
webcollector
基于 Java 的开源网路爬虫框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 269 次浏览 • 2020-05-15 08:00
WebCollector 是一个无须配置、便于二次开发的Java爬虫框架(内核),它提供精简的的 API,只需少量代码即可实现一个功能强悍的爬虫。WebCollector-Hadoop 是 WebCollector 的 Hadoop 版本,支持分布式爬取。
目前WebCollector-Python项目已在Github上开源,欢迎诸位前来贡献代码:
WebCollector 致力于维护一个稳定、可扩的爬虫内核,便于开发者进行灵活的二次开发。内核具有太强的扩展性,用户可以在内核基础上开发自己想要的爬虫。源码中集成了 Jsoup,可进行精准的网页解析。2.x 版本中集成了 selenium,可以处理 JavaScript 生成的数据。
Maven:
最新Maven地址请参考文档:
文档地址:
内核架构图:
自定义遍历策略,可完成更为复杂的遍历业务,例如分页、AJAX
可以为每位 URL 设置附加信息(MetaData),利用附加信息可以完成好多复杂业务,例如深度获取、锚文本获取、引用页面获取、POST 参数传递、增量更新等。
使用插件机制,用户可订制自己的Http请求、过滤器、执行器等插件。
内置一套基于显存的插件(RamCrawler),不依赖文件系统或数据库,适合一次性爬取,例如实时爬取搜索引擎。
内置一套基于 Berkeley DB(BreadthCrawler)的插件:适合处理常年和大量级的任务java单机爬虫框架,并具有断点爬取功能,不会由于宕机、关闭造成数据遗失。
集成 selenium,可以对 JavaScript 生成信息进行抽取
可轻松自定义 http 请求,并外置多代理随机切换功能。 可通过定义 http 请求实现模拟登陆。
使用 slf4j 作为日志店面,可对接多种日志
使用类似Hadoop的Configuration机制,可为每位爬虫订制配置信息。
网页正文提取项目 ContentExtractor 已划入 WebCollector 维护。
WebCollector 的正文抽取 API 都被封装为 ContentExtractor 类的静态方式。可以抽取结构化新闻,也可以只抽取网页的正文(或正文所在 Element)。
正文抽取疗效指标 :
标题抽取和日期抽取使用简单启发式算法java单机爬虫框架,并没有象正文抽取算法一样在标准数据集上测试,算法仍在更新中。 查看全部
目前WebCollector-Python项目已在Github上开源,欢迎诸位前来贡献代码:
WebCollector 致力于维护一个稳定、可扩的爬虫内核,便于开发者进行灵活的二次开发。内核具有太强的扩展性,用户可以在内核基础上开发自己想要的爬虫。源码中集成了 Jsoup,可进行精准的网页解析。2.x 版本中集成了 selenium,可以处理 JavaScript 生成的数据。
Maven:
最新Maven地址请参考文档:
文档地址:
内核架构图:
自定义遍历策略,可完成更为复杂的遍历业务,例如分页、AJAX
可以为每位 URL 设置附加信息(MetaData),利用附加信息可以完成好多复杂业务,例如深度获取、锚文本获取、引用页面获取、POST 参数传递、增量更新等。
使用插件机制,用户可订制自己的Http请求、过滤器、执行器等插件。
内置一套基于显存的插件(RamCrawler),不依赖文件系统或数据库,适合一次性爬取,例如实时爬取搜索引擎。
内置一套基于 Berkeley DB(BreadthCrawler)的插件:适合处理常年和大量级的任务java单机爬虫框架,并具有断点爬取功能,不会由于宕机、关闭造成数据遗失。
集成 selenium,可以对 JavaScript 生成信息进行抽取
可轻松自定义 http 请求,并外置多代理随机切换功能。 可通过定义 http 请求实现模拟登陆。
使用 slf4j 作为日志店面,可对接多种日志
使用类似Hadoop的Configuration机制,可为每位爬虫订制配置信息。
网页正文提取项目 ContentExtractor 已划入 WebCollector 维护。
WebCollector 的正文抽取 API 都被封装为 ContentExtractor 类的静态方式。可以抽取结构化新闻,也可以只抽取网页的正文(或正文所在 Element)。
正文抽取疗效指标 :
标题抽取和日期抽取使用简单启发式算法java单机爬虫框架,并没有象正文抽取算法一样在标准数据集上测试,算法仍在更新中。 查看全部
WebCollector 是一个无须配置、便于二次开发的Java爬虫框架(内核),它提供精简的的 API,只需少量代码即可实现一个功能强悍的爬虫。WebCollector-Hadoop 是 WebCollector 的 Hadoop 版本,支持分布式爬取。
目前WebCollector-Python项目已在Github上开源,欢迎诸位前来贡献代码:
WebCollector 致力于维护一个稳定、可扩的爬虫内核,便于开发者进行灵活的二次开发。内核具有太强的扩展性,用户可以在内核基础上开发自己想要的爬虫。源码中集成了 Jsoup,可进行精准的网页解析。2.x 版本中集成了 selenium,可以处理 JavaScript 生成的数据。
Maven:

最新Maven地址请参考文档:
文档地址:
内核架构图:
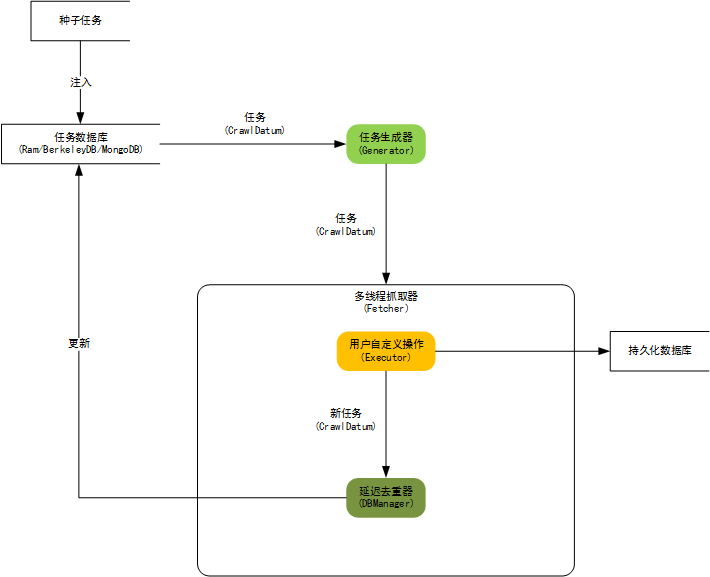
自定义遍历策略,可完成更为复杂的遍历业务,例如分页、AJAX
可以为每位 URL 设置附加信息(MetaData),利用附加信息可以完成好多复杂业务,例如深度获取、锚文本获取、引用页面获取、POST 参数传递、增量更新等。
使用插件机制,用户可订制自己的Http请求、过滤器、执行器等插件。
内置一套基于显存的插件(RamCrawler),不依赖文件系统或数据库,适合一次性爬取,例如实时爬取搜索引擎。
内置一套基于 Berkeley DB(BreadthCrawler)的插件:适合处理常年和大量级的任务java单机爬虫框架,并具有断点爬取功能,不会由于宕机、关闭造成数据遗失。
集成 selenium,可以对 JavaScript 生成信息进行抽取
可轻松自定义 http 请求,并外置多代理随机切换功能。 可通过定义 http 请求实现模拟登陆。
使用 slf4j 作为日志店面,可对接多种日志
使用类似Hadoop的Configuration机制,可为每位爬虫订制配置信息。
网页正文提取项目 ContentExtractor 已划入 WebCollector 维护。
WebCollector 的正文抽取 API 都被封装为 ContentExtractor 类的静态方式。可以抽取结构化新闻,也可以只抽取网页的正文(或正文所在 Element)。
正文抽取疗效指标 :
标题抽取和日期抽取使用简单启发式算法java单机爬虫框架,并没有象正文抽取算法一样在标准数据集上测试,算法仍在更新中。
基于 Java 的开源网路爬虫框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 269 次浏览 • 2020-05-15 08:00
WebCollector 是一个无须配置、便于二次开发的Java爬虫框架(内核),它提供精简的的 API,只需少量代码即可实现一个功能强悍的爬虫。WebCollector-Hadoop 是 WebCollector 的 Hadoop 版本,支持分布式爬取。
目前WebCollector-Python项目已在Github上开源,欢迎诸位前来贡献代码:
WebCollector 致力于维护一个稳定、可扩的爬虫内核,便于开发者进行灵活的二次开发。内核具有太强的扩展性,用户可以在内核基础上开发自己想要的爬虫。源码中集成了 Jsoup,可进行精准的网页解析。2.x 版本中集成了 selenium,可以处理 JavaScript 生成的数据。
Maven:
最新Maven地址请参考文档:
文档地址:
内核架构图:
自定义遍历策略,可完成更为复杂的遍历业务,例如分页、AJAX
可以为每位 URL 设置附加信息(MetaData),利用附加信息可以完成好多复杂业务,例如深度获取、锚文本获取、引用页面获取、POST 参数传递、增量更新等。
使用插件机制,用户可订制自己的Http请求、过滤器、执行器等插件。
内置一套基于显存的插件(RamCrawler),不依赖文件系统或数据库,适合一次性爬取,例如实时爬取搜索引擎。
内置一套基于 Berkeley DB(BreadthCrawler)的插件:适合处理常年和大量级的任务java单机爬虫框架,并具有断点爬取功能,不会由于宕机、关闭造成数据遗失。
集成 selenium,可以对 JavaScript 生成信息进行抽取
可轻松自定义 http 请求,并外置多代理随机切换功能。 可通过定义 http 请求实现模拟登陆。
使用 slf4j 作为日志店面,可对接多种日志
使用类似Hadoop的Configuration机制,可为每位爬虫订制配置信息。
网页正文提取项目 ContentExtractor 已划入 WebCollector 维护。
WebCollector 的正文抽取 API 都被封装为 ContentExtractor 类的静态方式。可以抽取结构化新闻,也可以只抽取网页的正文(或正文所在 Element)。
正文抽取疗效指标 :
标题抽取和日期抽取使用简单启发式算法java单机爬虫框架,并没有象正文抽取算法一样在标准数据集上测试,算法仍在更新中。 查看全部
目前WebCollector-Python项目已在Github上开源,欢迎诸位前来贡献代码:
WebCollector 致力于维护一个稳定、可扩的爬虫内核,便于开发者进行灵活的二次开发。内核具有太强的扩展性,用户可以在内核基础上开发自己想要的爬虫。源码中集成了 Jsoup,可进行精准的网页解析。2.x 版本中集成了 selenium,可以处理 JavaScript 生成的数据。
Maven:
最新Maven地址请参考文档:
文档地址:
内核架构图:
自定义遍历策略,可完成更为复杂的遍历业务,例如分页、AJAX
可以为每位 URL 设置附加信息(MetaData),利用附加信息可以完成好多复杂业务,例如深度获取、锚文本获取、引用页面获取、POST 参数传递、增量更新等。
使用插件机制,用户可订制自己的Http请求、过滤器、执行器等插件。
内置一套基于显存的插件(RamCrawler),不依赖文件系统或数据库,适合一次性爬取,例如实时爬取搜索引擎。
内置一套基于 Berkeley DB(BreadthCrawler)的插件:适合处理常年和大量级的任务java单机爬虫框架,并具有断点爬取功能,不会由于宕机、关闭造成数据遗失。
集成 selenium,可以对 JavaScript 生成信息进行抽取
可轻松自定义 http 请求,并外置多代理随机切换功能。 可通过定义 http 请求实现模拟登陆。
使用 slf4j 作为日志店面,可对接多种日志
使用类似Hadoop的Configuration机制,可为每位爬虫订制配置信息。
网页正文提取项目 ContentExtractor 已划入 WebCollector 维护。
WebCollector 的正文抽取 API 都被封装为 ContentExtractor 类的静态方式。可以抽取结构化新闻,也可以只抽取网页的正文(或正文所在 Element)。
正文抽取疗效指标 :
标题抽取和日期抽取使用简单启发式算法java单机爬虫框架,并没有象正文抽取算法一样在标准数据集上测试,算法仍在更新中。 查看全部
WebCollector 是一个无须配置、便于二次开发的Java爬虫框架(内核),它提供精简的的 API,只需少量代码即可实现一个功能强悍的爬虫。WebCollector-Hadoop 是 WebCollector 的 Hadoop 版本,支持分布式爬取。
目前WebCollector-Python项目已在Github上开源,欢迎诸位前来贡献代码:
WebCollector 致力于维护一个稳定、可扩的爬虫内核,便于开发者进行灵活的二次开发。内核具有太强的扩展性,用户可以在内核基础上开发自己想要的爬虫。源码中集成了 Jsoup,可进行精准的网页解析。2.x 版本中集成了 selenium,可以处理 JavaScript 生成的数据。
Maven:
最新Maven地址请参考文档:
文档地址:
内核架构图:
自定义遍历策略,可完成更为复杂的遍历业务,例如分页、AJAX
可以为每位 URL 设置附加信息(MetaData),利用附加信息可以完成好多复杂业务,例如深度获取、锚文本获取、引用页面获取、POST 参数传递、增量更新等。
使用插件机制,用户可订制自己的Http请求、过滤器、执行器等插件。
内置一套基于显存的插件(RamCrawler),不依赖文件系统或数据库,适合一次性爬取,例如实时爬取搜索引擎。
内置一套基于 Berkeley DB(BreadthCrawler)的插件:适合处理常年和大量级的任务java单机爬虫框架,并具有断点爬取功能,不会由于宕机、关闭造成数据遗失。
集成 selenium,可以对 JavaScript 生成信息进行抽取
可轻松自定义 http 请求,并外置多代理随机切换功能。 可通过定义 http 请求实现模拟登陆。
使用 slf4j 作为日志店面,可对接多种日志
使用类似Hadoop的Configuration机制,可为每位爬虫订制配置信息。
网页正文提取项目 ContentExtractor 已划入 WebCollector 维护。
WebCollector 的正文抽取 API 都被封装为 ContentExtractor 类的静态方式。可以抽取结构化新闻,也可以只抽取网页的正文(或正文所在 Element)。
正文抽取疗效指标 :
标题抽取和日期抽取使用简单启发式算法java单机爬虫框架,并没有象正文抽取算法一样在标准数据集上测试,算法仍在更新中。

