
c爬虫抓取网页数据
c爬虫抓取网页数据(一个网站抓站过程中遇到的奇特网站,分享思路和抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-09-25 13:20
在我们学习的过程中,打开一个网站,想抓取一次数据,但并不是所有的网站都能以一种方式抓取数据。有的是特殊的网页结构,有的是json数据包。不一样。慢慢写一些自己在抓取网站过程中遇到的奇葩网站,分享一下思路和抓取方法!
工具、目标\
工具:pycharm、python3.6 版本
库:请求库
目标:普世网热门图片直播页面,所有图片信息
注:此网站有一个热门图片页面,其中收录活动的相关照片。根据活动情况,所有图片信息将写入txt文件(不下载图片,以免影响服务器)!
目标分析\
首先打开上图首页,点击右上角,出现选项后,点击进入热图直播选项(注意:部分浏览器需要放大页面才能看到热图直播广播选项),进入后页如下\
在这里,我已放大到 30%。下面是一页一页的活动现场图片。#价位@762459510 免费采集蟒蛇爬虫配套实操资料#点个活动,看页面\
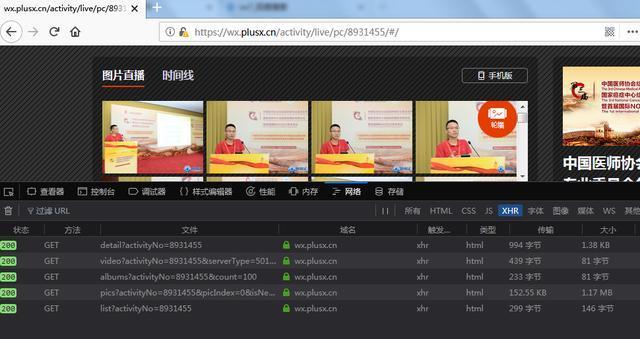
看到页面上的图片加载这么慢,应该是动态加载的,右键查看源码,果然如此!\
没有任何图片信息,那我们就需要使用浏览器的页面审核工具了!我这里用的是火狐,按F12可以打开,然后点击网络,清除内容,刷新页面,看看加载了哪些数据。\
经过简单的检查,我们发现了2个数据收录我们想要的数据\
\
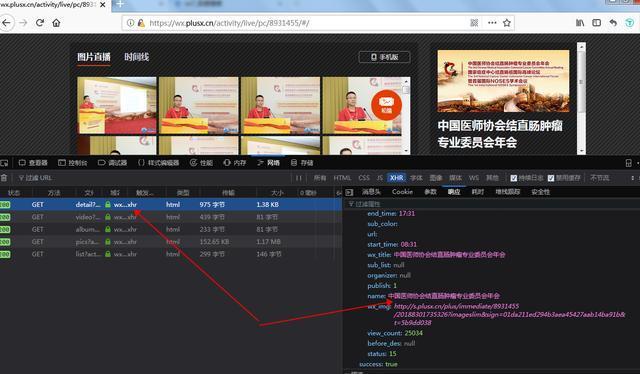
一个是activity相关的信息,一个是image相关的信息,都是json格式加载的。这个很简单,可以请求相关的URL。这时候我突然想到,如果之前的多个活动页面也是动态加载的,那么是否可以通过这种方式捕获所有活动?来看看\
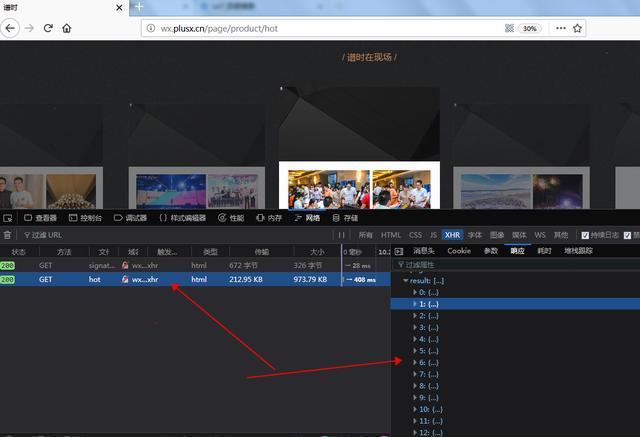
在这个json数据中,收录了页面加载的所有活动信息!没有翻页。. . 难怪加载这么慢【手动申诉】。\
代码\
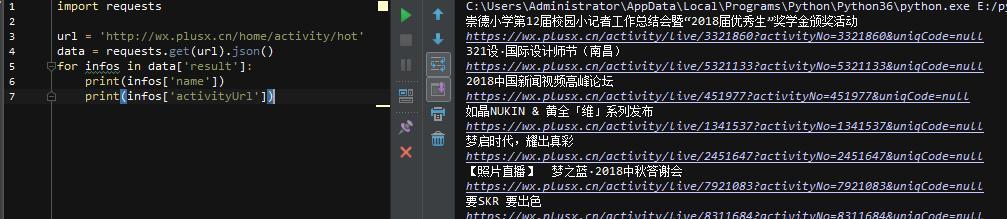
通过上面的分析,我们了解了目标数据的位置,接下来就可以开始尝试写代码了
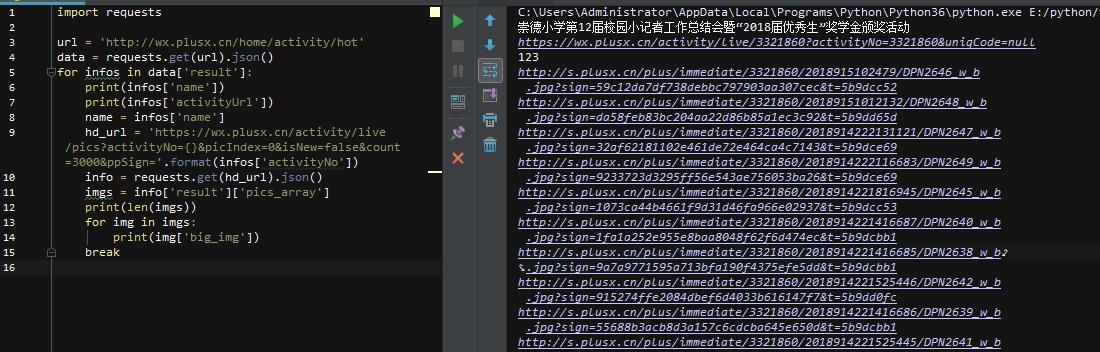
导入requests库,然后直接请求真实的URL,得到名称和对应的URL(真实的URL在消息头中),然后在页面中构造真实的URL。上面得到的网址实际上是网页的网址,而不是网页的网址。如何获取json包所在的真实地址?我们对比一下获取到的几个页面的真实URL,不难发现其规律性。
通过对比发现activityNo的值其实是不一样的,而且这个值也存在于上面抓到的json包中!
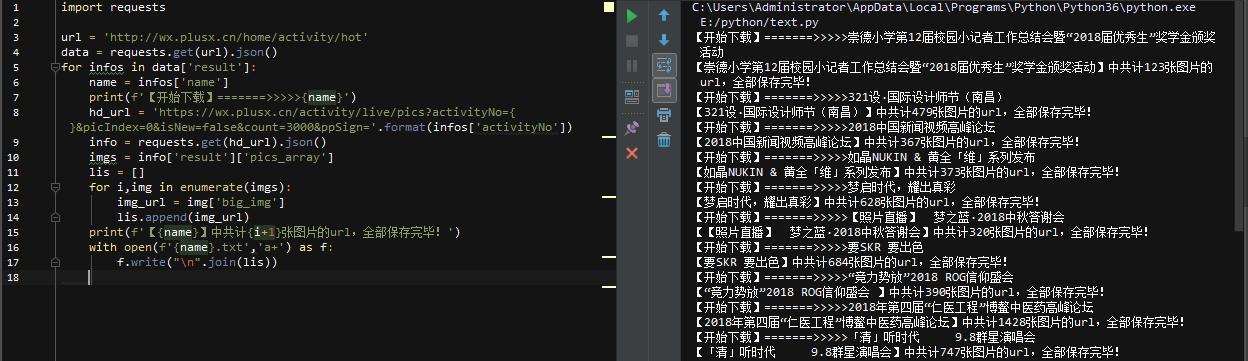
构造下一个页面的真实请求地址,然后抓取json包得到所有图片url!至此,核心代码已经写好,完善一下,整体代码和效果如下:\
\
不到1分钟,这个页面上的所有活动和图片url都被保存了,整体代码不到20行,很简单的一个网站!如果要下载图片,可以把所有的url复制到下载工具,批量下载!\最后,如果你的时间不是很紧,想要快速提高,最重要的是你不怕吃苦。我建议你可以定价@762459510。那真的很好。很多人都在快速进步。你需要害怕困难。!可以去加进去看看~
后记\
这个网站的整体结构比较清晰,数据也很容易获取。今天之所以拿这个网站来分享,是因为当我开始抓包的时候,简直不敢相信,一页之间竟然加载了400多张图片。. . 而且看页面结构,没想到这么简单!
总的来说,网站更适合新手学习抓包获取数据。希望对大家有帮助,加油! 查看全部
c爬虫抓取网页数据(一个网站抓站过程中遇到的奇特网站,分享思路和抓取方法)
在我们学习的过程中,打开一个网站,想抓取一次数据,但并不是所有的网站都能以一种方式抓取数据。有的是特殊的网页结构,有的是json数据包。不一样。慢慢写一些自己在抓取网站过程中遇到的奇葩网站,分享一下思路和抓取方法!
工具、目标\
工具:pycharm、python3.6 版本
库:请求库
目标:普世网热门图片直播页面,所有图片信息
注:此网站有一个热门图片页面,其中收录活动的相关照片。根据活动情况,所有图片信息将写入txt文件(不下载图片,以免影响服务器)!
目标分析\
首先打开上图首页,点击右上角,出现选项后,点击进入热图直播选项(注意:部分浏览器需要放大页面才能看到热图直播广播选项),进入后页如下\
在这里,我已放大到 30%。下面是一页一页的活动现场图片。#价位@762459510 免费采集蟒蛇爬虫配套实操资料#点个活动,看页面\
看到页面上的图片加载这么慢,应该是动态加载的,右键查看源码,果然如此!\
没有任何图片信息,那我们就需要使用浏览器的页面审核工具了!我这里用的是火狐,按F12可以打开,然后点击网络,清除内容,刷新页面,看看加载了哪些数据。\
经过简单的检查,我们发现了2个数据收录我们想要的数据\
\
一个是activity相关的信息,一个是image相关的信息,都是json格式加载的。这个很简单,可以请求相关的URL。这时候我突然想到,如果之前的多个活动页面也是动态加载的,那么是否可以通过这种方式捕获所有活动?来看看\
在这个json数据中,收录了页面加载的所有活动信息!没有翻页。. . 难怪加载这么慢【手动申诉】。\
代码\
通过上面的分析,我们了解了目标数据的位置,接下来就可以开始尝试写代码了
导入requests库,然后直接请求真实的URL,得到名称和对应的URL(真实的URL在消息头中),然后在页面中构造真实的URL。上面得到的网址实际上是网页的网址,而不是网页的网址。如何获取json包所在的真实地址?我们对比一下获取到的几个页面的真实URL,不难发现其规律性。
通过对比发现activityNo的值其实是不一样的,而且这个值也存在于上面抓到的json包中!
构造下一个页面的真实请求地址,然后抓取json包得到所有图片url!至此,核心代码已经写好,完善一下,整体代码和效果如下:\
\
不到1分钟,这个页面上的所有活动和图片url都被保存了,整体代码不到20行,很简单的一个网站!如果要下载图片,可以把所有的url复制到下载工具,批量下载!\最后,如果你的时间不是很紧,想要快速提高,最重要的是你不怕吃苦。我建议你可以定价@762459510。那真的很好。很多人都在快速进步。你需要害怕困难。!可以去加进去看看~

后记\
这个网站的整体结构比较清晰,数据也很容易获取。今天之所以拿这个网站来分享,是因为当我开始抓包的时候,简直不敢相信,一页之间竟然加载了400多张图片。. . 而且看页面结构,没想到这么简单!
总的来说,网站更适合新手学习抓包获取数据。希望对大家有帮助,加油!
c爬虫抓取网页数据(爬虫爬虫抓取系统的重要组成部分工具爬虫的用法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-09-25 13:17
)
爬虫
简单的说,爬虫就是编写程序模拟浏览器上网,然后让它去网上抓取数据的过程。浏览器可以简单理解为一个原创的自然爬虫工具
爬行动物的作用
可以获得有价值的信息。比如在渗透测试中,我们可以通过编写python脚本或者爬取网站有价值的数据来批量验证漏洞
爬虫的合法性
爬虫技术本身是合法的,但是利用它非法获取数据是违法的。喜欢
恶意爬虫
履带分类
1. 通用爬虫
各大搜索引擎爬虫系统的重要组成部分,爬取整页数据。喜欢
2. 关注爬虫
它建立在通用爬虫的基础上,抓取页面上特定的部分内容
3. 增量爬虫
监控网站中数据更新的状态,只抓取网站中最新更新的数据
防爬机构
门户网站制定相应策略或技术手段防止爬虫爬取网站数据
防反爬策略
爬虫程序可以通过制定相关策略或技术手段破解门户网站中的反爬虫机制,从而获取门户网站的数据
robots.txt 协议(君子协议)
机器人协议,又称爬虫协议、机器人协议等,其全称是“机器人排除协议(Robots Exclusion Protocol)”。网站 通过Robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。Robots还有两种用途,一种是告诉搜索引擎你不能爬取哪些页面(其他的默认可以爬取);另一种是告诉搜索引擎你只能爬取哪些页面(其他的默认不能爬取)。
搜索机器人(蜘蛛)访问站点时,首先会检查网站的根目录下是否存在robots.txt。如果存在,则根据文件内容确定访问范围。如果不存在,它会跟随链接进行爬取。
但是,机器人协议对个人不是强制性的,可能不会被遵守。
查看全部
c爬虫抓取网页数据(爬虫爬虫抓取系统的重要组成部分工具爬虫的用法
)
爬虫
简单的说,爬虫就是编写程序模拟浏览器上网,然后让它去网上抓取数据的过程。浏览器可以简单理解为一个原创的自然爬虫工具
爬行动物的作用
可以获得有价值的信息。比如在渗透测试中,我们可以通过编写python脚本或者爬取网站有价值的数据来批量验证漏洞
爬虫的合法性
爬虫技术本身是合法的,但是利用它非法获取数据是违法的。喜欢
恶意爬虫
履带分类
1. 通用爬虫
各大搜索引擎爬虫系统的重要组成部分,爬取整页数据。喜欢
2. 关注爬虫
它建立在通用爬虫的基础上,抓取页面上特定的部分内容
3. 增量爬虫
监控网站中数据更新的状态,只抓取网站中最新更新的数据
防爬机构
门户网站制定相应策略或技术手段防止爬虫爬取网站数据
防反爬策略
爬虫程序可以通过制定相关策略或技术手段破解门户网站中的反爬虫机制,从而获取门户网站的数据
robots.txt 协议(君子协议)
机器人协议,又称爬虫协议、机器人协议等,其全称是“机器人排除协议(Robots Exclusion Protocol)”。网站 通过Robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。Robots还有两种用途,一种是告诉搜索引擎你不能爬取哪些页面(其他的默认可以爬取);另一种是告诉搜索引擎你只能爬取哪些页面(其他的默认不能爬取)。
搜索机器人(蜘蛛)访问站点时,首先会检查网站的根目录下是否存在robots.txt。如果存在,则根据文件内容确定访问范围。如果不存在,它会跟随链接进行爬取。
但是,机器人协议对个人不是强制性的,可能不会被遵守。

c爬虫抓取网页数据(异步和非阻塞的区别同步过程中的应用框架 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-23 21:17
)
scratch简介
Scrapy是一个应用程序框架,用于抓取网站数据和提取结构数据。我们只需要实现少量代码就可以快速爬行。Scrapy使用twisted异步网络框架来加快我们的下载速度
Scratch是异步爬虫的框架,是爬虫的必要技术。很少有语言有专门的爬虫框架。Python中的scratch框架专门用于crawler;使爬虫程序更加稳定和高效。sweep框架的许多内容被封装;高配置和可扩展性。在固定框架下,可以直接添加内容和调用;它是基于异步的。扭曲(扭曲)封装在内部。实现逻辑非常复杂。大量的闭包被采用。基于高阶函数(函数作为返回值或函数对象作为参数),小函数嵌套在大函数中。内部函数需要引用外部函数的变量,以确保变量的安全性,形成闭包。下载速度非常快。它是一个异步网络框架。下载的原理是基于内部封装的多线程,可以直接调用。下载效率也很高。内部封装方法可以控制爬行速度。通过修改配置项可以达到控制爬行速度的目的
异步和非阻塞的区别
在同步过程中,从上到下,只能等待蓝色函数执行,获取return,然后执行黄色函数。它就像一条管道。完成上述工作后,您只能执行以下操作
在异步过程中,蓝色函数对黄色函数没有影响。蓝色函数向网站发送请求,黄色函数可以在等待网站反馈的时间段内向另一个页面发送请求,充分利用等待时间,提高爬网效率
异步:发出调用后,调用直接返回,而不管结果如何
非阻塞:它关注等待调用结果的程序的状态,这意味着在无法立即获得结果之前,调用不会阻塞当前线程
潦草的工作流程
我们通常不只是请求一个URL来抓取多个页面。此时,我们可以在URL列表中放置多个页面。从URL列表中提取URL,向其发送请求,获取相应数据,提取数据,解析数据,保存内容等数据处理;然后对下一个URL循环执行相同的操作
有两个队列。队列1存储每个页面的URL。运行线程从队列1获取URL,发送请求,获取对应的URL,解析每个页面的数据,将解析后的数据放入队列2(如解析图片的名称和URL),然后放入下一个线程下载保存
Scratch是基于异步的。它具有很高的可配置性和可扩展性,结构特殊而复杂。引擎负责整个场景框架的调度。无论它是请求还是获得相应的信息,都必须通过引擎,这相当于人脑。第一步是将目标URL发送到引擎。引擎下面有一个爬虫程序,带有我们需要的URL地址。将URL地址发送到引擎。引擎只负责调度,下载是一个下载器;步骤2:引擎获取URL后,首先将其交给调度器,调度器接收请求的URL并列出;在列出第三个步骤后,调度器给下载程序,下载程序连接到网络以执行请求-响应操作。调度器启动请求以获取响应结果。在步骤4中,下载程序不处理响应结果。下载程序获得响应结果后,将其移交给爬虫程序进行处理。爬虫获取响应结果后,进行数据分析处理;第五步是将解析后的数据发送到管道进行处理,管道专用于保存数据。然后循环,直到调度程序中没有URL
一般工作流:引擎将找到爬虫以获取URL(可能有多个URL),通过爬虫获取URL并将其发送给调度程序。该URL列在调度器中,取出其中一个URL返回到下载器发送请求,获取相应结果,并将相应结果发送给爬虫进行解析,最后爬虫将解析后的数据保存到管道中。此进程将循环,直到计划程序中没有URL为止
1.crawler将URL发送到引擎,2.engine将URL发送到调度程序以供登录,3.scheduler将向引擎发送一个爬网URL,4.engine通过下载中间件将URL发送到下载程序。下载器获取URL后,需要在线发送请求获取相应的URL,5.downloader通过下载中间件将生成的响应发送给引擎,6.engine将接收到的响应发送给爬虫进行解析。爬虫和引擎通过爬虫中间件连接,7.爬虫通过引擎将解析后的数据发送到管道文件保存,8.通过解析后的数据,页面中可能有新的URL需要处理。继续执行上述步骤
名称函数的实现
刮擦发动机
整个框架的核心,总指挥:负责不同模块之间的数据和信号传输
Scratch已经实现
调度程序
存储引擎发送的请求、接收引擎发送的URL并执行列表操作的队列
Scratch已经实现
下载器
发送请求,获取相应的,下载引擎发送的请求,并将其返回到引擎
Scratch已经实现
爬行器(爬虫文件)
分析数据,处理引擎发送的响应,提取数据,提取URL,并将其提供给引擎
需要重写
项目管道
存储数据并处理发动机传输的数据,如存储器
需要重写
下载中间件
它位于引擎和下载器之间,用于处理请求和它们之间的通信(更多使用)。您可以自定义下载扩展,例如设置代理
一般来说,你不必手写
蜘蛛中间件
您可以自定义请求和筛选响应
一般来说,你不必手写
爬虫中间件
位于引擎和爬虫程序之间,用于处理爬虫程序的响应、输出结果和新请求(较少使用)
一般来说,你不必手写
框架已经构建,里面有封装的程序。爬虫文件和管道需要重写,下载中间件可能需要重写
使用scratch爬行数据的基本步骤
第一步是创建一个临时项目。您需要使用以下命令:scratch startproject(fixed)+project name,并且开始项目后面跟着项目名称
第二部分创建一个爬虫程序:scratch genspider(固定)+爬虫文件名+爬虫范围(域名)
执行扫描爬虫程序的命令:扫描爬虫程序文件的名称
1 创建一个scrapy项目
scrapy startproject mySpider
2 生成一个爬虫
scrapy genspider demo demo.cn
https://www.baidu.com/ --> baidu.com
https://www.douban.com/ --> douban.com
3 提取数据
完善spider 使用xpath等
4 保存数据
pipeline中保存数据
具体步骤:点击pycham下的terminal进入路径界面,根据路径依次输入CD crawler、CD 21day,然后输入D:\pycharmprojects\crawler\21day>;路径,然后创建myspider文件夹,并执行命令“scratch startproject myspider”
现在,新项目文件已成功创建,并且成功创建的文件夹显示在pycham的左侧
依次展开mysprider文件夹,将显示以下文件。打开script.cfg文件,该文件将提示自动创建该文件,其中收录最新帮助文档的地址,并告诉我们其他配置文件的来源以及如何创建它们
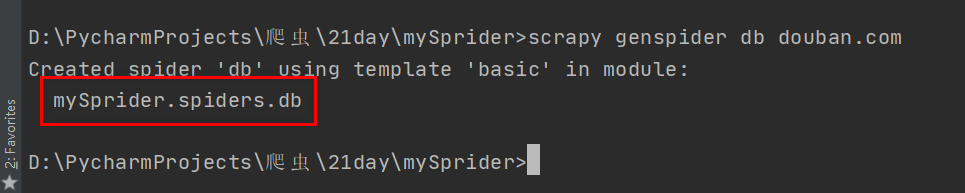
创建文件夹后,您可以通过CD myspirder输入文件夹来创建scratch genspider爬虫。在这里,首先创建豆瓣爬虫文件,scratch genspider dB
它表示已创建爬网程序文件。我们可以在myspirder和spider目录中看到创建的DB文件
在创建的DB文件中,parse函数中将有一个突出显示的提示和一个警告。在继承父类的过程中,需要修改父类,这涉及到面向对象重写和重载的概念。重写是子类重写父类的实现方法。此时返回值和形式参数不能更改,只能修改函数中的代码,不能修改头和尾,即外壳不能更改,内部的东西可以重写;重载意味着方法名相同,参数和返回值类型不同。在这里,需要重载函数,并且修改了参数的数量。有不一致之处。代码源文件中有三个参数(DEF parse(self、response、**kwargs):),只有两个。此提示不影响后续爬网和程序操作。您还可以复制源代码来替换它
此时,程序在21day文件夹下运行mysprider。如果你删除 查看全部
c爬虫抓取网页数据(异步和非阻塞的区别同步过程中的应用框架
)
scratch简介
Scrapy是一个应用程序框架,用于抓取网站数据和提取结构数据。我们只需要实现少量代码就可以快速爬行。Scrapy使用twisted异步网络框架来加快我们的下载速度
Scratch是异步爬虫的框架,是爬虫的必要技术。很少有语言有专门的爬虫框架。Python中的scratch框架专门用于crawler;使爬虫程序更加稳定和高效。sweep框架的许多内容被封装;高配置和可扩展性。在固定框架下,可以直接添加内容和调用;它是基于异步的。扭曲(扭曲)封装在内部。实现逻辑非常复杂。大量的闭包被采用。基于高阶函数(函数作为返回值或函数对象作为参数),小函数嵌套在大函数中。内部函数需要引用外部函数的变量,以确保变量的安全性,形成闭包。下载速度非常快。它是一个异步网络框架。下载的原理是基于内部封装的多线程,可以直接调用。下载效率也很高。内部封装方法可以控制爬行速度。通过修改配置项可以达到控制爬行速度的目的
异步和非阻塞的区别

在同步过程中,从上到下,只能等待蓝色函数执行,获取return,然后执行黄色函数。它就像一条管道。完成上述工作后,您只能执行以下操作
在异步过程中,蓝色函数对黄色函数没有影响。蓝色函数向网站发送请求,黄色函数可以在等待网站反馈的时间段内向另一个页面发送请求,充分利用等待时间,提高爬网效率
异步:发出调用后,调用直接返回,而不管结果如何
非阻塞:它关注等待调用结果的程序的状态,这意味着在无法立即获得结果之前,调用不会阻塞当前线程
潦草的工作流程
我们通常不只是请求一个URL来抓取多个页面。此时,我们可以在URL列表中放置多个页面。从URL列表中提取URL,向其发送请求,获取相应数据,提取数据,解析数据,保存内容等数据处理;然后对下一个URL循环执行相同的操作

有两个队列。队列1存储每个页面的URL。运行线程从队列1获取URL,发送请求,获取对应的URL,解析每个页面的数据,将解析后的数据放入队列2(如解析图片的名称和URL),然后放入下一个线程下载保存

Scratch是基于异步的。它具有很高的可配置性和可扩展性,结构特殊而复杂。引擎负责整个场景框架的调度。无论它是请求还是获得相应的信息,都必须通过引擎,这相当于人脑。第一步是将目标URL发送到引擎。引擎下面有一个爬虫程序,带有我们需要的URL地址。将URL地址发送到引擎。引擎只负责调度,下载是一个下载器;步骤2:引擎获取URL后,首先将其交给调度器,调度器接收请求的URL并列出;在列出第三个步骤后,调度器给下载程序,下载程序连接到网络以执行请求-响应操作。调度器启动请求以获取响应结果。在步骤4中,下载程序不处理响应结果。下载程序获得响应结果后,将其移交给爬虫程序进行处理。爬虫获取响应结果后,进行数据分析处理;第五步是将解析后的数据发送到管道进行处理,管道专用于保存数据。然后循环,直到调度程序中没有URL
一般工作流:引擎将找到爬虫以获取URL(可能有多个URL),通过爬虫获取URL并将其发送给调度程序。该URL列在调度器中,取出其中一个URL返回到下载器发送请求,获取相应结果,并将相应结果发送给爬虫进行解析,最后爬虫将解析后的数据保存到管道中。此进程将循环,直到计划程序中没有URL为止

1.crawler将URL发送到引擎,2.engine将URL发送到调度程序以供登录,3.scheduler将向引擎发送一个爬网URL,4.engine通过下载中间件将URL发送到下载程序。下载器获取URL后,需要在线发送请求获取相应的URL,5.downloader通过下载中间件将生成的响应发送给引擎,6.engine将接收到的响应发送给爬虫进行解析。爬虫和引擎通过爬虫中间件连接,7.爬虫通过引擎将解析后的数据发送到管道文件保存,8.通过解析后的数据,页面中可能有新的URL需要处理。继续执行上述步骤

名称函数的实现
刮擦发动机
整个框架的核心,总指挥:负责不同模块之间的数据和信号传输
Scratch已经实现
调度程序
存储引擎发送的请求、接收引擎发送的URL并执行列表操作的队列
Scratch已经实现
下载器
发送请求,获取相应的,下载引擎发送的请求,并将其返回到引擎
Scratch已经实现
爬行器(爬虫文件)
分析数据,处理引擎发送的响应,提取数据,提取URL,并将其提供给引擎
需要重写
项目管道
存储数据并处理发动机传输的数据,如存储器
需要重写
下载中间件
它位于引擎和下载器之间,用于处理请求和它们之间的通信(更多使用)。您可以自定义下载扩展,例如设置代理
一般来说,你不必手写
蜘蛛中间件
您可以自定义请求和筛选响应
一般来说,你不必手写
爬虫中间件
位于引擎和爬虫程序之间,用于处理爬虫程序的响应、输出结果和新请求(较少使用)
一般来说,你不必手写
框架已经构建,里面有封装的程序。爬虫文件和管道需要重写,下载中间件可能需要重写
使用scratch爬行数据的基本步骤
第一步是创建一个临时项目。您需要使用以下命令:scratch startproject(fixed)+project name,并且开始项目后面跟着项目名称
第二部分创建一个爬虫程序:scratch genspider(固定)+爬虫文件名+爬虫范围(域名)
执行扫描爬虫程序的命令:扫描爬虫程序文件的名称
1 创建一个scrapy项目
scrapy startproject mySpider
2 生成一个爬虫
scrapy genspider demo demo.cn
https://www.baidu.com/ --> baidu.com
https://www.douban.com/ --> douban.com
3 提取数据
完善spider 使用xpath等
4 保存数据
pipeline中保存数据
具体步骤:点击pycham下的terminal进入路径界面,根据路径依次输入CD crawler、CD 21day,然后输入D:\pycharmprojects\crawler\21day>;路径,然后创建myspider文件夹,并执行命令“scratch startproject myspider”

现在,新项目文件已成功创建,并且成功创建的文件夹显示在pycham的左侧

依次展开mysprider文件夹,将显示以下文件。打开script.cfg文件,该文件将提示自动创建该文件,其中收录最新帮助文档的地址,并告诉我们其他配置文件的来源以及如何创建它们

创建文件夹后,您可以通过CD myspirder输入文件夹来创建scratch genspider爬虫。在这里,首先创建豆瓣爬虫文件,scratch genspider dB
它表示已创建爬网程序文件。我们可以在myspirder和spider目录中看到创建的DB文件

在创建的DB文件中,parse函数中将有一个突出显示的提示和一个警告。在继承父类的过程中,需要修改父类,这涉及到面向对象重写和重载的概念。重写是子类重写父类的实现方法。此时返回值和形式参数不能更改,只能修改函数中的代码,不能修改头和尾,即外壳不能更改,内部的东西可以重写;重载意味着方法名相同,参数和返回值类型不同。在这里,需要重载函数,并且修改了参数的数量。有不一致之处。代码源文件中有三个参数(DEF parse(self、response、**kwargs):),只有两个。此提示不影响后续爬网和程序操作。您还可以复制源代码来替换它
此时,程序在21day文件夹下运行mysprider。如果你删除
c爬虫抓取网页数据(ScreamingFrogSEOSpiderforMac安装包功能特色开发工具 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-23 21:14
)
尖叫青蛙SEO蜘蛛为Mac是一个网络爬虫开发工具,专门用于捕捉URL。您可以通过尖叫青蛙Mac版快速捕捉网站可能损坏的链接。和服务器错误,或找出网站的链接,永久重定向的链接,并检查URL,网页标题,描述和内容等信息的信息中心。
安装包
功能
1、查找断开链路
累加网站并找到损坏的链接(404S)和服务器错误。批量导出的错误和进行维修源URL,或发送给开发者。
2、审查重定向
查找临时和永久重定向,识别重定向链和循环,或上传的URL列表来审查网站迁移。
3、分析页面标题和元数据
分析期间抓取过程的页面标题和meticown,并确定网站@@ķ中中,短缺,缺失或重复的内容。
4、查询重复的内容
检查完全重复URL,部分重复的元素(如页面标题,描述或标题),并查找低内容页。
5、使用XPath提取数据
使用CSS PATH,XPATH或REGEX采集来自所述网页的HTML的任何数据。这可能包括社会性标签,其他标题,价格,单品或更多!
6、审查机器人和指令
查看网址robots.txt阻止的,Yuanci或X-Robots标签,比如 'NOINDEX',或 'nofollow的',和说明书和rel = “next” 和rel = “PREV”。
7、成成X站点地图
快速创建一个XML站点地图和图像XML站点地图,这是由URL先进,包括最后的修改,优先级,和改变频率。
8、 G G欧蒂龙整合
对于捕捉功能,连接到谷歌AnalyticsAPI并获得用户数据,如会话或跳率和改造,目标,事务,收入为目标网页。
9、抓斗的JavaScript 网站
使用集成铬WRS渲染网页以捕获动态的,丰富在JavaScript 网站和框架,如角,反应,和Vue.js。
1 0、可视化位点的体系结构
强制交互式抓取和目录来强制引导件和树图现场可视化评价内部链接和URL结构。
查看全部
c爬虫抓取网页数据(ScreamingFrogSEOSpiderforMac安装包功能特色开发工具
)
尖叫青蛙SEO蜘蛛为Mac是一个网络爬虫开发工具,专门用于捕捉URL。您可以通过尖叫青蛙Mac版快速捕捉网站可能损坏的链接。和服务器错误,或找出网站的链接,永久重定向的链接,并检查URL,网页标题,描述和内容等信息的信息中心。
安装包
功能
1、查找断开链路
累加网站并找到损坏的链接(404S)和服务器错误。批量导出的错误和进行维修源URL,或发送给开发者。
2、审查重定向
查找临时和永久重定向,识别重定向链和循环,或上传的URL列表来审查网站迁移。
3、分析页面标题和元数据
分析期间抓取过程的页面标题和meticown,并确定网站@@ķ中中,短缺,缺失或重复的内容。
4、查询重复的内容
检查完全重复URL,部分重复的元素(如页面标题,描述或标题),并查找低内容页。
5、使用XPath提取数据
使用CSS PATH,XPATH或REGEX采集来自所述网页的HTML的任何数据。这可能包括社会性标签,其他标题,价格,单品或更多!
6、审查机器人和指令
查看网址robots.txt阻止的,Yuanci或X-Robots标签,比如 'NOINDEX',或 'nofollow的',和说明书和rel = “next” 和rel = “PREV”。
7、成成X站点地图
快速创建一个XML站点地图和图像XML站点地图,这是由URL先进,包括最后的修改,优先级,和改变频率。
8、 G G欧蒂龙整合
对于捕捉功能,连接到谷歌AnalyticsAPI并获得用户数据,如会话或跳率和改造,目标,事务,收入为目标网页。
9、抓斗的JavaScript 网站
使用集成铬WRS渲染网页以捕获动态的,丰富在JavaScript 网站和框架,如角,反应,和Vue.js。
1 0、可视化位点的体系结构
强制交互式抓取和目录来强制引导件和树图现场可视化评价内部链接和URL结构。
c爬虫抓取网页数据(四内容分析4.1搜索,正逢最近福建疫情再起疫情)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-09-23 21:12
一个背景
有一个最近的想法,我想获得指定时间段的新闻/ 文章信息,只需做一个情绪分析。然后,最基本的是获得文章 List。有一些与舆论相关的接口,如微博的舆论监测平台,有更多成熟的apis;阿里巴巴云,百度云也有一个舆论界面。但是,它限于某些因素或成本问题,或者API本身可以提供的新闻时间范围不符与期望,导致无法使用它。然后考虑暂时捕获一些信息以支持此工作内容。
p> 2在公开舆论检测中
监控,指关键词获取公共意见信息,包括新闻,论坛,博客,微博,微信,贴吧等,京东云的京东万象,发现是一个很好的API聚合入口。以情绪API为例,涵盖了许多服务:
实现各种服务提供商的能力,还可以通过自己的接口和合作等采集有关新闻爬网的基本信息等,良好的频道覆盖,公众舆论分析,然后再次在本地商店,并提供外部结果。简单,但涉及检索,模型的一部分仍然很困难。
三个信息源
回归主题。我们要做的第一步是选择合适的数据来源来采集文章。考虑到采集成本,使用每个搜索引擎/流量平台是一个不错的选择,因为作为流量输入,它帮助我们完成了渠道资源采集的工作。
另一方面,所有主要流平台都是爬行动物,并且对于各种爬行动物策略,如果它是大量的抓取,则更容易发现。它只是一个少量,偶尔获取信息,它只是为了学习和使用,并且不会引起太多的交通影响,因此通常不关心。有一个底线,一英寸,它非常重要!
四个内容分析4. 1搜索示例
最近,福建会开始流行病,我们将首先把它作为关键词搜搜:
结果相应链路:%E7%A6%8F%E5%BB%Ba%20%E7%96%AB%E6%83%85& rsv_spt = 1& RSV_IQID = 0xFF465A7D00029162& issp = 1& f = 8& RSV_BP = 1& rsv_idx = 2& IE = UTF-8& tn = baiduhome_pg& rsv_enter = 1& RSV_DL = IB& RSV_SUG3 = 28& rsv_sug1 = 19& RSV_SUG7 = 101& rsv_sug2 = 0& RSV_BTYPE = I&输入= 6747&amp rsv_sug4 = 11869
4. 2搜索结果内容分析
这里,我们专注于对网站结构的分析来确认分析方法。
颁发的几个搜索结果,全部:
1、标题(累计“6 + 18”,一篇文章读取福建省的现状和涂抹链,“ 查看全部
c爬虫抓取网页数据(四内容分析4.1搜索,正逢最近福建疫情再起疫情)
一个背景
有一个最近的想法,我想获得指定时间段的新闻/ 文章信息,只需做一个情绪分析。然后,最基本的是获得文章 List。有一些与舆论相关的接口,如微博的舆论监测平台,有更多成熟的apis;阿里巴巴云,百度云也有一个舆论界面。但是,它限于某些因素或成本问题,或者API本身可以提供的新闻时间范围不符与期望,导致无法使用它。然后考虑暂时捕获一些信息以支持此工作内容。
p> 2在公开舆论检测中
监控,指关键词获取公共意见信息,包括新闻,论坛,博客,微博,微信,贴吧等,京东云的京东万象,发现是一个很好的API聚合入口。以情绪API为例,涵盖了许多服务:
实现各种服务提供商的能力,还可以通过自己的接口和合作等采集有关新闻爬网的基本信息等,良好的频道覆盖,公众舆论分析,然后再次在本地商店,并提供外部结果。简单,但涉及检索,模型的一部分仍然很困难。
三个信息源
回归主题。我们要做的第一步是选择合适的数据来源来采集文章。考虑到采集成本,使用每个搜索引擎/流量平台是一个不错的选择,因为作为流量输入,它帮助我们完成了渠道资源采集的工作。
另一方面,所有主要流平台都是爬行动物,并且对于各种爬行动物策略,如果它是大量的抓取,则更容易发现。它只是一个少量,偶尔获取信息,它只是为了学习和使用,并且不会引起太多的交通影响,因此通常不关心。有一个底线,一英寸,它非常重要!
四个内容分析4. 1搜索示例
最近,福建会开始流行病,我们将首先把它作为关键词搜搜:
结果相应链路:%E7%A6%8F%E5%BB%Ba%20%E7%96%AB%E6%83%85& rsv_spt = 1& RSV_IQID = 0xFF465A7D00029162& issp = 1& f = 8& RSV_BP = 1& rsv_idx = 2& IE = UTF-8& tn = baiduhome_pg& rsv_enter = 1& RSV_DL = IB& RSV_SUG3 = 28& rsv_sug1 = 19& RSV_SUG7 = 101& rsv_sug2 = 0& RSV_BTYPE = I&输入= 6747&amp rsv_sug4 = 11869
4. 2搜索结果内容分析
这里,我们专注于对网站结构的分析来确认分析方法。
颁发的几个搜索结果,全部:
1、标题(累计“6 + 18”,一篇文章读取福建省的现状和涂抹链,“
c爬虫抓取网页数据(百度蜘蛛(baiduspider)毕业设计的部分内容的第二章)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-09-23 21:10
以下是我毕业设计的第二部分“搜索引擎的工作原理”。第一章是导言,所以你不必把它写出来。因为这是一篇论文,是邹写的
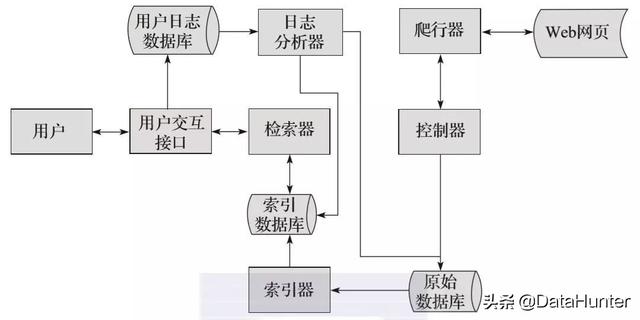
2搜索引擎的工作原理2.1搜索引擎爬虫
不同的搜索引擎对爬虫有不同的通用名称。例如,百度爬虫称它们为“百度蜘蛛”,谷歌称它们为“谷歌机器人”。爬虫的作用:互联网上有数百亿个网页。爬虫程序需要做的第一件事是将如此大量的网页数据下载到本地服务器,以形成互联网页面的镜像备份。在转移到本地后,这些页面将通过一些后续算法处理,并显示在搜索结果上
2.@1.1搜索引擎爬虫框架
一般的爬虫框架流程如下:首先从海量的互联网页面中抓取一些高质量的页面,提取其中收录的URL,并将这些URL放入要抓取的队列中。爬虫程序依次读取队列中的URL,通过DNS解析将这些URL转换为相应的网站IP地址,web Downloader通过该IP地址下载页面的所有内容
对于已下载到本地服务器的页面,一方面等待索引和后续处理;另一方面,记录这些下载的页面以避免再次被捕获
对于新下载的页面,抓取页面中收录的未从页面爬网的URL,并将其放入要爬网的队列中。在随后的爬网过程中,将下载与URL对应的页面内容。当知道要爬网的队列为空时,此循环将完成一轮爬网。如图所示:
图2-1
当然,在当今互联网信息海量的时代,爬虫通常会持续工作以确保效率
因此,从宏观的角度来看,我们可以理解,互联网的页面可以分为以下五个部分:
a) 下载网页集
b) 过期页面集合
c) 要下载的页面集合
d) 已知页面集合
e) 不可知页面集合
当然,为了保证页面质量,在上述爬虫捕获过程中涉及了很多技术手段
2.@1.2搜索引擎爬虫分类
大多数搜索引擎爬虫系统都是按照上述流程工作的,但是不同搜索引擎的爬虫会有所不同。此外,同一搜索引擎的爬虫有多种分类。按功能分类:
a) 批量爬虫
b) 强化爬行动物
c) 直立爬行动物
百度搜索引擎分为:
a) 网络搜索百度皮德尔
b) 无线搜索Baiduspider Mobile
c) 图像搜索拜杜斯皮德图像
d) 视频搜索百度派珀视频
e) 新闻搜索百度风笛新闻
f) 百度方面的青睐
g) 百度领头羊CPRO
h) 移动搜索百度+转码器
2.@1.3搜索引擎爬虫的特点
由于互联网上有大量的信息和巨大的数据,搜索引擎必须有优秀的爬虫来完成高效的爬虫过程
a) 高性能
搜索引擎爬虫的高性能主要体现在单位时间内可以下载多少网页。互联网上的网页数量浩如烟海,网页的下载速度直接关系到工作效率。另外,程序访问磁盘的操作方式也非常重要,因此高性能的数据结构对爬虫的性能也有很大的影响
b) 健壮性
因为蜘蛛需要抓取的网页数量非常多。虽然下载速度很快,但完成爬网过程仍然需要很长的周期。因此,spider系统需要能够通过增加服务器和爬虫的数量灵活地提高效率
c) 友好
爬行动物的友好性主要体现在两个方面
一方面,需要考虑网站服务器的网络负载,因为不同的服务器具有不同的性能和承载能力。如果蜘蛛在太大的压力下爬行,可能会造成类似DDoS攻击的效果,可能会影响网站的访问,所以蜘蛛爬行互联网时需要注意网站负载
另一方面,网站的隐私需要得到保护,因为不是互联网上的所有页面都允许搜索引擎蜘蛛爬行,收录是因为其他人不想被搜索引擎收录搜索,所以他们不能被其他人从互联网上搜索
通常有三种方法限制蜘蛛的爬行:
1)机器人排除协议
网站所有者在网站的根目录中制定了一个robots.txt文件,该文件描述了网站中哪些目录和页面不允许百度蜘蛛抓取
通用robots.txt文件格式如下:
用户代理:baiduspider
不允许:/wp admin/
不允许:/wp包括/
“用户代理”字段指定搜索引擎的爬网程序的目标,而“禁止”字段指定不允许爬网的目录或路径
2)robot元标记
在页面头部添加网页捕获禁止标记,以禁止收录页面。有两种形式:
此表单说明不允许搜索引擎爬虫对此页面的内容编制索引
此表单告诉爬虫程序不允许爬虫页面中收录的所有链接
2.@1.4爬虫的爬行策略
在整个爬虫系统中,要爬虫的队列是核心,因此如何确定要爬虫的队列中的URL顺序是非常重要的。除了前面提到的将新下载页面中收录的URL自动附加到队列末尾的技术外,在许多情况下,还需要使用其他技术来确定要爬网的队列中的URL顺序以及所有爬网策略,它的基本目标是一样的:优先捕获重要的网页
常用的爬虫爬行策略包括:宽度优先遍历策略、不完全PageRank策略、opic策略和大站点优先策略
2.@1.5网页更新策略
该算法的意义在于,互联网上有很多页面,更新速度很快。因此,当互联网上某个页面的内容被更新时,爬虫程序需要及时对该页面进行重新爬网,索引并将其重新显示给用户。否则,很容易看到用户在搜索引擎搜索结果列表中看到的结果与实际页面内容不一致。有三种常见的更新策略:历史参考策略、用户体验策略和集群抽样策略
a) 历史参考策略
历史参考策略在很大程度上取决于网页历史的更新频率。根据历史更新频率判断页面未来的更新时间,从而指导爬虫的工作。更新策略还根据页面的更新区域判断内容更新。例如,网站页面的导航和底部不会改变
b) 用户体验策略
顾名思义,更新策略与用户体验数据直接相关,也就是说,如果一个页面不是很重要,那么以后更新它并不重要。如何判断页面的重要性?由于搜索引擎的爬虫系统和排名系统是相对独立的,当页面质量发生变化时,其用户体验数据也会发生变化,从而导致排名的变化。从那时起,判断一个页面质量的变化,即对用户体验影响较大的页面应该更新得更快
c) 整群抽样策略
上述两种更新策略有许多局限性。为互联网的每个网页保存历史页面的成本是巨大的。此外,捕获的第一个页面没有历史数据,因此无法确定更新周期。因此,整群抽样策略解决了上述两种策略的缺点。也就是说,每个页面都根据其属性进行分类。同一类别中的页面具有相似的更新周期。因此,更新周期是根据页面的类别确定的
对于每个类别的更新周期:从其各自的类别中提取代表性页面,并根据前两种更新策略计算其更新周期
页面属性分类:动态特征和静态特征
静态特性通常是:页面内容的特性,如文本、大小、图片大小、大小、链接深度、PageRank值、页面大小等
动态特征是静态特征随时间的变化,如图片数量、字数、页面大小等
整群抽样策略看似粗糙,但在实际应用中,效果优于前两种策略
第二章:简要分析搜索引擎的索引过程 查看全部
c爬虫抓取网页数据(百度蜘蛛(baiduspider)毕业设计的部分内容的第二章)
以下是我毕业设计的第二部分“搜索引擎的工作原理”。第一章是导言,所以你不必把它写出来。因为这是一篇论文,是邹写的
2搜索引擎的工作原理2.1搜索引擎爬虫
不同的搜索引擎对爬虫有不同的通用名称。例如,百度爬虫称它们为“百度蜘蛛”,谷歌称它们为“谷歌机器人”。爬虫的作用:互联网上有数百亿个网页。爬虫程序需要做的第一件事是将如此大量的网页数据下载到本地服务器,以形成互联网页面的镜像备份。在转移到本地后,这些页面将通过一些后续算法处理,并显示在搜索结果上
2.@1.1搜索引擎爬虫框架
一般的爬虫框架流程如下:首先从海量的互联网页面中抓取一些高质量的页面,提取其中收录的URL,并将这些URL放入要抓取的队列中。爬虫程序依次读取队列中的URL,通过DNS解析将这些URL转换为相应的网站IP地址,web Downloader通过该IP地址下载页面的所有内容
对于已下载到本地服务器的页面,一方面等待索引和后续处理;另一方面,记录这些下载的页面以避免再次被捕获
对于新下载的页面,抓取页面中收录的未从页面爬网的URL,并将其放入要爬网的队列中。在随后的爬网过程中,将下载与URL对应的页面内容。当知道要爬网的队列为空时,此循环将完成一轮爬网。如图所示:
图2-1
 https://www.vuln.cn/wp-content ... 4.jpg 300w" />
https://www.vuln.cn/wp-content ... 4.jpg 300w" />当然,在当今互联网信息海量的时代,爬虫通常会持续工作以确保效率
因此,从宏观的角度来看,我们可以理解,互联网的页面可以分为以下五个部分:
a) 下载网页集
b) 过期页面集合
c) 要下载的页面集合
d) 已知页面集合
e) 不可知页面集合
当然,为了保证页面质量,在上述爬虫捕获过程中涉及了很多技术手段
2.@1.2搜索引擎爬虫分类
大多数搜索引擎爬虫系统都是按照上述流程工作的,但是不同搜索引擎的爬虫会有所不同。此外,同一搜索引擎的爬虫有多种分类。按功能分类:
a) 批量爬虫
b) 强化爬行动物
c) 直立爬行动物
百度搜索引擎分为:
a) 网络搜索百度皮德尔
b) 无线搜索Baiduspider Mobile
c) 图像搜索拜杜斯皮德图像
d) 视频搜索百度派珀视频
e) 新闻搜索百度风笛新闻
f) 百度方面的青睐
g) 百度领头羊CPRO
h) 移动搜索百度+转码器
2.@1.3搜索引擎爬虫的特点
由于互联网上有大量的信息和巨大的数据,搜索引擎必须有优秀的爬虫来完成高效的爬虫过程
a) 高性能
搜索引擎爬虫的高性能主要体现在单位时间内可以下载多少网页。互联网上的网页数量浩如烟海,网页的下载速度直接关系到工作效率。另外,程序访问磁盘的操作方式也非常重要,因此高性能的数据结构对爬虫的性能也有很大的影响
b) 健壮性
因为蜘蛛需要抓取的网页数量非常多。虽然下载速度很快,但完成爬网过程仍然需要很长的周期。因此,spider系统需要能够通过增加服务器和爬虫的数量灵活地提高效率
c) 友好
爬行动物的友好性主要体现在两个方面
一方面,需要考虑网站服务器的网络负载,因为不同的服务器具有不同的性能和承载能力。如果蜘蛛在太大的压力下爬行,可能会造成类似DDoS攻击的效果,可能会影响网站的访问,所以蜘蛛爬行互联网时需要注意网站负载
另一方面,网站的隐私需要得到保护,因为不是互联网上的所有页面都允许搜索引擎蜘蛛爬行,收录是因为其他人不想被搜索引擎收录搜索,所以他们不能被其他人从互联网上搜索
通常有三种方法限制蜘蛛的爬行:
1)机器人排除协议
网站所有者在网站的根目录中制定了一个robots.txt文件,该文件描述了网站中哪些目录和页面不允许百度蜘蛛抓取
通用robots.txt文件格式如下:
用户代理:baiduspider
不允许:/wp admin/
不允许:/wp包括/
“用户代理”字段指定搜索引擎的爬网程序的目标,而“禁止”字段指定不允许爬网的目录或路径
2)robot元标记
在页面头部添加网页捕获禁止标记,以禁止收录页面。有两种形式:
此表单说明不允许搜索引擎爬虫对此页面的内容编制索引
此表单告诉爬虫程序不允许爬虫页面中收录的所有链接
2.@1.4爬虫的爬行策略
在整个爬虫系统中,要爬虫的队列是核心,因此如何确定要爬虫的队列中的URL顺序是非常重要的。除了前面提到的将新下载页面中收录的URL自动附加到队列末尾的技术外,在许多情况下,还需要使用其他技术来确定要爬网的队列中的URL顺序以及所有爬网策略,它的基本目标是一样的:优先捕获重要的网页
常用的爬虫爬行策略包括:宽度优先遍历策略、不完全PageRank策略、opic策略和大站点优先策略
2.@1.5网页更新策略
该算法的意义在于,互联网上有很多页面,更新速度很快。因此,当互联网上某个页面的内容被更新时,爬虫程序需要及时对该页面进行重新爬网,索引并将其重新显示给用户。否则,很容易看到用户在搜索引擎搜索结果列表中看到的结果与实际页面内容不一致。有三种常见的更新策略:历史参考策略、用户体验策略和集群抽样策略
a) 历史参考策略
历史参考策略在很大程度上取决于网页历史的更新频率。根据历史更新频率判断页面未来的更新时间,从而指导爬虫的工作。更新策略还根据页面的更新区域判断内容更新。例如,网站页面的导航和底部不会改变
b) 用户体验策略
顾名思义,更新策略与用户体验数据直接相关,也就是说,如果一个页面不是很重要,那么以后更新它并不重要。如何判断页面的重要性?由于搜索引擎的爬虫系统和排名系统是相对独立的,当页面质量发生变化时,其用户体验数据也会发生变化,从而导致排名的变化。从那时起,判断一个页面质量的变化,即对用户体验影响较大的页面应该更新得更快
c) 整群抽样策略
上述两种更新策略有许多局限性。为互联网的每个网页保存历史页面的成本是巨大的。此外,捕获的第一个页面没有历史数据,因此无法确定更新周期。因此,整群抽样策略解决了上述两种策略的缺点。也就是说,每个页面都根据其属性进行分类。同一类别中的页面具有相似的更新周期。因此,更新周期是根据页面的类别确定的
对于每个类别的更新周期:从其各自的类别中提取代表性页面,并根据前两种更新策略计算其更新周期
页面属性分类:动态特征和静态特征
静态特性通常是:页面内容的特性,如文本、大小、图片大小、大小、链接深度、PageRank值、页面大小等
动态特征是静态特征随时间的变化,如图片数量、字数、页面大小等
整群抽样策略看似粗糙,但在实际应用中,效果优于前两种策略
第二章:简要分析搜索引擎的索引过程
c爬虫抓取网页数据(执行capyxpath,获取标题元素在当前父节点的xpath执行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-09-23 15:08
前言
谁写的爬行动物和网页知道,在定位上,XPath的道路上获得了大量的时间,有时后爬虫框架是成熟的人,它基本上是页面的解析。
在没有这些辅助工具的日子里,我们只能找到一些ID通过搜索HTML源代码,非常麻烦,而且常常错误找到相应的位置。
共享Chrome浏览器
的小技巧
例如,现在我们正在抓住博客园首页文章的XPath路径
打开显影剂工具,标题元件上,右按钮“CAPY得到的XPath。
执行CAPY的XPath,得到标题元件的XPath
当前父节点的
//*[@id="post_list"]/div[1]/div[2]/h3/a
执行CAPY完整的XPath,得到充分的XPath
在HTML文档中
/html/body/div[1]/div[4]/div[6]/div[1]/div[2]/h3/a
我觉得这是不够方便,毕竟,你不能查看它瞬间。因此,我们需要这个开源爬虫!
的xpath辅助
的XPath助手插件是一个免费的Chrome爬虫幅解析工具。
可以帮助用户解决问题时,他们得到的XPath路径。
该插件可以帮助您提取您通过按Shift键按下Shift键要查看的页面元素的代码,你可以编辑查询,编辑结果框中的结果会立即显示该代码旁边。
的xpath调试
安装的XPath助手后,让我们把握文章 XPath的路径在博客园的主页。
这可以在输入文本框调试,并且将提取的结果将被显示在结果文本框旁边。
当然,这也是对我的Chrome浏览器的一个插件! 查看全部
c爬虫抓取网页数据(执行capyxpath,获取标题元素在当前父节点的xpath执行)
前言
谁写的爬行动物和网页知道,在定位上,XPath的道路上获得了大量的时间,有时后爬虫框架是成熟的人,它基本上是页面的解析。
在没有这些辅助工具的日子里,我们只能找到一些ID通过搜索HTML源代码,非常麻烦,而且常常错误找到相应的位置。
共享Chrome浏览器
的小技巧
例如,现在我们正在抓住博客园首页文章的XPath路径
打开显影剂工具,标题元件上,右按钮“CAPY得到的XPath。
执行CAPY的XPath,得到标题元件的XPath
当前父节点的
//*[@id="post_list"]/div[1]/div[2]/h3/a
执行CAPY完整的XPath,得到充分的XPath
在HTML文档中
/html/body/div[1]/div[4]/div[6]/div[1]/div[2]/h3/a
我觉得这是不够方便,毕竟,你不能查看它瞬间。因此,我们需要这个开源爬虫!
的xpath辅助
的XPath助手插件是一个免费的Chrome爬虫幅解析工具。
可以帮助用户解决问题时,他们得到的XPath路径。
该插件可以帮助您提取您通过按Shift键按下Shift键要查看的页面元素的代码,你可以编辑查询,编辑结果框中的结果会立即显示该代码旁边。
的xpath调试
安装的XPath助手后,让我们把握文章 XPath的路径在博客园的主页。
这可以在输入文本框调试,并且将提取的结果将被显示在结果文本框旁边。
当然,这也是对我的Chrome浏览器的一个插件!
c爬虫抓取网页数据(前段时间写了爬取美团商家信息的博客爬虫抓取美团网上)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-09-20 22:02
前段时间,我写了一篇关于抓取美团商业信息的博客。爬虫会抓取美团所有的商业信息。这一次,我说的是爬行糯米。由于某些原因,我无法提供源代码。然而,代码不是关键,关键是思想。理解了这个思想之后,代码就很容易编写了
对于爬虫来说,最重要的是根据实际的请求过程分析请求过程和请求数据
分析是否需要处理cookie。有些网站是严格的。从某些接口请求数据时需要cookie。获取cookies的链接通常是主页。通常,系统将有一个jsessionid来维护会话。由于您访问一个页面,服务器将向您返回此jsessionid,但是如果您访问一些没有此cookie的接口,服务器将不会向您返回数据。您可以看到我之前写的关于使用Python对12306以上的所有车次数据进行爬网的内容。爬行12306时需要处理Cookie
分析网站的请求限制,因为爬虫程序将增加其服务器压力、流量浪费和数据丢失。因此,许多网站将对请求数量进行限制。然而,由于他们的数据是开放的,他们可以爬行。这只是成本问题。一般来说,他们会根据IP限制请求,当请求达到一定次数时会有一个验证码。例如,攀爬天眼检查数据时会遇到此问题。你可以使用代理。现在获得代理既容易又便宜
是否通过Ajax加载网站分析的数据,返回的数据是否加密。通常,这种情况可以由没有界面的浏览器请求,浏览器将自行处理这些事情
抓取页面并解析所需数据更容易。页面已被捕获。您可以使用一些开源框架来解析页面中的数据,也可以使用常规框架
下面分析如何在线获取糯米数据
经过分析,发现糯米不需要处理cookies,没有Ajax加载,并且有请求限制,所以只需要使用代理
我们现在分析如何抓取所有数据
从链接中,我们可以猜测北京是北京,364是火锅的分类,307-1388是区域。提前采集这些数据,爬行回来时直接拼接,方便快捷
我在这里只对城市进行分类,而不是地区,所以当我们攀登时,地区和商业区需要被处理。我们可以先拼接城市和分类,然后获得区/县
然后遍历各区县,得到商圈,再遍历,最后得到团购数据
# 区/县
def getArea(cityUrl,cityName,type,subType,subTypeCode):
url=cityUrl+"/"+subTypeCode
soup=download_soup_waitting(url)
try:
geo_filter_wrapper=soup.find("div",attrs={"class":"filterDistrict"})
J_filter_list=geo_filter_wrapper.find("div",attrs={"class":"district-list-ab"})
lis=J_filter_list.findAll("a")
for li in lis :
# a=li.find("a")
url='http:'+li['href']
area=li.text
getSubArea(url,area,cityName,type,subType)
except:
getBusiness(url,"","",cityName,type,subType)
# 商圈
def getSubArea(url,area,cityName,type,subType):
soup=download_soup_waitting(url)
geo_filter_wrapper=soup.find("div",attrs={"class":"district-sub-list-ab"})
if geo_filter_wrapper==None:
getBusiness(url,"",area,cityName,type,subType)
return
lis=geo_filter_wrapper.findAll("a")[1:]
for li in lis :
# a=li.find("a")
url=li['href']
subArea=li.text
getBusiness("http:"+url,subArea,area,cityName,type,subType)
现在我们来分析团购信息
可以发现,这不是一个商户,而是一个集团购买的商品,表明这些集团购买的许多商品都是同一个商户。我们把它分为两层,因为这一层依次是一个城市和一个类别。但是,没有通过团购获取商户信息的订单
爬上这一层后,结果如下
我们无法在这一层获得有关商户的更多详细信息,但我们可以通过此团购链接获得更多详细信息。我们将整理这些团购链接,然后在第二层爬行
这是我们需要的数据,但在实际爬网过程中发现捕获的页面没有这些数据。您可以猜测它是通过Ajax加载的
现在打开firebug并刷新页面
我发现这和我的猜测是一样的。这些数据是通过Ajax加载的。检查链接,发现只要交易成功,就可以拼接链接
最后,只需解析并保存捕获的数据
在分析整个过程并编写代码后,可以让程序缓慢运行。我的数据运行了一个月才有结果。然后整理数据。最终数据如下:
453792糯米食品数据
149002糯米寿命数据
糯米娱乐74932条数据
诺米美容73123条数据
数据总数为750849
时间:20170404
有关技术问题或此数据,请联系Zhenpeng_#Lin#替换为@ 查看全部
c爬虫抓取网页数据(前段时间写了爬取美团商家信息的博客爬虫抓取美团网上)
前段时间,我写了一篇关于抓取美团商业信息的博客。爬虫会抓取美团所有的商业信息。这一次,我说的是爬行糯米。由于某些原因,我无法提供源代码。然而,代码不是关键,关键是思想。理解了这个思想之后,代码就很容易编写了
对于爬虫来说,最重要的是根据实际的请求过程分析请求过程和请求数据
分析是否需要处理cookie。有些网站是严格的。从某些接口请求数据时需要cookie。获取cookies的链接通常是主页。通常,系统将有一个jsessionid来维护会话。由于您访问一个页面,服务器将向您返回此jsessionid,但是如果您访问一些没有此cookie的接口,服务器将不会向您返回数据。您可以看到我之前写的关于使用Python对12306以上的所有车次数据进行爬网的内容。爬行12306时需要处理Cookie
分析网站的请求限制,因为爬虫程序将增加其服务器压力、流量浪费和数据丢失。因此,许多网站将对请求数量进行限制。然而,由于他们的数据是开放的,他们可以爬行。这只是成本问题。一般来说,他们会根据IP限制请求,当请求达到一定次数时会有一个验证码。例如,攀爬天眼检查数据时会遇到此问题。你可以使用代理。现在获得代理既容易又便宜
是否通过Ajax加载网站分析的数据,返回的数据是否加密。通常,这种情况可以由没有界面的浏览器请求,浏览器将自行处理这些事情
抓取页面并解析所需数据更容易。页面已被捕获。您可以使用一些开源框架来解析页面中的数据,也可以使用常规框架
下面分析如何在线获取糯米数据
经过分析,发现糯米不需要处理cookies,没有Ajax加载,并且有请求限制,所以只需要使用代理
我们现在分析如何抓取所有数据
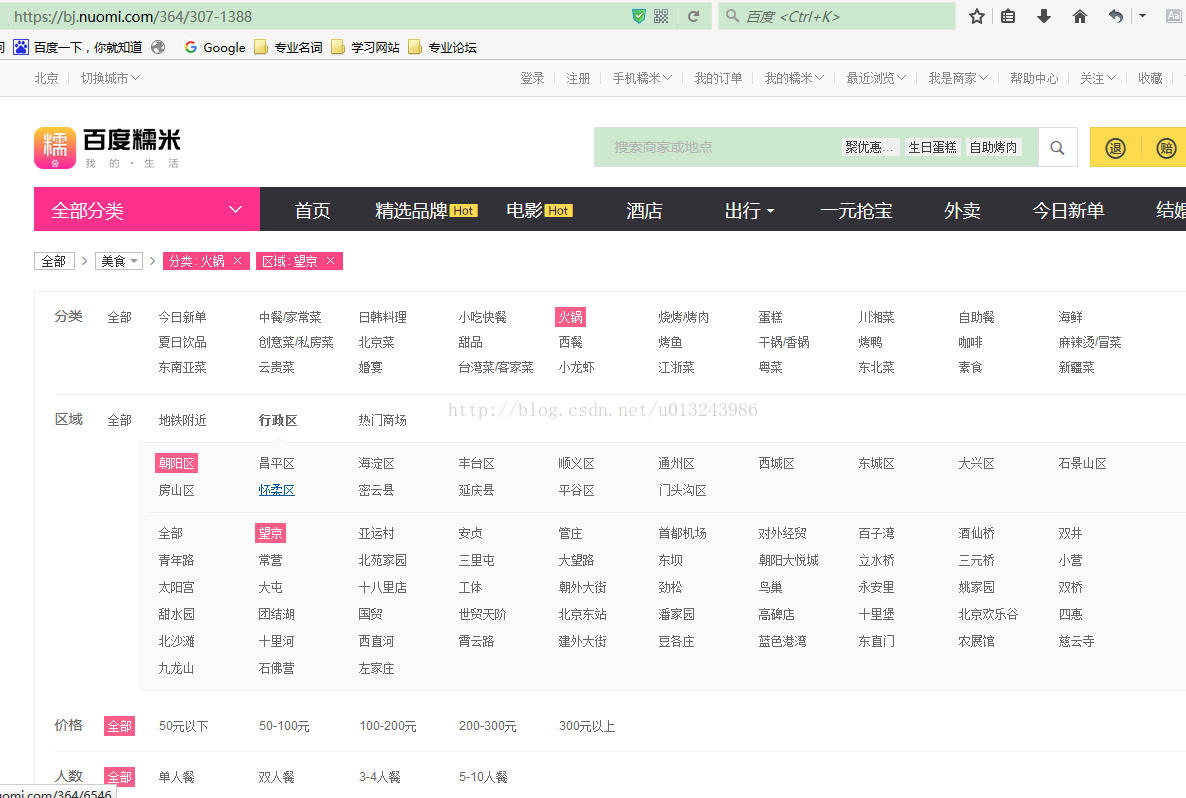
从链接中,我们可以猜测北京是北京,364是火锅的分类,307-1388是区域。提前采集这些数据,爬行回来时直接拼接,方便快捷
我在这里只对城市进行分类,而不是地区,所以当我们攀登时,地区和商业区需要被处理。我们可以先拼接城市和分类,然后获得区/县
然后遍历各区县,得到商圈,再遍历,最后得到团购数据
# 区/县
def getArea(cityUrl,cityName,type,subType,subTypeCode):
url=cityUrl+"/"+subTypeCode
soup=download_soup_waitting(url)
try:
geo_filter_wrapper=soup.find("div",attrs={"class":"filterDistrict"})
J_filter_list=geo_filter_wrapper.find("div",attrs={"class":"district-list-ab"})
lis=J_filter_list.findAll("a")
for li in lis :
# a=li.find("a")
url='http:'+li['href']
area=li.text
getSubArea(url,area,cityName,type,subType)
except:
getBusiness(url,"","",cityName,type,subType)
# 商圈
def getSubArea(url,area,cityName,type,subType):
soup=download_soup_waitting(url)
geo_filter_wrapper=soup.find("div",attrs={"class":"district-sub-list-ab"})
if geo_filter_wrapper==None:
getBusiness(url,"",area,cityName,type,subType)
return
lis=geo_filter_wrapper.findAll("a")[1:]
for li in lis :
# a=li.find("a")
url=li['href']
subArea=li.text
getBusiness("http:"+url,subArea,area,cityName,type,subType)
现在我们来分析团购信息

可以发现,这不是一个商户,而是一个集团购买的商品,表明这些集团购买的许多商品都是同一个商户。我们把它分为两层,因为这一层依次是一个城市和一个类别。但是,没有通过团购获取商户信息的订单
爬上这一层后,结果如下
我们无法在这一层获得有关商户的更多详细信息,但我们可以通过此团购链接获得更多详细信息。我们将整理这些团购链接,然后在第二层爬行
这是我们需要的数据,但在实际爬网过程中发现捕获的页面没有这些数据。您可以猜测它是通过Ajax加载的
现在打开firebug并刷新页面
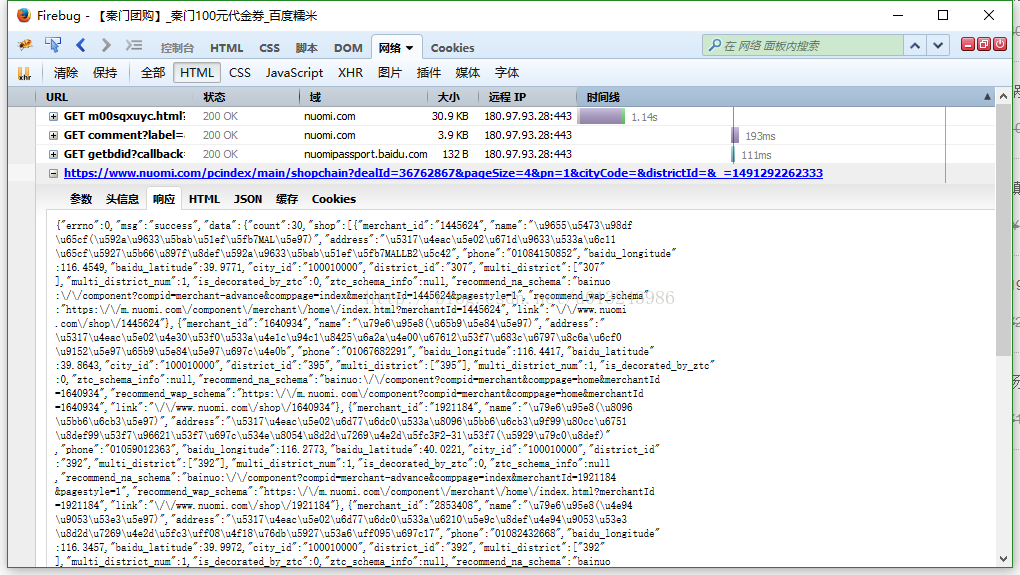
我发现这和我的猜测是一样的。这些数据是通过Ajax加载的。检查链接,发现只要交易成功,就可以拼接链接
最后,只需解析并保存捕获的数据
在分析整个过程并编写代码后,可以让程序缓慢运行。我的数据运行了一个月才有结果。然后整理数据。最终数据如下:
453792糯米食品数据
149002糯米寿命数据
糯米娱乐74932条数据
诺米美容73123条数据
数据总数为750849
时间:20170404
有关技术问题或此数据,请联系Zhenpeng_#Lin#替换为@
c爬虫抓取网页数据(Scraoy入门实例一--Scrapy介绍与安装ampamp的安装)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-09-20 22:00
scraoy示例1介绍——scrapy&;安装pycharm&;项目实践
一、Scrapy安装
1.Scrapy导言
Scrapy是一个应用程序框架,用于抓取网站数据和提取结构数据。它可以应用于一系列程序中,包括数据挖掘、信息处理或存储历史数据。它最初设计用于页面爬行(更具体地说,web爬行),也可以用于获取API(如Amazon Associates web services)或通用web爬行器返回的数据
2.Scrapy装置
建议Anaconda安装slapy
Anaconda是一个开源软件包和环境管理工件。Anaconda包括180多个科学包及其依赖项,包括CONDA和python。从官网下载并安装Anaconda(个人版),选择根据自己的系统下载并安装,选择“下一步”继续安装,选择“仅为我安装”选项,选择安装位置后等待安装完成
安装完成后,打开命令行,输入CONDA install sweep,然后根据提示按y下载所有scrapy及其相关软件包,从而完成安装
注意:使用命令行安装sweep包时,将出现下载超时,即下载失败。我们可以通过修改扫描包的图像文件来提高其下载速度。请参阅博客:
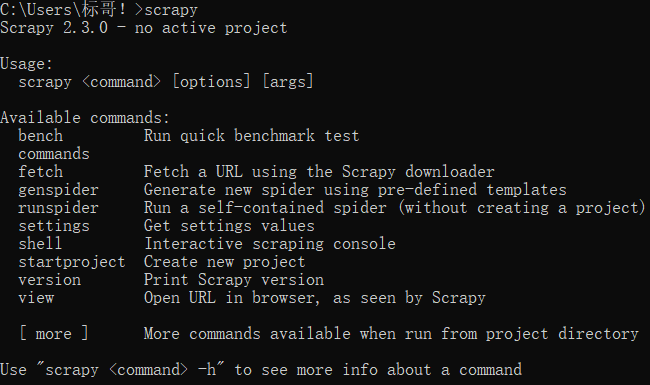
此时,测试scratch的安装是否成功:在命令行窗口中输入scratch。如果显示以下界面,则安装成功:
二、PyCharm安装
1.PyCharm导言
Pycharm是一个python ide,它有一套工具可以帮助用户在使用python语言开发时提高效率,如调试、语法突出显示、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制。此外,IDE还提供了一些高级功能来支持Django框架下的专业web开发
2.PyCharm装置
进入pycharm官网,直接点击下载即可下载。专业版在左边,社区版在右边。社区版免费,专业版免费试用
如果之前没有下载过Python解释器,可以在等待安装时下载Python解释器,进入Python官网,根据系统和版本下载相应的压缩包。安装后,在环境变量path中配置Python解释器的安装路径。请参阅博客:
三、Scrapy抓豆瓣工程实战
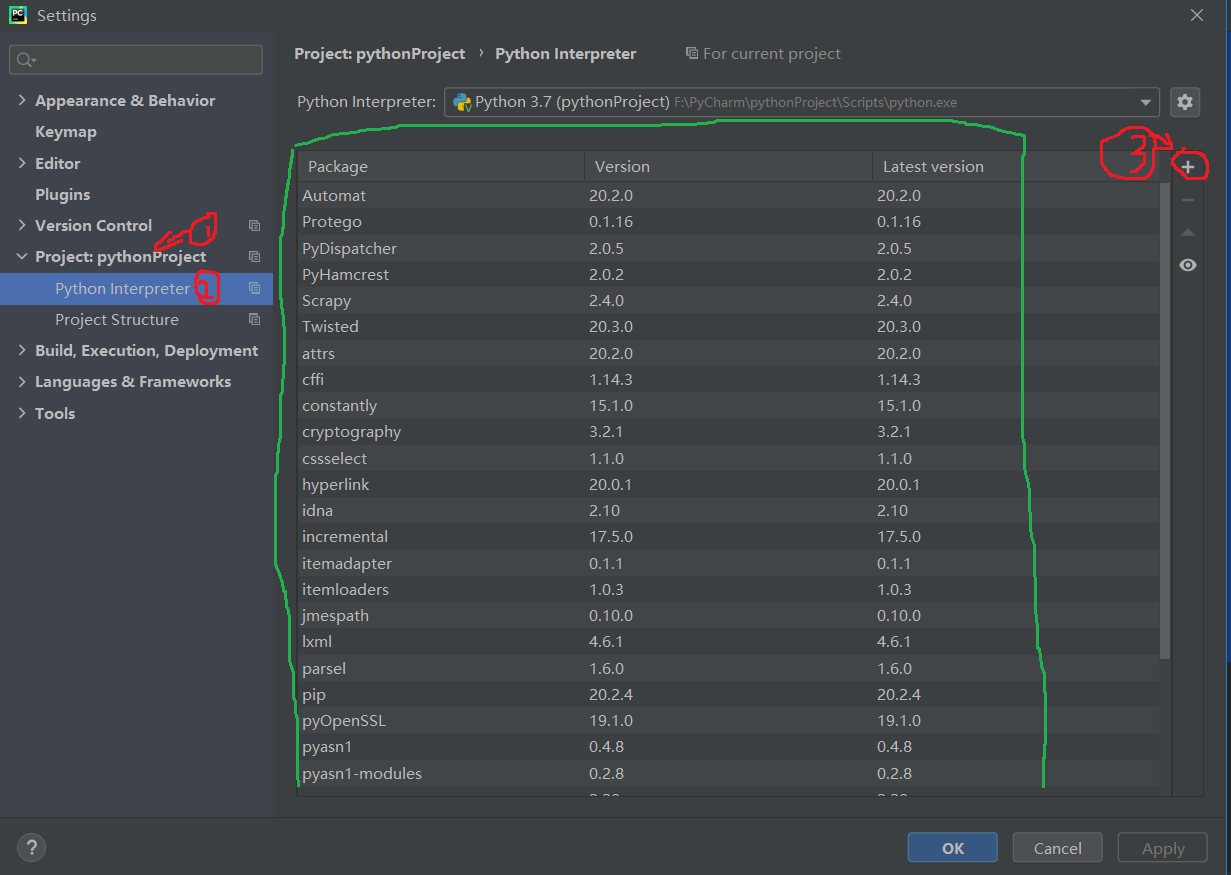
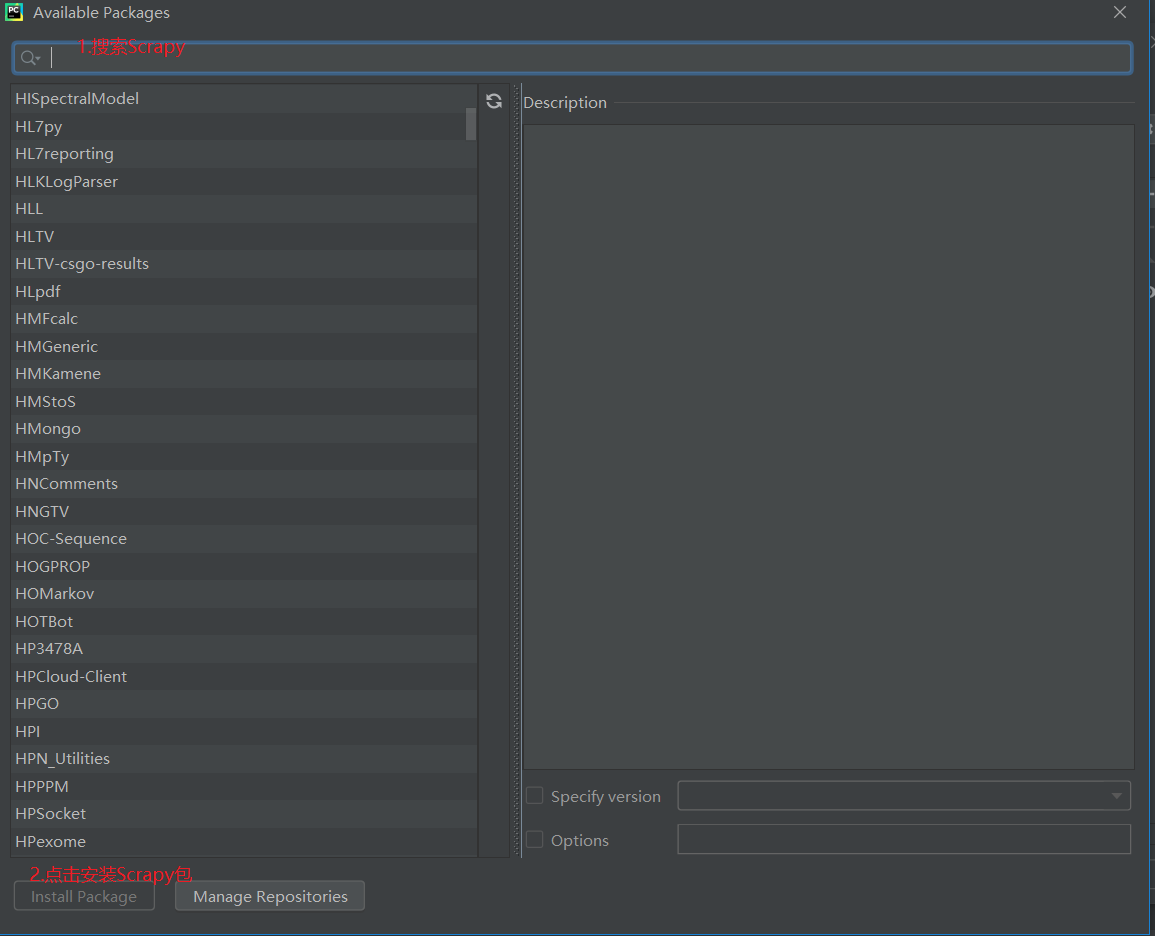
前提:如果要在pycharm中使用scripy,必须首先在pycharm中安装受支持的scripy软件包。流程如下,单击文件>>;设置步骤(设置…)如下图所示。在安装scripy之前,绿色框中只有两个软件包。如果单击并看到scripy软件包,则无需安装它。继续进行下一个操作
如果没有scripy软件包,请单击“+”搜索scripy软件包,然后单击Install package安装它
等待安装完成
1.新项目
打开新安装的pycharm并使用pycharm工具安装软件终端。如果找不到pycharm终端,只需找到左下角底部的终端即可
输入命令:scratch startproject doublan。使用命令行创建一个新的爬虫项目,如下图所示。图中所示的项目名为Python project
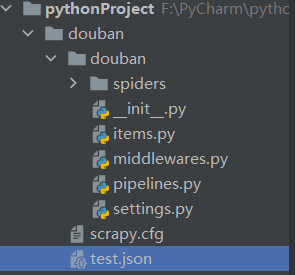
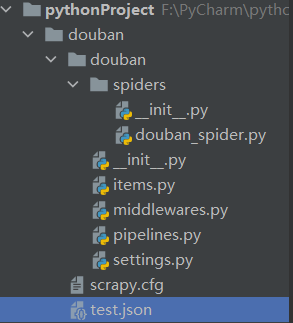
然后在命令行中输入cddoublan命令,以输入生成项目的根目录
然后继续在终端中键入命令:scratch genspider double_uu2;Spider生成一个double_u2;Spider爬虫文件
项目结构如下图所示:
2.明确目标
我们要网站做的是:
假设我们捕获了top250电影的序列号、电影名称、简介、星级、评论数量和电影描述选项
此时,我们在items.py文件中定义捕获的数据项。代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.next,我们需要制作爬虫并存储爬虫内容
在doublan_u中,spider.py爬虫文件编译特定的逻辑代码,如下所示:
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
# 允许的域名
allowed_domains = ['movie.douban.com']
# 入口URL
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//div[@class='hd']/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
此时,我们不需要运行这个Python文件,因为我们不单独使用它,所以我们不需要运行它,如果允许,将报告错误。导入、主目录的绝对路径和相对路径引入问题的原因是我们使用相对路径“.items”。有兴趣的学生可以到网上找到这些问题的解释
4.存储内容
以JSON或CSV格式存储已爬网的内容
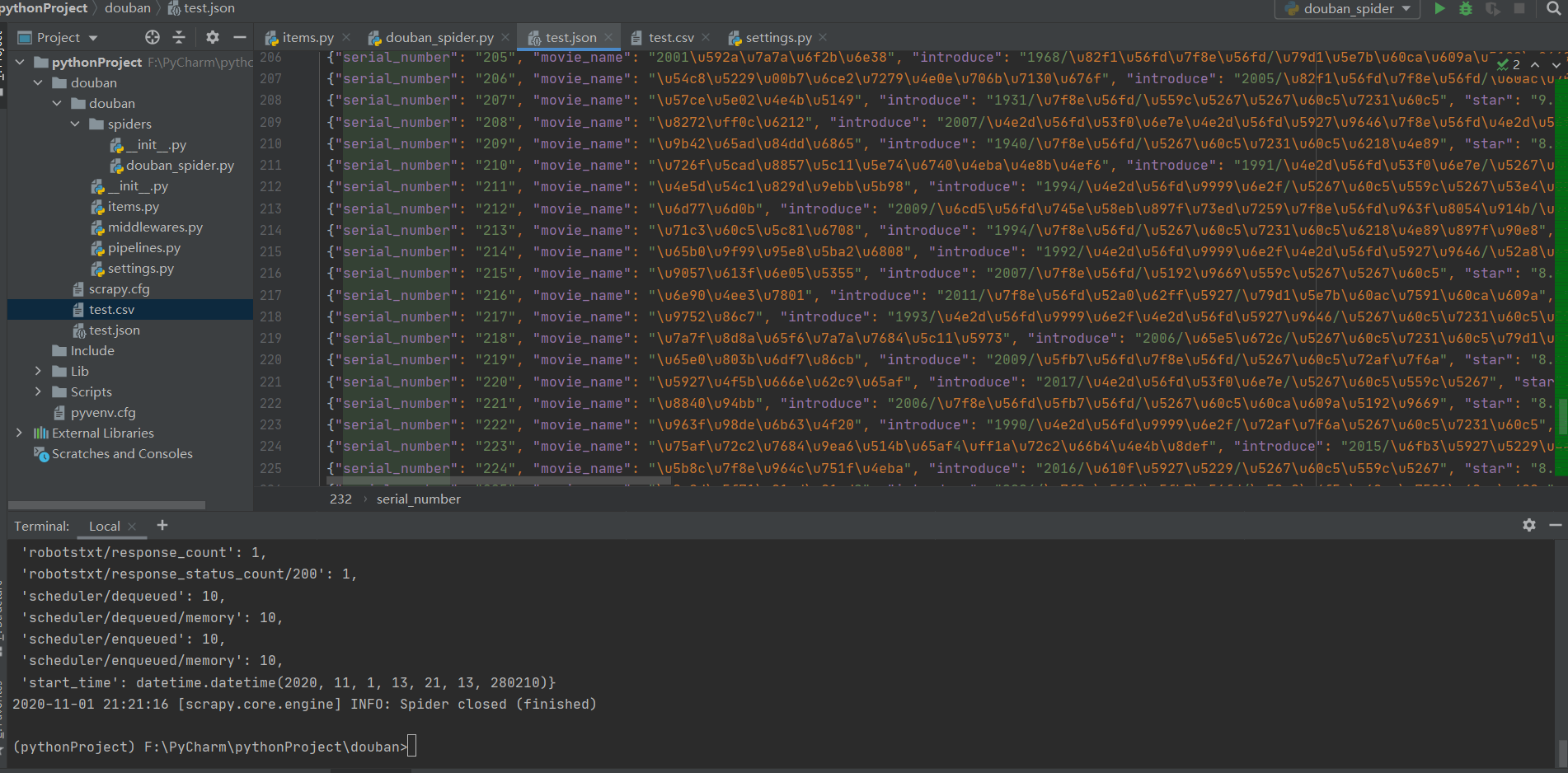
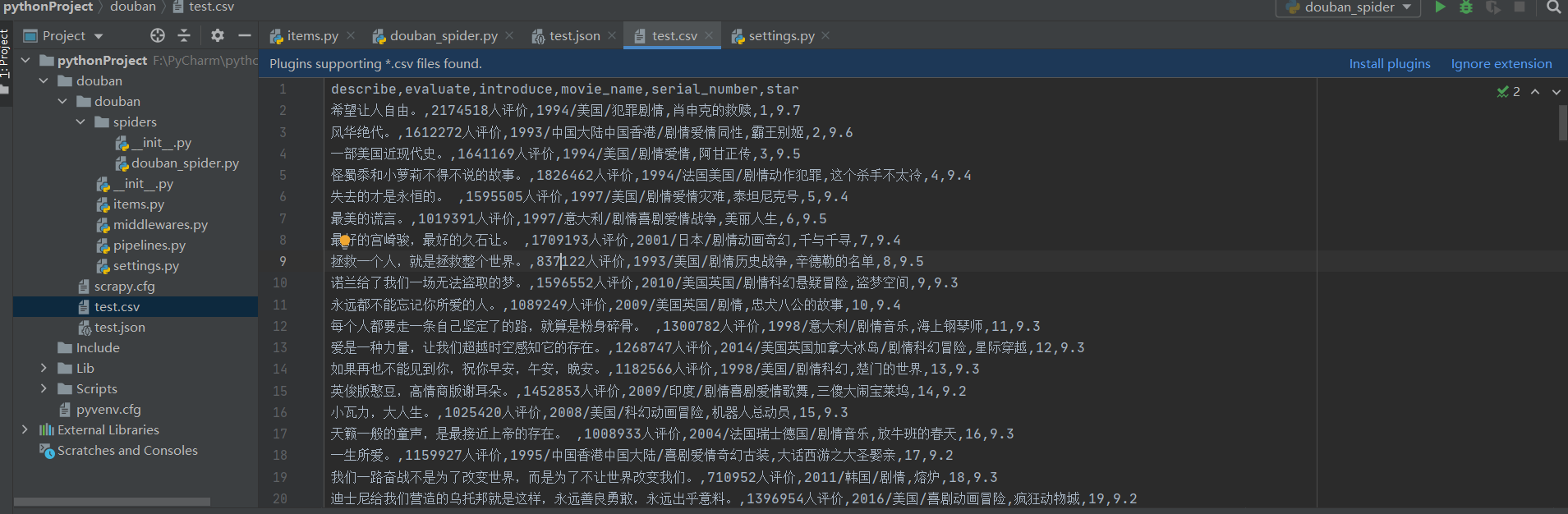
在命令行中,输入:scratch-crawl-double\uspider-O test.json或scratch-crawl-double\uspider-O test.csv
将爬网数据存储在JSON文件或CSV文件中
执行爬网命令后,当鼠标焦点位于项目面板上时,将显示born JSON文件或CSV文件。打开JSON或CSV文件后,如果其中没有任何内容,则需要修改代理的代理用户内容
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36'
如果存储在JSON文件中,所有内容都将以十六进制形式显示,并且可以通过相应的方法进行转码。此处说明不多,如下图所示:
存储在CSV文件中,我们想要爬网的所有内容将直接显示,如下图所示:
到目前为止,我们已经完成了对网站特定内容的爬网。接下来,我们需要处理爬行数据
分割线----------------------------------------------------------------------分割线
Scraoy入口示例2-使用管道实现
在这场实际的战斗中,您需要重新创建一个项目或安装scratch包。参考上述内容。创建新项目的方法也参考了上述内容,这里不再重复
项目目录结构如下图所示:
一、Pipeline导言
当我们通过spider抓取数据并通过item采集数据时,我们需要处理数据,因为我们抓取的数据不一定是我们想要的最终数据。我们可能还需要清理数据并验证数据的有效性。scripy中的管道组件用于数据处理。管道组件是收录特定接口的类。它通常只负责一个函数的数据处理。可以在一个项目中同时启用多个管道
二、定义要在items.py中获取的数据
首先,打开一个新的pychart项目,通过终端创建一个新的项目教程,并定义要在项目中捕获的数据,例如电影名称。代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、define pipeline.py文件
每个项目管道组件都是一个独立的pyhton类,必须实现流程项目(self、item、spider)方法。每个项目管道组件都需要调用此方法。此方法必须返回收录数据的dict、项对象或引发dropitem异常。后续管道组件将不会处理丢弃的项目。定义的pipelines.py代码如下:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/lat ... .html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class TutorialPipeline(object):
def process_item(self, item, spider):
return item
import time
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
now = time.strftime('%Y-%m-%d', time.localtime())
fileName = 'douban' + now + '.txt'
with open(fileName, 'a', encoding='utf-8') as fp:
fp.write(item['moiveName'][0]+"\n")
return item
四、configuring setting.py
由于这次使用管道,我们需要在settings.py中打开管道通道注释,并在管道中添加新记录,如下图所示:
五、write爬虫文件
在tutorial/Spider目录\uspider.py文件中创建引号,目录结构如下,并编写初步代码:
quotes\ spider.py代码如下:
import scrapy
from items import DoubanmovieItem
class QuotesSpider(scrapy.Spider):
name = "doubanSpider"
allowed_domains = ['douban.com']
start_urls = ['http://movie.douban.com/cinema/nowplaying',
'http://movie.douban.com/cinema/nowplaying/beijing/']
def parse(self, response):
print("--" * 20 )
#print(response.body)
print("==" * 20 )
subSelector = response.xpath('//li[@class="stitle"]')
items = []
for sub in subSelector:
#print(sub.xpath('normalize-space(./a/text())').extract())
print(sub)
item = DoubanmovieItem()
item['moiveName'] = sub.xpath('normalize-space(./a/text())').extract()
items.append(item)
print(items)
return items
六、从启动文件运行
在doublan文件目录spider uuRun.py中创建一个新的启动文件(文件名可以单独获取),运行该文件,查看结果,并按如下方式编写代码:
from scrapy import cmdline
cmdline.execute("scrapy crawl doubanSpider".split())
最后,处理后的爬网数据如下图(部分)所示:
最后,我希望您在编写代码时要小心,不要粗心大意。在我的实验过程中,这是因为要介绍的方法doublanmovieitem被编写为doublanmovieitem,这导致了整个程序的失败。此外,pycharm没有告诉我出了什么问题。我到处找,没有找到解决问题的办法。最后,我检查了很多次,只有在生成方法时才发现,所以您必须小心。此错误如下图所示。表示找不到dobanmovieitem模块。它可能告诉我错误的地方。我没有找到,因为我太好吃了,所以花了很长时间。我希望你能接受一个警告
到目前为止,用刮擦法抓取web内容并对捕获的内容进行清理和处理的实验已经完成。在这个过程中,需要熟悉和使用代码和操作,而不是查找在线内容,消化和吸收,并牢记在心。这才是真正要学的知识,不是画葫芦 查看全部
c爬虫抓取网页数据(Scraoy入门实例一--Scrapy介绍与安装ampamp的安装)
scraoy示例1介绍——scrapy&;安装pycharm&;项目实践
一、Scrapy安装
1.Scrapy导言
Scrapy是一个应用程序框架,用于抓取网站数据和提取结构数据。它可以应用于一系列程序中,包括数据挖掘、信息处理或存储历史数据。它最初设计用于页面爬行(更具体地说,web爬行),也可以用于获取API(如Amazon Associates web services)或通用web爬行器返回的数据
2.Scrapy装置
建议Anaconda安装slapy
Anaconda是一个开源软件包和环境管理工件。Anaconda包括180多个科学包及其依赖项,包括CONDA和python。从官网下载并安装Anaconda(个人版),选择根据自己的系统下载并安装,选择“下一步”继续安装,选择“仅为我安装”选项,选择安装位置后等待安装完成
安装完成后,打开命令行,输入CONDA install sweep,然后根据提示按y下载所有scrapy及其相关软件包,从而完成安装
注意:使用命令行安装sweep包时,将出现下载超时,即下载失败。我们可以通过修改扫描包的图像文件来提高其下载速度。请参阅博客:
此时,测试scratch的安装是否成功:在命令行窗口中输入scratch。如果显示以下界面,则安装成功:
二、PyCharm安装
1.PyCharm导言
Pycharm是一个python ide,它有一套工具可以帮助用户在使用python语言开发时提高效率,如调试、语法突出显示、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制。此外,IDE还提供了一些高级功能来支持Django框架下的专业web开发
2.PyCharm装置
进入pycharm官网,直接点击下载即可下载。专业版在左边,社区版在右边。社区版免费,专业版免费试用
如果之前没有下载过Python解释器,可以在等待安装时下载Python解释器,进入Python官网,根据系统和版本下载相应的压缩包。安装后,在环境变量path中配置Python解释器的安装路径。请参阅博客:
三、Scrapy抓豆瓣工程实战
前提:如果要在pycharm中使用scripy,必须首先在pycharm中安装受支持的scripy软件包。流程如下,单击文件>>;设置步骤(设置…)如下图所示。在安装scripy之前,绿色框中只有两个软件包。如果单击并看到scripy软件包,则无需安装它。继续进行下一个操作
如果没有scripy软件包,请单击“+”搜索scripy软件包,然后单击Install package安装它
等待安装完成
1.新项目
打开新安装的pycharm并使用pycharm工具安装软件终端。如果找不到pycharm终端,只需找到左下角底部的终端即可

输入命令:scratch startproject doublan。使用命令行创建一个新的爬虫项目,如下图所示。图中所示的项目名为Python project
然后在命令行中输入cddoublan命令,以输入生成项目的根目录
然后继续在终端中键入命令:scratch genspider double_uu2;Spider生成一个double_u2;Spider爬虫文件
项目结构如下图所示:
2.明确目标
我们要网站做的是:
假设我们捕获了top250电影的序列号、电影名称、简介、星级、评论数量和电影描述选项
此时,我们在items.py文件中定义捕获的数据项。代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.next,我们需要制作爬虫并存储爬虫内容
在doublan_u中,spider.py爬虫文件编译特定的逻辑代码,如下所示:
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
# 允许的域名
allowed_domains = ['movie.douban.com']
# 入口URL
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//div[@class='hd']/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
此时,我们不需要运行这个Python文件,因为我们不单独使用它,所以我们不需要运行它,如果允许,将报告错误。导入、主目录的绝对路径和相对路径引入问题的原因是我们使用相对路径“.items”。有兴趣的学生可以到网上找到这些问题的解释
4.存储内容
以JSON或CSV格式存储已爬网的内容
在命令行中,输入:scratch-crawl-double\uspider-O test.json或scratch-crawl-double\uspider-O test.csv
将爬网数据存储在JSON文件或CSV文件中
执行爬网命令后,当鼠标焦点位于项目面板上时,将显示born JSON文件或CSV文件。打开JSON或CSV文件后,如果其中没有任何内容,则需要修改代理的代理用户内容
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36'
如果存储在JSON文件中,所有内容都将以十六进制形式显示,并且可以通过相应的方法进行转码。此处说明不多,如下图所示:
存储在CSV文件中,我们想要爬网的所有内容将直接显示,如下图所示:
到目前为止,我们已经完成了对网站特定内容的爬网。接下来,我们需要处理爬行数据
分割线----------------------------------------------------------------------分割线
Scraoy入口示例2-使用管道实现
在这场实际的战斗中,您需要重新创建一个项目或安装scratch包。参考上述内容。创建新项目的方法也参考了上述内容,这里不再重复
项目目录结构如下图所示:
一、Pipeline导言
当我们通过spider抓取数据并通过item采集数据时,我们需要处理数据,因为我们抓取的数据不一定是我们想要的最终数据。我们可能还需要清理数据并验证数据的有效性。scripy中的管道组件用于数据处理。管道组件是收录特定接口的类。它通常只负责一个函数的数据处理。可以在一个项目中同时启用多个管道
二、定义要在items.py中获取的数据
首先,打开一个新的pychart项目,通过终端创建一个新的项目教程,并定义要在项目中捕获的数据,例如电影名称。代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、define pipeline.py文件
每个项目管道组件都是一个独立的pyhton类,必须实现流程项目(self、item、spider)方法。每个项目管道组件都需要调用此方法。此方法必须返回收录数据的dict、项对象或引发dropitem异常。后续管道组件将不会处理丢弃的项目。定义的pipelines.py代码如下:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/lat ... .html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class TutorialPipeline(object):
def process_item(self, item, spider):
return item
import time
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
now = time.strftime('%Y-%m-%d', time.localtime())
fileName = 'douban' + now + '.txt'
with open(fileName, 'a', encoding='utf-8') as fp:
fp.write(item['moiveName'][0]+"\n")
return item
四、configuring setting.py
由于这次使用管道,我们需要在settings.py中打开管道通道注释,并在管道中添加新记录,如下图所示:
五、write爬虫文件
在tutorial/Spider目录\uspider.py文件中创建引号,目录结构如下,并编写初步代码:
quotes\ spider.py代码如下:
import scrapy
from items import DoubanmovieItem
class QuotesSpider(scrapy.Spider):
name = "doubanSpider"
allowed_domains = ['douban.com']
start_urls = ['http://movie.douban.com/cinema/nowplaying',
'http://movie.douban.com/cinema/nowplaying/beijing/']
def parse(self, response):
print("--" * 20 )
#print(response.body)
print("==" * 20 )
subSelector = response.xpath('//li[@class="stitle"]')
items = []
for sub in subSelector:
#print(sub.xpath('normalize-space(./a/text())').extract())
print(sub)
item = DoubanmovieItem()
item['moiveName'] = sub.xpath('normalize-space(./a/text())').extract()
items.append(item)
print(items)
return items
六、从启动文件运行
在doublan文件目录spider uuRun.py中创建一个新的启动文件(文件名可以单独获取),运行该文件,查看结果,并按如下方式编写代码:
from scrapy import cmdline
cmdline.execute("scrapy crawl doubanSpider".split())
最后,处理后的爬网数据如下图(部分)所示:
最后,我希望您在编写代码时要小心,不要粗心大意。在我的实验过程中,这是因为要介绍的方法doublanmovieitem被编写为doublanmovieitem,这导致了整个程序的失败。此外,pycharm没有告诉我出了什么问题。我到处找,没有找到解决问题的办法。最后,我检查了很多次,只有在生成方法时才发现,所以您必须小心。此错误如下图所示。表示找不到dobanmovieitem模块。它可能告诉我错误的地方。我没有找到,因为我太好吃了,所以花了很长时间。我希望你能接受一个警告
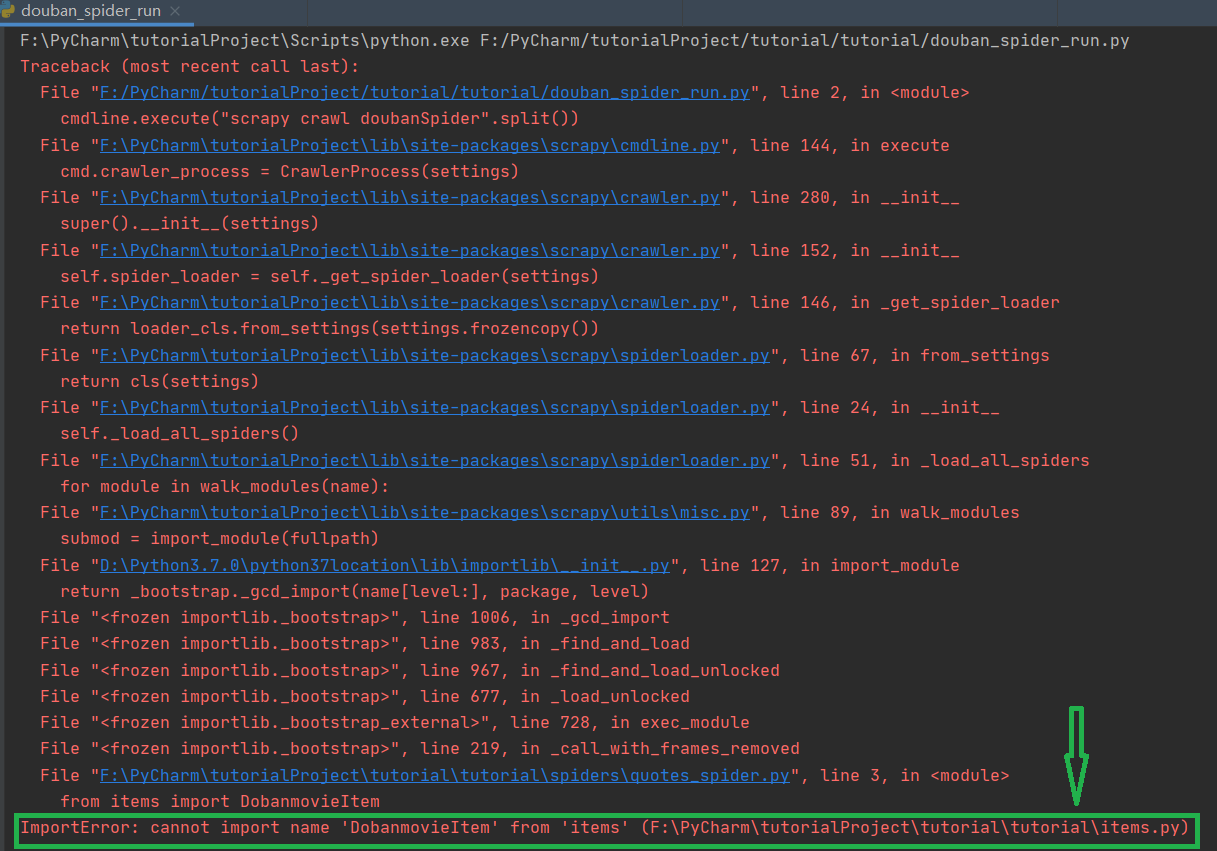
到目前为止,用刮擦法抓取web内容并对捕获的内容进行清理和处理的实验已经完成。在这个过程中,需要熟悉和使用代码和操作,而不是查找在线内容,消化和吸收,并牢记在心。这才是真正要学的知识,不是画葫芦
c爬虫抓取网页数据(利用Java模拟的一个程序,聚焦爬虫工作原理以及关键技术 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-20 21:32
)
网络爬虫网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中更常被称为网络追踪器)是一种程序或脚本,根据特定规则自动获取万维网信息
聚焦爬虫的工作原理及关键技术综述
网络爬虫是一个程序,自动提取网页。它为搜索引擎从万维网下载网页。它是搜索引擎的重要组成部分。传统的爬虫从一个或多个初始网页的URL获取初始网页上的URL。在抓取网页的过程中,它不断地从当前网页中提取新的URL并将其放入队列,直到满足系统的某些停止条件。焦点爬虫的工作流程很复杂。有必要根据特定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待捕获的URL队列中。然后,它将根据一定的搜索策略从队列中选择下一个网页URL,并重复上述过程,直到达到系统的一定条件。此外,爬虫捕获的所有网页将由系统存储、分析、过滤和索引,以便将来查询和检索;对于聚焦爬虫,在这个过程中获得的分析结果也可以为未来的抓取过程提供反馈和指导
与普通网络爬虫相比,焦点爬虫还需要解决三个主要问题:
(1)捕获目标的描述或定义
(2)网页或数据的分析和过滤
(3)URL搜索策略)
网络爬虫的实现原理
根据这一原理,编写一个简单的网络爬虫程序。该程序的功能是获取网站返回的数据并提取网址。获取的网址存储在一个文件夹中。除了提取网址,我们还可以提取我们想要的其他种类的信息,只要我们修改filte的表达式红色数据
下面是一个由java模拟的程序,用于提取新浪网页上的链接并将其存储在文件中
单击以获取信息
源代码如下:
package com.cellstrain.icell.util; import java.io.*;import java.net.*;import java.util.regex.Matcher;import java.util.regex.Pattern; /** * java实现爬虫 */public class Robot { public static void main(String[] args) { URL url = null; URLConnection urlconn = null; BufferedReader br = null; PrintWriter pw = null;// String regex = "http://[w+.?/?]+.[A-Za-z]+"; String regex = "https://[w+.?/?]+.[A-Za-z]+";//url匹配规则 Pattern p = Pattern.compile(regex); try { url = new URL("https://www.rndsystems.com/cn");//爬取的网址、这里爬取的是一个生物网站 urlconn = url.openConnection(); pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中 br = new BufferedReader(new InputStreamReader( urlconn.getInputStream())); String buf = null; while ((buf = br.readLine()) != null) { Matcher buf_m = p.matcher(buf); while (buf_m.find()) { pw.println(buf_m.group()); } } System.out.println("爬取成功^_^"); } catch (MalformedURLException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { try { br.close(); } catch (IOException e) { e.printStackTrace(); } pw.close(); } }} 查看全部
c爬虫抓取网页数据(利用Java模拟的一个程序,聚焦爬虫工作原理以及关键技术
)
网络爬虫网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中更常被称为网络追踪器)是一种程序或脚本,根据特定规则自动获取万维网信息

聚焦爬虫的工作原理及关键技术综述
网络爬虫是一个程序,自动提取网页。它为搜索引擎从万维网下载网页。它是搜索引擎的重要组成部分。传统的爬虫从一个或多个初始网页的URL获取初始网页上的URL。在抓取网页的过程中,它不断地从当前网页中提取新的URL并将其放入队列,直到满足系统的某些停止条件。焦点爬虫的工作流程很复杂。有必要根据特定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待捕获的URL队列中。然后,它将根据一定的搜索策略从队列中选择下一个网页URL,并重复上述过程,直到达到系统的一定条件。此外,爬虫捕获的所有网页将由系统存储、分析、过滤和索引,以便将来查询和检索;对于聚焦爬虫,在这个过程中获得的分析结果也可以为未来的抓取过程提供反馈和指导
与普通网络爬虫相比,焦点爬虫还需要解决三个主要问题:
(1)捕获目标的描述或定义
(2)网页或数据的分析和过滤
(3)URL搜索策略)
网络爬虫的实现原理
根据这一原理,编写一个简单的网络爬虫程序。该程序的功能是获取网站返回的数据并提取网址。获取的网址存储在一个文件夹中。除了提取网址,我们还可以提取我们想要的其他种类的信息,只要我们修改filte的表达式红色数据
下面是一个由java模拟的程序,用于提取新浪网页上的链接并将其存储在文件中
单击以获取信息
源代码如下:
package com.cellstrain.icell.util; import java.io.*;import java.net.*;import java.util.regex.Matcher;import java.util.regex.Pattern; /** * java实现爬虫 */public class Robot { public static void main(String[] args) { URL url = null; URLConnection urlconn = null; BufferedReader br = null; PrintWriter pw = null;// String regex = "http://[w+.?/?]+.[A-Za-z]+"; String regex = "https://[w+.?/?]+.[A-Za-z]+";//url匹配规则 Pattern p = Pattern.compile(regex); try { url = new URL("https://www.rndsystems.com/cn";);//爬取的网址、这里爬取的是一个生物网站 urlconn = url.openConnection(); pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中 br = new BufferedReader(new InputStreamReader( urlconn.getInputStream())); String buf = null; while ((buf = br.readLine()) != null) { Matcher buf_m = p.matcher(buf); while (buf_m.find()) { pw.println(buf_m.group()); } } System.out.println("爬取成功^_^"); } catch (MalformedURLException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { try { br.close(); } catch (IOException e) { e.printStackTrace(); } pw.close(); } }}
c爬虫抓取网页数据(Python中解析网页的基本流程及方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-09-20 07:05
)
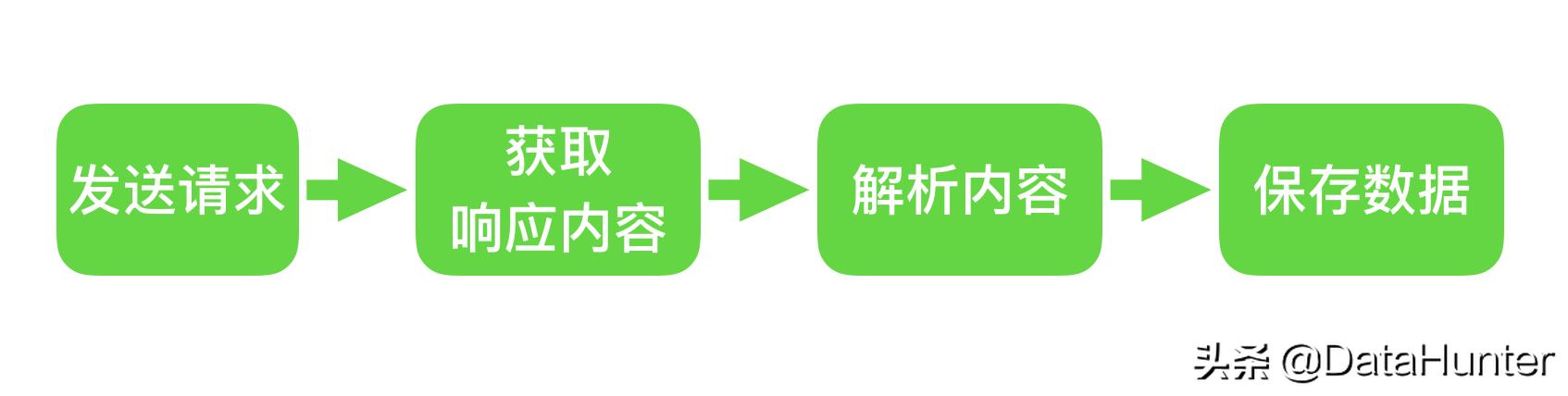
爬虫是Python的一个重要应用。使用PythonCrawler,我们可以轻松地从互联网上获取我们想要的数据
本文将以B站视频热点搜索列表数据存储为例,详细介绍Python爬虫的基本过程
PS:如果你需要Python学习材料,你可以点击下面的链接自己获取
Python免费学习资料和组通信解决方案。点击加入
如果您仍处于介绍阶段或不知道爬虫程序的具体工作流程,则应仔细阅读本文
步骤1:尝试请求
首先,进入B站主页,点击排名列表,复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动Jupiter笔记本并运行以下代码
import requests
url = 'https://www.bilibili.com/ranki ... 39%3B
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
您可以看到返回值是200,表示服务器响应正常,这意味着我们可以继续
步骤2:解析页面
在上一步中,通过请求从网站请求数据后,我们成功获得了一个收录服务器资源的响应对象。现在我们可以使用。文本以查看其内容
您可以看到返回了一个字符串,其中收录我们需要的热列表视频数据,但是直接从字符串中提取内容既复杂又低效。因此,我们需要对其进行解析,并将字符串转换为网页结构化数据,这样我们就可以轻松地找到HTML标记及其属性和内容
在Python中有许多解析网页的方法。您可以使用正则表达式、beautulsoup、pyquery或lxml。本文将基于beautulsoup进行解释
Beauty soup是一个第三方库,可以从HTML或XML文件中提取数据
安装也很简单。您可以使用PIP安装BS4来安装它
让我们用一个简单的例子来说明它是如何工作的
from bs4 import BeautifulSoup
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.text
print(title)
# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
在上面的代码中,我们通过BS4中的Beauty soup类将上一步获得的HTML格式字符串转换为Beauty soup对象。注意,使用解析器时需要开发解析器。这里使用html.parser
然后您可以得到一个结构化元素及其属性。例如,可以使用soup.title.text获取页面标题。你也可以用汤。身体,汤。P、 等,以获取任何必需的元素
步骤3:提取内容
在以上两个步骤中,我们使用请求从web页面请求数据,并使用BS4解析页面。现在我们进入最关键的一步:如何从解析的页面中提取所需的内容
在BeautifulSoup中,我们可以使用find/find_uuuAll来定位元素,但我更习惯于使用CSS选择器。选择,因为我可以访问DOM树,就像使用CSS选择元素一样
现在,让我们使用代码解释如何从解析的页面中提取站点B的热列表数据。首先,我们需要找到存储数据的标签,按列表页面上的F12键,然后根据下图中的说明找到它
您可以看到,每个视频消息都包装在class=“rank item”的Li标记下,然后代码可以写为:point\uuudown:
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
在上面的代码中,我们首先使用soup。选择('li.Rank项')。此时,我们返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取所需的字段信息,并将其以字典的形式存储在开头定义的空列表中
您可以注意到,我使用了多种选择方法来提取元素,这也是选择方法的灵活性。有兴趣的读者可以自己进一步研究
步骤4:存储数据
通过前三个步骤,我们使用requests+BS4成功地从网站提取了所需的数据。最后,我们只需将数据写入excel并保存即可
如果您不熟悉熊猫,可以使用CSV模块编写。请注意,您应该设置encoding='utf-8-sig',否则中文代码将被乱码
import csv
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果您熟悉pandas,可以轻松地将字典转换为dataframe,只需一行代码即可完成
import pandas as pd
keys = all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
总结
到目前为止,我们已经成功地使用Python在本地存储了站点B的流行视频列表数据。大多数基于请求的爬虫程序基本上遵循上述四个步骤
然而,尽管看起来很简单,但在真实场景中的每一步都不是那么容易。从数据的要求来看,目标网站有多种形式的反爬行和加密,还有很多需要在以后的数据分析、提取甚至存储中进一步探索和学习
本文选择B站的视频热点列表正是因为它足够简单。我希望通过这个案例让您了解crawler的基本流程,最后附上完整的代码
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
url = 'https://www.bilibili.com/ranki ... 39%3B
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig') 查看全部
c爬虫抓取网页数据(Python中解析网页的基本流程及方法
)
爬虫是Python的一个重要应用。使用PythonCrawler,我们可以轻松地从互联网上获取我们想要的数据
本文将以B站视频热点搜索列表数据存储为例,详细介绍Python爬虫的基本过程
PS:如果你需要Python学习材料,你可以点击下面的链接自己获取
Python免费学习资料和组通信解决方案。点击加入
如果您仍处于介绍阶段或不知道爬虫程序的具体工作流程,则应仔细阅读本文
步骤1:尝试请求
首先,进入B站主页,点击排名列表,复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动Jupiter笔记本并运行以下代码
import requests
url = 'https://www.bilibili.com/ranki ... 39%3B
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
您可以看到返回值是200,表示服务器响应正常,这意味着我们可以继续
步骤2:解析页面
在上一步中,通过请求从网站请求数据后,我们成功获得了一个收录服务器资源的响应对象。现在我们可以使用。文本以查看其内容

您可以看到返回了一个字符串,其中收录我们需要的热列表视频数据,但是直接从字符串中提取内容既复杂又低效。因此,我们需要对其进行解析,并将字符串转换为网页结构化数据,这样我们就可以轻松地找到HTML标记及其属性和内容
在Python中有许多解析网页的方法。您可以使用正则表达式、beautulsoup、pyquery或lxml。本文将基于beautulsoup进行解释
Beauty soup是一个第三方库,可以从HTML或XML文件中提取数据
安装也很简单。您可以使用PIP安装BS4来安装它
让我们用一个简单的例子来说明它是如何工作的
from bs4 import BeautifulSoup
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.text
print(title)
# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
在上面的代码中,我们通过BS4中的Beauty soup类将上一步获得的HTML格式字符串转换为Beauty soup对象。注意,使用解析器时需要开发解析器。这里使用html.parser
然后您可以得到一个结构化元素及其属性。例如,可以使用soup.title.text获取页面标题。你也可以用汤。身体,汤。P、 等,以获取任何必需的元素
步骤3:提取内容
在以上两个步骤中,我们使用请求从web页面请求数据,并使用BS4解析页面。现在我们进入最关键的一步:如何从解析的页面中提取所需的内容
在BeautifulSoup中,我们可以使用find/find_uuuAll来定位元素,但我更习惯于使用CSS选择器。选择,因为我可以访问DOM树,就像使用CSS选择元素一样
现在,让我们使用代码解释如何从解析的页面中提取站点B的热列表数据。首先,我们需要找到存储数据的标签,按列表页面上的F12键,然后根据下图中的说明找到它
您可以看到,每个视频消息都包装在class=“rank item”的Li标记下,然后代码可以写为:point\uuudown:
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
在上面的代码中,我们首先使用soup。选择('li.Rank项')。此时,我们返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取所需的字段信息,并将其以字典的形式存储在开头定义的空列表中
您可以注意到,我使用了多种选择方法来提取元素,这也是选择方法的灵活性。有兴趣的读者可以自己进一步研究
步骤4:存储数据
通过前三个步骤,我们使用requests+BS4成功地从网站提取了所需的数据。最后,我们只需将数据写入excel并保存即可
如果您不熟悉熊猫,可以使用CSV模块编写。请注意,您应该设置encoding='utf-8-sig',否则中文代码将被乱码
import csv
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果您熟悉pandas,可以轻松地将字典转换为dataframe,只需一行代码即可完成
import pandas as pd
keys = all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
总结
到目前为止,我们已经成功地使用Python在本地存储了站点B的流行视频列表数据。大多数基于请求的爬虫程序基本上遵循上述四个步骤
然而,尽管看起来很简单,但在真实场景中的每一步都不是那么容易。从数据的要求来看,目标网站有多种形式的反爬行和加密,还有很多需要在以后的数据分析、提取甚至存储中进一步探索和学习
本文选择B站的视频热点列表正是因为它足够简单。我希望通过这个案例让您了解crawler的基本流程,最后附上完整的代码
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
url = 'https://www.bilibili.com/ranki ... 39%3B
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
c爬虫抓取网页数据(爬虫在数据分析领域的应用,如何帮助我们提升数据分析质量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-09-18 10:16
在当今的信息和数字时代,人们离不开网络搜索,但想想看,你可以在搜索过程中真正获得相关信息,因为有人在帮助你过滤并向你展示相关内容
就像在餐馆里一样,你点土豆就可以吃,因为有人帮你在土豆、萝卜、西红柿等中找到土豆,然后有人把它们带到你的桌子上。在互联网上,这两个动作是由一个叫爬虫的同学实现的
换句话说,没有爬虫,今天就没有检索,也就无法准确地找到信息并有效地获取数据。今天,datahunter digital hunter将介绍crawler在数据分析领域的应用,以及它如何帮助我们提高数据分析的质量
一、在数据时代,爬虫的本质是提高效率
网络爬虫,又称网络机器人,可以代替人们自动浏览网络中的信息,并对采集和数据进行分类
这是一个程序。其基本原理是向网站/网络发送请求,获取资源,分析和提取有用数据。从技术层面来说,就是通过程序模拟浏览器请求站点的行为,爬升站点本地返回的HTML代码/JSON数据/二进制数据(图片和视频),然后提取需要的数据并存储起来使用
每个程序都有自己的规则,网络爬虫也不例外。它穿梭于世界各地的网站中心,并将根据人们强加的规则提供采集信息。我们称这些规则为网络爬虫算法。规则是由人们根据自己的目标和需要制定的。因此,根据用户的目标,爬虫可以具有不同的功能。然而,所有爬虫的本质都是为了方便人们在海量的互联网信息中找到并下载自己想要的类型,从而提高信息获取的效率
二、crawler的应用:搜索和帮助企业加强业务
1.search engine:攀爬网站,为网络用户提供便利
在网络发展之初,全球可提供的网站信息数量并不多,用户也不多。Internet只是文件传输协议(FTP)站点的集合,用户可以在其中导航以查找特定的共享文件。为了发现和整合互联网上的分布式数据,人们创建了一个称为Web Crawler/robot的自动程序,该程序可以捕获互联网上的所有网页,然后将所有网页的内容复制到数据库中进行索引。这也是最早的搜索引擎
如今,随着互联网的快速发展,我们可以在任何搜索引擎中看到来自网站世界各地的信息。百度搜索引擎的爬虫称为百度蜘蛛、360蜘蛛、搜狗蜘蛛和必应机器人。搜索引擎离不开爬虫
例如,百度蜘蛛每天都会在大量的互联网信息中爬行,以获取高质量的信息和信息收录. 当用户在百度搜索引擎上搜索对应的关键词时,百度会对关键词进行分析,从收录页面中找出相关页面,按照一定的排名规则进行排序,并将结果显示给用户。工作原理如图所示。现在,我们可以大胆地说,您每天都在免费享受爬行动物带来的好处
2.Enterprises:监控公众舆论,高效获取有价值的信息
正如我们所说,爬行动物的本质是提高效率,爬行动物的规则是由人设定的;然后企业可以根据自己的业务需求设计一个爬虫,在第一时间获取网络上的相关信息,并对其进行清理和集成
大数据时代的数据分析,首先要有数据源,网络爬虫可以让我们获得更多的数据源,进行采集,从而去除很多不相关的数据
例如,在大数据分析或数据挖掘中,数据源可以从提供数据统计的网站源以及一些文献或内部材料中获得。然而,这些获取数据的方法有时难以满足我们的数据需求。此时,我们可以利用爬虫技术从互联网上自动获取更多我们感兴趣的数据内容,从而进行更深入的数据分析,获取更多有价值的信息
此外,网络爬虫还可以用于财务分析,分析采集的财务数据,用于投资分析;应用于舆情监测分析、目标客户精准营销等领域
三、4企业常用的网络爬虫
根据实现技术和结构,网络爬虫可分为通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫等。然而,由于复杂的网络环境,实际的网络爬虫通常是这几种爬虫的组合
1.universalwebcrawler
通用网络爬虫也称为全网络爬虫。顾名思义,在整个互联网上,被抓取的目标资源是巨大的,抓取的范围也是非常大的。由于它所爬行的数据是海量数据,因此对这种爬行器的性能要求非常高。这种网络爬虫主要用于大型搜索引擎,具有很高的应用价值
通用网络爬虫主要由初始URL集、URL队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块等组成。通用网络爬虫在爬行时会采用一定的爬行策略,主要包括深度优先爬行策略和广度优先爬行策略。具体细节将在后面介绍
2.关注网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是一种根据预定义主题选择性地抓取网页的爬虫。聚焦网络爬虫主要用于抓取特定信息,并为特定类别的人提供服务
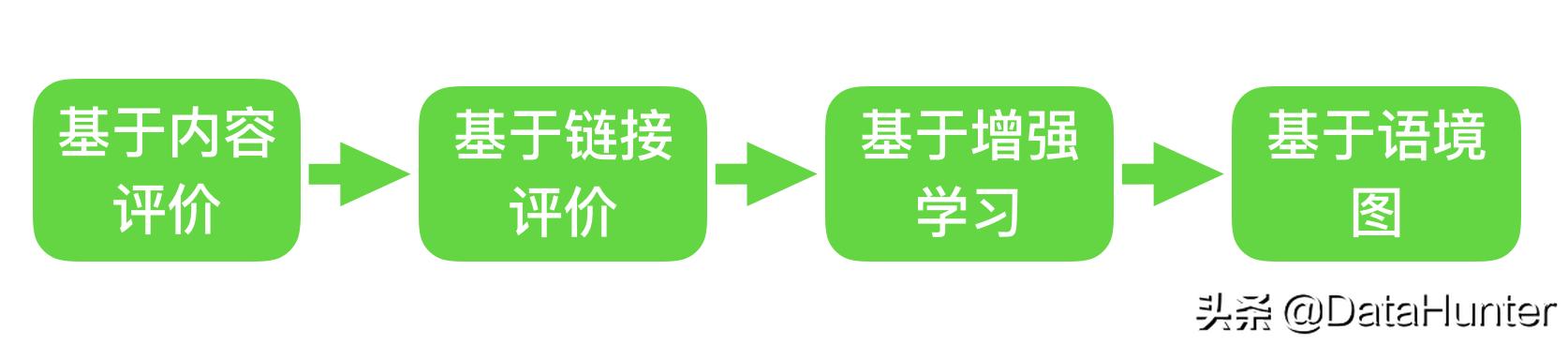
聚焦网络爬虫还包括初始URL集、URL队列、页面爬网模块、页面分析模块、页面数据库、链接过滤模块、内容评估模块、链接评估模块、,内容评估模块和链接评估模块可以根据链接和内容的重要性确定首先访问哪些页面。有四种主要的抓取策略用于关注网络爬虫,如图所示:
由于聚焦网络爬虫可以根据相应的主题有目的地进行爬网,在实际应用过程中可以节省大量的服务器资源和宽带资源,因此具有很强的实用性。这里,我们以focus网络爬虫为例,了解爬虫操作的工作原理和过程
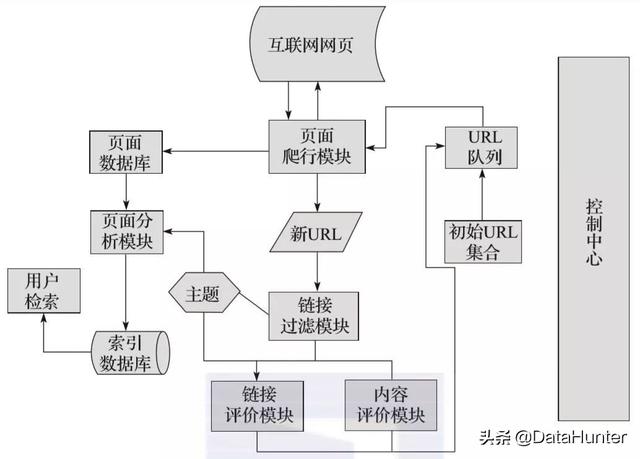
如图所示,focus web crawler有一个控制中心,负责管理和监控整个爬虫系统,主要包括控制用户交互、初始化爬虫、确定主题、协调各模块之间的工作、控制爬虫过程等
(1)control center将初始URL集合传递给URL队列,页面爬行模块将从URL队列读取第一批URL列表
(2)根据这些URL地址从互联网上抓取相应的页面;抓取后,将抓取的内容转移到页面数据库中存储
(3)在爬网过程中,会对一些新的URL进行爬网,此时需要使用链接过滤模块根据确定的主题过滤掉不相关的链接,然后使用链接评估模块或内容评估模块根据主题对剩余的URL链接进行优先级排序。完成后,新的URL地址ess将被传递到URL队列,供页面爬网模块使用
(4)抓取页面并存储在页面数据库中后,需要使用页面分析模块根据主题对抓取的页面进行分析处理,并根据处理结果建立索引数据库,当您检索到相应的信息时,可以从索引数据库中检索到,并获得相应结果
3.incremental网络爬虫
这里的“增量”对应增量更新,增量更新是指在更新过程中只更新更改的位置,而不更新未更改的位置
增量网络爬虫,在抓取网页时,只抓取内容发生变化的网页或新生成的网页,对于没有内容变化的网页,不会抓取,增量网络爬虫可以保证被抓取的网页在一定程度上尽可能的新
4.deepweb爬虫
在互联网上,网页按其存在方式可分为表层网页和深层网页。表层网页是指不提交表单就可以通过静态链接访问的静态网页;深层网页是指只有在一定数量的关键词提交后才能获得的网页。在互联网上,深层网页的数量是年龄通常比表面页面的年龄大得多
Deep web Crawler可以在Internet上抓取深度页面。要抓取深度页面,需要找到一种方法来自动填写相应的表单。Deep web Crawler主要包括URL列表和LVS列表(LVS指标记/值集,即填写表单的数据源)、爬行控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器等
四、webcrawler的爬行策略
如前所述,网络爬虫算法是为了采集信息 查看全部
c爬虫抓取网页数据(爬虫在数据分析领域的应用,如何帮助我们提升数据分析质量)
在当今的信息和数字时代,人们离不开网络搜索,但想想看,你可以在搜索过程中真正获得相关信息,因为有人在帮助你过滤并向你展示相关内容

就像在餐馆里一样,你点土豆就可以吃,因为有人帮你在土豆、萝卜、西红柿等中找到土豆,然后有人把它们带到你的桌子上。在互联网上,这两个动作是由一个叫爬虫的同学实现的
换句话说,没有爬虫,今天就没有检索,也就无法准确地找到信息并有效地获取数据。今天,datahunter digital hunter将介绍crawler在数据分析领域的应用,以及它如何帮助我们提高数据分析的质量
一、在数据时代,爬虫的本质是提高效率
网络爬虫,又称网络机器人,可以代替人们自动浏览网络中的信息,并对采集和数据进行分类
这是一个程序。其基本原理是向网站/网络发送请求,获取资源,分析和提取有用数据。从技术层面来说,就是通过程序模拟浏览器请求站点的行为,爬升站点本地返回的HTML代码/JSON数据/二进制数据(图片和视频),然后提取需要的数据并存储起来使用
每个程序都有自己的规则,网络爬虫也不例外。它穿梭于世界各地的网站中心,并将根据人们强加的规则提供采集信息。我们称这些规则为网络爬虫算法。规则是由人们根据自己的目标和需要制定的。因此,根据用户的目标,爬虫可以具有不同的功能。然而,所有爬虫的本质都是为了方便人们在海量的互联网信息中找到并下载自己想要的类型,从而提高信息获取的效率
二、crawler的应用:搜索和帮助企业加强业务
1.search engine:攀爬网站,为网络用户提供便利
在网络发展之初,全球可提供的网站信息数量并不多,用户也不多。Internet只是文件传输协议(FTP)站点的集合,用户可以在其中导航以查找特定的共享文件。为了发现和整合互联网上的分布式数据,人们创建了一个称为Web Crawler/robot的自动程序,该程序可以捕获互联网上的所有网页,然后将所有网页的内容复制到数据库中进行索引。这也是最早的搜索引擎
如今,随着互联网的快速发展,我们可以在任何搜索引擎中看到来自网站世界各地的信息。百度搜索引擎的爬虫称为百度蜘蛛、360蜘蛛、搜狗蜘蛛和必应机器人。搜索引擎离不开爬虫
例如,百度蜘蛛每天都会在大量的互联网信息中爬行,以获取高质量的信息和信息收录. 当用户在百度搜索引擎上搜索对应的关键词时,百度会对关键词进行分析,从收录页面中找出相关页面,按照一定的排名规则进行排序,并将结果显示给用户。工作原理如图所示。现在,我们可以大胆地说,您每天都在免费享受爬行动物带来的好处
2.Enterprises:监控公众舆论,高效获取有价值的信息
正如我们所说,爬行动物的本质是提高效率,爬行动物的规则是由人设定的;然后企业可以根据自己的业务需求设计一个爬虫,在第一时间获取网络上的相关信息,并对其进行清理和集成
大数据时代的数据分析,首先要有数据源,网络爬虫可以让我们获得更多的数据源,进行采集,从而去除很多不相关的数据

例如,在大数据分析或数据挖掘中,数据源可以从提供数据统计的网站源以及一些文献或内部材料中获得。然而,这些获取数据的方法有时难以满足我们的数据需求。此时,我们可以利用爬虫技术从互联网上自动获取更多我们感兴趣的数据内容,从而进行更深入的数据分析,获取更多有价值的信息
此外,网络爬虫还可以用于财务分析,分析采集的财务数据,用于投资分析;应用于舆情监测分析、目标客户精准营销等领域
三、4企业常用的网络爬虫
根据实现技术和结构,网络爬虫可分为通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫等。然而,由于复杂的网络环境,实际的网络爬虫通常是这几种爬虫的组合
1.universalwebcrawler
通用网络爬虫也称为全网络爬虫。顾名思义,在整个互联网上,被抓取的目标资源是巨大的,抓取的范围也是非常大的。由于它所爬行的数据是海量数据,因此对这种爬行器的性能要求非常高。这种网络爬虫主要用于大型搜索引擎,具有很高的应用价值

通用网络爬虫主要由初始URL集、URL队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块等组成。通用网络爬虫在爬行时会采用一定的爬行策略,主要包括深度优先爬行策略和广度优先爬行策略。具体细节将在后面介绍
2.关注网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是一种根据预定义主题选择性地抓取网页的爬虫。聚焦网络爬虫主要用于抓取特定信息,并为特定类别的人提供服务
聚焦网络爬虫还包括初始URL集、URL队列、页面爬网模块、页面分析模块、页面数据库、链接过滤模块、内容评估模块、链接评估模块、,内容评估模块和链接评估模块可以根据链接和内容的重要性确定首先访问哪些页面。有四种主要的抓取策略用于关注网络爬虫,如图所示:
由于聚焦网络爬虫可以根据相应的主题有目的地进行爬网,在实际应用过程中可以节省大量的服务器资源和宽带资源,因此具有很强的实用性。这里,我们以focus网络爬虫为例,了解爬虫操作的工作原理和过程
如图所示,focus web crawler有一个控制中心,负责管理和监控整个爬虫系统,主要包括控制用户交互、初始化爬虫、确定主题、协调各模块之间的工作、控制爬虫过程等
(1)control center将初始URL集合传递给URL队列,页面爬行模块将从URL队列读取第一批URL列表
(2)根据这些URL地址从互联网上抓取相应的页面;抓取后,将抓取的内容转移到页面数据库中存储
(3)在爬网过程中,会对一些新的URL进行爬网,此时需要使用链接过滤模块根据确定的主题过滤掉不相关的链接,然后使用链接评估模块或内容评估模块根据主题对剩余的URL链接进行优先级排序。完成后,新的URL地址ess将被传递到URL队列,供页面爬网模块使用
(4)抓取页面并存储在页面数据库中后,需要使用页面分析模块根据主题对抓取的页面进行分析处理,并根据处理结果建立索引数据库,当您检索到相应的信息时,可以从索引数据库中检索到,并获得相应结果
3.incremental网络爬虫
这里的“增量”对应增量更新,增量更新是指在更新过程中只更新更改的位置,而不更新未更改的位置
增量网络爬虫,在抓取网页时,只抓取内容发生变化的网页或新生成的网页,对于没有内容变化的网页,不会抓取,增量网络爬虫可以保证被抓取的网页在一定程度上尽可能的新
4.deepweb爬虫
在互联网上,网页按其存在方式可分为表层网页和深层网页。表层网页是指不提交表单就可以通过静态链接访问的静态网页;深层网页是指只有在一定数量的关键词提交后才能获得的网页。在互联网上,深层网页的数量是年龄通常比表面页面的年龄大得多

Deep web Crawler可以在Internet上抓取深度页面。要抓取深度页面,需要找到一种方法来自动填写相应的表单。Deep web Crawler主要包括URL列表和LVS列表(LVS指标记/值集,即填写表单的数据源)、爬行控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器等
四、webcrawler的爬行策略
如前所述,网络爬虫算法是为了采集信息
c爬虫抓取网页数据(搜索引擎就是在网上爬来爬去的蜘蛛怎样设置蜘蛛(spider))
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-14 02:13
搜索引擎用来抓取和访问页面的程序称为蜘蛛,也称为机器人如何设置蜘蛛。当搜索引擎蜘蛛访问网站页面时,它类似于使用浏览器的普通用户。蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。搜索引擎旨在提高爬行和爬行。拿速度来说,都是用多只蜘蛛来分布爬取。
蜘蛛访问网站时,首先会访问网站根目录下的robots.txt文件。如果robots.txt文件禁止搜索引擎抓取某些网页或内容,或者网站,蜘蛛会遵守协议,如何设置蜘蛛不抓取。
蜘蛛也有自己的代理名称。你可以在站长的日志中看到蜘蛛爬行的痕迹。所以很多站长在回答问题的时候,总是说先查看网站日志(作为一个优秀的SEO,你必须有能力在不借助任何软件的情况下查看网站日志,并且非常熟悉其代码的含义)如何设置蜘蛛。
一、搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛是Spider,这是一个很形象的名字。它将互联网比作蜘蛛网。那么蜘蛛就是在网上爬行的蜘蛛如何设置蜘蛛。
网络蜘蛛通过网页的链接地址搜索网页。从某个页面网站(通常是首页)开始,读取网页内容,找到网页中的其他链接地址,然后通过这些链接地址搜索下一个网页如何设置蜘蛛,以及继续循环直到所有网站 网页都被抓取。
如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页以及如何设置蜘蛛。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,爬取互联网上的所有网页几乎是不可能的。根据目前公布的数据,容量最大的搜索引擎只抓取了整个网页的 4%。如何在十点左右设置蜘蛛。
一方面是因为爬虫技术的瓶颈。 100亿个网页的容量为100×2000G字节。即使可以存储,下载还是有问题(按照一台机器每秒下载20K计算,需要340个单元。机器不停下载一年才能完成所有网页的下载。同时,由于数据量大,在提供搜索时也会影响如何设置蜘蛛的效率。
因此,很多搜索引擎的网络蜘蛛只抓取那些重要的网页,抓取时评价重要性的主要依据是如何设置蜘蛛对某个网页的链接深度。
由于无法抓取所有网页,如何设置蜘蛛,部分网络蜘蛛对一些不太重要的网站设置了访问级别数,例如如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A为起始网页,属于第0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。 如接入层数网络蜘蛛设置的是2的情况下,我的网页不会被访问,这也允许网站上的部分网页在搜索引擎上搜索到,其他部分搜索不到如何设置蜘蛛。
对于网站 设计师而言,扁平化的网站 结构设计有助于搜索引擎抓取更多网页。如何设置蜘蛛。
网络蜘蛛在访问网站网页时,经常会遇到加密数据和网络权限的问题。某些网页需要会员权限才能访问如何设置蜘蛛。
当然网站的站长可以通过协议防止网络蜘蛛爬行,但是对于一些卖报告的网站来说,他们希望搜索引擎可以搜索到他们的报告,但他们做不到完全免费。搜索者查看,因此需要向网络蜘蛛提供相应的用户名和密码。如何设置蜘蛛。
网络蜘蛛可以通过给定的权限抓取这些网页提供搜索,当搜索者点击查看网页时,搜索者还需要提供相应的权限来验证如何设置蜘蛛。
二、tracking 链接
因为搜索引擎蜘蛛可以在网络上抓取尽可能多的页面,所以它们会跟随网页上的链接从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样。这是搜索引擎蜘蛛。如何设置蜘蛛的名字来源。
整个互联网网站是由相互链接组成的,也就是说,从任何一个页面开始,搜索引擎蜘蛛最终都会爬上所有页面。如何设置蜘蛛。
搜索引擎蜘蛛的基本原理和工作流程
当然网站和页面链接结构太复杂了。如何设置蜘蛛,让蜘蛛只能通过某些方法抓取所有页面。据我了解,最简单的爬取策略有3种:
1、最佳优先级
最佳优先级搜索策略根据一定的网页分析算法预测候选网址与目标页面的相似度或与主题的相关性,选择一个或几个评价最好的网址进行抓取,只访问如何为网页分析算法预测为“有用”的网页设置蜘蛛。
一个问题是爬虫的爬取路径中很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要将最佳优先级与具体应用结合起来进行改进。为了跳出局部最优,根据研究结果,这样的闭环调整可以将不相关网页的数量减少30%到90%。
2、深度优先
深度优先是指蜘蛛沿着找到的链接向前爬行,直到没有更多的链接在它之前,然后返回第一页,沿着另一个链接爬行,然后向前爬行。如何设置蜘蛛。
3、广度优先
广度优先是指当蜘蛛在一个页面上发现多个链接时,它不会一直沿着一个链接前进,而是爬取页面上的所有链接,然后沿着第二层进入页面的第二层找到的链接爬到页面的第三层。如何设置蜘蛛。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它们就可以抓取整个互联网。
实际工作中如何设置爬虫?蜘蛛的带宽资源和时间不是无限的,也不能爬取所有页面。事实上,最大的搜索引擎只是爬取和收录互联网的一小部分。当然不是搜索引擎蜘蛛爬的越多越好,这一点
因此,为了捕捉尽可能多的用户信息,通常深度优先和广度优先混合使用,这样可以照顾到尽可能多的网站,也可以照顾到如何设置一个网站 内部页面蜘蛛的一部分。
三、搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。 “蜘蛛”这个名字描述了信息采集模块如何在网络数据形成的“Web”上设置蜘蛛进行信息采集。
一般来说,网络蜘蛛从种子网页开始,通过反复下载网页和搜索文档中看不见的网址,如何设置蜘蛛以访问其他网页和遍历网络。
并且其工作策略一般可以分为累积爬行(cumulative crawling)和增量爬行(incremental crawling)两种设置蜘蛛的方式。
1、累积爬取
累积爬取是指如何设置蜘蛛从某个时间点爬取系统允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证可以爬取相当数量的网页集合。
似乎由于网络数据的动态性,采集到的网页的时间不同,页面更新的情况也不同。因此,累积爬取所爬取的网页集合实际上与真实环境中的并不相同。网络数据与如何设置蜘蛛一致。
2、增量爬取
与累积爬取不同,增量爬取是指对具有一定规模的网页集合,采用更新数据的方式,在现有集合中选择过时的网页进行爬取,从而保证所有抓取到的数据足够接近真实的网络数据。如何设置蜘蛛。
增量爬取的前提是系统已经爬取了足够多的网页,并且有这些页面被爬取的时间信息。如何设置蜘蛛。在面向实际应用环境的网络蜘蛛设计中,通常包括累积爬取和增量爬取两种策略。
累积爬取一般用于数据集合的整体建立或大规模更新阶段,而增量爬取主要是针对数据集合的日常维护以及如何设置蜘蛛进行实时更新。
在确定爬取策略后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛操作策略的核心问题。如何设置蜘蛛。
总的来说,在合理利用软硬件资源实时采集网络数据方面,已经形成了比较成熟的技术和实用的解决方案。我认为这方面需要解决的主要问题是更好地处理动态网络数据问题(如Web2.0数据量不断增加等),以及更好地如何基于网页设置蜘蛛质量以纠正抓取策略。
四、database
为了避免重复抓取和抓取网址,如何设置蜘蛛,搜索引擎会建立一个数据库来记录已经发现没有被抓取的页面和已经被抓取的页面。那么数据库中的URL是怎么来的呢? ?
1、手动输入种子网站
简单来说,就是我们新建一个网站提交给百度、谷歌或者360之后的网址收录如何设置蜘蛛。
2、蜘蛛抓取页面
如果搜索引擎蜘蛛在爬取过程中发现了新的连接网址,但不在数据库中,则会存储在待访问的数据库中(网站测期)如何设置蜘蛛。
蜘蛛根据重要性从要访问的数据库中提取URL,访问并爬取页面,然后从要访问的地址数据库中删除该URL并将其放入已访问地址数据库中,因此建议站长访问网站 观察期间需要定期更新网站。如何设置蜘蛛。
3、站长Submitted网站
一般来说,提交网站只是将网站保存到数据库中进行访问。如果网站 Durable 不更新蜘蛛,则不会光顾。搜索引擎收录的页面都是蜘蛛通过链接获取的。如何设置蜘蛛。
所以如果你把它提交给搜索引擎,它不是很有用。稍后您仍然需要考虑您的网站 更新级别。搜索引擎更喜欢沿着链接本身发现新页面。当然,如果你的SEO技巧足够高深,并且如果你有这个能力,你可以尝试一下。可能会有意想不到的结果。不过对于一般站长来说,还是建议让蜘蛛自然爬行,爬到新的站点页面。如何设置蜘蛛。
五、吸引蜘蛛
虽然理论上说蜘蛛可以爬取所有页面,但实际上是做不到的。所以想要收录更多页面的SEO人员只能想办法引诱蜘蛛爬行以及如何设置蜘蛛。
既然我们不能抓取所有页面以及如何设置蜘蛛,那我们就得让它抓取重要页面,因为重要页面在索引中起着重要的作用,直接影响排名因素。哪些页面更重要?对此,我还专门整理了以下我认为比较重要的页面,具体有这些特点:
1、网站 和页面权重
高质量和老网站被赋予了很高的权重。这种蜘蛛在网站上的页面爬行深度比较高,所以收录如何设置蜘蛛的内页会比较多。
2、page 更新度
蜘蛛每次爬行都会存储页面数据。如果在第二次爬取时发现这个页面的内容和第一个收录完全一样,说明该页面没有更新,蜘蛛不需要频繁爬取和爬取。如何设置蜘蛛。
如果页面内容更新频繁,如何设置蜘蛛,蜘蛛会频繁爬行,那么页面上的新链接自然会被蜘蛛更快地跟踪和抓取,这就是为什么它需要每天更新文章
3、import 链接
无论是外链还是同一个网站的内链,要想被蜘蛛爬取,必须有导入链接才能进入页面,否则蜘蛛不知道怎么设置蜘蛛为页面的存在。这时候URL链接就发挥了非常重要的作用,内链的重要性就发挥出来了。
另外,我个人觉得高质量的导入链接往往会增加页面导出链接的爬取深度。如何设置蜘蛛。
这就是为什么大部分站长或者SEO都需要高质量友情链接的原因,因为蜘蛛从对方网站爬到你网站的次数很多,而且深度也很高。如何设置蜘蛛。 查看全部
c爬虫抓取网页数据(搜索引擎就是在网上爬来爬去的蜘蛛怎样设置蜘蛛(spider))
搜索引擎用来抓取和访问页面的程序称为蜘蛛,也称为机器人如何设置蜘蛛。当搜索引擎蜘蛛访问网站页面时,它类似于使用浏览器的普通用户。蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。搜索引擎旨在提高爬行和爬行。拿速度来说,都是用多只蜘蛛来分布爬取。
蜘蛛访问网站时,首先会访问网站根目录下的robots.txt文件。如果robots.txt文件禁止搜索引擎抓取某些网页或内容,或者网站,蜘蛛会遵守协议,如何设置蜘蛛不抓取。
蜘蛛也有自己的代理名称。你可以在站长的日志中看到蜘蛛爬行的痕迹。所以很多站长在回答问题的时候,总是说先查看网站日志(作为一个优秀的SEO,你必须有能力在不借助任何软件的情况下查看网站日志,并且非常熟悉其代码的含义)如何设置蜘蛛。
一、搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛是Spider,这是一个很形象的名字。它将互联网比作蜘蛛网。那么蜘蛛就是在网上爬行的蜘蛛如何设置蜘蛛。
网络蜘蛛通过网页的链接地址搜索网页。从某个页面网站(通常是首页)开始,读取网页内容,找到网页中的其他链接地址,然后通过这些链接地址搜索下一个网页如何设置蜘蛛,以及继续循环直到所有网站 网页都被抓取。
如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页以及如何设置蜘蛛。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,爬取互联网上的所有网页几乎是不可能的。根据目前公布的数据,容量最大的搜索引擎只抓取了整个网页的 4%。如何在十点左右设置蜘蛛。
一方面是因为爬虫技术的瓶颈。 100亿个网页的容量为100×2000G字节。即使可以存储,下载还是有问题(按照一台机器每秒下载20K计算,需要340个单元。机器不停下载一年才能完成所有网页的下载。同时,由于数据量大,在提供搜索时也会影响如何设置蜘蛛的效率。
因此,很多搜索引擎的网络蜘蛛只抓取那些重要的网页,抓取时评价重要性的主要依据是如何设置蜘蛛对某个网页的链接深度。
由于无法抓取所有网页,如何设置蜘蛛,部分网络蜘蛛对一些不太重要的网站设置了访问级别数,例如如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A为起始网页,属于第0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。 如接入层数网络蜘蛛设置的是2的情况下,我的网页不会被访问,这也允许网站上的部分网页在搜索引擎上搜索到,其他部分搜索不到如何设置蜘蛛。
对于网站 设计师而言,扁平化的网站 结构设计有助于搜索引擎抓取更多网页。如何设置蜘蛛。
网络蜘蛛在访问网站网页时,经常会遇到加密数据和网络权限的问题。某些网页需要会员权限才能访问如何设置蜘蛛。
当然网站的站长可以通过协议防止网络蜘蛛爬行,但是对于一些卖报告的网站来说,他们希望搜索引擎可以搜索到他们的报告,但他们做不到完全免费。搜索者查看,因此需要向网络蜘蛛提供相应的用户名和密码。如何设置蜘蛛。
网络蜘蛛可以通过给定的权限抓取这些网页提供搜索,当搜索者点击查看网页时,搜索者还需要提供相应的权限来验证如何设置蜘蛛。
二、tracking 链接
因为搜索引擎蜘蛛可以在网络上抓取尽可能多的页面,所以它们会跟随网页上的链接从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样。这是搜索引擎蜘蛛。如何设置蜘蛛的名字来源。
整个互联网网站是由相互链接组成的,也就是说,从任何一个页面开始,搜索引擎蜘蛛最终都会爬上所有页面。如何设置蜘蛛。
搜索引擎蜘蛛的基本原理和工作流程
当然网站和页面链接结构太复杂了。如何设置蜘蛛,让蜘蛛只能通过某些方法抓取所有页面。据我了解,最简单的爬取策略有3种:
1、最佳优先级
最佳优先级搜索策略根据一定的网页分析算法预测候选网址与目标页面的相似度或与主题的相关性,选择一个或几个评价最好的网址进行抓取,只访问如何为网页分析算法预测为“有用”的网页设置蜘蛛。
一个问题是爬虫的爬取路径中很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要将最佳优先级与具体应用结合起来进行改进。为了跳出局部最优,根据研究结果,这样的闭环调整可以将不相关网页的数量减少30%到90%。
2、深度优先
深度优先是指蜘蛛沿着找到的链接向前爬行,直到没有更多的链接在它之前,然后返回第一页,沿着另一个链接爬行,然后向前爬行。如何设置蜘蛛。
3、广度优先
广度优先是指当蜘蛛在一个页面上发现多个链接时,它不会一直沿着一个链接前进,而是爬取页面上的所有链接,然后沿着第二层进入页面的第二层找到的链接爬到页面的第三层。如何设置蜘蛛。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它们就可以抓取整个互联网。
实际工作中如何设置爬虫?蜘蛛的带宽资源和时间不是无限的,也不能爬取所有页面。事实上,最大的搜索引擎只是爬取和收录互联网的一小部分。当然不是搜索引擎蜘蛛爬的越多越好,这一点
因此,为了捕捉尽可能多的用户信息,通常深度优先和广度优先混合使用,这样可以照顾到尽可能多的网站,也可以照顾到如何设置一个网站 内部页面蜘蛛的一部分。
三、搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。 “蜘蛛”这个名字描述了信息采集模块如何在网络数据形成的“Web”上设置蜘蛛进行信息采集。
一般来说,网络蜘蛛从种子网页开始,通过反复下载网页和搜索文档中看不见的网址,如何设置蜘蛛以访问其他网页和遍历网络。
并且其工作策略一般可以分为累积爬行(cumulative crawling)和增量爬行(incremental crawling)两种设置蜘蛛的方式。
1、累积爬取
累积爬取是指如何设置蜘蛛从某个时间点爬取系统允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证可以爬取相当数量的网页集合。
似乎由于网络数据的动态性,采集到的网页的时间不同,页面更新的情况也不同。因此,累积爬取所爬取的网页集合实际上与真实环境中的并不相同。网络数据与如何设置蜘蛛一致。
2、增量爬取
与累积爬取不同,增量爬取是指对具有一定规模的网页集合,采用更新数据的方式,在现有集合中选择过时的网页进行爬取,从而保证所有抓取到的数据足够接近真实的网络数据。如何设置蜘蛛。
增量爬取的前提是系统已经爬取了足够多的网页,并且有这些页面被爬取的时间信息。如何设置蜘蛛。在面向实际应用环境的网络蜘蛛设计中,通常包括累积爬取和增量爬取两种策略。
累积爬取一般用于数据集合的整体建立或大规模更新阶段,而增量爬取主要是针对数据集合的日常维护以及如何设置蜘蛛进行实时更新。
在确定爬取策略后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛操作策略的核心问题。如何设置蜘蛛。
总的来说,在合理利用软硬件资源实时采集网络数据方面,已经形成了比较成熟的技术和实用的解决方案。我认为这方面需要解决的主要问题是更好地处理动态网络数据问题(如Web2.0数据量不断增加等),以及更好地如何基于网页设置蜘蛛质量以纠正抓取策略。
四、database
为了避免重复抓取和抓取网址,如何设置蜘蛛,搜索引擎会建立一个数据库来记录已经发现没有被抓取的页面和已经被抓取的页面。那么数据库中的URL是怎么来的呢? ?
1、手动输入种子网站
简单来说,就是我们新建一个网站提交给百度、谷歌或者360之后的网址收录如何设置蜘蛛。
2、蜘蛛抓取页面
如果搜索引擎蜘蛛在爬取过程中发现了新的连接网址,但不在数据库中,则会存储在待访问的数据库中(网站测期)如何设置蜘蛛。
蜘蛛根据重要性从要访问的数据库中提取URL,访问并爬取页面,然后从要访问的地址数据库中删除该URL并将其放入已访问地址数据库中,因此建议站长访问网站 观察期间需要定期更新网站。如何设置蜘蛛。
3、站长Submitted网站
一般来说,提交网站只是将网站保存到数据库中进行访问。如果网站 Durable 不更新蜘蛛,则不会光顾。搜索引擎收录的页面都是蜘蛛通过链接获取的。如何设置蜘蛛。
所以如果你把它提交给搜索引擎,它不是很有用。稍后您仍然需要考虑您的网站 更新级别。搜索引擎更喜欢沿着链接本身发现新页面。当然,如果你的SEO技巧足够高深,并且如果你有这个能力,你可以尝试一下。可能会有意想不到的结果。不过对于一般站长来说,还是建议让蜘蛛自然爬行,爬到新的站点页面。如何设置蜘蛛。
五、吸引蜘蛛
虽然理论上说蜘蛛可以爬取所有页面,但实际上是做不到的。所以想要收录更多页面的SEO人员只能想办法引诱蜘蛛爬行以及如何设置蜘蛛。
既然我们不能抓取所有页面以及如何设置蜘蛛,那我们就得让它抓取重要页面,因为重要页面在索引中起着重要的作用,直接影响排名因素。哪些页面更重要?对此,我还专门整理了以下我认为比较重要的页面,具体有这些特点:
1、网站 和页面权重
高质量和老网站被赋予了很高的权重。这种蜘蛛在网站上的页面爬行深度比较高,所以收录如何设置蜘蛛的内页会比较多。
2、page 更新度
蜘蛛每次爬行都会存储页面数据。如果在第二次爬取时发现这个页面的内容和第一个收录完全一样,说明该页面没有更新,蜘蛛不需要频繁爬取和爬取。如何设置蜘蛛。
如果页面内容更新频繁,如何设置蜘蛛,蜘蛛会频繁爬行,那么页面上的新链接自然会被蜘蛛更快地跟踪和抓取,这就是为什么它需要每天更新文章
3、import 链接
无论是外链还是同一个网站的内链,要想被蜘蛛爬取,必须有导入链接才能进入页面,否则蜘蛛不知道怎么设置蜘蛛为页面的存在。这时候URL链接就发挥了非常重要的作用,内链的重要性就发挥出来了。
另外,我个人觉得高质量的导入链接往往会增加页面导出链接的爬取深度。如何设置蜘蛛。
这就是为什么大部分站长或者SEO都需要高质量友情链接的原因,因为蜘蛛从对方网站爬到你网站的次数很多,而且深度也很高。如何设置蜘蛛。
c爬虫抓取网页数据(58同城:PythonDesignDesignonPython报纸杂志)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-09-13 04:02
摘要:为了快速获取职位信息,根据“无忧”网页的特点,设计了三个基于Python的爬虫来抓取职位相关数据。通过提取关键词,匹配符合条件的职位信息,抓取相关内容存入Excel文件,方便查找相关职位信息和具体需求。实验结果表明,该程序能够快速、海量地捕捉相关职位信息,针对性强,简单易读,有利于对职位信息的进一步挖掘和分析。
关键词:Python;爬虫;位置; 51job;
基于Python的51-job数据抓取程序设计
摘要:为了快速获取职位信息,根据“未来无忧”网页的特点,设计了三种基于Python的爬虫程序来抓取职位相关数据。通过提取关键词,匹配职位信息,将相关内容抓取到Excel文件中,方便查找相关职位信息和具体要求。实验结果表明,该程序能够快速、海量地捕获相关职位信息,且针对性强、易读,有利于对职位信息的进一步挖掘和分析。
关键字:Python;爬虫;位置;未来无忧;
0、引言
随着互联网时代的飞速发展,可以通过互联网获取海量数据,足不出户就可以了解瞬息万变的世界[1]。我们可以在互联网上获取招聘信息,而不仅限于互联网。报纸、杂志等纸质媒体可以让求职者快速有效地获取自己想要的招聘信息。每年9、4月是毕业生求职的高峰期,快速有效地获取招聘信息成为求职过程中的关键环节。为此,本文设计了一个基于python的爬虫程序。目前国内最著名的求职软件有“智联招聘”、“51job”、“”等,本文主要介绍“51job”的招聘信息。抓住并分析。现有数据采集程序的采集方式单一,用户无法选择最快的采集方式。程序针对这个问题做了进一步的优化,设计了三种数据采集方法。用户可以选择和输入关键字,匹配招聘信息的位置。设计更合理,用户体验会更好[2]。
本文提出的程序使用爬虫获取职位信息,包括:职位名称、职位、地点、公司名称、薪资范围、职位内容、招聘网址、发布日期。并将获取的信息保存在本地,用于后续的数据挖掘和分析。本文中的爬虫程序收录三种爬虫方法,分别是Re、XPath、Beatuiful Soup。用户可以自行选择自己想要的爬虫方式,输入位置的关键词,通过关键词匹配,获取对应的位置信息。
1、相关概念
1.1 Python 语言
Python 语言语法简单、清晰、功能强大且易于理解。可以运行在Windows、Linux等操作系统上; Python是一种面向对象语言,具有效率高、面向对象编程简单等优点[3-4]。 Python是一种语法简洁的脚本语言,并且支持动态输入,使得Python成为许多操作系统平台上的理想脚本语言,特别适合快速应用开发[5]。 Python 收录了一个网络协议标准库,可以抽象和封装各种层次的网络协议,这使得用户可以进一步优化程序逻辑。其次,Python非常擅长处理各种模式的字节流,开发速度非常快[6-7]。
1.2 网络爬虫
Web Crawler[8](Web Crawler),是一种根据一定的规则自动提取网页的应用程序或脚本。是在搜索引擎上完成数据爬取的关键步骤,可在互联网网站页面下载。爬虫用于将互联网上的网页保存在本地,以供参考[9-10]。爬虫程序用于通过分析页面源文件的 URL,从一个或多个初始页面的 URL 中检索新的 Web 链接。网页链接,然后继续寻找新的网页链接[11],如此循环往复,直到所有页面都被抓取并分析完毕。当然,这是一种理想的情况。根据目前公布的数据,最好的搜索引擎只抓取了整个互联网不到一半的网页[12]。
2、程序设计
本文的爬虫程序主要分为5个模块。首先根据Request URL获取需要爬取数据的页面,使用关键词通过Re、XPath、Beautiful Soup三种方法过滤符合条件的职位信息,包括职位名称、职位、地点、公司名称、薪资范围、职位内容、招聘网站、发布日期均保存在本地,方便后续数据挖掘和分析。
2.1 获取网页信息
在抓取网页信息之前,需要获取网页的信息,从中找出需要的信息进行抓取。首先打开Chrome浏览器,进入51job网页,打开开发者选项,找到网络,获取请求头中的URL和headers[13]。在预览中可以看到当前网页的源代码,可以从源代码中找到需要爬取的信息,即职位名称、职称、职位、公司名称、薪资范围、职位内容、招聘网址、发布日期,并找到当前页和下一页的偏移值,以便后面的爬虫可以抓取到设计中使用。
2.2 主程序设计
将Beautiful Soup、XPath、Regex的文件名打包成字典,并标注序号,设计进入程序的页面,并在页面上显示提示信息。请根据用户的选择选择一种爬虫方式,进入对应的程序,等待用户输入需要查询的位置关键词,启动爬虫程序,开始抓取数据[14]。抓取完成后,提示用户数据抓取完成,保存到本地文件,供用户使用和分析。
2.3 重新编程
正则表达式 (Re) 是对字符串(包括普通字符(例如 a 和 z 之间的字母)和特殊字符(称为“元字符”))进行运算的逻辑公式。一些定义的特定字符和这些特定字符的组合形成一个“规则串”[15],这个“规则串”用于表达对字符串的过滤逻辑。正则表达式是一种文本模式,用于描述搜索文本时要匹配的一个或多个字符串。
根据上面得到的网页信息,所需信息的字符串可以用Re表示,其中:
通过获取日期,用户可以了解最新的工作信息。根据职位的详细信息,求职者可以快速了解公司的要求和该职位的相关职位信息。通过上述正则表达式得到的信息保存在本地Excel文件中,方便求职者查看。
2.4 XPath 编程
XPath 是 XML 路径语言。它是一种用于确定 XML(标准通用标记语言的子集)文档中某个部分的位置的语言 [16]。 XPath 基于 XML 的树结构,具有不同类型的节点,包括元素节点、属性节点和文本节点,提供在数据结构树中查找节点的能力。最初,XPath 的初衷是将其用作 XPointer 和 XSLT 之间的通用语法模型。但 XPath 很快就被开发人员采用为一种小型查询语言。
XPath 比 Re 简单。 Re语言容易出错,无法正确获取所需信息。通常可以在 Chrome 中添加 XPath Helper 插件。可以直接将网页源代码复制成XPath格式,方便快捷。通常不容易犯错。
在 XPath 程序中,其中:
对比XPath和Re的代码,很明显XPath的代码比Re的代码简洁。
2.5 Beautiful Soup 程序设计
Beautiful Soup 提供了一些简单的、python 风格的函数来处理导航、搜索、修改分析树和其他功能 [16]。它是一个工具箱,为用户提供需要通过解析文档获取的数据,因为它简单,所以不用太多代码就可以写出一个完整的应用程序。 Beautiful Soup 自动将输入文档转换为 Unicode 编码,输出文档为 utf-8 编码。无需考虑编码方式,除非文档没有指定编码方式,此时Beautiful Soup无法自动识别编码方式。那么,只需要解释一下原来的编码方式即可。
2.5.1 解析库
本文介绍几个python解析库并进行比较。如表1所示,本文使用的解析器为python标准解析器。
2.5.2 标签选择器
标签选择器可以选择元素,获取名称、属性和内容,可以进行嵌套选择,可以获取子节点、后代节点、父节点、祖先节点等。标签选择器可以分为标准选择器和CSS 选择器。标签选择器可以根据标签名称、属性和内容查找文档。有两个常用的函数。其中, find_all (name, attrs, recursive, text, **kwargs ) 用于返回所有符合条件的元素; find (name, attrs, recursive, text, **kwargs) 用于返回第一个符合条件的元素。 CSS选择器直接将select()传入CSS选择器完成元素选择。
本文设计的程序中选择了CSS选择器,通过select()函数完成数据选择,其中:'int(str(soup.select('div.rt span.dw_c_orange' ) [0]. next Sibling))'#获取当前页码
3、实验结果
使用本文设计的爬虫程序进行如下实验:首先进入主程序,点击运行程序,程序返回图1所示界面。
接下来,如图2,输入数字“2”选择BeautifulSoup解析方式,输入关键词python启动爬虫,程序正常运行。
程序运行后,可以在本地文件夹中找到名为“python position”的Excel文件。打开文件,可以看到如图3所示的信息。
4、结论
本文根据Python语言简洁易读的特点,设计了三种爬取程序的方法。用户可以自行选择数据分析的方法,输入需要查询的关键词,就可以从海量的作业数据中提取自己的需求,数据方便快捷。本程序通过匹配职位关键词、工作地点等信息,在一定程度上为用户提供了方便。提取的详细职业信息描述可以进一步细分,可以统计词频,可以观察到单词的出现。可以更快的了解公司和相应职位的要求,找到符合求职者的招聘信息。
参考资料
[1] 方锦堂。基于网络爬虫的在线教育平台设计与实现[D].北京:北京交通大学,2016.
[2] 王八耀。基于Python的Web爬虫技术研究[J].数字技术与应用, 2017 (5):76-76.
[3] 周中华,张惠然,谢江.基于Python的新浪微博数据爬虫[J].计算机应用, 2014, 34 (11):3131-3134.
[4] 涂小琴。基于Python爬虫的影评情感倾向分析[J].现代计算机, 2017 (35):52-55.
[5]郭立荣.基于Python的网络爬虫程序设计[J].电子技术与软件工程, 2017 (23) :248-249.
[6]Lutz M.学习 Python[M]。北京:机械工业出版社,2009.
[7] 刘志凯,张太红,刘磊。基于Web的Python3编程环境[J].计算机系统应用, 2015, 24 (7):236-239.
[8] 王大伟。基于Python的Web API自动测试方法研究[J].电子科技,2015,2(5):573-581.
[9]Hetland M L. Python 基础课程 [M]。北京:人民邮电出版社,2014:243-245.
[10] 涂辉,汪峰,尚清伟。 Python3编程实现网络图像爬虫[J].计算机编程技巧与维护,2017 (23):21-22.
[11] 高森. Python 网络编程基础[M].北京:电子工业出版社,2007.
[12] 周丽珠,林玲。爬虫技术研究综述[J].计算机应用, 2005, 25 (9):1965-1969.
[13] 蒋善标,黄开林,卢玉江等.基于Python的专业网络爬虫的设计与实现[J].企业技术与发展, 2016 (8):17-19.
[14] 陈琳,任芳。基于Python的新浪微博数据爬虫程序设计[J].信息系统工程, 2016 (9):97-99.
[15] 刘娜。 Python正则表达式高级特性研究[J].计算机编程技巧与维护,2015 (22):12-13.
[16] 齐鹏,李银峰,宋雨薇。基于Python采集技术的Web数据[J].电子科学与技术, 2012, 25 (11):118-120. 查看全部
c爬虫抓取网页数据(58同城:PythonDesignDesignonPython报纸杂志)
摘要:为了快速获取职位信息,根据“无忧”网页的特点,设计了三个基于Python的爬虫来抓取职位相关数据。通过提取关键词,匹配符合条件的职位信息,抓取相关内容存入Excel文件,方便查找相关职位信息和具体需求。实验结果表明,该程序能够快速、海量地捕捉相关职位信息,针对性强,简单易读,有利于对职位信息的进一步挖掘和分析。
关键词:Python;爬虫;位置; 51job;
基于Python的51-job数据抓取程序设计
摘要:为了快速获取职位信息,根据“未来无忧”网页的特点,设计了三种基于Python的爬虫程序来抓取职位相关数据。通过提取关键词,匹配职位信息,将相关内容抓取到Excel文件中,方便查找相关职位信息和具体要求。实验结果表明,该程序能够快速、海量地捕获相关职位信息,且针对性强、易读,有利于对职位信息的进一步挖掘和分析。
关键字:Python;爬虫;位置;未来无忧;

0、引言
随着互联网时代的飞速发展,可以通过互联网获取海量数据,足不出户就可以了解瞬息万变的世界[1]。我们可以在互联网上获取招聘信息,而不仅限于互联网。报纸、杂志等纸质媒体可以让求职者快速有效地获取自己想要的招聘信息。每年9、4月是毕业生求职的高峰期,快速有效地获取招聘信息成为求职过程中的关键环节。为此,本文设计了一个基于python的爬虫程序。目前国内最著名的求职软件有“智联招聘”、“51job”、“”等,本文主要介绍“51job”的招聘信息。抓住并分析。现有数据采集程序的采集方式单一,用户无法选择最快的采集方式。程序针对这个问题做了进一步的优化,设计了三种数据采集方法。用户可以选择和输入关键字,匹配招聘信息的位置。设计更合理,用户体验会更好[2]。
本文提出的程序使用爬虫获取职位信息,包括:职位名称、职位、地点、公司名称、薪资范围、职位内容、招聘网址、发布日期。并将获取的信息保存在本地,用于后续的数据挖掘和分析。本文中的爬虫程序收录三种爬虫方法,分别是Re、XPath、Beatuiful Soup。用户可以自行选择自己想要的爬虫方式,输入位置的关键词,通过关键词匹配,获取对应的位置信息。
1、相关概念
1.1 Python 语言
Python 语言语法简单、清晰、功能强大且易于理解。可以运行在Windows、Linux等操作系统上; Python是一种面向对象语言,具有效率高、面向对象编程简单等优点[3-4]。 Python是一种语法简洁的脚本语言,并且支持动态输入,使得Python成为许多操作系统平台上的理想脚本语言,特别适合快速应用开发[5]。 Python 收录了一个网络协议标准库,可以抽象和封装各种层次的网络协议,这使得用户可以进一步优化程序逻辑。其次,Python非常擅长处理各种模式的字节流,开发速度非常快[6-7]。
1.2 网络爬虫
Web Crawler[8](Web Crawler),是一种根据一定的规则自动提取网页的应用程序或脚本。是在搜索引擎上完成数据爬取的关键步骤,可在互联网网站页面下载。爬虫用于将互联网上的网页保存在本地,以供参考[9-10]。爬虫程序用于通过分析页面源文件的 URL,从一个或多个初始页面的 URL 中检索新的 Web 链接。网页链接,然后继续寻找新的网页链接[11],如此循环往复,直到所有页面都被抓取并分析完毕。当然,这是一种理想的情况。根据目前公布的数据,最好的搜索引擎只抓取了整个互联网不到一半的网页[12]。
2、程序设计
本文的爬虫程序主要分为5个模块。首先根据Request URL获取需要爬取数据的页面,使用关键词通过Re、XPath、Beautiful Soup三种方法过滤符合条件的职位信息,包括职位名称、职位、地点、公司名称、薪资范围、职位内容、招聘网站、发布日期均保存在本地,方便后续数据挖掘和分析。
2.1 获取网页信息
在抓取网页信息之前,需要获取网页的信息,从中找出需要的信息进行抓取。首先打开Chrome浏览器,进入51job网页,打开开发者选项,找到网络,获取请求头中的URL和headers[13]。在预览中可以看到当前网页的源代码,可以从源代码中找到需要爬取的信息,即职位名称、职称、职位、公司名称、薪资范围、职位内容、招聘网址、发布日期,并找到当前页和下一页的偏移值,以便后面的爬虫可以抓取到设计中使用。
2.2 主程序设计
将Beautiful Soup、XPath、Regex的文件名打包成字典,并标注序号,设计进入程序的页面,并在页面上显示提示信息。请根据用户的选择选择一种爬虫方式,进入对应的程序,等待用户输入需要查询的位置关键词,启动爬虫程序,开始抓取数据[14]。抓取完成后,提示用户数据抓取完成,保存到本地文件,供用户使用和分析。
2.3 重新编程
正则表达式 (Re) 是对字符串(包括普通字符(例如 a 和 z 之间的字母)和特殊字符(称为“元字符”))进行运算的逻辑公式。一些定义的特定字符和这些特定字符的组合形成一个“规则串”[15],这个“规则串”用于表达对字符串的过滤逻辑。正则表达式是一种文本模式,用于描述搜索文本时要匹配的一个或多个字符串。
根据上面得到的网页信息,所需信息的字符串可以用Re表示,其中:

通过获取日期,用户可以了解最新的工作信息。根据职位的详细信息,求职者可以快速了解公司的要求和该职位的相关职位信息。通过上述正则表达式得到的信息保存在本地Excel文件中,方便求职者查看。
2.4 XPath 编程
XPath 是 XML 路径语言。它是一种用于确定 XML(标准通用标记语言的子集)文档中某个部分的位置的语言 [16]。 XPath 基于 XML 的树结构,具有不同类型的节点,包括元素节点、属性节点和文本节点,提供在数据结构树中查找节点的能力。最初,XPath 的初衷是将其用作 XPointer 和 XSLT 之间的通用语法模型。但 XPath 很快就被开发人员采用为一种小型查询语言。
XPath 比 Re 简单。 Re语言容易出错,无法正确获取所需信息。通常可以在 Chrome 中添加 XPath Helper 插件。可以直接将网页源代码复制成XPath格式,方便快捷。通常不容易犯错。
在 XPath 程序中,其中:

对比XPath和Re的代码,很明显XPath的代码比Re的代码简洁。
2.5 Beautiful Soup 程序设计
Beautiful Soup 提供了一些简单的、python 风格的函数来处理导航、搜索、修改分析树和其他功能 [16]。它是一个工具箱,为用户提供需要通过解析文档获取的数据,因为它简单,所以不用太多代码就可以写出一个完整的应用程序。 Beautiful Soup 自动将输入文档转换为 Unicode 编码,输出文档为 utf-8 编码。无需考虑编码方式,除非文档没有指定编码方式,此时Beautiful Soup无法自动识别编码方式。那么,只需要解释一下原来的编码方式即可。
2.5.1 解析库
本文介绍几个python解析库并进行比较。如表1所示,本文使用的解析器为python标准解析器。

2.5.2 标签选择器
标签选择器可以选择元素,获取名称、属性和内容,可以进行嵌套选择,可以获取子节点、后代节点、父节点、祖先节点等。标签选择器可以分为标准选择器和CSS 选择器。标签选择器可以根据标签名称、属性和内容查找文档。有两个常用的函数。其中, find_all (name, attrs, recursive, text, **kwargs ) 用于返回所有符合条件的元素; find (name, attrs, recursive, text, **kwargs) 用于返回第一个符合条件的元素。 CSS选择器直接将select()传入CSS选择器完成元素选择。
本文设计的程序中选择了CSS选择器,通过select()函数完成数据选择,其中:'int(str(soup.select('div.rt span.dw_c_orange' ) [0]. next Sibling))'#获取当前页码

3、实验结果
使用本文设计的爬虫程序进行如下实验:首先进入主程序,点击运行程序,程序返回图1所示界面。

接下来,如图2,输入数字“2”选择BeautifulSoup解析方式,输入关键词python启动爬虫,程序正常运行。

程序运行后,可以在本地文件夹中找到名为“python position”的Excel文件。打开文件,可以看到如图3所示的信息。

4、结论
本文根据Python语言简洁易读的特点,设计了三种爬取程序的方法。用户可以自行选择数据分析的方法,输入需要查询的关键词,就可以从海量的作业数据中提取自己的需求,数据方便快捷。本程序通过匹配职位关键词、工作地点等信息,在一定程度上为用户提供了方便。提取的详细职业信息描述可以进一步细分,可以统计词频,可以观察到单词的出现。可以更快的了解公司和相应职位的要求,找到符合求职者的招聘信息。
参考资料
[1] 方锦堂。基于网络爬虫的在线教育平台设计与实现[D].北京:北京交通大学,2016.
[2] 王八耀。基于Python的Web爬虫技术研究[J].数字技术与应用, 2017 (5):76-76.
[3] 周中华,张惠然,谢江.基于Python的新浪微博数据爬虫[J].计算机应用, 2014, 34 (11):3131-3134.
[4] 涂小琴。基于Python爬虫的影评情感倾向分析[J].现代计算机, 2017 (35):52-55.
[5]郭立荣.基于Python的网络爬虫程序设计[J].电子技术与软件工程, 2017 (23) :248-249.
[6]Lutz M.学习 Python[M]。北京:机械工业出版社,2009.
[7] 刘志凯,张太红,刘磊。基于Web的Python3编程环境[J].计算机系统应用, 2015, 24 (7):236-239.
[8] 王大伟。基于Python的Web API自动测试方法研究[J].电子科技,2015,2(5):573-581.
[9]Hetland M L. Python 基础课程 [M]。北京:人民邮电出版社,2014:243-245.
[10] 涂辉,汪峰,尚清伟。 Python3编程实现网络图像爬虫[J].计算机编程技巧与维护,2017 (23):21-22.
[11] 高森. Python 网络编程基础[M].北京:电子工业出版社,2007.
[12] 周丽珠,林玲。爬虫技术研究综述[J].计算机应用, 2005, 25 (9):1965-1969.
[13] 蒋善标,黄开林,卢玉江等.基于Python的专业网络爬虫的设计与实现[J].企业技术与发展, 2016 (8):17-19.
[14] 陈琳,任芳。基于Python的新浪微博数据爬虫程序设计[J].信息系统工程, 2016 (9):97-99.
[15] 刘娜。 Python正则表达式高级特性研究[J].计算机编程技巧与维护,2015 (22):12-13.
[16] 齐鹏,李银峰,宋雨薇。基于Python采集技术的Web数据[J].电子科学与技术, 2012, 25 (11):118-120.
c爬虫抓取网页数据(搜索引擎蜘蛛的基本原理及工作流程对于SEO的流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-09-13 03:18
搜索引擎用来抓取和访问页面的程序称为蜘蛛程序或机器人程序。当搜索引擎蜘蛛访问网站页面时,它类似于使用浏览器的普通用户。蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。搜索引擎旨在提高爬行和爬行。拿速度,用多个蜘蛛来分布爬取。
蜘蛛访问网站时,首先会访问网站根目录下的robots.txt文件。如果robots.txt文件禁止搜索引擎抓取某些网页或内容,或者网站,蜘蛛会遵守协议,不会被抓取。
蜘蛛也有自己的代理名称。你可以在站长的日志中看到蜘蛛爬行的痕迹。所以很多站长在回答问题的时候,总是说先查看网站日志(作为一个优秀的SEO,你必须有能力在不借助任何软件的情况下查看网站日志,并且非常熟悉其代码的含义)。
一、搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛是Spider,这是一个很形象的名字。它将互联网比作蜘蛛网,然后蜘蛛就是在网上爬行的蜘蛛。
网络蜘蛛通过网页的链接地址搜索网页。从某个页面网站(通常是首页)开始,读取该网页的内容,找到该网页中的其他链接地址,然后通过这些链接地址搜索下一个网页,这个循环一直持续到所有网站网页已被抓取。
如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,爬取互联网上的所有网页几乎是不可能的。根据目前公布的数据,容量最大的搜索引擎只抓取了整个网页的 4%。大约十个。
一方面是因为爬虫技术的瓶颈。 100亿个网页的容量为100×2000G字节。就算能存储,下载还是有问题(按一台机器每秒下载20K计算,需要340个单元,机器不停下载一年才能完成所有网页的下载)。同时,由于数据量大,在提供搜索时也会影响效率。
因此,很多搜索引擎网络蜘蛛只抓取那些重要的网页,而评价抓取重要性的主要依据是某个网页的链接深度。
因为不可能爬取所有网页,所以一些网络蜘蛛对一些不太重要的网站设置了访问级别的数量,例如如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A为起始网页,属于第0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。 如接入层数网络蜘蛛设置的是2的情况下,网页我不会被访问,这也使得网站之前的一些页面在搜索引擎上搜索到,其他部分搜索不到。
对于网站designers,扁平化的网站结构设计有助于搜索引擎抓取更多网页。
网络蜘蛛在访问网站网页时,经常会遇到加密数据和网络权限的问题。某些网页需要会员权限才能访问。
当然网站的拥有者可以通过协议防止网络蜘蛛爬行,但是对于一些卖报告的网站来说,他们希望自己的报告能被搜索引擎搜索到,但不可能完全免费搜索者查看,所以需要向网络蜘蛛提供相应的用户名和密码。
网络蜘蛛可以抓取这些具有给定权限的网页提供搜索,当搜索者点击查看网页时,搜索者还需要提供相应的权限验证。
二、tracking 链接
因为搜索引擎蜘蛛可以在网络上抓取尽可能多的页面,所以它们会跟随网页上的链接从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样。这是搜索引擎蜘蛛。名字的由来。
整个互联网网站是由相互链接组成的,这意味着搜索引擎蜘蛛最终会从任何页面开始抓取所有页面。
搜索引擎蜘蛛的基本原理和工作流程
当然网站和页面链接结构太复杂了,所以蜘蛛只能通过一定的方法抓取所有页面。根据我的理解,有3种简单的爬取策略:
1、最佳优先级
最佳优先级搜索策略根据一定的网页分析算法预测候选网址与目标页面的相似度或与主题的相关性,选择一个或几个评价最好的网址进行抓取,只访问被网络分析算法预测为“有用”的网页。
一个问题是爬虫的爬取路径中很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要将最佳优先级与具体应用结合起来进行改进。为了跳出局部最优,根据研究结果,这种闭环调整可以将不相关网页的数量减少30%到90%。
2、深度优先
深度优先是指蜘蛛沿着找到的链接向前爬,直到没有更多的链接在它前面,然后回到第一页,沿着另一个链接向前爬。
3、广度优先
广度优先是指当蜘蛛在一个页面上发现多个链接时,它不会一直沿着一个链接前进,而是爬取页面上的所有链接,然后沿着第二级进入第二级页面找到的链接爬到三级页面。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它们就可以抓取整个互联网。
在实际工作中,蜘蛛的带宽资源和时间不是无限的,也不是可以抓取所有页面。其实最大的搜索引擎只是爬取而收录了互联网的一小部分,当然不是搜索引擎蜘蛛爬的越多越好,这一点
因此,为了捕捉尽可能多的用户信息,通常深度优先和广度优先混合使用,这样可以兼顾到尽可能多的网站,以及网站的一部分内部页面。
三、搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。 “蜘蛛”这个名字描述了信息采集模块在网络数据形成的“Web”上获取信息的功能。
一般情况下,网络蜘蛛从种子网页开始,反复下载网页,寻找文档中从未见过的网址,从而访问其他网页并遍历网络。
其工作策略一般可分为累积爬行(cumulative crawling)和增量爬行(incremental crawling)两种。
1、累积爬取
累积爬取是指从某个时间点开始,以遍历的方式爬取系统允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证可以爬取相当数量的网页集合。
似乎由于网络数据的动态性,采集到的网页的时间不同,页面更新的情况也不同。因此,累积爬取所爬取的网页集合实际上与真实环境中的并不相同。网络数据保持一致。
2、增量爬取
与累积爬取不同,增量爬取是指对具有一定规模的网页集合,采用更新数据的方式,在现有集合中选择过时的网页进行爬取,从而保证所有抓取到的数据足够接近真实网络数据。
增量爬取的前提是系统已经爬取了足够多的网页,并且有这些页面被爬取的时间信息。在面向实际应用环境的网络蜘蛛设计中,通常包括累积爬取和增量爬取两种策略。
累积爬取一般用于数据集合的整体建立或大规模更新阶段,而增量爬取主要用于数据集合的日常维护和实时更新。
在确定爬取策略后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛运行策略的核心问题。
总的来说,在合理利用软硬件资源实时采集网络数据方面,已经形成了比较成熟的技术和实用的解决方案。我认为这方面需要解决的主要问题是更好地处理动态网络数据问题(如Web2.0数据量不断增加等),更好地修正基于网页的爬取策略问题质量。
四、database
为了避免重复抓取和抓取网址,搜索引擎会建立一个数据库来记录已发现未抓取的页面和已抓取的页面。那么数据库中的URL是怎么来的呢?
1、手动输入种子网站
简单来说就是我们新建网站后提交给百度、谷歌或360的网址收录。
2、蜘蛛抓取页面
如果搜索引擎蜘蛛在爬取过程中发现了新的连接网址,但不在数据库中,则会存储在数据库中以供访问(网站测期)。
蜘蛛根据重要性从要访问的数据库中提取URL,访问并抓取页面,然后从要访问的地址数据库中删除该URL并将其放入已访问地址数据库中,因此建议站长访问网站,观察期间需要定期更新网站。
3、站长Submitted网站
一般来说,提交网站只是将网站保存到数据库中进行访问。如果网站 Durable 不更新蜘蛛,就不会光顾。搜索引擎收录的页面都是蜘蛛通过链接获取的。 .
所以如果你把它提交给搜索引擎,它不是很有用。稍后您仍然需要考虑您的网站 更新级别。搜索引擎更喜欢沿着链接发现新页面。当然,如果你的SEO技巧足够高深,并且有了这个能力,你也可以试试。可能会有意想不到的结果。不过对于一般站长来说,还是建议让蜘蛛爬行,自然爬到新的网站页面。
五、吸引蜘蛛
虽然理论上说蜘蛛可以爬取所有页面,但实际上是做不到的。所以想要收录更多页面的SEO人员只能想办法引诱蜘蛛爬行。
既然不能抓取所有的页面,那我们就得让它抓取重要的页面,因为重要的页面在索引中起着重要的作用,直接影响排名因素。哪些页面更重要?对此,我还专门整理了以下我认为比较重要的页面,具体有这些特点:
1、网站 和页面权重
高质量和老网站 被赋予了很高的权重。这种蜘蛛在网站上的页面爬行深度比较高,所以更多的内页会是收录。
2、page 更新度
蜘蛛每次爬行都会存储页面数据。如果在第二次抓取时发现该页面的内容与第一个收录完全相同,则说明该页面尚未更新,蜘蛛不需要频繁抓取和抓取。 .
如果页面内容更新频繁,蜘蛛就会频繁爬行爬行,那么页面上的新链接自然会被蜘蛛更快地跟踪和抓取,这也是为什么每天都要更新文章
3、import 链接
无论是外部链接还是同一个网站的内部链接,为了被蜘蛛爬取,必须有导入链接才能进入页面,否则蜘蛛不知道存在页。这时候URL链接就发挥了非常重要的作用,内链的重要性就发挥出来了。
另外,我个人觉得高质量的导入链接往往会增加页面导出链接的爬取深度。
这就是为什么大部分站长或者SEO都需要高质量友情链接的原因,因为蜘蛛经常从对方网站爬到你网站,深度高。 查看全部
c爬虫抓取网页数据(搜索引擎蜘蛛的基本原理及工作流程对于SEO的流程)
搜索引擎用来抓取和访问页面的程序称为蜘蛛程序或机器人程序。当搜索引擎蜘蛛访问网站页面时,它类似于使用浏览器的普通用户。蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。搜索引擎旨在提高爬行和爬行。拿速度,用多个蜘蛛来分布爬取。

蜘蛛访问网站时,首先会访问网站根目录下的robots.txt文件。如果robots.txt文件禁止搜索引擎抓取某些网页或内容,或者网站,蜘蛛会遵守协议,不会被抓取。
蜘蛛也有自己的代理名称。你可以在站长的日志中看到蜘蛛爬行的痕迹。所以很多站长在回答问题的时候,总是说先查看网站日志(作为一个优秀的SEO,你必须有能力在不借助任何软件的情况下查看网站日志,并且非常熟悉其代码的含义)。
一、搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛是Spider,这是一个很形象的名字。它将互联网比作蜘蛛网,然后蜘蛛就是在网上爬行的蜘蛛。
网络蜘蛛通过网页的链接地址搜索网页。从某个页面网站(通常是首页)开始,读取该网页的内容,找到该网页中的其他链接地址,然后通过这些链接地址搜索下一个网页,这个循环一直持续到所有网站网页已被抓取。
如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,爬取互联网上的所有网页几乎是不可能的。根据目前公布的数据,容量最大的搜索引擎只抓取了整个网页的 4%。大约十个。
一方面是因为爬虫技术的瓶颈。 100亿个网页的容量为100×2000G字节。就算能存储,下载还是有问题(按一台机器每秒下载20K计算,需要340个单元,机器不停下载一年才能完成所有网页的下载)。同时,由于数据量大,在提供搜索时也会影响效率。
因此,很多搜索引擎网络蜘蛛只抓取那些重要的网页,而评价抓取重要性的主要依据是某个网页的链接深度。
因为不可能爬取所有网页,所以一些网络蜘蛛对一些不太重要的网站设置了访问级别的数量,例如如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A为起始网页,属于第0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。 如接入层数网络蜘蛛设置的是2的情况下,网页我不会被访问,这也使得网站之前的一些页面在搜索引擎上搜索到,其他部分搜索不到。
对于网站designers,扁平化的网站结构设计有助于搜索引擎抓取更多网页。
网络蜘蛛在访问网站网页时,经常会遇到加密数据和网络权限的问题。某些网页需要会员权限才能访问。
当然网站的拥有者可以通过协议防止网络蜘蛛爬行,但是对于一些卖报告的网站来说,他们希望自己的报告能被搜索引擎搜索到,但不可能完全免费搜索者查看,所以需要向网络蜘蛛提供相应的用户名和密码。
网络蜘蛛可以抓取这些具有给定权限的网页提供搜索,当搜索者点击查看网页时,搜索者还需要提供相应的权限验证。
二、tracking 链接
因为搜索引擎蜘蛛可以在网络上抓取尽可能多的页面,所以它们会跟随网页上的链接从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样。这是搜索引擎蜘蛛。名字的由来。
整个互联网网站是由相互链接组成的,这意味着搜索引擎蜘蛛最终会从任何页面开始抓取所有页面。
搜索引擎蜘蛛的基本原理和工作流程
当然网站和页面链接结构太复杂了,所以蜘蛛只能通过一定的方法抓取所有页面。根据我的理解,有3种简单的爬取策略:
1、最佳优先级
最佳优先级搜索策略根据一定的网页分析算法预测候选网址与目标页面的相似度或与主题的相关性,选择一个或几个评价最好的网址进行抓取,只访问被网络分析算法预测为“有用”的网页。
一个问题是爬虫的爬取路径中很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要将最佳优先级与具体应用结合起来进行改进。为了跳出局部最优,根据研究结果,这种闭环调整可以将不相关网页的数量减少30%到90%。
2、深度优先
深度优先是指蜘蛛沿着找到的链接向前爬,直到没有更多的链接在它前面,然后回到第一页,沿着另一个链接向前爬。
3、广度优先
广度优先是指当蜘蛛在一个页面上发现多个链接时,它不会一直沿着一个链接前进,而是爬取页面上的所有链接,然后沿着第二级进入第二级页面找到的链接爬到三级页面。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它们就可以抓取整个互联网。
在实际工作中,蜘蛛的带宽资源和时间不是无限的,也不是可以抓取所有页面。其实最大的搜索引擎只是爬取而收录了互联网的一小部分,当然不是搜索引擎蜘蛛爬的越多越好,这一点
因此,为了捕捉尽可能多的用户信息,通常深度优先和广度优先混合使用,这样可以兼顾到尽可能多的网站,以及网站的一部分内部页面。
三、搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。 “蜘蛛”这个名字描述了信息采集模块在网络数据形成的“Web”上获取信息的功能。
一般情况下,网络蜘蛛从种子网页开始,反复下载网页,寻找文档中从未见过的网址,从而访问其他网页并遍历网络。
其工作策略一般可分为累积爬行(cumulative crawling)和增量爬行(incremental crawling)两种。
1、累积爬取
累积爬取是指从某个时间点开始,以遍历的方式爬取系统允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证可以爬取相当数量的网页集合。
似乎由于网络数据的动态性,采集到的网页的时间不同,页面更新的情况也不同。因此,累积爬取所爬取的网页集合实际上与真实环境中的并不相同。网络数据保持一致。
2、增量爬取
与累积爬取不同,增量爬取是指对具有一定规模的网页集合,采用更新数据的方式,在现有集合中选择过时的网页进行爬取,从而保证所有抓取到的数据足够接近真实网络数据。
增量爬取的前提是系统已经爬取了足够多的网页,并且有这些页面被爬取的时间信息。在面向实际应用环境的网络蜘蛛设计中,通常包括累积爬取和增量爬取两种策略。
累积爬取一般用于数据集合的整体建立或大规模更新阶段,而增量爬取主要用于数据集合的日常维护和实时更新。
在确定爬取策略后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛运行策略的核心问题。
总的来说,在合理利用软硬件资源实时采集网络数据方面,已经形成了比较成熟的技术和实用的解决方案。我认为这方面需要解决的主要问题是更好地处理动态网络数据问题(如Web2.0数据量不断增加等),更好地修正基于网页的爬取策略问题质量。
四、database
为了避免重复抓取和抓取网址,搜索引擎会建立一个数据库来记录已发现未抓取的页面和已抓取的页面。那么数据库中的URL是怎么来的呢?
1、手动输入种子网站
简单来说就是我们新建网站后提交给百度、谷歌或360的网址收录。
2、蜘蛛抓取页面
如果搜索引擎蜘蛛在爬取过程中发现了新的连接网址,但不在数据库中,则会存储在数据库中以供访问(网站测期)。
蜘蛛根据重要性从要访问的数据库中提取URL,访问并抓取页面,然后从要访问的地址数据库中删除该URL并将其放入已访问地址数据库中,因此建议站长访问网站,观察期间需要定期更新网站。
3、站长Submitted网站
一般来说,提交网站只是将网站保存到数据库中进行访问。如果网站 Durable 不更新蜘蛛,就不会光顾。搜索引擎收录的页面都是蜘蛛通过链接获取的。 .
所以如果你把它提交给搜索引擎,它不是很有用。稍后您仍然需要考虑您的网站 更新级别。搜索引擎更喜欢沿着链接发现新页面。当然,如果你的SEO技巧足够高深,并且有了这个能力,你也可以试试。可能会有意想不到的结果。不过对于一般站长来说,还是建议让蜘蛛爬行,自然爬到新的网站页面。
五、吸引蜘蛛
虽然理论上说蜘蛛可以爬取所有页面,但实际上是做不到的。所以想要收录更多页面的SEO人员只能想办法引诱蜘蛛爬行。
既然不能抓取所有的页面,那我们就得让它抓取重要的页面,因为重要的页面在索引中起着重要的作用,直接影响排名因素。哪些页面更重要?对此,我还专门整理了以下我认为比较重要的页面,具体有这些特点:
1、网站 和页面权重
高质量和老网站 被赋予了很高的权重。这种蜘蛛在网站上的页面爬行深度比较高,所以更多的内页会是收录。
2、page 更新度
蜘蛛每次爬行都会存储页面数据。如果在第二次抓取时发现该页面的内容与第一个收录完全相同,则说明该页面尚未更新,蜘蛛不需要频繁抓取和抓取。 .
如果页面内容更新频繁,蜘蛛就会频繁爬行爬行,那么页面上的新链接自然会被蜘蛛更快地跟踪和抓取,这也是为什么每天都要更新文章
3、import 链接
无论是外部链接还是同一个网站的内部链接,为了被蜘蛛爬取,必须有导入链接才能进入页面,否则蜘蛛不知道存在页。这时候URL链接就发挥了非常重要的作用,内链的重要性就发挥出来了。
另外,我个人觉得高质量的导入链接往往会增加页面导出链接的爬取深度。
这就是为什么大部分站长或者SEO都需要高质量友情链接的原因,因为蜘蛛经常从对方网站爬到你网站,深度高。
c爬虫抓取网页数据(Python內建使用urllib.request获取网页urllib是什么意思? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-13 03:14
)
1. 使用 urllib.request 获取网页
urllib 是 Python 中的内置 HTTP 库。使用 urllib 可以很高效采集数据,步骤非常简单;配合Beautiful等HTML解析库,可以为采集网络数据编写大型爬虫;
注:示例代码是用Python3编写的; urllib 是 Python2 中 urllib 和 urllib2 的组合,Python2 中的 urllib2 对应于 Python3 中的 urllib.request。
简单例子:
2.伪造的请求头信息
有时候爬虫发起的请求会被服务器拒绝。这时候就需要将爬虫伪装成人类用户的浏览器。这通常是通过伪造请求头信息来实现的,例如:
3.伪造的请求体
爬取一些网站时,需要POST数据到服务器,然后需要伪造请求体;
为了实现有道词典的在线翻译脚本,在Chrome中打开开发工具,在Network下找到方法为POST的请求。观察数据,可以发现请求体中的'i'是需要翻译的URL编码内容。因此,可以伪造请求体,例如:
也可以使用add_header()方法来伪造请求头,比如:
4. 使用代理IP
为了避免采集爬虫过于频繁导致的IP阻塞问题,可以使用代理IP,如:
注意:使用爬虫过于频繁地访问目标站点会占用大量服务器资源。大型分布式爬虫可以爬取某个站点甚至对该站点发起DDOS攻击;因此,应该合理使用爬虫来抓取数据 安排抓取频率和时间;如:在服务器相对空闲的时间(如:清晨)爬取,完成一个爬取任务后暂停一段时间等;
5. 检测网页的编码方式
虽然大部分网页都采用UTF-8编码,但有时也会遇到使用其他编码方式的网页,所以必须了解网页的编码方式才能正确解码抓取到的页面;
chardet是python的第三方模块,使用chardet可以自动检测网页的编码;
安装chardet:pip install charest
使用:
6.获取跳转链接
有时网页的某个页面需要在原创URL的基础上进行一次甚至多次重定向才能最终到达目的页面,因此需要正确处理重定向;
通过requests模块的head()函数获取跳转链接的URL,如
查看全部
c爬虫抓取网页数据(Python內建使用urllib.request获取网页urllib是什么意思?
)
1. 使用 urllib.request 获取网页
urllib 是 Python 中的内置 HTTP 库。使用 urllib 可以很高效采集数据,步骤非常简单;配合Beautiful等HTML解析库,可以为采集网络数据编写大型爬虫;
注:示例代码是用Python3编写的; urllib 是 Python2 中 urllib 和 urllib2 的组合,Python2 中的 urllib2 对应于 Python3 中的 urllib.request。
简单例子:

2.伪造的请求头信息
有时候爬虫发起的请求会被服务器拒绝。这时候就需要将爬虫伪装成人类用户的浏览器。这通常是通过伪造请求头信息来实现的,例如:
3.伪造的请求体
爬取一些网站时,需要POST数据到服务器,然后需要伪造请求体;
为了实现有道词典的在线翻译脚本,在Chrome中打开开发工具,在Network下找到方法为POST的请求。观察数据,可以发现请求体中的'i'是需要翻译的URL编码内容。因此,可以伪造请求体,例如:
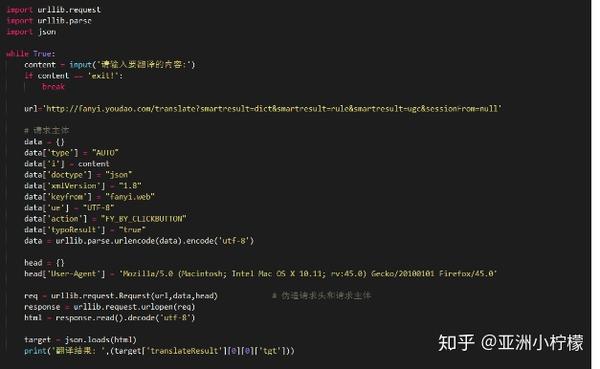
也可以使用add_header()方法来伪造请求头,比如:
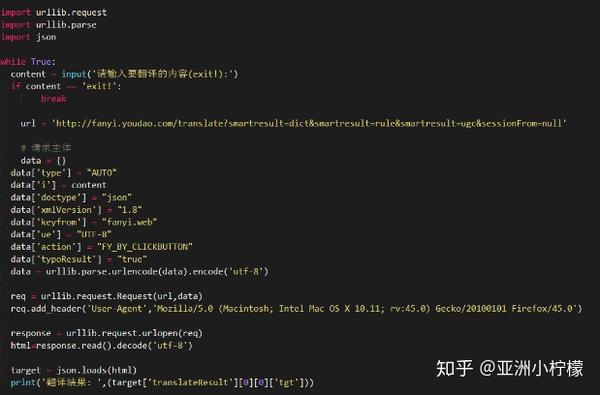
4. 使用代理IP
为了避免采集爬虫过于频繁导致的IP阻塞问题,可以使用代理IP,如:
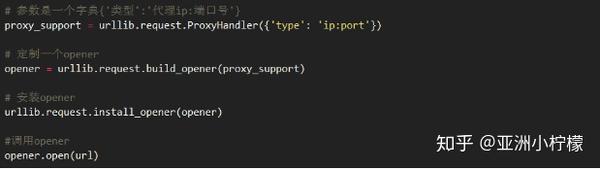
注意:使用爬虫过于频繁地访问目标站点会占用大量服务器资源。大型分布式爬虫可以爬取某个站点甚至对该站点发起DDOS攻击;因此,应该合理使用爬虫来抓取数据 安排抓取频率和时间;如:在服务器相对空闲的时间(如:清晨)爬取,完成一个爬取任务后暂停一段时间等;
5. 检测网页的编码方式
虽然大部分网页都采用UTF-8编码,但有时也会遇到使用其他编码方式的网页,所以必须了解网页的编码方式才能正确解码抓取到的页面;
chardet是python的第三方模块,使用chardet可以自动检测网页的编码;
安装chardet:pip install charest
使用:

6.获取跳转链接
有时网页的某个页面需要在原创URL的基础上进行一次甚至多次重定向才能最终到达目的页面,因此需要正确处理重定向;
通过requests模块的head()函数获取跳转链接的URL,如

c爬虫抓取网页数据( 2019-03-24我想发网络爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-10 05:06
2019-03-24我想发网络爬虫)
基于C#实现网络爬虫C#抓取网页Html源码
时间:2019-03-24
本文章给大家介绍了基于C#实现网络爬虫C#抓取网页的Html源代码,主要包括使用C#实现网络爬虫C#抓取网页的Html源代码,应用技巧,基本知识点总结和注意事项,有一定的参考价值,有需要的朋友可以参考。
我最近刚刚完成了一个简单的网络爬虫。起初我很困惑,不知道如何开始。后来查了很多资料,确实能满足我的需求。有用的信息——代码很难找到。所以想发这个文章,让想做这个功能的朋友少走一些弯路。
首先抓取Html源代码,选择节点的href:使用System.IO添加;使用 System.Net;
private void Search(string url)
{
string rl;
WebRequest Request = WebRequest.Create(url.Trim());
WebResponse Response = Request.GetResponse();
Stream resStream = Response.GetResponseStream();
StreamReader sr = new StreamReader(resStream, Encoding.Default);
StringBuilder sb = new StringBuilder();
while ((rl = sr.ReadLine()) != null)
{
sb.Append(rl);
}
string str = sb.ToString().ToLower();
string str_get = mid(str, "", "");
int start = 0;
while (true)
{
if (str_get == null)
break;
string strResult = mid(str_get, "href=\"", "\"", out start);
if (strResult == null)
break;
else
{
lab[url] += strResult;
str_get = str_get.Substring(start);
}
}
}
private string mid(string istr, string startString, string endString)
{
int iBodyStart = istr.IndexOf(startString, 0); //开始位置
if (iBodyStart == -1)
return null;
iBodyStart += startString.Length; //第一次字符位置起的长度
int iBodyEnd = istr.IndexOf(endString, iBodyStart); //第二次字符在第一次字符位置起的首次位置
if (iBodyEnd == -1)
return null;
iBodyEnd += endString.Length; //第二次字符位置起的长度
string strResult = istr.Substring(iBodyStart, iBodyEnd - iBodyStart - 1);
return strResult;
}
private string mid(string istr, string startString, string endString, out int iBodyEnd)
{
//初始化out参数,否则不能return
iBodyEnd = 0;
int iBodyStart = istr.IndexOf(startString, 0); //开始位置
if (iBodyStart == -1)
return null;
iBodyStart += startString.Length; //第一次字符位置起的长度
iBodyEnd = istr.IndexOf(endString, iBodyStart); //第二次字符在第一次字符位置起的首次位置
if (iBodyEnd == -1)
return null;
iBodyEnd += endString.Length; //第二次字符位置起的长度
string strResult = istr.Substring(iBodyStart, iBodyEnd - iBodyStart - 1);
return strResult;
}
好的,以上就是全部代码了。如果你想运行它,你必须自己修改一些细节。 查看全部
c爬虫抓取网页数据(
2019-03-24我想发网络爬虫)
基于C#实现网络爬虫C#抓取网页Html源码
时间:2019-03-24
本文章给大家介绍了基于C#实现网络爬虫C#抓取网页的Html源代码,主要包括使用C#实现网络爬虫C#抓取网页的Html源代码,应用技巧,基本知识点总结和注意事项,有一定的参考价值,有需要的朋友可以参考。
我最近刚刚完成了一个简单的网络爬虫。起初我很困惑,不知道如何开始。后来查了很多资料,确实能满足我的需求。有用的信息——代码很难找到。所以想发这个文章,让想做这个功能的朋友少走一些弯路。
首先抓取Html源代码,选择节点的href:使用System.IO添加;使用 System.Net;
private void Search(string url)
{
string rl;
WebRequest Request = WebRequest.Create(url.Trim());
WebResponse Response = Request.GetResponse();
Stream resStream = Response.GetResponseStream();
StreamReader sr = new StreamReader(resStream, Encoding.Default);
StringBuilder sb = new StringBuilder();
while ((rl = sr.ReadLine()) != null)
{
sb.Append(rl);
}
string str = sb.ToString().ToLower();
string str_get = mid(str, "", "");
int start = 0;
while (true)
{
if (str_get == null)
break;
string strResult = mid(str_get, "href=\"", "\"", out start);
if (strResult == null)
break;
else
{
lab[url] += strResult;
str_get = str_get.Substring(start);
}
}
}
private string mid(string istr, string startString, string endString)
{
int iBodyStart = istr.IndexOf(startString, 0); //开始位置
if (iBodyStart == -1)
return null;
iBodyStart += startString.Length; //第一次字符位置起的长度
int iBodyEnd = istr.IndexOf(endString, iBodyStart); //第二次字符在第一次字符位置起的首次位置
if (iBodyEnd == -1)
return null;
iBodyEnd += endString.Length; //第二次字符位置起的长度
string strResult = istr.Substring(iBodyStart, iBodyEnd - iBodyStart - 1);
return strResult;
}
private string mid(string istr, string startString, string endString, out int iBodyEnd)
{
//初始化out参数,否则不能return
iBodyEnd = 0;
int iBodyStart = istr.IndexOf(startString, 0); //开始位置
if (iBodyStart == -1)
return null;
iBodyStart += startString.Length; //第一次字符位置起的长度
iBodyEnd = istr.IndexOf(endString, iBodyStart); //第二次字符在第一次字符位置起的首次位置
if (iBodyEnd == -1)
return null;
iBodyEnd += endString.Length; //第二次字符位置起的长度
string strResult = istr.Substring(iBodyStart, iBodyEnd - iBodyStart - 1);
return strResult;
}
好的,以上就是全部代码了。如果你想运行它,你必须自己修改一些细节。
c爬虫抓取网页数据(网络爬虫网页蜘蛛怎么用获取数据的方法?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-10 05:05
介绍网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更多时候称为网络追逐者):
是根据一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。其实现在流行的是通过程序在网页上获取你想要的数据,即自动抓取数据。爬虫能做什么?可以使用爬虫来爬取图片、爬取视频等,你要爬取的数据,只要能通过浏览器访问数据,就可以通过爬虫获取。当你在浏览器中输入地址时,通过DNS服务器找到服务器主机,并向服务器发送请求。服务端解析后,将结果发送到用户浏览器,包括html、js、css等文件内容,浏览器解析出来,最后呈现给用户在浏览器上看到的结果。所以用户看到的浏览器的结果是由HTML代码组成的。我们的爬虫就是获取这些内容,通过对html代码进行分析过滤,从中获取我们想要的资源。页面访问
1) 根据 URL 获取网页
URL 处理模块(库) import urllib.request as req 创建一个类似文件的对象,表示远程 url req.urlopen('') 像本地文件一样读取内容 import urllib.request as req # 获取网络页面根据url: # url ='' pages = req.urlopen(url) #以class文件的方式打开网页#读取网页的所有数据并转换为uft-8编码 data = pages.read ().decode('utf-8') 打印(数据)
2)保存网页数据到文件
#将读取的网页数据写入文件: outfile = open("enrollnudt.txt",'w') # 打开文件 outfile.write(data) # 将网页数据写入文件 outfile.close()
此时我们从网页中获取的数据已经保存在我们指定的文件中了,如下图
网页访问
从图中可以看出,网页的所有数据都存储在本地,但我们需要的大部分数据是文本或数字信息,代码对我们没有用处。那么接下来我们要做的就是清除无用的数据。 (这里我会得到派出所新闻的内容)
3)提取内容
分析网页,找到需要的内容《警校新闻》
内容范围
...
如何提取表格中的所有内容?
导入re包(正则表达式包) import re re.findall(pattern, string [, flags] )以列表的形式返回字符串中匹配模式的非重叠子串。字符串将从左到右扫描。 , 返回的列表也是从左到右匹配一次
如果模式中有组,则返回匹配的组
组列表的正则表达式
使用正则表达式进行匹配
'(.*?)'
数据清洗
清洗前后的数据 x.strip() 数据内部清洗 x.replace('','')
到此,本地已经获取到需要的内容,爬虫基本完成。 查看全部
c爬虫抓取网页数据(网络爬虫网页蜘蛛怎么用获取数据的方法?)
介绍网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更多时候称为网络追逐者):
是根据一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。其实现在流行的是通过程序在网页上获取你想要的数据,即自动抓取数据。爬虫能做什么?可以使用爬虫来爬取图片、爬取视频等,你要爬取的数据,只要能通过浏览器访问数据,就可以通过爬虫获取。当你在浏览器中输入地址时,通过DNS服务器找到服务器主机,并向服务器发送请求。服务端解析后,将结果发送到用户浏览器,包括html、js、css等文件内容,浏览器解析出来,最后呈现给用户在浏览器上看到的结果。所以用户看到的浏览器的结果是由HTML代码组成的。我们的爬虫就是获取这些内容,通过对html代码进行分析过滤,从中获取我们想要的资源。页面访问
1) 根据 URL 获取网页
URL 处理模块(库) import urllib.request as req 创建一个类似文件的对象,表示远程 url req.urlopen('') 像本地文件一样读取内容 import urllib.request as req # 获取网络页面根据url: # url ='' pages = req.urlopen(url) #以class文件的方式打开网页#读取网页的所有数据并转换为uft-8编码 data = pages.read ().decode('utf-8') 打印(数据)
2)保存网页数据到文件
#将读取的网页数据写入文件: outfile = open("enrollnudt.txt",'w') # 打开文件 outfile.write(data) # 将网页数据写入文件 outfile.close()
此时我们从网页中获取的数据已经保存在我们指定的文件中了,如下图
网页访问
从图中可以看出,网页的所有数据都存储在本地,但我们需要的大部分数据是文本或数字信息,代码对我们没有用处。那么接下来我们要做的就是清除无用的数据。 (这里我会得到派出所新闻的内容)
3)提取内容
分析网页,找到需要的内容《警校新闻》
内容范围
...
如何提取表格中的所有内容?
导入re包(正则表达式包) import re re.findall(pattern, string [, flags] )以列表的形式返回字符串中匹配模式的非重叠子串。字符串将从左到右扫描。 , 返回的列表也是从左到右匹配一次
如果模式中有组,则返回匹配的组
组列表的正则表达式
使用正则表达式进行匹配
'(.*?)'
数据清洗
清洗前后的数据 x.strip() 数据内部清洗 x.replace('','')
到此,本地已经获取到需要的内容,爬虫基本完成。
c爬虫抓取网页数据(Python学习群:审查网页元素与网页源码是什么? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-10 05:03
)
简介
以下代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。
我创建了一个学习Python的小学习圈,为大家提供了一个共同讨论和学习Python的平台。欢迎加入Python学习群:960410445讨论视频分享学习。 Python是未来的发展方向,正在挑战我们的分析能力和认识世界的方式。因此,我们与时俱进,迎接变化,不断成长。掌握Python核心技术才是真正的价值。
以上是网页的源代码
以上是回顾网页元素
所以在这里你不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实施思路:
抓取实际访问的动态页面的url-使用正则表达式获取需要的内容-解析内容-存储内容
以上过程部分文字说明:
获取实际访问过的动态页面的url:
在火狐浏览器中,右键打开插件,使用**firebug review element** *(如果没有该项,安装firebug插件),找到并打开**网络(NET)** 选项卡。重新加载网页,获取网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。这个网站动态网页的访问地址是:
源代码
注:python版本为2.7
查看全部
c爬虫抓取网页数据(Python学习群:审查网页元素与网页源码是什么?
)
简介
以下代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。

我创建了一个学习Python的小学习圈,为大家提供了一个共同讨论和学习Python的平台。欢迎加入Python学习群:960410445讨论视频分享学习。 Python是未来的发展方向,正在挑战我们的分析能力和认识世界的方式。因此,我们与时俱进,迎接变化,不断成长。掌握Python核心技术才是真正的价值。
以上是网页的源代码
以上是回顾网页元素
所以在这里你不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实施思路:
抓取实际访问的动态页面的url-使用正则表达式获取需要的内容-解析内容-存储内容
以上过程部分文字说明:
获取实际访问过的动态页面的url:
在火狐浏览器中,右键打开插件,使用**firebug review element** *(如果没有该项,安装firebug插件),找到并打开**网络(NET)** 选项卡。重新加载网页,获取网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。这个网站动态网页的访问地址是:
源代码
注:python版本为2.7
c爬虫抓取网页数据(乌云网我写的一个公用的HttpUtils..例子 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-09-10 05:03
)
我最近在公司建立了一个系统。因为想获取一些网页数据和一些网页数据,所以写了一个公开的HttpUtils。下面是我为乌云网写的一个例子。
一、 首先获取指定路径下的网页内容。
public static String httpGet(String urlStr, Map params) throws Exception {
StringBuilder sb = new StringBuilder();
if (null != params && params.size() > 0) {
sb.append("?");
Entry en;
for (Iterator ir = params.entrySet().iterator(); ir.hasNext();) {
en = ir.next();
sb.append(en.getKey() + "=" + URLEncoder.encode(en.getValue(),"utf-8") + (ir.hasNext() ? "&" : ""));
}
}
URL url = new URL(urlStr + sb);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(5000);
conn.setReadTimeout(5000);
conn.setRequestMethod("GET");
if (conn.getResponseCode() != 200)
throw new Exception("请求异常状态值:" + conn.getResponseCode());
BufferedInputStream bis = new BufferedInputStream(conn.getInputStream());
Reader reader = new InputStreamReader(bis,"gbk");
char[] buffer = new char[2048];
int len = 0;
CharArrayWriter caw = new CharArrayWriter();
while ((len = reader.read(buffer)) > -1)
caw.write(buffer, 0, len);
reader.close();
bis.close();
conn.disconnect();
//System.out.println(caw);
return caw.toString();
}
浏览器查询结果:
代码查询结果与上面一致:
二、通过指定url获取你想要的数据。
此方法需要导入Jsoup包,可以从网上下载。
Document doc = null;
try {
doc = Jsoup.connect("http://www.wooyun.org//bugs//w ... 6quot;).userAgent("Mozilla/5.0 (Windows NT 10.0; Trident/7.0; rv:11.0) like Gecko").timeout(30000).get();
} catch (IOException e) {
e.printStackTrace();
}
for(Iterator ir = doc.select("h3").iterator();ir.hasNext();){
System.out.println(ir.next().text());
}
对于select选择器,根据条件选择,doc.select("h3").iterator(),Jsoup的规则如下:
jsoup 是一个基于 Java 的 HTML 解析器,可以直接解析 URL 地址或 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
jsoup 的强大之处在于它对文档元素的检索。 Select 方法将返回元素集合并提供一组方法来提取和处理结果。要掌握Jsoup,首先要熟悉它的选择器语法。
1、Selector 选择器的基本语法
2、Selector 选择器组合语法
3、Selector 伪选择器语法
注意:上面的伪选择器索引从0开始,表示第一个元素的索引为0,第二个元素的索引为1,以此类推。
浏览器访问:
代码访问:
查看全部
c爬虫抓取网页数据(乌云网我写的一个公用的HttpUtils..例子
)
我最近在公司建立了一个系统。因为想获取一些网页数据和一些网页数据,所以写了一个公开的HttpUtils。下面是我为乌云网写的一个例子。
一、 首先获取指定路径下的网页内容。
public static String httpGet(String urlStr, Map params) throws Exception {
StringBuilder sb = new StringBuilder();
if (null != params && params.size() > 0) {
sb.append("?");
Entry en;
for (Iterator ir = params.entrySet().iterator(); ir.hasNext();) {
en = ir.next();
sb.append(en.getKey() + "=" + URLEncoder.encode(en.getValue(),"utf-8") + (ir.hasNext() ? "&" : ""));
}
}
URL url = new URL(urlStr + sb);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(5000);
conn.setReadTimeout(5000);
conn.setRequestMethod("GET");
if (conn.getResponseCode() != 200)
throw new Exception("请求异常状态值:" + conn.getResponseCode());
BufferedInputStream bis = new BufferedInputStream(conn.getInputStream());
Reader reader = new InputStreamReader(bis,"gbk");
char[] buffer = new char[2048];
int len = 0;
CharArrayWriter caw = new CharArrayWriter();
while ((len = reader.read(buffer)) > -1)
caw.write(buffer, 0, len);
reader.close();
bis.close();
conn.disconnect();
//System.out.println(caw);
return caw.toString();
}
浏览器查询结果:
代码查询结果与上面一致:

二、通过指定url获取你想要的数据。
此方法需要导入Jsoup包,可以从网上下载。
Document doc = null;
try {
doc = Jsoup.connect("http://www.wooyun.org//bugs//w ... 6quot;).userAgent("Mozilla/5.0 (Windows NT 10.0; Trident/7.0; rv:11.0) like Gecko").timeout(30000).get();
} catch (IOException e) {
e.printStackTrace();
}
for(Iterator ir = doc.select("h3").iterator();ir.hasNext();){
System.out.println(ir.next().text());
}
对于select选择器,根据条件选择,doc.select("h3").iterator(),Jsoup的规则如下:
jsoup 是一个基于 Java 的 HTML 解析器,可以直接解析 URL 地址或 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
jsoup 的强大之处在于它对文档元素的检索。 Select 方法将返回元素集合并提供一组方法来提取和处理结果。要掌握Jsoup,首先要熟悉它的选择器语法。
1、Selector 选择器的基本语法
2、Selector 选择器组合语法
3、Selector 伪选择器语法
注意:上面的伪选择器索引从0开始,表示第一个元素的索引为0,第二个元素的索引为1,以此类推。
浏览器访问:
代码访问:
c爬虫抓取网页数据(一个网站抓站过程中遇到的奇特网站,分享思路和抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-09-25 13:20
在我们学习的过程中,打开一个网站,想抓取一次数据,但并不是所有的网站都能以一种方式抓取数据。有的是特殊的网页结构,有的是json数据包。不一样。慢慢写一些自己在抓取网站过程中遇到的奇葩网站,分享一下思路和抓取方法!
工具、目标\
工具:pycharm、python3.6 版本
库:请求库
目标:普世网热门图片直播页面,所有图片信息
注:此网站有一个热门图片页面,其中收录活动的相关照片。根据活动情况,所有图片信息将写入txt文件(不下载图片,以免影响服务器)!
目标分析\
首先打开上图首页,点击右上角,出现选项后,点击进入热图直播选项(注意:部分浏览器需要放大页面才能看到热图直播广播选项),进入后页如下\
在这里,我已放大到 30%。下面是一页一页的活动现场图片。#价位@762459510 免费采集蟒蛇爬虫配套实操资料#点个活动,看页面\
看到页面上的图片加载这么慢,应该是动态加载的,右键查看源码,果然如此!\
没有任何图片信息,那我们就需要使用浏览器的页面审核工具了!我这里用的是火狐,按F12可以打开,然后点击网络,清除内容,刷新页面,看看加载了哪些数据。\
经过简单的检查,我们发现了2个数据收录我们想要的数据\
\
一个是activity相关的信息,一个是image相关的信息,都是json格式加载的。这个很简单,可以请求相关的URL。这时候我突然想到,如果之前的多个活动页面也是动态加载的,那么是否可以通过这种方式捕获所有活动?来看看\
在这个json数据中,收录了页面加载的所有活动信息!没有翻页。. . 难怪加载这么慢【手动申诉】。\
代码\
通过上面的分析,我们了解了目标数据的位置,接下来就可以开始尝试写代码了
导入requests库,然后直接请求真实的URL,得到名称和对应的URL(真实的URL在消息头中),然后在页面中构造真实的URL。上面得到的网址实际上是网页的网址,而不是网页的网址。如何获取json包所在的真实地址?我们对比一下获取到的几个页面的真实URL,不难发现其规律性。
通过对比发现activityNo的值其实是不一样的,而且这个值也存在于上面抓到的json包中!
构造下一个页面的真实请求地址,然后抓取json包得到所有图片url!至此,核心代码已经写好,完善一下,整体代码和效果如下:\
\
不到1分钟,这个页面上的所有活动和图片url都被保存了,整体代码不到20行,很简单的一个网站!如果要下载图片,可以把所有的url复制到下载工具,批量下载!\最后,如果你的时间不是很紧,想要快速提高,最重要的是你不怕吃苦。我建议你可以定价@762459510。那真的很好。很多人都在快速进步。你需要害怕困难。!可以去加进去看看~
后记\
这个网站的整体结构比较清晰,数据也很容易获取。今天之所以拿这个网站来分享,是因为当我开始抓包的时候,简直不敢相信,一页之间竟然加载了400多张图片。. . 而且看页面结构,没想到这么简单!
总的来说,网站更适合新手学习抓包获取数据。希望对大家有帮助,加油! 查看全部
c爬虫抓取网页数据(一个网站抓站过程中遇到的奇特网站,分享思路和抓取方法)
在我们学习的过程中,打开一个网站,想抓取一次数据,但并不是所有的网站都能以一种方式抓取数据。有的是特殊的网页结构,有的是json数据包。不一样。慢慢写一些自己在抓取网站过程中遇到的奇葩网站,分享一下思路和抓取方法!
工具、目标\
工具:pycharm、python3.6 版本
库:请求库
目标:普世网热门图片直播页面,所有图片信息
注:此网站有一个热门图片页面,其中收录活动的相关照片。根据活动情况,所有图片信息将写入txt文件(不下载图片,以免影响服务器)!
目标分析\
首先打开上图首页,点击右上角,出现选项后,点击进入热图直播选项(注意:部分浏览器需要放大页面才能看到热图直播广播选项),进入后页如下\
在这里,我已放大到 30%。下面是一页一页的活动现场图片。#价位@762459510 免费采集蟒蛇爬虫配套实操资料#点个活动,看页面\
看到页面上的图片加载这么慢,应该是动态加载的,右键查看源码,果然如此!\
没有任何图片信息,那我们就需要使用浏览器的页面审核工具了!我这里用的是火狐,按F12可以打开,然后点击网络,清除内容,刷新页面,看看加载了哪些数据。\
经过简单的检查,我们发现了2个数据收录我们想要的数据\
\
一个是activity相关的信息,一个是image相关的信息,都是json格式加载的。这个很简单,可以请求相关的URL。这时候我突然想到,如果之前的多个活动页面也是动态加载的,那么是否可以通过这种方式捕获所有活动?来看看\
在这个json数据中,收录了页面加载的所有活动信息!没有翻页。. . 难怪加载这么慢【手动申诉】。\
代码\
通过上面的分析,我们了解了目标数据的位置,接下来就可以开始尝试写代码了
导入requests库,然后直接请求真实的URL,得到名称和对应的URL(真实的URL在消息头中),然后在页面中构造真实的URL。上面得到的网址实际上是网页的网址,而不是网页的网址。如何获取json包所在的真实地址?我们对比一下获取到的几个页面的真实URL,不难发现其规律性。
通过对比发现activityNo的值其实是不一样的,而且这个值也存在于上面抓到的json包中!
构造下一个页面的真实请求地址,然后抓取json包得到所有图片url!至此,核心代码已经写好,完善一下,整体代码和效果如下:\
\
不到1分钟,这个页面上的所有活动和图片url都被保存了,整体代码不到20行,很简单的一个网站!如果要下载图片,可以把所有的url复制到下载工具,批量下载!\最后,如果你的时间不是很紧,想要快速提高,最重要的是你不怕吃苦。我建议你可以定价@762459510。那真的很好。很多人都在快速进步。你需要害怕困难。!可以去加进去看看~
后记\
这个网站的整体结构比较清晰,数据也很容易获取。今天之所以拿这个网站来分享,是因为当我开始抓包的时候,简直不敢相信,一页之间竟然加载了400多张图片。. . 而且看页面结构,没想到这么简单!
总的来说,网站更适合新手学习抓包获取数据。希望对大家有帮助,加油!
c爬虫抓取网页数据(爬虫爬虫抓取系统的重要组成部分工具爬虫的用法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-09-25 13:17
)
爬虫
简单的说,爬虫就是编写程序模拟浏览器上网,然后让它去网上抓取数据的过程。浏览器可以简单理解为一个原创的自然爬虫工具
爬行动物的作用
可以获得有价值的信息。比如在渗透测试中,我们可以通过编写python脚本或者爬取网站有价值的数据来批量验证漏洞
爬虫的合法性
爬虫技术本身是合法的,但是利用它非法获取数据是违法的。喜欢
恶意爬虫
履带分类
1. 通用爬虫
各大搜索引擎爬虫系统的重要组成部分,爬取整页数据。喜欢
2. 关注爬虫
它建立在通用爬虫的基础上,抓取页面上特定的部分内容
3. 增量爬虫
监控网站中数据更新的状态,只抓取网站中最新更新的数据
防爬机构
门户网站制定相应策略或技术手段防止爬虫爬取网站数据
防反爬策略
爬虫程序可以通过制定相关策略或技术手段破解门户网站中的反爬虫机制,从而获取门户网站的数据
robots.txt 协议(君子协议)
机器人协议,又称爬虫协议、机器人协议等,其全称是“机器人排除协议(Robots Exclusion Protocol)”。网站 通过Robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。Robots还有两种用途,一种是告诉搜索引擎你不能爬取哪些页面(其他的默认可以爬取);另一种是告诉搜索引擎你只能爬取哪些页面(其他的默认不能爬取)。
搜索机器人(蜘蛛)访问站点时,首先会检查网站的根目录下是否存在robots.txt。如果存在,则根据文件内容确定访问范围。如果不存在,它会跟随链接进行爬取。
但是,机器人协议对个人不是强制性的,可能不会被遵守。
查看全部
c爬虫抓取网页数据(爬虫爬虫抓取系统的重要组成部分工具爬虫的用法
)
爬虫
简单的说,爬虫就是编写程序模拟浏览器上网,然后让它去网上抓取数据的过程。浏览器可以简单理解为一个原创的自然爬虫工具
爬行动物的作用
可以获得有价值的信息。比如在渗透测试中,我们可以通过编写python脚本或者爬取网站有价值的数据来批量验证漏洞
爬虫的合法性
爬虫技术本身是合法的,但是利用它非法获取数据是违法的。喜欢
恶意爬虫
履带分类
1. 通用爬虫
各大搜索引擎爬虫系统的重要组成部分,爬取整页数据。喜欢
2. 关注爬虫
它建立在通用爬虫的基础上,抓取页面上特定的部分内容
3. 增量爬虫
监控网站中数据更新的状态,只抓取网站中最新更新的数据
防爬机构
门户网站制定相应策略或技术手段防止爬虫爬取网站数据
防反爬策略
爬虫程序可以通过制定相关策略或技术手段破解门户网站中的反爬虫机制,从而获取门户网站的数据
robots.txt 协议(君子协议)
机器人协议,又称爬虫协议、机器人协议等,其全称是“机器人排除协议(Robots Exclusion Protocol)”。网站 通过Robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。Robots还有两种用途,一种是告诉搜索引擎你不能爬取哪些页面(其他的默认可以爬取);另一种是告诉搜索引擎你只能爬取哪些页面(其他的默认不能爬取)。
搜索机器人(蜘蛛)访问站点时,首先会检查网站的根目录下是否存在robots.txt。如果存在,则根据文件内容确定访问范围。如果不存在,它会跟随链接进行爬取。
但是,机器人协议对个人不是强制性的,可能不会被遵守。
c爬虫抓取网页数据(异步和非阻塞的区别同步过程中的应用框架 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-23 21:17
)
scratch简介
Scrapy是一个应用程序框架,用于抓取网站数据和提取结构数据。我们只需要实现少量代码就可以快速爬行。Scrapy使用twisted异步网络框架来加快我们的下载速度
Scratch是异步爬虫的框架,是爬虫的必要技术。很少有语言有专门的爬虫框架。Python中的scratch框架专门用于crawler;使爬虫程序更加稳定和高效。sweep框架的许多内容被封装;高配置和可扩展性。在固定框架下,可以直接添加内容和调用;它是基于异步的。扭曲(扭曲)封装在内部。实现逻辑非常复杂。大量的闭包被采用。基于高阶函数(函数作为返回值或函数对象作为参数),小函数嵌套在大函数中。内部函数需要引用外部函数的变量,以确保变量的安全性,形成闭包。下载速度非常快。它是一个异步网络框架。下载的原理是基于内部封装的多线程,可以直接调用。下载效率也很高。内部封装方法可以控制爬行速度。通过修改配置项可以达到控制爬行速度的目的
异步和非阻塞的区别
在同步过程中,从上到下,只能等待蓝色函数执行,获取return,然后执行黄色函数。它就像一条管道。完成上述工作后,您只能执行以下操作
在异步过程中,蓝色函数对黄色函数没有影响。蓝色函数向网站发送请求,黄色函数可以在等待网站反馈的时间段内向另一个页面发送请求,充分利用等待时间,提高爬网效率
异步:发出调用后,调用直接返回,而不管结果如何
非阻塞:它关注等待调用结果的程序的状态,这意味着在无法立即获得结果之前,调用不会阻塞当前线程
潦草的工作流程
我们通常不只是请求一个URL来抓取多个页面。此时,我们可以在URL列表中放置多个页面。从URL列表中提取URL,向其发送请求,获取相应数据,提取数据,解析数据,保存内容等数据处理;然后对下一个URL循环执行相同的操作
有两个队列。队列1存储每个页面的URL。运行线程从队列1获取URL,发送请求,获取对应的URL,解析每个页面的数据,将解析后的数据放入队列2(如解析图片的名称和URL),然后放入下一个线程下载保存
Scratch是基于异步的。它具有很高的可配置性和可扩展性,结构特殊而复杂。引擎负责整个场景框架的调度。无论它是请求还是获得相应的信息,都必须通过引擎,这相当于人脑。第一步是将目标URL发送到引擎。引擎下面有一个爬虫程序,带有我们需要的URL地址。将URL地址发送到引擎。引擎只负责调度,下载是一个下载器;步骤2:引擎获取URL后,首先将其交给调度器,调度器接收请求的URL并列出;在列出第三个步骤后,调度器给下载程序,下载程序连接到网络以执行请求-响应操作。调度器启动请求以获取响应结果。在步骤4中,下载程序不处理响应结果。下载程序获得响应结果后,将其移交给爬虫程序进行处理。爬虫获取响应结果后,进行数据分析处理;第五步是将解析后的数据发送到管道进行处理,管道专用于保存数据。然后循环,直到调度程序中没有URL
一般工作流:引擎将找到爬虫以获取URL(可能有多个URL),通过爬虫获取URL并将其发送给调度程序。该URL列在调度器中,取出其中一个URL返回到下载器发送请求,获取相应结果,并将相应结果发送给爬虫进行解析,最后爬虫将解析后的数据保存到管道中。此进程将循环,直到计划程序中没有URL为止
1.crawler将URL发送到引擎,2.engine将URL发送到调度程序以供登录,3.scheduler将向引擎发送一个爬网URL,4.engine通过下载中间件将URL发送到下载程序。下载器获取URL后,需要在线发送请求获取相应的URL,5.downloader通过下载中间件将生成的响应发送给引擎,6.engine将接收到的响应发送给爬虫进行解析。爬虫和引擎通过爬虫中间件连接,7.爬虫通过引擎将解析后的数据发送到管道文件保存,8.通过解析后的数据,页面中可能有新的URL需要处理。继续执行上述步骤
名称函数的实现
刮擦发动机
整个框架的核心,总指挥:负责不同模块之间的数据和信号传输
Scratch已经实现
调度程序
存储引擎发送的请求、接收引擎发送的URL并执行列表操作的队列
Scratch已经实现
下载器
发送请求,获取相应的,下载引擎发送的请求,并将其返回到引擎
Scratch已经实现
爬行器(爬虫文件)
分析数据,处理引擎发送的响应,提取数据,提取URL,并将其提供给引擎
需要重写
项目管道
存储数据并处理发动机传输的数据,如存储器
需要重写
下载中间件
它位于引擎和下载器之间,用于处理请求和它们之间的通信(更多使用)。您可以自定义下载扩展,例如设置代理
一般来说,你不必手写
蜘蛛中间件
您可以自定义请求和筛选响应
一般来说,你不必手写
爬虫中间件
位于引擎和爬虫程序之间,用于处理爬虫程序的响应、输出结果和新请求(较少使用)
一般来说,你不必手写
框架已经构建,里面有封装的程序。爬虫文件和管道需要重写,下载中间件可能需要重写
使用scratch爬行数据的基本步骤
第一步是创建一个临时项目。您需要使用以下命令:scratch startproject(fixed)+project name,并且开始项目后面跟着项目名称
第二部分创建一个爬虫程序:scratch genspider(固定)+爬虫文件名+爬虫范围(域名)
执行扫描爬虫程序的命令:扫描爬虫程序文件的名称
1 创建一个scrapy项目
scrapy startproject mySpider
2 生成一个爬虫
scrapy genspider demo demo.cn
https://www.baidu.com/ --> baidu.com
https://www.douban.com/ --> douban.com
3 提取数据
完善spider 使用xpath等
4 保存数据
pipeline中保存数据
具体步骤:点击pycham下的terminal进入路径界面,根据路径依次输入CD crawler、CD 21day,然后输入D:\pycharmprojects\crawler\21day>;路径,然后创建myspider文件夹,并执行命令“scratch startproject myspider”
现在,新项目文件已成功创建,并且成功创建的文件夹显示在pycham的左侧
依次展开mysprider文件夹,将显示以下文件。打开script.cfg文件,该文件将提示自动创建该文件,其中收录最新帮助文档的地址,并告诉我们其他配置文件的来源以及如何创建它们
创建文件夹后,您可以通过CD myspirder输入文件夹来创建scratch genspider爬虫。在这里,首先创建豆瓣爬虫文件,scratch genspider dB
它表示已创建爬网程序文件。我们可以在myspirder和spider目录中看到创建的DB文件
在创建的DB文件中,parse函数中将有一个突出显示的提示和一个警告。在继承父类的过程中,需要修改父类,这涉及到面向对象重写和重载的概念。重写是子类重写父类的实现方法。此时返回值和形式参数不能更改,只能修改函数中的代码,不能修改头和尾,即外壳不能更改,内部的东西可以重写;重载意味着方法名相同,参数和返回值类型不同。在这里,需要重载函数,并且修改了参数的数量。有不一致之处。代码源文件中有三个参数(DEF parse(self、response、**kwargs):),只有两个。此提示不影响后续爬网和程序操作。您还可以复制源代码来替换它
此时,程序在21day文件夹下运行mysprider。如果你删除 查看全部
c爬虫抓取网页数据(异步和非阻塞的区别同步过程中的应用框架
)
scratch简介
Scrapy是一个应用程序框架,用于抓取网站数据和提取结构数据。我们只需要实现少量代码就可以快速爬行。Scrapy使用twisted异步网络框架来加快我们的下载速度
Scratch是异步爬虫的框架,是爬虫的必要技术。很少有语言有专门的爬虫框架。Python中的scratch框架专门用于crawler;使爬虫程序更加稳定和高效。sweep框架的许多内容被封装;高配置和可扩展性。在固定框架下,可以直接添加内容和调用;它是基于异步的。扭曲(扭曲)封装在内部。实现逻辑非常复杂。大量的闭包被采用。基于高阶函数(函数作为返回值或函数对象作为参数),小函数嵌套在大函数中。内部函数需要引用外部函数的变量,以确保变量的安全性,形成闭包。下载速度非常快。它是一个异步网络框架。下载的原理是基于内部封装的多线程,可以直接调用。下载效率也很高。内部封装方法可以控制爬行速度。通过修改配置项可以达到控制爬行速度的目的
异步和非阻塞的区别
在同步过程中,从上到下,只能等待蓝色函数执行,获取return,然后执行黄色函数。它就像一条管道。完成上述工作后,您只能执行以下操作
在异步过程中,蓝色函数对黄色函数没有影响。蓝色函数向网站发送请求,黄色函数可以在等待网站反馈的时间段内向另一个页面发送请求,充分利用等待时间,提高爬网效率
异步:发出调用后,调用直接返回,而不管结果如何
非阻塞:它关注等待调用结果的程序的状态,这意味着在无法立即获得结果之前,调用不会阻塞当前线程
潦草的工作流程
我们通常不只是请求一个URL来抓取多个页面。此时,我们可以在URL列表中放置多个页面。从URL列表中提取URL,向其发送请求,获取相应数据,提取数据,解析数据,保存内容等数据处理;然后对下一个URL循环执行相同的操作
有两个队列。队列1存储每个页面的URL。运行线程从队列1获取URL,发送请求,获取对应的URL,解析每个页面的数据,将解析后的数据放入队列2(如解析图片的名称和URL),然后放入下一个线程下载保存
Scratch是基于异步的。它具有很高的可配置性和可扩展性,结构特殊而复杂。引擎负责整个场景框架的调度。无论它是请求还是获得相应的信息,都必须通过引擎,这相当于人脑。第一步是将目标URL发送到引擎。引擎下面有一个爬虫程序,带有我们需要的URL地址。将URL地址发送到引擎。引擎只负责调度,下载是一个下载器;步骤2:引擎获取URL后,首先将其交给调度器,调度器接收请求的URL并列出;在列出第三个步骤后,调度器给下载程序,下载程序连接到网络以执行请求-响应操作。调度器启动请求以获取响应结果。在步骤4中,下载程序不处理响应结果。下载程序获得响应结果后,将其移交给爬虫程序进行处理。爬虫获取响应结果后,进行数据分析处理;第五步是将解析后的数据发送到管道进行处理,管道专用于保存数据。然后循环,直到调度程序中没有URL
一般工作流:引擎将找到爬虫以获取URL(可能有多个URL),通过爬虫获取URL并将其发送给调度程序。该URL列在调度器中,取出其中一个URL返回到下载器发送请求,获取相应结果,并将相应结果发送给爬虫进行解析,最后爬虫将解析后的数据保存到管道中。此进程将循环,直到计划程序中没有URL为止
1.crawler将URL发送到引擎,2.engine将URL发送到调度程序以供登录,3.scheduler将向引擎发送一个爬网URL,4.engine通过下载中间件将URL发送到下载程序。下载器获取URL后,需要在线发送请求获取相应的URL,5.downloader通过下载中间件将生成的响应发送给引擎,6.engine将接收到的响应发送给爬虫进行解析。爬虫和引擎通过爬虫中间件连接,7.爬虫通过引擎将解析后的数据发送到管道文件保存,8.通过解析后的数据,页面中可能有新的URL需要处理。继续执行上述步骤
名称函数的实现
刮擦发动机
整个框架的核心,总指挥:负责不同模块之间的数据和信号传输
Scratch已经实现
调度程序
存储引擎发送的请求、接收引擎发送的URL并执行列表操作的队列
Scratch已经实现
下载器
发送请求,获取相应的,下载引擎发送的请求,并将其返回到引擎
Scratch已经实现
爬行器(爬虫文件)
分析数据,处理引擎发送的响应,提取数据,提取URL,并将其提供给引擎
需要重写
项目管道
存储数据并处理发动机传输的数据,如存储器
需要重写
下载中间件
它位于引擎和下载器之间,用于处理请求和它们之间的通信(更多使用)。您可以自定义下载扩展,例如设置代理
一般来说,你不必手写
蜘蛛中间件
您可以自定义请求和筛选响应
一般来说,你不必手写
爬虫中间件
位于引擎和爬虫程序之间,用于处理爬虫程序的响应、输出结果和新请求(较少使用)
一般来说,你不必手写
框架已经构建,里面有封装的程序。爬虫文件和管道需要重写,下载中间件可能需要重写
使用scratch爬行数据的基本步骤
第一步是创建一个临时项目。您需要使用以下命令:scratch startproject(fixed)+project name,并且开始项目后面跟着项目名称
第二部分创建一个爬虫程序:scratch genspider(固定)+爬虫文件名+爬虫范围(域名)
执行扫描爬虫程序的命令:扫描爬虫程序文件的名称
1 创建一个scrapy项目
scrapy startproject mySpider
2 生成一个爬虫
scrapy genspider demo demo.cn
https://www.baidu.com/ --> baidu.com
https://www.douban.com/ --> douban.com
3 提取数据
完善spider 使用xpath等
4 保存数据
pipeline中保存数据
具体步骤:点击pycham下的terminal进入路径界面,根据路径依次输入CD crawler、CD 21day,然后输入D:\pycharmprojects\crawler\21day>;路径,然后创建myspider文件夹,并执行命令“scratch startproject myspider”
现在,新项目文件已成功创建,并且成功创建的文件夹显示在pycham的左侧
依次展开mysprider文件夹,将显示以下文件。打开script.cfg文件,该文件将提示自动创建该文件,其中收录最新帮助文档的地址,并告诉我们其他配置文件的来源以及如何创建它们
创建文件夹后,您可以通过CD myspirder输入文件夹来创建scratch genspider爬虫。在这里,首先创建豆瓣爬虫文件,scratch genspider dB
它表示已创建爬网程序文件。我们可以在myspirder和spider目录中看到创建的DB文件
在创建的DB文件中,parse函数中将有一个突出显示的提示和一个警告。在继承父类的过程中,需要修改父类,这涉及到面向对象重写和重载的概念。重写是子类重写父类的实现方法。此时返回值和形式参数不能更改,只能修改函数中的代码,不能修改头和尾,即外壳不能更改,内部的东西可以重写;重载意味着方法名相同,参数和返回值类型不同。在这里,需要重载函数,并且修改了参数的数量。有不一致之处。代码源文件中有三个参数(DEF parse(self、response、**kwargs):),只有两个。此提示不影响后续爬网和程序操作。您还可以复制源代码来替换它
此时,程序在21day文件夹下运行mysprider。如果你删除
c爬虫抓取网页数据(ScreamingFrogSEOSpiderforMac安装包功能特色开发工具 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-23 21:14
)
尖叫青蛙SEO蜘蛛为Mac是一个网络爬虫开发工具,专门用于捕捉URL。您可以通过尖叫青蛙Mac版快速捕捉网站可能损坏的链接。和服务器错误,或找出网站的链接,永久重定向的链接,并检查URL,网页标题,描述和内容等信息的信息中心。
安装包
功能
1、查找断开链路
累加网站并找到损坏的链接(404S)和服务器错误。批量导出的错误和进行维修源URL,或发送给开发者。
2、审查重定向
查找临时和永久重定向,识别重定向链和循环,或上传的URL列表来审查网站迁移。
3、分析页面标题和元数据
分析期间抓取过程的页面标题和meticown,并确定网站@@ķ中中,短缺,缺失或重复的内容。
4、查询重复的内容
检查完全重复URL,部分重复的元素(如页面标题,描述或标题),并查找低内容页。
5、使用XPath提取数据
使用CSS PATH,XPATH或REGEX采集来自所述网页的HTML的任何数据。这可能包括社会性标签,其他标题,价格,单品或更多!
6、审查机器人和指令
查看网址robots.txt阻止的,Yuanci或X-Robots标签,比如 'NOINDEX',或 'nofollow的',和说明书和rel = “next” 和rel = “PREV”。
7、成成X站点地图
快速创建一个XML站点地图和图像XML站点地图,这是由URL先进,包括最后的修改,优先级,和改变频率。
8、 G G欧蒂龙整合
对于捕捉功能,连接到谷歌AnalyticsAPI并获得用户数据,如会话或跳率和改造,目标,事务,收入为目标网页。
9、抓斗的JavaScript 网站
使用集成铬WRS渲染网页以捕获动态的,丰富在JavaScript 网站和框架,如角,反应,和Vue.js。
1 0、可视化位点的体系结构
强制交互式抓取和目录来强制引导件和树图现场可视化评价内部链接和URL结构。
查看全部
c爬虫抓取网页数据(ScreamingFrogSEOSpiderforMac安装包功能特色开发工具
)
尖叫青蛙SEO蜘蛛为Mac是一个网络爬虫开发工具,专门用于捕捉URL。您可以通过尖叫青蛙Mac版快速捕捉网站可能损坏的链接。和服务器错误,或找出网站的链接,永久重定向的链接,并检查URL,网页标题,描述和内容等信息的信息中心。
安装包
功能
1、查找断开链路
累加网站并找到损坏的链接(404S)和服务器错误。批量导出的错误和进行维修源URL,或发送给开发者。
2、审查重定向
查找临时和永久重定向,识别重定向链和循环,或上传的URL列表来审查网站迁移。
3、分析页面标题和元数据
分析期间抓取过程的页面标题和meticown,并确定网站@@ķ中中,短缺,缺失或重复的内容。
4、查询重复的内容
检查完全重复URL,部分重复的元素(如页面标题,描述或标题),并查找低内容页。
5、使用XPath提取数据
使用CSS PATH,XPATH或REGEX采集来自所述网页的HTML的任何数据。这可能包括社会性标签,其他标题,价格,单品或更多!
6、审查机器人和指令
查看网址robots.txt阻止的,Yuanci或X-Robots标签,比如 'NOINDEX',或 'nofollow的',和说明书和rel = “next” 和rel = “PREV”。
7、成成X站点地图
快速创建一个XML站点地图和图像XML站点地图,这是由URL先进,包括最后的修改,优先级,和改变频率。
8、 G G欧蒂龙整合
对于捕捉功能,连接到谷歌AnalyticsAPI并获得用户数据,如会话或跳率和改造,目标,事务,收入为目标网页。
9、抓斗的JavaScript 网站
使用集成铬WRS渲染网页以捕获动态的,丰富在JavaScript 网站和框架,如角,反应,和Vue.js。
1 0、可视化位点的体系结构
强制交互式抓取和目录来强制引导件和树图现场可视化评价内部链接和URL结构。
c爬虫抓取网页数据(四内容分析4.1搜索,正逢最近福建疫情再起疫情)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-09-23 21:12
一个背景
有一个最近的想法,我想获得指定时间段的新闻/ 文章信息,只需做一个情绪分析。然后,最基本的是获得文章 List。有一些与舆论相关的接口,如微博的舆论监测平台,有更多成熟的apis;阿里巴巴云,百度云也有一个舆论界面。但是,它限于某些因素或成本问题,或者API本身可以提供的新闻时间范围不符与期望,导致无法使用它。然后考虑暂时捕获一些信息以支持此工作内容。
p> 2在公开舆论检测中
监控,指关键词获取公共意见信息,包括新闻,论坛,博客,微博,微信,贴吧等,京东云的京东万象,发现是一个很好的API聚合入口。以情绪API为例,涵盖了许多服务:
实现各种服务提供商的能力,还可以通过自己的接口和合作等采集有关新闻爬网的基本信息等,良好的频道覆盖,公众舆论分析,然后再次在本地商店,并提供外部结果。简单,但涉及检索,模型的一部分仍然很困难。
三个信息源
回归主题。我们要做的第一步是选择合适的数据来源来采集文章。考虑到采集成本,使用每个搜索引擎/流量平台是一个不错的选择,因为作为流量输入,它帮助我们完成了渠道资源采集的工作。
另一方面,所有主要流平台都是爬行动物,并且对于各种爬行动物策略,如果它是大量的抓取,则更容易发现。它只是一个少量,偶尔获取信息,它只是为了学习和使用,并且不会引起太多的交通影响,因此通常不关心。有一个底线,一英寸,它非常重要!
四个内容分析4. 1搜索示例
最近,福建会开始流行病,我们将首先把它作为关键词搜搜:
结果相应链路:%E7%A6%8F%E5%BB%Ba%20%E7%96%AB%E6%83%85&amp; rsv_spt = 1&amp; RSV_IQID = 0xFF465A7D00029162&amp; issp = 1&amp; f = 8&amp; RSV_BP = 1&amp; rsv_idx = 2&amp; IE = UTF-8&amp; tn = baiduhome_pg&amp; rsv_enter = 1&amp; RSV_DL = IB&amp; RSV_SUG3 = 28&amp; rsv_sug1 = 19&amp; RSV_SUG7 = 101&amp; rsv_sug2 = 0&amp; RSV_BTYPE = I&amp;输入= 6747&amp rsv_sug4 = 11869
4. 2搜索结果内容分析
这里,我们专注于对网站结构的分析来确认分析方法。
颁发的几个搜索结果,全部:
1、标题(累计“6 + 18”,一篇文章读取福建省的现状和涂抹链,“ 查看全部
c爬虫抓取网页数据(四内容分析4.1搜索,正逢最近福建疫情再起疫情)
一个背景
有一个最近的想法,我想获得指定时间段的新闻/ 文章信息,只需做一个情绪分析。然后,最基本的是获得文章 List。有一些与舆论相关的接口,如微博的舆论监测平台,有更多成熟的apis;阿里巴巴云,百度云也有一个舆论界面。但是,它限于某些因素或成本问题,或者API本身可以提供的新闻时间范围不符与期望,导致无法使用它。然后考虑暂时捕获一些信息以支持此工作内容。
p> 2在公开舆论检测中
监控,指关键词获取公共意见信息,包括新闻,论坛,博客,微博,微信,贴吧等,京东云的京东万象,发现是一个很好的API聚合入口。以情绪API为例,涵盖了许多服务:
实现各种服务提供商的能力,还可以通过自己的接口和合作等采集有关新闻爬网的基本信息等,良好的频道覆盖,公众舆论分析,然后再次在本地商店,并提供外部结果。简单,但涉及检索,模型的一部分仍然很困难。
三个信息源
回归主题。我们要做的第一步是选择合适的数据来源来采集文章。考虑到采集成本,使用每个搜索引擎/流量平台是一个不错的选择,因为作为流量输入,它帮助我们完成了渠道资源采集的工作。
另一方面,所有主要流平台都是爬行动物,并且对于各种爬行动物策略,如果它是大量的抓取,则更容易发现。它只是一个少量,偶尔获取信息,它只是为了学习和使用,并且不会引起太多的交通影响,因此通常不关心。有一个底线,一英寸,它非常重要!
四个内容分析4. 1搜索示例
最近,福建会开始流行病,我们将首先把它作为关键词搜搜:
结果相应链路:%E7%A6%8F%E5%BB%Ba%20%E7%96%AB%E6%83%85&amp; rsv_spt = 1&amp; RSV_IQID = 0xFF465A7D00029162&amp; issp = 1&amp; f = 8&amp; RSV_BP = 1&amp; rsv_idx = 2&amp; IE = UTF-8&amp; tn = baiduhome_pg&amp; rsv_enter = 1&amp; RSV_DL = IB&amp; RSV_SUG3 = 28&amp; rsv_sug1 = 19&amp; RSV_SUG7 = 101&amp; rsv_sug2 = 0&amp; RSV_BTYPE = I&amp;输入= 6747&amp rsv_sug4 = 11869
4. 2搜索结果内容分析
这里,我们专注于对网站结构的分析来确认分析方法。
颁发的几个搜索结果,全部:
1、标题(累计“6 + 18”,一篇文章读取福建省的现状和涂抹链,“
c爬虫抓取网页数据(百度蜘蛛(baiduspider)毕业设计的部分内容的第二章)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-09-23 21:10
以下是我毕业设计的第二部分“搜索引擎的工作原理”。第一章是导言,所以你不必把它写出来。因为这是一篇论文,是邹写的
2搜索引擎的工作原理2.1搜索引擎爬虫
不同的搜索引擎对爬虫有不同的通用名称。例如,百度爬虫称它们为“百度蜘蛛”,谷歌称它们为“谷歌机器人”。爬虫的作用:互联网上有数百亿个网页。爬虫程序需要做的第一件事是将如此大量的网页数据下载到本地服务器,以形成互联网页面的镜像备份。在转移到本地后,这些页面将通过一些后续算法处理,并显示在搜索结果上
2.@1.1搜索引擎爬虫框架
一般的爬虫框架流程如下:首先从海量的互联网页面中抓取一些高质量的页面,提取其中收录的URL,并将这些URL放入要抓取的队列中。爬虫程序依次读取队列中的URL,通过DNS解析将这些URL转换为相应的网站IP地址,web Downloader通过该IP地址下载页面的所有内容
对于已下载到本地服务器的页面,一方面等待索引和后续处理;另一方面,记录这些下载的页面以避免再次被捕获
对于新下载的页面,抓取页面中收录的未从页面爬网的URL,并将其放入要爬网的队列中。在随后的爬网过程中,将下载与URL对应的页面内容。当知道要爬网的队列为空时,此循环将完成一轮爬网。如图所示:
图2-1
当然,在当今互联网信息海量的时代,爬虫通常会持续工作以确保效率
因此,从宏观的角度来看,我们可以理解,互联网的页面可以分为以下五个部分:
a) 下载网页集
b) 过期页面集合
c) 要下载的页面集合
d) 已知页面集合
e) 不可知页面集合
当然,为了保证页面质量,在上述爬虫捕获过程中涉及了很多技术手段
2.@1.2搜索引擎爬虫分类
大多数搜索引擎爬虫系统都是按照上述流程工作的,但是不同搜索引擎的爬虫会有所不同。此外,同一搜索引擎的爬虫有多种分类。按功能分类:
a) 批量爬虫
b) 强化爬行动物
c) 直立爬行动物
百度搜索引擎分为:
a) 网络搜索百度皮德尔
b) 无线搜索Baiduspider Mobile
c) 图像搜索拜杜斯皮德图像
d) 视频搜索百度派珀视频
e) 新闻搜索百度风笛新闻
f) 百度方面的青睐
g) 百度领头羊CPRO
h) 移动搜索百度+转码器
2.@1.3搜索引擎爬虫的特点
由于互联网上有大量的信息和巨大的数据,搜索引擎必须有优秀的爬虫来完成高效的爬虫过程
a) 高性能
搜索引擎爬虫的高性能主要体现在单位时间内可以下载多少网页。互联网上的网页数量浩如烟海,网页的下载速度直接关系到工作效率。另外,程序访问磁盘的操作方式也非常重要,因此高性能的数据结构对爬虫的性能也有很大的影响
b) 健壮性
因为蜘蛛需要抓取的网页数量非常多。虽然下载速度很快,但完成爬网过程仍然需要很长的周期。因此,spider系统需要能够通过增加服务器和爬虫的数量灵活地提高效率
c) 友好
爬行动物的友好性主要体现在两个方面
一方面,需要考虑网站服务器的网络负载,因为不同的服务器具有不同的性能和承载能力。如果蜘蛛在太大的压力下爬行,可能会造成类似DDoS攻击的效果,可能会影响网站的访问,所以蜘蛛爬行互联网时需要注意网站负载
另一方面,网站的隐私需要得到保护,因为不是互联网上的所有页面都允许搜索引擎蜘蛛爬行,收录是因为其他人不想被搜索引擎收录搜索,所以他们不能被其他人从互联网上搜索
通常有三种方法限制蜘蛛的爬行:
1)机器人排除协议
网站所有者在网站的根目录中制定了一个robots.txt文件,该文件描述了网站中哪些目录和页面不允许百度蜘蛛抓取
通用robots.txt文件格式如下:
用户代理:baiduspider
不允许:/wp admin/
不允许:/wp包括/
“用户代理”字段指定搜索引擎的爬网程序的目标,而“禁止”字段指定不允许爬网的目录或路径
2)robot元标记
在页面头部添加网页捕获禁止标记,以禁止收录页面。有两种形式:
此表单说明不允许搜索引擎爬虫对此页面的内容编制索引
此表单告诉爬虫程序不允许爬虫页面中收录的所有链接
2.@1.4爬虫的爬行策略
在整个爬虫系统中,要爬虫的队列是核心,因此如何确定要爬虫的队列中的URL顺序是非常重要的。除了前面提到的将新下载页面中收录的URL自动附加到队列末尾的技术外,在许多情况下,还需要使用其他技术来确定要爬网的队列中的URL顺序以及所有爬网策略,它的基本目标是一样的:优先捕获重要的网页
常用的爬虫爬行策略包括:宽度优先遍历策略、不完全PageRank策略、opic策略和大站点优先策略
2.@1.5网页更新策略
该算法的意义在于,互联网上有很多页面,更新速度很快。因此,当互联网上某个页面的内容被更新时,爬虫程序需要及时对该页面进行重新爬网,索引并将其重新显示给用户。否则,很容易看到用户在搜索引擎搜索结果列表中看到的结果与实际页面内容不一致。有三种常见的更新策略:历史参考策略、用户体验策略和集群抽样策略
a) 历史参考策略
历史参考策略在很大程度上取决于网页历史的更新频率。根据历史更新频率判断页面未来的更新时间,从而指导爬虫的工作。更新策略还根据页面的更新区域判断内容更新。例如,网站页面的导航和底部不会改变
b) 用户体验策略
顾名思义,更新策略与用户体验数据直接相关,也就是说,如果一个页面不是很重要,那么以后更新它并不重要。如何判断页面的重要性?由于搜索引擎的爬虫系统和排名系统是相对独立的,当页面质量发生变化时,其用户体验数据也会发生变化,从而导致排名的变化。从那时起,判断一个页面质量的变化,即对用户体验影响较大的页面应该更新得更快
c) 整群抽样策略
上述两种更新策略有许多局限性。为互联网的每个网页保存历史页面的成本是巨大的。此外,捕获的第一个页面没有历史数据,因此无法确定更新周期。因此,整群抽样策略解决了上述两种策略的缺点。也就是说,每个页面都根据其属性进行分类。同一类别中的页面具有相似的更新周期。因此,更新周期是根据页面的类别确定的
对于每个类别的更新周期:从其各自的类别中提取代表性页面,并根据前两种更新策略计算其更新周期
页面属性分类:动态特征和静态特征
静态特性通常是:页面内容的特性,如文本、大小、图片大小、大小、链接深度、PageRank值、页面大小等
动态特征是静态特征随时间的变化,如图片数量、字数、页面大小等
整群抽样策略看似粗糙,但在实际应用中,效果优于前两种策略
第二章:简要分析搜索引擎的索引过程 查看全部
c爬虫抓取网页数据(百度蜘蛛(baiduspider)毕业设计的部分内容的第二章)
以下是我毕业设计的第二部分“搜索引擎的工作原理”。第一章是导言,所以你不必把它写出来。因为这是一篇论文,是邹写的
2搜索引擎的工作原理2.1搜索引擎爬虫
不同的搜索引擎对爬虫有不同的通用名称。例如,百度爬虫称它们为“百度蜘蛛”,谷歌称它们为“谷歌机器人”。爬虫的作用:互联网上有数百亿个网页。爬虫程序需要做的第一件事是将如此大量的网页数据下载到本地服务器,以形成互联网页面的镜像备份。在转移到本地后,这些页面将通过一些后续算法处理,并显示在搜索结果上
2.@1.1搜索引擎爬虫框架
一般的爬虫框架流程如下:首先从海量的互联网页面中抓取一些高质量的页面,提取其中收录的URL,并将这些URL放入要抓取的队列中。爬虫程序依次读取队列中的URL,通过DNS解析将这些URL转换为相应的网站IP地址,web Downloader通过该IP地址下载页面的所有内容
对于已下载到本地服务器的页面,一方面等待索引和后续处理;另一方面,记录这些下载的页面以避免再次被捕获
对于新下载的页面,抓取页面中收录的未从页面爬网的URL,并将其放入要爬网的队列中。在随后的爬网过程中,将下载与URL对应的页面内容。当知道要爬网的队列为空时,此循环将完成一轮爬网。如图所示:
图2-1
https://www.vuln.cn/wp-content ... 4.jpg 300w" />当然,在当今互联网信息海量的时代,爬虫通常会持续工作以确保效率
因此,从宏观的角度来看,我们可以理解,互联网的页面可以分为以下五个部分:
a) 下载网页集
b) 过期页面集合
c) 要下载的页面集合
d) 已知页面集合
e) 不可知页面集合
当然,为了保证页面质量,在上述爬虫捕获过程中涉及了很多技术手段
2.@1.2搜索引擎爬虫分类
大多数搜索引擎爬虫系统都是按照上述流程工作的,但是不同搜索引擎的爬虫会有所不同。此外,同一搜索引擎的爬虫有多种分类。按功能分类:
a) 批量爬虫
b) 强化爬行动物
c) 直立爬行动物
百度搜索引擎分为:
a) 网络搜索百度皮德尔
b) 无线搜索Baiduspider Mobile
c) 图像搜索拜杜斯皮德图像
d) 视频搜索百度派珀视频
e) 新闻搜索百度风笛新闻
f) 百度方面的青睐
g) 百度领头羊CPRO
h) 移动搜索百度+转码器
2.@1.3搜索引擎爬虫的特点
由于互联网上有大量的信息和巨大的数据,搜索引擎必须有优秀的爬虫来完成高效的爬虫过程
a) 高性能
搜索引擎爬虫的高性能主要体现在单位时间内可以下载多少网页。互联网上的网页数量浩如烟海,网页的下载速度直接关系到工作效率。另外,程序访问磁盘的操作方式也非常重要,因此高性能的数据结构对爬虫的性能也有很大的影响
b) 健壮性
因为蜘蛛需要抓取的网页数量非常多。虽然下载速度很快,但完成爬网过程仍然需要很长的周期。因此,spider系统需要能够通过增加服务器和爬虫的数量灵活地提高效率
c) 友好
爬行动物的友好性主要体现在两个方面
一方面,需要考虑网站服务器的网络负载,因为不同的服务器具有不同的性能和承载能力。如果蜘蛛在太大的压力下爬行,可能会造成类似DDoS攻击的效果,可能会影响网站的访问,所以蜘蛛爬行互联网时需要注意网站负载
另一方面,网站的隐私需要得到保护,因为不是互联网上的所有页面都允许搜索引擎蜘蛛爬行,收录是因为其他人不想被搜索引擎收录搜索,所以他们不能被其他人从互联网上搜索
通常有三种方法限制蜘蛛的爬行:
1)机器人排除协议
网站所有者在网站的根目录中制定了一个robots.txt文件,该文件描述了网站中哪些目录和页面不允许百度蜘蛛抓取
通用robots.txt文件格式如下:
用户代理:baiduspider
不允许:/wp admin/
不允许:/wp包括/
“用户代理”字段指定搜索引擎的爬网程序的目标,而“禁止”字段指定不允许爬网的目录或路径
2)robot元标记
在页面头部添加网页捕获禁止标记,以禁止收录页面。有两种形式:
此表单说明不允许搜索引擎爬虫对此页面的内容编制索引
此表单告诉爬虫程序不允许爬虫页面中收录的所有链接
2.@1.4爬虫的爬行策略
在整个爬虫系统中,要爬虫的队列是核心,因此如何确定要爬虫的队列中的URL顺序是非常重要的。除了前面提到的将新下载页面中收录的URL自动附加到队列末尾的技术外,在许多情况下,还需要使用其他技术来确定要爬网的队列中的URL顺序以及所有爬网策略,它的基本目标是一样的:优先捕获重要的网页
常用的爬虫爬行策略包括:宽度优先遍历策略、不完全PageRank策略、opic策略和大站点优先策略
2.@1.5网页更新策略
该算法的意义在于,互联网上有很多页面,更新速度很快。因此,当互联网上某个页面的内容被更新时,爬虫程序需要及时对该页面进行重新爬网,索引并将其重新显示给用户。否则,很容易看到用户在搜索引擎搜索结果列表中看到的结果与实际页面内容不一致。有三种常见的更新策略:历史参考策略、用户体验策略和集群抽样策略
a) 历史参考策略
历史参考策略在很大程度上取决于网页历史的更新频率。根据历史更新频率判断页面未来的更新时间,从而指导爬虫的工作。更新策略还根据页面的更新区域判断内容更新。例如,网站页面的导航和底部不会改变
b) 用户体验策略
顾名思义,更新策略与用户体验数据直接相关,也就是说,如果一个页面不是很重要,那么以后更新它并不重要。如何判断页面的重要性?由于搜索引擎的爬虫系统和排名系统是相对独立的,当页面质量发生变化时,其用户体验数据也会发生变化,从而导致排名的变化。从那时起,判断一个页面质量的变化,即对用户体验影响较大的页面应该更新得更快
c) 整群抽样策略
上述两种更新策略有许多局限性。为互联网的每个网页保存历史页面的成本是巨大的。此外,捕获的第一个页面没有历史数据,因此无法确定更新周期。因此,整群抽样策略解决了上述两种策略的缺点。也就是说,每个页面都根据其属性进行分类。同一类别中的页面具有相似的更新周期。因此,更新周期是根据页面的类别确定的
对于每个类别的更新周期:从其各自的类别中提取代表性页面,并根据前两种更新策略计算其更新周期
页面属性分类:动态特征和静态特征
静态特性通常是:页面内容的特性,如文本、大小、图片大小、大小、链接深度、PageRank值、页面大小等
动态特征是静态特征随时间的变化,如图片数量、字数、页面大小等
整群抽样策略看似粗糙,但在实际应用中,效果优于前两种策略
第二章:简要分析搜索引擎的索引过程
c爬虫抓取网页数据(执行capyxpath,获取标题元素在当前父节点的xpath执行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-09-23 15:08
前言
谁写的爬行动物和网页知道,在定位上,XPath的道路上获得了大量的时间,有时后爬虫框架是成熟的人,它基本上是页面的解析。
在没有这些辅助工具的日子里,我们只能找到一些ID通过搜索HTML源代码,非常麻烦,而且常常错误找到相应的位置。
共享Chrome浏览器
的小技巧
例如,现在我们正在抓住博客园首页文章的XPath路径
打开显影剂工具,标题元件上,右按钮“CAPY得到的XPath。
执行CAPY的XPath,得到标题元件的XPath
当前父节点的
//*[@id="post_list"]/div[1]/div[2]/h3/a
执行CAPY完整的XPath,得到充分的XPath
在HTML文档中
/html/body/div[1]/div[4]/div[6]/div[1]/div[2]/h3/a
我觉得这是不够方便,毕竟,你不能查看它瞬间。因此,我们需要这个开源爬虫!
的xpath辅助
的XPath助手插件是一个免费的Chrome爬虫幅解析工具。
可以帮助用户解决问题时,他们得到的XPath路径。
该插件可以帮助您提取您通过按Shift键按下Shift键要查看的页面元素的代码,你可以编辑查询,编辑结果框中的结果会立即显示该代码旁边。
的xpath调试
安装的XPath助手后,让我们把握文章 XPath的路径在博客园的主页。
这可以在输入文本框调试,并且将提取的结果将被显示在结果文本框旁边。
当然,这也是对我的Chrome浏览器的一个插件! 查看全部
c爬虫抓取网页数据(执行capyxpath,获取标题元素在当前父节点的xpath执行)
前言
谁写的爬行动物和网页知道,在定位上,XPath的道路上获得了大量的时间,有时后爬虫框架是成熟的人,它基本上是页面的解析。
在没有这些辅助工具的日子里,我们只能找到一些ID通过搜索HTML源代码,非常麻烦,而且常常错误找到相应的位置。
共享Chrome浏览器
的小技巧
例如,现在我们正在抓住博客园首页文章的XPath路径
打开显影剂工具,标题元件上,右按钮“CAPY得到的XPath。
执行CAPY的XPath,得到标题元件的XPath
当前父节点的
//*[@id="post_list"]/div[1]/div[2]/h3/a
执行CAPY完整的XPath,得到充分的XPath
在HTML文档中
/html/body/div[1]/div[4]/div[6]/div[1]/div[2]/h3/a
我觉得这是不够方便,毕竟,你不能查看它瞬间。因此,我们需要这个开源爬虫!
的xpath辅助
的XPath助手插件是一个免费的Chrome爬虫幅解析工具。
可以帮助用户解决问题时,他们得到的XPath路径。
该插件可以帮助您提取您通过按Shift键按下Shift键要查看的页面元素的代码,你可以编辑查询,编辑结果框中的结果会立即显示该代码旁边。
的xpath调试
安装的XPath助手后,让我们把握文章 XPath的路径在博客园的主页。
这可以在输入文本框调试,并且将提取的结果将被显示在结果文本框旁边。
当然,这也是对我的Chrome浏览器的一个插件!
c爬虫抓取网页数据(前段时间写了爬取美团商家信息的博客爬虫抓取美团网上)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-09-20 22:02
前段时间,我写了一篇关于抓取美团商业信息的博客。爬虫会抓取美团所有的商业信息。这一次,我说的是爬行糯米。由于某些原因,我无法提供源代码。然而,代码不是关键,关键是思想。理解了这个思想之后,代码就很容易编写了
对于爬虫来说,最重要的是根据实际的请求过程分析请求过程和请求数据
分析是否需要处理cookie。有些网站是严格的。从某些接口请求数据时需要cookie。获取cookies的链接通常是主页。通常,系统将有一个jsessionid来维护会话。由于您访问一个页面,服务器将向您返回此jsessionid,但是如果您访问一些没有此cookie的接口,服务器将不会向您返回数据。您可以看到我之前写的关于使用Python对12306以上的所有车次数据进行爬网的内容。爬行12306时需要处理Cookie
分析网站的请求限制,因为爬虫程序将增加其服务器压力、流量浪费和数据丢失。因此,许多网站将对请求数量进行限制。然而,由于他们的数据是开放的,他们可以爬行。这只是成本问题。一般来说,他们会根据IP限制请求,当请求达到一定次数时会有一个验证码。例如,攀爬天眼检查数据时会遇到此问题。你可以使用代理。现在获得代理既容易又便宜
是否通过Ajax加载网站分析的数据,返回的数据是否加密。通常,这种情况可以由没有界面的浏览器请求,浏览器将自行处理这些事情
抓取页面并解析所需数据更容易。页面已被捕获。您可以使用一些开源框架来解析页面中的数据,也可以使用常规框架
下面分析如何在线获取糯米数据
经过分析,发现糯米不需要处理cookies,没有Ajax加载,并且有请求限制,所以只需要使用代理
我们现在分析如何抓取所有数据
从链接中,我们可以猜测北京是北京,364是火锅的分类,307-1388是区域。提前采集这些数据,爬行回来时直接拼接,方便快捷
我在这里只对城市进行分类,而不是地区,所以当我们攀登时,地区和商业区需要被处理。我们可以先拼接城市和分类,然后获得区/县
然后遍历各区县,得到商圈,再遍历,最后得到团购数据
# 区/县
def getArea(cityUrl,cityName,type,subType,subTypeCode):
url=cityUrl+"/"+subTypeCode
soup=download_soup_waitting(url)
try:
geo_filter_wrapper=soup.find("div",attrs={"class":"filterDistrict"})
J_filter_list=geo_filter_wrapper.find("div",attrs={"class":"district-list-ab"})
lis=J_filter_list.findAll("a")
for li in lis :
# a=li.find("a")
url='http:'+li['href']
area=li.text
getSubArea(url,area,cityName,type,subType)
except:
getBusiness(url,"","",cityName,type,subType)
# 商圈
def getSubArea(url,area,cityName,type,subType):
soup=download_soup_waitting(url)
geo_filter_wrapper=soup.find("div",attrs={"class":"district-sub-list-ab"})
if geo_filter_wrapper==None:
getBusiness(url,"",area,cityName,type,subType)
return
lis=geo_filter_wrapper.findAll("a")[1:]
for li in lis :
# a=li.find("a")
url=li['href']
subArea=li.text
getBusiness("http:"+url,subArea,area,cityName,type,subType)
现在我们来分析团购信息
可以发现,这不是一个商户,而是一个集团购买的商品,表明这些集团购买的许多商品都是同一个商户。我们把它分为两层,因为这一层依次是一个城市和一个类别。但是,没有通过团购获取商户信息的订单
爬上这一层后,结果如下
我们无法在这一层获得有关商户的更多详细信息,但我们可以通过此团购链接获得更多详细信息。我们将整理这些团购链接,然后在第二层爬行
这是我们需要的数据,但在实际爬网过程中发现捕获的页面没有这些数据。您可以猜测它是通过Ajax加载的
现在打开firebug并刷新页面
我发现这和我的猜测是一样的。这些数据是通过Ajax加载的。检查链接,发现只要交易成功,就可以拼接链接
最后,只需解析并保存捕获的数据
在分析整个过程并编写代码后,可以让程序缓慢运行。我的数据运行了一个月才有结果。然后整理数据。最终数据如下:
453792糯米食品数据
149002糯米寿命数据
糯米娱乐74932条数据
诺米美容73123条数据
数据总数为750849
时间:20170404
有关技术问题或此数据,请联系Zhenpeng_#Lin#替换为@ 查看全部
c爬虫抓取网页数据(前段时间写了爬取美团商家信息的博客爬虫抓取美团网上)
前段时间,我写了一篇关于抓取美团商业信息的博客。爬虫会抓取美团所有的商业信息。这一次,我说的是爬行糯米。由于某些原因,我无法提供源代码。然而,代码不是关键,关键是思想。理解了这个思想之后,代码就很容易编写了
对于爬虫来说,最重要的是根据实际的请求过程分析请求过程和请求数据
分析是否需要处理cookie。有些网站是严格的。从某些接口请求数据时需要cookie。获取cookies的链接通常是主页。通常,系统将有一个jsessionid来维护会话。由于您访问一个页面,服务器将向您返回此jsessionid,但是如果您访问一些没有此cookie的接口,服务器将不会向您返回数据。您可以看到我之前写的关于使用Python对12306以上的所有车次数据进行爬网的内容。爬行12306时需要处理Cookie
分析网站的请求限制,因为爬虫程序将增加其服务器压力、流量浪费和数据丢失。因此,许多网站将对请求数量进行限制。然而,由于他们的数据是开放的,他们可以爬行。这只是成本问题。一般来说,他们会根据IP限制请求,当请求达到一定次数时会有一个验证码。例如,攀爬天眼检查数据时会遇到此问题。你可以使用代理。现在获得代理既容易又便宜
是否通过Ajax加载网站分析的数据,返回的数据是否加密。通常,这种情况可以由没有界面的浏览器请求,浏览器将自行处理这些事情
抓取页面并解析所需数据更容易。页面已被捕获。您可以使用一些开源框架来解析页面中的数据,也可以使用常规框架
下面分析如何在线获取糯米数据
经过分析,发现糯米不需要处理cookies,没有Ajax加载,并且有请求限制,所以只需要使用代理
我们现在分析如何抓取所有数据
从链接中,我们可以猜测北京是北京,364是火锅的分类,307-1388是区域。提前采集这些数据,爬行回来时直接拼接,方便快捷
我在这里只对城市进行分类,而不是地区,所以当我们攀登时,地区和商业区需要被处理。我们可以先拼接城市和分类,然后获得区/县
然后遍历各区县,得到商圈,再遍历,最后得到团购数据
# 区/县
def getArea(cityUrl,cityName,type,subType,subTypeCode):
url=cityUrl+"/"+subTypeCode
soup=download_soup_waitting(url)
try:
geo_filter_wrapper=soup.find("div",attrs={"class":"filterDistrict"})
J_filter_list=geo_filter_wrapper.find("div",attrs={"class":"district-list-ab"})
lis=J_filter_list.findAll("a")
for li in lis :
# a=li.find("a")
url='http:'+li['href']
area=li.text
getSubArea(url,area,cityName,type,subType)
except:
getBusiness(url,"","",cityName,type,subType)
# 商圈
def getSubArea(url,area,cityName,type,subType):
soup=download_soup_waitting(url)
geo_filter_wrapper=soup.find("div",attrs={"class":"district-sub-list-ab"})
if geo_filter_wrapper==None:
getBusiness(url,"",area,cityName,type,subType)
return
lis=geo_filter_wrapper.findAll("a")[1:]
for li in lis :
# a=li.find("a")
url=li['href']
subArea=li.text
getBusiness("http:"+url,subArea,area,cityName,type,subType)
现在我们来分析团购信息
可以发现,这不是一个商户,而是一个集团购买的商品,表明这些集团购买的许多商品都是同一个商户。我们把它分为两层,因为这一层依次是一个城市和一个类别。但是,没有通过团购获取商户信息的订单
爬上这一层后,结果如下
我们无法在这一层获得有关商户的更多详细信息,但我们可以通过此团购链接获得更多详细信息。我们将整理这些团购链接,然后在第二层爬行
这是我们需要的数据,但在实际爬网过程中发现捕获的页面没有这些数据。您可以猜测它是通过Ajax加载的
现在打开firebug并刷新页面
我发现这和我的猜测是一样的。这些数据是通过Ajax加载的。检查链接,发现只要交易成功,就可以拼接链接
最后,只需解析并保存捕获的数据
在分析整个过程并编写代码后,可以让程序缓慢运行。我的数据运行了一个月才有结果。然后整理数据。最终数据如下:
453792糯米食品数据
149002糯米寿命数据
糯米娱乐74932条数据
诺米美容73123条数据
数据总数为750849
时间:20170404
有关技术问题或此数据,请联系Zhenpeng_#Lin#替换为@
c爬虫抓取网页数据(Scraoy入门实例一--Scrapy介绍与安装ampamp的安装)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-09-20 22:00
scraoy示例1介绍——scrapy&;安装pycharm&;项目实践
一、Scrapy安装
1.Scrapy导言
Scrapy是一个应用程序框架,用于抓取网站数据和提取结构数据。它可以应用于一系列程序中,包括数据挖掘、信息处理或存储历史数据。它最初设计用于页面爬行(更具体地说,web爬行),也可以用于获取API(如Amazon Associates web services)或通用web爬行器返回的数据
2.Scrapy装置
建议Anaconda安装slapy
Anaconda是一个开源软件包和环境管理工件。Anaconda包括180多个科学包及其依赖项,包括CONDA和python。从官网下载并安装Anaconda(个人版),选择根据自己的系统下载并安装,选择“下一步”继续安装,选择“仅为我安装”选项,选择安装位置后等待安装完成
安装完成后,打开命令行,输入CONDA install sweep,然后根据提示按y下载所有scrapy及其相关软件包,从而完成安装
注意:使用命令行安装sweep包时,将出现下载超时,即下载失败。我们可以通过修改扫描包的图像文件来提高其下载速度。请参阅博客:
此时,测试scratch的安装是否成功:在命令行窗口中输入scratch。如果显示以下界面,则安装成功:
二、PyCharm安装
1.PyCharm导言
Pycharm是一个python ide,它有一套工具可以帮助用户在使用python语言开发时提高效率,如调试、语法突出显示、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制。此外,IDE还提供了一些高级功能来支持Django框架下的专业web开发
2.PyCharm装置
进入pycharm官网,直接点击下载即可下载。专业版在左边,社区版在右边。社区版免费,专业版免费试用
如果之前没有下载过Python解释器,可以在等待安装时下载Python解释器,进入Python官网,根据系统和版本下载相应的压缩包。安装后,在环境变量path中配置Python解释器的安装路径。请参阅博客:
三、Scrapy抓豆瓣工程实战
前提:如果要在pycharm中使用scripy,必须首先在pycharm中安装受支持的scripy软件包。流程如下,单击文件>>;设置步骤(设置…)如下图所示。在安装scripy之前,绿色框中只有两个软件包。如果单击并看到scripy软件包,则无需安装它。继续进行下一个操作
如果没有scripy软件包,请单击“+”搜索scripy软件包,然后单击Install package安装它
等待安装完成
1.新项目
打开新安装的pycharm并使用pycharm工具安装软件终端。如果找不到pycharm终端,只需找到左下角底部的终端即可
输入命令:scratch startproject doublan。使用命令行创建一个新的爬虫项目,如下图所示。图中所示的项目名为Python project
然后在命令行中输入cddoublan命令,以输入生成项目的根目录
然后继续在终端中键入命令:scratch genspider double_uu2;Spider生成一个double_u2;Spider爬虫文件
项目结构如下图所示:
2.明确目标
我们要网站做的是:
假设我们捕获了top250电影的序列号、电影名称、简介、星级、评论数量和电影描述选项
此时,我们在items.py文件中定义捕获的数据项。代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.next,我们需要制作爬虫并存储爬虫内容
在doublan_u中,spider.py爬虫文件编译特定的逻辑代码,如下所示:
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
# 允许的域名
allowed_domains = ['movie.douban.com']
# 入口URL
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//div[@class='hd']/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
此时,我们不需要运行这个Python文件,因为我们不单独使用它,所以我们不需要运行它,如果允许,将报告错误。导入、主目录的绝对路径和相对路径引入问题的原因是我们使用相对路径“.items”。有兴趣的学生可以到网上找到这些问题的解释
4.存储内容
以JSON或CSV格式存储已爬网的内容
在命令行中,输入:scratch-crawl-double\uspider-O test.json或scratch-crawl-double\uspider-O test.csv
将爬网数据存储在JSON文件或CSV文件中
执行爬网命令后,当鼠标焦点位于项目面板上时,将显示born JSON文件或CSV文件。打开JSON或CSV文件后,如果其中没有任何内容,则需要修改代理的代理用户内容
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36'
如果存储在JSON文件中,所有内容都将以十六进制形式显示,并且可以通过相应的方法进行转码。此处说明不多,如下图所示:
存储在CSV文件中,我们想要爬网的所有内容将直接显示,如下图所示:
到目前为止,我们已经完成了对网站特定内容的爬网。接下来,我们需要处理爬行数据
分割线----------------------------------------------------------------------分割线
Scraoy入口示例2-使用管道实现
在这场实际的战斗中,您需要重新创建一个项目或安装scratch包。参考上述内容。创建新项目的方法也参考了上述内容,这里不再重复
项目目录结构如下图所示:
一、Pipeline导言
当我们通过spider抓取数据并通过item采集数据时,我们需要处理数据,因为我们抓取的数据不一定是我们想要的最终数据。我们可能还需要清理数据并验证数据的有效性。scripy中的管道组件用于数据处理。管道组件是收录特定接口的类。它通常只负责一个函数的数据处理。可以在一个项目中同时启用多个管道
二、定义要在items.py中获取的数据
首先,打开一个新的pychart项目,通过终端创建一个新的项目教程,并定义要在项目中捕获的数据,例如电影名称。代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、define pipeline.py文件
每个项目管道组件都是一个独立的pyhton类,必须实现流程项目(self、item、spider)方法。每个项目管道组件都需要调用此方法。此方法必须返回收录数据的dict、项对象或引发dropitem异常。后续管道组件将不会处理丢弃的项目。定义的pipelines.py代码如下:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/lat ... .html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class TutorialPipeline(object):
def process_item(self, item, spider):
return item
import time
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
now = time.strftime('%Y-%m-%d', time.localtime())
fileName = 'douban' + now + '.txt'
with open(fileName, 'a', encoding='utf-8') as fp:
fp.write(item['moiveName'][0]+"\n")
return item
四、configuring setting.py
由于这次使用管道,我们需要在settings.py中打开管道通道注释,并在管道中添加新记录,如下图所示:
五、write爬虫文件
在tutorial/Spider目录\uspider.py文件中创建引号,目录结构如下,并编写初步代码:
quotes\ spider.py代码如下:
import scrapy
from items import DoubanmovieItem
class QuotesSpider(scrapy.Spider):
name = "doubanSpider"
allowed_domains = ['douban.com']
start_urls = ['http://movie.douban.com/cinema/nowplaying',
'http://movie.douban.com/cinema/nowplaying/beijing/']
def parse(self, response):
print("--" * 20 )
#print(response.body)
print("==" * 20 )
subSelector = response.xpath('//li[@class="stitle"]')
items = []
for sub in subSelector:
#print(sub.xpath('normalize-space(./a/text())').extract())
print(sub)
item = DoubanmovieItem()
item['moiveName'] = sub.xpath('normalize-space(./a/text())').extract()
items.append(item)
print(items)
return items
六、从启动文件运行
在doublan文件目录spider uuRun.py中创建一个新的启动文件(文件名可以单独获取),运行该文件,查看结果,并按如下方式编写代码:
from scrapy import cmdline
cmdline.execute("scrapy crawl doubanSpider".split())
最后,处理后的爬网数据如下图(部分)所示:
最后,我希望您在编写代码时要小心,不要粗心大意。在我的实验过程中,这是因为要介绍的方法doublanmovieitem被编写为doublanmovieitem,这导致了整个程序的失败。此外,pycharm没有告诉我出了什么问题。我到处找,没有找到解决问题的办法。最后,我检查了很多次,只有在生成方法时才发现,所以您必须小心。此错误如下图所示。表示找不到dobanmovieitem模块。它可能告诉我错误的地方。我没有找到,因为我太好吃了,所以花了很长时间。我希望你能接受一个警告
到目前为止,用刮擦法抓取web内容并对捕获的内容进行清理和处理的实验已经完成。在这个过程中,需要熟悉和使用代码和操作,而不是查找在线内容,消化和吸收,并牢记在心。这才是真正要学的知识,不是画葫芦 查看全部
c爬虫抓取网页数据(Scraoy入门实例一--Scrapy介绍与安装ampamp的安装)
scraoy示例1介绍——scrapy&;安装pycharm&;项目实践
一、Scrapy安装
1.Scrapy导言
Scrapy是一个应用程序框架,用于抓取网站数据和提取结构数据。它可以应用于一系列程序中,包括数据挖掘、信息处理或存储历史数据。它最初设计用于页面爬行(更具体地说,web爬行),也可以用于获取API(如Amazon Associates web services)或通用web爬行器返回的数据
2.Scrapy装置
建议Anaconda安装slapy
Anaconda是一个开源软件包和环境管理工件。Anaconda包括180多个科学包及其依赖项,包括CONDA和python。从官网下载并安装Anaconda(个人版),选择根据自己的系统下载并安装,选择“下一步”继续安装,选择“仅为我安装”选项,选择安装位置后等待安装完成
安装完成后,打开命令行,输入CONDA install sweep,然后根据提示按y下载所有scrapy及其相关软件包,从而完成安装
注意:使用命令行安装sweep包时,将出现下载超时,即下载失败。我们可以通过修改扫描包的图像文件来提高其下载速度。请参阅博客:
此时,测试scratch的安装是否成功:在命令行窗口中输入scratch。如果显示以下界面,则安装成功:
二、PyCharm安装
1.PyCharm导言
Pycharm是一个python ide,它有一套工具可以帮助用户在使用python语言开发时提高效率,如调试、语法突出显示、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制。此外,IDE还提供了一些高级功能来支持Django框架下的专业web开发
2.PyCharm装置
进入pycharm官网,直接点击下载即可下载。专业版在左边,社区版在右边。社区版免费,专业版免费试用
如果之前没有下载过Python解释器,可以在等待安装时下载Python解释器,进入Python官网,根据系统和版本下载相应的压缩包。安装后,在环境变量path中配置Python解释器的安装路径。请参阅博客:
三、Scrapy抓豆瓣工程实战
前提:如果要在pycharm中使用scripy,必须首先在pycharm中安装受支持的scripy软件包。流程如下,单击文件>>;设置步骤(设置…)如下图所示。在安装scripy之前,绿色框中只有两个软件包。如果单击并看到scripy软件包,则无需安装它。继续进行下一个操作
如果没有scripy软件包,请单击“+”搜索scripy软件包,然后单击Install package安装它
等待安装完成
1.新项目
打开新安装的pycharm并使用pycharm工具安装软件终端。如果找不到pycharm终端,只需找到左下角底部的终端即可
输入命令:scratch startproject doublan。使用命令行创建一个新的爬虫项目,如下图所示。图中所示的项目名为Python project
然后在命令行中输入cddoublan命令,以输入生成项目的根目录
然后继续在终端中键入命令:scratch genspider double_uu2;Spider生成一个double_u2;Spider爬虫文件
项目结构如下图所示:
2.明确目标
我们要网站做的是:
假设我们捕获了top250电影的序列号、电影名称、简介、星级、评论数量和电影描述选项
此时,我们在items.py文件中定义捕获的数据项。代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.next,我们需要制作爬虫并存储爬虫内容
在doublan_u中,spider.py爬虫文件编译特定的逻辑代码,如下所示:
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
# 允许的域名
allowed_domains = ['movie.douban.com']
# 入口URL
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//div[@class='hd']/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
此时,我们不需要运行这个Python文件,因为我们不单独使用它,所以我们不需要运行它,如果允许,将报告错误。导入、主目录的绝对路径和相对路径引入问题的原因是我们使用相对路径“.items”。有兴趣的学生可以到网上找到这些问题的解释
4.存储内容
以JSON或CSV格式存储已爬网的内容
在命令行中,输入:scratch-crawl-double\uspider-O test.json或scratch-crawl-double\uspider-O test.csv
将爬网数据存储在JSON文件或CSV文件中
执行爬网命令后,当鼠标焦点位于项目面板上时,将显示born JSON文件或CSV文件。打开JSON或CSV文件后,如果其中没有任何内容,则需要修改代理的代理用户内容
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36'
如果存储在JSON文件中,所有内容都将以十六进制形式显示,并且可以通过相应的方法进行转码。此处说明不多,如下图所示:
存储在CSV文件中,我们想要爬网的所有内容将直接显示,如下图所示:
到目前为止,我们已经完成了对网站特定内容的爬网。接下来,我们需要处理爬行数据
分割线----------------------------------------------------------------------分割线
Scraoy入口示例2-使用管道实现
在这场实际的战斗中,您需要重新创建一个项目或安装scratch包。参考上述内容。创建新项目的方法也参考了上述内容,这里不再重复
项目目录结构如下图所示:
一、Pipeline导言
当我们通过spider抓取数据并通过item采集数据时,我们需要处理数据,因为我们抓取的数据不一定是我们想要的最终数据。我们可能还需要清理数据并验证数据的有效性。scripy中的管道组件用于数据处理。管道组件是收录特定接口的类。它通常只负责一个函数的数据处理。可以在一个项目中同时启用多个管道
二、定义要在items.py中获取的数据
首先,打开一个新的pychart项目,通过终端创建一个新的项目教程,并定义要在项目中捕获的数据,例如电影名称。代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、define pipeline.py文件
每个项目管道组件都是一个独立的pyhton类,必须实现流程项目(self、item、spider)方法。每个项目管道组件都需要调用此方法。此方法必须返回收录数据的dict、项对象或引发dropitem异常。后续管道组件将不会处理丢弃的项目。定义的pipelines.py代码如下:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/lat ... .html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class TutorialPipeline(object):
def process_item(self, item, spider):
return item
import time
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
now = time.strftime('%Y-%m-%d', time.localtime())
fileName = 'douban' + now + '.txt'
with open(fileName, 'a', encoding='utf-8') as fp:
fp.write(item['moiveName'][0]+"\n")
return item
四、configuring setting.py
由于这次使用管道,我们需要在settings.py中打开管道通道注释,并在管道中添加新记录,如下图所示:
五、write爬虫文件
在tutorial/Spider目录\uspider.py文件中创建引号,目录结构如下,并编写初步代码:
quotes\ spider.py代码如下:
import scrapy
from items import DoubanmovieItem
class QuotesSpider(scrapy.Spider):
name = "doubanSpider"
allowed_domains = ['douban.com']
start_urls = ['http://movie.douban.com/cinema/nowplaying',
'http://movie.douban.com/cinema/nowplaying/beijing/']
def parse(self, response):
print("--" * 20 )
#print(response.body)
print("==" * 20 )
subSelector = response.xpath('//li[@class="stitle"]')
items = []
for sub in subSelector:
#print(sub.xpath('normalize-space(./a/text())').extract())
print(sub)
item = DoubanmovieItem()
item['moiveName'] = sub.xpath('normalize-space(./a/text())').extract()
items.append(item)
print(items)
return items
六、从启动文件运行
在doublan文件目录spider uuRun.py中创建一个新的启动文件(文件名可以单独获取),运行该文件,查看结果,并按如下方式编写代码:
from scrapy import cmdline
cmdline.execute("scrapy crawl doubanSpider".split())
最后,处理后的爬网数据如下图(部分)所示:
最后,我希望您在编写代码时要小心,不要粗心大意。在我的实验过程中,这是因为要介绍的方法doublanmovieitem被编写为doublanmovieitem,这导致了整个程序的失败。此外,pycharm没有告诉我出了什么问题。我到处找,没有找到解决问题的办法。最后,我检查了很多次,只有在生成方法时才发现,所以您必须小心。此错误如下图所示。表示找不到dobanmovieitem模块。它可能告诉我错误的地方。我没有找到,因为我太好吃了,所以花了很长时间。我希望你能接受一个警告
到目前为止,用刮擦法抓取web内容并对捕获的内容进行清理和处理的实验已经完成。在这个过程中,需要熟悉和使用代码和操作,而不是查找在线内容,消化和吸收,并牢记在心。这才是真正要学的知识,不是画葫芦
c爬虫抓取网页数据(利用Java模拟的一个程序,聚焦爬虫工作原理以及关键技术 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-20 21:32
)
网络爬虫网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中更常被称为网络追踪器)是一种程序或脚本,根据特定规则自动获取万维网信息
聚焦爬虫的工作原理及关键技术综述
网络爬虫是一个程序,自动提取网页。它为搜索引擎从万维网下载网页。它是搜索引擎的重要组成部分。传统的爬虫从一个或多个初始网页的URL获取初始网页上的URL。在抓取网页的过程中,它不断地从当前网页中提取新的URL并将其放入队列,直到满足系统的某些停止条件。焦点爬虫的工作流程很复杂。有必要根据特定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待捕获的URL队列中。然后,它将根据一定的搜索策略从队列中选择下一个网页URL,并重复上述过程,直到达到系统的一定条件。此外,爬虫捕获的所有网页将由系统存储、分析、过滤和索引,以便将来查询和检索;对于聚焦爬虫,在这个过程中获得的分析结果也可以为未来的抓取过程提供反馈和指导
与普通网络爬虫相比,焦点爬虫还需要解决三个主要问题:
(1)捕获目标的描述或定义
(2)网页或数据的分析和过滤
(3)URL搜索策略)
网络爬虫的实现原理
根据这一原理,编写一个简单的网络爬虫程序。该程序的功能是获取网站返回的数据并提取网址。获取的网址存储在一个文件夹中。除了提取网址,我们还可以提取我们想要的其他种类的信息,只要我们修改filte的表达式红色数据
下面是一个由java模拟的程序,用于提取新浪网页上的链接并将其存储在文件中
单击以获取信息
源代码如下:
package com.cellstrain.icell.util; import java.io.*;import java.net.*;import java.util.regex.Matcher;import java.util.regex.Pattern; /** * java实现爬虫 */public class Robot { public static void main(String[] args) { URL url = null; URLConnection urlconn = null; BufferedReader br = null; PrintWriter pw = null;// String regex = "http://[w+.?/?]+.[A-Za-z]+"; String regex = "https://[w+.?/?]+.[A-Za-z]+";//url匹配规则 Pattern p = Pattern.compile(regex); try { url = new URL("https://www.rndsystems.com/cn");//爬取的网址、这里爬取的是一个生物网站 urlconn = url.openConnection(); pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中 br = new BufferedReader(new InputStreamReader( urlconn.getInputStream())); String buf = null; while ((buf = br.readLine()) != null) { Matcher buf_m = p.matcher(buf); while (buf_m.find()) { pw.println(buf_m.group()); } } System.out.println("爬取成功^_^"); } catch (MalformedURLException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { try { br.close(); } catch (IOException e) { e.printStackTrace(); } pw.close(); } }} 查看全部
c爬虫抓取网页数据(利用Java模拟的一个程序,聚焦爬虫工作原理以及关键技术
)
网络爬虫网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中更常被称为网络追踪器)是一种程序或脚本,根据特定规则自动获取万维网信息
聚焦爬虫的工作原理及关键技术综述
网络爬虫是一个程序,自动提取网页。它为搜索引擎从万维网下载网页。它是搜索引擎的重要组成部分。传统的爬虫从一个或多个初始网页的URL获取初始网页上的URL。在抓取网页的过程中,它不断地从当前网页中提取新的URL并将其放入队列,直到满足系统的某些停止条件。焦点爬虫的工作流程很复杂。有必要根据特定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待捕获的URL队列中。然后,它将根据一定的搜索策略从队列中选择下一个网页URL,并重复上述过程,直到达到系统的一定条件。此外,爬虫捕获的所有网页将由系统存储、分析、过滤和索引,以便将来查询和检索;对于聚焦爬虫,在这个过程中获得的分析结果也可以为未来的抓取过程提供反馈和指导
与普通网络爬虫相比,焦点爬虫还需要解决三个主要问题:
(1)捕获目标的描述或定义
(2)网页或数据的分析和过滤
(3)URL搜索策略)
网络爬虫的实现原理
根据这一原理,编写一个简单的网络爬虫程序。该程序的功能是获取网站返回的数据并提取网址。获取的网址存储在一个文件夹中。除了提取网址,我们还可以提取我们想要的其他种类的信息,只要我们修改filte的表达式红色数据
下面是一个由java模拟的程序,用于提取新浪网页上的链接并将其存储在文件中
单击以获取信息
源代码如下:
package com.cellstrain.icell.util; import java.io.*;import java.net.*;import java.util.regex.Matcher;import java.util.regex.Pattern; /** * java实现爬虫 */public class Robot { public static void main(String[] args) { URL url = null; URLConnection urlconn = null; BufferedReader br = null; PrintWriter pw = null;// String regex = "http://[w+.?/?]+.[A-Za-z]+"; String regex = "https://[w+.?/?]+.[A-Za-z]+";//url匹配规则 Pattern p = Pattern.compile(regex); try { url = new URL("https://www.rndsystems.com/cn";);//爬取的网址、这里爬取的是一个生物网站 urlconn = url.openConnection(); pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中 br = new BufferedReader(new InputStreamReader( urlconn.getInputStream())); String buf = null; while ((buf = br.readLine()) != null) { Matcher buf_m = p.matcher(buf); while (buf_m.find()) { pw.println(buf_m.group()); } } System.out.println("爬取成功^_^"); } catch (MalformedURLException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { try { br.close(); } catch (IOException e) { e.printStackTrace(); } pw.close(); } }}
c爬虫抓取网页数据(Python中解析网页的基本流程及方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-09-20 07:05
)
爬虫是Python的一个重要应用。使用PythonCrawler,我们可以轻松地从互联网上获取我们想要的数据
本文将以B站视频热点搜索列表数据存储为例,详细介绍Python爬虫的基本过程
PS:如果你需要Python学习材料,你可以点击下面的链接自己获取
Python免费学习资料和组通信解决方案。点击加入
如果您仍处于介绍阶段或不知道爬虫程序的具体工作流程,则应仔细阅读本文
步骤1:尝试请求
首先,进入B站主页,点击排名列表,复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动Jupiter笔记本并运行以下代码
import requests
url = 'https://www.bilibili.com/ranki ... 39%3B
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
您可以看到返回值是200,表示服务器响应正常,这意味着我们可以继续
步骤2:解析页面
在上一步中,通过请求从网站请求数据后,我们成功获得了一个收录服务器资源的响应对象。现在我们可以使用。文本以查看其内容
您可以看到返回了一个字符串,其中收录我们需要的热列表视频数据,但是直接从字符串中提取内容既复杂又低效。因此,我们需要对其进行解析,并将字符串转换为网页结构化数据,这样我们就可以轻松地找到HTML标记及其属性和内容
在Python中有许多解析网页的方法。您可以使用正则表达式、beautulsoup、pyquery或lxml。本文将基于beautulsoup进行解释
Beauty soup是一个第三方库,可以从HTML或XML文件中提取数据
安装也很简单。您可以使用PIP安装BS4来安装它
让我们用一个简单的例子来说明它是如何工作的
from bs4 import BeautifulSoup
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.text
print(title)
# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
在上面的代码中,我们通过BS4中的Beauty soup类将上一步获得的HTML格式字符串转换为Beauty soup对象。注意,使用解析器时需要开发解析器。这里使用html.parser
然后您可以得到一个结构化元素及其属性。例如,可以使用soup.title.text获取页面标题。你也可以用汤。身体,汤。P、 等,以获取任何必需的元素
步骤3:提取内容
在以上两个步骤中,我们使用请求从web页面请求数据,并使用BS4解析页面。现在我们进入最关键的一步:如何从解析的页面中提取所需的内容
在BeautifulSoup中,我们可以使用find/find_uuuAll来定位元素,但我更习惯于使用CSS选择器。选择,因为我可以访问DOM树,就像使用CSS选择元素一样
现在,让我们使用代码解释如何从解析的页面中提取站点B的热列表数据。首先,我们需要找到存储数据的标签,按列表页面上的F12键,然后根据下图中的说明找到它
您可以看到,每个视频消息都包装在class=“rank item”的Li标记下,然后代码可以写为:point\uuudown:
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
在上面的代码中,我们首先使用soup。选择('li.Rank项')。此时,我们返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取所需的字段信息,并将其以字典的形式存储在开头定义的空列表中
您可以注意到,我使用了多种选择方法来提取元素,这也是选择方法的灵活性。有兴趣的读者可以自己进一步研究
步骤4:存储数据
通过前三个步骤,我们使用requests+BS4成功地从网站提取了所需的数据。最后,我们只需将数据写入excel并保存即可
如果您不熟悉熊猫,可以使用CSV模块编写。请注意,您应该设置encoding='utf-8-sig',否则中文代码将被乱码
import csv
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果您熟悉pandas,可以轻松地将字典转换为dataframe,只需一行代码即可完成
import pandas as pd
keys = all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
总结
到目前为止,我们已经成功地使用Python在本地存储了站点B的流行视频列表数据。大多数基于请求的爬虫程序基本上遵循上述四个步骤
然而,尽管看起来很简单,但在真实场景中的每一步都不是那么容易。从数据的要求来看,目标网站有多种形式的反爬行和加密,还有很多需要在以后的数据分析、提取甚至存储中进一步探索和学习
本文选择B站的视频热点列表正是因为它足够简单。我希望通过这个案例让您了解crawler的基本流程,最后附上完整的代码
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
url = 'https://www.bilibili.com/ranki ... 39%3B
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig') 查看全部
c爬虫抓取网页数据(Python中解析网页的基本流程及方法
)
爬虫是Python的一个重要应用。使用PythonCrawler,我们可以轻松地从互联网上获取我们想要的数据
本文将以B站视频热点搜索列表数据存储为例,详细介绍Python爬虫的基本过程
PS:如果你需要Python学习材料,你可以点击下面的链接自己获取
Python免费学习资料和组通信解决方案。点击加入
如果您仍处于介绍阶段或不知道爬虫程序的具体工作流程,则应仔细阅读本文
步骤1:尝试请求
首先,进入B站主页,点击排名列表,复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动Jupiter笔记本并运行以下代码
import requests
url = 'https://www.bilibili.com/ranki ... 39%3B
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
您可以看到返回值是200,表示服务器响应正常,这意味着我们可以继续
步骤2:解析页面
在上一步中,通过请求从网站请求数据后,我们成功获得了一个收录服务器资源的响应对象。现在我们可以使用。文本以查看其内容
您可以看到返回了一个字符串,其中收录我们需要的热列表视频数据,但是直接从字符串中提取内容既复杂又低效。因此,我们需要对其进行解析,并将字符串转换为网页结构化数据,这样我们就可以轻松地找到HTML标记及其属性和内容
在Python中有许多解析网页的方法。您可以使用正则表达式、beautulsoup、pyquery或lxml。本文将基于beautulsoup进行解释
Beauty soup是一个第三方库,可以从HTML或XML文件中提取数据
安装也很简单。您可以使用PIP安装BS4来安装它
让我们用一个简单的例子来说明它是如何工作的
from bs4 import BeautifulSoup
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.text
print(title)
# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
在上面的代码中,我们通过BS4中的Beauty soup类将上一步获得的HTML格式字符串转换为Beauty soup对象。注意,使用解析器时需要开发解析器。这里使用html.parser
然后您可以得到一个结构化元素及其属性。例如,可以使用soup.title.text获取页面标题。你也可以用汤。身体,汤。P、 等,以获取任何必需的元素
步骤3:提取内容
在以上两个步骤中,我们使用请求从web页面请求数据,并使用BS4解析页面。现在我们进入最关键的一步:如何从解析的页面中提取所需的内容
在BeautifulSoup中,我们可以使用find/find_uuuAll来定位元素,但我更习惯于使用CSS选择器。选择,因为我可以访问DOM树,就像使用CSS选择元素一样
现在,让我们使用代码解释如何从解析的页面中提取站点B的热列表数据。首先,我们需要找到存储数据的标签,按列表页面上的F12键,然后根据下图中的说明找到它
您可以看到,每个视频消息都包装在class=“rank item”的Li标记下,然后代码可以写为:point\uuudown:
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
在上面的代码中,我们首先使用soup。选择('li.Rank项')。此时,我们返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取所需的字段信息,并将其以字典的形式存储在开头定义的空列表中
您可以注意到,我使用了多种选择方法来提取元素,这也是选择方法的灵活性。有兴趣的读者可以自己进一步研究
步骤4:存储数据
通过前三个步骤,我们使用requests+BS4成功地从网站提取了所需的数据。最后,我们只需将数据写入excel并保存即可
如果您不熟悉熊猫,可以使用CSV模块编写。请注意,您应该设置encoding='utf-8-sig',否则中文代码将被乱码
import csv
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果您熟悉pandas,可以轻松地将字典转换为dataframe,只需一行代码即可完成
import pandas as pd
keys = all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
总结
到目前为止,我们已经成功地使用Python在本地存储了站点B的流行视频列表数据。大多数基于请求的爬虫程序基本上遵循上述四个步骤
然而,尽管看起来很简单,但在真实场景中的每一步都不是那么容易。从数据的要求来看,目标网站有多种形式的反爬行和加密,还有很多需要在以后的数据分析、提取甚至存储中进一步探索和学习
本文选择B站的视频热点列表正是因为它足够简单。我希望通过这个案例让您了解crawler的基本流程,最后附上完整的代码
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
url = 'https://www.bilibili.com/ranki ... 39%3B
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
c爬虫抓取网页数据(爬虫在数据分析领域的应用,如何帮助我们提升数据分析质量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-09-18 10:16
在当今的信息和数字时代,人们离不开网络搜索,但想想看,你可以在搜索过程中真正获得相关信息,因为有人在帮助你过滤并向你展示相关内容
就像在餐馆里一样,你点土豆就可以吃,因为有人帮你在土豆、萝卜、西红柿等中找到土豆,然后有人把它们带到你的桌子上。在互联网上,这两个动作是由一个叫爬虫的同学实现的
换句话说,没有爬虫,今天就没有检索,也就无法准确地找到信息并有效地获取数据。今天,datahunter digital hunter将介绍crawler在数据分析领域的应用,以及它如何帮助我们提高数据分析的质量
一、在数据时代,爬虫的本质是提高效率
网络爬虫,又称网络机器人,可以代替人们自动浏览网络中的信息,并对采集和数据进行分类
这是一个程序。其基本原理是向网站/网络发送请求,获取资源,分析和提取有用数据。从技术层面来说,就是通过程序模拟浏览器请求站点的行为,爬升站点本地返回的HTML代码/JSON数据/二进制数据(图片和视频),然后提取需要的数据并存储起来使用
每个程序都有自己的规则,网络爬虫也不例外。它穿梭于世界各地的网站中心,并将根据人们强加的规则提供采集信息。我们称这些规则为网络爬虫算法。规则是由人们根据自己的目标和需要制定的。因此,根据用户的目标,爬虫可以具有不同的功能。然而,所有爬虫的本质都是为了方便人们在海量的互联网信息中找到并下载自己想要的类型,从而提高信息获取的效率
二、crawler的应用:搜索和帮助企业加强业务
1.search engine:攀爬网站,为网络用户提供便利
在网络发展之初,全球可提供的网站信息数量并不多,用户也不多。Internet只是文件传输协议(FTP)站点的集合,用户可以在其中导航以查找特定的共享文件。为了发现和整合互联网上的分布式数据,人们创建了一个称为Web Crawler/robot的自动程序,该程序可以捕获互联网上的所有网页,然后将所有网页的内容复制到数据库中进行索引。这也是最早的搜索引擎
如今,随着互联网的快速发展,我们可以在任何搜索引擎中看到来自网站世界各地的信息。百度搜索引擎的爬虫称为百度蜘蛛、360蜘蛛、搜狗蜘蛛和必应机器人。搜索引擎离不开爬虫
例如,百度蜘蛛每天都会在大量的互联网信息中爬行,以获取高质量的信息和信息收录. 当用户在百度搜索引擎上搜索对应的关键词时,百度会对关键词进行分析,从收录页面中找出相关页面,按照一定的排名规则进行排序,并将结果显示给用户。工作原理如图所示。现在,我们可以大胆地说,您每天都在免费享受爬行动物带来的好处
2.Enterprises:监控公众舆论,高效获取有价值的信息
正如我们所说,爬行动物的本质是提高效率,爬行动物的规则是由人设定的;然后企业可以根据自己的业务需求设计一个爬虫,在第一时间获取网络上的相关信息,并对其进行清理和集成
大数据时代的数据分析,首先要有数据源,网络爬虫可以让我们获得更多的数据源,进行采集,从而去除很多不相关的数据
例如,在大数据分析或数据挖掘中,数据源可以从提供数据统计的网站源以及一些文献或内部材料中获得。然而,这些获取数据的方法有时难以满足我们的数据需求。此时,我们可以利用爬虫技术从互联网上自动获取更多我们感兴趣的数据内容,从而进行更深入的数据分析,获取更多有价值的信息
此外,网络爬虫还可以用于财务分析,分析采集的财务数据,用于投资分析;应用于舆情监测分析、目标客户精准营销等领域
三、4企业常用的网络爬虫
根据实现技术和结构,网络爬虫可分为通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫等。然而,由于复杂的网络环境,实际的网络爬虫通常是这几种爬虫的组合
1.universalwebcrawler
通用网络爬虫也称为全网络爬虫。顾名思义,在整个互联网上,被抓取的目标资源是巨大的,抓取的范围也是非常大的。由于它所爬行的数据是海量数据,因此对这种爬行器的性能要求非常高。这种网络爬虫主要用于大型搜索引擎,具有很高的应用价值
通用网络爬虫主要由初始URL集、URL队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块等组成。通用网络爬虫在爬行时会采用一定的爬行策略,主要包括深度优先爬行策略和广度优先爬行策略。具体细节将在后面介绍
2.关注网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是一种根据预定义主题选择性地抓取网页的爬虫。聚焦网络爬虫主要用于抓取特定信息,并为特定类别的人提供服务
聚焦网络爬虫还包括初始URL集、URL队列、页面爬网模块、页面分析模块、页面数据库、链接过滤模块、内容评估模块、链接评估模块、,内容评估模块和链接评估模块可以根据链接和内容的重要性确定首先访问哪些页面。有四种主要的抓取策略用于关注网络爬虫,如图所示:
由于聚焦网络爬虫可以根据相应的主题有目的地进行爬网,在实际应用过程中可以节省大量的服务器资源和宽带资源,因此具有很强的实用性。这里,我们以focus网络爬虫为例,了解爬虫操作的工作原理和过程
如图所示,focus web crawler有一个控制中心,负责管理和监控整个爬虫系统,主要包括控制用户交互、初始化爬虫、确定主题、协调各模块之间的工作、控制爬虫过程等
(1)control center将初始URL集合传递给URL队列,页面爬行模块将从URL队列读取第一批URL列表
(2)根据这些URL地址从互联网上抓取相应的页面;抓取后,将抓取的内容转移到页面数据库中存储
(3)在爬网过程中,会对一些新的URL进行爬网,此时需要使用链接过滤模块根据确定的主题过滤掉不相关的链接,然后使用链接评估模块或内容评估模块根据主题对剩余的URL链接进行优先级排序。完成后,新的URL地址ess将被传递到URL队列,供页面爬网模块使用
(4)抓取页面并存储在页面数据库中后,需要使用页面分析模块根据主题对抓取的页面进行分析处理,并根据处理结果建立索引数据库,当您检索到相应的信息时,可以从索引数据库中检索到,并获得相应结果
3.incremental网络爬虫
这里的“增量”对应增量更新,增量更新是指在更新过程中只更新更改的位置,而不更新未更改的位置
增量网络爬虫,在抓取网页时,只抓取内容发生变化的网页或新生成的网页,对于没有内容变化的网页,不会抓取,增量网络爬虫可以保证被抓取的网页在一定程度上尽可能的新
4.deepweb爬虫
在互联网上,网页按其存在方式可分为表层网页和深层网页。表层网页是指不提交表单就可以通过静态链接访问的静态网页;深层网页是指只有在一定数量的关键词提交后才能获得的网页。在互联网上,深层网页的数量是年龄通常比表面页面的年龄大得多
Deep web Crawler可以在Internet上抓取深度页面。要抓取深度页面,需要找到一种方法来自动填写相应的表单。Deep web Crawler主要包括URL列表和LVS列表(LVS指标记/值集,即填写表单的数据源)、爬行控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器等
四、webcrawler的爬行策略
如前所述,网络爬虫算法是为了采集信息 查看全部
c爬虫抓取网页数据(爬虫在数据分析领域的应用,如何帮助我们提升数据分析质量)
在当今的信息和数字时代,人们离不开网络搜索,但想想看,你可以在搜索过程中真正获得相关信息,因为有人在帮助你过滤并向你展示相关内容
就像在餐馆里一样,你点土豆就可以吃,因为有人帮你在土豆、萝卜、西红柿等中找到土豆,然后有人把它们带到你的桌子上。在互联网上,这两个动作是由一个叫爬虫的同学实现的
换句话说,没有爬虫,今天就没有检索,也就无法准确地找到信息并有效地获取数据。今天,datahunter digital hunter将介绍crawler在数据分析领域的应用,以及它如何帮助我们提高数据分析的质量
一、在数据时代,爬虫的本质是提高效率
网络爬虫,又称网络机器人,可以代替人们自动浏览网络中的信息,并对采集和数据进行分类
这是一个程序。其基本原理是向网站/网络发送请求,获取资源,分析和提取有用数据。从技术层面来说,就是通过程序模拟浏览器请求站点的行为,爬升站点本地返回的HTML代码/JSON数据/二进制数据(图片和视频),然后提取需要的数据并存储起来使用
每个程序都有自己的规则,网络爬虫也不例外。它穿梭于世界各地的网站中心,并将根据人们强加的规则提供采集信息。我们称这些规则为网络爬虫算法。规则是由人们根据自己的目标和需要制定的。因此,根据用户的目标,爬虫可以具有不同的功能。然而,所有爬虫的本质都是为了方便人们在海量的互联网信息中找到并下载自己想要的类型,从而提高信息获取的效率
二、crawler的应用:搜索和帮助企业加强业务
1.search engine:攀爬网站,为网络用户提供便利
在网络发展之初,全球可提供的网站信息数量并不多,用户也不多。Internet只是文件传输协议(FTP)站点的集合,用户可以在其中导航以查找特定的共享文件。为了发现和整合互联网上的分布式数据,人们创建了一个称为Web Crawler/robot的自动程序,该程序可以捕获互联网上的所有网页,然后将所有网页的内容复制到数据库中进行索引。这也是最早的搜索引擎
如今,随着互联网的快速发展,我们可以在任何搜索引擎中看到来自网站世界各地的信息。百度搜索引擎的爬虫称为百度蜘蛛、360蜘蛛、搜狗蜘蛛和必应机器人。搜索引擎离不开爬虫
例如,百度蜘蛛每天都会在大量的互联网信息中爬行,以获取高质量的信息和信息收录. 当用户在百度搜索引擎上搜索对应的关键词时,百度会对关键词进行分析,从收录页面中找出相关页面,按照一定的排名规则进行排序,并将结果显示给用户。工作原理如图所示。现在,我们可以大胆地说,您每天都在免费享受爬行动物带来的好处
2.Enterprises:监控公众舆论,高效获取有价值的信息
正如我们所说,爬行动物的本质是提高效率,爬行动物的规则是由人设定的;然后企业可以根据自己的业务需求设计一个爬虫,在第一时间获取网络上的相关信息,并对其进行清理和集成
大数据时代的数据分析,首先要有数据源,网络爬虫可以让我们获得更多的数据源,进行采集,从而去除很多不相关的数据
例如,在大数据分析或数据挖掘中,数据源可以从提供数据统计的网站源以及一些文献或内部材料中获得。然而,这些获取数据的方法有时难以满足我们的数据需求。此时,我们可以利用爬虫技术从互联网上自动获取更多我们感兴趣的数据内容,从而进行更深入的数据分析,获取更多有价值的信息
此外,网络爬虫还可以用于财务分析,分析采集的财务数据,用于投资分析;应用于舆情监测分析、目标客户精准营销等领域
三、4企业常用的网络爬虫
根据实现技术和结构,网络爬虫可分为通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫等。然而,由于复杂的网络环境,实际的网络爬虫通常是这几种爬虫的组合
1.universalwebcrawler
通用网络爬虫也称为全网络爬虫。顾名思义,在整个互联网上,被抓取的目标资源是巨大的,抓取的范围也是非常大的。由于它所爬行的数据是海量数据,因此对这种爬行器的性能要求非常高。这种网络爬虫主要用于大型搜索引擎,具有很高的应用价值
通用网络爬虫主要由初始URL集、URL队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块等组成。通用网络爬虫在爬行时会采用一定的爬行策略,主要包括深度优先爬行策略和广度优先爬行策略。具体细节将在后面介绍
2.关注网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是一种根据预定义主题选择性地抓取网页的爬虫。聚焦网络爬虫主要用于抓取特定信息,并为特定类别的人提供服务
聚焦网络爬虫还包括初始URL集、URL队列、页面爬网模块、页面分析模块、页面数据库、链接过滤模块、内容评估模块、链接评估模块、,内容评估模块和链接评估模块可以根据链接和内容的重要性确定首先访问哪些页面。有四种主要的抓取策略用于关注网络爬虫,如图所示:
由于聚焦网络爬虫可以根据相应的主题有目的地进行爬网,在实际应用过程中可以节省大量的服务器资源和宽带资源,因此具有很强的实用性。这里,我们以focus网络爬虫为例,了解爬虫操作的工作原理和过程
如图所示,focus web crawler有一个控制中心,负责管理和监控整个爬虫系统,主要包括控制用户交互、初始化爬虫、确定主题、协调各模块之间的工作、控制爬虫过程等
(1)control center将初始URL集合传递给URL队列,页面爬行模块将从URL队列读取第一批URL列表
(2)根据这些URL地址从互联网上抓取相应的页面;抓取后,将抓取的内容转移到页面数据库中存储
(3)在爬网过程中,会对一些新的URL进行爬网,此时需要使用链接过滤模块根据确定的主题过滤掉不相关的链接,然后使用链接评估模块或内容评估模块根据主题对剩余的URL链接进行优先级排序。完成后,新的URL地址ess将被传递到URL队列,供页面爬网模块使用
(4)抓取页面并存储在页面数据库中后,需要使用页面分析模块根据主题对抓取的页面进行分析处理,并根据处理结果建立索引数据库,当您检索到相应的信息时,可以从索引数据库中检索到,并获得相应结果
3.incremental网络爬虫
这里的“增量”对应增量更新,增量更新是指在更新过程中只更新更改的位置,而不更新未更改的位置
增量网络爬虫,在抓取网页时,只抓取内容发生变化的网页或新生成的网页,对于没有内容变化的网页,不会抓取,增量网络爬虫可以保证被抓取的网页在一定程度上尽可能的新
4.deepweb爬虫
在互联网上,网页按其存在方式可分为表层网页和深层网页。表层网页是指不提交表单就可以通过静态链接访问的静态网页;深层网页是指只有在一定数量的关键词提交后才能获得的网页。在互联网上,深层网页的数量是年龄通常比表面页面的年龄大得多
Deep web Crawler可以在Internet上抓取深度页面。要抓取深度页面,需要找到一种方法来自动填写相应的表单。Deep web Crawler主要包括URL列表和LVS列表(LVS指标记/值集,即填写表单的数据源)、爬行控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器等
四、webcrawler的爬行策略
如前所述,网络爬虫算法是为了采集信息
c爬虫抓取网页数据(搜索引擎就是在网上爬来爬去的蜘蛛怎样设置蜘蛛(spider))
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-14 02:13
搜索引擎用来抓取和访问页面的程序称为蜘蛛,也称为机器人如何设置蜘蛛。当搜索引擎蜘蛛访问网站页面时,它类似于使用浏览器的普通用户。蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。搜索引擎旨在提高爬行和爬行。拿速度来说,都是用多只蜘蛛来分布爬取。
蜘蛛访问网站时,首先会访问网站根目录下的robots.txt文件。如果robots.txt文件禁止搜索引擎抓取某些网页或内容,或者网站,蜘蛛会遵守协议,如何设置蜘蛛不抓取。
蜘蛛也有自己的代理名称。你可以在站长的日志中看到蜘蛛爬行的痕迹。所以很多站长在回答问题的时候,总是说先查看网站日志(作为一个优秀的SEO,你必须有能力在不借助任何软件的情况下查看网站日志,并且非常熟悉其代码的含义)如何设置蜘蛛。
一、搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛是Spider,这是一个很形象的名字。它将互联网比作蜘蛛网。那么蜘蛛就是在网上爬行的蜘蛛如何设置蜘蛛。
网络蜘蛛通过网页的链接地址搜索网页。从某个页面网站(通常是首页)开始,读取网页内容,找到网页中的其他链接地址,然后通过这些链接地址搜索下一个网页如何设置蜘蛛,以及继续循环直到所有网站 网页都被抓取。
如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页以及如何设置蜘蛛。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,爬取互联网上的所有网页几乎是不可能的。根据目前公布的数据,容量最大的搜索引擎只抓取了整个网页的 4%。如何在十点左右设置蜘蛛。
一方面是因为爬虫技术的瓶颈。 100亿个网页的容量为100×2000G字节。即使可以存储,下载还是有问题(按照一台机器每秒下载20K计算,需要340个单元。机器不停下载一年才能完成所有网页的下载。同时,由于数据量大,在提供搜索时也会影响如何设置蜘蛛的效率。
因此,很多搜索引擎的网络蜘蛛只抓取那些重要的网页,抓取时评价重要性的主要依据是如何设置蜘蛛对某个网页的链接深度。
由于无法抓取所有网页,如何设置蜘蛛,部分网络蜘蛛对一些不太重要的网站设置了访问级别数,例如如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A为起始网页,属于第0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。 如接入层数网络蜘蛛设置的是2的情况下,我的网页不会被访问,这也允许网站上的部分网页在搜索引擎上搜索到,其他部分搜索不到如何设置蜘蛛。
对于网站 设计师而言,扁平化的网站 结构设计有助于搜索引擎抓取更多网页。如何设置蜘蛛。
网络蜘蛛在访问网站网页时,经常会遇到加密数据和网络权限的问题。某些网页需要会员权限才能访问如何设置蜘蛛。
当然网站的站长可以通过协议防止网络蜘蛛爬行,但是对于一些卖报告的网站来说,他们希望搜索引擎可以搜索到他们的报告,但他们做不到完全免费。搜索者查看,因此需要向网络蜘蛛提供相应的用户名和密码。如何设置蜘蛛。
网络蜘蛛可以通过给定的权限抓取这些网页提供搜索,当搜索者点击查看网页时,搜索者还需要提供相应的权限来验证如何设置蜘蛛。
二、tracking 链接
因为搜索引擎蜘蛛可以在网络上抓取尽可能多的页面,所以它们会跟随网页上的链接从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样。这是搜索引擎蜘蛛。如何设置蜘蛛的名字来源。
整个互联网网站是由相互链接组成的,也就是说,从任何一个页面开始,搜索引擎蜘蛛最终都会爬上所有页面。如何设置蜘蛛。
搜索引擎蜘蛛的基本原理和工作流程
当然网站和页面链接结构太复杂了。如何设置蜘蛛,让蜘蛛只能通过某些方法抓取所有页面。据我了解,最简单的爬取策略有3种:
1、最佳优先级
最佳优先级搜索策略根据一定的网页分析算法预测候选网址与目标页面的相似度或与主题的相关性,选择一个或几个评价最好的网址进行抓取,只访问如何为网页分析算法预测为“有用”的网页设置蜘蛛。
一个问题是爬虫的爬取路径中很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要将最佳优先级与具体应用结合起来进行改进。为了跳出局部最优,根据研究结果,这样的闭环调整可以将不相关网页的数量减少30%到90%。
2、深度优先
深度优先是指蜘蛛沿着找到的链接向前爬行,直到没有更多的链接在它之前,然后返回第一页,沿着另一个链接爬行,然后向前爬行。如何设置蜘蛛。
3、广度优先
广度优先是指当蜘蛛在一个页面上发现多个链接时,它不会一直沿着一个链接前进,而是爬取页面上的所有链接,然后沿着第二层进入页面的第二层找到的链接爬到页面的第三层。如何设置蜘蛛。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它们就可以抓取整个互联网。
实际工作中如何设置爬虫?蜘蛛的带宽资源和时间不是无限的,也不能爬取所有页面。事实上,最大的搜索引擎只是爬取和收录互联网的一小部分。当然不是搜索引擎蜘蛛爬的越多越好,这一点
因此,为了捕捉尽可能多的用户信息,通常深度优先和广度优先混合使用,这样可以照顾到尽可能多的网站,也可以照顾到如何设置一个网站 内部页面蜘蛛的一部分。
三、搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。 “蜘蛛”这个名字描述了信息采集模块如何在网络数据形成的“Web”上设置蜘蛛进行信息采集。
一般来说,网络蜘蛛从种子网页开始,通过反复下载网页和搜索文档中看不见的网址,如何设置蜘蛛以访问其他网页和遍历网络。
并且其工作策略一般可以分为累积爬行(cumulative crawling)和增量爬行(incremental crawling)两种设置蜘蛛的方式。
1、累积爬取
累积爬取是指如何设置蜘蛛从某个时间点爬取系统允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证可以爬取相当数量的网页集合。
似乎由于网络数据的动态性,采集到的网页的时间不同,页面更新的情况也不同。因此,累积爬取所爬取的网页集合实际上与真实环境中的并不相同。网络数据与如何设置蜘蛛一致。
2、增量爬取
与累积爬取不同,增量爬取是指对具有一定规模的网页集合,采用更新数据的方式,在现有集合中选择过时的网页进行爬取,从而保证所有抓取到的数据足够接近真实的网络数据。如何设置蜘蛛。
增量爬取的前提是系统已经爬取了足够多的网页,并且有这些页面被爬取的时间信息。如何设置蜘蛛。在面向实际应用环境的网络蜘蛛设计中,通常包括累积爬取和增量爬取两种策略。
累积爬取一般用于数据集合的整体建立或大规模更新阶段,而增量爬取主要是针对数据集合的日常维护以及如何设置蜘蛛进行实时更新。
在确定爬取策略后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛操作策略的核心问题。如何设置蜘蛛。
总的来说,在合理利用软硬件资源实时采集网络数据方面,已经形成了比较成熟的技术和实用的解决方案。我认为这方面需要解决的主要问题是更好地处理动态网络数据问题(如Web2.0数据量不断增加等),以及更好地如何基于网页设置蜘蛛质量以纠正抓取策略。
四、database
为了避免重复抓取和抓取网址,如何设置蜘蛛,搜索引擎会建立一个数据库来记录已经发现没有被抓取的页面和已经被抓取的页面。那么数据库中的URL是怎么来的呢? ?
1、手动输入种子网站
简单来说,就是我们新建一个网站提交给百度、谷歌或者360之后的网址收录如何设置蜘蛛。
2、蜘蛛抓取页面
如果搜索引擎蜘蛛在爬取过程中发现了新的连接网址,但不在数据库中,则会存储在待访问的数据库中(网站测期)如何设置蜘蛛。
蜘蛛根据重要性从要访问的数据库中提取URL,访问并爬取页面,然后从要访问的地址数据库中删除该URL并将其放入已访问地址数据库中,因此建议站长访问网站 观察期间需要定期更新网站。如何设置蜘蛛。
3、站长Submitted网站
一般来说,提交网站只是将网站保存到数据库中进行访问。如果网站 Durable 不更新蜘蛛,则不会光顾。搜索引擎收录的页面都是蜘蛛通过链接获取的。如何设置蜘蛛。
所以如果你把它提交给搜索引擎,它不是很有用。稍后您仍然需要考虑您的网站 更新级别。搜索引擎更喜欢沿着链接本身发现新页面。当然,如果你的SEO技巧足够高深,并且如果你有这个能力,你可以尝试一下。可能会有意想不到的结果。不过对于一般站长来说,还是建议让蜘蛛自然爬行,爬到新的站点页面。如何设置蜘蛛。
五、吸引蜘蛛
虽然理论上说蜘蛛可以爬取所有页面,但实际上是做不到的。所以想要收录更多页面的SEO人员只能想办法引诱蜘蛛爬行以及如何设置蜘蛛。
既然我们不能抓取所有页面以及如何设置蜘蛛,那我们就得让它抓取重要页面,因为重要页面在索引中起着重要的作用,直接影响排名因素。哪些页面更重要?对此,我还专门整理了以下我认为比较重要的页面,具体有这些特点:
1、网站 和页面权重
高质量和老网站被赋予了很高的权重。这种蜘蛛在网站上的页面爬行深度比较高,所以收录如何设置蜘蛛的内页会比较多。
2、page 更新度
蜘蛛每次爬行都会存储页面数据。如果在第二次爬取时发现这个页面的内容和第一个收录完全一样,说明该页面没有更新,蜘蛛不需要频繁爬取和爬取。如何设置蜘蛛。
如果页面内容更新频繁,如何设置蜘蛛,蜘蛛会频繁爬行,那么页面上的新链接自然会被蜘蛛更快地跟踪和抓取,这就是为什么它需要每天更新文章
3、import 链接
无论是外链还是同一个网站的内链,要想被蜘蛛爬取,必须有导入链接才能进入页面,否则蜘蛛不知道怎么设置蜘蛛为页面的存在。这时候URL链接就发挥了非常重要的作用,内链的重要性就发挥出来了。
另外,我个人觉得高质量的导入链接往往会增加页面导出链接的爬取深度。如何设置蜘蛛。
这就是为什么大部分站长或者SEO都需要高质量友情链接的原因,因为蜘蛛从对方网站爬到你网站的次数很多,而且深度也很高。如何设置蜘蛛。 查看全部
c爬虫抓取网页数据(搜索引擎就是在网上爬来爬去的蜘蛛怎样设置蜘蛛(spider))
搜索引擎用来抓取和访问页面的程序称为蜘蛛,也称为机器人如何设置蜘蛛。当搜索引擎蜘蛛访问网站页面时,它类似于使用浏览器的普通用户。蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。搜索引擎旨在提高爬行和爬行。拿速度来说,都是用多只蜘蛛来分布爬取。
蜘蛛访问网站时,首先会访问网站根目录下的robots.txt文件。如果robots.txt文件禁止搜索引擎抓取某些网页或内容,或者网站,蜘蛛会遵守协议,如何设置蜘蛛不抓取。
蜘蛛也有自己的代理名称。你可以在站长的日志中看到蜘蛛爬行的痕迹。所以很多站长在回答问题的时候,总是说先查看网站日志(作为一个优秀的SEO,你必须有能力在不借助任何软件的情况下查看网站日志,并且非常熟悉其代码的含义)如何设置蜘蛛。
一、搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛是Spider,这是一个很形象的名字。它将互联网比作蜘蛛网。那么蜘蛛就是在网上爬行的蜘蛛如何设置蜘蛛。
网络蜘蛛通过网页的链接地址搜索网页。从某个页面网站(通常是首页)开始,读取网页内容,找到网页中的其他链接地址,然后通过这些链接地址搜索下一个网页如何设置蜘蛛,以及继续循环直到所有网站 网页都被抓取。
如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页以及如何设置蜘蛛。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,爬取互联网上的所有网页几乎是不可能的。根据目前公布的数据,容量最大的搜索引擎只抓取了整个网页的 4%。如何在十点左右设置蜘蛛。
一方面是因为爬虫技术的瓶颈。 100亿个网页的容量为100×2000G字节。即使可以存储,下载还是有问题(按照一台机器每秒下载20K计算,需要340个单元。机器不停下载一年才能完成所有网页的下载。同时,由于数据量大,在提供搜索时也会影响如何设置蜘蛛的效率。
因此,很多搜索引擎的网络蜘蛛只抓取那些重要的网页,抓取时评价重要性的主要依据是如何设置蜘蛛对某个网页的链接深度。
由于无法抓取所有网页,如何设置蜘蛛,部分网络蜘蛛对一些不太重要的网站设置了访问级别数,例如如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A为起始网页,属于第0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。 如接入层数网络蜘蛛设置的是2的情况下,我的网页不会被访问,这也允许网站上的部分网页在搜索引擎上搜索到,其他部分搜索不到如何设置蜘蛛。
对于网站 设计师而言,扁平化的网站 结构设计有助于搜索引擎抓取更多网页。如何设置蜘蛛。
网络蜘蛛在访问网站网页时,经常会遇到加密数据和网络权限的问题。某些网页需要会员权限才能访问如何设置蜘蛛。
当然网站的站长可以通过协议防止网络蜘蛛爬行,但是对于一些卖报告的网站来说,他们希望搜索引擎可以搜索到他们的报告,但他们做不到完全免费。搜索者查看,因此需要向网络蜘蛛提供相应的用户名和密码。如何设置蜘蛛。
网络蜘蛛可以通过给定的权限抓取这些网页提供搜索,当搜索者点击查看网页时,搜索者还需要提供相应的权限来验证如何设置蜘蛛。
二、tracking 链接
因为搜索引擎蜘蛛可以在网络上抓取尽可能多的页面,所以它们会跟随网页上的链接从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样。这是搜索引擎蜘蛛。如何设置蜘蛛的名字来源。
整个互联网网站是由相互链接组成的,也就是说,从任何一个页面开始,搜索引擎蜘蛛最终都会爬上所有页面。如何设置蜘蛛。
搜索引擎蜘蛛的基本原理和工作流程
当然网站和页面链接结构太复杂了。如何设置蜘蛛,让蜘蛛只能通过某些方法抓取所有页面。据我了解,最简单的爬取策略有3种:
1、最佳优先级
最佳优先级搜索策略根据一定的网页分析算法预测候选网址与目标页面的相似度或与主题的相关性,选择一个或几个评价最好的网址进行抓取,只访问如何为网页分析算法预测为“有用”的网页设置蜘蛛。
一个问题是爬虫的爬取路径中很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要将最佳优先级与具体应用结合起来进行改进。为了跳出局部最优,根据研究结果,这样的闭环调整可以将不相关网页的数量减少30%到90%。
2、深度优先
深度优先是指蜘蛛沿着找到的链接向前爬行,直到没有更多的链接在它之前,然后返回第一页,沿着另一个链接爬行,然后向前爬行。如何设置蜘蛛。
3、广度优先
广度优先是指当蜘蛛在一个页面上发现多个链接时,它不会一直沿着一个链接前进,而是爬取页面上的所有链接,然后沿着第二层进入页面的第二层找到的链接爬到页面的第三层。如何设置蜘蛛。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它们就可以抓取整个互联网。
实际工作中如何设置爬虫?蜘蛛的带宽资源和时间不是无限的,也不能爬取所有页面。事实上,最大的搜索引擎只是爬取和收录互联网的一小部分。当然不是搜索引擎蜘蛛爬的越多越好,这一点
因此,为了捕捉尽可能多的用户信息,通常深度优先和广度优先混合使用,这样可以照顾到尽可能多的网站,也可以照顾到如何设置一个网站 内部页面蜘蛛的一部分。
三、搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。 “蜘蛛”这个名字描述了信息采集模块如何在网络数据形成的“Web”上设置蜘蛛进行信息采集。
一般来说,网络蜘蛛从种子网页开始,通过反复下载网页和搜索文档中看不见的网址,如何设置蜘蛛以访问其他网页和遍历网络。
并且其工作策略一般可以分为累积爬行(cumulative crawling)和增量爬行(incremental crawling)两种设置蜘蛛的方式。
1、累积爬取
累积爬取是指如何设置蜘蛛从某个时间点爬取系统允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证可以爬取相当数量的网页集合。
似乎由于网络数据的动态性,采集到的网页的时间不同,页面更新的情况也不同。因此,累积爬取所爬取的网页集合实际上与真实环境中的并不相同。网络数据与如何设置蜘蛛一致。
2、增量爬取
与累积爬取不同,增量爬取是指对具有一定规模的网页集合,采用更新数据的方式,在现有集合中选择过时的网页进行爬取,从而保证所有抓取到的数据足够接近真实的网络数据。如何设置蜘蛛。
增量爬取的前提是系统已经爬取了足够多的网页,并且有这些页面被爬取的时间信息。如何设置蜘蛛。在面向实际应用环境的网络蜘蛛设计中,通常包括累积爬取和增量爬取两种策略。
累积爬取一般用于数据集合的整体建立或大规模更新阶段,而增量爬取主要是针对数据集合的日常维护以及如何设置蜘蛛进行实时更新。
在确定爬取策略后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛操作策略的核心问题。如何设置蜘蛛。
总的来说,在合理利用软硬件资源实时采集网络数据方面,已经形成了比较成熟的技术和实用的解决方案。我认为这方面需要解决的主要问题是更好地处理动态网络数据问题(如Web2.0数据量不断增加等),以及更好地如何基于网页设置蜘蛛质量以纠正抓取策略。
四、database
为了避免重复抓取和抓取网址,如何设置蜘蛛,搜索引擎会建立一个数据库来记录已经发现没有被抓取的页面和已经被抓取的页面。那么数据库中的URL是怎么来的呢? ?
1、手动输入种子网站
简单来说,就是我们新建一个网站提交给百度、谷歌或者360之后的网址收录如何设置蜘蛛。
2、蜘蛛抓取页面
如果搜索引擎蜘蛛在爬取过程中发现了新的连接网址,但不在数据库中,则会存储在待访问的数据库中(网站测期)如何设置蜘蛛。
蜘蛛根据重要性从要访问的数据库中提取URL,访问并爬取页面,然后从要访问的地址数据库中删除该URL并将其放入已访问地址数据库中,因此建议站长访问网站 观察期间需要定期更新网站。如何设置蜘蛛。
3、站长Submitted网站
一般来说,提交网站只是将网站保存到数据库中进行访问。如果网站 Durable 不更新蜘蛛,则不会光顾。搜索引擎收录的页面都是蜘蛛通过链接获取的。如何设置蜘蛛。
所以如果你把它提交给搜索引擎,它不是很有用。稍后您仍然需要考虑您的网站 更新级别。搜索引擎更喜欢沿着链接本身发现新页面。当然,如果你的SEO技巧足够高深,并且如果你有这个能力,你可以尝试一下。可能会有意想不到的结果。不过对于一般站长来说,还是建议让蜘蛛自然爬行,爬到新的站点页面。如何设置蜘蛛。
五、吸引蜘蛛
虽然理论上说蜘蛛可以爬取所有页面,但实际上是做不到的。所以想要收录更多页面的SEO人员只能想办法引诱蜘蛛爬行以及如何设置蜘蛛。
既然我们不能抓取所有页面以及如何设置蜘蛛,那我们就得让它抓取重要页面,因为重要页面在索引中起着重要的作用,直接影响排名因素。哪些页面更重要?对此,我还专门整理了以下我认为比较重要的页面,具体有这些特点:
1、网站 和页面权重
高质量和老网站被赋予了很高的权重。这种蜘蛛在网站上的页面爬行深度比较高,所以收录如何设置蜘蛛的内页会比较多。
2、page 更新度
蜘蛛每次爬行都会存储页面数据。如果在第二次爬取时发现这个页面的内容和第一个收录完全一样,说明该页面没有更新,蜘蛛不需要频繁爬取和爬取。如何设置蜘蛛。
如果页面内容更新频繁,如何设置蜘蛛,蜘蛛会频繁爬行,那么页面上的新链接自然会被蜘蛛更快地跟踪和抓取,这就是为什么它需要每天更新文章
3、import 链接
无论是外链还是同一个网站的内链,要想被蜘蛛爬取,必须有导入链接才能进入页面,否则蜘蛛不知道怎么设置蜘蛛为页面的存在。这时候URL链接就发挥了非常重要的作用,内链的重要性就发挥出来了。
另外,我个人觉得高质量的导入链接往往会增加页面导出链接的爬取深度。如何设置蜘蛛。
这就是为什么大部分站长或者SEO都需要高质量友情链接的原因,因为蜘蛛从对方网站爬到你网站的次数很多,而且深度也很高。如何设置蜘蛛。
c爬虫抓取网页数据(58同城:PythonDesignDesignonPython报纸杂志)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-09-13 04:02
摘要:为了快速获取职位信息,根据“无忧”网页的特点,设计了三个基于Python的爬虫来抓取职位相关数据。通过提取关键词,匹配符合条件的职位信息,抓取相关内容存入Excel文件,方便查找相关职位信息和具体需求。实验结果表明,该程序能够快速、海量地捕捉相关职位信息,针对性强,简单易读,有利于对职位信息的进一步挖掘和分析。
关键词:Python;爬虫;位置; 51job;
基于Python的51-job数据抓取程序设计
摘要:为了快速获取职位信息,根据“未来无忧”网页的特点,设计了三种基于Python的爬虫程序来抓取职位相关数据。通过提取关键词,匹配职位信息,将相关内容抓取到Excel文件中,方便查找相关职位信息和具体要求。实验结果表明,该程序能够快速、海量地捕获相关职位信息,且针对性强、易读,有利于对职位信息的进一步挖掘和分析。
关键字:Python;爬虫;位置;未来无忧;
0、引言
随着互联网时代的飞速发展,可以通过互联网获取海量数据,足不出户就可以了解瞬息万变的世界[1]。我们可以在互联网上获取招聘信息,而不仅限于互联网。报纸、杂志等纸质媒体可以让求职者快速有效地获取自己想要的招聘信息。每年9、4月是毕业生求职的高峰期,快速有效地获取招聘信息成为求职过程中的关键环节。为此,本文设计了一个基于python的爬虫程序。目前国内最著名的求职软件有“智联招聘”、“51job”、“”等,本文主要介绍“51job”的招聘信息。抓住并分析。现有数据采集程序的采集方式单一,用户无法选择最快的采集方式。程序针对这个问题做了进一步的优化,设计了三种数据采集方法。用户可以选择和输入关键字,匹配招聘信息的位置。设计更合理,用户体验会更好[2]。
本文提出的程序使用爬虫获取职位信息,包括:职位名称、职位、地点、公司名称、薪资范围、职位内容、招聘网址、发布日期。并将获取的信息保存在本地,用于后续的数据挖掘和分析。本文中的爬虫程序收录三种爬虫方法,分别是Re、XPath、Beatuiful Soup。用户可以自行选择自己想要的爬虫方式,输入位置的关键词,通过关键词匹配,获取对应的位置信息。
1、相关概念
1.1 Python 语言
Python 语言语法简单、清晰、功能强大且易于理解。可以运行在Windows、Linux等操作系统上; Python是一种面向对象语言,具有效率高、面向对象编程简单等优点[3-4]。 Python是一种语法简洁的脚本语言,并且支持动态输入,使得Python成为许多操作系统平台上的理想脚本语言,特别适合快速应用开发[5]。 Python 收录了一个网络协议标准库,可以抽象和封装各种层次的网络协议,这使得用户可以进一步优化程序逻辑。其次,Python非常擅长处理各种模式的字节流,开发速度非常快[6-7]。
1.2 网络爬虫
Web Crawler[8](Web Crawler),是一种根据一定的规则自动提取网页的应用程序或脚本。是在搜索引擎上完成数据爬取的关键步骤,可在互联网网站页面下载。爬虫用于将互联网上的网页保存在本地,以供参考[9-10]。爬虫程序用于通过分析页面源文件的 URL,从一个或多个初始页面的 URL 中检索新的 Web 链接。网页链接,然后继续寻找新的网页链接[11],如此循环往复,直到所有页面都被抓取并分析完毕。当然,这是一种理想的情况。根据目前公布的数据,最好的搜索引擎只抓取了整个互联网不到一半的网页[12]。
2、程序设计
本文的爬虫程序主要分为5个模块。首先根据Request URL获取需要爬取数据的页面,使用关键词通过Re、XPath、Beautiful Soup三种方法过滤符合条件的职位信息,包括职位名称、职位、地点、公司名称、薪资范围、职位内容、招聘网站、发布日期均保存在本地,方便后续数据挖掘和分析。
2.1 获取网页信息
在抓取网页信息之前,需要获取网页的信息,从中找出需要的信息进行抓取。首先打开Chrome浏览器,进入51job网页,打开开发者选项,找到网络,获取请求头中的URL和headers[13]。在预览中可以看到当前网页的源代码,可以从源代码中找到需要爬取的信息,即职位名称、职称、职位、公司名称、薪资范围、职位内容、招聘网址、发布日期,并找到当前页和下一页的偏移值,以便后面的爬虫可以抓取到设计中使用。
2.2 主程序设计
将Beautiful Soup、XPath、Regex的文件名打包成字典,并标注序号,设计进入程序的页面,并在页面上显示提示信息。请根据用户的选择选择一种爬虫方式,进入对应的程序,等待用户输入需要查询的位置关键词,启动爬虫程序,开始抓取数据[14]。抓取完成后,提示用户数据抓取完成,保存到本地文件,供用户使用和分析。
2.3 重新编程
正则表达式 (Re) 是对字符串(包括普通字符(例如 a 和 z 之间的字母)和特殊字符(称为“元字符”))进行运算的逻辑公式。一些定义的特定字符和这些特定字符的组合形成一个“规则串”[15],这个“规则串”用于表达对字符串的过滤逻辑。正则表达式是一种文本模式,用于描述搜索文本时要匹配的一个或多个字符串。
根据上面得到的网页信息,所需信息的字符串可以用Re表示,其中:
通过获取日期,用户可以了解最新的工作信息。根据职位的详细信息,求职者可以快速了解公司的要求和该职位的相关职位信息。通过上述正则表达式得到的信息保存在本地Excel文件中,方便求职者查看。
2.4 XPath 编程
XPath 是 XML 路径语言。它是一种用于确定 XML(标准通用标记语言的子集)文档中某个部分的位置的语言 [16]。 XPath 基于 XML 的树结构,具有不同类型的节点,包括元素节点、属性节点和文本节点,提供在数据结构树中查找节点的能力。最初,XPath 的初衷是将其用作 XPointer 和 XSLT 之间的通用语法模型。但 XPath 很快就被开发人员采用为一种小型查询语言。
XPath 比 Re 简单。 Re语言容易出错,无法正确获取所需信息。通常可以在 Chrome 中添加 XPath Helper 插件。可以直接将网页源代码复制成XPath格式,方便快捷。通常不容易犯错。
在 XPath 程序中,其中:
对比XPath和Re的代码,很明显XPath的代码比Re的代码简洁。
2.5 Beautiful Soup 程序设计
Beautiful Soup 提供了一些简单的、python 风格的函数来处理导航、搜索、修改分析树和其他功能 [16]。它是一个工具箱,为用户提供需要通过解析文档获取的数据,因为它简单,所以不用太多代码就可以写出一个完整的应用程序。 Beautiful Soup 自动将输入文档转换为 Unicode 编码,输出文档为 utf-8 编码。无需考虑编码方式,除非文档没有指定编码方式,此时Beautiful Soup无法自动识别编码方式。那么,只需要解释一下原来的编码方式即可。
2.5.1 解析库
本文介绍几个python解析库并进行比较。如表1所示,本文使用的解析器为python标准解析器。
2.5.2 标签选择器
标签选择器可以选择元素,获取名称、属性和内容,可以进行嵌套选择,可以获取子节点、后代节点、父节点、祖先节点等。标签选择器可以分为标准选择器和CSS 选择器。标签选择器可以根据标签名称、属性和内容查找文档。有两个常用的函数。其中, find_all (name, attrs, recursive, text, **kwargs ) 用于返回所有符合条件的元素; find (name, attrs, recursive, text, **kwargs) 用于返回第一个符合条件的元素。 CSS选择器直接将select()传入CSS选择器完成元素选择。
本文设计的程序中选择了CSS选择器,通过select()函数完成数据选择,其中:'int(str(soup.select('div.rt span.dw_c_orange' ) [0]. next Sibling))'#获取当前页码
3、实验结果
使用本文设计的爬虫程序进行如下实验:首先进入主程序,点击运行程序,程序返回图1所示界面。
接下来,如图2,输入数字“2”选择BeautifulSoup解析方式,输入关键词python启动爬虫,程序正常运行。
程序运行后,可以在本地文件夹中找到名为“python position”的Excel文件。打开文件,可以看到如图3所示的信息。
4、结论
本文根据Python语言简洁易读的特点,设计了三种爬取程序的方法。用户可以自行选择数据分析的方法,输入需要查询的关键词,就可以从海量的作业数据中提取自己的需求,数据方便快捷。本程序通过匹配职位关键词、工作地点等信息,在一定程度上为用户提供了方便。提取的详细职业信息描述可以进一步细分,可以统计词频,可以观察到单词的出现。可以更快的了解公司和相应职位的要求,找到符合求职者的招聘信息。
参考资料
[1] 方锦堂。基于网络爬虫的在线教育平台设计与实现[D].北京:北京交通大学,2016.
[2] 王八耀。基于Python的Web爬虫技术研究[J].数字技术与应用, 2017 (5):76-76.
[3] 周中华,张惠然,谢江.基于Python的新浪微博数据爬虫[J].计算机应用, 2014, 34 (11):3131-3134.
[4] 涂小琴。基于Python爬虫的影评情感倾向分析[J].现代计算机, 2017 (35):52-55.
[5]郭立荣.基于Python的网络爬虫程序设计[J].电子技术与软件工程, 2017 (23) :248-249.
[6]Lutz M.学习 Python[M]。北京:机械工业出版社,2009.
[7] 刘志凯,张太红,刘磊。基于Web的Python3编程环境[J].计算机系统应用, 2015, 24 (7):236-239.
[8] 王大伟。基于Python的Web API自动测试方法研究[J].电子科技,2015,2(5):573-581.
[9]Hetland M L. Python 基础课程 [M]。北京:人民邮电出版社,2014:243-245.
[10] 涂辉,汪峰,尚清伟。 Python3编程实现网络图像爬虫[J].计算机编程技巧与维护,2017 (23):21-22.
[11] 高森. Python 网络编程基础[M].北京:电子工业出版社,2007.
[12] 周丽珠,林玲。爬虫技术研究综述[J].计算机应用, 2005, 25 (9):1965-1969.
[13] 蒋善标,黄开林,卢玉江等.基于Python的专业网络爬虫的设计与实现[J].企业技术与发展, 2016 (8):17-19.
[14] 陈琳,任芳。基于Python的新浪微博数据爬虫程序设计[J].信息系统工程, 2016 (9):97-99.
[15] 刘娜。 Python正则表达式高级特性研究[J].计算机编程技巧与维护,2015 (22):12-13.
[16] 齐鹏,李银峰,宋雨薇。基于Python采集技术的Web数据[J].电子科学与技术, 2012, 25 (11):118-120. 查看全部
c爬虫抓取网页数据(58同城:PythonDesignDesignonPython报纸杂志)
摘要:为了快速获取职位信息,根据“无忧”网页的特点,设计了三个基于Python的爬虫来抓取职位相关数据。通过提取关键词,匹配符合条件的职位信息,抓取相关内容存入Excel文件,方便查找相关职位信息和具体需求。实验结果表明,该程序能够快速、海量地捕捉相关职位信息,针对性强,简单易读,有利于对职位信息的进一步挖掘和分析。
关键词:Python;爬虫;位置; 51job;
基于Python的51-job数据抓取程序设计
摘要:为了快速获取职位信息,根据“未来无忧”网页的特点,设计了三种基于Python的爬虫程序来抓取职位相关数据。通过提取关键词,匹配职位信息,将相关内容抓取到Excel文件中,方便查找相关职位信息和具体要求。实验结果表明,该程序能够快速、海量地捕获相关职位信息,且针对性强、易读,有利于对职位信息的进一步挖掘和分析。
关键字:Python;爬虫;位置;未来无忧;
0、引言
随着互联网时代的飞速发展,可以通过互联网获取海量数据,足不出户就可以了解瞬息万变的世界[1]。我们可以在互联网上获取招聘信息,而不仅限于互联网。报纸、杂志等纸质媒体可以让求职者快速有效地获取自己想要的招聘信息。每年9、4月是毕业生求职的高峰期,快速有效地获取招聘信息成为求职过程中的关键环节。为此,本文设计了一个基于python的爬虫程序。目前国内最著名的求职软件有“智联招聘”、“51job”、“”等,本文主要介绍“51job”的招聘信息。抓住并分析。现有数据采集程序的采集方式单一,用户无法选择最快的采集方式。程序针对这个问题做了进一步的优化,设计了三种数据采集方法。用户可以选择和输入关键字,匹配招聘信息的位置。设计更合理,用户体验会更好[2]。
本文提出的程序使用爬虫获取职位信息,包括:职位名称、职位、地点、公司名称、薪资范围、职位内容、招聘网址、发布日期。并将获取的信息保存在本地,用于后续的数据挖掘和分析。本文中的爬虫程序收录三种爬虫方法,分别是Re、XPath、Beatuiful Soup。用户可以自行选择自己想要的爬虫方式,输入位置的关键词,通过关键词匹配,获取对应的位置信息。
1、相关概念
1.1 Python 语言
Python 语言语法简单、清晰、功能强大且易于理解。可以运行在Windows、Linux等操作系统上; Python是一种面向对象语言,具有效率高、面向对象编程简单等优点[3-4]。 Python是一种语法简洁的脚本语言,并且支持动态输入,使得Python成为许多操作系统平台上的理想脚本语言,特别适合快速应用开发[5]。 Python 收录了一个网络协议标准库,可以抽象和封装各种层次的网络协议,这使得用户可以进一步优化程序逻辑。其次,Python非常擅长处理各种模式的字节流,开发速度非常快[6-7]。
1.2 网络爬虫
Web Crawler[8](Web Crawler),是一种根据一定的规则自动提取网页的应用程序或脚本。是在搜索引擎上完成数据爬取的关键步骤,可在互联网网站页面下载。爬虫用于将互联网上的网页保存在本地,以供参考[9-10]。爬虫程序用于通过分析页面源文件的 URL,从一个或多个初始页面的 URL 中检索新的 Web 链接。网页链接,然后继续寻找新的网页链接[11],如此循环往复,直到所有页面都被抓取并分析完毕。当然,这是一种理想的情况。根据目前公布的数据,最好的搜索引擎只抓取了整个互联网不到一半的网页[12]。
2、程序设计
本文的爬虫程序主要分为5个模块。首先根据Request URL获取需要爬取数据的页面,使用关键词通过Re、XPath、Beautiful Soup三种方法过滤符合条件的职位信息,包括职位名称、职位、地点、公司名称、薪资范围、职位内容、招聘网站、发布日期均保存在本地,方便后续数据挖掘和分析。
2.1 获取网页信息
在抓取网页信息之前,需要获取网页的信息,从中找出需要的信息进行抓取。首先打开Chrome浏览器,进入51job网页,打开开发者选项,找到网络,获取请求头中的URL和headers[13]。在预览中可以看到当前网页的源代码,可以从源代码中找到需要爬取的信息,即职位名称、职称、职位、公司名称、薪资范围、职位内容、招聘网址、发布日期,并找到当前页和下一页的偏移值,以便后面的爬虫可以抓取到设计中使用。
2.2 主程序设计
将Beautiful Soup、XPath、Regex的文件名打包成字典,并标注序号,设计进入程序的页面,并在页面上显示提示信息。请根据用户的选择选择一种爬虫方式,进入对应的程序,等待用户输入需要查询的位置关键词,启动爬虫程序,开始抓取数据[14]。抓取完成后,提示用户数据抓取完成,保存到本地文件,供用户使用和分析。
2.3 重新编程
正则表达式 (Re) 是对字符串(包括普通字符(例如 a 和 z 之间的字母)和特殊字符(称为“元字符”))进行运算的逻辑公式。一些定义的特定字符和这些特定字符的组合形成一个“规则串”[15],这个“规则串”用于表达对字符串的过滤逻辑。正则表达式是一种文本模式,用于描述搜索文本时要匹配的一个或多个字符串。
根据上面得到的网页信息,所需信息的字符串可以用Re表示,其中:
通过获取日期,用户可以了解最新的工作信息。根据职位的详细信息,求职者可以快速了解公司的要求和该职位的相关职位信息。通过上述正则表达式得到的信息保存在本地Excel文件中,方便求职者查看。
2.4 XPath 编程
XPath 是 XML 路径语言。它是一种用于确定 XML(标准通用标记语言的子集)文档中某个部分的位置的语言 [16]。 XPath 基于 XML 的树结构,具有不同类型的节点,包括元素节点、属性节点和文本节点,提供在数据结构树中查找节点的能力。最初,XPath 的初衷是将其用作 XPointer 和 XSLT 之间的通用语法模型。但 XPath 很快就被开发人员采用为一种小型查询语言。
XPath 比 Re 简单。 Re语言容易出错,无法正确获取所需信息。通常可以在 Chrome 中添加 XPath Helper 插件。可以直接将网页源代码复制成XPath格式,方便快捷。通常不容易犯错。
在 XPath 程序中,其中:
对比XPath和Re的代码,很明显XPath的代码比Re的代码简洁。
2.5 Beautiful Soup 程序设计
Beautiful Soup 提供了一些简单的、python 风格的函数来处理导航、搜索、修改分析树和其他功能 [16]。它是一个工具箱,为用户提供需要通过解析文档获取的数据,因为它简单,所以不用太多代码就可以写出一个完整的应用程序。 Beautiful Soup 自动将输入文档转换为 Unicode 编码,输出文档为 utf-8 编码。无需考虑编码方式,除非文档没有指定编码方式,此时Beautiful Soup无法自动识别编码方式。那么,只需要解释一下原来的编码方式即可。
2.5.1 解析库
本文介绍几个python解析库并进行比较。如表1所示,本文使用的解析器为python标准解析器。
2.5.2 标签选择器
标签选择器可以选择元素,获取名称、属性和内容,可以进行嵌套选择,可以获取子节点、后代节点、父节点、祖先节点等。标签选择器可以分为标准选择器和CSS 选择器。标签选择器可以根据标签名称、属性和内容查找文档。有两个常用的函数。其中, find_all (name, attrs, recursive, text, **kwargs ) 用于返回所有符合条件的元素; find (name, attrs, recursive, text, **kwargs) 用于返回第一个符合条件的元素。 CSS选择器直接将select()传入CSS选择器完成元素选择。
本文设计的程序中选择了CSS选择器,通过select()函数完成数据选择,其中:'int(str(soup.select('div.rt span.dw_c_orange' ) [0]. next Sibling))'#获取当前页码
3、实验结果
使用本文设计的爬虫程序进行如下实验:首先进入主程序,点击运行程序,程序返回图1所示界面。
接下来,如图2,输入数字“2”选择BeautifulSoup解析方式,输入关键词python启动爬虫,程序正常运行。
程序运行后,可以在本地文件夹中找到名为“python position”的Excel文件。打开文件,可以看到如图3所示的信息。
4、结论
本文根据Python语言简洁易读的特点,设计了三种爬取程序的方法。用户可以自行选择数据分析的方法,输入需要查询的关键词,就可以从海量的作业数据中提取自己的需求,数据方便快捷。本程序通过匹配职位关键词、工作地点等信息,在一定程度上为用户提供了方便。提取的详细职业信息描述可以进一步细分,可以统计词频,可以观察到单词的出现。可以更快的了解公司和相应职位的要求,找到符合求职者的招聘信息。
参考资料
[1] 方锦堂。基于网络爬虫的在线教育平台设计与实现[D].北京:北京交通大学,2016.
[2] 王八耀。基于Python的Web爬虫技术研究[J].数字技术与应用, 2017 (5):76-76.
[3] 周中华,张惠然,谢江.基于Python的新浪微博数据爬虫[J].计算机应用, 2014, 34 (11):3131-3134.
[4] 涂小琴。基于Python爬虫的影评情感倾向分析[J].现代计算机, 2017 (35):52-55.
[5]郭立荣.基于Python的网络爬虫程序设计[J].电子技术与软件工程, 2017 (23) :248-249.
[6]Lutz M.学习 Python[M]。北京:机械工业出版社,2009.
[7] 刘志凯,张太红,刘磊。基于Web的Python3编程环境[J].计算机系统应用, 2015, 24 (7):236-239.
[8] 王大伟。基于Python的Web API自动测试方法研究[J].电子科技,2015,2(5):573-581.
[9]Hetland M L. Python 基础课程 [M]。北京:人民邮电出版社,2014:243-245.
[10] 涂辉,汪峰,尚清伟。 Python3编程实现网络图像爬虫[J].计算机编程技巧与维护,2017 (23):21-22.
[11] 高森. Python 网络编程基础[M].北京:电子工业出版社,2007.
[12] 周丽珠,林玲。爬虫技术研究综述[J].计算机应用, 2005, 25 (9):1965-1969.
[13] 蒋善标,黄开林,卢玉江等.基于Python的专业网络爬虫的设计与实现[J].企业技术与发展, 2016 (8):17-19.
[14] 陈琳,任芳。基于Python的新浪微博数据爬虫程序设计[J].信息系统工程, 2016 (9):97-99.
[15] 刘娜。 Python正则表达式高级特性研究[J].计算机编程技巧与维护,2015 (22):12-13.
[16] 齐鹏,李银峰,宋雨薇。基于Python采集技术的Web数据[J].电子科学与技术, 2012, 25 (11):118-120.
c爬虫抓取网页数据(搜索引擎蜘蛛的基本原理及工作流程对于SEO的流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-09-13 03:18
搜索引擎用来抓取和访问页面的程序称为蜘蛛程序或机器人程序。当搜索引擎蜘蛛访问网站页面时,它类似于使用浏览器的普通用户。蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。搜索引擎旨在提高爬行和爬行。拿速度,用多个蜘蛛来分布爬取。
蜘蛛访问网站时,首先会访问网站根目录下的robots.txt文件。如果robots.txt文件禁止搜索引擎抓取某些网页或内容,或者网站,蜘蛛会遵守协议,不会被抓取。
蜘蛛也有自己的代理名称。你可以在站长的日志中看到蜘蛛爬行的痕迹。所以很多站长在回答问题的时候,总是说先查看网站日志(作为一个优秀的SEO,你必须有能力在不借助任何软件的情况下查看网站日志,并且非常熟悉其代码的含义)。
一、搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛是Spider,这是一个很形象的名字。它将互联网比作蜘蛛网,然后蜘蛛就是在网上爬行的蜘蛛。
网络蜘蛛通过网页的链接地址搜索网页。从某个页面网站(通常是首页)开始,读取该网页的内容,找到该网页中的其他链接地址,然后通过这些链接地址搜索下一个网页,这个循环一直持续到所有网站网页已被抓取。
如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,爬取互联网上的所有网页几乎是不可能的。根据目前公布的数据,容量最大的搜索引擎只抓取了整个网页的 4%。大约十个。
一方面是因为爬虫技术的瓶颈。 100亿个网页的容量为100×2000G字节。就算能存储,下载还是有问题(按一台机器每秒下载20K计算,需要340个单元,机器不停下载一年才能完成所有网页的下载)。同时,由于数据量大,在提供搜索时也会影响效率。
因此,很多搜索引擎网络蜘蛛只抓取那些重要的网页,而评价抓取重要性的主要依据是某个网页的链接深度。
因为不可能爬取所有网页,所以一些网络蜘蛛对一些不太重要的网站设置了访问级别的数量,例如如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A为起始网页,属于第0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。 如接入层数网络蜘蛛设置的是2的情况下,网页我不会被访问,这也使得网站之前的一些页面在搜索引擎上搜索到,其他部分搜索不到。
对于网站designers,扁平化的网站结构设计有助于搜索引擎抓取更多网页。
网络蜘蛛在访问网站网页时,经常会遇到加密数据和网络权限的问题。某些网页需要会员权限才能访问。
当然网站的拥有者可以通过协议防止网络蜘蛛爬行,但是对于一些卖报告的网站来说,他们希望自己的报告能被搜索引擎搜索到,但不可能完全免费搜索者查看,所以需要向网络蜘蛛提供相应的用户名和密码。
网络蜘蛛可以抓取这些具有给定权限的网页提供搜索,当搜索者点击查看网页时,搜索者还需要提供相应的权限验证。
二、tracking 链接
因为搜索引擎蜘蛛可以在网络上抓取尽可能多的页面,所以它们会跟随网页上的链接从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样。这是搜索引擎蜘蛛。名字的由来。
整个互联网网站是由相互链接组成的,这意味着搜索引擎蜘蛛最终会从任何页面开始抓取所有页面。
搜索引擎蜘蛛的基本原理和工作流程
当然网站和页面链接结构太复杂了,所以蜘蛛只能通过一定的方法抓取所有页面。根据我的理解,有3种简单的爬取策略:
1、最佳优先级
最佳优先级搜索策略根据一定的网页分析算法预测候选网址与目标页面的相似度或与主题的相关性,选择一个或几个评价最好的网址进行抓取,只访问被网络分析算法预测为“有用”的网页。
一个问题是爬虫的爬取路径中很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要将最佳优先级与具体应用结合起来进行改进。为了跳出局部最优,根据研究结果,这种闭环调整可以将不相关网页的数量减少30%到90%。
2、深度优先
深度优先是指蜘蛛沿着找到的链接向前爬,直到没有更多的链接在它前面,然后回到第一页,沿着另一个链接向前爬。
3、广度优先
广度优先是指当蜘蛛在一个页面上发现多个链接时,它不会一直沿着一个链接前进,而是爬取页面上的所有链接,然后沿着第二级进入第二级页面找到的链接爬到三级页面。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它们就可以抓取整个互联网。
在实际工作中,蜘蛛的带宽资源和时间不是无限的,也不是可以抓取所有页面。其实最大的搜索引擎只是爬取而收录了互联网的一小部分,当然不是搜索引擎蜘蛛爬的越多越好,这一点
因此,为了捕捉尽可能多的用户信息,通常深度优先和广度优先混合使用,这样可以兼顾到尽可能多的网站,以及网站的一部分内部页面。
三、搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。 “蜘蛛”这个名字描述了信息采集模块在网络数据形成的“Web”上获取信息的功能。
一般情况下,网络蜘蛛从种子网页开始,反复下载网页,寻找文档中从未见过的网址,从而访问其他网页并遍历网络。
其工作策略一般可分为累积爬行(cumulative crawling)和增量爬行(incremental crawling)两种。
1、累积爬取
累积爬取是指从某个时间点开始,以遍历的方式爬取系统允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证可以爬取相当数量的网页集合。
似乎由于网络数据的动态性,采集到的网页的时间不同,页面更新的情况也不同。因此,累积爬取所爬取的网页集合实际上与真实环境中的并不相同。网络数据保持一致。
2、增量爬取
与累积爬取不同,增量爬取是指对具有一定规模的网页集合,采用更新数据的方式,在现有集合中选择过时的网页进行爬取,从而保证所有抓取到的数据足够接近真实网络数据。
增量爬取的前提是系统已经爬取了足够多的网页,并且有这些页面被爬取的时间信息。在面向实际应用环境的网络蜘蛛设计中,通常包括累积爬取和增量爬取两种策略。
累积爬取一般用于数据集合的整体建立或大规模更新阶段,而增量爬取主要用于数据集合的日常维护和实时更新。
在确定爬取策略后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛运行策略的核心问题。
总的来说,在合理利用软硬件资源实时采集网络数据方面,已经形成了比较成熟的技术和实用的解决方案。我认为这方面需要解决的主要问题是更好地处理动态网络数据问题(如Web2.0数据量不断增加等),更好地修正基于网页的爬取策略问题质量。
四、database
为了避免重复抓取和抓取网址,搜索引擎会建立一个数据库来记录已发现未抓取的页面和已抓取的页面。那么数据库中的URL是怎么来的呢?
1、手动输入种子网站
简单来说就是我们新建网站后提交给百度、谷歌或360的网址收录。
2、蜘蛛抓取页面
如果搜索引擎蜘蛛在爬取过程中发现了新的连接网址,但不在数据库中,则会存储在数据库中以供访问(网站测期)。
蜘蛛根据重要性从要访问的数据库中提取URL,访问并抓取页面,然后从要访问的地址数据库中删除该URL并将其放入已访问地址数据库中,因此建议站长访问网站,观察期间需要定期更新网站。
3、站长Submitted网站
一般来说,提交网站只是将网站保存到数据库中进行访问。如果网站 Durable 不更新蜘蛛,就不会光顾。搜索引擎收录的页面都是蜘蛛通过链接获取的。 .
所以如果你把它提交给搜索引擎,它不是很有用。稍后您仍然需要考虑您的网站 更新级别。搜索引擎更喜欢沿着链接发现新页面。当然,如果你的SEO技巧足够高深,并且有了这个能力,你也可以试试。可能会有意想不到的结果。不过对于一般站长来说,还是建议让蜘蛛爬行,自然爬到新的网站页面。
五、吸引蜘蛛
虽然理论上说蜘蛛可以爬取所有页面,但实际上是做不到的。所以想要收录更多页面的SEO人员只能想办法引诱蜘蛛爬行。
既然不能抓取所有的页面,那我们就得让它抓取重要的页面,因为重要的页面在索引中起着重要的作用,直接影响排名因素。哪些页面更重要?对此,我还专门整理了以下我认为比较重要的页面,具体有这些特点:
1、网站 和页面权重
高质量和老网站 被赋予了很高的权重。这种蜘蛛在网站上的页面爬行深度比较高,所以更多的内页会是收录。
2、page 更新度
蜘蛛每次爬行都会存储页面数据。如果在第二次抓取时发现该页面的内容与第一个收录完全相同,则说明该页面尚未更新,蜘蛛不需要频繁抓取和抓取。 .
如果页面内容更新频繁,蜘蛛就会频繁爬行爬行,那么页面上的新链接自然会被蜘蛛更快地跟踪和抓取,这也是为什么每天都要更新文章
3、import 链接
无论是外部链接还是同一个网站的内部链接,为了被蜘蛛爬取,必须有导入链接才能进入页面,否则蜘蛛不知道存在页。这时候URL链接就发挥了非常重要的作用,内链的重要性就发挥出来了。
另外,我个人觉得高质量的导入链接往往会增加页面导出链接的爬取深度。
这就是为什么大部分站长或者SEO都需要高质量友情链接的原因,因为蜘蛛经常从对方网站爬到你网站,深度高。 查看全部
c爬虫抓取网页数据(搜索引擎蜘蛛的基本原理及工作流程对于SEO的流程)
搜索引擎用来抓取和访问页面的程序称为蜘蛛程序或机器人程序。当搜索引擎蜘蛛访问网站页面时,它类似于使用浏览器的普通用户。蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。搜索引擎旨在提高爬行和爬行。拿速度,用多个蜘蛛来分布爬取。
蜘蛛访问网站时,首先会访问网站根目录下的robots.txt文件。如果robots.txt文件禁止搜索引擎抓取某些网页或内容,或者网站,蜘蛛会遵守协议,不会被抓取。
蜘蛛也有自己的代理名称。你可以在站长的日志中看到蜘蛛爬行的痕迹。所以很多站长在回答问题的时候,总是说先查看网站日志(作为一个优秀的SEO,你必须有能力在不借助任何软件的情况下查看网站日志,并且非常熟悉其代码的含义)。
一、搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛是Spider,这是一个很形象的名字。它将互联网比作蜘蛛网,然后蜘蛛就是在网上爬行的蜘蛛。
网络蜘蛛通过网页的链接地址搜索网页。从某个页面网站(通常是首页)开始,读取该网页的内容,找到该网页中的其他链接地址,然后通过这些链接地址搜索下一个网页,这个循环一直持续到所有网站网页已被抓取。
如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,爬取互联网上的所有网页几乎是不可能的。根据目前公布的数据,容量最大的搜索引擎只抓取了整个网页的 4%。大约十个。
一方面是因为爬虫技术的瓶颈。 100亿个网页的容量为100×2000G字节。就算能存储,下载还是有问题(按一台机器每秒下载20K计算,需要340个单元,机器不停下载一年才能完成所有网页的下载)。同时,由于数据量大,在提供搜索时也会影响效率。
因此,很多搜索引擎网络蜘蛛只抓取那些重要的网页,而评价抓取重要性的主要依据是某个网页的链接深度。
因为不可能爬取所有网页,所以一些网络蜘蛛对一些不太重要的网站设置了访问级别的数量,例如如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A为起始网页,属于第0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。 如接入层数网络蜘蛛设置的是2的情况下,网页我不会被访问,这也使得网站之前的一些页面在搜索引擎上搜索到,其他部分搜索不到。
对于网站designers,扁平化的网站结构设计有助于搜索引擎抓取更多网页。
网络蜘蛛在访问网站网页时,经常会遇到加密数据和网络权限的问题。某些网页需要会员权限才能访问。
当然网站的拥有者可以通过协议防止网络蜘蛛爬行,但是对于一些卖报告的网站来说,他们希望自己的报告能被搜索引擎搜索到,但不可能完全免费搜索者查看,所以需要向网络蜘蛛提供相应的用户名和密码。
网络蜘蛛可以抓取这些具有给定权限的网页提供搜索,当搜索者点击查看网页时,搜索者还需要提供相应的权限验证。
二、tracking 链接
因为搜索引擎蜘蛛可以在网络上抓取尽可能多的页面,所以它们会跟随网页上的链接从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样。这是搜索引擎蜘蛛。名字的由来。
整个互联网网站是由相互链接组成的,这意味着搜索引擎蜘蛛最终会从任何页面开始抓取所有页面。
搜索引擎蜘蛛的基本原理和工作流程
当然网站和页面链接结构太复杂了,所以蜘蛛只能通过一定的方法抓取所有页面。根据我的理解,有3种简单的爬取策略:
1、最佳优先级
最佳优先级搜索策略根据一定的网页分析算法预测候选网址与目标页面的相似度或与主题的相关性,选择一个或几个评价最好的网址进行抓取,只访问被网络分析算法预测为“有用”的网页。
一个问题是爬虫的爬取路径中很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要将最佳优先级与具体应用结合起来进行改进。为了跳出局部最优,根据研究结果,这种闭环调整可以将不相关网页的数量减少30%到90%。
2、深度优先
深度优先是指蜘蛛沿着找到的链接向前爬,直到没有更多的链接在它前面,然后回到第一页,沿着另一个链接向前爬。
3、广度优先
广度优先是指当蜘蛛在一个页面上发现多个链接时,它不会一直沿着一个链接前进,而是爬取页面上的所有链接,然后沿着第二级进入第二级页面找到的链接爬到三级页面。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它们就可以抓取整个互联网。
在实际工作中,蜘蛛的带宽资源和时间不是无限的,也不是可以抓取所有页面。其实最大的搜索引擎只是爬取而收录了互联网的一小部分,当然不是搜索引擎蜘蛛爬的越多越好,这一点
因此,为了捕捉尽可能多的用户信息,通常深度优先和广度优先混合使用,这样可以兼顾到尽可能多的网站,以及网站的一部分内部页面。
三、搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。 “蜘蛛”这个名字描述了信息采集模块在网络数据形成的“Web”上获取信息的功能。
一般情况下,网络蜘蛛从种子网页开始,反复下载网页,寻找文档中从未见过的网址,从而访问其他网页并遍历网络。
其工作策略一般可分为累积爬行(cumulative crawling)和增量爬行(incremental crawling)两种。
1、累积爬取
累积爬取是指从某个时间点开始,以遍历的方式爬取系统允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证可以爬取相当数量的网页集合。
似乎由于网络数据的动态性,采集到的网页的时间不同,页面更新的情况也不同。因此,累积爬取所爬取的网页集合实际上与真实环境中的并不相同。网络数据保持一致。
2、增量爬取
与累积爬取不同,增量爬取是指对具有一定规模的网页集合,采用更新数据的方式,在现有集合中选择过时的网页进行爬取,从而保证所有抓取到的数据足够接近真实网络数据。
增量爬取的前提是系统已经爬取了足够多的网页,并且有这些页面被爬取的时间信息。在面向实际应用环境的网络蜘蛛设计中,通常包括累积爬取和增量爬取两种策略。
累积爬取一般用于数据集合的整体建立或大规模更新阶段,而增量爬取主要用于数据集合的日常维护和实时更新。
在确定爬取策略后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛运行策略的核心问题。
总的来说,在合理利用软硬件资源实时采集网络数据方面,已经形成了比较成熟的技术和实用的解决方案。我认为这方面需要解决的主要问题是更好地处理动态网络数据问题(如Web2.0数据量不断增加等),更好地修正基于网页的爬取策略问题质量。
四、database
为了避免重复抓取和抓取网址,搜索引擎会建立一个数据库来记录已发现未抓取的页面和已抓取的页面。那么数据库中的URL是怎么来的呢?
1、手动输入种子网站
简单来说就是我们新建网站后提交给百度、谷歌或360的网址收录。
2、蜘蛛抓取页面
如果搜索引擎蜘蛛在爬取过程中发现了新的连接网址,但不在数据库中,则会存储在数据库中以供访问(网站测期)。
蜘蛛根据重要性从要访问的数据库中提取URL,访问并抓取页面,然后从要访问的地址数据库中删除该URL并将其放入已访问地址数据库中,因此建议站长访问网站,观察期间需要定期更新网站。
3、站长Submitted网站
一般来说,提交网站只是将网站保存到数据库中进行访问。如果网站 Durable 不更新蜘蛛,就不会光顾。搜索引擎收录的页面都是蜘蛛通过链接获取的。 .
所以如果你把它提交给搜索引擎,它不是很有用。稍后您仍然需要考虑您的网站 更新级别。搜索引擎更喜欢沿着链接发现新页面。当然,如果你的SEO技巧足够高深,并且有了这个能力,你也可以试试。可能会有意想不到的结果。不过对于一般站长来说,还是建议让蜘蛛爬行,自然爬到新的网站页面。
五、吸引蜘蛛
虽然理论上说蜘蛛可以爬取所有页面,但实际上是做不到的。所以想要收录更多页面的SEO人员只能想办法引诱蜘蛛爬行。
既然不能抓取所有的页面,那我们就得让它抓取重要的页面,因为重要的页面在索引中起着重要的作用,直接影响排名因素。哪些页面更重要?对此,我还专门整理了以下我认为比较重要的页面,具体有这些特点:
1、网站 和页面权重
高质量和老网站 被赋予了很高的权重。这种蜘蛛在网站上的页面爬行深度比较高,所以更多的内页会是收录。
2、page 更新度
蜘蛛每次爬行都会存储页面数据。如果在第二次抓取时发现该页面的内容与第一个收录完全相同,则说明该页面尚未更新,蜘蛛不需要频繁抓取和抓取。 .
如果页面内容更新频繁,蜘蛛就会频繁爬行爬行,那么页面上的新链接自然会被蜘蛛更快地跟踪和抓取,这也是为什么每天都要更新文章
3、import 链接
无论是外部链接还是同一个网站的内部链接,为了被蜘蛛爬取,必须有导入链接才能进入页面,否则蜘蛛不知道存在页。这时候URL链接就发挥了非常重要的作用,内链的重要性就发挥出来了。
另外,我个人觉得高质量的导入链接往往会增加页面导出链接的爬取深度。
这就是为什么大部分站长或者SEO都需要高质量友情链接的原因,因为蜘蛛经常从对方网站爬到你网站,深度高。
c爬虫抓取网页数据(Python內建使用urllib.request获取网页urllib是什么意思? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-13 03:14
)
1. 使用 urllib.request 获取网页
urllib 是 Python 中的内置 HTTP 库。使用 urllib 可以很高效采集数据,步骤非常简单;配合Beautiful等HTML解析库,可以为采集网络数据编写大型爬虫;
注:示例代码是用Python3编写的; urllib 是 Python2 中 urllib 和 urllib2 的组合,Python2 中的 urllib2 对应于 Python3 中的 urllib.request。
简单例子:
2.伪造的请求头信息
有时候爬虫发起的请求会被服务器拒绝。这时候就需要将爬虫伪装成人类用户的浏览器。这通常是通过伪造请求头信息来实现的,例如:
3.伪造的请求体
爬取一些网站时,需要POST数据到服务器,然后需要伪造请求体;
为了实现有道词典的在线翻译脚本,在Chrome中打开开发工具,在Network下找到方法为POST的请求。观察数据,可以发现请求体中的'i'是需要翻译的URL编码内容。因此,可以伪造请求体,例如:
也可以使用add_header()方法来伪造请求头,比如:
4. 使用代理IP
为了避免采集爬虫过于频繁导致的IP阻塞问题,可以使用代理IP,如:
注意:使用爬虫过于频繁地访问目标站点会占用大量服务器资源。大型分布式爬虫可以爬取某个站点甚至对该站点发起DDOS攻击;因此,应该合理使用爬虫来抓取数据 安排抓取频率和时间;如:在服务器相对空闲的时间(如:清晨)爬取,完成一个爬取任务后暂停一段时间等;
5. 检测网页的编码方式
虽然大部分网页都采用UTF-8编码,但有时也会遇到使用其他编码方式的网页,所以必须了解网页的编码方式才能正确解码抓取到的页面;
chardet是python的第三方模块,使用chardet可以自动检测网页的编码;
安装chardet:pip install charest
使用:
6.获取跳转链接
有时网页的某个页面需要在原创URL的基础上进行一次甚至多次重定向才能最终到达目的页面,因此需要正确处理重定向;
通过requests模块的head()函数获取跳转链接的URL,如
查看全部
c爬虫抓取网页数据(Python內建使用urllib.request获取网页urllib是什么意思?
)
1. 使用 urllib.request 获取网页
urllib 是 Python 中的内置 HTTP 库。使用 urllib 可以很高效采集数据,步骤非常简单;配合Beautiful等HTML解析库,可以为采集网络数据编写大型爬虫;
注:示例代码是用Python3编写的; urllib 是 Python2 中 urllib 和 urllib2 的组合,Python2 中的 urllib2 对应于 Python3 中的 urllib.request。
简单例子:
2.伪造的请求头信息
有时候爬虫发起的请求会被服务器拒绝。这时候就需要将爬虫伪装成人类用户的浏览器。这通常是通过伪造请求头信息来实现的,例如:
3.伪造的请求体
爬取一些网站时,需要POST数据到服务器,然后需要伪造请求体;
为了实现有道词典的在线翻译脚本,在Chrome中打开开发工具,在Network下找到方法为POST的请求。观察数据,可以发现请求体中的'i'是需要翻译的URL编码内容。因此,可以伪造请求体,例如:
也可以使用add_header()方法来伪造请求头,比如:
4. 使用代理IP
为了避免采集爬虫过于频繁导致的IP阻塞问题,可以使用代理IP,如:
注意:使用爬虫过于频繁地访问目标站点会占用大量服务器资源。大型分布式爬虫可以爬取某个站点甚至对该站点发起DDOS攻击;因此,应该合理使用爬虫来抓取数据 安排抓取频率和时间;如:在服务器相对空闲的时间(如:清晨)爬取,完成一个爬取任务后暂停一段时间等;
5. 检测网页的编码方式
虽然大部分网页都采用UTF-8编码,但有时也会遇到使用其他编码方式的网页,所以必须了解网页的编码方式才能正确解码抓取到的页面;
chardet是python的第三方模块,使用chardet可以自动检测网页的编码;
安装chardet:pip install charest
使用:
6.获取跳转链接
有时网页的某个页面需要在原创URL的基础上进行一次甚至多次重定向才能最终到达目的页面,因此需要正确处理重定向;
通过requests模块的head()函数获取跳转链接的URL,如
c爬虫抓取网页数据( 2019-03-24我想发网络爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-10 05:06
2019-03-24我想发网络爬虫)
基于C#实现网络爬虫C#抓取网页Html源码
时间:2019-03-24
本文章给大家介绍了基于C#实现网络爬虫C#抓取网页的Html源代码,主要包括使用C#实现网络爬虫C#抓取网页的Html源代码,应用技巧,基本知识点总结和注意事项,有一定的参考价值,有需要的朋友可以参考。
我最近刚刚完成了一个简单的网络爬虫。起初我很困惑,不知道如何开始。后来查了很多资料,确实能满足我的需求。有用的信息——代码很难找到。所以想发这个文章,让想做这个功能的朋友少走一些弯路。
首先抓取Html源代码,选择节点的href:使用System.IO添加;使用 System.Net;
private void Search(string url)
{
string rl;
WebRequest Request = WebRequest.Create(url.Trim());
WebResponse Response = Request.GetResponse();
Stream resStream = Response.GetResponseStream();
StreamReader sr = new StreamReader(resStream, Encoding.Default);
StringBuilder sb = new StringBuilder();
while ((rl = sr.ReadLine()) != null)
{
sb.Append(rl);
}
string str = sb.ToString().ToLower();
string str_get = mid(str, "", "");
int start = 0;
while (true)
{
if (str_get == null)
break;
string strResult = mid(str_get, "href=\"", "\"", out start);
if (strResult == null)
break;
else
{
lab[url] += strResult;
str_get = str_get.Substring(start);
}
}
}
private string mid(string istr, string startString, string endString)
{
int iBodyStart = istr.IndexOf(startString, 0); //开始位置
if (iBodyStart == -1)
return null;
iBodyStart += startString.Length; //第一次字符位置起的长度
int iBodyEnd = istr.IndexOf(endString, iBodyStart); //第二次字符在第一次字符位置起的首次位置
if (iBodyEnd == -1)
return null;
iBodyEnd += endString.Length; //第二次字符位置起的长度
string strResult = istr.Substring(iBodyStart, iBodyEnd - iBodyStart - 1);
return strResult;
}
private string mid(string istr, string startString, string endString, out int iBodyEnd)
{
//初始化out参数,否则不能return
iBodyEnd = 0;
int iBodyStart = istr.IndexOf(startString, 0); //开始位置
if (iBodyStart == -1)
return null;
iBodyStart += startString.Length; //第一次字符位置起的长度
iBodyEnd = istr.IndexOf(endString, iBodyStart); //第二次字符在第一次字符位置起的首次位置
if (iBodyEnd == -1)
return null;
iBodyEnd += endString.Length; //第二次字符位置起的长度
string strResult = istr.Substring(iBodyStart, iBodyEnd - iBodyStart - 1);
return strResult;
}
好的,以上就是全部代码了。如果你想运行它,你必须自己修改一些细节。 查看全部
c爬虫抓取网页数据(
2019-03-24我想发网络爬虫)
基于C#实现网络爬虫C#抓取网页Html源码
时间:2019-03-24
本文章给大家介绍了基于C#实现网络爬虫C#抓取网页的Html源代码,主要包括使用C#实现网络爬虫C#抓取网页的Html源代码,应用技巧,基本知识点总结和注意事项,有一定的参考价值,有需要的朋友可以参考。
我最近刚刚完成了一个简单的网络爬虫。起初我很困惑,不知道如何开始。后来查了很多资料,确实能满足我的需求。有用的信息——代码很难找到。所以想发这个文章,让想做这个功能的朋友少走一些弯路。
首先抓取Html源代码,选择节点的href:使用System.IO添加;使用 System.Net;
private void Search(string url)
{
string rl;
WebRequest Request = WebRequest.Create(url.Trim());
WebResponse Response = Request.GetResponse();
Stream resStream = Response.GetResponseStream();
StreamReader sr = new StreamReader(resStream, Encoding.Default);
StringBuilder sb = new StringBuilder();
while ((rl = sr.ReadLine()) != null)
{
sb.Append(rl);
}
string str = sb.ToString().ToLower();
string str_get = mid(str, "", "");
int start = 0;
while (true)
{
if (str_get == null)
break;
string strResult = mid(str_get, "href=\"", "\"", out start);
if (strResult == null)
break;
else
{
lab[url] += strResult;
str_get = str_get.Substring(start);
}
}
}
private string mid(string istr, string startString, string endString)
{
int iBodyStart = istr.IndexOf(startString, 0); //开始位置
if (iBodyStart == -1)
return null;
iBodyStart += startString.Length; //第一次字符位置起的长度
int iBodyEnd = istr.IndexOf(endString, iBodyStart); //第二次字符在第一次字符位置起的首次位置
if (iBodyEnd == -1)
return null;
iBodyEnd += endString.Length; //第二次字符位置起的长度
string strResult = istr.Substring(iBodyStart, iBodyEnd - iBodyStart - 1);
return strResult;
}
private string mid(string istr, string startString, string endString, out int iBodyEnd)
{
//初始化out参数,否则不能return
iBodyEnd = 0;
int iBodyStart = istr.IndexOf(startString, 0); //开始位置
if (iBodyStart == -1)
return null;
iBodyStart += startString.Length; //第一次字符位置起的长度
iBodyEnd = istr.IndexOf(endString, iBodyStart); //第二次字符在第一次字符位置起的首次位置
if (iBodyEnd == -1)
return null;
iBodyEnd += endString.Length; //第二次字符位置起的长度
string strResult = istr.Substring(iBodyStart, iBodyEnd - iBodyStart - 1);
return strResult;
}
好的,以上就是全部代码了。如果你想运行它,你必须自己修改一些细节。
c爬虫抓取网页数据(网络爬虫网页蜘蛛怎么用获取数据的方法?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-10 05:05
介绍网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更多时候称为网络追逐者):
是根据一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。其实现在流行的是通过程序在网页上获取你想要的数据,即自动抓取数据。爬虫能做什么?可以使用爬虫来爬取图片、爬取视频等,你要爬取的数据,只要能通过浏览器访问数据,就可以通过爬虫获取。当你在浏览器中输入地址时,通过DNS服务器找到服务器主机,并向服务器发送请求。服务端解析后,将结果发送到用户浏览器,包括html、js、css等文件内容,浏览器解析出来,最后呈现给用户在浏览器上看到的结果。所以用户看到的浏览器的结果是由HTML代码组成的。我们的爬虫就是获取这些内容,通过对html代码进行分析过滤,从中获取我们想要的资源。页面访问
1) 根据 URL 获取网页
URL 处理模块(库) import urllib.request as req 创建一个类似文件的对象,表示远程 url req.urlopen('') 像本地文件一样读取内容 import urllib.request as req # 获取网络页面根据url: # url ='' pages = req.urlopen(url) #以class文件的方式打开网页#读取网页的所有数据并转换为uft-8编码 data = pages.read ().decode('utf-8') 打印(数据)
2)保存网页数据到文件
#将读取的网页数据写入文件: outfile = open("enrollnudt.txt",'w') # 打开文件 outfile.write(data) # 将网页数据写入文件 outfile.close()
此时我们从网页中获取的数据已经保存在我们指定的文件中了,如下图
网页访问
从图中可以看出,网页的所有数据都存储在本地,但我们需要的大部分数据是文本或数字信息,代码对我们没有用处。那么接下来我们要做的就是清除无用的数据。 (这里我会得到派出所新闻的内容)
3)提取内容
分析网页,找到需要的内容《警校新闻》
内容范围
...
如何提取表格中的所有内容?
导入re包(正则表达式包) import re re.findall(pattern, string [, flags] )以列表的形式返回字符串中匹配模式的非重叠子串。字符串将从左到右扫描。 , 返回的列表也是从左到右匹配一次
如果模式中有组,则返回匹配的组
组列表的正则表达式
使用正则表达式进行匹配
'(.*?)'
数据清洗
清洗前后的数据 x.strip() 数据内部清洗 x.replace('','')
到此,本地已经获取到需要的内容,爬虫基本完成。 查看全部
c爬虫抓取网页数据(网络爬虫网页蜘蛛怎么用获取数据的方法?)
介绍网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更多时候称为网络追逐者):
是根据一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。其实现在流行的是通过程序在网页上获取你想要的数据,即自动抓取数据。爬虫能做什么?可以使用爬虫来爬取图片、爬取视频等,你要爬取的数据,只要能通过浏览器访问数据,就可以通过爬虫获取。当你在浏览器中输入地址时,通过DNS服务器找到服务器主机,并向服务器发送请求。服务端解析后,将结果发送到用户浏览器,包括html、js、css等文件内容,浏览器解析出来,最后呈现给用户在浏览器上看到的结果。所以用户看到的浏览器的结果是由HTML代码组成的。我们的爬虫就是获取这些内容,通过对html代码进行分析过滤,从中获取我们想要的资源。页面访问
1) 根据 URL 获取网页
URL 处理模块(库) import urllib.request as req 创建一个类似文件的对象,表示远程 url req.urlopen('') 像本地文件一样读取内容 import urllib.request as req # 获取网络页面根据url: # url ='' pages = req.urlopen(url) #以class文件的方式打开网页#读取网页的所有数据并转换为uft-8编码 data = pages.read ().decode('utf-8') 打印(数据)
2)保存网页数据到文件
#将读取的网页数据写入文件: outfile = open("enrollnudt.txt",'w') # 打开文件 outfile.write(data) # 将网页数据写入文件 outfile.close()
此时我们从网页中获取的数据已经保存在我们指定的文件中了,如下图
网页访问
从图中可以看出,网页的所有数据都存储在本地,但我们需要的大部分数据是文本或数字信息,代码对我们没有用处。那么接下来我们要做的就是清除无用的数据。 (这里我会得到派出所新闻的内容)
3)提取内容
分析网页,找到需要的内容《警校新闻》
内容范围
...
如何提取表格中的所有内容?
导入re包(正则表达式包) import re re.findall(pattern, string [, flags] )以列表的形式返回字符串中匹配模式的非重叠子串。字符串将从左到右扫描。 , 返回的列表也是从左到右匹配一次
如果模式中有组,则返回匹配的组
组列表的正则表达式
使用正则表达式进行匹配
'(.*?)'
数据清洗
清洗前后的数据 x.strip() 数据内部清洗 x.replace('','')
到此,本地已经获取到需要的内容,爬虫基本完成。
c爬虫抓取网页数据(Python学习群:审查网页元素与网页源码是什么? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-10 05:03
)
简介
以下代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。
我创建了一个学习Python的小学习圈,为大家提供了一个共同讨论和学习Python的平台。欢迎加入Python学习群:960410445讨论视频分享学习。 Python是未来的发展方向,正在挑战我们的分析能力和认识世界的方式。因此,我们与时俱进,迎接变化,不断成长。掌握Python核心技术才是真正的价值。
以上是网页的源代码
以上是回顾网页元素
所以在这里你不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实施思路:
抓取实际访问的动态页面的url-使用正则表达式获取需要的内容-解析内容-存储内容
以上过程部分文字说明:
获取实际访问过的动态页面的url:
在火狐浏览器中,右键打开插件,使用**firebug review element** *(如果没有该项,安装firebug插件),找到并打开**网络(NET)** 选项卡。重新加载网页,获取网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。这个网站动态网页的访问地址是:
源代码
注:python版本为2.7
查看全部
c爬虫抓取网页数据(Python学习群:审查网页元素与网页源码是什么?
)
简介
以下代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。
我创建了一个学习Python的小学习圈,为大家提供了一个共同讨论和学习Python的平台。欢迎加入Python学习群:960410445讨论视频分享学习。 Python是未来的发展方向,正在挑战我们的分析能力和认识世界的方式。因此,我们与时俱进,迎接变化,不断成长。掌握Python核心技术才是真正的价值。
以上是网页的源代码
以上是回顾网页元素
所以在这里你不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实施思路:
抓取实际访问的动态页面的url-使用正则表达式获取需要的内容-解析内容-存储内容
以上过程部分文字说明:
获取实际访问过的动态页面的url:
在火狐浏览器中,右键打开插件,使用**firebug review element** *(如果没有该项,安装firebug插件),找到并打开**网络(NET)** 选项卡。重新加载网页,获取网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。这个网站动态网页的访问地址是:
源代码
注:python版本为2.7
c爬虫抓取网页数据(乌云网我写的一个公用的HttpUtils..例子 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-09-10 05:03
)
我最近在公司建立了一个系统。因为想获取一些网页数据和一些网页数据,所以写了一个公开的HttpUtils。下面是我为乌云网写的一个例子。
一、 首先获取指定路径下的网页内容。
public static String httpGet(String urlStr, Map params) throws Exception {
StringBuilder sb = new StringBuilder();
if (null != params && params.size() > 0) {
sb.append("?");
Entry en;
for (Iterator ir = params.entrySet().iterator(); ir.hasNext();) {
en = ir.next();
sb.append(en.getKey() + "=" + URLEncoder.encode(en.getValue(),"utf-8") + (ir.hasNext() ? "&" : ""));
}
}
URL url = new URL(urlStr + sb);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(5000);
conn.setReadTimeout(5000);
conn.setRequestMethod("GET");
if (conn.getResponseCode() != 200)
throw new Exception("请求异常状态值:" + conn.getResponseCode());
BufferedInputStream bis = new BufferedInputStream(conn.getInputStream());
Reader reader = new InputStreamReader(bis,"gbk");
char[] buffer = new char[2048];
int len = 0;
CharArrayWriter caw = new CharArrayWriter();
while ((len = reader.read(buffer)) > -1)
caw.write(buffer, 0, len);
reader.close();
bis.close();
conn.disconnect();
//System.out.println(caw);
return caw.toString();
}
浏览器查询结果:
代码查询结果与上面一致:
二、通过指定url获取你想要的数据。
此方法需要导入Jsoup包,可以从网上下载。
Document doc = null;
try {
doc = Jsoup.connect("http://www.wooyun.org//bugs//w ... 6quot;).userAgent("Mozilla/5.0 (Windows NT 10.0; Trident/7.0; rv:11.0) like Gecko").timeout(30000).get();
} catch (IOException e) {
e.printStackTrace();
}
for(Iterator ir = doc.select("h3").iterator();ir.hasNext();){
System.out.println(ir.next().text());
}
对于select选择器,根据条件选择,doc.select("h3").iterator(),Jsoup的规则如下:
jsoup 是一个基于 Java 的 HTML 解析器,可以直接解析 URL 地址或 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
jsoup 的强大之处在于它对文档元素的检索。 Select 方法将返回元素集合并提供一组方法来提取和处理结果。要掌握Jsoup,首先要熟悉它的选择器语法。
1、Selector 选择器的基本语法
2、Selector 选择器组合语法
3、Selector 伪选择器语法
注意:上面的伪选择器索引从0开始,表示第一个元素的索引为0,第二个元素的索引为1,以此类推。
浏览器访问:
代码访问:
查看全部
c爬虫抓取网页数据(乌云网我写的一个公用的HttpUtils..例子
)
我最近在公司建立了一个系统。因为想获取一些网页数据和一些网页数据,所以写了一个公开的HttpUtils。下面是我为乌云网写的一个例子。
一、 首先获取指定路径下的网页内容。
public static String httpGet(String urlStr, Map params) throws Exception {
StringBuilder sb = new StringBuilder();
if (null != params && params.size() > 0) {
sb.append("?");
Entry en;
for (Iterator ir = params.entrySet().iterator(); ir.hasNext();) {
en = ir.next();
sb.append(en.getKey() + "=" + URLEncoder.encode(en.getValue(),"utf-8") + (ir.hasNext() ? "&" : ""));
}
}
URL url = new URL(urlStr + sb);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(5000);
conn.setReadTimeout(5000);
conn.setRequestMethod("GET");
if (conn.getResponseCode() != 200)
throw new Exception("请求异常状态值:" + conn.getResponseCode());
BufferedInputStream bis = new BufferedInputStream(conn.getInputStream());
Reader reader = new InputStreamReader(bis,"gbk");
char[] buffer = new char[2048];
int len = 0;
CharArrayWriter caw = new CharArrayWriter();
while ((len = reader.read(buffer)) > -1)
caw.write(buffer, 0, len);
reader.close();
bis.close();
conn.disconnect();
//System.out.println(caw);
return caw.toString();
}
浏览器查询结果:
代码查询结果与上面一致:
二、通过指定url获取你想要的数据。
此方法需要导入Jsoup包,可以从网上下载。
Document doc = null;
try {
doc = Jsoup.connect("http://www.wooyun.org//bugs//w ... 6quot;).userAgent("Mozilla/5.0 (Windows NT 10.0; Trident/7.0; rv:11.0) like Gecko").timeout(30000).get();
} catch (IOException e) {
e.printStackTrace();
}
for(Iterator ir = doc.select("h3").iterator();ir.hasNext();){
System.out.println(ir.next().text());
}
对于select选择器,根据条件选择,doc.select("h3").iterator(),Jsoup的规则如下:
jsoup 是一个基于 Java 的 HTML 解析器,可以直接解析 URL 地址或 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
jsoup 的强大之处在于它对文档元素的检索。 Select 方法将返回元素集合并提供一组方法来提取和处理结果。要掌握Jsoup,首先要熟悉它的选择器语法。
1、Selector 选择器的基本语法
2、Selector 选择器组合语法
3、Selector 伪选择器语法
注意:上面的伪选择器索引从0开始,表示第一个元素的索引为0,第二个元素的索引为1,以此类推。
浏览器访问:
代码访问:

