
php抓取网页title
核心方法:如何使用 ProxyCrawl 和 Scrapy 抓取网页
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-09-24 01:09
网页抓取,也称为网页抓取或屏幕抓取,软件开发人员将其定义为“编写软件以迭代一组网页以提取内容”,是出于各种原因从网页提取数据的出色工具。
<p>使用网络爬虫,你可以从一组文章中抓取数据,挖掘大型博客文章,或者从亚马逊抓取定量数据进行价格监控和机器学习,克服无法从 查看全部
核心方法:如何使用 ProxyCrawl 和 Scrapy 抓取网页
网页抓取,也称为网页抓取或屏幕抓取,软件开发人员将其定义为“编写软件以迭代一组网页以提取内容”,是出于各种原因从网页提取数据的出色工具。
<p>使用网络爬虫,你可以从一组文章中抓取数据,挖掘大型博客文章,或者从亚马逊抓取定量数据进行价格监控和机器学习,克服无法从
PHP实现页面静态化
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-05-05 08:00
随着网站的内容的增多和用户访问量的增多,无可避免的是网站加载会越来越慢,受限于带宽和服务器同一时间的请求次数的限制,我们往往需要在此时对我们的网站进行代码优化和服务器配置的优化。
一般情况下会从以下方面来做优化
1、动态页面静态化
2、优化数据库
3、使用负载均衡
4、使用缓存
5、使用CDN加速
现在很多网站在建设的时候都要进行静态化的处理,为什么网站要进行静态化处理呢?我们都知道纯静态网站是所有的网页都是独立的一个html页面,当我们访问的时候不需要经过数据的处理直接就能读取到文件,访问速度就可想而知了,而其对于搜索引擎而言也是非常友好的一个方式。
纯静态网站在网站中是怎么实现的?
纯静态的制作技术是需要先把网站的页面总结出来,分为多少个样式,然后把这些页面做成模板,生成的时候需要先读取源文件然后生成独立的以.html结尾的页面文件,所以说纯静态网站需要更大的空间,不过其实需要的空间也不会大多少的,尤其是对于中小型企业网站来说,从技术上来讲,大型网站想要全站实现纯静态化是比较困难的,生成的时间也太过于长了。不过中小型网站还是做成纯静态的比较,这样做的优点是很多的。
而动态网站又是怎么进行静态处理的?
页面静态化是指将动态页面变成html/htm静态页面。动态页面一般由asp,php,jsp,.net等程序语言编写而成,非常便于管理。但是访问网页时还需要程序先处理一遍,所以导致访问速度相对较慢。而静态页面访问速度快,却又不便于管理。那么动态页面静态化即可以将两种页面的好处集中到一起。
静态处理后又给网站带来了哪些好处?
1、静态页面相对于动态页面更容易被搜索引擎收录。
2、访问静态页面不需要经过程序处理,因此可以提高运行速度。
3、减轻服务器负担。
4、HTML页面不会受Asp相关漏洞的影响。
静态处理后的网站相对没有静态化处理的网站来讲还比较有安全性,因为静态网站是不会是黑客攻击的首选对象,因为黑客在不知道你后台系统的情况下,黑 客从前台的静态页面很难进行攻击。同时还具有一定的稳定性,比如数据库或者网站的程序出了问题,他不会干扰到静态处理后的页面,不会因为程序或数据影响而 打不开页面。
搜索引擎蜘蛛程序更喜欢这样的网址,也可以减轻蜘蛛程序的工作负担,虽然有的人会认为现在搜索引擎完全有能力去抓取和识别动态的网址,在这里还是建议大家能做成静态的尽量做成静态网址。
下面我们主要来讲一讲页面静态化这个概念,希望对你有所帮助!
什么是HTML静态化:
常说的页面静态化分为两种,一种是伪静态,即url 重写,一种是真静态化。
在PHP网站开发中为了网站推广和SEO等需要,需要对网站进行全站或局部静态化处理,PHP生成静态HTML页面有多种方法,比如利用PHP模板、缓存等实现页面静态化。
PHP静态化的简单理解就是使网站生成页面以静态HTML的形式展现在访客面前,PHP静态化分纯静态化和伪静态化,两者的区别在于PHP生成静态页面的处理机制不同。
PHP伪静态:利用Apache mod_rewrite实现URL重写的方法。
HTML静态化的好处:
一、减轻服务器负担,浏览网页无需调用系统数据库。
二、有利于搜索引擎优化SEO,Baidu、Google都会优先收录静态页面,不仅被收录的快还收录的全;
三、加快页面打开速度,静态页面无需连接数据库打开速度较动态页面有明显提高;
四、网站更安全,HTML页面不会受php程序相关漏洞的影响;观看一下大一点的网站基本全是静态页面,而且可以减少攻击,防sql注入。数据库出错时,不影响网站正常访问。
五、数据库出错时,不影响网站的正常访问。
最主要是可以增加访问速度,减轻服务器负担,当数据量有几万,几十万或是更多的时候你知道哪个更快了. 而且还容易被搜索引擎找到。生成html文章虽操作上麻烦些,程序上繁杂些,但为了更利于搜索,为了速度更快些,更安全,这些牺牲还是值得的。
实现HTML静态化的策略与实例讲解:
基本方式
file_put_contents()函数
使用php内置缓存机制实现页面静态化 —output-bufferring.
方法1:利用PHP模板生成静态页面
PHP模板实现静态化非常方便,比如安装和使用PHP Smarty实现网站静态化。
在使用Smarty的情况下,也可以实现页面静态化。下面先简单说一下使用Smarty时通常动态读取的做法。
一般分这几步:
1、通过URL传递一个参数(ID);
2、然后根据此ID查询数据库;
3、取得数据后根据需要修改显示内容;
4、assign需要显示的数据;
5、display模板文件。
Smarty静态化过程只需要在上述过程中添加两个步骤。
第一:在1之前使用 ob_start() 打开缓冲区。
第二:在5之后使用 ob_get_contents() 获取内存未输出内容,然后使用fwrite()将内容写入目标html文件。
根据上述描述,此过程是在网站前台实现的,而内容管理(添加、修改、删除)通常是在后台进行,为了能有效利用上述过程,可以使用一点小手段,那就是Header()。具体过程是这样的:在添加、修改程序完成之后,使用Header() 跳到前台读取,这样可以实现页面HTML化,然后在生成html后再跳回后台管理侧,而这两个跳转过程是不可见的。
方法2:使用PHP文件读写功能生成静态页面
<p style="padding: 0.5em;max-width: 100%;line-height: 18px;font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);margin-left: 16px;margin-right: 16px;box-sizing: border-box !important;overflow-wrap: normal !important;display: block !important;word-break: normal !important;overflow: auto !important;"><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /></p>
方法3:使用PHP输出控制函数(Output Control)/ob缓存机制生成静态页面
输出控制函数(Output Control)也就是使用和控制缓存来生成静态HTML页面,也会使用到PHP文件读写函数。
比如某个商品的动态详情页地址是:
那么这里我们根据这个地址读取一次这个详情页的内容,然后保存为静态页,下次有人访问这个商品详情页动态地址时,我们可以直接把已生成好的对应静态内容文件输出出来。
PHP生成静态页面实例代码 1
<p style="padding: 0.5em;max-width: 100%;line-height: 18px;font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);margin-left: 16px;margin-right: 16px;box-sizing: border-box !important;overflow-wrap: normal !important;display: block !important;word-break: normal !important;overflow: auto !important;"><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /></p>
PHP生成静态页面实例代码 2
<p style="padding: 0.5em;max-width: 100%;line-height: 18px;font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);margin-left: 16px;margin-right: 16px;box-sizing: border-box !important;overflow-wrap: normal !important;display: block !important;word-break: normal !important;overflow: auto !important;"><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /></p>
我们知道使用PHP进行网站开发,一般执行结果直接输出到游览器,为了使用PHP生成静态页面,就需要使用输出控制函数控制缓存区,以便获取缓存区的内容,然后再输出到静态HTML页面文件中以实现网站静态化。
PHP生成静态页面的思路为:首先开启缓存,然后输出了HTML内容(你也可以通过include将HTML内容以文件形式包含进来),之后获取缓存中的内容,清空缓存后通过PHP文件读写函数将缓存内容写入到静态HTML页面文件中。
获得输出的缓存内容以生成静态HTML页面的过程需要使用三个函数:ob_start()、ob_get_contents()、ob_end_clean()。
知识点:
1、ob_start函数一般主要是用来开启缓存,注意使用ob_start之前不能有任何输出,如空格、字符等。
2、ob_get_contents函数主要用来获取缓存中的内容以字符串形式返回,注意此函数必须在ob_end_clean函数之前调用,否则获取不到缓存内容。
3、ob_end_clean函数主要是清空缓存中的内容并关闭缓存,成功则返回True,失败则返回False
方法4:使用nosql从内存中读取内容(其实这个已经不算静态化了而是缓存);
以memcache为例:
<p style="padding: 0.5em;max-width: 100%;line-height: 18px;font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);margin-left: 16px;margin-right: 16px;box-sizing: border-box !important;overflow-wrap: normal !important;display: block !important;word-break: normal !important;overflow: auto !important;"><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /></p>
memcached是键值一一对应,key默认最大不能超过128个字节,value默认大小是1M,因此1M大小满足大多数网页大小的存储。
以上内容希望帮助到大家,有需要的可以添加下方二维码进群交流学习PHP中高级技术。
如果你想和PHP大神交流加微信,拉你入群
如果你想获得学习资料加微信,送你资源
扫码关注菲菲
php实战资源免费送
COME BABY
查看全部
PHP实现页面静态化
随着网站的内容的增多和用户访问量的增多,无可避免的是网站加载会越来越慢,受限于带宽和服务器同一时间的请求次数的限制,我们往往需要在此时对我们的网站进行代码优化和服务器配置的优化。
一般情况下会从以下方面来做优化
1、动态页面静态化
2、优化数据库
3、使用负载均衡
4、使用缓存
5、使用CDN加速
现在很多网站在建设的时候都要进行静态化的处理,为什么网站要进行静态化处理呢?我们都知道纯静态网站是所有的网页都是独立的一个html页面,当我们访问的时候不需要经过数据的处理直接就能读取到文件,访问速度就可想而知了,而其对于搜索引擎而言也是非常友好的一个方式。
纯静态网站在网站中是怎么实现的?
纯静态的制作技术是需要先把网站的页面总结出来,分为多少个样式,然后把这些页面做成模板,生成的时候需要先读取源文件然后生成独立的以.html结尾的页面文件,所以说纯静态网站需要更大的空间,不过其实需要的空间也不会大多少的,尤其是对于中小型企业网站来说,从技术上来讲,大型网站想要全站实现纯静态化是比较困难的,生成的时间也太过于长了。不过中小型网站还是做成纯静态的比较,这样做的优点是很多的。
而动态网站又是怎么进行静态处理的?
页面静态化是指将动态页面变成html/htm静态页面。动态页面一般由asp,php,jsp,.net等程序语言编写而成,非常便于管理。但是访问网页时还需要程序先处理一遍,所以导致访问速度相对较慢。而静态页面访问速度快,却又不便于管理。那么动态页面静态化即可以将两种页面的好处集中到一起。
静态处理后又给网站带来了哪些好处?
1、静态页面相对于动态页面更容易被搜索引擎收录。
2、访问静态页面不需要经过程序处理,因此可以提高运行速度。
3、减轻服务器负担。
4、HTML页面不会受Asp相关漏洞的影响。
静态处理后的网站相对没有静态化处理的网站来讲还比较有安全性,因为静态网站是不会是黑客攻击的首选对象,因为黑客在不知道你后台系统的情况下,黑 客从前台的静态页面很难进行攻击。同时还具有一定的稳定性,比如数据库或者网站的程序出了问题,他不会干扰到静态处理后的页面,不会因为程序或数据影响而 打不开页面。
搜索引擎蜘蛛程序更喜欢这样的网址,也可以减轻蜘蛛程序的工作负担,虽然有的人会认为现在搜索引擎完全有能力去抓取和识别动态的网址,在这里还是建议大家能做成静态的尽量做成静态网址。
下面我们主要来讲一讲页面静态化这个概念,希望对你有所帮助!
什么是HTML静态化:
常说的页面静态化分为两种,一种是伪静态,即url 重写,一种是真静态化。
在PHP网站开发中为了网站推广和SEO等需要,需要对网站进行全站或局部静态化处理,PHP生成静态HTML页面有多种方法,比如利用PHP模板、缓存等实现页面静态化。
PHP静态化的简单理解就是使网站生成页面以静态HTML的形式展现在访客面前,PHP静态化分纯静态化和伪静态化,两者的区别在于PHP生成静态页面的处理机制不同。
PHP伪静态:利用Apache mod_rewrite实现URL重写的方法。
HTML静态化的好处:
一、减轻服务器负担,浏览网页无需调用系统数据库。
二、有利于搜索引擎优化SEO,Baidu、Google都会优先收录静态页面,不仅被收录的快还收录的全;
三、加快页面打开速度,静态页面无需连接数据库打开速度较动态页面有明显提高;
四、网站更安全,HTML页面不会受php程序相关漏洞的影响;观看一下大一点的网站基本全是静态页面,而且可以减少攻击,防sql注入。数据库出错时,不影响网站正常访问。
五、数据库出错时,不影响网站的正常访问。
最主要是可以增加访问速度,减轻服务器负担,当数据量有几万,几十万或是更多的时候你知道哪个更快了. 而且还容易被搜索引擎找到。生成html文章虽操作上麻烦些,程序上繁杂些,但为了更利于搜索,为了速度更快些,更安全,这些牺牲还是值得的。
实现HTML静态化的策略与实例讲解:
基本方式
file_put_contents()函数
使用php内置缓存机制实现页面静态化 —output-bufferring.
方法1:利用PHP模板生成静态页面
PHP模板实现静态化非常方便,比如安装和使用PHP Smarty实现网站静态化。
在使用Smarty的情况下,也可以实现页面静态化。下面先简单说一下使用Smarty时通常动态读取的做法。
一般分这几步:
1、通过URL传递一个参数(ID);
2、然后根据此ID查询数据库;
3、取得数据后根据需要修改显示内容;
4、assign需要显示的数据;
5、display模板文件。
Smarty静态化过程只需要在上述过程中添加两个步骤。
第一:在1之前使用 ob_start() 打开缓冲区。
第二:在5之后使用 ob_get_contents() 获取内存未输出内容,然后使用fwrite()将内容写入目标html文件。
根据上述描述,此过程是在网站前台实现的,而内容管理(添加、修改、删除)通常是在后台进行,为了能有效利用上述过程,可以使用一点小手段,那就是Header()。具体过程是这样的:在添加、修改程序完成之后,使用Header() 跳到前台读取,这样可以实现页面HTML化,然后在生成html后再跳回后台管理侧,而这两个跳转过程是不可见的。
方法2:使用PHP文件读写功能生成静态页面
<p style="padding: 0.5em;max-width: 100%;line-height: 18px;font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);margin-left: 16px;margin-right: 16px;box-sizing: border-box !important;overflow-wrap: normal !important;display: block !important;word-break: normal !important;overflow: auto !important;"><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /></p>
方法3:使用PHP输出控制函数(Output Control)/ob缓存机制生成静态页面
输出控制函数(Output Control)也就是使用和控制缓存来生成静态HTML页面,也会使用到PHP文件读写函数。
比如某个商品的动态详情页地址是:
那么这里我们根据这个地址读取一次这个详情页的内容,然后保存为静态页,下次有人访问这个商品详情页动态地址时,我们可以直接把已生成好的对应静态内容文件输出出来。
PHP生成静态页面实例代码 1
<p style="padding: 0.5em;max-width: 100%;line-height: 18px;font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);margin-left: 16px;margin-right: 16px;box-sizing: border-box !important;overflow-wrap: normal !important;display: block !important;word-break: normal !important;overflow: auto !important;"><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /></p>
PHP生成静态页面实例代码 2
<p style="padding: 0.5em;max-width: 100%;line-height: 18px;font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);margin-left: 16px;margin-right: 16px;box-sizing: border-box !important;overflow-wrap: normal !important;display: block !important;word-break: normal !important;overflow: auto !important;"><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /></p>
我们知道使用PHP进行网站开发,一般执行结果直接输出到游览器,为了使用PHP生成静态页面,就需要使用输出控制函数控制缓存区,以便获取缓存区的内容,然后再输出到静态HTML页面文件中以实现网站静态化。
PHP生成静态页面的思路为:首先开启缓存,然后输出了HTML内容(你也可以通过include将HTML内容以文件形式包含进来),之后获取缓存中的内容,清空缓存后通过PHP文件读写函数将缓存内容写入到静态HTML页面文件中。
获得输出的缓存内容以生成静态HTML页面的过程需要使用三个函数:ob_start()、ob_get_contents()、ob_end_clean()。
知识点:
1、ob_start函数一般主要是用来开启缓存,注意使用ob_start之前不能有任何输出,如空格、字符等。
2、ob_get_contents函数主要用来获取缓存中的内容以字符串形式返回,注意此函数必须在ob_end_clean函数之前调用,否则获取不到缓存内容。
3、ob_end_clean函数主要是清空缓存中的内容并关闭缓存,成功则返回True,失败则返回False
方法4:使用nosql从内存中读取内容(其实这个已经不算静态化了而是缓存);
以memcache为例:
<p style="padding: 0.5em;max-width: 100%;line-height: 18px;font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);margin-left: 16px;margin-right: 16px;box-sizing: border-box !important;overflow-wrap: normal !important;display: block !important;word-break: normal !important;overflow: auto !important;"><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /></p>
memcached是键值一一对应,key默认最大不能超过128个字节,value默认大小是1M,因此1M大小满足大多数网页大小的存储。
以上内容希望帮助到大家,有需要的可以添加下方二维码进群交流学习PHP中高级技术。
如果你想和PHP大神交流加微信,拉你入群
如果你想获得学习资料加微信,送你资源
扫码关注菲菲
php实战资源免费送
COME BABY
php抓取网页title(一个开源的浏览器引擎,与之相对应的引擎有Gecko)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-04-13 17:19
WebKit是一个开源的浏览器引擎,对应的引擎有Gecko(Mozilla Firefox等使用)和Trident(又称MSHTML,IE使用)
参考来源:
代码示例:
phantomjs 和 slimerjs,都是服务端 js。简而言之,它们都封装了浏览器解析引擎。不同的是webkti是用phantomjs封装的,而slimerjs是用Gecko(firefox)封装的。权衡利弊后,我决定研究phantomjs,所以我使用phantomjs来生成网站快照。 phantomjs的项目地址是:
代码涉及两部分,一是设计业务的index.php,二是生成快照的js脚本snapshot.js。代码比较简单,只是实现功能,没有做太多修改。代码如下:
php:
html
快照生成
* {
margin: 0;
padding: 0;
}
form {
padding: 20px;
}
div {
margin: 20px 0 0;
}
input {
width: 200px;
padding: 4px 2px;
}
#placeholder {
display: none;
}
生成快照
$(function(){
$('#form').submit(function(){
if (typeof($(this).data('generate')) !== 'undefined' && $(this).data('generate') === true)
{
alert('正在生成网站快照,请耐心等待...');
return false;
}
$(this).data('generate', true);
$('button').text('正在生成快照...').attr('disabled', true);
$.ajax({
type: 'GET',
url: '?',
data: 'url=' + $('#url').val(),
success: function(data){
$('#placeholder').attr('src', data).show();
$('#form').data('generate', false);
$('button').text('生成快照').attr('disabled', false);
}
});
return false;
});
});
php使用CutyCapt实现网页高清截图:
网页截图功能,必须安装IE+CutyCapturl:要截图的网页:图片保存路径路径:CutyCapt路径cmd:CutyCapt执行命令如:你的php path.php?url=
CutyCapt下载地址:http://sourceforge.net/project ... capt/
windows的不用安装的,直接下载解压放到相对应的路径即可
linux安装CutyCapt教程:http://niutuku9.com/tech/php/273578.shtml
组织参考来自:软联盟 查看全部
php抓取网页title(一个开源的浏览器引擎,与之相对应的引擎有Gecko)
WebKit是一个开源的浏览器引擎,对应的引擎有Gecko(Mozilla Firefox等使用)和Trident(又称MSHTML,IE使用)
参考来源:
代码示例:
phantomjs 和 slimerjs,都是服务端 js。简而言之,它们都封装了浏览器解析引擎。不同的是webkti是用phantomjs封装的,而slimerjs是用Gecko(firefox)封装的。权衡利弊后,我决定研究phantomjs,所以我使用phantomjs来生成网站快照。 phantomjs的项目地址是:
代码涉及两部分,一是设计业务的index.php,二是生成快照的js脚本snapshot.js。代码比较简单,只是实现功能,没有做太多修改。代码如下:
php:
html
快照生成
* {
margin: 0;
padding: 0;
}
form {
padding: 20px;
}
div {
margin: 20px 0 0;
}
input {
width: 200px;
padding: 4px 2px;
}
#placeholder {
display: none;
}
生成快照
$(function(){
$('#form').submit(function(){
if (typeof($(this).data('generate')) !== 'undefined' && $(this).data('generate') === true)
{
alert('正在生成网站快照,请耐心等待...');
return false;
}
$(this).data('generate', true);
$('button').text('正在生成快照...').attr('disabled', true);
$.ajax({
type: 'GET',
url: '?',
data: 'url=' + $('#url').val(),
success: function(data){
$('#placeholder').attr('src', data).show();
$('#form').data('generate', false);
$('button').text('生成快照').attr('disabled', false);
}
});
return false;
});
});
php使用CutyCapt实现网页高清截图:
网页截图功能,必须安装IE+CutyCapturl:要截图的网页:图片保存路径路径:CutyCapt路径cmd:CutyCapt执行命令如:你的php path.php?url=
CutyCapt下载地址:http://sourceforge.net/project ... capt/
windows的不用安装的,直接下载解压放到相对应的路径即可
linux安装CutyCapt教程:http://niutuku9.com/tech/php/273578.shtml
组织参考来自:软联盟
php抓取网页title(2022-01-20众所周周,网站的标题来自网页的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-04-04 09:00
2022-01-20
众所周知,网站的标题来自于网页的标题标签。谷歌这样做了,百度更是如此。TITLE 在搜索结果页面上显示 网站 标题方面起着关键作用。,如果这段代码出现在网页中间,一旦页面是收录,在搜索结果的显示页面中,我们面前的标题当然是不可思议的网站TITLE,但随着搜索引擎算法的不断合理化和各种因素的调整,对SEO提出了更高的要求。让我们看下面的例子:
上图是搜索“经典家具”的自然结果。可以看第二条,标题是公司名,但是没有描述,所以我们打开他的网站:
我们可以清楚的看到网站的标题:华艺家具文化艺术馆,和搜索结果不一样。标题标签有什么神秘之处吗?我们来看看他的源文件:
网页的源码很清楚,和网站的标题一样,只是没有说明。验证了两点:1、网站本身没有优化,标题标签没有问题2、没有描述,所以搜索结果中没有对应的显示内容(很可怕的)。所以也说明了本文的问题文章:为什么网站的TITLE标签的内容没有被搜索引擎抓取,哪些因素影响了搜索引擎的抓取?我认为主要原因如下:
1、网站本身的原因:打开这个网站,首页是flash,非常不利于搜索引擎抓取。首页上可供爬取的信息只有title和keywords,也就是说搜索引擎不可能根据网站的title来爬取。(这个域名已经很老了,域名本身的权重会增加。相信如果新站也采用这种方式的话,搜索引擎会很难爬到)
2、外部原因:
既然搜索引擎有收录网站,我们可以搜索网站的域名,不难发现公司名是伴随频率最高的域名,而不是 网站 标题。如果所有的外部链接都能使用正确的锚文本,相信搜索结果会得到更好的体现。
搜索引擎的智能化也是我们不能忽视的一个方面,也就是我们所说的“算法”或“机制”。搜索引擎获取网站的方式并不固定。当搜索引擎无法获取 网站 本身的信息时,它们会定期从整个网页集合中采集信息。从这个角度来看,搜索引擎已经人性化了。当它无法理解你时,它会回到网站的成长阶段,发现更多、更有效、更准确的关于你的信息。
这个案例告诉我们,搜索引擎对SEO提出了更高的要求,人性化的优化会越来越受到主流搜索引擎的欢迎,单纯堆叠关键词和链接字段的作弊手段也越来越多。 . 搜索引擎发现并处罚。建立一个网站不会在一夜之间发生,SEO 也是如此。
分类:
技术要点:
相关文章: 查看全部
php抓取网页title(2022-01-20众所周周,网站的标题来自网页的)
2022-01-20
众所周知,网站的标题来自于网页的标题标签。谷歌这样做了,百度更是如此。TITLE 在搜索结果页面上显示 网站 标题方面起着关键作用。,如果这段代码出现在网页中间,一旦页面是收录,在搜索结果的显示页面中,我们面前的标题当然是不可思议的网站TITLE,但随着搜索引擎算法的不断合理化和各种因素的调整,对SEO提出了更高的要求。让我们看下面的例子:
上图是搜索“经典家具”的自然结果。可以看第二条,标题是公司名,但是没有描述,所以我们打开他的网站:
我们可以清楚的看到网站的标题:华艺家具文化艺术馆,和搜索结果不一样。标题标签有什么神秘之处吗?我们来看看他的源文件:
网页的源码很清楚,和网站的标题一样,只是没有说明。验证了两点:1、网站本身没有优化,标题标签没有问题2、没有描述,所以搜索结果中没有对应的显示内容(很可怕的)。所以也说明了本文的问题文章:为什么网站的TITLE标签的内容没有被搜索引擎抓取,哪些因素影响了搜索引擎的抓取?我认为主要原因如下:
1、网站本身的原因:打开这个网站,首页是flash,非常不利于搜索引擎抓取。首页上可供爬取的信息只有title和keywords,也就是说搜索引擎不可能根据网站的title来爬取。(这个域名已经很老了,域名本身的权重会增加。相信如果新站也采用这种方式的话,搜索引擎会很难爬到)
2、外部原因:
既然搜索引擎有收录网站,我们可以搜索网站的域名,不难发现公司名是伴随频率最高的域名,而不是 网站 标题。如果所有的外部链接都能使用正确的锚文本,相信搜索结果会得到更好的体现。
搜索引擎的智能化也是我们不能忽视的一个方面,也就是我们所说的“算法”或“机制”。搜索引擎获取网站的方式并不固定。当搜索引擎无法获取 网站 本身的信息时,它们会定期从整个网页集合中采集信息。从这个角度来看,搜索引擎已经人性化了。当它无法理解你时,它会回到网站的成长阶段,发现更多、更有效、更准确的关于你的信息。
这个案例告诉我们,搜索引擎对SEO提出了更高的要求,人性化的优化会越来越受到主流搜索引擎的欢迎,单纯堆叠关键词和链接字段的作弊手段也越来越多。 . 搜索引擎发现并处罚。建立一个网站不会在一夜之间发生,SEO 也是如此。
分类:
技术要点:
相关文章:
php抓取网页title(开源库PHPDOMParser的核心代码解析方法解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-04-03 10:27
GitHub:github_trending_crawler
介绍
由于GitHub官方提供的API不收录GitHub Trending相关接口,作为好学的开发者,大家都会关注Trending Trending,获取GitHub上相关编程语言的最新项目和开发者。此外,我们在开发第三方 GitHub App 时,通常还需要展示 Trending 数据。如果我们直接在客户端捕获解析,那就吃力不讨好,国内访问速度慢。这时,服务器需要提供相关的接口来解决问题。.
本仓库提供了一个小型的PHP爬虫,用于周期性的抓取和解析服务器上的GitHub Trending数据并缓存,从而为客户端提供一个快速(秒级)的查询接口。可以从Daily、Weekly、Monthly三个维度抓取各种编程语言中最受关注的Repositories和Developers。
阐明
这个小爬虫的核心代码主要是爬虫文件夹下的simple_html_dom.php和github_trending_crawler.php这两个文件。
simple_html_dom.php
该文件来自开源库PHP Simple HTML DOM Parser,提供了简单易用、功能强大的HTML DOM解析方法,方便我们使用PHP抓取网页的HTML并进行分析.
github_trending_crawler.php
该文件主要用于抓取和解析 GitHub Trending 数据,包括以下方法:
该方法需要传入一个url参数,用于获取指定url下的HTML,并返回一个simple_html_dom对象,方便后续解析HTML中不同标签中的数据。
该方法用于获取GitHub Trending页面右侧推荐的当前流行编程语言(注意:每个人在登录状态下看到的结果可能会有所不同,此方法是在未登录时捕获的) ,并返回一个languages数组,数组中的每一项都收录name和id两个字段,大致如下:
1
{"languages":[{"name":"C++","id":"c++"},{"name":"PHP","id":"php"}, ... ]}
该方法用于获取 GitHub 的所有编程语言,同时返回一个结构类似上述的语言数组。
该方法接收两个参数lang和since,其中lang的值来自上述语言返回的id,since的值包括daily、weekly、monthly,用于获取指定时间内最关注的编程语言方面。的开源项目,返回一个仓库数组,大致如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
{
"repositories": [{
"author": "airbnb",
"title": "lottie-ios",
"url": "https://github.com/airbnb/lottie-ios",
"description": "An iOS library to natively render After Effects vector animations",
"language": "Objective-C",
"stars": "13,084",
"forks": "1,683",
"newStars": "25 stars today",
"contributors": [{
"id": "buba447",
"avatar": "https://avatars1.githubusercon ... ot%3B
}, {
"id": "welshm",
"avatar": "https://avatars0.githubusercon ... ot%3B
}, {
"id": "valeriyvan",
"avatar": "https://avatars0.githubusercon ... ot%3B
}, {
"id": "hansemannn",
"avatar": "https://avatars3.githubusercon ... ot%3B
}, {
"id": "fnazrala",
"avatar": "https://avatars2.githubusercon ... ot%3B
}]
},
...
]}
该方法还接收两个参数lang和since,其值类似于gt_get_repositories()方法的值。用于获取一种编程语言在指定时间维度下最受欢迎的开发者,并返回一个开发者数组,大致如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
{
"developers": [{
"url": "https://github.com\/facebook",
"avatar": "https://avatars2.githubusercon ... ot%3B,
"name": "Facebook",
"id": "facebook",
"repository": {
"url": "https://github.com/facebook/Shimmer",
"title": "Shimmer",
"desp": "An easy way to add a simple, shimmering effect to any view in an iOS app."
}
},
...
]}
注意:如果 GitHub Trending 访问失败、超时,或者页面没有某个维度的数据,或者解析异常,上述方法会返回 null,如果 GitHub Trending 页面的 HTML 结构发生变化以后,上述方法的解析逻辑也应该做相应的修改。
使用示例
为了方便正确使用github_trending_crawler.php,我写了一个示例脚本example.php,
把爬虫文件夹和example.php文件放到你的Web目录下,访问如下URL路径,就可以得到对应的结果。具体逻辑请参考example.php文件,不再赘述(在PHP 5. 6 测试通过)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// 默认获取今日所有编程语言下开源项目的 Trending 数据
https://path/to/example.php
// 获取今日 Swift 语言下开源项目的 Trending 数据
https://path/to/example.php%3F ... daily
// 获取本月 Swift 语言下开源项目的 Trending 数据
https://path/to/example.php%3F ... nthly
// 获取本周 Objective-C 语言下开发者的 Trending 数据
https://path/to/example.php%3F ... eekly
// 获取最受关注的编程语言和所有的编程语言列表
https://path/to/example.php?action=top_languages
https://path/to/example.php?action=all_languages
其中,URL的查询请求参数默认值如下:
当然,每次访问example.php脚本都实时取数据显然是很费时间的,而且GitHub Trending页面的更新频率也不是很快,所以我们可以通过Redis将数据缓存在服务器端,下次访问,如果缓存中有数据,直接返回,可以大大提高访问速度。有关详细信息,请参阅 example_with_redis.php 文件。
另外,你可以在你的服务器上启动一些crontab定时任务,定时抓取数据更新缓存,这样提供给客户端的接口可以快速响应。
请注意,如果您的 PHP 脚本在执行过程中报告以下错误:
1
file_get_contents(): SSL operation failed with code 1. OpenSSL Error messages: error:1407742E:SSL routines:SSL23_GET_SERVER_HELLO:tlsv1 alert protocol version in /path/to/simple_html_dom.php on line 75.
这是因为自 2018 年 2 月 1 日起,GitHub 将 HTTPS 访问限制为仅 TLSv1.2,请参阅此处了解详细信息,因此您可能需要更新服务器的 OpenSSL 版本。
测试界面
为了让大家更直观的感受一下上面这个小爬虫的效果,我在自己的服务器上部署了一个环境。您可以直接访问以下示例 URL 以获取相关结果:
// 默认获取所有编程语言的开源项目今日趋势数据
// 获取当今 Swift 语言开源项目的 Trending 数据
// 获取本月 Swift 语言开源项目的 Trending 数据
// 获取本周开发者在 Objective-C 中的 Trending 数据
// 获取最受关注的编程语言列表
// 获取所有编程语言的列表
重要提示:第一次访问上述接口获取相关数据时,如果缓存中有数据,则直接返回;如果缓存中没有数据,则会实时抓取GitHub Trending页面数据进行解析和缓存。这时候界面返回的速度会变慢。另外,因为是用来测试的,一旦缓存了数据,我并没有定期更新,所以上面测试接口返回的数据有时可能会过期。
!!!以上界面仅供大家体验,不建议直接在你的服务或app中使用,因为我随时可能离线。
顺便一提
如果你问我为什么我用 PHP 而不是 Python 来写爬虫,那当然是因为 PHP...
图片来自《神秘程序员》
执照
这个存储库是在 MIT 许可下发布的。有关详细信息,请参阅许可证。 查看全部
php抓取网页title(开源库PHPDOMParser的核心代码解析方法解析)
GitHub:github_trending_crawler
介绍
由于GitHub官方提供的API不收录GitHub Trending相关接口,作为好学的开发者,大家都会关注Trending Trending,获取GitHub上相关编程语言的最新项目和开发者。此外,我们在开发第三方 GitHub App 时,通常还需要展示 Trending 数据。如果我们直接在客户端捕获解析,那就吃力不讨好,国内访问速度慢。这时,服务器需要提供相关的接口来解决问题。.
本仓库提供了一个小型的PHP爬虫,用于周期性的抓取和解析服务器上的GitHub Trending数据并缓存,从而为客户端提供一个快速(秒级)的查询接口。可以从Daily、Weekly、Monthly三个维度抓取各种编程语言中最受关注的Repositories和Developers。
阐明
这个小爬虫的核心代码主要是爬虫文件夹下的simple_html_dom.php和github_trending_crawler.php这两个文件。
simple_html_dom.php
该文件来自开源库PHP Simple HTML DOM Parser,提供了简单易用、功能强大的HTML DOM解析方法,方便我们使用PHP抓取网页的HTML并进行分析.
github_trending_crawler.php
该文件主要用于抓取和解析 GitHub Trending 数据,包括以下方法:
该方法需要传入一个url参数,用于获取指定url下的HTML,并返回一个simple_html_dom对象,方便后续解析HTML中不同标签中的数据。
该方法用于获取GitHub Trending页面右侧推荐的当前流行编程语言(注意:每个人在登录状态下看到的结果可能会有所不同,此方法是在未登录时捕获的) ,并返回一个languages数组,数组中的每一项都收录name和id两个字段,大致如下:
1
{"languages":[{"name":"C++","id":"c++"},{"name":"PHP","id":"php"}, ... ]}
该方法用于获取 GitHub 的所有编程语言,同时返回一个结构类似上述的语言数组。
该方法接收两个参数lang和since,其中lang的值来自上述语言返回的id,since的值包括daily、weekly、monthly,用于获取指定时间内最关注的编程语言方面。的开源项目,返回一个仓库数组,大致如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
{
"repositories": [{
"author": "airbnb",
"title": "lottie-ios",
"url": "https://github.com/airbnb/lottie-ios",
"description": "An iOS library to natively render After Effects vector animations",
"language": "Objective-C",
"stars": "13,084",
"forks": "1,683",
"newStars": "25 stars today",
"contributors": [{
"id": "buba447",
"avatar": "https://avatars1.githubusercon ... ot%3B
}, {
"id": "welshm",
"avatar": "https://avatars0.githubusercon ... ot%3B
}, {
"id": "valeriyvan",
"avatar": "https://avatars0.githubusercon ... ot%3B
}, {
"id": "hansemannn",
"avatar": "https://avatars3.githubusercon ... ot%3B
}, {
"id": "fnazrala",
"avatar": "https://avatars2.githubusercon ... ot%3B
}]
},
...
]}
该方法还接收两个参数lang和since,其值类似于gt_get_repositories()方法的值。用于获取一种编程语言在指定时间维度下最受欢迎的开发者,并返回一个开发者数组,大致如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
{
"developers": [{
"url": "https://github.com\/facebook",
"avatar": "https://avatars2.githubusercon ... ot%3B,
"name": "Facebook",
"id": "facebook",
"repository": {
"url": "https://github.com/facebook/Shimmer",
"title": "Shimmer",
"desp": "An easy way to add a simple, shimmering effect to any view in an iOS app."
}
},
...
]}
注意:如果 GitHub Trending 访问失败、超时,或者页面没有某个维度的数据,或者解析异常,上述方法会返回 null,如果 GitHub Trending 页面的 HTML 结构发生变化以后,上述方法的解析逻辑也应该做相应的修改。
使用示例
为了方便正确使用github_trending_crawler.php,我写了一个示例脚本example.php,
把爬虫文件夹和example.php文件放到你的Web目录下,访问如下URL路径,就可以得到对应的结果。具体逻辑请参考example.php文件,不再赘述(在PHP 5. 6 测试通过)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// 默认获取今日所有编程语言下开源项目的 Trending 数据
https://path/to/example.php
// 获取今日 Swift 语言下开源项目的 Trending 数据
https://path/to/example.php%3F ... daily
// 获取本月 Swift 语言下开源项目的 Trending 数据
https://path/to/example.php%3F ... nthly
// 获取本周 Objective-C 语言下开发者的 Trending 数据
https://path/to/example.php%3F ... eekly
// 获取最受关注的编程语言和所有的编程语言列表
https://path/to/example.php?action=top_languages
https://path/to/example.php?action=all_languages
其中,URL的查询请求参数默认值如下:
当然,每次访问example.php脚本都实时取数据显然是很费时间的,而且GitHub Trending页面的更新频率也不是很快,所以我们可以通过Redis将数据缓存在服务器端,下次访问,如果缓存中有数据,直接返回,可以大大提高访问速度。有关详细信息,请参阅 example_with_redis.php 文件。
另外,你可以在你的服务器上启动一些crontab定时任务,定时抓取数据更新缓存,这样提供给客户端的接口可以快速响应。
请注意,如果您的 PHP 脚本在执行过程中报告以下错误:
1
file_get_contents(): SSL operation failed with code 1. OpenSSL Error messages: error:1407742E:SSL routines:SSL23_GET_SERVER_HELLO:tlsv1 alert protocol version in /path/to/simple_html_dom.php on line 75.
这是因为自 2018 年 2 月 1 日起,GitHub 将 HTTPS 访问限制为仅 TLSv1.2,请参阅此处了解详细信息,因此您可能需要更新服务器的 OpenSSL 版本。
测试界面
为了让大家更直观的感受一下上面这个小爬虫的效果,我在自己的服务器上部署了一个环境。您可以直接访问以下示例 URL 以获取相关结果:
// 默认获取所有编程语言的开源项目今日趋势数据
// 获取当今 Swift 语言开源项目的 Trending 数据
// 获取本月 Swift 语言开源项目的 Trending 数据
// 获取本周开发者在 Objective-C 中的 Trending 数据
// 获取最受关注的编程语言列表
// 获取所有编程语言的列表
重要提示:第一次访问上述接口获取相关数据时,如果缓存中有数据,则直接返回;如果缓存中没有数据,则会实时抓取GitHub Trending页面数据进行解析和缓存。这时候界面返回的速度会变慢。另外,因为是用来测试的,一旦缓存了数据,我并没有定期更新,所以上面测试接口返回的数据有时可能会过期。
!!!以上界面仅供大家体验,不建议直接在你的服务或app中使用,因为我随时可能离线。
顺便一提
如果你问我为什么我用 PHP 而不是 Python 来写爬虫,那当然是因为 PHP...

图片来自《神秘程序员》
执照
这个存储库是在 MIT 许可下发布的。有关详细信息,请参阅许可证。
php抓取网页title(编程要求请仔细阅读代码代码进行测试:预期输出:html加载 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-03-30 07:14
)
内容
任务详情
这一关的任务:编写一个爬虫来爬取网页的标题。
相关信息
为了完成这个任务,需要几个基本技能。首先,你需要对 Python 语言有一定的掌握。了解其中的 Urllib 库、Re 库、Random 库。其中,Urllib库主要实现网页的爬取。Re 库实现了数据的正则化表示。Random 库实现数据的随机生成。
网络爬虫是根据一定的规则自动爬取互联网信息的程序或脚本。爬虫的行为可以分为三个部分:
网络爬虫
在使用Python进行数据爬取的过程中,我们首先需要了解爬虫的基本技能树,包括静态网页采集。动态网页采集,爬虫框架设计和数据存储。
在获取静态网页的过程中,需要涉及到正则化规则和一些Python库。比如 Request 和 beautifulSoup。在动态网页爬取过程中,需要解决验证码的自动识别问题。在爬虫框架设计过程中,需要掌握Pyspider和Scrapy。在数据存储过程中,需要掌握CSV、EXCEL TXT等格式文件和MongDB等数据库。
网络爬虫:加载
加载是将目标网站数据下载到本地。主要步骤如下:
实际操作:抓取静态网页步骤
网络爬虫:动态加载
有些页面的数据是动态加载的,比如Ajax异步请求。网页中的一些数据需要浏览器渲染或者用户的某些点击和下拉操作触发,即Ajax异步请求。
当面对动态加载的页面时,我们可以通过抓包工具分析某个操作触发的请求,并使用智能工具:selenium + webdriver,通过代码实现对应的请求。
网络爬虫:解析
从加载的结果中提取特定数据。加载的结果主要分为三类:html、json、xml。
编程要求
请仔细阅读右侧代码,结合相关知识,补充Begin-End区代码,编写爬虫爬取网页标题。具体要求如下:
测试介绍
该平台测试您编写的代码:
预期输出:
html获取成功的标题匹配成功
import urllib.request
import csv
import re
#打开京东,读取并爬到内存中,解码, 并赋值给data
#将data保存到本地
# ********** Begin ********** #
data=urllib.request.urlopen("http://www.jd.com").read().decode("utf-8","ignore")
urllib.request.urlretrieve("http://www.jd.com",filename="./step1/京东.html")
# ********** End ********** #
#使用正则提取title
#保存数据到csv文件中
# ********** Begin ********** #
pattern="(.*?)"
title=set(re.compile(pattern,re.S).findall(data))
with open("./step1/csv_file.csv", 'w') as f:
f_csv = csv.writer(f)
f_csv.writerow(title)
# ********** End ********** # 查看全部
php抓取网页title(编程要求请仔细阅读代码代码进行测试:预期输出:html加载
)
内容
任务详情
这一关的任务:编写一个爬虫来爬取网页的标题。
相关信息
为了完成这个任务,需要几个基本技能。首先,你需要对 Python 语言有一定的掌握。了解其中的 Urllib 库、Re 库、Random 库。其中,Urllib库主要实现网页的爬取。Re 库实现了数据的正则化表示。Random 库实现数据的随机生成。
网络爬虫是根据一定的规则自动爬取互联网信息的程序或脚本。爬虫的行为可以分为三个部分:
网络爬虫
在使用Python进行数据爬取的过程中,我们首先需要了解爬虫的基本技能树,包括静态网页采集。动态网页采集,爬虫框架设计和数据存储。
在获取静态网页的过程中,需要涉及到正则化规则和一些Python库。比如 Request 和 beautifulSoup。在动态网页爬取过程中,需要解决验证码的自动识别问题。在爬虫框架设计过程中,需要掌握Pyspider和Scrapy。在数据存储过程中,需要掌握CSV、EXCEL TXT等格式文件和MongDB等数据库。

网络爬虫:加载
加载是将目标网站数据下载到本地。主要步骤如下:
实际操作:抓取静态网页步骤
网络爬虫:动态加载
有些页面的数据是动态加载的,比如Ajax异步请求。网页中的一些数据需要浏览器渲染或者用户的某些点击和下拉操作触发,即Ajax异步请求。
当面对动态加载的页面时,我们可以通过抓包工具分析某个操作触发的请求,并使用智能工具:selenium + webdriver,通过代码实现对应的请求。
网络爬虫:解析
从加载的结果中提取特定数据。加载的结果主要分为三类:html、json、xml。
编程要求
请仔细阅读右侧代码,结合相关知识,补充Begin-End区代码,编写爬虫爬取网页标题。具体要求如下:

测试介绍
该平台测试您编写的代码:
预期输出:
html获取成功的标题匹配成功
import urllib.request
import csv
import re
#打开京东,读取并爬到内存中,解码, 并赋值给data
#将data保存到本地
# ********** Begin ********** #
data=urllib.request.urlopen("http://www.jd.com";).read().decode("utf-8","ignore")
urllib.request.urlretrieve("http://www.jd.com",filename="./step1/京东.html")
# ********** End ********** #
#使用正则提取title
#保存数据到csv文件中
# ********** Begin ********** #
pattern="(.*?)"
title=set(re.compile(pattern,re.S).findall(data))
with open("./step1/csv_file.csv", 'w') as f:
f_csv = csv.writer(f)
f_csv.writerow(title)
# ********** End ********** #
php抓取网页title(Javaexample参数分析及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-25 12:07
PhantomJS 是一个基于 WebKit 的服务器端 API。它完全支持没有浏览器支持的 Web,并且速度很快并且原生支持各种 Web 标准:DOM 操作、CSS 选择器、JSON、Canvas 和 SVG。PhantomJS 可用于页面自动化、网络监控、网页截图和无界面测试。
一、安装
安装包下载地址:,包括Windows、Mac OS、Linux版本,可以选择对应的版本下载解压(为了方便可以自己设置phantomjs的环境变量),里面有一个example文件夹,里面有很多写的好用的代码。本文假设 phantomjs 已经安装并设置了环境变量。
二、使用你好,世界!
使用以下两行脚本创建一个新的文本文件:
console.log('Hello, world!');
phantom.exit();
将文件保存为 hello.js,然后执行它:
phantomjs hello.js
输出是:你好,世界!
第一行将字符串打印到终端,第二行 phantom.exit 将退出。
在这个脚本中调用 phantom.exit 非常重要,否则 PhantomJS 根本不会停止。
脚本参数 – 脚本参数
Phantomjs如何传递参数?如下:
phantomjs examples/arguments.js foo bar baz
其中,foo、bar、baz是要传递的参数。如何获得它们:
var system = require('system');
if (system.args.length === 1) {
console.log('Try to pass some args when invoking this script!');
} else {
system.args.forEach(function (arg, i) {
console.log(i + ': ' + arg);
});
}
phantom.exit();
它将输出:
0: foo
1: bar
2: baz
页面加载——页面加载
通过创建网页对象,可以加载、解析和呈现网页。
以下脚本显示了示例页面对象的最简单用法,它加载它并将其保存为图像 example.png。
var page = require('webpage').create();
page.open('http://example.com', function () {
page.render('example.png');
phantom.exit();
});
因为这个特性,PhantomJS可以用来对网页进行截图,对一些内容进行快照,比如将网页、SVG保存为图片、PDF等。这个功能非常好。
下一个 loadspeed.js 脚本加载一个特殊的 URL(不要忘记 http 协议)并测量加载页面的时间。
var page = require('webpage').create(),
system = require('system'),
t, address;
if (system.args.length === 1) {
console.log('Usage: loadspeed.js ');
phantom.exit();
}
t = Date.now();
address = system.args[1];
page.open(address, function (status) {
if (status !== 'success') {
console.log('FAIL to load the address');
} else {
t = Date.now() - t;
console.log('Loading time ' + t + ' msec');
}
phantom.exit();
});
在命令行运行脚本:
phantomjs loadspeed.js http://www.google.com
它输出如下内容:
加载加载时间 719 毫秒
代码评估 - 代码评估
要在网页上下文中评估 JavaScript 或 CoffeeScript,请使用 evaluate() 方法。代码在“沙箱”中运行,它无法读取其所属页面上下文之外的任何 JavaScript 对象和变量。evaluate() 将返回一个对象,但它仅限于简单对象,不能收录方法或闭包。
这是显示页面标题的示例:
var page = require('webpage').create();
page.open(url, function (status) {
var title = page.evaluate(function () {
return document.title;
});
console.log('Page title is ' + title);
});
默认情况下,不会显示来自网页并收录evaluate() 内部代码的任何控制台消息。要覆盖此行为,使用 onConsoleMessage 回调函数,可以将前面的示例重写为:
var page = require('webpage').create();
page.onConsoleMessage = function (msg) {
console.log('Page title is ' + msg);
};
page.open(url, function (status) {
page.evaluate(function () {
console.log(document.title);
});
});
DOM 操作 – DOM 操作
由于该脚本似乎在 Web 浏览器上运行,因此标准 DOM 脚本和 CSS 选择器可以正常工作。这使得 PhantomJS 适合支持各种页面自动化任务。
以下 useragent.js 将读取 id 为 myagent 的元素的 textContent 属性:
var page = require('webpage').create();
console.log('The default user agent is ' + page.settings.userAgent);
page.settings.userAgent = 'SpecialAgent';
page.open('http://www.httpuseragent.org', function (status) {
if (status !== 'success') {
console.log('Unable to access network');
} else {
var ua = page.evaluate(function () {
return document.getElementById('myagent').textContent;
});
console.log(ua);
}
phantom.exit();
});
上面的示例还提供了一种自定义用户代理的方法。
使用 JQuery 和其他库:
var page = require('webpage').create();
page.open('http://www.sample.com', function() {
page.includeJs("http://ajax.googleapis.com/aja ... ot%3B, function() {
page.evaluate(function() {
$("button").click();
});
phantom.exit()
});
});
网络请求和响应——网络请求和响应
当页面向远程服务器请求资源时,可以通过 onResourceRequested 和 onResourceReceived 回调方法跟踪请求和响应。示例 netlog.js:
var page = require('webpage').create();
page.onResourceRequested = function (request) {
console.log('Request ' + JSON.stringify(request, undefined, 4));
};
page.onResourceReceived = function (response) {
console.log('Receive ' + JSON.stringify(response, undefined, 4));
};
page.open(url);
有关如何将此功能用于 HAR 输出和基于 YSlow 的性能分析的更多信息,请参阅网络监控页面。
PhantomJs官网:
GitHub:
以上帮助说明来自woiweb:
windows下使用php执行phantomjs
下面直接给出执行代码:
echo '';
exec('H:wampwwwphantomjsinphantomjs --output-encoding=utf8 H:wampwwwXss_Scanner est.js ',$output_main);
var_dump($output_main);
// $str = implode('',$output_main);
// var_dump($str);
test.js 文件内容如下:
console.log('Loading a web page');
var page = require('webpage').create();
var url = 'http://www.mafutian.net/';
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
console.log(page.content);
}
phantom.exit();
});
执行结果如下图所示:
请注意,要实现上述执行结果,需要以下几点:
(1)PHP的安全模式不能开启,即需要在php.ini中将sql.safe_mode设置为Off。(并且重启服务器,当然php本身并没有开启安全模式)默认模式)
(2)无论phantomjs是否加入系统环境变量,都应该是exec()中的绝对路径,以下执行无效:
exec('phantomjs --output-encoding=utf8 H:wampwwwXss_Scanner est.js ',$output_main);
你需要走phantomjs的绝对路径。
需要注意的是,js文件不能走绝对路径。可以相对于网站根目录,如下执行成功:
exec('H:wampwwwphantomjsinphantomjs --output-encoding=utf8 test.js ',$output_main);
注意:test.js 放在网站 的根目录下。
另外:PHP下执行phantomjs也可以使用另外一个函数systom()来执行
以上内容参考:链接地址:
php-phantomjs中文API整理的合集DEMO
<p> 查看全部
php抓取网页title(Javaexample参数分析及应用)
PhantomJS 是一个基于 WebKit 的服务器端 API。它完全支持没有浏览器支持的 Web,并且速度很快并且原生支持各种 Web 标准:DOM 操作、CSS 选择器、JSON、Canvas 和 SVG。PhantomJS 可用于页面自动化、网络监控、网页截图和无界面测试。
一、安装
安装包下载地址:,包括Windows、Mac OS、Linux版本,可以选择对应的版本下载解压(为了方便可以自己设置phantomjs的环境变量),里面有一个example文件夹,里面有很多写的好用的代码。本文假设 phantomjs 已经安装并设置了环境变量。
二、使用你好,世界!
使用以下两行脚本创建一个新的文本文件:
console.log('Hello, world!');
phantom.exit();
将文件保存为 hello.js,然后执行它:
phantomjs hello.js
输出是:你好,世界!
第一行将字符串打印到终端,第二行 phantom.exit 将退出。
在这个脚本中调用 phantom.exit 非常重要,否则 PhantomJS 根本不会停止。
脚本参数 – 脚本参数
Phantomjs如何传递参数?如下:
phantomjs examples/arguments.js foo bar baz
其中,foo、bar、baz是要传递的参数。如何获得它们:
var system = require('system');
if (system.args.length === 1) {
console.log('Try to pass some args when invoking this script!');
} else {
system.args.forEach(function (arg, i) {
console.log(i + ': ' + arg);
});
}
phantom.exit();
它将输出:
0: foo
1: bar
2: baz
页面加载——页面加载
通过创建网页对象,可以加载、解析和呈现网页。
以下脚本显示了示例页面对象的最简单用法,它加载它并将其保存为图像 example.png。
var page = require('webpage').create();
page.open('http://example.com', function () {
page.render('example.png');
phantom.exit();
});
因为这个特性,PhantomJS可以用来对网页进行截图,对一些内容进行快照,比如将网页、SVG保存为图片、PDF等。这个功能非常好。
下一个 loadspeed.js 脚本加载一个特殊的 URL(不要忘记 http 协议)并测量加载页面的时间。
var page = require('webpage').create(),
system = require('system'),
t, address;
if (system.args.length === 1) {
console.log('Usage: loadspeed.js ');
phantom.exit();
}
t = Date.now();
address = system.args[1];
page.open(address, function (status) {
if (status !== 'success') {
console.log('FAIL to load the address');
} else {
t = Date.now() - t;
console.log('Loading time ' + t + ' msec');
}
phantom.exit();
});
在命令行运行脚本:
phantomjs loadspeed.js http://www.google.com
它输出如下内容:
加载加载时间 719 毫秒
代码评估 - 代码评估
要在网页上下文中评估 JavaScript 或 CoffeeScript,请使用 evaluate() 方法。代码在“沙箱”中运行,它无法读取其所属页面上下文之外的任何 JavaScript 对象和变量。evaluate() 将返回一个对象,但它仅限于简单对象,不能收录方法或闭包。
这是显示页面标题的示例:
var page = require('webpage').create();
page.open(url, function (status) {
var title = page.evaluate(function () {
return document.title;
});
console.log('Page title is ' + title);
});
默认情况下,不会显示来自网页并收录evaluate() 内部代码的任何控制台消息。要覆盖此行为,使用 onConsoleMessage 回调函数,可以将前面的示例重写为:
var page = require('webpage').create();
page.onConsoleMessage = function (msg) {
console.log('Page title is ' + msg);
};
page.open(url, function (status) {
page.evaluate(function () {
console.log(document.title);
});
});
DOM 操作 – DOM 操作
由于该脚本似乎在 Web 浏览器上运行,因此标准 DOM 脚本和 CSS 选择器可以正常工作。这使得 PhantomJS 适合支持各种页面自动化任务。
以下 useragent.js 将读取 id 为 myagent 的元素的 textContent 属性:
var page = require('webpage').create();
console.log('The default user agent is ' + page.settings.userAgent);
page.settings.userAgent = 'SpecialAgent';
page.open('http://www.httpuseragent.org', function (status) {
if (status !== 'success') {
console.log('Unable to access network');
} else {
var ua = page.evaluate(function () {
return document.getElementById('myagent').textContent;
});
console.log(ua);
}
phantom.exit();
});
上面的示例还提供了一种自定义用户代理的方法。
使用 JQuery 和其他库:
var page = require('webpage').create();
page.open('http://www.sample.com', function() {
page.includeJs("http://ajax.googleapis.com/aja ... ot%3B, function() {
page.evaluate(function() {
$("button").click();
});
phantom.exit()
});
});
网络请求和响应——网络请求和响应
当页面向远程服务器请求资源时,可以通过 onResourceRequested 和 onResourceReceived 回调方法跟踪请求和响应。示例 netlog.js:
var page = require('webpage').create();
page.onResourceRequested = function (request) {
console.log('Request ' + JSON.stringify(request, undefined, 4));
};
page.onResourceReceived = function (response) {
console.log('Receive ' + JSON.stringify(response, undefined, 4));
};
page.open(url);
有关如何将此功能用于 HAR 输出和基于 YSlow 的性能分析的更多信息,请参阅网络监控页面。
PhantomJs官网:
GitHub:
以上帮助说明来自woiweb:
windows下使用php执行phantomjs
下面直接给出执行代码:
echo '';
exec('H:wampwwwphantomjsinphantomjs --output-encoding=utf8 H:wampwwwXss_Scanner est.js ',$output_main);
var_dump($output_main);
// $str = implode('',$output_main);
// var_dump($str);
test.js 文件内容如下:
console.log('Loading a web page');
var page = require('webpage').create();
var url = 'http://www.mafutian.net/';
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
console.log(page.content);
}
phantom.exit();
});
执行结果如下图所示:

请注意,要实现上述执行结果,需要以下几点:
(1)PHP的安全模式不能开启,即需要在php.ini中将sql.safe_mode设置为Off。(并且重启服务器,当然php本身并没有开启安全模式)默认模式)
(2)无论phantomjs是否加入系统环境变量,都应该是exec()中的绝对路径,以下执行无效:
exec('phantomjs --output-encoding=utf8 H:wampwwwXss_Scanner est.js ',$output_main);
你需要走phantomjs的绝对路径。
需要注意的是,js文件不能走绝对路径。可以相对于网站根目录,如下执行成功:
exec('H:wampwwwphantomjsinphantomjs --output-encoding=utf8 test.js ',$output_main);
注意:test.js 放在网站 的根目录下。
另外:PHP下执行phantomjs也可以使用另外一个函数systom()来执行
以上内容参考:链接地址:
php-phantomjs中文API整理的合集DEMO
<p>
php抓取网页title(如何将canvas图形转换成图片和下载canvas图像的javascript工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2022-02-10 12:11
之前写过如何将canvas图形转为图片和下载canvas图片,都是为这个插件做的技术准备。
技术路线非常清晰。将网页某个区域的内容生成一张图片,保存在canvas中,然后将canvas内容转换成图片,保存在本地,最后上传到微博。
我在网上搜索,找到了 html2canvas,这是一个 javascript 工具,可以从指定网页元素的内容生成画布图像。这个js工具的使用很简单,只需要将它的js文件导入页面,然后调用html2canvas()函数即可:
html2canvas(document.body, {
onrendered: function(canvas) {
/* canvas is the actual canvas element,
to append it to the page call for example
document.body.appendChild( canvas );
*/
}
});
这个 html2canvas() 函数有一个参数。在上面的例子中,传入的参数是document.body,它将捕获整个页面的图像。如果你只想截取一个区域,比如对某个p或者某个table进行截图,就将这个p或者某个table作为参数传入。
最终没有选择js工具html2canvas,因为我在实验中发现了几个问题。
一是跨域问题。让我举一个例子来说明这个问题。比如我的网页网址是,我在这个页面上有一张图片。这张图片不是来自域,而是来自CDN图片服务器。那么,这个图片和这个网页就不一样了。在同一个域中,那么 html2canvas 不能对这种图片进行截图。如果你的 网站 的所有图片都放在一个单独的图片服务器上,那么使用 html2canvas 截取整个网页的截图就是所有图片的位置。都是空白。
这个问题还有一个补救办法,就是使用代理:
html2canvas php proxy
//
<p>
</p>
这种方法只能在自己的服务器上使用,如果是截图别人的网页,还是不行。
在实验过程中,还发现html2canvas捕获的图像有时会有重叠的文字。我猜是因为 html2canvas 在解析页面内容和处理 css 时并不完美。
最后在火狐浏览器的官方网站上找到了drawWindow()方法。这个方法和上面提到的html2canvas的区别在于它不分析页面元素,它只针对区域,也就是它接受的参数是一个由四个数字标记的区域,无论在这个区域的哪个位置,都没有页面内容。
void drawWindow(
in nsIDOMWindow window,
in float x,
in float y,
in float w,
in float h,
in DOMString bgColor,
in unsigned long flags [optional]
);
这个原生 JavaScript 方法看起来很完美,正是我需要的,但是这个方法不能在普通网页中使用,因为 Firefox 官方发现这个方法会造成安全漏洞,直到这个 bug 被修复,只有用“Chrome 权限”的代码来使用这个 drawWindow() 函数。
虽然有很大的限制,但在遇到挫折后仍然可以使用。在我开发的 Firefox 插件中,main.js 是具有“Chrome 权限”的代码。我在网上找到了一个Firefox插件SDK的代码示例:
var window = require('window/utils').getMostRecentBrowserWindow();
var tab = require('tabs/utils').getActiveTab(window);
var thumbnail = window.document.createElementNS("http://www.w3.org/1999/xhtml", "canvas");
thumbnail.mozOpaque = true;
window = tab.linkedBrowser.contentWindow;
thumbnail.width = Math.ceil(window.screen.availWidth / 5.75);
var aspectRatio = 0.5625; // 16:9
thumbnail.height = Math.round(thumbnail.width * aspectRatio);
var ctx = thumbnail.getContext("2d");
var snippetWidth = window.innerWidth * .6;
var scale = thumbnail.width / snippetWidth;
ctx.scale(scale, scale);
ctx.drawWindow(window, window.scrollX, window.scrollY, snippetWidth, snippetWidth * aspectRatio, "rgb(255,255,255)");
// thumbnail now represents a thumbnail of the tab
这段代码写得很清楚,你只需要稍微修改一下就可以满足你的需要。
这里的小编是一位有10年工作经验的前端高级工程师。关于web前端的技术干货很多,包括但不限于各大厂最新面试题系列、前端项目、最新前端路线等。需要伙伴可以私信我
发送【前端信息】
您可以获取取货地址并免费发送给所有人。如果你有任何关于学习web前端的问题(学习方法、学习效率、如何就业),都可以问我。希望你也可以通过自己的努力,成为下一个优秀的程序员。 查看全部
php抓取网页title(如何将canvas图形转换成图片和下载canvas图像的javascript工具)
之前写过如何将canvas图形转为图片和下载canvas图片,都是为这个插件做的技术准备。
技术路线非常清晰。将网页某个区域的内容生成一张图片,保存在canvas中,然后将canvas内容转换成图片,保存在本地,最后上传到微博。
我在网上搜索,找到了 html2canvas,这是一个 javascript 工具,可以从指定网页元素的内容生成画布图像。这个js工具的使用很简单,只需要将它的js文件导入页面,然后调用html2canvas()函数即可:
html2canvas(document.body, {
onrendered: function(canvas) {
/* canvas is the actual canvas element,
to append it to the page call for example
document.body.appendChild( canvas );
*/
}
});
这个 html2canvas() 函数有一个参数。在上面的例子中,传入的参数是document.body,它将捕获整个页面的图像。如果你只想截取一个区域,比如对某个p或者某个table进行截图,就将这个p或者某个table作为参数传入。
最终没有选择js工具html2canvas,因为我在实验中发现了几个问题。
一是跨域问题。让我举一个例子来说明这个问题。比如我的网页网址是,我在这个页面上有一张图片。这张图片不是来自域,而是来自CDN图片服务器。那么,这个图片和这个网页就不一样了。在同一个域中,那么 html2canvas 不能对这种图片进行截图。如果你的 网站 的所有图片都放在一个单独的图片服务器上,那么使用 html2canvas 截取整个网页的截图就是所有图片的位置。都是空白。
这个问题还有一个补救办法,就是使用代理:
html2canvas php proxy
//
<p>
</p>
这种方法只能在自己的服务器上使用,如果是截图别人的网页,还是不行。
在实验过程中,还发现html2canvas捕获的图像有时会有重叠的文字。我猜是因为 html2canvas 在解析页面内容和处理 css 时并不完美。
最后在火狐浏览器的官方网站上找到了drawWindow()方法。这个方法和上面提到的html2canvas的区别在于它不分析页面元素,它只针对区域,也就是它接受的参数是一个由四个数字标记的区域,无论在这个区域的哪个位置,都没有页面内容。
void drawWindow(
in nsIDOMWindow window,
in float x,
in float y,
in float w,
in float h,
in DOMString bgColor,
in unsigned long flags [optional]
);
这个原生 JavaScript 方法看起来很完美,正是我需要的,但是这个方法不能在普通网页中使用,因为 Firefox 官方发现这个方法会造成安全漏洞,直到这个 bug 被修复,只有用“Chrome 权限”的代码来使用这个 drawWindow() 函数。
虽然有很大的限制,但在遇到挫折后仍然可以使用。在我开发的 Firefox 插件中,main.js 是具有“Chrome 权限”的代码。我在网上找到了一个Firefox插件SDK的代码示例:
var window = require('window/utils').getMostRecentBrowserWindow();
var tab = require('tabs/utils').getActiveTab(window);
var thumbnail = window.document.createElementNS("http://www.w3.org/1999/xhtml", "canvas");
thumbnail.mozOpaque = true;
window = tab.linkedBrowser.contentWindow;
thumbnail.width = Math.ceil(window.screen.availWidth / 5.75);
var aspectRatio = 0.5625; // 16:9
thumbnail.height = Math.round(thumbnail.width * aspectRatio);
var ctx = thumbnail.getContext("2d");
var snippetWidth = window.innerWidth * .6;
var scale = thumbnail.width / snippetWidth;
ctx.scale(scale, scale);
ctx.drawWindow(window, window.scrollX, window.scrollY, snippetWidth, snippetWidth * aspectRatio, "rgb(255,255,255)");
// thumbnail now represents a thumbnail of the tab
这段代码写得很清楚,你只需要稍微修改一下就可以满足你的需要。
这里的小编是一位有10年工作经验的前端高级工程师。关于web前端的技术干货很多,包括但不限于各大厂最新面试题系列、前端项目、最新前端路线等。需要伙伴可以私信我
发送【前端信息】
您可以获取取货地址并免费发送给所有人。如果你有任何关于学习web前端的问题(学习方法、学习效率、如何就业),都可以问我。希望你也可以通过自己的努力,成为下一个优秀的程序员。
php抓取网页title(wordpress网站主题模板开发过程中怎样实现不同的页面调用不同)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-01-17 20:09
一个wordpress网站,它的首页是千变万化的,不同的页面必须有不同的内容和标题。如果一个wordpress网站,所有的页面都有相同的标题,对搜索引擎很不友好。那么,在wordpress网站主题模板的开发过程中,如何实现不同的页面调用不同的标题呢?这并不难,我们可以通过两种方式做到这一点。
方法一:实现wordpress网站不同页面通过判断调用不同标题。
WordPress 提供了模板页面的判断功能。我们可以通过这些函数来判断当前页面,然后调用这些页面标题函数。例如分类页面调用分类页面标题函数;文章 页面调用 文章 页面标题函数。代码显示如下:
if (is_home()) { //如果是首页,则调用首页标题
博客信息(“名称”);
}elseif(is_single()||is_page()) { //如果是文章详情页或者页面单页
标题(); //文章 和页面标题
回声“-”;
博客信息(“名称”);
}别的{
single_cat_title('', false); //类别和标签页的标题
回声“-”;
博客信息(“名称”);
}
通过以上判断,我们可以实现:直接在wordpress网站首页显示首页标题;如果是 文章 和 page 单页,使用 the_title() 调用它们的标题;如果是类别和单页标签标签,请使用 single_cat_title() 来调用它们的标题。
方法二:使用wordpress的标题函数wp_title()来实现。
wp_title() 是 WordPress 提供的 网站 标题函数。可以在网站首页以外的其他网站页面上调用相应的title,也可以达到方法1的效果。我们先来看看这个函数。
wp_title($sep, $display, $seplocation);
从上面的代码中,我们可以看到 wp_title() 函数可以有 3 个参数:
$sep:字符串类型数据,可选。这里是wordpress网站首页标题分隔符,默认值为 » ,如果要使用其他分隔符,可以使用该参数。$display:布尔数据类型,可选。该参数表示,是否打印标题到页面显示。默认为true,表示显示。如果只想给变量赋值,可以设置为false。$seplocation:字符串类型数据,可选。该参数的作用是显示分隔符的显示位置。默认设置在左侧。如果要显示在标题的右侧,可以将其设置为右侧。
案件:
当这个wp_title()在首页时,因为无法调用数据,所以不会显示任何内容;但它可以在wordpress的其他模板页面网站中发挥作用,并且在文章模板页面中,会调用文章@的标题>,页面的标题会被调用页面单页模板页面,网站分类页面调用分类目录标题,tags标签页面调用标签标题。也就是说,WordPress已经在wp_title()函数内部做出了网站模板页面的判断,然后根据不同的网站模板页面调用不同页面的标题。
如果你喜欢我的文章,请点击“关注”按钮关注我。我会每天定期发布新内容。以上是我的看法,如有不同意见,欢迎评论。 查看全部
php抓取网页title(wordpress网站主题模板开发过程中怎样实现不同的页面调用不同)
一个wordpress网站,它的首页是千变万化的,不同的页面必须有不同的内容和标题。如果一个wordpress网站,所有的页面都有相同的标题,对搜索引擎很不友好。那么,在wordpress网站主题模板的开发过程中,如何实现不同的页面调用不同的标题呢?这并不难,我们可以通过两种方式做到这一点。
方法一:实现wordpress网站不同页面通过判断调用不同标题。
WordPress 提供了模板页面的判断功能。我们可以通过这些函数来判断当前页面,然后调用这些页面标题函数。例如分类页面调用分类页面标题函数;文章 页面调用 文章 页面标题函数。代码显示如下:
if (is_home()) { //如果是首页,则调用首页标题
博客信息(“名称”);
}elseif(is_single()||is_page()) { //如果是文章详情页或者页面单页
标题(); //文章 和页面标题
回声“-”;
博客信息(“名称”);
}别的{
single_cat_title('', false); //类别和标签页的标题
回声“-”;
博客信息(“名称”);
}
通过以上判断,我们可以实现:直接在wordpress网站首页显示首页标题;如果是 文章 和 page 单页,使用 the_title() 调用它们的标题;如果是类别和单页标签标签,请使用 single_cat_title() 来调用它们的标题。
方法二:使用wordpress的标题函数wp_title()来实现。
wp_title() 是 WordPress 提供的 网站 标题函数。可以在网站首页以外的其他网站页面上调用相应的title,也可以达到方法1的效果。我们先来看看这个函数。
wp_title($sep, $display, $seplocation);
从上面的代码中,我们可以看到 wp_title() 函数可以有 3 个参数:
$sep:字符串类型数据,可选。这里是wordpress网站首页标题分隔符,默认值为 » ,如果要使用其他分隔符,可以使用该参数。$display:布尔数据类型,可选。该参数表示,是否打印标题到页面显示。默认为true,表示显示。如果只想给变量赋值,可以设置为false。$seplocation:字符串类型数据,可选。该参数的作用是显示分隔符的显示位置。默认设置在左侧。如果要显示在标题的右侧,可以将其设置为右侧。
案件:
当这个wp_title()在首页时,因为无法调用数据,所以不会显示任何内容;但它可以在wordpress的其他模板页面网站中发挥作用,并且在文章模板页面中,会调用文章@的标题>,页面的标题会被调用页面单页模板页面,网站分类页面调用分类目录标题,tags标签页面调用标签标题。也就是说,WordPress已经在wp_title()函数内部做出了网站模板页面的判断,然后根据不同的网站模板页面调用不同页面的标题。
如果你喜欢我的文章,请点击“关注”按钮关注我。我会每天定期发布新内容。以上是我的看法,如有不同意见,欢迎评论。
php抓取网页title(如何融合到一个更灵活的网站爬虫中?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-14 08:17
在本文 文章 中,您将学习将这些基本方法合并到一个更灵活的 网站 爬虫中,该爬虫可以跟踪遵循特定 URL 模式的任何链接。
这种爬虫非常适合从一个 网站 中抓取所有数据的项目,但不适用于从特定搜索结果或页面列表中抓取数据的项目。它也适用于组织不善或非常分散的 网站 页面。
这些类型的爬虫不需要像上一节“通过搜索页面进行爬取”中使用的结构化方法来定位链接,因此不需要在网站对象中收录描述搜索页面的属性。但是由于爬虫不知道要在哪里寻找链接,因此您需要一些规则来告诉它选择哪个页面。您可以使用 targetPattern(目标 URL 的正则表达式)和布尔变量 absoluteUrl 来实现:
class Website:
def __init__(self, name, url, targetPattern, absoluteUrl,
titleTag, bodyTag):
self.name = name
self.url = url
self.targetPattern = targetPattern
self.absoluteUrl=absoluteUrl
self.titleTag = titleTag
self.bodyTag = bodyTag
class Content:
def __init__(self, url, title, body):
self.url = url
self.title = title
self.body = body
def print(self):
print("URL: {}".format(self.url))
print("TITLE: {}".format(self.title))
print("BODY:\n{}".format(self.body))
Content 类与第一个爬虫示例中使用的相同。
Crawler 类从每个 网站 的主页开始,定位内部链接,并解析每个内部链接页面上找到的内容:
import re
class Crawler:
def __init__(self, site):
self.site = site
self.visited = []
def getPage(self, url):
try:
req = requests.get(url)
except requests.exceptions.RequestException:
return None
return BeautifulSoup(req.text, 'html.parser')
def safeGet(self, pageObj, selector):
selectedElems = pageObj.select(selector)
if selectedElems is not None and len(selectedElems) > 0:
return '\n'.join([elem.get_text() for
elem in selectedElems])
return ''
def parse(self, url):
bs = self.getPage(url)
if bs is not None:
title = self.safeGet(bs, self.site.titleTag)
body = self.safeGet(bs, self.site.bodyTag)
if title != '' and body != '':
content = Content(url, title, body)
content.print()
def crawl(self):
"""
获取网站主页的页面链接
"""
bs = self.getPage(self.site.url)
targetPages = bs.findAll('a',
href=re.compile(self.site.targetPattern))
for targetPage in targetPages:
targetPage = targetPage.attrs['href']
if targetPage not in self.visited:
self.visited.append(targetPage)
if not self.site.absoluteUrl:
targetPage = '{}{}'.format(self.site.url, targetPage)
self.parse(targetPage)
reuters = Website('Reuters', 'https://www.reuters.com', '^(/article/)', False,
'h1', 'div.StandardArticleBody_body_1gnLA')
crawler = Crawler(reuters)
crawler.crawl()
与前面示例的另一个变化是网站对象(在本例中为变量 reuters)是 Crawler 对象本身的属性。这样做的效果是将访问过的页面存储在爬虫中,但这也意味着必须为每个 网站 实例化一个新的爬虫,而不是重复使用爬虫来爬取 网站 的列表。
无论是选择与网站无关的爬虫,还是使用网站作为爬虫的一个属性,这都是需要根据自己的需求权衡的决定。两种方法在功能实现上都没有问题。
还有一点需要注意的是,这个爬虫会从首页开始爬取,但是在所有页面都记录下来之后就不会继续爬取了。您可能想要编写一个收录第 3 章介绍的模式之一的爬虫,然后为您访问的每个页面查看更多目标 URL。您甚至可以跟踪每个页面中涉及的所有 URL(不仅仅是那些与目标模式匹配的 URL),并查看这些 URL 是否收录目标模式。
以上就是关于python爬取的相关知识点网站,感谢大家对Scripting Home的学习和支持。 查看全部
php抓取网页title(如何融合到一个更灵活的网站爬虫中?)
在本文 文章 中,您将学习将这些基本方法合并到一个更灵活的 网站 爬虫中,该爬虫可以跟踪遵循特定 URL 模式的任何链接。
这种爬虫非常适合从一个 网站 中抓取所有数据的项目,但不适用于从特定搜索结果或页面列表中抓取数据的项目。它也适用于组织不善或非常分散的 网站 页面。
这些类型的爬虫不需要像上一节“通过搜索页面进行爬取”中使用的结构化方法来定位链接,因此不需要在网站对象中收录描述搜索页面的属性。但是由于爬虫不知道要在哪里寻找链接,因此您需要一些规则来告诉它选择哪个页面。您可以使用 targetPattern(目标 URL 的正则表达式)和布尔变量 absoluteUrl 来实现:
class Website:
def __init__(self, name, url, targetPattern, absoluteUrl,
titleTag, bodyTag):
self.name = name
self.url = url
self.targetPattern = targetPattern
self.absoluteUrl=absoluteUrl
self.titleTag = titleTag
self.bodyTag = bodyTag
class Content:
def __init__(self, url, title, body):
self.url = url
self.title = title
self.body = body
def print(self):
print("URL: {}".format(self.url))
print("TITLE: {}".format(self.title))
print("BODY:\n{}".format(self.body))
Content 类与第一个爬虫示例中使用的相同。
Crawler 类从每个 网站 的主页开始,定位内部链接,并解析每个内部链接页面上找到的内容:
import re
class Crawler:
def __init__(self, site):
self.site = site
self.visited = []
def getPage(self, url):
try:
req = requests.get(url)
except requests.exceptions.RequestException:
return None
return BeautifulSoup(req.text, 'html.parser')
def safeGet(self, pageObj, selector):
selectedElems = pageObj.select(selector)
if selectedElems is not None and len(selectedElems) > 0:
return '\n'.join([elem.get_text() for
elem in selectedElems])
return ''
def parse(self, url):
bs = self.getPage(url)
if bs is not None:
title = self.safeGet(bs, self.site.titleTag)
body = self.safeGet(bs, self.site.bodyTag)
if title != '' and body != '':
content = Content(url, title, body)
content.print()
def crawl(self):
"""
获取网站主页的页面链接
"""
bs = self.getPage(self.site.url)
targetPages = bs.findAll('a',
href=re.compile(self.site.targetPattern))
for targetPage in targetPages:
targetPage = targetPage.attrs['href']
if targetPage not in self.visited:
self.visited.append(targetPage)
if not self.site.absoluteUrl:
targetPage = '{}{}'.format(self.site.url, targetPage)
self.parse(targetPage)
reuters = Website('Reuters', 'https://www.reuters.com', '^(/article/)', False,
'h1', 'div.StandardArticleBody_body_1gnLA')
crawler = Crawler(reuters)
crawler.crawl()
与前面示例的另一个变化是网站对象(在本例中为变量 reuters)是 Crawler 对象本身的属性。这样做的效果是将访问过的页面存储在爬虫中,但这也意味着必须为每个 网站 实例化一个新的爬虫,而不是重复使用爬虫来爬取 网站 的列表。
无论是选择与网站无关的爬虫,还是使用网站作为爬虫的一个属性,这都是需要根据自己的需求权衡的决定。两种方法在功能实现上都没有问题。
还有一点需要注意的是,这个爬虫会从首页开始爬取,但是在所有页面都记录下来之后就不会继续爬取了。您可能想要编写一个收录第 3 章介绍的模式之一的爬虫,然后为您访问的每个页面查看更多目标 URL。您甚至可以跟踪每个页面中涉及的所有 URL(不仅仅是那些与目标模式匹配的 URL),并查看这些 URL 是否收录目标模式。
以上就是关于python爬取的相关知识点网站,感谢大家对Scripting Home的学习和支持。
php抓取网页title(与抓取预定义好的页面集合不同,抓取一个会带来一个挑战)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-14 08:16
与抓取预定义的页面集合不同,抓取 网站 的所有内部链接会带来不知道会发生什么的挑战。幸运的是,有一些识别页面类型的基本方法。
通过网址
网站 中的所有博客文章 都可能收录一个 URL(例如)。
根据 网站 中特定字段的存在与否
如果页面收录日期,但不收录作者姓名,您可以将其归类为新闻稿。如果它有标题、主要图片、价格,但没有主要内容,那么它可能是一个产品页面。
通过页面中出现的特定标签识别页面
即使您不抓取标签内的数据,您仍然可以利用该标签。你的爬虫可以寻找类似的东西
此类元素用于识别产品页面,即使爬虫对相关产品的内容不感兴趣。
为了跟踪多种页面类型,您需要在 Python 中拥有多种类型的页面对象。这是通过两种方式实现的。
如果页面都相似(它们基本上是相同类型的内容),您可能需要在现有页面对象中添加一个 pageType 属性:
class Website:
"""所有文章/网页的共同基类"""
def __init__(self, type, name, url, searchUrl, resultListing,
resultUrl, absoluteUrl, titleTag, bodyTag):
self.name = name
self.url = url
self.titleTag = titleTag
self.bodyTag = bodyTag
self.pageType = pageType
如果您在类似 SQL 的数据库中对这些页面进行排序,则此模式类型意味着这些页面应该存储在同一个表中,并带有一个额外的 pageType 列。
如果您抓取不同的页面或内容(它们收录不同类型的字段),您将需要为每种页面类型创建一个新对象。当然,所有网页都有一些共同点——它们都有一个 URL,可能还有一个名称或页面标题。这种情况非常适合子类化:
class Website:
"""所有文章/网页的共同基类"""
def __init__(self, name, url, titleTag):
self.name = name
self.url = url
self.titleTag = titleTag
这不是您的爬虫直接使用的对象,而是您的页面类型将引用的对象:
class Product(Website):
"""产品页面要抓取的信息"""
def __init__(self, name, url, titleTag, productNumber, price):
Website.__init__(self, name, url, TitleTag)
self.productNumberTag = productNumberTag
self.priceTag = priceTag
class Article(Website):
"""文章页面要抓取的信息"""
def __init__(self, name, url, titleTag, bodyTag, dateTag):
Website.__init__(self, name, url, titleTag)
self.bodyTag = bodyTag
self.dateTag = dateTag
这个产品页面扩展了Website基类,增加了仅适用于产品的productNumber和price属性,而Article类增加了不适用于产品的body和date属性。
您可以使用这两个类来抓取商店网站,该商店除了产品之外,还可能收录博客文章 或新闻稿。
希望以上知识点能对您有所帮助,也感谢您对脚本之家的支持。 查看全部
php抓取网页title(与抓取预定义好的页面集合不同,抓取一个会带来一个挑战)
与抓取预定义的页面集合不同,抓取 网站 的所有内部链接会带来不知道会发生什么的挑战。幸运的是,有一些识别页面类型的基本方法。
通过网址
网站 中的所有博客文章 都可能收录一个 URL(例如)。
根据 网站 中特定字段的存在与否
如果页面收录日期,但不收录作者姓名,您可以将其归类为新闻稿。如果它有标题、主要图片、价格,但没有主要内容,那么它可能是一个产品页面。
通过页面中出现的特定标签识别页面
即使您不抓取标签内的数据,您仍然可以利用该标签。你的爬虫可以寻找类似的东西
此类元素用于识别产品页面,即使爬虫对相关产品的内容不感兴趣。
为了跟踪多种页面类型,您需要在 Python 中拥有多种类型的页面对象。这是通过两种方式实现的。
如果页面都相似(它们基本上是相同类型的内容),您可能需要在现有页面对象中添加一个 pageType 属性:
class Website:
"""所有文章/网页的共同基类"""
def __init__(self, type, name, url, searchUrl, resultListing,
resultUrl, absoluteUrl, titleTag, bodyTag):
self.name = name
self.url = url
self.titleTag = titleTag
self.bodyTag = bodyTag
self.pageType = pageType
如果您在类似 SQL 的数据库中对这些页面进行排序,则此模式类型意味着这些页面应该存储在同一个表中,并带有一个额外的 pageType 列。
如果您抓取不同的页面或内容(它们收录不同类型的字段),您将需要为每种页面类型创建一个新对象。当然,所有网页都有一些共同点——它们都有一个 URL,可能还有一个名称或页面标题。这种情况非常适合子类化:
class Website:
"""所有文章/网页的共同基类"""
def __init__(self, name, url, titleTag):
self.name = name
self.url = url
self.titleTag = titleTag
这不是您的爬虫直接使用的对象,而是您的页面类型将引用的对象:
class Product(Website):
"""产品页面要抓取的信息"""
def __init__(self, name, url, titleTag, productNumber, price):
Website.__init__(self, name, url, TitleTag)
self.productNumberTag = productNumberTag
self.priceTag = priceTag
class Article(Website):
"""文章页面要抓取的信息"""
def __init__(self, name, url, titleTag, bodyTag, dateTag):
Website.__init__(self, name, url, titleTag)
self.bodyTag = bodyTag
self.dateTag = dateTag
这个产品页面扩展了Website基类,增加了仅适用于产品的productNumber和price属性,而Article类增加了不适用于产品的body和date属性。
您可以使用这两个类来抓取商店网站,该商店除了产品之外,还可能收录博客文章 或新闻稿。
希望以上知识点能对您有所帮助,也感谢您对脚本之家的支持。
php抓取网页title(与抓取预定义好的页面集合不同,抓取一个会带来一个挑战)
网站优化 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-12-16 05:11
与抓取一组预定义的页面不同,抓取一个网站的所有内链会带来一个挑战,就是你不知道你会得到什么。幸运的是,有几种基本的方法可以识别页面类型。
按网址
网站 中的所有博客 文章 都可能收录一个 URL(例如)。
传递 网站 中存在或缺失的特定字段
如果页面收录日期但不收录作者姓名,您可以将其归类为新闻稿。如果它有标题、主图、价格,但没有主要内容,那么它可能是一个产品页面。
通过出现在页面上的特定标签识别页面
即使您没有捕获某个标签中的数据,您仍然可以使用该标签。你的爬虫可以寻找类似的东西
此类元素用于标识产品页面,即使爬虫对相关产品的内容不感兴趣。
为了跟踪多种页面类型,您需要在 Python 中拥有多种类型的页面对象。这是通过两种方式实现的。
如果页面相似(它们的内容类型基本相同),则可能需要在现有页面对象中添加 pageType 属性:
class Website:
"""所有文章/网页的共同基类"""
def __init__(self, type, name, url, searchUrl, resultListing,
resultUrl, absoluteUrl, titleTag, bodyTag):
self.name = name
self.url = url
self.titleTag = titleTag
self.bodyTag = bodyTag
self.pageType = pageType
如果在类 SQL 的数据库中对这些页面进行排序,则此模式类型意味着这些页面应存储在同一个表中,并添加了一个额外的 pageType 列。
如果抓取不同的页面或内容(它们收录不同类型的字段),则需要为每种页面类型创建一个新对象。当然,有些东西是所有网页共有的——它们都有一个 URL,它们也可能有一个名称或页面标题。这种情况非常适合子类:
class Website:
"""所有文章/网页的共同基类"""
def __init__(self, name, url, titleTag):
self.name = name
self.url = url
self.titleTag = titleTag
这不是您的爬虫直接使用的对象,而是您的页面类型将引用的对象:
class Product(Website):
"""产品页面要抓取的信息"""
def __init__(self, name, url, titleTag, productNumber, price):
Website.__init__(self, name, url, TitleTag)
self.productNumberTag = productNumberTag
self.priceTag = priceTag
class Article(Website):
"""文章页面要抓取的信息"""
def __init__(self, name, url, titleTag, bodyTag, dateTag):
Website.__init__(self, name, url, titleTag)
self.bodyTag = bodyTag
self.dateTag = dateTag
该产品页面扩展了Website 基类,增加了仅适用于产品的productNumber 和price 属性,而Article 类增加了不适用于产品的body 和date 属性。
您可以使用这两个类别来抓取商店网站。除了产品,这个 网站 还可能收录博客 文章 或新闻稿。
希望以上知识点可以帮助到您,感谢您对脚本之家的支持。 查看全部
php抓取网页title(与抓取预定义好的页面集合不同,抓取一个会带来一个挑战)
与抓取一组预定义的页面不同,抓取一个网站的所有内链会带来一个挑战,就是你不知道你会得到什么。幸运的是,有几种基本的方法可以识别页面类型。
按网址
网站 中的所有博客 文章 都可能收录一个 URL(例如)。
传递 网站 中存在或缺失的特定字段
如果页面收录日期但不收录作者姓名,您可以将其归类为新闻稿。如果它有标题、主图、价格,但没有主要内容,那么它可能是一个产品页面。
通过出现在页面上的特定标签识别页面
即使您没有捕获某个标签中的数据,您仍然可以使用该标签。你的爬虫可以寻找类似的东西
此类元素用于标识产品页面,即使爬虫对相关产品的内容不感兴趣。
为了跟踪多种页面类型,您需要在 Python 中拥有多种类型的页面对象。这是通过两种方式实现的。
如果页面相似(它们的内容类型基本相同),则可能需要在现有页面对象中添加 pageType 属性:
class Website:
"""所有文章/网页的共同基类"""
def __init__(self, type, name, url, searchUrl, resultListing,
resultUrl, absoluteUrl, titleTag, bodyTag):
self.name = name
self.url = url
self.titleTag = titleTag
self.bodyTag = bodyTag
self.pageType = pageType
如果在类 SQL 的数据库中对这些页面进行排序,则此模式类型意味着这些页面应存储在同一个表中,并添加了一个额外的 pageType 列。
如果抓取不同的页面或内容(它们收录不同类型的字段),则需要为每种页面类型创建一个新对象。当然,有些东西是所有网页共有的——它们都有一个 URL,它们也可能有一个名称或页面标题。这种情况非常适合子类:
class Website:
"""所有文章/网页的共同基类"""
def __init__(self, name, url, titleTag):
self.name = name
self.url = url
self.titleTag = titleTag
这不是您的爬虫直接使用的对象,而是您的页面类型将引用的对象:
class Product(Website):
"""产品页面要抓取的信息"""
def __init__(self, name, url, titleTag, productNumber, price):
Website.__init__(self, name, url, TitleTag)
self.productNumberTag = productNumberTag
self.priceTag = priceTag
class Article(Website):
"""文章页面要抓取的信息"""
def __init__(self, name, url, titleTag, bodyTag, dateTag):
Website.__init__(self, name, url, titleTag)
self.bodyTag = bodyTag
self.dateTag = dateTag
该产品页面扩展了Website 基类,增加了仅适用于产品的productNumber 和price 属性,而Article 类增加了不适用于产品的body 和date 属性。
您可以使用这两个类别来抓取商店网站。除了产品,这个 网站 还可能收录博客 文章 或新闻稿。
希望以上知识点可以帮助到您,感谢您对脚本之家的支持。
php抓取网页title( 用Pyhton自带的urllib或urllib2模块(二)|,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-09 22:12
用Pyhton自带的urllib或urllib2模块(二)|,)
Python使用lxml模块和Requests模块抓取HTML页面教程
更新时间:2016 年 5 月 16 日 18:53:56 作者:Kenneth Reitz
使用 Pyhton 的内置 urllib 或 urllib2 模块来抓取网页可能有点陈词滥调。今天我们将玩一些新鲜的。查看有关使用 lxml 模块和请求模块抓取 HTML 页面的 Python 教程:
万维网
网站是用 HTML 描述的,这意味着每个网页都是一个结构化的文档。有时在保持其结构的同时从中获取数据很有用。网站并不总是以易于处理的格式(例如 csv 或 json)提供其数据。
现在是网络抢占该领域的时候了。网页抓取是使用计算机程序采集网页数据并将其组织成所需格式的做法,同时保留其结构。
lxml 和请求
lxml() 是一个漂亮的扩展库,用于快速解析 XML 和 HTML 文档,即使处理的标签非常混乱。我们还将使用 Requests (#) 模块来替换内置的 urllib2 模块,因为它更快且更具可读性。您可以使用 pip install lxml 和 pip install requests 命令安装这两个模块。
让我们从以下导入开始:
from lxml import html
import requests
在下一步中,我们将使用 requests.get 从网页中获取我们的数据,使用 html 模块对其进行解析,并将结果保存在树中。
page = requests.get('http://econpy.pythonanywhere.com/ex/001.html')
tree = html.fromstring(page.text)
tree 现在将整个 HTML 文件收录成一个优雅的树状结构,我们可以使用两种方法来访问:XPath 和 CSS 选择器。在本例中,我们将选择前者。
XPath 是一种在结构化文档(如 HTML 或 XML)中定位信息的方法。有关 XPath 的详细介绍,请参阅 W3Schools。
有很多工具可以获取元素的 XPath,例如 Firefox 的 FireBug 或 Chrome 的 Inspector。如果您使用 Chrome,您可以右键单击该元素,选择“检查元素”,突出显示此代码,再次右键单击,然后选择“复制 XPath”。
经过快速分析,我们看到页面上的数据存储在两个元素中,一个是标题为'buyer-name'的div,另一个是类为'item-price'的span:
Carson Busses
$29.95
知道了这一点,我们就可以创建正确的 XPath 查询并使用 lxml 的 xpath 函数,如下所示:
#这将创建buyers的列表:
buyers = tree.xpath('//div[@title="buyer-name"]/text()')
#这将创建prices的列表:
prices = tree.xpath('//span[@class="item-price"]/text()')
让我们看看我们得到了什么:
print 'Buyers: ', buyers
print 'Prices: ', prices
Buyers: ['Carson Busses', 'Earl E. Byrd', 'Patty Cakes',
'Derri Anne Connecticut', 'Moe Dess', 'Leda Doggslife', 'Dan Druff',
'Al Fresco', 'Ido Hoe', 'Howie Kisses', 'Len Lease', 'Phil Meup',
'Ira Pent', 'Ben D. Rules', 'Ave Sectomy', 'Gary Shattire',
'Bobbi Soks', 'Sheila Takya', 'Rose Tattoo', 'Moe Tell']
Prices: ['$29.95', '$8.37', '$15.26', '$19.25', '$19.25',
'$13.99', '$31.57', '$8.49', '$14.47', '$15.86', '$11.11',
'$15.98', '$16.27', '$7.50', '$50.85', '$14.26', '$5.68',
'$15.00', '$114.07', '$10.09']
恭喜!我们已经成功通过lxml和Request从一个网页中抓取了我们想要的所有数据。我们以列表的形式将它们存储在内存中。现在我们可以用它做各种很酷的事情:我们可以用 Python 分析它,或者我们可以将它保存为文件并与世界分享。
我们可以考虑一些更酷的想法:修改此脚本以遍历本示例中数据集中的剩余页面,或者使用多个线程重写此应用程序以提高其速度。 查看全部
php抓取网页title(
用Pyhton自带的urllib或urllib2模块(二)|,)
Python使用lxml模块和Requests模块抓取HTML页面教程
更新时间:2016 年 5 月 16 日 18:53:56 作者:Kenneth Reitz
使用 Pyhton 的内置 urllib 或 urllib2 模块来抓取网页可能有点陈词滥调。今天我们将玩一些新鲜的。查看有关使用 lxml 模块和请求模块抓取 HTML 页面的 Python 教程:
万维网
网站是用 HTML 描述的,这意味着每个网页都是一个结构化的文档。有时在保持其结构的同时从中获取数据很有用。网站并不总是以易于处理的格式(例如 csv 或 json)提供其数据。
现在是网络抢占该领域的时候了。网页抓取是使用计算机程序采集网页数据并将其组织成所需格式的做法,同时保留其结构。
lxml 和请求
lxml() 是一个漂亮的扩展库,用于快速解析 XML 和 HTML 文档,即使处理的标签非常混乱。我们还将使用 Requests (#) 模块来替换内置的 urllib2 模块,因为它更快且更具可读性。您可以使用 pip install lxml 和 pip install requests 命令安装这两个模块。
让我们从以下导入开始:
from lxml import html
import requests
在下一步中,我们将使用 requests.get 从网页中获取我们的数据,使用 html 模块对其进行解析,并将结果保存在树中。
page = requests.get('http://econpy.pythonanywhere.com/ex/001.html')
tree = html.fromstring(page.text)
tree 现在将整个 HTML 文件收录成一个优雅的树状结构,我们可以使用两种方法来访问:XPath 和 CSS 选择器。在本例中,我们将选择前者。
XPath 是一种在结构化文档(如 HTML 或 XML)中定位信息的方法。有关 XPath 的详细介绍,请参阅 W3Schools。
有很多工具可以获取元素的 XPath,例如 Firefox 的 FireBug 或 Chrome 的 Inspector。如果您使用 Chrome,您可以右键单击该元素,选择“检查元素”,突出显示此代码,再次右键单击,然后选择“复制 XPath”。
经过快速分析,我们看到页面上的数据存储在两个元素中,一个是标题为'buyer-name'的div,另一个是类为'item-price'的span:
Carson Busses
$29.95
知道了这一点,我们就可以创建正确的 XPath 查询并使用 lxml 的 xpath 函数,如下所示:
#这将创建buyers的列表:
buyers = tree.xpath('//div[@title="buyer-name"]/text()')
#这将创建prices的列表:
prices = tree.xpath('//span[@class="item-price"]/text()')
让我们看看我们得到了什么:
print 'Buyers: ', buyers
print 'Prices: ', prices
Buyers: ['Carson Busses', 'Earl E. Byrd', 'Patty Cakes',
'Derri Anne Connecticut', 'Moe Dess', 'Leda Doggslife', 'Dan Druff',
'Al Fresco', 'Ido Hoe', 'Howie Kisses', 'Len Lease', 'Phil Meup',
'Ira Pent', 'Ben D. Rules', 'Ave Sectomy', 'Gary Shattire',
'Bobbi Soks', 'Sheila Takya', 'Rose Tattoo', 'Moe Tell']
Prices: ['$29.95', '$8.37', '$15.26', '$19.25', '$19.25',
'$13.99', '$31.57', '$8.49', '$14.47', '$15.86', '$11.11',
'$15.98', '$16.27', '$7.50', '$50.85', '$14.26', '$5.68',
'$15.00', '$114.07', '$10.09']
恭喜!我们已经成功通过lxml和Request从一个网页中抓取了我们想要的所有数据。我们以列表的形式将它们存储在内存中。现在我们可以用它做各种很酷的事情:我们可以用 Python 分析它,或者我们可以将它保存为文件并与世界分享。
我们可以考虑一些更酷的想法:修改此脚本以遍历本示例中数据集中的剩余页面,或者使用多个线程重写此应用程序以提高其速度。
php抓取网页title(这里有新鲜出炉的精品教程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-23 09:06
这里是新鲜出炉的优质教程,看程序狗的速度!
ASP.NET ASP.NET 是 .NET FrameWork 的一部分。它是微软公司的一项技术。它是一种服务器端脚本技术,可使嵌入在网页中的脚本由 Internet 服务器执行。它们是在服务器上动态创建的。指的是Active Server Pages,一个运行在IIS(Internet Information Server service,Windows开发的Web服务器)中的程序。
我们知道一般网页中的信息都是在不断更新的,这也需要我们定期抓取这些新信息,但是如何理解这个“定期”,也就是页面需要多久被抓取一次,在其实这个时间段也是Page cache时间。在页面缓存期间,我们没有必要再次抓取网页,但会对其他服务器造成压力。
一:网页更新
我们知道一般网页中的信息都是在不断更新的,这也需要我们定期抓取这些新信息,但是如何理解这个“定期”,也就是页面需要多久被抓取一次,在其实这个时间段也是Page cache时间。在页面缓存期间,我们不需要再次抓取网页,但会对其他服务器造成压力。
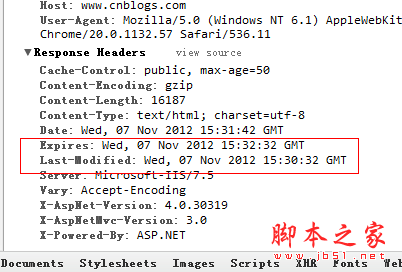
比如我想抓取博客园的首页,先清除页面缓存,
从Last-Modified到Expires,可以看到博客园的缓存时间是2分钟,我还可以看到当前服务器时间Date,如果我再做一次
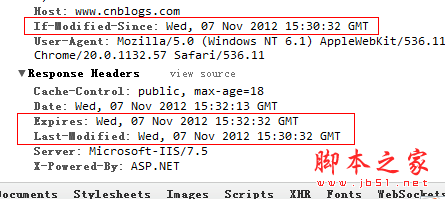
如果页面刷新,这里的Date会变成下图中的If-Modified-Since,然后发送到服务器判断浏览器的缓存是否已经过期?
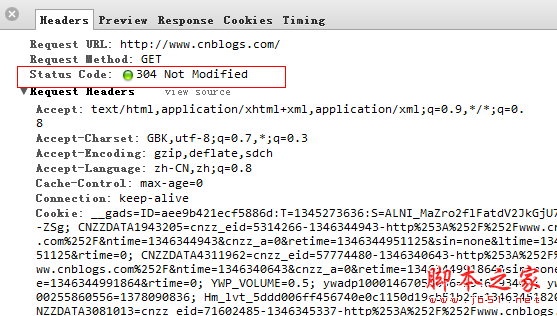
最后服务端发现if-Modified-Since >= Last-Modifined时间,服务端也返回了304,但是发现cookie信息真的是很多小偷。
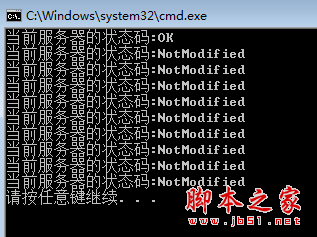
在实际开发中,如果知道网站的缓存策略,就可以让爬虫每2分钟爬一次。当然,这些可以由数据团队进行配置和维护。好的,让我们使用爬虫。模拟它。
using System;
using System.Net;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
DateTime prevDateTime = DateTime.MinValue;
for (int i = 0; i < 10; i++)
{
try
{
var url = "http://cnblogs.com";
var request = (HttpWebRequest)HttpWebRequest.Create(url);
request.Method = "Head";
if (i > 0)
{
request.IfModifiedSince = prevDateTime;
}
request.Timeout = 3000;
var response = (HttpWebResponse)request.GetResponse();
var code = response.StatusCode;
//如果服务器返回状态是200,则认为网页已更新,记得当时的服务器时间
if (code == HttpStatusCode.OK)
{
prevDateTime = Convert.ToDateTime(response.Headers[HttpResponseHeader.Date]);
}
Console.WriteLine("当前服务器的状态码:{0}", code);
}
catch (WebException ex)
{
if (ex.Response != null)
{
var code = (ex.Response as HttpWebResponse).StatusCode;
Console.WriteLine("当前服务器的状态码:{0}", code);
}
}
}
}
}
}
二:网页编码的问题
有时候我们已经抓取了网页,准备解析的时候,tmd全是乱码,真他妈的,比如下面这样,
可能我们依稀记得html的meta中有一个叫做charset的属性,里面记录了编码方式。另一个重要的一点是 response.CharacterSet 也记录了编码方式。让我们再试一次。
还是乱码,蛋疼。这个时候需要去官网看看http头信息里面交互的是什么。为什么浏览器能正常显示,爬虫就爬不过去了。
查看http头信息后,我们终于知道了。浏览器说可以解析gzip、deflate、sdch三种压缩方式。服务器发送 gzip 压缩。至此,我们也应该知道常用的web性能优化了。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using HtmlAgilityPack;
using System.Text.RegularExpressions;
using System.Net;
using System.IO;
using System.IO.Compression;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
//var currentUrl = "http://www.mm5mm.com/";
var currentUrl = "http://www.sohu.com/";
var request = WebRequest.Create(currentUrl) as HttpWebRequest;
var response = request.GetResponse() as HttpWebResponse;
var encode = string.Empty;
if (response.CharacterSet == "ISO-8859-1")
encode = "gb2312";
else
encode = response.CharacterSet;
Stream stream;
if (response.ContentEncoding.ToLower() == "gzip")
{
stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
}
else
{
stream = response.GetResponseStream();
}
var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
var html = sr.ReadToEnd();
}
}
}
三:网页分析
现在网页经过一番折腾得到了,接下来就解析下一个。当然,正则匹配是一个不错的方法。毕竟工作量还是比较大的。或许业界也推荐HtmlAgilityPack,一个可以将Html解析成XML的解析工具,然后可以使用XPath提取指定的内容,大大提高了开发速度,性能也不错。毕竟,敏捷意味着敏捷。关于XPath的内容,可以看一下W3CSchool的两张图。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using HtmlAgilityPack;
using System.Text.RegularExpressions;
using System.Net;
using System.IO;
using System.IO.Compression;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
//var currentUrl = "http://www.mm5mm.com/";
var currentUrl = "http://www.sohu.com/";
var request = WebRequest.Create(currentUrl) as HttpWebRequest;
var response = request.GetResponse() as HttpWebResponse;
var encode = string.Empty;
if (response.CharacterSet == "ISO-8859-1")
encode = "gb2312";
else
encode = response.CharacterSet;
Stream stream;
if (response.ContentEncoding.ToLower() == "gzip")
{
stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
}
else
{
stream = response.GetResponseStream();
}
var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
var html = sr.ReadToEnd();
sr.Close();
HtmlDocument document = new HtmlDocument();
document.LoadHtml(html);
//提取title
var title = document.DocumentNode.SelectSingleNode("//title").InnerText;
//提取keywords
var keywords = document.DocumentNode.SelectSingleNode("//meta[@name='Keywords']").Attributes["content"].Value;
}
}
}
好了,结束工作,去睡觉吧。. . 查看全部
php抓取网页title(这里有新鲜出炉的精品教程,程序狗速度看过来!)
这里是新鲜出炉的优质教程,看程序狗的速度!
ASP.NET ASP.NET 是 .NET FrameWork 的一部分。它是微软公司的一项技术。它是一种服务器端脚本技术,可使嵌入在网页中的脚本由 Internet 服务器执行。它们是在服务器上动态创建的。指的是Active Server Pages,一个运行在IIS(Internet Information Server service,Windows开发的Web服务器)中的程序。
我们知道一般网页中的信息都是在不断更新的,这也需要我们定期抓取这些新信息,但是如何理解这个“定期”,也就是页面需要多久被抓取一次,在其实这个时间段也是Page cache时间。在页面缓存期间,我们没有必要再次抓取网页,但会对其他服务器造成压力。
一:网页更新
我们知道一般网页中的信息都是在不断更新的,这也需要我们定期抓取这些新信息,但是如何理解这个“定期”,也就是页面需要多久被抓取一次,在其实这个时间段也是Page cache时间。在页面缓存期间,我们不需要再次抓取网页,但会对其他服务器造成压力。
比如我想抓取博客园的首页,先清除页面缓存,
从Last-Modified到Expires,可以看到博客园的缓存时间是2分钟,我还可以看到当前服务器时间Date,如果我再做一次
如果页面刷新,这里的Date会变成下图中的If-Modified-Since,然后发送到服务器判断浏览器的缓存是否已经过期?
最后服务端发现if-Modified-Since >= Last-Modifined时间,服务端也返回了304,但是发现cookie信息真的是很多小偷。
在实际开发中,如果知道网站的缓存策略,就可以让爬虫每2分钟爬一次。当然,这些可以由数据团队进行配置和维护。好的,让我们使用爬虫。模拟它。
using System;
using System.Net;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
DateTime prevDateTime = DateTime.MinValue;
for (int i = 0; i < 10; i++)
{
try
{
var url = "http://cnblogs.com";
var request = (HttpWebRequest)HttpWebRequest.Create(url);
request.Method = "Head";
if (i > 0)
{
request.IfModifiedSince = prevDateTime;
}
request.Timeout = 3000;
var response = (HttpWebResponse)request.GetResponse();
var code = response.StatusCode;
//如果服务器返回状态是200,则认为网页已更新,记得当时的服务器时间
if (code == HttpStatusCode.OK)
{
prevDateTime = Convert.ToDateTime(response.Headers[HttpResponseHeader.Date]);
}
Console.WriteLine("当前服务器的状态码:{0}", code);
}
catch (WebException ex)
{
if (ex.Response != null)
{
var code = (ex.Response as HttpWebResponse).StatusCode;
Console.WriteLine("当前服务器的状态码:{0}", code);
}
}
}
}
}
}
二:网页编码的问题
有时候我们已经抓取了网页,准备解析的时候,tmd全是乱码,真他妈的,比如下面这样,

可能我们依稀记得html的meta中有一个叫做charset的属性,里面记录了编码方式。另一个重要的一点是 response.CharacterSet 也记录了编码方式。让我们再试一次。

还是乱码,蛋疼。这个时候需要去官网看看http头信息里面交互的是什么。为什么浏览器能正常显示,爬虫就爬不过去了。

查看http头信息后,我们终于知道了。浏览器说可以解析gzip、deflate、sdch三种压缩方式。服务器发送 gzip 压缩。至此,我们也应该知道常用的web性能优化了。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using HtmlAgilityPack;
using System.Text.RegularExpressions;
using System.Net;
using System.IO;
using System.IO.Compression;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
//var currentUrl = "http://www.mm5mm.com/";
var currentUrl = "http://www.sohu.com/";
var request = WebRequest.Create(currentUrl) as HttpWebRequest;
var response = request.GetResponse() as HttpWebResponse;
var encode = string.Empty;
if (response.CharacterSet == "ISO-8859-1")
encode = "gb2312";
else
encode = response.CharacterSet;
Stream stream;
if (response.ContentEncoding.ToLower() == "gzip")
{
stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
}
else
{
stream = response.GetResponseStream();
}
var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
var html = sr.ReadToEnd();
}
}
}

三:网页分析
现在网页经过一番折腾得到了,接下来就解析下一个。当然,正则匹配是一个不错的方法。毕竟工作量还是比较大的。或许业界也推荐HtmlAgilityPack,一个可以将Html解析成XML的解析工具,然后可以使用XPath提取指定的内容,大大提高了开发速度,性能也不错。毕竟,敏捷意味着敏捷。关于XPath的内容,可以看一下W3CSchool的两张图。

using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using HtmlAgilityPack;
using System.Text.RegularExpressions;
using System.Net;
using System.IO;
using System.IO.Compression;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
//var currentUrl = "http://www.mm5mm.com/";
var currentUrl = "http://www.sohu.com/";
var request = WebRequest.Create(currentUrl) as HttpWebRequest;
var response = request.GetResponse() as HttpWebResponse;
var encode = string.Empty;
if (response.CharacterSet == "ISO-8859-1")
encode = "gb2312";
else
encode = response.CharacterSet;
Stream stream;
if (response.ContentEncoding.ToLower() == "gzip")
{
stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
}
else
{
stream = response.GetResponseStream();
}
var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
var html = sr.ReadToEnd();
sr.Close();
HtmlDocument document = new HtmlDocument();
document.LoadHtml(html);
//提取title
var title = document.DocumentNode.SelectSingleNode("//title").InnerText;
//提取keywords
var keywords = document.DocumentNode.SelectSingleNode("//meta[@name='Keywords']").Attributes["content"].Value;
}
}
}

好了,结束工作,去睡觉吧。. .
php抓取网页title(Python代码的适用实例有哪些?WebScraping的基本原理步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-23 01:09
本文主要介绍Web Scraping的基本原理,基于Python语言,白话文,面向可爱的小白(^-^)。
混淆名称:
很多时候,人们将互联网上获取数据的代码统称为“爬虫”。
但实际上,所谓的“爬行动物”并不是特别准确,因为“爬行动物”也是分物种的。
有两种常见的“爬虫”:
网络爬虫,又称蜘蛛;Spiderbot Web Scraper,也称为 Web Harvesting;网页数据提取
不过这篇文章文章主要是讲解第二个“爬虫”(Web Scraper)的原理。
什么是网页抓取?
简单地说,Web Scraping(本文中)是指使用Python代码从肉眼可见的网页中抓取数据。
为什么需要网页抓取?
因为重复性工作太多,自己做的话可能会累死!
代码的适用示例有哪些?比如你需要下载交易所50只不同股票的当前价格,或者你想打印出所有最新消息的头条新闻网站,或者你只想把所有产品在网站上列出价格,放到Excel中进行对比等等,你可以发挥你的想象力.....
Web Scraping的基本原理:
首先,您需要了解网页在我们的屏幕上是如何呈现的;
事实上,我们发送了一个Request,一百公里外的服务器给了我们一个Response;然后我们看了一大堆文字,最后,浏览器偷偷把这一堆文字排列起来,放到了我们的屏幕上。在; 更详细的原理可以看我之前的博文《HTTP下午茶-小白介绍》中的书
然后,我们需要了解如何使用 Python 来实现它。实现原理基本分为四步:
首先,代码需要向服务器发送一个Request,然后接收一个Response(html文件)。然后,我们需要处理接收到的 Response 并找到我们需要的文本。然后,我们需要设计代码流来处理重复的任务。最后导出我们得到的数据,最后最好是一个漂亮的Excel表格汇总:
本文章重点讲解实现的思路和过程,
因此,它并不详尽,并且没有给出实际的代码。
不过,这个思路几乎是网页抓取的通用套路。
就写到这里吧,记得更新什么,
有写的地方不对的地方还请见谅! 查看全部
php抓取网页title(Python代码的适用实例有哪些?WebScraping的基本原理步骤)
本文主要介绍Web Scraping的基本原理,基于Python语言,白话文,面向可爱的小白(^-^)。
混淆名称:
很多时候,人们将互联网上获取数据的代码统称为“爬虫”。
但实际上,所谓的“爬行动物”并不是特别准确,因为“爬行动物”也是分物种的。
有两种常见的“爬虫”:
网络爬虫,又称蜘蛛;Spiderbot Web Scraper,也称为 Web Harvesting;网页数据提取
不过这篇文章文章主要是讲解第二个“爬虫”(Web Scraper)的原理。
什么是网页抓取?
简单地说,Web Scraping(本文中)是指使用Python代码从肉眼可见的网页中抓取数据。
为什么需要网页抓取?
因为重复性工作太多,自己做的话可能会累死!
代码的适用示例有哪些?比如你需要下载交易所50只不同股票的当前价格,或者你想打印出所有最新消息的头条新闻网站,或者你只想把所有产品在网站上列出价格,放到Excel中进行对比等等,你可以发挥你的想象力.....
Web Scraping的基本原理:
首先,您需要了解网页在我们的屏幕上是如何呈现的;
事实上,我们发送了一个Request,一百公里外的服务器给了我们一个Response;然后我们看了一大堆文字,最后,浏览器偷偷把这一堆文字排列起来,放到了我们的屏幕上。在; 更详细的原理可以看我之前的博文《HTTP下午茶-小白介绍》中的书
然后,我们需要了解如何使用 Python 来实现它。实现原理基本分为四步:
首先,代码需要向服务器发送一个Request,然后接收一个Response(html文件)。然后,我们需要处理接收到的 Response 并找到我们需要的文本。然后,我们需要设计代码流来处理重复的任务。最后导出我们得到的数据,最后最好是一个漂亮的Excel表格汇总:
本文章重点讲解实现的思路和过程,
因此,它并不详尽,并且没有给出实际的代码。
不过,这个思路几乎是网页抓取的通用套路。
就写到这里吧,记得更新什么,
有写的地方不对的地方还请见谅!
php抓取网页title(本节使用Python爬虫抓取猫眼(电影网排行榜)影片信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 218 次浏览 • 2021-10-12 05:38
本节使用Python爬虫抓取猫眼电影TOP100榜单()电影信息,包括电影名称、上映时间、主演信息。
在开始编写程序之前,首先确定页面类型(静态页面或动态页面),其次找出页面的url规则,最后通过分析网页元素的结构来确定正则表达式,从而提取网页信息。
确定页面类型
右击查看页面源码,判断页面中是否存在要抓取的数据。通过浏览可知,所有要抓取的信息都存在于源代码中,因此页面输入为静态页面。如下:
<p class="name">
我不是药神
主演:徐峥,周一围,王传君
</p>
发布时间:2018-07-05
确定url规则
确定url规则,需要多浏览几页,才能总结url规则,如下图:
第一页:
第二页:
第三页:
…
第 n 页:(n-1)*10
确定正则表达式
通过分析网页元素的结构来确定正则表达式,如下图:
<p class="name">我不是药神
主演:徐峥,周一围,王传君
</p>
发布时间:2018-07-05
使用 Chrome Developer Debugging Tools 确定要捕获的元素的结构。这样做的原因是可以避免正则表达式的冗余,提高编写正则表达式的速度。正则表达式如下:
.*?title="(.*?)".*?class="star">(.*?).*?releasetime">(.*?)
编写正则表达式时,使用(.*?)替换需要提取的信息,使用.*? 替换不需要的内容(包括元素标签)。
编写爬虫
下面用面向对象的方法写一个爬虫程序,主要写了四个函数,分别是请求函数、分析函数、数据保存函数、主函数。最后,如果你的时间不是很紧,想快速提高,最重要的是你不怕吃苦。我建议你可以定价@762459510。那真的很好。很多人都在快速进步。你需要害怕困难!可以去加进去看看~
1. from urllib import request
2. import re
3. import time
4. import random
5. import csv
6. from ua_info import ua_list
7. # 定义一个爬虫类
8. class MaoyanSpider(object):
9. # 初始化
10. # 定义初始页面url
11. def __init__(self):
12. self.url = 'https://maoyan.com/board/4?offset={}'
13. # 请求函数
14. def get_html(self,url):
15. headers = {'User-Agent':random.choice(ua_list)}
16. req = request.Request(url=url,headers=headers)
17. res = request.urlopen(req)
18. html = res.read().decode()
19. # 直接调用解析函数
20. self.parse_html(html)
21. # 解析函数
22. def parse_html(self,html):
23. # 正则表达式
24. re_bds = '.*?title="(.*?)".*?<p class="star">(.*?)
25. .*?class="releasetime">(.*?)</p>'
26. # 生成正则表达式对象
27. pattern = re.compile(re_bds,re.S)
28. # r_list: [('我不是药神','徐峥,周一围,王传君','2018-07-05'),...] 列表元组
29. r_list = pattern.findall(html)
30. self.save_html(r_list)
31. # 保存数据函数,使用python内置csv模块
32. def save_html(self,r_list):
33. #生成文件对象
34. with open('maoyan.csv','a',newline='',encoding="utf-8") as f:
35. #生成csv操作对象
36. writer = csv.writer(f)
37. #整理数据
38. for r in r_list:
39. name = r[0].strip()
40. star = r[1].strip()[3:]
41. # 上映时间:2018-07-05
42. # 切片截取时间
43. time = r[2].strip()[5:15]
44. L = [name,star,time]
45. # 写入csv文件
46. writer.writerow(L)
47. print(name,time,star)
48. # 主函数
49. def run(self):
50. #抓取第一页数据
51. for offset in range(0,11,10):
52. url = self.url.format(offset)
53. self.get_html(url)
54. #生成1-2之间的浮点数
55. time.sleep(random.uniform(1,2))
56. # 以脚本方式启动
57. if __name__ == '__main__':
58. #捕捉异常错误
59. try:
60. spider = MaoyanSpider()
61. spider.run()
62. except Exception as e:
63. print("错误:",e)
</p>
输出结果:
我不是药神 2018-07-05 徐峥、周以伟、王传君
肖申克的救赎 1994-09-10 蒂姆·罗宾斯、摩根·弗里曼、鲍勃·冈顿
绿皮书 2019-03-01 Vigo Mortensen, Mahsala Ali, Linda Cardrini
海上钢琴家 2019-11-15 蒂姆·罗斯、比尔·纳恩、克兰伦斯·威廉姆斯三世
小偷家族 2018-08-03 中川雅也、安藤樱、松冈墨鱼
霸王别姬 1993-07-26 张国荣、张凤仪、巩俐
哪吒魔童降临人间
美丽人生 2020-01-03 罗伯托·贝尼尼、朱斯蒂诺·杜拉诺、塞尔吉奥·比尼·巴斯特里克
这个杀手不太冷 1994-09-14 让·雷诺、加里·奥德曼、娜塔莉·波特曼
2010-09-01 莱昂纳多·迪卡普里奥、渡边谦、约瑟夫·高登-莱维特 查看全部
php抓取网页title(本节使用Python爬虫抓取猫眼(电影网排行榜)影片信息)
本节使用Python爬虫抓取猫眼电影TOP100榜单()电影信息,包括电影名称、上映时间、主演信息。
在开始编写程序之前,首先确定页面类型(静态页面或动态页面),其次找出页面的url规则,最后通过分析网页元素的结构来确定正则表达式,从而提取网页信息。
确定页面类型
右击查看页面源码,判断页面中是否存在要抓取的数据。通过浏览可知,所有要抓取的信息都存在于源代码中,因此页面输入为静态页面。如下:
<p class="name">
我不是药神
主演:徐峥,周一围,王传君
</p>
发布时间:2018-07-05
确定url规则
确定url规则,需要多浏览几页,才能总结url规则,如下图:
第一页:
第二页:
第三页:
…
第 n 页:(n-1)*10
确定正则表达式
通过分析网页元素的结构来确定正则表达式,如下图:
<p class="name">我不是药神
主演:徐峥,周一围,王传君
</p>
发布时间:2018-07-05
使用 Chrome Developer Debugging Tools 确定要捕获的元素的结构。这样做的原因是可以避免正则表达式的冗余,提高编写正则表达式的速度。正则表达式如下:
.*?title="(.*?)".*?class="star">(.*?).*?releasetime">(.*?)
编写正则表达式时,使用(.*?)替换需要提取的信息,使用.*? 替换不需要的内容(包括元素标签)。
编写爬虫
下面用面向对象的方法写一个爬虫程序,主要写了四个函数,分别是请求函数、分析函数、数据保存函数、主函数。最后,如果你的时间不是很紧,想快速提高,最重要的是你不怕吃苦。我建议你可以定价@762459510。那真的很好。很多人都在快速进步。你需要害怕困难!可以去加进去看看~
1. from urllib import request
2. import re
3. import time
4. import random
5. import csv
6. from ua_info import ua_list
7. # 定义一个爬虫类
8. class MaoyanSpider(object):
9. # 初始化
10. # 定义初始页面url
11. def __init__(self):
12. self.url = 'https://maoyan.com/board/4?offset={}'
13. # 请求函数
14. def get_html(self,url):
15. headers = {'User-Agent':random.choice(ua_list)}
16. req = request.Request(url=url,headers=headers)
17. res = request.urlopen(req)
18. html = res.read().decode()
19. # 直接调用解析函数
20. self.parse_html(html)
21. # 解析函数
22. def parse_html(self,html):
23. # 正则表达式
24. re_bds = '.*?title="(.*?)".*?<p class="star">(.*?)
25. .*?class="releasetime">(.*?)</p>'
26. # 生成正则表达式对象
27. pattern = re.compile(re_bds,re.S)
28. # r_list: [('我不是药神','徐峥,周一围,王传君','2018-07-05'),...] 列表元组
29. r_list = pattern.findall(html)
30. self.save_html(r_list)
31. # 保存数据函数,使用python内置csv模块
32. def save_html(self,r_list):
33. #生成文件对象
34. with open('maoyan.csv','a',newline='',encoding="utf-8") as f:
35. #生成csv操作对象
36. writer = csv.writer(f)
37. #整理数据
38. for r in r_list:
39. name = r[0].strip()
40. star = r[1].strip()[3:]
41. # 上映时间:2018-07-05
42. # 切片截取时间
43. time = r[2].strip()[5:15]
44. L = [name,star,time]
45. # 写入csv文件
46. writer.writerow(L)
47. print(name,time,star)
48. # 主函数
49. def run(self):
50. #抓取第一页数据
51. for offset in range(0,11,10):
52. url = self.url.format(offset)
53. self.get_html(url)
54. #生成1-2之间的浮点数
55. time.sleep(random.uniform(1,2))
56. # 以脚本方式启动
57. if __name__ == '__main__':
58. #捕捉异常错误
59. try:
60. spider = MaoyanSpider()
61. spider.run()
62. except Exception as e:
63. print("错误:",e)
</p>
输出结果:
我不是药神 2018-07-05 徐峥、周以伟、王传君
肖申克的救赎 1994-09-10 蒂姆·罗宾斯、摩根·弗里曼、鲍勃·冈顿
绿皮书 2019-03-01 Vigo Mortensen, Mahsala Ali, Linda Cardrini
海上钢琴家 2019-11-15 蒂姆·罗斯、比尔·纳恩、克兰伦斯·威廉姆斯三世
小偷家族 2018-08-03 中川雅也、安藤樱、松冈墨鱼
霸王别姬 1993-07-26 张国荣、张凤仪、巩俐
哪吒魔童降临人间
美丽人生 2020-01-03 罗伯托·贝尼尼、朱斯蒂诺·杜拉诺、塞尔吉奥·比尼·巴斯特里克
这个杀手不太冷 1994-09-14 让·雷诺、加里·奥德曼、娜塔莉·波特曼
2010-09-01 莱昂纳多·迪卡普里奥、渡边谦、约瑟夫·高登-莱维特
php抓取网页title(更多写博客安全系列之二:如何防止CSRF攻击?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-07 10:31
阿里云>云栖社区>主题图>P>php抢域名标题
推荐活动:
更多优惠>
当前主题:php抓取域名标题并添加到采集夹
相关话题:
php抢域名相关博客 查看更多博客
前端安全系列之二:如何防范CSRF攻击?
作者:小技术专家 2211人浏览评论:12年前
背景 随着互联网的飞速发展,信息安全问题成为企业最关注的焦点之一,而前端是引发企业安全问题的高风险基地。移动互联网时代,除了传统的XSS、CSRF等安全问题外,前端人员经常会遇到网络劫持、非法调用Hybrid API等新的安全问题。当然,浏览
阅读全文
网站被黑后被黑了被黑了,我是怎么解决网站被黑的!
作者:网站安全者937人查看评论:03年前
1、我发现我被黑了。网站 被黑的症状。两年前,我用wordpress搭建了一个网站。平时没什么好写的文章玩。但是前几天突然发现网站的流量突然减少了。我在网站上查了百度收录,发现不对劲,网站被黑了。大多数百度抓取收录的页面标题和描述
阅读全文
网站被黑后被黑了被黑了,我是怎么解决网站被黑的!
作者:网站安全1247人浏览评论:03年前
1、我发现我被黑了。网站被黑的症状 两年前我用wordpress搭建了一个网站,平时也没什么好写的文章玩。但是前几天突然发现网站的流量突然减少了。我在网站上查了百度收录,发现不对劲,网站被黑了。大多数百度爬取收录的页面标题和descriptorio
阅读全文
一键分享QQ空间、新浪微博、腾讯微博、豆瓣等API链接代码。
作者:小美科技 1212人浏览评论:03年前
1.新浪微博:count=表示是否显示当前页面的共享页数(1显示)(可选,允许为空) &url=将页面地址转换为短域名并显示在内容后面文本。(可选,允许为空)&ap
阅读全文
搜索引擎优化的55个技巧
作者:文艺小青年1602人浏览评论:03年前
每个人都喜欢易于使用的技术,对吧?这里有 55 个搜索引擎优化技巧,即使您的妈妈也可以轻松使用。哦,不是我妈妈,但你知道我的意思。这意味着大多数网页设计师和 SEO 新手可以毫无困难地快速上手。如果一定要使用Java脚本的下拉菜单,图片
阅读全文
一键分享QQ空间、新浪微博、腾讯微博、豆瓣等API链接代码。
作者:小科技专家1424人浏览评论:03年前
1.新浪微博:count=表示是否显示当前页面的共享页数(1显示)(可选,允许为空) &url=将页面地址转换为短域名并显示在内容后面文本。(可选,允许为空)&ap
阅读全文
ThinkPHP3.2.3 集成微信分享JS-SDK实践
作者:思梦php1055人浏览评论:04年前
先来看看微信分享的效果: 微信分享js-sdk集成之前是这样的:没有摘要,缩略图可以随意抓取文字。微信分享js-sdk集成后是这样的:title、summary、thumbnail 从Define一、下载微信SDK开发包下载地址:
阅读全文
在微信上分享自定义图片和摘要
作者:ap0581w9c1088 浏览评论人数:05年前
参考:微信分享实现微信现在是很多企业营销的重点。你可能每天都在朋友圈和消息群里看到html5,但是自从微信更新了官方api之后,对整个微信页面的控制就很严格了。官方分享卡是微信生态中众多html5静态页面传播的重点。但是很
阅读全文 查看全部
php抓取网页title(更多写博客安全系列之二:如何防止CSRF攻击?(组图))
阿里云>云栖社区>主题图>P>php抢域名标题

推荐活动:
更多优惠>
当前主题:php抓取域名标题并添加到采集夹
相关话题:
php抢域名相关博客 查看更多博客
前端安全系列之二:如何防范CSRF攻击?

作者:小技术专家 2211人浏览评论:12年前
背景 随着互联网的飞速发展,信息安全问题成为企业最关注的焦点之一,而前端是引发企业安全问题的高风险基地。移动互联网时代,除了传统的XSS、CSRF等安全问题外,前端人员经常会遇到网络劫持、非法调用Hybrid API等新的安全问题。当然,浏览
阅读全文
网站被黑后被黑了被黑了,我是怎么解决网站被黑的!


作者:网站安全者937人查看评论:03年前
1、我发现我被黑了。网站 被黑的症状。两年前,我用wordpress搭建了一个网站。平时没什么好写的文章玩。但是前几天突然发现网站的流量突然减少了。我在网站上查了百度收录,发现不对劲,网站被黑了。大多数百度抓取收录的页面标题和描述
阅读全文
网站被黑后被黑了被黑了,我是怎么解决网站被黑的!


作者:网站安全1247人浏览评论:03年前
1、我发现我被黑了。网站被黑的症状 两年前我用wordpress搭建了一个网站,平时也没什么好写的文章玩。但是前几天突然发现网站的流量突然减少了。我在网站上查了百度收录,发现不对劲,网站被黑了。大多数百度爬取收录的页面标题和descriptorio
阅读全文
一键分享QQ空间、新浪微博、腾讯微博、豆瓣等API链接代码。

作者:小美科技 1212人浏览评论:03年前
1.新浪微博:count=表示是否显示当前页面的共享页数(1显示)(可选,允许为空) &url=将页面地址转换为短域名并显示在内容后面文本。(可选,允许为空)&ap
阅读全文
搜索引擎优化的55个技巧

作者:文艺小青年1602人浏览评论:03年前
每个人都喜欢易于使用的技术,对吧?这里有 55 个搜索引擎优化技巧,即使您的妈妈也可以轻松使用。哦,不是我妈妈,但你知道我的意思。这意味着大多数网页设计师和 SEO 新手可以毫无困难地快速上手。如果一定要使用Java脚本的下拉菜单,图片
阅读全文
一键分享QQ空间、新浪微博、腾讯微博、豆瓣等API链接代码。
作者:小科技专家1424人浏览评论:03年前
1.新浪微博:count=表示是否显示当前页面的共享页数(1显示)(可选,允许为空) &url=将页面地址转换为短域名并显示在内容后面文本。(可选,允许为空)&ap
阅读全文
ThinkPHP3.2.3 集成微信分享JS-SDK实践


作者:思梦php1055人浏览评论:04年前
先来看看微信分享的效果: 微信分享js-sdk集成之前是这样的:没有摘要,缩略图可以随意抓取文字。微信分享js-sdk集成后是这样的:title、summary、thumbnail 从Define一、下载微信SDK开发包下载地址:
阅读全文
在微信上分享自定义图片和摘要

作者:ap0581w9c1088 浏览评论人数:05年前
参考:微信分享实现微信现在是很多企业营销的重点。你可能每天都在朋友圈和消息群里看到html5,但是自从微信更新了官方api之后,对整个微信页面的控制就很严格了。官方分享卡是微信生态中众多html5静态页面传播的重点。但是很
阅读全文
php抓取网页title(PHP程序Pocket抓取知乎专栏的问题(一)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-10-05 03:19
口袋抓取知乎列问题
Pocket 是一种网络服务,我通常会在以后阅读时使用更多。对在线文章文字进行采集爬取效果更好。可以去除页面广告等无关内容。支持标注和搜索,同步速度也高。没关系。免费会员限制很小,所以如果我看到一些来不及阅读和消化的文章,我会先将其添加到Pocket队列中,有空时查看存档。
只是由于目前抓取网页正文的原理的限制,Pocket 基本上不支持越来越多的 AJAX 动态网页。最典型的就是知乎栏文章。之前的知乎列是用来支持Pocket的直接取的,改成AJAX加载数据后,将文章发送到Pocket会有这样的效果:
Pocket正常抓取的文章应该可以显示文章中的摘要文本或图片,知乎栏文章为空,点击文章@ >入口也是直接跳转到知乎栏目链接,并没有表现出Pocket抓取优化的效果。
问题分析
稍微看一下知乎专栏网页的代码,可以发现,如果在浏览器中访问这样的专栏,文章链接:
下面的文章内容数据API链接会实际加载,直到数据加载完毕才会显示知乎栏目页面:
这种动态加载显然是 Pocket 不支持的,但是很容易处理。我们用PHP或者Node.js实现一个简单的程序读取文章栏目的内容并输出,然后放到VPS或者其他虚拟主机上运行,然后访问我自己的网站并发送到 Pocket,Pocket 应该能够正确捕获它。另外,这种方法比较好的一面是输出内容中没有其他知乎相关网页代码,只有列文章内容,更便于Pocket抓取和处理。
PHP程序Pocket抓取效果
这个PHP程序真的没有技术含量。我只是写了一个简单的PHP文件,接受列页面ID的page参数,输出文章的内容:
上面的程序只是一个简单的判断。如果请求头收录Referer信息(例如从Pocket跳转网站等)或者请求地址中的redirect参数值为1,则直接跳转到知乎列页面,内容文章 列的默认输出。另外,程序使用getallheaders函数获取HTTP请求头信息。默认情况下,仅支持 Apache。如果想在nginx等服务器上使用,可以稍微修改一下。
此外,程序还将referrer值指定为never,防止页面引用知乎图片等资源时触发知乎的反盗链机制。
将上面的PHP程序放在虚拟主机上,访问类似如下的链接(仅供演示,需要翻墙):
~nocwat/知乎-grub.php?page=21542817
正确显示文章的内容后,把上面的链接发给Pocket。过一会就可以在Pocket队列中看到爬取的列文章。
暗示
由于知乎栏的图片有防盗链策略,直接访问上面的链接可能会导致文章中的图片无法正确显示的问题,不过没关系,Pocket会自动抓拍保存对于我们文章 在图片中。
最后来看看我的Pocket队列中的显示效果:
并点击文章条目进入,还可以看到Pocket优化文章的内容。在Pocket中点击查看原文档还可以自动跳转到知乎的栏目文章页面,这样你就不用担心专栏作家是否删除了文章而不会被能够再次查看它。
没有相关的文章。 查看全部
php抓取网页title(PHP程序Pocket抓取知乎专栏的问题(一)_)
口袋抓取知乎列问题
Pocket 是一种网络服务,我通常会在以后阅读时使用更多。对在线文章文字进行采集爬取效果更好。可以去除页面广告等无关内容。支持标注和搜索,同步速度也高。没关系。免费会员限制很小,所以如果我看到一些来不及阅读和消化的文章,我会先将其添加到Pocket队列中,有空时查看存档。
只是由于目前抓取网页正文的原理的限制,Pocket 基本上不支持越来越多的 AJAX 动态网页。最典型的就是知乎栏文章。之前的知乎列是用来支持Pocket的直接取的,改成AJAX加载数据后,将文章发送到Pocket会有这样的效果:

Pocket正常抓取的文章应该可以显示文章中的摘要文本或图片,知乎栏文章为空,点击文章@ >入口也是直接跳转到知乎栏目链接,并没有表现出Pocket抓取优化的效果。
问题分析
稍微看一下知乎专栏网页的代码,可以发现,如果在浏览器中访问这样的专栏,文章链接:
下面的文章内容数据API链接会实际加载,直到数据加载完毕才会显示知乎栏目页面:
这种动态加载显然是 Pocket 不支持的,但是很容易处理。我们用PHP或者Node.js实现一个简单的程序读取文章栏目的内容并输出,然后放到VPS或者其他虚拟主机上运行,然后访问我自己的网站并发送到 Pocket,Pocket 应该能够正确捕获它。另外,这种方法比较好的一面是输出内容中没有其他知乎相关网页代码,只有列文章内容,更便于Pocket抓取和处理。
PHP程序Pocket抓取效果
这个PHP程序真的没有技术含量。我只是写了一个简单的PHP文件,接受列页面ID的page参数,输出文章的内容:
上面的程序只是一个简单的判断。如果请求头收录Referer信息(例如从Pocket跳转网站等)或者请求地址中的redirect参数值为1,则直接跳转到知乎列页面,内容文章 列的默认输出。另外,程序使用getallheaders函数获取HTTP请求头信息。默认情况下,仅支持 Apache。如果想在nginx等服务器上使用,可以稍微修改一下。
此外,程序还将referrer值指定为never,防止页面引用知乎图片等资源时触发知乎的反盗链机制。
将上面的PHP程序放在虚拟主机上,访问类似如下的链接(仅供演示,需要翻墙):
~nocwat/知乎-grub.php?page=21542817
正确显示文章的内容后,把上面的链接发给Pocket。过一会就可以在Pocket队列中看到爬取的列文章。
暗示
由于知乎栏的图片有防盗链策略,直接访问上面的链接可能会导致文章中的图片无法正确显示的问题,不过没关系,Pocket会自动抓拍保存对于我们文章 在图片中。
最后来看看我的Pocket队列中的显示效果:

并点击文章条目进入,还可以看到Pocket优化文章的内容。在Pocket中点击查看原文档还可以自动跳转到知乎的栏目文章页面,这样你就不用担心专栏作家是否删除了文章而不会被能够再次查看它。
没有相关的文章。
php抓取网页title(Javaexample参数分析及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-09-30 04:27
PhantomJS 是一个基于 WebKit 的服务器端 API。它完全支持网络,无需浏览器支持。它速度快,并且本机支持各种 Web 标准:DOM 处理、CSS 选择器、JSON、Canvas 和 SVG。PhantomJS 可用于页面自动化、网络监控、网页截图和无界面测试。
一、安装
安装包下载地址:包括Windows、Mac OS、Linux版本,可以选择对应版本下载解压(为了方便,可以自己设置phantomjs的环境变量),里面有example文件夹,很多已经写好的代码使用。本文假设已安装phantomjs并设置好环境变量。
二、使用你好,世界!
创建一个收录以下两行脚本的新文本文件:
console.log('Hello, world!');
phantom.exit();
将文件保存为hello.js,然后执行:
phantomjs hello.js
输出结果是:你好,世界!
第一行将在终端中打印一个字符串,第二行 phantom.exit 将退出。
在这个脚本中调用phantom.exit非常重要,否则PhantomJS根本不会停止。
脚本参数 – 脚本参数
Phantomjs 是如何传递参数的?如下:
phantomjs examples/arguments.js foo bar baz
其中foo、bar、baz是要传递的参数,如何获取:
var system = require('system');
if (system.args.length === 1) {
console.log('Try to pass some args when invoking this script!');
} else {
system.args.forEach(function (arg, i) {
console.log(i + ': ' + arg);
});
}
phantom.exit();
它会输出:
0: foo
1: bar
2: baz
页面加载-页面加载
通过创建网页对象,可以加载、分析和呈现网页。
以下脚本将是示例页面对象的最简单用法,它加载并将其保存为图像,example.png。
var page = require('webpage').create();
page.open('http://example.com', function () {
page.render('example.png');
phantom.exit();
});
由于这个特性,PhantomJS 可以用来截取网页的截图和一些内容的快照,比如保存网页、SVG 为图片、PDF 等,这个功能非常好。
下一个 loadspeed.js 脚本加载一个特殊的 URL(不要忘记 http 协议)并测量加载页面的时间。
var page = require('webpage').create(),
system = require('system'),
t, address;
if (system.args.length === 1) {
console.log('Usage: loadspeed.js ');
phantom.exit();
}
t = Date.now();
address = system.args[1];
page.open(address, function (status) {
if (status !== 'success') {
console.log('FAIL to load the address');
} else {
t = Date.now() - t;
console.log('Loading time ' + t + ' msec');
}
phantom.exit();
});
在命令行上运行脚本:
phantomjs loadspeed.js http://www.google.com
它输出如下内容:
加载加载时间 719 毫秒
代码评估 – 代码评估
要在网页上下文中对 JavaScript 或 CoffeeScript 执行操作,请使用evaluate() 方法。代码在“沙箱”中运行,它无法读取其所属页面上下文之外的任何 JavaScript 对象和变量。evaluate() 将返回一个对象,但它仅限于简单对象,不能收录方法或闭包。
这是显示页面标题的示例:
var page = require('webpage').create();
page.open(url, function (status) {
var title = page.evaluate(function () {
return document.title;
});
console.log('Page title is ' + title);
});
默认情况下不会显示来自网页的任何控制台信息,包括evaluate() 的内部代码。要覆盖此行为,请使用 onConsoleMessage 回调函数。前面的例子可以改写为:
var page = require('webpage').create();
page.onConsoleMessage = function (msg) {
console.log('Page title is ' + msg);
};
page.open(url, function (status) {
page.evaluate(function () {
console.log(document.title);
});
});
DOM操作-DOM操作
由于脚本似乎在 Web 浏览器上运行,因此标准 DOM 脚本和 CSS 选择器可以很好地工作。这使得 PhantomJS 适合支持各种页面自动化任务。
下面的 useragent.js 将读取 id 为 myagent 的元素的 textContent 属性:
var page = require('webpage').create();
console.log('The default user agent is ' + page.settings.userAgent);
page.settings.userAgent = 'SpecialAgent';
page.open('http://www.httpuseragent.org', function (status) {
if (status !== 'success') {
console.log('Unable to access network');
} else {
var ua = page.evaluate(function () {
return document.getElementById('myagent').textContent;
});
console.log(ua);
}
phantom.exit();
});
上面的例子还提供了一种自定义用户代理的方法。
使用 JQuery 和其他库:
var page = require('webpage').create();
page.open('http://www.sample.com', function() {
page.includeJs("http://ajax.googleapis.com/aja ... ot%3B, function() {
page.evaluate(function() {
$("button").click();
});
phantom.exit()
});
});
网络请求和响应-网络请求和响应
当页面从远程服务器请求资源时,可以通过 onResourceRequested 和 onResourceReceived 回调方法跟踪请求和响应。示例 netlog.js:
var page = require('webpage').create();
page.onResourceRequested = function (request) {
console.log('Request ' + JSON.stringify(request, undefined, 4));
};
page.onResourceReceived = function (response) {
console.log('Receive ' + JSON.stringify(response, undefined, 4));
};
page.open(url);
关于如何使用此功能进行基于 YSlow 的 HAR 输出和性能分析的更多信息,请参阅网络监控页面。
PhantomJs 官网:
GitHub:
以上帮助说明来自woiweb:
windows下使用PHP执行phantomjs
下面直接给出执行代码:
echo '';
exec('H:\wamp\www\phantomjs\bin\phantomjs --output-encoding=utf8 H:\wamp\www\Xss_Scanner\test.js ',$output_main);
var_dump($output_main);
// $str = implode('',$output_main);
// var_dump($str);
test.js文件内容如下:
console.log('Loading a web page');
var page = require('webpage').create();
var url = 'http://www.mafutian.net/';
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
console.log(page.content);
}
phantom.exit();
});
执行结果如下图所示:
注意,要达到上述执行结果,需要以下几点:
(1) 不能开启PHP的安全模式,即需要在php.ini中将sql.safe_mode设置为Off。(并重启服务器,当然php本身并没有开启安全模式默认情况下)
(2) 不管phantomjs是否加到系统环境变量中,在exec()中应该是绝对路径。以下执行无效:
exec('phantomjs --output-encoding=utf8 H:\wamp\www\Xss_Scanner\test.js ',$output_main);
需要走phantomjs的绝对路径。
需要注意的是,js文件不需要走绝对路径。可以相对于网站的根目录,如下执行成功:
exec('H:\wamp\www\phantomjs\bin\phantomjs --output-encoding=utf8 test.js ',$output_main);
注意:test.js放在网站的根目录下。
另外:在PHP下执行phantomjs也可以使用另一个函数systom()来执行
参考以上内容:链接地址:
php-phantomjs中文API整理的合集DEMO
<p> 查看全部
php抓取网页title(Javaexample参数分析及应用)
PhantomJS 是一个基于 WebKit 的服务器端 API。它完全支持网络,无需浏览器支持。它速度快,并且本机支持各种 Web 标准:DOM 处理、CSS 选择器、JSON、Canvas 和 SVG。PhantomJS 可用于页面自动化、网络监控、网页截图和无界面测试。
一、安装
安装包下载地址:包括Windows、Mac OS、Linux版本,可以选择对应版本下载解压(为了方便,可以自己设置phantomjs的环境变量),里面有example文件夹,很多已经写好的代码使用。本文假设已安装phantomjs并设置好环境变量。
二、使用你好,世界!
创建一个收录以下两行脚本的新文本文件:
console.log('Hello, world!');
phantom.exit();
将文件保存为hello.js,然后执行:
phantomjs hello.js
输出结果是:你好,世界!
第一行将在终端中打印一个字符串,第二行 phantom.exit 将退出。
在这个脚本中调用phantom.exit非常重要,否则PhantomJS根本不会停止。
脚本参数 – 脚本参数
Phantomjs 是如何传递参数的?如下:
phantomjs examples/arguments.js foo bar baz
其中foo、bar、baz是要传递的参数,如何获取:
var system = require('system');
if (system.args.length === 1) {
console.log('Try to pass some args when invoking this script!');
} else {
system.args.forEach(function (arg, i) {
console.log(i + ': ' + arg);
});
}
phantom.exit();
它会输出:
0: foo
1: bar
2: baz
页面加载-页面加载
通过创建网页对象,可以加载、分析和呈现网页。
以下脚本将是示例页面对象的最简单用法,它加载并将其保存为图像,example.png。
var page = require('webpage').create();
page.open('http://example.com', function () {
page.render('example.png');
phantom.exit();
});
由于这个特性,PhantomJS 可以用来截取网页的截图和一些内容的快照,比如保存网页、SVG 为图片、PDF 等,这个功能非常好。
下一个 loadspeed.js 脚本加载一个特殊的 URL(不要忘记 http 协议)并测量加载页面的时间。
var page = require('webpage').create(),
system = require('system'),
t, address;
if (system.args.length === 1) {
console.log('Usage: loadspeed.js ');
phantom.exit();
}
t = Date.now();
address = system.args[1];
page.open(address, function (status) {
if (status !== 'success') {
console.log('FAIL to load the address');
} else {
t = Date.now() - t;
console.log('Loading time ' + t + ' msec');
}
phantom.exit();
});
在命令行上运行脚本:
phantomjs loadspeed.js http://www.google.com
它输出如下内容:
加载加载时间 719 毫秒
代码评估 – 代码评估
要在网页上下文中对 JavaScript 或 CoffeeScript 执行操作,请使用evaluate() 方法。代码在“沙箱”中运行,它无法读取其所属页面上下文之外的任何 JavaScript 对象和变量。evaluate() 将返回一个对象,但它仅限于简单对象,不能收录方法或闭包。
这是显示页面标题的示例:
var page = require('webpage').create();
page.open(url, function (status) {
var title = page.evaluate(function () {
return document.title;
});
console.log('Page title is ' + title);
});
默认情况下不会显示来自网页的任何控制台信息,包括evaluate() 的内部代码。要覆盖此行为,请使用 onConsoleMessage 回调函数。前面的例子可以改写为:
var page = require('webpage').create();
page.onConsoleMessage = function (msg) {
console.log('Page title is ' + msg);
};
page.open(url, function (status) {
page.evaluate(function () {
console.log(document.title);
});
});
DOM操作-DOM操作
由于脚本似乎在 Web 浏览器上运行,因此标准 DOM 脚本和 CSS 选择器可以很好地工作。这使得 PhantomJS 适合支持各种页面自动化任务。
下面的 useragent.js 将读取 id 为 myagent 的元素的 textContent 属性:
var page = require('webpage').create();
console.log('The default user agent is ' + page.settings.userAgent);
page.settings.userAgent = 'SpecialAgent';
page.open('http://www.httpuseragent.org', function (status) {
if (status !== 'success') {
console.log('Unable to access network');
} else {
var ua = page.evaluate(function () {
return document.getElementById('myagent').textContent;
});
console.log(ua);
}
phantom.exit();
});
上面的例子还提供了一种自定义用户代理的方法。
使用 JQuery 和其他库:
var page = require('webpage').create();
page.open('http://www.sample.com', function() {
page.includeJs("http://ajax.googleapis.com/aja ... ot%3B, function() {
page.evaluate(function() {
$("button").click();
});
phantom.exit()
});
});
网络请求和响应-网络请求和响应
当页面从远程服务器请求资源时,可以通过 onResourceRequested 和 onResourceReceived 回调方法跟踪请求和响应。示例 netlog.js:
var page = require('webpage').create();
page.onResourceRequested = function (request) {
console.log('Request ' + JSON.stringify(request, undefined, 4));
};
page.onResourceReceived = function (response) {
console.log('Receive ' + JSON.stringify(response, undefined, 4));
};
page.open(url);
关于如何使用此功能进行基于 YSlow 的 HAR 输出和性能分析的更多信息,请参阅网络监控页面。
PhantomJs 官网:
GitHub:
以上帮助说明来自woiweb:
windows下使用PHP执行phantomjs
下面直接给出执行代码:
echo '';
exec('H:\wamp\www\phantomjs\bin\phantomjs --output-encoding=utf8 H:\wamp\www\Xss_Scanner\test.js ',$output_main);
var_dump($output_main);
// $str = implode('',$output_main);
// var_dump($str);
test.js文件内容如下:
console.log('Loading a web page');
var page = require('webpage').create();
var url = 'http://www.mafutian.net/';
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
console.log(page.content);
}
phantom.exit();
});
执行结果如下图所示:

注意,要达到上述执行结果,需要以下几点:
(1) 不能开启PHP的安全模式,即需要在php.ini中将sql.safe_mode设置为Off。(并重启服务器,当然php本身并没有开启安全模式默认情况下)
(2) 不管phantomjs是否加到系统环境变量中,在exec()中应该是绝对路径。以下执行无效:
exec('phantomjs --output-encoding=utf8 H:\wamp\www\Xss_Scanner\test.js ',$output_main);
需要走phantomjs的绝对路径。
需要注意的是,js文件不需要走绝对路径。可以相对于网站的根目录,如下执行成功:
exec('H:\wamp\www\phantomjs\bin\phantomjs --output-encoding=utf8 test.js ',$output_main);
注意:test.js放在网站的根目录下。
另外:在PHP下执行phantomjs也可以使用另一个函数systom()来执行
参考以上内容:链接地址:
php-phantomjs中文API整理的合集DEMO
<p>
核心方法:如何使用 ProxyCrawl 和 Scrapy 抓取网页
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-09-24 01:09
网页抓取,也称为网页抓取或屏幕抓取,软件开发人员将其定义为“编写软件以迭代一组网页以提取内容”,是出于各种原因从网页提取数据的出色工具。
<p>使用网络爬虫,你可以从一组文章中抓取数据,挖掘大型博客文章,或者从亚马逊抓取定量数据进行价格监控和机器学习,克服无法从 查看全部
核心方法:如何使用 ProxyCrawl 和 Scrapy 抓取网页
网页抓取,也称为网页抓取或屏幕抓取,软件开发人员将其定义为“编写软件以迭代一组网页以提取内容”,是出于各种原因从网页提取数据的出色工具。
<p>使用网络爬虫,你可以从一组文章中抓取数据,挖掘大型博客文章,或者从亚马逊抓取定量数据进行价格监控和机器学习,克服无法从
PHP实现页面静态化
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-05-05 08:00
随着网站的内容的增多和用户访问量的增多,无可避免的是网站加载会越来越慢,受限于带宽和服务器同一时间的请求次数的限制,我们往往需要在此时对我们的网站进行代码优化和服务器配置的优化。
一般情况下会从以下方面来做优化
1、动态页面静态化
2、优化数据库
3、使用负载均衡
4、使用缓存
5、使用CDN加速
现在很多网站在建设的时候都要进行静态化的处理,为什么网站要进行静态化处理呢?我们都知道纯静态网站是所有的网页都是独立的一个html页面,当我们访问的时候不需要经过数据的处理直接就能读取到文件,访问速度就可想而知了,而其对于搜索引擎而言也是非常友好的一个方式。
纯静态网站在网站中是怎么实现的?
纯静态的制作技术是需要先把网站的页面总结出来,分为多少个样式,然后把这些页面做成模板,生成的时候需要先读取源文件然后生成独立的以.html结尾的页面文件,所以说纯静态网站需要更大的空间,不过其实需要的空间也不会大多少的,尤其是对于中小型企业网站来说,从技术上来讲,大型网站想要全站实现纯静态化是比较困难的,生成的时间也太过于长了。不过中小型网站还是做成纯静态的比较,这样做的优点是很多的。
而动态网站又是怎么进行静态处理的?
页面静态化是指将动态页面变成html/htm静态页面。动态页面一般由asp,php,jsp,.net等程序语言编写而成,非常便于管理。但是访问网页时还需要程序先处理一遍,所以导致访问速度相对较慢。而静态页面访问速度快,却又不便于管理。那么动态页面静态化即可以将两种页面的好处集中到一起。
静态处理后又给网站带来了哪些好处?
1、静态页面相对于动态页面更容易被搜索引擎收录。
2、访问静态页面不需要经过程序处理,因此可以提高运行速度。
3、减轻服务器负担。
4、HTML页面不会受Asp相关漏洞的影响。
静态处理后的网站相对没有静态化处理的网站来讲还比较有安全性,因为静态网站是不会是黑客攻击的首选对象,因为黑客在不知道你后台系统的情况下,黑 客从前台的静态页面很难进行攻击。同时还具有一定的稳定性,比如数据库或者网站的程序出了问题,他不会干扰到静态处理后的页面,不会因为程序或数据影响而 打不开页面。
搜索引擎蜘蛛程序更喜欢这样的网址,也可以减轻蜘蛛程序的工作负担,虽然有的人会认为现在搜索引擎完全有能力去抓取和识别动态的网址,在这里还是建议大家能做成静态的尽量做成静态网址。
下面我们主要来讲一讲页面静态化这个概念,希望对你有所帮助!
什么是HTML静态化:
常说的页面静态化分为两种,一种是伪静态,即url 重写,一种是真静态化。
在PHP网站开发中为了网站推广和SEO等需要,需要对网站进行全站或局部静态化处理,PHP生成静态HTML页面有多种方法,比如利用PHP模板、缓存等实现页面静态化。
PHP静态化的简单理解就是使网站生成页面以静态HTML的形式展现在访客面前,PHP静态化分纯静态化和伪静态化,两者的区别在于PHP生成静态页面的处理机制不同。
PHP伪静态:利用Apache mod_rewrite实现URL重写的方法。
HTML静态化的好处:
一、减轻服务器负担,浏览网页无需调用系统数据库。
二、有利于搜索引擎优化SEO,Baidu、Google都会优先收录静态页面,不仅被收录的快还收录的全;
三、加快页面打开速度,静态页面无需连接数据库打开速度较动态页面有明显提高;
四、网站更安全,HTML页面不会受php程序相关漏洞的影响;观看一下大一点的网站基本全是静态页面,而且可以减少攻击,防sql注入。数据库出错时,不影响网站正常访问。
五、数据库出错时,不影响网站的正常访问。
最主要是可以增加访问速度,减轻服务器负担,当数据量有几万,几十万或是更多的时候你知道哪个更快了. 而且还容易被搜索引擎找到。生成html文章虽操作上麻烦些,程序上繁杂些,但为了更利于搜索,为了速度更快些,更安全,这些牺牲还是值得的。
实现HTML静态化的策略与实例讲解:
基本方式
file_put_contents()函数
使用php内置缓存机制实现页面静态化 —output-bufferring.
方法1:利用PHP模板生成静态页面
PHP模板实现静态化非常方便,比如安装和使用PHP Smarty实现网站静态化。
在使用Smarty的情况下,也可以实现页面静态化。下面先简单说一下使用Smarty时通常动态读取的做法。
一般分这几步:
1、通过URL传递一个参数(ID);
2、然后根据此ID查询数据库;
3、取得数据后根据需要修改显示内容;
4、assign需要显示的数据;
5、display模板文件。
Smarty静态化过程只需要在上述过程中添加两个步骤。
第一:在1之前使用 ob_start() 打开缓冲区。
第二:在5之后使用 ob_get_contents() 获取内存未输出内容,然后使用fwrite()将内容写入目标html文件。
根据上述描述,此过程是在网站前台实现的,而内容管理(添加、修改、删除)通常是在后台进行,为了能有效利用上述过程,可以使用一点小手段,那就是Header()。具体过程是这样的:在添加、修改程序完成之后,使用Header() 跳到前台读取,这样可以实现页面HTML化,然后在生成html后再跳回后台管理侧,而这两个跳转过程是不可见的。
方法2:使用PHP文件读写功能生成静态页面
<p style="padding: 0.5em;max-width: 100%;line-height: 18px;font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);margin-left: 16px;margin-right: 16px;box-sizing: border-box !important;overflow-wrap: normal !important;display: block !important;word-break: normal !important;overflow: auto !important;"><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /></p>
方法3:使用PHP输出控制函数(Output Control)/ob缓存机制生成静态页面
输出控制函数(Output Control)也就是使用和控制缓存来生成静态HTML页面,也会使用到PHP文件读写函数。
比如某个商品的动态详情页地址是:
那么这里我们根据这个地址读取一次这个详情页的内容,然后保存为静态页,下次有人访问这个商品详情页动态地址时,我们可以直接把已生成好的对应静态内容文件输出出来。
PHP生成静态页面实例代码 1
<p style="padding: 0.5em;max-width: 100%;line-height: 18px;font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);margin-left: 16px;margin-right: 16px;box-sizing: border-box !important;overflow-wrap: normal !important;display: block !important;word-break: normal !important;overflow: auto !important;"><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /></p>
PHP生成静态页面实例代码 2
<p style="padding: 0.5em;max-width: 100%;line-height: 18px;font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);margin-left: 16px;margin-right: 16px;box-sizing: border-box !important;overflow-wrap: normal !important;display: block !important;word-break: normal !important;overflow: auto !important;"><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /></p>
我们知道使用PHP进行网站开发,一般执行结果直接输出到游览器,为了使用PHP生成静态页面,就需要使用输出控制函数控制缓存区,以便获取缓存区的内容,然后再输出到静态HTML页面文件中以实现网站静态化。
PHP生成静态页面的思路为:首先开启缓存,然后输出了HTML内容(你也可以通过include将HTML内容以文件形式包含进来),之后获取缓存中的内容,清空缓存后通过PHP文件读写函数将缓存内容写入到静态HTML页面文件中。
获得输出的缓存内容以生成静态HTML页面的过程需要使用三个函数:ob_start()、ob_get_contents()、ob_end_clean()。
知识点:
1、ob_start函数一般主要是用来开启缓存,注意使用ob_start之前不能有任何输出,如空格、字符等。
2、ob_get_contents函数主要用来获取缓存中的内容以字符串形式返回,注意此函数必须在ob_end_clean函数之前调用,否则获取不到缓存内容。
3、ob_end_clean函数主要是清空缓存中的内容并关闭缓存,成功则返回True,失败则返回False
方法4:使用nosql从内存中读取内容(其实这个已经不算静态化了而是缓存);
以memcache为例:
<p style="padding: 0.5em;max-width: 100%;line-height: 18px;font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);margin-left: 16px;margin-right: 16px;box-sizing: border-box !important;overflow-wrap: normal !important;display: block !important;word-break: normal !important;overflow: auto !important;"><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /></p>
memcached是键值一一对应,key默认最大不能超过128个字节,value默认大小是1M,因此1M大小满足大多数网页大小的存储。
以上内容希望帮助到大家,有需要的可以添加下方二维码进群交流学习PHP中高级技术。
如果你想和PHP大神交流加微信,拉你入群
如果你想获得学习资料加微信,送你资源
扫码关注菲菲
php实战资源免费送
COME BABY
查看全部
PHP实现页面静态化
随着网站的内容的增多和用户访问量的增多,无可避免的是网站加载会越来越慢,受限于带宽和服务器同一时间的请求次数的限制,我们往往需要在此时对我们的网站进行代码优化和服务器配置的优化。
一般情况下会从以下方面来做优化
1、动态页面静态化
2、优化数据库
3、使用负载均衡
4、使用缓存
5、使用CDN加速
现在很多网站在建设的时候都要进行静态化的处理,为什么网站要进行静态化处理呢?我们都知道纯静态网站是所有的网页都是独立的一个html页面,当我们访问的时候不需要经过数据的处理直接就能读取到文件,访问速度就可想而知了,而其对于搜索引擎而言也是非常友好的一个方式。
纯静态网站在网站中是怎么实现的?
纯静态的制作技术是需要先把网站的页面总结出来,分为多少个样式,然后把这些页面做成模板,生成的时候需要先读取源文件然后生成独立的以.html结尾的页面文件,所以说纯静态网站需要更大的空间,不过其实需要的空间也不会大多少的,尤其是对于中小型企业网站来说,从技术上来讲,大型网站想要全站实现纯静态化是比较困难的,生成的时间也太过于长了。不过中小型网站还是做成纯静态的比较,这样做的优点是很多的。
而动态网站又是怎么进行静态处理的?
页面静态化是指将动态页面变成html/htm静态页面。动态页面一般由asp,php,jsp,.net等程序语言编写而成,非常便于管理。但是访问网页时还需要程序先处理一遍,所以导致访问速度相对较慢。而静态页面访问速度快,却又不便于管理。那么动态页面静态化即可以将两种页面的好处集中到一起。
静态处理后又给网站带来了哪些好处?
1、静态页面相对于动态页面更容易被搜索引擎收录。
2、访问静态页面不需要经过程序处理,因此可以提高运行速度。
3、减轻服务器负担。
4、HTML页面不会受Asp相关漏洞的影响。
静态处理后的网站相对没有静态化处理的网站来讲还比较有安全性,因为静态网站是不会是黑客攻击的首选对象,因为黑客在不知道你后台系统的情况下,黑 客从前台的静态页面很难进行攻击。同时还具有一定的稳定性,比如数据库或者网站的程序出了问题,他不会干扰到静态处理后的页面,不会因为程序或数据影响而 打不开页面。
搜索引擎蜘蛛程序更喜欢这样的网址,也可以减轻蜘蛛程序的工作负担,虽然有的人会认为现在搜索引擎完全有能力去抓取和识别动态的网址,在这里还是建议大家能做成静态的尽量做成静态网址。
下面我们主要来讲一讲页面静态化这个概念,希望对你有所帮助!
什么是HTML静态化:
常说的页面静态化分为两种,一种是伪静态,即url 重写,一种是真静态化。
在PHP网站开发中为了网站推广和SEO等需要,需要对网站进行全站或局部静态化处理,PHP生成静态HTML页面有多种方法,比如利用PHP模板、缓存等实现页面静态化。
PHP静态化的简单理解就是使网站生成页面以静态HTML的形式展现在访客面前,PHP静态化分纯静态化和伪静态化,两者的区别在于PHP生成静态页面的处理机制不同。
PHP伪静态:利用Apache mod_rewrite实现URL重写的方法。
HTML静态化的好处:
一、减轻服务器负担,浏览网页无需调用系统数据库。
二、有利于搜索引擎优化SEO,Baidu、Google都会优先收录静态页面,不仅被收录的快还收录的全;
三、加快页面打开速度,静态页面无需连接数据库打开速度较动态页面有明显提高;
四、网站更安全,HTML页面不会受php程序相关漏洞的影响;观看一下大一点的网站基本全是静态页面,而且可以减少攻击,防sql注入。数据库出错时,不影响网站正常访问。
五、数据库出错时,不影响网站的正常访问。
最主要是可以增加访问速度,减轻服务器负担,当数据量有几万,几十万或是更多的时候你知道哪个更快了. 而且还容易被搜索引擎找到。生成html文章虽操作上麻烦些,程序上繁杂些,但为了更利于搜索,为了速度更快些,更安全,这些牺牲还是值得的。
实现HTML静态化的策略与实例讲解:
基本方式
file_put_contents()函数
使用php内置缓存机制实现页面静态化 —output-bufferring.
方法1:利用PHP模板生成静态页面
PHP模板实现静态化非常方便,比如安装和使用PHP Smarty实现网站静态化。
在使用Smarty的情况下,也可以实现页面静态化。下面先简单说一下使用Smarty时通常动态读取的做法。
一般分这几步:
1、通过URL传递一个参数(ID);
2、然后根据此ID查询数据库;
3、取得数据后根据需要修改显示内容;
4、assign需要显示的数据;
5、display模板文件。
Smarty静态化过程只需要在上述过程中添加两个步骤。
第一:在1之前使用 ob_start() 打开缓冲区。
第二:在5之后使用 ob_get_contents() 获取内存未输出内容,然后使用fwrite()将内容写入目标html文件。
根据上述描述,此过程是在网站前台实现的,而内容管理(添加、修改、删除)通常是在后台进行,为了能有效利用上述过程,可以使用一点小手段,那就是Header()。具体过程是这样的:在添加、修改程序完成之后,使用Header() 跳到前台读取,这样可以实现页面HTML化,然后在生成html后再跳回后台管理侧,而这两个跳转过程是不可见的。
方法2:使用PHP文件读写功能生成静态页面
<p style="padding: 0.5em;max-width: 100%;line-height: 18px;font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);margin-left: 16px;margin-right: 16px;box-sizing: border-box !important;overflow-wrap: normal !important;display: block !important;word-break: normal !important;overflow: auto !important;"><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /></p>
方法3:使用PHP输出控制函数(Output Control)/ob缓存机制生成静态页面
输出控制函数(Output Control)也就是使用和控制缓存来生成静态HTML页面,也会使用到PHP文件读写函数。
比如某个商品的动态详情页地址是:
那么这里我们根据这个地址读取一次这个详情页的内容,然后保存为静态页,下次有人访问这个商品详情页动态地址时,我们可以直接把已生成好的对应静态内容文件输出出来。
PHP生成静态页面实例代码 1
<p style="padding: 0.5em;max-width: 100%;line-height: 18px;font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);margin-left: 16px;margin-right: 16px;box-sizing: border-box !important;overflow-wrap: normal !important;display: block !important;word-break: normal !important;overflow: auto !important;"><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /></p>
PHP生成静态页面实例代码 2
<p style="padding: 0.5em;max-width: 100%;line-height: 18px;font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);margin-left: 16px;margin-right: 16px;box-sizing: border-box !important;overflow-wrap: normal !important;display: block !important;word-break: normal !important;overflow: auto !important;"><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /></p>
我们知道使用PHP进行网站开发,一般执行结果直接输出到游览器,为了使用PHP生成静态页面,就需要使用输出控制函数控制缓存区,以便获取缓存区的内容,然后再输出到静态HTML页面文件中以实现网站静态化。
PHP生成静态页面的思路为:首先开启缓存,然后输出了HTML内容(你也可以通过include将HTML内容以文件形式包含进来),之后获取缓存中的内容,清空缓存后通过PHP文件读写函数将缓存内容写入到静态HTML页面文件中。
获得输出的缓存内容以生成静态HTML页面的过程需要使用三个函数:ob_start()、ob_get_contents()、ob_end_clean()。
知识点:
1、ob_start函数一般主要是用来开启缓存,注意使用ob_start之前不能有任何输出,如空格、字符等。
2、ob_get_contents函数主要用来获取缓存中的内容以字符串形式返回,注意此函数必须在ob_end_clean函数之前调用,否则获取不到缓存内容。
3、ob_end_clean函数主要是清空缓存中的内容并关闭缓存,成功则返回True,失败则返回False
方法4:使用nosql从内存中读取内容(其实这个已经不算静态化了而是缓存);
以memcache为例:
<p style="padding: 0.5em;max-width: 100%;line-height: 18px;font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);margin-left: 16px;margin-right: 16px;box-sizing: border-box !important;overflow-wrap: normal !important;display: block !important;word-break: normal !important;overflow: auto !important;"><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /></p>
memcached是键值一一对应,key默认最大不能超过128个字节,value默认大小是1M,因此1M大小满足大多数网页大小的存储。
以上内容希望帮助到大家,有需要的可以添加下方二维码进群交流学习PHP中高级技术。
如果你想和PHP大神交流加微信,拉你入群
如果你想获得学习资料加微信,送你资源
扫码关注菲菲
php实战资源免费送
COME BABY
php抓取网页title(一个开源的浏览器引擎,与之相对应的引擎有Gecko)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-04-13 17:19
WebKit是一个开源的浏览器引擎,对应的引擎有Gecko(Mozilla Firefox等使用)和Trident(又称MSHTML,IE使用)
参考来源:
代码示例:
phantomjs 和 slimerjs,都是服务端 js。简而言之,它们都封装了浏览器解析引擎。不同的是webkti是用phantomjs封装的,而slimerjs是用Gecko(firefox)封装的。权衡利弊后,我决定研究phantomjs,所以我使用phantomjs来生成网站快照。 phantomjs的项目地址是:
代码涉及两部分,一是设计业务的index.php,二是生成快照的js脚本snapshot.js。代码比较简单,只是实现功能,没有做太多修改。代码如下:
php:
html
快照生成
* {
margin: 0;
padding: 0;
}
form {
padding: 20px;
}
div {
margin: 20px 0 0;
}
input {
width: 200px;
padding: 4px 2px;
}
#placeholder {
display: none;
}
生成快照
$(function(){
$('#form').submit(function(){
if (typeof($(this).data('generate')) !== 'undefined' && $(this).data('generate') === true)
{
alert('正在生成网站快照,请耐心等待...');
return false;
}
$(this).data('generate', true);
$('button').text('正在生成快照...').attr('disabled', true);
$.ajax({
type: 'GET',
url: '?',
data: 'url=' + $('#url').val(),
success: function(data){
$('#placeholder').attr('src', data).show();
$('#form').data('generate', false);
$('button').text('生成快照').attr('disabled', false);
}
});
return false;
});
});
php使用CutyCapt实现网页高清截图:
网页截图功能,必须安装IE+CutyCapturl:要截图的网页:图片保存路径路径:CutyCapt路径cmd:CutyCapt执行命令如:你的php path.php?url=
CutyCapt下载地址:http://sourceforge.net/project ... capt/
windows的不用安装的,直接下载解压放到相对应的路径即可
linux安装CutyCapt教程:http://niutuku9.com/tech/php/273578.shtml
组织参考来自:软联盟 查看全部
php抓取网页title(一个开源的浏览器引擎,与之相对应的引擎有Gecko)
WebKit是一个开源的浏览器引擎,对应的引擎有Gecko(Mozilla Firefox等使用)和Trident(又称MSHTML,IE使用)
参考来源:
代码示例:
phantomjs 和 slimerjs,都是服务端 js。简而言之,它们都封装了浏览器解析引擎。不同的是webkti是用phantomjs封装的,而slimerjs是用Gecko(firefox)封装的。权衡利弊后,我决定研究phantomjs,所以我使用phantomjs来生成网站快照。 phantomjs的项目地址是:
代码涉及两部分,一是设计业务的index.php,二是生成快照的js脚本snapshot.js。代码比较简单,只是实现功能,没有做太多修改。代码如下:
php:
html
快照生成
* {
margin: 0;
padding: 0;
}
form {
padding: 20px;
}
div {
margin: 20px 0 0;
}
input {
width: 200px;
padding: 4px 2px;
}
#placeholder {
display: none;
}
生成快照
$(function(){
$('#form').submit(function(){
if (typeof($(this).data('generate')) !== 'undefined' && $(this).data('generate') === true)
{
alert('正在生成网站快照,请耐心等待...');
return false;
}
$(this).data('generate', true);
$('button').text('正在生成快照...').attr('disabled', true);
$.ajax({
type: 'GET',
url: '?',
data: 'url=' + $('#url').val(),
success: function(data){
$('#placeholder').attr('src', data).show();
$('#form').data('generate', false);
$('button').text('生成快照').attr('disabled', false);
}
});
return false;
});
});
php使用CutyCapt实现网页高清截图:
网页截图功能,必须安装IE+CutyCapturl:要截图的网页:图片保存路径路径:CutyCapt路径cmd:CutyCapt执行命令如:你的php path.php?url=
CutyCapt下载地址:http://sourceforge.net/project ... capt/
windows的不用安装的,直接下载解压放到相对应的路径即可
linux安装CutyCapt教程:http://niutuku9.com/tech/php/273578.shtml
组织参考来自:软联盟
php抓取网页title(2022-01-20众所周周,网站的标题来自网页的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-04-04 09:00
2022-01-20
众所周知,网站的标题来自于网页的标题标签。谷歌这样做了,百度更是如此。TITLE 在搜索结果页面上显示 网站 标题方面起着关键作用。,如果这段代码出现在网页中间,一旦页面是收录,在搜索结果的显示页面中,我们面前的标题当然是不可思议的网站TITLE,但随着搜索引擎算法的不断合理化和各种因素的调整,对SEO提出了更高的要求。让我们看下面的例子:
上图是搜索“经典家具”的自然结果。可以看第二条,标题是公司名,但是没有描述,所以我们打开他的网站:
我们可以清楚的看到网站的标题:华艺家具文化艺术馆,和搜索结果不一样。标题标签有什么神秘之处吗?我们来看看他的源文件:
网页的源码很清楚,和网站的标题一样,只是没有说明。验证了两点:1、网站本身没有优化,标题标签没有问题2、没有描述,所以搜索结果中没有对应的显示内容(很可怕的)。所以也说明了本文的问题文章:为什么网站的TITLE标签的内容没有被搜索引擎抓取,哪些因素影响了搜索引擎的抓取?我认为主要原因如下:
1、网站本身的原因:打开这个网站,首页是flash,非常不利于搜索引擎抓取。首页上可供爬取的信息只有title和keywords,也就是说搜索引擎不可能根据网站的title来爬取。(这个域名已经很老了,域名本身的权重会增加。相信如果新站也采用这种方式的话,搜索引擎会很难爬到)
2、外部原因:
既然搜索引擎有收录网站,我们可以搜索网站的域名,不难发现公司名是伴随频率最高的域名,而不是 网站 标题。如果所有的外部链接都能使用正确的锚文本,相信搜索结果会得到更好的体现。
搜索引擎的智能化也是我们不能忽视的一个方面,也就是我们所说的“算法”或“机制”。搜索引擎获取网站的方式并不固定。当搜索引擎无法获取 网站 本身的信息时,它们会定期从整个网页集合中采集信息。从这个角度来看,搜索引擎已经人性化了。当它无法理解你时,它会回到网站的成长阶段,发现更多、更有效、更准确的关于你的信息。
这个案例告诉我们,搜索引擎对SEO提出了更高的要求,人性化的优化会越来越受到主流搜索引擎的欢迎,单纯堆叠关键词和链接字段的作弊手段也越来越多。 . 搜索引擎发现并处罚。建立一个网站不会在一夜之间发生,SEO 也是如此。
分类:
技术要点:
相关文章: 查看全部
php抓取网页title(2022-01-20众所周周,网站的标题来自网页的)
2022-01-20
众所周知,网站的标题来自于网页的标题标签。谷歌这样做了,百度更是如此。TITLE 在搜索结果页面上显示 网站 标题方面起着关键作用。,如果这段代码出现在网页中间,一旦页面是收录,在搜索结果的显示页面中,我们面前的标题当然是不可思议的网站TITLE,但随着搜索引擎算法的不断合理化和各种因素的调整,对SEO提出了更高的要求。让我们看下面的例子:
上图是搜索“经典家具”的自然结果。可以看第二条,标题是公司名,但是没有描述,所以我们打开他的网站:
我们可以清楚的看到网站的标题:华艺家具文化艺术馆,和搜索结果不一样。标题标签有什么神秘之处吗?我们来看看他的源文件:
网页的源码很清楚,和网站的标题一样,只是没有说明。验证了两点:1、网站本身没有优化,标题标签没有问题2、没有描述,所以搜索结果中没有对应的显示内容(很可怕的)。所以也说明了本文的问题文章:为什么网站的TITLE标签的内容没有被搜索引擎抓取,哪些因素影响了搜索引擎的抓取?我认为主要原因如下:
1、网站本身的原因:打开这个网站,首页是flash,非常不利于搜索引擎抓取。首页上可供爬取的信息只有title和keywords,也就是说搜索引擎不可能根据网站的title来爬取。(这个域名已经很老了,域名本身的权重会增加。相信如果新站也采用这种方式的话,搜索引擎会很难爬到)
2、外部原因:
既然搜索引擎有收录网站,我们可以搜索网站的域名,不难发现公司名是伴随频率最高的域名,而不是 网站 标题。如果所有的外部链接都能使用正确的锚文本,相信搜索结果会得到更好的体现。
搜索引擎的智能化也是我们不能忽视的一个方面,也就是我们所说的“算法”或“机制”。搜索引擎获取网站的方式并不固定。当搜索引擎无法获取 网站 本身的信息时,它们会定期从整个网页集合中采集信息。从这个角度来看,搜索引擎已经人性化了。当它无法理解你时,它会回到网站的成长阶段,发现更多、更有效、更准确的关于你的信息。
这个案例告诉我们,搜索引擎对SEO提出了更高的要求,人性化的优化会越来越受到主流搜索引擎的欢迎,单纯堆叠关键词和链接字段的作弊手段也越来越多。 . 搜索引擎发现并处罚。建立一个网站不会在一夜之间发生,SEO 也是如此。
分类:
技术要点:
相关文章:
php抓取网页title(开源库PHPDOMParser的核心代码解析方法解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-04-03 10:27
GitHub:github_trending_crawler
介绍
由于GitHub官方提供的API不收录GitHub Trending相关接口,作为好学的开发者,大家都会关注Trending Trending,获取GitHub上相关编程语言的最新项目和开发者。此外,我们在开发第三方 GitHub App 时,通常还需要展示 Trending 数据。如果我们直接在客户端捕获解析,那就吃力不讨好,国内访问速度慢。这时,服务器需要提供相关的接口来解决问题。.
本仓库提供了一个小型的PHP爬虫,用于周期性的抓取和解析服务器上的GitHub Trending数据并缓存,从而为客户端提供一个快速(秒级)的查询接口。可以从Daily、Weekly、Monthly三个维度抓取各种编程语言中最受关注的Repositories和Developers。
阐明
这个小爬虫的核心代码主要是爬虫文件夹下的simple_html_dom.php和github_trending_crawler.php这两个文件。
simple_html_dom.php
该文件来自开源库PHP Simple HTML DOM Parser,提供了简单易用、功能强大的HTML DOM解析方法,方便我们使用PHP抓取网页的HTML并进行分析.
github_trending_crawler.php
该文件主要用于抓取和解析 GitHub Trending 数据,包括以下方法:
该方法需要传入一个url参数,用于获取指定url下的HTML,并返回一个simple_html_dom对象,方便后续解析HTML中不同标签中的数据。
该方法用于获取GitHub Trending页面右侧推荐的当前流行编程语言(注意:每个人在登录状态下看到的结果可能会有所不同,此方法是在未登录时捕获的) ,并返回一个languages数组,数组中的每一项都收录name和id两个字段,大致如下:
1
{"languages":[{"name":"C++","id":"c++"},{"name":"PHP","id":"php"}, ... ]}
该方法用于获取 GitHub 的所有编程语言,同时返回一个结构类似上述的语言数组。
该方法接收两个参数lang和since,其中lang的值来自上述语言返回的id,since的值包括daily、weekly、monthly,用于获取指定时间内最关注的编程语言方面。的开源项目,返回一个仓库数组,大致如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
{
"repositories": [{
"author": "airbnb",
"title": "lottie-ios",
"url": "https://github.com/airbnb/lottie-ios",
"description": "An iOS library to natively render After Effects vector animations",
"language": "Objective-C",
"stars": "13,084",
"forks": "1,683",
"newStars": "25 stars today",
"contributors": [{
"id": "buba447",
"avatar": "https://avatars1.githubusercon ... ot%3B
}, {
"id": "welshm",
"avatar": "https://avatars0.githubusercon ... ot%3B
}, {
"id": "valeriyvan",
"avatar": "https://avatars0.githubusercon ... ot%3B
}, {
"id": "hansemannn",
"avatar": "https://avatars3.githubusercon ... ot%3B
}, {
"id": "fnazrala",
"avatar": "https://avatars2.githubusercon ... ot%3B
}]
},
...
]}
该方法还接收两个参数lang和since,其值类似于gt_get_repositories()方法的值。用于获取一种编程语言在指定时间维度下最受欢迎的开发者,并返回一个开发者数组,大致如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
{
"developers": [{
"url": "https://github.com\/facebook",
"avatar": "https://avatars2.githubusercon ... ot%3B,
"name": "Facebook",
"id": "facebook",
"repository": {
"url": "https://github.com/facebook/Shimmer",
"title": "Shimmer",
"desp": "An easy way to add a simple, shimmering effect to any view in an iOS app."
}
},
...
]}
注意:如果 GitHub Trending 访问失败、超时,或者页面没有某个维度的数据,或者解析异常,上述方法会返回 null,如果 GitHub Trending 页面的 HTML 结构发生变化以后,上述方法的解析逻辑也应该做相应的修改。
使用示例
为了方便正确使用github_trending_crawler.php,我写了一个示例脚本example.php,
把爬虫文件夹和example.php文件放到你的Web目录下,访问如下URL路径,就可以得到对应的结果。具体逻辑请参考example.php文件,不再赘述(在PHP 5. 6 测试通过)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// 默认获取今日所有编程语言下开源项目的 Trending 数据
https://path/to/example.php
// 获取今日 Swift 语言下开源项目的 Trending 数据
https://path/to/example.php%3F ... daily
// 获取本月 Swift 语言下开源项目的 Trending 数据
https://path/to/example.php%3F ... nthly
// 获取本周 Objective-C 语言下开发者的 Trending 数据
https://path/to/example.php%3F ... eekly
// 获取最受关注的编程语言和所有的编程语言列表
https://path/to/example.php?action=top_languages
https://path/to/example.php?action=all_languages
其中,URL的查询请求参数默认值如下:
当然,每次访问example.php脚本都实时取数据显然是很费时间的,而且GitHub Trending页面的更新频率也不是很快,所以我们可以通过Redis将数据缓存在服务器端,下次访问,如果缓存中有数据,直接返回,可以大大提高访问速度。有关详细信息,请参阅 example_with_redis.php 文件。
另外,你可以在你的服务器上启动一些crontab定时任务,定时抓取数据更新缓存,这样提供给客户端的接口可以快速响应。
请注意,如果您的 PHP 脚本在执行过程中报告以下错误:
1
file_get_contents(): SSL operation failed with code 1. OpenSSL Error messages: error:1407742E:SSL routines:SSL23_GET_SERVER_HELLO:tlsv1 alert protocol version in /path/to/simple_html_dom.php on line 75.
这是因为自 2018 年 2 月 1 日起,GitHub 将 HTTPS 访问限制为仅 TLSv1.2,请参阅此处了解详细信息,因此您可能需要更新服务器的 OpenSSL 版本。
测试界面
为了让大家更直观的感受一下上面这个小爬虫的效果,我在自己的服务器上部署了一个环境。您可以直接访问以下示例 URL 以获取相关结果:
// 默认获取所有编程语言的开源项目今日趋势数据
// 获取当今 Swift 语言开源项目的 Trending 数据
// 获取本月 Swift 语言开源项目的 Trending 数据
// 获取本周开发者在 Objective-C 中的 Trending 数据
// 获取最受关注的编程语言列表
// 获取所有编程语言的列表
重要提示:第一次访问上述接口获取相关数据时,如果缓存中有数据,则直接返回;如果缓存中没有数据,则会实时抓取GitHub Trending页面数据进行解析和缓存。这时候界面返回的速度会变慢。另外,因为是用来测试的,一旦缓存了数据,我并没有定期更新,所以上面测试接口返回的数据有时可能会过期。
!!!以上界面仅供大家体验,不建议直接在你的服务或app中使用,因为我随时可能离线。
顺便一提
如果你问我为什么我用 PHP 而不是 Python 来写爬虫,那当然是因为 PHP...
图片来自《神秘程序员》
执照
这个存储库是在 MIT 许可下发布的。有关详细信息,请参阅许可证。 查看全部
php抓取网页title(开源库PHPDOMParser的核心代码解析方法解析)
GitHub:github_trending_crawler
介绍
由于GitHub官方提供的API不收录GitHub Trending相关接口,作为好学的开发者,大家都会关注Trending Trending,获取GitHub上相关编程语言的最新项目和开发者。此外,我们在开发第三方 GitHub App 时,通常还需要展示 Trending 数据。如果我们直接在客户端捕获解析,那就吃力不讨好,国内访问速度慢。这时,服务器需要提供相关的接口来解决问题。.
本仓库提供了一个小型的PHP爬虫,用于周期性的抓取和解析服务器上的GitHub Trending数据并缓存,从而为客户端提供一个快速(秒级)的查询接口。可以从Daily、Weekly、Monthly三个维度抓取各种编程语言中最受关注的Repositories和Developers。
阐明
这个小爬虫的核心代码主要是爬虫文件夹下的simple_html_dom.php和github_trending_crawler.php这两个文件。
simple_html_dom.php
该文件来自开源库PHP Simple HTML DOM Parser,提供了简单易用、功能强大的HTML DOM解析方法,方便我们使用PHP抓取网页的HTML并进行分析.
github_trending_crawler.php
该文件主要用于抓取和解析 GitHub Trending 数据,包括以下方法:
该方法需要传入一个url参数,用于获取指定url下的HTML,并返回一个simple_html_dom对象,方便后续解析HTML中不同标签中的数据。
该方法用于获取GitHub Trending页面右侧推荐的当前流行编程语言(注意:每个人在登录状态下看到的结果可能会有所不同,此方法是在未登录时捕获的) ,并返回一个languages数组,数组中的每一项都收录name和id两个字段,大致如下:
1
{"languages":[{"name":"C++","id":"c++"},{"name":"PHP","id":"php"}, ... ]}
该方法用于获取 GitHub 的所有编程语言,同时返回一个结构类似上述的语言数组。
该方法接收两个参数lang和since,其中lang的值来自上述语言返回的id,since的值包括daily、weekly、monthly,用于获取指定时间内最关注的编程语言方面。的开源项目,返回一个仓库数组,大致如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
{
"repositories": [{
"author": "airbnb",
"title": "lottie-ios",
"url": "https://github.com/airbnb/lottie-ios",
"description": "An iOS library to natively render After Effects vector animations",
"language": "Objective-C",
"stars": "13,084",
"forks": "1,683",
"newStars": "25 stars today",
"contributors": [{
"id": "buba447",
"avatar": "https://avatars1.githubusercon ... ot%3B
}, {
"id": "welshm",
"avatar": "https://avatars0.githubusercon ... ot%3B
}, {
"id": "valeriyvan",
"avatar": "https://avatars0.githubusercon ... ot%3B
}, {
"id": "hansemannn",
"avatar": "https://avatars3.githubusercon ... ot%3B
}, {
"id": "fnazrala",
"avatar": "https://avatars2.githubusercon ... ot%3B
}]
},
...
]}
该方法还接收两个参数lang和since,其值类似于gt_get_repositories()方法的值。用于获取一种编程语言在指定时间维度下最受欢迎的开发者,并返回一个开发者数组,大致如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
{
"developers": [{
"url": "https://github.com\/facebook",
"avatar": "https://avatars2.githubusercon ... ot%3B,
"name": "Facebook",
"id": "facebook",
"repository": {
"url": "https://github.com/facebook/Shimmer",
"title": "Shimmer",
"desp": "An easy way to add a simple, shimmering effect to any view in an iOS app."
}
},
...
]}
注意:如果 GitHub Trending 访问失败、超时,或者页面没有某个维度的数据,或者解析异常,上述方法会返回 null,如果 GitHub Trending 页面的 HTML 结构发生变化以后,上述方法的解析逻辑也应该做相应的修改。
使用示例
为了方便正确使用github_trending_crawler.php,我写了一个示例脚本example.php,
把爬虫文件夹和example.php文件放到你的Web目录下,访问如下URL路径,就可以得到对应的结果。具体逻辑请参考example.php文件,不再赘述(在PHP 5. 6 测试通过)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// 默认获取今日所有编程语言下开源项目的 Trending 数据
https://path/to/example.php
// 获取今日 Swift 语言下开源项目的 Trending 数据
https://path/to/example.php%3F ... daily
// 获取本月 Swift 语言下开源项目的 Trending 数据
https://path/to/example.php%3F ... nthly
// 获取本周 Objective-C 语言下开发者的 Trending 数据
https://path/to/example.php%3F ... eekly
// 获取最受关注的编程语言和所有的编程语言列表
https://path/to/example.php?action=top_languages
https://path/to/example.php?action=all_languages
其中,URL的查询请求参数默认值如下:
当然,每次访问example.php脚本都实时取数据显然是很费时间的,而且GitHub Trending页面的更新频率也不是很快,所以我们可以通过Redis将数据缓存在服务器端,下次访问,如果缓存中有数据,直接返回,可以大大提高访问速度。有关详细信息,请参阅 example_with_redis.php 文件。
另外,你可以在你的服务器上启动一些crontab定时任务,定时抓取数据更新缓存,这样提供给客户端的接口可以快速响应。
请注意,如果您的 PHP 脚本在执行过程中报告以下错误:
1
file_get_contents(): SSL operation failed with code 1. OpenSSL Error messages: error:1407742E:SSL routines:SSL23_GET_SERVER_HELLO:tlsv1 alert protocol version in /path/to/simple_html_dom.php on line 75.
这是因为自 2018 年 2 月 1 日起,GitHub 将 HTTPS 访问限制为仅 TLSv1.2,请参阅此处了解详细信息,因此您可能需要更新服务器的 OpenSSL 版本。
测试界面
为了让大家更直观的感受一下上面这个小爬虫的效果,我在自己的服务器上部署了一个环境。您可以直接访问以下示例 URL 以获取相关结果:
// 默认获取所有编程语言的开源项目今日趋势数据
// 获取当今 Swift 语言开源项目的 Trending 数据
// 获取本月 Swift 语言开源项目的 Trending 数据
// 获取本周开发者在 Objective-C 中的 Trending 数据
// 获取最受关注的编程语言列表
// 获取所有编程语言的列表
重要提示:第一次访问上述接口获取相关数据时,如果缓存中有数据,则直接返回;如果缓存中没有数据,则会实时抓取GitHub Trending页面数据进行解析和缓存。这时候界面返回的速度会变慢。另外,因为是用来测试的,一旦缓存了数据,我并没有定期更新,所以上面测试接口返回的数据有时可能会过期。
!!!以上界面仅供大家体验,不建议直接在你的服务或app中使用,因为我随时可能离线。
顺便一提
如果你问我为什么我用 PHP 而不是 Python 来写爬虫,那当然是因为 PHP...
图片来自《神秘程序员》
执照
这个存储库是在 MIT 许可下发布的。有关详细信息,请参阅许可证。
php抓取网页title(编程要求请仔细阅读代码代码进行测试:预期输出:html加载 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-03-30 07:14
)
内容
任务详情
这一关的任务:编写一个爬虫来爬取网页的标题。
相关信息
为了完成这个任务,需要几个基本技能。首先,你需要对 Python 语言有一定的掌握。了解其中的 Urllib 库、Re 库、Random 库。其中,Urllib库主要实现网页的爬取。Re 库实现了数据的正则化表示。Random 库实现数据的随机生成。
网络爬虫是根据一定的规则自动爬取互联网信息的程序或脚本。爬虫的行为可以分为三个部分:
网络爬虫
在使用Python进行数据爬取的过程中,我们首先需要了解爬虫的基本技能树,包括静态网页采集。动态网页采集,爬虫框架设计和数据存储。
在获取静态网页的过程中,需要涉及到正则化规则和一些Python库。比如 Request 和 beautifulSoup。在动态网页爬取过程中,需要解决验证码的自动识别问题。在爬虫框架设计过程中,需要掌握Pyspider和Scrapy。在数据存储过程中,需要掌握CSV、EXCEL TXT等格式文件和MongDB等数据库。
网络爬虫:加载
加载是将目标网站数据下载到本地。主要步骤如下:
实际操作:抓取静态网页步骤
网络爬虫:动态加载
有些页面的数据是动态加载的,比如Ajax异步请求。网页中的一些数据需要浏览器渲染或者用户的某些点击和下拉操作触发,即Ajax异步请求。
当面对动态加载的页面时,我们可以通过抓包工具分析某个操作触发的请求,并使用智能工具:selenium + webdriver,通过代码实现对应的请求。
网络爬虫:解析
从加载的结果中提取特定数据。加载的结果主要分为三类:html、json、xml。
编程要求
请仔细阅读右侧代码,结合相关知识,补充Begin-End区代码,编写爬虫爬取网页标题。具体要求如下:
测试介绍
该平台测试您编写的代码:
预期输出:
html获取成功的标题匹配成功
import urllib.request
import csv
import re
#打开京东,读取并爬到内存中,解码, 并赋值给data
#将data保存到本地
# ********** Begin ********** #
data=urllib.request.urlopen("http://www.jd.com").read().decode("utf-8","ignore")
urllib.request.urlretrieve("http://www.jd.com",filename="./step1/京东.html")
# ********** End ********** #
#使用正则提取title
#保存数据到csv文件中
# ********** Begin ********** #
pattern="(.*?)"
title=set(re.compile(pattern,re.S).findall(data))
with open("./step1/csv_file.csv", 'w') as f:
f_csv = csv.writer(f)
f_csv.writerow(title)
# ********** End ********** # 查看全部
php抓取网页title(编程要求请仔细阅读代码代码进行测试:预期输出:html加载
)
内容
任务详情
这一关的任务:编写一个爬虫来爬取网页的标题。
相关信息
为了完成这个任务,需要几个基本技能。首先,你需要对 Python 语言有一定的掌握。了解其中的 Urllib 库、Re 库、Random 库。其中,Urllib库主要实现网页的爬取。Re 库实现了数据的正则化表示。Random 库实现数据的随机生成。
网络爬虫是根据一定的规则自动爬取互联网信息的程序或脚本。爬虫的行为可以分为三个部分:
网络爬虫
在使用Python进行数据爬取的过程中,我们首先需要了解爬虫的基本技能树,包括静态网页采集。动态网页采集,爬虫框架设计和数据存储。
在获取静态网页的过程中,需要涉及到正则化规则和一些Python库。比如 Request 和 beautifulSoup。在动态网页爬取过程中,需要解决验证码的自动识别问题。在爬虫框架设计过程中,需要掌握Pyspider和Scrapy。在数据存储过程中,需要掌握CSV、EXCEL TXT等格式文件和MongDB等数据库。
网络爬虫:加载
加载是将目标网站数据下载到本地。主要步骤如下:
实际操作:抓取静态网页步骤
网络爬虫:动态加载
有些页面的数据是动态加载的,比如Ajax异步请求。网页中的一些数据需要浏览器渲染或者用户的某些点击和下拉操作触发,即Ajax异步请求。
当面对动态加载的页面时,我们可以通过抓包工具分析某个操作触发的请求,并使用智能工具:selenium + webdriver,通过代码实现对应的请求。
网络爬虫:解析
从加载的结果中提取特定数据。加载的结果主要分为三类:html、json、xml。
编程要求
请仔细阅读右侧代码,结合相关知识,补充Begin-End区代码,编写爬虫爬取网页标题。具体要求如下:
测试介绍
该平台测试您编写的代码:
预期输出:
html获取成功的标题匹配成功
import urllib.request
import csv
import re
#打开京东,读取并爬到内存中,解码, 并赋值给data
#将data保存到本地
# ********** Begin ********** #
data=urllib.request.urlopen("http://www.jd.com";).read().decode("utf-8","ignore")
urllib.request.urlretrieve("http://www.jd.com",filename="./step1/京东.html")
# ********** End ********** #
#使用正则提取title
#保存数据到csv文件中
# ********** Begin ********** #
pattern="(.*?)"
title=set(re.compile(pattern,re.S).findall(data))
with open("./step1/csv_file.csv", 'w') as f:
f_csv = csv.writer(f)
f_csv.writerow(title)
# ********** End ********** #
php抓取网页title(Javaexample参数分析及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-25 12:07
PhantomJS 是一个基于 WebKit 的服务器端 API。它完全支持没有浏览器支持的 Web,并且速度很快并且原生支持各种 Web 标准:DOM 操作、CSS 选择器、JSON、Canvas 和 SVG。PhantomJS 可用于页面自动化、网络监控、网页截图和无界面测试。
一、安装
安装包下载地址:,包括Windows、Mac OS、Linux版本,可以选择对应的版本下载解压(为了方便可以自己设置phantomjs的环境变量),里面有一个example文件夹,里面有很多写的好用的代码。本文假设 phantomjs 已经安装并设置了环境变量。
二、使用你好,世界!
使用以下两行脚本创建一个新的文本文件:
console.log('Hello, world!');
phantom.exit();
将文件保存为 hello.js,然后执行它:
phantomjs hello.js
输出是:你好,世界!
第一行将字符串打印到终端,第二行 phantom.exit 将退出。
在这个脚本中调用 phantom.exit 非常重要,否则 PhantomJS 根本不会停止。
脚本参数 – 脚本参数
Phantomjs如何传递参数?如下:
phantomjs examples/arguments.js foo bar baz
其中,foo、bar、baz是要传递的参数。如何获得它们:
var system = require('system');
if (system.args.length === 1) {
console.log('Try to pass some args when invoking this script!');
} else {
system.args.forEach(function (arg, i) {
console.log(i + ': ' + arg);
});
}
phantom.exit();
它将输出:
0: foo
1: bar
2: baz
页面加载——页面加载
通过创建网页对象,可以加载、解析和呈现网页。
以下脚本显示了示例页面对象的最简单用法,它加载它并将其保存为图像 example.png。
var page = require('webpage').create();
page.open('http://example.com', function () {
page.render('example.png');
phantom.exit();
});
因为这个特性,PhantomJS可以用来对网页进行截图,对一些内容进行快照,比如将网页、SVG保存为图片、PDF等。这个功能非常好。
下一个 loadspeed.js 脚本加载一个特殊的 URL(不要忘记 http 协议)并测量加载页面的时间。
var page = require('webpage').create(),
system = require('system'),
t, address;
if (system.args.length === 1) {
console.log('Usage: loadspeed.js ');
phantom.exit();
}
t = Date.now();
address = system.args[1];
page.open(address, function (status) {
if (status !== 'success') {
console.log('FAIL to load the address');
} else {
t = Date.now() - t;
console.log('Loading time ' + t + ' msec');
}
phantom.exit();
});
在命令行运行脚本:
phantomjs loadspeed.js http://www.google.com
它输出如下内容:
加载加载时间 719 毫秒
代码评估 - 代码评估
要在网页上下文中评估 JavaScript 或 CoffeeScript,请使用 evaluate() 方法。代码在“沙箱”中运行,它无法读取其所属页面上下文之外的任何 JavaScript 对象和变量。evaluate() 将返回一个对象,但它仅限于简单对象,不能收录方法或闭包。
这是显示页面标题的示例:
var page = require('webpage').create();
page.open(url, function (status) {
var title = page.evaluate(function () {
return document.title;
});
console.log('Page title is ' + title);
});
默认情况下,不会显示来自网页并收录evaluate() 内部代码的任何控制台消息。要覆盖此行为,使用 onConsoleMessage 回调函数,可以将前面的示例重写为:
var page = require('webpage').create();
page.onConsoleMessage = function (msg) {
console.log('Page title is ' + msg);
};
page.open(url, function (status) {
page.evaluate(function () {
console.log(document.title);
});
});
DOM 操作 – DOM 操作
由于该脚本似乎在 Web 浏览器上运行,因此标准 DOM 脚本和 CSS 选择器可以正常工作。这使得 PhantomJS 适合支持各种页面自动化任务。
以下 useragent.js 将读取 id 为 myagent 的元素的 textContent 属性:
var page = require('webpage').create();
console.log('The default user agent is ' + page.settings.userAgent);
page.settings.userAgent = 'SpecialAgent';
page.open('http://www.httpuseragent.org', function (status) {
if (status !== 'success') {
console.log('Unable to access network');
} else {
var ua = page.evaluate(function () {
return document.getElementById('myagent').textContent;
});
console.log(ua);
}
phantom.exit();
});
上面的示例还提供了一种自定义用户代理的方法。
使用 JQuery 和其他库:
var page = require('webpage').create();
page.open('http://www.sample.com', function() {
page.includeJs("http://ajax.googleapis.com/aja ... ot%3B, function() {
page.evaluate(function() {
$("button").click();
});
phantom.exit()
});
});
网络请求和响应——网络请求和响应
当页面向远程服务器请求资源时,可以通过 onResourceRequested 和 onResourceReceived 回调方法跟踪请求和响应。示例 netlog.js:
var page = require('webpage').create();
page.onResourceRequested = function (request) {
console.log('Request ' + JSON.stringify(request, undefined, 4));
};
page.onResourceReceived = function (response) {
console.log('Receive ' + JSON.stringify(response, undefined, 4));
};
page.open(url);
有关如何将此功能用于 HAR 输出和基于 YSlow 的性能分析的更多信息,请参阅网络监控页面。
PhantomJs官网:
GitHub:
以上帮助说明来自woiweb:
windows下使用php执行phantomjs
下面直接给出执行代码:
echo '';
exec('H:wampwwwphantomjsinphantomjs --output-encoding=utf8 H:wampwwwXss_Scanner est.js ',$output_main);
var_dump($output_main);
// $str = implode('',$output_main);
// var_dump($str);
test.js 文件内容如下:
console.log('Loading a web page');
var page = require('webpage').create();
var url = 'http://www.mafutian.net/';
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
console.log(page.content);
}
phantom.exit();
});
执行结果如下图所示:
请注意,要实现上述执行结果,需要以下几点:
(1)PHP的安全模式不能开启,即需要在php.ini中将sql.safe_mode设置为Off。(并且重启服务器,当然php本身并没有开启安全模式)默认模式)
(2)无论phantomjs是否加入系统环境变量,都应该是exec()中的绝对路径,以下执行无效:
exec('phantomjs --output-encoding=utf8 H:wampwwwXss_Scanner est.js ',$output_main);
你需要走phantomjs的绝对路径。
需要注意的是,js文件不能走绝对路径。可以相对于网站根目录,如下执行成功:
exec('H:wampwwwphantomjsinphantomjs --output-encoding=utf8 test.js ',$output_main);
注意:test.js 放在网站 的根目录下。
另外:PHP下执行phantomjs也可以使用另外一个函数systom()来执行
以上内容参考:链接地址:
php-phantomjs中文API整理的合集DEMO
<p> 查看全部
php抓取网页title(Javaexample参数分析及应用)
PhantomJS 是一个基于 WebKit 的服务器端 API。它完全支持没有浏览器支持的 Web,并且速度很快并且原生支持各种 Web 标准:DOM 操作、CSS 选择器、JSON、Canvas 和 SVG。PhantomJS 可用于页面自动化、网络监控、网页截图和无界面测试。
一、安装
安装包下载地址:,包括Windows、Mac OS、Linux版本,可以选择对应的版本下载解压(为了方便可以自己设置phantomjs的环境变量),里面有一个example文件夹,里面有很多写的好用的代码。本文假设 phantomjs 已经安装并设置了环境变量。
二、使用你好,世界!
使用以下两行脚本创建一个新的文本文件:
console.log('Hello, world!');
phantom.exit();
将文件保存为 hello.js,然后执行它:
phantomjs hello.js
输出是:你好,世界!
第一行将字符串打印到终端,第二行 phantom.exit 将退出。
在这个脚本中调用 phantom.exit 非常重要,否则 PhantomJS 根本不会停止。
脚本参数 – 脚本参数
Phantomjs如何传递参数?如下:
phantomjs examples/arguments.js foo bar baz
其中,foo、bar、baz是要传递的参数。如何获得它们:
var system = require('system');
if (system.args.length === 1) {
console.log('Try to pass some args when invoking this script!');
} else {
system.args.forEach(function (arg, i) {
console.log(i + ': ' + arg);
});
}
phantom.exit();
它将输出:
0: foo
1: bar
2: baz
页面加载——页面加载
通过创建网页对象,可以加载、解析和呈现网页。
以下脚本显示了示例页面对象的最简单用法,它加载它并将其保存为图像 example.png。
var page = require('webpage').create();
page.open('http://example.com', function () {
page.render('example.png');
phantom.exit();
});
因为这个特性,PhantomJS可以用来对网页进行截图,对一些内容进行快照,比如将网页、SVG保存为图片、PDF等。这个功能非常好。
下一个 loadspeed.js 脚本加载一个特殊的 URL(不要忘记 http 协议)并测量加载页面的时间。
var page = require('webpage').create(),
system = require('system'),
t, address;
if (system.args.length === 1) {
console.log('Usage: loadspeed.js ');
phantom.exit();
}
t = Date.now();
address = system.args[1];
page.open(address, function (status) {
if (status !== 'success') {
console.log('FAIL to load the address');
} else {
t = Date.now() - t;
console.log('Loading time ' + t + ' msec');
}
phantom.exit();
});
在命令行运行脚本:
phantomjs loadspeed.js http://www.google.com
它输出如下内容:
加载加载时间 719 毫秒
代码评估 - 代码评估
要在网页上下文中评估 JavaScript 或 CoffeeScript,请使用 evaluate() 方法。代码在“沙箱”中运行,它无法读取其所属页面上下文之外的任何 JavaScript 对象和变量。evaluate() 将返回一个对象,但它仅限于简单对象,不能收录方法或闭包。
这是显示页面标题的示例:
var page = require('webpage').create();
page.open(url, function (status) {
var title = page.evaluate(function () {
return document.title;
});
console.log('Page title is ' + title);
});
默认情况下,不会显示来自网页并收录evaluate() 内部代码的任何控制台消息。要覆盖此行为,使用 onConsoleMessage 回调函数,可以将前面的示例重写为:
var page = require('webpage').create();
page.onConsoleMessage = function (msg) {
console.log('Page title is ' + msg);
};
page.open(url, function (status) {
page.evaluate(function () {
console.log(document.title);
});
});
DOM 操作 – DOM 操作
由于该脚本似乎在 Web 浏览器上运行,因此标准 DOM 脚本和 CSS 选择器可以正常工作。这使得 PhantomJS 适合支持各种页面自动化任务。
以下 useragent.js 将读取 id 为 myagent 的元素的 textContent 属性:
var page = require('webpage').create();
console.log('The default user agent is ' + page.settings.userAgent);
page.settings.userAgent = 'SpecialAgent';
page.open('http://www.httpuseragent.org', function (status) {
if (status !== 'success') {
console.log('Unable to access network');
} else {
var ua = page.evaluate(function () {
return document.getElementById('myagent').textContent;
});
console.log(ua);
}
phantom.exit();
});
上面的示例还提供了一种自定义用户代理的方法。
使用 JQuery 和其他库:
var page = require('webpage').create();
page.open('http://www.sample.com', function() {
page.includeJs("http://ajax.googleapis.com/aja ... ot%3B, function() {
page.evaluate(function() {
$("button").click();
});
phantom.exit()
});
});
网络请求和响应——网络请求和响应
当页面向远程服务器请求资源时,可以通过 onResourceRequested 和 onResourceReceived 回调方法跟踪请求和响应。示例 netlog.js:
var page = require('webpage').create();
page.onResourceRequested = function (request) {
console.log('Request ' + JSON.stringify(request, undefined, 4));
};
page.onResourceReceived = function (response) {
console.log('Receive ' + JSON.stringify(response, undefined, 4));
};
page.open(url);
有关如何将此功能用于 HAR 输出和基于 YSlow 的性能分析的更多信息,请参阅网络监控页面。
PhantomJs官网:
GitHub:
以上帮助说明来自woiweb:
windows下使用php执行phantomjs
下面直接给出执行代码:
echo '';
exec('H:wampwwwphantomjsinphantomjs --output-encoding=utf8 H:wampwwwXss_Scanner est.js ',$output_main);
var_dump($output_main);
// $str = implode('',$output_main);
// var_dump($str);
test.js 文件内容如下:
console.log('Loading a web page');
var page = require('webpage').create();
var url = 'http://www.mafutian.net/';
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
console.log(page.content);
}
phantom.exit();
});
执行结果如下图所示:
请注意,要实现上述执行结果,需要以下几点:
(1)PHP的安全模式不能开启,即需要在php.ini中将sql.safe_mode设置为Off。(并且重启服务器,当然php本身并没有开启安全模式)默认模式)
(2)无论phantomjs是否加入系统环境变量,都应该是exec()中的绝对路径,以下执行无效:
exec('phantomjs --output-encoding=utf8 H:wampwwwXss_Scanner est.js ',$output_main);
你需要走phantomjs的绝对路径。
需要注意的是,js文件不能走绝对路径。可以相对于网站根目录,如下执行成功:
exec('H:wampwwwphantomjsinphantomjs --output-encoding=utf8 test.js ',$output_main);
注意:test.js 放在网站 的根目录下。
另外:PHP下执行phantomjs也可以使用另外一个函数systom()来执行
以上内容参考:链接地址:
php-phantomjs中文API整理的合集DEMO
<p>
php抓取网页title(如何将canvas图形转换成图片和下载canvas图像的javascript工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2022-02-10 12:11
之前写过如何将canvas图形转为图片和下载canvas图片,都是为这个插件做的技术准备。
技术路线非常清晰。将网页某个区域的内容生成一张图片,保存在canvas中,然后将canvas内容转换成图片,保存在本地,最后上传到微博。
我在网上搜索,找到了 html2canvas,这是一个 javascript 工具,可以从指定网页元素的内容生成画布图像。这个js工具的使用很简单,只需要将它的js文件导入页面,然后调用html2canvas()函数即可:
html2canvas(document.body, {
onrendered: function(canvas) {
/* canvas is the actual canvas element,
to append it to the page call for example
document.body.appendChild( canvas );
*/
}
});
这个 html2canvas() 函数有一个参数。在上面的例子中,传入的参数是document.body,它将捕获整个页面的图像。如果你只想截取一个区域,比如对某个p或者某个table进行截图,就将这个p或者某个table作为参数传入。
最终没有选择js工具html2canvas,因为我在实验中发现了几个问题。
一是跨域问题。让我举一个例子来说明这个问题。比如我的网页网址是,我在这个页面上有一张图片。这张图片不是来自域,而是来自CDN图片服务器。那么,这个图片和这个网页就不一样了。在同一个域中,那么 html2canvas 不能对这种图片进行截图。如果你的 网站 的所有图片都放在一个单独的图片服务器上,那么使用 html2canvas 截取整个网页的截图就是所有图片的位置。都是空白。
这个问题还有一个补救办法,就是使用代理:
html2canvas php proxy
//
<p>
</p>
这种方法只能在自己的服务器上使用,如果是截图别人的网页,还是不行。
在实验过程中,还发现html2canvas捕获的图像有时会有重叠的文字。我猜是因为 html2canvas 在解析页面内容和处理 css 时并不完美。
最后在火狐浏览器的官方网站上找到了drawWindow()方法。这个方法和上面提到的html2canvas的区别在于它不分析页面元素,它只针对区域,也就是它接受的参数是一个由四个数字标记的区域,无论在这个区域的哪个位置,都没有页面内容。
void drawWindow(
in nsIDOMWindow window,
in float x,
in float y,
in float w,
in float h,
in DOMString bgColor,
in unsigned long flags [optional]
);
这个原生 JavaScript 方法看起来很完美,正是我需要的,但是这个方法不能在普通网页中使用,因为 Firefox 官方发现这个方法会造成安全漏洞,直到这个 bug 被修复,只有用“Chrome 权限”的代码来使用这个 drawWindow() 函数。
虽然有很大的限制,但在遇到挫折后仍然可以使用。在我开发的 Firefox 插件中,main.js 是具有“Chrome 权限”的代码。我在网上找到了一个Firefox插件SDK的代码示例:
var window = require('window/utils').getMostRecentBrowserWindow();
var tab = require('tabs/utils').getActiveTab(window);
var thumbnail = window.document.createElementNS("http://www.w3.org/1999/xhtml", "canvas");
thumbnail.mozOpaque = true;
window = tab.linkedBrowser.contentWindow;
thumbnail.width = Math.ceil(window.screen.availWidth / 5.75);
var aspectRatio = 0.5625; // 16:9
thumbnail.height = Math.round(thumbnail.width * aspectRatio);
var ctx = thumbnail.getContext("2d");
var snippetWidth = window.innerWidth * .6;
var scale = thumbnail.width / snippetWidth;
ctx.scale(scale, scale);
ctx.drawWindow(window, window.scrollX, window.scrollY, snippetWidth, snippetWidth * aspectRatio, "rgb(255,255,255)");
// thumbnail now represents a thumbnail of the tab
这段代码写得很清楚,你只需要稍微修改一下就可以满足你的需要。
这里的小编是一位有10年工作经验的前端高级工程师。关于web前端的技术干货很多,包括但不限于各大厂最新面试题系列、前端项目、最新前端路线等。需要伙伴可以私信我
发送【前端信息】
您可以获取取货地址并免费发送给所有人。如果你有任何关于学习web前端的问题(学习方法、学习效率、如何就业),都可以问我。希望你也可以通过自己的努力,成为下一个优秀的程序员。 查看全部
php抓取网页title(如何将canvas图形转换成图片和下载canvas图像的javascript工具)
之前写过如何将canvas图形转为图片和下载canvas图片,都是为这个插件做的技术准备。
技术路线非常清晰。将网页某个区域的内容生成一张图片,保存在canvas中,然后将canvas内容转换成图片,保存在本地,最后上传到微博。
我在网上搜索,找到了 html2canvas,这是一个 javascript 工具,可以从指定网页元素的内容生成画布图像。这个js工具的使用很简单,只需要将它的js文件导入页面,然后调用html2canvas()函数即可:
html2canvas(document.body, {
onrendered: function(canvas) {
/* canvas is the actual canvas element,
to append it to the page call for example
document.body.appendChild( canvas );
*/
}
});
这个 html2canvas() 函数有一个参数。在上面的例子中,传入的参数是document.body,它将捕获整个页面的图像。如果你只想截取一个区域,比如对某个p或者某个table进行截图,就将这个p或者某个table作为参数传入。
最终没有选择js工具html2canvas,因为我在实验中发现了几个问题。
一是跨域问题。让我举一个例子来说明这个问题。比如我的网页网址是,我在这个页面上有一张图片。这张图片不是来自域,而是来自CDN图片服务器。那么,这个图片和这个网页就不一样了。在同一个域中,那么 html2canvas 不能对这种图片进行截图。如果你的 网站 的所有图片都放在一个单独的图片服务器上,那么使用 html2canvas 截取整个网页的截图就是所有图片的位置。都是空白。
这个问题还有一个补救办法,就是使用代理:
html2canvas php proxy
//
<p>
</p>
这种方法只能在自己的服务器上使用,如果是截图别人的网页,还是不行。
在实验过程中,还发现html2canvas捕获的图像有时会有重叠的文字。我猜是因为 html2canvas 在解析页面内容和处理 css 时并不完美。
最后在火狐浏览器的官方网站上找到了drawWindow()方法。这个方法和上面提到的html2canvas的区别在于它不分析页面元素,它只针对区域,也就是它接受的参数是一个由四个数字标记的区域,无论在这个区域的哪个位置,都没有页面内容。
void drawWindow(
in nsIDOMWindow window,
in float x,
in float y,
in float w,
in float h,
in DOMString bgColor,
in unsigned long flags [optional]
);
这个原生 JavaScript 方法看起来很完美,正是我需要的,但是这个方法不能在普通网页中使用,因为 Firefox 官方发现这个方法会造成安全漏洞,直到这个 bug 被修复,只有用“Chrome 权限”的代码来使用这个 drawWindow() 函数。
虽然有很大的限制,但在遇到挫折后仍然可以使用。在我开发的 Firefox 插件中,main.js 是具有“Chrome 权限”的代码。我在网上找到了一个Firefox插件SDK的代码示例:
var window = require('window/utils').getMostRecentBrowserWindow();
var tab = require('tabs/utils').getActiveTab(window);
var thumbnail = window.document.createElementNS("http://www.w3.org/1999/xhtml", "canvas");
thumbnail.mozOpaque = true;
window = tab.linkedBrowser.contentWindow;
thumbnail.width = Math.ceil(window.screen.availWidth / 5.75);
var aspectRatio = 0.5625; // 16:9
thumbnail.height = Math.round(thumbnail.width * aspectRatio);
var ctx = thumbnail.getContext("2d");
var snippetWidth = window.innerWidth * .6;
var scale = thumbnail.width / snippetWidth;
ctx.scale(scale, scale);
ctx.drawWindow(window, window.scrollX, window.scrollY, snippetWidth, snippetWidth * aspectRatio, "rgb(255,255,255)");
// thumbnail now represents a thumbnail of the tab
这段代码写得很清楚,你只需要稍微修改一下就可以满足你的需要。
这里的小编是一位有10年工作经验的前端高级工程师。关于web前端的技术干货很多,包括但不限于各大厂最新面试题系列、前端项目、最新前端路线等。需要伙伴可以私信我
发送【前端信息】
您可以获取取货地址并免费发送给所有人。如果你有任何关于学习web前端的问题(学习方法、学习效率、如何就业),都可以问我。希望你也可以通过自己的努力,成为下一个优秀的程序员。
php抓取网页title(wordpress网站主题模板开发过程中怎样实现不同的页面调用不同)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-01-17 20:09
一个wordpress网站,它的首页是千变万化的,不同的页面必须有不同的内容和标题。如果一个wordpress网站,所有的页面都有相同的标题,对搜索引擎很不友好。那么,在wordpress网站主题模板的开发过程中,如何实现不同的页面调用不同的标题呢?这并不难,我们可以通过两种方式做到这一点。
方法一:实现wordpress网站不同页面通过判断调用不同标题。
WordPress 提供了模板页面的判断功能。我们可以通过这些函数来判断当前页面,然后调用这些页面标题函数。例如分类页面调用分类页面标题函数;文章 页面调用 文章 页面标题函数。代码显示如下:
if (is_home()) { //如果是首页,则调用首页标题
博客信息(“名称”);
}elseif(is_single()||is_page()) { //如果是文章详情页或者页面单页
标题(); //文章 和页面标题
回声“-”;
博客信息(“名称”);
}别的{
single_cat_title('', false); //类别和标签页的标题
回声“-”;
博客信息(“名称”);
}
通过以上判断,我们可以实现:直接在wordpress网站首页显示首页标题;如果是 文章 和 page 单页,使用 the_title() 调用它们的标题;如果是类别和单页标签标签,请使用 single_cat_title() 来调用它们的标题。
方法二:使用wordpress的标题函数wp_title()来实现。
wp_title() 是 WordPress 提供的 网站 标题函数。可以在网站首页以外的其他网站页面上调用相应的title,也可以达到方法1的效果。我们先来看看这个函数。
wp_title($sep, $display, $seplocation);
从上面的代码中,我们可以看到 wp_title() 函数可以有 3 个参数:
$sep:字符串类型数据,可选。这里是wordpress网站首页标题分隔符,默认值为 » ,如果要使用其他分隔符,可以使用该参数。$display:布尔数据类型,可选。该参数表示,是否打印标题到页面显示。默认为true,表示显示。如果只想给变量赋值,可以设置为false。$seplocation:字符串类型数据,可选。该参数的作用是显示分隔符的显示位置。默认设置在左侧。如果要显示在标题的右侧,可以将其设置为右侧。
案件:
当这个wp_title()在首页时,因为无法调用数据,所以不会显示任何内容;但它可以在wordpress的其他模板页面网站中发挥作用,并且在文章模板页面中,会调用文章@的标题>,页面的标题会被调用页面单页模板页面,网站分类页面调用分类目录标题,tags标签页面调用标签标题。也就是说,WordPress已经在wp_title()函数内部做出了网站模板页面的判断,然后根据不同的网站模板页面调用不同页面的标题。
如果你喜欢我的文章,请点击“关注”按钮关注我。我会每天定期发布新内容。以上是我的看法,如有不同意见,欢迎评论。 查看全部
php抓取网页title(wordpress网站主题模板开发过程中怎样实现不同的页面调用不同)
一个wordpress网站,它的首页是千变万化的,不同的页面必须有不同的内容和标题。如果一个wordpress网站,所有的页面都有相同的标题,对搜索引擎很不友好。那么,在wordpress网站主题模板的开发过程中,如何实现不同的页面调用不同的标题呢?这并不难,我们可以通过两种方式做到这一点。
方法一:实现wordpress网站不同页面通过判断调用不同标题。
WordPress 提供了模板页面的判断功能。我们可以通过这些函数来判断当前页面,然后调用这些页面标题函数。例如分类页面调用分类页面标题函数;文章 页面调用 文章 页面标题函数。代码显示如下:
if (is_home()) { //如果是首页,则调用首页标题
博客信息(“名称”);
}elseif(is_single()||is_page()) { //如果是文章详情页或者页面单页
标题(); //文章 和页面标题
回声“-”;
博客信息(“名称”);
}别的{
single_cat_title('', false); //类别和标签页的标题
回声“-”;
博客信息(“名称”);
}
通过以上判断,我们可以实现:直接在wordpress网站首页显示首页标题;如果是 文章 和 page 单页,使用 the_title() 调用它们的标题;如果是类别和单页标签标签,请使用 single_cat_title() 来调用它们的标题。
方法二:使用wordpress的标题函数wp_title()来实现。
wp_title() 是 WordPress 提供的 网站 标题函数。可以在网站首页以外的其他网站页面上调用相应的title,也可以达到方法1的效果。我们先来看看这个函数。
wp_title($sep, $display, $seplocation);
从上面的代码中,我们可以看到 wp_title() 函数可以有 3 个参数:
$sep:字符串类型数据,可选。这里是wordpress网站首页标题分隔符,默认值为 » ,如果要使用其他分隔符,可以使用该参数。$display:布尔数据类型,可选。该参数表示,是否打印标题到页面显示。默认为true,表示显示。如果只想给变量赋值,可以设置为false。$seplocation:字符串类型数据,可选。该参数的作用是显示分隔符的显示位置。默认设置在左侧。如果要显示在标题的右侧,可以将其设置为右侧。
案件:
当这个wp_title()在首页时,因为无法调用数据,所以不会显示任何内容;但它可以在wordpress的其他模板页面网站中发挥作用,并且在文章模板页面中,会调用文章@的标题>,页面的标题会被调用页面单页模板页面,网站分类页面调用分类目录标题,tags标签页面调用标签标题。也就是说,WordPress已经在wp_title()函数内部做出了网站模板页面的判断,然后根据不同的网站模板页面调用不同页面的标题。
如果你喜欢我的文章,请点击“关注”按钮关注我。我会每天定期发布新内容。以上是我的看法,如有不同意见,欢迎评论。
php抓取网页title(如何融合到一个更灵活的网站爬虫中?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-14 08:17
在本文 文章 中,您将学习将这些基本方法合并到一个更灵活的 网站 爬虫中,该爬虫可以跟踪遵循特定 URL 模式的任何链接。
这种爬虫非常适合从一个 网站 中抓取所有数据的项目,但不适用于从特定搜索结果或页面列表中抓取数据的项目。它也适用于组织不善或非常分散的 网站 页面。
这些类型的爬虫不需要像上一节“通过搜索页面进行爬取”中使用的结构化方法来定位链接,因此不需要在网站对象中收录描述搜索页面的属性。但是由于爬虫不知道要在哪里寻找链接,因此您需要一些规则来告诉它选择哪个页面。您可以使用 targetPattern(目标 URL 的正则表达式)和布尔变量 absoluteUrl 来实现:
class Website:
def __init__(self, name, url, targetPattern, absoluteUrl,
titleTag, bodyTag):
self.name = name
self.url = url
self.targetPattern = targetPattern
self.absoluteUrl=absoluteUrl
self.titleTag = titleTag
self.bodyTag = bodyTag
class Content:
def __init__(self, url, title, body):
self.url = url
self.title = title
self.body = body
def print(self):
print("URL: {}".format(self.url))
print("TITLE: {}".format(self.title))
print("BODY:\n{}".format(self.body))
Content 类与第一个爬虫示例中使用的相同。
Crawler 类从每个 网站 的主页开始,定位内部链接,并解析每个内部链接页面上找到的内容:
import re
class Crawler:
def __init__(self, site):
self.site = site
self.visited = []
def getPage(self, url):
try:
req = requests.get(url)
except requests.exceptions.RequestException:
return None
return BeautifulSoup(req.text, 'html.parser')
def safeGet(self, pageObj, selector):
selectedElems = pageObj.select(selector)
if selectedElems is not None and len(selectedElems) > 0:
return '\n'.join([elem.get_text() for
elem in selectedElems])
return ''
def parse(self, url):
bs = self.getPage(url)
if bs is not None:
title = self.safeGet(bs, self.site.titleTag)
body = self.safeGet(bs, self.site.bodyTag)
if title != '' and body != '':
content = Content(url, title, body)
content.print()
def crawl(self):
"""
获取网站主页的页面链接
"""
bs = self.getPage(self.site.url)
targetPages = bs.findAll('a',
href=re.compile(self.site.targetPattern))
for targetPage in targetPages:
targetPage = targetPage.attrs['href']
if targetPage not in self.visited:
self.visited.append(targetPage)
if not self.site.absoluteUrl:
targetPage = '{}{}'.format(self.site.url, targetPage)
self.parse(targetPage)
reuters = Website('Reuters', 'https://www.reuters.com', '^(/article/)', False,
'h1', 'div.StandardArticleBody_body_1gnLA')
crawler = Crawler(reuters)
crawler.crawl()
与前面示例的另一个变化是网站对象(在本例中为变量 reuters)是 Crawler 对象本身的属性。这样做的效果是将访问过的页面存储在爬虫中,但这也意味着必须为每个 网站 实例化一个新的爬虫,而不是重复使用爬虫来爬取 网站 的列表。
无论是选择与网站无关的爬虫,还是使用网站作为爬虫的一个属性,这都是需要根据自己的需求权衡的决定。两种方法在功能实现上都没有问题。
还有一点需要注意的是,这个爬虫会从首页开始爬取,但是在所有页面都记录下来之后就不会继续爬取了。您可能想要编写一个收录第 3 章介绍的模式之一的爬虫,然后为您访问的每个页面查看更多目标 URL。您甚至可以跟踪每个页面中涉及的所有 URL(不仅仅是那些与目标模式匹配的 URL),并查看这些 URL 是否收录目标模式。
以上就是关于python爬取的相关知识点网站,感谢大家对Scripting Home的学习和支持。 查看全部
php抓取网页title(如何融合到一个更灵活的网站爬虫中?)
在本文 文章 中,您将学习将这些基本方法合并到一个更灵活的 网站 爬虫中,该爬虫可以跟踪遵循特定 URL 模式的任何链接。
这种爬虫非常适合从一个 网站 中抓取所有数据的项目,但不适用于从特定搜索结果或页面列表中抓取数据的项目。它也适用于组织不善或非常分散的 网站 页面。
这些类型的爬虫不需要像上一节“通过搜索页面进行爬取”中使用的结构化方法来定位链接,因此不需要在网站对象中收录描述搜索页面的属性。但是由于爬虫不知道要在哪里寻找链接,因此您需要一些规则来告诉它选择哪个页面。您可以使用 targetPattern(目标 URL 的正则表达式)和布尔变量 absoluteUrl 来实现:
class Website:
def __init__(self, name, url, targetPattern, absoluteUrl,
titleTag, bodyTag):
self.name = name
self.url = url
self.targetPattern = targetPattern
self.absoluteUrl=absoluteUrl
self.titleTag = titleTag
self.bodyTag = bodyTag
class Content:
def __init__(self, url, title, body):
self.url = url
self.title = title
self.body = body
def print(self):
print("URL: {}".format(self.url))
print("TITLE: {}".format(self.title))
print("BODY:\n{}".format(self.body))
Content 类与第一个爬虫示例中使用的相同。
Crawler 类从每个 网站 的主页开始,定位内部链接,并解析每个内部链接页面上找到的内容:
import re
class Crawler:
def __init__(self, site):
self.site = site
self.visited = []
def getPage(self, url):
try:
req = requests.get(url)
except requests.exceptions.RequestException:
return None
return BeautifulSoup(req.text, 'html.parser')
def safeGet(self, pageObj, selector):
selectedElems = pageObj.select(selector)
if selectedElems is not None and len(selectedElems) > 0:
return '\n'.join([elem.get_text() for
elem in selectedElems])
return ''
def parse(self, url):
bs = self.getPage(url)
if bs is not None:
title = self.safeGet(bs, self.site.titleTag)
body = self.safeGet(bs, self.site.bodyTag)
if title != '' and body != '':
content = Content(url, title, body)
content.print()
def crawl(self):
"""
获取网站主页的页面链接
"""
bs = self.getPage(self.site.url)
targetPages = bs.findAll('a',
href=re.compile(self.site.targetPattern))
for targetPage in targetPages:
targetPage = targetPage.attrs['href']
if targetPage not in self.visited:
self.visited.append(targetPage)
if not self.site.absoluteUrl:
targetPage = '{}{}'.format(self.site.url, targetPage)
self.parse(targetPage)
reuters = Website('Reuters', 'https://www.reuters.com', '^(/article/)', False,
'h1', 'div.StandardArticleBody_body_1gnLA')
crawler = Crawler(reuters)
crawler.crawl()
与前面示例的另一个变化是网站对象(在本例中为变量 reuters)是 Crawler 对象本身的属性。这样做的效果是将访问过的页面存储在爬虫中,但这也意味着必须为每个 网站 实例化一个新的爬虫,而不是重复使用爬虫来爬取 网站 的列表。
无论是选择与网站无关的爬虫,还是使用网站作为爬虫的一个属性,这都是需要根据自己的需求权衡的决定。两种方法在功能实现上都没有问题。
还有一点需要注意的是,这个爬虫会从首页开始爬取,但是在所有页面都记录下来之后就不会继续爬取了。您可能想要编写一个收录第 3 章介绍的模式之一的爬虫,然后为您访问的每个页面查看更多目标 URL。您甚至可以跟踪每个页面中涉及的所有 URL(不仅仅是那些与目标模式匹配的 URL),并查看这些 URL 是否收录目标模式。
以上就是关于python爬取的相关知识点网站,感谢大家对Scripting Home的学习和支持。
php抓取网页title(与抓取预定义好的页面集合不同,抓取一个会带来一个挑战)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-14 08:16
与抓取预定义的页面集合不同,抓取 网站 的所有内部链接会带来不知道会发生什么的挑战。幸运的是,有一些识别页面类型的基本方法。
通过网址
网站 中的所有博客文章 都可能收录一个 URL(例如)。
根据 网站 中特定字段的存在与否
如果页面收录日期,但不收录作者姓名,您可以将其归类为新闻稿。如果它有标题、主要图片、价格,但没有主要内容,那么它可能是一个产品页面。
通过页面中出现的特定标签识别页面
即使您不抓取标签内的数据,您仍然可以利用该标签。你的爬虫可以寻找类似的东西
此类元素用于识别产品页面,即使爬虫对相关产品的内容不感兴趣。
为了跟踪多种页面类型,您需要在 Python 中拥有多种类型的页面对象。这是通过两种方式实现的。
如果页面都相似(它们基本上是相同类型的内容),您可能需要在现有页面对象中添加一个 pageType 属性:
class Website:
"""所有文章/网页的共同基类"""
def __init__(self, type, name, url, searchUrl, resultListing,
resultUrl, absoluteUrl, titleTag, bodyTag):
self.name = name
self.url = url
self.titleTag = titleTag
self.bodyTag = bodyTag
self.pageType = pageType
如果您在类似 SQL 的数据库中对这些页面进行排序,则此模式类型意味着这些页面应该存储在同一个表中,并带有一个额外的 pageType 列。
如果您抓取不同的页面或内容(它们收录不同类型的字段),您将需要为每种页面类型创建一个新对象。当然,所有网页都有一些共同点——它们都有一个 URL,可能还有一个名称或页面标题。这种情况非常适合子类化:
class Website:
"""所有文章/网页的共同基类"""
def __init__(self, name, url, titleTag):
self.name = name
self.url = url
self.titleTag = titleTag
这不是您的爬虫直接使用的对象,而是您的页面类型将引用的对象:
class Product(Website):
"""产品页面要抓取的信息"""
def __init__(self, name, url, titleTag, productNumber, price):
Website.__init__(self, name, url, TitleTag)
self.productNumberTag = productNumberTag
self.priceTag = priceTag
class Article(Website):
"""文章页面要抓取的信息"""
def __init__(self, name, url, titleTag, bodyTag, dateTag):
Website.__init__(self, name, url, titleTag)
self.bodyTag = bodyTag
self.dateTag = dateTag
这个产品页面扩展了Website基类,增加了仅适用于产品的productNumber和price属性,而Article类增加了不适用于产品的body和date属性。
您可以使用这两个类来抓取商店网站,该商店除了产品之外,还可能收录博客文章 或新闻稿。
希望以上知识点能对您有所帮助,也感谢您对脚本之家的支持。 查看全部
php抓取网页title(与抓取预定义好的页面集合不同,抓取一个会带来一个挑战)
与抓取预定义的页面集合不同,抓取 网站 的所有内部链接会带来不知道会发生什么的挑战。幸运的是,有一些识别页面类型的基本方法。
通过网址
网站 中的所有博客文章 都可能收录一个 URL(例如)。
根据 网站 中特定字段的存在与否
如果页面收录日期,但不收录作者姓名,您可以将其归类为新闻稿。如果它有标题、主要图片、价格,但没有主要内容,那么它可能是一个产品页面。
通过页面中出现的特定标签识别页面
即使您不抓取标签内的数据,您仍然可以利用该标签。你的爬虫可以寻找类似的东西
此类元素用于识别产品页面,即使爬虫对相关产品的内容不感兴趣。
为了跟踪多种页面类型,您需要在 Python 中拥有多种类型的页面对象。这是通过两种方式实现的。
如果页面都相似(它们基本上是相同类型的内容),您可能需要在现有页面对象中添加一个 pageType 属性:
class Website:
"""所有文章/网页的共同基类"""
def __init__(self, type, name, url, searchUrl, resultListing,
resultUrl, absoluteUrl, titleTag, bodyTag):
self.name = name
self.url = url
self.titleTag = titleTag
self.bodyTag = bodyTag
self.pageType = pageType
如果您在类似 SQL 的数据库中对这些页面进行排序,则此模式类型意味着这些页面应该存储在同一个表中,并带有一个额外的 pageType 列。
如果您抓取不同的页面或内容(它们收录不同类型的字段),您将需要为每种页面类型创建一个新对象。当然,所有网页都有一些共同点——它们都有一个 URL,可能还有一个名称或页面标题。这种情况非常适合子类化:
class Website:
"""所有文章/网页的共同基类"""
def __init__(self, name, url, titleTag):
self.name = name
self.url = url
self.titleTag = titleTag
这不是您的爬虫直接使用的对象,而是您的页面类型将引用的对象:
class Product(Website):
"""产品页面要抓取的信息"""
def __init__(self, name, url, titleTag, productNumber, price):
Website.__init__(self, name, url, TitleTag)
self.productNumberTag = productNumberTag
self.priceTag = priceTag
class Article(Website):
"""文章页面要抓取的信息"""
def __init__(self, name, url, titleTag, bodyTag, dateTag):
Website.__init__(self, name, url, titleTag)
self.bodyTag = bodyTag
self.dateTag = dateTag
这个产品页面扩展了Website基类,增加了仅适用于产品的productNumber和price属性,而Article类增加了不适用于产品的body和date属性。
您可以使用这两个类来抓取商店网站,该商店除了产品之外,还可能收录博客文章 或新闻稿。
希望以上知识点能对您有所帮助,也感谢您对脚本之家的支持。
php抓取网页title(与抓取预定义好的页面集合不同,抓取一个会带来一个挑战)
网站优化 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-12-16 05:11
与抓取一组预定义的页面不同,抓取一个网站的所有内链会带来一个挑战,就是你不知道你会得到什么。幸运的是,有几种基本的方法可以识别页面类型。
按网址
网站 中的所有博客 文章 都可能收录一个 URL(例如)。
传递 网站 中存在或缺失的特定字段
如果页面收录日期但不收录作者姓名,您可以将其归类为新闻稿。如果它有标题、主图、价格,但没有主要内容,那么它可能是一个产品页面。
通过出现在页面上的特定标签识别页面
即使您没有捕获某个标签中的数据,您仍然可以使用该标签。你的爬虫可以寻找类似的东西
此类元素用于标识产品页面,即使爬虫对相关产品的内容不感兴趣。
为了跟踪多种页面类型,您需要在 Python 中拥有多种类型的页面对象。这是通过两种方式实现的。
如果页面相似(它们的内容类型基本相同),则可能需要在现有页面对象中添加 pageType 属性:
class Website:
"""所有文章/网页的共同基类"""
def __init__(self, type, name, url, searchUrl, resultListing,
resultUrl, absoluteUrl, titleTag, bodyTag):
self.name = name
self.url = url
self.titleTag = titleTag
self.bodyTag = bodyTag
self.pageType = pageType
如果在类 SQL 的数据库中对这些页面进行排序,则此模式类型意味着这些页面应存储在同一个表中,并添加了一个额外的 pageType 列。
如果抓取不同的页面或内容(它们收录不同类型的字段),则需要为每种页面类型创建一个新对象。当然,有些东西是所有网页共有的——它们都有一个 URL,它们也可能有一个名称或页面标题。这种情况非常适合子类:
class Website:
"""所有文章/网页的共同基类"""
def __init__(self, name, url, titleTag):
self.name = name
self.url = url
self.titleTag = titleTag
这不是您的爬虫直接使用的对象,而是您的页面类型将引用的对象:
class Product(Website):
"""产品页面要抓取的信息"""
def __init__(self, name, url, titleTag, productNumber, price):
Website.__init__(self, name, url, TitleTag)
self.productNumberTag = productNumberTag
self.priceTag = priceTag
class Article(Website):
"""文章页面要抓取的信息"""
def __init__(self, name, url, titleTag, bodyTag, dateTag):
Website.__init__(self, name, url, titleTag)
self.bodyTag = bodyTag
self.dateTag = dateTag
该产品页面扩展了Website 基类,增加了仅适用于产品的productNumber 和price 属性,而Article 类增加了不适用于产品的body 和date 属性。
您可以使用这两个类别来抓取商店网站。除了产品,这个 网站 还可能收录博客 文章 或新闻稿。
希望以上知识点可以帮助到您,感谢您对脚本之家的支持。 查看全部
php抓取网页title(与抓取预定义好的页面集合不同,抓取一个会带来一个挑战)
与抓取一组预定义的页面不同,抓取一个网站的所有内链会带来一个挑战,就是你不知道你会得到什么。幸运的是,有几种基本的方法可以识别页面类型。
按网址
网站 中的所有博客 文章 都可能收录一个 URL(例如)。
传递 网站 中存在或缺失的特定字段
如果页面收录日期但不收录作者姓名,您可以将其归类为新闻稿。如果它有标题、主图、价格,但没有主要内容,那么它可能是一个产品页面。
通过出现在页面上的特定标签识别页面
即使您没有捕获某个标签中的数据,您仍然可以使用该标签。你的爬虫可以寻找类似的东西
此类元素用于标识产品页面,即使爬虫对相关产品的内容不感兴趣。
为了跟踪多种页面类型,您需要在 Python 中拥有多种类型的页面对象。这是通过两种方式实现的。
如果页面相似(它们的内容类型基本相同),则可能需要在现有页面对象中添加 pageType 属性:
class Website:
"""所有文章/网页的共同基类"""
def __init__(self, type, name, url, searchUrl, resultListing,
resultUrl, absoluteUrl, titleTag, bodyTag):
self.name = name
self.url = url
self.titleTag = titleTag
self.bodyTag = bodyTag
self.pageType = pageType
如果在类 SQL 的数据库中对这些页面进行排序,则此模式类型意味着这些页面应存储在同一个表中,并添加了一个额外的 pageType 列。
如果抓取不同的页面或内容(它们收录不同类型的字段),则需要为每种页面类型创建一个新对象。当然,有些东西是所有网页共有的——它们都有一个 URL,它们也可能有一个名称或页面标题。这种情况非常适合子类:
class Website:
"""所有文章/网页的共同基类"""
def __init__(self, name, url, titleTag):
self.name = name
self.url = url
self.titleTag = titleTag
这不是您的爬虫直接使用的对象,而是您的页面类型将引用的对象:
class Product(Website):
"""产品页面要抓取的信息"""
def __init__(self, name, url, titleTag, productNumber, price):
Website.__init__(self, name, url, TitleTag)
self.productNumberTag = productNumberTag
self.priceTag = priceTag
class Article(Website):
"""文章页面要抓取的信息"""
def __init__(self, name, url, titleTag, bodyTag, dateTag):
Website.__init__(self, name, url, titleTag)
self.bodyTag = bodyTag
self.dateTag = dateTag
该产品页面扩展了Website 基类,增加了仅适用于产品的productNumber 和price 属性,而Article 类增加了不适用于产品的body 和date 属性。
您可以使用这两个类别来抓取商店网站。除了产品,这个 网站 还可能收录博客 文章 或新闻稿。
希望以上知识点可以帮助到您,感谢您对脚本之家的支持。
php抓取网页title( 用Pyhton自带的urllib或urllib2模块(二)|,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-09 22:12
用Pyhton自带的urllib或urllib2模块(二)|,)
Python使用lxml模块和Requests模块抓取HTML页面教程
更新时间:2016 年 5 月 16 日 18:53:56 作者:Kenneth Reitz
使用 Pyhton 的内置 urllib 或 urllib2 模块来抓取网页可能有点陈词滥调。今天我们将玩一些新鲜的。查看有关使用 lxml 模块和请求模块抓取 HTML 页面的 Python 教程:
万维网
网站是用 HTML 描述的,这意味着每个网页都是一个结构化的文档。有时在保持其结构的同时从中获取数据很有用。网站并不总是以易于处理的格式(例如 csv 或 json)提供其数据。
现在是网络抢占该领域的时候了。网页抓取是使用计算机程序采集网页数据并将其组织成所需格式的做法,同时保留其结构。
lxml 和请求
lxml() 是一个漂亮的扩展库,用于快速解析 XML 和 HTML 文档,即使处理的标签非常混乱。我们还将使用 Requests (#) 模块来替换内置的 urllib2 模块,因为它更快且更具可读性。您可以使用 pip install lxml 和 pip install requests 命令安装这两个模块。
让我们从以下导入开始:
from lxml import html
import requests
在下一步中,我们将使用 requests.get 从网页中获取我们的数据,使用 html 模块对其进行解析,并将结果保存在树中。
page = requests.get('http://econpy.pythonanywhere.com/ex/001.html')
tree = html.fromstring(page.text)
tree 现在将整个 HTML 文件收录成一个优雅的树状结构,我们可以使用两种方法来访问:XPath 和 CSS 选择器。在本例中,我们将选择前者。
XPath 是一种在结构化文档(如 HTML 或 XML)中定位信息的方法。有关 XPath 的详细介绍,请参阅 W3Schools。
有很多工具可以获取元素的 XPath,例如 Firefox 的 FireBug 或 Chrome 的 Inspector。如果您使用 Chrome,您可以右键单击该元素,选择“检查元素”,突出显示此代码,再次右键单击,然后选择“复制 XPath”。
经过快速分析,我们看到页面上的数据存储在两个元素中,一个是标题为'buyer-name'的div,另一个是类为'item-price'的span:
Carson Busses
$29.95
知道了这一点,我们就可以创建正确的 XPath 查询并使用 lxml 的 xpath 函数,如下所示:
#这将创建buyers的列表:
buyers = tree.xpath('//div[@title="buyer-name"]/text()')
#这将创建prices的列表:
prices = tree.xpath('//span[@class="item-price"]/text()')
让我们看看我们得到了什么:
print 'Buyers: ', buyers
print 'Prices: ', prices
Buyers: ['Carson Busses', 'Earl E. Byrd', 'Patty Cakes',
'Derri Anne Connecticut', 'Moe Dess', 'Leda Doggslife', 'Dan Druff',
'Al Fresco', 'Ido Hoe', 'Howie Kisses', 'Len Lease', 'Phil Meup',
'Ira Pent', 'Ben D. Rules', 'Ave Sectomy', 'Gary Shattire',
'Bobbi Soks', 'Sheila Takya', 'Rose Tattoo', 'Moe Tell']
Prices: ['$29.95', '$8.37', '$15.26', '$19.25', '$19.25',
'$13.99', '$31.57', '$8.49', '$14.47', '$15.86', '$11.11',
'$15.98', '$16.27', '$7.50', '$50.85', '$14.26', '$5.68',
'$15.00', '$114.07', '$10.09']
恭喜!我们已经成功通过lxml和Request从一个网页中抓取了我们想要的所有数据。我们以列表的形式将它们存储在内存中。现在我们可以用它做各种很酷的事情:我们可以用 Python 分析它,或者我们可以将它保存为文件并与世界分享。
我们可以考虑一些更酷的想法:修改此脚本以遍历本示例中数据集中的剩余页面,或者使用多个线程重写此应用程序以提高其速度。 查看全部
php抓取网页title(
用Pyhton自带的urllib或urllib2模块(二)|,)
Python使用lxml模块和Requests模块抓取HTML页面教程
更新时间:2016 年 5 月 16 日 18:53:56 作者:Kenneth Reitz
使用 Pyhton 的内置 urllib 或 urllib2 模块来抓取网页可能有点陈词滥调。今天我们将玩一些新鲜的。查看有关使用 lxml 模块和请求模块抓取 HTML 页面的 Python 教程:
万维网
网站是用 HTML 描述的,这意味着每个网页都是一个结构化的文档。有时在保持其结构的同时从中获取数据很有用。网站并不总是以易于处理的格式(例如 csv 或 json)提供其数据。
现在是网络抢占该领域的时候了。网页抓取是使用计算机程序采集网页数据并将其组织成所需格式的做法,同时保留其结构。
lxml 和请求
lxml() 是一个漂亮的扩展库,用于快速解析 XML 和 HTML 文档,即使处理的标签非常混乱。我们还将使用 Requests (#) 模块来替换内置的 urllib2 模块,因为它更快且更具可读性。您可以使用 pip install lxml 和 pip install requests 命令安装这两个模块。
让我们从以下导入开始:
from lxml import html
import requests
在下一步中,我们将使用 requests.get 从网页中获取我们的数据,使用 html 模块对其进行解析,并将结果保存在树中。
page = requests.get('http://econpy.pythonanywhere.com/ex/001.html')
tree = html.fromstring(page.text)
tree 现在将整个 HTML 文件收录成一个优雅的树状结构,我们可以使用两种方法来访问:XPath 和 CSS 选择器。在本例中,我们将选择前者。
XPath 是一种在结构化文档(如 HTML 或 XML)中定位信息的方法。有关 XPath 的详细介绍,请参阅 W3Schools。
有很多工具可以获取元素的 XPath,例如 Firefox 的 FireBug 或 Chrome 的 Inspector。如果您使用 Chrome,您可以右键单击该元素,选择“检查元素”,突出显示此代码,再次右键单击,然后选择“复制 XPath”。
经过快速分析,我们看到页面上的数据存储在两个元素中,一个是标题为'buyer-name'的div,另一个是类为'item-price'的span:
Carson Busses
$29.95
知道了这一点,我们就可以创建正确的 XPath 查询并使用 lxml 的 xpath 函数,如下所示:
#这将创建buyers的列表:
buyers = tree.xpath('//div[@title="buyer-name"]/text()')
#这将创建prices的列表:
prices = tree.xpath('//span[@class="item-price"]/text()')
让我们看看我们得到了什么:
print 'Buyers: ', buyers
print 'Prices: ', prices
Buyers: ['Carson Busses', 'Earl E. Byrd', 'Patty Cakes',
'Derri Anne Connecticut', 'Moe Dess', 'Leda Doggslife', 'Dan Druff',
'Al Fresco', 'Ido Hoe', 'Howie Kisses', 'Len Lease', 'Phil Meup',
'Ira Pent', 'Ben D. Rules', 'Ave Sectomy', 'Gary Shattire',
'Bobbi Soks', 'Sheila Takya', 'Rose Tattoo', 'Moe Tell']
Prices: ['$29.95', '$8.37', '$15.26', '$19.25', '$19.25',
'$13.99', '$31.57', '$8.49', '$14.47', '$15.86', '$11.11',
'$15.98', '$16.27', '$7.50', '$50.85', '$14.26', '$5.68',
'$15.00', '$114.07', '$10.09']
恭喜!我们已经成功通过lxml和Request从一个网页中抓取了我们想要的所有数据。我们以列表的形式将它们存储在内存中。现在我们可以用它做各种很酷的事情:我们可以用 Python 分析它,或者我们可以将它保存为文件并与世界分享。
我们可以考虑一些更酷的想法:修改此脚本以遍历本示例中数据集中的剩余页面,或者使用多个线程重写此应用程序以提高其速度。
php抓取网页title(这里有新鲜出炉的精品教程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-23 09:06
这里是新鲜出炉的优质教程,看程序狗的速度!
ASP.NET ASP.NET 是 .NET FrameWork 的一部分。它是微软公司的一项技术。它是一种服务器端脚本技术,可使嵌入在网页中的脚本由 Internet 服务器执行。它们是在服务器上动态创建的。指的是Active Server Pages,一个运行在IIS(Internet Information Server service,Windows开发的Web服务器)中的程序。
我们知道一般网页中的信息都是在不断更新的,这也需要我们定期抓取这些新信息,但是如何理解这个“定期”,也就是页面需要多久被抓取一次,在其实这个时间段也是Page cache时间。在页面缓存期间,我们没有必要再次抓取网页,但会对其他服务器造成压力。
一:网页更新
我们知道一般网页中的信息都是在不断更新的,这也需要我们定期抓取这些新信息,但是如何理解这个“定期”,也就是页面需要多久被抓取一次,在其实这个时间段也是Page cache时间。在页面缓存期间,我们不需要再次抓取网页,但会对其他服务器造成压力。
比如我想抓取博客园的首页,先清除页面缓存,
从Last-Modified到Expires,可以看到博客园的缓存时间是2分钟,我还可以看到当前服务器时间Date,如果我再做一次
如果页面刷新,这里的Date会变成下图中的If-Modified-Since,然后发送到服务器判断浏览器的缓存是否已经过期?
最后服务端发现if-Modified-Since >= Last-Modifined时间,服务端也返回了304,但是发现cookie信息真的是很多小偷。
在实际开发中,如果知道网站的缓存策略,就可以让爬虫每2分钟爬一次。当然,这些可以由数据团队进行配置和维护。好的,让我们使用爬虫。模拟它。
using System;
using System.Net;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
DateTime prevDateTime = DateTime.MinValue;
for (int i = 0; i < 10; i++)
{
try
{
var url = "http://cnblogs.com";
var request = (HttpWebRequest)HttpWebRequest.Create(url);
request.Method = "Head";
if (i > 0)
{
request.IfModifiedSince = prevDateTime;
}
request.Timeout = 3000;
var response = (HttpWebResponse)request.GetResponse();
var code = response.StatusCode;
//如果服务器返回状态是200,则认为网页已更新,记得当时的服务器时间
if (code == HttpStatusCode.OK)
{
prevDateTime = Convert.ToDateTime(response.Headers[HttpResponseHeader.Date]);
}
Console.WriteLine("当前服务器的状态码:{0}", code);
}
catch (WebException ex)
{
if (ex.Response != null)
{
var code = (ex.Response as HttpWebResponse).StatusCode;
Console.WriteLine("当前服务器的状态码:{0}", code);
}
}
}
}
}
}
二:网页编码的问题
有时候我们已经抓取了网页,准备解析的时候,tmd全是乱码,真他妈的,比如下面这样,
可能我们依稀记得html的meta中有一个叫做charset的属性,里面记录了编码方式。另一个重要的一点是 response.CharacterSet 也记录了编码方式。让我们再试一次。
还是乱码,蛋疼。这个时候需要去官网看看http头信息里面交互的是什么。为什么浏览器能正常显示,爬虫就爬不过去了。
查看http头信息后,我们终于知道了。浏览器说可以解析gzip、deflate、sdch三种压缩方式。服务器发送 gzip 压缩。至此,我们也应该知道常用的web性能优化了。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using HtmlAgilityPack;
using System.Text.RegularExpressions;
using System.Net;
using System.IO;
using System.IO.Compression;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
//var currentUrl = "http://www.mm5mm.com/";
var currentUrl = "http://www.sohu.com/";
var request = WebRequest.Create(currentUrl) as HttpWebRequest;
var response = request.GetResponse() as HttpWebResponse;
var encode = string.Empty;
if (response.CharacterSet == "ISO-8859-1")
encode = "gb2312";
else
encode = response.CharacterSet;
Stream stream;
if (response.ContentEncoding.ToLower() == "gzip")
{
stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
}
else
{
stream = response.GetResponseStream();
}
var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
var html = sr.ReadToEnd();
}
}
}
三:网页分析
现在网页经过一番折腾得到了,接下来就解析下一个。当然,正则匹配是一个不错的方法。毕竟工作量还是比较大的。或许业界也推荐HtmlAgilityPack,一个可以将Html解析成XML的解析工具,然后可以使用XPath提取指定的内容,大大提高了开发速度,性能也不错。毕竟,敏捷意味着敏捷。关于XPath的内容,可以看一下W3CSchool的两张图。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using HtmlAgilityPack;
using System.Text.RegularExpressions;
using System.Net;
using System.IO;
using System.IO.Compression;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
//var currentUrl = "http://www.mm5mm.com/";
var currentUrl = "http://www.sohu.com/";
var request = WebRequest.Create(currentUrl) as HttpWebRequest;
var response = request.GetResponse() as HttpWebResponse;
var encode = string.Empty;
if (response.CharacterSet == "ISO-8859-1")
encode = "gb2312";
else
encode = response.CharacterSet;
Stream stream;
if (response.ContentEncoding.ToLower() == "gzip")
{
stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
}
else
{
stream = response.GetResponseStream();
}
var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
var html = sr.ReadToEnd();
sr.Close();
HtmlDocument document = new HtmlDocument();
document.LoadHtml(html);
//提取title
var title = document.DocumentNode.SelectSingleNode("//title").InnerText;
//提取keywords
var keywords = document.DocumentNode.SelectSingleNode("//meta[@name='Keywords']").Attributes["content"].Value;
}
}
}
好了,结束工作,去睡觉吧。. . 查看全部
php抓取网页title(这里有新鲜出炉的精品教程,程序狗速度看过来!)
这里是新鲜出炉的优质教程,看程序狗的速度!
ASP.NET ASP.NET 是 .NET FrameWork 的一部分。它是微软公司的一项技术。它是一种服务器端脚本技术,可使嵌入在网页中的脚本由 Internet 服务器执行。它们是在服务器上动态创建的。指的是Active Server Pages,一个运行在IIS(Internet Information Server service,Windows开发的Web服务器)中的程序。
我们知道一般网页中的信息都是在不断更新的,这也需要我们定期抓取这些新信息,但是如何理解这个“定期”,也就是页面需要多久被抓取一次,在其实这个时间段也是Page cache时间。在页面缓存期间,我们没有必要再次抓取网页,但会对其他服务器造成压力。
一:网页更新
我们知道一般网页中的信息都是在不断更新的,这也需要我们定期抓取这些新信息,但是如何理解这个“定期”,也就是页面需要多久被抓取一次,在其实这个时间段也是Page cache时间。在页面缓存期间,我们不需要再次抓取网页,但会对其他服务器造成压力。
比如我想抓取博客园的首页,先清除页面缓存,
从Last-Modified到Expires,可以看到博客园的缓存时间是2分钟,我还可以看到当前服务器时间Date,如果我再做一次
如果页面刷新,这里的Date会变成下图中的If-Modified-Since,然后发送到服务器判断浏览器的缓存是否已经过期?
最后服务端发现if-Modified-Since >= Last-Modifined时间,服务端也返回了304,但是发现cookie信息真的是很多小偷。
在实际开发中,如果知道网站的缓存策略,就可以让爬虫每2分钟爬一次。当然,这些可以由数据团队进行配置和维护。好的,让我们使用爬虫。模拟它。
using System;
using System.Net;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
DateTime prevDateTime = DateTime.MinValue;
for (int i = 0; i < 10; i++)
{
try
{
var url = "http://cnblogs.com";
var request = (HttpWebRequest)HttpWebRequest.Create(url);
request.Method = "Head";
if (i > 0)
{
request.IfModifiedSince = prevDateTime;
}
request.Timeout = 3000;
var response = (HttpWebResponse)request.GetResponse();
var code = response.StatusCode;
//如果服务器返回状态是200,则认为网页已更新,记得当时的服务器时间
if (code == HttpStatusCode.OK)
{
prevDateTime = Convert.ToDateTime(response.Headers[HttpResponseHeader.Date]);
}
Console.WriteLine("当前服务器的状态码:{0}", code);
}
catch (WebException ex)
{
if (ex.Response != null)
{
var code = (ex.Response as HttpWebResponse).StatusCode;
Console.WriteLine("当前服务器的状态码:{0}", code);
}
}
}
}
}
}
二:网页编码的问题
有时候我们已经抓取了网页,准备解析的时候,tmd全是乱码,真他妈的,比如下面这样,
可能我们依稀记得html的meta中有一个叫做charset的属性,里面记录了编码方式。另一个重要的一点是 response.CharacterSet 也记录了编码方式。让我们再试一次。
还是乱码,蛋疼。这个时候需要去官网看看http头信息里面交互的是什么。为什么浏览器能正常显示,爬虫就爬不过去了。
查看http头信息后,我们终于知道了。浏览器说可以解析gzip、deflate、sdch三种压缩方式。服务器发送 gzip 压缩。至此,我们也应该知道常用的web性能优化了。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using HtmlAgilityPack;
using System.Text.RegularExpressions;
using System.Net;
using System.IO;
using System.IO.Compression;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
//var currentUrl = "http://www.mm5mm.com/";
var currentUrl = "http://www.sohu.com/";
var request = WebRequest.Create(currentUrl) as HttpWebRequest;
var response = request.GetResponse() as HttpWebResponse;
var encode = string.Empty;
if (response.CharacterSet == "ISO-8859-1")
encode = "gb2312";
else
encode = response.CharacterSet;
Stream stream;
if (response.ContentEncoding.ToLower() == "gzip")
{
stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
}
else
{
stream = response.GetResponseStream();
}
var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
var html = sr.ReadToEnd();
}
}
}
三:网页分析
现在网页经过一番折腾得到了,接下来就解析下一个。当然,正则匹配是一个不错的方法。毕竟工作量还是比较大的。或许业界也推荐HtmlAgilityPack,一个可以将Html解析成XML的解析工具,然后可以使用XPath提取指定的内容,大大提高了开发速度,性能也不错。毕竟,敏捷意味着敏捷。关于XPath的内容,可以看一下W3CSchool的两张图。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using HtmlAgilityPack;
using System.Text.RegularExpressions;
using System.Net;
using System.IO;
using System.IO.Compression;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
//var currentUrl = "http://www.mm5mm.com/";
var currentUrl = "http://www.sohu.com/";
var request = WebRequest.Create(currentUrl) as HttpWebRequest;
var response = request.GetResponse() as HttpWebResponse;
var encode = string.Empty;
if (response.CharacterSet == "ISO-8859-1")
encode = "gb2312";
else
encode = response.CharacterSet;
Stream stream;
if (response.ContentEncoding.ToLower() == "gzip")
{
stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
}
else
{
stream = response.GetResponseStream();
}
var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
var html = sr.ReadToEnd();
sr.Close();
HtmlDocument document = new HtmlDocument();
document.LoadHtml(html);
//提取title
var title = document.DocumentNode.SelectSingleNode("//title").InnerText;
//提取keywords
var keywords = document.DocumentNode.SelectSingleNode("//meta[@name='Keywords']").Attributes["content"].Value;
}
}
}
好了,结束工作,去睡觉吧。. .
php抓取网页title(Python代码的适用实例有哪些?WebScraping的基本原理步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-23 01:09
本文主要介绍Web Scraping的基本原理,基于Python语言,白话文,面向可爱的小白(^-^)。
混淆名称:
很多时候,人们将互联网上获取数据的代码统称为“爬虫”。
但实际上,所谓的“爬行动物”并不是特别准确,因为“爬行动物”也是分物种的。
有两种常见的“爬虫”:
网络爬虫,又称蜘蛛;Spiderbot Web Scraper,也称为 Web Harvesting;网页数据提取
不过这篇文章文章主要是讲解第二个“爬虫”(Web Scraper)的原理。
什么是网页抓取?
简单地说,Web Scraping(本文中)是指使用Python代码从肉眼可见的网页中抓取数据。
为什么需要网页抓取?
因为重复性工作太多,自己做的话可能会累死!
代码的适用示例有哪些?比如你需要下载交易所50只不同股票的当前价格,或者你想打印出所有最新消息的头条新闻网站,或者你只想把所有产品在网站上列出价格,放到Excel中进行对比等等,你可以发挥你的想象力.....
Web Scraping的基本原理:
首先,您需要了解网页在我们的屏幕上是如何呈现的;
事实上,我们发送了一个Request,一百公里外的服务器给了我们一个Response;然后我们看了一大堆文字,最后,浏览器偷偷把这一堆文字排列起来,放到了我们的屏幕上。在; 更详细的原理可以看我之前的博文《HTTP下午茶-小白介绍》中的书
然后,我们需要了解如何使用 Python 来实现它。实现原理基本分为四步:
首先,代码需要向服务器发送一个Request,然后接收一个Response(html文件)。然后,我们需要处理接收到的 Response 并找到我们需要的文本。然后,我们需要设计代码流来处理重复的任务。最后导出我们得到的数据,最后最好是一个漂亮的Excel表格汇总:
本文章重点讲解实现的思路和过程,
因此,它并不详尽,并且没有给出实际的代码。
不过,这个思路几乎是网页抓取的通用套路。
就写到这里吧,记得更新什么,
有写的地方不对的地方还请见谅! 查看全部
php抓取网页title(Python代码的适用实例有哪些?WebScraping的基本原理步骤)
本文主要介绍Web Scraping的基本原理,基于Python语言,白话文,面向可爱的小白(^-^)。
混淆名称:
很多时候,人们将互联网上获取数据的代码统称为“爬虫”。
但实际上,所谓的“爬行动物”并不是特别准确,因为“爬行动物”也是分物种的。
有两种常见的“爬虫”:
网络爬虫,又称蜘蛛;Spiderbot Web Scraper,也称为 Web Harvesting;网页数据提取
不过这篇文章文章主要是讲解第二个“爬虫”(Web Scraper)的原理。
什么是网页抓取?
简单地说,Web Scraping(本文中)是指使用Python代码从肉眼可见的网页中抓取数据。
为什么需要网页抓取?
因为重复性工作太多,自己做的话可能会累死!
代码的适用示例有哪些?比如你需要下载交易所50只不同股票的当前价格,或者你想打印出所有最新消息的头条新闻网站,或者你只想把所有产品在网站上列出价格,放到Excel中进行对比等等,你可以发挥你的想象力.....
Web Scraping的基本原理:
首先,您需要了解网页在我们的屏幕上是如何呈现的;
事实上,我们发送了一个Request,一百公里外的服务器给了我们一个Response;然后我们看了一大堆文字,最后,浏览器偷偷把这一堆文字排列起来,放到了我们的屏幕上。在; 更详细的原理可以看我之前的博文《HTTP下午茶-小白介绍》中的书
然后,我们需要了解如何使用 Python 来实现它。实现原理基本分为四步:
首先,代码需要向服务器发送一个Request,然后接收一个Response(html文件)。然后,我们需要处理接收到的 Response 并找到我们需要的文本。然后,我们需要设计代码流来处理重复的任务。最后导出我们得到的数据,最后最好是一个漂亮的Excel表格汇总:
本文章重点讲解实现的思路和过程,
因此,它并不详尽,并且没有给出实际的代码。
不过,这个思路几乎是网页抓取的通用套路。
就写到这里吧,记得更新什么,
有写的地方不对的地方还请见谅!
php抓取网页title(本节使用Python爬虫抓取猫眼(电影网排行榜)影片信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 218 次浏览 • 2021-10-12 05:38
本节使用Python爬虫抓取猫眼电影TOP100榜单()电影信息,包括电影名称、上映时间、主演信息。
在开始编写程序之前,首先确定页面类型(静态页面或动态页面),其次找出页面的url规则,最后通过分析网页元素的结构来确定正则表达式,从而提取网页信息。
确定页面类型
右击查看页面源码,判断页面中是否存在要抓取的数据。通过浏览可知,所有要抓取的信息都存在于源代码中,因此页面输入为静态页面。如下:
<p class="name">
我不是药神
主演:徐峥,周一围,王传君
</p>
发布时间:2018-07-05
确定url规则
确定url规则,需要多浏览几页,才能总结url规则,如下图:
第一页:
第二页:
第三页:
…
第 n 页:(n-1)*10
确定正则表达式
通过分析网页元素的结构来确定正则表达式,如下图:
<p class="name">我不是药神
主演:徐峥,周一围,王传君
</p>
发布时间:2018-07-05
使用 Chrome Developer Debugging Tools 确定要捕获的元素的结构。这样做的原因是可以避免正则表达式的冗余,提高编写正则表达式的速度。正则表达式如下:
.*?title="(.*?)".*?class="star">(.*?).*?releasetime">(.*?)
编写正则表达式时,使用(.*?)替换需要提取的信息,使用.*? 替换不需要的内容(包括元素标签)。
编写爬虫
下面用面向对象的方法写一个爬虫程序,主要写了四个函数,分别是请求函数、分析函数、数据保存函数、主函数。最后,如果你的时间不是很紧,想快速提高,最重要的是你不怕吃苦。我建议你可以定价@762459510。那真的很好。很多人都在快速进步。你需要害怕困难!可以去加进去看看~
1. from urllib import request
2. import re
3. import time
4. import random
5. import csv
6. from ua_info import ua_list
7. # 定义一个爬虫类
8. class MaoyanSpider(object):
9. # 初始化
10. # 定义初始页面url
11. def __init__(self):
12. self.url = 'https://maoyan.com/board/4?offset={}'
13. # 请求函数
14. def get_html(self,url):
15. headers = {'User-Agent':random.choice(ua_list)}
16. req = request.Request(url=url,headers=headers)
17. res = request.urlopen(req)
18. html = res.read().decode()
19. # 直接调用解析函数
20. self.parse_html(html)
21. # 解析函数
22. def parse_html(self,html):
23. # 正则表达式
24. re_bds = '.*?title="(.*?)".*?<p class="star">(.*?)
25. .*?class="releasetime">(.*?)</p>'
26. # 生成正则表达式对象
27. pattern = re.compile(re_bds,re.S)
28. # r_list: [('我不是药神','徐峥,周一围,王传君','2018-07-05'),...] 列表元组
29. r_list = pattern.findall(html)
30. self.save_html(r_list)
31. # 保存数据函数,使用python内置csv模块
32. def save_html(self,r_list):
33. #生成文件对象
34. with open('maoyan.csv','a',newline='',encoding="utf-8") as f:
35. #生成csv操作对象
36. writer = csv.writer(f)
37. #整理数据
38. for r in r_list:
39. name = r[0].strip()
40. star = r[1].strip()[3:]
41. # 上映时间:2018-07-05
42. # 切片截取时间
43. time = r[2].strip()[5:15]
44. L = [name,star,time]
45. # 写入csv文件
46. writer.writerow(L)
47. print(name,time,star)
48. # 主函数
49. def run(self):
50. #抓取第一页数据
51. for offset in range(0,11,10):
52. url = self.url.format(offset)
53. self.get_html(url)
54. #生成1-2之间的浮点数
55. time.sleep(random.uniform(1,2))
56. # 以脚本方式启动
57. if __name__ == '__main__':
58. #捕捉异常错误
59. try:
60. spider = MaoyanSpider()
61. spider.run()
62. except Exception as e:
63. print("错误:",e)
</p>
输出结果:
我不是药神 2018-07-05 徐峥、周以伟、王传君
肖申克的救赎 1994-09-10 蒂姆·罗宾斯、摩根·弗里曼、鲍勃·冈顿
绿皮书 2019-03-01 Vigo Mortensen, Mahsala Ali, Linda Cardrini
海上钢琴家 2019-11-15 蒂姆·罗斯、比尔·纳恩、克兰伦斯·威廉姆斯三世
小偷家族 2018-08-03 中川雅也、安藤樱、松冈墨鱼
霸王别姬 1993-07-26 张国荣、张凤仪、巩俐
哪吒魔童降临人间
美丽人生 2020-01-03 罗伯托·贝尼尼、朱斯蒂诺·杜拉诺、塞尔吉奥·比尼·巴斯特里克
这个杀手不太冷 1994-09-14 让·雷诺、加里·奥德曼、娜塔莉·波特曼
2010-09-01 莱昂纳多·迪卡普里奥、渡边谦、约瑟夫·高登-莱维特 查看全部
php抓取网页title(本节使用Python爬虫抓取猫眼(电影网排行榜)影片信息)
本节使用Python爬虫抓取猫眼电影TOP100榜单()电影信息,包括电影名称、上映时间、主演信息。
在开始编写程序之前,首先确定页面类型(静态页面或动态页面),其次找出页面的url规则,最后通过分析网页元素的结构来确定正则表达式,从而提取网页信息。
确定页面类型
右击查看页面源码,判断页面中是否存在要抓取的数据。通过浏览可知,所有要抓取的信息都存在于源代码中,因此页面输入为静态页面。如下:
<p class="name">
我不是药神
主演:徐峥,周一围,王传君
</p>
发布时间:2018-07-05
确定url规则
确定url规则,需要多浏览几页,才能总结url规则,如下图:
第一页:
第二页:
第三页:
…
第 n 页:(n-1)*10
确定正则表达式
通过分析网页元素的结构来确定正则表达式,如下图:
<p class="name">我不是药神
主演:徐峥,周一围,王传君
</p>
发布时间:2018-07-05
使用 Chrome Developer Debugging Tools 确定要捕获的元素的结构。这样做的原因是可以避免正则表达式的冗余,提高编写正则表达式的速度。正则表达式如下:
.*?title="(.*?)".*?class="star">(.*?).*?releasetime">(.*?)
编写正则表达式时,使用(.*?)替换需要提取的信息,使用.*? 替换不需要的内容(包括元素标签)。
编写爬虫
下面用面向对象的方法写一个爬虫程序,主要写了四个函数,分别是请求函数、分析函数、数据保存函数、主函数。最后,如果你的时间不是很紧,想快速提高,最重要的是你不怕吃苦。我建议你可以定价@762459510。那真的很好。很多人都在快速进步。你需要害怕困难!可以去加进去看看~
1. from urllib import request
2. import re
3. import time
4. import random
5. import csv
6. from ua_info import ua_list
7. # 定义一个爬虫类
8. class MaoyanSpider(object):
9. # 初始化
10. # 定义初始页面url
11. def __init__(self):
12. self.url = 'https://maoyan.com/board/4?offset={}'
13. # 请求函数
14. def get_html(self,url):
15. headers = {'User-Agent':random.choice(ua_list)}
16. req = request.Request(url=url,headers=headers)
17. res = request.urlopen(req)
18. html = res.read().decode()
19. # 直接调用解析函数
20. self.parse_html(html)
21. # 解析函数
22. def parse_html(self,html):
23. # 正则表达式
24. re_bds = '.*?title="(.*?)".*?<p class="star">(.*?)
25. .*?class="releasetime">(.*?)</p>'
26. # 生成正则表达式对象
27. pattern = re.compile(re_bds,re.S)
28. # r_list: [('我不是药神','徐峥,周一围,王传君','2018-07-05'),...] 列表元组
29. r_list = pattern.findall(html)
30. self.save_html(r_list)
31. # 保存数据函数,使用python内置csv模块
32. def save_html(self,r_list):
33. #生成文件对象
34. with open('maoyan.csv','a',newline='',encoding="utf-8") as f:
35. #生成csv操作对象
36. writer = csv.writer(f)
37. #整理数据
38. for r in r_list:
39. name = r[0].strip()
40. star = r[1].strip()[3:]
41. # 上映时间:2018-07-05
42. # 切片截取时间
43. time = r[2].strip()[5:15]
44. L = [name,star,time]
45. # 写入csv文件
46. writer.writerow(L)
47. print(name,time,star)
48. # 主函数
49. def run(self):
50. #抓取第一页数据
51. for offset in range(0,11,10):
52. url = self.url.format(offset)
53. self.get_html(url)
54. #生成1-2之间的浮点数
55. time.sleep(random.uniform(1,2))
56. # 以脚本方式启动
57. if __name__ == '__main__':
58. #捕捉异常错误
59. try:
60. spider = MaoyanSpider()
61. spider.run()
62. except Exception as e:
63. print("错误:",e)
</p>
输出结果:
我不是药神 2018-07-05 徐峥、周以伟、王传君
肖申克的救赎 1994-09-10 蒂姆·罗宾斯、摩根·弗里曼、鲍勃·冈顿
绿皮书 2019-03-01 Vigo Mortensen, Mahsala Ali, Linda Cardrini
海上钢琴家 2019-11-15 蒂姆·罗斯、比尔·纳恩、克兰伦斯·威廉姆斯三世
小偷家族 2018-08-03 中川雅也、安藤樱、松冈墨鱼
霸王别姬 1993-07-26 张国荣、张凤仪、巩俐
哪吒魔童降临人间
美丽人生 2020-01-03 罗伯托·贝尼尼、朱斯蒂诺·杜拉诺、塞尔吉奥·比尼·巴斯特里克
这个杀手不太冷 1994-09-14 让·雷诺、加里·奥德曼、娜塔莉·波特曼
2010-09-01 莱昂纳多·迪卡普里奥、渡边谦、约瑟夫·高登-莱维特
php抓取网页title(更多写博客安全系列之二:如何防止CSRF攻击?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-07 10:31
阿里云>云栖社区>主题图>P>php抢域名标题
推荐活动:
更多优惠>
当前主题:php抓取域名标题并添加到采集夹
相关话题:
php抢域名相关博客 查看更多博客
前端安全系列之二:如何防范CSRF攻击?
作者:小技术专家 2211人浏览评论:12年前
背景 随着互联网的飞速发展,信息安全问题成为企业最关注的焦点之一,而前端是引发企业安全问题的高风险基地。移动互联网时代,除了传统的XSS、CSRF等安全问题外,前端人员经常会遇到网络劫持、非法调用Hybrid API等新的安全问题。当然,浏览
阅读全文
网站被黑后被黑了被黑了,我是怎么解决网站被黑的!
作者:网站安全者937人查看评论:03年前
1、我发现我被黑了。网站 被黑的症状。两年前,我用wordpress搭建了一个网站。平时没什么好写的文章玩。但是前几天突然发现网站的流量突然减少了。我在网站上查了百度收录,发现不对劲,网站被黑了。大多数百度抓取收录的页面标题和描述
阅读全文
网站被黑后被黑了被黑了,我是怎么解决网站被黑的!
作者:网站安全1247人浏览评论:03年前
1、我发现我被黑了。网站被黑的症状 两年前我用wordpress搭建了一个网站,平时也没什么好写的文章玩。但是前几天突然发现网站的流量突然减少了。我在网站上查了百度收录,发现不对劲,网站被黑了。大多数百度爬取收录的页面标题和descriptorio
阅读全文
一键分享QQ空间、新浪微博、腾讯微博、豆瓣等API链接代码。
作者:小美科技 1212人浏览评论:03年前
1.新浪微博:count=表示是否显示当前页面的共享页数(1显示)(可选,允许为空) &url=将页面地址转换为短域名并显示在内容后面文本。(可选,允许为空)&ap
阅读全文
搜索引擎优化的55个技巧
作者:文艺小青年1602人浏览评论:03年前
每个人都喜欢易于使用的技术,对吧?这里有 55 个搜索引擎优化技巧,即使您的妈妈也可以轻松使用。哦,不是我妈妈,但你知道我的意思。这意味着大多数网页设计师和 SEO 新手可以毫无困难地快速上手。如果一定要使用Java脚本的下拉菜单,图片
阅读全文
一键分享QQ空间、新浪微博、腾讯微博、豆瓣等API链接代码。
作者:小科技专家1424人浏览评论:03年前
1.新浪微博:count=表示是否显示当前页面的共享页数(1显示)(可选,允许为空) &url=将页面地址转换为短域名并显示在内容后面文本。(可选,允许为空)&ap
阅读全文
ThinkPHP3.2.3 集成微信分享JS-SDK实践
作者:思梦php1055人浏览评论:04年前
先来看看微信分享的效果: 微信分享js-sdk集成之前是这样的:没有摘要,缩略图可以随意抓取文字。微信分享js-sdk集成后是这样的:title、summary、thumbnail 从Define一、下载微信SDK开发包下载地址:
阅读全文
在微信上分享自定义图片和摘要
作者:ap0581w9c1088 浏览评论人数:05年前
参考:微信分享实现微信现在是很多企业营销的重点。你可能每天都在朋友圈和消息群里看到html5,但是自从微信更新了官方api之后,对整个微信页面的控制就很严格了。官方分享卡是微信生态中众多html5静态页面传播的重点。但是很
阅读全文 查看全部
php抓取网页title(更多写博客安全系列之二:如何防止CSRF攻击?(组图))
阿里云>云栖社区>主题图>P>php抢域名标题
推荐活动:
更多优惠>
当前主题:php抓取域名标题并添加到采集夹
相关话题:
php抢域名相关博客 查看更多博客
前端安全系列之二:如何防范CSRF攻击?
作者:小技术专家 2211人浏览评论:12年前
背景 随着互联网的飞速发展,信息安全问题成为企业最关注的焦点之一,而前端是引发企业安全问题的高风险基地。移动互联网时代,除了传统的XSS、CSRF等安全问题外,前端人员经常会遇到网络劫持、非法调用Hybrid API等新的安全问题。当然,浏览
阅读全文
网站被黑后被黑了被黑了,我是怎么解决网站被黑的!
作者:网站安全者937人查看评论:03年前
1、我发现我被黑了。网站 被黑的症状。两年前,我用wordpress搭建了一个网站。平时没什么好写的文章玩。但是前几天突然发现网站的流量突然减少了。我在网站上查了百度收录,发现不对劲,网站被黑了。大多数百度抓取收录的页面标题和描述
阅读全文
网站被黑后被黑了被黑了,我是怎么解决网站被黑的!
作者:网站安全1247人浏览评论:03年前
1、我发现我被黑了。网站被黑的症状 两年前我用wordpress搭建了一个网站,平时也没什么好写的文章玩。但是前几天突然发现网站的流量突然减少了。我在网站上查了百度收录,发现不对劲,网站被黑了。大多数百度爬取收录的页面标题和descriptorio
阅读全文
一键分享QQ空间、新浪微博、腾讯微博、豆瓣等API链接代码。
作者:小美科技 1212人浏览评论:03年前
1.新浪微博:count=表示是否显示当前页面的共享页数(1显示)(可选,允许为空) &url=将页面地址转换为短域名并显示在内容后面文本。(可选,允许为空)&ap
阅读全文
搜索引擎优化的55个技巧
作者:文艺小青年1602人浏览评论:03年前
每个人都喜欢易于使用的技术,对吧?这里有 55 个搜索引擎优化技巧,即使您的妈妈也可以轻松使用。哦,不是我妈妈,但你知道我的意思。这意味着大多数网页设计师和 SEO 新手可以毫无困难地快速上手。如果一定要使用Java脚本的下拉菜单,图片
阅读全文
一键分享QQ空间、新浪微博、腾讯微博、豆瓣等API链接代码。
作者:小科技专家1424人浏览评论:03年前
1.新浪微博:count=表示是否显示当前页面的共享页数(1显示)(可选,允许为空) &url=将页面地址转换为短域名并显示在内容后面文本。(可选,允许为空)&ap
阅读全文
ThinkPHP3.2.3 集成微信分享JS-SDK实践
作者:思梦php1055人浏览评论:04年前
先来看看微信分享的效果: 微信分享js-sdk集成之前是这样的:没有摘要,缩略图可以随意抓取文字。微信分享js-sdk集成后是这样的:title、summary、thumbnail 从Define一、下载微信SDK开发包下载地址:
阅读全文
在微信上分享自定义图片和摘要
作者:ap0581w9c1088 浏览评论人数:05年前
参考:微信分享实现微信现在是很多企业营销的重点。你可能每天都在朋友圈和消息群里看到html5,但是自从微信更新了官方api之后,对整个微信页面的控制就很严格了。官方分享卡是微信生态中众多html5静态页面传播的重点。但是很
阅读全文
php抓取网页title(PHP程序Pocket抓取知乎专栏的问题(一)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-10-05 03:19
口袋抓取知乎列问题
Pocket 是一种网络服务,我通常会在以后阅读时使用更多。对在线文章文字进行采集爬取效果更好。可以去除页面广告等无关内容。支持标注和搜索,同步速度也高。没关系。免费会员限制很小,所以如果我看到一些来不及阅读和消化的文章,我会先将其添加到Pocket队列中,有空时查看存档。
只是由于目前抓取网页正文的原理的限制,Pocket 基本上不支持越来越多的 AJAX 动态网页。最典型的就是知乎栏文章。之前的知乎列是用来支持Pocket的直接取的,改成AJAX加载数据后,将文章发送到Pocket会有这样的效果:
Pocket正常抓取的文章应该可以显示文章中的摘要文本或图片,知乎栏文章为空,点击文章@ >入口也是直接跳转到知乎栏目链接,并没有表现出Pocket抓取优化的效果。
问题分析
稍微看一下知乎专栏网页的代码,可以发现,如果在浏览器中访问这样的专栏,文章链接:
下面的文章内容数据API链接会实际加载,直到数据加载完毕才会显示知乎栏目页面:
这种动态加载显然是 Pocket 不支持的,但是很容易处理。我们用PHP或者Node.js实现一个简单的程序读取文章栏目的内容并输出,然后放到VPS或者其他虚拟主机上运行,然后访问我自己的网站并发送到 Pocket,Pocket 应该能够正确捕获它。另外,这种方法比较好的一面是输出内容中没有其他知乎相关网页代码,只有列文章内容,更便于Pocket抓取和处理。
PHP程序Pocket抓取效果
这个PHP程序真的没有技术含量。我只是写了一个简单的PHP文件,接受列页面ID的page参数,输出文章的内容:
上面的程序只是一个简单的判断。如果请求头收录Referer信息(例如从Pocket跳转网站等)或者请求地址中的redirect参数值为1,则直接跳转到知乎列页面,内容文章 列的默认输出。另外,程序使用getallheaders函数获取HTTP请求头信息。默认情况下,仅支持 Apache。如果想在nginx等服务器上使用,可以稍微修改一下。
此外,程序还将referrer值指定为never,防止页面引用知乎图片等资源时触发知乎的反盗链机制。
将上面的PHP程序放在虚拟主机上,访问类似如下的链接(仅供演示,需要翻墙):
~nocwat/知乎-grub.php?page=21542817
正确显示文章的内容后,把上面的链接发给Pocket。过一会就可以在Pocket队列中看到爬取的列文章。
暗示
由于知乎栏的图片有防盗链策略,直接访问上面的链接可能会导致文章中的图片无法正确显示的问题,不过没关系,Pocket会自动抓拍保存对于我们文章 在图片中。
最后来看看我的Pocket队列中的显示效果:
并点击文章条目进入,还可以看到Pocket优化文章的内容。在Pocket中点击查看原文档还可以自动跳转到知乎的栏目文章页面,这样你就不用担心专栏作家是否删除了文章而不会被能够再次查看它。
没有相关的文章。 查看全部
php抓取网页title(PHP程序Pocket抓取知乎专栏的问题(一)_)
口袋抓取知乎列问题
Pocket 是一种网络服务,我通常会在以后阅读时使用更多。对在线文章文字进行采集爬取效果更好。可以去除页面广告等无关内容。支持标注和搜索,同步速度也高。没关系。免费会员限制很小,所以如果我看到一些来不及阅读和消化的文章,我会先将其添加到Pocket队列中,有空时查看存档。
只是由于目前抓取网页正文的原理的限制,Pocket 基本上不支持越来越多的 AJAX 动态网页。最典型的就是知乎栏文章。之前的知乎列是用来支持Pocket的直接取的,改成AJAX加载数据后,将文章发送到Pocket会有这样的效果:
Pocket正常抓取的文章应该可以显示文章中的摘要文本或图片,知乎栏文章为空,点击文章@ >入口也是直接跳转到知乎栏目链接,并没有表现出Pocket抓取优化的效果。
问题分析
稍微看一下知乎专栏网页的代码,可以发现,如果在浏览器中访问这样的专栏,文章链接:
下面的文章内容数据API链接会实际加载,直到数据加载完毕才会显示知乎栏目页面:
这种动态加载显然是 Pocket 不支持的,但是很容易处理。我们用PHP或者Node.js实现一个简单的程序读取文章栏目的内容并输出,然后放到VPS或者其他虚拟主机上运行,然后访问我自己的网站并发送到 Pocket,Pocket 应该能够正确捕获它。另外,这种方法比较好的一面是输出内容中没有其他知乎相关网页代码,只有列文章内容,更便于Pocket抓取和处理。
PHP程序Pocket抓取效果
这个PHP程序真的没有技术含量。我只是写了一个简单的PHP文件,接受列页面ID的page参数,输出文章的内容:
上面的程序只是一个简单的判断。如果请求头收录Referer信息(例如从Pocket跳转网站等)或者请求地址中的redirect参数值为1,则直接跳转到知乎列页面,内容文章 列的默认输出。另外,程序使用getallheaders函数获取HTTP请求头信息。默认情况下,仅支持 Apache。如果想在nginx等服务器上使用,可以稍微修改一下。
此外,程序还将referrer值指定为never,防止页面引用知乎图片等资源时触发知乎的反盗链机制。
将上面的PHP程序放在虚拟主机上,访问类似如下的链接(仅供演示,需要翻墙):
~nocwat/知乎-grub.php?page=21542817
正确显示文章的内容后,把上面的链接发给Pocket。过一会就可以在Pocket队列中看到爬取的列文章。
暗示
由于知乎栏的图片有防盗链策略,直接访问上面的链接可能会导致文章中的图片无法正确显示的问题,不过没关系,Pocket会自动抓拍保存对于我们文章 在图片中。
最后来看看我的Pocket队列中的显示效果:
并点击文章条目进入,还可以看到Pocket优化文章的内容。在Pocket中点击查看原文档还可以自动跳转到知乎的栏目文章页面,这样你就不用担心专栏作家是否删除了文章而不会被能够再次查看它。
没有相关的文章。
php抓取网页title(Javaexample参数分析及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-09-30 04:27
PhantomJS 是一个基于 WebKit 的服务器端 API。它完全支持网络,无需浏览器支持。它速度快,并且本机支持各种 Web 标准:DOM 处理、CSS 选择器、JSON、Canvas 和 SVG。PhantomJS 可用于页面自动化、网络监控、网页截图和无界面测试。
一、安装
安装包下载地址:包括Windows、Mac OS、Linux版本,可以选择对应版本下载解压(为了方便,可以自己设置phantomjs的环境变量),里面有example文件夹,很多已经写好的代码使用。本文假设已安装phantomjs并设置好环境变量。
二、使用你好,世界!
创建一个收录以下两行脚本的新文本文件:
console.log('Hello, world!');
phantom.exit();
将文件保存为hello.js,然后执行:
phantomjs hello.js
输出结果是:你好,世界!
第一行将在终端中打印一个字符串,第二行 phantom.exit 将退出。
在这个脚本中调用phantom.exit非常重要,否则PhantomJS根本不会停止。
脚本参数 – 脚本参数
Phantomjs 是如何传递参数的?如下:
phantomjs examples/arguments.js foo bar baz
其中foo、bar、baz是要传递的参数,如何获取:
var system = require('system');
if (system.args.length === 1) {
console.log('Try to pass some args when invoking this script!');
} else {
system.args.forEach(function (arg, i) {
console.log(i + ': ' + arg);
});
}
phantom.exit();
它会输出:
0: foo
1: bar
2: baz
页面加载-页面加载
通过创建网页对象,可以加载、分析和呈现网页。
以下脚本将是示例页面对象的最简单用法,它加载并将其保存为图像,example.png。
var page = require('webpage').create();
page.open('http://example.com', function () {
page.render('example.png');
phantom.exit();
});
由于这个特性,PhantomJS 可以用来截取网页的截图和一些内容的快照,比如保存网页、SVG 为图片、PDF 等,这个功能非常好。
下一个 loadspeed.js 脚本加载一个特殊的 URL(不要忘记 http 协议)并测量加载页面的时间。
var page = require('webpage').create(),
system = require('system'),
t, address;
if (system.args.length === 1) {
console.log('Usage: loadspeed.js ');
phantom.exit();
}
t = Date.now();
address = system.args[1];
page.open(address, function (status) {
if (status !== 'success') {
console.log('FAIL to load the address');
} else {
t = Date.now() - t;
console.log('Loading time ' + t + ' msec');
}
phantom.exit();
});
在命令行上运行脚本:
phantomjs loadspeed.js http://www.google.com
它输出如下内容:
加载加载时间 719 毫秒
代码评估 – 代码评估
要在网页上下文中对 JavaScript 或 CoffeeScript 执行操作,请使用evaluate() 方法。代码在“沙箱”中运行,它无法读取其所属页面上下文之外的任何 JavaScript 对象和变量。evaluate() 将返回一个对象,但它仅限于简单对象,不能收录方法或闭包。
这是显示页面标题的示例:
var page = require('webpage').create();
page.open(url, function (status) {
var title = page.evaluate(function () {
return document.title;
});
console.log('Page title is ' + title);
});
默认情况下不会显示来自网页的任何控制台信息,包括evaluate() 的内部代码。要覆盖此行为,请使用 onConsoleMessage 回调函数。前面的例子可以改写为:
var page = require('webpage').create();
page.onConsoleMessage = function (msg) {
console.log('Page title is ' + msg);
};
page.open(url, function (status) {
page.evaluate(function () {
console.log(document.title);
});
});
DOM操作-DOM操作
由于脚本似乎在 Web 浏览器上运行,因此标准 DOM 脚本和 CSS 选择器可以很好地工作。这使得 PhantomJS 适合支持各种页面自动化任务。
下面的 useragent.js 将读取 id 为 myagent 的元素的 textContent 属性:
var page = require('webpage').create();
console.log('The default user agent is ' + page.settings.userAgent);
page.settings.userAgent = 'SpecialAgent';
page.open('http://www.httpuseragent.org', function (status) {
if (status !== 'success') {
console.log('Unable to access network');
} else {
var ua = page.evaluate(function () {
return document.getElementById('myagent').textContent;
});
console.log(ua);
}
phantom.exit();
});
上面的例子还提供了一种自定义用户代理的方法。
使用 JQuery 和其他库:
var page = require('webpage').create();
page.open('http://www.sample.com', function() {
page.includeJs("http://ajax.googleapis.com/aja ... ot%3B, function() {
page.evaluate(function() {
$("button").click();
});
phantom.exit()
});
});
网络请求和响应-网络请求和响应
当页面从远程服务器请求资源时,可以通过 onResourceRequested 和 onResourceReceived 回调方法跟踪请求和响应。示例 netlog.js:
var page = require('webpage').create();
page.onResourceRequested = function (request) {
console.log('Request ' + JSON.stringify(request, undefined, 4));
};
page.onResourceReceived = function (response) {
console.log('Receive ' + JSON.stringify(response, undefined, 4));
};
page.open(url);
关于如何使用此功能进行基于 YSlow 的 HAR 输出和性能分析的更多信息,请参阅网络监控页面。
PhantomJs 官网:
GitHub:
以上帮助说明来自woiweb:
windows下使用PHP执行phantomjs
下面直接给出执行代码:
echo '';
exec('H:\wamp\www\phantomjs\bin\phantomjs --output-encoding=utf8 H:\wamp\www\Xss_Scanner\test.js ',$output_main);
var_dump($output_main);
// $str = implode('',$output_main);
// var_dump($str);
test.js文件内容如下:
console.log('Loading a web page');
var page = require('webpage').create();
var url = 'http://www.mafutian.net/';
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
console.log(page.content);
}
phantom.exit();
});
执行结果如下图所示:
注意,要达到上述执行结果,需要以下几点:
(1) 不能开启PHP的安全模式,即需要在php.ini中将sql.safe_mode设置为Off。(并重启服务器,当然php本身并没有开启安全模式默认情况下)
(2) 不管phantomjs是否加到系统环境变量中,在exec()中应该是绝对路径。以下执行无效:
exec('phantomjs --output-encoding=utf8 H:\wamp\www\Xss_Scanner\test.js ',$output_main);
需要走phantomjs的绝对路径。
需要注意的是,js文件不需要走绝对路径。可以相对于网站的根目录,如下执行成功:
exec('H:\wamp\www\phantomjs\bin\phantomjs --output-encoding=utf8 test.js ',$output_main);
注意:test.js放在网站的根目录下。
另外:在PHP下执行phantomjs也可以使用另一个函数systom()来执行
参考以上内容:链接地址:
php-phantomjs中文API整理的合集DEMO
<p> 查看全部
php抓取网页title(Javaexample参数分析及应用)
PhantomJS 是一个基于 WebKit 的服务器端 API。它完全支持网络,无需浏览器支持。它速度快,并且本机支持各种 Web 标准:DOM 处理、CSS 选择器、JSON、Canvas 和 SVG。PhantomJS 可用于页面自动化、网络监控、网页截图和无界面测试。
一、安装
安装包下载地址:包括Windows、Mac OS、Linux版本,可以选择对应版本下载解压(为了方便,可以自己设置phantomjs的环境变量),里面有example文件夹,很多已经写好的代码使用。本文假设已安装phantomjs并设置好环境变量。
二、使用你好,世界!
创建一个收录以下两行脚本的新文本文件:
console.log('Hello, world!');
phantom.exit();
将文件保存为hello.js,然后执行:
phantomjs hello.js
输出结果是:你好,世界!
第一行将在终端中打印一个字符串,第二行 phantom.exit 将退出。
在这个脚本中调用phantom.exit非常重要,否则PhantomJS根本不会停止。
脚本参数 – 脚本参数
Phantomjs 是如何传递参数的?如下:
phantomjs examples/arguments.js foo bar baz
其中foo、bar、baz是要传递的参数,如何获取:
var system = require('system');
if (system.args.length === 1) {
console.log('Try to pass some args when invoking this script!');
} else {
system.args.forEach(function (arg, i) {
console.log(i + ': ' + arg);
});
}
phantom.exit();
它会输出:
0: foo
1: bar
2: baz
页面加载-页面加载
通过创建网页对象,可以加载、分析和呈现网页。
以下脚本将是示例页面对象的最简单用法,它加载并将其保存为图像,example.png。
var page = require('webpage').create();
page.open('http://example.com', function () {
page.render('example.png');
phantom.exit();
});
由于这个特性,PhantomJS 可以用来截取网页的截图和一些内容的快照,比如保存网页、SVG 为图片、PDF 等,这个功能非常好。
下一个 loadspeed.js 脚本加载一个特殊的 URL(不要忘记 http 协议)并测量加载页面的时间。
var page = require('webpage').create(),
system = require('system'),
t, address;
if (system.args.length === 1) {
console.log('Usage: loadspeed.js ');
phantom.exit();
}
t = Date.now();
address = system.args[1];
page.open(address, function (status) {
if (status !== 'success') {
console.log('FAIL to load the address');
} else {
t = Date.now() - t;
console.log('Loading time ' + t + ' msec');
}
phantom.exit();
});
在命令行上运行脚本:
phantomjs loadspeed.js http://www.google.com
它输出如下内容:
加载加载时间 719 毫秒
代码评估 – 代码评估
要在网页上下文中对 JavaScript 或 CoffeeScript 执行操作,请使用evaluate() 方法。代码在“沙箱”中运行,它无法读取其所属页面上下文之外的任何 JavaScript 对象和变量。evaluate() 将返回一个对象,但它仅限于简单对象,不能收录方法或闭包。
这是显示页面标题的示例:
var page = require('webpage').create();
page.open(url, function (status) {
var title = page.evaluate(function () {
return document.title;
});
console.log('Page title is ' + title);
});
默认情况下不会显示来自网页的任何控制台信息,包括evaluate() 的内部代码。要覆盖此行为,请使用 onConsoleMessage 回调函数。前面的例子可以改写为:
var page = require('webpage').create();
page.onConsoleMessage = function (msg) {
console.log('Page title is ' + msg);
};
page.open(url, function (status) {
page.evaluate(function () {
console.log(document.title);
});
});
DOM操作-DOM操作
由于脚本似乎在 Web 浏览器上运行,因此标准 DOM 脚本和 CSS 选择器可以很好地工作。这使得 PhantomJS 适合支持各种页面自动化任务。
下面的 useragent.js 将读取 id 为 myagent 的元素的 textContent 属性:
var page = require('webpage').create();
console.log('The default user agent is ' + page.settings.userAgent);
page.settings.userAgent = 'SpecialAgent';
page.open('http://www.httpuseragent.org', function (status) {
if (status !== 'success') {
console.log('Unable to access network');
} else {
var ua = page.evaluate(function () {
return document.getElementById('myagent').textContent;
});
console.log(ua);
}
phantom.exit();
});
上面的例子还提供了一种自定义用户代理的方法。
使用 JQuery 和其他库:
var page = require('webpage').create();
page.open('http://www.sample.com', function() {
page.includeJs("http://ajax.googleapis.com/aja ... ot%3B, function() {
page.evaluate(function() {
$("button").click();
});
phantom.exit()
});
});
网络请求和响应-网络请求和响应
当页面从远程服务器请求资源时,可以通过 onResourceRequested 和 onResourceReceived 回调方法跟踪请求和响应。示例 netlog.js:
var page = require('webpage').create();
page.onResourceRequested = function (request) {
console.log('Request ' + JSON.stringify(request, undefined, 4));
};
page.onResourceReceived = function (response) {
console.log('Receive ' + JSON.stringify(response, undefined, 4));
};
page.open(url);
关于如何使用此功能进行基于 YSlow 的 HAR 输出和性能分析的更多信息,请参阅网络监控页面。
PhantomJs 官网:
GitHub:
以上帮助说明来自woiweb:
windows下使用PHP执行phantomjs
下面直接给出执行代码:
echo '';
exec('H:\wamp\www\phantomjs\bin\phantomjs --output-encoding=utf8 H:\wamp\www\Xss_Scanner\test.js ',$output_main);
var_dump($output_main);
// $str = implode('',$output_main);
// var_dump($str);
test.js文件内容如下:
console.log('Loading a web page');
var page = require('webpage').create();
var url = 'http://www.mafutian.net/';
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
console.log(page.content);
}
phantom.exit();
});
执行结果如下图所示:
注意,要达到上述执行结果,需要以下几点:
(1) 不能开启PHP的安全模式,即需要在php.ini中将sql.safe_mode设置为Off。(并重启服务器,当然php本身并没有开启安全模式默认情况下)
(2) 不管phantomjs是否加到系统环境变量中,在exec()中应该是绝对路径。以下执行无效:
exec('phantomjs --output-encoding=utf8 H:\wamp\www\Xss_Scanner\test.js ',$output_main);
需要走phantomjs的绝对路径。
需要注意的是,js文件不需要走绝对路径。可以相对于网站的根目录,如下执行成功:
exec('H:\wamp\www\phantomjs\bin\phantomjs --output-encoding=utf8 test.js ',$output_main);
注意:test.js放在网站的根目录下。
另外:在PHP下执行phantomjs也可以使用另一个函数systom()来执行
参考以上内容:链接地址:
php-phantomjs中文API整理的合集DEMO
<p>

