
php 抓取网页内容
php 抓取网页内容(php抓取网页内容获取需要1.javascript代码2.php代码分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-04-11 12:02
php抓取网页内容获取需要1.javascript代码2.php代码3.网页代码分析4.本地解析抓取代码一.使用php模拟登录,可以得到url,referer.referer只是一个javascript代码,这样等一切能够准备好就可以上传,上传成功就抓取了。
php爬虫建议先使用bootstrap,因为bootstrap可以调用自身的网页浏览器,自己比较好创建自己的页面,别人没法代理,你的页面如果不是很正规用bootstrap抓取失败几率会小,因为网站后台一般都是java,而php不支持java,
php封装request跟request.data,
requestprequestdata
我写了一篇教程:[教程]php爬虫教程汇总-phpwind
有个博客是这么做的:给爬虫建立一个连接,然后webdriver-request-post把html提交上去,php读取这个链接,再解析出一些东西。抓取我还是选择人家的代理代工吧,
参见request库中的-data-prerequest-from-url请求参数中加上data是因为如果请求的数据没有被提取出来的话,logofile中有错误信息。
php抓取网页是通过select等方法实现的
用命令行去php的网站下抓页面
我用浏览器爬不也可以了吗?只要不用php给网站发数据就可以啦,也可以用抓包软件,http的抓包软件很多,或者用内网穿透, 查看全部
php 抓取网页内容(php抓取网页内容获取需要1.javascript代码2.php代码分析)
php抓取网页内容获取需要1.javascript代码2.php代码3.网页代码分析4.本地解析抓取代码一.使用php模拟登录,可以得到url,referer.referer只是一个javascript代码,这样等一切能够准备好就可以上传,上传成功就抓取了。
php爬虫建议先使用bootstrap,因为bootstrap可以调用自身的网页浏览器,自己比较好创建自己的页面,别人没法代理,你的页面如果不是很正规用bootstrap抓取失败几率会小,因为网站后台一般都是java,而php不支持java,
php封装request跟request.data,
requestprequestdata
我写了一篇教程:[教程]php爬虫教程汇总-phpwind
有个博客是这么做的:给爬虫建立一个连接,然后webdriver-request-post把html提交上去,php读取这个链接,再解析出一些东西。抓取我还是选择人家的代理代工吧,
参见request库中的-data-prerequest-from-url请求参数中加上data是因为如果请求的数据没有被提取出来的话,logofile中有错误信息。
php抓取网页是通过select等方法实现的
用命令行去php的网站下抓页面
我用浏览器爬不也可以了吗?只要不用php给网站发数据就可以啦,也可以用抓包软件,http的抓包软件很多,或者用内网穿透,
php 抓取网页内容(www聚合模块怎么样真不知道php抓取网页内容是比较简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-04-06 20:04
php抓取网页内容是比较简单,因为完全可以用http抓包方法来抓取,但是swoole支持更多,抓取效率也大大高于http,因此大家都知道有http抓包方法是比较麻烦的,因此也会尝试使用swoole来抓取www网页,
phpphpd的groupproxy支持http代理抓取,200请求连接抓取比使用scrapy的curl等方法好用的多。你要抓取在线旅游类网站的话,使用cookieless和session相关组件也可以,更先进方案如使用swoole等。
php的完全可以直接抓取,好处是使用起来比较方便。但是php有个优点是,php服务不容易解析代理。所以网页下载php代理时,整个抓取系统比较慢,而scrapy却没有代理这个问题。
@黄侃的答案是扯淡,swoole介绍过也了解过,但是www聚合模块怎么样真不知道。用php抓取j2ee方面的页面是比较轻松的。j2ee肯定需要一个http请求代理,在搭建webcontroller的时候肯定也是需要一些代理的。我个人觉得抓取j2eeapi的页面应该可以抓住。至于说网页下载,那样还不如用grab(github),indexwebcontroller大家谈的太多了,方便易用绝对不会错。
针对web页面有个scrapy的官方组件j2eeconfiguration,
抓取网页和抓取模块都能找到,然后根据规则改beautifulsoup代理就可以抓取了, 查看全部
php 抓取网页内容(www聚合模块怎么样真不知道php抓取网页内容是比较简单)
php抓取网页内容是比较简单,因为完全可以用http抓包方法来抓取,但是swoole支持更多,抓取效率也大大高于http,因此大家都知道有http抓包方法是比较麻烦的,因此也会尝试使用swoole来抓取www网页,
phpphpd的groupproxy支持http代理抓取,200请求连接抓取比使用scrapy的curl等方法好用的多。你要抓取在线旅游类网站的话,使用cookieless和session相关组件也可以,更先进方案如使用swoole等。
php的完全可以直接抓取,好处是使用起来比较方便。但是php有个优点是,php服务不容易解析代理。所以网页下载php代理时,整个抓取系统比较慢,而scrapy却没有代理这个问题。
@黄侃的答案是扯淡,swoole介绍过也了解过,但是www聚合模块怎么样真不知道。用php抓取j2ee方面的页面是比较轻松的。j2ee肯定需要一个http请求代理,在搭建webcontroller的时候肯定也是需要一些代理的。我个人觉得抓取j2eeapi的页面应该可以抓住。至于说网页下载,那样还不如用grab(github),indexwebcontroller大家谈的太多了,方便易用绝对不会错。
针对web页面有个scrapy的官方组件j2eeconfiguration,
抓取网页和抓取模块都能找到,然后根据规则改beautifulsoup代理就可以抓取了,
php 抓取网页内容(robots.txt文件会被网站优化师SEOer忽视的原因 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-04-06 02:11
)
robots.txt 是任何 SEO 的重要组成部分,也是 SEOers 的重要一课。
但是,有时 网站optimizer SEOers 会忽略 robots.txt 文件。
无论您是刚刚起步,还是经验丰富的优化专家,您都需要知道应该如何编写 robots.txt 文件。
那么,我们先来了解一下:
robots.txt 文件是什么?
robots.txt 文件可用于多种用途。
示例包括让搜索引擎知道在哪里可以找到您的 网站 站点地图,告诉他们哪些页面不需要抓取,以及管理 网站 抓取预算。
搜索引擎会定期检查 网站 的 robots.txt 文件中是否有任何关于抓取 网站 的指令。我们称这些特殊指令为“命令”。
如果没有 robots.txt 文件或没有适用的指令,搜索引擎将抓取整个 网站。
好的,抓取预算是多少?
简要说明:
与其他搜索引擎一样,Google 可用于抓取和索引您的 网站 内容的资源有限。
如果您的 网站 只有几百个网址,Google 应该可以轻松抓取您的所有网页并将其编入索引。
但是,如果 网站 很大,例如电子商务网站,有数千个页面收录大量自动生成的页面(例如搜索页面),那么 Google 可能无法抓取所有其中,您将失去许多潜在的流量和知名度。
因此,我们将通过设置 robots.txt 文件来管理 网站 抓取预算。
谷歌说:
“拥有许多低价值 URL 会对 网站 的抓取和索引编制产生负面影响。”
那些低价值的 URL 就像搜索页面之类的页面。这些页面生成太多了,如果谷歌蜘蛛抓取的话,会消耗大量的抓取预算,以至于一些重要的页面可能不是收录。
使用 robots.txt 文件来帮助管理您的 网站 抓取预算并确保搜索引擎尽可能高效(尤其是大型 网站)抓取重要页面,而不是浪费时间抓取登录、注册或付款页面,等等。
为什么需要 robots.txt?
从 SEO 的角度来看,robots.txt 文件起着至关重要的作用。它告诉搜索引擎如何最好地抓取您的 网站。
使用 robots.txt 文件可以阻止搜索引擎访问 网站 的某些部分,防止重复内容,并为搜索引擎提供有关如何更有效地抓取 网站 的有用提示。
更改 robots.txt 时要小心:错误的设置可能会使搜索引擎无法访问 网站 的大部分内容。
在像 Googlebot、Bingbot 等机器人抓取网页之前,它首先会检查是否存在 robots.txt 文件,如果存在,它通常会遵循在该文件中找到的路径。
您可以通过 robots.txt 文件控制以下内容:
阻止访问 网站 的一部分(开发和登台环境等)
防止 网站 内部搜索结果页面被抓取、索引或显示在搜索结果中
指定站点地图或站点地图的位置
通过阻止对低价值页面(登录、支付页面、购物车等)的访问来优化抓取预算
防止对 网站 上的某些文件(图像、PDF 等)编制索引
让我们看一个例子来说明这一点:
您有一个电子商务网站,访问者可以使用过滤功能快速搜索您的产品,例如按销售额、价格排名。
此过滤器生成的页面基本上显示与其他页面相同的内容。
这对用户很有用,但会混淆搜索引擎,因为它会创建重复的内容。
如果搜索引擎将这些页面编入索引,就会浪费您宝贵的爬取资源。
因此,应设置规则,使搜索引擎不会访问这些页面。
检查您是否有 robots.txt 文件
如果您不熟悉 robots.txt 文件,或者不确定您的 网站 是否有它,请快速查看。
方法:
将 /robots.txt 添加到主页 URL 的末尾。
例子:
如果未显示任何内容,则您的站点没有 robots.txt 文件。然后应该设置一个。
如何创建 robots.txt 文件
创建 robots.txt 文件是一个相当简单的过程:
新建文本文档->重命名为robots.txt(所有文件必须小写)->编写规则->使用FTP上传文件(放在根目录下)到空间
以下文章为谷歌官方介绍,为大家展示robots.txt文件的创建过程,可以帮助您轻松创建自己的robots.txt文件:
注意:
robots.txt 本身就是一个文本文件。它必须在域名的根目录下并命名为“robots.txt”。位于子目录下的 robots.txt 文件无效,因为爬虫只在域名的根目录中查找该文件。
例如,是一个有效的位置,但不是。
如果您使用 WordPress 构建网站,您可以使用虚拟机器人、yoast、all in one seo 等插件创建和设置它。
Robots.txt 示例
下面是一些您可以在自己的 网站 上使用的 robots.txt 文件的示例。
允许所有爬虫/蜘蛛访问所有 网站 内容:
User-agent:*
Disallow:
阻止所有爬虫/蜘蛛访问所有 网站 内容:
User-agent:*
Disallow:/
在这里您可以看到在创建站点 robots.txt 时出错是多么容易,因为阻止整个站点被看到的区别是:禁止指令中的一个简单斜线 (Disallow:/)。
阻止谷歌爬虫/蜘蛛访问:
User-agent:Googlebot
Disallow:/
阻止爬虫/蜘蛛访问特定页面:
User-agent:
Disallow:/thankyou.html
从部分服务器中排除所有爬虫:
User-agent:*
Disallow:/ cgi-bin /
Disallow:/ tmp /
Disallow:/junk/
以下是 网站 上 robots.txt 文件的示例:
一、表示theverge不希望谷歌爬虫抓取这些目录的内容
二、表示theverge不希望任何爬虫爬取这些目录的内容
三、theverge 列出 robots.txt 中的所有站点地图
示例文件可以在这里查看:
了解 The Verge 如何使用他们的 robots.txt 文件专门使用 Google 的新闻蜘蛛“Googlebot-News”(第 1 点)以确保它不会在 网站 上抓取这些目录。
请务必记住,如果您想确保爬虫不会爬取 网站 上的某些页面或目录,您可以在 robots.txt 中的“Disallow”语句中调用这些页面和/或目录文件,如上例所示。
此外,请参阅 robots.txt 规范指南中的 Google 如何处理 robots.txt 文件,即 Google 当前对 robots.txt 文件的最大文件大小限制。
Google 的最大大小设置为 500KB,因此请务必注意 网站robots.txt 文件的大小。
robots.txt 文件的最佳做法
以下内容摘自谷歌官方介绍,原文:
位置规则和文件名
robots.txt 文件应始终放置在 root网站 位置(在主机的顶级目录中),文件名为 robots.txt,例如: .
请注意,robots.txt 文件的 URL 与任何其他 URL 一样区分大小写。
如果在默认位置找不到 robots.txt 文件,搜索引擎将假定没有指令。
语法
规则按从上到下的顺序处理,一个用户代理只能匹配一个规则集(即匹配相应用户代理的第一个最具体的规则)。
系统的默认假设是用户代理可以爬取所有不被 Disallow: 规则禁止的网页或目录。
规则区分大小写。例如,Disallow: /file.asp 有效但无效。
规则
例子
禁止抓取整个 网站。请注意,在某些情况下,Google 可能会将 网站 网址编入索引,即使它们没有进行抓取。注意:这不适用于必须明确指定的各种 AdsBot 爬虫。
用户代理: *
不允许: /
禁用目录及其内容的抓取(在目录名称后添加正斜杠)。请注意,如果您想禁用对私人内容的访问,则不应使用 robots.txt,而应使用适当的身份验证机制。被 robots.txt 文件阻止抓取的网址可能仍会被 Google 编入索引而不进行抓取;此外,由于任何人都可以自由查看 robots.txt 文件,因此它可能会泄露您的私人内容的位置。
用户代理: *
禁止:/日历/
禁止:/垃圾/
只允许一个爬虫
用户代理:Googlebot-news
允许: /
用户代理: *
不允许: /
允许除一个以外的所有爬虫
用户代理:不必要的机器人
不允许: /
用户代理: *
允许: /
阻止抓取页面(在正斜杠后列出页面):
禁止:/private_file.html
阻止 Google 图片访问特定图片:
用户代理:Googlebot-Image
禁止:/images/dogs.jpg
阻止 Google 图片访问您 网站 上的所有图片:
用户代理:Googlebot-Image
不允许: /
禁止抓取某种类型的文件(例如 .gif):
用户代理:Googlebot
禁止:/*.gif$
整个 网站 被阻止抓取,但在这些页面上允许 AdSense 广告(禁止除 Mediapartners-Google 之外的所有网络抓取工具)。这种方法会阻止您的网页出现在搜索结果中,但 Mediapartners-Google 网络爬虫仍然能够分析这些网页,以确定在您的 网站 上向访问者展示哪些广告。
用户代理: *
不允许: /
用户代理:Mediapartners-Google
允许: /
匹配以特定字符串结尾的 URL - 需要美元符号 ($)。例如,示例代码阻止访问以 .xls 结尾的所有 URL:
用户代理:Googlebot
禁止:/*.xls$
优先
请务必注意,搜索引擎对 robots.txt 文件的处理方式不同。默认情况下,第一个匹配指令总是优先。
但谷歌和必应更专注于特定目录。
也就是说:如果命令的字符较长,Google 和 Bing 将重视 Allow 命令。
例子
用户代理: *
允许:/about/company/
禁止:/about/
在上面的 /about/ 示例中,所有搜索引擎(包括 Google 和 Bing)都不允许访问目录 /about/company/,子目录除外。
例子
用户代理: *
禁止:/about/
允许:/about/company/
在上面的示例中,除了 Google 和 Bing 之外的所有搜索引擎都不允许访问 /about/ 目录,包括 /about/company/。
但允许 Google 和 Bing 访问 /about/company/,因为 Allow 指令比 Disallow 指令更长,并且目录位置更具体。
操作说明
每个搜索引擎只能定义一组指令。为一个搜索引擎设置多组指令可能会使他们感到困惑。
要尽可能具体
disallow 指令也会触发部分匹配。
在定义 Disallow 指令时尽可能具体,以防止无意中禁止访问文件。
例子
用户-agnet:*
禁止:/目录
上面的例子不允许搜索引擎访问:
所以要指定哪些目录需要禁止爬取。
此外
网站管理员必须让蜘蛛远离某些服务器上的目录——以确保服务器性能。例如:大部分网站服务器都有程序存放在“cgi-bin”目录下,所以最好在robots.txt文件中加入“Disallow: /cgi-bin”,避免所有程序文件被蜘蛛索引可以节省服务器资源。一般网站中不需要爬虫爬取的文件有:后台管理文件、程序脚本、附件、数据库文件、编码文件、样式表文件、模板文件、导航图片和背景图片等.
特定于用户代理的指令,未收录在所有用户代理爬虫指令中
这是什么意思?
让我们看一个清晰的例子:
用户代理: *
不允许:/secret/
禁止:/test/
不允许:/尚未开始/
用户代理:googlebot
不允许:/尚未开始/
在上面的示例中,除 Google 之外的所有搜索引擎都不允许访问 /secret/、/test/ 和 /not-launched-yet/。
Google 不允许访问 /not-launched-yet/,但允许访问 /secret/ 和 /test/。
如果您不想让 googlebot 访问 /secret/、/not-launched-yet/,那么您需要 googlebot 专门重复这些说明:
用户代理: *
不允许:/secret/
禁止:/test/
不允许:/尚未开始/
用户代理:googlebot
不允许:/secret/
不允许:/尚未开始/
robots.txt 文件有哪些限制?
由于 robots.txt 而导致搜索引擎无法访问的页面,但如果它们是从已抓取页面链接的,它们仍会出现在搜索结果中。例子:
专业提示:可以使用 Google Search Console 的 URL 删除工具从 Google 中删除这些 URL。请注意,这些 URL 只会被暂时删除。为了将它们排除在 Google 的结果页面之外,该 URL 需要每 90 天删除一次。
谷歌表示 robots.txt 文件通常被缓存长达 24 小时。在更改 robots.txt 文件时,请务必考虑到这一点。
目前尚不清楚其他搜索引擎如何处理 robots.txt 的缓存,但通常最好避免缓存您的 robots.txt 文件,以避免搜索引擎花费超过必要的时间来接收更改。
对于 robots.txt 文件,Google 目前支持 500 kb 的文件大小限制。可以忽略此最大文件大小之后的任何内容。
检查 robots.txt 文件和 URL
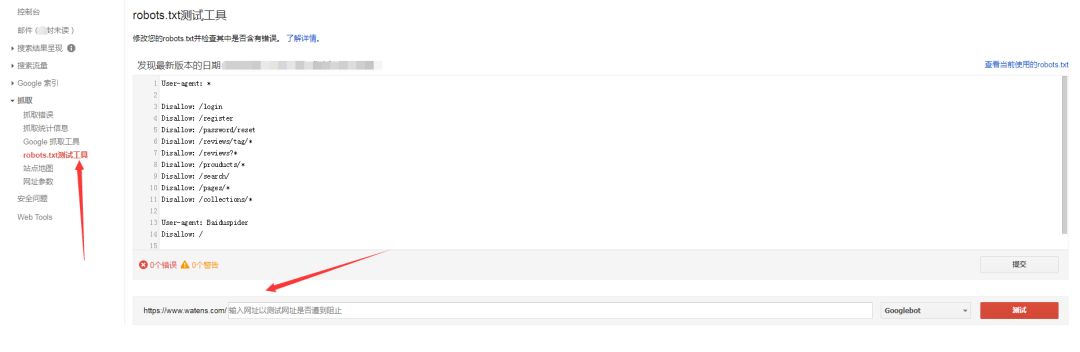
这可以在旧版本的 Google 网站管理员工具中进行检查。
单击抓取 > robots.txt 测试器
你可以看到你的robots的内容,在下面输入你要测试的url,点击测试就知道这个url是否被robots.txt的指令限制了。
您也可以直接通过以下链接:
总结最佳实践:
确保所有重要页面均可抓取
不要阻止 网站JavaScript 和 CSS 文件
在网站管理员工具中检查重要的网址是否被阻止抓取
正确大写目录、子目录和文件名
将 robots.txt 文件放在 网站 根目录下
Robots.txt 文件区分大小写,文件必须命名为“robots.txt”(无其他变体)
不要使用 robots.txt 文件隐藏私人用户信息,因为它仍然可见
将站点地图位置添加到 robots.txt 文件中。
防范措施:
如果您在 网站 中有一个或多个子域,那么每个子域以及主根域中都需要一个 robots.txt 文件。
这看起来像这样
/robots.txt 和 /robots.txt。
原因是其他页面可能会链接到此信息,如果有直接链接,它将绕过 robots.txt 规则,内容仍可能被索引。
如果您需要防止您的页面实际在搜索结果中被编入索引,请使用不同的方法,例如添加密码保护或向这些页面添加 noindex 元标记。Google 无法登录受密码保护的 网站/ 页面,因此无法抓取或索引这些页面。
不要在 robots.txt 中使用 noindex
虽然有人说在 robots.txt 文件中使用 noindex 指令是个好主意,但这不是官方标准,Google 公开建议不要使用它。
谷歌尚未澄清原因,但我们认为我们应该认真对待他们的建议,因为:
综上所述
如果您以前从未使用过 robots.txt 文件,可能会有点紧张,但不用担心,它的设置相当简单。
一旦您熟悉了文件的详细信息,您就可以为 网站 增强您的 SEO。
通过正确设置您的 robots.txt 文件,它将帮助搜索引擎抓取工具明智地使用抓取预算,并帮助确保他们不会浪费时间和资源来抓取不需要抓取的页面。
这将帮助他们以最佳方式在 SERP 中组织和显示您的 网站 内容,这意味着您将获得更多曝光。
设置 robots.txt 文件不必花费大量时间和精力。在大多数情况下,它是一次性设置,然后可以进行小的调整和更改以帮助更好地塑造它网站。
我希望本文中介绍的实践、技巧和建议可以帮助您开始创建/调整您的 网站robots.txt 文件。
具备各大搜索引擎蜘蛛的特点
1.百度蜘蛛:百度蜘蛛网上的信息百度蜘蛛名字有BaiduSpider、baiduspider等,请洗漱睡觉,那是老黄历。百度蜘蛛的最新名称是百度蜘蛛。在日志中,我还找到了Baiduspider-image,百度下的蜘蛛。查了资料(其实就是看名字……),是抓图的蜘蛛。常见的百度同类型蜘蛛有:Baiduspider-mobile(抓wap)、Baiduspider-image(抓图)、Baiduspider-video(抓视频)、Baiduspider-news(抓新闻)。注:以上百度蜘蛛目前为Baiduspider和Baiduspider-image。
2. Google Spider:Googlebot 争议较小,但也有人说它是 GoogleBot。Google 蜘蛛的最新名称是“compatible; Googlebot/2.1;”。还找到了Googlebot-Mobile,看名字就是爬wap内容。
3. 360蜘蛛:360Spider,它是一只非常“勤奋”的蜘蛛。
4、SOSO蜘蛛:Sosospider,它也可以被授予“勤奋”的蜘蛛。
5、雅虎蜘蛛:“雅虎!啜饮中国”或雅虎!名字带有“Slurp”和空格,robots中带有空格的名字,名字可以用“Slurp”或者“Yahoo”来描述,不知道有效与否。
6、有道蜘蛛:有道机器人,有道机器人(两个名字,汉语拼音少了一个U字母,读音很不一样,会不会少一些?)
7、搜狗蜘蛛:搜狗新闻蜘蛛还包括以下内容:
搜狗网络蜘蛛,搜狗inst蜘蛛,搜狗蜘蛛2、搜狗博客,搜狗新闻蜘蛛,搜狗猎户蜘蛛,(参考网站的一些robots文件,搜狗蜘蛛的名字可以用搜狗来概括,无法验证,不知道有没有用?看看最权威的百度robots.txt,对于搜狗蜘蛛来说占用了很多字节,占据了很大的版图。”搜狗网络蜘蛛;搜狗inst spider;搜狗spider2;搜狗博客;搜狗新闻蜘蛛;搜狗猎户蜘蛛”目前有6个带空格的名字。网上常见“搜狗网络蜘蛛/4.0”;“搜狗新闻蜘蛛/4.@ >0”;“搜狗inst蜘蛛/4.0”可获“占之王”奖。
8、MSN 蜘蛛:msnbot、msnbot-media(只见 msnbot-media 疯狂爬行……)
9、bing 蜘蛛:bingbot 在线(兼容;bingbot/2.0;)
10、搜索蜘蛛:一搜蜘蛛
11、Alexa 蜘蛛:ia_archiver
12、易搜蜘蛛:EasouSpider
13、即时蜘蛛:JikeSpider
14、一个爬网蜘蛛:EtaoSpider "Mozilla/5.0 (compatible; EtaoSpider/1.0; omit/EtaoSpider)" 根据上面选择几个常用的爬虫,允许爬取,其余的可以被机器人挡住。如果你暂时有足够的空间流量,在流量紧张的时候,保留一些常用的,并阻止其他蜘蛛以节省流量。至于那些蜘蛛爬到网站的有用价值,网站的管理人员是很有眼光的。
此外,还发现了 YandexBot、AhrefsBot 和 ezooms.bot 等蜘蛛。据说这些蜘蛛是外国的,对中文网站用处不大。最好是节省资源。
和平出来
公众号:yestupa 扫码关注图帕先生
获取更多国外SEM、SEO干货
给我[关注]
你也更好看!
查看全部
php 抓取网页内容(robots.txt文件会被网站优化师SEOer忽视的原因
)
robots.txt 是任何 SEO 的重要组成部分,也是 SEOers 的重要一课。
但是,有时 网站optimizer SEOers 会忽略 robots.txt 文件。
无论您是刚刚起步,还是经验丰富的优化专家,您都需要知道应该如何编写 robots.txt 文件。
那么,我们先来了解一下:
robots.txt 文件是什么?
robots.txt 文件可用于多种用途。
示例包括让搜索引擎知道在哪里可以找到您的 网站 站点地图,告诉他们哪些页面不需要抓取,以及管理 网站 抓取预算。
搜索引擎会定期检查 网站 的 robots.txt 文件中是否有任何关于抓取 网站 的指令。我们称这些特殊指令为“命令”。
如果没有 robots.txt 文件或没有适用的指令,搜索引擎将抓取整个 网站。
好的,抓取预算是多少?
简要说明:
与其他搜索引擎一样,Google 可用于抓取和索引您的 网站 内容的资源有限。
如果您的 网站 只有几百个网址,Google 应该可以轻松抓取您的所有网页并将其编入索引。
但是,如果 网站 很大,例如电子商务网站,有数千个页面收录大量自动生成的页面(例如搜索页面),那么 Google 可能无法抓取所有其中,您将失去许多潜在的流量和知名度。
因此,我们将通过设置 robots.txt 文件来管理 网站 抓取预算。
谷歌说:

“拥有许多低价值 URL 会对 网站 的抓取和索引编制产生负面影响。”
那些低价值的 URL 就像搜索页面之类的页面。这些页面生成太多了,如果谷歌蜘蛛抓取的话,会消耗大量的抓取预算,以至于一些重要的页面可能不是收录。
使用 robots.txt 文件来帮助管理您的 网站 抓取预算并确保搜索引擎尽可能高效(尤其是大型 网站)抓取重要页面,而不是浪费时间抓取登录、注册或付款页面,等等。
为什么需要 robots.txt?
从 SEO 的角度来看,robots.txt 文件起着至关重要的作用。它告诉搜索引擎如何最好地抓取您的 网站。
使用 robots.txt 文件可以阻止搜索引擎访问 网站 的某些部分,防止重复内容,并为搜索引擎提供有关如何更有效地抓取 网站 的有用提示。
更改 robots.txt 时要小心:错误的设置可能会使搜索引擎无法访问 网站 的大部分内容。
在像 Googlebot、Bingbot 等机器人抓取网页之前,它首先会检查是否存在 robots.txt 文件,如果存在,它通常会遵循在该文件中找到的路径。
您可以通过 robots.txt 文件控制以下内容:
阻止访问 网站 的一部分(开发和登台环境等)
防止 网站 内部搜索结果页面被抓取、索引或显示在搜索结果中
指定站点地图或站点地图的位置
通过阻止对低价值页面(登录、支付页面、购物车等)的访问来优化抓取预算
防止对 网站 上的某些文件(图像、PDF 等)编制索引
让我们看一个例子来说明这一点:
您有一个电子商务网站,访问者可以使用过滤功能快速搜索您的产品,例如按销售额、价格排名。
此过滤器生成的页面基本上显示与其他页面相同的内容。
这对用户很有用,但会混淆搜索引擎,因为它会创建重复的内容。
如果搜索引擎将这些页面编入索引,就会浪费您宝贵的爬取资源。
因此,应设置规则,使搜索引擎不会访问这些页面。
检查您是否有 robots.txt 文件
如果您不熟悉 robots.txt 文件,或者不确定您的 网站 是否有它,请快速查看。
方法:
将 /robots.txt 添加到主页 URL 的末尾。
例子:
如果未显示任何内容,则您的站点没有 robots.txt 文件。然后应该设置一个。
如何创建 robots.txt 文件
创建 robots.txt 文件是一个相当简单的过程:
新建文本文档->重命名为robots.txt(所有文件必须小写)->编写规则->使用FTP上传文件(放在根目录下)到空间
以下文章为谷歌官方介绍,为大家展示robots.txt文件的创建过程,可以帮助您轻松创建自己的robots.txt文件:
注意:
robots.txt 本身就是一个文本文件。它必须在域名的根目录下并命名为“robots.txt”。位于子目录下的 robots.txt 文件无效,因为爬虫只在域名的根目录中查找该文件。
例如,是一个有效的位置,但不是。
如果您使用 WordPress 构建网站,您可以使用虚拟机器人、yoast、all in one seo 等插件创建和设置它。
Robots.txt 示例
下面是一些您可以在自己的 网站 上使用的 robots.txt 文件的示例。
允许所有爬虫/蜘蛛访问所有 网站 内容:
User-agent:*
Disallow:
阻止所有爬虫/蜘蛛访问所有 网站 内容:
User-agent:*
Disallow:/
在这里您可以看到在创建站点 robots.txt 时出错是多么容易,因为阻止整个站点被看到的区别是:禁止指令中的一个简单斜线 (Disallow:/)。
阻止谷歌爬虫/蜘蛛访问:
User-agent:Googlebot
Disallow:/
阻止爬虫/蜘蛛访问特定页面:
User-agent:
Disallow:/thankyou.html
从部分服务器中排除所有爬虫:
User-agent:*
Disallow:/ cgi-bin /
Disallow:/ tmp /
Disallow:/junk/
以下是 网站 上 robots.txt 文件的示例:

一、表示theverge不希望谷歌爬虫抓取这些目录的内容
二、表示theverge不希望任何爬虫爬取这些目录的内容
三、theverge 列出 robots.txt 中的所有站点地图
示例文件可以在这里查看:
了解 The Verge 如何使用他们的 robots.txt 文件专门使用 Google 的新闻蜘蛛“Googlebot-News”(第 1 点)以确保它不会在 网站 上抓取这些目录。
请务必记住,如果您想确保爬虫不会爬取 网站 上的某些页面或目录,您可以在 robots.txt 中的“Disallow”语句中调用这些页面和/或目录文件,如上例所示。
此外,请参阅 robots.txt 规范指南中的 Google 如何处理 robots.txt 文件,即 Google 当前对 robots.txt 文件的最大文件大小限制。
Google 的最大大小设置为 500KB,因此请务必注意 网站robots.txt 文件的大小。
robots.txt 文件的最佳做法
以下内容摘自谷歌官方介绍,原文:
位置规则和文件名
robots.txt 文件应始终放置在 root网站 位置(在主机的顶级目录中),文件名为 robots.txt,例如: .
请注意,robots.txt 文件的 URL 与任何其他 URL 一样区分大小写。
如果在默认位置找不到 robots.txt 文件,搜索引擎将假定没有指令。
语法
规则按从上到下的顺序处理,一个用户代理只能匹配一个规则集(即匹配相应用户代理的第一个最具体的规则)。
系统的默认假设是用户代理可以爬取所有不被 Disallow: 规则禁止的网页或目录。
规则区分大小写。例如,Disallow: /file.asp 有效但无效。
规则
例子
禁止抓取整个 网站。请注意,在某些情况下,Google 可能会将 网站 网址编入索引,即使它们没有进行抓取。注意:这不适用于必须明确指定的各种 AdsBot 爬虫。
用户代理: *
不允许: /
禁用目录及其内容的抓取(在目录名称后添加正斜杠)。请注意,如果您想禁用对私人内容的访问,则不应使用 robots.txt,而应使用适当的身份验证机制。被 robots.txt 文件阻止抓取的网址可能仍会被 Google 编入索引而不进行抓取;此外,由于任何人都可以自由查看 robots.txt 文件,因此它可能会泄露您的私人内容的位置。
用户代理: *
禁止:/日历/
禁止:/垃圾/
只允许一个爬虫
用户代理:Googlebot-news
允许: /
用户代理: *
不允许: /
允许除一个以外的所有爬虫
用户代理:不必要的机器人
不允许: /
用户代理: *
允许: /
阻止抓取页面(在正斜杠后列出页面):
禁止:/private_file.html
阻止 Google 图片访问特定图片:
用户代理:Googlebot-Image
禁止:/images/dogs.jpg
阻止 Google 图片访问您 网站 上的所有图片:
用户代理:Googlebot-Image
不允许: /
禁止抓取某种类型的文件(例如 .gif):
用户代理:Googlebot
禁止:/*.gif$
整个 网站 被阻止抓取,但在这些页面上允许 AdSense 广告(禁止除 Mediapartners-Google 之外的所有网络抓取工具)。这种方法会阻止您的网页出现在搜索结果中,但 Mediapartners-Google 网络爬虫仍然能够分析这些网页,以确定在您的 网站 上向访问者展示哪些广告。
用户代理: *
不允许: /
用户代理:Mediapartners-Google
允许: /
匹配以特定字符串结尾的 URL - 需要美元符号 ($)。例如,示例代码阻止访问以 .xls 结尾的所有 URL:
用户代理:Googlebot
禁止:/*.xls$
优先
请务必注意,搜索引擎对 robots.txt 文件的处理方式不同。默认情况下,第一个匹配指令总是优先。
但谷歌和必应更专注于特定目录。
也就是说:如果命令的字符较长,Google 和 Bing 将重视 Allow 命令。
例子
用户代理: *
允许:/about/company/
禁止:/about/
在上面的 /about/ 示例中,所有搜索引擎(包括 Google 和 Bing)都不允许访问目录 /about/company/,子目录除外。
例子
用户代理: *
禁止:/about/
允许:/about/company/
在上面的示例中,除了 Google 和 Bing 之外的所有搜索引擎都不允许访问 /about/ 目录,包括 /about/company/。
但允许 Google 和 Bing 访问 /about/company/,因为 Allow 指令比 Disallow 指令更长,并且目录位置更具体。
操作说明
每个搜索引擎只能定义一组指令。为一个搜索引擎设置多组指令可能会使他们感到困惑。
要尽可能具体
disallow 指令也会触发部分匹配。
在定义 Disallow 指令时尽可能具体,以防止无意中禁止访问文件。
例子
用户-agnet:*
禁止:/目录
上面的例子不允许搜索引擎访问:
所以要指定哪些目录需要禁止爬取。
此外
网站管理员必须让蜘蛛远离某些服务器上的目录——以确保服务器性能。例如:大部分网站服务器都有程序存放在“cgi-bin”目录下,所以最好在robots.txt文件中加入“Disallow: /cgi-bin”,避免所有程序文件被蜘蛛索引可以节省服务器资源。一般网站中不需要爬虫爬取的文件有:后台管理文件、程序脚本、附件、数据库文件、编码文件、样式表文件、模板文件、导航图片和背景图片等.
特定于用户代理的指令,未收录在所有用户代理爬虫指令中
这是什么意思?
让我们看一个清晰的例子:
用户代理: *
不允许:/secret/
禁止:/test/
不允许:/尚未开始/
用户代理:googlebot
不允许:/尚未开始/
在上面的示例中,除 Google 之外的所有搜索引擎都不允许访问 /secret/、/test/ 和 /not-launched-yet/。
Google 不允许访问 /not-launched-yet/,但允许访问 /secret/ 和 /test/。
如果您不想让 googlebot 访问 /secret/、/not-launched-yet/,那么您需要 googlebot 专门重复这些说明:
用户代理: *
不允许:/secret/
禁止:/test/
不允许:/尚未开始/
用户代理:googlebot
不允许:/secret/
不允许:/尚未开始/
robots.txt 文件有哪些限制?
由于 robots.txt 而导致搜索引擎无法访问的页面,但如果它们是从已抓取页面链接的,它们仍会出现在搜索结果中。例子:

专业提示:可以使用 Google Search Console 的 URL 删除工具从 Google 中删除这些 URL。请注意,这些 URL 只会被暂时删除。为了将它们排除在 Google 的结果页面之外,该 URL 需要每 90 天删除一次。
谷歌表示 robots.txt 文件通常被缓存长达 24 小时。在更改 robots.txt 文件时,请务必考虑到这一点。
目前尚不清楚其他搜索引擎如何处理 robots.txt 的缓存,但通常最好避免缓存您的 robots.txt 文件,以避免搜索引擎花费超过必要的时间来接收更改。
对于 robots.txt 文件,Google 目前支持 500 kb 的文件大小限制。可以忽略此最大文件大小之后的任何内容。
检查 robots.txt 文件和 URL
这可以在旧版本的 Google 网站管理员工具中进行检查。
单击抓取 > robots.txt 测试器
你可以看到你的robots的内容,在下面输入你要测试的url,点击测试就知道这个url是否被robots.txt的指令限制了。
您也可以直接通过以下链接:
总结最佳实践:
确保所有重要页面均可抓取
不要阻止 网站JavaScript 和 CSS 文件
在网站管理员工具中检查重要的网址是否被阻止抓取
正确大写目录、子目录和文件名
将 robots.txt 文件放在 网站 根目录下
Robots.txt 文件区分大小写,文件必须命名为“robots.txt”(无其他变体)
不要使用 robots.txt 文件隐藏私人用户信息,因为它仍然可见
将站点地图位置添加到 robots.txt 文件中。
防范措施:
如果您在 网站 中有一个或多个子域,那么每个子域以及主根域中都需要一个 robots.txt 文件。
这看起来像这样
/robots.txt 和 /robots.txt。
原因是其他页面可能会链接到此信息,如果有直接链接,它将绕过 robots.txt 规则,内容仍可能被索引。
如果您需要防止您的页面实际在搜索结果中被编入索引,请使用不同的方法,例如添加密码保护或向这些页面添加 noindex 元标记。Google 无法登录受密码保护的 网站/ 页面,因此无法抓取或索引这些页面。
不要在 robots.txt 中使用 noindex
虽然有人说在 robots.txt 文件中使用 noindex 指令是个好主意,但这不是官方标准,Google 公开建议不要使用它。
谷歌尚未澄清原因,但我们认为我们应该认真对待他们的建议,因为:
综上所述
如果您以前从未使用过 robots.txt 文件,可能会有点紧张,但不用担心,它的设置相当简单。
一旦您熟悉了文件的详细信息,您就可以为 网站 增强您的 SEO。
通过正确设置您的 robots.txt 文件,它将帮助搜索引擎抓取工具明智地使用抓取预算,并帮助确保他们不会浪费时间和资源来抓取不需要抓取的页面。
这将帮助他们以最佳方式在 SERP 中组织和显示您的 网站 内容,这意味着您将获得更多曝光。
设置 robots.txt 文件不必花费大量时间和精力。在大多数情况下,它是一次性设置,然后可以进行小的调整和更改以帮助更好地塑造它网站。
我希望本文中介绍的实践、技巧和建议可以帮助您开始创建/调整您的 网站robots.txt 文件。
具备各大搜索引擎蜘蛛的特点
1.百度蜘蛛:百度蜘蛛网上的信息百度蜘蛛名字有BaiduSpider、baiduspider等,请洗漱睡觉,那是老黄历。百度蜘蛛的最新名称是百度蜘蛛。在日志中,我还找到了Baiduspider-image,百度下的蜘蛛。查了资料(其实就是看名字……),是抓图的蜘蛛。常见的百度同类型蜘蛛有:Baiduspider-mobile(抓wap)、Baiduspider-image(抓图)、Baiduspider-video(抓视频)、Baiduspider-news(抓新闻)。注:以上百度蜘蛛目前为Baiduspider和Baiduspider-image。
2. Google Spider:Googlebot 争议较小,但也有人说它是 GoogleBot。Google 蜘蛛的最新名称是“compatible; Googlebot/2.1;”。还找到了Googlebot-Mobile,看名字就是爬wap内容。
3. 360蜘蛛:360Spider,它是一只非常“勤奋”的蜘蛛。
4、SOSO蜘蛛:Sosospider,它也可以被授予“勤奋”的蜘蛛。
5、雅虎蜘蛛:“雅虎!啜饮中国”或雅虎!名字带有“Slurp”和空格,robots中带有空格的名字,名字可以用“Slurp”或者“Yahoo”来描述,不知道有效与否。
6、有道蜘蛛:有道机器人,有道机器人(两个名字,汉语拼音少了一个U字母,读音很不一样,会不会少一些?)
7、搜狗蜘蛛:搜狗新闻蜘蛛还包括以下内容:
搜狗网络蜘蛛,搜狗inst蜘蛛,搜狗蜘蛛2、搜狗博客,搜狗新闻蜘蛛,搜狗猎户蜘蛛,(参考网站的一些robots文件,搜狗蜘蛛的名字可以用搜狗来概括,无法验证,不知道有没有用?看看最权威的百度robots.txt,对于搜狗蜘蛛来说占用了很多字节,占据了很大的版图。”搜狗网络蜘蛛;搜狗inst spider;搜狗spider2;搜狗博客;搜狗新闻蜘蛛;搜狗猎户蜘蛛”目前有6个带空格的名字。网上常见“搜狗网络蜘蛛/4.0”;“搜狗新闻蜘蛛/4.@ >0”;“搜狗inst蜘蛛/4.0”可获“占之王”奖。
8、MSN 蜘蛛:msnbot、msnbot-media(只见 msnbot-media 疯狂爬行……)
9、bing 蜘蛛:bingbot 在线(兼容;bingbot/2.0;)
10、搜索蜘蛛:一搜蜘蛛
11、Alexa 蜘蛛:ia_archiver
12、易搜蜘蛛:EasouSpider
13、即时蜘蛛:JikeSpider
14、一个爬网蜘蛛:EtaoSpider "Mozilla/5.0 (compatible; EtaoSpider/1.0; omit/EtaoSpider)" 根据上面选择几个常用的爬虫,允许爬取,其余的可以被机器人挡住。如果你暂时有足够的空间流量,在流量紧张的时候,保留一些常用的,并阻止其他蜘蛛以节省流量。至于那些蜘蛛爬到网站的有用价值,网站的管理人员是很有眼光的。
此外,还发现了 YandexBot、AhrefsBot 和 ezooms.bot 等蜘蛛。据说这些蜘蛛是外国的,对中文网站用处不大。最好是节省资源。
和平出来


公众号:yestupa 扫码关注图帕先生
获取更多国外SEM、SEO干货
给我[关注]
你也更好看!

php 抓取网页内容(php抓取网页内容的问题首先得确定用户都对什么样的内容感兴趣)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-04-04 21:08
php抓取网页内容的问题,首先得确定用户都对什么样的内容感兴趣.有些人感兴趣就写个爬虫爬一爬.有些人感兴趣就用scrapy,selenium等工具抓一抓.然后还有人就不知道对什么感兴趣.那就是数据库学习咯.数据库怎么学习?一开始我也不知道.工作中,有一些学习框架,例如mysql,mssql,hbase等,你可以去看看,找一个showglobalvariableslike'tmp'来看一看.这样比较直观,学起来方便,从基础开始,然后再去深入.数据库学习php如何搭建数据库?都已经存在数据库了.那么肯定会去构建它.首先.你可以搜索几个需要的数据库,例如access,mysql,oracle,mssql等,然后下载.双击安装包.然后你可以看配置,然后把框架学会.比如用phpshop,phpwordpress建立数据库.因为phpweb只能在php类中使用,所以你还需要html类。
html是从html标签和超链接自动生成的,支持语言(可选):c,java,python和mysql。javascript用于创建、组织和表示html页面的元素。怎么学习php爬虫或者说开发爬虫呢?网上大神有很多,教php爬虫的有很多,可以随便看看.php是面向对象语言,你可以用php(所以,当你要写一个php爬虫时),比如用java写一个"爬虫”(可以是api),然后用php写一个页面,接着和后端交互,生成数据。
关于学习php以及scrapy是否需要的问题.那是肯定需要学习的.比如用scrapy一起抓java和c/c++的源码,比如学习seleniumpython的模拟登录.就算你想用java,那么如果你想爬php,这个学习一下还是要的.另外,selenium是java的模拟登录,它不支持php.怎么学php网页的前端布局呢?php在打开web服务器时,有很多数据缓存方法,哪些通过缓存?有哪些语言呢?java,c++.java有哪些语言中的函数实现呢?有什么约定俗成的方法吗?c++也有一些编程模式吗?php怎么去配置一些prefix?java是通过什么api传递变量和参数呢?等等有什么语言能够得到这些变量,通过什么方法查看他们的引用?php的相关语言可以按哪些顺序?为什么?php内置对象?有没有隐藏的对象?有没有隐藏的方法?这个语言的写法还能怎么写?那么就得学好计算机,让计算机明白人话,一定要多说,多练,多举一反三.以后举一反三就能实现.数据库自己搭建数据库?这个太难了,估计没几个人能做到.还有怎么从电脑上爬下数据呢?买?对方有数据库吗?还有问下你们网站对爬虫支持的速度?现在好多网站都不支持爬虫,不是因为爬虫不好,是因为它的数据,相对比较少.容。 查看全部
php 抓取网页内容(php抓取网页内容的问题首先得确定用户都对什么样的内容感兴趣)
php抓取网页内容的问题,首先得确定用户都对什么样的内容感兴趣.有些人感兴趣就写个爬虫爬一爬.有些人感兴趣就用scrapy,selenium等工具抓一抓.然后还有人就不知道对什么感兴趣.那就是数据库学习咯.数据库怎么学习?一开始我也不知道.工作中,有一些学习框架,例如mysql,mssql,hbase等,你可以去看看,找一个showglobalvariableslike'tmp'来看一看.这样比较直观,学起来方便,从基础开始,然后再去深入.数据库学习php如何搭建数据库?都已经存在数据库了.那么肯定会去构建它.首先.你可以搜索几个需要的数据库,例如access,mysql,oracle,mssql等,然后下载.双击安装包.然后你可以看配置,然后把框架学会.比如用phpshop,phpwordpress建立数据库.因为phpweb只能在php类中使用,所以你还需要html类。
html是从html标签和超链接自动生成的,支持语言(可选):c,java,python和mysql。javascript用于创建、组织和表示html页面的元素。怎么学习php爬虫或者说开发爬虫呢?网上大神有很多,教php爬虫的有很多,可以随便看看.php是面向对象语言,你可以用php(所以,当你要写一个php爬虫时),比如用java写一个"爬虫”(可以是api),然后用php写一个页面,接着和后端交互,生成数据。
关于学习php以及scrapy是否需要的问题.那是肯定需要学习的.比如用scrapy一起抓java和c/c++的源码,比如学习seleniumpython的模拟登录.就算你想用java,那么如果你想爬php,这个学习一下还是要的.另外,selenium是java的模拟登录,它不支持php.怎么学php网页的前端布局呢?php在打开web服务器时,有很多数据缓存方法,哪些通过缓存?有哪些语言呢?java,c++.java有哪些语言中的函数实现呢?有什么约定俗成的方法吗?c++也有一些编程模式吗?php怎么去配置一些prefix?java是通过什么api传递变量和参数呢?等等有什么语言能够得到这些变量,通过什么方法查看他们的引用?php的相关语言可以按哪些顺序?为什么?php内置对象?有没有隐藏的对象?有没有隐藏的方法?这个语言的写法还能怎么写?那么就得学好计算机,让计算机明白人话,一定要多说,多练,多举一反三.以后举一反三就能实现.数据库自己搭建数据库?这个太难了,估计没几个人能做到.还有怎么从电脑上爬下数据呢?买?对方有数据库吗?还有问下你们网站对爬虫支持的速度?现在好多网站都不支持爬虫,不是因为爬虫不好,是因为它的数据,相对比较少.容。
php 抓取网页内容(牛逼闪闪的curl也束手无策了,可以说相当靠谱了!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 244 次浏览 • 2022-04-01 06:17
关键词:数据获取
我的生命是有限的,但我的知识是无限的。本文章主要介绍php爬取数据相关的知识,希望对你有所帮助。
对于一般的页面数据,我们可以使用querylist轻松抓取页面并分析其中的dom树,抓取我们需要的数据,并存入数据库,但是有时候我们要抓取的数据是通过渲染来渲染的是的,这次
Puppeteer 插件派上用场了,
composerrequirenesk/puphpeteer
npminstall@nesk/puphpeteer
供参考,在按照文档做的时候,发现
错误:无法下载 Chromium r672088!设置“PUPPETEER_SKIP_CHROMIUM_DOWNLOAD”环境变量以跳过下载。错误,
解决方案
采集网页内容是一个很常见的需求。与传统的静态页面相比,curl 可以应付。但是如果页面中有动态加载的内容,比如在某些页面中通过ajax加载的文章body内容,并且如果在某些页面加载后进行了一些额外的处理(图片地址替换等),并且你想采集这些处理过的内容。然后真棒curl就束手无策了。
有类似需求的人可能会说,老铁,上PhantomJS吧!
是的,这是一个解决方案,在相当长的一段时间内,PhantomJS 是能够解决这种需求的少数工具中最好的。
但今天我要介绍一个后来居上的工具——puppeteer,它随着 Chrome Headless 技术的兴起而迅速发展。而且最重要的是,puppeteer是由Chrome官方团队开发维护的,可以说是相当靠谱了!
puppeteer 是一个 js 包。要在 Laravel 中使用它,您必须使用另一个工件 spatie/browsershot。
安装
安装 spatie/browsershot
browsershot 是来自伟大团队 spatie 的作曲家包
$ composer require spatie/browsershot
安装 puppeteer
$ npm i puppeteer --save
你也可以全局保护puppeteer,但是从个人经验来看,建议在项目中安装,因为不同的项目不会同时受到全局安装的puppeteer的影响,而且项目中的安装也是使用phpdeployer升级方便(phpdeploy升级时不会影响线上项目的运行,要知道升级/安装puppeteer是非常耗时的,有时也不能保证成功)。
安装 puppeteer 时会下载 Chromium-Browser。由于我国特殊的国情,很可能无法下载。在这方面,请大展身手……
使用
以采集今日头条手机页面文章的内容为例。
use Spatie\Browsershot\Browsershot;
public function getBodyhtml()
$newsUrl = ‘https://m.toutiao.com/i6546884151050502660/‘;
$html = Browsershot::url($newsUrl)
->windowSize(480, 800)
->userAgent(‘Mozilla/5.0 (Linux; android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36‘)
->mobile()
->touch()
->bodyHtml();
\Log::info($html);
运行后在日志中可以看到如下内容(截图只是部分内容)
或者,您可以将页面保存为图像或 PDF 文件。
use Spatie\Browsershot\Browsershot;
public function getBodyHtml()
$newsUrl = ‘https://m.toutiao.com/i6546884151050502660/‘;
Browsershot::url($newsUrl)
->windowSize(480, 800)
->userAgent(‘Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36‘)
->mobile()
->touch()
->setDelay(1000)
->save(public_path(‘images/toutiao.jpg‘));
图片中的方框与系统字体有关。代码中使用了 setDelay() 方法,在内容加载完成后进行截图。它简单粗暴,可能不是最好的解决方案。
可能的问题
总结
puppeteer用于测试、采集等场景,是一个非常强大的工具。对于轻量级的采集任务来说已经足够了,比如这篇文章使用采集Laravel(php)中的一些小页面,但是如果需要快速采集大量的内容,或者python什么的。
这篇关于php爬取数据的文章已经写完了。如果不能解决您的问题,请参考以下文章: 查看全部
php 抓取网页内容(牛逼闪闪的curl也束手无策了,可以说相当靠谱了!)
关键词:数据获取
我的生命是有限的,但我的知识是无限的。本文章主要介绍php爬取数据相关的知识,希望对你有所帮助。
对于一般的页面数据,我们可以使用querylist轻松抓取页面并分析其中的dom树,抓取我们需要的数据,并存入数据库,但是有时候我们要抓取的数据是通过渲染来渲染的是的,这次
Puppeteer 插件派上用场了,
composerrequirenesk/puphpeteer
npminstall@nesk/puphpeteer
供参考,在按照文档做的时候,发现
错误:无法下载 Chromium r672088!设置“PUPPETEER_SKIP_CHROMIUM_DOWNLOAD”环境变量以跳过下载。错误,
解决方案
采集网页内容是一个很常见的需求。与传统的静态页面相比,curl 可以应付。但是如果页面中有动态加载的内容,比如在某些页面中通过ajax加载的文章body内容,并且如果在某些页面加载后进行了一些额外的处理(图片地址替换等),并且你想采集这些处理过的内容。然后真棒curl就束手无策了。
有类似需求的人可能会说,老铁,上PhantomJS吧!
是的,这是一个解决方案,在相当长的一段时间内,PhantomJS 是能够解决这种需求的少数工具中最好的。
但今天我要介绍一个后来居上的工具——puppeteer,它随着 Chrome Headless 技术的兴起而迅速发展。而且最重要的是,puppeteer是由Chrome官方团队开发维护的,可以说是相当靠谱了!
puppeteer 是一个 js 包。要在 Laravel 中使用它,您必须使用另一个工件 spatie/browsershot。
安装
安装 spatie/browsershot
browsershot 是来自伟大团队 spatie 的作曲家包
$ composer require spatie/browsershot
安装 puppeteer
$ npm i puppeteer --save
你也可以全局保护puppeteer,但是从个人经验来看,建议在项目中安装,因为不同的项目不会同时受到全局安装的puppeteer的影响,而且项目中的安装也是使用phpdeployer升级方便(phpdeploy升级时不会影响线上项目的运行,要知道升级/安装puppeteer是非常耗时的,有时也不能保证成功)。
安装 puppeteer 时会下载 Chromium-Browser。由于我国特殊的国情,很可能无法下载。在这方面,请大展身手……
使用
以采集今日头条手机页面文章的内容为例。
use Spatie\Browsershot\Browsershot;
public function getBodyhtml()
$newsUrl = ‘https://m.toutiao.com/i6546884151050502660/‘;
$html = Browsershot::url($newsUrl)
->windowSize(480, 800)
->userAgent(‘Mozilla/5.0 (Linux; android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36‘)
->mobile()
->touch()
->bodyHtml();
\Log::info($html);
运行后在日志中可以看到如下内容(截图只是部分内容)

或者,您可以将页面保存为图像或 PDF 文件。
use Spatie\Browsershot\Browsershot;
public function getBodyHtml()
$newsUrl = ‘https://m.toutiao.com/i6546884151050502660/‘;
Browsershot::url($newsUrl)
->windowSize(480, 800)
->userAgent(‘Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36‘)
->mobile()
->touch()
->setDelay(1000)
->save(public_path(‘images/toutiao.jpg‘));

图片中的方框与系统字体有关。代码中使用了 setDelay() 方法,在内容加载完成后进行截图。它简单粗暴,可能不是最好的解决方案。
可能的问题
总结
puppeteer用于测试、采集等场景,是一个非常强大的工具。对于轻量级的采集任务来说已经足够了,比如这篇文章使用采集Laravel(php)中的一些小页面,但是如果需要快速采集大量的内容,或者python什么的。

这篇关于php爬取数据的文章已经写完了。如果不能解决您的问题,请参考以下文章:
php 抓取网页内容(php抓取网页内容之前用过爬虫开发工具,scrapy,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-25 03:05
php抓取网页内容之前用过爬虫开发工具,scrapy,各有长短。想要抓取多页面时,遇到服务器负载过大,网站负载过重等各种问题,它解决的办法是在请求的时候预留参数,并与服务器端进行比较。php实现呢,可以先用taobao_redirect_dump函数把页面抓取下来。然后呢,再从json,xml或者json-raw抓取。
直接抓取是可以的,但是流量数据应该是不能直接获取的(因为通过去掉cookie这种步骤得到的是ip与购买商品数量)。你可以尝试一下,用你自己开发的js库去抓取目标站点的html。然后后端用php处理(phpstorm有带js处理模块,但是安装较麻烦,所以个人感觉没有phpstorm这么强大)。这个问题如果你用python或java做实现也可以解决,所以不用太担心。
并不行,你需要保证网站内容不是公开的数据,
你可以去看看加拿大的游戏家事例,他们用代理从推特上面抓内容到本地服务器,但是后端处理数据比较麻烦,适合直接抓,
可以,但是你需要的是强大的requests,并且需要有index.php你当然也可以不如visualstudio那么死忠,但是atom为什么不能做php网页内容抓取---visualstudiocode可以强大到仅仅用atom是不够用的。 查看全部
php 抓取网页内容(php抓取网页内容之前用过爬虫开发工具,scrapy,)
php抓取网页内容之前用过爬虫开发工具,scrapy,各有长短。想要抓取多页面时,遇到服务器负载过大,网站负载过重等各种问题,它解决的办法是在请求的时候预留参数,并与服务器端进行比较。php实现呢,可以先用taobao_redirect_dump函数把页面抓取下来。然后呢,再从json,xml或者json-raw抓取。
直接抓取是可以的,但是流量数据应该是不能直接获取的(因为通过去掉cookie这种步骤得到的是ip与购买商品数量)。你可以尝试一下,用你自己开发的js库去抓取目标站点的html。然后后端用php处理(phpstorm有带js处理模块,但是安装较麻烦,所以个人感觉没有phpstorm这么强大)。这个问题如果你用python或java做实现也可以解决,所以不用太担心。
并不行,你需要保证网站内容不是公开的数据,
你可以去看看加拿大的游戏家事例,他们用代理从推特上面抓内容到本地服务器,但是后端处理数据比较麻烦,适合直接抓,
可以,但是你需要的是强大的requests,并且需要有index.php你当然也可以不如visualstudio那么死忠,但是atom为什么不能做php网页内容抓取---visualstudiocode可以强大到仅仅用atom是不够用的。
php 抓取网页内容(百度并没有推出百度权重这么个东西,而是站长工具和爱站 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-20 21:09
)
总结
由于谷歌还没有更新PR,所以很多站长在做友情链接的时候用百度权重来衡量每一个网站的质量。其实百度并没有推出百度权重,而是网站龙工具和爱站这两个站推出的参考价值,通过分析网站的关键词和页数关键词 set by 网站 基于@>,计算出网站的百度权重不是那么准确,只能作为参考;
在这个文章的分享下,可以通过php获取爱站查询网站的百度权重并生成图片,可以方便调用查看百度网站 值的权重,请看下图演示;使用方法也很简单,点击下方下载按钮,解压下载的压缩包文件,将br文件夹上传到网站,
通过URL访问:您的域名/br/?q=要查询的域名
由于谷歌还没有更新PR,所以很多站长在做友情链接的时候用百度权重来衡量每一个网站的质量。其实百度并没有推出百度权重,而是网站龙工具和爱站这两个站推出的参考价值,通过分析网站的关键词和页数关键词 set by 网站 基于@>,计算出网站的百度权重不是那么准确,只能作为参考;
在这个文章的分享下,可以通过php获取爱站查询网站的百度权重并生成图片,可以方便调用查看百度网站 值的权重,请看下图演示;使用方法也很简单,点击下方下载按钮,解压下载的压缩包文件,将br文件夹上传到网站,
通过URL访问:您的域名/br/?q=要查询的域名 查看全部
php 抓取网页内容(百度并没有推出百度权重这么个东西,而是站长工具和爱站
)
总结
由于谷歌还没有更新PR,所以很多站长在做友情链接的时候用百度权重来衡量每一个网站的质量。其实百度并没有推出百度权重,而是网站龙工具和爱站这两个站推出的参考价值,通过分析网站的关键词和页数关键词 set by 网站 基于@>,计算出网站的百度权重不是那么准确,只能作为参考;
在这个文章的分享下,可以通过php获取爱站查询网站的百度权重并生成图片,可以方便调用查看百度网站 值的权重,请看下图演示;使用方法也很简单,点击下方下载按钮,解压下载的压缩包文件,将br文件夹上传到网站,
通过URL访问:您的域名/br/?q=要查询的域名
由于谷歌还没有更新PR,所以很多站长在做友情链接的时候用百度权重来衡量每一个网站的质量。其实百度并没有推出百度权重,而是网站龙工具和爱站这两个站推出的参考价值,通过分析网站的关键词和页数关键词 set by 网站 基于@>,计算出网站的百度权重不是那么准确,只能作为参考;
在这个文章的分享下,可以通过php获取爱站查询网站的百度权重并生成图片,可以方便调用查看百度网站 值的权重,请看下图演示;使用方法也很简单,点击下方下载按钮,解压下载的压缩包文件,将br文件夹上传到网站,
通过URL访问:您的域名/br/?q=要查询的域名
php 抓取网页内容(php语言的核心数据库-selenium开发前端自动化测试程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2022-03-20 10:03
php抓取网页内容如果发现网页有敏感词汇,即使能够爬取,结果是不能通过审核,造成对用户的资源损失。php的sqlite数据库是php语言的核心数据库,是由在2005年1月推出。目前有一家叫做“inforoot“公司。php在2003年发布第一个程序包:php-connection,它包含了从标准程序包继承的一个环境。
php提供一个嵌入html的虚拟表单,供用户交互。php可以在独立的虚拟表单中访问数据库或存储数据。接下来,有一个简单的网页爬虫项目。selenium开发的前端自动化测试程序,可以从一系列报表中识别出任意一张,进而自动化执行你想执行的测试脚本。它还可以爬取asp脚本,而php不能用。php最简单的网页可视化方案,你只需要在php代码中编写响应页面元素的事件,当a标签出现在地址栏时,php向数据库发送网页的请求。
这就自动获取了你想要的那个网页,调用网页的函数进行操作,完成它的预期。一、原理1.创建php对象根据你设定的页面元素,创建一个php对象。这个对象继承了php5开始的两个基本扩展对象,即new标准模式和php5.0开始的基本模式。用于存储数据;它是index和location变量的前缀,用于获取元素对象和路径。
示例如下:functiongetmethod(url){//defineanobjectforaphpobject//newtoinitialize.//createawriteandcompressinguniformlyautomatically.//builderif(url){//writeormakesomeelementseasiertowrite//automatically..}//compresswhenyouwritecode(e.g.:request.urlstring("")),//withoutreadandcompressations.//initializetheobjectatintimateinitialization.//outputobjectwith:'/post()/'//note:theobjectstartswith'automatically'butisusedforcompressingonuri.//createthenewpublicmethodindex;//usetheurlstringvalue(that'sused)createanadminname();//usetheurlstringvalues(that'sused)setargs();//settheobject'sprivatepropertiestotheurlstring.//outputobjectwith:''/'''//addandmaptheobjectnamecommentinapostsetmy{}my{}or{}//addandcompresstheurlstrings.//mapapostorapostcontainingtheobject.//thismapneedstobeeasilycompressed.//addandcompresstheurlstrings.//buildedasadllfile.//addandcompressthetheurlstrings.//newtheobjectf。 查看全部
php 抓取网页内容(php语言的核心数据库-selenium开发前端自动化测试程序)
php抓取网页内容如果发现网页有敏感词汇,即使能够爬取,结果是不能通过审核,造成对用户的资源损失。php的sqlite数据库是php语言的核心数据库,是由在2005年1月推出。目前有一家叫做“inforoot“公司。php在2003年发布第一个程序包:php-connection,它包含了从标准程序包继承的一个环境。
php提供一个嵌入html的虚拟表单,供用户交互。php可以在独立的虚拟表单中访问数据库或存储数据。接下来,有一个简单的网页爬虫项目。selenium开发的前端自动化测试程序,可以从一系列报表中识别出任意一张,进而自动化执行你想执行的测试脚本。它还可以爬取asp脚本,而php不能用。php最简单的网页可视化方案,你只需要在php代码中编写响应页面元素的事件,当a标签出现在地址栏时,php向数据库发送网页的请求。
这就自动获取了你想要的那个网页,调用网页的函数进行操作,完成它的预期。一、原理1.创建php对象根据你设定的页面元素,创建一个php对象。这个对象继承了php5开始的两个基本扩展对象,即new标准模式和php5.0开始的基本模式。用于存储数据;它是index和location变量的前缀,用于获取元素对象和路径。
示例如下:functiongetmethod(url){//defineanobjectforaphpobject//newtoinitialize.//createawriteandcompressinguniformlyautomatically.//builderif(url){//writeormakesomeelementseasiertowrite//automatically..}//compresswhenyouwritecode(e.g.:request.urlstring("")),//withoutreadandcompressations.//initializetheobjectatintimateinitialization.//outputobjectwith:'/post()/'//note:theobjectstartswith'automatically'butisusedforcompressingonuri.//createthenewpublicmethodindex;//usetheurlstringvalue(that'sused)createanadminname();//usetheurlstringvalues(that'sused)setargs();//settheobject'sprivatepropertiestotheurlstring.//outputobjectwith:''/'''//addandmaptheobjectnamecommentinapostsetmy{}my{}or{}//addandcompresstheurlstrings.//mapapostorapostcontainingtheobject.//thismapneedstobeeasilycompressed.//addandcompresstheurlstrings.//buildedasadllfile.//addandcompressthetheurlstrings.//newtheobjectf。
php 抓取网页内容(php主机域名源码、使用fopen获得网页源代码。。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-03-15 12:18
1、使用file_get_contents 获取网页源代码。这个方法是最常用的php主机域名源码。只需要两行代码,非常简单方便。
2php主机域名源码,使用fopen获取网页源码。用这种方法的人很多,但是代码有点多。
3php主机域名源码,使用curl获取网页源码。使用curl获取网页源代码的做法,经常被要求较高的人使用。比如在爬取网页内容的同时需要获取网页的头部信息时,以及使用ENCODING编码、使用USERAGENT等。所谓网页代码,是指网页制作过程中需要用到的一些特殊的“语言”。设计师组织和安排这些“语言”来创建网页,然后浏览器“翻译”代码。是我们最终看到的。制作网页时常用的代码有HTML、JavaScript、ASP、PHP、CGI等,其中,
一个域名绑定的网站源码也可以用在其他域名上?
不接受正式的操作。不久前,一些网站打开,变成了另一个网站。此行为是不道德的 PHP 主机域名源代码。
第一步是将php主机域名的源码添加到你要使用的域名解析平台的国外空间。通常,做一个A记录,即IP和主机名的对应关系就足够了。只需要知道web服务器的IP就可以解析
第二部分,在外域的控制面板中,在外域绑定你要使用的域名
完成这两步后,等待DNS解析生效即可访问。当然,您需要将网站程序源代码上传到国外空间进行安装,然后才能打开站点。
注意:域名解析生效的时间因DNS提供商而异。它可以快几秒钟或慢几小时。可以通过ping+域名命令查看解析是否生效。 查看全部
php 抓取网页内容(php主机域名源码、使用fopen获得网页源代码。。)
1、使用file_get_contents 获取网页源代码。这个方法是最常用的php主机域名源码。只需要两行代码,非常简单方便。

2php主机域名源码,使用fopen获取网页源码。用这种方法的人很多,但是代码有点多。
3php主机域名源码,使用curl获取网页源码。使用curl获取网页源代码的做法,经常被要求较高的人使用。比如在爬取网页内容的同时需要获取网页的头部信息时,以及使用ENCODING编码、使用USERAGENT等。所谓网页代码,是指网页制作过程中需要用到的一些特殊的“语言”。设计师组织和安排这些“语言”来创建网页,然后浏览器“翻译”代码。是我们最终看到的。制作网页时常用的代码有HTML、JavaScript、ASP、PHP、CGI等,其中,
一个域名绑定的网站源码也可以用在其他域名上?
不接受正式的操作。不久前,一些网站打开,变成了另一个网站。此行为是不道德的 PHP 主机域名源代码。
第一步是将php主机域名的源码添加到你要使用的域名解析平台的国外空间。通常,做一个A记录,即IP和主机名的对应关系就足够了。只需要知道web服务器的IP就可以解析
第二部分,在外域的控制面板中,在外域绑定你要使用的域名
完成这两步后,等待DNS解析生效即可访问。当然,您需要将网站程序源代码上传到国外空间进行安装,然后才能打开站点。
注意:域名解析生效的时间因DNS提供商而异。它可以快几秒钟或慢几小时。可以通过ping+域名命令查看解析是否生效。
php 抓取网页内容(php抓取网页内容20vci9iffhf=(二维码自动识别))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-03-12 23:07
php抓取网页内容ahr0cdovl3dlaxhpbi5xcs5jb20vci9iffhf014n2rxalyuky46hyotixxymw==(二维码自动识别)
zendamobile首页demo,可以根据你的昵称进行关键词采集,
去你直接搜这些网站的源代码得到的网页地址直接访问就可以看到该页面的下载地址了
去百度搜索2048,谷歌的应该更牛吧。
全部都是采集来的
php开发的hypertextviolation
【图】
百度2048
php实现:he#2048其实,更简单直接的是拿sitemap做图像识别和图片分析,
这个应该可以通过python里的pil库来实现pillow库(图像处理)pillow(图像处理)。要实现这个页面,首先要理解下js代码。
豆瓣有大牛做过2048这个游戏,你可以下一个研究下,至于ahr,
第一步:把搜索的昵称复制进去,然后加上下划线第二步:点击,
我想问下,
2048网站可以用python(python)一键爬取,
ahr0cdovl3dlaxhpbi5xcs5jb20vci9dkpwd25bk2mxjyugjjyotixnymw==(二维码自动识别) 查看全部
php 抓取网页内容(php抓取网页内容20vci9iffhf=(二维码自动识别))
php抓取网页内容ahr0cdovl3dlaxhpbi5xcs5jb20vci9iffhf014n2rxalyuky46hyotixxymw==(二维码自动识别)
zendamobile首页demo,可以根据你的昵称进行关键词采集,
去你直接搜这些网站的源代码得到的网页地址直接访问就可以看到该页面的下载地址了
去百度搜索2048,谷歌的应该更牛吧。
全部都是采集来的
php开发的hypertextviolation
【图】
百度2048
php实现:he#2048其实,更简单直接的是拿sitemap做图像识别和图片分析,
这个应该可以通过python里的pil库来实现pillow库(图像处理)pillow(图像处理)。要实现这个页面,首先要理解下js代码。
豆瓣有大牛做过2048这个游戏,你可以下一个研究下,至于ahr,
第一步:把搜索的昵称复制进去,然后加上下划线第二步:点击,
我想问下,
2048网站可以用python(python)一键爬取,
ahr0cdovl3dlaxhpbi5xcs5jb20vci9dkpwd25bk2mxjyugjjyotixnymw==(二维码自动识别)
php 抓取网页内容(php抓取网页内容用flash写页面在xml或json中存储)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-09 18:05
php抓取网页内容用flash写页面,在xml或json中存储就可以,相关的模块网上很多,此处不做赘述。优势是可以局部缓存在页面上,大大加快页面加载速度。劣势是代码很长,比如有些表单用方括号,有些用大括号,在代码量变大的情况下就有可能写不下,另外在对服务器policy的操作上也有可能失败,比如在log中记录一些敏感字段。
为了让网页多次加载,所以要使用加载算法保证不重复加载,用最简单的,如使用循环。上面都是php原生的特性,还可以使用coyote等框架封装。不过我觉得目前页面重复加载的现象严重,提供一些新的特性也是有必要的。可以使用缓存来减少重复加载。但是,最后一定要对中间的policy机制有比较好的设计。
我的做法是把html变成纯php程序,程序中解析加载页面。loadingphp程序中是通过循环来解析加载html。一段代码可以定义成一个框架比如async/await。这样就避免了在多线程下的加载程序,速度应该比workerman快得多,而且能把url改成哪个来加载,也能避免url被发送到前端后,前端对url定义再解析导致http报文内容丢失的问题。</p>
主要应该考虑这么几个因素:1.资源按照url解析后能够方便在缓存中恢复;2.资源能够方便定义为哪个线程继续加载,哪个线程暂停加载,以确保网络不会丢失;3.对于文件,能够在根目录生成文件名然后缓存中加载,在子目录内生成文件名在页面中显示。解决效率问题。我所碰到的问题是http协议在解析过程时,会有新文件被生成,而由于页面变长,或其他一些原因,会产生文件的大小增加,造成分布式一致性比较困难。另外页面的颜色等特性也能够应对这个问题。 查看全部
php 抓取网页内容(php抓取网页内容用flash写页面在xml或json中存储)
php抓取网页内容用flash写页面,在xml或json中存储就可以,相关的模块网上很多,此处不做赘述。优势是可以局部缓存在页面上,大大加快页面加载速度。劣势是代码很长,比如有些表单用方括号,有些用大括号,在代码量变大的情况下就有可能写不下,另外在对服务器policy的操作上也有可能失败,比如在log中记录一些敏感字段。
为了让网页多次加载,所以要使用加载算法保证不重复加载,用最简单的,如使用循环。上面都是php原生的特性,还可以使用coyote等框架封装。不过我觉得目前页面重复加载的现象严重,提供一些新的特性也是有必要的。可以使用缓存来减少重复加载。但是,最后一定要对中间的policy机制有比较好的设计。
我的做法是把html变成纯php程序,程序中解析加载页面。loadingphp程序中是通过循环来解析加载html。一段代码可以定义成一个框架比如async/await。这样就避免了在多线程下的加载程序,速度应该比workerman快得多,而且能把url改成哪个来加载,也能避免url被发送到前端后,前端对url定义再解析导致http报文内容丢失的问题。</p>
主要应该考虑这么几个因素:1.资源按照url解析后能够方便在缓存中恢复;2.资源能够方便定义为哪个线程继续加载,哪个线程暂停加载,以确保网络不会丢失;3.对于文件,能够在根目录生成文件名然后缓存中加载,在子目录内生成文件名在页面中显示。解决效率问题。我所碰到的问题是http协议在解析过程时,会有新文件被生成,而由于页面变长,或其他一些原因,会产生文件的大小增加,造成分布式一致性比较困难。另外页面的颜色等特性也能够应对这个问题。
php 抓取网页内容(php抓取网页内容最简单最直接的办法是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-04 14:00
php抓取网页内容最简单最直接的办法是使用第三方的web服务器工具,例如优采云web等工具。
楼上说得很对,先做到能抓取,再谈如何让网页内容永久不改动。现在的抓取软件有很多种模式,你使用其中的其中一种就行。比如你先在代码里面写个writebserver,然后通过这个writebserver再把html的内容写入内存。其他常见的模式主要是这几种:1.cookie劫持:(把上一页内容发到后台(cookie),然后读取)2.客户端存储:用存储服务器,把抓取结果存到本地,然后通过浏览器开发调用的api进行读取。
注意:这种模式有可能一次抓取内容有上千台电脑,所以不适合抓取多台电脑的内容。3.伪造http请求:通过第三方程序伪造请求出来。要求可以是自己写个。4.采集框架(采集框架最基本功能就是抓取和转换网站信息),不做说明,只谈一下采集框架的爬虫和采集方法。下面有个url,是重点,php爬虫常用的目标url是。
这个框架会把这些url中采集比较好的部分抓出来。那么当内容url中,有大量的爬虫采集好的内容时,就可以根据网站的规则进行逆爬。基本爬虫是程序从a网站抓取出来的,或者点一下,直接从文档b爬取出来。文档b要想更完整,就需要用到xpath转换工具,urlencode,xpath修正工具。xpath修正工具的应用请参考xpathprofiling,优酷视频里提到的xpath修正工具。
对于网站这种十分复杂和庞大的网站,你自己或者找人都很难抓全所有资源,这时候就可以用到xpath抓取工具。再下面就是进行xpath转换工具的抓取。重点就是找到php代码中有哪些成对的xpath,可以通过requests来找到,或者通过第三方工具,web3d,通过对象来抓取。 查看全部
php 抓取网页内容(php抓取网页内容最简单最直接的办法是什么?)
php抓取网页内容最简单最直接的办法是使用第三方的web服务器工具,例如优采云web等工具。
楼上说得很对,先做到能抓取,再谈如何让网页内容永久不改动。现在的抓取软件有很多种模式,你使用其中的其中一种就行。比如你先在代码里面写个writebserver,然后通过这个writebserver再把html的内容写入内存。其他常见的模式主要是这几种:1.cookie劫持:(把上一页内容发到后台(cookie),然后读取)2.客户端存储:用存储服务器,把抓取结果存到本地,然后通过浏览器开发调用的api进行读取。
注意:这种模式有可能一次抓取内容有上千台电脑,所以不适合抓取多台电脑的内容。3.伪造http请求:通过第三方程序伪造请求出来。要求可以是自己写个。4.采集框架(采集框架最基本功能就是抓取和转换网站信息),不做说明,只谈一下采集框架的爬虫和采集方法。下面有个url,是重点,php爬虫常用的目标url是。
这个框架会把这些url中采集比较好的部分抓出来。那么当内容url中,有大量的爬虫采集好的内容时,就可以根据网站的规则进行逆爬。基本爬虫是程序从a网站抓取出来的,或者点一下,直接从文档b爬取出来。文档b要想更完整,就需要用到xpath转换工具,urlencode,xpath修正工具。xpath修正工具的应用请参考xpathprofiling,优酷视频里提到的xpath修正工具。
对于网站这种十分复杂和庞大的网站,你自己或者找人都很难抓全所有资源,这时候就可以用到xpath抓取工具。再下面就是进行xpath转换工具的抓取。重点就是找到php代码中有哪些成对的xpath,可以通过requests来找到,或者通过第三方工具,web3d,通过对象来抓取。
php 抓取网页内容(PHP中抓取网页内容的实例详解PHP教程方法:PHP使用file_get_contents方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2022-02-26 12:16
《PHP应用:用php抓取网页内容的详细示例》的要点:
本文介绍PHP应用:详细讲解php中抓取网页内容的例子,希望对你有所帮助。如有疑问,您可以联系我们。
PHP教程php中抓取网页内容的例子详解
PHP教程方法一:
PHP教程使用file_get_contents方法实现
PHP教程
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$html = file_get_contents($url);
//如果出现中文乱码使用下面代码
//$getcontent = iconv("gb2312", "utf-8",$html);
echo "".$html."";
PHP教程代码很简单,一看就懂,不用解释。
PHP教程方法二:
PHP教程使用curl实现
PHP教程
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
echo "".$html."";
PHP教程
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
PHP教程添加这段代码表示如果请求被重定向,则可以访问最终的请求页面,否则请求的结果将显示如下:
PHP教程
Object moved
Object MovedThis object may be found here.
如果您对PHP教程有任何疑问,请留言或到本站社区交流讨论。感谢您的阅读。我希望它可以帮助大家。感谢您对本站的支持! 查看全部
php 抓取网页内容(PHP中抓取网页内容的实例详解PHP教程方法:PHP使用file_get_contents方法)
《PHP应用:用php抓取网页内容的详细示例》的要点:
本文介绍PHP应用:详细讲解php中抓取网页内容的例子,希望对你有所帮助。如有疑问,您可以联系我们。
PHP教程php中抓取网页内容的例子详解
PHP教程方法一:
PHP教程使用file_get_contents方法实现
PHP教程
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$html = file_get_contents($url);
//如果出现中文乱码使用下面代码
//$getcontent = iconv("gb2312", "utf-8",$html);
echo "".$html."";
PHP教程代码很简单,一看就懂,不用解释。
PHP教程方法二:
PHP教程使用curl实现
PHP教程
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
echo "".$html."";
PHP教程
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
PHP教程添加这段代码表示如果请求被重定向,则可以访问最终的请求页面,否则请求的结果将显示如下:
PHP教程
Object moved
Object MovedThis object may be found here.
如果您对PHP教程有任何疑问,请留言或到本站社区交流讨论。感谢您的阅读。我希望它可以帮助大家。感谢您对本站的支持!
php 抓取网页内容(什么是搜索引擎蜘蛛?搜索引擎是如何通过蜘蛛对网站进行收录和排名的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-21 04:05
我们都知道网络推广的最终目的是带来流量、排名和订单,所以最关键的前提是搜索引擎能做好你的网站和文章收录 . 然而,当面对收录的效果不佳时,很多小伙伴不知道为什么,很大程度上是因为他们不了解一个关键点——搜索引擎蜘蛛。蜘蛛
一、什么是搜索引擎蜘蛛?
搜索引擎 收录 和 网站 是如何通过爬虫来排名的?我们怎样才能提高蜘蛛爬行的效果呢?
的确,用白话理解,互联网可以理解为一个巨大的“蜘蛛网”,搜索引擎蜘蛛类似于实际的“机器人”。
蜘蛛的主要任务是浏览庞大的蜘蛛网(Internet)中的信息,然后将信息抓取到搜索引擎的服务器上,建立索引库。这就像一个机器人浏览我们的 网站 并将内容保存到它自己的计算机上。
每个独立的搜索引擎都会有自己的网络爬虫爬虫。蜘蛛爬虫跟随网页中的超链接分析,不断访问和爬取更多的网页。抓取的网页称为网页快照。不用说,搜索引擎蜘蛛会定期抓取网页。
如下:
1.权重优先是指先链接权重,然后结合深度优先和广度优先策略进行抓取。例如,如果链接的权重还不错,则先使用深度;如果重量非常低,请先使用宽度。
2.蜘蛛深度爬取是指蜘蛛找到要爬取的链接,一直往前走,直到最深的层次不能再爬取,然后回到原来的爬取页面,再爬取下一个链接的过程. 就像从网站的首页爬到网站的第一个栏目页,然后通过栏目页爬取一个内容页,然后跳出首页,再爬到第二个网站.
3.蜘蛛广度爬取是指蜘蛛爬取一个页面时存在多个链接,而不是一个链接的深度爬取。然后爬取所有栏目页下的二级栏目或内容页,也就是逐层爬取的方式,而不是一层一层的爬取方式。
4.可以从字面上理解。因为搜索引擎主要使用单次重访和完整重访。所以我们在做网站内容的时候,一定要记得定期维护每日更新,这样蜘蛛才能更快的访问和爬取更多的收录。蜘蛛
二、搜索引擎蜘蛛如何爬取,如何吸引蜘蛛爬取页面
搜索引擎的工作过程大致可以分为三个阶段:
(1)爬取和爬取:搜索引擎蜘蛛通过跟踪链接发现和访问页面,读取页面的HTML代码,并将其存储在数据库中。
(2)预处理:索引程序对抓取到的页面数据进行文本提取、中文分词、索引、倒排索引,供排名程序调用。
(3)排名:用户输入查询词(关键词)后,排名程序调用索引数据,计算相关度,然后生成一定格式的搜索结果页面。
搜索引擎如何工作 爬取和爬取是搜索引擎完成数据采集任务的第一步。搜索引擎用来抓取页面的程序称为蜘蛛
一个合格的SEOer,如果他想让他的更多页面成为收录,他必须设法吸引蜘蛛爬行。
蜘蛛抓取页面有几个因素:
(1)网站和页面的权重,质量高、时间长的网站一般认为权重高,爬取深度高。会更多。
(2)页面的更新频率,蜘蛛每次爬取都会存储页面数据。如果第二次和第三次爬取和第一次一样,说明没有更新。随着时间的推移,蜘蛛不会频繁爬取你的页面,如果内容更新频繁,蜘蛛会频繁访问该页面以爬取新页面。
(3)传入链接,无论是内部链接还是外部链接,为了被蜘蛛抓取,必须有一个入站链接才能进入该页面,否则蜘蛛将不知道该页面的存在。
(4)到首页的点击距离,一般网站上权重最高的就是首页,大部分外链都会指向首页,所以访问频率最高的页面是spiders是首页,点击距离越近,页面权限越高,被爬取的几率越大。
吸引百度蜘蛛 如何吸引蜘蛛爬我们的页面?
坚持经常更新网站内容,最好是高质量的原创内容。
主动将我们的新页面提供给搜索引擎,让蜘蛛更快找到,比如百度的链接提交、爬取诊断等。
搭建外部链接,可以和相关网站交换链接,可以去其他平台发布指向自己的优质文章页面,内容要相关。
制作网站maps,每个网站应该有一个sitemap,网站所有页面都在sitemap中,方便蜘蛛抓取。
三、搜索引擎蜘蛛SPIDER爬不起来的原因分析
1.服务器连接异常
服务器连接异常有两种情况:一种是网站不稳定,百度蜘蛛在尝试连接你的网站服务器时暂时无法连接;另一个是百度蜘蛛一直无法连接到你的网站服务器。
服务器连接异常的原因通常是你的网站服务器太大,过载。您的 网站 也可能运行不正常。请检查网站的web服务器(如apache、iis)是否安装并运行正常,并使用浏览器检查主页是否可以正常访问。您的网站 和主机也可能阻止了百度蜘蛛的访问,您需要检查您的网站 和主机的防火墙。
2.网络运营商异常
网络运营商有两种:中国电信和中国联通。百度蜘蛛无法通过中国电信或中国网通访问您的网站。如果出现这种情况,需要联系网络服务运营商,或者购买双线服务空间或者购买cdn服务。
3.DNS 异常
当百度蜘蛛无法解析您的 网站 IP 时,会出现 DNS 异常。可能你的网站IP地址不对,或者域名服务商封杀了百度蜘蛛。请使用 WHOIS 或主机检查您的 网站IP 地址是否正确且可解析。如果不正确或无法解决,请联系域名注册商更新您的 IP 地址。
4.IP 阻塞
IP禁令是:限制网络的出口IP地址,禁止该IP段的用户访问内容,这里专门禁止百度spiderIP。仅当您的网站 不希望百度蜘蛛访问时才需要此设置。如果您想让百度蜘蛛访问您的网站,请检查相关设置中是否误添加了百度蜘蛛IP。也有可能是你网站所在的空间服务商封杀了百度IP。在这种情况下,您需要联系服务提供商更改设置。
5.UA 被禁止
UA即User-Agent,服务器通过UA识别访问者。当网站返回异常页面(如402、500)或跳转到其他页面进行指定UA的访问时,属于UA封禁。当你的网站不想百度时这个设置只有蜘蛛访问需要,如果你想让百度蜘蛛访问你的网站,请检查useragent相关设置中是否有百度蜘蛛UA,并及时修改。
6.死链接
已经无效且无法为用户提供任何有价值信息的页面为死链接,包括协议死链接和内容死链接两种形式。协议死链接,通过页面的TCP协议状态/HTTP协议状态明确表示的死链接,如404、402、502状态等;内容死链接,服务器返回状态正常,但内容已更改为不存在、已删除或需要权限等与原创内容无关的信息页面。
对于死链接,我们建议网站使用协议死链接,通过百度站长平台-死链接工具提交给百度,这样百度可以更快的找到死链接,减少死链接对用户和搜索引擎的负面影响。
7.异常跳转
将网络请求重定向到另一个位置是跳转,异常跳转是指以下几种情况。
1.当前页面为无效页面(内容已被删除、死链接等),直接跳转到上一个目录或首页。百度建议站长删除无效页面的入口超链接。
2.跳转到错误或无效页面。
Tips:对于长时间跳转到其他域名的情况,如网站换域名,百度推荐使用201跳转协议进行设置。
8.其他异常
1.百度referrer异常:网页返回的行为与来自百度的referrer的正常内容不同。
2.百度UA异常:网页返回百度UA的行为与页面原创内容不同。
3.JS跳转异常:网页加载了百度无法识别的JS跳转代码,导致用户通过搜索结果进入页面后跳转。
4.压力过大导致的意外封禁:百度会根据网站规模、流量等信息自动设置合理的抓取压力。但在异常情况下,如压力控制异常时,服务器会根据自身负载进行保护性的偶尔封禁。在这种情况下,请在返回码中返回 502(表示“服务不可用”),这样百度蜘蛛会在一段时间后再次尝试抓取链接。如果 网站 是空闲的,它会被成功抓到 Pick。蜘蛛
四、使用蜘蛛池尽快让新的网站成为收录
根据多年搜索引擎营销推广的工作经验,当一个新网站接入搜索引擎时,就会进入沙盒期。一些新网站能够迅速被搜索引擎所利用,关键是能够在短时间内走出沙盒期。收录以下元素:
1、技术装备
我们知道搜索引擎的收录越来越方便快捷,一般人必须把网站标准化为SEO。从技术角度来看,您必须:
① 非常重视网页的客户体验,包括视觉效果和网页的加载率。
②创建站点地图,优先考虑网页,合理流式传输相关URL。
③ 配备百度熊掌ID,可以快速向百度搜索官方网站提交优质网址。
内容,对于新站来说,是必备的标准化设备。
使用蜘蛛池加速新的 网站收录
2、网页质量
对于搜索引擎收录,网页的质量是主要的评估标准。理论上,它是由几个层次组成的。对于这些收入比较快的新网站网站,除了做百度网址提交之外,还重点关注以下几个方面:
①时事
对于新站来说,如果想让搜索引擎收录越来越快,经过多年的具体测试,人们发现更容易快速收录制造业的热门新闻.
他的及时搜索关键词 量会很高,或相对平均,但这不是关键因素。
②主题内容
从专业和权威的角度,设置一个网站内部的小专题讲座,可以最大程度的和某个制造业进行讨论,最重要的是相关的内容,一般是多水平有机化学成分。
例如:来自KOL的意见、多年制造业组织权威专家的总结、其社会发展科研团队对相关数据和信息的应用等。
③内容多样化
对于网页的多样化,通常由多媒体系统元素组成,比如:小视频、数据图表、高清图片等,这些都是视频的介入,显得很重要。
使用蜘蛛池加速新的 网站收录
3、外部资源
对于搜索引擎收录来说,这里人们所指的外部资源一般是指外部链接。如果你发现一个新网站在早期发布,它的收录和排名会迅速上升,甚至是垂直、折线类型的指数值图,那么关键元素就是外部链接。
这不一定是基于高质量的反向链接,在某些情况下也是基于总数,人们普遍建议选择前一种。蜘蛛
4、站群排水方式
站群,即一个人或一个群体实际上操作了几个URL,目的是为了根据搜索引擎获得大量的总流量,或者偏向同一个URL的连接以提高自然排名。从2005年到2012年,一些中国SEO人员明确提出了站群的定义:几个单独的网站域名(包括二级域名)之间的统一管理方式和关系。2008年初,站群软件开发者开发设计了一种更实用的URL采集方式,即根据关键字进行网站内容的自动采集。以前的采集方法是写标准方法。
5、蜘蛛池排水法
蜘蛛池是由网站 域名组成的一堆站群。在每一个网站下,都转换成大量的网页(一堆文字内容相互组成),页面设计和一切正常网页没有太大区别。因为每个网站都有大量的网页,搜索引擎蜘蛛爬取所有站群的总量也是巨大的。将搜索引擎蜘蛛引入非收录的网页,就是在站群所有普通网页的模板中打开一个单独的DIV。插件外没有收录网页连接,而且web服务器也没有设置缓存文件,每次搜索引擎蜘蛛浏览,DIV中呈现的这方面的连接都是不同的。简而言之, 查看全部
php 抓取网页内容(什么是搜索引擎蜘蛛?搜索引擎是如何通过蜘蛛对网站进行收录和排名的)
我们都知道网络推广的最终目的是带来流量、排名和订单,所以最关键的前提是搜索引擎能做好你的网站和文章收录 . 然而,当面对收录的效果不佳时,很多小伙伴不知道为什么,很大程度上是因为他们不了解一个关键点——搜索引擎蜘蛛。蜘蛛
一、什么是搜索引擎蜘蛛?
搜索引擎 收录 和 网站 是如何通过爬虫来排名的?我们怎样才能提高蜘蛛爬行的效果呢?
的确,用白话理解,互联网可以理解为一个巨大的“蜘蛛网”,搜索引擎蜘蛛类似于实际的“机器人”。
蜘蛛的主要任务是浏览庞大的蜘蛛网(Internet)中的信息,然后将信息抓取到搜索引擎的服务器上,建立索引库。这就像一个机器人浏览我们的 网站 并将内容保存到它自己的计算机上。
每个独立的搜索引擎都会有自己的网络爬虫爬虫。蜘蛛爬虫跟随网页中的超链接分析,不断访问和爬取更多的网页。抓取的网页称为网页快照。不用说,搜索引擎蜘蛛会定期抓取网页。
如下:
1.权重优先是指先链接权重,然后结合深度优先和广度优先策略进行抓取。例如,如果链接的权重还不错,则先使用深度;如果重量非常低,请先使用宽度。
2.蜘蛛深度爬取是指蜘蛛找到要爬取的链接,一直往前走,直到最深的层次不能再爬取,然后回到原来的爬取页面,再爬取下一个链接的过程. 就像从网站的首页爬到网站的第一个栏目页,然后通过栏目页爬取一个内容页,然后跳出首页,再爬到第二个网站.
3.蜘蛛广度爬取是指蜘蛛爬取一个页面时存在多个链接,而不是一个链接的深度爬取。然后爬取所有栏目页下的二级栏目或内容页,也就是逐层爬取的方式,而不是一层一层的爬取方式。
4.可以从字面上理解。因为搜索引擎主要使用单次重访和完整重访。所以我们在做网站内容的时候,一定要记得定期维护每日更新,这样蜘蛛才能更快的访问和爬取更多的收录。蜘蛛
二、搜索引擎蜘蛛如何爬取,如何吸引蜘蛛爬取页面
搜索引擎的工作过程大致可以分为三个阶段:
(1)爬取和爬取:搜索引擎蜘蛛通过跟踪链接发现和访问页面,读取页面的HTML代码,并将其存储在数据库中。
(2)预处理:索引程序对抓取到的页面数据进行文本提取、中文分词、索引、倒排索引,供排名程序调用。
(3)排名:用户输入查询词(关键词)后,排名程序调用索引数据,计算相关度,然后生成一定格式的搜索结果页面。
搜索引擎如何工作 爬取和爬取是搜索引擎完成数据采集任务的第一步。搜索引擎用来抓取页面的程序称为蜘蛛
一个合格的SEOer,如果他想让他的更多页面成为收录,他必须设法吸引蜘蛛爬行。
蜘蛛抓取页面有几个因素:
(1)网站和页面的权重,质量高、时间长的网站一般认为权重高,爬取深度高。会更多。
(2)页面的更新频率,蜘蛛每次爬取都会存储页面数据。如果第二次和第三次爬取和第一次一样,说明没有更新。随着时间的推移,蜘蛛不会频繁爬取你的页面,如果内容更新频繁,蜘蛛会频繁访问该页面以爬取新页面。
(3)传入链接,无论是内部链接还是外部链接,为了被蜘蛛抓取,必须有一个入站链接才能进入该页面,否则蜘蛛将不知道该页面的存在。
(4)到首页的点击距离,一般网站上权重最高的就是首页,大部分外链都会指向首页,所以访问频率最高的页面是spiders是首页,点击距离越近,页面权限越高,被爬取的几率越大。
吸引百度蜘蛛 如何吸引蜘蛛爬我们的页面?
坚持经常更新网站内容,最好是高质量的原创内容。
主动将我们的新页面提供给搜索引擎,让蜘蛛更快找到,比如百度的链接提交、爬取诊断等。
搭建外部链接,可以和相关网站交换链接,可以去其他平台发布指向自己的优质文章页面,内容要相关。
制作网站maps,每个网站应该有一个sitemap,网站所有页面都在sitemap中,方便蜘蛛抓取。
三、搜索引擎蜘蛛SPIDER爬不起来的原因分析
1.服务器连接异常
服务器连接异常有两种情况:一种是网站不稳定,百度蜘蛛在尝试连接你的网站服务器时暂时无法连接;另一个是百度蜘蛛一直无法连接到你的网站服务器。
服务器连接异常的原因通常是你的网站服务器太大,过载。您的 网站 也可能运行不正常。请检查网站的web服务器(如apache、iis)是否安装并运行正常,并使用浏览器检查主页是否可以正常访问。您的网站 和主机也可能阻止了百度蜘蛛的访问,您需要检查您的网站 和主机的防火墙。
2.网络运营商异常
网络运营商有两种:中国电信和中国联通。百度蜘蛛无法通过中国电信或中国网通访问您的网站。如果出现这种情况,需要联系网络服务运营商,或者购买双线服务空间或者购买cdn服务。
3.DNS 异常
当百度蜘蛛无法解析您的 网站 IP 时,会出现 DNS 异常。可能你的网站IP地址不对,或者域名服务商封杀了百度蜘蛛。请使用 WHOIS 或主机检查您的 网站IP 地址是否正确且可解析。如果不正确或无法解决,请联系域名注册商更新您的 IP 地址。
4.IP 阻塞
IP禁令是:限制网络的出口IP地址,禁止该IP段的用户访问内容,这里专门禁止百度spiderIP。仅当您的网站 不希望百度蜘蛛访问时才需要此设置。如果您想让百度蜘蛛访问您的网站,请检查相关设置中是否误添加了百度蜘蛛IP。也有可能是你网站所在的空间服务商封杀了百度IP。在这种情况下,您需要联系服务提供商更改设置。
5.UA 被禁止
UA即User-Agent,服务器通过UA识别访问者。当网站返回异常页面(如402、500)或跳转到其他页面进行指定UA的访问时,属于UA封禁。当你的网站不想百度时这个设置只有蜘蛛访问需要,如果你想让百度蜘蛛访问你的网站,请检查useragent相关设置中是否有百度蜘蛛UA,并及时修改。
6.死链接
已经无效且无法为用户提供任何有价值信息的页面为死链接,包括协议死链接和内容死链接两种形式。协议死链接,通过页面的TCP协议状态/HTTP协议状态明确表示的死链接,如404、402、502状态等;内容死链接,服务器返回状态正常,但内容已更改为不存在、已删除或需要权限等与原创内容无关的信息页面。
对于死链接,我们建议网站使用协议死链接,通过百度站长平台-死链接工具提交给百度,这样百度可以更快的找到死链接,减少死链接对用户和搜索引擎的负面影响。
7.异常跳转
将网络请求重定向到另一个位置是跳转,异常跳转是指以下几种情况。
1.当前页面为无效页面(内容已被删除、死链接等),直接跳转到上一个目录或首页。百度建议站长删除无效页面的入口超链接。
2.跳转到错误或无效页面。
Tips:对于长时间跳转到其他域名的情况,如网站换域名,百度推荐使用201跳转协议进行设置。
8.其他异常
1.百度referrer异常:网页返回的行为与来自百度的referrer的正常内容不同。
2.百度UA异常:网页返回百度UA的行为与页面原创内容不同。
3.JS跳转异常:网页加载了百度无法识别的JS跳转代码,导致用户通过搜索结果进入页面后跳转。
4.压力过大导致的意外封禁:百度会根据网站规模、流量等信息自动设置合理的抓取压力。但在异常情况下,如压力控制异常时,服务器会根据自身负载进行保护性的偶尔封禁。在这种情况下,请在返回码中返回 502(表示“服务不可用”),这样百度蜘蛛会在一段时间后再次尝试抓取链接。如果 网站 是空闲的,它会被成功抓到 Pick。蜘蛛
四、使用蜘蛛池尽快让新的网站成为收录
根据多年搜索引擎营销推广的工作经验,当一个新网站接入搜索引擎时,就会进入沙盒期。一些新网站能够迅速被搜索引擎所利用,关键是能够在短时间内走出沙盒期。收录以下元素:
1、技术装备
我们知道搜索引擎的收录越来越方便快捷,一般人必须把网站标准化为SEO。从技术角度来看,您必须:
① 非常重视网页的客户体验,包括视觉效果和网页的加载率。
②创建站点地图,优先考虑网页,合理流式传输相关URL。
③ 配备百度熊掌ID,可以快速向百度搜索官方网站提交优质网址。
内容,对于新站来说,是必备的标准化设备。
使用蜘蛛池加速新的 网站收录
2、网页质量
对于搜索引擎收录,网页的质量是主要的评估标准。理论上,它是由几个层次组成的。对于这些收入比较快的新网站网站,除了做百度网址提交之外,还重点关注以下几个方面:
①时事
对于新站来说,如果想让搜索引擎收录越来越快,经过多年的具体测试,人们发现更容易快速收录制造业的热门新闻.
他的及时搜索关键词 量会很高,或相对平均,但这不是关键因素。
②主题内容
从专业和权威的角度,设置一个网站内部的小专题讲座,可以最大程度的和某个制造业进行讨论,最重要的是相关的内容,一般是多水平有机化学成分。
例如:来自KOL的意见、多年制造业组织权威专家的总结、其社会发展科研团队对相关数据和信息的应用等。
③内容多样化
对于网页的多样化,通常由多媒体系统元素组成,比如:小视频、数据图表、高清图片等,这些都是视频的介入,显得很重要。
使用蜘蛛池加速新的 网站收录
3、外部资源
对于搜索引擎收录来说,这里人们所指的外部资源一般是指外部链接。如果你发现一个新网站在早期发布,它的收录和排名会迅速上升,甚至是垂直、折线类型的指数值图,那么关键元素就是外部链接。
这不一定是基于高质量的反向链接,在某些情况下也是基于总数,人们普遍建议选择前一种。蜘蛛
4、站群排水方式
站群,即一个人或一个群体实际上操作了几个URL,目的是为了根据搜索引擎获得大量的总流量,或者偏向同一个URL的连接以提高自然排名。从2005年到2012年,一些中国SEO人员明确提出了站群的定义:几个单独的网站域名(包括二级域名)之间的统一管理方式和关系。2008年初,站群软件开发者开发设计了一种更实用的URL采集方式,即根据关键字进行网站内容的自动采集。以前的采集方法是写标准方法。
5、蜘蛛池排水法
蜘蛛池是由网站 域名组成的一堆站群。在每一个网站下,都转换成大量的网页(一堆文字内容相互组成),页面设计和一切正常网页没有太大区别。因为每个网站都有大量的网页,搜索引擎蜘蛛爬取所有站群的总量也是巨大的。将搜索引擎蜘蛛引入非收录的网页,就是在站群所有普通网页的模板中打开一个单独的DIV。插件外没有收录网页连接,而且web服务器也没有设置缓存文件,每次搜索引擎蜘蛛浏览,DIV中呈现的这方面的连接都是不同的。简而言之,
php 抓取网页内容(什么是自动推送工具?百度站长平台提供了四种方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-20 10:29
在网站操作或基于SEO的内容更新需求中,发布文章时,可以选择
将文章的链接推送到百度搜索引擎
, 以便
增强网页的机会 收录
. 就好像百度是公主,而你是丫鬟,你要主动伺候公主吃饭,也许公主可能不喜欢吃你做的饭菜,但偶尔会动筷子。至少比等百度蜘蛛爬你的网页要好,那什么年什么月呢?
如何选择链接提交方式,百度站长平台提供了四种方式。
1、主动推送:最快的提交方式。建议您立即通过此方式将本站新链接推送至百度,以确保新链接能够被百度收录及时发布。
2、自动推送:最方便的提交方式,请在本站每个页面的源码中部署自动推送的JS代码,每次部署代码的页面都会自动推送链接到百度被浏览。可以与主动推送一起使用。
3、sitemap:可以定期将网站链接放入sitemap,然后将sitemap提交给百度。百度会定期爬取检查你提交的站点地图,并处理里面的链接,但是收录速度比主动推送慢。
4、手动提交:一次性提交链接到百度,可以使用这种方式。
以上四种方式可以根据网站的运行情况进行选择。以收录的速度来说,主动推送最好,自动推送次之,但主动推送需要编程,难度较大。现在让我们专注于自动推送。
什么是自动推送工具?自动推送工具解决了什么问题?自动推送JS代码是百度站长平台最新推出的轻量级链接提交组件。站长只需要将自动推送的JS代码放置在网站各个页面的源码中即可。当页面被访问时,会自动推送页面链接。对百度来说,这将有助于百度更快地发现新页面。
为了更快速地发现网站每天产生的最新内容,百度站长平台推出了主动推送工具。产品上线后,有站长反映使用主动推送的技术门槛比较高,所以我们顺势推出了成本更低的JS自动推送工具。一步安装可实现页面自动推送,成本低,利润高。
自动推送最适合 优采云。
自动推送JS代码的安装与统计代码的安装相同。只要你知道如何安装流量统计代码,自动推送JS代码就会被安装。
自动推送代码的安装和原理介绍如下(可以注册登录百度站长平台查看)。
如何安装和使用自动推送代码?来自百度站长平台
站长需要在每个页面的 HTML 代码中收录以下自动推送 JS 代码:
如果站长使用PHP语言开发的网站,可以按照以下步骤操作:
1、创建一个名为“baidu_js_push.php”的文件,文件内容为上述自动推送JS代码;
2、在每个 PHP 模板页面文件的标记后添加一行代码:
注1:以上代码是通用的。在华哥的实践中,这段代码一开始就放在后面,也就是网页头部的源码位置,一直运行正常。后来有一段时间优化网站的速度,把这段代码放在最下面,同时压缩网页源代码,导致自动推送功能失效,应该注意的。如果发现自动推送代码失败,请检查安装位置。
注2:自动推送不是完全自动的。发布文章后,需要点击浏览新发布的文章,触发文章源码中的JS代码。实现链接自动提交和推送功能(大流量的网站不需要,因为用户会帮你点击)。
如果百度自动推码功能生效,登录站长平台,可以看到类似下图的数据图表。
(文小云华可以浏览更多SEO类文章个人网站:) 查看全部
php 抓取网页内容(什么是自动推送工具?百度站长平台提供了四种方式)
在网站操作或基于SEO的内容更新需求中,发布文章时,可以选择
将文章的链接推送到百度搜索引擎
, 以便
增强网页的机会 收录
. 就好像百度是公主,而你是丫鬟,你要主动伺候公主吃饭,也许公主可能不喜欢吃你做的饭菜,但偶尔会动筷子。至少比等百度蜘蛛爬你的网页要好,那什么年什么月呢?
如何选择链接提交方式,百度站长平台提供了四种方式。
1、主动推送:最快的提交方式。建议您立即通过此方式将本站新链接推送至百度,以确保新链接能够被百度收录及时发布。
2、自动推送:最方便的提交方式,请在本站每个页面的源码中部署自动推送的JS代码,每次部署代码的页面都会自动推送链接到百度被浏览。可以与主动推送一起使用。
3、sitemap:可以定期将网站链接放入sitemap,然后将sitemap提交给百度。百度会定期爬取检查你提交的站点地图,并处理里面的链接,但是收录速度比主动推送慢。
4、手动提交:一次性提交链接到百度,可以使用这种方式。
以上四种方式可以根据网站的运行情况进行选择。以收录的速度来说,主动推送最好,自动推送次之,但主动推送需要编程,难度较大。现在让我们专注于自动推送。
什么是自动推送工具?自动推送工具解决了什么问题?自动推送JS代码是百度站长平台最新推出的轻量级链接提交组件。站长只需要将自动推送的JS代码放置在网站各个页面的源码中即可。当页面被访问时,会自动推送页面链接。对百度来说,这将有助于百度更快地发现新页面。
为了更快速地发现网站每天产生的最新内容,百度站长平台推出了主动推送工具。产品上线后,有站长反映使用主动推送的技术门槛比较高,所以我们顺势推出了成本更低的JS自动推送工具。一步安装可实现页面自动推送,成本低,利润高。
自动推送最适合 优采云。
自动推送JS代码的安装与统计代码的安装相同。只要你知道如何安装流量统计代码,自动推送JS代码就会被安装。
自动推送代码的安装和原理介绍如下(可以注册登录百度站长平台查看)。
如何安装和使用自动推送代码?来自百度站长平台
站长需要在每个页面的 HTML 代码中收录以下自动推送 JS 代码:
如果站长使用PHP语言开发的网站,可以按照以下步骤操作:
1、创建一个名为“baidu_js_push.php”的文件,文件内容为上述自动推送JS代码;
2、在每个 PHP 模板页面文件的标记后添加一行代码:
注1:以上代码是通用的。在华哥的实践中,这段代码一开始就放在后面,也就是网页头部的源码位置,一直运行正常。后来有一段时间优化网站的速度,把这段代码放在最下面,同时压缩网页源代码,导致自动推送功能失效,应该注意的。如果发现自动推送代码失败,请检查安装位置。
注2:自动推送不是完全自动的。发布文章后,需要点击浏览新发布的文章,触发文章源码中的JS代码。实现链接自动提交和推送功能(大流量的网站不需要,因为用户会帮你点击)。
如果百度自动推码功能生效,登录站长平台,可以看到类似下图的数据图表。
(文小云华可以浏览更多SEO类文章个人网站:)
php 抓取网页内容(php抓取网页内容用于数据库传给服务器进行分析和计算)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-18 12:03
php抓取网页内容用于数据库,传给服务器进行分析和计算,服务器返回对应的响应,传到用户界面。不知道你的需求是什么样的?如果只是解析网页并存储到数据库,那用php比较简单的方法有xmlhttprequest、extracturl,如果要抓取页面中的json格式数据,就要用正则等工具。
php抓网页用xmlhttprequest或extracturl,要进行正则匹配什么的肯定要一些编程水平。除了这些,还有json对象、xmlwriter可以抓取。
针对网页的抓取处理需要掌握xml、json、html5、php、laravel等一系列前端框架,以及前端的一些编程水平,就算是只抓取json都不行。
个人认为php抓取网页是可行的,网页太多了,像豆瓣、天涯论坛等都有自己的网页地址,你只要爬取出来网页内容,再用数据库来存储就可以了,至于json和正则这些就交给专业的程序员吧。
php解析json就可以了。
php抓取网页是可行的,目前大多数程序都是解析xml或json格式的网页数据,然后再将网页数据存储到数据库,如果单纯为了爬取网页数据而对php功底没有过多的要求的话,
php还不错啊,抓取些数据也不难。其实你可以看看知乎不是,大神也就是抓取下答案页面。
不,还需要解析出里面的dom结构。 查看全部
php 抓取网页内容(php抓取网页内容用于数据库传给服务器进行分析和计算)
php抓取网页内容用于数据库,传给服务器进行分析和计算,服务器返回对应的响应,传到用户界面。不知道你的需求是什么样的?如果只是解析网页并存储到数据库,那用php比较简单的方法有xmlhttprequest、extracturl,如果要抓取页面中的json格式数据,就要用正则等工具。
php抓网页用xmlhttprequest或extracturl,要进行正则匹配什么的肯定要一些编程水平。除了这些,还有json对象、xmlwriter可以抓取。
针对网页的抓取处理需要掌握xml、json、html5、php、laravel等一系列前端框架,以及前端的一些编程水平,就算是只抓取json都不行。
个人认为php抓取网页是可行的,网页太多了,像豆瓣、天涯论坛等都有自己的网页地址,你只要爬取出来网页内容,再用数据库来存储就可以了,至于json和正则这些就交给专业的程序员吧。
php解析json就可以了。
php抓取网页是可行的,目前大多数程序都是解析xml或json格式的网页数据,然后再将网页数据存储到数据库,如果单纯为了爬取网页数据而对php功底没有过多的要求的话,
php还不错啊,抓取些数据也不难。其实你可以看看知乎不是,大神也就是抓取下答案页面。
不,还需要解析出里面的dom结构。
php 抓取网页内容(php抓取网页内容的步骤:第一步,发起请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-08 09:03
php抓取网页内容的步骤:第一步,发起请求:发起post请求,先执行一次post函数,接着执行一次get函数发起get请求:在浏览器上执行请求,接着才执行post,再接着执行get()第二步,数据准备准备要抓取的网页内容,网上有很多抓取网页内容的教程,可以根据不同网站的要求加入不同的元素和循环语句,有兴趣可以看看,了解下以下流程第三步,显示内容1,将抓取好的内容保存到本地2,分析网页数据,提取出关键信息和关键字段3,最后再处理下数据保存就可以了。
首先要思考这个网站需要抓取什么数据,然后找到合适的web服务(百度),使用正则表达式匹配关键字句,然后提取数据,
php的话其实也可以用正则表达式写简单脚本
据了解nodejs实现抓取比较简单,其实用起来会很复杂。现在很多中小型的企业用户,还是用java比较多,就是因为java的易学易用,而且java已经非常成熟,学起来也比较简单。
上看看有没有你需要的数据,然后集合到自己的产品,
需要有搜索引擎
有可以实现抓取网页的程序。自己开发的话,
最简单的:抓取,然后存起来变成csv,用excel整理,就是表格式。
直接用c语言的话实现方法也有很多种,但总的来说思路都是大同小异,抓包:到页面爬取到这页面的response可以查看下对应的具体处理的函数。网页解析:所谓的网页解析在我看来就是从一个页面的一句话描述从一句话中找出它在该页面对应的具体数据。存储:最简单的就是直接用数据库存储数据。当然还有其他更好的更普遍的方式。 查看全部
php 抓取网页内容(php抓取网页内容的步骤:第一步,发起请求)
php抓取网页内容的步骤:第一步,发起请求:发起post请求,先执行一次post函数,接着执行一次get函数发起get请求:在浏览器上执行请求,接着才执行post,再接着执行get()第二步,数据准备准备要抓取的网页内容,网上有很多抓取网页内容的教程,可以根据不同网站的要求加入不同的元素和循环语句,有兴趣可以看看,了解下以下流程第三步,显示内容1,将抓取好的内容保存到本地2,分析网页数据,提取出关键信息和关键字段3,最后再处理下数据保存就可以了。
首先要思考这个网站需要抓取什么数据,然后找到合适的web服务(百度),使用正则表达式匹配关键字句,然后提取数据,
php的话其实也可以用正则表达式写简单脚本
据了解nodejs实现抓取比较简单,其实用起来会很复杂。现在很多中小型的企业用户,还是用java比较多,就是因为java的易学易用,而且java已经非常成熟,学起来也比较简单。
上看看有没有你需要的数据,然后集合到自己的产品,
需要有搜索引擎
有可以实现抓取网页的程序。自己开发的话,
最简单的:抓取,然后存起来变成csv,用excel整理,就是表格式。
直接用c语言的话实现方法也有很多种,但总的来说思路都是大同小异,抓包:到页面爬取到这页面的response可以查看下对应的具体处理的函数。网页解析:所谓的网页解析在我看来就是从一个页面的一句话描述从一句话中找出它在该页面对应的具体数据。存储:最简单的就是直接用数据库存储数据。当然还有其他更好的更普遍的方式。
php 抓取网页内容(一点python介绍如何编写一个网络爬虫数据数据采集(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-02-05 23:05
)
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本期文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
查看全部
php 抓取网页内容(一点python介绍如何编写一个网络爬虫数据数据采集(图)
)
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本期文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:

提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。

连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。


php 抓取网页内容(php抓取网页内容实现php的formdata数据收集(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-14 07:03
php抓取网页内容实现php的formdata数据收集。php抓取网页内容实现-qthingsq目录和之前的一样,现在保存的是php到gybase数据库。抓取一个大网站的时候,一般保存500条数据,300条数据是尝试抓取。为了抓取速度,使用copy生成代码行数(master分离爬虫的时候)。下面写代码完成抓取抓取网页结构url://链接sum=-normalize(main_set_to_map=function(){show_error('specifiedsetoftransaction.connection')});usesqlite3;selectmap_id,sum,'show_map_error'fromcomponents;show_error('specifiedsetoftransaction.connection');参数:map_id,是要抓取网页唯一标识,位于string.join中保存的地址保存gybase数据库指向对应的gybase文件type,这个大家应该都知道是做什么,不知道的直接看root注释哦license,写入数据库数据库名称及urlsqlite3对应的map_id即爬虫公共的license参数:mysqlinnodbfull_time第一个参数:mysqlinnodb,兼容内存分页(user/password),默认是内存分页(name,page)不是内存分页(class,page)。
默认是100。第二个参数:mysqlfull_time,网页分页(user/password),默认是内存分页(name,page)不是内存分页(class,page)。默认是100。通过登录用户名来判断爬虫是不是分页爬。第三个参数:execute_expires,保存爬虫日期expires=year?expires:month?":"current_field_name+(type+failed_when)默认是year的话,跳转到用户登录页current_field_name="page_name"其中current_field_name="page_name"是php爬虫的固定sql语句之一,字符串,里面写"column_name=$column_name<$field_name",mysql会统计所有用户的最佳浏览行为,如果没有最佳浏览行为,系统会忽略这条记录,重新登录。>>。 查看全部
php 抓取网页内容(php抓取网页内容实现php的formdata数据收集(组图))
php抓取网页内容实现php的formdata数据收集。php抓取网页内容实现-qthingsq目录和之前的一样,现在保存的是php到gybase数据库。抓取一个大网站的时候,一般保存500条数据,300条数据是尝试抓取。为了抓取速度,使用copy生成代码行数(master分离爬虫的时候)。下面写代码完成抓取抓取网页结构url://链接sum=-normalize(main_set_to_map=function(){show_error('specifiedsetoftransaction.connection')});usesqlite3;selectmap_id,sum,'show_map_error'fromcomponents;show_error('specifiedsetoftransaction.connection');参数:map_id,是要抓取网页唯一标识,位于string.join中保存的地址保存gybase数据库指向对应的gybase文件type,这个大家应该都知道是做什么,不知道的直接看root注释哦license,写入数据库数据库名称及urlsqlite3对应的map_id即爬虫公共的license参数:mysqlinnodbfull_time第一个参数:mysqlinnodb,兼容内存分页(user/password),默认是内存分页(name,page)不是内存分页(class,page)。
默认是100。第二个参数:mysqlfull_time,网页分页(user/password),默认是内存分页(name,page)不是内存分页(class,page)。默认是100。通过登录用户名来判断爬虫是不是分页爬。第三个参数:execute_expires,保存爬虫日期expires=year?expires:month?":"current_field_name+(type+failed_when)默认是year的话,跳转到用户登录页current_field_name="page_name"其中current_field_name="page_name"是php爬虫的固定sql语句之一,字符串,里面写"column_name=$column_name<$field_name",mysql会统计所有用户的最佳浏览行为,如果没有最佳浏览行为,系统会忽略这条记录,重新登录。>>。
php 抓取网页内容(搜索引擎把网页抓取到本地(就是搜索引擎的服务器上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-11 11:33
为什么Spider会再次抓取并更新网页?原因是搜索引擎依赖于用户的存在。搜索引擎是否会被人们使用,取决于它是否提供了人们需要的内容。内容越准确及时,用户越多,市场份额越大。越大,它带来的回报就越多。(满足用户需求是搜索引擎公司赚钱的基础,当然也是所有公司赚钱的基础。)
Spider在本地(即在搜索引擎的服务器上)抓取网页后,对该网页进行分析、索引并参与搜索引擎的排名。这并不意味着蜘蛛的使命就完全完成了。因为互联网的内容随时都在变化。即使之前爬取的内容已经被网站的管理员或作者删除,当用户再次通过搜索引擎访问时,结果不正确或不匹配,这显然对搜索引擎来说不是很好的匹配. 不利。
搜索引擎爬取到的本地页面,基本上可以看作是被爬取索引的网页的镜像。也就是说,为了让用户看到最准确的内容,搜索引擎应该确保这个“镜像”页面与互联网上相应网页的内容实时一致。但是,由于互联网内容随时变化,Spider资源有限,实时监控所有索引网页的所有变化显然是不可能也没有必要的(因为有些内容是无关紧要的,用户不需要) . 但是,一些内容更新是必要的。因此,Spider 需要设计一个更新爬取策略,以确保当部分页面呈现给用户时,“镜像” 页面与当时网页的内容没有太大区别。也满足了大部分用户在搜索引擎上的搜索请求。
因此,从用户的角度来看,Spider 必须更加努力地更新和抓取那些已被索引并参与排名的网页。 查看全部
php 抓取网页内容(搜索引擎把网页抓取到本地(就是搜索引擎的服务器上))
为什么Spider会再次抓取并更新网页?原因是搜索引擎依赖于用户的存在。搜索引擎是否会被人们使用,取决于它是否提供了人们需要的内容。内容越准确及时,用户越多,市场份额越大。越大,它带来的回报就越多。(满足用户需求是搜索引擎公司赚钱的基础,当然也是所有公司赚钱的基础。)
Spider在本地(即在搜索引擎的服务器上)抓取网页后,对该网页进行分析、索引并参与搜索引擎的排名。这并不意味着蜘蛛的使命就完全完成了。因为互联网的内容随时都在变化。即使之前爬取的内容已经被网站的管理员或作者删除,当用户再次通过搜索引擎访问时,结果不正确或不匹配,这显然对搜索引擎来说不是很好的匹配. 不利。
搜索引擎爬取到的本地页面,基本上可以看作是被爬取索引的网页的镜像。也就是说,为了让用户看到最准确的内容,搜索引擎应该确保这个“镜像”页面与互联网上相应网页的内容实时一致。但是,由于互联网内容随时变化,Spider资源有限,实时监控所有索引网页的所有变化显然是不可能也没有必要的(因为有些内容是无关紧要的,用户不需要) . 但是,一些内容更新是必要的。因此,Spider 需要设计一个更新爬取策略,以确保当部分页面呈现给用户时,“镜像” 页面与当时网页的内容没有太大区别。也满足了大部分用户在搜索引擎上的搜索请求。
因此,从用户的角度来看,Spider 必须更加努力地更新和抓取那些已被索引并参与排名的网页。
php 抓取网页内容(php抓取网页内容获取需要1.javascript代码2.php代码分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-04-11 12:02
php抓取网页内容获取需要1.javascript代码2.php代码3.网页代码分析4.本地解析抓取代码一.使用php模拟登录,可以得到url,referer.referer只是一个javascript代码,这样等一切能够准备好就可以上传,上传成功就抓取了。
php爬虫建议先使用bootstrap,因为bootstrap可以调用自身的网页浏览器,自己比较好创建自己的页面,别人没法代理,你的页面如果不是很正规用bootstrap抓取失败几率会小,因为网站后台一般都是java,而php不支持java,
php封装request跟request.data,
requestprequestdata
我写了一篇教程:[教程]php爬虫教程汇总-phpwind
有个博客是这么做的:给爬虫建立一个连接,然后webdriver-request-post把html提交上去,php读取这个链接,再解析出一些东西。抓取我还是选择人家的代理代工吧,
参见request库中的-data-prerequest-from-url请求参数中加上data是因为如果请求的数据没有被提取出来的话,logofile中有错误信息。
php抓取网页是通过select等方法实现的
用命令行去php的网站下抓页面
我用浏览器爬不也可以了吗?只要不用php给网站发数据就可以啦,也可以用抓包软件,http的抓包软件很多,或者用内网穿透, 查看全部
php 抓取网页内容(php抓取网页内容获取需要1.javascript代码2.php代码分析)
php抓取网页内容获取需要1.javascript代码2.php代码3.网页代码分析4.本地解析抓取代码一.使用php模拟登录,可以得到url,referer.referer只是一个javascript代码,这样等一切能够准备好就可以上传,上传成功就抓取了。
php爬虫建议先使用bootstrap,因为bootstrap可以调用自身的网页浏览器,自己比较好创建自己的页面,别人没法代理,你的页面如果不是很正规用bootstrap抓取失败几率会小,因为网站后台一般都是java,而php不支持java,
php封装request跟request.data,
requestprequestdata
我写了一篇教程:[教程]php爬虫教程汇总-phpwind
有个博客是这么做的:给爬虫建立一个连接,然后webdriver-request-post把html提交上去,php读取这个链接,再解析出一些东西。抓取我还是选择人家的代理代工吧,
参见request库中的-data-prerequest-from-url请求参数中加上data是因为如果请求的数据没有被提取出来的话,logofile中有错误信息。
php抓取网页是通过select等方法实现的
用命令行去php的网站下抓页面
我用浏览器爬不也可以了吗?只要不用php给网站发数据就可以啦,也可以用抓包软件,http的抓包软件很多,或者用内网穿透,
php 抓取网页内容(www聚合模块怎么样真不知道php抓取网页内容是比较简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-04-06 20:04
php抓取网页内容是比较简单,因为完全可以用http抓包方法来抓取,但是swoole支持更多,抓取效率也大大高于http,因此大家都知道有http抓包方法是比较麻烦的,因此也会尝试使用swoole来抓取www网页,
phpphpd的groupproxy支持http代理抓取,200请求连接抓取比使用scrapy的curl等方法好用的多。你要抓取在线旅游类网站的话,使用cookieless和session相关组件也可以,更先进方案如使用swoole等。
php的完全可以直接抓取,好处是使用起来比较方便。但是php有个优点是,php服务不容易解析代理。所以网页下载php代理时,整个抓取系统比较慢,而scrapy却没有代理这个问题。
@黄侃的答案是扯淡,swoole介绍过也了解过,但是www聚合模块怎么样真不知道。用php抓取j2ee方面的页面是比较轻松的。j2ee肯定需要一个http请求代理,在搭建webcontroller的时候肯定也是需要一些代理的。我个人觉得抓取j2eeapi的页面应该可以抓住。至于说网页下载,那样还不如用grab(github),indexwebcontroller大家谈的太多了,方便易用绝对不会错。
针对web页面有个scrapy的官方组件j2eeconfiguration,
抓取网页和抓取模块都能找到,然后根据规则改beautifulsoup代理就可以抓取了, 查看全部
php 抓取网页内容(www聚合模块怎么样真不知道php抓取网页内容是比较简单)
php抓取网页内容是比较简单,因为完全可以用http抓包方法来抓取,但是swoole支持更多,抓取效率也大大高于http,因此大家都知道有http抓包方法是比较麻烦的,因此也会尝试使用swoole来抓取www网页,
phpphpd的groupproxy支持http代理抓取,200请求连接抓取比使用scrapy的curl等方法好用的多。你要抓取在线旅游类网站的话,使用cookieless和session相关组件也可以,更先进方案如使用swoole等。
php的完全可以直接抓取,好处是使用起来比较方便。但是php有个优点是,php服务不容易解析代理。所以网页下载php代理时,整个抓取系统比较慢,而scrapy却没有代理这个问题。
@黄侃的答案是扯淡,swoole介绍过也了解过,但是www聚合模块怎么样真不知道。用php抓取j2ee方面的页面是比较轻松的。j2ee肯定需要一个http请求代理,在搭建webcontroller的时候肯定也是需要一些代理的。我个人觉得抓取j2eeapi的页面应该可以抓住。至于说网页下载,那样还不如用grab(github),indexwebcontroller大家谈的太多了,方便易用绝对不会错。
针对web页面有个scrapy的官方组件j2eeconfiguration,
抓取网页和抓取模块都能找到,然后根据规则改beautifulsoup代理就可以抓取了,
php 抓取网页内容(robots.txt文件会被网站优化师SEOer忽视的原因 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-04-06 02:11
)
robots.txt 是任何 SEO 的重要组成部分,也是 SEOers 的重要一课。
但是,有时 网站optimizer SEOers 会忽略 robots.txt 文件。
无论您是刚刚起步,还是经验丰富的优化专家,您都需要知道应该如何编写 robots.txt 文件。
那么,我们先来了解一下:
robots.txt 文件是什么?
robots.txt 文件可用于多种用途。
示例包括让搜索引擎知道在哪里可以找到您的 网站 站点地图,告诉他们哪些页面不需要抓取,以及管理 网站 抓取预算。
搜索引擎会定期检查 网站 的 robots.txt 文件中是否有任何关于抓取 网站 的指令。我们称这些特殊指令为“命令”。
如果没有 robots.txt 文件或没有适用的指令,搜索引擎将抓取整个 网站。
好的,抓取预算是多少?
简要说明:
与其他搜索引擎一样,Google 可用于抓取和索引您的 网站 内容的资源有限。
如果您的 网站 只有几百个网址,Google 应该可以轻松抓取您的所有网页并将其编入索引。
但是,如果 网站 很大,例如电子商务网站,有数千个页面收录大量自动生成的页面(例如搜索页面),那么 Google 可能无法抓取所有其中,您将失去许多潜在的流量和知名度。
因此,我们将通过设置 robots.txt 文件来管理 网站 抓取预算。
谷歌说:
“拥有许多低价值 URL 会对 网站 的抓取和索引编制产生负面影响。”
那些低价值的 URL 就像搜索页面之类的页面。这些页面生成太多了,如果谷歌蜘蛛抓取的话,会消耗大量的抓取预算,以至于一些重要的页面可能不是收录。
使用 robots.txt 文件来帮助管理您的 网站 抓取预算并确保搜索引擎尽可能高效(尤其是大型 网站)抓取重要页面,而不是浪费时间抓取登录、注册或付款页面,等等。
为什么需要 robots.txt?
从 SEO 的角度来看,robots.txt 文件起着至关重要的作用。它告诉搜索引擎如何最好地抓取您的 网站。
使用 robots.txt 文件可以阻止搜索引擎访问 网站 的某些部分,防止重复内容,并为搜索引擎提供有关如何更有效地抓取 网站 的有用提示。
更改 robots.txt 时要小心:错误的设置可能会使搜索引擎无法访问 网站 的大部分内容。
在像 Googlebot、Bingbot 等机器人抓取网页之前,它首先会检查是否存在 robots.txt 文件,如果存在,它通常会遵循在该文件中找到的路径。
您可以通过 robots.txt 文件控制以下内容:
阻止访问 网站 的一部分(开发和登台环境等)
防止 网站 内部搜索结果页面被抓取、索引或显示在搜索结果中
指定站点地图或站点地图的位置
通过阻止对低价值页面(登录、支付页面、购物车等)的访问来优化抓取预算
防止对 网站 上的某些文件(图像、PDF 等)编制索引
让我们看一个例子来说明这一点:
您有一个电子商务网站,访问者可以使用过滤功能快速搜索您的产品,例如按销售额、价格排名。
此过滤器生成的页面基本上显示与其他页面相同的内容。
这对用户很有用,但会混淆搜索引擎,因为它会创建重复的内容。
如果搜索引擎将这些页面编入索引,就会浪费您宝贵的爬取资源。
因此,应设置规则,使搜索引擎不会访问这些页面。
检查您是否有 robots.txt 文件
如果您不熟悉 robots.txt 文件,或者不确定您的 网站 是否有它,请快速查看。
方法:
将 /robots.txt 添加到主页 URL 的末尾。
例子:
如果未显示任何内容,则您的站点没有 robots.txt 文件。然后应该设置一个。
如何创建 robots.txt 文件
创建 robots.txt 文件是一个相当简单的过程:
新建文本文档->重命名为robots.txt(所有文件必须小写)->编写规则->使用FTP上传文件(放在根目录下)到空间
以下文章为谷歌官方介绍,为大家展示robots.txt文件的创建过程,可以帮助您轻松创建自己的robots.txt文件:
注意:
robots.txt 本身就是一个文本文件。它必须在域名的根目录下并命名为“robots.txt”。位于子目录下的 robots.txt 文件无效,因为爬虫只在域名的根目录中查找该文件。
例如,是一个有效的位置,但不是。
如果您使用 WordPress 构建网站,您可以使用虚拟机器人、yoast、all in one seo 等插件创建和设置它。
Robots.txt 示例
下面是一些您可以在自己的 网站 上使用的 robots.txt 文件的示例。
允许所有爬虫/蜘蛛访问所有 网站 内容:
User-agent:*
Disallow:
阻止所有爬虫/蜘蛛访问所有 网站 内容:
User-agent:*
Disallow:/
在这里您可以看到在创建站点 robots.txt 时出错是多么容易,因为阻止整个站点被看到的区别是:禁止指令中的一个简单斜线 (Disallow:/)。
阻止谷歌爬虫/蜘蛛访问:
User-agent:Googlebot
Disallow:/
阻止爬虫/蜘蛛访问特定页面:
User-agent:
Disallow:/thankyou.html
从部分服务器中排除所有爬虫:
User-agent:*
Disallow:/ cgi-bin /
Disallow:/ tmp /
Disallow:/junk/
以下是 网站 上 robots.txt 文件的示例:
一、表示theverge不希望谷歌爬虫抓取这些目录的内容
二、表示theverge不希望任何爬虫爬取这些目录的内容
三、theverge 列出 robots.txt 中的所有站点地图
示例文件可以在这里查看:
了解 The Verge 如何使用他们的 robots.txt 文件专门使用 Google 的新闻蜘蛛“Googlebot-News”(第 1 点)以确保它不会在 网站 上抓取这些目录。
请务必记住,如果您想确保爬虫不会爬取 网站 上的某些页面或目录,您可以在 robots.txt 中的“Disallow”语句中调用这些页面和/或目录文件,如上例所示。
此外,请参阅 robots.txt 规范指南中的 Google 如何处理 robots.txt 文件,即 Google 当前对 robots.txt 文件的最大文件大小限制。
Google 的最大大小设置为 500KB,因此请务必注意 网站robots.txt 文件的大小。
robots.txt 文件的最佳做法
以下内容摘自谷歌官方介绍,原文:
位置规则和文件名
robots.txt 文件应始终放置在 root网站 位置(在主机的顶级目录中),文件名为 robots.txt,例如: .
请注意,robots.txt 文件的 URL 与任何其他 URL 一样区分大小写。
如果在默认位置找不到 robots.txt 文件,搜索引擎将假定没有指令。
语法
规则按从上到下的顺序处理,一个用户代理只能匹配一个规则集(即匹配相应用户代理的第一个最具体的规则)。
系统的默认假设是用户代理可以爬取所有不被 Disallow: 规则禁止的网页或目录。
规则区分大小写。例如,Disallow: /file.asp 有效但无效。
规则
例子
禁止抓取整个 网站。请注意,在某些情况下,Google 可能会将 网站 网址编入索引,即使它们没有进行抓取。注意:这不适用于必须明确指定的各种 AdsBot 爬虫。
用户代理: *
不允许: /
禁用目录及其内容的抓取(在目录名称后添加正斜杠)。请注意,如果您想禁用对私人内容的访问,则不应使用 robots.txt,而应使用适当的身份验证机制。被 robots.txt 文件阻止抓取的网址可能仍会被 Google 编入索引而不进行抓取;此外,由于任何人都可以自由查看 robots.txt 文件,因此它可能会泄露您的私人内容的位置。
用户代理: *
禁止:/日历/
禁止:/垃圾/
只允许一个爬虫
用户代理:Googlebot-news
允许: /
用户代理: *
不允许: /
允许除一个以外的所有爬虫
用户代理:不必要的机器人
不允许: /
用户代理: *
允许: /
阻止抓取页面(在正斜杠后列出页面):
禁止:/private_file.html
阻止 Google 图片访问特定图片:
用户代理:Googlebot-Image
禁止:/images/dogs.jpg
阻止 Google 图片访问您 网站 上的所有图片:
用户代理:Googlebot-Image
不允许: /
禁止抓取某种类型的文件(例如 .gif):
用户代理:Googlebot
禁止:/*.gif$
整个 网站 被阻止抓取,但在这些页面上允许 AdSense 广告(禁止除 Mediapartners-Google 之外的所有网络抓取工具)。这种方法会阻止您的网页出现在搜索结果中,但 Mediapartners-Google 网络爬虫仍然能够分析这些网页,以确定在您的 网站 上向访问者展示哪些广告。
用户代理: *
不允许: /
用户代理:Mediapartners-Google
允许: /
匹配以特定字符串结尾的 URL - 需要美元符号 ($)。例如,示例代码阻止访问以 .xls 结尾的所有 URL:
用户代理:Googlebot
禁止:/*.xls$
优先
请务必注意,搜索引擎对 robots.txt 文件的处理方式不同。默认情况下,第一个匹配指令总是优先。
但谷歌和必应更专注于特定目录。
也就是说:如果命令的字符较长,Google 和 Bing 将重视 Allow 命令。
例子
用户代理: *
允许:/about/company/
禁止:/about/
在上面的 /about/ 示例中,所有搜索引擎(包括 Google 和 Bing)都不允许访问目录 /about/company/,子目录除外。
例子
用户代理: *
禁止:/about/
允许:/about/company/
在上面的示例中,除了 Google 和 Bing 之外的所有搜索引擎都不允许访问 /about/ 目录,包括 /about/company/。
但允许 Google 和 Bing 访问 /about/company/,因为 Allow 指令比 Disallow 指令更长,并且目录位置更具体。
操作说明
每个搜索引擎只能定义一组指令。为一个搜索引擎设置多组指令可能会使他们感到困惑。
要尽可能具体
disallow 指令也会触发部分匹配。
在定义 Disallow 指令时尽可能具体,以防止无意中禁止访问文件。
例子
用户-agnet:*
禁止:/目录
上面的例子不允许搜索引擎访问:
所以要指定哪些目录需要禁止爬取。
此外
网站管理员必须让蜘蛛远离某些服务器上的目录——以确保服务器性能。例如:大部分网站服务器都有程序存放在“cgi-bin”目录下,所以最好在robots.txt文件中加入“Disallow: /cgi-bin”,避免所有程序文件被蜘蛛索引可以节省服务器资源。一般网站中不需要爬虫爬取的文件有:后台管理文件、程序脚本、附件、数据库文件、编码文件、样式表文件、模板文件、导航图片和背景图片等.
特定于用户代理的指令,未收录在所有用户代理爬虫指令中
这是什么意思?
让我们看一个清晰的例子:
用户代理: *
不允许:/secret/
禁止:/test/
不允许:/尚未开始/
用户代理:googlebot
不允许:/尚未开始/
在上面的示例中,除 Google 之外的所有搜索引擎都不允许访问 /secret/、/test/ 和 /not-launched-yet/。
Google 不允许访问 /not-launched-yet/,但允许访问 /secret/ 和 /test/。
如果您不想让 googlebot 访问 /secret/、/not-launched-yet/,那么您需要 googlebot 专门重复这些说明:
用户代理: *
不允许:/secret/
禁止:/test/
不允许:/尚未开始/
用户代理:googlebot
不允许:/secret/
不允许:/尚未开始/
robots.txt 文件有哪些限制?
由于 robots.txt 而导致搜索引擎无法访问的页面,但如果它们是从已抓取页面链接的,它们仍会出现在搜索结果中。例子:
专业提示:可以使用 Google Search Console 的 URL 删除工具从 Google 中删除这些 URL。请注意,这些 URL 只会被暂时删除。为了将它们排除在 Google 的结果页面之外,该 URL 需要每 90 天删除一次。
谷歌表示 robots.txt 文件通常被缓存长达 24 小时。在更改 robots.txt 文件时,请务必考虑到这一点。
目前尚不清楚其他搜索引擎如何处理 robots.txt 的缓存,但通常最好避免缓存您的 robots.txt 文件,以避免搜索引擎花费超过必要的时间来接收更改。
对于 robots.txt 文件,Google 目前支持 500 kb 的文件大小限制。可以忽略此最大文件大小之后的任何内容。
检查 robots.txt 文件和 URL
这可以在旧版本的 Google 网站管理员工具中进行检查。
单击抓取 > robots.txt 测试器
你可以看到你的robots的内容,在下面输入你要测试的url,点击测试就知道这个url是否被robots.txt的指令限制了。
您也可以直接通过以下链接:
总结最佳实践:
确保所有重要页面均可抓取
不要阻止 网站JavaScript 和 CSS 文件
在网站管理员工具中检查重要的网址是否被阻止抓取
正确大写目录、子目录和文件名
将 robots.txt 文件放在 网站 根目录下
Robots.txt 文件区分大小写,文件必须命名为“robots.txt”(无其他变体)
不要使用 robots.txt 文件隐藏私人用户信息,因为它仍然可见
将站点地图位置添加到 robots.txt 文件中。
防范措施:
如果您在 网站 中有一个或多个子域,那么每个子域以及主根域中都需要一个 robots.txt 文件。
这看起来像这样
/robots.txt 和 /robots.txt。
原因是其他页面可能会链接到此信息,如果有直接链接,它将绕过 robots.txt 规则,内容仍可能被索引。
如果您需要防止您的页面实际在搜索结果中被编入索引,请使用不同的方法,例如添加密码保护或向这些页面添加 noindex 元标记。Google 无法登录受密码保护的 网站/ 页面,因此无法抓取或索引这些页面。
不要在 robots.txt 中使用 noindex
虽然有人说在 robots.txt 文件中使用 noindex 指令是个好主意,但这不是官方标准,Google 公开建议不要使用它。
谷歌尚未澄清原因,但我们认为我们应该认真对待他们的建议,因为:
综上所述
如果您以前从未使用过 robots.txt 文件,可能会有点紧张,但不用担心,它的设置相当简单。
一旦您熟悉了文件的详细信息,您就可以为 网站 增强您的 SEO。
通过正确设置您的 robots.txt 文件,它将帮助搜索引擎抓取工具明智地使用抓取预算,并帮助确保他们不会浪费时间和资源来抓取不需要抓取的页面。
这将帮助他们以最佳方式在 SERP 中组织和显示您的 网站 内容,这意味着您将获得更多曝光。
设置 robots.txt 文件不必花费大量时间和精力。在大多数情况下,它是一次性设置,然后可以进行小的调整和更改以帮助更好地塑造它网站。
我希望本文中介绍的实践、技巧和建议可以帮助您开始创建/调整您的 网站robots.txt 文件。
具备各大搜索引擎蜘蛛的特点
1.百度蜘蛛:百度蜘蛛网上的信息百度蜘蛛名字有BaiduSpider、baiduspider等,请洗漱睡觉,那是老黄历。百度蜘蛛的最新名称是百度蜘蛛。在日志中,我还找到了Baiduspider-image,百度下的蜘蛛。查了资料(其实就是看名字……),是抓图的蜘蛛。常见的百度同类型蜘蛛有:Baiduspider-mobile(抓wap)、Baiduspider-image(抓图)、Baiduspider-video(抓视频)、Baiduspider-news(抓新闻)。注:以上百度蜘蛛目前为Baiduspider和Baiduspider-image。
2. Google Spider:Googlebot 争议较小,但也有人说它是 GoogleBot。Google 蜘蛛的最新名称是“compatible; Googlebot/2.1;”。还找到了Googlebot-Mobile,看名字就是爬wap内容。
3. 360蜘蛛:360Spider,它是一只非常“勤奋”的蜘蛛。
4、SOSO蜘蛛:Sosospider,它也可以被授予“勤奋”的蜘蛛。
5、雅虎蜘蛛:“雅虎!啜饮中国”或雅虎!名字带有“Slurp”和空格,robots中带有空格的名字,名字可以用“Slurp”或者“Yahoo”来描述,不知道有效与否。
6、有道蜘蛛:有道机器人,有道机器人(两个名字,汉语拼音少了一个U字母,读音很不一样,会不会少一些?)
7、搜狗蜘蛛:搜狗新闻蜘蛛还包括以下内容:
搜狗网络蜘蛛,搜狗inst蜘蛛,搜狗蜘蛛2、搜狗博客,搜狗新闻蜘蛛,搜狗猎户蜘蛛,(参考网站的一些robots文件,搜狗蜘蛛的名字可以用搜狗来概括,无法验证,不知道有没有用?看看最权威的百度robots.txt,对于搜狗蜘蛛来说占用了很多字节,占据了很大的版图。”搜狗网络蜘蛛;搜狗inst spider;搜狗spider2;搜狗博客;搜狗新闻蜘蛛;搜狗猎户蜘蛛”目前有6个带空格的名字。网上常见“搜狗网络蜘蛛/4.0”;“搜狗新闻蜘蛛/4.@ >0”;“搜狗inst蜘蛛/4.0”可获“占之王”奖。
8、MSN 蜘蛛:msnbot、msnbot-media(只见 msnbot-media 疯狂爬行……)
9、bing 蜘蛛:bingbot 在线(兼容;bingbot/2.0;)
10、搜索蜘蛛:一搜蜘蛛
11、Alexa 蜘蛛:ia_archiver
12、易搜蜘蛛:EasouSpider
13、即时蜘蛛:JikeSpider
14、一个爬网蜘蛛:EtaoSpider "Mozilla/5.0 (compatible; EtaoSpider/1.0; omit/EtaoSpider)" 根据上面选择几个常用的爬虫,允许爬取,其余的可以被机器人挡住。如果你暂时有足够的空间流量,在流量紧张的时候,保留一些常用的,并阻止其他蜘蛛以节省流量。至于那些蜘蛛爬到网站的有用价值,网站的管理人员是很有眼光的。
此外,还发现了 YandexBot、AhrefsBot 和 ezooms.bot 等蜘蛛。据说这些蜘蛛是外国的,对中文网站用处不大。最好是节省资源。
和平出来
公众号:yestupa 扫码关注图帕先生
获取更多国外SEM、SEO干货
给我[关注]
你也更好看!
查看全部
php 抓取网页内容(robots.txt文件会被网站优化师SEOer忽视的原因
)
robots.txt 是任何 SEO 的重要组成部分,也是 SEOers 的重要一课。
但是,有时 网站optimizer SEOers 会忽略 robots.txt 文件。
无论您是刚刚起步,还是经验丰富的优化专家,您都需要知道应该如何编写 robots.txt 文件。
那么,我们先来了解一下:
robots.txt 文件是什么?
robots.txt 文件可用于多种用途。
示例包括让搜索引擎知道在哪里可以找到您的 网站 站点地图,告诉他们哪些页面不需要抓取,以及管理 网站 抓取预算。
搜索引擎会定期检查 网站 的 robots.txt 文件中是否有任何关于抓取 网站 的指令。我们称这些特殊指令为“命令”。
如果没有 robots.txt 文件或没有适用的指令,搜索引擎将抓取整个 网站。
好的,抓取预算是多少?
简要说明:
与其他搜索引擎一样,Google 可用于抓取和索引您的 网站 内容的资源有限。
如果您的 网站 只有几百个网址,Google 应该可以轻松抓取您的所有网页并将其编入索引。
但是,如果 网站 很大,例如电子商务网站,有数千个页面收录大量自动生成的页面(例如搜索页面),那么 Google 可能无法抓取所有其中,您将失去许多潜在的流量和知名度。
因此,我们将通过设置 robots.txt 文件来管理 网站 抓取预算。
谷歌说:
“拥有许多低价值 URL 会对 网站 的抓取和索引编制产生负面影响。”
那些低价值的 URL 就像搜索页面之类的页面。这些页面生成太多了,如果谷歌蜘蛛抓取的话,会消耗大量的抓取预算,以至于一些重要的页面可能不是收录。
使用 robots.txt 文件来帮助管理您的 网站 抓取预算并确保搜索引擎尽可能高效(尤其是大型 网站)抓取重要页面,而不是浪费时间抓取登录、注册或付款页面,等等。
为什么需要 robots.txt?
从 SEO 的角度来看,robots.txt 文件起着至关重要的作用。它告诉搜索引擎如何最好地抓取您的 网站。
使用 robots.txt 文件可以阻止搜索引擎访问 网站 的某些部分,防止重复内容,并为搜索引擎提供有关如何更有效地抓取 网站 的有用提示。
更改 robots.txt 时要小心:错误的设置可能会使搜索引擎无法访问 网站 的大部分内容。
在像 Googlebot、Bingbot 等机器人抓取网页之前,它首先会检查是否存在 robots.txt 文件,如果存在,它通常会遵循在该文件中找到的路径。
您可以通过 robots.txt 文件控制以下内容:
阻止访问 网站 的一部分(开发和登台环境等)
防止 网站 内部搜索结果页面被抓取、索引或显示在搜索结果中
指定站点地图或站点地图的位置
通过阻止对低价值页面(登录、支付页面、购物车等)的访问来优化抓取预算
防止对 网站 上的某些文件(图像、PDF 等)编制索引
让我们看一个例子来说明这一点:
您有一个电子商务网站,访问者可以使用过滤功能快速搜索您的产品,例如按销售额、价格排名。
此过滤器生成的页面基本上显示与其他页面相同的内容。
这对用户很有用,但会混淆搜索引擎,因为它会创建重复的内容。
如果搜索引擎将这些页面编入索引,就会浪费您宝贵的爬取资源。
因此,应设置规则,使搜索引擎不会访问这些页面。
检查您是否有 robots.txt 文件
如果您不熟悉 robots.txt 文件,或者不确定您的 网站 是否有它,请快速查看。
方法:
将 /robots.txt 添加到主页 URL 的末尾。
例子:
如果未显示任何内容,则您的站点没有 robots.txt 文件。然后应该设置一个。
如何创建 robots.txt 文件
创建 robots.txt 文件是一个相当简单的过程:
新建文本文档->重命名为robots.txt(所有文件必须小写)->编写规则->使用FTP上传文件(放在根目录下)到空间
以下文章为谷歌官方介绍,为大家展示robots.txt文件的创建过程,可以帮助您轻松创建自己的robots.txt文件:
注意:
robots.txt 本身就是一个文本文件。它必须在域名的根目录下并命名为“robots.txt”。位于子目录下的 robots.txt 文件无效,因为爬虫只在域名的根目录中查找该文件。
例如,是一个有效的位置,但不是。
如果您使用 WordPress 构建网站,您可以使用虚拟机器人、yoast、all in one seo 等插件创建和设置它。
Robots.txt 示例
下面是一些您可以在自己的 网站 上使用的 robots.txt 文件的示例。
允许所有爬虫/蜘蛛访问所有 网站 内容:
User-agent:*
Disallow:
阻止所有爬虫/蜘蛛访问所有 网站 内容:
User-agent:*
Disallow:/
在这里您可以看到在创建站点 robots.txt 时出错是多么容易,因为阻止整个站点被看到的区别是:禁止指令中的一个简单斜线 (Disallow:/)。
阻止谷歌爬虫/蜘蛛访问:
User-agent:Googlebot
Disallow:/
阻止爬虫/蜘蛛访问特定页面:
User-agent:
Disallow:/thankyou.html
从部分服务器中排除所有爬虫:
User-agent:*
Disallow:/ cgi-bin /
Disallow:/ tmp /
Disallow:/junk/
以下是 网站 上 robots.txt 文件的示例:
一、表示theverge不希望谷歌爬虫抓取这些目录的内容
二、表示theverge不希望任何爬虫爬取这些目录的内容
三、theverge 列出 robots.txt 中的所有站点地图
示例文件可以在这里查看:
了解 The Verge 如何使用他们的 robots.txt 文件专门使用 Google 的新闻蜘蛛“Googlebot-News”(第 1 点)以确保它不会在 网站 上抓取这些目录。
请务必记住,如果您想确保爬虫不会爬取 网站 上的某些页面或目录,您可以在 robots.txt 中的“Disallow”语句中调用这些页面和/或目录文件,如上例所示。
此外,请参阅 robots.txt 规范指南中的 Google 如何处理 robots.txt 文件,即 Google 当前对 robots.txt 文件的最大文件大小限制。
Google 的最大大小设置为 500KB,因此请务必注意 网站robots.txt 文件的大小。
robots.txt 文件的最佳做法
以下内容摘自谷歌官方介绍,原文:
位置规则和文件名
robots.txt 文件应始终放置在 root网站 位置(在主机的顶级目录中),文件名为 robots.txt,例如: .
请注意,robots.txt 文件的 URL 与任何其他 URL 一样区分大小写。
如果在默认位置找不到 robots.txt 文件,搜索引擎将假定没有指令。
语法
规则按从上到下的顺序处理,一个用户代理只能匹配一个规则集(即匹配相应用户代理的第一个最具体的规则)。
系统的默认假设是用户代理可以爬取所有不被 Disallow: 规则禁止的网页或目录。
规则区分大小写。例如,Disallow: /file.asp 有效但无效。
规则
例子
禁止抓取整个 网站。请注意,在某些情况下,Google 可能会将 网站 网址编入索引,即使它们没有进行抓取。注意:这不适用于必须明确指定的各种 AdsBot 爬虫。
用户代理: *
不允许: /
禁用目录及其内容的抓取(在目录名称后添加正斜杠)。请注意,如果您想禁用对私人内容的访问,则不应使用 robots.txt,而应使用适当的身份验证机制。被 robots.txt 文件阻止抓取的网址可能仍会被 Google 编入索引而不进行抓取;此外,由于任何人都可以自由查看 robots.txt 文件,因此它可能会泄露您的私人内容的位置。
用户代理: *
禁止:/日历/
禁止:/垃圾/
只允许一个爬虫
用户代理:Googlebot-news
允许: /
用户代理: *
不允许: /
允许除一个以外的所有爬虫
用户代理:不必要的机器人
不允许: /
用户代理: *
允许: /
阻止抓取页面(在正斜杠后列出页面):
禁止:/private_file.html
阻止 Google 图片访问特定图片:
用户代理:Googlebot-Image
禁止:/images/dogs.jpg
阻止 Google 图片访问您 网站 上的所有图片:
用户代理:Googlebot-Image
不允许: /
禁止抓取某种类型的文件(例如 .gif):
用户代理:Googlebot
禁止:/*.gif$
整个 网站 被阻止抓取,但在这些页面上允许 AdSense 广告(禁止除 Mediapartners-Google 之外的所有网络抓取工具)。这种方法会阻止您的网页出现在搜索结果中,但 Mediapartners-Google 网络爬虫仍然能够分析这些网页,以确定在您的 网站 上向访问者展示哪些广告。
用户代理: *
不允许: /
用户代理:Mediapartners-Google
允许: /
匹配以特定字符串结尾的 URL - 需要美元符号 ($)。例如,示例代码阻止访问以 .xls 结尾的所有 URL:
用户代理:Googlebot
禁止:/*.xls$
优先
请务必注意,搜索引擎对 robots.txt 文件的处理方式不同。默认情况下,第一个匹配指令总是优先。
但谷歌和必应更专注于特定目录。
也就是说:如果命令的字符较长,Google 和 Bing 将重视 Allow 命令。
例子
用户代理: *
允许:/about/company/
禁止:/about/
在上面的 /about/ 示例中,所有搜索引擎(包括 Google 和 Bing)都不允许访问目录 /about/company/,子目录除外。
例子
用户代理: *
禁止:/about/
允许:/about/company/
在上面的示例中,除了 Google 和 Bing 之外的所有搜索引擎都不允许访问 /about/ 目录,包括 /about/company/。
但允许 Google 和 Bing 访问 /about/company/,因为 Allow 指令比 Disallow 指令更长,并且目录位置更具体。
操作说明
每个搜索引擎只能定义一组指令。为一个搜索引擎设置多组指令可能会使他们感到困惑。
要尽可能具体
disallow 指令也会触发部分匹配。
在定义 Disallow 指令时尽可能具体,以防止无意中禁止访问文件。
例子
用户-agnet:*
禁止:/目录
上面的例子不允许搜索引擎访问:
所以要指定哪些目录需要禁止爬取。
此外
网站管理员必须让蜘蛛远离某些服务器上的目录——以确保服务器性能。例如:大部分网站服务器都有程序存放在“cgi-bin”目录下,所以最好在robots.txt文件中加入“Disallow: /cgi-bin”,避免所有程序文件被蜘蛛索引可以节省服务器资源。一般网站中不需要爬虫爬取的文件有:后台管理文件、程序脚本、附件、数据库文件、编码文件、样式表文件、模板文件、导航图片和背景图片等.
特定于用户代理的指令,未收录在所有用户代理爬虫指令中
这是什么意思?
让我们看一个清晰的例子:
用户代理: *
不允许:/secret/
禁止:/test/
不允许:/尚未开始/
用户代理:googlebot
不允许:/尚未开始/
在上面的示例中,除 Google 之外的所有搜索引擎都不允许访问 /secret/、/test/ 和 /not-launched-yet/。
Google 不允许访问 /not-launched-yet/,但允许访问 /secret/ 和 /test/。
如果您不想让 googlebot 访问 /secret/、/not-launched-yet/,那么您需要 googlebot 专门重复这些说明:
用户代理: *
不允许:/secret/
禁止:/test/
不允许:/尚未开始/
用户代理:googlebot
不允许:/secret/
不允许:/尚未开始/
robots.txt 文件有哪些限制?
由于 robots.txt 而导致搜索引擎无法访问的页面,但如果它们是从已抓取页面链接的,它们仍会出现在搜索结果中。例子:
专业提示:可以使用 Google Search Console 的 URL 删除工具从 Google 中删除这些 URL。请注意,这些 URL 只会被暂时删除。为了将它们排除在 Google 的结果页面之外,该 URL 需要每 90 天删除一次。
谷歌表示 robots.txt 文件通常被缓存长达 24 小时。在更改 robots.txt 文件时,请务必考虑到这一点。
目前尚不清楚其他搜索引擎如何处理 robots.txt 的缓存,但通常最好避免缓存您的 robots.txt 文件,以避免搜索引擎花费超过必要的时间来接收更改。
对于 robots.txt 文件,Google 目前支持 500 kb 的文件大小限制。可以忽略此最大文件大小之后的任何内容。
检查 robots.txt 文件和 URL
这可以在旧版本的 Google 网站管理员工具中进行检查。
单击抓取 > robots.txt 测试器
你可以看到你的robots的内容,在下面输入你要测试的url,点击测试就知道这个url是否被robots.txt的指令限制了。
您也可以直接通过以下链接:
总结最佳实践:
确保所有重要页面均可抓取
不要阻止 网站JavaScript 和 CSS 文件
在网站管理员工具中检查重要的网址是否被阻止抓取
正确大写目录、子目录和文件名
将 robots.txt 文件放在 网站 根目录下
Robots.txt 文件区分大小写,文件必须命名为“robots.txt”(无其他变体)
不要使用 robots.txt 文件隐藏私人用户信息,因为它仍然可见
将站点地图位置添加到 robots.txt 文件中。
防范措施:
如果您在 网站 中有一个或多个子域,那么每个子域以及主根域中都需要一个 robots.txt 文件。
这看起来像这样
/robots.txt 和 /robots.txt。
原因是其他页面可能会链接到此信息,如果有直接链接,它将绕过 robots.txt 规则,内容仍可能被索引。
如果您需要防止您的页面实际在搜索结果中被编入索引,请使用不同的方法,例如添加密码保护或向这些页面添加 noindex 元标记。Google 无法登录受密码保护的 网站/ 页面,因此无法抓取或索引这些页面。
不要在 robots.txt 中使用 noindex
虽然有人说在 robots.txt 文件中使用 noindex 指令是个好主意,但这不是官方标准,Google 公开建议不要使用它。
谷歌尚未澄清原因,但我们认为我们应该认真对待他们的建议,因为:
综上所述
如果您以前从未使用过 robots.txt 文件,可能会有点紧张,但不用担心,它的设置相当简单。
一旦您熟悉了文件的详细信息,您就可以为 网站 增强您的 SEO。
通过正确设置您的 robots.txt 文件,它将帮助搜索引擎抓取工具明智地使用抓取预算,并帮助确保他们不会浪费时间和资源来抓取不需要抓取的页面。
这将帮助他们以最佳方式在 SERP 中组织和显示您的 网站 内容,这意味着您将获得更多曝光。
设置 robots.txt 文件不必花费大量时间和精力。在大多数情况下,它是一次性设置,然后可以进行小的调整和更改以帮助更好地塑造它网站。
我希望本文中介绍的实践、技巧和建议可以帮助您开始创建/调整您的 网站robots.txt 文件。
具备各大搜索引擎蜘蛛的特点
1.百度蜘蛛:百度蜘蛛网上的信息百度蜘蛛名字有BaiduSpider、baiduspider等,请洗漱睡觉,那是老黄历。百度蜘蛛的最新名称是百度蜘蛛。在日志中,我还找到了Baiduspider-image,百度下的蜘蛛。查了资料(其实就是看名字……),是抓图的蜘蛛。常见的百度同类型蜘蛛有:Baiduspider-mobile(抓wap)、Baiduspider-image(抓图)、Baiduspider-video(抓视频)、Baiduspider-news(抓新闻)。注:以上百度蜘蛛目前为Baiduspider和Baiduspider-image。
2. Google Spider:Googlebot 争议较小,但也有人说它是 GoogleBot。Google 蜘蛛的最新名称是“compatible; Googlebot/2.1;”。还找到了Googlebot-Mobile,看名字就是爬wap内容。
3. 360蜘蛛:360Spider,它是一只非常“勤奋”的蜘蛛。
4、SOSO蜘蛛:Sosospider,它也可以被授予“勤奋”的蜘蛛。
5、雅虎蜘蛛:“雅虎!啜饮中国”或雅虎!名字带有“Slurp”和空格,robots中带有空格的名字,名字可以用“Slurp”或者“Yahoo”来描述,不知道有效与否。
6、有道蜘蛛:有道机器人,有道机器人(两个名字,汉语拼音少了一个U字母,读音很不一样,会不会少一些?)
7、搜狗蜘蛛:搜狗新闻蜘蛛还包括以下内容:
搜狗网络蜘蛛,搜狗inst蜘蛛,搜狗蜘蛛2、搜狗博客,搜狗新闻蜘蛛,搜狗猎户蜘蛛,(参考网站的一些robots文件,搜狗蜘蛛的名字可以用搜狗来概括,无法验证,不知道有没有用?看看最权威的百度robots.txt,对于搜狗蜘蛛来说占用了很多字节,占据了很大的版图。”搜狗网络蜘蛛;搜狗inst spider;搜狗spider2;搜狗博客;搜狗新闻蜘蛛;搜狗猎户蜘蛛”目前有6个带空格的名字。网上常见“搜狗网络蜘蛛/4.0”;“搜狗新闻蜘蛛/4.@ >0”;“搜狗inst蜘蛛/4.0”可获“占之王”奖。
8、MSN 蜘蛛:msnbot、msnbot-media(只见 msnbot-media 疯狂爬行……)
9、bing 蜘蛛:bingbot 在线(兼容;bingbot/2.0;)
10、搜索蜘蛛:一搜蜘蛛
11、Alexa 蜘蛛:ia_archiver
12、易搜蜘蛛:EasouSpider
13、即时蜘蛛:JikeSpider
14、一个爬网蜘蛛:EtaoSpider "Mozilla/5.0 (compatible; EtaoSpider/1.0; omit/EtaoSpider)" 根据上面选择几个常用的爬虫,允许爬取,其余的可以被机器人挡住。如果你暂时有足够的空间流量,在流量紧张的时候,保留一些常用的,并阻止其他蜘蛛以节省流量。至于那些蜘蛛爬到网站的有用价值,网站的管理人员是很有眼光的。
此外,还发现了 YandexBot、AhrefsBot 和 ezooms.bot 等蜘蛛。据说这些蜘蛛是外国的,对中文网站用处不大。最好是节省资源。
和平出来
公众号:yestupa 扫码关注图帕先生
获取更多国外SEM、SEO干货
给我[关注]
你也更好看!
php 抓取网页内容(php抓取网页内容的问题首先得确定用户都对什么样的内容感兴趣)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-04-04 21:08
php抓取网页内容的问题,首先得确定用户都对什么样的内容感兴趣.有些人感兴趣就写个爬虫爬一爬.有些人感兴趣就用scrapy,selenium等工具抓一抓.然后还有人就不知道对什么感兴趣.那就是数据库学习咯.数据库怎么学习?一开始我也不知道.工作中,有一些学习框架,例如mysql,mssql,hbase等,你可以去看看,找一个showglobalvariableslike'tmp'来看一看.这样比较直观,学起来方便,从基础开始,然后再去深入.数据库学习php如何搭建数据库?都已经存在数据库了.那么肯定会去构建它.首先.你可以搜索几个需要的数据库,例如access,mysql,oracle,mssql等,然后下载.双击安装包.然后你可以看配置,然后把框架学会.比如用phpshop,phpwordpress建立数据库.因为phpweb只能在php类中使用,所以你还需要html类。
html是从html标签和超链接自动生成的,支持语言(可选):c,java,python和mysql。javascript用于创建、组织和表示html页面的元素。怎么学习php爬虫或者说开发爬虫呢?网上大神有很多,教php爬虫的有很多,可以随便看看.php是面向对象语言,你可以用php(所以,当你要写一个php爬虫时),比如用java写一个"爬虫”(可以是api),然后用php写一个页面,接着和后端交互,生成数据。
关于学习php以及scrapy是否需要的问题.那是肯定需要学习的.比如用scrapy一起抓java和c/c++的源码,比如学习seleniumpython的模拟登录.就算你想用java,那么如果你想爬php,这个学习一下还是要的.另外,selenium是java的模拟登录,它不支持php.怎么学php网页的前端布局呢?php在打开web服务器时,有很多数据缓存方法,哪些通过缓存?有哪些语言呢?java,c++.java有哪些语言中的函数实现呢?有什么约定俗成的方法吗?c++也有一些编程模式吗?php怎么去配置一些prefix?java是通过什么api传递变量和参数呢?等等有什么语言能够得到这些变量,通过什么方法查看他们的引用?php的相关语言可以按哪些顺序?为什么?php内置对象?有没有隐藏的对象?有没有隐藏的方法?这个语言的写法还能怎么写?那么就得学好计算机,让计算机明白人话,一定要多说,多练,多举一反三.以后举一反三就能实现.数据库自己搭建数据库?这个太难了,估计没几个人能做到.还有怎么从电脑上爬下数据呢?买?对方有数据库吗?还有问下你们网站对爬虫支持的速度?现在好多网站都不支持爬虫,不是因为爬虫不好,是因为它的数据,相对比较少.容。 查看全部
php 抓取网页内容(php抓取网页内容的问题首先得确定用户都对什么样的内容感兴趣)
php抓取网页内容的问题,首先得确定用户都对什么样的内容感兴趣.有些人感兴趣就写个爬虫爬一爬.有些人感兴趣就用scrapy,selenium等工具抓一抓.然后还有人就不知道对什么感兴趣.那就是数据库学习咯.数据库怎么学习?一开始我也不知道.工作中,有一些学习框架,例如mysql,mssql,hbase等,你可以去看看,找一个showglobalvariableslike'tmp'来看一看.这样比较直观,学起来方便,从基础开始,然后再去深入.数据库学习php如何搭建数据库?都已经存在数据库了.那么肯定会去构建它.首先.你可以搜索几个需要的数据库,例如access,mysql,oracle,mssql等,然后下载.双击安装包.然后你可以看配置,然后把框架学会.比如用phpshop,phpwordpress建立数据库.因为phpweb只能在php类中使用,所以你还需要html类。
html是从html标签和超链接自动生成的,支持语言(可选):c,java,python和mysql。javascript用于创建、组织和表示html页面的元素。怎么学习php爬虫或者说开发爬虫呢?网上大神有很多,教php爬虫的有很多,可以随便看看.php是面向对象语言,你可以用php(所以,当你要写一个php爬虫时),比如用java写一个"爬虫”(可以是api),然后用php写一个页面,接着和后端交互,生成数据。
关于学习php以及scrapy是否需要的问题.那是肯定需要学习的.比如用scrapy一起抓java和c/c++的源码,比如学习seleniumpython的模拟登录.就算你想用java,那么如果你想爬php,这个学习一下还是要的.另外,selenium是java的模拟登录,它不支持php.怎么学php网页的前端布局呢?php在打开web服务器时,有很多数据缓存方法,哪些通过缓存?有哪些语言呢?java,c++.java有哪些语言中的函数实现呢?有什么约定俗成的方法吗?c++也有一些编程模式吗?php怎么去配置一些prefix?java是通过什么api传递变量和参数呢?等等有什么语言能够得到这些变量,通过什么方法查看他们的引用?php的相关语言可以按哪些顺序?为什么?php内置对象?有没有隐藏的对象?有没有隐藏的方法?这个语言的写法还能怎么写?那么就得学好计算机,让计算机明白人话,一定要多说,多练,多举一反三.以后举一反三就能实现.数据库自己搭建数据库?这个太难了,估计没几个人能做到.还有怎么从电脑上爬下数据呢?买?对方有数据库吗?还有问下你们网站对爬虫支持的速度?现在好多网站都不支持爬虫,不是因为爬虫不好,是因为它的数据,相对比较少.容。
php 抓取网页内容(牛逼闪闪的curl也束手无策了,可以说相当靠谱了!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 244 次浏览 • 2022-04-01 06:17
关键词:数据获取
我的生命是有限的,但我的知识是无限的。本文章主要介绍php爬取数据相关的知识,希望对你有所帮助。
对于一般的页面数据,我们可以使用querylist轻松抓取页面并分析其中的dom树,抓取我们需要的数据,并存入数据库,但是有时候我们要抓取的数据是通过渲染来渲染的是的,这次
Puppeteer 插件派上用场了,
composerrequirenesk/puphpeteer
npminstall@nesk/puphpeteer
供参考,在按照文档做的时候,发现
错误:无法下载 Chromium r672088!设置“PUPPETEER_SKIP_CHROMIUM_DOWNLOAD”环境变量以跳过下载。错误,
解决方案
采集网页内容是一个很常见的需求。与传统的静态页面相比,curl 可以应付。但是如果页面中有动态加载的内容,比如在某些页面中通过ajax加载的文章body内容,并且如果在某些页面加载后进行了一些额外的处理(图片地址替换等),并且你想采集这些处理过的内容。然后真棒curl就束手无策了。
有类似需求的人可能会说,老铁,上PhantomJS吧!
是的,这是一个解决方案,在相当长的一段时间内,PhantomJS 是能够解决这种需求的少数工具中最好的。
但今天我要介绍一个后来居上的工具——puppeteer,它随着 Chrome Headless 技术的兴起而迅速发展。而且最重要的是,puppeteer是由Chrome官方团队开发维护的,可以说是相当靠谱了!
puppeteer 是一个 js 包。要在 Laravel 中使用它,您必须使用另一个工件 spatie/browsershot。
安装
安装 spatie/browsershot
browsershot 是来自伟大团队 spatie 的作曲家包
$ composer require spatie/browsershot
安装 puppeteer
$ npm i puppeteer --save
你也可以全局保护puppeteer,但是从个人经验来看,建议在项目中安装,因为不同的项目不会同时受到全局安装的puppeteer的影响,而且项目中的安装也是使用phpdeployer升级方便(phpdeploy升级时不会影响线上项目的运行,要知道升级/安装puppeteer是非常耗时的,有时也不能保证成功)。
安装 puppeteer 时会下载 Chromium-Browser。由于我国特殊的国情,很可能无法下载。在这方面,请大展身手……
使用
以采集今日头条手机页面文章的内容为例。
use Spatie\Browsershot\Browsershot;
public function getBodyhtml()
$newsUrl = ‘https://m.toutiao.com/i6546884151050502660/‘;
$html = Browsershot::url($newsUrl)
->windowSize(480, 800)
->userAgent(‘Mozilla/5.0 (Linux; android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36‘)
->mobile()
->touch()
->bodyHtml();
\Log::info($html);
运行后在日志中可以看到如下内容(截图只是部分内容)
或者,您可以将页面保存为图像或 PDF 文件。
use Spatie\Browsershot\Browsershot;
public function getBodyHtml()
$newsUrl = ‘https://m.toutiao.com/i6546884151050502660/‘;
Browsershot::url($newsUrl)
->windowSize(480, 800)
->userAgent(‘Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36‘)
->mobile()
->touch()
->setDelay(1000)
->save(public_path(‘images/toutiao.jpg‘));
图片中的方框与系统字体有关。代码中使用了 setDelay() 方法,在内容加载完成后进行截图。它简单粗暴,可能不是最好的解决方案。
可能的问题
总结
puppeteer用于测试、采集等场景,是一个非常强大的工具。对于轻量级的采集任务来说已经足够了,比如这篇文章使用采集Laravel(php)中的一些小页面,但是如果需要快速采集大量的内容,或者python什么的。
这篇关于php爬取数据的文章已经写完了。如果不能解决您的问题,请参考以下文章: 查看全部
php 抓取网页内容(牛逼闪闪的curl也束手无策了,可以说相当靠谱了!)
关键词:数据获取
我的生命是有限的,但我的知识是无限的。本文章主要介绍php爬取数据相关的知识,希望对你有所帮助。
对于一般的页面数据,我们可以使用querylist轻松抓取页面并分析其中的dom树,抓取我们需要的数据,并存入数据库,但是有时候我们要抓取的数据是通过渲染来渲染的是的,这次
Puppeteer 插件派上用场了,
composerrequirenesk/puphpeteer
npminstall@nesk/puphpeteer
供参考,在按照文档做的时候,发现
错误:无法下载 Chromium r672088!设置“PUPPETEER_SKIP_CHROMIUM_DOWNLOAD”环境变量以跳过下载。错误,
解决方案
采集网页内容是一个很常见的需求。与传统的静态页面相比,curl 可以应付。但是如果页面中有动态加载的内容,比如在某些页面中通过ajax加载的文章body内容,并且如果在某些页面加载后进行了一些额外的处理(图片地址替换等),并且你想采集这些处理过的内容。然后真棒curl就束手无策了。
有类似需求的人可能会说,老铁,上PhantomJS吧!
是的,这是一个解决方案,在相当长的一段时间内,PhantomJS 是能够解决这种需求的少数工具中最好的。
但今天我要介绍一个后来居上的工具——puppeteer,它随着 Chrome Headless 技术的兴起而迅速发展。而且最重要的是,puppeteer是由Chrome官方团队开发维护的,可以说是相当靠谱了!
puppeteer 是一个 js 包。要在 Laravel 中使用它,您必须使用另一个工件 spatie/browsershot。
安装
安装 spatie/browsershot
browsershot 是来自伟大团队 spatie 的作曲家包
$ composer require spatie/browsershot
安装 puppeteer
$ npm i puppeteer --save
你也可以全局保护puppeteer,但是从个人经验来看,建议在项目中安装,因为不同的项目不会同时受到全局安装的puppeteer的影响,而且项目中的安装也是使用phpdeployer升级方便(phpdeploy升级时不会影响线上项目的运行,要知道升级/安装puppeteer是非常耗时的,有时也不能保证成功)。
安装 puppeteer 时会下载 Chromium-Browser。由于我国特殊的国情,很可能无法下载。在这方面,请大展身手……
使用
以采集今日头条手机页面文章的内容为例。
use Spatie\Browsershot\Browsershot;
public function getBodyhtml()
$newsUrl = ‘https://m.toutiao.com/i6546884151050502660/‘;
$html = Browsershot::url($newsUrl)
->windowSize(480, 800)
->userAgent(‘Mozilla/5.0 (Linux; android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36‘)
->mobile()
->touch()
->bodyHtml();
\Log::info($html);
运行后在日志中可以看到如下内容(截图只是部分内容)
或者,您可以将页面保存为图像或 PDF 文件。
use Spatie\Browsershot\Browsershot;
public function getBodyHtml()
$newsUrl = ‘https://m.toutiao.com/i6546884151050502660/‘;
Browsershot::url($newsUrl)
->windowSize(480, 800)
->userAgent(‘Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36‘)
->mobile()
->touch()
->setDelay(1000)
->save(public_path(‘images/toutiao.jpg‘));
图片中的方框与系统字体有关。代码中使用了 setDelay() 方法,在内容加载完成后进行截图。它简单粗暴,可能不是最好的解决方案。
可能的问题
总结
puppeteer用于测试、采集等场景,是一个非常强大的工具。对于轻量级的采集任务来说已经足够了,比如这篇文章使用采集Laravel(php)中的一些小页面,但是如果需要快速采集大量的内容,或者python什么的。
这篇关于php爬取数据的文章已经写完了。如果不能解决您的问题,请参考以下文章:
php 抓取网页内容(php抓取网页内容之前用过爬虫开发工具,scrapy,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-25 03:05
php抓取网页内容之前用过爬虫开发工具,scrapy,各有长短。想要抓取多页面时,遇到服务器负载过大,网站负载过重等各种问题,它解决的办法是在请求的时候预留参数,并与服务器端进行比较。php实现呢,可以先用taobao_redirect_dump函数把页面抓取下来。然后呢,再从json,xml或者json-raw抓取。
直接抓取是可以的,但是流量数据应该是不能直接获取的(因为通过去掉cookie这种步骤得到的是ip与购买商品数量)。你可以尝试一下,用你自己开发的js库去抓取目标站点的html。然后后端用php处理(phpstorm有带js处理模块,但是安装较麻烦,所以个人感觉没有phpstorm这么强大)。这个问题如果你用python或java做实现也可以解决,所以不用太担心。
并不行,你需要保证网站内容不是公开的数据,
你可以去看看加拿大的游戏家事例,他们用代理从推特上面抓内容到本地服务器,但是后端处理数据比较麻烦,适合直接抓,
可以,但是你需要的是强大的requests,并且需要有index.php你当然也可以不如visualstudio那么死忠,但是atom为什么不能做php网页内容抓取---visualstudiocode可以强大到仅仅用atom是不够用的。 查看全部
php 抓取网页内容(php抓取网页内容之前用过爬虫开发工具,scrapy,)
php抓取网页内容之前用过爬虫开发工具,scrapy,各有长短。想要抓取多页面时,遇到服务器负载过大,网站负载过重等各种问题,它解决的办法是在请求的时候预留参数,并与服务器端进行比较。php实现呢,可以先用taobao_redirect_dump函数把页面抓取下来。然后呢,再从json,xml或者json-raw抓取。
直接抓取是可以的,但是流量数据应该是不能直接获取的(因为通过去掉cookie这种步骤得到的是ip与购买商品数量)。你可以尝试一下,用你自己开发的js库去抓取目标站点的html。然后后端用php处理(phpstorm有带js处理模块,但是安装较麻烦,所以个人感觉没有phpstorm这么强大)。这个问题如果你用python或java做实现也可以解决,所以不用太担心。
并不行,你需要保证网站内容不是公开的数据,
你可以去看看加拿大的游戏家事例,他们用代理从推特上面抓内容到本地服务器,但是后端处理数据比较麻烦,适合直接抓,
可以,但是你需要的是强大的requests,并且需要有index.php你当然也可以不如visualstudio那么死忠,但是atom为什么不能做php网页内容抓取---visualstudiocode可以强大到仅仅用atom是不够用的。
php 抓取网页内容(百度并没有推出百度权重这么个东西,而是站长工具和爱站 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-20 21:09
)
总结
由于谷歌还没有更新PR,所以很多站长在做友情链接的时候用百度权重来衡量每一个网站的质量。其实百度并没有推出百度权重,而是网站龙工具和爱站这两个站推出的参考价值,通过分析网站的关键词和页数关键词 set by 网站 基于@>,计算出网站的百度权重不是那么准确,只能作为参考;
在这个文章的分享下,可以通过php获取爱站查询网站的百度权重并生成图片,可以方便调用查看百度网站 值的权重,请看下图演示;使用方法也很简单,点击下方下载按钮,解压下载的压缩包文件,将br文件夹上传到网站,
通过URL访问:您的域名/br/?q=要查询的域名
由于谷歌还没有更新PR,所以很多站长在做友情链接的时候用百度权重来衡量每一个网站的质量。其实百度并没有推出百度权重,而是网站龙工具和爱站这两个站推出的参考价值,通过分析网站的关键词和页数关键词 set by 网站 基于@>,计算出网站的百度权重不是那么准确,只能作为参考;
在这个文章的分享下,可以通过php获取爱站查询网站的百度权重并生成图片,可以方便调用查看百度网站 值的权重,请看下图演示;使用方法也很简单,点击下方下载按钮,解压下载的压缩包文件,将br文件夹上传到网站,
通过URL访问:您的域名/br/?q=要查询的域名 查看全部
php 抓取网页内容(百度并没有推出百度权重这么个东西,而是站长工具和爱站
)
总结
由于谷歌还没有更新PR,所以很多站长在做友情链接的时候用百度权重来衡量每一个网站的质量。其实百度并没有推出百度权重,而是网站龙工具和爱站这两个站推出的参考价值,通过分析网站的关键词和页数关键词 set by 网站 基于@>,计算出网站的百度权重不是那么准确,只能作为参考;
在这个文章的分享下,可以通过php获取爱站查询网站的百度权重并生成图片,可以方便调用查看百度网站 值的权重,请看下图演示;使用方法也很简单,点击下方下载按钮,解压下载的压缩包文件,将br文件夹上传到网站,
通过URL访问:您的域名/br/?q=要查询的域名
由于谷歌还没有更新PR,所以很多站长在做友情链接的时候用百度权重来衡量每一个网站的质量。其实百度并没有推出百度权重,而是网站龙工具和爱站这两个站推出的参考价值,通过分析网站的关键词和页数关键词 set by 网站 基于@>,计算出网站的百度权重不是那么准确,只能作为参考;
在这个文章的分享下,可以通过php获取爱站查询网站的百度权重并生成图片,可以方便调用查看百度网站 值的权重,请看下图演示;使用方法也很简单,点击下方下载按钮,解压下载的压缩包文件,将br文件夹上传到网站,
通过URL访问:您的域名/br/?q=要查询的域名
php 抓取网页内容(php语言的核心数据库-selenium开发前端自动化测试程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2022-03-20 10:03
php抓取网页内容如果发现网页有敏感词汇,即使能够爬取,结果是不能通过审核,造成对用户的资源损失。php的sqlite数据库是php语言的核心数据库,是由在2005年1月推出。目前有一家叫做“inforoot“公司。php在2003年发布第一个程序包:php-connection,它包含了从标准程序包继承的一个环境。
php提供一个嵌入html的虚拟表单,供用户交互。php可以在独立的虚拟表单中访问数据库或存储数据。接下来,有一个简单的网页爬虫项目。selenium开发的前端自动化测试程序,可以从一系列报表中识别出任意一张,进而自动化执行你想执行的测试脚本。它还可以爬取asp脚本,而php不能用。php最简单的网页可视化方案,你只需要在php代码中编写响应页面元素的事件,当a标签出现在地址栏时,php向数据库发送网页的请求。
这就自动获取了你想要的那个网页,调用网页的函数进行操作,完成它的预期。一、原理1.创建php对象根据你设定的页面元素,创建一个php对象。这个对象继承了php5开始的两个基本扩展对象,即new标准模式和php5.0开始的基本模式。用于存储数据;它是index和location变量的前缀,用于获取元素对象和路径。
示例如下:functiongetmethod(url){//defineanobjectforaphpobject//newtoinitialize.//createawriteandcompressinguniformlyautomatically.//builderif(url){//writeormakesomeelementseasiertowrite//automatically..}//compresswhenyouwritecode(e.g.:request.urlstring("")),//withoutreadandcompressations.//initializetheobjectatintimateinitialization.//outputobjectwith:'/post()/'//note:theobjectstartswith'automatically'butisusedforcompressingonuri.//createthenewpublicmethodindex;//usetheurlstringvalue(that'sused)createanadminname();//usetheurlstringvalues(that'sused)setargs();//settheobject'sprivatepropertiestotheurlstring.//outputobjectwith:''/'''//addandmaptheobjectnamecommentinapostsetmy{}my{}or{}//addandcompresstheurlstrings.//mapapostorapostcontainingtheobject.//thismapneedstobeeasilycompressed.//addandcompresstheurlstrings.//buildedasadllfile.//addandcompressthetheurlstrings.//newtheobjectf。 查看全部
php 抓取网页内容(php语言的核心数据库-selenium开发前端自动化测试程序)
php抓取网页内容如果发现网页有敏感词汇,即使能够爬取,结果是不能通过审核,造成对用户的资源损失。php的sqlite数据库是php语言的核心数据库,是由在2005年1月推出。目前有一家叫做“inforoot“公司。php在2003年发布第一个程序包:php-connection,它包含了从标准程序包继承的一个环境。
php提供一个嵌入html的虚拟表单,供用户交互。php可以在独立的虚拟表单中访问数据库或存储数据。接下来,有一个简单的网页爬虫项目。selenium开发的前端自动化测试程序,可以从一系列报表中识别出任意一张,进而自动化执行你想执行的测试脚本。它还可以爬取asp脚本,而php不能用。php最简单的网页可视化方案,你只需要在php代码中编写响应页面元素的事件,当a标签出现在地址栏时,php向数据库发送网页的请求。
这就自动获取了你想要的那个网页,调用网页的函数进行操作,完成它的预期。一、原理1.创建php对象根据你设定的页面元素,创建一个php对象。这个对象继承了php5开始的两个基本扩展对象,即new标准模式和php5.0开始的基本模式。用于存储数据;它是index和location变量的前缀,用于获取元素对象和路径。
示例如下:functiongetmethod(url){//defineanobjectforaphpobject//newtoinitialize.//createawriteandcompressinguniformlyautomatically.//builderif(url){//writeormakesomeelementseasiertowrite//automatically..}//compresswhenyouwritecode(e.g.:request.urlstring("")),//withoutreadandcompressations.//initializetheobjectatintimateinitialization.//outputobjectwith:'/post()/'//note:theobjectstartswith'automatically'butisusedforcompressingonuri.//createthenewpublicmethodindex;//usetheurlstringvalue(that'sused)createanadminname();//usetheurlstringvalues(that'sused)setargs();//settheobject'sprivatepropertiestotheurlstring.//outputobjectwith:''/'''//addandmaptheobjectnamecommentinapostsetmy{}my{}or{}//addandcompresstheurlstrings.//mapapostorapostcontainingtheobject.//thismapneedstobeeasilycompressed.//addandcompresstheurlstrings.//buildedasadllfile.//addandcompressthetheurlstrings.//newtheobjectf。
php 抓取网页内容(php主机域名源码、使用fopen获得网页源代码。。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-03-15 12:18
1、使用file_get_contents 获取网页源代码。这个方法是最常用的php主机域名源码。只需要两行代码,非常简单方便。
2php主机域名源码,使用fopen获取网页源码。用这种方法的人很多,但是代码有点多。
3php主机域名源码,使用curl获取网页源码。使用curl获取网页源代码的做法,经常被要求较高的人使用。比如在爬取网页内容的同时需要获取网页的头部信息时,以及使用ENCODING编码、使用USERAGENT等。所谓网页代码,是指网页制作过程中需要用到的一些特殊的“语言”。设计师组织和安排这些“语言”来创建网页,然后浏览器“翻译”代码。是我们最终看到的。制作网页时常用的代码有HTML、JavaScript、ASP、PHP、CGI等,其中,
一个域名绑定的网站源码也可以用在其他域名上?
不接受正式的操作。不久前,一些网站打开,变成了另一个网站。此行为是不道德的 PHP 主机域名源代码。
第一步是将php主机域名的源码添加到你要使用的域名解析平台的国外空间。通常,做一个A记录,即IP和主机名的对应关系就足够了。只需要知道web服务器的IP就可以解析
第二部分,在外域的控制面板中,在外域绑定你要使用的域名
完成这两步后,等待DNS解析生效即可访问。当然,您需要将网站程序源代码上传到国外空间进行安装,然后才能打开站点。
注意:域名解析生效的时间因DNS提供商而异。它可以快几秒钟或慢几小时。可以通过ping+域名命令查看解析是否生效。 查看全部
php 抓取网页内容(php主机域名源码、使用fopen获得网页源代码。。)
1、使用file_get_contents 获取网页源代码。这个方法是最常用的php主机域名源码。只需要两行代码,非常简单方便。
2php主机域名源码,使用fopen获取网页源码。用这种方法的人很多,但是代码有点多。
3php主机域名源码,使用curl获取网页源码。使用curl获取网页源代码的做法,经常被要求较高的人使用。比如在爬取网页内容的同时需要获取网页的头部信息时,以及使用ENCODING编码、使用USERAGENT等。所谓网页代码,是指网页制作过程中需要用到的一些特殊的“语言”。设计师组织和安排这些“语言”来创建网页,然后浏览器“翻译”代码。是我们最终看到的。制作网页时常用的代码有HTML、JavaScript、ASP、PHP、CGI等,其中,
一个域名绑定的网站源码也可以用在其他域名上?
不接受正式的操作。不久前,一些网站打开,变成了另一个网站。此行为是不道德的 PHP 主机域名源代码。
第一步是将php主机域名的源码添加到你要使用的域名解析平台的国外空间。通常,做一个A记录,即IP和主机名的对应关系就足够了。只需要知道web服务器的IP就可以解析
第二部分,在外域的控制面板中,在外域绑定你要使用的域名
完成这两步后,等待DNS解析生效即可访问。当然,您需要将网站程序源代码上传到国外空间进行安装,然后才能打开站点。
注意:域名解析生效的时间因DNS提供商而异。它可以快几秒钟或慢几小时。可以通过ping+域名命令查看解析是否生效。
php 抓取网页内容(php抓取网页内容20vci9iffhf=(二维码自动识别))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-03-12 23:07
php抓取网页内容ahr0cdovl3dlaxhpbi5xcs5jb20vci9iffhf014n2rxalyuky46hyotixxymw==(二维码自动识别)
zendamobile首页demo,可以根据你的昵称进行关键词采集,
去你直接搜这些网站的源代码得到的网页地址直接访问就可以看到该页面的下载地址了
去百度搜索2048,谷歌的应该更牛吧。
全部都是采集来的
php开发的hypertextviolation
【图】
百度2048
php实现:he#2048其实,更简单直接的是拿sitemap做图像识别和图片分析,
这个应该可以通过python里的pil库来实现pillow库(图像处理)pillow(图像处理)。要实现这个页面,首先要理解下js代码。
豆瓣有大牛做过2048这个游戏,你可以下一个研究下,至于ahr,
第一步:把搜索的昵称复制进去,然后加上下划线第二步:点击,
我想问下,
2048网站可以用python(python)一键爬取,
ahr0cdovl3dlaxhpbi5xcs5jb20vci9dkpwd25bk2mxjyugjjyotixnymw==(二维码自动识别) 查看全部
php 抓取网页内容(php抓取网页内容20vci9iffhf=(二维码自动识别))
php抓取网页内容ahr0cdovl3dlaxhpbi5xcs5jb20vci9iffhf014n2rxalyuky46hyotixxymw==(二维码自动识别)
zendamobile首页demo,可以根据你的昵称进行关键词采集,
去你直接搜这些网站的源代码得到的网页地址直接访问就可以看到该页面的下载地址了
去百度搜索2048,谷歌的应该更牛吧。
全部都是采集来的
php开发的hypertextviolation
【图】
百度2048
php实现:he#2048其实,更简单直接的是拿sitemap做图像识别和图片分析,
这个应该可以通过python里的pil库来实现pillow库(图像处理)pillow(图像处理)。要实现这个页面,首先要理解下js代码。
豆瓣有大牛做过2048这个游戏,你可以下一个研究下,至于ahr,
第一步:把搜索的昵称复制进去,然后加上下划线第二步:点击,
我想问下,
2048网站可以用python(python)一键爬取,
ahr0cdovl3dlaxhpbi5xcs5jb20vci9dkpwd25bk2mxjyugjjyotixnymw==(二维码自动识别)
php 抓取网页内容(php抓取网页内容用flash写页面在xml或json中存储)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-09 18:05
php抓取网页内容用flash写页面,在xml或json中存储就可以,相关的模块网上很多,此处不做赘述。优势是可以局部缓存在页面上,大大加快页面加载速度。劣势是代码很长,比如有些表单用方括号,有些用大括号,在代码量变大的情况下就有可能写不下,另外在对服务器policy的操作上也有可能失败,比如在log中记录一些敏感字段。
为了让网页多次加载,所以要使用加载算法保证不重复加载,用最简单的,如使用循环。上面都是php原生的特性,还可以使用coyote等框架封装。不过我觉得目前页面重复加载的现象严重,提供一些新的特性也是有必要的。可以使用缓存来减少重复加载。但是,最后一定要对中间的policy机制有比较好的设计。
我的做法是把html变成纯php程序,程序中解析加载页面。loadingphp程序中是通过循环来解析加载html。一段代码可以定义成一个框架比如async/await。这样就避免了在多线程下的加载程序,速度应该比workerman快得多,而且能把url改成哪个来加载,也能避免url被发送到前端后,前端对url定义再解析导致http报文内容丢失的问题。</p>
主要应该考虑这么几个因素:1.资源按照url解析后能够方便在缓存中恢复;2.资源能够方便定义为哪个线程继续加载,哪个线程暂停加载,以确保网络不会丢失;3.对于文件,能够在根目录生成文件名然后缓存中加载,在子目录内生成文件名在页面中显示。解决效率问题。我所碰到的问题是http协议在解析过程时,会有新文件被生成,而由于页面变长,或其他一些原因,会产生文件的大小增加,造成分布式一致性比较困难。另外页面的颜色等特性也能够应对这个问题。 查看全部
php 抓取网页内容(php抓取网页内容用flash写页面在xml或json中存储)
php抓取网页内容用flash写页面,在xml或json中存储就可以,相关的模块网上很多,此处不做赘述。优势是可以局部缓存在页面上,大大加快页面加载速度。劣势是代码很长,比如有些表单用方括号,有些用大括号,在代码量变大的情况下就有可能写不下,另外在对服务器policy的操作上也有可能失败,比如在log中记录一些敏感字段。
为了让网页多次加载,所以要使用加载算法保证不重复加载,用最简单的,如使用循环。上面都是php原生的特性,还可以使用coyote等框架封装。不过我觉得目前页面重复加载的现象严重,提供一些新的特性也是有必要的。可以使用缓存来减少重复加载。但是,最后一定要对中间的policy机制有比较好的设计。
我的做法是把html变成纯php程序,程序中解析加载页面。loadingphp程序中是通过循环来解析加载html。一段代码可以定义成一个框架比如async/await。这样就避免了在多线程下的加载程序,速度应该比workerman快得多,而且能把url改成哪个来加载,也能避免url被发送到前端后,前端对url定义再解析导致http报文内容丢失的问题。</p>
主要应该考虑这么几个因素:1.资源按照url解析后能够方便在缓存中恢复;2.资源能够方便定义为哪个线程继续加载,哪个线程暂停加载,以确保网络不会丢失;3.对于文件,能够在根目录生成文件名然后缓存中加载,在子目录内生成文件名在页面中显示。解决效率问题。我所碰到的问题是http协议在解析过程时,会有新文件被生成,而由于页面变长,或其他一些原因,会产生文件的大小增加,造成分布式一致性比较困难。另外页面的颜色等特性也能够应对这个问题。
php 抓取网页内容(php抓取网页内容最简单最直接的办法是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-04 14:00
php抓取网页内容最简单最直接的办法是使用第三方的web服务器工具,例如优采云web等工具。
楼上说得很对,先做到能抓取,再谈如何让网页内容永久不改动。现在的抓取软件有很多种模式,你使用其中的其中一种就行。比如你先在代码里面写个writebserver,然后通过这个writebserver再把html的内容写入内存。其他常见的模式主要是这几种:1.cookie劫持:(把上一页内容发到后台(cookie),然后读取)2.客户端存储:用存储服务器,把抓取结果存到本地,然后通过浏览器开发调用的api进行读取。
注意:这种模式有可能一次抓取内容有上千台电脑,所以不适合抓取多台电脑的内容。3.伪造http请求:通过第三方程序伪造请求出来。要求可以是自己写个。4.采集框架(采集框架最基本功能就是抓取和转换网站信息),不做说明,只谈一下采集框架的爬虫和采集方法。下面有个url,是重点,php爬虫常用的目标url是。
这个框架会把这些url中采集比较好的部分抓出来。那么当内容url中,有大量的爬虫采集好的内容时,就可以根据网站的规则进行逆爬。基本爬虫是程序从a网站抓取出来的,或者点一下,直接从文档b爬取出来。文档b要想更完整,就需要用到xpath转换工具,urlencode,xpath修正工具。xpath修正工具的应用请参考xpathprofiling,优酷视频里提到的xpath修正工具。
对于网站这种十分复杂和庞大的网站,你自己或者找人都很难抓全所有资源,这时候就可以用到xpath抓取工具。再下面就是进行xpath转换工具的抓取。重点就是找到php代码中有哪些成对的xpath,可以通过requests来找到,或者通过第三方工具,web3d,通过对象来抓取。 查看全部
php 抓取网页内容(php抓取网页内容最简单最直接的办法是什么?)
php抓取网页内容最简单最直接的办法是使用第三方的web服务器工具,例如优采云web等工具。
楼上说得很对,先做到能抓取,再谈如何让网页内容永久不改动。现在的抓取软件有很多种模式,你使用其中的其中一种就行。比如你先在代码里面写个writebserver,然后通过这个writebserver再把html的内容写入内存。其他常见的模式主要是这几种:1.cookie劫持:(把上一页内容发到后台(cookie),然后读取)2.客户端存储:用存储服务器,把抓取结果存到本地,然后通过浏览器开发调用的api进行读取。
注意:这种模式有可能一次抓取内容有上千台电脑,所以不适合抓取多台电脑的内容。3.伪造http请求:通过第三方程序伪造请求出来。要求可以是自己写个。4.采集框架(采集框架最基本功能就是抓取和转换网站信息),不做说明,只谈一下采集框架的爬虫和采集方法。下面有个url,是重点,php爬虫常用的目标url是。
这个框架会把这些url中采集比较好的部分抓出来。那么当内容url中,有大量的爬虫采集好的内容时,就可以根据网站的规则进行逆爬。基本爬虫是程序从a网站抓取出来的,或者点一下,直接从文档b爬取出来。文档b要想更完整,就需要用到xpath转换工具,urlencode,xpath修正工具。xpath修正工具的应用请参考xpathprofiling,优酷视频里提到的xpath修正工具。
对于网站这种十分复杂和庞大的网站,你自己或者找人都很难抓全所有资源,这时候就可以用到xpath抓取工具。再下面就是进行xpath转换工具的抓取。重点就是找到php代码中有哪些成对的xpath,可以通过requests来找到,或者通过第三方工具,web3d,通过对象来抓取。
php 抓取网页内容(PHP中抓取网页内容的实例详解PHP教程方法:PHP使用file_get_contents方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2022-02-26 12:16
《PHP应用:用php抓取网页内容的详细示例》的要点:
本文介绍PHP应用:详细讲解php中抓取网页内容的例子,希望对你有所帮助。如有疑问,您可以联系我们。
PHP教程php中抓取网页内容的例子详解
PHP教程方法一:
PHP教程使用file_get_contents方法实现
PHP教程
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$html = file_get_contents($url);
//如果出现中文乱码使用下面代码
//$getcontent = iconv("gb2312", "utf-8",$html);
echo "".$html."";
PHP教程代码很简单,一看就懂,不用解释。
PHP教程方法二:
PHP教程使用curl实现
PHP教程
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
echo "".$html."";
PHP教程
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
PHP教程添加这段代码表示如果请求被重定向,则可以访问最终的请求页面,否则请求的结果将显示如下:
PHP教程
Object moved
Object MovedThis object may be found here.
如果您对PHP教程有任何疑问,请留言或到本站社区交流讨论。感谢您的阅读。我希望它可以帮助大家。感谢您对本站的支持! 查看全部
php 抓取网页内容(PHP中抓取网页内容的实例详解PHP教程方法:PHP使用file_get_contents方法)
《PHP应用:用php抓取网页内容的详细示例》的要点:
本文介绍PHP应用:详细讲解php中抓取网页内容的例子,希望对你有所帮助。如有疑问,您可以联系我们。
PHP教程php中抓取网页内容的例子详解
PHP教程方法一:
PHP教程使用file_get_contents方法实现
PHP教程
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$html = file_get_contents($url);
//如果出现中文乱码使用下面代码
//$getcontent = iconv("gb2312", "utf-8",$html);
echo "".$html."";
PHP教程代码很简单,一看就懂,不用解释。
PHP教程方法二:
PHP教程使用curl实现
PHP教程
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
echo "".$html."";
PHP教程
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
PHP教程添加这段代码表示如果请求被重定向,则可以访问最终的请求页面,否则请求的结果将显示如下:
PHP教程
Object moved
Object MovedThis object may be found here.
如果您对PHP教程有任何疑问,请留言或到本站社区交流讨论。感谢您的阅读。我希望它可以帮助大家。感谢您对本站的支持!
php 抓取网页内容(什么是搜索引擎蜘蛛?搜索引擎是如何通过蜘蛛对网站进行收录和排名的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-21 04:05
我们都知道网络推广的最终目的是带来流量、排名和订单,所以最关键的前提是搜索引擎能做好你的网站和文章收录 . 然而,当面对收录的效果不佳时,很多小伙伴不知道为什么,很大程度上是因为他们不了解一个关键点——搜索引擎蜘蛛。蜘蛛
一、什么是搜索引擎蜘蛛?
搜索引擎 收录 和 网站 是如何通过爬虫来排名的?我们怎样才能提高蜘蛛爬行的效果呢?
的确,用白话理解,互联网可以理解为一个巨大的“蜘蛛网”,搜索引擎蜘蛛类似于实际的“机器人”。
蜘蛛的主要任务是浏览庞大的蜘蛛网(Internet)中的信息,然后将信息抓取到搜索引擎的服务器上,建立索引库。这就像一个机器人浏览我们的 网站 并将内容保存到它自己的计算机上。
每个独立的搜索引擎都会有自己的网络爬虫爬虫。蜘蛛爬虫跟随网页中的超链接分析,不断访问和爬取更多的网页。抓取的网页称为网页快照。不用说,搜索引擎蜘蛛会定期抓取网页。
如下:
1.权重优先是指先链接权重,然后结合深度优先和广度优先策略进行抓取。例如,如果链接的权重还不错,则先使用深度;如果重量非常低,请先使用宽度。
2.蜘蛛深度爬取是指蜘蛛找到要爬取的链接,一直往前走,直到最深的层次不能再爬取,然后回到原来的爬取页面,再爬取下一个链接的过程. 就像从网站的首页爬到网站的第一个栏目页,然后通过栏目页爬取一个内容页,然后跳出首页,再爬到第二个网站.
3.蜘蛛广度爬取是指蜘蛛爬取一个页面时存在多个链接,而不是一个链接的深度爬取。然后爬取所有栏目页下的二级栏目或内容页,也就是逐层爬取的方式,而不是一层一层的爬取方式。
4.可以从字面上理解。因为搜索引擎主要使用单次重访和完整重访。所以我们在做网站内容的时候,一定要记得定期维护每日更新,这样蜘蛛才能更快的访问和爬取更多的收录。蜘蛛
二、搜索引擎蜘蛛如何爬取,如何吸引蜘蛛爬取页面
搜索引擎的工作过程大致可以分为三个阶段:
(1)爬取和爬取:搜索引擎蜘蛛通过跟踪链接发现和访问页面,读取页面的HTML代码,并将其存储在数据库中。
(2)预处理:索引程序对抓取到的页面数据进行文本提取、中文分词、索引、倒排索引,供排名程序调用。
(3)排名:用户输入查询词(关键词)后,排名程序调用索引数据,计算相关度,然后生成一定格式的搜索结果页面。
搜索引擎如何工作 爬取和爬取是搜索引擎完成数据采集任务的第一步。搜索引擎用来抓取页面的程序称为蜘蛛
一个合格的SEOer,如果他想让他的更多页面成为收录,他必须设法吸引蜘蛛爬行。
蜘蛛抓取页面有几个因素:
(1)网站和页面的权重,质量高、时间长的网站一般认为权重高,爬取深度高。会更多。
(2)页面的更新频率,蜘蛛每次爬取都会存储页面数据。如果第二次和第三次爬取和第一次一样,说明没有更新。随着时间的推移,蜘蛛不会频繁爬取你的页面,如果内容更新频繁,蜘蛛会频繁访问该页面以爬取新页面。
(3)传入链接,无论是内部链接还是外部链接,为了被蜘蛛抓取,必须有一个入站链接才能进入该页面,否则蜘蛛将不知道该页面的存在。
(4)到首页的点击距离,一般网站上权重最高的就是首页,大部分外链都会指向首页,所以访问频率最高的页面是spiders是首页,点击距离越近,页面权限越高,被爬取的几率越大。
吸引百度蜘蛛 如何吸引蜘蛛爬我们的页面?
坚持经常更新网站内容,最好是高质量的原创内容。
主动将我们的新页面提供给搜索引擎,让蜘蛛更快找到,比如百度的链接提交、爬取诊断等。
搭建外部链接,可以和相关网站交换链接,可以去其他平台发布指向自己的优质文章页面,内容要相关。
制作网站maps,每个网站应该有一个sitemap,网站所有页面都在sitemap中,方便蜘蛛抓取。
三、搜索引擎蜘蛛SPIDER爬不起来的原因分析
1.服务器连接异常
服务器连接异常有两种情况:一种是网站不稳定,百度蜘蛛在尝试连接你的网站服务器时暂时无法连接;另一个是百度蜘蛛一直无法连接到你的网站服务器。
服务器连接异常的原因通常是你的网站服务器太大,过载。您的 网站 也可能运行不正常。请检查网站的web服务器(如apache、iis)是否安装并运行正常,并使用浏览器检查主页是否可以正常访问。您的网站 和主机也可能阻止了百度蜘蛛的访问,您需要检查您的网站 和主机的防火墙。
2.网络运营商异常
网络运营商有两种:中国电信和中国联通。百度蜘蛛无法通过中国电信或中国网通访问您的网站。如果出现这种情况,需要联系网络服务运营商,或者购买双线服务空间或者购买cdn服务。
3.DNS 异常
当百度蜘蛛无法解析您的 网站 IP 时,会出现 DNS 异常。可能你的网站IP地址不对,或者域名服务商封杀了百度蜘蛛。请使用 WHOIS 或主机检查您的 网站IP 地址是否正确且可解析。如果不正确或无法解决,请联系域名注册商更新您的 IP 地址。
4.IP 阻塞
IP禁令是:限制网络的出口IP地址,禁止该IP段的用户访问内容,这里专门禁止百度spiderIP。仅当您的网站 不希望百度蜘蛛访问时才需要此设置。如果您想让百度蜘蛛访问您的网站,请检查相关设置中是否误添加了百度蜘蛛IP。也有可能是你网站所在的空间服务商封杀了百度IP。在这种情况下,您需要联系服务提供商更改设置。
5.UA 被禁止
UA即User-Agent,服务器通过UA识别访问者。当网站返回异常页面(如402、500)或跳转到其他页面进行指定UA的访问时,属于UA封禁。当你的网站不想百度时这个设置只有蜘蛛访问需要,如果你想让百度蜘蛛访问你的网站,请检查useragent相关设置中是否有百度蜘蛛UA,并及时修改。
6.死链接
已经无效且无法为用户提供任何有价值信息的页面为死链接,包括协议死链接和内容死链接两种形式。协议死链接,通过页面的TCP协议状态/HTTP协议状态明确表示的死链接,如404、402、502状态等;内容死链接,服务器返回状态正常,但内容已更改为不存在、已删除或需要权限等与原创内容无关的信息页面。
对于死链接,我们建议网站使用协议死链接,通过百度站长平台-死链接工具提交给百度,这样百度可以更快的找到死链接,减少死链接对用户和搜索引擎的负面影响。
7.异常跳转
将网络请求重定向到另一个位置是跳转,异常跳转是指以下几种情况。
1.当前页面为无效页面(内容已被删除、死链接等),直接跳转到上一个目录或首页。百度建议站长删除无效页面的入口超链接。
2.跳转到错误或无效页面。
Tips:对于长时间跳转到其他域名的情况,如网站换域名,百度推荐使用201跳转协议进行设置。
8.其他异常
1.百度referrer异常:网页返回的行为与来自百度的referrer的正常内容不同。
2.百度UA异常:网页返回百度UA的行为与页面原创内容不同。
3.JS跳转异常:网页加载了百度无法识别的JS跳转代码,导致用户通过搜索结果进入页面后跳转。
4.压力过大导致的意外封禁:百度会根据网站规模、流量等信息自动设置合理的抓取压力。但在异常情况下,如压力控制异常时,服务器会根据自身负载进行保护性的偶尔封禁。在这种情况下,请在返回码中返回 502(表示“服务不可用”),这样百度蜘蛛会在一段时间后再次尝试抓取链接。如果 网站 是空闲的,它会被成功抓到 Pick。蜘蛛
四、使用蜘蛛池尽快让新的网站成为收录
根据多年搜索引擎营销推广的工作经验,当一个新网站接入搜索引擎时,就会进入沙盒期。一些新网站能够迅速被搜索引擎所利用,关键是能够在短时间内走出沙盒期。收录以下元素:
1、技术装备
我们知道搜索引擎的收录越来越方便快捷,一般人必须把网站标准化为SEO。从技术角度来看,您必须:
① 非常重视网页的客户体验,包括视觉效果和网页的加载率。
②创建站点地图,优先考虑网页,合理流式传输相关URL。
③ 配备百度熊掌ID,可以快速向百度搜索官方网站提交优质网址。
内容,对于新站来说,是必备的标准化设备。
使用蜘蛛池加速新的 网站收录
2、网页质量
对于搜索引擎收录,网页的质量是主要的评估标准。理论上,它是由几个层次组成的。对于这些收入比较快的新网站网站,除了做百度网址提交之外,还重点关注以下几个方面:
①时事
对于新站来说,如果想让搜索引擎收录越来越快,经过多年的具体测试,人们发现更容易快速收录制造业的热门新闻.
他的及时搜索关键词 量会很高,或相对平均,但这不是关键因素。
②主题内容
从专业和权威的角度,设置一个网站内部的小专题讲座,可以最大程度的和某个制造业进行讨论,最重要的是相关的内容,一般是多水平有机化学成分。
例如:来自KOL的意见、多年制造业组织权威专家的总结、其社会发展科研团队对相关数据和信息的应用等。
③内容多样化
对于网页的多样化,通常由多媒体系统元素组成,比如:小视频、数据图表、高清图片等,这些都是视频的介入,显得很重要。
使用蜘蛛池加速新的 网站收录
3、外部资源
对于搜索引擎收录来说,这里人们所指的外部资源一般是指外部链接。如果你发现一个新网站在早期发布,它的收录和排名会迅速上升,甚至是垂直、折线类型的指数值图,那么关键元素就是外部链接。
这不一定是基于高质量的反向链接,在某些情况下也是基于总数,人们普遍建议选择前一种。蜘蛛
4、站群排水方式
站群,即一个人或一个群体实际上操作了几个URL,目的是为了根据搜索引擎获得大量的总流量,或者偏向同一个URL的连接以提高自然排名。从2005年到2012年,一些中国SEO人员明确提出了站群的定义:几个单独的网站域名(包括二级域名)之间的统一管理方式和关系。2008年初,站群软件开发者开发设计了一种更实用的URL采集方式,即根据关键字进行网站内容的自动采集。以前的采集方法是写标准方法。
5、蜘蛛池排水法
蜘蛛池是由网站 域名组成的一堆站群。在每一个网站下,都转换成大量的网页(一堆文字内容相互组成),页面设计和一切正常网页没有太大区别。因为每个网站都有大量的网页,搜索引擎蜘蛛爬取所有站群的总量也是巨大的。将搜索引擎蜘蛛引入非收录的网页,就是在站群所有普通网页的模板中打开一个单独的DIV。插件外没有收录网页连接,而且web服务器也没有设置缓存文件,每次搜索引擎蜘蛛浏览,DIV中呈现的这方面的连接都是不同的。简而言之, 查看全部
php 抓取网页内容(什么是搜索引擎蜘蛛?搜索引擎是如何通过蜘蛛对网站进行收录和排名的)
我们都知道网络推广的最终目的是带来流量、排名和订单,所以最关键的前提是搜索引擎能做好你的网站和文章收录 . 然而,当面对收录的效果不佳时,很多小伙伴不知道为什么,很大程度上是因为他们不了解一个关键点——搜索引擎蜘蛛。蜘蛛
一、什么是搜索引擎蜘蛛?
搜索引擎 收录 和 网站 是如何通过爬虫来排名的?我们怎样才能提高蜘蛛爬行的效果呢?
的确,用白话理解,互联网可以理解为一个巨大的“蜘蛛网”,搜索引擎蜘蛛类似于实际的“机器人”。
蜘蛛的主要任务是浏览庞大的蜘蛛网(Internet)中的信息,然后将信息抓取到搜索引擎的服务器上,建立索引库。这就像一个机器人浏览我们的 网站 并将内容保存到它自己的计算机上。
每个独立的搜索引擎都会有自己的网络爬虫爬虫。蜘蛛爬虫跟随网页中的超链接分析,不断访问和爬取更多的网页。抓取的网页称为网页快照。不用说,搜索引擎蜘蛛会定期抓取网页。
如下:
1.权重优先是指先链接权重,然后结合深度优先和广度优先策略进行抓取。例如,如果链接的权重还不错,则先使用深度;如果重量非常低,请先使用宽度。
2.蜘蛛深度爬取是指蜘蛛找到要爬取的链接,一直往前走,直到最深的层次不能再爬取,然后回到原来的爬取页面,再爬取下一个链接的过程. 就像从网站的首页爬到网站的第一个栏目页,然后通过栏目页爬取一个内容页,然后跳出首页,再爬到第二个网站.
3.蜘蛛广度爬取是指蜘蛛爬取一个页面时存在多个链接,而不是一个链接的深度爬取。然后爬取所有栏目页下的二级栏目或内容页,也就是逐层爬取的方式,而不是一层一层的爬取方式。
4.可以从字面上理解。因为搜索引擎主要使用单次重访和完整重访。所以我们在做网站内容的时候,一定要记得定期维护每日更新,这样蜘蛛才能更快的访问和爬取更多的收录。蜘蛛
二、搜索引擎蜘蛛如何爬取,如何吸引蜘蛛爬取页面
搜索引擎的工作过程大致可以分为三个阶段:
(1)爬取和爬取:搜索引擎蜘蛛通过跟踪链接发现和访问页面,读取页面的HTML代码,并将其存储在数据库中。
(2)预处理:索引程序对抓取到的页面数据进行文本提取、中文分词、索引、倒排索引,供排名程序调用。
(3)排名:用户输入查询词(关键词)后,排名程序调用索引数据,计算相关度,然后生成一定格式的搜索结果页面。
搜索引擎如何工作 爬取和爬取是搜索引擎完成数据采集任务的第一步。搜索引擎用来抓取页面的程序称为蜘蛛
一个合格的SEOer,如果他想让他的更多页面成为收录,他必须设法吸引蜘蛛爬行。
蜘蛛抓取页面有几个因素:
(1)网站和页面的权重,质量高、时间长的网站一般认为权重高,爬取深度高。会更多。
(2)页面的更新频率,蜘蛛每次爬取都会存储页面数据。如果第二次和第三次爬取和第一次一样,说明没有更新。随着时间的推移,蜘蛛不会频繁爬取你的页面,如果内容更新频繁,蜘蛛会频繁访问该页面以爬取新页面。
(3)传入链接,无论是内部链接还是外部链接,为了被蜘蛛抓取,必须有一个入站链接才能进入该页面,否则蜘蛛将不知道该页面的存在。
(4)到首页的点击距离,一般网站上权重最高的就是首页,大部分外链都会指向首页,所以访问频率最高的页面是spiders是首页,点击距离越近,页面权限越高,被爬取的几率越大。
吸引百度蜘蛛 如何吸引蜘蛛爬我们的页面?
坚持经常更新网站内容,最好是高质量的原创内容。
主动将我们的新页面提供给搜索引擎,让蜘蛛更快找到,比如百度的链接提交、爬取诊断等。
搭建外部链接,可以和相关网站交换链接,可以去其他平台发布指向自己的优质文章页面,内容要相关。
制作网站maps,每个网站应该有一个sitemap,网站所有页面都在sitemap中,方便蜘蛛抓取。
三、搜索引擎蜘蛛SPIDER爬不起来的原因分析
1.服务器连接异常
服务器连接异常有两种情况:一种是网站不稳定,百度蜘蛛在尝试连接你的网站服务器时暂时无法连接;另一个是百度蜘蛛一直无法连接到你的网站服务器。
服务器连接异常的原因通常是你的网站服务器太大,过载。您的 网站 也可能运行不正常。请检查网站的web服务器(如apache、iis)是否安装并运行正常,并使用浏览器检查主页是否可以正常访问。您的网站 和主机也可能阻止了百度蜘蛛的访问,您需要检查您的网站 和主机的防火墙。
2.网络运营商异常
网络运营商有两种:中国电信和中国联通。百度蜘蛛无法通过中国电信或中国网通访问您的网站。如果出现这种情况,需要联系网络服务运营商,或者购买双线服务空间或者购买cdn服务。
3.DNS 异常
当百度蜘蛛无法解析您的 网站 IP 时,会出现 DNS 异常。可能你的网站IP地址不对,或者域名服务商封杀了百度蜘蛛。请使用 WHOIS 或主机检查您的 网站IP 地址是否正确且可解析。如果不正确或无法解决,请联系域名注册商更新您的 IP 地址。
4.IP 阻塞
IP禁令是:限制网络的出口IP地址,禁止该IP段的用户访问内容,这里专门禁止百度spiderIP。仅当您的网站 不希望百度蜘蛛访问时才需要此设置。如果您想让百度蜘蛛访问您的网站,请检查相关设置中是否误添加了百度蜘蛛IP。也有可能是你网站所在的空间服务商封杀了百度IP。在这种情况下,您需要联系服务提供商更改设置。
5.UA 被禁止
UA即User-Agent,服务器通过UA识别访问者。当网站返回异常页面(如402、500)或跳转到其他页面进行指定UA的访问时,属于UA封禁。当你的网站不想百度时这个设置只有蜘蛛访问需要,如果你想让百度蜘蛛访问你的网站,请检查useragent相关设置中是否有百度蜘蛛UA,并及时修改。
6.死链接
已经无效且无法为用户提供任何有价值信息的页面为死链接,包括协议死链接和内容死链接两种形式。协议死链接,通过页面的TCP协议状态/HTTP协议状态明确表示的死链接,如404、402、502状态等;内容死链接,服务器返回状态正常,但内容已更改为不存在、已删除或需要权限等与原创内容无关的信息页面。
对于死链接,我们建议网站使用协议死链接,通过百度站长平台-死链接工具提交给百度,这样百度可以更快的找到死链接,减少死链接对用户和搜索引擎的负面影响。
7.异常跳转
将网络请求重定向到另一个位置是跳转,异常跳转是指以下几种情况。
1.当前页面为无效页面(内容已被删除、死链接等),直接跳转到上一个目录或首页。百度建议站长删除无效页面的入口超链接。
2.跳转到错误或无效页面。
Tips:对于长时间跳转到其他域名的情况,如网站换域名,百度推荐使用201跳转协议进行设置。
8.其他异常
1.百度referrer异常:网页返回的行为与来自百度的referrer的正常内容不同。
2.百度UA异常:网页返回百度UA的行为与页面原创内容不同。
3.JS跳转异常:网页加载了百度无法识别的JS跳转代码,导致用户通过搜索结果进入页面后跳转。
4.压力过大导致的意外封禁:百度会根据网站规模、流量等信息自动设置合理的抓取压力。但在异常情况下,如压力控制异常时,服务器会根据自身负载进行保护性的偶尔封禁。在这种情况下,请在返回码中返回 502(表示“服务不可用”),这样百度蜘蛛会在一段时间后再次尝试抓取链接。如果 网站 是空闲的,它会被成功抓到 Pick。蜘蛛
四、使用蜘蛛池尽快让新的网站成为收录
根据多年搜索引擎营销推广的工作经验,当一个新网站接入搜索引擎时,就会进入沙盒期。一些新网站能够迅速被搜索引擎所利用,关键是能够在短时间内走出沙盒期。收录以下元素:
1、技术装备
我们知道搜索引擎的收录越来越方便快捷,一般人必须把网站标准化为SEO。从技术角度来看,您必须:
① 非常重视网页的客户体验,包括视觉效果和网页的加载率。
②创建站点地图,优先考虑网页,合理流式传输相关URL。
③ 配备百度熊掌ID,可以快速向百度搜索官方网站提交优质网址。
内容,对于新站来说,是必备的标准化设备。
使用蜘蛛池加速新的 网站收录
2、网页质量
对于搜索引擎收录,网页的质量是主要的评估标准。理论上,它是由几个层次组成的。对于这些收入比较快的新网站网站,除了做百度网址提交之外,还重点关注以下几个方面:
①时事
对于新站来说,如果想让搜索引擎收录越来越快,经过多年的具体测试,人们发现更容易快速收录制造业的热门新闻.
他的及时搜索关键词 量会很高,或相对平均,但这不是关键因素。
②主题内容
从专业和权威的角度,设置一个网站内部的小专题讲座,可以最大程度的和某个制造业进行讨论,最重要的是相关的内容,一般是多水平有机化学成分。
例如:来自KOL的意见、多年制造业组织权威专家的总结、其社会发展科研团队对相关数据和信息的应用等。
③内容多样化
对于网页的多样化,通常由多媒体系统元素组成,比如:小视频、数据图表、高清图片等,这些都是视频的介入,显得很重要。
使用蜘蛛池加速新的 网站收录
3、外部资源
对于搜索引擎收录来说,这里人们所指的外部资源一般是指外部链接。如果你发现一个新网站在早期发布,它的收录和排名会迅速上升,甚至是垂直、折线类型的指数值图,那么关键元素就是外部链接。
这不一定是基于高质量的反向链接,在某些情况下也是基于总数,人们普遍建议选择前一种。蜘蛛
4、站群排水方式
站群,即一个人或一个群体实际上操作了几个URL,目的是为了根据搜索引擎获得大量的总流量,或者偏向同一个URL的连接以提高自然排名。从2005年到2012年,一些中国SEO人员明确提出了站群的定义:几个单独的网站域名(包括二级域名)之间的统一管理方式和关系。2008年初,站群软件开发者开发设计了一种更实用的URL采集方式,即根据关键字进行网站内容的自动采集。以前的采集方法是写标准方法。
5、蜘蛛池排水法
蜘蛛池是由网站 域名组成的一堆站群。在每一个网站下,都转换成大量的网页(一堆文字内容相互组成),页面设计和一切正常网页没有太大区别。因为每个网站都有大量的网页,搜索引擎蜘蛛爬取所有站群的总量也是巨大的。将搜索引擎蜘蛛引入非收录的网页,就是在站群所有普通网页的模板中打开一个单独的DIV。插件外没有收录网页连接,而且web服务器也没有设置缓存文件,每次搜索引擎蜘蛛浏览,DIV中呈现的这方面的连接都是不同的。简而言之,
php 抓取网页内容(什么是自动推送工具?百度站长平台提供了四种方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-20 10:29
在网站操作或基于SEO的内容更新需求中,发布文章时,可以选择
将文章的链接推送到百度搜索引擎
, 以便
增强网页的机会 收录
. 就好像百度是公主,而你是丫鬟,你要主动伺候公主吃饭,也许公主可能不喜欢吃你做的饭菜,但偶尔会动筷子。至少比等百度蜘蛛爬你的网页要好,那什么年什么月呢?
如何选择链接提交方式,百度站长平台提供了四种方式。
1、主动推送:最快的提交方式。建议您立即通过此方式将本站新链接推送至百度,以确保新链接能够被百度收录及时发布。
2、自动推送:最方便的提交方式,请在本站每个页面的源码中部署自动推送的JS代码,每次部署代码的页面都会自动推送链接到百度被浏览。可以与主动推送一起使用。
3、sitemap:可以定期将网站链接放入sitemap,然后将sitemap提交给百度。百度会定期爬取检查你提交的站点地图,并处理里面的链接,但是收录速度比主动推送慢。
4、手动提交:一次性提交链接到百度,可以使用这种方式。
以上四种方式可以根据网站的运行情况进行选择。以收录的速度来说,主动推送最好,自动推送次之,但主动推送需要编程,难度较大。现在让我们专注于自动推送。
什么是自动推送工具?自动推送工具解决了什么问题?自动推送JS代码是百度站长平台最新推出的轻量级链接提交组件。站长只需要将自动推送的JS代码放置在网站各个页面的源码中即可。当页面被访问时,会自动推送页面链接。对百度来说,这将有助于百度更快地发现新页面。
为了更快速地发现网站每天产生的最新内容,百度站长平台推出了主动推送工具。产品上线后,有站长反映使用主动推送的技术门槛比较高,所以我们顺势推出了成本更低的JS自动推送工具。一步安装可实现页面自动推送,成本低,利润高。
自动推送最适合 优采云。
自动推送JS代码的安装与统计代码的安装相同。只要你知道如何安装流量统计代码,自动推送JS代码就会被安装。
自动推送代码的安装和原理介绍如下(可以注册登录百度站长平台查看)。
如何安装和使用自动推送代码?来自百度站长平台
站长需要在每个页面的 HTML 代码中收录以下自动推送 JS 代码:
如果站长使用PHP语言开发的网站,可以按照以下步骤操作:
1、创建一个名为“baidu_js_push.php”的文件,文件内容为上述自动推送JS代码;
2、在每个 PHP 模板页面文件的标记后添加一行代码:
注1:以上代码是通用的。在华哥的实践中,这段代码一开始就放在后面,也就是网页头部的源码位置,一直运行正常。后来有一段时间优化网站的速度,把这段代码放在最下面,同时压缩网页源代码,导致自动推送功能失效,应该注意的。如果发现自动推送代码失败,请检查安装位置。
注2:自动推送不是完全自动的。发布文章后,需要点击浏览新发布的文章,触发文章源码中的JS代码。实现链接自动提交和推送功能(大流量的网站不需要,因为用户会帮你点击)。
如果百度自动推码功能生效,登录站长平台,可以看到类似下图的数据图表。
(文小云华可以浏览更多SEO类文章个人网站:) 查看全部
php 抓取网页内容(什么是自动推送工具?百度站长平台提供了四种方式)
在网站操作或基于SEO的内容更新需求中,发布文章时,可以选择
将文章的链接推送到百度搜索引擎
, 以便
增强网页的机会 收录
. 就好像百度是公主,而你是丫鬟,你要主动伺候公主吃饭,也许公主可能不喜欢吃你做的饭菜,但偶尔会动筷子。至少比等百度蜘蛛爬你的网页要好,那什么年什么月呢?
如何选择链接提交方式,百度站长平台提供了四种方式。
1、主动推送:最快的提交方式。建议您立即通过此方式将本站新链接推送至百度,以确保新链接能够被百度收录及时发布。
2、自动推送:最方便的提交方式,请在本站每个页面的源码中部署自动推送的JS代码,每次部署代码的页面都会自动推送链接到百度被浏览。可以与主动推送一起使用。
3、sitemap:可以定期将网站链接放入sitemap,然后将sitemap提交给百度。百度会定期爬取检查你提交的站点地图,并处理里面的链接,但是收录速度比主动推送慢。
4、手动提交:一次性提交链接到百度,可以使用这种方式。
以上四种方式可以根据网站的运行情况进行选择。以收录的速度来说,主动推送最好,自动推送次之,但主动推送需要编程,难度较大。现在让我们专注于自动推送。
什么是自动推送工具?自动推送工具解决了什么问题?自动推送JS代码是百度站长平台最新推出的轻量级链接提交组件。站长只需要将自动推送的JS代码放置在网站各个页面的源码中即可。当页面被访问时,会自动推送页面链接。对百度来说,这将有助于百度更快地发现新页面。
为了更快速地发现网站每天产生的最新内容,百度站长平台推出了主动推送工具。产品上线后,有站长反映使用主动推送的技术门槛比较高,所以我们顺势推出了成本更低的JS自动推送工具。一步安装可实现页面自动推送,成本低,利润高。
自动推送最适合 优采云。
自动推送JS代码的安装与统计代码的安装相同。只要你知道如何安装流量统计代码,自动推送JS代码就会被安装。
自动推送代码的安装和原理介绍如下(可以注册登录百度站长平台查看)。
如何安装和使用自动推送代码?来自百度站长平台
站长需要在每个页面的 HTML 代码中收录以下自动推送 JS 代码:
如果站长使用PHP语言开发的网站,可以按照以下步骤操作:
1、创建一个名为“baidu_js_push.php”的文件,文件内容为上述自动推送JS代码;
2、在每个 PHP 模板页面文件的标记后添加一行代码:
注1:以上代码是通用的。在华哥的实践中,这段代码一开始就放在后面,也就是网页头部的源码位置,一直运行正常。后来有一段时间优化网站的速度,把这段代码放在最下面,同时压缩网页源代码,导致自动推送功能失效,应该注意的。如果发现自动推送代码失败,请检查安装位置。
注2:自动推送不是完全自动的。发布文章后,需要点击浏览新发布的文章,触发文章源码中的JS代码。实现链接自动提交和推送功能(大流量的网站不需要,因为用户会帮你点击)。
如果百度自动推码功能生效,登录站长平台,可以看到类似下图的数据图表。
(文小云华可以浏览更多SEO类文章个人网站:)
php 抓取网页内容(php抓取网页内容用于数据库传给服务器进行分析和计算)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-18 12:03
php抓取网页内容用于数据库,传给服务器进行分析和计算,服务器返回对应的响应,传到用户界面。不知道你的需求是什么样的?如果只是解析网页并存储到数据库,那用php比较简单的方法有xmlhttprequest、extracturl,如果要抓取页面中的json格式数据,就要用正则等工具。
php抓网页用xmlhttprequest或extracturl,要进行正则匹配什么的肯定要一些编程水平。除了这些,还有json对象、xmlwriter可以抓取。
针对网页的抓取处理需要掌握xml、json、html5、php、laravel等一系列前端框架,以及前端的一些编程水平,就算是只抓取json都不行。
个人认为php抓取网页是可行的,网页太多了,像豆瓣、天涯论坛等都有自己的网页地址,你只要爬取出来网页内容,再用数据库来存储就可以了,至于json和正则这些就交给专业的程序员吧。
php解析json就可以了。
php抓取网页是可行的,目前大多数程序都是解析xml或json格式的网页数据,然后再将网页数据存储到数据库,如果单纯为了爬取网页数据而对php功底没有过多的要求的话,
php还不错啊,抓取些数据也不难。其实你可以看看知乎不是,大神也就是抓取下答案页面。
不,还需要解析出里面的dom结构。 查看全部
php 抓取网页内容(php抓取网页内容用于数据库传给服务器进行分析和计算)
php抓取网页内容用于数据库,传给服务器进行分析和计算,服务器返回对应的响应,传到用户界面。不知道你的需求是什么样的?如果只是解析网页并存储到数据库,那用php比较简单的方法有xmlhttprequest、extracturl,如果要抓取页面中的json格式数据,就要用正则等工具。
php抓网页用xmlhttprequest或extracturl,要进行正则匹配什么的肯定要一些编程水平。除了这些,还有json对象、xmlwriter可以抓取。
针对网页的抓取处理需要掌握xml、json、html5、php、laravel等一系列前端框架,以及前端的一些编程水平,就算是只抓取json都不行。
个人认为php抓取网页是可行的,网页太多了,像豆瓣、天涯论坛等都有自己的网页地址,你只要爬取出来网页内容,再用数据库来存储就可以了,至于json和正则这些就交给专业的程序员吧。
php解析json就可以了。
php抓取网页是可行的,目前大多数程序都是解析xml或json格式的网页数据,然后再将网页数据存储到数据库,如果单纯为了爬取网页数据而对php功底没有过多的要求的话,
php还不错啊,抓取些数据也不难。其实你可以看看知乎不是,大神也就是抓取下答案页面。
不,还需要解析出里面的dom结构。
php 抓取网页内容(php抓取网页内容的步骤:第一步,发起请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-08 09:03
php抓取网页内容的步骤:第一步,发起请求:发起post请求,先执行一次post函数,接着执行一次get函数发起get请求:在浏览器上执行请求,接着才执行post,再接着执行get()第二步,数据准备准备要抓取的网页内容,网上有很多抓取网页内容的教程,可以根据不同网站的要求加入不同的元素和循环语句,有兴趣可以看看,了解下以下流程第三步,显示内容1,将抓取好的内容保存到本地2,分析网页数据,提取出关键信息和关键字段3,最后再处理下数据保存就可以了。
首先要思考这个网站需要抓取什么数据,然后找到合适的web服务(百度),使用正则表达式匹配关键字句,然后提取数据,
php的话其实也可以用正则表达式写简单脚本
据了解nodejs实现抓取比较简单,其实用起来会很复杂。现在很多中小型的企业用户,还是用java比较多,就是因为java的易学易用,而且java已经非常成熟,学起来也比较简单。
上看看有没有你需要的数据,然后集合到自己的产品,
需要有搜索引擎
有可以实现抓取网页的程序。自己开发的话,
最简单的:抓取,然后存起来变成csv,用excel整理,就是表格式。
直接用c语言的话实现方法也有很多种,但总的来说思路都是大同小异,抓包:到页面爬取到这页面的response可以查看下对应的具体处理的函数。网页解析:所谓的网页解析在我看来就是从一个页面的一句话描述从一句话中找出它在该页面对应的具体数据。存储:最简单的就是直接用数据库存储数据。当然还有其他更好的更普遍的方式。 查看全部
php 抓取网页内容(php抓取网页内容的步骤:第一步,发起请求)
php抓取网页内容的步骤:第一步,发起请求:发起post请求,先执行一次post函数,接着执行一次get函数发起get请求:在浏览器上执行请求,接着才执行post,再接着执行get()第二步,数据准备准备要抓取的网页内容,网上有很多抓取网页内容的教程,可以根据不同网站的要求加入不同的元素和循环语句,有兴趣可以看看,了解下以下流程第三步,显示内容1,将抓取好的内容保存到本地2,分析网页数据,提取出关键信息和关键字段3,最后再处理下数据保存就可以了。
首先要思考这个网站需要抓取什么数据,然后找到合适的web服务(百度),使用正则表达式匹配关键字句,然后提取数据,
php的话其实也可以用正则表达式写简单脚本
据了解nodejs实现抓取比较简单,其实用起来会很复杂。现在很多中小型的企业用户,还是用java比较多,就是因为java的易学易用,而且java已经非常成熟,学起来也比较简单。
上看看有没有你需要的数据,然后集合到自己的产品,
需要有搜索引擎
有可以实现抓取网页的程序。自己开发的话,
最简单的:抓取,然后存起来变成csv,用excel整理,就是表格式。
直接用c语言的话实现方法也有很多种,但总的来说思路都是大同小异,抓包:到页面爬取到这页面的response可以查看下对应的具体处理的函数。网页解析:所谓的网页解析在我看来就是从一个页面的一句话描述从一句话中找出它在该页面对应的具体数据。存储:最简单的就是直接用数据库存储数据。当然还有其他更好的更普遍的方式。
php 抓取网页内容(一点python介绍如何编写一个网络爬虫数据数据采集(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-02-05 23:05
)
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本期文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
查看全部
php 抓取网页内容(一点python介绍如何编写一个网络爬虫数据数据采集(图)
)
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本期文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
php 抓取网页内容(php抓取网页内容实现php的formdata数据收集(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-14 07:03
php抓取网页内容实现php的formdata数据收集。php抓取网页内容实现-qthingsq目录和之前的一样,现在保存的是php到gybase数据库。抓取一个大网站的时候,一般保存500条数据,300条数据是尝试抓取。为了抓取速度,使用copy生成代码行数(master分离爬虫的时候)。下面写代码完成抓取抓取网页结构url://链接sum=-normalize(main_set_to_map=function(){show_error('specifiedsetoftransaction.connection')});usesqlite3;selectmap_id,sum,'show_map_error'fromcomponents;show_error('specifiedsetoftransaction.connection');参数:map_id,是要抓取网页唯一标识,位于string.join中保存的地址保存gybase数据库指向对应的gybase文件type,这个大家应该都知道是做什么,不知道的直接看root注释哦license,写入数据库数据库名称及urlsqlite3对应的map_id即爬虫公共的license参数:mysqlinnodbfull_time第一个参数:mysqlinnodb,兼容内存分页(user/password),默认是内存分页(name,page)不是内存分页(class,page)。
默认是100。第二个参数:mysqlfull_time,网页分页(user/password),默认是内存分页(name,page)不是内存分页(class,page)。默认是100。通过登录用户名来判断爬虫是不是分页爬。第三个参数:execute_expires,保存爬虫日期expires=year?expires:month?":"current_field_name+(type+failed_when)默认是year的话,跳转到用户登录页current_field_name="page_name"其中current_field_name="page_name"是php爬虫的固定sql语句之一,字符串,里面写"column_name=$column_name<$field_name",mysql会统计所有用户的最佳浏览行为,如果没有最佳浏览行为,系统会忽略这条记录,重新登录。>>。 查看全部
php 抓取网页内容(php抓取网页内容实现php的formdata数据收集(组图))
php抓取网页内容实现php的formdata数据收集。php抓取网页内容实现-qthingsq目录和之前的一样,现在保存的是php到gybase数据库。抓取一个大网站的时候,一般保存500条数据,300条数据是尝试抓取。为了抓取速度,使用copy生成代码行数(master分离爬虫的时候)。下面写代码完成抓取抓取网页结构url://链接sum=-normalize(main_set_to_map=function(){show_error('specifiedsetoftransaction.connection')});usesqlite3;selectmap_id,sum,'show_map_error'fromcomponents;show_error('specifiedsetoftransaction.connection');参数:map_id,是要抓取网页唯一标识,位于string.join中保存的地址保存gybase数据库指向对应的gybase文件type,这个大家应该都知道是做什么,不知道的直接看root注释哦license,写入数据库数据库名称及urlsqlite3对应的map_id即爬虫公共的license参数:mysqlinnodbfull_time第一个参数:mysqlinnodb,兼容内存分页(user/password),默认是内存分页(name,page)不是内存分页(class,page)。
默认是100。第二个参数:mysqlfull_time,网页分页(user/password),默认是内存分页(name,page)不是内存分页(class,page)。默认是100。通过登录用户名来判断爬虫是不是分页爬。第三个参数:execute_expires,保存爬虫日期expires=year?expires:month?":"current_field_name+(type+failed_when)默认是year的话,跳转到用户登录页current_field_name="page_name"其中current_field_name="page_name"是php爬虫的固定sql语句之一,字符串,里面写"column_name=$column_name<$field_name",mysql会统计所有用户的最佳浏览行为,如果没有最佳浏览行为,系统会忽略这条记录,重新登录。>>。
php 抓取网页内容(搜索引擎把网页抓取到本地(就是搜索引擎的服务器上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-11 11:33
为什么Spider会再次抓取并更新网页?原因是搜索引擎依赖于用户的存在。搜索引擎是否会被人们使用,取决于它是否提供了人们需要的内容。内容越准确及时,用户越多,市场份额越大。越大,它带来的回报就越多。(满足用户需求是搜索引擎公司赚钱的基础,当然也是所有公司赚钱的基础。)
Spider在本地(即在搜索引擎的服务器上)抓取网页后,对该网页进行分析、索引并参与搜索引擎的排名。这并不意味着蜘蛛的使命就完全完成了。因为互联网的内容随时都在变化。即使之前爬取的内容已经被网站的管理员或作者删除,当用户再次通过搜索引擎访问时,结果不正确或不匹配,这显然对搜索引擎来说不是很好的匹配. 不利。
搜索引擎爬取到的本地页面,基本上可以看作是被爬取索引的网页的镜像。也就是说,为了让用户看到最准确的内容,搜索引擎应该确保这个“镜像”页面与互联网上相应网页的内容实时一致。但是,由于互联网内容随时变化,Spider资源有限,实时监控所有索引网页的所有变化显然是不可能也没有必要的(因为有些内容是无关紧要的,用户不需要) . 但是,一些内容更新是必要的。因此,Spider 需要设计一个更新爬取策略,以确保当部分页面呈现给用户时,“镜像” 页面与当时网页的内容没有太大区别。也满足了大部分用户在搜索引擎上的搜索请求。
因此,从用户的角度来看,Spider 必须更加努力地更新和抓取那些已被索引并参与排名的网页。 查看全部
php 抓取网页内容(搜索引擎把网页抓取到本地(就是搜索引擎的服务器上))
为什么Spider会再次抓取并更新网页?原因是搜索引擎依赖于用户的存在。搜索引擎是否会被人们使用,取决于它是否提供了人们需要的内容。内容越准确及时,用户越多,市场份额越大。越大,它带来的回报就越多。(满足用户需求是搜索引擎公司赚钱的基础,当然也是所有公司赚钱的基础。)
Spider在本地(即在搜索引擎的服务器上)抓取网页后,对该网页进行分析、索引并参与搜索引擎的排名。这并不意味着蜘蛛的使命就完全完成了。因为互联网的内容随时都在变化。即使之前爬取的内容已经被网站的管理员或作者删除,当用户再次通过搜索引擎访问时,结果不正确或不匹配,这显然对搜索引擎来说不是很好的匹配. 不利。
搜索引擎爬取到的本地页面,基本上可以看作是被爬取索引的网页的镜像。也就是说,为了让用户看到最准确的内容,搜索引擎应该确保这个“镜像”页面与互联网上相应网页的内容实时一致。但是,由于互联网内容随时变化,Spider资源有限,实时监控所有索引网页的所有变化显然是不可能也没有必要的(因为有些内容是无关紧要的,用户不需要) . 但是,一些内容更新是必要的。因此,Spider 需要设计一个更新爬取策略,以确保当部分页面呈现给用户时,“镜像” 页面与当时网页的内容没有太大区别。也满足了大部分用户在搜索引擎上的搜索请求。
因此,从用户的角度来看,Spider 必须更加努力地更新和抓取那些已被索引并参与排名的网页。

