
htmlunit抓取动态网页
htmlunit抓取动态网页(这是一个的最新版本是什么?一个 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-12-03 09:01
)
最近在写爬虫的时候,在使用httpclient爬取一些网页的时候出现了一些问题,就是爬取的内容收录了大量的加密文本(通过javascript脚本),无法获取到真正的内容(即即,网页是用浏览器打开的)呈现的内容)。所以一般需要配合js引擎来解决这个问题。经过搜索,我发现htmlunit工具可以提供帮助。在了解和使用的过程中,我发现这是一个非常棒的开源工具。虽然名气不如httpclient,但实力不容小觑。少说八卦。目前最新的htmlunit版本是2.15,可以从这里下载:
String url="http://xxxx.xx/";//想采集的网址
String refer="http://xxx.xx/";
URL link=new URL(url);
WebClient wc=new WebClient();
WebRequest request=new WebRequest(link);
request.setCharset("UTF-8");
request.setProxyHost("x.120.120.x");
request.setProxyPort(8080);
request.setAdditionalHeader("Referer", refer);//设置请求报文头里的refer字段
////设置请求报文头里的User-Agent字段
request.setAdditionalHeader("User-Agent", "Mozilla/5.0 (Windows NT 5.1; rv:6.0.2) Gecko/20100101 Firefox/6.0.2");
//wc.addRequestHeader("User-Agent", "Mozilla/5.0 (Windows NT 5.1; rv:6.0.2) Gecko/20100101 Firefox/6.0.2");
//wc.addRequestHeader和request.setAdditionalHeader功能应该是一样的。选择一个即可。
//其他报文头字段可以根据需要添加
wc.getCookieManager().setCookiesEnabled(true);//开启cookie管理
wc.getOptions().setJavaScriptEnabled(true);//开启js解析。对于变态网页,这个是必须的
wc.getOptions().setCssEnabled(true);//开启css解析。对于变态网页,这个是必须的。
wc.getOptions().setThrowExceptionOnFailingStatusCode(false);
wc.getOptions().setThrowExceptionOnScriptError(false);
wc.getOptions().setTimeout(10000);
//设置cookie。如果你有cookie,可以在这里设置
Set cookies=null;
Iterator i = cookies.iterator();
while (i.hasNext())
{
wc.getCookieManager().addCookie(i.next());
}
//准备工作已经做好了
HtmlPage page=null;
page = wc.getPage(request);
if(page==null)
{
System.out.println("采集 "+url+" 失败!!!");
return ;
}
String content=page.asText();//网页内容保存在content里
if(content==null)
{
System.out.println("采集 "+url+" 失败!!!");
return ;
}
//搞定了
CookieManager CM = wc.getCookieManager(); //WC = Your WebClient's name
Set cookies_ret = CM.getCookies();//返回的Cookie在这里,下次请求的时候可能可以用上啦。 查看全部
htmlunit抓取动态网页(这是一个的最新版本是什么?一个
)
最近在写爬虫的时候,在使用httpclient爬取一些网页的时候出现了一些问题,就是爬取的内容收录了大量的加密文本(通过javascript脚本),无法获取到真正的内容(即即,网页是用浏览器打开的)呈现的内容)。所以一般需要配合js引擎来解决这个问题。经过搜索,我发现htmlunit工具可以提供帮助。在了解和使用的过程中,我发现这是一个非常棒的开源工具。虽然名气不如httpclient,但实力不容小觑。少说八卦。目前最新的htmlunit版本是2.15,可以从这里下载:
String url="http://xxxx.xx/";//想采集的网址
String refer="http://xxx.xx/";
URL link=new URL(url);
WebClient wc=new WebClient();
WebRequest request=new WebRequest(link);
request.setCharset("UTF-8");
request.setProxyHost("x.120.120.x");
request.setProxyPort(8080);
request.setAdditionalHeader("Referer", refer);//设置请求报文头里的refer字段
////设置请求报文头里的User-Agent字段
request.setAdditionalHeader("User-Agent", "Mozilla/5.0 (Windows NT 5.1; rv:6.0.2) Gecko/20100101 Firefox/6.0.2");
//wc.addRequestHeader("User-Agent", "Mozilla/5.0 (Windows NT 5.1; rv:6.0.2) Gecko/20100101 Firefox/6.0.2");
//wc.addRequestHeader和request.setAdditionalHeader功能应该是一样的。选择一个即可。
//其他报文头字段可以根据需要添加
wc.getCookieManager().setCookiesEnabled(true);//开启cookie管理
wc.getOptions().setJavaScriptEnabled(true);//开启js解析。对于变态网页,这个是必须的
wc.getOptions().setCssEnabled(true);//开启css解析。对于变态网页,这个是必须的。
wc.getOptions().setThrowExceptionOnFailingStatusCode(false);
wc.getOptions().setThrowExceptionOnScriptError(false);
wc.getOptions().setTimeout(10000);
//设置cookie。如果你有cookie,可以在这里设置
Set cookies=null;
Iterator i = cookies.iterator();
while (i.hasNext())
{
wc.getCookieManager().addCookie(i.next());
}
//准备工作已经做好了
HtmlPage page=null;
page = wc.getPage(request);
if(page==null)
{
System.out.println("采集 "+url+" 失败!!!");
return ;
}
String content=page.asText();//网页内容保存在content里
if(content==null)
{
System.out.println("采集 "+url+" 失败!!!");
return ;
}
//搞定了
CookieManager CM = wc.getCookieManager(); //WC = Your WebClient's name
Set cookies_ret = CM.getCookies();//返回的Cookie在这里,下次请求的时候可能可以用上啦。
htmlunit抓取动态网页(什么是动态网站?是界面有动态效果的网站吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-12-03 08:22
什么是动态网站?界面有没有动态效果网站?还是数据是可变的网站?这两种说法都对,只是理解不同。如果界面有动态效果,以前是用FLASH实现的,现在是用HTML5实现的。前者打开速度慢,后者打开速度快,效果好。如果数据可以更改,实际上有一个后端可以更新相关数据。那么动态网站怎么做呢?
做动态网站 首先,搞清楚动态是什么意思。这两种动力并不冲突,也不能只有一种可以存在。可以是界面动态+后台动态,这样就没有问题了,完全可以实现。如果界面是动态的,可以达到什么动态效果?刚才我们提供了FLASH。FLASH就是设计你想做的所有动态元素。它实际上是一个完成的动态效果包,有点类似于视频。但是现在HTML5的动态效果不同了,可以结合文字和图片。例如,对于很多图片,我们通常会直接在图片列表中显示它们,但是HTML5可以从两侧移动,或者其他动态效果。文字动态效果可以通过移位实现上下文词的重叠,或者一个字一个字的效果,这些字是不能固定的,背景是可以改变的。这也是技术进步的好处之一,就是可以兼具美感和主观控制力,没有那么死板。另一个动态网站 区别于静态网站。这个静态的 网站 通常是一个页面,一两页。界面上的信息一般由图片组成。在后台进行相关管理。动态和静态网站的区别在于前台界面的数据是否可以在后台进行管理。另一个动态网站 区别于静态网站。这个静态的 网站 通常是一个页面,一两页。界面上的信息一般由图片组成。在后台进行相关管理。动态和静态网站的区别在于前台界面的数据是否可以在后台进行管理。另一个动态网站 区别于静态网站。这个静态的 网站 通常是一个页面,一两页。界面上的信息一般由图片组成。在后台进行相关管理。动态和静态网站的区别在于前台界面的数据是否可以在后台进行管理。
做动态网站 首先区分接口动态和数据动态。接口动态和数据动态可以同时存在。界面动态目前采用H5技术实现,可以被搜索引擎识别,是目前主流的界面实现技术。而数据动态意味着可以在后台管理数据。如果没有后台,界面上的数据,无论是图片还是文字,只能通过代码进行管理,没有相应的后台管理相关数据,那么这就是静态的。网站 up。做动态网站先搞清楚需求再建站,没有问题。 查看全部
htmlunit抓取动态网页(什么是动态网站?是界面有动态效果的网站吗?)
什么是动态网站?界面有没有动态效果网站?还是数据是可变的网站?这两种说法都对,只是理解不同。如果界面有动态效果,以前是用FLASH实现的,现在是用HTML5实现的。前者打开速度慢,后者打开速度快,效果好。如果数据可以更改,实际上有一个后端可以更新相关数据。那么动态网站怎么做呢?
做动态网站 首先,搞清楚动态是什么意思。这两种动力并不冲突,也不能只有一种可以存在。可以是界面动态+后台动态,这样就没有问题了,完全可以实现。如果界面是动态的,可以达到什么动态效果?刚才我们提供了FLASH。FLASH就是设计你想做的所有动态元素。它实际上是一个完成的动态效果包,有点类似于视频。但是现在HTML5的动态效果不同了,可以结合文字和图片。例如,对于很多图片,我们通常会直接在图片列表中显示它们,但是HTML5可以从两侧移动,或者其他动态效果。文字动态效果可以通过移位实现上下文词的重叠,或者一个字一个字的效果,这些字是不能固定的,背景是可以改变的。这也是技术进步的好处之一,就是可以兼具美感和主观控制力,没有那么死板。另一个动态网站 区别于静态网站。这个静态的 网站 通常是一个页面,一两页。界面上的信息一般由图片组成。在后台进行相关管理。动态和静态网站的区别在于前台界面的数据是否可以在后台进行管理。另一个动态网站 区别于静态网站。这个静态的 网站 通常是一个页面,一两页。界面上的信息一般由图片组成。在后台进行相关管理。动态和静态网站的区别在于前台界面的数据是否可以在后台进行管理。另一个动态网站 区别于静态网站。这个静态的 网站 通常是一个页面,一两页。界面上的信息一般由图片组成。在后台进行相关管理。动态和静态网站的区别在于前台界面的数据是否可以在后台进行管理。
做动态网站 首先区分接口动态和数据动态。接口动态和数据动态可以同时存在。界面动态目前采用H5技术实现,可以被搜索引擎识别,是目前主流的界面实现技术。而数据动态意味着可以在后台管理数据。如果没有后台,界面上的数据,无论是图片还是文字,只能通过代码进行管理,没有相应的后台管理相关数据,那么这就是静态的。网站 up。做动态网站先搞清楚需求再建站,没有问题。
htmlunit抓取动态网页(HttpClient抓取网页js生成内容的问题的侠客们。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-11-30 03:02
HttpClient抓取网页js生成内容的问题。曾经的骑士。来看看
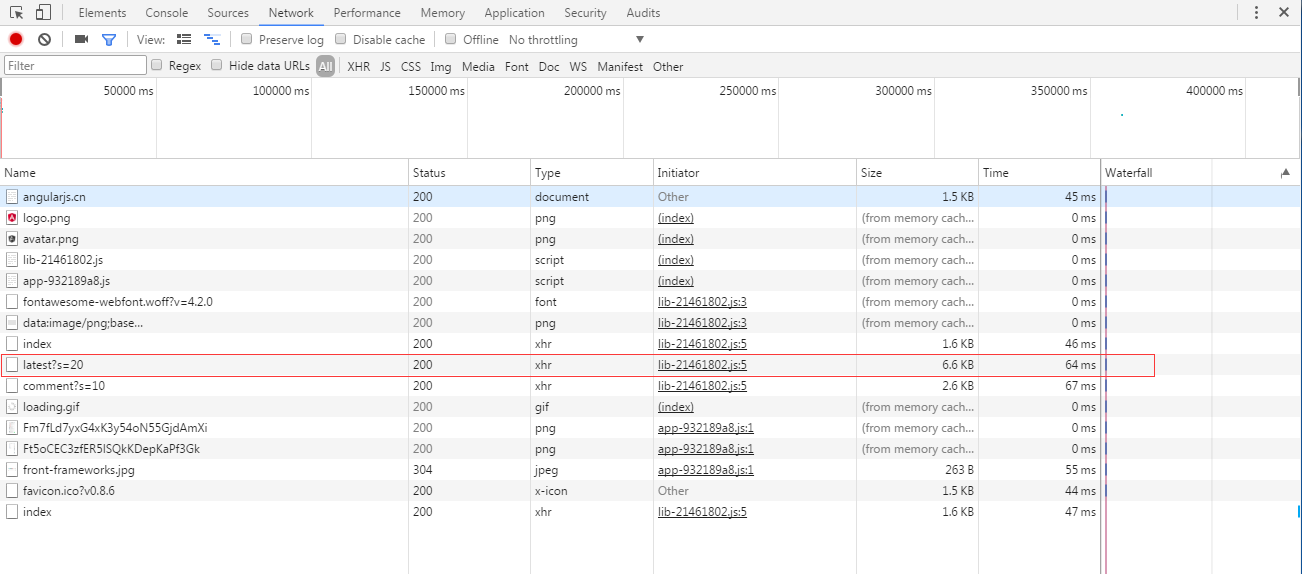
非常感谢您来看我的问题。我要去抢京东产品的产品标题。红色部分的title后面是通过js加载的。这是不可用的。有什么办法可以好起来吗?有类似经历的同胞能指点一下吗?
- - - 解决方案 - - - - - - - - - - - - - - - - - - - - - - -------------
需要抓取ajax的内容,这个是js动态加载的httpclient无法获取
然后需要直接模拟ajax请求
我根据你的需要看了一下
需要访问标题的红色部分
添加产品地址是
获取到它的页面后,搜索 skuidkey 并获取它的值
然后访问
字符串 skuidkey = "";
String url = ""+skuidkey+"&callback=";
使用 Get 访问这个 url
它将返回类似 ({"html":"\u76F4\u964D900\u5143\uFF0C\u4EC5\u9650\u4ECA\u592914:00-18:00\u9650\u65F6\u62A2\u8D2D\u4B04Eu4E \u6279\uFF01"})
结果获得了红色部分的标题
当然,您需要将 unicode 编码的文本转换为中文。不知道怎么传到百度。
附:我写的从java版unicode转中文到C++的版本 查看全部
htmlunit抓取动态网页(HttpClient抓取网页js生成内容的问题的侠客们。)
HttpClient抓取网页js生成内容的问题。曾经的骑士。来看看
非常感谢您来看我的问题。我要去抢京东产品的产品标题。红色部分的title后面是通过js加载的。这是不可用的。有什么办法可以好起来吗?有类似经历的同胞能指点一下吗?
- - - 解决方案 - - - - - - - - - - - - - - - - - - - - - - -------------
需要抓取ajax的内容,这个是js动态加载的httpclient无法获取
然后需要直接模拟ajax请求
我根据你的需要看了一下
需要访问标题的红色部分
添加产品地址是
获取到它的页面后,搜索 skuidkey 并获取它的值
然后访问
字符串 skuidkey = "";
String url = ""+skuidkey+"&callback=";
使用 Get 访问这个 url
它将返回类似 ({"html":"\u76F4\u964D900\u5143\uFF0C\u4EC5\u9650\u4ECA\u592914:00-18:00\u9650\u65F6\u62A2\u8D2D\u4B04Eu4E \u6279\uFF01"})
结果获得了红色部分的标题
当然,您需要将 unicode 编码的文本转换为中文。不知道怎么传到百度。
附:我写的从java版unicode转中文到C++的版本
htmlunit抓取动态网页(SIMONE2012-01-12:14:11:00的html源码一并)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-11-30 02:19
我找到了一个很好的模拟浏览器包htmlunit,可以直接访问网站地址并执行相应的JavaScript脚本;这个功能对网站爬虫很有帮助,一些网站Ajax用的。如果使用简单的http访问,则只能抓取原创html源码,无法获取页面中执行的ajax;使用这个包后,可以在执行ajax后抓取html源代码。取下来。
网站地址:
网站下面也提到了几个类似的包:HtmlUnit 被不同的开源工具用作底层“浏览器”,如 Canoo WebTest、JWebUnit、WebDriver、JSFUnit、Celerity ......
看看canoo WebTest,但是不知道怎么用,也不想多了解。
jwebunit 用于 网站 测试。集成了JUnit、htmlunit、selenium封装框架;主要功能是做白盒测试和压力测试。
webDriver 后来更名为 selenium,它集成了 htmlunit、Firefox 浏览器、IE 浏览器、opare 浏览器驱动。如果使用 htmlunitDriver,则使用 htmlunit 包访问站点;如果使用FirefoxDriver,则直接调用Firefox浏览器,然后在浏览器上模拟文本输入等鼠标键盘事件。
访问htmlunit包后网站,获取html源码后可以修改源码; jwebunit和selenium暂时没有找到修改的功能,只是用来模拟用户操作。
西蒙尼 2012-01-12 14:11 查看全部
htmlunit抓取动态网页(SIMONE2012-01-12:14:11:00的html源码一并)
我找到了一个很好的模拟浏览器包htmlunit,可以直接访问网站地址并执行相应的JavaScript脚本;这个功能对网站爬虫很有帮助,一些网站Ajax用的。如果使用简单的http访问,则只能抓取原创html源码,无法获取页面中执行的ajax;使用这个包后,可以在执行ajax后抓取html源代码。取下来。
网站地址:
网站下面也提到了几个类似的包:HtmlUnit 被不同的开源工具用作底层“浏览器”,如 Canoo WebTest、JWebUnit、WebDriver、JSFUnit、Celerity ......
看看canoo WebTest,但是不知道怎么用,也不想多了解。
jwebunit 用于 网站 测试。集成了JUnit、htmlunit、selenium封装框架;主要功能是做白盒测试和压力测试。
webDriver 后来更名为 selenium,它集成了 htmlunit、Firefox 浏览器、IE 浏览器、opare 浏览器驱动。如果使用 htmlunitDriver,则使用 htmlunit 包访问站点;如果使用FirefoxDriver,则直接调用Firefox浏览器,然后在浏览器上模拟文本输入等鼠标键盘事件。
访问htmlunit包后网站,获取html源码后可以修改源码; jwebunit和selenium暂时没有找到修改的功能,只是用来模拟用户操作。
西蒙尼 2012-01-12 14:11
htmlunit抓取动态网页(基于浏览器内核来开发的动态页面渲染处理服务器(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-11-23 03:23
前言
曾几何时,从动态页面中提取信息(ajax、内部js二次渲染等)一直是爬虫开发者的心病。总之,真的没有合适的工具。尤其是在Java中,像htmlunit这样的工具可以算是解析动态页面的神器了,但是还不够完善,无法达到浏览器级别的解析效果,遇到稍微复杂一点的页面就不行了。在经历了各种痛苦和仇恨之后,作者决定开发一个动态页面渲染处理服务器,专门用于抓取、监控和测试此类场景。要实现浏览器级别的效果,必须基于浏览器内核进行开发。幸运的是,我们有开源的webkit,更幸运的是,我们有QtWebkit,这对开发人员更友好。于是 SeimiAgent 诞生了。
SeimiAgent 简介
SeimiAgent 是基于 QtWebkit 开发的可以在服务器端后台运行的 webkit 服务。它可以通过SeimiAgent提供的http接口向SeimiAgent发送加载请求(要加载的URL和该页面接受的渲染时间或使用什么代理等参数),通过SeimiAgent加载并渲染动态页面要处理,然后直接将渲染好的页面返回给调用者进行后续处理,所以运行的SeimiAgent服务是语言无关的,任何语言或框架都可以通过SeimiAgent提供标准的http接口来获取服务。SeimiAgent 的加载和渲染环境都是通用浏览器级别的,所以不用担心他处理动态页面的能力。目前,SeimiAgent 只支持返回渲染的 HTML 文档。未来将增加图片快照和PDF支持,以方便更多样化的使用需求。
使用演示
SeimiCrawler 简介
SeimiCrawler 是一个敏捷、独立部署、支持分布式Java 爬虫框架。希望最大限度地降低新手开发高可用低性能爬虫系统的门槛,提高爬虫系统的开发效率。在 SeimiCrawler 的世界里,大部分人只需要关心编写爬行的业务逻辑,剩下的 Seimi 会为你做。在设计方面,SeimiCrawler 的灵感来自于 Python 的爬虫框架 Scrapy。同时结合Java语言的特点和Spring的特点,希望在国内使用更高效的XPath来更方便、更通用的解析HTML,所以SeimiCrawler默认的HTML解析处理器是JsoupXpath(独立扩展项目) ,不收录在 jsoup 中),
集成和部署 SeimiAgent
下载和解压就不显示了,上面的动态图片里也有演示,下载地址可以在SeimiAgent主页上找到。进入SeimiAgent的bin目录,执行:
./SeimiAgent -p 8000
这就是启动SeimiAgent服务,监听8000端口。接下来其实可以用任何语言通过http请求发送加载页面的请求,然后得到渲染结果。当然,我们这里介绍的是SeimiCrawler是如何集成和使用SeimiAgent的。
SeimiCrawler 配置
SeimiCrawler 在 v0.3.0 版本中内置了对 SeimiAgent 的支持。开发者只需要配置SeimiAgent的地址和端口,然后在生成具体的Request时选择是否提交给SeimiAgent,并指定如何提交。我们直接在评论中解释最后一个完整的例子:
package cn.wanghaomiao.crawlers;
import cn.wanghaomiao.seimi.annotation.Crawler;
import cn.wanghaomiao.seimi.def.BaseSeimiCrawler;
import cn.wanghaomiao.seimi.struct.Request;
import cn.wanghaomiao.seimi.struct.Response;
import cn.wanghaomiao.xpath.model.JXDocument;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Value;
/**
* 这个例子演示如何使用SeimiAgent进行复杂动态页面信息抓取
* @author 汪浩淼 et.tw@163.com
* @since 2016/4/14.
*/
@Crawler(name = "seimiagent")
public class SeimiAgentDemo extends BaseSeimiCrawler{
/**
* 在resource/config/seimi.properties中配置方便更换,当然也可以自行根据情况使用自己的统一配置中心等服务。这里配置SeimiAgent服务所在地址。
*/
@Value("${seimiAgentHost}")
private String seimiAgentHost;
//SeimiAgent监听的端口好,如上文中的8000
@Value("${seimiAgentPort}")
private int seimiAgentPort;
@Override
public String[] startUrls() {
return new String[]{"https://www.baidu.com"};
}
@Override
public String seiAgentHost() {
return this.seimiAgentHost;
}
@Override
public int seimiAgentPort() {
return this.seimiAgentPort;
}
@Override
public void start(Response response) {
Request seimiAgentReq = Request.build("https://www.souyidai.com","getTotalTransactions")
.useSeimiAgent()
// 告诉SeimiAgent针对这个请求是否使用cookie,如果没有设置使用当前Crawler关于cookie使用条件作为默认值。
//.setSeimiAgentUseCookie(true)
// 设置全部load完成后给SeimiAgent多少时间用于执行js并渲染页面,单位为毫秒
.setSeimiAgentRenderTime(5000);
push(seimiAgentReq);
}
/**
* 获取搜易贷首页总成交额
* @param response
*/
public void getTotalTransactions(Response response){
JXDocument doc = response.document();
try {
String trans = StringUtils.join(doc.sel("//div[@class='homepage-amount']/div[@class='number font-arial']/div/span/text()"),"");
logger.info("Final Res:{}",trans);
} catch (Exception e) {
e.printStackTrace();
}
}
}
配置文件seimi.properties
seimiAgentHost=127.0.0.1
seimiAgentPort=8000
启动
public class Boot {
public static void main(String[] args){
Seimi s = new Seimi();
s.start("seimiagent");
}
}
SeimiCrawler 启动后,您可以看到您想要的搜一贷交易总额。
完整演示地址
演示 查看全部
htmlunit抓取动态网页(基于浏览器内核来开发的动态页面渲染处理服务器(组图))
前言
曾几何时,从动态页面中提取信息(ajax、内部js二次渲染等)一直是爬虫开发者的心病。总之,真的没有合适的工具。尤其是在Java中,像htmlunit这样的工具可以算是解析动态页面的神器了,但是还不够完善,无法达到浏览器级别的解析效果,遇到稍微复杂一点的页面就不行了。在经历了各种痛苦和仇恨之后,作者决定开发一个动态页面渲染处理服务器,专门用于抓取、监控和测试此类场景。要实现浏览器级别的效果,必须基于浏览器内核进行开发。幸运的是,我们有开源的webkit,更幸运的是,我们有QtWebkit,这对开发人员更友好。于是 SeimiAgent 诞生了。
SeimiAgent 简介
SeimiAgent 是基于 QtWebkit 开发的可以在服务器端后台运行的 webkit 服务。它可以通过SeimiAgent提供的http接口向SeimiAgent发送加载请求(要加载的URL和该页面接受的渲染时间或使用什么代理等参数),通过SeimiAgent加载并渲染动态页面要处理,然后直接将渲染好的页面返回给调用者进行后续处理,所以运行的SeimiAgent服务是语言无关的,任何语言或框架都可以通过SeimiAgent提供标准的http接口来获取服务。SeimiAgent 的加载和渲染环境都是通用浏览器级别的,所以不用担心他处理动态页面的能力。目前,SeimiAgent 只支持返回渲染的 HTML 文档。未来将增加图片快照和PDF支持,以方便更多样化的使用需求。
使用演示

SeimiCrawler 简介
SeimiCrawler 是一个敏捷、独立部署、支持分布式Java 爬虫框架。希望最大限度地降低新手开发高可用低性能爬虫系统的门槛,提高爬虫系统的开发效率。在 SeimiCrawler 的世界里,大部分人只需要关心编写爬行的业务逻辑,剩下的 Seimi 会为你做。在设计方面,SeimiCrawler 的灵感来自于 Python 的爬虫框架 Scrapy。同时结合Java语言的特点和Spring的特点,希望在国内使用更高效的XPath来更方便、更通用的解析HTML,所以SeimiCrawler默认的HTML解析处理器是JsoupXpath(独立扩展项目) ,不收录在 jsoup 中),
集成和部署 SeimiAgent
下载和解压就不显示了,上面的动态图片里也有演示,下载地址可以在SeimiAgent主页上找到。进入SeimiAgent的bin目录,执行:
./SeimiAgent -p 8000
这就是启动SeimiAgent服务,监听8000端口。接下来其实可以用任何语言通过http请求发送加载页面的请求,然后得到渲染结果。当然,我们这里介绍的是SeimiCrawler是如何集成和使用SeimiAgent的。
SeimiCrawler 配置
SeimiCrawler 在 v0.3.0 版本中内置了对 SeimiAgent 的支持。开发者只需要配置SeimiAgent的地址和端口,然后在生成具体的Request时选择是否提交给SeimiAgent,并指定如何提交。我们直接在评论中解释最后一个完整的例子:
package cn.wanghaomiao.crawlers;
import cn.wanghaomiao.seimi.annotation.Crawler;
import cn.wanghaomiao.seimi.def.BaseSeimiCrawler;
import cn.wanghaomiao.seimi.struct.Request;
import cn.wanghaomiao.seimi.struct.Response;
import cn.wanghaomiao.xpath.model.JXDocument;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Value;
/**
* 这个例子演示如何使用SeimiAgent进行复杂动态页面信息抓取
* @author 汪浩淼 et.tw@163.com
* @since 2016/4/14.
*/
@Crawler(name = "seimiagent")
public class SeimiAgentDemo extends BaseSeimiCrawler{
/**
* 在resource/config/seimi.properties中配置方便更换,当然也可以自行根据情况使用自己的统一配置中心等服务。这里配置SeimiAgent服务所在地址。
*/
@Value("${seimiAgentHost}")
private String seimiAgentHost;
//SeimiAgent监听的端口好,如上文中的8000
@Value("${seimiAgentPort}")
private int seimiAgentPort;
@Override
public String[] startUrls() {
return new String[]{"https://www.baidu.com"};
}
@Override
public String seiAgentHost() {
return this.seimiAgentHost;
}
@Override
public int seimiAgentPort() {
return this.seimiAgentPort;
}
@Override
public void start(Response response) {
Request seimiAgentReq = Request.build("https://www.souyidai.com","getTotalTransactions")
.useSeimiAgent()
// 告诉SeimiAgent针对这个请求是否使用cookie,如果没有设置使用当前Crawler关于cookie使用条件作为默认值。
//.setSeimiAgentUseCookie(true)
// 设置全部load完成后给SeimiAgent多少时间用于执行js并渲染页面,单位为毫秒
.setSeimiAgentRenderTime(5000);
push(seimiAgentReq);
}
/**
* 获取搜易贷首页总成交额
* @param response
*/
public void getTotalTransactions(Response response){
JXDocument doc = response.document();
try {
String trans = StringUtils.join(doc.sel("//div[@class='homepage-amount']/div[@class='number font-arial']/div/span/text()"),"");
logger.info("Final Res:{}",trans);
} catch (Exception e) {
e.printStackTrace();
}
}
}
配置文件seimi.properties
seimiAgentHost=127.0.0.1
seimiAgentPort=8000
启动
public class Boot {
public static void main(String[] args){
Seimi s = new Seimi();
s.start("seimiagent");
}
}
SeimiCrawler 启动后,您可以看到您想要的搜一贷交易总额。
完整演示地址
演示
htmlunit抓取动态网页(Java爬取博客阅读文章最多)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-22 13:16
更新,这很尴尬。这个文章博客阅读量最多文章,但也被最讨厌。
爬行思路:
所谓动态,就是可以通过请求后台动态改变对应的html页面,一开始页面并不是全部显示出来的。
大多数操作都是通过请求来完成的,一个请求,一个返回。在大多数网页中,请求往往被开发者隐藏在js代码中。
因此,爬取动态网页的思路转化为寻找对应的js代码,并执行对应的js代码,从而通过java代码动态改变页面。
而当页面能够正确显示时,我们就可以像抓取静态网页一样抓取数据了!
首先可以使用htmlunit来模拟鼠标点击事件,实现起来很简单:
/**
* 通过htmlunit来获得一些搜狗的网址。
* 通过模拟鼠标点击事件来实现
* @param key
* @return
* @throws Exception
*/
public String getNextUrl(String key){
String page = new String();
try {
WebClient webClient = new WebClient();
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
//去拿网页
HtmlPage htmlPage = webClient.getPage("http://pic.sogou.com/");
//得到表单
HtmlForm form = htmlPage.getFormByName("searchForm");
//得到提交按钮
HtmlSubmitInput button = form.getInputByValue("搜狗搜索");
//得到输入框
HtmlTextInput textField = form.getInputByName("query");
//输入内容
textField.setValueAttribute(key);
//点一下按钮
HtmlPage nextPage = button.click();
String str = nextPage.toString();
page = cutString(str);
webClient.close();
} catch (Exception e) {
e.printStackTrace();
}
return page;
}
如上图,我通过java代码将关键字填入搜索我的,然后通过getInputByValue方法获取按钮控件,最后直接button.click(),
也就是说可以模拟点击,点击后返回的http请求可以解析成htmlpage。
这个功能其实非常强大。例如,您可以使用此功能来模拟抢票,或使用点击事件和搜索相关知识将整个系统下线并保存在 html 中。
下一步就是使用强大的htmlunit来执行js代码了。
先写一个简单的jsp页面:
Insert title here
原数字
function change(value) {
document.getElementById("test").innerHTML = value;
return "hello htmlUnit";
}
从上面可以看出,jsp页面很简单,只是一个函数的变化,用来调用htmlUnit。
接下来是一个使用 htmlunit 的类。这个类支持 JavaScript 解释器,
然后将自己编写的JavaScript代码嵌入到页面中执行,执行后得到返回结果返回页面。
package com.blog.anla;
import com.gargoylesoftware.htmlunit.ScriptResult;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
public class TestMyOwnPage {
private void action() {
WebClient webClient = new WebClient();
try {
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true); // 设置支持JavaScript。
// 去拿网页
HtmlPage htmlPage = webClient
.getPage("http://localhost:8989/testHtmlScrop/index.jsp");
String s = "更改后的数字";
ScriptResult t = htmlPage.executeJavaScript("change(\"" + s
+ "\");", "injected script", 500);
// 这里是在500行插入这一小行JavaScript代码段,因为如果在默认的1行,那不会有结果
// 因为js是顺序执行的,当你执行第一行js代码时,可能还没有渲染body里面的标签。
HtmlPage myPage = (HtmlPage) t.getNewPage();
String nextPage = myPage.asXml().toString();
String nextPage2 = myPage.asText().toString();
} catch (Exception e) {
e.printStackTrace();
} finally {
webClient.close();
}
}
public static void main(String[] args) {
TestMyOwnPage tmop = new TestMyOwnPage();
tmop.action();
}
}
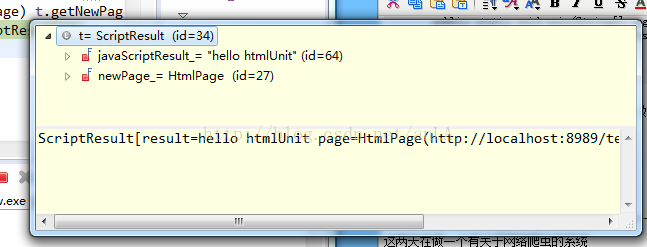
t.getNewPage() 中有两个属性,一个是
javaScriptResult:执行代码后返回的结果,如果有(如我上面写的,返回hello htmlunit),如果没有(返回Undefined)。
newPage_:执行这段代码后返回的整个页面。
结果如图:
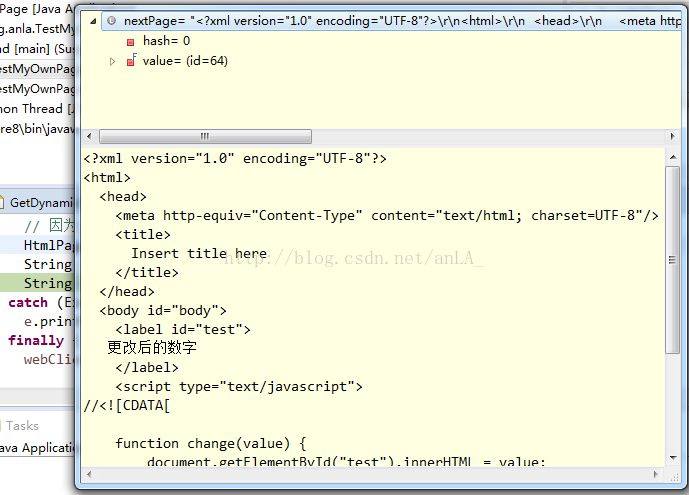
这段代码执行的最终结果如下:
asXml():将整个页面的html代码返回给我们:
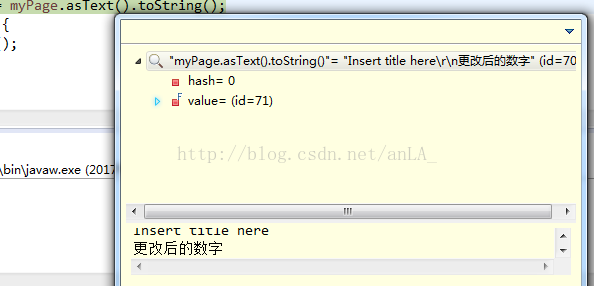
而asText()只返回页面上可以显示的值,即head标签和label标签:
这种执行思路也可以动态的执行对应的js代码,从而抓取到需要的数据。
-------------------------------------------------- -------------------------------------- 2017 年 7 月更新------- ------------------------------------------------- - ----------------------------------------------
这两天一直在研究一个关于网络爬虫的系统
但是第一次爬的时候就发现了这个问题,js的动态页面爬不下来。
网上找了很多方法,google也问了,主要是指htmlunit,下面是核心代码,
使用htmlunit的主要目的是模拟浏览器操作,因为有些链接点击无法通过src直接获取url,通常使用JavaScript
简单拼接后的URL,这样一来,相比之下,直接用htmlunit模拟浏览器点击就简单多了。
WebClient webClient = new WebClient();
webClient.getOptions().setJavaScriptEnabled(true); //启用JS解释器,默认为true
webClient.getOptions().setCssEnabled(false); //禁用css支持
webClient.getOptions().setThrowExceptionOnScriptError(false); //js运行错误时,是否抛出异常
webClient.getOptions().setTimeout(20000);
HtmlPage page = wc.getPage("http://www.hao123.com");
//我认为这个最重要
String pageXml = page.asXml(); //以xml的形式获取响应文本
/**jsoup解析文档*/
Document doc = Jsoup.parse(pageXml, "http://cq.qq.com");
这个时候,就可以得到jsoup中的document对象了,接下来就好写了,就像爬普通静态网页一样了。
不过,webclient解析是还是会出现一些问题,js的问题,
主要是由于目标url的js写的有些问题,但在实际的浏览器中却会忽略,eclipse中会报异常。
今天看到的时候,很多人都踩到了。也许他们当时没有认真写博客。如果想找java爬虫项目可以到我的专栏。
图片搜索包括使用jsoup抓取图片,lire来索引和搜索图片。
给玫瑰手留下余香。有什么问题可以多多讨论哦! 查看全部
htmlunit抓取动态网页(Java爬取博客阅读文章最多)
更新,这很尴尬。这个文章博客阅读量最多文章,但也被最讨厌。
爬行思路:
所谓动态,就是可以通过请求后台动态改变对应的html页面,一开始页面并不是全部显示出来的。
大多数操作都是通过请求来完成的,一个请求,一个返回。在大多数网页中,请求往往被开发者隐藏在js代码中。
因此,爬取动态网页的思路转化为寻找对应的js代码,并执行对应的js代码,从而通过java代码动态改变页面。
而当页面能够正确显示时,我们就可以像抓取静态网页一样抓取数据了!
首先可以使用htmlunit来模拟鼠标点击事件,实现起来很简单:
/**
* 通过htmlunit来获得一些搜狗的网址。
* 通过模拟鼠标点击事件来实现
* @param key
* @return
* @throws Exception
*/
public String getNextUrl(String key){
String page = new String();
try {
WebClient webClient = new WebClient();
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
//去拿网页
HtmlPage htmlPage = webClient.getPage("http://pic.sogou.com/";);
//得到表单
HtmlForm form = htmlPage.getFormByName("searchForm");
//得到提交按钮
HtmlSubmitInput button = form.getInputByValue("搜狗搜索");
//得到输入框
HtmlTextInput textField = form.getInputByName("query");
//输入内容
textField.setValueAttribute(key);
//点一下按钮
HtmlPage nextPage = button.click();
String str = nextPage.toString();
page = cutString(str);
webClient.close();
} catch (Exception e) {
e.printStackTrace();
}
return page;
}
如上图,我通过java代码将关键字填入搜索我的,然后通过getInputByValue方法获取按钮控件,最后直接button.click(),
也就是说可以模拟点击,点击后返回的http请求可以解析成htmlpage。

这个功能其实非常强大。例如,您可以使用此功能来模拟抢票,或使用点击事件和搜索相关知识将整个系统下线并保存在 html 中。
下一步就是使用强大的htmlunit来执行js代码了。
先写一个简单的jsp页面:
Insert title here
原数字
function change(value) {
document.getElementById("test").innerHTML = value;
return "hello htmlUnit";
}
从上面可以看出,jsp页面很简单,只是一个函数的变化,用来调用htmlUnit。
接下来是一个使用 htmlunit 的类。这个类支持 JavaScript 解释器,
然后将自己编写的JavaScript代码嵌入到页面中执行,执行后得到返回结果返回页面。
package com.blog.anla;
import com.gargoylesoftware.htmlunit.ScriptResult;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
public class TestMyOwnPage {
private void action() {
WebClient webClient = new WebClient();
try {
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true); // 设置支持JavaScript。
// 去拿网页
HtmlPage htmlPage = webClient
.getPage("http://localhost:8989/testHtmlScrop/index.jsp";);
String s = "更改后的数字";
ScriptResult t = htmlPage.executeJavaScript("change(\"" + s
+ "\");", "injected script", 500);
// 这里是在500行插入这一小行JavaScript代码段,因为如果在默认的1行,那不会有结果
// 因为js是顺序执行的,当你执行第一行js代码时,可能还没有渲染body里面的标签。
HtmlPage myPage = (HtmlPage) t.getNewPage();
String nextPage = myPage.asXml().toString();
String nextPage2 = myPage.asText().toString();
} catch (Exception e) {
e.printStackTrace();
} finally {
webClient.close();
}
}
public static void main(String[] args) {
TestMyOwnPage tmop = new TestMyOwnPage();
tmop.action();
}
}
t.getNewPage() 中有两个属性,一个是
javaScriptResult:执行代码后返回的结果,如果有(如我上面写的,返回hello htmlunit),如果没有(返回Undefined)。
newPage_:执行这段代码后返回的整个页面。
结果如图:
这段代码执行的最终结果如下:
asXml():将整个页面的html代码返回给我们:
而asText()只返回页面上可以显示的值,即head标签和label标签:
这种执行思路也可以动态的执行对应的js代码,从而抓取到需要的数据。
-------------------------------------------------- -------------------------------------- 2017 年 7 月更新------- ------------------------------------------------- - ----------------------------------------------
这两天一直在研究一个关于网络爬虫的系统
但是第一次爬的时候就发现了这个问题,js的动态页面爬不下来。
网上找了很多方法,google也问了,主要是指htmlunit,下面是核心代码,
使用htmlunit的主要目的是模拟浏览器操作,因为有些链接点击无法通过src直接获取url,通常使用JavaScript
简单拼接后的URL,这样一来,相比之下,直接用htmlunit模拟浏览器点击就简单多了。
WebClient webClient = new WebClient();
webClient.getOptions().setJavaScriptEnabled(true); //启用JS解释器,默认为true
webClient.getOptions().setCssEnabled(false); //禁用css支持
webClient.getOptions().setThrowExceptionOnScriptError(false); //js运行错误时,是否抛出异常
webClient.getOptions().setTimeout(20000);
HtmlPage page = wc.getPage("http://www.hao123.com";);
//我认为这个最重要
String pageXml = page.asXml(); //以xml的形式获取响应文本
/**jsoup解析文档*/
Document doc = Jsoup.parse(pageXml, "http://cq.qq.com";);
这个时候,就可以得到jsoup中的document对象了,接下来就好写了,就像爬普通静态网页一样了。
不过,webclient解析是还是会出现一些问题,js的问题,
主要是由于目标url的js写的有些问题,但在实际的浏览器中却会忽略,eclipse中会报异常。
今天看到的时候,很多人都踩到了。也许他们当时没有认真写博客。如果想找java爬虫项目可以到我的专栏。
图片搜索包括使用jsoup抓取图片,lire来索引和搜索图片。
给玫瑰手留下余香。有什么问题可以多多讨论哦!
htmlunit抓取动态网页(HtmlUnit在多线程环境下怎么使用才能避免网页抓取失败的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-21 13:03
如何在多线程环境下使用HtmlUnit避免网页爬取失败的问题。我们来谈谈这个问题的解决方案。
这个问题的原因其实很简单。例如,线程 A 正在使用 WebClient 对象来获取网页。在整个抓取过程结束之前,当前线程被 CPU 挂起,所以线程 B 被激活,然后 B 使用 A 使用的 WebClient 对象正在做其他网页抓取工作,那么此时 WebCLient 对象将清除未完成的工作留下的数据,等等,共享一个WebClient的线程越多,出现问题的频率就越高。丢失网页的概率更高。但其实这个问题并不难解决,它的解决方案也有广泛的适用性:不管是什么对象,在多线程环境中遇到资源共享问题时,通常有两种解决方案,一种是使用对于 JDK1.2 之后的 ThreadLocal 对象,
早在JDK1.2 版本中就提供的java.lang.ThreadLocal 和ThreadLocal 为解决多线程程序的并发问题提供了新思路。使用这个工具类可以写得非常简洁漂亮。多线程程序。其原理是为每个线程保存一个局部变量的副本,以确保该变量不会与其他线程共享——这是一种保守但有效的方法。本文不是要介绍ThreadLocal的用法(具体用法请参考百度百科),而是要使用ThreadLocal解决多线程环境下HtmlUnit的WebClient对象的共享问题。
请看如何使用ThreadLocal对象解决以上问题:
package cn.ysh.studio.crawler.htmlunit;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.WebClient;/**
*
* @author Shenghany
* @date 2013-5-27
*/publicclassThreadLocalClientFactory{
//单例工厂模式privatefinalstaticThreadLocalClientFactory instance =newThreadLocalClientFactory();//线程的本地实例存储器,用于存储WebClient实例privateThreadLocal clientThreadLocal;/**
* 构造方法,初始时线程的本地变量存储器
*/publicThreadLocalClientFactory(){
clientThreadLocal =newThreadLocal();}/**
* 获取工厂实例
* @return 工厂实例
*/publicstaticThreadLocalClientFactory getInstance(){
return instance;}/**
* 获取一个模拟FireFox3.6版本的WebClient实例
* @return 模拟FireFox3.6版本的WebClient实例
*/publicWebClient getClient(){
WebClient client =null;/**
* 如果当前线程已有WebClient实例,则直接返回该实例
* 否则重新创建一个WebClient实例并存储于当前线程的本地变量存储器
*/if((client = clientThreadLocal.get())==null){
client =newWebClient(BrowserVersion.FIREFOX_3_6);
client.setCssEnabled(false);
client.setJavaScriptEnabled(false);
clientThreadLocal.set(client);System.out.println("为线程 [ "+Thread.currentThread().getName()+" ] 创建新的WebClient实例!");}else{
System.out.println("线程 [ "+Thread.currentThread().getName()+" ] 已有WebClient实例,直接使用. . .");}return client;}}
测试代码:
<p>package cn.ysh.studio.crawler.htmlunit;import com.gargoylesoftware.htmlunit.WebClient;import com.gargoylesoftware.htmlunit.html.HtmlPage;/**
*
* @author Shenghany
* @date 2013-5-27
*/publicclassThreadLocalHtmlUnitTester{
/**
* 获取目标页面,并打印网页标题
* @param url 目标页面地址
*/publicstaticvoid getPage(String url){
//从工厂中获取一个WebClient实例WebClient client =ThreadLocalClientFactory.getInstance().getClient();try{
//抓取网页HtmlPage page =(HtmlPage)client.getPage(url);//打印当前线程名称及网页标题System.out.println(Thread.currentThread().getName()+" [ "+ url +" ] : "+ page.getTitleText());}catch(Exception e){
e.printStackTrace();}}/**
* 测试程序执行入口
* @param s
*/publicstaticvoid main(String[] s){
//文章编号int postId =50;//目标网页的部分内容String http ="http://www.yshjava.cn/post/4";/**
* 共16篇文章,每个线程抓取两篇,共计将产生8个线程
*/for(int i = postId; i 查看全部
htmlunit抓取动态网页(HtmlUnit在多线程环境下怎么使用才能避免网页抓取失败的问题)
如何在多线程环境下使用HtmlUnit避免网页爬取失败的问题。我们来谈谈这个问题的解决方案。
这个问题的原因其实很简单。例如,线程 A 正在使用 WebClient 对象来获取网页。在整个抓取过程结束之前,当前线程被 CPU 挂起,所以线程 B 被激活,然后 B 使用 A 使用的 WebClient 对象正在做其他网页抓取工作,那么此时 WebCLient 对象将清除未完成的工作留下的数据,等等,共享一个WebClient的线程越多,出现问题的频率就越高。丢失网页的概率更高。但其实这个问题并不难解决,它的解决方案也有广泛的适用性:不管是什么对象,在多线程环境中遇到资源共享问题时,通常有两种解决方案,一种是使用对于 JDK1.2 之后的 ThreadLocal 对象,
早在JDK1.2 版本中就提供的java.lang.ThreadLocal 和ThreadLocal 为解决多线程程序的并发问题提供了新思路。使用这个工具类可以写得非常简洁漂亮。多线程程序。其原理是为每个线程保存一个局部变量的副本,以确保该变量不会与其他线程共享——这是一种保守但有效的方法。本文不是要介绍ThreadLocal的用法(具体用法请参考百度百科),而是要使用ThreadLocal解决多线程环境下HtmlUnit的WebClient对象的共享问题。
请看如何使用ThreadLocal对象解决以上问题:
package cn.ysh.studio.crawler.htmlunit;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.WebClient;/**
*
* @author Shenghany
* @date 2013-5-27
*/publicclassThreadLocalClientFactory{
//单例工厂模式privatefinalstaticThreadLocalClientFactory instance =newThreadLocalClientFactory();//线程的本地实例存储器,用于存储WebClient实例privateThreadLocal clientThreadLocal;/**
* 构造方法,初始时线程的本地变量存储器
*/publicThreadLocalClientFactory(){
clientThreadLocal =newThreadLocal();}/**
* 获取工厂实例
* @return 工厂实例
*/publicstaticThreadLocalClientFactory getInstance(){
return instance;}/**
* 获取一个模拟FireFox3.6版本的WebClient实例
* @return 模拟FireFox3.6版本的WebClient实例
*/publicWebClient getClient(){
WebClient client =null;/**
* 如果当前线程已有WebClient实例,则直接返回该实例
* 否则重新创建一个WebClient实例并存储于当前线程的本地变量存储器
*/if((client = clientThreadLocal.get())==null){
client =newWebClient(BrowserVersion.FIREFOX_3_6);
client.setCssEnabled(false);
client.setJavaScriptEnabled(false);
clientThreadLocal.set(client);System.out.println("为线程 [ "+Thread.currentThread().getName()+" ] 创建新的WebClient实例!");}else{
System.out.println("线程 [ "+Thread.currentThread().getName()+" ] 已有WebClient实例,直接使用. . .");}return client;}}
测试代码:
<p>package cn.ysh.studio.crawler.htmlunit;import com.gargoylesoftware.htmlunit.WebClient;import com.gargoylesoftware.htmlunit.html.HtmlPage;/**
*
* @author Shenghany
* @date 2013-5-27
*/publicclassThreadLocalHtmlUnitTester{
/**
* 获取目标页面,并打印网页标题
* @param url 目标页面地址
*/publicstaticvoid getPage(String url){
//从工厂中获取一个WebClient实例WebClient client =ThreadLocalClientFactory.getInstance().getClient();try{
//抓取网页HtmlPage page =(HtmlPage)client.getPage(url);//打印当前线程名称及网页标题System.out.println(Thread.currentThread().getName()+" [ "+ url +" ] : "+ page.getTitleText());}catch(Exception e){
e.printStackTrace();}}/**
* 测试程序执行入口
* @param s
*/publicstaticvoid main(String[] s){
//文章编号int postId =50;//目标网页的部分内容String http ="http://www.yshjava.cn/post/4";/**
* 共16篇文章,每个线程抓取两篇,共计将产生8个线程
*/for(int i = postId; i
htmlunit抓取动态网页(习近平出席上合成员国元首理事会会议会议)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-11-18 21:10
一、HtmlUnit 介绍
HtmlUnit 是一个开源的网络分析工具。它模仿浏览器的操作,可用于网络爬虫。它的优点是:
1、模仿浏览器操作,可以点击相关网页操作;
2、支持css、js操作;
3、有对应的文档解析方法;
缺点:
1、速度慢,需要进行页面渲染等各种操作;
2、对jquery等的支持不理想;
二、例子
1、添加maven依赖
net.sourceforge.htmlunit htmlunit 2.24
2、代码示例
public class HtmlUnitCrawlerMain { public static void main(String[] args) throws Exception { htmlunitCrawler(); } static void htmlunitCrawler() throws Exception { String url = "http://www.ifeng.com/"; WebClient webClient = new WebClient(BrowserVersion.CHROME); WebClientOptions options = webClient.getOptions(); options.setTimeout(5000); options.setThrowExceptionOnScriptError(false); options.setCssEnabled(false); HtmlPage page = webClient.getPage(url); List eles = (List) page.getByXPath("//*[@id=\"headLineDefault\"]/h1/a"); if(Objects.nonNull(eles) && eles.size()>0){ String result = eles.get(0).asText(); System.out.println("ifeng headline is : " + result); } }}
运行结果:
ifeng 标题是:习近平出席上海合作组织成员国元首理事会会议 查看全部
htmlunit抓取动态网页(习近平出席上合成员国元首理事会会议会议)
一、HtmlUnit 介绍
HtmlUnit 是一个开源的网络分析工具。它模仿浏览器的操作,可用于网络爬虫。它的优点是:
1、模仿浏览器操作,可以点击相关网页操作;
2、支持css、js操作;
3、有对应的文档解析方法;
缺点:
1、速度慢,需要进行页面渲染等各种操作;
2、对jquery等的支持不理想;
二、例子
1、添加maven依赖
net.sourceforge.htmlunit htmlunit 2.24
2、代码示例
public class HtmlUnitCrawlerMain { public static void main(String[] args) throws Exception { htmlunitCrawler(); } static void htmlunitCrawler() throws Exception { String url = "http://www.ifeng.com/"; WebClient webClient = new WebClient(BrowserVersion.CHROME); WebClientOptions options = webClient.getOptions(); options.setTimeout(5000); options.setThrowExceptionOnScriptError(false); options.setCssEnabled(false); HtmlPage page = webClient.getPage(url); List eles = (List) page.getByXPath("//*[@id=\"headLineDefault\"]/h1/a"); if(Objects.nonNull(eles) && eles.size()>0){ String result = eles.get(0).asText(); System.out.println("ifeng headline is : " + result); } }}
运行结果:
ifeng 标题是:习近平出席上海合作组织成员国元首理事会会议
htmlunit抓取动态网页(jsoup的简单使用方法-htmlunit的使用教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-16 02:15
jsoup 只能解析静态 html 页面。如果页面是js动态生成的,jsoup将无法启动。使用htmlunit获取js运行后的页面,还可以模拟浏览器点击页面上的元素,非常强大,本文介绍htmlunit的简单使用。步骤如下:
1、引入依赖
net.sourceforge.htmlunit
htmlunit
2.36.0
org.jsoup
jsoup
1.12.1
2、我们爬取我们绘制的页面,首先绘制一个简单的页面,页面中content的id的div的原创内容是hello,页面加载后内容变成
HtmlUnit 太强大了
,访问此页面查看结果
Title
HtmlUnit简单使用
hello
document.getElementById("content").innerHTML = "HtmlUnit好强大";
3、写测试类,先用jsoup直接爬取,看内容里面的内容是什么,我们打印出来,可以看到是hello
@Test
public void testJsoup() throws IOException {
Document document = Jsoup.connect("http://localhost:8080/index.html").get();
System.out.println(document.getElementById("content").html());
}
4、用htmlunit看看效果
@Test
public void test() {
final WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
HtmlPage page = null;
try {
page = webClient.getPage("http://localhost:8080/index.html");
} catch (Exception e) {
e.printStackTrace();
}finally {
webClient.close();
}
webClient.waitForBackgroundJavaScript(30000);
String pageXml = page.asXml();
Document document = Jsoup.parse(pageXml);//获取html文档
System.out.println(document.getElementById("content").html());
}
可以看到js运行后的内容,与浏览器看到的结果一致 查看全部
htmlunit抓取动态网页(jsoup的简单使用方法-htmlunit的使用教程)
jsoup 只能解析静态 html 页面。如果页面是js动态生成的,jsoup将无法启动。使用htmlunit获取js运行后的页面,还可以模拟浏览器点击页面上的元素,非常强大,本文介绍htmlunit的简单使用。步骤如下:
1、引入依赖
net.sourceforge.htmlunit
htmlunit
2.36.0
org.jsoup
jsoup
1.12.1
2、我们爬取我们绘制的页面,首先绘制一个简单的页面,页面中content的id的div的原创内容是hello,页面加载后内容变成
HtmlUnit 太强大了
,访问此页面查看结果
Title
HtmlUnit简单使用
hello
document.getElementById("content").innerHTML = "HtmlUnit好强大";

3、写测试类,先用jsoup直接爬取,看内容里面的内容是什么,我们打印出来,可以看到是hello
@Test
public void testJsoup() throws IOException {
Document document = Jsoup.connect("http://localhost:8080/index.html";).get();
System.out.println(document.getElementById("content").html());
}
4、用htmlunit看看效果
@Test
public void test() {
final WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
HtmlPage page = null;
try {
page = webClient.getPage("http://localhost:8080/index.html";);
} catch (Exception e) {
e.printStackTrace();
}finally {
webClient.close();
}
webClient.waitForBackgroundJavaScript(30000);
String pageXml = page.asXml();
Document document = Jsoup.parse(pageXml);//获取html文档
System.out.println(document.getElementById("content").html());
}

可以看到js运行后的内容,与浏览器看到的结果一致
htmlunit抓取动态网页( JSoup依赖:2、使用模拟浏览器方式获取动态页面使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-11-15 12:12
JSoup依赖:2、使用模拟浏览器方式获取动态页面使用)
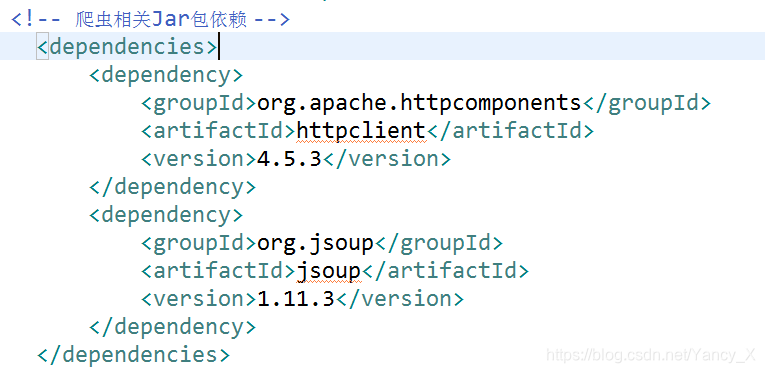
<br /> <br /> org.apache.httpcomponents<br /> httpclient<br /> 4.5.2<br /> <br />
JSoup 取决于:
<br /> <br /> <br /> org.jsoup<br /> jsoup<br /> 1.10.3<br /> <br />
<br />[color=red]<br />此处需要特别强调,对于很多网站,对爬虫都有一定的防范,因此在获取页面时,必须要补齐浏览器信息,否则很容易会导致被封IP!<br />[/color]<br />
2、使用模拟浏览器方式获取动态页面
使用模拟浏览器真的很无奈,因为这种方法确实很慢,但是对于异步加载内容的网页来说特别有效。只有在发现无法直接通过Http拉取页面获取元素值时,才能使用此方法。
HtmlUnit 获取网页:
<br /> /**<br /> * 通过模拟浏览器的方式下载完整页面。<br /> * <br /> * @param url<br /> * @return<br /> * @throws FailingHttpStatusCodeException<br /> * @throws IOException<br /> */<br /> public static String downloadHtml(String url, int timeout)<br /> throws FailingHttpStatusCodeException, IOException {<br /> try (final WebClient webClient = new WebClient(BrowserVersion.CHROME)) {<br /> webClient.getOptions().setJavaScriptEnabled(true);<br /> webClient.getOptions().setCssEnabled(false);<br /> webClient.getOptions().setRedirectEnabled(true);<br /> webClient.getOptions().setThrowExceptionOnScriptError(false);<br /> webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);<br /><br /> webClient<br /> .setAjaxController(new NicelyResynchronizingAjaxController());<br /> webClient.getOptions().setTimeout(timeout);<br /><br /> WebRequest webRequest = new WebRequest(new URL(url));<br /> webRequest.setHttpMethod(HttpMethod.GET);<br /> final HtmlPage page = webClient.getPage(webRequest);<br /> webClient.waitForBackgroundJavaScriptStartingBefore(500);<br /> webClient.waitForBackgroundJavaScript(20000);<br /><br /> final String pageAsXml = page.asXml();<br /><br /> return pageAsXml;<br /> }<br /> }<br />
HtmlUnit 取决于:
<br /> <br /> net.sourceforge.htmlunit<br /> htmlunit<br /> 2.30<br /> <br />
常见问题二:如何避免IP被封
处理方法比较简单,就是不使用并发,或者长时间连续抓取网站的内容。爬行时最好保持一定的时间间隔。根据我爬不同网站的经验,每3-5秒获取一个网页是最安全的。有些网站的IP一旦被封,可能需要一周左右的时间才能解锁,所以对于有固定外网IP的用户来说,在进行大规模爬取之前一定要注意这个限制。
以下爬取代码供参考:
<br /> /*<br /> * (non-Javadoc)<br /> * <br /> * @see<br /> * com.hna.tech.spider.service.SpiderService#setPageArticleDetail(java.lang<br /> * .String)<br /> */<br /> public List setPageArticleDetail(<br /> List pageList) throws IOException,<br /> InterruptedException {<br /> for (Map item : pageList) {<br />[color=red]<br /> // 最小延迟3秒,少于3秒将可能被封IP<br /> Thread.sleep(3000);<br />[/color]<br /> String articleUrl = item.get(KEY_LINK);<br /> Document doc = getArticleDocument(articleUrl);<br /><br /> String articleHtml = getArticleContentHtml(doc);<br /> item.put(KEY_CONTENT_HTML, articleHtml);<br /><br /> String articleContent = getArticleContent(doc);<br /> item.put(KEY_CONTENT, articleContent);<br /> }<br /><br /> return pageList;<br /> }<br />
那么如何提高爬取效率呢?一般网站无论是DDOS攻击还是恶意网页扫描都会根据Session和IP加锁,所以问题很简单。请求通过多个线程发起,保证每个Session请求的时间间隔。另外,不要太并发,只要不对网站造成压力,IP一般不会被阻塞。
常见问题三:元素选择问题
获取元素的方式有很多种,可以通过ID、CSS样式、元素类型(比如
) 等根据个人喜好,通常可以获取元素的内容,例如文章标题,文章正文等。
下面分享我个人使用JSoup获取页面元素内容的一些经验。
1、 分步获取
即先获取顶级节点,比如文章的内容的顶级节点,然后先获取第一个顶级节点,再通过获取低级节点的内容JSoup,避免在有多个节点时获取访问的内容超出预期。
2、CSS 样式的选择
当有多个类样式时,例如:
...
, 使用JSoup选择:
<br />doc.select("div.css1.css2")<br />
使用点将它们连接在一起。 查看全部
htmlunit抓取动态网页(
JSoup依赖:2、使用模拟浏览器方式获取动态页面使用)
<br /> <br /> org.apache.httpcomponents<br /> httpclient<br /> 4.5.2<br /> <br />
JSoup 取决于:
<br /> <br /> <br /> org.jsoup<br /> jsoup<br /> 1.10.3<br /> <br />
<br />[color=red]<br />此处需要特别强调,对于很多网站,对爬虫都有一定的防范,因此在获取页面时,必须要补齐浏览器信息,否则很容易会导致被封IP!<br />[/color]<br />
2、使用模拟浏览器方式获取动态页面
使用模拟浏览器真的很无奈,因为这种方法确实很慢,但是对于异步加载内容的网页来说特别有效。只有在发现无法直接通过Http拉取页面获取元素值时,才能使用此方法。
HtmlUnit 获取网页:
<br /> /**<br /> * 通过模拟浏览器的方式下载完整页面。<br /> * <br /> * @param url<br /> * @return<br /> * @throws FailingHttpStatusCodeException<br /> * @throws IOException<br /> */<br /> public static String downloadHtml(String url, int timeout)<br /> throws FailingHttpStatusCodeException, IOException {<br /> try (final WebClient webClient = new WebClient(BrowserVersion.CHROME)) {<br /> webClient.getOptions().setJavaScriptEnabled(true);<br /> webClient.getOptions().setCssEnabled(false);<br /> webClient.getOptions().setRedirectEnabled(true);<br /> webClient.getOptions().setThrowExceptionOnScriptError(false);<br /> webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);<br /><br /> webClient<br /> .setAjaxController(new NicelyResynchronizingAjaxController());<br /> webClient.getOptions().setTimeout(timeout);<br /><br /> WebRequest webRequest = new WebRequest(new URL(url));<br /> webRequest.setHttpMethod(HttpMethod.GET);<br /> final HtmlPage page = webClient.getPage(webRequest);<br /> webClient.waitForBackgroundJavaScriptStartingBefore(500);<br /> webClient.waitForBackgroundJavaScript(20000);<br /><br /> final String pageAsXml = page.asXml();<br /><br /> return pageAsXml;<br /> }<br /> }<br />
HtmlUnit 取决于:
<br /> <br /> net.sourceforge.htmlunit<br /> htmlunit<br /> 2.30<br /> <br />
常见问题二:如何避免IP被封
处理方法比较简单,就是不使用并发,或者长时间连续抓取网站的内容。爬行时最好保持一定的时间间隔。根据我爬不同网站的经验,每3-5秒获取一个网页是最安全的。有些网站的IP一旦被封,可能需要一周左右的时间才能解锁,所以对于有固定外网IP的用户来说,在进行大规模爬取之前一定要注意这个限制。
以下爬取代码供参考:
<br /> /*<br /> * (non-Javadoc)<br /> * <br /> * @see<br /> * com.hna.tech.spider.service.SpiderService#setPageArticleDetail(java.lang<br /> * .String)<br /> */<br /> public List setPageArticleDetail(<br /> List pageList) throws IOException,<br /> InterruptedException {<br /> for (Map item : pageList) {<br />[color=red]<br /> // 最小延迟3秒,少于3秒将可能被封IP<br /> Thread.sleep(3000);<br />[/color]<br /> String articleUrl = item.get(KEY_LINK);<br /> Document doc = getArticleDocument(articleUrl);<br /><br /> String articleHtml = getArticleContentHtml(doc);<br /> item.put(KEY_CONTENT_HTML, articleHtml);<br /><br /> String articleContent = getArticleContent(doc);<br /> item.put(KEY_CONTENT, articleContent);<br /> }<br /><br /> return pageList;<br /> }<br />
那么如何提高爬取效率呢?一般网站无论是DDOS攻击还是恶意网页扫描都会根据Session和IP加锁,所以问题很简单。请求通过多个线程发起,保证每个Session请求的时间间隔。另外,不要太并发,只要不对网站造成压力,IP一般不会被阻塞。
常见问题三:元素选择问题
获取元素的方式有很多种,可以通过ID、CSS样式、元素类型(比如
) 等根据个人喜好,通常可以获取元素的内容,例如文章标题,文章正文等。
下面分享我个人使用JSoup获取页面元素内容的一些经验。
1、 分步获取
即先获取顶级节点,比如文章的内容的顶级节点,然后先获取第一个顶级节点,再通过获取低级节点的内容JSoup,避免在有多个节点时获取访问的内容超出预期。
2、CSS 样式的选择
当有多个类样式时,例如:
...
, 使用JSoup选择:
<br />doc.select("div.css1.css2")<br />
使用点将它们连接在一起。
htmlunit抓取动态网页(何为Ajax动态网页,我想不用我多说了吧 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 266 次浏览 • 2021-11-15 12:10
)
什么是 Ajax 动态网页?我想我不需要多说了。如果你连 Ajax 是什么都不知道,那么你应该先去谷歌学习 Ajax。为形象起见,这里以抓取本网页为例进行说明。网页链接如下:
很明显,我们要爬取的数据是
打开谷歌浏览器的开发者工具,我们会发现其实是Ajax动态加载的,通过jsonp跨域方法返回的。分析如图:
由此可以推断,部分分页信息是通过javaScript动态插入到DOM中的。如果单纯使用HttpClient之类的工具来模拟Http请求获取网页信息,你得到的网页内容是不完整的。HtmlUnit 可以做到。
OK,回到正题,也许你是第一次听说HtmlUnit,也许你很久以前就听说过它,但我仍然认为官方的解释是最权威的,我不会盲目的。看图:
总之一句话,HtmlUnit其实就是一个方便测试人员进行功能测试的测试工具。可以模拟谷歌Chrome、火狐、Internet Explorer等常见主流浏览器的行为。废话不多说,直接上demo:
/**
* 上海证券交易所数据抓取测试
* @since 1.0
* @author Lanxiaowei@citic-finance.com
* @date 2015-8-27下午6:16:14
*
*/
public class ShangHaiStockTest {
public static void main(String[] args) throws Exception {
downloadListPage();
}
public static void downloadListPage() throws Exception {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_38);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setAppletEnabled(false);
webClient.getOptions().setRedirectEnabled(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setUseInsecureSSL(false);
webClient.getOptions().setTimeout(10000000);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
int totalPage = 22;
boolean first = true;
HtmlPage page = null;
do {
if(first) {
page = (HtmlPage)webClient.getPage("http://www.sse.com.cn/assortme ... 6quot;);
FileUtils.writeFile(page.asXml(), "C:/shh/list/" + totalPage + ".html", "UTF-8", false);
first = false;
} else {
HtmlAnchor anchor = null;
if(totalPage == 22 -1) {
anchor = (HtmlAnchor) page.getHtmlElementById("xsgf_next");
} else {
anchor = (HtmlAnchor) page.getHtmlElementById("dateList_container_next");
}
page = (HtmlPage) anchor.click();
FileUtils.writeFile(page.asXml(), "C:/shh/list/" + totalPage + ".html", "UTF-8", false);
}
totalPage--;
} while(totalPage > 0);
//关闭模拟窗口
webClient.closeAllWindows();
}
}
重点:
1.webClient.getOptions().setJavaScriptEnabled(true);
启用 JavaScript
2.webClient.setAjaxController(new NicelyResynchronizingAjaxController());
设置 Ajax 异步处理控制器以启用 Ajax 支持
3.webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
这两句话非常重要。前者表示当发生Http错误时,程序不会抛出异常继续执行,后者表示在JavaScript执行中发生异常时,将被忽略,否则Java代码会直接抛出异常,程序将被中断。
演示代码演示了如何使用代码模拟点击“下一页”超链接进行分页,获取每个页面的网页内容,然后写入磁盘指定目录。程序很简单,希望能有个好的开始。程序依赖的jar包如图:
查看全部
htmlunit抓取动态网页(何为Ajax动态网页,我想不用我多说了吧
)
什么是 Ajax 动态网页?我想我不需要多说了。如果你连 Ajax 是什么都不知道,那么你应该先去谷歌学习 Ajax。为形象起见,这里以抓取本网页为例进行说明。网页链接如下:
很明显,我们要爬取的数据是

打开谷歌浏览器的开发者工具,我们会发现其实是Ajax动态加载的,通过jsonp跨域方法返回的。分析如图:



由此可以推断,部分分页信息是通过javaScript动态插入到DOM中的。如果单纯使用HttpClient之类的工具来模拟Http请求获取网页信息,你得到的网页内容是不完整的。HtmlUnit 可以做到。
OK,回到正题,也许你是第一次听说HtmlUnit,也许你很久以前就听说过它,但我仍然认为官方的解释是最权威的,我不会盲目的。看图:

总之一句话,HtmlUnit其实就是一个方便测试人员进行功能测试的测试工具。可以模拟谷歌Chrome、火狐、Internet Explorer等常见主流浏览器的行为。废话不多说,直接上demo:
/**
* 上海证券交易所数据抓取测试
* @since 1.0
* @author Lanxiaowei@citic-finance.com
* @date 2015-8-27下午6:16:14
*
*/
public class ShangHaiStockTest {
public static void main(String[] args) throws Exception {
downloadListPage();
}
public static void downloadListPage() throws Exception {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_38);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setAppletEnabled(false);
webClient.getOptions().setRedirectEnabled(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setUseInsecureSSL(false);
webClient.getOptions().setTimeout(10000000);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
int totalPage = 22;
boolean first = true;
HtmlPage page = null;
do {
if(first) {
page = (HtmlPage)webClient.getPage("http://www.sse.com.cn/assortme ... 6quot;);
FileUtils.writeFile(page.asXml(), "C:/shh/list/" + totalPage + ".html", "UTF-8", false);
first = false;
} else {
HtmlAnchor anchor = null;
if(totalPage == 22 -1) {
anchor = (HtmlAnchor) page.getHtmlElementById("xsgf_next");
} else {
anchor = (HtmlAnchor) page.getHtmlElementById("dateList_container_next");
}
page = (HtmlPage) anchor.click();
FileUtils.writeFile(page.asXml(), "C:/shh/list/" + totalPage + ".html", "UTF-8", false);
}
totalPage--;
} while(totalPage > 0);
//关闭模拟窗口
webClient.closeAllWindows();
}
}
重点:
1.webClient.getOptions().setJavaScriptEnabled(true);
启用 JavaScript
2.webClient.setAjaxController(new NicelyResynchronizingAjaxController());
设置 Ajax 异步处理控制器以启用 Ajax 支持
3.webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
这两句话非常重要。前者表示当发生Http错误时,程序不会抛出异常继续执行,后者表示在JavaScript执行中发生异常时,将被忽略,否则Java代码会直接抛出异常,程序将被中断。
演示代码演示了如何使用代码模拟点击“下一页”超链接进行分页,获取每个页面的网页内容,然后写入磁盘指定目录。程序很简单,希望能有个好的开始。程序依赖的jar包如图:

htmlunit抓取动态网页(发现一个很不错的模拟浏览器包访问网站后的html源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-11-15 02:17
我找到了一个很好的模拟浏览器包htmlunit,可以直接访问网站地址并执行相应的JavaScript脚本;这个功能对网站爬虫很有帮助,一些网站Ajax用的。如果使用简单的http访问,只能抓取原创html源代码,无法获取页面中执行的ajax;使用这个包后,可以在执行ajax后抓取html源代码。取下来。
网站地址:
网站下面也提到了几个类似的包:HtmlUnit 被不同的开源工具用作底层的“浏览器”,如 Canoo WebTest、JWebUnit、WebDriver、JSFUnit、Celerity、...
看看canoo WebTest,但是不知道怎么用,也不想多了解。
jwebunit 用于 网站 测试。集成了JUnit、htmlunit、selenium包框架;主要功能是做白盒测试和压力测试。
webDriver 后来更名为 selenium,它集成了 htmlunit、Firefox 浏览器、IE 浏览器、opare 浏览器驱动。如果使用 htmlunitDriver,则使用 htmlunit 包访问站点;如果使用FirefoxDriver,则直接调用Firefox浏览器,然后在浏览器上模拟文本输入等鼠标键盘事件。
htmlunit包访问网站后,获取html源码后可以修改源码; jwebunit和selenium暂时没有找到修改的功能,只是用来模拟用户操作。
具体应用示例:
%D0%C7%D2%B9%BB%D8%D4%B5/blog/item/27ccf9963443c2177af48042.html 查看全部
htmlunit抓取动态网页(发现一个很不错的模拟浏览器包访问网站后的html源码)
我找到了一个很好的模拟浏览器包htmlunit,可以直接访问网站地址并执行相应的JavaScript脚本;这个功能对网站爬虫很有帮助,一些网站Ajax用的。如果使用简单的http访问,只能抓取原创html源代码,无法获取页面中执行的ajax;使用这个包后,可以在执行ajax后抓取html源代码。取下来。
网站地址:
网站下面也提到了几个类似的包:HtmlUnit 被不同的开源工具用作底层的“浏览器”,如 Canoo WebTest、JWebUnit、WebDriver、JSFUnit、Celerity、...
看看canoo WebTest,但是不知道怎么用,也不想多了解。
jwebunit 用于 网站 测试。集成了JUnit、htmlunit、selenium包框架;主要功能是做白盒测试和压力测试。
webDriver 后来更名为 selenium,它集成了 htmlunit、Firefox 浏览器、IE 浏览器、opare 浏览器驱动。如果使用 htmlunitDriver,则使用 htmlunit 包访问站点;如果使用FirefoxDriver,则直接调用Firefox浏览器,然后在浏览器上模拟文本输入等鼠标键盘事件。
htmlunit包访问网站后,获取html源码后可以修改源码; jwebunit和selenium暂时没有找到修改的功能,只是用来模拟用户操作。
具体应用示例:
%D0%C7%D2%B9%BB%D8%D4%B5/blog/item/27ccf9963443c2177af48042.html
htmlunit抓取动态网页( jsoup可以用来获取HTML页面并且分析读取页面内容吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-14 02:06
jsoup可以用来获取HTML页面并且分析读取页面内容吗?)
如何使用工具获取动态HTML页面内容
我们知道jsoup可以用来获取HTML页面,分析读取页面内容。
例如:
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test {
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
Document doc = Jsoup.connect("http://www.XXX.com/path/to/page.htm").get();
System.out.println(doc.title());
Elements newsHeadlines = doc.select("#mp-itn b a");
for (Element headline : newsHeadlines) {
System.out.printf("%s\n\t%s",
headline.attr("title"), headline.absUrl("href"));
}
}
}
但是jsoup有一个缺点,就是只能访问静态页面。对于动态页面,包括动态加载的元素,jsoup 无法处理;原因是有些网页为了浏览器的显示效果增加了用户的体检,而不是一次生成整个页面,而是在页面的基本框架显示出来后,使用js/ajax技术动态刷新和填写页面。对于这种页面,只需要解析HTML页面,执行JS代码就可以完成整个页面的加载;也就是说,需要尽可能模拟浏览器的加载行为。
最近发现HtmlUnit可以支持这个功能。
但顾名思义,它并不是一个完整的产品,它仅用于测试以模拟浏览器的行为。
举个例子:
import java.io.IOException;
import java.util.List;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.DomElement;
import com.gargoylesoftware.htmlunit.html.HtmlDivision;
import com.gargoylesoftware.htmlunit.html.HtmlListItem;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.html.HtmlUnorderedList;
public class Test {
private static WebClient webClient;
public static void main(String[] args) throws IOException {
//webClient = new WebClient(BrowserVersion.CHROME, "proxy.com", 80);
webClient = new WebClient(BrowserVersion.CHROME);
HtmlPage page = webClient.getPage(""http://www.XXX.com/path/to/page.htm"");
HtmlDivision div1 = page.getHtmlElementById("ksorder");
List divs = div1.getByXPath("//div[@class='sourceshow']");
assert(divs.size() == 1);
HtmlDivision div2 = divs.get(0);
Iterable uls = div2.getChildElements();
for (DomElement eul : uls) {
HtmlUnorderedList ul = (HtmlUnorderedList)eul;
Iterable lis = ul.getChildElements();
for (DomElement eli : lis) {
HtmlListItem li = (HtmlListItem)eli;
System.out.printf("data=[%s], class=[%s]\n", li.getAttribute("data-id"), li.getAttribute("class"));
}
}
}
}
HTML页面内容的分析框架与jsoup类似,具体可以参考文档。 查看全部
htmlunit抓取动态网页(
jsoup可以用来获取HTML页面并且分析读取页面内容吗?)
如何使用工具获取动态HTML页面内容
我们知道jsoup可以用来获取HTML页面,分析读取页面内容。
例如:
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test {
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
Document doc = Jsoup.connect("http://www.XXX.com/path/to/page.htm";).get();
System.out.println(doc.title());
Elements newsHeadlines = doc.select("#mp-itn b a");
for (Element headline : newsHeadlines) {
System.out.printf("%s\n\t%s",
headline.attr("title"), headline.absUrl("href"));
}
}
}
但是jsoup有一个缺点,就是只能访问静态页面。对于动态页面,包括动态加载的元素,jsoup 无法处理;原因是有些网页为了浏览器的显示效果增加了用户的体检,而不是一次生成整个页面,而是在页面的基本框架显示出来后,使用js/ajax技术动态刷新和填写页面。对于这种页面,只需要解析HTML页面,执行JS代码就可以完成整个页面的加载;也就是说,需要尽可能模拟浏览器的加载行为。
最近发现HtmlUnit可以支持这个功能。
但顾名思义,它并不是一个完整的产品,它仅用于测试以模拟浏览器的行为。
举个例子:
import java.io.IOException;
import java.util.List;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.DomElement;
import com.gargoylesoftware.htmlunit.html.HtmlDivision;
import com.gargoylesoftware.htmlunit.html.HtmlListItem;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.html.HtmlUnorderedList;
public class Test {
private static WebClient webClient;
public static void main(String[] args) throws IOException {
//webClient = new WebClient(BrowserVersion.CHROME, "proxy.com", 80);
webClient = new WebClient(BrowserVersion.CHROME);
HtmlPage page = webClient.getPage(""http://www.XXX.com/path/to/page.htm"";);
HtmlDivision div1 = page.getHtmlElementById("ksorder");
List divs = div1.getByXPath("//div[@class='sourceshow']");
assert(divs.size() == 1);
HtmlDivision div2 = divs.get(0);
Iterable uls = div2.getChildElements();
for (DomElement eul : uls) {
HtmlUnorderedList ul = (HtmlUnorderedList)eul;
Iterable lis = ul.getChildElements();
for (DomElement eli : lis) {
HtmlListItem li = (HtmlListItem)eli;
System.out.printf("data=[%s], class=[%s]\n", li.getAttribute("data-id"), li.getAttribute("class"));
}
}
}
}
HTML页面内容的分析框架与jsoup类似,具体可以参考文档。
htmlunit抓取动态网页(.xmlmaven依赖代码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-11-13 19:17
)
今天在使用jsoup做爬虫功能的时候发现jsoup只能抓取静态页面,对ajax和json动态生成的页面的支持不友好。
所以我尝试着把param和data header直接和request一起发送,希望能直接返回json数据,但是可能不成功,因为网站接口不支持。
尝试其他方法后,从网上发现可以用htmlunit模拟浏览器生成动态网页,然后用jsoup解析生成的动态网页
以下是 pom.xml maven 依赖代码
下面是java代码
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class JsoupTest {
public static void main(String[] args) {
queryDocument("北斗");
}
public static void queryDocument(String documentName){
WebClient browser = new WebClient();
browser.getOptions().setCssEnabled(false);
browser.getOptions().setJavaScriptEnabled(true);
browser.getOptions().setThrowExceptionOnScriptError(false);
String url = "http://oar.nstl.gov.cn/Paper/S ... 3B%3B
try {
HtmlPage htmlPage = browser.getPage(url);
browser.waitForBackgroundJavaScript(3000);
Document document = Jsoup.parse(htmlPage.asXml());
Element paper = document.getElementById("paper");
System.out.println(paper);
} catch (IOException e) {
e.printStackTrace();
}
}
} 查看全部
htmlunit抓取动态网页(.xmlmaven依赖代码
)
今天在使用jsoup做爬虫功能的时候发现jsoup只能抓取静态页面,对ajax和json动态生成的页面的支持不友好。
所以我尝试着把param和data header直接和request一起发送,希望能直接返回json数据,但是可能不成功,因为网站接口不支持。
尝试其他方法后,从网上发现可以用htmlunit模拟浏览器生成动态网页,然后用jsoup解析生成的动态网页
以下是 pom.xml maven 依赖代码
下面是java代码
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class JsoupTest {
public static void main(String[] args) {
queryDocument("北斗");
}
public static void queryDocument(String documentName){
WebClient browser = new WebClient();
browser.getOptions().setCssEnabled(false);
browser.getOptions().setJavaScriptEnabled(true);
browser.getOptions().setThrowExceptionOnScriptError(false);
String url = "http://oar.nstl.gov.cn/Paper/S ... 3B%3B
try {
HtmlPage htmlPage = browser.getPage(url);
browser.waitForBackgroundJavaScript(3000);
Document document = Jsoup.parse(htmlPage.asXml());
Element paper = document.getElementById("paper");
System.out.println(paper);
} catch (IOException e) {
e.printStackTrace();
}
}
}
htmlunit抓取动态网页(1024程序员节#通过java实现爬虫动态获取网站数据通过)
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-11-10 23:20
#1024程序员节#
通过java实现爬虫动态获取网站数据
通过上次demo的实现,对爬虫有了一定的了解和认识,并进行了深入的研究和学习,成功的动态获取了更多的数据。
上次demo后发现每次通过商品列表获取的数据都是有限的,只有几个。我在想如何自动点击产品,进入产品详情页面,获取更多数据,然后返回产品列表。页。这形成了一个循环以获取更多数据。经过思考和尝试,终于实现了这个功能。
1.创建一个maven项目
首先,创建一个maven项目。
2.介绍相关jar包
由于工作原因,一直没有时间将数据导出到excel文件,所以还是只有控制台输出。导入jar包如下。
3.代码编写
这段代码中增加了自动跳转到商品详情页,获取数据后返回商品列表页,循环进行获取。
代码中最外层的for循环的作用就是实现翻页操作。当产品第一页的数据采集完成后,跳转到产品列表页面的第二页,继续循环获取详细的产品数据。
4.运行结果
成功获取多页产品的详细数据,结果如图。因为我用的是海外购物网站,所以得到的数据不是中文的。
总结:
通过这次实战,对爬虫有了更深入的了解,掌握了动态获取数据的方式。美中不足的是,暂时没有时间将数据导出到excel文件。我会抓紧时间实现自己的这个想法,把外文数据转换成中文。这就是我需要继续学习和尝试的地方,这样我才能逐渐成长。 查看全部
htmlunit抓取动态网页(1024程序员节#通过java实现爬虫动态获取网站数据通过)
#1024程序员节#
通过java实现爬虫动态获取网站数据
通过上次demo的实现,对爬虫有了一定的了解和认识,并进行了深入的研究和学习,成功的动态获取了更多的数据。
上次demo后发现每次通过商品列表获取的数据都是有限的,只有几个。我在想如何自动点击产品,进入产品详情页面,获取更多数据,然后返回产品列表。页。这形成了一个循环以获取更多数据。经过思考和尝试,终于实现了这个功能。
1.创建一个maven项目
首先,创建一个maven项目。
2.介绍相关jar包
由于工作原因,一直没有时间将数据导出到excel文件,所以还是只有控制台输出。导入jar包如下。
3.代码编写
这段代码中增加了自动跳转到商品详情页,获取数据后返回商品列表页,循环进行获取。
代码中最外层的for循环的作用就是实现翻页操作。当产品第一页的数据采集完成后,跳转到产品列表页面的第二页,继续循环获取详细的产品数据。

4.运行结果
成功获取多页产品的详细数据,结果如图。因为我用的是海外购物网站,所以得到的数据不是中文的。
总结:
通过这次实战,对爬虫有了更深入的了解,掌握了动态获取数据的方式。美中不足的是,暂时没有时间将数据导出到excel文件。我会抓紧时间实现自己的这个想法,把外文数据转换成中文。这就是我需要继续学习和尝试的地方,这样我才能逐渐成长。
htmlunit抓取动态网页(webmagic渲染网页的爬取过程,你知道几个?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-11-10 23:12
最近突然了解到,我以后的工作有很多数据采集。朋友推荐了webmagic项目,于是就开始玩了。发现这个爬虫项目还是很有用的,爬取静态网站几乎不需要自己写任何代码(当然是小爬虫~~|)。好了,废话少说。以此文记录渲染网页的爬取过程。先找个js渲染网站。这里我们直接取学习文档中给出的网址。
打开网页是这样的
像这样查看源代码
源代码这么小,不用说,必须渲染。我搜索了一条记录,果然,在源代码中没有找到任何结果。
然后开始解析URL。我从浏览器开发人员工具中找到了这样的请求记录。
只需开始查看数据量最大的请求,如上图红线所示。从xhr可以看出这是一个ajax请求的数据,打开请求的数据是这样的
从网页中找到源代码中找不到的一条记录,在这个json数据中搜索。幸运的是,我找到了。
不用说,就是这样!!接下来直接解析这个json就可以得到所有渲染出来的链接了。
直接从网页上点击一个链接进入,发现链接是这样的:
然后回到json文件,找到这个标题
发现了惊人的东西!那是 id,后跟链接。大胆推测所有链接都是这种尿性!!(其实我还点了几个链接才敢确认这个尿性)
然后就很简单了,写代码解析这个json数据,然后把所有的链接拼凑起来加入爬取队列进行爬取。
原来通过首页链接点进来的下级链接还是js渲染的。. .
没办法,拿着链接要求继续分析
获取这样的请求数据:
直接看xhr列,就是ajax请求的数据
还是从大到小看json数据,匹配页面内容,直到找到第三个。++|
然后得到了最终数据的请求链接:
然后就可以写代码了:
1 public class SpiderTest implements PageProcessor {
2 // 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
3 private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
4 // 先从浏览器中分析出隐藏请求可得出以下匹配规则
5 private static final String URLRULE = "http://angularjs\\.cn/api/article/latest.*";
6 private static String firstUrl = "http://angularjs.cn/api/article/";
7
8 @Override
9 public Site getSite() {
10 // TODO Auto-generated method stub
11 return site;
12 }
13
14 @Override
15 public void process(Page page) {
16 // TODO Auto-generated method stub
17 /**
18 * 筛选出所有符合条件的url,手动添加到爬取队列。
19 */
20 if (page.getUrl().regex(URLRULE).match()) {
21 //通过jsonpath得到json数据中的id内容,之后再拼凑待爬取链接
22 List endUrls = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
23 if (CollectionUtils.isNotEmpty(endUrls)) {
24 for (String endUrl : endUrls) {
25 page.addTargetRequest(firstUrl + endUrl);
26 }
27 }
28 } else {
29 //通过jsonpath从爬取到的json数据中提取出id和content内容
30 page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
31 page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
32 }
33
34 }
35
36 @Test
37 public void test(){
38 Spider.create(new SpiderTest()).addUrl("http://angularjs.cn/api/article/latest?s=20").run();
39 }
40 }
此时,一个渲染的网页就被爬下来了。超过 查看全部
htmlunit抓取动态网页(webmagic渲染网页的爬取过程,你知道几个?)
最近突然了解到,我以后的工作有很多数据采集。朋友推荐了webmagic项目,于是就开始玩了。发现这个爬虫项目还是很有用的,爬取静态网站几乎不需要自己写任何代码(当然是小爬虫~~|)。好了,废话少说。以此文记录渲染网页的爬取过程。先找个js渲染网站。这里我们直接取学习文档中给出的网址。
打开网页是这样的
像这样查看源代码
源代码这么小,不用说,必须渲染。我搜索了一条记录,果然,在源代码中没有找到任何结果。
然后开始解析URL。我从浏览器开发人员工具中找到了这样的请求记录。
只需开始查看数据量最大的请求,如上图红线所示。从xhr可以看出这是一个ajax请求的数据,打开请求的数据是这样的
从网页中找到源代码中找不到的一条记录,在这个json数据中搜索。幸运的是,我找到了。
不用说,就是这样!!接下来直接解析这个json就可以得到所有渲染出来的链接了。
直接从网页上点击一个链接进入,发现链接是这样的:
然后回到json文件,找到这个标题
发现了惊人的东西!那是 id,后跟链接。大胆推测所有链接都是这种尿性!!(其实我还点了几个链接才敢确认这个尿性)
然后就很简单了,写代码解析这个json数据,然后把所有的链接拼凑起来加入爬取队列进行爬取。
原来通过首页链接点进来的下级链接还是js渲染的。. .
没办法,拿着链接要求继续分析
获取这样的请求数据:
直接看xhr列,就是ajax请求的数据
还是从大到小看json数据,匹配页面内容,直到找到第三个。++|
然后得到了最终数据的请求链接:
然后就可以写代码了:
1 public class SpiderTest implements PageProcessor {
2 // 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
3 private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
4 // 先从浏览器中分析出隐藏请求可得出以下匹配规则
5 private static final String URLRULE = "http://angularjs\\.cn/api/article/latest.*";
6 private static String firstUrl = "http://angularjs.cn/api/article/";
7
8 @Override
9 public Site getSite() {
10 // TODO Auto-generated method stub
11 return site;
12 }
13
14 @Override
15 public void process(Page page) {
16 // TODO Auto-generated method stub
17 /**
18 * 筛选出所有符合条件的url,手动添加到爬取队列。
19 */
20 if (page.getUrl().regex(URLRULE).match()) {
21 //通过jsonpath得到json数据中的id内容,之后再拼凑待爬取链接
22 List endUrls = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
23 if (CollectionUtils.isNotEmpty(endUrls)) {
24 for (String endUrl : endUrls) {
25 page.addTargetRequest(firstUrl + endUrl);
26 }
27 }
28 } else {
29 //通过jsonpath从爬取到的json数据中提取出id和content内容
30 page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
31 page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
32 }
33
34 }
35
36 @Test
37 public void test(){
38 Spider.create(new SpiderTest()).addUrl("http://angularjs.cn/api/article/latest?s=20";).run();
39 }
40 }
此时,一个渲染的网页就被爬下来了。超过
htmlunit抓取动态网页(为GET和POST请求添加请求参数和请求头(使用HttpClient) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-11-09 19:04
)
缺点是需要手动查找post请求的url和对应的参数。
参考:
1.为GET和POST请求添加请求参数和请求头(使用HttpClient,Java)
2.关于抓取js加载的内容(参考博客流程,比如找到实际的请求url)
以一条新闻为例:
1.使用F12,先在网络文件列表中找到网页,双击弹出详细信息。“Body”查看了网页内容,发现网页上没有显示该信息对应的信息,说明是后来加载的。
2.尝试在文中搜索关键字,看看是请求哪些文档来获取数据。例如,如果您搜索文本中的第一个词“海关总署”,您可能会发现多个文件,需要判断和选择。
对应的请求体为“id:98212”,即请求参数
3.查看“标题”
主要取决于请求url和请求方式,有时需要设置user-agent。需要使用post方法
4.代码编写
创建 Java Maven 项目并添加依赖项:
org.apache.httpcomponents
httpclient
4.5.6
com.google.code.gson
gson
2.2.4
下载的jar包如下图:
代码如下,我只拿到了文章的body:
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Map;
import org.apache.http.HttpEntity;
import org.apache.http.NameValuePair;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
import com.google.gson.Gson;
/**
* http://news.cqcoal.com/blank/nc.jsp?mid=98212
* 该网页的新闻主题是动态生成的,希望获取内容
* @author yangc_cong
*
*/
public class TestNewContent {
/**
* 针对请求的链接,使用post方法获取返回的数据
* @param urlStr String类型
* @return 这里是Map类型
*/
private Map getPageContByHttpCl(String urlStr) {
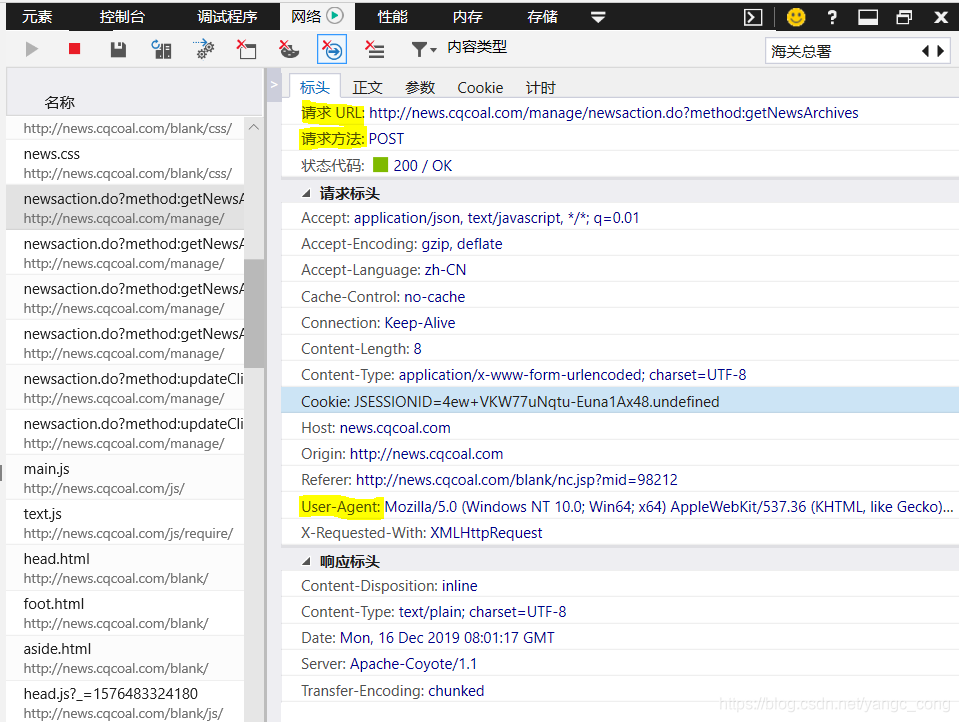
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpPost post = new HttpPost(urlStr);
String userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362";
post.setHeader("User-Agent", userAgent);
CloseableHttpResponse response = null;
String result = null;
// 创建请求参数
List list = new LinkedList();
BasicNameValuePair param1 = new BasicNameValuePair("id", "98212");
list.add(param1);
// 使用URL实体转换工具
UrlEncodedFormEntity entityParam = null;
try {
entityParam = new UrlEncodedFormEntity(list, "UTF-8");
post.setEntity(entityParam);
} catch (UnsupportedEncodingException e1) {
e1.printStackTrace();
}
try {
response = httpclient.execute(post);
HttpEntity entity = response.getEntity();
result = EntityUtils.toString(entity, "UTF-8");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
response.close();
httpclient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println(result);
Gson gson = new Gson();
Map map = gson.fromJson(result, Map.class);
return map;
}
private void parse_content(Map map) {
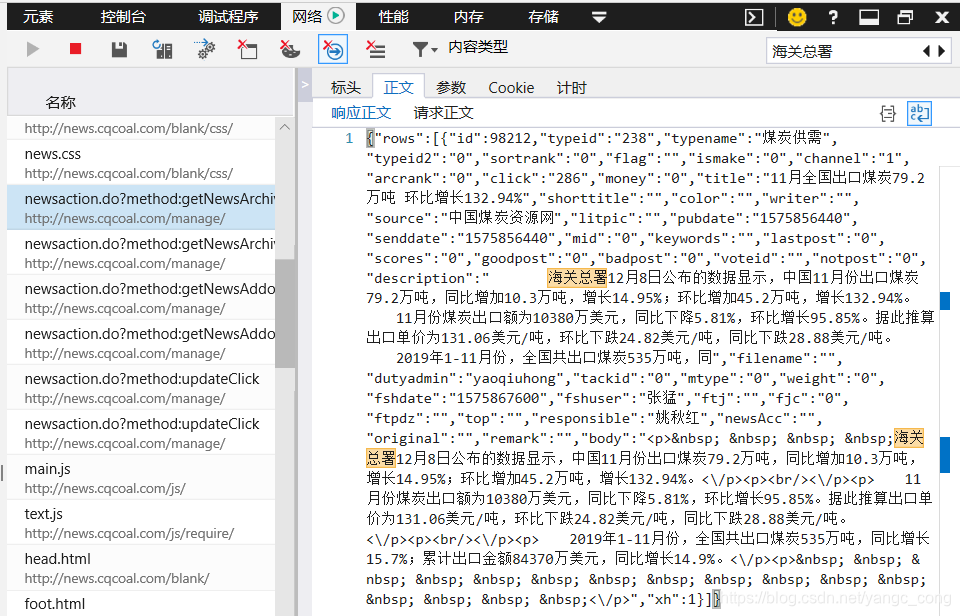
//java.lang.ClassCastException: java.util.ArrayList cannot be cast to java.util.Map
ArrayList arrayList = (ArrayList)(map.get("rows"));
Map innerMap = (Map) arrayList.get(0);
String source = (String) innerMap.get("source");
String bodyhtml = (String) innerMap.get("body");
System.out.println("source: "+source);
System.out.println("bodyhtml:"+'\n'+bodyhtml);
}
public static void main(String[] args) {
TestNewContent test1 = new TestNewContent();
String urlStr = "http://news.cqcoal.com/manage/ ... 3B%3B
Map map = test1.getPageContByHttpCl(urlStr);
test1.parse_content(map);
}
}
运行截图:
补充:使用HtmlUnit抓取网页动态加载的body部分(一个简单的应用)
参考:HtmlUnit+Jsoup学习总结
1.maven项目中的配置
net.sourceforge.htmlunit
htmlunit
2.27
下载的jar包如下,有很多,所以建议使用maven进行配置:
2. 代码部分(根据参考博客写的)
import java.io.IOException;
import java.net.MalformedURLException;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
public class HtmlUnitTest {
public static void main(String[] args) {
String url ="http://www.qidian.com";
url = "http://news.cqcoal.com/blank/n ... 3B%3B
// 1创建WebClient
WebClient webClient=new WebClient(BrowserVersion.CHROME);
// 2 启动JS
webClient.getOptions().setJavaScriptEnabled(true);
// 3 禁用Css,可避免自动二次請求CSS进行渲染
webClient.getOptions().setCssEnabled(false);
// 4 启动客戶端重定向
webClient.getOptions().setRedirectEnabled(true);
// 5 js运行错誤時,是否拋出异常
webClient.getOptions().setThrowExceptionOnScriptError(false);
// 6 设置超时
webClient.getOptions().setTimeout(50000); //获取网页
HtmlPage htmlPage = null;
try {
htmlPage = webClient.getPage(url);
} catch (FailingHttpStatusCodeException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// 等待JS驱动dom完成获得还原后的网页
webClient.waitForBackgroundJavaScript(10000);
// 网页内容
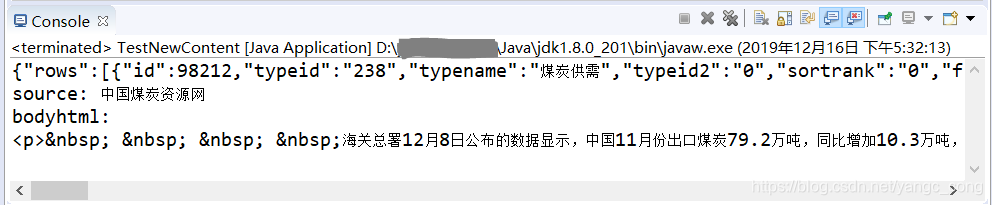
String pageHtml = htmlPage.asXml();
System.out.println(pageHtml);
System.out.println("\n------\n");
//网页内容---纯文本形式
String pageText = htmlPage.asText();
System.out.println(pageText );
//输出网页的title
String title = htmlPage.getTitleText();
System.out.println(title );
//close
webClient.close();
}
}
3.运行结果(代码需要加载js后的输出,收录标签的网页内容,纯文本---网页的文本部分,网页的标题---值title 属性的。这里只贴出纯文本输出的部分结果)
查看全部
htmlunit抓取动态网页(为GET和POST请求添加请求参数和请求头(使用HttpClient)
)
缺点是需要手动查找post请求的url和对应的参数。
参考:
1.为GET和POST请求添加请求参数和请求头(使用HttpClient,Java)
2.关于抓取js加载的内容(参考博客流程,比如找到实际的请求url)
以一条新闻为例:
1.使用F12,先在网络文件列表中找到网页,双击弹出详细信息。“Body”查看了网页内容,发现网页上没有显示该信息对应的信息,说明是后来加载的。
2.尝试在文中搜索关键字,看看是请求哪些文档来获取数据。例如,如果您搜索文本中的第一个词“海关总署”,您可能会发现多个文件,需要判断和选择。
对应的请求体为“id:98212”,即请求参数
3.查看“标题”
主要取决于请求url和请求方式,有时需要设置user-agent。需要使用post方法
4.代码编写
创建 Java Maven 项目并添加依赖项:
org.apache.httpcomponents
httpclient
4.5.6
com.google.code.gson
gson
2.2.4
下载的jar包如下图:
代码如下,我只拿到了文章的body:
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Map;
import org.apache.http.HttpEntity;
import org.apache.http.NameValuePair;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
import com.google.gson.Gson;
/**
* http://news.cqcoal.com/blank/nc.jsp?mid=98212
* 该网页的新闻主题是动态生成的,希望获取内容
* @author yangc_cong
*
*/
public class TestNewContent {
/**
* 针对请求的链接,使用post方法获取返回的数据
* @param urlStr String类型
* @return 这里是Map类型
*/
private Map getPageContByHttpCl(String urlStr) {
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpPost post = new HttpPost(urlStr);
String userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362";
post.setHeader("User-Agent", userAgent);
CloseableHttpResponse response = null;
String result = null;
// 创建请求参数
List list = new LinkedList();
BasicNameValuePair param1 = new BasicNameValuePair("id", "98212");
list.add(param1);
// 使用URL实体转换工具
UrlEncodedFormEntity entityParam = null;
try {
entityParam = new UrlEncodedFormEntity(list, "UTF-8");
post.setEntity(entityParam);
} catch (UnsupportedEncodingException e1) {
e1.printStackTrace();
}
try {
response = httpclient.execute(post);
HttpEntity entity = response.getEntity();
result = EntityUtils.toString(entity, "UTF-8");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
response.close();
httpclient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println(result);
Gson gson = new Gson();
Map map = gson.fromJson(result, Map.class);
return map;
}
private void parse_content(Map map) {
//java.lang.ClassCastException: java.util.ArrayList cannot be cast to java.util.Map
ArrayList arrayList = (ArrayList)(map.get("rows"));
Map innerMap = (Map) arrayList.get(0);
String source = (String) innerMap.get("source");
String bodyhtml = (String) innerMap.get("body");
System.out.println("source: "+source);
System.out.println("bodyhtml:"+'\n'+bodyhtml);
}
public static void main(String[] args) {
TestNewContent test1 = new TestNewContent();
String urlStr = "http://news.cqcoal.com/manage/ ... 3B%3B
Map map = test1.getPageContByHttpCl(urlStr);
test1.parse_content(map);
}
}
运行截图:
补充:使用HtmlUnit抓取网页动态加载的body部分(一个简单的应用)
参考:HtmlUnit+Jsoup学习总结
1.maven项目中的配置
net.sourceforge.htmlunit
htmlunit
2.27
下载的jar包如下,有很多,所以建议使用maven进行配置:
2. 代码部分(根据参考博客写的)
import java.io.IOException;
import java.net.MalformedURLException;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
public class HtmlUnitTest {
public static void main(String[] args) {
String url ="http://www.qidian.com";
url = "http://news.cqcoal.com/blank/n ... 3B%3B
// 1创建WebClient
WebClient webClient=new WebClient(BrowserVersion.CHROME);
// 2 启动JS
webClient.getOptions().setJavaScriptEnabled(true);
// 3 禁用Css,可避免自动二次請求CSS进行渲染
webClient.getOptions().setCssEnabled(false);
// 4 启动客戶端重定向
webClient.getOptions().setRedirectEnabled(true);
// 5 js运行错誤時,是否拋出异常
webClient.getOptions().setThrowExceptionOnScriptError(false);
// 6 设置超时
webClient.getOptions().setTimeout(50000); //获取网页
HtmlPage htmlPage = null;
try {
htmlPage = webClient.getPage(url);
} catch (FailingHttpStatusCodeException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// 等待JS驱动dom完成获得还原后的网页
webClient.waitForBackgroundJavaScript(10000);
// 网页内容
String pageHtml = htmlPage.asXml();
System.out.println(pageHtml);
System.out.println("\n------\n");
//网页内容---纯文本形式
String pageText = htmlPage.asText();
System.out.println(pageText );
//输出网页的title
String title = htmlPage.getTitleText();
System.out.println(title );
//close
webClient.close();
}
}
3.运行结果(代码需要加载js后的输出,收录标签的网页内容,纯文本---网页的文本部分,网页的标题---值title 属性的。这里只贴出纯文本输出的部分结果)

htmlunit抓取动态网页(基于现有的动态网页爬虫系统-DynCrawler系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-07 05:21
【摘要】:随着网页数量的爆发式增长,传统的中心化爬虫难以满足实际应用。此外,Ajax 技术在网络应用中的广泛普及,也给传统的Web 开发带来了全新的变化。部分刷新功能提升了用户体验,用户可以很好地与远程服务器进行交互。典型应用包括校园论坛、博客网站等,这些大量动态网页的出现给传统的网络爬虫带来了极大的障碍。在影响爬虫效率的同时,也影响到网页内容的获取。针对以上两个问题,本文基于WebMagic爬虫框架设计了分布式动态网络爬虫系统Dis-Dyn Crawler。系统采用SOA架构的思想,将动态页面解析工具HtmlUnit在动态页面过程中的耗时操作作为独立的服务分离出来;为了提高解析效率,系统将HtmlUnit所需的JavaScript等文件缓存在Redis数据库中。页面渲染时无需每次都从网络下载,减少了网络请求,提高了解析效率;异步页面下载器的实现进一步提高了系统的整体效率。本文从功能和性能两个方面对Dis-Dyn Crawler系统进行了实验分析。通过与现有分布式网络爬虫工具的爬虫能力对比,验证了本文基于Webmagic的动态网络爬虫是高效的。通过与现有动态网页分析工具的对比,验证了本文Dis-Dyn Crawler系统的效率和可行性。 查看全部
htmlunit抓取动态网页(基于现有的动态网页爬虫系统-DynCrawler系统)
【摘要】:随着网页数量的爆发式增长,传统的中心化爬虫难以满足实际应用。此外,Ajax 技术在网络应用中的广泛普及,也给传统的Web 开发带来了全新的变化。部分刷新功能提升了用户体验,用户可以很好地与远程服务器进行交互。典型应用包括校园论坛、博客网站等,这些大量动态网页的出现给传统的网络爬虫带来了极大的障碍。在影响爬虫效率的同时,也影响到网页内容的获取。针对以上两个问题,本文基于WebMagic爬虫框架设计了分布式动态网络爬虫系统Dis-Dyn Crawler。系统采用SOA架构的思想,将动态页面解析工具HtmlUnit在动态页面过程中的耗时操作作为独立的服务分离出来;为了提高解析效率,系统将HtmlUnit所需的JavaScript等文件缓存在Redis数据库中。页面渲染时无需每次都从网络下载,减少了网络请求,提高了解析效率;异步页面下载器的实现进一步提高了系统的整体效率。本文从功能和性能两个方面对Dis-Dyn Crawler系统进行了实验分析。通过与现有分布式网络爬虫工具的爬虫能力对比,验证了本文基于Webmagic的动态网络爬虫是高效的。通过与现有动态网页分析工具的对比,验证了本文Dis-Dyn Crawler系统的效率和可行性。
htmlunit抓取动态网页(一种面向动态网页的定向信息提取模型模型研究)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-11-02 22:18
【摘要】随着Web2.0技术的出现和快速发展,互联网上出现了越来越多的动态网页。Ajax技术实现了客户端和服务器之间的异步数据传输操作,不仅提高了用户体验,而且促进了动态网页的普及和互联网的发展。但是,这也使得传统的网络爬虫无法根据HTML源代码提取信息,从动态网页中提取动态信息。因此,支持动态网页信息提取的研究具有一定的现实意义。为此,本文提出了一种动态网页的定向信息提取模型。首先,分析了动态网页方向信息提取的相关理论和技术。同时将研究对象网页分为静态网页和动态网页,并进行详细的对比分析。在此基础上,分析了动态网页中广泛使用的Ajax技术给信息抽取带来的挑战。最后,详细介绍了超文本标记语言、DOM模型和正则表达式在信息抽取中的作用。其次,分析了传统网络爬虫抓取动态网页的缺陷和不足,提出了动态网页的定向信息抽取模型。工作流程是先通过HTTP请求获取网页,然后使用HtmlUnit解析并执行动态脚本,并模拟页面表单的提交;最后,使用jsoup构建DOM树,提取页面信息和URL并存入数据库。第三,结合所提出的面向Web的动态定向信息抽取模型,给出了各个组件模块的具体实现方法:采用广度优先搜索策略对网站中的网页进行爬取,布隆过滤器用于链接 URL。进行去重处理,使用正则表达式和jsoup选择器提取网页信息和URL链接,使用多线程爬虫技术提升模型性能。最后,基于提出的面向Web的动态信息抽取模型,以燕山大学百度贴吧为抓取对象进行实验,并从模型的效率和性能上进行实验设计。通过对爬取结果的分析可以看出,所提模型在准确率、召回率、F值等评价指标下均取得了较好的效果,验证了所提模型的高效、高性能。 查看全部
htmlunit抓取动态网页(一种面向动态网页的定向信息提取模型模型研究)
【摘要】随着Web2.0技术的出现和快速发展,互联网上出现了越来越多的动态网页。Ajax技术实现了客户端和服务器之间的异步数据传输操作,不仅提高了用户体验,而且促进了动态网页的普及和互联网的发展。但是,这也使得传统的网络爬虫无法根据HTML源代码提取信息,从动态网页中提取动态信息。因此,支持动态网页信息提取的研究具有一定的现实意义。为此,本文提出了一种动态网页的定向信息提取模型。首先,分析了动态网页方向信息提取的相关理论和技术。同时将研究对象网页分为静态网页和动态网页,并进行详细的对比分析。在此基础上,分析了动态网页中广泛使用的Ajax技术给信息抽取带来的挑战。最后,详细介绍了超文本标记语言、DOM模型和正则表达式在信息抽取中的作用。其次,分析了传统网络爬虫抓取动态网页的缺陷和不足,提出了动态网页的定向信息抽取模型。工作流程是先通过HTTP请求获取网页,然后使用HtmlUnit解析并执行动态脚本,并模拟页面表单的提交;最后,使用jsoup构建DOM树,提取页面信息和URL并存入数据库。第三,结合所提出的面向Web的动态定向信息抽取模型,给出了各个组件模块的具体实现方法:采用广度优先搜索策略对网站中的网页进行爬取,布隆过滤器用于链接 URL。进行去重处理,使用正则表达式和jsoup选择器提取网页信息和URL链接,使用多线程爬虫技术提升模型性能。最后,基于提出的面向Web的动态信息抽取模型,以燕山大学百度贴吧为抓取对象进行实验,并从模型的效率和性能上进行实验设计。通过对爬取结果的分析可以看出,所提模型在准确率、召回率、F值等评价指标下均取得了较好的效果,验证了所提模型的高效、高性能。
htmlunit抓取动态网页(.xmlmaven依赖代码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-11-01 12:20
)
今天在使用jsoup做爬虫功能的时候发现jsoup只能抓取静态页面,对ajax和json动态生成的页面的支持不友好。
所以我尝试直接用request发送param和data header,希望直接返回json数据,但是可能不成功,因为网站接口不支持。
尝试其他方法后,从网上发现可以用htmlunit模拟浏览器生成动态网页,然后用jsoup解析生成的动态网页
以下是 pom.xml maven 依赖代码
下面是java代码
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class JsoupTest {
public static void main(String[] args) {
queryDocument("北斗");
}
public static void queryDocument(String documentName){
WebClient browser = new WebClient();
browser.getOptions().setCssEnabled(false);
browser.getOptions().setJavaScriptEnabled(true);
browser.getOptions().setThrowExceptionOnScriptError(false);
String url = "http://oar.nstl.gov.cn/Paper/S ... 3B%3B
try {
HtmlPage htmlPage = browser.getPage(url);
browser.waitForBackgroundJavaScript(3000);
Document document = Jsoup.parse(htmlPage.asXml());
Element paper = document.getElementById("paper");
System.out.println(paper);
} catch (IOException e) {
e.printStackTrace();
}
}
} 查看全部
htmlunit抓取动态网页(.xmlmaven依赖代码
)
今天在使用jsoup做爬虫功能的时候发现jsoup只能抓取静态页面,对ajax和json动态生成的页面的支持不友好。
所以我尝试直接用request发送param和data header,希望直接返回json数据,但是可能不成功,因为网站接口不支持。
尝试其他方法后,从网上发现可以用htmlunit模拟浏览器生成动态网页,然后用jsoup解析生成的动态网页
以下是 pom.xml maven 依赖代码
下面是java代码
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class JsoupTest {
public static void main(String[] args) {
queryDocument("北斗");
}
public static void queryDocument(String documentName){
WebClient browser = new WebClient();
browser.getOptions().setCssEnabled(false);
browser.getOptions().setJavaScriptEnabled(true);
browser.getOptions().setThrowExceptionOnScriptError(false);
String url = "http://oar.nstl.gov.cn/Paper/S ... 3B%3B
try {
HtmlPage htmlPage = browser.getPage(url);
browser.waitForBackgroundJavaScript(3000);
Document document = Jsoup.parse(htmlPage.asXml());
Element paper = document.getElementById("paper");
System.out.println(paper);
} catch (IOException e) {
e.printStackTrace();
}
}
}
htmlunit抓取动态网页(这是一个的最新版本是什么?一个 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-12-03 09:01
)
最近在写爬虫的时候,在使用httpclient爬取一些网页的时候出现了一些问题,就是爬取的内容收录了大量的加密文本(通过javascript脚本),无法获取到真正的内容(即即,网页是用浏览器打开的)呈现的内容)。所以一般需要配合js引擎来解决这个问题。经过搜索,我发现htmlunit工具可以提供帮助。在了解和使用的过程中,我发现这是一个非常棒的开源工具。虽然名气不如httpclient,但实力不容小觑。少说八卦。目前最新的htmlunit版本是2.15,可以从这里下载:
String url="http://xxxx.xx/";//想采集的网址
String refer="http://xxx.xx/";
URL link=new URL(url);
WebClient wc=new WebClient();
WebRequest request=new WebRequest(link);
request.setCharset("UTF-8");
request.setProxyHost("x.120.120.x");
request.setProxyPort(8080);
request.setAdditionalHeader("Referer", refer);//设置请求报文头里的refer字段
////设置请求报文头里的User-Agent字段
request.setAdditionalHeader("User-Agent", "Mozilla/5.0 (Windows NT 5.1; rv:6.0.2) Gecko/20100101 Firefox/6.0.2");
//wc.addRequestHeader("User-Agent", "Mozilla/5.0 (Windows NT 5.1; rv:6.0.2) Gecko/20100101 Firefox/6.0.2");
//wc.addRequestHeader和request.setAdditionalHeader功能应该是一样的。选择一个即可。
//其他报文头字段可以根据需要添加
wc.getCookieManager().setCookiesEnabled(true);//开启cookie管理
wc.getOptions().setJavaScriptEnabled(true);//开启js解析。对于变态网页,这个是必须的
wc.getOptions().setCssEnabled(true);//开启css解析。对于变态网页,这个是必须的。
wc.getOptions().setThrowExceptionOnFailingStatusCode(false);
wc.getOptions().setThrowExceptionOnScriptError(false);
wc.getOptions().setTimeout(10000);
//设置cookie。如果你有cookie,可以在这里设置
Set cookies=null;
Iterator i = cookies.iterator();
while (i.hasNext())
{
wc.getCookieManager().addCookie(i.next());
}
//准备工作已经做好了
HtmlPage page=null;
page = wc.getPage(request);
if(page==null)
{
System.out.println("采集 "+url+" 失败!!!");
return ;
}
String content=page.asText();//网页内容保存在content里
if(content==null)
{
System.out.println("采集 "+url+" 失败!!!");
return ;
}
//搞定了
CookieManager CM = wc.getCookieManager(); //WC = Your WebClient's name
Set cookies_ret = CM.getCookies();//返回的Cookie在这里,下次请求的时候可能可以用上啦。 查看全部
htmlunit抓取动态网页(这是一个的最新版本是什么?一个
)
最近在写爬虫的时候,在使用httpclient爬取一些网页的时候出现了一些问题,就是爬取的内容收录了大量的加密文本(通过javascript脚本),无法获取到真正的内容(即即,网页是用浏览器打开的)呈现的内容)。所以一般需要配合js引擎来解决这个问题。经过搜索,我发现htmlunit工具可以提供帮助。在了解和使用的过程中,我发现这是一个非常棒的开源工具。虽然名气不如httpclient,但实力不容小觑。少说八卦。目前最新的htmlunit版本是2.15,可以从这里下载:
String url="http://xxxx.xx/";//想采集的网址
String refer="http://xxx.xx/";
URL link=new URL(url);
WebClient wc=new WebClient();
WebRequest request=new WebRequest(link);
request.setCharset("UTF-8");
request.setProxyHost("x.120.120.x");
request.setProxyPort(8080);
request.setAdditionalHeader("Referer", refer);//设置请求报文头里的refer字段
////设置请求报文头里的User-Agent字段
request.setAdditionalHeader("User-Agent", "Mozilla/5.0 (Windows NT 5.1; rv:6.0.2) Gecko/20100101 Firefox/6.0.2");
//wc.addRequestHeader("User-Agent", "Mozilla/5.0 (Windows NT 5.1; rv:6.0.2) Gecko/20100101 Firefox/6.0.2");
//wc.addRequestHeader和request.setAdditionalHeader功能应该是一样的。选择一个即可。
//其他报文头字段可以根据需要添加
wc.getCookieManager().setCookiesEnabled(true);//开启cookie管理
wc.getOptions().setJavaScriptEnabled(true);//开启js解析。对于变态网页,这个是必须的
wc.getOptions().setCssEnabled(true);//开启css解析。对于变态网页,这个是必须的。
wc.getOptions().setThrowExceptionOnFailingStatusCode(false);
wc.getOptions().setThrowExceptionOnScriptError(false);
wc.getOptions().setTimeout(10000);
//设置cookie。如果你有cookie,可以在这里设置
Set cookies=null;
Iterator i = cookies.iterator();
while (i.hasNext())
{
wc.getCookieManager().addCookie(i.next());
}
//准备工作已经做好了
HtmlPage page=null;
page = wc.getPage(request);
if(page==null)
{
System.out.println("采集 "+url+" 失败!!!");
return ;
}
String content=page.asText();//网页内容保存在content里
if(content==null)
{
System.out.println("采集 "+url+" 失败!!!");
return ;
}
//搞定了
CookieManager CM = wc.getCookieManager(); //WC = Your WebClient's name
Set cookies_ret = CM.getCookies();//返回的Cookie在这里,下次请求的时候可能可以用上啦。
htmlunit抓取动态网页(什么是动态网站?是界面有动态效果的网站吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-12-03 08:22
什么是动态网站?界面有没有动态效果网站?还是数据是可变的网站?这两种说法都对,只是理解不同。如果界面有动态效果,以前是用FLASH实现的,现在是用HTML5实现的。前者打开速度慢,后者打开速度快,效果好。如果数据可以更改,实际上有一个后端可以更新相关数据。那么动态网站怎么做呢?
做动态网站 首先,搞清楚动态是什么意思。这两种动力并不冲突,也不能只有一种可以存在。可以是界面动态+后台动态,这样就没有问题了,完全可以实现。如果界面是动态的,可以达到什么动态效果?刚才我们提供了FLASH。FLASH就是设计你想做的所有动态元素。它实际上是一个完成的动态效果包,有点类似于视频。但是现在HTML5的动态效果不同了,可以结合文字和图片。例如,对于很多图片,我们通常会直接在图片列表中显示它们,但是HTML5可以从两侧移动,或者其他动态效果。文字动态效果可以通过移位实现上下文词的重叠,或者一个字一个字的效果,这些字是不能固定的,背景是可以改变的。这也是技术进步的好处之一,就是可以兼具美感和主观控制力,没有那么死板。另一个动态网站 区别于静态网站。这个静态的 网站 通常是一个页面,一两页。界面上的信息一般由图片组成。在后台进行相关管理。动态和静态网站的区别在于前台界面的数据是否可以在后台进行管理。另一个动态网站 区别于静态网站。这个静态的 网站 通常是一个页面,一两页。界面上的信息一般由图片组成。在后台进行相关管理。动态和静态网站的区别在于前台界面的数据是否可以在后台进行管理。另一个动态网站 区别于静态网站。这个静态的 网站 通常是一个页面,一两页。界面上的信息一般由图片组成。在后台进行相关管理。动态和静态网站的区别在于前台界面的数据是否可以在后台进行管理。
做动态网站 首先区分接口动态和数据动态。接口动态和数据动态可以同时存在。界面动态目前采用H5技术实现,可以被搜索引擎识别,是目前主流的界面实现技术。而数据动态意味着可以在后台管理数据。如果没有后台,界面上的数据,无论是图片还是文字,只能通过代码进行管理,没有相应的后台管理相关数据,那么这就是静态的。网站 up。做动态网站先搞清楚需求再建站,没有问题。 查看全部
htmlunit抓取动态网页(什么是动态网站?是界面有动态效果的网站吗?)
什么是动态网站?界面有没有动态效果网站?还是数据是可变的网站?这两种说法都对,只是理解不同。如果界面有动态效果,以前是用FLASH实现的,现在是用HTML5实现的。前者打开速度慢,后者打开速度快,效果好。如果数据可以更改,实际上有一个后端可以更新相关数据。那么动态网站怎么做呢?
做动态网站 首先,搞清楚动态是什么意思。这两种动力并不冲突,也不能只有一种可以存在。可以是界面动态+后台动态,这样就没有问题了,完全可以实现。如果界面是动态的,可以达到什么动态效果?刚才我们提供了FLASH。FLASH就是设计你想做的所有动态元素。它实际上是一个完成的动态效果包,有点类似于视频。但是现在HTML5的动态效果不同了,可以结合文字和图片。例如,对于很多图片,我们通常会直接在图片列表中显示它们,但是HTML5可以从两侧移动,或者其他动态效果。文字动态效果可以通过移位实现上下文词的重叠,或者一个字一个字的效果,这些字是不能固定的,背景是可以改变的。这也是技术进步的好处之一,就是可以兼具美感和主观控制力,没有那么死板。另一个动态网站 区别于静态网站。这个静态的 网站 通常是一个页面,一两页。界面上的信息一般由图片组成。在后台进行相关管理。动态和静态网站的区别在于前台界面的数据是否可以在后台进行管理。另一个动态网站 区别于静态网站。这个静态的 网站 通常是一个页面,一两页。界面上的信息一般由图片组成。在后台进行相关管理。动态和静态网站的区别在于前台界面的数据是否可以在后台进行管理。另一个动态网站 区别于静态网站。这个静态的 网站 通常是一个页面,一两页。界面上的信息一般由图片组成。在后台进行相关管理。动态和静态网站的区别在于前台界面的数据是否可以在后台进行管理。
做动态网站 首先区分接口动态和数据动态。接口动态和数据动态可以同时存在。界面动态目前采用H5技术实现,可以被搜索引擎识别,是目前主流的界面实现技术。而数据动态意味着可以在后台管理数据。如果没有后台,界面上的数据,无论是图片还是文字,只能通过代码进行管理,没有相应的后台管理相关数据,那么这就是静态的。网站 up。做动态网站先搞清楚需求再建站,没有问题。
htmlunit抓取动态网页(HttpClient抓取网页js生成内容的问题的侠客们。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-11-30 03:02
HttpClient抓取网页js生成内容的问题。曾经的骑士。来看看
非常感谢您来看我的问题。我要去抢京东产品的产品标题。红色部分的title后面是通过js加载的。这是不可用的。有什么办法可以好起来吗?有类似经历的同胞能指点一下吗?
- - - 解决方案 - - - - - - - - - - - - - - - - - - - - - - -------------
需要抓取ajax的内容,这个是js动态加载的httpclient无法获取
然后需要直接模拟ajax请求
我根据你的需要看了一下
需要访问标题的红色部分
添加产品地址是
获取到它的页面后,搜索 skuidkey 并获取它的值
然后访问
字符串 skuidkey = "";
String url = ""+skuidkey+"&callback=";
使用 Get 访问这个 url
它将返回类似 ({"html":"\u76F4\u964D900\u5143\uFF0C\u4EC5\u9650\u4ECA\u592914:00-18:00\u9650\u65F6\u62A2\u8D2D\u4B04Eu4E \u6279\uFF01"})
结果获得了红色部分的标题
当然,您需要将 unicode 编码的文本转换为中文。不知道怎么传到百度。
附:我写的从java版unicode转中文到C++的版本 查看全部
htmlunit抓取动态网页(HttpClient抓取网页js生成内容的问题的侠客们。)
HttpClient抓取网页js生成内容的问题。曾经的骑士。来看看
非常感谢您来看我的问题。我要去抢京东产品的产品标题。红色部分的title后面是通过js加载的。这是不可用的。有什么办法可以好起来吗?有类似经历的同胞能指点一下吗?
- - - 解决方案 - - - - - - - - - - - - - - - - - - - - - - -------------
需要抓取ajax的内容,这个是js动态加载的httpclient无法获取
然后需要直接模拟ajax请求
我根据你的需要看了一下
需要访问标题的红色部分
添加产品地址是
获取到它的页面后,搜索 skuidkey 并获取它的值
然后访问
字符串 skuidkey = "";
String url = ""+skuidkey+"&callback=";
使用 Get 访问这个 url
它将返回类似 ({"html":"\u76F4\u964D900\u5143\uFF0C\u4EC5\u9650\u4ECA\u592914:00-18:00\u9650\u65F6\u62A2\u8D2D\u4B04Eu4E \u6279\uFF01"})
结果获得了红色部分的标题
当然,您需要将 unicode 编码的文本转换为中文。不知道怎么传到百度。
附:我写的从java版unicode转中文到C++的版本
htmlunit抓取动态网页(SIMONE2012-01-12:14:11:00的html源码一并)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-11-30 02:19
我找到了一个很好的模拟浏览器包htmlunit,可以直接访问网站地址并执行相应的JavaScript脚本;这个功能对网站爬虫很有帮助,一些网站Ajax用的。如果使用简单的http访问,则只能抓取原创html源码,无法获取页面中执行的ajax;使用这个包后,可以在执行ajax后抓取html源代码。取下来。
网站地址:
网站下面也提到了几个类似的包:HtmlUnit 被不同的开源工具用作底层“浏览器”,如 Canoo WebTest、JWebUnit、WebDriver、JSFUnit、Celerity ......
看看canoo WebTest,但是不知道怎么用,也不想多了解。
jwebunit 用于 网站 测试。集成了JUnit、htmlunit、selenium封装框架;主要功能是做白盒测试和压力测试。
webDriver 后来更名为 selenium,它集成了 htmlunit、Firefox 浏览器、IE 浏览器、opare 浏览器驱动。如果使用 htmlunitDriver,则使用 htmlunit 包访问站点;如果使用FirefoxDriver,则直接调用Firefox浏览器,然后在浏览器上模拟文本输入等鼠标键盘事件。
访问htmlunit包后网站,获取html源码后可以修改源码; jwebunit和selenium暂时没有找到修改的功能,只是用来模拟用户操作。
西蒙尼 2012-01-12 14:11 查看全部
htmlunit抓取动态网页(SIMONE2012-01-12:14:11:00的html源码一并)
我找到了一个很好的模拟浏览器包htmlunit,可以直接访问网站地址并执行相应的JavaScript脚本;这个功能对网站爬虫很有帮助,一些网站Ajax用的。如果使用简单的http访问,则只能抓取原创html源码,无法获取页面中执行的ajax;使用这个包后,可以在执行ajax后抓取html源代码。取下来。
网站地址:
网站下面也提到了几个类似的包:HtmlUnit 被不同的开源工具用作底层“浏览器”,如 Canoo WebTest、JWebUnit、WebDriver、JSFUnit、Celerity ......
看看canoo WebTest,但是不知道怎么用,也不想多了解。
jwebunit 用于 网站 测试。集成了JUnit、htmlunit、selenium封装框架;主要功能是做白盒测试和压力测试。
webDriver 后来更名为 selenium,它集成了 htmlunit、Firefox 浏览器、IE 浏览器、opare 浏览器驱动。如果使用 htmlunitDriver,则使用 htmlunit 包访问站点;如果使用FirefoxDriver,则直接调用Firefox浏览器,然后在浏览器上模拟文本输入等鼠标键盘事件。
访问htmlunit包后网站,获取html源码后可以修改源码; jwebunit和selenium暂时没有找到修改的功能,只是用来模拟用户操作。
西蒙尼 2012-01-12 14:11
htmlunit抓取动态网页(基于浏览器内核来开发的动态页面渲染处理服务器(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-11-23 03:23
前言
曾几何时,从动态页面中提取信息(ajax、内部js二次渲染等)一直是爬虫开发者的心病。总之,真的没有合适的工具。尤其是在Java中,像htmlunit这样的工具可以算是解析动态页面的神器了,但是还不够完善,无法达到浏览器级别的解析效果,遇到稍微复杂一点的页面就不行了。在经历了各种痛苦和仇恨之后,作者决定开发一个动态页面渲染处理服务器,专门用于抓取、监控和测试此类场景。要实现浏览器级别的效果,必须基于浏览器内核进行开发。幸运的是,我们有开源的webkit,更幸运的是,我们有QtWebkit,这对开发人员更友好。于是 SeimiAgent 诞生了。
SeimiAgent 简介
SeimiAgent 是基于 QtWebkit 开发的可以在服务器端后台运行的 webkit 服务。它可以通过SeimiAgent提供的http接口向SeimiAgent发送加载请求(要加载的URL和该页面接受的渲染时间或使用什么代理等参数),通过SeimiAgent加载并渲染动态页面要处理,然后直接将渲染好的页面返回给调用者进行后续处理,所以运行的SeimiAgent服务是语言无关的,任何语言或框架都可以通过SeimiAgent提供标准的http接口来获取服务。SeimiAgent 的加载和渲染环境都是通用浏览器级别的,所以不用担心他处理动态页面的能力。目前,SeimiAgent 只支持返回渲染的 HTML 文档。未来将增加图片快照和PDF支持,以方便更多样化的使用需求。
使用演示
SeimiCrawler 简介
SeimiCrawler 是一个敏捷、独立部署、支持分布式Java 爬虫框架。希望最大限度地降低新手开发高可用低性能爬虫系统的门槛,提高爬虫系统的开发效率。在 SeimiCrawler 的世界里,大部分人只需要关心编写爬行的业务逻辑,剩下的 Seimi 会为你做。在设计方面,SeimiCrawler 的灵感来自于 Python 的爬虫框架 Scrapy。同时结合Java语言的特点和Spring的特点,希望在国内使用更高效的XPath来更方便、更通用的解析HTML,所以SeimiCrawler默认的HTML解析处理器是JsoupXpath(独立扩展项目) ,不收录在 jsoup 中),
集成和部署 SeimiAgent
下载和解压就不显示了,上面的动态图片里也有演示,下载地址可以在SeimiAgent主页上找到。进入SeimiAgent的bin目录,执行:
./SeimiAgent -p 8000
这就是启动SeimiAgent服务,监听8000端口。接下来其实可以用任何语言通过http请求发送加载页面的请求,然后得到渲染结果。当然,我们这里介绍的是SeimiCrawler是如何集成和使用SeimiAgent的。
SeimiCrawler 配置
SeimiCrawler 在 v0.3.0 版本中内置了对 SeimiAgent 的支持。开发者只需要配置SeimiAgent的地址和端口,然后在生成具体的Request时选择是否提交给SeimiAgent,并指定如何提交。我们直接在评论中解释最后一个完整的例子:
package cn.wanghaomiao.crawlers;
import cn.wanghaomiao.seimi.annotation.Crawler;
import cn.wanghaomiao.seimi.def.BaseSeimiCrawler;
import cn.wanghaomiao.seimi.struct.Request;
import cn.wanghaomiao.seimi.struct.Response;
import cn.wanghaomiao.xpath.model.JXDocument;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Value;
/**
* 这个例子演示如何使用SeimiAgent进行复杂动态页面信息抓取
* @author 汪浩淼 et.tw@163.com
* @since 2016/4/14.
*/
@Crawler(name = "seimiagent")
public class SeimiAgentDemo extends BaseSeimiCrawler{
/**
* 在resource/config/seimi.properties中配置方便更换,当然也可以自行根据情况使用自己的统一配置中心等服务。这里配置SeimiAgent服务所在地址。
*/
@Value("${seimiAgentHost}")
private String seimiAgentHost;
//SeimiAgent监听的端口好,如上文中的8000
@Value("${seimiAgentPort}")
private int seimiAgentPort;
@Override
public String[] startUrls() {
return new String[]{"https://www.baidu.com"};
}
@Override
public String seiAgentHost() {
return this.seimiAgentHost;
}
@Override
public int seimiAgentPort() {
return this.seimiAgentPort;
}
@Override
public void start(Response response) {
Request seimiAgentReq = Request.build("https://www.souyidai.com","getTotalTransactions")
.useSeimiAgent()
// 告诉SeimiAgent针对这个请求是否使用cookie,如果没有设置使用当前Crawler关于cookie使用条件作为默认值。
//.setSeimiAgentUseCookie(true)
// 设置全部load完成后给SeimiAgent多少时间用于执行js并渲染页面,单位为毫秒
.setSeimiAgentRenderTime(5000);
push(seimiAgentReq);
}
/**
* 获取搜易贷首页总成交额
* @param response
*/
public void getTotalTransactions(Response response){
JXDocument doc = response.document();
try {
String trans = StringUtils.join(doc.sel("//div[@class='homepage-amount']/div[@class='number font-arial']/div/span/text()"),"");
logger.info("Final Res:{}",trans);
} catch (Exception e) {
e.printStackTrace();
}
}
}
配置文件seimi.properties
seimiAgentHost=127.0.0.1
seimiAgentPort=8000
启动
public class Boot {
public static void main(String[] args){
Seimi s = new Seimi();
s.start("seimiagent");
}
}
SeimiCrawler 启动后,您可以看到您想要的搜一贷交易总额。
完整演示地址
演示 查看全部
htmlunit抓取动态网页(基于浏览器内核来开发的动态页面渲染处理服务器(组图))
前言
曾几何时,从动态页面中提取信息(ajax、内部js二次渲染等)一直是爬虫开发者的心病。总之,真的没有合适的工具。尤其是在Java中,像htmlunit这样的工具可以算是解析动态页面的神器了,但是还不够完善,无法达到浏览器级别的解析效果,遇到稍微复杂一点的页面就不行了。在经历了各种痛苦和仇恨之后,作者决定开发一个动态页面渲染处理服务器,专门用于抓取、监控和测试此类场景。要实现浏览器级别的效果,必须基于浏览器内核进行开发。幸运的是,我们有开源的webkit,更幸运的是,我们有QtWebkit,这对开发人员更友好。于是 SeimiAgent 诞生了。
SeimiAgent 简介
SeimiAgent 是基于 QtWebkit 开发的可以在服务器端后台运行的 webkit 服务。它可以通过SeimiAgent提供的http接口向SeimiAgent发送加载请求(要加载的URL和该页面接受的渲染时间或使用什么代理等参数),通过SeimiAgent加载并渲染动态页面要处理,然后直接将渲染好的页面返回给调用者进行后续处理,所以运行的SeimiAgent服务是语言无关的,任何语言或框架都可以通过SeimiAgent提供标准的http接口来获取服务。SeimiAgent 的加载和渲染环境都是通用浏览器级别的,所以不用担心他处理动态页面的能力。目前,SeimiAgent 只支持返回渲染的 HTML 文档。未来将增加图片快照和PDF支持,以方便更多样化的使用需求。
使用演示
SeimiCrawler 简介
SeimiCrawler 是一个敏捷、独立部署、支持分布式Java 爬虫框架。希望最大限度地降低新手开发高可用低性能爬虫系统的门槛,提高爬虫系统的开发效率。在 SeimiCrawler 的世界里,大部分人只需要关心编写爬行的业务逻辑,剩下的 Seimi 会为你做。在设计方面,SeimiCrawler 的灵感来自于 Python 的爬虫框架 Scrapy。同时结合Java语言的特点和Spring的特点,希望在国内使用更高效的XPath来更方便、更通用的解析HTML,所以SeimiCrawler默认的HTML解析处理器是JsoupXpath(独立扩展项目) ,不收录在 jsoup 中),
集成和部署 SeimiAgent
下载和解压就不显示了,上面的动态图片里也有演示,下载地址可以在SeimiAgent主页上找到。进入SeimiAgent的bin目录,执行:
./SeimiAgent -p 8000
这就是启动SeimiAgent服务,监听8000端口。接下来其实可以用任何语言通过http请求发送加载页面的请求,然后得到渲染结果。当然,我们这里介绍的是SeimiCrawler是如何集成和使用SeimiAgent的。
SeimiCrawler 配置
SeimiCrawler 在 v0.3.0 版本中内置了对 SeimiAgent 的支持。开发者只需要配置SeimiAgent的地址和端口,然后在生成具体的Request时选择是否提交给SeimiAgent,并指定如何提交。我们直接在评论中解释最后一个完整的例子:
package cn.wanghaomiao.crawlers;
import cn.wanghaomiao.seimi.annotation.Crawler;
import cn.wanghaomiao.seimi.def.BaseSeimiCrawler;
import cn.wanghaomiao.seimi.struct.Request;
import cn.wanghaomiao.seimi.struct.Response;
import cn.wanghaomiao.xpath.model.JXDocument;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Value;
/**
* 这个例子演示如何使用SeimiAgent进行复杂动态页面信息抓取
* @author 汪浩淼 et.tw@163.com
* @since 2016/4/14.
*/
@Crawler(name = "seimiagent")
public class SeimiAgentDemo extends BaseSeimiCrawler{
/**
* 在resource/config/seimi.properties中配置方便更换,当然也可以自行根据情况使用自己的统一配置中心等服务。这里配置SeimiAgent服务所在地址。
*/
@Value("${seimiAgentHost}")
private String seimiAgentHost;
//SeimiAgent监听的端口好,如上文中的8000
@Value("${seimiAgentPort}")
private int seimiAgentPort;
@Override
public String[] startUrls() {
return new String[]{"https://www.baidu.com"};
}
@Override
public String seiAgentHost() {
return this.seimiAgentHost;
}
@Override
public int seimiAgentPort() {
return this.seimiAgentPort;
}
@Override
public void start(Response response) {
Request seimiAgentReq = Request.build("https://www.souyidai.com","getTotalTransactions")
.useSeimiAgent()
// 告诉SeimiAgent针对这个请求是否使用cookie,如果没有设置使用当前Crawler关于cookie使用条件作为默认值。
//.setSeimiAgentUseCookie(true)
// 设置全部load完成后给SeimiAgent多少时间用于执行js并渲染页面,单位为毫秒
.setSeimiAgentRenderTime(5000);
push(seimiAgentReq);
}
/**
* 获取搜易贷首页总成交额
* @param response
*/
public void getTotalTransactions(Response response){
JXDocument doc = response.document();
try {
String trans = StringUtils.join(doc.sel("//div[@class='homepage-amount']/div[@class='number font-arial']/div/span/text()"),"");
logger.info("Final Res:{}",trans);
} catch (Exception e) {
e.printStackTrace();
}
}
}
配置文件seimi.properties
seimiAgentHost=127.0.0.1
seimiAgentPort=8000
启动
public class Boot {
public static void main(String[] args){
Seimi s = new Seimi();
s.start("seimiagent");
}
}
SeimiCrawler 启动后,您可以看到您想要的搜一贷交易总额。
完整演示地址
演示
htmlunit抓取动态网页(Java爬取博客阅读文章最多)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-22 13:16
更新,这很尴尬。这个文章博客阅读量最多文章,但也被最讨厌。
爬行思路:
所谓动态,就是可以通过请求后台动态改变对应的html页面,一开始页面并不是全部显示出来的。
大多数操作都是通过请求来完成的,一个请求,一个返回。在大多数网页中,请求往往被开发者隐藏在js代码中。
因此,爬取动态网页的思路转化为寻找对应的js代码,并执行对应的js代码,从而通过java代码动态改变页面。
而当页面能够正确显示时,我们就可以像抓取静态网页一样抓取数据了!
首先可以使用htmlunit来模拟鼠标点击事件,实现起来很简单:
/**
* 通过htmlunit来获得一些搜狗的网址。
* 通过模拟鼠标点击事件来实现
* @param key
* @return
* @throws Exception
*/
public String getNextUrl(String key){
String page = new String();
try {
WebClient webClient = new WebClient();
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
//去拿网页
HtmlPage htmlPage = webClient.getPage("http://pic.sogou.com/");
//得到表单
HtmlForm form = htmlPage.getFormByName("searchForm");
//得到提交按钮
HtmlSubmitInput button = form.getInputByValue("搜狗搜索");
//得到输入框
HtmlTextInput textField = form.getInputByName("query");
//输入内容
textField.setValueAttribute(key);
//点一下按钮
HtmlPage nextPage = button.click();
String str = nextPage.toString();
page = cutString(str);
webClient.close();
} catch (Exception e) {
e.printStackTrace();
}
return page;
}
如上图,我通过java代码将关键字填入搜索我的,然后通过getInputByValue方法获取按钮控件,最后直接button.click(),
也就是说可以模拟点击,点击后返回的http请求可以解析成htmlpage。
这个功能其实非常强大。例如,您可以使用此功能来模拟抢票,或使用点击事件和搜索相关知识将整个系统下线并保存在 html 中。
下一步就是使用强大的htmlunit来执行js代码了。
先写一个简单的jsp页面:
Insert title here
原数字
function change(value) {
document.getElementById("test").innerHTML = value;
return "hello htmlUnit";
}
从上面可以看出,jsp页面很简单,只是一个函数的变化,用来调用htmlUnit。
接下来是一个使用 htmlunit 的类。这个类支持 JavaScript 解释器,
然后将自己编写的JavaScript代码嵌入到页面中执行,执行后得到返回结果返回页面。
package com.blog.anla;
import com.gargoylesoftware.htmlunit.ScriptResult;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
public class TestMyOwnPage {
private void action() {
WebClient webClient = new WebClient();
try {
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true); // 设置支持JavaScript。
// 去拿网页
HtmlPage htmlPage = webClient
.getPage("http://localhost:8989/testHtmlScrop/index.jsp");
String s = "更改后的数字";
ScriptResult t = htmlPage.executeJavaScript("change(\"" + s
+ "\");", "injected script", 500);
// 这里是在500行插入这一小行JavaScript代码段,因为如果在默认的1行,那不会有结果
// 因为js是顺序执行的,当你执行第一行js代码时,可能还没有渲染body里面的标签。
HtmlPage myPage = (HtmlPage) t.getNewPage();
String nextPage = myPage.asXml().toString();
String nextPage2 = myPage.asText().toString();
} catch (Exception e) {
e.printStackTrace();
} finally {
webClient.close();
}
}
public static void main(String[] args) {
TestMyOwnPage tmop = new TestMyOwnPage();
tmop.action();
}
}
t.getNewPage() 中有两个属性,一个是
javaScriptResult:执行代码后返回的结果,如果有(如我上面写的,返回hello htmlunit),如果没有(返回Undefined)。
newPage_:执行这段代码后返回的整个页面。
结果如图:
这段代码执行的最终结果如下:
asXml():将整个页面的html代码返回给我们:
而asText()只返回页面上可以显示的值,即head标签和label标签:
这种执行思路也可以动态的执行对应的js代码,从而抓取到需要的数据。
-------------------------------------------------- -------------------------------------- 2017 年 7 月更新------- ------------------------------------------------- - ----------------------------------------------
这两天一直在研究一个关于网络爬虫的系统
但是第一次爬的时候就发现了这个问题,js的动态页面爬不下来。
网上找了很多方法,google也问了,主要是指htmlunit,下面是核心代码,
使用htmlunit的主要目的是模拟浏览器操作,因为有些链接点击无法通过src直接获取url,通常使用JavaScript
简单拼接后的URL,这样一来,相比之下,直接用htmlunit模拟浏览器点击就简单多了。
WebClient webClient = new WebClient();
webClient.getOptions().setJavaScriptEnabled(true); //启用JS解释器,默认为true
webClient.getOptions().setCssEnabled(false); //禁用css支持
webClient.getOptions().setThrowExceptionOnScriptError(false); //js运行错误时,是否抛出异常
webClient.getOptions().setTimeout(20000);
HtmlPage page = wc.getPage("http://www.hao123.com");
//我认为这个最重要
String pageXml = page.asXml(); //以xml的形式获取响应文本
/**jsoup解析文档*/
Document doc = Jsoup.parse(pageXml, "http://cq.qq.com");
这个时候,就可以得到jsoup中的document对象了,接下来就好写了,就像爬普通静态网页一样了。
不过,webclient解析是还是会出现一些问题,js的问题,
主要是由于目标url的js写的有些问题,但在实际的浏览器中却会忽略,eclipse中会报异常。
今天看到的时候,很多人都踩到了。也许他们当时没有认真写博客。如果想找java爬虫项目可以到我的专栏。
图片搜索包括使用jsoup抓取图片,lire来索引和搜索图片。
给玫瑰手留下余香。有什么问题可以多多讨论哦! 查看全部
htmlunit抓取动态网页(Java爬取博客阅读文章最多)
更新,这很尴尬。这个文章博客阅读量最多文章,但也被最讨厌。
爬行思路:
所谓动态,就是可以通过请求后台动态改变对应的html页面,一开始页面并不是全部显示出来的。
大多数操作都是通过请求来完成的,一个请求,一个返回。在大多数网页中,请求往往被开发者隐藏在js代码中。
因此,爬取动态网页的思路转化为寻找对应的js代码,并执行对应的js代码,从而通过java代码动态改变页面。
而当页面能够正确显示时,我们就可以像抓取静态网页一样抓取数据了!
首先可以使用htmlunit来模拟鼠标点击事件,实现起来很简单:
/**
* 通过htmlunit来获得一些搜狗的网址。
* 通过模拟鼠标点击事件来实现
* @param key
* @return
* @throws Exception
*/
public String getNextUrl(String key){
String page = new String();
try {
WebClient webClient = new WebClient();
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
//去拿网页
HtmlPage htmlPage = webClient.getPage("http://pic.sogou.com/";);
//得到表单
HtmlForm form = htmlPage.getFormByName("searchForm");
//得到提交按钮
HtmlSubmitInput button = form.getInputByValue("搜狗搜索");
//得到输入框
HtmlTextInput textField = form.getInputByName("query");
//输入内容
textField.setValueAttribute(key);
//点一下按钮
HtmlPage nextPage = button.click();
String str = nextPage.toString();
page = cutString(str);
webClient.close();
} catch (Exception e) {
e.printStackTrace();
}
return page;
}
如上图,我通过java代码将关键字填入搜索我的,然后通过getInputByValue方法获取按钮控件,最后直接button.click(),
也就是说可以模拟点击,点击后返回的http请求可以解析成htmlpage。
这个功能其实非常强大。例如,您可以使用此功能来模拟抢票,或使用点击事件和搜索相关知识将整个系统下线并保存在 html 中。
下一步就是使用强大的htmlunit来执行js代码了。
先写一个简单的jsp页面:
Insert title here
原数字
function change(value) {
document.getElementById("test").innerHTML = value;
return "hello htmlUnit";
}
从上面可以看出,jsp页面很简单,只是一个函数的变化,用来调用htmlUnit。
接下来是一个使用 htmlunit 的类。这个类支持 JavaScript 解释器,
然后将自己编写的JavaScript代码嵌入到页面中执行,执行后得到返回结果返回页面。
package com.blog.anla;
import com.gargoylesoftware.htmlunit.ScriptResult;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
public class TestMyOwnPage {
private void action() {
WebClient webClient = new WebClient();
try {
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true); // 设置支持JavaScript。
// 去拿网页
HtmlPage htmlPage = webClient
.getPage("http://localhost:8989/testHtmlScrop/index.jsp";);
String s = "更改后的数字";
ScriptResult t = htmlPage.executeJavaScript("change(\"" + s
+ "\");", "injected script", 500);
// 这里是在500行插入这一小行JavaScript代码段,因为如果在默认的1行,那不会有结果
// 因为js是顺序执行的,当你执行第一行js代码时,可能还没有渲染body里面的标签。
HtmlPage myPage = (HtmlPage) t.getNewPage();
String nextPage = myPage.asXml().toString();
String nextPage2 = myPage.asText().toString();
} catch (Exception e) {
e.printStackTrace();
} finally {
webClient.close();
}
}
public static void main(String[] args) {
TestMyOwnPage tmop = new TestMyOwnPage();
tmop.action();
}
}
t.getNewPage() 中有两个属性,一个是
javaScriptResult:执行代码后返回的结果,如果有(如我上面写的,返回hello htmlunit),如果没有(返回Undefined)。
newPage_:执行这段代码后返回的整个页面。
结果如图:
这段代码执行的最终结果如下:
asXml():将整个页面的html代码返回给我们:
而asText()只返回页面上可以显示的值,即head标签和label标签:
这种执行思路也可以动态的执行对应的js代码,从而抓取到需要的数据。
-------------------------------------------------- -------------------------------------- 2017 年 7 月更新------- ------------------------------------------------- - ----------------------------------------------
这两天一直在研究一个关于网络爬虫的系统
但是第一次爬的时候就发现了这个问题,js的动态页面爬不下来。
网上找了很多方法,google也问了,主要是指htmlunit,下面是核心代码,
使用htmlunit的主要目的是模拟浏览器操作,因为有些链接点击无法通过src直接获取url,通常使用JavaScript
简单拼接后的URL,这样一来,相比之下,直接用htmlunit模拟浏览器点击就简单多了。
WebClient webClient = new WebClient();
webClient.getOptions().setJavaScriptEnabled(true); //启用JS解释器,默认为true
webClient.getOptions().setCssEnabled(false); //禁用css支持
webClient.getOptions().setThrowExceptionOnScriptError(false); //js运行错误时,是否抛出异常
webClient.getOptions().setTimeout(20000);
HtmlPage page = wc.getPage("http://www.hao123.com";);
//我认为这个最重要
String pageXml = page.asXml(); //以xml的形式获取响应文本
/**jsoup解析文档*/
Document doc = Jsoup.parse(pageXml, "http://cq.qq.com";);
这个时候,就可以得到jsoup中的document对象了,接下来就好写了,就像爬普通静态网页一样了。
不过,webclient解析是还是会出现一些问题,js的问题,
主要是由于目标url的js写的有些问题,但在实际的浏览器中却会忽略,eclipse中会报异常。
今天看到的时候,很多人都踩到了。也许他们当时没有认真写博客。如果想找java爬虫项目可以到我的专栏。
图片搜索包括使用jsoup抓取图片,lire来索引和搜索图片。
给玫瑰手留下余香。有什么问题可以多多讨论哦!
htmlunit抓取动态网页(HtmlUnit在多线程环境下怎么使用才能避免网页抓取失败的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-21 13:03
如何在多线程环境下使用HtmlUnit避免网页爬取失败的问题。我们来谈谈这个问题的解决方案。
这个问题的原因其实很简单。例如,线程 A 正在使用 WebClient 对象来获取网页。在整个抓取过程结束之前,当前线程被 CPU 挂起,所以线程 B 被激活,然后 B 使用 A 使用的 WebClient 对象正在做其他网页抓取工作,那么此时 WebCLient 对象将清除未完成的工作留下的数据,等等,共享一个WebClient的线程越多,出现问题的频率就越高。丢失网页的概率更高。但其实这个问题并不难解决,它的解决方案也有广泛的适用性:不管是什么对象,在多线程环境中遇到资源共享问题时,通常有两种解决方案,一种是使用对于 JDK1.2 之后的 ThreadLocal 对象,
早在JDK1.2 版本中就提供的java.lang.ThreadLocal 和ThreadLocal 为解决多线程程序的并发问题提供了新思路。使用这个工具类可以写得非常简洁漂亮。多线程程序。其原理是为每个线程保存一个局部变量的副本,以确保该变量不会与其他线程共享——这是一种保守但有效的方法。本文不是要介绍ThreadLocal的用法(具体用法请参考百度百科),而是要使用ThreadLocal解决多线程环境下HtmlUnit的WebClient对象的共享问题。
请看如何使用ThreadLocal对象解决以上问题:
package cn.ysh.studio.crawler.htmlunit;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.WebClient;/**
*
* @author Shenghany
* @date 2013-5-27
*/publicclassThreadLocalClientFactory{
//单例工厂模式privatefinalstaticThreadLocalClientFactory instance =newThreadLocalClientFactory();//线程的本地实例存储器,用于存储WebClient实例privateThreadLocal clientThreadLocal;/**
* 构造方法,初始时线程的本地变量存储器
*/publicThreadLocalClientFactory(){
clientThreadLocal =newThreadLocal();}/**
* 获取工厂实例
* @return 工厂实例
*/publicstaticThreadLocalClientFactory getInstance(){
return instance;}/**
* 获取一个模拟FireFox3.6版本的WebClient实例
* @return 模拟FireFox3.6版本的WebClient实例
*/publicWebClient getClient(){
WebClient client =null;/**
* 如果当前线程已有WebClient实例,则直接返回该实例
* 否则重新创建一个WebClient实例并存储于当前线程的本地变量存储器
*/if((client = clientThreadLocal.get())==null){
client =newWebClient(BrowserVersion.FIREFOX_3_6);
client.setCssEnabled(false);
client.setJavaScriptEnabled(false);
clientThreadLocal.set(client);System.out.println("为线程 [ "+Thread.currentThread().getName()+" ] 创建新的WebClient实例!");}else{
System.out.println("线程 [ "+Thread.currentThread().getName()+" ] 已有WebClient实例,直接使用. . .");}return client;}}
测试代码:
<p>package cn.ysh.studio.crawler.htmlunit;import com.gargoylesoftware.htmlunit.WebClient;import com.gargoylesoftware.htmlunit.html.HtmlPage;/**
*
* @author Shenghany
* @date 2013-5-27
*/publicclassThreadLocalHtmlUnitTester{
/**
* 获取目标页面,并打印网页标题
* @param url 目标页面地址
*/publicstaticvoid getPage(String url){
//从工厂中获取一个WebClient实例WebClient client =ThreadLocalClientFactory.getInstance().getClient();try{
//抓取网页HtmlPage page =(HtmlPage)client.getPage(url);//打印当前线程名称及网页标题System.out.println(Thread.currentThread().getName()+" [ "+ url +" ] : "+ page.getTitleText());}catch(Exception e){
e.printStackTrace();}}/**
* 测试程序执行入口
* @param s
*/publicstaticvoid main(String[] s){
//文章编号int postId =50;//目标网页的部分内容String http ="http://www.yshjava.cn/post/4";/**
* 共16篇文章,每个线程抓取两篇,共计将产生8个线程
*/for(int i = postId; i 查看全部
htmlunit抓取动态网页(HtmlUnit在多线程环境下怎么使用才能避免网页抓取失败的问题)
如何在多线程环境下使用HtmlUnit避免网页爬取失败的问题。我们来谈谈这个问题的解决方案。
这个问题的原因其实很简单。例如,线程 A 正在使用 WebClient 对象来获取网页。在整个抓取过程结束之前,当前线程被 CPU 挂起,所以线程 B 被激活,然后 B 使用 A 使用的 WebClient 对象正在做其他网页抓取工作,那么此时 WebCLient 对象将清除未完成的工作留下的数据,等等,共享一个WebClient的线程越多,出现问题的频率就越高。丢失网页的概率更高。但其实这个问题并不难解决,它的解决方案也有广泛的适用性:不管是什么对象,在多线程环境中遇到资源共享问题时,通常有两种解决方案,一种是使用对于 JDK1.2 之后的 ThreadLocal 对象,
早在JDK1.2 版本中就提供的java.lang.ThreadLocal 和ThreadLocal 为解决多线程程序的并发问题提供了新思路。使用这个工具类可以写得非常简洁漂亮。多线程程序。其原理是为每个线程保存一个局部变量的副本,以确保该变量不会与其他线程共享——这是一种保守但有效的方法。本文不是要介绍ThreadLocal的用法(具体用法请参考百度百科),而是要使用ThreadLocal解决多线程环境下HtmlUnit的WebClient对象的共享问题。
请看如何使用ThreadLocal对象解决以上问题:
package cn.ysh.studio.crawler.htmlunit;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.WebClient;/**
*
* @author Shenghany
* @date 2013-5-27
*/publicclassThreadLocalClientFactory{
//单例工厂模式privatefinalstaticThreadLocalClientFactory instance =newThreadLocalClientFactory();//线程的本地实例存储器,用于存储WebClient实例privateThreadLocal clientThreadLocal;/**
* 构造方法,初始时线程的本地变量存储器
*/publicThreadLocalClientFactory(){
clientThreadLocal =newThreadLocal();}/**
* 获取工厂实例
* @return 工厂实例
*/publicstaticThreadLocalClientFactory getInstance(){
return instance;}/**
* 获取一个模拟FireFox3.6版本的WebClient实例
* @return 模拟FireFox3.6版本的WebClient实例
*/publicWebClient getClient(){
WebClient client =null;/**
* 如果当前线程已有WebClient实例,则直接返回该实例
* 否则重新创建一个WebClient实例并存储于当前线程的本地变量存储器
*/if((client = clientThreadLocal.get())==null){
client =newWebClient(BrowserVersion.FIREFOX_3_6);
client.setCssEnabled(false);
client.setJavaScriptEnabled(false);
clientThreadLocal.set(client);System.out.println("为线程 [ "+Thread.currentThread().getName()+" ] 创建新的WebClient实例!");}else{
System.out.println("线程 [ "+Thread.currentThread().getName()+" ] 已有WebClient实例,直接使用. . .");}return client;}}
测试代码:
<p>package cn.ysh.studio.crawler.htmlunit;import com.gargoylesoftware.htmlunit.WebClient;import com.gargoylesoftware.htmlunit.html.HtmlPage;/**
*
* @author Shenghany
* @date 2013-5-27
*/publicclassThreadLocalHtmlUnitTester{
/**
* 获取目标页面,并打印网页标题
* @param url 目标页面地址
*/publicstaticvoid getPage(String url){
//从工厂中获取一个WebClient实例WebClient client =ThreadLocalClientFactory.getInstance().getClient();try{
//抓取网页HtmlPage page =(HtmlPage)client.getPage(url);//打印当前线程名称及网页标题System.out.println(Thread.currentThread().getName()+" [ "+ url +" ] : "+ page.getTitleText());}catch(Exception e){
e.printStackTrace();}}/**
* 测试程序执行入口
* @param s
*/publicstaticvoid main(String[] s){
//文章编号int postId =50;//目标网页的部分内容String http ="http://www.yshjava.cn/post/4";/**
* 共16篇文章,每个线程抓取两篇,共计将产生8个线程
*/for(int i = postId; i
htmlunit抓取动态网页(习近平出席上合成员国元首理事会会议会议)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-11-18 21:10
一、HtmlUnit 介绍
HtmlUnit 是一个开源的网络分析工具。它模仿浏览器的操作,可用于网络爬虫。它的优点是:
1、模仿浏览器操作,可以点击相关网页操作;
2、支持css、js操作;
3、有对应的文档解析方法;
缺点:
1、速度慢,需要进行页面渲染等各种操作;
2、对jquery等的支持不理想;
二、例子
1、添加maven依赖
net.sourceforge.htmlunit htmlunit 2.24
2、代码示例
public class HtmlUnitCrawlerMain { public static void main(String[] args) throws Exception { htmlunitCrawler(); } static void htmlunitCrawler() throws Exception { String url = "http://www.ifeng.com/"; WebClient webClient = new WebClient(BrowserVersion.CHROME); WebClientOptions options = webClient.getOptions(); options.setTimeout(5000); options.setThrowExceptionOnScriptError(false); options.setCssEnabled(false); HtmlPage page = webClient.getPage(url); List eles = (List) page.getByXPath("//*[@id=\"headLineDefault\"]/h1/a"); if(Objects.nonNull(eles) && eles.size()>0){ String result = eles.get(0).asText(); System.out.println("ifeng headline is : " + result); } }}
运行结果:
ifeng 标题是:习近平出席上海合作组织成员国元首理事会会议 查看全部
htmlunit抓取动态网页(习近平出席上合成员国元首理事会会议会议)
一、HtmlUnit 介绍
HtmlUnit 是一个开源的网络分析工具。它模仿浏览器的操作,可用于网络爬虫。它的优点是:
1、模仿浏览器操作,可以点击相关网页操作;
2、支持css、js操作;
3、有对应的文档解析方法;
缺点:
1、速度慢,需要进行页面渲染等各种操作;
2、对jquery等的支持不理想;
二、例子
1、添加maven依赖
net.sourceforge.htmlunit htmlunit 2.24
2、代码示例
public class HtmlUnitCrawlerMain { public static void main(String[] args) throws Exception { htmlunitCrawler(); } static void htmlunitCrawler() throws Exception { String url = "http://www.ifeng.com/"; WebClient webClient = new WebClient(BrowserVersion.CHROME); WebClientOptions options = webClient.getOptions(); options.setTimeout(5000); options.setThrowExceptionOnScriptError(false); options.setCssEnabled(false); HtmlPage page = webClient.getPage(url); List eles = (List) page.getByXPath("//*[@id=\"headLineDefault\"]/h1/a"); if(Objects.nonNull(eles) && eles.size()>0){ String result = eles.get(0).asText(); System.out.println("ifeng headline is : " + result); } }}
运行结果:
ifeng 标题是:习近平出席上海合作组织成员国元首理事会会议
htmlunit抓取动态网页(jsoup的简单使用方法-htmlunit的使用教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-16 02:15
jsoup 只能解析静态 html 页面。如果页面是js动态生成的,jsoup将无法启动。使用htmlunit获取js运行后的页面,还可以模拟浏览器点击页面上的元素,非常强大,本文介绍htmlunit的简单使用。步骤如下:
1、引入依赖
net.sourceforge.htmlunit
htmlunit
2.36.0
org.jsoup
jsoup
1.12.1
2、我们爬取我们绘制的页面,首先绘制一个简单的页面,页面中content的id的div的原创内容是hello,页面加载后内容变成
HtmlUnit 太强大了
,访问此页面查看结果
Title
HtmlUnit简单使用
hello
document.getElementById("content").innerHTML = "HtmlUnit好强大";
3、写测试类,先用jsoup直接爬取,看内容里面的内容是什么,我们打印出来,可以看到是hello
@Test
public void testJsoup() throws IOException {
Document document = Jsoup.connect("http://localhost:8080/index.html").get();
System.out.println(document.getElementById("content").html());
}
4、用htmlunit看看效果
@Test
public void test() {
final WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
HtmlPage page = null;
try {
page = webClient.getPage("http://localhost:8080/index.html");
} catch (Exception e) {
e.printStackTrace();
}finally {
webClient.close();
}
webClient.waitForBackgroundJavaScript(30000);
String pageXml = page.asXml();
Document document = Jsoup.parse(pageXml);//获取html文档
System.out.println(document.getElementById("content").html());
}
可以看到js运行后的内容,与浏览器看到的结果一致 查看全部
htmlunit抓取动态网页(jsoup的简单使用方法-htmlunit的使用教程)
jsoup 只能解析静态 html 页面。如果页面是js动态生成的,jsoup将无法启动。使用htmlunit获取js运行后的页面,还可以模拟浏览器点击页面上的元素,非常强大,本文介绍htmlunit的简单使用。步骤如下:
1、引入依赖
net.sourceforge.htmlunit
htmlunit
2.36.0
org.jsoup
jsoup
1.12.1
2、我们爬取我们绘制的页面,首先绘制一个简单的页面,页面中content的id的div的原创内容是hello,页面加载后内容变成
HtmlUnit 太强大了
,访问此页面查看结果
Title
HtmlUnit简单使用
hello
document.getElementById("content").innerHTML = "HtmlUnit好强大";
3、写测试类,先用jsoup直接爬取,看内容里面的内容是什么,我们打印出来,可以看到是hello
@Test
public void testJsoup() throws IOException {
Document document = Jsoup.connect("http://localhost:8080/index.html";).get();
System.out.println(document.getElementById("content").html());
}
4、用htmlunit看看效果
@Test
public void test() {
final WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
HtmlPage page = null;
try {
page = webClient.getPage("http://localhost:8080/index.html";);
} catch (Exception e) {
e.printStackTrace();
}finally {
webClient.close();
}
webClient.waitForBackgroundJavaScript(30000);
String pageXml = page.asXml();
Document document = Jsoup.parse(pageXml);//获取html文档
System.out.println(document.getElementById("content").html());
}
可以看到js运行后的内容,与浏览器看到的结果一致
htmlunit抓取动态网页( JSoup依赖:2、使用模拟浏览器方式获取动态页面使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-11-15 12:12
JSoup依赖:2、使用模拟浏览器方式获取动态页面使用)
<br /> <br /> org.apache.httpcomponents<br /> httpclient<br /> 4.5.2<br /> <br />
JSoup 取决于:
<br /> <br /> <br /> org.jsoup<br /> jsoup<br /> 1.10.3<br /> <br />
<br />[color=red]<br />此处需要特别强调,对于很多网站,对爬虫都有一定的防范,因此在获取页面时,必须要补齐浏览器信息,否则很容易会导致被封IP!<br />[/color]<br />
2、使用模拟浏览器方式获取动态页面
使用模拟浏览器真的很无奈,因为这种方法确实很慢,但是对于异步加载内容的网页来说特别有效。只有在发现无法直接通过Http拉取页面获取元素值时,才能使用此方法。
HtmlUnit 获取网页:
<br /> /**<br /> * 通过模拟浏览器的方式下载完整页面。<br /> * <br /> * @param url<br /> * @return<br /> * @throws FailingHttpStatusCodeException<br /> * @throws IOException<br /> */<br /> public static String downloadHtml(String url, int timeout)<br /> throws FailingHttpStatusCodeException, IOException {<br /> try (final WebClient webClient = new WebClient(BrowserVersion.CHROME)) {<br /> webClient.getOptions().setJavaScriptEnabled(true);<br /> webClient.getOptions().setCssEnabled(false);<br /> webClient.getOptions().setRedirectEnabled(true);<br /> webClient.getOptions().setThrowExceptionOnScriptError(false);<br /> webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);<br /><br /> webClient<br /> .setAjaxController(new NicelyResynchronizingAjaxController());<br /> webClient.getOptions().setTimeout(timeout);<br /><br /> WebRequest webRequest = new WebRequest(new URL(url));<br /> webRequest.setHttpMethod(HttpMethod.GET);<br /> final HtmlPage page = webClient.getPage(webRequest);<br /> webClient.waitForBackgroundJavaScriptStartingBefore(500);<br /> webClient.waitForBackgroundJavaScript(20000);<br /><br /> final String pageAsXml = page.asXml();<br /><br /> return pageAsXml;<br /> }<br /> }<br />
HtmlUnit 取决于:
<br /> <br /> net.sourceforge.htmlunit<br /> htmlunit<br /> 2.30<br /> <br />
常见问题二:如何避免IP被封
处理方法比较简单,就是不使用并发,或者长时间连续抓取网站的内容。爬行时最好保持一定的时间间隔。根据我爬不同网站的经验,每3-5秒获取一个网页是最安全的。有些网站的IP一旦被封,可能需要一周左右的时间才能解锁,所以对于有固定外网IP的用户来说,在进行大规模爬取之前一定要注意这个限制。
以下爬取代码供参考:
<br /> /*<br /> * (non-Javadoc)<br /> * <br /> * @see<br /> * com.hna.tech.spider.service.SpiderService#setPageArticleDetail(java.lang<br /> * .String)<br /> */<br /> public List setPageArticleDetail(<br /> List pageList) throws IOException,<br /> InterruptedException {<br /> for (Map item : pageList) {<br />[color=red]<br /> // 最小延迟3秒,少于3秒将可能被封IP<br /> Thread.sleep(3000);<br />[/color]<br /> String articleUrl = item.get(KEY_LINK);<br /> Document doc = getArticleDocument(articleUrl);<br /><br /> String articleHtml = getArticleContentHtml(doc);<br /> item.put(KEY_CONTENT_HTML, articleHtml);<br /><br /> String articleContent = getArticleContent(doc);<br /> item.put(KEY_CONTENT, articleContent);<br /> }<br /><br /> return pageList;<br /> }<br />
那么如何提高爬取效率呢?一般网站无论是DDOS攻击还是恶意网页扫描都会根据Session和IP加锁,所以问题很简单。请求通过多个线程发起,保证每个Session请求的时间间隔。另外,不要太并发,只要不对网站造成压力,IP一般不会被阻塞。
常见问题三:元素选择问题
获取元素的方式有很多种,可以通过ID、CSS样式、元素类型(比如
) 等根据个人喜好,通常可以获取元素的内容,例如文章标题,文章正文等。
下面分享我个人使用JSoup获取页面元素内容的一些经验。
1、 分步获取
即先获取顶级节点,比如文章的内容的顶级节点,然后先获取第一个顶级节点,再通过获取低级节点的内容JSoup,避免在有多个节点时获取访问的内容超出预期。
2、CSS 样式的选择
当有多个类样式时,例如:
...
, 使用JSoup选择:
<br />doc.select("div.css1.css2")<br />
使用点将它们连接在一起。 查看全部
htmlunit抓取动态网页(
JSoup依赖:2、使用模拟浏览器方式获取动态页面使用)
<br /> <br /> org.apache.httpcomponents<br /> httpclient<br /> 4.5.2<br /> <br />
JSoup 取决于:
<br /> <br /> <br /> org.jsoup<br /> jsoup<br /> 1.10.3<br /> <br />
<br />[color=red]<br />此处需要特别强调,对于很多网站,对爬虫都有一定的防范,因此在获取页面时,必须要补齐浏览器信息,否则很容易会导致被封IP!<br />[/color]<br />
2、使用模拟浏览器方式获取动态页面
使用模拟浏览器真的很无奈,因为这种方法确实很慢,但是对于异步加载内容的网页来说特别有效。只有在发现无法直接通过Http拉取页面获取元素值时,才能使用此方法。
HtmlUnit 获取网页:
<br /> /**<br /> * 通过模拟浏览器的方式下载完整页面。<br /> * <br /> * @param url<br /> * @return<br /> * @throws FailingHttpStatusCodeException<br /> * @throws IOException<br /> */<br /> public static String downloadHtml(String url, int timeout)<br /> throws FailingHttpStatusCodeException, IOException {<br /> try (final WebClient webClient = new WebClient(BrowserVersion.CHROME)) {<br /> webClient.getOptions().setJavaScriptEnabled(true);<br /> webClient.getOptions().setCssEnabled(false);<br /> webClient.getOptions().setRedirectEnabled(true);<br /> webClient.getOptions().setThrowExceptionOnScriptError(false);<br /> webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);<br /><br /> webClient<br /> .setAjaxController(new NicelyResynchronizingAjaxController());<br /> webClient.getOptions().setTimeout(timeout);<br /><br /> WebRequest webRequest = new WebRequest(new URL(url));<br /> webRequest.setHttpMethod(HttpMethod.GET);<br /> final HtmlPage page = webClient.getPage(webRequest);<br /> webClient.waitForBackgroundJavaScriptStartingBefore(500);<br /> webClient.waitForBackgroundJavaScript(20000);<br /><br /> final String pageAsXml = page.asXml();<br /><br /> return pageAsXml;<br /> }<br /> }<br />
HtmlUnit 取决于:
<br /> <br /> net.sourceforge.htmlunit<br /> htmlunit<br /> 2.30<br /> <br />
常见问题二:如何避免IP被封
处理方法比较简单,就是不使用并发,或者长时间连续抓取网站的内容。爬行时最好保持一定的时间间隔。根据我爬不同网站的经验,每3-5秒获取一个网页是最安全的。有些网站的IP一旦被封,可能需要一周左右的时间才能解锁,所以对于有固定外网IP的用户来说,在进行大规模爬取之前一定要注意这个限制。
以下爬取代码供参考:
<br /> /*<br /> * (non-Javadoc)<br /> * <br /> * @see<br /> * com.hna.tech.spider.service.SpiderService#setPageArticleDetail(java.lang<br /> * .String)<br /> */<br /> public List setPageArticleDetail(<br /> List pageList) throws IOException,<br /> InterruptedException {<br /> for (Map item : pageList) {<br />[color=red]<br /> // 最小延迟3秒,少于3秒将可能被封IP<br /> Thread.sleep(3000);<br />[/color]<br /> String articleUrl = item.get(KEY_LINK);<br /> Document doc = getArticleDocument(articleUrl);<br /><br /> String articleHtml = getArticleContentHtml(doc);<br /> item.put(KEY_CONTENT_HTML, articleHtml);<br /><br /> String articleContent = getArticleContent(doc);<br /> item.put(KEY_CONTENT, articleContent);<br /> }<br /><br /> return pageList;<br /> }<br />
那么如何提高爬取效率呢?一般网站无论是DDOS攻击还是恶意网页扫描都会根据Session和IP加锁,所以问题很简单。请求通过多个线程发起,保证每个Session请求的时间间隔。另外,不要太并发,只要不对网站造成压力,IP一般不会被阻塞。
常见问题三:元素选择问题
获取元素的方式有很多种,可以通过ID、CSS样式、元素类型(比如
) 等根据个人喜好,通常可以获取元素的内容,例如文章标题,文章正文等。
下面分享我个人使用JSoup获取页面元素内容的一些经验。
1、 分步获取
即先获取顶级节点,比如文章的内容的顶级节点,然后先获取第一个顶级节点,再通过获取低级节点的内容JSoup,避免在有多个节点时获取访问的内容超出预期。
2、CSS 样式的选择
当有多个类样式时,例如:
...
, 使用JSoup选择:
<br />doc.select("div.css1.css2")<br />
使用点将它们连接在一起。
htmlunit抓取动态网页(何为Ajax动态网页,我想不用我多说了吧 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 266 次浏览 • 2021-11-15 12:10
)
什么是 Ajax 动态网页?我想我不需要多说了。如果你连 Ajax 是什么都不知道,那么你应该先去谷歌学习 Ajax。为形象起见,这里以抓取本网页为例进行说明。网页链接如下:
很明显,我们要爬取的数据是
打开谷歌浏览器的开发者工具,我们会发现其实是Ajax动态加载的,通过jsonp跨域方法返回的。分析如图:
由此可以推断,部分分页信息是通过javaScript动态插入到DOM中的。如果单纯使用HttpClient之类的工具来模拟Http请求获取网页信息,你得到的网页内容是不完整的。HtmlUnit 可以做到。
OK,回到正题,也许你是第一次听说HtmlUnit,也许你很久以前就听说过它,但我仍然认为官方的解释是最权威的,我不会盲目的。看图:
总之一句话,HtmlUnit其实就是一个方便测试人员进行功能测试的测试工具。可以模拟谷歌Chrome、火狐、Internet Explorer等常见主流浏览器的行为。废话不多说,直接上demo:
/**
* 上海证券交易所数据抓取测试
* @since 1.0
* @author Lanxiaowei@citic-finance.com
* @date 2015-8-27下午6:16:14
*
*/
public class ShangHaiStockTest {
public static void main(String[] args) throws Exception {
downloadListPage();
}
public static void downloadListPage() throws Exception {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_38);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setAppletEnabled(false);
webClient.getOptions().setRedirectEnabled(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setUseInsecureSSL(false);
webClient.getOptions().setTimeout(10000000);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
int totalPage = 22;
boolean first = true;
HtmlPage page = null;
do {
if(first) {
page = (HtmlPage)webClient.getPage("http://www.sse.com.cn/assortme ... 6quot;);
FileUtils.writeFile(page.asXml(), "C:/shh/list/" + totalPage + ".html", "UTF-8", false);
first = false;
} else {
HtmlAnchor anchor = null;
if(totalPage == 22 -1) {
anchor = (HtmlAnchor) page.getHtmlElementById("xsgf_next");
} else {
anchor = (HtmlAnchor) page.getHtmlElementById("dateList_container_next");
}
page = (HtmlPage) anchor.click();
FileUtils.writeFile(page.asXml(), "C:/shh/list/" + totalPage + ".html", "UTF-8", false);
}
totalPage--;
} while(totalPage > 0);
//关闭模拟窗口
webClient.closeAllWindows();
}
}
重点:
1.webClient.getOptions().setJavaScriptEnabled(true);
启用 JavaScript
2.webClient.setAjaxController(new NicelyResynchronizingAjaxController());
设置 Ajax 异步处理控制器以启用 Ajax 支持
3.webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
这两句话非常重要。前者表示当发生Http错误时,程序不会抛出异常继续执行,后者表示在JavaScript执行中发生异常时,将被忽略,否则Java代码会直接抛出异常,程序将被中断。
演示代码演示了如何使用代码模拟点击“下一页”超链接进行分页,获取每个页面的网页内容,然后写入磁盘指定目录。程序很简单,希望能有个好的开始。程序依赖的jar包如图:
查看全部
htmlunit抓取动态网页(何为Ajax动态网页,我想不用我多说了吧
)
什么是 Ajax 动态网页?我想我不需要多说了。如果你连 Ajax 是什么都不知道,那么你应该先去谷歌学习 Ajax。为形象起见,这里以抓取本网页为例进行说明。网页链接如下:
很明显,我们要爬取的数据是
打开谷歌浏览器的开发者工具,我们会发现其实是Ajax动态加载的,通过jsonp跨域方法返回的。分析如图:
由此可以推断,部分分页信息是通过javaScript动态插入到DOM中的。如果单纯使用HttpClient之类的工具来模拟Http请求获取网页信息,你得到的网页内容是不完整的。HtmlUnit 可以做到。
OK,回到正题,也许你是第一次听说HtmlUnit,也许你很久以前就听说过它,但我仍然认为官方的解释是最权威的,我不会盲目的。看图:
总之一句话,HtmlUnit其实就是一个方便测试人员进行功能测试的测试工具。可以模拟谷歌Chrome、火狐、Internet Explorer等常见主流浏览器的行为。废话不多说,直接上demo:
/**
* 上海证券交易所数据抓取测试
* @since 1.0
* @author Lanxiaowei@citic-finance.com
* @date 2015-8-27下午6:16:14
*
*/
public class ShangHaiStockTest {
public static void main(String[] args) throws Exception {
downloadListPage();
}
public static void downloadListPage() throws Exception {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_38);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setAppletEnabled(false);
webClient.getOptions().setRedirectEnabled(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setUseInsecureSSL(false);
webClient.getOptions().setTimeout(10000000);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
int totalPage = 22;
boolean first = true;
HtmlPage page = null;
do {
if(first) {
page = (HtmlPage)webClient.getPage("http://www.sse.com.cn/assortme ... 6quot;);
FileUtils.writeFile(page.asXml(), "C:/shh/list/" + totalPage + ".html", "UTF-8", false);
first = false;
} else {
HtmlAnchor anchor = null;
if(totalPage == 22 -1) {
anchor = (HtmlAnchor) page.getHtmlElementById("xsgf_next");
} else {
anchor = (HtmlAnchor) page.getHtmlElementById("dateList_container_next");
}
page = (HtmlPage) anchor.click();
FileUtils.writeFile(page.asXml(), "C:/shh/list/" + totalPage + ".html", "UTF-8", false);
}
totalPage--;
} while(totalPage > 0);
//关闭模拟窗口
webClient.closeAllWindows();
}
}
重点:
1.webClient.getOptions().setJavaScriptEnabled(true);
启用 JavaScript
2.webClient.setAjaxController(new NicelyResynchronizingAjaxController());
设置 Ajax 异步处理控制器以启用 Ajax 支持
3.webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
这两句话非常重要。前者表示当发生Http错误时,程序不会抛出异常继续执行,后者表示在JavaScript执行中发生异常时,将被忽略,否则Java代码会直接抛出异常,程序将被中断。
演示代码演示了如何使用代码模拟点击“下一页”超链接进行分页,获取每个页面的网页内容,然后写入磁盘指定目录。程序很简单,希望能有个好的开始。程序依赖的jar包如图:
htmlunit抓取动态网页(发现一个很不错的模拟浏览器包访问网站后的html源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-11-15 02:17
我找到了一个很好的模拟浏览器包htmlunit,可以直接访问网站地址并执行相应的JavaScript脚本;这个功能对网站爬虫很有帮助,一些网站Ajax用的。如果使用简单的http访问,只能抓取原创html源代码,无法获取页面中执行的ajax;使用这个包后,可以在执行ajax后抓取html源代码。取下来。
网站地址:
网站下面也提到了几个类似的包:HtmlUnit 被不同的开源工具用作底层的“浏览器”,如 Canoo WebTest、JWebUnit、WebDriver、JSFUnit、Celerity、...
看看canoo WebTest,但是不知道怎么用,也不想多了解。
jwebunit 用于 网站 测试。集成了JUnit、htmlunit、selenium包框架;主要功能是做白盒测试和压力测试。
webDriver 后来更名为 selenium,它集成了 htmlunit、Firefox 浏览器、IE 浏览器、opare 浏览器驱动。如果使用 htmlunitDriver,则使用 htmlunit 包访问站点;如果使用FirefoxDriver,则直接调用Firefox浏览器,然后在浏览器上模拟文本输入等鼠标键盘事件。
htmlunit包访问网站后,获取html源码后可以修改源码; jwebunit和selenium暂时没有找到修改的功能,只是用来模拟用户操作。
具体应用示例:
%D0%C7%D2%B9%BB%D8%D4%B5/blog/item/27ccf9963443c2177af48042.html 查看全部
htmlunit抓取动态网页(发现一个很不错的模拟浏览器包访问网站后的html源码)
我找到了一个很好的模拟浏览器包htmlunit,可以直接访问网站地址并执行相应的JavaScript脚本;这个功能对网站爬虫很有帮助,一些网站Ajax用的。如果使用简单的http访问,只能抓取原创html源代码,无法获取页面中执行的ajax;使用这个包后,可以在执行ajax后抓取html源代码。取下来。
网站地址:
网站下面也提到了几个类似的包:HtmlUnit 被不同的开源工具用作底层的“浏览器”,如 Canoo WebTest、JWebUnit、WebDriver、JSFUnit、Celerity、...
看看canoo WebTest,但是不知道怎么用,也不想多了解。
jwebunit 用于 网站 测试。集成了JUnit、htmlunit、selenium包框架;主要功能是做白盒测试和压力测试。
webDriver 后来更名为 selenium,它集成了 htmlunit、Firefox 浏览器、IE 浏览器、opare 浏览器驱动。如果使用 htmlunitDriver,则使用 htmlunit 包访问站点;如果使用FirefoxDriver,则直接调用Firefox浏览器,然后在浏览器上模拟文本输入等鼠标键盘事件。
htmlunit包访问网站后,获取html源码后可以修改源码; jwebunit和selenium暂时没有找到修改的功能,只是用来模拟用户操作。
具体应用示例:
%D0%C7%D2%B9%BB%D8%D4%B5/blog/item/27ccf9963443c2177af48042.html
htmlunit抓取动态网页( jsoup可以用来获取HTML页面并且分析读取页面内容吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-14 02:06
jsoup可以用来获取HTML页面并且分析读取页面内容吗?)
如何使用工具获取动态HTML页面内容
我们知道jsoup可以用来获取HTML页面,分析读取页面内容。
例如:
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test {
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
Document doc = Jsoup.connect("http://www.XXX.com/path/to/page.htm").get();
System.out.println(doc.title());
Elements newsHeadlines = doc.select("#mp-itn b a");
for (Element headline : newsHeadlines) {
System.out.printf("%s\n\t%s",
headline.attr("title"), headline.absUrl("href"));
}
}
}
但是jsoup有一个缺点,就是只能访问静态页面。对于动态页面,包括动态加载的元素,jsoup 无法处理;原因是有些网页为了浏览器的显示效果增加了用户的体检,而不是一次生成整个页面,而是在页面的基本框架显示出来后,使用js/ajax技术动态刷新和填写页面。对于这种页面,只需要解析HTML页面,执行JS代码就可以完成整个页面的加载;也就是说,需要尽可能模拟浏览器的加载行为。
最近发现HtmlUnit可以支持这个功能。
但顾名思义,它并不是一个完整的产品,它仅用于测试以模拟浏览器的行为。
举个例子:
import java.io.IOException;
import java.util.List;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.DomElement;
import com.gargoylesoftware.htmlunit.html.HtmlDivision;
import com.gargoylesoftware.htmlunit.html.HtmlListItem;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.html.HtmlUnorderedList;
public class Test {
private static WebClient webClient;
public static void main(String[] args) throws IOException {
//webClient = new WebClient(BrowserVersion.CHROME, "proxy.com", 80);
webClient = new WebClient(BrowserVersion.CHROME);
HtmlPage page = webClient.getPage(""http://www.XXX.com/path/to/page.htm"");
HtmlDivision div1 = page.getHtmlElementById("ksorder");
List divs = div1.getByXPath("//div[@class='sourceshow']");
assert(divs.size() == 1);
HtmlDivision div2 = divs.get(0);
Iterable uls = div2.getChildElements();
for (DomElement eul : uls) {
HtmlUnorderedList ul = (HtmlUnorderedList)eul;
Iterable lis = ul.getChildElements();
for (DomElement eli : lis) {
HtmlListItem li = (HtmlListItem)eli;
System.out.printf("data=[%s], class=[%s]\n", li.getAttribute("data-id"), li.getAttribute("class"));
}
}
}
}
HTML页面内容的分析框架与jsoup类似,具体可以参考文档。 查看全部
htmlunit抓取动态网页(
jsoup可以用来获取HTML页面并且分析读取页面内容吗?)
如何使用工具获取动态HTML页面内容
我们知道jsoup可以用来获取HTML页面,分析读取页面内容。
例如:
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test {
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
Document doc = Jsoup.connect("http://www.XXX.com/path/to/page.htm";).get();
System.out.println(doc.title());
Elements newsHeadlines = doc.select("#mp-itn b a");
for (Element headline : newsHeadlines) {
System.out.printf("%s\n\t%s",
headline.attr("title"), headline.absUrl("href"));
}
}
}
但是jsoup有一个缺点,就是只能访问静态页面。对于动态页面,包括动态加载的元素,jsoup 无法处理;原因是有些网页为了浏览器的显示效果增加了用户的体检,而不是一次生成整个页面,而是在页面的基本框架显示出来后,使用js/ajax技术动态刷新和填写页面。对于这种页面,只需要解析HTML页面,执行JS代码就可以完成整个页面的加载;也就是说,需要尽可能模拟浏览器的加载行为。
最近发现HtmlUnit可以支持这个功能。
但顾名思义,它并不是一个完整的产品,它仅用于测试以模拟浏览器的行为。
举个例子:
import java.io.IOException;
import java.util.List;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.DomElement;
import com.gargoylesoftware.htmlunit.html.HtmlDivision;
import com.gargoylesoftware.htmlunit.html.HtmlListItem;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.html.HtmlUnorderedList;
public class Test {
private static WebClient webClient;
public static void main(String[] args) throws IOException {
//webClient = new WebClient(BrowserVersion.CHROME, "proxy.com", 80);
webClient = new WebClient(BrowserVersion.CHROME);
HtmlPage page = webClient.getPage(""http://www.XXX.com/path/to/page.htm"";);
HtmlDivision div1 = page.getHtmlElementById("ksorder");
List divs = div1.getByXPath("//div[@class='sourceshow']");
assert(divs.size() == 1);
HtmlDivision div2 = divs.get(0);
Iterable uls = div2.getChildElements();
for (DomElement eul : uls) {
HtmlUnorderedList ul = (HtmlUnorderedList)eul;
Iterable lis = ul.getChildElements();
for (DomElement eli : lis) {
HtmlListItem li = (HtmlListItem)eli;
System.out.printf("data=[%s], class=[%s]\n", li.getAttribute("data-id"), li.getAttribute("class"));
}
}
}
}
HTML页面内容的分析框架与jsoup类似,具体可以参考文档。
htmlunit抓取动态网页(.xmlmaven依赖代码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-11-13 19:17
)
今天在使用jsoup做爬虫功能的时候发现jsoup只能抓取静态页面,对ajax和json动态生成的页面的支持不友好。
所以我尝试着把param和data header直接和request一起发送,希望能直接返回json数据,但是可能不成功,因为网站接口不支持。
尝试其他方法后,从网上发现可以用htmlunit模拟浏览器生成动态网页,然后用jsoup解析生成的动态网页
以下是 pom.xml maven 依赖代码
下面是java代码
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class JsoupTest {
public static void main(String[] args) {
queryDocument("北斗");
}
public static void queryDocument(String documentName){
WebClient browser = new WebClient();
browser.getOptions().setCssEnabled(false);
browser.getOptions().setJavaScriptEnabled(true);
browser.getOptions().setThrowExceptionOnScriptError(false);
String url = "http://oar.nstl.gov.cn/Paper/S ... 3B%3B
try {
HtmlPage htmlPage = browser.getPage(url);
browser.waitForBackgroundJavaScript(3000);
Document document = Jsoup.parse(htmlPage.asXml());
Element paper = document.getElementById("paper");
System.out.println(paper);
} catch (IOException e) {
e.printStackTrace();
}
}
} 查看全部
htmlunit抓取动态网页(.xmlmaven依赖代码
)
今天在使用jsoup做爬虫功能的时候发现jsoup只能抓取静态页面,对ajax和json动态生成的页面的支持不友好。
所以我尝试着把param和data header直接和request一起发送,希望能直接返回json数据,但是可能不成功,因为网站接口不支持。
尝试其他方法后,从网上发现可以用htmlunit模拟浏览器生成动态网页,然后用jsoup解析生成的动态网页
以下是 pom.xml maven 依赖代码
下面是java代码
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class JsoupTest {
public static void main(String[] args) {
queryDocument("北斗");
}
public static void queryDocument(String documentName){
WebClient browser = new WebClient();
browser.getOptions().setCssEnabled(false);
browser.getOptions().setJavaScriptEnabled(true);
browser.getOptions().setThrowExceptionOnScriptError(false);
String url = "http://oar.nstl.gov.cn/Paper/S ... 3B%3B
try {
HtmlPage htmlPage = browser.getPage(url);
browser.waitForBackgroundJavaScript(3000);
Document document = Jsoup.parse(htmlPage.asXml());
Element paper = document.getElementById("paper");
System.out.println(paper);
} catch (IOException e) {
e.printStackTrace();
}
}
}
htmlunit抓取动态网页(1024程序员节#通过java实现爬虫动态获取网站数据通过)
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-11-10 23:20
#1024程序员节#
通过java实现爬虫动态获取网站数据
通过上次demo的实现,对爬虫有了一定的了解和认识,并进行了深入的研究和学习,成功的动态获取了更多的数据。
上次demo后发现每次通过商品列表获取的数据都是有限的,只有几个。我在想如何自动点击产品,进入产品详情页面,获取更多数据,然后返回产品列表。页。这形成了一个循环以获取更多数据。经过思考和尝试,终于实现了这个功能。
1.创建一个maven项目
首先,创建一个maven项目。
2.介绍相关jar包
由于工作原因,一直没有时间将数据导出到excel文件,所以还是只有控制台输出。导入jar包如下。
3.代码编写
这段代码中增加了自动跳转到商品详情页,获取数据后返回商品列表页,循环进行获取。
代码中最外层的for循环的作用就是实现翻页操作。当产品第一页的数据采集完成后,跳转到产品列表页面的第二页,继续循环获取详细的产品数据。
4.运行结果
成功获取多页产品的详细数据,结果如图。因为我用的是海外购物网站,所以得到的数据不是中文的。
总结:
通过这次实战,对爬虫有了更深入的了解,掌握了动态获取数据的方式。美中不足的是,暂时没有时间将数据导出到excel文件。我会抓紧时间实现自己的这个想法,把外文数据转换成中文。这就是我需要继续学习和尝试的地方,这样我才能逐渐成长。 查看全部
htmlunit抓取动态网页(1024程序员节#通过java实现爬虫动态获取网站数据通过)
#1024程序员节#
通过java实现爬虫动态获取网站数据
通过上次demo的实现,对爬虫有了一定的了解和认识,并进行了深入的研究和学习,成功的动态获取了更多的数据。
上次demo后发现每次通过商品列表获取的数据都是有限的,只有几个。我在想如何自动点击产品,进入产品详情页面,获取更多数据,然后返回产品列表。页。这形成了一个循环以获取更多数据。经过思考和尝试,终于实现了这个功能。
1.创建一个maven项目
首先,创建一个maven项目。
2.介绍相关jar包
由于工作原因,一直没有时间将数据导出到excel文件,所以还是只有控制台输出。导入jar包如下。
3.代码编写
这段代码中增加了自动跳转到商品详情页,获取数据后返回商品列表页,循环进行获取。
代码中最外层的for循环的作用就是实现翻页操作。当产品第一页的数据采集完成后,跳转到产品列表页面的第二页,继续循环获取详细的产品数据。
4.运行结果
成功获取多页产品的详细数据,结果如图。因为我用的是海外购物网站,所以得到的数据不是中文的。
总结:
通过这次实战,对爬虫有了更深入的了解,掌握了动态获取数据的方式。美中不足的是,暂时没有时间将数据导出到excel文件。我会抓紧时间实现自己的这个想法,把外文数据转换成中文。这就是我需要继续学习和尝试的地方,这样我才能逐渐成长。
htmlunit抓取动态网页(webmagic渲染网页的爬取过程,你知道几个?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-11-10 23:12
最近突然了解到,我以后的工作有很多数据采集。朋友推荐了webmagic项目,于是就开始玩了。发现这个爬虫项目还是很有用的,爬取静态网站几乎不需要自己写任何代码(当然是小爬虫~~|)。好了,废话少说。以此文记录渲染网页的爬取过程。先找个js渲染网站。这里我们直接取学习文档中给出的网址。
打开网页是这样的
像这样查看源代码
源代码这么小,不用说,必须渲染。我搜索了一条记录,果然,在源代码中没有找到任何结果。
然后开始解析URL。我从浏览器开发人员工具中找到了这样的请求记录。
只需开始查看数据量最大的请求,如上图红线所示。从xhr可以看出这是一个ajax请求的数据,打开请求的数据是这样的
从网页中找到源代码中找不到的一条记录,在这个json数据中搜索。幸运的是,我找到了。
不用说,就是这样!!接下来直接解析这个json就可以得到所有渲染出来的链接了。
直接从网页上点击一个链接进入,发现链接是这样的:
然后回到json文件,找到这个标题
发现了惊人的东西!那是 id,后跟链接。大胆推测所有链接都是这种尿性!!(其实我还点了几个链接才敢确认这个尿性)
然后就很简单了,写代码解析这个json数据,然后把所有的链接拼凑起来加入爬取队列进行爬取。
原来通过首页链接点进来的下级链接还是js渲染的。. .
没办法,拿着链接要求继续分析
获取这样的请求数据:
直接看xhr列,就是ajax请求的数据
还是从大到小看json数据,匹配页面内容,直到找到第三个。++|
然后得到了最终数据的请求链接:
然后就可以写代码了:
1 public class SpiderTest implements PageProcessor {
2 // 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
3 private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
4 // 先从浏览器中分析出隐藏请求可得出以下匹配规则
5 private static final String URLRULE = "http://angularjs\\.cn/api/article/latest.*";
6 private static String firstUrl = "http://angularjs.cn/api/article/";
7
8 @Override
9 public Site getSite() {
10 // TODO Auto-generated method stub
11 return site;
12 }
13
14 @Override
15 public void process(Page page) {
16 // TODO Auto-generated method stub
17 /**
18 * 筛选出所有符合条件的url,手动添加到爬取队列。
19 */
20 if (page.getUrl().regex(URLRULE).match()) {
21 //通过jsonpath得到json数据中的id内容,之后再拼凑待爬取链接
22 List endUrls = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
23 if (CollectionUtils.isNotEmpty(endUrls)) {
24 for (String endUrl : endUrls) {
25 page.addTargetRequest(firstUrl + endUrl);
26 }
27 }
28 } else {
29 //通过jsonpath从爬取到的json数据中提取出id和content内容
30 page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
31 page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
32 }
33
34 }
35
36 @Test
37 public void test(){
38 Spider.create(new SpiderTest()).addUrl("http://angularjs.cn/api/article/latest?s=20").run();
39 }
40 }
此时,一个渲染的网页就被爬下来了。超过 查看全部
htmlunit抓取动态网页(webmagic渲染网页的爬取过程,你知道几个?)
最近突然了解到,我以后的工作有很多数据采集。朋友推荐了webmagic项目,于是就开始玩了。发现这个爬虫项目还是很有用的,爬取静态网站几乎不需要自己写任何代码(当然是小爬虫~~|)。好了,废话少说。以此文记录渲染网页的爬取过程。先找个js渲染网站。这里我们直接取学习文档中给出的网址。
打开网页是这样的
像这样查看源代码
源代码这么小,不用说,必须渲染。我搜索了一条记录,果然,在源代码中没有找到任何结果。
然后开始解析URL。我从浏览器开发人员工具中找到了这样的请求记录。
只需开始查看数据量最大的请求,如上图红线所示。从xhr可以看出这是一个ajax请求的数据,打开请求的数据是这样的
从网页中找到源代码中找不到的一条记录,在这个json数据中搜索。幸运的是,我找到了。
不用说,就是这样!!接下来直接解析这个json就可以得到所有渲染出来的链接了。
直接从网页上点击一个链接进入,发现链接是这样的:
然后回到json文件,找到这个标题
发现了惊人的东西!那是 id,后跟链接。大胆推测所有链接都是这种尿性!!(其实我还点了几个链接才敢确认这个尿性)
然后就很简单了,写代码解析这个json数据,然后把所有的链接拼凑起来加入爬取队列进行爬取。
原来通过首页链接点进来的下级链接还是js渲染的。. .
没办法,拿着链接要求继续分析
获取这样的请求数据:
直接看xhr列,就是ajax请求的数据
还是从大到小看json数据,匹配页面内容,直到找到第三个。++|
然后得到了最终数据的请求链接:
然后就可以写代码了:
1 public class SpiderTest implements PageProcessor {
2 // 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
3 private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
4 // 先从浏览器中分析出隐藏请求可得出以下匹配规则
5 private static final String URLRULE = "http://angularjs\\.cn/api/article/latest.*";
6 private static String firstUrl = "http://angularjs.cn/api/article/";
7
8 @Override
9 public Site getSite() {
10 // TODO Auto-generated method stub
11 return site;
12 }
13
14 @Override
15 public void process(Page page) {
16 // TODO Auto-generated method stub
17 /**
18 * 筛选出所有符合条件的url,手动添加到爬取队列。
19 */
20 if (page.getUrl().regex(URLRULE).match()) {
21 //通过jsonpath得到json数据中的id内容,之后再拼凑待爬取链接
22 List endUrls = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
23 if (CollectionUtils.isNotEmpty(endUrls)) {
24 for (String endUrl : endUrls) {
25 page.addTargetRequest(firstUrl + endUrl);
26 }
27 }
28 } else {
29 //通过jsonpath从爬取到的json数据中提取出id和content内容
30 page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
31 page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
32 }
33
34 }
35
36 @Test
37 public void test(){
38 Spider.create(new SpiderTest()).addUrl("http://angularjs.cn/api/article/latest?s=20";).run();
39 }
40 }
此时,一个渲染的网页就被爬下来了。超过
htmlunit抓取动态网页(为GET和POST请求添加请求参数和请求头(使用HttpClient) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-11-09 19:04
)
缺点是需要手动查找post请求的url和对应的参数。
参考:
1.为GET和POST请求添加请求参数和请求头(使用HttpClient,Java)
2.关于抓取js加载的内容(参考博客流程,比如找到实际的请求url)
以一条新闻为例:
1.使用F12,先在网络文件列表中找到网页,双击弹出详细信息。“Body”查看了网页内容,发现网页上没有显示该信息对应的信息,说明是后来加载的。
2.尝试在文中搜索关键字,看看是请求哪些文档来获取数据。例如,如果您搜索文本中的第一个词“海关总署”,您可能会发现多个文件,需要判断和选择。
对应的请求体为“id:98212”,即请求参数
3.查看“标题”
主要取决于请求url和请求方式,有时需要设置user-agent。需要使用post方法
4.代码编写
创建 Java Maven 项目并添加依赖项:
org.apache.httpcomponents
httpclient
4.5.6
com.google.code.gson
gson
2.2.4
下载的jar包如下图:
代码如下,我只拿到了文章的body:
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Map;
import org.apache.http.HttpEntity;
import org.apache.http.NameValuePair;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
import com.google.gson.Gson;
/**
* http://news.cqcoal.com/blank/nc.jsp?mid=98212
* 该网页的新闻主题是动态生成的,希望获取内容
* @author yangc_cong
*
*/
public class TestNewContent {
/**
* 针对请求的链接,使用post方法获取返回的数据
* @param urlStr String类型
* @return 这里是Map类型
*/
private Map getPageContByHttpCl(String urlStr) {
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpPost post = new HttpPost(urlStr);
String userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362";
post.setHeader("User-Agent", userAgent);
CloseableHttpResponse response = null;
String result = null;
// 创建请求参数
List list = new LinkedList();
BasicNameValuePair param1 = new BasicNameValuePair("id", "98212");
list.add(param1);
// 使用URL实体转换工具
UrlEncodedFormEntity entityParam = null;
try {
entityParam = new UrlEncodedFormEntity(list, "UTF-8");
post.setEntity(entityParam);
} catch (UnsupportedEncodingException e1) {
e1.printStackTrace();
}
try {
response = httpclient.execute(post);
HttpEntity entity = response.getEntity();
result = EntityUtils.toString(entity, "UTF-8");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
response.close();
httpclient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println(result);
Gson gson = new Gson();
Map map = gson.fromJson(result, Map.class);
return map;
}
private void parse_content(Map map) {
//java.lang.ClassCastException: java.util.ArrayList cannot be cast to java.util.Map
ArrayList arrayList = (ArrayList)(map.get("rows"));
Map innerMap = (Map) arrayList.get(0);
String source = (String) innerMap.get("source");
String bodyhtml = (String) innerMap.get("body");
System.out.println("source: "+source);
System.out.println("bodyhtml:"+'\n'+bodyhtml);
}
public static void main(String[] args) {
TestNewContent test1 = new TestNewContent();
String urlStr = "http://news.cqcoal.com/manage/ ... 3B%3B
Map map = test1.getPageContByHttpCl(urlStr);
test1.parse_content(map);
}
}
运行截图:
补充:使用HtmlUnit抓取网页动态加载的body部分(一个简单的应用)
参考:HtmlUnit+Jsoup学习总结
1.maven项目中的配置
net.sourceforge.htmlunit
htmlunit
2.27
下载的jar包如下,有很多,所以建议使用maven进行配置:
2. 代码部分(根据参考博客写的)
import java.io.IOException;
import java.net.MalformedURLException;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
public class HtmlUnitTest {
public static void main(String[] args) {
String url ="http://www.qidian.com";
url = "http://news.cqcoal.com/blank/n ... 3B%3B
// 1创建WebClient
WebClient webClient=new WebClient(BrowserVersion.CHROME);
// 2 启动JS
webClient.getOptions().setJavaScriptEnabled(true);
// 3 禁用Css,可避免自动二次請求CSS进行渲染
webClient.getOptions().setCssEnabled(false);
// 4 启动客戶端重定向
webClient.getOptions().setRedirectEnabled(true);
// 5 js运行错誤時,是否拋出异常
webClient.getOptions().setThrowExceptionOnScriptError(false);
// 6 设置超时
webClient.getOptions().setTimeout(50000); //获取网页
HtmlPage htmlPage = null;
try {
htmlPage = webClient.getPage(url);
} catch (FailingHttpStatusCodeException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// 等待JS驱动dom完成获得还原后的网页
webClient.waitForBackgroundJavaScript(10000);
// 网页内容
String pageHtml = htmlPage.asXml();
System.out.println(pageHtml);
System.out.println("\n------\n");
//网页内容---纯文本形式
String pageText = htmlPage.asText();
System.out.println(pageText );
//输出网页的title
String title = htmlPage.getTitleText();
System.out.println(title );
//close
webClient.close();
}
}
3.运行结果(代码需要加载js后的输出,收录标签的网页内容,纯文本---网页的文本部分,网页的标题---值title 属性的。这里只贴出纯文本输出的部分结果)
查看全部
htmlunit抓取动态网页(为GET和POST请求添加请求参数和请求头(使用HttpClient)
)
缺点是需要手动查找post请求的url和对应的参数。
参考:
1.为GET和POST请求添加请求参数和请求头(使用HttpClient,Java)
2.关于抓取js加载的内容(参考博客流程,比如找到实际的请求url)
以一条新闻为例:
1.使用F12,先在网络文件列表中找到网页,双击弹出详细信息。“Body”查看了网页内容,发现网页上没有显示该信息对应的信息,说明是后来加载的。
2.尝试在文中搜索关键字,看看是请求哪些文档来获取数据。例如,如果您搜索文本中的第一个词“海关总署”,您可能会发现多个文件,需要判断和选择。
对应的请求体为“id:98212”,即请求参数
3.查看“标题”
主要取决于请求url和请求方式,有时需要设置user-agent。需要使用post方法
4.代码编写
创建 Java Maven 项目并添加依赖项:
org.apache.httpcomponents
httpclient
4.5.6
com.google.code.gson
gson
2.2.4
下载的jar包如下图:
代码如下,我只拿到了文章的body:
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Map;
import org.apache.http.HttpEntity;
import org.apache.http.NameValuePair;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
import com.google.gson.Gson;
/**
* http://news.cqcoal.com/blank/nc.jsp?mid=98212
* 该网页的新闻主题是动态生成的,希望获取内容
* @author yangc_cong
*
*/
public class TestNewContent {
/**
* 针对请求的链接,使用post方法获取返回的数据
* @param urlStr String类型
* @return 这里是Map类型
*/
private Map getPageContByHttpCl(String urlStr) {
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpPost post = new HttpPost(urlStr);
String userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362";
post.setHeader("User-Agent", userAgent);
CloseableHttpResponse response = null;
String result = null;
// 创建请求参数
List list = new LinkedList();
BasicNameValuePair param1 = new BasicNameValuePair("id", "98212");
list.add(param1);
// 使用URL实体转换工具
UrlEncodedFormEntity entityParam = null;
try {
entityParam = new UrlEncodedFormEntity(list, "UTF-8");
post.setEntity(entityParam);
} catch (UnsupportedEncodingException e1) {
e1.printStackTrace();
}
try {
response = httpclient.execute(post);
HttpEntity entity = response.getEntity();
result = EntityUtils.toString(entity, "UTF-8");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
response.close();
httpclient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println(result);
Gson gson = new Gson();
Map map = gson.fromJson(result, Map.class);
return map;
}
private void parse_content(Map map) {
//java.lang.ClassCastException: java.util.ArrayList cannot be cast to java.util.Map
ArrayList arrayList = (ArrayList)(map.get("rows"));
Map innerMap = (Map) arrayList.get(0);
String source = (String) innerMap.get("source");
String bodyhtml = (String) innerMap.get("body");
System.out.println("source: "+source);
System.out.println("bodyhtml:"+'\n'+bodyhtml);
}
public static void main(String[] args) {
TestNewContent test1 = new TestNewContent();
String urlStr = "http://news.cqcoal.com/manage/ ... 3B%3B
Map map = test1.getPageContByHttpCl(urlStr);
test1.parse_content(map);
}
}
运行截图:
补充:使用HtmlUnit抓取网页动态加载的body部分(一个简单的应用)
参考:HtmlUnit+Jsoup学习总结
1.maven项目中的配置
net.sourceforge.htmlunit
htmlunit
2.27
下载的jar包如下,有很多,所以建议使用maven进行配置:
2. 代码部分(根据参考博客写的)
import java.io.IOException;
import java.net.MalformedURLException;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
public class HtmlUnitTest {
public static void main(String[] args) {
String url ="http://www.qidian.com";
url = "http://news.cqcoal.com/blank/n ... 3B%3B
// 1创建WebClient
WebClient webClient=new WebClient(BrowserVersion.CHROME);
// 2 启动JS
webClient.getOptions().setJavaScriptEnabled(true);
// 3 禁用Css,可避免自动二次請求CSS进行渲染
webClient.getOptions().setCssEnabled(false);
// 4 启动客戶端重定向
webClient.getOptions().setRedirectEnabled(true);
// 5 js运行错誤時,是否拋出异常
webClient.getOptions().setThrowExceptionOnScriptError(false);
// 6 设置超时
webClient.getOptions().setTimeout(50000); //获取网页
HtmlPage htmlPage = null;
try {
htmlPage = webClient.getPage(url);
} catch (FailingHttpStatusCodeException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// 等待JS驱动dom完成获得还原后的网页
webClient.waitForBackgroundJavaScript(10000);
// 网页内容
String pageHtml = htmlPage.asXml();
System.out.println(pageHtml);
System.out.println("\n------\n");
//网页内容---纯文本形式
String pageText = htmlPage.asText();
System.out.println(pageText );
//输出网页的title
String title = htmlPage.getTitleText();
System.out.println(title );
//close
webClient.close();
}
}
3.运行结果(代码需要加载js后的输出,收录标签的网页内容,纯文本---网页的文本部分,网页的标题---值title 属性的。这里只贴出纯文本输出的部分结果)
htmlunit抓取动态网页(基于现有的动态网页爬虫系统-DynCrawler系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-07 05:21
【摘要】:随着网页数量的爆发式增长,传统的中心化爬虫难以满足实际应用。此外,Ajax 技术在网络应用中的广泛普及,也给传统的Web 开发带来了全新的变化。部分刷新功能提升了用户体验,用户可以很好地与远程服务器进行交互。典型应用包括校园论坛、博客网站等,这些大量动态网页的出现给传统的网络爬虫带来了极大的障碍。在影响爬虫效率的同时,也影响到网页内容的获取。针对以上两个问题,本文基于WebMagic爬虫框架设计了分布式动态网络爬虫系统Dis-Dyn Crawler。系统采用SOA架构的思想,将动态页面解析工具HtmlUnit在动态页面过程中的耗时操作作为独立的服务分离出来;为了提高解析效率,系统将HtmlUnit所需的JavaScript等文件缓存在Redis数据库中。页面渲染时无需每次都从网络下载,减少了网络请求,提高了解析效率;异步页面下载器的实现进一步提高了系统的整体效率。本文从功能和性能两个方面对Dis-Dyn Crawler系统进行了实验分析。通过与现有分布式网络爬虫工具的爬虫能力对比,验证了本文基于Webmagic的动态网络爬虫是高效的。通过与现有动态网页分析工具的对比,验证了本文Dis-Dyn Crawler系统的效率和可行性。 查看全部
htmlunit抓取动态网页(基于现有的动态网页爬虫系统-DynCrawler系统)
【摘要】:随着网页数量的爆发式增长,传统的中心化爬虫难以满足实际应用。此外,Ajax 技术在网络应用中的广泛普及,也给传统的Web 开发带来了全新的变化。部分刷新功能提升了用户体验,用户可以很好地与远程服务器进行交互。典型应用包括校园论坛、博客网站等,这些大量动态网页的出现给传统的网络爬虫带来了极大的障碍。在影响爬虫效率的同时,也影响到网页内容的获取。针对以上两个问题,本文基于WebMagic爬虫框架设计了分布式动态网络爬虫系统Dis-Dyn Crawler。系统采用SOA架构的思想,将动态页面解析工具HtmlUnit在动态页面过程中的耗时操作作为独立的服务分离出来;为了提高解析效率,系统将HtmlUnit所需的JavaScript等文件缓存在Redis数据库中。页面渲染时无需每次都从网络下载,减少了网络请求,提高了解析效率;异步页面下载器的实现进一步提高了系统的整体效率。本文从功能和性能两个方面对Dis-Dyn Crawler系统进行了实验分析。通过与现有分布式网络爬虫工具的爬虫能力对比,验证了本文基于Webmagic的动态网络爬虫是高效的。通过与现有动态网页分析工具的对比,验证了本文Dis-Dyn Crawler系统的效率和可行性。
htmlunit抓取动态网页(一种面向动态网页的定向信息提取模型模型研究)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-11-02 22:18
【摘要】随着Web2.0技术的出现和快速发展,互联网上出现了越来越多的动态网页。Ajax技术实现了客户端和服务器之间的异步数据传输操作,不仅提高了用户体验,而且促进了动态网页的普及和互联网的发展。但是,这也使得传统的网络爬虫无法根据HTML源代码提取信息,从动态网页中提取动态信息。因此,支持动态网页信息提取的研究具有一定的现实意义。为此,本文提出了一种动态网页的定向信息提取模型。首先,分析了动态网页方向信息提取的相关理论和技术。同时将研究对象网页分为静态网页和动态网页,并进行详细的对比分析。在此基础上,分析了动态网页中广泛使用的Ajax技术给信息抽取带来的挑战。最后,详细介绍了超文本标记语言、DOM模型和正则表达式在信息抽取中的作用。其次,分析了传统网络爬虫抓取动态网页的缺陷和不足,提出了动态网页的定向信息抽取模型。工作流程是先通过HTTP请求获取网页,然后使用HtmlUnit解析并执行动态脚本,并模拟页面表单的提交;最后,使用jsoup构建DOM树,提取页面信息和URL并存入数据库。第三,结合所提出的面向Web的动态定向信息抽取模型,给出了各个组件模块的具体实现方法:采用广度优先搜索策略对网站中的网页进行爬取,布隆过滤器用于链接 URL。进行去重处理,使用正则表达式和jsoup选择器提取网页信息和URL链接,使用多线程爬虫技术提升模型性能。最后,基于提出的面向Web的动态信息抽取模型,以燕山大学百度贴吧为抓取对象进行实验,并从模型的效率和性能上进行实验设计。通过对爬取结果的分析可以看出,所提模型在准确率、召回率、F值等评价指标下均取得了较好的效果,验证了所提模型的高效、高性能。 查看全部
htmlunit抓取动态网页(一种面向动态网页的定向信息提取模型模型研究)
【摘要】随着Web2.0技术的出现和快速发展,互联网上出现了越来越多的动态网页。Ajax技术实现了客户端和服务器之间的异步数据传输操作,不仅提高了用户体验,而且促进了动态网页的普及和互联网的发展。但是,这也使得传统的网络爬虫无法根据HTML源代码提取信息,从动态网页中提取动态信息。因此,支持动态网页信息提取的研究具有一定的现实意义。为此,本文提出了一种动态网页的定向信息提取模型。首先,分析了动态网页方向信息提取的相关理论和技术。同时将研究对象网页分为静态网页和动态网页,并进行详细的对比分析。在此基础上,分析了动态网页中广泛使用的Ajax技术给信息抽取带来的挑战。最后,详细介绍了超文本标记语言、DOM模型和正则表达式在信息抽取中的作用。其次,分析了传统网络爬虫抓取动态网页的缺陷和不足,提出了动态网页的定向信息抽取模型。工作流程是先通过HTTP请求获取网页,然后使用HtmlUnit解析并执行动态脚本,并模拟页面表单的提交;最后,使用jsoup构建DOM树,提取页面信息和URL并存入数据库。第三,结合所提出的面向Web的动态定向信息抽取模型,给出了各个组件模块的具体实现方法:采用广度优先搜索策略对网站中的网页进行爬取,布隆过滤器用于链接 URL。进行去重处理,使用正则表达式和jsoup选择器提取网页信息和URL链接,使用多线程爬虫技术提升模型性能。最后,基于提出的面向Web的动态信息抽取模型,以燕山大学百度贴吧为抓取对象进行实验,并从模型的效率和性能上进行实验设计。通过对爬取结果的分析可以看出,所提模型在准确率、召回率、F值等评价指标下均取得了较好的效果,验证了所提模型的高效、高性能。
htmlunit抓取动态网页(.xmlmaven依赖代码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-11-01 12:20
)
今天在使用jsoup做爬虫功能的时候发现jsoup只能抓取静态页面,对ajax和json动态生成的页面的支持不友好。
所以我尝试直接用request发送param和data header,希望直接返回json数据,但是可能不成功,因为网站接口不支持。
尝试其他方法后,从网上发现可以用htmlunit模拟浏览器生成动态网页,然后用jsoup解析生成的动态网页
以下是 pom.xml maven 依赖代码
下面是java代码
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class JsoupTest {
public static void main(String[] args) {
queryDocument("北斗");
}
public static void queryDocument(String documentName){
WebClient browser = new WebClient();
browser.getOptions().setCssEnabled(false);
browser.getOptions().setJavaScriptEnabled(true);
browser.getOptions().setThrowExceptionOnScriptError(false);
String url = "http://oar.nstl.gov.cn/Paper/S ... 3B%3B
try {
HtmlPage htmlPage = browser.getPage(url);
browser.waitForBackgroundJavaScript(3000);
Document document = Jsoup.parse(htmlPage.asXml());
Element paper = document.getElementById("paper");
System.out.println(paper);
} catch (IOException e) {
e.printStackTrace();
}
}
} 查看全部
htmlunit抓取动态网页(.xmlmaven依赖代码
)
今天在使用jsoup做爬虫功能的时候发现jsoup只能抓取静态页面,对ajax和json动态生成的页面的支持不友好。
所以我尝试直接用request发送param和data header,希望直接返回json数据,但是可能不成功,因为网站接口不支持。
尝试其他方法后,从网上发现可以用htmlunit模拟浏览器生成动态网页,然后用jsoup解析生成的动态网页
以下是 pom.xml maven 依赖代码
下面是java代码
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class JsoupTest {
public static void main(String[] args) {
queryDocument("北斗");
}
public static void queryDocument(String documentName){
WebClient browser = new WebClient();
browser.getOptions().setCssEnabled(false);
browser.getOptions().setJavaScriptEnabled(true);
browser.getOptions().setThrowExceptionOnScriptError(false);
String url = "http://oar.nstl.gov.cn/Paper/S ... 3B%3B
try {
HtmlPage htmlPage = browser.getPage(url);
browser.waitForBackgroundJavaScript(3000);
Document document = Jsoup.parse(htmlPage.asXml());
Element paper = document.getElementById("paper");
System.out.println(paper);
} catch (IOException e) {
e.printStackTrace();
}
}
}

