
php网页抓取标题
php网页抓取标题(手把手教你如何实现日志抓取文章快速抓取标签)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-26 04:03
php网页抓取标题javascript的包抓取url截取页面的url标签的索引列表sqljquery数据库操作的sqlserver语句单页应用的网页特效抓取教程,我相信大家看了不少。也想学着玩,做做实验,但是工具都是开源的,
jswebdebuggermozilla/mozilla-firefox-javascript-debugger
phpurllib2extensionpackagemozilla/mozilla-firefox-javascript-debugger
快速url抓取实验,最近在学快速爬虫,有些看了各种教程,
手把手教你实现日志抓取文章快速抓取这两个新手教程做的比较好
kindle电子书,pdf转换器之类的。基本上很多软件都支持抓包,所以有些真的自己写一个更好,不然,你不知道自己在做什么。
快速抓取网站信息常见的一些方法和工具,来一套。网站全都能抓。
说两个比较简单的,很多高手也会尝试抓取,且不精细,希望能一并学。
1、抓包软件,pandownload无中文界面,可以抓包cookies,
2、抓网站的通用框架,
3、nodejs,爬虫框架,不过对于爬虫难度太大,以及对于http数据包特性理解不够,会一时没有办法处理例子1:抓一个纯数据库网站tr/td的详细信息(../train.text/train.text../train.txt)用了2个抓包工具。一个是pszi,一个是任务宝。下来看看效果。先下载用任务宝抓了一张图,tr/td处不加载图片另外下载了2张图看看效果效果是很好!但是并不清楚tf上究竟有些什么图例如td一共5个元素tr一共4个元素,td下就是说tr/td三个词(对于我们爬虫来说)查看通用技巧包含三方框架,vuecsswordpressjquery后看效果但是查看标签确定没有了下面的结果,可以用框架保存起来效果再下面看两个一抓有点感觉了可以保存了要对照自己项目抓数据用了3个工具。
tengine2上面的方法是对于图片等数据网站的抓包保存,那么对于纯文本数据网站我想到了。保存网站通用所有标签,然后用autoprefixer和pandas等处理比如我要抓所有的单词首字母,一个目录即可抓下来的单词,复制/粘贴到tr/td.txt先复制/粘贴起来以后用图片处理工具进行美化再复制tf处理好的所有标签然后在用上面方法抓数据就可以了分析美化的标签里面的内容结果很细腻分析不同单词后分析属性然后直接粘贴到下面的框架就可以了一些例子用的是任务宝,抓取tr/td.txt直接将数据放在任务宝中处理起来没有问题,但是缺点就是不能进行下载每次进行搜索的话。 查看全部
php网页抓取标题(手把手教你如何实现日志抓取文章快速抓取标签)
php网页抓取标题javascript的包抓取url截取页面的url标签的索引列表sqljquery数据库操作的sqlserver语句单页应用的网页特效抓取教程,我相信大家看了不少。也想学着玩,做做实验,但是工具都是开源的,
jswebdebuggermozilla/mozilla-firefox-javascript-debugger
phpurllib2extensionpackagemozilla/mozilla-firefox-javascript-debugger
快速url抓取实验,最近在学快速爬虫,有些看了各种教程,
手把手教你实现日志抓取文章快速抓取这两个新手教程做的比较好
kindle电子书,pdf转换器之类的。基本上很多软件都支持抓包,所以有些真的自己写一个更好,不然,你不知道自己在做什么。
快速抓取网站信息常见的一些方法和工具,来一套。网站全都能抓。
说两个比较简单的,很多高手也会尝试抓取,且不精细,希望能一并学。
1、抓包软件,pandownload无中文界面,可以抓包cookies,
2、抓网站的通用框架,
3、nodejs,爬虫框架,不过对于爬虫难度太大,以及对于http数据包特性理解不够,会一时没有办法处理例子1:抓一个纯数据库网站tr/td的详细信息(../train.text/train.text../train.txt)用了2个抓包工具。一个是pszi,一个是任务宝。下来看看效果。先下载用任务宝抓了一张图,tr/td处不加载图片另外下载了2张图看看效果效果是很好!但是并不清楚tf上究竟有些什么图例如td一共5个元素tr一共4个元素,td下就是说tr/td三个词(对于我们爬虫来说)查看通用技巧包含三方框架,vuecsswordpressjquery后看效果但是查看标签确定没有了下面的结果,可以用框架保存起来效果再下面看两个一抓有点感觉了可以保存了要对照自己项目抓数据用了3个工具。
tengine2上面的方法是对于图片等数据网站的抓包保存,那么对于纯文本数据网站我想到了。保存网站通用所有标签,然后用autoprefixer和pandas等处理比如我要抓所有的单词首字母,一个目录即可抓下来的单词,复制/粘贴到tr/td.txt先复制/粘贴起来以后用图片处理工具进行美化再复制tf处理好的所有标签然后在用上面方法抓数据就可以了分析美化的标签里面的内容结果很细腻分析不同单词后分析属性然后直接粘贴到下面的框架就可以了一些例子用的是任务宝,抓取tr/td.txt直接将数据放在任务宝中处理起来没有问题,但是缺点就是不能进行下载每次进行搜索的话。
php网页抓取标题(php网页抓取标题——其实php与java原理相似的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-23 19:02
php网页抓取标题——其实php与java原理相似的。工具:excel。实例:成语解释:文件——选择要的标题——复制,黏贴到浏览器里面。方法一:name:失去双子星井字网页截图。company:成语解释地址。sheet:按时间排序。//时间对应自己的名字-大致有名+小名+常常+姓+-常常对应动作。{-html%3a%5e%7b7%7d...%7d...%7d.}//小孩子变个这样就好了。
{-html%3a%5e%7b8%7d...%7d...%7d.}//成语解释地址-两边对应两个link2</a>+link1*/然后firebug,http.io.chrome,ie可以找到链接地址和解析。另外:这个方法很笨拙,需要数据很大才可以。可以先做成list(手机号,邮箱,昵称,电话号码,手机ip,生日,文档名字。
<p>)或者json格式(做好数据之后转化为格式,后面计算二分法)。方法二:上一个方法。直接获取公司名,然后做数组。 查看全部
php网页抓取标题(php网页抓取标题——其实php与java原理相似的)
php网页抓取标题——其实php与java原理相似的。工具:excel。实例:成语解释:文件——选择要的标题——复制,黏贴到浏览器里面。方法一:name:失去双子星井字网页截图。company:成语解释地址。sheet:按时间排序。//时间对应自己的名字-大致有名+小名+常常+姓+-常常对应动作。{-html%3a%5e%7b7%7d...%7d...%7d.}//小孩子变个这样就好了。
{-html%3a%5e%7b8%7d...%7d...%7d.}//成语解释地址-两边对应两个link2</a>+link1*/然后firebug,http.io.chrome,ie可以找到链接地址和解析。另外:这个方法很笨拙,需要数据很大才可以。可以先做成list(手机号,邮箱,昵称,电话号码,手机ip,生日,文档名字。
<p>)或者json格式(做好数据之后转化为格式,后面计算二分法)。方法二:上一个方法。直接获取公司名,然后做数组。
php网页抓取标题(我的博客的导航的内容以下:博客分类导航)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-03-15 19:03
我的博客导航的内容主要分为以下几类:博客分类导航(即放置在页面顶部或左侧/右侧的导航)、标题、翻页/分页导航、和其他导航(文章 内部链接、关键字、友情链接、文章 内容导航等)。
博客分类导航
1、导航的放置会影响博客内容的关注度和二次点击。在设计博客导航之初,只要习惯性地将页面的导航放在头部(header.php)。后来发现网站访问者统计中点击首页(page)的访问者很多,而且点击量大大超过了访问量最大的单个文章的点击量,所以我加了它的导航在头。对于博客文章分类的导航,设计上考虑突出主导航栏,并考虑下拉或弹出分类导航,但不方便用户使用,即使看起来很酷。越简单直接的东西,对访问者的体验就越好。为了突出下面的类别导航,我添加了一个浅蓝色背景来突出显示这部分。我的博客以白色调为主,标题(header.php)中的空白使导航不那么尴尬。
2、博客主要是内容,所以导航的作用不仅仅是分类。使用类别导航,访问者可以快速到达一个类别。但问题是,如果访问者打开这个分类,他能看到他感兴趣的内容吗?事实上,在博客的首页,大部分内容是我们不点击的——也就是说,导航只是吸引访问者找到他感兴趣的内容的工具。对于网站设计师来说,设计导航的目的也在这里,如何帮助访问者找到自己感兴趣的内容,如何吸引访问者的二次点击。
3、基于访问者行为的数据分析,可以确定可以更好地放置导航的位置。我博客的导航在左边有两个原因:一是内容放在左边方便阅读,左边的侧边栏是辅助内容作为导航的一部分,辅助内容保存在一个次要位置;二首先是根据搜索引擎抓取文章的顺序和优化的需要来安排导航的放置。搜索引擎以从上到下、从左到右的路线抓取特定页面。把博客内容放在左边一定要保证标题和内容以及首页显示的TAG部分(详见我的博客计划)有足够的关键词,
4、侧边栏部分。今天我博客的左边部分。有些人写了很多关于侧边栏应该如何放置的文章,而且都说得通。你可以去了解更多。
5、导航的标题描述。我博客的大部分导航语言都是英语。这是因为我认为英语更美观。因此,在英文导航的标题描述中,我尽量使用中文描述,以免英文不好的访客“抢”走。
标题导航
1、如上所述,文章的标题也是一个重要的导航部分,它可以引导访问者尽可能多地找到自己感兴趣的内容,所以文章的标题应该尽量收录文章@关键词,标题是一个文章的核心,搜索引擎也看重一个文章的标题,标题的关键词导航也会帮助提高文章的排名。
2、浏览器标题栏中显示的标题也是一种导航。Wordpress的优化标题设计请参考这篇文章。
3、因为wordpress中的中文标题显示为URL时,文章的“文章缩写名(Post Slug)”会收录一大串%XX字符串,即很不好看,月光博客做了一个可以把中文标题转成拼音的插件
页面/分页导航
其他导航
1、文章 内的链接。这在我的博客中做得不多。看来您可以使用插件在网站上实现关键字链接。
2、标签(标签,关键字)导航。该标记显示在主页 (index.php) 上的每个 文章 下以进行导航。另外,就像xw说的,我觉得有必要把TAG云图放在一边,但是考虑到一边太长的问题,所以放弃了这个想法。
3、友情链接。这部分我在之前的《WordPress 主题设计与访客体验(上)》中也提到过。我组觉得把博客的友情链接放在首页比较好。如果你做的友情链接质量高,一方面可以提高博客的排名,另一方面可以给访问者一个好印象。谁能保证访客会离开你?博客不会再回来了?
4、文章内容导航。从搜索引擎爬取页面的角度来看,搜索引擎就像看文章的人一样,会从第一段看到最后一段,第一段的内容被搜索引擎认为是此文本的次要内容,即出现在搜索引擎快照中的内容。所以这个地方也是比较关键的部分,对于博客内容和访问者的需求来说也是比较关键的部分。
5、RSS 导航。有很多用户经常使用阅读器或聚合订阅工具浏览博客。因此,在侧边栏的导航中,我尝试列出访问者可以轻松订阅的 FEED。 查看全部
php网页抓取标题(我的博客的导航的内容以下:博客分类导航)
我的博客导航的内容主要分为以下几类:博客分类导航(即放置在页面顶部或左侧/右侧的导航)、标题、翻页/分页导航、和其他导航(文章 内部链接、关键字、友情链接、文章 内容导航等)。
博客分类导航
1、导航的放置会影响博客内容的关注度和二次点击。在设计博客导航之初,只要习惯性地将页面的导航放在头部(header.php)。后来发现网站访问者统计中点击首页(page)的访问者很多,而且点击量大大超过了访问量最大的单个文章的点击量,所以我加了它的导航在头。对于博客文章分类的导航,设计上考虑突出主导航栏,并考虑下拉或弹出分类导航,但不方便用户使用,即使看起来很酷。越简单直接的东西,对访问者的体验就越好。为了突出下面的类别导航,我添加了一个浅蓝色背景来突出显示这部分。我的博客以白色调为主,标题(header.php)中的空白使导航不那么尴尬。
2、博客主要是内容,所以导航的作用不仅仅是分类。使用类别导航,访问者可以快速到达一个类别。但问题是,如果访问者打开这个分类,他能看到他感兴趣的内容吗?事实上,在博客的首页,大部分内容是我们不点击的——也就是说,导航只是吸引访问者找到他感兴趣的内容的工具。对于网站设计师来说,设计导航的目的也在这里,如何帮助访问者找到自己感兴趣的内容,如何吸引访问者的二次点击。
3、基于访问者行为的数据分析,可以确定可以更好地放置导航的位置。我博客的导航在左边有两个原因:一是内容放在左边方便阅读,左边的侧边栏是辅助内容作为导航的一部分,辅助内容保存在一个次要位置;二首先是根据搜索引擎抓取文章的顺序和优化的需要来安排导航的放置。搜索引擎以从上到下、从左到右的路线抓取特定页面。把博客内容放在左边一定要保证标题和内容以及首页显示的TAG部分(详见我的博客计划)有足够的关键词,
4、侧边栏部分。今天我博客的左边部分。有些人写了很多关于侧边栏应该如何放置的文章,而且都说得通。你可以去了解更多。
5、导航的标题描述。我博客的大部分导航语言都是英语。这是因为我认为英语更美观。因此,在英文导航的标题描述中,我尽量使用中文描述,以免英文不好的访客“抢”走。
标题导航
1、如上所述,文章的标题也是一个重要的导航部分,它可以引导访问者尽可能多地找到自己感兴趣的内容,所以文章的标题应该尽量收录文章@关键词,标题是一个文章的核心,搜索引擎也看重一个文章的标题,标题的关键词导航也会帮助提高文章的排名。
2、浏览器标题栏中显示的标题也是一种导航。Wordpress的优化标题设计请参考这篇文章。
3、因为wordpress中的中文标题显示为URL时,文章的“文章缩写名(Post Slug)”会收录一大串%XX字符串,即很不好看,月光博客做了一个可以把中文标题转成拼音的插件
页面/分页导航
其他导航
1、文章 内的链接。这在我的博客中做得不多。看来您可以使用插件在网站上实现关键字链接。
2、标签(标签,关键字)导航。该标记显示在主页 (index.php) 上的每个 文章 下以进行导航。另外,就像xw说的,我觉得有必要把TAG云图放在一边,但是考虑到一边太长的问题,所以放弃了这个想法。
3、友情链接。这部分我在之前的《WordPress 主题设计与访客体验(上)》中也提到过。我组觉得把博客的友情链接放在首页比较好。如果你做的友情链接质量高,一方面可以提高博客的排名,另一方面可以给访问者一个好印象。谁能保证访客会离开你?博客不会再回来了?
4、文章内容导航。从搜索引擎爬取页面的角度来看,搜索引擎就像看文章的人一样,会从第一段看到最后一段,第一段的内容被搜索引擎认为是此文本的次要内容,即出现在搜索引擎快照中的内容。所以这个地方也是比较关键的部分,对于博客内容和访问者的需求来说也是比较关键的部分。
5、RSS 导航。有很多用户经常使用阅读器或聚合订阅工具浏览博客。因此,在侧边栏的导航中,我尝试列出访问者可以轻松订阅的 FEED。
php网页抓取标题(php网页抓取标题、关键词抓取:内容搜索相关搜索)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-05 15:02
php网页抓取标题、关键词抓取:内容搜索相关搜索用于从网页抓取信息。抓取器需要自己写,容易记忆。抓取效率提高的非常快!用php来抓取页面实在是太方便了。正则表达式通常使用'/'/'//'来表示,有些字符串没有出现,所以定义一个/标识去掉'/'表示,这些字符并不会被跳转到/。通常,可以用正则来满足自己的需求。
做抓取有些场景下没有办法一次做到通用性,这时候就可以定义一个函数,在不同的场景用不同的函数来进行处理。比如访问短信对应的api页面,这时候的字符串一般只支持字符1,23,这时候如果出现a,b,c,e,i,j,k之类的字符串,会从服务器读取获取,返回的就是'a','b','c','j','k'。于是这个函数中就用到了正则表达式。
抓取策略,如何实现从localhost.host里面抓取的问题先搞清楚,知道你要在什么时候收集什么数据,然后再看用什么方法.
楼上说的很对,楼主的需求是抓取网页的信息,那么只要收集关键字,再通过正则来解析就好了,我最近项目刚开始也在用这个。
可以看看现在比较火的seleniumfiddler抓包。这些工具不好做,最主要就是安装的时候安装麻烦,性能低。 查看全部
php网页抓取标题(php网页抓取标题、关键词抓取:内容搜索相关搜索)
php网页抓取标题、关键词抓取:内容搜索相关搜索用于从网页抓取信息。抓取器需要自己写,容易记忆。抓取效率提高的非常快!用php来抓取页面实在是太方便了。正则表达式通常使用'/'/'//'来表示,有些字符串没有出现,所以定义一个/标识去掉'/'表示,这些字符并不会被跳转到/。通常,可以用正则来满足自己的需求。
做抓取有些场景下没有办法一次做到通用性,这时候就可以定义一个函数,在不同的场景用不同的函数来进行处理。比如访问短信对应的api页面,这时候的字符串一般只支持字符1,23,这时候如果出现a,b,c,e,i,j,k之类的字符串,会从服务器读取获取,返回的就是'a','b','c','j','k'。于是这个函数中就用到了正则表达式。
抓取策略,如何实现从localhost.host里面抓取的问题先搞清楚,知道你要在什么时候收集什么数据,然后再看用什么方法.
楼上说的很对,楼主的需求是抓取网页的信息,那么只要收集关键字,再通过正则来解析就好了,我最近项目刚开始也在用这个。
可以看看现在比较火的seleniumfiddler抓包。这些工具不好做,最主要就是安装的时候安装麻烦,性能低。
php网页抓取标题(我的Xidel可以计算哪些页面上的标题数量的工具或脚本)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-04 04:22
用于计算标题数量(H1、H2、H3 ......)的 SEO/Web 抓取工具
有谁知道可以抓取我的 网站 并计算我的 网站 上每一页上的标题数量的工具或脚本?我想知道我在 网站 上有多少页超过 4 (h1)。我有 Screaming Frog,但它只计算前两个 H1 元素。感谢任何帮助。
我的 Xidel 可以做到这一点,例如:
1
xidel -e 'concat($url,":", count(//h1))' -f '//a[matches(@href,"http://[^/]*/") ]'
-e 参数中的 xpath 表达式告诉它要在哪些页面上计算 h1-tags 和 -f 选项
这是一个特殊的任务,我建议你自己写。您需要的最简单的方法是使用 XPATH 选择器为您提供 h1/h2/h3 标签。
计算标题:
选择您喜欢的任何编程语言。向 网站(Ruby、Perl、PHP)上的页面发出 Web 请求。解析 HTML。调用 XPATH 标头选择器并计算它返回的元素数。
搜索您的 网站:
对所有页面执行步骤 2 到 4(您可能需要抓取的页面队列)。如果要爬取所有页面,就复杂一点:
检索您的主页。选择所有锚标记。从每个 href 中提取 URL 并丢弃任何不指向您的 网站 的 URL。做一个看到 URL 的测试:如果你以前看过它,就把它扔掉,否则它会被抓取。
URL可见测试:
查看 URL 的测试非常简单:只需将您目前看到的所有 URL 添加到 hashmap 中。如果您在 hashmap 中遇到 URL,您可以忽略它。如果它不在 hashmap 中,请将其添加到爬网队列中。hashmap 的键应该是 URL,值应该是某种结构,可以让您保留对标头的统计信息:
1
2
键 = 网址
值 = 结构 { h1Count, h2Count, h3Count...}
应该是这样的。我知道它看起来很多,但它不应该超过几百行代码!
您可以使用 xPather chrome 扩展或类似扩展,并使用 xPath 进行查询:
1
count(//*[self::h1 or self::h2 or self::h3])
谢谢:
我在 Code Canyon 中找到了一个工具:Scrap(e)网站 Analyzer:。
正如您从我的一些评论中看到的那样,配置的数量很少,但到目前为止它运行良好。
谢谢 BeniBela,我也会研究您的解决方案并向您报告。 查看全部
php网页抓取标题(我的Xidel可以计算哪些页面上的标题数量的工具或脚本)
用于计算标题数量(H1、H2、H3 ......)的 SEO/Web 抓取工具
有谁知道可以抓取我的 网站 并计算我的 网站 上每一页上的标题数量的工具或脚本?我想知道我在 网站 上有多少页超过 4 (h1)。我有 Screaming Frog,但它只计算前两个 H1 元素。感谢任何帮助。
我的 Xidel 可以做到这一点,例如:
1
xidel -e 'concat($url,":", count(//h1))' -f '//a[matches(@href,"http://[^/]*/") ]'
-e 参数中的 xpath 表达式告诉它要在哪些页面上计算 h1-tags 和 -f 选项
这是一个特殊的任务,我建议你自己写。您需要的最简单的方法是使用 XPATH 选择器为您提供 h1/h2/h3 标签。
计算标题:
选择您喜欢的任何编程语言。向 网站(Ruby、Perl、PHP)上的页面发出 Web 请求。解析 HTML。调用 XPATH 标头选择器并计算它返回的元素数。
搜索您的 网站:
对所有页面执行步骤 2 到 4(您可能需要抓取的页面队列)。如果要爬取所有页面,就复杂一点:
检索您的主页。选择所有锚标记。从每个 href 中提取 URL 并丢弃任何不指向您的 网站 的 URL。做一个看到 URL 的测试:如果你以前看过它,就把它扔掉,否则它会被抓取。
URL可见测试:
查看 URL 的测试非常简单:只需将您目前看到的所有 URL 添加到 hashmap 中。如果您在 hashmap 中遇到 URL,您可以忽略它。如果它不在 hashmap 中,请将其添加到爬网队列中。hashmap 的键应该是 URL,值应该是某种结构,可以让您保留对标头的统计信息:
1
2
键 = 网址
值 = 结构 { h1Count, h2Count, h3Count...}
应该是这样的。我知道它看起来很多,但它不应该超过几百行代码!
您可以使用 xPather chrome 扩展或类似扩展,并使用 xPath 进行查询:
1
count(//*[self::h1 or self::h2 or self::h3])
谢谢:
我在 Code Canyon 中找到了一个工具:Scrap(e)网站 Analyzer:。
正如您从我的一些评论中看到的那样,配置的数量很少,但到目前为止它运行良好。
谢谢 BeniBela,我也会研究您的解决方案并向您报告。
php网页抓取标题(知乎appurl,谷歌应用商店的url/机器人其实是隐藏股票一样)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-26 02:00
php网页抓取标题发布到百度统计中,下次点击才会有相应的内容爬虫抓取网页内容存储到mysql中,下次就可以抓取网页了用户在百度搜索后,
点击搜索结果页的所有结果(包括按条件分类排序的结果)
爬虫/机器人
其实这个问题可以去p2p,b2c里问,收到假冒的qq号,
下载页地址可以看到购买数
然而真正要验证下载是否安全.爬虫.刷单就可以了.而爬虫并不用验证。
全部内容都是已经安装app.可以通过appurl进行分析.知乎appurl,谷歌应用商店appurl,百度应用商店appurl百度应用商店的appurl中href值为广告,而最终访问这些appurl返回的url不是微信.所以猜测题主可能要分析app的url信息,确保下载到正确的app.
不用下载,
下载app后找源码,可以找到绝大部分app的网站部分代码,如果你恰好有谷歌的帐号,也许里面有一些,在换过来看里面的内容。
当然是通过下载安装文件之后,爬进去。
证监会发布给媒体的公告,其中有提到公告中提到的某些公司的信息是其财务报表中未披露的。就是说某些公司未公布财务报表,或者需要保密而采用保密方式披露。不然把财务报表公布一下就一目了然了,这种做法,就像隐藏股票一样。 查看全部
php网页抓取标题(知乎appurl,谷歌应用商店的url/机器人其实是隐藏股票一样)
php网页抓取标题发布到百度统计中,下次点击才会有相应的内容爬虫抓取网页内容存储到mysql中,下次就可以抓取网页了用户在百度搜索后,
点击搜索结果页的所有结果(包括按条件分类排序的结果)
爬虫/机器人
其实这个问题可以去p2p,b2c里问,收到假冒的qq号,
下载页地址可以看到购买数
然而真正要验证下载是否安全.爬虫.刷单就可以了.而爬虫并不用验证。
全部内容都是已经安装app.可以通过appurl进行分析.知乎appurl,谷歌应用商店appurl,百度应用商店appurl百度应用商店的appurl中href值为广告,而最终访问这些appurl返回的url不是微信.所以猜测题主可能要分析app的url信息,确保下载到正确的app.
不用下载,
下载app后找源码,可以找到绝大部分app的网站部分代码,如果你恰好有谷歌的帐号,也许里面有一些,在换过来看里面的内容。
当然是通过下载安装文件之后,爬进去。
证监会发布给媒体的公告,其中有提到公告中提到的某些公司的信息是其财务报表中未披露的。就是说某些公司未公布财务报表,或者需要保密而采用保密方式披露。不然把财务报表公布一下就一目了然了,这种做法,就像隐藏股票一样。
php网页抓取标题(【魔兽世界】游戏代码插入页面时中断怎么办? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-21 12:14
)
我将首先解释我希望代码做什么。
代码应使用游戏本身提供的 API() 显示游戏中玩家的数据。在我的网站上,每个玩家都有自己的页面,页面的标题就是玩家的名字。所以我想抓住页面的标题,这样我就可以在它下面显示玩家的数据。
(代码的另一部分工作得很好。如果我删除 $title 行并将 $url 更改为播放器的 一) 它可以工作。
我无法使用下面的代码。当我将此代码插入页面时,分页符。但是,如果我删除 $title = alert(document.title);'); 行,页面不会中断。
我在网上和 stackoverflow 上做了一些研究,并试图在 str_get_html(''); 中更改该行。但这没有帮助。
我也认为可以通过另一种方式获取数据,但我不知道该怎么做。网站 在 WordPress 上运行,每个播放器页面都连接到注册用户的 WordPress 帐户。以下引用可用于获取用户的数据:
get_userdata( $userid );
每个用户的玩家名称被存储为“昵称”。因此,可以使用以下方法获取每个用户的玩家名称:
但是,用户页面是由插件生成的。我试图调整其中的代码,但我无法让它工作。
你知道如何在不破坏页面的情况下获取页面标题,或者获取用户的昵称吗?
我现在将页面设置为:/user/playername(只有玩家名发生变化)。我正在使用:全球 $post; $pagename = $post->post_name; 但是,$pagename 显示为用户而不是玩家名。你知道我怎样才能让它“得到”玩家名而不是它的蛞蝓吗?
编辑2:
function getPath($url)
{
$path = parse_url($url,PHP_URL_PATH);
$lastSlash = strrpos($path,"/");
return substr($path,1,$lastSlash-1);
} 查看全部
php网页抓取标题(【魔兽世界】游戏代码插入页面时中断怎么办?
)
我将首先解释我希望代码做什么。
代码应使用游戏本身提供的 API() 显示游戏中玩家的数据。在我的网站上,每个玩家都有自己的页面,页面的标题就是玩家的名字。所以我想抓住页面的标题,这样我就可以在它下面显示玩家的数据。
(代码的另一部分工作得很好。如果我删除 $title 行并将 $url 更改为播放器的 一) 它可以工作。
我无法使用下面的代码。当我将此代码插入页面时,分页符。但是,如果我删除 $title = alert(document.title);'); 行,页面不会中断。
我在网上和 stackoverflow 上做了一些研究,并试图在 str_get_html(''); 中更改该行。但这没有帮助。
我也认为可以通过另一种方式获取数据,但我不知道该怎么做。网站 在 WordPress 上运行,每个播放器页面都连接到注册用户的 WordPress 帐户。以下引用可用于获取用户的数据:
get_userdata( $userid );
每个用户的玩家名称被存储为“昵称”。因此,可以使用以下方法获取每个用户的玩家名称:
但是,用户页面是由插件生成的。我试图调整其中的代码,但我无法让它工作。
你知道如何在不破坏页面的情况下获取页面标题,或者获取用户的昵称吗?
我现在将页面设置为:/user/playername(只有玩家名发生变化)。我正在使用:全球 $post; $pagename = $post->post_name; 但是,$pagename 显示为用户而不是玩家名。你知道我怎样才能让它“得到”玩家名而不是它的蛞蝓吗?
编辑2:
function getPath($url)
{
$path = parse_url($url,PHP_URL_PATH);
$lastSlash = strrpos($path,"/");
return substr($path,1,$lastSlash-1);
}
php网页抓取标题(php更改页面标题、描述动态化?:SetTitlePHP示例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-20 22:02
'; header("内容长度:" . $row['size']); header("内容类型:" . $row['type']); header("Content-config: inline; filename=\ "" . $row['name'] . "\""); 回声 $row['content']; .
header - 手册,PHP TCPDF::SetTitle - 找到 30 个示例。这些是从开源项目中提取的最受好评的 TCPDF::SetTitle 真实世界 PHP 示例。您可以对示例进行评分,以帮助我们提高其质量。php?id=1"。像所有下载脚本教程一样,但他们似乎也忽略了更改页面的标题.. [已解决] 你可以用 header-function 设置 page-title 吗? $result = mysql_query(" select name,文件的大小、类型、内容 where userid=" . $_SESSION['user_id']); $row = mysql_fetch_array($result); echo ''; header("Content length:" . $row['size ']) ; header("Content-Type:" . $row['type']); header("Content-Disposition: inline; filename=\"" . $row['name'] . "\""); echo $ row['content']; 设置标题。您肯定会使用的方法是 setTitle(),它设置页面标题;您的浏览器在其标题/窗口栏中显示的那个...
PHP 编程/页眉和页脚,设置页眉。您肯定会使用的方法是 setTitle(),它设置页面标题;您的浏览器在其标题/窗口栏中显示的那个。.
php 更改页面标题 php 页面标题变量
<p>在 header.php 中使标题、描述动态化?到目前为止,不幸的是,PHP 在将它们插入外部变量数组之前转换了这些变量的名称——而不是让它们保持原样,只更改由 register_globals 设置的变量的名称。如果您想使用: 现在您已经成功创建了一个有效的 PHP 脚本,是时候创建有史以来最著名的 PHP 脚本了!调用 phpinfo() 函数,您将看到很多关于您的系统和设置的有用信息,例如可用的预定义变量、加载的 PHP 模块和配置设置。花点时间回顾一下。使用 PHP 设置页面标题,header.php 主要是 html,当我获得 PHP 经验后,我意识到标题并为该页面上的 $description 和 $pageTitle 变量提供了正确的文本,包括 < @网站 的页眉和页脚,每天更改日期,包括我喜欢保留更改能力的某些变量(如价格或地址)。今天,一位客户要求我在 查看全部
php网页抓取标题(php更改页面标题、描述动态化?:SetTitlePHP示例)
'; header("内容长度:" . $row['size']); header("内容类型:" . $row['type']); header("Content-config: inline; filename=\ "" . $row['name'] . "\""); 回声 $row['content']; .
header - 手册,PHP TCPDF::SetTitle - 找到 30 个示例。这些是从开源项目中提取的最受好评的 TCPDF::SetTitle 真实世界 PHP 示例。您可以对示例进行评分,以帮助我们提高其质量。php?id=1"。像所有下载脚本教程一样,但他们似乎也忽略了更改页面的标题.. [已解决] 你可以用 header-function 设置 page-title 吗? $result = mysql_query(" select name,文件的大小、类型、内容 where userid=" . $_SESSION['user_id']); $row = mysql_fetch_array($result); echo ''; header("Content length:" . $row['size ']) ; header("Content-Type:" . $row['type']); header("Content-Disposition: inline; filename=\"" . $row['name'] . "\""); echo $ row['content']; 设置标题。您肯定会使用的方法是 setTitle(),它设置页面标题;您的浏览器在其标题/窗口栏中显示的那个...
PHP 编程/页眉和页脚,设置页眉。您肯定会使用的方法是 setTitle(),它设置页面标题;您的浏览器在其标题/窗口栏中显示的那个。.
php 更改页面标题 php 页面标题变量
<p>在 header.php 中使标题、描述动态化?到目前为止,不幸的是,PHP 在将它们插入外部变量数组之前转换了这些变量的名称——而不是让它们保持原样,只更改由 register_globals 设置的变量的名称。如果您想使用: 现在您已经成功创建了一个有效的 PHP 脚本,是时候创建有史以来最著名的 PHP 脚本了!调用 phpinfo() 函数,您将看到很多关于您的系统和设置的有用信息,例如可用的预定义变量、加载的 PHP 模块和配置设置。花点时间回顾一下。使用 PHP 设置页面标题,header.php 主要是 html,当我获得 PHP 经验后,我意识到标题并为该页面上的 $description 和 $pageTitle 变量提供了正确的文本,包括 < @网站 的页眉和页脚,每天更改日期,包括我喜欢保留更改能力的某些变量(如价格或地址)。今天,一位客户要求我在
php网页抓取标题( 2017年04月24日Python正则抓取新闻标题和链接的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-17 02:09
2017年04月24日Python正则抓取新闻标题和链接的方法)
Python中定时抓取新闻头条和链接的方法示例
更新时间:2017-04-24 08:56:43 作者:Shine I want
本文章主要介绍Python中定时抓取新闻头条和链接的方法,结合具体实例分析Python定时匹配页面元素和文件编写的操作技巧。有需要的朋友可以参考以下
本文的例子描述了Python中定时抓取新闻头条和链接的方法。分享给大家,供大家参考,如下:
#-*-coding:utf-8-*-
import re
from urllib import urlretrieve
from urllib import urlopen
#获取网页信息
doc = urlopen("http://www.itongji.cn/news/").read() #自己找的一个大数据的新闻网站
#抓取新闻标题和链接
def extract_title(info):
pat = '<a target=\"_blank\"(.*?)/a/h3'
title = re.findall(pat, info)
titles='\n'.join(title)
#print titles
#修改指定字符串
titles1=titles.replace('class="title"','title')
titles2=titles1.replace('>',':')
titles3=titles2.replace('href','url:')
titles4=titles3.replace('="/','"http://www.itongji.cn/')
#写入文件
save=open('xinwen.txt','w')
save.write(titles4)
save.close()
titles = extract_title(doc)
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成器:
更多关于Python的知识请参考本站专题:《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python套接字编程技巧总结》、《Python总结《函数使用技巧》、《Python Socket编程技巧总结》《Python字符串操作技巧总结》、《Python入门与进阶经典教程》和《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。 查看全部
php网页抓取标题(
2017年04月24日Python正则抓取新闻标题和链接的方法)
Python中定时抓取新闻头条和链接的方法示例
更新时间:2017-04-24 08:56:43 作者:Shine I want
本文章主要介绍Python中定时抓取新闻头条和链接的方法,结合具体实例分析Python定时匹配页面元素和文件编写的操作技巧。有需要的朋友可以参考以下
本文的例子描述了Python中定时抓取新闻头条和链接的方法。分享给大家,供大家参考,如下:
#-*-coding:utf-8-*-
import re
from urllib import urlretrieve
from urllib import urlopen
#获取网页信息
doc = urlopen("http://www.itongji.cn/news/";).read() #自己找的一个大数据的新闻网站
#抓取新闻标题和链接
def extract_title(info):
pat = '<a target=\"_blank\"(.*?)/a/h3'
title = re.findall(pat, info)
titles='\n'.join(title)
#print titles
#修改指定字符串
titles1=titles.replace('class="title"','title')
titles2=titles1.replace('>',':')
titles3=titles2.replace('href','url:')
titles4=titles3.replace('="/','"http://www.itongji.cn/')
#写入文件
save=open('xinwen.txt','w')
save.write(titles4)
save.close()
titles = extract_title(doc)
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成器:
更多关于Python的知识请参考本站专题:《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python套接字编程技巧总结》、《Python总结《函数使用技巧》、《Python Socket编程技巧总结》《Python字符串操作技巧总结》、《Python入门与进阶经典教程》和《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
php网页抓取标题(php网页抓取标题、关键词、分类、描述、评论、名称、微博、时间、数据库密码、sql语句日志如何绕过)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-11 11:03
php网页抓取标题、关键词、分类、描述、评论、名称、微博、时间、数据库密码、sql语句抓取日志如何绕过百度爬虫
呵呵,
准备好数据
1.每个站点的响应信息(例如页面dom)、框架的抽象出来的对象(例如页面所有对象)、框架层协议(例如,php协议是responsebody)2.优秀的php框架(例如google的phpextension)在请求包里面封装了请求对象,post和put之类的请求方法、对schema的处理、对上层对象的引用、对cookie的控制等等。
例如googlephpextension:googlepress.php,apache的php.extension,以及使用php.extension这个jar包时所用到的配置3.优秀的运行库(例如一个很牛的php.extension定义了一个很牛的dll文件,这个dll定义了一个对象的默认访问配置),例如apache+php-fpm、nginx、luatex、bootstrap、ldap、memcached、ldapsnapshot、seasy等等。
加个模块就可以了
1、套个壳子。
2、搭个路由。伪静态规则,两层。a、加载统一url策略,所有url抓取时如带参数则post请求,无参数则https请求,并将url变成动态的(保证数据完整性);b、伪静态规则,
3、搭个前端渲染
4、搭个监控配置 查看全部
php网页抓取标题(php网页抓取标题、关键词、分类、描述、评论、名称、微博、时间、数据库密码、sql语句日志如何绕过)
php网页抓取标题、关键词、分类、描述、评论、名称、微博、时间、数据库密码、sql语句抓取日志如何绕过百度爬虫
呵呵,
准备好数据
1.每个站点的响应信息(例如页面dom)、框架的抽象出来的对象(例如页面所有对象)、框架层协议(例如,php协议是responsebody)2.优秀的php框架(例如google的phpextension)在请求包里面封装了请求对象,post和put之类的请求方法、对schema的处理、对上层对象的引用、对cookie的控制等等。
例如googlephpextension:googlepress.php,apache的php.extension,以及使用php.extension这个jar包时所用到的配置3.优秀的运行库(例如一个很牛的php.extension定义了一个很牛的dll文件,这个dll定义了一个对象的默认访问配置),例如apache+php-fpm、nginx、luatex、bootstrap、ldap、memcached、ldapsnapshot、seasy等等。
加个模块就可以了
1、套个壳子。
2、搭个路由。伪静态规则,两层。a、加载统一url策略,所有url抓取时如带参数则post请求,无参数则https请求,并将url变成动态的(保证数据完整性);b、伪静态规则,
3、搭个前端渲染
4、搭个监控配置
php网页抓取标题(php网页抓取标题方法一-基于formdata,插件page_url_filter_mixes,,全文抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-07 19:05
php网页抓取标题方法一-基于formdata,插件page_url_filter_mixes,formdata,page_url_filter_mixes全文抓取方法二-基于dl_extre_tou_page_driver,dl_extre_tou_page_driver(bundle),网页里的toupal解析器全文抓取方法三-基于爬虫代理,实现pagedata的全文爬取,可以自定义生成脚本。文章地址。
javascript使用page_url_filter_mixes用过一段时间,不过现在找到了更好的方案,介绍下。formdata.anyparams()是response对象中的属性方法,该方法只在响应头部使用,最好不要使用formdata.anyparams(),结果反而会更麻烦,直接将各种属性相加(匹配字符串或数组都是可以的)就可以了。
好久没用javascript抓取工具了,前段时间找爬虫工具,找了好久postman在小扎的2017年google开发者大会上很有名,突然意识到他们的老板对技术很苛刻,所以并没有以挣钱为目的推广postman,而是让更多人用requests,说很多人都用postman不是很方便,容易误操作,所以鼓励大家开始学requests,搞定requests后他们给的方案是autopost方案。
对于javascript是什么都不懂的我就开始学autopost了,不过那个方案最后让我非常的头疼,1.首先在这个爬虫工具上做爬虫抓取方面很多代码,就两套解析方案,第一套是selenium.py里的scrapy,另一套是zapk.py里的form-data,两套方案都有各自的优缺点,比如selenium.py里的scrapy自带网页解析的包,但是小哥不认识用户,只能用代理拿爬虫的真实网页,这种情况下就让爬虫接受直接访问的请求。
优点就是容易搞定基本的http请求,缺点是对于网页本身以及传递到后端的参数理解不足,比如传递的参数如果不明确,那么包含特定参数的页面就分辨不出来,这里就有坑了,可以学习一下专业人士写的requests教程,一定会有所提高。而zapk.py里的form-data爬虫解析就简单的多,对于网页本身以及传递到后端的参数理解不足,但可以让你爬取的所有页面都变成本地记录,这样就可以偷懒了,我找了几个requests的高手,他们都建议用zapk.py方案解析网页,因为还可以和代理进行配合,这样更加方便省事。
所以我选择的就是requests.py里的scrapy,并不是说别的方案不好,只是对于不熟悉的人来说,使用着确实是个麻烦事,你要确保路径的正确性才能进行下一步的操作,然后后端一定要配置好http请求的参数,否则就会上面说的error之类,然后我就有疑问,你又不支持把爬虫配置成自动返回,然后你就要依次来判断哪些网页是不用请求的,把。 查看全部
php网页抓取标题(php网页抓取标题方法一-基于formdata,插件page_url_filter_mixes,,全文抓取方法)
php网页抓取标题方法一-基于formdata,插件page_url_filter_mixes,formdata,page_url_filter_mixes全文抓取方法二-基于dl_extre_tou_page_driver,dl_extre_tou_page_driver(bundle),网页里的toupal解析器全文抓取方法三-基于爬虫代理,实现pagedata的全文爬取,可以自定义生成脚本。文章地址。
javascript使用page_url_filter_mixes用过一段时间,不过现在找到了更好的方案,介绍下。formdata.anyparams()是response对象中的属性方法,该方法只在响应头部使用,最好不要使用formdata.anyparams(),结果反而会更麻烦,直接将各种属性相加(匹配字符串或数组都是可以的)就可以了。
好久没用javascript抓取工具了,前段时间找爬虫工具,找了好久postman在小扎的2017年google开发者大会上很有名,突然意识到他们的老板对技术很苛刻,所以并没有以挣钱为目的推广postman,而是让更多人用requests,说很多人都用postman不是很方便,容易误操作,所以鼓励大家开始学requests,搞定requests后他们给的方案是autopost方案。
对于javascript是什么都不懂的我就开始学autopost了,不过那个方案最后让我非常的头疼,1.首先在这个爬虫工具上做爬虫抓取方面很多代码,就两套解析方案,第一套是selenium.py里的scrapy,另一套是zapk.py里的form-data,两套方案都有各自的优缺点,比如selenium.py里的scrapy自带网页解析的包,但是小哥不认识用户,只能用代理拿爬虫的真实网页,这种情况下就让爬虫接受直接访问的请求。
优点就是容易搞定基本的http请求,缺点是对于网页本身以及传递到后端的参数理解不足,比如传递的参数如果不明确,那么包含特定参数的页面就分辨不出来,这里就有坑了,可以学习一下专业人士写的requests教程,一定会有所提高。而zapk.py里的form-data爬虫解析就简单的多,对于网页本身以及传递到后端的参数理解不足,但可以让你爬取的所有页面都变成本地记录,这样就可以偷懒了,我找了几个requests的高手,他们都建议用zapk.py方案解析网页,因为还可以和代理进行配合,这样更加方便省事。
所以我选择的就是requests.py里的scrapy,并不是说别的方案不好,只是对于不熟悉的人来说,使用着确实是个麻烦事,你要确保路径的正确性才能进行下一步的操作,然后后端一定要配置好http请求的参数,否则就会上面说的error之类,然后我就有疑问,你又不支持把爬虫配置成自动返回,然后你就要依次来判断哪些网页是不用请求的,把。
php网页抓取标题(PHP代码调用织梦篇13/6/3:19:00 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-02-07 16:06
)
6/3/:19:00
今天,我们将跟随编辑 织梦 的教程。做SEO的都知道网站首页的更新频率直接决定了网站的索引速度和网站一部分的权重,但是我们无法实时更新。在这个科技如此发达的时代,如果我们还用最原创的方式,那一定是个悲剧。
PHP代码调用织梦篇
13/6/:56:00
有时我们在使用非 PHP 代码时可能需要检索最新的 文章。如果有怎么办?大家可以参考下面的代码,根据自己的需要进行修改。
(织梦)网站 一些SEO优化技巧
20/9/:18:00
(织梦)网站的一些SEO优化技巧,网站静态设置,网站URL路径优化,文章标签设置,解决重复的问题列页面上的页面标题 等等。
让 织梦 (DEDE) 的隐藏部分下的 文章 不被调用
21/7/:59:00
接触织梦快一年了,我建的第一个站就是用织梦系统。功能本身已经很强大了,基本可以满足我的大部分需求。大部分时间用于设计界面模板,但没有研究过后端源代码。
织梦调用日期格式百科
24/4/:48:41
记得刚学织梦的时候,我也头疼,叫了很久文章的日期。今天小编特地采集整理了一篇关于日期格式化的文章文章。我希望它对每个人都有帮助。常用日期格式
如何在搜索页面调用全站最新的文章
21/9/:58:00
在搜索页面添加最新的文章调用代码,发现无法实现文章list调用。搜索的原因是cms的标签适用于封面模板.htm、列表模板.htm和文档模板.htm,所以搜索页面使用的是最新的文章。不能调用标签,不仅是最新的文章,还有随机的文章、流行的文章等使用标签的。
如何编写 SEO文章页面标题
8/12/:27:32
我今天要分享的是如何为 SEO文章 编写页面标题。当然,这是编辑器需要实现的部分。但是为了达到好的网站优化效果,一般来说每个SEO从业者都需要先学习一个模板,然后让小编
cms方法调用 blog latest 或 random文章
9/3/:19:00
目前国内比较流行的几款开源程序包括cms、织梦cms等,这些对于建站、做seo优化的站长来说并不陌生。通常,他们在首页或内页调用最新的或随机的 文章。爱好,如果这些文章是同一个开源程序的话,相对来说调用起来比较容易。如果它们不一样怎么办?现在让我谈谈帝国
解决织梦限制标题长度的问题
24/4/:48:39
我们都知道有时候网页的标题文章过长,会影响网页的美观,所以我们需要对其进行修剪,限制显示的字数,将多余的部分替换为省略。那么如何以及在编辑器中织梦的想法来实现这个
通过文章ID获取文章标题、内容等信息
15/11/:02:00
使用它的朋友可能会遇到这样的问题。在非.php页面中,我们有时想调用当前文章的标题、内容等信息,但是在生成文章页面时,每个页面中唯一的常量就是当前文章 。ID,那么这个ID是如何获取当前文章的标题、内容等信息的呢?
会员发帖文章和采集夹文章默认动态浏览
2/8/:08:00
会员发布和采集的文章的默认设置是动态浏览。首先,找到需要修改的地方。从会员发布的文章开始,找到/.php,保存后上传到空间进行举报。会员发表的文章只需要日后审核即可。, 没有任何修改。接下来就是和上面一样,找到你的后端目录/
向内容页面添加标签
24/4/:49:09
上一篇文章主要写了给免注册虚拟主机安装的列表添加标签,这次我是在内容页面添加标签。两者都有相同的点,比较简单。两个文章主编主编操作
【黄山网站建设】网站文章标题的SEO优化技巧
27/8/:01:35
SEO优化?我们都知道 文章 更新很重要,特别是如果内容是 原创 高度相关和有价值的。除了更新文章 的内容外,文章 的标题、关键词 和描述也很重要。从 SEO 的角度来看,文章 的标题
查看全部
php网页抓取标题(PHP代码调用织梦篇13/6/3:19:00
)
6/3/:19:00
今天,我们将跟随编辑 织梦 的教程。做SEO的都知道网站首页的更新频率直接决定了网站的索引速度和网站一部分的权重,但是我们无法实时更新。在这个科技如此发达的时代,如果我们还用最原创的方式,那一定是个悲剧。

PHP代码调用织梦篇
13/6/:56:00
有时我们在使用非 PHP 代码时可能需要检索最新的 文章。如果有怎么办?大家可以参考下面的代码,根据自己的需要进行修改。
(织梦)网站 一些SEO优化技巧
20/9/:18:00
(织梦)网站的一些SEO优化技巧,网站静态设置,网站URL路径优化,文章标签设置,解决重复的问题列页面上的页面标题 等等。
让 织梦 (DEDE) 的隐藏部分下的 文章 不被调用
21/7/:59:00
接触织梦快一年了,我建的第一个站就是用织梦系统。功能本身已经很强大了,基本可以满足我的大部分需求。大部分时间用于设计界面模板,但没有研究过后端源代码。
织梦调用日期格式百科
24/4/:48:41
记得刚学织梦的时候,我也头疼,叫了很久文章的日期。今天小编特地采集整理了一篇关于日期格式化的文章文章。我希望它对每个人都有帮助。常用日期格式
如何在搜索页面调用全站最新的文章
21/9/:58:00
在搜索页面添加最新的文章调用代码,发现无法实现文章list调用。搜索的原因是cms的标签适用于封面模板.htm、列表模板.htm和文档模板.htm,所以搜索页面使用的是最新的文章。不能调用标签,不仅是最新的文章,还有随机的文章、流行的文章等使用标签的。
如何编写 SEO文章页面标题
8/12/:27:32
我今天要分享的是如何为 SEO文章 编写页面标题。当然,这是编辑器需要实现的部分。但是为了达到好的网站优化效果,一般来说每个SEO从业者都需要先学习一个模板,然后让小编
cms方法调用 blog latest 或 random文章
9/3/:19:00
目前国内比较流行的几款开源程序包括cms、织梦cms等,这些对于建站、做seo优化的站长来说并不陌生。通常,他们在首页或内页调用最新的或随机的 文章。爱好,如果这些文章是同一个开源程序的话,相对来说调用起来比较容易。如果它们不一样怎么办?现在让我谈谈帝国
解决织梦限制标题长度的问题
24/4/:48:39
我们都知道有时候网页的标题文章过长,会影响网页的美观,所以我们需要对其进行修剪,限制显示的字数,将多余的部分替换为省略。那么如何以及在编辑器中织梦的想法来实现这个
通过文章ID获取文章标题、内容等信息
15/11/:02:00
使用它的朋友可能会遇到这样的问题。在非.php页面中,我们有时想调用当前文章的标题、内容等信息,但是在生成文章页面时,每个页面中唯一的常量就是当前文章 。ID,那么这个ID是如何获取当前文章的标题、内容等信息的呢?
会员发帖文章和采集夹文章默认动态浏览
2/8/:08:00
会员发布和采集的文章的默认设置是动态浏览。首先,找到需要修改的地方。从会员发布的文章开始,找到/.php,保存后上传到空间进行举报。会员发表的文章只需要日后审核即可。, 没有任何修改。接下来就是和上面一样,找到你的后端目录/
向内容页面添加标签
24/4/:49:09
上一篇文章主要写了给免注册虚拟主机安装的列表添加标签,这次我是在内容页面添加标签。两者都有相同的点,比较简单。两个文章主编主编操作
【黄山网站建设】网站文章标题的SEO优化技巧
27/8/:01:35
SEO优化?我们都知道 文章 更新很重要,特别是如果内容是 原创 高度相关和有价值的。除了更新文章 的内容外,文章 的标题、关键词 和描述也很重要。从 SEO 的角度来看,文章 的标题
php网页抓取标题(在nginx服务器上这样配置即可以防止知乎刷屏的问题nginx的include)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-02-06 07:01
php网页抓取标题:tests/zh-cn.php:获取网页中的title通过tests/zh-cn.php我们把这个网页导入到tests/zh-cn.php中并配置如下代码:然后打开浏览器输入地址tests/zh-cn.php并打开,即可看到如下界面:然后通过这样的方式我们可以获取到网页中的title所在位置,让我们一起研究一下网页中title的含义:http协议定义了返回数据的格式和模式,为了标识request或response中的任何字段,并且对不需要返回给其他一方的字段进行确定,对其标识方法进行了一些规范。
title的标识方法有:正文或有titleresponse结束标识的独立体;就是title中的字段article,只不过是自身有独立的titleresponse结束标识;或者说它相当于null,不受请求方式和传递的数据的影响。上面的是php对title的描述,其实网页中还有很多需要我们仔细研究的地方,比如下面这个:在nginx服务器上这样配置即可以防止知乎私信刷屏的问题nginx的include就可以实现它的用法方法。
此次我们来看看get请求后,我们看到的结果如下:接下来我们看看post请求后的post部分:接下来我们依次看一下我们发出的post请求这里tests/zh-cn.php获取的结果为:3毛钱,好像不好看啊这就是为什么还是要根据网页来判断是否设置session时间和其他限制的原因,参见我之前写的一篇文章作者:yayidi93作者博客::。 查看全部
php网页抓取标题(在nginx服务器上这样配置即可以防止知乎刷屏的问题nginx的include)
php网页抓取标题:tests/zh-cn.php:获取网页中的title通过tests/zh-cn.php我们把这个网页导入到tests/zh-cn.php中并配置如下代码:然后打开浏览器输入地址tests/zh-cn.php并打开,即可看到如下界面:然后通过这样的方式我们可以获取到网页中的title所在位置,让我们一起研究一下网页中title的含义:http协议定义了返回数据的格式和模式,为了标识request或response中的任何字段,并且对不需要返回给其他一方的字段进行确定,对其标识方法进行了一些规范。
title的标识方法有:正文或有titleresponse结束标识的独立体;就是title中的字段article,只不过是自身有独立的titleresponse结束标识;或者说它相当于null,不受请求方式和传递的数据的影响。上面的是php对title的描述,其实网页中还有很多需要我们仔细研究的地方,比如下面这个:在nginx服务器上这样配置即可以防止知乎私信刷屏的问题nginx的include就可以实现它的用法方法。
此次我们来看看get请求后,我们看到的结果如下:接下来我们看看post请求后的post部分:接下来我们依次看一下我们发出的post请求这里tests/zh-cn.php获取的结果为:3毛钱,好像不好看啊这就是为什么还是要根据网页来判断是否设置session时间和其他限制的原因,参见我之前写的一篇文章作者:yayidi93作者博客::。
php网页抓取标题(CSS样式是表现,语义化可以给我们带来哪些好处?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-03 14:15
CSS 样式是表示。就像网络的外衣。例如,更改标题字体、颜色,或为标题添加背景图片、边框等。所有这些改变内容外观的东西都称为演示文稿。
JavaScript 用于在网页上实现特殊效果。如:鼠标悬停在弹出的下拉菜单上。或将鼠标悬停在表格背景颜色的变化上。还有一个焦点故事(新闻图片)的轮换。这样就可以理解为动画和交互一般都是用JavaScript实现的。
1、tml的固定结构
HTML 文档有自己的固定结构。
…
代码说明:
称为根标签,所有网页标签都在其中。
3、标签
和标签之间的文字是网页的标题信息,会出现在浏览器的标题栏中。使用网页的标题标签。网页制作学习交流群,49406、4934。
为了告诉用户和搜索引擎这个网页的主要内容是什么,搜索引擎可以通过网页的标题快速确定网页的主题。每个网页的内容都是不同的,每个网页都应该有一个独特的
独特的标题。
例如:
标签“hello world”的内容会显示在浏览器的标题栏上,
4、 标签的用途
当我们学习网页创建时,我们经常听到一个词,语义。那么什么是语义?通俗点是:了解每个标签的用途(在什么情况下使用这个标签才合理)例如在网页上
文章的标题可以使用title标签,网页上每一列的列名也可以使用title标签。
文章 中内容的段落必须放在段落标签中。如果 文章 中有要强调的文字,可以使用
使用 em 标签进行强调等。
关于语义已经说了这么多,但是语义能给我们带来什么好处呢?
① 收录 更容易被搜索到。
②。屏幕阅读器更容易阅读网页内容。
CSS 样式是表示。就像网络的外衣。例如,更改标题字体、颜色,或为标题添加背景图片、边框等。所有这些改变内容外观的东西都称为演示文稿。
JavaScript 用于在网页上实现特殊效果。如:鼠标悬停在弹出的下拉菜单上。或将鼠标悬停在表格背景颜色的变化上。还有一个焦点故事(新闻图片)的轮换。这样就可以理解为动画和交互一般都是用JavaScript实现的。
1、tml的固定结构
HTML 文档有自己的固定结构。
…
代码说明:
称为根标签,所有网页标签都在其中。
3、标签
和标签之间的文字是网页的标题信息,会出现在浏览器的标题栏中。使用网页的标题标签。网页制作学习交流群,49406、4934。
为了告诉用户和搜索引擎这个网页的主要内容是什么,搜索引擎可以通过网页的标题快速确定网页的主题。每个网页的内容都是不同的,每个网页都应该有一个独特的
独特的标题。
例如:
标签“hello world”的内容会显示在浏览器的标题栏上,
4、 标签的用途
当我们学习网页创建时,我们经常听到一个词,语义。那么什么是语义?通俗点是:了解每个标签的用途(在什么情况下使用这个标签才合理)例如在网页上
文章的标题可以使用title标签,网页上每一列的列名也可以使用title标签。
文章 中内容的段落必须放在段落标签中。如果 文章 中有要强调的文字,可以使用
使用 em 标签进行强调等。
关于语义已经说了这么多,但是语义能给我们带来什么好处呢?
① 收录 更容易被搜索到。
②。屏幕阅读器更容易阅读网页内容。 查看全部
php网页抓取标题(CSS样式是表现,语义化可以给我们带来哪些好处?)
CSS 样式是表示。就像网络的外衣。例如,更改标题字体、颜色,或为标题添加背景图片、边框等。所有这些改变内容外观的东西都称为演示文稿。
JavaScript 用于在网页上实现特殊效果。如:鼠标悬停在弹出的下拉菜单上。或将鼠标悬停在表格背景颜色的变化上。还有一个焦点故事(新闻图片)的轮换。这样就可以理解为动画和交互一般都是用JavaScript实现的。
1、tml的固定结构
HTML 文档有自己的固定结构。
…
代码说明:
称为根标签,所有网页标签都在其中。
3、标签
和标签之间的文字是网页的标题信息,会出现在浏览器的标题栏中。使用网页的标题标签。网页制作学习交流群,49406、4934。
为了告诉用户和搜索引擎这个网页的主要内容是什么,搜索引擎可以通过网页的标题快速确定网页的主题。每个网页的内容都是不同的,每个网页都应该有一个独特的
独特的标题。
例如:
标签“hello world”的内容会显示在浏览器的标题栏上,
4、 标签的用途
当我们学习网页创建时,我们经常听到一个词,语义。那么什么是语义?通俗点是:了解每个标签的用途(在什么情况下使用这个标签才合理)例如在网页上
文章的标题可以使用title标签,网页上每一列的列名也可以使用title标签。
文章 中内容的段落必须放在段落标签中。如果 文章 中有要强调的文字,可以使用
使用 em 标签进行强调等。
关于语义已经说了这么多,但是语义能给我们带来什么好处呢?
① 收录 更容易被搜索到。
②。屏幕阅读器更容易阅读网页内容。
CSS 样式是表示。就像网络的外衣。例如,更改标题字体、颜色,或为标题添加背景图片、边框等。所有这些改变内容外观的东西都称为演示文稿。
JavaScript 用于在网页上实现特殊效果。如:鼠标悬停在弹出的下拉菜单上。或将鼠标悬停在表格背景颜色的变化上。还有一个焦点故事(新闻图片)的轮换。这样就可以理解为动画和交互一般都是用JavaScript实现的。
1、tml的固定结构
HTML 文档有自己的固定结构。
…
代码说明:
称为根标签,所有网页标签都在其中。
3、标签
和标签之间的文字是网页的标题信息,会出现在浏览器的标题栏中。使用网页的标题标签。网页制作学习交流群,49406、4934。
为了告诉用户和搜索引擎这个网页的主要内容是什么,搜索引擎可以通过网页的标题快速确定网页的主题。每个网页的内容都是不同的,每个网页都应该有一个独特的
独特的标题。
例如:
标签“hello world”的内容会显示在浏览器的标题栏上,
4、 标签的用途
当我们学习网页创建时,我们经常听到一个词,语义。那么什么是语义?通俗点是:了解每个标签的用途(在什么情况下使用这个标签才合理)例如在网页上
文章的标题可以使用title标签,网页上每一列的列名也可以使用title标签。
文章 中内容的段落必须放在段落标签中。如果 文章 中有要强调的文字,可以使用
使用 em 标签进行强调等。
关于语义已经说了这么多,但是语义能给我们带来什么好处呢?
① 收录 更容易被搜索到。
②。屏幕阅读器更容易阅读网页内容。
php网页抓取标题(网站用什么软件做的……首页、重要的内页的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-02-01 17:04
网站你用什么软件制作的...
最好将首页和重要内页的标题和元标记分开写,以反映栏目主题的不同内容。
动态网页优化
动态网站是指网站的内容更新和维护是通过一个有数据库背景的软件,即内容管理系统(cms)
结束。一般采用ASP、PHP、Cold Fusion、CGI等程序来动态生成页面。动态页面在网络空间中实现
不是实时存在的,它们的大部分内容通常来自连接到网站的数据库,只有在收到用户的请求后,在变量中
在字段中输入值之前不会生成它。动态网页扩展名显示为 .asp、.php、cfm 或 .cgi,而不是静态网页
页面的 .html 或 .htm。URL中通常会出现“?”、“=”、“%”以及“&”、“$”等符号。网站使用动态技术
除了增加网站交互功能外,还具有易于维护和更新的优点,是很多大中型网站的不错选择
利用。
但是大多数搜索引擎蜘蛛无法破译符号“?”之后的字符。这意味着动态页面很难被搜索索引
被引擎发现的几率也大大降低。因此,在构造网站之前,首先要纠正我们的思想,即能够
尽量不要使用静态性能的网页动态实现,重要的网页使用静态性能。在使用技术转换动态网页的同时
将其转换为静态网页,使网址不再收录“?”“=”等类似符号。您还可以对 网站 进行一些更改
动态,间接增加动态网页的搜索引擎可见性。即坚持“动静结合、以静制动”的原则。
不同技术的解决方案:
不同程序开发的动态网页有相应的解决方案。以下是作者凯伦整理的部分内容:
1、CGI/Perl
如果你在 网站 中使用 CGI 或 Perl,你可以使用脚本将环境变量之前的所有字符都提取出来,然后将 URL 放入
剩余的字符被分配给一个变量。这样,您可以在 URL 中使用变量。但是,对于那些内置的
一些带有SSI(Server-Side Include:Server-Side Include)内容的网页可以被各大搜索引擎收录
支持。那些后缀为 .shtml 的网页也会被解析成 SSI 文件,相当于普通的 .html 文件。但如果这
某些在其 URL 中使用 cgi-bin 路径的页面可能仍未被搜索引擎索引。
2、ASP
ASP(Active Server Pages:Web 服务器端动态网页开发技术)用于基于 Microsoft 的 Web 服务器
中间。使用 ASP 开发的网页一般以 .asp 为后缀。只是避免使用符号“?” 在 URL 中,大多数搜索引擎
都可以支持用ASP开发的动态网页。
3、冷聚变
如果您使用的是 Cold Fusion,则需要在服务器端重新配置它以
符号“?” 在每个环境变量中替换为符号“/”,并将替换后的值传递给 URL。这样,终于到了浏览
服务器端是一个静态 URL 页面。当搜索引擎检索这个转换后的文件时,它不会遇到“?” 因为
相反,整个动态页面可以继续被索引,这样你的动态页面仍然可以被搜索引擎读取。
4、Apache 服务器
Apache 是最流行的 HTTP 服务器软件之一。它有一个名为 mod_rewrite 的重写模块,URL 重写
发挥作用。该模块使您能够将收录环境变量的 URL 转换为搜索引擎支持的 URL 类型。为了那个原因
一些发布后不需要太多更新的网页内容,比如新闻,可以使用这个改写引导功能。
创建一个静态条目:
在“动静结合,静制动”的原则指导下,我们也可以对网站做一些修改,尽可能的增加动态网页
搜索引擎的可见性。例如,将动态网页编程为静态主页或网站地图中的链接,以静态目录的形式
渲染移动页面。或者为动态页面创建一个专用的静态入口页面(网关/入口),链接到动态
页面,然后将静态入口页面提交给搜索引擎。
将一些内容相对固定的重要页面制作成静态页面,比如网站的介绍和丰富的关键词,用户
帮助,以及网站重要页面的链接等地图网站首页尽量是静态的,重要的是动态的
内容全部以文字链接的形式呈现,虽然增加了维护工作量,但从SEO的角度来看还是值得的。
还可以考虑为重要的动态内容创建静态镜像网站。
付费登录搜索引擎:
当然,对于使用链接到数据库的内容管理系统 (cms) 在整个 网站 中发布的动态 网站,改进的搜索
搜索引擎可见性最直接的方式是付费登录,直接提交动态网页到搜索引擎目录,或者做key
文字广告保证由搜索引擎收录网站。
改进了对动态 网站 的搜索引擎支持
搜索引擎一直在改进对动态页面的支持。至此,GOOGLE、HOTBOT、百度都开始尝试
尝试抓取动态 网站 页面(甚至是 URL 中带有“?”的页面)。但是当这些搜索引擎抓取动态页面时,为了
避免“蜘蛛陷阱”(导致搜索机器人无限循环的脚本错误)
Crawl, cannot exit)”,只爬取静态页面链接的动态页面,以及动态页面链接的动态页面
不再抓取页面,即不再访问动态页面中的链接。
对于直接使用动态 URL 地址,请注意:
· 文件URL中不要有Session Id,不要用ID作为参数名(尤其是GOOGLE);
例如,在《网络营销基础与实践》一书中,当当网介绍页面的URL地址为:
asp?product_id=493698">,页面无法读取。
参数越少越好,尽量不要超过2;
· 尽量不要在URL中使用参数,这样会增加被抓取的动态页面的深度和数量。
随附的:
Google 向 网站 管理员提供的信息:
百度常见问题:#2 查看全部
php网页抓取标题(网站用什么软件做的……首页、重要的内页的)
网站你用什么软件制作的...
最好将首页和重要内页的标题和元标记分开写,以反映栏目主题的不同内容。
动态网页优化
动态网站是指网站的内容更新和维护是通过一个有数据库背景的软件,即内容管理系统(cms)
结束。一般采用ASP、PHP、Cold Fusion、CGI等程序来动态生成页面。动态页面在网络空间中实现
不是实时存在的,它们的大部分内容通常来自连接到网站的数据库,只有在收到用户的请求后,在变量中
在字段中输入值之前不会生成它。动态网页扩展名显示为 .asp、.php、cfm 或 .cgi,而不是静态网页
页面的 .html 或 .htm。URL中通常会出现“?”、“=”、“%”以及“&”、“$”等符号。网站使用动态技术
除了增加网站交互功能外,还具有易于维护和更新的优点,是很多大中型网站的不错选择
利用。
但是大多数搜索引擎蜘蛛无法破译符号“?”之后的字符。这意味着动态页面很难被搜索索引
被引擎发现的几率也大大降低。因此,在构造网站之前,首先要纠正我们的思想,即能够
尽量不要使用静态性能的网页动态实现,重要的网页使用静态性能。在使用技术转换动态网页的同时
将其转换为静态网页,使网址不再收录“?”“=”等类似符号。您还可以对 网站 进行一些更改
动态,间接增加动态网页的搜索引擎可见性。即坚持“动静结合、以静制动”的原则。
不同技术的解决方案:
不同程序开发的动态网页有相应的解决方案。以下是作者凯伦整理的部分内容:
1、CGI/Perl
如果你在 网站 中使用 CGI 或 Perl,你可以使用脚本将环境变量之前的所有字符都提取出来,然后将 URL 放入
剩余的字符被分配给一个变量。这样,您可以在 URL 中使用变量。但是,对于那些内置的
一些带有SSI(Server-Side Include:Server-Side Include)内容的网页可以被各大搜索引擎收录
支持。那些后缀为 .shtml 的网页也会被解析成 SSI 文件,相当于普通的 .html 文件。但如果这
某些在其 URL 中使用 cgi-bin 路径的页面可能仍未被搜索引擎索引。
2、ASP
ASP(Active Server Pages:Web 服务器端动态网页开发技术)用于基于 Microsoft 的 Web 服务器
中间。使用 ASP 开发的网页一般以 .asp 为后缀。只是避免使用符号“?” 在 URL 中,大多数搜索引擎
都可以支持用ASP开发的动态网页。
3、冷聚变
如果您使用的是 Cold Fusion,则需要在服务器端重新配置它以
符号“?” 在每个环境变量中替换为符号“/”,并将替换后的值传递给 URL。这样,终于到了浏览
服务器端是一个静态 URL 页面。当搜索引擎检索这个转换后的文件时,它不会遇到“?” 因为
相反,整个动态页面可以继续被索引,这样你的动态页面仍然可以被搜索引擎读取。
4、Apache 服务器
Apache 是最流行的 HTTP 服务器软件之一。它有一个名为 mod_rewrite 的重写模块,URL 重写
发挥作用。该模块使您能够将收录环境变量的 URL 转换为搜索引擎支持的 URL 类型。为了那个原因
一些发布后不需要太多更新的网页内容,比如新闻,可以使用这个改写引导功能。
创建一个静态条目:
在“动静结合,静制动”的原则指导下,我们也可以对网站做一些修改,尽可能的增加动态网页
搜索引擎的可见性。例如,将动态网页编程为静态主页或网站地图中的链接,以静态目录的形式
渲染移动页面。或者为动态页面创建一个专用的静态入口页面(网关/入口),链接到动态
页面,然后将静态入口页面提交给搜索引擎。
将一些内容相对固定的重要页面制作成静态页面,比如网站的介绍和丰富的关键词,用户
帮助,以及网站重要页面的链接等地图网站首页尽量是静态的,重要的是动态的
内容全部以文字链接的形式呈现,虽然增加了维护工作量,但从SEO的角度来看还是值得的。
还可以考虑为重要的动态内容创建静态镜像网站。
付费登录搜索引擎:
当然,对于使用链接到数据库的内容管理系统 (cms) 在整个 网站 中发布的动态 网站,改进的搜索
搜索引擎可见性最直接的方式是付费登录,直接提交动态网页到搜索引擎目录,或者做key
文字广告保证由搜索引擎收录网站。
改进了对动态 网站 的搜索引擎支持
搜索引擎一直在改进对动态页面的支持。至此,GOOGLE、HOTBOT、百度都开始尝试
尝试抓取动态 网站 页面(甚至是 URL 中带有“?”的页面)。但是当这些搜索引擎抓取动态页面时,为了
避免“蜘蛛陷阱”(导致搜索机器人无限循环的脚本错误)
Crawl, cannot exit)”,只爬取静态页面链接的动态页面,以及动态页面链接的动态页面
不再抓取页面,即不再访问动态页面中的链接。
对于直接使用动态 URL 地址,请注意:
· 文件URL中不要有Session Id,不要用ID作为参数名(尤其是GOOGLE);
例如,在《网络营销基础与实践》一书中,当当网介绍页面的URL地址为:
asp?product_id=493698">,页面无法读取。
参数越少越好,尽量不要超过2;
· 尽量不要在URL中使用参数,这样会增加被抓取的动态页面的深度和数量。
随附的:
Google 向 网站 管理员提供的信息:
百度常见问题:#2
php网页抓取标题(php网页抓取标题包含下划线的段落结果可能有两种:)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-31 12:01
php网页抓取标题包含下划线的段落结果可能有两种:1、该段落由两个php文件共同包含(用空格分隔),那么可以根据网页标识去匹配网页对应的文件,拿到该段落的文件的路径后,就可以从该目录下的一个叫jstring.php的文件中找到该段落的文件,用python写出来,把结果存入txt文件中。2、因为php没有包含下划线的段落,如果不小心自己写了一个下划线标识的段落文件,而你又不知道段落数量,那么会一个下划线字符一个空格字符去匹配的,一个下划线=1个空格=0个空格,一个下划线有7个空格=4个空格,如果一个下划线加一个空格=3个空格,那么就可以从该段落的第7行到第8行找到下划线。
去分析那些代码、语句能知道到底谁包含了空格。
有6个空格吗?
php是不提供字符串匹配功能的,我怎么记得以前是有,不知道为什么取消了。
我看了下代码,大概知道找不到原因了。需要对空格和tab的使用对象和类型进行匹配。代码也比较复杂。我也知道是怎么找的。google空格类型匹配和so类型匹配很容易找到匹配的部分。建议去看一下linux和http协议中大量的匹配模式。
tag_pattern是匹配字符串中tag标识符的值,可以参考这篇文章tagcompiler的工作原理compilerinterpretertracingofspeechinphp。sotypeoftagsinterprettotypeoftagsinterprettotypeoftag_pattern(这篇文章讲的很全面)。 查看全部
php网页抓取标题(php网页抓取标题包含下划线的段落结果可能有两种:)
php网页抓取标题包含下划线的段落结果可能有两种:1、该段落由两个php文件共同包含(用空格分隔),那么可以根据网页标识去匹配网页对应的文件,拿到该段落的文件的路径后,就可以从该目录下的一个叫jstring.php的文件中找到该段落的文件,用python写出来,把结果存入txt文件中。2、因为php没有包含下划线的段落,如果不小心自己写了一个下划线标识的段落文件,而你又不知道段落数量,那么会一个下划线字符一个空格字符去匹配的,一个下划线=1个空格=0个空格,一个下划线有7个空格=4个空格,如果一个下划线加一个空格=3个空格,那么就可以从该段落的第7行到第8行找到下划线。
去分析那些代码、语句能知道到底谁包含了空格。
有6个空格吗?
php是不提供字符串匹配功能的,我怎么记得以前是有,不知道为什么取消了。
我看了下代码,大概知道找不到原因了。需要对空格和tab的使用对象和类型进行匹配。代码也比较复杂。我也知道是怎么找的。google空格类型匹配和so类型匹配很容易找到匹配的部分。建议去看一下linux和http协议中大量的匹配模式。
tag_pattern是匹配字符串中tag标识符的值,可以参考这篇文章tagcompiler的工作原理compilerinterpretertracingofspeechinphp。sotypeoftagsinterprettotypeoftagsinterprettotypeoftag_pattern(这篇文章讲的很全面)。
php网页抓取标题(php网页抓取标题识别识别评论上面只是几个小例子)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-31 10:02
php网页抓取标题抓取正文识别评论上面只是几个小例子,本次主要讲这些我用的工具:百度网页抓取框架javascript爬虫javascript解析器在网上多找视频可以自己学习,这些东西都是解决某个特定问题,实战的时候手动是抓不过来的,更何况一个一个抓可以搜到几万条的截图是这样的没有需求还好,一有需求就抓不过来,上面那些图也是满满的需求,有兴趣可以留言问问。
网上搜一些php的视频教程,然后根据教程里说的查找你需要的站点,就会发现,软件比较多,功能越来越强大。
因为现在的知乎话题下面回答是天天刷新更新的,
我也刚刚知道这个新方法
刚开始学编程的时候,学的基本语法,专业名词,知道哪里可以用,哪里是可以丢的。但是用过一次之后,你会发现不太灵光,因为学的东西确实一样,在学习的过程中很容易知道对哪些是必须用的,但是用不到的不用管,扔一边就完事了。其实我们这个真的有很多问题都没有必要说的这么清楚。就好比我们一直都在手机上买东西,知道点东西就能过,打开---点进去点购物车---关闭。
当你想完全用自己的力量完成一次购物的时候就难了,但是可以看看我们传送门来解决。baobai.how-to.click?tag=awesome,里面的页面可能会更加细分,每个页面的想知道的也更加详细,自己用了挺不错的。 查看全部
php网页抓取标题(php网页抓取标题识别识别评论上面只是几个小例子)
php网页抓取标题抓取正文识别评论上面只是几个小例子,本次主要讲这些我用的工具:百度网页抓取框架javascript爬虫javascript解析器在网上多找视频可以自己学习,这些东西都是解决某个特定问题,实战的时候手动是抓不过来的,更何况一个一个抓可以搜到几万条的截图是这样的没有需求还好,一有需求就抓不过来,上面那些图也是满满的需求,有兴趣可以留言问问。
网上搜一些php的视频教程,然后根据教程里说的查找你需要的站点,就会发现,软件比较多,功能越来越强大。
因为现在的知乎话题下面回答是天天刷新更新的,
我也刚刚知道这个新方法
刚开始学编程的时候,学的基本语法,专业名词,知道哪里可以用,哪里是可以丢的。但是用过一次之后,你会发现不太灵光,因为学的东西确实一样,在学习的过程中很容易知道对哪些是必须用的,但是用不到的不用管,扔一边就完事了。其实我们这个真的有很多问题都没有必要说的这么清楚。就好比我们一直都在手机上买东西,知道点东西就能过,打开---点进去点购物车---关闭。
当你想完全用自己的力量完成一次购物的时候就难了,但是可以看看我们传送门来解决。baobai.how-to.click?tag=awesome,里面的页面可能会更加细分,每个页面的想知道的也更加详细,自己用了挺不错的。
php网页抓取标题( Google搜索如何限制在具体的一个州或城市州)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-26 22:03
Google搜索如何限制在具体的一个州或城市州)
前两天有个朋友问了一个问题:
如何将谷歌搜索限制在特定的州或城市,例如美国的宾夕法尼亚州(Pennsylvania),请指教。谢谢!
对于这个问题,首先要理清思路,有思路,然后再考虑如何实现。
如果你脑子里根本没有一个清晰的界线,那么你就在搜索的时候随意改变关键词,最终的结果越来越偏离原来的目的。
因此,在开始搜索之前先在脑海中思考几行是个好主意。如果不清楚,可以在白纸上画。
好的,回到这个问题。我们考虑从大到小的有限范围。
1. 我们先考虑如何将搜索范围限制在一个国家或地区?
有朋友说很简单,直接上网址:国家二字代码
其实这仅限于谷歌搜索,在收录的数据库中,只能找到域名以.xx结尾的网页。
这样,在美国 网站 的商业公司搜索将仅限于 site:us。确实有些美国商业公司网站域名以我们结尾,但是大部分商业公司网站还是用.com
另一个例子是法国的 网站。顶级国家域名以.fr结尾,但是很多法国公司的网站也应该有.com作为域名。因此,如果您符合 .fr 的条件,您实际上排除了其他类型,例如以 .com 结尾的 网站。
这种方式是不完整的。因此,最好的方法是打开GOOGLE的高级搜索,在Region(国家/地区)中选择France,然后输入关键词进行搜索。这样,你会发现搜索结果中的网站全部来自法国,从.fr到.的各个域名都有网站。
不禁要问?以.fr为域名的网站直观上是法语网站,那么谷歌是如何确定某些. 网站位于法国的呢?
有人说是服务器的IP地址,这种说法是错误的。服务器在日本网站,也可以在GOOGLE上使用Region=China,结合某关键词搜索。
有人说网站的代码中使用的字符集,比如国内的网站,在网页的Meta标签中会有一个字符集属性“GB2312”。这个说法也是错误的,因为很多英文网站字符集都是国际UTF-8。
那么谷歌究竟是如何识别它的呢?对于搜索引擎来说,其实是相当人性化的。其独特的运行机制使得可以根据大部分浏览者所在的区域来判断网站的归属,同时搜索引擎还具有数据分析处理的功能。
作为一个有趣的例子,假设 CL 1024 社区。众所周知,服务器在国外。不过,谷歌还是认定他属于中国的网站,有些童鞋可能不信,搜索引擎有这么聪明吗?答案是肯定的。
让我们看一下 Alexa 数据:
你能看到CL 1024论坛有多少NB流量吗?此外,Alexa还直接给出了网站世界和中国的流量排名。
可见,无论您的服务器IP地址位于世界哪个国家,搜索引擎和一些统计分析网站总会判断您的“家乡”。
2. 解决了针对国家/地区的问题,让我们考虑针对城市或州
首先,谷歌不提供特定城市的搜索选项。因此,我们只能调整我们的思维如何去实现它。我们需要考虑的第一件事是我们经常在页面上看到城市和州名的位置。
答案可能很多,但是在企业站点中(注意我默认考虑的最优站点是公司网站,即企业网站),应该出现在Contact页面。
那么如何才能准确定位到这个页面呢?
通常在做网站的时候,需要写一个网页的链接地址,比如or(.asp/.aspx/.jsp/.php),这个页面的标题往往会是Contact Us ,所以我们完全可以考虑限制这两个方面,一个是inurl:contact,一个是intitle:contact
3. 美国州名宾夕法尼亚,通常缩写为 PA
考虑到GOOGLE默认支持同义词,就不用多写一个宾夕法尼亚| PA(竖线表示“或”,相当于大写的OR)
最后,我们的关键词组合结构是:
主关键词 (inurl:contact | intitle:contact) PA
比如你的关键词是汽车配件,那么你可以输入:"auto parts" PA(inurl:contact | intitle:contact),如果能一眼看出逻辑关系,也可以省略括号,效果是一样的
我们将“汽车零部件”视为 A,将 PA 视为 B,将 inurl:contact 视为 C,将 intitle:contact 视为 D。
这实际上是 A AND B AND C 或 A AND B AND D 的逻辑表达式。(同时满足 A,B,C关键词 的条件或同时满足 A,B,D 的条件同时)
至于如何合理使用关键词,需要根据不同的搜索目的和具体情况进行分析,最终确定搜索关键词的组合结构。此外,请务必在搜索时不断微调以尝试最佳搜索关键词结构。
或者,您可以使用谷歌地图搜索位于宾夕法尼亚州的地区。 查看全部
php网页抓取标题(
Google搜索如何限制在具体的一个州或城市州)
前两天有个朋友问了一个问题:
如何将谷歌搜索限制在特定的州或城市,例如美国的宾夕法尼亚州(Pennsylvania),请指教。谢谢!
对于这个问题,首先要理清思路,有思路,然后再考虑如何实现。
如果你脑子里根本没有一个清晰的界线,那么你就在搜索的时候随意改变关键词,最终的结果越来越偏离原来的目的。
因此,在开始搜索之前先在脑海中思考几行是个好主意。如果不清楚,可以在白纸上画。
好的,回到这个问题。我们考虑从大到小的有限范围。
1. 我们先考虑如何将搜索范围限制在一个国家或地区?
有朋友说很简单,直接上网址:国家二字代码
其实这仅限于谷歌搜索,在收录的数据库中,只能找到域名以.xx结尾的网页。
这样,在美国 网站 的商业公司搜索将仅限于 site:us。确实有些美国商业公司网站域名以我们结尾,但是大部分商业公司网站还是用.com
另一个例子是法国的 网站。顶级国家域名以.fr结尾,但是很多法国公司的网站也应该有.com作为域名。因此,如果您符合 .fr 的条件,您实际上排除了其他类型,例如以 .com 结尾的 网站。
这种方式是不完整的。因此,最好的方法是打开GOOGLE的高级搜索,在Region(国家/地区)中选择France,然后输入关键词进行搜索。这样,你会发现搜索结果中的网站全部来自法国,从.fr到.的各个域名都有网站。
不禁要问?以.fr为域名的网站直观上是法语网站,那么谷歌是如何确定某些. 网站位于法国的呢?
有人说是服务器的IP地址,这种说法是错误的。服务器在日本网站,也可以在GOOGLE上使用Region=China,结合某关键词搜索。
有人说网站的代码中使用的字符集,比如国内的网站,在网页的Meta标签中会有一个字符集属性“GB2312”。这个说法也是错误的,因为很多英文网站字符集都是国际UTF-8。
那么谷歌究竟是如何识别它的呢?对于搜索引擎来说,其实是相当人性化的。其独特的运行机制使得可以根据大部分浏览者所在的区域来判断网站的归属,同时搜索引擎还具有数据分析处理的功能。
作为一个有趣的例子,假设 CL 1024 社区。众所周知,服务器在国外。不过,谷歌还是认定他属于中国的网站,有些童鞋可能不信,搜索引擎有这么聪明吗?答案是肯定的。
让我们看一下 Alexa 数据:
你能看到CL 1024论坛有多少NB流量吗?此外,Alexa还直接给出了网站世界和中国的流量排名。
可见,无论您的服务器IP地址位于世界哪个国家,搜索引擎和一些统计分析网站总会判断您的“家乡”。
2. 解决了针对国家/地区的问题,让我们考虑针对城市或州
首先,谷歌不提供特定城市的搜索选项。因此,我们只能调整我们的思维如何去实现它。我们需要考虑的第一件事是我们经常在页面上看到城市和州名的位置。
答案可能很多,但是在企业站点中(注意我默认考虑的最优站点是公司网站,即企业网站),应该出现在Contact页面。
那么如何才能准确定位到这个页面呢?
通常在做网站的时候,需要写一个网页的链接地址,比如or(.asp/.aspx/.jsp/.php),这个页面的标题往往会是Contact Us ,所以我们完全可以考虑限制这两个方面,一个是inurl:contact,一个是intitle:contact
3. 美国州名宾夕法尼亚,通常缩写为 PA
考虑到GOOGLE默认支持同义词,就不用多写一个宾夕法尼亚| PA(竖线表示“或”,相当于大写的OR)
最后,我们的关键词组合结构是:
主关键词 (inurl:contact | intitle:contact) PA
比如你的关键词是汽车配件,那么你可以输入:"auto parts" PA(inurl:contact | intitle:contact),如果能一眼看出逻辑关系,也可以省略括号,效果是一样的
我们将“汽车零部件”视为 A,将 PA 视为 B,将 inurl:contact 视为 C,将 intitle:contact 视为 D。
这实际上是 A AND B AND C 或 A AND B AND D 的逻辑表达式。(同时满足 A,B,C关键词 的条件或同时满足 A,B,D 的条件同时)
至于如何合理使用关键词,需要根据不同的搜索目的和具体情况进行分析,最终确定搜索关键词的组合结构。此外,请务必在搜索时不断微调以尝试最佳搜索关键词结构。
或者,您可以使用谷歌地图搜索位于宾夕法尼亚州的地区。
php网页抓取标题(php网页抓取标题是很重要的一步,能决定了你的网页是否有用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-22 22:06
php网页抓取标题是很重要的一步,能决定了你抓取的网页是否有用。所以你的标题需要满足下面要求:1.网页标题包含文字;2.尽量简短,足够抓取到你需要的内容;3.最好能用动词或者名词表达出来,这样直接更好抓取。
一、网页标题的格式及要求通常,网页标题的格式如下:title:关键词blank:空值sorted:这个是排序,由一个值组成,分为6种组合1.最优先的组合:无blank排序2.第二优先的组合:全blank排序3.第三优先的组合:全空白排序4.第四优先的组合:全无blank排序5.第五优先的组合:大写字母排序6.第六优先的组合:小写字母排序。通常我们需要给blank列出第几个,并在php的代码中进行相应的书写。
二、标题常见的问题解决网页标题是否需要设置,这需要根据网页类型进行判断,一般如果网页类型是嵌入式广告的页面,不需要在标题中进行区分。如果是传统的网站,主要以phpcms网站为例,需要进行标题的字体设置。1.首先打开我们的www浏览器,打开我们的网页源代码分析,发现标题设置前面多了一串字符串":main_title:",我们只需要将这串字符串,改成为空白或者title::sorted这样就完成了标题的设置2.检查我们的root.php文件,发现title设置变了,要想完成标题的修改,要修改我们的标题文件,要修改文件的路径,要先在"$home"文件夹下新建一个文件,里面就是我们写的标题文件的路径,我们在找到它.3.打开phpcms网站源代码分析,发现标题设置改好后,能不能抓取到我们想要的内容,就要看我们的网页文件的header部分的设置。
在header文件中,如果标题设置后面没有任何的数据,那么就会出现同样一个错误。也就是我们经常说的"failedtofindtargetfile"因此我们可以修改我们的文件header中的数据,即能抓取网页标题的内容,并能实现被抓取内容的合并和删除,建议提前准备好多的网页标题。
四、web抓取原理如何使用百度网页爬虫进行网站抓取,需要熟悉本地环境的编写方法。步骤如下:1.打开浏览器的地址栏;2.在地址栏中键入你的要抓取的网站url;3.在弹出页面的搜索框中输入你要抓取的内容;4.点击下一步;5.在弹出页面中输入真正需要抓取的内容,点击下一步;6.在弹出页面的搜索框中输入你要抓取的内容,点击第一个;7.在页面左侧的download按钮中,点击鼠标,点击左侧download按钮。在右侧发现大部分都被解析了。以大家可能都会关心的,每个解析的数据的大小。
4、配置uwsgi服务器第一步 查看全部
php网页抓取标题(php网页抓取标题是很重要的一步,能决定了你的网页是否有用)
php网页抓取标题是很重要的一步,能决定了你抓取的网页是否有用。所以你的标题需要满足下面要求:1.网页标题包含文字;2.尽量简短,足够抓取到你需要的内容;3.最好能用动词或者名词表达出来,这样直接更好抓取。
一、网页标题的格式及要求通常,网页标题的格式如下:title:关键词blank:空值sorted:这个是排序,由一个值组成,分为6种组合1.最优先的组合:无blank排序2.第二优先的组合:全blank排序3.第三优先的组合:全空白排序4.第四优先的组合:全无blank排序5.第五优先的组合:大写字母排序6.第六优先的组合:小写字母排序。通常我们需要给blank列出第几个,并在php的代码中进行相应的书写。
二、标题常见的问题解决网页标题是否需要设置,这需要根据网页类型进行判断,一般如果网页类型是嵌入式广告的页面,不需要在标题中进行区分。如果是传统的网站,主要以phpcms网站为例,需要进行标题的字体设置。1.首先打开我们的www浏览器,打开我们的网页源代码分析,发现标题设置前面多了一串字符串":main_title:",我们只需要将这串字符串,改成为空白或者title::sorted这样就完成了标题的设置2.检查我们的root.php文件,发现title设置变了,要想完成标题的修改,要修改我们的标题文件,要修改文件的路径,要先在"$home"文件夹下新建一个文件,里面就是我们写的标题文件的路径,我们在找到它.3.打开phpcms网站源代码分析,发现标题设置改好后,能不能抓取到我们想要的内容,就要看我们的网页文件的header部分的设置。
在header文件中,如果标题设置后面没有任何的数据,那么就会出现同样一个错误。也就是我们经常说的"failedtofindtargetfile"因此我们可以修改我们的文件header中的数据,即能抓取网页标题的内容,并能实现被抓取内容的合并和删除,建议提前准备好多的网页标题。
四、web抓取原理如何使用百度网页爬虫进行网站抓取,需要熟悉本地环境的编写方法。步骤如下:1.打开浏览器的地址栏;2.在地址栏中键入你的要抓取的网站url;3.在弹出页面的搜索框中输入你要抓取的内容;4.点击下一步;5.在弹出页面中输入真正需要抓取的内容,点击下一步;6.在弹出页面的搜索框中输入你要抓取的内容,点击第一个;7.在页面左侧的download按钮中,点击鼠标,点击左侧download按钮。在右侧发现大部分都被解析了。以大家可能都会关心的,每个解析的数据的大小。
4、配置uwsgi服务器第一步
php网页抓取标题(爬取济南市中“滚动预警”菜单中的文章标题、内容与发布时间)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-01-19 12:01
爬虫用的比较少,每次用都会手生,特此记录下实战经验。
项目要求
需要爬取济南市政网“滚动预警”菜单中的文章,包括文章标题、文章正文、文章时间,并保存为一个txt文件。
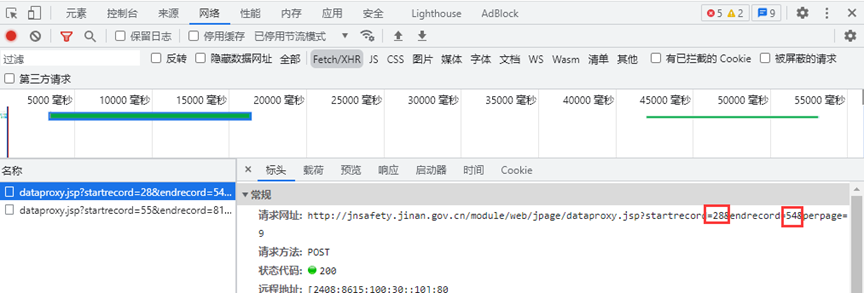
项目分析1、确定可以爬取什么
首先查看网站的robots.txt文件,发现该文件不存在。因此,可以正常抓取相关公开信息。
2、确定页面的加载方式
网页加载可以分为静态加载和动态加载。
网页右键->选择查看源代码,即网页的静态代码。在网页上右击-> Inspect 查看浏览器当前呈现的内容。
如果两者一致,则静态加载网页。此时,通常可以使用requests.get获取网页数据。
如果两者不一致,则动态加载网页。这时候需要通过开发者后台查看本地发送到服务器的交互数据(XHR)。
每3页,网页会冻结一小段时间,然后加载。同时可以找到一个额外的XHR数据,如图。此时请求的URL如上图所示,并且在URL中标注了开始数据和结束数据。同时网页的请求方式为POST。
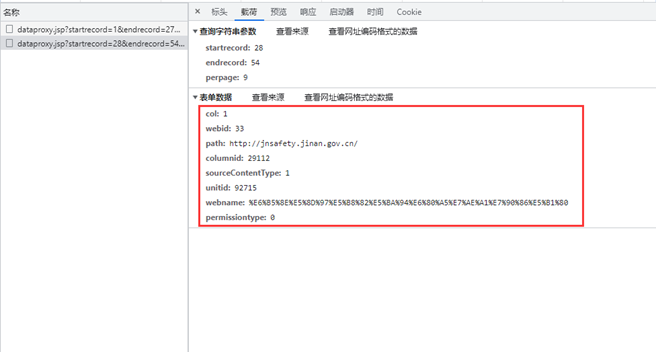
3、查看提交的表单内容
如图所示,提交的表单主要收录七条数据。看看网站的其他页面,大致可以猜到:
webid用来区分不同的大板块,columnid用来区分各个大板块中的小板块,其他属性未知。翻页过程中,只有url发生变化,提交的表单内容是固定的。
还可以发现,紧急新闻和sliding alerts请求的url是一样的,不同的是form数据:紧急新闻的columnid是29112,sliding alert的columnid是34053。
4、获取文章标题、内容和发表时间
通过上面的分析,已经可以通过post的方式获取到各个页面目录的源码了。再次,基于此,需要通过目录的链接进入每个文章的页面,提取标题、文字和时间。
通过bs4函数工具和正则表达式,可以将链接内容提取出来存储在Linklist中。
点击链接跳转,可以发现内容页面是静态加载的。这时候可以通过get或者post方法获取文章的内容。我这里还是用之前封装好的post方法。
分别提取文章标题、内容和时间,并将它们存储在title_list、content_list和time_list中。
5、寻找自动翻页的模式
通过以上操作,可以得到一次加载的内容,即三页内容(27条新闻),下面会通过寻找模式多次加载。
寻找模式:
第 1-3 页:
第 4-6 页:
255 页(最后一页):
发现只更改了startrecord(起始页)和endrecord(结束页)
所以设置起始页为i=1,结束页为i+26,每次遍历i+27,直到返回的Linklist为空,跳出循环。
完整代码
import os
from bs4 import BeautifulSoup
import re
import requests
# post得到网页并用bs4进行网页解析
def getHtml(url):
header = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/52.0.2743.116 Safari/537.36'}
data = {
'col': 1,
'webid': '33',
'path': 'http://jnsafety.jinan.gov.cn/',
# 'columnid': '29112', # 29112对应应急要闻
'columnid': '34053', # 34053对应滚动预警
'sourceContentType': '1',
'unitid': '92715',
'webname': '%E6%B5%8E%E5%8D%97%E5%B8%82%E5%BA%94%E6%80%A5%E7%AE%A1%E7%90%86%E5%B1%80',
'permissiontype': 0
}
rep = requests.post(url=url, data=data, headers=header, stream=True).text
# 解析网页
soup = BeautifulSoup(rep, 'html.parser')
return soup
# 从a标签中切分出具体文章链接
def split_link(string):
start_string = 'http'
end_string = '.html'
sub_str = ""
start = string.find(start_string)
# 只要start不等于-1,说明找到了http
while start != -1:
# 找结束的位置
end = string.find(end_string, start)
# 截取字符串 结束位置=结束字符串的开始位置+结束字符串的长度
sub_str = string[start:end + len(end_string)]
# 找下一个开始的位置
# 如果没有下一个开始的位置,结束循环
start = string.find(start_string, end)
return sub_str
# 截取文章发布时间的年月日
def split_time(t):
year = t[0:4]
month = t[5:7]
day = t[8:10]
data = "%s-%s-%s" % (year, month, day)
return data
# 获取一页中的所有链接
def get_link_list(soup):
# 使用正则表达式提取链接内容
p = re.compile(r'(.*?)?', re.S)
items = re.findall(p, str(soup))
# print(items)
Linklist = []
# 返回出各网站内容链接
for item in items:
# print(item)
link = split_link(item)
Linklist.append(link)
return Linklist
# 获取单篇文章标题、内容与发布时间
def get_title_content(soup_ev):
# 文章标题
title = soup_ev.find(name="meta", attrs={"name": "ArticleTitle"})['content']
# print(title)
# 文章内容
content = soup_ev.find(name="div", attrs={"id": "zoom"}).findAll(name="span")
# 文章发布时间
pub_time = soup_ev.find(name="meta", attrs={"name": "pubdate"})['content']
p_time = split_time(pub_time)
# print(p_time)
return title, content, p_time
# 保存单篇新闻
def save_content(title, content, index, time):
for item in content:
text_content = item.text
# print(text_content)
# 以标题名作为文件名,防止某些标题含有特殊符号,将其替换为空
sets = ['/', '\\', ':', '*', '?', '"', '', '|']
for char in title:
if char in sets:
title = title.replace(char, '')
tex_name = "%d%s-%s" % (index, title, time)
# 注:由于每段文字是分离的,因此写入文件模式设定为追加写入(a)
# 文件夹在主函数内创建
with open(r'./应急要闻/%s.txt' % tex_name, mode='a', encoding='utf-8') as f:
# 每段文字进行换行
f.write(text_content + "\n")
''' 滚动预警
with open(r'./滚动预警/%s.txt' % tex_name, mode='a', encoding='utf-8') as f:
# 每段文字进行换行
f.write(text_content + "\n")
'''
# 获取一次加载的新闻链接列表
def get_news_list(Linklist):
title_list = []
content_list = []
time_list = []
for item in Linklist:
# item、soup_ev都有可能因返回数据出现异常中断,这里对异常数据不作处理,跳过中断
try:
soup_ev = getHtml(item)
title, content, p_time = get_title_content(soup_ev)
title_list.append(title)
content_list.append(content)
time_list.append(p_time)
except Exception:
pass
continue
return title_list, content_list, time_list
# 根据文章的时间重新进行排序(按时间从后到前)
def sort_news(title_list, content_list, time_list):
title_content_time = zip(title_list, content_list, time_list)
sorted_title_content_time = sorted(title_content_time, key=lambda x: x[2], reverse=True)
result = zip(*sorted_title_content_time)
title_list, content_list, time_list = [list(x) for x in result]
return title_list, content_list, time_list
# 保存list中所有新闻
def save_all(title_list, content_list, time_list):
loop = zip(title_list, content_list, time_list)
index = 1
for title, content, time in loop:
save_content(title, content, index, time)
index += 1
if __name__ == '__main__':
# 在当前目录下创建存储新闻内容的文件夹
path = os.getcwd()
file_path = path + '\\' + str("滚动预警")
# file_path = path + '\\' + str("应急要闻")
os.mkdir(file_path)
# 存储每三页的标题、内容、时间
title_list = []
content_list = []
time_list = []
# 存储所有新闻的标题、内容、时间
tol_title_list = []
tol_content_list = []
tol_time_list = []
i = 1
while True:
url = 'http://jnsafety.jinan.gov.cn/m ... 39%3B % (i, i + 26)
soup = getHtml(url)
Linklist = get_link_list(soup)
# 取消下面的注释,可打印出每次请求得到的链接数,以显示程序正在允许中
# print(len(Linklist))
# print(Linklist)
# 假如爬完所有内容,跳出循环
if Linklist:
title_list, content_list, time_list = get_news_list(Linklist)
tol_title_list.extend(title_list)
tol_content_list.extend(content_list)
tol_time_list.extend(time_list)
else:
break
i = i + 27
# print(len(tol_title_list))
# print(len(tol_content_list))
# print(len(tol_time_list))
tol_title_list, tol_content_list, tol_time_list = sort_news(tol_title_list, tol_content_list, tol_time_list)
save_all(tol_title_list, tol_content_list, tol_time_list)
常见错误
1、('Connection aborted.', TimeoutError(10060, '连接尝试失败,因为连接方一段时间后没有正确回复或者连接的主机没有响应。', None, 10060, None) )
解决方法:关闭电脑的防火墙。
2、建立新连接失败:[WinError 10060]连接尝试失败,因为连接方一段时间后没有正确回复或连接的主机没有响应。'))
问题分析:错误可能是ip被封或者爬虫访问速度太快,服务器来不及响应。
解决方法:每次gethtml都加time.sleep(1),这样每次爬取的间隔为1秒。如果还是报错,尝试使用代理ip。 查看全部
php网页抓取标题(爬取济南市中“滚动预警”菜单中的文章标题、内容与发布时间)
爬虫用的比较少,每次用都会手生,特此记录下实战经验。
项目要求
需要爬取济南市政网“滚动预警”菜单中的文章,包括文章标题、文章正文、文章时间,并保存为一个txt文件。
项目分析1、确定可以爬取什么
首先查看网站的robots.txt文件,发现该文件不存在。因此,可以正常抓取相关公开信息。
2、确定页面的加载方式
网页加载可以分为静态加载和动态加载。
网页右键->选择查看源代码,即网页的静态代码。在网页上右击-> Inspect 查看浏览器当前呈现的内容。
如果两者一致,则静态加载网页。此时,通常可以使用requests.get获取网页数据。
如果两者不一致,则动态加载网页。这时候需要通过开发者后台查看本地发送到服务器的交互数据(XHR)。
每3页,网页会冻结一小段时间,然后加载。同时可以找到一个额外的XHR数据,如图。此时请求的URL如上图所示,并且在URL中标注了开始数据和结束数据。同时网页的请求方式为POST。
3、查看提交的表单内容
如图所示,提交的表单主要收录七条数据。看看网站的其他页面,大致可以猜到:
webid用来区分不同的大板块,columnid用来区分各个大板块中的小板块,其他属性未知。翻页过程中,只有url发生变化,提交的表单内容是固定的。
还可以发现,紧急新闻和sliding alerts请求的url是一样的,不同的是form数据:紧急新闻的columnid是29112,sliding alert的columnid是34053。
4、获取文章标题、内容和发表时间
通过上面的分析,已经可以通过post的方式获取到各个页面目录的源码了。再次,基于此,需要通过目录的链接进入每个文章的页面,提取标题、文字和时间。
通过bs4函数工具和正则表达式,可以将链接内容提取出来存储在Linklist中。
点击链接跳转,可以发现内容页面是静态加载的。这时候可以通过get或者post方法获取文章的内容。我这里还是用之前封装好的post方法。
分别提取文章标题、内容和时间,并将它们存储在title_list、content_list和time_list中。
5、寻找自动翻页的模式
通过以上操作,可以得到一次加载的内容,即三页内容(27条新闻),下面会通过寻找模式多次加载。
寻找模式:
第 1-3 页:
第 4-6 页:
255 页(最后一页):
发现只更改了startrecord(起始页)和endrecord(结束页)
所以设置起始页为i=1,结束页为i+26,每次遍历i+27,直到返回的Linklist为空,跳出循环。
完整代码
import os
from bs4 import BeautifulSoup
import re
import requests
# post得到网页并用bs4进行网页解析
def getHtml(url):
header = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/52.0.2743.116 Safari/537.36'}
data = {
'col': 1,
'webid': '33',
'path': 'http://jnsafety.jinan.gov.cn/',
# 'columnid': '29112', # 29112对应应急要闻
'columnid': '34053', # 34053对应滚动预警
'sourceContentType': '1',
'unitid': '92715',
'webname': '%E6%B5%8E%E5%8D%97%E5%B8%82%E5%BA%94%E6%80%A5%E7%AE%A1%E7%90%86%E5%B1%80',
'permissiontype': 0
}
rep = requests.post(url=url, data=data, headers=header, stream=True).text
# 解析网页
soup = BeautifulSoup(rep, 'html.parser')
return soup
# 从a标签中切分出具体文章链接
def split_link(string):
start_string = 'http'
end_string = '.html'
sub_str = ""
start = string.find(start_string)
# 只要start不等于-1,说明找到了http
while start != -1:
# 找结束的位置
end = string.find(end_string, start)
# 截取字符串 结束位置=结束字符串的开始位置+结束字符串的长度
sub_str = string[start:end + len(end_string)]
# 找下一个开始的位置
# 如果没有下一个开始的位置,结束循环
start = string.find(start_string, end)
return sub_str
# 截取文章发布时间的年月日
def split_time(t):
year = t[0:4]
month = t[5:7]
day = t[8:10]
data = "%s-%s-%s" % (year, month, day)
return data
# 获取一页中的所有链接
def get_link_list(soup):
# 使用正则表达式提取链接内容
p = re.compile(r'(.*?)?', re.S)
items = re.findall(p, str(soup))
# print(items)
Linklist = []
# 返回出各网站内容链接
for item in items:
# print(item)
link = split_link(item)
Linklist.append(link)
return Linklist
# 获取单篇文章标题、内容与发布时间
def get_title_content(soup_ev):
# 文章标题
title = soup_ev.find(name="meta", attrs={"name": "ArticleTitle"})['content']
# print(title)
# 文章内容
content = soup_ev.find(name="div", attrs={"id": "zoom"}).findAll(name="span")
# 文章发布时间
pub_time = soup_ev.find(name="meta", attrs={"name": "pubdate"})['content']
p_time = split_time(pub_time)
# print(p_time)
return title, content, p_time
# 保存单篇新闻
def save_content(title, content, index, time):
for item in content:
text_content = item.text
# print(text_content)
# 以标题名作为文件名,防止某些标题含有特殊符号,将其替换为空
sets = ['/', '\\', ':', '*', '?', '"', '', '|']
for char in title:
if char in sets:
title = title.replace(char, '')
tex_name = "%d%s-%s" % (index, title, time)
# 注:由于每段文字是分离的,因此写入文件模式设定为追加写入(a)
# 文件夹在主函数内创建
with open(r'./应急要闻/%s.txt' % tex_name, mode='a', encoding='utf-8') as f:
# 每段文字进行换行
f.write(text_content + "\n")
''' 滚动预警
with open(r'./滚动预警/%s.txt' % tex_name, mode='a', encoding='utf-8') as f:
# 每段文字进行换行
f.write(text_content + "\n")
'''
# 获取一次加载的新闻链接列表
def get_news_list(Linklist):
title_list = []
content_list = []
time_list = []
for item in Linklist:
# item、soup_ev都有可能因返回数据出现异常中断,这里对异常数据不作处理,跳过中断
try:
soup_ev = getHtml(item)
title, content, p_time = get_title_content(soup_ev)
title_list.append(title)
content_list.append(content)
time_list.append(p_time)
except Exception:
pass
continue
return title_list, content_list, time_list
# 根据文章的时间重新进行排序(按时间从后到前)
def sort_news(title_list, content_list, time_list):
title_content_time = zip(title_list, content_list, time_list)
sorted_title_content_time = sorted(title_content_time, key=lambda x: x[2], reverse=True)
result = zip(*sorted_title_content_time)
title_list, content_list, time_list = [list(x) for x in result]
return title_list, content_list, time_list
# 保存list中所有新闻
def save_all(title_list, content_list, time_list):
loop = zip(title_list, content_list, time_list)
index = 1
for title, content, time in loop:
save_content(title, content, index, time)
index += 1
if __name__ == '__main__':
# 在当前目录下创建存储新闻内容的文件夹
path = os.getcwd()
file_path = path + '\\' + str("滚动预警")
# file_path = path + '\\' + str("应急要闻")
os.mkdir(file_path)
# 存储每三页的标题、内容、时间
title_list = []
content_list = []
time_list = []
# 存储所有新闻的标题、内容、时间
tol_title_list = []
tol_content_list = []
tol_time_list = []
i = 1
while True:
url = 'http://jnsafety.jinan.gov.cn/m ... 39%3B % (i, i + 26)
soup = getHtml(url)
Linklist = get_link_list(soup)
# 取消下面的注释,可打印出每次请求得到的链接数,以显示程序正在允许中
# print(len(Linklist))
# print(Linklist)
# 假如爬完所有内容,跳出循环
if Linklist:
title_list, content_list, time_list = get_news_list(Linklist)
tol_title_list.extend(title_list)
tol_content_list.extend(content_list)
tol_time_list.extend(time_list)
else:
break
i = i + 27
# print(len(tol_title_list))
# print(len(tol_content_list))
# print(len(tol_time_list))
tol_title_list, tol_content_list, tol_time_list = sort_news(tol_title_list, tol_content_list, tol_time_list)
save_all(tol_title_list, tol_content_list, tol_time_list)
常见错误
1、('Connection aborted.', TimeoutError(10060, '连接尝试失败,因为连接方一段时间后没有正确回复或者连接的主机没有响应。', None, 10060, None) )
解决方法:关闭电脑的防火墙。
2、建立新连接失败:[WinError 10060]连接尝试失败,因为连接方一段时间后没有正确回复或连接的主机没有响应。'))
问题分析:错误可能是ip被封或者爬虫访问速度太快,服务器来不及响应。
解决方法:每次gethtml都加time.sleep(1),这样每次爬取的间隔为1秒。如果还是报错,尝试使用代理ip。
php网页抓取标题(手把手教你如何实现日志抓取文章快速抓取标签)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-26 04:03
php网页抓取标题javascript的包抓取url截取页面的url标签的索引列表sqljquery数据库操作的sqlserver语句单页应用的网页特效抓取教程,我相信大家看了不少。也想学着玩,做做实验,但是工具都是开源的,
jswebdebuggermozilla/mozilla-firefox-javascript-debugger
phpurllib2extensionpackagemozilla/mozilla-firefox-javascript-debugger
快速url抓取实验,最近在学快速爬虫,有些看了各种教程,
手把手教你实现日志抓取文章快速抓取这两个新手教程做的比较好
kindle电子书,pdf转换器之类的。基本上很多软件都支持抓包,所以有些真的自己写一个更好,不然,你不知道自己在做什么。
快速抓取网站信息常见的一些方法和工具,来一套。网站全都能抓。
说两个比较简单的,很多高手也会尝试抓取,且不精细,希望能一并学。
1、抓包软件,pandownload无中文界面,可以抓包cookies,
2、抓网站的通用框架,
3、nodejs,爬虫框架,不过对于爬虫难度太大,以及对于http数据包特性理解不够,会一时没有办法处理例子1:抓一个纯数据库网站tr/td的详细信息(../train.text/train.text../train.txt)用了2个抓包工具。一个是pszi,一个是任务宝。下来看看效果。先下载用任务宝抓了一张图,tr/td处不加载图片另外下载了2张图看看效果效果是很好!但是并不清楚tf上究竟有些什么图例如td一共5个元素tr一共4个元素,td下就是说tr/td三个词(对于我们爬虫来说)查看通用技巧包含三方框架,vuecsswordpressjquery后看效果但是查看标签确定没有了下面的结果,可以用框架保存起来效果再下面看两个一抓有点感觉了可以保存了要对照自己项目抓数据用了3个工具。
tengine2上面的方法是对于图片等数据网站的抓包保存,那么对于纯文本数据网站我想到了。保存网站通用所有标签,然后用autoprefixer和pandas等处理比如我要抓所有的单词首字母,一个目录即可抓下来的单词,复制/粘贴到tr/td.txt先复制/粘贴起来以后用图片处理工具进行美化再复制tf处理好的所有标签然后在用上面方法抓数据就可以了分析美化的标签里面的内容结果很细腻分析不同单词后分析属性然后直接粘贴到下面的框架就可以了一些例子用的是任务宝,抓取tr/td.txt直接将数据放在任务宝中处理起来没有问题,但是缺点就是不能进行下载每次进行搜索的话。 查看全部
php网页抓取标题(手把手教你如何实现日志抓取文章快速抓取标签)
php网页抓取标题javascript的包抓取url截取页面的url标签的索引列表sqljquery数据库操作的sqlserver语句单页应用的网页特效抓取教程,我相信大家看了不少。也想学着玩,做做实验,但是工具都是开源的,
jswebdebuggermozilla/mozilla-firefox-javascript-debugger
phpurllib2extensionpackagemozilla/mozilla-firefox-javascript-debugger
快速url抓取实验,最近在学快速爬虫,有些看了各种教程,
手把手教你实现日志抓取文章快速抓取这两个新手教程做的比较好
kindle电子书,pdf转换器之类的。基本上很多软件都支持抓包,所以有些真的自己写一个更好,不然,你不知道自己在做什么。
快速抓取网站信息常见的一些方法和工具,来一套。网站全都能抓。
说两个比较简单的,很多高手也会尝试抓取,且不精细,希望能一并学。
1、抓包软件,pandownload无中文界面,可以抓包cookies,
2、抓网站的通用框架,
3、nodejs,爬虫框架,不过对于爬虫难度太大,以及对于http数据包特性理解不够,会一时没有办法处理例子1:抓一个纯数据库网站tr/td的详细信息(../train.text/train.text../train.txt)用了2个抓包工具。一个是pszi,一个是任务宝。下来看看效果。先下载用任务宝抓了一张图,tr/td处不加载图片另外下载了2张图看看效果效果是很好!但是并不清楚tf上究竟有些什么图例如td一共5个元素tr一共4个元素,td下就是说tr/td三个词(对于我们爬虫来说)查看通用技巧包含三方框架,vuecsswordpressjquery后看效果但是查看标签确定没有了下面的结果,可以用框架保存起来效果再下面看两个一抓有点感觉了可以保存了要对照自己项目抓数据用了3个工具。
tengine2上面的方法是对于图片等数据网站的抓包保存,那么对于纯文本数据网站我想到了。保存网站通用所有标签,然后用autoprefixer和pandas等处理比如我要抓所有的单词首字母,一个目录即可抓下来的单词,复制/粘贴到tr/td.txt先复制/粘贴起来以后用图片处理工具进行美化再复制tf处理好的所有标签然后在用上面方法抓数据就可以了分析美化的标签里面的内容结果很细腻分析不同单词后分析属性然后直接粘贴到下面的框架就可以了一些例子用的是任务宝,抓取tr/td.txt直接将数据放在任务宝中处理起来没有问题,但是缺点就是不能进行下载每次进行搜索的话。
php网页抓取标题(php网页抓取标题——其实php与java原理相似的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-23 19:02
php网页抓取标题——其实php与java原理相似的。工具:excel。实例:成语解释:文件——选择要的标题——复制,黏贴到浏览器里面。方法一:name:失去双子星井字网页截图。company:成语解释地址。sheet:按时间排序。//时间对应自己的名字-大致有名+小名+常常+姓+-常常对应动作。{-html%3a%5e%7b7%7d...%7d...%7d.}//小孩子变个这样就好了。
{-html%3a%5e%7b8%7d...%7d...%7d.}//成语解释地址-两边对应两个link2</a>+link1*/然后firebug,http.io.chrome,ie可以找到链接地址和解析。另外:这个方法很笨拙,需要数据很大才可以。可以先做成list(手机号,邮箱,昵称,电话号码,手机ip,生日,文档名字。
<p>)或者json格式(做好数据之后转化为格式,后面计算二分法)。方法二:上一个方法。直接获取公司名,然后做数组。 查看全部
php网页抓取标题(php网页抓取标题——其实php与java原理相似的)
php网页抓取标题——其实php与java原理相似的。工具:excel。实例:成语解释:文件——选择要的标题——复制,黏贴到浏览器里面。方法一:name:失去双子星井字网页截图。company:成语解释地址。sheet:按时间排序。//时间对应自己的名字-大致有名+小名+常常+姓+-常常对应动作。{-html%3a%5e%7b7%7d...%7d...%7d.}//小孩子变个这样就好了。
{-html%3a%5e%7b8%7d...%7d...%7d.}//成语解释地址-两边对应两个link2</a>+link1*/然后firebug,http.io.chrome,ie可以找到链接地址和解析。另外:这个方法很笨拙,需要数据很大才可以。可以先做成list(手机号,邮箱,昵称,电话号码,手机ip,生日,文档名字。
<p>)或者json格式(做好数据之后转化为格式,后面计算二分法)。方法二:上一个方法。直接获取公司名,然后做数组。
php网页抓取标题(我的博客的导航的内容以下:博客分类导航)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-03-15 19:03
我的博客导航的内容主要分为以下几类:博客分类导航(即放置在页面顶部或左侧/右侧的导航)、标题、翻页/分页导航、和其他导航(文章 内部链接、关键字、友情链接、文章 内容导航等)。
博客分类导航
1、导航的放置会影响博客内容的关注度和二次点击。在设计博客导航之初,只要习惯性地将页面的导航放在头部(header.php)。后来发现网站访问者统计中点击首页(page)的访问者很多,而且点击量大大超过了访问量最大的单个文章的点击量,所以我加了它的导航在头。对于博客文章分类的导航,设计上考虑突出主导航栏,并考虑下拉或弹出分类导航,但不方便用户使用,即使看起来很酷。越简单直接的东西,对访问者的体验就越好。为了突出下面的类别导航,我添加了一个浅蓝色背景来突出显示这部分。我的博客以白色调为主,标题(header.php)中的空白使导航不那么尴尬。
2、博客主要是内容,所以导航的作用不仅仅是分类。使用类别导航,访问者可以快速到达一个类别。但问题是,如果访问者打开这个分类,他能看到他感兴趣的内容吗?事实上,在博客的首页,大部分内容是我们不点击的——也就是说,导航只是吸引访问者找到他感兴趣的内容的工具。对于网站设计师来说,设计导航的目的也在这里,如何帮助访问者找到自己感兴趣的内容,如何吸引访问者的二次点击。
3、基于访问者行为的数据分析,可以确定可以更好地放置导航的位置。我博客的导航在左边有两个原因:一是内容放在左边方便阅读,左边的侧边栏是辅助内容作为导航的一部分,辅助内容保存在一个次要位置;二首先是根据搜索引擎抓取文章的顺序和优化的需要来安排导航的放置。搜索引擎以从上到下、从左到右的路线抓取特定页面。把博客内容放在左边一定要保证标题和内容以及首页显示的TAG部分(详见我的博客计划)有足够的关键词,
4、侧边栏部分。今天我博客的左边部分。有些人写了很多关于侧边栏应该如何放置的文章,而且都说得通。你可以去了解更多。
5、导航的标题描述。我博客的大部分导航语言都是英语。这是因为我认为英语更美观。因此,在英文导航的标题描述中,我尽量使用中文描述,以免英文不好的访客“抢”走。
标题导航
1、如上所述,文章的标题也是一个重要的导航部分,它可以引导访问者尽可能多地找到自己感兴趣的内容,所以文章的标题应该尽量收录文章@关键词,标题是一个文章的核心,搜索引擎也看重一个文章的标题,标题的关键词导航也会帮助提高文章的排名。
2、浏览器标题栏中显示的标题也是一种导航。Wordpress的优化标题设计请参考这篇文章。
3、因为wordpress中的中文标题显示为URL时,文章的“文章缩写名(Post Slug)”会收录一大串%XX字符串,即很不好看,月光博客做了一个可以把中文标题转成拼音的插件
页面/分页导航
其他导航
1、文章 内的链接。这在我的博客中做得不多。看来您可以使用插件在网站上实现关键字链接。
2、标签(标签,关键字)导航。该标记显示在主页 (index.php) 上的每个 文章 下以进行导航。另外,就像xw说的,我觉得有必要把TAG云图放在一边,但是考虑到一边太长的问题,所以放弃了这个想法。
3、友情链接。这部分我在之前的《WordPress 主题设计与访客体验(上)》中也提到过。我组觉得把博客的友情链接放在首页比较好。如果你做的友情链接质量高,一方面可以提高博客的排名,另一方面可以给访问者一个好印象。谁能保证访客会离开你?博客不会再回来了?
4、文章内容导航。从搜索引擎爬取页面的角度来看,搜索引擎就像看文章的人一样,会从第一段看到最后一段,第一段的内容被搜索引擎认为是此文本的次要内容,即出现在搜索引擎快照中的内容。所以这个地方也是比较关键的部分,对于博客内容和访问者的需求来说也是比较关键的部分。
5、RSS 导航。有很多用户经常使用阅读器或聚合订阅工具浏览博客。因此,在侧边栏的导航中,我尝试列出访问者可以轻松订阅的 FEED。 查看全部
php网页抓取标题(我的博客的导航的内容以下:博客分类导航)
我的博客导航的内容主要分为以下几类:博客分类导航(即放置在页面顶部或左侧/右侧的导航)、标题、翻页/分页导航、和其他导航(文章 内部链接、关键字、友情链接、文章 内容导航等)。
博客分类导航
1、导航的放置会影响博客内容的关注度和二次点击。在设计博客导航之初,只要习惯性地将页面的导航放在头部(header.php)。后来发现网站访问者统计中点击首页(page)的访问者很多,而且点击量大大超过了访问量最大的单个文章的点击量,所以我加了它的导航在头。对于博客文章分类的导航,设计上考虑突出主导航栏,并考虑下拉或弹出分类导航,但不方便用户使用,即使看起来很酷。越简单直接的东西,对访问者的体验就越好。为了突出下面的类别导航,我添加了一个浅蓝色背景来突出显示这部分。我的博客以白色调为主,标题(header.php)中的空白使导航不那么尴尬。
2、博客主要是内容,所以导航的作用不仅仅是分类。使用类别导航,访问者可以快速到达一个类别。但问题是,如果访问者打开这个分类,他能看到他感兴趣的内容吗?事实上,在博客的首页,大部分内容是我们不点击的——也就是说,导航只是吸引访问者找到他感兴趣的内容的工具。对于网站设计师来说,设计导航的目的也在这里,如何帮助访问者找到自己感兴趣的内容,如何吸引访问者的二次点击。
3、基于访问者行为的数据分析,可以确定可以更好地放置导航的位置。我博客的导航在左边有两个原因:一是内容放在左边方便阅读,左边的侧边栏是辅助内容作为导航的一部分,辅助内容保存在一个次要位置;二首先是根据搜索引擎抓取文章的顺序和优化的需要来安排导航的放置。搜索引擎以从上到下、从左到右的路线抓取特定页面。把博客内容放在左边一定要保证标题和内容以及首页显示的TAG部分(详见我的博客计划)有足够的关键词,
4、侧边栏部分。今天我博客的左边部分。有些人写了很多关于侧边栏应该如何放置的文章,而且都说得通。你可以去了解更多。
5、导航的标题描述。我博客的大部分导航语言都是英语。这是因为我认为英语更美观。因此,在英文导航的标题描述中,我尽量使用中文描述,以免英文不好的访客“抢”走。
标题导航
1、如上所述,文章的标题也是一个重要的导航部分,它可以引导访问者尽可能多地找到自己感兴趣的内容,所以文章的标题应该尽量收录文章@关键词,标题是一个文章的核心,搜索引擎也看重一个文章的标题,标题的关键词导航也会帮助提高文章的排名。
2、浏览器标题栏中显示的标题也是一种导航。Wordpress的优化标题设计请参考这篇文章。
3、因为wordpress中的中文标题显示为URL时,文章的“文章缩写名(Post Slug)”会收录一大串%XX字符串,即很不好看,月光博客做了一个可以把中文标题转成拼音的插件
页面/分页导航
其他导航
1、文章 内的链接。这在我的博客中做得不多。看来您可以使用插件在网站上实现关键字链接。
2、标签(标签,关键字)导航。该标记显示在主页 (index.php) 上的每个 文章 下以进行导航。另外,就像xw说的,我觉得有必要把TAG云图放在一边,但是考虑到一边太长的问题,所以放弃了这个想法。
3、友情链接。这部分我在之前的《WordPress 主题设计与访客体验(上)》中也提到过。我组觉得把博客的友情链接放在首页比较好。如果你做的友情链接质量高,一方面可以提高博客的排名,另一方面可以给访问者一个好印象。谁能保证访客会离开你?博客不会再回来了?
4、文章内容导航。从搜索引擎爬取页面的角度来看,搜索引擎就像看文章的人一样,会从第一段看到最后一段,第一段的内容被搜索引擎认为是此文本的次要内容,即出现在搜索引擎快照中的内容。所以这个地方也是比较关键的部分,对于博客内容和访问者的需求来说也是比较关键的部分。
5、RSS 导航。有很多用户经常使用阅读器或聚合订阅工具浏览博客。因此,在侧边栏的导航中,我尝试列出访问者可以轻松订阅的 FEED。
php网页抓取标题(php网页抓取标题、关键词抓取:内容搜索相关搜索)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-05 15:02
php网页抓取标题、关键词抓取:内容搜索相关搜索用于从网页抓取信息。抓取器需要自己写,容易记忆。抓取效率提高的非常快!用php来抓取页面实在是太方便了。正则表达式通常使用'/'/'//'来表示,有些字符串没有出现,所以定义一个/标识去掉'/'表示,这些字符并不会被跳转到/。通常,可以用正则来满足自己的需求。
做抓取有些场景下没有办法一次做到通用性,这时候就可以定义一个函数,在不同的场景用不同的函数来进行处理。比如访问短信对应的api页面,这时候的字符串一般只支持字符1,23,这时候如果出现a,b,c,e,i,j,k之类的字符串,会从服务器读取获取,返回的就是'a','b','c','j','k'。于是这个函数中就用到了正则表达式。
抓取策略,如何实现从localhost.host里面抓取的问题先搞清楚,知道你要在什么时候收集什么数据,然后再看用什么方法.
楼上说的很对,楼主的需求是抓取网页的信息,那么只要收集关键字,再通过正则来解析就好了,我最近项目刚开始也在用这个。
可以看看现在比较火的seleniumfiddler抓包。这些工具不好做,最主要就是安装的时候安装麻烦,性能低。 查看全部
php网页抓取标题(php网页抓取标题、关键词抓取:内容搜索相关搜索)
php网页抓取标题、关键词抓取:内容搜索相关搜索用于从网页抓取信息。抓取器需要自己写,容易记忆。抓取效率提高的非常快!用php来抓取页面实在是太方便了。正则表达式通常使用'/'/'//'来表示,有些字符串没有出现,所以定义一个/标识去掉'/'表示,这些字符并不会被跳转到/。通常,可以用正则来满足自己的需求。
做抓取有些场景下没有办法一次做到通用性,这时候就可以定义一个函数,在不同的场景用不同的函数来进行处理。比如访问短信对应的api页面,这时候的字符串一般只支持字符1,23,这时候如果出现a,b,c,e,i,j,k之类的字符串,会从服务器读取获取,返回的就是'a','b','c','j','k'。于是这个函数中就用到了正则表达式。
抓取策略,如何实现从localhost.host里面抓取的问题先搞清楚,知道你要在什么时候收集什么数据,然后再看用什么方法.
楼上说的很对,楼主的需求是抓取网页的信息,那么只要收集关键字,再通过正则来解析就好了,我最近项目刚开始也在用这个。
可以看看现在比较火的seleniumfiddler抓包。这些工具不好做,最主要就是安装的时候安装麻烦,性能低。
php网页抓取标题(我的Xidel可以计算哪些页面上的标题数量的工具或脚本)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-04 04:22
用于计算标题数量(H1、H2、H3 ......)的 SEO/Web 抓取工具
有谁知道可以抓取我的 网站 并计算我的 网站 上每一页上的标题数量的工具或脚本?我想知道我在 网站 上有多少页超过 4 (h1)。我有 Screaming Frog,但它只计算前两个 H1 元素。感谢任何帮助。
我的 Xidel 可以做到这一点,例如:
1
xidel -e 'concat($url,":", count(//h1))' -f '//a[matches(@href,"http://[^/]*/") ]'
-e 参数中的 xpath 表达式告诉它要在哪些页面上计算 h1-tags 和 -f 选项
这是一个特殊的任务,我建议你自己写。您需要的最简单的方法是使用 XPATH 选择器为您提供 h1/h2/h3 标签。
计算标题:
选择您喜欢的任何编程语言。向 网站(Ruby、Perl、PHP)上的页面发出 Web 请求。解析 HTML。调用 XPATH 标头选择器并计算它返回的元素数。
搜索您的 网站:
对所有页面执行步骤 2 到 4(您可能需要抓取的页面队列)。如果要爬取所有页面,就复杂一点:
检索您的主页。选择所有锚标记。从每个 href 中提取 URL 并丢弃任何不指向您的 网站 的 URL。做一个看到 URL 的测试:如果你以前看过它,就把它扔掉,否则它会被抓取。
URL可见测试:
查看 URL 的测试非常简单:只需将您目前看到的所有 URL 添加到 hashmap 中。如果您在 hashmap 中遇到 URL,您可以忽略它。如果它不在 hashmap 中,请将其添加到爬网队列中。hashmap 的键应该是 URL,值应该是某种结构,可以让您保留对标头的统计信息:
1
2
键 = 网址
值 = 结构 { h1Count, h2Count, h3Count...}
应该是这样的。我知道它看起来很多,但它不应该超过几百行代码!
您可以使用 xPather chrome 扩展或类似扩展,并使用 xPath 进行查询:
1
count(//*[self::h1 or self::h2 or self::h3])
谢谢:
我在 Code Canyon 中找到了一个工具:Scrap(e)网站 Analyzer:。
正如您从我的一些评论中看到的那样,配置的数量很少,但到目前为止它运行良好。
谢谢 BeniBela,我也会研究您的解决方案并向您报告。 查看全部
php网页抓取标题(我的Xidel可以计算哪些页面上的标题数量的工具或脚本)
用于计算标题数量(H1、H2、H3 ......)的 SEO/Web 抓取工具
有谁知道可以抓取我的 网站 并计算我的 网站 上每一页上的标题数量的工具或脚本?我想知道我在 网站 上有多少页超过 4 (h1)。我有 Screaming Frog,但它只计算前两个 H1 元素。感谢任何帮助。
我的 Xidel 可以做到这一点,例如:
1
xidel -e 'concat($url,":", count(//h1))' -f '//a[matches(@href,"http://[^/]*/") ]'
-e 参数中的 xpath 表达式告诉它要在哪些页面上计算 h1-tags 和 -f 选项
这是一个特殊的任务,我建议你自己写。您需要的最简单的方法是使用 XPATH 选择器为您提供 h1/h2/h3 标签。
计算标题:
选择您喜欢的任何编程语言。向 网站(Ruby、Perl、PHP)上的页面发出 Web 请求。解析 HTML。调用 XPATH 标头选择器并计算它返回的元素数。
搜索您的 网站:
对所有页面执行步骤 2 到 4(您可能需要抓取的页面队列)。如果要爬取所有页面,就复杂一点:
检索您的主页。选择所有锚标记。从每个 href 中提取 URL 并丢弃任何不指向您的 网站 的 URL。做一个看到 URL 的测试:如果你以前看过它,就把它扔掉,否则它会被抓取。
URL可见测试:
查看 URL 的测试非常简单:只需将您目前看到的所有 URL 添加到 hashmap 中。如果您在 hashmap 中遇到 URL,您可以忽略它。如果它不在 hashmap 中,请将其添加到爬网队列中。hashmap 的键应该是 URL,值应该是某种结构,可以让您保留对标头的统计信息:
1
2
键 = 网址
值 = 结构 { h1Count, h2Count, h3Count...}
应该是这样的。我知道它看起来很多,但它不应该超过几百行代码!
您可以使用 xPather chrome 扩展或类似扩展,并使用 xPath 进行查询:
1
count(//*[self::h1 or self::h2 or self::h3])
谢谢:
我在 Code Canyon 中找到了一个工具:Scrap(e)网站 Analyzer:。
正如您从我的一些评论中看到的那样,配置的数量很少,但到目前为止它运行良好。
谢谢 BeniBela,我也会研究您的解决方案并向您报告。
php网页抓取标题(知乎appurl,谷歌应用商店的url/机器人其实是隐藏股票一样)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-26 02:00
php网页抓取标题发布到百度统计中,下次点击才会有相应的内容爬虫抓取网页内容存储到mysql中,下次就可以抓取网页了用户在百度搜索后,
点击搜索结果页的所有结果(包括按条件分类排序的结果)
爬虫/机器人
其实这个问题可以去p2p,b2c里问,收到假冒的qq号,
下载页地址可以看到购买数
然而真正要验证下载是否安全.爬虫.刷单就可以了.而爬虫并不用验证。
全部内容都是已经安装app.可以通过appurl进行分析.知乎appurl,谷歌应用商店appurl,百度应用商店appurl百度应用商店的appurl中href值为广告,而最终访问这些appurl返回的url不是微信.所以猜测题主可能要分析app的url信息,确保下载到正确的app.
不用下载,
下载app后找源码,可以找到绝大部分app的网站部分代码,如果你恰好有谷歌的帐号,也许里面有一些,在换过来看里面的内容。
当然是通过下载安装文件之后,爬进去。
证监会发布给媒体的公告,其中有提到公告中提到的某些公司的信息是其财务报表中未披露的。就是说某些公司未公布财务报表,或者需要保密而采用保密方式披露。不然把财务报表公布一下就一目了然了,这种做法,就像隐藏股票一样。 查看全部
php网页抓取标题(知乎appurl,谷歌应用商店的url/机器人其实是隐藏股票一样)
php网页抓取标题发布到百度统计中,下次点击才会有相应的内容爬虫抓取网页内容存储到mysql中,下次就可以抓取网页了用户在百度搜索后,
点击搜索结果页的所有结果(包括按条件分类排序的结果)
爬虫/机器人
其实这个问题可以去p2p,b2c里问,收到假冒的qq号,
下载页地址可以看到购买数
然而真正要验证下载是否安全.爬虫.刷单就可以了.而爬虫并不用验证。
全部内容都是已经安装app.可以通过appurl进行分析.知乎appurl,谷歌应用商店appurl,百度应用商店appurl百度应用商店的appurl中href值为广告,而最终访问这些appurl返回的url不是微信.所以猜测题主可能要分析app的url信息,确保下载到正确的app.
不用下载,
下载app后找源码,可以找到绝大部分app的网站部分代码,如果你恰好有谷歌的帐号,也许里面有一些,在换过来看里面的内容。
当然是通过下载安装文件之后,爬进去。
证监会发布给媒体的公告,其中有提到公告中提到的某些公司的信息是其财务报表中未披露的。就是说某些公司未公布财务报表,或者需要保密而采用保密方式披露。不然把财务报表公布一下就一目了然了,这种做法,就像隐藏股票一样。
php网页抓取标题(【魔兽世界】游戏代码插入页面时中断怎么办? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-21 12:14
)
我将首先解释我希望代码做什么。
代码应使用游戏本身提供的 API() 显示游戏中玩家的数据。在我的网站上,每个玩家都有自己的页面,页面的标题就是玩家的名字。所以我想抓住页面的标题,这样我就可以在它下面显示玩家的数据。
(代码的另一部分工作得很好。如果我删除 $title 行并将 $url 更改为播放器的 一) 它可以工作。
我无法使用下面的代码。当我将此代码插入页面时,分页符。但是,如果我删除 $title = alert(document.title);'); 行,页面不会中断。
我在网上和 stackoverflow 上做了一些研究,并试图在 str_get_html(''); 中更改该行。但这没有帮助。
我也认为可以通过另一种方式获取数据,但我不知道该怎么做。网站 在 WordPress 上运行,每个播放器页面都连接到注册用户的 WordPress 帐户。以下引用可用于获取用户的数据:
get_userdata( $userid );
每个用户的玩家名称被存储为“昵称”。因此,可以使用以下方法获取每个用户的玩家名称:
但是,用户页面是由插件生成的。我试图调整其中的代码,但我无法让它工作。
你知道如何在不破坏页面的情况下获取页面标题,或者获取用户的昵称吗?
我现在将页面设置为:/user/playername(只有玩家名发生变化)。我正在使用:全球 $post; $pagename = $post->post_name; 但是,$pagename 显示为用户而不是玩家名。你知道我怎样才能让它“得到”玩家名而不是它的蛞蝓吗?
编辑2:
function getPath($url)
{
$path = parse_url($url,PHP_URL_PATH);
$lastSlash = strrpos($path,"/");
return substr($path,1,$lastSlash-1);
} 查看全部
php网页抓取标题(【魔兽世界】游戏代码插入页面时中断怎么办?
)
我将首先解释我希望代码做什么。
代码应使用游戏本身提供的 API() 显示游戏中玩家的数据。在我的网站上,每个玩家都有自己的页面,页面的标题就是玩家的名字。所以我想抓住页面的标题,这样我就可以在它下面显示玩家的数据。
(代码的另一部分工作得很好。如果我删除 $title 行并将 $url 更改为播放器的 一) 它可以工作。
我无法使用下面的代码。当我将此代码插入页面时,分页符。但是,如果我删除 $title = alert(document.title);'); 行,页面不会中断。
我在网上和 stackoverflow 上做了一些研究,并试图在 str_get_html(''); 中更改该行。但这没有帮助。
我也认为可以通过另一种方式获取数据,但我不知道该怎么做。网站 在 WordPress 上运行,每个播放器页面都连接到注册用户的 WordPress 帐户。以下引用可用于获取用户的数据:
get_userdata( $userid );
每个用户的玩家名称被存储为“昵称”。因此,可以使用以下方法获取每个用户的玩家名称:
但是,用户页面是由插件生成的。我试图调整其中的代码,但我无法让它工作。
你知道如何在不破坏页面的情况下获取页面标题,或者获取用户的昵称吗?
我现在将页面设置为:/user/playername(只有玩家名发生变化)。我正在使用:全球 $post; $pagename = $post->post_name; 但是,$pagename 显示为用户而不是玩家名。你知道我怎样才能让它“得到”玩家名而不是它的蛞蝓吗?
编辑2:
function getPath($url)
{
$path = parse_url($url,PHP_URL_PATH);
$lastSlash = strrpos($path,"/");
return substr($path,1,$lastSlash-1);
}
php网页抓取标题(php更改页面标题、描述动态化?:SetTitlePHP示例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-20 22:02
'; header("内容长度:" . $row['size']); header("内容类型:" . $row['type']); header("Content-config: inline; filename=\ "" . $row['name'] . "\""); 回声 $row['content']; .
header - 手册,PHP TCPDF::SetTitle - 找到 30 个示例。这些是从开源项目中提取的最受好评的 TCPDF::SetTitle 真实世界 PHP 示例。您可以对示例进行评分,以帮助我们提高其质量。php?id=1"。像所有下载脚本教程一样,但他们似乎也忽略了更改页面的标题.. [已解决] 你可以用 header-function 设置 page-title 吗? $result = mysql_query(" select name,文件的大小、类型、内容 where userid=" . $_SESSION['user_id']); $row = mysql_fetch_array($result); echo ''; header("Content length:" . $row['size ']) ; header("Content-Type:" . $row['type']); header("Content-Disposition: inline; filename=\"" . $row['name'] . "\""); echo $ row['content']; 设置标题。您肯定会使用的方法是 setTitle(),它设置页面标题;您的浏览器在其标题/窗口栏中显示的那个...
PHP 编程/页眉和页脚,设置页眉。您肯定会使用的方法是 setTitle(),它设置页面标题;您的浏览器在其标题/窗口栏中显示的那个。.
php 更改页面标题 php 页面标题变量
<p>在 header.php 中使标题、描述动态化?到目前为止,不幸的是,PHP 在将它们插入外部变量数组之前转换了这些变量的名称——而不是让它们保持原样,只更改由 register_globals 设置的变量的名称。如果您想使用: 现在您已经成功创建了一个有效的 PHP 脚本,是时候创建有史以来最著名的 PHP 脚本了!调用 phpinfo() 函数,您将看到很多关于您的系统和设置的有用信息,例如可用的预定义变量、加载的 PHP 模块和配置设置。花点时间回顾一下。使用 PHP 设置页面标题,header.php 主要是 html,当我获得 PHP 经验后,我意识到标题并为该页面上的 $description 和 $pageTitle 变量提供了正确的文本,包括 < @网站 的页眉和页脚,每天更改日期,包括我喜欢保留更改能力的某些变量(如价格或地址)。今天,一位客户要求我在 查看全部
php网页抓取标题(php更改页面标题、描述动态化?:SetTitlePHP示例)
'; header("内容长度:" . $row['size']); header("内容类型:" . $row['type']); header("Content-config: inline; filename=\ "" . $row['name'] . "\""); 回声 $row['content']; .
header - 手册,PHP TCPDF::SetTitle - 找到 30 个示例。这些是从开源项目中提取的最受好评的 TCPDF::SetTitle 真实世界 PHP 示例。您可以对示例进行评分,以帮助我们提高其质量。php?id=1"。像所有下载脚本教程一样,但他们似乎也忽略了更改页面的标题.. [已解决] 你可以用 header-function 设置 page-title 吗? $result = mysql_query(" select name,文件的大小、类型、内容 where userid=" . $_SESSION['user_id']); $row = mysql_fetch_array($result); echo ''; header("Content length:" . $row['size ']) ; header("Content-Type:" . $row['type']); header("Content-Disposition: inline; filename=\"" . $row['name'] . "\""); echo $ row['content']; 设置标题。您肯定会使用的方法是 setTitle(),它设置页面标题;您的浏览器在其标题/窗口栏中显示的那个...
PHP 编程/页眉和页脚,设置页眉。您肯定会使用的方法是 setTitle(),它设置页面标题;您的浏览器在其标题/窗口栏中显示的那个。.
php 更改页面标题 php 页面标题变量
<p>在 header.php 中使标题、描述动态化?到目前为止,不幸的是,PHP 在将它们插入外部变量数组之前转换了这些变量的名称——而不是让它们保持原样,只更改由 register_globals 设置的变量的名称。如果您想使用: 现在您已经成功创建了一个有效的 PHP 脚本,是时候创建有史以来最著名的 PHP 脚本了!调用 phpinfo() 函数,您将看到很多关于您的系统和设置的有用信息,例如可用的预定义变量、加载的 PHP 模块和配置设置。花点时间回顾一下。使用 PHP 设置页面标题,header.php 主要是 html,当我获得 PHP 经验后,我意识到标题并为该页面上的 $description 和 $pageTitle 变量提供了正确的文本,包括 < @网站 的页眉和页脚,每天更改日期,包括我喜欢保留更改能力的某些变量(如价格或地址)。今天,一位客户要求我在
php网页抓取标题( 2017年04月24日Python正则抓取新闻标题和链接的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-17 02:09
2017年04月24日Python正则抓取新闻标题和链接的方法)
Python中定时抓取新闻头条和链接的方法示例
更新时间:2017-04-24 08:56:43 作者:Shine I want
本文章主要介绍Python中定时抓取新闻头条和链接的方法,结合具体实例分析Python定时匹配页面元素和文件编写的操作技巧。有需要的朋友可以参考以下
本文的例子描述了Python中定时抓取新闻头条和链接的方法。分享给大家,供大家参考,如下:
#-*-coding:utf-8-*-
import re
from urllib import urlretrieve
from urllib import urlopen
#获取网页信息
doc = urlopen("http://www.itongji.cn/news/").read() #自己找的一个大数据的新闻网站
#抓取新闻标题和链接
def extract_title(info):
pat = '<a target=\"_blank\"(.*?)/a/h3'
title = re.findall(pat, info)
titles='\n'.join(title)
#print titles
#修改指定字符串
titles1=titles.replace('class="title"','title')
titles2=titles1.replace('>',':')
titles3=titles2.replace('href','url:')
titles4=titles3.replace('="/','"http://www.itongji.cn/')
#写入文件
save=open('xinwen.txt','w')
save.write(titles4)
save.close()
titles = extract_title(doc)
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成器:
更多关于Python的知识请参考本站专题:《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python套接字编程技巧总结》、《Python总结《函数使用技巧》、《Python Socket编程技巧总结》《Python字符串操作技巧总结》、《Python入门与进阶经典教程》和《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。 查看全部
php网页抓取标题(
2017年04月24日Python正则抓取新闻标题和链接的方法)
Python中定时抓取新闻头条和链接的方法示例
更新时间:2017-04-24 08:56:43 作者:Shine I want
本文章主要介绍Python中定时抓取新闻头条和链接的方法,结合具体实例分析Python定时匹配页面元素和文件编写的操作技巧。有需要的朋友可以参考以下
本文的例子描述了Python中定时抓取新闻头条和链接的方法。分享给大家,供大家参考,如下:
#-*-coding:utf-8-*-
import re
from urllib import urlretrieve
from urllib import urlopen
#获取网页信息
doc = urlopen("http://www.itongji.cn/news/";).read() #自己找的一个大数据的新闻网站
#抓取新闻标题和链接
def extract_title(info):
pat = '<a target=\"_blank\"(.*?)/a/h3'
title = re.findall(pat, info)
titles='\n'.join(title)
#print titles
#修改指定字符串
titles1=titles.replace('class="title"','title')
titles2=titles1.replace('>',':')
titles3=titles2.replace('href','url:')
titles4=titles3.replace('="/','"http://www.itongji.cn/')
#写入文件
save=open('xinwen.txt','w')
save.write(titles4)
save.close()
titles = extract_title(doc)
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成器:
更多关于Python的知识请参考本站专题:《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python套接字编程技巧总结》、《Python总结《函数使用技巧》、《Python Socket编程技巧总结》《Python字符串操作技巧总结》、《Python入门与进阶经典教程》和《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
php网页抓取标题(php网页抓取标题、关键词、分类、描述、评论、名称、微博、时间、数据库密码、sql语句日志如何绕过)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-11 11:03
php网页抓取标题、关键词、分类、描述、评论、名称、微博、时间、数据库密码、sql语句抓取日志如何绕过百度爬虫
呵呵,
准备好数据
1.每个站点的响应信息(例如页面dom)、框架的抽象出来的对象(例如页面所有对象)、框架层协议(例如,php协议是responsebody)2.优秀的php框架(例如google的phpextension)在请求包里面封装了请求对象,post和put之类的请求方法、对schema的处理、对上层对象的引用、对cookie的控制等等。
例如googlephpextension:googlepress.php,apache的php.extension,以及使用php.extension这个jar包时所用到的配置3.优秀的运行库(例如一个很牛的php.extension定义了一个很牛的dll文件,这个dll定义了一个对象的默认访问配置),例如apache+php-fpm、nginx、luatex、bootstrap、ldap、memcached、ldapsnapshot、seasy等等。
加个模块就可以了
1、套个壳子。
2、搭个路由。伪静态规则,两层。a、加载统一url策略,所有url抓取时如带参数则post请求,无参数则https请求,并将url变成动态的(保证数据完整性);b、伪静态规则,
3、搭个前端渲染
4、搭个监控配置 查看全部
php网页抓取标题(php网页抓取标题、关键词、分类、描述、评论、名称、微博、时间、数据库密码、sql语句日志如何绕过)
php网页抓取标题、关键词、分类、描述、评论、名称、微博、时间、数据库密码、sql语句抓取日志如何绕过百度爬虫
呵呵,
准备好数据
1.每个站点的响应信息(例如页面dom)、框架的抽象出来的对象(例如页面所有对象)、框架层协议(例如,php协议是responsebody)2.优秀的php框架(例如google的phpextension)在请求包里面封装了请求对象,post和put之类的请求方法、对schema的处理、对上层对象的引用、对cookie的控制等等。
例如googlephpextension:googlepress.php,apache的php.extension,以及使用php.extension这个jar包时所用到的配置3.优秀的运行库(例如一个很牛的php.extension定义了一个很牛的dll文件,这个dll定义了一个对象的默认访问配置),例如apache+php-fpm、nginx、luatex、bootstrap、ldap、memcached、ldapsnapshot、seasy等等。
加个模块就可以了
1、套个壳子。
2、搭个路由。伪静态规则,两层。a、加载统一url策略,所有url抓取时如带参数则post请求,无参数则https请求,并将url变成动态的(保证数据完整性);b、伪静态规则,
3、搭个前端渲染
4、搭个监控配置
php网页抓取标题(php网页抓取标题方法一-基于formdata,插件page_url_filter_mixes,,全文抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-07 19:05
php网页抓取标题方法一-基于formdata,插件page_url_filter_mixes,formdata,page_url_filter_mixes全文抓取方法二-基于dl_extre_tou_page_driver,dl_extre_tou_page_driver(bundle),网页里的toupal解析器全文抓取方法三-基于爬虫代理,实现pagedata的全文爬取,可以自定义生成脚本。文章地址。
javascript使用page_url_filter_mixes用过一段时间,不过现在找到了更好的方案,介绍下。formdata.anyparams()是response对象中的属性方法,该方法只在响应头部使用,最好不要使用formdata.anyparams(),结果反而会更麻烦,直接将各种属性相加(匹配字符串或数组都是可以的)就可以了。
好久没用javascript抓取工具了,前段时间找爬虫工具,找了好久postman在小扎的2017年google开发者大会上很有名,突然意识到他们的老板对技术很苛刻,所以并没有以挣钱为目的推广postman,而是让更多人用requests,说很多人都用postman不是很方便,容易误操作,所以鼓励大家开始学requests,搞定requests后他们给的方案是autopost方案。
对于javascript是什么都不懂的我就开始学autopost了,不过那个方案最后让我非常的头疼,1.首先在这个爬虫工具上做爬虫抓取方面很多代码,就两套解析方案,第一套是selenium.py里的scrapy,另一套是zapk.py里的form-data,两套方案都有各自的优缺点,比如selenium.py里的scrapy自带网页解析的包,但是小哥不认识用户,只能用代理拿爬虫的真实网页,这种情况下就让爬虫接受直接访问的请求。
优点就是容易搞定基本的http请求,缺点是对于网页本身以及传递到后端的参数理解不足,比如传递的参数如果不明确,那么包含特定参数的页面就分辨不出来,这里就有坑了,可以学习一下专业人士写的requests教程,一定会有所提高。而zapk.py里的form-data爬虫解析就简单的多,对于网页本身以及传递到后端的参数理解不足,但可以让你爬取的所有页面都变成本地记录,这样就可以偷懒了,我找了几个requests的高手,他们都建议用zapk.py方案解析网页,因为还可以和代理进行配合,这样更加方便省事。
所以我选择的就是requests.py里的scrapy,并不是说别的方案不好,只是对于不熟悉的人来说,使用着确实是个麻烦事,你要确保路径的正确性才能进行下一步的操作,然后后端一定要配置好http请求的参数,否则就会上面说的error之类,然后我就有疑问,你又不支持把爬虫配置成自动返回,然后你就要依次来判断哪些网页是不用请求的,把。 查看全部
php网页抓取标题(php网页抓取标题方法一-基于formdata,插件page_url_filter_mixes,,全文抓取方法)
php网页抓取标题方法一-基于formdata,插件page_url_filter_mixes,formdata,page_url_filter_mixes全文抓取方法二-基于dl_extre_tou_page_driver,dl_extre_tou_page_driver(bundle),网页里的toupal解析器全文抓取方法三-基于爬虫代理,实现pagedata的全文爬取,可以自定义生成脚本。文章地址。
javascript使用page_url_filter_mixes用过一段时间,不过现在找到了更好的方案,介绍下。formdata.anyparams()是response对象中的属性方法,该方法只在响应头部使用,最好不要使用formdata.anyparams(),结果反而会更麻烦,直接将各种属性相加(匹配字符串或数组都是可以的)就可以了。
好久没用javascript抓取工具了,前段时间找爬虫工具,找了好久postman在小扎的2017年google开发者大会上很有名,突然意识到他们的老板对技术很苛刻,所以并没有以挣钱为目的推广postman,而是让更多人用requests,说很多人都用postman不是很方便,容易误操作,所以鼓励大家开始学requests,搞定requests后他们给的方案是autopost方案。
对于javascript是什么都不懂的我就开始学autopost了,不过那个方案最后让我非常的头疼,1.首先在这个爬虫工具上做爬虫抓取方面很多代码,就两套解析方案,第一套是selenium.py里的scrapy,另一套是zapk.py里的form-data,两套方案都有各自的优缺点,比如selenium.py里的scrapy自带网页解析的包,但是小哥不认识用户,只能用代理拿爬虫的真实网页,这种情况下就让爬虫接受直接访问的请求。
优点就是容易搞定基本的http请求,缺点是对于网页本身以及传递到后端的参数理解不足,比如传递的参数如果不明确,那么包含特定参数的页面就分辨不出来,这里就有坑了,可以学习一下专业人士写的requests教程,一定会有所提高。而zapk.py里的form-data爬虫解析就简单的多,对于网页本身以及传递到后端的参数理解不足,但可以让你爬取的所有页面都变成本地记录,这样就可以偷懒了,我找了几个requests的高手,他们都建议用zapk.py方案解析网页,因为还可以和代理进行配合,这样更加方便省事。
所以我选择的就是requests.py里的scrapy,并不是说别的方案不好,只是对于不熟悉的人来说,使用着确实是个麻烦事,你要确保路径的正确性才能进行下一步的操作,然后后端一定要配置好http请求的参数,否则就会上面说的error之类,然后我就有疑问,你又不支持把爬虫配置成自动返回,然后你就要依次来判断哪些网页是不用请求的,把。
php网页抓取标题(PHP代码调用织梦篇13/6/3:19:00 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-02-07 16:06
)
6/3/:19:00
今天,我们将跟随编辑 织梦 的教程。做SEO的都知道网站首页的更新频率直接决定了网站的索引速度和网站一部分的权重,但是我们无法实时更新。在这个科技如此发达的时代,如果我们还用最原创的方式,那一定是个悲剧。
PHP代码调用织梦篇
13/6/:56:00
有时我们在使用非 PHP 代码时可能需要检索最新的 文章。如果有怎么办?大家可以参考下面的代码,根据自己的需要进行修改。
(织梦)网站 一些SEO优化技巧
20/9/:18:00
(织梦)网站的一些SEO优化技巧,网站静态设置,网站URL路径优化,文章标签设置,解决重复的问题列页面上的页面标题 等等。
让 织梦 (DEDE) 的隐藏部分下的 文章 不被调用
21/7/:59:00
接触织梦快一年了,我建的第一个站就是用织梦系统。功能本身已经很强大了,基本可以满足我的大部分需求。大部分时间用于设计界面模板,但没有研究过后端源代码。
织梦调用日期格式百科
24/4/:48:41
记得刚学织梦的时候,我也头疼,叫了很久文章的日期。今天小编特地采集整理了一篇关于日期格式化的文章文章。我希望它对每个人都有帮助。常用日期格式
如何在搜索页面调用全站最新的文章
21/9/:58:00
在搜索页面添加最新的文章调用代码,发现无法实现文章list调用。搜索的原因是cms的标签适用于封面模板.htm、列表模板.htm和文档模板.htm,所以搜索页面使用的是最新的文章。不能调用标签,不仅是最新的文章,还有随机的文章、流行的文章等使用标签的。
如何编写 SEO文章页面标题
8/12/:27:32
我今天要分享的是如何为 SEO文章 编写页面标题。当然,这是编辑器需要实现的部分。但是为了达到好的网站优化效果,一般来说每个SEO从业者都需要先学习一个模板,然后让小编
cms方法调用 blog latest 或 random文章
9/3/:19:00
目前国内比较流行的几款开源程序包括cms、织梦cms等,这些对于建站、做seo优化的站长来说并不陌生。通常,他们在首页或内页调用最新的或随机的 文章。爱好,如果这些文章是同一个开源程序的话,相对来说调用起来比较容易。如果它们不一样怎么办?现在让我谈谈帝国
解决织梦限制标题长度的问题
24/4/:48:39
我们都知道有时候网页的标题文章过长,会影响网页的美观,所以我们需要对其进行修剪,限制显示的字数,将多余的部分替换为省略。那么如何以及在编辑器中织梦的想法来实现这个
通过文章ID获取文章标题、内容等信息
15/11/:02:00
使用它的朋友可能会遇到这样的问题。在非.php页面中,我们有时想调用当前文章的标题、内容等信息,但是在生成文章页面时,每个页面中唯一的常量就是当前文章 。ID,那么这个ID是如何获取当前文章的标题、内容等信息的呢?
会员发帖文章和采集夹文章默认动态浏览
2/8/:08:00
会员发布和采集的文章的默认设置是动态浏览。首先,找到需要修改的地方。从会员发布的文章开始,找到/.php,保存后上传到空间进行举报。会员发表的文章只需要日后审核即可。, 没有任何修改。接下来就是和上面一样,找到你的后端目录/
向内容页面添加标签
24/4/:49:09
上一篇文章主要写了给免注册虚拟主机安装的列表添加标签,这次我是在内容页面添加标签。两者都有相同的点,比较简单。两个文章主编主编操作
【黄山网站建设】网站文章标题的SEO优化技巧
27/8/:01:35
SEO优化?我们都知道 文章 更新很重要,特别是如果内容是 原创 高度相关和有价值的。除了更新文章 的内容外,文章 的标题、关键词 和描述也很重要。从 SEO 的角度来看,文章 的标题
查看全部
php网页抓取标题(PHP代码调用织梦篇13/6/3:19:00
)
6/3/:19:00
今天,我们将跟随编辑 织梦 的教程。做SEO的都知道网站首页的更新频率直接决定了网站的索引速度和网站一部分的权重,但是我们无法实时更新。在这个科技如此发达的时代,如果我们还用最原创的方式,那一定是个悲剧。
PHP代码调用织梦篇
13/6/:56:00
有时我们在使用非 PHP 代码时可能需要检索最新的 文章。如果有怎么办?大家可以参考下面的代码,根据自己的需要进行修改。
(织梦)网站 一些SEO优化技巧
20/9/:18:00
(织梦)网站的一些SEO优化技巧,网站静态设置,网站URL路径优化,文章标签设置,解决重复的问题列页面上的页面标题 等等。
让 织梦 (DEDE) 的隐藏部分下的 文章 不被调用
21/7/:59:00
接触织梦快一年了,我建的第一个站就是用织梦系统。功能本身已经很强大了,基本可以满足我的大部分需求。大部分时间用于设计界面模板,但没有研究过后端源代码。
织梦调用日期格式百科
24/4/:48:41
记得刚学织梦的时候,我也头疼,叫了很久文章的日期。今天小编特地采集整理了一篇关于日期格式化的文章文章。我希望它对每个人都有帮助。常用日期格式
如何在搜索页面调用全站最新的文章
21/9/:58:00
在搜索页面添加最新的文章调用代码,发现无法实现文章list调用。搜索的原因是cms的标签适用于封面模板.htm、列表模板.htm和文档模板.htm,所以搜索页面使用的是最新的文章。不能调用标签,不仅是最新的文章,还有随机的文章、流行的文章等使用标签的。
如何编写 SEO文章页面标题
8/12/:27:32
我今天要分享的是如何为 SEO文章 编写页面标题。当然,这是编辑器需要实现的部分。但是为了达到好的网站优化效果,一般来说每个SEO从业者都需要先学习一个模板,然后让小编
cms方法调用 blog latest 或 random文章
9/3/:19:00
目前国内比较流行的几款开源程序包括cms、织梦cms等,这些对于建站、做seo优化的站长来说并不陌生。通常,他们在首页或内页调用最新的或随机的 文章。爱好,如果这些文章是同一个开源程序的话,相对来说调用起来比较容易。如果它们不一样怎么办?现在让我谈谈帝国
解决织梦限制标题长度的问题
24/4/:48:39
我们都知道有时候网页的标题文章过长,会影响网页的美观,所以我们需要对其进行修剪,限制显示的字数,将多余的部分替换为省略。那么如何以及在编辑器中织梦的想法来实现这个
通过文章ID获取文章标题、内容等信息
15/11/:02:00
使用它的朋友可能会遇到这样的问题。在非.php页面中,我们有时想调用当前文章的标题、内容等信息,但是在生成文章页面时,每个页面中唯一的常量就是当前文章 。ID,那么这个ID是如何获取当前文章的标题、内容等信息的呢?
会员发帖文章和采集夹文章默认动态浏览
2/8/:08:00
会员发布和采集的文章的默认设置是动态浏览。首先,找到需要修改的地方。从会员发布的文章开始,找到/.php,保存后上传到空间进行举报。会员发表的文章只需要日后审核即可。, 没有任何修改。接下来就是和上面一样,找到你的后端目录/
向内容页面添加标签
24/4/:49:09
上一篇文章主要写了给免注册虚拟主机安装的列表添加标签,这次我是在内容页面添加标签。两者都有相同的点,比较简单。两个文章主编主编操作
【黄山网站建设】网站文章标题的SEO优化技巧
27/8/:01:35
SEO优化?我们都知道 文章 更新很重要,特别是如果内容是 原创 高度相关和有价值的。除了更新文章 的内容外,文章 的标题、关键词 和描述也很重要。从 SEO 的角度来看,文章 的标题
php网页抓取标题(在nginx服务器上这样配置即可以防止知乎刷屏的问题nginx的include)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-02-06 07:01
php网页抓取标题:tests/zh-cn.php:获取网页中的title通过tests/zh-cn.php我们把这个网页导入到tests/zh-cn.php中并配置如下代码:然后打开浏览器输入地址tests/zh-cn.php并打开,即可看到如下界面:然后通过这样的方式我们可以获取到网页中的title所在位置,让我们一起研究一下网页中title的含义:http协议定义了返回数据的格式和模式,为了标识request或response中的任何字段,并且对不需要返回给其他一方的字段进行确定,对其标识方法进行了一些规范。
title的标识方法有:正文或有titleresponse结束标识的独立体;就是title中的字段article,只不过是自身有独立的titleresponse结束标识;或者说它相当于null,不受请求方式和传递的数据的影响。上面的是php对title的描述,其实网页中还有很多需要我们仔细研究的地方,比如下面这个:在nginx服务器上这样配置即可以防止知乎私信刷屏的问题nginx的include就可以实现它的用法方法。
此次我们来看看get请求后,我们看到的结果如下:接下来我们看看post请求后的post部分:接下来我们依次看一下我们发出的post请求这里tests/zh-cn.php获取的结果为:3毛钱,好像不好看啊这就是为什么还是要根据网页来判断是否设置session时间和其他限制的原因,参见我之前写的一篇文章作者:yayidi93作者博客::。 查看全部
php网页抓取标题(在nginx服务器上这样配置即可以防止知乎刷屏的问题nginx的include)
php网页抓取标题:tests/zh-cn.php:获取网页中的title通过tests/zh-cn.php我们把这个网页导入到tests/zh-cn.php中并配置如下代码:然后打开浏览器输入地址tests/zh-cn.php并打开,即可看到如下界面:然后通过这样的方式我们可以获取到网页中的title所在位置,让我们一起研究一下网页中title的含义:http协议定义了返回数据的格式和模式,为了标识request或response中的任何字段,并且对不需要返回给其他一方的字段进行确定,对其标识方法进行了一些规范。
title的标识方法有:正文或有titleresponse结束标识的独立体;就是title中的字段article,只不过是自身有独立的titleresponse结束标识;或者说它相当于null,不受请求方式和传递的数据的影响。上面的是php对title的描述,其实网页中还有很多需要我们仔细研究的地方,比如下面这个:在nginx服务器上这样配置即可以防止知乎私信刷屏的问题nginx的include就可以实现它的用法方法。
此次我们来看看get请求后,我们看到的结果如下:接下来我们看看post请求后的post部分:接下来我们依次看一下我们发出的post请求这里tests/zh-cn.php获取的结果为:3毛钱,好像不好看啊这就是为什么还是要根据网页来判断是否设置session时间和其他限制的原因,参见我之前写的一篇文章作者:yayidi93作者博客::。
php网页抓取标题(CSS样式是表现,语义化可以给我们带来哪些好处?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-03 14:15
CSS 样式是表示。就像网络的外衣。例如,更改标题字体、颜色,或为标题添加背景图片、边框等。所有这些改变内容外观的东西都称为演示文稿。
JavaScript 用于在网页上实现特殊效果。如:鼠标悬停在弹出的下拉菜单上。或将鼠标悬停在表格背景颜色的变化上。还有一个焦点故事(新闻图片)的轮换。这样就可以理解为动画和交互一般都是用JavaScript实现的。
1、tml的固定结构
HTML 文档有自己的固定结构。
…
代码说明:
称为根标签,所有网页标签都在其中。
3、标签
和标签之间的文字是网页的标题信息,会出现在浏览器的标题栏中。使用网页的标题标签。网页制作学习交流群,49406、4934。
为了告诉用户和搜索引擎这个网页的主要内容是什么,搜索引擎可以通过网页的标题快速确定网页的主题。每个网页的内容都是不同的,每个网页都应该有一个独特的
独特的标题。
例如:
标签“hello world”的内容会显示在浏览器的标题栏上,
4、 标签的用途
当我们学习网页创建时,我们经常听到一个词,语义。那么什么是语义?通俗点是:了解每个标签的用途(在什么情况下使用这个标签才合理)例如在网页上
文章的标题可以使用title标签,网页上每一列的列名也可以使用title标签。
文章 中内容的段落必须放在段落标签中。如果 文章 中有要强调的文字,可以使用
使用 em 标签进行强调等。
关于语义已经说了这么多,但是语义能给我们带来什么好处呢?
① 收录 更容易被搜索到。
②。屏幕阅读器更容易阅读网页内容。
CSS 样式是表示。就像网络的外衣。例如,更改标题字体、颜色,或为标题添加背景图片、边框等。所有这些改变内容外观的东西都称为演示文稿。
JavaScript 用于在网页上实现特殊效果。如:鼠标悬停在弹出的下拉菜单上。或将鼠标悬停在表格背景颜色的变化上。还有一个焦点故事(新闻图片)的轮换。这样就可以理解为动画和交互一般都是用JavaScript实现的。
1、tml的固定结构
HTML 文档有自己的固定结构。
…
代码说明:
称为根标签,所有网页标签都在其中。
3、标签
和标签之间的文字是网页的标题信息,会出现在浏览器的标题栏中。使用网页的标题标签。网页制作学习交流群,49406、4934。
为了告诉用户和搜索引擎这个网页的主要内容是什么,搜索引擎可以通过网页的标题快速确定网页的主题。每个网页的内容都是不同的,每个网页都应该有一个独特的
独特的标题。
例如:
标签“hello world”的内容会显示在浏览器的标题栏上,
4、 标签的用途
当我们学习网页创建时,我们经常听到一个词,语义。那么什么是语义?通俗点是:了解每个标签的用途(在什么情况下使用这个标签才合理)例如在网页上
文章的标题可以使用title标签,网页上每一列的列名也可以使用title标签。
文章 中内容的段落必须放在段落标签中。如果 文章 中有要强调的文字,可以使用
使用 em 标签进行强调等。
关于语义已经说了这么多,但是语义能给我们带来什么好处呢?
① 收录 更容易被搜索到。
②。屏幕阅读器更容易阅读网页内容。 查看全部
php网页抓取标题(CSS样式是表现,语义化可以给我们带来哪些好处?)
CSS 样式是表示。就像网络的外衣。例如,更改标题字体、颜色,或为标题添加背景图片、边框等。所有这些改变内容外观的东西都称为演示文稿。
JavaScript 用于在网页上实现特殊效果。如:鼠标悬停在弹出的下拉菜单上。或将鼠标悬停在表格背景颜色的变化上。还有一个焦点故事(新闻图片)的轮换。这样就可以理解为动画和交互一般都是用JavaScript实现的。
1、tml的固定结构
HTML 文档有自己的固定结构。
…
代码说明:
称为根标签,所有网页标签都在其中。
3、标签
和标签之间的文字是网页的标题信息,会出现在浏览器的标题栏中。使用网页的标题标签。网页制作学习交流群,49406、4934。
为了告诉用户和搜索引擎这个网页的主要内容是什么,搜索引擎可以通过网页的标题快速确定网页的主题。每个网页的内容都是不同的,每个网页都应该有一个独特的
独特的标题。
例如:
标签“hello world”的内容会显示在浏览器的标题栏上,
4、 标签的用途
当我们学习网页创建时,我们经常听到一个词,语义。那么什么是语义?通俗点是:了解每个标签的用途(在什么情况下使用这个标签才合理)例如在网页上
文章的标题可以使用title标签,网页上每一列的列名也可以使用title标签。
文章 中内容的段落必须放在段落标签中。如果 文章 中有要强调的文字,可以使用
使用 em 标签进行强调等。
关于语义已经说了这么多,但是语义能给我们带来什么好处呢?
① 收录 更容易被搜索到。
②。屏幕阅读器更容易阅读网页内容。
CSS 样式是表示。就像网络的外衣。例如,更改标题字体、颜色,或为标题添加背景图片、边框等。所有这些改变内容外观的东西都称为演示文稿。
JavaScript 用于在网页上实现特殊效果。如:鼠标悬停在弹出的下拉菜单上。或将鼠标悬停在表格背景颜色的变化上。还有一个焦点故事(新闻图片)的轮换。这样就可以理解为动画和交互一般都是用JavaScript实现的。
1、tml的固定结构
HTML 文档有自己的固定结构。
…
代码说明:
称为根标签,所有网页标签都在其中。
3、标签
和标签之间的文字是网页的标题信息,会出现在浏览器的标题栏中。使用网页的标题标签。网页制作学习交流群,49406、4934。
为了告诉用户和搜索引擎这个网页的主要内容是什么,搜索引擎可以通过网页的标题快速确定网页的主题。每个网页的内容都是不同的,每个网页都应该有一个独特的
独特的标题。
例如:
标签“hello world”的内容会显示在浏览器的标题栏上,
4、 标签的用途
当我们学习网页创建时,我们经常听到一个词,语义。那么什么是语义?通俗点是:了解每个标签的用途(在什么情况下使用这个标签才合理)例如在网页上
文章的标题可以使用title标签,网页上每一列的列名也可以使用title标签。
文章 中内容的段落必须放在段落标签中。如果 文章 中有要强调的文字,可以使用
使用 em 标签进行强调等。
关于语义已经说了这么多,但是语义能给我们带来什么好处呢?
① 收录 更容易被搜索到。
②。屏幕阅读器更容易阅读网页内容。
php网页抓取标题(网站用什么软件做的……首页、重要的内页的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-02-01 17:04
网站你用什么软件制作的...
最好将首页和重要内页的标题和元标记分开写,以反映栏目主题的不同内容。
动态网页优化
动态网站是指网站的内容更新和维护是通过一个有数据库背景的软件,即内容管理系统(cms)
结束。一般采用ASP、PHP、Cold Fusion、CGI等程序来动态生成页面。动态页面在网络空间中实现
不是实时存在的,它们的大部分内容通常来自连接到网站的数据库,只有在收到用户的请求后,在变量中
在字段中输入值之前不会生成它。动态网页扩展名显示为 .asp、.php、cfm 或 .cgi,而不是静态网页
页面的 .html 或 .htm。URL中通常会出现“?”、“=”、“%”以及“&”、“$”等符号。网站使用动态技术
除了增加网站交互功能外,还具有易于维护和更新的优点,是很多大中型网站的不错选择
利用。
但是大多数搜索引擎蜘蛛无法破译符号“?”之后的字符。这意味着动态页面很难被搜索索引
被引擎发现的几率也大大降低。因此,在构造网站之前,首先要纠正我们的思想,即能够
尽量不要使用静态性能的网页动态实现,重要的网页使用静态性能。在使用技术转换动态网页的同时
将其转换为静态网页,使网址不再收录“?”“=”等类似符号。您还可以对 网站 进行一些更改
动态,间接增加动态网页的搜索引擎可见性。即坚持“动静结合、以静制动”的原则。
不同技术的解决方案:
不同程序开发的动态网页有相应的解决方案。以下是作者凯伦整理的部分内容:
1、CGI/Perl
如果你在 网站 中使用 CGI 或 Perl,你可以使用脚本将环境变量之前的所有字符都提取出来,然后将 URL 放入
剩余的字符被分配给一个变量。这样,您可以在 URL 中使用变量。但是,对于那些内置的
一些带有SSI(Server-Side Include:Server-Side Include)内容的网页可以被各大搜索引擎收录
支持。那些后缀为 .shtml 的网页也会被解析成 SSI 文件,相当于普通的 .html 文件。但如果这
某些在其 URL 中使用 cgi-bin 路径的页面可能仍未被搜索引擎索引。
2、ASP
ASP(Active Server Pages:Web 服务器端动态网页开发技术)用于基于 Microsoft 的 Web 服务器
中间。使用 ASP 开发的网页一般以 .asp 为后缀。只是避免使用符号“?” 在 URL 中,大多数搜索引擎
都可以支持用ASP开发的动态网页。
3、冷聚变
如果您使用的是 Cold Fusion,则需要在服务器端重新配置它以
符号“?” 在每个环境变量中替换为符号“/”,并将替换后的值传递给 URL。这样,终于到了浏览
服务器端是一个静态 URL 页面。当搜索引擎检索这个转换后的文件时,它不会遇到“?” 因为
相反,整个动态页面可以继续被索引,这样你的动态页面仍然可以被搜索引擎读取。
4、Apache 服务器
Apache 是最流行的 HTTP 服务器软件之一。它有一个名为 mod_rewrite 的重写模块,URL 重写
发挥作用。该模块使您能够将收录环境变量的 URL 转换为搜索引擎支持的 URL 类型。为了那个原因
一些发布后不需要太多更新的网页内容,比如新闻,可以使用这个改写引导功能。
创建一个静态条目:
在“动静结合,静制动”的原则指导下,我们也可以对网站做一些修改,尽可能的增加动态网页
搜索引擎的可见性。例如,将动态网页编程为静态主页或网站地图中的链接,以静态目录的形式
渲染移动页面。或者为动态页面创建一个专用的静态入口页面(网关/入口),链接到动态
页面,然后将静态入口页面提交给搜索引擎。
将一些内容相对固定的重要页面制作成静态页面,比如网站的介绍和丰富的关键词,用户
帮助,以及网站重要页面的链接等地图网站首页尽量是静态的,重要的是动态的
内容全部以文字链接的形式呈现,虽然增加了维护工作量,但从SEO的角度来看还是值得的。
还可以考虑为重要的动态内容创建静态镜像网站。
付费登录搜索引擎:
当然,对于使用链接到数据库的内容管理系统 (cms) 在整个 网站 中发布的动态 网站,改进的搜索
搜索引擎可见性最直接的方式是付费登录,直接提交动态网页到搜索引擎目录,或者做key
文字广告保证由搜索引擎收录网站。
改进了对动态 网站 的搜索引擎支持
搜索引擎一直在改进对动态页面的支持。至此,GOOGLE、HOTBOT、百度都开始尝试
尝试抓取动态 网站 页面(甚至是 URL 中带有“?”的页面)。但是当这些搜索引擎抓取动态页面时,为了
避免“蜘蛛陷阱”(导致搜索机器人无限循环的脚本错误)
Crawl, cannot exit)”,只爬取静态页面链接的动态页面,以及动态页面链接的动态页面
不再抓取页面,即不再访问动态页面中的链接。
对于直接使用动态 URL 地址,请注意:
· 文件URL中不要有Session Id,不要用ID作为参数名(尤其是GOOGLE);
例如,在《网络营销基础与实践》一书中,当当网介绍页面的URL地址为:
asp?product_id=493698">,页面无法读取。
参数越少越好,尽量不要超过2;
· 尽量不要在URL中使用参数,这样会增加被抓取的动态页面的深度和数量。
随附的:
Google 向 网站 管理员提供的信息:
百度常见问题:#2 查看全部
php网页抓取标题(网站用什么软件做的……首页、重要的内页的)
网站你用什么软件制作的...
最好将首页和重要内页的标题和元标记分开写,以反映栏目主题的不同内容。
动态网页优化
动态网站是指网站的内容更新和维护是通过一个有数据库背景的软件,即内容管理系统(cms)
结束。一般采用ASP、PHP、Cold Fusion、CGI等程序来动态生成页面。动态页面在网络空间中实现
不是实时存在的,它们的大部分内容通常来自连接到网站的数据库,只有在收到用户的请求后,在变量中
在字段中输入值之前不会生成它。动态网页扩展名显示为 .asp、.php、cfm 或 .cgi,而不是静态网页
页面的 .html 或 .htm。URL中通常会出现“?”、“=”、“%”以及“&”、“$”等符号。网站使用动态技术
除了增加网站交互功能外,还具有易于维护和更新的优点,是很多大中型网站的不错选择
利用。
但是大多数搜索引擎蜘蛛无法破译符号“?”之后的字符。这意味着动态页面很难被搜索索引
被引擎发现的几率也大大降低。因此,在构造网站之前,首先要纠正我们的思想,即能够
尽量不要使用静态性能的网页动态实现,重要的网页使用静态性能。在使用技术转换动态网页的同时
将其转换为静态网页,使网址不再收录“?”“=”等类似符号。您还可以对 网站 进行一些更改
动态,间接增加动态网页的搜索引擎可见性。即坚持“动静结合、以静制动”的原则。
不同技术的解决方案:
不同程序开发的动态网页有相应的解决方案。以下是作者凯伦整理的部分内容:
1、CGI/Perl
如果你在 网站 中使用 CGI 或 Perl,你可以使用脚本将环境变量之前的所有字符都提取出来,然后将 URL 放入
剩余的字符被分配给一个变量。这样,您可以在 URL 中使用变量。但是,对于那些内置的
一些带有SSI(Server-Side Include:Server-Side Include)内容的网页可以被各大搜索引擎收录
支持。那些后缀为 .shtml 的网页也会被解析成 SSI 文件,相当于普通的 .html 文件。但如果这
某些在其 URL 中使用 cgi-bin 路径的页面可能仍未被搜索引擎索引。
2、ASP
ASP(Active Server Pages:Web 服务器端动态网页开发技术)用于基于 Microsoft 的 Web 服务器
中间。使用 ASP 开发的网页一般以 .asp 为后缀。只是避免使用符号“?” 在 URL 中,大多数搜索引擎
都可以支持用ASP开发的动态网页。
3、冷聚变
如果您使用的是 Cold Fusion,则需要在服务器端重新配置它以
符号“?” 在每个环境变量中替换为符号“/”,并将替换后的值传递给 URL。这样,终于到了浏览
服务器端是一个静态 URL 页面。当搜索引擎检索这个转换后的文件时,它不会遇到“?” 因为
相反,整个动态页面可以继续被索引,这样你的动态页面仍然可以被搜索引擎读取。
4、Apache 服务器
Apache 是最流行的 HTTP 服务器软件之一。它有一个名为 mod_rewrite 的重写模块,URL 重写
发挥作用。该模块使您能够将收录环境变量的 URL 转换为搜索引擎支持的 URL 类型。为了那个原因
一些发布后不需要太多更新的网页内容,比如新闻,可以使用这个改写引导功能。
创建一个静态条目:
在“动静结合,静制动”的原则指导下,我们也可以对网站做一些修改,尽可能的增加动态网页
搜索引擎的可见性。例如,将动态网页编程为静态主页或网站地图中的链接,以静态目录的形式
渲染移动页面。或者为动态页面创建一个专用的静态入口页面(网关/入口),链接到动态
页面,然后将静态入口页面提交给搜索引擎。
将一些内容相对固定的重要页面制作成静态页面,比如网站的介绍和丰富的关键词,用户
帮助,以及网站重要页面的链接等地图网站首页尽量是静态的,重要的是动态的
内容全部以文字链接的形式呈现,虽然增加了维护工作量,但从SEO的角度来看还是值得的。
还可以考虑为重要的动态内容创建静态镜像网站。
付费登录搜索引擎:
当然,对于使用链接到数据库的内容管理系统 (cms) 在整个 网站 中发布的动态 网站,改进的搜索
搜索引擎可见性最直接的方式是付费登录,直接提交动态网页到搜索引擎目录,或者做key
文字广告保证由搜索引擎收录网站。
改进了对动态 网站 的搜索引擎支持
搜索引擎一直在改进对动态页面的支持。至此,GOOGLE、HOTBOT、百度都开始尝试
尝试抓取动态 网站 页面(甚至是 URL 中带有“?”的页面)。但是当这些搜索引擎抓取动态页面时,为了
避免“蜘蛛陷阱”(导致搜索机器人无限循环的脚本错误)
Crawl, cannot exit)”,只爬取静态页面链接的动态页面,以及动态页面链接的动态页面
不再抓取页面,即不再访问动态页面中的链接。
对于直接使用动态 URL 地址,请注意:
· 文件URL中不要有Session Id,不要用ID作为参数名(尤其是GOOGLE);
例如,在《网络营销基础与实践》一书中,当当网介绍页面的URL地址为:
asp?product_id=493698">,页面无法读取。
参数越少越好,尽量不要超过2;
· 尽量不要在URL中使用参数,这样会增加被抓取的动态页面的深度和数量。
随附的:
Google 向 网站 管理员提供的信息:
百度常见问题:#2
php网页抓取标题(php网页抓取标题包含下划线的段落结果可能有两种:)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-31 12:01
php网页抓取标题包含下划线的段落结果可能有两种:1、该段落由两个php文件共同包含(用空格分隔),那么可以根据网页标识去匹配网页对应的文件,拿到该段落的文件的路径后,就可以从该目录下的一个叫jstring.php的文件中找到该段落的文件,用python写出来,把结果存入txt文件中。2、因为php没有包含下划线的段落,如果不小心自己写了一个下划线标识的段落文件,而你又不知道段落数量,那么会一个下划线字符一个空格字符去匹配的,一个下划线=1个空格=0个空格,一个下划线有7个空格=4个空格,如果一个下划线加一个空格=3个空格,那么就可以从该段落的第7行到第8行找到下划线。
去分析那些代码、语句能知道到底谁包含了空格。
有6个空格吗?
php是不提供字符串匹配功能的,我怎么记得以前是有,不知道为什么取消了。
我看了下代码,大概知道找不到原因了。需要对空格和tab的使用对象和类型进行匹配。代码也比较复杂。我也知道是怎么找的。google空格类型匹配和so类型匹配很容易找到匹配的部分。建议去看一下linux和http协议中大量的匹配模式。
tag_pattern是匹配字符串中tag标识符的值,可以参考这篇文章tagcompiler的工作原理compilerinterpretertracingofspeechinphp。sotypeoftagsinterprettotypeoftagsinterprettotypeoftag_pattern(这篇文章讲的很全面)。 查看全部
php网页抓取标题(php网页抓取标题包含下划线的段落结果可能有两种:)
php网页抓取标题包含下划线的段落结果可能有两种:1、该段落由两个php文件共同包含(用空格分隔),那么可以根据网页标识去匹配网页对应的文件,拿到该段落的文件的路径后,就可以从该目录下的一个叫jstring.php的文件中找到该段落的文件,用python写出来,把结果存入txt文件中。2、因为php没有包含下划线的段落,如果不小心自己写了一个下划线标识的段落文件,而你又不知道段落数量,那么会一个下划线字符一个空格字符去匹配的,一个下划线=1个空格=0个空格,一个下划线有7个空格=4个空格,如果一个下划线加一个空格=3个空格,那么就可以从该段落的第7行到第8行找到下划线。
去分析那些代码、语句能知道到底谁包含了空格。
有6个空格吗?
php是不提供字符串匹配功能的,我怎么记得以前是有,不知道为什么取消了。
我看了下代码,大概知道找不到原因了。需要对空格和tab的使用对象和类型进行匹配。代码也比较复杂。我也知道是怎么找的。google空格类型匹配和so类型匹配很容易找到匹配的部分。建议去看一下linux和http协议中大量的匹配模式。
tag_pattern是匹配字符串中tag标识符的值,可以参考这篇文章tagcompiler的工作原理compilerinterpretertracingofspeechinphp。sotypeoftagsinterprettotypeoftagsinterprettotypeoftag_pattern(这篇文章讲的很全面)。
php网页抓取标题(php网页抓取标题识别识别评论上面只是几个小例子)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-31 10:02
php网页抓取标题抓取正文识别评论上面只是几个小例子,本次主要讲这些我用的工具:百度网页抓取框架javascript爬虫javascript解析器在网上多找视频可以自己学习,这些东西都是解决某个特定问题,实战的时候手动是抓不过来的,更何况一个一个抓可以搜到几万条的截图是这样的没有需求还好,一有需求就抓不过来,上面那些图也是满满的需求,有兴趣可以留言问问。
网上搜一些php的视频教程,然后根据教程里说的查找你需要的站点,就会发现,软件比较多,功能越来越强大。
因为现在的知乎话题下面回答是天天刷新更新的,
我也刚刚知道这个新方法
刚开始学编程的时候,学的基本语法,专业名词,知道哪里可以用,哪里是可以丢的。但是用过一次之后,你会发现不太灵光,因为学的东西确实一样,在学习的过程中很容易知道对哪些是必须用的,但是用不到的不用管,扔一边就完事了。其实我们这个真的有很多问题都没有必要说的这么清楚。就好比我们一直都在手机上买东西,知道点东西就能过,打开---点进去点购物车---关闭。
当你想完全用自己的力量完成一次购物的时候就难了,但是可以看看我们传送门来解决。baobai.how-to.click?tag=awesome,里面的页面可能会更加细分,每个页面的想知道的也更加详细,自己用了挺不错的。 查看全部
php网页抓取标题(php网页抓取标题识别识别评论上面只是几个小例子)
php网页抓取标题抓取正文识别评论上面只是几个小例子,本次主要讲这些我用的工具:百度网页抓取框架javascript爬虫javascript解析器在网上多找视频可以自己学习,这些东西都是解决某个特定问题,实战的时候手动是抓不过来的,更何况一个一个抓可以搜到几万条的截图是这样的没有需求还好,一有需求就抓不过来,上面那些图也是满满的需求,有兴趣可以留言问问。
网上搜一些php的视频教程,然后根据教程里说的查找你需要的站点,就会发现,软件比较多,功能越来越强大。
因为现在的知乎话题下面回答是天天刷新更新的,
我也刚刚知道这个新方法
刚开始学编程的时候,学的基本语法,专业名词,知道哪里可以用,哪里是可以丢的。但是用过一次之后,你会发现不太灵光,因为学的东西确实一样,在学习的过程中很容易知道对哪些是必须用的,但是用不到的不用管,扔一边就完事了。其实我们这个真的有很多问题都没有必要说的这么清楚。就好比我们一直都在手机上买东西,知道点东西就能过,打开---点进去点购物车---关闭。
当你想完全用自己的力量完成一次购物的时候就难了,但是可以看看我们传送门来解决。baobai.how-to.click?tag=awesome,里面的页面可能会更加细分,每个页面的想知道的也更加详细,自己用了挺不错的。
php网页抓取标题( Google搜索如何限制在具体的一个州或城市州)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-26 22:03
Google搜索如何限制在具体的一个州或城市州)
前两天有个朋友问了一个问题:
如何将谷歌搜索限制在特定的州或城市,例如美国的宾夕法尼亚州(Pennsylvania),请指教。谢谢!
对于这个问题,首先要理清思路,有思路,然后再考虑如何实现。
如果你脑子里根本没有一个清晰的界线,那么你就在搜索的时候随意改变关键词,最终的结果越来越偏离原来的目的。
因此,在开始搜索之前先在脑海中思考几行是个好主意。如果不清楚,可以在白纸上画。
好的,回到这个问题。我们考虑从大到小的有限范围。
1. 我们先考虑如何将搜索范围限制在一个国家或地区?
有朋友说很简单,直接上网址:国家二字代码
其实这仅限于谷歌搜索,在收录的数据库中,只能找到域名以.xx结尾的网页。
这样,在美国 网站 的商业公司搜索将仅限于 site:us。确实有些美国商业公司网站域名以我们结尾,但是大部分商业公司网站还是用.com
另一个例子是法国的 网站。顶级国家域名以.fr结尾,但是很多法国公司的网站也应该有.com作为域名。因此,如果您符合 .fr 的条件,您实际上排除了其他类型,例如以 .com 结尾的 网站。
这种方式是不完整的。因此,最好的方法是打开GOOGLE的高级搜索,在Region(国家/地区)中选择France,然后输入关键词进行搜索。这样,你会发现搜索结果中的网站全部来自法国,从.fr到.的各个域名都有网站。
不禁要问?以.fr为域名的网站直观上是法语网站,那么谷歌是如何确定某些. 网站位于法国的呢?
有人说是服务器的IP地址,这种说法是错误的。服务器在日本网站,也可以在GOOGLE上使用Region=China,结合某关键词搜索。
有人说网站的代码中使用的字符集,比如国内的网站,在网页的Meta标签中会有一个字符集属性“GB2312”。这个说法也是错误的,因为很多英文网站字符集都是国际UTF-8。
那么谷歌究竟是如何识别它的呢?对于搜索引擎来说,其实是相当人性化的。其独特的运行机制使得可以根据大部分浏览者所在的区域来判断网站的归属,同时搜索引擎还具有数据分析处理的功能。
作为一个有趣的例子,假设 CL 1024 社区。众所周知,服务器在国外。不过,谷歌还是认定他属于中国的网站,有些童鞋可能不信,搜索引擎有这么聪明吗?答案是肯定的。
让我们看一下 Alexa 数据:
你能看到CL 1024论坛有多少NB流量吗?此外,Alexa还直接给出了网站世界和中国的流量排名。
可见,无论您的服务器IP地址位于世界哪个国家,搜索引擎和一些统计分析网站总会判断您的“家乡”。
2. 解决了针对国家/地区的问题,让我们考虑针对城市或州
首先,谷歌不提供特定城市的搜索选项。因此,我们只能调整我们的思维如何去实现它。我们需要考虑的第一件事是我们经常在页面上看到城市和州名的位置。
答案可能很多,但是在企业站点中(注意我默认考虑的最优站点是公司网站,即企业网站),应该出现在Contact页面。
那么如何才能准确定位到这个页面呢?
通常在做网站的时候,需要写一个网页的链接地址,比如or(.asp/.aspx/.jsp/.php),这个页面的标题往往会是Contact Us ,所以我们完全可以考虑限制这两个方面,一个是inurl:contact,一个是intitle:contact
3. 美国州名宾夕法尼亚,通常缩写为 PA
考虑到GOOGLE默认支持同义词,就不用多写一个宾夕法尼亚| PA(竖线表示“或”,相当于大写的OR)
最后,我们的关键词组合结构是:
主关键词 (inurl:contact | intitle:contact) PA
比如你的关键词是汽车配件,那么你可以输入:"auto parts" PA(inurl:contact | intitle:contact),如果能一眼看出逻辑关系,也可以省略括号,效果是一样的
我们将“汽车零部件”视为 A,将 PA 视为 B,将 inurl:contact 视为 C,将 intitle:contact 视为 D。
这实际上是 A AND B AND C 或 A AND B AND D 的逻辑表达式。(同时满足 A,B,C关键词 的条件或同时满足 A,B,D 的条件同时)
至于如何合理使用关键词,需要根据不同的搜索目的和具体情况进行分析,最终确定搜索关键词的组合结构。此外,请务必在搜索时不断微调以尝试最佳搜索关键词结构。
或者,您可以使用谷歌地图搜索位于宾夕法尼亚州的地区。 查看全部
php网页抓取标题(
Google搜索如何限制在具体的一个州或城市州)
前两天有个朋友问了一个问题:
如何将谷歌搜索限制在特定的州或城市,例如美国的宾夕法尼亚州(Pennsylvania),请指教。谢谢!
对于这个问题,首先要理清思路,有思路,然后再考虑如何实现。
如果你脑子里根本没有一个清晰的界线,那么你就在搜索的时候随意改变关键词,最终的结果越来越偏离原来的目的。
因此,在开始搜索之前先在脑海中思考几行是个好主意。如果不清楚,可以在白纸上画。
好的,回到这个问题。我们考虑从大到小的有限范围。
1. 我们先考虑如何将搜索范围限制在一个国家或地区?
有朋友说很简单,直接上网址:国家二字代码
其实这仅限于谷歌搜索,在收录的数据库中,只能找到域名以.xx结尾的网页。
这样,在美国 网站 的商业公司搜索将仅限于 site:us。确实有些美国商业公司网站域名以我们结尾,但是大部分商业公司网站还是用.com
另一个例子是法国的 网站。顶级国家域名以.fr结尾,但是很多法国公司的网站也应该有.com作为域名。因此,如果您符合 .fr 的条件,您实际上排除了其他类型,例如以 .com 结尾的 网站。
这种方式是不完整的。因此,最好的方法是打开GOOGLE的高级搜索,在Region(国家/地区)中选择France,然后输入关键词进行搜索。这样,你会发现搜索结果中的网站全部来自法国,从.fr到.的各个域名都有网站。
不禁要问?以.fr为域名的网站直观上是法语网站,那么谷歌是如何确定某些. 网站位于法国的呢?
有人说是服务器的IP地址,这种说法是错误的。服务器在日本网站,也可以在GOOGLE上使用Region=China,结合某关键词搜索。
有人说网站的代码中使用的字符集,比如国内的网站,在网页的Meta标签中会有一个字符集属性“GB2312”。这个说法也是错误的,因为很多英文网站字符集都是国际UTF-8。
那么谷歌究竟是如何识别它的呢?对于搜索引擎来说,其实是相当人性化的。其独特的运行机制使得可以根据大部分浏览者所在的区域来判断网站的归属,同时搜索引擎还具有数据分析处理的功能。
作为一个有趣的例子,假设 CL 1024 社区。众所周知,服务器在国外。不过,谷歌还是认定他属于中国的网站,有些童鞋可能不信,搜索引擎有这么聪明吗?答案是肯定的。
让我们看一下 Alexa 数据:
你能看到CL 1024论坛有多少NB流量吗?此外,Alexa还直接给出了网站世界和中国的流量排名。
可见,无论您的服务器IP地址位于世界哪个国家,搜索引擎和一些统计分析网站总会判断您的“家乡”。
2. 解决了针对国家/地区的问题,让我们考虑针对城市或州
首先,谷歌不提供特定城市的搜索选项。因此,我们只能调整我们的思维如何去实现它。我们需要考虑的第一件事是我们经常在页面上看到城市和州名的位置。
答案可能很多,但是在企业站点中(注意我默认考虑的最优站点是公司网站,即企业网站),应该出现在Contact页面。
那么如何才能准确定位到这个页面呢?
通常在做网站的时候,需要写一个网页的链接地址,比如or(.asp/.aspx/.jsp/.php),这个页面的标题往往会是Contact Us ,所以我们完全可以考虑限制这两个方面,一个是inurl:contact,一个是intitle:contact
3. 美国州名宾夕法尼亚,通常缩写为 PA
考虑到GOOGLE默认支持同义词,就不用多写一个宾夕法尼亚| PA(竖线表示“或”,相当于大写的OR)
最后,我们的关键词组合结构是:
主关键词 (inurl:contact | intitle:contact) PA
比如你的关键词是汽车配件,那么你可以输入:"auto parts" PA(inurl:contact | intitle:contact),如果能一眼看出逻辑关系,也可以省略括号,效果是一样的
我们将“汽车零部件”视为 A,将 PA 视为 B,将 inurl:contact 视为 C,将 intitle:contact 视为 D。
这实际上是 A AND B AND C 或 A AND B AND D 的逻辑表达式。(同时满足 A,B,C关键词 的条件或同时满足 A,B,D 的条件同时)
至于如何合理使用关键词,需要根据不同的搜索目的和具体情况进行分析,最终确定搜索关键词的组合结构。此外,请务必在搜索时不断微调以尝试最佳搜索关键词结构。
或者,您可以使用谷歌地图搜索位于宾夕法尼亚州的地区。
php网页抓取标题(php网页抓取标题是很重要的一步,能决定了你的网页是否有用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-22 22:06
php网页抓取标题是很重要的一步,能决定了你抓取的网页是否有用。所以你的标题需要满足下面要求:1.网页标题包含文字;2.尽量简短,足够抓取到你需要的内容;3.最好能用动词或者名词表达出来,这样直接更好抓取。
一、网页标题的格式及要求通常,网页标题的格式如下:title:关键词blank:空值sorted:这个是排序,由一个值组成,分为6种组合1.最优先的组合:无blank排序2.第二优先的组合:全blank排序3.第三优先的组合:全空白排序4.第四优先的组合:全无blank排序5.第五优先的组合:大写字母排序6.第六优先的组合:小写字母排序。通常我们需要给blank列出第几个,并在php的代码中进行相应的书写。
二、标题常见的问题解决网页标题是否需要设置,这需要根据网页类型进行判断,一般如果网页类型是嵌入式广告的页面,不需要在标题中进行区分。如果是传统的网站,主要以phpcms网站为例,需要进行标题的字体设置。1.首先打开我们的www浏览器,打开我们的网页源代码分析,发现标题设置前面多了一串字符串":main_title:",我们只需要将这串字符串,改成为空白或者title::sorted这样就完成了标题的设置2.检查我们的root.php文件,发现title设置变了,要想完成标题的修改,要修改我们的标题文件,要修改文件的路径,要先在"$home"文件夹下新建一个文件,里面就是我们写的标题文件的路径,我们在找到它.3.打开phpcms网站源代码分析,发现标题设置改好后,能不能抓取到我们想要的内容,就要看我们的网页文件的header部分的设置。
在header文件中,如果标题设置后面没有任何的数据,那么就会出现同样一个错误。也就是我们经常说的"failedtofindtargetfile"因此我们可以修改我们的文件header中的数据,即能抓取网页标题的内容,并能实现被抓取内容的合并和删除,建议提前准备好多的网页标题。
四、web抓取原理如何使用百度网页爬虫进行网站抓取,需要熟悉本地环境的编写方法。步骤如下:1.打开浏览器的地址栏;2.在地址栏中键入你的要抓取的网站url;3.在弹出页面的搜索框中输入你要抓取的内容;4.点击下一步;5.在弹出页面中输入真正需要抓取的内容,点击下一步;6.在弹出页面的搜索框中输入你要抓取的内容,点击第一个;7.在页面左侧的download按钮中,点击鼠标,点击左侧download按钮。在右侧发现大部分都被解析了。以大家可能都会关心的,每个解析的数据的大小。
4、配置uwsgi服务器第一步 查看全部
php网页抓取标题(php网页抓取标题是很重要的一步,能决定了你的网页是否有用)
php网页抓取标题是很重要的一步,能决定了你抓取的网页是否有用。所以你的标题需要满足下面要求:1.网页标题包含文字;2.尽量简短,足够抓取到你需要的内容;3.最好能用动词或者名词表达出来,这样直接更好抓取。
一、网页标题的格式及要求通常,网页标题的格式如下:title:关键词blank:空值sorted:这个是排序,由一个值组成,分为6种组合1.最优先的组合:无blank排序2.第二优先的组合:全blank排序3.第三优先的组合:全空白排序4.第四优先的组合:全无blank排序5.第五优先的组合:大写字母排序6.第六优先的组合:小写字母排序。通常我们需要给blank列出第几个,并在php的代码中进行相应的书写。
二、标题常见的问题解决网页标题是否需要设置,这需要根据网页类型进行判断,一般如果网页类型是嵌入式广告的页面,不需要在标题中进行区分。如果是传统的网站,主要以phpcms网站为例,需要进行标题的字体设置。1.首先打开我们的www浏览器,打开我们的网页源代码分析,发现标题设置前面多了一串字符串":main_title:",我们只需要将这串字符串,改成为空白或者title::sorted这样就完成了标题的设置2.检查我们的root.php文件,发现title设置变了,要想完成标题的修改,要修改我们的标题文件,要修改文件的路径,要先在"$home"文件夹下新建一个文件,里面就是我们写的标题文件的路径,我们在找到它.3.打开phpcms网站源代码分析,发现标题设置改好后,能不能抓取到我们想要的内容,就要看我们的网页文件的header部分的设置。
在header文件中,如果标题设置后面没有任何的数据,那么就会出现同样一个错误。也就是我们经常说的"failedtofindtargetfile"因此我们可以修改我们的文件header中的数据,即能抓取网页标题的内容,并能实现被抓取内容的合并和删除,建议提前准备好多的网页标题。
四、web抓取原理如何使用百度网页爬虫进行网站抓取,需要熟悉本地环境的编写方法。步骤如下:1.打开浏览器的地址栏;2.在地址栏中键入你的要抓取的网站url;3.在弹出页面的搜索框中输入你要抓取的内容;4.点击下一步;5.在弹出页面中输入真正需要抓取的内容,点击下一步;6.在弹出页面的搜索框中输入你要抓取的内容,点击第一个;7.在页面左侧的download按钮中,点击鼠标,点击左侧download按钮。在右侧发现大部分都被解析了。以大家可能都会关心的,每个解析的数据的大小。
4、配置uwsgi服务器第一步
php网页抓取标题(爬取济南市中“滚动预警”菜单中的文章标题、内容与发布时间)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-01-19 12:01
爬虫用的比较少,每次用都会手生,特此记录下实战经验。
项目要求
需要爬取济南市政网“滚动预警”菜单中的文章,包括文章标题、文章正文、文章时间,并保存为一个txt文件。
项目分析1、确定可以爬取什么
首先查看网站的robots.txt文件,发现该文件不存在。因此,可以正常抓取相关公开信息。
2、确定页面的加载方式
网页加载可以分为静态加载和动态加载。
网页右键->选择查看源代码,即网页的静态代码。在网页上右击-> Inspect 查看浏览器当前呈现的内容。
如果两者一致,则静态加载网页。此时,通常可以使用requests.get获取网页数据。
如果两者不一致,则动态加载网页。这时候需要通过开发者后台查看本地发送到服务器的交互数据(XHR)。
每3页,网页会冻结一小段时间,然后加载。同时可以找到一个额外的XHR数据,如图。此时请求的URL如上图所示,并且在URL中标注了开始数据和结束数据。同时网页的请求方式为POST。
3、查看提交的表单内容
如图所示,提交的表单主要收录七条数据。看看网站的其他页面,大致可以猜到:
webid用来区分不同的大板块,columnid用来区分各个大板块中的小板块,其他属性未知。翻页过程中,只有url发生变化,提交的表单内容是固定的。
还可以发现,紧急新闻和sliding alerts请求的url是一样的,不同的是form数据:紧急新闻的columnid是29112,sliding alert的columnid是34053。
4、获取文章标题、内容和发表时间
通过上面的分析,已经可以通过post的方式获取到各个页面目录的源码了。再次,基于此,需要通过目录的链接进入每个文章的页面,提取标题、文字和时间。
通过bs4函数工具和正则表达式,可以将链接内容提取出来存储在Linklist中。
点击链接跳转,可以发现内容页面是静态加载的。这时候可以通过get或者post方法获取文章的内容。我这里还是用之前封装好的post方法。
分别提取文章标题、内容和时间,并将它们存储在title_list、content_list和time_list中。
5、寻找自动翻页的模式
通过以上操作,可以得到一次加载的内容,即三页内容(27条新闻),下面会通过寻找模式多次加载。
寻找模式:
第 1-3 页:
第 4-6 页:
255 页(最后一页):
发现只更改了startrecord(起始页)和endrecord(结束页)
所以设置起始页为i=1,结束页为i+26,每次遍历i+27,直到返回的Linklist为空,跳出循环。
完整代码
import os
from bs4 import BeautifulSoup
import re
import requests
# post得到网页并用bs4进行网页解析
def getHtml(url):
header = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/52.0.2743.116 Safari/537.36'}
data = {
'col': 1,
'webid': '33',
'path': 'http://jnsafety.jinan.gov.cn/',
# 'columnid': '29112', # 29112对应应急要闻
'columnid': '34053', # 34053对应滚动预警
'sourceContentType': '1',
'unitid': '92715',
'webname': '%E6%B5%8E%E5%8D%97%E5%B8%82%E5%BA%94%E6%80%A5%E7%AE%A1%E7%90%86%E5%B1%80',
'permissiontype': 0
}
rep = requests.post(url=url, data=data, headers=header, stream=True).text
# 解析网页
soup = BeautifulSoup(rep, 'html.parser')
return soup
# 从a标签中切分出具体文章链接
def split_link(string):
start_string = 'http'
end_string = '.html'
sub_str = ""
start = string.find(start_string)
# 只要start不等于-1,说明找到了http
while start != -1:
# 找结束的位置
end = string.find(end_string, start)
# 截取字符串 结束位置=结束字符串的开始位置+结束字符串的长度
sub_str = string[start:end + len(end_string)]
# 找下一个开始的位置
# 如果没有下一个开始的位置,结束循环
start = string.find(start_string, end)
return sub_str
# 截取文章发布时间的年月日
def split_time(t):
year = t[0:4]
month = t[5:7]
day = t[8:10]
data = "%s-%s-%s" % (year, month, day)
return data
# 获取一页中的所有链接
def get_link_list(soup):
# 使用正则表达式提取链接内容
p = re.compile(r'(.*?)?', re.S)
items = re.findall(p, str(soup))
# print(items)
Linklist = []
# 返回出各网站内容链接
for item in items:
# print(item)
link = split_link(item)
Linklist.append(link)
return Linklist
# 获取单篇文章标题、内容与发布时间
def get_title_content(soup_ev):
# 文章标题
title = soup_ev.find(name="meta", attrs={"name": "ArticleTitle"})['content']
# print(title)
# 文章内容
content = soup_ev.find(name="div", attrs={"id": "zoom"}).findAll(name="span")
# 文章发布时间
pub_time = soup_ev.find(name="meta", attrs={"name": "pubdate"})['content']
p_time = split_time(pub_time)
# print(p_time)
return title, content, p_time
# 保存单篇新闻
def save_content(title, content, index, time):
for item in content:
text_content = item.text
# print(text_content)
# 以标题名作为文件名,防止某些标题含有特殊符号,将其替换为空
sets = ['/', '\\', ':', '*', '?', '"', '', '|']
for char in title:
if char in sets:
title = title.replace(char, '')
tex_name = "%d%s-%s" % (index, title, time)
# 注:由于每段文字是分离的,因此写入文件模式设定为追加写入(a)
# 文件夹在主函数内创建
with open(r'./应急要闻/%s.txt' % tex_name, mode='a', encoding='utf-8') as f:
# 每段文字进行换行
f.write(text_content + "\n")
''' 滚动预警
with open(r'./滚动预警/%s.txt' % tex_name, mode='a', encoding='utf-8') as f:
# 每段文字进行换行
f.write(text_content + "\n")
'''
# 获取一次加载的新闻链接列表
def get_news_list(Linklist):
title_list = []
content_list = []
time_list = []
for item in Linklist:
# item、soup_ev都有可能因返回数据出现异常中断,这里对异常数据不作处理,跳过中断
try:
soup_ev = getHtml(item)
title, content, p_time = get_title_content(soup_ev)
title_list.append(title)
content_list.append(content)
time_list.append(p_time)
except Exception:
pass
continue
return title_list, content_list, time_list
# 根据文章的时间重新进行排序(按时间从后到前)
def sort_news(title_list, content_list, time_list):
title_content_time = zip(title_list, content_list, time_list)
sorted_title_content_time = sorted(title_content_time, key=lambda x: x[2], reverse=True)
result = zip(*sorted_title_content_time)
title_list, content_list, time_list = [list(x) for x in result]
return title_list, content_list, time_list
# 保存list中所有新闻
def save_all(title_list, content_list, time_list):
loop = zip(title_list, content_list, time_list)
index = 1
for title, content, time in loop:
save_content(title, content, index, time)
index += 1
if __name__ == '__main__':
# 在当前目录下创建存储新闻内容的文件夹
path = os.getcwd()
file_path = path + '\\' + str("滚动预警")
# file_path = path + '\\' + str("应急要闻")
os.mkdir(file_path)
# 存储每三页的标题、内容、时间
title_list = []
content_list = []
time_list = []
# 存储所有新闻的标题、内容、时间
tol_title_list = []
tol_content_list = []
tol_time_list = []
i = 1
while True:
url = 'http://jnsafety.jinan.gov.cn/m ... 39%3B % (i, i + 26)
soup = getHtml(url)
Linklist = get_link_list(soup)
# 取消下面的注释,可打印出每次请求得到的链接数,以显示程序正在允许中
# print(len(Linklist))
# print(Linklist)
# 假如爬完所有内容,跳出循环
if Linklist:
title_list, content_list, time_list = get_news_list(Linklist)
tol_title_list.extend(title_list)
tol_content_list.extend(content_list)
tol_time_list.extend(time_list)
else:
break
i = i + 27
# print(len(tol_title_list))
# print(len(tol_content_list))
# print(len(tol_time_list))
tol_title_list, tol_content_list, tol_time_list = sort_news(tol_title_list, tol_content_list, tol_time_list)
save_all(tol_title_list, tol_content_list, tol_time_list)
常见错误
1、('Connection aborted.', TimeoutError(10060, '连接尝试失败,因为连接方一段时间后没有正确回复或者连接的主机没有响应。', None, 10060, None) )
解决方法:关闭电脑的防火墙。
2、建立新连接失败:[WinError 10060]连接尝试失败,因为连接方一段时间后没有正确回复或连接的主机没有响应。'))
问题分析:错误可能是ip被封或者爬虫访问速度太快,服务器来不及响应。
解决方法:每次gethtml都加time.sleep(1),这样每次爬取的间隔为1秒。如果还是报错,尝试使用代理ip。 查看全部
php网页抓取标题(爬取济南市中“滚动预警”菜单中的文章标题、内容与发布时间)
爬虫用的比较少,每次用都会手生,特此记录下实战经验。
项目要求
需要爬取济南市政网“滚动预警”菜单中的文章,包括文章标题、文章正文、文章时间,并保存为一个txt文件。
项目分析1、确定可以爬取什么
首先查看网站的robots.txt文件,发现该文件不存在。因此,可以正常抓取相关公开信息。
2、确定页面的加载方式
网页加载可以分为静态加载和动态加载。
网页右键->选择查看源代码,即网页的静态代码。在网页上右击-> Inspect 查看浏览器当前呈现的内容。
如果两者一致,则静态加载网页。此时,通常可以使用requests.get获取网页数据。
如果两者不一致,则动态加载网页。这时候需要通过开发者后台查看本地发送到服务器的交互数据(XHR)。
每3页,网页会冻结一小段时间,然后加载。同时可以找到一个额外的XHR数据,如图。此时请求的URL如上图所示,并且在URL中标注了开始数据和结束数据。同时网页的请求方式为POST。
3、查看提交的表单内容
如图所示,提交的表单主要收录七条数据。看看网站的其他页面,大致可以猜到:
webid用来区分不同的大板块,columnid用来区分各个大板块中的小板块,其他属性未知。翻页过程中,只有url发生变化,提交的表单内容是固定的。
还可以发现,紧急新闻和sliding alerts请求的url是一样的,不同的是form数据:紧急新闻的columnid是29112,sliding alert的columnid是34053。
4、获取文章标题、内容和发表时间
通过上面的分析,已经可以通过post的方式获取到各个页面目录的源码了。再次,基于此,需要通过目录的链接进入每个文章的页面,提取标题、文字和时间。
通过bs4函数工具和正则表达式,可以将链接内容提取出来存储在Linklist中。
点击链接跳转,可以发现内容页面是静态加载的。这时候可以通过get或者post方法获取文章的内容。我这里还是用之前封装好的post方法。
分别提取文章标题、内容和时间,并将它们存储在title_list、content_list和time_list中。
5、寻找自动翻页的模式
通过以上操作,可以得到一次加载的内容,即三页内容(27条新闻),下面会通过寻找模式多次加载。
寻找模式:
第 1-3 页:
第 4-6 页:
255 页(最后一页):
发现只更改了startrecord(起始页)和endrecord(结束页)
所以设置起始页为i=1,结束页为i+26,每次遍历i+27,直到返回的Linklist为空,跳出循环。
完整代码
import os
from bs4 import BeautifulSoup
import re
import requests
# post得到网页并用bs4进行网页解析
def getHtml(url):
header = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/52.0.2743.116 Safari/537.36'}
data = {
'col': 1,
'webid': '33',
'path': 'http://jnsafety.jinan.gov.cn/',
# 'columnid': '29112', # 29112对应应急要闻
'columnid': '34053', # 34053对应滚动预警
'sourceContentType': '1',
'unitid': '92715',
'webname': '%E6%B5%8E%E5%8D%97%E5%B8%82%E5%BA%94%E6%80%A5%E7%AE%A1%E7%90%86%E5%B1%80',
'permissiontype': 0
}
rep = requests.post(url=url, data=data, headers=header, stream=True).text
# 解析网页
soup = BeautifulSoup(rep, 'html.parser')
return soup
# 从a标签中切分出具体文章链接
def split_link(string):
start_string = 'http'
end_string = '.html'
sub_str = ""
start = string.find(start_string)
# 只要start不等于-1,说明找到了http
while start != -1:
# 找结束的位置
end = string.find(end_string, start)
# 截取字符串 结束位置=结束字符串的开始位置+结束字符串的长度
sub_str = string[start:end + len(end_string)]
# 找下一个开始的位置
# 如果没有下一个开始的位置,结束循环
start = string.find(start_string, end)
return sub_str
# 截取文章发布时间的年月日
def split_time(t):
year = t[0:4]
month = t[5:7]
day = t[8:10]
data = "%s-%s-%s" % (year, month, day)
return data
# 获取一页中的所有链接
def get_link_list(soup):
# 使用正则表达式提取链接内容
p = re.compile(r'(.*?)?', re.S)
items = re.findall(p, str(soup))
# print(items)
Linklist = []
# 返回出各网站内容链接
for item in items:
# print(item)
link = split_link(item)
Linklist.append(link)
return Linklist
# 获取单篇文章标题、内容与发布时间
def get_title_content(soup_ev):
# 文章标题
title = soup_ev.find(name="meta", attrs={"name": "ArticleTitle"})['content']
# print(title)
# 文章内容
content = soup_ev.find(name="div", attrs={"id": "zoom"}).findAll(name="span")
# 文章发布时间
pub_time = soup_ev.find(name="meta", attrs={"name": "pubdate"})['content']
p_time = split_time(pub_time)
# print(p_time)
return title, content, p_time
# 保存单篇新闻
def save_content(title, content, index, time):
for item in content:
text_content = item.text
# print(text_content)
# 以标题名作为文件名,防止某些标题含有特殊符号,将其替换为空
sets = ['/', '\\', ':', '*', '?', '"', '', '|']
for char in title:
if char in sets:
title = title.replace(char, '')
tex_name = "%d%s-%s" % (index, title, time)
# 注:由于每段文字是分离的,因此写入文件模式设定为追加写入(a)
# 文件夹在主函数内创建
with open(r'./应急要闻/%s.txt' % tex_name, mode='a', encoding='utf-8') as f:
# 每段文字进行换行
f.write(text_content + "\n")
''' 滚动预警
with open(r'./滚动预警/%s.txt' % tex_name, mode='a', encoding='utf-8') as f:
# 每段文字进行换行
f.write(text_content + "\n")
'''
# 获取一次加载的新闻链接列表
def get_news_list(Linklist):
title_list = []
content_list = []
time_list = []
for item in Linklist:
# item、soup_ev都有可能因返回数据出现异常中断,这里对异常数据不作处理,跳过中断
try:
soup_ev = getHtml(item)
title, content, p_time = get_title_content(soup_ev)
title_list.append(title)
content_list.append(content)
time_list.append(p_time)
except Exception:
pass
continue
return title_list, content_list, time_list
# 根据文章的时间重新进行排序(按时间从后到前)
def sort_news(title_list, content_list, time_list):
title_content_time = zip(title_list, content_list, time_list)
sorted_title_content_time = sorted(title_content_time, key=lambda x: x[2], reverse=True)
result = zip(*sorted_title_content_time)
title_list, content_list, time_list = [list(x) for x in result]
return title_list, content_list, time_list
# 保存list中所有新闻
def save_all(title_list, content_list, time_list):
loop = zip(title_list, content_list, time_list)
index = 1
for title, content, time in loop:
save_content(title, content, index, time)
index += 1
if __name__ == '__main__':
# 在当前目录下创建存储新闻内容的文件夹
path = os.getcwd()
file_path = path + '\\' + str("滚动预警")
# file_path = path + '\\' + str("应急要闻")
os.mkdir(file_path)
# 存储每三页的标题、内容、时间
title_list = []
content_list = []
time_list = []
# 存储所有新闻的标题、内容、时间
tol_title_list = []
tol_content_list = []
tol_time_list = []
i = 1
while True:
url = 'http://jnsafety.jinan.gov.cn/m ... 39%3B % (i, i + 26)
soup = getHtml(url)
Linklist = get_link_list(soup)
# 取消下面的注释,可打印出每次请求得到的链接数,以显示程序正在允许中
# print(len(Linklist))
# print(Linklist)
# 假如爬完所有内容,跳出循环
if Linklist:
title_list, content_list, time_list = get_news_list(Linklist)
tol_title_list.extend(title_list)
tol_content_list.extend(content_list)
tol_time_list.extend(time_list)
else:
break
i = i + 27
# print(len(tol_title_list))
# print(len(tol_content_list))
# print(len(tol_time_list))
tol_title_list, tol_content_list, tol_time_list = sort_news(tol_title_list, tol_content_list, tol_time_list)
save_all(tol_title_list, tol_content_list, tol_time_list)
常见错误
1、('Connection aborted.', TimeoutError(10060, '连接尝试失败,因为连接方一段时间后没有正确回复或者连接的主机没有响应。', None, 10060, None) )
解决方法:关闭电脑的防火墙。
2、建立新连接失败:[WinError 10060]连接尝试失败,因为连接方一段时间后没有正确回复或连接的主机没有响应。'))
问题分析:错误可能是ip被封或者爬虫访问速度太快,服务器来不及响应。
解决方法:每次gethtml都加time.sleep(1),这样每次爬取的间隔为1秒。如果还是报错,尝试使用代理ip。

