋友,很多百度搜索数据都须要自己去抓取,大家就会选择用 八爪鱼爬虫工具进行百度搜索结果的数据采集,大批量又高效。如何配置百度搜 索的采集任务呢,接下来本文将介绍使用八爪鱼采集百度搜索结果的方式。采集网站:使用功能点:? 分页列表信息采集 ? Xpath ? AJAX 点击和翻页步骤 1:创建采集任务1)进入主界面,选择“自定义模式”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 12)将要采集的网址复制粘贴到网站输入框中,点击“保存网址”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 2步骤 2:输入文本1)在页面右上角,打开“流程”,以突显出“流程设计器”和“定制当前操作” 两个蓝筹股。点击搜索框,在操作提示框中,选择“输入文字”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 32)输入要采集的文本,这里以输入“八爪鱼采集器”为例。完成后,点击“确 定”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 43)输入的文本手动填充到搜索框后,点击“百度一下”按钮。在操作提示框中, 选择“点击该按键”百度搜索结果爬虫方式图 5此步骤涉及 Ajax 技术。
打开“高级选项”,勾选“Ajax 加载数据”,设置时间 为“2 秒”。完成后,点击“确定”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 6步骤 3:创建翻页循环1)将页面下拉到顶部,点击“下一页”按钮,在两侧的操作提示框中,选择“循 环点击下一页”,以完善一个翻页循环八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 72)选中“循环翻页”步骤,打开“高级选项”,将单个元素中的这条 Xpath: //A[@class='n',复制粘贴到火狐浏览器中的相应位置八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 8可以看见,当在第 1 页的时侯,使用此条 Xpath,可以定位到“下一页”百度搜索结果爬虫方式图 9八爪鱼·云采集服务平台 当翻到第 2 页的时侯,使用此条 Xpath,既可定位到“上一页”,又可定位到 “下一页”百度搜索结果爬虫方式图 103)返回八爪鱼采集器,点击“自定义”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 114)勾选“元素文本=下一页>”百度爬虫,对应生成的 Xpath 为://A[@text()='下一 页']。完成后,点击“确定”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 125)将修改后的 Xpath://A[@text()='下一页'],再次复制粘贴到火狐浏览器 中。
可以看见,当翻到第 2 页的时侯,可正常定位到“下一页”,第 3、4、5、 6 等也可正常定位到“下一页”,翻页循环可正常运行八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 13步骤 4:创建列表循环并提取数据1)移动滑鼠,选中页面里第一条搜索结果的区块,再选中页面内另一条搜索结 果的区块。系统会手动辨识并选中,页面里其他搜索结果的区块,以完善一个列 表循环。在操作提示框中,选择“采集以下元素文本”。整个区块里的信息,作 为一个数组,被采集下来八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 142)选中“循环”步骤,打开“高级选项”,将不固定元素列表中的这条 Xpath: //DIV[@id='content_left']/DIV,复制粘贴到火狐浏览器中的相应位置八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 153)将八爪鱼中的 Xpath,复制到火狐浏览器中的相应位置。观察页面,我们不 需要采集的“相关搜索”和“广告”内容也被定位了八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 164 ) 观 察 网 页 源 码 , 我 们 要 采 集 的 区 块 , 具 有 相 同 的 tpl 属 性 , tpl="se_com_default"(如图红框中所示),通过 tpl 属性,可即将采集的县 块与不需要采集的广告、推荐内容分辨开来。
将 Xpath 修改为: //DIV[@id='content_left']/DIV[@tpl="se_com_default"]。再观察页面, 要采集的内容都被定位了,不需要采集的广告、推荐内容未被定位八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 175)将修改后的 Xpath: //DIV[@id='content_left']/DIV[@tpl="se_com_default"], 复制粘贴到八 爪虾采集器的相应位置。完成后,点击“确定”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 186)在这里,我们还想采集每条搜索结果的链接 URL。选中页面内一条搜索结果 的链接,在操作提示框中,选择“采集该链接地址”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 197)字段选择完成后,选中相应的数组,可以进行数组的自定义命名。完成后, 点击左上角的“保存并启动”,选择“启动本地采集”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 20步骤 5:数据采集及导入1)采集完成后,会跳出提示,选择“导出数据”。选择“合适的导入方法”, 将采集好的数据导入八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 212)这里我们选择 excel 作为导入为格式,数据导入后如下图百度搜索结果爬虫方式图 22八爪鱼·云采集服务平台 相关采集教程: 百度爬虫 百度地图店家采集工具 百度地图数据采集 百度搜索结果抓取和采集详细教程 使用八爪鱼 v7.0 简易模式采集百度百科内容 百度地图店家地址采集 百度文库数据采集方法,以列表页为例 百度贴吧内容采集 百度相关搜索关键词采集 百度知道问答采集八爪鱼·云采集服务平台 http://www.bazhuayu.com/tutorial/bdzhidaocj八爪鱼——百万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机百度爬虫,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
Python网络爬虫四大选择器(正则表达式、BS4、Xpath、CSS)总结
采集交流 • 优采云 发表了文章 • 0 个评论 • 481 次浏览 • 2020-05-12 08:01
一、正则表达式
正则表达式为我们提供了抓取数据的快捷方法。虽然该正则表达式更容易适应未来变化网络爬虫 正则表达式,但又存在无法构造、可读性差的问题。当在爬京东网的时侯,正则表达式如下图所示:
利用正则表达式实现对目标信息的精准采集
此外 ,我们都晓得,网页经常会形成变更,导致网页中会发生一些微小的布局变化时,此时也会促使之前写好的正则表达式未能满足需求,而且还不太好调试。当须要匹配的内容有很多的时侯,使用正则表达式提取目标信息会导致程序运行的速率减缓,需要消耗更多显存。
二、BeautifulSoup
BeautifulSoup是一个十分流行的 Pyhon 模块。该模块可以解析网页,并提供定位内容的方便插口。通过'pip install beautifulsoup4'就可以实现该模块的安装了。
利用美丽的汤去提取目标信息
使用 BeautifulSoup的第一步是将己下载的 HTML 内容解析为 soup文档。由 于大多数网页都不具备良好的HTML 格式,因此BeautifulSoup须要对实际格式进行确定。BeautifulSoup才能正确解析缺位的冒号并闭合标签,此外都会添加<html >和<body>标签让其成为完整的HTML文档。通常使用find() 和find_all()方法来定位我们须要的元素。
如果你想了解BeautifulSoup全部方式和参数,可以查阅BeautifulSoup的官方文档。虽然BeautifulSoup在代码的理解上比正则表达式要复杂一些,但是其愈发容易构造和理解。
三、Lxml
Lxml模块使用 C语言编撰,其解析速率比 BeautiflSoup更快,而且其安装过程也更为复杂,在此小编就不赘言啦。XPath 使用路径表达式在 XML 文档中选定节点。节点是通过顺着路径或则 step 来选定的。
Xpath选择器
使用 lxml 模块的第一步和BeautifulSoup一样,也是将有可能不合法的HTML 解析为 统一格式。 虽然Lxml可以正确解析属性两边缺位的冒号网络爬虫 正则表达式,并闭合标签,不过该模块没有额外添加<html >和<body>标签 。
在线复制Xpath表达式可以很方便的复制Xpath表达式。但是通过该方式得到的Xpath表达式置于程序中通常不能用,而且长的无法看。所以Xpath表达式通常还是要自己亲自上手。
四、CSS
CSS选择器表示选择元素所使用 的模式。BeautifulSoup整合了CSS选择器的句型和自身便捷使用API。在网路爬虫的开发过程中,对于熟悉CSS选择器句型的人,使用CSS选择器是个十分便捷的方式。
CSS选择器
下面是一些常用的选择器示例。 查看全部
前几天小编连续写了四篇关于Python选择器的文章,分别用正则表达式、BeautifulSoup、Xpath、CSS选择器分别抓取京东网的商品信息。今天小编来给你们总结一下这四个选择器,让你们愈发深刻的理解和熟悉Python选择器。
一、正则表达式
正则表达式为我们提供了抓取数据的快捷方法。虽然该正则表达式更容易适应未来变化网络爬虫 正则表达式,但又存在无法构造、可读性差的问题。当在爬京东网的时侯,正则表达式如下图所示:

利用正则表达式实现对目标信息的精准采集
此外 ,我们都晓得,网页经常会形成变更,导致网页中会发生一些微小的布局变化时,此时也会促使之前写好的正则表达式未能满足需求,而且还不太好调试。当须要匹配的内容有很多的时侯,使用正则表达式提取目标信息会导致程序运行的速率减缓,需要消耗更多显存。
二、BeautifulSoup
BeautifulSoup是一个十分流行的 Pyhon 模块。该模块可以解析网页,并提供定位内容的方便插口。通过'pip install beautifulsoup4'就可以实现该模块的安装了。

利用美丽的汤去提取目标信息
使用 BeautifulSoup的第一步是将己下载的 HTML 内容解析为 soup文档。由 于大多数网页都不具备良好的HTML 格式,因此BeautifulSoup须要对实际格式进行确定。BeautifulSoup才能正确解析缺位的冒号并闭合标签,此外都会添加<html >和<body>标签让其成为完整的HTML文档。通常使用find() 和find_all()方法来定位我们须要的元素。
如果你想了解BeautifulSoup全部方式和参数,可以查阅BeautifulSoup的官方文档。虽然BeautifulSoup在代码的理解上比正则表达式要复杂一些,但是其愈发容易构造和理解。
三、Lxml
Lxml模块使用 C语言编撰,其解析速率比 BeautiflSoup更快,而且其安装过程也更为复杂,在此小编就不赘言啦。XPath 使用路径表达式在 XML 文档中选定节点。节点是通过顺着路径或则 step 来选定的。

Xpath选择器
使用 lxml 模块的第一步和BeautifulSoup一样,也是将有可能不合法的HTML 解析为 统一格式。 虽然Lxml可以正确解析属性两边缺位的冒号网络爬虫 正则表达式,并闭合标签,不过该模块没有额外添加<html >和<body>标签 。
在线复制Xpath表达式可以很方便的复制Xpath表达式。但是通过该方式得到的Xpath表达式置于程序中通常不能用,而且长的无法看。所以Xpath表达式通常还是要自己亲自上手。
四、CSS
CSS选择器表示选择元素所使用 的模式。BeautifulSoup整合了CSS选择器的句型和自身便捷使用API。在网路爬虫的开发过程中,对于熟悉CSS选择器句型的人,使用CSS选择器是个十分便捷的方式。

CSS选择器
下面是一些常用的选择器示例。
Scrapy爬虫框架:抓取天猫淘宝数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 416 次浏览 • 2020-05-05 08:05
通过天猫的搜索,获取搜索下来的每件商品的销量、收藏数、价格。
所以,最终的目的是通过获取两个页面的内容,一个是搜索结果,从上面找下来每一个商品的详尽地址,然后第二个是商品详尽内容,从上面获取到销量、价格等。
有了思路如今我们先下载搜索结果页面,然后再下载页面中每一项详尽信息页面。
def _parse_handler(self, response):
''' 下载页面 """
self.driver.get(response.url)
pass
很简单,通过self.driver.get(response.url)就能使用selenium下载内容,如果直接使用response中的网页内容是静态的。
上面说了怎样下载内容,当我们下载好内容后,需要从上面去获取我们想要的有用信息,这里就要用到选择器,选择器构造方法比较多,只介绍一种,这里看详尽信息:
>>> body = '<html><body><span>good</span></body></html>'
>>> Selector(text=body).xpath('//span/text()').extract()
[u'good']
这样就通过xpath取下来了good这个词组,更详尽的xpath教程点击这儿。
Selector 提供了好多形式出了xpath,还有css选择器,正则表达式,中文教程看这个,具体内容就不多说,只须要晓得这样可以快速获取我们须要的内容。
简单的介绍了如何获取内容后,现在我们从第一个搜索结果中获取我们想要的商品详尽链接,通过查看网页源代码可以看见,商品的链接在这里:
...
<p class="title">
<a class="J_ClickStat" data-nid="523242229702" href="//detail.tmall.com/item.htm?spm=a230r.1.14.46.Mnbjq5&id=523242229702&ns=1&abbucket=14" target="_blank" trace="msrp_auction" traceidx="5" trace-pid="" data-spm-anchor-id="a230r.1.14.46">WD/西部数据 WD30EZRZ台式机3T电脑<span class="H">硬盘</span> 西数蓝盘3TB 替绿盘</a>
</p>
...
使用之前的规则来获取到a元素的href属性就是须要的内容:
selector = Selector(text=self.driver.page_source) # 这里不要省略text因为省略后Selector使用的是另外一个构造函数,self.driver.page_source是这个网页的html内容
selector.css(".title").css(".J_ClickStat").xpath("./@href").extract()
简单说一下,这里通过css工具取了class叫title的p元素,然后又获取了class是J_ClickStat的a元素,最后通过xpath规则获取a元素的href中的内容。啰嗦一句css中若果是取id则应当是selector.css("#title"),这个和css中的选择器是一致的。
同理,我们获取到商品详情后,以获取销量为例,查看源代码:
<ul class="tm-ind-panel">
<li class="tm-ind-item tm-ind-sellCount" data-label="月销量"><div class="tm-indcon"><span class="tm-label">月销量</span><span class="tm-count">881</span></div></li>
<li class="tm-ind-item tm-ind-reviewCount canClick tm-line3" id="J_ItemRates"><div class="tm-indcon"><span class="tm-label">累计评价</span><span class="tm-count">4593</span></div></li>
<li class="tm-ind-item tm-ind-emPointCount" data-spm="1000988"><div class="tm-indcon"><a href="//vip.tmall.com/vip/index.htm" target="_blank"><span class="tm-label">送天猫积分</span><span class="tm-count">55</span></a></div></li>
</ul>
获取月销量:
selector.css(".tm-ind-sellCount").xpath("./div/span[@class='tm-count']/text()").extract_first()
获取累计评价:
selector.css(".tm-ind-reviewCount").xpath("./div[@class='tm-indcon']/span[@class='tm-count']/text()").extract_first()
最后把获取下来的数据包装成Item返回。淘宝或则淘宝她们的页面内容不一样,所以规则也不同,需要分开去获取想要的内容。
Item是scrapy中获取下来的结果,后面可以处理这种结果。
Item通常是放在items.py中
import scrapy
class Product(scrapy.Item):
name = scrapy.Field()
price = scrapy.Field()
stock = scrapy.Field()
last_updated = scrapy.Field(serializer=str)
>>> product = Product(name='Desktop PC', price=1000)
>>> print product
Product(name='Desktop PC', price=1000)
>>> product['name']
Desktop PC
>>> product.get('name')
Desktop PC
>>> product['price']
1000
>>> product['last_updated']
Traceback (most recent call last):
...
KeyError: 'last_updated'
>>> product.get('last_updated', 'not set')
not set
>>> product['lala'] # getting unknown field
Traceback (most recent call last):
...
KeyError: 'lala'
>>> product.get('lala', 'unknown field')
'unknown field'
>>> 'name' in product # is name field populated?
True
>>> 'last_updated' in product # is last_updated populated?
False
>>> 'last_updated' in product.fields # is last_updated a declared field?
True
>>> 'lala' in product.fields # is lala a declared field?
False
>>> product['last_updated'] = 'today'
>>> product['last_updated']
today
>>> product['lala'] = 'test' # setting unknown field
Traceback (most recent call last):
...
KeyError: 'Product does not support field: lala'
这里只须要注意一个地方,不能通过product.name的方法获取,也不能通过product.name = "name"的形式设置值。
当Item在Spider中被搜集以后,它将会被传递到Item Pipeline,一些组件会根据一定的次序执行对Item的处理。
每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方式的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被遗弃而不再进行处理。
以下是item pipeline的一些典型应用:
现在实现一个Item过滤器,我们把获取下来若果是None的数据形参为0,如果Item对象是None则丢弃这条数据。
pipeline通常是放在pipelines.py中
def process_item(self, item, spider):
if item is not None:
if item["p_standard_price"] is None:
item["p_standard_price"] = item["p_shop_price"]
if item["p_shop_price"] is None:
item["p_shop_price"] = item["p_standard_price"]
item["p_collect_count"] = text_utils.to_int(item["p_collect_count"])
item["p_comment_count"] = text_utils.to_int(item["p_comment_count"])
item["p_month_sale_count"] = text_utils.to_int(item["p_month_sale_count"])
item["p_sale_count"] = text_utils.to_int(item["p_sale_count"])
item["p_standard_price"] = text_utils.to_string(item["p_standard_price"], "0")
item["p_shop_price"] = text_utils.to_string(item["p_shop_price"], "0")
item["p_pay_count"] = item["p_pay_count"] if item["p_pay_count"] is not "-" else "0"
return item
else:
raise DropItem("Item is None %s" % item)
最后须要在settings.py中添加这个pipeline
ITEM_PIPELINES = {
'TaoBao.pipelines.TTDataHandlerPipeline': 250,
'TaoBao.pipelines.MysqlPipeline': 300,
}
后面那种数字越小,则执行的次序越靠前,这里先过滤处理数据,获取到正确的数据后,再执行TaoBao.pipelines.MysqlPipeline添加数据到数据库。
完整的代码:[不带数据库版本][ 数据库版本]。
之前说的方法都是直接通过命令scrapy crawl tts来启动。怎么用IDE的调试功能呢?很简单通过main函数启动爬虫:
# 写到Spider里面
if __name__ == "__main__":
settings = get_project_settings()
process = CrawlerProcess(settings)
spider = TmallAndTaoBaoSpider
process.crawl(spider)
process.start()
在获取数据的时侯,很多时侯会碰到网页重定向的问题,scrapy会返回302之后不会手动重定向后继续爬取新地址,在scrapy的设置中,可以通过配置来开启重定向,这样虽然域名是重定向的scrapy也会手动到最终的地址获取内容。
解决方案:settings.py中添加REDIRECT_ENABLED = True
很多时侯爬虫都有自定义数据,比如之前写的是硬碟关键字,现在通过参数的方法如何传递呢?
解决方案:
大部分时侯,我们可以取到完整的网页信息,如果网页的ajax恳求太多,网速很慢的时侯,selenium并不知道什么时候ajax恳求完成,这个时侯假如通过self.driver.get(response.url)获取页面天猫反爬虫,然后通过Selector取数据天猫反爬虫,很可能还没加载完成取不到数据。
解决方案:通过selenium提供的工具来延后获取内容,直到获取到数据,或者超时。 查看全部
有了前两篇的基础,接下来通过抓取天猫和淘宝的数据来详尽说明,如何通过Scrapy爬取想要的内容。完整的代码:[不带数据库版本][ 数据库版本]。
通过天猫的搜索,获取搜索下来的每件商品的销量、收藏数、价格。
所以,最终的目的是通过获取两个页面的内容,一个是搜索结果,从上面找下来每一个商品的详尽地址,然后第二个是商品详尽内容,从上面获取到销量、价格等。
有了思路如今我们先下载搜索结果页面,然后再下载页面中每一项详尽信息页面。
def _parse_handler(self, response):
''' 下载页面 """
self.driver.get(response.url)
pass
很简单,通过self.driver.get(response.url)就能使用selenium下载内容,如果直接使用response中的网页内容是静态的。
上面说了怎样下载内容,当我们下载好内容后,需要从上面去获取我们想要的有用信息,这里就要用到选择器,选择器构造方法比较多,只介绍一种,这里看详尽信息:
>>> body = '<html><body><span>good</span></body></html>'
>>> Selector(text=body).xpath('//span/text()').extract()
[u'good']
这样就通过xpath取下来了good这个词组,更详尽的xpath教程点击这儿。
Selector 提供了好多形式出了xpath,还有css选择器,正则表达式,中文教程看这个,具体内容就不多说,只须要晓得这样可以快速获取我们须要的内容。
简单的介绍了如何获取内容后,现在我们从第一个搜索结果中获取我们想要的商品详尽链接,通过查看网页源代码可以看见,商品的链接在这里:
...
<p class="title">
<a class="J_ClickStat" data-nid="523242229702" href="//detail.tmall.com/item.htm?spm=a230r.1.14.46.Mnbjq5&id=523242229702&ns=1&abbucket=14" target="_blank" trace="msrp_auction" traceidx="5" trace-pid="" data-spm-anchor-id="a230r.1.14.46">WD/西部数据 WD30EZRZ台式机3T电脑<span class="H">硬盘</span> 西数蓝盘3TB 替绿盘</a>
</p>
...
使用之前的规则来获取到a元素的href属性就是须要的内容:
selector = Selector(text=self.driver.page_source) # 这里不要省略text因为省略后Selector使用的是另外一个构造函数,self.driver.page_source是这个网页的html内容
selector.css(".title").css(".J_ClickStat").xpath("./@href").extract()
简单说一下,这里通过css工具取了class叫title的p元素,然后又获取了class是J_ClickStat的a元素,最后通过xpath规则获取a元素的href中的内容。啰嗦一句css中若果是取id则应当是selector.css("#title"),这个和css中的选择器是一致的。
同理,我们获取到商品详情后,以获取销量为例,查看源代码:
<ul class="tm-ind-panel">
<li class="tm-ind-item tm-ind-sellCount" data-label="月销量"><div class="tm-indcon"><span class="tm-label">月销量</span><span class="tm-count">881</span></div></li>
<li class="tm-ind-item tm-ind-reviewCount canClick tm-line3" id="J_ItemRates"><div class="tm-indcon"><span class="tm-label">累计评价</span><span class="tm-count">4593</span></div></li>
<li class="tm-ind-item tm-ind-emPointCount" data-spm="1000988"><div class="tm-indcon"><a href="//vip.tmall.com/vip/index.htm" target="_blank"><span class="tm-label">送天猫积分</span><span class="tm-count">55</span></a></div></li>
</ul>
获取月销量:
selector.css(".tm-ind-sellCount").xpath("./div/span[@class='tm-count']/text()").extract_first()
获取累计评价:
selector.css(".tm-ind-reviewCount").xpath("./div[@class='tm-indcon']/span[@class='tm-count']/text()").extract_first()
最后把获取下来的数据包装成Item返回。淘宝或则淘宝她们的页面内容不一样,所以规则也不同,需要分开去获取想要的内容。
Item是scrapy中获取下来的结果,后面可以处理这种结果。
Item通常是放在items.py中
import scrapy
class Product(scrapy.Item):
name = scrapy.Field()
price = scrapy.Field()
stock = scrapy.Field()
last_updated = scrapy.Field(serializer=str)
>>> product = Product(name='Desktop PC', price=1000)
>>> print product
Product(name='Desktop PC', price=1000)
>>> product['name']
Desktop PC
>>> product.get('name')
Desktop PC
>>> product['price']
1000
>>> product['last_updated']
Traceback (most recent call last):
...
KeyError: 'last_updated'
>>> product.get('last_updated', 'not set')
not set
>>> product['lala'] # getting unknown field
Traceback (most recent call last):
...
KeyError: 'lala'
>>> product.get('lala', 'unknown field')
'unknown field'
>>> 'name' in product # is name field populated?
True
>>> 'last_updated' in product # is last_updated populated?
False
>>> 'last_updated' in product.fields # is last_updated a declared field?
True
>>> 'lala' in product.fields # is lala a declared field?
False
>>> product['last_updated'] = 'today'
>>> product['last_updated']
today
>>> product['lala'] = 'test' # setting unknown field
Traceback (most recent call last):
...
KeyError: 'Product does not support field: lala'
这里只须要注意一个地方,不能通过product.name的方法获取,也不能通过product.name = "name"的形式设置值。
当Item在Spider中被搜集以后,它将会被传递到Item Pipeline,一些组件会根据一定的次序执行对Item的处理。
每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方式的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被遗弃而不再进行处理。
以下是item pipeline的一些典型应用:
现在实现一个Item过滤器,我们把获取下来若果是None的数据形参为0,如果Item对象是None则丢弃这条数据。
pipeline通常是放在pipelines.py中
def process_item(self, item, spider):
if item is not None:
if item["p_standard_price"] is None:
item["p_standard_price"] = item["p_shop_price"]
if item["p_shop_price"] is None:
item["p_shop_price"] = item["p_standard_price"]
item["p_collect_count"] = text_utils.to_int(item["p_collect_count"])
item["p_comment_count"] = text_utils.to_int(item["p_comment_count"])
item["p_month_sale_count"] = text_utils.to_int(item["p_month_sale_count"])
item["p_sale_count"] = text_utils.to_int(item["p_sale_count"])
item["p_standard_price"] = text_utils.to_string(item["p_standard_price"], "0")
item["p_shop_price"] = text_utils.to_string(item["p_shop_price"], "0")
item["p_pay_count"] = item["p_pay_count"] if item["p_pay_count"] is not "-" else "0"
return item
else:
raise DropItem("Item is None %s" % item)
最后须要在settings.py中添加这个pipeline
ITEM_PIPELINES = {
'TaoBao.pipelines.TTDataHandlerPipeline': 250,
'TaoBao.pipelines.MysqlPipeline': 300,
}
后面那种数字越小,则执行的次序越靠前,这里先过滤处理数据,获取到正确的数据后,再执行TaoBao.pipelines.MysqlPipeline添加数据到数据库。
完整的代码:[不带数据库版本][ 数据库版本]。
之前说的方法都是直接通过命令scrapy crawl tts来启动。怎么用IDE的调试功能呢?很简单通过main函数启动爬虫:
# 写到Spider里面
if __name__ == "__main__":
settings = get_project_settings()
process = CrawlerProcess(settings)
spider = TmallAndTaoBaoSpider
process.crawl(spider)
process.start()
在获取数据的时侯,很多时侯会碰到网页重定向的问题,scrapy会返回302之后不会手动重定向后继续爬取新地址,在scrapy的设置中,可以通过配置来开启重定向,这样虽然域名是重定向的scrapy也会手动到最终的地址获取内容。
解决方案:settings.py中添加REDIRECT_ENABLED = True
很多时侯爬虫都有自定义数据,比如之前写的是硬碟关键字,现在通过参数的方法如何传递呢?
解决方案:
大部分时侯,我们可以取到完整的网页信息,如果网页的ajax恳求太多,网速很慢的时侯,selenium并不知道什么时候ajax恳求完成,这个时侯假如通过self.driver.get(response.url)获取页面天猫反爬虫,然后通过Selector取数据天猫反爬虫,很可能还没加载完成取不到数据。
解决方案:通过selenium提供的工具来延后获取内容,直到获取到数据,或者超时。
关键词采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 658 次浏览 • 2020-05-04 08:07
八爪鱼·云采集网络爬虫软件 3)创建好循环文本输入后, 点击页面上的搜索框, 创建输入文本的步骤, 注意, 不需要输入任何文本即可,若是手动生成的是在循环外边,拖入进去,再勾选循 环即可。八爪鱼·云采集网络爬虫软件 4)右键选择页面上的搜索按键,设置好点击元素,这样,循环文本输入就设置 好了,流程下方就是搜索下来的长尾关键词。步骤 3:创建数字翻页1)由于该搜索结果页面没有下一页按键,只有数字页数,所以我们须要用到 xpath 的一些相关知识,来设置特殊的数字翻页。首先去火狐浏览器里把该网页 打开并搜索相应关键词后,打开浏览器右上角的 firebug 工具--小瓢虫(不懂的 同学可以去官网教程看一下相应的 xpath 教程)八爪鱼·云采集网络爬虫软件 2)翻到页面下方输入关键词采集文章, 找到数字位置的源码, 可以看见当前页面的数字跟其他数字, 在源码里节点的属性 class 是有所不同的八爪鱼·云采集网络爬虫软件 3)收 益 我 们 首 先 定 位 到 该 页 面 的 数 字 位 置 , 手 写 xpath : //div[@id="page"]/a[contains(@class,'current')]八爪鱼·云采集网络爬虫软件 4)再利用固定函数 following-sibling 来定位到该节点后的第一个同类节点, 注意,该函数前面接::是固定格式,a[1]是指该节点后的第一个同类节点八爪鱼·云采集网络爬虫软件 5)可以查看翻页后还是正常定位到下一页的数字上,说明该 xpath 没有问题6)再回到八爪鱼, 在两侧流程页面拖一个循环进来, 高级选项里选择单个元素, 并把 xpath 放入进去,点确定保存好八爪鱼·云采集网络爬虫软件 7)再从左边拖一个点击元素进来,并在中级选项里勾选好循环,特殊数字翻页 循环就创建好了八爪鱼·云采集网络爬虫软件 步骤 4:创建循环列表1)我们安装常规方式创建循环列表,发现,由于搜索结果后的表格中出现了这 个无用的一整行信息。
八爪鱼·云采集网络爬虫软件 2)于是在八爪鱼上面是难以正常的创建好循环列表的,因为这个无用的信息导 致八爪鱼手动生成的列表会定位不准八爪鱼·云采集网络爬虫软件 3)所以我们还是得用到 xpath 的知识,去火狐浏览器上面自动创建一个循环列 表的 xpath。首先定位到第一行第一列的源码位置4)再找到每一行的源码位置,发现她们都是 tbody 父节点下相同的 tr 标签八爪鱼·云采集网络爬虫软件 5)再观察每一行真正的 tr 节点里都有一个共同的属性“id”,并且 id 属性都 有 一 个 共 同 的 tr 值 , 所 以 我 们 以 此 为 共 同 点 ,手 写 该 xpath:.//tbody/tr[contains(@id,'tr')]输入关键词采集文章,来定位到所有的 tr 节点,并把所有无 用的 tr 给过滤掉,这样,循环列表的 xpath 就创建好了八爪鱼·云采集网络爬虫软件 6)再从左边拖一个循环进去,循环形式选择不固定元素,把该 xpath 放入八爪 鱼里,并以第一个循环为例,设置相应的采集字段(由于部份数组源码里是没有 的,所以采集不到),八爪鱼·云采集网络爬虫软件 步骤 5:启动采集八爪鱼·云采集网络爬虫软件 1)点击保存任务后,运行采集,以本地采集为例2)采集完成后,会跳出提示,选择“导出数据”。
选择“合适的导入方法”, 将采集好的数据导入。八爪鱼·云采集网络爬虫软件 本文来自于:相关采集教程:京东商品信息采集(通过搜索关键词) 阿里巴巴关键词采集: 八爪鱼·云采集网络爬虫软件 爱站关键词采集: 百度相关搜索关键词采集: 亚马逊关键词采集: 易迅关键词采集: 新浪微博关键词采集: 关键词提取八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。八爪鱼·云采集网络爬虫软件 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部
八爪鱼·云采集网络爬虫软件 关键词采集方法本文将介绍怎样借助【词库】批量挖掘并采集长尾词的方式,对 SEOSEM 站长 来说十分实用。 本来还将介绍一款免费好用的数据采集工具 【八爪鱼数据采集】 , 让站长采集关键词的工作事半功倍。长尾词对于站长来说是提升网站流量的核心之技能之一, 是不容忽略的一项方法, 在搜索引擎营销中对关键词策略的拟定是十分重要的, 这些长尾关键词能为网站 贡献很大的一部分流量,并且带来的客人转化率也很不错。下面就以【词库】为例,教诸位站长怎么是用【八爪鱼数据采集器】批量采集关 键词。采集网站:本文就以一组(100 个 B2B 行业有指数的关键词)为例,来采集关于这一组关 键词的所有相关长尾关键词。八爪鱼·云采集网络爬虫软件 采集的内容包括:搜索后的长尾关键词,360 指数,该长尾关键词搜索量以及搜 索量的第一位网站(页面)这四个有效数组。使用功能点:? 循环文本输入?Xpathxpath 入门教程 1 xpath 入门 2 相对 XPATH 教程-7.0 版 ? 数字翻页步骤 1:创建词库网采集任务1)进入主界面,选择“自定义采集”八爪鱼·云采集网络爬虫软件 2)将要采集的网址 URL 复制粘贴到网站输入框中,点击“保存网址”八爪鱼·云采集网络爬虫软件 步骤 2:创建循环输入文本八爪鱼·云采集网络爬虫软件 1)打开网页以后,点开右上角的流程,然后从左边拖一个循环进来2)点击循环步骤,在它的中级选项哪里选择文本列表,再点开下边的 A,把复 制好的关键词全部粘贴进去,注意换行,再点击确定保存。
八爪鱼·云采集网络爬虫软件 3)创建好循环文本输入后, 点击页面上的搜索框, 创建输入文本的步骤, 注意, 不需要输入任何文本即可,若是手动生成的是在循环外边,拖入进去,再勾选循 环即可。八爪鱼·云采集网络爬虫软件 4)右键选择页面上的搜索按键,设置好点击元素,这样,循环文本输入就设置 好了,流程下方就是搜索下来的长尾关键词。步骤 3:创建数字翻页1)由于该搜索结果页面没有下一页按键,只有数字页数,所以我们须要用到 xpath 的一些相关知识,来设置特殊的数字翻页。首先去火狐浏览器里把该网页 打开并搜索相应关键词后,打开浏览器右上角的 firebug 工具--小瓢虫(不懂的 同学可以去官网教程看一下相应的 xpath 教程)八爪鱼·云采集网络爬虫软件 2)翻到页面下方输入关键词采集文章, 找到数字位置的源码, 可以看见当前页面的数字跟其他数字, 在源码里节点的属性 class 是有所不同的八爪鱼·云采集网络爬虫软件 3)收 益 我 们 首 先 定 位 到 该 页 面 的 数 字 位 置 , 手 写 xpath : //div[@id="page"]/a[contains(@class,'current')]八爪鱼·云采集网络爬虫软件 4)再利用固定函数 following-sibling 来定位到该节点后的第一个同类节点, 注意,该函数前面接::是固定格式,a[1]是指该节点后的第一个同类节点八爪鱼·云采集网络爬虫软件 5)可以查看翻页后还是正常定位到下一页的数字上,说明该 xpath 没有问题6)再回到八爪鱼, 在两侧流程页面拖一个循环进来, 高级选项里选择单个元素, 并把 xpath 放入进去,点确定保存好八爪鱼·云采集网络爬虫软件 7)再从左边拖一个点击元素进来,并在中级选项里勾选好循环,特殊数字翻页 循环就创建好了八爪鱼·云采集网络爬虫软件 步骤 4:创建循环列表1)我们安装常规方式创建循环列表,发现,由于搜索结果后的表格中出现了这 个无用的一整行信息。
八爪鱼·云采集网络爬虫软件 2)于是在八爪鱼上面是难以正常的创建好循环列表的,因为这个无用的信息导 致八爪鱼手动生成的列表会定位不准八爪鱼·云采集网络爬虫软件 3)所以我们还是得用到 xpath 的知识,去火狐浏览器上面自动创建一个循环列 表的 xpath。首先定位到第一行第一列的源码位置4)再找到每一行的源码位置,发现她们都是 tbody 父节点下相同的 tr 标签八爪鱼·云采集网络爬虫软件 5)再观察每一行真正的 tr 节点里都有一个共同的属性“id”,并且 id 属性都 有 一 个 共 同 的 tr 值 , 所 以 我 们 以 此 为 共 同 点 ,手 写 该 xpath:.//tbody/tr[contains(@id,'tr')]输入关键词采集文章,来定位到所有的 tr 节点,并把所有无 用的 tr 给过滤掉,这样,循环列表的 xpath 就创建好了八爪鱼·云采集网络爬虫软件 6)再从左边拖一个循环进去,循环形式选择不固定元素,把该 xpath 放入八爪 鱼里,并以第一个循环为例,设置相应的采集字段(由于部份数组源码里是没有 的,所以采集不到),八爪鱼·云采集网络爬虫软件 步骤 5:启动采集八爪鱼·云采集网络爬虫软件 1)点击保存任务后,运行采集,以本地采集为例2)采集完成后,会跳出提示,选择“导出数据”。
选择“合适的导入方法”, 将采集好的数据导入。八爪鱼·云采集网络爬虫软件 本文来自于:相关采集教程:京东商品信息采集(通过搜索关键词) 阿里巴巴关键词采集: 八爪鱼·云采集网络爬虫软件 爱站关键词采集: 百度相关搜索关键词采集: 亚马逊关键词采集: 易迅关键词采集: 新浪微博关键词采集: 关键词提取八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。八爪鱼·云采集网络爬虫软件 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
Python手动搜索关键词采集信息—以易迅为例!
采集交流 • 优采云 发表了文章 • 0 个评论 • 664 次浏览 • 2020-08-03 10:55
如果网页上有搜索框,但是搜索结果页面没有独立网址,想要采集搜索结果,直接做规则是采集不到的,要先做连续动作(输入+点击)来实现手动输入关键词并搜索,然后才会采集数据。下面用易迅搜索为例,演示手动搜索采集,操作步骤如下:
Python资源共享群:626017123
二、案例规则+操作步骤
注意:本案例易迅搜索是有独立网址的,对于具有独立网址的页面,最简单的方式就是构造出每位关键词的搜索网址,然后把线索网址导出到规则里,就可以批量采集,而不是设置连续动作
第一步:定义第一级规则
1.1打开集搜客网络爬虫,输入网址并Enter,加载出网页后再点击“定义规则”按钮,看到一个浮窗显示下来,称为工作台,在前面定义规则;
注意:这里的截图和文字说明都是集搜客网络爬虫版本,如果您安装的是傲游插件版,那么就没有“定义规则”按钮,而是应当运行MS谋数台
1.2在工作台北输入一级规则的主题名,再点击“查重”,提示“该名可以使用”或“该名已被占用,可编辑:是”,就可以使用这个主题名,否则请重命名。
1.3本级规则主要是设置连续动作,所以,整理箱可以随便抓取一个信息,用来给爬虫判定是否执行采集。双击网页上的信息,输入标签名,并打勾确认,再勾上关键内容,首次标明还要输入整理箱的名子,然后就完成标明映射了。
Tips:为了能确切定位网页信息,点击定义规则会把整个网页定格住,不能跳转网页链接,再次点击定义规则,才会恢复回普通的网页模式。
第二步:定义连续动作
点击工作台的“连续动作”页签,点击新建按键构建一个新动作,每个动作的设置方式都是一样,基本操作如下:
2.1 ,输入目标主题名
这里的目标主题名是填第二级主题名,点击“谁在用”查看目标主题名是否可用,如果早已被占用,换一个主题名就行
2.2, 创建第一个动作:输入
新建一个动作,并选择动作类型为输入。
2.2.1,填写定位表达式
首先键盘单击输入框,定位输入框的节点,然后点击“自动生成XPath”按钮,可以选择“偏好id”或者“偏好class”,就可以得到输入框的xpath表达式,再点击“搜索”按钮,检查一下这个xpath是否能惟一定位到输入框,没有问题就把xpath复制到定位表达式方框里。
注意:定位表达式里的xpath是要锁定动作对象的整个有效操作范围,具体就是指键盘就能点击或输入成功的网页模块,不要定位到最底层的text()节点。
2.2.2,输入关键词
输入关键词填写你想搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词要用双分号;;将每位关键词隔开,免费版只支持5个以内的关键词,旗舰版可以使用连发弹仓功能,支持1万以内的关键词
2.2.3,输入动作名称
告诉自己这一步动作是拿来干嘛的,方便之后更改。
2.3,创建第二个动作:点击
参考2.2的操作,创建第二个动作,选择类型为点击,定位到搜索按键,然后手动生成xpath,检验是否锁定到惟一节点,没问题的话填到定位表达式里就行了。
2.4,存规则
点击“存规则”按钮保存已完成的第一级规则
第三步:定义第二级规则
3.1,新建规则
创建第二级规则,点击“定义规则”恢复到普通网页模式,输入关键词搜索出结果后,再次点击“定义规则”切换到做规则模式,点击左上角“规则”菜单->“新建”,输入主题名,这里的主题名就是第一级规则的连续动作里填写的目标主题名。
3.2,标注想要采集的信息
3.2.1,标注网页上想要采集的信息,这里是对商品名称和价位做标明,因为标明只对文本信息有效,商品详情的链接是属性节点@href,所以,不能对链接做这样的直观标明,而要做内容映射,具体看下边的操作。
3.2.2,点击商品名称,下面的DOM节点定位到A标签,展开A标签下的attributes节点,就可以找到代表网址的@href节点,右击节点,选择“新建抓取内容“,输入一个名子,一般给这个抓取内容起一个和地址有关的名子,比如“下级网址“,或者”下级链接“等等。然后在工作台上,看到这个抓取内容有了。如果还要步入商品详情页采集,就要对着这个抓取内容勾选下级线索关键词自动采集,做层级抓取。
3.2.3,设置“关键内容”选项,这样爬虫就能判别出采集规则是否合适。在整理箱里选一个网页上必然能采到的标签关键词自动采集,勾上“关键内容”。这里选择的是“名称”做为“关键内容”。
3.2.4,前面只对一个商品做标明,也才能得到一个商品信息,如果想把一整页上每一个商品都采集下来,可以做样例复制,不懂的请参考基础教程《采集列表数据》
3.3,设置翻页路线
在爬虫路线设置翻页,这里用的是记号线索,不懂的请参考基础教程《设置翻页采集》
3.4,存规则
点击“测试”,检查信息完整性。不完整的话,重新标明就可以覆盖之前的内容。检查没问题后点击“存规则”。
第四步:抓数据
4.1,连续动作是连续执行的,所以只要运行第一级主题,第二级主题不用运行。打开DS打数机,搜索出第一级主题名,点击“单搜”或“集搜”,此时可以看见浏览器窗口里会手动输入关键词而且搜索,然后调用第二级主题手动采集搜索结果。
4.2,第一级主题没采到有意义的信息,所以,我们只看第二级主题的文件夹,就能看见采集的搜索结果数据,并且搜索的关键词是默认记录在xml文件的actionvalue数组中,这样才能一一对应上去。 查看全部
Python数据剖析之numpy字段全解析一、操作步骤
如果网页上有搜索框,但是搜索结果页面没有独立网址,想要采集搜索结果,直接做规则是采集不到的,要先做连续动作(输入+点击)来实现手动输入关键词并搜索,然后才会采集数据。下面用易迅搜索为例,演示手动搜索采集,操作步骤如下:
Python资源共享群:626017123
二、案例规则+操作步骤
注意:本案例易迅搜索是有独立网址的,对于具有独立网址的页面,最简单的方式就是构造出每位关键词的搜索网址,然后把线索网址导出到规则里,就可以批量采集,而不是设置连续动作
第一步:定义第一级规则
1.1打开集搜客网络爬虫,输入网址并Enter,加载出网页后再点击“定义规则”按钮,看到一个浮窗显示下来,称为工作台,在前面定义规则;
注意:这里的截图和文字说明都是集搜客网络爬虫版本,如果您安装的是傲游插件版,那么就没有“定义规则”按钮,而是应当运行MS谋数台
1.2在工作台北输入一级规则的主题名,再点击“查重”,提示“该名可以使用”或“该名已被占用,可编辑:是”,就可以使用这个主题名,否则请重命名。
1.3本级规则主要是设置连续动作,所以,整理箱可以随便抓取一个信息,用来给爬虫判定是否执行采集。双击网页上的信息,输入标签名,并打勾确认,再勾上关键内容,首次标明还要输入整理箱的名子,然后就完成标明映射了。
Tips:为了能确切定位网页信息,点击定义规则会把整个网页定格住,不能跳转网页链接,再次点击定义规则,才会恢复回普通的网页模式。
第二步:定义连续动作
点击工作台的“连续动作”页签,点击新建按键构建一个新动作,每个动作的设置方式都是一样,基本操作如下:
2.1 ,输入目标主题名
这里的目标主题名是填第二级主题名,点击“谁在用”查看目标主题名是否可用,如果早已被占用,换一个主题名就行
2.2, 创建第一个动作:输入
新建一个动作,并选择动作类型为输入。
2.2.1,填写定位表达式
首先键盘单击输入框,定位输入框的节点,然后点击“自动生成XPath”按钮,可以选择“偏好id”或者“偏好class”,就可以得到输入框的xpath表达式,再点击“搜索”按钮,检查一下这个xpath是否能惟一定位到输入框,没有问题就把xpath复制到定位表达式方框里。
注意:定位表达式里的xpath是要锁定动作对象的整个有效操作范围,具体就是指键盘就能点击或输入成功的网页模块,不要定位到最底层的text()节点。
2.2.2,输入关键词
输入关键词填写你想搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词要用双分号;;将每位关键词隔开,免费版只支持5个以内的关键词,旗舰版可以使用连发弹仓功能,支持1万以内的关键词
2.2.3,输入动作名称
告诉自己这一步动作是拿来干嘛的,方便之后更改。
2.3,创建第二个动作:点击
参考2.2的操作,创建第二个动作,选择类型为点击,定位到搜索按键,然后手动生成xpath,检验是否锁定到惟一节点,没问题的话填到定位表达式里就行了。
2.4,存规则
点击“存规则”按钮保存已完成的第一级规则
第三步:定义第二级规则
3.1,新建规则
创建第二级规则,点击“定义规则”恢复到普通网页模式,输入关键词搜索出结果后,再次点击“定义规则”切换到做规则模式,点击左上角“规则”菜单->“新建”,输入主题名,这里的主题名就是第一级规则的连续动作里填写的目标主题名。
3.2,标注想要采集的信息
3.2.1,标注网页上想要采集的信息,这里是对商品名称和价位做标明,因为标明只对文本信息有效,商品详情的链接是属性节点@href,所以,不能对链接做这样的直观标明,而要做内容映射,具体看下边的操作。
3.2.2,点击商品名称,下面的DOM节点定位到A标签,展开A标签下的attributes节点,就可以找到代表网址的@href节点,右击节点,选择“新建抓取内容“,输入一个名子,一般给这个抓取内容起一个和地址有关的名子,比如“下级网址“,或者”下级链接“等等。然后在工作台上,看到这个抓取内容有了。如果还要步入商品详情页采集,就要对着这个抓取内容勾选下级线索关键词自动采集,做层级抓取。
3.2.3,设置“关键内容”选项,这样爬虫就能判别出采集规则是否合适。在整理箱里选一个网页上必然能采到的标签关键词自动采集,勾上“关键内容”。这里选择的是“名称”做为“关键内容”。
3.2.4,前面只对一个商品做标明,也才能得到一个商品信息,如果想把一整页上每一个商品都采集下来,可以做样例复制,不懂的请参考基础教程《采集列表数据》
3.3,设置翻页路线
在爬虫路线设置翻页,这里用的是记号线索,不懂的请参考基础教程《设置翻页采集》
3.4,存规则
点击“测试”,检查信息完整性。不完整的话,重新标明就可以覆盖之前的内容。检查没问题后点击“存规则”。
第四步:抓数据
4.1,连续动作是连续执行的,所以只要运行第一级主题,第二级主题不用运行。打开DS打数机,搜索出第一级主题名,点击“单搜”或“集搜”,此时可以看见浏览器窗口里会手动输入关键词而且搜索,然后调用第二级主题手动采集搜索结果。
4.2,第一级主题没采到有意义的信息,所以,我们只看第二级主题的文件夹,就能看见采集的搜索结果数据,并且搜索的关键词是默认记录在xml文件的actionvalue数组中,这样才能一一对应上去。
R爬虫之上市公司公告批量下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 382 次浏览 • 2020-06-03 08:01
2017-4-13 17:46|发布者: 炼数成金_小数|查看: 22744|评论: 1|原作者: 黄耀鹏|来自: R语言英文社区
摘要: Selenium是一个用于测试网页应用的开源软件。它提供了浏览器中的点击,滚动,滑动,及文字输入等驱动程序。这样,利用Selenium即可以通过脚本程序来代替人工进行测试一个开发软件的各类功能。在处理爬虫任务中,经常 ...
tm
Python
测试
案例
开源软件
函数
selenium的安装及使用介绍
Selenium是一个用于测试网页应用的开源软件。它提供了浏览器中的点击r软件爬虫,滚动,滑动r软件爬虫,及文字输入等驱动程序。这样,利用Selenium即可以通过脚本程序来代替人工进行测试一个开发软件的各类功能。
在处理爬虫任务中,经常碰到须要输入文字,进行下拉菜单选择,以及滑鼠点击等情境。这个时侯,selenium就派上大用场了。
下面,我们先介绍一下Selenium的使用环境配置,接着介绍怎样通过R的拓展包Rwebdriver来使用Selenium,最后,展示一个爬虫案例应用。
安装配置
安装jre:
下载地址:#win
配置jre环境变量
下载selenium,并放至指定位置
下载地址:
启动selenium
打开命令提示符
进入selenium所在路径
启动selenium
cd "C:\Program Files (x86)\Rwebdriver"
java -jar selenium-server-standalone-2.49.0.jar
### selenium接口函数介绍
『Automated Data Collection with R』一书的作者开发了R包Rwebdriver,用于联接启用selenium。
该R包重要的函数如下:
更多细节请参考:
-『Automated Data Collection with R』第9章P253-P259
Selenium with Python
网页开发工具的使用介绍
(手动演示)
XML提取器相关函数的使用
xpathSApply(doc,path,fun = NULL)
可传入的fun如下:
案例演示——爬取上海证券交易所上市公司公告信息
#### packages we need ####
## ----------------------------------------------------------------------- ##
require(stringr)
require(XML)
require(RCurl)
library(Rwebdriver)
# set path
setwd("ListedCompanyAnnouncement")
# base url
BaseUrl<-"http://www.sse.com.cn/disclosu ... ot%3B
#start a session
quit_session()
start_session(root = "http://localhost:4444/wd/hub/",browser = "firefox")
# post Base Url
post.url(url = BaseUrl)
# get xpath
StockCodeField<-element_xpath_find(value = '//*[@id="inputCode"]')
ClassificationField<-element_xpath_find(value = '/html/body/div[7]/div[2]/div[2]/div[2]/div/div/div/div/div[2]/div[1]/div[3]/div/button')
StartDateField<-element_xpath_find(value = '//*[@id="start_date"]')
EndDateField<-element_xpath_find(value = '//*[@id="end_date"]')
SearchField<-element_xpath_find(value = '//*[@id="btnQuery"]')
# fill stock code
StockCode<-"600000"
element_click(StockCodeField)
keys(StockCode)
Sys.sleep(2)
#fill classification field
element_click(ClassificationField)
# get announcement xpath
RegularAnnouncement<-element_xpath_find(value = '/html/body/div[7]/div[2]/div[2]/div[2]/div/div/div/div/div[2]/div[1]/div[3]/div/div/ul/li[2]')
Sys.sleep(2)
element_click(RegularAnnouncement)
# #fill start and end date
# element_click(StartDateField)
# today's xpath
EndToday<-element_xpath_find(value = '/html/body/div[13]/div[3]/table/tfoot/tr/th')
Sys.sleep(2)
element_click(EndDateField)
Sys.sleep(2)
element_click(EndToday)
#click search
element_click(SearchField)
###################################
####获得所有文件的link ##
all_links<-character() 查看全部
2017-4-13 17:46|发布者: 炼数成金_小数|查看: 22744|评论: 1|原作者: 黄耀鹏|来自: R语言英文社区
摘要: Selenium是一个用于测试网页应用的开源软件。它提供了浏览器中的点击,滚动,滑动,及文字输入等驱动程序。这样,利用Selenium即可以通过脚本程序来代替人工进行测试一个开发软件的各类功能。在处理爬虫任务中,经常 ...
tm
Python
测试
案例
开源软件
函数
selenium的安装及使用介绍
Selenium是一个用于测试网页应用的开源软件。它提供了浏览器中的点击r软件爬虫,滚动,滑动r软件爬虫,及文字输入等驱动程序。这样,利用Selenium即可以通过脚本程序来代替人工进行测试一个开发软件的各类功能。
在处理爬虫任务中,经常碰到须要输入文字,进行下拉菜单选择,以及滑鼠点击等情境。这个时侯,selenium就派上大用场了。
下面,我们先介绍一下Selenium的使用环境配置,接着介绍怎样通过R的拓展包Rwebdriver来使用Selenium,最后,展示一个爬虫案例应用。
安装配置
安装jre:
下载地址:#win
配置jre环境变量
下载selenium,并放至指定位置
下载地址:
启动selenium
打开命令提示符
进入selenium所在路径
启动selenium
cd "C:\Program Files (x86)\Rwebdriver"
java -jar selenium-server-standalone-2.49.0.jar
### selenium接口函数介绍
『Automated Data Collection with R』一书的作者开发了R包Rwebdriver,用于联接启用selenium。
该R包重要的函数如下:
更多细节请参考:
-『Automated Data Collection with R』第9章P253-P259
Selenium with Python
网页开发工具的使用介绍
(手动演示)
XML提取器相关函数的使用
xpathSApply(doc,path,fun = NULL)
可传入的fun如下:
案例演示——爬取上海证券交易所上市公司公告信息
#### packages we need ####
## ----------------------------------------------------------------------- ##
require(stringr)
require(XML)
require(RCurl)
library(Rwebdriver)
# set path
setwd("ListedCompanyAnnouncement")
# base url
BaseUrl<-"http://www.sse.com.cn/disclosu ... ot%3B
#start a session
quit_session()
start_session(root = "http://localhost:4444/wd/hub/",browser = "firefox")
# post Base Url
post.url(url = BaseUrl)
# get xpath
StockCodeField<-element_xpath_find(value = '//*[@id="inputCode"]')
ClassificationField<-element_xpath_find(value = '/html/body/div[7]/div[2]/div[2]/div[2]/div/div/div/div/div[2]/div[1]/div[3]/div/button')
StartDateField<-element_xpath_find(value = '//*[@id="start_date"]')
EndDateField<-element_xpath_find(value = '//*[@id="end_date"]')
SearchField<-element_xpath_find(value = '//*[@id="btnQuery"]')
# fill stock code
StockCode<-"600000"
element_click(StockCodeField)
keys(StockCode)
Sys.sleep(2)
#fill classification field
element_click(ClassificationField)
# get announcement xpath
RegularAnnouncement<-element_xpath_find(value = '/html/body/div[7]/div[2]/div[2]/div[2]/div/div/div/div/div[2]/div[1]/div[3]/div/div/ul/li[2]')
Sys.sleep(2)
element_click(RegularAnnouncement)
# #fill start and end date
# element_click(StartDateField)
# today's xpath
EndToday<-element_xpath_find(value = '/html/body/div[13]/div[3]/table/tfoot/tr/th')
Sys.sleep(2)
element_click(EndDateField)
Sys.sleep(2)
element_click(EndToday)
#click search
element_click(SearchField)
###################################
####获得所有文件的link ##
all_links<-character()
百度搜索结果爬虫实现方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 351 次浏览 • 2020-05-12 08:03
八爪鱼·云采集服务平台 百度搜索结果爬虫实现方式做 SEO 做流量的朋友,很多百度搜索数据都须要自己去抓取,大家就会选择用 八爪鱼爬虫工具进行百度搜索结果的数据采集,大批量又高效。如何配置百度搜 索的采集任务呢,接下来本文将介绍使用八爪鱼采集百度搜索结果的方式。采集网站:使用功能点:? 分页列表信息采集 ? Xpath ? AJAX 点击和翻页步骤 1:创建采集任务1)进入主界面,选择“自定义模式”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 12)将要采集的网址复制粘贴到网站输入框中,点击“保存网址”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 2步骤 2:输入文本1)在页面右上角,打开“流程”,以突显出“流程设计器”和“定制当前操作” 两个蓝筹股。点击搜索框,在操作提示框中,选择“输入文字”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 32)输入要采集的文本,这里以输入“八爪鱼采集器”为例。完成后,点击“确 定”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 43)输入的文本手动填充到搜索框后,点击“百度一下”按钮。在操作提示框中, 选择“点击该按键”百度搜索结果爬虫方式图 5此步骤涉及 Ajax 技术。
打开“高级选项”,勾选“Ajax 加载数据”,设置时间 为“2 秒”。完成后,点击“确定”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 6步骤 3:创建翻页循环1)将页面下拉到顶部,点击“下一页”按钮,在两侧的操作提示框中,选择“循 环点击下一页”,以完善一个翻页循环八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 72)选中“循环翻页”步骤,打开“高级选项”,将单个元素中的这条 Xpath: //A[@class='n',复制粘贴到火狐浏览器中的相应位置八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 8可以看见,当在第 1 页的时侯,使用此条 Xpath,可以定位到“下一页”百度搜索结果爬虫方式图 9八爪鱼·云采集服务平台 当翻到第 2 页的时侯,使用此条 Xpath,既可定位到“上一页”,又可定位到 “下一页”百度搜索结果爬虫方式图 103)返回八爪鱼采集器,点击“自定义”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 114)勾选“元素文本=下一页>”百度爬虫,对应生成的 Xpath 为://A[@text()='下一 页']。完成后,点击“确定”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 125)将修改后的 Xpath://A[@text()='下一页'],再次复制粘贴到火狐浏览器 中。
可以看见,当翻到第 2 页的时侯,可正常定位到“下一页”,第 3、4、5、 6 等也可正常定位到“下一页”,翻页循环可正常运行八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 13步骤 4:创建列表循环并提取数据1)移动滑鼠,选中页面里第一条搜索结果的区块,再选中页面内另一条搜索结 果的区块。系统会手动辨识并选中,页面里其他搜索结果的区块,以完善一个列 表循环。在操作提示框中,选择“采集以下元素文本”。整个区块里的信息,作 为一个数组,被采集下来八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 142)选中“循环”步骤,打开“高级选项”,将不固定元素列表中的这条 Xpath: //DIV[@id='content_left']/DIV,复制粘贴到火狐浏览器中的相应位置八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 153)将八爪鱼中的 Xpath,复制到火狐浏览器中的相应位置。观察页面,我们不 需要采集的“相关搜索”和“广告”内容也被定位了八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 164 ) 观 察 网 页 源 码 , 我 们 要 采 集 的 区 块 , 具 有 相 同 的 tpl 属 性 , tpl="se_com_default"(如图红框中所示),通过 tpl 属性,可即将采集的县 块与不需要采集的广告、推荐内容分辨开来。
将 Xpath 修改为: //DIV[@id='content_left']/DIV[@tpl="se_com_default"]。再观察页面, 要采集的内容都被定位了,不需要采集的广告、推荐内容未被定位八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 175)将修改后的 Xpath: //DIV[@id='content_left']/DIV[@tpl="se_com_default"], 复制粘贴到八 爪虾采集器的相应位置。完成后,点击“确定”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 186)在这里,我们还想采集每条搜索结果的链接 URL。选中页面内一条搜索结果 的链接,在操作提示框中,选择“采集该链接地址”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 197)字段选择完成后,选中相应的数组,可以进行数组的自定义命名。完成后, 点击左上角的“保存并启动”,选择“启动本地采集”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 20步骤 5:数据采集及导入1)采集完成后,会跳出提示,选择“导出数据”。选择“合适的导入方法”, 将采集好的数据导入八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 212)这里我们选择 excel 作为导入为格式,数据导入后如下图百度搜索结果爬虫方式图 22八爪鱼·云采集服务平台 相关采集教程: 百度爬虫 百度地图店家采集工具 百度地图数据采集 百度搜索结果抓取和采集详细教程 使用八爪鱼 v7.0 简易模式采集百度百科内容 百度地图店家地址采集 百度文库数据采集方法,以列表页为例 百度贴吧内容采集 百度相关搜索关键词采集 百度知道问答采集八爪鱼·云采集服务平台 http://www.bazhuayu.com/tutorial/bdzhidaocj八爪鱼——百万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机百度爬虫,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部
八爪鱼·云采集服务平台 百度搜索结果爬虫实现方式做 SEO 做流量的朋友,很多百度搜索数据都须要自己去抓取,大家就会选择用 八爪鱼爬虫工具进行百度搜索结果的数据采集,大批量又高效。如何配置百度搜 索的采集任务呢,接下来本文将介绍使用八爪鱼采集百度搜索结果的方式。采集网站:使用功能点:? 分页列表信息采集 ? Xpath ? AJAX 点击和翻页步骤 1:创建采集任务1)进入主界面,选择“自定义模式”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 12)将要采集的网址复制粘贴到网站输入框中,点击“保存网址”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 2步骤 2:输入文本1)在页面右上角,打开“流程”,以突显出“流程设计器”和“定制当前操作” 两个蓝筹股。点击搜索框,在操作提示框中,选择“输入文字”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 32)输入要采集的文本,这里以输入“八爪鱼采集器”为例。完成后,点击“确 定”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 43)输入的文本手动填充到搜索框后,点击“百度一下”按钮。在操作提示框中, 选择“点击该按键”百度搜索结果爬虫方式图 5此步骤涉及 Ajax 技术。
打开“高级选项”,勾选“Ajax 加载数据”,设置时间 为“2 秒”。完成后,点击“确定”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 6步骤 3:创建翻页循环1)将页面下拉到顶部,点击“下一页”按钮,在两侧的操作提示框中,选择“循 环点击下一页”,以完善一个翻页循环八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 72)选中“循环翻页”步骤,打开“高级选项”,将单个元素中的这条 Xpath: //A[@class='n',复制粘贴到火狐浏览器中的相应位置八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 8可以看见,当在第 1 页的时侯,使用此条 Xpath,可以定位到“下一页”百度搜索结果爬虫方式图 9八爪鱼·云采集服务平台 当翻到第 2 页的时侯,使用此条 Xpath,既可定位到“上一页”,又可定位到 “下一页”百度搜索结果爬虫方式图 103)返回八爪鱼采集器,点击“自定义”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 114)勾选“元素文本=下一页>”百度爬虫,对应生成的 Xpath 为://A[@text()='下一 页']。完成后,点击“确定”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 125)将修改后的 Xpath://A[@text()='下一页'],再次复制粘贴到火狐浏览器 中。
可以看见,当翻到第 2 页的时侯,可正常定位到“下一页”,第 3、4、5、 6 等也可正常定位到“下一页”,翻页循环可正常运行八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 13步骤 4:创建列表循环并提取数据1)移动滑鼠,选中页面里第一条搜索结果的区块,再选中页面内另一条搜索结 果的区块。系统会手动辨识并选中,页面里其他搜索结果的区块,以完善一个列 表循环。在操作提示框中,选择“采集以下元素文本”。整个区块里的信息,作 为一个数组,被采集下来八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 142)选中“循环”步骤,打开“高级选项”,将不固定元素列表中的这条 Xpath: //DIV[@id='content_left']/DIV,复制粘贴到火狐浏览器中的相应位置八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 153)将八爪鱼中的 Xpath,复制到火狐浏览器中的相应位置。观察页面,我们不 需要采集的“相关搜索”和“广告”内容也被定位了八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 164 ) 观 察 网 页 源 码 , 我 们 要 采 集 的 区 块 , 具 有 相 同 的 tpl 属 性 , tpl="se_com_default"(如图红框中所示),通过 tpl 属性,可即将采集的县 块与不需要采集的广告、推荐内容分辨开来。
将 Xpath 修改为: //DIV[@id='content_left']/DIV[@tpl="se_com_default"]。再观察页面, 要采集的内容都被定位了,不需要采集的广告、推荐内容未被定位八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 175)将修改后的 Xpath: //DIV[@id='content_left']/DIV[@tpl="se_com_default"], 复制粘贴到八 爪虾采集器的相应位置。完成后,点击“确定”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 186)在这里,我们还想采集每条搜索结果的链接 URL。选中页面内一条搜索结果 的链接,在操作提示框中,选择“采集该链接地址”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 197)字段选择完成后,选中相应的数组,可以进行数组的自定义命名。完成后, 点击左上角的“保存并启动”,选择“启动本地采集”八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 20步骤 5:数据采集及导入1)采集完成后,会跳出提示,选择“导出数据”。选择“合适的导入方法”, 将采集好的数据导入八爪鱼·云采集服务平台 百度搜索结果爬虫方式图 212)这里我们选择 excel 作为导入为格式,数据导入后如下图百度搜索结果爬虫方式图 22八爪鱼·云采集服务平台 相关采集教程: 百度爬虫 百度地图店家采集工具 百度地图数据采集 百度搜索结果抓取和采集详细教程 使用八爪鱼 v7.0 简易模式采集百度百科内容 百度地图店家地址采集 百度文库数据采集方法,以列表页为例 百度贴吧内容采集 百度相关搜索关键词采集 百度知道问答采集八爪鱼·云采集服务平台 http://www.bazhuayu.com/tutorial/bdzhidaocj八爪鱼——百万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机百度爬虫,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
Python网络爬虫四大选择器(正则表达式、BS4、Xpath、CSS)总结
采集交流 • 优采云 发表了文章 • 0 个评论 • 481 次浏览 • 2020-05-12 08:01
一、正则表达式
正则表达式为我们提供了抓取数据的快捷方法。虽然该正则表达式更容易适应未来变化网络爬虫 正则表达式,但又存在无法构造、可读性差的问题。当在爬京东网的时侯,正则表达式如下图所示:
利用正则表达式实现对目标信息的精准采集
此外 ,我们都晓得,网页经常会形成变更,导致网页中会发生一些微小的布局变化时,此时也会促使之前写好的正则表达式未能满足需求,而且还不太好调试。当须要匹配的内容有很多的时侯,使用正则表达式提取目标信息会导致程序运行的速率减缓,需要消耗更多显存。
二、BeautifulSoup
BeautifulSoup是一个十分流行的 Pyhon 模块。该模块可以解析网页,并提供定位内容的方便插口。通过'pip install beautifulsoup4'就可以实现该模块的安装了。
利用美丽的汤去提取目标信息
使用 BeautifulSoup的第一步是将己下载的 HTML 内容解析为 soup文档。由 于大多数网页都不具备良好的HTML 格式,因此BeautifulSoup须要对实际格式进行确定。BeautifulSoup才能正确解析缺位的冒号并闭合标签,此外都会添加<html >和<body>标签让其成为完整的HTML文档。通常使用find() 和find_all()方法来定位我们须要的元素。
如果你想了解BeautifulSoup全部方式和参数,可以查阅BeautifulSoup的官方文档。虽然BeautifulSoup在代码的理解上比正则表达式要复杂一些,但是其愈发容易构造和理解。
三、Lxml
Lxml模块使用 C语言编撰,其解析速率比 BeautiflSoup更快,而且其安装过程也更为复杂,在此小编就不赘言啦。XPath 使用路径表达式在 XML 文档中选定节点。节点是通过顺着路径或则 step 来选定的。
Xpath选择器
使用 lxml 模块的第一步和BeautifulSoup一样,也是将有可能不合法的HTML 解析为 统一格式。 虽然Lxml可以正确解析属性两边缺位的冒号网络爬虫 正则表达式,并闭合标签,不过该模块没有额外添加<html >和<body>标签 。
在线复制Xpath表达式可以很方便的复制Xpath表达式。但是通过该方式得到的Xpath表达式置于程序中通常不能用,而且长的无法看。所以Xpath表达式通常还是要自己亲自上手。
四、CSS
CSS选择器表示选择元素所使用 的模式。BeautifulSoup整合了CSS选择器的句型和自身便捷使用API。在网路爬虫的开发过程中,对于熟悉CSS选择器句型的人,使用CSS选择器是个十分便捷的方式。
CSS选择器
下面是一些常用的选择器示例。 查看全部
前几天小编连续写了四篇关于Python选择器的文章,分别用正则表达式、BeautifulSoup、Xpath、CSS选择器分别抓取京东网的商品信息。今天小编来给你们总结一下这四个选择器,让你们愈发深刻的理解和熟悉Python选择器。
一、正则表达式
正则表达式为我们提供了抓取数据的快捷方法。虽然该正则表达式更容易适应未来变化网络爬虫 正则表达式,但又存在无法构造、可读性差的问题。当在爬京东网的时侯,正则表达式如下图所示:
利用正则表达式实现对目标信息的精准采集
此外 ,我们都晓得,网页经常会形成变更,导致网页中会发生一些微小的布局变化时,此时也会促使之前写好的正则表达式未能满足需求,而且还不太好调试。当须要匹配的内容有很多的时侯,使用正则表达式提取目标信息会导致程序运行的速率减缓,需要消耗更多显存。
二、BeautifulSoup
BeautifulSoup是一个十分流行的 Pyhon 模块。该模块可以解析网页,并提供定位内容的方便插口。通过'pip install beautifulsoup4'就可以实现该模块的安装了。
利用美丽的汤去提取目标信息
使用 BeautifulSoup的第一步是将己下载的 HTML 内容解析为 soup文档。由 于大多数网页都不具备良好的HTML 格式,因此BeautifulSoup须要对实际格式进行确定。BeautifulSoup才能正确解析缺位的冒号并闭合标签,此外都会添加<html >和<body>标签让其成为完整的HTML文档。通常使用find() 和find_all()方法来定位我们须要的元素。
如果你想了解BeautifulSoup全部方式和参数,可以查阅BeautifulSoup的官方文档。虽然BeautifulSoup在代码的理解上比正则表达式要复杂一些,但是其愈发容易构造和理解。
三、Lxml
Lxml模块使用 C语言编撰,其解析速率比 BeautiflSoup更快,而且其安装过程也更为复杂,在此小编就不赘言啦。XPath 使用路径表达式在 XML 文档中选定节点。节点是通过顺着路径或则 step 来选定的。
Xpath选择器
使用 lxml 模块的第一步和BeautifulSoup一样,也是将有可能不合法的HTML 解析为 统一格式。 虽然Lxml可以正确解析属性两边缺位的冒号网络爬虫 正则表达式,并闭合标签,不过该模块没有额外添加<html >和<body>标签 。
在线复制Xpath表达式可以很方便的复制Xpath表达式。但是通过该方式得到的Xpath表达式置于程序中通常不能用,而且长的无法看。所以Xpath表达式通常还是要自己亲自上手。
四、CSS
CSS选择器表示选择元素所使用 的模式。BeautifulSoup整合了CSS选择器的句型和自身便捷使用API。在网路爬虫的开发过程中,对于熟悉CSS选择器句型的人,使用CSS选择器是个十分便捷的方式。
CSS选择器
下面是一些常用的选择器示例。
Scrapy爬虫框架:抓取天猫淘宝数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 416 次浏览 • 2020-05-05 08:05
通过天猫的搜索,获取搜索下来的每件商品的销量、收藏数、价格。
所以,最终的目的是通过获取两个页面的内容,一个是搜索结果,从上面找下来每一个商品的详尽地址,然后第二个是商品详尽内容,从上面获取到销量、价格等。
有了思路如今我们先下载搜索结果页面,然后再下载页面中每一项详尽信息页面。
def _parse_handler(self, response):
''' 下载页面 """
self.driver.get(response.url)
pass
很简单,通过self.driver.get(response.url)就能使用selenium下载内容,如果直接使用response中的网页内容是静态的。
上面说了怎样下载内容,当我们下载好内容后,需要从上面去获取我们想要的有用信息,这里就要用到选择器,选择器构造方法比较多,只介绍一种,这里看详尽信息:
>>> body = '<html><body><span>good</span></body></html>'
>>> Selector(text=body).xpath('//span/text()').extract()
[u'good']
这样就通过xpath取下来了good这个词组,更详尽的xpath教程点击这儿。
Selector 提供了好多形式出了xpath,还有css选择器,正则表达式,中文教程看这个,具体内容就不多说,只须要晓得这样可以快速获取我们须要的内容。
简单的介绍了如何获取内容后,现在我们从第一个搜索结果中获取我们想要的商品详尽链接,通过查看网页源代码可以看见,商品的链接在这里:
...
<p class="title">
<a class="J_ClickStat" data-nid="523242229702" href="//detail.tmall.com/item.htm?spm=a230r.1.14.46.Mnbjq5&id=523242229702&ns=1&abbucket=14" target="_blank" trace="msrp_auction" traceidx="5" trace-pid="" data-spm-anchor-id="a230r.1.14.46">WD/西部数据 WD30EZRZ台式机3T电脑<span class="H">硬盘</span> 西数蓝盘3TB 替绿盘</a>
</p>
...
使用之前的规则来获取到a元素的href属性就是须要的内容:
selector = Selector(text=self.driver.page_source) # 这里不要省略text因为省略后Selector使用的是另外一个构造函数,self.driver.page_source是这个网页的html内容
selector.css(".title").css(".J_ClickStat").xpath("./@href").extract()
简单说一下,这里通过css工具取了class叫title的p元素,然后又获取了class是J_ClickStat的a元素,最后通过xpath规则获取a元素的href中的内容。啰嗦一句css中若果是取id则应当是selector.css("#title"),这个和css中的选择器是一致的。
同理,我们获取到商品详情后,以获取销量为例,查看源代码:
<ul class="tm-ind-panel">
<li class="tm-ind-item tm-ind-sellCount" data-label="月销量"><div class="tm-indcon"><span class="tm-label">月销量</span><span class="tm-count">881</span></div></li>
<li class="tm-ind-item tm-ind-reviewCount canClick tm-line3" id="J_ItemRates"><div class="tm-indcon"><span class="tm-label">累计评价</span><span class="tm-count">4593</span></div></li>
<li class="tm-ind-item tm-ind-emPointCount" data-spm="1000988"><div class="tm-indcon"><a href="//vip.tmall.com/vip/index.htm" target="_blank"><span class="tm-label">送天猫积分</span><span class="tm-count">55</span></a></div></li>
</ul>
获取月销量:
selector.css(".tm-ind-sellCount").xpath("./div/span[@class='tm-count']/text()").extract_first()
获取累计评价:
selector.css(".tm-ind-reviewCount").xpath("./div[@class='tm-indcon']/span[@class='tm-count']/text()").extract_first()
最后把获取下来的数据包装成Item返回。淘宝或则淘宝她们的页面内容不一样,所以规则也不同,需要分开去获取想要的内容。
Item是scrapy中获取下来的结果,后面可以处理这种结果。
Item通常是放在items.py中
import scrapy
class Product(scrapy.Item):
name = scrapy.Field()
price = scrapy.Field()
stock = scrapy.Field()
last_updated = scrapy.Field(serializer=str)
>>> product = Product(name='Desktop PC', price=1000)
>>> print product
Product(name='Desktop PC', price=1000)
>>> product['name']
Desktop PC
>>> product.get('name')
Desktop PC
>>> product['price']
1000
>>> product['last_updated']
Traceback (most recent call last):
...
KeyError: 'last_updated'
>>> product.get('last_updated', 'not set')
not set
>>> product['lala'] # getting unknown field
Traceback (most recent call last):
...
KeyError: 'lala'
>>> product.get('lala', 'unknown field')
'unknown field'
>>> 'name' in product # is name field populated?
True
>>> 'last_updated' in product # is last_updated populated?
False
>>> 'last_updated' in product.fields # is last_updated a declared field?
True
>>> 'lala' in product.fields # is lala a declared field?
False
>>> product['last_updated'] = 'today'
>>> product['last_updated']
today
>>> product['lala'] = 'test' # setting unknown field
Traceback (most recent call last):
...
KeyError: 'Product does not support field: lala'
这里只须要注意一个地方,不能通过product.name的方法获取,也不能通过product.name = "name"的形式设置值。
当Item在Spider中被搜集以后,它将会被传递到Item Pipeline,一些组件会根据一定的次序执行对Item的处理。
每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方式的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被遗弃而不再进行处理。
以下是item pipeline的一些典型应用:
现在实现一个Item过滤器,我们把获取下来若果是None的数据形参为0,如果Item对象是None则丢弃这条数据。
pipeline通常是放在pipelines.py中
def process_item(self, item, spider):
if item is not None:
if item["p_standard_price"] is None:
item["p_standard_price"] = item["p_shop_price"]
if item["p_shop_price"] is None:
item["p_shop_price"] = item["p_standard_price"]
item["p_collect_count"] = text_utils.to_int(item["p_collect_count"])
item["p_comment_count"] = text_utils.to_int(item["p_comment_count"])
item["p_month_sale_count"] = text_utils.to_int(item["p_month_sale_count"])
item["p_sale_count"] = text_utils.to_int(item["p_sale_count"])
item["p_standard_price"] = text_utils.to_string(item["p_standard_price"], "0")
item["p_shop_price"] = text_utils.to_string(item["p_shop_price"], "0")
item["p_pay_count"] = item["p_pay_count"] if item["p_pay_count"] is not "-" else "0"
return item
else:
raise DropItem("Item is None %s" % item)
最后须要在settings.py中添加这个pipeline
ITEM_PIPELINES = {
'TaoBao.pipelines.TTDataHandlerPipeline': 250,
'TaoBao.pipelines.MysqlPipeline': 300,
}
后面那种数字越小,则执行的次序越靠前,这里先过滤处理数据,获取到正确的数据后,再执行TaoBao.pipelines.MysqlPipeline添加数据到数据库。
完整的代码:[不带数据库版本][ 数据库版本]。
之前说的方法都是直接通过命令scrapy crawl tts来启动。怎么用IDE的调试功能呢?很简单通过main函数启动爬虫:
# 写到Spider里面
if __name__ == "__main__":
settings = get_project_settings()
process = CrawlerProcess(settings)
spider = TmallAndTaoBaoSpider
process.crawl(spider)
process.start()
在获取数据的时侯,很多时侯会碰到网页重定向的问题,scrapy会返回302之后不会手动重定向后继续爬取新地址,在scrapy的设置中,可以通过配置来开启重定向,这样虽然域名是重定向的scrapy也会手动到最终的地址获取内容。
解决方案:settings.py中添加REDIRECT_ENABLED = True
很多时侯爬虫都有自定义数据,比如之前写的是硬碟关键字,现在通过参数的方法如何传递呢?
解决方案:
大部分时侯,我们可以取到完整的网页信息,如果网页的ajax恳求太多,网速很慢的时侯,selenium并不知道什么时候ajax恳求完成,这个时侯假如通过self.driver.get(response.url)获取页面天猫反爬虫,然后通过Selector取数据天猫反爬虫,很可能还没加载完成取不到数据。
解决方案:通过selenium提供的工具来延后获取内容,直到获取到数据,或者超时。 查看全部
有了前两篇的基础,接下来通过抓取天猫和淘宝的数据来详尽说明,如何通过Scrapy爬取想要的内容。完整的代码:[不带数据库版本][ 数据库版本]。
通过天猫的搜索,获取搜索下来的每件商品的销量、收藏数、价格。
所以,最终的目的是通过获取两个页面的内容,一个是搜索结果,从上面找下来每一个商品的详尽地址,然后第二个是商品详尽内容,从上面获取到销量、价格等。
有了思路如今我们先下载搜索结果页面,然后再下载页面中每一项详尽信息页面。
def _parse_handler(self, response):
''' 下载页面 """
self.driver.get(response.url)
pass
很简单,通过self.driver.get(response.url)就能使用selenium下载内容,如果直接使用response中的网页内容是静态的。
上面说了怎样下载内容,当我们下载好内容后,需要从上面去获取我们想要的有用信息,这里就要用到选择器,选择器构造方法比较多,只介绍一种,这里看详尽信息:
>>> body = '<html><body><span>good</span></body></html>'
>>> Selector(text=body).xpath('//span/text()').extract()
[u'good']
这样就通过xpath取下来了good这个词组,更详尽的xpath教程点击这儿。
Selector 提供了好多形式出了xpath,还有css选择器,正则表达式,中文教程看这个,具体内容就不多说,只须要晓得这样可以快速获取我们须要的内容。
简单的介绍了如何获取内容后,现在我们从第一个搜索结果中获取我们想要的商品详尽链接,通过查看网页源代码可以看见,商品的链接在这里:
...
<p class="title">
<a class="J_ClickStat" data-nid="523242229702" href="//detail.tmall.com/item.htm?spm=a230r.1.14.46.Mnbjq5&id=523242229702&ns=1&abbucket=14" target="_blank" trace="msrp_auction" traceidx="5" trace-pid="" data-spm-anchor-id="a230r.1.14.46">WD/西部数据 WD30EZRZ台式机3T电脑<span class="H">硬盘</span> 西数蓝盘3TB 替绿盘</a>
</p>
...
使用之前的规则来获取到a元素的href属性就是须要的内容:
selector = Selector(text=self.driver.page_source) # 这里不要省略text因为省略后Selector使用的是另外一个构造函数,self.driver.page_source是这个网页的html内容
selector.css(".title").css(".J_ClickStat").xpath("./@href").extract()
简单说一下,这里通过css工具取了class叫title的p元素,然后又获取了class是J_ClickStat的a元素,最后通过xpath规则获取a元素的href中的内容。啰嗦一句css中若果是取id则应当是selector.css("#title"),这个和css中的选择器是一致的。
同理,我们获取到商品详情后,以获取销量为例,查看源代码:
<ul class="tm-ind-panel">
<li class="tm-ind-item tm-ind-sellCount" data-label="月销量"><div class="tm-indcon"><span class="tm-label">月销量</span><span class="tm-count">881</span></div></li>
<li class="tm-ind-item tm-ind-reviewCount canClick tm-line3" id="J_ItemRates"><div class="tm-indcon"><span class="tm-label">累计评价</span><span class="tm-count">4593</span></div></li>
<li class="tm-ind-item tm-ind-emPointCount" data-spm="1000988"><div class="tm-indcon"><a href="//vip.tmall.com/vip/index.htm" target="_blank"><span class="tm-label">送天猫积分</span><span class="tm-count">55</span></a></div></li>
</ul>
获取月销量:
selector.css(".tm-ind-sellCount").xpath("./div/span[@class='tm-count']/text()").extract_first()
获取累计评价:
selector.css(".tm-ind-reviewCount").xpath("./div[@class='tm-indcon']/span[@class='tm-count']/text()").extract_first()
最后把获取下来的数据包装成Item返回。淘宝或则淘宝她们的页面内容不一样,所以规则也不同,需要分开去获取想要的内容。
Item是scrapy中获取下来的结果,后面可以处理这种结果。
Item通常是放在items.py中
import scrapy
class Product(scrapy.Item):
name = scrapy.Field()
price = scrapy.Field()
stock = scrapy.Field()
last_updated = scrapy.Field(serializer=str)
>>> product = Product(name='Desktop PC', price=1000)
>>> print product
Product(name='Desktop PC', price=1000)
>>> product['name']
Desktop PC
>>> product.get('name')
Desktop PC
>>> product['price']
1000
>>> product['last_updated']
Traceback (most recent call last):
...
KeyError: 'last_updated'
>>> product.get('last_updated', 'not set')
not set
>>> product['lala'] # getting unknown field
Traceback (most recent call last):
...
KeyError: 'lala'
>>> product.get('lala', 'unknown field')
'unknown field'
>>> 'name' in product # is name field populated?
True
>>> 'last_updated' in product # is last_updated populated?
False
>>> 'last_updated' in product.fields # is last_updated a declared field?
True
>>> 'lala' in product.fields # is lala a declared field?
False
>>> product['last_updated'] = 'today'
>>> product['last_updated']
today
>>> product['lala'] = 'test' # setting unknown field
Traceback (most recent call last):
...
KeyError: 'Product does not support field: lala'
这里只须要注意一个地方,不能通过product.name的方法获取,也不能通过product.name = "name"的形式设置值。
当Item在Spider中被搜集以后,它将会被传递到Item Pipeline,一些组件会根据一定的次序执行对Item的处理。
每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方式的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被遗弃而不再进行处理。
以下是item pipeline的一些典型应用:
现在实现一个Item过滤器,我们把获取下来若果是None的数据形参为0,如果Item对象是None则丢弃这条数据。
pipeline通常是放在pipelines.py中
def process_item(self, item, spider):
if item is not None:
if item["p_standard_price"] is None:
item["p_standard_price"] = item["p_shop_price"]
if item["p_shop_price"] is None:
item["p_shop_price"] = item["p_standard_price"]
item["p_collect_count"] = text_utils.to_int(item["p_collect_count"])
item["p_comment_count"] = text_utils.to_int(item["p_comment_count"])
item["p_month_sale_count"] = text_utils.to_int(item["p_month_sale_count"])
item["p_sale_count"] = text_utils.to_int(item["p_sale_count"])
item["p_standard_price"] = text_utils.to_string(item["p_standard_price"], "0")
item["p_shop_price"] = text_utils.to_string(item["p_shop_price"], "0")
item["p_pay_count"] = item["p_pay_count"] if item["p_pay_count"] is not "-" else "0"
return item
else:
raise DropItem("Item is None %s" % item)
最后须要在settings.py中添加这个pipeline
ITEM_PIPELINES = {
'TaoBao.pipelines.TTDataHandlerPipeline': 250,
'TaoBao.pipelines.MysqlPipeline': 300,
}
后面那种数字越小,则执行的次序越靠前,这里先过滤处理数据,获取到正确的数据后,再执行TaoBao.pipelines.MysqlPipeline添加数据到数据库。
完整的代码:[不带数据库版本][ 数据库版本]。
之前说的方法都是直接通过命令scrapy crawl tts来启动。怎么用IDE的调试功能呢?很简单通过main函数启动爬虫:
# 写到Spider里面
if __name__ == "__main__":
settings = get_project_settings()
process = CrawlerProcess(settings)
spider = TmallAndTaoBaoSpider
process.crawl(spider)
process.start()
在获取数据的时侯,很多时侯会碰到网页重定向的问题,scrapy会返回302之后不会手动重定向后继续爬取新地址,在scrapy的设置中,可以通过配置来开启重定向,这样虽然域名是重定向的scrapy也会手动到最终的地址获取内容。
解决方案:settings.py中添加REDIRECT_ENABLED = True
很多时侯爬虫都有自定义数据,比如之前写的是硬碟关键字,现在通过参数的方法如何传递呢?
解决方案:
大部分时侯,我们可以取到完整的网页信息,如果网页的ajax恳求太多,网速很慢的时侯,selenium并不知道什么时候ajax恳求完成,这个时侯假如通过self.driver.get(response.url)获取页面天猫反爬虫,然后通过Selector取数据天猫反爬虫,很可能还没加载完成取不到数据。
解决方案:通过selenium提供的工具来延后获取内容,直到获取到数据,或者超时。
关键词采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 658 次浏览 • 2020-05-04 08:07
八爪鱼·云采集网络爬虫软件 3)创建好循环文本输入后, 点击页面上的搜索框, 创建输入文本的步骤, 注意, 不需要输入任何文本即可,若是手动生成的是在循环外边,拖入进去,再勾选循 环即可。八爪鱼·云采集网络爬虫软件 4)右键选择页面上的搜索按键,设置好点击元素,这样,循环文本输入就设置 好了,流程下方就是搜索下来的长尾关键词。步骤 3:创建数字翻页1)由于该搜索结果页面没有下一页按键,只有数字页数,所以我们须要用到 xpath 的一些相关知识,来设置特殊的数字翻页。首先去火狐浏览器里把该网页 打开并搜索相应关键词后,打开浏览器右上角的 firebug 工具--小瓢虫(不懂的 同学可以去官网教程看一下相应的 xpath 教程)八爪鱼·云采集网络爬虫软件 2)翻到页面下方输入关键词采集文章, 找到数字位置的源码, 可以看见当前页面的数字跟其他数字, 在源码里节点的属性 class 是有所不同的八爪鱼·云采集网络爬虫软件 3)收 益 我 们 首 先 定 位 到 该 页 面 的 数 字 位 置 , 手 写 xpath : //div[@id="page"]/a[contains(@class,'current')]八爪鱼·云采集网络爬虫软件 4)再利用固定函数 following-sibling 来定位到该节点后的第一个同类节点, 注意,该函数前面接::是固定格式,a[1]是指该节点后的第一个同类节点八爪鱼·云采集网络爬虫软件 5)可以查看翻页后还是正常定位到下一页的数字上,说明该 xpath 没有问题6)再回到八爪鱼, 在两侧流程页面拖一个循环进来, 高级选项里选择单个元素, 并把 xpath 放入进去,点确定保存好八爪鱼·云采集网络爬虫软件 7)再从左边拖一个点击元素进来,并在中级选项里勾选好循环,特殊数字翻页 循环就创建好了八爪鱼·云采集网络爬虫软件 步骤 4:创建循环列表1)我们安装常规方式创建循环列表,发现,由于搜索结果后的表格中出现了这 个无用的一整行信息。
八爪鱼·云采集网络爬虫软件 2)于是在八爪鱼上面是难以正常的创建好循环列表的,因为这个无用的信息导 致八爪鱼手动生成的列表会定位不准八爪鱼·云采集网络爬虫软件 3)所以我们还是得用到 xpath 的知识,去火狐浏览器上面自动创建一个循环列 表的 xpath。首先定位到第一行第一列的源码位置4)再找到每一行的源码位置,发现她们都是 tbody 父节点下相同的 tr 标签八爪鱼·云采集网络爬虫软件 5)再观察每一行真正的 tr 节点里都有一个共同的属性“id”,并且 id 属性都 有 一 个 共 同 的 tr 值 , 所 以 我 们 以 此 为 共 同 点 ,手 写 该 xpath:.//tbody/tr[contains(@id,'tr')]输入关键词采集文章,来定位到所有的 tr 节点,并把所有无 用的 tr 给过滤掉,这样,循环列表的 xpath 就创建好了八爪鱼·云采集网络爬虫软件 6)再从左边拖一个循环进去,循环形式选择不固定元素,把该 xpath 放入八爪 鱼里,并以第一个循环为例,设置相应的采集字段(由于部份数组源码里是没有 的,所以采集不到),八爪鱼·云采集网络爬虫软件 步骤 5:启动采集八爪鱼·云采集网络爬虫软件 1)点击保存任务后,运行采集,以本地采集为例2)采集完成后,会跳出提示,选择“导出数据”。
选择“合适的导入方法”, 将采集好的数据导入。八爪鱼·云采集网络爬虫软件 本文来自于:相关采集教程:京东商品信息采集(通过搜索关键词) 阿里巴巴关键词采集: 八爪鱼·云采集网络爬虫软件 爱站关键词采集: 百度相关搜索关键词采集: 亚马逊关键词采集: 易迅关键词采集: 新浪微博关键词采集: 关键词提取八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。八爪鱼·云采集网络爬虫软件 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部
八爪鱼·云采集网络爬虫软件 关键词采集方法本文将介绍怎样借助【词库】批量挖掘并采集长尾词的方式,对 SEOSEM 站长 来说十分实用。 本来还将介绍一款免费好用的数据采集工具 【八爪鱼数据采集】 , 让站长采集关键词的工作事半功倍。长尾词对于站长来说是提升网站流量的核心之技能之一, 是不容忽略的一项方法, 在搜索引擎营销中对关键词策略的拟定是十分重要的, 这些长尾关键词能为网站 贡献很大的一部分流量,并且带来的客人转化率也很不错。下面就以【词库】为例,教诸位站长怎么是用【八爪鱼数据采集器】批量采集关 键词。采集网站:本文就以一组(100 个 B2B 行业有指数的关键词)为例,来采集关于这一组关 键词的所有相关长尾关键词。八爪鱼·云采集网络爬虫软件 采集的内容包括:搜索后的长尾关键词,360 指数,该长尾关键词搜索量以及搜 索量的第一位网站(页面)这四个有效数组。使用功能点:? 循环文本输入?Xpathxpath 入门教程 1 xpath 入门 2 相对 XPATH 教程-7.0 版 ? 数字翻页步骤 1:创建词库网采集任务1)进入主界面,选择“自定义采集”八爪鱼·云采集网络爬虫软件 2)将要采集的网址 URL 复制粘贴到网站输入框中,点击“保存网址”八爪鱼·云采集网络爬虫软件 步骤 2:创建循环输入文本八爪鱼·云采集网络爬虫软件 1)打开网页以后,点开右上角的流程,然后从左边拖一个循环进来2)点击循环步骤,在它的中级选项哪里选择文本列表,再点开下边的 A,把复 制好的关键词全部粘贴进去,注意换行,再点击确定保存。
八爪鱼·云采集网络爬虫软件 3)创建好循环文本输入后, 点击页面上的搜索框, 创建输入文本的步骤, 注意, 不需要输入任何文本即可,若是手动生成的是在循环外边,拖入进去,再勾选循 环即可。八爪鱼·云采集网络爬虫软件 4)右键选择页面上的搜索按键,设置好点击元素,这样,循环文本输入就设置 好了,流程下方就是搜索下来的长尾关键词。步骤 3:创建数字翻页1)由于该搜索结果页面没有下一页按键,只有数字页数,所以我们须要用到 xpath 的一些相关知识,来设置特殊的数字翻页。首先去火狐浏览器里把该网页 打开并搜索相应关键词后,打开浏览器右上角的 firebug 工具--小瓢虫(不懂的 同学可以去官网教程看一下相应的 xpath 教程)八爪鱼·云采集网络爬虫软件 2)翻到页面下方输入关键词采集文章, 找到数字位置的源码, 可以看见当前页面的数字跟其他数字, 在源码里节点的属性 class 是有所不同的八爪鱼·云采集网络爬虫软件 3)收 益 我 们 首 先 定 位 到 该 页 面 的 数 字 位 置 , 手 写 xpath : //div[@id="page"]/a[contains(@class,'current')]八爪鱼·云采集网络爬虫软件 4)再利用固定函数 following-sibling 来定位到该节点后的第一个同类节点, 注意,该函数前面接::是固定格式,a[1]是指该节点后的第一个同类节点八爪鱼·云采集网络爬虫软件 5)可以查看翻页后还是正常定位到下一页的数字上,说明该 xpath 没有问题6)再回到八爪鱼, 在两侧流程页面拖一个循环进来, 高级选项里选择单个元素, 并把 xpath 放入进去,点确定保存好八爪鱼·云采集网络爬虫软件 7)再从左边拖一个点击元素进来,并在中级选项里勾选好循环,特殊数字翻页 循环就创建好了八爪鱼·云采集网络爬虫软件 步骤 4:创建循环列表1)我们安装常规方式创建循环列表,发现,由于搜索结果后的表格中出现了这 个无用的一整行信息。
八爪鱼·云采集网络爬虫软件 2)于是在八爪鱼上面是难以正常的创建好循环列表的,因为这个无用的信息导 致八爪鱼手动生成的列表会定位不准八爪鱼·云采集网络爬虫软件 3)所以我们还是得用到 xpath 的知识,去火狐浏览器上面自动创建一个循环列 表的 xpath。首先定位到第一行第一列的源码位置4)再找到每一行的源码位置,发现她们都是 tbody 父节点下相同的 tr 标签八爪鱼·云采集网络爬虫软件 5)再观察每一行真正的 tr 节点里都有一个共同的属性“id”,并且 id 属性都 有 一 个 共 同 的 tr 值 , 所 以 我 们 以 此 为 共 同 点 ,手 写 该 xpath:.//tbody/tr[contains(@id,'tr')]输入关键词采集文章,来定位到所有的 tr 节点,并把所有无 用的 tr 给过滤掉,这样,循环列表的 xpath 就创建好了八爪鱼·云采集网络爬虫软件 6)再从左边拖一个循环进去,循环形式选择不固定元素,把该 xpath 放入八爪 鱼里,并以第一个循环为例,设置相应的采集字段(由于部份数组源码里是没有 的,所以采集不到),八爪鱼·云采集网络爬虫软件 步骤 5:启动采集八爪鱼·云采集网络爬虫软件 1)点击保存任务后,运行采集,以本地采集为例2)采集完成后,会跳出提示,选择“导出数据”。
选择“合适的导入方法”, 将采集好的数据导入。八爪鱼·云采集网络爬虫软件 本文来自于:相关采集教程:京东商品信息采集(通过搜索关键词) 阿里巴巴关键词采集: 八爪鱼·云采集网络爬虫软件 爱站关键词采集: 百度相关搜索关键词采集: 亚马逊关键词采集: 易迅关键词采集: 新浪微博关键词采集: 关键词提取八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。八爪鱼·云采集网络爬虫软件 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。

