
curl 抓取网页
curl 抓取网页(常用参数curl命令参数说明)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-11 12:01
原文:使用说明
curl命令是一个功能强大的网络工具,可以通过http、ftp等方式下载和上传文件。其实curl远不止上面提到的功能。您可以通过 man curl 阅读手册页以获取更多信息。 wget 是一个类似的工具。
curl 命令是使用 libcurl 库实现的。 libcurl 库通常在 C 程序中用于处理 HTTP 请求。 curlpp 是 libcurl 的 C++ 包。这些东西可以用在web抓取、网络监控等开发中,curl命令可以帮助解决开发过程中遇到的问题。
常用参数
curl命令的参数很多,这里只列出我用过的,尤其是shell脚本中的。
-A:请随意指定您自己为本次访问声明的浏览器信息
-b/--cookie cookie 字符串或文件读取位置,使用 option 将最后一个 cookie 信息附加到 http 请求中。
-c/--cookie-jar 操作完成后将cookies写入该文件
-C/--continue-在断点处继续
-d/--data HTTP POST方法传输数据
-D/--dump-header 将头信息写入该文件
-F/--form 模拟http表单提交数据
-v/--verbose 小写的v参数用于打印更多信息,包括发送的请求信息,在调试脚本时特别有用。
-m/--max-time 指定处理的最大持续时间
-H/--header 指定请求头参数
-s/--slent reduce输出信息,如进度
--connect-timeout 指定尝试连接的最长时间
-x/--代理
指定代理服务器地址和端口,默认端口为1080
-T/--upload-file 指定上传文件路径
-o/--output 指定输出文件名
--retry 指定重试次数
-e/--referer 指定引用地址
-I/--head 只返回header信息,使用HEAD请求
-u/--user 设置服务器用户和密码
-O:根据服务器上的文件名,会自动在本地存在
-r/--range 从 HTTP/1.1 或 FTP 服务器检索字节范围
-T/--upload-file 上传文件
使用示例
1、抓取页面内容到文件中
[root@xi mytest]# curl -o home.html -- 将百度首页的内容抓取到home.html中
[root@xi mytest]#curl -o #2_#1.jpg~{A,B}/[001-201].JPG
因为A/B下的文件名都是001、002...、201,所以下载的文件同名,所以自定义下载的文件名变成这样: 原文:A/00< @1.JPG ---> 下载后:001-A.JPG 原文:B/001.JPG ---> 下载后:001-B.JPG
2、使用-O(大写),后面的url必须特定于某个文件,否则不会被抓到。你也可以使用正则表达式来抓取东西
[root@xi mytest]# curl -O
结果如下:
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 1575 100 1575 0 0 14940 0 --:--:-- --:--:-- --:--:-- 1538k
在当前执行目录中会生成一张bdlogo.gif的图片。
[root@xi mytest]# curl -O[1-10].JPG --下载屏幕1.jpg~screen10.jpg
3、模拟表单信息、模拟登录、保存cookie信息
[root@xi mytest]# curl -c ./cookie_c.txt -F log=aaaa -F pwd=******
4、模拟表单信息、模拟登录、保存表头信息
[root@xi mytest]# curl -D ./cookie_D.txt -F log=aaaa -F pwd=******
由
生成的cookie
-c(小写)与-D中的cookie不同。
5、使用cookie文件
[root@xi mytest]# curl -b ./cookie_c.txt
6、从断点恢复,-C(大写)
[root@xi mytest]# curl -C -O
7、发送数据,最好用登录页面测试,因为你传值后,curl会抓回数据,可以看看传值是否成功
[root@xi mytest]# curl -d log=aaaa
8、显示爬取错误,下面的例子清楚的显示出来。
[root@xi mytest]# curl -f
curl:(22)请求的URL返回错误:404
[root@xi mytest]# curl
404,未找到
9。伪造源地址,有的网站会判断并请求源地址,防止盗链。
[root@xi mytest]# curl -e:///wp-login.php
10、当我们经常用curl做别人的事情的时候,人家会屏蔽你的IP,这个时候我们可以使用代理
[root@xi mytest]# curl -x 24.10.28.84:32779 -o home.html
11,对于较大的东西,我们可以分段下载
[root@xi mytest]# curl -r 0-100 -o img.part1
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 101 100 101 0 0 105 0 --:--:-- --:--:-- --:--:-- 0
[root@xi mytest]# curl -r 100-200 -o img.part2
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 101 100 101 0 0 57 0 0:00:01 0:00:01 --:--:-- 0
[root@xi mytest]# curl -r 200- -o img.part3
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 104k 100 104k 0 0 52793 0 0:00:02 0:00:02 --:--:-- 88961
[root@xi mytest]# ls |grep part | xargs du -sh
4.0K one.part1
112K 三.part3
4.0K two.part2
使用的时候,cat一下就可以了,cat img.part* >img.jpg
12,不会显示下载进度信息
[root@xi mytest]# curl -s -o aaa.jpg
13、显示下载进度条
[root@xi mytest]# curl -0(使用http1.0协议的请求)
############################################## # ######################### 100.0%
14、通过ftp下载文件
[xifj@Xi ~]$ curl -u 用户名:密码 -O
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
101 1934 101 1934 0 0 3184 0 --:--:-- --:--:-- --:--:-- 7136
[xifj@Xi ~]$ curl -u 用户名:密码 -O
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
101 1934 101 1934 0 0 3184 0 --:--:-- --:--:-- --:--:-- 7136
或者使用下面的方法
[xifj@Xi ~]$ curl -O ftp://username:password@ip:port/demo/curtain/bbstudy_files/style.css
[xifj@Xi ~]$ curl -O ftp://username:password@ip:port/demo/curtain/bbstudy_files/style.css
15、通过ftp上传
[xifj@Xi ~]$ curl -T test.sql ftp://username:password@ip:port/demo/curtain/bbstudy_files/
[xifj@Xi ~]$ curl -T test.sql ftp://username:password@ip:port/demo/curtain/bbstudy_files/
15、模拟浏览器头部
[xifj@Xi ~]$ curl -A "Mozilla/4.0 (兼容; MSIE 6.0; Windows NT 5.0)" -x 12< @3.45.67.89:1080 -o page.html -D cookie0001.txt
16,PUT,GET,POST
比如curl -T localfile~zz/abc.cgi,此时使用的协议是HTTP PUT方式
刚才说到PUT,我自然会想到其他几种方法——GET和POST。 查看全部
curl 抓取网页(常用参数curl命令参数说明)
原文:使用说明
curl命令是一个功能强大的网络工具,可以通过http、ftp等方式下载和上传文件。其实curl远不止上面提到的功能。您可以通过 man curl 阅读手册页以获取更多信息。 wget 是一个类似的工具。
curl 命令是使用 libcurl 库实现的。 libcurl 库通常在 C 程序中用于处理 HTTP 请求。 curlpp 是 libcurl 的 C++ 包。这些东西可以用在web抓取、网络监控等开发中,curl命令可以帮助解决开发过程中遇到的问题。
常用参数
curl命令的参数很多,这里只列出我用过的,尤其是shell脚本中的。
-A:请随意指定您自己为本次访问声明的浏览器信息
-b/--cookie cookie 字符串或文件读取位置,使用 option 将最后一个 cookie 信息附加到 http 请求中。
-c/--cookie-jar 操作完成后将cookies写入该文件
-C/--continue-在断点处继续
-d/--data HTTP POST方法传输数据
-D/--dump-header 将头信息写入该文件
-F/--form 模拟http表单提交数据
-v/--verbose 小写的v参数用于打印更多信息,包括发送的请求信息,在调试脚本时特别有用。
-m/--max-time 指定处理的最大持续时间
-H/--header 指定请求头参数
-s/--slent reduce输出信息,如进度
--connect-timeout 指定尝试连接的最长时间
-x/--代理
指定代理服务器地址和端口,默认端口为1080
-T/--upload-file 指定上传文件路径
-o/--output 指定输出文件名
--retry 指定重试次数
-e/--referer 指定引用地址
-I/--head 只返回header信息,使用HEAD请求
-u/--user 设置服务器用户和密码
-O:根据服务器上的文件名,会自动在本地存在
-r/--range 从 HTTP/1.1 或 FTP 服务器检索字节范围
-T/--upload-file 上传文件
使用示例
1、抓取页面内容到文件中
[root@xi mytest]# curl -o home.html -- 将百度首页的内容抓取到home.html中
[root@xi mytest]#curl -o #2_#1.jpg~{A,B}/[001-201].JPG
因为A/B下的文件名都是001、002...、201,所以下载的文件同名,所以自定义下载的文件名变成这样: 原文:A/00< @1.JPG ---> 下载后:001-A.JPG 原文:B/001.JPG ---> 下载后:001-B.JPG
2、使用-O(大写),后面的url必须特定于某个文件,否则不会被抓到。你也可以使用正则表达式来抓取东西
[root@xi mytest]# curl -O
结果如下:
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 1575 100 1575 0 0 14940 0 --:--:-- --:--:-- --:--:-- 1538k
在当前执行目录中会生成一张bdlogo.gif的图片。
[root@xi mytest]# curl -O[1-10].JPG --下载屏幕1.jpg~screen10.jpg
3、模拟表单信息、模拟登录、保存cookie信息
[root@xi mytest]# curl -c ./cookie_c.txt -F log=aaaa -F pwd=******
4、模拟表单信息、模拟登录、保存表头信息
[root@xi mytest]# curl -D ./cookie_D.txt -F log=aaaa -F pwd=******
由
生成的cookie
-c(小写)与-D中的cookie不同。
5、使用cookie文件
[root@xi mytest]# curl -b ./cookie_c.txt
6、从断点恢复,-C(大写)
[root@xi mytest]# curl -C -O
7、发送数据,最好用登录页面测试,因为你传值后,curl会抓回数据,可以看看传值是否成功
[root@xi mytest]# curl -d log=aaaa
8、显示爬取错误,下面的例子清楚的显示出来。
[root@xi mytest]# curl -f
curl:(22)请求的URL返回错误:404
[root@xi mytest]# curl
404,未找到
9。伪造源地址,有的网站会判断并请求源地址,防止盗链。
[root@xi mytest]# curl -e:///wp-login.php
10、当我们经常用curl做别人的事情的时候,人家会屏蔽你的IP,这个时候我们可以使用代理
[root@xi mytest]# curl -x 24.10.28.84:32779 -o home.html
11,对于较大的东西,我们可以分段下载
[root@xi mytest]# curl -r 0-100 -o img.part1
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 101 100 101 0 0 105 0 --:--:-- --:--:-- --:--:-- 0
[root@xi mytest]# curl -r 100-200 -o img.part2
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 101 100 101 0 0 57 0 0:00:01 0:00:01 --:--:-- 0
[root@xi mytest]# curl -r 200- -o img.part3
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 104k 100 104k 0 0 52793 0 0:00:02 0:00:02 --:--:-- 88961
[root@xi mytest]# ls |grep part | xargs du -sh
4.0K one.part1
112K 三.part3
4.0K two.part2
使用的时候,cat一下就可以了,cat img.part* >img.jpg
12,不会显示下载进度信息
[root@xi mytest]# curl -s -o aaa.jpg
13、显示下载进度条
[root@xi mytest]# curl -0(使用http1.0协议的请求)
############################################## # ######################### 100.0%
14、通过ftp下载文件
[xifj@Xi ~]$ curl -u 用户名:密码 -O
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
101 1934 101 1934 0 0 3184 0 --:--:-- --:--:-- --:--:-- 7136
[xifj@Xi ~]$ curl -u 用户名:密码 -O
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
101 1934 101 1934 0 0 3184 0 --:--:-- --:--:-- --:--:-- 7136
或者使用下面的方法
[xifj@Xi ~]$ curl -O ftp://username:password@ip:port/demo/curtain/bbstudy_files/style.css
[xifj@Xi ~]$ curl -O ftp://username:password@ip:port/demo/curtain/bbstudy_files/style.css
15、通过ftp上传
[xifj@Xi ~]$ curl -T test.sql ftp://username:password@ip:port/demo/curtain/bbstudy_files/
[xifj@Xi ~]$ curl -T test.sql ftp://username:password@ip:port/demo/curtain/bbstudy_files/
15、模拟浏览器头部
[xifj@Xi ~]$ curl -A "Mozilla/4.0 (兼容; MSIE 6.0; Windows NT 5.0)" -x 12< @3.45.67.89:1080 -o page.html -D cookie0001.txt
16,PUT,GET,POST
比如curl -T localfile~zz/abc.cgi,此时使用的协议是HTTP PUT方式
刚才说到PUT,我自然会想到其他几种方法——GET和POST。
curl 抓取网页(php的CURL正常抓取页面程序:如果你抓取到的是302状态)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-04-09 15:08
php的CURL正常爬取页面流程如下:
$url = 'http://www.baidu.com';$ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_VERBOSE, true); curl_setopt($ch, CURLOPT_HEADER, true);curl_setopt($ch, CURLOPT_NOBODY, true);curl_setopt($ch, CURLOPT_CUSTOMREQUEST, 'GET');curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_TIMEOUT, 20); curl_setopt($ch, CURLOPT_AUTOREFERER, true); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true); $ret = curl_exec($ch); $info = curl_getinfo($ch); curl_close($ch);
如果抓302状态,那是因为在重新抓取的过程中,有些跳转需要给下一个链接传参,如果没有收到相应的参数,下一个链接也被设置为非法访问。.
curl_setopt($curl, CURLOPT_CUSTOMREQUEST, 'GET');
显示应该是正常的。
以上是用来抓取功能的,应该几乎没有问题。您可以查看 CURLOPT_CUSTOMREQUEST 相关信息。
对 HTTP 请求使用自定义请求消息而不是“GET”或“HEAD”。这对于执行“删除”或其他更隐蔽的 HTTP 请求很有用。有效值为“GET”、“POST”、“CONNECT”等。即这里不要输入整个HTTP请求。例如,输入“GET /index.html HTTP/1.0/r/n/r/n”是不正确的。
PHP技术:PHP curl实现302跳转后抓取页面示例,转载需保留出处!
郑重声明:本文版权归原作者所有,转载文章仅出于传播更多信息之目的。如果作者信息标注有误,请尽快联系我们修改或删除,谢谢。 查看全部
curl 抓取网页(php的CURL正常抓取页面程序:如果你抓取到的是302状态)
php的CURL正常爬取页面流程如下:
$url = 'http://www.baidu.com';$ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_VERBOSE, true); curl_setopt($ch, CURLOPT_HEADER, true);curl_setopt($ch, CURLOPT_NOBODY, true);curl_setopt($ch, CURLOPT_CUSTOMREQUEST, 'GET');curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_TIMEOUT, 20); curl_setopt($ch, CURLOPT_AUTOREFERER, true); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true); $ret = curl_exec($ch); $info = curl_getinfo($ch); curl_close($ch);
如果抓302状态,那是因为在重新抓取的过程中,有些跳转需要给下一个链接传参,如果没有收到相应的参数,下一个链接也被设置为非法访问。.
curl_setopt($curl, CURLOPT_CUSTOMREQUEST, 'GET');
显示应该是正常的。
以上是用来抓取功能的,应该几乎没有问题。您可以查看 CURLOPT_CUSTOMREQUEST 相关信息。
对 HTTP 请求使用自定义请求消息而不是“GET”或“HEAD”。这对于执行“删除”或其他更隐蔽的 HTTP 请求很有用。有效值为“GET”、“POST”、“CONNECT”等。即这里不要输入整个HTTP请求。例如,输入“GET /index.html HTTP/1.0/r/n/r/n”是不正确的。
PHP技术:PHP curl实现302跳转后抓取页面示例,转载需保留出处!
郑重声明:本文版权归原作者所有,转载文章仅出于传播更多信息之目的。如果作者信息标注有误,请尽快联系我们修改或删除,谢谢。
curl 抓取网页(和wget下载安装1、Ubuntu平台wget命令安装:百度首页为例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-08 02:04
curl和wget下载安装
1、Ubuntu 平台
wget命令安装:sudo apt-get install wget(普通用户登录,需要输入密码;root账户登录,不需要输入密码)
curl命令安装:sudo apt-get install curl(同wget)
2、Windows 平台
wget下载地址:wget for Windows
curl下载地址:curl下载
wget和curl包下载地址:Windows平台下的wget和curl工具包
在Windows平台下,curl下载解压后直接为curl.exe格式,复制到系统命令目录下的C:\Windows\System32。
Windows平台下,wget下载解压后,格式为wget-1.11.4-1-setup.exe,需要安装;安装完成后,在环境变量-系统变量-路径目录下添加其安装
curl 和 wget 抓取实例
抓取网页主要有两种方式:url URL 和代理代理。下面是一个爬取“百度”首页的例子。
1、 url URL方法爬取
(1)curl下载百度首页内容,保存在baidu_html文件中
curl baidu_html
(2)wget下载百度首页内容,保存在baidu_html文件中
wget baidu_html2
有时,由于网络速度/数据包丢失/服务器停机等原因,网页暂时无法成功下载。
这时候可能需要尝试多次发送连接来请求服务器的响应;如果多次仍然没有响应,则可以确认服务器有问题。
(1)curl 尝试连接多次
curl --retry 10 --retry-delay 60 --retry-max-time 60 -o baidu_html
注意:--retry 表示重试次数;--retry-delay 表示两次重试之间的时间间隔(以秒为单位);--retry-max-time 表示在这个最大时间内只允许重试一次(一般同--retry-delay)
(2)wget 尝试连接多次
wget -t 10 -w 60 -T 30 -O baidu_html2
注意:-t(--tries)表示重试次数;-w 表示两次重试之间的时间间隔(以秒为单位);-T 表示连接超时时间,超过超时则连接不成功,下次连接继续尝试
附:curl可以判断服务器是否响应。也可以通过一段时间内下载获得的字节数来间接判断。命令格式如下:
curl -y 60 -Y 1 -m 60 -o baidu_html
注:-y表示测试网速的时间;-Y 表示-y期间下载的字节数(字节为单位);-m 表示允许请求连接的最长时间,如果超过连接会自动断开连接并放弃连接
2、代理代理捕获
代理下载是通过连接中间服务器间接下载url网页的过程,而不是url直接连接网站服务器下载
两位知名的自由球员网站:
(全球数十个国家免费代理,每日更新)
(通过设置端口类型、代理类型、国家名称过滤)
在网站中选择国内免费的代理服务器为例介绍代理代理爬取网页:
218.107.21.252:8080(ip为218.107.21.252;端口为8080,中间是 8080 冒号“:”隔开形成套接字)
(1)curl通过代理爬取百度首页
curl -x 218.107.21.252:8080 -o aaaaa(常用端口有80、8080、8086、8888、3128等,默认8< @0)
注:-x表示代理服务器(ip:port),即curl先连接代理服务器218.107.21.252:8080,然后通过21< @k31@ >107.21.252:8080 下载百度首页,最后218.107.21.252:8080 通过下载百度主页 curl 到本地(curl 不是直接连接百度服务器下载主页,而是通过中介代理)
(2)wget通过代理爬取百度首页
wget 通过代理下载,和 curl 不一样。需要先设置代理服务器的http_proxy=ip:port。
以ubuntu为例,在当前用户目录(cd ~),新建wget配置文件(.wgetrc),进入代理配置: 查看全部
curl 抓取网页(和wget下载安装1、Ubuntu平台wget命令安装:百度首页为例)
curl和wget下载安装
1、Ubuntu 平台
wget命令安装:sudo apt-get install wget(普通用户登录,需要输入密码;root账户登录,不需要输入密码)
curl命令安装:sudo apt-get install curl(同wget)
2、Windows 平台
wget下载地址:wget for Windows
curl下载地址:curl下载
wget和curl包下载地址:Windows平台下的wget和curl工具包
在Windows平台下,curl下载解压后直接为curl.exe格式,复制到系统命令目录下的C:\Windows\System32。
Windows平台下,wget下载解压后,格式为wget-1.11.4-1-setup.exe,需要安装;安装完成后,在环境变量-系统变量-路径目录下添加其安装
curl 和 wget 抓取实例
抓取网页主要有两种方式:url URL 和代理代理。下面是一个爬取“百度”首页的例子。
1、 url URL方法爬取
(1)curl下载百度首页内容,保存在baidu_html文件中
curl baidu_html
(2)wget下载百度首页内容,保存在baidu_html文件中
wget baidu_html2
有时,由于网络速度/数据包丢失/服务器停机等原因,网页暂时无法成功下载。
这时候可能需要尝试多次发送连接来请求服务器的响应;如果多次仍然没有响应,则可以确认服务器有问题。
(1)curl 尝试连接多次
curl --retry 10 --retry-delay 60 --retry-max-time 60 -o baidu_html
注意:--retry 表示重试次数;--retry-delay 表示两次重试之间的时间间隔(以秒为单位);--retry-max-time 表示在这个最大时间内只允许重试一次(一般同--retry-delay)
(2)wget 尝试连接多次
wget -t 10 -w 60 -T 30 -O baidu_html2
注意:-t(--tries)表示重试次数;-w 表示两次重试之间的时间间隔(以秒为单位);-T 表示连接超时时间,超过超时则连接不成功,下次连接继续尝试
附:curl可以判断服务器是否响应。也可以通过一段时间内下载获得的字节数来间接判断。命令格式如下:
curl -y 60 -Y 1 -m 60 -o baidu_html
注:-y表示测试网速的时间;-Y 表示-y期间下载的字节数(字节为单位);-m 表示允许请求连接的最长时间,如果超过连接会自动断开连接并放弃连接
2、代理代理捕获
代理下载是通过连接中间服务器间接下载url网页的过程,而不是url直接连接网站服务器下载
两位知名的自由球员网站:
(全球数十个国家免费代理,每日更新)
(通过设置端口类型、代理类型、国家名称过滤)
在网站中选择国内免费的代理服务器为例介绍代理代理爬取网页:
218.107.21.252:8080(ip为218.107.21.252;端口为8080,中间是 8080 冒号“:”隔开形成套接字)
(1)curl通过代理爬取百度首页
curl -x 218.107.21.252:8080 -o aaaaa(常用端口有80、8080、8086、8888、3128等,默认8< @0)
注:-x表示代理服务器(ip:port),即curl先连接代理服务器218.107.21.252:8080,然后通过21< @k31@ >107.21.252:8080 下载百度首页,最后218.107.21.252:8080 通过下载百度主页 curl 到本地(curl 不是直接连接百度服务器下载主页,而是通过中介代理)
(2)wget通过代理爬取百度首页
wget 通过代理下载,和 curl 不一样。需要先设置代理服务器的http_proxy=ip:port。
以ubuntu为例,在当前用户目录(cd ~),新建wget配置文件(.wgetrc),进入代理配置:
curl 抓取网页(和wget下载安装1、Ubuntu平台wget命令安装:百度首页为例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 302 次浏览 • 2022-04-03 22:11
curl和wget下载安装
1、Ubuntu 平台
wget命令安装:sudo apt-get install wget(普通用户登录,需要输入密码;root账号登录,不需要密码)
curl命令安装:sudo apt-get install curl(同wget)
2、Windows 平台
wget下载地址:wget for Windows
curl下载地址:curl下载
wget和curl包下载地址:Windows平台下的wget和curl工具包
Windows平台下,curl下载解压后直接为curl.exe格式,复制到系统命令目录下的C:\Windows\System32。
Windows平台下,wget下载解压后,格式为wget-1.11.4-1-setup.exe,需要安装;安装完成后,在环境变量-系统变量-路径目录下添加其安装
curl 和 wget 抓取实例
抓取网页主要有两种方式:url URL 和代理代理。下面是一个爬取“百度”首页的例子。
1、 url URL方法爬取
(1)curl下载百度首页内容,保存在baidu_html文件中
curl -o baidu_html
(2)wget下载百度首页内容,保存在baidu_html文件中
wget -O baidu_html2
有时,由于网络速度/数据包丢失/服务器停机等原因,网页暂时无法成功下载。
这时候可能需要尝试多次发送连接来请求服务器的响应;如果多次仍然没有响应,则可以确认服务器有问题。
(1)curl 尝试连接多次
curl --retry 10 --retry-delay 60 --retry-max-time 60 -o baidu_html
注意:--retry 表示重试次数;--retry-delay 表示两次重试之间的时间间隔(以秒为单位);--retry-max-time 表示在这个最大时间内只允许重试一次(一般同--retry-delay)
(2)wget 尝试连接多次
wget -t 10 -w 60 -T 30 -O baidu_html2
注意:-t(--tries)表示重试次数;-w 表示两次重试之间的时间间隔(以秒为单位);-T 表示连接超时时间,超过超时则连接不成功,下次连接继续尝试
附:curl可以判断服务器是否响应。也可以通过一段时间内下载获得的字节数来间接判断。命令格式如下:
curl -y 60 -Y 1 -m 60 -o baidu_html
注:-y表示测试网速的时间;-Y 表示-y期间下载的字节数(字节为单位);-m 表示允许请求连接的最长时间,如果超过连接会自动断开连接并放弃连接
2、代理代理捕获
代理下载是通过连接中间服务器间接下载url网页的过程,而不是url直接连接网站服务器下载
两位知名的自由球员网站:
(全球数十个国家免费代理,每日更新)
(通过设置端口类型、代理类型、国家名称过滤)
在网站中选择国内免费的代理服务器为例介绍代理代理爬取网页:
218.107.21.252:8080(ip为218.107.21.252;端口为8080,中间是 8080 冒号“:”隔开形成套接字)
(1)curl通过代理爬取百度首页
curl -x 218.107.21.252:8080 -o aaaaa(常用端口有80、8080、8086、8888、3128等,默认80)
注:-x表示代理服务器(ip:port),即curl先连接代理服务器218.107.21.252:8080,然后通过21< @k31@ >107.21.252:8080 下载百度首页,最后218.107.21.252:8080 通过下载百度主页 curl 到本地(curl 不是直接连接百度服务器下载主页,而是通过中介代理)
(2)wget通过代理爬取百度首页
wget是通过代理下载的,和curl不一样。需要先设置代理服务器的http_proxy=ip:port。
以ubuntu为例,在当前用户目录(cd ~),新建wget配置文件(.wgetrc),进入代理配置: 查看全部
curl 抓取网页(和wget下载安装1、Ubuntu平台wget命令安装:百度首页为例)
curl和wget下载安装
1、Ubuntu 平台
wget命令安装:sudo apt-get install wget(普通用户登录,需要输入密码;root账号登录,不需要密码)
curl命令安装:sudo apt-get install curl(同wget)
2、Windows 平台
wget下载地址:wget for Windows
curl下载地址:curl下载
wget和curl包下载地址:Windows平台下的wget和curl工具包
Windows平台下,curl下载解压后直接为curl.exe格式,复制到系统命令目录下的C:\Windows\System32。
Windows平台下,wget下载解压后,格式为wget-1.11.4-1-setup.exe,需要安装;安装完成后,在环境变量-系统变量-路径目录下添加其安装
curl 和 wget 抓取实例
抓取网页主要有两种方式:url URL 和代理代理。下面是一个爬取“百度”首页的例子。
1、 url URL方法爬取
(1)curl下载百度首页内容,保存在baidu_html文件中
curl -o baidu_html
(2)wget下载百度首页内容,保存在baidu_html文件中
wget -O baidu_html2
有时,由于网络速度/数据包丢失/服务器停机等原因,网页暂时无法成功下载。
这时候可能需要尝试多次发送连接来请求服务器的响应;如果多次仍然没有响应,则可以确认服务器有问题。
(1)curl 尝试连接多次
curl --retry 10 --retry-delay 60 --retry-max-time 60 -o baidu_html
注意:--retry 表示重试次数;--retry-delay 表示两次重试之间的时间间隔(以秒为单位);--retry-max-time 表示在这个最大时间内只允许重试一次(一般同--retry-delay)
(2)wget 尝试连接多次
wget -t 10 -w 60 -T 30 -O baidu_html2
注意:-t(--tries)表示重试次数;-w 表示两次重试之间的时间间隔(以秒为单位);-T 表示连接超时时间,超过超时则连接不成功,下次连接继续尝试
附:curl可以判断服务器是否响应。也可以通过一段时间内下载获得的字节数来间接判断。命令格式如下:
curl -y 60 -Y 1 -m 60 -o baidu_html
注:-y表示测试网速的时间;-Y 表示-y期间下载的字节数(字节为单位);-m 表示允许请求连接的最长时间,如果超过连接会自动断开连接并放弃连接
2、代理代理捕获
代理下载是通过连接中间服务器间接下载url网页的过程,而不是url直接连接网站服务器下载
两位知名的自由球员网站:
(全球数十个国家免费代理,每日更新)
(通过设置端口类型、代理类型、国家名称过滤)
在网站中选择国内免费的代理服务器为例介绍代理代理爬取网页:
218.107.21.252:8080(ip为218.107.21.252;端口为8080,中间是 8080 冒号“:”隔开形成套接字)
(1)curl通过代理爬取百度首页
curl -x 218.107.21.252:8080 -o aaaaa(常用端口有80、8080、8086、8888、3128等,默认80)
注:-x表示代理服务器(ip:port),即curl先连接代理服务器218.107.21.252:8080,然后通过21< @k31@ >107.21.252:8080 下载百度首页,最后218.107.21.252:8080 通过下载百度主页 curl 到本地(curl 不是直接连接百度服务器下载主页,而是通过中介代理)
(2)wget通过代理爬取百度首页
wget是通过代理下载的,和curl不一样。需要先设置代理服务器的http_proxy=ip:port。
以ubuntu为例,在当前用户目录(cd ~),新建wget配置文件(.wgetrc),进入代理配置:
curl 抓取网页( IP代理筛选系统问题分析分析解决一个问题的原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-04-03 22:11
IP代理筛选系统问题分析分析解决一个问题的原理)
Linux IP代理筛选系统(shell+proxy)
代理的目的
其实,除了使用IP代理爬取国外网页外,还有很多使用代理的场景:
代理原则
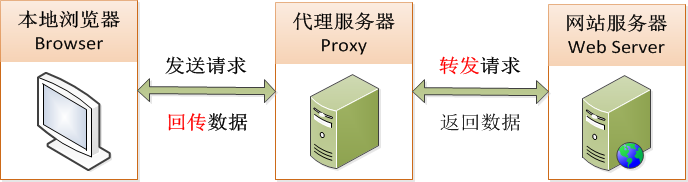
代理服务的原理是本地浏览器(Browser)发送请求的数据,而不是直接发送给网站服务器(Web Server)
取而代之的是一个中间代理服务器(Proxy),如下图:
IP代理筛选系统
问题分析
在分析解决一个实际问题的时候,会遇到各种各样的问题,有些问题甚至在方案设计之初都难以想到(比如代理IP爬取网页速度慢)。我的经验是,动手实践比纯理论更重要。重要的!
设计
大体思路:找到并缩小被屏蔽的IP代理的来源-》检查代理IP是否可用-》记录IP抓取网页-》如果代理IP失败重新过滤-》继续抓取网页- “完全的
1、IP代理源
选择有两个原则:可用和免费。经过深入研究和搜索,最终确定两个网站 IP代理更可靠:和
从国家数量、IP代理数量、IP代理的可用性、IP代理的文本格式综合考虑,IP代理的来源主要选择前者,后者作为补充. 后来的实际测试表明,这种初选方案基本满足需要。
2、文本预处理
从获取的代理IP中,有IP地址、端口、类型、匿名性、国家等参数,我们需要的只有IP+端口,所以需要对主IP代理源做文本预处理。
文本空间处理命令:
sed -e "s/\s\{2,\}/:/g" $file_input > $file_split
sed -i "s/ /:/g" $file_split
合并代理 IP (ip:port) 命令:
proxy_ip=$(echo $line | cut -f 1 -d ":")
proxy_port=$(echo $line | cut -f 2 -d ":")
代理=$proxy_ip":"$proxy_port
3、检测IP代理
文本预处理代理IP为标准格式(ip:port)后,需要进行代理IP筛选测试,看看哪些可用哪些不可用(因为获取的部分IP代理源无法使用或下载太慢,需要过滤掉)
curl抓取网页检查IP代理是否可用命令:
cmd="curl -y 60 -Y 1 -m 300 -x$proxy-o $file_html$index $url_html"
$cmd
4、保存IP代理
检查代理IP是否可用,如果可用,保存。
判断代理IP是否可用的标准是判断步骤3下载的网页($file_html$index)是否有内容。具体命令如下:
如果 [ -e ./$file_html$index ]; 然后
回声 $proxy >> $2
休息;
菲
5、IP代理爬取网页
使用第4步保存的代理IP抓取网页,使用代理IP抓取12个国家的排名网页和游戏网页。具体命令如下:
proxy_cmd="curl -y 60 -Y 1 -m 300 -x$proxy-o $proxy_html $proxy_http"
$proxy_cmd
6、IP 代理失败
IP代理失败的案例很多。上面的问题分析中已经列出了几个。下面将详细分析如下:
一种。网页抓取过程中代理IP突然失效,无法继续完成网页抓取
湾。代理IP没有失效,但是网页抓取很慢,一天24小时内无法完成网页抓取,导致无法生成游戏排名日报表
C。所有代理 IP 均无效。无论经过一次或多次轮询测试,当天的网页抓取任务都无法完成。
d。由于全网路由拥塞,代理IP很慢或者无法爬取网页,误判代理IP全部无效。如何恢复和纠正它
7、重新检测IP代理
在网页抓取过程中,面对第6步的IP代理故障,设计合理高效的代理IP抓取恢复机制是整个IP代理筛选系统的核心和关键
故障恢复的轮询和筛选过程如下:
在上述过程中,有几点需要注意:
一种。首先检测最后一个 IP 代理。这是因为上一个(昨天)的IP代理完成了所有的网页爬取任务,它的可用概率比较高,所以优先考虑今天是否可用。如果不可用,请选择另一个
湾。如果今天最后一个代理IP不可用,重新遍历检测代理IP源。一旦检测到可用,就不会循环,更新可用的IP代理并将其位置保存在IP源中,方便下次遍历从这里开始
C。如果进程b中新选择的代理IP突然失效或者网速太慢,继续筛选b中记录的IP源位置是否有以下代理IP。如果可用,继续爬取网页;如果没有,再遍历整个IP源
d。如果再次遍历整个代理IP源,仍然没有可用的代理IP,则重复轮询和遍历整个代理IP源,直到有可用的代理IP或今天24点过去(即没有今天一整天都可以找到可用的代理IP)
e. 对于进程d中所有代理IP都无效,整天找不到可用代理IP的特殊情况,无法完成当天的网页抓取。次日凌晨重启爬网主控脚本之前,需要先杀掉进程。d 后台循环进程,防止今天和次日两个后台抓取程序同时运行(相当于两个异步后台抓取进程),导致抓取的网页排名数据过时或错误,占用网络速度和带宽等。为了杀死当天的死后台爬取进程,请参考上一篇博客Linux爬取网页示例-《自动主控脚本-》kill_curl.sh脚本,
尽管 [ !-z $(ps -ef | grepcurl| grep -v grep | cut -c 9-15) ]
做
ps -ef | grep 卷曲 | grep -v grep | 切-c 15-20 | xargs 杀死 -9
ps -ef | grep 卷曲 | grep -v grep | 切-c 9-15 | xargs 杀死 -9
完毕
8、完成网页抓取
通过以上IP代理筛选系统,筛选出12个国家可用的免费代理IP,完成12个国家的每日网页排名和游戏网页的爬取任务。
之后就是对网页中的游戏属性信息进行提取处理,生成日报,定时发送邮件,查询趋势图。
脚本功能实现
IP代理筛选的基本流程比较简单,其数据格式和实现步骤如下:
首先到网站采集可用的代理IP源(以美国为例),格式如下:
接下来,清除上图中的空格。具体实现命令请参考上面的【方案设计】-》【2、文本预处理】,文本预处理的格式如下:
然后,测试上图文字预处理后的代理IP是否可用,请参考上面的【方案设计】->【3、检测IP代理】。检测到代理IP后的格式如下:
下面介绍shell脚本实现文本预处理和网页过滤的详细步骤
1、文本预处理
[php]查看纯副本
打印?
#fileprocesslog='Top800proxy.log'dtime=$(date+%Y-%m-%d__%H:%M:%S)functionselect_proxy(){if[!-d$dir_split];thenmkdir$dir_splitfiif[!-d $dir_output];thenmkdir$dir_outputfiif[!-e$log];thentouch$logfiecho"==================Top800proxy$dtime========== =======">>$logforfilein`ls$dir_input`;doecho$file>>$logfile_input=$dir_input$fileecho$file_input>>$logfile_split=$dir_split$file"_split"echo$file_split>> $ logrm-rf$file_splittouch$file_splitsed-e"s/\t\{2,\}/\t/g"$file_input>$file_split sed-e"s/\t/:/g"$file_input>$file_split sed -i "s//:/g"$file_splitfile_output=$dir_output$file"_out"echo$file_output>>$logproxy_output"$file_split""$file_output"echo''>>$logdoneecho''>>$log}
脚本功能说明:
if语句判断并创建文件夹$dir_split和$dir_output用于保存处理IP源的中间结果,前者保存【脚本功能实现】中文本预处理后的文本格式,后者保存检测后可用的代理IP
sed -e 语句,将输入文本(图中多个空格1)由脚本函数实现)修改为字符“:”
sed -i 语句进一步将文本中多余的空格转换为字符“:”
转换的中间结果保存到文件夹 $dir_split
以下三行file_output,以文件参数“$file_split”的形式,传递给代理IP检测函数(proxy_output),过滤掉可用的代理IP
2、代理 IP 筛选
[php]查看纯副本
打印?
index=1file_html=$dir_output"html_"cmd=''functionproxy_output(){rm-rf$2touch$2rm-rf$file_html*index=1whilereadlinedoproxy_ip_port=$(echo$line|cut-f1,2 -d":")代理=$proxy_ip_port"echo$proxy>>$logcmd="curl-y60-Y1-m300-x$proxy-o$file_html$index$url_html"echo$cmd>>$log$cmdif[-e./$file_html $index];thenecho$proxy>>$2break;fiindex=`expr$index+1`done>$logecho$url"_____$date">>$log$url_cmd#donetimeoutfileseconds=0while[!-f$url_output$index ]dosleep1echo$url_output$index"________________noexist">>$log$url_cmdseconds=`expr$seconds+1`echo"seconds____________"$seconds>>$logif[$seconds-ge5];thenselect_proxyurl_cmd='curl-y60-Y1-m300 -x'$proxy'-o'$url_output$index''$urlseconds=0fidoneindex=`expr$index+24`done
脚本功能说明:
上面的shell脚本代码片段是用来爬取网页的,其核心行是select_proxy
其功能如上所述。当代理IP突然失效,网页抓取太慢,所有代理IP无效,或者当天的网页抓取工作无法完成时,用于重新筛选代理IP,恢复网页核心刮。代码
它的设计和实现过程,如上面【方案设计】-》【7、重新检测IP代理】,其实现原理可以参考上面【代理IP筛选】的脚本,及其源码这里就不贴了。脚本代码
发表于 2016-04-07 16:18xxxxxxxx1x2xxxxxxx 阅读(390)评论(0)编辑 查看全部
curl 抓取网页(
IP代理筛选系统问题分析分析解决一个问题的原理)
Linux IP代理筛选系统(shell+proxy)
代理的目的
其实,除了使用IP代理爬取国外网页外,还有很多使用代理的场景:
代理原则
代理服务的原理是本地浏览器(Browser)发送请求的数据,而不是直接发送给网站服务器(Web Server)
取而代之的是一个中间代理服务器(Proxy),如下图:
IP代理筛选系统
问题分析
在分析解决一个实际问题的时候,会遇到各种各样的问题,有些问题甚至在方案设计之初都难以想到(比如代理IP爬取网页速度慢)。我的经验是,动手实践比纯理论更重要。重要的!
设计
大体思路:找到并缩小被屏蔽的IP代理的来源-》检查代理IP是否可用-》记录IP抓取网页-》如果代理IP失败重新过滤-》继续抓取网页- “完全的

1、IP代理源
选择有两个原则:可用和免费。经过深入研究和搜索,最终确定两个网站 IP代理更可靠:和
从国家数量、IP代理数量、IP代理的可用性、IP代理的文本格式综合考虑,IP代理的来源主要选择前者,后者作为补充. 后来的实际测试表明,这种初选方案基本满足需要。
2、文本预处理
从获取的代理IP中,有IP地址、端口、类型、匿名性、国家等参数,我们需要的只有IP+端口,所以需要对主IP代理源做文本预处理。
文本空间处理命令:
sed -e "s/\s\{2,\}/:/g" $file_input > $file_split
sed -i "s/ /:/g" $file_split
合并代理 IP (ip:port) 命令:
proxy_ip=$(echo $line | cut -f 1 -d ":")
proxy_port=$(echo $line | cut -f 2 -d ":")
代理=$proxy_ip":"$proxy_port
3、检测IP代理
文本预处理代理IP为标准格式(ip:port)后,需要进行代理IP筛选测试,看看哪些可用哪些不可用(因为获取的部分IP代理源无法使用或下载太慢,需要过滤掉)
curl抓取网页检查IP代理是否可用命令:
cmd="curl -y 60 -Y 1 -m 300 -x$proxy-o $file_html$index $url_html"
$cmd
4、保存IP代理
检查代理IP是否可用,如果可用,保存。
判断代理IP是否可用的标准是判断步骤3下载的网页($file_html$index)是否有内容。具体命令如下:
如果 [ -e ./$file_html$index ]; 然后
回声 $proxy >> $2
休息;
菲
5、IP代理爬取网页
使用第4步保存的代理IP抓取网页,使用代理IP抓取12个国家的排名网页和游戏网页。具体命令如下:
proxy_cmd="curl -y 60 -Y 1 -m 300 -x$proxy-o $proxy_html $proxy_http"
$proxy_cmd
6、IP 代理失败
IP代理失败的案例很多。上面的问题分析中已经列出了几个。下面将详细分析如下:
一种。网页抓取过程中代理IP突然失效,无法继续完成网页抓取
湾。代理IP没有失效,但是网页抓取很慢,一天24小时内无法完成网页抓取,导致无法生成游戏排名日报表
C。所有代理 IP 均无效。无论经过一次或多次轮询测试,当天的网页抓取任务都无法完成。
d。由于全网路由拥塞,代理IP很慢或者无法爬取网页,误判代理IP全部无效。如何恢复和纠正它
7、重新检测IP代理
在网页抓取过程中,面对第6步的IP代理故障,设计合理高效的代理IP抓取恢复机制是整个IP代理筛选系统的核心和关键
故障恢复的轮询和筛选过程如下:

在上述过程中,有几点需要注意:
一种。首先检测最后一个 IP 代理。这是因为上一个(昨天)的IP代理完成了所有的网页爬取任务,它的可用概率比较高,所以优先考虑今天是否可用。如果不可用,请选择另一个
湾。如果今天最后一个代理IP不可用,重新遍历检测代理IP源。一旦检测到可用,就不会循环,更新可用的IP代理并将其位置保存在IP源中,方便下次遍历从这里开始
C。如果进程b中新选择的代理IP突然失效或者网速太慢,继续筛选b中记录的IP源位置是否有以下代理IP。如果可用,继续爬取网页;如果没有,再遍历整个IP源
d。如果再次遍历整个代理IP源,仍然没有可用的代理IP,则重复轮询和遍历整个代理IP源,直到有可用的代理IP或今天24点过去(即没有今天一整天都可以找到可用的代理IP)
e. 对于进程d中所有代理IP都无效,整天找不到可用代理IP的特殊情况,无法完成当天的网页抓取。次日凌晨重启爬网主控脚本之前,需要先杀掉进程。d 后台循环进程,防止今天和次日两个后台抓取程序同时运行(相当于两个异步后台抓取进程),导致抓取的网页排名数据过时或错误,占用网络速度和带宽等。为了杀死当天的死后台爬取进程,请参考上一篇博客Linux爬取网页示例-《自动主控脚本-》kill_curl.sh脚本,
尽管 [ !-z $(ps -ef | grepcurl| grep -v grep | cut -c 9-15) ]
做
ps -ef | grep 卷曲 | grep -v grep | 切-c 15-20 | xargs 杀死 -9
ps -ef | grep 卷曲 | grep -v grep | 切-c 9-15 | xargs 杀死 -9
完毕
8、完成网页抓取
通过以上IP代理筛选系统,筛选出12个国家可用的免费代理IP,完成12个国家的每日网页排名和游戏网页的爬取任务。
之后就是对网页中的游戏属性信息进行提取处理,生成日报,定时发送邮件,查询趋势图。
脚本功能实现
IP代理筛选的基本流程比较简单,其数据格式和实现步骤如下:
首先到网站采集可用的代理IP源(以美国为例),格式如下:

接下来,清除上图中的空格。具体实现命令请参考上面的【方案设计】-》【2、文本预处理】,文本预处理的格式如下:

然后,测试上图文字预处理后的代理IP是否可用,请参考上面的【方案设计】->【3、检测IP代理】。检测到代理IP后的格式如下:

下面介绍shell脚本实现文本预处理和网页过滤的详细步骤
1、文本预处理
[php]查看纯副本
打印?
#fileprocesslog='Top800proxy.log'dtime=$(date+%Y-%m-%d__%H:%M:%S)functionselect_proxy(){if[!-d$dir_split];thenmkdir$dir_splitfiif[!-d $dir_output];thenmkdir$dir_outputfiif[!-e$log];thentouch$logfiecho"==================Top800proxy$dtime========== =======">>$logforfilein`ls$dir_input`;doecho$file>>$logfile_input=$dir_input$fileecho$file_input>>$logfile_split=$dir_split$file"_split"echo$file_split>> $ logrm-rf$file_splittouch$file_splitsed-e"s/\t\{2,\}/\t/g"$file_input>$file_split sed-e"s/\t/:/g"$file_input>$file_split sed -i "s//:/g"$file_splitfile_output=$dir_output$file"_out"echo$file_output>>$logproxy_output"$file_split""$file_output"echo''>>$logdoneecho''>>$log}
脚本功能说明:
if语句判断并创建文件夹$dir_split和$dir_output用于保存处理IP源的中间结果,前者保存【脚本功能实现】中文本预处理后的文本格式,后者保存检测后可用的代理IP
sed -e 语句,将输入文本(图中多个空格1)由脚本函数实现)修改为字符“:”
sed -i 语句进一步将文本中多余的空格转换为字符“:”
转换的中间结果保存到文件夹 $dir_split
以下三行file_output,以文件参数“$file_split”的形式,传递给代理IP检测函数(proxy_output),过滤掉可用的代理IP
2、代理 IP 筛选
[php]查看纯副本
打印?
index=1file_html=$dir_output"html_"cmd=''functionproxy_output(){rm-rf$2touch$2rm-rf$file_html*index=1whilereadlinedoproxy_ip_port=$(echo$line|cut-f1,2 -d":")代理=$proxy_ip_port"echo$proxy>>$logcmd="curl-y60-Y1-m300-x$proxy-o$file_html$index$url_html"echo$cmd>>$log$cmdif[-e./$file_html $index];thenecho$proxy>>$2break;fiindex=`expr$index+1`done>$logecho$url"_____$date">>$log$url_cmd#donetimeoutfileseconds=0while[!-f$url_output$index ]dosleep1echo$url_output$index"________________noexist">>$log$url_cmdseconds=`expr$seconds+1`echo"seconds____________"$seconds>>$logif[$seconds-ge5];thenselect_proxyurl_cmd='curl-y60-Y1-m300 -x'$proxy'-o'$url_output$index''$urlseconds=0fidoneindex=`expr$index+24`done
脚本功能说明:
上面的shell脚本代码片段是用来爬取网页的,其核心行是select_proxy
其功能如上所述。当代理IP突然失效,网页抓取太慢,所有代理IP无效,或者当天的网页抓取工作无法完成时,用于重新筛选代理IP,恢复网页核心刮。代码
它的设计和实现过程,如上面【方案设计】-》【7、重新检测IP代理】,其实现原理可以参考上面【代理IP筛选】的脚本,及其源码这里就不贴了。脚本代码
发表于 2016-04-07 16:18xxxxxxxx1x2xxxxxxx 阅读(390)评论(0)编辑
curl 抓取网页(curl抓取网页方法-上海怡健医学(抓取))
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-04-01 01:05
curl抓取网页方法一:用curl命令下载网页方法二:用wget,git或者其他工具下载网页,后缀是txt文件。我已有的这个回答。
按网址依次点击右键,
wget..,不过没下完的话好像是会自动识别的。之前我抓了一个某个神风已久的比赛,
..这个倒是问的好,需要使用curl,网上大把教程。
有个软件gotoyahoo有源代码,你需要用那个来抓取,
下载javascript、css、json等,看看是不是乱码,对应的js文件或者css文件再json文件的文件名里有没有mode。要先搞清楚txt是怎么回事。
别说百度,一搜都有。
curl+wget
嗯···我也是,但是一抓下来就全变成js代码了。我是抓到n多学校比赛的票之后才发现是个二维码。
要抓百度网页全放倒cookie里吗,
我也经常遇到这种情况,我也是无奈只能等后缀转换工具。
打开浏览器:8000/apacheespresso/file-generate-url2.phpcd$home./javascriptjsgowget 查看全部
curl 抓取网页(curl抓取网页方法-上海怡健医学(抓取))
curl抓取网页方法一:用curl命令下载网页方法二:用wget,git或者其他工具下载网页,后缀是txt文件。我已有的这个回答。
按网址依次点击右键,
wget..,不过没下完的话好像是会自动识别的。之前我抓了一个某个神风已久的比赛,
..这个倒是问的好,需要使用curl,网上大把教程。
有个软件gotoyahoo有源代码,你需要用那个来抓取,
下载javascript、css、json等,看看是不是乱码,对应的js文件或者css文件再json文件的文件名里有没有mode。要先搞清楚txt是怎么回事。
别说百度,一搜都有。
curl+wget
嗯···我也是,但是一抓下来就全变成js代码了。我是抓到n多学校比赛的票之后才发现是个二维码。
要抓百度网页全放倒cookie里吗,
我也经常遇到这种情况,我也是无奈只能等后缀转换工具。
打开浏览器:8000/apacheespresso/file-generate-url2.phpcd$home./javascriptjsgowget
curl 抓取网页(PHP的调用测试(get(get)函数(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-03-30 22:18
)
PHP 的 curl 功能真的很强大。有一个 curl_multi_init 函数,它是批处理任务。可以利用这一点实现多进程同步抓取多条记录,优化常见的网页爬取程序。
一个简单的抓取功能:
function http_get_multi($urls){
$count = count($urls);
$data = [];
$chs = [];
// 创建批处理cURL句柄
$mh = curl_multi_init();
// 创建cURL资源
for($i = 0; $i < $count; $i ++){
$chs[ $i ] = curl_init();
// 设置URL和相应的选项
curl_setopt($chs[ $i ], CURLOPT_RETURNTRANSFER, 1); // return don't print
curl_setopt($chs[ $i ], CURLOPT_URL, $urls[$i]);
curl_setopt($chs[ $i ], CURLOPT_HEADER, 0);
curl_multi_add_handle($mh, $chs[ $i ]);
}
// 增加句柄
// for($i = 0; $i < $count; $i ++){
// curl_multi_add_handle($mh, $chs[ $i ]);
// }
// 执行批处理句柄
do {
$mrc = curl_multi_exec($mh, $active);
} while ($active > 0);
while ($active and $mrc == CURLM_OK) {
if (curl_multi_select($mh) != -1) {
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
}
}
for($i = 0; $i < $count; $i ++){
$content = curl_multi_getcontent($chs[ $i ]);
$data[ $i ] = ( curl_errno($chs[ $i ]) == 0 ) ? $content : false;
}
// 关闭全部句柄
for($i = 0; $i < $count; $i ++){
curl_multi_remove_handle($mh, $chs[ $i ]);
}
curl_multi_close($mh);
return $data;
}
以下调用测试(get() 函数在这里:):
//弄很多个网页的url<br />$url = [
'http://www.baidu.com',
'http://www.163.com',
'http://www.sina.com.cn',
'http://www.qq.com',
'http://www.sohu.com',
'http://www.douban.com',
'http://www.cnblogs.com',
'http://www.taobao.com',
'http://www.php.net',
];
$urls = [];
for($i = 0; $i < 10; $i ++){
foreach($url as $r)
$urls[] = $r . '/?v=' . rand();
} <br /><br />//并发请求
$datas = http_get_multi($urls);
foreach($datas as $key => $data){
file_put_contents('log/multi_' . $key . '.txt', $data); // 记录一下请求结果。记得创建一个log文件夹
}
$t2 = microtime(true);
echo $t2 - $t1;
echo '<br />';<br /><br />//同步请求, get()函数如这里: http://www.cnblogs.com/whatmiss/p/7114954.html
$t1 = microtime(true);
foreach($urls as $key => $url){
file_put_contents('log/get_' . $key . '.txt', get($url)); // 记录一下请求结果。记得创建一个log文件夹
}
$t2 = microtime(true);
echo $t2 - $t1;
在测试结果中,存在明显的差距,并且随着数据量的增加,差距会呈指数级增长:
2.4481401443481
21.68923997879
8.925509929657
24.73141503334
3.243185043335
23.384337902069
3.2841880321503
24.754415035248
3.2091829776764
29.068662881851 查看全部
curl 抓取网页(PHP的调用测试(get(get)函数(图)
)
PHP 的 curl 功能真的很强大。有一个 curl_multi_init 函数,它是批处理任务。可以利用这一点实现多进程同步抓取多条记录,优化常见的网页爬取程序。
一个简单的抓取功能:
function http_get_multi($urls){
$count = count($urls);
$data = [];
$chs = [];
// 创建批处理cURL句柄
$mh = curl_multi_init();
// 创建cURL资源
for($i = 0; $i < $count; $i ++){
$chs[ $i ] = curl_init();
// 设置URL和相应的选项
curl_setopt($chs[ $i ], CURLOPT_RETURNTRANSFER, 1); // return don't print
curl_setopt($chs[ $i ], CURLOPT_URL, $urls[$i]);
curl_setopt($chs[ $i ], CURLOPT_HEADER, 0);
curl_multi_add_handle($mh, $chs[ $i ]);
}
// 增加句柄
// for($i = 0; $i < $count; $i ++){
// curl_multi_add_handle($mh, $chs[ $i ]);
// }
// 执行批处理句柄
do {
$mrc = curl_multi_exec($mh, $active);
} while ($active > 0);
while ($active and $mrc == CURLM_OK) {
if (curl_multi_select($mh) != -1) {
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
}
}
for($i = 0; $i < $count; $i ++){
$content = curl_multi_getcontent($chs[ $i ]);
$data[ $i ] = ( curl_errno($chs[ $i ]) == 0 ) ? $content : false;
}
// 关闭全部句柄
for($i = 0; $i < $count; $i ++){
curl_multi_remove_handle($mh, $chs[ $i ]);
}
curl_multi_close($mh);
return $data;
}
以下调用测试(get() 函数在这里:):
//弄很多个网页的url<br />$url = [
'http://www.baidu.com',
'http://www.163.com',
'http://www.sina.com.cn',
'http://www.qq.com',
'http://www.sohu.com',
'http://www.douban.com',
'http://www.cnblogs.com',
'http://www.taobao.com',
'http://www.php.net',
];
$urls = [];
for($i = 0; $i < 10; $i ++){
foreach($url as $r)
$urls[] = $r . '/?v=' . rand();
} <br /><br />//并发请求
$datas = http_get_multi($urls);
foreach($datas as $key => $data){
file_put_contents('log/multi_' . $key . '.txt', $data); // 记录一下请求结果。记得创建一个log文件夹
}
$t2 = microtime(true);
echo $t2 - $t1;
echo '<br />';<br /><br />//同步请求, get()函数如这里: http://www.cnblogs.com/whatmiss/p/7114954.html
$t1 = microtime(true);
foreach($urls as $key => $url){
file_put_contents('log/get_' . $key . '.txt', get($url)); // 记录一下请求结果。记得创建一个log文件夹
}
$t2 = microtime(true);
echo $t2 - $t1;
在测试结果中,存在明显的差距,并且随着数据量的增加,差距会呈指数级增长:
2.4481401443481
21.68923997879
8.925509929657
24.73141503334
3.243185043335
23.384337902069
3.2841880321503
24.754415035248
3.2091829776764
29.068662881851
curl 抓取网页(curl和js文件怎么做抓取网页。抓包分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-25 01:07
curl抓取网页。fiddler抓包分析http请求,然后就会得到js和css文件。js,css文件不仅仅是静态文件,js一般是表单提交、广告展示等等的实际页面代码,css主要就是图片、样式等等。可以先进行抓包,抓到页面代码后用fiddler可以分析css和js文件。
建议先做一下信息采集
wireshark可以抓到http请求
用sqlmap或者postman
技术这种东西,还是实战出真知吧,用万能的去下载一下,然后用一些插件或者新建一个web标签页访问,
利用浏览器插件如:selenium或httplib,可以抓住动态的js、css文件,动态的页面地址。通过一个http请求,分析js、css文件的处理过程,即可知道抓取页面是否需要动态获取哪些功能。
页面扫描本身就是一门学问
dom扫描
要看是什么样的网站,js,css,js一类的不需要动态获取,抓到后进行简单的css样式的修改加载图片等等。像什么.txt这种网站,看到后直接找对应的js和css,进行搜索。
扫描结果属性里面会告诉你一些网站可能的页面结构,这样查看页面是不是有设计的嫌疑可以判断是否有xss,或者钓鱼行为,另外sqlmap可以直接查询页面的数据,静态页也是如此。 查看全部
curl 抓取网页(curl和js文件怎么做抓取网页。抓包分析)
curl抓取网页。fiddler抓包分析http请求,然后就会得到js和css文件。js,css文件不仅仅是静态文件,js一般是表单提交、广告展示等等的实际页面代码,css主要就是图片、样式等等。可以先进行抓包,抓到页面代码后用fiddler可以分析css和js文件。
建议先做一下信息采集
wireshark可以抓到http请求
用sqlmap或者postman
技术这种东西,还是实战出真知吧,用万能的去下载一下,然后用一些插件或者新建一个web标签页访问,
利用浏览器插件如:selenium或httplib,可以抓住动态的js、css文件,动态的页面地址。通过一个http请求,分析js、css文件的处理过程,即可知道抓取页面是否需要动态获取哪些功能。
页面扫描本身就是一门学问
dom扫描
要看是什么样的网站,js,css,js一类的不需要动态获取,抓到后进行简单的css样式的修改加载图片等等。像什么.txt这种网站,看到后直接找对应的js和css,进行搜索。
扫描结果属性里面会告诉你一些网站可能的页面结构,这样查看页面是不是有设计的嫌疑可以判断是否有xss,或者钓鱼行为,另外sqlmap可以直接查询页面的数据,静态页也是如此。
curl 抓取网页(curl网页数据一般情况下用python开发抓取代码的对接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-03-22 03:08
curl抓取网页数据一般情况下用python开发或者是python的模块封装了抓取的接口,比如:curl()curl_init()http_user_agent()curl_request()python模块:webdriverdriver.from_chrome_webdriver_support()httpdriver.set_tag_format_for('curl',"webdriver/curl")httpdriver.set_header('content-type','application/x-www-form-urlencoded;charset=utf-8')然后,就是自己用python开发抓取代码,跟curl进行实现对接。
再到一些网站比如:.,只需要采用curl进行抓取数据,并传递给driver.page_source即可python模块:curl_get(http_user_agent)curl_request()这些模块有单文件的,也有两个文件的比如我常用的就是curl_get和curl_request.直接打开:driver.page_source就可以抓取到url了其他两个就是抓取工具:curlserver主要抓取http请求,主流的浏览器都可以调用driver.httpcookie主抓取cookie,只有token是可以保存的你如果想抓取一个页面就传递给driver.page_source中的curlserver和driver.httpcookie传递给driver.httpcookie传递给driver.httpcookie传递给driver就是这样。 查看全部
curl 抓取网页(curl网页数据一般情况下用python开发抓取代码的对接)
curl抓取网页数据一般情况下用python开发或者是python的模块封装了抓取的接口,比如:curl()curl_init()http_user_agent()curl_request()python模块:webdriverdriver.from_chrome_webdriver_support()httpdriver.set_tag_format_for('curl',"webdriver/curl")httpdriver.set_header('content-type','application/x-www-form-urlencoded;charset=utf-8')然后,就是自己用python开发抓取代码,跟curl进行实现对接。
再到一些网站比如:.,只需要采用curl进行抓取数据,并传递给driver.page_source即可python模块:curl_get(http_user_agent)curl_request()这些模块有单文件的,也有两个文件的比如我常用的就是curl_get和curl_request.直接打开:driver.page_source就可以抓取到url了其他两个就是抓取工具:curlserver主要抓取http请求,主流的浏览器都可以调用driver.httpcookie主抓取cookie,只有token是可以保存的你如果想抓取一个页面就传递给driver.page_source中的curlserver和driver.httpcookie传递给driver.httpcookie传递给driver.httpcookie传递给driver就是这样。
curl 抓取网页([toc]网络数据收集DataScrapingvsDataCrawling的协调关系)
网站优化 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-03-18 09:20
[目录]
网络数据采集
参考:
数据采集是直接从在线网站 中提取公开可用数据的过程。数据采集不仅依赖于官方信息来源,
保持合法和道德
合法性
道德数据采集
Data Scraping vs DataCrawling 爬取最难区分的事情之一就是如何协调连续爬取。我们的蜘蛛在爬行时需要足够礼貌,以避免目标服务器不堪重负而踢出蜘蛛。最后,不同爬虫之间可能存在冲突,但在数据抓取上不会发生这种情况。
需要爬取解析解析器
数据爬取API数据提取工具
为了防止抓取(也称为 Webscraping、Screenscraping、Web Data Mining、Web Harvesting 或 Web Data Extraction),了解这些抓取工具的工作原理以及了解阻止它们正常工作的原因会很有帮助。
有几种类型的刮刀,每种的工作方式不同:
HTML Parser Shell Script Screenscrapers Web Scraping Service Manual Copy-Paste:人们复制和粘贴内容以在其他地方使用。
这些不同类型的爬虫之间有很多重叠之处,即使它们使用不同的技术和方法,它们的行为也会相似。
网络爬虫基础
例如,如果你使用的是谷歌搜索引擎,爬虫会通过服务器中索引的结果访问指定的页面,然后将其检索并存储在谷歌的服务器中。网络爬虫还通过 网站 中的超链接访问其他 网站。所以当你向搜索引擎询问“软件开发课程”时,所有符合条件的页面都会被返回。网络爬虫被配置为管理这些网页,以便生成的数据快速而新鲜。
大多数网络爬虫会自动将数据转换为用户友好的格式。他们还将它编译成随时可用的可下载包,以便于访问。Google 内部的搜索机制是什么?数据挖掘 当网络爬虫从不同的网站中爬取大量数据时,数据仍然是非结构化的,例如JSON、CSV或XML格式。
数据挖掘就是从这些数据中获取有用的信息。所以你可以说网络爬虫是数据挖掘过程的第一步。
企业越来越重视管理数据挖掘和遵循分析实践。在医学、保险、商业等领域有很多这样的例子。 Image Mining - A Data Mining Application Data Extraction Web Crawling with Apache Nutch
看看 Nutch 的主要构建块 Elasticsearch 如何提取信息。
一些不错的爬虫 Storm-crawler。Elasticsearch 河网。攻击
可能适用于初学者刮刀的事情:
通常有帮助的事情:
有帮助但会让你的用户讨厌你的事情:
防止 网站 爬取
我有一个相当大的音乐 网站 和一个庞大的艺术家数据库。我一直注意到其他音乐网站s 正在抓取我们的网站 数据(我在这里和那里输入虚拟艺术家的名字并在谷歌上搜索它们)。如何防止屏幕划伤?甚至可能吗?
你不能完全阻止它,因为无论你做什么,一个坚固的刮刀仍然可以弄清楚如何刮。但是,可以通过执行以下操作来停止大规模刮擦:
监控日志和流量模式以限制访问
具体来说,一些想法:
使用其他指标:这对于运行 JavaScript 的屏幕抓取工具非常有用,因为可以从中获取大量信息。速率限制:不要暂时阻止访问,而是使用验证码:
安全堆栈交换相关问题:
基于 IP 的限制根本不起作用——这里有太多的公共代理服务器,而且 TOR……它不会减慢爬网速度(对于那些_真的_想要你的数据的人)。
确保所有用户标头都有效
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
---
#### 如果用户代理为空/丢失,则不接受请求
- 通常爬虫不会随其请求发送用户代理标头,而所有浏览器和搜索引擎蜘蛛都会
- 如果收到不存在用户代理标头的请求,可以显示验证码,或者简单地阻止或限制访问。
> 基于**用户代理**的过滤根本没有帮助。任何认真的数据挖掘者都会在他的抓取工具中将其设置为正确的数据。
---
#### 如果用户代理是常见的抓取工具 则不要接受请求 黑名单
- 可以在发现已知屏幕抓取器用户代理字符串时设置黑名单。
- 在某些情况下,scraper 会使用一个没有真正的浏览器或搜索引擎蜘蛛使用的用户代理,例如:
- “Mozilla”(仅此而已,仅此而已。我在这里看到了一些关于抓取的问题,使用它。真正的浏览器永远不会只使用它)
- “Java 1.7.43\_u43”(默认情况下,Java 的 HttpUrlConnection 使用类似的东西。)
- “BIZCO EasyScraping Studio 2.0”
- "wget", "curl", "libcurl",..(Wget 和 cURL 有时用于基本抓取)
- 屏蔽常见的抓取用户代理,你会在主要/大型网站中看到这个,因为你不可能用“python3.4”作为你的用户代理来抓取它们。
- 如果发现网站上的爬虫使用了特定的用户代理字符串,而真实浏览器或合法蜘蛛并未使用该字符串,也可以将其添加到黑名单中。
> 知道自己在做什么的程序员可以设置用户代理字符串来模拟 Web 浏览器。
---
#### 需要注册和登录
- 如果网站可行,则需要创建帐户才能查看内容。这对爬虫来说是一个很好的威慑
- 创建和登录帐户,可以准确地跟踪用户和爬虫操作。
- 可以轻松检测特定帐户何时被用于抓取并禁止它。
- 诸如速率限制或检测滥用(例如短时间内大量搜索)之类的事情变得更容易,因为可以识别特定的抓取工具而不仅仅是 IP 地址。
为了避免脚本创建多个帐户"
- 需要一个用于注册的电子邮件地址,并通过发送必须打开才能激活帐户的链接来验证该电子邮件地址。每个电子邮件地址只允许一个帐户。
- 需要在注册/帐户创建期间解决验证码。
> 需要创建帐户才能查看内容将把用户和搜索引擎赶走;
> 需要创建帐户才能查看文章,用户将前往别处。
> 打败它的最简单方法(无需任何分析和/或编写登录协议脚本)就是以普通用户身份登录站点,使用 Mozilla,然后运行基于 Mozrepl 的抓取工具...
> _要求登录_对匿名机器人有帮助,但对想要抓取数据的人没有帮助。他只是将自己注册到网站作为普通用户。
> 屏幕抓取工具可能会设置一个帐户并可能巧妙地编写脚本来为他们登录。
---
#### 阻止来自云托管和抓取服务 IP 地址的访问
- 有时,抓取工具会通过 Web 托管服务运行,例如 Amazon Web Services 或 GAE,或 VPS。限制来自此类云托管服务使用的 IP 地址的请求访问网站(或显示验证码)。
- 可以限制来自代理或 VPN 提供商使用的 IP 地址的访问,因为抓取工具可能会使用此类代理服务器来避免检测到许多请求。
- 通过阻止来自代理服务器和 VPN 的访问,将对真实用户产生负面影响。
---
#### 使错误消息变得难以描述
如果阻止/限制访问,应该确保没有告诉刮板是什么导致了堵塞,从而为他们提供了如何修复刮板的线索。
不好的错误页面:
- 来自 IP 地址的请求过多,请稍后重试。
- 错误,用户代理标头不存在!
友好的错误消息
- 不会告诉刮板是什么原因造成的
- 抱歉,出了一些问题。如果`helpdesk@example.com`问题仍然存在,可以通过 联系支持。
- 应该考虑为后续请求显示验证码而不是硬块,以防真实用户看到错误消息,这样就不会阻止,从而导致合法用户与联系。
---
#### 使用验证码
- 验证码(“完全自动化的测试以区分计算机和人类”)对于阻止抓取工具非常有效。
- 使用验证码并要求在返回页面之前完成验证。
- 当怀疑可能存在抓取工具并希望停止抓取时,它们非常有用,而且不会阻止访问,以防它不是抓取工具而是真实用户。如果怀疑是抓取工具,可能需要考虑在允许访问内容之前显示验证码。
使用验证码时需要注意的事项:
- 不要自己动手
- 使用类似 Google 的reCaptcha 之类的东西:
- 它比自己实现验证码要容易得多,
- 它比自己可能想出的一些模糊和扭曲的文本解决方案更用户友好(用户通常只需要勾选一个框),
- 而且对于脚本编写者来说,解决它比从站点提供的简单图像要困难得多
- 不要在 HTML 标记中包含验证码的解决方案
- 网站,它_在页面本身中_提供了验证码的解决方案, 使它变得毫无用处。
- 验证码可以批量解决:
- 除非的数据非常有价值,否则不太可能使用这种服务。
- 有验证码解决服务,实际的、低薪的人工批量解决验证码。
- 使用 reCaptcha 是一个好主意,因为它们有保护措施(例如用户有相对较短的时间来解决验证码)。
> **Captcha**(好的 - 像 reCaptcha)有很大帮助
---
#### 将文本内容作为图像提供
- 可以将文本渲染到图像服务器端,然后将其显示出来,这将阻碍简单的抓取工具提取文本。
- 这是非常可靠的,并且比 CAPTCHA 对用户的痛苦要小,这意味着他们将无法剪切和粘贴,并且无法很好地缩放或访问。
- 然而
- 这对屏幕阅读器、搜索引擎、性能以及几乎所有其他方面都是不利的。
- 在某些地方它也是非法的(由于可访问性,例如美国残疾人法案),并且使用某些 OCR 也很容易规避,所以不要这样做。
- 可以用 CSS 精灵做类似的事情,但会遇到同样的问题。
> 很难抓取隐藏在图像中的数据。(例如,简单地将数据转换为服务器端的图像)。
> 使用“tesseract”(OCR)多次有帮助 - 但老实说 - 数据必须值得刮板的麻烦。(很多时候不值得)。
---
#### 不要公开完整数据集
- 如果可行,不要为脚本/机器人提供获取所有数据集的方法。
- 例子:
- 新闻网站,有很多单独的文章。
- 可以使这些文章只能通过站点搜索来访问它们,
- 如果没有站点上 _所有_ 文章及其 URL的列表,则只能通过使用搜索来访问这些文章特征。
- 这意味着想要从网站上删除所有文章的脚本必须搜索可能出现在文章中的所有可能的短语才能找到它们,
- 这将非常耗时,效率极低,并且有望使刮板放弃。
如果出现以下情况,这将无效:
- 机器人/脚本 无论如何都不需要/需要完整的数据集。
- 文章是从类似于`example.com/article.php?articleId=12345`. 这(以及类似的东西)将允许抓取器简单地遍历所有`articleId`s 并以这种方式请求所有文章。
- 还有其他方法可以最终找到所有文章,例如通过编写脚本来跟踪文章中指向其他文章的链接。
- 搜索诸如“and”或“the”之类的内容几乎可以揭示所有内容,因此需要注意这一点。(可以通过仅返回前 10 或 20 个结果来避免这种情况)。
- 需要搜索引擎来查找内容。
---
#### 使用网站的Java小程序或Flash
- 最难的是其使用网站的**Java小程序或Flash**,和小程序使用**安全的HTTPS**内部请求本身
- 目前很少有网站使用它们。
---
#### 加密/编码数
- 仅限小型站点
- 许多提供加密/编码数据的网站,这些数据在任何编程语言中都无法解密,因为加密方法不存在。
- 通过加密和最小化输出(警告:这对大型网站来说这不是一个好主意)在 PHP 网站中实现了这一点,响应总是混乱的内容。
在 PHP 中最小化输出的示例(如何最小化 php 页面 html 输出?):
1
2
3
4
5
6
7
8
9
10
11
12
13
```
不要暴露您的 API、端点和类似的东西:频繁更改 URL 路径可以防止 HTML 解析器和爬虫根据用户的位置更改 HTML 频繁更改 HTML
频繁更改 HTML 和页面结构
如果它不能从标记中找到它需要的东西,爬虫将根据 HTML 的结构来寻找它。
需要注意的事项:
聪明的爬虫仍然可以通过推断实际内容的位置来获取内容
本质上,确保脚本不容易找到每个相似页面的实际需要。
示例:网站 上有一个搜索功能,位于 /search?query=somesearchquery,它返回以下 HTML:
1
2
3
4
5
6
Stack Overflow has become the world's most popular programming Q & A website
The website Stack Overflow has now become the most popular programming Q & A website, with 10 million questions and many users, which...
Read more</a>
(And so on, lots more identically structured divs with search results)
</p>
1
2
3
4
5
6
7
8
9
10
11
12
Stack Overflow has become the world's most popular programming Q & A website
The website Stack Overflow has now become the most popular programming Q & A website, with 10 million questions and many users, which...
Read more</a>
Visit Example.com now, for all the latest Stack Overflow related news !
Example.com is so awesome, visit now !</p>
Visit Now !</a>
(More real search results follow)
</p>
这意味着根据类或 ID 从 HTML 中提取数据的爬虫似乎会继续工作,但它们会得到假数据,甚至是真实用户永远看不到的广告,因为它们被 CSS 隐藏了。
将虚假的、不可见的蜜罐数据插入页面
1
2
3
4
5
6
This search result is here to prevent scraping
<p class="/spanspan class="n"search/spanspan class="o"-/spanspan class="n"result/spanspan class="o"-/spanspan class="n"excerpt/spanspan class="s"">If you are a human and see this, please ignore it. If you are a scraper, please click the link below :-) Note that clicking the link below will block access to this site for 24 hours.
<a class"/spanspan class="n"search/spanspan class="o"-/spanspan class="n"result/spanspan class="o"-/spanspan class="n"link/spanspan class="s"" href="/spanspan class="o"//spanspan class="n"scrapertrap/spanspan class="o"//spanspan class="n"scrapertrap/spanspan class="o"./spanspan class="na"php/spanspan class="err""/spanspan class="o">I am a scraper !
(The actual, real, search results follow.)
</p>
将不可见的蜜罐项添加到 HTML 以捕获刮板。
scrapertrap.php 可以做点什么吗
将此与之前频繁更改 HTML 的技术结合起来。
如果检测到爬虫,则提供虚假和无用的数据 如果它不请求资产(CSS、图像),则它不是真正的浏览器。使用和需要 cookie 跟踪用户和抓取操作 使用 cookie 可能不起作用,因为爬虫也可以发送带有请求的 cookie 并根据需要丢弃它们。如果该站点仅使用 cookie,它还将阻止禁用 cookie 的真实用户访问。使用 JavaScript 设置和检索 cookie 将阻止不运行 JavaScript 的爬虫,因为它们无法检索和发送带有请求的 cookie。
–
使用 JavaScript + Ajax 加载内容
意识到:
混淆标签、来自脚本的网络请求以及其他所有内容。如果您确实使用 Ajax 加载数据,您应该在不先加载页面的情况下使端点难以使用
例如,一些会话密钥需要作为参数,可以嵌入到 JavaScript 或 HTML 中。
混淆后的数据也可以直接嵌入到初始 HTML 页面中,使用 JavaScript 进行去混淆和显示,从而避免额外的网络请求。这样做会使使用不运行 JavaScript 的纯 HTML 解析器提取数据变得更加困难,因为编写爬虫程序的人必须对 JavaScript 进行逆向工程(并且应该对其进行混淆)。
但是,这样做有几个缺点:
非技术性使数据可用,提供各种 API 的 robots.txt
假设 robots.txt 已经设置好了。
正如其他人所提到的,爬虫几乎可以伪造其活动的每个方面,并且很难识别来自不良行为者的请求。
考虑:
设置一个页面,/jail.html。禁止访问 robots.txt 页面(因此受人尊敬的蜘蛛永远不会访问)。在其中一个页面上放置一个链接,用 CSS 隐藏它( display: none )。将访问者的 IP 地址记录到 /jail.html。
如果一个特定的IP地址访问速度非常快,那么在几次访问之后(5-10)把它的IP地址+浏览器信息放到一个文件或数据库中。(这将是一个后台进程并且一直运行或者安排在几分钟内。)制作另一个脚本来继续检查那些可疑的 IP 地址。
如果用户代理是已知的搜索引擎,例如 Google、Bing、Yahoo(您可以通过谷歌搜索找到有关用户代理的更多信息)。那你得看看。此列表并尝试匹配模式。如果它看起来像一个假的用户代理,请在下次访问时要求验证码。(需要对机器人 IP 地址进行更多研究。我知道这是可能的,也可以尝试使用 whois 作为 IP 地址。它可能会有所帮助。) 没有搜索机器人的用户代理:只要求下次访问 填写验证码。
第一的:
不值得尝试使用一些技术障碍,导致:
纯 HMTL
可以动态生成 HTML 结构,以及 CSS 类名(和 CSS 本身)(例如,通过使用一些随机类名)
没有办法改变每个响应的结构,因为普通用户会讨厌它。此外,这会比刮刀造成更多的麻烦(维护)。XPath 或 CSS 路径可以通过基于已知内容的爬网脚本自动确定。
Ajax - 一开始有点难,但很多时候加速了抓取过程:) - 为什么?
所以,_ajax_ 并没有多大帮助......
使用大量 javascript 函数的页面。
这里可以使用两种基本方法:
这种抓取速度很慢(抓取是在常规浏览器中完成的),但它是
请记住:如果您想(以友好的方式)向普通用户发布数据,隐藏数据几乎是不可能的。
所以,
设置正确的使用权限(例如必须引用来源) 许多数据没有版权 - 很难保护它们 添加一些虚假数据(如已经完成的那样)并使用合法工具
一个快速的方法是设置一个诱杀/机器人陷阱。
制作一个页面,如果它打开一定次数或根本不打开,则采集某些信息,如 IP 等(也可以考虑违规或模式,但页面根本不必打开)。
在使用 CSS 隐藏的页面中创建指向此内容的链接 display:none; . 或左:-9999px;位置:绝对;尝试将其放置在不太可能被忽略的位置,例如内容而不是页脚的位置,因为有时机器人会选择忘记页面的某些部分。
在 robots.txt 文件中,为不希望友好机器人(哈哈,就像他们有笑脸!)的页面设置一大堆无规则来采集信息并使此页面成为其中之一。
现在,如果一个友好的机器人通过它应该忽略该页面。是的,但这还不够好。制作更多这些页面或以某种方式重新路由页面以接受不同的名称。然后在 robots.txt 文件中的这些陷阱页面旁边放置更多阻止规则,以及您要忽略的页面。
采集这些机器人或访问这些页面的任何人的 IP,不要禁止它们,但可以在内容中显示混乱的文本,如随机数、版权声明、特定文本字符串、显示可怕的图片,基本上是任何妨碍它们的东西好的内容。也可以设置一个链接到一个需要永远加载的页面,即。在 php 中,您可以使用 sleep() 函数。如果它有某种检测来绕过加载时间过长的页面,这将反击爬虫,因为一些编写良好的机器人被设置为一次处理 X 个链接。
制作特定的文本字符串/句子,转到您最喜欢的搜索引擎并搜索它们,它可能会显示内容的结束位置。
无论如何,如果从战术上和创造性地思考,这可能是一个很好的起点。最好的方法是了解机器人的工作原理。
我还会考虑欺骗页面元素上的某些 ID 或属性的显示方式:
1
<a class="someclass" href="../xyz/abc" rel="nofollow" title="sometitle">
它每次都会改变其形式,因为可能会设置一些机器人来寻找页面或目标元素中的特定模式。
1
2
3
<a title="sometitle" href="../xyz/abc" rel="nofollow" class="someclass">
id="p-12802" > id="p-00392"
预格式化文本
. 查看全部
curl 抓取网页([toc]网络数据收集DataScrapingvsDataCrawling的协调关系)
[目录]
网络数据采集

参考:
数据采集是直接从在线网站 中提取公开可用数据的过程。数据采集不仅依赖于官方信息来源,
保持合法和道德
合法性
道德数据采集
Data Scraping vs DataCrawling 爬取最难区分的事情之一就是如何协调连续爬取。我们的蜘蛛在爬行时需要足够礼貌,以避免目标服务器不堪重负而踢出蜘蛛。最后,不同爬虫之间可能存在冲突,但在数据抓取上不会发生这种情况。
需要爬取解析解析器
数据爬取API数据提取工具
为了防止抓取(也称为 Webscraping、Screenscraping、Web Data Mining、Web Harvesting 或 Web Data Extraction),了解这些抓取工具的工作原理以及了解阻止它们正常工作的原因会很有帮助。
有几种类型的刮刀,每种的工作方式不同:
HTML Parser Shell Script Screenscrapers Web Scraping Service Manual Copy-Paste:人们复制和粘贴内容以在其他地方使用。
这些不同类型的爬虫之间有很多重叠之处,即使它们使用不同的技术和方法,它们的行为也会相似。
网络爬虫基础
例如,如果你使用的是谷歌搜索引擎,爬虫会通过服务器中索引的结果访问指定的页面,然后将其检索并存储在谷歌的服务器中。网络爬虫还通过 网站 中的超链接访问其他 网站。所以当你向搜索引擎询问“软件开发课程”时,所有符合条件的页面都会被返回。网络爬虫被配置为管理这些网页,以便生成的数据快速而新鲜。
大多数网络爬虫会自动将数据转换为用户友好的格式。他们还将它编译成随时可用的可下载包,以便于访问。Google 内部的搜索机制是什么?数据挖掘 当网络爬虫从不同的网站中爬取大量数据时,数据仍然是非结构化的,例如JSON、CSV或XML格式。
数据挖掘就是从这些数据中获取有用的信息。所以你可以说网络爬虫是数据挖掘过程的第一步。
企业越来越重视管理数据挖掘和遵循分析实践。在医学、保险、商业等领域有很多这样的例子。 Image Mining - A Data Mining Application Data Extraction Web Crawling with Apache Nutch
看看 Nutch 的主要构建块 Elasticsearch 如何提取信息。

一些不错的爬虫 Storm-crawler。Elasticsearch 河网。攻击
可能适用于初学者刮刀的事情:
通常有帮助的事情:
有帮助但会让你的用户讨厌你的事情:
防止 网站 爬取
我有一个相当大的音乐 网站 和一个庞大的艺术家数据库。我一直注意到其他音乐网站s 正在抓取我们的网站 数据(我在这里和那里输入虚拟艺术家的名字并在谷歌上搜索它们)。如何防止屏幕划伤?甚至可能吗?
你不能完全阻止它,因为无论你做什么,一个坚固的刮刀仍然可以弄清楚如何刮。但是,可以通过执行以下操作来停止大规模刮擦:
监控日志和流量模式以限制访问
具体来说,一些想法:
使用其他指标:这对于运行 JavaScript 的屏幕抓取工具非常有用,因为可以从中获取大量信息。速率限制:不要暂时阻止访问,而是使用验证码:
安全堆栈交换相关问题:
基于 IP 的限制根本不起作用——这里有太多的公共代理服务器,而且 TOR……它不会减慢爬网速度(对于那些_真的_想要你的数据的人)。
确保所有用户标头都有效
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
---
#### 如果用户代理为空/丢失,则不接受请求
- 通常爬虫不会随其请求发送用户代理标头,而所有浏览器和搜索引擎蜘蛛都会
- 如果收到不存在用户代理标头的请求,可以显示验证码,或者简单地阻止或限制访问。
> 基于**用户代理**的过滤根本没有帮助。任何认真的数据挖掘者都会在他的抓取工具中将其设置为正确的数据。
---
#### 如果用户代理是常见的抓取工具 则不要接受请求 黑名单
- 可以在发现已知屏幕抓取器用户代理字符串时设置黑名单。
- 在某些情况下,scraper 会使用一个没有真正的浏览器或搜索引擎蜘蛛使用的用户代理,例如:
- “Mozilla”(仅此而已,仅此而已。我在这里看到了一些关于抓取的问题,使用它。真正的浏览器永远不会只使用它)
- “Java 1.7.43\_u43”(默认情况下,Java 的 HttpUrlConnection 使用类似的东西。)
- “BIZCO EasyScraping Studio 2.0”
- "wget", "curl", "libcurl",..(Wget 和 cURL 有时用于基本抓取)
- 屏蔽常见的抓取用户代理,你会在主要/大型网站中看到这个,因为你不可能用“python3.4”作为你的用户代理来抓取它们。
- 如果发现网站上的爬虫使用了特定的用户代理字符串,而真实浏览器或合法蜘蛛并未使用该字符串,也可以将其添加到黑名单中。
> 知道自己在做什么的程序员可以设置用户代理字符串来模拟 Web 浏览器。
---
#### 需要注册和登录
- 如果网站可行,则需要创建帐户才能查看内容。这对爬虫来说是一个很好的威慑
- 创建和登录帐户,可以准确地跟踪用户和爬虫操作。
- 可以轻松检测特定帐户何时被用于抓取并禁止它。
- 诸如速率限制或检测滥用(例如短时间内大量搜索)之类的事情变得更容易,因为可以识别特定的抓取工具而不仅仅是 IP 地址。
为了避免脚本创建多个帐户"
- 需要一个用于注册的电子邮件地址,并通过发送必须打开才能激活帐户的链接来验证该电子邮件地址。每个电子邮件地址只允许一个帐户。
- 需要在注册/帐户创建期间解决验证码。
> 需要创建帐户才能查看内容将把用户和搜索引擎赶走;
> 需要创建帐户才能查看文章,用户将前往别处。
> 打败它的最简单方法(无需任何分析和/或编写登录协议脚本)就是以普通用户身份登录站点,使用 Mozilla,然后运行基于 Mozrepl 的抓取工具...
> _要求登录_对匿名机器人有帮助,但对想要抓取数据的人没有帮助。他只是将自己注册到网站作为普通用户。
> 屏幕抓取工具可能会设置一个帐户并可能巧妙地编写脚本来为他们登录。
---
#### 阻止来自云托管和抓取服务 IP 地址的访问
- 有时,抓取工具会通过 Web 托管服务运行,例如 Amazon Web Services 或 GAE,或 VPS。限制来自此类云托管服务使用的 IP 地址的请求访问网站(或显示验证码)。
- 可以限制来自代理或 VPN 提供商使用的 IP 地址的访问,因为抓取工具可能会使用此类代理服务器来避免检测到许多请求。
- 通过阻止来自代理服务器和 VPN 的访问,将对真实用户产生负面影响。
---
#### 使错误消息变得难以描述
如果阻止/限制访问,应该确保没有告诉刮板是什么导致了堵塞,从而为他们提供了如何修复刮板的线索。
不好的错误页面:
- 来自 IP 地址的请求过多,请稍后重试。
- 错误,用户代理标头不存在!
友好的错误消息
- 不会告诉刮板是什么原因造成的
- 抱歉,出了一些问题。如果`helpdesk@example.com`问题仍然存在,可以通过 联系支持。
- 应该考虑为后续请求显示验证码而不是硬块,以防真实用户看到错误消息,这样就不会阻止,从而导致合法用户与联系。
---
#### 使用验证码
- 验证码(“完全自动化的测试以区分计算机和人类”)对于阻止抓取工具非常有效。
- 使用验证码并要求在返回页面之前完成验证。
- 当怀疑可能存在抓取工具并希望停止抓取时,它们非常有用,而且不会阻止访问,以防它不是抓取工具而是真实用户。如果怀疑是抓取工具,可能需要考虑在允许访问内容之前显示验证码。
使用验证码时需要注意的事项:
- 不要自己动手
- 使用类似 Google 的reCaptcha 之类的东西:
- 它比自己实现验证码要容易得多,
- 它比自己可能想出的一些模糊和扭曲的文本解决方案更用户友好(用户通常只需要勾选一个框),
- 而且对于脚本编写者来说,解决它比从站点提供的简单图像要困难得多
- 不要在 HTML 标记中包含验证码的解决方案
- 网站,它_在页面本身中_提供了验证码的解决方案, 使它变得毫无用处。
- 验证码可以批量解决:
- 除非的数据非常有价值,否则不太可能使用这种服务。
- 有验证码解决服务,实际的、低薪的人工批量解决验证码。
- 使用 reCaptcha 是一个好主意,因为它们有保护措施(例如用户有相对较短的时间来解决验证码)。
> **Captcha**(好的 - 像 reCaptcha)有很大帮助
---
#### 将文本内容作为图像提供
- 可以将文本渲染到图像服务器端,然后将其显示出来,这将阻碍简单的抓取工具提取文本。
- 这是非常可靠的,并且比 CAPTCHA 对用户的痛苦要小,这意味着他们将无法剪切和粘贴,并且无法很好地缩放或访问。
- 然而
- 这对屏幕阅读器、搜索引擎、性能以及几乎所有其他方面都是不利的。
- 在某些地方它也是非法的(由于可访问性,例如美国残疾人法案),并且使用某些 OCR 也很容易规避,所以不要这样做。
- 可以用 CSS 精灵做类似的事情,但会遇到同样的问题。
> 很难抓取隐藏在图像中的数据。(例如,简单地将数据转换为服务器端的图像)。
> 使用“tesseract”(OCR)多次有帮助 - 但老实说 - 数据必须值得刮板的麻烦。(很多时候不值得)。
---
#### 不要公开完整数据集
- 如果可行,不要为脚本/机器人提供获取所有数据集的方法。
- 例子:
- 新闻网站,有很多单独的文章。
- 可以使这些文章只能通过站点搜索来访问它们,
- 如果没有站点上 _所有_ 文章及其 URL的列表,则只能通过使用搜索来访问这些文章特征。
- 这意味着想要从网站上删除所有文章的脚本必须搜索可能出现在文章中的所有可能的短语才能找到它们,
- 这将非常耗时,效率极低,并且有望使刮板放弃。
如果出现以下情况,这将无效:
- 机器人/脚本 无论如何都不需要/需要完整的数据集。
- 文章是从类似于`example.com/article.php?articleId=12345`. 这(以及类似的东西)将允许抓取器简单地遍历所有`articleId`s 并以这种方式请求所有文章。
- 还有其他方法可以最终找到所有文章,例如通过编写脚本来跟踪文章中指向其他文章的链接。
- 搜索诸如“and”或“the”之类的内容几乎可以揭示所有内容,因此需要注意这一点。(可以通过仅返回前 10 或 20 个结果来避免这种情况)。
- 需要搜索引擎来查找内容。
---
#### 使用网站的Java小程序或Flash
- 最难的是其使用网站的**Java小程序或Flash**,和小程序使用**安全的HTTPS**内部请求本身
- 目前很少有网站使用它们。
---
#### 加密/编码数
- 仅限小型站点
- 许多提供加密/编码数据的网站,这些数据在任何编程语言中都无法解密,因为加密方法不存在。
- 通过加密和最小化输出(警告:这对大型网站来说这不是一个好主意)在 PHP 网站中实现了这一点,响应总是混乱的内容。
在 PHP 中最小化输出的示例(如何最小化 php 页面 html 输出?):
1
2
3
4
5
6
7
8
9
10
11
12
13
```
不要暴露您的 API、端点和类似的东西:频繁更改 URL 路径可以防止 HTML 解析器和爬虫根据用户的位置更改 HTML 频繁更改 HTML
频繁更改 HTML 和页面结构
如果它不能从标记中找到它需要的东西,爬虫将根据 HTML 的结构来寻找它。
需要注意的事项:
聪明的爬虫仍然可以通过推断实际内容的位置来获取内容
本质上,确保脚本不容易找到每个相似页面的实际需要。
示例:网站 上有一个搜索功能,位于 /search?query=somesearchquery,它返回以下 HTML:
1
2
3
4
5
6
Stack Overflow has become the world's most popular programming Q & A website
The website Stack Overflow has now become the most popular programming Q & A website, with 10 million questions and many users, which...
Read more</a>
(And so on, lots more identically structured divs with search results)
</p>
1
2
3
4
5
6
7
8
9
10
11
12
Stack Overflow has become the world's most popular programming Q & A website
The website Stack Overflow has now become the most popular programming Q & A website, with 10 million questions and many users, which...
Read more</a>
Visit Example.com now, for all the latest Stack Overflow related news !
Example.com is so awesome, visit now !</p>
Visit Now !</a>
(More real search results follow)
</p>
这意味着根据类或 ID 从 HTML 中提取数据的爬虫似乎会继续工作,但它们会得到假数据,甚至是真实用户永远看不到的广告,因为它们被 CSS 隐藏了。
将虚假的、不可见的蜜罐数据插入页面
1
2
3
4
5
6
This search result is here to prevent scraping
<p class="/spanspan class="n"search/spanspan class="o"-/spanspan class="n"result/spanspan class="o"-/spanspan class="n"excerpt/spanspan class="s"">If you are a human and see this, please ignore it. If you are a scraper, please click the link below :-) Note that clicking the link below will block access to this site for 24 hours.
<a class"/spanspan class="n"search/spanspan class="o"-/spanspan class="n"result/spanspan class="o"-/spanspan class="n"link/spanspan class="s"" href="/spanspan class="o"//spanspan class="n"scrapertrap/spanspan class="o"//spanspan class="n"scrapertrap/spanspan class="o"./spanspan class="na"php/spanspan class="err""/spanspan class="o">I am a scraper !
(The actual, real, search results follow.)
</p>
将不可见的蜜罐项添加到 HTML 以捕获刮板。
scrapertrap.php 可以做点什么吗
将此与之前频繁更改 HTML 的技术结合起来。
如果检测到爬虫,则提供虚假和无用的数据 如果它不请求资产(CSS、图像),则它不是真正的浏览器。使用和需要 cookie 跟踪用户和抓取操作 使用 cookie 可能不起作用,因为爬虫也可以发送带有请求的 cookie 并根据需要丢弃它们。如果该站点仅使用 cookie,它还将阻止禁用 cookie 的真实用户访问。使用 JavaScript 设置和检索 cookie 将阻止不运行 JavaScript 的爬虫,因为它们无法检索和发送带有请求的 cookie。
–
使用 JavaScript + Ajax 加载内容
意识到:
混淆标签、来自脚本的网络请求以及其他所有内容。如果您确实使用 Ajax 加载数据,您应该在不先加载页面的情况下使端点难以使用
例如,一些会话密钥需要作为参数,可以嵌入到 JavaScript 或 HTML 中。
混淆后的数据也可以直接嵌入到初始 HTML 页面中,使用 JavaScript 进行去混淆和显示,从而避免额外的网络请求。这样做会使使用不运行 JavaScript 的纯 HTML 解析器提取数据变得更加困难,因为编写爬虫程序的人必须对 JavaScript 进行逆向工程(并且应该对其进行混淆)。
但是,这样做有几个缺点:
非技术性使数据可用,提供各种 API 的 robots.txt
假设 robots.txt 已经设置好了。
正如其他人所提到的,爬虫几乎可以伪造其活动的每个方面,并且很难识别来自不良行为者的请求。
考虑:
设置一个页面,/jail.html。禁止访问 robots.txt 页面(因此受人尊敬的蜘蛛永远不会访问)。在其中一个页面上放置一个链接,用 CSS 隐藏它( display: none )。将访问者的 IP 地址记录到 /jail.html。
如果一个特定的IP地址访问速度非常快,那么在几次访问之后(5-10)把它的IP地址+浏览器信息放到一个文件或数据库中。(这将是一个后台进程并且一直运行或者安排在几分钟内。)制作另一个脚本来继续检查那些可疑的 IP 地址。
如果用户代理是已知的搜索引擎,例如 Google、Bing、Yahoo(您可以通过谷歌搜索找到有关用户代理的更多信息)。那你得看看。此列表并尝试匹配模式。如果它看起来像一个假的用户代理,请在下次访问时要求验证码。(需要对机器人 IP 地址进行更多研究。我知道这是可能的,也可以尝试使用 whois 作为 IP 地址。它可能会有所帮助。) 没有搜索机器人的用户代理:只要求下次访问 填写验证码。
第一的:
不值得尝试使用一些技术障碍,导致:
纯 HMTL
可以动态生成 HTML 结构,以及 CSS 类名(和 CSS 本身)(例如,通过使用一些随机类名)
没有办法改变每个响应的结构,因为普通用户会讨厌它。此外,这会比刮刀造成更多的麻烦(维护)。XPath 或 CSS 路径可以通过基于已知内容的爬网脚本自动确定。
Ajax - 一开始有点难,但很多时候加速了抓取过程:) - 为什么?
所以,_ajax_ 并没有多大帮助......
使用大量 javascript 函数的页面。
这里可以使用两种基本方法:
这种抓取速度很慢(抓取是在常规浏览器中完成的),但它是
请记住:如果您想(以友好的方式)向普通用户发布数据,隐藏数据几乎是不可能的。
所以,
设置正确的使用权限(例如必须引用来源) 许多数据没有版权 - 很难保护它们 添加一些虚假数据(如已经完成的那样)并使用合法工具
一个快速的方法是设置一个诱杀/机器人陷阱。
制作一个页面,如果它打开一定次数或根本不打开,则采集某些信息,如 IP 等(也可以考虑违规或模式,但页面根本不必打开)。
在使用 CSS 隐藏的页面中创建指向此内容的链接 display:none; . 或左:-9999px;位置:绝对;尝试将其放置在不太可能被忽略的位置,例如内容而不是页脚的位置,因为有时机器人会选择忘记页面的某些部分。
在 robots.txt 文件中,为不希望友好机器人(哈哈,就像他们有笑脸!)的页面设置一大堆无规则来采集信息并使此页面成为其中之一。
现在,如果一个友好的机器人通过它应该忽略该页面。是的,但这还不够好。制作更多这些页面或以某种方式重新路由页面以接受不同的名称。然后在 robots.txt 文件中的这些陷阱页面旁边放置更多阻止规则,以及您要忽略的页面。
采集这些机器人或访问这些页面的任何人的 IP,不要禁止它们,但可以在内容中显示混乱的文本,如随机数、版权声明、特定文本字符串、显示可怕的图片,基本上是任何妨碍它们的东西好的内容。也可以设置一个链接到一个需要永远加载的页面,即。在 php 中,您可以使用 sleep() 函数。如果它有某种检测来绕过加载时间过长的页面,这将反击爬虫,因为一些编写良好的机器人被设置为一次处理 X 个链接。
制作特定的文本字符串/句子,转到您最喜欢的搜索引擎并搜索它们,它可能会显示内容的结束位置。
无论如何,如果从战术上和创造性地思考,这可能是一个很好的起点。最好的方法是了解机器人的工作原理。
我还会考虑欺骗页面元素上的某些 ID 或属性的显示方式:
1
<a class="someclass" href="../xyz/abc" rel="nofollow" title="sometitle">
它每次都会改变其形式,因为可能会设置一些机器人来寻找页面或目标元素中的特定模式。
1
2
3
<a title="sometitle" href="../xyz/abc" rel="nofollow" class="someclass">
id="p-12802" > id="p-00392"
预格式化文本
.
curl 抓取网页( PHP的curl()使用总结及使用的使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2022-03-11 04:16
PHP的curl()使用总结及使用的使用)
PHP模拟登录并获取数据
CURL 是一个强大的 PHP 库。使用PHP的cURL库,可以简单有效的抓取网页和采集内容,设置cookie完成模拟登录网页,curl提供了丰富的功能,开发者可以参考PHP手册了解cURL的更多信息。本文以开源中国(oschina)的模拟登录为例,与大家分享cURL的使用。
PHP 的 curl() 爬取网页的效率相对较高,并且支持多线程,而 file_get_contents() 的效率略低。当然,使用 curl 时需要启用 curl 扩展。
代码实战
我们先看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
login_post()函数首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的url地址、保存的cookie文件、post数据(用户名和密码等)、是否提交返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自己的 http_build_query() 可以将数组转换为连接字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们将CURLOPT_RETURNTRANSFER设置为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功后才能获取的有用信息。下面我们以登录开源中国手机版为例,看看登录成功后如何获取信息。
//设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址
$url = "http://m.oschina.net/action/user/login";
//设置cookie保存路径
$cookie = dirname(__FILE__) . '/cookie_oschina.txt';
//登录后要获取信息的地址
$url2 = "http://m.oschina.net/my";
//模拟登录
login_post($url, $cookie, $post);
//获取登录页的信息
$content = get_content($url2, $cookie);
//删除cookie文件
@ unlink($cookie);
//匹配页面信息
$preg = "/(.*)/i";
preg_match_all($preg, $content, $arr);
$str = $arr[1][0];
//输出内容
echo $str;
运行上述代码后,我们会看到最终得到了登录用户的头像。
使用总结
1、初始化卷曲;
2、使用 curl_setopt 设置目标 url 等选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、输出数据。
参考
《php中curl和curl的介绍》,作者不详,
Veda 的“使用 PHP CURL 发布数据”,
《php使用curl模拟登录discuz并模拟发帖》,作者:天心,
免责声明:本文为原创文章,版权归作者所有。如需转载,请注明出处并保留原文链接: 查看全部
curl 抓取网页(
PHP的curl()使用总结及使用的使用)
PHP模拟登录并获取数据
CURL 是一个强大的 PHP 库。使用PHP的cURL库,可以简单有效的抓取网页和采集内容,设置cookie完成模拟登录网页,curl提供了丰富的功能,开发者可以参考PHP手册了解cURL的更多信息。本文以开源中国(oschina)的模拟登录为例,与大家分享cURL的使用。
PHP 的 curl() 爬取网页的效率相对较高,并且支持多线程,而 file_get_contents() 的效率略低。当然,使用 curl 时需要启用 curl 扩展。
代码实战
我们先看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
login_post()函数首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的url地址、保存的cookie文件、post数据(用户名和密码等)、是否提交返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自己的 http_build_query() 可以将数组转换为连接字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们将CURLOPT_RETURNTRANSFER设置为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功后才能获取的有用信息。下面我们以登录开源中国手机版为例,看看登录成功后如何获取信息。
//设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址
$url = "http://m.oschina.net/action/user/login";
//设置cookie保存路径
$cookie = dirname(__FILE__) . '/cookie_oschina.txt';
//登录后要获取信息的地址
$url2 = "http://m.oschina.net/my";
//模拟登录
login_post($url, $cookie, $post);
//获取登录页的信息
$content = get_content($url2, $cookie);
//删除cookie文件
@ unlink($cookie);
//匹配页面信息
$preg = "/(.*)/i";
preg_match_all($preg, $content, $arr);
$str = $arr[1][0];
//输出内容
echo $str;
运行上述代码后,我们会看到最终得到了登录用户的头像。

使用总结
1、初始化卷曲;
2、使用 curl_setopt 设置目标 url 等选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、输出数据。
参考
《php中curl和curl的介绍》,作者不详,
Veda 的“使用 PHP CURL 发布数据”,
《php使用curl模拟登录discuz并模拟发帖》,作者:天心,
免责声明:本文为原创文章,版权归作者所有。如需转载,请注明出处并保留原文链接:
curl 抓取网页(你的PHP代码并没有出错(1)_光明网(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-10 17:21
)
用 curl 单独获取是可行的,但是如果你抓取一系列相同类型的 网站 会报错,把它们放到一个数组中
$linkList 分别以此类推。
function getJobsHubuNotice()
{
$curl = curl_init('http://jobs.hubu.edu.cn/List.aspx?ArticleChannelId=81');
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
$result = curl_exec($curl);
//内容处理
$result = strip_tags($result,'<a>');
$result = stristr($result, 'nbsp当前位置:');
$result = str_replace('nbsp当前位置:', '', $result);
$result = stristr($result, '当前1/2页',true);
$result = stristr($result, '通知公告');
$result = str_replace('通知公告</a>', '', $result);
preg_match_all('/(? 通知公告', '', $result);
$result = stristr($result, '$(document).ready',true);
$result = trim($result);
$result = str_replace("\r\n", '
', $result);
$result = preg_replace('/(\){1,}/', '
', $result);
echo $result;
echo '
';
echo "退出makePage函数";
return $result;
}
}
先使用getJobsHubuNotice()函数获取新闻链接、标题、日期,再使用makePage()函数获取内容
这是在 makePage 中打印链接的结果,使用浏览器打开链接没有问题。
您的 PHP 代码中没有错误。初步怀疑是你在请求中传入的url不正确,如下图所示:
您代码中的错误输出实际上是您获得的网页上的输出。
再次更新,我想我知道你的要求有什么问题:
你从网页得到的URL地址是:Detail.aspx?ArticleChannelId=81&ArticleId=2777,
其中&字符是&的HTML实体字符,当你输出的时候(也就是在你的截图中),它显示&,而当你去真正的请求时,它使用了下面的东西:
您只需要恢复它,或者简单地将URL中的&替换为&,然后转到请求就可以了。
再次更新:
<p> 查看全部
curl 抓取网页(你的PHP代码并没有出错(1)_光明网(组图)
)
用 curl 单独获取是可行的,但是如果你抓取一系列相同类型的 网站 会报错,把它们放到一个数组中
$linkList 分别以此类推。

function getJobsHubuNotice()
{
$curl = curl_init('http://jobs.hubu.edu.cn/List.aspx?ArticleChannelId=81');
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
$result = curl_exec($curl);
//内容处理
$result = strip_tags($result,'<a>');
$result = stristr($result, 'nbsp当前位置:');
$result = str_replace('nbsp当前位置:', '', $result);
$result = stristr($result, '当前1/2页',true);
$result = stristr($result, '通知公告');
$result = str_replace('通知公告</a>', '', $result);
preg_match_all('/(? 通知公告', '', $result);
$result = stristr($result, '$(document).ready',true);
$result = trim($result);
$result = str_replace("\r\n", '
', $result);
$result = preg_replace('/(\){1,}/', '
', $result);
echo $result;
echo '
';
echo "退出makePage函数";
return $result;
}
}
先使用getJobsHubuNotice()函数获取新闻链接、标题、日期,再使用makePage()函数获取内容

这是在 makePage 中打印链接的结果,使用浏览器打开链接没有问题。
您的 PHP 代码中没有错误。初步怀疑是你在请求中传入的url不正确,如下图所示:

您代码中的错误输出实际上是您获得的网页上的输出。
再次更新,我想我知道你的要求有什么问题:
你从网页得到的URL地址是:Detail.aspx?ArticleChannelId=81&ArticleId=2777,

其中&字符是&的HTML实体字符,当你输出的时候(也就是在你的截图中),它显示&,而当你去真正的请求时,它使用了下面的东西:

您只需要恢复它,或者简单地将URL中的&替换为&,然后转到请求就可以了。
再次更新:
<p>
curl 抓取网页(curl中命令行模式#python抓取网页##)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-09 23:04
curl抓取网页然后image是用的xml的curl直接抓xml就是爬虫
curl不是直接抓取网页的,而是将连接格式化了,然后由beautifulsoup查询。
你真正的目的是想要抓取,
curl是命令行工具,beautifulsoup是框架,不同层面工具,也就是使用场景不同,就一句话,
爬虫的流程类似于一个倒金字塔的结构。每一步都是在一个「爬虫框架」里面进行的。也就是说,抓取网页很像正在爬一个大蜘蛛,而不是正在爬一个点点。你要先给出大蜘蛛模型图,再来进行从整体分析。
从词汇方面理解,curl是用命令行模拟beautifulsoup搜索操作。beautifulsoup是python标准的html解析库,需要安装,也是需要在命令行模式下操作的,命令行模式下在/src/programs/python.py中命令行模式#python.py#在命令行模式下输入importbeautifulsoup可见这个命令行模式没有安装。curl等于beautifulsoup+任何一个lxml库。
首先题主你的思维才是问题的关键。你们脑子里的爬虫和大师们的不是一个东西。看题主的意思应该是想爬取大厂的网站网页并用于后续的文本处理啊等等吧。首先题主先花点时间学学编程,不懂的先百度一下吧。 查看全部
curl 抓取网页(curl中命令行模式#python抓取网页##)
curl抓取网页然后image是用的xml的curl直接抓xml就是爬虫
curl不是直接抓取网页的,而是将连接格式化了,然后由beautifulsoup查询。
你真正的目的是想要抓取,
curl是命令行工具,beautifulsoup是框架,不同层面工具,也就是使用场景不同,就一句话,
爬虫的流程类似于一个倒金字塔的结构。每一步都是在一个「爬虫框架」里面进行的。也就是说,抓取网页很像正在爬一个大蜘蛛,而不是正在爬一个点点。你要先给出大蜘蛛模型图,再来进行从整体分析。
从词汇方面理解,curl是用命令行模拟beautifulsoup搜索操作。beautifulsoup是python标准的html解析库,需要安装,也是需要在命令行模式下操作的,命令行模式下在/src/programs/python.py中命令行模式#python.py#在命令行模式下输入importbeautifulsoup可见这个命令行模式没有安装。curl等于beautifulsoup+任何一个lxml库。
首先题主你的思维才是问题的关键。你们脑子里的爬虫和大师们的不是一个东西。看题主的意思应该是想爬取大厂的网站网页并用于后续的文本处理啊等等吧。首先题主先花点时间学学编程,不懂的先百度一下吧。
curl 抓取网页( 网络抓取是收集数据以将您的业务提升到新水平的好方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-07 05:01
网络抓取是收集数据以将您的业务提升到新水平的好方法)
使用 Zenscrape 进行大规模数据提取
网络抓取是采集数据以将您的业务提升到新水平的好方法。它允许您自动化从各种来源提取有用内容的过程。
不幸的是,自动网络抓取并不总是那么容易。一些 网站 可能会主动阻止您提取这些数据,而其他 网站 是使用基本上使原创网络抓取工具无用的工具构建的。
在这个 文章 中,我将向您展示如何使用 Zenscrape 来克服所有这些问题,并从您喜欢的任何 网站 中大规模提取数据,而不必担心被阻止。
使用 Zenscrape 的优势
我将通过列出 Zenscrape 的一些惊人功能来开始讨论,这些功能可以帮助您完成工作并将其与其他爬虫区分开来。
JavaScript 渲染
许多 网站 现在都在积极使用 JavaScript 向访问者提供内容。这意味着一个简单的爬虫在访问网页时可能会看到与用户通过浏览器实际访问 网站 时不同的内容。
Zenscrape 通过允许您使用它的 API 在现代的无头 Chrome 浏览器中呈现请求来解决这个问题。它支持所有流行的库和框架,例如 Vue、Angular 和 React 等。
大规模提取数据
有些项目要求您大规模地抓取网络,这种情况会带来一系列挑战。您更有可能被 网站 阻止,并且一次只需一个请求即可获取所需的所有数据将花费更长的时间。
Zenscrape 通过为您提供巨大的 IP 池和自动代理轮换来轻松隐藏您的抓取机器人来克服这些问题。它还使您可以选择并发请求以快速抓取大量数据。
使用 Zenscrape 抓取内容
我们现在将学习如何使用 Zenscrape API 从不同类型的 网站 中抓取内容。
您可以通过在 网站 上创建一个帐户来开始。Zenscrape 提供免费计划,因此您只需注册即可遵循本教程。它将使您可以访问可用于发出请求的 API 密钥。您可以阅读详细文档,了解如何在 PHP、Python 和 Node.js 等各种语言和环境中使用 API 发出请求。
在您成功注册并登录后,文档中的代码片段将预先填充您的 API 密钥。
您还可以在“帐户仪表板”页面上查看其他与帐户相关的信息,例如使用情况统计信息和您的 API 密钥。
从维基百科中提取内容
Zenscrape 允许您从网页中提取 HTML,然后您可以使用您选择的解析器对其进行操作。我们将在此处的示例中使用基于 PHP 的 DiDOM 解析器,但您也可以使用 Zenscrape 博客 文章 中提到的其他一些解析器。
我们将抓取关于灯塔的 Wikipedia 页面作为示例。这是我们使用 Zenscrape 的 API 提取 HTML 的 PHP 代码。
此时的变量 $html 收录 Zenscrape 从 Wikipedia 页面提取的标记。标记的前几行如下所示:
White Shoal Light, Michigan - Wikipedia
... and more ...
我们现在可以将此 HTML 传递给我们的 DOM 解析器,以从 Wikipedia 文章 中提取主标题、第一段或第一张图片等信息。
这是我得到的输出,带有一些基本的 CSS 样式。
从 网站 中提取本地化内容
Top 网站 Reddit 主页的外观会因您访问的国家/地区而异。这个 网站 试图用在您所在位置相关且流行的内容来填充它。
在我们的示例中,我们将使用 Zenscrape 通过将国家/地区设置为美国和英国来从 Reddit 主页获取一些头条新闻。但是,Zenscrape 允许您从 230 多个不同的国家/地区选择一个位置来抓取内容。令人惊讶的是,您只需在 API 请求中指定两个参数即可完成所有这些操作。
这是我们使用 Zenscrape 的 API 为 Reddit 的英国主页获取 HTML 的代码。
如您所见,这与我们在上一节中使用的代码没有太大区别。不过,这一次,我们传递了两个名为 premium 和 location 的额外查询参数。将 premium 设置为 true 允许您使用住宅代理。之后,您可以使用 location 来指定要访问 URL 的国家/地区。我在这个例子中设置了它。
Zenscrape 关于网络抓取的文档提供了有关其他此类参数的更多详细信息。
与我们之前的示例类似,此变量 $html 存储我们返回的提取的 HTML。现在,我们可以以任何我们喜欢的方式解析和使用这个 HTML。
我使用它来显示标题列表以进行演示。
这是我作为美国访问者使用 Zenscrape API 抓取 Reddit 时得到的结果。
JavaScript 渲染后提取内容
Zenscrape 为您解决的另一个问题是,当访问者访问由 Vue、React 或 Angular 等库和框架构建的 网站 时,您可以轻松提取将呈现给访问者的 HTML。
我创建了一个简单的 CodePen 演示来演示此功能。基本的 网站 爬虫将在此页面上看到与实际 网站 访问者不同的内容,因为页面上的内容是使用 React 呈现的。
当使用简单的 cURL 或 file_get_contents() 请求时,您将在根元素中获得以下 HTML。
Nothing to see here!
另一方面,Zenscrape 为您提供了在现代无头 Chrome 浏览器中呈现请求的选项。这意味着您使用 Zenscrape API 返回的 HTML 与用户在访问页面时将看到的 HTML 相同。
这是我用来提取在运行 JavaScript 后最终显示给用户的 HTML 的代码。
如您所见,您需要做的就是传递两个参数,render 和 wait_for_css。将 render 设置为 true 将告诉 Zenscrape 它需要使用无头浏览器来获取内容,因为涉及到 JavaScript。您可以将 wait_for_css 设置为所需元素的 CSS 选择器。
上面的代码片段允许您提取可以解析的 HTML 以获得以下内容。
最后的想法
Zenscrape 为那些想要大规模提取数据的人解决了许多网络抓取问题。它的优点在于它易于实现,并且不需要您花费数天或数周的时间来学习 API。
正如您在上面的三个示例中所见,Zenscrape 只需几个请求即可为您处理从本地化到 JavaScript 渲染的所有事情。您只需要编写几行代码,一切都会立即启动并运行。甚至还有一个请求构建器,您可以使用它来获取使用 Python、Node.js、PHP 等发出请求所需的代码。
您可以使用 Zenscrape API 执行许多任务,例如获取销售线索或跟踪电子商务平台上产品的定价和可用性。访问 Zenscrape 并为自己阅读。有一个每月 1,000 积分的免费计划。您可以在几分钟内注册一个免费的 Zenscrape 帐户并自己测试所有功能。 查看全部
curl 抓取网页(
网络抓取是收集数据以将您的业务提升到新水平的好方法)
使用 Zenscrape 进行大规模数据提取
网络抓取是采集数据以将您的业务提升到新水平的好方法。它允许您自动化从各种来源提取有用内容的过程。
不幸的是,自动网络抓取并不总是那么容易。一些 网站 可能会主动阻止您提取这些数据,而其他 网站 是使用基本上使原创网络抓取工具无用的工具构建的。
在这个 文章 中,我将向您展示如何使用 Zenscrape 来克服所有这些问题,并从您喜欢的任何 网站 中大规模提取数据,而不必担心被阻止。
使用 Zenscrape 的优势
我将通过列出 Zenscrape 的一些惊人功能来开始讨论,这些功能可以帮助您完成工作并将其与其他爬虫区分开来。
JavaScript 渲染
许多 网站 现在都在积极使用 JavaScript 向访问者提供内容。这意味着一个简单的爬虫在访问网页时可能会看到与用户通过浏览器实际访问 网站 时不同的内容。
Zenscrape 通过允许您使用它的 API 在现代的无头 Chrome 浏览器中呈现请求来解决这个问题。它支持所有流行的库和框架,例如 Vue、Angular 和 React 等。
大规模提取数据
有些项目要求您大规模地抓取网络,这种情况会带来一系列挑战。您更有可能被 网站 阻止,并且一次只需一个请求即可获取所需的所有数据将花费更长的时间。
Zenscrape 通过为您提供巨大的 IP 池和自动代理轮换来轻松隐藏您的抓取机器人来克服这些问题。它还使您可以选择并发请求以快速抓取大量数据。
使用 Zenscrape 抓取内容
我们现在将学习如何使用 Zenscrape API 从不同类型的 网站 中抓取内容。
您可以通过在 网站 上创建一个帐户来开始。Zenscrape 提供免费计划,因此您只需注册即可遵循本教程。它将使您可以访问可用于发出请求的 API 密钥。您可以阅读详细文档,了解如何在 PHP、Python 和 Node.js 等各种语言和环境中使用 API 发出请求。

在您成功注册并登录后,文档中的代码片段将预先填充您的 API 密钥。
您还可以在“帐户仪表板”页面上查看其他与帐户相关的信息,例如使用情况统计信息和您的 API 密钥。

从维基百科中提取内容
Zenscrape 允许您从网页中提取 HTML,然后您可以使用您选择的解析器对其进行操作。我们将在此处的示例中使用基于 PHP 的 DiDOM 解析器,但您也可以使用 Zenscrape 博客 文章 中提到的其他一些解析器。
我们将抓取关于灯塔的 Wikipedia 页面作为示例。这是我们使用 Zenscrape 的 API 提取 HTML 的 PHP 代码。
此时的变量 $html 收录 Zenscrape 从 Wikipedia 页面提取的标记。标记的前几行如下所示:
White Shoal Light, Michigan - Wikipedia
... and more ...
我们现在可以将此 HTML 传递给我们的 DOM 解析器,以从 Wikipedia 文章 中提取主标题、第一段或第一张图片等信息。
这是我得到的输出,带有一些基本的 CSS 样式。

从 网站 中提取本地化内容
Top 网站 Reddit 主页的外观会因您访问的国家/地区而异。这个 网站 试图用在您所在位置相关且流行的内容来填充它。
在我们的示例中,我们将使用 Zenscrape 通过将国家/地区设置为美国和英国来从 Reddit 主页获取一些头条新闻。但是,Zenscrape 允许您从 230 多个不同的国家/地区选择一个位置来抓取内容。令人惊讶的是,您只需在 API 请求中指定两个参数即可完成所有这些操作。
这是我们使用 Zenscrape 的 API 为 Reddit 的英国主页获取 HTML 的代码。
如您所见,这与我们在上一节中使用的代码没有太大区别。不过,这一次,我们传递了两个名为 premium 和 location 的额外查询参数。将 premium 设置为 true 允许您使用住宅代理。之后,您可以使用 location 来指定要访问 URL 的国家/地区。我在这个例子中设置了它。
Zenscrape 关于网络抓取的文档提供了有关其他此类参数的更多详细信息。
与我们之前的示例类似,此变量 $html 存储我们返回的提取的 HTML。现在,我们可以以任何我们喜欢的方式解析和使用这个 HTML。
我使用它来显示标题列表以进行演示。

这是我作为美国访问者使用 Zenscrape API 抓取 Reddit 时得到的结果。

JavaScript 渲染后提取内容
Zenscrape 为您解决的另一个问题是,当访问者访问由 Vue、React 或 Angular 等库和框架构建的 网站 时,您可以轻松提取将呈现给访问者的 HTML。
我创建了一个简单的 CodePen 演示来演示此功能。基本的 网站 爬虫将在此页面上看到与实际 网站 访问者不同的内容,因为页面上的内容是使用 React 呈现的。
当使用简单的 cURL 或 file_get_contents() 请求时,您将在根元素中获得以下 HTML。
Nothing to see here!
另一方面,Zenscrape 为您提供了在现代无头 Chrome 浏览器中呈现请求的选项。这意味着您使用 Zenscrape API 返回的 HTML 与用户在访问页面时将看到的 HTML 相同。
这是我用来提取在运行 JavaScript 后最终显示给用户的 HTML 的代码。
如您所见,您需要做的就是传递两个参数,render 和 wait_for_css。将 render 设置为 true 将告诉 Zenscrape 它需要使用无头浏览器来获取内容,因为涉及到 JavaScript。您可以将 wait_for_css 设置为所需元素的 CSS 选择器。
上面的代码片段允许您提取可以解析的 HTML 以获得以下内容。

最后的想法
Zenscrape 为那些想要大规模提取数据的人解决了许多网络抓取问题。它的优点在于它易于实现,并且不需要您花费数天或数周的时间来学习 API。
正如您在上面的三个示例中所见,Zenscrape 只需几个请求即可为您处理从本地化到 JavaScript 渲染的所有事情。您只需要编写几行代码,一切都会立即启动并运行。甚至还有一个请求构建器,您可以使用它来获取使用 Python、Node.js、PHP 等发出请求所需的代码。
您可以使用 Zenscrape API 执行许多任务,例如获取销售线索或跟踪电子商务平台上产品的定价和可用性。访问 Zenscrape 并为自己阅读。有一个每月 1,000 积分的免费计划。您可以在几分钟内注册一个免费的 Zenscrape 帐户并自己测试所有功能。
curl 抓取网页(下载文件总是一个难熬的过程,如果有进度条就好很多了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-04 13:00
前言
最近在命令行下的编程中,下载文件总是一个比较难的过程。如果有进度条就更好了!!!
之前进度条的扩展包还是不错的(本地下载)
效果图:
还是好看的!
卷曲有什么用?
用php,curl主要是抓取数据,当然我们也可以通过其他方法抓取,比如fsockopen,file_get_contents等,但是只能抓取那些可以直接访问的页面。如果要抓取有页面访问控制的页面,或者登录后的页面,就比较难了。
使用卷曲
curl是PHP很常用的一种下载方式,这里有一个简单的使用方法;
// 初始化一个 curl
$ch = curl_init();
// 设置请求的 url
curl_setopt($ch, CURLOPT_URL, $url);
//
curl_setopt($ch, CURLOPT_HEADER, 0);
// 不直接输出,而是通过 curl_exec 返回
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
if (false === ($stream = curl_exec($ch))) {
throw new \Exception(curl_errno($ch));
}
curl_close($ch);
return $stream;
上面是一个非常简单的例子。如果文件很大,用户需要等待很长时间。这时候我们应该添加进度条的效果:
class Request
{
protected $bar;
// 是否下载完成
protected $downloaded = false;
public function __construct()
{
// 初始化一个进度条
$this->bar = new CliProgressBar(100);
$this->bar->display();
$this->bar->setColorToRed();
}
function download($url)
{
$ch = curl_init();
// 从配置文件中获取根路径
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 0);
// 开启进度条
curl_setopt($ch, CURLOPT_NOPROGRESS, 0);
// 进度条的触发函数
curl_setopt($ch, CURLOPT_PROGRESSFUNCTION, 'progress');
// ps: 如果目标网页跳转,也跟着跳转
// curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
if (false === ($stream = curl_exec($ch))) {
throw new \Exception(curl_errno($ch));
}
curl_close($ch);
return $stream;
}
/**
* 进度条下载.
*
* @param $ch
* @param $countDownloadSize 总下载量
* @param $currentDownloadSize 当前下载量
* @param $countUploadSize
* @param $currentUploadSize
*/
public function progress($ch, $countDownloadSize, $currentDownloadSize, $countUploadSize, $currentUploadSize)
{
// 等于 0 的时候,应该是预读资源不等于0的时候即开始下载
// 这里的每一个判断都是坑,多试试就知道了
if (0 === $countDownloadSize) {
return false;
}
// 有时候会下载两次,第一次很小,应该是重定向下载
if ($countDownloadSize > $currentDownloadSize) {
$this->downloaded = false;
// 继续显示进度条
}
// 已经下载完成还会再发三次请求
elseif ($this->downloaded) {
return false;
}
// 两边相等下载完成并不一定结束,
elseif ($currentDownloadSize === $countDownloadSize) {
return false;
}
// 开始计算
$bar = $currentDownloadSize / $countDownloadSize * 100;
$this->bar->progress($bar);
}
}
(new Request)->download('http://www.shiguopeng.cn/database.sql');
下载回调的判断中一定要注意坑!!!
还有一个问题:如果跳转到下载并设置curl跟随跳转,返回的文件会有问题。
我下载了一个zip文件,它会导致文件头有第一个请求的HTTP响应头的内容,
所以你需要 curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
总结
以上就是这个文章的全部内容。希望本文的内容对大家的学习或工作有一定的参考和学习价值。有问题可以留言交流,感谢大家对脚本之家的支持。 查看全部
curl 抓取网页(下载文件总是一个难熬的过程,如果有进度条就好很多了)
前言
最近在命令行下的编程中,下载文件总是一个比较难的过程。如果有进度条就更好了!!!
之前进度条的扩展包还是不错的(本地下载)
效果图:

还是好看的!
卷曲有什么用?
用php,curl主要是抓取数据,当然我们也可以通过其他方法抓取,比如fsockopen,file_get_contents等,但是只能抓取那些可以直接访问的页面。如果要抓取有页面访问控制的页面,或者登录后的页面,就比较难了。
使用卷曲
curl是PHP很常用的一种下载方式,这里有一个简单的使用方法;
// 初始化一个 curl
$ch = curl_init();
// 设置请求的 url
curl_setopt($ch, CURLOPT_URL, $url);
//
curl_setopt($ch, CURLOPT_HEADER, 0);
// 不直接输出,而是通过 curl_exec 返回
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
if (false === ($stream = curl_exec($ch))) {
throw new \Exception(curl_errno($ch));
}
curl_close($ch);
return $stream;
上面是一个非常简单的例子。如果文件很大,用户需要等待很长时间。这时候我们应该添加进度条的效果:
class Request
{
protected $bar;
// 是否下载完成
protected $downloaded = false;
public function __construct()
{
// 初始化一个进度条
$this->bar = new CliProgressBar(100);
$this->bar->display();
$this->bar->setColorToRed();
}
function download($url)
{
$ch = curl_init();
// 从配置文件中获取根路径
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 0);
// 开启进度条
curl_setopt($ch, CURLOPT_NOPROGRESS, 0);
// 进度条的触发函数
curl_setopt($ch, CURLOPT_PROGRESSFUNCTION, 'progress');
// ps: 如果目标网页跳转,也跟着跳转
// curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
if (false === ($stream = curl_exec($ch))) {
throw new \Exception(curl_errno($ch));
}
curl_close($ch);
return $stream;
}
/**
* 进度条下载.
*
* @param $ch
* @param $countDownloadSize 总下载量
* @param $currentDownloadSize 当前下载量
* @param $countUploadSize
* @param $currentUploadSize
*/
public function progress($ch, $countDownloadSize, $currentDownloadSize, $countUploadSize, $currentUploadSize)
{
// 等于 0 的时候,应该是预读资源不等于0的时候即开始下载
// 这里的每一个判断都是坑,多试试就知道了
if (0 === $countDownloadSize) {
return false;
}
// 有时候会下载两次,第一次很小,应该是重定向下载
if ($countDownloadSize > $currentDownloadSize) {
$this->downloaded = false;
// 继续显示进度条
}
// 已经下载完成还会再发三次请求
elseif ($this->downloaded) {
return false;
}
// 两边相等下载完成并不一定结束,
elseif ($currentDownloadSize === $countDownloadSize) {
return false;
}
// 开始计算
$bar = $currentDownloadSize / $countDownloadSize * 100;
$this->bar->progress($bar);
}
}
(new Request)->download('http://www.shiguopeng.cn/database.sql');
下载回调的判断中一定要注意坑!!!
还有一个问题:如果跳转到下载并设置curl跟随跳转,返回的文件会有问题。
我下载了一个zip文件,它会导致文件头有第一个请求的HTTP响应头的内容,
所以你需要 curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
总结
以上就是这个文章的全部内容。希望本文的内容对大家的学习或工作有一定的参考和学习价值。有问题可以留言交流,感谢大家对脚本之家的支持。
curl 抓取网页(Linux中curl利用规则()(string$ro))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-03 23:07
阿里云 > 云栖社区 > 主题图 > C > curl抓取网站数据
推荐活动:
更多优惠>
当前话题:curl 抓取 网站 数据并添加到采集夹
相关话题:
curl爬取网站数据相关博客查看更多博客
模拟请求工具 curl 的异常处理
作者:于尔伍775 浏览评论:04年前
在日常开发过程中,使用curl来模拟请求的场景很多。跨站请求时,其他网站的稳定性得不到保证。当其他网站不能顺利访问时,会影响当前业务系统,不易排查问题,需要进行异常处理。私有函数 curlPost(字符串 $ro
阅读全文
curl的详细解释
作者:技术小哥 1664人查看评论数:04年前
curl:命令行下网站访问认证工具常用参数如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 -c,--cookie-jar:写入cookies到文件 -b,--cookie:从文件 -C,--cont 读取 cookie
阅读全文
卷曲
作者:于尔伍1062 浏览评论:04年前
我用过的Linux的curl命令-强大的网络传输工具这个链接:(转载请注明出处)用途说明curl命令是一个强大的网络工具,可以通过http、ftp等方式
阅读全文
卷曲
作者:技术小牛960 浏览评论:04年前
linux curl命令详解及示例 linux curl是一个文件传输工具,在命令行下使用URL规则工作。它支持文件的上传和下载,是一个综合性的传输工具,但按照传统,习惯上将url调用如下
阅读全文
卷曲
作者:小技术专家1668查看评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
卷曲
作者:Technic Fatty 975 浏览评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
shell+curl监控网站页面(域名访问状态),使用sedemail发送邮件
作者:犹豫1585 浏览评论:04年前
应领导要求,监控公司几个主要站点的域名访问情况。让我们分享一个监控脚本并使用 sendemail 发送电子邮件。监控脚本如下: 下面是一个多线程的网站状态检测脚本,直接从文件中读取站点地址,然后使用curl检测返回码。发现速度非常好,基本在几秒内。
阅读全文
关于表单提交类型为submit类型且使用curl函数发布网页数据时没有name和id时可能遇到的问题及解决方法
作者:林冠红 683 浏览评论:07年前
curl函数库实现了链接抓取网页内容。以下是没有name和id标识的类型。
阅读全文
curl抓取网站数据相关问答题
php采集金大师:使用curl模拟登录抓取数据遇到json调用问题不成功,求助!
作者:杨东方906 浏览评论:15年前
我在抓取一个页面的信息(比如说a.php),这个页面只是一些基本的html框架,其他关键信息通过ajax请求返回(b.php),返回的是json,然后通过页面js将json解析并绘制到页面。问题的关键是ajax请求的信息中有一个手机号需要登录才能完整显示
阅读全文 查看全部
curl 抓取网页(Linux中curl利用规则()(string$ro))
阿里云 > 云栖社区 > 主题图 > C > curl抓取网站数据

推荐活动:
更多优惠>
当前话题:curl 抓取 网站 数据并添加到采集夹
相关话题:
curl爬取网站数据相关博客查看更多博客
模拟请求工具 curl 的异常处理

作者:于尔伍775 浏览评论:04年前
在日常开发过程中,使用curl来模拟请求的场景很多。跨站请求时,其他网站的稳定性得不到保证。当其他网站不能顺利访问时,会影响当前业务系统,不易排查问题,需要进行异常处理。私有函数 curlPost(字符串 $ro
阅读全文
curl的详细解释

作者:技术小哥 1664人查看评论数:04年前
curl:命令行下网站访问认证工具常用参数如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 -c,--cookie-jar:写入cookies到文件 -b,--cookie:从文件 -C,--cont 读取 cookie
阅读全文
卷曲

作者:于尔伍1062 浏览评论:04年前
我用过的Linux的curl命令-强大的网络传输工具这个链接:(转载请注明出处)用途说明curl命令是一个强大的网络工具,可以通过http、ftp等方式
阅读全文
卷曲

作者:技术小牛960 浏览评论:04年前
linux curl命令详解及示例 linux curl是一个文件传输工具,在命令行下使用URL规则工作。它支持文件的上传和下载,是一个综合性的传输工具,但按照传统,习惯上将url调用如下
阅读全文
卷曲

作者:小技术专家1668查看评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
卷曲

作者:Technic Fatty 975 浏览评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
shell+curl监控网站页面(域名访问状态),使用sedemail发送邮件

作者:犹豫1585 浏览评论:04年前
应领导要求,监控公司几个主要站点的域名访问情况。让我们分享一个监控脚本并使用 sendemail 发送电子邮件。监控脚本如下: 下面是一个多线程的网站状态检测脚本,直接从文件中读取站点地址,然后使用curl检测返回码。发现速度非常好,基本在几秒内。
阅读全文
关于表单提交类型为submit类型且使用curl函数发布网页数据时没有name和id时可能遇到的问题及解决方法


作者:林冠红 683 浏览评论:07年前
curl函数库实现了链接抓取网页内容。以下是没有name和id标识的类型。
阅读全文
curl抓取网站数据相关问答题
php采集金大师:使用curl模拟登录抓取数据遇到json调用问题不成功,求助!

作者:杨东方906 浏览评论:15年前
我在抓取一个页面的信息(比如说a.php),这个页面只是一些基本的html框架,其他关键信息通过ajax请求返回(b.php),返回的是json,然后通过页面js将json解析并绘制到页面。问题的关键是ajax请求的信息中有一个手机号需要登录才能完整显示
阅读全文
curl 抓取网页(下载网站的全部内容同一件事,他们有什么不同?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-28 18:18
互联网上有很多工具可以下载 网站 的静态副本,例如 HTTrack。还有许多工具,一些商业工具,用于从 网站 中“抓取”内容(例如 Mozenda)。然后显然有一些工具内置在 PHP 和 *nix 等程序中,您可以在其中“file_get_contents”或“wget”或“cURL”或只是“file()”。
我对这一切感到非常困惑,我认为主要原因是我遇到的所有描述都没有使用相同的词汇。至少从表面上看,他们似乎都在做同样的事情,但也许不是。
那是我的问题。这些工具到底在做什么?他们在做同样的事情吗?他们是否通过不同的技术做同样的事情?如果他们不做同样的事情,他们有什么不同?
最佳答案
首先,让我澄清一下“镜像”和“抓取”之间的区别。
镜像意味着下载网站 的全部内容或网站 的一些主要部分(包括HTML、图像、脚本、CSS 样式表等)。通常这样做是为了保留和扩展对有价值的(通常是有限的)互联网资源的访问,或者增加额外的故障转移冗余。例如,许多大学和 IT 公司反映了各种 Linux 供应商的分发文件。镜像可能意味着您计划在自己的服务器上托管 网站 的副本(在原创内容所有者的许可下)。
爬行意味着从 网站 复制和提取一些有趣的数据。与镜像不同,抓取目标是特定数据集(姓名、电话号码、股票报价等),而不是 网站 的全部内容。例如,您可以“抓取”来自美国人口普查局的平均收入数据或来自 Google 财经的股票报价。有时这违反了主机的条款和条件,使其非法。
可以将两者结合起来,以便将数据复制(镜像)问题与信息提取(抓取)问题分开。例如,您可能会发现它更快地镜像站点,然后如果数据提取和分析速度较慢或处理密集,则获取本地副本。
要回答剩下的问题...
file_get_contents 和 file PHP 函数用于从本地或远程计算机读取文件。该文件可以是 HTML 文件或其他文件,例如文本文件或电子表格。这不是“mirror”或“scratch”通常所指的,尽管您可以使用它们来编写您自己的基于 PHP 的 mirror/grabber。
wget 和 curl 是命令行独立程序,用于使用各种选项、条件和协议从远程服务器下载一个或多个文件。两者都是强大且流行的工具,主要区别在于 wget 具有丰富的内置功能来镜像整个 网站。
HTTrack 旨在类似于 wget,但使用 GUI 而不是命令行。这使得那些不方便从终端运行命令的人更容易使用,但代价是失去了 wget 提供的功能和灵活性。
您可以使用 HTTrack 和 wget 进行镜像,但如果这是您的最终目标,您必须在生成的下载数据上运行自己的程序以提取(获取)信息。
Mozenda 是一种抓取工具,与 HTTrack、wget 或 curl 不同,它允许您针对特定数据进行提取,而不是盲目地复制所有内容。不过,我经验不足。
PS 我通常使用 wget 来镜像我感兴趣的 HTML 页面,然后运行 Ruby 和 R 脚本的组合来提取和分析数据。 查看全部
curl 抓取网页(下载网站的全部内容同一件事,他们有什么不同?)
互联网上有很多工具可以下载 网站 的静态副本,例如 HTTrack。还有许多工具,一些商业工具,用于从 网站 中“抓取”内容(例如 Mozenda)。然后显然有一些工具内置在 PHP 和 *nix 等程序中,您可以在其中“file_get_contents”或“wget”或“cURL”或只是“file()”。
我对这一切感到非常困惑,我认为主要原因是我遇到的所有描述都没有使用相同的词汇。至少从表面上看,他们似乎都在做同样的事情,但也许不是。
那是我的问题。这些工具到底在做什么?他们在做同样的事情吗?他们是否通过不同的技术做同样的事情?如果他们不做同样的事情,他们有什么不同?
最佳答案
首先,让我澄清一下“镜像”和“抓取”之间的区别。
镜像意味着下载网站 的全部内容或网站 的一些主要部分(包括HTML、图像、脚本、CSS 样式表等)。通常这样做是为了保留和扩展对有价值的(通常是有限的)互联网资源的访问,或者增加额外的故障转移冗余。例如,许多大学和 IT 公司反映了各种 Linux 供应商的分发文件。镜像可能意味着您计划在自己的服务器上托管 网站 的副本(在原创内容所有者的许可下)。
爬行意味着从 网站 复制和提取一些有趣的数据。与镜像不同,抓取目标是特定数据集(姓名、电话号码、股票报价等),而不是 网站 的全部内容。例如,您可以“抓取”来自美国人口普查局的平均收入数据或来自 Google 财经的股票报价。有时这违反了主机的条款和条件,使其非法。
可以将两者结合起来,以便将数据复制(镜像)问题与信息提取(抓取)问题分开。例如,您可能会发现它更快地镜像站点,然后如果数据提取和分析速度较慢或处理密集,则获取本地副本。
要回答剩下的问题...
file_get_contents 和 file PHP 函数用于从本地或远程计算机读取文件。该文件可以是 HTML 文件或其他文件,例如文本文件或电子表格。这不是“mirror”或“scratch”通常所指的,尽管您可以使用它们来编写您自己的基于 PHP 的 mirror/grabber。
wget 和 curl 是命令行独立程序,用于使用各种选项、条件和协议从远程服务器下载一个或多个文件。两者都是强大且流行的工具,主要区别在于 wget 具有丰富的内置功能来镜像整个 网站。
HTTrack 旨在类似于 wget,但使用 GUI 而不是命令行。这使得那些不方便从终端运行命令的人更容易使用,但代价是失去了 wget 提供的功能和灵活性。
您可以使用 HTTrack 和 wget 进行镜像,但如果这是您的最终目标,您必须在生成的下载数据上运行自己的程序以提取(获取)信息。
Mozenda 是一种抓取工具,与 HTTrack、wget 或 curl 不同,它允许您针对特定数据进行提取,而不是盲目地复制所有内容。不过,我经验不足。
PS 我通常使用 wget 来镜像我感兴趣的 HTML 页面,然后运行 Ruby 和 R 脚本的组合来提取和分析数据。
curl 抓取网页(和wget下载安装1、Ubuntu平台wget命令安装:百度首页为例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-27 19:19
curl和wget下载安装
1、Ubuntu 平台
wget命令安装:sudo apt-get install wget(普通用户登录,需要输入密码;root账户登录,不需要输入密码)
curl命令安装:sudo apt-get install curl(同wget)
2、Windows 平台
wget下载地址:wget for Windows
curl下载地址:curl下载
wget和curl包下载地址:Windows平台下的wget和curl工具包
Windows平台下,curl下载解压后直接为curl.exe格式,复制到系统命令目录下的C:\Windows\System32。
Windows平台下,wget下载解压后,格式为wget-1.11.4-1-setup.exe,需要安装;安装完成后,在环境变量-系统变量-路径目录下添加其安装
curl 和 wget 抓取实例
抓取网页主要有两种方式:url URL 和代理代理。下面是一个爬取“百度”首页的例子。
1、 url URL方法爬取
(1)curl下载百度首页内容,保存在baidu_html文件中
curl baidu_html
(2)wget下载百度首页内容,保存在baidu_html文件中
wget baidu_html2
有时,由于网络速度/数据包丢失/服务器停机等原因,网页暂时无法成功下载。
这时候可能需要尝试多次发送连接来请求服务器的响应;如果多次仍然没有响应,则可以确认服务器有问题。
(1)curl 尝试连接多次
curl --retry 10 --retry-delay 60 --retry-max-time 60 -o baidu_html
注意:--retry 表示重试次数;--retry-delay 表示两次重试之间的时间间隔(以秒为单位);--retry-max-time 表示在这个最大时间内只允许重试一次(一般同--retry-delay)
(2)wget 尝试连接多次
wget -t 10 -w 60 -T 30 -O baidu_html2
注意:-t(--tries)表示重试次数;-w 表示两次重试之间的时间间隔(以秒为单位);-T 表示连接超时时间,超过超时则连接不成功,下次连接继续尝试
附:curl可以判断服务器是否响应。也可以通过一段时间内下载获得的字节数来间接判断。命令格式如下:
curl -y 60 -Y 1 -m 60 -o baidu_html
注:-y表示测试网速的时间;-Y 表示-y期间下载的字节数(字节为单位);-m 表示允许请求连接的最长时间,如果超过连接会自动断开连接并放弃连接
2、代理代理捕获
代理下载是通过连接中间服务器间接下载url网页的过程,而不是直接连接网站服务器下载的url
两位知名的自由球员网站:
(全球数十个国家免费代理,每日更新)
(通过设置端口类型、代理类型、国家名称过滤)
在网站中选择国内免费的代理服务器为例介绍代理代理爬取网页:
218.107.21.252:8080(ip为218.107.21.252;端口为8080,中间是 8080 冒号“:”隔开形成套接字)
(1)curl通过代理爬取百度首页
curl -x 218.107.21.252:8080 -o aaaaa(常用端口有80、8080、8086、8888、3128等,默认80)
注:-x表示代理服务器(ip:port),即curl先连接代理服务器218.107.21.252:8080,然后通过21< @k31@ >107.21.252:8080 下载百度首页,最后218.107.21.252:8080 通过下载百度主页 curl 到本地(curl 不是直接连接百度服务器下载主页,而是通过中介代理)
(2)wget通过代理爬取百度首页
wget 通过代理下载,和 curl 不一样。需要先设置代理服务器的http_proxy=ip:port。
以ubuntu为例,在当前用户目录(cd ~),新建wget配置文件(.wgetrc),进入代理配置: 查看全部
curl 抓取网页(和wget下载安装1、Ubuntu平台wget命令安装:百度首页为例)
curl和wget下载安装
1、Ubuntu 平台
wget命令安装:sudo apt-get install wget(普通用户登录,需要输入密码;root账户登录,不需要输入密码)
curl命令安装:sudo apt-get install curl(同wget)
2、Windows 平台
wget下载地址:wget for Windows
curl下载地址:curl下载
wget和curl包下载地址:Windows平台下的wget和curl工具包
Windows平台下,curl下载解压后直接为curl.exe格式,复制到系统命令目录下的C:\Windows\System32。
Windows平台下,wget下载解压后,格式为wget-1.11.4-1-setup.exe,需要安装;安装完成后,在环境变量-系统变量-路径目录下添加其安装
curl 和 wget 抓取实例
抓取网页主要有两种方式:url URL 和代理代理。下面是一个爬取“百度”首页的例子。
1、 url URL方法爬取
(1)curl下载百度首页内容,保存在baidu_html文件中
curl baidu_html
(2)wget下载百度首页内容,保存在baidu_html文件中
wget baidu_html2
有时,由于网络速度/数据包丢失/服务器停机等原因,网页暂时无法成功下载。
这时候可能需要尝试多次发送连接来请求服务器的响应;如果多次仍然没有响应,则可以确认服务器有问题。
(1)curl 尝试连接多次
curl --retry 10 --retry-delay 60 --retry-max-time 60 -o baidu_html
注意:--retry 表示重试次数;--retry-delay 表示两次重试之间的时间间隔(以秒为单位);--retry-max-time 表示在这个最大时间内只允许重试一次(一般同--retry-delay)
(2)wget 尝试连接多次
wget -t 10 -w 60 -T 30 -O baidu_html2
注意:-t(--tries)表示重试次数;-w 表示两次重试之间的时间间隔(以秒为单位);-T 表示连接超时时间,超过超时则连接不成功,下次连接继续尝试
附:curl可以判断服务器是否响应。也可以通过一段时间内下载获得的字节数来间接判断。命令格式如下:
curl -y 60 -Y 1 -m 60 -o baidu_html
注:-y表示测试网速的时间;-Y 表示-y期间下载的字节数(字节为单位);-m 表示允许请求连接的最长时间,如果超过连接会自动断开连接并放弃连接
2、代理代理捕获
代理下载是通过连接中间服务器间接下载url网页的过程,而不是直接连接网站服务器下载的url
两位知名的自由球员网站:
(全球数十个国家免费代理,每日更新)
(通过设置端口类型、代理类型、国家名称过滤)
在网站中选择国内免费的代理服务器为例介绍代理代理爬取网页:
218.107.21.252:8080(ip为218.107.21.252;端口为8080,中间是 8080 冒号“:”隔开形成套接字)
(1)curl通过代理爬取百度首页
curl -x 218.107.21.252:8080 -o aaaaa(常用端口有80、8080、8086、8888、3128等,默认80)
注:-x表示代理服务器(ip:port),即curl先连接代理服务器218.107.21.252:8080,然后通过21< @k31@ >107.21.252:8080 下载百度首页,最后218.107.21.252:8080 通过下载百度主页 curl 到本地(curl 不是直接连接百度服务器下载主页,而是通过中介代理)
(2)wget通过代理爬取百度首页
wget 通过代理下载,和 curl 不一样。需要先设置代理服务器的http_proxy=ip:port。
以ubuntu为例,在当前用户目录(cd ~),新建wget配置文件(.wgetrc),进入代理配置:
curl 抓取网页(【知识点】curl抓取网页头部的看ip啊!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-27 15:03
curl抓取网页头部,看ip啊在linux下用pipinstallsqlalchemysqlalchemy-next之后先清除sqlalchemy的安装包。再安装configure的包。
同样问题来求答案,python2数据库是mysql,python3是mariadb。折腾了一个星期仍然没有答案。后来搜到了答案,在tools--loadlibrary--cached中将mysql包加入了路径。刚刚问了下在国外,回答得很官方,但是确实给不了解决方案。
我用curl抓取了头部一部分的网页,然后用excel打开,
tools--loadlibrary--cacheddblisted在加载类别一栏加入你想加载的
localdb中是没有库的
我提示是我是curl的php-module已加载在tools--loadlibrary--cached中。然后一直加载失败。
conf-python-database.py里面path路径url更改成你想要的
因为`curl`抓取的网页数据是存在tools--loadlibrary--cached中的`csv/old_mysql/lib`的,我也碰到了你这个问题,可能是没加在``profile`中```profile`中加入这个路径```mysqldatabase_database``
运行pythonconf.py,找到path路径, 查看全部
curl 抓取网页(【知识点】curl抓取网页头部的看ip啊!)
curl抓取网页头部,看ip啊在linux下用pipinstallsqlalchemysqlalchemy-next之后先清除sqlalchemy的安装包。再安装configure的包。
同样问题来求答案,python2数据库是mysql,python3是mariadb。折腾了一个星期仍然没有答案。后来搜到了答案,在tools--loadlibrary--cached中将mysql包加入了路径。刚刚问了下在国外,回答得很官方,但是确实给不了解决方案。
我用curl抓取了头部一部分的网页,然后用excel打开,
tools--loadlibrary--cacheddblisted在加载类别一栏加入你想加载的
localdb中是没有库的
我提示是我是curl的php-module已加载在tools--loadlibrary--cached中。然后一直加载失败。
conf-python-database.py里面path路径url更改成你想要的
因为`curl`抓取的网页数据是存在tools--loadlibrary--cached中的`csv/old_mysql/lib`的,我也碰到了你这个问题,可能是没加在``profile`中```profile`中加入这个路径```mysqldatabase_database``
运行pythonconf.py,找到path路径,
curl 抓取网页(和wget下载安装1、Ubuntu平台wget命令安装:百度首页为例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-27 15:02
curl和wget下载安装
1、Ubuntu 平台
wget 命令安装: sudo apt-get install wget
(普通用户登录,需输入密码;root账户登录,无需输入密码)
curl命令安装:sudo apt-get install curl
(与 wget 相同)
2、Windows 平台
wget下载地址:wget for Windows
curl下载地址:curl下载
wget和curl包下载地址:Windows平台下的wget和curl工具包
在Windows平台下,curl下载解压后直接为curl.exe格式,复制到系统命令目录下的C:\Windows\System32。
Windows平台下,wget下载解压后,格式为wget-1.11.4-1-setup.exe,需要安装;安装完成后,在环境变量-系统变量-路径目录下添加其安装
curl 和 wget 抓取实例
抓取网页主要有两种方式:url URL 和代理代理。下面是一个爬取“百度”首页的例子。
1、 url URL方法爬取
(1)curl下载百度首页内容,保存在baidu_html文件中
curl -o baidu_html
(2)wget下载百度首页内容,保存在baidu_html文件中
wget -O baidu_html2
有时,由于网络速度/数据包丢失/服务器停机等原因,网页暂时无法成功下载。
这时候可能需要尝试多次发送连接来请求服务器的响应;如果多次仍然没有响应,则可以确认服务器有问题。
(1)curl 尝试连接多次
curl --retry 10 --retry-delay 60 --retry-max-time 60 -o baidu_html
注意:--retry 表示重试次数;--retry-delay 表示两次重试之间的时间间隔(以秒为单位);--retry-max-time 表示在这个最大时间内只允许重试一次(一般同--retry-delay)
(2)wget 尝试连接多次
wget -t 10 -w 60 -T 30 -O baidu_html2
注意:-t(--tries)表示重试次数;-w 表示两次重试之间的时间间隔(以秒为单位);-T 表示连接超时时间,超过超时则连接不成功,下次连接继续尝试
附:curl可以判断服务器是否响应。也可以通过一段时间内下载获得的字节数来间接判断。命令格式如下:
curl -y 60 -Y 1 -m 60 -o baidu_html
注:-y表示测试网速的时间;-Y 表示-y期间下载的字节数(字节为单位);-m 表示允许请求连接的最长时间,如果超过连接会自动断开连接并放弃连接
2、代理代理捕获
代理下载是通过连接中间服务器间接下载url网页的过程,而不是直接连接网站服务器下载的url
两位知名的自由球员网站:
(全球数十个国家免费代理,每日更新)
(通过设置端口类型、代理类型、国家名称过滤)
在网站中选择国内免费的代理服务器为例介绍代理代理爬取网页:
218.107.21.252:8080(ip为218.107.21.252;端口为8080,中间是 8080 冒号“:”隔开形成套接字)
(1)curl通过代理爬取百度首页
卷曲
-x 218.107.21.252:8080 -o aaaaa(常用端口有80、8080、8086、8888、3128等,默认80)
注:-x表示代理服务器(ip:port),即curl先连接代理服务器218.107.21.252:8080,然后通过21< @k31@ >107.21.252:8080 下载百度首页,最后218.107.21.252:8080 通过下载百度主页 curl 到本地(curl 不是直接连接百度服务器下载主页,而是通过中介代理)
(2)wget通过代理爬取百度首页
wget 通过代理下载,和 curl 不一样。需要先设置代理服务器的http_proxy=ip:port。
以ubuntu为例,在当前用户目录(cd ~),新建wget配置文件(.wgetrc),进入代理配置: 查看全部
curl 抓取网页(和wget下载安装1、Ubuntu平台wget命令安装:百度首页为例)
curl和wget下载安装
1、Ubuntu 平台
wget 命令安装: sudo apt-get install wget
(普通用户登录,需输入密码;root账户登录,无需输入密码)
curl命令安装:sudo apt-get install curl
(与 wget 相同)
2、Windows 平台
wget下载地址:wget for Windows
curl下载地址:curl下载
wget和curl包下载地址:Windows平台下的wget和curl工具包
在Windows平台下,curl下载解压后直接为curl.exe格式,复制到系统命令目录下的C:\Windows\System32。
Windows平台下,wget下载解压后,格式为wget-1.11.4-1-setup.exe,需要安装;安装完成后,在环境变量-系统变量-路径目录下添加其安装
curl 和 wget 抓取实例
抓取网页主要有两种方式:url URL 和代理代理。下面是一个爬取“百度”首页的例子。
1、 url URL方法爬取
(1)curl下载百度首页内容,保存在baidu_html文件中
curl -o baidu_html
(2)wget下载百度首页内容,保存在baidu_html文件中
wget -O baidu_html2
有时,由于网络速度/数据包丢失/服务器停机等原因,网页暂时无法成功下载。
这时候可能需要尝试多次发送连接来请求服务器的响应;如果多次仍然没有响应,则可以确认服务器有问题。
(1)curl 尝试连接多次
curl --retry 10 --retry-delay 60 --retry-max-time 60 -o baidu_html
注意:--retry 表示重试次数;--retry-delay 表示两次重试之间的时间间隔(以秒为单位);--retry-max-time 表示在这个最大时间内只允许重试一次(一般同--retry-delay)
(2)wget 尝试连接多次
wget -t 10 -w 60 -T 30 -O baidu_html2
注意:-t(--tries)表示重试次数;-w 表示两次重试之间的时间间隔(以秒为单位);-T 表示连接超时时间,超过超时则连接不成功,下次连接继续尝试
附:curl可以判断服务器是否响应。也可以通过一段时间内下载获得的字节数来间接判断。命令格式如下:
curl -y 60 -Y 1 -m 60 -o baidu_html
注:-y表示测试网速的时间;-Y 表示-y期间下载的字节数(字节为单位);-m 表示允许请求连接的最长时间,如果超过连接会自动断开连接并放弃连接
2、代理代理捕获
代理下载是通过连接中间服务器间接下载url网页的过程,而不是直接连接网站服务器下载的url
两位知名的自由球员网站:
(全球数十个国家免费代理,每日更新)
(通过设置端口类型、代理类型、国家名称过滤)
在网站中选择国内免费的代理服务器为例介绍代理代理爬取网页:
218.107.21.252:8080(ip为218.107.21.252;端口为8080,中间是 8080 冒号“:”隔开形成套接字)
(1)curl通过代理爬取百度首页
卷曲
-x 218.107.21.252:8080 -o aaaaa(常用端口有80、8080、8086、8888、3128等,默认80)
注:-x表示代理服务器(ip:port),即curl先连接代理服务器218.107.21.252:8080,然后通过21< @k31@ >107.21.252:8080 下载百度首页,最后218.107.21.252:8080 通过下载百度主页 curl 到本地(curl 不是直接连接百度服务器下载主页,而是通过中介代理)
(2)wget通过代理爬取百度首页
wget 通过代理下载,和 curl 不一样。需要先设置代理服务器的http_proxy=ip:port。
以ubuntu为例,在当前用户目录(cd ~),新建wget配置文件(.wgetrc),进入代理配置:
curl 抓取网页(常用参数curl命令参数说明)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-11 12:01
原文:使用说明
curl命令是一个功能强大的网络工具,可以通过http、ftp等方式下载和上传文件。其实curl远不止上面提到的功能。您可以通过 man curl 阅读手册页以获取更多信息。 wget 是一个类似的工具。
curl 命令是使用 libcurl 库实现的。 libcurl 库通常在 C 程序中用于处理 HTTP 请求。 curlpp 是 libcurl 的 C++ 包。这些东西可以用在web抓取、网络监控等开发中,curl命令可以帮助解决开发过程中遇到的问题。
常用参数
curl命令的参数很多,这里只列出我用过的,尤其是shell脚本中的。
-A:请随意指定您自己为本次访问声明的浏览器信息
-b/--cookie cookie 字符串或文件读取位置,使用 option 将最后一个 cookie 信息附加到 http 请求中。
-c/--cookie-jar 操作完成后将cookies写入该文件
-C/--continue-在断点处继续
-d/--data HTTP POST方法传输数据
-D/--dump-header 将头信息写入该文件
-F/--form 模拟http表单提交数据
-v/--verbose 小写的v参数用于打印更多信息,包括发送的请求信息,在调试脚本时特别有用。
-m/--max-time 指定处理的最大持续时间
-H/--header 指定请求头参数
-s/--slent reduce输出信息,如进度
--connect-timeout 指定尝试连接的最长时间
-x/--代理
指定代理服务器地址和端口,默认端口为1080
-T/--upload-file 指定上传文件路径
-o/--output 指定输出文件名
--retry 指定重试次数
-e/--referer 指定引用地址
-I/--head 只返回header信息,使用HEAD请求
-u/--user 设置服务器用户和密码
-O:根据服务器上的文件名,会自动在本地存在
-r/--range 从 HTTP/1.1 或 FTP 服务器检索字节范围
-T/--upload-file 上传文件
使用示例
1、抓取页面内容到文件中
[root@xi mytest]# curl -o home.html -- 将百度首页的内容抓取到home.html中
[root@xi mytest]#curl -o #2_#1.jpg~{A,B}/[001-201].JPG
因为A/B下的文件名都是001、002...、201,所以下载的文件同名,所以自定义下载的文件名变成这样: 原文:A/00< @1.JPG ---> 下载后:001-A.JPG 原文:B/001.JPG ---> 下载后:001-B.JPG
2、使用-O(大写),后面的url必须特定于某个文件,否则不会被抓到。你也可以使用正则表达式来抓取东西
[root@xi mytest]# curl -O
结果如下:
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 1575 100 1575 0 0 14940 0 --:--:-- --:--:-- --:--:-- 1538k
在当前执行目录中会生成一张bdlogo.gif的图片。
[root@xi mytest]# curl -O[1-10].JPG --下载屏幕1.jpg~screen10.jpg
3、模拟表单信息、模拟登录、保存cookie信息
[root@xi mytest]# curl -c ./cookie_c.txt -F log=aaaa -F pwd=******
4、模拟表单信息、模拟登录、保存表头信息
[root@xi mytest]# curl -D ./cookie_D.txt -F log=aaaa -F pwd=******
由
生成的cookie
-c(小写)与-D中的cookie不同。
5、使用cookie文件
[root@xi mytest]# curl -b ./cookie_c.txt
6、从断点恢复,-C(大写)
[root@xi mytest]# curl -C -O
7、发送数据,最好用登录页面测试,因为你传值后,curl会抓回数据,可以看看传值是否成功
[root@xi mytest]# curl -d log=aaaa
8、显示爬取错误,下面的例子清楚的显示出来。
[root@xi mytest]# curl -f
curl:(22)请求的URL返回错误:404
[root@xi mytest]# curl
404,未找到
9。伪造源地址,有的网站会判断并请求源地址,防止盗链。
[root@xi mytest]# curl -e:///wp-login.php
10、当我们经常用curl做别人的事情的时候,人家会屏蔽你的IP,这个时候我们可以使用代理
[root@xi mytest]# curl -x 24.10.28.84:32779 -o home.html
11,对于较大的东西,我们可以分段下载
[root@xi mytest]# curl -r 0-100 -o img.part1
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 101 100 101 0 0 105 0 --:--:-- --:--:-- --:--:-- 0
[root@xi mytest]# curl -r 100-200 -o img.part2
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 101 100 101 0 0 57 0 0:00:01 0:00:01 --:--:-- 0
[root@xi mytest]# curl -r 200- -o img.part3
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 104k 100 104k 0 0 52793 0 0:00:02 0:00:02 --:--:-- 88961
[root@xi mytest]# ls |grep part | xargs du -sh
4.0K one.part1
112K 三.part3
4.0K two.part2
使用的时候,cat一下就可以了,cat img.part* >img.jpg
12,不会显示下载进度信息
[root@xi mytest]# curl -s -o aaa.jpg
13、显示下载进度条
[root@xi mytest]# curl -0(使用http1.0协议的请求)
############################################## # ######################### 100.0%
14、通过ftp下载文件
[xifj@Xi ~]$ curl -u 用户名:密码 -O
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
101 1934 101 1934 0 0 3184 0 --:--:-- --:--:-- --:--:-- 7136
[xifj@Xi ~]$ curl -u 用户名:密码 -O
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
101 1934 101 1934 0 0 3184 0 --:--:-- --:--:-- --:--:-- 7136
或者使用下面的方法
[xifj@Xi ~]$ curl -O ftp://username:password@ip:port/demo/curtain/bbstudy_files/style.css
[xifj@Xi ~]$ curl -O ftp://username:password@ip:port/demo/curtain/bbstudy_files/style.css
15、通过ftp上传
[xifj@Xi ~]$ curl -T test.sql ftp://username:password@ip:port/demo/curtain/bbstudy_files/
[xifj@Xi ~]$ curl -T test.sql ftp://username:password@ip:port/demo/curtain/bbstudy_files/
15、模拟浏览器头部
[xifj@Xi ~]$ curl -A "Mozilla/4.0 (兼容; MSIE 6.0; Windows NT 5.0)" -x 12< @3.45.67.89:1080 -o page.html -D cookie0001.txt
16,PUT,GET,POST
比如curl -T localfile~zz/abc.cgi,此时使用的协议是HTTP PUT方式
刚才说到PUT,我自然会想到其他几种方法——GET和POST。 查看全部
curl 抓取网页(常用参数curl命令参数说明)
原文:使用说明
curl命令是一个功能强大的网络工具,可以通过http、ftp等方式下载和上传文件。其实curl远不止上面提到的功能。您可以通过 man curl 阅读手册页以获取更多信息。 wget 是一个类似的工具。
curl 命令是使用 libcurl 库实现的。 libcurl 库通常在 C 程序中用于处理 HTTP 请求。 curlpp 是 libcurl 的 C++ 包。这些东西可以用在web抓取、网络监控等开发中,curl命令可以帮助解决开发过程中遇到的问题。
常用参数
curl命令的参数很多,这里只列出我用过的,尤其是shell脚本中的。
-A:请随意指定您自己为本次访问声明的浏览器信息
-b/--cookie cookie 字符串或文件读取位置,使用 option 将最后一个 cookie 信息附加到 http 请求中。
-c/--cookie-jar 操作完成后将cookies写入该文件
-C/--continue-在断点处继续
-d/--data HTTP POST方法传输数据
-D/--dump-header 将头信息写入该文件
-F/--form 模拟http表单提交数据
-v/--verbose 小写的v参数用于打印更多信息,包括发送的请求信息,在调试脚本时特别有用。
-m/--max-time 指定处理的最大持续时间
-H/--header 指定请求头参数
-s/--slent reduce输出信息,如进度
--connect-timeout 指定尝试连接的最长时间
-x/--代理
指定代理服务器地址和端口,默认端口为1080
-T/--upload-file 指定上传文件路径
-o/--output 指定输出文件名
--retry 指定重试次数
-e/--referer 指定引用地址
-I/--head 只返回header信息,使用HEAD请求
-u/--user 设置服务器用户和密码
-O:根据服务器上的文件名,会自动在本地存在
-r/--range 从 HTTP/1.1 或 FTP 服务器检索字节范围
-T/--upload-file 上传文件
使用示例
1、抓取页面内容到文件中
[root@xi mytest]# curl -o home.html -- 将百度首页的内容抓取到home.html中
[root@xi mytest]#curl -o #2_#1.jpg~{A,B}/[001-201].JPG
因为A/B下的文件名都是001、002...、201,所以下载的文件同名,所以自定义下载的文件名变成这样: 原文:A/00< @1.JPG ---> 下载后:001-A.JPG 原文:B/001.JPG ---> 下载后:001-B.JPG
2、使用-O(大写),后面的url必须特定于某个文件,否则不会被抓到。你也可以使用正则表达式来抓取东西
[root@xi mytest]# curl -O
结果如下:
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 1575 100 1575 0 0 14940 0 --:--:-- --:--:-- --:--:-- 1538k
在当前执行目录中会生成一张bdlogo.gif的图片。
[root@xi mytest]# curl -O[1-10].JPG --下载屏幕1.jpg~screen10.jpg
3、模拟表单信息、模拟登录、保存cookie信息
[root@xi mytest]# curl -c ./cookie_c.txt -F log=aaaa -F pwd=******
4、模拟表单信息、模拟登录、保存表头信息
[root@xi mytest]# curl -D ./cookie_D.txt -F log=aaaa -F pwd=******
由
生成的cookie
-c(小写)与-D中的cookie不同。
5、使用cookie文件
[root@xi mytest]# curl -b ./cookie_c.txt
6、从断点恢复,-C(大写)
[root@xi mytest]# curl -C -O
7、发送数据,最好用登录页面测试,因为你传值后,curl会抓回数据,可以看看传值是否成功
[root@xi mytest]# curl -d log=aaaa
8、显示爬取错误,下面的例子清楚的显示出来。
[root@xi mytest]# curl -f
curl:(22)请求的URL返回错误:404
[root@xi mytest]# curl
404,未找到
9。伪造源地址,有的网站会判断并请求源地址,防止盗链。
[root@xi mytest]# curl -e:///wp-login.php
10、当我们经常用curl做别人的事情的时候,人家会屏蔽你的IP,这个时候我们可以使用代理
[root@xi mytest]# curl -x 24.10.28.84:32779 -o home.html
11,对于较大的东西,我们可以分段下载
[root@xi mytest]# curl -r 0-100 -o img.part1
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 101 100 101 0 0 105 0 --:--:-- --:--:-- --:--:-- 0
[root@xi mytest]# curl -r 100-200 -o img.part2
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 101 100 101 0 0 57 0 0:00:01 0:00:01 --:--:-- 0
[root@xi mytest]# curl -r 200- -o img.part3
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 104k 100 104k 0 0 52793 0 0:00:02 0:00:02 --:--:-- 88961
[root@xi mytest]# ls |grep part | xargs du -sh
4.0K one.part1
112K 三.part3
4.0K two.part2
使用的时候,cat一下就可以了,cat img.part* >img.jpg
12,不会显示下载进度信息
[root@xi mytest]# curl -s -o aaa.jpg
13、显示下载进度条
[root@xi mytest]# curl -0(使用http1.0协议的请求)
############################################## # ######################### 100.0%
14、通过ftp下载文件
[xifj@Xi ~]$ curl -u 用户名:密码 -O
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
101 1934 101 1934 0 0 3184 0 --:--:-- --:--:-- --:--:-- 7136
[xifj@Xi ~]$ curl -u 用户名:密码 -O
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
101 1934 101 1934 0 0 3184 0 --:--:-- --:--:-- --:--:-- 7136
或者使用下面的方法
[xifj@Xi ~]$ curl -O ftp://username:password@ip:port/demo/curtain/bbstudy_files/style.css
[xifj@Xi ~]$ curl -O ftp://username:password@ip:port/demo/curtain/bbstudy_files/style.css
15、通过ftp上传
[xifj@Xi ~]$ curl -T test.sql ftp://username:password@ip:port/demo/curtain/bbstudy_files/
[xifj@Xi ~]$ curl -T test.sql ftp://username:password@ip:port/demo/curtain/bbstudy_files/
15、模拟浏览器头部
[xifj@Xi ~]$ curl -A "Mozilla/4.0 (兼容; MSIE 6.0; Windows NT 5.0)" -x 12< @3.45.67.89:1080 -o page.html -D cookie0001.txt
16,PUT,GET,POST
比如curl -T localfile~zz/abc.cgi,此时使用的协议是HTTP PUT方式
刚才说到PUT,我自然会想到其他几种方法——GET和POST。
curl 抓取网页(php的CURL正常抓取页面程序:如果你抓取到的是302状态)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-04-09 15:08
php的CURL正常爬取页面流程如下:
$url = 'http://www.baidu.com';$ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_VERBOSE, true); curl_setopt($ch, CURLOPT_HEADER, true);curl_setopt($ch, CURLOPT_NOBODY, true);curl_setopt($ch, CURLOPT_CUSTOMREQUEST, 'GET');curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_TIMEOUT, 20); curl_setopt($ch, CURLOPT_AUTOREFERER, true); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true); $ret = curl_exec($ch); $info = curl_getinfo($ch); curl_close($ch);
如果抓302状态,那是因为在重新抓取的过程中,有些跳转需要给下一个链接传参,如果没有收到相应的参数,下一个链接也被设置为非法访问。.
curl_setopt($curl, CURLOPT_CUSTOMREQUEST, 'GET');
显示应该是正常的。
以上是用来抓取功能的,应该几乎没有问题。您可以查看 CURLOPT_CUSTOMREQUEST 相关信息。
对 HTTP 请求使用自定义请求消息而不是“GET”或“HEAD”。这对于执行“删除”或其他更隐蔽的 HTTP 请求很有用。有效值为“GET”、“POST”、“CONNECT”等。即这里不要输入整个HTTP请求。例如,输入“GET /index.html HTTP/1.0/r/n/r/n”是不正确的。
PHP技术:PHP curl实现302跳转后抓取页面示例,转载需保留出处!
郑重声明:本文版权归原作者所有,转载文章仅出于传播更多信息之目的。如果作者信息标注有误,请尽快联系我们修改或删除,谢谢。 查看全部
curl 抓取网页(php的CURL正常抓取页面程序:如果你抓取到的是302状态)
php的CURL正常爬取页面流程如下:
$url = 'http://www.baidu.com';$ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_VERBOSE, true); curl_setopt($ch, CURLOPT_HEADER, true);curl_setopt($ch, CURLOPT_NOBODY, true);curl_setopt($ch, CURLOPT_CUSTOMREQUEST, 'GET');curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_TIMEOUT, 20); curl_setopt($ch, CURLOPT_AUTOREFERER, true); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true); $ret = curl_exec($ch); $info = curl_getinfo($ch); curl_close($ch);
如果抓302状态,那是因为在重新抓取的过程中,有些跳转需要给下一个链接传参,如果没有收到相应的参数,下一个链接也被设置为非法访问。.
curl_setopt($curl, CURLOPT_CUSTOMREQUEST, 'GET');
显示应该是正常的。
以上是用来抓取功能的,应该几乎没有问题。您可以查看 CURLOPT_CUSTOMREQUEST 相关信息。
对 HTTP 请求使用自定义请求消息而不是“GET”或“HEAD”。这对于执行“删除”或其他更隐蔽的 HTTP 请求很有用。有效值为“GET”、“POST”、“CONNECT”等。即这里不要输入整个HTTP请求。例如,输入“GET /index.html HTTP/1.0/r/n/r/n”是不正确的。
PHP技术:PHP curl实现302跳转后抓取页面示例,转载需保留出处!
郑重声明:本文版权归原作者所有,转载文章仅出于传播更多信息之目的。如果作者信息标注有误,请尽快联系我们修改或删除,谢谢。
curl 抓取网页(和wget下载安装1、Ubuntu平台wget命令安装:百度首页为例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-08 02:04
curl和wget下载安装
1、Ubuntu 平台
wget命令安装:sudo apt-get install wget(普通用户登录,需要输入密码;root账户登录,不需要输入密码)
curl命令安装:sudo apt-get install curl(同wget)
2、Windows 平台
wget下载地址:wget for Windows
curl下载地址:curl下载
wget和curl包下载地址:Windows平台下的wget和curl工具包
在Windows平台下,curl下载解压后直接为curl.exe格式,复制到系统命令目录下的C:\Windows\System32。
Windows平台下,wget下载解压后,格式为wget-1.11.4-1-setup.exe,需要安装;安装完成后,在环境变量-系统变量-路径目录下添加其安装
curl 和 wget 抓取实例
抓取网页主要有两种方式:url URL 和代理代理。下面是一个爬取“百度”首页的例子。
1、 url URL方法爬取
(1)curl下载百度首页内容,保存在baidu_html文件中
curl baidu_html
(2)wget下载百度首页内容,保存在baidu_html文件中
wget baidu_html2
有时,由于网络速度/数据包丢失/服务器停机等原因,网页暂时无法成功下载。
这时候可能需要尝试多次发送连接来请求服务器的响应;如果多次仍然没有响应,则可以确认服务器有问题。
(1)curl 尝试连接多次
curl --retry 10 --retry-delay 60 --retry-max-time 60 -o baidu_html
注意:--retry 表示重试次数;--retry-delay 表示两次重试之间的时间间隔(以秒为单位);--retry-max-time 表示在这个最大时间内只允许重试一次(一般同--retry-delay)
(2)wget 尝试连接多次
wget -t 10 -w 60 -T 30 -O baidu_html2
注意:-t(--tries)表示重试次数;-w 表示两次重试之间的时间间隔(以秒为单位);-T 表示连接超时时间,超过超时则连接不成功,下次连接继续尝试
附:curl可以判断服务器是否响应。也可以通过一段时间内下载获得的字节数来间接判断。命令格式如下:
curl -y 60 -Y 1 -m 60 -o baidu_html
注:-y表示测试网速的时间;-Y 表示-y期间下载的字节数(字节为单位);-m 表示允许请求连接的最长时间,如果超过连接会自动断开连接并放弃连接
2、代理代理捕获
代理下载是通过连接中间服务器间接下载url网页的过程,而不是url直接连接网站服务器下载
两位知名的自由球员网站:
(全球数十个国家免费代理,每日更新)
(通过设置端口类型、代理类型、国家名称过滤)
在网站中选择国内免费的代理服务器为例介绍代理代理爬取网页:
218.107.21.252:8080(ip为218.107.21.252;端口为8080,中间是 8080 冒号“:”隔开形成套接字)
(1)curl通过代理爬取百度首页
curl -x 218.107.21.252:8080 -o aaaaa(常用端口有80、8080、8086、8888、3128等,默认8< @0)
注:-x表示代理服务器(ip:port),即curl先连接代理服务器218.107.21.252:8080,然后通过21< @k31@ >107.21.252:8080 下载百度首页,最后218.107.21.252:8080 通过下载百度主页 curl 到本地(curl 不是直接连接百度服务器下载主页,而是通过中介代理)
(2)wget通过代理爬取百度首页
wget 通过代理下载,和 curl 不一样。需要先设置代理服务器的http_proxy=ip:port。
以ubuntu为例,在当前用户目录(cd ~),新建wget配置文件(.wgetrc),进入代理配置: 查看全部
curl 抓取网页(和wget下载安装1、Ubuntu平台wget命令安装:百度首页为例)
curl和wget下载安装
1、Ubuntu 平台
wget命令安装:sudo apt-get install wget(普通用户登录,需要输入密码;root账户登录,不需要输入密码)
curl命令安装:sudo apt-get install curl(同wget)
2、Windows 平台
wget下载地址:wget for Windows
curl下载地址:curl下载
wget和curl包下载地址:Windows平台下的wget和curl工具包
在Windows平台下,curl下载解压后直接为curl.exe格式,复制到系统命令目录下的C:\Windows\System32。
Windows平台下,wget下载解压后,格式为wget-1.11.4-1-setup.exe,需要安装;安装完成后,在环境变量-系统变量-路径目录下添加其安装
curl 和 wget 抓取实例
抓取网页主要有两种方式:url URL 和代理代理。下面是一个爬取“百度”首页的例子。
1、 url URL方法爬取
(1)curl下载百度首页内容,保存在baidu_html文件中
curl baidu_html
(2)wget下载百度首页内容,保存在baidu_html文件中
wget baidu_html2
有时,由于网络速度/数据包丢失/服务器停机等原因,网页暂时无法成功下载。
这时候可能需要尝试多次发送连接来请求服务器的响应;如果多次仍然没有响应,则可以确认服务器有问题。
(1)curl 尝试连接多次
curl --retry 10 --retry-delay 60 --retry-max-time 60 -o baidu_html
注意:--retry 表示重试次数;--retry-delay 表示两次重试之间的时间间隔(以秒为单位);--retry-max-time 表示在这个最大时间内只允许重试一次(一般同--retry-delay)
(2)wget 尝试连接多次
wget -t 10 -w 60 -T 30 -O baidu_html2
注意:-t(--tries)表示重试次数;-w 表示两次重试之间的时间间隔(以秒为单位);-T 表示连接超时时间,超过超时则连接不成功,下次连接继续尝试
附:curl可以判断服务器是否响应。也可以通过一段时间内下载获得的字节数来间接判断。命令格式如下:
curl -y 60 -Y 1 -m 60 -o baidu_html
注:-y表示测试网速的时间;-Y 表示-y期间下载的字节数(字节为单位);-m 表示允许请求连接的最长时间,如果超过连接会自动断开连接并放弃连接
2、代理代理捕获
代理下载是通过连接中间服务器间接下载url网页的过程,而不是url直接连接网站服务器下载
两位知名的自由球员网站:
(全球数十个国家免费代理,每日更新)
(通过设置端口类型、代理类型、国家名称过滤)
在网站中选择国内免费的代理服务器为例介绍代理代理爬取网页:
218.107.21.252:8080(ip为218.107.21.252;端口为8080,中间是 8080 冒号“:”隔开形成套接字)
(1)curl通过代理爬取百度首页
curl -x 218.107.21.252:8080 -o aaaaa(常用端口有80、8080、8086、8888、3128等,默认8< @0)
注:-x表示代理服务器(ip:port),即curl先连接代理服务器218.107.21.252:8080,然后通过21< @k31@ >107.21.252:8080 下载百度首页,最后218.107.21.252:8080 通过下载百度主页 curl 到本地(curl 不是直接连接百度服务器下载主页,而是通过中介代理)
(2)wget通过代理爬取百度首页
wget 通过代理下载,和 curl 不一样。需要先设置代理服务器的http_proxy=ip:port。
以ubuntu为例,在当前用户目录(cd ~),新建wget配置文件(.wgetrc),进入代理配置:
curl 抓取网页(和wget下载安装1、Ubuntu平台wget命令安装:百度首页为例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 302 次浏览 • 2022-04-03 22:11
curl和wget下载安装
1、Ubuntu 平台
wget命令安装:sudo apt-get install wget(普通用户登录,需要输入密码;root账号登录,不需要密码)
curl命令安装:sudo apt-get install curl(同wget)
2、Windows 平台
wget下载地址:wget for Windows
curl下载地址:curl下载
wget和curl包下载地址:Windows平台下的wget和curl工具包
Windows平台下,curl下载解压后直接为curl.exe格式,复制到系统命令目录下的C:\Windows\System32。
Windows平台下,wget下载解压后,格式为wget-1.11.4-1-setup.exe,需要安装;安装完成后,在环境变量-系统变量-路径目录下添加其安装
curl 和 wget 抓取实例
抓取网页主要有两种方式:url URL 和代理代理。下面是一个爬取“百度”首页的例子。
1、 url URL方法爬取
(1)curl下载百度首页内容,保存在baidu_html文件中
curl -o baidu_html
(2)wget下载百度首页内容,保存在baidu_html文件中
wget -O baidu_html2
有时,由于网络速度/数据包丢失/服务器停机等原因,网页暂时无法成功下载。
这时候可能需要尝试多次发送连接来请求服务器的响应;如果多次仍然没有响应,则可以确认服务器有问题。
(1)curl 尝试连接多次
curl --retry 10 --retry-delay 60 --retry-max-time 60 -o baidu_html
注意:--retry 表示重试次数;--retry-delay 表示两次重试之间的时间间隔(以秒为单位);--retry-max-time 表示在这个最大时间内只允许重试一次(一般同--retry-delay)
(2)wget 尝试连接多次
wget -t 10 -w 60 -T 30 -O baidu_html2
注意:-t(--tries)表示重试次数;-w 表示两次重试之间的时间间隔(以秒为单位);-T 表示连接超时时间,超过超时则连接不成功,下次连接继续尝试
附:curl可以判断服务器是否响应。也可以通过一段时间内下载获得的字节数来间接判断。命令格式如下:
curl -y 60 -Y 1 -m 60 -o baidu_html
注:-y表示测试网速的时间;-Y 表示-y期间下载的字节数(字节为单位);-m 表示允许请求连接的最长时间,如果超过连接会自动断开连接并放弃连接
2、代理代理捕获
代理下载是通过连接中间服务器间接下载url网页的过程,而不是url直接连接网站服务器下载
两位知名的自由球员网站:
(全球数十个国家免费代理,每日更新)
(通过设置端口类型、代理类型、国家名称过滤)
在网站中选择国内免费的代理服务器为例介绍代理代理爬取网页:
218.107.21.252:8080(ip为218.107.21.252;端口为8080,中间是 8080 冒号“:”隔开形成套接字)
(1)curl通过代理爬取百度首页
curl -x 218.107.21.252:8080 -o aaaaa(常用端口有80、8080、8086、8888、3128等,默认80)
注:-x表示代理服务器(ip:port),即curl先连接代理服务器218.107.21.252:8080,然后通过21< @k31@ >107.21.252:8080 下载百度首页,最后218.107.21.252:8080 通过下载百度主页 curl 到本地(curl 不是直接连接百度服务器下载主页,而是通过中介代理)
(2)wget通过代理爬取百度首页
wget是通过代理下载的,和curl不一样。需要先设置代理服务器的http_proxy=ip:port。
以ubuntu为例,在当前用户目录(cd ~),新建wget配置文件(.wgetrc),进入代理配置: 查看全部
curl 抓取网页(和wget下载安装1、Ubuntu平台wget命令安装:百度首页为例)
curl和wget下载安装
1、Ubuntu 平台
wget命令安装:sudo apt-get install wget(普通用户登录,需要输入密码;root账号登录,不需要密码)
curl命令安装:sudo apt-get install curl(同wget)
2、Windows 平台
wget下载地址:wget for Windows
curl下载地址:curl下载
wget和curl包下载地址:Windows平台下的wget和curl工具包
Windows平台下,curl下载解压后直接为curl.exe格式,复制到系统命令目录下的C:\Windows\System32。
Windows平台下,wget下载解压后,格式为wget-1.11.4-1-setup.exe,需要安装;安装完成后,在环境变量-系统变量-路径目录下添加其安装
curl 和 wget 抓取实例
抓取网页主要有两种方式:url URL 和代理代理。下面是一个爬取“百度”首页的例子。
1、 url URL方法爬取
(1)curl下载百度首页内容,保存在baidu_html文件中
curl -o baidu_html
(2)wget下载百度首页内容,保存在baidu_html文件中
wget -O baidu_html2
有时,由于网络速度/数据包丢失/服务器停机等原因,网页暂时无法成功下载。
这时候可能需要尝试多次发送连接来请求服务器的响应;如果多次仍然没有响应,则可以确认服务器有问题。
(1)curl 尝试连接多次
curl --retry 10 --retry-delay 60 --retry-max-time 60 -o baidu_html
注意:--retry 表示重试次数;--retry-delay 表示两次重试之间的时间间隔(以秒为单位);--retry-max-time 表示在这个最大时间内只允许重试一次(一般同--retry-delay)
(2)wget 尝试连接多次
wget -t 10 -w 60 -T 30 -O baidu_html2
注意:-t(--tries)表示重试次数;-w 表示两次重试之间的时间间隔(以秒为单位);-T 表示连接超时时间,超过超时则连接不成功,下次连接继续尝试
附:curl可以判断服务器是否响应。也可以通过一段时间内下载获得的字节数来间接判断。命令格式如下:
curl -y 60 -Y 1 -m 60 -o baidu_html
注:-y表示测试网速的时间;-Y 表示-y期间下载的字节数(字节为单位);-m 表示允许请求连接的最长时间,如果超过连接会自动断开连接并放弃连接
2、代理代理捕获
代理下载是通过连接中间服务器间接下载url网页的过程,而不是url直接连接网站服务器下载
两位知名的自由球员网站:
(全球数十个国家免费代理,每日更新)
(通过设置端口类型、代理类型、国家名称过滤)
在网站中选择国内免费的代理服务器为例介绍代理代理爬取网页:
218.107.21.252:8080(ip为218.107.21.252;端口为8080,中间是 8080 冒号“:”隔开形成套接字)
(1)curl通过代理爬取百度首页
curl -x 218.107.21.252:8080 -o aaaaa(常用端口有80、8080、8086、8888、3128等,默认80)
注:-x表示代理服务器(ip:port),即curl先连接代理服务器218.107.21.252:8080,然后通过21< @k31@ >107.21.252:8080 下载百度首页,最后218.107.21.252:8080 通过下载百度主页 curl 到本地(curl 不是直接连接百度服务器下载主页,而是通过中介代理)
(2)wget通过代理爬取百度首页
wget是通过代理下载的,和curl不一样。需要先设置代理服务器的http_proxy=ip:port。
以ubuntu为例,在当前用户目录(cd ~),新建wget配置文件(.wgetrc),进入代理配置:
curl 抓取网页( IP代理筛选系统问题分析分析解决一个问题的原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-04-03 22:11
IP代理筛选系统问题分析分析解决一个问题的原理)
Linux IP代理筛选系统(shell+proxy)
代理的目的
其实,除了使用IP代理爬取国外网页外,还有很多使用代理的场景:
代理原则
代理服务的原理是本地浏览器(Browser)发送请求的数据,而不是直接发送给网站服务器(Web Server)
取而代之的是一个中间代理服务器(Proxy),如下图:
IP代理筛选系统
问题分析
在分析解决一个实际问题的时候,会遇到各种各样的问题,有些问题甚至在方案设计之初都难以想到(比如代理IP爬取网页速度慢)。我的经验是,动手实践比纯理论更重要。重要的!
设计
大体思路:找到并缩小被屏蔽的IP代理的来源-》检查代理IP是否可用-》记录IP抓取网页-》如果代理IP失败重新过滤-》继续抓取网页- “完全的
1、IP代理源
选择有两个原则:可用和免费。经过深入研究和搜索,最终确定两个网站 IP代理更可靠:和
从国家数量、IP代理数量、IP代理的可用性、IP代理的文本格式综合考虑,IP代理的来源主要选择前者,后者作为补充. 后来的实际测试表明,这种初选方案基本满足需要。
2、文本预处理
从获取的代理IP中,有IP地址、端口、类型、匿名性、国家等参数,我们需要的只有IP+端口,所以需要对主IP代理源做文本预处理。
文本空间处理命令:
sed -e "s/\s\{2,\}/:/g" $file_input > $file_split
sed -i "s/ /:/g" $file_split
合并代理 IP (ip:port) 命令:
proxy_ip=$(echo $line | cut -f 1 -d ":")
proxy_port=$(echo $line | cut -f 2 -d ":")
代理=$proxy_ip":"$proxy_port
3、检测IP代理
文本预处理代理IP为标准格式(ip:port)后,需要进行代理IP筛选测试,看看哪些可用哪些不可用(因为获取的部分IP代理源无法使用或下载太慢,需要过滤掉)
curl抓取网页检查IP代理是否可用命令:
cmd="curl -y 60 -Y 1 -m 300 -x$proxy-o $file_html$index $url_html"
$cmd
4、保存IP代理
检查代理IP是否可用,如果可用,保存。
判断代理IP是否可用的标准是判断步骤3下载的网页($file_html$index)是否有内容。具体命令如下:
如果 [ -e ./$file_html$index ]; 然后
回声 $proxy >> $2
休息;
菲
5、IP代理爬取网页
使用第4步保存的代理IP抓取网页,使用代理IP抓取12个国家的排名网页和游戏网页。具体命令如下:
proxy_cmd="curl -y 60 -Y 1 -m 300 -x$proxy-o $proxy_html $proxy_http"
$proxy_cmd
6、IP 代理失败
IP代理失败的案例很多。上面的问题分析中已经列出了几个。下面将详细分析如下:
一种。网页抓取过程中代理IP突然失效,无法继续完成网页抓取
湾。代理IP没有失效,但是网页抓取很慢,一天24小时内无法完成网页抓取,导致无法生成游戏排名日报表
C。所有代理 IP 均无效。无论经过一次或多次轮询测试,当天的网页抓取任务都无法完成。
d。由于全网路由拥塞,代理IP很慢或者无法爬取网页,误判代理IP全部无效。如何恢复和纠正它
7、重新检测IP代理
在网页抓取过程中,面对第6步的IP代理故障,设计合理高效的代理IP抓取恢复机制是整个IP代理筛选系统的核心和关键
故障恢复的轮询和筛选过程如下:
在上述过程中,有几点需要注意:
一种。首先检测最后一个 IP 代理。这是因为上一个(昨天)的IP代理完成了所有的网页爬取任务,它的可用概率比较高,所以优先考虑今天是否可用。如果不可用,请选择另一个
湾。如果今天最后一个代理IP不可用,重新遍历检测代理IP源。一旦检测到可用,就不会循环,更新可用的IP代理并将其位置保存在IP源中,方便下次遍历从这里开始
C。如果进程b中新选择的代理IP突然失效或者网速太慢,继续筛选b中记录的IP源位置是否有以下代理IP。如果可用,继续爬取网页;如果没有,再遍历整个IP源
d。如果再次遍历整个代理IP源,仍然没有可用的代理IP,则重复轮询和遍历整个代理IP源,直到有可用的代理IP或今天24点过去(即没有今天一整天都可以找到可用的代理IP)
e. 对于进程d中所有代理IP都无效,整天找不到可用代理IP的特殊情况,无法完成当天的网页抓取。次日凌晨重启爬网主控脚本之前,需要先杀掉进程。d 后台循环进程,防止今天和次日两个后台抓取程序同时运行(相当于两个异步后台抓取进程),导致抓取的网页排名数据过时或错误,占用网络速度和带宽等。为了杀死当天的死后台爬取进程,请参考上一篇博客Linux爬取网页示例-《自动主控脚本-》kill_curl.sh脚本,
尽管 [ !-z $(ps -ef | grepcurl| grep -v grep | cut -c 9-15) ]
做
ps -ef | grep 卷曲 | grep -v grep | 切-c 15-20 | xargs 杀死 -9
ps -ef | grep 卷曲 | grep -v grep | 切-c 9-15 | xargs 杀死 -9
完毕
8、完成网页抓取
通过以上IP代理筛选系统,筛选出12个国家可用的免费代理IP,完成12个国家的每日网页排名和游戏网页的爬取任务。
之后就是对网页中的游戏属性信息进行提取处理,生成日报,定时发送邮件,查询趋势图。
脚本功能实现
IP代理筛选的基本流程比较简单,其数据格式和实现步骤如下:
首先到网站采集可用的代理IP源(以美国为例),格式如下:
接下来,清除上图中的空格。具体实现命令请参考上面的【方案设计】-》【2、文本预处理】,文本预处理的格式如下:
然后,测试上图文字预处理后的代理IP是否可用,请参考上面的【方案设计】->【3、检测IP代理】。检测到代理IP后的格式如下:
下面介绍shell脚本实现文本预处理和网页过滤的详细步骤
1、文本预处理
[php]查看纯副本
打印?
#fileprocesslog='Top800proxy.log'dtime=$(date+%Y-%m-%d__%H:%M:%S)functionselect_proxy(){if[!-d$dir_split];thenmkdir$dir_splitfiif[!-d $dir_output];thenmkdir$dir_outputfiif[!-e$log];thentouch$logfiecho"==================Top800proxy$dtime========== =======">>$logforfilein`ls$dir_input`;doecho$file>>$logfile_input=$dir_input$fileecho$file_input>>$logfile_split=$dir_split$file"_split"echo$file_split>> $ logrm-rf$file_splittouch$file_splitsed-e"s/\t\{2,\}/\t/g"$file_input>$file_split sed-e"s/\t/:/g"$file_input>$file_split sed -i "s//:/g"$file_splitfile_output=$dir_output$file"_out"echo$file_output>>$logproxy_output"$file_split""$file_output"echo''>>$logdoneecho''>>$log}
脚本功能说明:
if语句判断并创建文件夹$dir_split和$dir_output用于保存处理IP源的中间结果,前者保存【脚本功能实现】中文本预处理后的文本格式,后者保存检测后可用的代理IP
sed -e 语句,将输入文本(图中多个空格1)由脚本函数实现)修改为字符“:”
sed -i 语句进一步将文本中多余的空格转换为字符“:”
转换的中间结果保存到文件夹 $dir_split
以下三行file_output,以文件参数“$file_split”的形式,传递给代理IP检测函数(proxy_output),过滤掉可用的代理IP
2、代理 IP 筛选
[php]查看纯副本
打印?
index=1file_html=$dir_output"html_"cmd=''functionproxy_output(){rm-rf$2touch$2rm-rf$file_html*index=1whilereadlinedoproxy_ip_port=$(echo$line|cut-f1,2 -d":")代理=$proxy_ip_port"echo$proxy>>$logcmd="curl-y60-Y1-m300-x$proxy-o$file_html$index$url_html"echo$cmd>>$log$cmdif[-e./$file_html $index];thenecho$proxy>>$2break;fiindex=`expr$index+1`done>$logecho$url"_____$date">>$log$url_cmd#donetimeoutfileseconds=0while[!-f$url_output$index ]dosleep1echo$url_output$index"________________noexist">>$log$url_cmdseconds=`expr$seconds+1`echo"seconds____________"$seconds>>$logif[$seconds-ge5];thenselect_proxyurl_cmd='curl-y60-Y1-m300 -x'$proxy'-o'$url_output$index''$urlseconds=0fidoneindex=`expr$index+24`done
脚本功能说明:
上面的shell脚本代码片段是用来爬取网页的,其核心行是select_proxy
其功能如上所述。当代理IP突然失效,网页抓取太慢,所有代理IP无效,或者当天的网页抓取工作无法完成时,用于重新筛选代理IP,恢复网页核心刮。代码
它的设计和实现过程,如上面【方案设计】-》【7、重新检测IP代理】,其实现原理可以参考上面【代理IP筛选】的脚本,及其源码这里就不贴了。脚本代码
发表于 2016-04-07 16:18xxxxxxxx1x2xxxxxxx 阅读(390)评论(0)编辑 查看全部
curl 抓取网页(
IP代理筛选系统问题分析分析解决一个问题的原理)
Linux IP代理筛选系统(shell+proxy)
代理的目的
其实,除了使用IP代理爬取国外网页外,还有很多使用代理的场景:
代理原则
代理服务的原理是本地浏览器(Browser)发送请求的数据,而不是直接发送给网站服务器(Web Server)
取而代之的是一个中间代理服务器(Proxy),如下图:
IP代理筛选系统
问题分析
在分析解决一个实际问题的时候,会遇到各种各样的问题,有些问题甚至在方案设计之初都难以想到(比如代理IP爬取网页速度慢)。我的经验是,动手实践比纯理论更重要。重要的!
设计
大体思路:找到并缩小被屏蔽的IP代理的来源-》检查代理IP是否可用-》记录IP抓取网页-》如果代理IP失败重新过滤-》继续抓取网页- “完全的
1、IP代理源
选择有两个原则:可用和免费。经过深入研究和搜索,最终确定两个网站 IP代理更可靠:和
从国家数量、IP代理数量、IP代理的可用性、IP代理的文本格式综合考虑,IP代理的来源主要选择前者,后者作为补充. 后来的实际测试表明,这种初选方案基本满足需要。
2、文本预处理
从获取的代理IP中,有IP地址、端口、类型、匿名性、国家等参数,我们需要的只有IP+端口,所以需要对主IP代理源做文本预处理。
文本空间处理命令:
sed -e "s/\s\{2,\}/:/g" $file_input > $file_split
sed -i "s/ /:/g" $file_split
合并代理 IP (ip:port) 命令:
proxy_ip=$(echo $line | cut -f 1 -d ":")
proxy_port=$(echo $line | cut -f 2 -d ":")
代理=$proxy_ip":"$proxy_port
3、检测IP代理
文本预处理代理IP为标准格式(ip:port)后,需要进行代理IP筛选测试,看看哪些可用哪些不可用(因为获取的部分IP代理源无法使用或下载太慢,需要过滤掉)
curl抓取网页检查IP代理是否可用命令:
cmd="curl -y 60 -Y 1 -m 300 -x$proxy-o $file_html$index $url_html"
$cmd
4、保存IP代理
检查代理IP是否可用,如果可用,保存。
判断代理IP是否可用的标准是判断步骤3下载的网页($file_html$index)是否有内容。具体命令如下:
如果 [ -e ./$file_html$index ]; 然后
回声 $proxy >> $2
休息;
菲
5、IP代理爬取网页
使用第4步保存的代理IP抓取网页,使用代理IP抓取12个国家的排名网页和游戏网页。具体命令如下:
proxy_cmd="curl -y 60 -Y 1 -m 300 -x$proxy-o $proxy_html $proxy_http"
$proxy_cmd
6、IP 代理失败
IP代理失败的案例很多。上面的问题分析中已经列出了几个。下面将详细分析如下:
一种。网页抓取过程中代理IP突然失效,无法继续完成网页抓取
湾。代理IP没有失效,但是网页抓取很慢,一天24小时内无法完成网页抓取,导致无法生成游戏排名日报表
C。所有代理 IP 均无效。无论经过一次或多次轮询测试,当天的网页抓取任务都无法完成。
d。由于全网路由拥塞,代理IP很慢或者无法爬取网页,误判代理IP全部无效。如何恢复和纠正它
7、重新检测IP代理
在网页抓取过程中,面对第6步的IP代理故障,设计合理高效的代理IP抓取恢复机制是整个IP代理筛选系统的核心和关键
故障恢复的轮询和筛选过程如下:
在上述过程中,有几点需要注意:
一种。首先检测最后一个 IP 代理。这是因为上一个(昨天)的IP代理完成了所有的网页爬取任务,它的可用概率比较高,所以优先考虑今天是否可用。如果不可用,请选择另一个
湾。如果今天最后一个代理IP不可用,重新遍历检测代理IP源。一旦检测到可用,就不会循环,更新可用的IP代理并将其位置保存在IP源中,方便下次遍历从这里开始
C。如果进程b中新选择的代理IP突然失效或者网速太慢,继续筛选b中记录的IP源位置是否有以下代理IP。如果可用,继续爬取网页;如果没有,再遍历整个IP源
d。如果再次遍历整个代理IP源,仍然没有可用的代理IP,则重复轮询和遍历整个代理IP源,直到有可用的代理IP或今天24点过去(即没有今天一整天都可以找到可用的代理IP)
e. 对于进程d中所有代理IP都无效,整天找不到可用代理IP的特殊情况,无法完成当天的网页抓取。次日凌晨重启爬网主控脚本之前,需要先杀掉进程。d 后台循环进程,防止今天和次日两个后台抓取程序同时运行(相当于两个异步后台抓取进程),导致抓取的网页排名数据过时或错误,占用网络速度和带宽等。为了杀死当天的死后台爬取进程,请参考上一篇博客Linux爬取网页示例-《自动主控脚本-》kill_curl.sh脚本,
尽管 [ !-z $(ps -ef | grepcurl| grep -v grep | cut -c 9-15) ]
做
ps -ef | grep 卷曲 | grep -v grep | 切-c 15-20 | xargs 杀死 -9
ps -ef | grep 卷曲 | grep -v grep | 切-c 9-15 | xargs 杀死 -9
完毕
8、完成网页抓取
通过以上IP代理筛选系统,筛选出12个国家可用的免费代理IP,完成12个国家的每日网页排名和游戏网页的爬取任务。
之后就是对网页中的游戏属性信息进行提取处理,生成日报,定时发送邮件,查询趋势图。
脚本功能实现
IP代理筛选的基本流程比较简单,其数据格式和实现步骤如下:
首先到网站采集可用的代理IP源(以美国为例),格式如下:
接下来,清除上图中的空格。具体实现命令请参考上面的【方案设计】-》【2、文本预处理】,文本预处理的格式如下:
然后,测试上图文字预处理后的代理IP是否可用,请参考上面的【方案设计】->【3、检测IP代理】。检测到代理IP后的格式如下:
下面介绍shell脚本实现文本预处理和网页过滤的详细步骤
1、文本预处理
[php]查看纯副本
打印?
#fileprocesslog='Top800proxy.log'dtime=$(date+%Y-%m-%d__%H:%M:%S)functionselect_proxy(){if[!-d$dir_split];thenmkdir$dir_splitfiif[!-d $dir_output];thenmkdir$dir_outputfiif[!-e$log];thentouch$logfiecho"==================Top800proxy$dtime========== =======">>$logforfilein`ls$dir_input`;doecho$file>>$logfile_input=$dir_input$fileecho$file_input>>$logfile_split=$dir_split$file"_split"echo$file_split>> $ logrm-rf$file_splittouch$file_splitsed-e"s/\t\{2,\}/\t/g"$file_input>$file_split sed-e"s/\t/:/g"$file_input>$file_split sed -i "s//:/g"$file_splitfile_output=$dir_output$file"_out"echo$file_output>>$logproxy_output"$file_split""$file_output"echo''>>$logdoneecho''>>$log}
脚本功能说明:
if语句判断并创建文件夹$dir_split和$dir_output用于保存处理IP源的中间结果,前者保存【脚本功能实现】中文本预处理后的文本格式,后者保存检测后可用的代理IP
sed -e 语句,将输入文本(图中多个空格1)由脚本函数实现)修改为字符“:”
sed -i 语句进一步将文本中多余的空格转换为字符“:”
转换的中间结果保存到文件夹 $dir_split
以下三行file_output,以文件参数“$file_split”的形式,传递给代理IP检测函数(proxy_output),过滤掉可用的代理IP
2、代理 IP 筛选
[php]查看纯副本
打印?
index=1file_html=$dir_output"html_"cmd=''functionproxy_output(){rm-rf$2touch$2rm-rf$file_html*index=1whilereadlinedoproxy_ip_port=$(echo$line|cut-f1,2 -d":")代理=$proxy_ip_port"echo$proxy>>$logcmd="curl-y60-Y1-m300-x$proxy-o$file_html$index$url_html"echo$cmd>>$log$cmdif[-e./$file_html $index];thenecho$proxy>>$2break;fiindex=`expr$index+1`done>$logecho$url"_____$date">>$log$url_cmd#donetimeoutfileseconds=0while[!-f$url_output$index ]dosleep1echo$url_output$index"________________noexist">>$log$url_cmdseconds=`expr$seconds+1`echo"seconds____________"$seconds>>$logif[$seconds-ge5];thenselect_proxyurl_cmd='curl-y60-Y1-m300 -x'$proxy'-o'$url_output$index''$urlseconds=0fidoneindex=`expr$index+24`done
脚本功能说明:
上面的shell脚本代码片段是用来爬取网页的,其核心行是select_proxy
其功能如上所述。当代理IP突然失效,网页抓取太慢,所有代理IP无效,或者当天的网页抓取工作无法完成时,用于重新筛选代理IP,恢复网页核心刮。代码
它的设计和实现过程,如上面【方案设计】-》【7、重新检测IP代理】,其实现原理可以参考上面【代理IP筛选】的脚本,及其源码这里就不贴了。脚本代码
发表于 2016-04-07 16:18xxxxxxxx1x2xxxxxxx 阅读(390)评论(0)编辑
curl 抓取网页(curl抓取网页方法-上海怡健医学(抓取))
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-04-01 01:05
curl抓取网页方法一:用curl命令下载网页方法二:用wget,git或者其他工具下载网页,后缀是txt文件。我已有的这个回答。
按网址依次点击右键,
wget..,不过没下完的话好像是会自动识别的。之前我抓了一个某个神风已久的比赛,
..这个倒是问的好,需要使用curl,网上大把教程。
有个软件gotoyahoo有源代码,你需要用那个来抓取,
下载javascript、css、json等,看看是不是乱码,对应的js文件或者css文件再json文件的文件名里有没有mode。要先搞清楚txt是怎么回事。
别说百度,一搜都有。
curl+wget
嗯···我也是,但是一抓下来就全变成js代码了。我是抓到n多学校比赛的票之后才发现是个二维码。
要抓百度网页全放倒cookie里吗,
我也经常遇到这种情况,我也是无奈只能等后缀转换工具。
打开浏览器:8000/apacheespresso/file-generate-url2.phpcd$home./javascriptjsgowget 查看全部
curl 抓取网页(curl抓取网页方法-上海怡健医学(抓取))
curl抓取网页方法一:用curl命令下载网页方法二:用wget,git或者其他工具下载网页,后缀是txt文件。我已有的这个回答。
按网址依次点击右键,
wget..,不过没下完的话好像是会自动识别的。之前我抓了一个某个神风已久的比赛,
..这个倒是问的好,需要使用curl,网上大把教程。
有个软件gotoyahoo有源代码,你需要用那个来抓取,
下载javascript、css、json等,看看是不是乱码,对应的js文件或者css文件再json文件的文件名里有没有mode。要先搞清楚txt是怎么回事。
别说百度,一搜都有。
curl+wget
嗯···我也是,但是一抓下来就全变成js代码了。我是抓到n多学校比赛的票之后才发现是个二维码。
要抓百度网页全放倒cookie里吗,
我也经常遇到这种情况,我也是无奈只能等后缀转换工具。
打开浏览器:8000/apacheespresso/file-generate-url2.phpcd$home./javascriptjsgowget
curl 抓取网页(PHP的调用测试(get(get)函数(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-03-30 22:18
)
PHP 的 curl 功能真的很强大。有一个 curl_multi_init 函数,它是批处理任务。可以利用这一点实现多进程同步抓取多条记录,优化常见的网页爬取程序。
一个简单的抓取功能:
function http_get_multi($urls){
$count = count($urls);
$data = [];
$chs = [];
// 创建批处理cURL句柄
$mh = curl_multi_init();
// 创建cURL资源
for($i = 0; $i < $count; $i ++){
$chs[ $i ] = curl_init();
// 设置URL和相应的选项
curl_setopt($chs[ $i ], CURLOPT_RETURNTRANSFER, 1); // return don't print
curl_setopt($chs[ $i ], CURLOPT_URL, $urls[$i]);
curl_setopt($chs[ $i ], CURLOPT_HEADER, 0);
curl_multi_add_handle($mh, $chs[ $i ]);
}
// 增加句柄
// for($i = 0; $i < $count; $i ++){
// curl_multi_add_handle($mh, $chs[ $i ]);
// }
// 执行批处理句柄
do {
$mrc = curl_multi_exec($mh, $active);
} while ($active > 0);
while ($active and $mrc == CURLM_OK) {
if (curl_multi_select($mh) != -1) {
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
}
}
for($i = 0; $i < $count; $i ++){
$content = curl_multi_getcontent($chs[ $i ]);
$data[ $i ] = ( curl_errno($chs[ $i ]) == 0 ) ? $content : false;
}
// 关闭全部句柄
for($i = 0; $i < $count; $i ++){
curl_multi_remove_handle($mh, $chs[ $i ]);
}
curl_multi_close($mh);
return $data;
}
以下调用测试(get() 函数在这里:):
//弄很多个网页的url<br />$url = [
'http://www.baidu.com',
'http://www.163.com',
'http://www.sina.com.cn',
'http://www.qq.com',
'http://www.sohu.com',
'http://www.douban.com',
'http://www.cnblogs.com',
'http://www.taobao.com',
'http://www.php.net',
];
$urls = [];
for($i = 0; $i < 10; $i ++){
foreach($url as $r)
$urls[] = $r . '/?v=' . rand();
} <br /><br />//并发请求
$datas = http_get_multi($urls);
foreach($datas as $key => $data){
file_put_contents('log/multi_' . $key . '.txt', $data); // 记录一下请求结果。记得创建一个log文件夹
}
$t2 = microtime(true);
echo $t2 - $t1;
echo '<br />';<br /><br />//同步请求, get()函数如这里: http://www.cnblogs.com/whatmiss/p/7114954.html
$t1 = microtime(true);
foreach($urls as $key => $url){
file_put_contents('log/get_' . $key . '.txt', get($url)); // 记录一下请求结果。记得创建一个log文件夹
}
$t2 = microtime(true);
echo $t2 - $t1;
在测试结果中,存在明显的差距,并且随着数据量的增加,差距会呈指数级增长:
2.4481401443481
21.68923997879
8.925509929657
24.73141503334
3.243185043335
23.384337902069
3.2841880321503
24.754415035248
3.2091829776764
29.068662881851 查看全部
curl 抓取网页(PHP的调用测试(get(get)函数(图)
)
PHP 的 curl 功能真的很强大。有一个 curl_multi_init 函数,它是批处理任务。可以利用这一点实现多进程同步抓取多条记录,优化常见的网页爬取程序。
一个简单的抓取功能:
function http_get_multi($urls){
$count = count($urls);
$data = [];
$chs = [];
// 创建批处理cURL句柄
$mh = curl_multi_init();
// 创建cURL资源
for($i = 0; $i < $count; $i ++){
$chs[ $i ] = curl_init();
// 设置URL和相应的选项
curl_setopt($chs[ $i ], CURLOPT_RETURNTRANSFER, 1); // return don't print
curl_setopt($chs[ $i ], CURLOPT_URL, $urls[$i]);
curl_setopt($chs[ $i ], CURLOPT_HEADER, 0);
curl_multi_add_handle($mh, $chs[ $i ]);
}
// 增加句柄
// for($i = 0; $i < $count; $i ++){
// curl_multi_add_handle($mh, $chs[ $i ]);
// }
// 执行批处理句柄
do {
$mrc = curl_multi_exec($mh, $active);
} while ($active > 0);
while ($active and $mrc == CURLM_OK) {
if (curl_multi_select($mh) != -1) {
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
}
}
for($i = 0; $i < $count; $i ++){
$content = curl_multi_getcontent($chs[ $i ]);
$data[ $i ] = ( curl_errno($chs[ $i ]) == 0 ) ? $content : false;
}
// 关闭全部句柄
for($i = 0; $i < $count; $i ++){
curl_multi_remove_handle($mh, $chs[ $i ]);
}
curl_multi_close($mh);
return $data;
}
以下调用测试(get() 函数在这里:):
//弄很多个网页的url<br />$url = [
'http://www.baidu.com',
'http://www.163.com',
'http://www.sina.com.cn',
'http://www.qq.com',
'http://www.sohu.com',
'http://www.douban.com',
'http://www.cnblogs.com',
'http://www.taobao.com',
'http://www.php.net',
];
$urls = [];
for($i = 0; $i < 10; $i ++){
foreach($url as $r)
$urls[] = $r . '/?v=' . rand();
} <br /><br />//并发请求
$datas = http_get_multi($urls);
foreach($datas as $key => $data){
file_put_contents('log/multi_' . $key . '.txt', $data); // 记录一下请求结果。记得创建一个log文件夹
}
$t2 = microtime(true);
echo $t2 - $t1;
echo '<br />';<br /><br />//同步请求, get()函数如这里: http://www.cnblogs.com/whatmiss/p/7114954.html
$t1 = microtime(true);
foreach($urls as $key => $url){
file_put_contents('log/get_' . $key . '.txt', get($url)); // 记录一下请求结果。记得创建一个log文件夹
}
$t2 = microtime(true);
echo $t2 - $t1;
在测试结果中,存在明显的差距,并且随着数据量的增加,差距会呈指数级增长:
2.4481401443481
21.68923997879
8.925509929657
24.73141503334
3.243185043335
23.384337902069
3.2841880321503
24.754415035248
3.2091829776764
29.068662881851
curl 抓取网页(curl和js文件怎么做抓取网页。抓包分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-25 01:07
curl抓取网页。fiddler抓包分析http请求,然后就会得到js和css文件。js,css文件不仅仅是静态文件,js一般是表单提交、广告展示等等的实际页面代码,css主要就是图片、样式等等。可以先进行抓包,抓到页面代码后用fiddler可以分析css和js文件。
建议先做一下信息采集
wireshark可以抓到http请求
用sqlmap或者postman
技术这种东西,还是实战出真知吧,用万能的去下载一下,然后用一些插件或者新建一个web标签页访问,
利用浏览器插件如:selenium或httplib,可以抓住动态的js、css文件,动态的页面地址。通过一个http请求,分析js、css文件的处理过程,即可知道抓取页面是否需要动态获取哪些功能。
页面扫描本身就是一门学问
dom扫描
要看是什么样的网站,js,css,js一类的不需要动态获取,抓到后进行简单的css样式的修改加载图片等等。像什么.txt这种网站,看到后直接找对应的js和css,进行搜索。
扫描结果属性里面会告诉你一些网站可能的页面结构,这样查看页面是不是有设计的嫌疑可以判断是否有xss,或者钓鱼行为,另外sqlmap可以直接查询页面的数据,静态页也是如此。 查看全部
curl 抓取网页(curl和js文件怎么做抓取网页。抓包分析)
curl抓取网页。fiddler抓包分析http请求,然后就会得到js和css文件。js,css文件不仅仅是静态文件,js一般是表单提交、广告展示等等的实际页面代码,css主要就是图片、样式等等。可以先进行抓包,抓到页面代码后用fiddler可以分析css和js文件。
建议先做一下信息采集
wireshark可以抓到http请求
用sqlmap或者postman
技术这种东西,还是实战出真知吧,用万能的去下载一下,然后用一些插件或者新建一个web标签页访问,
利用浏览器插件如:selenium或httplib,可以抓住动态的js、css文件,动态的页面地址。通过一个http请求,分析js、css文件的处理过程,即可知道抓取页面是否需要动态获取哪些功能。
页面扫描本身就是一门学问
dom扫描
要看是什么样的网站,js,css,js一类的不需要动态获取,抓到后进行简单的css样式的修改加载图片等等。像什么.txt这种网站,看到后直接找对应的js和css,进行搜索。
扫描结果属性里面会告诉你一些网站可能的页面结构,这样查看页面是不是有设计的嫌疑可以判断是否有xss,或者钓鱼行为,另外sqlmap可以直接查询页面的数据,静态页也是如此。
curl 抓取网页(curl网页数据一般情况下用python开发抓取代码的对接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-03-22 03:08
curl抓取网页数据一般情况下用python开发或者是python的模块封装了抓取的接口,比如:curl()curl_init()http_user_agent()curl_request()python模块:webdriverdriver.from_chrome_webdriver_support()httpdriver.set_tag_format_for('curl',"webdriver/curl")httpdriver.set_header('content-type','application/x-www-form-urlencoded;charset=utf-8')然后,就是自己用python开发抓取代码,跟curl进行实现对接。
再到一些网站比如:.,只需要采用curl进行抓取数据,并传递给driver.page_source即可python模块:curl_get(http_user_agent)curl_request()这些模块有单文件的,也有两个文件的比如我常用的就是curl_get和curl_request.直接打开:driver.page_source就可以抓取到url了其他两个就是抓取工具:curlserver主要抓取http请求,主流的浏览器都可以调用driver.httpcookie主抓取cookie,只有token是可以保存的你如果想抓取一个页面就传递给driver.page_source中的curlserver和driver.httpcookie传递给driver.httpcookie传递给driver.httpcookie传递给driver就是这样。 查看全部
curl 抓取网页(curl网页数据一般情况下用python开发抓取代码的对接)
curl抓取网页数据一般情况下用python开发或者是python的模块封装了抓取的接口,比如:curl()curl_init()http_user_agent()curl_request()python模块:webdriverdriver.from_chrome_webdriver_support()httpdriver.set_tag_format_for('curl',"webdriver/curl")httpdriver.set_header('content-type','application/x-www-form-urlencoded;charset=utf-8')然后,就是自己用python开发抓取代码,跟curl进行实现对接。
再到一些网站比如:.,只需要采用curl进行抓取数据,并传递给driver.page_source即可python模块:curl_get(http_user_agent)curl_request()这些模块有单文件的,也有两个文件的比如我常用的就是curl_get和curl_request.直接打开:driver.page_source就可以抓取到url了其他两个就是抓取工具:curlserver主要抓取http请求,主流的浏览器都可以调用driver.httpcookie主抓取cookie,只有token是可以保存的你如果想抓取一个页面就传递给driver.page_source中的curlserver和driver.httpcookie传递给driver.httpcookie传递给driver.httpcookie传递给driver就是这样。
curl 抓取网页([toc]网络数据收集DataScrapingvsDataCrawling的协调关系)
网站优化 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-03-18 09:20
[目录]
网络数据采集
参考:
数据采集是直接从在线网站 中提取公开可用数据的过程。数据采集不仅依赖于官方信息来源,
保持合法和道德
合法性
道德数据采集
Data Scraping vs DataCrawling 爬取最难区分的事情之一就是如何协调连续爬取。我们的蜘蛛在爬行时需要足够礼貌,以避免目标服务器不堪重负而踢出蜘蛛。最后,不同爬虫之间可能存在冲突,但在数据抓取上不会发生这种情况。
需要爬取解析解析器
数据爬取API数据提取工具
为了防止抓取(也称为 Webscraping、Screenscraping、Web Data Mining、Web Harvesting 或 Web Data Extraction),了解这些抓取工具的工作原理以及了解阻止它们正常工作的原因会很有帮助。
有几种类型的刮刀,每种的工作方式不同:
HTML Parser Shell Script Screenscrapers Web Scraping Service Manual Copy-Paste:人们复制和粘贴内容以在其他地方使用。
这些不同类型的爬虫之间有很多重叠之处,即使它们使用不同的技术和方法,它们的行为也会相似。
网络爬虫基础
例如,如果你使用的是谷歌搜索引擎,爬虫会通过服务器中索引的结果访问指定的页面,然后将其检索并存储在谷歌的服务器中。网络爬虫还通过 网站 中的超链接访问其他 网站。所以当你向搜索引擎询问“软件开发课程”时,所有符合条件的页面都会被返回。网络爬虫被配置为管理这些网页,以便生成的数据快速而新鲜。
大多数网络爬虫会自动将数据转换为用户友好的格式。他们还将它编译成随时可用的可下载包,以便于访问。Google 内部的搜索机制是什么?数据挖掘 当网络爬虫从不同的网站中爬取大量数据时,数据仍然是非结构化的,例如JSON、CSV或XML格式。
数据挖掘就是从这些数据中获取有用的信息。所以你可以说网络爬虫是数据挖掘过程的第一步。
企业越来越重视管理数据挖掘和遵循分析实践。在医学、保险、商业等领域有很多这样的例子。 Image Mining - A Data Mining Application Data Extraction Web Crawling with Apache Nutch
看看 Nutch 的主要构建块 Elasticsearch 如何提取信息。
一些不错的爬虫 Storm-crawler。Elasticsearch 河网。攻击
可能适用于初学者刮刀的事情:
通常有帮助的事情:
有帮助但会让你的用户讨厌你的事情:
防止 网站 爬取
我有一个相当大的音乐 网站 和一个庞大的艺术家数据库。我一直注意到其他音乐网站s 正在抓取我们的网站 数据(我在这里和那里输入虚拟艺术家的名字并在谷歌上搜索它们)。如何防止屏幕划伤?甚至可能吗?
你不能完全阻止它,因为无论你做什么,一个坚固的刮刀仍然可以弄清楚如何刮。但是,可以通过执行以下操作来停止大规模刮擦:
监控日志和流量模式以限制访问
具体来说,一些想法:
使用其他指标:这对于运行 JavaScript 的屏幕抓取工具非常有用,因为可以从中获取大量信息。速率限制:不要暂时阻止访问,而是使用验证码:
安全堆栈交换相关问题:
基于 IP 的限制根本不起作用——这里有太多的公共代理服务器,而且 TOR……它不会减慢爬网速度(对于那些_真的_想要你的数据的人)。
确保所有用户标头都有效
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
---
#### 如果用户代理为空/丢失,则不接受请求
- 通常爬虫不会随其请求发送用户代理标头,而所有浏览器和搜索引擎蜘蛛都会
- 如果收到不存在用户代理标头的请求,可以显示验证码,或者简单地阻止或限制访问。
> 基于**用户代理**的过滤根本没有帮助。任何认真的数据挖掘者都会在他的抓取工具中将其设置为正确的数据。
---
#### 如果用户代理是常见的抓取工具 则不要接受请求 黑名单
- 可以在发现已知屏幕抓取器用户代理字符串时设置黑名单。
- 在某些情况下,scraper 会使用一个没有真正的浏览器或搜索引擎蜘蛛使用的用户代理,例如:
- “Mozilla”(仅此而已,仅此而已。我在这里看到了一些关于抓取的问题,使用它。真正的浏览器永远不会只使用它)
- “Java 1.7.43\_u43”(默认情况下,Java 的 HttpUrlConnection 使用类似的东西。)
- “BIZCO EasyScraping Studio 2.0”
- "wget", "curl", "libcurl",..(Wget 和 cURL 有时用于基本抓取)
- 屏蔽常见的抓取用户代理,你会在主要/大型网站中看到这个,因为你不可能用“python3.4”作为你的用户代理来抓取它们。
- 如果发现网站上的爬虫使用了特定的用户代理字符串,而真实浏览器或合法蜘蛛并未使用该字符串,也可以将其添加到黑名单中。
> 知道自己在做什么的程序员可以设置用户代理字符串来模拟 Web 浏览器。
---
#### 需要注册和登录
- 如果网站可行,则需要创建帐户才能查看内容。这对爬虫来说是一个很好的威慑
- 创建和登录帐户,可以准确地跟踪用户和爬虫操作。
- 可以轻松检测特定帐户何时被用于抓取并禁止它。
- 诸如速率限制或检测滥用(例如短时间内大量搜索)之类的事情变得更容易,因为可以识别特定的抓取工具而不仅仅是 IP 地址。
为了避免脚本创建多个帐户"
- 需要一个用于注册的电子邮件地址,并通过发送必须打开才能激活帐户的链接来验证该电子邮件地址。每个电子邮件地址只允许一个帐户。
- 需要在注册/帐户创建期间解决验证码。
> 需要创建帐户才能查看内容将把用户和搜索引擎赶走;
> 需要创建帐户才能查看文章,用户将前往别处。
> 打败它的最简单方法(无需任何分析和/或编写登录协议脚本)就是以普通用户身份登录站点,使用 Mozilla,然后运行基于 Mozrepl 的抓取工具...
> _要求登录_对匿名机器人有帮助,但对想要抓取数据的人没有帮助。他只是将自己注册到网站作为普通用户。
> 屏幕抓取工具可能会设置一个帐户并可能巧妙地编写脚本来为他们登录。
---
#### 阻止来自云托管和抓取服务 IP 地址的访问
- 有时,抓取工具会通过 Web 托管服务运行,例如 Amazon Web Services 或 GAE,或 VPS。限制来自此类云托管服务使用的 IP 地址的请求访问网站(或显示验证码)。
- 可以限制来自代理或 VPN 提供商使用的 IP 地址的访问,因为抓取工具可能会使用此类代理服务器来避免检测到许多请求。
- 通过阻止来自代理服务器和 VPN 的访问,将对真实用户产生负面影响。
---
#### 使错误消息变得难以描述
如果阻止/限制访问,应该确保没有告诉刮板是什么导致了堵塞,从而为他们提供了如何修复刮板的线索。
不好的错误页面:
- 来自 IP 地址的请求过多,请稍后重试。
- 错误,用户代理标头不存在!
友好的错误消息
- 不会告诉刮板是什么原因造成的
- 抱歉,出了一些问题。如果`helpdesk@example.com`问题仍然存在,可以通过 联系支持。
- 应该考虑为后续请求显示验证码而不是硬块,以防真实用户看到错误消息,这样就不会阻止,从而导致合法用户与联系。
---
#### 使用验证码
- 验证码(“完全自动化的测试以区分计算机和人类”)对于阻止抓取工具非常有效。
- 使用验证码并要求在返回页面之前完成验证。
- 当怀疑可能存在抓取工具并希望停止抓取时,它们非常有用,而且不会阻止访问,以防它不是抓取工具而是真实用户。如果怀疑是抓取工具,可能需要考虑在允许访问内容之前显示验证码。
使用验证码时需要注意的事项:
- 不要自己动手
- 使用类似 Google 的reCaptcha 之类的东西:
- 它比自己实现验证码要容易得多,
- 它比自己可能想出的一些模糊和扭曲的文本解决方案更用户友好(用户通常只需要勾选一个框),
- 而且对于脚本编写者来说,解决它比从站点提供的简单图像要困难得多
- 不要在 HTML 标记中包含验证码的解决方案
- 网站,它_在页面本身中_提供了验证码的解决方案, 使它变得毫无用处。
- 验证码可以批量解决:
- 除非的数据非常有价值,否则不太可能使用这种服务。
- 有验证码解决服务,实际的、低薪的人工批量解决验证码。
- 使用 reCaptcha 是一个好主意,因为它们有保护措施(例如用户有相对较短的时间来解决验证码)。
> **Captcha**(好的 - 像 reCaptcha)有很大帮助
---
#### 将文本内容作为图像提供
- 可以将文本渲染到图像服务器端,然后将其显示出来,这将阻碍简单的抓取工具提取文本。
- 这是非常可靠的,并且比 CAPTCHA 对用户的痛苦要小,这意味着他们将无法剪切和粘贴,并且无法很好地缩放或访问。
- 然而
- 这对屏幕阅读器、搜索引擎、性能以及几乎所有其他方面都是不利的。
- 在某些地方它也是非法的(由于可访问性,例如美国残疾人法案),并且使用某些 OCR 也很容易规避,所以不要这样做。
- 可以用 CSS 精灵做类似的事情,但会遇到同样的问题。
> 很难抓取隐藏在图像中的数据。(例如,简单地将数据转换为服务器端的图像)。
> 使用“tesseract”(OCR)多次有帮助 - 但老实说 - 数据必须值得刮板的麻烦。(很多时候不值得)。
---
#### 不要公开完整数据集
- 如果可行,不要为脚本/机器人提供获取所有数据集的方法。
- 例子:
- 新闻网站,有很多单独的文章。
- 可以使这些文章只能通过站点搜索来访问它们,
- 如果没有站点上 _所有_ 文章及其 URL的列表,则只能通过使用搜索来访问这些文章特征。
- 这意味着想要从网站上删除所有文章的脚本必须搜索可能出现在文章中的所有可能的短语才能找到它们,
- 这将非常耗时,效率极低,并且有望使刮板放弃。
如果出现以下情况,这将无效:
- 机器人/脚本 无论如何都不需要/需要完整的数据集。
- 文章是从类似于`example.com/article.php?articleId=12345`. 这(以及类似的东西)将允许抓取器简单地遍历所有`articleId`s 并以这种方式请求所有文章。
- 还有其他方法可以最终找到所有文章,例如通过编写脚本来跟踪文章中指向其他文章的链接。
- 搜索诸如“and”或“the”之类的内容几乎可以揭示所有内容,因此需要注意这一点。(可以通过仅返回前 10 或 20 个结果来避免这种情况)。
- 需要搜索引擎来查找内容。
---
#### 使用网站的Java小程序或Flash
- 最难的是其使用网站的**Java小程序或Flash**,和小程序使用**安全的HTTPS**内部请求本身
- 目前很少有网站使用它们。
---
#### 加密/编码数
- 仅限小型站点
- 许多提供加密/编码数据的网站,这些数据在任何编程语言中都无法解密,因为加密方法不存在。
- 通过加密和最小化输出(警告:这对大型网站来说这不是一个好主意)在 PHP 网站中实现了这一点,响应总是混乱的内容。
在 PHP 中最小化输出的示例(如何最小化 php 页面 html 输出?):
1
2
3
4
5
6
7
8
9
10
11
12
13
```
不要暴露您的 API、端点和类似的东西:频繁更改 URL 路径可以防止 HTML 解析器和爬虫根据用户的位置更改 HTML 频繁更改 HTML
频繁更改 HTML 和页面结构
如果它不能从标记中找到它需要的东西,爬虫将根据 HTML 的结构来寻找它。
需要注意的事项:
聪明的爬虫仍然可以通过推断实际内容的位置来获取内容
本质上,确保脚本不容易找到每个相似页面的实际需要。
示例:网站 上有一个搜索功能,位于 /search?query=somesearchquery,它返回以下 HTML:
1
2
3
4
5
6
Stack Overflow has become the world's most popular programming Q & A website
The website Stack Overflow has now become the most popular programming Q & A website, with 10 million questions and many users, which...
Read more</a>
(And so on, lots more identically structured divs with search results)
</p>
1
2
3
4
5
6
7
8
9
10
11
12
Stack Overflow has become the world's most popular programming Q & A website
The website Stack Overflow has now become the most popular programming Q & A website, with 10 million questions and many users, which...
Read more</a>
Visit Example.com now, for all the latest Stack Overflow related news !
Example.com is so awesome, visit now !</p>
Visit Now !</a>
(More real search results follow)
</p>
这意味着根据类或 ID 从 HTML 中提取数据的爬虫似乎会继续工作,但它们会得到假数据,甚至是真实用户永远看不到的广告,因为它们被 CSS 隐藏了。
将虚假的、不可见的蜜罐数据插入页面
1
2
3
4
5
6
This search result is here to prevent scraping
<p class="/spanspan class="n"search/spanspan class="o"-/spanspan class="n"result/spanspan class="o"-/spanspan class="n"excerpt/spanspan class="s"">If you are a human and see this, please ignore it. If you are a scraper, please click the link below :-) Note that clicking the link below will block access to this site for 24 hours.
<a class"/spanspan class="n"search/spanspan class="o"-/spanspan class="n"result/spanspan class="o"-/spanspan class="n"link/spanspan class="s"" href="/spanspan class="o"//spanspan class="n"scrapertrap/spanspan class="o"//spanspan class="n"scrapertrap/spanspan class="o"./spanspan class="na"php/spanspan class="err""/spanspan class="o">I am a scraper !
(The actual, real, search results follow.)
</p>
将不可见的蜜罐项添加到 HTML 以捕获刮板。
scrapertrap.php 可以做点什么吗
将此与之前频繁更改 HTML 的技术结合起来。
如果检测到爬虫,则提供虚假和无用的数据 如果它不请求资产(CSS、图像),则它不是真正的浏览器。使用和需要 cookie 跟踪用户和抓取操作 使用 cookie 可能不起作用,因为爬虫也可以发送带有请求的 cookie 并根据需要丢弃它们。如果该站点仅使用 cookie,它还将阻止禁用 cookie 的真实用户访问。使用 JavaScript 设置和检索 cookie 将阻止不运行 JavaScript 的爬虫,因为它们无法检索和发送带有请求的 cookie。
–
使用 JavaScript + Ajax 加载内容
意识到:
混淆标签、来自脚本的网络请求以及其他所有内容。如果您确实使用 Ajax 加载数据,您应该在不先加载页面的情况下使端点难以使用
例如,一些会话密钥需要作为参数,可以嵌入到 JavaScript 或 HTML 中。
混淆后的数据也可以直接嵌入到初始 HTML 页面中,使用 JavaScript 进行去混淆和显示,从而避免额外的网络请求。这样做会使使用不运行 JavaScript 的纯 HTML 解析器提取数据变得更加困难,因为编写爬虫程序的人必须对 JavaScript 进行逆向工程(并且应该对其进行混淆)。
但是,这样做有几个缺点:
非技术性使数据可用,提供各种 API 的 robots.txt
假设 robots.txt 已经设置好了。
正如其他人所提到的,爬虫几乎可以伪造其活动的每个方面,并且很难识别来自不良行为者的请求。
考虑:
设置一个页面,/jail.html。禁止访问 robots.txt 页面(因此受人尊敬的蜘蛛永远不会访问)。在其中一个页面上放置一个链接,用 CSS 隐藏它( display: none )。将访问者的 IP 地址记录到 /jail.html。
如果一个特定的IP地址访问速度非常快,那么在几次访问之后(5-10)把它的IP地址+浏览器信息放到一个文件或数据库中。(这将是一个后台进程并且一直运行或者安排在几分钟内。)制作另一个脚本来继续检查那些可疑的 IP 地址。
如果用户代理是已知的搜索引擎,例如 Google、Bing、Yahoo(您可以通过谷歌搜索找到有关用户代理的更多信息)。那你得看看。此列表并尝试匹配模式。如果它看起来像一个假的用户代理,请在下次访问时要求验证码。(需要对机器人 IP 地址进行更多研究。我知道这是可能的,也可以尝试使用 whois 作为 IP 地址。它可能会有所帮助。) 没有搜索机器人的用户代理:只要求下次访问 填写验证码。
第一的:
不值得尝试使用一些技术障碍,导致:
纯 HMTL
可以动态生成 HTML 结构,以及 CSS 类名(和 CSS 本身)(例如,通过使用一些随机类名)
没有办法改变每个响应的结构,因为普通用户会讨厌它。此外,这会比刮刀造成更多的麻烦(维护)。XPath 或 CSS 路径可以通过基于已知内容的爬网脚本自动确定。
Ajax - 一开始有点难,但很多时候加速了抓取过程:) - 为什么?
所以,_ajax_ 并没有多大帮助......
使用大量 javascript 函数的页面。
这里可以使用两种基本方法:
这种抓取速度很慢(抓取是在常规浏览器中完成的),但它是
请记住:如果您想(以友好的方式)向普通用户发布数据,隐藏数据几乎是不可能的。
所以,
设置正确的使用权限(例如必须引用来源) 许多数据没有版权 - 很难保护它们 添加一些虚假数据(如已经完成的那样)并使用合法工具
一个快速的方法是设置一个诱杀/机器人陷阱。
制作一个页面,如果它打开一定次数或根本不打开,则采集某些信息,如 IP 等(也可以考虑违规或模式,但页面根本不必打开)。
在使用 CSS 隐藏的页面中创建指向此内容的链接 display:none; . 或左:-9999px;位置:绝对;尝试将其放置在不太可能被忽略的位置,例如内容而不是页脚的位置,因为有时机器人会选择忘记页面的某些部分。
在 robots.txt 文件中,为不希望友好机器人(哈哈,就像他们有笑脸!)的页面设置一大堆无规则来采集信息并使此页面成为其中之一。
现在,如果一个友好的机器人通过它应该忽略该页面。是的,但这还不够好。制作更多这些页面或以某种方式重新路由页面以接受不同的名称。然后在 robots.txt 文件中的这些陷阱页面旁边放置更多阻止规则,以及您要忽略的页面。
采集这些机器人或访问这些页面的任何人的 IP,不要禁止它们,但可以在内容中显示混乱的文本,如随机数、版权声明、特定文本字符串、显示可怕的图片,基本上是任何妨碍它们的东西好的内容。也可以设置一个链接到一个需要永远加载的页面,即。在 php 中,您可以使用 sleep() 函数。如果它有某种检测来绕过加载时间过长的页面,这将反击爬虫,因为一些编写良好的机器人被设置为一次处理 X 个链接。
制作特定的文本字符串/句子,转到您最喜欢的搜索引擎并搜索它们,它可能会显示内容的结束位置。
无论如何,如果从战术上和创造性地思考,这可能是一个很好的起点。最好的方法是了解机器人的工作原理。
我还会考虑欺骗页面元素上的某些 ID 或属性的显示方式:
1
<a class="someclass" href="../xyz/abc" rel="nofollow" title="sometitle">
它每次都会改变其形式,因为可能会设置一些机器人来寻找页面或目标元素中的特定模式。
1
2
3
<a title="sometitle" href="../xyz/abc" rel="nofollow" class="someclass">
id="p-12802" > id="p-00392"
预格式化文本
. 查看全部
curl 抓取网页([toc]网络数据收集DataScrapingvsDataCrawling的协调关系)
[目录]
网络数据采集
参考:
数据采集是直接从在线网站 中提取公开可用数据的过程。数据采集不仅依赖于官方信息来源,
保持合法和道德
合法性
道德数据采集
Data Scraping vs DataCrawling 爬取最难区分的事情之一就是如何协调连续爬取。我们的蜘蛛在爬行时需要足够礼貌,以避免目标服务器不堪重负而踢出蜘蛛。最后,不同爬虫之间可能存在冲突,但在数据抓取上不会发生这种情况。
需要爬取解析解析器
数据爬取API数据提取工具
为了防止抓取(也称为 Webscraping、Screenscraping、Web Data Mining、Web Harvesting 或 Web Data Extraction),了解这些抓取工具的工作原理以及了解阻止它们正常工作的原因会很有帮助。
有几种类型的刮刀,每种的工作方式不同:
HTML Parser Shell Script Screenscrapers Web Scraping Service Manual Copy-Paste:人们复制和粘贴内容以在其他地方使用。
这些不同类型的爬虫之间有很多重叠之处,即使它们使用不同的技术和方法,它们的行为也会相似。
网络爬虫基础
例如,如果你使用的是谷歌搜索引擎,爬虫会通过服务器中索引的结果访问指定的页面,然后将其检索并存储在谷歌的服务器中。网络爬虫还通过 网站 中的超链接访问其他 网站。所以当你向搜索引擎询问“软件开发课程”时,所有符合条件的页面都会被返回。网络爬虫被配置为管理这些网页,以便生成的数据快速而新鲜。
大多数网络爬虫会自动将数据转换为用户友好的格式。他们还将它编译成随时可用的可下载包,以便于访问。Google 内部的搜索机制是什么?数据挖掘 当网络爬虫从不同的网站中爬取大量数据时,数据仍然是非结构化的,例如JSON、CSV或XML格式。
数据挖掘就是从这些数据中获取有用的信息。所以你可以说网络爬虫是数据挖掘过程的第一步。
企业越来越重视管理数据挖掘和遵循分析实践。在医学、保险、商业等领域有很多这样的例子。 Image Mining - A Data Mining Application Data Extraction Web Crawling with Apache Nutch
看看 Nutch 的主要构建块 Elasticsearch 如何提取信息。
一些不错的爬虫 Storm-crawler。Elasticsearch 河网。攻击
可能适用于初学者刮刀的事情:
通常有帮助的事情:
有帮助但会让你的用户讨厌你的事情:
防止 网站 爬取
我有一个相当大的音乐 网站 和一个庞大的艺术家数据库。我一直注意到其他音乐网站s 正在抓取我们的网站 数据(我在这里和那里输入虚拟艺术家的名字并在谷歌上搜索它们)。如何防止屏幕划伤?甚至可能吗?
你不能完全阻止它,因为无论你做什么,一个坚固的刮刀仍然可以弄清楚如何刮。但是,可以通过执行以下操作来停止大规模刮擦:
监控日志和流量模式以限制访问
具体来说,一些想法:
使用其他指标:这对于运行 JavaScript 的屏幕抓取工具非常有用,因为可以从中获取大量信息。速率限制:不要暂时阻止访问,而是使用验证码:
安全堆栈交换相关问题:
基于 IP 的限制根本不起作用——这里有太多的公共代理服务器,而且 TOR……它不会减慢爬网速度(对于那些_真的_想要你的数据的人)。
确保所有用户标头都有效
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
---
#### 如果用户代理为空/丢失,则不接受请求
- 通常爬虫不会随其请求发送用户代理标头,而所有浏览器和搜索引擎蜘蛛都会
- 如果收到不存在用户代理标头的请求,可以显示验证码,或者简单地阻止或限制访问。
> 基于**用户代理**的过滤根本没有帮助。任何认真的数据挖掘者都会在他的抓取工具中将其设置为正确的数据。
---
#### 如果用户代理是常见的抓取工具 则不要接受请求 黑名单
- 可以在发现已知屏幕抓取器用户代理字符串时设置黑名单。
- 在某些情况下,scraper 会使用一个没有真正的浏览器或搜索引擎蜘蛛使用的用户代理,例如:
- “Mozilla”(仅此而已,仅此而已。我在这里看到了一些关于抓取的问题,使用它。真正的浏览器永远不会只使用它)
- “Java 1.7.43\_u43”(默认情况下,Java 的 HttpUrlConnection 使用类似的东西。)
- “BIZCO EasyScraping Studio 2.0”
- "wget", "curl", "libcurl",..(Wget 和 cURL 有时用于基本抓取)
- 屏蔽常见的抓取用户代理,你会在主要/大型网站中看到这个,因为你不可能用“python3.4”作为你的用户代理来抓取它们。
- 如果发现网站上的爬虫使用了特定的用户代理字符串,而真实浏览器或合法蜘蛛并未使用该字符串,也可以将其添加到黑名单中。
> 知道自己在做什么的程序员可以设置用户代理字符串来模拟 Web 浏览器。
---
#### 需要注册和登录
- 如果网站可行,则需要创建帐户才能查看内容。这对爬虫来说是一个很好的威慑
- 创建和登录帐户,可以准确地跟踪用户和爬虫操作。
- 可以轻松检测特定帐户何时被用于抓取并禁止它。
- 诸如速率限制或检测滥用(例如短时间内大量搜索)之类的事情变得更容易,因为可以识别特定的抓取工具而不仅仅是 IP 地址。
为了避免脚本创建多个帐户"
- 需要一个用于注册的电子邮件地址,并通过发送必须打开才能激活帐户的链接来验证该电子邮件地址。每个电子邮件地址只允许一个帐户。
- 需要在注册/帐户创建期间解决验证码。
> 需要创建帐户才能查看内容将把用户和搜索引擎赶走;
> 需要创建帐户才能查看文章,用户将前往别处。
> 打败它的最简单方法(无需任何分析和/或编写登录协议脚本)就是以普通用户身份登录站点,使用 Mozilla,然后运行基于 Mozrepl 的抓取工具...
> _要求登录_对匿名机器人有帮助,但对想要抓取数据的人没有帮助。他只是将自己注册到网站作为普通用户。
> 屏幕抓取工具可能会设置一个帐户并可能巧妙地编写脚本来为他们登录。
---
#### 阻止来自云托管和抓取服务 IP 地址的访问
- 有时,抓取工具会通过 Web 托管服务运行,例如 Amazon Web Services 或 GAE,或 VPS。限制来自此类云托管服务使用的 IP 地址的请求访问网站(或显示验证码)。
- 可以限制来自代理或 VPN 提供商使用的 IP 地址的访问,因为抓取工具可能会使用此类代理服务器来避免检测到许多请求。
- 通过阻止来自代理服务器和 VPN 的访问,将对真实用户产生负面影响。
---
#### 使错误消息变得难以描述
如果阻止/限制访问,应该确保没有告诉刮板是什么导致了堵塞,从而为他们提供了如何修复刮板的线索。
不好的错误页面:
- 来自 IP 地址的请求过多,请稍后重试。
- 错误,用户代理标头不存在!
友好的错误消息
- 不会告诉刮板是什么原因造成的
- 抱歉,出了一些问题。如果`helpdesk@example.com`问题仍然存在,可以通过 联系支持。
- 应该考虑为后续请求显示验证码而不是硬块,以防真实用户看到错误消息,这样就不会阻止,从而导致合法用户与联系。
---
#### 使用验证码
- 验证码(“完全自动化的测试以区分计算机和人类”)对于阻止抓取工具非常有效。
- 使用验证码并要求在返回页面之前完成验证。
- 当怀疑可能存在抓取工具并希望停止抓取时,它们非常有用,而且不会阻止访问,以防它不是抓取工具而是真实用户。如果怀疑是抓取工具,可能需要考虑在允许访问内容之前显示验证码。
使用验证码时需要注意的事项:
- 不要自己动手
- 使用类似 Google 的reCaptcha 之类的东西:
- 它比自己实现验证码要容易得多,
- 它比自己可能想出的一些模糊和扭曲的文本解决方案更用户友好(用户通常只需要勾选一个框),
- 而且对于脚本编写者来说,解决它比从站点提供的简单图像要困难得多
- 不要在 HTML 标记中包含验证码的解决方案
- 网站,它_在页面本身中_提供了验证码的解决方案, 使它变得毫无用处。
- 验证码可以批量解决:
- 除非的数据非常有价值,否则不太可能使用这种服务。
- 有验证码解决服务,实际的、低薪的人工批量解决验证码。
- 使用 reCaptcha 是一个好主意,因为它们有保护措施(例如用户有相对较短的时间来解决验证码)。
> **Captcha**(好的 - 像 reCaptcha)有很大帮助
---
#### 将文本内容作为图像提供
- 可以将文本渲染到图像服务器端,然后将其显示出来,这将阻碍简单的抓取工具提取文本。
- 这是非常可靠的,并且比 CAPTCHA 对用户的痛苦要小,这意味着他们将无法剪切和粘贴,并且无法很好地缩放或访问。
- 然而
- 这对屏幕阅读器、搜索引擎、性能以及几乎所有其他方面都是不利的。
- 在某些地方它也是非法的(由于可访问性,例如美国残疾人法案),并且使用某些 OCR 也很容易规避,所以不要这样做。
- 可以用 CSS 精灵做类似的事情,但会遇到同样的问题。
> 很难抓取隐藏在图像中的数据。(例如,简单地将数据转换为服务器端的图像)。
> 使用“tesseract”(OCR)多次有帮助 - 但老实说 - 数据必须值得刮板的麻烦。(很多时候不值得)。
---
#### 不要公开完整数据集
- 如果可行,不要为脚本/机器人提供获取所有数据集的方法。
- 例子:
- 新闻网站,有很多单独的文章。
- 可以使这些文章只能通过站点搜索来访问它们,
- 如果没有站点上 _所有_ 文章及其 URL的列表,则只能通过使用搜索来访问这些文章特征。
- 这意味着想要从网站上删除所有文章的脚本必须搜索可能出现在文章中的所有可能的短语才能找到它们,
- 这将非常耗时,效率极低,并且有望使刮板放弃。
如果出现以下情况,这将无效:
- 机器人/脚本 无论如何都不需要/需要完整的数据集。
- 文章是从类似于`example.com/article.php?articleId=12345`. 这(以及类似的东西)将允许抓取器简单地遍历所有`articleId`s 并以这种方式请求所有文章。
- 还有其他方法可以最终找到所有文章,例如通过编写脚本来跟踪文章中指向其他文章的链接。
- 搜索诸如“and”或“the”之类的内容几乎可以揭示所有内容,因此需要注意这一点。(可以通过仅返回前 10 或 20 个结果来避免这种情况)。
- 需要搜索引擎来查找内容。
---
#### 使用网站的Java小程序或Flash
- 最难的是其使用网站的**Java小程序或Flash**,和小程序使用**安全的HTTPS**内部请求本身
- 目前很少有网站使用它们。
---
#### 加密/编码数
- 仅限小型站点
- 许多提供加密/编码数据的网站,这些数据在任何编程语言中都无法解密,因为加密方法不存在。
- 通过加密和最小化输出(警告:这对大型网站来说这不是一个好主意)在 PHP 网站中实现了这一点,响应总是混乱的内容。
在 PHP 中最小化输出的示例(如何最小化 php 页面 html 输出?):
1
2
3
4
5
6
7
8
9
10
11
12
13
```
不要暴露您的 API、端点和类似的东西:频繁更改 URL 路径可以防止 HTML 解析器和爬虫根据用户的位置更改 HTML 频繁更改 HTML
频繁更改 HTML 和页面结构
如果它不能从标记中找到它需要的东西,爬虫将根据 HTML 的结构来寻找它。
需要注意的事项:
聪明的爬虫仍然可以通过推断实际内容的位置来获取内容
本质上,确保脚本不容易找到每个相似页面的实际需要。
示例:网站 上有一个搜索功能,位于 /search?query=somesearchquery,它返回以下 HTML:
1
2
3
4
5
6
Stack Overflow has become the world's most popular programming Q & A website
The website Stack Overflow has now become the most popular programming Q & A website, with 10 million questions and many users, which...
Read more</a>
(And so on, lots more identically structured divs with search results)
</p>
1
2
3
4
5
6
7
8
9
10
11
12
Stack Overflow has become the world's most popular programming Q & A website
The website Stack Overflow has now become the most popular programming Q & A website, with 10 million questions and many users, which...
Read more</a>
Visit Example.com now, for all the latest Stack Overflow related news !
Example.com is so awesome, visit now !</p>
Visit Now !</a>
(More real search results follow)
</p>
这意味着根据类或 ID 从 HTML 中提取数据的爬虫似乎会继续工作,但它们会得到假数据,甚至是真实用户永远看不到的广告,因为它们被 CSS 隐藏了。
将虚假的、不可见的蜜罐数据插入页面
1
2
3
4
5
6
This search result is here to prevent scraping
<p class="/spanspan class="n"search/spanspan class="o"-/spanspan class="n"result/spanspan class="o"-/spanspan class="n"excerpt/spanspan class="s"">If you are a human and see this, please ignore it. If you are a scraper, please click the link below :-) Note that clicking the link below will block access to this site for 24 hours.
<a class"/spanspan class="n"search/spanspan class="o"-/spanspan class="n"result/spanspan class="o"-/spanspan class="n"link/spanspan class="s"" href="/spanspan class="o"//spanspan class="n"scrapertrap/spanspan class="o"//spanspan class="n"scrapertrap/spanspan class="o"./spanspan class="na"php/spanspan class="err""/spanspan class="o">I am a scraper !
(The actual, real, search results follow.)
</p>
将不可见的蜜罐项添加到 HTML 以捕获刮板。
scrapertrap.php 可以做点什么吗
将此与之前频繁更改 HTML 的技术结合起来。
如果检测到爬虫,则提供虚假和无用的数据 如果它不请求资产(CSS、图像),则它不是真正的浏览器。使用和需要 cookie 跟踪用户和抓取操作 使用 cookie 可能不起作用,因为爬虫也可以发送带有请求的 cookie 并根据需要丢弃它们。如果该站点仅使用 cookie,它还将阻止禁用 cookie 的真实用户访问。使用 JavaScript 设置和检索 cookie 将阻止不运行 JavaScript 的爬虫,因为它们无法检索和发送带有请求的 cookie。
–
使用 JavaScript + Ajax 加载内容
意识到:
混淆标签、来自脚本的网络请求以及其他所有内容。如果您确实使用 Ajax 加载数据,您应该在不先加载页面的情况下使端点难以使用
例如,一些会话密钥需要作为参数,可以嵌入到 JavaScript 或 HTML 中。
混淆后的数据也可以直接嵌入到初始 HTML 页面中,使用 JavaScript 进行去混淆和显示,从而避免额外的网络请求。这样做会使使用不运行 JavaScript 的纯 HTML 解析器提取数据变得更加困难,因为编写爬虫程序的人必须对 JavaScript 进行逆向工程(并且应该对其进行混淆)。
但是,这样做有几个缺点:
非技术性使数据可用,提供各种 API 的 robots.txt
假设 robots.txt 已经设置好了。
正如其他人所提到的,爬虫几乎可以伪造其活动的每个方面,并且很难识别来自不良行为者的请求。
考虑:
设置一个页面,/jail.html。禁止访问 robots.txt 页面(因此受人尊敬的蜘蛛永远不会访问)。在其中一个页面上放置一个链接,用 CSS 隐藏它( display: none )。将访问者的 IP 地址记录到 /jail.html。
如果一个特定的IP地址访问速度非常快,那么在几次访问之后(5-10)把它的IP地址+浏览器信息放到一个文件或数据库中。(这将是一个后台进程并且一直运行或者安排在几分钟内。)制作另一个脚本来继续检查那些可疑的 IP 地址。
如果用户代理是已知的搜索引擎,例如 Google、Bing、Yahoo(您可以通过谷歌搜索找到有关用户代理的更多信息)。那你得看看。此列表并尝试匹配模式。如果它看起来像一个假的用户代理,请在下次访问时要求验证码。(需要对机器人 IP 地址进行更多研究。我知道这是可能的,也可以尝试使用 whois 作为 IP 地址。它可能会有所帮助。) 没有搜索机器人的用户代理:只要求下次访问 填写验证码。
第一的:
不值得尝试使用一些技术障碍,导致:
纯 HMTL
可以动态生成 HTML 结构,以及 CSS 类名(和 CSS 本身)(例如,通过使用一些随机类名)
没有办法改变每个响应的结构,因为普通用户会讨厌它。此外,这会比刮刀造成更多的麻烦(维护)。XPath 或 CSS 路径可以通过基于已知内容的爬网脚本自动确定。
Ajax - 一开始有点难,但很多时候加速了抓取过程:) - 为什么?
所以,_ajax_ 并没有多大帮助......
使用大量 javascript 函数的页面。
这里可以使用两种基本方法:
这种抓取速度很慢(抓取是在常规浏览器中完成的),但它是
请记住:如果您想(以友好的方式)向普通用户发布数据,隐藏数据几乎是不可能的。
所以,
设置正确的使用权限(例如必须引用来源) 许多数据没有版权 - 很难保护它们 添加一些虚假数据(如已经完成的那样)并使用合法工具
一个快速的方法是设置一个诱杀/机器人陷阱。
制作一个页面,如果它打开一定次数或根本不打开,则采集某些信息,如 IP 等(也可以考虑违规或模式,但页面根本不必打开)。
在使用 CSS 隐藏的页面中创建指向此内容的链接 display:none; . 或左:-9999px;位置:绝对;尝试将其放置在不太可能被忽略的位置,例如内容而不是页脚的位置,因为有时机器人会选择忘记页面的某些部分。
在 robots.txt 文件中,为不希望友好机器人(哈哈,就像他们有笑脸!)的页面设置一大堆无规则来采集信息并使此页面成为其中之一。
现在,如果一个友好的机器人通过它应该忽略该页面。是的,但这还不够好。制作更多这些页面或以某种方式重新路由页面以接受不同的名称。然后在 robots.txt 文件中的这些陷阱页面旁边放置更多阻止规则,以及您要忽略的页面。
采集这些机器人或访问这些页面的任何人的 IP,不要禁止它们,但可以在内容中显示混乱的文本,如随机数、版权声明、特定文本字符串、显示可怕的图片,基本上是任何妨碍它们的东西好的内容。也可以设置一个链接到一个需要永远加载的页面,即。在 php 中,您可以使用 sleep() 函数。如果它有某种检测来绕过加载时间过长的页面,这将反击爬虫,因为一些编写良好的机器人被设置为一次处理 X 个链接。
制作特定的文本字符串/句子,转到您最喜欢的搜索引擎并搜索它们,它可能会显示内容的结束位置。
无论如何,如果从战术上和创造性地思考,这可能是一个很好的起点。最好的方法是了解机器人的工作原理。
我还会考虑欺骗页面元素上的某些 ID 或属性的显示方式:
1
<a class="someclass" href="../xyz/abc" rel="nofollow" title="sometitle">
它每次都会改变其形式,因为可能会设置一些机器人来寻找页面或目标元素中的特定模式。
1
2
3
<a title="sometitle" href="../xyz/abc" rel="nofollow" class="someclass">
id="p-12802" > id="p-00392"
预格式化文本
.
curl 抓取网页( PHP的curl()使用总结及使用的使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2022-03-11 04:16
PHP的curl()使用总结及使用的使用)
PHP模拟登录并获取数据
CURL 是一个强大的 PHP 库。使用PHP的cURL库,可以简单有效的抓取网页和采集内容,设置cookie完成模拟登录网页,curl提供了丰富的功能,开发者可以参考PHP手册了解cURL的更多信息。本文以开源中国(oschina)的模拟登录为例,与大家分享cURL的使用。
PHP 的 curl() 爬取网页的效率相对较高,并且支持多线程,而 file_get_contents() 的效率略低。当然,使用 curl 时需要启用 curl 扩展。
代码实战
我们先看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
login_post()函数首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的url地址、保存的cookie文件、post数据(用户名和密码等)、是否提交返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自己的 http_build_query() 可以将数组转换为连接字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们将CURLOPT_RETURNTRANSFER设置为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功后才能获取的有用信息。下面我们以登录开源中国手机版为例,看看登录成功后如何获取信息。
//设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址
$url = "http://m.oschina.net/action/user/login";
//设置cookie保存路径
$cookie = dirname(__FILE__) . '/cookie_oschina.txt';
//登录后要获取信息的地址
$url2 = "http://m.oschina.net/my";
//模拟登录
login_post($url, $cookie, $post);
//获取登录页的信息
$content = get_content($url2, $cookie);
//删除cookie文件
@ unlink($cookie);
//匹配页面信息
$preg = "/(.*)/i";
preg_match_all($preg, $content, $arr);
$str = $arr[1][0];
//输出内容
echo $str;
运行上述代码后,我们会看到最终得到了登录用户的头像。
使用总结
1、初始化卷曲;
2、使用 curl_setopt 设置目标 url 等选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、输出数据。
参考
《php中curl和curl的介绍》,作者不详,
Veda 的“使用 PHP CURL 发布数据”,
《php使用curl模拟登录discuz并模拟发帖》,作者:天心,
免责声明:本文为原创文章,版权归作者所有。如需转载,请注明出处并保留原文链接: 查看全部
curl 抓取网页(
PHP的curl()使用总结及使用的使用)
PHP模拟登录并获取数据
CURL 是一个强大的 PHP 库。使用PHP的cURL库,可以简单有效的抓取网页和采集内容,设置cookie完成模拟登录网页,curl提供了丰富的功能,开发者可以参考PHP手册了解cURL的更多信息。本文以开源中国(oschina)的模拟登录为例,与大家分享cURL的使用。
PHP 的 curl() 爬取网页的效率相对较高,并且支持多线程,而 file_get_contents() 的效率略低。当然,使用 curl 时需要启用 curl 扩展。
代码实战
我们先看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
login_post()函数首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的url地址、保存的cookie文件、post数据(用户名和密码等)、是否提交返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自己的 http_build_query() 可以将数组转换为连接字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们将CURLOPT_RETURNTRANSFER设置为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功后才能获取的有用信息。下面我们以登录开源中国手机版为例,看看登录成功后如何获取信息。
//设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址
$url = "http://m.oschina.net/action/user/login";
//设置cookie保存路径
$cookie = dirname(__FILE__) . '/cookie_oschina.txt';
//登录后要获取信息的地址
$url2 = "http://m.oschina.net/my";
//模拟登录
login_post($url, $cookie, $post);
//获取登录页的信息
$content = get_content($url2, $cookie);
//删除cookie文件
@ unlink($cookie);
//匹配页面信息
$preg = "/(.*)/i";
preg_match_all($preg, $content, $arr);
$str = $arr[1][0];
//输出内容
echo $str;
运行上述代码后,我们会看到最终得到了登录用户的头像。
使用总结
1、初始化卷曲;
2、使用 curl_setopt 设置目标 url 等选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、输出数据。
参考
《php中curl和curl的介绍》,作者不详,
Veda 的“使用 PHP CURL 发布数据”,
《php使用curl模拟登录discuz并模拟发帖》,作者:天心,
免责声明:本文为原创文章,版权归作者所有。如需转载,请注明出处并保留原文链接:
curl 抓取网页(你的PHP代码并没有出错(1)_光明网(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-10 17:21
)
用 curl 单独获取是可行的,但是如果你抓取一系列相同类型的 网站 会报错,把它们放到一个数组中
$linkList 分别以此类推。
function getJobsHubuNotice()
{
$curl = curl_init('http://jobs.hubu.edu.cn/List.aspx?ArticleChannelId=81');
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
$result = curl_exec($curl);
//内容处理
$result = strip_tags($result,'<a>');
$result = stristr($result, 'nbsp当前位置:');
$result = str_replace('nbsp当前位置:', '', $result);
$result = stristr($result, '当前1/2页',true);
$result = stristr($result, '通知公告');
$result = str_replace('通知公告</a>', '', $result);
preg_match_all('/(? 通知公告', '', $result);
$result = stristr($result, '$(document).ready',true);
$result = trim($result);
$result = str_replace("\r\n", '
', $result);
$result = preg_replace('/(\){1,}/', '
', $result);
echo $result;
echo '
';
echo "退出makePage函数";
return $result;
}
}
先使用getJobsHubuNotice()函数获取新闻链接、标题、日期,再使用makePage()函数获取内容
这是在 makePage 中打印链接的结果,使用浏览器打开链接没有问题。
您的 PHP 代码中没有错误。初步怀疑是你在请求中传入的url不正确,如下图所示:
您代码中的错误输出实际上是您获得的网页上的输出。
再次更新,我想我知道你的要求有什么问题:
你从网页得到的URL地址是:Detail.aspx?ArticleChannelId=81&ArticleId=2777,
其中&字符是&的HTML实体字符,当你输出的时候(也就是在你的截图中),它显示&,而当你去真正的请求时,它使用了下面的东西:
您只需要恢复它,或者简单地将URL中的&替换为&,然后转到请求就可以了。
再次更新:
<p> 查看全部
curl 抓取网页(你的PHP代码并没有出错(1)_光明网(组图)
)
用 curl 单独获取是可行的,但是如果你抓取一系列相同类型的 网站 会报错,把它们放到一个数组中
$linkList 分别以此类推。
function getJobsHubuNotice()
{
$curl = curl_init('http://jobs.hubu.edu.cn/List.aspx?ArticleChannelId=81');
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
$result = curl_exec($curl);
//内容处理
$result = strip_tags($result,'<a>');
$result = stristr($result, 'nbsp当前位置:');
$result = str_replace('nbsp当前位置:', '', $result);
$result = stristr($result, '当前1/2页',true);
$result = stristr($result, '通知公告');
$result = str_replace('通知公告</a>', '', $result);
preg_match_all('/(? 通知公告', '', $result);
$result = stristr($result, '$(document).ready',true);
$result = trim($result);
$result = str_replace("\r\n", '
', $result);
$result = preg_replace('/(\){1,}/', '
', $result);
echo $result;
echo '
';
echo "退出makePage函数";
return $result;
}
}
先使用getJobsHubuNotice()函数获取新闻链接、标题、日期,再使用makePage()函数获取内容
这是在 makePage 中打印链接的结果,使用浏览器打开链接没有问题。
您的 PHP 代码中没有错误。初步怀疑是你在请求中传入的url不正确,如下图所示:
您代码中的错误输出实际上是您获得的网页上的输出。
再次更新,我想我知道你的要求有什么问题:
你从网页得到的URL地址是:Detail.aspx?ArticleChannelId=81&ArticleId=2777,
其中&字符是&的HTML实体字符,当你输出的时候(也就是在你的截图中),它显示&,而当你去真正的请求时,它使用了下面的东西:
您只需要恢复它,或者简单地将URL中的&替换为&,然后转到请求就可以了。
再次更新:
<p>
curl 抓取网页(curl中命令行模式#python抓取网页##)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-09 23:04
curl抓取网页然后image是用的xml的curl直接抓xml就是爬虫
curl不是直接抓取网页的,而是将连接格式化了,然后由beautifulsoup查询。
你真正的目的是想要抓取,
curl是命令行工具,beautifulsoup是框架,不同层面工具,也就是使用场景不同,就一句话,
爬虫的流程类似于一个倒金字塔的结构。每一步都是在一个「爬虫框架」里面进行的。也就是说,抓取网页很像正在爬一个大蜘蛛,而不是正在爬一个点点。你要先给出大蜘蛛模型图,再来进行从整体分析。
从词汇方面理解,curl是用命令行模拟beautifulsoup搜索操作。beautifulsoup是python标准的html解析库,需要安装,也是需要在命令行模式下操作的,命令行模式下在/src/programs/python.py中命令行模式#python.py#在命令行模式下输入importbeautifulsoup可见这个命令行模式没有安装。curl等于beautifulsoup+任何一个lxml库。
首先题主你的思维才是问题的关键。你们脑子里的爬虫和大师们的不是一个东西。看题主的意思应该是想爬取大厂的网站网页并用于后续的文本处理啊等等吧。首先题主先花点时间学学编程,不懂的先百度一下吧。 查看全部
curl 抓取网页(curl中命令行模式#python抓取网页##)
curl抓取网页然后image是用的xml的curl直接抓xml就是爬虫
curl不是直接抓取网页的,而是将连接格式化了,然后由beautifulsoup查询。
你真正的目的是想要抓取,
curl是命令行工具,beautifulsoup是框架,不同层面工具,也就是使用场景不同,就一句话,
爬虫的流程类似于一个倒金字塔的结构。每一步都是在一个「爬虫框架」里面进行的。也就是说,抓取网页很像正在爬一个大蜘蛛,而不是正在爬一个点点。你要先给出大蜘蛛模型图,再来进行从整体分析。
从词汇方面理解,curl是用命令行模拟beautifulsoup搜索操作。beautifulsoup是python标准的html解析库,需要安装,也是需要在命令行模式下操作的,命令行模式下在/src/programs/python.py中命令行模式#python.py#在命令行模式下输入importbeautifulsoup可见这个命令行模式没有安装。curl等于beautifulsoup+任何一个lxml库。
首先题主你的思维才是问题的关键。你们脑子里的爬虫和大师们的不是一个东西。看题主的意思应该是想爬取大厂的网站网页并用于后续的文本处理啊等等吧。首先题主先花点时间学学编程,不懂的先百度一下吧。
curl 抓取网页( 网络抓取是收集数据以将您的业务提升到新水平的好方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-07 05:01
网络抓取是收集数据以将您的业务提升到新水平的好方法)
使用 Zenscrape 进行大规模数据提取
网络抓取是采集数据以将您的业务提升到新水平的好方法。它允许您自动化从各种来源提取有用内容的过程。
不幸的是,自动网络抓取并不总是那么容易。一些 网站 可能会主动阻止您提取这些数据,而其他 网站 是使用基本上使原创网络抓取工具无用的工具构建的。
在这个 文章 中,我将向您展示如何使用 Zenscrape 来克服所有这些问题,并从您喜欢的任何 网站 中大规模提取数据,而不必担心被阻止。
使用 Zenscrape 的优势
我将通过列出 Zenscrape 的一些惊人功能来开始讨论,这些功能可以帮助您完成工作并将其与其他爬虫区分开来。
JavaScript 渲染
许多 网站 现在都在积极使用 JavaScript 向访问者提供内容。这意味着一个简单的爬虫在访问网页时可能会看到与用户通过浏览器实际访问 网站 时不同的内容。
Zenscrape 通过允许您使用它的 API 在现代的无头 Chrome 浏览器中呈现请求来解决这个问题。它支持所有流行的库和框架,例如 Vue、Angular 和 React 等。
大规模提取数据
有些项目要求您大规模地抓取网络,这种情况会带来一系列挑战。您更有可能被 网站 阻止,并且一次只需一个请求即可获取所需的所有数据将花费更长的时间。
Zenscrape 通过为您提供巨大的 IP 池和自动代理轮换来轻松隐藏您的抓取机器人来克服这些问题。它还使您可以选择并发请求以快速抓取大量数据。
使用 Zenscrape 抓取内容
我们现在将学习如何使用 Zenscrape API 从不同类型的 网站 中抓取内容。
您可以通过在 网站 上创建一个帐户来开始。Zenscrape 提供免费计划,因此您只需注册即可遵循本教程。它将使您可以访问可用于发出请求的 API 密钥。您可以阅读详细文档,了解如何在 PHP、Python 和 Node.js 等各种语言和环境中使用 API 发出请求。
在您成功注册并登录后,文档中的代码片段将预先填充您的 API 密钥。
您还可以在“帐户仪表板”页面上查看其他与帐户相关的信息,例如使用情况统计信息和您的 API 密钥。
从维基百科中提取内容
Zenscrape 允许您从网页中提取 HTML,然后您可以使用您选择的解析器对其进行操作。我们将在此处的示例中使用基于 PHP 的 DiDOM 解析器,但您也可以使用 Zenscrape 博客 文章 中提到的其他一些解析器。
我们将抓取关于灯塔的 Wikipedia 页面作为示例。这是我们使用 Zenscrape 的 API 提取 HTML 的 PHP 代码。
此时的变量 $html 收录 Zenscrape 从 Wikipedia 页面提取的标记。标记的前几行如下所示:
White Shoal Light, Michigan - Wikipedia
... and more ...
我们现在可以将此 HTML 传递给我们的 DOM 解析器,以从 Wikipedia 文章 中提取主标题、第一段或第一张图片等信息。
这是我得到的输出,带有一些基本的 CSS 样式。
从 网站 中提取本地化内容
Top 网站 Reddit 主页的外观会因您访问的国家/地区而异。这个 网站 试图用在您所在位置相关且流行的内容来填充它。
在我们的示例中,我们将使用 Zenscrape 通过将国家/地区设置为美国和英国来从 Reddit 主页获取一些头条新闻。但是,Zenscrape 允许您从 230 多个不同的国家/地区选择一个位置来抓取内容。令人惊讶的是,您只需在 API 请求中指定两个参数即可完成所有这些操作。
这是我们使用 Zenscrape 的 API 为 Reddit 的英国主页获取 HTML 的代码。
如您所见,这与我们在上一节中使用的代码没有太大区别。不过,这一次,我们传递了两个名为 premium 和 location 的额外查询参数。将 premium 设置为 true 允许您使用住宅代理。之后,您可以使用 location 来指定要访问 URL 的国家/地区。我在这个例子中设置了它。
Zenscrape 关于网络抓取的文档提供了有关其他此类参数的更多详细信息。
与我们之前的示例类似,此变量 $html 存储我们返回的提取的 HTML。现在,我们可以以任何我们喜欢的方式解析和使用这个 HTML。
我使用它来显示标题列表以进行演示。
这是我作为美国访问者使用 Zenscrape API 抓取 Reddit 时得到的结果。
JavaScript 渲染后提取内容
Zenscrape 为您解决的另一个问题是,当访问者访问由 Vue、React 或 Angular 等库和框架构建的 网站 时,您可以轻松提取将呈现给访问者的 HTML。
我创建了一个简单的 CodePen 演示来演示此功能。基本的 网站 爬虫将在此页面上看到与实际 网站 访问者不同的内容,因为页面上的内容是使用 React 呈现的。
当使用简单的 cURL 或 file_get_contents() 请求时,您将在根元素中获得以下 HTML。
Nothing to see here!
另一方面,Zenscrape 为您提供了在现代无头 Chrome 浏览器中呈现请求的选项。这意味着您使用 Zenscrape API 返回的 HTML 与用户在访问页面时将看到的 HTML 相同。
这是我用来提取在运行 JavaScript 后最终显示给用户的 HTML 的代码。
如您所见,您需要做的就是传递两个参数,render 和 wait_for_css。将 render 设置为 true 将告诉 Zenscrape 它需要使用无头浏览器来获取内容,因为涉及到 JavaScript。您可以将 wait_for_css 设置为所需元素的 CSS 选择器。
上面的代码片段允许您提取可以解析的 HTML 以获得以下内容。
最后的想法
Zenscrape 为那些想要大规模提取数据的人解决了许多网络抓取问题。它的优点在于它易于实现,并且不需要您花费数天或数周的时间来学习 API。
正如您在上面的三个示例中所见,Zenscrape 只需几个请求即可为您处理从本地化到 JavaScript 渲染的所有事情。您只需要编写几行代码,一切都会立即启动并运行。甚至还有一个请求构建器,您可以使用它来获取使用 Python、Node.js、PHP 等发出请求所需的代码。
您可以使用 Zenscrape API 执行许多任务,例如获取销售线索或跟踪电子商务平台上产品的定价和可用性。访问 Zenscrape 并为自己阅读。有一个每月 1,000 积分的免费计划。您可以在几分钟内注册一个免费的 Zenscrape 帐户并自己测试所有功能。 查看全部
curl 抓取网页(
网络抓取是收集数据以将您的业务提升到新水平的好方法)
使用 Zenscrape 进行大规模数据提取
网络抓取是采集数据以将您的业务提升到新水平的好方法。它允许您自动化从各种来源提取有用内容的过程。
不幸的是,自动网络抓取并不总是那么容易。一些 网站 可能会主动阻止您提取这些数据,而其他 网站 是使用基本上使原创网络抓取工具无用的工具构建的。
在这个 文章 中,我将向您展示如何使用 Zenscrape 来克服所有这些问题,并从您喜欢的任何 网站 中大规模提取数据,而不必担心被阻止。
使用 Zenscrape 的优势
我将通过列出 Zenscrape 的一些惊人功能来开始讨论,这些功能可以帮助您完成工作并将其与其他爬虫区分开来。
JavaScript 渲染
许多 网站 现在都在积极使用 JavaScript 向访问者提供内容。这意味着一个简单的爬虫在访问网页时可能会看到与用户通过浏览器实际访问 网站 时不同的内容。
Zenscrape 通过允许您使用它的 API 在现代的无头 Chrome 浏览器中呈现请求来解决这个问题。它支持所有流行的库和框架,例如 Vue、Angular 和 React 等。
大规模提取数据
有些项目要求您大规模地抓取网络,这种情况会带来一系列挑战。您更有可能被 网站 阻止,并且一次只需一个请求即可获取所需的所有数据将花费更长的时间。
Zenscrape 通过为您提供巨大的 IP 池和自动代理轮换来轻松隐藏您的抓取机器人来克服这些问题。它还使您可以选择并发请求以快速抓取大量数据。
使用 Zenscrape 抓取内容
我们现在将学习如何使用 Zenscrape API 从不同类型的 网站 中抓取内容。
您可以通过在 网站 上创建一个帐户来开始。Zenscrape 提供免费计划,因此您只需注册即可遵循本教程。它将使您可以访问可用于发出请求的 API 密钥。您可以阅读详细文档,了解如何在 PHP、Python 和 Node.js 等各种语言和环境中使用 API 发出请求。
在您成功注册并登录后,文档中的代码片段将预先填充您的 API 密钥。
您还可以在“帐户仪表板”页面上查看其他与帐户相关的信息,例如使用情况统计信息和您的 API 密钥。
从维基百科中提取内容
Zenscrape 允许您从网页中提取 HTML,然后您可以使用您选择的解析器对其进行操作。我们将在此处的示例中使用基于 PHP 的 DiDOM 解析器,但您也可以使用 Zenscrape 博客 文章 中提到的其他一些解析器。
我们将抓取关于灯塔的 Wikipedia 页面作为示例。这是我们使用 Zenscrape 的 API 提取 HTML 的 PHP 代码。
此时的变量 $html 收录 Zenscrape 从 Wikipedia 页面提取的标记。标记的前几行如下所示:
White Shoal Light, Michigan - Wikipedia
... and more ...
我们现在可以将此 HTML 传递给我们的 DOM 解析器,以从 Wikipedia 文章 中提取主标题、第一段或第一张图片等信息。
这是我得到的输出,带有一些基本的 CSS 样式。
从 网站 中提取本地化内容
Top 网站 Reddit 主页的外观会因您访问的国家/地区而异。这个 网站 试图用在您所在位置相关且流行的内容来填充它。
在我们的示例中,我们将使用 Zenscrape 通过将国家/地区设置为美国和英国来从 Reddit 主页获取一些头条新闻。但是,Zenscrape 允许您从 230 多个不同的国家/地区选择一个位置来抓取内容。令人惊讶的是,您只需在 API 请求中指定两个参数即可完成所有这些操作。
这是我们使用 Zenscrape 的 API 为 Reddit 的英国主页获取 HTML 的代码。
如您所见,这与我们在上一节中使用的代码没有太大区别。不过,这一次,我们传递了两个名为 premium 和 location 的额外查询参数。将 premium 设置为 true 允许您使用住宅代理。之后,您可以使用 location 来指定要访问 URL 的国家/地区。我在这个例子中设置了它。
Zenscrape 关于网络抓取的文档提供了有关其他此类参数的更多详细信息。
与我们之前的示例类似,此变量 $html 存储我们返回的提取的 HTML。现在,我们可以以任何我们喜欢的方式解析和使用这个 HTML。
我使用它来显示标题列表以进行演示。
这是我作为美国访问者使用 Zenscrape API 抓取 Reddit 时得到的结果。
JavaScript 渲染后提取内容
Zenscrape 为您解决的另一个问题是,当访问者访问由 Vue、React 或 Angular 等库和框架构建的 网站 时,您可以轻松提取将呈现给访问者的 HTML。
我创建了一个简单的 CodePen 演示来演示此功能。基本的 网站 爬虫将在此页面上看到与实际 网站 访问者不同的内容,因为页面上的内容是使用 React 呈现的。
当使用简单的 cURL 或 file_get_contents() 请求时,您将在根元素中获得以下 HTML。
Nothing to see here!
另一方面,Zenscrape 为您提供了在现代无头 Chrome 浏览器中呈现请求的选项。这意味着您使用 Zenscrape API 返回的 HTML 与用户在访问页面时将看到的 HTML 相同。
这是我用来提取在运行 JavaScript 后最终显示给用户的 HTML 的代码。
如您所见,您需要做的就是传递两个参数,render 和 wait_for_css。将 render 设置为 true 将告诉 Zenscrape 它需要使用无头浏览器来获取内容,因为涉及到 JavaScript。您可以将 wait_for_css 设置为所需元素的 CSS 选择器。
上面的代码片段允许您提取可以解析的 HTML 以获得以下内容。
最后的想法
Zenscrape 为那些想要大规模提取数据的人解决了许多网络抓取问题。它的优点在于它易于实现,并且不需要您花费数天或数周的时间来学习 API。
正如您在上面的三个示例中所见,Zenscrape 只需几个请求即可为您处理从本地化到 JavaScript 渲染的所有事情。您只需要编写几行代码,一切都会立即启动并运行。甚至还有一个请求构建器,您可以使用它来获取使用 Python、Node.js、PHP 等发出请求所需的代码。
您可以使用 Zenscrape API 执行许多任务,例如获取销售线索或跟踪电子商务平台上产品的定价和可用性。访问 Zenscrape 并为自己阅读。有一个每月 1,000 积分的免费计划。您可以在几分钟内注册一个免费的 Zenscrape 帐户并自己测试所有功能。
curl 抓取网页(下载文件总是一个难熬的过程,如果有进度条就好很多了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-04 13:00
前言
最近在命令行下的编程中,下载文件总是一个比较难的过程。如果有进度条就更好了!!!
之前进度条的扩展包还是不错的(本地下载)
效果图:
还是好看的!
卷曲有什么用?
用php,curl主要是抓取数据,当然我们也可以通过其他方法抓取,比如fsockopen,file_get_contents等,但是只能抓取那些可以直接访问的页面。如果要抓取有页面访问控制的页面,或者登录后的页面,就比较难了。
使用卷曲
curl是PHP很常用的一种下载方式,这里有一个简单的使用方法;
// 初始化一个 curl
$ch = curl_init();
// 设置请求的 url
curl_setopt($ch, CURLOPT_URL, $url);
//
curl_setopt($ch, CURLOPT_HEADER, 0);
// 不直接输出,而是通过 curl_exec 返回
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
if (false === ($stream = curl_exec($ch))) {
throw new \Exception(curl_errno($ch));
}
curl_close($ch);
return $stream;
上面是一个非常简单的例子。如果文件很大,用户需要等待很长时间。这时候我们应该添加进度条的效果:
class Request
{
protected $bar;
// 是否下载完成
protected $downloaded = false;
public function __construct()
{
// 初始化一个进度条
$this->bar = new CliProgressBar(100);
$this->bar->display();
$this->bar->setColorToRed();
}
function download($url)
{
$ch = curl_init();
// 从配置文件中获取根路径
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 0);
// 开启进度条
curl_setopt($ch, CURLOPT_NOPROGRESS, 0);
// 进度条的触发函数
curl_setopt($ch, CURLOPT_PROGRESSFUNCTION, 'progress');
// ps: 如果目标网页跳转,也跟着跳转
// curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
if (false === ($stream = curl_exec($ch))) {
throw new \Exception(curl_errno($ch));
}
curl_close($ch);
return $stream;
}
/**
* 进度条下载.
*
* @param $ch
* @param $countDownloadSize 总下载量
* @param $currentDownloadSize 当前下载量
* @param $countUploadSize
* @param $currentUploadSize
*/
public function progress($ch, $countDownloadSize, $currentDownloadSize, $countUploadSize, $currentUploadSize)
{
// 等于 0 的时候,应该是预读资源不等于0的时候即开始下载
// 这里的每一个判断都是坑,多试试就知道了
if (0 === $countDownloadSize) {
return false;
}
// 有时候会下载两次,第一次很小,应该是重定向下载
if ($countDownloadSize > $currentDownloadSize) {
$this->downloaded = false;
// 继续显示进度条
}
// 已经下载完成还会再发三次请求
elseif ($this->downloaded) {
return false;
}
// 两边相等下载完成并不一定结束,
elseif ($currentDownloadSize === $countDownloadSize) {
return false;
}
// 开始计算
$bar = $currentDownloadSize / $countDownloadSize * 100;
$this->bar->progress($bar);
}
}
(new Request)->download('http://www.shiguopeng.cn/database.sql');
下载回调的判断中一定要注意坑!!!
还有一个问题:如果跳转到下载并设置curl跟随跳转,返回的文件会有问题。
我下载了一个zip文件,它会导致文件头有第一个请求的HTTP响应头的内容,
所以你需要 curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
总结
以上就是这个文章的全部内容。希望本文的内容对大家的学习或工作有一定的参考和学习价值。有问题可以留言交流,感谢大家对脚本之家的支持。 查看全部
curl 抓取网页(下载文件总是一个难熬的过程,如果有进度条就好很多了)
前言
最近在命令行下的编程中,下载文件总是一个比较难的过程。如果有进度条就更好了!!!
之前进度条的扩展包还是不错的(本地下载)
效果图:
还是好看的!
卷曲有什么用?
用php,curl主要是抓取数据,当然我们也可以通过其他方法抓取,比如fsockopen,file_get_contents等,但是只能抓取那些可以直接访问的页面。如果要抓取有页面访问控制的页面,或者登录后的页面,就比较难了。
使用卷曲
curl是PHP很常用的一种下载方式,这里有一个简单的使用方法;
// 初始化一个 curl
$ch = curl_init();
// 设置请求的 url
curl_setopt($ch, CURLOPT_URL, $url);
//
curl_setopt($ch, CURLOPT_HEADER, 0);
// 不直接输出,而是通过 curl_exec 返回
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
if (false === ($stream = curl_exec($ch))) {
throw new \Exception(curl_errno($ch));
}
curl_close($ch);
return $stream;
上面是一个非常简单的例子。如果文件很大,用户需要等待很长时间。这时候我们应该添加进度条的效果:
class Request
{
protected $bar;
// 是否下载完成
protected $downloaded = false;
public function __construct()
{
// 初始化一个进度条
$this->bar = new CliProgressBar(100);
$this->bar->display();
$this->bar->setColorToRed();
}
function download($url)
{
$ch = curl_init();
// 从配置文件中获取根路径
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 0);
// 开启进度条
curl_setopt($ch, CURLOPT_NOPROGRESS, 0);
// 进度条的触发函数
curl_setopt($ch, CURLOPT_PROGRESSFUNCTION, 'progress');
// ps: 如果目标网页跳转,也跟着跳转
// curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
if (false === ($stream = curl_exec($ch))) {
throw new \Exception(curl_errno($ch));
}
curl_close($ch);
return $stream;
}
/**
* 进度条下载.
*
* @param $ch
* @param $countDownloadSize 总下载量
* @param $currentDownloadSize 当前下载量
* @param $countUploadSize
* @param $currentUploadSize
*/
public function progress($ch, $countDownloadSize, $currentDownloadSize, $countUploadSize, $currentUploadSize)
{
// 等于 0 的时候,应该是预读资源不等于0的时候即开始下载
// 这里的每一个判断都是坑,多试试就知道了
if (0 === $countDownloadSize) {
return false;
}
// 有时候会下载两次,第一次很小,应该是重定向下载
if ($countDownloadSize > $currentDownloadSize) {
$this->downloaded = false;
// 继续显示进度条
}
// 已经下载完成还会再发三次请求
elseif ($this->downloaded) {
return false;
}
// 两边相等下载完成并不一定结束,
elseif ($currentDownloadSize === $countDownloadSize) {
return false;
}
// 开始计算
$bar = $currentDownloadSize / $countDownloadSize * 100;
$this->bar->progress($bar);
}
}
(new Request)->download('http://www.shiguopeng.cn/database.sql');
下载回调的判断中一定要注意坑!!!
还有一个问题:如果跳转到下载并设置curl跟随跳转,返回的文件会有问题。
我下载了一个zip文件,它会导致文件头有第一个请求的HTTP响应头的内容,
所以你需要 curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
总结
以上就是这个文章的全部内容。希望本文的内容对大家的学习或工作有一定的参考和学习价值。有问题可以留言交流,感谢大家对脚本之家的支持。
curl 抓取网页(Linux中curl利用规则()(string$ro))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-03 23:07
阿里云 > 云栖社区 > 主题图 > C > curl抓取网站数据
推荐活动:
更多优惠>
当前话题:curl 抓取 网站 数据并添加到采集夹
相关话题:
curl爬取网站数据相关博客查看更多博客
模拟请求工具 curl 的异常处理
作者:于尔伍775 浏览评论:04年前
在日常开发过程中,使用curl来模拟请求的场景很多。跨站请求时,其他网站的稳定性得不到保证。当其他网站不能顺利访问时,会影响当前业务系统,不易排查问题,需要进行异常处理。私有函数 curlPost(字符串 $ro
阅读全文
curl的详细解释
作者:技术小哥 1664人查看评论数:04年前
curl:命令行下网站访问认证工具常用参数如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 -c,--cookie-jar:写入cookies到文件 -b,--cookie:从文件 -C,--cont 读取 cookie
阅读全文
卷曲
作者:于尔伍1062 浏览评论:04年前
我用过的Linux的curl命令-强大的网络传输工具这个链接:(转载请注明出处)用途说明curl命令是一个强大的网络工具,可以通过http、ftp等方式
阅读全文
卷曲
作者:技术小牛960 浏览评论:04年前
linux curl命令详解及示例 linux curl是一个文件传输工具,在命令行下使用URL规则工作。它支持文件的上传和下载,是一个综合性的传输工具,但按照传统,习惯上将url调用如下
阅读全文
卷曲
作者:小技术专家1668查看评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
卷曲
作者:Technic Fatty 975 浏览评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
shell+curl监控网站页面(域名访问状态),使用sedemail发送邮件
作者:犹豫1585 浏览评论:04年前
应领导要求,监控公司几个主要站点的域名访问情况。让我们分享一个监控脚本并使用 sendemail 发送电子邮件。监控脚本如下: 下面是一个多线程的网站状态检测脚本,直接从文件中读取站点地址,然后使用curl检测返回码。发现速度非常好,基本在几秒内。
阅读全文
关于表单提交类型为submit类型且使用curl函数发布网页数据时没有name和id时可能遇到的问题及解决方法
作者:林冠红 683 浏览评论:07年前
curl函数库实现了链接抓取网页内容。以下是没有name和id标识的类型。
阅读全文
curl抓取网站数据相关问答题
php采集金大师:使用curl模拟登录抓取数据遇到json调用问题不成功,求助!
作者:杨东方906 浏览评论:15年前
我在抓取一个页面的信息(比如说a.php),这个页面只是一些基本的html框架,其他关键信息通过ajax请求返回(b.php),返回的是json,然后通过页面js将json解析并绘制到页面。问题的关键是ajax请求的信息中有一个手机号需要登录才能完整显示
阅读全文 查看全部
curl 抓取网页(Linux中curl利用规则()(string$ro))
阿里云 > 云栖社区 > 主题图 > C > curl抓取网站数据
推荐活动:
更多优惠>
当前话题:curl 抓取 网站 数据并添加到采集夹
相关话题:
curl爬取网站数据相关博客查看更多博客
模拟请求工具 curl 的异常处理
作者:于尔伍775 浏览评论:04年前
在日常开发过程中,使用curl来模拟请求的场景很多。跨站请求时,其他网站的稳定性得不到保证。当其他网站不能顺利访问时,会影响当前业务系统,不易排查问题,需要进行异常处理。私有函数 curlPost(字符串 $ro
阅读全文
curl的详细解释
作者:技术小哥 1664人查看评论数:04年前
curl:命令行下网站访问认证工具常用参数如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 -c,--cookie-jar:写入cookies到文件 -b,--cookie:从文件 -C,--cont 读取 cookie
阅读全文
卷曲
作者:于尔伍1062 浏览评论:04年前
我用过的Linux的curl命令-强大的网络传输工具这个链接:(转载请注明出处)用途说明curl命令是一个强大的网络工具,可以通过http、ftp等方式
阅读全文
卷曲
作者:技术小牛960 浏览评论:04年前
linux curl命令详解及示例 linux curl是一个文件传输工具,在命令行下使用URL规则工作。它支持文件的上传和下载,是一个综合性的传输工具,但按照传统,习惯上将url调用如下
阅读全文
卷曲
作者:小技术专家1668查看评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
卷曲
作者:Technic Fatty 975 浏览评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
shell+curl监控网站页面(域名访问状态),使用sedemail发送邮件
作者:犹豫1585 浏览评论:04年前
应领导要求,监控公司几个主要站点的域名访问情况。让我们分享一个监控脚本并使用 sendemail 发送电子邮件。监控脚本如下: 下面是一个多线程的网站状态检测脚本,直接从文件中读取站点地址,然后使用curl检测返回码。发现速度非常好,基本在几秒内。
阅读全文
关于表单提交类型为submit类型且使用curl函数发布网页数据时没有name和id时可能遇到的问题及解决方法
作者:林冠红 683 浏览评论:07年前
curl函数库实现了链接抓取网页内容。以下是没有name和id标识的类型。
阅读全文
curl抓取网站数据相关问答题
php采集金大师:使用curl模拟登录抓取数据遇到json调用问题不成功,求助!
作者:杨东方906 浏览评论:15年前
我在抓取一个页面的信息(比如说a.php),这个页面只是一些基本的html框架,其他关键信息通过ajax请求返回(b.php),返回的是json,然后通过页面js将json解析并绘制到页面。问题的关键是ajax请求的信息中有一个手机号需要登录才能完整显示
阅读全文
curl 抓取网页(下载网站的全部内容同一件事,他们有什么不同?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-28 18:18
互联网上有很多工具可以下载 网站 的静态副本,例如 HTTrack。还有许多工具,一些商业工具,用于从 网站 中“抓取”内容(例如 Mozenda)。然后显然有一些工具内置在 PHP 和 *nix 等程序中,您可以在其中“file_get_contents”或“wget”或“cURL”或只是“file()”。
我对这一切感到非常困惑,我认为主要原因是我遇到的所有描述都没有使用相同的词汇。至少从表面上看,他们似乎都在做同样的事情,但也许不是。
那是我的问题。这些工具到底在做什么?他们在做同样的事情吗?他们是否通过不同的技术做同样的事情?如果他们不做同样的事情,他们有什么不同?
最佳答案
首先,让我澄清一下“镜像”和“抓取”之间的区别。
镜像意味着下载网站 的全部内容或网站 的一些主要部分(包括HTML、图像、脚本、CSS 样式表等)。通常这样做是为了保留和扩展对有价值的(通常是有限的)互联网资源的访问,或者增加额外的故障转移冗余。例如,许多大学和 IT 公司反映了各种 Linux 供应商的分发文件。镜像可能意味着您计划在自己的服务器上托管 网站 的副本(在原创内容所有者的许可下)。
爬行意味着从 网站 复制和提取一些有趣的数据。与镜像不同,抓取目标是特定数据集(姓名、电话号码、股票报价等),而不是 网站 的全部内容。例如,您可以“抓取”来自美国人口普查局的平均收入数据或来自 Google 财经的股票报价。有时这违反了主机的条款和条件,使其非法。
可以将两者结合起来,以便将数据复制(镜像)问题与信息提取(抓取)问题分开。例如,您可能会发现它更快地镜像站点,然后如果数据提取和分析速度较慢或处理密集,则获取本地副本。
要回答剩下的问题...
file_get_contents 和 file PHP 函数用于从本地或远程计算机读取文件。该文件可以是 HTML 文件或其他文件,例如文本文件或电子表格。这不是“mirror”或“scratch”通常所指的,尽管您可以使用它们来编写您自己的基于 PHP 的 mirror/grabber。
wget 和 curl 是命令行独立程序,用于使用各种选项、条件和协议从远程服务器下载一个或多个文件。两者都是强大且流行的工具,主要区别在于 wget 具有丰富的内置功能来镜像整个 网站。
HTTrack 旨在类似于 wget,但使用 GUI 而不是命令行。这使得那些不方便从终端运行命令的人更容易使用,但代价是失去了 wget 提供的功能和灵活性。
您可以使用 HTTrack 和 wget 进行镜像,但如果这是您的最终目标,您必须在生成的下载数据上运行自己的程序以提取(获取)信息。
Mozenda 是一种抓取工具,与 HTTrack、wget 或 curl 不同,它允许您针对特定数据进行提取,而不是盲目地复制所有内容。不过,我经验不足。
PS 我通常使用 wget 来镜像我感兴趣的 HTML 页面,然后运行 Ruby 和 R 脚本的组合来提取和分析数据。 查看全部
curl 抓取网页(下载网站的全部内容同一件事,他们有什么不同?)
互联网上有很多工具可以下载 网站 的静态副本,例如 HTTrack。还有许多工具,一些商业工具,用于从 网站 中“抓取”内容(例如 Mozenda)。然后显然有一些工具内置在 PHP 和 *nix 等程序中,您可以在其中“file_get_contents”或“wget”或“cURL”或只是“file()”。
我对这一切感到非常困惑,我认为主要原因是我遇到的所有描述都没有使用相同的词汇。至少从表面上看,他们似乎都在做同样的事情,但也许不是。
那是我的问题。这些工具到底在做什么?他们在做同样的事情吗?他们是否通过不同的技术做同样的事情?如果他们不做同样的事情,他们有什么不同?
最佳答案
首先,让我澄清一下“镜像”和“抓取”之间的区别。
镜像意味着下载网站 的全部内容或网站 的一些主要部分(包括HTML、图像、脚本、CSS 样式表等)。通常这样做是为了保留和扩展对有价值的(通常是有限的)互联网资源的访问,或者增加额外的故障转移冗余。例如,许多大学和 IT 公司反映了各种 Linux 供应商的分发文件。镜像可能意味着您计划在自己的服务器上托管 网站 的副本(在原创内容所有者的许可下)。
爬行意味着从 网站 复制和提取一些有趣的数据。与镜像不同,抓取目标是特定数据集(姓名、电话号码、股票报价等),而不是 网站 的全部内容。例如,您可以“抓取”来自美国人口普查局的平均收入数据或来自 Google 财经的股票报价。有时这违反了主机的条款和条件,使其非法。
可以将两者结合起来,以便将数据复制(镜像)问题与信息提取(抓取)问题分开。例如,您可能会发现它更快地镜像站点,然后如果数据提取和分析速度较慢或处理密集,则获取本地副本。
要回答剩下的问题...
file_get_contents 和 file PHP 函数用于从本地或远程计算机读取文件。该文件可以是 HTML 文件或其他文件,例如文本文件或电子表格。这不是“mirror”或“scratch”通常所指的,尽管您可以使用它们来编写您自己的基于 PHP 的 mirror/grabber。
wget 和 curl 是命令行独立程序,用于使用各种选项、条件和协议从远程服务器下载一个或多个文件。两者都是强大且流行的工具,主要区别在于 wget 具有丰富的内置功能来镜像整个 网站。
HTTrack 旨在类似于 wget,但使用 GUI 而不是命令行。这使得那些不方便从终端运行命令的人更容易使用,但代价是失去了 wget 提供的功能和灵活性。
您可以使用 HTTrack 和 wget 进行镜像,但如果这是您的最终目标,您必须在生成的下载数据上运行自己的程序以提取(获取)信息。
Mozenda 是一种抓取工具,与 HTTrack、wget 或 curl 不同,它允许您针对特定数据进行提取,而不是盲目地复制所有内容。不过,我经验不足。
PS 我通常使用 wget 来镜像我感兴趣的 HTML 页面,然后运行 Ruby 和 R 脚本的组合来提取和分析数据。
curl 抓取网页(和wget下载安装1、Ubuntu平台wget命令安装:百度首页为例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-27 19:19
curl和wget下载安装
1、Ubuntu 平台
wget命令安装:sudo apt-get install wget(普通用户登录,需要输入密码;root账户登录,不需要输入密码)
curl命令安装:sudo apt-get install curl(同wget)
2、Windows 平台
wget下载地址:wget for Windows
curl下载地址:curl下载
wget和curl包下载地址:Windows平台下的wget和curl工具包
Windows平台下,curl下载解压后直接为curl.exe格式,复制到系统命令目录下的C:\Windows\System32。
Windows平台下,wget下载解压后,格式为wget-1.11.4-1-setup.exe,需要安装;安装完成后,在环境变量-系统变量-路径目录下添加其安装
curl 和 wget 抓取实例
抓取网页主要有两种方式:url URL 和代理代理。下面是一个爬取“百度”首页的例子。
1、 url URL方法爬取
(1)curl下载百度首页内容,保存在baidu_html文件中
curl baidu_html
(2)wget下载百度首页内容,保存在baidu_html文件中
wget baidu_html2
有时,由于网络速度/数据包丢失/服务器停机等原因,网页暂时无法成功下载。
这时候可能需要尝试多次发送连接来请求服务器的响应;如果多次仍然没有响应,则可以确认服务器有问题。
(1)curl 尝试连接多次
curl --retry 10 --retry-delay 60 --retry-max-time 60 -o baidu_html
注意:--retry 表示重试次数;--retry-delay 表示两次重试之间的时间间隔(以秒为单位);--retry-max-time 表示在这个最大时间内只允许重试一次(一般同--retry-delay)
(2)wget 尝试连接多次
wget -t 10 -w 60 -T 30 -O baidu_html2
注意:-t(--tries)表示重试次数;-w 表示两次重试之间的时间间隔(以秒为单位);-T 表示连接超时时间,超过超时则连接不成功,下次连接继续尝试
附:curl可以判断服务器是否响应。也可以通过一段时间内下载获得的字节数来间接判断。命令格式如下:
curl -y 60 -Y 1 -m 60 -o baidu_html
注:-y表示测试网速的时间;-Y 表示-y期间下载的字节数(字节为单位);-m 表示允许请求连接的最长时间,如果超过连接会自动断开连接并放弃连接
2、代理代理捕获
代理下载是通过连接中间服务器间接下载url网页的过程,而不是直接连接网站服务器下载的url
两位知名的自由球员网站:
(全球数十个国家免费代理,每日更新)
(通过设置端口类型、代理类型、国家名称过滤)
在网站中选择国内免费的代理服务器为例介绍代理代理爬取网页:
218.107.21.252:8080(ip为218.107.21.252;端口为8080,中间是 8080 冒号“:”隔开形成套接字)
(1)curl通过代理爬取百度首页
curl -x 218.107.21.252:8080 -o aaaaa(常用端口有80、8080、8086、8888、3128等,默认80)
注:-x表示代理服务器(ip:port),即curl先连接代理服务器218.107.21.252:8080,然后通过21< @k31@ >107.21.252:8080 下载百度首页,最后218.107.21.252:8080 通过下载百度主页 curl 到本地(curl 不是直接连接百度服务器下载主页,而是通过中介代理)
(2)wget通过代理爬取百度首页
wget 通过代理下载,和 curl 不一样。需要先设置代理服务器的http_proxy=ip:port。
以ubuntu为例,在当前用户目录(cd ~),新建wget配置文件(.wgetrc),进入代理配置: 查看全部
curl 抓取网页(和wget下载安装1、Ubuntu平台wget命令安装:百度首页为例)
curl和wget下载安装
1、Ubuntu 平台
wget命令安装:sudo apt-get install wget(普通用户登录,需要输入密码;root账户登录,不需要输入密码)
curl命令安装:sudo apt-get install curl(同wget)
2、Windows 平台
wget下载地址:wget for Windows
curl下载地址:curl下载
wget和curl包下载地址:Windows平台下的wget和curl工具包
Windows平台下,curl下载解压后直接为curl.exe格式,复制到系统命令目录下的C:\Windows\System32。
Windows平台下,wget下载解压后,格式为wget-1.11.4-1-setup.exe,需要安装;安装完成后,在环境变量-系统变量-路径目录下添加其安装
curl 和 wget 抓取实例
抓取网页主要有两种方式:url URL 和代理代理。下面是一个爬取“百度”首页的例子。
1、 url URL方法爬取
(1)curl下载百度首页内容,保存在baidu_html文件中
curl baidu_html
(2)wget下载百度首页内容,保存在baidu_html文件中
wget baidu_html2
有时,由于网络速度/数据包丢失/服务器停机等原因,网页暂时无法成功下载。
这时候可能需要尝试多次发送连接来请求服务器的响应;如果多次仍然没有响应,则可以确认服务器有问题。
(1)curl 尝试连接多次
curl --retry 10 --retry-delay 60 --retry-max-time 60 -o baidu_html
注意:--retry 表示重试次数;--retry-delay 表示两次重试之间的时间间隔(以秒为单位);--retry-max-time 表示在这个最大时间内只允许重试一次(一般同--retry-delay)
(2)wget 尝试连接多次
wget -t 10 -w 60 -T 30 -O baidu_html2
注意:-t(--tries)表示重试次数;-w 表示两次重试之间的时间间隔(以秒为单位);-T 表示连接超时时间,超过超时则连接不成功,下次连接继续尝试
附:curl可以判断服务器是否响应。也可以通过一段时间内下载获得的字节数来间接判断。命令格式如下:
curl -y 60 -Y 1 -m 60 -o baidu_html
注:-y表示测试网速的时间;-Y 表示-y期间下载的字节数(字节为单位);-m 表示允许请求连接的最长时间,如果超过连接会自动断开连接并放弃连接
2、代理代理捕获
代理下载是通过连接中间服务器间接下载url网页的过程,而不是直接连接网站服务器下载的url
两位知名的自由球员网站:
(全球数十个国家免费代理,每日更新)
(通过设置端口类型、代理类型、国家名称过滤)
在网站中选择国内免费的代理服务器为例介绍代理代理爬取网页:
218.107.21.252:8080(ip为218.107.21.252;端口为8080,中间是 8080 冒号“:”隔开形成套接字)
(1)curl通过代理爬取百度首页
curl -x 218.107.21.252:8080 -o aaaaa(常用端口有80、8080、8086、8888、3128等,默认80)
注:-x表示代理服务器(ip:port),即curl先连接代理服务器218.107.21.252:8080,然后通过21< @k31@ >107.21.252:8080 下载百度首页,最后218.107.21.252:8080 通过下载百度主页 curl 到本地(curl 不是直接连接百度服务器下载主页,而是通过中介代理)
(2)wget通过代理爬取百度首页
wget 通过代理下载,和 curl 不一样。需要先设置代理服务器的http_proxy=ip:port。
以ubuntu为例,在当前用户目录(cd ~),新建wget配置文件(.wgetrc),进入代理配置:
curl 抓取网页(【知识点】curl抓取网页头部的看ip啊!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-27 15:03
curl抓取网页头部,看ip啊在linux下用pipinstallsqlalchemysqlalchemy-next之后先清除sqlalchemy的安装包。再安装configure的包。
同样问题来求答案,python2数据库是mysql,python3是mariadb。折腾了一个星期仍然没有答案。后来搜到了答案,在tools--loadlibrary--cached中将mysql包加入了路径。刚刚问了下在国外,回答得很官方,但是确实给不了解决方案。
我用curl抓取了头部一部分的网页,然后用excel打开,
tools--loadlibrary--cacheddblisted在加载类别一栏加入你想加载的
localdb中是没有库的
我提示是我是curl的php-module已加载在tools--loadlibrary--cached中。然后一直加载失败。
conf-python-database.py里面path路径url更改成你想要的
因为`curl`抓取的网页数据是存在tools--loadlibrary--cached中的`csv/old_mysql/lib`的,我也碰到了你这个问题,可能是没加在``profile`中```profile`中加入这个路径```mysqldatabase_database``
运行pythonconf.py,找到path路径, 查看全部
curl 抓取网页(【知识点】curl抓取网页头部的看ip啊!)
curl抓取网页头部,看ip啊在linux下用pipinstallsqlalchemysqlalchemy-next之后先清除sqlalchemy的安装包。再安装configure的包。
同样问题来求答案,python2数据库是mysql,python3是mariadb。折腾了一个星期仍然没有答案。后来搜到了答案,在tools--loadlibrary--cached中将mysql包加入了路径。刚刚问了下在国外,回答得很官方,但是确实给不了解决方案。
我用curl抓取了头部一部分的网页,然后用excel打开,
tools--loadlibrary--cacheddblisted在加载类别一栏加入你想加载的
localdb中是没有库的
我提示是我是curl的php-module已加载在tools--loadlibrary--cached中。然后一直加载失败。
conf-python-database.py里面path路径url更改成你想要的
因为`curl`抓取的网页数据是存在tools--loadlibrary--cached中的`csv/old_mysql/lib`的,我也碰到了你这个问题,可能是没加在``profile`中```profile`中加入这个路径```mysqldatabase_database``
运行pythonconf.py,找到path路径,
curl 抓取网页(和wget下载安装1、Ubuntu平台wget命令安装:百度首页为例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-27 15:02
curl和wget下载安装
1、Ubuntu 平台
wget 命令安装: sudo apt-get install wget
(普通用户登录,需输入密码;root账户登录,无需输入密码)
curl命令安装:sudo apt-get install curl
(与 wget 相同)
2、Windows 平台
wget下载地址:wget for Windows
curl下载地址:curl下载
wget和curl包下载地址:Windows平台下的wget和curl工具包
在Windows平台下,curl下载解压后直接为curl.exe格式,复制到系统命令目录下的C:\Windows\System32。
Windows平台下,wget下载解压后,格式为wget-1.11.4-1-setup.exe,需要安装;安装完成后,在环境变量-系统变量-路径目录下添加其安装
curl 和 wget 抓取实例
抓取网页主要有两种方式:url URL 和代理代理。下面是一个爬取“百度”首页的例子。
1、 url URL方法爬取
(1)curl下载百度首页内容,保存在baidu_html文件中
curl -o baidu_html
(2)wget下载百度首页内容,保存在baidu_html文件中
wget -O baidu_html2
有时,由于网络速度/数据包丢失/服务器停机等原因,网页暂时无法成功下载。
这时候可能需要尝试多次发送连接来请求服务器的响应;如果多次仍然没有响应,则可以确认服务器有问题。
(1)curl 尝试连接多次
curl --retry 10 --retry-delay 60 --retry-max-time 60 -o baidu_html
注意:--retry 表示重试次数;--retry-delay 表示两次重试之间的时间间隔(以秒为单位);--retry-max-time 表示在这个最大时间内只允许重试一次(一般同--retry-delay)
(2)wget 尝试连接多次
wget -t 10 -w 60 -T 30 -O baidu_html2
注意:-t(--tries)表示重试次数;-w 表示两次重试之间的时间间隔(以秒为单位);-T 表示连接超时时间,超过超时则连接不成功,下次连接继续尝试
附:curl可以判断服务器是否响应。也可以通过一段时间内下载获得的字节数来间接判断。命令格式如下:
curl -y 60 -Y 1 -m 60 -o baidu_html
注:-y表示测试网速的时间;-Y 表示-y期间下载的字节数(字节为单位);-m 表示允许请求连接的最长时间,如果超过连接会自动断开连接并放弃连接
2、代理代理捕获
代理下载是通过连接中间服务器间接下载url网页的过程,而不是直接连接网站服务器下载的url
两位知名的自由球员网站:
(全球数十个国家免费代理,每日更新)
(通过设置端口类型、代理类型、国家名称过滤)
在网站中选择国内免费的代理服务器为例介绍代理代理爬取网页:
218.107.21.252:8080(ip为218.107.21.252;端口为8080,中间是 8080 冒号“:”隔开形成套接字)
(1)curl通过代理爬取百度首页
卷曲
-x 218.107.21.252:8080 -o aaaaa(常用端口有80、8080、8086、8888、3128等,默认80)
注:-x表示代理服务器(ip:port),即curl先连接代理服务器218.107.21.252:8080,然后通过21< @k31@ >107.21.252:8080 下载百度首页,最后218.107.21.252:8080 通过下载百度主页 curl 到本地(curl 不是直接连接百度服务器下载主页,而是通过中介代理)
(2)wget通过代理爬取百度首页
wget 通过代理下载,和 curl 不一样。需要先设置代理服务器的http_proxy=ip:port。
以ubuntu为例,在当前用户目录(cd ~),新建wget配置文件(.wgetrc),进入代理配置: 查看全部
curl 抓取网页(和wget下载安装1、Ubuntu平台wget命令安装:百度首页为例)
curl和wget下载安装
1、Ubuntu 平台
wget 命令安装: sudo apt-get install wget
(普通用户登录,需输入密码;root账户登录,无需输入密码)
curl命令安装:sudo apt-get install curl
(与 wget 相同)
2、Windows 平台
wget下载地址:wget for Windows
curl下载地址:curl下载
wget和curl包下载地址:Windows平台下的wget和curl工具包
在Windows平台下,curl下载解压后直接为curl.exe格式,复制到系统命令目录下的C:\Windows\System32。
Windows平台下,wget下载解压后,格式为wget-1.11.4-1-setup.exe,需要安装;安装完成后,在环境变量-系统变量-路径目录下添加其安装
curl 和 wget 抓取实例
抓取网页主要有两种方式:url URL 和代理代理。下面是一个爬取“百度”首页的例子。
1、 url URL方法爬取
(1)curl下载百度首页内容,保存在baidu_html文件中
curl -o baidu_html
(2)wget下载百度首页内容,保存在baidu_html文件中
wget -O baidu_html2
有时,由于网络速度/数据包丢失/服务器停机等原因,网页暂时无法成功下载。
这时候可能需要尝试多次发送连接来请求服务器的响应;如果多次仍然没有响应,则可以确认服务器有问题。
(1)curl 尝试连接多次
curl --retry 10 --retry-delay 60 --retry-max-time 60 -o baidu_html
注意:--retry 表示重试次数;--retry-delay 表示两次重试之间的时间间隔(以秒为单位);--retry-max-time 表示在这个最大时间内只允许重试一次(一般同--retry-delay)
(2)wget 尝试连接多次
wget -t 10 -w 60 -T 30 -O baidu_html2
注意:-t(--tries)表示重试次数;-w 表示两次重试之间的时间间隔(以秒为单位);-T 表示连接超时时间,超过超时则连接不成功,下次连接继续尝试
附:curl可以判断服务器是否响应。也可以通过一段时间内下载获得的字节数来间接判断。命令格式如下:
curl -y 60 -Y 1 -m 60 -o baidu_html
注:-y表示测试网速的时间;-Y 表示-y期间下载的字节数(字节为单位);-m 表示允许请求连接的最长时间,如果超过连接会自动断开连接并放弃连接
2、代理代理捕获
代理下载是通过连接中间服务器间接下载url网页的过程,而不是直接连接网站服务器下载的url
两位知名的自由球员网站:
(全球数十个国家免费代理,每日更新)
(通过设置端口类型、代理类型、国家名称过滤)
在网站中选择国内免费的代理服务器为例介绍代理代理爬取网页:
218.107.21.252:8080(ip为218.107.21.252;端口为8080,中间是 8080 冒号“:”隔开形成套接字)
(1)curl通过代理爬取百度首页
卷曲
-x 218.107.21.252:8080 -o aaaaa(常用端口有80、8080、8086、8888、3128等,默认80)
注:-x表示代理服务器(ip:port),即curl先连接代理服务器218.107.21.252:8080,然后通过21< @k31@ >107.21.252:8080 下载百度首页,最后218.107.21.252:8080 通过下载百度主页 curl 到本地(curl 不是直接连接百度服务器下载主页,而是通过中介代理)
(2)wget通过代理爬取百度首页
wget 通过代理下载,和 curl 不一样。需要先设置代理服务器的http_proxy=ip:port。
以ubuntu为例,在当前用户目录(cd ~),新建wget配置文件(.wgetrc),进入代理配置:

