
scrapy
从零开始基于Scrapy框架的网路爬虫开发流程
采集交流 • 优采云 发表了文章 • 0 个评论 • 398 次浏览 • 2020-07-06 08:01
前节介绍了哪些网路爬虫,什么是Scrapy框架并怎样安装
本节介绍基于Scrapy框架的网路爬虫开发流程
安装好Scrapy框架后,就可以基于Scrapy框架开发爬虫项目了。基于框架开发项目,不需要从零开始编撰代码,只须要把握怎样使用框架,如何添加与自己应用相关的代码即可。
进入准备新建爬虫项目的路径中,使用命令:
scrapy startproject project_name
请用爬虫项目名称替换命令中的project_name爬虫软件开发,例如,本文准备创建一个爬取新浪网的爬虫,取名为sina_spider,则新建爬虫项目的命令为:
scrapy startproject sina_spider
命令运行结果,如下图所示。
新建爬虫项目
“scrapy startproject sina_spider”命令会创建包含下述内容的sina_spider目录,如图13-5所示。
爬虫文件夹结构
新建好Scrapy爬虫项目后,接下来就是创建爬虫文件。请先步入sina_spider项目路径,用命令:
scrapy genspider spider_filename(爬虫文件名) (待爬取的网站域名)
创建爬虫文件。例如,本文的爬虫文件名为:sinaSpider,待爬取的网站域名:,则创建爬虫文件sinaSpider的命令为:
scrapy genspider sinaSpider
现在好多网站都有防爬虫举措,为了反网站的防爬虫举措,需要添加user agent信息。请settings.py文件的第19行更改如下所示:
18. # Crawl responsibly by identifying yourself (and your website) on the user-agent
19. import random
20. # user agent 列表
21. USER_AGENT_LIST = [
22. "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
23. "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
24. "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
25. "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
26. "Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)",
27. "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
28. "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0",
29. "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0",
30. "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0",
31. "Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)",
32. "Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)" ]
33. USER_AGENT = random.choice(USER_AGENT_LIST) # 随机生成user agent
网站的服务器中保存一个robots.txt 文件,其作用是,告诉搜索引擎爬虫,本网站哪些目录下的网页不希望被爬取收录。Scrapy启动后,会在第一时间访问网站的 robots.txt 文件,然后决定该网站的爬取范围。
由于本文的项目并非搜索引擎爬虫,而且很有可能我们想要获取的内容恰恰是被 robots.txt所严禁访问的,所以请把settings.py文件的ROBOTSTXT_OBEY值设置为False,表示拒绝遵循Robot合同,如下所示
1. # Obey robots.txt rules
2. ROBOTSTXT_OBEY = False # False表示拒绝遵守Robot协议
查看由Scrapy生成的sinaSpider.py文件,在SinaspiderSpider类中,有一个parse()方法须要用户编撰,如下图所示
编写parse()方法
Scrapy框架把爬取出来的网页源代码储存在response对象中爬虫软件开发,我们只须要对response对象中的网页源代码做解析,提取想要的数据即可。本范例目标是抓取新浪网页的新闻的标题和对应的链接,如下图所示。
HTML源代码
parse()方法的实现代码,如下所示
1. # -*- coding: utf-8 -*-
2. import scrapy
3.
4. class SinaspiderSpider(scrapy.Spider):
5. name = 'sinaSpider'
6. allowed_domains = ['www.sina.com.cn']
7. start_urls = ['http://www.sina.com.cn/']
8.
9. def parse(self, response):
10. data_list = [] #用于存储解析到的数据
11. #解析HTML源代码,定位新闻内容
12. lis = response.xpath("//div[@class='top_newslist']/ul[@class='list-a news_top']//li")
13. #将新闻主题和超链接解析出来并整理到列表中
14. for li in lis:
15. titles = li.xpath(".//a/text()")
16. linkes = li.xpath(".//a/@href")
17. for title, link in zip(titles, linkes):
18. #将新闻主题和对应的超链接组合成字典
19. data_dict = {'标题': title.extract(), '链接': link.extract()}
20. #将字典数据存储到data_list这个列表中
21. data_list.append(data_dict)
22. return data_list
parse()方法在解析HTML源代码时,使用了XPath路径表达式。XPath是一门在HTML/XML文档中查找信息的语言,常用于在网页HTML源代码中,查找特定标签里的数据。在网络爬虫中使用XPath,只须要把握 XPath路径表达式即可。XPath 使用路径表达式来选定 HTML/XML文档中的节点或则节点集。
parse()方法编撰好后,就可以运行爬虫程序并保存抓取数据了。用命令:
scrapy crawl 爬虫文件名 –o 保存数据文件名.[csv|json|xml]
保存数据的文件格式可以是csv 或 json 或 xml,本例的爬虫文件名为:sinaSpider.py,数据储存选择csv格式,命令为:
scrapy crawl sinaSpider -o sinaNews.csv
运行疗效,如下图所示
运行爬虫
到此,本例基于Scrapy框架从零开始实现了一个网络爬虫程序,爬取了新浪网页并从中解析出新闻的标题和对应的超链接,最后把解析出的数据保存为csv文件供后续使用。 查看全部
前节介绍了哪些网路爬虫,什么是Scrapy框架并怎样安装
本节介绍基于Scrapy框架的网路爬虫开发流程
安装好Scrapy框架后,就可以基于Scrapy框架开发爬虫项目了。基于框架开发项目,不需要从零开始编撰代码,只须要把握怎样使用框架,如何添加与自己应用相关的代码即可。
进入准备新建爬虫项目的路径中,使用命令:
scrapy startproject project_name
请用爬虫项目名称替换命令中的project_name爬虫软件开发,例如,本文准备创建一个爬取新浪网的爬虫,取名为sina_spider,则新建爬虫项目的命令为:
scrapy startproject sina_spider
命令运行结果,如下图所示。

新建爬虫项目
“scrapy startproject sina_spider”命令会创建包含下述内容的sina_spider目录,如图13-5所示。

爬虫文件夹结构
新建好Scrapy爬虫项目后,接下来就是创建爬虫文件。请先步入sina_spider项目路径,用命令:
scrapy genspider spider_filename(爬虫文件名) (待爬取的网站域名)
创建爬虫文件。例如,本文的爬虫文件名为:sinaSpider,待爬取的网站域名:,则创建爬虫文件sinaSpider的命令为:
scrapy genspider sinaSpider
现在好多网站都有防爬虫举措,为了反网站的防爬虫举措,需要添加user agent信息。请settings.py文件的第19行更改如下所示:
18. # Crawl responsibly by identifying yourself (and your website) on the user-agent
19. import random
20. # user agent 列表
21. USER_AGENT_LIST = [
22. "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
23. "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
24. "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
25. "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
26. "Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)",
27. "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
28. "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0",
29. "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0",
30. "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0",
31. "Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)",
32. "Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)" ]
33. USER_AGENT = random.choice(USER_AGENT_LIST) # 随机生成user agent
网站的服务器中保存一个robots.txt 文件,其作用是,告诉搜索引擎爬虫,本网站哪些目录下的网页不希望被爬取收录。Scrapy启动后,会在第一时间访问网站的 robots.txt 文件,然后决定该网站的爬取范围。
由于本文的项目并非搜索引擎爬虫,而且很有可能我们想要获取的内容恰恰是被 robots.txt所严禁访问的,所以请把settings.py文件的ROBOTSTXT_OBEY值设置为False,表示拒绝遵循Robot合同,如下所示
1. # Obey robots.txt rules
2. ROBOTSTXT_OBEY = False # False表示拒绝遵守Robot协议
查看由Scrapy生成的sinaSpider.py文件,在SinaspiderSpider类中,有一个parse()方法须要用户编撰,如下图所示

编写parse()方法
Scrapy框架把爬取出来的网页源代码储存在response对象中爬虫软件开发,我们只须要对response对象中的网页源代码做解析,提取想要的数据即可。本范例目标是抓取新浪网页的新闻的标题和对应的链接,如下图所示。

HTML源代码
parse()方法的实现代码,如下所示
1. # -*- coding: utf-8 -*-
2. import scrapy
3.
4. class SinaspiderSpider(scrapy.Spider):
5. name = 'sinaSpider'
6. allowed_domains = ['www.sina.com.cn']
7. start_urls = ['http://www.sina.com.cn/']
8.
9. def parse(self, response):
10. data_list = [] #用于存储解析到的数据
11. #解析HTML源代码,定位新闻内容
12. lis = response.xpath("//div[@class='top_newslist']/ul[@class='list-a news_top']//li")
13. #将新闻主题和超链接解析出来并整理到列表中
14. for li in lis:
15. titles = li.xpath(".//a/text()")
16. linkes = li.xpath(".//a/@href")
17. for title, link in zip(titles, linkes):
18. #将新闻主题和对应的超链接组合成字典
19. data_dict = {'标题': title.extract(), '链接': link.extract()}
20. #将字典数据存储到data_list这个列表中
21. data_list.append(data_dict)
22. return data_list
parse()方法在解析HTML源代码时,使用了XPath路径表达式。XPath是一门在HTML/XML文档中查找信息的语言,常用于在网页HTML源代码中,查找特定标签里的数据。在网络爬虫中使用XPath,只须要把握 XPath路径表达式即可。XPath 使用路径表达式来选定 HTML/XML文档中的节点或则节点集。
parse()方法编撰好后,就可以运行爬虫程序并保存抓取数据了。用命令:
scrapy crawl 爬虫文件名 –o 保存数据文件名.[csv|json|xml]
保存数据的文件格式可以是csv 或 json 或 xml,本例的爬虫文件名为:sinaSpider.py,数据储存选择csv格式,命令为:
scrapy crawl sinaSpider -o sinaNews.csv
运行疗效,如下图所示

运行爬虫
到此,本例基于Scrapy框架从零开始实现了一个网络爬虫程序,爬取了新浪网页并从中解析出新闻的标题和对应的超链接,最后把解析出的数据保存为csv文件供后续使用。
爬虫框架(scrapy构架)
采集交流 • 优采云 发表了文章 • 0 个评论 • 577 次浏览 • 2020-07-03 08:00
scrapy主要包括了以下组件: 1.)引擎(scrapy):用来处理整个系统的数据流,触发事务(框架核心) 2.)调度器(Scheduler):用来接受引擎发过来的恳求,压入队列中,并在引擎再度恳求的时侯返回,可以想像成一个url(抓取网页的网址或则说链接)的优先队列,由它来决定下一个要抓取的网址是哪些,同时除去重复的网址。 3.)下载器(Downloader):用于下载网页的内容,并将网页内容返回给蜘蛛(Scrapy下载器是构建在twisted这个高效的异步模型上的) 4.)爬虫(Spiders):爬虫是主要干活的,用于从特定的网页中提取自己想要的信息,即所谓的实体(item)。用户也可以从中提取到链接,让Scrapy继续抓取下一个页面。 5.)项目管线(Pipeline):负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管线,并经过几个特定的顺序处理数据。 (只有当调度器中不存在任何request时,整个程序就会停止。(对于下载失败的url,Scrapy也会重新下载))
前置要求: pip下载scrapy模块 yum下载tree包
-确定url地址; -获取页面信息;(urllib,requests) -解析页面提取须要的信息;(xpath,bs4,正则表达时) -保存到本地(scv,json,pymysql,redis) -清洗数据(删除不必要的内容------正则表达式) -分析数据(词云wordcloud,jieba)
-确定url地址(spider) -获取页面信息(Downloader) -解析页面提取须要的信息(spider) -保存到本地(pipeline)
scrapy1.6.0
1.工程创建 1.)命令行在当前目录下创建mySpider
scrapy startproject mySpider
2.)创建成功后,进入mySpider ,tree查看
cd mySpider tree
2.创建一个爬虫
#scrapy genspider 项目名 url scrapy genspider mooc ‘’
3.定义爬取的items内容(items.py)
class CourseItem(scrapy.Item):
#课程标题 title=scrapy.Field() #课程的url地址 url=scrapy.Field() #课程图片的url地址 image_url=scrapy.Field() #课程的描述 introduction=scrapy.Field() #学习人数 student=scrapy.Field()
4.编写spider代码,解析 4.1确定url地址,提取页面须要的信息(mooc.py)
class MoocSpider(scrapy,spider):
#name用于区别爬虫,必须惟一 name=‘mooc’ #允许爬取的域名,其他网站的页面直接跳过 allowd_domains=[‘’,‘’] #爬虫开启时第一个装入调度器的url地址 start_urls=[‘’] #被调用时,每个新的url完成下载后爬虫框架,返回一个响应对象 #下面的方式负责将响应的数据剖析,提取出须要的数据items以及生成下一步须要处理的url地址恳求; def parser(self,response):
##用来检查代码是否达到指定位置,并拿来调试并解析页面信息; #from scrapy.shell import inspect_response #inspect_response(response,self) #1.)实例化对象,CourseItem course=CourseItem() #分析响应的内容 #scrapy剖析页面使用的是xpath方式 #2.)获取每位课程的信息 courseDetails=course.xpath(’.//div[@class=“course-card-container”]’) for courseDetail in courseDetails:
#爬取新的网站, Scrapy上面进行调试(parse命令logging) course[‘title’] = courseDetail.xpath(’.//h3[@class=“course-card-name”]/text()’).extract()[0] #学习人数 course[‘student’] = courseDetail.xpath(’.//span/text()’).extract()[1] #课程描述: course[‘introduction’] = courseDetail.xpath(".//p[@class=‘course-card-desc’]/text()").extract()[0] #课程链接, h获取/learn/9 ====》 course[‘url’] = “” + courseDetail.xpath(’.//a/@href’).extract()[0] #课程的图片url: course[‘image_url’] = ‘http:’ + courseDetail.xpath(’.//img/@src’).extract()[0] yield course #url跟进,获取下一步是否有链接;href url=response.xpath(’.//a[contains[text(),“下一页”]/@href’)[0].extract() if url:
#构建新的url page=‘’+url yield scrapy.Request(page,callback=slef.parse)
4.2保存我们提取的信息(文件格式:scv爬虫框架,json,pymysql)(pipeline.py) 如果多线程,记得在settings.py中分配多个管线并设置优先级:
(1).将爬取的信息保存成json格式
class MyspiderPipeline(object):
def init(self):
self.f=open(Moocfilename,‘w’) #Moocfilename是写在settings.py里的文件名,写在setting.py是因为便捷更改
def process_item(self,item,spider):
#默认传过来的格式是json格式 import json #读取item中的数据,并转化为json格式 line=json.dumps(dict(item),ensure_ascii=False,indent=4) self.f.write(line+’\n’) #一定要返回给调度器 return item
def close_spider(self,spider):
self.f.close()
(2).保存为scv格式
class CsvPipeline(object):
def init(self):
self.f=open(’'mooc.csv",‘w’)
def process_item(self,item,spider):
item=dict(item) self.f.write("{0}:{1}:{2}\n".format(item[‘title’] , item[‘student’] , item[‘url’])) return item
def close_spider(self,spider):
self.f.close()
(3).将爬取的信息保存到数据库中 首先打开数据库创建mooc表
class MysqlPipeline(object):
def init(self):
self.conn=pymysql.connect( host=‘localhost’, user=‘root’, password=‘redhat’, db=‘Mooc’, charset=‘utf8’, ) self.cursor=self.conn.cursor()
def process_item(self,item,spider):
item=dict(item) info=(item[’‘item"] , item[“url”] , item[“image_url”] , item[“introduction”] , item[“student”]) insert_sqil="insert into moocinfo values(’%s’ , ‘%s’ , ‘%s’, ‘%s’ , ‘%s’); " %(info) self.cursor.execute(insert_sqil) mit() return item
def open_spider(self,spider):
create_sqli=“create table if not exists moocinfo (title varchar(50),url varchar(200), image_url varchar(200), introduction varchar(500), student int)” self.cursor.execute(create_sqli)
def close_spider(self,spider):
self.cursor.close() self.conn.close()
(4).通过爬取的图片链接下载图片
class ImagePipeline(object):
def get_media_requests(self,item,info):
#返回一个request请求,包含图片的url
yield scrapy.Request(item['image_url'])
def item_conpleted(self,results,item,info):
#获取下载的地址
image_xpath=[x['path'] for ok , x in results if ok]
if not image_path:
raise Exception('不包含图片')
else:
return item
1.策略一:设置download_delay –作用:设置下载的等待时间,大规模集中的访问对服务器的影响最大,相当于短时间内减小服务器的负载 –缺点:下载等待时间长,不能满足段时间大规模抓取的要求,太短则大大降低了被ban的机率
2.策略二:禁止cookies –cookie有时也用作复数方式cookies,指个别网站为了分辨用户的身分,进行session跟踪而存储在用户本地终端上的数据(通常经过加密)。 –作用:禁止cookies也就避免了可能使用cookies辨识爬虫轨迹的网站得逞 –实现:COOKIES_ENABLES=False
3.策略三:使用user_agent池(拓展:用户代理中间件) –为什么要使用?scrapy本身是使用Scrapy/0.22.2来表明自己的身分。这也就曝露了自己是爬虫的信息。 –user agent ,是指包含浏览器信息,操作系统信息等的一个字符串,也称之为一种特殊的网路合同。服务器通过它判定当前的访问对象是浏览器,邮件客户端还是爬虫。
4.策略四:使用代理中间件 –web server应对爬虫的策略之一就是直接将你的ip或则是整个ip段都封掉严禁访问,这时候,当ip封掉后,转换到其他的ip继续访问即可。
5.策略五:分布式爬虫Scrapy+redis+mysql # 多进程 –Scrapy-Redis则是一个基于Redis的Scrapy分布式组件。它借助Redis对用于爬取的恳求(Requests)进行储存和调度(Schedule),并对爬取形成rapy一些比较关键的代码,将Scrapy弄成一个可以在多个主机上同时运行的分布式爬虫。
米鼠网自创立以来仍然专注于从事政府采购、软件项目、人才外包、猎头服务、综合项目等,始终秉持“专业的服务,易用的产品”的经营理念,以“提供高品质的服务、满足顾客的需求、携手共创多赢”为企业目标,为中国境内企业提供国际化、专业化、个性化、的软件项目解决方案,我司拥有一流的项目总监团队,具备过硬的软件项目设计和施行能力,为全省不同行业顾客提供优质的产品和服务,得到了顾客的广泛赞扬。
如有侵权请联系邮箱() 查看全部
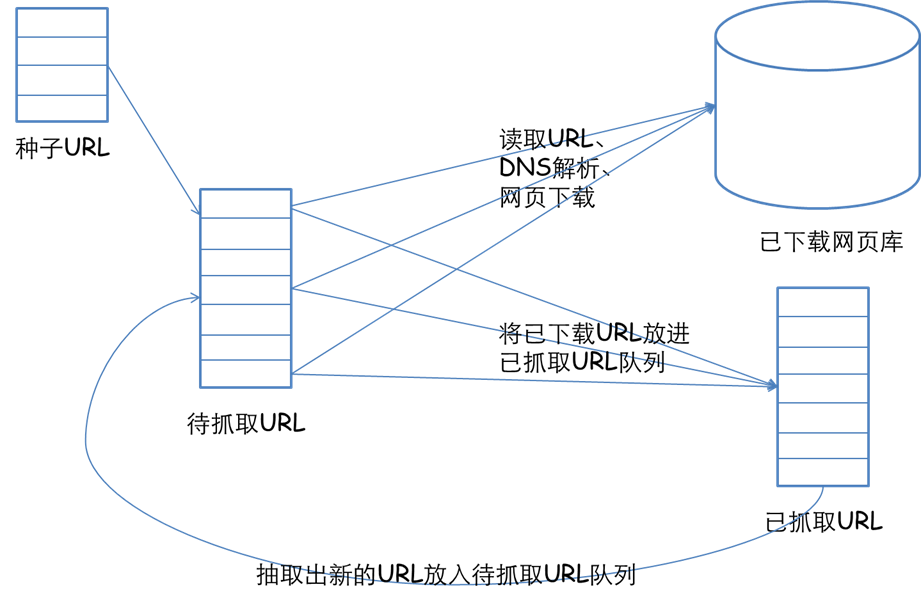
1.scrapy构架流程:

scrapy主要包括了以下组件: 1.)引擎(scrapy):用来处理整个系统的数据流,触发事务(框架核心) 2.)调度器(Scheduler):用来接受引擎发过来的恳求,压入队列中,并在引擎再度恳求的时侯返回,可以想像成一个url(抓取网页的网址或则说链接)的优先队列,由它来决定下一个要抓取的网址是哪些,同时除去重复的网址。 3.)下载器(Downloader):用于下载网页的内容,并将网页内容返回给蜘蛛(Scrapy下载器是构建在twisted这个高效的异步模型上的) 4.)爬虫(Spiders):爬虫是主要干活的,用于从特定的网页中提取自己想要的信息,即所谓的实体(item)。用户也可以从中提取到链接,让Scrapy继续抓取下一个页面。 5.)项目管线(Pipeline):负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管线,并经过几个特定的顺序处理数据。 (只有当调度器中不存在任何request时,整个程序就会停止。(对于下载失败的url,Scrapy也会重新下载))
前置要求: pip下载scrapy模块 yum下载tree包
-确定url地址; -获取页面信息;(urllib,requests) -解析页面提取须要的信息;(xpath,bs4,正则表达时) -保存到本地(scv,json,pymysql,redis) -清洗数据(删除不必要的内容------正则表达式) -分析数据(词云wordcloud,jieba)
-确定url地址(spider) -获取页面信息(Downloader) -解析页面提取须要的信息(spider) -保存到本地(pipeline)
scrapy1.6.0
1.工程创建 1.)命令行在当前目录下创建mySpider
scrapy startproject mySpider
2.)创建成功后,进入mySpider ,tree查看
cd mySpider tree

2.创建一个爬虫
#scrapy genspider 项目名 url scrapy genspider mooc ‘’
3.定义爬取的items内容(items.py)
class CourseItem(scrapy.Item):
#课程标题 title=scrapy.Field() #课程的url地址 url=scrapy.Field() #课程图片的url地址 image_url=scrapy.Field() #课程的描述 introduction=scrapy.Field() #学习人数 student=scrapy.Field()
4.编写spider代码,解析 4.1确定url地址,提取页面须要的信息(mooc.py)
class MoocSpider(scrapy,spider):
#name用于区别爬虫,必须惟一 name=‘mooc’ #允许爬取的域名,其他网站的页面直接跳过 allowd_domains=[‘’,‘’] #爬虫开启时第一个装入调度器的url地址 start_urls=[‘’] #被调用时,每个新的url完成下载后爬虫框架,返回一个响应对象 #下面的方式负责将响应的数据剖析,提取出须要的数据items以及生成下一步须要处理的url地址恳求; def parser(self,response):
##用来检查代码是否达到指定位置,并拿来调试并解析页面信息; #from scrapy.shell import inspect_response #inspect_response(response,self) #1.)实例化对象,CourseItem course=CourseItem() #分析响应的内容 #scrapy剖析页面使用的是xpath方式 #2.)获取每位课程的信息 courseDetails=course.xpath(’.//div[@class=“course-card-container”]’) for courseDetail in courseDetails:
#爬取新的网站, Scrapy上面进行调试(parse命令logging) course[‘title’] = courseDetail.xpath(’.//h3[@class=“course-card-name”]/text()’).extract()[0] #学习人数 course[‘student’] = courseDetail.xpath(’.//span/text()’).extract()[1] #课程描述: course[‘introduction’] = courseDetail.xpath(".//p[@class=‘course-card-desc’]/text()").extract()[0] #课程链接, h获取/learn/9 ====》 course[‘url’] = “” + courseDetail.xpath(’.//a/@href’).extract()[0] #课程的图片url: course[‘image_url’] = ‘http:’ + courseDetail.xpath(’.//img/@src’).extract()[0] yield course #url跟进,获取下一步是否有链接;href url=response.xpath(’.//a[contains[text(),“下一页”]/@href’)[0].extract() if url:
#构建新的url page=‘’+url yield scrapy.Request(page,callback=slef.parse)
4.2保存我们提取的信息(文件格式:scv爬虫框架,json,pymysql)(pipeline.py) 如果多线程,记得在settings.py中分配多个管线并设置优先级:

(1).将爬取的信息保存成json格式
class MyspiderPipeline(object):
def init(self):
self.f=open(Moocfilename,‘w’) #Moocfilename是写在settings.py里的文件名,写在setting.py是因为便捷更改
def process_item(self,item,spider):
#默认传过来的格式是json格式 import json #读取item中的数据,并转化为json格式 line=json.dumps(dict(item),ensure_ascii=False,indent=4) self.f.write(line+’\n’) #一定要返回给调度器 return item
def close_spider(self,spider):
self.f.close()
(2).保存为scv格式
class CsvPipeline(object):
def init(self):
self.f=open(’'mooc.csv",‘w’)
def process_item(self,item,spider):
item=dict(item) self.f.write("{0}:{1}:{2}\n".format(item[‘title’] , item[‘student’] , item[‘url’])) return item
def close_spider(self,spider):
self.f.close()
(3).将爬取的信息保存到数据库中 首先打开数据库创建mooc表
class MysqlPipeline(object):
def init(self):
self.conn=pymysql.connect( host=‘localhost’, user=‘root’, password=‘redhat’, db=‘Mooc’, charset=‘utf8’, ) self.cursor=self.conn.cursor()
def process_item(self,item,spider):
item=dict(item) info=(item[’‘item"] , item[“url”] , item[“image_url”] , item[“introduction”] , item[“student”]) insert_sqil="insert into moocinfo values(’%s’ , ‘%s’ , ‘%s’, ‘%s’ , ‘%s’); " %(info) self.cursor.execute(insert_sqil) mit() return item
def open_spider(self,spider):
create_sqli=“create table if not exists moocinfo (title varchar(50),url varchar(200), image_url varchar(200), introduction varchar(500), student int)” self.cursor.execute(create_sqli)
def close_spider(self,spider):
self.cursor.close() self.conn.close()
(4).通过爬取的图片链接下载图片
class ImagePipeline(object):
def get_media_requests(self,item,info):
#返回一个request请求,包含图片的url
yield scrapy.Request(item['image_url'])
def item_conpleted(self,results,item,info):
#获取下载的地址
image_xpath=[x['path'] for ok , x in results if ok]
if not image_path:
raise Exception('不包含图片')
else:
return item
1.策略一:设置download_delay –作用:设置下载的等待时间,大规模集中的访问对服务器的影响最大,相当于短时间内减小服务器的负载 –缺点:下载等待时间长,不能满足段时间大规模抓取的要求,太短则大大降低了被ban的机率
2.策略二:禁止cookies –cookie有时也用作复数方式cookies,指个别网站为了分辨用户的身分,进行session跟踪而存储在用户本地终端上的数据(通常经过加密)。 –作用:禁止cookies也就避免了可能使用cookies辨识爬虫轨迹的网站得逞 –实现:COOKIES_ENABLES=False
3.策略三:使用user_agent池(拓展:用户代理中间件) –为什么要使用?scrapy本身是使用Scrapy/0.22.2来表明自己的身分。这也就曝露了自己是爬虫的信息。 –user agent ,是指包含浏览器信息,操作系统信息等的一个字符串,也称之为一种特殊的网路合同。服务器通过它判定当前的访问对象是浏览器,邮件客户端还是爬虫。
4.策略四:使用代理中间件 –web server应对爬虫的策略之一就是直接将你的ip或则是整个ip段都封掉严禁访问,这时候,当ip封掉后,转换到其他的ip继续访问即可。
5.策略五:分布式爬虫Scrapy+redis+mysql # 多进程 –Scrapy-Redis则是一个基于Redis的Scrapy分布式组件。它借助Redis对用于爬取的恳求(Requests)进行储存和调度(Schedule),并对爬取形成rapy一些比较关键的代码,将Scrapy弄成一个可以在多个主机上同时运行的分布式爬虫。
米鼠网自创立以来仍然专注于从事政府采购、软件项目、人才外包、猎头服务、综合项目等,始终秉持“专业的服务,易用的产品”的经营理念,以“提供高品质的服务、满足顾客的需求、携手共创多赢”为企业目标,为中国境内企业提供国际化、专业化、个性化、的软件项目解决方案,我司拥有一流的项目总监团队,具备过硬的软件项目设计和施行能力,为全省不同行业顾客提供优质的产品和服务,得到了顾客的广泛赞扬。

如有侵权请联系邮箱()
基于Scrapy框架的分布式网路爬虫实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 271 次浏览 • 2020-05-14 08:09
2.2 用户登入 由于网站对于旅客的访问有限制,为了爬取所需信息,必须在程序中实现用户登陆,其原 理就是能获取到有效的本地 cookie,并借助该 cookie 进行网站访问,除了通常还能用第三方库 进行图象辨识的验证方法外,一般采用浏览器中自动登入,通过网路工具截取有效的 cookie, 然后在爬虫生成 request 时附送上 cookie。 2.3 url 的去重 龙源期刊网 scrapy_redis 有一个 dupefilter 文件中包含 RFPDupeFilter 类用于过滤新增的 url,可以在该 类 request_seen 中借助 redis 的 key 的查找功能,如果所爬取的任务数以亿计则建议 Bloomfilter 去重的方法对于 URL 的储存和操作方法进行优化,虽然该方法会导致大于万分之一的过滤遗 失率。 2.4 数据写入 选择非关系性数据库 MongoDB 作为硬碟数据库与 scrapy 进行搭配使用,在 pipeline 中对 item 数据进行 MongoDB 的写入操作。 3 基本实现步骤 配置:Windows7 64-bit、Python:2.7.11、 Anaconda 4.0.0 (64-bit)、IDE:Pycharm 3.4.1、Scrapy:1.3.2Redis:X64-3.2、MongoDB:3.2.12 代码实现须要对几个文件进行设置和编撰:items、settings、spiders、pipelines。
Items:这是一个爬取数据的基础数据结构类,由其来储存爬虫爬取的键值性数据,关键 的就是这条句子:_id = Field() _id 表示的生成一个数据对象,在 Items 中可以按照须要设定 多个数据对象。 Settings:ITEM_PIPELINES 该参数决定了 item 的处理方式;DOWNLOAD_DELAY 这个 是下载的间隔时间;SCHEDULER 指定作为总的任务协调器的类; SCHEDULER_QUEUE_CLASS 这个参数是设定处理 URL 的队列的工作模式一共有四种,一般 选用 SpiderSimpleQueue 即可。 spiders:该文件就是爬虫主要功能的实现,首先设定该爬虫的基本信息:name、domain、 redis_key、start_urls。爬虫的第一步都是执行方式 start_requests,其中核心句子 yield Request (url,callback)用以按照 url 产生一个 request 并且将 response 结果回传给 callback 方法。 callback 的方式中通常借助 xpath 或者正则表达式对 response 中包含的 html 代码进行解析,产 生所须要的数据以及新的任务 url。
pipelines:该文件作为数据处理、存储的代码段分布式爬虫框架,将在 items 数据被创建后被调用,其中 process_item 的方式就是被调用的方式,所以一定要将其重画,根据实际须要把数据借助方式 dict()转化为字典数据,最后写入 MongoDB。 完成编撰后,在布署的时侯,start_url 的队列只能是第一个运行的爬虫进行初始化,后续 运行的爬虫只能是把新的 url 进行写入不能对其进行再度初始化,部署爬虫的步骤也很简单, 只须要把相关的代码拷贝到目标笔记本上,让后 cmd 命令步入 spiders 的文件夹,运行命令 scrapy crawl XXXX,其中 XXXX 就是爬虫的名子,就完成了爬虫的布署和运行了。 龙源期刊网 4 结语 爬虫的实现,除了基本的步骤和参数设置之外,需要开发者按照实际网站以及数据情况, 针对性的对爬取的策略、数据的去重、数据筛选进行处理,对于爬虫的性能进行有效优化,为 之后的数据剖析做好良好的数据打算。同时,根据须要可以考虑时间的诱因加入到数据结构 中,这就要求爬虫还能通过数据的时间去进行增量爬取。 参考文献 [1]使用 redis 如何实现一个网络分布式爬虫[OL].http: //www.oschina.net/code/snippet_209440_20495/. [2]scrapy_redis 的使用解读[OL].http://www.cnblogs.com/kylinlin/p/5198233.html.http: //blog.csdn.net/u012150179/art 查看全部
龙源期刊网 基于 Scrapy 框架的分布式网路爬虫实现 作者:陶兴海 来源:《电子技术与软件工程》2017 年第 11 期 摘 要按照互联网实际情况,提出分布式爬虫模型,基于 Scrapy 框架,进行代码实现,且 该开发方法可以迅速进行对不同主题的数据爬取的移植,满足不同专业方向的基于互联网大数 据剖析须要。 【关键词】网络爬虫 Scrapy-redis 分布式 1 基本概念 分布式爬虫:分布式方法是以共同爬取为目标,形成多爬虫协同工作的模式,每个爬虫需 要独立完成单项爬取任务,下载网页并保存。 Scrapy-redis:一个三方的基于 redis 数据库实现的分布式方法,配合 scrapy 爬虫框架让 用,让 scrapy 具有了分布式爬取的功能。 2 分布式爬虫技术方案 Scrapy-redis 分布式爬虫的基本设计理念为主从模式,由作为主控端负责所有网络子爬虫 的管理,子爬虫只须要从主控端那儿接收任务分布式爬虫框架,并把新生成任务递交给主控端,在整个爬取的 过程中毋须与其他爬虫通讯。 主要有几个技术关键点: 2.1 子爬虫爬取任务的分发 通过在主控端安装一个 redis 数据库,维护统一的任务列表,子爬虫每次联接 redis 库调用 lpop()方法,生成一个任务,并生成一个 request,接下去就是就像通常爬虫工作。
2.2 用户登入 由于网站对于旅客的访问有限制,为了爬取所需信息,必须在程序中实现用户登陆,其原 理就是能获取到有效的本地 cookie,并借助该 cookie 进行网站访问,除了通常还能用第三方库 进行图象辨识的验证方法外,一般采用浏览器中自动登入,通过网路工具截取有效的 cookie, 然后在爬虫生成 request 时附送上 cookie。 2.3 url 的去重 龙源期刊网 scrapy_redis 有一个 dupefilter 文件中包含 RFPDupeFilter 类用于过滤新增的 url,可以在该 类 request_seen 中借助 redis 的 key 的查找功能,如果所爬取的任务数以亿计则建议 Bloomfilter 去重的方法对于 URL 的储存和操作方法进行优化,虽然该方法会导致大于万分之一的过滤遗 失率。 2.4 数据写入 选择非关系性数据库 MongoDB 作为硬碟数据库与 scrapy 进行搭配使用,在 pipeline 中对 item 数据进行 MongoDB 的写入操作。 3 基本实现步骤 配置:Windows7 64-bit、Python:2.7.11、 Anaconda 4.0.0 (64-bit)、IDE:Pycharm 3.4.1、Scrapy:1.3.2Redis:X64-3.2、MongoDB:3.2.12 代码实现须要对几个文件进行设置和编撰:items、settings、spiders、pipelines。
Items:这是一个爬取数据的基础数据结构类,由其来储存爬虫爬取的键值性数据,关键 的就是这条句子:_id = Field() _id 表示的生成一个数据对象,在 Items 中可以按照须要设定 多个数据对象。 Settings:ITEM_PIPELINES 该参数决定了 item 的处理方式;DOWNLOAD_DELAY 这个 是下载的间隔时间;SCHEDULER 指定作为总的任务协调器的类; SCHEDULER_QUEUE_CLASS 这个参数是设定处理 URL 的队列的工作模式一共有四种,一般 选用 SpiderSimpleQueue 即可。 spiders:该文件就是爬虫主要功能的实现,首先设定该爬虫的基本信息:name、domain、 redis_key、start_urls。爬虫的第一步都是执行方式 start_requests,其中核心句子 yield Request (url,callback)用以按照 url 产生一个 request 并且将 response 结果回传给 callback 方法。 callback 的方式中通常借助 xpath 或者正则表达式对 response 中包含的 html 代码进行解析,产 生所须要的数据以及新的任务 url。
pipelines:该文件作为数据处理、存储的代码段分布式爬虫框架,将在 items 数据被创建后被调用,其中 process_item 的方式就是被调用的方式,所以一定要将其重画,根据实际须要把数据借助方式 dict()转化为字典数据,最后写入 MongoDB。 完成编撰后,在布署的时侯,start_url 的队列只能是第一个运行的爬虫进行初始化,后续 运行的爬虫只能是把新的 url 进行写入不能对其进行再度初始化,部署爬虫的步骤也很简单, 只须要把相关的代码拷贝到目标笔记本上,让后 cmd 命令步入 spiders 的文件夹,运行命令 scrapy crawl XXXX,其中 XXXX 就是爬虫的名子,就完成了爬虫的布署和运行了。 龙源期刊网 4 结语 爬虫的实现,除了基本的步骤和参数设置之外,需要开发者按照实际网站以及数据情况, 针对性的对爬取的策略、数据的去重、数据筛选进行处理,对于爬虫的性能进行有效优化,为 之后的数据剖析做好良好的数据打算。同时,根据须要可以考虑时间的诱因加入到数据结构 中,这就要求爬虫还能通过数据的时间去进行增量爬取。 参考文献 [1]使用 redis 如何实现一个网络分布式爬虫[OL].http: //www.oschina.net/code/snippet_209440_20495/. [2]scrapy_redis 的使用解读[OL].http://www.cnblogs.com/kylinlin/p/5198233.html.http: //blog.csdn.net/u012150179/art
利用 scrapy 集成社区爬虫功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2020-05-13 08:00
当前只爬取了用户主页上一些简单的信息,如果有需求请讲到我们的
:
代码放到了github上,源码
如图所示,在之前的构架上(),我降低了黑色实线框内的部份,包括:
scrapy是一个python爬虫框架,想要快速实现爬虫推荐使用这个。
可以参考如下资料自行学习:
官方文档和官方事例
一个简单明了的入门博客,注意:博客中scrapy的安装步骤可以简化,直接使用 pip install scrapy,安装过程中可能会缺乏几个lib,ubuntu使用 apt-get install libffi-dev libxml2-dev libxslt1-dev -y
mongo特别适宜储存爬虫数据,支持异构数据。这意味着你可以随时改变爬虫策略抓取不同的数据,而不用害怕会和先前的数据冲突(使用sql就须要操蛋的更改表结构了)。
通过scrapy的pipline来集成mongo,非常便捷。
安装mongo
apt-get install mongodb
pip install pymongo
在编撰爬虫的过程中须要使用xpath表达式来提取页面数据,在chrome中可以使用XPath Helper来定位元素,非常便捷。使用方式:
打开XPath Helper插件
鼠标点击一下页面,按住shift键,把键盘联通到须要选定的元素上,插件会将该元素标记为红色,并给出对应的xpath表达式,如下图:
在爬虫程序中使用这个表达式selector.xpath(..../text()").extract()
编写好爬虫后,我门可以通过执行scrapy crawl spidername命令来运行爬虫程序,但这还不够。
通常我们通过自动或则定时任务(cron)来执行爬虫爬虫社区,而这儿我们须要通过web应用来触发爬虫。即,当用户更新绑定的社交帐号时,去执行一次爬虫。来剖析一下:
爬虫执行过程中会阻塞当前进程,为了不阻塞用户恳求,必须通过异步的方法来运行爬虫。
可能有多个用户同时更新资料,这就要求才能同时执行多个爬虫,并且要保证系统不会超员。
可以扩充成分布式的爬虫。
鉴于项目当前的构架,准备使用celery来执行异步爬虫。但是遇到了两个问题:
scrapy框架下,需要在scrapy目录下执行爬虫,否则难以获取到settings,这个用上去有点别扭,不过能够解决。
celery中反复运行scrapy的爬虫会报错:raise error.ReactorNotRestartable()。原因是scrapy用的twisted调度框架,不可以在进程中重启。
stackoverflow上有讨论过这个问题,尝试了一下,搞不定,放弃这个方案。如果你有解决这个问题的方式,期待分享:)
scrapy文档中提及了可以使用scrapyd来布署,scrapyd是一个用于运行scrapy爬虫的webservice,使用者才能通过http请求来运行爬虫。
你只须要使用scrapyd-client将爬虫发布到scrapyd中,然后通过如下命令就可以运行爬虫程序。
$ curl http://localhost:6800/schedule.json -d project=myproject -d spider=spider2
{"status": "ok", "jobid": "26d1b1a6d6f111e0be5c001e648c57f8"}
这意味哪些:
爬虫应用和自己的web应用完全前馈,只有一个http插口。
由于使用http插口,爬虫可以放到任何还能被访问的主机上运行。一个简易的分布式爬虫,不是吗?
scrapyd使用sqlite队列来保存爬虫任务,实现异步执行。
scrapyd可以同时执行多个爬虫,最大进程数可配,防止系统过载。
欢迎使用我们的爬虫功能来搜集社交资料。
成为雨点儿网用户爬虫社区,进入用户主页,点击编辑按键
填写社交帐号,点击更新按键
爬虫会在几秒内完成工作,刷新个人主页能够看见你的社区资料了,你也可以把个人主页链接附在电子简历中哟:) 查看全部
社区活跃度或则贡献越来越遭到注重,往往会作为获得工作或则承接项目的加分项。为了便捷用户展示自己的社区资料,中降低了一个社区爬虫功能。
当前只爬取了用户主页上一些简单的信息,如果有需求请讲到我们的
:

代码放到了github上,源码
如图所示,在之前的构架上(),我降低了黑色实线框内的部份,包括:

scrapy是一个python爬虫框架,想要快速实现爬虫推荐使用这个。
可以参考如下资料自行学习:
官方文档和官方事例
一个简单明了的入门博客,注意:博客中scrapy的安装步骤可以简化,直接使用 pip install scrapy,安装过程中可能会缺乏几个lib,ubuntu使用 apt-get install libffi-dev libxml2-dev libxslt1-dev -y
mongo特别适宜储存爬虫数据,支持异构数据。这意味着你可以随时改变爬虫策略抓取不同的数据,而不用害怕会和先前的数据冲突(使用sql就须要操蛋的更改表结构了)。
通过scrapy的pipline来集成mongo,非常便捷。
安装mongo
apt-get install mongodb
pip install pymongo
在编撰爬虫的过程中须要使用xpath表达式来提取页面数据,在chrome中可以使用XPath Helper来定位元素,非常便捷。使用方式:
打开XPath Helper插件
鼠标点击一下页面,按住shift键,把键盘联通到须要选定的元素上,插件会将该元素标记为红色,并给出对应的xpath表达式,如下图:

在爬虫程序中使用这个表达式selector.xpath(..../text()").extract()
编写好爬虫后,我门可以通过执行scrapy crawl spidername命令来运行爬虫程序,但这还不够。
通常我们通过自动或则定时任务(cron)来执行爬虫爬虫社区,而这儿我们须要通过web应用来触发爬虫。即,当用户更新绑定的社交帐号时,去执行一次爬虫。来剖析一下:
爬虫执行过程中会阻塞当前进程,为了不阻塞用户恳求,必须通过异步的方法来运行爬虫。
可能有多个用户同时更新资料,这就要求才能同时执行多个爬虫,并且要保证系统不会超员。
可以扩充成分布式的爬虫。
鉴于项目当前的构架,准备使用celery来执行异步爬虫。但是遇到了两个问题:
scrapy框架下,需要在scrapy目录下执行爬虫,否则难以获取到settings,这个用上去有点别扭,不过能够解决。
celery中反复运行scrapy的爬虫会报错:raise error.ReactorNotRestartable()。原因是scrapy用的twisted调度框架,不可以在进程中重启。
stackoverflow上有讨论过这个问题,尝试了一下,搞不定,放弃这个方案。如果你有解决这个问题的方式,期待分享:)
scrapy文档中提及了可以使用scrapyd来布署,scrapyd是一个用于运行scrapy爬虫的webservice,使用者才能通过http请求来运行爬虫。
你只须要使用scrapyd-client将爬虫发布到scrapyd中,然后通过如下命令就可以运行爬虫程序。
$ curl http://localhost:6800/schedule.json -d project=myproject -d spider=spider2
{"status": "ok", "jobid": "26d1b1a6d6f111e0be5c001e648c57f8"}
这意味哪些:
爬虫应用和自己的web应用完全前馈,只有一个http插口。
由于使用http插口,爬虫可以放到任何还能被访问的主机上运行。一个简易的分布式爬虫,不是吗?
scrapyd使用sqlite队列来保存爬虫任务,实现异步执行。
scrapyd可以同时执行多个爬虫,最大进程数可配,防止系统过载。
欢迎使用我们的爬虫功能来搜集社交资料。
成为雨点儿网用户爬虫社区,进入用户主页,点击编辑按键

填写社交帐号,点击更新按键

爬虫会在几秒内完成工作,刷新个人主页能够看见你的社区资料了,你也可以把个人主页链接附在电子简历中哟:)
[读后笔记] python网路爬虫实战 (李松涛)
采集交流 • 优采云 发表了文章 • 0 个评论 • 332 次浏览 • 2020-05-12 08:03
用了大约一个晚上的时间,就把这本书看完了。
前面4章是基础的python知识,有基础的朋友可以略过。
scrapy爬虫部份,用了实例给你们说明scrapy的用法网络爬虫实例,不过若果之前没用过scrapy的话,需要渐渐上机敲击代码。
其实书中的事例都是很简单的事例,基本没哪些反爬的限制,书中一句话说的十分赞成,用scrapy写爬虫,就是做填空题,而用urllib2写爬虫,就是习作题,可以自由发挥。
书中没有用更为便捷的requests库。 内容搜索用的最多的是beatifulsoup, 对于xpah或则lxml介绍的比较少。 因为scrapy自带的response就是可以直接用xpath,更为便捷。
对于scrapy的中间和pipeline的使用了一个事例,也是比较简单的反例。
书中没有对验证码,分布式等流行的反爬进行讲解,应该适宜爬虫入门的朋友去看吧。
书中一点挺好的就是代码都十分规范,而且虽然是写习作的使用urllib2,也有意模仿scrapy的框架去写, 需要抓取的数据 独立一个类,类似于scrapy的item,数据处理用的也是叫pipleline的方式。
这样写的益处就是, 每个模块的功能都一目了然,看完第一个反例的类和函数定义,后面的事例都是大同小异,可以推动读者的阅读速率,非常赞。(这一点之后自己要学习,增加代码的可复用性)
很多页面url如今早已过期了,再次运行作者的源码会返回好多404的结果。
失效的项目:
金逸影城
天气预报
获取代理:
本书的一些错误的地方:
1. 获取金逸影厅的spider中,所有关于movie的拼写都拼错为moive了。这个属于德语错误。
2. 在testProxy.py 代码中网络爬虫实例, 由于在同一个类中,一直在形成线程,最后造成线程过多,不能再形成线程。程序会中途退出。
File "C:\Python27\lib\threading.py", line 736, in start<br />
_start_new_thread(self.__bootstrap, ())<br />
thread.error: can't start new thread
可以更改成独立函数的方式,而不是类函数。
待续。 查看全部

用了大约一个晚上的时间,就把这本书看完了。
前面4章是基础的python知识,有基础的朋友可以略过。
scrapy爬虫部份,用了实例给你们说明scrapy的用法网络爬虫实例,不过若果之前没用过scrapy的话,需要渐渐上机敲击代码。
其实书中的事例都是很简单的事例,基本没哪些反爬的限制,书中一句话说的十分赞成,用scrapy写爬虫,就是做填空题,而用urllib2写爬虫,就是习作题,可以自由发挥。
书中没有用更为便捷的requests库。 内容搜索用的最多的是beatifulsoup, 对于xpah或则lxml介绍的比较少。 因为scrapy自带的response就是可以直接用xpath,更为便捷。
对于scrapy的中间和pipeline的使用了一个事例,也是比较简单的反例。
书中没有对验证码,分布式等流行的反爬进行讲解,应该适宜爬虫入门的朋友去看吧。
书中一点挺好的就是代码都十分规范,而且虽然是写习作的使用urllib2,也有意模仿scrapy的框架去写, 需要抓取的数据 独立一个类,类似于scrapy的item,数据处理用的也是叫pipleline的方式。
这样写的益处就是, 每个模块的功能都一目了然,看完第一个反例的类和函数定义,后面的事例都是大同小异,可以推动读者的阅读速率,非常赞。(这一点之后自己要学习,增加代码的可复用性)
很多页面url如今早已过期了,再次运行作者的源码会返回好多404的结果。
失效的项目:
金逸影城
天气预报
获取代理:
本书的一些错误的地方:
1. 获取金逸影厅的spider中,所有关于movie的拼写都拼错为moive了。这个属于德语错误。
2. 在testProxy.py 代码中网络爬虫实例, 由于在同一个类中,一直在形成线程,最后造成线程过多,不能再形成线程。程序会中途退出。
File "C:\Python27\lib\threading.py", line 736, in start<br />
_start_new_thread(self.__bootstrap, ())<br />
thread.error: can't start new thread
可以更改成独立函数的方式,而不是类函数。
待续。
【Scrapy】走进成熟的爬虫框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2020-05-10 08:02
今天简单说说Scrapy的安装。
前几天有小伙伴留言说能不能介绍推荐一下爬虫框架,我给他推荐了Scrapy,本来想偷个懒,推荐他去看官方文档,里面有一些demo代码可供学习测试。结果收到回复说文档中演示用到的网站已经难以访问了。所以只能自己来简单写一下了,也算是自己一个学习记录。
Scrapy是哪些?
定义介绍我也不复制粘贴了。简单来说,Scrapy是一个中小型的爬虫框架,框架的意义就在于帮你预设好了好多可以用的东西,让你可以从复杂的数据流和底层控制中抽离下来,专心于页面的解析即可完成中大项目爬虫,甚至是分布式爬虫。
但是爬虫入门是不推荐直接从框架入手的,直接从框架入手会使你头晕目眩,觉得哪里哪里都看不懂,有点类似于还没学会基础的措词造句就直接套用模板写成文章,自然是非常费力的。所以还是推荐你们有一定的手写爬虫基础再深入了解框架。(当然还没有入门爬虫的朋友…可以催更我的爬虫入门文章…)
那么首先是安装。
Python的版本选择之前提过,推荐你们全面拥抱Python 3.x。
很久以前,大概是我刚入门学习Scrapy时爬虫框架,Scrapy还没有支持Python 3.x,那时一部分爬虫工程师把Scrapy不支持Python 3.x作为不进行迁移的理由。当然了,那时更具体的缘由是Scrapy所依赖的twisted和mitmproxy不支持Python 3.x。
现在我仍然推荐你们全面拥抱Python 3.x。
先安装Python
这次我们以本地环境来进行安装(Windows+Anaconda),由于Python的跨平台特点爬虫框架,我们本地写的代码可以很容易迁移到别的笔记本或服务器使用。(当然了,从规范使用的角度上推荐你们使用单独的env,或者直接使用docker或则vagrant,不过那就说来话长了…以后可以考虑单独介绍)
按照惯例,我们直接使用 pip install scrapy 进行安装。
那么,你大几率会碰到这样的错误:
具体的错误缘由…缺少Microsoft Visual C++ 14.0…你也可以自己通过其他渠道解决,当然我们最推荐的做法是直接使用 conda install scrapy 命令(前提是你安装了Anaconda而非普通Python)。
如果碰到写入权限错误,请用管理员模式运行cmd。
之后我们可以写一个太小的demo,依然是官方案例中的DMOZ,DMOZ网站是一个知名的开放式分类目录(Open DirectoryProject),原版的DMOZ已于今年的3月17日停止了营运,目前网站处于403状态。但是网上大量过去的教程都是以DMOZ为案例的。我为你们找到了原DMOZ网站的静态镜像站,大家可以直接访问
大家根据官方文档的步骤继续做就可以了,后续的问题不大。
()
需要注意的就是工作目录问题。
启动Scrapy项目。
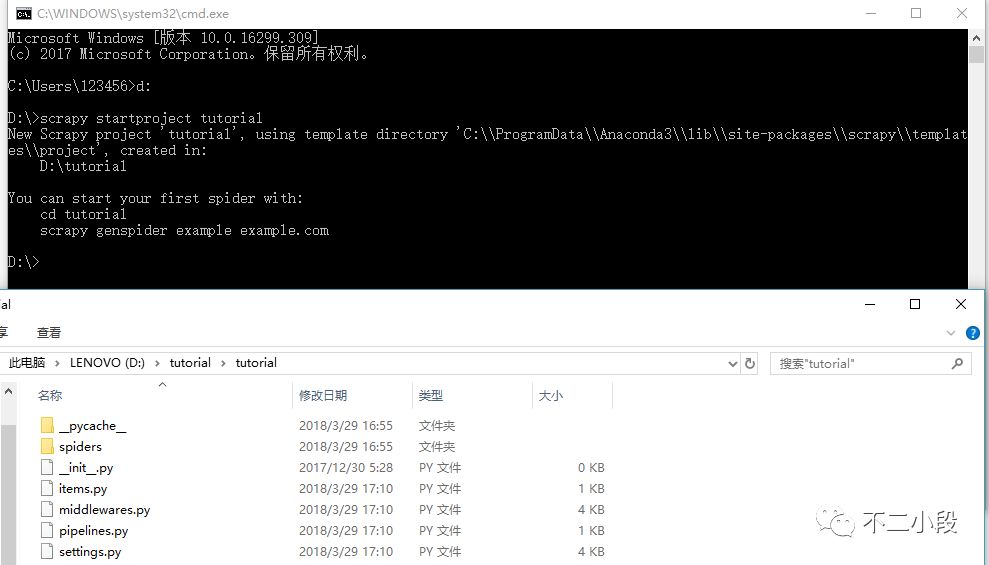
scrapy startproject tutorial
进入目录,我们可以看见手动生成的一些文件,这些文件就是scrapy框架所须要的最基础的组织结构。
scrapy.cfg: 项目的配置文件
tutorial/: 该项目的python模块。之后您将在此加入代码。
tutorial/items.py: 项目中的item文件.
tutorial/pipelines.py: 项目中的pipelines文件.
tutorial/settings.py: 项目的设置文件.
tutorial/spiders/: 放置spider代码的目录. 查看全部
今天简单说说Scrapy的安装。
前几天有小伙伴留言说能不能介绍推荐一下爬虫框架,我给他推荐了Scrapy,本来想偷个懒,推荐他去看官方文档,里面有一些demo代码可供学习测试。结果收到回复说文档中演示用到的网站已经难以访问了。所以只能自己来简单写一下了,也算是自己一个学习记录。
Scrapy是哪些?
定义介绍我也不复制粘贴了。简单来说,Scrapy是一个中小型的爬虫框架,框架的意义就在于帮你预设好了好多可以用的东西,让你可以从复杂的数据流和底层控制中抽离下来,专心于页面的解析即可完成中大项目爬虫,甚至是分布式爬虫。
但是爬虫入门是不推荐直接从框架入手的,直接从框架入手会使你头晕目眩,觉得哪里哪里都看不懂,有点类似于还没学会基础的措词造句就直接套用模板写成文章,自然是非常费力的。所以还是推荐你们有一定的手写爬虫基础再深入了解框架。(当然还没有入门爬虫的朋友…可以催更我的爬虫入门文章…)
那么首先是安装。
Python的版本选择之前提过,推荐你们全面拥抱Python 3.x。
很久以前,大概是我刚入门学习Scrapy时爬虫框架,Scrapy还没有支持Python 3.x,那时一部分爬虫工程师把Scrapy不支持Python 3.x作为不进行迁移的理由。当然了,那时更具体的缘由是Scrapy所依赖的twisted和mitmproxy不支持Python 3.x。
现在我仍然推荐你们全面拥抱Python 3.x。
先安装Python
这次我们以本地环境来进行安装(Windows+Anaconda),由于Python的跨平台特点爬虫框架,我们本地写的代码可以很容易迁移到别的笔记本或服务器使用。(当然了,从规范使用的角度上推荐你们使用单独的env,或者直接使用docker或则vagrant,不过那就说来话长了…以后可以考虑单独介绍)
按照惯例,我们直接使用 pip install scrapy 进行安装。
那么,你大几率会碰到这样的错误:

具体的错误缘由…缺少Microsoft Visual C++ 14.0…你也可以自己通过其他渠道解决,当然我们最推荐的做法是直接使用 conda install scrapy 命令(前提是你安装了Anaconda而非普通Python)。
如果碰到写入权限错误,请用管理员模式运行cmd。
之后我们可以写一个太小的demo,依然是官方案例中的DMOZ,DMOZ网站是一个知名的开放式分类目录(Open DirectoryProject),原版的DMOZ已于今年的3月17日停止了营运,目前网站处于403状态。但是网上大量过去的教程都是以DMOZ为案例的。我为你们找到了原DMOZ网站的静态镜像站,大家可以直接访问
大家根据官方文档的步骤继续做就可以了,后续的问题不大。
()
需要注意的就是工作目录问题。
启动Scrapy项目。
scrapy startproject tutorial
进入目录,我们可以看见手动生成的一些文件,这些文件就是scrapy框架所须要的最基础的组织结构。
scrapy.cfg: 项目的配置文件
tutorial/: 该项目的python模块。之后您将在此加入代码。
tutorial/items.py: 项目中的item文件.
tutorial/pipelines.py: 项目中的pipelines文件.
tutorial/settings.py: 项目的设置文件.
tutorial/spiders/: 放置spider代码的目录.
Scrapy爬虫框架:抓取天猫淘宝数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 414 次浏览 • 2020-05-05 08:05
通过天猫的搜索,获取搜索下来的每件商品的销量、收藏数、价格。
所以,最终的目的是通过获取两个页面的内容,一个是搜索结果,从上面找下来每一个商品的详尽地址,然后第二个是商品详尽内容,从上面获取到销量、价格等。
有了思路如今我们先下载搜索结果页面,然后再下载页面中每一项详尽信息页面。
def _parse_handler(self, response):
''' 下载页面 """
self.driver.get(response.url)
pass
很简单,通过self.driver.get(response.url)就能使用selenium下载内容,如果直接使用response中的网页内容是静态的。
上面说了怎样下载内容,当我们下载好内容后,需要从上面去获取我们想要的有用信息,这里就要用到选择器,选择器构造方法比较多,只介绍一种,这里看详尽信息:
>>> body = '<html><body><span>good</span></body></html>'
>>> Selector(text=body).xpath('//span/text()').extract()
[u'good']
这样就通过xpath取下来了good这个词组,更详尽的xpath教程点击这儿。
Selector 提供了好多形式出了xpath,还有css选择器,正则表达式,中文教程看这个,具体内容就不多说,只须要晓得这样可以快速获取我们须要的内容。
简单的介绍了如何获取内容后,现在我们从第一个搜索结果中获取我们想要的商品详尽链接,通过查看网页源代码可以看见,商品的链接在这里:
...
<p class="title">
<a class="J_ClickStat" data-nid="523242229702" href="//detail.tmall.com/item.htm?spm=a230r.1.14.46.Mnbjq5&id=523242229702&ns=1&abbucket=14" target="_blank" trace="msrp_auction" traceidx="5" trace-pid="" data-spm-anchor-id="a230r.1.14.46">WD/西部数据 WD30EZRZ台式机3T电脑<span class="H">硬盘</span> 西数蓝盘3TB 替绿盘</a>
</p>
...
使用之前的规则来获取到a元素的href属性就是须要的内容:
selector = Selector(text=self.driver.page_source) # 这里不要省略text因为省略后Selector使用的是另外一个构造函数,self.driver.page_source是这个网页的html内容
selector.css(".title").css(".J_ClickStat").xpath("./@href").extract()
简单说一下,这里通过css工具取了class叫title的p元素,然后又获取了class是J_ClickStat的a元素,最后通过xpath规则获取a元素的href中的内容。啰嗦一句css中若果是取id则应当是selector.css("#title"),这个和css中的选择器是一致的。
同理,我们获取到商品详情后,以获取销量为例,查看源代码:
<ul class="tm-ind-panel">
<li class="tm-ind-item tm-ind-sellCount" data-label="月销量"><div class="tm-indcon"><span class="tm-label">月销量</span><span class="tm-count">881</span></div></li>
<li class="tm-ind-item tm-ind-reviewCount canClick tm-line3" id="J_ItemRates"><div class="tm-indcon"><span class="tm-label">累计评价</span><span class="tm-count">4593</span></div></li>
<li class="tm-ind-item tm-ind-emPointCount" data-spm="1000988"><div class="tm-indcon"><a href="//vip.tmall.com/vip/index.htm" target="_blank"><span class="tm-label">送天猫积分</span><span class="tm-count">55</span></a></div></li>
</ul>
获取月销量:
selector.css(".tm-ind-sellCount").xpath("./div/span[@class='tm-count']/text()").extract_first()
获取累计评价:
selector.css(".tm-ind-reviewCount").xpath("./div[@class='tm-indcon']/span[@class='tm-count']/text()").extract_first()
最后把获取下来的数据包装成Item返回。淘宝或则淘宝她们的页面内容不一样,所以规则也不同,需要分开去获取想要的内容。
Item是scrapy中获取下来的结果,后面可以处理这种结果。
Item通常是放在items.py中
import scrapy
class Product(scrapy.Item):
name = scrapy.Field()
price = scrapy.Field()
stock = scrapy.Field()
last_updated = scrapy.Field(serializer=str)
>>> product = Product(name='Desktop PC', price=1000)
>>> print product
Product(name='Desktop PC', price=1000)
>>> product['name']
Desktop PC
>>> product.get('name')
Desktop PC
>>> product['price']
1000
>>> product['last_updated']
Traceback (most recent call last):
...
KeyError: 'last_updated'
>>> product.get('last_updated', 'not set')
not set
>>> product['lala'] # getting unknown field
Traceback (most recent call last):
...
KeyError: 'lala'
>>> product.get('lala', 'unknown field')
'unknown field'
>>> 'name' in product # is name field populated?
True
>>> 'last_updated' in product # is last_updated populated?
False
>>> 'last_updated' in product.fields # is last_updated a declared field?
True
>>> 'lala' in product.fields # is lala a declared field?
False
>>> product['last_updated'] = 'today'
>>> product['last_updated']
today
>>> product['lala'] = 'test' # setting unknown field
Traceback (most recent call last):
...
KeyError: 'Product does not support field: lala'
这里只须要注意一个地方,不能通过product.name的方法获取,也不能通过product.name = "name"的形式设置值。
当Item在Spider中被搜集以后,它将会被传递到Item Pipeline,一些组件会根据一定的次序执行对Item的处理。
每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方式的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被遗弃而不再进行处理。
以下是item pipeline的一些典型应用:
现在实现一个Item过滤器,我们把获取下来若果是None的数据形参为0,如果Item对象是None则丢弃这条数据。
pipeline通常是放在pipelines.py中
def process_item(self, item, spider):
if item is not None:
if item["p_standard_price"] is None:
item["p_standard_price"] = item["p_shop_price"]
if item["p_shop_price"] is None:
item["p_shop_price"] = item["p_standard_price"]
item["p_collect_count"] = text_utils.to_int(item["p_collect_count"])
item["p_comment_count"] = text_utils.to_int(item["p_comment_count"])
item["p_month_sale_count"] = text_utils.to_int(item["p_month_sale_count"])
item["p_sale_count"] = text_utils.to_int(item["p_sale_count"])
item["p_standard_price"] = text_utils.to_string(item["p_standard_price"], "0")
item["p_shop_price"] = text_utils.to_string(item["p_shop_price"], "0")
item["p_pay_count"] = item["p_pay_count"] if item["p_pay_count"] is not "-" else "0"
return item
else:
raise DropItem("Item is None %s" % item)
最后须要在settings.py中添加这个pipeline
ITEM_PIPELINES = {
'TaoBao.pipelines.TTDataHandlerPipeline': 250,
'TaoBao.pipelines.MysqlPipeline': 300,
}
后面那种数字越小,则执行的次序越靠前,这里先过滤处理数据,获取到正确的数据后,再执行TaoBao.pipelines.MysqlPipeline添加数据到数据库。
完整的代码:[不带数据库版本][ 数据库版本]。
之前说的方法都是直接通过命令scrapy crawl tts来启动。怎么用IDE的调试功能呢?很简单通过main函数启动爬虫:
# 写到Spider里面
if __name__ == "__main__":
settings = get_project_settings()
process = CrawlerProcess(settings)
spider = TmallAndTaoBaoSpider
process.crawl(spider)
process.start()
在获取数据的时侯,很多时侯会碰到网页重定向的问题,scrapy会返回302之后不会手动重定向后继续爬取新地址,在scrapy的设置中,可以通过配置来开启重定向,这样虽然域名是重定向的scrapy也会手动到最终的地址获取内容。
解决方案:settings.py中添加REDIRECT_ENABLED = True
很多时侯爬虫都有自定义数据,比如之前写的是硬碟关键字,现在通过参数的方法如何传递呢?
解决方案:
大部分时侯,我们可以取到完整的网页信息,如果网页的ajax恳求太多,网速很慢的时侯,selenium并不知道什么时候ajax恳求完成,这个时侯假如通过self.driver.get(response.url)获取页面天猫反爬虫,然后通过Selector取数据天猫反爬虫,很可能还没加载完成取不到数据。
解决方案:通过selenium提供的工具来延后获取内容,直到获取到数据,或者超时。 查看全部
有了前两篇的基础,接下来通过抓取天猫和淘宝的数据来详尽说明,如何通过Scrapy爬取想要的内容。完整的代码:[不带数据库版本][ 数据库版本]。
通过天猫的搜索,获取搜索下来的每件商品的销量、收藏数、价格。
所以,最终的目的是通过获取两个页面的内容,一个是搜索结果,从上面找下来每一个商品的详尽地址,然后第二个是商品详尽内容,从上面获取到销量、价格等。
有了思路如今我们先下载搜索结果页面,然后再下载页面中每一项详尽信息页面。
def _parse_handler(self, response):
''' 下载页面 """
self.driver.get(response.url)
pass
很简单,通过self.driver.get(response.url)就能使用selenium下载内容,如果直接使用response中的网页内容是静态的。
上面说了怎样下载内容,当我们下载好内容后,需要从上面去获取我们想要的有用信息,这里就要用到选择器,选择器构造方法比较多,只介绍一种,这里看详尽信息:
>>> body = '<html><body><span>good</span></body></html>'
>>> Selector(text=body).xpath('//span/text()').extract()
[u'good']
这样就通过xpath取下来了good这个词组,更详尽的xpath教程点击这儿。
Selector 提供了好多形式出了xpath,还有css选择器,正则表达式,中文教程看这个,具体内容就不多说,只须要晓得这样可以快速获取我们须要的内容。
简单的介绍了如何获取内容后,现在我们从第一个搜索结果中获取我们想要的商品详尽链接,通过查看网页源代码可以看见,商品的链接在这里:
...
<p class="title">
<a class="J_ClickStat" data-nid="523242229702" href="//detail.tmall.com/item.htm?spm=a230r.1.14.46.Mnbjq5&id=523242229702&ns=1&abbucket=14" target="_blank" trace="msrp_auction" traceidx="5" trace-pid="" data-spm-anchor-id="a230r.1.14.46">WD/西部数据 WD30EZRZ台式机3T电脑<span class="H">硬盘</span> 西数蓝盘3TB 替绿盘</a>
</p>
...
使用之前的规则来获取到a元素的href属性就是须要的内容:
selector = Selector(text=self.driver.page_source) # 这里不要省略text因为省略后Selector使用的是另外一个构造函数,self.driver.page_source是这个网页的html内容
selector.css(".title").css(".J_ClickStat").xpath("./@href").extract()
简单说一下,这里通过css工具取了class叫title的p元素,然后又获取了class是J_ClickStat的a元素,最后通过xpath规则获取a元素的href中的内容。啰嗦一句css中若果是取id则应当是selector.css("#title"),这个和css中的选择器是一致的。
同理,我们获取到商品详情后,以获取销量为例,查看源代码:
<ul class="tm-ind-panel">
<li class="tm-ind-item tm-ind-sellCount" data-label="月销量"><div class="tm-indcon"><span class="tm-label">月销量</span><span class="tm-count">881</span></div></li>
<li class="tm-ind-item tm-ind-reviewCount canClick tm-line3" id="J_ItemRates"><div class="tm-indcon"><span class="tm-label">累计评价</span><span class="tm-count">4593</span></div></li>
<li class="tm-ind-item tm-ind-emPointCount" data-spm="1000988"><div class="tm-indcon"><a href="//vip.tmall.com/vip/index.htm" target="_blank"><span class="tm-label">送天猫积分</span><span class="tm-count">55</span></a></div></li>
</ul>
获取月销量:
selector.css(".tm-ind-sellCount").xpath("./div/span[@class='tm-count']/text()").extract_first()
获取累计评价:
selector.css(".tm-ind-reviewCount").xpath("./div[@class='tm-indcon']/span[@class='tm-count']/text()").extract_first()
最后把获取下来的数据包装成Item返回。淘宝或则淘宝她们的页面内容不一样,所以规则也不同,需要分开去获取想要的内容。
Item是scrapy中获取下来的结果,后面可以处理这种结果。
Item通常是放在items.py中
import scrapy
class Product(scrapy.Item):
name = scrapy.Field()
price = scrapy.Field()
stock = scrapy.Field()
last_updated = scrapy.Field(serializer=str)
>>> product = Product(name='Desktop PC', price=1000)
>>> print product
Product(name='Desktop PC', price=1000)
>>> product['name']
Desktop PC
>>> product.get('name')
Desktop PC
>>> product['price']
1000
>>> product['last_updated']
Traceback (most recent call last):
...
KeyError: 'last_updated'
>>> product.get('last_updated', 'not set')
not set
>>> product['lala'] # getting unknown field
Traceback (most recent call last):
...
KeyError: 'lala'
>>> product.get('lala', 'unknown field')
'unknown field'
>>> 'name' in product # is name field populated?
True
>>> 'last_updated' in product # is last_updated populated?
False
>>> 'last_updated' in product.fields # is last_updated a declared field?
True
>>> 'lala' in product.fields # is lala a declared field?
False
>>> product['last_updated'] = 'today'
>>> product['last_updated']
today
>>> product['lala'] = 'test' # setting unknown field
Traceback (most recent call last):
...
KeyError: 'Product does not support field: lala'
这里只须要注意一个地方,不能通过product.name的方法获取,也不能通过product.name = "name"的形式设置值。
当Item在Spider中被搜集以后,它将会被传递到Item Pipeline,一些组件会根据一定的次序执行对Item的处理。
每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方式的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被遗弃而不再进行处理。
以下是item pipeline的一些典型应用:
现在实现一个Item过滤器,我们把获取下来若果是None的数据形参为0,如果Item对象是None则丢弃这条数据。
pipeline通常是放在pipelines.py中
def process_item(self, item, spider):
if item is not None:
if item["p_standard_price"] is None:
item["p_standard_price"] = item["p_shop_price"]
if item["p_shop_price"] is None:
item["p_shop_price"] = item["p_standard_price"]
item["p_collect_count"] = text_utils.to_int(item["p_collect_count"])
item["p_comment_count"] = text_utils.to_int(item["p_comment_count"])
item["p_month_sale_count"] = text_utils.to_int(item["p_month_sale_count"])
item["p_sale_count"] = text_utils.to_int(item["p_sale_count"])
item["p_standard_price"] = text_utils.to_string(item["p_standard_price"], "0")
item["p_shop_price"] = text_utils.to_string(item["p_shop_price"], "0")
item["p_pay_count"] = item["p_pay_count"] if item["p_pay_count"] is not "-" else "0"
return item
else:
raise DropItem("Item is None %s" % item)
最后须要在settings.py中添加这个pipeline
ITEM_PIPELINES = {
'TaoBao.pipelines.TTDataHandlerPipeline': 250,
'TaoBao.pipelines.MysqlPipeline': 300,
}
后面那种数字越小,则执行的次序越靠前,这里先过滤处理数据,获取到正确的数据后,再执行TaoBao.pipelines.MysqlPipeline添加数据到数据库。
完整的代码:[不带数据库版本][ 数据库版本]。
之前说的方法都是直接通过命令scrapy crawl tts来启动。怎么用IDE的调试功能呢?很简单通过main函数启动爬虫:
# 写到Spider里面
if __name__ == "__main__":
settings = get_project_settings()
process = CrawlerProcess(settings)
spider = TmallAndTaoBaoSpider
process.crawl(spider)
process.start()
在获取数据的时侯,很多时侯会碰到网页重定向的问题,scrapy会返回302之后不会手动重定向后继续爬取新地址,在scrapy的设置中,可以通过配置来开启重定向,这样虽然域名是重定向的scrapy也会手动到最终的地址获取内容。
解决方案:settings.py中添加REDIRECT_ENABLED = True
很多时侯爬虫都有自定义数据,比如之前写的是硬碟关键字,现在通过参数的方法如何传递呢?
解决方案:
大部分时侯,我们可以取到完整的网页信息,如果网页的ajax恳求太多,网速很慢的时侯,selenium并不知道什么时候ajax恳求完成,这个时侯假如通过self.driver.get(response.url)获取页面天猫反爬虫,然后通过Selector取数据天猫反爬虫,很可能还没加载完成取不到数据。
解决方案:通过selenium提供的工具来延后获取内容,直到获取到数据,或者超时。
网络爬虫:使用Scrapy框架编撰一个抓取书籍信息的爬虫服务
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2020-05-04 08:06
BeautifulSoup是一个十分流行的Python网路抓取库,它提供了一个基于HTML结构的Python对象。
虽然简单易懂,又能非常好的处理HTML数据,
但是相比Scrapy而言网络爬虫程序书,BeautifulSoup有一个最大的缺点:慢。
Scrapy 是一个开源的 Python 数据抓取框架,速度快,强大,而且使用简单。
来看一个官网主页上的简单并完整的爬虫:
虽然只有10行左右的代码,但是它的确是一个完整的爬虫服务:
Scrapy所有的恳求都是异步的:
安装(Mac)
pip install scrapy
其他操作系统请参考完整安装指导:
Spider类想要抒发的是:如何抓取一个确定了的网站的数据。比如在start_urls里定义的去那个链接抓取,parse()方法中定义的要抓取什么样的数据。
当一个Spider开始执行的时侯,它首先从start_urls()中的第一个链接开始发起恳求网络爬虫程序书,然后在callback里处理返回的数据。
Item类提供低格的数据,可以理解为数据Model类。
Scrapy的Selector类基于lxml库,提供HTML或XML转换功能。以response对象作为参数生成的Selector实例即可通过实例对象的xpath()方法获取节点的数据。
接下来将上一个Beautiful Soup版的抓取书籍信息的事例( 使用Beautiful Soup编撰一个爬虫 系列随笔汇总)改写成Scrapy版本。
scrapy startproject book_project
这行命令会创建一个名为book_project的项目。
即实体类,代码如下:
import scrapy
class BookItem(scrapy.Item):
title = scrapy.Field()
isbn = scrapy.Field()
price = scrapy.Field()
设置这个Spider的名称,允许爬取的域名和从那个链接开始:
class BookInfoSpider(scrapy.Spider):
name = "bookinfo"
allowed_domains = ["allitebooks.com", "amazon.com"]
start_urls = [
"http://www.allitebooks.com/security/",
]
def parse(self, response):
# response.xpath('//a[contains(@title, "Last Page →")]/@href').re(r'(\d+)')[0]
num_pages = int(response.xpath('//a[contains(@title, "Last Page →")]/text()').extract_first())
base_url = "http://www.allitebooks.com/security/page/{0}/"
for page in range(1, num_pages):
yield scrapy.Request(base_url.format(page), dont_filter=True, callback=self.parse_page) 查看全部
上周学习了BeautifulSoup的基础知识并用它完成了一个网络爬虫( 使用Beautiful Soup编撰一个爬虫 系列随笔汇总),
BeautifulSoup是一个十分流行的Python网路抓取库,它提供了一个基于HTML结构的Python对象。
虽然简单易懂,又能非常好的处理HTML数据,
但是相比Scrapy而言网络爬虫程序书,BeautifulSoup有一个最大的缺点:慢。
Scrapy 是一个开源的 Python 数据抓取框架,速度快,强大,而且使用简单。
来看一个官网主页上的简单并完整的爬虫:

虽然只有10行左右的代码,但是它的确是一个完整的爬虫服务:
Scrapy所有的恳求都是异步的:
安装(Mac)
pip install scrapy
其他操作系统请参考完整安装指导:
Spider类想要抒发的是:如何抓取一个确定了的网站的数据。比如在start_urls里定义的去那个链接抓取,parse()方法中定义的要抓取什么样的数据。
当一个Spider开始执行的时侯,它首先从start_urls()中的第一个链接开始发起恳求网络爬虫程序书,然后在callback里处理返回的数据。
Item类提供低格的数据,可以理解为数据Model类。
Scrapy的Selector类基于lxml库,提供HTML或XML转换功能。以response对象作为参数生成的Selector实例即可通过实例对象的xpath()方法获取节点的数据。
接下来将上一个Beautiful Soup版的抓取书籍信息的事例( 使用Beautiful Soup编撰一个爬虫 系列随笔汇总)改写成Scrapy版本。
scrapy startproject book_project
这行命令会创建一个名为book_project的项目。
即实体类,代码如下:
import scrapy
class BookItem(scrapy.Item):
title = scrapy.Field()
isbn = scrapy.Field()
price = scrapy.Field()
设置这个Spider的名称,允许爬取的域名和从那个链接开始:
class BookInfoSpider(scrapy.Spider):
name = "bookinfo"
allowed_domains = ["allitebooks.com", "amazon.com"]
start_urls = [
"http://www.allitebooks.com/security/",
]
def parse(self, response):
# response.xpath('//a[contains(@title, "Last Page →")]/@href').re(r'(\d+)')[0]
num_pages = int(response.xpath('//a[contains(@title, "Last Page →")]/text()').extract_first())
base_url = "http://www.allitebooks.com/security/page/{0}/"
for page in range(1, num_pages):
yield scrapy.Request(base_url.format(page), dont_filter=True, callback=self.parse_page)
从零开始基于Scrapy框架的网路爬虫开发流程
采集交流 • 优采云 发表了文章 • 0 个评论 • 398 次浏览 • 2020-07-06 08:01
前节介绍了哪些网路爬虫,什么是Scrapy框架并怎样安装
本节介绍基于Scrapy框架的网路爬虫开发流程
安装好Scrapy框架后,就可以基于Scrapy框架开发爬虫项目了。基于框架开发项目,不需要从零开始编撰代码,只须要把握怎样使用框架,如何添加与自己应用相关的代码即可。
进入准备新建爬虫项目的路径中,使用命令:
scrapy startproject project_name
请用爬虫项目名称替换命令中的project_name爬虫软件开发,例如,本文准备创建一个爬取新浪网的爬虫,取名为sina_spider,则新建爬虫项目的命令为:
scrapy startproject sina_spider
命令运行结果,如下图所示。
新建爬虫项目
“scrapy startproject sina_spider”命令会创建包含下述内容的sina_spider目录,如图13-5所示。
爬虫文件夹结构
新建好Scrapy爬虫项目后,接下来就是创建爬虫文件。请先步入sina_spider项目路径,用命令:
scrapy genspider spider_filename(爬虫文件名) (待爬取的网站域名)
创建爬虫文件。例如,本文的爬虫文件名为:sinaSpider,待爬取的网站域名:,则创建爬虫文件sinaSpider的命令为:
scrapy genspider sinaSpider
现在好多网站都有防爬虫举措,为了反网站的防爬虫举措,需要添加user agent信息。请settings.py文件的第19行更改如下所示:
18. # Crawl responsibly by identifying yourself (and your website) on the user-agent
19. import random
20. # user agent 列表
21. USER_AGENT_LIST = [
22. "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
23. "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
24. "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
25. "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
26. "Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)",
27. "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
28. "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0",
29. "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0",
30. "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0",
31. "Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)",
32. "Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)" ]
33. USER_AGENT = random.choice(USER_AGENT_LIST) # 随机生成user agent
网站的服务器中保存一个robots.txt 文件,其作用是,告诉搜索引擎爬虫,本网站哪些目录下的网页不希望被爬取收录。Scrapy启动后,会在第一时间访问网站的 robots.txt 文件,然后决定该网站的爬取范围。
由于本文的项目并非搜索引擎爬虫,而且很有可能我们想要获取的内容恰恰是被 robots.txt所严禁访问的,所以请把settings.py文件的ROBOTSTXT_OBEY值设置为False,表示拒绝遵循Robot合同,如下所示
1. # Obey robots.txt rules
2. ROBOTSTXT_OBEY = False # False表示拒绝遵守Robot协议
查看由Scrapy生成的sinaSpider.py文件,在SinaspiderSpider类中,有一个parse()方法须要用户编撰,如下图所示
编写parse()方法
Scrapy框架把爬取出来的网页源代码储存在response对象中爬虫软件开发,我们只须要对response对象中的网页源代码做解析,提取想要的数据即可。本范例目标是抓取新浪网页的新闻的标题和对应的链接,如下图所示。
HTML源代码
parse()方法的实现代码,如下所示
1. # -*- coding: utf-8 -*-
2. import scrapy
3.
4. class SinaspiderSpider(scrapy.Spider):
5. name = 'sinaSpider'
6. allowed_domains = ['www.sina.com.cn']
7. start_urls = ['http://www.sina.com.cn/']
8.
9. def parse(self, response):
10. data_list = [] #用于存储解析到的数据
11. #解析HTML源代码,定位新闻内容
12. lis = response.xpath("//div[@class='top_newslist']/ul[@class='list-a news_top']//li")
13. #将新闻主题和超链接解析出来并整理到列表中
14. for li in lis:
15. titles = li.xpath(".//a/text()")
16. linkes = li.xpath(".//a/@href")
17. for title, link in zip(titles, linkes):
18. #将新闻主题和对应的超链接组合成字典
19. data_dict = {'标题': title.extract(), '链接': link.extract()}
20. #将字典数据存储到data_list这个列表中
21. data_list.append(data_dict)
22. return data_list
parse()方法在解析HTML源代码时,使用了XPath路径表达式。XPath是一门在HTML/XML文档中查找信息的语言,常用于在网页HTML源代码中,查找特定标签里的数据。在网络爬虫中使用XPath,只须要把握 XPath路径表达式即可。XPath 使用路径表达式来选定 HTML/XML文档中的节点或则节点集。
parse()方法编撰好后,就可以运行爬虫程序并保存抓取数据了。用命令:
scrapy crawl 爬虫文件名 –o 保存数据文件名.[csv|json|xml]
保存数据的文件格式可以是csv 或 json 或 xml,本例的爬虫文件名为:sinaSpider.py,数据储存选择csv格式,命令为:
scrapy crawl sinaSpider -o sinaNews.csv
运行疗效,如下图所示
运行爬虫
到此,本例基于Scrapy框架从零开始实现了一个网络爬虫程序,爬取了新浪网页并从中解析出新闻的标题和对应的超链接,最后把解析出的数据保存为csv文件供后续使用。 查看全部
前节介绍了哪些网路爬虫,什么是Scrapy框架并怎样安装
本节介绍基于Scrapy框架的网路爬虫开发流程
安装好Scrapy框架后,就可以基于Scrapy框架开发爬虫项目了。基于框架开发项目,不需要从零开始编撰代码,只须要把握怎样使用框架,如何添加与自己应用相关的代码即可。
进入准备新建爬虫项目的路径中,使用命令:
scrapy startproject project_name
请用爬虫项目名称替换命令中的project_name爬虫软件开发,例如,本文准备创建一个爬取新浪网的爬虫,取名为sina_spider,则新建爬虫项目的命令为:
scrapy startproject sina_spider
命令运行结果,如下图所示。
新建爬虫项目
“scrapy startproject sina_spider”命令会创建包含下述内容的sina_spider目录,如图13-5所示。
爬虫文件夹结构
新建好Scrapy爬虫项目后,接下来就是创建爬虫文件。请先步入sina_spider项目路径,用命令:
scrapy genspider spider_filename(爬虫文件名) (待爬取的网站域名)
创建爬虫文件。例如,本文的爬虫文件名为:sinaSpider,待爬取的网站域名:,则创建爬虫文件sinaSpider的命令为:
scrapy genspider sinaSpider
现在好多网站都有防爬虫举措,为了反网站的防爬虫举措,需要添加user agent信息。请settings.py文件的第19行更改如下所示:
18. # Crawl responsibly by identifying yourself (and your website) on the user-agent
19. import random
20. # user agent 列表
21. USER_AGENT_LIST = [
22. "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
23. "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
24. "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
25. "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
26. "Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)",
27. "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
28. "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0",
29. "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0",
30. "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0",
31. "Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)",
32. "Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)" ]
33. USER_AGENT = random.choice(USER_AGENT_LIST) # 随机生成user agent
网站的服务器中保存一个robots.txt 文件,其作用是,告诉搜索引擎爬虫,本网站哪些目录下的网页不希望被爬取收录。Scrapy启动后,会在第一时间访问网站的 robots.txt 文件,然后决定该网站的爬取范围。
由于本文的项目并非搜索引擎爬虫,而且很有可能我们想要获取的内容恰恰是被 robots.txt所严禁访问的,所以请把settings.py文件的ROBOTSTXT_OBEY值设置为False,表示拒绝遵循Robot合同,如下所示
1. # Obey robots.txt rules
2. ROBOTSTXT_OBEY = False # False表示拒绝遵守Robot协议
查看由Scrapy生成的sinaSpider.py文件,在SinaspiderSpider类中,有一个parse()方法须要用户编撰,如下图所示
编写parse()方法
Scrapy框架把爬取出来的网页源代码储存在response对象中爬虫软件开发,我们只须要对response对象中的网页源代码做解析,提取想要的数据即可。本范例目标是抓取新浪网页的新闻的标题和对应的链接,如下图所示。
HTML源代码
parse()方法的实现代码,如下所示
1. # -*- coding: utf-8 -*-
2. import scrapy
3.
4. class SinaspiderSpider(scrapy.Spider):
5. name = 'sinaSpider'
6. allowed_domains = ['www.sina.com.cn']
7. start_urls = ['http://www.sina.com.cn/']
8.
9. def parse(self, response):
10. data_list = [] #用于存储解析到的数据
11. #解析HTML源代码,定位新闻内容
12. lis = response.xpath("//div[@class='top_newslist']/ul[@class='list-a news_top']//li")
13. #将新闻主题和超链接解析出来并整理到列表中
14. for li in lis:
15. titles = li.xpath(".//a/text()")
16. linkes = li.xpath(".//a/@href")
17. for title, link in zip(titles, linkes):
18. #将新闻主题和对应的超链接组合成字典
19. data_dict = {'标题': title.extract(), '链接': link.extract()}
20. #将字典数据存储到data_list这个列表中
21. data_list.append(data_dict)
22. return data_list
parse()方法在解析HTML源代码时,使用了XPath路径表达式。XPath是一门在HTML/XML文档中查找信息的语言,常用于在网页HTML源代码中,查找特定标签里的数据。在网络爬虫中使用XPath,只须要把握 XPath路径表达式即可。XPath 使用路径表达式来选定 HTML/XML文档中的节点或则节点集。
parse()方法编撰好后,就可以运行爬虫程序并保存抓取数据了。用命令:
scrapy crawl 爬虫文件名 –o 保存数据文件名.[csv|json|xml]
保存数据的文件格式可以是csv 或 json 或 xml,本例的爬虫文件名为:sinaSpider.py,数据储存选择csv格式,命令为:
scrapy crawl sinaSpider -o sinaNews.csv
运行疗效,如下图所示
运行爬虫
到此,本例基于Scrapy框架从零开始实现了一个网络爬虫程序,爬取了新浪网页并从中解析出新闻的标题和对应的超链接,最后把解析出的数据保存为csv文件供后续使用。
爬虫框架(scrapy构架)
采集交流 • 优采云 发表了文章 • 0 个评论 • 577 次浏览 • 2020-07-03 08:00
scrapy主要包括了以下组件: 1.)引擎(scrapy):用来处理整个系统的数据流,触发事务(框架核心) 2.)调度器(Scheduler):用来接受引擎发过来的恳求,压入队列中,并在引擎再度恳求的时侯返回,可以想像成一个url(抓取网页的网址或则说链接)的优先队列,由它来决定下一个要抓取的网址是哪些,同时除去重复的网址。 3.)下载器(Downloader):用于下载网页的内容,并将网页内容返回给蜘蛛(Scrapy下载器是构建在twisted这个高效的异步模型上的) 4.)爬虫(Spiders):爬虫是主要干活的,用于从特定的网页中提取自己想要的信息,即所谓的实体(item)。用户也可以从中提取到链接,让Scrapy继续抓取下一个页面。 5.)项目管线(Pipeline):负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管线,并经过几个特定的顺序处理数据。 (只有当调度器中不存在任何request时,整个程序就会停止。(对于下载失败的url,Scrapy也会重新下载))
前置要求: pip下载scrapy模块 yum下载tree包
-确定url地址; -获取页面信息;(urllib,requests) -解析页面提取须要的信息;(xpath,bs4,正则表达时) -保存到本地(scv,json,pymysql,redis) -清洗数据(删除不必要的内容------正则表达式) -分析数据(词云wordcloud,jieba)
-确定url地址(spider) -获取页面信息(Downloader) -解析页面提取须要的信息(spider) -保存到本地(pipeline)
scrapy1.6.0
1.工程创建 1.)命令行在当前目录下创建mySpider
scrapy startproject mySpider
2.)创建成功后,进入mySpider ,tree查看
cd mySpider tree
2.创建一个爬虫
#scrapy genspider 项目名 url scrapy genspider mooc ‘’
3.定义爬取的items内容(items.py)
class CourseItem(scrapy.Item):
#课程标题 title=scrapy.Field() #课程的url地址 url=scrapy.Field() #课程图片的url地址 image_url=scrapy.Field() #课程的描述 introduction=scrapy.Field() #学习人数 student=scrapy.Field()
4.编写spider代码,解析 4.1确定url地址,提取页面须要的信息(mooc.py)
class MoocSpider(scrapy,spider):
#name用于区别爬虫,必须惟一 name=‘mooc’ #允许爬取的域名,其他网站的页面直接跳过 allowd_domains=[‘’,‘’] #爬虫开启时第一个装入调度器的url地址 start_urls=[‘’] #被调用时,每个新的url完成下载后爬虫框架,返回一个响应对象 #下面的方式负责将响应的数据剖析,提取出须要的数据items以及生成下一步须要处理的url地址恳求; def parser(self,response):
##用来检查代码是否达到指定位置,并拿来调试并解析页面信息; #from scrapy.shell import inspect_response #inspect_response(response,self) #1.)实例化对象,CourseItem course=CourseItem() #分析响应的内容 #scrapy剖析页面使用的是xpath方式 #2.)获取每位课程的信息 courseDetails=course.xpath(’.//div[@class=“course-card-container”]’) for courseDetail in courseDetails:
#爬取新的网站, Scrapy上面进行调试(parse命令logging) course[‘title’] = courseDetail.xpath(’.//h3[@class=“course-card-name”]/text()’).extract()[0] #学习人数 course[‘student’] = courseDetail.xpath(’.//span/text()’).extract()[1] #课程描述: course[‘introduction’] = courseDetail.xpath(".//p[@class=‘course-card-desc’]/text()").extract()[0] #课程链接, h获取/learn/9 ====》 course[‘url’] = “” + courseDetail.xpath(’.//a/@href’).extract()[0] #课程的图片url: course[‘image_url’] = ‘http:’ + courseDetail.xpath(’.//img/@src’).extract()[0] yield course #url跟进,获取下一步是否有链接;href url=response.xpath(’.//a[contains[text(),“下一页”]/@href’)[0].extract() if url:
#构建新的url page=‘’+url yield scrapy.Request(page,callback=slef.parse)
4.2保存我们提取的信息(文件格式:scv爬虫框架,json,pymysql)(pipeline.py) 如果多线程,记得在settings.py中分配多个管线并设置优先级:
(1).将爬取的信息保存成json格式
class MyspiderPipeline(object):
def init(self):
self.f=open(Moocfilename,‘w’) #Moocfilename是写在settings.py里的文件名,写在setting.py是因为便捷更改
def process_item(self,item,spider):
#默认传过来的格式是json格式 import json #读取item中的数据,并转化为json格式 line=json.dumps(dict(item),ensure_ascii=False,indent=4) self.f.write(line+’\n’) #一定要返回给调度器 return item
def close_spider(self,spider):
self.f.close()
(2).保存为scv格式
class CsvPipeline(object):
def init(self):
self.f=open(’'mooc.csv",‘w’)
def process_item(self,item,spider):
item=dict(item) self.f.write("{0}:{1}:{2}\n".format(item[‘title’] , item[‘student’] , item[‘url’])) return item
def close_spider(self,spider):
self.f.close()
(3).将爬取的信息保存到数据库中 首先打开数据库创建mooc表
class MysqlPipeline(object):
def init(self):
self.conn=pymysql.connect( host=‘localhost’, user=‘root’, password=‘redhat’, db=‘Mooc’, charset=‘utf8’, ) self.cursor=self.conn.cursor()
def process_item(self,item,spider):
item=dict(item) info=(item[’‘item"] , item[“url”] , item[“image_url”] , item[“introduction”] , item[“student”]) insert_sqil="insert into moocinfo values(’%s’ , ‘%s’ , ‘%s’, ‘%s’ , ‘%s’); " %(info) self.cursor.execute(insert_sqil) mit() return item
def open_spider(self,spider):
create_sqli=“create table if not exists moocinfo (title varchar(50),url varchar(200), image_url varchar(200), introduction varchar(500), student int)” self.cursor.execute(create_sqli)
def close_spider(self,spider):
self.cursor.close() self.conn.close()
(4).通过爬取的图片链接下载图片
class ImagePipeline(object):
def get_media_requests(self,item,info):
#返回一个request请求,包含图片的url
yield scrapy.Request(item['image_url'])
def item_conpleted(self,results,item,info):
#获取下载的地址
image_xpath=[x['path'] for ok , x in results if ok]
if not image_path:
raise Exception('不包含图片')
else:
return item
1.策略一:设置download_delay –作用:设置下载的等待时间,大规模集中的访问对服务器的影响最大,相当于短时间内减小服务器的负载 –缺点:下载等待时间长,不能满足段时间大规模抓取的要求,太短则大大降低了被ban的机率
2.策略二:禁止cookies –cookie有时也用作复数方式cookies,指个别网站为了分辨用户的身分,进行session跟踪而存储在用户本地终端上的数据(通常经过加密)。 –作用:禁止cookies也就避免了可能使用cookies辨识爬虫轨迹的网站得逞 –实现:COOKIES_ENABLES=False
3.策略三:使用user_agent池(拓展:用户代理中间件) –为什么要使用?scrapy本身是使用Scrapy/0.22.2来表明自己的身分。这也就曝露了自己是爬虫的信息。 –user agent ,是指包含浏览器信息,操作系统信息等的一个字符串,也称之为一种特殊的网路合同。服务器通过它判定当前的访问对象是浏览器,邮件客户端还是爬虫。
4.策略四:使用代理中间件 –web server应对爬虫的策略之一就是直接将你的ip或则是整个ip段都封掉严禁访问,这时候,当ip封掉后,转换到其他的ip继续访问即可。
5.策略五:分布式爬虫Scrapy+redis+mysql # 多进程 –Scrapy-Redis则是一个基于Redis的Scrapy分布式组件。它借助Redis对用于爬取的恳求(Requests)进行储存和调度(Schedule),并对爬取形成rapy一些比较关键的代码,将Scrapy弄成一个可以在多个主机上同时运行的分布式爬虫。
米鼠网自创立以来仍然专注于从事政府采购、软件项目、人才外包、猎头服务、综合项目等,始终秉持“专业的服务,易用的产品”的经营理念,以“提供高品质的服务、满足顾客的需求、携手共创多赢”为企业目标,为中国境内企业提供国际化、专业化、个性化、的软件项目解决方案,我司拥有一流的项目总监团队,具备过硬的软件项目设计和施行能力,为全省不同行业顾客提供优质的产品和服务,得到了顾客的广泛赞扬。
如有侵权请联系邮箱() 查看全部
1.scrapy构架流程:
scrapy主要包括了以下组件: 1.)引擎(scrapy):用来处理整个系统的数据流,触发事务(框架核心) 2.)调度器(Scheduler):用来接受引擎发过来的恳求,压入队列中,并在引擎再度恳求的时侯返回,可以想像成一个url(抓取网页的网址或则说链接)的优先队列,由它来决定下一个要抓取的网址是哪些,同时除去重复的网址。 3.)下载器(Downloader):用于下载网页的内容,并将网页内容返回给蜘蛛(Scrapy下载器是构建在twisted这个高效的异步模型上的) 4.)爬虫(Spiders):爬虫是主要干活的,用于从特定的网页中提取自己想要的信息,即所谓的实体(item)。用户也可以从中提取到链接,让Scrapy继续抓取下一个页面。 5.)项目管线(Pipeline):负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管线,并经过几个特定的顺序处理数据。 (只有当调度器中不存在任何request时,整个程序就会停止。(对于下载失败的url,Scrapy也会重新下载))
前置要求: pip下载scrapy模块 yum下载tree包
-确定url地址; -获取页面信息;(urllib,requests) -解析页面提取须要的信息;(xpath,bs4,正则表达时) -保存到本地(scv,json,pymysql,redis) -清洗数据(删除不必要的内容------正则表达式) -分析数据(词云wordcloud,jieba)
-确定url地址(spider) -获取页面信息(Downloader) -解析页面提取须要的信息(spider) -保存到本地(pipeline)
scrapy1.6.0
1.工程创建 1.)命令行在当前目录下创建mySpider
scrapy startproject mySpider
2.)创建成功后,进入mySpider ,tree查看
cd mySpider tree
2.创建一个爬虫
#scrapy genspider 项目名 url scrapy genspider mooc ‘’
3.定义爬取的items内容(items.py)
class CourseItem(scrapy.Item):
#课程标题 title=scrapy.Field() #课程的url地址 url=scrapy.Field() #课程图片的url地址 image_url=scrapy.Field() #课程的描述 introduction=scrapy.Field() #学习人数 student=scrapy.Field()
4.编写spider代码,解析 4.1确定url地址,提取页面须要的信息(mooc.py)
class MoocSpider(scrapy,spider):
#name用于区别爬虫,必须惟一 name=‘mooc’ #允许爬取的域名,其他网站的页面直接跳过 allowd_domains=[‘’,‘’] #爬虫开启时第一个装入调度器的url地址 start_urls=[‘’] #被调用时,每个新的url完成下载后爬虫框架,返回一个响应对象 #下面的方式负责将响应的数据剖析,提取出须要的数据items以及生成下一步须要处理的url地址恳求; def parser(self,response):
##用来检查代码是否达到指定位置,并拿来调试并解析页面信息; #from scrapy.shell import inspect_response #inspect_response(response,self) #1.)实例化对象,CourseItem course=CourseItem() #分析响应的内容 #scrapy剖析页面使用的是xpath方式 #2.)获取每位课程的信息 courseDetails=course.xpath(’.//div[@class=“course-card-container”]’) for courseDetail in courseDetails:
#爬取新的网站, Scrapy上面进行调试(parse命令logging) course[‘title’] = courseDetail.xpath(’.//h3[@class=“course-card-name”]/text()’).extract()[0] #学习人数 course[‘student’] = courseDetail.xpath(’.//span/text()’).extract()[1] #课程描述: course[‘introduction’] = courseDetail.xpath(".//p[@class=‘course-card-desc’]/text()").extract()[0] #课程链接, h获取/learn/9 ====》 course[‘url’] = “” + courseDetail.xpath(’.//a/@href’).extract()[0] #课程的图片url: course[‘image_url’] = ‘http:’ + courseDetail.xpath(’.//img/@src’).extract()[0] yield course #url跟进,获取下一步是否有链接;href url=response.xpath(’.//a[contains[text(),“下一页”]/@href’)[0].extract() if url:
#构建新的url page=‘’+url yield scrapy.Request(page,callback=slef.parse)
4.2保存我们提取的信息(文件格式:scv爬虫框架,json,pymysql)(pipeline.py) 如果多线程,记得在settings.py中分配多个管线并设置优先级:
(1).将爬取的信息保存成json格式
class MyspiderPipeline(object):
def init(self):
self.f=open(Moocfilename,‘w’) #Moocfilename是写在settings.py里的文件名,写在setting.py是因为便捷更改
def process_item(self,item,spider):
#默认传过来的格式是json格式 import json #读取item中的数据,并转化为json格式 line=json.dumps(dict(item),ensure_ascii=False,indent=4) self.f.write(line+’\n’) #一定要返回给调度器 return item
def close_spider(self,spider):
self.f.close()
(2).保存为scv格式
class CsvPipeline(object):
def init(self):
self.f=open(’'mooc.csv",‘w’)
def process_item(self,item,spider):
item=dict(item) self.f.write("{0}:{1}:{2}\n".format(item[‘title’] , item[‘student’] , item[‘url’])) return item
def close_spider(self,spider):
self.f.close()
(3).将爬取的信息保存到数据库中 首先打开数据库创建mooc表
class MysqlPipeline(object):
def init(self):
self.conn=pymysql.connect( host=‘localhost’, user=‘root’, password=‘redhat’, db=‘Mooc’, charset=‘utf8’, ) self.cursor=self.conn.cursor()
def process_item(self,item,spider):
item=dict(item) info=(item[’‘item"] , item[“url”] , item[“image_url”] , item[“introduction”] , item[“student”]) insert_sqil="insert into moocinfo values(’%s’ , ‘%s’ , ‘%s’, ‘%s’ , ‘%s’); " %(info) self.cursor.execute(insert_sqil) mit() return item
def open_spider(self,spider):
create_sqli=“create table if not exists moocinfo (title varchar(50),url varchar(200), image_url varchar(200), introduction varchar(500), student int)” self.cursor.execute(create_sqli)
def close_spider(self,spider):
self.cursor.close() self.conn.close()
(4).通过爬取的图片链接下载图片
class ImagePipeline(object):
def get_media_requests(self,item,info):
#返回一个request请求,包含图片的url
yield scrapy.Request(item['image_url'])
def item_conpleted(self,results,item,info):
#获取下载的地址
image_xpath=[x['path'] for ok , x in results if ok]
if not image_path:
raise Exception('不包含图片')
else:
return item
1.策略一:设置download_delay –作用:设置下载的等待时间,大规模集中的访问对服务器的影响最大,相当于短时间内减小服务器的负载 –缺点:下载等待时间长,不能满足段时间大规模抓取的要求,太短则大大降低了被ban的机率
2.策略二:禁止cookies –cookie有时也用作复数方式cookies,指个别网站为了分辨用户的身分,进行session跟踪而存储在用户本地终端上的数据(通常经过加密)。 –作用:禁止cookies也就避免了可能使用cookies辨识爬虫轨迹的网站得逞 –实现:COOKIES_ENABLES=False
3.策略三:使用user_agent池(拓展:用户代理中间件) –为什么要使用?scrapy本身是使用Scrapy/0.22.2来表明自己的身分。这也就曝露了自己是爬虫的信息。 –user agent ,是指包含浏览器信息,操作系统信息等的一个字符串,也称之为一种特殊的网路合同。服务器通过它判定当前的访问对象是浏览器,邮件客户端还是爬虫。
4.策略四:使用代理中间件 –web server应对爬虫的策略之一就是直接将你的ip或则是整个ip段都封掉严禁访问,这时候,当ip封掉后,转换到其他的ip继续访问即可。
5.策略五:分布式爬虫Scrapy+redis+mysql # 多进程 –Scrapy-Redis则是一个基于Redis的Scrapy分布式组件。它借助Redis对用于爬取的恳求(Requests)进行储存和调度(Schedule),并对爬取形成rapy一些比较关键的代码,将Scrapy弄成一个可以在多个主机上同时运行的分布式爬虫。
米鼠网自创立以来仍然专注于从事政府采购、软件项目、人才外包、猎头服务、综合项目等,始终秉持“专业的服务,易用的产品”的经营理念,以“提供高品质的服务、满足顾客的需求、携手共创多赢”为企业目标,为中国境内企业提供国际化、专业化、个性化、的软件项目解决方案,我司拥有一流的项目总监团队,具备过硬的软件项目设计和施行能力,为全省不同行业顾客提供优质的产品和服务,得到了顾客的广泛赞扬。
如有侵权请联系邮箱()
基于Scrapy框架的分布式网路爬虫实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 271 次浏览 • 2020-05-14 08:09
2.2 用户登入 由于网站对于旅客的访问有限制,为了爬取所需信息,必须在程序中实现用户登陆,其原 理就是能获取到有效的本地 cookie,并借助该 cookie 进行网站访问,除了通常还能用第三方库 进行图象辨识的验证方法外,一般采用浏览器中自动登入,通过网路工具截取有效的 cookie, 然后在爬虫生成 request 时附送上 cookie。 2.3 url 的去重 龙源期刊网 scrapy_redis 有一个 dupefilter 文件中包含 RFPDupeFilter 类用于过滤新增的 url,可以在该 类 request_seen 中借助 redis 的 key 的查找功能,如果所爬取的任务数以亿计则建议 Bloomfilter 去重的方法对于 URL 的储存和操作方法进行优化,虽然该方法会导致大于万分之一的过滤遗 失率。 2.4 数据写入 选择非关系性数据库 MongoDB 作为硬碟数据库与 scrapy 进行搭配使用,在 pipeline 中对 item 数据进行 MongoDB 的写入操作。 3 基本实现步骤 配置:Windows7 64-bit、Python:2.7.11、 Anaconda 4.0.0 (64-bit)、IDE:Pycharm 3.4.1、Scrapy:1.3.2Redis:X64-3.2、MongoDB:3.2.12 代码实现须要对几个文件进行设置和编撰:items、settings、spiders、pipelines。
Items:这是一个爬取数据的基础数据结构类,由其来储存爬虫爬取的键值性数据,关键 的就是这条句子:_id = Field() _id 表示的生成一个数据对象,在 Items 中可以按照须要设定 多个数据对象。 Settings:ITEM_PIPELINES 该参数决定了 item 的处理方式;DOWNLOAD_DELAY 这个 是下载的间隔时间;SCHEDULER 指定作为总的任务协调器的类; SCHEDULER_QUEUE_CLASS 这个参数是设定处理 URL 的队列的工作模式一共有四种,一般 选用 SpiderSimpleQueue 即可。 spiders:该文件就是爬虫主要功能的实现,首先设定该爬虫的基本信息:name、domain、 redis_key、start_urls。爬虫的第一步都是执行方式 start_requests,其中核心句子 yield Request (url,callback)用以按照 url 产生一个 request 并且将 response 结果回传给 callback 方法。 callback 的方式中通常借助 xpath 或者正则表达式对 response 中包含的 html 代码进行解析,产 生所须要的数据以及新的任务 url。
pipelines:该文件作为数据处理、存储的代码段分布式爬虫框架,将在 items 数据被创建后被调用,其中 process_item 的方式就是被调用的方式,所以一定要将其重画,根据实际须要把数据借助方式 dict()转化为字典数据,最后写入 MongoDB。 完成编撰后,在布署的时侯,start_url 的队列只能是第一个运行的爬虫进行初始化,后续 运行的爬虫只能是把新的 url 进行写入不能对其进行再度初始化,部署爬虫的步骤也很简单, 只须要把相关的代码拷贝到目标笔记本上,让后 cmd 命令步入 spiders 的文件夹,运行命令 scrapy crawl XXXX,其中 XXXX 就是爬虫的名子,就完成了爬虫的布署和运行了。 龙源期刊网 4 结语 爬虫的实现,除了基本的步骤和参数设置之外,需要开发者按照实际网站以及数据情况, 针对性的对爬取的策略、数据的去重、数据筛选进行处理,对于爬虫的性能进行有效优化,为 之后的数据剖析做好良好的数据打算。同时,根据须要可以考虑时间的诱因加入到数据结构 中,这就要求爬虫还能通过数据的时间去进行增量爬取。 参考文献 [1]使用 redis 如何实现一个网络分布式爬虫[OL].http: //www.oschina.net/code/snippet_209440_20495/. [2]scrapy_redis 的使用解读[OL].http://www.cnblogs.com/kylinlin/p/5198233.html.http: //blog.csdn.net/u012150179/art 查看全部
龙源期刊网 基于 Scrapy 框架的分布式网路爬虫实现 作者:陶兴海 来源:《电子技术与软件工程》2017 年第 11 期 摘 要按照互联网实际情况,提出分布式爬虫模型,基于 Scrapy 框架,进行代码实现,且 该开发方法可以迅速进行对不同主题的数据爬取的移植,满足不同专业方向的基于互联网大数 据剖析须要。 【关键词】网络爬虫 Scrapy-redis 分布式 1 基本概念 分布式爬虫:分布式方法是以共同爬取为目标,形成多爬虫协同工作的模式,每个爬虫需 要独立完成单项爬取任务,下载网页并保存。 Scrapy-redis:一个三方的基于 redis 数据库实现的分布式方法,配合 scrapy 爬虫框架让 用,让 scrapy 具有了分布式爬取的功能。 2 分布式爬虫技术方案 Scrapy-redis 分布式爬虫的基本设计理念为主从模式,由作为主控端负责所有网络子爬虫 的管理,子爬虫只须要从主控端那儿接收任务分布式爬虫框架,并把新生成任务递交给主控端,在整个爬取的 过程中毋须与其他爬虫通讯。 主要有几个技术关键点: 2.1 子爬虫爬取任务的分发 通过在主控端安装一个 redis 数据库,维护统一的任务列表,子爬虫每次联接 redis 库调用 lpop()方法,生成一个任务,并生成一个 request,接下去就是就像通常爬虫工作。
2.2 用户登入 由于网站对于旅客的访问有限制,为了爬取所需信息,必须在程序中实现用户登陆,其原 理就是能获取到有效的本地 cookie,并借助该 cookie 进行网站访问,除了通常还能用第三方库 进行图象辨识的验证方法外,一般采用浏览器中自动登入,通过网路工具截取有效的 cookie, 然后在爬虫生成 request 时附送上 cookie。 2.3 url 的去重 龙源期刊网 scrapy_redis 有一个 dupefilter 文件中包含 RFPDupeFilter 类用于过滤新增的 url,可以在该 类 request_seen 中借助 redis 的 key 的查找功能,如果所爬取的任务数以亿计则建议 Bloomfilter 去重的方法对于 URL 的储存和操作方法进行优化,虽然该方法会导致大于万分之一的过滤遗 失率。 2.4 数据写入 选择非关系性数据库 MongoDB 作为硬碟数据库与 scrapy 进行搭配使用,在 pipeline 中对 item 数据进行 MongoDB 的写入操作。 3 基本实现步骤 配置:Windows7 64-bit、Python:2.7.11、 Anaconda 4.0.0 (64-bit)、IDE:Pycharm 3.4.1、Scrapy:1.3.2Redis:X64-3.2、MongoDB:3.2.12 代码实现须要对几个文件进行设置和编撰:items、settings、spiders、pipelines。
Items:这是一个爬取数据的基础数据结构类,由其来储存爬虫爬取的键值性数据,关键 的就是这条句子:_id = Field() _id 表示的生成一个数据对象,在 Items 中可以按照须要设定 多个数据对象。 Settings:ITEM_PIPELINES 该参数决定了 item 的处理方式;DOWNLOAD_DELAY 这个 是下载的间隔时间;SCHEDULER 指定作为总的任务协调器的类; SCHEDULER_QUEUE_CLASS 这个参数是设定处理 URL 的队列的工作模式一共有四种,一般 选用 SpiderSimpleQueue 即可。 spiders:该文件就是爬虫主要功能的实现,首先设定该爬虫的基本信息:name、domain、 redis_key、start_urls。爬虫的第一步都是执行方式 start_requests,其中核心句子 yield Request (url,callback)用以按照 url 产生一个 request 并且将 response 结果回传给 callback 方法。 callback 的方式中通常借助 xpath 或者正则表达式对 response 中包含的 html 代码进行解析,产 生所须要的数据以及新的任务 url。
pipelines:该文件作为数据处理、存储的代码段分布式爬虫框架,将在 items 数据被创建后被调用,其中 process_item 的方式就是被调用的方式,所以一定要将其重画,根据实际须要把数据借助方式 dict()转化为字典数据,最后写入 MongoDB。 完成编撰后,在布署的时侯,start_url 的队列只能是第一个运行的爬虫进行初始化,后续 运行的爬虫只能是把新的 url 进行写入不能对其进行再度初始化,部署爬虫的步骤也很简单, 只须要把相关的代码拷贝到目标笔记本上,让后 cmd 命令步入 spiders 的文件夹,运行命令 scrapy crawl XXXX,其中 XXXX 就是爬虫的名子,就完成了爬虫的布署和运行了。 龙源期刊网 4 结语 爬虫的实现,除了基本的步骤和参数设置之外,需要开发者按照实际网站以及数据情况, 针对性的对爬取的策略、数据的去重、数据筛选进行处理,对于爬虫的性能进行有效优化,为 之后的数据剖析做好良好的数据打算。同时,根据须要可以考虑时间的诱因加入到数据结构 中,这就要求爬虫还能通过数据的时间去进行增量爬取。 参考文献 [1]使用 redis 如何实现一个网络分布式爬虫[OL].http: //www.oschina.net/code/snippet_209440_20495/. [2]scrapy_redis 的使用解读[OL].http://www.cnblogs.com/kylinlin/p/5198233.html.http: //blog.csdn.net/u012150179/art
利用 scrapy 集成社区爬虫功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2020-05-13 08:00
当前只爬取了用户主页上一些简单的信息,如果有需求请讲到我们的
:
代码放到了github上,源码
如图所示,在之前的构架上(),我降低了黑色实线框内的部份,包括:
scrapy是一个python爬虫框架,想要快速实现爬虫推荐使用这个。
可以参考如下资料自行学习:
官方文档和官方事例
一个简单明了的入门博客,注意:博客中scrapy的安装步骤可以简化,直接使用 pip install scrapy,安装过程中可能会缺乏几个lib,ubuntu使用 apt-get install libffi-dev libxml2-dev libxslt1-dev -y
mongo特别适宜储存爬虫数据,支持异构数据。这意味着你可以随时改变爬虫策略抓取不同的数据,而不用害怕会和先前的数据冲突(使用sql就须要操蛋的更改表结构了)。
通过scrapy的pipline来集成mongo,非常便捷。
安装mongo
apt-get install mongodb
pip install pymongo
在编撰爬虫的过程中须要使用xpath表达式来提取页面数据,在chrome中可以使用XPath Helper来定位元素,非常便捷。使用方式:
打开XPath Helper插件
鼠标点击一下页面,按住shift键,把键盘联通到须要选定的元素上,插件会将该元素标记为红色,并给出对应的xpath表达式,如下图:
在爬虫程序中使用这个表达式selector.xpath(..../text()").extract()
编写好爬虫后,我门可以通过执行scrapy crawl spidername命令来运行爬虫程序,但这还不够。
通常我们通过自动或则定时任务(cron)来执行爬虫爬虫社区,而这儿我们须要通过web应用来触发爬虫。即,当用户更新绑定的社交帐号时,去执行一次爬虫。来剖析一下:
爬虫执行过程中会阻塞当前进程,为了不阻塞用户恳求,必须通过异步的方法来运行爬虫。
可能有多个用户同时更新资料,这就要求才能同时执行多个爬虫,并且要保证系统不会超员。
可以扩充成分布式的爬虫。
鉴于项目当前的构架,准备使用celery来执行异步爬虫。但是遇到了两个问题:
scrapy框架下,需要在scrapy目录下执行爬虫,否则难以获取到settings,这个用上去有点别扭,不过能够解决。
celery中反复运行scrapy的爬虫会报错:raise error.ReactorNotRestartable()。原因是scrapy用的twisted调度框架,不可以在进程中重启。
stackoverflow上有讨论过这个问题,尝试了一下,搞不定,放弃这个方案。如果你有解决这个问题的方式,期待分享:)
scrapy文档中提及了可以使用scrapyd来布署,scrapyd是一个用于运行scrapy爬虫的webservice,使用者才能通过http请求来运行爬虫。
你只须要使用scrapyd-client将爬虫发布到scrapyd中,然后通过如下命令就可以运行爬虫程序。
$ curl http://localhost:6800/schedule.json -d project=myproject -d spider=spider2
{"status": "ok", "jobid": "26d1b1a6d6f111e0be5c001e648c57f8"}
这意味哪些:
爬虫应用和自己的web应用完全前馈,只有一个http插口。
由于使用http插口,爬虫可以放到任何还能被访问的主机上运行。一个简易的分布式爬虫,不是吗?
scrapyd使用sqlite队列来保存爬虫任务,实现异步执行。
scrapyd可以同时执行多个爬虫,最大进程数可配,防止系统过载。
欢迎使用我们的爬虫功能来搜集社交资料。
成为雨点儿网用户爬虫社区,进入用户主页,点击编辑按键
填写社交帐号,点击更新按键
爬虫会在几秒内完成工作,刷新个人主页能够看见你的社区资料了,你也可以把个人主页链接附在电子简历中哟:) 查看全部
社区活跃度或则贡献越来越遭到注重,往往会作为获得工作或则承接项目的加分项。为了便捷用户展示自己的社区资料,中降低了一个社区爬虫功能。
当前只爬取了用户主页上一些简单的信息,如果有需求请讲到我们的
:
代码放到了github上,源码
如图所示,在之前的构架上(),我降低了黑色实线框内的部份,包括:
scrapy是一个python爬虫框架,想要快速实现爬虫推荐使用这个。
可以参考如下资料自行学习:
官方文档和官方事例
一个简单明了的入门博客,注意:博客中scrapy的安装步骤可以简化,直接使用 pip install scrapy,安装过程中可能会缺乏几个lib,ubuntu使用 apt-get install libffi-dev libxml2-dev libxslt1-dev -y
mongo特别适宜储存爬虫数据,支持异构数据。这意味着你可以随时改变爬虫策略抓取不同的数据,而不用害怕会和先前的数据冲突(使用sql就须要操蛋的更改表结构了)。
通过scrapy的pipline来集成mongo,非常便捷。
安装mongo
apt-get install mongodb
pip install pymongo
在编撰爬虫的过程中须要使用xpath表达式来提取页面数据,在chrome中可以使用XPath Helper来定位元素,非常便捷。使用方式:
打开XPath Helper插件
鼠标点击一下页面,按住shift键,把键盘联通到须要选定的元素上,插件会将该元素标记为红色,并给出对应的xpath表达式,如下图:
在爬虫程序中使用这个表达式selector.xpath(..../text()").extract()
编写好爬虫后,我门可以通过执行scrapy crawl spidername命令来运行爬虫程序,但这还不够。
通常我们通过自动或则定时任务(cron)来执行爬虫爬虫社区,而这儿我们须要通过web应用来触发爬虫。即,当用户更新绑定的社交帐号时,去执行一次爬虫。来剖析一下:
爬虫执行过程中会阻塞当前进程,为了不阻塞用户恳求,必须通过异步的方法来运行爬虫。
可能有多个用户同时更新资料,这就要求才能同时执行多个爬虫,并且要保证系统不会超员。
可以扩充成分布式的爬虫。
鉴于项目当前的构架,准备使用celery来执行异步爬虫。但是遇到了两个问题:
scrapy框架下,需要在scrapy目录下执行爬虫,否则难以获取到settings,这个用上去有点别扭,不过能够解决。
celery中反复运行scrapy的爬虫会报错:raise error.ReactorNotRestartable()。原因是scrapy用的twisted调度框架,不可以在进程中重启。
stackoverflow上有讨论过这个问题,尝试了一下,搞不定,放弃这个方案。如果你有解决这个问题的方式,期待分享:)
scrapy文档中提及了可以使用scrapyd来布署,scrapyd是一个用于运行scrapy爬虫的webservice,使用者才能通过http请求来运行爬虫。
你只须要使用scrapyd-client将爬虫发布到scrapyd中,然后通过如下命令就可以运行爬虫程序。
$ curl http://localhost:6800/schedule.json -d project=myproject -d spider=spider2
{"status": "ok", "jobid": "26d1b1a6d6f111e0be5c001e648c57f8"}
这意味哪些:
爬虫应用和自己的web应用完全前馈,只有一个http插口。
由于使用http插口,爬虫可以放到任何还能被访问的主机上运行。一个简易的分布式爬虫,不是吗?
scrapyd使用sqlite队列来保存爬虫任务,实现异步执行。
scrapyd可以同时执行多个爬虫,最大进程数可配,防止系统过载。
欢迎使用我们的爬虫功能来搜集社交资料。
成为雨点儿网用户爬虫社区,进入用户主页,点击编辑按键
填写社交帐号,点击更新按键
爬虫会在几秒内完成工作,刷新个人主页能够看见你的社区资料了,你也可以把个人主页链接附在电子简历中哟:)
[读后笔记] python网路爬虫实战 (李松涛)
采集交流 • 优采云 发表了文章 • 0 个评论 • 332 次浏览 • 2020-05-12 08:03
用了大约一个晚上的时间,就把这本书看完了。
前面4章是基础的python知识,有基础的朋友可以略过。
scrapy爬虫部份,用了实例给你们说明scrapy的用法网络爬虫实例,不过若果之前没用过scrapy的话,需要渐渐上机敲击代码。
其实书中的事例都是很简单的事例,基本没哪些反爬的限制,书中一句话说的十分赞成,用scrapy写爬虫,就是做填空题,而用urllib2写爬虫,就是习作题,可以自由发挥。
书中没有用更为便捷的requests库。 内容搜索用的最多的是beatifulsoup, 对于xpah或则lxml介绍的比较少。 因为scrapy自带的response就是可以直接用xpath,更为便捷。
对于scrapy的中间和pipeline的使用了一个事例,也是比较简单的反例。
书中没有对验证码,分布式等流行的反爬进行讲解,应该适宜爬虫入门的朋友去看吧。
书中一点挺好的就是代码都十分规范,而且虽然是写习作的使用urllib2,也有意模仿scrapy的框架去写, 需要抓取的数据 独立一个类,类似于scrapy的item,数据处理用的也是叫pipleline的方式。
这样写的益处就是, 每个模块的功能都一目了然,看完第一个反例的类和函数定义,后面的事例都是大同小异,可以推动读者的阅读速率,非常赞。(这一点之后自己要学习,增加代码的可复用性)
很多页面url如今早已过期了,再次运行作者的源码会返回好多404的结果。
失效的项目:
金逸影城
天气预报
获取代理:
本书的一些错误的地方:
1. 获取金逸影厅的spider中,所有关于movie的拼写都拼错为moive了。这个属于德语错误。
2. 在testProxy.py 代码中网络爬虫实例, 由于在同一个类中,一直在形成线程,最后造成线程过多,不能再形成线程。程序会中途退出。
File "C:\Python27\lib\threading.py", line 736, in start<br />
_start_new_thread(self.__bootstrap, ())<br />
thread.error: can't start new thread
可以更改成独立函数的方式,而不是类函数。
待续。 查看全部
用了大约一个晚上的时间,就把这本书看完了。
前面4章是基础的python知识,有基础的朋友可以略过。
scrapy爬虫部份,用了实例给你们说明scrapy的用法网络爬虫实例,不过若果之前没用过scrapy的话,需要渐渐上机敲击代码。
其实书中的事例都是很简单的事例,基本没哪些反爬的限制,书中一句话说的十分赞成,用scrapy写爬虫,就是做填空题,而用urllib2写爬虫,就是习作题,可以自由发挥。
书中没有用更为便捷的requests库。 内容搜索用的最多的是beatifulsoup, 对于xpah或则lxml介绍的比较少。 因为scrapy自带的response就是可以直接用xpath,更为便捷。
对于scrapy的中间和pipeline的使用了一个事例,也是比较简单的反例。
书中没有对验证码,分布式等流行的反爬进行讲解,应该适宜爬虫入门的朋友去看吧。
书中一点挺好的就是代码都十分规范,而且虽然是写习作的使用urllib2,也有意模仿scrapy的框架去写, 需要抓取的数据 独立一个类,类似于scrapy的item,数据处理用的也是叫pipleline的方式。
这样写的益处就是, 每个模块的功能都一目了然,看完第一个反例的类和函数定义,后面的事例都是大同小异,可以推动读者的阅读速率,非常赞。(这一点之后自己要学习,增加代码的可复用性)
很多页面url如今早已过期了,再次运行作者的源码会返回好多404的结果。
失效的项目:
金逸影城
天气预报
获取代理:
本书的一些错误的地方:
1. 获取金逸影厅的spider中,所有关于movie的拼写都拼错为moive了。这个属于德语错误。
2. 在testProxy.py 代码中网络爬虫实例, 由于在同一个类中,一直在形成线程,最后造成线程过多,不能再形成线程。程序会中途退出。
File "C:\Python27\lib\threading.py", line 736, in start<br />
_start_new_thread(self.__bootstrap, ())<br />
thread.error: can't start new thread
可以更改成独立函数的方式,而不是类函数。
待续。
【Scrapy】走进成熟的爬虫框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2020-05-10 08:02
今天简单说说Scrapy的安装。
前几天有小伙伴留言说能不能介绍推荐一下爬虫框架,我给他推荐了Scrapy,本来想偷个懒,推荐他去看官方文档,里面有一些demo代码可供学习测试。结果收到回复说文档中演示用到的网站已经难以访问了。所以只能自己来简单写一下了,也算是自己一个学习记录。
Scrapy是哪些?
定义介绍我也不复制粘贴了。简单来说,Scrapy是一个中小型的爬虫框架,框架的意义就在于帮你预设好了好多可以用的东西,让你可以从复杂的数据流和底层控制中抽离下来,专心于页面的解析即可完成中大项目爬虫,甚至是分布式爬虫。
但是爬虫入门是不推荐直接从框架入手的,直接从框架入手会使你头晕目眩,觉得哪里哪里都看不懂,有点类似于还没学会基础的措词造句就直接套用模板写成文章,自然是非常费力的。所以还是推荐你们有一定的手写爬虫基础再深入了解框架。(当然还没有入门爬虫的朋友…可以催更我的爬虫入门文章…)
那么首先是安装。
Python的版本选择之前提过,推荐你们全面拥抱Python 3.x。
很久以前,大概是我刚入门学习Scrapy时爬虫框架,Scrapy还没有支持Python 3.x,那时一部分爬虫工程师把Scrapy不支持Python 3.x作为不进行迁移的理由。当然了,那时更具体的缘由是Scrapy所依赖的twisted和mitmproxy不支持Python 3.x。
现在我仍然推荐你们全面拥抱Python 3.x。
先安装Python
这次我们以本地环境来进行安装(Windows+Anaconda),由于Python的跨平台特点爬虫框架,我们本地写的代码可以很容易迁移到别的笔记本或服务器使用。(当然了,从规范使用的角度上推荐你们使用单独的env,或者直接使用docker或则vagrant,不过那就说来话长了…以后可以考虑单独介绍)
按照惯例,我们直接使用 pip install scrapy 进行安装。
那么,你大几率会碰到这样的错误:
具体的错误缘由…缺少Microsoft Visual C++ 14.0…你也可以自己通过其他渠道解决,当然我们最推荐的做法是直接使用 conda install scrapy 命令(前提是你安装了Anaconda而非普通Python)。
如果碰到写入权限错误,请用管理员模式运行cmd。
之后我们可以写一个太小的demo,依然是官方案例中的DMOZ,DMOZ网站是一个知名的开放式分类目录(Open DirectoryProject),原版的DMOZ已于今年的3月17日停止了营运,目前网站处于403状态。但是网上大量过去的教程都是以DMOZ为案例的。我为你们找到了原DMOZ网站的静态镜像站,大家可以直接访问
大家根据官方文档的步骤继续做就可以了,后续的问题不大。
()
需要注意的就是工作目录问题。
启动Scrapy项目。
scrapy startproject tutorial
进入目录,我们可以看见手动生成的一些文件,这些文件就是scrapy框架所须要的最基础的组织结构。
scrapy.cfg: 项目的配置文件
tutorial/: 该项目的python模块。之后您将在此加入代码。
tutorial/items.py: 项目中的item文件.
tutorial/pipelines.py: 项目中的pipelines文件.
tutorial/settings.py: 项目的设置文件.
tutorial/spiders/: 放置spider代码的目录. 查看全部
今天简单说说Scrapy的安装。
前几天有小伙伴留言说能不能介绍推荐一下爬虫框架,我给他推荐了Scrapy,本来想偷个懒,推荐他去看官方文档,里面有一些demo代码可供学习测试。结果收到回复说文档中演示用到的网站已经难以访问了。所以只能自己来简单写一下了,也算是自己一个学习记录。
Scrapy是哪些?
定义介绍我也不复制粘贴了。简单来说,Scrapy是一个中小型的爬虫框架,框架的意义就在于帮你预设好了好多可以用的东西,让你可以从复杂的数据流和底层控制中抽离下来,专心于页面的解析即可完成中大项目爬虫,甚至是分布式爬虫。
但是爬虫入门是不推荐直接从框架入手的,直接从框架入手会使你头晕目眩,觉得哪里哪里都看不懂,有点类似于还没学会基础的措词造句就直接套用模板写成文章,自然是非常费力的。所以还是推荐你们有一定的手写爬虫基础再深入了解框架。(当然还没有入门爬虫的朋友…可以催更我的爬虫入门文章…)
那么首先是安装。
Python的版本选择之前提过,推荐你们全面拥抱Python 3.x。
很久以前,大概是我刚入门学习Scrapy时爬虫框架,Scrapy还没有支持Python 3.x,那时一部分爬虫工程师把Scrapy不支持Python 3.x作为不进行迁移的理由。当然了,那时更具体的缘由是Scrapy所依赖的twisted和mitmproxy不支持Python 3.x。
现在我仍然推荐你们全面拥抱Python 3.x。
先安装Python
这次我们以本地环境来进行安装(Windows+Anaconda),由于Python的跨平台特点爬虫框架,我们本地写的代码可以很容易迁移到别的笔记本或服务器使用。(当然了,从规范使用的角度上推荐你们使用单独的env,或者直接使用docker或则vagrant,不过那就说来话长了…以后可以考虑单独介绍)
按照惯例,我们直接使用 pip install scrapy 进行安装。
那么,你大几率会碰到这样的错误:
具体的错误缘由…缺少Microsoft Visual C++ 14.0…你也可以自己通过其他渠道解决,当然我们最推荐的做法是直接使用 conda install scrapy 命令(前提是你安装了Anaconda而非普通Python)。
如果碰到写入权限错误,请用管理员模式运行cmd。
之后我们可以写一个太小的demo,依然是官方案例中的DMOZ,DMOZ网站是一个知名的开放式分类目录(Open DirectoryProject),原版的DMOZ已于今年的3月17日停止了营运,目前网站处于403状态。但是网上大量过去的教程都是以DMOZ为案例的。我为你们找到了原DMOZ网站的静态镜像站,大家可以直接访问
大家根据官方文档的步骤继续做就可以了,后续的问题不大。
()
需要注意的就是工作目录问题。
启动Scrapy项目。
scrapy startproject tutorial
进入目录,我们可以看见手动生成的一些文件,这些文件就是scrapy框架所须要的最基础的组织结构。
scrapy.cfg: 项目的配置文件
tutorial/: 该项目的python模块。之后您将在此加入代码。
tutorial/items.py: 项目中的item文件.
tutorial/pipelines.py: 项目中的pipelines文件.
tutorial/settings.py: 项目的设置文件.
tutorial/spiders/: 放置spider代码的目录.
Scrapy爬虫框架:抓取天猫淘宝数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 414 次浏览 • 2020-05-05 08:05
通过天猫的搜索,获取搜索下来的每件商品的销量、收藏数、价格。
所以,最终的目的是通过获取两个页面的内容,一个是搜索结果,从上面找下来每一个商品的详尽地址,然后第二个是商品详尽内容,从上面获取到销量、价格等。
有了思路如今我们先下载搜索结果页面,然后再下载页面中每一项详尽信息页面。
def _parse_handler(self, response):
''' 下载页面 """
self.driver.get(response.url)
pass
很简单,通过self.driver.get(response.url)就能使用selenium下载内容,如果直接使用response中的网页内容是静态的。
上面说了怎样下载内容,当我们下载好内容后,需要从上面去获取我们想要的有用信息,这里就要用到选择器,选择器构造方法比较多,只介绍一种,这里看详尽信息:
>>> body = '<html><body><span>good</span></body></html>'
>>> Selector(text=body).xpath('//span/text()').extract()
[u'good']
这样就通过xpath取下来了good这个词组,更详尽的xpath教程点击这儿。
Selector 提供了好多形式出了xpath,还有css选择器,正则表达式,中文教程看这个,具体内容就不多说,只须要晓得这样可以快速获取我们须要的内容。
简单的介绍了如何获取内容后,现在我们从第一个搜索结果中获取我们想要的商品详尽链接,通过查看网页源代码可以看见,商品的链接在这里:
...
<p class="title">
<a class="J_ClickStat" data-nid="523242229702" href="//detail.tmall.com/item.htm?spm=a230r.1.14.46.Mnbjq5&id=523242229702&ns=1&abbucket=14" target="_blank" trace="msrp_auction" traceidx="5" trace-pid="" data-spm-anchor-id="a230r.1.14.46">WD/西部数据 WD30EZRZ台式机3T电脑<span class="H">硬盘</span> 西数蓝盘3TB 替绿盘</a>
</p>
...
使用之前的规则来获取到a元素的href属性就是须要的内容:
selector = Selector(text=self.driver.page_source) # 这里不要省略text因为省略后Selector使用的是另外一个构造函数,self.driver.page_source是这个网页的html内容
selector.css(".title").css(".J_ClickStat").xpath("./@href").extract()
简单说一下,这里通过css工具取了class叫title的p元素,然后又获取了class是J_ClickStat的a元素,最后通过xpath规则获取a元素的href中的内容。啰嗦一句css中若果是取id则应当是selector.css("#title"),这个和css中的选择器是一致的。
同理,我们获取到商品详情后,以获取销量为例,查看源代码:
<ul class="tm-ind-panel">
<li class="tm-ind-item tm-ind-sellCount" data-label="月销量"><div class="tm-indcon"><span class="tm-label">月销量</span><span class="tm-count">881</span></div></li>
<li class="tm-ind-item tm-ind-reviewCount canClick tm-line3" id="J_ItemRates"><div class="tm-indcon"><span class="tm-label">累计评价</span><span class="tm-count">4593</span></div></li>
<li class="tm-ind-item tm-ind-emPointCount" data-spm="1000988"><div class="tm-indcon"><a href="//vip.tmall.com/vip/index.htm" target="_blank"><span class="tm-label">送天猫积分</span><span class="tm-count">55</span></a></div></li>
</ul>
获取月销量:
selector.css(".tm-ind-sellCount").xpath("./div/span[@class='tm-count']/text()").extract_first()
获取累计评价:
selector.css(".tm-ind-reviewCount").xpath("./div[@class='tm-indcon']/span[@class='tm-count']/text()").extract_first()
最后把获取下来的数据包装成Item返回。淘宝或则淘宝她们的页面内容不一样,所以规则也不同,需要分开去获取想要的内容。
Item是scrapy中获取下来的结果,后面可以处理这种结果。
Item通常是放在items.py中
import scrapy
class Product(scrapy.Item):
name = scrapy.Field()
price = scrapy.Field()
stock = scrapy.Field()
last_updated = scrapy.Field(serializer=str)
>>> product = Product(name='Desktop PC', price=1000)
>>> print product
Product(name='Desktop PC', price=1000)
>>> product['name']
Desktop PC
>>> product.get('name')
Desktop PC
>>> product['price']
1000
>>> product['last_updated']
Traceback (most recent call last):
...
KeyError: 'last_updated'
>>> product.get('last_updated', 'not set')
not set
>>> product['lala'] # getting unknown field
Traceback (most recent call last):
...
KeyError: 'lala'
>>> product.get('lala', 'unknown field')
'unknown field'
>>> 'name' in product # is name field populated?
True
>>> 'last_updated' in product # is last_updated populated?
False
>>> 'last_updated' in product.fields # is last_updated a declared field?
True
>>> 'lala' in product.fields # is lala a declared field?
False
>>> product['last_updated'] = 'today'
>>> product['last_updated']
today
>>> product['lala'] = 'test' # setting unknown field
Traceback (most recent call last):
...
KeyError: 'Product does not support field: lala'
这里只须要注意一个地方,不能通过product.name的方法获取,也不能通过product.name = "name"的形式设置值。
当Item在Spider中被搜集以后,它将会被传递到Item Pipeline,一些组件会根据一定的次序执行对Item的处理。
每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方式的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被遗弃而不再进行处理。
以下是item pipeline的一些典型应用:
现在实现一个Item过滤器,我们把获取下来若果是None的数据形参为0,如果Item对象是None则丢弃这条数据。
pipeline通常是放在pipelines.py中
def process_item(self, item, spider):
if item is not None:
if item["p_standard_price"] is None:
item["p_standard_price"] = item["p_shop_price"]
if item["p_shop_price"] is None:
item["p_shop_price"] = item["p_standard_price"]
item["p_collect_count"] = text_utils.to_int(item["p_collect_count"])
item["p_comment_count"] = text_utils.to_int(item["p_comment_count"])
item["p_month_sale_count"] = text_utils.to_int(item["p_month_sale_count"])
item["p_sale_count"] = text_utils.to_int(item["p_sale_count"])
item["p_standard_price"] = text_utils.to_string(item["p_standard_price"], "0")
item["p_shop_price"] = text_utils.to_string(item["p_shop_price"], "0")
item["p_pay_count"] = item["p_pay_count"] if item["p_pay_count"] is not "-" else "0"
return item
else:
raise DropItem("Item is None %s" % item)
最后须要在settings.py中添加这个pipeline
ITEM_PIPELINES = {
'TaoBao.pipelines.TTDataHandlerPipeline': 250,
'TaoBao.pipelines.MysqlPipeline': 300,
}
后面那种数字越小,则执行的次序越靠前,这里先过滤处理数据,获取到正确的数据后,再执行TaoBao.pipelines.MysqlPipeline添加数据到数据库。
完整的代码:[不带数据库版本][ 数据库版本]。
之前说的方法都是直接通过命令scrapy crawl tts来启动。怎么用IDE的调试功能呢?很简单通过main函数启动爬虫:
# 写到Spider里面
if __name__ == "__main__":
settings = get_project_settings()
process = CrawlerProcess(settings)
spider = TmallAndTaoBaoSpider
process.crawl(spider)
process.start()
在获取数据的时侯,很多时侯会碰到网页重定向的问题,scrapy会返回302之后不会手动重定向后继续爬取新地址,在scrapy的设置中,可以通过配置来开启重定向,这样虽然域名是重定向的scrapy也会手动到最终的地址获取内容。
解决方案:settings.py中添加REDIRECT_ENABLED = True
很多时侯爬虫都有自定义数据,比如之前写的是硬碟关键字,现在通过参数的方法如何传递呢?
解决方案:
大部分时侯,我们可以取到完整的网页信息,如果网页的ajax恳求太多,网速很慢的时侯,selenium并不知道什么时候ajax恳求完成,这个时侯假如通过self.driver.get(response.url)获取页面天猫反爬虫,然后通过Selector取数据天猫反爬虫,很可能还没加载完成取不到数据。
解决方案:通过selenium提供的工具来延后获取内容,直到获取到数据,或者超时。 查看全部
有了前两篇的基础,接下来通过抓取天猫和淘宝的数据来详尽说明,如何通过Scrapy爬取想要的内容。完整的代码:[不带数据库版本][ 数据库版本]。
通过天猫的搜索,获取搜索下来的每件商品的销量、收藏数、价格。
所以,最终的目的是通过获取两个页面的内容,一个是搜索结果,从上面找下来每一个商品的详尽地址,然后第二个是商品详尽内容,从上面获取到销量、价格等。
有了思路如今我们先下载搜索结果页面,然后再下载页面中每一项详尽信息页面。
def _parse_handler(self, response):
''' 下载页面 """
self.driver.get(response.url)
pass
很简单,通过self.driver.get(response.url)就能使用selenium下载内容,如果直接使用response中的网页内容是静态的。
上面说了怎样下载内容,当我们下载好内容后,需要从上面去获取我们想要的有用信息,这里就要用到选择器,选择器构造方法比较多,只介绍一种,这里看详尽信息:
>>> body = '<html><body><span>good</span></body></html>'
>>> Selector(text=body).xpath('//span/text()').extract()
[u'good']
这样就通过xpath取下来了good这个词组,更详尽的xpath教程点击这儿。
Selector 提供了好多形式出了xpath,还有css选择器,正则表达式,中文教程看这个,具体内容就不多说,只须要晓得这样可以快速获取我们须要的内容。
简单的介绍了如何获取内容后,现在我们从第一个搜索结果中获取我们想要的商品详尽链接,通过查看网页源代码可以看见,商品的链接在这里:
...
<p class="title">
<a class="J_ClickStat" data-nid="523242229702" href="//detail.tmall.com/item.htm?spm=a230r.1.14.46.Mnbjq5&id=523242229702&ns=1&abbucket=14" target="_blank" trace="msrp_auction" traceidx="5" trace-pid="" data-spm-anchor-id="a230r.1.14.46">WD/西部数据 WD30EZRZ台式机3T电脑<span class="H">硬盘</span> 西数蓝盘3TB 替绿盘</a>
</p>
...
使用之前的规则来获取到a元素的href属性就是须要的内容:
selector = Selector(text=self.driver.page_source) # 这里不要省略text因为省略后Selector使用的是另外一个构造函数,self.driver.page_source是这个网页的html内容
selector.css(".title").css(".J_ClickStat").xpath("./@href").extract()
简单说一下,这里通过css工具取了class叫title的p元素,然后又获取了class是J_ClickStat的a元素,最后通过xpath规则获取a元素的href中的内容。啰嗦一句css中若果是取id则应当是selector.css("#title"),这个和css中的选择器是一致的。
同理,我们获取到商品详情后,以获取销量为例,查看源代码:
<ul class="tm-ind-panel">
<li class="tm-ind-item tm-ind-sellCount" data-label="月销量"><div class="tm-indcon"><span class="tm-label">月销量</span><span class="tm-count">881</span></div></li>
<li class="tm-ind-item tm-ind-reviewCount canClick tm-line3" id="J_ItemRates"><div class="tm-indcon"><span class="tm-label">累计评价</span><span class="tm-count">4593</span></div></li>
<li class="tm-ind-item tm-ind-emPointCount" data-spm="1000988"><div class="tm-indcon"><a href="//vip.tmall.com/vip/index.htm" target="_blank"><span class="tm-label">送天猫积分</span><span class="tm-count">55</span></a></div></li>
</ul>
获取月销量:
selector.css(".tm-ind-sellCount").xpath("./div/span[@class='tm-count']/text()").extract_first()
获取累计评价:
selector.css(".tm-ind-reviewCount").xpath("./div[@class='tm-indcon']/span[@class='tm-count']/text()").extract_first()
最后把获取下来的数据包装成Item返回。淘宝或则淘宝她们的页面内容不一样,所以规则也不同,需要分开去获取想要的内容。
Item是scrapy中获取下来的结果,后面可以处理这种结果。
Item通常是放在items.py中
import scrapy
class Product(scrapy.Item):
name = scrapy.Field()
price = scrapy.Field()
stock = scrapy.Field()
last_updated = scrapy.Field(serializer=str)
>>> product = Product(name='Desktop PC', price=1000)
>>> print product
Product(name='Desktop PC', price=1000)
>>> product['name']
Desktop PC
>>> product.get('name')
Desktop PC
>>> product['price']
1000
>>> product['last_updated']
Traceback (most recent call last):
...
KeyError: 'last_updated'
>>> product.get('last_updated', 'not set')
not set
>>> product['lala'] # getting unknown field
Traceback (most recent call last):
...
KeyError: 'lala'
>>> product.get('lala', 'unknown field')
'unknown field'
>>> 'name' in product # is name field populated?
True
>>> 'last_updated' in product # is last_updated populated?
False
>>> 'last_updated' in product.fields # is last_updated a declared field?
True
>>> 'lala' in product.fields # is lala a declared field?
False
>>> product['last_updated'] = 'today'
>>> product['last_updated']
today
>>> product['lala'] = 'test' # setting unknown field
Traceback (most recent call last):
...
KeyError: 'Product does not support field: lala'
这里只须要注意一个地方,不能通过product.name的方法获取,也不能通过product.name = "name"的形式设置值。
当Item在Spider中被搜集以后,它将会被传递到Item Pipeline,一些组件会根据一定的次序执行对Item的处理。
每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方式的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被遗弃而不再进行处理。
以下是item pipeline的一些典型应用:
现在实现一个Item过滤器,我们把获取下来若果是None的数据形参为0,如果Item对象是None则丢弃这条数据。
pipeline通常是放在pipelines.py中
def process_item(self, item, spider):
if item is not None:
if item["p_standard_price"] is None:
item["p_standard_price"] = item["p_shop_price"]
if item["p_shop_price"] is None:
item["p_shop_price"] = item["p_standard_price"]
item["p_collect_count"] = text_utils.to_int(item["p_collect_count"])
item["p_comment_count"] = text_utils.to_int(item["p_comment_count"])
item["p_month_sale_count"] = text_utils.to_int(item["p_month_sale_count"])
item["p_sale_count"] = text_utils.to_int(item["p_sale_count"])
item["p_standard_price"] = text_utils.to_string(item["p_standard_price"], "0")
item["p_shop_price"] = text_utils.to_string(item["p_shop_price"], "0")
item["p_pay_count"] = item["p_pay_count"] if item["p_pay_count"] is not "-" else "0"
return item
else:
raise DropItem("Item is None %s" % item)
最后须要在settings.py中添加这个pipeline
ITEM_PIPELINES = {
'TaoBao.pipelines.TTDataHandlerPipeline': 250,
'TaoBao.pipelines.MysqlPipeline': 300,
}
后面那种数字越小,则执行的次序越靠前,这里先过滤处理数据,获取到正确的数据后,再执行TaoBao.pipelines.MysqlPipeline添加数据到数据库。
完整的代码:[不带数据库版本][ 数据库版本]。
之前说的方法都是直接通过命令scrapy crawl tts来启动。怎么用IDE的调试功能呢?很简单通过main函数启动爬虫:
# 写到Spider里面
if __name__ == "__main__":
settings = get_project_settings()
process = CrawlerProcess(settings)
spider = TmallAndTaoBaoSpider
process.crawl(spider)
process.start()
在获取数据的时侯,很多时侯会碰到网页重定向的问题,scrapy会返回302之后不会手动重定向后继续爬取新地址,在scrapy的设置中,可以通过配置来开启重定向,这样虽然域名是重定向的scrapy也会手动到最终的地址获取内容。
解决方案:settings.py中添加REDIRECT_ENABLED = True
很多时侯爬虫都有自定义数据,比如之前写的是硬碟关键字,现在通过参数的方法如何传递呢?
解决方案:
大部分时侯,我们可以取到完整的网页信息,如果网页的ajax恳求太多,网速很慢的时侯,selenium并不知道什么时候ajax恳求完成,这个时侯假如通过self.driver.get(response.url)获取页面天猫反爬虫,然后通过Selector取数据天猫反爬虫,很可能还没加载完成取不到数据。
解决方案:通过selenium提供的工具来延后获取内容,直到获取到数据,或者超时。
网络爬虫:使用Scrapy框架编撰一个抓取书籍信息的爬虫服务
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2020-05-04 08:06
BeautifulSoup是一个十分流行的Python网路抓取库,它提供了一个基于HTML结构的Python对象。
虽然简单易懂,又能非常好的处理HTML数据,
但是相比Scrapy而言网络爬虫程序书,BeautifulSoup有一个最大的缺点:慢。
Scrapy 是一个开源的 Python 数据抓取框架,速度快,强大,而且使用简单。
来看一个官网主页上的简单并完整的爬虫:
虽然只有10行左右的代码,但是它的确是一个完整的爬虫服务:
Scrapy所有的恳求都是异步的:
安装(Mac)
pip install scrapy
其他操作系统请参考完整安装指导:
Spider类想要抒发的是:如何抓取一个确定了的网站的数据。比如在start_urls里定义的去那个链接抓取,parse()方法中定义的要抓取什么样的数据。
当一个Spider开始执行的时侯,它首先从start_urls()中的第一个链接开始发起恳求网络爬虫程序书,然后在callback里处理返回的数据。
Item类提供低格的数据,可以理解为数据Model类。
Scrapy的Selector类基于lxml库,提供HTML或XML转换功能。以response对象作为参数生成的Selector实例即可通过实例对象的xpath()方法获取节点的数据。
接下来将上一个Beautiful Soup版的抓取书籍信息的事例( 使用Beautiful Soup编撰一个爬虫 系列随笔汇总)改写成Scrapy版本。
scrapy startproject book_project
这行命令会创建一个名为book_project的项目。
即实体类,代码如下:
import scrapy
class BookItem(scrapy.Item):
title = scrapy.Field()
isbn = scrapy.Field()
price = scrapy.Field()
设置这个Spider的名称,允许爬取的域名和从那个链接开始:
class BookInfoSpider(scrapy.Spider):
name = "bookinfo"
allowed_domains = ["allitebooks.com", "amazon.com"]
start_urls = [
"http://www.allitebooks.com/security/",
]
def parse(self, response):
# response.xpath('//a[contains(@title, "Last Page →")]/@href').re(r'(\d+)')[0]
num_pages = int(response.xpath('//a[contains(@title, "Last Page →")]/text()').extract_first())
base_url = "http://www.allitebooks.com/security/page/{0}/"
for page in range(1, num_pages):
yield scrapy.Request(base_url.format(page), dont_filter=True, callback=self.parse_page) 查看全部
上周学习了BeautifulSoup的基础知识并用它完成了一个网络爬虫( 使用Beautiful Soup编撰一个爬虫 系列随笔汇总),
BeautifulSoup是一个十分流行的Python网路抓取库,它提供了一个基于HTML结构的Python对象。
虽然简单易懂,又能非常好的处理HTML数据,
但是相比Scrapy而言网络爬虫程序书,BeautifulSoup有一个最大的缺点:慢。
Scrapy 是一个开源的 Python 数据抓取框架,速度快,强大,而且使用简单。
来看一个官网主页上的简单并完整的爬虫:
虽然只有10行左右的代码,但是它的确是一个完整的爬虫服务:
Scrapy所有的恳求都是异步的:
安装(Mac)
pip install scrapy
其他操作系统请参考完整安装指导:
Spider类想要抒发的是:如何抓取一个确定了的网站的数据。比如在start_urls里定义的去那个链接抓取,parse()方法中定义的要抓取什么样的数据。
当一个Spider开始执行的时侯,它首先从start_urls()中的第一个链接开始发起恳求网络爬虫程序书,然后在callback里处理返回的数据。
Item类提供低格的数据,可以理解为数据Model类。
Scrapy的Selector类基于lxml库,提供HTML或XML转换功能。以response对象作为参数生成的Selector实例即可通过实例对象的xpath()方法获取节点的数据。
接下来将上一个Beautiful Soup版的抓取书籍信息的事例( 使用Beautiful Soup编撰一个爬虫 系列随笔汇总)改写成Scrapy版本。
scrapy startproject book_project
这行命令会创建一个名为book_project的项目。
即实体类,代码如下:
import scrapy
class BookItem(scrapy.Item):
title = scrapy.Field()
isbn = scrapy.Field()
price = scrapy.Field()
设置这个Spider的名称,允许爬取的域名和从那个链接开始:
class BookInfoSpider(scrapy.Spider):
name = "bookinfo"
allowed_domains = ["allitebooks.com", "amazon.com"]
start_urls = [
"http://www.allitebooks.com/security/",
]
def parse(self, response):
# response.xpath('//a[contains(@title, "Last Page →")]/@href').re(r'(\d+)')[0]
num_pages = int(response.xpath('//a[contains(@title, "Last Page →")]/text()').extract_first())
base_url = "http://www.allitebooks.com/security/page/{0}/"
for page in range(1, num_pages):
yield scrapy.Request(base_url.format(page), dont_filter=True, callback=self.parse_page)

