
htmlunit抓取动态网页
htmlunit抓取动态网页(中小微公司网络爬虫技术总结及解决办法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-31 11:19
网络爬虫技术总结
对于大数据行业来说,数据的价值不言而喻。在这个信息爆炸的时代,互联网上的信息数据太多了。对于中小微企业来说,合理利用爬虫爬取有价值的数据,是为了弥补自身先天的数据短缺。板子的最佳选择,本文主要从爬虫原理、架构、分类和反爬虫技术方面总结了爬虫技术。
1、爬虫技术概述
网络爬虫是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。它们广泛应用于互联网搜索引擎或其他类似的网站,并且可以自动采集所有它可以访问的页面的内容来获取或更新这些网站的内容和检索方式. 从功能上来说,爬虫一般分为数据采集、处理、存储三部分。
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。另外,爬虫爬取的所有网页都会被系统存储,进行一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1)爬取目标的描述或定义;
(2)网页或数据的分析和过滤;
(3)URL 的搜索策略。
2、爬虫原理
2.1网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、SqlServer等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。.
这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,因此广度优先搜索算法一般使用采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个网址,下载其对应的网页,
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列;
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历路径:AF-GE-H-IBCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDE-FGHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4PartialPageRank 策略
PartialPageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值。计算完成后,计算待爬取的URL队列中的URL。按 PageRank 值排序并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发使Nutch适合提取业务,那你基本上会破坏Nutch的框架,把Nutch改得面目全非,而且有能力修改Nutch,还不如自己写一个新的。分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。事实上,这是针对Nutch的声誉。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发很简单,难点和复杂的问题已经被前人解决了(比如DOM树解析定位、字符集检测、海量URL去重),可以说没有技术含量。包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于deepweb(深网)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSSSELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
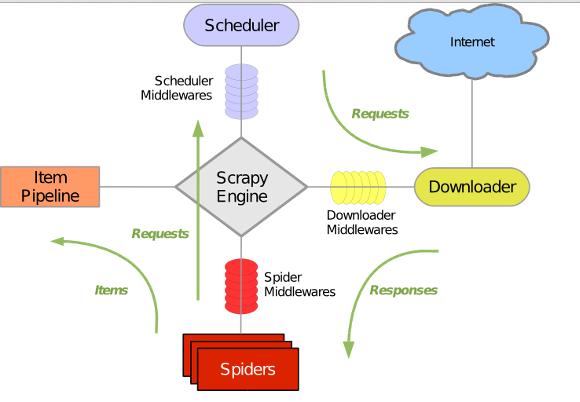
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给Spider进行分析,将要保存的数据发送到ItemPipeline。那就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,无论大小。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力较差,经常会循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这样的反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
[评论:它经常很容易被忽视。通过对请求的抓包分析,确定referer并添加到程序中模拟访问请求的header中]
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一页面,或者同一账号在短时间内多次执行同一操作。 查看全部
htmlunit抓取动态网页(中小微公司网络爬虫技术总结及解决办法(一))
网络爬虫技术总结
对于大数据行业来说,数据的价值不言而喻。在这个信息爆炸的时代,互联网上的信息数据太多了。对于中小微企业来说,合理利用爬虫爬取有价值的数据,是为了弥补自身先天的数据短缺。板子的最佳选择,本文主要从爬虫原理、架构、分类和反爬虫技术方面总结了爬虫技术。
1、爬虫技术概述
网络爬虫是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。它们广泛应用于互联网搜索引擎或其他类似的网站,并且可以自动采集所有它可以访问的页面的内容来获取或更新这些网站的内容和检索方式. 从功能上来说,爬虫一般分为数据采集、处理、存储三部分。
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。另外,爬虫爬取的所有网页都会被系统存储,进行一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1)爬取目标的描述或定义;
(2)网页或数据的分析和过滤;
(3)URL 的搜索策略。
2、爬虫原理
2.1网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、SqlServer等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。.
这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,因此广度优先搜索算法一般使用采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个网址,下载其对应的网页,
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列;
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历路径:AF-GE-H-IBCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDE-FGHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4PartialPageRank 策略
PartialPageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值。计算完成后,计算待爬取的URL队列中的URL。按 PageRank 值排序并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发使Nutch适合提取业务,那你基本上会破坏Nutch的框架,把Nutch改得面目全非,而且有能力修改Nutch,还不如自己写一个新的。分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。事实上,这是针对Nutch的声誉。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发很简单,难点和复杂的问题已经被前人解决了(比如DOM树解析定位、字符集检测、海量URL去重),可以说没有技术含量。包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于deepweb(深网)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSSSELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给Spider进行分析,将要保存的数据发送到ItemPipeline。那就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,无论大小。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力较差,经常会循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这样的反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
[评论:它经常很容易被忽视。通过对请求的抓包分析,确定referer并添加到程序中模拟访问请求的header中]
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一页面,或者同一账号在短时间内多次执行同一操作。
htmlunit抓取动态网页(网站的爬虫调试的时候发现问题(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-30 02:04
网站的爬虫脚本在调试时发现问题:
脚本运行:content-type用text/xml可以发帖成功,但是post中body的内容不生效,所有回复都是当前日期;有申请,发帖不成功(即没有返回数据)
工具发:content-type用text/xml可以发帖成功,但是post中body的内容不生效,所有回复都是当前日期;有申请,发帖成功,正文中日期修改有效
即用型脚本完全没有接收到返回的数据,但是很奇怪可以使用工具fiddler或者Burpsuite来正常查看包的内容。直到后来才发现我爬的网站是动态的==
动态网页(参考百度百科:%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5/6327050)
-------------------------------------------------- ------------------
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是通过动态网站技术生成的,都可以称为动态网页。
总之,动态网页是基本的html语法规范与Java、VB、VC等高级编程语言、数据库编程等技术的融合,以实现网站@的高效、动态、交互的内容和风格。 > 管理。因此,从这个意义上说,任何由网页编程技术结合HTML以外的高级编程语言和数据库技术生成的网页都是动态网页。
-------------------------------------------------- ------------------
也可以解释为动态网页不执行javascript,仅使用data=response.read()获取的静态html没有要爬取的内容
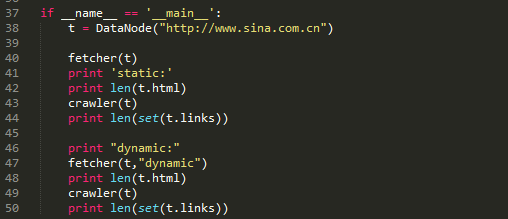
网上用Python解决这个问题只有两种方法:采集内容直接来自JavaScript代码,或者使用Python的第三方库运行JavaScript,直接采集浏览器中看到的页。我用selenium做web自动化,我用的是第二种(其实selenium+PhantomJS就是模拟浏览器访问url,然后把动态网页的所有内容转换成静态html返回,所以速度会很慢)
安装PhantomJS:下载第三方库,放到python\scripts下
爬虫网易播放列表中,播放量过千万的歌名和链接保存到excel
Chrome按F12查看网页源代码
检查页面上的元素,首先将frame切换为id='g_iframe'
播放量nb及对应的标题和链接
mysongList1000.xls 结果截图 查看全部
htmlunit抓取动态网页(网站的爬虫调试的时候发现问题(一)(组图))
网站的爬虫脚本在调试时发现问题:
脚本运行:content-type用text/xml可以发帖成功,但是post中body的内容不生效,所有回复都是当前日期;有申请,发帖不成功(即没有返回数据)
工具发:content-type用text/xml可以发帖成功,但是post中body的内容不生效,所有回复都是当前日期;有申请,发帖成功,正文中日期修改有效
即用型脚本完全没有接收到返回的数据,但是很奇怪可以使用工具fiddler或者Burpsuite来正常查看包的内容。直到后来才发现我爬的网站是动态的==
动态网页(参考百度百科:%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5/6327050)
-------------------------------------------------- ------------------
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是通过动态网站技术生成的,都可以称为动态网页。
总之,动态网页是基本的html语法规范与Java、VB、VC等高级编程语言、数据库编程等技术的融合,以实现网站@的高效、动态、交互的内容和风格。 > 管理。因此,从这个意义上说,任何由网页编程技术结合HTML以外的高级编程语言和数据库技术生成的网页都是动态网页。
-------------------------------------------------- ------------------
也可以解释为动态网页不执行javascript,仅使用data=response.read()获取的静态html没有要爬取的内容
网上用Python解决这个问题只有两种方法:采集内容直接来自JavaScript代码,或者使用Python的第三方库运行JavaScript,直接采集浏览器中看到的页。我用selenium做web自动化,我用的是第二种(其实selenium+PhantomJS就是模拟浏览器访问url,然后把动态网页的所有内容转换成静态html返回,所以速度会很慢)
安装PhantomJS:下载第三方库,放到python\scripts下
爬虫网易播放列表中,播放量过千万的歌名和链接保存到excel
Chrome按F12查看网页源代码
检查页面上的元素,首先将frame切换为id='g_iframe'
播放量nb及对应的标题和链接
mysongList1000.xls 结果截图
htmlunit抓取动态网页(Java爬取博客阅读文章最多)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-26 19:21
更新,这很尴尬,这个文章博客是阅读最多的文章,但也是最被践踏的。
爬取思路:
所谓动态,是指通过请求后台,可以动态改变对应的html页面,开始时页面并不是全部显示出来的。
大多数操作都是通过请求完成的,一个请求,一个返回。在大多数网页中,请求往往被开发者隐藏在 js 代码中。
因此,将爬取动态网页的思路转化为找到对应的js代码并执行对应的js代码,从而可以通过java代码动态改变页面。
而当页面能够正确显示的时候,我们就可以像爬静态网页一样爬取数据了!
首先,可以使用htmlunit来模拟鼠标点击事件,很容易实现:
/**
* 通过htmlunit来获得一些搜狗的网址。
* 通过模拟鼠标点击事件来实现
* @param key
* @return
* @throws Exception
*/
public String getNextUrl(String key){
String page = new String();
try {
WebClient webClient = new WebClient();
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
//去拿网页
HtmlPage htmlPage = webClient.getPage("http://pic.sogou.com/");
//得到表单
HtmlForm form = htmlPage.getFormByName("searchForm");
//得到提交按钮
HtmlSubmitInput button = form.getInputByValue("搜狗搜索");
//得到输入框
HtmlTextInput textField = form.getInputByName("query");
//输入内容
textField.setValueAttribute(key);
//点一下按钮
HtmlPage nextPage = button.click();
String str = nextPage.toString();
page = cutString(str);
webClient.close();
} catch (Exception e) {
e.printStackTrace();
}
return page;
}
如上图,我只是通过java代码将关键字填入搜索我的,然后通过getInputByValue方法得到按钮控件,最后直接button.click(),
即可以模拟点击,将点击后返回的http请求解析成html页面。
这个功能其实很强大。比如你可以使用这个功能来模拟抢票,或者使用点击事件,加上搜索相关知识,将整个系统下线,并以html的形式保存。
接下来就是使用强大的htmlunit来执行js代码了。
先写一个简单的jsp页面:
Insert title here
原数字
function change(value) {
document.getElementById("test").innerHTML = value;
return "hello htmlUnit";
}
从上面可以看出,jsp页面很简单,只是一个函数变化,用来调用htmlUnit。
接下来是一个使用 htmlunit 的类。此类通过支持 JavaScript 解释器来工作,
然后将自己编写的JavaScript代码嵌入到页面中执行,获取执行后的返回结果并返回页面。
package com.blog.anla;
import com.gargoylesoftware.htmlunit.ScriptResult;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
public class TestMyOwnPage {
private void action() {
WebClient webClient = new WebClient();
try {
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true); // 设置支持JavaScript。
// 去拿网页
HtmlPage htmlPage = webClient
.getPage("http://localhost:8989/testHtmlScrop/index.jsp");
String s = "更改后的数字";
ScriptResult t = htmlPage.executeJavaScript("change(\"" + s
+ "\");", "injected script", 500);
// 这里是在500行插入这一小行JavaScript代码段,因为如果在默认的1行,那不会有结果
// 因为js是顺序执行的,当你执行第一行js代码时,可能还没有渲染body里面的标签。
HtmlPage myPage = (HtmlPage) t.getNewPage();
String nextPage = myPage.asXml().toString();
String nextPage2 = myPage.asText().toString();
} catch (Exception e) {
e.printStackTrace();
} finally {
webClient.close();
}
}
public static void main(String[] args) {
TestMyOwnPage tmop = new TestMyOwnPage();
tmop.action();
}
}
t.getNewPage()中有两个属性,一个是
javaScriptResult:执行这段代码后返回的结果,如果有(我上面写的,返回hello htmlunit),如果没有(返回Undefined)。
newPage_:执行此代码后返回的整个页面。
结果如下:
这段代码执行的最终结果如下:
asXml():将整个页面的html代码返回给我们:
而asText()只返回页面上可以显示的值,即head标签和label标签:
这种执行思路还可以动态执行相应的js代码,从而爬取需要的数据。
-------------------------------------------------- --------------------------------------2017 年 7 月更新---------- -------------------------------------- -------------------------------------------------- -----
这两天一直在做一个关于网络爬虫的系统
然而,当我开始攀爬时,我发现了一个问题。js的动态页面爬不下来。
网上找了很多方法,google也问了,主要是指htmlunit,下面是核心代码,
使用htmlunit的主要目的是模拟浏览器操作,因为有些链接点击无法直接通过src获取url,一般使用JavaScript。
简单拼接后的URL,所以用htmlunit直接模拟浏览器点击比较简单。
WebClient webClient = new WebClient();
webClient.getOptions().setJavaScriptEnabled(true); //启用JS解释器,默认为true
webClient.getOptions().setCssEnabled(false); //禁用css支持
webClient.getOptions().setThrowExceptionOnScriptError(false); //js运行错误时,是否抛出异常
webClient.getOptions().setTimeout(20000);
HtmlPage page = wc.getPage("http://www.hao123.com");
//我认为这个最重要
String pageXml = page.asXml(); //以xml的形式获取响应文本
/**jsoup解析文档*/
Document doc = Jsoup.parse(pageXml, "http://cq.qq.com");
这个时候,就可以得到jsoup中的document对象了,接下来就好写了,就像爬普通静态网页一样了。
不过,webclient解析是还是会出现一些问题,js的问题,
主要是由于目标url的js写的有些问题,但在实际的浏览器中却会忽略,eclipse中会报异常。
今天看,好多人踩了,可能我当时没认真写博客吧。如果想找java爬虫项目,可以去我的专栏
图片搜索包括使用jsoup爬取图片,以及lire索引和搜索图片。
玫瑰会在你的手中留下挥之不去的芬芳。有什么问题可以多多讨论! 查看全部
htmlunit抓取动态网页(Java爬取博客阅读文章最多)
更新,这很尴尬,这个文章博客是阅读最多的文章,但也是最被践踏的。
爬取思路:
所谓动态,是指通过请求后台,可以动态改变对应的html页面,开始时页面并不是全部显示出来的。
大多数操作都是通过请求完成的,一个请求,一个返回。在大多数网页中,请求往往被开发者隐藏在 js 代码中。
因此,将爬取动态网页的思路转化为找到对应的js代码并执行对应的js代码,从而可以通过java代码动态改变页面。
而当页面能够正确显示的时候,我们就可以像爬静态网页一样爬取数据了!
首先,可以使用htmlunit来模拟鼠标点击事件,很容易实现:
/**
* 通过htmlunit来获得一些搜狗的网址。
* 通过模拟鼠标点击事件来实现
* @param key
* @return
* @throws Exception
*/
public String getNextUrl(String key){
String page = new String();
try {
WebClient webClient = new WebClient();
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
//去拿网页
HtmlPage htmlPage = webClient.getPage("http://pic.sogou.com/";);
//得到表单
HtmlForm form = htmlPage.getFormByName("searchForm");
//得到提交按钮
HtmlSubmitInput button = form.getInputByValue("搜狗搜索");
//得到输入框
HtmlTextInput textField = form.getInputByName("query");
//输入内容
textField.setValueAttribute(key);
//点一下按钮
HtmlPage nextPage = button.click();
String str = nextPage.toString();
page = cutString(str);
webClient.close();
} catch (Exception e) {
e.printStackTrace();
}
return page;
}
如上图,我只是通过java代码将关键字填入搜索我的,然后通过getInputByValue方法得到按钮控件,最后直接button.click(),
即可以模拟点击,将点击后返回的http请求解析成html页面。

这个功能其实很强大。比如你可以使用这个功能来模拟抢票,或者使用点击事件,加上搜索相关知识,将整个系统下线,并以html的形式保存。
接下来就是使用强大的htmlunit来执行js代码了。
先写一个简单的jsp页面:
Insert title here
原数字
function change(value) {
document.getElementById("test").innerHTML = value;
return "hello htmlUnit";
}
从上面可以看出,jsp页面很简单,只是一个函数变化,用来调用htmlUnit。
接下来是一个使用 htmlunit 的类。此类通过支持 JavaScript 解释器来工作,
然后将自己编写的JavaScript代码嵌入到页面中执行,获取执行后的返回结果并返回页面。
package com.blog.anla;
import com.gargoylesoftware.htmlunit.ScriptResult;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
public class TestMyOwnPage {
private void action() {
WebClient webClient = new WebClient();
try {
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true); // 设置支持JavaScript。
// 去拿网页
HtmlPage htmlPage = webClient
.getPage("http://localhost:8989/testHtmlScrop/index.jsp";);
String s = "更改后的数字";
ScriptResult t = htmlPage.executeJavaScript("change(\"" + s
+ "\");", "injected script", 500);
// 这里是在500行插入这一小行JavaScript代码段,因为如果在默认的1行,那不会有结果
// 因为js是顺序执行的,当你执行第一行js代码时,可能还没有渲染body里面的标签。
HtmlPage myPage = (HtmlPage) t.getNewPage();
String nextPage = myPage.asXml().toString();
String nextPage2 = myPage.asText().toString();
} catch (Exception e) {
e.printStackTrace();
} finally {
webClient.close();
}
}
public static void main(String[] args) {
TestMyOwnPage tmop = new TestMyOwnPage();
tmop.action();
}
}
t.getNewPage()中有两个属性,一个是
javaScriptResult:执行这段代码后返回的结果,如果有(我上面写的,返回hello htmlunit),如果没有(返回Undefined)。
newPage_:执行此代码后返回的整个页面。
结果如下:
这段代码执行的最终结果如下:
asXml():将整个页面的html代码返回给我们:
而asText()只返回页面上可以显示的值,即head标签和label标签:
这种执行思路还可以动态执行相应的js代码,从而爬取需要的数据。
-------------------------------------------------- --------------------------------------2017 年 7 月更新---------- -------------------------------------- -------------------------------------------------- -----
这两天一直在做一个关于网络爬虫的系统
然而,当我开始攀爬时,我发现了一个问题。js的动态页面爬不下来。
网上找了很多方法,google也问了,主要是指htmlunit,下面是核心代码,
使用htmlunit的主要目的是模拟浏览器操作,因为有些链接点击无法直接通过src获取url,一般使用JavaScript。
简单拼接后的URL,所以用htmlunit直接模拟浏览器点击比较简单。
WebClient webClient = new WebClient();
webClient.getOptions().setJavaScriptEnabled(true); //启用JS解释器,默认为true
webClient.getOptions().setCssEnabled(false); //禁用css支持
webClient.getOptions().setThrowExceptionOnScriptError(false); //js运行错误时,是否抛出异常
webClient.getOptions().setTimeout(20000);
HtmlPage page = wc.getPage("http://www.hao123.com";);
//我认为这个最重要
String pageXml = page.asXml(); //以xml的形式获取响应文本
/**jsoup解析文档*/
Document doc = Jsoup.parse(pageXml, "http://cq.qq.com";);
这个时候,就可以得到jsoup中的document对象了,接下来就好写了,就像爬普通静态网页一样了。
不过,webclient解析是还是会出现一些问题,js的问题,
主要是由于目标url的js写的有些问题,但在实际的浏览器中却会忽略,eclipse中会报异常。
今天看,好多人踩了,可能我当时没认真写博客吧。如果想找java爬虫项目,可以去我的专栏
图片搜索包括使用jsoup爬取图片,以及lire索引和搜索图片。
玫瑰会在你的手中留下挥之不去的芬芳。有什么问题可以多多讨论!
htmlunit抓取动态网页(2019独角兽企业重金招聘Python工程师标准(原网页+Javascript返回数据))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-24 09:03
2019独角兽企业招聘Python工程师标准>>>
我在做人人网页爬虫的时候,爬人人新新闻搜索页源码的时候,改curpage=后面的数字后,爬到的内容竟然是一样的,每次都是第一页。在不同的页面右击“查看页面源代码”,发现确实是第一页的新内容,并没有什么变化。
然后右击火狐和“查看元素”,发现每次翻页时只有新闻版块的HTML标签发生变化(闪烁橙色)。估计是用 JAVASCRIPT 来动态更新/加载数据,而不是重新请求一个新的 URL。关联
知道问题后,开始百度,发现这样一篇文章文章:Java抓取网页数据(原网页+Javascript返回数据)
有时网站为了保护自己的数据,不是直接在网页源代码中返回数据,而是采用异步方式用JS返回数据,这样可以避免搜索引擎等工具从网站 数据捕获。
按照博文的方法,一步一步,用火狐查看元素中的“网络”进行分析,发现果然如预期,当页面发生变化时,使用js异步返回数据,而真正的请求的链接自然和你在浏览器中看到的一样。不同的到达。如下所示:
查看响应内容:
真的!正是您正在寻找的!一共10个新故事,一个还不错,正是我们想要的页码
之后,只需将原来爬取HTML页面的java爬虫代码的url改成这个真实的请求地址(而不是在浏览器地址栏中看清楚),其他什么都不需要改。 查看全部
htmlunit抓取动态网页(2019独角兽企业重金招聘Python工程师标准(原网页+Javascript返回数据))
2019独角兽企业招聘Python工程师标准>>>

我在做人人网页爬虫的时候,爬人人新新闻搜索页源码的时候,改curpage=后面的数字后,爬到的内容竟然是一样的,每次都是第一页。在不同的页面右击“查看页面源代码”,发现确实是第一页的新内容,并没有什么变化。
然后右击火狐和“查看元素”,发现每次翻页时只有新闻版块的HTML标签发生变化(闪烁橙色)。估计是用 JAVASCRIPT 来动态更新/加载数据,而不是重新请求一个新的 URL。关联
知道问题后,开始百度,发现这样一篇文章文章:Java抓取网页数据(原网页+Javascript返回数据)
有时网站为了保护自己的数据,不是直接在网页源代码中返回数据,而是采用异步方式用JS返回数据,这样可以避免搜索引擎等工具从网站 数据捕获。
按照博文的方法,一步一步,用火狐查看元素中的“网络”进行分析,发现果然如预期,当页面发生变化时,使用js异步返回数据,而真正的请求的链接自然和你在浏览器中看到的一样。不同的到达。如下所示:

查看响应内容:

真的!正是您正在寻找的!一共10个新故事,一个还不错,正是我们想要的页码
之后,只需将原来爬取HTML页面的java爬虫代码的url改成这个真实的请求地址(而不是在浏览器地址栏中看清楚),其他什么都不需要改。
htmlunit抓取动态网页(需要的jar包代码如下:链接不支持xpath解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-23 02:24
需要的jar包:
1
2 org.jsoup
3 jsoup
4 1.10.3
5
代码如下:
1 // 请求超时时间,30秒
2 public static final int TIME_OUT = 30*1000;
3 // 模拟浏览器请求头信息
4 public static Map headers = new HashMap();
5 static{
6 headers.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0");
7 headers.put("Accept", "text/html");
8 headers.put("Accept-Language", "zh-CN,zh");
9 }
10
11 //根据url获取html文档
12 protected Document getDoc(String url) throws IOException{
13 if(logger.isDebugEnabled())
14 logger.debug(url);
15 //新建一个连接
16 Connection conn = Jsoup.connect(url).timeout(TIME_OUT);
17 conn = conn.headers(headers);
18 conn = conn.proxy(Proxy.NO_PROXY);
19 Document doc = conn.get();
20
21 if(logger.isTraceEnabled()){
22 logger.trace("["+url+"]\n"+doc);
23 }
24 return doc;
25 }
1 public static final String CHINAZ_ICP_URL = "http://icp.chinaz.com/?type=host&s=%s";
2 public List doHandler(String domain) {
3 List results = new ArrayList();
4 String url = String.format(CHINAZ_ICP_URL, domain);
5 Document doc;
6 try {
7 doc = this.getDoc(url);
8 // 获取当前页ICP信息所在标签
9 Elements eles = doc.select("ul.IcpMain01>li:lt(7)>p");
10
11 if(null == eles || eles.isEmpty()){
12 return results;
13 }
14 //获取ICP信息
15 for (Element element : eles) {
16 //当前元素为认证信息时,跳过
17 if("safe".equals(element.attr("id"))){
18 continue;
19 }
20 Node firstNode = element.childNode(0);
21 if(firstNode.childNodeSize() > 0){
22 results.add(element.child(0).text());
23 }else{
24 results.add(((TextNode)firstNode).text());
25 }
26 }
27 } catch (IOException e) {
28 logger.error("get Chinaz ICP message error :",e);
29 }
30 doc = null;
31 return results;
32 }
参考Jsoup的文档:链接
Jsoup不支持xpath解析,很蛋疼,不过有人要弄个支持xpath的东西---JsoupXpath,链接,有兴趣的网友可以自己试试!
三、htmlunit
支持Xpath解析,可以模拟浏览器动作,比如点击下一页,加载越来越多。文档链接:
需要的jar包
1
2 net.sourceforge.htmlunit
3 htmlunit
4 2.18
5
代码如下:
1 import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
2 import com.gargoylesoftware.htmlunit.TopLevelWindow;
3 import com.gargoylesoftware.htmlunit.WebClient;
4 import com.gargoylesoftware.htmlunit.html.HtmlPage;
5 import com.gargoylesoftware.htmlunit.html.HtmlTableRow;
6
7 import java.io.IOException;
8 import java.util.ArrayList;
9 import java.util.List;
10
11
12 public class UrlTest {
13
14 public static void main(String[] args) {
15 BaseCollector baseCollector = new BaseCollector();
16 WebClient webClient = baseCollector.getWebClient();
17 String url="http://htmlunit.sourceforge.net/";
18 HtmlPage homePage= null;
19 try {
20 homePage = webClient.getPage(url);
21 if (homePage != null && homePage instanceof HtmlPage) {
22 homePage.getEnclosingWindow().setName("IpHomePage");
23 System.out.println("打开 IPHomePage ");
24 System.out.println("内容是: "+homePage.getBody().getTextContent());
25
26 List htmlTableRows = (List) homePage.getByXPath("/html/body/pre");
27 if (htmlTableRows != null && htmlTableRows.size() > 0) {
28 for (int i = 0; i < htmlTableRows.size(); i++) {
29 HtmlTableRow htmlTableRow = htmlTableRows.get(i);
30 //日期
31 String firstTime = htmlTableRow.getCell(0).getTextContent().trim();
32 System.out.println(firstTime);
33 }
34
35 }
36 closeWindowByName(webClient, "IPHomePage");
37 System.out.println("关闭 IPHomePage ");
38 }
39 webClient.close();
40
41 } catch (IOException e) {
42 System.out.println(e.getMessage()+" ===="+e);
43 }catch (FailingHttpStatusCodeException e){
44 System.out.println(e.getMessage()+" ===="+e);
45 }
46 System.out.println("内容是: "+homePage.getBody().getTextContent());
47 }
48
49 public static void closeWindowByName(WebClient webClient, String name){
50 List list = webClient.getTopLevelWindows();
51 List windowNames = new ArrayList();
52 for (int j = 0; j < list.size(); j++) {
53 if(list.get(j).getName().equals(name)){
54 list.get(j).close();
55 }
56 windowNames.add(list.get(j).getName());
57 }
58 System.out.println("当前窗口 : {}"+list.toString());
59 }
60 }
61
62
四、HeadlessChrome1,HeadlessChrome 与 PhantomJS 对比
在 Chrome 不提供原生无头模式之前,Web 开发者可以使用 PhantomJS 等第三方无头浏览器。现在 Headless 已经正式准备就绪,PhantomJS 的维护者 VitalySlobodin 在邮件列表中宣布了他的辞职。另一个流行的浏览器 Firefox 也准备提供 Headless 模式。
2、什么是HeadlessChrome
HeadlessChrome 是一种无界面形式的 Chrome 浏览器。您可以使用 Chrome 支持的所有功能运行您的程序,而无需打开浏览器。与现代浏览器相比,HeadlessChrome更方便测试web应用、获取网站的截图、爬取信息等。
3、环境配置
您需要先下载 chrome-driver。不同版本的 Chrome 对应不同的 Chrome 驱动程序。您可以通过此链接下载相应的Chrome驱动程序
支持各种元素的获取,List elements = driver.findElements(By.xpath("//*[@id=\"body\"]/ul[2]/li"));
可以模拟浏览器的各种动作,driver.findElement(By.linkText("Next")).click();
用Python做HeadlessChrome更方便简单,简直太神奇了。 . . . 链接:
你可以参考一下
需要的jar包:
1
2 org.seleniumhq.selenium
3 selenium-chrome-driver
4 3.11.0
5
代码如下:
<p> 1 import org.jsoup.Jsoup;
2 import org.jsoup.nodes.Document;
3 import org.openqa.selenium.By;
4 import org.openqa.selenium.WebDriver;
5 import org.openqa.selenium.WebElement;
6 import org.openqa.selenium.chrome.ChromeDriver;
7 import org.openqa.selenium.chrome.ChromeOptions;
8
9 import java.util.List;
10 import java.util.concurrent.TimeUnit;
11
12 /**
13 * Created by sqy on 2018/5/2.
14 */
15 public class HeadlessChromeTest {
16
17 public static void main(String args[]) {
18
19
20
21 //G:\chromedriver
22 System.setProperty("webdriver.chrome.driver","G:\\chromedriver\\chromedriver.exe");
23 ChromeOptions chromeOptions = new ChromeOptions();
24 // 设置为 headless 模式 (必须)
25 chromeOptions.addArguments("--headless");
26 // 设置浏览器窗口打开大小 (非必须)
27 chromeOptions.addArguments("--window-size=1920,1080");
28 WebDriver driver = new ChromeDriver(chromeOptions);
29 driver.get("https://lvyou.baidu.com/scene/s-feb/");
30
31 System.out.println("url: "+driver.getCurrentUrl());
32
33 for(int i=0;i 查看全部
htmlunit抓取动态网页(需要的jar包代码如下:链接不支持xpath解析)
需要的jar包:
1
2 org.jsoup
3 jsoup
4 1.10.3
5
代码如下:
1 // 请求超时时间,30秒
2 public static final int TIME_OUT = 30*1000;
3 // 模拟浏览器请求头信息
4 public static Map headers = new HashMap();
5 static{
6 headers.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0");
7 headers.put("Accept", "text/html");
8 headers.put("Accept-Language", "zh-CN,zh");
9 }
10
11 //根据url获取html文档
12 protected Document getDoc(String url) throws IOException{
13 if(logger.isDebugEnabled())
14 logger.debug(url);
15 //新建一个连接
16 Connection conn = Jsoup.connect(url).timeout(TIME_OUT);
17 conn = conn.headers(headers);
18 conn = conn.proxy(Proxy.NO_PROXY);
19 Document doc = conn.get();
20
21 if(logger.isTraceEnabled()){
22 logger.trace("["+url+"]\n"+doc);
23 }
24 return doc;
25 }
1 public static final String CHINAZ_ICP_URL = "http://icp.chinaz.com/?type=host&s=%s";
2 public List doHandler(String domain) {
3 List results = new ArrayList();
4 String url = String.format(CHINAZ_ICP_URL, domain);
5 Document doc;
6 try {
7 doc = this.getDoc(url);
8 // 获取当前页ICP信息所在标签
9 Elements eles = doc.select("ul.IcpMain01>li:lt(7)>p");
10
11 if(null == eles || eles.isEmpty()){
12 return results;
13 }
14 //获取ICP信息
15 for (Element element : eles) {
16 //当前元素为认证信息时,跳过
17 if("safe".equals(element.attr("id"))){
18 continue;
19 }
20 Node firstNode = element.childNode(0);
21 if(firstNode.childNodeSize() > 0){
22 results.add(element.child(0).text());
23 }else{
24 results.add(((TextNode)firstNode).text());
25 }
26 }
27 } catch (IOException e) {
28 logger.error("get Chinaz ICP message error :",e);
29 }
30 doc = null;
31 return results;
32 }
参考Jsoup的文档:链接
Jsoup不支持xpath解析,很蛋疼,不过有人要弄个支持xpath的东西---JsoupXpath,链接,有兴趣的网友可以自己试试!
三、htmlunit
支持Xpath解析,可以模拟浏览器动作,比如点击下一页,加载越来越多。文档链接:
需要的jar包
1
2 net.sourceforge.htmlunit
3 htmlunit
4 2.18
5
代码如下:
1 import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
2 import com.gargoylesoftware.htmlunit.TopLevelWindow;
3 import com.gargoylesoftware.htmlunit.WebClient;
4 import com.gargoylesoftware.htmlunit.html.HtmlPage;
5 import com.gargoylesoftware.htmlunit.html.HtmlTableRow;
6
7 import java.io.IOException;
8 import java.util.ArrayList;
9 import java.util.List;
10
11
12 public class UrlTest {
13
14 public static void main(String[] args) {
15 BaseCollector baseCollector = new BaseCollector();
16 WebClient webClient = baseCollector.getWebClient();
17 String url="http://htmlunit.sourceforge.net/";
18 HtmlPage homePage= null;
19 try {
20 homePage = webClient.getPage(url);
21 if (homePage != null && homePage instanceof HtmlPage) {
22 homePage.getEnclosingWindow().setName("IpHomePage");
23 System.out.println("打开 IPHomePage ");
24 System.out.println("内容是: "+homePage.getBody().getTextContent());
25
26 List htmlTableRows = (List) homePage.getByXPath("/html/body/pre");
27 if (htmlTableRows != null && htmlTableRows.size() > 0) {
28 for (int i = 0; i < htmlTableRows.size(); i++) {
29 HtmlTableRow htmlTableRow = htmlTableRows.get(i);
30 //日期
31 String firstTime = htmlTableRow.getCell(0).getTextContent().trim();
32 System.out.println(firstTime);
33 }
34
35 }
36 closeWindowByName(webClient, "IPHomePage");
37 System.out.println("关闭 IPHomePage ");
38 }
39 webClient.close();
40
41 } catch (IOException e) {
42 System.out.println(e.getMessage()+" ===="+e);
43 }catch (FailingHttpStatusCodeException e){
44 System.out.println(e.getMessage()+" ===="+e);
45 }
46 System.out.println("内容是: "+homePage.getBody().getTextContent());
47 }
48
49 public static void closeWindowByName(WebClient webClient, String name){
50 List list = webClient.getTopLevelWindows();
51 List windowNames = new ArrayList();
52 for (int j = 0; j < list.size(); j++) {
53 if(list.get(j).getName().equals(name)){
54 list.get(j).close();
55 }
56 windowNames.add(list.get(j).getName());
57 }
58 System.out.println("当前窗口 : {}"+list.toString());
59 }
60 }
61
62
四、HeadlessChrome1,HeadlessChrome 与 PhantomJS 对比
在 Chrome 不提供原生无头模式之前,Web 开发者可以使用 PhantomJS 等第三方无头浏览器。现在 Headless 已经正式准备就绪,PhantomJS 的维护者 VitalySlobodin 在邮件列表中宣布了他的辞职。另一个流行的浏览器 Firefox 也准备提供 Headless 模式。
2、什么是HeadlessChrome
HeadlessChrome 是一种无界面形式的 Chrome 浏览器。您可以使用 Chrome 支持的所有功能运行您的程序,而无需打开浏览器。与现代浏览器相比,HeadlessChrome更方便测试web应用、获取网站的截图、爬取信息等。
3、环境配置
您需要先下载 chrome-driver。不同版本的 Chrome 对应不同的 Chrome 驱动程序。您可以通过此链接下载相应的Chrome驱动程序
支持各种元素的获取,List elements = driver.findElements(By.xpath("//*[@id=\"body\"]/ul[2]/li"));
可以模拟浏览器的各种动作,driver.findElement(By.linkText("Next")).click();
用Python做HeadlessChrome更方便简单,简直太神奇了。 . . . 链接:
你可以参考一下
需要的jar包:
1
2 org.seleniumhq.selenium
3 selenium-chrome-driver
4 3.11.0
5
代码如下:
<p> 1 import org.jsoup.Jsoup;
2 import org.jsoup.nodes.Document;
3 import org.openqa.selenium.By;
4 import org.openqa.selenium.WebDriver;
5 import org.openqa.selenium.WebElement;
6 import org.openqa.selenium.chrome.ChromeDriver;
7 import org.openqa.selenium.chrome.ChromeOptions;
8
9 import java.util.List;
10 import java.util.concurrent.TimeUnit;
11
12 /**
13 * Created by sqy on 2018/5/2.
14 */
15 public class HeadlessChromeTest {
16
17 public static void main(String args[]) {
18
19
20
21 //G:\chromedriver
22 System.setProperty("webdriver.chrome.driver","G:\\chromedriver\\chromedriver.exe");
23 ChromeOptions chromeOptions = new ChromeOptions();
24 // 设置为 headless 模式 (必须)
25 chromeOptions.addArguments("--headless");
26 // 设置浏览器窗口打开大小 (非必须)
27 chromeOptions.addArguments("--window-size=1920,1080");
28 WebDriver driver = new ChromeDriver(chromeOptions);
29 driver.get("https://lvyou.baidu.com/scene/s-feb/";);
30
31 System.out.println("url: "+driver.getCurrentUrl());
32
33 for(int i=0;i
htmlunit抓取动态网页(代码不好使怎么获取后台js完后的完整页面?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-14 09:10
很多网站使用js或者jquery来生成数据。后台获取数据后,使用 document.write() 或 ("#id").html="" 写入页面,此时用浏览器查看源码是看不到数据的。
HttpClient 不起作用。我在网上看了HtmlUnit,说后台js加载后可以得到完整的页面,但是我按照文章说的写了,还是不行。
String url = "http://xinjinqiao.tprtc.com/ad ... 3B%3B
try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10);
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//webClient.getOptions().setTimeout(50000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url);
System.out.println("为了获取js执行的数据 线程开始沉睡等待");
Thread.sleep(3000);//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡");
String html = rootPage.asText();
System.out.println(html);
} catch (Exception e) {
}
其实这段代码是行不通的。
对于答案,典型的是链接页面,如何获取java程序中的数据? 查看全部
htmlunit抓取动态网页(代码不好使怎么获取后台js完后的完整页面?)
很多网站使用js或者jquery来生成数据。后台获取数据后,使用 document.write() 或 ("#id").html="" 写入页面,此时用浏览器查看源码是看不到数据的。
HttpClient 不起作用。我在网上看了HtmlUnit,说后台js加载后可以得到完整的页面,但是我按照文章说的写了,还是不行。
String url = "http://xinjinqiao.tprtc.com/ad ... 3B%3B
try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10);
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//webClient.getOptions().setTimeout(50000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url);
System.out.println("为了获取js执行的数据 线程开始沉睡等待");
Thread.sleep(3000);//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡");
String html = rootPage.asText();
System.out.println(html);
} catch (Exception e) {
}
其实这段代码是行不通的。
对于答案,典型的是链接页面,如何获取java程序中的数据?
htmlunit抓取动态网页(使用本文中推荐的开源工具——HtmlUnit,一款能够模拟浏览器的抓包神器!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-11 23:14
之前,一峰写过一篇关于使用Jsoup爬取网页内容的文章文章:
[Jsoup] HTML解析器,轻松获取网页内容
Jsoup提供的api非常方便,完全类似于JQuery操作,轻松抓取网页数据。但是像Jsoup这样的普通爬虫工具的缺点是不能处理js生成的内容。
做过Html开发的都知道现在很多网站都是用ajax和JavaScript来获取和处理数据,普通爬虫工具已经无法处理js中的内容了。
比如我们在本地新建一个测试web文件text.html,源码如下:
main.html
a {
line-height: 30px;
margin: 20px;
}
var datas = [ {
href : "http://www.jianshu.com/p/8d8edf25850d",
title : "推荐一款编程字体,让代码看着更美"
}, {
href : "http://www.jianshu.com/p/153d9f31288d",
title : "Android 利用Camera实现中轴3D卡牌翻转效果"
}, {
href : "http://www.jianshu.com/p/d6fb0c9c9c26",
title : "【Eclipse】挖掘专属最有用的快捷键组合"
}, {
href : "http://www.jianshu.com/p/72d69b49d135",
title : "【IIS】Windows下利用IIS建立网站并实现局域网共享"
} ];
window.onload = function() {
var infos = document.getElementById("infos");
for( var i = 0 ; i < datas.length ; i++)
{
var a = document.createElement("a");
a.href = datas[i].href ;
a.innerText = datas[i].title;
infos.appendChild(a);
infos.appendChild(document.createElement("br"))
}
}
HtmlUnit 测试网页内容!
通过IIS发布本地网站(参考之前逸峰写的文章:
【IIS】在Windows下使用IIS建立网站,实现局域网共享),
网页在浏览器中显示的效果如下:
网页显示效果.jpg
虽然通过网页检查元素,可以看到body中收录了网页显示的文字内容:
网络评论元素.jpg
但是,它根本无法通过 Jsoup 工具获得!从网页源码中可以看出,我们需要爬取的内容是在页面显示出来后通过ajax和JavaScript加载的。
那么该怎么办?使用本文推荐的开源工具——HtmlUnit,一个可以模拟浏览器的抓包神器!
在官网下载对应的jar包,添加到项目工程的lib中。简单的测试代码如下:
import java.io.IOException;
import java.net.MalformedURLException;
import java.text.ParseException;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.DomElement;
import com.gargoylesoftware.htmlunit.html.DomNodeList;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
/**
* @author 亦枫
* @created_time 2016年1月12日
* @file_user_todo Java测试类
* @blog http://www.jianshu.com/users/1 ... icles
*/
public class JavaTest {
/**
* 入口函数
* @param args
* @throws ParseException
*/
public static void main(String[] args) throws ParseException {
try {
WebClient webClient = new WebClient(BrowserVersion.CHROME);
HtmlPage htmlPage = (HtmlPage) webClient.getPage("http://localhost/test.html");
DomNodeList domNodeList = htmlPage.getElementsByTagName("a");
for (int i = 0; i < domNodeList.size(); i++) {
DomElement domElement = (DomElement) domNodeList.get(i);
System.out.println(domElement.asText());
}
webClient.close();
} catch (FailingHttpStatusCodeException e) {
e.printStackTrace();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行后,控制台打印出结果:
HtmlUnit测试结果.jpg
可以看出,HtmlUnit 能够抓取 AJAX 和 JavaScript 加载的内容。
HtmlUnit的介绍在官网上很详细。以下内容为易峰翻译的部分内容,供大家参考:
HtmlUnit 是一个基于 Java 的浏览器程序,没有图形界面。它可以调用 HTML 文档并提供 API,使开发人员可以像在普通浏览器上一样访问 Web 内容、填写表单、单击超链接等。
它对 JavaScript 的支持非常好并且还在改进中,可以解析非常复杂的 AJAX 库,模拟不同配置下的 Chrome、Firefox 和 IE 浏览器。
HtmlUnit 通常用于测试目的和检索 网站 信息。
HtmlUnit 提供了很多测试网络请求和爬取网页内容的功能。可以去官网或者其他网站学习使用。 查看全部
htmlunit抓取动态网页(使用本文中推荐的开源工具——HtmlUnit,一款能够模拟浏览器的抓包神器!)
之前,一峰写过一篇关于使用Jsoup爬取网页内容的文章文章:
[Jsoup] HTML解析器,轻松获取网页内容
Jsoup提供的api非常方便,完全类似于JQuery操作,轻松抓取网页数据。但是像Jsoup这样的普通爬虫工具的缺点是不能处理js生成的内容。
做过Html开发的都知道现在很多网站都是用ajax和JavaScript来获取和处理数据,普通爬虫工具已经无法处理js中的内容了。
比如我们在本地新建一个测试web文件text.html,源码如下:
main.html
a {
line-height: 30px;
margin: 20px;
}
var datas = [ {
href : "http://www.jianshu.com/p/8d8edf25850d",
title : "推荐一款编程字体,让代码看着更美"
}, {
href : "http://www.jianshu.com/p/153d9f31288d",
title : "Android 利用Camera实现中轴3D卡牌翻转效果"
}, {
href : "http://www.jianshu.com/p/d6fb0c9c9c26",
title : "【Eclipse】挖掘专属最有用的快捷键组合"
}, {
href : "http://www.jianshu.com/p/72d69b49d135",
title : "【IIS】Windows下利用IIS建立网站并实现局域网共享"
} ];
window.onload = function() {
var infos = document.getElementById("infos");
for( var i = 0 ; i < datas.length ; i++)
{
var a = document.createElement("a");
a.href = datas[i].href ;
a.innerText = datas[i].title;
infos.appendChild(a);
infos.appendChild(document.createElement("br"))
}
}
HtmlUnit 测试网页内容!
通过IIS发布本地网站(参考之前逸峰写的文章:
【IIS】在Windows下使用IIS建立网站,实现局域网共享),
网页在浏览器中显示的效果如下:
网页显示效果.jpg
虽然通过网页检查元素,可以看到body中收录了网页显示的文字内容:
网络评论元素.jpg
但是,它根本无法通过 Jsoup 工具获得!从网页源码中可以看出,我们需要爬取的内容是在页面显示出来后通过ajax和JavaScript加载的。
那么该怎么办?使用本文推荐的开源工具——HtmlUnit,一个可以模拟浏览器的抓包神器!
在官网下载对应的jar包,添加到项目工程的lib中。简单的测试代码如下:
import java.io.IOException;
import java.net.MalformedURLException;
import java.text.ParseException;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.DomElement;
import com.gargoylesoftware.htmlunit.html.DomNodeList;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
/**
* @author 亦枫
* @created_time 2016年1月12日
* @file_user_todo Java测试类
* @blog http://www.jianshu.com/users/1 ... icles
*/
public class JavaTest {
/**
* 入口函数
* @param args
* @throws ParseException
*/
public static void main(String[] args) throws ParseException {
try {
WebClient webClient = new WebClient(BrowserVersion.CHROME);
HtmlPage htmlPage = (HtmlPage) webClient.getPage("http://localhost/test.html";);
DomNodeList domNodeList = htmlPage.getElementsByTagName("a");
for (int i = 0; i < domNodeList.size(); i++) {
DomElement domElement = (DomElement) domNodeList.get(i);
System.out.println(domElement.asText());
}
webClient.close();
} catch (FailingHttpStatusCodeException e) {
e.printStackTrace();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行后,控制台打印出结果:
HtmlUnit测试结果.jpg
可以看出,HtmlUnit 能够抓取 AJAX 和 JavaScript 加载的内容。
HtmlUnit的介绍在官网上很详细。以下内容为易峰翻译的部分内容,供大家参考:
HtmlUnit 是一个基于 Java 的浏览器程序,没有图形界面。它可以调用 HTML 文档并提供 API,使开发人员可以像在普通浏览器上一样访问 Web 内容、填写表单、单击超链接等。
它对 JavaScript 的支持非常好并且还在改进中,可以解析非常复杂的 AJAX 库,模拟不同配置下的 Chrome、Firefox 和 IE 浏览器。
HtmlUnit 通常用于测试目的和检索 网站 信息。
HtmlUnit 提供了很多测试网络请求和爬取网页内容的功能。可以去官网或者其他网站学习使用。
htmlunit抓取动态网页( 基于python(asynchronousjavascriptandxml)的动态网页爬虫系统及其开发方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-09 02:13
基于python(asynchronousjavascriptandxml)的动态网页爬虫系统及其开发方法)
本发明属于计算机领域,涉及爬虫系统,尤其是一种动态网页爬虫系统。
背景技术
网络爬虫是一种自动提取网页的程序。传统爬虫从一个或多个初始网页的url开始,获取初始网页上的url(统一资源定位器),在抓取网页的过程中不断从当前页面中提取。新的url被放入队列中,直到满足系统预设的停止条件。
随着互联网从web1.0时代迅速进入web1.0时代,基于ajax(异步javascript和xml)的动态页面加载技术成为各大公司的首选。随着移动互联网的兴起,javascript在移动端和pc端的优秀特性被广泛挖掘,基于前端mvc/mvm的模型逐渐进入各大互联网公司的首选方案。动态网页的迅速崛起使得基于动态网页的网络爬虫越来越重要。
例如,一个 网站? courseid=id#/学习/视频?课程ID=课程ID&c。通常,对于动态url对应的动态页面,后面跟问号、等号等字符的参数就是要查询的数据库数据。为了获取动态页面的数据,动态页面的内容一般通过浏览器的脚本解析或者渲染动态页面的方式来获取。但是,脚本解析的前提是异步加载信息中存在部分或全部目标动态页面信息,请求规则可以是获取和目标页面有规律的分布;使用浏览器渲染只能针对不完整的DOM(文档对象模型)数据结构,而部分或全部的目标信息存在于使用浏览器渲染中。
技术实施要素:
为了解决脚本解析和浏览器渲染的局限性,提高动态网页爬取的准确性和完整性,本发明提供了一种基于scrapy(scrapy是一个基于python开发的快速、高级的屏幕抓取和网页抓取) Crawl framework)动态网络爬虫系统,包括爬虫引擎、调度器、解析模块、项目管道、下载器,爬虫引擎用于处理数据流和触发事务;
调度器用于接收爬虫引擎或解析模块发送的请求,将请求推入队列调度下载器下载,当爬虫引擎再次请求时返回;
解析模块用于构造或解析动态网页的异步加载信息,分析从下载器中提取的网页中的数据元素;
项目管道用于处理解析器从网页中提取的数据或响应爬虫引擎的请求;
下载器,用于响应调度器的任务请求,下载网页内容,并将网页内容返回给解析器;
解析模块包括脚本解析器、渲染器和切换模块;
脚本解析器通过网络抓包工具搜索查询动态信息的文件类型,根据动态信息的文件类型对动态信息文件的结构进行建模,构造动态网页的请求规则,解析动态网页中的所有文件。并将动态网页的内容提取出来,交给项目管道;如果解析失败,则交由切换模块处理;
渲染器通过加载动态网页的异步加载信息构建完整的动态网页dom树,并通过模拟操作解析出动态网页中服务器返回的异步加载内容,直到动态网页内容完整提取。交给切换模块交给脚本解析器处理;
切换模块检测脚本解析器或渲染器解析动态网页所花费的时间以及解析的内容是否完整,如果所需时间超过阈值或内容不完整则切换。
作为本发明的一个优选方案,渲染器为无界面浏览器。
作为本发明的一个优选方案,无界面浏览器包括selenium、splash、htmlunit、phantomjs。在本发明的一个实施例中,无界面浏览器使用闪屏渲染容器来渲染动态网页。
为了避免使用动态解析或者用浏览器渲染来提取动态网页的盲目性,在本发明的一个实施例中,解析模块还包括预解析模块,从url库中随机抽取样本。然后交给脚本解析器或渲染器进行爬取,记录爬取信息的完整性、爬取时间、资源消耗等。
本发明第二方面的目的在于提供一种动态网页提取方法,包括以下步骤:
s1:获取url库,对url库进行聚类分析,如果有聚类,进行步骤s2,如果没有聚类,结束;
s2:从集群中抽取至少一个随机样本url;
s3:使用脚本解析、渲染,或者脚本解析和渲染相结合的方式爬取url;
s4:记录爬取信息的完整性、爬取时间、资源消耗等信息,通过优先级算法选择最优爬虫方案,使用最优方案爬取集群内所有动态网页;
s5:处理爬取信息,执行步骤s1。
作为本发明的一个优选方案,所述脚本解析还包括:
根据动态网页或URL信息生成请求规则,通过服务器验证获取访问权限,根据请求规则获取异步加载信息。
进一步地,通过服务器的验证包括cookie认证、用户认证、301认证、302认证、图文认证、ip认证。
作为本发明的一个优选方案,所述渲染包括:使用无界面浏览器渲染异步加载的信息,使用无界面浏览器的api模拟用户点击,从模拟事件的结果中提取目标信息.
作为本发明的一种优选方案,脚本解析和渲染混合的具体步骤如下:通过脚本解析获取动态网页的请求规则,然后通过无界面浏览器加载,使用脚本解析解析缺失的渲染参数构造完整的请求规则,直到获得完整的异步加载信息。
作为本发明的优选方案,s4中的优先级算法如下:以提取的动态页面提取信息的完整性、时间、资源消耗率为变量,采用单纯形法得到最优解。
本发明的有益效果是:
1.本发明是对目前大部分动态网页网站的结构和常规动态网页的爬取方法进行分析,利用资源消耗低和脚本解析速度快的优点,并且在渲染方面集成了webdriver爬虫的优点,可以提高爬虫的爬取精度和适应性。
2.设置切换模块,避免使用单一爬取方式时,因特殊情况导致无法爬取,陷入死循环的情况。
3.通过预检测机制,对收录不同动态异步加载机制的动态网页采用不同的爬取策略,提高了解析性能,减少了对内存和网络资源的占用,使得在本发明对动态页面的爬取更具自适应性和智能性。
图纸说明
图1为本发明的基本原理图;
图2为本发明的解析模块框架示意图;
图3是本发明的动态爬取方法的流程图;
图4是本发明采用脚本解析动态网页的流程图;
图5是本发明中采用脚本通过服务器认证结构分析动态网页的组成;
无花果。图6是本发明中脚本解析和渲染的流程图。
详细说明
为更好地理解本发明所提出的技术方案,下面结合附图1-6和具体实施例对本发明作进一步的说明。
如图1和图2所示,动态网络爬虫系统包括爬虫引擎、调度器、解析模块、项目流水线和下载器。
爬虫引擎用于处理数据流和触发事务;
调度器用于接收爬虫引擎或解析模块发送的请求,将请求推入队列调度下载器下载,当爬虫引擎再次请求时返回;
解析模块用于构造或解析动态网页的异步加载信息,分析从下载器中提取的网页中的数据元素;
项目管道用于处理解析器从网页中提取的数据或响应爬虫引擎的请求;
下载器用于响应调度器的任务请求,下载网页内容,并将网页内容返回给解析器;解析模块包括脚本解析器、渲染器和切换模块,
脚本解析器通过网络抓包工具搜索查询动态信息的文件类型,根据动态信息的文件类型对动态信息文件的结构进行建模,构造动态网页的请求规则,解析动态网页中的所有文件。并将动态网页的内容提取出来,交给项目管道;如果解析失败,则交由切换模块处理;
渲染器通过加载动态网页的异步加载信息构建完整的动态网页dom树,并通过模拟操作解析出动态网页中服务器返回的异步加载内容,直到动态网页内容完整提取。交给切换模块交给脚本解析器处理;
切换模块检测脚本解析器或渲染器解析动态网页所花费的时间以及解析的内容是否完整,如果所需时间超过阈值或内容不完整则切换。
在本发明的一个实施例中,切换阈值时间选择为150ms,即当脚本解析或渲染器解析动态页面超过150ms仍无法返回时,切换器切换未解析的url使用的方法。
在本发明的另一个实施例中,考虑到现有爬虫系统可能是分布式架构,可以优化解析时间和资源消耗,因此切换器的切换条件考虑解析出的动态页面的信息是否完整。
在本发明的一个实施例中,渲染器为无界面浏览器,常见的无界面浏览器有benv、browser、launcher、browserjet、casperjs、dalekjsghostbuster、headlessbrowser、htmlunit、jasmine-headless-webkit、jaunt、jbrowserdriver、jedi-爬虫,乐天,噩梦,phantomjs,硒,slimerjs,triflejs,zombie.js。
进一步地,在本发明实施例中,无界面浏览器包括selenium、splash、htmlunit、phantomjs。
进一步地,在本发明的一个实施例中,使用selenium与webdriver或hantomjs相结合的方法进行动态页面提取。
为了避免使用浏览器进行动态解析或渲染的盲目性,在本发明的一个实施例中,解析模块还包括预解析模块,从url库中随机抽取样本,然后提交给脚本解析器或渲染器爬取并记录爬取信息的完整性、爬取时间和资源消耗。
如图4至图6所示,本发明还提供了一种基于上述动态网页爬虫系统的动态网页提取方法,包括以下步骤:
s1:获取url库,对url库进行聚类分析,如果有聚类,进行步骤s2,如果没有聚类,结束;
s2:从集群中抽取至少一个随机样本url;
s3:使用脚本解析、渲染,或者脚本解析和渲染相结合的方式爬取url;
s4:记录爬取信息的完整性、爬取时间、资源消耗等信息,通过优先级算法选择最优爬虫方案,使用最优方案爬取集群内所有动态网页;
s5:处理爬取信息,执行步骤s1。
作为本发明的一个优选方案,所述脚本解析还包括:根据动态网页或网站信息生成请求规则,通过服务器验证获取访问权限,根据请求规则获取异步加载信息。进一步地,通过服务器的验证包括cookie认证、用户认证、301认证、302认证、图文认证、ip认证。
基于以上描述的公开和教导,本发明所属领域的技术人员还可以对上述实施例的相关模块和软件架构进行适应性改变和修改。因此,本发明不限于上述所公开和描述的具体实施例,对本发明的一些修改和变化也应落入本发明权利要求的保护范围之内。此外,虽然在本说明书中使用了一些特定的术语,但这些术语只是为了描述的方便,并不构成对本发明的任何限制。
当前第 1 页,共 12 页 查看全部
htmlunit抓取动态网页(
基于python(asynchronousjavascriptandxml)的动态网页爬虫系统及其开发方法)

本发明属于计算机领域,涉及爬虫系统,尤其是一种动态网页爬虫系统。
背景技术
网络爬虫是一种自动提取网页的程序。传统爬虫从一个或多个初始网页的url开始,获取初始网页上的url(统一资源定位器),在抓取网页的过程中不断从当前页面中提取。新的url被放入队列中,直到满足系统预设的停止条件。
随着互联网从web1.0时代迅速进入web1.0时代,基于ajax(异步javascript和xml)的动态页面加载技术成为各大公司的首选。随着移动互联网的兴起,javascript在移动端和pc端的优秀特性被广泛挖掘,基于前端mvc/mvm的模型逐渐进入各大互联网公司的首选方案。动态网页的迅速崛起使得基于动态网页的网络爬虫越来越重要。
例如,一个 网站? courseid=id#/学习/视频?课程ID=课程ID&c。通常,对于动态url对应的动态页面,后面跟问号、等号等字符的参数就是要查询的数据库数据。为了获取动态页面的数据,动态页面的内容一般通过浏览器的脚本解析或者渲染动态页面的方式来获取。但是,脚本解析的前提是异步加载信息中存在部分或全部目标动态页面信息,请求规则可以是获取和目标页面有规律的分布;使用浏览器渲染只能针对不完整的DOM(文档对象模型)数据结构,而部分或全部的目标信息存在于使用浏览器渲染中。
技术实施要素:
为了解决脚本解析和浏览器渲染的局限性,提高动态网页爬取的准确性和完整性,本发明提供了一种基于scrapy(scrapy是一个基于python开发的快速、高级的屏幕抓取和网页抓取) Crawl framework)动态网络爬虫系统,包括爬虫引擎、调度器、解析模块、项目管道、下载器,爬虫引擎用于处理数据流和触发事务;
调度器用于接收爬虫引擎或解析模块发送的请求,将请求推入队列调度下载器下载,当爬虫引擎再次请求时返回;
解析模块用于构造或解析动态网页的异步加载信息,分析从下载器中提取的网页中的数据元素;
项目管道用于处理解析器从网页中提取的数据或响应爬虫引擎的请求;
下载器,用于响应调度器的任务请求,下载网页内容,并将网页内容返回给解析器;
解析模块包括脚本解析器、渲染器和切换模块;
脚本解析器通过网络抓包工具搜索查询动态信息的文件类型,根据动态信息的文件类型对动态信息文件的结构进行建模,构造动态网页的请求规则,解析动态网页中的所有文件。并将动态网页的内容提取出来,交给项目管道;如果解析失败,则交由切换模块处理;
渲染器通过加载动态网页的异步加载信息构建完整的动态网页dom树,并通过模拟操作解析出动态网页中服务器返回的异步加载内容,直到动态网页内容完整提取。交给切换模块交给脚本解析器处理;
切换模块检测脚本解析器或渲染器解析动态网页所花费的时间以及解析的内容是否完整,如果所需时间超过阈值或内容不完整则切换。
作为本发明的一个优选方案,渲染器为无界面浏览器。
作为本发明的一个优选方案,无界面浏览器包括selenium、splash、htmlunit、phantomjs。在本发明的一个实施例中,无界面浏览器使用闪屏渲染容器来渲染动态网页。
为了避免使用动态解析或者用浏览器渲染来提取动态网页的盲目性,在本发明的一个实施例中,解析模块还包括预解析模块,从url库中随机抽取样本。然后交给脚本解析器或渲染器进行爬取,记录爬取信息的完整性、爬取时间、资源消耗等。
本发明第二方面的目的在于提供一种动态网页提取方法,包括以下步骤:
s1:获取url库,对url库进行聚类分析,如果有聚类,进行步骤s2,如果没有聚类,结束;
s2:从集群中抽取至少一个随机样本url;
s3:使用脚本解析、渲染,或者脚本解析和渲染相结合的方式爬取url;
s4:记录爬取信息的完整性、爬取时间、资源消耗等信息,通过优先级算法选择最优爬虫方案,使用最优方案爬取集群内所有动态网页;
s5:处理爬取信息,执行步骤s1。
作为本发明的一个优选方案,所述脚本解析还包括:
根据动态网页或URL信息生成请求规则,通过服务器验证获取访问权限,根据请求规则获取异步加载信息。
进一步地,通过服务器的验证包括cookie认证、用户认证、301认证、302认证、图文认证、ip认证。
作为本发明的一个优选方案,所述渲染包括:使用无界面浏览器渲染异步加载的信息,使用无界面浏览器的api模拟用户点击,从模拟事件的结果中提取目标信息.
作为本发明的一种优选方案,脚本解析和渲染混合的具体步骤如下:通过脚本解析获取动态网页的请求规则,然后通过无界面浏览器加载,使用脚本解析解析缺失的渲染参数构造完整的请求规则,直到获得完整的异步加载信息。
作为本发明的优选方案,s4中的优先级算法如下:以提取的动态页面提取信息的完整性、时间、资源消耗率为变量,采用单纯形法得到最优解。
本发明的有益效果是:
1.本发明是对目前大部分动态网页网站的结构和常规动态网页的爬取方法进行分析,利用资源消耗低和脚本解析速度快的优点,并且在渲染方面集成了webdriver爬虫的优点,可以提高爬虫的爬取精度和适应性。
2.设置切换模块,避免使用单一爬取方式时,因特殊情况导致无法爬取,陷入死循环的情况。
3.通过预检测机制,对收录不同动态异步加载机制的动态网页采用不同的爬取策略,提高了解析性能,减少了对内存和网络资源的占用,使得在本发明对动态页面的爬取更具自适应性和智能性。
图纸说明
图1为本发明的基本原理图;
图2为本发明的解析模块框架示意图;
图3是本发明的动态爬取方法的流程图;
图4是本发明采用脚本解析动态网页的流程图;
图5是本发明中采用脚本通过服务器认证结构分析动态网页的组成;
无花果。图6是本发明中脚本解析和渲染的流程图。
详细说明
为更好地理解本发明所提出的技术方案,下面结合附图1-6和具体实施例对本发明作进一步的说明。
如图1和图2所示,动态网络爬虫系统包括爬虫引擎、调度器、解析模块、项目流水线和下载器。
爬虫引擎用于处理数据流和触发事务;
调度器用于接收爬虫引擎或解析模块发送的请求,将请求推入队列调度下载器下载,当爬虫引擎再次请求时返回;
解析模块用于构造或解析动态网页的异步加载信息,分析从下载器中提取的网页中的数据元素;
项目管道用于处理解析器从网页中提取的数据或响应爬虫引擎的请求;
下载器用于响应调度器的任务请求,下载网页内容,并将网页内容返回给解析器;解析模块包括脚本解析器、渲染器和切换模块,
脚本解析器通过网络抓包工具搜索查询动态信息的文件类型,根据动态信息的文件类型对动态信息文件的结构进行建模,构造动态网页的请求规则,解析动态网页中的所有文件。并将动态网页的内容提取出来,交给项目管道;如果解析失败,则交由切换模块处理;
渲染器通过加载动态网页的异步加载信息构建完整的动态网页dom树,并通过模拟操作解析出动态网页中服务器返回的异步加载内容,直到动态网页内容完整提取。交给切换模块交给脚本解析器处理;
切换模块检测脚本解析器或渲染器解析动态网页所花费的时间以及解析的内容是否完整,如果所需时间超过阈值或内容不完整则切换。
在本发明的一个实施例中,切换阈值时间选择为150ms,即当脚本解析或渲染器解析动态页面超过150ms仍无法返回时,切换器切换未解析的url使用的方法。
在本发明的另一个实施例中,考虑到现有爬虫系统可能是分布式架构,可以优化解析时间和资源消耗,因此切换器的切换条件考虑解析出的动态页面的信息是否完整。
在本发明的一个实施例中,渲染器为无界面浏览器,常见的无界面浏览器有benv、browser、launcher、browserjet、casperjs、dalekjsghostbuster、headlessbrowser、htmlunit、jasmine-headless-webkit、jaunt、jbrowserdriver、jedi-爬虫,乐天,噩梦,phantomjs,硒,slimerjs,triflejs,zombie.js。
进一步地,在本发明实施例中,无界面浏览器包括selenium、splash、htmlunit、phantomjs。
进一步地,在本发明的一个实施例中,使用selenium与webdriver或hantomjs相结合的方法进行动态页面提取。
为了避免使用浏览器进行动态解析或渲染的盲目性,在本发明的一个实施例中,解析模块还包括预解析模块,从url库中随机抽取样本,然后提交给脚本解析器或渲染器爬取并记录爬取信息的完整性、爬取时间和资源消耗。
如图4至图6所示,本发明还提供了一种基于上述动态网页爬虫系统的动态网页提取方法,包括以下步骤:
s1:获取url库,对url库进行聚类分析,如果有聚类,进行步骤s2,如果没有聚类,结束;
s2:从集群中抽取至少一个随机样本url;
s3:使用脚本解析、渲染,或者脚本解析和渲染相结合的方式爬取url;
s4:记录爬取信息的完整性、爬取时间、资源消耗等信息,通过优先级算法选择最优爬虫方案,使用最优方案爬取集群内所有动态网页;
s5:处理爬取信息,执行步骤s1。
作为本发明的一个优选方案,所述脚本解析还包括:根据动态网页或网站信息生成请求规则,通过服务器验证获取访问权限,根据请求规则获取异步加载信息。进一步地,通过服务器的验证包括cookie认证、用户认证、301认证、302认证、图文认证、ip认证。
基于以上描述的公开和教导,本发明所属领域的技术人员还可以对上述实施例的相关模块和软件架构进行适应性改变和修改。因此,本发明不限于上述所公开和描述的具体实施例,对本发明的一些修改和变化也应落入本发明权利要求的保护范围之内。此外,虽然在本说明书中使用了一些特定的术语,但这些术语只是为了描述的方便,并不构成对本发明的任何限制。
当前第 1 页,共 12 页
htmlunit抓取动态网页(Java环境下的一下配置实现思路 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-03-08 14:17
)
爬取网页数据时,传统的jsoup方案只能对静态页面有效,而一些网页数据往往是由js生成的,此时就需要其他的方案了。
第一个思路是分析js程序,再次爬取js请求,适合爬取特定页面,但要实现不同目标url的通用性比较麻烦。
第二种思路,也比较成熟,就是使用第三方驱动渲染页面,然后下载。这是第二个实现思路。
Selenium 是一个模拟浏览器的自动化测试工具。它提供了一组 API 来与真正的浏览器内核交互。
Java环境下的maven配置如下:
org.seleniumhq.selenium
selenium-java
2.46.0
第三方驱动主要有IEDriver、FirefoxDriver、ChromeDriver、HtmlUnitDriver。
htmlUnit 也是一个自动化测试的工具。您可以使用 HtmlUnit 来模拟浏览器运行并获取执行的 html 页面。其中,HtmlUnitDriver是对htmlUnit的封装。
由于htmlunit对js解析的支持有限,在实际项目中并不常用。
以chrome为例,下载对应的驱动:.
下载驱动时,需要注意与selenium版本的兼容性。可能有例外。一般来说,最好下载最新版本。
在运行程序之前,一定要指定驱动位置,比如在Windows下
System.getProperties().setProperty("webdriver.chrome.driver",
"D:\\chromedriver\\chromedriver.exe");
获取整个页面
public static void testChromeDriver() {
System.getProperties().setProperty("webdriver.chrome.driver",
"D:\\chromedriver\\chromedriver.exe");
WebDriver webDriver = new ChromeDriver();
webDriver.get("http://picture.youth.cn/qtdb/2 ... 6quot;);
String responseBody = webDriver.getPageSource();
System.out.println(responseBody);
webDriver.close();
} 查看全部
htmlunit抓取动态网页(Java环境下的一下配置实现思路
)
爬取网页数据时,传统的jsoup方案只能对静态页面有效,而一些网页数据往往是由js生成的,此时就需要其他的方案了。
第一个思路是分析js程序,再次爬取js请求,适合爬取特定页面,但要实现不同目标url的通用性比较麻烦。
第二种思路,也比较成熟,就是使用第三方驱动渲染页面,然后下载。这是第二个实现思路。
Selenium 是一个模拟浏览器的自动化测试工具。它提供了一组 API 来与真正的浏览器内核交互。
Java环境下的maven配置如下:
org.seleniumhq.selenium
selenium-java
2.46.0
第三方驱动主要有IEDriver、FirefoxDriver、ChromeDriver、HtmlUnitDriver。
htmlUnit 也是一个自动化测试的工具。您可以使用 HtmlUnit 来模拟浏览器运行并获取执行的 html 页面。其中,HtmlUnitDriver是对htmlUnit的封装。
由于htmlunit对js解析的支持有限,在实际项目中并不常用。
以chrome为例,下载对应的驱动:.
下载驱动时,需要注意与selenium版本的兼容性。可能有例外。一般来说,最好下载最新版本。
在运行程序之前,一定要指定驱动位置,比如在Windows下
System.getProperties().setProperty("webdriver.chrome.driver",
"D:\\chromedriver\\chromedriver.exe");
获取整个页面
public static void testChromeDriver() {
System.getProperties().setProperty("webdriver.chrome.driver",
"D:\\chromedriver\\chromedriver.exe");
WebDriver webDriver = new ChromeDriver();
webDriver.get("http://picture.youth.cn/qtdb/2 ... 6quot;);
String responseBody = webDriver.getPageSource();
System.out.println(responseBody);
webDriver.close();
}
htmlunit抓取动态网页(西安蟠龍网络给大家简单的介绍一下动态网页与静态网页的一些简单区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-03-04 02:00
西安盘龙网络将简单介绍一下动态网页和静态网页的一些简单区别:
一、动态网页是指网页与数据库的连接。页面内容根据客户要求显示不同内容,实时读取数据库内容。动态网页一般以.php.asp.jsp等结尾,静态网页一般以.html结尾,内容不变,每个用户看到的内容都是一样的。
二、动态网页是实时读取数据库的,所以速度相对静态网页要慢一些。如果是很大的网站,而且流量很大,那么实时读取数据库需要特别大的服务器。
三、静态网页速度快,URL参数快,对搜索引擎友好,有利于网页收录和排名。
四、静态网页也可以使用ajax技术实现本地动态内容,根据用户请求本地读取数据库数据。
误解:带有动画、飘动等的页面不是动态网页。动态网页是指与数据库的交互,而页面动画、滚动、飘动是用脚本语言 JavaScript 实现的,而不是动态网页的衡量指标。
综上所述,如果网页需要根据不同的用户实时显示不同的内容,就需要使用动态网页。如果网页内容固定或本地内容发生变化,一般采用生成静态网页的方法,这样用户访问速度快,有利于搜索引擎优化,西安盘龙网络提供服务以生成静态网页的形式发给客户!欢迎您来电咨询。 查看全部
htmlunit抓取动态网页(西安蟠龍网络给大家简单的介绍一下动态网页与静态网页的一些简单区别)
西安盘龙网络将简单介绍一下动态网页和静态网页的一些简单区别:
一、动态网页是指网页与数据库的连接。页面内容根据客户要求显示不同内容,实时读取数据库内容。动态网页一般以.php.asp.jsp等结尾,静态网页一般以.html结尾,内容不变,每个用户看到的内容都是一样的。
二、动态网页是实时读取数据库的,所以速度相对静态网页要慢一些。如果是很大的网站,而且流量很大,那么实时读取数据库需要特别大的服务器。
三、静态网页速度快,URL参数快,对搜索引擎友好,有利于网页收录和排名。
四、静态网页也可以使用ajax技术实现本地动态内容,根据用户请求本地读取数据库数据。
误解:带有动画、飘动等的页面不是动态网页。动态网页是指与数据库的交互,而页面动画、滚动、飘动是用脚本语言 JavaScript 实现的,而不是动态网页的衡量指标。
综上所述,如果网页需要根据不同的用户实时显示不同的内容,就需要使用动态网页。如果网页内容固定或本地内容发生变化,一般采用生成静态网页的方法,这样用户访问速度快,有利于搜索引擎优化,西安盘龙网络提供服务以生成静态网页的形式发给客户!欢迎您来电咨询。
htmlunit抓取动态网页(2019独角兽企业重金招聘Python工程师用户体验策略(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-03 11:17
2019独角兽企业招聘Python工程师标准>>>
四、更新政策
互联网实时变化并且非常动态。网页更新策略主要决定何时更新之前已经下载的页面。常见的更新策略有以下三种:
1.历史参考政策
顾名思义,它根据页面过去的历史更新数据来预测未来页面何时会发生变化。通常,预测是通过泊松过程建模来进行的。
2.用户体验策略
尽管搜索引擎可以为某个查询返回大量结果,但用户通常只关注结果的前几页。因此,爬虫系统可以优先更新那些实际在查询结果前几页的页面,然后再更新后面的那些页面。这个更新策略也需要用到历史信息。UX 策略保留网页的多个历史版本,并根据每个过去内容更改对搜索质量的影响得出一个平均值,并以此值作为决定何时重新抓取的基础。
3.聚类抽样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页完全没有历史信息,就无法确定更新策略。
该策略认为网页具有许多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某一类别网页的更新频率,只需对该类别的网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如下:
五、分布式抓取系统结构
一般来说,爬虫系统需要处理整个互联网上数以亿计的网页。单个爬虫不可能完成这样的任务。通常需要多个爬虫程序一起处理它们。一般来说,爬虫系统往往是分布式的三层结构。如图所示:
最底层是分布在不同地理位置的数据中心。每个数据中心有多个爬虫服务器,每个爬虫服务器可能部署多套爬虫程序。这样就构成了一个基本的分布式爬虫系统。
对于数据中心中的不同服务器,有几种方法可以协同工作:
1.主从
主从基本结构如图:
对于主从类型,有一个专门的主服务器来维护要爬取的URL队列,负责每次将URL分发给不同的从服务器,从服务器负责实际的网页下载工作。Master服务器除了维护要爬取的URL队列和分发URL外,还负责调解每个Slave服务器的负载。为了避免一些从服务器过于空闲或过度工作。
在这种模式下,Master往往会成为系统的瓶颈。
2.点对点
等价的基本结构如图所示:
在这种模式下,所有爬虫服务器之间的分工没有区别。每个爬取服务器可以从待爬取的URL队列中获取URL,然后计算该URL主域名的哈希值H,进而计算H mod m(其中m为服务器数量,取上图例如,m 对于 3),计算出来的数字就是处理 URL 的主机号。
例子:假设对于URL,计算器hash值H=8,m=3,那么H mod m=2,那么编号为2的服务器会抓取该链接。假设此时服务器 0 获取了 URL,它会将 URL 传输到服务器 2,服务器 2 将获取它。
这种模式有一个问题,当一个服务器死掉或添加一个新服务器时,所有 URL 的哈希余数的结果都会改变。也就是说,这种方法不能很好地扩展。针对这种情况,提出了另一种改进方案。这种改进的方案是一致的散列以确定服务器划分。其基本结构如图所示:
一致散列对 URL 的主域名进行散列,并将其映射到 0-232 范围内的数字。这个范围平均分配给m台服务器,根据主URL域名的hash运算值的范围来确定要爬取哪个服务器。
如果某台服务器出现问题,本应负责该服务器的网页将由下一个服务器顺时针获取。在这种情况下,即使一台服务器出现问题,也不会影响其他工作。
转载于: 查看全部
htmlunit抓取动态网页(2019独角兽企业重金招聘Python工程师用户体验策略(图))
2019独角兽企业招聘Python工程师标准>>>
四、更新政策
互联网实时变化并且非常动态。网页更新策略主要决定何时更新之前已经下载的页面。常见的更新策略有以下三种:
1.历史参考政策
顾名思义,它根据页面过去的历史更新数据来预测未来页面何时会发生变化。通常,预测是通过泊松过程建模来进行的。
2.用户体验策略
尽管搜索引擎可以为某个查询返回大量结果,但用户通常只关注结果的前几页。因此,爬虫系统可以优先更新那些实际在查询结果前几页的页面,然后再更新后面的那些页面。这个更新策略也需要用到历史信息。UX 策略保留网页的多个历史版本,并根据每个过去内容更改对搜索质量的影响得出一个平均值,并以此值作为决定何时重新抓取的基础。
3.聚类抽样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页完全没有历史信息,就无法确定更新策略。
该策略认为网页具有许多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某一类别网页的更新频率,只需对该类别的网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如下:
五、分布式抓取系统结构
一般来说,爬虫系统需要处理整个互联网上数以亿计的网页。单个爬虫不可能完成这样的任务。通常需要多个爬虫程序一起处理它们。一般来说,爬虫系统往往是分布式的三层结构。如图所示:
最底层是分布在不同地理位置的数据中心。每个数据中心有多个爬虫服务器,每个爬虫服务器可能部署多套爬虫程序。这样就构成了一个基本的分布式爬虫系统。
对于数据中心中的不同服务器,有几种方法可以协同工作:
1.主从
主从基本结构如图:
对于主从类型,有一个专门的主服务器来维护要爬取的URL队列,负责每次将URL分发给不同的从服务器,从服务器负责实际的网页下载工作。Master服务器除了维护要爬取的URL队列和分发URL外,还负责调解每个Slave服务器的负载。为了避免一些从服务器过于空闲或过度工作。
在这种模式下,Master往往会成为系统的瓶颈。
2.点对点
等价的基本结构如图所示:
在这种模式下,所有爬虫服务器之间的分工没有区别。每个爬取服务器可以从待爬取的URL队列中获取URL,然后计算该URL主域名的哈希值H,进而计算H mod m(其中m为服务器数量,取上图例如,m 对于 3),计算出来的数字就是处理 URL 的主机号。
例子:假设对于URL,计算器hash值H=8,m=3,那么H mod m=2,那么编号为2的服务器会抓取该链接。假设此时服务器 0 获取了 URL,它会将 URL 传输到服务器 2,服务器 2 将获取它。
这种模式有一个问题,当一个服务器死掉或添加一个新服务器时,所有 URL 的哈希余数的结果都会改变。也就是说,这种方法不能很好地扩展。针对这种情况,提出了另一种改进方案。这种改进的方案是一致的散列以确定服务器划分。其基本结构如图所示:
一致散列对 URL 的主域名进行散列,并将其映射到 0-232 范围内的数字。这个范围平均分配给m台服务器,根据主URL域名的hash运算值的范围来确定要爬取哪个服务器。
如果某台服务器出现问题,本应负责该服务器的网页将由下一个服务器顺时针获取。在这种情况下,即使一台服务器出现问题,也不会影响其他工作。
转载于:
htmlunit抓取动态网页(“动态网页特点有哪些?什么是动态网站”?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-03-02 07:05
这两年,全球都笼罩在疫情的气氛中。为了减少人与人之间的接触造成的感染,互联网已成为人与人之间的主要交流方式。对此,网站的建设也迎来了飞速发展的阶段。但是,在当前时代要求和消费需求下,很多企业都希望通过互联网给企业带来新的活力,那么“动态网页有什么特点?什么是动态网站”,我们来看看看看
动态网页的特点是什么?
我们将动态网页的一般特征简单总结如下:
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站配合动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是一个独立存在于服务器上的网页文件,服务器只有在用户请求时才返回一个完整的网页;
(4)动态网页中的“?”一般不可能让搜索引擎从一个网站数据库中访问所有网页,或者由于技术原因,搜索蜘蛛不会抓取网址网站动态网页中“?”后面的内容在搜索引擎推广时,为了适应搜索引擎的要求,需要做一定的技术处理。
另外,如果扩展名是.asp但没有连接数据库,它是一个完全静态的页面,也是静态的网站.asp只是一个扩展名。
(5)静态网站因为没有连接数据库,要产生动态网站的效果,需要创建大量的网页,很多只能是假网页。动态网站功能不可用。
什么是动态网站?
Dynamic网站不是指具有动画功能的网站,而是指可以根据不同情况动态改变内容的网站。一般情况下,动态网站Schema 通过数据库。动态网站除了设计网页,还通过数据库和编程让网站拥有更多自动化和高级的功能。动态网站体现在网页一般基于asp、jsp、php、aspx等技术,而静态网页一般以HTML(标准通用标记语言的子集)结尾。动态网站服务器空间配置优于静态网页,要求高,成本也高,但动态网页有利于网站内容的更新,适合企业建站。动态相对于静态网站。
以上是上格信息科技小编整理的《动态网页有什么特点?2021年动态是什么网站》的相关知识,希望对大家有所帮助 查看全部
htmlunit抓取动态网页(“动态网页特点有哪些?什么是动态网站”?)
这两年,全球都笼罩在疫情的气氛中。为了减少人与人之间的接触造成的感染,互联网已成为人与人之间的主要交流方式。对此,网站的建设也迎来了飞速发展的阶段。但是,在当前时代要求和消费需求下,很多企业都希望通过互联网给企业带来新的活力,那么“动态网页有什么特点?什么是动态网站”,我们来看看看看
动态网页的特点是什么?

我们将动态网页的一般特征简单总结如下:
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站配合动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是一个独立存在于服务器上的网页文件,服务器只有在用户请求时才返回一个完整的网页;
(4)动态网页中的“?”一般不可能让搜索引擎从一个网站数据库中访问所有网页,或者由于技术原因,搜索蜘蛛不会抓取网址网站动态网页中“?”后面的内容在搜索引擎推广时,为了适应搜索引擎的要求,需要做一定的技术处理。
另外,如果扩展名是.asp但没有连接数据库,它是一个完全静态的页面,也是静态的网站.asp只是一个扩展名。
(5)静态网站因为没有连接数据库,要产生动态网站的效果,需要创建大量的网页,很多只能是假网页。动态网站功能不可用。
什么是动态网站?

Dynamic网站不是指具有动画功能的网站,而是指可以根据不同情况动态改变内容的网站。一般情况下,动态网站Schema 通过数据库。动态网站除了设计网页,还通过数据库和编程让网站拥有更多自动化和高级的功能。动态网站体现在网页一般基于asp、jsp、php、aspx等技术,而静态网页一般以HTML(标准通用标记语言的子集)结尾。动态网站服务器空间配置优于静态网页,要求高,成本也高,但动态网页有利于网站内容的更新,适合企业建站。动态相对于静态网站。
以上是上格信息科技小编整理的《动态网页有什么特点?2021年动态是什么网站》的相关知识,希望对大家有所帮助
htmlunit抓取动态网页(基于现有的动态网页爬虫系统-DynCrawler系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-02-28 14:12
【摘要】 随着网页数量的爆炸式增长,传统的集中式爬虫难以满足实际应用。此外,Ajax技术在网络应用中的广泛普及,给传统的Web开发带来了新的革命。通过部分刷新功能提升了用户体验,用户可以与远程服务器进行良好的交互。典型应用包括校园论坛、博客网站等。这些大量动态网页的出现给传统的网络爬虫带来了很大的障碍。它影响爬虫的效率,也影响网页内容的获取。针对以上两个问题,本文设计了一种基于WebMagic爬虫框架的分布式动态网络爬虫系统Dis-Dyn Crawler。系统采用SOA架构的思想,将动态网页解析工具HtmlUnit在动态页面过程中的耗时操作分离为一个独立的服务;为了提高解析效率,系统将HtmlUnit所需的JavaScript等文件缓存在Redis数据库中。页面渲染时,不必每次都从网络下载,减少了网络请求,提高了解析效率;异步页面下载器的实现进一步提高了系统的整体效率。本文从功能和性能两个方面对Dis-Dyn Crawler系统进行了实验分析。通过与现有分布式网络爬虫工具的爬取能力对比,验证了本文基于Webmagic的动态网络爬虫是高效的。通过与现有动态网页解析工具的对比,验证了本文提出的Dis-Dyn爬虫系统的效率和可行性。 查看全部
htmlunit抓取动态网页(基于现有的动态网页爬虫系统-DynCrawler系统)
【摘要】 随着网页数量的爆炸式增长,传统的集中式爬虫难以满足实际应用。此外,Ajax技术在网络应用中的广泛普及,给传统的Web开发带来了新的革命。通过部分刷新功能提升了用户体验,用户可以与远程服务器进行良好的交互。典型应用包括校园论坛、博客网站等。这些大量动态网页的出现给传统的网络爬虫带来了很大的障碍。它影响爬虫的效率,也影响网页内容的获取。针对以上两个问题,本文设计了一种基于WebMagic爬虫框架的分布式动态网络爬虫系统Dis-Dyn Crawler。系统采用SOA架构的思想,将动态网页解析工具HtmlUnit在动态页面过程中的耗时操作分离为一个独立的服务;为了提高解析效率,系统将HtmlUnit所需的JavaScript等文件缓存在Redis数据库中。页面渲染时,不必每次都从网络下载,减少了网络请求,提高了解析效率;异步页面下载器的实现进一步提高了系统的整体效率。本文从功能和性能两个方面对Dis-Dyn Crawler系统进行了实验分析。通过与现有分布式网络爬虫工具的爬取能力对比,验证了本文基于Webmagic的动态网络爬虫是高效的。通过与现有动态网页解析工具的对比,验证了本文提出的Dis-Dyn爬虫系统的效率和可行性。
htmlunit抓取动态网页(Python开发的一个快速,高层次高层次架构架构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-02-27 11:00
8.参考文章
0x01 爬虫架构
说到爬虫架构,不得不提Scrapy的爬虫架构。Scrapy 是一个用 Python 开发的快速、高级的爬虫框架,用于爬取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还为各种类型的爬虫提供了基类,例如BaseSpider、站点地图爬虫等。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
0x02 页面下载和解析页面下载
页面下载分为静态下载和动态下载两种方式。
传统爬虫采用静态下载方式。静态下载的好处是下载过程很快,但是页面只是一个乏味的html。所以在页面链接分析中只获取标签的href属性,或者高手自行分析js、form等标签。捕获一些链接。在python中,可以使用urllib2模块或者requests模块来实现功能。动态爬虫在 web2.0 时代具有特殊的优势。由于网页是通过javascript处理的,所以网页的内容是通过Ajax异步获取的。因此,动态爬虫需要对页面经过javascript处理和ajax进行分析才能获取内容。目前简单的解决方法是直接通过基于 webkit 的模块来处理它。PYQT4、的三个模块 Splinter 和 Selenium 都可以达到目的。对于爬虫来说,不需要浏览器界面,所以使用无头浏览器是非常划算的。HtmlUnit 和 phantomjs 都是可以使用的无头浏览器。
以上代码是访问新浪网的主站。通过比较静态爬虫页面和动态爬虫页面的长度,比较静态爬虫页面和动态爬虫页面爬取的链接数。
静态爬取时,页面长度为563838,页面内爬取的链接数只有166个。动态爬取时,页面长度增加到695991,链接数达到1422,接近10-倍增。
抓取链接表达式
常规:pile(“href=\”([^\”]*)\””)
Xpath: xpath('//*[@href]')
页面解析
页面解析是一个模块,它捕获页面内的链接并爬取特定数据。页面解析主要处理的是字符串,而html是一个特殊的字符串。在Python中,re、beautifulsoup、HTMLParser、lxml等模块都可以解决问题。对于链接,主要是抓取a标签下的href属性,以及其他一些标签的src属性。
0x03 URL去重
URL去重是爬虫操作的关键步骤。由于正在运行的爬虫主要被阻塞在网络交互中,因此避免重复的网络交互非常重要。爬虫一般将要爬取的 URL 放入队列中,从爬取的网页中提取新的 URL。在将它们放入队列之前,它们必须首先确保这些新 URL 未被抓取。如果之前已经爬过,不再放入队列中。
哈希表
使用哈希表进行去重一般是最容易想到的方法,因为哈希表查询的时间复杂度是O(1),而当哈希表足够大的时候,哈希冲突的概率就变得非常高了所以判断URL是否重复的准确率是很高的,使用哈希表去重是比较简单的解决方案,但是普通的哈希表也有明显的缺陷,考虑到内存,使用大的哈希表是不合适。字典数据结构可以在Python中使用。
网址压缩
如果在哈希表中,当每个节点以str的形式存储一个特定的URL时,是非常占用内存的。如果将 URL 压缩成 int 类型的变量,内存使用量将减少 3 倍以上。因此,您可以使用 Python 的 hashlib 模块进行 URL 压缩。思路:将哈希表的节点数据结构设置为集合,将压缩后的URL存放在集合中。
布隆过滤器
Bloom Filter 可以节省大量存储空间,而且错误很少。Bloom Filter 是一组定义在 n 个输入键上的 k 个哈希函数,将上述 n 个键映射到 m 位上的数据容器。
上图清楚地说明了布隆过滤器的优势。在可控容器长度内,当所有哈希函数对同一元素计算的哈希值为1时,判断该元素存在。Python中的hashlib自带了多种hash函数,包括MD5、sha1、sha224、sha256、sha384、sha512。代码也可以加盐,非常方便。Bloom Filter 也会造成冲突,详见文章末尾的参考文章。
在Python编程过程中,可以使用jaybaird提供的BloomFilter接口,也可以自己搭建轮子。
细节
有个小细节,在构建哈希表的时候选择容器很重要。哈希表占用太多空间是一个非常令人不快的问题。因此,以下方法可以解决爬虫去重的一些问题。
上面的代码只是简单地验证了生成容器的运行时间。
从上图可以看出,在构建一个长度为1亿的容器时,选择列表容器程序耗时7.2s,选择一个字符串作为运行时间的容器。
接下来,查看内存使用情况。
如果构建一个1亿的列表占用794660k的内存。
但是创建一个1亿长度的字符串会占用109,720k的内存,空间占用减少了大约700,000k。
0x04 网址相似度
主要算法
对于URL相似度,我只是实践了一个很简单的方法。
在保证不重复爬取的情况下,还需要对相似的URL进行判断。我使用海绵和ly5066113提供的想法。具体信息参考文章。
下面是一组可以判断为相似的URL组
正如预期的那样,上面的 URL 应该合并到
思路如下,需要提取以下特征
1、主机串
2.目录深度(用'/'隔开)
3. 最后一页功能
具体算法
算法本身很好,一看就懂。
实际效果:
上图显示了8个不同的url,计算了2个值。通过实践,在上千万的哈希表中,冲突情况是可以接受的。
0x05 并发操作
Python中并发操作涉及的主要模型有:多线程模型、多进程模型、协程模型。Elias 专门写了一篇文章文章,对比了几种常用模型并发方案的性能。对于爬虫本身来说,限制爬虫的速度主要来自于目标服务器的响应速度,所以选择一个容易控制的模块是对的。
多线程模型
多线程模型是最容易上手的。Python自带的threading模块可以很好的实现并发需求,配合Queue模块实现数据共享。
多进程模型
多处理模型类似于多线程模型,多处理模块中有类似的Queue模块来实现数据共享。在linux中,用户态进程可以利用多核,所以在多核的上下文中,可以解决爬虫并发的问题。
协程模型
协程模型,在 Elias 的 文章 中,基于 greenlet 的协程程序的性能仅次于 Stackless Python,速度大约是 Stackless Python 的两倍,比其他解决方案快近一个数量级。因此,基于gevent(封装greenlets)的并发程序将具有良好的性能优势。
具体描述gevent(非阻塞异步IO)。, “Gevent是一个基于协程的Python网络库,使用Greenlet提供的高级同步API,封装了libevent事件循环。”
从实际编程效果来看,协程模型确实表现得非常好,运行结果的可控性明显更强,gevent库的封装非常好用。
0x06 数据存储
有许多技术是为数据存储本身而设计的。作为配菜不敢多说,但还是有一些工作中的小经验可以分享。
前提:使用关系型数据库,测试中选择mysql,其他和sqlite差不多,和SqlServer的思路没有区别。
我们做数据存储的时候,目的是减少与数据库的交互,这样可以提高性能。通常,每读取一个 URL 节点,就进行一次数据存储,这样的逻辑就会进行一次无限循环。其实这样的性能体验很差,存储速度也很慢。
对于高级方法,为了减少与数据库的交互次数,每次与数据库的交互从发送1个节点变为发送10个节点到发送100个节点内容,因此效率提高了10到100倍。在实际应用中,效果非常好。:D 查看全部
htmlunit抓取动态网页(Python开发的一个快速,高层次高层次架构架构)
8.参考文章
0x01 爬虫架构
说到爬虫架构,不得不提Scrapy的爬虫架构。Scrapy 是一个用 Python 开发的快速、高级的爬虫框架,用于爬取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还为各种类型的爬虫提供了基类,例如BaseSpider、站点地图爬虫等。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
0x02 页面下载和解析页面下载
页面下载分为静态下载和动态下载两种方式。
传统爬虫采用静态下载方式。静态下载的好处是下载过程很快,但是页面只是一个乏味的html。所以在页面链接分析中只获取标签的href属性,或者高手自行分析js、form等标签。捕获一些链接。在python中,可以使用urllib2模块或者requests模块来实现功能。动态爬虫在 web2.0 时代具有特殊的优势。由于网页是通过javascript处理的,所以网页的内容是通过Ajax异步获取的。因此,动态爬虫需要对页面经过javascript处理和ajax进行分析才能获取内容。目前简单的解决方法是直接通过基于 webkit 的模块来处理它。PYQT4、的三个模块 Splinter 和 Selenium 都可以达到目的。对于爬虫来说,不需要浏览器界面,所以使用无头浏览器是非常划算的。HtmlUnit 和 phantomjs 都是可以使用的无头浏览器。
以上代码是访问新浪网的主站。通过比较静态爬虫页面和动态爬虫页面的长度,比较静态爬虫页面和动态爬虫页面爬取的链接数。

静态爬取时,页面长度为563838,页面内爬取的链接数只有166个。动态爬取时,页面长度增加到695991,链接数达到1422,接近10-倍增。
抓取链接表达式
常规:pile(“href=\”([^\”]*)\””)
Xpath: xpath('//*[@href]')
页面解析
页面解析是一个模块,它捕获页面内的链接并爬取特定数据。页面解析主要处理的是字符串,而html是一个特殊的字符串。在Python中,re、beautifulsoup、HTMLParser、lxml等模块都可以解决问题。对于链接,主要是抓取a标签下的href属性,以及其他一些标签的src属性。
0x03 URL去重
URL去重是爬虫操作的关键步骤。由于正在运行的爬虫主要被阻塞在网络交互中,因此避免重复的网络交互非常重要。爬虫一般将要爬取的 URL 放入队列中,从爬取的网页中提取新的 URL。在将它们放入队列之前,它们必须首先确保这些新 URL 未被抓取。如果之前已经爬过,不再放入队列中。
哈希表
使用哈希表进行去重一般是最容易想到的方法,因为哈希表查询的时间复杂度是O(1),而当哈希表足够大的时候,哈希冲突的概率就变得非常高了所以判断URL是否重复的准确率是很高的,使用哈希表去重是比较简单的解决方案,但是普通的哈希表也有明显的缺陷,考虑到内存,使用大的哈希表是不合适。字典数据结构可以在Python中使用。
网址压缩
如果在哈希表中,当每个节点以str的形式存储一个特定的URL时,是非常占用内存的。如果将 URL 压缩成 int 类型的变量,内存使用量将减少 3 倍以上。因此,您可以使用 Python 的 hashlib 模块进行 URL 压缩。思路:将哈希表的节点数据结构设置为集合,将压缩后的URL存放在集合中。
布隆过滤器
Bloom Filter 可以节省大量存储空间,而且错误很少。Bloom Filter 是一组定义在 n 个输入键上的 k 个哈希函数,将上述 n 个键映射到 m 位上的数据容器。
上图清楚地说明了布隆过滤器的优势。在可控容器长度内,当所有哈希函数对同一元素计算的哈希值为1时,判断该元素存在。Python中的hashlib自带了多种hash函数,包括MD5、sha1、sha224、sha256、sha384、sha512。代码也可以加盐,非常方便。Bloom Filter 也会造成冲突,详见文章末尾的参考文章。
在Python编程过程中,可以使用jaybaird提供的BloomFilter接口,也可以自己搭建轮子。
细节
有个小细节,在构建哈希表的时候选择容器很重要。哈希表占用太多空间是一个非常令人不快的问题。因此,以下方法可以解决爬虫去重的一些问题。
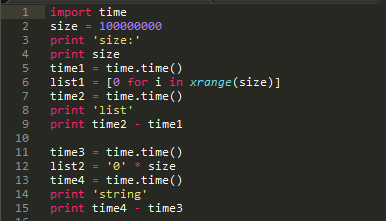
上面的代码只是简单地验证了生成容器的运行时间。
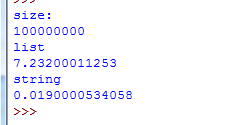
从上图可以看出,在构建一个长度为1亿的容器时,选择列表容器程序耗时7.2s,选择一个字符串作为运行时间的容器。
接下来,查看内存使用情况。
如果构建一个1亿的列表占用794660k的内存。
但是创建一个1亿长度的字符串会占用109,720k的内存,空间占用减少了大约700,000k。
0x04 网址相似度
主要算法
对于URL相似度,我只是实践了一个很简单的方法。
在保证不重复爬取的情况下,还需要对相似的URL进行判断。我使用海绵和ly5066113提供的想法。具体信息参考文章。
下面是一组可以判断为相似的URL组
正如预期的那样,上面的 URL 应该合并到
思路如下,需要提取以下特征
1、主机串
2.目录深度(用'/'隔开)
3. 最后一页功能
具体算法
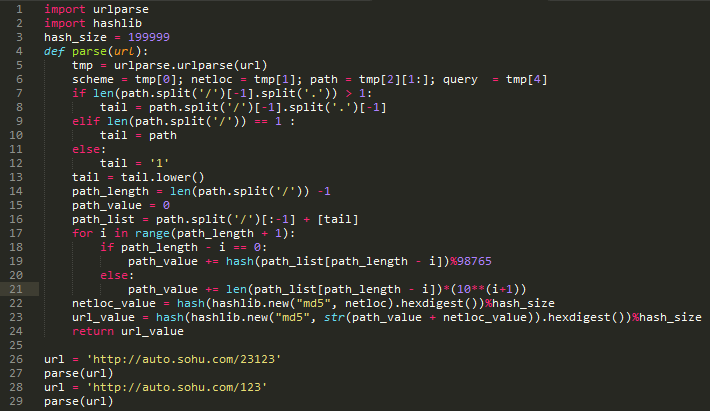
算法本身很好,一看就懂。
实际效果:
上图显示了8个不同的url,计算了2个值。通过实践,在上千万的哈希表中,冲突情况是可以接受的。
0x05 并发操作
Python中并发操作涉及的主要模型有:多线程模型、多进程模型、协程模型。Elias 专门写了一篇文章文章,对比了几种常用模型并发方案的性能。对于爬虫本身来说,限制爬虫的速度主要来自于目标服务器的响应速度,所以选择一个容易控制的模块是对的。
多线程模型
多线程模型是最容易上手的。Python自带的threading模块可以很好的实现并发需求,配合Queue模块实现数据共享。
多进程模型
多处理模型类似于多线程模型,多处理模块中有类似的Queue模块来实现数据共享。在linux中,用户态进程可以利用多核,所以在多核的上下文中,可以解决爬虫并发的问题。
协程模型
协程模型,在 Elias 的 文章 中,基于 greenlet 的协程程序的性能仅次于 Stackless Python,速度大约是 Stackless Python 的两倍,比其他解决方案快近一个数量级。因此,基于gevent(封装greenlets)的并发程序将具有良好的性能优势。
具体描述gevent(非阻塞异步IO)。, “Gevent是一个基于协程的Python网络库,使用Greenlet提供的高级同步API,封装了libevent事件循环。”
从实际编程效果来看,协程模型确实表现得非常好,运行结果的可控性明显更强,gevent库的封装非常好用。
0x06 数据存储
有许多技术是为数据存储本身而设计的。作为配菜不敢多说,但还是有一些工作中的小经验可以分享。
前提:使用关系型数据库,测试中选择mysql,其他和sqlite差不多,和SqlServer的思路没有区别。
我们做数据存储的时候,目的是减少与数据库的交互,这样可以提高性能。通常,每读取一个 URL 节点,就进行一次数据存储,这样的逻辑就会进行一次无限循环。其实这样的性能体验很差,存储速度也很慢。
对于高级方法,为了减少与数据库的交互次数,每次与数据库的交互从发送1个节点变为发送10个节点到发送100个节点内容,因此效率提高了10到100倍。在实际应用中,效果非常好。:D
htmlunit抓取动态网页(编程之家为你收集整理的全部内容(1,3)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-27 10:23
概述如果要使用自定义登录页面的动态管理资源,最简单的方法是在数据库中将登录页面对应的权限设置为IS_AUTHENTICATED_ANONYMOUSLY。所以在数据库中添加一个资源信息。INSERT INTO RESC VALUES(1,'','URL','/login.jsp*',1,'') 这里/login.jsp*是我们自定义登录页面的地址。然后为匿名用户添加一个角色信息: INSERT INTO ROLE VALUES(3,'IS_AUTHENTICATED_ANONYMOUSLY','anonymous') 最后将这两条记录关联起来。INSERT INTO RESC_ROLE VALUES(1,3)这样实现了动态管理资源和自定义登录页面的结合,例子在ch008。
如果要一起使用动态管理资源,最简单的方法是在数据库中将登录页面对应的权限设置为IS_AUTHENTICATED_ANONYMOUSLY。
所以在数据库中添加一个资源信息。
INSERT INTO RESC VALUES(1,'','URL','/login.jsP*',1,'')
这里 /login.jsP* 是我们的地址。
然后为匿名用户添加一个角色信息:
INSERT INTO ROLE VALUES(3,'IS_AUTHENTICATED_ANONYMOUSLY','anonymous')
最后,您可以将这两条记录关联起来。
INSERT INTO RESC_ROLE VALUES(1,3)
这样,资源的动态管理与执行相结合。
示例在 ch008 中。
总结
以上就是编程之家采集整理的spring security动态管理资源结合自定义登录页面的全部内容。希望文章可以帮助大家解决spring security动态管理资源结合自定义登录页面遇到的程序开发问题。.
如果你觉得编程之家网站的内容还不错,欢迎你把编程之家网站推荐给你的程序员朋友。 查看全部
htmlunit抓取动态网页(编程之家为你收集整理的全部内容(1,3)(图))
概述如果要使用自定义登录页面的动态管理资源,最简单的方法是在数据库中将登录页面对应的权限设置为IS_AUTHENTICATED_ANONYMOUSLY。所以在数据库中添加一个资源信息。INSERT INTO RESC VALUES(1,'','URL','/login.jsp*',1,'') 这里/login.jsp*是我们自定义登录页面的地址。然后为匿名用户添加一个角色信息: INSERT INTO ROLE VALUES(3,'IS_AUTHENTICATED_ANONYMOUSLY','anonymous') 最后将这两条记录关联起来。INSERT INTO RESC_ROLE VALUES(1,3)这样实现了动态管理资源和自定义登录页面的结合,例子在ch008。
如果要一起使用动态管理资源,最简单的方法是在数据库中将登录页面对应的权限设置为IS_AUTHENTICATED_ANONYMOUSLY。
所以在数据库中添加一个资源信息。
INSERT INTO RESC VALUES(1,'','URL','/login.jsP*',1,'')
这里 /login.jsP* 是我们的地址。
然后为匿名用户添加一个角色信息:
INSERT INTO ROLE VALUES(3,'IS_AUTHENTICATED_ANONYMOUSLY','anonymous')
最后,您可以将这两条记录关联起来。
INSERT INTO RESC_ROLE VALUES(1,3)
这样,资源的动态管理与执行相结合。
示例在 ch008 中。
总结
以上就是编程之家采集整理的spring security动态管理资源结合自定义登录页面的全部内容。希望文章可以帮助大家解决spring security动态管理资源结合自定义登录页面遇到的程序开发问题。.
如果你觉得编程之家网站的内容还不错,欢迎你把编程之家网站推荐给你的程序员朋友。
htmlunit抓取动态网页(HtmlUnit+Jsoup背景在开发爬虫进行动态规则)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-02-26 00:17
HtmlUnit + Jsoup
背景
在开发爬虫用动态规则爬取数据的时候,遇到HtmlUnit登录后无法访问cookie的情况,网上的一系列文章都失效了;
HtmlUnit
可以理解为一个沙盒浏览器,会得到整个网页的最终显示代码(包括动态加载数据的js),人眼看到的就是你得到的
汤
只访问网页内容(不包括js执行后的动态内容),优点是可以通过jquery选择器提取元素,如#id、.class等。htmlUnit只能从文档原生js中提取
问题描述
html单元代码
/** HtmlUnit请求web页面 */
WebClient wc = new WebClient(BrowserVersion.CHROME);
wc.getOptions().setUseInsecureSSL(true);
wc.getOptions().setJavaScriptEnabled(true); // 启用JS解释器,默认为true
wc.getOptions().setCssEnabled(false); // 禁用css支持
wc.getOptions().setThrowExceptionOnScriptError(false); // js运行错误时,是否抛出异常
wc.getOptions().setTimeout(10 * 1000); // 设置连接超时时间 ,这里是10S。如果为0,则无限期等待
wc.waitForBackgroundJavaScript(10 * 1000); // 等待js后台执行30秒
wc.getOptions().setDoNotTrackEnabled(false);
//其他文章一贯的cookie设置方式-无效
//wc.getCookieManager().addCookie(new Cookie("domain域名","JSESSIONID","11"));
//改为以下方式
wc.addCookie("Cookie value长串不需要切割",new URL("目标网址"),"domain域名");
HtmlPage page = wc.getPage("目标网址");
另外遇到以下棘手问题(未解决)
<p>//失败:通过改变支持ajax支持方式
wc.setAjaxControllr(new NicelyResynchronizingAjaxController());
//失败:循环判断内容,增加js-ajax执行时间
for (int i = 0; i 查看全部
htmlunit抓取动态网页(HtmlUnit+Jsoup背景在开发爬虫进行动态规则)
HtmlUnit + Jsoup
背景
在开发爬虫用动态规则爬取数据的时候,遇到HtmlUnit登录后无法访问cookie的情况,网上的一系列文章都失效了;
HtmlUnit
可以理解为一个沙盒浏览器,会得到整个网页的最终显示代码(包括动态加载数据的js),人眼看到的就是你得到的
汤
只访问网页内容(不包括js执行后的动态内容),优点是可以通过jquery选择器提取元素,如#id、.class等。htmlUnit只能从文档原生js中提取
问题描述
html单元代码
/** HtmlUnit请求web页面 */
WebClient wc = new WebClient(BrowserVersion.CHROME);
wc.getOptions().setUseInsecureSSL(true);
wc.getOptions().setJavaScriptEnabled(true); // 启用JS解释器,默认为true
wc.getOptions().setCssEnabled(false); // 禁用css支持
wc.getOptions().setThrowExceptionOnScriptError(false); // js运行错误时,是否抛出异常
wc.getOptions().setTimeout(10 * 1000); // 设置连接超时时间 ,这里是10S。如果为0,则无限期等待
wc.waitForBackgroundJavaScript(10 * 1000); // 等待js后台执行30秒
wc.getOptions().setDoNotTrackEnabled(false);
//其他文章一贯的cookie设置方式-无效
//wc.getCookieManager().addCookie(new Cookie("domain域名","JSESSIONID","11"));
//改为以下方式
wc.addCookie("Cookie value长串不需要切割",new URL("目标网址"),"domain域名");
HtmlPage page = wc.getPage("目标网址");
另外遇到以下棘手问题(未解决)
<p>//失败:通过改变支持ajax支持方式
wc.setAjaxControllr(new NicelyResynchronizingAjaxController());
//失败:循环判断内容,增加js-ajax执行时间
for (int i = 0; i
htmlunit抓取动态网页(开源的Java页面分析工具,被誉为Java浏览器的开源实现 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-02-23 13:20
)
一、简介
它是一个开源的Java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容
可以模拟浏览器的操作,被称为Java浏览器的开源实现
1、是一个无界面浏览器Java程序
对HTML文档进行建模,提供调用页面、填写表单、单机链接等API。
和浏览器一样
2、拥有不断改进的 JavaScript 支持,甚至可以使用相当复杂的 AJAX 库
根据配置模拟 Chrome、Firefox 或 IE 等浏览器
3、通常用于测试或从网站检索信息二、使用场景
一般情况下,可以使用Apache的HttpClient组件来获取HTML页面信息。 HttpClient实现的http请求返回的响应一般是纯文本文档页面,也就是最原创的html页面。
对于静态页面,使用HttpClient爬取所需信息。
但是对于动态网页,更多的数据是通过异步JS代码获取和渲染的,初始的html页面是不收录这部分数据的。
三、代码演示
1、获取页面
public class HtmlUnitDemo {
public static void main(String[] args) throws IOException {
String str;
// 创建一个 webClient
// WebClient webClient = new WebClient(); // 任意浏览器打开
WebClient webClient = new WebClient(BrowserVersion.CHROME); // 使用 Chrome 读取页面
// htmlunit 对 JS 和 CSS 的支持不好,所以关闭
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
// 获取页面
HtmlPage page = webClient.getPage("http://www.baidu.com"); // 抛出 IOException
// System.out.println(page);
// 获取页面的标题
str = page.getTitleText();
System.out.println("Title: " + str);
// 获取页面的 XML 代码
str = page.asXml();
System.out.println("XML: \n" + str);
// 获取页面的文本
str = page.asText();
System.out.println("文本: \n" + str);
// 关闭 webClient
webClient.close();
}
}
2、获取页面的指定元素
public class HtmlUnitDemo {
public static void main(String[] args) throws IOException {
// 创建一个 webClient
// WebClient webClient = new WebClient(); // 任意浏览器打开
WebClient webClient = new WebClient(BrowserVersion.CHROME); // 使用 Chrome 读取页面
// htmlunit 对 JS 和 CSS 的支持不好,所以关闭
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = webClient.getPage("http://www.baidu.com");
// 获得页面的指定元素
// 通过 id 获得“百度一下”按钮
HtmlInput btn = page.getHtmlElementById("su");
System.out.println(btn.getDefaultValue());
// 关闭 webClient
webClient.close();
}
}
3、元素检索
public class HtmlUnitDemo {
public static void main(String[] args) throws IOException {
// 创建一个 webClient
// WebClient webClient = new WebClient(); // 任意浏览器打开
WebClient webClient = new WebClient(BrowserVersion.CHROME); // 使用 Chrome 读取页面
// htmlunit 对 JS 和 CSS 的支持不好,所以关闭
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = webClient.getPage("http://www.baidu.com");
// 元素检索
// 查找所有的 div
List hbList = page.getByXPath("//div");
// System.out.println(hbList);
HtmlDivision hb = (HtmlDivision)hbList.get(0); // 只获取第一个 div
System.out.println(hb.toString());
// 查找并获取特定的 input
List inputList = page.getByXPath("//input[@id='su']");
HtmlInput input = (HtmlInput) inputList.get(0);
System.out.println(input.toString());
// 关闭 webClient
webClient.close();
}
}
4、提交搜索
public class HtmlUnitDemo {
public static void main(String[] args) throws IOException {
// 创建一个 webClient
// WebClient webClient = new WebClient(); // 任意浏览器打开
WebClient webClient = new WebClient(BrowserVersion.CHROME); // 使用 Chrome 读取页面
// htmlunit 对 JS 和 CSS 的支持不好,所以关闭
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = webClient.getPage("http://www.baidu.com");
// 提交搜索
// 获取搜索输入框并提交搜索内容
HtmlInput input = page.getHtmlElementById("kw");
System.out.println(input.toString());
input.setValueAttribute("htmlunit API");
System.out.println(input.toString());
// 获取搜索按钮并点击
HtmlInput btn = page.getHtmlElementById("su");
HtmlPage page1 = btn.click();
// 输出新页面的文本
System.out.println(page1.asText());
// 关闭 webClient
webClient.close();
}
} 查看全部
htmlunit抓取动态网页(开源的Java页面分析工具,被誉为Java浏览器的开源实现
)
一、简介
它是一个开源的Java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容
可以模拟浏览器的操作,被称为Java浏览器的开源实现
1、是一个无界面浏览器Java程序
对HTML文档进行建模,提供调用页面、填写表单、单机链接等API。
和浏览器一样
2、拥有不断改进的 JavaScript 支持,甚至可以使用相当复杂的 AJAX 库
根据配置模拟 Chrome、Firefox 或 IE 等浏览器
3、通常用于测试或从网站检索信息二、使用场景
一般情况下,可以使用Apache的HttpClient组件来获取HTML页面信息。 HttpClient实现的http请求返回的响应一般是纯文本文档页面,也就是最原创的html页面。
对于静态页面,使用HttpClient爬取所需信息。
但是对于动态网页,更多的数据是通过异步JS代码获取和渲染的,初始的html页面是不收录这部分数据的。
三、代码演示
1、获取页面
public class HtmlUnitDemo {
public static void main(String[] args) throws IOException {
String str;
// 创建一个 webClient
// WebClient webClient = new WebClient(); // 任意浏览器打开
WebClient webClient = new WebClient(BrowserVersion.CHROME); // 使用 Chrome 读取页面
// htmlunit 对 JS 和 CSS 的支持不好,所以关闭
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
// 获取页面
HtmlPage page = webClient.getPage("http://www.baidu.com";); // 抛出 IOException
// System.out.println(page);
// 获取页面的标题
str = page.getTitleText();
System.out.println("Title: " + str);
// 获取页面的 XML 代码
str = page.asXml();
System.out.println("XML: \n" + str);
// 获取页面的文本
str = page.asText();
System.out.println("文本: \n" + str);
// 关闭 webClient
webClient.close();
}
}
2、获取页面的指定元素
public class HtmlUnitDemo {
public static void main(String[] args) throws IOException {
// 创建一个 webClient
// WebClient webClient = new WebClient(); // 任意浏览器打开
WebClient webClient = new WebClient(BrowserVersion.CHROME); // 使用 Chrome 读取页面
// htmlunit 对 JS 和 CSS 的支持不好,所以关闭
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = webClient.getPage("http://www.baidu.com";);
// 获得页面的指定元素
// 通过 id 获得“百度一下”按钮
HtmlInput btn = page.getHtmlElementById("su");
System.out.println(btn.getDefaultValue());
// 关闭 webClient
webClient.close();
}
}
3、元素检索
public class HtmlUnitDemo {
public static void main(String[] args) throws IOException {
// 创建一个 webClient
// WebClient webClient = new WebClient(); // 任意浏览器打开
WebClient webClient = new WebClient(BrowserVersion.CHROME); // 使用 Chrome 读取页面
// htmlunit 对 JS 和 CSS 的支持不好,所以关闭
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = webClient.getPage("http://www.baidu.com";);
// 元素检索
// 查找所有的 div
List hbList = page.getByXPath("//div");
// System.out.println(hbList);
HtmlDivision hb = (HtmlDivision)hbList.get(0); // 只获取第一个 div
System.out.println(hb.toString());
// 查找并获取特定的 input
List inputList = page.getByXPath("//input[@id='su']");
HtmlInput input = (HtmlInput) inputList.get(0);
System.out.println(input.toString());
// 关闭 webClient
webClient.close();
}
}
4、提交搜索
public class HtmlUnitDemo {
public static void main(String[] args) throws IOException {
// 创建一个 webClient
// WebClient webClient = new WebClient(); // 任意浏览器打开
WebClient webClient = new WebClient(BrowserVersion.CHROME); // 使用 Chrome 读取页面
// htmlunit 对 JS 和 CSS 的支持不好,所以关闭
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = webClient.getPage("http://www.baidu.com";);
// 提交搜索
// 获取搜索输入框并提交搜索内容
HtmlInput input = page.getHtmlElementById("kw");
System.out.println(input.toString());
input.setValueAttribute("htmlunit API");
System.out.println(input.toString());
// 获取搜索按钮并点击
HtmlInput btn = page.getHtmlElementById("su");
HtmlPage page1 = btn.click();
// 输出新页面的文本
System.out.println(page1.asText());
// 关闭 webClient
webClient.close();
}
}
htmlunit抓取动态网页(搜狗微信公众号更新公告(2015.03.23) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-02-23 06:13
)
最后更新于 2018.1.3
只为自己留个记录
要添加的功能:
1.获取历史中的所有消息
2. 爬取10多条数据
3.公众号信息自定义抓取
下面是搜狗微信公众号搜索微信公众号的例子!
搜狗微信公众号作为分析入口:[此处填写公众号]&ie=utf8&sug=n&sug_type=
DEMO 中的完整 URL 为:%E6%AF%8F%E6%97%A5%E8%8A%82%E5%A5%8F&ie=utf8&sug=n&sug_type=
package cc.buckler.test;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.junit.Test;
import java.io.IOException;
public class TestData {
private String ENTRY_URL = "http://weixin.sogou.com/weixin ... %3B//入口地址
private String QUERY_WORD = "DOTA每日节奏";//查询参数
private String BASE_URL = "";//从入口进入公众号后的公众号地址
private String WE_CHAT_URL = "http://mp.weixin.qq.com";//微信公众号官方入口
private int NEW_MSG_ID = 0;//最新msgId
private int MSG_NUM = 20;//需要获取的数量
@Test
public void getData() {
String url = String.format(ENTRY_URL, QUERY_WORD);
//System.out.println(url);
WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setRedirectEnabled(true);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setTimeout(50000);
Document doc = null;
try {
//首先用jsoup获取搜狗入口公众号连接
doc = Jsoup.connect(url).get();
//System.out.println("doc:" + doc);
BASE_URL = doc.select("p a").attr("href");
//System.out.println(BASE_URL);
//使用htmlunit加载公众号文章列表
HtmlPage htmlPage = webClient.getPage(BASE_URL);
webClient.waitForBackgroundJavaScript(10000);
doc = Jsoup.parse(htmlPage.asXml());
//System.out.println("doc:" + doc);
//获取最新文章msgid,之后的循环用msgid-1
String lastMsgId = doc.select(".weui_media_box").attr("msgid");
NEW_MSG_ID = Integer.parseInt(lastMsgId);
//System.out.println(NEW_MSG_ID);
for (int i = NEW_MSG_ID; i >= NEW_MSG_ID - MSG_NUM; i--) {
String articalPrev = "#WXAPPMSG";
String articalId = articalPrev + i;
String h4 = articalId + " h4";
String weui_media_desc = articalId + " .weui_media_desc";
String weui_media_extra_info = articalId + " .weui_media_extra_info";
System.out.println(articalId);
String title = doc.select(h4).text();
System.out.println(title);
String detailUrl = doc.select(h4).attr("hrefs");//2018.1.3 ok
System.out.println(WE_CHAT_URL + detailUrl);
String note = doc.select(weui_media_desc).text();//2018.1.3 ok
if (note.compareToIgnoreCase("") == 0) {
continue;
}
System.out.println(note);
String releaseDate = doc.select(weui_media_extra_info).text().toString();//2018.1.3 ok
if (releaseDate.compareToIgnoreCase("") == 0) {
continue;
}
System.out.println(releaseDate);
}
webClient.close();
} catch (IOException e) {
e.printStackTrace();
webClient.close();
}
}
} 查看全部
htmlunit抓取动态网页(搜狗微信公众号更新公告(2015.03.23)
)
最后更新于 2018.1.3
只为自己留个记录
要添加的功能:
1.获取历史中的所有消息
2. 爬取10多条数据
3.公众号信息自定义抓取
下面是搜狗微信公众号搜索微信公众号的例子!
搜狗微信公众号作为分析入口:[此处填写公众号]&ie=utf8&sug=n&sug_type=
DEMO 中的完整 URL 为:%E6%AF%8F%E6%97%A5%E8%8A%82%E5%A5%8F&ie=utf8&sug=n&sug_type=
package cc.buckler.test;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.junit.Test;
import java.io.IOException;
public class TestData {
private String ENTRY_URL = "http://weixin.sogou.com/weixin ... %3B//入口地址
private String QUERY_WORD = "DOTA每日节奏";//查询参数
private String BASE_URL = "";//从入口进入公众号后的公众号地址
private String WE_CHAT_URL = "http://mp.weixin.qq.com";//微信公众号官方入口
private int NEW_MSG_ID = 0;//最新msgId
private int MSG_NUM = 20;//需要获取的数量
@Test
public void getData() {
String url = String.format(ENTRY_URL, QUERY_WORD);
//System.out.println(url);
WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setRedirectEnabled(true);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setTimeout(50000);
Document doc = null;
try {
//首先用jsoup获取搜狗入口公众号连接
doc = Jsoup.connect(url).get();
//System.out.println("doc:" + doc);
BASE_URL = doc.select("p a").attr("href");
//System.out.println(BASE_URL);
//使用htmlunit加载公众号文章列表
HtmlPage htmlPage = webClient.getPage(BASE_URL);
webClient.waitForBackgroundJavaScript(10000);
doc = Jsoup.parse(htmlPage.asXml());
//System.out.println("doc:" + doc);
//获取最新文章msgid,之后的循环用msgid-1
String lastMsgId = doc.select(".weui_media_box").attr("msgid");
NEW_MSG_ID = Integer.parseInt(lastMsgId);
//System.out.println(NEW_MSG_ID);
for (int i = NEW_MSG_ID; i >= NEW_MSG_ID - MSG_NUM; i--) {
String articalPrev = "#WXAPPMSG";
String articalId = articalPrev + i;
String h4 = articalId + " h4";
String weui_media_desc = articalId + " .weui_media_desc";
String weui_media_extra_info = articalId + " .weui_media_extra_info";
System.out.println(articalId);
String title = doc.select(h4).text();
System.out.println(title);
String detailUrl = doc.select(h4).attr("hrefs");//2018.1.3 ok
System.out.println(WE_CHAT_URL + detailUrl);
String note = doc.select(weui_media_desc).text();//2018.1.3 ok
if (note.compareToIgnoreCase("") == 0) {
continue;
}
System.out.println(note);
String releaseDate = doc.select(weui_media_extra_info).text().toString();//2018.1.3 ok
if (releaseDate.compareToIgnoreCase("") == 0) {
continue;
}
System.out.println(releaseDate);
}
webClient.close();
} catch (IOException e) {
e.printStackTrace();
webClient.close();
}
}
}
htmlunit抓取动态网页(如何实现静态页面名字和动态页面的名字的含义?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-02-22 05:00
在构建非常大的 网站 时,动态生成的网页是必不可少的。但是,动态页面的名称(即其 URL)往往缺乏明确的含义。例如,名为 product.asp?Id=4 的页面不像名为 /applicances/dishwashers/Model3809.htm 的页面那样令人难忘。本文介绍如何实现静态页面名称与动态页面的映射。
概述
除了静态页面名称更有意义的优势之外,另一个优势是搜索引擎可以索引这些页面。大多数搜索引擎,如 Alta Vista 和 Yahoo,不会检索 URL 中带有问号的页面,因为它们担心会进入一个永无止境的链接迷宫。将动态页面名称转换为静态页面名称后,搜索引擎会对这些页面进行索引和分类,从而为网站带来更多流量。
要使用本文中描述的方法将动态名称转换为静态名称,您必须使用 Windows 2000 和 IIS 5.0。IIS 5.0 中使这种转换成为可能的两项改进是:使用 Server.Transfer 的“自定义错误消息”功能和在 ASP 页面中使用 Server.Transfer 的能力。虽然IIS4.0也支持自定义错误信息,但是它使用了Response.Redirect,没什么用,所以这个方法需要使用IIS5.0。Response.Redirect 是无用的,因为搜索引擎不遵循重定向。
使用本文中描述的方法,网站开发人员首先使用静态样式 URL 链接实际不存在的页面。然后设置 IIS 服务器并告诉它使用指定的 ASP 页面 (404.asp) 来处理 网站 上的所有 404 错误。在这个 404.asp 页面中,将原创 URL 转换为正式的动态 URL,用 Server.Transfer 执行,将目标页面返回给用户的浏览器。
假设您有以下网址:
替换为网站的域名,会返回404错误。我们要做的第一件事是使用一些专用的 .asp 页面来处理所有这些 404 错误。这可以使用 IIS 5.0 的“自定义错误消息”功能来完成。设置此功能的过程如下:
●在MMC中打开IIS服务器管理器
● 右键单击 Web网站 节点并选择属性
●点击“自定义错误信息”页面
●向下滚动直到找到 404 错误
双击 404 错误以打开错误映射属性对话框
●将消息类型更改为URL
●在URL框中输入“/404.asp” 查看全部
htmlunit抓取动态网页(如何实现静态页面名字和动态页面的名字的含义?)
在构建非常大的 网站 时,动态生成的网页是必不可少的。但是,动态页面的名称(即其 URL)往往缺乏明确的含义。例如,名为 product.asp?Id=4 的页面不像名为 /applicances/dishwashers/Model3809.htm 的页面那样令人难忘。本文介绍如何实现静态页面名称与动态页面的映射。
概述
除了静态页面名称更有意义的优势之外,另一个优势是搜索引擎可以索引这些页面。大多数搜索引擎,如 Alta Vista 和 Yahoo,不会检索 URL 中带有问号的页面,因为它们担心会进入一个永无止境的链接迷宫。将动态页面名称转换为静态页面名称后,搜索引擎会对这些页面进行索引和分类,从而为网站带来更多流量。
要使用本文中描述的方法将动态名称转换为静态名称,您必须使用 Windows 2000 和 IIS 5.0。IIS 5.0 中使这种转换成为可能的两项改进是:使用 Server.Transfer 的“自定义错误消息”功能和在 ASP 页面中使用 Server.Transfer 的能力。虽然IIS4.0也支持自定义错误信息,但是它使用了Response.Redirect,没什么用,所以这个方法需要使用IIS5.0。Response.Redirect 是无用的,因为搜索引擎不遵循重定向。
使用本文中描述的方法,网站开发人员首先使用静态样式 URL 链接实际不存在的页面。然后设置 IIS 服务器并告诉它使用指定的 ASP 页面 (404.asp) 来处理 网站 上的所有 404 错误。在这个 404.asp 页面中,将原创 URL 转换为正式的动态 URL,用 Server.Transfer 执行,将目标页面返回给用户的浏览器。
假设您有以下网址:
替换为网站的域名,会返回404错误。我们要做的第一件事是使用一些专用的 .asp 页面来处理所有这些 404 错误。这可以使用 IIS 5.0 的“自定义错误消息”功能来完成。设置此功能的过程如下:
●在MMC中打开IIS服务器管理器
● 右键单击 Web网站 节点并选择属性
●点击“自定义错误信息”页面
●向下滚动直到找到 404 错误
双击 404 错误以打开错误映射属性对话框
●将消息类型更改为URL
●在URL框中输入“/404.asp”
htmlunit抓取动态网页(搜索引擎来说静态页面的优点和html结尾有什么区别?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-02-22 04:23
首先,原则上我们要知道,静态页面对于搜索引擎来说绝对是最好的,具有最快的抓取和响应速度。另外,伪静态链接本质上是动态链接,只是动态链接是通过相应的算法规则伪装的。进入静态链接,htm或者html结束页面一般都是静态或者伪静态页面。本站采用伪静态处理,一小部分是我自己写的静态页面。zblog 主题静态插件可以在商店中找到并使用。
一、动态链接地址(例如 /?13.sd234554 )
一般来说,带有问号等参数的链接可以称为动态链接。与程序开发相比,这一步一般都会做。
优点:占用空间很小,使用动态页面时文件会很小,因为数据是从数据库中调出来的。如果需要修改某个具体的值,可以直接在数据库上修改,然后所有的动态页面都会自动更新。现在,服务器的数据占用会很小,特别是一些大公司平台本身的数据量是企业级的。
(据我所知,很多b2b平台每次生成一个页面都需要几个小时来更新缓存)
缺点:由于需要进行计算,用户访问速度较慢,动态页面的数据是从数据库中获取的。如果访问者数量很大,对数据库的压力就会很大。虽然目前的动态程序大多使用缓存技术,但总的来说,动态页面对服务器的压力更大。同时,动态页面的网站一般对服务器有更高的要求,同时访问的人越多,对服务器的压力就越大。另外,对于搜索引擎来说,动态页面是非常不友好的,所以也会有爬取和收录,但是相比其他静态和伪静态,还是少了很多。很多懂SEO的公司都会做伪静态处理。.
二、静态链接地址(例如 /2343.html )
优点:与其他两种动态和伪静态页面相比,静态页面的访问速度最快,而且访问时不需要从数据库中调用数据,不仅访问速度快,而且不会造成服务器上的任何压力。
缺点:由于数据全部存储在HTML中,文件数据非常大。更严重的是,如果需要更改,必须更改所有源代码,而不仅仅是一个地方。而如果是很大的网站,就会有很多数据,占用大部分服务器空间资源,每次添加内容都会生成一个新的静态页面。它比动态和伪静态更麻烦。
三、伪静态链接地址
优点:结合了动态链接和静态链接,主要是让搜索引擎把自己的网页当成静态页面
缺点:如果流量有轻微波动,使用伪静态会导致CPU使用率超载。由于伪静态使用的是正则判断而不是真实地址,所以区分显示哪个页面的职责也是直接指定并转交给CPU,所以CPU占用的增加确实是伪静态最大的缺点。
总结:我个人建议小网站单页,以后很少更新。可以使用静态页面。如果批量多或大网站建议使用伪静态页面,而动态页面适合无搜索引擎爬取。对于注册、会员等功能,对于需要登录的功能,建议使用动态页面。
PS:如果肉眼无法判断是静态页面还是伪静态怎么办?我们可以在谷歌浏览器(360也可以使用谷歌内核)、火狐浏览器等中按crtl+shift+j打开控制台,在控制台输入alert()代码,记录当前页面的时间,然后重新输入一遍,并再次记录时间,如果每次时间都不一样,则可以判断该页面是伪静态页面。 查看全部
htmlunit抓取动态网页(搜索引擎来说静态页面的优点和html结尾有什么区别?)
首先,原则上我们要知道,静态页面对于搜索引擎来说绝对是最好的,具有最快的抓取和响应速度。另外,伪静态链接本质上是动态链接,只是动态链接是通过相应的算法规则伪装的。进入静态链接,htm或者html结束页面一般都是静态或者伪静态页面。本站采用伪静态处理,一小部分是我自己写的静态页面。zblog 主题静态插件可以在商店中找到并使用。

一、动态链接地址(例如 /?13.sd234554 )
一般来说,带有问号等参数的链接可以称为动态链接。与程序开发相比,这一步一般都会做。
优点:占用空间很小,使用动态页面时文件会很小,因为数据是从数据库中调出来的。如果需要修改某个具体的值,可以直接在数据库上修改,然后所有的动态页面都会自动更新。现在,服务器的数据占用会很小,特别是一些大公司平台本身的数据量是企业级的。
(据我所知,很多b2b平台每次生成一个页面都需要几个小时来更新缓存)
缺点:由于需要进行计算,用户访问速度较慢,动态页面的数据是从数据库中获取的。如果访问者数量很大,对数据库的压力就会很大。虽然目前的动态程序大多使用缓存技术,但总的来说,动态页面对服务器的压力更大。同时,动态页面的网站一般对服务器有更高的要求,同时访问的人越多,对服务器的压力就越大。另外,对于搜索引擎来说,动态页面是非常不友好的,所以也会有爬取和收录,但是相比其他静态和伪静态,还是少了很多。很多懂SEO的公司都会做伪静态处理。.
二、静态链接地址(例如 /2343.html )
优点:与其他两种动态和伪静态页面相比,静态页面的访问速度最快,而且访问时不需要从数据库中调用数据,不仅访问速度快,而且不会造成服务器上的任何压力。
缺点:由于数据全部存储在HTML中,文件数据非常大。更严重的是,如果需要更改,必须更改所有源代码,而不仅仅是一个地方。而如果是很大的网站,就会有很多数据,占用大部分服务器空间资源,每次添加内容都会生成一个新的静态页面。它比动态和伪静态更麻烦。
三、伪静态链接地址
优点:结合了动态链接和静态链接,主要是让搜索引擎把自己的网页当成静态页面
缺点:如果流量有轻微波动,使用伪静态会导致CPU使用率超载。由于伪静态使用的是正则判断而不是真实地址,所以区分显示哪个页面的职责也是直接指定并转交给CPU,所以CPU占用的增加确实是伪静态最大的缺点。
总结:我个人建议小网站单页,以后很少更新。可以使用静态页面。如果批量多或大网站建议使用伪静态页面,而动态页面适合无搜索引擎爬取。对于注册、会员等功能,对于需要登录的功能,建议使用动态页面。
PS:如果肉眼无法判断是静态页面还是伪静态怎么办?我们可以在谷歌浏览器(360也可以使用谷歌内核)、火狐浏览器等中按crtl+shift+j打开控制台,在控制台输入alert()代码,记录当前页面的时间,然后重新输入一遍,并再次记录时间,如果每次时间都不一样,则可以判断该页面是伪静态页面。
htmlunit抓取动态网页(中小微公司网络爬虫技术总结及解决办法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-31 11:19
网络爬虫技术总结
对于大数据行业来说,数据的价值不言而喻。在这个信息爆炸的时代,互联网上的信息数据太多了。对于中小微企业来说,合理利用爬虫爬取有价值的数据,是为了弥补自身先天的数据短缺。板子的最佳选择,本文主要从爬虫原理、架构、分类和反爬虫技术方面总结了爬虫技术。
1、爬虫技术概述
网络爬虫是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。它们广泛应用于互联网搜索引擎或其他类似的网站,并且可以自动采集所有它可以访问的页面的内容来获取或更新这些网站的内容和检索方式. 从功能上来说,爬虫一般分为数据采集、处理、存储三部分。
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。另外,爬虫爬取的所有网页都会被系统存储,进行一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1)爬取目标的描述或定义;
(2)网页或数据的分析和过滤;
(3)URL 的搜索策略。
2、爬虫原理
2.1网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、SqlServer等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。.
这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,因此广度优先搜索算法一般使用采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个网址,下载其对应的网页,
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列;
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历路径:AF-GE-H-IBCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDE-FGHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4PartialPageRank 策略
PartialPageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值。计算完成后,计算待爬取的URL队列中的URL。按 PageRank 值排序并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发使Nutch适合提取业务,那你基本上会破坏Nutch的框架,把Nutch改得面目全非,而且有能力修改Nutch,还不如自己写一个新的。分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。事实上,这是针对Nutch的声誉。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发很简单,难点和复杂的问题已经被前人解决了(比如DOM树解析定位、字符集检测、海量URL去重),可以说没有技术含量。包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于deepweb(深网)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSSSELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给Spider进行分析,将要保存的数据发送到ItemPipeline。那就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,无论大小。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力较差,经常会循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这样的反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
[评论:它经常很容易被忽视。通过对请求的抓包分析,确定referer并添加到程序中模拟访问请求的header中]
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一页面,或者同一账号在短时间内多次执行同一操作。 查看全部
htmlunit抓取动态网页(中小微公司网络爬虫技术总结及解决办法(一))
网络爬虫技术总结
对于大数据行业来说,数据的价值不言而喻。在这个信息爆炸的时代,互联网上的信息数据太多了。对于中小微企业来说,合理利用爬虫爬取有价值的数据,是为了弥补自身先天的数据短缺。板子的最佳选择,本文主要从爬虫原理、架构、分类和反爬虫技术方面总结了爬虫技术。
1、爬虫技术概述
网络爬虫是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。它们广泛应用于互联网搜索引擎或其他类似的网站,并且可以自动采集所有它可以访问的页面的内容来获取或更新这些网站的内容和检索方式. 从功能上来说,爬虫一般分为数据采集、处理、存储三部分。
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。另外,爬虫爬取的所有网页都会被系统存储,进行一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1)爬取目标的描述或定义;
(2)网页或数据的分析和过滤;
(3)URL 的搜索策略。
2、爬虫原理
2.1网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、SqlServer等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。.
这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,因此广度优先搜索算法一般使用采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个网址,下载其对应的网页,
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列;
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历路径:AF-GE-H-IBCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDE-FGHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4PartialPageRank 策略
PartialPageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值。计算完成后,计算待爬取的URL队列中的URL。按 PageRank 值排序并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发使Nutch适合提取业务,那你基本上会破坏Nutch的框架,把Nutch改得面目全非,而且有能力修改Nutch,还不如自己写一个新的。分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。事实上,这是针对Nutch的声誉。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发很简单,难点和复杂的问题已经被前人解决了(比如DOM树解析定位、字符集检测、海量URL去重),可以说没有技术含量。包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于deepweb(深网)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSSSELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给Spider进行分析,将要保存的数据发送到ItemPipeline。那就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,无论大小。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力较差,经常会循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这样的反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
[评论:它经常很容易被忽视。通过对请求的抓包分析,确定referer并添加到程序中模拟访问请求的header中]
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一页面,或者同一账号在短时间内多次执行同一操作。
htmlunit抓取动态网页(网站的爬虫调试的时候发现问题(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-30 02:04
网站的爬虫脚本在调试时发现问题:
脚本运行:content-type用text/xml可以发帖成功,但是post中body的内容不生效,所有回复都是当前日期;有申请,发帖不成功(即没有返回数据)
工具发:content-type用text/xml可以发帖成功,但是post中body的内容不生效,所有回复都是当前日期;有申请,发帖成功,正文中日期修改有效
即用型脚本完全没有接收到返回的数据,但是很奇怪可以使用工具fiddler或者Burpsuite来正常查看包的内容。直到后来才发现我爬的网站是动态的==
动态网页(参考百度百科:%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5/6327050)
-------------------------------------------------- ------------------
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是通过动态网站技术生成的,都可以称为动态网页。
总之,动态网页是基本的html语法规范与Java、VB、VC等高级编程语言、数据库编程等技术的融合,以实现网站@的高效、动态、交互的内容和风格。 > 管理。因此,从这个意义上说,任何由网页编程技术结合HTML以外的高级编程语言和数据库技术生成的网页都是动态网页。
-------------------------------------------------- ------------------
也可以解释为动态网页不执行javascript,仅使用data=response.read()获取的静态html没有要爬取的内容
网上用Python解决这个问题只有两种方法:采集内容直接来自JavaScript代码,或者使用Python的第三方库运行JavaScript,直接采集浏览器中看到的页。我用selenium做web自动化,我用的是第二种(其实selenium+PhantomJS就是模拟浏览器访问url,然后把动态网页的所有内容转换成静态html返回,所以速度会很慢)
安装PhantomJS:下载第三方库,放到python\scripts下
爬虫网易播放列表中,播放量过千万的歌名和链接保存到excel
Chrome按F12查看网页源代码
检查页面上的元素,首先将frame切换为id='g_iframe'
播放量nb及对应的标题和链接
mysongList1000.xls 结果截图 查看全部
htmlunit抓取动态网页(网站的爬虫调试的时候发现问题(一)(组图))
网站的爬虫脚本在调试时发现问题:
脚本运行:content-type用text/xml可以发帖成功,但是post中body的内容不生效,所有回复都是当前日期;有申请,发帖不成功(即没有返回数据)
工具发:content-type用text/xml可以发帖成功,但是post中body的内容不生效,所有回复都是当前日期;有申请,发帖成功,正文中日期修改有效
即用型脚本完全没有接收到返回的数据,但是很奇怪可以使用工具fiddler或者Burpsuite来正常查看包的内容。直到后来才发现我爬的网站是动态的==
动态网页(参考百度百科:%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5/6327050)
-------------------------------------------------- ------------------
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是通过动态网站技术生成的,都可以称为动态网页。
总之,动态网页是基本的html语法规范与Java、VB、VC等高级编程语言、数据库编程等技术的融合,以实现网站@的高效、动态、交互的内容和风格。 > 管理。因此,从这个意义上说,任何由网页编程技术结合HTML以外的高级编程语言和数据库技术生成的网页都是动态网页。
-------------------------------------------------- ------------------
也可以解释为动态网页不执行javascript,仅使用data=response.read()获取的静态html没有要爬取的内容
网上用Python解决这个问题只有两种方法:采集内容直接来自JavaScript代码,或者使用Python的第三方库运行JavaScript,直接采集浏览器中看到的页。我用selenium做web自动化,我用的是第二种(其实selenium+PhantomJS就是模拟浏览器访问url,然后把动态网页的所有内容转换成静态html返回,所以速度会很慢)
安装PhantomJS:下载第三方库,放到python\scripts下
爬虫网易播放列表中,播放量过千万的歌名和链接保存到excel
Chrome按F12查看网页源代码
检查页面上的元素,首先将frame切换为id='g_iframe'
播放量nb及对应的标题和链接
mysongList1000.xls 结果截图
htmlunit抓取动态网页(Java爬取博客阅读文章最多)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-26 19:21
更新,这很尴尬,这个文章博客是阅读最多的文章,但也是最被践踏的。
爬取思路:
所谓动态,是指通过请求后台,可以动态改变对应的html页面,开始时页面并不是全部显示出来的。
大多数操作都是通过请求完成的,一个请求,一个返回。在大多数网页中,请求往往被开发者隐藏在 js 代码中。
因此,将爬取动态网页的思路转化为找到对应的js代码并执行对应的js代码,从而可以通过java代码动态改变页面。
而当页面能够正确显示的时候,我们就可以像爬静态网页一样爬取数据了!
首先,可以使用htmlunit来模拟鼠标点击事件,很容易实现:
/**
* 通过htmlunit来获得一些搜狗的网址。
* 通过模拟鼠标点击事件来实现
* @param key
* @return
* @throws Exception
*/
public String getNextUrl(String key){
String page = new String();
try {
WebClient webClient = new WebClient();
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
//去拿网页
HtmlPage htmlPage = webClient.getPage("http://pic.sogou.com/");
//得到表单
HtmlForm form = htmlPage.getFormByName("searchForm");
//得到提交按钮
HtmlSubmitInput button = form.getInputByValue("搜狗搜索");
//得到输入框
HtmlTextInput textField = form.getInputByName("query");
//输入内容
textField.setValueAttribute(key);
//点一下按钮
HtmlPage nextPage = button.click();
String str = nextPage.toString();
page = cutString(str);
webClient.close();
} catch (Exception e) {
e.printStackTrace();
}
return page;
}
如上图,我只是通过java代码将关键字填入搜索我的,然后通过getInputByValue方法得到按钮控件,最后直接button.click(),
即可以模拟点击,将点击后返回的http请求解析成html页面。
这个功能其实很强大。比如你可以使用这个功能来模拟抢票,或者使用点击事件,加上搜索相关知识,将整个系统下线,并以html的形式保存。
接下来就是使用强大的htmlunit来执行js代码了。
先写一个简单的jsp页面:
Insert title here
原数字
function change(value) {
document.getElementById("test").innerHTML = value;
return "hello htmlUnit";
}
从上面可以看出,jsp页面很简单,只是一个函数变化,用来调用htmlUnit。
接下来是一个使用 htmlunit 的类。此类通过支持 JavaScript 解释器来工作,
然后将自己编写的JavaScript代码嵌入到页面中执行,获取执行后的返回结果并返回页面。
package com.blog.anla;
import com.gargoylesoftware.htmlunit.ScriptResult;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
public class TestMyOwnPage {
private void action() {
WebClient webClient = new WebClient();
try {
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true); // 设置支持JavaScript。
// 去拿网页
HtmlPage htmlPage = webClient
.getPage("http://localhost:8989/testHtmlScrop/index.jsp");
String s = "更改后的数字";
ScriptResult t = htmlPage.executeJavaScript("change(\"" + s
+ "\");", "injected script", 500);
// 这里是在500行插入这一小行JavaScript代码段,因为如果在默认的1行,那不会有结果
// 因为js是顺序执行的,当你执行第一行js代码时,可能还没有渲染body里面的标签。
HtmlPage myPage = (HtmlPage) t.getNewPage();
String nextPage = myPage.asXml().toString();
String nextPage2 = myPage.asText().toString();
} catch (Exception e) {
e.printStackTrace();
} finally {
webClient.close();
}
}
public static void main(String[] args) {
TestMyOwnPage tmop = new TestMyOwnPage();
tmop.action();
}
}
t.getNewPage()中有两个属性,一个是
javaScriptResult:执行这段代码后返回的结果,如果有(我上面写的,返回hello htmlunit),如果没有(返回Undefined)。
newPage_:执行此代码后返回的整个页面。
结果如下:
这段代码执行的最终结果如下:
asXml():将整个页面的html代码返回给我们:
而asText()只返回页面上可以显示的值,即head标签和label标签:
这种执行思路还可以动态执行相应的js代码,从而爬取需要的数据。
-------------------------------------------------- --------------------------------------2017 年 7 月更新---------- -------------------------------------- -------------------------------------------------- -----
这两天一直在做一个关于网络爬虫的系统
然而,当我开始攀爬时,我发现了一个问题。js的动态页面爬不下来。
网上找了很多方法,google也问了,主要是指htmlunit,下面是核心代码,
使用htmlunit的主要目的是模拟浏览器操作,因为有些链接点击无法直接通过src获取url,一般使用JavaScript。
简单拼接后的URL,所以用htmlunit直接模拟浏览器点击比较简单。
WebClient webClient = new WebClient();
webClient.getOptions().setJavaScriptEnabled(true); //启用JS解释器,默认为true
webClient.getOptions().setCssEnabled(false); //禁用css支持
webClient.getOptions().setThrowExceptionOnScriptError(false); //js运行错误时,是否抛出异常
webClient.getOptions().setTimeout(20000);
HtmlPage page = wc.getPage("http://www.hao123.com");
//我认为这个最重要
String pageXml = page.asXml(); //以xml的形式获取响应文本
/**jsoup解析文档*/
Document doc = Jsoup.parse(pageXml, "http://cq.qq.com");
这个时候,就可以得到jsoup中的document对象了,接下来就好写了,就像爬普通静态网页一样了。
不过,webclient解析是还是会出现一些问题,js的问题,
主要是由于目标url的js写的有些问题,但在实际的浏览器中却会忽略,eclipse中会报异常。
今天看,好多人踩了,可能我当时没认真写博客吧。如果想找java爬虫项目,可以去我的专栏
图片搜索包括使用jsoup爬取图片,以及lire索引和搜索图片。
玫瑰会在你的手中留下挥之不去的芬芳。有什么问题可以多多讨论! 查看全部
htmlunit抓取动态网页(Java爬取博客阅读文章最多)
更新,这很尴尬,这个文章博客是阅读最多的文章,但也是最被践踏的。
爬取思路:
所谓动态,是指通过请求后台,可以动态改变对应的html页面,开始时页面并不是全部显示出来的。
大多数操作都是通过请求完成的,一个请求,一个返回。在大多数网页中,请求往往被开发者隐藏在 js 代码中。
因此,将爬取动态网页的思路转化为找到对应的js代码并执行对应的js代码,从而可以通过java代码动态改变页面。
而当页面能够正确显示的时候,我们就可以像爬静态网页一样爬取数据了!
首先,可以使用htmlunit来模拟鼠标点击事件,很容易实现:
/**
* 通过htmlunit来获得一些搜狗的网址。
* 通过模拟鼠标点击事件来实现
* @param key
* @return
* @throws Exception
*/
public String getNextUrl(String key){
String page = new String();
try {
WebClient webClient = new WebClient();
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
//去拿网页
HtmlPage htmlPage = webClient.getPage("http://pic.sogou.com/";);
//得到表单
HtmlForm form = htmlPage.getFormByName("searchForm");
//得到提交按钮
HtmlSubmitInput button = form.getInputByValue("搜狗搜索");
//得到输入框
HtmlTextInput textField = form.getInputByName("query");
//输入内容
textField.setValueAttribute(key);
//点一下按钮
HtmlPage nextPage = button.click();
String str = nextPage.toString();
page = cutString(str);
webClient.close();
} catch (Exception e) {
e.printStackTrace();
}
return page;
}
如上图,我只是通过java代码将关键字填入搜索我的,然后通过getInputByValue方法得到按钮控件,最后直接button.click(),
即可以模拟点击,将点击后返回的http请求解析成html页面。
这个功能其实很强大。比如你可以使用这个功能来模拟抢票,或者使用点击事件,加上搜索相关知识,将整个系统下线,并以html的形式保存。
接下来就是使用强大的htmlunit来执行js代码了。
先写一个简单的jsp页面:
Insert title here
原数字
function change(value) {
document.getElementById("test").innerHTML = value;
return "hello htmlUnit";
}
从上面可以看出,jsp页面很简单,只是一个函数变化,用来调用htmlUnit。
接下来是一个使用 htmlunit 的类。此类通过支持 JavaScript 解释器来工作,
然后将自己编写的JavaScript代码嵌入到页面中执行,获取执行后的返回结果并返回页面。
package com.blog.anla;
import com.gargoylesoftware.htmlunit.ScriptResult;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
public class TestMyOwnPage {
private void action() {
WebClient webClient = new WebClient();
try {
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true); // 设置支持JavaScript。
// 去拿网页
HtmlPage htmlPage = webClient
.getPage("http://localhost:8989/testHtmlScrop/index.jsp";);
String s = "更改后的数字";
ScriptResult t = htmlPage.executeJavaScript("change(\"" + s
+ "\");", "injected script", 500);
// 这里是在500行插入这一小行JavaScript代码段,因为如果在默认的1行,那不会有结果
// 因为js是顺序执行的,当你执行第一行js代码时,可能还没有渲染body里面的标签。
HtmlPage myPage = (HtmlPage) t.getNewPage();
String nextPage = myPage.asXml().toString();
String nextPage2 = myPage.asText().toString();
} catch (Exception e) {
e.printStackTrace();
} finally {
webClient.close();
}
}
public static void main(String[] args) {
TestMyOwnPage tmop = new TestMyOwnPage();
tmop.action();
}
}
t.getNewPage()中有两个属性,一个是
javaScriptResult:执行这段代码后返回的结果,如果有(我上面写的,返回hello htmlunit),如果没有(返回Undefined)。
newPage_:执行此代码后返回的整个页面。
结果如下:
这段代码执行的最终结果如下:
asXml():将整个页面的html代码返回给我们:
而asText()只返回页面上可以显示的值,即head标签和label标签:
这种执行思路还可以动态执行相应的js代码,从而爬取需要的数据。
-------------------------------------------------- --------------------------------------2017 年 7 月更新---------- -------------------------------------- -------------------------------------------------- -----
这两天一直在做一个关于网络爬虫的系统
然而,当我开始攀爬时,我发现了一个问题。js的动态页面爬不下来。
网上找了很多方法,google也问了,主要是指htmlunit,下面是核心代码,
使用htmlunit的主要目的是模拟浏览器操作,因为有些链接点击无法直接通过src获取url,一般使用JavaScript。
简单拼接后的URL,所以用htmlunit直接模拟浏览器点击比较简单。
WebClient webClient = new WebClient();
webClient.getOptions().setJavaScriptEnabled(true); //启用JS解释器,默认为true
webClient.getOptions().setCssEnabled(false); //禁用css支持
webClient.getOptions().setThrowExceptionOnScriptError(false); //js运行错误时,是否抛出异常
webClient.getOptions().setTimeout(20000);
HtmlPage page = wc.getPage("http://www.hao123.com";);
//我认为这个最重要
String pageXml = page.asXml(); //以xml的形式获取响应文本
/**jsoup解析文档*/
Document doc = Jsoup.parse(pageXml, "http://cq.qq.com";);
这个时候,就可以得到jsoup中的document对象了,接下来就好写了,就像爬普通静态网页一样了。
不过,webclient解析是还是会出现一些问题,js的问题,
主要是由于目标url的js写的有些问题,但在实际的浏览器中却会忽略,eclipse中会报异常。
今天看,好多人踩了,可能我当时没认真写博客吧。如果想找java爬虫项目,可以去我的专栏
图片搜索包括使用jsoup爬取图片,以及lire索引和搜索图片。
玫瑰会在你的手中留下挥之不去的芬芳。有什么问题可以多多讨论!
htmlunit抓取动态网页(2019独角兽企业重金招聘Python工程师标准(原网页+Javascript返回数据))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-24 09:03
2019独角兽企业招聘Python工程师标准>>>
我在做人人网页爬虫的时候,爬人人新新闻搜索页源码的时候,改curpage=后面的数字后,爬到的内容竟然是一样的,每次都是第一页。在不同的页面右击“查看页面源代码”,发现确实是第一页的新内容,并没有什么变化。
然后右击火狐和“查看元素”,发现每次翻页时只有新闻版块的HTML标签发生变化(闪烁橙色)。估计是用 JAVASCRIPT 来动态更新/加载数据,而不是重新请求一个新的 URL。关联
知道问题后,开始百度,发现这样一篇文章文章:Java抓取网页数据(原网页+Javascript返回数据)
有时网站为了保护自己的数据,不是直接在网页源代码中返回数据,而是采用异步方式用JS返回数据,这样可以避免搜索引擎等工具从网站 数据捕获。
按照博文的方法,一步一步,用火狐查看元素中的“网络”进行分析,发现果然如预期,当页面发生变化时,使用js异步返回数据,而真正的请求的链接自然和你在浏览器中看到的一样。不同的到达。如下所示:
查看响应内容:
真的!正是您正在寻找的!一共10个新故事,一个还不错,正是我们想要的页码
之后,只需将原来爬取HTML页面的java爬虫代码的url改成这个真实的请求地址(而不是在浏览器地址栏中看清楚),其他什么都不需要改。 查看全部
htmlunit抓取动态网页(2019独角兽企业重金招聘Python工程师标准(原网页+Javascript返回数据))
2019独角兽企业招聘Python工程师标准>>>
我在做人人网页爬虫的时候,爬人人新新闻搜索页源码的时候,改curpage=后面的数字后,爬到的内容竟然是一样的,每次都是第一页。在不同的页面右击“查看页面源代码”,发现确实是第一页的新内容,并没有什么变化。
然后右击火狐和“查看元素”,发现每次翻页时只有新闻版块的HTML标签发生变化(闪烁橙色)。估计是用 JAVASCRIPT 来动态更新/加载数据,而不是重新请求一个新的 URL。关联
知道问题后,开始百度,发现这样一篇文章文章:Java抓取网页数据(原网页+Javascript返回数据)
有时网站为了保护自己的数据,不是直接在网页源代码中返回数据,而是采用异步方式用JS返回数据,这样可以避免搜索引擎等工具从网站 数据捕获。
按照博文的方法,一步一步,用火狐查看元素中的“网络”进行分析,发现果然如预期,当页面发生变化时,使用js异步返回数据,而真正的请求的链接自然和你在浏览器中看到的一样。不同的到达。如下所示:
查看响应内容:
真的!正是您正在寻找的!一共10个新故事,一个还不错,正是我们想要的页码
之后,只需将原来爬取HTML页面的java爬虫代码的url改成这个真实的请求地址(而不是在浏览器地址栏中看清楚),其他什么都不需要改。
htmlunit抓取动态网页(需要的jar包代码如下:链接不支持xpath解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-23 02:24
需要的jar包:
1
2 org.jsoup
3 jsoup
4 1.10.3
5
代码如下:
1 // 请求超时时间,30秒
2 public static final int TIME_OUT = 30*1000;
3 // 模拟浏览器请求头信息
4 public static Map headers = new HashMap();
5 static{
6 headers.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0");
7 headers.put("Accept", "text/html");
8 headers.put("Accept-Language", "zh-CN,zh");
9 }
10
11 //根据url获取html文档
12 protected Document getDoc(String url) throws IOException{
13 if(logger.isDebugEnabled())
14 logger.debug(url);
15 //新建一个连接
16 Connection conn = Jsoup.connect(url).timeout(TIME_OUT);
17 conn = conn.headers(headers);
18 conn = conn.proxy(Proxy.NO_PROXY);
19 Document doc = conn.get();
20
21 if(logger.isTraceEnabled()){
22 logger.trace("["+url+"]\n"+doc);
23 }
24 return doc;
25 }
1 public static final String CHINAZ_ICP_URL = "http://icp.chinaz.com/?type=host&s=%s";
2 public List doHandler(String domain) {
3 List results = new ArrayList();
4 String url = String.format(CHINAZ_ICP_URL, domain);
5 Document doc;
6 try {
7 doc = this.getDoc(url);
8 // 获取当前页ICP信息所在标签
9 Elements eles = doc.select("ul.IcpMain01>li:lt(7)>p");
10
11 if(null == eles || eles.isEmpty()){
12 return results;
13 }
14 //获取ICP信息
15 for (Element element : eles) {
16 //当前元素为认证信息时,跳过
17 if("safe".equals(element.attr("id"))){
18 continue;
19 }
20 Node firstNode = element.childNode(0);
21 if(firstNode.childNodeSize() > 0){
22 results.add(element.child(0).text());
23 }else{
24 results.add(((TextNode)firstNode).text());
25 }
26 }
27 } catch (IOException e) {
28 logger.error("get Chinaz ICP message error :",e);
29 }
30 doc = null;
31 return results;
32 }
参考Jsoup的文档:链接
Jsoup不支持xpath解析,很蛋疼,不过有人要弄个支持xpath的东西---JsoupXpath,链接,有兴趣的网友可以自己试试!
三、htmlunit
支持Xpath解析,可以模拟浏览器动作,比如点击下一页,加载越来越多。文档链接:
需要的jar包
1
2 net.sourceforge.htmlunit
3 htmlunit
4 2.18
5
代码如下:
1 import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
2 import com.gargoylesoftware.htmlunit.TopLevelWindow;
3 import com.gargoylesoftware.htmlunit.WebClient;
4 import com.gargoylesoftware.htmlunit.html.HtmlPage;
5 import com.gargoylesoftware.htmlunit.html.HtmlTableRow;
6
7 import java.io.IOException;
8 import java.util.ArrayList;
9 import java.util.List;
10
11
12 public class UrlTest {
13
14 public static void main(String[] args) {
15 BaseCollector baseCollector = new BaseCollector();
16 WebClient webClient = baseCollector.getWebClient();
17 String url="http://htmlunit.sourceforge.net/";
18 HtmlPage homePage= null;
19 try {
20 homePage = webClient.getPage(url);
21 if (homePage != null && homePage instanceof HtmlPage) {
22 homePage.getEnclosingWindow().setName("IpHomePage");
23 System.out.println("打开 IPHomePage ");
24 System.out.println("内容是: "+homePage.getBody().getTextContent());
25
26 List htmlTableRows = (List) homePage.getByXPath("/html/body/pre");
27 if (htmlTableRows != null && htmlTableRows.size() > 0) {
28 for (int i = 0; i < htmlTableRows.size(); i++) {
29 HtmlTableRow htmlTableRow = htmlTableRows.get(i);
30 //日期
31 String firstTime = htmlTableRow.getCell(0).getTextContent().trim();
32 System.out.println(firstTime);
33 }
34
35 }
36 closeWindowByName(webClient, "IPHomePage");
37 System.out.println("关闭 IPHomePage ");
38 }
39 webClient.close();
40
41 } catch (IOException e) {
42 System.out.println(e.getMessage()+" ===="+e);
43 }catch (FailingHttpStatusCodeException e){
44 System.out.println(e.getMessage()+" ===="+e);
45 }
46 System.out.println("内容是: "+homePage.getBody().getTextContent());
47 }
48
49 public static void closeWindowByName(WebClient webClient, String name){
50 List list = webClient.getTopLevelWindows();
51 List windowNames = new ArrayList();
52 for (int j = 0; j < list.size(); j++) {
53 if(list.get(j).getName().equals(name)){
54 list.get(j).close();
55 }
56 windowNames.add(list.get(j).getName());
57 }
58 System.out.println("当前窗口 : {}"+list.toString());
59 }
60 }
61
62
四、HeadlessChrome1,HeadlessChrome 与 PhantomJS 对比
在 Chrome 不提供原生无头模式之前,Web 开发者可以使用 PhantomJS 等第三方无头浏览器。现在 Headless 已经正式准备就绪,PhantomJS 的维护者 VitalySlobodin 在邮件列表中宣布了他的辞职。另一个流行的浏览器 Firefox 也准备提供 Headless 模式。
2、什么是HeadlessChrome
HeadlessChrome 是一种无界面形式的 Chrome 浏览器。您可以使用 Chrome 支持的所有功能运行您的程序,而无需打开浏览器。与现代浏览器相比,HeadlessChrome更方便测试web应用、获取网站的截图、爬取信息等。
3、环境配置
您需要先下载 chrome-driver。不同版本的 Chrome 对应不同的 Chrome 驱动程序。您可以通过此链接下载相应的Chrome驱动程序
支持各种元素的获取,List elements = driver.findElements(By.xpath("//*[@id=\"body\"]/ul[2]/li"));
可以模拟浏览器的各种动作,driver.findElement(By.linkText("Next")).click();
用Python做HeadlessChrome更方便简单,简直太神奇了。 . . . 链接:
你可以参考一下
需要的jar包:
1
2 org.seleniumhq.selenium
3 selenium-chrome-driver
4 3.11.0
5
代码如下:
<p> 1 import org.jsoup.Jsoup;
2 import org.jsoup.nodes.Document;
3 import org.openqa.selenium.By;
4 import org.openqa.selenium.WebDriver;
5 import org.openqa.selenium.WebElement;
6 import org.openqa.selenium.chrome.ChromeDriver;
7 import org.openqa.selenium.chrome.ChromeOptions;
8
9 import java.util.List;
10 import java.util.concurrent.TimeUnit;
11
12 /**
13 * Created by sqy on 2018/5/2.
14 */
15 public class HeadlessChromeTest {
16
17 public static void main(String args[]) {
18
19
20
21 //G:\chromedriver
22 System.setProperty("webdriver.chrome.driver","G:\\chromedriver\\chromedriver.exe");
23 ChromeOptions chromeOptions = new ChromeOptions();
24 // 设置为 headless 模式 (必须)
25 chromeOptions.addArguments("--headless");
26 // 设置浏览器窗口打开大小 (非必须)
27 chromeOptions.addArguments("--window-size=1920,1080");
28 WebDriver driver = new ChromeDriver(chromeOptions);
29 driver.get("https://lvyou.baidu.com/scene/s-feb/");
30
31 System.out.println("url: "+driver.getCurrentUrl());
32
33 for(int i=0;i 查看全部
htmlunit抓取动态网页(需要的jar包代码如下:链接不支持xpath解析)
需要的jar包:
1
2 org.jsoup
3 jsoup
4 1.10.3
5
代码如下:
1 // 请求超时时间,30秒
2 public static final int TIME_OUT = 30*1000;
3 // 模拟浏览器请求头信息
4 public static Map headers = new HashMap();
5 static{
6 headers.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0");
7 headers.put("Accept", "text/html");
8 headers.put("Accept-Language", "zh-CN,zh");
9 }
10
11 //根据url获取html文档
12 protected Document getDoc(String url) throws IOException{
13 if(logger.isDebugEnabled())
14 logger.debug(url);
15 //新建一个连接
16 Connection conn = Jsoup.connect(url).timeout(TIME_OUT);
17 conn = conn.headers(headers);
18 conn = conn.proxy(Proxy.NO_PROXY);
19 Document doc = conn.get();
20
21 if(logger.isTraceEnabled()){
22 logger.trace("["+url+"]\n"+doc);
23 }
24 return doc;
25 }
1 public static final String CHINAZ_ICP_URL = "http://icp.chinaz.com/?type=host&s=%s";
2 public List doHandler(String domain) {
3 List results = new ArrayList();
4 String url = String.format(CHINAZ_ICP_URL, domain);
5 Document doc;
6 try {
7 doc = this.getDoc(url);
8 // 获取当前页ICP信息所在标签
9 Elements eles = doc.select("ul.IcpMain01>li:lt(7)>p");
10
11 if(null == eles || eles.isEmpty()){
12 return results;
13 }
14 //获取ICP信息
15 for (Element element : eles) {
16 //当前元素为认证信息时,跳过
17 if("safe".equals(element.attr("id"))){
18 continue;
19 }
20 Node firstNode = element.childNode(0);
21 if(firstNode.childNodeSize() > 0){
22 results.add(element.child(0).text());
23 }else{
24 results.add(((TextNode)firstNode).text());
25 }
26 }
27 } catch (IOException e) {
28 logger.error("get Chinaz ICP message error :",e);
29 }
30 doc = null;
31 return results;
32 }
参考Jsoup的文档:链接
Jsoup不支持xpath解析,很蛋疼,不过有人要弄个支持xpath的东西---JsoupXpath,链接,有兴趣的网友可以自己试试!
三、htmlunit
支持Xpath解析,可以模拟浏览器动作,比如点击下一页,加载越来越多。文档链接:
需要的jar包
1
2 net.sourceforge.htmlunit
3 htmlunit
4 2.18
5
代码如下:
1 import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
2 import com.gargoylesoftware.htmlunit.TopLevelWindow;
3 import com.gargoylesoftware.htmlunit.WebClient;
4 import com.gargoylesoftware.htmlunit.html.HtmlPage;
5 import com.gargoylesoftware.htmlunit.html.HtmlTableRow;
6
7 import java.io.IOException;
8 import java.util.ArrayList;
9 import java.util.List;
10
11
12 public class UrlTest {
13
14 public static void main(String[] args) {
15 BaseCollector baseCollector = new BaseCollector();
16 WebClient webClient = baseCollector.getWebClient();
17 String url="http://htmlunit.sourceforge.net/";
18 HtmlPage homePage= null;
19 try {
20 homePage = webClient.getPage(url);
21 if (homePage != null && homePage instanceof HtmlPage) {
22 homePage.getEnclosingWindow().setName("IpHomePage");
23 System.out.println("打开 IPHomePage ");
24 System.out.println("内容是: "+homePage.getBody().getTextContent());
25
26 List htmlTableRows = (List) homePage.getByXPath("/html/body/pre");
27 if (htmlTableRows != null && htmlTableRows.size() > 0) {
28 for (int i = 0; i < htmlTableRows.size(); i++) {
29 HtmlTableRow htmlTableRow = htmlTableRows.get(i);
30 //日期
31 String firstTime = htmlTableRow.getCell(0).getTextContent().trim();
32 System.out.println(firstTime);
33 }
34
35 }
36 closeWindowByName(webClient, "IPHomePage");
37 System.out.println("关闭 IPHomePage ");
38 }
39 webClient.close();
40
41 } catch (IOException e) {
42 System.out.println(e.getMessage()+" ===="+e);
43 }catch (FailingHttpStatusCodeException e){
44 System.out.println(e.getMessage()+" ===="+e);
45 }
46 System.out.println("内容是: "+homePage.getBody().getTextContent());
47 }
48
49 public static void closeWindowByName(WebClient webClient, String name){
50 List list = webClient.getTopLevelWindows();
51 List windowNames = new ArrayList();
52 for (int j = 0; j < list.size(); j++) {
53 if(list.get(j).getName().equals(name)){
54 list.get(j).close();
55 }
56 windowNames.add(list.get(j).getName());
57 }
58 System.out.println("当前窗口 : {}"+list.toString());
59 }
60 }
61
62
四、HeadlessChrome1,HeadlessChrome 与 PhantomJS 对比
在 Chrome 不提供原生无头模式之前,Web 开发者可以使用 PhantomJS 等第三方无头浏览器。现在 Headless 已经正式准备就绪,PhantomJS 的维护者 VitalySlobodin 在邮件列表中宣布了他的辞职。另一个流行的浏览器 Firefox 也准备提供 Headless 模式。
2、什么是HeadlessChrome
HeadlessChrome 是一种无界面形式的 Chrome 浏览器。您可以使用 Chrome 支持的所有功能运行您的程序,而无需打开浏览器。与现代浏览器相比,HeadlessChrome更方便测试web应用、获取网站的截图、爬取信息等。
3、环境配置
您需要先下载 chrome-driver。不同版本的 Chrome 对应不同的 Chrome 驱动程序。您可以通过此链接下载相应的Chrome驱动程序
支持各种元素的获取,List elements = driver.findElements(By.xpath("//*[@id=\"body\"]/ul[2]/li"));
可以模拟浏览器的各种动作,driver.findElement(By.linkText("Next")).click();
用Python做HeadlessChrome更方便简单,简直太神奇了。 . . . 链接:
你可以参考一下
需要的jar包:
1
2 org.seleniumhq.selenium
3 selenium-chrome-driver
4 3.11.0
5
代码如下:
<p> 1 import org.jsoup.Jsoup;
2 import org.jsoup.nodes.Document;
3 import org.openqa.selenium.By;
4 import org.openqa.selenium.WebDriver;
5 import org.openqa.selenium.WebElement;
6 import org.openqa.selenium.chrome.ChromeDriver;
7 import org.openqa.selenium.chrome.ChromeOptions;
8
9 import java.util.List;
10 import java.util.concurrent.TimeUnit;
11
12 /**
13 * Created by sqy on 2018/5/2.
14 */
15 public class HeadlessChromeTest {
16
17 public static void main(String args[]) {
18
19
20
21 //G:\chromedriver
22 System.setProperty("webdriver.chrome.driver","G:\\chromedriver\\chromedriver.exe");
23 ChromeOptions chromeOptions = new ChromeOptions();
24 // 设置为 headless 模式 (必须)
25 chromeOptions.addArguments("--headless");
26 // 设置浏览器窗口打开大小 (非必须)
27 chromeOptions.addArguments("--window-size=1920,1080");
28 WebDriver driver = new ChromeDriver(chromeOptions);
29 driver.get("https://lvyou.baidu.com/scene/s-feb/";);
30
31 System.out.println("url: "+driver.getCurrentUrl());
32
33 for(int i=0;i
htmlunit抓取动态网页(代码不好使怎么获取后台js完后的完整页面?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-14 09:10
很多网站使用js或者jquery来生成数据。后台获取数据后,使用 document.write() 或 ("#id").html="" 写入页面,此时用浏览器查看源码是看不到数据的。
HttpClient 不起作用。我在网上看了HtmlUnit,说后台js加载后可以得到完整的页面,但是我按照文章说的写了,还是不行。
String url = "http://xinjinqiao.tprtc.com/ad ... 3B%3B
try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10);
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//webClient.getOptions().setTimeout(50000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url);
System.out.println("为了获取js执行的数据 线程开始沉睡等待");
Thread.sleep(3000);//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡");
String html = rootPage.asText();
System.out.println(html);
} catch (Exception e) {
}
其实这段代码是行不通的。
对于答案,典型的是链接页面,如何获取java程序中的数据? 查看全部
htmlunit抓取动态网页(代码不好使怎么获取后台js完后的完整页面?)
很多网站使用js或者jquery来生成数据。后台获取数据后,使用 document.write() 或 ("#id").html="" 写入页面,此时用浏览器查看源码是看不到数据的。
HttpClient 不起作用。我在网上看了HtmlUnit,说后台js加载后可以得到完整的页面,但是我按照文章说的写了,还是不行。
String url = "http://xinjinqiao.tprtc.com/ad ... 3B%3B
try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10);
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//webClient.getOptions().setTimeout(50000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url);
System.out.println("为了获取js执行的数据 线程开始沉睡等待");
Thread.sleep(3000);//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡");
String html = rootPage.asText();
System.out.println(html);
} catch (Exception e) {
}
其实这段代码是行不通的。
对于答案,典型的是链接页面,如何获取java程序中的数据?
htmlunit抓取动态网页(使用本文中推荐的开源工具——HtmlUnit,一款能够模拟浏览器的抓包神器!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-11 23:14
之前,一峰写过一篇关于使用Jsoup爬取网页内容的文章文章:
[Jsoup] HTML解析器,轻松获取网页内容
Jsoup提供的api非常方便,完全类似于JQuery操作,轻松抓取网页数据。但是像Jsoup这样的普通爬虫工具的缺点是不能处理js生成的内容。
做过Html开发的都知道现在很多网站都是用ajax和JavaScript来获取和处理数据,普通爬虫工具已经无法处理js中的内容了。
比如我们在本地新建一个测试web文件text.html,源码如下:
main.html
a {
line-height: 30px;
margin: 20px;
}
var datas = [ {
href : "http://www.jianshu.com/p/8d8edf25850d",
title : "推荐一款编程字体,让代码看着更美"
}, {
href : "http://www.jianshu.com/p/153d9f31288d",
title : "Android 利用Camera实现中轴3D卡牌翻转效果"
}, {
href : "http://www.jianshu.com/p/d6fb0c9c9c26",
title : "【Eclipse】挖掘专属最有用的快捷键组合"
}, {
href : "http://www.jianshu.com/p/72d69b49d135",
title : "【IIS】Windows下利用IIS建立网站并实现局域网共享"
} ];
window.onload = function() {
var infos = document.getElementById("infos");
for( var i = 0 ; i < datas.length ; i++)
{
var a = document.createElement("a");
a.href = datas[i].href ;
a.innerText = datas[i].title;
infos.appendChild(a);
infos.appendChild(document.createElement("br"))
}
}
HtmlUnit 测试网页内容!
通过IIS发布本地网站(参考之前逸峰写的文章:
【IIS】在Windows下使用IIS建立网站,实现局域网共享),
网页在浏览器中显示的效果如下:
网页显示效果.jpg
虽然通过网页检查元素,可以看到body中收录了网页显示的文字内容:
网络评论元素.jpg
但是,它根本无法通过 Jsoup 工具获得!从网页源码中可以看出,我们需要爬取的内容是在页面显示出来后通过ajax和JavaScript加载的。
那么该怎么办?使用本文推荐的开源工具——HtmlUnit,一个可以模拟浏览器的抓包神器!
在官网下载对应的jar包,添加到项目工程的lib中。简单的测试代码如下:
import java.io.IOException;
import java.net.MalformedURLException;
import java.text.ParseException;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.DomElement;
import com.gargoylesoftware.htmlunit.html.DomNodeList;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
/**
* @author 亦枫
* @created_time 2016年1月12日
* @file_user_todo Java测试类
* @blog http://www.jianshu.com/users/1 ... icles
*/
public class JavaTest {
/**
* 入口函数
* @param args
* @throws ParseException
*/
public static void main(String[] args) throws ParseException {
try {
WebClient webClient = new WebClient(BrowserVersion.CHROME);
HtmlPage htmlPage = (HtmlPage) webClient.getPage("http://localhost/test.html");
DomNodeList domNodeList = htmlPage.getElementsByTagName("a");
for (int i = 0; i < domNodeList.size(); i++) {
DomElement domElement = (DomElement) domNodeList.get(i);
System.out.println(domElement.asText());
}
webClient.close();
} catch (FailingHttpStatusCodeException e) {
e.printStackTrace();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行后,控制台打印出结果:
HtmlUnit测试结果.jpg
可以看出,HtmlUnit 能够抓取 AJAX 和 JavaScript 加载的内容。
HtmlUnit的介绍在官网上很详细。以下内容为易峰翻译的部分内容,供大家参考:
HtmlUnit 是一个基于 Java 的浏览器程序,没有图形界面。它可以调用 HTML 文档并提供 API,使开发人员可以像在普通浏览器上一样访问 Web 内容、填写表单、单击超链接等。
它对 JavaScript 的支持非常好并且还在改进中,可以解析非常复杂的 AJAX 库,模拟不同配置下的 Chrome、Firefox 和 IE 浏览器。
HtmlUnit 通常用于测试目的和检索 网站 信息。
HtmlUnit 提供了很多测试网络请求和爬取网页内容的功能。可以去官网或者其他网站学习使用。 查看全部
htmlunit抓取动态网页(使用本文中推荐的开源工具——HtmlUnit,一款能够模拟浏览器的抓包神器!)
之前,一峰写过一篇关于使用Jsoup爬取网页内容的文章文章:
[Jsoup] HTML解析器,轻松获取网页内容
Jsoup提供的api非常方便,完全类似于JQuery操作,轻松抓取网页数据。但是像Jsoup这样的普通爬虫工具的缺点是不能处理js生成的内容。
做过Html开发的都知道现在很多网站都是用ajax和JavaScript来获取和处理数据,普通爬虫工具已经无法处理js中的内容了。
比如我们在本地新建一个测试web文件text.html,源码如下:
main.html
a {
line-height: 30px;
margin: 20px;
}
var datas = [ {
href : "http://www.jianshu.com/p/8d8edf25850d",
title : "推荐一款编程字体,让代码看着更美"
}, {
href : "http://www.jianshu.com/p/153d9f31288d",
title : "Android 利用Camera实现中轴3D卡牌翻转效果"
}, {
href : "http://www.jianshu.com/p/d6fb0c9c9c26",
title : "【Eclipse】挖掘专属最有用的快捷键组合"
}, {
href : "http://www.jianshu.com/p/72d69b49d135",
title : "【IIS】Windows下利用IIS建立网站并实现局域网共享"
} ];
window.onload = function() {
var infos = document.getElementById("infos");
for( var i = 0 ; i < datas.length ; i++)
{
var a = document.createElement("a");
a.href = datas[i].href ;
a.innerText = datas[i].title;
infos.appendChild(a);
infos.appendChild(document.createElement("br"))
}
}
HtmlUnit 测试网页内容!
通过IIS发布本地网站(参考之前逸峰写的文章:
【IIS】在Windows下使用IIS建立网站,实现局域网共享),
网页在浏览器中显示的效果如下:
网页显示效果.jpg
虽然通过网页检查元素,可以看到body中收录了网页显示的文字内容:
网络评论元素.jpg
但是,它根本无法通过 Jsoup 工具获得!从网页源码中可以看出,我们需要爬取的内容是在页面显示出来后通过ajax和JavaScript加载的。
那么该怎么办?使用本文推荐的开源工具——HtmlUnit,一个可以模拟浏览器的抓包神器!
在官网下载对应的jar包,添加到项目工程的lib中。简单的测试代码如下:
import java.io.IOException;
import java.net.MalformedURLException;
import java.text.ParseException;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.DomElement;
import com.gargoylesoftware.htmlunit.html.DomNodeList;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
/**
* @author 亦枫
* @created_time 2016年1月12日
* @file_user_todo Java测试类
* @blog http://www.jianshu.com/users/1 ... icles
*/
public class JavaTest {
/**
* 入口函数
* @param args
* @throws ParseException
*/
public static void main(String[] args) throws ParseException {
try {
WebClient webClient = new WebClient(BrowserVersion.CHROME);
HtmlPage htmlPage = (HtmlPage) webClient.getPage("http://localhost/test.html";);
DomNodeList domNodeList = htmlPage.getElementsByTagName("a");
for (int i = 0; i < domNodeList.size(); i++) {
DomElement domElement = (DomElement) domNodeList.get(i);
System.out.println(domElement.asText());
}
webClient.close();
} catch (FailingHttpStatusCodeException e) {
e.printStackTrace();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行后,控制台打印出结果:
HtmlUnit测试结果.jpg
可以看出,HtmlUnit 能够抓取 AJAX 和 JavaScript 加载的内容。
HtmlUnit的介绍在官网上很详细。以下内容为易峰翻译的部分内容,供大家参考:
HtmlUnit 是一个基于 Java 的浏览器程序,没有图形界面。它可以调用 HTML 文档并提供 API,使开发人员可以像在普通浏览器上一样访问 Web 内容、填写表单、单击超链接等。
它对 JavaScript 的支持非常好并且还在改进中,可以解析非常复杂的 AJAX 库,模拟不同配置下的 Chrome、Firefox 和 IE 浏览器。
HtmlUnit 通常用于测试目的和检索 网站 信息。
HtmlUnit 提供了很多测试网络请求和爬取网页内容的功能。可以去官网或者其他网站学习使用。
htmlunit抓取动态网页( 基于python(asynchronousjavascriptandxml)的动态网页爬虫系统及其开发方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-09 02:13
基于python(asynchronousjavascriptandxml)的动态网页爬虫系统及其开发方法)
本发明属于计算机领域,涉及爬虫系统,尤其是一种动态网页爬虫系统。
背景技术
网络爬虫是一种自动提取网页的程序。传统爬虫从一个或多个初始网页的url开始,获取初始网页上的url(统一资源定位器),在抓取网页的过程中不断从当前页面中提取。新的url被放入队列中,直到满足系统预设的停止条件。
随着互联网从web1.0时代迅速进入web1.0时代,基于ajax(异步javascript和xml)的动态页面加载技术成为各大公司的首选。随着移动互联网的兴起,javascript在移动端和pc端的优秀特性被广泛挖掘,基于前端mvc/mvm的模型逐渐进入各大互联网公司的首选方案。动态网页的迅速崛起使得基于动态网页的网络爬虫越来越重要。
例如,一个 网站? courseid=id#/学习/视频?课程ID=课程ID&c。通常,对于动态url对应的动态页面,后面跟问号、等号等字符的参数就是要查询的数据库数据。为了获取动态页面的数据,动态页面的内容一般通过浏览器的脚本解析或者渲染动态页面的方式来获取。但是,脚本解析的前提是异步加载信息中存在部分或全部目标动态页面信息,请求规则可以是获取和目标页面有规律的分布;使用浏览器渲染只能针对不完整的DOM(文档对象模型)数据结构,而部分或全部的目标信息存在于使用浏览器渲染中。
技术实施要素:
为了解决脚本解析和浏览器渲染的局限性,提高动态网页爬取的准确性和完整性,本发明提供了一种基于scrapy(scrapy是一个基于python开发的快速、高级的屏幕抓取和网页抓取) Crawl framework)动态网络爬虫系统,包括爬虫引擎、调度器、解析模块、项目管道、下载器,爬虫引擎用于处理数据流和触发事务;
调度器用于接收爬虫引擎或解析模块发送的请求,将请求推入队列调度下载器下载,当爬虫引擎再次请求时返回;
解析模块用于构造或解析动态网页的异步加载信息,分析从下载器中提取的网页中的数据元素;
项目管道用于处理解析器从网页中提取的数据或响应爬虫引擎的请求;
下载器,用于响应调度器的任务请求,下载网页内容,并将网页内容返回给解析器;
解析模块包括脚本解析器、渲染器和切换模块;
脚本解析器通过网络抓包工具搜索查询动态信息的文件类型,根据动态信息的文件类型对动态信息文件的结构进行建模,构造动态网页的请求规则,解析动态网页中的所有文件。并将动态网页的内容提取出来,交给项目管道;如果解析失败,则交由切换模块处理;
渲染器通过加载动态网页的异步加载信息构建完整的动态网页dom树,并通过模拟操作解析出动态网页中服务器返回的异步加载内容,直到动态网页内容完整提取。交给切换模块交给脚本解析器处理;
切换模块检测脚本解析器或渲染器解析动态网页所花费的时间以及解析的内容是否完整,如果所需时间超过阈值或内容不完整则切换。
作为本发明的一个优选方案,渲染器为无界面浏览器。
作为本发明的一个优选方案,无界面浏览器包括selenium、splash、htmlunit、phantomjs。在本发明的一个实施例中,无界面浏览器使用闪屏渲染容器来渲染动态网页。
为了避免使用动态解析或者用浏览器渲染来提取动态网页的盲目性,在本发明的一个实施例中,解析模块还包括预解析模块,从url库中随机抽取样本。然后交给脚本解析器或渲染器进行爬取,记录爬取信息的完整性、爬取时间、资源消耗等。
本发明第二方面的目的在于提供一种动态网页提取方法,包括以下步骤:
s1:获取url库,对url库进行聚类分析,如果有聚类,进行步骤s2,如果没有聚类,结束;
s2:从集群中抽取至少一个随机样本url;
s3:使用脚本解析、渲染,或者脚本解析和渲染相结合的方式爬取url;
s4:记录爬取信息的完整性、爬取时间、资源消耗等信息,通过优先级算法选择最优爬虫方案,使用最优方案爬取集群内所有动态网页;
s5:处理爬取信息,执行步骤s1。
作为本发明的一个优选方案,所述脚本解析还包括:
根据动态网页或URL信息生成请求规则,通过服务器验证获取访问权限,根据请求规则获取异步加载信息。
进一步地,通过服务器的验证包括cookie认证、用户认证、301认证、302认证、图文认证、ip认证。
作为本发明的一个优选方案,所述渲染包括:使用无界面浏览器渲染异步加载的信息,使用无界面浏览器的api模拟用户点击,从模拟事件的结果中提取目标信息.
作为本发明的一种优选方案,脚本解析和渲染混合的具体步骤如下:通过脚本解析获取动态网页的请求规则,然后通过无界面浏览器加载,使用脚本解析解析缺失的渲染参数构造完整的请求规则,直到获得完整的异步加载信息。
作为本发明的优选方案,s4中的优先级算法如下:以提取的动态页面提取信息的完整性、时间、资源消耗率为变量,采用单纯形法得到最优解。
本发明的有益效果是:
1.本发明是对目前大部分动态网页网站的结构和常规动态网页的爬取方法进行分析,利用资源消耗低和脚本解析速度快的优点,并且在渲染方面集成了webdriver爬虫的优点,可以提高爬虫的爬取精度和适应性。
2.设置切换模块,避免使用单一爬取方式时,因特殊情况导致无法爬取,陷入死循环的情况。
3.通过预检测机制,对收录不同动态异步加载机制的动态网页采用不同的爬取策略,提高了解析性能,减少了对内存和网络资源的占用,使得在本发明对动态页面的爬取更具自适应性和智能性。
图纸说明
图1为本发明的基本原理图;
图2为本发明的解析模块框架示意图;
图3是本发明的动态爬取方法的流程图;
图4是本发明采用脚本解析动态网页的流程图;
图5是本发明中采用脚本通过服务器认证结构分析动态网页的组成;
无花果。图6是本发明中脚本解析和渲染的流程图。
详细说明
为更好地理解本发明所提出的技术方案,下面结合附图1-6和具体实施例对本发明作进一步的说明。
如图1和图2所示,动态网络爬虫系统包括爬虫引擎、调度器、解析模块、项目流水线和下载器。
爬虫引擎用于处理数据流和触发事务;
调度器用于接收爬虫引擎或解析模块发送的请求,将请求推入队列调度下载器下载,当爬虫引擎再次请求时返回;
解析模块用于构造或解析动态网页的异步加载信息,分析从下载器中提取的网页中的数据元素;
项目管道用于处理解析器从网页中提取的数据或响应爬虫引擎的请求;
下载器用于响应调度器的任务请求,下载网页内容,并将网页内容返回给解析器;解析模块包括脚本解析器、渲染器和切换模块,
脚本解析器通过网络抓包工具搜索查询动态信息的文件类型,根据动态信息的文件类型对动态信息文件的结构进行建模,构造动态网页的请求规则,解析动态网页中的所有文件。并将动态网页的内容提取出来,交给项目管道;如果解析失败,则交由切换模块处理;
渲染器通过加载动态网页的异步加载信息构建完整的动态网页dom树,并通过模拟操作解析出动态网页中服务器返回的异步加载内容,直到动态网页内容完整提取。交给切换模块交给脚本解析器处理;
切换模块检测脚本解析器或渲染器解析动态网页所花费的时间以及解析的内容是否完整,如果所需时间超过阈值或内容不完整则切换。
在本发明的一个实施例中,切换阈值时间选择为150ms,即当脚本解析或渲染器解析动态页面超过150ms仍无法返回时,切换器切换未解析的url使用的方法。
在本发明的另一个实施例中,考虑到现有爬虫系统可能是分布式架构,可以优化解析时间和资源消耗,因此切换器的切换条件考虑解析出的动态页面的信息是否完整。
在本发明的一个实施例中,渲染器为无界面浏览器,常见的无界面浏览器有benv、browser、launcher、browserjet、casperjs、dalekjsghostbuster、headlessbrowser、htmlunit、jasmine-headless-webkit、jaunt、jbrowserdriver、jedi-爬虫,乐天,噩梦,phantomjs,硒,slimerjs,triflejs,zombie.js。
进一步地,在本发明实施例中,无界面浏览器包括selenium、splash、htmlunit、phantomjs。
进一步地,在本发明的一个实施例中,使用selenium与webdriver或hantomjs相结合的方法进行动态页面提取。
为了避免使用浏览器进行动态解析或渲染的盲目性,在本发明的一个实施例中,解析模块还包括预解析模块,从url库中随机抽取样本,然后提交给脚本解析器或渲染器爬取并记录爬取信息的完整性、爬取时间和资源消耗。
如图4至图6所示,本发明还提供了一种基于上述动态网页爬虫系统的动态网页提取方法,包括以下步骤:
s1:获取url库,对url库进行聚类分析,如果有聚类,进行步骤s2,如果没有聚类,结束;
s2:从集群中抽取至少一个随机样本url;
s3:使用脚本解析、渲染,或者脚本解析和渲染相结合的方式爬取url;
s4:记录爬取信息的完整性、爬取时间、资源消耗等信息,通过优先级算法选择最优爬虫方案,使用最优方案爬取集群内所有动态网页;
s5:处理爬取信息,执行步骤s1。
作为本发明的一个优选方案,所述脚本解析还包括:根据动态网页或网站信息生成请求规则,通过服务器验证获取访问权限,根据请求规则获取异步加载信息。进一步地,通过服务器的验证包括cookie认证、用户认证、301认证、302认证、图文认证、ip认证。
基于以上描述的公开和教导,本发明所属领域的技术人员还可以对上述实施例的相关模块和软件架构进行适应性改变和修改。因此,本发明不限于上述所公开和描述的具体实施例,对本发明的一些修改和变化也应落入本发明权利要求的保护范围之内。此外,虽然在本说明书中使用了一些特定的术语,但这些术语只是为了描述的方便,并不构成对本发明的任何限制。
当前第 1 页,共 12 页 查看全部
htmlunit抓取动态网页(
基于python(asynchronousjavascriptandxml)的动态网页爬虫系统及其开发方法)
本发明属于计算机领域,涉及爬虫系统,尤其是一种动态网页爬虫系统。
背景技术
网络爬虫是一种自动提取网页的程序。传统爬虫从一个或多个初始网页的url开始,获取初始网页上的url(统一资源定位器),在抓取网页的过程中不断从当前页面中提取。新的url被放入队列中,直到满足系统预设的停止条件。
随着互联网从web1.0时代迅速进入web1.0时代,基于ajax(异步javascript和xml)的动态页面加载技术成为各大公司的首选。随着移动互联网的兴起,javascript在移动端和pc端的优秀特性被广泛挖掘,基于前端mvc/mvm的模型逐渐进入各大互联网公司的首选方案。动态网页的迅速崛起使得基于动态网页的网络爬虫越来越重要。
例如,一个 网站? courseid=id#/学习/视频?课程ID=课程ID&c。通常,对于动态url对应的动态页面,后面跟问号、等号等字符的参数就是要查询的数据库数据。为了获取动态页面的数据,动态页面的内容一般通过浏览器的脚本解析或者渲染动态页面的方式来获取。但是,脚本解析的前提是异步加载信息中存在部分或全部目标动态页面信息,请求规则可以是获取和目标页面有规律的分布;使用浏览器渲染只能针对不完整的DOM(文档对象模型)数据结构,而部分或全部的目标信息存在于使用浏览器渲染中。
技术实施要素:
为了解决脚本解析和浏览器渲染的局限性,提高动态网页爬取的准确性和完整性,本发明提供了一种基于scrapy(scrapy是一个基于python开发的快速、高级的屏幕抓取和网页抓取) Crawl framework)动态网络爬虫系统,包括爬虫引擎、调度器、解析模块、项目管道、下载器,爬虫引擎用于处理数据流和触发事务;
调度器用于接收爬虫引擎或解析模块发送的请求,将请求推入队列调度下载器下载,当爬虫引擎再次请求时返回;
解析模块用于构造或解析动态网页的异步加载信息,分析从下载器中提取的网页中的数据元素;
项目管道用于处理解析器从网页中提取的数据或响应爬虫引擎的请求;
下载器,用于响应调度器的任务请求,下载网页内容,并将网页内容返回给解析器;
解析模块包括脚本解析器、渲染器和切换模块;
脚本解析器通过网络抓包工具搜索查询动态信息的文件类型,根据动态信息的文件类型对动态信息文件的结构进行建模,构造动态网页的请求规则,解析动态网页中的所有文件。并将动态网页的内容提取出来,交给项目管道;如果解析失败,则交由切换模块处理;
渲染器通过加载动态网页的异步加载信息构建完整的动态网页dom树,并通过模拟操作解析出动态网页中服务器返回的异步加载内容,直到动态网页内容完整提取。交给切换模块交给脚本解析器处理;
切换模块检测脚本解析器或渲染器解析动态网页所花费的时间以及解析的内容是否完整,如果所需时间超过阈值或内容不完整则切换。
作为本发明的一个优选方案,渲染器为无界面浏览器。
作为本发明的一个优选方案,无界面浏览器包括selenium、splash、htmlunit、phantomjs。在本发明的一个实施例中,无界面浏览器使用闪屏渲染容器来渲染动态网页。
为了避免使用动态解析或者用浏览器渲染来提取动态网页的盲目性,在本发明的一个实施例中,解析模块还包括预解析模块,从url库中随机抽取样本。然后交给脚本解析器或渲染器进行爬取,记录爬取信息的完整性、爬取时间、资源消耗等。
本发明第二方面的目的在于提供一种动态网页提取方法,包括以下步骤:
s1:获取url库,对url库进行聚类分析,如果有聚类,进行步骤s2,如果没有聚类,结束;
s2:从集群中抽取至少一个随机样本url;
s3:使用脚本解析、渲染,或者脚本解析和渲染相结合的方式爬取url;
s4:记录爬取信息的完整性、爬取时间、资源消耗等信息,通过优先级算法选择最优爬虫方案,使用最优方案爬取集群内所有动态网页;
s5:处理爬取信息,执行步骤s1。
作为本发明的一个优选方案,所述脚本解析还包括:
根据动态网页或URL信息生成请求规则,通过服务器验证获取访问权限,根据请求规则获取异步加载信息。
进一步地,通过服务器的验证包括cookie认证、用户认证、301认证、302认证、图文认证、ip认证。
作为本发明的一个优选方案,所述渲染包括:使用无界面浏览器渲染异步加载的信息,使用无界面浏览器的api模拟用户点击,从模拟事件的结果中提取目标信息.
作为本发明的一种优选方案,脚本解析和渲染混合的具体步骤如下:通过脚本解析获取动态网页的请求规则,然后通过无界面浏览器加载,使用脚本解析解析缺失的渲染参数构造完整的请求规则,直到获得完整的异步加载信息。
作为本发明的优选方案,s4中的优先级算法如下:以提取的动态页面提取信息的完整性、时间、资源消耗率为变量,采用单纯形法得到最优解。
本发明的有益效果是:
1.本发明是对目前大部分动态网页网站的结构和常规动态网页的爬取方法进行分析,利用资源消耗低和脚本解析速度快的优点,并且在渲染方面集成了webdriver爬虫的优点,可以提高爬虫的爬取精度和适应性。
2.设置切换模块,避免使用单一爬取方式时,因特殊情况导致无法爬取,陷入死循环的情况。
3.通过预检测机制,对收录不同动态异步加载机制的动态网页采用不同的爬取策略,提高了解析性能,减少了对内存和网络资源的占用,使得在本发明对动态页面的爬取更具自适应性和智能性。
图纸说明
图1为本发明的基本原理图;
图2为本发明的解析模块框架示意图;
图3是本发明的动态爬取方法的流程图;
图4是本发明采用脚本解析动态网页的流程图;
图5是本发明中采用脚本通过服务器认证结构分析动态网页的组成;
无花果。图6是本发明中脚本解析和渲染的流程图。
详细说明
为更好地理解本发明所提出的技术方案,下面结合附图1-6和具体实施例对本发明作进一步的说明。
如图1和图2所示,动态网络爬虫系统包括爬虫引擎、调度器、解析模块、项目流水线和下载器。
爬虫引擎用于处理数据流和触发事务;
调度器用于接收爬虫引擎或解析模块发送的请求,将请求推入队列调度下载器下载,当爬虫引擎再次请求时返回;
解析模块用于构造或解析动态网页的异步加载信息,分析从下载器中提取的网页中的数据元素;
项目管道用于处理解析器从网页中提取的数据或响应爬虫引擎的请求;
下载器用于响应调度器的任务请求,下载网页内容,并将网页内容返回给解析器;解析模块包括脚本解析器、渲染器和切换模块,
脚本解析器通过网络抓包工具搜索查询动态信息的文件类型,根据动态信息的文件类型对动态信息文件的结构进行建模,构造动态网页的请求规则,解析动态网页中的所有文件。并将动态网页的内容提取出来,交给项目管道;如果解析失败,则交由切换模块处理;
渲染器通过加载动态网页的异步加载信息构建完整的动态网页dom树,并通过模拟操作解析出动态网页中服务器返回的异步加载内容,直到动态网页内容完整提取。交给切换模块交给脚本解析器处理;
切换模块检测脚本解析器或渲染器解析动态网页所花费的时间以及解析的内容是否完整,如果所需时间超过阈值或内容不完整则切换。
在本发明的一个实施例中,切换阈值时间选择为150ms,即当脚本解析或渲染器解析动态页面超过150ms仍无法返回时,切换器切换未解析的url使用的方法。
在本发明的另一个实施例中,考虑到现有爬虫系统可能是分布式架构,可以优化解析时间和资源消耗,因此切换器的切换条件考虑解析出的动态页面的信息是否完整。
在本发明的一个实施例中,渲染器为无界面浏览器,常见的无界面浏览器有benv、browser、launcher、browserjet、casperjs、dalekjsghostbuster、headlessbrowser、htmlunit、jasmine-headless-webkit、jaunt、jbrowserdriver、jedi-爬虫,乐天,噩梦,phantomjs,硒,slimerjs,triflejs,zombie.js。
进一步地,在本发明实施例中,无界面浏览器包括selenium、splash、htmlunit、phantomjs。
进一步地,在本发明的一个实施例中,使用selenium与webdriver或hantomjs相结合的方法进行动态页面提取。
为了避免使用浏览器进行动态解析或渲染的盲目性,在本发明的一个实施例中,解析模块还包括预解析模块,从url库中随机抽取样本,然后提交给脚本解析器或渲染器爬取并记录爬取信息的完整性、爬取时间和资源消耗。
如图4至图6所示,本发明还提供了一种基于上述动态网页爬虫系统的动态网页提取方法,包括以下步骤:
s1:获取url库,对url库进行聚类分析,如果有聚类,进行步骤s2,如果没有聚类,结束;
s2:从集群中抽取至少一个随机样本url;
s3:使用脚本解析、渲染,或者脚本解析和渲染相结合的方式爬取url;
s4:记录爬取信息的完整性、爬取时间、资源消耗等信息,通过优先级算法选择最优爬虫方案,使用最优方案爬取集群内所有动态网页;
s5:处理爬取信息,执行步骤s1。
作为本发明的一个优选方案,所述脚本解析还包括:根据动态网页或网站信息生成请求规则,通过服务器验证获取访问权限,根据请求规则获取异步加载信息。进一步地,通过服务器的验证包括cookie认证、用户认证、301认证、302认证、图文认证、ip认证。
基于以上描述的公开和教导,本发明所属领域的技术人员还可以对上述实施例的相关模块和软件架构进行适应性改变和修改。因此,本发明不限于上述所公开和描述的具体实施例,对本发明的一些修改和变化也应落入本发明权利要求的保护范围之内。此外,虽然在本说明书中使用了一些特定的术语,但这些术语只是为了描述的方便,并不构成对本发明的任何限制。
当前第 1 页,共 12 页
htmlunit抓取动态网页(Java环境下的一下配置实现思路 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-03-08 14:17
)
爬取网页数据时,传统的jsoup方案只能对静态页面有效,而一些网页数据往往是由js生成的,此时就需要其他的方案了。
第一个思路是分析js程序,再次爬取js请求,适合爬取特定页面,但要实现不同目标url的通用性比较麻烦。
第二种思路,也比较成熟,就是使用第三方驱动渲染页面,然后下载。这是第二个实现思路。
Selenium 是一个模拟浏览器的自动化测试工具。它提供了一组 API 来与真正的浏览器内核交互。
Java环境下的maven配置如下:
org.seleniumhq.selenium
selenium-java
2.46.0
第三方驱动主要有IEDriver、FirefoxDriver、ChromeDriver、HtmlUnitDriver。
htmlUnit 也是一个自动化测试的工具。您可以使用 HtmlUnit 来模拟浏览器运行并获取执行的 html 页面。其中,HtmlUnitDriver是对htmlUnit的封装。
由于htmlunit对js解析的支持有限,在实际项目中并不常用。
以chrome为例,下载对应的驱动:.
下载驱动时,需要注意与selenium版本的兼容性。可能有例外。一般来说,最好下载最新版本。
在运行程序之前,一定要指定驱动位置,比如在Windows下
System.getProperties().setProperty("webdriver.chrome.driver",
"D:\\chromedriver\\chromedriver.exe");
获取整个页面
public static void testChromeDriver() {
System.getProperties().setProperty("webdriver.chrome.driver",
"D:\\chromedriver\\chromedriver.exe");
WebDriver webDriver = new ChromeDriver();
webDriver.get("http://picture.youth.cn/qtdb/2 ... 6quot;);
String responseBody = webDriver.getPageSource();
System.out.println(responseBody);
webDriver.close();
} 查看全部
htmlunit抓取动态网页(Java环境下的一下配置实现思路
)
爬取网页数据时,传统的jsoup方案只能对静态页面有效,而一些网页数据往往是由js生成的,此时就需要其他的方案了。
第一个思路是分析js程序,再次爬取js请求,适合爬取特定页面,但要实现不同目标url的通用性比较麻烦。
第二种思路,也比较成熟,就是使用第三方驱动渲染页面,然后下载。这是第二个实现思路。
Selenium 是一个模拟浏览器的自动化测试工具。它提供了一组 API 来与真正的浏览器内核交互。
Java环境下的maven配置如下:
org.seleniumhq.selenium
selenium-java
2.46.0
第三方驱动主要有IEDriver、FirefoxDriver、ChromeDriver、HtmlUnitDriver。
htmlUnit 也是一个自动化测试的工具。您可以使用 HtmlUnit 来模拟浏览器运行并获取执行的 html 页面。其中,HtmlUnitDriver是对htmlUnit的封装。
由于htmlunit对js解析的支持有限,在实际项目中并不常用。
以chrome为例,下载对应的驱动:.
下载驱动时,需要注意与selenium版本的兼容性。可能有例外。一般来说,最好下载最新版本。
在运行程序之前,一定要指定驱动位置,比如在Windows下
System.getProperties().setProperty("webdriver.chrome.driver",
"D:\\chromedriver\\chromedriver.exe");
获取整个页面
public static void testChromeDriver() {
System.getProperties().setProperty("webdriver.chrome.driver",
"D:\\chromedriver\\chromedriver.exe");
WebDriver webDriver = new ChromeDriver();
webDriver.get("http://picture.youth.cn/qtdb/2 ... 6quot;);
String responseBody = webDriver.getPageSource();
System.out.println(responseBody);
webDriver.close();
}
htmlunit抓取动态网页(西安蟠龍网络给大家简单的介绍一下动态网页与静态网页的一些简单区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-03-04 02:00
西安盘龙网络将简单介绍一下动态网页和静态网页的一些简单区别:
一、动态网页是指网页与数据库的连接。页面内容根据客户要求显示不同内容,实时读取数据库内容。动态网页一般以.php.asp.jsp等结尾,静态网页一般以.html结尾,内容不变,每个用户看到的内容都是一样的。
二、动态网页是实时读取数据库的,所以速度相对静态网页要慢一些。如果是很大的网站,而且流量很大,那么实时读取数据库需要特别大的服务器。
三、静态网页速度快,URL参数快,对搜索引擎友好,有利于网页收录和排名。
四、静态网页也可以使用ajax技术实现本地动态内容,根据用户请求本地读取数据库数据。
误解:带有动画、飘动等的页面不是动态网页。动态网页是指与数据库的交互,而页面动画、滚动、飘动是用脚本语言 JavaScript 实现的,而不是动态网页的衡量指标。
综上所述,如果网页需要根据不同的用户实时显示不同的内容,就需要使用动态网页。如果网页内容固定或本地内容发生变化,一般采用生成静态网页的方法,这样用户访问速度快,有利于搜索引擎优化,西安盘龙网络提供服务以生成静态网页的形式发给客户!欢迎您来电咨询。 查看全部
htmlunit抓取动态网页(西安蟠龍网络给大家简单的介绍一下动态网页与静态网页的一些简单区别)
西安盘龙网络将简单介绍一下动态网页和静态网页的一些简单区别:
一、动态网页是指网页与数据库的连接。页面内容根据客户要求显示不同内容,实时读取数据库内容。动态网页一般以.php.asp.jsp等结尾,静态网页一般以.html结尾,内容不变,每个用户看到的内容都是一样的。
二、动态网页是实时读取数据库的,所以速度相对静态网页要慢一些。如果是很大的网站,而且流量很大,那么实时读取数据库需要特别大的服务器。
三、静态网页速度快,URL参数快,对搜索引擎友好,有利于网页收录和排名。
四、静态网页也可以使用ajax技术实现本地动态内容,根据用户请求本地读取数据库数据。
误解:带有动画、飘动等的页面不是动态网页。动态网页是指与数据库的交互,而页面动画、滚动、飘动是用脚本语言 JavaScript 实现的,而不是动态网页的衡量指标。
综上所述,如果网页需要根据不同的用户实时显示不同的内容,就需要使用动态网页。如果网页内容固定或本地内容发生变化,一般采用生成静态网页的方法,这样用户访问速度快,有利于搜索引擎优化,西安盘龙网络提供服务以生成静态网页的形式发给客户!欢迎您来电咨询。
htmlunit抓取动态网页(2019独角兽企业重金招聘Python工程师用户体验策略(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-03 11:17
2019独角兽企业招聘Python工程师标准>>>
四、更新政策
互联网实时变化并且非常动态。网页更新策略主要决定何时更新之前已经下载的页面。常见的更新策略有以下三种:
1.历史参考政策
顾名思义,它根据页面过去的历史更新数据来预测未来页面何时会发生变化。通常,预测是通过泊松过程建模来进行的。
2.用户体验策略
尽管搜索引擎可以为某个查询返回大量结果,但用户通常只关注结果的前几页。因此,爬虫系统可以优先更新那些实际在查询结果前几页的页面,然后再更新后面的那些页面。这个更新策略也需要用到历史信息。UX 策略保留网页的多个历史版本,并根据每个过去内容更改对搜索质量的影响得出一个平均值,并以此值作为决定何时重新抓取的基础。
3.聚类抽样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页完全没有历史信息,就无法确定更新策略。
该策略认为网页具有许多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某一类别网页的更新频率,只需对该类别的网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如下:
五、分布式抓取系统结构
一般来说,爬虫系统需要处理整个互联网上数以亿计的网页。单个爬虫不可能完成这样的任务。通常需要多个爬虫程序一起处理它们。一般来说,爬虫系统往往是分布式的三层结构。如图所示:
最底层是分布在不同地理位置的数据中心。每个数据中心有多个爬虫服务器,每个爬虫服务器可能部署多套爬虫程序。这样就构成了一个基本的分布式爬虫系统。
对于数据中心中的不同服务器,有几种方法可以协同工作:
1.主从
主从基本结构如图:
对于主从类型,有一个专门的主服务器来维护要爬取的URL队列,负责每次将URL分发给不同的从服务器,从服务器负责实际的网页下载工作。Master服务器除了维护要爬取的URL队列和分发URL外,还负责调解每个Slave服务器的负载。为了避免一些从服务器过于空闲或过度工作。
在这种模式下,Master往往会成为系统的瓶颈。
2.点对点
等价的基本结构如图所示:
在这种模式下,所有爬虫服务器之间的分工没有区别。每个爬取服务器可以从待爬取的URL队列中获取URL,然后计算该URL主域名的哈希值H,进而计算H mod m(其中m为服务器数量,取上图例如,m 对于 3),计算出来的数字就是处理 URL 的主机号。
例子:假设对于URL,计算器hash值H=8,m=3,那么H mod m=2,那么编号为2的服务器会抓取该链接。假设此时服务器 0 获取了 URL,它会将 URL 传输到服务器 2,服务器 2 将获取它。
这种模式有一个问题,当一个服务器死掉或添加一个新服务器时,所有 URL 的哈希余数的结果都会改变。也就是说,这种方法不能很好地扩展。针对这种情况,提出了另一种改进方案。这种改进的方案是一致的散列以确定服务器划分。其基本结构如图所示:
一致散列对 URL 的主域名进行散列,并将其映射到 0-232 范围内的数字。这个范围平均分配给m台服务器,根据主URL域名的hash运算值的范围来确定要爬取哪个服务器。
如果某台服务器出现问题,本应负责该服务器的网页将由下一个服务器顺时针获取。在这种情况下,即使一台服务器出现问题,也不会影响其他工作。
转载于: 查看全部
htmlunit抓取动态网页(2019独角兽企业重金招聘Python工程师用户体验策略(图))
2019独角兽企业招聘Python工程师标准>>>
四、更新政策
互联网实时变化并且非常动态。网页更新策略主要决定何时更新之前已经下载的页面。常见的更新策略有以下三种:
1.历史参考政策
顾名思义,它根据页面过去的历史更新数据来预测未来页面何时会发生变化。通常,预测是通过泊松过程建模来进行的。
2.用户体验策略
尽管搜索引擎可以为某个查询返回大量结果,但用户通常只关注结果的前几页。因此,爬虫系统可以优先更新那些实际在查询结果前几页的页面,然后再更新后面的那些页面。这个更新策略也需要用到历史信息。UX 策略保留网页的多个历史版本,并根据每个过去内容更改对搜索质量的影响得出一个平均值,并以此值作为决定何时重新抓取的基础。
3.聚类抽样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页完全没有历史信息,就无法确定更新策略。
该策略认为网页具有许多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某一类别网页的更新频率,只需对该类别的网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如下:
五、分布式抓取系统结构
一般来说,爬虫系统需要处理整个互联网上数以亿计的网页。单个爬虫不可能完成这样的任务。通常需要多个爬虫程序一起处理它们。一般来说,爬虫系统往往是分布式的三层结构。如图所示:
最底层是分布在不同地理位置的数据中心。每个数据中心有多个爬虫服务器,每个爬虫服务器可能部署多套爬虫程序。这样就构成了一个基本的分布式爬虫系统。
对于数据中心中的不同服务器,有几种方法可以协同工作:
1.主从
主从基本结构如图:
对于主从类型,有一个专门的主服务器来维护要爬取的URL队列,负责每次将URL分发给不同的从服务器,从服务器负责实际的网页下载工作。Master服务器除了维护要爬取的URL队列和分发URL外,还负责调解每个Slave服务器的负载。为了避免一些从服务器过于空闲或过度工作。
在这种模式下,Master往往会成为系统的瓶颈。
2.点对点
等价的基本结构如图所示:
在这种模式下,所有爬虫服务器之间的分工没有区别。每个爬取服务器可以从待爬取的URL队列中获取URL,然后计算该URL主域名的哈希值H,进而计算H mod m(其中m为服务器数量,取上图例如,m 对于 3),计算出来的数字就是处理 URL 的主机号。
例子:假设对于URL,计算器hash值H=8,m=3,那么H mod m=2,那么编号为2的服务器会抓取该链接。假设此时服务器 0 获取了 URL,它会将 URL 传输到服务器 2,服务器 2 将获取它。
这种模式有一个问题,当一个服务器死掉或添加一个新服务器时,所有 URL 的哈希余数的结果都会改变。也就是说,这种方法不能很好地扩展。针对这种情况,提出了另一种改进方案。这种改进的方案是一致的散列以确定服务器划分。其基本结构如图所示:
一致散列对 URL 的主域名进行散列,并将其映射到 0-232 范围内的数字。这个范围平均分配给m台服务器,根据主URL域名的hash运算值的范围来确定要爬取哪个服务器。
如果某台服务器出现问题,本应负责该服务器的网页将由下一个服务器顺时针获取。在这种情况下,即使一台服务器出现问题,也不会影响其他工作。
转载于:
htmlunit抓取动态网页(“动态网页特点有哪些?什么是动态网站”?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-03-02 07:05
这两年,全球都笼罩在疫情的气氛中。为了减少人与人之间的接触造成的感染,互联网已成为人与人之间的主要交流方式。对此,网站的建设也迎来了飞速发展的阶段。但是,在当前时代要求和消费需求下,很多企业都希望通过互联网给企业带来新的活力,那么“动态网页有什么特点?什么是动态网站”,我们来看看看看
动态网页的特点是什么?
我们将动态网页的一般特征简单总结如下:
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站配合动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是一个独立存在于服务器上的网页文件,服务器只有在用户请求时才返回一个完整的网页;
(4)动态网页中的“?”一般不可能让搜索引擎从一个网站数据库中访问所有网页,或者由于技术原因,搜索蜘蛛不会抓取网址网站动态网页中“?”后面的内容在搜索引擎推广时,为了适应搜索引擎的要求,需要做一定的技术处理。
另外,如果扩展名是.asp但没有连接数据库,它是一个完全静态的页面,也是静态的网站.asp只是一个扩展名。
(5)静态网站因为没有连接数据库,要产生动态网站的效果,需要创建大量的网页,很多只能是假网页。动态网站功能不可用。
什么是动态网站?
Dynamic网站不是指具有动画功能的网站,而是指可以根据不同情况动态改变内容的网站。一般情况下,动态网站Schema 通过数据库。动态网站除了设计网页,还通过数据库和编程让网站拥有更多自动化和高级的功能。动态网站体现在网页一般基于asp、jsp、php、aspx等技术,而静态网页一般以HTML(标准通用标记语言的子集)结尾。动态网站服务器空间配置优于静态网页,要求高,成本也高,但动态网页有利于网站内容的更新,适合企业建站。动态相对于静态网站。
以上是上格信息科技小编整理的《动态网页有什么特点?2021年动态是什么网站》的相关知识,希望对大家有所帮助 查看全部
htmlunit抓取动态网页(“动态网页特点有哪些?什么是动态网站”?)
这两年,全球都笼罩在疫情的气氛中。为了减少人与人之间的接触造成的感染,互联网已成为人与人之间的主要交流方式。对此,网站的建设也迎来了飞速发展的阶段。但是,在当前时代要求和消费需求下,很多企业都希望通过互联网给企业带来新的活力,那么“动态网页有什么特点?什么是动态网站”,我们来看看看看
动态网页的特点是什么?
我们将动态网页的一般特征简单总结如下:
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站配合动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是一个独立存在于服务器上的网页文件,服务器只有在用户请求时才返回一个完整的网页;
(4)动态网页中的“?”一般不可能让搜索引擎从一个网站数据库中访问所有网页,或者由于技术原因,搜索蜘蛛不会抓取网址网站动态网页中“?”后面的内容在搜索引擎推广时,为了适应搜索引擎的要求,需要做一定的技术处理。
另外,如果扩展名是.asp但没有连接数据库,它是一个完全静态的页面,也是静态的网站.asp只是一个扩展名。
(5)静态网站因为没有连接数据库,要产生动态网站的效果,需要创建大量的网页,很多只能是假网页。动态网站功能不可用。
什么是动态网站?
Dynamic网站不是指具有动画功能的网站,而是指可以根据不同情况动态改变内容的网站。一般情况下,动态网站Schema 通过数据库。动态网站除了设计网页,还通过数据库和编程让网站拥有更多自动化和高级的功能。动态网站体现在网页一般基于asp、jsp、php、aspx等技术,而静态网页一般以HTML(标准通用标记语言的子集)结尾。动态网站服务器空间配置优于静态网页,要求高,成本也高,但动态网页有利于网站内容的更新,适合企业建站。动态相对于静态网站。
以上是上格信息科技小编整理的《动态网页有什么特点?2021年动态是什么网站》的相关知识,希望对大家有所帮助
htmlunit抓取动态网页(基于现有的动态网页爬虫系统-DynCrawler系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-02-28 14:12
【摘要】 随着网页数量的爆炸式增长,传统的集中式爬虫难以满足实际应用。此外,Ajax技术在网络应用中的广泛普及,给传统的Web开发带来了新的革命。通过部分刷新功能提升了用户体验,用户可以与远程服务器进行良好的交互。典型应用包括校园论坛、博客网站等。这些大量动态网页的出现给传统的网络爬虫带来了很大的障碍。它影响爬虫的效率,也影响网页内容的获取。针对以上两个问题,本文设计了一种基于WebMagic爬虫框架的分布式动态网络爬虫系统Dis-Dyn Crawler。系统采用SOA架构的思想,将动态网页解析工具HtmlUnit在动态页面过程中的耗时操作分离为一个独立的服务;为了提高解析效率,系统将HtmlUnit所需的JavaScript等文件缓存在Redis数据库中。页面渲染时,不必每次都从网络下载,减少了网络请求,提高了解析效率;异步页面下载器的实现进一步提高了系统的整体效率。本文从功能和性能两个方面对Dis-Dyn Crawler系统进行了实验分析。通过与现有分布式网络爬虫工具的爬取能力对比,验证了本文基于Webmagic的动态网络爬虫是高效的。通过与现有动态网页解析工具的对比,验证了本文提出的Dis-Dyn爬虫系统的效率和可行性。 查看全部
htmlunit抓取动态网页(基于现有的动态网页爬虫系统-DynCrawler系统)
【摘要】 随着网页数量的爆炸式增长,传统的集中式爬虫难以满足实际应用。此外,Ajax技术在网络应用中的广泛普及,给传统的Web开发带来了新的革命。通过部分刷新功能提升了用户体验,用户可以与远程服务器进行良好的交互。典型应用包括校园论坛、博客网站等。这些大量动态网页的出现给传统的网络爬虫带来了很大的障碍。它影响爬虫的效率,也影响网页内容的获取。针对以上两个问题,本文设计了一种基于WebMagic爬虫框架的分布式动态网络爬虫系统Dis-Dyn Crawler。系统采用SOA架构的思想,将动态网页解析工具HtmlUnit在动态页面过程中的耗时操作分离为一个独立的服务;为了提高解析效率,系统将HtmlUnit所需的JavaScript等文件缓存在Redis数据库中。页面渲染时,不必每次都从网络下载,减少了网络请求,提高了解析效率;异步页面下载器的实现进一步提高了系统的整体效率。本文从功能和性能两个方面对Dis-Dyn Crawler系统进行了实验分析。通过与现有分布式网络爬虫工具的爬取能力对比,验证了本文基于Webmagic的动态网络爬虫是高效的。通过与现有动态网页解析工具的对比,验证了本文提出的Dis-Dyn爬虫系统的效率和可行性。
htmlunit抓取动态网页(Python开发的一个快速,高层次高层次架构架构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-02-27 11:00
8.参考文章
0x01 爬虫架构
说到爬虫架构,不得不提Scrapy的爬虫架构。Scrapy 是一个用 Python 开发的快速、高级的爬虫框架,用于爬取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还为各种类型的爬虫提供了基类,例如BaseSpider、站点地图爬虫等。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
0x02 页面下载和解析页面下载
页面下载分为静态下载和动态下载两种方式。
传统爬虫采用静态下载方式。静态下载的好处是下载过程很快,但是页面只是一个乏味的html。所以在页面链接分析中只获取标签的href属性,或者高手自行分析js、form等标签。捕获一些链接。在python中,可以使用urllib2模块或者requests模块来实现功能。动态爬虫在 web2.0 时代具有特殊的优势。由于网页是通过javascript处理的,所以网页的内容是通过Ajax异步获取的。因此,动态爬虫需要对页面经过javascript处理和ajax进行分析才能获取内容。目前简单的解决方法是直接通过基于 webkit 的模块来处理它。PYQT4、的三个模块 Splinter 和 Selenium 都可以达到目的。对于爬虫来说,不需要浏览器界面,所以使用无头浏览器是非常划算的。HtmlUnit 和 phantomjs 都是可以使用的无头浏览器。
以上代码是访问新浪网的主站。通过比较静态爬虫页面和动态爬虫页面的长度,比较静态爬虫页面和动态爬虫页面爬取的链接数。
静态爬取时,页面长度为563838,页面内爬取的链接数只有166个。动态爬取时,页面长度增加到695991,链接数达到1422,接近10-倍增。
抓取链接表达式
常规:pile(“href=\”([^\”]*)\””)
Xpath: xpath('//*[@href]')
页面解析
页面解析是一个模块,它捕获页面内的链接并爬取特定数据。页面解析主要处理的是字符串,而html是一个特殊的字符串。在Python中,re、beautifulsoup、HTMLParser、lxml等模块都可以解决问题。对于链接,主要是抓取a标签下的href属性,以及其他一些标签的src属性。
0x03 URL去重
URL去重是爬虫操作的关键步骤。由于正在运行的爬虫主要被阻塞在网络交互中,因此避免重复的网络交互非常重要。爬虫一般将要爬取的 URL 放入队列中,从爬取的网页中提取新的 URL。在将它们放入队列之前,它们必须首先确保这些新 URL 未被抓取。如果之前已经爬过,不再放入队列中。
哈希表
使用哈希表进行去重一般是最容易想到的方法,因为哈希表查询的时间复杂度是O(1),而当哈希表足够大的时候,哈希冲突的概率就变得非常高了所以判断URL是否重复的准确率是很高的,使用哈希表去重是比较简单的解决方案,但是普通的哈希表也有明显的缺陷,考虑到内存,使用大的哈希表是不合适。字典数据结构可以在Python中使用。
网址压缩
如果在哈希表中,当每个节点以str的形式存储一个特定的URL时,是非常占用内存的。如果将 URL 压缩成 int 类型的变量,内存使用量将减少 3 倍以上。因此,您可以使用 Python 的 hashlib 模块进行 URL 压缩。思路:将哈希表的节点数据结构设置为集合,将压缩后的URL存放在集合中。
布隆过滤器
Bloom Filter 可以节省大量存储空间,而且错误很少。Bloom Filter 是一组定义在 n 个输入键上的 k 个哈希函数,将上述 n 个键映射到 m 位上的数据容器。
上图清楚地说明了布隆过滤器的优势。在可控容器长度内,当所有哈希函数对同一元素计算的哈希值为1时,判断该元素存在。Python中的hashlib自带了多种hash函数,包括MD5、sha1、sha224、sha256、sha384、sha512。代码也可以加盐,非常方便。Bloom Filter 也会造成冲突,详见文章末尾的参考文章。
在Python编程过程中,可以使用jaybaird提供的BloomFilter接口,也可以自己搭建轮子。
细节
有个小细节,在构建哈希表的时候选择容器很重要。哈希表占用太多空间是一个非常令人不快的问题。因此,以下方法可以解决爬虫去重的一些问题。
上面的代码只是简单地验证了生成容器的运行时间。
从上图可以看出,在构建一个长度为1亿的容器时,选择列表容器程序耗时7.2s,选择一个字符串作为运行时间的容器。
接下来,查看内存使用情况。
如果构建一个1亿的列表占用794660k的内存。
但是创建一个1亿长度的字符串会占用109,720k的内存,空间占用减少了大约700,000k。
0x04 网址相似度
主要算法
对于URL相似度,我只是实践了一个很简单的方法。
在保证不重复爬取的情况下,还需要对相似的URL进行判断。我使用海绵和ly5066113提供的想法。具体信息参考文章。
下面是一组可以判断为相似的URL组
正如预期的那样,上面的 URL 应该合并到
思路如下,需要提取以下特征
1、主机串
2.目录深度(用'/'隔开)
3. 最后一页功能
具体算法
算法本身很好,一看就懂。
实际效果:
上图显示了8个不同的url,计算了2个值。通过实践,在上千万的哈希表中,冲突情况是可以接受的。
0x05 并发操作
Python中并发操作涉及的主要模型有:多线程模型、多进程模型、协程模型。Elias 专门写了一篇文章文章,对比了几种常用模型并发方案的性能。对于爬虫本身来说,限制爬虫的速度主要来自于目标服务器的响应速度,所以选择一个容易控制的模块是对的。
多线程模型
多线程模型是最容易上手的。Python自带的threading模块可以很好的实现并发需求,配合Queue模块实现数据共享。
多进程模型
多处理模型类似于多线程模型,多处理模块中有类似的Queue模块来实现数据共享。在linux中,用户态进程可以利用多核,所以在多核的上下文中,可以解决爬虫并发的问题。
协程模型
协程模型,在 Elias 的 文章 中,基于 greenlet 的协程程序的性能仅次于 Stackless Python,速度大约是 Stackless Python 的两倍,比其他解决方案快近一个数量级。因此,基于gevent(封装greenlets)的并发程序将具有良好的性能优势。
具体描述gevent(非阻塞异步IO)。, “Gevent是一个基于协程的Python网络库,使用Greenlet提供的高级同步API,封装了libevent事件循环。”
从实际编程效果来看,协程模型确实表现得非常好,运行结果的可控性明显更强,gevent库的封装非常好用。
0x06 数据存储
有许多技术是为数据存储本身而设计的。作为配菜不敢多说,但还是有一些工作中的小经验可以分享。
前提:使用关系型数据库,测试中选择mysql,其他和sqlite差不多,和SqlServer的思路没有区别。
我们做数据存储的时候,目的是减少与数据库的交互,这样可以提高性能。通常,每读取一个 URL 节点,就进行一次数据存储,这样的逻辑就会进行一次无限循环。其实这样的性能体验很差,存储速度也很慢。
对于高级方法,为了减少与数据库的交互次数,每次与数据库的交互从发送1个节点变为发送10个节点到发送100个节点内容,因此效率提高了10到100倍。在实际应用中,效果非常好。:D 查看全部
htmlunit抓取动态网页(Python开发的一个快速,高层次高层次架构架构)
8.参考文章
0x01 爬虫架构
说到爬虫架构,不得不提Scrapy的爬虫架构。Scrapy 是一个用 Python 开发的快速、高级的爬虫框架,用于爬取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还为各种类型的爬虫提供了基类,例如BaseSpider、站点地图爬虫等。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
0x02 页面下载和解析页面下载
页面下载分为静态下载和动态下载两种方式。
传统爬虫采用静态下载方式。静态下载的好处是下载过程很快,但是页面只是一个乏味的html。所以在页面链接分析中只获取标签的href属性,或者高手自行分析js、form等标签。捕获一些链接。在python中,可以使用urllib2模块或者requests模块来实现功能。动态爬虫在 web2.0 时代具有特殊的优势。由于网页是通过javascript处理的,所以网页的内容是通过Ajax异步获取的。因此,动态爬虫需要对页面经过javascript处理和ajax进行分析才能获取内容。目前简单的解决方法是直接通过基于 webkit 的模块来处理它。PYQT4、的三个模块 Splinter 和 Selenium 都可以达到目的。对于爬虫来说,不需要浏览器界面,所以使用无头浏览器是非常划算的。HtmlUnit 和 phantomjs 都是可以使用的无头浏览器。
以上代码是访问新浪网的主站。通过比较静态爬虫页面和动态爬虫页面的长度,比较静态爬虫页面和动态爬虫页面爬取的链接数。
静态爬取时,页面长度为563838,页面内爬取的链接数只有166个。动态爬取时,页面长度增加到695991,链接数达到1422,接近10-倍增。
抓取链接表达式
常规:pile(“href=\”([^\”]*)\””)
Xpath: xpath('//*[@href]')
页面解析
页面解析是一个模块,它捕获页面内的链接并爬取特定数据。页面解析主要处理的是字符串,而html是一个特殊的字符串。在Python中,re、beautifulsoup、HTMLParser、lxml等模块都可以解决问题。对于链接,主要是抓取a标签下的href属性,以及其他一些标签的src属性。
0x03 URL去重
URL去重是爬虫操作的关键步骤。由于正在运行的爬虫主要被阻塞在网络交互中,因此避免重复的网络交互非常重要。爬虫一般将要爬取的 URL 放入队列中,从爬取的网页中提取新的 URL。在将它们放入队列之前,它们必须首先确保这些新 URL 未被抓取。如果之前已经爬过,不再放入队列中。
哈希表
使用哈希表进行去重一般是最容易想到的方法,因为哈希表查询的时间复杂度是O(1),而当哈希表足够大的时候,哈希冲突的概率就变得非常高了所以判断URL是否重复的准确率是很高的,使用哈希表去重是比较简单的解决方案,但是普通的哈希表也有明显的缺陷,考虑到内存,使用大的哈希表是不合适。字典数据结构可以在Python中使用。
网址压缩
如果在哈希表中,当每个节点以str的形式存储一个特定的URL时,是非常占用内存的。如果将 URL 压缩成 int 类型的变量,内存使用量将减少 3 倍以上。因此,您可以使用 Python 的 hashlib 模块进行 URL 压缩。思路:将哈希表的节点数据结构设置为集合,将压缩后的URL存放在集合中。
布隆过滤器
Bloom Filter 可以节省大量存储空间,而且错误很少。Bloom Filter 是一组定义在 n 个输入键上的 k 个哈希函数,将上述 n 个键映射到 m 位上的数据容器。
上图清楚地说明了布隆过滤器的优势。在可控容器长度内,当所有哈希函数对同一元素计算的哈希值为1时,判断该元素存在。Python中的hashlib自带了多种hash函数,包括MD5、sha1、sha224、sha256、sha384、sha512。代码也可以加盐,非常方便。Bloom Filter 也会造成冲突,详见文章末尾的参考文章。
在Python编程过程中,可以使用jaybaird提供的BloomFilter接口,也可以自己搭建轮子。
细节
有个小细节,在构建哈希表的时候选择容器很重要。哈希表占用太多空间是一个非常令人不快的问题。因此,以下方法可以解决爬虫去重的一些问题。
上面的代码只是简单地验证了生成容器的运行时间。
从上图可以看出,在构建一个长度为1亿的容器时,选择列表容器程序耗时7.2s,选择一个字符串作为运行时间的容器。
接下来,查看内存使用情况。
如果构建一个1亿的列表占用794660k的内存。
但是创建一个1亿长度的字符串会占用109,720k的内存,空间占用减少了大约700,000k。
0x04 网址相似度
主要算法
对于URL相似度,我只是实践了一个很简单的方法。
在保证不重复爬取的情况下,还需要对相似的URL进行判断。我使用海绵和ly5066113提供的想法。具体信息参考文章。
下面是一组可以判断为相似的URL组
正如预期的那样,上面的 URL 应该合并到
思路如下,需要提取以下特征
1、主机串
2.目录深度(用'/'隔开)
3. 最后一页功能
具体算法
算法本身很好,一看就懂。
实际效果:
上图显示了8个不同的url,计算了2个值。通过实践,在上千万的哈希表中,冲突情况是可以接受的。
0x05 并发操作
Python中并发操作涉及的主要模型有:多线程模型、多进程模型、协程模型。Elias 专门写了一篇文章文章,对比了几种常用模型并发方案的性能。对于爬虫本身来说,限制爬虫的速度主要来自于目标服务器的响应速度,所以选择一个容易控制的模块是对的。
多线程模型
多线程模型是最容易上手的。Python自带的threading模块可以很好的实现并发需求,配合Queue模块实现数据共享。
多进程模型
多处理模型类似于多线程模型,多处理模块中有类似的Queue模块来实现数据共享。在linux中,用户态进程可以利用多核,所以在多核的上下文中,可以解决爬虫并发的问题。
协程模型
协程模型,在 Elias 的 文章 中,基于 greenlet 的协程程序的性能仅次于 Stackless Python,速度大约是 Stackless Python 的两倍,比其他解决方案快近一个数量级。因此,基于gevent(封装greenlets)的并发程序将具有良好的性能优势。
具体描述gevent(非阻塞异步IO)。, “Gevent是一个基于协程的Python网络库,使用Greenlet提供的高级同步API,封装了libevent事件循环。”
从实际编程效果来看,协程模型确实表现得非常好,运行结果的可控性明显更强,gevent库的封装非常好用。
0x06 数据存储
有许多技术是为数据存储本身而设计的。作为配菜不敢多说,但还是有一些工作中的小经验可以分享。
前提:使用关系型数据库,测试中选择mysql,其他和sqlite差不多,和SqlServer的思路没有区别。
我们做数据存储的时候,目的是减少与数据库的交互,这样可以提高性能。通常,每读取一个 URL 节点,就进行一次数据存储,这样的逻辑就会进行一次无限循环。其实这样的性能体验很差,存储速度也很慢。
对于高级方法,为了减少与数据库的交互次数,每次与数据库的交互从发送1个节点变为发送10个节点到发送100个节点内容,因此效率提高了10到100倍。在实际应用中,效果非常好。:D
htmlunit抓取动态网页(编程之家为你收集整理的全部内容(1,3)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-27 10:23
概述如果要使用自定义登录页面的动态管理资源,最简单的方法是在数据库中将登录页面对应的权限设置为IS_AUTHENTICATED_ANONYMOUSLY。所以在数据库中添加一个资源信息。INSERT INTO RESC VALUES(1,'','URL','/login.jsp*',1,'') 这里/login.jsp*是我们自定义登录页面的地址。然后为匿名用户添加一个角色信息: INSERT INTO ROLE VALUES(3,'IS_AUTHENTICATED_ANONYMOUSLY','anonymous') 最后将这两条记录关联起来。INSERT INTO RESC_ROLE VALUES(1,3)这样实现了动态管理资源和自定义登录页面的结合,例子在ch008。
如果要一起使用动态管理资源,最简单的方法是在数据库中将登录页面对应的权限设置为IS_AUTHENTICATED_ANONYMOUSLY。
所以在数据库中添加一个资源信息。
INSERT INTO RESC VALUES(1,'','URL','/login.jsP*',1,'')
这里 /login.jsP* 是我们的地址。
然后为匿名用户添加一个角色信息:
INSERT INTO ROLE VALUES(3,'IS_AUTHENTICATED_ANONYMOUSLY','anonymous')
最后,您可以将这两条记录关联起来。
INSERT INTO RESC_ROLE VALUES(1,3)
这样,资源的动态管理与执行相结合。
示例在 ch008 中。
总结
以上就是编程之家采集整理的spring security动态管理资源结合自定义登录页面的全部内容。希望文章可以帮助大家解决spring security动态管理资源结合自定义登录页面遇到的程序开发问题。.
如果你觉得编程之家网站的内容还不错,欢迎你把编程之家网站推荐给你的程序员朋友。 查看全部
htmlunit抓取动态网页(编程之家为你收集整理的全部内容(1,3)(图))
概述如果要使用自定义登录页面的动态管理资源,最简单的方法是在数据库中将登录页面对应的权限设置为IS_AUTHENTICATED_ANONYMOUSLY。所以在数据库中添加一个资源信息。INSERT INTO RESC VALUES(1,'','URL','/login.jsp*',1,'') 这里/login.jsp*是我们自定义登录页面的地址。然后为匿名用户添加一个角色信息: INSERT INTO ROLE VALUES(3,'IS_AUTHENTICATED_ANONYMOUSLY','anonymous') 最后将这两条记录关联起来。INSERT INTO RESC_ROLE VALUES(1,3)这样实现了动态管理资源和自定义登录页面的结合,例子在ch008。
如果要一起使用动态管理资源,最简单的方法是在数据库中将登录页面对应的权限设置为IS_AUTHENTICATED_ANONYMOUSLY。
所以在数据库中添加一个资源信息。
INSERT INTO RESC VALUES(1,'','URL','/login.jsP*',1,'')
这里 /login.jsP* 是我们的地址。
然后为匿名用户添加一个角色信息:
INSERT INTO ROLE VALUES(3,'IS_AUTHENTICATED_ANONYMOUSLY','anonymous')
最后,您可以将这两条记录关联起来。
INSERT INTO RESC_ROLE VALUES(1,3)
这样,资源的动态管理与执行相结合。
示例在 ch008 中。
总结
以上就是编程之家采集整理的spring security动态管理资源结合自定义登录页面的全部内容。希望文章可以帮助大家解决spring security动态管理资源结合自定义登录页面遇到的程序开发问题。.
如果你觉得编程之家网站的内容还不错,欢迎你把编程之家网站推荐给你的程序员朋友。
htmlunit抓取动态网页(HtmlUnit+Jsoup背景在开发爬虫进行动态规则)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-02-26 00:17
HtmlUnit + Jsoup
背景
在开发爬虫用动态规则爬取数据的时候,遇到HtmlUnit登录后无法访问cookie的情况,网上的一系列文章都失效了;
HtmlUnit
可以理解为一个沙盒浏览器,会得到整个网页的最终显示代码(包括动态加载数据的js),人眼看到的就是你得到的
汤
只访问网页内容(不包括js执行后的动态内容),优点是可以通过jquery选择器提取元素,如#id、.class等。htmlUnit只能从文档原生js中提取
问题描述
html单元代码
/** HtmlUnit请求web页面 */
WebClient wc = new WebClient(BrowserVersion.CHROME);
wc.getOptions().setUseInsecureSSL(true);
wc.getOptions().setJavaScriptEnabled(true); // 启用JS解释器,默认为true
wc.getOptions().setCssEnabled(false); // 禁用css支持
wc.getOptions().setThrowExceptionOnScriptError(false); // js运行错误时,是否抛出异常
wc.getOptions().setTimeout(10 * 1000); // 设置连接超时时间 ,这里是10S。如果为0,则无限期等待
wc.waitForBackgroundJavaScript(10 * 1000); // 等待js后台执行30秒
wc.getOptions().setDoNotTrackEnabled(false);
//其他文章一贯的cookie设置方式-无效
//wc.getCookieManager().addCookie(new Cookie("domain域名","JSESSIONID","11"));
//改为以下方式
wc.addCookie("Cookie value长串不需要切割",new URL("目标网址"),"domain域名");
HtmlPage page = wc.getPage("目标网址");
另外遇到以下棘手问题(未解决)
<p>//失败:通过改变支持ajax支持方式
wc.setAjaxControllr(new NicelyResynchronizingAjaxController());
//失败:循环判断内容,增加js-ajax执行时间
for (int i = 0; i 查看全部
htmlunit抓取动态网页(HtmlUnit+Jsoup背景在开发爬虫进行动态规则)
HtmlUnit + Jsoup
背景
在开发爬虫用动态规则爬取数据的时候,遇到HtmlUnit登录后无法访问cookie的情况,网上的一系列文章都失效了;
HtmlUnit
可以理解为一个沙盒浏览器,会得到整个网页的最终显示代码(包括动态加载数据的js),人眼看到的就是你得到的
汤
只访问网页内容(不包括js执行后的动态内容),优点是可以通过jquery选择器提取元素,如#id、.class等。htmlUnit只能从文档原生js中提取
问题描述
html单元代码
/** HtmlUnit请求web页面 */
WebClient wc = new WebClient(BrowserVersion.CHROME);
wc.getOptions().setUseInsecureSSL(true);
wc.getOptions().setJavaScriptEnabled(true); // 启用JS解释器,默认为true
wc.getOptions().setCssEnabled(false); // 禁用css支持
wc.getOptions().setThrowExceptionOnScriptError(false); // js运行错误时,是否抛出异常
wc.getOptions().setTimeout(10 * 1000); // 设置连接超时时间 ,这里是10S。如果为0,则无限期等待
wc.waitForBackgroundJavaScript(10 * 1000); // 等待js后台执行30秒
wc.getOptions().setDoNotTrackEnabled(false);
//其他文章一贯的cookie设置方式-无效
//wc.getCookieManager().addCookie(new Cookie("domain域名","JSESSIONID","11"));
//改为以下方式
wc.addCookie("Cookie value长串不需要切割",new URL("目标网址"),"domain域名");
HtmlPage page = wc.getPage("目标网址");
另外遇到以下棘手问题(未解决)
<p>//失败:通过改变支持ajax支持方式
wc.setAjaxControllr(new NicelyResynchronizingAjaxController());
//失败:循环判断内容,增加js-ajax执行时间
for (int i = 0; i
htmlunit抓取动态网页(开源的Java页面分析工具,被誉为Java浏览器的开源实现 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-02-23 13:20
)
一、简介
它是一个开源的Java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容
可以模拟浏览器的操作,被称为Java浏览器的开源实现
1、是一个无界面浏览器Java程序
对HTML文档进行建模,提供调用页面、填写表单、单机链接等API。
和浏览器一样
2、拥有不断改进的 JavaScript 支持,甚至可以使用相当复杂的 AJAX 库
根据配置模拟 Chrome、Firefox 或 IE 等浏览器
3、通常用于测试或从网站检索信息二、使用场景
一般情况下,可以使用Apache的HttpClient组件来获取HTML页面信息。 HttpClient实现的http请求返回的响应一般是纯文本文档页面,也就是最原创的html页面。
对于静态页面,使用HttpClient爬取所需信息。
但是对于动态网页,更多的数据是通过异步JS代码获取和渲染的,初始的html页面是不收录这部分数据的。
三、代码演示
1、获取页面
public class HtmlUnitDemo {
public static void main(String[] args) throws IOException {
String str;
// 创建一个 webClient
// WebClient webClient = new WebClient(); // 任意浏览器打开
WebClient webClient = new WebClient(BrowserVersion.CHROME); // 使用 Chrome 读取页面
// htmlunit 对 JS 和 CSS 的支持不好,所以关闭
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
// 获取页面
HtmlPage page = webClient.getPage("http://www.baidu.com"); // 抛出 IOException
// System.out.println(page);
// 获取页面的标题
str = page.getTitleText();
System.out.println("Title: " + str);
// 获取页面的 XML 代码
str = page.asXml();
System.out.println("XML: \n" + str);
// 获取页面的文本
str = page.asText();
System.out.println("文本: \n" + str);
// 关闭 webClient
webClient.close();
}
}
2、获取页面的指定元素
public class HtmlUnitDemo {
public static void main(String[] args) throws IOException {
// 创建一个 webClient
// WebClient webClient = new WebClient(); // 任意浏览器打开
WebClient webClient = new WebClient(BrowserVersion.CHROME); // 使用 Chrome 读取页面
// htmlunit 对 JS 和 CSS 的支持不好,所以关闭
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = webClient.getPage("http://www.baidu.com");
// 获得页面的指定元素
// 通过 id 获得“百度一下”按钮
HtmlInput btn = page.getHtmlElementById("su");
System.out.println(btn.getDefaultValue());
// 关闭 webClient
webClient.close();
}
}
3、元素检索
public class HtmlUnitDemo {
public static void main(String[] args) throws IOException {
// 创建一个 webClient
// WebClient webClient = new WebClient(); // 任意浏览器打开
WebClient webClient = new WebClient(BrowserVersion.CHROME); // 使用 Chrome 读取页面
// htmlunit 对 JS 和 CSS 的支持不好,所以关闭
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = webClient.getPage("http://www.baidu.com");
// 元素检索
// 查找所有的 div
List hbList = page.getByXPath("//div");
// System.out.println(hbList);
HtmlDivision hb = (HtmlDivision)hbList.get(0); // 只获取第一个 div
System.out.println(hb.toString());
// 查找并获取特定的 input
List inputList = page.getByXPath("//input[@id='su']");
HtmlInput input = (HtmlInput) inputList.get(0);
System.out.println(input.toString());
// 关闭 webClient
webClient.close();
}
}
4、提交搜索
public class HtmlUnitDemo {
public static void main(String[] args) throws IOException {
// 创建一个 webClient
// WebClient webClient = new WebClient(); // 任意浏览器打开
WebClient webClient = new WebClient(BrowserVersion.CHROME); // 使用 Chrome 读取页面
// htmlunit 对 JS 和 CSS 的支持不好,所以关闭
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = webClient.getPage("http://www.baidu.com");
// 提交搜索
// 获取搜索输入框并提交搜索内容
HtmlInput input = page.getHtmlElementById("kw");
System.out.println(input.toString());
input.setValueAttribute("htmlunit API");
System.out.println(input.toString());
// 获取搜索按钮并点击
HtmlInput btn = page.getHtmlElementById("su");
HtmlPage page1 = btn.click();
// 输出新页面的文本
System.out.println(page1.asText());
// 关闭 webClient
webClient.close();
}
} 查看全部
htmlunit抓取动态网页(开源的Java页面分析工具,被誉为Java浏览器的开源实现
)
一、简介
它是一个开源的Java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容
可以模拟浏览器的操作,被称为Java浏览器的开源实现
1、是一个无界面浏览器Java程序
对HTML文档进行建模,提供调用页面、填写表单、单机链接等API。
和浏览器一样
2、拥有不断改进的 JavaScript 支持,甚至可以使用相当复杂的 AJAX 库
根据配置模拟 Chrome、Firefox 或 IE 等浏览器
3、通常用于测试或从网站检索信息二、使用场景
一般情况下,可以使用Apache的HttpClient组件来获取HTML页面信息。 HttpClient实现的http请求返回的响应一般是纯文本文档页面,也就是最原创的html页面。
对于静态页面,使用HttpClient爬取所需信息。
但是对于动态网页,更多的数据是通过异步JS代码获取和渲染的,初始的html页面是不收录这部分数据的。
三、代码演示
1、获取页面
public class HtmlUnitDemo {
public static void main(String[] args) throws IOException {
String str;
// 创建一个 webClient
// WebClient webClient = new WebClient(); // 任意浏览器打开
WebClient webClient = new WebClient(BrowserVersion.CHROME); // 使用 Chrome 读取页面
// htmlunit 对 JS 和 CSS 的支持不好,所以关闭
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
// 获取页面
HtmlPage page = webClient.getPage("http://www.baidu.com";); // 抛出 IOException
// System.out.println(page);
// 获取页面的标题
str = page.getTitleText();
System.out.println("Title: " + str);
// 获取页面的 XML 代码
str = page.asXml();
System.out.println("XML: \n" + str);
// 获取页面的文本
str = page.asText();
System.out.println("文本: \n" + str);
// 关闭 webClient
webClient.close();
}
}
2、获取页面的指定元素
public class HtmlUnitDemo {
public static void main(String[] args) throws IOException {
// 创建一个 webClient
// WebClient webClient = new WebClient(); // 任意浏览器打开
WebClient webClient = new WebClient(BrowserVersion.CHROME); // 使用 Chrome 读取页面
// htmlunit 对 JS 和 CSS 的支持不好,所以关闭
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = webClient.getPage("http://www.baidu.com";);
// 获得页面的指定元素
// 通过 id 获得“百度一下”按钮
HtmlInput btn = page.getHtmlElementById("su");
System.out.println(btn.getDefaultValue());
// 关闭 webClient
webClient.close();
}
}
3、元素检索
public class HtmlUnitDemo {
public static void main(String[] args) throws IOException {
// 创建一个 webClient
// WebClient webClient = new WebClient(); // 任意浏览器打开
WebClient webClient = new WebClient(BrowserVersion.CHROME); // 使用 Chrome 读取页面
// htmlunit 对 JS 和 CSS 的支持不好,所以关闭
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = webClient.getPage("http://www.baidu.com";);
// 元素检索
// 查找所有的 div
List hbList = page.getByXPath("//div");
// System.out.println(hbList);
HtmlDivision hb = (HtmlDivision)hbList.get(0); // 只获取第一个 div
System.out.println(hb.toString());
// 查找并获取特定的 input
List inputList = page.getByXPath("//input[@id='su']");
HtmlInput input = (HtmlInput) inputList.get(0);
System.out.println(input.toString());
// 关闭 webClient
webClient.close();
}
}
4、提交搜索
public class HtmlUnitDemo {
public static void main(String[] args) throws IOException {
// 创建一个 webClient
// WebClient webClient = new WebClient(); // 任意浏览器打开
WebClient webClient = new WebClient(BrowserVersion.CHROME); // 使用 Chrome 读取页面
// htmlunit 对 JS 和 CSS 的支持不好,所以关闭
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = webClient.getPage("http://www.baidu.com";);
// 提交搜索
// 获取搜索输入框并提交搜索内容
HtmlInput input = page.getHtmlElementById("kw");
System.out.println(input.toString());
input.setValueAttribute("htmlunit API");
System.out.println(input.toString());
// 获取搜索按钮并点击
HtmlInput btn = page.getHtmlElementById("su");
HtmlPage page1 = btn.click();
// 输出新页面的文本
System.out.println(page1.asText());
// 关闭 webClient
webClient.close();
}
}
htmlunit抓取动态网页(搜狗微信公众号更新公告(2015.03.23) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-02-23 06:13
)
最后更新于 2018.1.3
只为自己留个记录
要添加的功能:
1.获取历史中的所有消息
2. 爬取10多条数据
3.公众号信息自定义抓取
下面是搜狗微信公众号搜索微信公众号的例子!
搜狗微信公众号作为分析入口:[此处填写公众号]&ie=utf8&sug=n&sug_type=
DEMO 中的完整 URL 为:%E6%AF%8F%E6%97%A5%E8%8A%82%E5%A5%8F&ie=utf8&sug=n&sug_type=
package cc.buckler.test;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.junit.Test;
import java.io.IOException;
public class TestData {
private String ENTRY_URL = "http://weixin.sogou.com/weixin ... %3B//入口地址
private String QUERY_WORD = "DOTA每日节奏";//查询参数
private String BASE_URL = "";//从入口进入公众号后的公众号地址
private String WE_CHAT_URL = "http://mp.weixin.qq.com";//微信公众号官方入口
private int NEW_MSG_ID = 0;//最新msgId
private int MSG_NUM = 20;//需要获取的数量
@Test
public void getData() {
String url = String.format(ENTRY_URL, QUERY_WORD);
//System.out.println(url);
WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setRedirectEnabled(true);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setTimeout(50000);
Document doc = null;
try {
//首先用jsoup获取搜狗入口公众号连接
doc = Jsoup.connect(url).get();
//System.out.println("doc:" + doc);
BASE_URL = doc.select("p a").attr("href");
//System.out.println(BASE_URL);
//使用htmlunit加载公众号文章列表
HtmlPage htmlPage = webClient.getPage(BASE_URL);
webClient.waitForBackgroundJavaScript(10000);
doc = Jsoup.parse(htmlPage.asXml());
//System.out.println("doc:" + doc);
//获取最新文章msgid,之后的循环用msgid-1
String lastMsgId = doc.select(".weui_media_box").attr("msgid");
NEW_MSG_ID = Integer.parseInt(lastMsgId);
//System.out.println(NEW_MSG_ID);
for (int i = NEW_MSG_ID; i >= NEW_MSG_ID - MSG_NUM; i--) {
String articalPrev = "#WXAPPMSG";
String articalId = articalPrev + i;
String h4 = articalId + " h4";
String weui_media_desc = articalId + " .weui_media_desc";
String weui_media_extra_info = articalId + " .weui_media_extra_info";
System.out.println(articalId);
String title = doc.select(h4).text();
System.out.println(title);
String detailUrl = doc.select(h4).attr("hrefs");//2018.1.3 ok
System.out.println(WE_CHAT_URL + detailUrl);
String note = doc.select(weui_media_desc).text();//2018.1.3 ok
if (note.compareToIgnoreCase("") == 0) {
continue;
}
System.out.println(note);
String releaseDate = doc.select(weui_media_extra_info).text().toString();//2018.1.3 ok
if (releaseDate.compareToIgnoreCase("") == 0) {
continue;
}
System.out.println(releaseDate);
}
webClient.close();
} catch (IOException e) {
e.printStackTrace();
webClient.close();
}
}
} 查看全部
htmlunit抓取动态网页(搜狗微信公众号更新公告(2015.03.23)
)
最后更新于 2018.1.3
只为自己留个记录
要添加的功能:
1.获取历史中的所有消息
2. 爬取10多条数据
3.公众号信息自定义抓取
下面是搜狗微信公众号搜索微信公众号的例子!
搜狗微信公众号作为分析入口:[此处填写公众号]&ie=utf8&sug=n&sug_type=
DEMO 中的完整 URL 为:%E6%AF%8F%E6%97%A5%E8%8A%82%E5%A5%8F&ie=utf8&sug=n&sug_type=
package cc.buckler.test;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.junit.Test;
import java.io.IOException;
public class TestData {
private String ENTRY_URL = "http://weixin.sogou.com/weixin ... %3B//入口地址
private String QUERY_WORD = "DOTA每日节奏";//查询参数
private String BASE_URL = "";//从入口进入公众号后的公众号地址
private String WE_CHAT_URL = "http://mp.weixin.qq.com";//微信公众号官方入口
private int NEW_MSG_ID = 0;//最新msgId
private int MSG_NUM = 20;//需要获取的数量
@Test
public void getData() {
String url = String.format(ENTRY_URL, QUERY_WORD);
//System.out.println(url);
WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setRedirectEnabled(true);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setTimeout(50000);
Document doc = null;
try {
//首先用jsoup获取搜狗入口公众号连接
doc = Jsoup.connect(url).get();
//System.out.println("doc:" + doc);
BASE_URL = doc.select("p a").attr("href");
//System.out.println(BASE_URL);
//使用htmlunit加载公众号文章列表
HtmlPage htmlPage = webClient.getPage(BASE_URL);
webClient.waitForBackgroundJavaScript(10000);
doc = Jsoup.parse(htmlPage.asXml());
//System.out.println("doc:" + doc);
//获取最新文章msgid,之后的循环用msgid-1
String lastMsgId = doc.select(".weui_media_box").attr("msgid");
NEW_MSG_ID = Integer.parseInt(lastMsgId);
//System.out.println(NEW_MSG_ID);
for (int i = NEW_MSG_ID; i >= NEW_MSG_ID - MSG_NUM; i--) {
String articalPrev = "#WXAPPMSG";
String articalId = articalPrev + i;
String h4 = articalId + " h4";
String weui_media_desc = articalId + " .weui_media_desc";
String weui_media_extra_info = articalId + " .weui_media_extra_info";
System.out.println(articalId);
String title = doc.select(h4).text();
System.out.println(title);
String detailUrl = doc.select(h4).attr("hrefs");//2018.1.3 ok
System.out.println(WE_CHAT_URL + detailUrl);
String note = doc.select(weui_media_desc).text();//2018.1.3 ok
if (note.compareToIgnoreCase("") == 0) {
continue;
}
System.out.println(note);
String releaseDate = doc.select(weui_media_extra_info).text().toString();//2018.1.3 ok
if (releaseDate.compareToIgnoreCase("") == 0) {
continue;
}
System.out.println(releaseDate);
}
webClient.close();
} catch (IOException e) {
e.printStackTrace();
webClient.close();
}
}
}
htmlunit抓取动态网页(如何实现静态页面名字和动态页面的名字的含义?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-02-22 05:00
在构建非常大的 网站 时,动态生成的网页是必不可少的。但是,动态页面的名称(即其 URL)往往缺乏明确的含义。例如,名为 product.asp?Id=4 的页面不像名为 /applicances/dishwashers/Model3809.htm 的页面那样令人难忘。本文介绍如何实现静态页面名称与动态页面的映射。
概述
除了静态页面名称更有意义的优势之外,另一个优势是搜索引擎可以索引这些页面。大多数搜索引擎,如 Alta Vista 和 Yahoo,不会检索 URL 中带有问号的页面,因为它们担心会进入一个永无止境的链接迷宫。将动态页面名称转换为静态页面名称后,搜索引擎会对这些页面进行索引和分类,从而为网站带来更多流量。
要使用本文中描述的方法将动态名称转换为静态名称,您必须使用 Windows 2000 和 IIS 5.0。IIS 5.0 中使这种转换成为可能的两项改进是:使用 Server.Transfer 的“自定义错误消息”功能和在 ASP 页面中使用 Server.Transfer 的能力。虽然IIS4.0也支持自定义错误信息,但是它使用了Response.Redirect,没什么用,所以这个方法需要使用IIS5.0。Response.Redirect 是无用的,因为搜索引擎不遵循重定向。
使用本文中描述的方法,网站开发人员首先使用静态样式 URL 链接实际不存在的页面。然后设置 IIS 服务器并告诉它使用指定的 ASP 页面 (404.asp) 来处理 网站 上的所有 404 错误。在这个 404.asp 页面中,将原创 URL 转换为正式的动态 URL,用 Server.Transfer 执行,将目标页面返回给用户的浏览器。
假设您有以下网址:
替换为网站的域名,会返回404错误。我们要做的第一件事是使用一些专用的 .asp 页面来处理所有这些 404 错误。这可以使用 IIS 5.0 的“自定义错误消息”功能来完成。设置此功能的过程如下:
●在MMC中打开IIS服务器管理器
● 右键单击 Web网站 节点并选择属性
●点击“自定义错误信息”页面
●向下滚动直到找到 404 错误
双击 404 错误以打开错误映射属性对话框
●将消息类型更改为URL
●在URL框中输入“/404.asp” 查看全部
htmlunit抓取动态网页(如何实现静态页面名字和动态页面的名字的含义?)
在构建非常大的 网站 时,动态生成的网页是必不可少的。但是,动态页面的名称(即其 URL)往往缺乏明确的含义。例如,名为 product.asp?Id=4 的页面不像名为 /applicances/dishwashers/Model3809.htm 的页面那样令人难忘。本文介绍如何实现静态页面名称与动态页面的映射。
概述
除了静态页面名称更有意义的优势之外,另一个优势是搜索引擎可以索引这些页面。大多数搜索引擎,如 Alta Vista 和 Yahoo,不会检索 URL 中带有问号的页面,因为它们担心会进入一个永无止境的链接迷宫。将动态页面名称转换为静态页面名称后,搜索引擎会对这些页面进行索引和分类,从而为网站带来更多流量。
要使用本文中描述的方法将动态名称转换为静态名称,您必须使用 Windows 2000 和 IIS 5.0。IIS 5.0 中使这种转换成为可能的两项改进是:使用 Server.Transfer 的“自定义错误消息”功能和在 ASP 页面中使用 Server.Transfer 的能力。虽然IIS4.0也支持自定义错误信息,但是它使用了Response.Redirect,没什么用,所以这个方法需要使用IIS5.0。Response.Redirect 是无用的,因为搜索引擎不遵循重定向。
使用本文中描述的方法,网站开发人员首先使用静态样式 URL 链接实际不存在的页面。然后设置 IIS 服务器并告诉它使用指定的 ASP 页面 (404.asp) 来处理 网站 上的所有 404 错误。在这个 404.asp 页面中,将原创 URL 转换为正式的动态 URL,用 Server.Transfer 执行,将目标页面返回给用户的浏览器。
假设您有以下网址:
替换为网站的域名,会返回404错误。我们要做的第一件事是使用一些专用的 .asp 页面来处理所有这些 404 错误。这可以使用 IIS 5.0 的“自定义错误消息”功能来完成。设置此功能的过程如下:
●在MMC中打开IIS服务器管理器
● 右键单击 Web网站 节点并选择属性
●点击“自定义错误信息”页面
●向下滚动直到找到 404 错误
双击 404 错误以打开错误映射属性对话框
●将消息类型更改为URL
●在URL框中输入“/404.asp”
htmlunit抓取动态网页(搜索引擎来说静态页面的优点和html结尾有什么区别?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-02-22 04:23
首先,原则上我们要知道,静态页面对于搜索引擎来说绝对是最好的,具有最快的抓取和响应速度。另外,伪静态链接本质上是动态链接,只是动态链接是通过相应的算法规则伪装的。进入静态链接,htm或者html结束页面一般都是静态或者伪静态页面。本站采用伪静态处理,一小部分是我自己写的静态页面。zblog 主题静态插件可以在商店中找到并使用。
一、动态链接地址(例如 /?13.sd234554 )
一般来说,带有问号等参数的链接可以称为动态链接。与程序开发相比,这一步一般都会做。
优点:占用空间很小,使用动态页面时文件会很小,因为数据是从数据库中调出来的。如果需要修改某个具体的值,可以直接在数据库上修改,然后所有的动态页面都会自动更新。现在,服务器的数据占用会很小,特别是一些大公司平台本身的数据量是企业级的。
(据我所知,很多b2b平台每次生成一个页面都需要几个小时来更新缓存)
缺点:由于需要进行计算,用户访问速度较慢,动态页面的数据是从数据库中获取的。如果访问者数量很大,对数据库的压力就会很大。虽然目前的动态程序大多使用缓存技术,但总的来说,动态页面对服务器的压力更大。同时,动态页面的网站一般对服务器有更高的要求,同时访问的人越多,对服务器的压力就越大。另外,对于搜索引擎来说,动态页面是非常不友好的,所以也会有爬取和收录,但是相比其他静态和伪静态,还是少了很多。很多懂SEO的公司都会做伪静态处理。.
二、静态链接地址(例如 /2343.html )
优点:与其他两种动态和伪静态页面相比,静态页面的访问速度最快,而且访问时不需要从数据库中调用数据,不仅访问速度快,而且不会造成服务器上的任何压力。
缺点:由于数据全部存储在HTML中,文件数据非常大。更严重的是,如果需要更改,必须更改所有源代码,而不仅仅是一个地方。而如果是很大的网站,就会有很多数据,占用大部分服务器空间资源,每次添加内容都会生成一个新的静态页面。它比动态和伪静态更麻烦。
三、伪静态链接地址
优点:结合了动态链接和静态链接,主要是让搜索引擎把自己的网页当成静态页面
缺点:如果流量有轻微波动,使用伪静态会导致CPU使用率超载。由于伪静态使用的是正则判断而不是真实地址,所以区分显示哪个页面的职责也是直接指定并转交给CPU,所以CPU占用的增加确实是伪静态最大的缺点。
总结:我个人建议小网站单页,以后很少更新。可以使用静态页面。如果批量多或大网站建议使用伪静态页面,而动态页面适合无搜索引擎爬取。对于注册、会员等功能,对于需要登录的功能,建议使用动态页面。
PS:如果肉眼无法判断是静态页面还是伪静态怎么办?我们可以在谷歌浏览器(360也可以使用谷歌内核)、火狐浏览器等中按crtl+shift+j打开控制台,在控制台输入alert()代码,记录当前页面的时间,然后重新输入一遍,并再次记录时间,如果每次时间都不一样,则可以判断该页面是伪静态页面。 查看全部
htmlunit抓取动态网页(搜索引擎来说静态页面的优点和html结尾有什么区别?)
首先,原则上我们要知道,静态页面对于搜索引擎来说绝对是最好的,具有最快的抓取和响应速度。另外,伪静态链接本质上是动态链接,只是动态链接是通过相应的算法规则伪装的。进入静态链接,htm或者html结束页面一般都是静态或者伪静态页面。本站采用伪静态处理,一小部分是我自己写的静态页面。zblog 主题静态插件可以在商店中找到并使用。
一、动态链接地址(例如 /?13.sd234554 )
一般来说,带有问号等参数的链接可以称为动态链接。与程序开发相比,这一步一般都会做。
优点:占用空间很小,使用动态页面时文件会很小,因为数据是从数据库中调出来的。如果需要修改某个具体的值,可以直接在数据库上修改,然后所有的动态页面都会自动更新。现在,服务器的数据占用会很小,特别是一些大公司平台本身的数据量是企业级的。
(据我所知,很多b2b平台每次生成一个页面都需要几个小时来更新缓存)
缺点:由于需要进行计算,用户访问速度较慢,动态页面的数据是从数据库中获取的。如果访问者数量很大,对数据库的压力就会很大。虽然目前的动态程序大多使用缓存技术,但总的来说,动态页面对服务器的压力更大。同时,动态页面的网站一般对服务器有更高的要求,同时访问的人越多,对服务器的压力就越大。另外,对于搜索引擎来说,动态页面是非常不友好的,所以也会有爬取和收录,但是相比其他静态和伪静态,还是少了很多。很多懂SEO的公司都会做伪静态处理。.
二、静态链接地址(例如 /2343.html )
优点:与其他两种动态和伪静态页面相比,静态页面的访问速度最快,而且访问时不需要从数据库中调用数据,不仅访问速度快,而且不会造成服务器上的任何压力。
缺点:由于数据全部存储在HTML中,文件数据非常大。更严重的是,如果需要更改,必须更改所有源代码,而不仅仅是一个地方。而如果是很大的网站,就会有很多数据,占用大部分服务器空间资源,每次添加内容都会生成一个新的静态页面。它比动态和伪静态更麻烦。
三、伪静态链接地址
优点:结合了动态链接和静态链接,主要是让搜索引擎把自己的网页当成静态页面
缺点:如果流量有轻微波动,使用伪静态会导致CPU使用率超载。由于伪静态使用的是正则判断而不是真实地址,所以区分显示哪个页面的职责也是直接指定并转交给CPU,所以CPU占用的增加确实是伪静态最大的缺点。
总结:我个人建议小网站单页,以后很少更新。可以使用静态页面。如果批量多或大网站建议使用伪静态页面,而动态页面适合无搜索引擎爬取。对于注册、会员等功能,对于需要登录的功能,建议使用动态页面。
PS:如果肉眼无法判断是静态页面还是伪静态怎么办?我们可以在谷歌浏览器(360也可以使用谷歌内核)、火狐浏览器等中按crtl+shift+j打开控制台,在控制台输入alert()代码,记录当前页面的时间,然后重新输入一遍,并再次记录时间,如果每次时间都不一样,则可以判断该页面是伪静态页面。

