
excel抓取网页数据
excel抓取网页数据(这是2020#阿里的法拍住宅数量(119万))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-01-17 04:19
#学Wave2020#
今天阿里的止赎数量是119万,但是昨天截图的时候还是118万,而且这个数字应该还在快速增长。我们今天正在尝试抓取 Alifa 住宅数据。
网站分析
参考昨天的思路,没有任何有用的线索。Ali网站 不提供现成的 JSON 或 JSONP 数据。
但是阿里网站的url直接有页码。是不是意味着我们可以通过url直接抓取呢?
有兴趣的可以直接试一试。果然可以直接定义一个函数来抓取它:
爬取结果:
真的那么容易吗?我不敢相信。在 Power Query 中,150 页中每页只有 6,000 40 个条目。显然有问题。虽然预览成功了,但数据本身也有问题。数值以万元为单位,不规范,所以这个数据应该是有问题的。放弃这种方法。
不过,这也提供了一个思路。可以尝试通过url直接爬取。
我们来到元素视图,发现了这么一段内容,仔细观察,这是一个JSON数据,复制到Power Query可以解析出来:
它是非常标准的 json 数据:
展开后得到的数据比我们之前刮的要好很多。
我们可以通过 Web.BrowserContents 函数获取这个文本,然后从文本中提取 json 数据。
我们还在此文本的页面上找到了统计信息:
您还可以找出有多少页数据:
对应这个位置:
至此,我们的把握思路基本清晰。
我们可以按照区县一级的行政区划来采集数据。此级别的数据捕获需要两个参数,管理代码和页码范围。行政代码可通过相关网站直接获取,页码可在首页找到的各区县查询。
为了捕获特定的数据,可以定义一个函数来从每个页面的代码中提取 JSON 数据。
但是,119万条具体的房屋信息对我们来说是没有用的。我们感兴趣的是统计数据。我们直接从县级行政区划的首页找到这个统计信息就够了。
定义函数
fp函数:获取页码范围的函数,使用Text.Split函数拆分书
fn function:获取统计结果的函数
fd函数:获取特定房屋信息的函数
试着抓
抓取沉河区具体房屋信息数据:
沉河区统计:
抓
抓取沉阳房屋具体信息:
先找到这一段,复制出来:
将其复制到 Power Query 中是这样的。处理后可以得到沉阳市的区县和代码:
处理结果:
然后我们参考fp函数得到页码范围:
生成所有页码:
展开并添加 fd 函数来抓取数据:
展开数据:
这样,特定的住房信息数据就被捕获了。
抓取全国县级行政区的统计信息有点麻烦,我发现阿里的行政区号和国家区号有点不一样,会导致数据缺失。大部分还是可以匹配的,少数不一致。我们来看看全国各区县的行政代码列表:
完成结果:
在此基础上,参考fn函数抓取统计信息:
这个过程很慢,耐心点,一共大概有3000左右。
将数据加载到 Power BI Desktop 并制作几个图表以查看:
热图:
条形图:
分解树:
我可以看到总数是119万。我这里只有107万,少了12万,是编码不一致造成的。 查看全部
excel抓取网页数据(这是2020#阿里的法拍住宅数量(119万))
#学Wave2020#
今天阿里的止赎数量是119万,但是昨天截图的时候还是118万,而且这个数字应该还在快速增长。我们今天正在尝试抓取 Alifa 住宅数据。
网站分析
参考昨天的思路,没有任何有用的线索。Ali网站 不提供现成的 JSON 或 JSONP 数据。
但是阿里网站的url直接有页码。是不是意味着我们可以通过url直接抓取呢?
有兴趣的可以直接试一试。果然可以直接定义一个函数来抓取它:
爬取结果:
真的那么容易吗?我不敢相信。在 Power Query 中,150 页中每页只有 6,000 40 个条目。显然有问题。虽然预览成功了,但数据本身也有问题。数值以万元为单位,不规范,所以这个数据应该是有问题的。放弃这种方法。
不过,这也提供了一个思路。可以尝试通过url直接爬取。
我们来到元素视图,发现了这么一段内容,仔细观察,这是一个JSON数据,复制到Power Query可以解析出来:
它是非常标准的 json 数据:
展开后得到的数据比我们之前刮的要好很多。
我们可以通过 Web.BrowserContents 函数获取这个文本,然后从文本中提取 json 数据。
我们还在此文本的页面上找到了统计信息:
您还可以找出有多少页数据:
对应这个位置:
至此,我们的把握思路基本清晰。
我们可以按照区县一级的行政区划来采集数据。此级别的数据捕获需要两个参数,管理代码和页码范围。行政代码可通过相关网站直接获取,页码可在首页找到的各区县查询。
为了捕获特定的数据,可以定义一个函数来从每个页面的代码中提取 JSON 数据。
但是,119万条具体的房屋信息对我们来说是没有用的。我们感兴趣的是统计数据。我们直接从县级行政区划的首页找到这个统计信息就够了。
定义函数
fp函数:获取页码范围的函数,使用Text.Split函数拆分书
fn function:获取统计结果的函数
fd函数:获取特定房屋信息的函数
试着抓
抓取沉河区具体房屋信息数据:
沉河区统计:
抓
抓取沉阳房屋具体信息:
先找到这一段,复制出来:
将其复制到 Power Query 中是这样的。处理后可以得到沉阳市的区县和代码:
处理结果:
然后我们参考fp函数得到页码范围:
生成所有页码:
展开并添加 fd 函数来抓取数据:
展开数据:
这样,特定的住房信息数据就被捕获了。
抓取全国县级行政区的统计信息有点麻烦,我发现阿里的行政区号和国家区号有点不一样,会导致数据缺失。大部分还是可以匹配的,少数不一致。我们来看看全国各区县的行政代码列表:
完成结果:
在此基础上,参考fn函数抓取统计信息:
这个过程很慢,耐心点,一共大概有3000左右。
将数据加载到 Power BI Desktop 并制作几个图表以查看:
热图:
条形图:
分解树:
我可以看到总数是119万。我这里只有107万,少了12万,是编码不一致造成的。
excel抓取网页数据(如何应对数据匮乏?最简单的方法在这里!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-17 04:18
介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!想要获得更多数据来训练我们的机器学习模型是一个持续存在的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吧?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络抓取。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 中采集数据。今天,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这就是网络抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接深入 Python 以了解如何使用流行且高效的 BeautifulSoup 库执行网页抓取。
请注意,网络抓取受许多准则和规则的约束。并非每个 网站 都允许用户抓取内容,因此存在法律限制。在尝试执行此操作之前,请确保您已阅读 网站 的网站 条款和条件。
3 种流行的 Python 网络爬虫工具和库 用于网络爬取的 Python 组件 抓取解析和转换 网页抓取 URL 和电子邮件 ID 抓取图像 在页面加载时抓取数据 3 个流行的 Python 网络爬取工具和库
您将在 Python 中遇到几个用于 Web 抓取的库和框架。以下是三种用于高效完成工作的流行工具:
美丽汤
刮擦
硒
网络爬虫的组成部分
这是构成网络抓取的三个主要组件的绝佳说明:
让我们详细了解这些组件。我们将通过 goibibo网站 获取酒店详细信息,例如酒店名称和每间客房的价格以执行此操作:
注意:始终遵循目标 网站 的 robots.txt 文件,也称为机器人排除协议。这告诉网络机器人不要抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴为我们的网络机器人编写脚本。开始吧!
第 1 步:爬行
网页抓取的第一步是导航到目标 网站 并下载网页的源代码。我们将使用 requests 库来执行此操作。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页的源代码后,我们需要过滤我们想要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换
网页抓取的下一步是将这些数据解析为 HTML 解析器,为此我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,与大多数页面一样,特定酒店的详细信息在不同的卡片上。
所以下一步是从完整的源代码中过滤卡片数据。接下来,我们将选择该卡并单击“检查元素”选项以获取该特定卡的源代码。你会得到这样的东西:
所有卡片都有相同的类名,我们可以通过传递标签名称和具有如下名称的属性(如标签)来获取这些卡片的列表:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,其中每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在对于每张卡,我们必须找到上面的酒店名称,只能从
从标签中提取。这是因为每张卡和费率只有一个标签和标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
第三步:存储(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后我们最终将它添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络抓取工具。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的评级和地址。现在,让我们看看如何执行一些常见任务,例如在页面加载时抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试通过网络抓取来抓取的两个最常见的功能是 网站URL 和电子邮件 ID。我确定您参与过需要大量提取电子邮件 ID 的项目或挑战。那么让我们看看如何在 Python 中抓取这些内容。
使用 Web 浏览器的控制台 查看全部
excel抓取网页数据(如何应对数据匮乏?最简单的方法在这里!!)
介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!想要获得更多数据来训练我们的机器学习模型是一个持续存在的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吧?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络抓取。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 中采集数据。今天,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这就是网络抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接深入 Python 以了解如何使用流行且高效的 BeautifulSoup 库执行网页抓取。
请注意,网络抓取受许多准则和规则的约束。并非每个 网站 都允许用户抓取内容,因此存在法律限制。在尝试执行此操作之前,请确保您已阅读 网站 的网站 条款和条件。
3 种流行的 Python 网络爬虫工具和库 用于网络爬取的 Python 组件 抓取解析和转换 网页抓取 URL 和电子邮件 ID 抓取图像 在页面加载时抓取数据 3 个流行的 Python 网络爬取工具和库
您将在 Python 中遇到几个用于 Web 抓取的库和框架。以下是三种用于高效完成工作的流行工具:
美丽汤
刮擦
硒
网络爬虫的组成部分
这是构成网络抓取的三个主要组件的绝佳说明:
让我们详细了解这些组件。我们将通过 goibibo网站 获取酒店详细信息,例如酒店名称和每间客房的价格以执行此操作:
注意:始终遵循目标 网站 的 robots.txt 文件,也称为机器人排除协议。这告诉网络机器人不要抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴为我们的网络机器人编写脚本。开始吧!
第 1 步:爬行
网页抓取的第一步是导航到目标 网站 并下载网页的源代码。我们将使用 requests 库来执行此操作。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页的源代码后,我们需要过滤我们想要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换
网页抓取的下一步是将这些数据解析为 HTML 解析器,为此我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,与大多数页面一样,特定酒店的详细信息在不同的卡片上。
所以下一步是从完整的源代码中过滤卡片数据。接下来,我们将选择该卡并单击“检查元素”选项以获取该特定卡的源代码。你会得到这样的东西:
所有卡片都有相同的类名,我们可以通过传递标签名称和具有如下名称的属性(如标签)来获取这些卡片的列表:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,其中每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在对于每张卡,我们必须找到上面的酒店名称,只能从
从标签中提取。这是因为每张卡和费率只有一个标签和标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
第三步:存储(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后我们最终将它添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络抓取工具。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的评级和地址。现在,让我们看看如何执行一些常见任务,例如在页面加载时抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试通过网络抓取来抓取的两个最常见的功能是 网站URL 和电子邮件 ID。我确定您参与过需要大量提取电子邮件 ID 的项目或挑战。那么让我们看看如何在 Python 中抓取这些内容。
使用 Web 浏览器的控制台
excel抓取网页数据(Python编程语言Excel爬虫函数学起来容易些什么?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-01-10 07:04
近年来,Python编程语言非常流行,很多人使用Python开发网络爬虫工具。Python虽然简单,但学习起来并不容易,需要一定的基础。今天小编给大家介绍一个Excel爬虫功能,比较容易学习,可以满足数据采集在特定场景下的需求。
有一个基金网页#qdiie,网页中有一个数据表格,如下图,需要将红框内标注的数据抓取到Excel表格中,并定期更新表格数据。
爬取过程有六个步骤
第一步是使用火狐或Chrome打开目标网页,右键查看代码找到表单的id。如果表格没有 id,请改用表格类样式。
第二步,写公式=GetTableByIdW(B1,"flex_qdiie"),其中B1指的是要爬取的URL,“flex_qdiie”指的是网页中表格元素的id号。函数名中的 W 表示当前函数需要使用 Excel 浏览器。细心的朋友可能会有疑问,为什么要用Excel浏览器呢?原因是现在的网页越来越复杂,通过传统的HttpGet()或者HttpPost()方法无法读取完整的网页,所以需要使用浏览器来读取所有的网页数据。
第三步,打开Excel浏览器,设置网页循环爬取任务。因为网页数据需要定期更新,所以需要Excel浏览器循环抓取网页。
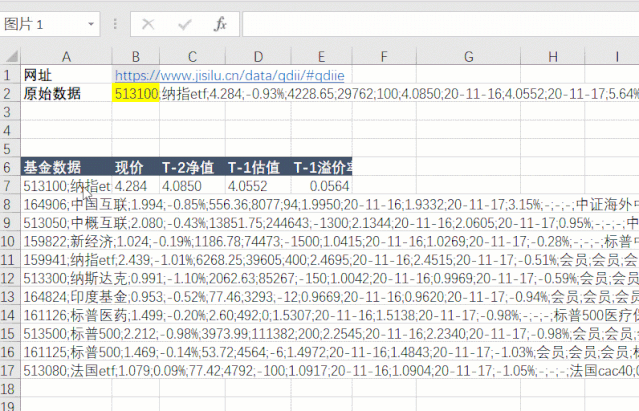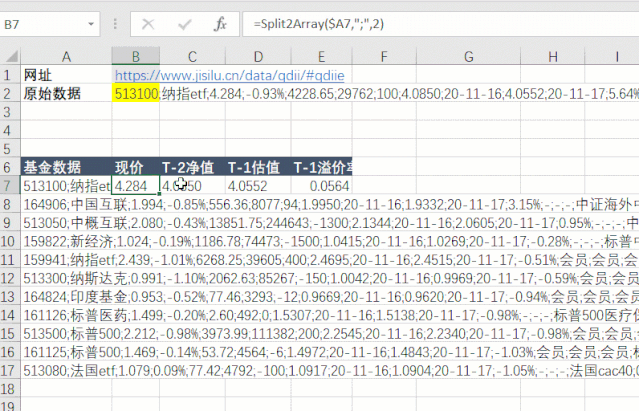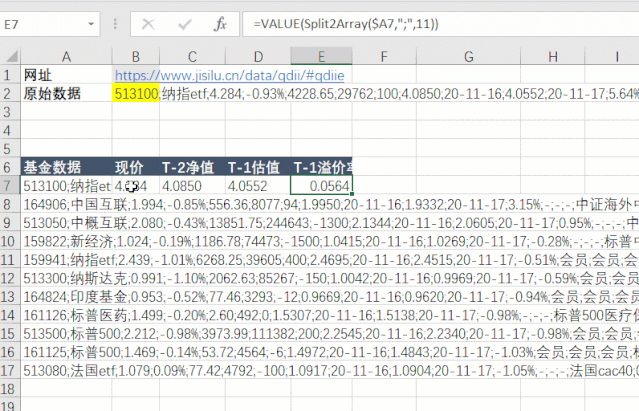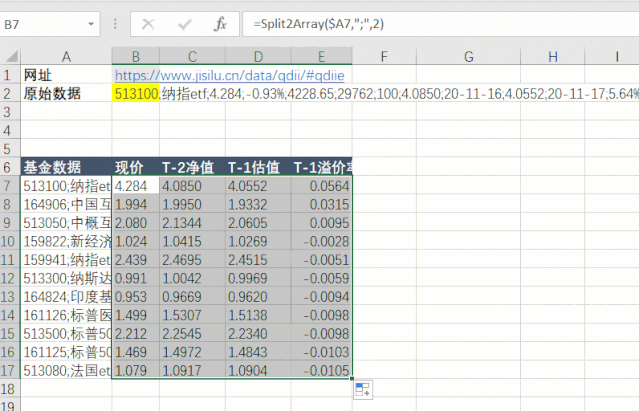
第四步,刷新Excel中的公式。这时候抓取函数会返回“flex_qdiie”表的所有数据,是一长串文本。可以发现,每一列用分号隔开,每一行用两个分号隔开。找到一个模式,我们可以使用 Split2Array() 函数来拆分和提取数据。
513100;纳指etf;4.284;-0.93%;4228.65;29762;100;4.0850;20-11-16;4.0552;20-11-17;5.64%;会员;会员;会员;纳斯达克100;-0.30%;0.50%;0.50%;国泰基金;;164906;中国互联;1.994;-0.85%;556.36;8077;94;1.9950;20-11-16;1.9332;20-11-17;3.15%;-;-;-;中证海外中国互联网指数;-3.26%;1.20%;1.50%;交银施罗德;;513050;中概互联;2.080;-0.43%;13851.75;244643;-1300;2.1344;20-11-16;2.0605;20-11-17;0.95%;-;-;-;中国互联网50;-3.03%;0.50%;0.50%;易方达;;159822;新经济;1.024;-0.19%;1186.78;74473;-1500;1.0415;20-11-16;1.0269;20-11-17;-0.28%;-;-;-;标普中国新经济行业指数;-1.05%;;1.50%;银华基金;;159941;纳指etf;2.439;-1.01%;6268.25;39605;400;2.4695;20-11-16;2.4515;20-11-17;-0.51%;会员;会员;会员;纳斯达克100;-0.30%;0.50%;0.50%;广发基金;;513300;纳斯达克;0.991;-1.10%;2062.63;85267;-150;1.0042;20-11-16;0.9969;20-11-17;-0.59%;会员;会员;会员;纳斯达克100;-0.30%;0.50%;0.50%;华夏基金;;164824;印度基金;0.953;-0.52%;77.46;3293;-12;0.9669;20-11-16;0.9620;20-11-17;-0.94%;会员;会员;会员;印度etp指数;-;1.20%;1.50%;工银瑞信;;...
第五步是拆分和提取数据。先拆分每一行的数据,再拆分每一列的数据。
第六步,使用=AutoRefresh(120)公式设置定时刷新任务,每120秒自动刷新表数据。
一共六步,完美抓取一张表的数据,实现自动定时刷新。有了实时数据,可以对数据进行处理和计算,达到监测预警的目的。怎么样,很简单,你可以写公式来进行网页数据采集。
如果你觉得这个技巧有用,请帮忙转发给你的朋友 查看全部
excel抓取网页数据(Python编程语言Excel爬虫函数学起来容易些什么?(图))
近年来,Python编程语言非常流行,很多人使用Python开发网络爬虫工具。Python虽然简单,但学习起来并不容易,需要一定的基础。今天小编给大家介绍一个Excel爬虫功能,比较容易学习,可以满足数据采集在特定场景下的需求。

有一个基金网页#qdiie,网页中有一个数据表格,如下图,需要将红框内标注的数据抓取到Excel表格中,并定期更新表格数据。

爬取过程有六个步骤
第一步是使用火狐或Chrome打开目标网页,右键查看代码找到表单的id。如果表格没有 id,请改用表格类样式。
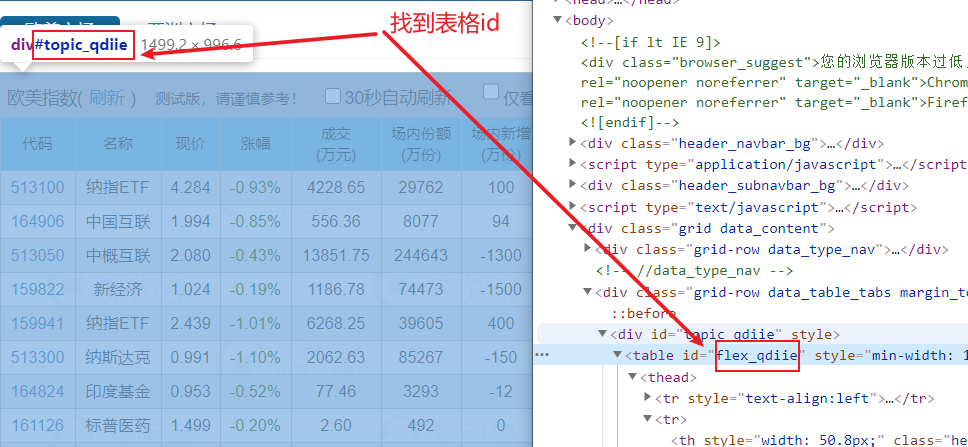
第二步,写公式=GetTableByIdW(B1,"flex_qdiie"),其中B1指的是要爬取的URL,“flex_qdiie”指的是网页中表格元素的id号。函数名中的 W 表示当前函数需要使用 Excel 浏览器。细心的朋友可能会有疑问,为什么要用Excel浏览器呢?原因是现在的网页越来越复杂,通过传统的HttpGet()或者HttpPost()方法无法读取完整的网页,所以需要使用浏览器来读取所有的网页数据。
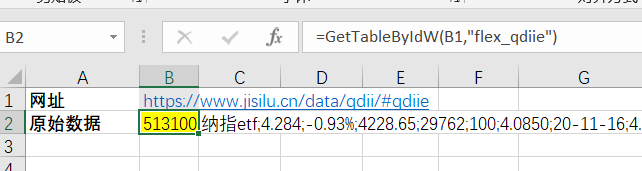
第三步,打开Excel浏览器,设置网页循环爬取任务。因为网页数据需要定期更新,所以需要Excel浏览器循环抓取网页。
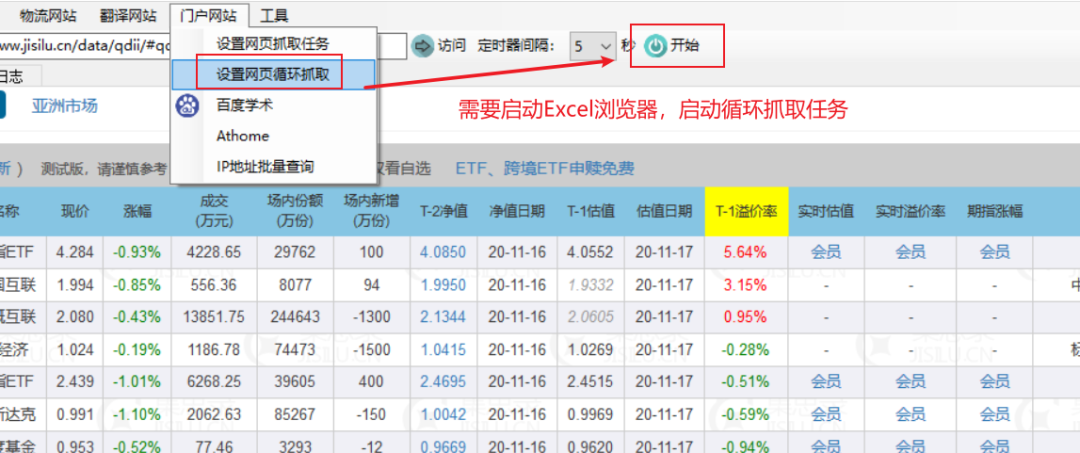
第四步,刷新Excel中的公式。这时候抓取函数会返回“flex_qdiie”表的所有数据,是一长串文本。可以发现,每一列用分号隔开,每一行用两个分号隔开。找到一个模式,我们可以使用 Split2Array() 函数来拆分和提取数据。
513100;纳指etf;4.284;-0.93%;4228.65;29762;100;4.0850;20-11-16;4.0552;20-11-17;5.64%;会员;会员;会员;纳斯达克100;-0.30%;0.50%;0.50%;国泰基金;;164906;中国互联;1.994;-0.85%;556.36;8077;94;1.9950;20-11-16;1.9332;20-11-17;3.15%;-;-;-;中证海外中国互联网指数;-3.26%;1.20%;1.50%;交银施罗德;;513050;中概互联;2.080;-0.43%;13851.75;244643;-1300;2.1344;20-11-16;2.0605;20-11-17;0.95%;-;-;-;中国互联网50;-3.03%;0.50%;0.50%;易方达;;159822;新经济;1.024;-0.19%;1186.78;74473;-1500;1.0415;20-11-16;1.0269;20-11-17;-0.28%;-;-;-;标普中国新经济行业指数;-1.05%;;1.50%;银华基金;;159941;纳指etf;2.439;-1.01%;6268.25;39605;400;2.4695;20-11-16;2.4515;20-11-17;-0.51%;会员;会员;会员;纳斯达克100;-0.30%;0.50%;0.50%;广发基金;;513300;纳斯达克;0.991;-1.10%;2062.63;85267;-150;1.0042;20-11-16;0.9969;20-11-17;-0.59%;会员;会员;会员;纳斯达克100;-0.30%;0.50%;0.50%;华夏基金;;164824;印度基金;0.953;-0.52%;77.46;3293;-12;0.9669;20-11-16;0.9620;20-11-17;-0.94%;会员;会员;会员;印度etp指数;-;1.20%;1.50%;工银瑞信;;...
第五步是拆分和提取数据。先拆分每一行的数据,再拆分每一列的数据。
第六步,使用=AutoRefresh(120)公式设置定时刷新任务,每120秒自动刷新表数据。
一共六步,完美抓取一张表的数据,实现自动定时刷新。有了实时数据,可以对数据进行处理和计算,达到监测预警的目的。怎么样,很简单,你可以写公式来进行网页数据采集。
如果你觉得这个技巧有用,请帮忙转发给你的朋友
excel抓取网页数据(excel抓取网页数据-石家庄地铁线路图制作数据可视化高仿地铁图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-01-08 05:03
excel抓取网页数据-石家庄地铁线路图制作数据可视化高仿地铁图放到github上请参考代码,算法应该是基于javascript的一个库。【代码加公众号,
看下butting
给你几个我觉得应该去看看的免费资源-logo-gallery/,或者网上能找到一些ms的产品包,各家大厂都有。再者你可以看看地铁类的top5网站还有百度经验里应该都有,很详细的,不难的。最后做不出来可以用其他地方的数据。
我没开发过oracle数据库。网上找相关源码吧。确定是一个structure。加指针,加loadlist。实现起来方便又好玩。
之前一直用freemason做ide,虽然性能不是很好,
网上有一个mapbox开源的xml地图数据,可以直接通过javascript函数拼接到excel表中。这可能是首次拼接数据的开源方案吧,效果还不错。
试试这个?xuqing.github.io/heremapa-here-data-studio/heremapa-heremapa·github国人开发的,纯go实现,
广州地铁图上海地铁图。
目前地铁信息分析最多的大概是resharpo地图api了
除了楼上说的,我想分享一个在excel表格上找到某些街道某站的列车总数的excel图,最大的城市广州大约200,河南郑州某些地区的城市200左右,这些数据是有他自己的历史数据做的,把找到的周期内每一天每一站都找到了, 查看全部
excel抓取网页数据(excel抓取网页数据-石家庄地铁线路图制作数据可视化高仿地铁图)
excel抓取网页数据-石家庄地铁线路图制作数据可视化高仿地铁图放到github上请参考代码,算法应该是基于javascript的一个库。【代码加公众号,
看下butting
给你几个我觉得应该去看看的免费资源-logo-gallery/,或者网上能找到一些ms的产品包,各家大厂都有。再者你可以看看地铁类的top5网站还有百度经验里应该都有,很详细的,不难的。最后做不出来可以用其他地方的数据。
我没开发过oracle数据库。网上找相关源码吧。确定是一个structure。加指针,加loadlist。实现起来方便又好玩。
之前一直用freemason做ide,虽然性能不是很好,
网上有一个mapbox开源的xml地图数据,可以直接通过javascript函数拼接到excel表中。这可能是首次拼接数据的开源方案吧,效果还不错。
试试这个?xuqing.github.io/heremapa-here-data-studio/heremapa-heremapa·github国人开发的,纯go实现,
广州地铁图上海地铁图。
目前地铁信息分析最多的大概是resharpo地图api了
除了楼上说的,我想分享一个在excel表格上找到某些街道某站的列车总数的excel图,最大的城市广州大约200,河南郑州某些地区的城市200左右,这些数据是有他自己的历史数据做的,把找到的周期内每一天每一站都找到了,
excel抓取网页数据(excel抓取网页数据:search_div()和lookup_all())
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-05 14:04
excel抓取网页数据:search_div()#这个是查找内容引擎抓取网页,但不是正则可能存在封闭式的表,不方便查看发散式的表,也不方便取值#这个是网页排序引擎对要抓取的数据按照排序对其进行匹配查找,匹配过程如下#引擎对查找到的数据进行解析,不匹配的话就给你全自动提示,
search_div()和lookup_all()
首先,分析box1/box2/box3中的标签是什么,发现是aiahv的形式,故称该三个标签为abc,所以就用match(1)=3匹配到box4的第一个元素。然后根据需要用search()找到相应元素。
search_div()就是对div进行匹配查找,lookup_all()就是对元素或者if函数的匹配查找,感觉都是一个意思。
封闭div里找不到就自动提示
用match/search就好了啊,没有matchmatchsearch什么的?(ps:黑名单函数,
还有matchmatchsearch?
searchvar是search查找函数
区别在于,search找的是id是连续的匹配单元格,而lookup查找是要查找lookup属性的值。
楼上都说了,我来补充一下吧,如果是要只要找所有用户的话,可以使用matchvar或者searchfunction,前者需要对于id进行匹配,然后返回匹配出来的值,而后者返回所有匹配出来的值,前者是针对单元格或者box的,后者需要返回所有abcn的所有匹配出来的值。 查看全部
excel抓取网页数据(excel抓取网页数据:search_div()和lookup_all())
excel抓取网页数据:search_div()#这个是查找内容引擎抓取网页,但不是正则可能存在封闭式的表,不方便查看发散式的表,也不方便取值#这个是网页排序引擎对要抓取的数据按照排序对其进行匹配查找,匹配过程如下#引擎对查找到的数据进行解析,不匹配的话就给你全自动提示,
search_div()和lookup_all()
首先,分析box1/box2/box3中的标签是什么,发现是aiahv的形式,故称该三个标签为abc,所以就用match(1)=3匹配到box4的第一个元素。然后根据需要用search()找到相应元素。
search_div()就是对div进行匹配查找,lookup_all()就是对元素或者if函数的匹配查找,感觉都是一个意思。
封闭div里找不到就自动提示
用match/search就好了啊,没有matchmatchsearch什么的?(ps:黑名单函数,
还有matchmatchsearch?
searchvar是search查找函数
区别在于,search找的是id是连续的匹配单元格,而lookup查找是要查找lookup属性的值。
楼上都说了,我来补充一下吧,如果是要只要找所有用户的话,可以使用matchvar或者searchfunction,前者需要对于id进行匹配,然后返回匹配出来的值,而后者返回所有匹配出来的值,前者是针对单元格或者box的,后者需要返回所有abcn的所有匹配出来的值。
excel抓取网页数据(Excel教程Excel函数Excel表格制作Excel2010自带工具--从网页获取数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-01-02 20:13
)
很多时候,一些数据来自网络。如果我们要采集网页数据并使用Excel进行分析,是否需要将网页上的数据一一输入Excel?其实还有一个很方便的方法,那就是使用Excel 2013自带的工具---网页获取数据,不仅可以快速获取数据,还可以与网页内容同步更新下面是详细的操作方法。
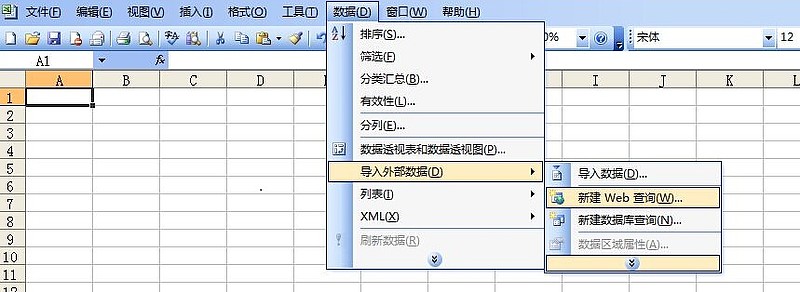
1、首先打开Excel,点击菜单栏:数据--来自网站。
2、你会看到一个打开的查询对话框,你的IE主页会自动打开,在地址栏中输入你想要的网址,然后点击Go。
我们看到一个网页被打开了。如果我们要导入这个表中的数据,我们看下面的第二张图,点击左上角的黄色按钮。选择表格后,黄色按钮变为绿色。
3、 然后点击导入按钮,你会看到下面的第二张图片,等待几秒钟。
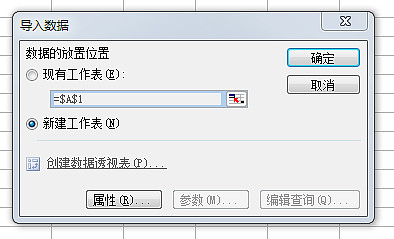
4、打开一个对话框,提示数据放在哪里,点击确定导入数据。
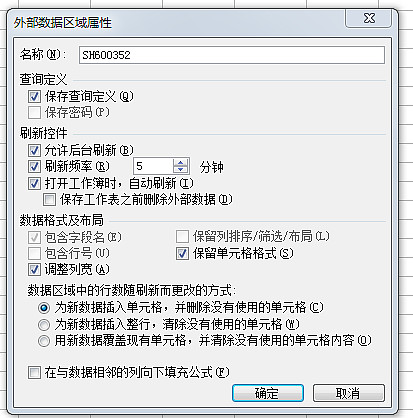
5、 也可以点击属性设置导入,如下图。下图二,如果设置刷新率,会看到Excel表格中的数据可以根据网页的数据进行更新,是不是很强大。
6、好的,这是我们导入的数据。 Excel 2013 现在很强大吗?哈哈,赶紧装个Office 2013,试试它的强大功能吧。
查看全部
excel抓取网页数据(Excel教程Excel函数Excel表格制作Excel2010自带工具--从网页获取数据
)
很多时候,一些数据来自网络。如果我们要采集网页数据并使用Excel进行分析,是否需要将网页上的数据一一输入Excel?其实还有一个很方便的方法,那就是使用Excel 2013自带的工具---网页获取数据,不仅可以快速获取数据,还可以与网页内容同步更新下面是详细的操作方法。
1、首先打开Excel,点击菜单栏:数据--来自网站。

2、你会看到一个打开的查询对话框,你的IE主页会自动打开,在地址栏中输入你想要的网址,然后点击Go。
我们看到一个网页被打开了。如果我们要导入这个表中的数据,我们看下面的第二张图,点击左上角的黄色按钮。选择表格后,黄色按钮变为绿色。

3、 然后点击导入按钮,你会看到下面的第二张图片,等待几秒钟。

4、打开一个对话框,提示数据放在哪里,点击确定导入数据。

5、 也可以点击属性设置导入,如下图。下图二,如果设置刷新率,会看到Excel表格中的数据可以根据网页的数据进行更新,是不是很强大。

6、好的,这是我们导入的数据。 Excel 2013 现在很强大吗?哈哈,赶紧装个Office 2013,试试它的强大功能吧。

excel抓取网页数据(Excel教程Excel函数Excel表格制作Excel2010自带工具--从网页获取数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-12-28 06:12
)
很多时候,一些数据来自网络。如果我们要采集
网页数据并使用Excel进行分析,是否需要将网页上的数据一一输入Excel?其实还有一个很方便的方法,那就是使用Excel 2013自带的工具---从网页获取数据,不仅可以快速获取数据,还可以与网页内容同步更新。下面是详细的操作方法。
1、首先打开Excel,点击菜单栏:数据--来自网站。
2、 你会看到一个打开的查询对话框,你的IE主页会自动打开,在地址栏中输入你想要的URL,然后点击Go。
我们看到打开了一个网页。如果我们要导入这个表中的数据,我们看下面的第二张图,点击左上角的黄色按钮。选择表格后,黄色按钮变为绿色。
3、 然后点击导入按钮,你会看到下面的第二张图片,等待几秒钟。
4、打开一个对话框,提示你把数据放在哪里,点击确定导入数据。
5、也可以点击属性设置导入,如图,下图二,如果设置刷新频率,会看到Excel表格中的数据可以基于网页上的数据更新,是不是很厉害。
6、好的,这就是我们导入的数据。Excel 2013 现在很强大吗?哈哈,赶紧装个Office 2013,试试它的强大功能吧。
查看全部
excel抓取网页数据(Excel教程Excel函数Excel表格制作Excel2010自带工具--从网页获取数据
)
很多时候,一些数据来自网络。如果我们要采集
网页数据并使用Excel进行分析,是否需要将网页上的数据一一输入Excel?其实还有一个很方便的方法,那就是使用Excel 2013自带的工具---从网页获取数据,不仅可以快速获取数据,还可以与网页内容同步更新。下面是详细的操作方法。
1、首先打开Excel,点击菜单栏:数据--来自网站。

2、 你会看到一个打开的查询对话框,你的IE主页会自动打开,在地址栏中输入你想要的URL,然后点击Go。
我们看到打开了一个网页。如果我们要导入这个表中的数据,我们看下面的第二张图,点击左上角的黄色按钮。选择表格后,黄色按钮变为绿色。

3、 然后点击导入按钮,你会看到下面的第二张图片,等待几秒钟。

4、打开一个对话框,提示你把数据放在哪里,点击确定导入数据。

5、也可以点击属性设置导入,如图,下图二,如果设置刷新频率,会看到Excel表格中的数据可以基于网页上的数据更新,是不是很厉害。

6、好的,这就是我们导入的数据。Excel 2013 现在很强大吗?哈哈,赶紧装个Office 2013,试试它的强大功能吧。

excel抓取网页数据(一起学微软PowerBI系列-官方文档-入门指南(2)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-12-27 18:14
阿里云>云栖社区>主题地图>E>Excel获取网站数据
推荐活动:
更多优惠>
当前主题:excel获取网站数据并添加到采集
夹
相关话题:
excel获取网站数据相关博客查看更多博客
七周成为数据分析师-Excel实践
作者:夏至3561人浏览评论:14年前
本文是《七周内成为数据分析师》的第三篇教程。如果你想了解写作的初衷,你可以先阅读《七周指南》。提醒:如果您已经熟悉Excel,则无需再次阅读本文,或者只需选择部分内容即可。在Excel技巧和Excel函数之后,今天的文章讲解了如何利用前两篇文章的知识进行分析。内容是新的
阅读全文
一起学习微软Power BI系列-官方文档-入门指南(2)获取源数据
作者:老朱八号 1548人浏览评论:04年前
阅读目录1.系列文章说明2.入门指南(2)获取数据源3.资源我们在文章:一起学习微软Power BI系列-官方文档- 入门指南(1)在Power BI的初步介绍中,我们介绍了官方介绍文档的第一章,今天继续给大家介绍官方文档,如何获取数据的相关内容来源。虽然
阅读全文
基于Excel2013的数据导入
作者:潇撒坤1232人浏览评论:03年前
请确认已安装 Excel2013。Excel2013的安装方法请上网搜索。Excel2013下载网盘链接: 密码:rxuv 这个安装包里面有破解软件KMSpic
阅读全文
python xlrd读取excel
作者:程序员tx1067人浏览评论:03年前
文章链接:上一篇介绍了写excel表格的方法。最近在做一个网站,涉及到读取excel然后将数据存入数据库,所以记录一下操作excel的过程。
阅读全文
如何使用R和API免费获取网络数据?
作者:王淑仪 809人浏览评论:04年前
API是获取网页数据的重要途径之一。您想知道如何使用R调用API来提取和组织您需要的免费网络数据吗?本文将逐步为您详细展示操作过程。称谓“巧妇难为无米之炊”。就算你掌握了数据分析的18门功课,没有数据也是一件很苦恼的事情。“拔剑望心”是大事
阅读全文
使用Excel COM组件导出数据后,释放后无法正常终止Excel进程
作者:nothingfinal535人浏览评论:011年前
分析我自己的错误:首先,我得到了一个带有GetItem of Range的VARIANT,其中收录
IDispatch接口。一直以为里面有BSTR,所以直接用了_bstr_t bs(rg.GetItem(_variant_t((short)1),_v
阅读全文
使用Excel COM组件导出数据后,释放后无法正常终止Excel进程
作者:xumaojun483人浏览评论:011年前
分析我自己的错误:首先,我得到了一个带有GetItem of Range的VARIANT,其中收录
IDispatch接口。一直以为里面有BSTR,所以直接用了_bstr_t bs(rg.GetItem(_variant_t((short)1),_v
阅读全文
使用Excel COM组件导出数据后,释放后无法正常终止Excel进程
作者:maojunxu435 人浏览评论:011年前
分析我自己的错误:首先,我得到了一个带有GetItem of Range的VARIANT,其中收录
IDispatch接口。一直以为里面有BSTR,所以直接用了_bstr_t bs(rg.GetItem(_variant_t((sh
阅读全文
excel获取网站数据相关问答
【Java学习全家桶】1460道Java热点题,百位阿里巴巴技术专家答疑解惑
作者:管理贝贝19522人浏览评论:153年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你迷茫只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来了云栖为您解答技术难题。他们使用自己手中的技术来帮助用户成长。本次活动邀请了数百位阿里巴巴技术
阅读全文 查看全部
excel抓取网页数据(一起学微软PowerBI系列-官方文档-入门指南(2)(组图))
阿里云>云栖社区>主题地图>E>Excel获取网站数据

推荐活动:
更多优惠>
当前主题:excel获取网站数据并添加到采集
夹
相关话题:
excel获取网站数据相关博客查看更多博客
七周成为数据分析师-Excel实践

作者:夏至3561人浏览评论:14年前
本文是《七周内成为数据分析师》的第三篇教程。如果你想了解写作的初衷,你可以先阅读《七周指南》。提醒:如果您已经熟悉Excel,则无需再次阅读本文,或者只需选择部分内容即可。在Excel技巧和Excel函数之后,今天的文章讲解了如何利用前两篇文章的知识进行分析。内容是新的
阅读全文
一起学习微软Power BI系列-官方文档-入门指南(2)获取源数据

作者:老朱八号 1548人浏览评论:04年前
阅读目录1.系列文章说明2.入门指南(2)获取数据源3.资源我们在文章:一起学习微软Power BI系列-官方文档- 入门指南(1)在Power BI的初步介绍中,我们介绍了官方介绍文档的第一章,今天继续给大家介绍官方文档,如何获取数据的相关内容来源。虽然
阅读全文
基于Excel2013的数据导入


作者:潇撒坤1232人浏览评论:03年前
请确认已安装 Excel2013。Excel2013的安装方法请上网搜索。Excel2013下载网盘链接: 密码:rxuv 这个安装包里面有破解软件KMSpic
阅读全文
python xlrd读取excel


作者:程序员tx1067人浏览评论:03年前
文章链接:上一篇介绍了写excel表格的方法。最近在做一个网站,涉及到读取excel然后将数据存入数据库,所以记录一下操作excel的过程。
阅读全文
如何使用R和API免费获取网络数据?


作者:王淑仪 809人浏览评论:04年前
API是获取网页数据的重要途径之一。您想知道如何使用R调用API来提取和组织您需要的免费网络数据吗?本文将逐步为您详细展示操作过程。称谓“巧妇难为无米之炊”。就算你掌握了数据分析的18门功课,没有数据也是一件很苦恼的事情。“拔剑望心”是大事
阅读全文
使用Excel COM组件导出数据后,释放后无法正常终止Excel进程


作者:nothingfinal535人浏览评论:011年前
分析我自己的错误:首先,我得到了一个带有GetItem of Range的VARIANT,其中收录
IDispatch接口。一直以为里面有BSTR,所以直接用了_bstr_t bs(rg.GetItem(_variant_t((short)1),_v
阅读全文
使用Excel COM组件导出数据后,释放后无法正常终止Excel进程


作者:xumaojun483人浏览评论:011年前
分析我自己的错误:首先,我得到了一个带有GetItem of Range的VARIANT,其中收录
IDispatch接口。一直以为里面有BSTR,所以直接用了_bstr_t bs(rg.GetItem(_variant_t((short)1),_v
阅读全文
使用Excel COM组件导出数据后,释放后无法正常终止Excel进程

作者:maojunxu435 人浏览评论:011年前
分析我自己的错误:首先,我得到了一个带有GetItem of Range的VARIANT,其中收录
IDispatch接口。一直以为里面有BSTR,所以直接用了_bstr_t bs(rg.GetItem(_variant_t((sh
阅读全文
excel获取网站数据相关问答
【Java学习全家桶】1460道Java热点题,百位阿里巴巴技术专家答疑解惑


作者:管理贝贝19522人浏览评论:153年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你迷茫只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来了云栖为您解答技术难题。他们使用自己手中的技术来帮助用户成长。本次活动邀请了数百位阿里巴巴技术
阅读全文
excel抓取网页数据(怎样使用微软的Excel爬取一个网页的后台数据,注)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-12-26 15:04
看完这篇文章,你是否还沉浸在python爬虫的迷恋中?今天教大家如何使用Microsoft Excel抓取网页的后台数据。注意:此方法仅适用于爬行。对数据感兴趣但不会使用Python等工具爬取网页数据的人,虽然方便好用,但是非常有限。只能抓取单个网页的数据,受网页数据影响。如果页面布局不适合抓取,则需要手动更改格式。
这里我们以抓取空气质量排名网页为例:
首先新建一个Excel表格,打开数据,从网站中,出现一个提示框,将我们要爬取的网站粘贴到搜索框中点击搜索
第四步,进入网页,可以看到如图所示的数据,然后我们点击导入按钮:
点击Import后,不要着急,点击OK,点击Properties,修改一些我们会用到的常用属性:
请看下图
一分钟刷新控制设置可以保证更快的数据替换,打开文件时刷新数据项也保证了我们打开文件时数据项是最新的。其他变化根据自己的需要进行调整。
最后一步是点击确定将网页数据完美下载到您的工作文件中。
怎么样,对朋友来说是不是特别方便?但这只是对不懂python的爬虫有用,普通人需要一些数据的时候可以自己下载一些数据。也很方便,欢迎在下方留言讨论!
特别声明:以上内容(包括图片或视频,如有)由自媒体平台“网易”用户上传发布。本平台仅提供信息存储服务。 查看全部
excel抓取网页数据(怎样使用微软的Excel爬取一个网页的后台数据,注)
看完这篇文章,你是否还沉浸在python爬虫的迷恋中?今天教大家如何使用Microsoft Excel抓取网页的后台数据。注意:此方法仅适用于爬行。对数据感兴趣但不会使用Python等工具爬取网页数据的人,虽然方便好用,但是非常有限。只能抓取单个网页的数据,受网页数据影响。如果页面布局不适合抓取,则需要手动更改格式。
这里我们以抓取空气质量排名网页为例:
首先新建一个Excel表格,打开数据,从网站中,出现一个提示框,将我们要爬取的网站粘贴到搜索框中点击搜索
第四步,进入网页,可以看到如图所示的数据,然后我们点击导入按钮:
点击Import后,不要着急,点击OK,点击Properties,修改一些我们会用到的常用属性:
请看下图
一分钟刷新控制设置可以保证更快的数据替换,打开文件时刷新数据项也保证了我们打开文件时数据项是最新的。其他变化根据自己的需要进行调整。
最后一步是点击确定将网页数据完美下载到您的工作文件中。
怎么样,对朋友来说是不是特别方便?但这只是对不懂python的爬虫有用,普通人需要一些数据的时候可以自己下载一些数据。也很方便,欢迎在下方留言讨论!
特别声明:以上内容(包括图片或视频,如有)由自媒体平台“网易”用户上传发布。本平台仅提供信息存储服务。
excel抓取网页数据(如何快速地从网站上来获取自己需要的数据哦! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-12-22 05:01
)
有时候我们在做Excel表格的时候,很多数据源可能来自网上,所以我们需要从网站下载数据给我们使用,或者我们需要自己手动一一输入……但是太麻烦了,今天教大家一个方法,从网站快速获取你需要的数据!喜欢的记得采集哦!
脚步:
1.首先我们打开一个网站,找到我们想要的数据,先复制网站的链接。这里我们选择个人所得税税率表,想抓取网页上所有的表格内容。
2. 然后打开你的Excel表格,点击【数据】-【来自网站】,就会弹出【新建网页】查询对话框。
然后将刚才复制的网站链接粘贴到地址栏中。然后选择【前往】,会自动跳转到网站的数据界面。
3. 然后在【新建Web查询】对话框中点击所需表的【箭头】按钮,然后点击右下角的【导入】。经过这个操作,我们需要的数据就会被添加到Excel表格中。
4. 要导入数据时,可以选择放置数据的位置,或者数据的起始位置,也可以新建一个工作表。选择完成后,点击【确定】即可。
这样你就可以看到网站中的数据一下子就添加到了你的Excel表格中。注意,如果数据量大,导入的时候可能会比较慢,但最终还是可以轻松抓取网站的数据!
最后可以用【Apply Table Style】稍微美化一下表格,就OK了~
最终效果:
这里还有一个GIF演示给大家看,不明白的可以看这里!
好吧~以上就是一个关于如何从网络上抓取数据的小技巧。经常需要上网搜集资料的朋友,希望能对你有所帮助。如果有用,请点赞、转发、采集!加油!
查看全部
excel抓取网页数据(如何快速地从网站上来获取自己需要的数据哦!
)
有时候我们在做Excel表格的时候,很多数据源可能来自网上,所以我们需要从网站下载数据给我们使用,或者我们需要自己手动一一输入……但是太麻烦了,今天教大家一个方法,从网站快速获取你需要的数据!喜欢的记得采集哦!

脚步:
1.首先我们打开一个网站,找到我们想要的数据,先复制网站的链接。这里我们选择个人所得税税率表,想抓取网页上所有的表格内容。

2. 然后打开你的Excel表格,点击【数据】-【来自网站】,就会弹出【新建网页】查询对话框。

然后将刚才复制的网站链接粘贴到地址栏中。然后选择【前往】,会自动跳转到网站的数据界面。

3. 然后在【新建Web查询】对话框中点击所需表的【箭头】按钮,然后点击右下角的【导入】。经过这个操作,我们需要的数据就会被添加到Excel表格中。

4. 要导入数据时,可以选择放置数据的位置,或者数据的起始位置,也可以新建一个工作表。选择完成后,点击【确定】即可。

这样你就可以看到网站中的数据一下子就添加到了你的Excel表格中。注意,如果数据量大,导入的时候可能会比较慢,但最终还是可以轻松抓取网站的数据!

最后可以用【Apply Table Style】稍微美化一下表格,就OK了~

最终效果:

这里还有一个GIF演示给大家看,不明白的可以看这里!

好吧~以上就是一个关于如何从网络上抓取数据的小技巧。经常需要上网搜集资料的朋友,希望能对你有所帮助。如果有用,请点赞、转发、采集!加油!

excel抓取网页数据(excel抓取网页数据并进行数据转换、统计分析、表格输出四步实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-12-09 16:03
excel抓取网页数据并进行数据转换、统计分析、表格输出四步实现。适用人群:需要利用excel处理各行各列数据的小伙伴。如需先完成excel基础功能的操作,再用python进行相关分析,请直接到微信公众号【白小白python】看本期视频。本文所有源代码已发布于b站,欢迎进行参观讨论。视频地址:-gx7g后期还会有这两个技术视频,敬请期待。要获取更多资源的小伙伴,请持续关注微信公众号【白小白python】。
是有办法的,但是最重要的是你要有对excel的掌握程度和懂python语言!最近在看monkey的视频,感觉好像相当不错,
excel相当于数据分析的基础,python的话会加分,不然很多数据分析过程不方便使用python。
要看你大概要做些什么了,一般excel处理一下,比如数据求和分类汇总都可以用python完成。其他更复杂的分析,比如根据月数来制定cumulative的组合等,使用python3+tabloid比较好,
编程没有上限,学什么都无所谓啊,关键还是要你想做什么。如果是做基础数据分析的话,只要你多看别人的代码,多动手试着写写就好了,网上也有很多在线的数据分析工具。如果是python的话,推荐datavisualization这本书,里面有许多场景的python编程实践可以去实现,而且包含了一些处理数据的算法工具(在中文社区)。
如果是做一个小型数据分析系统,那就学习python3吧。如果是爬虫网站的分析,只是要你能分析访问网站的url,那java已经足够用了,如果对性能有更高的要求那只能用python爬取网站数据,然后导入其他工具中。 查看全部
excel抓取网页数据(excel抓取网页数据并进行数据转换、统计分析、表格输出四步实现)
excel抓取网页数据并进行数据转换、统计分析、表格输出四步实现。适用人群:需要利用excel处理各行各列数据的小伙伴。如需先完成excel基础功能的操作,再用python进行相关分析,请直接到微信公众号【白小白python】看本期视频。本文所有源代码已发布于b站,欢迎进行参观讨论。视频地址:-gx7g后期还会有这两个技术视频,敬请期待。要获取更多资源的小伙伴,请持续关注微信公众号【白小白python】。
是有办法的,但是最重要的是你要有对excel的掌握程度和懂python语言!最近在看monkey的视频,感觉好像相当不错,
excel相当于数据分析的基础,python的话会加分,不然很多数据分析过程不方便使用python。
要看你大概要做些什么了,一般excel处理一下,比如数据求和分类汇总都可以用python完成。其他更复杂的分析,比如根据月数来制定cumulative的组合等,使用python3+tabloid比较好,
编程没有上限,学什么都无所谓啊,关键还是要你想做什么。如果是做基础数据分析的话,只要你多看别人的代码,多动手试着写写就好了,网上也有很多在线的数据分析工具。如果是python的话,推荐datavisualization这本书,里面有许多场景的python编程实践可以去实现,而且包含了一些处理数据的算法工具(在中文社区)。
如果是做一个小型数据分析系统,那就学习python3吧。如果是爬虫网站的分析,只是要你能分析访问网站的url,那java已经足够用了,如果对性能有更高的要求那只能用python爬取网站数据,然后导入其他工具中。
excel抓取网页数据(如何介绍M函数的应用方法?函数怎么做? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-12-09 10:08
)
通过前三节的学习,相信大家对M函数的基础知识有了一定的了解。从本节开始,我们将通过实际案例逐步介绍M功能的应用方法。
本节将介绍一个案例,让您使用Web.Page和Web.Contents函数从PM2.5历史数据网站中抓取不同城市、不同日期的历史空气质量相关数据。这种方式适用于在Power Query中输入URL可以直接获取所需数据的情况(这种情况是指网页地址中有可见表格数据的情况)。
在进入正文之前,先介绍一个简单的获取中文函数帮助信息的方法,方法如下:
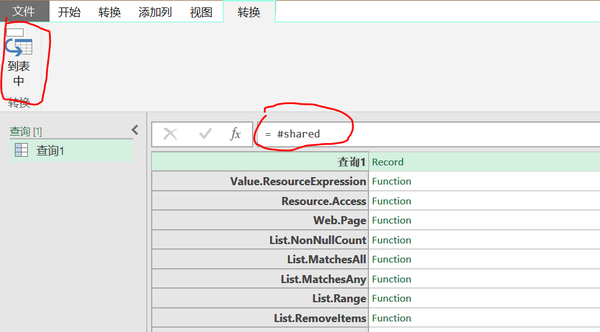
1.在 Power Query 查询编辑器中创建一个新的空查询
2.在编辑字段中输入=#shared
3.点击“到表”
4.通过过滤Name字段获取相关函数帮助信息
Web.Page 和 Web.Contents 功能说明:
1.Web.Page 函数:返回 HTML 文档的内容(分解为其组成结构),以及完整文档及其删除文本的表示
表达式:Function(html as any) as table
注:使用Web.Page函数获取网页HTML形式的相关信息,以表格形式返回结果
2.Web.Contents 函数:以二进制形式返回从 url 下载的内容。可以提供可选的记录参数选项来指定其他属性。记录可以收录以下字段...(更多内容省略,详情请使用#shared查询)
表达式:函数(url 为文本,可选选项为可空记录)asbinary
注:支付Web.Contents网页地址后,Web.Contents函数可以以二进制数的形式返回网页中的信息
这两个函数嵌套使用后,Web.Page(Web.Contents(URL))最终可以将网页中的信息以表格的形式呈现出来。操作逻辑是先使用Web.Contents函数获取指定URL中的二进制信息,然后使用Web.Page函数对二进制信息进行转换解析,最终得到我们能够理解的表格数据。
在PM2.5历史数据网页爬取各城市过去一天的历史空气质量数据:
主页地址:/historydata/
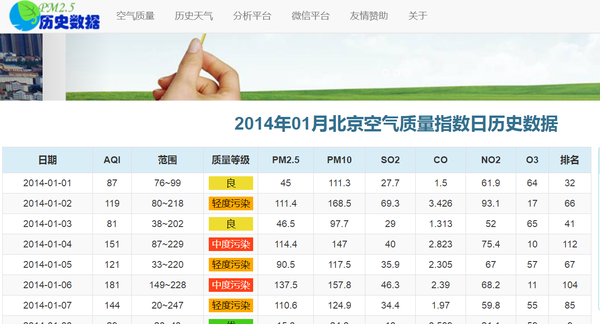
所需日均空气质量数据(以北京2014年1月为例):
网址:/historydata/daydata.php?city=Beijing&month=2014-01
使用Power Query抓取上述网页的目的是一次性批量抓取多个城市不同月份不同天的历史空气质量数据。
爬取步骤如下:
1. 分析网站特点后发现,只要将city=后面的部分改成想要的城市名,month=后面的部分改成想要的月份号,不同的城市和可以打开不同的月份。下的每日历史数据页面
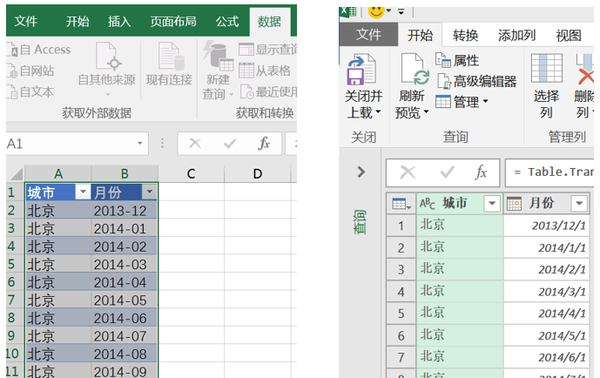
2.所以我们现在在Excel表格界面中建立一个收录城市名称和月份信息的表格,并将其添加到Power Query
3. 将【月份】字段转换为文本数据
4.在Power Query编辑器中添加自定义列,内容如下:
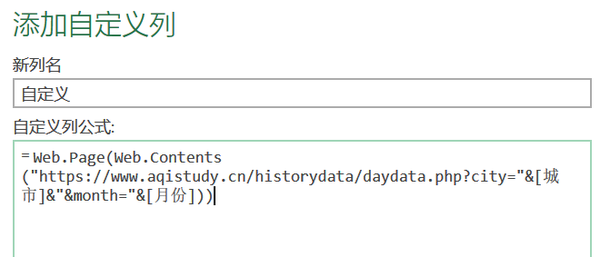
公式内容:
Web.Page(Web.Contents("/historydata/daydata.php?city="&[City]&"&month="&[month]))
5. 点击“Continue”,选择“Public”保存(数据量大,需要耐心等待,建议练习时只做两个城市的数据)
6.在自定义字段中展开数据
7.在自定义字段中再次展开相关字段(从日期到排名)
8.关闭并上传
以上内容就是抓取网页信息的所有步骤。好,我们来看看爬取到的数据。
查看全部
excel抓取网页数据(如何介绍M函数的应用方法?函数怎么做?
)
通过前三节的学习,相信大家对M函数的基础知识有了一定的了解。从本节开始,我们将通过实际案例逐步介绍M功能的应用方法。
本节将介绍一个案例,让您使用Web.Page和Web.Contents函数从PM2.5历史数据网站中抓取不同城市、不同日期的历史空气质量相关数据。这种方式适用于在Power Query中输入URL可以直接获取所需数据的情况(这种情况是指网页地址中有可见表格数据的情况)。
在进入正文之前,先介绍一个简单的获取中文函数帮助信息的方法,方法如下:
1.在 Power Query 查询编辑器中创建一个新的空查询
2.在编辑字段中输入=#shared
3.点击“到表”
4.通过过滤Name字段获取相关函数帮助信息
Web.Page 和 Web.Contents 功能说明:
1.Web.Page 函数:返回 HTML 文档的内容(分解为其组成结构),以及完整文档及其删除文本的表示
表达式:Function(html as any) as table
注:使用Web.Page函数获取网页HTML形式的相关信息,以表格形式返回结果
2.Web.Contents 函数:以二进制形式返回从 url 下载的内容。可以提供可选的记录参数选项来指定其他属性。记录可以收录以下字段...(更多内容省略,详情请使用#shared查询)
表达式:函数(url 为文本,可选选项为可空记录)asbinary
注:支付Web.Contents网页地址后,Web.Contents函数可以以二进制数的形式返回网页中的信息
这两个函数嵌套使用后,Web.Page(Web.Contents(URL))最终可以将网页中的信息以表格的形式呈现出来。操作逻辑是先使用Web.Contents函数获取指定URL中的二进制信息,然后使用Web.Page函数对二进制信息进行转换解析,最终得到我们能够理解的表格数据。
在PM2.5历史数据网页爬取各城市过去一天的历史空气质量数据:
主页地址:/historydata/
所需日均空气质量数据(以北京2014年1月为例):
网址:/historydata/daydata.php?city=Beijing&month=2014-01
使用Power Query抓取上述网页的目的是一次性批量抓取多个城市不同月份不同天的历史空气质量数据。
爬取步骤如下:
1. 分析网站特点后发现,只要将city=后面的部分改成想要的城市名,month=后面的部分改成想要的月份号,不同的城市和可以打开不同的月份。下的每日历史数据页面
2.所以我们现在在Excel表格界面中建立一个收录城市名称和月份信息的表格,并将其添加到Power Query
3. 将【月份】字段转换为文本数据
4.在Power Query编辑器中添加自定义列,内容如下:
公式内容:
Web.Page(Web.Contents("/historydata/daydata.php?city="&[City]&"&month="&[month]))
5. 点击“Continue”,选择“Public”保存(数据量大,需要耐心等待,建议练习时只做两个城市的数据)
6.在自定义字段中展开数据
7.在自定义字段中再次展开相关字段(从日期到排名)
8.关闭并上传
以上内容就是抓取网页信息的所有步骤。好,我们来看看爬取到的数据。
excel抓取网页数据(如何用Python构建一个带有GUI的爬虫小程序-之前)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-12-09 10:07
大家好,之前我们讲了如何在Python中构建一个带有GUI的爬虫小程序。很多文章会迎合热点,延续上次NBA爬虫GUI,讨论虎扑官网怎么爬。并将数据写入Excel并同时自动生成折线图,主要有以下几个步骤
本文将分为以下两部分来讲解
项目涉及的主要Python模块:
履带部分
整理爬虫部分的思路如下
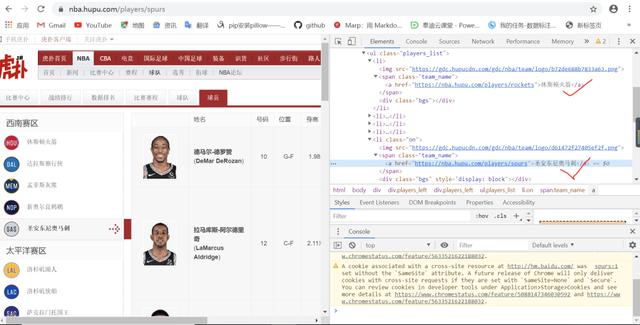
观察URL1的源码,找到球队名和对应的URL2 观察URL2的源码,找到球员对应的URL3
其实爬虫是对html进行操作的,html的结构很简单。只有一个,就是大盒子和小盒子,小盒子嵌套在小盒子中,一层一层嵌套。
目标网址如下:
先参考模块
from bs4 import BeautifulSoupimport requestsimport xlsxwriterimport os
查看URL1的源码,可以看到span标签下有团队名称及其对应的URL2,然后找到它的父框架和祖父框架。下面的思路都是一样的,如下图所示:
此时,可以使用 requests 模块和 bs4 模块进行有目的的索引以获取团队名称列表。
def Teamlists(url): TeamName=[] TeamURL=[] GET=requests.get(URL1) soup=BeautifulSoup(GET.content,'lxml') lables=soup.select('html body div div div ul li span a') for lable in lables: ballname=lable.get_text() TeamName.append(ballname) print(ballname) teamname=input("请输入想查询的球队名:")#此处可变为GUI界面中的按键值 c=TeamName.index(teamname) for item in lables: HREF=item.get('href') TeamURL.append(HREF) URL2=TeamURL[c] return URL2
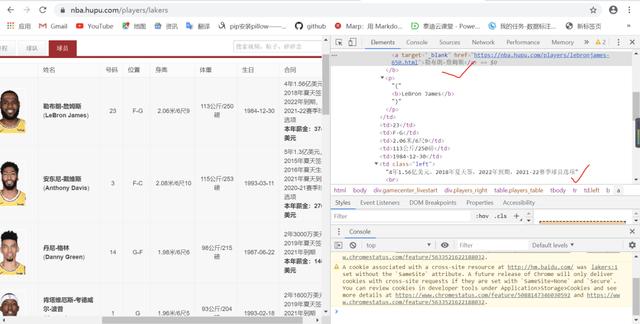
此时,我得到了对应球队的URL2,然后观察URL2网页的内容,可以看到标签a下是球员名字,同时也存储了对应球员的URL3,如图下图:
这时候还是通过requests模块和bs4模块进行对应的index来获取玩家名单和对应的URL3。
#自定义函数获取队员列表和对应的URLdef playerlists(URL2): PlayerName=[] PlayerURL=[] GET2=requests.get(URL1) soup2=BeautifulSoup(GET2.content,'lxml') lables2=soup2.select('html body div div table tbody tr td b a') for lable2 in lables2: playername=lable2.get_text() PlayerName.append(playername) print(playername) name=input("请输入球员名:") #此处可变为GUI界面中的按键值 d=PlayerName.index(name) for item2 in lables2: HREF2=item2.get('href') PlayerURL.append(HREF2) URL3=PlayerURL[d] return URL3,name
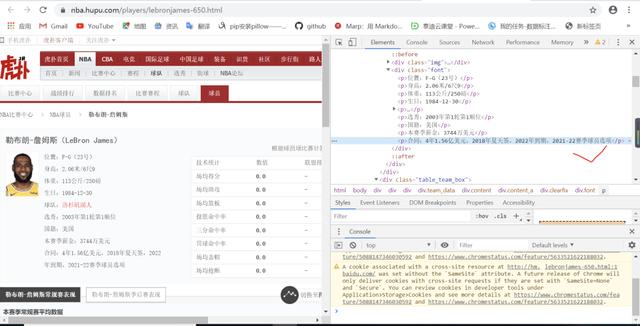
现在拿到对应队伍的URL3,然后观察URL3网页的内容。可以看到p标签下是球员基本信息,td标签下是球员的常规赛生涯数据和季后赛生涯数据,如下图:
同理,requests模块和bs4模块仍然用于相应的索引,获取球员基本信息和职业数据,并过滤存储球员的常规赛和季后赛生涯数据,得到数据列表。
以下数据是通过上述网络爬虫获取的,提供可视化数据,方便绑定后的GUI界面按键事件:
可视化部分
思路:创建文件夹来创建表格和折线图
自定义函数创建表,使用os模块写入,返回创建文件夹的路径。代码如下:
def file_add(path): #此时的内函数path可与GUI界面的Statictext绑定 creatpath=path+'Basketball' try: if not os.path.isdir(creatpath): os.makedirs(creatpath) except: print("文件夹存在") return creatpath
使用xlsxwriter模块在creatpath路径下创建带有自定义函数的excel表格,同时放入数据和构建折线图。代码如下:
def player_chart(name,data,creatpath): #此为表格名称——球员名称+chart EXCEL=xlsxwriter.Workbook(creatpath+''+name+'chart.xlsx') worksheet=EXCEL.add_worksheet(name) bold=EXCEL.add_format({'bold':1}) headings=data[:18] worksheet.write_row('A1',headings,bold) #写入表头 num=(len(data))//18 a=0 for i in range(num): a=a+18 c=a+18 i=i+1 worksheet.write_row('A'+str(i+1),data[a:c]) #写入数据 chart_col = EXCEL.add_chart({'type': 'line'}) #创建一个折线图 chart_col.add_series({ 'name': '='+name+'!$R$1', #设置折线描述名称 'categories':'='+name+'!$A$2:$A$'+str(num), #设置图表类别标签范围 'values': '='+name+'!$R$2:$R$'+str(num-1), #设置图表数据范围 'line': {'color': 'red'}, }) #设置图表线条属性 #设置图标的标题和想x,y轴信息 chart_col.set_title({'name': name+'生涯常规赛平均得分'}) chart_col.set_x_axis({'name': '年份 (年)'}) chart_col.set_y_axis({'name': '平均得分(分)'}) chart_col.set_style(1) #设置图表风格 worksheet.insert_chart('A14', chart_col, {'x_offset':25, 'y_offset':3,}) #把图标插入工作台中并设置偏移 EXCEL.close()
数据表效果如图,以James为例如下
而这时候打开自动生成的Excel,就会直接显示出相应的折线图,无需再整理!
现在结合任务一的网络爬虫和任务二的数据可视化,可以获得实时的球员常规赛数据和季后赛数据汇总,以及实时的球员生涯折线图。
顺便说一句,很多人在学习Python的过程中都会遇到各种各样的麻烦,谁也不会轻易放弃。编辑是python开发工程师。这里我整理了一套最新的python系统学习教程,包括基础python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等,想要这些资料的可以关注小编,私信后台编辑:“01”接收。 查看全部
excel抓取网页数据(如何用Python构建一个带有GUI的爬虫小程序-之前)
大家好,之前我们讲了如何在Python中构建一个带有GUI的爬虫小程序。很多文章会迎合热点,延续上次NBA爬虫GUI,讨论虎扑官网怎么爬。并将数据写入Excel并同时自动生成折线图,主要有以下几个步骤
本文将分为以下两部分来讲解
项目涉及的主要Python模块:
履带部分
整理爬虫部分的思路如下
观察URL1的源码,找到球队名和对应的URL2 观察URL2的源码,找到球员对应的URL3
其实爬虫是对html进行操作的,html的结构很简单。只有一个,就是大盒子和小盒子,小盒子嵌套在小盒子中,一层一层嵌套。
目标网址如下:
先参考模块
from bs4 import BeautifulSoupimport requestsimport xlsxwriterimport os
查看URL1的源码,可以看到span标签下有团队名称及其对应的URL2,然后找到它的父框架和祖父框架。下面的思路都是一样的,如下图所示:
此时,可以使用 requests 模块和 bs4 模块进行有目的的索引以获取团队名称列表。
def Teamlists(url): TeamName=[] TeamURL=[] GET=requests.get(URL1) soup=BeautifulSoup(GET.content,'lxml') lables=soup.select('html body div div div ul li span a') for lable in lables: ballname=lable.get_text() TeamName.append(ballname) print(ballname) teamname=input("请输入想查询的球队名:")#此处可变为GUI界面中的按键值 c=TeamName.index(teamname) for item in lables: HREF=item.get('href') TeamURL.append(HREF) URL2=TeamURL[c] return URL2
此时,我得到了对应球队的URL2,然后观察URL2网页的内容,可以看到标签a下是球员名字,同时也存储了对应球员的URL3,如图下图:
这时候还是通过requests模块和bs4模块进行对应的index来获取玩家名单和对应的URL3。
#自定义函数获取队员列表和对应的URLdef playerlists(URL2): PlayerName=[] PlayerURL=[] GET2=requests.get(URL1) soup2=BeautifulSoup(GET2.content,'lxml') lables2=soup2.select('html body div div table tbody tr td b a') for lable2 in lables2: playername=lable2.get_text() PlayerName.append(playername) print(playername) name=input("请输入球员名:") #此处可变为GUI界面中的按键值 d=PlayerName.index(name) for item2 in lables2: HREF2=item2.get('href') PlayerURL.append(HREF2) URL3=PlayerURL[d] return URL3,name
现在拿到对应队伍的URL3,然后观察URL3网页的内容。可以看到p标签下是球员基本信息,td标签下是球员的常规赛生涯数据和季后赛生涯数据,如下图:
同理,requests模块和bs4模块仍然用于相应的索引,获取球员基本信息和职业数据,并过滤存储球员的常规赛和季后赛生涯数据,得到数据列表。
以下数据是通过上述网络爬虫获取的,提供可视化数据,方便绑定后的GUI界面按键事件:
可视化部分
思路:创建文件夹来创建表格和折线图
自定义函数创建表,使用os模块写入,返回创建文件夹的路径。代码如下:
def file_add(path): #此时的内函数path可与GUI界面的Statictext绑定 creatpath=path+'Basketball' try: if not os.path.isdir(creatpath): os.makedirs(creatpath) except: print("文件夹存在") return creatpath
使用xlsxwriter模块在creatpath路径下创建带有自定义函数的excel表格,同时放入数据和构建折线图。代码如下:
def player_chart(name,data,creatpath): #此为表格名称——球员名称+chart EXCEL=xlsxwriter.Workbook(creatpath+''+name+'chart.xlsx') worksheet=EXCEL.add_worksheet(name) bold=EXCEL.add_format({'bold':1}) headings=data[:18] worksheet.write_row('A1',headings,bold) #写入表头 num=(len(data))//18 a=0 for i in range(num): a=a+18 c=a+18 i=i+1 worksheet.write_row('A'+str(i+1),data[a:c]) #写入数据 chart_col = EXCEL.add_chart({'type': 'line'}) #创建一个折线图 chart_col.add_series({ 'name': '='+name+'!$R$1', #设置折线描述名称 'categories':'='+name+'!$A$2:$A$'+str(num), #设置图表类别标签范围 'values': '='+name+'!$R$2:$R$'+str(num-1), #设置图表数据范围 'line': {'color': 'red'}, }) #设置图表线条属性 #设置图标的标题和想x,y轴信息 chart_col.set_title({'name': name+'生涯常规赛平均得分'}) chart_col.set_x_axis({'name': '年份 (年)'}) chart_col.set_y_axis({'name': '平均得分(分)'}) chart_col.set_style(1) #设置图表风格 worksheet.insert_chart('A14', chart_col, {'x_offset':25, 'y_offset':3,}) #把图标插入工作台中并设置偏移 EXCEL.close()
数据表效果如图,以James为例如下
而这时候打开自动生成的Excel,就会直接显示出相应的折线图,无需再整理!
现在结合任务一的网络爬虫和任务二的数据可视化,可以获得实时的球员常规赛数据和季后赛数据汇总,以及实时的球员生涯折线图。
顺便说一句,很多人在学习Python的过程中都会遇到各种各样的麻烦,谁也不会轻易放弃。编辑是python开发工程师。这里我整理了一套最新的python系统学习教程,包括基础python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等,想要这些资料的可以关注小编,私信后台编辑:“01”接收。
excel抓取网页数据(浙江龙盛()导入外部数据--新建Web查询)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-12-09 10:05
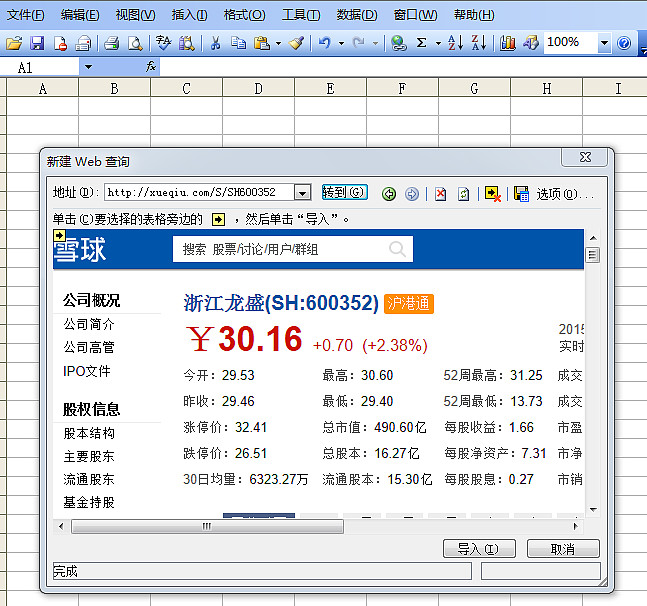
进行如下操作:
1、打开雪球股票页面复制网址链接:如:浙江龙盛网址
2、在电子表格中导入网页数据
第一步:点击【数据】菜单-导入外部数据-新建Web查询
第二步:在弹出的“新建网页查询”窗口地址栏中粘贴复制的雪球股票页面地址,点击【前往】按钮,窗口出现股票数据页面,然后点击【导入】;
第三步:将个股页面的相关数据导入到工作表中;
点击【导入】后,弹出“导入数据”对话框,可以选择数据放置位置(现有工作表或新建工作表,如选择新工作表)
在“导入数据”对话框中,也可以点击【属性】,在“外部数据区属性”对话框中设置数据相关的属性,主要是设置刷新频率;
设置好属性后,返回“导入数据”对话框,点击【确定】,导入工作表中的相关数据,如下图:
3、 提取个股最新价格数据
由于导入了雪球库存数据,很多单元格不是单个值,无法在电子表格中直接调用,需要进一步提取。第55行浙江龙盛最新价格单元格为“¥30.16+0.700 (+2.38%)”,包括价格符号、价格、数值和波动率,最新收盘价可以分别用“LEFT和RIGHT函数”提取。
使用单元格中的公式,先提取左边的6个字符“=LEFT(浙江龙盛!A55,6)”,然后提取右边的5个字符“=RIGHT(C1756,5) ”,即可以获得对应股票的最新收盘价,方便调用。
根据该方法,还可以将个股的成交量、市盈率等其他相关数据导入到电子表格中进行统计分析。 查看全部
excel抓取网页数据(浙江龙盛()导入外部数据--新建Web查询)
进行如下操作:
1、打开雪球股票页面复制网址链接:如:浙江龙盛网址
2、在电子表格中导入网页数据
第一步:点击【数据】菜单-导入外部数据-新建Web查询
第二步:在弹出的“新建网页查询”窗口地址栏中粘贴复制的雪球股票页面地址,点击【前往】按钮,窗口出现股票数据页面,然后点击【导入】;
第三步:将个股页面的相关数据导入到工作表中;
点击【导入】后,弹出“导入数据”对话框,可以选择数据放置位置(现有工作表或新建工作表,如选择新工作表)
在“导入数据”对话框中,也可以点击【属性】,在“外部数据区属性”对话框中设置数据相关的属性,主要是设置刷新频率;
设置好属性后,返回“导入数据”对话框,点击【确定】,导入工作表中的相关数据,如下图:
3、 提取个股最新价格数据
由于导入了雪球库存数据,很多单元格不是单个值,无法在电子表格中直接调用,需要进一步提取。第55行浙江龙盛最新价格单元格为“¥30.16+0.700 (+2.38%)”,包括价格符号、价格、数值和波动率,最新收盘价可以分别用“LEFT和RIGHT函数”提取。
使用单元格中的公式,先提取左边的6个字符“=LEFT(浙江龙盛!A55,6)”,然后提取右边的5个字符“=RIGHT(C1756,5) ”,即可以获得对应股票的最新收盘价,方便调用。

根据该方法,还可以将个股的成交量、市盈率等其他相关数据导入到电子表格中进行统计分析。
excel抓取网页数据(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-12-08 15:08
)
Excel 2013及以后版本提供了WEBSERVICE和FILTERXML函数,可以用于网页数据的抓取,但是只能抓取XML格式的数据。而现在网站的很多网页或者接口都返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?今天以豆瓣图书基本资料为例,给大家介绍一下如何使用Excel API网络函数库抓取JSON格式的网页数据。
第一步,找到豆瓣网的基本信息页面
豆瓣图书信息网站是9787111529385,网站最后一串数字是图书的ISBN号。
在火狐浏览器中,这个URL会返回如下信息,是标准的JSON格式,蓝色字体为属性名称,红色字体对应属性值。
第二步安装ExcelAPI网络函数库
访问ExcelAPI网络函数库官网,根据帮助页面安装函数库。
第三步,使用函数抓取JSON数据。
首先,使用函数 GetJsonSource(url,"UTF-8") 返回 JSON 原创数据。
然后,使用函数 GetJsonByPropertyName(json_source,property_name) 返回书籍的基本信息。使用GetJsonSource()函数一次性抓取所有数据,然后按需抓取。这样做的目的是提高爬行速度。毕竟,访问网页需要时间。
完整的操作如下:
查看全部
excel抓取网页数据(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据?
)
Excel 2013及以后版本提供了WEBSERVICE和FILTERXML函数,可以用于网页数据的抓取,但是只能抓取XML格式的数据。而现在网站的很多网页或者接口都返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?今天以豆瓣图书基本资料为例,给大家介绍一下如何使用Excel API网络函数库抓取JSON格式的网页数据。
第一步,找到豆瓣网的基本信息页面
豆瓣图书信息网站是9787111529385,网站最后一串数字是图书的ISBN号。
在火狐浏览器中,这个URL会返回如下信息,是标准的JSON格式,蓝色字体为属性名称,红色字体对应属性值。

第二步安装ExcelAPI网络函数库
访问ExcelAPI网络函数库官网,根据帮助页面安装函数库。
第三步,使用函数抓取JSON数据。
首先,使用函数 GetJsonSource(url,"UTF-8") 返回 JSON 原创数据。

然后,使用函数 GetJsonByPropertyName(json_source,property_name) 返回书籍的基本信息。使用GetJsonSource()函数一次性抓取所有数据,然后按需抓取。这样做的目的是提高爬行速度。毕竟,访问网页需要时间。

完整的操作如下:

excel抓取网页数据(风越网页批量填写数据提取软件,可自动分析网页中表单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-12-01 08:12
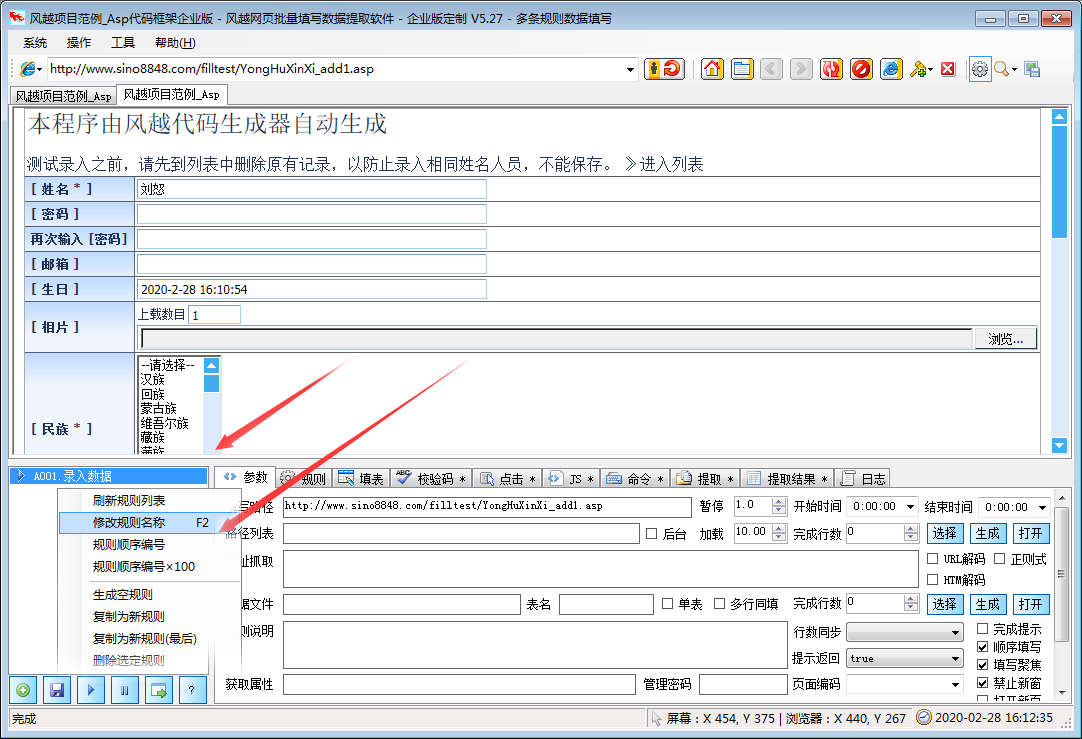
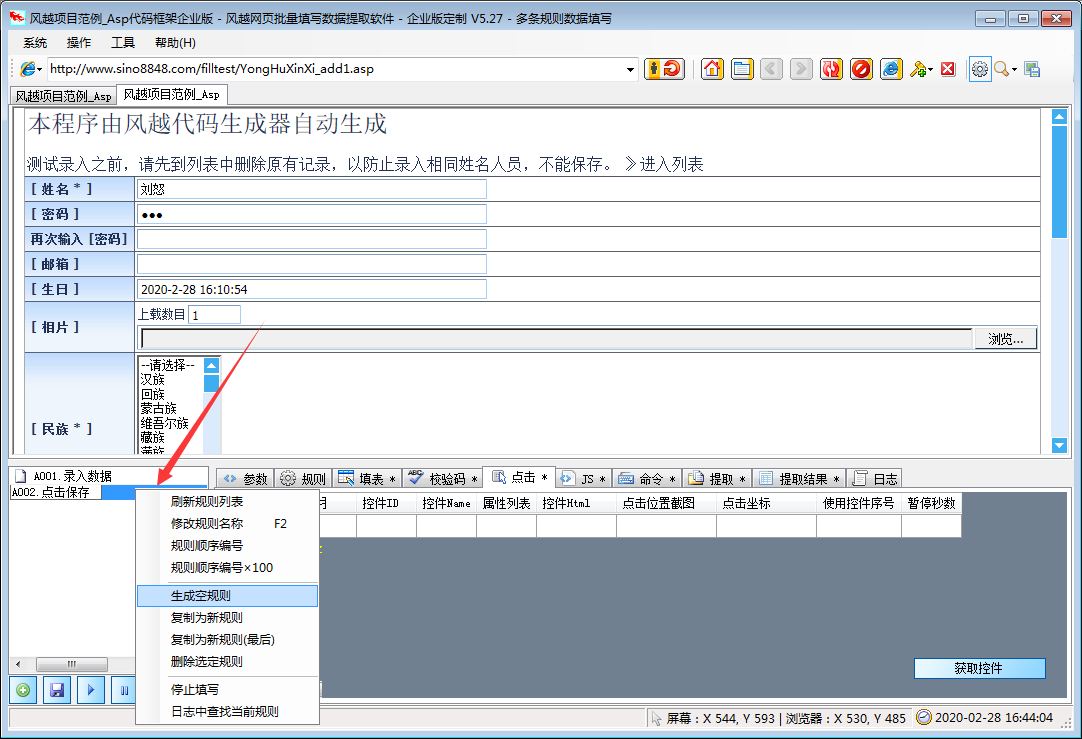
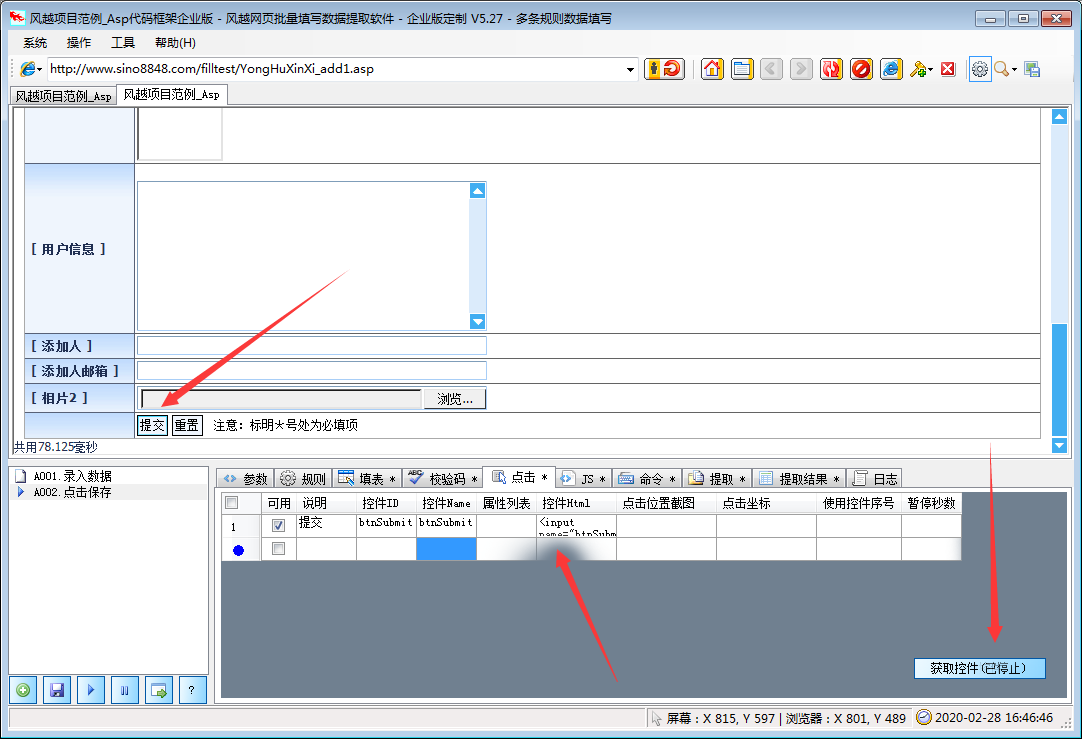
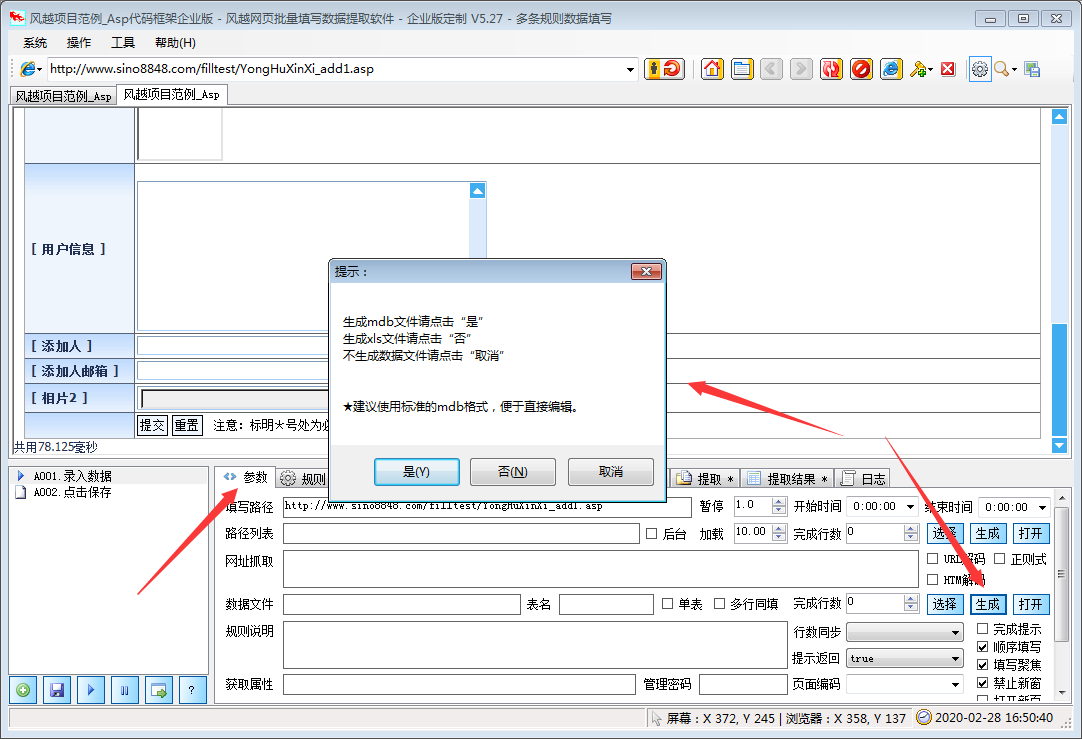
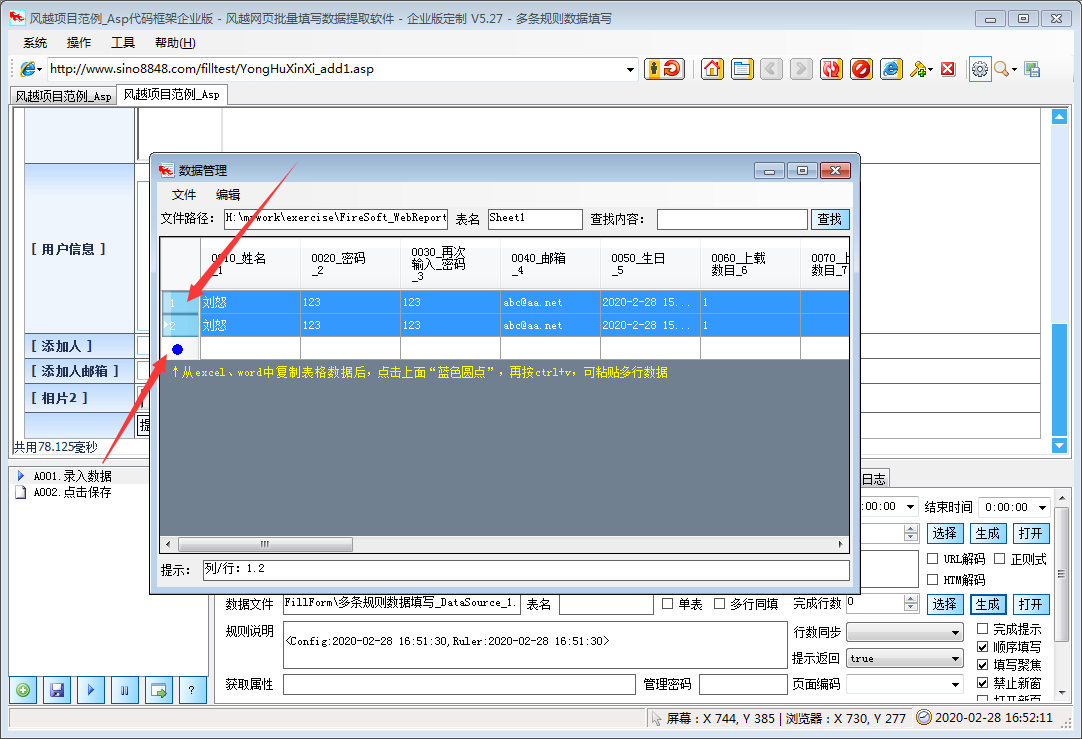
风月网页批量填写数据提取软件可以自动分析网页上表格的填写内容,并保存为填写规则。使用的时候只要调用这个规则就可以自动填表,点击网页元素,抓取网页的文字内容。下载指定的网页链接文件。
风月excel数据批量自动填充网页数据提取软件功能
本软件支持更多的页面填充类型和控制元素类型,精度更高。其他填表工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。
本软件不仅可以用于一般办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、征信、抢车牌等工具。
★支持从Excel和ACCESS文件中读取数据填写表格,并根据当前表格生成Xls文件,方便批量录入
★支持下载指定文件和抓取网页文本内容
★支持填充多边框页面中的控件元素
★支持在嵌入框架iframe的页面中填充控件元素
★支持网页结构分析,显示控件描述,方便分析和修改控件值
★支持填写各种页面控件元素:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框收音机
支持收音机复选框
★支持填写级联下拉菜单
★支持填写无ID控制
★支持在线识别校验码
★支持循环填充和输入
风月excel数据批量自动填充网页数据提取软件使用说明
1、点击菜单“系统”>“新建配置文件”
2、在软件中打开网页,手动填写需要输入的内容
3、 点击左下角的“New Rule with Plus Icon”按钮创建规则
4、勾选“填写表单”网格,根据情况删除不需要填写的行
至此,设置完成。测试过程中,只需刷新网页,使网页未填充,然后点击软件左下角的“开始填充三角形图标”按钮即可查看填充效果。
风月excel数据批量自动填写网页数据提取软件更新日志
把bug扫到最后
优化用户反馈,提升细节体验
华军编辑推荐:
风月excel数据批量自动填充网页数据提取软件这类软件编辑器已经用了很多年了,但是这款软件还是最好用的,{recommendWords}也是一款不错的软件,推荐大家下载使用. 查看全部
excel抓取网页数据(风越网页批量填写数据提取软件,可自动分析网页中表单)
风月网页批量填写数据提取软件可以自动分析网页上表格的填写内容,并保存为填写规则。使用的时候只要调用这个规则就可以自动填表,点击网页元素,抓取网页的文字内容。下载指定的网页链接文件。
风月excel数据批量自动填充网页数据提取软件功能
本软件支持更多的页面填充类型和控制元素类型,精度更高。其他填表工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。
本软件不仅可以用于一般办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、征信、抢车牌等工具。
★支持从Excel和ACCESS文件中读取数据填写表格,并根据当前表格生成Xls文件,方便批量录入
★支持下载指定文件和抓取网页文本内容
★支持填充多边框页面中的控件元素
★支持在嵌入框架iframe的页面中填充控件元素
★支持网页结构分析,显示控件描述,方便分析和修改控件值
★支持填写各种页面控件元素:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框收音机
支持收音机复选框
★支持填写级联下拉菜单
★支持填写无ID控制
★支持在线识别校验码
★支持循环填充和输入
风月excel数据批量自动填充网页数据提取软件使用说明
1、点击菜单“系统”>“新建配置文件”
2、在软件中打开网页,手动填写需要输入的内容
3、 点击左下角的“New Rule with Plus Icon”按钮创建规则
4、勾选“填写表单”网格,根据情况删除不需要填写的行
至此,设置完成。测试过程中,只需刷新网页,使网页未填充,然后点击软件左下角的“开始填充三角形图标”按钮即可查看填充效果。
风月excel数据批量自动填写网页数据提取软件更新日志
把bug扫到最后
优化用户反馈,提升细节体验
华军编辑推荐:
风月excel数据批量自动填充网页数据提取软件这类软件编辑器已经用了很多年了,但是这款软件还是最好用的,{recommendWords}也是一款不错的软件,推荐大家下载使用.
excel抓取网页数据(excel抓取网页数据,你们这么用浏览器,我很敬佩)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-11-29 08:01
excel抓取网页数据,你们这么用chrome浏览器,我很敬佩,但是我觉得不太合适,主要是他自身的安全性,抓取网页很麻烦,很多网站都限制了破解的方法,假如抓取一次就要把整个网页浏览一遍,chrome的这个特性就使得他在实际场景是很不合适的,在普通网页抓取时,
找个插件抓完一个网页就删掉,多重要你懂得。
我是真心求解决方案,不要老有一种自己很努力,却不解决问题的错觉。关键问题是你们要想好如何设计这个“放入去的数据”,什么样的数据应该放入“放入去的数据”。
1、分析下自己能接触到的几个数据源
2、分析下要做数据分析的产品,
3、把几个大概想法理清楚之后,
4、确定这些数据的自定义列
5、模拟实现这些数据的放入
6、加载对应数据源数据
7、设置分析原始出口,
8、实现“处理提示”以上是我近期研究了一遍ahk,看了几遍《ahk技术原理与实践》,连几本大v专家的数据分析书籍及源码,就搞定的问题,可是整个学习过程都是隔靴搔痒,没有实质性的效果。我觉得anytime、anything都不如一个“和之前一样的操作逻辑”实现提示与自定义列来的实在。再补充一句,“如何设计一个“放入去的数据”。
我想要的是一个应用层面的可以做profile或是决策支持等使用场景的api来实现“放入去的数据”这个操作。是的,你没看错,提示是一个或两个操作后的回调函数;回调函数的“放入去的数据”也是可以是一个或两个操作后的回调函数(甚至可以扩展一些特殊的类型),但是那不是核心的操作逻辑,本质上应该是分析出一个数据源,我的经验是两个选择:手动分析出一个数据源,使用csv等软件处理此数据或是两个操作后的数据分析结果,再上传至服务器进行保存;其实前者是更合适的,因为这有经验的分析人员能设计出合适的profile方案,等于提供了一个数据的持续生命周期数据分析的profile方案,不过这可能需要开发人员较高的经验来完成;所以我觉得后者成熟的解决方案更合适,当然,既然从来没有开发过这么专业的软件方案,而你又没有工作经验,那就用python实现这个操作吧。说到底,还是对软件工程的实践认识不足,缺乏对自己负责的态度。 查看全部
excel抓取网页数据(excel抓取网页数据,你们这么用浏览器,我很敬佩)
excel抓取网页数据,你们这么用chrome浏览器,我很敬佩,但是我觉得不太合适,主要是他自身的安全性,抓取网页很麻烦,很多网站都限制了破解的方法,假如抓取一次就要把整个网页浏览一遍,chrome的这个特性就使得他在实际场景是很不合适的,在普通网页抓取时,
找个插件抓完一个网页就删掉,多重要你懂得。
我是真心求解决方案,不要老有一种自己很努力,却不解决问题的错觉。关键问题是你们要想好如何设计这个“放入去的数据”,什么样的数据应该放入“放入去的数据”。
1、分析下自己能接触到的几个数据源
2、分析下要做数据分析的产品,
3、把几个大概想法理清楚之后,
4、确定这些数据的自定义列
5、模拟实现这些数据的放入
6、加载对应数据源数据
7、设置分析原始出口,
8、实现“处理提示”以上是我近期研究了一遍ahk,看了几遍《ahk技术原理与实践》,连几本大v专家的数据分析书籍及源码,就搞定的问题,可是整个学习过程都是隔靴搔痒,没有实质性的效果。我觉得anytime、anything都不如一个“和之前一样的操作逻辑”实现提示与自定义列来的实在。再补充一句,“如何设计一个“放入去的数据”。
我想要的是一个应用层面的可以做profile或是决策支持等使用场景的api来实现“放入去的数据”这个操作。是的,你没看错,提示是一个或两个操作后的回调函数;回调函数的“放入去的数据”也是可以是一个或两个操作后的回调函数(甚至可以扩展一些特殊的类型),但是那不是核心的操作逻辑,本质上应该是分析出一个数据源,我的经验是两个选择:手动分析出一个数据源,使用csv等软件处理此数据或是两个操作后的数据分析结果,再上传至服务器进行保存;其实前者是更合适的,因为这有经验的分析人员能设计出合适的profile方案,等于提供了一个数据的持续生命周期数据分析的profile方案,不过这可能需要开发人员较高的经验来完成;所以我觉得后者成熟的解决方案更合适,当然,既然从来没有开发过这么专业的软件方案,而你又没有工作经验,那就用python实现这个操作吧。说到底,还是对软件工程的实践认识不足,缺乏对自己负责的态度。
excel抓取网页数据(福利:利用自动化工具,统计分析数据,便捷的网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-21 03:01
excel抓取网页数据一直都是一个困扰很多人的问题,虽然在各大爬虫工具都可以做到分析网页数据,但是各家抓取工具的区别还是非常大的,下面介绍下一个福利:利用自动化工具,统计分析数据,对数据量要求不是很大的情况下,使用自动化工具快速便捷的抓取网页数据。使用工具:自动化工具:/~gohlke/pythonlibs/#library。方法:先在网页上找到需要抓取的数据,利用两种方法:。
1、先抓取工作表
2、统计工作表查看数据:我使用的是textkit,用于生成python代码,并且代码是自动化抓取,而对于数据量不大的网页数据,使用download-table-selection的方法并不是非常方便,另外,想起上一期介绍的myie数据,需要使用代码才能抓取的要求相当高,为了避免重复编写代码,本文的代码中没有提供可供使用的抓取工具代码,只提供抓取数据集,并提供一种统计分析网页数据的方法,在这种方法中,利用了pandas库,包括了常用的dataframe,list等,对于网页数据做统计分析是非常的友好。
另外这个网页数据抓取的工具可以免费体验5次,使用此工具只需要很少的代码,对于工作量不大的网页数据,还是非常不错的。
步骤:
1、获取全部数据的链接:输入获取到的网页地址,并回车,
2、使用自动化工具进行抓取:使用自动化工具的方法很简单,基本代码如下:#使用frompandasimportdataframeimportpandasaspd#打开对应数据的网页,
3、统计数据data。columns统计数据索引:all_data=pd。dataframe(data)all_data=data。reset_index(drop=true)all_data=data。
reset_index(drop=true)[['index','value']]。values统计数据行:1=0+all_data[['index','value']][['column','name']]。values统计数据列:1=0+all_data[['index','value']][['column','name']]。values。 查看全部
excel抓取网页数据(福利:利用自动化工具,统计分析数据,便捷的网页数据)
excel抓取网页数据一直都是一个困扰很多人的问题,虽然在各大爬虫工具都可以做到分析网页数据,但是各家抓取工具的区别还是非常大的,下面介绍下一个福利:利用自动化工具,统计分析数据,对数据量要求不是很大的情况下,使用自动化工具快速便捷的抓取网页数据。使用工具:自动化工具:/~gohlke/pythonlibs/#library。方法:先在网页上找到需要抓取的数据,利用两种方法:。
1、先抓取工作表
2、统计工作表查看数据:我使用的是textkit,用于生成python代码,并且代码是自动化抓取,而对于数据量不大的网页数据,使用download-table-selection的方法并不是非常方便,另外,想起上一期介绍的myie数据,需要使用代码才能抓取的要求相当高,为了避免重复编写代码,本文的代码中没有提供可供使用的抓取工具代码,只提供抓取数据集,并提供一种统计分析网页数据的方法,在这种方法中,利用了pandas库,包括了常用的dataframe,list等,对于网页数据做统计分析是非常的友好。
另外这个网页数据抓取的工具可以免费体验5次,使用此工具只需要很少的代码,对于工作量不大的网页数据,还是非常不错的。
步骤:
1、获取全部数据的链接:输入获取到的网页地址,并回车,
2、使用自动化工具进行抓取:使用自动化工具的方法很简单,基本代码如下:#使用frompandasimportdataframeimportpandasaspd#打开对应数据的网页,
3、统计数据data。columns统计数据索引:all_data=pd。dataframe(data)all_data=data。reset_index(drop=true)all_data=data。
reset_index(drop=true)[['index','value']]。values统计数据行:1=0+all_data[['index','value']][['column','name']]。values统计数据列:1=0+all_data[['index','value']][['column','name']]。values。
excel抓取网页数据(excel抓取网页数据——信息!文本搜索网页信息全靠这一招)
网站优化 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2021-11-20 20:08
excel抓取网页数据——信息!文本搜索网页信息全靠这一招
首先,您需要使用python实现一个基本的爬虫,而且爬虫在python中是核心,如果连基本的爬虫都写不好,那肯定也写不好别的。python发展很快,核心库丰富,同时兼容java,c++,scala,php等等语言。scrapy,numpy,pandas等库也十分完善。可以用python实现一些常见的python数据处理方法和计算方法。
其次,一个网站如果有多个数据库可以使用,那就看需求,一般一个数据库就够了,hive,mysql,sqlalchemy,oralce等等。一般网站也需要将爬取的数据写入数据库中,比如你可以调用mysql数据库,一般的,你可以爬取百度的数据,然后再写入mysql数据库中,这也方便你做一些数据分析。然后要学习网络编程和数据库基础知识,最好也学学编程语言,因为如果你是做数据分析的话,数据库连接数是一个很重要的东西。
接下来要学会爬虫开发工具,比如requests,正则表达式,爬虫框架,beautifulsoup等等,一般来说,最重要的是一个抓包工具,因为requests是整个爬虫开发的基础。最后,你要了解并掌握各种爬虫工具,比如beautifulsoup,zhuanzhiweijsx,scrapy框架等等,掌握了这些爬虫基本要点后,你要抓取的网站,也都不是问题了。 查看全部
excel抓取网页数据(excel抓取网页数据——信息!文本搜索网页信息全靠这一招)
excel抓取网页数据——信息!文本搜索网页信息全靠这一招
首先,您需要使用python实现一个基本的爬虫,而且爬虫在python中是核心,如果连基本的爬虫都写不好,那肯定也写不好别的。python发展很快,核心库丰富,同时兼容java,c++,scala,php等等语言。scrapy,numpy,pandas等库也十分完善。可以用python实现一些常见的python数据处理方法和计算方法。
其次,一个网站如果有多个数据库可以使用,那就看需求,一般一个数据库就够了,hive,mysql,sqlalchemy,oralce等等。一般网站也需要将爬取的数据写入数据库中,比如你可以调用mysql数据库,一般的,你可以爬取百度的数据,然后再写入mysql数据库中,这也方便你做一些数据分析。然后要学习网络编程和数据库基础知识,最好也学学编程语言,因为如果你是做数据分析的话,数据库连接数是一个很重要的东西。
接下来要学会爬虫开发工具,比如requests,正则表达式,爬虫框架,beautifulsoup等等,一般来说,最重要的是一个抓包工具,因为requests是整个爬虫开发的基础。最后,你要了解并掌握各种爬虫工具,比如beautifulsoup,zhuanzhiweijsx,scrapy框架等等,掌握了这些爬虫基本要点后,你要抓取的网站,也都不是问题了。
excel抓取网页数据(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 302 次浏览 • 2021-11-20 03:15
)
Excel 2013及以后版本提供了WEBSERVICE和FILTERXML函数,可以用于网页数据的抓取,但是只能抓取XML格式的数据。而现在网站的很多网页或者接口都返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?今天以豆瓣图书基本资料为例,给大家介绍一下如何使用Excel API网络函数库抓取JSON格式的网页数据。
第一步,找到豆瓣网的基本信息页面
豆瓣图书信息网站是9787111529385,网站最后一串数字是图书的ISBN号。
在火狐浏览器中,这个URL会返回如下信息,是标准的JSON格式,蓝色字体为属性名称,红色字体对应属性值。
第二步安装ExcelAPI网络函数库
访问ExcelAPI网络函数库官网,根据帮助页面安装函数库。
第三步,使用函数抓取JSON数据。
首先,使用函数 GetJsonSource(url,"UTF-8") 返回 JSON 原创数据。
然后,使用函数 GetJsonByPropertyName(json_source,property_name) 返回书籍的基本信息。使用GetJsonSource()函数一次性抓取所有数据,然后按需抓取。这样做的目的是提高爬行速度。毕竟,访问网页需要时间。
完整的操作如下:
查看全部
excel抓取网页数据(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据?
)
Excel 2013及以后版本提供了WEBSERVICE和FILTERXML函数,可以用于网页数据的抓取,但是只能抓取XML格式的数据。而现在网站的很多网页或者接口都返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?今天以豆瓣图书基本资料为例,给大家介绍一下如何使用Excel API网络函数库抓取JSON格式的网页数据。
第一步,找到豆瓣网的基本信息页面
豆瓣图书信息网站是9787111529385,网站最后一串数字是图书的ISBN号。
在火狐浏览器中,这个URL会返回如下信息,是标准的JSON格式,蓝色字体为属性名称,红色字体对应属性值。
第二步安装ExcelAPI网络函数库
访问ExcelAPI网络函数库官网,根据帮助页面安装函数库。
第三步,使用函数抓取JSON数据。
首先,使用函数 GetJsonSource(url,"UTF-8") 返回 JSON 原创数据。
然后,使用函数 GetJsonByPropertyName(json_source,property_name) 返回书籍的基本信息。使用GetJsonSource()函数一次性抓取所有数据,然后按需抓取。这样做的目的是提高爬行速度。毕竟,访问网页需要时间。
完整的操作如下:
excel抓取网页数据(这是2020#阿里的法拍住宅数量(119万))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-01-17 04:19
#学Wave2020#
今天阿里的止赎数量是119万,但是昨天截图的时候还是118万,而且这个数字应该还在快速增长。我们今天正在尝试抓取 Alifa 住宅数据。
网站分析
参考昨天的思路,没有任何有用的线索。Ali网站 不提供现成的 JSON 或 JSONP 数据。
但是阿里网站的url直接有页码。是不是意味着我们可以通过url直接抓取呢?
有兴趣的可以直接试一试。果然可以直接定义一个函数来抓取它:
爬取结果:
真的那么容易吗?我不敢相信。在 Power Query 中,150 页中每页只有 6,000 40 个条目。显然有问题。虽然预览成功了,但数据本身也有问题。数值以万元为单位,不规范,所以这个数据应该是有问题的。放弃这种方法。
不过,这也提供了一个思路。可以尝试通过url直接爬取。
我们来到元素视图,发现了这么一段内容,仔细观察,这是一个JSON数据,复制到Power Query可以解析出来:
它是非常标准的 json 数据:
展开后得到的数据比我们之前刮的要好很多。
我们可以通过 Web.BrowserContents 函数获取这个文本,然后从文本中提取 json 数据。
我们还在此文本的页面上找到了统计信息:
您还可以找出有多少页数据:
对应这个位置:
至此,我们的把握思路基本清晰。
我们可以按照区县一级的行政区划来采集数据。此级别的数据捕获需要两个参数,管理代码和页码范围。行政代码可通过相关网站直接获取,页码可在首页找到的各区县查询。
为了捕获特定的数据,可以定义一个函数来从每个页面的代码中提取 JSON 数据。
但是,119万条具体的房屋信息对我们来说是没有用的。我们感兴趣的是统计数据。我们直接从县级行政区划的首页找到这个统计信息就够了。
定义函数
fp函数:获取页码范围的函数,使用Text.Split函数拆分书
fn function:获取统计结果的函数
fd函数:获取特定房屋信息的函数
试着抓
抓取沉河区具体房屋信息数据:
沉河区统计:
抓
抓取沉阳房屋具体信息:
先找到这一段,复制出来:
将其复制到 Power Query 中是这样的。处理后可以得到沉阳市的区县和代码:
处理结果:
然后我们参考fp函数得到页码范围:
生成所有页码:
展开并添加 fd 函数来抓取数据:
展开数据:
这样,特定的住房信息数据就被捕获了。
抓取全国县级行政区的统计信息有点麻烦,我发现阿里的行政区号和国家区号有点不一样,会导致数据缺失。大部分还是可以匹配的,少数不一致。我们来看看全国各区县的行政代码列表:
完成结果:
在此基础上,参考fn函数抓取统计信息:
这个过程很慢,耐心点,一共大概有3000左右。
将数据加载到 Power BI Desktop 并制作几个图表以查看:
热图:
条形图:
分解树:
我可以看到总数是119万。我这里只有107万,少了12万,是编码不一致造成的。 查看全部
excel抓取网页数据(这是2020#阿里的法拍住宅数量(119万))
#学Wave2020#
今天阿里的止赎数量是119万,但是昨天截图的时候还是118万,而且这个数字应该还在快速增长。我们今天正在尝试抓取 Alifa 住宅数据。
网站分析
参考昨天的思路,没有任何有用的线索。Ali网站 不提供现成的 JSON 或 JSONP 数据。
但是阿里网站的url直接有页码。是不是意味着我们可以通过url直接抓取呢?
有兴趣的可以直接试一试。果然可以直接定义一个函数来抓取它:
爬取结果:
真的那么容易吗?我不敢相信。在 Power Query 中,150 页中每页只有 6,000 40 个条目。显然有问题。虽然预览成功了,但数据本身也有问题。数值以万元为单位,不规范,所以这个数据应该是有问题的。放弃这种方法。
不过,这也提供了一个思路。可以尝试通过url直接爬取。
我们来到元素视图,发现了这么一段内容,仔细观察,这是一个JSON数据,复制到Power Query可以解析出来:
它是非常标准的 json 数据:
展开后得到的数据比我们之前刮的要好很多。
我们可以通过 Web.BrowserContents 函数获取这个文本,然后从文本中提取 json 数据。
我们还在此文本的页面上找到了统计信息:
您还可以找出有多少页数据:
对应这个位置:
至此,我们的把握思路基本清晰。
我们可以按照区县一级的行政区划来采集数据。此级别的数据捕获需要两个参数,管理代码和页码范围。行政代码可通过相关网站直接获取,页码可在首页找到的各区县查询。
为了捕获特定的数据,可以定义一个函数来从每个页面的代码中提取 JSON 数据。
但是,119万条具体的房屋信息对我们来说是没有用的。我们感兴趣的是统计数据。我们直接从县级行政区划的首页找到这个统计信息就够了。
定义函数
fp函数:获取页码范围的函数,使用Text.Split函数拆分书
fn function:获取统计结果的函数
fd函数:获取特定房屋信息的函数
试着抓
抓取沉河区具体房屋信息数据:
沉河区统计:
抓
抓取沉阳房屋具体信息:
先找到这一段,复制出来:
将其复制到 Power Query 中是这样的。处理后可以得到沉阳市的区县和代码:
处理结果:
然后我们参考fp函数得到页码范围:
生成所有页码:
展开并添加 fd 函数来抓取数据:
展开数据:
这样,特定的住房信息数据就被捕获了。
抓取全国县级行政区的统计信息有点麻烦,我发现阿里的行政区号和国家区号有点不一样,会导致数据缺失。大部分还是可以匹配的,少数不一致。我们来看看全国各区县的行政代码列表:
完成结果:
在此基础上,参考fn函数抓取统计信息:
这个过程很慢,耐心点,一共大概有3000左右。
将数据加载到 Power BI Desktop 并制作几个图表以查看:
热图:
条形图:
分解树:
我可以看到总数是119万。我这里只有107万,少了12万,是编码不一致造成的。
excel抓取网页数据(如何应对数据匮乏?最简单的方法在这里!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-17 04:18
介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!想要获得更多数据来训练我们的机器学习模型是一个持续存在的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吧?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络抓取。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 中采集数据。今天,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这就是网络抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接深入 Python 以了解如何使用流行且高效的 BeautifulSoup 库执行网页抓取。
请注意,网络抓取受许多准则和规则的约束。并非每个 网站 都允许用户抓取内容,因此存在法律限制。在尝试执行此操作之前,请确保您已阅读 网站 的网站 条款和条件。
3 种流行的 Python 网络爬虫工具和库 用于网络爬取的 Python 组件 抓取解析和转换 网页抓取 URL 和电子邮件 ID 抓取图像 在页面加载时抓取数据 3 个流行的 Python 网络爬取工具和库
您将在 Python 中遇到几个用于 Web 抓取的库和框架。以下是三种用于高效完成工作的流行工具:
美丽汤
刮擦
硒
网络爬虫的组成部分
这是构成网络抓取的三个主要组件的绝佳说明:
让我们详细了解这些组件。我们将通过 goibibo网站 获取酒店详细信息,例如酒店名称和每间客房的价格以执行此操作:
注意:始终遵循目标 网站 的 robots.txt 文件,也称为机器人排除协议。这告诉网络机器人不要抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴为我们的网络机器人编写脚本。开始吧!
第 1 步:爬行
网页抓取的第一步是导航到目标 网站 并下载网页的源代码。我们将使用 requests 库来执行此操作。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页的源代码后,我们需要过滤我们想要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换
网页抓取的下一步是将这些数据解析为 HTML 解析器,为此我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,与大多数页面一样,特定酒店的详细信息在不同的卡片上。
所以下一步是从完整的源代码中过滤卡片数据。接下来,我们将选择该卡并单击“检查元素”选项以获取该特定卡的源代码。你会得到这样的东西:
所有卡片都有相同的类名,我们可以通过传递标签名称和具有如下名称的属性(如标签)来获取这些卡片的列表:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,其中每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在对于每张卡,我们必须找到上面的酒店名称,只能从
从标签中提取。这是因为每张卡和费率只有一个标签和标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
第三步:存储(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后我们最终将它添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络抓取工具。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的评级和地址。现在,让我们看看如何执行一些常见任务,例如在页面加载时抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试通过网络抓取来抓取的两个最常见的功能是 网站URL 和电子邮件 ID。我确定您参与过需要大量提取电子邮件 ID 的项目或挑战。那么让我们看看如何在 Python 中抓取这些内容。
使用 Web 浏览器的控制台 查看全部
excel抓取网页数据(如何应对数据匮乏?最简单的方法在这里!!)
介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!想要获得更多数据来训练我们的机器学习模型是一个持续存在的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吧?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络抓取。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 中采集数据。今天,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这就是网络抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接深入 Python 以了解如何使用流行且高效的 BeautifulSoup 库执行网页抓取。
请注意,网络抓取受许多准则和规则的约束。并非每个 网站 都允许用户抓取内容,因此存在法律限制。在尝试执行此操作之前,请确保您已阅读 网站 的网站 条款和条件。
3 种流行的 Python 网络爬虫工具和库 用于网络爬取的 Python 组件 抓取解析和转换 网页抓取 URL 和电子邮件 ID 抓取图像 在页面加载时抓取数据 3 个流行的 Python 网络爬取工具和库
您将在 Python 中遇到几个用于 Web 抓取的库和框架。以下是三种用于高效完成工作的流行工具:
美丽汤
刮擦
硒
网络爬虫的组成部分
这是构成网络抓取的三个主要组件的绝佳说明:
让我们详细了解这些组件。我们将通过 goibibo网站 获取酒店详细信息,例如酒店名称和每间客房的价格以执行此操作:
注意:始终遵循目标 网站 的 robots.txt 文件,也称为机器人排除协议。这告诉网络机器人不要抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴为我们的网络机器人编写脚本。开始吧!
第 1 步:爬行
网页抓取的第一步是导航到目标 网站 并下载网页的源代码。我们将使用 requests 库来执行此操作。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页的源代码后,我们需要过滤我们想要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换
网页抓取的下一步是将这些数据解析为 HTML 解析器,为此我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,与大多数页面一样,特定酒店的详细信息在不同的卡片上。
所以下一步是从完整的源代码中过滤卡片数据。接下来,我们将选择该卡并单击“检查元素”选项以获取该特定卡的源代码。你会得到这样的东西:
所有卡片都有相同的类名,我们可以通过传递标签名称和具有如下名称的属性(如标签)来获取这些卡片的列表:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,其中每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在对于每张卡,我们必须找到上面的酒店名称,只能从
从标签中提取。这是因为每张卡和费率只有一个标签和标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
第三步:存储(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后我们最终将它添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络抓取工具。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的评级和地址。现在,让我们看看如何执行一些常见任务,例如在页面加载时抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试通过网络抓取来抓取的两个最常见的功能是 网站URL 和电子邮件 ID。我确定您参与过需要大量提取电子邮件 ID 的项目或挑战。那么让我们看看如何在 Python 中抓取这些内容。
使用 Web 浏览器的控制台
excel抓取网页数据(Python编程语言Excel爬虫函数学起来容易些什么?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-01-10 07:04
近年来,Python编程语言非常流行,很多人使用Python开发网络爬虫工具。Python虽然简单,但学习起来并不容易,需要一定的基础。今天小编给大家介绍一个Excel爬虫功能,比较容易学习,可以满足数据采集在特定场景下的需求。
有一个基金网页#qdiie,网页中有一个数据表格,如下图,需要将红框内标注的数据抓取到Excel表格中,并定期更新表格数据。
爬取过程有六个步骤
第一步是使用火狐或Chrome打开目标网页,右键查看代码找到表单的id。如果表格没有 id,请改用表格类样式。
第二步,写公式=GetTableByIdW(B1,"flex_qdiie"),其中B1指的是要爬取的URL,“flex_qdiie”指的是网页中表格元素的id号。函数名中的 W 表示当前函数需要使用 Excel 浏览器。细心的朋友可能会有疑问,为什么要用Excel浏览器呢?原因是现在的网页越来越复杂,通过传统的HttpGet()或者HttpPost()方法无法读取完整的网页,所以需要使用浏览器来读取所有的网页数据。
第三步,打开Excel浏览器,设置网页循环爬取任务。因为网页数据需要定期更新,所以需要Excel浏览器循环抓取网页。
第四步,刷新Excel中的公式。这时候抓取函数会返回“flex_qdiie”表的所有数据,是一长串文本。可以发现,每一列用分号隔开,每一行用两个分号隔开。找到一个模式,我们可以使用 Split2Array() 函数来拆分和提取数据。
513100;纳指etf;4.284;-0.93%;4228.65;29762;100;4.0850;20-11-16;4.0552;20-11-17;5.64%;会员;会员;会员;纳斯达克100;-0.30%;0.50%;0.50%;国泰基金;;164906;中国互联;1.994;-0.85%;556.36;8077;94;1.9950;20-11-16;1.9332;20-11-17;3.15%;-;-;-;中证海外中国互联网指数;-3.26%;1.20%;1.50%;交银施罗德;;513050;中概互联;2.080;-0.43%;13851.75;244643;-1300;2.1344;20-11-16;2.0605;20-11-17;0.95%;-;-;-;中国互联网50;-3.03%;0.50%;0.50%;易方达;;159822;新经济;1.024;-0.19%;1186.78;74473;-1500;1.0415;20-11-16;1.0269;20-11-17;-0.28%;-;-;-;标普中国新经济行业指数;-1.05%;;1.50%;银华基金;;159941;纳指etf;2.439;-1.01%;6268.25;39605;400;2.4695;20-11-16;2.4515;20-11-17;-0.51%;会员;会员;会员;纳斯达克100;-0.30%;0.50%;0.50%;广发基金;;513300;纳斯达克;0.991;-1.10%;2062.63;85267;-150;1.0042;20-11-16;0.9969;20-11-17;-0.59%;会员;会员;会员;纳斯达克100;-0.30%;0.50%;0.50%;华夏基金;;164824;印度基金;0.953;-0.52%;77.46;3293;-12;0.9669;20-11-16;0.9620;20-11-17;-0.94%;会员;会员;会员;印度etp指数;-;1.20%;1.50%;工银瑞信;;...
第五步是拆分和提取数据。先拆分每一行的数据,再拆分每一列的数据。
第六步,使用=AutoRefresh(120)公式设置定时刷新任务,每120秒自动刷新表数据。
一共六步,完美抓取一张表的数据,实现自动定时刷新。有了实时数据,可以对数据进行处理和计算,达到监测预警的目的。怎么样,很简单,你可以写公式来进行网页数据采集。
如果你觉得这个技巧有用,请帮忙转发给你的朋友 查看全部
excel抓取网页数据(Python编程语言Excel爬虫函数学起来容易些什么?(图))
近年来,Python编程语言非常流行,很多人使用Python开发网络爬虫工具。Python虽然简单,但学习起来并不容易,需要一定的基础。今天小编给大家介绍一个Excel爬虫功能,比较容易学习,可以满足数据采集在特定场景下的需求。
有一个基金网页#qdiie,网页中有一个数据表格,如下图,需要将红框内标注的数据抓取到Excel表格中,并定期更新表格数据。
爬取过程有六个步骤
第一步是使用火狐或Chrome打开目标网页,右键查看代码找到表单的id。如果表格没有 id,请改用表格类样式。
第二步,写公式=GetTableByIdW(B1,"flex_qdiie"),其中B1指的是要爬取的URL,“flex_qdiie”指的是网页中表格元素的id号。函数名中的 W 表示当前函数需要使用 Excel 浏览器。细心的朋友可能会有疑问,为什么要用Excel浏览器呢?原因是现在的网页越来越复杂,通过传统的HttpGet()或者HttpPost()方法无法读取完整的网页,所以需要使用浏览器来读取所有的网页数据。
第三步,打开Excel浏览器,设置网页循环爬取任务。因为网页数据需要定期更新,所以需要Excel浏览器循环抓取网页。
第四步,刷新Excel中的公式。这时候抓取函数会返回“flex_qdiie”表的所有数据,是一长串文本。可以发现,每一列用分号隔开,每一行用两个分号隔开。找到一个模式,我们可以使用 Split2Array() 函数来拆分和提取数据。
513100;纳指etf;4.284;-0.93%;4228.65;29762;100;4.0850;20-11-16;4.0552;20-11-17;5.64%;会员;会员;会员;纳斯达克100;-0.30%;0.50%;0.50%;国泰基金;;164906;中国互联;1.994;-0.85%;556.36;8077;94;1.9950;20-11-16;1.9332;20-11-17;3.15%;-;-;-;中证海外中国互联网指数;-3.26%;1.20%;1.50%;交银施罗德;;513050;中概互联;2.080;-0.43%;13851.75;244643;-1300;2.1344;20-11-16;2.0605;20-11-17;0.95%;-;-;-;中国互联网50;-3.03%;0.50%;0.50%;易方达;;159822;新经济;1.024;-0.19%;1186.78;74473;-1500;1.0415;20-11-16;1.0269;20-11-17;-0.28%;-;-;-;标普中国新经济行业指数;-1.05%;;1.50%;银华基金;;159941;纳指etf;2.439;-1.01%;6268.25;39605;400;2.4695;20-11-16;2.4515;20-11-17;-0.51%;会员;会员;会员;纳斯达克100;-0.30%;0.50%;0.50%;广发基金;;513300;纳斯达克;0.991;-1.10%;2062.63;85267;-150;1.0042;20-11-16;0.9969;20-11-17;-0.59%;会员;会员;会员;纳斯达克100;-0.30%;0.50%;0.50%;华夏基金;;164824;印度基金;0.953;-0.52%;77.46;3293;-12;0.9669;20-11-16;0.9620;20-11-17;-0.94%;会员;会员;会员;印度etp指数;-;1.20%;1.50%;工银瑞信;;...
第五步是拆分和提取数据。先拆分每一行的数据,再拆分每一列的数据。
第六步,使用=AutoRefresh(120)公式设置定时刷新任务,每120秒自动刷新表数据。
一共六步,完美抓取一张表的数据,实现自动定时刷新。有了实时数据,可以对数据进行处理和计算,达到监测预警的目的。怎么样,很简单,你可以写公式来进行网页数据采集。
如果你觉得这个技巧有用,请帮忙转发给你的朋友
excel抓取网页数据(excel抓取网页数据-石家庄地铁线路图制作数据可视化高仿地铁图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-01-08 05:03
excel抓取网页数据-石家庄地铁线路图制作数据可视化高仿地铁图放到github上请参考代码,算法应该是基于javascript的一个库。【代码加公众号,
看下butting
给你几个我觉得应该去看看的免费资源-logo-gallery/,或者网上能找到一些ms的产品包,各家大厂都有。再者你可以看看地铁类的top5网站还有百度经验里应该都有,很详细的,不难的。最后做不出来可以用其他地方的数据。
我没开发过oracle数据库。网上找相关源码吧。确定是一个structure。加指针,加loadlist。实现起来方便又好玩。
之前一直用freemason做ide,虽然性能不是很好,
网上有一个mapbox开源的xml地图数据,可以直接通过javascript函数拼接到excel表中。这可能是首次拼接数据的开源方案吧,效果还不错。
试试这个?xuqing.github.io/heremapa-here-data-studio/heremapa-heremapa·github国人开发的,纯go实现,
广州地铁图上海地铁图。
目前地铁信息分析最多的大概是resharpo地图api了
除了楼上说的,我想分享一个在excel表格上找到某些街道某站的列车总数的excel图,最大的城市广州大约200,河南郑州某些地区的城市200左右,这些数据是有他自己的历史数据做的,把找到的周期内每一天每一站都找到了, 查看全部
excel抓取网页数据(excel抓取网页数据-石家庄地铁线路图制作数据可视化高仿地铁图)
excel抓取网页数据-石家庄地铁线路图制作数据可视化高仿地铁图放到github上请参考代码,算法应该是基于javascript的一个库。【代码加公众号,
看下butting
给你几个我觉得应该去看看的免费资源-logo-gallery/,或者网上能找到一些ms的产品包,各家大厂都有。再者你可以看看地铁类的top5网站还有百度经验里应该都有,很详细的,不难的。最后做不出来可以用其他地方的数据。
我没开发过oracle数据库。网上找相关源码吧。确定是一个structure。加指针,加loadlist。实现起来方便又好玩。
之前一直用freemason做ide,虽然性能不是很好,
网上有一个mapbox开源的xml地图数据,可以直接通过javascript函数拼接到excel表中。这可能是首次拼接数据的开源方案吧,效果还不错。
试试这个?xuqing.github.io/heremapa-here-data-studio/heremapa-heremapa·github国人开发的,纯go实现,
广州地铁图上海地铁图。
目前地铁信息分析最多的大概是resharpo地图api了
除了楼上说的,我想分享一个在excel表格上找到某些街道某站的列车总数的excel图,最大的城市广州大约200,河南郑州某些地区的城市200左右,这些数据是有他自己的历史数据做的,把找到的周期内每一天每一站都找到了,
excel抓取网页数据(excel抓取网页数据:search_div()和lookup_all())
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-05 14:04
excel抓取网页数据:search_div()#这个是查找内容引擎抓取网页,但不是正则可能存在封闭式的表,不方便查看发散式的表,也不方便取值#这个是网页排序引擎对要抓取的数据按照排序对其进行匹配查找,匹配过程如下#引擎对查找到的数据进行解析,不匹配的话就给你全自动提示,
search_div()和lookup_all()
首先,分析box1/box2/box3中的标签是什么,发现是aiahv的形式,故称该三个标签为abc,所以就用match(1)=3匹配到box4的第一个元素。然后根据需要用search()找到相应元素。
search_div()就是对div进行匹配查找,lookup_all()就是对元素或者if函数的匹配查找,感觉都是一个意思。
封闭div里找不到就自动提示
用match/search就好了啊,没有matchmatchsearch什么的?(ps:黑名单函数,
还有matchmatchsearch?
searchvar是search查找函数
区别在于,search找的是id是连续的匹配单元格,而lookup查找是要查找lookup属性的值。
楼上都说了,我来补充一下吧,如果是要只要找所有用户的话,可以使用matchvar或者searchfunction,前者需要对于id进行匹配,然后返回匹配出来的值,而后者返回所有匹配出来的值,前者是针对单元格或者box的,后者需要返回所有abcn的所有匹配出来的值。 查看全部
excel抓取网页数据(excel抓取网页数据:search_div()和lookup_all())
excel抓取网页数据:search_div()#这个是查找内容引擎抓取网页,但不是正则可能存在封闭式的表,不方便查看发散式的表,也不方便取值#这个是网页排序引擎对要抓取的数据按照排序对其进行匹配查找,匹配过程如下#引擎对查找到的数据进行解析,不匹配的话就给你全自动提示,
search_div()和lookup_all()
首先,分析box1/box2/box3中的标签是什么,发现是aiahv的形式,故称该三个标签为abc,所以就用match(1)=3匹配到box4的第一个元素。然后根据需要用search()找到相应元素。
search_div()就是对div进行匹配查找,lookup_all()就是对元素或者if函数的匹配查找,感觉都是一个意思。
封闭div里找不到就自动提示
用match/search就好了啊,没有matchmatchsearch什么的?(ps:黑名单函数,
还有matchmatchsearch?
searchvar是search查找函数
区别在于,search找的是id是连续的匹配单元格,而lookup查找是要查找lookup属性的值。
楼上都说了,我来补充一下吧,如果是要只要找所有用户的话,可以使用matchvar或者searchfunction,前者需要对于id进行匹配,然后返回匹配出来的值,而后者返回所有匹配出来的值,前者是针对单元格或者box的,后者需要返回所有abcn的所有匹配出来的值。
excel抓取网页数据(Excel教程Excel函数Excel表格制作Excel2010自带工具--从网页获取数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-01-02 20:13
)
很多时候,一些数据来自网络。如果我们要采集网页数据并使用Excel进行分析,是否需要将网页上的数据一一输入Excel?其实还有一个很方便的方法,那就是使用Excel 2013自带的工具---网页获取数据,不仅可以快速获取数据,还可以与网页内容同步更新下面是详细的操作方法。
1、首先打开Excel,点击菜单栏:数据--来自网站。
2、你会看到一个打开的查询对话框,你的IE主页会自动打开,在地址栏中输入你想要的网址,然后点击Go。
我们看到一个网页被打开了。如果我们要导入这个表中的数据,我们看下面的第二张图,点击左上角的黄色按钮。选择表格后,黄色按钮变为绿色。
3、 然后点击导入按钮,你会看到下面的第二张图片,等待几秒钟。
4、打开一个对话框,提示数据放在哪里,点击确定导入数据。
5、 也可以点击属性设置导入,如下图。下图二,如果设置刷新率,会看到Excel表格中的数据可以根据网页的数据进行更新,是不是很强大。
6、好的,这是我们导入的数据。 Excel 2013 现在很强大吗?哈哈,赶紧装个Office 2013,试试它的强大功能吧。
查看全部
excel抓取网页数据(Excel教程Excel函数Excel表格制作Excel2010自带工具--从网页获取数据
)
很多时候,一些数据来自网络。如果我们要采集网页数据并使用Excel进行分析,是否需要将网页上的数据一一输入Excel?其实还有一个很方便的方法,那就是使用Excel 2013自带的工具---网页获取数据,不仅可以快速获取数据,还可以与网页内容同步更新下面是详细的操作方法。
1、首先打开Excel,点击菜单栏:数据--来自网站。
2、你会看到一个打开的查询对话框,你的IE主页会自动打开,在地址栏中输入你想要的网址,然后点击Go。
我们看到一个网页被打开了。如果我们要导入这个表中的数据,我们看下面的第二张图,点击左上角的黄色按钮。选择表格后,黄色按钮变为绿色。
3、 然后点击导入按钮,你会看到下面的第二张图片,等待几秒钟。
4、打开一个对话框,提示数据放在哪里,点击确定导入数据。
5、 也可以点击属性设置导入,如下图。下图二,如果设置刷新率,会看到Excel表格中的数据可以根据网页的数据进行更新,是不是很强大。
6、好的,这是我们导入的数据。 Excel 2013 现在很强大吗?哈哈,赶紧装个Office 2013,试试它的强大功能吧。
excel抓取网页数据(Excel教程Excel函数Excel表格制作Excel2010自带工具--从网页获取数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-12-28 06:12
)
很多时候,一些数据来自网络。如果我们要采集
网页数据并使用Excel进行分析,是否需要将网页上的数据一一输入Excel?其实还有一个很方便的方法,那就是使用Excel 2013自带的工具---从网页获取数据,不仅可以快速获取数据,还可以与网页内容同步更新。下面是详细的操作方法。
1、首先打开Excel,点击菜单栏:数据--来自网站。
2、 你会看到一个打开的查询对话框,你的IE主页会自动打开,在地址栏中输入你想要的URL,然后点击Go。
我们看到打开了一个网页。如果我们要导入这个表中的数据,我们看下面的第二张图,点击左上角的黄色按钮。选择表格后,黄色按钮变为绿色。
3、 然后点击导入按钮,你会看到下面的第二张图片,等待几秒钟。
4、打开一个对话框,提示你把数据放在哪里,点击确定导入数据。
5、也可以点击属性设置导入,如图,下图二,如果设置刷新频率,会看到Excel表格中的数据可以基于网页上的数据更新,是不是很厉害。
6、好的,这就是我们导入的数据。Excel 2013 现在很强大吗?哈哈,赶紧装个Office 2013,试试它的强大功能吧。
查看全部
excel抓取网页数据(Excel教程Excel函数Excel表格制作Excel2010自带工具--从网页获取数据
)
很多时候,一些数据来自网络。如果我们要采集
网页数据并使用Excel进行分析,是否需要将网页上的数据一一输入Excel?其实还有一个很方便的方法,那就是使用Excel 2013自带的工具---从网页获取数据,不仅可以快速获取数据,还可以与网页内容同步更新。下面是详细的操作方法。
1、首先打开Excel,点击菜单栏:数据--来自网站。
2、 你会看到一个打开的查询对话框,你的IE主页会自动打开,在地址栏中输入你想要的URL,然后点击Go。
我们看到打开了一个网页。如果我们要导入这个表中的数据,我们看下面的第二张图,点击左上角的黄色按钮。选择表格后,黄色按钮变为绿色。
3、 然后点击导入按钮,你会看到下面的第二张图片,等待几秒钟。
4、打开一个对话框,提示你把数据放在哪里,点击确定导入数据。
5、也可以点击属性设置导入,如图,下图二,如果设置刷新频率,会看到Excel表格中的数据可以基于网页上的数据更新,是不是很厉害。
6、好的,这就是我们导入的数据。Excel 2013 现在很强大吗?哈哈,赶紧装个Office 2013,试试它的强大功能吧。
excel抓取网页数据(一起学微软PowerBI系列-官方文档-入门指南(2)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-12-27 18:14
阿里云>云栖社区>主题地图>E>Excel获取网站数据
推荐活动:
更多优惠>
当前主题:excel获取网站数据并添加到采集
夹
相关话题:
excel获取网站数据相关博客查看更多博客
七周成为数据分析师-Excel实践
作者:夏至3561人浏览评论:14年前
本文是《七周内成为数据分析师》的第三篇教程。如果你想了解写作的初衷,你可以先阅读《七周指南》。提醒:如果您已经熟悉Excel,则无需再次阅读本文,或者只需选择部分内容即可。在Excel技巧和Excel函数之后,今天的文章讲解了如何利用前两篇文章的知识进行分析。内容是新的
阅读全文
一起学习微软Power BI系列-官方文档-入门指南(2)获取源数据
作者:老朱八号 1548人浏览评论:04年前
阅读目录1.系列文章说明2.入门指南(2)获取数据源3.资源我们在文章:一起学习微软Power BI系列-官方文档- 入门指南(1)在Power BI的初步介绍中,我们介绍了官方介绍文档的第一章,今天继续给大家介绍官方文档,如何获取数据的相关内容来源。虽然
阅读全文
基于Excel2013的数据导入
作者:潇撒坤1232人浏览评论:03年前
请确认已安装 Excel2013。Excel2013的安装方法请上网搜索。Excel2013下载网盘链接: 密码:rxuv 这个安装包里面有破解软件KMSpic
阅读全文
python xlrd读取excel
作者:程序员tx1067人浏览评论:03年前
文章链接:上一篇介绍了写excel表格的方法。最近在做一个网站,涉及到读取excel然后将数据存入数据库,所以记录一下操作excel的过程。
阅读全文
如何使用R和API免费获取网络数据?
作者:王淑仪 809人浏览评论:04年前
API是获取网页数据的重要途径之一。您想知道如何使用R调用API来提取和组织您需要的免费网络数据吗?本文将逐步为您详细展示操作过程。称谓“巧妇难为无米之炊”。就算你掌握了数据分析的18门功课,没有数据也是一件很苦恼的事情。“拔剑望心”是大事
阅读全文
使用Excel COM组件导出数据后,释放后无法正常终止Excel进程
作者:nothingfinal535人浏览评论:011年前
分析我自己的错误:首先,我得到了一个带有GetItem of Range的VARIANT,其中收录
IDispatch接口。一直以为里面有BSTR,所以直接用了_bstr_t bs(rg.GetItem(_variant_t((short)1),_v
阅读全文
使用Excel COM组件导出数据后,释放后无法正常终止Excel进程
作者:xumaojun483人浏览评论:011年前
分析我自己的错误:首先,我得到了一个带有GetItem of Range的VARIANT,其中收录
IDispatch接口。一直以为里面有BSTR,所以直接用了_bstr_t bs(rg.GetItem(_variant_t((short)1),_v
阅读全文
使用Excel COM组件导出数据后,释放后无法正常终止Excel进程
作者:maojunxu435 人浏览评论:011年前
分析我自己的错误:首先,我得到了一个带有GetItem of Range的VARIANT,其中收录
IDispatch接口。一直以为里面有BSTR,所以直接用了_bstr_t bs(rg.GetItem(_variant_t((sh
阅读全文
excel获取网站数据相关问答
【Java学习全家桶】1460道Java热点题,百位阿里巴巴技术专家答疑解惑
作者:管理贝贝19522人浏览评论:153年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你迷茫只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来了云栖为您解答技术难题。他们使用自己手中的技术来帮助用户成长。本次活动邀请了数百位阿里巴巴技术
阅读全文 查看全部
excel抓取网页数据(一起学微软PowerBI系列-官方文档-入门指南(2)(组图))
阿里云>云栖社区>主题地图>E>Excel获取网站数据
推荐活动:
更多优惠>
当前主题:excel获取网站数据并添加到采集
夹
相关话题:
excel获取网站数据相关博客查看更多博客
七周成为数据分析师-Excel实践
作者:夏至3561人浏览评论:14年前
本文是《七周内成为数据分析师》的第三篇教程。如果你想了解写作的初衷,你可以先阅读《七周指南》。提醒:如果您已经熟悉Excel,则无需再次阅读本文,或者只需选择部分内容即可。在Excel技巧和Excel函数之后,今天的文章讲解了如何利用前两篇文章的知识进行分析。内容是新的
阅读全文
一起学习微软Power BI系列-官方文档-入门指南(2)获取源数据
作者:老朱八号 1548人浏览评论:04年前
阅读目录1.系列文章说明2.入门指南(2)获取数据源3.资源我们在文章:一起学习微软Power BI系列-官方文档- 入门指南(1)在Power BI的初步介绍中,我们介绍了官方介绍文档的第一章,今天继续给大家介绍官方文档,如何获取数据的相关内容来源。虽然
阅读全文
基于Excel2013的数据导入
作者:潇撒坤1232人浏览评论:03年前
请确认已安装 Excel2013。Excel2013的安装方法请上网搜索。Excel2013下载网盘链接: 密码:rxuv 这个安装包里面有破解软件KMSpic
阅读全文
python xlrd读取excel
作者:程序员tx1067人浏览评论:03年前
文章链接:上一篇介绍了写excel表格的方法。最近在做一个网站,涉及到读取excel然后将数据存入数据库,所以记录一下操作excel的过程。
阅读全文
如何使用R和API免费获取网络数据?
作者:王淑仪 809人浏览评论:04年前
API是获取网页数据的重要途径之一。您想知道如何使用R调用API来提取和组织您需要的免费网络数据吗?本文将逐步为您详细展示操作过程。称谓“巧妇难为无米之炊”。就算你掌握了数据分析的18门功课,没有数据也是一件很苦恼的事情。“拔剑望心”是大事
阅读全文
使用Excel COM组件导出数据后,释放后无法正常终止Excel进程
作者:nothingfinal535人浏览评论:011年前
分析我自己的错误:首先,我得到了一个带有GetItem of Range的VARIANT,其中收录
IDispatch接口。一直以为里面有BSTR,所以直接用了_bstr_t bs(rg.GetItem(_variant_t((short)1),_v
阅读全文
使用Excel COM组件导出数据后,释放后无法正常终止Excel进程
作者:xumaojun483人浏览评论:011年前
分析我自己的错误:首先,我得到了一个带有GetItem of Range的VARIANT,其中收录
IDispatch接口。一直以为里面有BSTR,所以直接用了_bstr_t bs(rg.GetItem(_variant_t((short)1),_v
阅读全文
使用Excel COM组件导出数据后,释放后无法正常终止Excel进程
作者:maojunxu435 人浏览评论:011年前
分析我自己的错误:首先,我得到了一个带有GetItem of Range的VARIANT,其中收录
IDispatch接口。一直以为里面有BSTR,所以直接用了_bstr_t bs(rg.GetItem(_variant_t((sh
阅读全文
excel获取网站数据相关问答
【Java学习全家桶】1460道Java热点题,百位阿里巴巴技术专家答疑解惑
作者:管理贝贝19522人浏览评论:153年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你迷茫只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来了云栖为您解答技术难题。他们使用自己手中的技术来帮助用户成长。本次活动邀请了数百位阿里巴巴技术
阅读全文
excel抓取网页数据(怎样使用微软的Excel爬取一个网页的后台数据,注)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-12-26 15:04
看完这篇文章,你是否还沉浸在python爬虫的迷恋中?今天教大家如何使用Microsoft Excel抓取网页的后台数据。注意:此方法仅适用于爬行。对数据感兴趣但不会使用Python等工具爬取网页数据的人,虽然方便好用,但是非常有限。只能抓取单个网页的数据,受网页数据影响。如果页面布局不适合抓取,则需要手动更改格式。
这里我们以抓取空气质量排名网页为例:
首先新建一个Excel表格,打开数据,从网站中,出现一个提示框,将我们要爬取的网站粘贴到搜索框中点击搜索
第四步,进入网页,可以看到如图所示的数据,然后我们点击导入按钮:
点击Import后,不要着急,点击OK,点击Properties,修改一些我们会用到的常用属性:
请看下图
一分钟刷新控制设置可以保证更快的数据替换,打开文件时刷新数据项也保证了我们打开文件时数据项是最新的。其他变化根据自己的需要进行调整。
最后一步是点击确定将网页数据完美下载到您的工作文件中。
怎么样,对朋友来说是不是特别方便?但这只是对不懂python的爬虫有用,普通人需要一些数据的时候可以自己下载一些数据。也很方便,欢迎在下方留言讨论!
特别声明:以上内容(包括图片或视频,如有)由自媒体平台“网易”用户上传发布。本平台仅提供信息存储服务。 查看全部
excel抓取网页数据(怎样使用微软的Excel爬取一个网页的后台数据,注)
看完这篇文章,你是否还沉浸在python爬虫的迷恋中?今天教大家如何使用Microsoft Excel抓取网页的后台数据。注意:此方法仅适用于爬行。对数据感兴趣但不会使用Python等工具爬取网页数据的人,虽然方便好用,但是非常有限。只能抓取单个网页的数据,受网页数据影响。如果页面布局不适合抓取,则需要手动更改格式。
这里我们以抓取空气质量排名网页为例:
首先新建一个Excel表格,打开数据,从网站中,出现一个提示框,将我们要爬取的网站粘贴到搜索框中点击搜索
第四步,进入网页,可以看到如图所示的数据,然后我们点击导入按钮:
点击Import后,不要着急,点击OK,点击Properties,修改一些我们会用到的常用属性:
请看下图
一分钟刷新控制设置可以保证更快的数据替换,打开文件时刷新数据项也保证了我们打开文件时数据项是最新的。其他变化根据自己的需要进行调整。
最后一步是点击确定将网页数据完美下载到您的工作文件中。
怎么样,对朋友来说是不是特别方便?但这只是对不懂python的爬虫有用,普通人需要一些数据的时候可以自己下载一些数据。也很方便,欢迎在下方留言讨论!
特别声明:以上内容(包括图片或视频,如有)由自媒体平台“网易”用户上传发布。本平台仅提供信息存储服务。
excel抓取网页数据(如何快速地从网站上来获取自己需要的数据哦! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-12-22 05:01
)
有时候我们在做Excel表格的时候,很多数据源可能来自网上,所以我们需要从网站下载数据给我们使用,或者我们需要自己手动一一输入……但是太麻烦了,今天教大家一个方法,从网站快速获取你需要的数据!喜欢的记得采集哦!
脚步:
1.首先我们打开一个网站,找到我们想要的数据,先复制网站的链接。这里我们选择个人所得税税率表,想抓取网页上所有的表格内容。
2. 然后打开你的Excel表格,点击【数据】-【来自网站】,就会弹出【新建网页】查询对话框。
然后将刚才复制的网站链接粘贴到地址栏中。然后选择【前往】,会自动跳转到网站的数据界面。
3. 然后在【新建Web查询】对话框中点击所需表的【箭头】按钮,然后点击右下角的【导入】。经过这个操作,我们需要的数据就会被添加到Excel表格中。
4. 要导入数据时,可以选择放置数据的位置,或者数据的起始位置,也可以新建一个工作表。选择完成后,点击【确定】即可。
这样你就可以看到网站中的数据一下子就添加到了你的Excel表格中。注意,如果数据量大,导入的时候可能会比较慢,但最终还是可以轻松抓取网站的数据!
最后可以用【Apply Table Style】稍微美化一下表格,就OK了~
最终效果:
这里还有一个GIF演示给大家看,不明白的可以看这里!
好吧~以上就是一个关于如何从网络上抓取数据的小技巧。经常需要上网搜集资料的朋友,希望能对你有所帮助。如果有用,请点赞、转发、采集!加油!
查看全部
excel抓取网页数据(如何快速地从网站上来获取自己需要的数据哦!
)
有时候我们在做Excel表格的时候,很多数据源可能来自网上,所以我们需要从网站下载数据给我们使用,或者我们需要自己手动一一输入……但是太麻烦了,今天教大家一个方法,从网站快速获取你需要的数据!喜欢的记得采集哦!
脚步:
1.首先我们打开一个网站,找到我们想要的数据,先复制网站的链接。这里我们选择个人所得税税率表,想抓取网页上所有的表格内容。
2. 然后打开你的Excel表格,点击【数据】-【来自网站】,就会弹出【新建网页】查询对话框。
然后将刚才复制的网站链接粘贴到地址栏中。然后选择【前往】,会自动跳转到网站的数据界面。
3. 然后在【新建Web查询】对话框中点击所需表的【箭头】按钮,然后点击右下角的【导入】。经过这个操作,我们需要的数据就会被添加到Excel表格中。
4. 要导入数据时,可以选择放置数据的位置,或者数据的起始位置,也可以新建一个工作表。选择完成后,点击【确定】即可。
这样你就可以看到网站中的数据一下子就添加到了你的Excel表格中。注意,如果数据量大,导入的时候可能会比较慢,但最终还是可以轻松抓取网站的数据!
最后可以用【Apply Table Style】稍微美化一下表格,就OK了~
最终效果:
这里还有一个GIF演示给大家看,不明白的可以看这里!
好吧~以上就是一个关于如何从网络上抓取数据的小技巧。经常需要上网搜集资料的朋友,希望能对你有所帮助。如果有用,请点赞、转发、采集!加油!
excel抓取网页数据(excel抓取网页数据并进行数据转换、统计分析、表格输出四步实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-12-09 16:03
excel抓取网页数据并进行数据转换、统计分析、表格输出四步实现。适用人群:需要利用excel处理各行各列数据的小伙伴。如需先完成excel基础功能的操作,再用python进行相关分析,请直接到微信公众号【白小白python】看本期视频。本文所有源代码已发布于b站,欢迎进行参观讨论。视频地址:-gx7g后期还会有这两个技术视频,敬请期待。要获取更多资源的小伙伴,请持续关注微信公众号【白小白python】。
是有办法的,但是最重要的是你要有对excel的掌握程度和懂python语言!最近在看monkey的视频,感觉好像相当不错,
excel相当于数据分析的基础,python的话会加分,不然很多数据分析过程不方便使用python。
要看你大概要做些什么了,一般excel处理一下,比如数据求和分类汇总都可以用python完成。其他更复杂的分析,比如根据月数来制定cumulative的组合等,使用python3+tabloid比较好,
编程没有上限,学什么都无所谓啊,关键还是要你想做什么。如果是做基础数据分析的话,只要你多看别人的代码,多动手试着写写就好了,网上也有很多在线的数据分析工具。如果是python的话,推荐datavisualization这本书,里面有许多场景的python编程实践可以去实现,而且包含了一些处理数据的算法工具(在中文社区)。
如果是做一个小型数据分析系统,那就学习python3吧。如果是爬虫网站的分析,只是要你能分析访问网站的url,那java已经足够用了,如果对性能有更高的要求那只能用python爬取网站数据,然后导入其他工具中。 查看全部
excel抓取网页数据(excel抓取网页数据并进行数据转换、统计分析、表格输出四步实现)
excel抓取网页数据并进行数据转换、统计分析、表格输出四步实现。适用人群:需要利用excel处理各行各列数据的小伙伴。如需先完成excel基础功能的操作,再用python进行相关分析,请直接到微信公众号【白小白python】看本期视频。本文所有源代码已发布于b站,欢迎进行参观讨论。视频地址:-gx7g后期还会有这两个技术视频,敬请期待。要获取更多资源的小伙伴,请持续关注微信公众号【白小白python】。
是有办法的,但是最重要的是你要有对excel的掌握程度和懂python语言!最近在看monkey的视频,感觉好像相当不错,
excel相当于数据分析的基础,python的话会加分,不然很多数据分析过程不方便使用python。
要看你大概要做些什么了,一般excel处理一下,比如数据求和分类汇总都可以用python完成。其他更复杂的分析,比如根据月数来制定cumulative的组合等,使用python3+tabloid比较好,
编程没有上限,学什么都无所谓啊,关键还是要你想做什么。如果是做基础数据分析的话,只要你多看别人的代码,多动手试着写写就好了,网上也有很多在线的数据分析工具。如果是python的话,推荐datavisualization这本书,里面有许多场景的python编程实践可以去实现,而且包含了一些处理数据的算法工具(在中文社区)。
如果是做一个小型数据分析系统,那就学习python3吧。如果是爬虫网站的分析,只是要你能分析访问网站的url,那java已经足够用了,如果对性能有更高的要求那只能用python爬取网站数据,然后导入其他工具中。
excel抓取网页数据(如何介绍M函数的应用方法?函数怎么做? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-12-09 10:08
)
通过前三节的学习,相信大家对M函数的基础知识有了一定的了解。从本节开始,我们将通过实际案例逐步介绍M功能的应用方法。
本节将介绍一个案例,让您使用Web.Page和Web.Contents函数从PM2.5历史数据网站中抓取不同城市、不同日期的历史空气质量相关数据。这种方式适用于在Power Query中输入URL可以直接获取所需数据的情况(这种情况是指网页地址中有可见表格数据的情况)。
在进入正文之前,先介绍一个简单的获取中文函数帮助信息的方法,方法如下:
1.在 Power Query 查询编辑器中创建一个新的空查询
2.在编辑字段中输入=#shared
3.点击“到表”
4.通过过滤Name字段获取相关函数帮助信息
Web.Page 和 Web.Contents 功能说明:
1.Web.Page 函数:返回 HTML 文档的内容(分解为其组成结构),以及完整文档及其删除文本的表示
表达式:Function(html as any) as table
注:使用Web.Page函数获取网页HTML形式的相关信息,以表格形式返回结果
2.Web.Contents 函数:以二进制形式返回从 url 下载的内容。可以提供可选的记录参数选项来指定其他属性。记录可以收录以下字段...(更多内容省略,详情请使用#shared查询)
表达式:函数(url 为文本,可选选项为可空记录)asbinary
注:支付Web.Contents网页地址后,Web.Contents函数可以以二进制数的形式返回网页中的信息
这两个函数嵌套使用后,Web.Page(Web.Contents(URL))最终可以将网页中的信息以表格的形式呈现出来。操作逻辑是先使用Web.Contents函数获取指定URL中的二进制信息,然后使用Web.Page函数对二进制信息进行转换解析,最终得到我们能够理解的表格数据。
在PM2.5历史数据网页爬取各城市过去一天的历史空气质量数据:
主页地址:/historydata/
所需日均空气质量数据(以北京2014年1月为例):
网址:/historydata/daydata.php?city=Beijing&month=2014-01
使用Power Query抓取上述网页的目的是一次性批量抓取多个城市不同月份不同天的历史空气质量数据。
爬取步骤如下:
1. 分析网站特点后发现,只要将city=后面的部分改成想要的城市名,month=后面的部分改成想要的月份号,不同的城市和可以打开不同的月份。下的每日历史数据页面
2.所以我们现在在Excel表格界面中建立一个收录城市名称和月份信息的表格,并将其添加到Power Query
3. 将【月份】字段转换为文本数据
4.在Power Query编辑器中添加自定义列,内容如下:
公式内容:
Web.Page(Web.Contents("/historydata/daydata.php?city="&[City]&"&month="&[month]))
5. 点击“Continue”,选择“Public”保存(数据量大,需要耐心等待,建议练习时只做两个城市的数据)
6.在自定义字段中展开数据
7.在自定义字段中再次展开相关字段(从日期到排名)
8.关闭并上传
以上内容就是抓取网页信息的所有步骤。好,我们来看看爬取到的数据。
查看全部
excel抓取网页数据(如何介绍M函数的应用方法?函数怎么做?
)
通过前三节的学习,相信大家对M函数的基础知识有了一定的了解。从本节开始,我们将通过实际案例逐步介绍M功能的应用方法。
本节将介绍一个案例,让您使用Web.Page和Web.Contents函数从PM2.5历史数据网站中抓取不同城市、不同日期的历史空气质量相关数据。这种方式适用于在Power Query中输入URL可以直接获取所需数据的情况(这种情况是指网页地址中有可见表格数据的情况)。
在进入正文之前,先介绍一个简单的获取中文函数帮助信息的方法,方法如下:
1.在 Power Query 查询编辑器中创建一个新的空查询
2.在编辑字段中输入=#shared
3.点击“到表”
4.通过过滤Name字段获取相关函数帮助信息
Web.Page 和 Web.Contents 功能说明:
1.Web.Page 函数:返回 HTML 文档的内容(分解为其组成结构),以及完整文档及其删除文本的表示
表达式:Function(html as any) as table
注:使用Web.Page函数获取网页HTML形式的相关信息,以表格形式返回结果
2.Web.Contents 函数:以二进制形式返回从 url 下载的内容。可以提供可选的记录参数选项来指定其他属性。记录可以收录以下字段...(更多内容省略,详情请使用#shared查询)
表达式:函数(url 为文本,可选选项为可空记录)asbinary
注:支付Web.Contents网页地址后,Web.Contents函数可以以二进制数的形式返回网页中的信息
这两个函数嵌套使用后,Web.Page(Web.Contents(URL))最终可以将网页中的信息以表格的形式呈现出来。操作逻辑是先使用Web.Contents函数获取指定URL中的二进制信息,然后使用Web.Page函数对二进制信息进行转换解析,最终得到我们能够理解的表格数据。
在PM2.5历史数据网页爬取各城市过去一天的历史空气质量数据:
主页地址:/historydata/
所需日均空气质量数据(以北京2014年1月为例):
网址:/historydata/daydata.php?city=Beijing&month=2014-01
使用Power Query抓取上述网页的目的是一次性批量抓取多个城市不同月份不同天的历史空气质量数据。
爬取步骤如下:
1. 分析网站特点后发现,只要将city=后面的部分改成想要的城市名,month=后面的部分改成想要的月份号,不同的城市和可以打开不同的月份。下的每日历史数据页面
2.所以我们现在在Excel表格界面中建立一个收录城市名称和月份信息的表格,并将其添加到Power Query
3. 将【月份】字段转换为文本数据
4.在Power Query编辑器中添加自定义列,内容如下:
公式内容:
Web.Page(Web.Contents("/historydata/daydata.php?city="&[City]&"&month="&[month]))
5. 点击“Continue”,选择“Public”保存(数据量大,需要耐心等待,建议练习时只做两个城市的数据)
6.在自定义字段中展开数据
7.在自定义字段中再次展开相关字段(从日期到排名)
8.关闭并上传
以上内容就是抓取网页信息的所有步骤。好,我们来看看爬取到的数据。
excel抓取网页数据(如何用Python构建一个带有GUI的爬虫小程序-之前)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-12-09 10:07
大家好,之前我们讲了如何在Python中构建一个带有GUI的爬虫小程序。很多文章会迎合热点,延续上次NBA爬虫GUI,讨论虎扑官网怎么爬。并将数据写入Excel并同时自动生成折线图,主要有以下几个步骤
本文将分为以下两部分来讲解
项目涉及的主要Python模块:
履带部分
整理爬虫部分的思路如下
观察URL1的源码,找到球队名和对应的URL2 观察URL2的源码,找到球员对应的URL3
其实爬虫是对html进行操作的,html的结构很简单。只有一个,就是大盒子和小盒子,小盒子嵌套在小盒子中,一层一层嵌套。
目标网址如下:
先参考模块
from bs4 import BeautifulSoupimport requestsimport xlsxwriterimport os
查看URL1的源码,可以看到span标签下有团队名称及其对应的URL2,然后找到它的父框架和祖父框架。下面的思路都是一样的,如下图所示:
此时,可以使用 requests 模块和 bs4 模块进行有目的的索引以获取团队名称列表。
def Teamlists(url): TeamName=[] TeamURL=[] GET=requests.get(URL1) soup=BeautifulSoup(GET.content,'lxml') lables=soup.select('html body div div div ul li span a') for lable in lables: ballname=lable.get_text() TeamName.append(ballname) print(ballname) teamname=input("请输入想查询的球队名:")#此处可变为GUI界面中的按键值 c=TeamName.index(teamname) for item in lables: HREF=item.get('href') TeamURL.append(HREF) URL2=TeamURL[c] return URL2
此时,我得到了对应球队的URL2,然后观察URL2网页的内容,可以看到标签a下是球员名字,同时也存储了对应球员的URL3,如图下图:
这时候还是通过requests模块和bs4模块进行对应的index来获取玩家名单和对应的URL3。
#自定义函数获取队员列表和对应的URLdef playerlists(URL2): PlayerName=[] PlayerURL=[] GET2=requests.get(URL1) soup2=BeautifulSoup(GET2.content,'lxml') lables2=soup2.select('html body div div table tbody tr td b a') for lable2 in lables2: playername=lable2.get_text() PlayerName.append(playername) print(playername) name=input("请输入球员名:") #此处可变为GUI界面中的按键值 d=PlayerName.index(name) for item2 in lables2: HREF2=item2.get('href') PlayerURL.append(HREF2) URL3=PlayerURL[d] return URL3,name
现在拿到对应队伍的URL3,然后观察URL3网页的内容。可以看到p标签下是球员基本信息,td标签下是球员的常规赛生涯数据和季后赛生涯数据,如下图:
同理,requests模块和bs4模块仍然用于相应的索引,获取球员基本信息和职业数据,并过滤存储球员的常规赛和季后赛生涯数据,得到数据列表。
以下数据是通过上述网络爬虫获取的,提供可视化数据,方便绑定后的GUI界面按键事件:
可视化部分
思路:创建文件夹来创建表格和折线图
自定义函数创建表,使用os模块写入,返回创建文件夹的路径。代码如下:
def file_add(path): #此时的内函数path可与GUI界面的Statictext绑定 creatpath=path+'Basketball' try: if not os.path.isdir(creatpath): os.makedirs(creatpath) except: print("文件夹存在") return creatpath
使用xlsxwriter模块在creatpath路径下创建带有自定义函数的excel表格,同时放入数据和构建折线图。代码如下:
def player_chart(name,data,creatpath): #此为表格名称——球员名称+chart EXCEL=xlsxwriter.Workbook(creatpath+''+name+'chart.xlsx') worksheet=EXCEL.add_worksheet(name) bold=EXCEL.add_format({'bold':1}) headings=data[:18] worksheet.write_row('A1',headings,bold) #写入表头 num=(len(data))//18 a=0 for i in range(num): a=a+18 c=a+18 i=i+1 worksheet.write_row('A'+str(i+1),data[a:c]) #写入数据 chart_col = EXCEL.add_chart({'type': 'line'}) #创建一个折线图 chart_col.add_series({ 'name': '='+name+'!$R$1', #设置折线描述名称 'categories':'='+name+'!$A$2:$A$'+str(num), #设置图表类别标签范围 'values': '='+name+'!$R$2:$R$'+str(num-1), #设置图表数据范围 'line': {'color': 'red'}, }) #设置图表线条属性 #设置图标的标题和想x,y轴信息 chart_col.set_title({'name': name+'生涯常规赛平均得分'}) chart_col.set_x_axis({'name': '年份 (年)'}) chart_col.set_y_axis({'name': '平均得分(分)'}) chart_col.set_style(1) #设置图表风格 worksheet.insert_chart('A14', chart_col, {'x_offset':25, 'y_offset':3,}) #把图标插入工作台中并设置偏移 EXCEL.close()
数据表效果如图,以James为例如下
而这时候打开自动生成的Excel,就会直接显示出相应的折线图,无需再整理!
现在结合任务一的网络爬虫和任务二的数据可视化,可以获得实时的球员常规赛数据和季后赛数据汇总,以及实时的球员生涯折线图。
顺便说一句,很多人在学习Python的过程中都会遇到各种各样的麻烦,谁也不会轻易放弃。编辑是python开发工程师。这里我整理了一套最新的python系统学习教程,包括基础python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等,想要这些资料的可以关注小编,私信后台编辑:“01”接收。 查看全部
excel抓取网页数据(如何用Python构建一个带有GUI的爬虫小程序-之前)
大家好,之前我们讲了如何在Python中构建一个带有GUI的爬虫小程序。很多文章会迎合热点,延续上次NBA爬虫GUI,讨论虎扑官网怎么爬。并将数据写入Excel并同时自动生成折线图,主要有以下几个步骤
本文将分为以下两部分来讲解
项目涉及的主要Python模块:
履带部分
整理爬虫部分的思路如下
观察URL1的源码,找到球队名和对应的URL2 观察URL2的源码,找到球员对应的URL3
其实爬虫是对html进行操作的,html的结构很简单。只有一个,就是大盒子和小盒子,小盒子嵌套在小盒子中,一层一层嵌套。
目标网址如下:
先参考模块
from bs4 import BeautifulSoupimport requestsimport xlsxwriterimport os
查看URL1的源码,可以看到span标签下有团队名称及其对应的URL2,然后找到它的父框架和祖父框架。下面的思路都是一样的,如下图所示:
此时,可以使用 requests 模块和 bs4 模块进行有目的的索引以获取团队名称列表。
def Teamlists(url): TeamName=[] TeamURL=[] GET=requests.get(URL1) soup=BeautifulSoup(GET.content,'lxml') lables=soup.select('html body div div div ul li span a') for lable in lables: ballname=lable.get_text() TeamName.append(ballname) print(ballname) teamname=input("请输入想查询的球队名:")#此处可变为GUI界面中的按键值 c=TeamName.index(teamname) for item in lables: HREF=item.get('href') TeamURL.append(HREF) URL2=TeamURL[c] return URL2
此时,我得到了对应球队的URL2,然后观察URL2网页的内容,可以看到标签a下是球员名字,同时也存储了对应球员的URL3,如图下图:
这时候还是通过requests模块和bs4模块进行对应的index来获取玩家名单和对应的URL3。
#自定义函数获取队员列表和对应的URLdef playerlists(URL2): PlayerName=[] PlayerURL=[] GET2=requests.get(URL1) soup2=BeautifulSoup(GET2.content,'lxml') lables2=soup2.select('html body div div table tbody tr td b a') for lable2 in lables2: playername=lable2.get_text() PlayerName.append(playername) print(playername) name=input("请输入球员名:") #此处可变为GUI界面中的按键值 d=PlayerName.index(name) for item2 in lables2: HREF2=item2.get('href') PlayerURL.append(HREF2) URL3=PlayerURL[d] return URL3,name
现在拿到对应队伍的URL3,然后观察URL3网页的内容。可以看到p标签下是球员基本信息,td标签下是球员的常规赛生涯数据和季后赛生涯数据,如下图:
同理,requests模块和bs4模块仍然用于相应的索引,获取球员基本信息和职业数据,并过滤存储球员的常规赛和季后赛生涯数据,得到数据列表。
以下数据是通过上述网络爬虫获取的,提供可视化数据,方便绑定后的GUI界面按键事件:
可视化部分
思路:创建文件夹来创建表格和折线图
自定义函数创建表,使用os模块写入,返回创建文件夹的路径。代码如下:
def file_add(path): #此时的内函数path可与GUI界面的Statictext绑定 creatpath=path+'Basketball' try: if not os.path.isdir(creatpath): os.makedirs(creatpath) except: print("文件夹存在") return creatpath
使用xlsxwriter模块在creatpath路径下创建带有自定义函数的excel表格,同时放入数据和构建折线图。代码如下:
def player_chart(name,data,creatpath): #此为表格名称——球员名称+chart EXCEL=xlsxwriter.Workbook(creatpath+''+name+'chart.xlsx') worksheet=EXCEL.add_worksheet(name) bold=EXCEL.add_format({'bold':1}) headings=data[:18] worksheet.write_row('A1',headings,bold) #写入表头 num=(len(data))//18 a=0 for i in range(num): a=a+18 c=a+18 i=i+1 worksheet.write_row('A'+str(i+1),data[a:c]) #写入数据 chart_col = EXCEL.add_chart({'type': 'line'}) #创建一个折线图 chart_col.add_series({ 'name': '='+name+'!$R$1', #设置折线描述名称 'categories':'='+name+'!$A$2:$A$'+str(num), #设置图表类别标签范围 'values': '='+name+'!$R$2:$R$'+str(num-1), #设置图表数据范围 'line': {'color': 'red'}, }) #设置图表线条属性 #设置图标的标题和想x,y轴信息 chart_col.set_title({'name': name+'生涯常规赛平均得分'}) chart_col.set_x_axis({'name': '年份 (年)'}) chart_col.set_y_axis({'name': '平均得分(分)'}) chart_col.set_style(1) #设置图表风格 worksheet.insert_chart('A14', chart_col, {'x_offset':25, 'y_offset':3,}) #把图标插入工作台中并设置偏移 EXCEL.close()
数据表效果如图,以James为例如下
而这时候打开自动生成的Excel,就会直接显示出相应的折线图,无需再整理!
现在结合任务一的网络爬虫和任务二的数据可视化,可以获得实时的球员常规赛数据和季后赛数据汇总,以及实时的球员生涯折线图。
顺便说一句,很多人在学习Python的过程中都会遇到各种各样的麻烦,谁也不会轻易放弃。编辑是python开发工程师。这里我整理了一套最新的python系统学习教程,包括基础python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等,想要这些资料的可以关注小编,私信后台编辑:“01”接收。
excel抓取网页数据(浙江龙盛()导入外部数据--新建Web查询)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-12-09 10:05
进行如下操作:
1、打开雪球股票页面复制网址链接:如:浙江龙盛网址
2、在电子表格中导入网页数据
第一步:点击【数据】菜单-导入外部数据-新建Web查询
第二步:在弹出的“新建网页查询”窗口地址栏中粘贴复制的雪球股票页面地址,点击【前往】按钮,窗口出现股票数据页面,然后点击【导入】;
第三步:将个股页面的相关数据导入到工作表中;
点击【导入】后,弹出“导入数据”对话框,可以选择数据放置位置(现有工作表或新建工作表,如选择新工作表)
在“导入数据”对话框中,也可以点击【属性】,在“外部数据区属性”对话框中设置数据相关的属性,主要是设置刷新频率;
设置好属性后,返回“导入数据”对话框,点击【确定】,导入工作表中的相关数据,如下图:
3、 提取个股最新价格数据
由于导入了雪球库存数据,很多单元格不是单个值,无法在电子表格中直接调用,需要进一步提取。第55行浙江龙盛最新价格单元格为“¥30.16+0.700 (+2.38%)”,包括价格符号、价格、数值和波动率,最新收盘价可以分别用“LEFT和RIGHT函数”提取。
使用单元格中的公式,先提取左边的6个字符“=LEFT(浙江龙盛!A55,6)”,然后提取右边的5个字符“=RIGHT(C1756,5) ”,即可以获得对应股票的最新收盘价,方便调用。
根据该方法,还可以将个股的成交量、市盈率等其他相关数据导入到电子表格中进行统计分析。 查看全部
excel抓取网页数据(浙江龙盛()导入外部数据--新建Web查询)
进行如下操作:
1、打开雪球股票页面复制网址链接:如:浙江龙盛网址
2、在电子表格中导入网页数据
第一步:点击【数据】菜单-导入外部数据-新建Web查询
第二步:在弹出的“新建网页查询”窗口地址栏中粘贴复制的雪球股票页面地址,点击【前往】按钮,窗口出现股票数据页面,然后点击【导入】;
第三步:将个股页面的相关数据导入到工作表中;
点击【导入】后,弹出“导入数据”对话框,可以选择数据放置位置(现有工作表或新建工作表,如选择新工作表)
在“导入数据”对话框中,也可以点击【属性】,在“外部数据区属性”对话框中设置数据相关的属性,主要是设置刷新频率;
设置好属性后,返回“导入数据”对话框,点击【确定】,导入工作表中的相关数据,如下图:
3、 提取个股最新价格数据
由于导入了雪球库存数据,很多单元格不是单个值,无法在电子表格中直接调用,需要进一步提取。第55行浙江龙盛最新价格单元格为“¥30.16+0.700 (+2.38%)”,包括价格符号、价格、数值和波动率,最新收盘价可以分别用“LEFT和RIGHT函数”提取。
使用单元格中的公式,先提取左边的6个字符“=LEFT(浙江龙盛!A55,6)”,然后提取右边的5个字符“=RIGHT(C1756,5) ”,即可以获得对应股票的最新收盘价,方便调用。
根据该方法,还可以将个股的成交量、市盈率等其他相关数据导入到电子表格中进行统计分析。
excel抓取网页数据(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-12-08 15:08
)
Excel 2013及以后版本提供了WEBSERVICE和FILTERXML函数,可以用于网页数据的抓取,但是只能抓取XML格式的数据。而现在网站的很多网页或者接口都返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?今天以豆瓣图书基本资料为例,给大家介绍一下如何使用Excel API网络函数库抓取JSON格式的网页数据。
第一步,找到豆瓣网的基本信息页面
豆瓣图书信息网站是9787111529385,网站最后一串数字是图书的ISBN号。
在火狐浏览器中,这个URL会返回如下信息,是标准的JSON格式,蓝色字体为属性名称,红色字体对应属性值。
第二步安装ExcelAPI网络函数库
访问ExcelAPI网络函数库官网,根据帮助页面安装函数库。
第三步,使用函数抓取JSON数据。
首先,使用函数 GetJsonSource(url,"UTF-8") 返回 JSON 原创数据。
然后,使用函数 GetJsonByPropertyName(json_source,property_name) 返回书籍的基本信息。使用GetJsonSource()函数一次性抓取所有数据,然后按需抓取。这样做的目的是提高爬行速度。毕竟,访问网页需要时间。
完整的操作如下:
查看全部
excel抓取网页数据(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据?
)
Excel 2013及以后版本提供了WEBSERVICE和FILTERXML函数,可以用于网页数据的抓取,但是只能抓取XML格式的数据。而现在网站的很多网页或者接口都返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?今天以豆瓣图书基本资料为例,给大家介绍一下如何使用Excel API网络函数库抓取JSON格式的网页数据。
第一步,找到豆瓣网的基本信息页面
豆瓣图书信息网站是9787111529385,网站最后一串数字是图书的ISBN号。
在火狐浏览器中,这个URL会返回如下信息,是标准的JSON格式,蓝色字体为属性名称,红色字体对应属性值。
第二步安装ExcelAPI网络函数库
访问ExcelAPI网络函数库官网,根据帮助页面安装函数库。
第三步,使用函数抓取JSON数据。
首先,使用函数 GetJsonSource(url,"UTF-8") 返回 JSON 原创数据。
然后,使用函数 GetJsonByPropertyName(json_source,property_name) 返回书籍的基本信息。使用GetJsonSource()函数一次性抓取所有数据,然后按需抓取。这样做的目的是提高爬行速度。毕竟,访问网页需要时间。
完整的操作如下:
excel抓取网页数据(风越网页批量填写数据提取软件,可自动分析网页中表单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-12-01 08:12
风月网页批量填写数据提取软件可以自动分析网页上表格的填写内容,并保存为填写规则。使用的时候只要调用这个规则就可以自动填表,点击网页元素,抓取网页的文字内容。下载指定的网页链接文件。
风月excel数据批量自动填充网页数据提取软件功能
本软件支持更多的页面填充类型和控制元素类型,精度更高。其他填表工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。
本软件不仅可以用于一般办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、征信、抢车牌等工具。
★支持从Excel和ACCESS文件中读取数据填写表格,并根据当前表格生成Xls文件,方便批量录入
★支持下载指定文件和抓取网页文本内容
★支持填充多边框页面中的控件元素
★支持在嵌入框架iframe的页面中填充控件元素
★支持网页结构分析,显示控件描述,方便分析和修改控件值
★支持填写各种页面控件元素:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框收音机
支持收音机复选框
★支持填写级联下拉菜单
★支持填写无ID控制
★支持在线识别校验码
★支持循环填充和输入
风月excel数据批量自动填充网页数据提取软件使用说明
1、点击菜单“系统”>“新建配置文件”
2、在软件中打开网页,手动填写需要输入的内容
3、 点击左下角的“New Rule with Plus Icon”按钮创建规则
4、勾选“填写表单”网格,根据情况删除不需要填写的行
至此,设置完成。测试过程中,只需刷新网页,使网页未填充,然后点击软件左下角的“开始填充三角形图标”按钮即可查看填充效果。
风月excel数据批量自动填写网页数据提取软件更新日志
把bug扫到最后
优化用户反馈,提升细节体验
华军编辑推荐:
风月excel数据批量自动填充网页数据提取软件这类软件编辑器已经用了很多年了,但是这款软件还是最好用的,{recommendWords}也是一款不错的软件,推荐大家下载使用. 查看全部
excel抓取网页数据(风越网页批量填写数据提取软件,可自动分析网页中表单)
风月网页批量填写数据提取软件可以自动分析网页上表格的填写内容,并保存为填写规则。使用的时候只要调用这个规则就可以自动填表,点击网页元素,抓取网页的文字内容。下载指定的网页链接文件。
风月excel数据批量自动填充网页数据提取软件功能
本软件支持更多的页面填充类型和控制元素类型,精度更高。其他填表工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。
本软件不仅可以用于一般办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、征信、抢车牌等工具。
★支持从Excel和ACCESS文件中读取数据填写表格,并根据当前表格生成Xls文件,方便批量录入
★支持下载指定文件和抓取网页文本内容
★支持填充多边框页面中的控件元素
★支持在嵌入框架iframe的页面中填充控件元素
★支持网页结构分析,显示控件描述,方便分析和修改控件值
★支持填写各种页面控件元素:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框收音机
支持收音机复选框
★支持填写级联下拉菜单
★支持填写无ID控制
★支持在线识别校验码
★支持循环填充和输入
风月excel数据批量自动填充网页数据提取软件使用说明
1、点击菜单“系统”>“新建配置文件”
2、在软件中打开网页,手动填写需要输入的内容
3、 点击左下角的“New Rule with Plus Icon”按钮创建规则
4、勾选“填写表单”网格,根据情况删除不需要填写的行
至此,设置完成。测试过程中,只需刷新网页,使网页未填充,然后点击软件左下角的“开始填充三角形图标”按钮即可查看填充效果。
风月excel数据批量自动填写网页数据提取软件更新日志
把bug扫到最后
优化用户反馈,提升细节体验
华军编辑推荐:
风月excel数据批量自动填充网页数据提取软件这类软件编辑器已经用了很多年了,但是这款软件还是最好用的,{recommendWords}也是一款不错的软件,推荐大家下载使用.
excel抓取网页数据(excel抓取网页数据,你们这么用浏览器,我很敬佩)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-11-29 08:01
excel抓取网页数据,你们这么用chrome浏览器,我很敬佩,但是我觉得不太合适,主要是他自身的安全性,抓取网页很麻烦,很多网站都限制了破解的方法,假如抓取一次就要把整个网页浏览一遍,chrome的这个特性就使得他在实际场景是很不合适的,在普通网页抓取时,
找个插件抓完一个网页就删掉,多重要你懂得。
我是真心求解决方案,不要老有一种自己很努力,却不解决问题的错觉。关键问题是你们要想好如何设计这个“放入去的数据”,什么样的数据应该放入“放入去的数据”。
1、分析下自己能接触到的几个数据源
2、分析下要做数据分析的产品,
3、把几个大概想法理清楚之后,
4、确定这些数据的自定义列
5、模拟实现这些数据的放入
6、加载对应数据源数据
7、设置分析原始出口,
8、实现“处理提示”以上是我近期研究了一遍ahk,看了几遍《ahk技术原理与实践》,连几本大v专家的数据分析书籍及源码,就搞定的问题,可是整个学习过程都是隔靴搔痒,没有实质性的效果。我觉得anytime、anything都不如一个“和之前一样的操作逻辑”实现提示与自定义列来的实在。再补充一句,“如何设计一个“放入去的数据”。
我想要的是一个应用层面的可以做profile或是决策支持等使用场景的api来实现“放入去的数据”这个操作。是的,你没看错,提示是一个或两个操作后的回调函数;回调函数的“放入去的数据”也是可以是一个或两个操作后的回调函数(甚至可以扩展一些特殊的类型),但是那不是核心的操作逻辑,本质上应该是分析出一个数据源,我的经验是两个选择:手动分析出一个数据源,使用csv等软件处理此数据或是两个操作后的数据分析结果,再上传至服务器进行保存;其实前者是更合适的,因为这有经验的分析人员能设计出合适的profile方案,等于提供了一个数据的持续生命周期数据分析的profile方案,不过这可能需要开发人员较高的经验来完成;所以我觉得后者成熟的解决方案更合适,当然,既然从来没有开发过这么专业的软件方案,而你又没有工作经验,那就用python实现这个操作吧。说到底,还是对软件工程的实践认识不足,缺乏对自己负责的态度。 查看全部
excel抓取网页数据(excel抓取网页数据,你们这么用浏览器,我很敬佩)
excel抓取网页数据,你们这么用chrome浏览器,我很敬佩,但是我觉得不太合适,主要是他自身的安全性,抓取网页很麻烦,很多网站都限制了破解的方法,假如抓取一次就要把整个网页浏览一遍,chrome的这个特性就使得他在实际场景是很不合适的,在普通网页抓取时,
找个插件抓完一个网页就删掉,多重要你懂得。
我是真心求解决方案,不要老有一种自己很努力,却不解决问题的错觉。关键问题是你们要想好如何设计这个“放入去的数据”,什么样的数据应该放入“放入去的数据”。
1、分析下自己能接触到的几个数据源
2、分析下要做数据分析的产品,
3、把几个大概想法理清楚之后,
4、确定这些数据的自定义列
5、模拟实现这些数据的放入
6、加载对应数据源数据
7、设置分析原始出口,
8、实现“处理提示”以上是我近期研究了一遍ahk,看了几遍《ahk技术原理与实践》,连几本大v专家的数据分析书籍及源码,就搞定的问题,可是整个学习过程都是隔靴搔痒,没有实质性的效果。我觉得anytime、anything都不如一个“和之前一样的操作逻辑”实现提示与自定义列来的实在。再补充一句,“如何设计一个“放入去的数据”。
我想要的是一个应用层面的可以做profile或是决策支持等使用场景的api来实现“放入去的数据”这个操作。是的,你没看错,提示是一个或两个操作后的回调函数;回调函数的“放入去的数据”也是可以是一个或两个操作后的回调函数(甚至可以扩展一些特殊的类型),但是那不是核心的操作逻辑,本质上应该是分析出一个数据源,我的经验是两个选择:手动分析出一个数据源,使用csv等软件处理此数据或是两个操作后的数据分析结果,再上传至服务器进行保存;其实前者是更合适的,因为这有经验的分析人员能设计出合适的profile方案,等于提供了一个数据的持续生命周期数据分析的profile方案,不过这可能需要开发人员较高的经验来完成;所以我觉得后者成熟的解决方案更合适,当然,既然从来没有开发过这么专业的软件方案,而你又没有工作经验,那就用python实现这个操作吧。说到底,还是对软件工程的实践认识不足,缺乏对自己负责的态度。
excel抓取网页数据(福利:利用自动化工具,统计分析数据,便捷的网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-21 03:01
excel抓取网页数据一直都是一个困扰很多人的问题,虽然在各大爬虫工具都可以做到分析网页数据,但是各家抓取工具的区别还是非常大的,下面介绍下一个福利:利用自动化工具,统计分析数据,对数据量要求不是很大的情况下,使用自动化工具快速便捷的抓取网页数据。使用工具:自动化工具:/~gohlke/pythonlibs/#library。方法:先在网页上找到需要抓取的数据,利用两种方法:。
1、先抓取工作表
2、统计工作表查看数据:我使用的是textkit,用于生成python代码,并且代码是自动化抓取,而对于数据量不大的网页数据,使用download-table-selection的方法并不是非常方便,另外,想起上一期介绍的myie数据,需要使用代码才能抓取的要求相当高,为了避免重复编写代码,本文的代码中没有提供可供使用的抓取工具代码,只提供抓取数据集,并提供一种统计分析网页数据的方法,在这种方法中,利用了pandas库,包括了常用的dataframe,list等,对于网页数据做统计分析是非常的友好。
另外这个网页数据抓取的工具可以免费体验5次,使用此工具只需要很少的代码,对于工作量不大的网页数据,还是非常不错的。
步骤:
1、获取全部数据的链接:输入获取到的网页地址,并回车,
2、使用自动化工具进行抓取:使用自动化工具的方法很简单,基本代码如下:#使用frompandasimportdataframeimportpandasaspd#打开对应数据的网页,
3、统计数据data。columns统计数据索引:all_data=pd。dataframe(data)all_data=data。reset_index(drop=true)all_data=data。
reset_index(drop=true)[['index','value']]。values统计数据行:1=0+all_data[['index','value']][['column','name']]。values统计数据列:1=0+all_data[['index','value']][['column','name']]。values。 查看全部
excel抓取网页数据(福利:利用自动化工具,统计分析数据,便捷的网页数据)
excel抓取网页数据一直都是一个困扰很多人的问题,虽然在各大爬虫工具都可以做到分析网页数据,但是各家抓取工具的区别还是非常大的,下面介绍下一个福利:利用自动化工具,统计分析数据,对数据量要求不是很大的情况下,使用自动化工具快速便捷的抓取网页数据。使用工具:自动化工具:/~gohlke/pythonlibs/#library。方法:先在网页上找到需要抓取的数据,利用两种方法:。
1、先抓取工作表
2、统计工作表查看数据:我使用的是textkit,用于生成python代码,并且代码是自动化抓取,而对于数据量不大的网页数据,使用download-table-selection的方法并不是非常方便,另外,想起上一期介绍的myie数据,需要使用代码才能抓取的要求相当高,为了避免重复编写代码,本文的代码中没有提供可供使用的抓取工具代码,只提供抓取数据集,并提供一种统计分析网页数据的方法,在这种方法中,利用了pandas库,包括了常用的dataframe,list等,对于网页数据做统计分析是非常的友好。
另外这个网页数据抓取的工具可以免费体验5次,使用此工具只需要很少的代码,对于工作量不大的网页数据,还是非常不错的。
步骤:
1、获取全部数据的链接:输入获取到的网页地址,并回车,
2、使用自动化工具进行抓取:使用自动化工具的方法很简单,基本代码如下:#使用frompandasimportdataframeimportpandasaspd#打开对应数据的网页,
3、统计数据data。columns统计数据索引:all_data=pd。dataframe(data)all_data=data。reset_index(drop=true)all_data=data。
reset_index(drop=true)[['index','value']]。values统计数据行:1=0+all_data[['index','value']][['column','name']]。values统计数据列:1=0+all_data[['index','value']][['column','name']]。values。
excel抓取网页数据(excel抓取网页数据——信息!文本搜索网页信息全靠这一招)
网站优化 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2021-11-20 20:08
excel抓取网页数据——信息!文本搜索网页信息全靠这一招
首先,您需要使用python实现一个基本的爬虫,而且爬虫在python中是核心,如果连基本的爬虫都写不好,那肯定也写不好别的。python发展很快,核心库丰富,同时兼容java,c++,scala,php等等语言。scrapy,numpy,pandas等库也十分完善。可以用python实现一些常见的python数据处理方法和计算方法。
其次,一个网站如果有多个数据库可以使用,那就看需求,一般一个数据库就够了,hive,mysql,sqlalchemy,oralce等等。一般网站也需要将爬取的数据写入数据库中,比如你可以调用mysql数据库,一般的,你可以爬取百度的数据,然后再写入mysql数据库中,这也方便你做一些数据分析。然后要学习网络编程和数据库基础知识,最好也学学编程语言,因为如果你是做数据分析的话,数据库连接数是一个很重要的东西。
接下来要学会爬虫开发工具,比如requests,正则表达式,爬虫框架,beautifulsoup等等,一般来说,最重要的是一个抓包工具,因为requests是整个爬虫开发的基础。最后,你要了解并掌握各种爬虫工具,比如beautifulsoup,zhuanzhiweijsx,scrapy框架等等,掌握了这些爬虫基本要点后,你要抓取的网站,也都不是问题了。 查看全部
excel抓取网页数据(excel抓取网页数据——信息!文本搜索网页信息全靠这一招)
excel抓取网页数据——信息!文本搜索网页信息全靠这一招
首先,您需要使用python实现一个基本的爬虫,而且爬虫在python中是核心,如果连基本的爬虫都写不好,那肯定也写不好别的。python发展很快,核心库丰富,同时兼容java,c++,scala,php等等语言。scrapy,numpy,pandas等库也十分完善。可以用python实现一些常见的python数据处理方法和计算方法。
其次,一个网站如果有多个数据库可以使用,那就看需求,一般一个数据库就够了,hive,mysql,sqlalchemy,oralce等等。一般网站也需要将爬取的数据写入数据库中,比如你可以调用mysql数据库,一般的,你可以爬取百度的数据,然后再写入mysql数据库中,这也方便你做一些数据分析。然后要学习网络编程和数据库基础知识,最好也学学编程语言,因为如果你是做数据分析的话,数据库连接数是一个很重要的东西。
接下来要学会爬虫开发工具,比如requests,正则表达式,爬虫框架,beautifulsoup等等,一般来说,最重要的是一个抓包工具,因为requests是整个爬虫开发的基础。最后,你要了解并掌握各种爬虫工具,比如beautifulsoup,zhuanzhiweijsx,scrapy框架等等,掌握了这些爬虫基本要点后,你要抓取的网站,也都不是问题了。
excel抓取网页数据(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 302 次浏览 • 2021-11-20 03:15
)
Excel 2013及以后版本提供了WEBSERVICE和FILTERXML函数,可以用于网页数据的抓取,但是只能抓取XML格式的数据。而现在网站的很多网页或者接口都返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?今天以豆瓣图书基本资料为例,给大家介绍一下如何使用Excel API网络函数库抓取JSON格式的网页数据。
第一步,找到豆瓣网的基本信息页面
豆瓣图书信息网站是9787111529385,网站最后一串数字是图书的ISBN号。
在火狐浏览器中,这个URL会返回如下信息,是标准的JSON格式,蓝色字体为属性名称,红色字体对应属性值。
第二步安装ExcelAPI网络函数库
访问ExcelAPI网络函数库官网,根据帮助页面安装函数库。
第三步,使用函数抓取JSON数据。
首先,使用函数 GetJsonSource(url,"UTF-8") 返回 JSON 原创数据。
然后,使用函数 GetJsonByPropertyName(json_source,property_name) 返回书籍的基本信息。使用GetJsonSource()函数一次性抓取所有数据,然后按需抓取。这样做的目的是提高爬行速度。毕竟,访问网页需要时间。
完整的操作如下:
查看全部
excel抓取网页数据(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据?
)
Excel 2013及以后版本提供了WEBSERVICE和FILTERXML函数,可以用于网页数据的抓取,但是只能抓取XML格式的数据。而现在网站的很多网页或者接口都返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?今天以豆瓣图书基本资料为例,给大家介绍一下如何使用Excel API网络函数库抓取JSON格式的网页数据。
第一步,找到豆瓣网的基本信息页面
豆瓣图书信息网站是9787111529385,网站最后一串数字是图书的ISBN号。
在火狐浏览器中,这个URL会返回如下信息,是标准的JSON格式,蓝色字体为属性名称,红色字体对应属性值。
第二步安装ExcelAPI网络函数库
访问ExcelAPI网络函数库官网,根据帮助页面安装函数库。
第三步,使用函数抓取JSON数据。
首先,使用函数 GetJsonSource(url,"UTF-8") 返回 JSON 原创数据。
然后,使用函数 GetJsonByPropertyName(json_source,property_name) 返回书籍的基本信息。使用GetJsonSource()函数一次性抓取所有数据,然后按需抓取。这样做的目的是提高爬行速度。毕竟,访问网页需要时间。
完整的操作如下:

