
python抓取动态网页
python抓取动态网页(以爬取中国电影网中国票房排行前500为例讲解下获取动态数据的一般步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-12 07:21
1.简介
说到抓取网页,我们一般的操作是先查看源码或者查看元素,找到信息所在的节点,然后使用beautifulsoup/xpth/re获取数据。这是我们处理静态网页的常用方式。
但是大家都知道,现在的网页大部分都是动态的,就是通过js渲染来加载数据的。处理静态网页的那一套就不太满意了。因此,掌握爬取动态加载数据的方法是非常有必要的。NS。
下面以爬取中国电影网中国票房500强排名为例,说明获取动态数据的一般步骤。
2.示例和步骤
2.1 首先打开数据页面,右键选择review元素,然后选择Network——>XHR,可以看到现在里面什么都没有了。
2.2 然后点击浏览器的刷新按钮或者按F5刷新页面,可以看到出现了一条数据,这个链接是获取数据的页面API,选择Response,可以看到它是以 Json 格式返回的数据,收录了我们需要的所有信息。
2.3 点击页面的下一页,获取更多的数据,以便找到它们之间的联系。
可以看到,只有图片上几个数据链接的最后一个页码不同,所以不要太友好!复制链接并保存作为代码模拟的参考。
2.4 知道了数据链路之间的关系,我们可以在代码中进行模拟。比如我们要获取前50页的信息,可以这样写。
for i in range(1, 51, 1):
src = 'http://www.cbooo.cn/Mdata/getM ... 39%3B + str(i)
getHtml(src)
2.5 通过上面的操作,我们得到了返回的数据,但是返回的数据是Json格式的,所以我们需要解析它,然后从中获取每部电影的ID(可以找到每部电影都是这样的格式:后面的数字就是电影的ID,这是我们需要从返回的Json数据中获取的。)获取到ID后,形成电影链接,然后静态的操作页。
import requests
import json
def getHtml(src):
html = requests.get(src).content.decode('utf-8')
for con in json.loads(html)['pData']:
url = 'http://www.cbooo.cn/m/' + str(con['ID'])
newhtml = requests.get(url).content.decode('utf-8')
3.总结
获取动态数据的关键是找到“从页面获取数据的API”,然后找到数据链接之间的关系,然后对返回的数据进行分析,得到需要的数据。 查看全部
python抓取动态网页(以爬取中国电影网中国票房排行前500为例讲解下获取动态数据的一般步骤)
1.简介
说到抓取网页,我们一般的操作是先查看源码或者查看元素,找到信息所在的节点,然后使用beautifulsoup/xpth/re获取数据。这是我们处理静态网页的常用方式。
但是大家都知道,现在的网页大部分都是动态的,就是通过js渲染来加载数据的。处理静态网页的那一套就不太满意了。因此,掌握爬取动态加载数据的方法是非常有必要的。NS。
下面以爬取中国电影网中国票房500强排名为例,说明获取动态数据的一般步骤。
2.示例和步骤
2.1 首先打开数据页面,右键选择review元素,然后选择Network——>XHR,可以看到现在里面什么都没有了。

2.2 然后点击浏览器的刷新按钮或者按F5刷新页面,可以看到出现了一条数据,这个链接是获取数据的页面API,选择Response,可以看到它是以 Json 格式返回的数据,收录了我们需要的所有信息。

2.3 点击页面的下一页,获取更多的数据,以便找到它们之间的联系。

可以看到,只有图片上几个数据链接的最后一个页码不同,所以不要太友好!复制链接并保存作为代码模拟的参考。
2.4 知道了数据链路之间的关系,我们可以在代码中进行模拟。比如我们要获取前50页的信息,可以这样写。
for i in range(1, 51, 1):
src = 'http://www.cbooo.cn/Mdata/getM ... 39%3B + str(i)
getHtml(src)
2.5 通过上面的操作,我们得到了返回的数据,但是返回的数据是Json格式的,所以我们需要解析它,然后从中获取每部电影的ID(可以找到每部电影都是这样的格式:后面的数字就是电影的ID,这是我们需要从返回的Json数据中获取的。)获取到ID后,形成电影链接,然后静态的操作页。
import requests
import json
def getHtml(src):
html = requests.get(src).content.decode('utf-8')
for con in json.loads(html)['pData']:
url = 'http://www.cbooo.cn/m/' + str(con['ID'])
newhtml = requests.get(url).content.decode('utf-8')
3.总结
获取动态数据的关键是找到“从页面获取数据的API”,然后找到数据链接之间的关系,然后对返回的数据进行分析,得到需要的数据。
python抓取动态网页(简单聊一聊如何用python来抓取页面中的JS动态加载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-11-11 04:17
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。如下图所示,我们在HTML中找不到对应的电影信息。怎么用PYTHON request.json读取下一层内容,直接把request中的json取出来变成dict和list组成的结构体,不就是随便读哪一个吗?python请求是否获得状态?1. 使用postman的时候,输入url和参数,调用post方法,接口会返回数据2. 然后我用python的requests来实现3.r= requests.request(' POST',req,data=value) python爬虫中的requestrequest对象是什么,就是从客户端向服务器发送一个请求,包括用户提交的信息和客户端的一些信息。客户端可以通过HTML表单或者在网页地址后面提供参数来提交数据,然后通过请求对象的相关方法获取这些数据。请求的各种方法主要用于处理客户端浏览器提交的请求中的各种参数和选项。python爬虫中的请求其实就是通过python向服务器发送请求请求,并获取返回的信息。python请求问题很容易实现。打开开发者工具,查看请求中的信息,获取上面你的tid等具体的查询参数。它只是一个参数,然后将这些参数做成字典,使用urlencode方法将参数字典转换成url格式,如下: url='' 查看全部
python抓取动态网页(简单聊一聊如何用python来抓取页面中的JS动态加载)
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。如下图所示,我们在HTML中找不到对应的电影信息。怎么用PYTHON request.json读取下一层内容,直接把request中的json取出来变成dict和list组成的结构体,不就是随便读哪一个吗?python请求是否获得状态?1. 使用postman的时候,输入url和参数,调用post方法,接口会返回数据2. 然后我用python的requests来实现3.r= requests.request(' POST',req,data=value) python爬虫中的requestrequest对象是什么,就是从客户端向服务器发送一个请求,包括用户提交的信息和客户端的一些信息。客户端可以通过HTML表单或者在网页地址后面提供参数来提交数据,然后通过请求对象的相关方法获取这些数据。请求的各种方法主要用于处理客户端浏览器提交的请求中的各种参数和选项。python爬虫中的请求其实就是通过python向服务器发送请求请求,并获取返回的信息。python请求问题很容易实现。打开开发者工具,查看请求中的信息,获取上面你的tid等具体的查询参数。它只是一个参数,然后将这些参数做成字典,使用urlencode方法将参数字典转换成url格式,如下: url=''
python抓取动态网页(.4win7框架:如何获取网页上动态加载的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-11 04:14
环境:python3.4
赢7
框架:scrapy
继上一篇之后,这次我将讲如何获取网页上动态加载的数据:
作为初学者,我们在第一次接触爬虫的时候,一般只会抓取一些静态内容(如何区分静态内容和动态内容,这里不讲理论,只教一些小方法):
首先打开谷歌浏览器,然后按F12,就会弹出谷歌自带的开发者工具,首先在“元素”下找到你需要抓取的内容;
然后,在网页可视化界面上右键,选择查看网页源代码。网页源代码就是我们抓取静态网页时在网页中可以看到的所有东西,开发者工具可以查看。有些东西我们在网页的源代码中是看不到的;
最后,通过将我们在F12中查看的内容与网页源代码中的内容进行比较,可以初步判断哪些数据是静态加载的,哪些数据是动态加载的。
--------- ---分割线-----------
一般的请求方法有两种,post请求方法和get请求方法。在这篇文章中,我们先说一下get请求方法。
说到get请求,这应该是最常用的请求之一。表达 get 请求的最直观方式是什么?其实我们把网址放在地址栏中打开网页,这是一个get请求。
--------- ---分割线-----------
好的,现在让我们进入主题:让我们先用一个例子来描述它。抓取大型购物的商品评论时网站:
当我们点击 1 或 2 3 4 时,我们会发现 URL 根本没有改变。这意味着这些注释是动态加载的。然后我们使用F12下的抓包工具尝试抓包:(F12,然后选择“网络”),出现下图:
接下来是最重要的:在可视化界面中,我们点击“2”按钮,让评论页面跳转到第二页,看看能否顺利抓包:
OK,可以看到有2个gif文件,2个png文件,还有一个脚本文件。一开始,我们不知道应该检查哪个文件。好吧,最笨的方法,一个一个的点击:所以你关心我都订购了,除了脚本文件,其他的都是这样的:
哈哈,如果没有next,那我们只能检查脚本文件了。看Response,发现是一堆代码,查起来好像不方便?好的,没问题,我们试试预览,效果会很好。. . . 很高兴找到结果:
你看到吗!评论评论,大家应该相信网站大写手的英文是绝对没问题的,不会像我一样给评论起个“pinglun”的吧!
然后点击这条评论看看里面有什么:
好的,正是我们想要的注释,所以这个文件所在的URL就是我们需要的,接下来我们通过查看Headers来获取URL!
URL就是我们需要的URL(URL被马赛克抹掉了,不好意思各位,因为小弟也怕被查水表),状态值为200表示访问成功,访问方法: GET,回显话题,使用get请求获取网页的动态加载数据。好了,今天的教程到此结束。什么?不构造一个获取请求?那请到我的第一篇博文找大神的爬虫教程链接~~~~
好了,这篇文章到此结束。我从头到尾都没有看到任何代码。哈哈,有时候教他们钓鱼不如教他们钓鱼。代码很重要,方法也很重要。有了这些分析方法,相信大家都能快速掌握获取动态网页内容的技巧。下一篇我们会讲如何使用post请求来获取网页的动态加载数据~我们下期再见 查看全部
python抓取动态网页(.4win7框架:如何获取网页上动态加载的数据)
环境:python3.4
赢7
框架:scrapy
继上一篇之后,这次我将讲如何获取网页上动态加载的数据:
作为初学者,我们在第一次接触爬虫的时候,一般只会抓取一些静态内容(如何区分静态内容和动态内容,这里不讲理论,只教一些小方法):
首先打开谷歌浏览器,然后按F12,就会弹出谷歌自带的开发者工具,首先在“元素”下找到你需要抓取的内容;
然后,在网页可视化界面上右键,选择查看网页源代码。网页源代码就是我们抓取静态网页时在网页中可以看到的所有东西,开发者工具可以查看。有些东西我们在网页的源代码中是看不到的;
最后,通过将我们在F12中查看的内容与网页源代码中的内容进行比较,可以初步判断哪些数据是静态加载的,哪些数据是动态加载的。
--------- ---分割线-----------
一般的请求方法有两种,post请求方法和get请求方法。在这篇文章中,我们先说一下get请求方法。
说到get请求,这应该是最常用的请求之一。表达 get 请求的最直观方式是什么?其实我们把网址放在地址栏中打开网页,这是一个get请求。
--------- ---分割线-----------
好的,现在让我们进入主题:让我们先用一个例子来描述它。抓取大型购物的商品评论时网站:

当我们点击 1 或 2 3 4 时,我们会发现 URL 根本没有改变。这意味着这些注释是动态加载的。然后我们使用F12下的抓包工具尝试抓包:(F12,然后选择“网络”),出现下图:

接下来是最重要的:在可视化界面中,我们点击“2”按钮,让评论页面跳转到第二页,看看能否顺利抓包:

OK,可以看到有2个gif文件,2个png文件,还有一个脚本文件。一开始,我们不知道应该检查哪个文件。好吧,最笨的方法,一个一个的点击:所以你关心我都订购了,除了脚本文件,其他的都是这样的:

哈哈,如果没有next,那我们只能检查脚本文件了。看Response,发现是一堆代码,查起来好像不方便?好的,没问题,我们试试预览,效果会很好。. . . 很高兴找到结果:

你看到吗!评论评论,大家应该相信网站大写手的英文是绝对没问题的,不会像我一样给评论起个“pinglun”的吧!
然后点击这条评论看看里面有什么:

好的,正是我们想要的注释,所以这个文件所在的URL就是我们需要的,接下来我们通过查看Headers来获取URL!

URL就是我们需要的URL(URL被马赛克抹掉了,不好意思各位,因为小弟也怕被查水表),状态值为200表示访问成功,访问方法: GET,回显话题,使用get请求获取网页的动态加载数据。好了,今天的教程到此结束。什么?不构造一个获取请求?那请到我的第一篇博文找大神的爬虫教程链接~~~~
好了,这篇文章到此结束。我从头到尾都没有看到任何代码。哈哈,有时候教他们钓鱼不如教他们钓鱼。代码很重要,方法也很重要。有了这些分析方法,相信大家都能快速掌握获取动态网页内容的技巧。下一篇我们会讲如何使用post请求来获取网页的动态加载数据~我们下期再见
python抓取动态网页(利用Python实现抓取知乎热点话题(一)_网页分析_光明网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-08 21:05
前言
用Python捕捉知乎热门话题,废话不多说。
让我们愉快的开始吧~
开发工具
Python版本:3.6.4
相关模块:
请求模块;
重新模块;
熊猫模块;
lxml 模块;
随机模块;
以及一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
思维分析
本文爬取了知乎的热门话题《网通向腾讯高管提出拒绝陪酒的相关规定》,腾讯实习生如何看待?“例如
目标网址
网络分析
检查网页源代码等后,确定网页的回答内容是动态加载的,需要进入浏览器的开发者工具进行抓包。进入Nonetwork→XHR,在网页上用鼠标下拉即可得到我们需要的数据包
获取准确的网址
https://www.zhihu.com/api/v4/q ... fault
https://www.zhihu.com/api/v4/q ... fault
URL 有很多不必要的参数,您可以在浏览器中删除它们。两个URL的区别在于后面的offset参数。第一个URL的offset参数为0,第二个为5,偏移量以5的容差递增;网页数据格式为json格式。
代码
import requests\
import pandas as pd\
import re\
import time\
import random\
\
df = pd.DataFrame()\
headers = {\
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'\
}\
for page in range(0, 1360, 5):\
url = f'https://www.zhihu.com/api/v4/q ... et%3D{page}&platform=desktop&sort_by=default'\
response = requests.get(url=url, headers=headers).json()\
data = response['data']\
for list_ in data:\
name = list_['author']['name'] # 知乎作者\
id_ = list_['author']['id'] # 作者id\
created_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(list_['created_time'] )) # 回答时间\
voteup_count = list_['voteup_count'] # 赞同数\
comment_count = list_['comment_count'] # 底下评论数\
content = list_['content'] # 回答内容\
content = ''.join(re.findall("[\u3002\uff1b\uff0c\uff1a\u201c\u201d\uff08\uff09\u3001\uff1f\u300a\u300b\u4e00-\u9fa5]", content)) # 正则表达式提取\
print(name, id_, created_time, comment_count, content, sep='|')\
dataFrame = pd.DataFrame(\
{'知乎作者': [name], '作者id': [id_], '回答时间': [created_time], '赞同数': [voteup_count], '底下评论数': [comment_count],\
'回答内容': [content]})\
df = pd.concat([df, dataFrame])\
time.sleep(random.uniform(2, 3))\
df.to_csv('知乎回答.csv', encoding='utf-8', index=False)\
print(df.shape)
显示结果
————————————————————————————————————————————— 查看全部
python抓取动态网页(利用Python实现抓取知乎热点话题(一)_网页分析_光明网)
前言
用Python捕捉知乎热门话题,废话不多说。
让我们愉快的开始吧~
开发工具
Python版本:3.6.4
相关模块:
请求模块;
重新模块;
熊猫模块;
lxml 模块;
随机模块;
以及一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
思维分析
本文爬取了知乎的热门话题《网通向腾讯高管提出拒绝陪酒的相关规定》,腾讯实习生如何看待?“例如
目标网址
网络分析
检查网页源代码等后,确定网页的回答内容是动态加载的,需要进入浏览器的开发者工具进行抓包。进入Nonetwork→XHR,在网页上用鼠标下拉即可得到我们需要的数据包
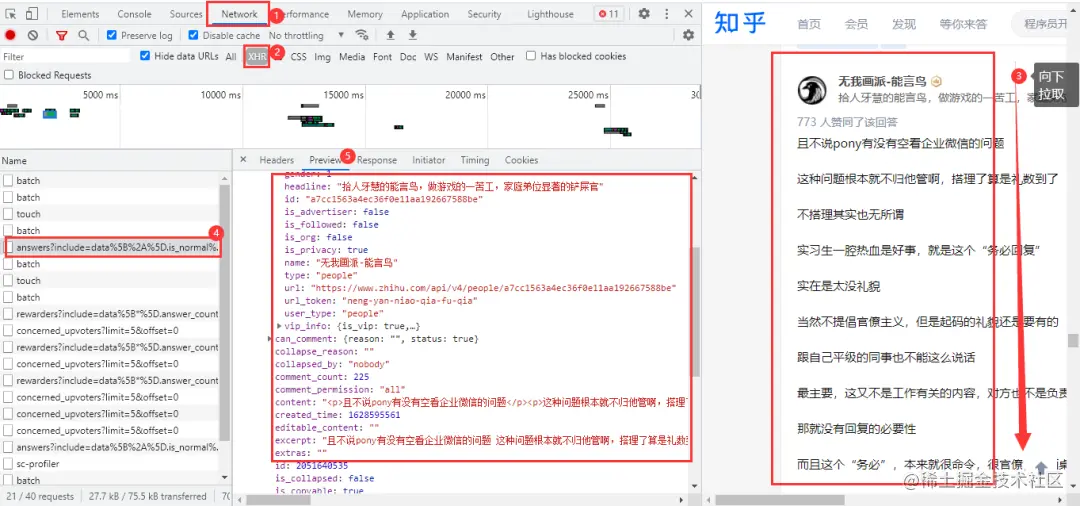
获取准确的网址
https://www.zhihu.com/api/v4/q ... fault
https://www.zhihu.com/api/v4/q ... fault
URL 有很多不必要的参数,您可以在浏览器中删除它们。两个URL的区别在于后面的offset参数。第一个URL的offset参数为0,第二个为5,偏移量以5的容差递增;网页数据格式为json格式。
代码
import requests\
import pandas as pd\
import re\
import time\
import random\
\
df = pd.DataFrame()\
headers = {\
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'\
}\
for page in range(0, 1360, 5):\
url = f'https://www.zhihu.com/api/v4/q ... et%3D{page}&platform=desktop&sort_by=default'\
response = requests.get(url=url, headers=headers).json()\
data = response['data']\
for list_ in data:\
name = list_['author']['name'] # 知乎作者\
id_ = list_['author']['id'] # 作者id\
created_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(list_['created_time'] )) # 回答时间\
voteup_count = list_['voteup_count'] # 赞同数\
comment_count = list_['comment_count'] # 底下评论数\
content = list_['content'] # 回答内容\
content = ''.join(re.findall("[\u3002\uff1b\uff0c\uff1a\u201c\u201d\uff08\uff09\u3001\uff1f\u300a\u300b\u4e00-\u9fa5]", content)) # 正则表达式提取\
print(name, id_, created_time, comment_count, content, sep='|')\
dataFrame = pd.DataFrame(\
{'知乎作者': [name], '作者id': [id_], '回答时间': [created_time], '赞同数': [voteup_count], '底下评论数': [comment_count],\
'回答内容': [content]})\
df = pd.concat([df, dataFrame])\
time.sleep(random.uniform(2, 3))\
df.to_csv('知乎回答.csv', encoding='utf-8', index=False)\
print(df.shape)
显示结果
—————————————————————————————————————————————
python抓取动态网页(如何用python来页面中的JS动态加载数据的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-05 20:01
)
本文文章与大家分享使用python抓取网页动态数据的方法。小编觉得很实用,分享给大家参考。跟着小编一起来看看吧。
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某一部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 都不是那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
python抓取动态网页(如何用python来页面中的JS动态加载数据的数据
)
本文文章与大家分享使用python抓取网页动态数据的方法。小编觉得很实用,分享给大家参考。跟着小编一起来看看吧。
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
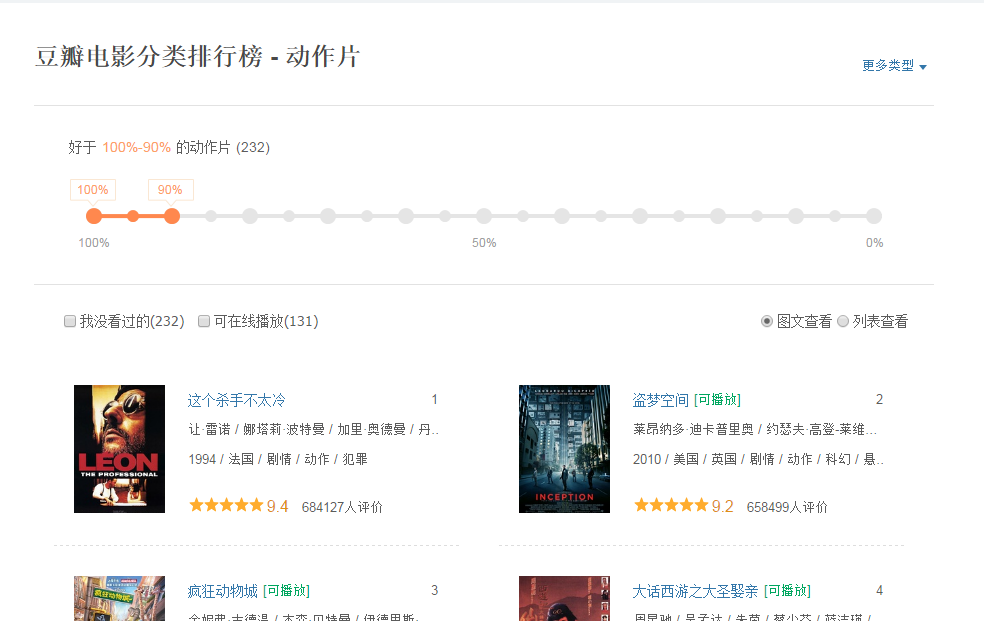
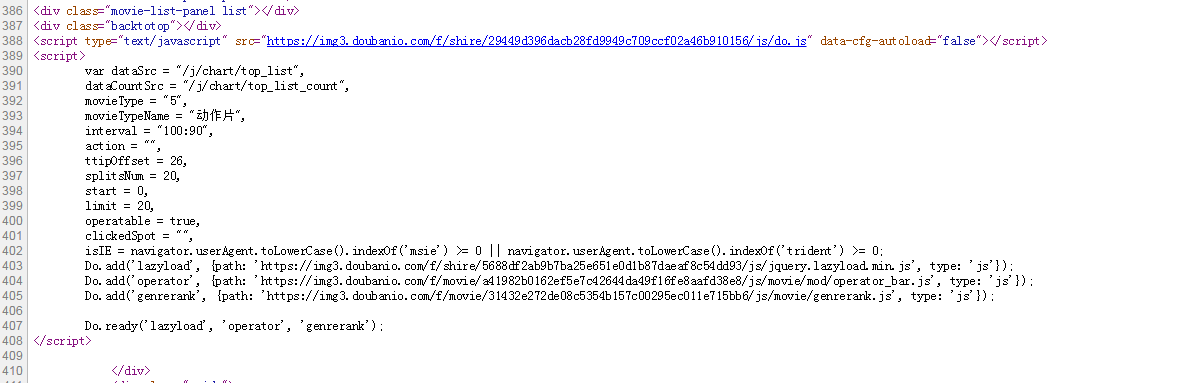
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
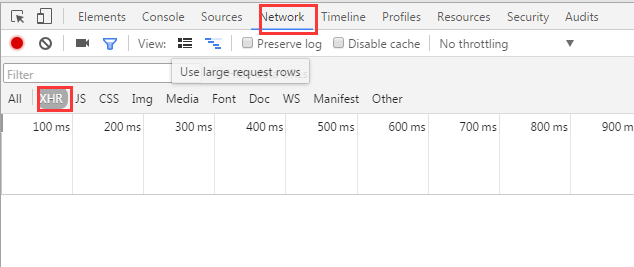
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某一部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。

查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 都不是那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
python抓取动态网页(基于requests+multiprocessing+pyspider的方法-python抓取动态网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-04 19:01
python抓取动态网页。今天介绍的是基于requests+multiprocessing+pyspider的方法。先来看效果:代码如下:#spider.pyimportrequestsfrommultiprocessingimportpoolfrompyspider.pagesimportmapdefurl_map(url,all_pages):try:r=requests.get(url)html=r.textreturnhtmlexceptexceptionase:return''response=pool.getresponse()returnresponse执行这个代码也非常简单:1.首先准备好请求路径和请求参数,请求函数我用的是get2.执行httpresponse对象的process方法,一边执行一边调用process方法的next方法,在一个请求被执行到底的时候next方法会被调用,完成接收返回值defnext(request):urls=requests.get(url).textreturnresponse.response(urls,"all_pages")这段代码我做了两点特别重要的事情:1.urls对象有了一个cookie参数cookie用来在请求的时候用来唯一标识一个url2.这时候获取到的url是一个整数,调用spider对象的get方法有返回值,而且返回值值为none(true返回的url是python自带的一个单例对象)我们来验证一下成功不。
frompyspider.controllersimportdispatchexportfrompyspider.spiderimportspiderurl=""try:r=requests.get(url).textexceptexceptionase:return''#1.将网页文件拿出来frompyspider.exceptionsimportspiderexceptionspiderexception=spiderexception('scrapy:error:trier')spiderexception=spiderexception('scrapy:error:filenotfound')spiderexception=spiderexception('scrapy:error:directoryerror')reload(spiderexception)finally:spiderexception=spiderexception('scrapy:spiderexception')spiderexception=spiderexception('scrapy:spiderexception')returnspiderexception通过httpresponse对象的get方法获取文件名,同时也拿到了请求路径的cookie值#2.获取返回值defget_response(filename):html=requests.get(url).textreturnhtml#3.将请求路径转换为urlopen(r'?charset=utf-8',formdata={'user-agent':'mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/59.0.3024.132safari/537.36'})withopen(filename,'wt')asf:f.write(response.response(newheader="c。 查看全部
python抓取动态网页(基于requests+multiprocessing+pyspider的方法-python抓取动态网页)
python抓取动态网页。今天介绍的是基于requests+multiprocessing+pyspider的方法。先来看效果:代码如下:#spider.pyimportrequestsfrommultiprocessingimportpoolfrompyspider.pagesimportmapdefurl_map(url,all_pages):try:r=requests.get(url)html=r.textreturnhtmlexceptexceptionase:return''response=pool.getresponse()returnresponse执行这个代码也非常简单:1.首先准备好请求路径和请求参数,请求函数我用的是get2.执行httpresponse对象的process方法,一边执行一边调用process方法的next方法,在一个请求被执行到底的时候next方法会被调用,完成接收返回值defnext(request):urls=requests.get(url).textreturnresponse.response(urls,"all_pages")这段代码我做了两点特别重要的事情:1.urls对象有了一个cookie参数cookie用来在请求的时候用来唯一标识一个url2.这时候获取到的url是一个整数,调用spider对象的get方法有返回值,而且返回值值为none(true返回的url是python自带的一个单例对象)我们来验证一下成功不。
frompyspider.controllersimportdispatchexportfrompyspider.spiderimportspiderurl=""try:r=requests.get(url).textexceptexceptionase:return''#1.将网页文件拿出来frompyspider.exceptionsimportspiderexceptionspiderexception=spiderexception('scrapy:error:trier')spiderexception=spiderexception('scrapy:error:filenotfound')spiderexception=spiderexception('scrapy:error:directoryerror')reload(spiderexception)finally:spiderexception=spiderexception('scrapy:spiderexception')spiderexception=spiderexception('scrapy:spiderexception')returnspiderexception通过httpresponse对象的get方法获取文件名,同时也拿到了请求路径的cookie值#2.获取返回值defget_response(filename):html=requests.get(url).textreturnhtml#3.将请求路径转换为urlopen(r'?charset=utf-8',formdata={'user-agent':'mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/59.0.3024.132safari/537.36'})withopen(filename,'wt')asf:f.write(response.response(newheader="c。
python抓取动态网页(python抓取动态网页的requests和urllib库的使用,介绍python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-04 15:05
python抓取动态网页的requests和urllib库的使用,介绍python抓取网页的方法。入门基础的爬虫的同学可以先去看看视频课程,其实有一个网页在讲这部分知识点。这是爬取页面的代码:第一步-使用requests.get将页面抓取下来,这里需要用到网页里面的url,也就是你需要的网址(page_name,page_id),抓取工具是urllib,获取工具是python自带的httplib库。
第二步-requests.set_user_agent(user_agent),即将用户请求用代理,也就是其他的浏览器。这里使用的是谷歌浏览器(googlechrome)。第三步-使用urllib.request()将请求的请求报文转换成html报文,这个工具是可选的,可以自己用到哪里就用哪里,能有一个需要就最好有,否则后续的都可以不用。
转换成html报文,以下代码解释说明如何将请求报文转换成html报文,google浏览器的解释如下,示例代码:#coding:utf-8defpage(url):'''循环请求页面..'''returnhtml(page_name,page_id)#请求一个网页,得到请求报文returnhtml(get(url).text)如果使用httplib.urllib.request方法,就要下载相应的httplib库,如下代码,详细用法请看代码:requests+urllib=requests.get(url)第四步-urllib.request.urlopen,获取页面内容,这里下载页面的内容使用的是urllib.request.urlopen方法。
同时下载下来的内容也可以再继续用get请求。动态网页的示例:importurllib.requestimportjsonfromfake_useragentimportuseragenttry:url=''response=urllib.request.urlopen(url)try:response=json.loads(response)except:raisenotimplementedfinally:try:response=json.loads(response)except:raisenotimplementedurllib.request.urlopen(url)以上代码获取到的页面内容为:知乎是3.05.1版本app,普通用户的话要过365天才能获取到你想要的内容。 查看全部
python抓取动态网页(python抓取动态网页的requests和urllib库的使用,介绍python)
python抓取动态网页的requests和urllib库的使用,介绍python抓取网页的方法。入门基础的爬虫的同学可以先去看看视频课程,其实有一个网页在讲这部分知识点。这是爬取页面的代码:第一步-使用requests.get将页面抓取下来,这里需要用到网页里面的url,也就是你需要的网址(page_name,page_id),抓取工具是urllib,获取工具是python自带的httplib库。
第二步-requests.set_user_agent(user_agent),即将用户请求用代理,也就是其他的浏览器。这里使用的是谷歌浏览器(googlechrome)。第三步-使用urllib.request()将请求的请求报文转换成html报文,这个工具是可选的,可以自己用到哪里就用哪里,能有一个需要就最好有,否则后续的都可以不用。
转换成html报文,以下代码解释说明如何将请求报文转换成html报文,google浏览器的解释如下,示例代码:#coding:utf-8defpage(url):'''循环请求页面..'''returnhtml(page_name,page_id)#请求一个网页,得到请求报文returnhtml(get(url).text)如果使用httplib.urllib.request方法,就要下载相应的httplib库,如下代码,详细用法请看代码:requests+urllib=requests.get(url)第四步-urllib.request.urlopen,获取页面内容,这里下载页面的内容使用的是urllib.request.urlopen方法。
同时下载下来的内容也可以再继续用get请求。动态网页的示例:importurllib.requestimportjsonfromfake_useragentimportuseragenttry:url=''response=urllib.request.urlopen(url)try:response=json.loads(response)except:raisenotimplementedfinally:try:response=json.loads(response)except:raisenotimplementedurllib.request.urlopen(url)以上代码获取到的页面内容为:知乎是3.05.1版本app,普通用户的话要过365天才能获取到你想要的内容。
python抓取动态网页(如何捕获到动态加载的数据?通过示例代码介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-11-03 16:01
本文文章主要介绍Python对网页动态加载的数据进行爬取的实现。通过示例代码介绍非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友关注小编,一起学习
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,说明数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击了解json序列化和反序列化。代码如下:
import requests import json # 获取商品价格的请求地址 url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \ "=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \ "pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921" jQuery_id = url.split("=")[-1] + "(" # 头部信息 headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) " "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36" } # 发送网络请求 response = requests.get(url, headers=headers) if response.status_code == 200: goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化 print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}") print(f"定价为: {goods_dict['stock']['jdPrice']['m']}") print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}") else: print("请求失败!")
作者写博文的时候,价格发生了变化,运行结果如下图所示:
注意:抓取动态加载数据信息时,需要根据不同的网页使用不同的方法进行数据提取。如果在运行源代码时出现错误,请按照步骤获取新的请求地址。
以上就是Python实现的爬取网页中动态加载数据的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
python抓取动态网页(如何捕获到动态加载的数据?通过示例代码介绍)
本文文章主要介绍Python对网页动态加载的数据进行爬取的实现。通过示例代码介绍非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友关注小编,一起学习
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。

1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,说明数据不是动态加载的。否则,数据是动态加载的。如图所示:

或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:

3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。

在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。

查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。

根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击了解json序列化和反序列化。代码如下:
import requests import json # 获取商品价格的请求地址 url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \ "=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \ "pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921" jQuery_id = url.split("=")[-1] + "(" # 头部信息 headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) " "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36" } # 发送网络请求 response = requests.get(url, headers=headers) if response.status_code == 200: goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化 print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}") print(f"定价为: {goods_dict['stock']['jdPrice']['m']}") print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}") else: print("请求失败!")
作者写博文的时候,价格发生了变化,运行结果如下图所示:

注意:抓取动态加载数据信息时,需要根据不同的网页使用不同的方法进行数据提取。如果在运行源代码时出现错误,请按照步骤获取新的请求地址。
以上就是Python实现的爬取网页中动态加载数据的详细内容。更多详情请关注其他相关html中文网站文章!
python抓取动态网页(AJAX动态加载网页一什么是动态网页J哥一向注重理论与实践)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-11-03 14:22
AJAX 动态加载网页
一
什么是动态网页
J哥一向注重理论与实践的结合,知道发生了什么也必须知道为什么,这样他才能在没有变化的情况下应对所有的变化。
所谓动态网页,是指一种与静态网页相对的网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。——来源百度百科
动态网页具有工作量少、内容更新快、功能更齐全的特点。被很多公司采用,如购动、速食宝、速食等。
二
什么是 AJAX
随着人们对动态网页的加载速度要求越来越高,AJAX 技术应运而生,成为许多网站的首选。AJAX 是一种用于创建快速动态网页的技术,通过在后台与服务器进行少量数据交换,使网页可以异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
三
如何抓取AJAX动态加载的网页
1. 分析界面
只要有数据发送,就一定有请求发送到服务器。我们只需要找出它静默加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站比较难解析。
2. 硒
什么是硒?它最初是一个自动化测试工具,但被广泛的用户抓取。是一个可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。 特点:代码比较简单,爬取速度慢,IP容易被封。
项目实践
理论这么多,老实说,J哥也不想这么啰嗦。但是,这些东西经常被问到,所以把它们写下来。下次有人问,就送他这个文章,一劳永逸!
好,让我们回到王律师的部分。作为资深律师,王律师深知,研究法院多年来公开的开庭信息和执行信息,对于提升业务能力具有重要作用。于是他兴高采烈地打开了法庭信息公开网页。
它看起来像这样:
然后,他按照J哥之前写的爬虫介绍文章抓取数据,成功提取到第一页。他异常兴奋。
紧接着,他又加了一个for循环,想着花几分钟把这个网站2164页共32457条宣判数据提取到excel中。
然后,就没有了。你也应该知道,看了前面的理论部分,这是一个AJAX动态加载的网页。无论你如何点击下一页,url都不会改变。如果你不相信我,我就给你看。左上角的url像山一样矗立在那里:
一
解析接口
既然如此,那我们就开始爬虫的正确姿势,先用解析接口的方法来写爬虫。
首先,找到真正的要求。右键勾选,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。没错,就是这么简单,真正的要求就藏在里面。
我们仔细看看这个jsp,这简直就是宝藏。有真实的请求url、post请求方法、Headers、Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!为了安全起见,我为我的 Cookie 做了马赛克。机智的朋友可能已经发现我顺便给自己打了广告。
让我们仔细看看这些参数, pagesnum 参数不只是代表页数!王律师顿时恍然大悟,原来他思考的那一页,竟然翻到了这里!穿越千山万水,终于找到了你!我们尝试点击翻页,发现只有 pagesnum 参数会发生变化。
既然找到了,赶紧抓起来吧。J哥以闪电般的速度打开了PyCharm,导入了爬虫需要的库。
1from urllib.parse import urlencode
2import csv
3import random
4import requests
5import traceback
6from time import sleep
7from lxml import etree #lxml为第三方网页解析库,强大且速度快
构造一个真正的请求并添加标题。J哥没有把他的User-Agent和Cookie贴在这里,主要是一向胆小的J哥被吓到了。
1base_url = 'http://www.hshfy.sh.cn/shfy/gw ... 39%3B #这里要换成对应Ajax请求中的链接
2
3headers = {
4 'Connection': 'keep-alive',
5 'Accept': '*/*',
6 'X-Requested-With': 'XMLHttpRequest',
7 'User-Agent': '你的User-Agent',
8 'Origin': 'http://www.hshfy.sh.cn',
9 'Referer': 'http://www.hshfy.sh.cn/shfy/gw ... 39%3B,
10 'Accept-Language': 'zh-CN,zh;q=0.9',
11 'Content-Type': 'application/x-www-form-urlencoded',
12 'Cookie': '你的Cookie'
13}
构造get_page函数,参数为page,即页数。创建字典类型的表单数据,并使用post请求网页数据。这里一定要注意返回数据的解码,编码为'gbk',否则返回数据会乱码!另外,我还优化了异常处理,防止意外。
1def get_page(page):
2 n = 3
3 while True:
4 try:
5 sleep(random.uniform(1, 2)) # 随机出现1-2之间的数,包含小数
6 data = {
7 'yzm': 'yxAH',
8 'ft':'',
9 'ktrqks': '2020-05-22',
10 'ktrqjs': '2020-06-22',
11 'spc':'',
12 'yg':'',
13 'bg':'',
14 'ah':'',
15 'pagesnum': page
16 }
17 url = base_url + urlencode(data)
18 print(url)
19 try:
20 response = requests.request("POST",url, headers = headers)
21 #print(response)
22 if response.status_code == 200:
23 re = response.content.decode('gbk')
24 # print(re)
25 return re # 解析内容
26 except requests.ConnectionError as e:
27 print('Error', e.args) # 输出异常信息
28 except (TimeoutError, Exception):
29 n -= 1
30 if n == 0:
31 print('请求3次均失败,放弃此url请求,检查请求条件')
32 return
33 else:
34 print('请求失败,重新请求')
35 continue
构造parse_page函数解析返回的网页数据,用Xpath提取所有字段内容,并保存为csv格式。有人会问为什么J哥那么喜欢用Xpath,因为它简单好用!!!这么简单的网页结构,我做不了普通的大法安装。J兄弟,我做不到。
1def parse_page(html):
2 try:
3 parse = etree.HTML(html) # 解析网页
4 items = parse.xpath('//*[@id="report"]/tbody/tr')
5 for item in items[1:]:
6 item = {
7 'a': ''.join(item.xpath('./td[1]/font/text()')).strip(),
8 'b': ''.join(item.xpath('./td[2]/font/text()')).strip(),
9 'c': ''.join(item.xpath('./td[3]/text()')).strip(),
10 'd': ''.join(item.xpath('./td[4]/text()')).strip(),
11 'e': ''.join(item.xpath('./td[5]/text()')).strip(),
12 'f': ''.join(item.xpath('./td[6]/div/text()')).strip(),
13 'g': ''.join(item.xpath('./td[7]/div/text()')).strip(),
14 'h': ''.join(item.xpath('./td[8]/text()')).strip(),
15 'i': ''.join(item.xpath('./td[9]/text()')).strip()
16 }
17 #print(item)
18 try:
19 with open('./law.csv', 'a', encoding='utf_8_sig', newline='') as fp:
20 # 'a'为追加模式(添加)
21 # utf_8_sig格式导出csv不乱码
22 fieldnames = ['a', 'b', 'c', 'd', 'e','f','g','h','i']
23 writer = csv.DictWriter(fp,fieldnames)
24 writer.writerow(item)
25 except Exception:
26 print(traceback.print_exc()) #代替print e 来输出详细的异常信息
27 except Exception:
28 print(traceback.print_exc())
最后遍历页数,调用函数。OK完成!
1 for page in range(1,5): #这里设置想要爬取的页数
2 html = get_page(page)
3 #print(html)
4 print("第" + str(page) + "页提取完成")
我们来看看最终的效果:
二
硒
热衷学习的朋友可能还想看看Selenium是如何爬取AJAX动态加载网页的。J哥自然会满足你的好奇心。于是赶紧新建了一个py文件,准备趁势而上,用Selenium把这个网站爬下来。
首先,导入相关库。
1from lxml import etree
2import time
3from selenium import webdriver
4from selenium. webdriver.support.wait import WebDriverWait
5from selenium.webdriver.support import expected_conditions as EC
6from selenium.webdriver.common.by import By
然后,使用chromedriver驱动打开这个网站。
1def main():
2 # 爬取首页url
3 url = "http://www.hshfy.sh.cn/shfy/gw ... ot%3B
4 # 定义谷歌webdriver
5 driver = webdriver.Chrome('./chromedriver')
6 driver.maximize_window() # 将浏览器最大化
7 driver.get(url)
所以,我惊讶地发现报告了一个错误。以CET-6英语的词汇储备,J哥居然听懂了!可能是我的驱动和浏览器版本不匹配,只支持79版本的浏览器。
J兄很郁闷,因为我之前用Selenium没遇到过这个问题。J哥不甘心,打开谷歌浏览器查看版本号。
我失去了它!他们都更新到了81版!遇到这种情况,请好奇的朋友,请等待J哥设置浏览器自动更新并重新下载最新驱动。下次你会听Selenium crawler。记得关注本公众号。不要错过刺激~
结束语
综上所述,对于网络爬虫的AJAX动态加载,一般有两种方式:解析接口;硒。J兄推荐解析接口的方式。如果是解析json数据,最好是爬取。如果你不知道如何使用Selenium,让我们使用Selenium。
后台私信编辑器01获取完整项目代码`1 查看全部
python抓取动态网页(AJAX动态加载网页一什么是动态网页J哥一向注重理论与实践)
AJAX 动态加载网页
一
什么是动态网页
J哥一向注重理论与实践的结合,知道发生了什么也必须知道为什么,这样他才能在没有变化的情况下应对所有的变化。
所谓动态网页,是指一种与静态网页相对的网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。——来源百度百科
动态网页具有工作量少、内容更新快、功能更齐全的特点。被很多公司采用,如购动、速食宝、速食等。
二
什么是 AJAX
随着人们对动态网页的加载速度要求越来越高,AJAX 技术应运而生,成为许多网站的首选。AJAX 是一种用于创建快速动态网页的技术,通过在后台与服务器进行少量数据交换,使网页可以异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
三
如何抓取AJAX动态加载的网页
1. 分析界面
只要有数据发送,就一定有请求发送到服务器。我们只需要找出它静默加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站比较难解析。
2. 硒
什么是硒?它最初是一个自动化测试工具,但被广泛的用户抓取。是一个可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。 特点:代码比较简单,爬取速度慢,IP容易被封。
项目实践
理论这么多,老实说,J哥也不想这么啰嗦。但是,这些东西经常被问到,所以把它们写下来。下次有人问,就送他这个文章,一劳永逸!
好,让我们回到王律师的部分。作为资深律师,王律师深知,研究法院多年来公开的开庭信息和执行信息,对于提升业务能力具有重要作用。于是他兴高采烈地打开了法庭信息公开网页。
它看起来像这样:
然后,他按照J哥之前写的爬虫介绍文章抓取数据,成功提取到第一页。他异常兴奋。
紧接着,他又加了一个for循环,想着花几分钟把这个网站2164页共32457条宣判数据提取到excel中。
然后,就没有了。你也应该知道,看了前面的理论部分,这是一个AJAX动态加载的网页。无论你如何点击下一页,url都不会改变。如果你不相信我,我就给你看。左上角的url像山一样矗立在那里:
一
解析接口
既然如此,那我们就开始爬虫的正确姿势,先用解析接口的方法来写爬虫。
首先,找到真正的要求。右键勾选,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。没错,就是这么简单,真正的要求就藏在里面。
我们仔细看看这个jsp,这简直就是宝藏。有真实的请求url、post请求方法、Headers、Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!为了安全起见,我为我的 Cookie 做了马赛克。机智的朋友可能已经发现我顺便给自己打了广告。
让我们仔细看看这些参数, pagesnum 参数不只是代表页数!王律师顿时恍然大悟,原来他思考的那一页,竟然翻到了这里!穿越千山万水,终于找到了你!我们尝试点击翻页,发现只有 pagesnum 参数会发生变化。
既然找到了,赶紧抓起来吧。J哥以闪电般的速度打开了PyCharm,导入了爬虫需要的库。
1from urllib.parse import urlencode
2import csv
3import random
4import requests
5import traceback
6from time import sleep
7from lxml import etree #lxml为第三方网页解析库,强大且速度快
构造一个真正的请求并添加标题。J哥没有把他的User-Agent和Cookie贴在这里,主要是一向胆小的J哥被吓到了。
1base_url = 'http://www.hshfy.sh.cn/shfy/gw ... 39%3B #这里要换成对应Ajax请求中的链接
2
3headers = {
4 'Connection': 'keep-alive',
5 'Accept': '*/*',
6 'X-Requested-With': 'XMLHttpRequest',
7 'User-Agent': '你的User-Agent',
8 'Origin': 'http://www.hshfy.sh.cn',
9 'Referer': 'http://www.hshfy.sh.cn/shfy/gw ... 39%3B,
10 'Accept-Language': 'zh-CN,zh;q=0.9',
11 'Content-Type': 'application/x-www-form-urlencoded',
12 'Cookie': '你的Cookie'
13}
构造get_page函数,参数为page,即页数。创建字典类型的表单数据,并使用post请求网页数据。这里一定要注意返回数据的解码,编码为'gbk',否则返回数据会乱码!另外,我还优化了异常处理,防止意外。
1def get_page(page):
2 n = 3
3 while True:
4 try:
5 sleep(random.uniform(1, 2)) # 随机出现1-2之间的数,包含小数
6 data = {
7 'yzm': 'yxAH',
8 'ft':'',
9 'ktrqks': '2020-05-22',
10 'ktrqjs': '2020-06-22',
11 'spc':'',
12 'yg':'',
13 'bg':'',
14 'ah':'',
15 'pagesnum': page
16 }
17 url = base_url + urlencode(data)
18 print(url)
19 try:
20 response = requests.request("POST",url, headers = headers)
21 #print(response)
22 if response.status_code == 200:
23 re = response.content.decode('gbk')
24 # print(re)
25 return re # 解析内容
26 except requests.ConnectionError as e:
27 print('Error', e.args) # 输出异常信息
28 except (TimeoutError, Exception):
29 n -= 1
30 if n == 0:
31 print('请求3次均失败,放弃此url请求,检查请求条件')
32 return
33 else:
34 print('请求失败,重新请求')
35 continue
构造parse_page函数解析返回的网页数据,用Xpath提取所有字段内容,并保存为csv格式。有人会问为什么J哥那么喜欢用Xpath,因为它简单好用!!!这么简单的网页结构,我做不了普通的大法安装。J兄弟,我做不到。
1def parse_page(html):
2 try:
3 parse = etree.HTML(html) # 解析网页
4 items = parse.xpath('//*[@id="report"]/tbody/tr')
5 for item in items[1:]:
6 item = {
7 'a': ''.join(item.xpath('./td[1]/font/text()')).strip(),
8 'b': ''.join(item.xpath('./td[2]/font/text()')).strip(),
9 'c': ''.join(item.xpath('./td[3]/text()')).strip(),
10 'd': ''.join(item.xpath('./td[4]/text()')).strip(),
11 'e': ''.join(item.xpath('./td[5]/text()')).strip(),
12 'f': ''.join(item.xpath('./td[6]/div/text()')).strip(),
13 'g': ''.join(item.xpath('./td[7]/div/text()')).strip(),
14 'h': ''.join(item.xpath('./td[8]/text()')).strip(),
15 'i': ''.join(item.xpath('./td[9]/text()')).strip()
16 }
17 #print(item)
18 try:
19 with open('./law.csv', 'a', encoding='utf_8_sig', newline='') as fp:
20 # 'a'为追加模式(添加)
21 # utf_8_sig格式导出csv不乱码
22 fieldnames = ['a', 'b', 'c', 'd', 'e','f','g','h','i']
23 writer = csv.DictWriter(fp,fieldnames)
24 writer.writerow(item)
25 except Exception:
26 print(traceback.print_exc()) #代替print e 来输出详细的异常信息
27 except Exception:
28 print(traceback.print_exc())
最后遍历页数,调用函数。OK完成!
1 for page in range(1,5): #这里设置想要爬取的页数
2 html = get_page(page)
3 #print(html)
4 print("第" + str(page) + "页提取完成")
我们来看看最终的效果:
二
硒
热衷学习的朋友可能还想看看Selenium是如何爬取AJAX动态加载网页的。J哥自然会满足你的好奇心。于是赶紧新建了一个py文件,准备趁势而上,用Selenium把这个网站爬下来。
首先,导入相关库。
1from lxml import etree
2import time
3from selenium import webdriver
4from selenium. webdriver.support.wait import WebDriverWait
5from selenium.webdriver.support import expected_conditions as EC
6from selenium.webdriver.common.by import By
然后,使用chromedriver驱动打开这个网站。
1def main():
2 # 爬取首页url
3 url = "http://www.hshfy.sh.cn/shfy/gw ... ot%3B
4 # 定义谷歌webdriver
5 driver = webdriver.Chrome('./chromedriver')
6 driver.maximize_window() # 将浏览器最大化
7 driver.get(url)
所以,我惊讶地发现报告了一个错误。以CET-6英语的词汇储备,J哥居然听懂了!可能是我的驱动和浏览器版本不匹配,只支持79版本的浏览器。
J兄很郁闷,因为我之前用Selenium没遇到过这个问题。J哥不甘心,打开谷歌浏览器查看版本号。
我失去了它!他们都更新到了81版!遇到这种情况,请好奇的朋友,请等待J哥设置浏览器自动更新并重新下载最新驱动。下次你会听Selenium crawler。记得关注本公众号。不要错过刺激~
结束语
综上所述,对于网络爬虫的AJAX动态加载,一般有两种方式:解析接口;硒。J兄推荐解析接口的方式。如果是解析json数据,最好是爬取。如果你不知道如何使用Selenium,让我们使用Selenium。
后台私信编辑器01获取完整项目代码`1
python抓取动态网页(使用scrapy框架写爬虫时一般会在start_urls中定义的路径网页爬取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-02 19:13
)
在使用scrapy框架编写爬虫时,我们一般都会在start_urls中指定我们需要爬取的网页的URL进行爬取,但是如何让我们的爬虫像搜索引擎中使用的爬虫一样具有自动多网页爬取的功能呢?本文通过自动抓取个人csdn博客的所有文章标题、读者数量和创建时间进行简单说明。本文使用了两种不同的方法来实现这一点。
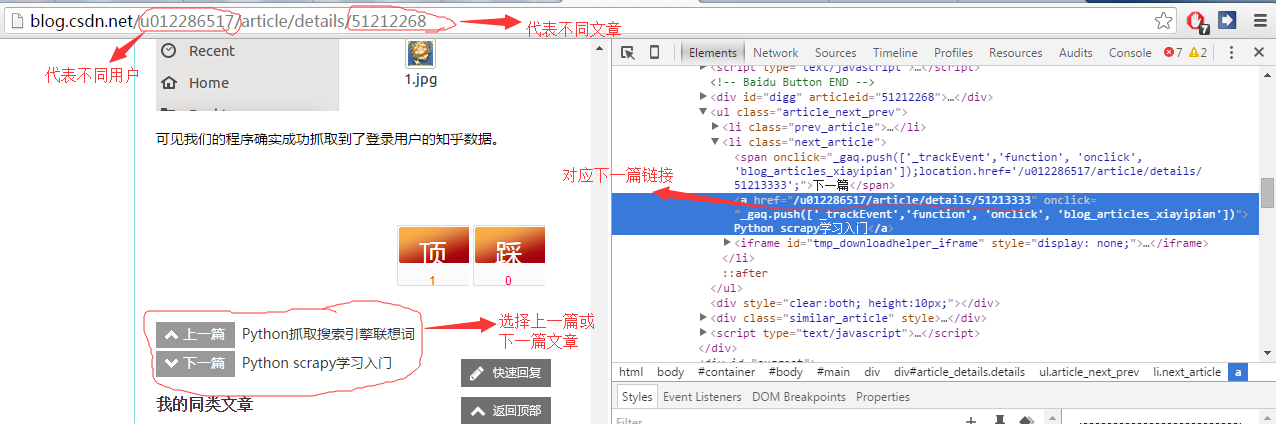
首先我们来分析一下cdsn中博客中文章的url。如图,我们可以发现不同的文章页面的url只是url末尾的一串数字不同,而在每篇文章文章下面@>都会有链接到上一个或下一个 文章。所以我们可以提取这个链接来实现网页的自动抓取。
在scrapy框架上写爬虫的整体流程和上一篇文章的流程是一样的。这里就不直接重复代码了。
项目.py
import scrapy
class CsdnItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
title=scrapy.Field()
time=scrapy.Field()
readtimes=scrapy.Field()
article_url=scrapy.Field()
pass
管道.py
import codecs
import json
from scrapy import signals
class CsdnPipeline(object):
def __init__(self):
self.file=codecs.open('data.json','w',encoding='utf-8')
def process_item(self, item, spider):
line=json.dumps(dict(item))+'\n'
self.file.write(line.decode("unicode_escape"))
return item
def spider_closed(self,spider):
self.file.close()
设置.py
# -*- coding: utf-8 -*-
# Scrapy settings for csdn project
#
# For simplicity, this file contains only the most important settings by
# default. All the other settings are documented here:
#
# http://doc.scrapy.org/en/lates ... .html
#
BOT_NAME = 'csdn'
SPIDER_MODULES = ['csdn.spiders']
NEWSPIDER_MODULE = 'csdn.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'csdn (+http://www.yourdomain.com)'
USER_AGENT = 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:37.0) Gecko/20100101 Firefox/37.0'
ITEM_PIPELINES = {
'csdn.pipelines.CsdnPipeline':300,
}
DOWNLOAD_DELAY = 2
COOKIES_ENABLED=False
然后是最关键的爬虫部分。我们仍然使用的第一种方法是普通的 Spider。将要爬取的第一篇文章文章的地址放在start_urls中。爬取完这篇文章文章的基本信息,放入定义好的item,然后提取下一篇文章的连接地址,结合python中的yield,通过请求的功能和要求退货页面的内容在回调函数进行处理。具体代码如下:
蜘蛛1.py
#-*- coding:utf-8 -*-
from scrapy.spider import Spider
from scrapy.http import Request
from scrapy.selector import Selector
from csdn.items import CsdnItem
class csdnSpider(Spider):
name="csdn"
download_delay=1
allowed_domains=["blog.csdn.net"]
start_urls=[
"http://blog.csdn.net/u01228651 ... ot%3B
]
def parse(self,response):
sel=Selector(response)
item=CsdnItem()
title=sel.xpath('//div[@id="article_details"]/div/h1/span/a/text()').extract()
article_url = str(response.url)
time=sel.xpath('//div[@id="article_details"]/div[2]/div/span[@class="link_postdate"]/text()').extract()
readtimes=sel.xpath('//div[@id="article_details"]/div[2]/div/span[@class="link_view"]/text()').extract()
item['title']=[n.encode('utf-8').replace("\r\n","").strip() for n in title]
item['time']=[n.encode('utf-8') for n in time]
item['readtimes']=[n.encode('utf-8') for n in readtimes]
yield item
#get next url
urls=sel.xpath('//li[@class="next_article"]/a/@href').extract()
for url in urls:
print url
url="http://blog.csdn.net"+url
print url
yield Request(url,callback=self.parse)
第二种方法我们使用scrapy框架提供的CrawlSpider,它是Spider的派生类。普通蜘蛛只会抓取start_urls中定义的路径网页,但CrawlSpider定义了一些规则(rules),为后续链接提供便利的机制。可能蜘蛛并不完全适合你的特定网站 或项目,但它在很多情况下都会用到。所以你可以以它为起点,根据你的需要修改一些方法。当然你也可以实现自己的蜘蛛。
除了继承自Spider的属性(你必须提供)之外,它还提供了一个新的属性:
规则:
收录一个(或多个)规则对象的集合(列表)。每个规则定义了爬行 网站 的特定性能。下面将介绍 Rule 对象。如果多个规则匹配同一个链接,将根据它们在此属性中定义的顺序使用第一个。
蜘蛛还提供了一个可覆盖的方法:
parse_start_url(响应)
当 start_url 请求返回时,将调用此方法。此方法分析初始返回值,并且必须返回 Item 对象或 Request 对象或收录两者的可迭代对象。
具体实现代码如下:
在规则中,我们定义如何提取从被抓取网页的链接。在本例中,链接满足'/u012286517/article/details'的正则表达式。同时,restrict_xpath 用于限制仅从页面的特定部分提取要抓取的链接。
运行代码,我们得到如下结果,其中红线代表一块文章:
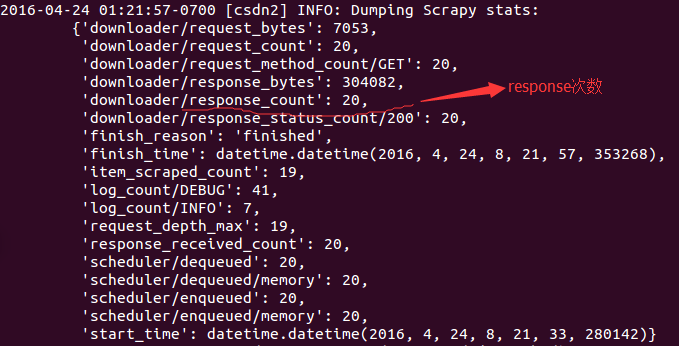
我们来看看爬取到的信息部分:其中,我们可以清楚地看到请求数和响应数为20,与博客中文章的数量一致。
下图是爬取返回的信息与csdn中的文章列表对比:
查看全部
python抓取动态网页(使用scrapy框架写爬虫时一般会在start_urls中定义的路径网页爬取
)
在使用scrapy框架编写爬虫时,我们一般都会在start_urls中指定我们需要爬取的网页的URL进行爬取,但是如何让我们的爬虫像搜索引擎中使用的爬虫一样具有自动多网页爬取的功能呢?本文通过自动抓取个人csdn博客的所有文章标题、读者数量和创建时间进行简单说明。本文使用了两种不同的方法来实现这一点。
首先我们来分析一下cdsn中博客中文章的url。如图,我们可以发现不同的文章页面的url只是url末尾的一串数字不同,而在每篇文章文章下面@>都会有链接到上一个或下一个 文章。所以我们可以提取这个链接来实现网页的自动抓取。
在scrapy框架上写爬虫的整体流程和上一篇文章的流程是一样的。这里就不直接重复代码了。
项目.py
import scrapy
class CsdnItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
title=scrapy.Field()
time=scrapy.Field()
readtimes=scrapy.Field()
article_url=scrapy.Field()
pass
管道.py
import codecs
import json
from scrapy import signals
class CsdnPipeline(object):
def __init__(self):
self.file=codecs.open('data.json','w',encoding='utf-8')
def process_item(self, item, spider):
line=json.dumps(dict(item))+'\n'
self.file.write(line.decode("unicode_escape"))
return item
def spider_closed(self,spider):
self.file.close()
设置.py
# -*- coding: utf-8 -*-
# Scrapy settings for csdn project
#
# For simplicity, this file contains only the most important settings by
# default. All the other settings are documented here:
#
# http://doc.scrapy.org/en/lates ... .html
#
BOT_NAME = 'csdn'
SPIDER_MODULES = ['csdn.spiders']
NEWSPIDER_MODULE = 'csdn.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'csdn (+http://www.yourdomain.com)'
USER_AGENT = 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:37.0) Gecko/20100101 Firefox/37.0'
ITEM_PIPELINES = {
'csdn.pipelines.CsdnPipeline':300,
}
DOWNLOAD_DELAY = 2
COOKIES_ENABLED=False
然后是最关键的爬虫部分。我们仍然使用的第一种方法是普通的 Spider。将要爬取的第一篇文章文章的地址放在start_urls中。爬取完这篇文章文章的基本信息,放入定义好的item,然后提取下一篇文章的连接地址,结合python中的yield,通过请求的功能和要求退货页面的内容在回调函数进行处理。具体代码如下:
蜘蛛1.py
#-*- coding:utf-8 -*-
from scrapy.spider import Spider
from scrapy.http import Request
from scrapy.selector import Selector
from csdn.items import CsdnItem
class csdnSpider(Spider):
name="csdn"
download_delay=1
allowed_domains=["blog.csdn.net"]
start_urls=[
"http://blog.csdn.net/u01228651 ... ot%3B
]
def parse(self,response):
sel=Selector(response)
item=CsdnItem()
title=sel.xpath('//div[@id="article_details"]/div/h1/span/a/text()').extract()
article_url = str(response.url)
time=sel.xpath('//div[@id="article_details"]/div[2]/div/span[@class="link_postdate"]/text()').extract()
readtimes=sel.xpath('//div[@id="article_details"]/div[2]/div/span[@class="link_view"]/text()').extract()
item['title']=[n.encode('utf-8').replace("\r\n","").strip() for n in title]
item['time']=[n.encode('utf-8') for n in time]
item['readtimes']=[n.encode('utf-8') for n in readtimes]
yield item
#get next url
urls=sel.xpath('//li[@class="next_article"]/a/@href').extract()
for url in urls:
print url
url="http://blog.csdn.net"+url
print url
yield Request(url,callback=self.parse)
第二种方法我们使用scrapy框架提供的CrawlSpider,它是Spider的派生类。普通蜘蛛只会抓取start_urls中定义的路径网页,但CrawlSpider定义了一些规则(rules),为后续链接提供便利的机制。可能蜘蛛并不完全适合你的特定网站 或项目,但它在很多情况下都会用到。所以你可以以它为起点,根据你的需要修改一些方法。当然你也可以实现自己的蜘蛛。
除了继承自Spider的属性(你必须提供)之外,它还提供了一个新的属性:
规则:
收录一个(或多个)规则对象的集合(列表)。每个规则定义了爬行 网站 的特定性能。下面将介绍 Rule 对象。如果多个规则匹配同一个链接,将根据它们在此属性中定义的顺序使用第一个。
蜘蛛还提供了一个可覆盖的方法:
parse_start_url(响应)
当 start_url 请求返回时,将调用此方法。此方法分析初始返回值,并且必须返回 Item 对象或 Request 对象或收录两者的可迭代对象。
具体实现代码如下:
在规则中,我们定义如何提取从被抓取网页的链接。在本例中,链接满足'/u012286517/article/details'的正则表达式。同时,restrict_xpath 用于限制仅从页面的特定部分提取要抓取的链接。
运行代码,我们得到如下结果,其中红线代表一块文章:
我们来看看爬取到的信息部分:其中,我们可以清楚地看到请求数和响应数为20,与博客中文章的数量一致。
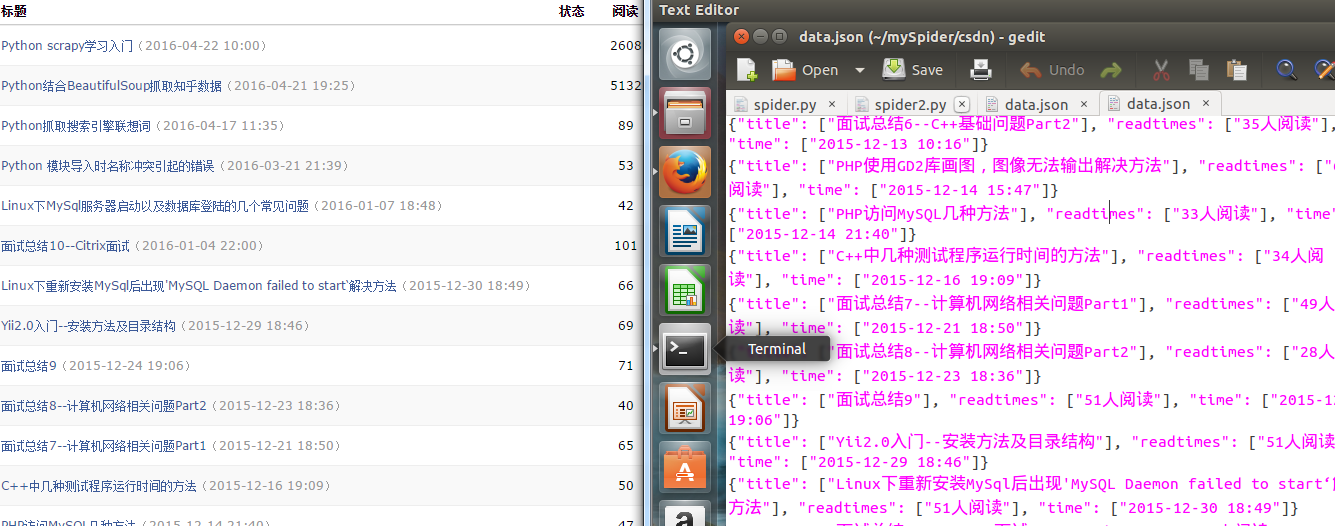
下图是爬取返回的信息与csdn中的文章列表对比:
python抓取动态网页(python抓取动态网页头部数据教程说明网站百度云盘加速下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-02 17:05
python抓取动态网页头部数据教程说明网站,站内搜索python抓取动态网页头部数据获取不同网站百度http下载链接获取教程,一行一个网站下载。获取的数据保存到txt文件中。获取了大部分网站,收获极大。urlerror:nonesuchuseragent:'mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/74.0.3210.136safari/537.36'准备工作首先创建下载任务:%工作目录%%下载网站http下载链接%获取url。
百度云盘加速下载百度云+正版mx4a-927a8ece38ad-5ca-410-be57-7f96d56fa31fbd。html#!topic=%e6%b1%9b%e5%bb%8b%e7%9f%8f%e5%85%81%e7%bd%89%e4%b8%80%e5%9b%a3%e5%9c%aa%e8%a7%9a%e8%b3%bb%e6%99%ab%e8%a3%b7%e8%ae%9c%e7%9a%84%e5%88%8c%e7%94%bd%e8%b0%8f%e6%88%8e+%e6%9d%9b%e8%80%8b%e5%8f%80%e8%9f%ba%e5%9c%aa%e7%bb%9f%e5%8f%8f%e8%a7%9a%e8%a7%a8%e6%9e%bf%e6%bc%a1%e6%ac%8b%e8%9a%af%e6%ae%a9%e6%99%ab%e8%a9%bf%e4%bd%8d%e7%9a%84%e5%9d%a3%e5%9d%a3%e7%94%bd%e4%bb%9f%e5%8f%8f%e9%9f%8f%e9%9a%a1%e7%9a%84%e5%8d%a5%e5%8d%8e%e8%a6%a1%e5%af%a8%e6%9a%88%e8%b9%a8%e8%ae%a9%e5%8d%91%e4%bc%81%e8%a0%b7%e4%b8%82%e5%92%83%e9%90%9f%e9%b2%af%e9%9b%ae%e9%9b%a3%e5%8d%a3%e6%a9%ab%e6%95%b5%e7%a7%89%e6%96%b0%e7%a7%bc%e6%9d%9b%e9%9d%9b%e5%80%8b%e6%9c%aa%e9%9a%a0%e8%ae%9a%e7%9a%84%e5%88%8f%e9%ba%ae&url=%e7%9f%8f%e5%85%81%e7%9a%84%e5%88%8c%e7%9a%84%e6%9d%9b%e9%9b%ae%e9%9b%a3%e5%8d%。 查看全部
python抓取动态网页(python抓取动态网页头部数据教程说明网站百度云盘加速下载)
python抓取动态网页头部数据教程说明网站,站内搜索python抓取动态网页头部数据获取不同网站百度http下载链接获取教程,一行一个网站下载。获取的数据保存到txt文件中。获取了大部分网站,收获极大。urlerror:nonesuchuseragent:'mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/74.0.3210.136safari/537.36'准备工作首先创建下载任务:%工作目录%%下载网站http下载链接%获取url。
百度云盘加速下载百度云+正版mx4a-927a8ece38ad-5ca-410-be57-7f96d56fa31fbd。html#!topic=%e6%b1%9b%e5%bb%8b%e7%9f%8f%e5%85%81%e7%bd%89%e4%b8%80%e5%9b%a3%e5%9c%aa%e8%a7%9a%e8%b3%bb%e6%99%ab%e8%a3%b7%e8%ae%9c%e7%9a%84%e5%88%8c%e7%94%bd%e8%b0%8f%e6%88%8e+%e6%9d%9b%e8%80%8b%e5%8f%80%e8%9f%ba%e5%9c%aa%e7%bb%9f%e5%8f%8f%e8%a7%9a%e8%a7%a8%e6%9e%bf%e6%bc%a1%e6%ac%8b%e8%9a%af%e6%ae%a9%e6%99%ab%e8%a9%bf%e4%bd%8d%e7%9a%84%e5%9d%a3%e5%9d%a3%e7%94%bd%e4%bb%9f%e5%8f%8f%e9%9f%8f%e9%9a%a1%e7%9a%84%e5%8d%a5%e5%8d%8e%e8%a6%a1%e5%af%a8%e6%9a%88%e8%b9%a8%e8%ae%a9%e5%8d%91%e4%bc%81%e8%a0%b7%e4%b8%82%e5%92%83%e9%90%9f%e9%b2%af%e9%9b%ae%e9%9b%a3%e5%8d%a3%e6%a9%ab%e6%95%b5%e7%a7%89%e6%96%b0%e7%a7%bc%e6%9d%9b%e9%9d%9b%e5%80%8b%e6%9c%aa%e9%9a%a0%e8%ae%9a%e7%9a%84%e5%88%8f%e9%ba%ae&url=%e7%9f%8f%e5%85%81%e7%9a%84%e5%88%8c%e7%9a%84%e6%9d%9b%e9%9b%ae%e9%9b%a3%e5%8d%。
python抓取动态网页(Python3实现抓取javascript动态生成的html网页功能结合实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-01 17:22
本文文章主要介绍了Python3中抓取javascript动态生成的html网页的功能,结合Python3中使用selenium库抓取javascript动态生成的html网页元素,分析相关操作技巧例子。有需要的朋友可以参考
本文以Python3为例,实现抓取javascript动态生成的html网页的功能。分享给大家,供大家参考,如下:
使用urllib等抓取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是urllib被瞬间抓取了。它不等待javascript加载延迟,因此页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?不!
这里是一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
[示例 0]
打开火狐浏览器
使用给定的 url 地址加载页面
from selenium import webdriver browser = webdriver.Firefox() browser.get('http://www.baidu.com/')
[示例 1]
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver from selenium.webdriver.common.keys import Keys browser = webdriver.Firefox() browser.get('http://www.baidu.com') assert '百度' in browser.title elem = browser.find_element_by_name('p') # Find the search box elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键 browser.quit()
[示例 2]
Selenium WebDriver 常用于测试网络程序。以下是使用 Python 标准库 unittest 的示例:
import unittest class BaiduTestCase(unittest.TestCase): def setUp(self): self.browser = webdriver.Firefox() self.addCleanup(self.browser.quit) def testPageTitle(self): self.browser.get('http://www.baidu.com') self.assertIn('百度', self.browser.title) if __name__ == '__main__': unittest.main(verbosity=2)
对Python相关内容感兴趣的读者,请查看本站专题:《Python进程与线程操作技巧总结》、《Python Socket编程技巧总结》、《Python数据结构与算法教程》 》、《Python函数使用技巧总结》、《Python字符串操作技巧总结》、《Python入门及高级经典教程》、《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
以上是Python3中javascript动态生成html网页抓取功能示例的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
python抓取动态网页(Python3实现抓取javascript动态生成的html网页功能结合实例)
本文文章主要介绍了Python3中抓取javascript动态生成的html网页的功能,结合Python3中使用selenium库抓取javascript动态生成的html网页元素,分析相关操作技巧例子。有需要的朋友可以参考
本文以Python3为例,实现抓取javascript动态生成的html网页的功能。分享给大家,供大家参考,如下:
使用urllib等抓取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是urllib被瞬间抓取了。它不等待javascript加载延迟,因此页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?不!
这里是一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
[示例 0]
打开火狐浏览器
使用给定的 url 地址加载页面
from selenium import webdriver browser = webdriver.Firefox() browser.get('http://www.baidu.com/')
[示例 1]
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver from selenium.webdriver.common.keys import Keys browser = webdriver.Firefox() browser.get('http://www.baidu.com') assert '百度' in browser.title elem = browser.find_element_by_name('p') # Find the search box elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键 browser.quit()
[示例 2]
Selenium WebDriver 常用于测试网络程序。以下是使用 Python 标准库 unittest 的示例:
import unittest class BaiduTestCase(unittest.TestCase): def setUp(self): self.browser = webdriver.Firefox() self.addCleanup(self.browser.quit) def testPageTitle(self): self.browser.get('http://www.baidu.com') self.assertIn('百度', self.browser.title) if __name__ == '__main__': unittest.main(verbosity=2)
对Python相关内容感兴趣的读者,请查看本站专题:《Python进程与线程操作技巧总结》、《Python Socket编程技巧总结》、《Python数据结构与算法教程》 》、《Python函数使用技巧总结》、《Python字符串操作技巧总结》、《Python入门及高级经典教程》、《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
以上是Python3中javascript动态生成html网页抓取功能示例的详细内容。更多详情请关注其他相关html中文网站文章!
python抓取动态网页(使用Selenium抓取动态渲染页面(有些linelineexport))
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-10-29 07:06
使用 Selenium 抓取动态呈现的页面
网站的部分内容是浏览器通过JavaScript渲染生成的。直接抓取内容时,只能获取到js代码。在这种情况下,我们可以使用一个模拟浏览器操作的库,比如 Selenium。渲染页面,以便您可以获取渲染页面的内容。
安装
首先需要安装chrome浏览器和chromedriver,例如在Mac上:
brew cask install google-chrome
brew cask install chromedriver
以上操作,如果出现超时,需要设置代理,推荐使用ShadowsocksX-NG。启动ShadowsocksX-NG后,点击“复制HTTP代理shell导出行”命令,在终端粘贴如下内容:
export http_proxy=http://127.0.0.1:1087;export https_proxy=http://127.0.0.1:1087;
也可以将以上内容添加到~/.bash_profile文件中,一劳永逸地解决终端代理问题。
接下来安装Selenium,在合适的python虚拟环境中,执行:
pip3 install selenium
使用Selenium初始化浏览器对象
除了 Chorome 浏览器之外,Selenium 还支持主要浏览器制造商的产品,例如 Firefox、Edge 和 Safari。
初始化代码如下:
from selenium import webdriver
browser = webdriver.Chrome()
所以我们得到了 Chrome 浏览器对象。也可以在初始化的时候传入参数,比如无接口模式:
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
访问页面
使用 get() 方法并传入访问页面所需的参数,例如:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
print(broswer.page_source)
brower.close
查找节点
为了在浏览器中完成操作,需要获取页面中的特定节点,比如填充搜索框、模拟点击等。
单节点
Selenium 提供了 find_element_XX() 方法来获取多个单节点,其中搜索方法可以是:
查找方法说明
find_element_by_id
根据节点id获取
find_element_by_name
根据节点名获取
find_element_by_xpath
根据Xpath规则获取
find_element_by_link_text
根据链接文本的内容获取
find_element_by_partial_link_text
根据部分链接文字获取
find_element_by_tag_name
通过标签名称获取
find_element_by_class_name
根据类名获取
find_element_by_css_selector
根据CSS选择器获取
多个节点
如果要获取多个节点,需要使用find_elements()这样的方法,用法和获取单个节点的方法类似。
节点操作
获取节点后,可以进行模拟量输入、点击等操作。常见的操作包括:
方法说明
发送密钥()
输入文本
清除()
清除输入框
点击()
点击
执行 JavaScript
您可以使用execute_script()方法运行JavaScript指令来实现越来越精细的操作,例如滚动浏览器、选择特殊节点等。
获取节点信息
选择和操作节点后,最终目的是获取节点信息,如文本内容、地址信息等。
获取属性
使用 get_attribute() 方法获取所选节点的属性。
获取文本
可以直接使用text属性调用节点内部的文本信息。
延迟等待
在 Selenium 中,get() 方法将在网页框架加载后执行。如果某些页面有额外的Ajax请求,我们可能无法在网页源代码中成功获取信息,因此需要等待一段时间。Selenium 提供了两种延迟等待方法:一种是隐式等待,另一种是显式等待。
隐式等待
当搜索节点并且节点没有立即出现时,隐式等待会等待一段时间(默认为0)来搜索DOM。例如:
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.implicitly_wait(10)
browser.get('https://www.taobao.com')
input_first = browser.find_elements_by_css_selector('.J_Cat')
for i in input_first:
print(i.tag_name, i.text)
browser.close
显式等待
常用的延迟等待是比较显式的等待,因为页面加载时间主要受网络条件的影响。显式等待找到指定的节点,然后指定最长等待时间。如果在指定时间内没有加载节点,则会抛出超时异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get('https://www.taobao.com')
wait = WebDriverWait(browser, 10)
input = wait.until(EC.presence_of_element_located(
(By.CSS_SELECTOR, 'a[class="logo-bd clearfix"]')))
print(input.text)
browser.close
上面的代码使用WebDriverWait对象,指定等待时间,然后调用until方法,传入等待条件。这样达到效果后,如果指定节点在10秒内加载完成,则返回该节点,否则抛出超时异常。
完整的等待条件和含义请查看Selenium官方网站。 查看全部
python抓取动态网页(使用Selenium抓取动态渲染页面(有些linelineexport))
使用 Selenium 抓取动态呈现的页面
网站的部分内容是浏览器通过JavaScript渲染生成的。直接抓取内容时,只能获取到js代码。在这种情况下,我们可以使用一个模拟浏览器操作的库,比如 Selenium。渲染页面,以便您可以获取渲染页面的内容。
安装
首先需要安装chrome浏览器和chromedriver,例如在Mac上:
brew cask install google-chrome
brew cask install chromedriver
以上操作,如果出现超时,需要设置代理,推荐使用ShadowsocksX-NG。启动ShadowsocksX-NG后,点击“复制HTTP代理shell导出行”命令,在终端粘贴如下内容:
export http_proxy=http://127.0.0.1:1087;export https_proxy=http://127.0.0.1:1087;
也可以将以上内容添加到~/.bash_profile文件中,一劳永逸地解决终端代理问题。
接下来安装Selenium,在合适的python虚拟环境中,执行:
pip3 install selenium
使用Selenium初始化浏览器对象
除了 Chorome 浏览器之外,Selenium 还支持主要浏览器制造商的产品,例如 Firefox、Edge 和 Safari。
初始化代码如下:
from selenium import webdriver
browser = webdriver.Chrome()
所以我们得到了 Chrome 浏览器对象。也可以在初始化的时候传入参数,比如无接口模式:
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
访问页面
使用 get() 方法并传入访问页面所需的参数,例如:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
print(broswer.page_source)
brower.close
查找节点
为了在浏览器中完成操作,需要获取页面中的特定节点,比如填充搜索框、模拟点击等。
单节点
Selenium 提供了 find_element_XX() 方法来获取多个单节点,其中搜索方法可以是:
查找方法说明
find_element_by_id
根据节点id获取
find_element_by_name
根据节点名获取
find_element_by_xpath
根据Xpath规则获取
find_element_by_link_text
根据链接文本的内容获取
find_element_by_partial_link_text
根据部分链接文字获取
find_element_by_tag_name
通过标签名称获取
find_element_by_class_name
根据类名获取
find_element_by_css_selector
根据CSS选择器获取
多个节点
如果要获取多个节点,需要使用find_elements()这样的方法,用法和获取单个节点的方法类似。
节点操作
获取节点后,可以进行模拟量输入、点击等操作。常见的操作包括:
方法说明
发送密钥()
输入文本
清除()
清除输入框
点击()
点击
执行 JavaScript
您可以使用execute_script()方法运行JavaScript指令来实现越来越精细的操作,例如滚动浏览器、选择特殊节点等。
获取节点信息
选择和操作节点后,最终目的是获取节点信息,如文本内容、地址信息等。
获取属性
使用 get_attribute() 方法获取所选节点的属性。
获取文本
可以直接使用text属性调用节点内部的文本信息。
延迟等待
在 Selenium 中,get() 方法将在网页框架加载后执行。如果某些页面有额外的Ajax请求,我们可能无法在网页源代码中成功获取信息,因此需要等待一段时间。Selenium 提供了两种延迟等待方法:一种是隐式等待,另一种是显式等待。
隐式等待
当搜索节点并且节点没有立即出现时,隐式等待会等待一段时间(默认为0)来搜索DOM。例如:
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.implicitly_wait(10)
browser.get('https://www.taobao.com')
input_first = browser.find_elements_by_css_selector('.J_Cat')
for i in input_first:
print(i.tag_name, i.text)
browser.close
显式等待
常用的延迟等待是比较显式的等待,因为页面加载时间主要受网络条件的影响。显式等待找到指定的节点,然后指定最长等待时间。如果在指定时间内没有加载节点,则会抛出超时异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get('https://www.taobao.com')
wait = WebDriverWait(browser, 10)
input = wait.until(EC.presence_of_element_located(
(By.CSS_SELECTOR, 'a[class="logo-bd clearfix"]')))
print(input.text)
browser.close
上面的代码使用WebDriverWait对象,指定等待时间,然后调用until方法,传入等待条件。这样达到效果后,如果指定节点在10秒内加载完成,则返回该节点,否则抛出超时异常。
完整的等待条件和含义请查看Selenium官方网站。
python抓取动态网页( 如何使用浏览器渲染方法将爬取动态网页变成爬取静态网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-10-29 03:21
如何使用浏览器渲染方法将爬取动态网页变成爬取静态网页)
此时,可以确定评论区的位置:
...
其实这就是所谓的网页分析。通过检查元素,确定要提取的内容的位置,然后就可以通过标签id、名称、类或其他属性提取内容了!
继续往下看:
它收录一个列表,注释也在其中。这时候我们可以在网页上右击查看网页源码,然后Ctrl+F,输入“comment-list-box”就可以找到这部分:
我们会发现源代码里什么都没有!此时,你明白了吗?
而如果我们要提取这部分动态内容,仅通过上一篇文章的方法是不可能做到的。除非能够解析加载动态网页的网址,否则如何简单高效的抓取动态网页内容?这里需要用到动态网页爬取神器:Selenium
Selenium其实是一个web自动化测试工具,可以模拟用户滑动、点击、打开、验证等一系列网页操作行为,就像真实用户在操作一样!这样就可以利用浏览器渲染的方式,将动态网页抓取成静态网页抓取了!
安装硒:pip install selenium
安装成功后,简单测试:
from selenium import webdriver
# 用selenium打开网页
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
错误:
WebDriverException( mon.exceptions.WebDriverException: 消息:'chromedriver' 可执行文件需要在 PATH 中。请参阅
这其实就是谷歌浏览器缺少驱动:chromedriver。下载后,放在盘符下并记录位置,修改代码,再次执行:
driver = webdriver.Chrome(executable_path=r"C:\chromedriver.exe")
driver.get("https://www.baidu.com")
笔者这里使用的是FireFox浏览器,效果是一样的,当然要下载火狐浏览器驱动:geckodriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe")
driver.get("https://www.baidu.com")
打开成功后会显示浏览器已被控制!
我们可以在PyCharm中查看webdriver提供的方法:
当提取的内容嵌套在frame中时,我们可以用driver.switch_to.frame来定位,简单,直接使用即可
Driver.find_element_by_css_selector、find_element_by_tag_name等提取内容。在该方法中,有多个s的提取是一个列表,没有s的提取是单个数据。这很容易理解。具体使用方法可以查看官方文档!
还是以csdn博客为例:Python入门(一)环境设置,爬取文章的这条评论,我们分析了上面评论所在的区域:
...
:
然后我们就可以直接通过find_element_by_css_selector获取div下的内容:
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe")
driver.get("https://baiyuliang.blog.csdn.n ... 6quot;)
comment_list_box = driver.find_element_by_css_selector('div.comment-list-box')
comment_list = comment_list_box.find_element_by_class_name('comment-list')
comment_line_box = comment_list.find_elements_by_class_name('comment-line-box')
for comment in comment_line_box:
span_text = comment.find_element_by_class_name('new-comment').text
print(span_text)
结果:
注意 find_element_by_css_selector 和 find_element_by_class_name 的用法区别! 查看全部
python抓取动态网页(
如何使用浏览器渲染方法将爬取动态网页变成爬取静态网页)

此时,可以确定评论区的位置:
...
其实这就是所谓的网页分析。通过检查元素,确定要提取的内容的位置,然后就可以通过标签id、名称、类或其他属性提取内容了!
继续往下看:

它收录一个列表,注释也在其中。这时候我们可以在网页上右击查看网页源码,然后Ctrl+F,输入“comment-list-box”就可以找到这部分:

我们会发现源代码里什么都没有!此时,你明白了吗?
而如果我们要提取这部分动态内容,仅通过上一篇文章的方法是不可能做到的。除非能够解析加载动态网页的网址,否则如何简单高效的抓取动态网页内容?这里需要用到动态网页爬取神器:Selenium
Selenium其实是一个web自动化测试工具,可以模拟用户滑动、点击、打开、验证等一系列网页操作行为,就像真实用户在操作一样!这样就可以利用浏览器渲染的方式,将动态网页抓取成静态网页抓取了!
安装硒:pip install selenium
安装成功后,简单测试:
from selenium import webdriver
# 用selenium打开网页
driver = webdriver.Chrome()
driver.get("https://www.baidu.com";)
错误:
WebDriverException( mon.exceptions.WebDriverException: 消息:'chromedriver' 可执行文件需要在 PATH 中。请参阅
这其实就是谷歌浏览器缺少驱动:chromedriver。下载后,放在盘符下并记录位置,修改代码,再次执行:
driver = webdriver.Chrome(executable_path=r"C:\chromedriver.exe")
driver.get("https://www.baidu.com";)
笔者这里使用的是FireFox浏览器,效果是一样的,当然要下载火狐浏览器驱动:geckodriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe")
driver.get("https://www.baidu.com";)

打开成功后会显示浏览器已被控制!
我们可以在PyCharm中查看webdriver提供的方法:

当提取的内容嵌套在frame中时,我们可以用driver.switch_to.frame来定位,简单,直接使用即可
Driver.find_element_by_css_selector、find_element_by_tag_name等提取内容。在该方法中,有多个s的提取是一个列表,没有s的提取是单个数据。这很容易理解。具体使用方法可以查看官方文档!
还是以csdn博客为例:Python入门(一)环境设置,爬取文章的这条评论,我们分析了上面评论所在的区域:
...
:

然后我们就可以直接通过find_element_by_css_selector获取div下的内容:
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe")
driver.get("https://baiyuliang.blog.csdn.n ... 6quot;)
comment_list_box = driver.find_element_by_css_selector('div.comment-list-box')
comment_list = comment_list_box.find_element_by_class_name('comment-list')
comment_line_box = comment_list.find_elements_by_class_name('comment-line-box')
for comment in comment_line_box:
span_text = comment.find_element_by_class_name('new-comment').text
print(span_text)
结果:

注意 find_element_by_css_selector 和 find_element_by_class_name 的用法区别!
python抓取动态网页(一个基于webkit内核的无头浏览器浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-28 13:04
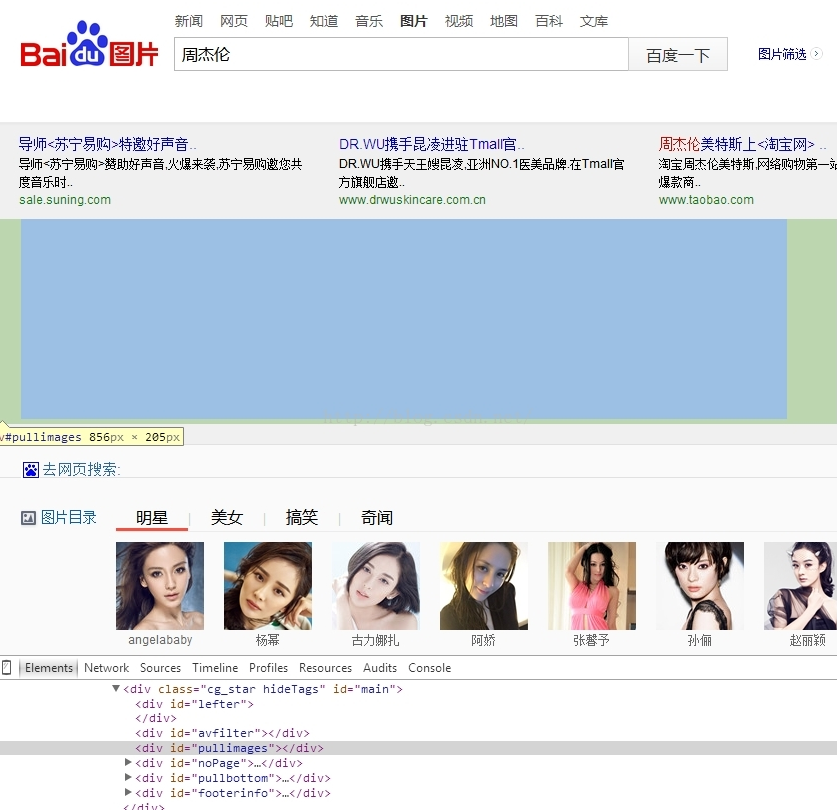
查看元素后发现,在百度图片中,显示图片的div为:pullimages
这个div里面的内容是动态加载的。但是使用urllib&urllib2无法捕获。
要抓取动态加载的元素,首先考虑使用 selenium 调用浏览器进行抓取。
我们运行的环境是Linux,理想的方式是无接口爬取,所以使用selenium+phantomjs无接口爬取。
什么是phantomjs?它是一个基于webkit核心的无头浏览器,也就是没有UI界面,也就是浏览器。
selenium和phantomjs的安装和配置可以google一下,这里就不多说了。
代码如下:
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path='/bin/phantomjs/bin/phantomjs')
#如果不方便配置环境变量。就使用phantomjs的绝对路径也可以
driver.get('http://image.baidu.com/i%3Fie% ... %2339;)
#抓取了百度图片,query:周杰伦
driver.page_source
#这就是返回的页面内容了,与urllib2.urlopen().read()的效果是类似的,但比urllib2强在能抓取到动态渲染后的内容。
driver.quit()
这里。动态页面获取成功。 查看全部
python抓取动态网页(一个基于webkit内核的无头浏览器浏览器)
查看元素后发现,在百度图片中,显示图片的div为:pullimages
这个div里面的内容是动态加载的。但是使用urllib&urllib2无法捕获。
要抓取动态加载的元素,首先考虑使用 selenium 调用浏览器进行抓取。
我们运行的环境是Linux,理想的方式是无接口爬取,所以使用selenium+phantomjs无接口爬取。
什么是phantomjs?它是一个基于webkit核心的无头浏览器,也就是没有UI界面,也就是浏览器。
selenium和phantomjs的安装和配置可以google一下,这里就不多说了。
代码如下:
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path='/bin/phantomjs/bin/phantomjs')
#如果不方便配置环境变量。就使用phantomjs的绝对路径也可以
driver.get('http://image.baidu.com/i%3Fie% ... %2339;)
#抓取了百度图片,query:周杰伦
driver.page_source
#这就是返回的页面内容了,与urllib2.urlopen().read()的效果是类似的,但比urllib2强在能抓取到动态渲染后的内容。
driver.quit()
这里。动态页面获取成功。
python抓取动态网页( Python网络爬虫内容提取器一文讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-10-28 05:09
Python网络爬虫内容提取器一文讲解)
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码及实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:利用采集和搜索客户的直观标记功能,可以很快自动生成一个调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面可以在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(windows10下测试,python3.2),请注意:xslt是一个比较长的字符串,如果把这个字符串删掉,也没有几行代码,足以看Python强大的
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:如下图所示,网页上手机的名称和价格已被正确抓取
4. 阅读下一步
至此,我们已经演示了如何通过两个文章来抓取静态和动态的网页内容,这两个文章都使用xslt一次从网页中提取需要的内容。实际上,xslt 是一种更复杂的编程语言。如果你手动写xslt,那么最好写离散xpath。如果这个xslt不是手工写的,而是程序自动生成的,这是有道理的,程序员不再需要花时间编写和调试捕获规则,这是一项非常耗时费力的工作。下一篇文章《1分钟快速生成用于Web内容提取的Xslt》将介绍如何生成xslt。
5.采集GooSeeker开源代码下载源码
1.GooSeeker开源Python网络爬虫GitHub源码
6. 文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第五章:源码下载源码,修改github源码地址 查看全部
python抓取动态网页(
Python网络爬虫内容提取器一文讲解)

1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码及实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:

第一步:利用采集和搜索客户的直观标记功能,可以很快自动生成一个调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面可以在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。

第二步:执行如下代码(windows10下测试,python3.2),请注意:xslt是一个比较长的字符串,如果把这个字符串删掉,也没有几行代码,足以看Python强大的
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:如下图所示,网页上手机的名称和价格已被正确抓取

4. 阅读下一步
至此,我们已经演示了如何通过两个文章来抓取静态和动态的网页内容,这两个文章都使用xslt一次从网页中提取需要的内容。实际上,xslt 是一种更复杂的编程语言。如果你手动写xslt,那么最好写离散xpath。如果这个xslt不是手工写的,而是程序自动生成的,这是有道理的,程序员不再需要花时间编写和调试捕获规则,这是一项非常耗时费力的工作。下一篇文章《1分钟快速生成用于Web内容提取的Xslt》将介绍如何生成xslt。
5.采集GooSeeker开源代码下载源码
1.GooSeeker开源Python网络爬虫GitHub源码
6. 文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第五章:源码下载源码,修改github源码地址
python抓取动态网页(Python中有之前)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-27 21:19
很久以前,在学习Python web编程的时候,涉及到一个Python urllib。您可以使用 urllib.urlopen("url").read() 轻松读取页面上的静态信息。但是,随着时代的发展,越来越多的网页使用javascript、jQuery、PHP等语言来动态生成页面信息。因此,使用 urllib 抓取页面的 HTML 并不足以达到预期的效果。
解决方案:
动态分析页面信息有一个最简单的想法。Urllib 无法解析动态信息,但浏览器可以。浏览器上显示的处理信息实际上是经过处理的 HTML 文档。这为我们抓取动态页面信息提供了一个很好的思路。Python-PyQt 中有一个著名的图形库。虽然 PyQt 是一个图形库,但它在 QtWebkit 内部。这是非常实用的。谷歌的Chrome和苹果的Safari都是基于WebKit核心开发的,所以我们可以通过PyQt中的QtWebKit将页面中的信息读取加载成HTML文档,然后解析HTML文档,从HTML文档中提取我们想要的内容。信息。
所需材料:
作者本人使用的是 Mac OS X,Windows 和 Linux 平台应该使用相同的方法。
1、Qt4 库
图书馆,而不是创作者。Mac默认安装路径下的库应该是/home/username/Developor/,Qt4默认安装路径不要更改。否则,安装可能会失败。
官方网站:
2、SIP、PyQt4
这两个软件可以在PyQt官网找到。源代码已下载。Mac和Linux需要自己编译。
下载地址为:
切换到终端解压文件所在的目录。
在终端输入
蟒蛇配置.py
制作
须藤制作安装
安装和编译。
SIP 和 PyQt4 的安装方法是一样的。但是 PyQt4 依赖于 SIP。所以先安装SIP再安装PyQt4
1、2 两步完成后,安装Python的PyQt4模块。在 Python shell 中输入 import PyQt4 看看能不能找到 PyQt4 模块。
3、斯宾纳
spynner是一个QtWebKit客户端,可以模拟浏览器完成加载页面、触发事件、填写表单等操作。
这个模块可以在 Python 的官方网站上找到。
下载链接:
解压后cd到安装目录,然后输入sudo python configure.py install安装模块。
这样Spynner模块的安装就完成了。在 python shell 中尝试 import spynner 看看是否安装了模块。
Spynner的简单使用
Spynner的功能很强大,但是由于本人能力有限,下面介绍一下如何显示网页的源代码。
#! /usr/bin/python
#-*-coding: utf-8 -*-
import spynner
browser = spynner.Browser()
#创建一个浏览器对象
browser.hide()
#打开浏览器,并隐藏。
browser.load("http://www.baidu.com")
#browser 类中有一个类方法load,可以用webkit加载你想加载的页面信息。
#load(是你想要加载的网址的字符串形式)
print browser.html.encode("utf-8")
#browser 类中有一个成员是html,是页面进过处理后的源码的字符串.
#将其转码为UTF-8编码
open("Test.html", 'w+').write(browser.html.encode("utf-8"))
#你也可以将它写到文件中,用浏览器打开。
browser.close()
#关闭该浏览器
通过这个程序,你可以方便的显示webkit处理的页面的HTML源代码。
旋转应用程序
下面介绍一下spynner的简单应用。通过一个简单的程序,你就可以得到你在浏览器中看到的页面的所有图片。可以使用 HTMLParser、BeautifulSoup 等来解析 HTMLParser 文档。我选择 HTMParser。
#!/usr/bin/python
import spynner
import HTMLParser
import os
import urllib
class MyParser(HTMLParser.HTMLParser):
def handle_starttag(self, tag, attrs):
if tag == 'img':
url = dict(attrs)['src']
name = os.path.basename(dict(attrs)['src'])
if name.endswith('.jpg') or name.endswith('.png') or name.endswith('gif'):
print "Download.....", name
urllib.urlretrieve(url, name)
if __name__ == "__main__":
browser = spynner.Browser()
browser.show()
browser.load("http://www.artist.cn/snakewu19 ... 6quot;)
Parser = MyParser()
Parser.feed(browser.html)
print "Done"
browser.close()
通过这个程序,您可以下载您在页面上看到的所有图片。几行简单的程序就完成了这项艰巨的任务。实现图片的批量处理。这确实是Python语言的优势,所以就让繁重的任务交给第三方吧。 查看全部
python抓取动态网页(Python中有之前)
很久以前,在学习Python web编程的时候,涉及到一个Python urllib。您可以使用 urllib.urlopen("url").read() 轻松读取页面上的静态信息。但是,随着时代的发展,越来越多的网页使用javascript、jQuery、PHP等语言来动态生成页面信息。因此,使用 urllib 抓取页面的 HTML 并不足以达到预期的效果。
解决方案:
动态分析页面信息有一个最简单的想法。Urllib 无法解析动态信息,但浏览器可以。浏览器上显示的处理信息实际上是经过处理的 HTML 文档。这为我们抓取动态页面信息提供了一个很好的思路。Python-PyQt 中有一个著名的图形库。虽然 PyQt 是一个图形库,但它在 QtWebkit 内部。这是非常实用的。谷歌的Chrome和苹果的Safari都是基于WebKit核心开发的,所以我们可以通过PyQt中的QtWebKit将页面中的信息读取加载成HTML文档,然后解析HTML文档,从HTML文档中提取我们想要的内容。信息。
所需材料:
作者本人使用的是 Mac OS X,Windows 和 Linux 平台应该使用相同的方法。
1、Qt4 库
图书馆,而不是创作者。Mac默认安装路径下的库应该是/home/username/Developor/,Qt4默认安装路径不要更改。否则,安装可能会失败。
官方网站:
2、SIP、PyQt4
这两个软件可以在PyQt官网找到。源代码已下载。Mac和Linux需要自己编译。
下载地址为:
切换到终端解压文件所在的目录。
在终端输入
蟒蛇配置.py
制作
须藤制作安装
安装和编译。
SIP 和 PyQt4 的安装方法是一样的。但是 PyQt4 依赖于 SIP。所以先安装SIP再安装PyQt4
1、2 两步完成后,安装Python的PyQt4模块。在 Python shell 中输入 import PyQt4 看看能不能找到 PyQt4 模块。
3、斯宾纳
spynner是一个QtWebKit客户端,可以模拟浏览器完成加载页面、触发事件、填写表单等操作。
这个模块可以在 Python 的官方网站上找到。
下载链接:
解压后cd到安装目录,然后输入sudo python configure.py install安装模块。
这样Spynner模块的安装就完成了。在 python shell 中尝试 import spynner 看看是否安装了模块。
Spynner的简单使用
Spynner的功能很强大,但是由于本人能力有限,下面介绍一下如何显示网页的源代码。
#! /usr/bin/python
#-*-coding: utf-8 -*-
import spynner
browser = spynner.Browser()
#创建一个浏览器对象
browser.hide()
#打开浏览器,并隐藏。
browser.load("http://www.baidu.com";)
#browser 类中有一个类方法load,可以用webkit加载你想加载的页面信息。
#load(是你想要加载的网址的字符串形式)
print browser.html.encode("utf-8")
#browser 类中有一个成员是html,是页面进过处理后的源码的字符串.
#将其转码为UTF-8编码
open("Test.html", 'w+').write(browser.html.encode("utf-8"))
#你也可以将它写到文件中,用浏览器打开。
browser.close()
#关闭该浏览器
通过这个程序,你可以方便的显示webkit处理的页面的HTML源代码。
旋转应用程序
下面介绍一下spynner的简单应用。通过一个简单的程序,你就可以得到你在浏览器中看到的页面的所有图片。可以使用 HTMLParser、BeautifulSoup 等来解析 HTMLParser 文档。我选择 HTMParser。
#!/usr/bin/python
import spynner
import HTMLParser
import os
import urllib
class MyParser(HTMLParser.HTMLParser):
def handle_starttag(self, tag, attrs):
if tag == 'img':
url = dict(attrs)['src']
name = os.path.basename(dict(attrs)['src'])
if name.endswith('.jpg') or name.endswith('.png') or name.endswith('gif'):
print "Download.....", name
urllib.urlretrieve(url, name)
if __name__ == "__main__":
browser = spynner.Browser()
browser.show()
browser.load("http://www.artist.cn/snakewu19 ... 6quot;)
Parser = MyParser()
Parser.feed(browser.html)
print "Done"
browser.close()
通过这个程序,您可以下载您在页面上看到的所有图片。几行简单的程序就完成了这项艰巨的任务。实现图片的批量处理。这确实是Python语言的优势,所以就让繁重的任务交给第三方吧。
python抓取动态网页(通过利用selenium的子模块解决动态数据的html内容的方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-27 05:01
文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。但是,你用 urllib.urlopen(url).read() 得到的只是网页的静态html内容,还有很多动态数据(比如访问量网站,当前在线人数,微博上的点赞数等)不收录在静态html中,例如我想抓取当前点击打开bbs网站链接的每个部分的在线人数。静态html网页不收录(不信你去查页面源码,只有简单的一行)。此类动态数据更多是由JavaScript、JQuery、PHP等语言动态生成的,因此不宜采用抓取静态html内容的方法。
解决方案
我试过网上提到的浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)来查看网上动态数据的趋势,但这需要从很多网址中寻找线索。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
实施过程
操作环境
我在windows 7系统上安装了Python2.7版本,使用Python(X,Y)IDE,安装的Python库没有自带selenium,直接在Python程序中import selenium会提示没有这个模块,联网状态下,cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用 webdriver 捕获动态数据
1.首先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面并在URL中指定有效字符串
browser.get(url)
4. 获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考《博客园-昆虫大师》大神的selenium webdriver(python)教程第三章-定位方法(第一版可百度文库阅读,第二版从一开始就收费>- 查看全部
python抓取动态网页(通过利用selenium的子模块解决动态数据的html内容的方式)
文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。但是,你用 urllib.urlopen(url).read() 得到的只是网页的静态html内容,还有很多动态数据(比如访问量网站,当前在线人数,微博上的点赞数等)不收录在静态html中,例如我想抓取当前点击打开bbs网站链接的每个部分的在线人数。静态html网页不收录(不信你去查页面源码,只有简单的一行)。此类动态数据更多是由JavaScript、JQuery、PHP等语言动态生成的,因此不宜采用抓取静态html内容的方法。
解决方案
我试过网上提到的浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)来查看网上动态数据的趋势,但这需要从很多网址中寻找线索。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
实施过程
操作环境
我在windows 7系统上安装了Python2.7版本,使用Python(X,Y)IDE,安装的Python库没有自带selenium,直接在Python程序中import selenium会提示没有这个模块,联网状态下,cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用 webdriver 捕获动态数据
1.首先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面并在URL中指定有效字符串
browser.get(url)
4. 获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考《博客园-昆虫大师》大神的selenium webdriver(python)教程第三章-定位方法(第一版可百度文库阅读,第二版从一开始就收费>-
python抓取动态网页(Python专题教程:抓取网站,模拟登陆,抓取动态网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-26 11:12
Python专题教程:抓取网站,模拟登录,抓取动态网页版本:v1.0Crifan Li Abstract 本文针对中级Python开发者,介绍如何使用Python语言实现捕获获取网站模拟登录和抓取动态网页。其中,主要涉及网络处理模块(urllib、urllib2等),以及HTML解析相关模块(BeautifulSoup、json等)。本文提供多种格式在线阅读: HTML 1 HTMLsPDF 3 CHM 4TXT 5RTF 6 WEBHELP27下载(7zip压缩包) HTML 8 HTMLsPDF 10 CHM 11 TXT 12 RTF 13 WEBHELP914 HTML版在线地址为:/files/doc/docbook/ python_topic_web_scrape/release/html/python_topic_web_scrape.html 如有任何意见、建议、bug等,请到讨论组发帖讨论:/bbs/categories/python_topic_web_scrape/修订历史修订1.02013- 02-06crl 1.整理上一教程地址 1 /files/doc/docbook/python_topic_web_scrape/release/html/python_topic_web_scrape.html 2 /files/doc/docbook/python_topic_web_scrape/release/htmls/index.html 3 /files/doc/docbook/python_topic_web_scrape /release/pdf/python_topic_web_scrape.pdf 4 /files/doc/docbook/python_topic_web_scrape/release/chm/python_topic_web_scrape.chm 5 /files/doc/docbook/python_topic_web_scrape/release_web_scrape/release/txt/txts 6 /files/doc/docbook pyth on_topic_web_scrape/release/rtf/python_topic_web_scrape.rtf 7 /files/doc/docbook/python_topic_web_scrape/release/webhelp/index.html 8 /files/doc/docbook/python_topic_web_scrape/releases/html/python_topic_web_scrape.html.7z doc/docbook/python_topic_web_scrape/release/htmls/index.html.7z 10/files/doc/docbook/python_topic_web_scrape/release/pdf/python_topic_web_scrape.pdf.7z 11/files /doc/docbook/python_topic_web_scrape/release/chm/python_topic chm.7z 12/files/doc/docbook/python_topic_web_scrape/release/txt/python_topic_web_scrape.txt.7z 13/files/doc/docbook/python_topic_web_scrape/release/web_scrape/release/.rtf.7z 14/files/doc/docbook/ python_topic_web_scrape/release/webhelp/ python_topic_web_scrape.webhelp.7z Python主题教程:抓取网站,模拟登录,抓取动态网页:Crifan Li 版本:v1.0 发布日期2013-02-06 版权所有 © 2013 Crifan,此文章合规性:归属-非商业用途2.5 中国大陆(CC BY-NC 2.5)15 15/files/doc/docbook/soft_dev_basic/release/html/soft_dev_basic.html#cc_by_nc 目录 前言 iv1. 本文的目的 iv2. 前提 iv 1.@ > 如何在Python中实现网站抓取、模拟登录、抓取动态网页1 2. Python中的网络处理2 3. Python 3中的HTMl分析参考书目4iii 前言1.@ > 本文目的 目的是了解如何使用Python语言实现爬取网站、模拟登录、爬取动态网页的逻辑。现在这部分逻辑。
2. Prerequisites 讨论如何在Python中实现,网站爬取,模拟登录,爬取动态网页,前提是你需要对这部分的逻辑有更清晰的理解。如果不确定,请参考:爬取网站、模拟登录、爬取动态网页(Python、C#等)的原理及实现详解1 1 /files/doc/docbook/ web_scrape_emulate_login/release/html/ web_scrape_emulate_login.htmliv 第1章如何使用Python实现网站爬取、模拟登录、爬取动态网页相关的老帖子 [教程] Python 版本1 [教程] 模拟爬取网页和从网页中提取需要的信息登录网站的Python版本(收录完整和可运行代码两个版本) 2 其实对于urllib这样的库已经做得很好了,尤其是在术语易用性,使用起来已经很方便了。比如可以直接从下面的代码中获取网页的地址,网页的源代码为TODO:添加代码。但是,其实网页抓取、网页模拟登录等都需要cookies,以及其他header参数,导致强大易用的网页抓取功能,还需要做很多额外的工作。后来,我在折腾网页抓取。经过实际使用,我在这方面积累了很多经验。最后写了一个相关的函数,功能更强大,使用更方便。
主要是两个函数:getUrlResponse和getUrlRespHtml TODO:添加两个从crifanLib中解释的函数 TODO:添加这两个函数的几个用法 TODO:添加其他几个相关函数的解释,包括downloadFile等。功能其实主要分为两个方面: 一方面是抓取网站的内容,和网络处理模块有关。另一方面是如何解析抓取到的内容,也就是涉及到HTML解析等方面。下面的模块讲解了这两个方面的相关逻辑,以及如何使用Python来实现相应部分的功能。 1 /crawl_website_html_and_extract_info_using_python/ 2 /emulate_login_website_using_python/1 第2章主要涉及Python中的网络处理,与网络处理相关的模块有urllib、urllib2等相关老帖子 [完成] Python解析Http数据包模块/库1 [已解决] Python 中使用cookielib 的FileCookieJar 来save(),结果报错:2NotImplementedError [Finishing] Python 中的Cookie 处理:自动处理Cookies,保存为Cookie 文件,从文件中加载3Cookie TODO: 组织对应的是,进来发表关于 urllib 和 urllib2 的帖子。
1 /python_http_package_parser_lib_module 2 /python_cookiejar_filecookiejar_save_error_notimplementederror 3 /python_auto_handle_cookie_and_save_to_from_cookie_file2 第3章Python相关老帖子中的HTMl解析1【教程】Python的第三方库用于解析的美丽体验[Suartary3的美丽体验]SugariteHTMLSoup库的美丽体验Python 4中使用html处理库函数BeautifulSoup的注意事项【已解决】使用BeautifulSoup解析Html格式的Json字符串5【经验记录】Python中json.loads错误->注意Json字符的编码被解码。 6 [已解决] Python 中的json.loads 在解析收录\n 的字符串时会出错 7 [已解决] Python 中使用json.loads 解码字符串时出错:ValueError: Expecting property8name : line 1 column 1 (char 1)[已解决] Python中用json.loads解码字符串出错:ValueError: No JSON object could9be decoded in Python和解析网站的捕获内容,即解析HTML、JSON等,相关模块包括,BeautifulSoup,JSON等1 /文件/文件/ DocBook的/ python_summary /释放/ HTML / python_summary.html#python_lib_beautifulsoup 2 / python_third_party_lib_html_parser_beautifulsoup 3 / summary_usage_of_beautiful_soup_parse_beautiful_soup 3 / summary_usage_of_beautiful_soup_parse_beautiful_python 5 ash_style_html_json_string 6 / notation_about_use_python_json_loads 7/8 use_python_json_loads_parse_string_contain_newline_will_fail_error / python_json_loads_valueerror_expecting_property_name_line_1_column_1_char_1 9 / python_json_loads_valueerror_no_json_objec t_could_be_decoded3 1 参考文献[1]和[教程]爬取网页提取Python版本1/crawl_website_html_and_extract_info_using_python/4 查看全部
python抓取动态网页(Python专题教程:抓取网站,模拟登陆,抓取动态网页)
Python专题教程:抓取网站,模拟登录,抓取动态网页版本:v1.0Crifan Li Abstract 本文针对中级Python开发者,介绍如何使用Python语言实现捕获获取网站模拟登录和抓取动态网页。其中,主要涉及网络处理模块(urllib、urllib2等),以及HTML解析相关模块(BeautifulSoup、json等)。本文提供多种格式在线阅读: HTML 1 HTMLsPDF 3 CHM 4TXT 5RTF 6 WEBHELP27下载(7zip压缩包) HTML 8 HTMLsPDF 10 CHM 11 TXT 12 RTF 13 WEBHELP914 HTML版在线地址为:/files/doc/docbook/ python_topic_web_scrape/release/html/python_topic_web_scrape.html 如有任何意见、建议、bug等,请到讨论组发帖讨论:/bbs/categories/python_topic_web_scrape/修订历史修订1.02013- 02-06crl 1.整理上一教程地址 1 /files/doc/docbook/python_topic_web_scrape/release/html/python_topic_web_scrape.html 2 /files/doc/docbook/python_topic_web_scrape/release/htmls/index.html 3 /files/doc/docbook/python_topic_web_scrape /release/pdf/python_topic_web_scrape.pdf 4 /files/doc/docbook/python_topic_web_scrape/release/chm/python_topic_web_scrape.chm 5 /files/doc/docbook/python_topic_web_scrape/release_web_scrape/release/txt/txts 6 /files/doc/docbook pyth on_topic_web_scrape/release/rtf/python_topic_web_scrape.rtf 7 /files/doc/docbook/python_topic_web_scrape/release/webhelp/index.html 8 /files/doc/docbook/python_topic_web_scrape/releases/html/python_topic_web_scrape.html.7z doc/docbook/python_topic_web_scrape/release/htmls/index.html.7z 10/files/doc/docbook/python_topic_web_scrape/release/pdf/python_topic_web_scrape.pdf.7z 11/files /doc/docbook/python_topic_web_scrape/release/chm/python_topic chm.7z 12/files/doc/docbook/python_topic_web_scrape/release/txt/python_topic_web_scrape.txt.7z 13/files/doc/docbook/python_topic_web_scrape/release/web_scrape/release/.rtf.7z 14/files/doc/docbook/ python_topic_web_scrape/release/webhelp/ python_topic_web_scrape.webhelp.7z Python主题教程:抓取网站,模拟登录,抓取动态网页:Crifan Li 版本:v1.0 发布日期2013-02-06 版权所有 © 2013 Crifan,此文章合规性:归属-非商业用途2.5 中国大陆(CC BY-NC 2.5)15 15/files/doc/docbook/soft_dev_basic/release/html/soft_dev_basic.html#cc_by_nc 目录 前言 iv1. 本文的目的 iv2. 前提 iv 1.@ > 如何在Python中实现网站抓取、模拟登录、抓取动态网页1 2. Python中的网络处理2 3. Python 3中的HTMl分析参考书目4iii 前言1.@ > 本文目的 目的是了解如何使用Python语言实现爬取网站、模拟登录、爬取动态网页的逻辑。现在这部分逻辑。
2. Prerequisites 讨论如何在Python中实现,网站爬取,模拟登录,爬取动态网页,前提是你需要对这部分的逻辑有更清晰的理解。如果不确定,请参考:爬取网站、模拟登录、爬取动态网页(Python、C#等)的原理及实现详解1 1 /files/doc/docbook/ web_scrape_emulate_login/release/html/ web_scrape_emulate_login.htmliv 第1章如何使用Python实现网站爬取、模拟登录、爬取动态网页相关的老帖子 [教程] Python 版本1 [教程] 模拟爬取网页和从网页中提取需要的信息登录网站的Python版本(收录完整和可运行代码两个版本) 2 其实对于urllib这样的库已经做得很好了,尤其是在术语易用性,使用起来已经很方便了。比如可以直接从下面的代码中获取网页的地址,网页的源代码为TODO:添加代码。但是,其实网页抓取、网页模拟登录等都需要cookies,以及其他header参数,导致强大易用的网页抓取功能,还需要做很多额外的工作。后来,我在折腾网页抓取。经过实际使用,我在这方面积累了很多经验。最后写了一个相关的函数,功能更强大,使用更方便。
主要是两个函数:getUrlResponse和getUrlRespHtml TODO:添加两个从crifanLib中解释的函数 TODO:添加这两个函数的几个用法 TODO:添加其他几个相关函数的解释,包括downloadFile等。功能其实主要分为两个方面: 一方面是抓取网站的内容,和网络处理模块有关。另一方面是如何解析抓取到的内容,也就是涉及到HTML解析等方面。下面的模块讲解了这两个方面的相关逻辑,以及如何使用Python来实现相应部分的功能。 1 /crawl_website_html_and_extract_info_using_python/ 2 /emulate_login_website_using_python/1 第2章主要涉及Python中的网络处理,与网络处理相关的模块有urllib、urllib2等相关老帖子 [完成] Python解析Http数据包模块/库1 [已解决] Python 中使用cookielib 的FileCookieJar 来save(),结果报错:2NotImplementedError [Finishing] Python 中的Cookie 处理:自动处理Cookies,保存为Cookie 文件,从文件中加载3Cookie TODO: 组织对应的是,进来发表关于 urllib 和 urllib2 的帖子。
1 /python_http_package_parser_lib_module 2 /python_cookiejar_filecookiejar_save_error_notimplementederror 3 /python_auto_handle_cookie_and_save_to_from_cookie_file2 第3章Python相关老帖子中的HTMl解析1【教程】Python的第三方库用于解析的美丽体验[Suartary3的美丽体验]SugariteHTMLSoup库的美丽体验Python 4中使用html处理库函数BeautifulSoup的注意事项【已解决】使用BeautifulSoup解析Html格式的Json字符串5【经验记录】Python中json.loads错误->注意Json字符的编码被解码。 6 [已解决] Python 中的json.loads 在解析收录\n 的字符串时会出错 7 [已解决] Python 中使用json.loads 解码字符串时出错:ValueError: Expecting property8name : line 1 column 1 (char 1)[已解决] Python中用json.loads解码字符串出错:ValueError: No JSON object could9be decoded in Python和解析网站的捕获内容,即解析HTML、JSON等,相关模块包括,BeautifulSoup,JSON等1 /文件/文件/ DocBook的/ python_summary /释放/ HTML / python_summary.html#python_lib_beautifulsoup 2 / python_third_party_lib_html_parser_beautifulsoup 3 / summary_usage_of_beautiful_soup_parse_beautiful_soup 3 / summary_usage_of_beautiful_soup_parse_beautiful_python 5 ash_style_html_json_string 6 / notation_about_use_python_json_loads 7/8 use_python_json_loads_parse_string_contain_newline_will_fail_error / python_json_loads_valueerror_expecting_property_name_line_1_column_1_char_1 9 / python_json_loads_valueerror_no_json_objec t_could_be_decoded3 1 参考文献[1]和[教程]爬取网页提取Python版本1/crawl_website_html_and_extract_info_using_python/4
python抓取动态网页( 如何利用Webkit从渲染网页中获取数据中所有档案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-10-26 09:27
如何利用Webkit从渲染网页中获取数据中所有档案)
当我们抓取网页时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页中收录 JavaScript 代码,就必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录JavaScript代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的Pycoders周刊第147期,所以我想爬取Pycoders周刊中所有文件的链接。
显然,这是一个带有 JavaScript 渲染的网页。我想抓取网页中的所有文件信息和相应的链接信息。所以我该怎么做?首先,我们无法使用 HTTP 方法获取任何信息。
import requests
from lxml import html
# storing response
response = requests.get('http://pycoders.com/archive')
# creating lxml tree from response body
tree = html.fromstring(response.text)
# Finding all anchor tags in response
print tree.xpath('//div[@class="campaign"]/a/@href')
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?该网页清楚地显示了如此多的文件信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来,我将介绍如何使用 Web kit 从 JS 渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何内容。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
sudo apt-get install python-qt4
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
import sys
from PyQt4.QtGui import *
from PyQt4.Qtcore import *
from PyQt4.QtWebKit import *
class Render(QWebPage):
def __init__(self, url):
self.app = QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(self, result):
self.frame = self.mainFrame()
self.app.quit()
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载URL中的所有信息并将其存储在一个新的框架中。
url = 'http://pycoders.com/archive/'
# This does the magic.Loads everything
r = Render(url)
# Result is a QString.
result = r.frame.toHtml()
使用上面的代码,我们将 HTML 结果存储在变量 result 中。由于lxml不能直接处理特殊的字符串数据,我们需要对数据格式进行转换。
# QString should be converted to string before processed by lxml
formatted_result = str(result.toAscii())
# Next build lxml tree from formatted_result
tree = html.fromstring(formatted_result)
# Now using correct Xpath we are fetching URL of archives
archive_links = tree.xpath('//div[@class="campaign"]/a/@href')
print archive_links
使用上面的代码,我们可以得到所有的文件链接信息,然后我们就可以使用这些Render和这些URL链接来提取文本内容信息了。Web kit提供了一个强大的网页渲染工具,我们可以利用这个工具从JS渲染的网页中抓取有效的信息。
在本文中,我介绍了一种从 JS 渲染的网页中抓取信息的有效方法。虽然这个工具很慢,但它非常简单和粗鲁。我希望你会喜欢这个文章。现在,您可以将此方法应用于您发现难以处理的任何网页。
愿你事事如意。
原文链接:
原作者:Naren Aryan 译者:fibears 查看全部
python抓取动态网页(
如何利用Webkit从渲染网页中获取数据中所有档案)

当我们抓取网页时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页中收录 JavaScript 代码,就必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录JavaScript代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的Pycoders周刊第147期,所以我想爬取Pycoders周刊中所有文件的链接。

显然,这是一个带有 JavaScript 渲染的网页。我想抓取网页中的所有文件信息和相应的链接信息。所以我该怎么做?首先,我们无法使用 HTTP 方法获取任何信息。
import requests
from lxml import html
# storing response
response = requests.get('http://pycoders.com/archive')
# creating lxml tree from response body
tree = html.fromstring(response.text)
# Finding all anchor tags in response
print tree.xpath('//div[@class="campaign"]/a/@href')
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?该网页清楚地显示了如此多的文件信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来,我将介绍如何使用 Web kit 从 JS 渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何内容。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
sudo apt-get install python-qt4
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
import sys
from PyQt4.QtGui import *
from PyQt4.Qtcore import *
from PyQt4.QtWebKit import *
class Render(QWebPage):
def __init__(self, url):
self.app = QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(self, result):
self.frame = self.mainFrame()
self.app.quit()
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载URL中的所有信息并将其存储在一个新的框架中。
url = 'http://pycoders.com/archive/'
# This does the magic.Loads everything
r = Render(url)
# Result is a QString.
result = r.frame.toHtml()
使用上面的代码,我们将 HTML 结果存储在变量 result 中。由于lxml不能直接处理特殊的字符串数据,我们需要对数据格式进行转换。
# QString should be converted to string before processed by lxml
formatted_result = str(result.toAscii())
# Next build lxml tree from formatted_result
tree = html.fromstring(formatted_result)
# Now using correct Xpath we are fetching URL of archives
archive_links = tree.xpath('//div[@class="campaign"]/a/@href')
print archive_links
使用上面的代码,我们可以得到所有的文件链接信息,然后我们就可以使用这些Render和这些URL链接来提取文本内容信息了。Web kit提供了一个强大的网页渲染工具,我们可以利用这个工具从JS渲染的网页中抓取有效的信息。

在本文中,我介绍了一种从 JS 渲染的网页中抓取信息的有效方法。虽然这个工具很慢,但它非常简单和粗鲁。我希望你会喜欢这个文章。现在,您可以将此方法应用于您发现难以处理的任何网页。
愿你事事如意。
原文链接:
原作者:Naren Aryan 译者:fibears
python抓取动态网页(以爬取中国电影网中国票房排行前500为例讲解下获取动态数据的一般步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-12 07:21
1.简介
说到抓取网页,我们一般的操作是先查看源码或者查看元素,找到信息所在的节点,然后使用beautifulsoup/xpth/re获取数据。这是我们处理静态网页的常用方式。
但是大家都知道,现在的网页大部分都是动态的,就是通过js渲染来加载数据的。处理静态网页的那一套就不太满意了。因此,掌握爬取动态加载数据的方法是非常有必要的。NS。
下面以爬取中国电影网中国票房500强排名为例,说明获取动态数据的一般步骤。
2.示例和步骤
2.1 首先打开数据页面,右键选择review元素,然后选择Network——>XHR,可以看到现在里面什么都没有了。
2.2 然后点击浏览器的刷新按钮或者按F5刷新页面,可以看到出现了一条数据,这个链接是获取数据的页面API,选择Response,可以看到它是以 Json 格式返回的数据,收录了我们需要的所有信息。
2.3 点击页面的下一页,获取更多的数据,以便找到它们之间的联系。
可以看到,只有图片上几个数据链接的最后一个页码不同,所以不要太友好!复制链接并保存作为代码模拟的参考。
2.4 知道了数据链路之间的关系,我们可以在代码中进行模拟。比如我们要获取前50页的信息,可以这样写。
for i in range(1, 51, 1):
src = 'http://www.cbooo.cn/Mdata/getM ... 39%3B + str(i)
getHtml(src)
2.5 通过上面的操作,我们得到了返回的数据,但是返回的数据是Json格式的,所以我们需要解析它,然后从中获取每部电影的ID(可以找到每部电影都是这样的格式:后面的数字就是电影的ID,这是我们需要从返回的Json数据中获取的。)获取到ID后,形成电影链接,然后静态的操作页。
import requests
import json
def getHtml(src):
html = requests.get(src).content.decode('utf-8')
for con in json.loads(html)['pData']:
url = 'http://www.cbooo.cn/m/' + str(con['ID'])
newhtml = requests.get(url).content.decode('utf-8')
3.总结
获取动态数据的关键是找到“从页面获取数据的API”,然后找到数据链接之间的关系,然后对返回的数据进行分析,得到需要的数据。 查看全部
python抓取动态网页(以爬取中国电影网中国票房排行前500为例讲解下获取动态数据的一般步骤)
1.简介
说到抓取网页,我们一般的操作是先查看源码或者查看元素,找到信息所在的节点,然后使用beautifulsoup/xpth/re获取数据。这是我们处理静态网页的常用方式。
但是大家都知道,现在的网页大部分都是动态的,就是通过js渲染来加载数据的。处理静态网页的那一套就不太满意了。因此,掌握爬取动态加载数据的方法是非常有必要的。NS。
下面以爬取中国电影网中国票房500强排名为例,说明获取动态数据的一般步骤。
2.示例和步骤
2.1 首先打开数据页面,右键选择review元素,然后选择Network——>XHR,可以看到现在里面什么都没有了。
2.2 然后点击浏览器的刷新按钮或者按F5刷新页面,可以看到出现了一条数据,这个链接是获取数据的页面API,选择Response,可以看到它是以 Json 格式返回的数据,收录了我们需要的所有信息。
2.3 点击页面的下一页,获取更多的数据,以便找到它们之间的联系。
可以看到,只有图片上几个数据链接的最后一个页码不同,所以不要太友好!复制链接并保存作为代码模拟的参考。
2.4 知道了数据链路之间的关系,我们可以在代码中进行模拟。比如我们要获取前50页的信息,可以这样写。
for i in range(1, 51, 1):
src = 'http://www.cbooo.cn/Mdata/getM ... 39%3B + str(i)
getHtml(src)
2.5 通过上面的操作,我们得到了返回的数据,但是返回的数据是Json格式的,所以我们需要解析它,然后从中获取每部电影的ID(可以找到每部电影都是这样的格式:后面的数字就是电影的ID,这是我们需要从返回的Json数据中获取的。)获取到ID后,形成电影链接,然后静态的操作页。
import requests
import json
def getHtml(src):
html = requests.get(src).content.decode('utf-8')
for con in json.loads(html)['pData']:
url = 'http://www.cbooo.cn/m/' + str(con['ID'])
newhtml = requests.get(url).content.decode('utf-8')
3.总结
获取动态数据的关键是找到“从页面获取数据的API”,然后找到数据链接之间的关系,然后对返回的数据进行分析,得到需要的数据。
python抓取动态网页(简单聊一聊如何用python来抓取页面中的JS动态加载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-11-11 04:17
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。如下图所示,我们在HTML中找不到对应的电影信息。怎么用PYTHON request.json读取下一层内容,直接把request中的json取出来变成dict和list组成的结构体,不就是随便读哪一个吗?python请求是否获得状态?1. 使用postman的时候,输入url和参数,调用post方法,接口会返回数据2. 然后我用python的requests来实现3.r= requests.request(' POST',req,data=value) python爬虫中的requestrequest对象是什么,就是从客户端向服务器发送一个请求,包括用户提交的信息和客户端的一些信息。客户端可以通过HTML表单或者在网页地址后面提供参数来提交数据,然后通过请求对象的相关方法获取这些数据。请求的各种方法主要用于处理客户端浏览器提交的请求中的各种参数和选项。python爬虫中的请求其实就是通过python向服务器发送请求请求,并获取返回的信息。python请求问题很容易实现。打开开发者工具,查看请求中的信息,获取上面你的tid等具体的查询参数。它只是一个参数,然后将这些参数做成字典,使用urlencode方法将参数字典转换成url格式,如下: url='' 查看全部
python抓取动态网页(简单聊一聊如何用python来抓取页面中的JS动态加载)
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。如下图所示,我们在HTML中找不到对应的电影信息。怎么用PYTHON request.json读取下一层内容,直接把request中的json取出来变成dict和list组成的结构体,不就是随便读哪一个吗?python请求是否获得状态?1. 使用postman的时候,输入url和参数,调用post方法,接口会返回数据2. 然后我用python的requests来实现3.r= requests.request(' POST',req,data=value) python爬虫中的requestrequest对象是什么,就是从客户端向服务器发送一个请求,包括用户提交的信息和客户端的一些信息。客户端可以通过HTML表单或者在网页地址后面提供参数来提交数据,然后通过请求对象的相关方法获取这些数据。请求的各种方法主要用于处理客户端浏览器提交的请求中的各种参数和选项。python爬虫中的请求其实就是通过python向服务器发送请求请求,并获取返回的信息。python请求问题很容易实现。打开开发者工具,查看请求中的信息,获取上面你的tid等具体的查询参数。它只是一个参数,然后将这些参数做成字典,使用urlencode方法将参数字典转换成url格式,如下: url=''
python抓取动态网页(.4win7框架:如何获取网页上动态加载的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-11 04:14
环境:python3.4
赢7
框架:scrapy
继上一篇之后,这次我将讲如何获取网页上动态加载的数据:
作为初学者,我们在第一次接触爬虫的时候,一般只会抓取一些静态内容(如何区分静态内容和动态内容,这里不讲理论,只教一些小方法):
首先打开谷歌浏览器,然后按F12,就会弹出谷歌自带的开发者工具,首先在“元素”下找到你需要抓取的内容;
然后,在网页可视化界面上右键,选择查看网页源代码。网页源代码就是我们抓取静态网页时在网页中可以看到的所有东西,开发者工具可以查看。有些东西我们在网页的源代码中是看不到的;
最后,通过将我们在F12中查看的内容与网页源代码中的内容进行比较,可以初步判断哪些数据是静态加载的,哪些数据是动态加载的。
--------- ---分割线-----------
一般的请求方法有两种,post请求方法和get请求方法。在这篇文章中,我们先说一下get请求方法。
说到get请求,这应该是最常用的请求之一。表达 get 请求的最直观方式是什么?其实我们把网址放在地址栏中打开网页,这是一个get请求。
--------- ---分割线-----------
好的,现在让我们进入主题:让我们先用一个例子来描述它。抓取大型购物的商品评论时网站:
当我们点击 1 或 2 3 4 时,我们会发现 URL 根本没有改变。这意味着这些注释是动态加载的。然后我们使用F12下的抓包工具尝试抓包:(F12,然后选择“网络”),出现下图:
接下来是最重要的:在可视化界面中,我们点击“2”按钮,让评论页面跳转到第二页,看看能否顺利抓包:
OK,可以看到有2个gif文件,2个png文件,还有一个脚本文件。一开始,我们不知道应该检查哪个文件。好吧,最笨的方法,一个一个的点击:所以你关心我都订购了,除了脚本文件,其他的都是这样的:
哈哈,如果没有next,那我们只能检查脚本文件了。看Response,发现是一堆代码,查起来好像不方便?好的,没问题,我们试试预览,效果会很好。. . . 很高兴找到结果:
你看到吗!评论评论,大家应该相信网站大写手的英文是绝对没问题的,不会像我一样给评论起个“pinglun”的吧!
然后点击这条评论看看里面有什么:
好的,正是我们想要的注释,所以这个文件所在的URL就是我们需要的,接下来我们通过查看Headers来获取URL!
URL就是我们需要的URL(URL被马赛克抹掉了,不好意思各位,因为小弟也怕被查水表),状态值为200表示访问成功,访问方法: GET,回显话题,使用get请求获取网页的动态加载数据。好了,今天的教程到此结束。什么?不构造一个获取请求?那请到我的第一篇博文找大神的爬虫教程链接~~~~
好了,这篇文章到此结束。我从头到尾都没有看到任何代码。哈哈,有时候教他们钓鱼不如教他们钓鱼。代码很重要,方法也很重要。有了这些分析方法,相信大家都能快速掌握获取动态网页内容的技巧。下一篇我们会讲如何使用post请求来获取网页的动态加载数据~我们下期再见 查看全部
python抓取动态网页(.4win7框架:如何获取网页上动态加载的数据)
环境:python3.4
赢7
框架:scrapy
继上一篇之后,这次我将讲如何获取网页上动态加载的数据:
作为初学者,我们在第一次接触爬虫的时候,一般只会抓取一些静态内容(如何区分静态内容和动态内容,这里不讲理论,只教一些小方法):
首先打开谷歌浏览器,然后按F12,就会弹出谷歌自带的开发者工具,首先在“元素”下找到你需要抓取的内容;
然后,在网页可视化界面上右键,选择查看网页源代码。网页源代码就是我们抓取静态网页时在网页中可以看到的所有东西,开发者工具可以查看。有些东西我们在网页的源代码中是看不到的;
最后,通过将我们在F12中查看的内容与网页源代码中的内容进行比较,可以初步判断哪些数据是静态加载的,哪些数据是动态加载的。
--------- ---分割线-----------
一般的请求方法有两种,post请求方法和get请求方法。在这篇文章中,我们先说一下get请求方法。
说到get请求,这应该是最常用的请求之一。表达 get 请求的最直观方式是什么?其实我们把网址放在地址栏中打开网页,这是一个get请求。
--------- ---分割线-----------
好的,现在让我们进入主题:让我们先用一个例子来描述它。抓取大型购物的商品评论时网站:
当我们点击 1 或 2 3 4 时,我们会发现 URL 根本没有改变。这意味着这些注释是动态加载的。然后我们使用F12下的抓包工具尝试抓包:(F12,然后选择“网络”),出现下图:
接下来是最重要的:在可视化界面中,我们点击“2”按钮,让评论页面跳转到第二页,看看能否顺利抓包:
OK,可以看到有2个gif文件,2个png文件,还有一个脚本文件。一开始,我们不知道应该检查哪个文件。好吧,最笨的方法,一个一个的点击:所以你关心我都订购了,除了脚本文件,其他的都是这样的:
哈哈,如果没有next,那我们只能检查脚本文件了。看Response,发现是一堆代码,查起来好像不方便?好的,没问题,我们试试预览,效果会很好。. . . 很高兴找到结果:
你看到吗!评论评论,大家应该相信网站大写手的英文是绝对没问题的,不会像我一样给评论起个“pinglun”的吧!
然后点击这条评论看看里面有什么:
好的,正是我们想要的注释,所以这个文件所在的URL就是我们需要的,接下来我们通过查看Headers来获取URL!
URL就是我们需要的URL(URL被马赛克抹掉了,不好意思各位,因为小弟也怕被查水表),状态值为200表示访问成功,访问方法: GET,回显话题,使用get请求获取网页的动态加载数据。好了,今天的教程到此结束。什么?不构造一个获取请求?那请到我的第一篇博文找大神的爬虫教程链接~~~~
好了,这篇文章到此结束。我从头到尾都没有看到任何代码。哈哈,有时候教他们钓鱼不如教他们钓鱼。代码很重要,方法也很重要。有了这些分析方法,相信大家都能快速掌握获取动态网页内容的技巧。下一篇我们会讲如何使用post请求来获取网页的动态加载数据~我们下期再见
python抓取动态网页(利用Python实现抓取知乎热点话题(一)_网页分析_光明网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-08 21:05
前言
用Python捕捉知乎热门话题,废话不多说。
让我们愉快的开始吧~
开发工具
Python版本:3.6.4
相关模块:
请求模块;
重新模块;
熊猫模块;
lxml 模块;
随机模块;
以及一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
思维分析
本文爬取了知乎的热门话题《网通向腾讯高管提出拒绝陪酒的相关规定》,腾讯实习生如何看待?“例如
目标网址
网络分析
检查网页源代码等后,确定网页的回答内容是动态加载的,需要进入浏览器的开发者工具进行抓包。进入Nonetwork→XHR,在网页上用鼠标下拉即可得到我们需要的数据包
获取准确的网址
https://www.zhihu.com/api/v4/q ... fault
https://www.zhihu.com/api/v4/q ... fault
URL 有很多不必要的参数,您可以在浏览器中删除它们。两个URL的区别在于后面的offset参数。第一个URL的offset参数为0,第二个为5,偏移量以5的容差递增;网页数据格式为json格式。
代码
import requests\
import pandas as pd\
import re\
import time\
import random\
\
df = pd.DataFrame()\
headers = {\
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'\
}\
for page in range(0, 1360, 5):\
url = f'https://www.zhihu.com/api/v4/q ... et%3D{page}&platform=desktop&sort_by=default'\
response = requests.get(url=url, headers=headers).json()\
data = response['data']\
for list_ in data:\
name = list_['author']['name'] # 知乎作者\
id_ = list_['author']['id'] # 作者id\
created_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(list_['created_time'] )) # 回答时间\
voteup_count = list_['voteup_count'] # 赞同数\
comment_count = list_['comment_count'] # 底下评论数\
content = list_['content'] # 回答内容\
content = ''.join(re.findall("[\u3002\uff1b\uff0c\uff1a\u201c\u201d\uff08\uff09\u3001\uff1f\u300a\u300b\u4e00-\u9fa5]", content)) # 正则表达式提取\
print(name, id_, created_time, comment_count, content, sep='|')\
dataFrame = pd.DataFrame(\
{'知乎作者': [name], '作者id': [id_], '回答时间': [created_time], '赞同数': [voteup_count], '底下评论数': [comment_count],\
'回答内容': [content]})\
df = pd.concat([df, dataFrame])\
time.sleep(random.uniform(2, 3))\
df.to_csv('知乎回答.csv', encoding='utf-8', index=False)\
print(df.shape)
显示结果
————————————————————————————————————————————— 查看全部
python抓取动态网页(利用Python实现抓取知乎热点话题(一)_网页分析_光明网)
前言
用Python捕捉知乎热门话题,废话不多说。
让我们愉快的开始吧~
开发工具
Python版本:3.6.4
相关模块:
请求模块;
重新模块;
熊猫模块;
lxml 模块;
随机模块;
以及一些 Python 自带的模块。
环境设置
安装Python并将其添加到环境变量中,pip安装所需的相关模块。
思维分析
本文爬取了知乎的热门话题《网通向腾讯高管提出拒绝陪酒的相关规定》,腾讯实习生如何看待?“例如
目标网址
网络分析
检查网页源代码等后,确定网页的回答内容是动态加载的,需要进入浏览器的开发者工具进行抓包。进入Nonetwork→XHR,在网页上用鼠标下拉即可得到我们需要的数据包
获取准确的网址
https://www.zhihu.com/api/v4/q ... fault
https://www.zhihu.com/api/v4/q ... fault
URL 有很多不必要的参数,您可以在浏览器中删除它们。两个URL的区别在于后面的offset参数。第一个URL的offset参数为0,第二个为5,偏移量以5的容差递增;网页数据格式为json格式。
代码
import requests\
import pandas as pd\
import re\
import time\
import random\
\
df = pd.DataFrame()\
headers = {\
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'\
}\
for page in range(0, 1360, 5):\
url = f'https://www.zhihu.com/api/v4/q ... et%3D{page}&platform=desktop&sort_by=default'\
response = requests.get(url=url, headers=headers).json()\
data = response['data']\
for list_ in data:\
name = list_['author']['name'] # 知乎作者\
id_ = list_['author']['id'] # 作者id\
created_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(list_['created_time'] )) # 回答时间\
voteup_count = list_['voteup_count'] # 赞同数\
comment_count = list_['comment_count'] # 底下评论数\
content = list_['content'] # 回答内容\
content = ''.join(re.findall("[\u3002\uff1b\uff0c\uff1a\u201c\u201d\uff08\uff09\u3001\uff1f\u300a\u300b\u4e00-\u9fa5]", content)) # 正则表达式提取\
print(name, id_, created_time, comment_count, content, sep='|')\
dataFrame = pd.DataFrame(\
{'知乎作者': [name], '作者id': [id_], '回答时间': [created_time], '赞同数': [voteup_count], '底下评论数': [comment_count],\
'回答内容': [content]})\
df = pd.concat([df, dataFrame])\
time.sleep(random.uniform(2, 3))\
df.to_csv('知乎回答.csv', encoding='utf-8', index=False)\
print(df.shape)
显示结果
—————————————————————————————————————————————
python抓取动态网页(如何用python来页面中的JS动态加载数据的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-05 20:01
)
本文文章与大家分享使用python抓取网页动态数据的方法。小编觉得很实用,分享给大家参考。跟着小编一起来看看吧。
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某一部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 都不是那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
python抓取动态网页(如何用python来页面中的JS动态加载数据的数据
)
本文文章与大家分享使用python抓取网页动态数据的方法。小编觉得很实用,分享给大家参考。跟着小编一起来看看吧。
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某一部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 都不是那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
python抓取动态网页(基于requests+multiprocessing+pyspider的方法-python抓取动态网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-04 19:01
python抓取动态网页。今天介绍的是基于requests+multiprocessing+pyspider的方法。先来看效果:代码如下:#spider.pyimportrequestsfrommultiprocessingimportpoolfrompyspider.pagesimportmapdefurl_map(url,all_pages):try:r=requests.get(url)html=r.textreturnhtmlexceptexceptionase:return''response=pool.getresponse()returnresponse执行这个代码也非常简单:1.首先准备好请求路径和请求参数,请求函数我用的是get2.执行httpresponse对象的process方法,一边执行一边调用process方法的next方法,在一个请求被执行到底的时候next方法会被调用,完成接收返回值defnext(request):urls=requests.get(url).textreturnresponse.response(urls,"all_pages")这段代码我做了两点特别重要的事情:1.urls对象有了一个cookie参数cookie用来在请求的时候用来唯一标识一个url2.这时候获取到的url是一个整数,调用spider对象的get方法有返回值,而且返回值值为none(true返回的url是python自带的一个单例对象)我们来验证一下成功不。
frompyspider.controllersimportdispatchexportfrompyspider.spiderimportspiderurl=""try:r=requests.get(url).textexceptexceptionase:return''#1.将网页文件拿出来frompyspider.exceptionsimportspiderexceptionspiderexception=spiderexception('scrapy:error:trier')spiderexception=spiderexception('scrapy:error:filenotfound')spiderexception=spiderexception('scrapy:error:directoryerror')reload(spiderexception)finally:spiderexception=spiderexception('scrapy:spiderexception')spiderexception=spiderexception('scrapy:spiderexception')returnspiderexception通过httpresponse对象的get方法获取文件名,同时也拿到了请求路径的cookie值#2.获取返回值defget_response(filename):html=requests.get(url).textreturnhtml#3.将请求路径转换为urlopen(r'?charset=utf-8',formdata={'user-agent':'mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/59.0.3024.132safari/537.36'})withopen(filename,'wt')asf:f.write(response.response(newheader="c。 查看全部
python抓取动态网页(基于requests+multiprocessing+pyspider的方法-python抓取动态网页)
python抓取动态网页。今天介绍的是基于requests+multiprocessing+pyspider的方法。先来看效果:代码如下:#spider.pyimportrequestsfrommultiprocessingimportpoolfrompyspider.pagesimportmapdefurl_map(url,all_pages):try:r=requests.get(url)html=r.textreturnhtmlexceptexceptionase:return''response=pool.getresponse()returnresponse执行这个代码也非常简单:1.首先准备好请求路径和请求参数,请求函数我用的是get2.执行httpresponse对象的process方法,一边执行一边调用process方法的next方法,在一个请求被执行到底的时候next方法会被调用,完成接收返回值defnext(request):urls=requests.get(url).textreturnresponse.response(urls,"all_pages")这段代码我做了两点特别重要的事情:1.urls对象有了一个cookie参数cookie用来在请求的时候用来唯一标识一个url2.这时候获取到的url是一个整数,调用spider对象的get方法有返回值,而且返回值值为none(true返回的url是python自带的一个单例对象)我们来验证一下成功不。
frompyspider.controllersimportdispatchexportfrompyspider.spiderimportspiderurl=""try:r=requests.get(url).textexceptexceptionase:return''#1.将网页文件拿出来frompyspider.exceptionsimportspiderexceptionspiderexception=spiderexception('scrapy:error:trier')spiderexception=spiderexception('scrapy:error:filenotfound')spiderexception=spiderexception('scrapy:error:directoryerror')reload(spiderexception)finally:spiderexception=spiderexception('scrapy:spiderexception')spiderexception=spiderexception('scrapy:spiderexception')returnspiderexception通过httpresponse对象的get方法获取文件名,同时也拿到了请求路径的cookie值#2.获取返回值defget_response(filename):html=requests.get(url).textreturnhtml#3.将请求路径转换为urlopen(r'?charset=utf-8',formdata={'user-agent':'mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/59.0.3024.132safari/537.36'})withopen(filename,'wt')asf:f.write(response.response(newheader="c。
python抓取动态网页(python抓取动态网页的requests和urllib库的使用,介绍python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-04 15:05
python抓取动态网页的requests和urllib库的使用,介绍python抓取网页的方法。入门基础的爬虫的同学可以先去看看视频课程,其实有一个网页在讲这部分知识点。这是爬取页面的代码:第一步-使用requests.get将页面抓取下来,这里需要用到网页里面的url,也就是你需要的网址(page_name,page_id),抓取工具是urllib,获取工具是python自带的httplib库。
第二步-requests.set_user_agent(user_agent),即将用户请求用代理,也就是其他的浏览器。这里使用的是谷歌浏览器(googlechrome)。第三步-使用urllib.request()将请求的请求报文转换成html报文,这个工具是可选的,可以自己用到哪里就用哪里,能有一个需要就最好有,否则后续的都可以不用。
转换成html报文,以下代码解释说明如何将请求报文转换成html报文,google浏览器的解释如下,示例代码:#coding:utf-8defpage(url):'''循环请求页面..'''returnhtml(page_name,page_id)#请求一个网页,得到请求报文returnhtml(get(url).text)如果使用httplib.urllib.request方法,就要下载相应的httplib库,如下代码,详细用法请看代码:requests+urllib=requests.get(url)第四步-urllib.request.urlopen,获取页面内容,这里下载页面的内容使用的是urllib.request.urlopen方法。
同时下载下来的内容也可以再继续用get请求。动态网页的示例:importurllib.requestimportjsonfromfake_useragentimportuseragenttry:url=''response=urllib.request.urlopen(url)try:response=json.loads(response)except:raisenotimplementedfinally:try:response=json.loads(response)except:raisenotimplementedurllib.request.urlopen(url)以上代码获取到的页面内容为:知乎是3.05.1版本app,普通用户的话要过365天才能获取到你想要的内容。 查看全部
python抓取动态网页(python抓取动态网页的requests和urllib库的使用,介绍python)
python抓取动态网页的requests和urllib库的使用,介绍python抓取网页的方法。入门基础的爬虫的同学可以先去看看视频课程,其实有一个网页在讲这部分知识点。这是爬取页面的代码:第一步-使用requests.get将页面抓取下来,这里需要用到网页里面的url,也就是你需要的网址(page_name,page_id),抓取工具是urllib,获取工具是python自带的httplib库。
第二步-requests.set_user_agent(user_agent),即将用户请求用代理,也就是其他的浏览器。这里使用的是谷歌浏览器(googlechrome)。第三步-使用urllib.request()将请求的请求报文转换成html报文,这个工具是可选的,可以自己用到哪里就用哪里,能有一个需要就最好有,否则后续的都可以不用。
转换成html报文,以下代码解释说明如何将请求报文转换成html报文,google浏览器的解释如下,示例代码:#coding:utf-8defpage(url):'''循环请求页面..'''returnhtml(page_name,page_id)#请求一个网页,得到请求报文returnhtml(get(url).text)如果使用httplib.urllib.request方法,就要下载相应的httplib库,如下代码,详细用法请看代码:requests+urllib=requests.get(url)第四步-urllib.request.urlopen,获取页面内容,这里下载页面的内容使用的是urllib.request.urlopen方法。
同时下载下来的内容也可以再继续用get请求。动态网页的示例:importurllib.requestimportjsonfromfake_useragentimportuseragenttry:url=''response=urllib.request.urlopen(url)try:response=json.loads(response)except:raisenotimplementedfinally:try:response=json.loads(response)except:raisenotimplementedurllib.request.urlopen(url)以上代码获取到的页面内容为:知乎是3.05.1版本app,普通用户的话要过365天才能获取到你想要的内容。
python抓取动态网页(如何捕获到动态加载的数据?通过示例代码介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-11-03 16:01
本文文章主要介绍Python对网页动态加载的数据进行爬取的实现。通过示例代码介绍非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友关注小编,一起学习
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,说明数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击了解json序列化和反序列化。代码如下:
import requests import json # 获取商品价格的请求地址 url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \ "=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \ "pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921" jQuery_id = url.split("=")[-1] + "(" # 头部信息 headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) " "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36" } # 发送网络请求 response = requests.get(url, headers=headers) if response.status_code == 200: goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化 print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}") print(f"定价为: {goods_dict['stock']['jdPrice']['m']}") print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}") else: print("请求失败!")
作者写博文的时候,价格发生了变化,运行结果如下图所示:
注意:抓取动态加载数据信息时,需要根据不同的网页使用不同的方法进行数据提取。如果在运行源代码时出现错误,请按照步骤获取新的请求地址。
以上就是Python实现的爬取网页中动态加载数据的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
python抓取动态网页(如何捕获到动态加载的数据?通过示例代码介绍)
本文文章主要介绍Python对网页动态加载的数据进行爬取的实现。通过示例代码介绍非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友关注小编,一起学习
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,说明数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击了解json序列化和反序列化。代码如下:
import requests import json # 获取商品价格的请求地址 url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \ "=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \ "pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921" jQuery_id = url.split("=")[-1] + "(" # 头部信息 headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) " "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36" } # 发送网络请求 response = requests.get(url, headers=headers) if response.status_code == 200: goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化 print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}") print(f"定价为: {goods_dict['stock']['jdPrice']['m']}") print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}") else: print("请求失败!")
作者写博文的时候,价格发生了变化,运行结果如下图所示:
注意:抓取动态加载数据信息时,需要根据不同的网页使用不同的方法进行数据提取。如果在运行源代码时出现错误,请按照步骤获取新的请求地址。
以上就是Python实现的爬取网页中动态加载数据的详细内容。更多详情请关注其他相关html中文网站文章!
python抓取动态网页(AJAX动态加载网页一什么是动态网页J哥一向注重理论与实践)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-11-03 14:22
AJAX 动态加载网页
一
什么是动态网页
J哥一向注重理论与实践的结合,知道发生了什么也必须知道为什么,这样他才能在没有变化的情况下应对所有的变化。
所谓动态网页,是指一种与静态网页相对的网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。——来源百度百科
动态网页具有工作量少、内容更新快、功能更齐全的特点。被很多公司采用,如购动、速食宝、速食等。
二
什么是 AJAX
随着人们对动态网页的加载速度要求越来越高,AJAX 技术应运而生,成为许多网站的首选。AJAX 是一种用于创建快速动态网页的技术,通过在后台与服务器进行少量数据交换,使网页可以异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
三
如何抓取AJAX动态加载的网页
1. 分析界面
只要有数据发送,就一定有请求发送到服务器。我们只需要找出它静默加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站比较难解析。
2. 硒
什么是硒?它最初是一个自动化测试工具,但被广泛的用户抓取。是一个可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。 特点:代码比较简单,爬取速度慢,IP容易被封。
项目实践
理论这么多,老实说,J哥也不想这么啰嗦。但是,这些东西经常被问到,所以把它们写下来。下次有人问,就送他这个文章,一劳永逸!
好,让我们回到王律师的部分。作为资深律师,王律师深知,研究法院多年来公开的开庭信息和执行信息,对于提升业务能力具有重要作用。于是他兴高采烈地打开了法庭信息公开网页。
它看起来像这样:
然后,他按照J哥之前写的爬虫介绍文章抓取数据,成功提取到第一页。他异常兴奋。
紧接着,他又加了一个for循环,想着花几分钟把这个网站2164页共32457条宣判数据提取到excel中。
然后,就没有了。你也应该知道,看了前面的理论部分,这是一个AJAX动态加载的网页。无论你如何点击下一页,url都不会改变。如果你不相信我,我就给你看。左上角的url像山一样矗立在那里:
一
解析接口
既然如此,那我们就开始爬虫的正确姿势,先用解析接口的方法来写爬虫。
首先,找到真正的要求。右键勾选,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。没错,就是这么简单,真正的要求就藏在里面。
我们仔细看看这个jsp,这简直就是宝藏。有真实的请求url、post请求方法、Headers、Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!为了安全起见,我为我的 Cookie 做了马赛克。机智的朋友可能已经发现我顺便给自己打了广告。
让我们仔细看看这些参数, pagesnum 参数不只是代表页数!王律师顿时恍然大悟,原来他思考的那一页,竟然翻到了这里!穿越千山万水,终于找到了你!我们尝试点击翻页,发现只有 pagesnum 参数会发生变化。
既然找到了,赶紧抓起来吧。J哥以闪电般的速度打开了PyCharm,导入了爬虫需要的库。
1from urllib.parse import urlencode
2import csv
3import random
4import requests
5import traceback
6from time import sleep
7from lxml import etree #lxml为第三方网页解析库,强大且速度快
构造一个真正的请求并添加标题。J哥没有把他的User-Agent和Cookie贴在这里,主要是一向胆小的J哥被吓到了。
1base_url = 'http://www.hshfy.sh.cn/shfy/gw ... 39%3B #这里要换成对应Ajax请求中的链接
2
3headers = {
4 'Connection': 'keep-alive',
5 'Accept': '*/*',
6 'X-Requested-With': 'XMLHttpRequest',
7 'User-Agent': '你的User-Agent',
8 'Origin': 'http://www.hshfy.sh.cn',
9 'Referer': 'http://www.hshfy.sh.cn/shfy/gw ... 39%3B,
10 'Accept-Language': 'zh-CN,zh;q=0.9',
11 'Content-Type': 'application/x-www-form-urlencoded',
12 'Cookie': '你的Cookie'
13}
构造get_page函数,参数为page,即页数。创建字典类型的表单数据,并使用post请求网页数据。这里一定要注意返回数据的解码,编码为'gbk',否则返回数据会乱码!另外,我还优化了异常处理,防止意外。
1def get_page(page):
2 n = 3
3 while True:
4 try:
5 sleep(random.uniform(1, 2)) # 随机出现1-2之间的数,包含小数
6 data = {
7 'yzm': 'yxAH',
8 'ft':'',
9 'ktrqks': '2020-05-22',
10 'ktrqjs': '2020-06-22',
11 'spc':'',
12 'yg':'',
13 'bg':'',
14 'ah':'',
15 'pagesnum': page
16 }
17 url = base_url + urlencode(data)
18 print(url)
19 try:
20 response = requests.request("POST",url, headers = headers)
21 #print(response)
22 if response.status_code == 200:
23 re = response.content.decode('gbk')
24 # print(re)
25 return re # 解析内容
26 except requests.ConnectionError as e:
27 print('Error', e.args) # 输出异常信息
28 except (TimeoutError, Exception):
29 n -= 1
30 if n == 0:
31 print('请求3次均失败,放弃此url请求,检查请求条件')
32 return
33 else:
34 print('请求失败,重新请求')
35 continue
构造parse_page函数解析返回的网页数据,用Xpath提取所有字段内容,并保存为csv格式。有人会问为什么J哥那么喜欢用Xpath,因为它简单好用!!!这么简单的网页结构,我做不了普通的大法安装。J兄弟,我做不到。
1def parse_page(html):
2 try:
3 parse = etree.HTML(html) # 解析网页
4 items = parse.xpath('//*[@id="report"]/tbody/tr')
5 for item in items[1:]:
6 item = {
7 'a': ''.join(item.xpath('./td[1]/font/text()')).strip(),
8 'b': ''.join(item.xpath('./td[2]/font/text()')).strip(),
9 'c': ''.join(item.xpath('./td[3]/text()')).strip(),
10 'd': ''.join(item.xpath('./td[4]/text()')).strip(),
11 'e': ''.join(item.xpath('./td[5]/text()')).strip(),
12 'f': ''.join(item.xpath('./td[6]/div/text()')).strip(),
13 'g': ''.join(item.xpath('./td[7]/div/text()')).strip(),
14 'h': ''.join(item.xpath('./td[8]/text()')).strip(),
15 'i': ''.join(item.xpath('./td[9]/text()')).strip()
16 }
17 #print(item)
18 try:
19 with open('./law.csv', 'a', encoding='utf_8_sig', newline='') as fp:
20 # 'a'为追加模式(添加)
21 # utf_8_sig格式导出csv不乱码
22 fieldnames = ['a', 'b', 'c', 'd', 'e','f','g','h','i']
23 writer = csv.DictWriter(fp,fieldnames)
24 writer.writerow(item)
25 except Exception:
26 print(traceback.print_exc()) #代替print e 来输出详细的异常信息
27 except Exception:
28 print(traceback.print_exc())
最后遍历页数,调用函数。OK完成!
1 for page in range(1,5): #这里设置想要爬取的页数
2 html = get_page(page)
3 #print(html)
4 print("第" + str(page) + "页提取完成")
我们来看看最终的效果:
二
硒
热衷学习的朋友可能还想看看Selenium是如何爬取AJAX动态加载网页的。J哥自然会满足你的好奇心。于是赶紧新建了一个py文件,准备趁势而上,用Selenium把这个网站爬下来。
首先,导入相关库。
1from lxml import etree
2import time
3from selenium import webdriver
4from selenium. webdriver.support.wait import WebDriverWait
5from selenium.webdriver.support import expected_conditions as EC
6from selenium.webdriver.common.by import By
然后,使用chromedriver驱动打开这个网站。
1def main():
2 # 爬取首页url
3 url = "http://www.hshfy.sh.cn/shfy/gw ... ot%3B
4 # 定义谷歌webdriver
5 driver = webdriver.Chrome('./chromedriver')
6 driver.maximize_window() # 将浏览器最大化
7 driver.get(url)
所以,我惊讶地发现报告了一个错误。以CET-6英语的词汇储备,J哥居然听懂了!可能是我的驱动和浏览器版本不匹配,只支持79版本的浏览器。
J兄很郁闷,因为我之前用Selenium没遇到过这个问题。J哥不甘心,打开谷歌浏览器查看版本号。
我失去了它!他们都更新到了81版!遇到这种情况,请好奇的朋友,请等待J哥设置浏览器自动更新并重新下载最新驱动。下次你会听Selenium crawler。记得关注本公众号。不要错过刺激~
结束语
综上所述,对于网络爬虫的AJAX动态加载,一般有两种方式:解析接口;硒。J兄推荐解析接口的方式。如果是解析json数据,最好是爬取。如果你不知道如何使用Selenium,让我们使用Selenium。
后台私信编辑器01获取完整项目代码`1 查看全部
python抓取动态网页(AJAX动态加载网页一什么是动态网页J哥一向注重理论与实践)
AJAX 动态加载网页
一
什么是动态网页
J哥一向注重理论与实践的结合,知道发生了什么也必须知道为什么,这样他才能在没有变化的情况下应对所有的变化。
所谓动态网页,是指一种与静态网页相对的网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。——来源百度百科
动态网页具有工作量少、内容更新快、功能更齐全的特点。被很多公司采用,如购动、速食宝、速食等。
二
什么是 AJAX
随着人们对动态网页的加载速度要求越来越高,AJAX 技术应运而生,成为许多网站的首选。AJAX 是一种用于创建快速动态网页的技术,通过在后台与服务器进行少量数据交换,使网页可以异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
三
如何抓取AJAX动态加载的网页
1. 分析界面
只要有数据发送,就一定有请求发送到服务器。我们只需要找出它静默加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站比较难解析。
2. 硒
什么是硒?它最初是一个自动化测试工具,但被广泛的用户抓取。是一个可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。 特点:代码比较简单,爬取速度慢,IP容易被封。
项目实践
理论这么多,老实说,J哥也不想这么啰嗦。但是,这些东西经常被问到,所以把它们写下来。下次有人问,就送他这个文章,一劳永逸!
好,让我们回到王律师的部分。作为资深律师,王律师深知,研究法院多年来公开的开庭信息和执行信息,对于提升业务能力具有重要作用。于是他兴高采烈地打开了法庭信息公开网页。
它看起来像这样:
然后,他按照J哥之前写的爬虫介绍文章抓取数据,成功提取到第一页。他异常兴奋。
紧接着,他又加了一个for循环,想着花几分钟把这个网站2164页共32457条宣判数据提取到excel中。
然后,就没有了。你也应该知道,看了前面的理论部分,这是一个AJAX动态加载的网页。无论你如何点击下一页,url都不会改变。如果你不相信我,我就给你看。左上角的url像山一样矗立在那里:
一
解析接口
既然如此,那我们就开始爬虫的正确姿势,先用解析接口的方法来写爬虫。
首先,找到真正的要求。右键勾选,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。没错,就是这么简单,真正的要求就藏在里面。
我们仔细看看这个jsp,这简直就是宝藏。有真实的请求url、post请求方法、Headers、Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!为了安全起见,我为我的 Cookie 做了马赛克。机智的朋友可能已经发现我顺便给自己打了广告。
让我们仔细看看这些参数, pagesnum 参数不只是代表页数!王律师顿时恍然大悟,原来他思考的那一页,竟然翻到了这里!穿越千山万水,终于找到了你!我们尝试点击翻页,发现只有 pagesnum 参数会发生变化。
既然找到了,赶紧抓起来吧。J哥以闪电般的速度打开了PyCharm,导入了爬虫需要的库。
1from urllib.parse import urlencode
2import csv
3import random
4import requests
5import traceback
6from time import sleep
7from lxml import etree #lxml为第三方网页解析库,强大且速度快
构造一个真正的请求并添加标题。J哥没有把他的User-Agent和Cookie贴在这里,主要是一向胆小的J哥被吓到了。
1base_url = 'http://www.hshfy.sh.cn/shfy/gw ... 39%3B #这里要换成对应Ajax请求中的链接
2
3headers = {
4 'Connection': 'keep-alive',
5 'Accept': '*/*',
6 'X-Requested-With': 'XMLHttpRequest',
7 'User-Agent': '你的User-Agent',
8 'Origin': 'http://www.hshfy.sh.cn',
9 'Referer': 'http://www.hshfy.sh.cn/shfy/gw ... 39%3B,
10 'Accept-Language': 'zh-CN,zh;q=0.9',
11 'Content-Type': 'application/x-www-form-urlencoded',
12 'Cookie': '你的Cookie'
13}
构造get_page函数,参数为page,即页数。创建字典类型的表单数据,并使用post请求网页数据。这里一定要注意返回数据的解码,编码为'gbk',否则返回数据会乱码!另外,我还优化了异常处理,防止意外。
1def get_page(page):
2 n = 3
3 while True:
4 try:
5 sleep(random.uniform(1, 2)) # 随机出现1-2之间的数,包含小数
6 data = {
7 'yzm': 'yxAH',
8 'ft':'',
9 'ktrqks': '2020-05-22',
10 'ktrqjs': '2020-06-22',
11 'spc':'',
12 'yg':'',
13 'bg':'',
14 'ah':'',
15 'pagesnum': page
16 }
17 url = base_url + urlencode(data)
18 print(url)
19 try:
20 response = requests.request("POST",url, headers = headers)
21 #print(response)
22 if response.status_code == 200:
23 re = response.content.decode('gbk')
24 # print(re)
25 return re # 解析内容
26 except requests.ConnectionError as e:
27 print('Error', e.args) # 输出异常信息
28 except (TimeoutError, Exception):
29 n -= 1
30 if n == 0:
31 print('请求3次均失败,放弃此url请求,检查请求条件')
32 return
33 else:
34 print('请求失败,重新请求')
35 continue
构造parse_page函数解析返回的网页数据,用Xpath提取所有字段内容,并保存为csv格式。有人会问为什么J哥那么喜欢用Xpath,因为它简单好用!!!这么简单的网页结构,我做不了普通的大法安装。J兄弟,我做不到。
1def parse_page(html):
2 try:
3 parse = etree.HTML(html) # 解析网页
4 items = parse.xpath('//*[@id="report"]/tbody/tr')
5 for item in items[1:]:
6 item = {
7 'a': ''.join(item.xpath('./td[1]/font/text()')).strip(),
8 'b': ''.join(item.xpath('./td[2]/font/text()')).strip(),
9 'c': ''.join(item.xpath('./td[3]/text()')).strip(),
10 'd': ''.join(item.xpath('./td[4]/text()')).strip(),
11 'e': ''.join(item.xpath('./td[5]/text()')).strip(),
12 'f': ''.join(item.xpath('./td[6]/div/text()')).strip(),
13 'g': ''.join(item.xpath('./td[7]/div/text()')).strip(),
14 'h': ''.join(item.xpath('./td[8]/text()')).strip(),
15 'i': ''.join(item.xpath('./td[9]/text()')).strip()
16 }
17 #print(item)
18 try:
19 with open('./law.csv', 'a', encoding='utf_8_sig', newline='') as fp:
20 # 'a'为追加模式(添加)
21 # utf_8_sig格式导出csv不乱码
22 fieldnames = ['a', 'b', 'c', 'd', 'e','f','g','h','i']
23 writer = csv.DictWriter(fp,fieldnames)
24 writer.writerow(item)
25 except Exception:
26 print(traceback.print_exc()) #代替print e 来输出详细的异常信息
27 except Exception:
28 print(traceback.print_exc())
最后遍历页数,调用函数。OK完成!
1 for page in range(1,5): #这里设置想要爬取的页数
2 html = get_page(page)
3 #print(html)
4 print("第" + str(page) + "页提取完成")
我们来看看最终的效果:
二
硒
热衷学习的朋友可能还想看看Selenium是如何爬取AJAX动态加载网页的。J哥自然会满足你的好奇心。于是赶紧新建了一个py文件,准备趁势而上,用Selenium把这个网站爬下来。
首先,导入相关库。
1from lxml import etree
2import time
3from selenium import webdriver
4from selenium. webdriver.support.wait import WebDriverWait
5from selenium.webdriver.support import expected_conditions as EC
6from selenium.webdriver.common.by import By
然后,使用chromedriver驱动打开这个网站。
1def main():
2 # 爬取首页url
3 url = "http://www.hshfy.sh.cn/shfy/gw ... ot%3B
4 # 定义谷歌webdriver
5 driver = webdriver.Chrome('./chromedriver')
6 driver.maximize_window() # 将浏览器最大化
7 driver.get(url)
所以,我惊讶地发现报告了一个错误。以CET-6英语的词汇储备,J哥居然听懂了!可能是我的驱动和浏览器版本不匹配,只支持79版本的浏览器。
J兄很郁闷,因为我之前用Selenium没遇到过这个问题。J哥不甘心,打开谷歌浏览器查看版本号。
我失去了它!他们都更新到了81版!遇到这种情况,请好奇的朋友,请等待J哥设置浏览器自动更新并重新下载最新驱动。下次你会听Selenium crawler。记得关注本公众号。不要错过刺激~
结束语
综上所述,对于网络爬虫的AJAX动态加载,一般有两种方式:解析接口;硒。J兄推荐解析接口的方式。如果是解析json数据,最好是爬取。如果你不知道如何使用Selenium,让我们使用Selenium。
后台私信编辑器01获取完整项目代码`1
python抓取动态网页(使用scrapy框架写爬虫时一般会在start_urls中定义的路径网页爬取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-02 19:13
)
在使用scrapy框架编写爬虫时,我们一般都会在start_urls中指定我们需要爬取的网页的URL进行爬取,但是如何让我们的爬虫像搜索引擎中使用的爬虫一样具有自动多网页爬取的功能呢?本文通过自动抓取个人csdn博客的所有文章标题、读者数量和创建时间进行简单说明。本文使用了两种不同的方法来实现这一点。
首先我们来分析一下cdsn中博客中文章的url。如图,我们可以发现不同的文章页面的url只是url末尾的一串数字不同,而在每篇文章文章下面@>都会有链接到上一个或下一个 文章。所以我们可以提取这个链接来实现网页的自动抓取。
在scrapy框架上写爬虫的整体流程和上一篇文章的流程是一样的。这里就不直接重复代码了。
项目.py
import scrapy
class CsdnItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
title=scrapy.Field()
time=scrapy.Field()
readtimes=scrapy.Field()
article_url=scrapy.Field()
pass
管道.py
import codecs
import json
from scrapy import signals
class CsdnPipeline(object):
def __init__(self):
self.file=codecs.open('data.json','w',encoding='utf-8')
def process_item(self, item, spider):
line=json.dumps(dict(item))+'\n'
self.file.write(line.decode("unicode_escape"))
return item
def spider_closed(self,spider):
self.file.close()
设置.py
# -*- coding: utf-8 -*-
# Scrapy settings for csdn project
#
# For simplicity, this file contains only the most important settings by
# default. All the other settings are documented here:
#
# http://doc.scrapy.org/en/lates ... .html
#
BOT_NAME = 'csdn'
SPIDER_MODULES = ['csdn.spiders']
NEWSPIDER_MODULE = 'csdn.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'csdn (+http://www.yourdomain.com)'
USER_AGENT = 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:37.0) Gecko/20100101 Firefox/37.0'
ITEM_PIPELINES = {
'csdn.pipelines.CsdnPipeline':300,
}
DOWNLOAD_DELAY = 2
COOKIES_ENABLED=False
然后是最关键的爬虫部分。我们仍然使用的第一种方法是普通的 Spider。将要爬取的第一篇文章文章的地址放在start_urls中。爬取完这篇文章文章的基本信息,放入定义好的item,然后提取下一篇文章的连接地址,结合python中的yield,通过请求的功能和要求退货页面的内容在回调函数进行处理。具体代码如下:
蜘蛛1.py
#-*- coding:utf-8 -*-
from scrapy.spider import Spider
from scrapy.http import Request
from scrapy.selector import Selector
from csdn.items import CsdnItem
class csdnSpider(Spider):
name="csdn"
download_delay=1
allowed_domains=["blog.csdn.net"]
start_urls=[
"http://blog.csdn.net/u01228651 ... ot%3B
]
def parse(self,response):
sel=Selector(response)
item=CsdnItem()
title=sel.xpath('//div[@id="article_details"]/div/h1/span/a/text()').extract()
article_url = str(response.url)
time=sel.xpath('//div[@id="article_details"]/div[2]/div/span[@class="link_postdate"]/text()').extract()
readtimes=sel.xpath('//div[@id="article_details"]/div[2]/div/span[@class="link_view"]/text()').extract()
item['title']=[n.encode('utf-8').replace("\r\n","").strip() for n in title]
item['time']=[n.encode('utf-8') for n in time]
item['readtimes']=[n.encode('utf-8') for n in readtimes]
yield item
#get next url
urls=sel.xpath('//li[@class="next_article"]/a/@href').extract()
for url in urls:
print url
url="http://blog.csdn.net"+url
print url
yield Request(url,callback=self.parse)
第二种方法我们使用scrapy框架提供的CrawlSpider,它是Spider的派生类。普通蜘蛛只会抓取start_urls中定义的路径网页,但CrawlSpider定义了一些规则(rules),为后续链接提供便利的机制。可能蜘蛛并不完全适合你的特定网站 或项目,但它在很多情况下都会用到。所以你可以以它为起点,根据你的需要修改一些方法。当然你也可以实现自己的蜘蛛。
除了继承自Spider的属性(你必须提供)之外,它还提供了一个新的属性:
规则:
收录一个(或多个)规则对象的集合(列表)。每个规则定义了爬行 网站 的特定性能。下面将介绍 Rule 对象。如果多个规则匹配同一个链接,将根据它们在此属性中定义的顺序使用第一个。
蜘蛛还提供了一个可覆盖的方法:
parse_start_url(响应)
当 start_url 请求返回时,将调用此方法。此方法分析初始返回值,并且必须返回 Item 对象或 Request 对象或收录两者的可迭代对象。
具体实现代码如下:
在规则中,我们定义如何提取从被抓取网页的链接。在本例中,链接满足'/u012286517/article/details'的正则表达式。同时,restrict_xpath 用于限制仅从页面的特定部分提取要抓取的链接。
运行代码,我们得到如下结果,其中红线代表一块文章:
我们来看看爬取到的信息部分:其中,我们可以清楚地看到请求数和响应数为20,与博客中文章的数量一致。
下图是爬取返回的信息与csdn中的文章列表对比:
查看全部
python抓取动态网页(使用scrapy框架写爬虫时一般会在start_urls中定义的路径网页爬取
)
在使用scrapy框架编写爬虫时,我们一般都会在start_urls中指定我们需要爬取的网页的URL进行爬取,但是如何让我们的爬虫像搜索引擎中使用的爬虫一样具有自动多网页爬取的功能呢?本文通过自动抓取个人csdn博客的所有文章标题、读者数量和创建时间进行简单说明。本文使用了两种不同的方法来实现这一点。
首先我们来分析一下cdsn中博客中文章的url。如图,我们可以发现不同的文章页面的url只是url末尾的一串数字不同,而在每篇文章文章下面@>都会有链接到上一个或下一个 文章。所以我们可以提取这个链接来实现网页的自动抓取。
在scrapy框架上写爬虫的整体流程和上一篇文章的流程是一样的。这里就不直接重复代码了。
项目.py
import scrapy
class CsdnItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
title=scrapy.Field()
time=scrapy.Field()
readtimes=scrapy.Field()
article_url=scrapy.Field()
pass
管道.py
import codecs
import json
from scrapy import signals
class CsdnPipeline(object):
def __init__(self):
self.file=codecs.open('data.json','w',encoding='utf-8')
def process_item(self, item, spider):
line=json.dumps(dict(item))+'\n'
self.file.write(line.decode("unicode_escape"))
return item
def spider_closed(self,spider):
self.file.close()
设置.py
# -*- coding: utf-8 -*-
# Scrapy settings for csdn project
#
# For simplicity, this file contains only the most important settings by
# default. All the other settings are documented here:
#
# http://doc.scrapy.org/en/lates ... .html
#
BOT_NAME = 'csdn'
SPIDER_MODULES = ['csdn.spiders']
NEWSPIDER_MODULE = 'csdn.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'csdn (+http://www.yourdomain.com)'
USER_AGENT = 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:37.0) Gecko/20100101 Firefox/37.0'
ITEM_PIPELINES = {
'csdn.pipelines.CsdnPipeline':300,
}
DOWNLOAD_DELAY = 2
COOKIES_ENABLED=False
然后是最关键的爬虫部分。我们仍然使用的第一种方法是普通的 Spider。将要爬取的第一篇文章文章的地址放在start_urls中。爬取完这篇文章文章的基本信息,放入定义好的item,然后提取下一篇文章的连接地址,结合python中的yield,通过请求的功能和要求退货页面的内容在回调函数进行处理。具体代码如下:
蜘蛛1.py
#-*- coding:utf-8 -*-
from scrapy.spider import Spider
from scrapy.http import Request
from scrapy.selector import Selector
from csdn.items import CsdnItem
class csdnSpider(Spider):
name="csdn"
download_delay=1
allowed_domains=["blog.csdn.net"]
start_urls=[
"http://blog.csdn.net/u01228651 ... ot%3B
]
def parse(self,response):
sel=Selector(response)
item=CsdnItem()
title=sel.xpath('//div[@id="article_details"]/div/h1/span/a/text()').extract()
article_url = str(response.url)
time=sel.xpath('//div[@id="article_details"]/div[2]/div/span[@class="link_postdate"]/text()').extract()
readtimes=sel.xpath('//div[@id="article_details"]/div[2]/div/span[@class="link_view"]/text()').extract()
item['title']=[n.encode('utf-8').replace("\r\n","").strip() for n in title]
item['time']=[n.encode('utf-8') for n in time]
item['readtimes']=[n.encode('utf-8') for n in readtimes]
yield item
#get next url
urls=sel.xpath('//li[@class="next_article"]/a/@href').extract()
for url in urls:
print url
url="http://blog.csdn.net"+url
print url
yield Request(url,callback=self.parse)
第二种方法我们使用scrapy框架提供的CrawlSpider,它是Spider的派生类。普通蜘蛛只会抓取start_urls中定义的路径网页,但CrawlSpider定义了一些规则(rules),为后续链接提供便利的机制。可能蜘蛛并不完全适合你的特定网站 或项目,但它在很多情况下都会用到。所以你可以以它为起点,根据你的需要修改一些方法。当然你也可以实现自己的蜘蛛。
除了继承自Spider的属性(你必须提供)之外,它还提供了一个新的属性:
规则:
收录一个(或多个)规则对象的集合(列表)。每个规则定义了爬行 网站 的特定性能。下面将介绍 Rule 对象。如果多个规则匹配同一个链接,将根据它们在此属性中定义的顺序使用第一个。
蜘蛛还提供了一个可覆盖的方法:
parse_start_url(响应)
当 start_url 请求返回时,将调用此方法。此方法分析初始返回值,并且必须返回 Item 对象或 Request 对象或收录两者的可迭代对象。
具体实现代码如下:
在规则中,我们定义如何提取从被抓取网页的链接。在本例中,链接满足'/u012286517/article/details'的正则表达式。同时,restrict_xpath 用于限制仅从页面的特定部分提取要抓取的链接。
运行代码,我们得到如下结果,其中红线代表一块文章:
我们来看看爬取到的信息部分:其中,我们可以清楚地看到请求数和响应数为20,与博客中文章的数量一致。
下图是爬取返回的信息与csdn中的文章列表对比:
python抓取动态网页(python抓取动态网页头部数据教程说明网站百度云盘加速下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-02 17:05
python抓取动态网页头部数据教程说明网站,站内搜索python抓取动态网页头部数据获取不同网站百度http下载链接获取教程,一行一个网站下载。获取的数据保存到txt文件中。获取了大部分网站,收获极大。urlerror:nonesuchuseragent:'mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/74.0.3210.136safari/537.36'准备工作首先创建下载任务:%工作目录%%下载网站http下载链接%获取url。
百度云盘加速下载百度云+正版mx4a-927a8ece38ad-5ca-410-be57-7f96d56fa31fbd。html#!topic=%e6%b1%9b%e5%bb%8b%e7%9f%8f%e5%85%81%e7%bd%89%e4%b8%80%e5%9b%a3%e5%9c%aa%e8%a7%9a%e8%b3%bb%e6%99%ab%e8%a3%b7%e8%ae%9c%e7%9a%84%e5%88%8c%e7%94%bd%e8%b0%8f%e6%88%8e+%e6%9d%9b%e8%80%8b%e5%8f%80%e8%9f%ba%e5%9c%aa%e7%bb%9f%e5%8f%8f%e8%a7%9a%e8%a7%a8%e6%9e%bf%e6%bc%a1%e6%ac%8b%e8%9a%af%e6%ae%a9%e6%99%ab%e8%a9%bf%e4%bd%8d%e7%9a%84%e5%9d%a3%e5%9d%a3%e7%94%bd%e4%bb%9f%e5%8f%8f%e9%9f%8f%e9%9a%a1%e7%9a%84%e5%8d%a5%e5%8d%8e%e8%a6%a1%e5%af%a8%e6%9a%88%e8%b9%a8%e8%ae%a9%e5%8d%91%e4%bc%81%e8%a0%b7%e4%b8%82%e5%92%83%e9%90%9f%e9%b2%af%e9%9b%ae%e9%9b%a3%e5%8d%a3%e6%a9%ab%e6%95%b5%e7%a7%89%e6%96%b0%e7%a7%bc%e6%9d%9b%e9%9d%9b%e5%80%8b%e6%9c%aa%e9%9a%a0%e8%ae%9a%e7%9a%84%e5%88%8f%e9%ba%ae&url=%e7%9f%8f%e5%85%81%e7%9a%84%e5%88%8c%e7%9a%84%e6%9d%9b%e9%9b%ae%e9%9b%a3%e5%8d%。 查看全部
python抓取动态网页(python抓取动态网页头部数据教程说明网站百度云盘加速下载)
python抓取动态网页头部数据教程说明网站,站内搜索python抓取动态网页头部数据获取不同网站百度http下载链接获取教程,一行一个网站下载。获取的数据保存到txt文件中。获取了大部分网站,收获极大。urlerror:nonesuchuseragent:'mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/74.0.3210.136safari/537.36'准备工作首先创建下载任务:%工作目录%%下载网站http下载链接%获取url。
百度云盘加速下载百度云+正版mx4a-927a8ece38ad-5ca-410-be57-7f96d56fa31fbd。html#!topic=%e6%b1%9b%e5%bb%8b%e7%9f%8f%e5%85%81%e7%bd%89%e4%b8%80%e5%9b%a3%e5%9c%aa%e8%a7%9a%e8%b3%bb%e6%99%ab%e8%a3%b7%e8%ae%9c%e7%9a%84%e5%88%8c%e7%94%bd%e8%b0%8f%e6%88%8e+%e6%9d%9b%e8%80%8b%e5%8f%80%e8%9f%ba%e5%9c%aa%e7%bb%9f%e5%8f%8f%e8%a7%9a%e8%a7%a8%e6%9e%bf%e6%bc%a1%e6%ac%8b%e8%9a%af%e6%ae%a9%e6%99%ab%e8%a9%bf%e4%bd%8d%e7%9a%84%e5%9d%a3%e5%9d%a3%e7%94%bd%e4%bb%9f%e5%8f%8f%e9%9f%8f%e9%9a%a1%e7%9a%84%e5%8d%a5%e5%8d%8e%e8%a6%a1%e5%af%a8%e6%9a%88%e8%b9%a8%e8%ae%a9%e5%8d%91%e4%bc%81%e8%a0%b7%e4%b8%82%e5%92%83%e9%90%9f%e9%b2%af%e9%9b%ae%e9%9b%a3%e5%8d%a3%e6%a9%ab%e6%95%b5%e7%a7%89%e6%96%b0%e7%a7%bc%e6%9d%9b%e9%9d%9b%e5%80%8b%e6%9c%aa%e9%9a%a0%e8%ae%9a%e7%9a%84%e5%88%8f%e9%ba%ae&url=%e7%9f%8f%e5%85%81%e7%9a%84%e5%88%8c%e7%9a%84%e6%9d%9b%e9%9b%ae%e9%9b%a3%e5%8d%。
python抓取动态网页(Python3实现抓取javascript动态生成的html网页功能结合实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-01 17:22
本文文章主要介绍了Python3中抓取javascript动态生成的html网页的功能,结合Python3中使用selenium库抓取javascript动态生成的html网页元素,分析相关操作技巧例子。有需要的朋友可以参考
本文以Python3为例,实现抓取javascript动态生成的html网页的功能。分享给大家,供大家参考,如下:
使用urllib等抓取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是urllib被瞬间抓取了。它不等待javascript加载延迟,因此页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?不!
这里是一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
[示例 0]
打开火狐浏览器
使用给定的 url 地址加载页面
from selenium import webdriver browser = webdriver.Firefox() browser.get('http://www.baidu.com/')
[示例 1]
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver from selenium.webdriver.common.keys import Keys browser = webdriver.Firefox() browser.get('http://www.baidu.com') assert '百度' in browser.title elem = browser.find_element_by_name('p') # Find the search box elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键 browser.quit()
[示例 2]
Selenium WebDriver 常用于测试网络程序。以下是使用 Python 标准库 unittest 的示例:
import unittest class BaiduTestCase(unittest.TestCase): def setUp(self): self.browser = webdriver.Firefox() self.addCleanup(self.browser.quit) def testPageTitle(self): self.browser.get('http://www.baidu.com') self.assertIn('百度', self.browser.title) if __name__ == '__main__': unittest.main(verbosity=2)
对Python相关内容感兴趣的读者,请查看本站专题:《Python进程与线程操作技巧总结》、《Python Socket编程技巧总结》、《Python数据结构与算法教程》 》、《Python函数使用技巧总结》、《Python字符串操作技巧总结》、《Python入门及高级经典教程》、《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
以上是Python3中javascript动态生成html网页抓取功能示例的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
python抓取动态网页(Python3实现抓取javascript动态生成的html网页功能结合实例)
本文文章主要介绍了Python3中抓取javascript动态生成的html网页的功能,结合Python3中使用selenium库抓取javascript动态生成的html网页元素,分析相关操作技巧例子。有需要的朋友可以参考
本文以Python3为例,实现抓取javascript动态生成的html网页的功能。分享给大家,供大家参考,如下:
使用urllib等抓取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是urllib被瞬间抓取了。它不等待javascript加载延迟,因此页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?不!
这里是一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
[示例 0]
打开火狐浏览器
使用给定的 url 地址加载页面
from selenium import webdriver browser = webdriver.Firefox() browser.get('http://www.baidu.com/')
[示例 1]
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver from selenium.webdriver.common.keys import Keys browser = webdriver.Firefox() browser.get('http://www.baidu.com') assert '百度' in browser.title elem = browser.find_element_by_name('p') # Find the search box elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键 browser.quit()
[示例 2]
Selenium WebDriver 常用于测试网络程序。以下是使用 Python 标准库 unittest 的示例:
import unittest class BaiduTestCase(unittest.TestCase): def setUp(self): self.browser = webdriver.Firefox() self.addCleanup(self.browser.quit) def testPageTitle(self): self.browser.get('http://www.baidu.com') self.assertIn('百度', self.browser.title) if __name__ == '__main__': unittest.main(verbosity=2)
对Python相关内容感兴趣的读者,请查看本站专题:《Python进程与线程操作技巧总结》、《Python Socket编程技巧总结》、《Python数据结构与算法教程》 》、《Python函数使用技巧总结》、《Python字符串操作技巧总结》、《Python入门及高级经典教程》、《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
以上是Python3中javascript动态生成html网页抓取功能示例的详细内容。更多详情请关注其他相关html中文网站文章!
python抓取动态网页(使用Selenium抓取动态渲染页面(有些linelineexport))
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-10-29 07:06
使用 Selenium 抓取动态呈现的页面
网站的部分内容是浏览器通过JavaScript渲染生成的。直接抓取内容时,只能获取到js代码。在这种情况下,我们可以使用一个模拟浏览器操作的库,比如 Selenium。渲染页面,以便您可以获取渲染页面的内容。
安装
首先需要安装chrome浏览器和chromedriver,例如在Mac上:
brew cask install google-chrome
brew cask install chromedriver
以上操作,如果出现超时,需要设置代理,推荐使用ShadowsocksX-NG。启动ShadowsocksX-NG后,点击“复制HTTP代理shell导出行”命令,在终端粘贴如下内容:
export http_proxy=http://127.0.0.1:1087;export https_proxy=http://127.0.0.1:1087;
也可以将以上内容添加到~/.bash_profile文件中,一劳永逸地解决终端代理问题。
接下来安装Selenium,在合适的python虚拟环境中,执行:
pip3 install selenium
使用Selenium初始化浏览器对象
除了 Chorome 浏览器之外,Selenium 还支持主要浏览器制造商的产品,例如 Firefox、Edge 和 Safari。
初始化代码如下:
from selenium import webdriver
browser = webdriver.Chrome()
所以我们得到了 Chrome 浏览器对象。也可以在初始化的时候传入参数,比如无接口模式:
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
访问页面
使用 get() 方法并传入访问页面所需的参数,例如:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
print(broswer.page_source)
brower.close
查找节点
为了在浏览器中完成操作,需要获取页面中的特定节点,比如填充搜索框、模拟点击等。
单节点
Selenium 提供了 find_element_XX() 方法来获取多个单节点,其中搜索方法可以是:
查找方法说明
find_element_by_id
根据节点id获取
find_element_by_name
根据节点名获取
find_element_by_xpath
根据Xpath规则获取
find_element_by_link_text
根据链接文本的内容获取
find_element_by_partial_link_text
根据部分链接文字获取
find_element_by_tag_name
通过标签名称获取
find_element_by_class_name
根据类名获取
find_element_by_css_selector
根据CSS选择器获取
多个节点
如果要获取多个节点,需要使用find_elements()这样的方法,用法和获取单个节点的方法类似。
节点操作
获取节点后,可以进行模拟量输入、点击等操作。常见的操作包括:
方法说明
发送密钥()
输入文本
清除()
清除输入框
点击()
点击
执行 JavaScript
您可以使用execute_script()方法运行JavaScript指令来实现越来越精细的操作,例如滚动浏览器、选择特殊节点等。
获取节点信息
选择和操作节点后,最终目的是获取节点信息,如文本内容、地址信息等。
获取属性
使用 get_attribute() 方法获取所选节点的属性。
获取文本
可以直接使用text属性调用节点内部的文本信息。
延迟等待
在 Selenium 中,get() 方法将在网页框架加载后执行。如果某些页面有额外的Ajax请求,我们可能无法在网页源代码中成功获取信息,因此需要等待一段时间。Selenium 提供了两种延迟等待方法:一种是隐式等待,另一种是显式等待。
隐式等待
当搜索节点并且节点没有立即出现时,隐式等待会等待一段时间(默认为0)来搜索DOM。例如:
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.implicitly_wait(10)
browser.get('https://www.taobao.com')
input_first = browser.find_elements_by_css_selector('.J_Cat')
for i in input_first:
print(i.tag_name, i.text)
browser.close
显式等待
常用的延迟等待是比较显式的等待,因为页面加载时间主要受网络条件的影响。显式等待找到指定的节点,然后指定最长等待时间。如果在指定时间内没有加载节点,则会抛出超时异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get('https://www.taobao.com')
wait = WebDriverWait(browser, 10)
input = wait.until(EC.presence_of_element_located(
(By.CSS_SELECTOR, 'a[class="logo-bd clearfix"]')))
print(input.text)
browser.close
上面的代码使用WebDriverWait对象,指定等待时间,然后调用until方法,传入等待条件。这样达到效果后,如果指定节点在10秒内加载完成,则返回该节点,否则抛出超时异常。
完整的等待条件和含义请查看Selenium官方网站。 查看全部
python抓取动态网页(使用Selenium抓取动态渲染页面(有些linelineexport))
使用 Selenium 抓取动态呈现的页面
网站的部分内容是浏览器通过JavaScript渲染生成的。直接抓取内容时,只能获取到js代码。在这种情况下,我们可以使用一个模拟浏览器操作的库,比如 Selenium。渲染页面,以便您可以获取渲染页面的内容。
安装
首先需要安装chrome浏览器和chromedriver,例如在Mac上:
brew cask install google-chrome
brew cask install chromedriver
以上操作,如果出现超时,需要设置代理,推荐使用ShadowsocksX-NG。启动ShadowsocksX-NG后,点击“复制HTTP代理shell导出行”命令,在终端粘贴如下内容:
export http_proxy=http://127.0.0.1:1087;export https_proxy=http://127.0.0.1:1087;
也可以将以上内容添加到~/.bash_profile文件中,一劳永逸地解决终端代理问题。
接下来安装Selenium,在合适的python虚拟环境中,执行:
pip3 install selenium
使用Selenium初始化浏览器对象
除了 Chorome 浏览器之外,Selenium 还支持主要浏览器制造商的产品,例如 Firefox、Edge 和 Safari。
初始化代码如下:
from selenium import webdriver
browser = webdriver.Chrome()
所以我们得到了 Chrome 浏览器对象。也可以在初始化的时候传入参数,比如无接口模式:
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
访问页面
使用 get() 方法并传入访问页面所需的参数,例如:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
print(broswer.page_source)
brower.close
查找节点
为了在浏览器中完成操作,需要获取页面中的特定节点,比如填充搜索框、模拟点击等。
单节点
Selenium 提供了 find_element_XX() 方法来获取多个单节点,其中搜索方法可以是:
查找方法说明
find_element_by_id
根据节点id获取
find_element_by_name
根据节点名获取
find_element_by_xpath
根据Xpath规则获取
find_element_by_link_text
根据链接文本的内容获取
find_element_by_partial_link_text
根据部分链接文字获取
find_element_by_tag_name
通过标签名称获取
find_element_by_class_name
根据类名获取
find_element_by_css_selector
根据CSS选择器获取
多个节点
如果要获取多个节点,需要使用find_elements()这样的方法,用法和获取单个节点的方法类似。
节点操作
获取节点后,可以进行模拟量输入、点击等操作。常见的操作包括:
方法说明
发送密钥()
输入文本
清除()
清除输入框
点击()
点击
执行 JavaScript
您可以使用execute_script()方法运行JavaScript指令来实现越来越精细的操作,例如滚动浏览器、选择特殊节点等。
获取节点信息
选择和操作节点后,最终目的是获取节点信息,如文本内容、地址信息等。
获取属性
使用 get_attribute() 方法获取所选节点的属性。
获取文本
可以直接使用text属性调用节点内部的文本信息。
延迟等待
在 Selenium 中,get() 方法将在网页框架加载后执行。如果某些页面有额外的Ajax请求,我们可能无法在网页源代码中成功获取信息,因此需要等待一段时间。Selenium 提供了两种延迟等待方法:一种是隐式等待,另一种是显式等待。
隐式等待
当搜索节点并且节点没有立即出现时,隐式等待会等待一段时间(默认为0)来搜索DOM。例如:
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.implicitly_wait(10)
browser.get('https://www.taobao.com')
input_first = browser.find_elements_by_css_selector('.J_Cat')
for i in input_first:
print(i.tag_name, i.text)
browser.close
显式等待
常用的延迟等待是比较显式的等待,因为页面加载时间主要受网络条件的影响。显式等待找到指定的节点,然后指定最长等待时间。如果在指定时间内没有加载节点,则会抛出超时异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get('https://www.taobao.com')
wait = WebDriverWait(browser, 10)
input = wait.until(EC.presence_of_element_located(
(By.CSS_SELECTOR, 'a[class="logo-bd clearfix"]')))
print(input.text)
browser.close
上面的代码使用WebDriverWait对象,指定等待时间,然后调用until方法,传入等待条件。这样达到效果后,如果指定节点在10秒内加载完成,则返回该节点,否则抛出超时异常。
完整的等待条件和含义请查看Selenium官方网站。
python抓取动态网页( 如何使用浏览器渲染方法将爬取动态网页变成爬取静态网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-10-29 03:21
如何使用浏览器渲染方法将爬取动态网页变成爬取静态网页)
此时,可以确定评论区的位置:
...
其实这就是所谓的网页分析。通过检查元素,确定要提取的内容的位置,然后就可以通过标签id、名称、类或其他属性提取内容了!
继续往下看:
它收录一个列表,注释也在其中。这时候我们可以在网页上右击查看网页源码,然后Ctrl+F,输入“comment-list-box”就可以找到这部分:
我们会发现源代码里什么都没有!此时,你明白了吗?
而如果我们要提取这部分动态内容,仅通过上一篇文章的方法是不可能做到的。除非能够解析加载动态网页的网址,否则如何简单高效的抓取动态网页内容?这里需要用到动态网页爬取神器:Selenium
Selenium其实是一个web自动化测试工具,可以模拟用户滑动、点击、打开、验证等一系列网页操作行为,就像真实用户在操作一样!这样就可以利用浏览器渲染的方式,将动态网页抓取成静态网页抓取了!
安装硒:pip install selenium
安装成功后,简单测试:
from selenium import webdriver
# 用selenium打开网页
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
错误:
WebDriverException( mon.exceptions.WebDriverException: 消息:'chromedriver' 可执行文件需要在 PATH 中。请参阅
这其实就是谷歌浏览器缺少驱动:chromedriver。下载后,放在盘符下并记录位置,修改代码,再次执行:
driver = webdriver.Chrome(executable_path=r"C:\chromedriver.exe")
driver.get("https://www.baidu.com")
笔者这里使用的是FireFox浏览器,效果是一样的,当然要下载火狐浏览器驱动:geckodriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe")
driver.get("https://www.baidu.com")
打开成功后会显示浏览器已被控制!
我们可以在PyCharm中查看webdriver提供的方法:
当提取的内容嵌套在frame中时,我们可以用driver.switch_to.frame来定位,简单,直接使用即可
Driver.find_element_by_css_selector、find_element_by_tag_name等提取内容。在该方法中,有多个s的提取是一个列表,没有s的提取是单个数据。这很容易理解。具体使用方法可以查看官方文档!
还是以csdn博客为例:Python入门(一)环境设置,爬取文章的这条评论,我们分析了上面评论所在的区域:
...
:
然后我们就可以直接通过find_element_by_css_selector获取div下的内容:
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe")
driver.get("https://baiyuliang.blog.csdn.n ... 6quot;)
comment_list_box = driver.find_element_by_css_selector('div.comment-list-box')
comment_list = comment_list_box.find_element_by_class_name('comment-list')
comment_line_box = comment_list.find_elements_by_class_name('comment-line-box')
for comment in comment_line_box:
span_text = comment.find_element_by_class_name('new-comment').text
print(span_text)
结果:
注意 find_element_by_css_selector 和 find_element_by_class_name 的用法区别! 查看全部
python抓取动态网页(
如何使用浏览器渲染方法将爬取动态网页变成爬取静态网页)
此时,可以确定评论区的位置:
...
其实这就是所谓的网页分析。通过检查元素,确定要提取的内容的位置,然后就可以通过标签id、名称、类或其他属性提取内容了!
继续往下看:
它收录一个列表,注释也在其中。这时候我们可以在网页上右击查看网页源码,然后Ctrl+F,输入“comment-list-box”就可以找到这部分:
我们会发现源代码里什么都没有!此时,你明白了吗?
而如果我们要提取这部分动态内容,仅通过上一篇文章的方法是不可能做到的。除非能够解析加载动态网页的网址,否则如何简单高效的抓取动态网页内容?这里需要用到动态网页爬取神器:Selenium
Selenium其实是一个web自动化测试工具,可以模拟用户滑动、点击、打开、验证等一系列网页操作行为,就像真实用户在操作一样!这样就可以利用浏览器渲染的方式,将动态网页抓取成静态网页抓取了!
安装硒:pip install selenium
安装成功后,简单测试:
from selenium import webdriver
# 用selenium打开网页
driver = webdriver.Chrome()
driver.get("https://www.baidu.com";)
错误:
WebDriverException( mon.exceptions.WebDriverException: 消息:'chromedriver' 可执行文件需要在 PATH 中。请参阅
这其实就是谷歌浏览器缺少驱动:chromedriver。下载后,放在盘符下并记录位置,修改代码,再次执行:
driver = webdriver.Chrome(executable_path=r"C:\chromedriver.exe")
driver.get("https://www.baidu.com";)
笔者这里使用的是FireFox浏览器,效果是一样的,当然要下载火狐浏览器驱动:geckodriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe")
driver.get("https://www.baidu.com";)
打开成功后会显示浏览器已被控制!
我们可以在PyCharm中查看webdriver提供的方法:
当提取的内容嵌套在frame中时,我们可以用driver.switch_to.frame来定位,简单,直接使用即可
Driver.find_element_by_css_selector、find_element_by_tag_name等提取内容。在该方法中,有多个s的提取是一个列表,没有s的提取是单个数据。这很容易理解。具体使用方法可以查看官方文档!
还是以csdn博客为例:Python入门(一)环境设置,爬取文章的这条评论,我们分析了上面评论所在的区域:
...
:
然后我们就可以直接通过find_element_by_css_selector获取div下的内容:
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe")
driver.get("https://baiyuliang.blog.csdn.n ... 6quot;)
comment_list_box = driver.find_element_by_css_selector('div.comment-list-box')
comment_list = comment_list_box.find_element_by_class_name('comment-list')
comment_line_box = comment_list.find_elements_by_class_name('comment-line-box')
for comment in comment_line_box:
span_text = comment.find_element_by_class_name('new-comment').text
print(span_text)
结果:
注意 find_element_by_css_selector 和 find_element_by_class_name 的用法区别!
python抓取动态网页(一个基于webkit内核的无头浏览器浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-28 13:04
查看元素后发现,在百度图片中,显示图片的div为:pullimages
这个div里面的内容是动态加载的。但是使用urllib&urllib2无法捕获。
要抓取动态加载的元素,首先考虑使用 selenium 调用浏览器进行抓取。
我们运行的环境是Linux,理想的方式是无接口爬取,所以使用selenium+phantomjs无接口爬取。
什么是phantomjs?它是一个基于webkit核心的无头浏览器,也就是没有UI界面,也就是浏览器。
selenium和phantomjs的安装和配置可以google一下,这里就不多说了。
代码如下:
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path='/bin/phantomjs/bin/phantomjs')
#如果不方便配置环境变量。就使用phantomjs的绝对路径也可以
driver.get('http://image.baidu.com/i%3Fie% ... %2339;)
#抓取了百度图片,query:周杰伦
driver.page_source
#这就是返回的页面内容了,与urllib2.urlopen().read()的效果是类似的,但比urllib2强在能抓取到动态渲染后的内容。
driver.quit()
这里。动态页面获取成功。 查看全部
python抓取动态网页(一个基于webkit内核的无头浏览器浏览器)
查看元素后发现,在百度图片中,显示图片的div为:pullimages
这个div里面的内容是动态加载的。但是使用urllib&urllib2无法捕获。
要抓取动态加载的元素,首先考虑使用 selenium 调用浏览器进行抓取。
我们运行的环境是Linux,理想的方式是无接口爬取,所以使用selenium+phantomjs无接口爬取。
什么是phantomjs?它是一个基于webkit核心的无头浏览器,也就是没有UI界面,也就是浏览器。
selenium和phantomjs的安装和配置可以google一下,这里就不多说了。
代码如下:
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path='/bin/phantomjs/bin/phantomjs')
#如果不方便配置环境变量。就使用phantomjs的绝对路径也可以
driver.get('http://image.baidu.com/i%3Fie% ... %2339;)
#抓取了百度图片,query:周杰伦
driver.page_source
#这就是返回的页面内容了,与urllib2.urlopen().read()的效果是类似的,但比urllib2强在能抓取到动态渲染后的内容。
driver.quit()
这里。动态页面获取成功。
python抓取动态网页( Python网络爬虫内容提取器一文讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-10-28 05:09
Python网络爬虫内容提取器一文讲解)
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码及实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:利用采集和搜索客户的直观标记功能,可以很快自动生成一个调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面可以在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(windows10下测试,python3.2),请注意:xslt是一个比较长的字符串,如果把这个字符串删掉,也没有几行代码,足以看Python强大的
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:如下图所示,网页上手机的名称和价格已被正确抓取
4. 阅读下一步
至此,我们已经演示了如何通过两个文章来抓取静态和动态的网页内容,这两个文章都使用xslt一次从网页中提取需要的内容。实际上,xslt 是一种更复杂的编程语言。如果你手动写xslt,那么最好写离散xpath。如果这个xslt不是手工写的,而是程序自动生成的,这是有道理的,程序员不再需要花时间编写和调试捕获规则,这是一项非常耗时费力的工作。下一篇文章《1分钟快速生成用于Web内容提取的Xslt》将介绍如何生成xslt。
5.采集GooSeeker开源代码下载源码
1.GooSeeker开源Python网络爬虫GitHub源码
6. 文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第五章:源码下载源码,修改github源码地址 查看全部
python抓取动态网页(
Python网络爬虫内容提取器一文讲解)
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码及实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:利用采集和搜索客户的直观标记功能,可以很快自动生成一个调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面可以在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(windows10下测试,python3.2),请注意:xslt是一个比较长的字符串,如果把这个字符串删掉,也没有几行代码,足以看Python强大的
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:如下图所示,网页上手机的名称和价格已被正确抓取
4. 阅读下一步
至此,我们已经演示了如何通过两个文章来抓取静态和动态的网页内容,这两个文章都使用xslt一次从网页中提取需要的内容。实际上,xslt 是一种更复杂的编程语言。如果你手动写xslt,那么最好写离散xpath。如果这个xslt不是手工写的,而是程序自动生成的,这是有道理的,程序员不再需要花时间编写和调试捕获规则,这是一项非常耗时费力的工作。下一篇文章《1分钟快速生成用于Web内容提取的Xslt》将介绍如何生成xslt。
5.采集GooSeeker开源代码下载源码
1.GooSeeker开源Python网络爬虫GitHub源码
6. 文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第五章:源码下载源码,修改github源码地址
python抓取动态网页(Python中有之前)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-27 21:19
很久以前,在学习Python web编程的时候,涉及到一个Python urllib。您可以使用 urllib.urlopen("url").read() 轻松读取页面上的静态信息。但是,随着时代的发展,越来越多的网页使用javascript、jQuery、PHP等语言来动态生成页面信息。因此,使用 urllib 抓取页面的 HTML 并不足以达到预期的效果。
解决方案:
动态分析页面信息有一个最简单的想法。Urllib 无法解析动态信息,但浏览器可以。浏览器上显示的处理信息实际上是经过处理的 HTML 文档。这为我们抓取动态页面信息提供了一个很好的思路。Python-PyQt 中有一个著名的图形库。虽然 PyQt 是一个图形库,但它在 QtWebkit 内部。这是非常实用的。谷歌的Chrome和苹果的Safari都是基于WebKit核心开发的,所以我们可以通过PyQt中的QtWebKit将页面中的信息读取加载成HTML文档,然后解析HTML文档,从HTML文档中提取我们想要的内容。信息。
所需材料:
作者本人使用的是 Mac OS X,Windows 和 Linux 平台应该使用相同的方法。
1、Qt4 库
图书馆,而不是创作者。Mac默认安装路径下的库应该是/home/username/Developor/,Qt4默认安装路径不要更改。否则,安装可能会失败。
官方网站:
2、SIP、PyQt4
这两个软件可以在PyQt官网找到。源代码已下载。Mac和Linux需要自己编译。
下载地址为:
切换到终端解压文件所在的目录。
在终端输入
蟒蛇配置.py
制作
须藤制作安装
安装和编译。
SIP 和 PyQt4 的安装方法是一样的。但是 PyQt4 依赖于 SIP。所以先安装SIP再安装PyQt4
1、2 两步完成后,安装Python的PyQt4模块。在 Python shell 中输入 import PyQt4 看看能不能找到 PyQt4 模块。
3、斯宾纳
spynner是一个QtWebKit客户端,可以模拟浏览器完成加载页面、触发事件、填写表单等操作。
这个模块可以在 Python 的官方网站上找到。
下载链接:
解压后cd到安装目录,然后输入sudo python configure.py install安装模块。
这样Spynner模块的安装就完成了。在 python shell 中尝试 import spynner 看看是否安装了模块。
Spynner的简单使用
Spynner的功能很强大,但是由于本人能力有限,下面介绍一下如何显示网页的源代码。
#! /usr/bin/python
#-*-coding: utf-8 -*-
import spynner
browser = spynner.Browser()
#创建一个浏览器对象
browser.hide()
#打开浏览器,并隐藏。
browser.load("http://www.baidu.com")
#browser 类中有一个类方法load,可以用webkit加载你想加载的页面信息。
#load(是你想要加载的网址的字符串形式)
print browser.html.encode("utf-8")
#browser 类中有一个成员是html,是页面进过处理后的源码的字符串.
#将其转码为UTF-8编码
open("Test.html", 'w+').write(browser.html.encode("utf-8"))
#你也可以将它写到文件中,用浏览器打开。
browser.close()
#关闭该浏览器
通过这个程序,你可以方便的显示webkit处理的页面的HTML源代码。
旋转应用程序
下面介绍一下spynner的简单应用。通过一个简单的程序,你就可以得到你在浏览器中看到的页面的所有图片。可以使用 HTMLParser、BeautifulSoup 等来解析 HTMLParser 文档。我选择 HTMParser。
#!/usr/bin/python
import spynner
import HTMLParser
import os
import urllib
class MyParser(HTMLParser.HTMLParser):
def handle_starttag(self, tag, attrs):
if tag == 'img':
url = dict(attrs)['src']
name = os.path.basename(dict(attrs)['src'])
if name.endswith('.jpg') or name.endswith('.png') or name.endswith('gif'):
print "Download.....", name
urllib.urlretrieve(url, name)
if __name__ == "__main__":
browser = spynner.Browser()
browser.show()
browser.load("http://www.artist.cn/snakewu19 ... 6quot;)
Parser = MyParser()
Parser.feed(browser.html)
print "Done"
browser.close()
通过这个程序,您可以下载您在页面上看到的所有图片。几行简单的程序就完成了这项艰巨的任务。实现图片的批量处理。这确实是Python语言的优势,所以就让繁重的任务交给第三方吧。 查看全部
python抓取动态网页(Python中有之前)
很久以前,在学习Python web编程的时候,涉及到一个Python urllib。您可以使用 urllib.urlopen("url").read() 轻松读取页面上的静态信息。但是,随着时代的发展,越来越多的网页使用javascript、jQuery、PHP等语言来动态生成页面信息。因此,使用 urllib 抓取页面的 HTML 并不足以达到预期的效果。
解决方案:
动态分析页面信息有一个最简单的想法。Urllib 无法解析动态信息,但浏览器可以。浏览器上显示的处理信息实际上是经过处理的 HTML 文档。这为我们抓取动态页面信息提供了一个很好的思路。Python-PyQt 中有一个著名的图形库。虽然 PyQt 是一个图形库,但它在 QtWebkit 内部。这是非常实用的。谷歌的Chrome和苹果的Safari都是基于WebKit核心开发的,所以我们可以通过PyQt中的QtWebKit将页面中的信息读取加载成HTML文档,然后解析HTML文档,从HTML文档中提取我们想要的内容。信息。
所需材料:
作者本人使用的是 Mac OS X,Windows 和 Linux 平台应该使用相同的方法。
1、Qt4 库
图书馆,而不是创作者。Mac默认安装路径下的库应该是/home/username/Developor/,Qt4默认安装路径不要更改。否则,安装可能会失败。
官方网站:
2、SIP、PyQt4
这两个软件可以在PyQt官网找到。源代码已下载。Mac和Linux需要自己编译。
下载地址为:
切换到终端解压文件所在的目录。
在终端输入
蟒蛇配置.py
制作
须藤制作安装
安装和编译。
SIP 和 PyQt4 的安装方法是一样的。但是 PyQt4 依赖于 SIP。所以先安装SIP再安装PyQt4
1、2 两步完成后,安装Python的PyQt4模块。在 Python shell 中输入 import PyQt4 看看能不能找到 PyQt4 模块。
3、斯宾纳
spynner是一个QtWebKit客户端,可以模拟浏览器完成加载页面、触发事件、填写表单等操作。
这个模块可以在 Python 的官方网站上找到。
下载链接:
解压后cd到安装目录,然后输入sudo python configure.py install安装模块。
这样Spynner模块的安装就完成了。在 python shell 中尝试 import spynner 看看是否安装了模块。
Spynner的简单使用
Spynner的功能很强大,但是由于本人能力有限,下面介绍一下如何显示网页的源代码。
#! /usr/bin/python
#-*-coding: utf-8 -*-
import spynner
browser = spynner.Browser()
#创建一个浏览器对象
browser.hide()
#打开浏览器,并隐藏。
browser.load("http://www.baidu.com";)
#browser 类中有一个类方法load,可以用webkit加载你想加载的页面信息。
#load(是你想要加载的网址的字符串形式)
print browser.html.encode("utf-8")
#browser 类中有一个成员是html,是页面进过处理后的源码的字符串.
#将其转码为UTF-8编码
open("Test.html", 'w+').write(browser.html.encode("utf-8"))
#你也可以将它写到文件中,用浏览器打开。
browser.close()
#关闭该浏览器
通过这个程序,你可以方便的显示webkit处理的页面的HTML源代码。
旋转应用程序
下面介绍一下spynner的简单应用。通过一个简单的程序,你就可以得到你在浏览器中看到的页面的所有图片。可以使用 HTMLParser、BeautifulSoup 等来解析 HTMLParser 文档。我选择 HTMParser。
#!/usr/bin/python
import spynner
import HTMLParser
import os
import urllib
class MyParser(HTMLParser.HTMLParser):
def handle_starttag(self, tag, attrs):
if tag == 'img':
url = dict(attrs)['src']
name = os.path.basename(dict(attrs)['src'])
if name.endswith('.jpg') or name.endswith('.png') or name.endswith('gif'):
print "Download.....", name
urllib.urlretrieve(url, name)
if __name__ == "__main__":
browser = spynner.Browser()
browser.show()
browser.load("http://www.artist.cn/snakewu19 ... 6quot;)
Parser = MyParser()
Parser.feed(browser.html)
print "Done"
browser.close()
通过这个程序,您可以下载您在页面上看到的所有图片。几行简单的程序就完成了这项艰巨的任务。实现图片的批量处理。这确实是Python语言的优势,所以就让繁重的任务交给第三方吧。
python抓取动态网页(通过利用selenium的子模块解决动态数据的html内容的方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-27 05:01
文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。但是,你用 urllib.urlopen(url).read() 得到的只是网页的静态html内容,还有很多动态数据(比如访问量网站,当前在线人数,微博上的点赞数等)不收录在静态html中,例如我想抓取当前点击打开bbs网站链接的每个部分的在线人数。静态html网页不收录(不信你去查页面源码,只有简单的一行)。此类动态数据更多是由JavaScript、JQuery、PHP等语言动态生成的,因此不宜采用抓取静态html内容的方法。
解决方案
我试过网上提到的浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)来查看网上动态数据的趋势,但这需要从很多网址中寻找线索。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
实施过程
操作环境
我在windows 7系统上安装了Python2.7版本,使用Python(X,Y)IDE,安装的Python库没有自带selenium,直接在Python程序中import selenium会提示没有这个模块,联网状态下,cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用 webdriver 捕获动态数据
1.首先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面并在URL中指定有效字符串
browser.get(url)
4. 获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考《博客园-昆虫大师》大神的selenium webdriver(python)教程第三章-定位方法(第一版可百度文库阅读,第二版从一开始就收费>- 查看全部
python抓取动态网页(通过利用selenium的子模块解决动态数据的html内容的方式)
文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。但是,你用 urllib.urlopen(url).read() 得到的只是网页的静态html内容,还有很多动态数据(比如访问量网站,当前在线人数,微博上的点赞数等)不收录在静态html中,例如我想抓取当前点击打开bbs网站链接的每个部分的在线人数。静态html网页不收录(不信你去查页面源码,只有简单的一行)。此类动态数据更多是由JavaScript、JQuery、PHP等语言动态生成的,因此不宜采用抓取静态html内容的方法。
解决方案
我试过网上提到的浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)来查看网上动态数据的趋势,但这需要从很多网址中寻找线索。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
实施过程
操作环境
我在windows 7系统上安装了Python2.7版本,使用Python(X,Y)IDE,安装的Python库没有自带selenium,直接在Python程序中import selenium会提示没有这个模块,联网状态下,cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用 webdriver 捕获动态数据
1.首先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面并在URL中指定有效字符串
browser.get(url)
4. 获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考《博客园-昆虫大师》大神的selenium webdriver(python)教程第三章-定位方法(第一版可百度文库阅读,第二版从一开始就收费>-
python抓取动态网页(Python专题教程:抓取网站,模拟登陆,抓取动态网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-26 11:12
Python专题教程:抓取网站,模拟登录,抓取动态网页版本:v1.0Crifan Li Abstract 本文针对中级Python开发者,介绍如何使用Python语言实现捕获获取网站模拟登录和抓取动态网页。其中,主要涉及网络处理模块(urllib、urllib2等),以及HTML解析相关模块(BeautifulSoup、json等)。本文提供多种格式在线阅读: HTML 1 HTMLsPDF 3 CHM 4TXT 5RTF 6 WEBHELP27下载(7zip压缩包) HTML 8 HTMLsPDF 10 CHM 11 TXT 12 RTF 13 WEBHELP914 HTML版在线地址为:/files/doc/docbook/ python_topic_web_scrape/release/html/python_topic_web_scrape.html 如有任何意见、建议、bug等,请到讨论组发帖讨论:/bbs/categories/python_topic_web_scrape/修订历史修订1.02013- 02-06crl 1.整理上一教程地址 1 /files/doc/docbook/python_topic_web_scrape/release/html/python_topic_web_scrape.html 2 /files/doc/docbook/python_topic_web_scrape/release/htmls/index.html 3 /files/doc/docbook/python_topic_web_scrape /release/pdf/python_topic_web_scrape.pdf 4 /files/doc/docbook/python_topic_web_scrape/release/chm/python_topic_web_scrape.chm 5 /files/doc/docbook/python_topic_web_scrape/release_web_scrape/release/txt/txts 6 /files/doc/docbook pyth on_topic_web_scrape/release/rtf/python_topic_web_scrape.rtf 7 /files/doc/docbook/python_topic_web_scrape/release/webhelp/index.html 8 /files/doc/docbook/python_topic_web_scrape/releases/html/python_topic_web_scrape.html.7z doc/docbook/python_topic_web_scrape/release/htmls/index.html.7z 10/files/doc/docbook/python_topic_web_scrape/release/pdf/python_topic_web_scrape.pdf.7z 11/files /doc/docbook/python_topic_web_scrape/release/chm/python_topic chm.7z 12/files/doc/docbook/python_topic_web_scrape/release/txt/python_topic_web_scrape.txt.7z 13/files/doc/docbook/python_topic_web_scrape/release/web_scrape/release/.rtf.7z 14/files/doc/docbook/ python_topic_web_scrape/release/webhelp/ python_topic_web_scrape.webhelp.7z Python主题教程:抓取网站,模拟登录,抓取动态网页:Crifan Li 版本:v1.0 发布日期2013-02-06 版权所有 © 2013 Crifan,此文章合规性:归属-非商业用途2.5 中国大陆(CC BY-NC 2.5)15 15/files/doc/docbook/soft_dev_basic/release/html/soft_dev_basic.html#cc_by_nc 目录 前言 iv1. 本文的目的 iv2. 前提 iv 1.@ > 如何在Python中实现网站抓取、模拟登录、抓取动态网页1 2. Python中的网络处理2 3. Python 3中的HTMl分析参考书目4iii 前言1.@ > 本文目的 目的是了解如何使用Python语言实现爬取网站、模拟登录、爬取动态网页的逻辑。现在这部分逻辑。
2. Prerequisites 讨论如何在Python中实现,网站爬取,模拟登录,爬取动态网页,前提是你需要对这部分的逻辑有更清晰的理解。如果不确定,请参考:爬取网站、模拟登录、爬取动态网页(Python、C#等)的原理及实现详解1 1 /files/doc/docbook/ web_scrape_emulate_login/release/html/ web_scrape_emulate_login.htmliv 第1章如何使用Python实现网站爬取、模拟登录、爬取动态网页相关的老帖子 [教程] Python 版本1 [教程] 模拟爬取网页和从网页中提取需要的信息登录网站的Python版本(收录完整和可运行代码两个版本) 2 其实对于urllib这样的库已经做得很好了,尤其是在术语易用性,使用起来已经很方便了。比如可以直接从下面的代码中获取网页的地址,网页的源代码为TODO:添加代码。但是,其实网页抓取、网页模拟登录等都需要cookies,以及其他header参数,导致强大易用的网页抓取功能,还需要做很多额外的工作。后来,我在折腾网页抓取。经过实际使用,我在这方面积累了很多经验。最后写了一个相关的函数,功能更强大,使用更方便。
主要是两个函数:getUrlResponse和getUrlRespHtml TODO:添加两个从crifanLib中解释的函数 TODO:添加这两个函数的几个用法 TODO:添加其他几个相关函数的解释,包括downloadFile等。功能其实主要分为两个方面: 一方面是抓取网站的内容,和网络处理模块有关。另一方面是如何解析抓取到的内容,也就是涉及到HTML解析等方面。下面的模块讲解了这两个方面的相关逻辑,以及如何使用Python来实现相应部分的功能。 1 /crawl_website_html_and_extract_info_using_python/ 2 /emulate_login_website_using_python/1 第2章主要涉及Python中的网络处理,与网络处理相关的模块有urllib、urllib2等相关老帖子 [完成] Python解析Http数据包模块/库1 [已解决] Python 中使用cookielib 的FileCookieJar 来save(),结果报错:2NotImplementedError [Finishing] Python 中的Cookie 处理:自动处理Cookies,保存为Cookie 文件,从文件中加载3Cookie TODO: 组织对应的是,进来发表关于 urllib 和 urllib2 的帖子。
1 /python_http_package_parser_lib_module 2 /python_cookiejar_filecookiejar_save_error_notimplementederror 3 /python_auto_handle_cookie_and_save_to_from_cookie_file2 第3章Python相关老帖子中的HTMl解析1【教程】Python的第三方库用于解析的美丽体验[Suartary3的美丽体验]SugariteHTMLSoup库的美丽体验Python 4中使用html处理库函数BeautifulSoup的注意事项【已解决】使用BeautifulSoup解析Html格式的Json字符串5【经验记录】Python中json.loads错误->注意Json字符的编码被解码。 6 [已解决] Python 中的json.loads 在解析收录\n 的字符串时会出错 7 [已解决] Python 中使用json.loads 解码字符串时出错:ValueError: Expecting property8name : line 1 column 1 (char 1)[已解决] Python中用json.loads解码字符串出错:ValueError: No JSON object could9be decoded in Python和解析网站的捕获内容,即解析HTML、JSON等,相关模块包括,BeautifulSoup,JSON等1 /文件/文件/ DocBook的/ python_summary /释放/ HTML / python_summary.html#python_lib_beautifulsoup 2 / python_third_party_lib_html_parser_beautifulsoup 3 / summary_usage_of_beautiful_soup_parse_beautiful_soup 3 / summary_usage_of_beautiful_soup_parse_beautiful_python 5 ash_style_html_json_string 6 / notation_about_use_python_json_loads 7/8 use_python_json_loads_parse_string_contain_newline_will_fail_error / python_json_loads_valueerror_expecting_property_name_line_1_column_1_char_1 9 / python_json_loads_valueerror_no_json_objec t_could_be_decoded3 1 参考文献[1]和[教程]爬取网页提取Python版本1/crawl_website_html_and_extract_info_using_python/4 查看全部
python抓取动态网页(Python专题教程:抓取网站,模拟登陆,抓取动态网页)
Python专题教程:抓取网站,模拟登录,抓取动态网页版本:v1.0Crifan Li Abstract 本文针对中级Python开发者,介绍如何使用Python语言实现捕获获取网站模拟登录和抓取动态网页。其中,主要涉及网络处理模块(urllib、urllib2等),以及HTML解析相关模块(BeautifulSoup、json等)。本文提供多种格式在线阅读: HTML 1 HTMLsPDF 3 CHM 4TXT 5RTF 6 WEBHELP27下载(7zip压缩包) HTML 8 HTMLsPDF 10 CHM 11 TXT 12 RTF 13 WEBHELP914 HTML版在线地址为:/files/doc/docbook/ python_topic_web_scrape/release/html/python_topic_web_scrape.html 如有任何意见、建议、bug等,请到讨论组发帖讨论:/bbs/categories/python_topic_web_scrape/修订历史修订1.02013- 02-06crl 1.整理上一教程地址 1 /files/doc/docbook/python_topic_web_scrape/release/html/python_topic_web_scrape.html 2 /files/doc/docbook/python_topic_web_scrape/release/htmls/index.html 3 /files/doc/docbook/python_topic_web_scrape /release/pdf/python_topic_web_scrape.pdf 4 /files/doc/docbook/python_topic_web_scrape/release/chm/python_topic_web_scrape.chm 5 /files/doc/docbook/python_topic_web_scrape/release_web_scrape/release/txt/txts 6 /files/doc/docbook pyth on_topic_web_scrape/release/rtf/python_topic_web_scrape.rtf 7 /files/doc/docbook/python_topic_web_scrape/release/webhelp/index.html 8 /files/doc/docbook/python_topic_web_scrape/releases/html/python_topic_web_scrape.html.7z doc/docbook/python_topic_web_scrape/release/htmls/index.html.7z 10/files/doc/docbook/python_topic_web_scrape/release/pdf/python_topic_web_scrape.pdf.7z 11/files /doc/docbook/python_topic_web_scrape/release/chm/python_topic chm.7z 12/files/doc/docbook/python_topic_web_scrape/release/txt/python_topic_web_scrape.txt.7z 13/files/doc/docbook/python_topic_web_scrape/release/web_scrape/release/.rtf.7z 14/files/doc/docbook/ python_topic_web_scrape/release/webhelp/ python_topic_web_scrape.webhelp.7z Python主题教程:抓取网站,模拟登录,抓取动态网页:Crifan Li 版本:v1.0 发布日期2013-02-06 版权所有 © 2013 Crifan,此文章合规性:归属-非商业用途2.5 中国大陆(CC BY-NC 2.5)15 15/files/doc/docbook/soft_dev_basic/release/html/soft_dev_basic.html#cc_by_nc 目录 前言 iv1. 本文的目的 iv2. 前提 iv 1.@ > 如何在Python中实现网站抓取、模拟登录、抓取动态网页1 2. Python中的网络处理2 3. Python 3中的HTMl分析参考书目4iii 前言1.@ > 本文目的 目的是了解如何使用Python语言实现爬取网站、模拟登录、爬取动态网页的逻辑。现在这部分逻辑。
2. Prerequisites 讨论如何在Python中实现,网站爬取,模拟登录,爬取动态网页,前提是你需要对这部分的逻辑有更清晰的理解。如果不确定,请参考:爬取网站、模拟登录、爬取动态网页(Python、C#等)的原理及实现详解1 1 /files/doc/docbook/ web_scrape_emulate_login/release/html/ web_scrape_emulate_login.htmliv 第1章如何使用Python实现网站爬取、模拟登录、爬取动态网页相关的老帖子 [教程] Python 版本1 [教程] 模拟爬取网页和从网页中提取需要的信息登录网站的Python版本(收录完整和可运行代码两个版本) 2 其实对于urllib这样的库已经做得很好了,尤其是在术语易用性,使用起来已经很方便了。比如可以直接从下面的代码中获取网页的地址,网页的源代码为TODO:添加代码。但是,其实网页抓取、网页模拟登录等都需要cookies,以及其他header参数,导致强大易用的网页抓取功能,还需要做很多额外的工作。后来,我在折腾网页抓取。经过实际使用,我在这方面积累了很多经验。最后写了一个相关的函数,功能更强大,使用更方便。
主要是两个函数:getUrlResponse和getUrlRespHtml TODO:添加两个从crifanLib中解释的函数 TODO:添加这两个函数的几个用法 TODO:添加其他几个相关函数的解释,包括downloadFile等。功能其实主要分为两个方面: 一方面是抓取网站的内容,和网络处理模块有关。另一方面是如何解析抓取到的内容,也就是涉及到HTML解析等方面。下面的模块讲解了这两个方面的相关逻辑,以及如何使用Python来实现相应部分的功能。 1 /crawl_website_html_and_extract_info_using_python/ 2 /emulate_login_website_using_python/1 第2章主要涉及Python中的网络处理,与网络处理相关的模块有urllib、urllib2等相关老帖子 [完成] Python解析Http数据包模块/库1 [已解决] Python 中使用cookielib 的FileCookieJar 来save(),结果报错:2NotImplementedError [Finishing] Python 中的Cookie 处理:自动处理Cookies,保存为Cookie 文件,从文件中加载3Cookie TODO: 组织对应的是,进来发表关于 urllib 和 urllib2 的帖子。
1 /python_http_package_parser_lib_module 2 /python_cookiejar_filecookiejar_save_error_notimplementederror 3 /python_auto_handle_cookie_and_save_to_from_cookie_file2 第3章Python相关老帖子中的HTMl解析1【教程】Python的第三方库用于解析的美丽体验[Suartary3的美丽体验]SugariteHTMLSoup库的美丽体验Python 4中使用html处理库函数BeautifulSoup的注意事项【已解决】使用BeautifulSoup解析Html格式的Json字符串5【经验记录】Python中json.loads错误->注意Json字符的编码被解码。 6 [已解决] Python 中的json.loads 在解析收录\n 的字符串时会出错 7 [已解决] Python 中使用json.loads 解码字符串时出错:ValueError: Expecting property8name : line 1 column 1 (char 1)[已解决] Python中用json.loads解码字符串出错:ValueError: No JSON object could9be decoded in Python和解析网站的捕获内容,即解析HTML、JSON等,相关模块包括,BeautifulSoup,JSON等1 /文件/文件/ DocBook的/ python_summary /释放/ HTML / python_summary.html#python_lib_beautifulsoup 2 / python_third_party_lib_html_parser_beautifulsoup 3 / summary_usage_of_beautiful_soup_parse_beautiful_soup 3 / summary_usage_of_beautiful_soup_parse_beautiful_python 5 ash_style_html_json_string 6 / notation_about_use_python_json_loads 7/8 use_python_json_loads_parse_string_contain_newline_will_fail_error / python_json_loads_valueerror_expecting_property_name_line_1_column_1_char_1 9 / python_json_loads_valueerror_no_json_objec t_could_be_decoded3 1 参考文献[1]和[教程]爬取网页提取Python版本1/crawl_website_html_and_extract_info_using_python/4
python抓取动态网页( 如何利用Webkit从渲染网页中获取数据中所有档案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-10-26 09:27
如何利用Webkit从渲染网页中获取数据中所有档案)
当我们抓取网页时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页中收录 JavaScript 代码,就必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录JavaScript代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的Pycoders周刊第147期,所以我想爬取Pycoders周刊中所有文件的链接。
显然,这是一个带有 JavaScript 渲染的网页。我想抓取网页中的所有文件信息和相应的链接信息。所以我该怎么做?首先,我们无法使用 HTTP 方法获取任何信息。
import requests
from lxml import html
# storing response
response = requests.get('http://pycoders.com/archive')
# creating lxml tree from response body
tree = html.fromstring(response.text)
# Finding all anchor tags in response
print tree.xpath('//div[@class="campaign"]/a/@href')
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?该网页清楚地显示了如此多的文件信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来,我将介绍如何使用 Web kit 从 JS 渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何内容。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
sudo apt-get install python-qt4
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
import sys
from PyQt4.QtGui import *
from PyQt4.Qtcore import *
from PyQt4.QtWebKit import *
class Render(QWebPage):
def __init__(self, url):
self.app = QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(self, result):
self.frame = self.mainFrame()
self.app.quit()
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载URL中的所有信息并将其存储在一个新的框架中。
url = 'http://pycoders.com/archive/'
# This does the magic.Loads everything
r = Render(url)
# Result is a QString.
result = r.frame.toHtml()
使用上面的代码,我们将 HTML 结果存储在变量 result 中。由于lxml不能直接处理特殊的字符串数据,我们需要对数据格式进行转换。
# QString should be converted to string before processed by lxml
formatted_result = str(result.toAscii())
# Next build lxml tree from formatted_result
tree = html.fromstring(formatted_result)
# Now using correct Xpath we are fetching URL of archives
archive_links = tree.xpath('//div[@class="campaign"]/a/@href')
print archive_links
使用上面的代码,我们可以得到所有的文件链接信息,然后我们就可以使用这些Render和这些URL链接来提取文本内容信息了。Web kit提供了一个强大的网页渲染工具,我们可以利用这个工具从JS渲染的网页中抓取有效的信息。
在本文中,我介绍了一种从 JS 渲染的网页中抓取信息的有效方法。虽然这个工具很慢,但它非常简单和粗鲁。我希望你会喜欢这个文章。现在,您可以将此方法应用于您发现难以处理的任何网页。
愿你事事如意。
原文链接:
原作者:Naren Aryan 译者:fibears 查看全部
python抓取动态网页(
如何利用Webkit从渲染网页中获取数据中所有档案)
当我们抓取网页时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页中收录 JavaScript 代码,就必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录JavaScript代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的Pycoders周刊第147期,所以我想爬取Pycoders周刊中所有文件的链接。
显然,这是一个带有 JavaScript 渲染的网页。我想抓取网页中的所有文件信息和相应的链接信息。所以我该怎么做?首先,我们无法使用 HTTP 方法获取任何信息。
import requests
from lxml import html
# storing response
response = requests.get('http://pycoders.com/archive')
# creating lxml tree from response body
tree = html.fromstring(response.text)
# Finding all anchor tags in response
print tree.xpath('//div[@class="campaign"]/a/@href')
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?该网页清楚地显示了如此多的文件信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来,我将介绍如何使用 Web kit 从 JS 渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何内容。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
sudo apt-get install python-qt4
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
import sys
from PyQt4.QtGui import *
from PyQt4.Qtcore import *
from PyQt4.QtWebKit import *
class Render(QWebPage):
def __init__(self, url):
self.app = QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(self, result):
self.frame = self.mainFrame()
self.app.quit()
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载URL中的所有信息并将其存储在一个新的框架中。
url = 'http://pycoders.com/archive/'
# This does the magic.Loads everything
r = Render(url)
# Result is a QString.
result = r.frame.toHtml()
使用上面的代码,我们将 HTML 结果存储在变量 result 中。由于lxml不能直接处理特殊的字符串数据,我们需要对数据格式进行转换。
# QString should be converted to string before processed by lxml
formatted_result = str(result.toAscii())
# Next build lxml tree from formatted_result
tree = html.fromstring(formatted_result)
# Now using correct Xpath we are fetching URL of archives
archive_links = tree.xpath('//div[@class="campaign"]/a/@href')
print archive_links
使用上面的代码,我们可以得到所有的文件链接信息,然后我们就可以使用这些Render和这些URL链接来提取文本内容信息了。Web kit提供了一个强大的网页渲染工具,我们可以利用这个工具从JS渲染的网页中抓取有效的信息。
在本文中,我介绍了一种从 JS 渲染的网页中抓取信息的有效方法。虽然这个工具很慢,但它非常简单和粗鲁。我希望你会喜欢这个文章。现在,您可以将此方法应用于您发现难以处理的任何网页。
愿你事事如意。
原文链接:
原作者:Naren Aryan 译者:fibears

