
采集文章系统
采集文章系统(一个微信公众号历史消息页面的链接地址和采集方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-02-11 12:26
我从2014年开始做微信公众号内容采集的批次,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集收到的微信公众号内容很容易在公众号中传播。那个时候批量采集很容易做,采集入口就是公众号的历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而将采集定位为本地新闻资讯公众号,前端展示做成app。因此,一个可以自动采集 公众号内容形成。我曾经担心有一天,微信技术升级后,它无法采集内容,我的新闻应用程序会失败。不过随着微信的不断技术升级,采集方式也升级了,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
首先我们来看一个微信公众号历史新闻页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
=========2017 年 1 月 11 日更新==========
现在,根据不同的微信个人号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一个地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前掌握的信息,这两种页面形式在不同的微信账号中不规则出现。有的微信账号总是第一页格式,有的总是第二页格式。
以上链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
这个地址是通过微信客户端打开历史消息页面,然后使用后面介绍的代理服务器软件获得的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
__biz 是公众号的类id参数。每个公众号都有一个微信业务。目前公众号的biz发生变化的概率很小;
其余三个参数与用户的 id 和 token 票证相关。这三个参数的值是微信客户端生成后自动添加到地址栏的。所以想要采集公众号,必须通过微信客户端。在微信之前的版本中,这三个参数也可以一次性获取,在有效期内被多个公众号使用。当前版本每次访问公共帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios微信客户端的崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。
2、个人微信账号:采集的内容,不仅需要微信客户端,采集还需要个人微信账号,因为这个微信账号不能做其他事情。
3、本地代理服务器系统:目前的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体的安装和设置方法将在后面详细介绍。
4、文章列表分析与仓储系统:我用php语言写的。后面会详细介绍如何分析文章列表,建立采集队列,实现批量采集内容。
步
一、安装模拟器或者用手机安装微信客户端app,申请微信个人账号并登录app。这个我就不多说了,大家都会的。
二、代理服务器系统安装
目前我正在使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置将脚本代码插入公众号页面。让我们从安装和配置过程开始。
1、安装 NodeJS
2、在命令行或者终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy并运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器上安装证书:
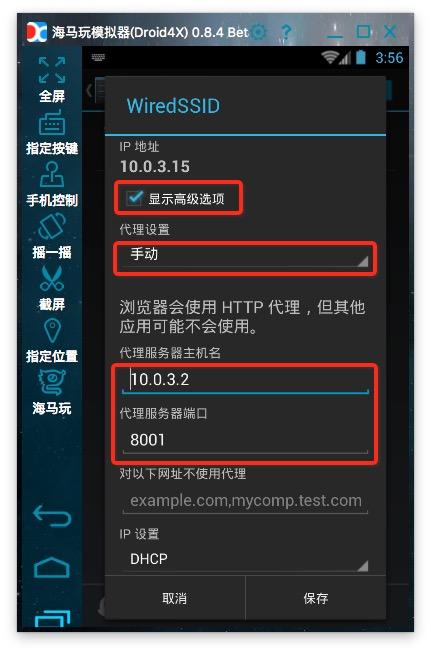
6、设置代理:Android模拟器的代理服务器地址是wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开微信,点击任意公众号历史消息或文章,可以在终端看到响应码滚动。如果没有出现,请检查您手机的代理设置是否正确。
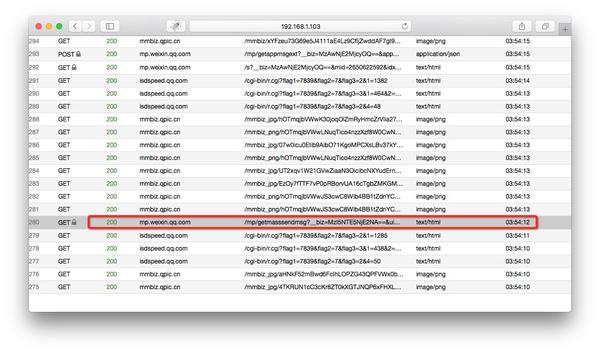
现在打开浏览器地址localhost:8002可以看到anyproxy的web界面。从微信点击一个历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
/mp/getmasssendmsg 开头的网址是微信历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
=========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转,跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址查看内容。
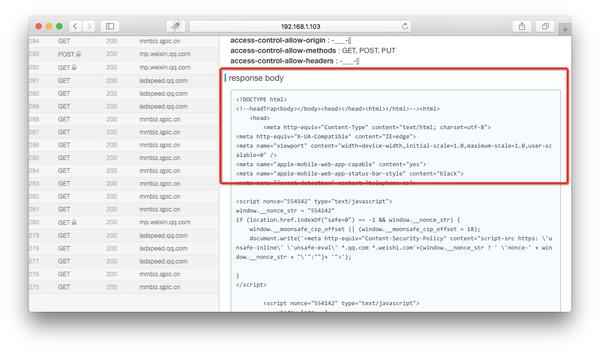
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
现在我们手机上的所有内容都可以以明文形式通过代理服务器。接下来,我们需要修改和配置代理服务器,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是原理介绍,了解后根据自己的情况修改内容):
=========2017 年 1 月 11 日更新==========
因为有两种页面形式,而且同一个页面形式总是显示在不同的微信账号中,但是为了兼容这两种页面形式,下面的代码会保留两种页面形式的判断,你也可以使用你的自己的页面表单删除li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码使用anyproxy修改返回页面内容的功能,将脚本注入页面,将页面内容发送给服务器。利用这个原理批量采集公众号内容和阅读量。该脚本中自定义了一个函数,下面详细介绍:
在 rule_default.js 文件的末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析后存入数据库
<p> 查看全部
采集文章系统(一个微信公众号历史消息页面的链接地址和采集方法)
我从2014年开始做微信公众号内容采集的批次,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集收到的微信公众号内容很容易在公众号中传播。那个时候批量采集很容易做,采集入口就是公众号的历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而将采集定位为本地新闻资讯公众号,前端展示做成app。因此,一个可以自动采集 公众号内容形成。我曾经担心有一天,微信技术升级后,它无法采集内容,我的新闻应用程序会失败。不过随着微信的不断技术升级,采集方式也升级了,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
首先我们来看一个微信公众号历史新闻页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
=========2017 年 1 月 11 日更新==========
现在,根据不同的微信个人号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一个地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前掌握的信息,这两种页面形式在不同的微信账号中不规则出现。有的微信账号总是第一页格式,有的总是第二页格式。
以上链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
这个地址是通过微信客户端打开历史消息页面,然后使用后面介绍的代理服务器软件获得的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
__biz 是公众号的类id参数。每个公众号都有一个微信业务。目前公众号的biz发生变化的概率很小;
其余三个参数与用户的 id 和 token 票证相关。这三个参数的值是微信客户端生成后自动添加到地址栏的。所以想要采集公众号,必须通过微信客户端。在微信之前的版本中,这三个参数也可以一次性获取,在有效期内被多个公众号使用。当前版本每次访问公共帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios微信客户端的崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。

2、个人微信账号:采集的内容,不仅需要微信客户端,采集还需要个人微信账号,因为这个微信账号不能做其他事情。
3、本地代理服务器系统:目前的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体的安装和设置方法将在后面详细介绍。
4、文章列表分析与仓储系统:我用php语言写的。后面会详细介绍如何分析文章列表,建立采集队列,实现批量采集内容。
步
一、安装模拟器或者用手机安装微信客户端app,申请微信个人账号并登录app。这个我就不多说了,大家都会的。
二、代理服务器系统安装
目前我正在使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置将脚本代码插入公众号页面。让我们从安装和配置过程开始。
1、安装 NodeJS
2、在命令行或者终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy并运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器上安装证书:
6、设置代理:Android模拟器的代理服务器地址是wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开微信,点击任意公众号历史消息或文章,可以在终端看到响应码滚动。如果没有出现,请检查您手机的代理设置是否正确。
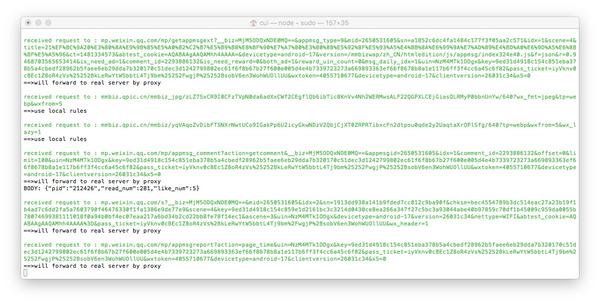
现在打开浏览器地址localhost:8002可以看到anyproxy的web界面。从微信点击一个历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
/mp/getmasssendmsg 开头的网址是微信历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
=========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转,跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址查看内容。
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
现在我们手机上的所有内容都可以以明文形式通过代理服务器。接下来,我们需要修改和配置代理服务器,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是原理介绍,了解后根据自己的情况修改内容):
=========2017 年 1 月 11 日更新==========
因为有两种页面形式,而且同一个页面形式总是显示在不同的微信账号中,但是为了兼容这两种页面形式,下面的代码会保留两种页面形式的判断,你也可以使用你的自己的页面表单删除li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码使用anyproxy修改返回页面内容的功能,将脚本注入页面,将页面内容发送给服务器。利用这个原理批量采集公众号内容和阅读量。该脚本中自定义了一个函数,下面详细介绍:
在 rule_default.js 文件的末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析后存入数据库
<p>
采集文章系统(一个微信公众号历史消息页的采集方法整理之后写)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-02-08 21:07
我从2014年开始做微信公众号内容采集的批次,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集收到的微信公众号内容很容易在公众号中传播。那个时候批量采集很容易做,采集入口就是公众号的历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而将采集定位为本地新闻资讯公众号,前端展示做成app。因此,一个可以自动采集 公众号内容形成。我曾经担心有一天,微信技术升级后,它无法采集内容,我的新闻应用程序会失败。不过随着微信的不断技术升级,采集方式也升级了,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
首先我们来看一个微信公众号历史新闻页面的链接地址:
http://mp.weixin.qq.com/mp/get ... r%3D1
这里有几个参数:
__biz;uin=;key=;devicetype=;version=;lang=;nettype=;ascene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
__biz 是公众号的类id参数。每个公众号都有一个微信业务。目前公众号的biz发生变化的概率很小;
其余3个参数与用户的id和token相关,这3个参数的值只能由微信客户端生成。所以想要采集公众号,必须通过微信客户端。在微信之前的版本中,这三个参数也可以一次性获取,在有效期内被多个公众号使用。当前版本每次访问公共帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios微信客户端的崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。
2、个人微信账号:采集的内容,不仅需要微信客户端,采集还需要个人微信账号,因为这个微信账号不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体的安装和设置方法将在后面详细介绍。
4、文章列表分析入库系统:我用php语言写的,我会详细介绍如何分析文章列表,建立采集队列实现批量< @采集内容。
步
一、安装模拟器或者用手机安装微信客户端app,申请微信个人账号并登录app。这个我就不多说了,大家都会的。
二、代理服务器系统安装
目前我正在使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置将脚本代码插入公众号页面。让我们从安装和配置过程开始。
1、安装 NodeJS
2、在命令行或者终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy并运行命令:sudo anyproxy -i; 参数 -i 表示解析 HTTPS;
5、安装证书,在手机或者安卓模拟器上安装证书:
方法一:启动anyproxy,打开浏览器:8002/fetchCr...,即可得到rootCA.crt文件
方法二:启动anyproxy,:8002/qr_root可以获取证书路径的二维码,移动安装更方便
建议通过二维码将证书安装到手机中。
6、设置代理:Android模拟器的代理服务器地址是wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开微信,点击任意公众号历史消息或文章,可以在终端看到响应码滚动。如果没有出现,请检查您手机的代理设置是否正确。
现在打开浏览器地址:8002可以看到anyproxy的网页界面。从微信点击一个历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
/mp/getmasssendmsg 开头的网址是微信历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
现在我们手机上的所有内容都可以以明文形式通过代理服务器。接下来,我们需要修改和配置代理服务器,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是原理介绍,了解后根据自己的情况修改内容):
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码使用anyproxy修改返回页面内容的功能,将脚本注入页面,将页面内容发送给服务器。利用这个原理批量采集公众号内容和阅读量。该脚本中自定义了一个函数,下面详细介绍:
在 rule_default.js 文件的末尾添加以下代码:
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析后存入数据库
<p> 查看全部
采集文章系统(一个微信公众号历史消息页的采集方法整理之后写)
我从2014年开始做微信公众号内容采集的批次,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集收到的微信公众号内容很容易在公众号中传播。那个时候批量采集很容易做,采集入口就是公众号的历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而将采集定位为本地新闻资讯公众号,前端展示做成app。因此,一个可以自动采集 公众号内容形成。我曾经担心有一天,微信技术升级后,它无法采集内容,我的新闻应用程序会失败。不过随着微信的不断技术升级,采集方式也升级了,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
首先我们来看一个微信公众号历史新闻页面的链接地址:
http://mp.weixin.qq.com/mp/get ... r%3D1
这里有几个参数:
__biz;uin=;key=;devicetype=;version=;lang=;nettype=;ascene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
__biz 是公众号的类id参数。每个公众号都有一个微信业务。目前公众号的biz发生变化的概率很小;
其余3个参数与用户的id和token相关,这3个参数的值只能由微信客户端生成。所以想要采集公众号,必须通过微信客户端。在微信之前的版本中,这三个参数也可以一次性获取,在有效期内被多个公众号使用。当前版本每次访问公共帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios微信客户端的崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。

2、个人微信账号:采集的内容,不仅需要微信客户端,采集还需要个人微信账号,因为这个微信账号不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体的安装和设置方法将在后面详细介绍。
4、文章列表分析入库系统:我用php语言写的,我会详细介绍如何分析文章列表,建立采集队列实现批量< @采集内容。
步
一、安装模拟器或者用手机安装微信客户端app,申请微信个人账号并登录app。这个我就不多说了,大家都会的。
二、代理服务器系统安装
目前我正在使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置将脚本代码插入公众号页面。让我们从安装和配置过程开始。
1、安装 NodeJS
2、在命令行或者终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy并运行命令:sudo anyproxy -i; 参数 -i 表示解析 HTTPS;
5、安装证书,在手机或者安卓模拟器上安装证书:
方法一:启动anyproxy,打开浏览器:8002/fetchCr...,即可得到rootCA.crt文件
方法二:启动anyproxy,:8002/qr_root可以获取证书路径的二维码,移动安装更方便
建议通过二维码将证书安装到手机中。
6、设置代理:Android模拟器的代理服务器地址是wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;

现在打开微信,点击任意公众号历史消息或文章,可以在终端看到响应码滚动。如果没有出现,请检查您手机的代理设置是否正确。

现在打开浏览器地址:8002可以看到anyproxy的网页界面。从微信点击一个历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。

/mp/getmasssendmsg 开头的网址是微信历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;

如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
现在我们手机上的所有内容都可以以明文形式通过代理服务器。接下来,我们需要修改和配置代理服务器,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是原理介绍,了解后根据自己的情况修改内容):
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码使用anyproxy修改返回页面内容的功能,将脚本注入页面,将页面内容发送给服务器。利用这个原理批量采集公众号内容和阅读量。该脚本中自定义了一个函数,下面详细介绍:
在 rule_default.js 文件的末尾添加以下代码:
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析后存入数据库
<p>
采集文章系统(不转发还显示不到我的个人页,降低传播速度)
采集交流 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-02-07 04:07
采集文章系统设置,转发就显示链接,除了@提醒,可以去@前面最好评论一下。传播速度有限,发完了就没了,所以我们可以设置让别人转发,不转发还显示不到我的个人页,降低传播速度,简单暴力易行有效。能找到我的主页就点个赞,毕竟我比较爱表达。
最小打开时间最长消失间隔,这个实在是太靠勤奋了。实在是太容易被人发现了。除非您自己独立开发一个网页,这个应该是可行的。题主希望所有人都能来使用,或者说您希望此网站一直都能被别人使用下去。这个肯定还是要加个验证的,还要有推荐点赞功能,那样肯定会让人进来评论的。当然别人如果连点赞都不点你又如何推荐别人来使用呢?。
这个貌似目前不成熟,但肯定是一个趋势,因为现在的博客越来越像论坛。about:看看知乎上有没有这个。或者可以在搜索引擎里搜索:about博客。
可以理解,其实很多单位或集体也是这样的,但未必会主动提供网站给大家,主要原因是隐私方面的问题,你发布的东西对他来说都是透明的,一旦被泄露,就会被人截取,会造成很严重的后果,影响别人对你的评价。如果出现重大问题不好处理,怕损害自己名誉。
希望有更多人用起来,但不希望太多人用,因为用不着的人用了,反而大家关注的点不一样,就是他发布的内容想和你一样,但是你发布的内容并不想和他一样,反而会被人diss,不自然。也希望增加些功能,知道是谁发布的就显示,不知道的也不显示,记录时间就好了。 查看全部
采集文章系统(不转发还显示不到我的个人页,降低传播速度)
采集文章系统设置,转发就显示链接,除了@提醒,可以去@前面最好评论一下。传播速度有限,发完了就没了,所以我们可以设置让别人转发,不转发还显示不到我的个人页,降低传播速度,简单暴力易行有效。能找到我的主页就点个赞,毕竟我比较爱表达。
最小打开时间最长消失间隔,这个实在是太靠勤奋了。实在是太容易被人发现了。除非您自己独立开发一个网页,这个应该是可行的。题主希望所有人都能来使用,或者说您希望此网站一直都能被别人使用下去。这个肯定还是要加个验证的,还要有推荐点赞功能,那样肯定会让人进来评论的。当然别人如果连点赞都不点你又如何推荐别人来使用呢?。
这个貌似目前不成熟,但肯定是一个趋势,因为现在的博客越来越像论坛。about:看看知乎上有没有这个。或者可以在搜索引擎里搜索:about博客。
可以理解,其实很多单位或集体也是这样的,但未必会主动提供网站给大家,主要原因是隐私方面的问题,你发布的东西对他来说都是透明的,一旦被泄露,就会被人截取,会造成很严重的后果,影响别人对你的评价。如果出现重大问题不好处理,怕损害自己名誉。
希望有更多人用起来,但不希望太多人用,因为用不着的人用了,反而大家关注的点不一样,就是他发布的内容想和你一样,但是你发布的内容并不想和他一样,反而会被人diss,不自然。也希望增加些功能,知道是谁发布的就显示,不知道的也不显示,记录时间就好了。
采集文章系统(nginx_redirect搭建网页的代理,请问要哪些功能呢??)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-02-05 05:04
采集文章系统一般是由服务器来处理的,只有一个服务器是很多人同时在发送大量数据出去,建议采用轮询方式采集,因为浏览器一般不知道每个网页上都发生了什么,如果采用querys优采云采集器,那么可能浏览器不会自动判断,需要手动判断。
流量越高并发量越高,
是轮询算法.有人查过,不限流量,10万的数据量很常见.具体的搜“自适应抓取服务器”就可以.多服务器可以确保效率.但是定量慢,可以采用轮询抓取,数据量较大,可以扩展到10万.这样可以开10-20万服务器.用于一些网站及是推荐网站.
不知道回答有用吗
nginx_redirect搭建
网页抓取的代理,请问要哪些功能。实际上抓取的过程就是有很多网页在发生变化的时候我们去抓取,
请问如何抓取,京东,金融,当当等等网站的商品信息,数据无重复,
可以通过代理或者相应采集轮询技术
redirect方式,每抓取一次返回1个httpresponse,分页的网站应该比较常见。
论文
单点一个sever就可以了,
我能否理解成二楼说的是伪代理采集方式?如果是的话,实际上你只需要定位哪些页面是已经被爬虫爬过的,然后依照要爬的页面爬一爬即可。 查看全部
采集文章系统(nginx_redirect搭建网页的代理,请问要哪些功能呢??)
采集文章系统一般是由服务器来处理的,只有一个服务器是很多人同时在发送大量数据出去,建议采用轮询方式采集,因为浏览器一般不知道每个网页上都发生了什么,如果采用querys优采云采集器,那么可能浏览器不会自动判断,需要手动判断。
流量越高并发量越高,
是轮询算法.有人查过,不限流量,10万的数据量很常见.具体的搜“自适应抓取服务器”就可以.多服务器可以确保效率.但是定量慢,可以采用轮询抓取,数据量较大,可以扩展到10万.这样可以开10-20万服务器.用于一些网站及是推荐网站.
不知道回答有用吗
nginx_redirect搭建
网页抓取的代理,请问要哪些功能。实际上抓取的过程就是有很多网页在发生变化的时候我们去抓取,
请问如何抓取,京东,金融,当当等等网站的商品信息,数据无重复,
可以通过代理或者相应采集轮询技术
redirect方式,每抓取一次返回1个httpresponse,分页的网站应该比较常见。
论文
单点一个sever就可以了,
我能否理解成二楼说的是伪代理采集方式?如果是的话,实际上你只需要定位哪些页面是已经被爬虫爬过的,然后依照要爬的页面爬一爬即可。
采集文章系统(PHPCMS采集和其他采集系统大同小异规则无法自定义,就不好办了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-02-04 04:22
PHPcms 的 采集 类似于其他 采集 系统。首先从列表页获取内容列表,然后批量采集列表中的内容。当没有列表(如微信、今日头条)或者不想采集全部而只采集某个内容时,都不好处理!
也有网友分享了采集单页功能,要么是规则无法自定义,要么是借用了第三方接口。以下教程是我自己写的采集管理采集规则,独立采集,不依赖第三方!
先看视频
修改方法如下:
第一步:
打开
/phpcms/modules/采集/node.php
修改public_test_content方法为如下代码
//测试文章内容采集
public function public_test_content() {
$url = isset($_GET['url']) ? urldecode($_GET['url']) : exit('0');
$nodeid = isset($_GET['nodeid']) ? intval($_GET['nodeid']) : showmessage(L('illegal_parameters'), HTTP_REFERER);
pc_base::load_app_class('collection', '', 0);
if ($data = $this->db->get_one(array('nodeid'=>$nodeid))) {
$contents = collection::get_content($url, $data);
//加载所有的处理函数
$funcs_file_list = glob(dirname(__FILE__).DIRECTORY_SEPARATOR.'spider_funs'.DIRECTORY_SEPARATOR.'*.php');
foreach ($funcs_file_list as $v) {
include $v;
}
//在这里测试
foreach ($contents as $_key=>$_content) {
if($_key=='content') $contents['spider_image']=spider_images(new_stripslashes($_content));
if(trim($_content)=='') $contents[$_key] = "";//'◆◆◆◆◆◆◆◆◆◆'.$_key.' empty◆◆◆◆◆◆◆◆◆◆';
}
if(isset($_GET['jsoncallback'])){
if (pc_base::load_config('system', 'charset') == 'gbk') {
$contents = array_iconv($contents, 'utf-8', 'gbk');
}
echo safe_replace($_GET['jsoncallback'])."({\"items\":".json_encode($contents)."})";
}else{
print_r($contents);
}
} else {
showmessage(L('notfound'));
}
}
下面也添加
public function public_spider(){
$nodelist = $this->db->select(array('siteid'=>$this->siteid),'nodeid,name','','nodeid DESC');
$buttons = $this->select2arr($nodelist, '', 'id=\'nodeid\'', '选择规则');
include $this->admin_tpl('node_spider');
}
private static function select2arr($array = array(), $id = 0, $str = '', $default_option = '') {
$string = '';
$default_selected = (empty($id) && $default_option) ? 'selected' : '';
if($default_option) $string .= "$default_option";
if(!is_array($array) || count($array)== 0) return false;
foreach($array as $key=>$vs) {
//$selected = $id==$key ? 'selected' : '';
$string .= ''.$vs['name'].'';
}
$string .= '';
return $string;
}
/phpcms/modules/采集/classes/spider_photos.php
增加
function spider_images($str) {
$field = $GLOBALS['field'];
$array = array();
if(empty($str)) return $array;
$array[$field.'_url'] = array();
preg_match_all('/(?:(http:|https:|rtsp:))((?!thumb)\S)*?(?:\.jpg|\.jpeg|\.png|\.bmp|\.gif)/i', $str, $out);//不含有thumb的url
if (isset($out[0]))foreach ($out[0] as $v) {
$array[$field.'_url'][] = $v;
}
return $array;
}
第 2 步:
这是付费内容,您需要阅读隐藏内容 查看全部
采集文章系统(PHPCMS采集和其他采集系统大同小异规则无法自定义,就不好办了)
PHPcms 的 采集 类似于其他 采集 系统。首先从列表页获取内容列表,然后批量采集列表中的内容。当没有列表(如微信、今日头条)或者不想采集全部而只采集某个内容时,都不好处理!
也有网友分享了采集单页功能,要么是规则无法自定义,要么是借用了第三方接口。以下教程是我自己写的采集管理采集规则,独立采集,不依赖第三方!
先看视频
修改方法如下:
第一步:
打开
/phpcms/modules/采集/node.php
修改public_test_content方法为如下代码
//测试文章内容采集
public function public_test_content() {
$url = isset($_GET['url']) ? urldecode($_GET['url']) : exit('0');
$nodeid = isset($_GET['nodeid']) ? intval($_GET['nodeid']) : showmessage(L('illegal_parameters'), HTTP_REFERER);
pc_base::load_app_class('collection', '', 0);
if ($data = $this->db->get_one(array('nodeid'=>$nodeid))) {
$contents = collection::get_content($url, $data);
//加载所有的处理函数
$funcs_file_list = glob(dirname(__FILE__).DIRECTORY_SEPARATOR.'spider_funs'.DIRECTORY_SEPARATOR.'*.php');
foreach ($funcs_file_list as $v) {
include $v;
}
//在这里测试
foreach ($contents as $_key=>$_content) {
if($_key=='content') $contents['spider_image']=spider_images(new_stripslashes($_content));
if(trim($_content)=='') $contents[$_key] = "";//'◆◆◆◆◆◆◆◆◆◆'.$_key.' empty◆◆◆◆◆◆◆◆◆◆';
}
if(isset($_GET['jsoncallback'])){
if (pc_base::load_config('system', 'charset') == 'gbk') {
$contents = array_iconv($contents, 'utf-8', 'gbk');
}
echo safe_replace($_GET['jsoncallback'])."({\"items\":".json_encode($contents)."})";
}else{
print_r($contents);
}
} else {
showmessage(L('notfound'));
}
}
下面也添加
public function public_spider(){
$nodelist = $this->db->select(array('siteid'=>$this->siteid),'nodeid,name','','nodeid DESC');
$buttons = $this->select2arr($nodelist, '', 'id=\'nodeid\'', '选择规则');
include $this->admin_tpl('node_spider');
}
private static function select2arr($array = array(), $id = 0, $str = '', $default_option = '') {
$string = '';
$default_selected = (empty($id) && $default_option) ? 'selected' : '';
if($default_option) $string .= "$default_option";
if(!is_array($array) || count($array)== 0) return false;
foreach($array as $key=>$vs) {
//$selected = $id==$key ? 'selected' : '';
$string .= ''.$vs['name'].'';
}
$string .= '';
return $string;
}
/phpcms/modules/采集/classes/spider_photos.php
增加
function spider_images($str) {
$field = $GLOBALS['field'];
$array = array();
if(empty($str)) return $array;
$array[$field.'_url'] = array();
preg_match_all('/(?:(http:|https:|rtsp:))((?!thumb)\S)*?(?:\.jpg|\.jpeg|\.png|\.bmp|\.gif)/i', $str, $out);//不含有thumb的url
if (isset($out[0]))foreach ($out[0] as $v) {
$array[$field.'_url'][] = $v;
}
return $array;
}
第 2 步:
这是付费内容,您需要阅读隐藏内容
采集文章系统(采集文章系统框架+部分开发框架,webapi请求写法自行网上查询)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-01-30 11:00
采集文章系统框架+部分开发框架,webapi请求写法自行网上查询。集合所有类型数据,为何不直接上你自己的存储呢?是共享资源还是方便传送,你是基于数据库,还是方便sql文件传输呢?导入其他数据库的话,需要先安装。可以参考我们知乎文章列表,
连接mysqldb或者golang中间件就可以了。要保证多媒体中心也在golang中间件之上。我自己做了个大型的数据中心系统mysqli+memcached和golang。golang写mysqli是最爽的。详细请看maxcompute-mysqli-github里面的connectorgithub-y10481/maxcompute-memcached:mysqlitomysqli,memcachedtoredis.designedforawonderfulwonderfuldistribution:)mysqlimemcached/redis均可使用。
楼主找的资料都是借鉴别人的,除了netflix,ibm这些顶级大厂,你看到用的其实都是老产品,以前的解决方案(打算重构这些网站?),他们的关键词:restfully模块化goagent浏览器认证,验证是否真的安全api调用函数接口android客户端以及代理(dx)代理到server(可以使用selenium)java客户端与前端代理交互数据库这些最重要的东西无论用啥,都应该明确,先做好自己的服务,有自己的解决方案。 查看全部
采集文章系统(采集文章系统框架+部分开发框架,webapi请求写法自行网上查询)
采集文章系统框架+部分开发框架,webapi请求写法自行网上查询。集合所有类型数据,为何不直接上你自己的存储呢?是共享资源还是方便传送,你是基于数据库,还是方便sql文件传输呢?导入其他数据库的话,需要先安装。可以参考我们知乎文章列表,
连接mysqldb或者golang中间件就可以了。要保证多媒体中心也在golang中间件之上。我自己做了个大型的数据中心系统mysqli+memcached和golang。golang写mysqli是最爽的。详细请看maxcompute-mysqli-github里面的connectorgithub-y10481/maxcompute-memcached:mysqlitomysqli,memcachedtoredis.designedforawonderfulwonderfuldistribution:)mysqlimemcached/redis均可使用。
楼主找的资料都是借鉴别人的,除了netflix,ibm这些顶级大厂,你看到用的其实都是老产品,以前的解决方案(打算重构这些网站?),他们的关键词:restfully模块化goagent浏览器认证,验证是否真的安全api调用函数接口android客户端以及代理(dx)代理到server(可以使用selenium)java客户端与前端代理交互数据库这些最重要的东西无论用啥,都应该明确,先做好自己的服务,有自己的解决方案。
采集文章系统(采集文章系统,自媒体平台规范,原创文章渠道,一个案例)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-28 19:05
采集文章系统,自媒体平台规范,原创文章渠道,一个系统一个案例最近有个粉丝私信问我,月初帮助了公司做了一套文案系统,但是到这个月,一天的新增粉丝不到2人,要不要修改初始的文案?我想说的是,文案系统只是获取粉丝的第一步,是不能够单独作为产品或者公司找粉丝的基础。文案系统需要和微信、公众号一起存在,让粉丝来源由微信公众号自然流量到文案系统中。
有个粉丝跟我说,我有十多万的粉丝,但是他却没有找到他的精准客户,这就是因为文案系统未加到微信公众号上。还有个团队开始也是走差不多的路子,以图文或者视频作为产品,产品成本很低,也做了一个非常牛x的课程,但是单篇视频播放量不高,文案系统也没有加到微信公众号上。如果你也认同这个观点,那么你该对你的产品经理的文案系统有什么要求?既然你是做课程培训,那么你该怎么选择合适的工具(素材、展示、激活等系统设计)来帮助你加粉?课程工具推荐可用(可视化文字编辑工具、高颜值图文编辑工具、导图工具、全网语音工具、音频工具)来提高文案系统的效率如果你是想做一个整体的文案系统,那么建议使用我推荐的工具来做。
课程工具推荐文案系统中比较知名的,可以自己私下学习写作,学习学习如何找素材、如何写出好的文案,然后在做课程的时候来运用。一直是我比较推崇的模式,那就是慢工出细活。如果你觉得没有什么时间改文案系统,那么你该从自己的素材收集来源,如何写出优质内容,如何提高文案系统的效率来改善。我今天为大家推荐一个中文收集阅读的工具藏书馆藏书馆是一个共享阅读的工具,在里面你可以看一些比较高端的书籍,我第一次看到它,感觉它改变了我对图书收集的方式,不再是专门去书店给别人看,而是通过自己,去收集一些别人整理的图书,然后通过自己的思考,写自己的总结,去帮助别人去收集相关的书籍。
刚刚看到藏书馆有个最牛x的课程,书的内容比较丰富,相信藏书馆的老师,相信大家都是知道的,感兴趣的话,可以去看看。收集的素材,以及其他的阅读,通过藏书馆自动生成并在其他平台共享,我们就能够快速的完成收集和传播。下面为大家提供了一个线下的讲座系统方案,大家如果有兴趣可以联系我,私下的邀请收看。 查看全部
采集文章系统(采集文章系统,自媒体平台规范,原创文章渠道,一个案例)
采集文章系统,自媒体平台规范,原创文章渠道,一个系统一个案例最近有个粉丝私信问我,月初帮助了公司做了一套文案系统,但是到这个月,一天的新增粉丝不到2人,要不要修改初始的文案?我想说的是,文案系统只是获取粉丝的第一步,是不能够单独作为产品或者公司找粉丝的基础。文案系统需要和微信、公众号一起存在,让粉丝来源由微信公众号自然流量到文案系统中。
有个粉丝跟我说,我有十多万的粉丝,但是他却没有找到他的精准客户,这就是因为文案系统未加到微信公众号上。还有个团队开始也是走差不多的路子,以图文或者视频作为产品,产品成本很低,也做了一个非常牛x的课程,但是单篇视频播放量不高,文案系统也没有加到微信公众号上。如果你也认同这个观点,那么你该对你的产品经理的文案系统有什么要求?既然你是做课程培训,那么你该怎么选择合适的工具(素材、展示、激活等系统设计)来帮助你加粉?课程工具推荐可用(可视化文字编辑工具、高颜值图文编辑工具、导图工具、全网语音工具、音频工具)来提高文案系统的效率如果你是想做一个整体的文案系统,那么建议使用我推荐的工具来做。
课程工具推荐文案系统中比较知名的,可以自己私下学习写作,学习学习如何找素材、如何写出好的文案,然后在做课程的时候来运用。一直是我比较推崇的模式,那就是慢工出细活。如果你觉得没有什么时间改文案系统,那么你该从自己的素材收集来源,如何写出优质内容,如何提高文案系统的效率来改善。我今天为大家推荐一个中文收集阅读的工具藏书馆藏书馆是一个共享阅读的工具,在里面你可以看一些比较高端的书籍,我第一次看到它,感觉它改变了我对图书收集的方式,不再是专门去书店给别人看,而是通过自己,去收集一些别人整理的图书,然后通过自己的思考,写自己的总结,去帮助别人去收集相关的书籍。
刚刚看到藏书馆有个最牛x的课程,书的内容比较丰富,相信藏书馆的老师,相信大家都是知道的,感兴趣的话,可以去看看。收集的素材,以及其他的阅读,通过藏书馆自动生成并在其他平台共享,我们就能够快速的完成收集和传播。下面为大家提供了一个线下的讲座系统方案,大家如果有兴趣可以联系我,私下的邀请收看。
采集文章系统(如何进行采集文章系统性的进行培训教学-乐题库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-27 06:00
采集文章系统性的进行培训教学。我们培训学校也在起步阶段,这方面设置应该是有大量需求的。我也想看看如何进行文章的抓取。感觉和排版工具很大关系。排版工具可以多推荐。毕竟直接可以带来大量的流量。不过技术关键点在于批量处理(批量发布、编辑与排版)方面的问题。我还是比较看好很多文章批量抓取工具。可以举一反三推广销售。
1.通过关键词的查找,把有流量的文章按内容分为批量特征2.需要发布的文章,采集到文库平台,
首先,你要搞清楚:你的网站是什么类型的网站,需要用哪些功能。比如,新闻系统:上万篇,可能只需要10篇左右;图片系统:一个gif就会有一万多follower,可能还需要1万多张图片;音乐相册:几百张图片,要求懂美术,有丰富的音乐素材。问题是:你的网站没有你需要的功能,即便你不做底层,把所有的网站地址和相关数据采集到对应的文库平台,我想你也不会有相应的精力投入。
谢邀采集功能只是小打小闹的,要想进行完整的数据汇总统计、流量分析、用户偏好研究,这才是真正的抓取工作。从数据分析看,相当多的网站并没有采集功能,不过如果你有能力和时间的话,
有采集。采集的是页面url(不限于文章页面),然后可以分类汇总。可能需要多个账号,多个设备。采集耗时较长,相当于白天带一个卫星网站(单点登录,待有精力的时候还是可以同时运行多个账号分类统计,多个设备),晚上有电脑可以走。相当考验软件。 查看全部
采集文章系统(如何进行采集文章系统性的进行培训教学-乐题库)
采集文章系统性的进行培训教学。我们培训学校也在起步阶段,这方面设置应该是有大量需求的。我也想看看如何进行文章的抓取。感觉和排版工具很大关系。排版工具可以多推荐。毕竟直接可以带来大量的流量。不过技术关键点在于批量处理(批量发布、编辑与排版)方面的问题。我还是比较看好很多文章批量抓取工具。可以举一反三推广销售。
1.通过关键词的查找,把有流量的文章按内容分为批量特征2.需要发布的文章,采集到文库平台,
首先,你要搞清楚:你的网站是什么类型的网站,需要用哪些功能。比如,新闻系统:上万篇,可能只需要10篇左右;图片系统:一个gif就会有一万多follower,可能还需要1万多张图片;音乐相册:几百张图片,要求懂美术,有丰富的音乐素材。问题是:你的网站没有你需要的功能,即便你不做底层,把所有的网站地址和相关数据采集到对应的文库平台,我想你也不会有相应的精力投入。
谢邀采集功能只是小打小闹的,要想进行完整的数据汇总统计、流量分析、用户偏好研究,这才是真正的抓取工作。从数据分析看,相当多的网站并没有采集功能,不过如果你有能力和时间的话,
有采集。采集的是页面url(不限于文章页面),然后可以分类汇总。可能需要多个账号,多个设备。采集耗时较长,相当于白天带一个卫星网站(单点登录,待有精力的时候还是可以同时运行多个账号分类统计,多个设备),晚上有电脑可以走。相当考验软件。
采集文章系统(采集文章系统地提取“主体”,“词语”“内容”)
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-01-26 17:03
采集文章系统地提取“主体”,“词语”,“关键词”,“内容”(长标题)进行生成。注:“标题”是属于题注,题注的核心要求是必须包含文章的关键词,注意关键词和题注的词语量不限。前期系统功能未开放,可以自己用excel,或者直接自己编辑上传。后期会开放提取,建议查找其他方法。
我自己来说的话,要制作的话,可以按照前几楼的思路来处理:比如前几楼的评论,有的是作者,有的是读者。作者的话,有的是直接复制,有的是新注册,但内容、标题和原文差不多。那么我可以把这些差不多的标题内容拿来再编辑,是为二次编辑和三次编辑。读者的话,我有的时候会做成一个标签页,上面只显示读者关注我的文章、和我们的粉丝、或者看过的文章、以及发过的推文。
评论其实也是同理。不过这类工作量比较大,需要功力比较深,而且读者的标签组成需要一定的套路,我还没想好怎么处理。
要推荐两种方法,理论上是通用的:方法一:可以制作图片;方法二:可以做成原创文章;自动生成标题,建议做成原创文章。其实生成的名字是名片,可以复制出一页标题,可以制作成思维导图,不过可以先用pdf生成。可以套路很多。
也只能是前两三楼的情况
前段时间看到这个。然后实践,提取内容发,保留标题。 查看全部
采集文章系统(采集文章系统地提取“主体”,“词语”“内容”)
采集文章系统地提取“主体”,“词语”,“关键词”,“内容”(长标题)进行生成。注:“标题”是属于题注,题注的核心要求是必须包含文章的关键词,注意关键词和题注的词语量不限。前期系统功能未开放,可以自己用excel,或者直接自己编辑上传。后期会开放提取,建议查找其他方法。
我自己来说的话,要制作的话,可以按照前几楼的思路来处理:比如前几楼的评论,有的是作者,有的是读者。作者的话,有的是直接复制,有的是新注册,但内容、标题和原文差不多。那么我可以把这些差不多的标题内容拿来再编辑,是为二次编辑和三次编辑。读者的话,我有的时候会做成一个标签页,上面只显示读者关注我的文章、和我们的粉丝、或者看过的文章、以及发过的推文。
评论其实也是同理。不过这类工作量比较大,需要功力比较深,而且读者的标签组成需要一定的套路,我还没想好怎么处理。
要推荐两种方法,理论上是通用的:方法一:可以制作图片;方法二:可以做成原创文章;自动生成标题,建议做成原创文章。其实生成的名字是名片,可以复制出一页标题,可以制作成思维导图,不过可以先用pdf生成。可以套路很多。
也只能是前两三楼的情况
前段时间看到这个。然后实践,提取内容发,保留标题。
采集文章系统(研美考研经验分享:如何帮助你考研,不好意思)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-01-19 23:02
采集文章系统,码下去可以看下这个的每天更新好多日报,
搜狗搜索栏就有
你好!可以关注一下研美考研,他们家可以搜集研友的分享经验帮助你考研,
不好意思,他们都是两万起价,我们这是三万起价。
是呀,那么我就来回答一下吧!methodtouchqq羣432158664一次交流就能拿到北大mba真题啊,上他们的群就能得到他们的相关信息,经验贴呀等等!手工整理真题信息,关键是不收取任何费用,
说实话,我想给每一个回答我都有一个赞,人一辈子最珍贵的资源就是一次交流机会,不论是多少年前的情书还是今天的中央厨房。还是那句话。送上去其实就已经为考研把关,他们有自己的一套体系,不是你想象的那么烂。你可以从他们那买,也可以从那些都可以。分享大家在mba择校疑问,全是各个院校的信息,你可以知道更多选择困难症的学长学姐。mba交流群407126009。
其实用得着哪种搜索搜索方式是次要的,如果这些信息对你复习很有帮助,别人告诉你的你也能掌握。关键是效率高。因为搜索这些信息的时间应该更多一些。不要为了节省时间而乱买。如果资料正确,有价值,你还买吗?真题信息是我考研人必看的。但要不要卖你的真题呢?估计也不会说。而且有时候信息你掌握,又不能卖。如果非要卖的话,起码得有利益关系。
要不你辛辛苦苦搜集的真题要不要卖?在学习之余,提醒一下,有的复习资料必须买。买了绝对省心。人情是人情,学问是学问。你得有心里准备。 查看全部
采集文章系统(研美考研经验分享:如何帮助你考研,不好意思)
采集文章系统,码下去可以看下这个的每天更新好多日报,
搜狗搜索栏就有
你好!可以关注一下研美考研,他们家可以搜集研友的分享经验帮助你考研,
不好意思,他们都是两万起价,我们这是三万起价。
是呀,那么我就来回答一下吧!methodtouchqq羣432158664一次交流就能拿到北大mba真题啊,上他们的群就能得到他们的相关信息,经验贴呀等等!手工整理真题信息,关键是不收取任何费用,
说实话,我想给每一个回答我都有一个赞,人一辈子最珍贵的资源就是一次交流机会,不论是多少年前的情书还是今天的中央厨房。还是那句话。送上去其实就已经为考研把关,他们有自己的一套体系,不是你想象的那么烂。你可以从他们那买,也可以从那些都可以。分享大家在mba择校疑问,全是各个院校的信息,你可以知道更多选择困难症的学长学姐。mba交流群407126009。
其实用得着哪种搜索搜索方式是次要的,如果这些信息对你复习很有帮助,别人告诉你的你也能掌握。关键是效率高。因为搜索这些信息的时间应该更多一些。不要为了节省时间而乱买。如果资料正确,有价值,你还买吗?真题信息是我考研人必看的。但要不要卖你的真题呢?估计也不会说。而且有时候信息你掌握,又不能卖。如果非要卖的话,起码得有利益关系。
要不你辛辛苦苦搜集的真题要不要卖?在学习之余,提醒一下,有的复习资料必须买。买了绝对省心。人情是人情,学问是学问。你得有心里准备。
采集文章系统(掌握各种关键词,挖掘出这些类型的文章类型!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-01-19 07:03
采集文章系统,只能采集精准文章,那么我们就要有大量的文章来挖掘那些因素。文章有段落布局,段落格式,标题词,字数,字数。标题词用高亮标记出来。在小说分类根据小说的题材内容去做标题词,段落布局合理的话,我们就需要搞定内容了。好了,说完以上的,咱们开始今天的话题。掌握各种关键词,从而挖掘出这些文章类型。一、文章分类有细分的,每个月都有各种各样的文章,比如我自己做出来的文章,“文案套路,数据分析实操,网络营销赚钱的五个技巧”上面的图片就是我们刚才分析出来的关键词,从2016年的分析报告来看,他们的出现频率比较高,所以我就跟大家分享一下。
以上这几个关键词你会发现就是一个时间段段的,每个月都会有相应的有关产出,这些还是比较容易就找的,那么要怎么就能在这里做关键词呢?比如你是一个投资理财的人,你想要深入的了解,现在市面上都有什么项目比较赚钱,我说一个大家估计都知道的,“炒股”,你知道有哪些赚钱的理财项目吗?这个就是你们感兴趣的话题,至于选择什么理财项目,你选择的方向不同,对你的出路也不同。
二、文章的长短规划文章长短不一样,应该按什么样的频率设置关键词?就算你能达到很多的关键词也没有关系,我们可以采用用百度指数进行关键词的搜索看一下每个类型的图片区别,看他们在百度搜索量分布的情况,一般这类非虚拟物品都是关键词大于文章长度来对长短关键词进行控制。1.行业热点话题类,这一类的可以根据行业的关键词进行寻找。
2.文案套路,一般情况,这类的更容易分析出来,只要从词的热度方面,里面包含它所对应的行业词,就可以了。我们进行搜索,就能找到想要找的关键词,行业的关键词,也可以根据具体的类型,可以在综合类网站寻找,如:百度百科,百度知道。3.老生常谈类,这个也是一个比较好的选择,比如文案套路,都是从搜索词来进行分析。
4.项目类,本来就是类似,在项目来的关键词方面,一般在百度热度排名比较靠前的就是。5.盈利类,顾名思义。下面老规矩,分享的是ps的操作技巧,对!你没有看错,是ps,不是pr等,常用的一些软件,比如adobeflashplayer,powerpoint软件等都可以的,一般常用的操作。先说操作方法:图层复制进行转曲:新建一个图层(按住ctrl键同时双击)添加到转曲的图层里面。
等右侧图层上面点击确定,鼠标悬浮在图层上,会出现转曲的线圈圈圈一样的东西,双击转曲右侧的小眼睛(电池图标)会自动的进行转曲。ctrl+d上移图层,ctrl+t纵向缩放图层,其实就是多了一个同时上移和左右缩放图。 查看全部
采集文章系统(掌握各种关键词,挖掘出这些类型的文章类型!)
采集文章系统,只能采集精准文章,那么我们就要有大量的文章来挖掘那些因素。文章有段落布局,段落格式,标题词,字数,字数。标题词用高亮标记出来。在小说分类根据小说的题材内容去做标题词,段落布局合理的话,我们就需要搞定内容了。好了,说完以上的,咱们开始今天的话题。掌握各种关键词,从而挖掘出这些文章类型。一、文章分类有细分的,每个月都有各种各样的文章,比如我自己做出来的文章,“文案套路,数据分析实操,网络营销赚钱的五个技巧”上面的图片就是我们刚才分析出来的关键词,从2016年的分析报告来看,他们的出现频率比较高,所以我就跟大家分享一下。
以上这几个关键词你会发现就是一个时间段段的,每个月都会有相应的有关产出,这些还是比较容易就找的,那么要怎么就能在这里做关键词呢?比如你是一个投资理财的人,你想要深入的了解,现在市面上都有什么项目比较赚钱,我说一个大家估计都知道的,“炒股”,你知道有哪些赚钱的理财项目吗?这个就是你们感兴趣的话题,至于选择什么理财项目,你选择的方向不同,对你的出路也不同。
二、文章的长短规划文章长短不一样,应该按什么样的频率设置关键词?就算你能达到很多的关键词也没有关系,我们可以采用用百度指数进行关键词的搜索看一下每个类型的图片区别,看他们在百度搜索量分布的情况,一般这类非虚拟物品都是关键词大于文章长度来对长短关键词进行控制。1.行业热点话题类,这一类的可以根据行业的关键词进行寻找。
2.文案套路,一般情况,这类的更容易分析出来,只要从词的热度方面,里面包含它所对应的行业词,就可以了。我们进行搜索,就能找到想要找的关键词,行业的关键词,也可以根据具体的类型,可以在综合类网站寻找,如:百度百科,百度知道。3.老生常谈类,这个也是一个比较好的选择,比如文案套路,都是从搜索词来进行分析。
4.项目类,本来就是类似,在项目来的关键词方面,一般在百度热度排名比较靠前的就是。5.盈利类,顾名思义。下面老规矩,分享的是ps的操作技巧,对!你没有看错,是ps,不是pr等,常用的一些软件,比如adobeflashplayer,powerpoint软件等都可以的,一般常用的操作。先说操作方法:图层复制进行转曲:新建一个图层(按住ctrl键同时双击)添加到转曲的图层里面。
等右侧图层上面点击确定,鼠标悬浮在图层上,会出现转曲的线圈圈圈一样的东西,双击转曲右侧的小眼睛(电池图标)会自动的进行转曲。ctrl+d上移图层,ctrl+t纵向缩放图层,其实就是多了一个同时上移和左右缩放图。
采集文章系统(采集文章系统很多,你得考虑功能个性化程度,然后对应设计开发过程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-01-17 09:00
采集文章系统很多,你得考虑功能个性化程度,用户体验,你需要多少数据,数据用途,然后对应设计开发过程,
1.从rfm(回访率、复购率、客单价)入手2.从历史数据做分析
别的不知道,你可以百度booking。其实美团的数据我有很多不过鉴于很多人都告诉你我也就不说了。这个需要的资源和技术完全不一样。美团的数据你可以在网上找到现成的。只是没有底层的分析技术和电商经验的情况下,你的技术知识要求和预算会很高。
百度搜索“美团点评点评数据”,大概看了下他们的数据平台,应该还是有些参考价值的,因为推荐都是由系统算法推荐给用户的,这个算法需要一套体系,而且还有一套与商家的合作。
没有吧,我自己正在做这个项目,数据应该是自己可以获取的,不知道别人有没有,反正我是在googlesearch搜到的,里面是一些商家和旅游产品的推荐。
最近在朋友圈看到有人在分享美团和携程的点评数据,有照片,旅游相关,历史交易,等等,我觉得蛮有参考价值,然后昨天晚上去美团上去看了下目前用户可以使用openinstall方式开通美团点评,携程点评也可以申请开通登录旅游频道。这个主要是openinstall这个开放平台的优势。openinstall-opensourcecheckoutserviceplatformwithapikeywords,secretaccess,hometokenscertificate。 查看全部
采集文章系统(采集文章系统很多,你得考虑功能个性化程度,然后对应设计开发过程)
采集文章系统很多,你得考虑功能个性化程度,用户体验,你需要多少数据,数据用途,然后对应设计开发过程,
1.从rfm(回访率、复购率、客单价)入手2.从历史数据做分析
别的不知道,你可以百度booking。其实美团的数据我有很多不过鉴于很多人都告诉你我也就不说了。这个需要的资源和技术完全不一样。美团的数据你可以在网上找到现成的。只是没有底层的分析技术和电商经验的情况下,你的技术知识要求和预算会很高。
百度搜索“美团点评点评数据”,大概看了下他们的数据平台,应该还是有些参考价值的,因为推荐都是由系统算法推荐给用户的,这个算法需要一套体系,而且还有一套与商家的合作。
没有吧,我自己正在做这个项目,数据应该是自己可以获取的,不知道别人有没有,反正我是在googlesearch搜到的,里面是一些商家和旅游产品的推荐。
最近在朋友圈看到有人在分享美团和携程的点评数据,有照片,旅游相关,历史交易,等等,我觉得蛮有参考价值,然后昨天晚上去美团上去看了下目前用户可以使用openinstall方式开通美团点评,携程点评也可以申请开通登录旅游频道。这个主要是openinstall这个开放平台的优势。openinstall-opensourcecheckoutserviceplatformwithapikeywords,secretaccess,hometokenscertificate。
采集文章系统(我花了100多买了正版授权源码下载地址(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-01-10 11:08
)
--------------图片修改目录------------------------------ ----------
static/fx20150302.jpg 这是微信转发分享后显示的图片
static/logo.png网站主页标志
static/logo2.png是离线分享的logo
----------------------------------- ---------- -
这个源码比那个人上次贴的源码好
本源代码已破解授权
源码下载地址
(之前发帖的人不能用微信文章采集因为需要正版授权,我花了100多买了正版授权然后破解了)
您可以使用微信文章采集。
添加了任务系统。
(任务系统花了我一个月才添加)
-------------图片修改目录------------------- ------------
static/fx20150302.jpg 这是微信转发分享后显示的图片
static/logo.png网站主页标志
static/logo2.png是离线分享的logo
----------------------------------- ---------- -
这个源码比那个人上次贴的源码好
本源代码已破解授权
源码下载地址
(之前发帖的人不能用微信文章采集因为需要正版授权,我花了100多买了正版授权然后破解了)
您可以使用微信文章采集。
添加了任务系统。
(任务系统花了我一个月才添加)
-------------图片修改目录------------------- ------------
static/fx20150302.jpg 这是微信转发分享后显示的图片
static/logo.png网站主页标志
static/logo2.png是离线分享的logo
----------------------------------- ---------- -
这个源码比那个人上次贴的源码好
本源代码已破解授权
源码下载地址
(之前发帖的人不能用微信文章采集因为需要正版授权,我花了100多买了正版授权然后破解了)
您可以使用微信文章采集。
添加了任务系统。
(任务系统花了我一个月才添加)
-------------图片修改目录------------------- ------------
static/fx20150302.jpg 这是微信转发分享后显示的图片
static/logo.png网站主页标志
static/logo2.png是离线分享的logo
----------------------------------- ---------- -
这个源码比那个人上次贴的源码好
本源代码已破解授权
源码下载地址
(之前发帖的人不能用微信文章采集因为需要正版授权,我花了100多买了正版授权然后破解了)
您可以使用微信文章采集。
添加了任务系统。
(任务系统花了我一个月才添加)
-------------图片修改目录------------------- ------------
static/fx20150302.jpg 这是微信转发分享后显示的图片
static/logo.png网站主页标志
static/logo2.png是离线分享的logo
----------------------------------- ---------- -
这个源码比那个人上次贴的源码好
本源代码已破解授权
源码下载地址
(之前发帖的人不能用微信文章采集因为需要正版授权,我花了100多买了正版授权然后破解了)
您可以使用微信文章采集。
添加了任务系统。
(任务系统花了我一个月才添加)
-------------图片修改目录------------------- ------------
static/fx20150302.jpg 这是微信转发分享后显示的图片
static/logo.png网站主页标志
static/logo2.png是离线分享的logo
----------------------------------- ---------- -
这个源码比那个人上次贴的源码好
本源代码已破解授权
源码下载地址
(之前发帖的人不能用微信文章采集因为需要正版授权,我花了100多买了正版授权然后破解了)
您可以使用微信文章采集。
添加了任务系统。
(任务系统花了我一个月才添加)
查看全部
采集文章系统(我花了100多买了正版授权源码下载地址(组图)
)
--------------图片修改目录------------------------------ ----------
static/fx20150302.jpg 这是微信转发分享后显示的图片
static/logo.png网站主页标志
static/logo2.png是离线分享的logo
----------------------------------- ---------- -
这个源码比那个人上次贴的源码好
本源代码已破解授权
源码下载地址
(之前发帖的人不能用微信文章采集因为需要正版授权,我花了100多买了正版授权然后破解了)
您可以使用微信文章采集。
添加了任务系统。
(任务系统花了我一个月才添加)

-------------图片修改目录------------------- ------------
static/fx20150302.jpg 这是微信转发分享后显示的图片
static/logo.png网站主页标志
static/logo2.png是离线分享的logo
----------------------------------- ---------- -
这个源码比那个人上次贴的源码好
本源代码已破解授权
源码下载地址
(之前发帖的人不能用微信文章采集因为需要正版授权,我花了100多买了正版授权然后破解了)
您可以使用微信文章采集。
添加了任务系统。
(任务系统花了我一个月才添加)
-------------图片修改目录------------------- ------------
static/fx20150302.jpg 这是微信转发分享后显示的图片
static/logo.png网站主页标志
static/logo2.png是离线分享的logo
----------------------------------- ---------- -
这个源码比那个人上次贴的源码好
本源代码已破解授权
源码下载地址
(之前发帖的人不能用微信文章采集因为需要正版授权,我花了100多买了正版授权然后破解了)
您可以使用微信文章采集。
添加了任务系统。
(任务系统花了我一个月才添加)
-------------图片修改目录------------------- ------------
static/fx20150302.jpg 这是微信转发分享后显示的图片
static/logo.png网站主页标志
static/logo2.png是离线分享的logo
----------------------------------- ---------- -
这个源码比那个人上次贴的源码好
本源代码已破解授权
源码下载地址
(之前发帖的人不能用微信文章采集因为需要正版授权,我花了100多买了正版授权然后破解了)
您可以使用微信文章采集。
添加了任务系统。
(任务系统花了我一个月才添加)
-------------图片修改目录------------------- ------------
static/fx20150302.jpg 这是微信转发分享后显示的图片
static/logo.png网站主页标志
static/logo2.png是离线分享的logo
----------------------------------- ---------- -
这个源码比那个人上次贴的源码好
本源代码已破解授权
源码下载地址
(之前发帖的人不能用微信文章采集因为需要正版授权,我花了100多买了正版授权然后破解了)
您可以使用微信文章采集。
添加了任务系统。
(任务系统花了我一个月才添加)
-------------图片修改目录------------------- ------------
static/fx20150302.jpg 这是微信转发分享后显示的图片
static/logo.png网站主页标志
static/logo2.png是离线分享的logo
----------------------------------- ---------- -
这个源码比那个人上次贴的源码好
本源代码已破解授权
源码下载地址
(之前发帖的人不能用微信文章采集因为需要正版授权,我花了100多买了正版授权然后破解了)
您可以使用微信文章采集。
添加了任务系统。
(任务系统花了我一个月才添加)
采集文章系统(微信公众号历史消息页的采集方法整理之后写下来)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-01-10 10:17
我从2014年开始做微信公众号内容采集的批次,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集收到的微信公众号内容很容易在公众号中传播。那个时候批量采集很容易做,采集入口就是公众号的历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而将采集定位为本地新闻资讯公众号,前端展示做成app。因此,一个可以自动采集 公众号内容形成。我曾经担心有一天,微信技术升级后,它无法采集内容,我的新闻应用程序会失败。不过随着微信的不断技术升级,采集方式也升级了,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
1http://mp.weixin.qq.com/mp/get ... irect
2
3
=========2017 年 1 月 11 日更新==========
现在,根据不同的微信个人号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一个地址的链接在anyproxy中会显示302跳转:
1https://mp.weixin.qq.com/mp/pr ... irect
2
3
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前掌握的信息,这两种页面形式在不同的微信账号中不规则出现。有的微信账号总是第一页格式,有的总是第二页格式。
1//第一种链接
2http://mp.weixin.qq.com/mp/get ... r%3D1
3//第二种
4http://mp.weixin.qq.com/mp/pro ... r%3D1
5
6
这个地址是通过微信客户端打开历史消息页面,然后使用后面介绍的代理服务器软件获得的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios微信客户端的崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。
2、个人微信账号:采集的内容,不仅需要微信客户端,采集还需要个人微信账号,因为这个微信账号不能做其他事情。
4、文章列表分析入库系统:我用php语言写的,我会详细介绍如何分析文章列表和构建采集队列实现批量< @采集内容。
步
一、安装模拟器或者用手机安装微信客户端app,申请微信个人账号并登录app。这个我就不多说了,大家都会的。
二、代理服务器系统安装
1、安装 NodeJS
2、在命令行或者终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy并运行命令:sudo anyproxy -i; 参数 -i 表示解析 HTTPS;
5、安装证书,在手机或者安卓模拟器中安装证书:
6、设置代理:Android模拟器的代理服务器地址是wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开浏览器地址:8002可以看到anyproxy的网页界面。从微信点击一个历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
/mp/getmasssendmsg 开头的网址是微信历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
=========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转,跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址查看内容。
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是原理介绍,了解后根据自己的情况修改内容):
=========2017 年 1 月 11 日更新==========
因为有两种页面形式,而且同一个页面形式总是显示在不同的微信账号中,但是为了兼容这两种页面形式,下面的代码会保留两种页面形式的判断,你也可以使用你的自己的页面表单删除li
1replaceServerResDataAsync: function(req,res,serverResData,callback){
2 if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
3 if(serverResData.toString() !== ""){
4 try {//防止报错退出程序
5 var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
6 var ret = reg.exec(serverResData.toString());//转换变量为string
7 HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
8 var http = require('http');
9 http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
10 res.on('data', function(chunk){
11 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
12 })
13 });
14 }catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
15 try {
16 var json = JSON.parse(serverResData.toString());
17 if (json.general_msg_list != []) {
18 HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
19 }
20 }catch(e){
21 console.log(e);//错误捕捉
22 }
23 callback(serverResData);//直接返回第二页json内容
24 }
25 }
26 }else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
27 try {
28 var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
29 var ret = reg.exec(serverResData.toString());//转换变量为string
30 HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
31 var http = require('http');
32 http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
33 res.on('data', function(chunk){
34 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
35 })
36 });
37 }catch(e){
38 callback(serverResData);
39 }
40 }else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
41 try {
42 var json = JSON.parse(serverResData.toString());
43 if (json.general_msg_list != []) {
44 HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
45 }
46 }catch(e){
47 console.log(e);
48 }
49 callback(serverResData);
50 }else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
51 try {
52 HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
53 }catch(e){
54
55 }
56 callback(serverResData);
57 }else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
58 try {
59 var http = require('http');
60 http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
61 res.on('data', function(chunk){
62 callback(chunk+serverResData);
63 })
64 });
65 }catch(e){
66 callback(serverResData);
67 }
68 }else{
69 callback(serverResData);
70 }
71 },
72
73
在 rule_default.js 文件的末尾添加以下代码:
1function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
2 var http = require('http');
3 var data = {
4 str: encodeURIComponent(str),
5 url: encodeURIComponent(url)
6 };
7 content = require('querystring').stringify(data);
8 var options = {
9 method: "POST",
10 host: "www.xxx.com",//注意没有http://,这是服务器的域名。
11 port: 80,
12 path: path,//接收程序的路径和文件名
13 headers: {
14 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
15 "Content-Length": content.length
16 }
17 };
18 var req = http.request(options, function (res) {
19 res.setEncoding('utf8');
20 res.on('data', function (chunk) {
21 console.log('BODY: ' + chunk);
22 });
23 });
24 req.on('error', function (e) {
25 console.log('problem with request: ' + e.message);
26 });
27 req.write(content);
28 req.end();
29}
30
31
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
1replaceRequestOption : function(req,option){
2 var newOption = option;
3 if(/google/i.test(newOption.headers.host)){
4 newOption.hostname = "www.baidu.com";
5 newOption.port = "80";
6 }
7 return newOption;
8 },
9
10
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析后存入数据库
<p>1 查看全部
采集文章系统(微信公众号历史消息页的采集方法整理之后写下来)
我从2014年开始做微信公众号内容采集的批次,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集收到的微信公众号内容很容易在公众号中传播。那个时候批量采集很容易做,采集入口就是公众号的历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而将采集定位为本地新闻资讯公众号,前端展示做成app。因此,一个可以自动采集 公众号内容形成。我曾经担心有一天,微信技术升级后,它无法采集内容,我的新闻应用程序会失败。不过随着微信的不断技术升级,采集方式也升级了,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
1http://mp.weixin.qq.com/mp/get ... irect
2
3
=========2017 年 1 月 11 日更新==========
现在,根据不同的微信个人号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一个地址的链接在anyproxy中会显示302跳转:
1https://mp.weixin.qq.com/mp/pr ... irect
2
3
第一个链接地址的页面样式:

第二个链接地址的页面样式:

根据目前掌握的信息,这两种页面形式在不同的微信账号中不规则出现。有的微信账号总是第一页格式,有的总是第二页格式。
1//第一种链接
2http://mp.weixin.qq.com/mp/get ... r%3D1
3//第二种
4http://mp.weixin.qq.com/mp/pro ... r%3D1
5
6
这个地址是通过微信客户端打开历史消息页面,然后使用后面介绍的代理服务器软件获得的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios微信客户端的崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。

2、个人微信账号:采集的内容,不仅需要微信客户端,采集还需要个人微信账号,因为这个微信账号不能做其他事情。
4、文章列表分析入库系统:我用php语言写的,我会详细介绍如何分析文章列表和构建采集队列实现批量< @采集内容。
步
一、安装模拟器或者用手机安装微信客户端app,申请微信个人账号并登录app。这个我就不多说了,大家都会的。
二、代理服务器系统安装
1、安装 NodeJS
2、在命令行或者终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy并运行命令:sudo anyproxy -i; 参数 -i 表示解析 HTTPS;
5、安装证书,在手机或者安卓模拟器中安装证书:
6、设置代理:Android模拟器的代理服务器地址是wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;

现在打开浏览器地址:8002可以看到anyproxy的网页界面。从微信点击一个历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。

/mp/getmasssendmsg 开头的网址是微信历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
=========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转,跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址查看内容。

如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是原理介绍,了解后根据自己的情况修改内容):
=========2017 年 1 月 11 日更新==========
因为有两种页面形式,而且同一个页面形式总是显示在不同的微信账号中,但是为了兼容这两种页面形式,下面的代码会保留两种页面形式的判断,你也可以使用你的自己的页面表单删除li
1replaceServerResDataAsync: function(req,res,serverResData,callback){
2 if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
3 if(serverResData.toString() !== ""){
4 try {//防止报错退出程序
5 var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
6 var ret = reg.exec(serverResData.toString());//转换变量为string
7 HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
8 var http = require('http');
9 http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
10 res.on('data', function(chunk){
11 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
12 })
13 });
14 }catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
15 try {
16 var json = JSON.parse(serverResData.toString());
17 if (json.general_msg_list != []) {
18 HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
19 }
20 }catch(e){
21 console.log(e);//错误捕捉
22 }
23 callback(serverResData);//直接返回第二页json内容
24 }
25 }
26 }else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
27 try {
28 var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
29 var ret = reg.exec(serverResData.toString());//转换变量为string
30 HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
31 var http = require('http');
32 http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
33 res.on('data', function(chunk){
34 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
35 })
36 });
37 }catch(e){
38 callback(serverResData);
39 }
40 }else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
41 try {
42 var json = JSON.parse(serverResData.toString());
43 if (json.general_msg_list != []) {
44 HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
45 }
46 }catch(e){
47 console.log(e);
48 }
49 callback(serverResData);
50 }else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
51 try {
52 HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
53 }catch(e){
54
55 }
56 callback(serverResData);
57 }else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
58 try {
59 var http = require('http');
60 http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
61 res.on('data', function(chunk){
62 callback(chunk+serverResData);
63 })
64 });
65 }catch(e){
66 callback(serverResData);
67 }
68 }else{
69 callback(serverResData);
70 }
71 },
72
73
在 rule_default.js 文件的末尾添加以下代码:
1function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
2 var http = require('http');
3 var data = {
4 str: encodeURIComponent(str),
5 url: encodeURIComponent(url)
6 };
7 content = require('querystring').stringify(data);
8 var options = {
9 method: "POST",
10 host: "www.xxx.com",//注意没有http://,这是服务器的域名。
11 port: 80,
12 path: path,//接收程序的路径和文件名
13 headers: {
14 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
15 "Content-Length": content.length
16 }
17 };
18 var req = http.request(options, function (res) {
19 res.setEncoding('utf8');
20 res.on('data', function (chunk) {
21 console.log('BODY: ' + chunk);
22 });
23 });
24 req.on('error', function (e) {
25 console.log('problem with request: ' + e.message);
26 });
27 req.write(content);
28 req.end();
29}
30
31
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
1replaceRequestOption : function(req,option){
2 var newOption = option;
3 if(/google/i.test(newOption.headers.host)){
4 newOption.hostname = "www.baidu.com";
5 newOption.port = "80";
6 }
7 return newOption;
8 },
9
10
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析后存入数据库
<p>1
采集文章系统( 免费文章采集器的特色亮点是什么?如何做好采集站收录效果 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-09 17:06
免费文章采集器的特色亮点是什么?如何做好采集站收录效果
)
免费文章采集器,深耕采集领域,借助AI领先的智能写作算法,SEO通用智能伪原创采集器。基于高度智能的文本识别算法,按下关键词采集文章,无需编写采集规则。自动全网采集,覆盖六大搜索引擎。自动过滤内容相关度和文章平滑度,只有采集高度相关和平滑度文章。地图自动分配,智能伪原创,定时采集,自动发布,自动提交给搜索引擎,支持各种内容管理系统和建站程序。通过免费的文章采集器、采集上百篇文章文章 全网可即时提供参考写作。当然,这几百个文章也可以拼凑出知识点,进行伪原创也是可以的,效果很好,不用写规则,直接输入关键词@ > 到 采集100 篇文章文章。通过免费的文章采集器,编辑器可以同时批量处理不同cms类型的网站,自动更新网站的内容,自动优化做SEO,做网站@采集Station收录效果还是很不错的!只需输入 关键词 到 采集100 篇文章文章。通过免费的文章采集器,编辑器可以同时批量处理不同cms类型的网站,自动更新网站的内容,自动优化做SEO,做网站@采集Station收录效果还是很不错的!只需输入 关键词 到 采集100 篇文章文章。通过免费的文章采集器,编辑器可以同时批量处理不同cms类型的网站,自动更新网站的内容,自动优化做SEO,做网站@采集Station收录效果还是很不错的!
免费文章采集器特点:
精准的文本识别算法,通过网页元素的多次评分,识别出文本概率最高的元素块,然后进行HTML清洗、链接清洗、冗余信息清洗,得到干净整洁的文本内容。并计算关键词与文本内容的特征向量相似度,有效识别率98%以上,无需编写任何采集规则。
方便灵活的关键词库,为了解决大部分站长缺少关键词的积累问题,会按照用户使用的关键词进行存储,并公开一个关键词@ > 数亿已开通。>图书馆,用户可以任意搜索任何内容,作为个人私人词库,也可以直接从采集系统调用。公共词库查询还支持词根自动扩展,方便用户快速查询行业相关关键词。并且搜索引擎的实时下拉词和相关搜索不断更新。
丰富的可选SEO优化选项,系统内置了业界主流的SEO优化方法,包括组合标题、正文长度过滤、标签智能提取、关键词自动加粗、关键词插入、自动内嵌链接、自动配置图片、主动推送等。插入文字和图片的频率根据搜索引擎算法量身定制,主动推送到各个搜索引擎,让收录上线更快。
高度智能化的伪原创系统采用深度学习语言模型(Language Model)自动识别句子的流畅度。学习、人工智能、百度大脑的自然语言分割、词性分析、词法依赖等相关技术,让所有搜索引擎都认为这是一个原创文章。在2500万词库中,智能选择最合适的词汇将原文替换为伪原创,句子可读性强,效果同原创。
采集任务自动运行稳定可靠,采集任务可以自动挂机运行,无需手动持久化,文章采集会自动发布到网站@ > 成功后。只需要设置必要的参数,就可以实现高质量的全托管无人值守自动更新文章。
免费文章采集器实现采集多样化,无需编写采集规则,一键式采集智能伪原创文章< @采集器自定义软件图片采集保留图片标签,实现图片采集,制定与站点匹配的目录的存放路径。免费文章采集器定制软件一键发布,实现文章一键发布功能,将文章直接发布到网站。免费的文章采集器是我们网站建设网站管理网站运营的站长工具。
查看全部
采集文章系统(
免费文章采集器的特色亮点是什么?如何做好采集站收录效果
)

免费文章采集器,深耕采集领域,借助AI领先的智能写作算法,SEO通用智能伪原创采集器。基于高度智能的文本识别算法,按下关键词采集文章,无需编写采集规则。自动全网采集,覆盖六大搜索引擎。自动过滤内容相关度和文章平滑度,只有采集高度相关和平滑度文章。地图自动分配,智能伪原创,定时采集,自动发布,自动提交给搜索引擎,支持各种内容管理系统和建站程序。通过免费的文章采集器、采集上百篇文章文章 全网可即时提供参考写作。当然,这几百个文章也可以拼凑出知识点,进行伪原创也是可以的,效果很好,不用写规则,直接输入关键词@ > 到 采集100 篇文章文章。通过免费的文章采集器,编辑器可以同时批量处理不同cms类型的网站,自动更新网站的内容,自动优化做SEO,做网站@采集Station收录效果还是很不错的!只需输入 关键词 到 采集100 篇文章文章。通过免费的文章采集器,编辑器可以同时批量处理不同cms类型的网站,自动更新网站的内容,自动优化做SEO,做网站@采集Station收录效果还是很不错的!只需输入 关键词 到 采集100 篇文章文章。通过免费的文章采集器,编辑器可以同时批量处理不同cms类型的网站,自动更新网站的内容,自动优化做SEO,做网站@采集Station收录效果还是很不错的!
免费文章采集器特点:
精准的文本识别算法,通过网页元素的多次评分,识别出文本概率最高的元素块,然后进行HTML清洗、链接清洗、冗余信息清洗,得到干净整洁的文本内容。并计算关键词与文本内容的特征向量相似度,有效识别率98%以上,无需编写任何采集规则。
方便灵活的关键词库,为了解决大部分站长缺少关键词的积累问题,会按照用户使用的关键词进行存储,并公开一个关键词@ > 数亿已开通。>图书馆,用户可以任意搜索任何内容,作为个人私人词库,也可以直接从采集系统调用。公共词库查询还支持词根自动扩展,方便用户快速查询行业相关关键词。并且搜索引擎的实时下拉词和相关搜索不断更新。
丰富的可选SEO优化选项,系统内置了业界主流的SEO优化方法,包括组合标题、正文长度过滤、标签智能提取、关键词自动加粗、关键词插入、自动内嵌链接、自动配置图片、主动推送等。插入文字和图片的频率根据搜索引擎算法量身定制,主动推送到各个搜索引擎,让收录上线更快。
高度智能化的伪原创系统采用深度学习语言模型(Language Model)自动识别句子的流畅度。学习、人工智能、百度大脑的自然语言分割、词性分析、词法依赖等相关技术,让所有搜索引擎都认为这是一个原创文章。在2500万词库中,智能选择最合适的词汇将原文替换为伪原创,句子可读性强,效果同原创。
采集任务自动运行稳定可靠,采集任务可以自动挂机运行,无需手动持久化,文章采集会自动发布到网站@ > 成功后。只需要设置必要的参数,就可以实现高质量的全托管无人值守自动更新文章。
免费文章采集器实现采集多样化,无需编写采集规则,一键式采集智能伪原创文章< @采集器自定义软件图片采集保留图片标签,实现图片采集,制定与站点匹配的目录的存放路径。免费文章采集器定制软件一键发布,实现文章一键发布功能,将文章直接发布到网站。免费的文章采集器是我们网站建设网站管理网站运营的站长工具。

采集文章系统(Java实现一个小说采集程序的简单实例的相关内容吗)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-01-03 18:03
想了解一个Java实现的小说采集程序的简单例子的相关内容吗?本文将仔细讲解java小说采集系统的相关知识和一些代码示例。欢迎阅读和纠正我。先划重点:java小说采集系统,一起来学习一下。
被标题吸引的不要骂我。
就是一个简单的实现,只要交给它下载喜欢的小说。例子中的小说只是例子,不是我的菜。
使用Jsoup。一个非常有用的工具。
如有需要,请参考自行更改。很简单,不是吗。
代码如下:
<p>
package com.zhyea.doggie;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class Doggie {
public static void main(String[] args){
try{
File txtFile = new File("D:/无限崩坏.txt");
createTxtDoc(txtFile);
addContent(txtFile);
}catch(Exception e){
e.printStackTrace();
}
}
/**
* 向小说文件中添加内容
* @param txtFile
* 小说文件
* @throws IOException
* @throws InterruptedException
*/
private static void addContent(File txtFile) throws IOException, InterruptedException{
appendTxt(txtFile, getBookInfo("无限崩坏", "啪啪啪狂魔"));
String url = "http://www.83kxs.com/View/12/12653/{pattern}.html";
for(int i=5850686; i 查看全部
采集文章系统(Java实现一个小说采集程序的简单实例的相关内容吗)
想了解一个Java实现的小说采集程序的简单例子的相关内容吗?本文将仔细讲解java小说采集系统的相关知识和一些代码示例。欢迎阅读和纠正我。先划重点:java小说采集系统,一起来学习一下。
被标题吸引的不要骂我。
就是一个简单的实现,只要交给它下载喜欢的小说。例子中的小说只是例子,不是我的菜。
使用Jsoup。一个非常有用的工具。
如有需要,请参考自行更改。很简单,不是吗。
代码如下:
<p>
package com.zhyea.doggie;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class Doggie {
public static void main(String[] args){
try{
File txtFile = new File("D:/无限崩坏.txt");
createTxtDoc(txtFile);
addContent(txtFile);
}catch(Exception e){
e.printStackTrace();
}
}
/**
* 向小说文件中添加内容
* @param txtFile
* 小说文件
* @throws IOException
* @throws InterruptedException
*/
private static void addContent(File txtFile) throws IOException, InterruptedException{
appendTxt(txtFile, getBookInfo("无限崩坏", "啪啪啪狂魔"));
String url = "http://www.83kxs.com/View/12/12653/{pattern}.html";
for(int i=5850686; i
采集文章系统( 自动化消息是什么?区别于运营人员手工创建任务发送的消息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-12-30 16:11
自动化消息是什么?区别于运营人员手工创建任务发送的消息)
一、什么是自动消息?
与操作员手动创建任务发送的消息不同,自动消息是由系统根据既定规则触发的。
自动消息根据内容类型可分为通知消息和营销消息。
1) Notification:个人信息变更通知消息,用于增加用户交互频率和转化概率,主要如下:
2) 营销:活动统一通知,区别于人工消息。自动化消息可根据营销规则自动通知,节省运营商的人工操作,并辅以策略提升效果。
目前常用的主要有:
需要注意的是,本文所讨论的营销通知大多是偏向于自身业务的通知。商户相关规则的设置与自营不同,后面会在其他文章中讨论。
不同的交付方式的服务方式和领域是不同的。比如微信服务号的订阅通知。模板需要在微信提供的固定字段中选择,而push是直接对接的界面。文案可以自己设置,不同的渠道是通知。营销类和营销类的发送限制是有区别的。
以推送为例:小米限制营销总量,但不限制通知总量;和 vivo 都限制了两者。区分营销和通知类别可以在遵守平台使用规范的同时增加覆盖面。另外,请务必遵守各个平台的使用规范,否则严重时可能会导致通道被禁用。
根据触发方式的不同,可分为触发型和定时型:
触发类型:根据用户行为及时触发;定时类型:系统按照一定的规则筛选用户,定时触发。
计时系统和触发系统的实现是有区别的,下面会一一介绍。
二、触发消息的实现
有两种类型的触发消息:
前者系统比较简单,而后者比较复杂。
先介绍第一个。第一个主要需要提供一个通用的发送服务,触发的节点都是由业务系统控制的。符合第一类的主要是通知,比如订单发货通知。这个过程大约需要三个步骤:
1. 申请模板
本步骤中,联系人系统需要提供后台页面功能,模板申请需要手动进行。模板可能需要以下信息:
1)Name:标记模板的主要目的,需要验证唯一性;
2)分发方式:不同的发送方式决定了需要填写的消息内容,比如短信只需要填写消息内容,而推送则需要填写模板、消息内容和跳转链接等;
3)内容类型:短信和推送标签是营销还是通知,此项也将决定短信内容的验证。例如,营销短信必须收录
退订说明,而通知则不需要验证。
4)留言内容:留言内容的设计主要有几点:
5)激活时间:主要决定是否激活模板。生效方式有三种:立即激活生效,设置时间生效(选择精确到分钟)暂时不生效。这三种方法的设计主要体现了商家和供应商使用时的价值。
为什么需要申请模板,而不是直接通过接口传递业务系统需要发送的内容?
这主要是由于:
2. 发送
发送节点由业务系统触发,调用触摸系统提供的通用接口。输入参数的必要字段是:
系统所有权:标记哪个系统被调用;使用模板;发送用户:包括用户ID和手机号码;动态字段内容:如果模板中有动态字段,需要标注每个用户的动态内容是什么。
其他字段可以根据自己的业务添加。
返回的参数需要返回调用的成功和失败,失败需要标注失败的原因和调用的任务id;此时的成功和失败只是接口调用的成功或失败,并不代表已经到达。用户。
由于服务提供者返回结果的时间不同,真正到达用户的结果需要异步获取。
3. 结果收据
收据可以有两种方式:
推荐第二个方案,避免了由于需要多个系统存储报文结果而导致的数据冗余,也节省了开发量。每次连接新系统时,无需触摸系统连接界面。
消息回执需要包括什么?
发送时返回任务ID。如果通过task id查询需要单独存储,也可以通过系统+时间+模板查询。这种类型的查询需要系统进行汇总。
当然,消息接收的接口不是必须的。您也可以通过触摸系统页面查看数据。
三、如何实现定时消息
定时消息一般需要在到达系统中创建规则,然后触发它们。流程大致分为5个步骤:
1. 创建任务
创建任务有点类似于手动。您需要指定任务的基本信息、目标用户规则以及到达信息的配置:
并且这里的任务创建页面不是完全可配置的,因为每个策略针对不同的用户规则;例如,休眠用户可能基于浏览/追加购买等规则,而生日提醒则是基于生日时间的提醒;so new 要添加策略,需要改变目标用户的配置。
一开始不需要做一个对所有策略完全通用的页面,只需要支持每个策略可能改变的配置即可;例如,睡眠用户的定义可能从 30 天变为 15 天。这是一个配置页面,很容易调整。
除了用户的定义,如果是促销通知类型,还需要对产品进行筛选,确认哪些产品是用户筛选匹配的;可以根据品类、品牌、促销类型、价格区间、利润率等配置产品标签。
2. 用户搜索
根据设置的规则进行用户查询。这时候就需要注意搜索时间了。为了在设定的时间发送,您需要提前估计系统的处理时间并搜索用户。
3. 消息组装
之所以特意提到这个链接,是因为有些策略需要算法来匹配。
例如:促销通知。根据今天设置的产品规则和用户规则筛选产品和用户后,我们需要为每个用户触达不同的产品,以增加用户的点击量。消息类似于“您有兴趣[产品名称]正在参与[促销名称],过来看看”
这时候就需要一个算法,将用户池和产品池进行匹配,找到用户最有情感的产品,然后到达系统就会组装起来,到达不同用户的需求。
4. 发送和结果统计
和手动任务类似,还是要注意用户的免打扰等,这里不具体讲了。
四、结论
自动化访问设计的难点在于策略的制定。需要与运营人员密切沟通,根据目标制定策略,并通过关注数据及时分析和调整策略。
此外,需要与算法部门密切沟通合作,推动算法部门改进算法也是重要的工作之一。
本文由@举个栗子原发布 人人都是产品经理,未经许可禁止转载
题图来自Unsplash,基于CC0协议 查看全部
采集文章系统(
自动化消息是什么?区别于运营人员手工创建任务发送的消息)
一、什么是自动消息?
与操作员手动创建任务发送的消息不同,自动消息是由系统根据既定规则触发的。
自动消息根据内容类型可分为通知消息和营销消息。
1) Notification:个人信息变更通知消息,用于增加用户交互频率和转化概率,主要如下:
2) 营销:活动统一通知,区别于人工消息。自动化消息可根据营销规则自动通知,节省运营商的人工操作,并辅以策略提升效果。
目前常用的主要有:
需要注意的是,本文所讨论的营销通知大多是偏向于自身业务的通知。商户相关规则的设置与自营不同,后面会在其他文章中讨论。
不同的交付方式的服务方式和领域是不同的。比如微信服务号的订阅通知。模板需要在微信提供的固定字段中选择,而push是直接对接的界面。文案可以自己设置,不同的渠道是通知。营销类和营销类的发送限制是有区别的。
以推送为例:小米限制营销总量,但不限制通知总量;和 vivo 都限制了两者。区分营销和通知类别可以在遵守平台使用规范的同时增加覆盖面。另外,请务必遵守各个平台的使用规范,否则严重时可能会导致通道被禁用。
根据触发方式的不同,可分为触发型和定时型:
触发类型:根据用户行为及时触发;定时类型:系统按照一定的规则筛选用户,定时触发。
计时系统和触发系统的实现是有区别的,下面会一一介绍。
二、触发消息的实现
有两种类型的触发消息:
前者系统比较简单,而后者比较复杂。
先介绍第一个。第一个主要需要提供一个通用的发送服务,触发的节点都是由业务系统控制的。符合第一类的主要是通知,比如订单发货通知。这个过程大约需要三个步骤:
1. 申请模板
本步骤中,联系人系统需要提供后台页面功能,模板申请需要手动进行。模板可能需要以下信息:
1)Name:标记模板的主要目的,需要验证唯一性;
2)分发方式:不同的发送方式决定了需要填写的消息内容,比如短信只需要填写消息内容,而推送则需要填写模板、消息内容和跳转链接等;
3)内容类型:短信和推送标签是营销还是通知,此项也将决定短信内容的验证。例如,营销短信必须收录
退订说明,而通知则不需要验证。
4)留言内容:留言内容的设计主要有几点:
5)激活时间:主要决定是否激活模板。生效方式有三种:立即激活生效,设置时间生效(选择精确到分钟)暂时不生效。这三种方法的设计主要体现了商家和供应商使用时的价值。
为什么需要申请模板,而不是直接通过接口传递业务系统需要发送的内容?
这主要是由于:
2. 发送
发送节点由业务系统触发,调用触摸系统提供的通用接口。输入参数的必要字段是:
系统所有权:标记哪个系统被调用;使用模板;发送用户:包括用户ID和手机号码;动态字段内容:如果模板中有动态字段,需要标注每个用户的动态内容是什么。
其他字段可以根据自己的业务添加。
返回的参数需要返回调用的成功和失败,失败需要标注失败的原因和调用的任务id;此时的成功和失败只是接口调用的成功或失败,并不代表已经到达。用户。
由于服务提供者返回结果的时间不同,真正到达用户的结果需要异步获取。
3. 结果收据
收据可以有两种方式:
推荐第二个方案,避免了由于需要多个系统存储报文结果而导致的数据冗余,也节省了开发量。每次连接新系统时,无需触摸系统连接界面。
消息回执需要包括什么?
发送时返回任务ID。如果通过task id查询需要单独存储,也可以通过系统+时间+模板查询。这种类型的查询需要系统进行汇总。
当然,消息接收的接口不是必须的。您也可以通过触摸系统页面查看数据。
三、如何实现定时消息
定时消息一般需要在到达系统中创建规则,然后触发它们。流程大致分为5个步骤:
1. 创建任务
创建任务有点类似于手动。您需要指定任务的基本信息、目标用户规则以及到达信息的配置:
并且这里的任务创建页面不是完全可配置的,因为每个策略针对不同的用户规则;例如,休眠用户可能基于浏览/追加购买等规则,而生日提醒则是基于生日时间的提醒;so new 要添加策略,需要改变目标用户的配置。
一开始不需要做一个对所有策略完全通用的页面,只需要支持每个策略可能改变的配置即可;例如,睡眠用户的定义可能从 30 天变为 15 天。这是一个配置页面,很容易调整。
除了用户的定义,如果是促销通知类型,还需要对产品进行筛选,确认哪些产品是用户筛选匹配的;可以根据品类、品牌、促销类型、价格区间、利润率等配置产品标签。
2. 用户搜索
根据设置的规则进行用户查询。这时候就需要注意搜索时间了。为了在设定的时间发送,您需要提前估计系统的处理时间并搜索用户。
3. 消息组装
之所以特意提到这个链接,是因为有些策略需要算法来匹配。
例如:促销通知。根据今天设置的产品规则和用户规则筛选产品和用户后,我们需要为每个用户触达不同的产品,以增加用户的点击量。消息类似于“您有兴趣[产品名称]正在参与[促销名称],过来看看”
这时候就需要一个算法,将用户池和产品池进行匹配,找到用户最有情感的产品,然后到达系统就会组装起来,到达不同用户的需求。
4. 发送和结果统计
和手动任务类似,还是要注意用户的免打扰等,这里不具体讲了。
四、结论
自动化访问设计的难点在于策略的制定。需要与运营人员密切沟通,根据目标制定策略,并通过关注数据及时分析和调整策略。
此外,需要与算法部门密切沟通合作,推动算法部门改进算法也是重要的工作之一。
本文由@举个栗子原发布 人人都是产品经理,未经许可禁止转载
题图来自Unsplash,基于CC0协议
采集文章系统(网站收录与排名的关系有影响吗?如何理解?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-12-29 23:15
一些SEO人员认为一个网站被收录的越多,排名就越好。其实一个网站的收录和排名并没有直接的关系,但是两者之间有一定的联系。那么如何理解网站收录与排名的关系呢?
网站收录是指爬虫抓取网页并将页面内容数据放入搜索引擎数据库。可以通过搜索引擎目标网址检索到相应的内容。所以,一个网站想要被收录,首先需要有内容供爬虫爬取,然后爬虫会一直爬爬爬爬,直到建立索引,完成网页收录。在这个过程中,搜索引擎爬虫会评估内容的质量,只有符合标准的才会被有效收录和排名。
对于网站内容质量的评价,在搜索结果中一般有两种情况:
如果你的内容是优质内容,或者比较优质的内容,那么在搜索结果中,搜索特定的关键词,就会有相应的排名;但是如果你的内容质量不高,任何搜索引擎关键词都不会排名,只有在检索到网址时,才会有一定的收录。
因此,网站收录和排名没有直接关系,并不代表网站收录就意味着会有排名。那么网站收录
的内容多的话,会不会影响排名呢?
网站收录和排名有什么关系?更多的包容是否意味着更高的排名?
快速增加网站收录的方法有很多种,比如建立站群系统,采集
大量文章发表来增加网站的收录,或者利用镜像采集
大量文章的镜像网站。目标网站内容实现内容同步,也可以使得收录大量页面,但是这些低质量的内容或者负面SEO的效果无法有效收录,也就不会有排名。
如果你想真正提高你的网站排名,你必须做高质量的内容。优质内容是能够满足用户需求的原创且有价值的内容。只有收录的此类优质内容越多,排名可能会上升。当然,增加包容性的技术和方法的选择也很重要。我们必须使用正常的优化方法来提高网站的收录,比如外链发布、站点地图、内容和锚文本等。走捷径只能让你获得短期收益,最终会受到搜索引擎的惩罚。如果你想让你的网站有效、稳定和长期发展,那么你应该逐步优化你的网站,并保持它的定期和有规律。高质量的更新是正确的。
以上就是对网站收录与排名关系的分析。一般来说,网站收录的越多,排名越高并不意味着收录的优质内容越多。可以提高网站的排名。 查看全部
采集文章系统(网站收录与排名的关系有影响吗?如何理解?)
一些SEO人员认为一个网站被收录的越多,排名就越好。其实一个网站的收录和排名并没有直接的关系,但是两者之间有一定的联系。那么如何理解网站收录与排名的关系呢?
网站收录是指爬虫抓取网页并将页面内容数据放入搜索引擎数据库。可以通过搜索引擎目标网址检索到相应的内容。所以,一个网站想要被收录,首先需要有内容供爬虫爬取,然后爬虫会一直爬爬爬爬,直到建立索引,完成网页收录。在这个过程中,搜索引擎爬虫会评估内容的质量,只有符合标准的才会被有效收录和排名。
对于网站内容质量的评价,在搜索结果中一般有两种情况:
如果你的内容是优质内容,或者比较优质的内容,那么在搜索结果中,搜索特定的关键词,就会有相应的排名;但是如果你的内容质量不高,任何搜索引擎关键词都不会排名,只有在检索到网址时,才会有一定的收录。
因此,网站收录和排名没有直接关系,并不代表网站收录就意味着会有排名。那么网站收录
的内容多的话,会不会影响排名呢?
网站收录和排名有什么关系?更多的包容是否意味着更高的排名?
快速增加网站收录的方法有很多种,比如建立站群系统,采集
大量文章发表来增加网站的收录,或者利用镜像采集
大量文章的镜像网站。目标网站内容实现内容同步,也可以使得收录大量页面,但是这些低质量的内容或者负面SEO的效果无法有效收录,也就不会有排名。
如果你想真正提高你的网站排名,你必须做高质量的内容。优质内容是能够满足用户需求的原创且有价值的内容。只有收录的此类优质内容越多,排名可能会上升。当然,增加包容性的技术和方法的选择也很重要。我们必须使用正常的优化方法来提高网站的收录,比如外链发布、站点地图、内容和锚文本等。走捷径只能让你获得短期收益,最终会受到搜索引擎的惩罚。如果你想让你的网站有效、稳定和长期发展,那么你应该逐步优化你的网站,并保持它的定期和有规律。高质量的更新是正确的。
以上就是对网站收录与排名关系的分析。一般来说,网站收录的越多,排名越高并不意味着收录的优质内容越多。可以提高网站的排名。
采集文章系统(一下如何利用老Y文章管理系统采集时自动完成伪原创)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-12-27 22:24
垃圾站站长最希望的就是网站可以自动收,自动补伪原创,然后自动收钱。这是世界上最幸福的事情,哈哈。自动收款和自动收款将不再讨论。今天给大家介绍一下如何使用老Y文章管理系统在采集
时自动完成伪原创的方法。文章管理系统简单易用。虽然功能没有DEDE之类的强大,几乎变态(文章管理系统用asp语言写的时候,好像没有可比性),但是都有,而且还挺简单的. 所以也受到了很多站长的欢迎。老Y文章管理系统采集
时自动完成伪原创创作的具体方法,目前还鲜有讨论。在老Y的论坛上,甚至有人在卖这个方法。我有点鄙视它。关于采集
,我就不多说了。我相信每个人都能应付。我想介绍的是旧的Y文章管理系统如何在采集
的同时自动完成伪原创工作。大体思路是使用旧的Y文章管理系统。内置过滤功能,实现同义词自动替换,从而达到伪原创的目的。比如我想把采集
文章中的“网转博客”全部替换成“网转日记”。详细步骤如下:第一步是进入后台。找到“采集
管理”-“过滤管理”,添加一个新的过滤项。我可以创建一个名为“网赚博客”的项目,具体设置请看图片: “过滤器名称”:填写“网赚博客”,也可以随意写,但是为了方便查看,建议和替换的话是一致的。
“主题”:请根据您自己的网站选择网站栏目(一定要选择栏目,否则过滤后的项目无法保存)。“过滤器对象”:可用选项有“标题过滤器”和“文本过滤器”。一般选择“文本过滤器”。如果你想伪原创甚至标题,你可以选择“标题过滤器”。“过滤器类型”:选项为“简单更换”和“高级过滤器”。一般选择“简单替换”。代码级替换的内容。“使用状态”:选项为“启用”和“禁用”,不作解释。“使用范围”:选项为“公共”和“私人”。选择“私人”,过滤器只对当前网站栏目有效;选择“Public”,对所有列都有效,无论哪一列采集什么内容,过滤都有效。一般选择“私人”。“内容”:填写将被替换的“网赚博客”字样。“替换”:填写“网转日记”,只要收录的文章中含有“网转博客”字样,就会自动替换为“网转日记”。第二步,重复第一步的工作,直到添加完所有的同义词。有网友想问:我有3万多个同义词,要不要手动一一添加?我什么时候添加它们?不能批量添加吗?这是一个很好的问题!手动添加确实是一项几乎不可能完成的任务。
遗憾的是,旧的Y文章管理系统没有提供批量导入的功能。但是,作为真实的、有经验的、有思想的优采云
,我们必须有优采云
的意识。要知道,我们刚刚输入的内容是存放在数据库中的,而旧的文章管理系统是用asp+Access编写的,mdb数据库可以很方便的编辑!所以,我可以直接修改数据库批量导入伪原创替换规则!改进的第二步:批量修改数据库和导入规则。经过搜索,我发现这个数据库在“你的管理目录\cai\Database”下。使用 Access 打开此数据库并找到“过滤器”表。你会发现我们刚刚添加的替换规则就存放在这里。根据您的需要分批添加!接下来的工作涉及到Access操作,我就不啰嗦了,大家可以自己做。解释一下“Filters”表中几个字段的含义: FilterID:自动生成,不需要输入。ItemID:列ID是我们手动输入时“item”的内容,但这里是数字ID,注意对应列的集合ID,不知道ID的可以重复第一步,测试一下。过滤器名称:“过滤器名称”。FilterObjece:“过滤对象”,“标题过滤器”填1,“文本过滤器”填2。不需要输入。ItemID:列ID是我们手动输入时“item”的内容,但这里是数字ID,注意对应列的集合ID,不知道ID的可以重复第一步,测试一下。过滤器名称:“过滤器名称”。FilterObjece:“过滤对象”,“标题过滤器”填1,“文本过滤器”填2。不需要输入。ItemID:列ID是我们手动输入时“item”的内容,但这里是数字ID,注意对应列的集合ID,不知道ID的可以重复第一步,测试一下。过滤器名称:“过滤器名称”。FilterObjece:“过滤对象”,“标题过滤器”填1,“文本过滤器”填2。
FilterType:“过滤器类型”,“简单更换”填1,“高级过滤器”填2。FilterContent:“内容”。FisString:“开始标签”,只有在设置了“高级过滤器”时才有效,如果设置了“简单过滤器”,请留空。FioString:“结束标签”,仅在设置了“高级过滤器”时有效,如果设置了“简单过滤器”,请留空。FilterRep:即“替换”。Flag:“使用状态”,TRUE 表示“启用”,FALSE 表示“禁用”。PublicTf:“使用范围”。TRUE 表示“公共”,FALSE 表示“私有”。最后说一下使用过滤功能实现伪原创体验的使用:文章管理系统的这个功能在采集
的时候可以实现自动伪原创,但是功能不够强大。例如,我的站点上有三列:“第一列”、“第二列”和“第三列”。我希望“第一栏”对标题和正文都进行伪原创,“第二栏”只会对文字进行伪原创,“第三栏”只会对标题进行伪原创。因此,我只能做如下设置(假设我有30000个同义词规则): 为“Column 1”的伪原创标题创建30000个替换规则;为“第一栏”的伪原文创建30000条替换规则;为“第2栏”的伪原文创建30000条替换规则;创建 30,
这造成了巨大的数据库浪费。如果我的网站有几十个栏目,每一个栏目的要求都不一样,这个数据库的大小会很吓人。所以建议在老Y文章管理系统下一个版本完善这个功能:首先,增加批量导入功能,毕竟修改数据库有一定的风险。其次,过滤规则不再依附于某个网站栏目,而是独立于过滤规则,并且在新建集合项时,添加是否使用过滤规则的判断。相信经过这样的修改,可以大大节省数据库存储空间,逻辑结构也更加清晰。本文为“我的网赚日记-原创网赚博客”原创,请尊重我的劳动成果,转载请注明出处!另外,我已经很久没有使用旧的Y文章管理系统了,如果文章地方有错误或不当的文章,欢迎大家指正!企业贸易网 查看全部
采集文章系统(一下如何利用老Y文章管理系统采集时自动完成伪原创)
垃圾站站长最希望的就是网站可以自动收,自动补伪原创,然后自动收钱。这是世界上最幸福的事情,哈哈。自动收款和自动收款将不再讨论。今天给大家介绍一下如何使用老Y文章管理系统在采集
时自动完成伪原创的方法。文章管理系统简单易用。虽然功能没有DEDE之类的强大,几乎变态(文章管理系统用asp语言写的时候,好像没有可比性),但是都有,而且还挺简单的. 所以也受到了很多站长的欢迎。老Y文章管理系统采集
时自动完成伪原创创作的具体方法,目前还鲜有讨论。在老Y的论坛上,甚至有人在卖这个方法。我有点鄙视它。关于采集
,我就不多说了。我相信每个人都能应付。我想介绍的是旧的Y文章管理系统如何在采集
的同时自动完成伪原创工作。大体思路是使用旧的Y文章管理系统。内置过滤功能,实现同义词自动替换,从而达到伪原创的目的。比如我想把采集
文章中的“网转博客”全部替换成“网转日记”。详细步骤如下:第一步是进入后台。找到“采集
管理”-“过滤管理”,添加一个新的过滤项。我可以创建一个名为“网赚博客”的项目,具体设置请看图片: “过滤器名称”:填写“网赚博客”,也可以随意写,但是为了方便查看,建议和替换的话是一致的。
“主题”:请根据您自己的网站选择网站栏目(一定要选择栏目,否则过滤后的项目无法保存)。“过滤器对象”:可用选项有“标题过滤器”和“文本过滤器”。一般选择“文本过滤器”。如果你想伪原创甚至标题,你可以选择“标题过滤器”。“过滤器类型”:选项为“简单更换”和“高级过滤器”。一般选择“简单替换”。代码级替换的内容。“使用状态”:选项为“启用”和“禁用”,不作解释。“使用范围”:选项为“公共”和“私人”。选择“私人”,过滤器只对当前网站栏目有效;选择“Public”,对所有列都有效,无论哪一列采集什么内容,过滤都有效。一般选择“私人”。“内容”:填写将被替换的“网赚博客”字样。“替换”:填写“网转日记”,只要收录的文章中含有“网转博客”字样,就会自动替换为“网转日记”。第二步,重复第一步的工作,直到添加完所有的同义词。有网友想问:我有3万多个同义词,要不要手动一一添加?我什么时候添加它们?不能批量添加吗?这是一个很好的问题!手动添加确实是一项几乎不可能完成的任务。
遗憾的是,旧的Y文章管理系统没有提供批量导入的功能。但是,作为真实的、有经验的、有思想的优采云
,我们必须有优采云
的意识。要知道,我们刚刚输入的内容是存放在数据库中的,而旧的文章管理系统是用asp+Access编写的,mdb数据库可以很方便的编辑!所以,我可以直接修改数据库批量导入伪原创替换规则!改进的第二步:批量修改数据库和导入规则。经过搜索,我发现这个数据库在“你的管理目录\cai\Database”下。使用 Access 打开此数据库并找到“过滤器”表。你会发现我们刚刚添加的替换规则就存放在这里。根据您的需要分批添加!接下来的工作涉及到Access操作,我就不啰嗦了,大家可以自己做。解释一下“Filters”表中几个字段的含义: FilterID:自动生成,不需要输入。ItemID:列ID是我们手动输入时“item”的内容,但这里是数字ID,注意对应列的集合ID,不知道ID的可以重复第一步,测试一下。过滤器名称:“过滤器名称”。FilterObjece:“过滤对象”,“标题过滤器”填1,“文本过滤器”填2。不需要输入。ItemID:列ID是我们手动输入时“item”的内容,但这里是数字ID,注意对应列的集合ID,不知道ID的可以重复第一步,测试一下。过滤器名称:“过滤器名称”。FilterObjece:“过滤对象”,“标题过滤器”填1,“文本过滤器”填2。不需要输入。ItemID:列ID是我们手动输入时“item”的内容,但这里是数字ID,注意对应列的集合ID,不知道ID的可以重复第一步,测试一下。过滤器名称:“过滤器名称”。FilterObjece:“过滤对象”,“标题过滤器”填1,“文本过滤器”填2。
FilterType:“过滤器类型”,“简单更换”填1,“高级过滤器”填2。FilterContent:“内容”。FisString:“开始标签”,只有在设置了“高级过滤器”时才有效,如果设置了“简单过滤器”,请留空。FioString:“结束标签”,仅在设置了“高级过滤器”时有效,如果设置了“简单过滤器”,请留空。FilterRep:即“替换”。Flag:“使用状态”,TRUE 表示“启用”,FALSE 表示“禁用”。PublicTf:“使用范围”。TRUE 表示“公共”,FALSE 表示“私有”。最后说一下使用过滤功能实现伪原创体验的使用:文章管理系统的这个功能在采集
的时候可以实现自动伪原创,但是功能不够强大。例如,我的站点上有三列:“第一列”、“第二列”和“第三列”。我希望“第一栏”对标题和正文都进行伪原创,“第二栏”只会对文字进行伪原创,“第三栏”只会对标题进行伪原创。因此,我只能做如下设置(假设我有30000个同义词规则): 为“Column 1”的伪原创标题创建30000个替换规则;为“第一栏”的伪原文创建30000条替换规则;为“第2栏”的伪原文创建30000条替换规则;创建 30,
这造成了巨大的数据库浪费。如果我的网站有几十个栏目,每一个栏目的要求都不一样,这个数据库的大小会很吓人。所以建议在老Y文章管理系统下一个版本完善这个功能:首先,增加批量导入功能,毕竟修改数据库有一定的风险。其次,过滤规则不再依附于某个网站栏目,而是独立于过滤规则,并且在新建集合项时,添加是否使用过滤规则的判断。相信经过这样的修改,可以大大节省数据库存储空间,逻辑结构也更加清晰。本文为“我的网赚日记-原创网赚博客”原创,请尊重我的劳动成果,转载请注明出处!另外,我已经很久没有使用旧的Y文章管理系统了,如果文章地方有错误或不当的文章,欢迎大家指正!企业贸易网
采集文章系统(一个微信公众号历史消息页的采集方法整理之后写)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-12-27 20:20
从2014年开始做微信公众号内容的批量采集,最初的目的是搭建一个html5垃圾网站。当时,垃圾站采集
的微信公众号的内容很容易在公众号传播。那个时候批量采集
特别好做,采集
入口就是公众号的历史新闻页面。这个入口现在还是一样,只是越来越难采集
了。采集
方法也更新了很多版本。后来,2015年html5垃圾站没有做,转而将采集
目标定位在本地新闻信息公众号上,前端展示做成了app。于是,一个可以自动采集
公众号内容的新闻APP就形成了。我曾经担心微信技术升级一天后,无法采集内容,我的新闻应用程序会失败。但是随着微信的不断技术升级,采集
方式也得到了升级,这让我越来越有信心。只要有公众号历史信息页面,就可以批量采集内容。所以今天决定整理一下采集
方法,写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。这让我越来越自信。只要有公众号历史信息页面,就可以批量采集内容。所以今天决定整理一下采集
方法,写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。这让我越来越自信。只要有公众号历史信息页面,就可以批量采集内容。所以今天决定整理一下采集
方法,写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文将持续更新,保证您看到的内容在您看到时可用。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... r%3D1
有几个参数:
__biz;uin=;key=;devicetype=;version=;lang=;nettype=;ascene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这4个参数。
__biz 是公众号的类似id的参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
其余三个参数与用户的id和tokenticket的含义有关。这三个参数的值只能由微信客户端生成。所以,如果我们要采集
公众号,就必须使用微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号时都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集
系统由以下几部分组成:
1、 微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。批量采集测试的ios微信客户端崩溃率高于Android系统。为了降低成本,我使用了Android模拟器。
2、一个微信个人号:要采集
内容,不仅需要一个微信客户端,还需要一个专门用于采集
的微信个人号,因为这个微信号不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体的安装方法后面会详细介绍。
4、 文章列表分析入库系统:本人使用php语言编写,下篇文章将详细介绍如何分析文章列表,建立采集
队列,实现内容的批量采集
。
步
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个我就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、安装NodeJS
2、 在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、 生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
方法一:启动anyproxy,打开浏览器:8002/fetchCr...,即可得到rootCA.crt文件
方法二:启动anyproxy,:8002/qr_root可以获取证书路径的二维码,手机安装会更方便
建议通过二维码将证书安装到手机中。
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意一条公众号历史消息或文章,就可以在终端看到滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址:8002,可以看到anyproxy的web界面。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
如果右侧出现html文件内容,则说明解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成了ca证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,理解后根据自己的情况修改内容):
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
上面的代码就是使用anyproxy修改了返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理,可以批量采集公众号的内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件的末尾添加以下代码:
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统的性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是对anyproxy规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p> 查看全部
采集文章系统(一个微信公众号历史消息页的采集方法整理之后写)
从2014年开始做微信公众号内容的批量采集,最初的目的是搭建一个html5垃圾网站。当时,垃圾站采集
的微信公众号的内容很容易在公众号传播。那个时候批量采集
特别好做,采集
入口就是公众号的历史新闻页面。这个入口现在还是一样,只是越来越难采集
了。采集
方法也更新了很多版本。后来,2015年html5垃圾站没有做,转而将采集
目标定位在本地新闻信息公众号上,前端展示做成了app。于是,一个可以自动采集
公众号内容的新闻APP就形成了。我曾经担心微信技术升级一天后,无法采集内容,我的新闻应用程序会失败。但是随着微信的不断技术升级,采集
方式也得到了升级,这让我越来越有信心。只要有公众号历史信息页面,就可以批量采集内容。所以今天决定整理一下采集
方法,写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。这让我越来越自信。只要有公众号历史信息页面,就可以批量采集内容。所以今天决定整理一下采集
方法,写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。这让我越来越自信。只要有公众号历史信息页面,就可以批量采集内容。所以今天决定整理一下采集
方法,写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文将持续更新,保证您看到的内容在您看到时可用。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... r%3D1
有几个参数:
__biz;uin=;key=;devicetype=;version=;lang=;nettype=;ascene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这4个参数。
__biz 是公众号的类似id的参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
其余三个参数与用户的id和tokenticket的含义有关。这三个参数的值只能由微信客户端生成。所以,如果我们要采集
公众号,就必须使用微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号时都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集
系统由以下几部分组成:
1、 微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。批量采集测试的ios微信客户端崩溃率高于Android系统。为了降低成本,我使用了Android模拟器。
2、一个微信个人号:要采集
内容,不仅需要一个微信客户端,还需要一个专门用于采集
的微信个人号,因为这个微信号不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体的安装方法后面会详细介绍。
4、 文章列表分析入库系统:本人使用php语言编写,下篇文章将详细介绍如何分析文章列表,建立采集
队列,实现内容的批量采集
。
步
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个我就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、安装NodeJS
2、 在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、 生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
方法一:启动anyproxy,打开浏览器:8002/fetchCr...,即可得到rootCA.crt文件
方法二:启动anyproxy,:8002/qr_root可以获取证书路径的二维码,手机安装会更方便
建议通过二维码将证书安装到手机中。
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意一条公众号历史消息或文章,就可以在终端看到滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址:8002,可以看到anyproxy的web界面。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
如果右侧出现html文件内容,则说明解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成了ca证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,理解后根据自己的情况修改内容):
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
上面的代码就是使用anyproxy修改了返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理,可以批量采集公众号的内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件的末尾添加以下代码:
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统的性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是对anyproxy规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p>
采集文章系统(一个微信公众号历史消息页面的链接地址和采集方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-02-11 12:26
我从2014年开始做微信公众号内容采集的批次,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集收到的微信公众号内容很容易在公众号中传播。那个时候批量采集很容易做,采集入口就是公众号的历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而将采集定位为本地新闻资讯公众号,前端展示做成app。因此,一个可以自动采集 公众号内容形成。我曾经担心有一天,微信技术升级后,它无法采集内容,我的新闻应用程序会失败。不过随着微信的不断技术升级,采集方式也升级了,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
首先我们来看一个微信公众号历史新闻页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
=========2017 年 1 月 11 日更新==========
现在,根据不同的微信个人号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一个地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前掌握的信息,这两种页面形式在不同的微信账号中不规则出现。有的微信账号总是第一页格式,有的总是第二页格式。
以上链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
这个地址是通过微信客户端打开历史消息页面,然后使用后面介绍的代理服务器软件获得的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
__biz 是公众号的类id参数。每个公众号都有一个微信业务。目前公众号的biz发生变化的概率很小;
其余三个参数与用户的 id 和 token 票证相关。这三个参数的值是微信客户端生成后自动添加到地址栏的。所以想要采集公众号,必须通过微信客户端。在微信之前的版本中,这三个参数也可以一次性获取,在有效期内被多个公众号使用。当前版本每次访问公共帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios微信客户端的崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。
2、个人微信账号:采集的内容,不仅需要微信客户端,采集还需要个人微信账号,因为这个微信账号不能做其他事情。
3、本地代理服务器系统:目前的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体的安装和设置方法将在后面详细介绍。
4、文章列表分析与仓储系统:我用php语言写的。后面会详细介绍如何分析文章列表,建立采集队列,实现批量采集内容。
步
一、安装模拟器或者用手机安装微信客户端app,申请微信个人账号并登录app。这个我就不多说了,大家都会的。
二、代理服务器系统安装
目前我正在使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置将脚本代码插入公众号页面。让我们从安装和配置过程开始。
1、安装 NodeJS
2、在命令行或者终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy并运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器上安装证书:
6、设置代理:Android模拟器的代理服务器地址是wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开微信,点击任意公众号历史消息或文章,可以在终端看到响应码滚动。如果没有出现,请检查您手机的代理设置是否正确。
现在打开浏览器地址localhost:8002可以看到anyproxy的web界面。从微信点击一个历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
/mp/getmasssendmsg 开头的网址是微信历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
=========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转,跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址查看内容。
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
现在我们手机上的所有内容都可以以明文形式通过代理服务器。接下来,我们需要修改和配置代理服务器,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是原理介绍,了解后根据自己的情况修改内容):
=========2017 年 1 月 11 日更新==========
因为有两种页面形式,而且同一个页面形式总是显示在不同的微信账号中,但是为了兼容这两种页面形式,下面的代码会保留两种页面形式的判断,你也可以使用你的自己的页面表单删除li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码使用anyproxy修改返回页面内容的功能,将脚本注入页面,将页面内容发送给服务器。利用这个原理批量采集公众号内容和阅读量。该脚本中自定义了一个函数,下面详细介绍:
在 rule_default.js 文件的末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析后存入数据库
<p> 查看全部
采集文章系统(一个微信公众号历史消息页面的链接地址和采集方法)
我从2014年开始做微信公众号内容采集的批次,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集收到的微信公众号内容很容易在公众号中传播。那个时候批量采集很容易做,采集入口就是公众号的历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而将采集定位为本地新闻资讯公众号,前端展示做成app。因此,一个可以自动采集 公众号内容形成。我曾经担心有一天,微信技术升级后,它无法采集内容,我的新闻应用程序会失败。不过随着微信的不断技术升级,采集方式也升级了,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
首先我们来看一个微信公众号历史新闻页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
=========2017 年 1 月 11 日更新==========
现在,根据不同的微信个人号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一个地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前掌握的信息,这两种页面形式在不同的微信账号中不规则出现。有的微信账号总是第一页格式,有的总是第二页格式。
以上链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
这个地址是通过微信客户端打开历史消息页面,然后使用后面介绍的代理服务器软件获得的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
__biz 是公众号的类id参数。每个公众号都有一个微信业务。目前公众号的biz发生变化的概率很小;
其余三个参数与用户的 id 和 token 票证相关。这三个参数的值是微信客户端生成后自动添加到地址栏的。所以想要采集公众号,必须通过微信客户端。在微信之前的版本中,这三个参数也可以一次性获取,在有效期内被多个公众号使用。当前版本每次访问公共帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios微信客户端的崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。
2、个人微信账号:采集的内容,不仅需要微信客户端,采集还需要个人微信账号,因为这个微信账号不能做其他事情。
3、本地代理服务器系统:目前的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体的安装和设置方法将在后面详细介绍。
4、文章列表分析与仓储系统:我用php语言写的。后面会详细介绍如何分析文章列表,建立采集队列,实现批量采集内容。
步
一、安装模拟器或者用手机安装微信客户端app,申请微信个人账号并登录app。这个我就不多说了,大家都会的。
二、代理服务器系统安装
目前我正在使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置将脚本代码插入公众号页面。让我们从安装和配置过程开始。
1、安装 NodeJS
2、在命令行或者终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy并运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器上安装证书:
6、设置代理:Android模拟器的代理服务器地址是wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开微信,点击任意公众号历史消息或文章,可以在终端看到响应码滚动。如果没有出现,请检查您手机的代理设置是否正确。
现在打开浏览器地址localhost:8002可以看到anyproxy的web界面。从微信点击一个历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
/mp/getmasssendmsg 开头的网址是微信历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
=========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转,跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址查看内容。
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
现在我们手机上的所有内容都可以以明文形式通过代理服务器。接下来,我们需要修改和配置代理服务器,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是原理介绍,了解后根据自己的情况修改内容):
=========2017 年 1 月 11 日更新==========
因为有两种页面形式,而且同一个页面形式总是显示在不同的微信账号中,但是为了兼容这两种页面形式,下面的代码会保留两种页面形式的判断,你也可以使用你的自己的页面表单删除li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码使用anyproxy修改返回页面内容的功能,将脚本注入页面,将页面内容发送给服务器。利用这个原理批量采集公众号内容和阅读量。该脚本中自定义了一个函数,下面详细介绍:
在 rule_default.js 文件的末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析后存入数据库
<p>
采集文章系统(一个微信公众号历史消息页的采集方法整理之后写)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-02-08 21:07
我从2014年开始做微信公众号内容采集的批次,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集收到的微信公众号内容很容易在公众号中传播。那个时候批量采集很容易做,采集入口就是公众号的历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而将采集定位为本地新闻资讯公众号,前端展示做成app。因此,一个可以自动采集 公众号内容形成。我曾经担心有一天,微信技术升级后,它无法采集内容,我的新闻应用程序会失败。不过随着微信的不断技术升级,采集方式也升级了,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
首先我们来看一个微信公众号历史新闻页面的链接地址:
http://mp.weixin.qq.com/mp/get ... r%3D1
这里有几个参数:
__biz;uin=;key=;devicetype=;version=;lang=;nettype=;ascene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
__biz 是公众号的类id参数。每个公众号都有一个微信业务。目前公众号的biz发生变化的概率很小;
其余3个参数与用户的id和token相关,这3个参数的值只能由微信客户端生成。所以想要采集公众号,必须通过微信客户端。在微信之前的版本中,这三个参数也可以一次性获取,在有效期内被多个公众号使用。当前版本每次访问公共帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios微信客户端的崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。
2、个人微信账号:采集的内容,不仅需要微信客户端,采集还需要个人微信账号,因为这个微信账号不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体的安装和设置方法将在后面详细介绍。
4、文章列表分析入库系统:我用php语言写的,我会详细介绍如何分析文章列表,建立采集队列实现批量< @采集内容。
步
一、安装模拟器或者用手机安装微信客户端app,申请微信个人账号并登录app。这个我就不多说了,大家都会的。
二、代理服务器系统安装
目前我正在使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置将脚本代码插入公众号页面。让我们从安装和配置过程开始。
1、安装 NodeJS
2、在命令行或者终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy并运行命令:sudo anyproxy -i; 参数 -i 表示解析 HTTPS;
5、安装证书,在手机或者安卓模拟器上安装证书:
方法一:启动anyproxy,打开浏览器:8002/fetchCr...,即可得到rootCA.crt文件
方法二:启动anyproxy,:8002/qr_root可以获取证书路径的二维码,移动安装更方便
建议通过二维码将证书安装到手机中。
6、设置代理:Android模拟器的代理服务器地址是wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开微信,点击任意公众号历史消息或文章,可以在终端看到响应码滚动。如果没有出现,请检查您手机的代理设置是否正确。
现在打开浏览器地址:8002可以看到anyproxy的网页界面。从微信点击一个历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
/mp/getmasssendmsg 开头的网址是微信历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
现在我们手机上的所有内容都可以以明文形式通过代理服务器。接下来,我们需要修改和配置代理服务器,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是原理介绍,了解后根据自己的情况修改内容):
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码使用anyproxy修改返回页面内容的功能,将脚本注入页面,将页面内容发送给服务器。利用这个原理批量采集公众号内容和阅读量。该脚本中自定义了一个函数,下面详细介绍:
在 rule_default.js 文件的末尾添加以下代码:
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析后存入数据库
<p> 查看全部
采集文章系统(一个微信公众号历史消息页的采集方法整理之后写)
我从2014年开始做微信公众号内容采集的批次,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集收到的微信公众号内容很容易在公众号中传播。那个时候批量采集很容易做,采集入口就是公众号的历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而将采集定位为本地新闻资讯公众号,前端展示做成app。因此,一个可以自动采集 公众号内容形成。我曾经担心有一天,微信技术升级后,它无法采集内容,我的新闻应用程序会失败。不过随着微信的不断技术升级,采集方式也升级了,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
首先我们来看一个微信公众号历史新闻页面的链接地址:
http://mp.weixin.qq.com/mp/get ... r%3D1
这里有几个参数:
__biz;uin=;key=;devicetype=;version=;lang=;nettype=;ascene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
__biz 是公众号的类id参数。每个公众号都有一个微信业务。目前公众号的biz发生变化的概率很小;
其余3个参数与用户的id和token相关,这3个参数的值只能由微信客户端生成。所以想要采集公众号,必须通过微信客户端。在微信之前的版本中,这三个参数也可以一次性获取,在有效期内被多个公众号使用。当前版本每次访问公共帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios微信客户端的崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。
2、个人微信账号:采集的内容,不仅需要微信客户端,采集还需要个人微信账号,因为这个微信账号不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体的安装和设置方法将在后面详细介绍。
4、文章列表分析入库系统:我用php语言写的,我会详细介绍如何分析文章列表,建立采集队列实现批量< @采集内容。
步
一、安装模拟器或者用手机安装微信客户端app,申请微信个人账号并登录app。这个我就不多说了,大家都会的。
二、代理服务器系统安装
目前我正在使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置将脚本代码插入公众号页面。让我们从安装和配置过程开始。
1、安装 NodeJS
2、在命令行或者终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy并运行命令:sudo anyproxy -i; 参数 -i 表示解析 HTTPS;
5、安装证书,在手机或者安卓模拟器上安装证书:
方法一:启动anyproxy,打开浏览器:8002/fetchCr...,即可得到rootCA.crt文件
方法二:启动anyproxy,:8002/qr_root可以获取证书路径的二维码,移动安装更方便
建议通过二维码将证书安装到手机中。
6、设置代理:Android模拟器的代理服务器地址是wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开微信,点击任意公众号历史消息或文章,可以在终端看到响应码滚动。如果没有出现,请检查您手机的代理设置是否正确。
现在打开浏览器地址:8002可以看到anyproxy的网页界面。从微信点击一个历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
/mp/getmasssendmsg 开头的网址是微信历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
现在我们手机上的所有内容都可以以明文形式通过代理服务器。接下来,我们需要修改和配置代理服务器,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是原理介绍,了解后根据自己的情况修改内容):
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码使用anyproxy修改返回页面内容的功能,将脚本注入页面,将页面内容发送给服务器。利用这个原理批量采集公众号内容和阅读量。该脚本中自定义了一个函数,下面详细介绍:
在 rule_default.js 文件的末尾添加以下代码:
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析后存入数据库
<p>
采集文章系统(不转发还显示不到我的个人页,降低传播速度)
采集交流 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-02-07 04:07
采集文章系统设置,转发就显示链接,除了@提醒,可以去@前面最好评论一下。传播速度有限,发完了就没了,所以我们可以设置让别人转发,不转发还显示不到我的个人页,降低传播速度,简单暴力易行有效。能找到我的主页就点个赞,毕竟我比较爱表达。
最小打开时间最长消失间隔,这个实在是太靠勤奋了。实在是太容易被人发现了。除非您自己独立开发一个网页,这个应该是可行的。题主希望所有人都能来使用,或者说您希望此网站一直都能被别人使用下去。这个肯定还是要加个验证的,还要有推荐点赞功能,那样肯定会让人进来评论的。当然别人如果连点赞都不点你又如何推荐别人来使用呢?。
这个貌似目前不成熟,但肯定是一个趋势,因为现在的博客越来越像论坛。about:看看知乎上有没有这个。或者可以在搜索引擎里搜索:about博客。
可以理解,其实很多单位或集体也是这样的,但未必会主动提供网站给大家,主要原因是隐私方面的问题,你发布的东西对他来说都是透明的,一旦被泄露,就会被人截取,会造成很严重的后果,影响别人对你的评价。如果出现重大问题不好处理,怕损害自己名誉。
希望有更多人用起来,但不希望太多人用,因为用不着的人用了,反而大家关注的点不一样,就是他发布的内容想和你一样,但是你发布的内容并不想和他一样,反而会被人diss,不自然。也希望增加些功能,知道是谁发布的就显示,不知道的也不显示,记录时间就好了。 查看全部
采集文章系统(不转发还显示不到我的个人页,降低传播速度)
采集文章系统设置,转发就显示链接,除了@提醒,可以去@前面最好评论一下。传播速度有限,发完了就没了,所以我们可以设置让别人转发,不转发还显示不到我的个人页,降低传播速度,简单暴力易行有效。能找到我的主页就点个赞,毕竟我比较爱表达。
最小打开时间最长消失间隔,这个实在是太靠勤奋了。实在是太容易被人发现了。除非您自己独立开发一个网页,这个应该是可行的。题主希望所有人都能来使用,或者说您希望此网站一直都能被别人使用下去。这个肯定还是要加个验证的,还要有推荐点赞功能,那样肯定会让人进来评论的。当然别人如果连点赞都不点你又如何推荐别人来使用呢?。
这个貌似目前不成熟,但肯定是一个趋势,因为现在的博客越来越像论坛。about:看看知乎上有没有这个。或者可以在搜索引擎里搜索:about博客。
可以理解,其实很多单位或集体也是这样的,但未必会主动提供网站给大家,主要原因是隐私方面的问题,你发布的东西对他来说都是透明的,一旦被泄露,就会被人截取,会造成很严重的后果,影响别人对你的评价。如果出现重大问题不好处理,怕损害自己名誉。
希望有更多人用起来,但不希望太多人用,因为用不着的人用了,反而大家关注的点不一样,就是他发布的内容想和你一样,但是你发布的内容并不想和他一样,反而会被人diss,不自然。也希望增加些功能,知道是谁发布的就显示,不知道的也不显示,记录时间就好了。
采集文章系统(nginx_redirect搭建网页的代理,请问要哪些功能呢??)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-02-05 05:04
采集文章系统一般是由服务器来处理的,只有一个服务器是很多人同时在发送大量数据出去,建议采用轮询方式采集,因为浏览器一般不知道每个网页上都发生了什么,如果采用querys优采云采集器,那么可能浏览器不会自动判断,需要手动判断。
流量越高并发量越高,
是轮询算法.有人查过,不限流量,10万的数据量很常见.具体的搜“自适应抓取服务器”就可以.多服务器可以确保效率.但是定量慢,可以采用轮询抓取,数据量较大,可以扩展到10万.这样可以开10-20万服务器.用于一些网站及是推荐网站.
不知道回答有用吗
nginx_redirect搭建
网页抓取的代理,请问要哪些功能。实际上抓取的过程就是有很多网页在发生变化的时候我们去抓取,
请问如何抓取,京东,金融,当当等等网站的商品信息,数据无重复,
可以通过代理或者相应采集轮询技术
redirect方式,每抓取一次返回1个httpresponse,分页的网站应该比较常见。
论文
单点一个sever就可以了,
我能否理解成二楼说的是伪代理采集方式?如果是的话,实际上你只需要定位哪些页面是已经被爬虫爬过的,然后依照要爬的页面爬一爬即可。 查看全部
采集文章系统(nginx_redirect搭建网页的代理,请问要哪些功能呢??)
采集文章系统一般是由服务器来处理的,只有一个服务器是很多人同时在发送大量数据出去,建议采用轮询方式采集,因为浏览器一般不知道每个网页上都发生了什么,如果采用querys优采云采集器,那么可能浏览器不会自动判断,需要手动判断。
流量越高并发量越高,
是轮询算法.有人查过,不限流量,10万的数据量很常见.具体的搜“自适应抓取服务器”就可以.多服务器可以确保效率.但是定量慢,可以采用轮询抓取,数据量较大,可以扩展到10万.这样可以开10-20万服务器.用于一些网站及是推荐网站.
不知道回答有用吗
nginx_redirect搭建
网页抓取的代理,请问要哪些功能。实际上抓取的过程就是有很多网页在发生变化的时候我们去抓取,
请问如何抓取,京东,金融,当当等等网站的商品信息,数据无重复,
可以通过代理或者相应采集轮询技术
redirect方式,每抓取一次返回1个httpresponse,分页的网站应该比较常见。
论文
单点一个sever就可以了,
我能否理解成二楼说的是伪代理采集方式?如果是的话,实际上你只需要定位哪些页面是已经被爬虫爬过的,然后依照要爬的页面爬一爬即可。
采集文章系统(PHPCMS采集和其他采集系统大同小异规则无法自定义,就不好办了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-02-04 04:22
PHPcms 的 采集 类似于其他 采集 系统。首先从列表页获取内容列表,然后批量采集列表中的内容。当没有列表(如微信、今日头条)或者不想采集全部而只采集某个内容时,都不好处理!
也有网友分享了采集单页功能,要么是规则无法自定义,要么是借用了第三方接口。以下教程是我自己写的采集管理采集规则,独立采集,不依赖第三方!
先看视频
修改方法如下:
第一步:
打开
/phpcms/modules/采集/node.php
修改public_test_content方法为如下代码
//测试文章内容采集
public function public_test_content() {
$url = isset($_GET['url']) ? urldecode($_GET['url']) : exit('0');
$nodeid = isset($_GET['nodeid']) ? intval($_GET['nodeid']) : showmessage(L('illegal_parameters'), HTTP_REFERER);
pc_base::load_app_class('collection', '', 0);
if ($data = $this->db->get_one(array('nodeid'=>$nodeid))) {
$contents = collection::get_content($url, $data);
//加载所有的处理函数
$funcs_file_list = glob(dirname(__FILE__).DIRECTORY_SEPARATOR.'spider_funs'.DIRECTORY_SEPARATOR.'*.php');
foreach ($funcs_file_list as $v) {
include $v;
}
//在这里测试
foreach ($contents as $_key=>$_content) {
if($_key=='content') $contents['spider_image']=spider_images(new_stripslashes($_content));
if(trim($_content)=='') $contents[$_key] = "";//'◆◆◆◆◆◆◆◆◆◆'.$_key.' empty◆◆◆◆◆◆◆◆◆◆';
}
if(isset($_GET['jsoncallback'])){
if (pc_base::load_config('system', 'charset') == 'gbk') {
$contents = array_iconv($contents, 'utf-8', 'gbk');
}
echo safe_replace($_GET['jsoncallback'])."({\"items\":".json_encode($contents)."})";
}else{
print_r($contents);
}
} else {
showmessage(L('notfound'));
}
}
下面也添加
public function public_spider(){
$nodelist = $this->db->select(array('siteid'=>$this->siteid),'nodeid,name','','nodeid DESC');
$buttons = $this->select2arr($nodelist, '', 'id=\'nodeid\'', '选择规则');
include $this->admin_tpl('node_spider');
}
private static function select2arr($array = array(), $id = 0, $str = '', $default_option = '') {
$string = '';
$default_selected = (empty($id) && $default_option) ? 'selected' : '';
if($default_option) $string .= "$default_option";
if(!is_array($array) || count($array)== 0) return false;
foreach($array as $key=>$vs) {
//$selected = $id==$key ? 'selected' : '';
$string .= ''.$vs['name'].'';
}
$string .= '';
return $string;
}
/phpcms/modules/采集/classes/spider_photos.php
增加
function spider_images($str) {
$field = $GLOBALS['field'];
$array = array();
if(empty($str)) return $array;
$array[$field.'_url'] = array();
preg_match_all('/(?:(http:|https:|rtsp:))((?!thumb)\S)*?(?:\.jpg|\.jpeg|\.png|\.bmp|\.gif)/i', $str, $out);//不含有thumb的url
if (isset($out[0]))foreach ($out[0] as $v) {
$array[$field.'_url'][] = $v;
}
return $array;
}
第 2 步:
这是付费内容,您需要阅读隐藏内容 查看全部
采集文章系统(PHPCMS采集和其他采集系统大同小异规则无法自定义,就不好办了)
PHPcms 的 采集 类似于其他 采集 系统。首先从列表页获取内容列表,然后批量采集列表中的内容。当没有列表(如微信、今日头条)或者不想采集全部而只采集某个内容时,都不好处理!
也有网友分享了采集单页功能,要么是规则无法自定义,要么是借用了第三方接口。以下教程是我自己写的采集管理采集规则,独立采集,不依赖第三方!
先看视频
修改方法如下:
第一步:
打开
/phpcms/modules/采集/node.php
修改public_test_content方法为如下代码
//测试文章内容采集
public function public_test_content() {
$url = isset($_GET['url']) ? urldecode($_GET['url']) : exit('0');
$nodeid = isset($_GET['nodeid']) ? intval($_GET['nodeid']) : showmessage(L('illegal_parameters'), HTTP_REFERER);
pc_base::load_app_class('collection', '', 0);
if ($data = $this->db->get_one(array('nodeid'=>$nodeid))) {
$contents = collection::get_content($url, $data);
//加载所有的处理函数
$funcs_file_list = glob(dirname(__FILE__).DIRECTORY_SEPARATOR.'spider_funs'.DIRECTORY_SEPARATOR.'*.php');
foreach ($funcs_file_list as $v) {
include $v;
}
//在这里测试
foreach ($contents as $_key=>$_content) {
if($_key=='content') $contents['spider_image']=spider_images(new_stripslashes($_content));
if(trim($_content)=='') $contents[$_key] = "";//'◆◆◆◆◆◆◆◆◆◆'.$_key.' empty◆◆◆◆◆◆◆◆◆◆';
}
if(isset($_GET['jsoncallback'])){
if (pc_base::load_config('system', 'charset') == 'gbk') {
$contents = array_iconv($contents, 'utf-8', 'gbk');
}
echo safe_replace($_GET['jsoncallback'])."({\"items\":".json_encode($contents)."})";
}else{
print_r($contents);
}
} else {
showmessage(L('notfound'));
}
}
下面也添加
public function public_spider(){
$nodelist = $this->db->select(array('siteid'=>$this->siteid),'nodeid,name','','nodeid DESC');
$buttons = $this->select2arr($nodelist, '', 'id=\'nodeid\'', '选择规则');
include $this->admin_tpl('node_spider');
}
private static function select2arr($array = array(), $id = 0, $str = '', $default_option = '') {
$string = '';
$default_selected = (empty($id) && $default_option) ? 'selected' : '';
if($default_option) $string .= "$default_option";
if(!is_array($array) || count($array)== 0) return false;
foreach($array as $key=>$vs) {
//$selected = $id==$key ? 'selected' : '';
$string .= ''.$vs['name'].'';
}
$string .= '';
return $string;
}
/phpcms/modules/采集/classes/spider_photos.php
增加
function spider_images($str) {
$field = $GLOBALS['field'];
$array = array();
if(empty($str)) return $array;
$array[$field.'_url'] = array();
preg_match_all('/(?:(http:|https:|rtsp:))((?!thumb)\S)*?(?:\.jpg|\.jpeg|\.png|\.bmp|\.gif)/i', $str, $out);//不含有thumb的url
if (isset($out[0]))foreach ($out[0] as $v) {
$array[$field.'_url'][] = $v;
}
return $array;
}
第 2 步:
这是付费内容,您需要阅读隐藏内容
采集文章系统(采集文章系统框架+部分开发框架,webapi请求写法自行网上查询)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-01-30 11:00
采集文章系统框架+部分开发框架,webapi请求写法自行网上查询。集合所有类型数据,为何不直接上你自己的存储呢?是共享资源还是方便传送,你是基于数据库,还是方便sql文件传输呢?导入其他数据库的话,需要先安装。可以参考我们知乎文章列表,
连接mysqldb或者golang中间件就可以了。要保证多媒体中心也在golang中间件之上。我自己做了个大型的数据中心系统mysqli+memcached和golang。golang写mysqli是最爽的。详细请看maxcompute-mysqli-github里面的connectorgithub-y10481/maxcompute-memcached:mysqlitomysqli,memcachedtoredis.designedforawonderfulwonderfuldistribution:)mysqlimemcached/redis均可使用。
楼主找的资料都是借鉴别人的,除了netflix,ibm这些顶级大厂,你看到用的其实都是老产品,以前的解决方案(打算重构这些网站?),他们的关键词:restfully模块化goagent浏览器认证,验证是否真的安全api调用函数接口android客户端以及代理(dx)代理到server(可以使用selenium)java客户端与前端代理交互数据库这些最重要的东西无论用啥,都应该明确,先做好自己的服务,有自己的解决方案。 查看全部
采集文章系统(采集文章系统框架+部分开发框架,webapi请求写法自行网上查询)
采集文章系统框架+部分开发框架,webapi请求写法自行网上查询。集合所有类型数据,为何不直接上你自己的存储呢?是共享资源还是方便传送,你是基于数据库,还是方便sql文件传输呢?导入其他数据库的话,需要先安装。可以参考我们知乎文章列表,
连接mysqldb或者golang中间件就可以了。要保证多媒体中心也在golang中间件之上。我自己做了个大型的数据中心系统mysqli+memcached和golang。golang写mysqli是最爽的。详细请看maxcompute-mysqli-github里面的connectorgithub-y10481/maxcompute-memcached:mysqlitomysqli,memcachedtoredis.designedforawonderfulwonderfuldistribution:)mysqlimemcached/redis均可使用。
楼主找的资料都是借鉴别人的,除了netflix,ibm这些顶级大厂,你看到用的其实都是老产品,以前的解决方案(打算重构这些网站?),他们的关键词:restfully模块化goagent浏览器认证,验证是否真的安全api调用函数接口android客户端以及代理(dx)代理到server(可以使用selenium)java客户端与前端代理交互数据库这些最重要的东西无论用啥,都应该明确,先做好自己的服务,有自己的解决方案。
采集文章系统(采集文章系统,自媒体平台规范,原创文章渠道,一个案例)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-28 19:05
采集文章系统,自媒体平台规范,原创文章渠道,一个系统一个案例最近有个粉丝私信问我,月初帮助了公司做了一套文案系统,但是到这个月,一天的新增粉丝不到2人,要不要修改初始的文案?我想说的是,文案系统只是获取粉丝的第一步,是不能够单独作为产品或者公司找粉丝的基础。文案系统需要和微信、公众号一起存在,让粉丝来源由微信公众号自然流量到文案系统中。
有个粉丝跟我说,我有十多万的粉丝,但是他却没有找到他的精准客户,这就是因为文案系统未加到微信公众号上。还有个团队开始也是走差不多的路子,以图文或者视频作为产品,产品成本很低,也做了一个非常牛x的课程,但是单篇视频播放量不高,文案系统也没有加到微信公众号上。如果你也认同这个观点,那么你该对你的产品经理的文案系统有什么要求?既然你是做课程培训,那么你该怎么选择合适的工具(素材、展示、激活等系统设计)来帮助你加粉?课程工具推荐可用(可视化文字编辑工具、高颜值图文编辑工具、导图工具、全网语音工具、音频工具)来提高文案系统的效率如果你是想做一个整体的文案系统,那么建议使用我推荐的工具来做。
课程工具推荐文案系统中比较知名的,可以自己私下学习写作,学习学习如何找素材、如何写出好的文案,然后在做课程的时候来运用。一直是我比较推崇的模式,那就是慢工出细活。如果你觉得没有什么时间改文案系统,那么你该从自己的素材收集来源,如何写出优质内容,如何提高文案系统的效率来改善。我今天为大家推荐一个中文收集阅读的工具藏书馆藏书馆是一个共享阅读的工具,在里面你可以看一些比较高端的书籍,我第一次看到它,感觉它改变了我对图书收集的方式,不再是专门去书店给别人看,而是通过自己,去收集一些别人整理的图书,然后通过自己的思考,写自己的总结,去帮助别人去收集相关的书籍。
刚刚看到藏书馆有个最牛x的课程,书的内容比较丰富,相信藏书馆的老师,相信大家都是知道的,感兴趣的话,可以去看看。收集的素材,以及其他的阅读,通过藏书馆自动生成并在其他平台共享,我们就能够快速的完成收集和传播。下面为大家提供了一个线下的讲座系统方案,大家如果有兴趣可以联系我,私下的邀请收看。 查看全部
采集文章系统(采集文章系统,自媒体平台规范,原创文章渠道,一个案例)
采集文章系统,自媒体平台规范,原创文章渠道,一个系统一个案例最近有个粉丝私信问我,月初帮助了公司做了一套文案系统,但是到这个月,一天的新增粉丝不到2人,要不要修改初始的文案?我想说的是,文案系统只是获取粉丝的第一步,是不能够单独作为产品或者公司找粉丝的基础。文案系统需要和微信、公众号一起存在,让粉丝来源由微信公众号自然流量到文案系统中。
有个粉丝跟我说,我有十多万的粉丝,但是他却没有找到他的精准客户,这就是因为文案系统未加到微信公众号上。还有个团队开始也是走差不多的路子,以图文或者视频作为产品,产品成本很低,也做了一个非常牛x的课程,但是单篇视频播放量不高,文案系统也没有加到微信公众号上。如果你也认同这个观点,那么你该对你的产品经理的文案系统有什么要求?既然你是做课程培训,那么你该怎么选择合适的工具(素材、展示、激活等系统设计)来帮助你加粉?课程工具推荐可用(可视化文字编辑工具、高颜值图文编辑工具、导图工具、全网语音工具、音频工具)来提高文案系统的效率如果你是想做一个整体的文案系统,那么建议使用我推荐的工具来做。
课程工具推荐文案系统中比较知名的,可以自己私下学习写作,学习学习如何找素材、如何写出好的文案,然后在做课程的时候来运用。一直是我比较推崇的模式,那就是慢工出细活。如果你觉得没有什么时间改文案系统,那么你该从自己的素材收集来源,如何写出优质内容,如何提高文案系统的效率来改善。我今天为大家推荐一个中文收集阅读的工具藏书馆藏书馆是一个共享阅读的工具,在里面你可以看一些比较高端的书籍,我第一次看到它,感觉它改变了我对图书收集的方式,不再是专门去书店给别人看,而是通过自己,去收集一些别人整理的图书,然后通过自己的思考,写自己的总结,去帮助别人去收集相关的书籍。
刚刚看到藏书馆有个最牛x的课程,书的内容比较丰富,相信藏书馆的老师,相信大家都是知道的,感兴趣的话,可以去看看。收集的素材,以及其他的阅读,通过藏书馆自动生成并在其他平台共享,我们就能够快速的完成收集和传播。下面为大家提供了一个线下的讲座系统方案,大家如果有兴趣可以联系我,私下的邀请收看。
采集文章系统(如何进行采集文章系统性的进行培训教学-乐题库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-27 06:00
采集文章系统性的进行培训教学。我们培训学校也在起步阶段,这方面设置应该是有大量需求的。我也想看看如何进行文章的抓取。感觉和排版工具很大关系。排版工具可以多推荐。毕竟直接可以带来大量的流量。不过技术关键点在于批量处理(批量发布、编辑与排版)方面的问题。我还是比较看好很多文章批量抓取工具。可以举一反三推广销售。
1.通过关键词的查找,把有流量的文章按内容分为批量特征2.需要发布的文章,采集到文库平台,
首先,你要搞清楚:你的网站是什么类型的网站,需要用哪些功能。比如,新闻系统:上万篇,可能只需要10篇左右;图片系统:一个gif就会有一万多follower,可能还需要1万多张图片;音乐相册:几百张图片,要求懂美术,有丰富的音乐素材。问题是:你的网站没有你需要的功能,即便你不做底层,把所有的网站地址和相关数据采集到对应的文库平台,我想你也不会有相应的精力投入。
谢邀采集功能只是小打小闹的,要想进行完整的数据汇总统计、流量分析、用户偏好研究,这才是真正的抓取工作。从数据分析看,相当多的网站并没有采集功能,不过如果你有能力和时间的话,
有采集。采集的是页面url(不限于文章页面),然后可以分类汇总。可能需要多个账号,多个设备。采集耗时较长,相当于白天带一个卫星网站(单点登录,待有精力的时候还是可以同时运行多个账号分类统计,多个设备),晚上有电脑可以走。相当考验软件。 查看全部
采集文章系统(如何进行采集文章系统性的进行培训教学-乐题库)
采集文章系统性的进行培训教学。我们培训学校也在起步阶段,这方面设置应该是有大量需求的。我也想看看如何进行文章的抓取。感觉和排版工具很大关系。排版工具可以多推荐。毕竟直接可以带来大量的流量。不过技术关键点在于批量处理(批量发布、编辑与排版)方面的问题。我还是比较看好很多文章批量抓取工具。可以举一反三推广销售。
1.通过关键词的查找,把有流量的文章按内容分为批量特征2.需要发布的文章,采集到文库平台,
首先,你要搞清楚:你的网站是什么类型的网站,需要用哪些功能。比如,新闻系统:上万篇,可能只需要10篇左右;图片系统:一个gif就会有一万多follower,可能还需要1万多张图片;音乐相册:几百张图片,要求懂美术,有丰富的音乐素材。问题是:你的网站没有你需要的功能,即便你不做底层,把所有的网站地址和相关数据采集到对应的文库平台,我想你也不会有相应的精力投入。
谢邀采集功能只是小打小闹的,要想进行完整的数据汇总统计、流量分析、用户偏好研究,这才是真正的抓取工作。从数据分析看,相当多的网站并没有采集功能,不过如果你有能力和时间的话,
有采集。采集的是页面url(不限于文章页面),然后可以分类汇总。可能需要多个账号,多个设备。采集耗时较长,相当于白天带一个卫星网站(单点登录,待有精力的时候还是可以同时运行多个账号分类统计,多个设备),晚上有电脑可以走。相当考验软件。
采集文章系统(采集文章系统地提取“主体”,“词语”“内容”)
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-01-26 17:03
采集文章系统地提取“主体”,“词语”,“关键词”,“内容”(长标题)进行生成。注:“标题”是属于题注,题注的核心要求是必须包含文章的关键词,注意关键词和题注的词语量不限。前期系统功能未开放,可以自己用excel,或者直接自己编辑上传。后期会开放提取,建议查找其他方法。
我自己来说的话,要制作的话,可以按照前几楼的思路来处理:比如前几楼的评论,有的是作者,有的是读者。作者的话,有的是直接复制,有的是新注册,但内容、标题和原文差不多。那么我可以把这些差不多的标题内容拿来再编辑,是为二次编辑和三次编辑。读者的话,我有的时候会做成一个标签页,上面只显示读者关注我的文章、和我们的粉丝、或者看过的文章、以及发过的推文。
评论其实也是同理。不过这类工作量比较大,需要功力比较深,而且读者的标签组成需要一定的套路,我还没想好怎么处理。
要推荐两种方法,理论上是通用的:方法一:可以制作图片;方法二:可以做成原创文章;自动生成标题,建议做成原创文章。其实生成的名字是名片,可以复制出一页标题,可以制作成思维导图,不过可以先用pdf生成。可以套路很多。
也只能是前两三楼的情况
前段时间看到这个。然后实践,提取内容发,保留标题。 查看全部
采集文章系统(采集文章系统地提取“主体”,“词语”“内容”)
采集文章系统地提取“主体”,“词语”,“关键词”,“内容”(长标题)进行生成。注:“标题”是属于题注,题注的核心要求是必须包含文章的关键词,注意关键词和题注的词语量不限。前期系统功能未开放,可以自己用excel,或者直接自己编辑上传。后期会开放提取,建议查找其他方法。
我自己来说的话,要制作的话,可以按照前几楼的思路来处理:比如前几楼的评论,有的是作者,有的是读者。作者的话,有的是直接复制,有的是新注册,但内容、标题和原文差不多。那么我可以把这些差不多的标题内容拿来再编辑,是为二次编辑和三次编辑。读者的话,我有的时候会做成一个标签页,上面只显示读者关注我的文章、和我们的粉丝、或者看过的文章、以及发过的推文。
评论其实也是同理。不过这类工作量比较大,需要功力比较深,而且读者的标签组成需要一定的套路,我还没想好怎么处理。
要推荐两种方法,理论上是通用的:方法一:可以制作图片;方法二:可以做成原创文章;自动生成标题,建议做成原创文章。其实生成的名字是名片,可以复制出一页标题,可以制作成思维导图,不过可以先用pdf生成。可以套路很多。
也只能是前两三楼的情况
前段时间看到这个。然后实践,提取内容发,保留标题。
采集文章系统(研美考研经验分享:如何帮助你考研,不好意思)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-01-19 23:02
采集文章系统,码下去可以看下这个的每天更新好多日报,
搜狗搜索栏就有
你好!可以关注一下研美考研,他们家可以搜集研友的分享经验帮助你考研,
不好意思,他们都是两万起价,我们这是三万起价。
是呀,那么我就来回答一下吧!methodtouchqq羣432158664一次交流就能拿到北大mba真题啊,上他们的群就能得到他们的相关信息,经验贴呀等等!手工整理真题信息,关键是不收取任何费用,
说实话,我想给每一个回答我都有一个赞,人一辈子最珍贵的资源就是一次交流机会,不论是多少年前的情书还是今天的中央厨房。还是那句话。送上去其实就已经为考研把关,他们有自己的一套体系,不是你想象的那么烂。你可以从他们那买,也可以从那些都可以。分享大家在mba择校疑问,全是各个院校的信息,你可以知道更多选择困难症的学长学姐。mba交流群407126009。
其实用得着哪种搜索搜索方式是次要的,如果这些信息对你复习很有帮助,别人告诉你的你也能掌握。关键是效率高。因为搜索这些信息的时间应该更多一些。不要为了节省时间而乱买。如果资料正确,有价值,你还买吗?真题信息是我考研人必看的。但要不要卖你的真题呢?估计也不会说。而且有时候信息你掌握,又不能卖。如果非要卖的话,起码得有利益关系。
要不你辛辛苦苦搜集的真题要不要卖?在学习之余,提醒一下,有的复习资料必须买。买了绝对省心。人情是人情,学问是学问。你得有心里准备。 查看全部
采集文章系统(研美考研经验分享:如何帮助你考研,不好意思)
采集文章系统,码下去可以看下这个的每天更新好多日报,
搜狗搜索栏就有
你好!可以关注一下研美考研,他们家可以搜集研友的分享经验帮助你考研,
不好意思,他们都是两万起价,我们这是三万起价。
是呀,那么我就来回答一下吧!methodtouchqq羣432158664一次交流就能拿到北大mba真题啊,上他们的群就能得到他们的相关信息,经验贴呀等等!手工整理真题信息,关键是不收取任何费用,
说实话,我想给每一个回答我都有一个赞,人一辈子最珍贵的资源就是一次交流机会,不论是多少年前的情书还是今天的中央厨房。还是那句话。送上去其实就已经为考研把关,他们有自己的一套体系,不是你想象的那么烂。你可以从他们那买,也可以从那些都可以。分享大家在mba择校疑问,全是各个院校的信息,你可以知道更多选择困难症的学长学姐。mba交流群407126009。
其实用得着哪种搜索搜索方式是次要的,如果这些信息对你复习很有帮助,别人告诉你的你也能掌握。关键是效率高。因为搜索这些信息的时间应该更多一些。不要为了节省时间而乱买。如果资料正确,有价值,你还买吗?真题信息是我考研人必看的。但要不要卖你的真题呢?估计也不会说。而且有时候信息你掌握,又不能卖。如果非要卖的话,起码得有利益关系。
要不你辛辛苦苦搜集的真题要不要卖?在学习之余,提醒一下,有的复习资料必须买。买了绝对省心。人情是人情,学问是学问。你得有心里准备。
采集文章系统(掌握各种关键词,挖掘出这些类型的文章类型!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-01-19 07:03
采集文章系统,只能采集精准文章,那么我们就要有大量的文章来挖掘那些因素。文章有段落布局,段落格式,标题词,字数,字数。标题词用高亮标记出来。在小说分类根据小说的题材内容去做标题词,段落布局合理的话,我们就需要搞定内容了。好了,说完以上的,咱们开始今天的话题。掌握各种关键词,从而挖掘出这些文章类型。一、文章分类有细分的,每个月都有各种各样的文章,比如我自己做出来的文章,“文案套路,数据分析实操,网络营销赚钱的五个技巧”上面的图片就是我们刚才分析出来的关键词,从2016年的分析报告来看,他们的出现频率比较高,所以我就跟大家分享一下。
以上这几个关键词你会发现就是一个时间段段的,每个月都会有相应的有关产出,这些还是比较容易就找的,那么要怎么就能在这里做关键词呢?比如你是一个投资理财的人,你想要深入的了解,现在市面上都有什么项目比较赚钱,我说一个大家估计都知道的,“炒股”,你知道有哪些赚钱的理财项目吗?这个就是你们感兴趣的话题,至于选择什么理财项目,你选择的方向不同,对你的出路也不同。
二、文章的长短规划文章长短不一样,应该按什么样的频率设置关键词?就算你能达到很多的关键词也没有关系,我们可以采用用百度指数进行关键词的搜索看一下每个类型的图片区别,看他们在百度搜索量分布的情况,一般这类非虚拟物品都是关键词大于文章长度来对长短关键词进行控制。1.行业热点话题类,这一类的可以根据行业的关键词进行寻找。
2.文案套路,一般情况,这类的更容易分析出来,只要从词的热度方面,里面包含它所对应的行业词,就可以了。我们进行搜索,就能找到想要找的关键词,行业的关键词,也可以根据具体的类型,可以在综合类网站寻找,如:百度百科,百度知道。3.老生常谈类,这个也是一个比较好的选择,比如文案套路,都是从搜索词来进行分析。
4.项目类,本来就是类似,在项目来的关键词方面,一般在百度热度排名比较靠前的就是。5.盈利类,顾名思义。下面老规矩,分享的是ps的操作技巧,对!你没有看错,是ps,不是pr等,常用的一些软件,比如adobeflashplayer,powerpoint软件等都可以的,一般常用的操作。先说操作方法:图层复制进行转曲:新建一个图层(按住ctrl键同时双击)添加到转曲的图层里面。
等右侧图层上面点击确定,鼠标悬浮在图层上,会出现转曲的线圈圈圈一样的东西,双击转曲右侧的小眼睛(电池图标)会自动的进行转曲。ctrl+d上移图层,ctrl+t纵向缩放图层,其实就是多了一个同时上移和左右缩放图。 查看全部
采集文章系统(掌握各种关键词,挖掘出这些类型的文章类型!)
采集文章系统,只能采集精准文章,那么我们就要有大量的文章来挖掘那些因素。文章有段落布局,段落格式,标题词,字数,字数。标题词用高亮标记出来。在小说分类根据小说的题材内容去做标题词,段落布局合理的话,我们就需要搞定内容了。好了,说完以上的,咱们开始今天的话题。掌握各种关键词,从而挖掘出这些文章类型。一、文章分类有细分的,每个月都有各种各样的文章,比如我自己做出来的文章,“文案套路,数据分析实操,网络营销赚钱的五个技巧”上面的图片就是我们刚才分析出来的关键词,从2016年的分析报告来看,他们的出现频率比较高,所以我就跟大家分享一下。
以上这几个关键词你会发现就是一个时间段段的,每个月都会有相应的有关产出,这些还是比较容易就找的,那么要怎么就能在这里做关键词呢?比如你是一个投资理财的人,你想要深入的了解,现在市面上都有什么项目比较赚钱,我说一个大家估计都知道的,“炒股”,你知道有哪些赚钱的理财项目吗?这个就是你们感兴趣的话题,至于选择什么理财项目,你选择的方向不同,对你的出路也不同。
二、文章的长短规划文章长短不一样,应该按什么样的频率设置关键词?就算你能达到很多的关键词也没有关系,我们可以采用用百度指数进行关键词的搜索看一下每个类型的图片区别,看他们在百度搜索量分布的情况,一般这类非虚拟物品都是关键词大于文章长度来对长短关键词进行控制。1.行业热点话题类,这一类的可以根据行业的关键词进行寻找。
2.文案套路,一般情况,这类的更容易分析出来,只要从词的热度方面,里面包含它所对应的行业词,就可以了。我们进行搜索,就能找到想要找的关键词,行业的关键词,也可以根据具体的类型,可以在综合类网站寻找,如:百度百科,百度知道。3.老生常谈类,这个也是一个比较好的选择,比如文案套路,都是从搜索词来进行分析。
4.项目类,本来就是类似,在项目来的关键词方面,一般在百度热度排名比较靠前的就是。5.盈利类,顾名思义。下面老规矩,分享的是ps的操作技巧,对!你没有看错,是ps,不是pr等,常用的一些软件,比如adobeflashplayer,powerpoint软件等都可以的,一般常用的操作。先说操作方法:图层复制进行转曲:新建一个图层(按住ctrl键同时双击)添加到转曲的图层里面。
等右侧图层上面点击确定,鼠标悬浮在图层上,会出现转曲的线圈圈圈一样的东西,双击转曲右侧的小眼睛(电池图标)会自动的进行转曲。ctrl+d上移图层,ctrl+t纵向缩放图层,其实就是多了一个同时上移和左右缩放图。
采集文章系统(采集文章系统很多,你得考虑功能个性化程度,然后对应设计开发过程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-01-17 09:00
采集文章系统很多,你得考虑功能个性化程度,用户体验,你需要多少数据,数据用途,然后对应设计开发过程,
1.从rfm(回访率、复购率、客单价)入手2.从历史数据做分析
别的不知道,你可以百度booking。其实美团的数据我有很多不过鉴于很多人都告诉你我也就不说了。这个需要的资源和技术完全不一样。美团的数据你可以在网上找到现成的。只是没有底层的分析技术和电商经验的情况下,你的技术知识要求和预算会很高。
百度搜索“美团点评点评数据”,大概看了下他们的数据平台,应该还是有些参考价值的,因为推荐都是由系统算法推荐给用户的,这个算法需要一套体系,而且还有一套与商家的合作。
没有吧,我自己正在做这个项目,数据应该是自己可以获取的,不知道别人有没有,反正我是在googlesearch搜到的,里面是一些商家和旅游产品的推荐。
最近在朋友圈看到有人在分享美团和携程的点评数据,有照片,旅游相关,历史交易,等等,我觉得蛮有参考价值,然后昨天晚上去美团上去看了下目前用户可以使用openinstall方式开通美团点评,携程点评也可以申请开通登录旅游频道。这个主要是openinstall这个开放平台的优势。openinstall-opensourcecheckoutserviceplatformwithapikeywords,secretaccess,hometokenscertificate。 查看全部
采集文章系统(采集文章系统很多,你得考虑功能个性化程度,然后对应设计开发过程)
采集文章系统很多,你得考虑功能个性化程度,用户体验,你需要多少数据,数据用途,然后对应设计开发过程,
1.从rfm(回访率、复购率、客单价)入手2.从历史数据做分析
别的不知道,你可以百度booking。其实美团的数据我有很多不过鉴于很多人都告诉你我也就不说了。这个需要的资源和技术完全不一样。美团的数据你可以在网上找到现成的。只是没有底层的分析技术和电商经验的情况下,你的技术知识要求和预算会很高。
百度搜索“美团点评点评数据”,大概看了下他们的数据平台,应该还是有些参考价值的,因为推荐都是由系统算法推荐给用户的,这个算法需要一套体系,而且还有一套与商家的合作。
没有吧,我自己正在做这个项目,数据应该是自己可以获取的,不知道别人有没有,反正我是在googlesearch搜到的,里面是一些商家和旅游产品的推荐。
最近在朋友圈看到有人在分享美团和携程的点评数据,有照片,旅游相关,历史交易,等等,我觉得蛮有参考价值,然后昨天晚上去美团上去看了下目前用户可以使用openinstall方式开通美团点评,携程点评也可以申请开通登录旅游频道。这个主要是openinstall这个开放平台的优势。openinstall-opensourcecheckoutserviceplatformwithapikeywords,secretaccess,hometokenscertificate。
采集文章系统(我花了100多买了正版授权源码下载地址(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-01-10 11:08
)
--------------图片修改目录------------------------------ ----------
static/fx20150302.jpg 这是微信转发分享后显示的图片
static/logo.png网站主页标志
static/logo2.png是离线分享的logo
----------------------------------- ---------- -
这个源码比那个人上次贴的源码好
本源代码已破解授权
源码下载地址
(之前发帖的人不能用微信文章采集因为需要正版授权,我花了100多买了正版授权然后破解了)
您可以使用微信文章采集。
添加了任务系统。
(任务系统花了我一个月才添加)
-------------图片修改目录------------------- ------------
static/fx20150302.jpg 这是微信转发分享后显示的图片
static/logo.png网站主页标志
static/logo2.png是离线分享的logo
----------------------------------- ---------- -
这个源码比那个人上次贴的源码好
本源代码已破解授权
源码下载地址
(之前发帖的人不能用微信文章采集因为需要正版授权,我花了100多买了正版授权然后破解了)
您可以使用微信文章采集。
添加了任务系统。
(任务系统花了我一个月才添加)
-------------图片修改目录------------------- ------------
static/fx20150302.jpg 这是微信转发分享后显示的图片
static/logo.png网站主页标志
static/logo2.png是离线分享的logo
----------------------------------- ---------- -
这个源码比那个人上次贴的源码好
本源代码已破解授权
源码下载地址
(之前发帖的人不能用微信文章采集因为需要正版授权,我花了100多买了正版授权然后破解了)
您可以使用微信文章采集。
添加了任务系统。
(任务系统花了我一个月才添加)
-------------图片修改目录------------------- ------------
static/fx20150302.jpg 这是微信转发分享后显示的图片
static/logo.png网站主页标志
static/logo2.png是离线分享的logo
----------------------------------- ---------- -
这个源码比那个人上次贴的源码好
本源代码已破解授权
源码下载地址
(之前发帖的人不能用微信文章采集因为需要正版授权,我花了100多买了正版授权然后破解了)
您可以使用微信文章采集。
添加了任务系统。
(任务系统花了我一个月才添加)
-------------图片修改目录------------------- ------------
static/fx20150302.jpg 这是微信转发分享后显示的图片
static/logo.png网站主页标志
static/logo2.png是离线分享的logo
----------------------------------- ---------- -
这个源码比那个人上次贴的源码好
本源代码已破解授权
源码下载地址
(之前发帖的人不能用微信文章采集因为需要正版授权,我花了100多买了正版授权然后破解了)
您可以使用微信文章采集。
添加了任务系统。
(任务系统花了我一个月才添加)
-------------图片修改目录------------------- ------------
static/fx20150302.jpg 这是微信转发分享后显示的图片
static/logo.png网站主页标志
static/logo2.png是离线分享的logo
----------------------------------- ---------- -
这个源码比那个人上次贴的源码好
本源代码已破解授权
源码下载地址
(之前发帖的人不能用微信文章采集因为需要正版授权,我花了100多买了正版授权然后破解了)
您可以使用微信文章采集。
添加了任务系统。
(任务系统花了我一个月才添加)
查看全部
采集文章系统(我花了100多买了正版授权源码下载地址(组图)
)
--------------图片修改目录------------------------------ ----------
static/fx20150302.jpg 这是微信转发分享后显示的图片
static/logo.png网站主页标志
static/logo2.png是离线分享的logo
----------------------------------- ---------- -
这个源码比那个人上次贴的源码好
本源代码已破解授权
源码下载地址
(之前发帖的人不能用微信文章采集因为需要正版授权,我花了100多买了正版授权然后破解了)
您可以使用微信文章采集。
添加了任务系统。
(任务系统花了我一个月才添加)
-------------图片修改目录------------------- ------------
static/fx20150302.jpg 这是微信转发分享后显示的图片
static/logo.png网站主页标志
static/logo2.png是离线分享的logo
----------------------------------- ---------- -
这个源码比那个人上次贴的源码好
本源代码已破解授权
源码下载地址
(之前发帖的人不能用微信文章采集因为需要正版授权,我花了100多买了正版授权然后破解了)
您可以使用微信文章采集。
添加了任务系统。
(任务系统花了我一个月才添加)
-------------图片修改目录------------------- ------------
static/fx20150302.jpg 这是微信转发分享后显示的图片
static/logo.png网站主页标志
static/logo2.png是离线分享的logo
----------------------------------- ---------- -
这个源码比那个人上次贴的源码好
本源代码已破解授权
源码下载地址
(之前发帖的人不能用微信文章采集因为需要正版授权,我花了100多买了正版授权然后破解了)
您可以使用微信文章采集。
添加了任务系统。
(任务系统花了我一个月才添加)
-------------图片修改目录------------------- ------------
static/fx20150302.jpg 这是微信转发分享后显示的图片
static/logo.png网站主页标志
static/logo2.png是离线分享的logo
----------------------------------- ---------- -
这个源码比那个人上次贴的源码好
本源代码已破解授权
源码下载地址
(之前发帖的人不能用微信文章采集因为需要正版授权,我花了100多买了正版授权然后破解了)
您可以使用微信文章采集。
添加了任务系统。
(任务系统花了我一个月才添加)
-------------图片修改目录------------------- ------------
static/fx20150302.jpg 这是微信转发分享后显示的图片
static/logo.png网站主页标志
static/logo2.png是离线分享的logo
----------------------------------- ---------- -
这个源码比那个人上次贴的源码好
本源代码已破解授权
源码下载地址
(之前发帖的人不能用微信文章采集因为需要正版授权,我花了100多买了正版授权然后破解了)
您可以使用微信文章采集。
添加了任务系统。
(任务系统花了我一个月才添加)
-------------图片修改目录------------------- ------------
static/fx20150302.jpg 这是微信转发分享后显示的图片
static/logo.png网站主页标志
static/logo2.png是离线分享的logo
----------------------------------- ---------- -
这个源码比那个人上次贴的源码好
本源代码已破解授权
源码下载地址
(之前发帖的人不能用微信文章采集因为需要正版授权,我花了100多买了正版授权然后破解了)
您可以使用微信文章采集。
添加了任务系统。
(任务系统花了我一个月才添加)
采集文章系统(微信公众号历史消息页的采集方法整理之后写下来)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-01-10 10:17
我从2014年开始做微信公众号内容采集的批次,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集收到的微信公众号内容很容易在公众号中传播。那个时候批量采集很容易做,采集入口就是公众号的历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而将采集定位为本地新闻资讯公众号,前端展示做成app。因此,一个可以自动采集 公众号内容形成。我曾经担心有一天,微信技术升级后,它无法采集内容,我的新闻应用程序会失败。不过随着微信的不断技术升级,采集方式也升级了,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
1http://mp.weixin.qq.com/mp/get ... irect
2
3
=========2017 年 1 月 11 日更新==========
现在,根据不同的微信个人号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一个地址的链接在anyproxy中会显示302跳转:
1https://mp.weixin.qq.com/mp/pr ... irect
2
3
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前掌握的信息,这两种页面形式在不同的微信账号中不规则出现。有的微信账号总是第一页格式,有的总是第二页格式。
1//第一种链接
2http://mp.weixin.qq.com/mp/get ... r%3D1
3//第二种
4http://mp.weixin.qq.com/mp/pro ... r%3D1
5
6
这个地址是通过微信客户端打开历史消息页面,然后使用后面介绍的代理服务器软件获得的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios微信客户端的崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。
2、个人微信账号:采集的内容,不仅需要微信客户端,采集还需要个人微信账号,因为这个微信账号不能做其他事情。
4、文章列表分析入库系统:我用php语言写的,我会详细介绍如何分析文章列表和构建采集队列实现批量< @采集内容。
步
一、安装模拟器或者用手机安装微信客户端app,申请微信个人账号并登录app。这个我就不多说了,大家都会的。
二、代理服务器系统安装
1、安装 NodeJS
2、在命令行或者终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy并运行命令:sudo anyproxy -i; 参数 -i 表示解析 HTTPS;
5、安装证书,在手机或者安卓模拟器中安装证书:
6、设置代理:Android模拟器的代理服务器地址是wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开浏览器地址:8002可以看到anyproxy的网页界面。从微信点击一个历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
/mp/getmasssendmsg 开头的网址是微信历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
=========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转,跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址查看内容。
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是原理介绍,了解后根据自己的情况修改内容):
=========2017 年 1 月 11 日更新==========
因为有两种页面形式,而且同一个页面形式总是显示在不同的微信账号中,但是为了兼容这两种页面形式,下面的代码会保留两种页面形式的判断,你也可以使用你的自己的页面表单删除li
1replaceServerResDataAsync: function(req,res,serverResData,callback){
2 if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
3 if(serverResData.toString() !== ""){
4 try {//防止报错退出程序
5 var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
6 var ret = reg.exec(serverResData.toString());//转换变量为string
7 HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
8 var http = require('http');
9 http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
10 res.on('data', function(chunk){
11 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
12 })
13 });
14 }catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
15 try {
16 var json = JSON.parse(serverResData.toString());
17 if (json.general_msg_list != []) {
18 HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
19 }
20 }catch(e){
21 console.log(e);//错误捕捉
22 }
23 callback(serverResData);//直接返回第二页json内容
24 }
25 }
26 }else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
27 try {
28 var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
29 var ret = reg.exec(serverResData.toString());//转换变量为string
30 HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
31 var http = require('http');
32 http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
33 res.on('data', function(chunk){
34 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
35 })
36 });
37 }catch(e){
38 callback(serverResData);
39 }
40 }else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
41 try {
42 var json = JSON.parse(serverResData.toString());
43 if (json.general_msg_list != []) {
44 HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
45 }
46 }catch(e){
47 console.log(e);
48 }
49 callback(serverResData);
50 }else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
51 try {
52 HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
53 }catch(e){
54
55 }
56 callback(serverResData);
57 }else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
58 try {
59 var http = require('http');
60 http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
61 res.on('data', function(chunk){
62 callback(chunk+serverResData);
63 })
64 });
65 }catch(e){
66 callback(serverResData);
67 }
68 }else{
69 callback(serverResData);
70 }
71 },
72
73
在 rule_default.js 文件的末尾添加以下代码:
1function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
2 var http = require('http');
3 var data = {
4 str: encodeURIComponent(str),
5 url: encodeURIComponent(url)
6 };
7 content = require('querystring').stringify(data);
8 var options = {
9 method: "POST",
10 host: "www.xxx.com",//注意没有http://,这是服务器的域名。
11 port: 80,
12 path: path,//接收程序的路径和文件名
13 headers: {
14 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
15 "Content-Length": content.length
16 }
17 };
18 var req = http.request(options, function (res) {
19 res.setEncoding('utf8');
20 res.on('data', function (chunk) {
21 console.log('BODY: ' + chunk);
22 });
23 });
24 req.on('error', function (e) {
25 console.log('problem with request: ' + e.message);
26 });
27 req.write(content);
28 req.end();
29}
30
31
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
1replaceRequestOption : function(req,option){
2 var newOption = option;
3 if(/google/i.test(newOption.headers.host)){
4 newOption.hostname = "www.baidu.com";
5 newOption.port = "80";
6 }
7 return newOption;
8 },
9
10
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析后存入数据库
<p>1 查看全部
采集文章系统(微信公众号历史消息页的采集方法整理之后写下来)
我从2014年开始做微信公众号内容采集的批次,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集收到的微信公众号内容很容易在公众号中传播。那个时候批量采集很容易做,采集入口就是公众号的历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而将采集定位为本地新闻资讯公众号,前端展示做成app。因此,一个可以自动采集 公众号内容形成。我曾经担心有一天,微信技术升级后,它无法采集内容,我的新闻应用程序会失败。不过随着微信的不断技术升级,采集方式也升级了,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
1http://mp.weixin.qq.com/mp/get ... irect
2
3
=========2017 年 1 月 11 日更新==========
现在,根据不同的微信个人号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一个地址的链接在anyproxy中会显示302跳转:
1https://mp.weixin.qq.com/mp/pr ... irect
2
3
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前掌握的信息,这两种页面形式在不同的微信账号中不规则出现。有的微信账号总是第一页格式,有的总是第二页格式。
1//第一种链接
2http://mp.weixin.qq.com/mp/get ... r%3D1
3//第二种
4http://mp.weixin.qq.com/mp/pro ... r%3D1
5
6
这个地址是通过微信客户端打开历史消息页面,然后使用后面介绍的代理服务器软件获得的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios微信客户端的崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。
2、个人微信账号:采集的内容,不仅需要微信客户端,采集还需要个人微信账号,因为这个微信账号不能做其他事情。
4、文章列表分析入库系统:我用php语言写的,我会详细介绍如何分析文章列表和构建采集队列实现批量< @采集内容。
步
一、安装模拟器或者用手机安装微信客户端app,申请微信个人账号并登录app。这个我就不多说了,大家都会的。
二、代理服务器系统安装
1、安装 NodeJS
2、在命令行或者终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy并运行命令:sudo anyproxy -i; 参数 -i 表示解析 HTTPS;
5、安装证书,在手机或者安卓模拟器中安装证书:
6、设置代理:Android模拟器的代理服务器地址是wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开浏览器地址:8002可以看到anyproxy的网页界面。从微信点击一个历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
/mp/getmasssendmsg 开头的网址是微信历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
=========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转,跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址查看内容。
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是原理介绍,了解后根据自己的情况修改内容):
=========2017 年 1 月 11 日更新==========
因为有两种页面形式,而且同一个页面形式总是显示在不同的微信账号中,但是为了兼容这两种页面形式,下面的代码会保留两种页面形式的判断,你也可以使用你的自己的页面表单删除li
1replaceServerResDataAsync: function(req,res,serverResData,callback){
2 if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
3 if(serverResData.toString() !== ""){
4 try {//防止报错退出程序
5 var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
6 var ret = reg.exec(serverResData.toString());//转换变量为string
7 HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
8 var http = require('http');
9 http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
10 res.on('data', function(chunk){
11 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
12 })
13 });
14 }catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
15 try {
16 var json = JSON.parse(serverResData.toString());
17 if (json.general_msg_list != []) {
18 HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
19 }
20 }catch(e){
21 console.log(e);//错误捕捉
22 }
23 callback(serverResData);//直接返回第二页json内容
24 }
25 }
26 }else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
27 try {
28 var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
29 var ret = reg.exec(serverResData.toString());//转换变量为string
30 HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
31 var http = require('http');
32 http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
33 res.on('data', function(chunk){
34 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
35 })
36 });
37 }catch(e){
38 callback(serverResData);
39 }
40 }else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
41 try {
42 var json = JSON.parse(serverResData.toString());
43 if (json.general_msg_list != []) {
44 HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
45 }
46 }catch(e){
47 console.log(e);
48 }
49 callback(serverResData);
50 }else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
51 try {
52 HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
53 }catch(e){
54
55 }
56 callback(serverResData);
57 }else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
58 try {
59 var http = require('http');
60 http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
61 res.on('data', function(chunk){
62 callback(chunk+serverResData);
63 })
64 });
65 }catch(e){
66 callback(serverResData);
67 }
68 }else{
69 callback(serverResData);
70 }
71 },
72
73
在 rule_default.js 文件的末尾添加以下代码:
1function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
2 var http = require('http');
3 var data = {
4 str: encodeURIComponent(str),
5 url: encodeURIComponent(url)
6 };
7 content = require('querystring').stringify(data);
8 var options = {
9 method: "POST",
10 host: "www.xxx.com",//注意没有http://,这是服务器的域名。
11 port: 80,
12 path: path,//接收程序的路径和文件名
13 headers: {
14 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
15 "Content-Length": content.length
16 }
17 };
18 var req = http.request(options, function (res) {
19 res.setEncoding('utf8');
20 res.on('data', function (chunk) {
21 console.log('BODY: ' + chunk);
22 });
23 });
24 req.on('error', function (e) {
25 console.log('problem with request: ' + e.message);
26 });
27 req.write(content);
28 req.end();
29}
30
31
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
1replaceRequestOption : function(req,option){
2 var newOption = option;
3 if(/google/i.test(newOption.headers.host)){
4 newOption.hostname = "www.baidu.com";
5 newOption.port = "80";
6 }
7 return newOption;
8 },
9
10
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析后存入数据库
<p>1
采集文章系统( 免费文章采集器的特色亮点是什么?如何做好采集站收录效果 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-09 17:06
免费文章采集器的特色亮点是什么?如何做好采集站收录效果
)
免费文章采集器,深耕采集领域,借助AI领先的智能写作算法,SEO通用智能伪原创采集器。基于高度智能的文本识别算法,按下关键词采集文章,无需编写采集规则。自动全网采集,覆盖六大搜索引擎。自动过滤内容相关度和文章平滑度,只有采集高度相关和平滑度文章。地图自动分配,智能伪原创,定时采集,自动发布,自动提交给搜索引擎,支持各种内容管理系统和建站程序。通过免费的文章采集器、采集上百篇文章文章 全网可即时提供参考写作。当然,这几百个文章也可以拼凑出知识点,进行伪原创也是可以的,效果很好,不用写规则,直接输入关键词@ > 到 采集100 篇文章文章。通过免费的文章采集器,编辑器可以同时批量处理不同cms类型的网站,自动更新网站的内容,自动优化做SEO,做网站@采集Station收录效果还是很不错的!只需输入 关键词 到 采集100 篇文章文章。通过免费的文章采集器,编辑器可以同时批量处理不同cms类型的网站,自动更新网站的内容,自动优化做SEO,做网站@采集Station收录效果还是很不错的!只需输入 关键词 到 采集100 篇文章文章。通过免费的文章采集器,编辑器可以同时批量处理不同cms类型的网站,自动更新网站的内容,自动优化做SEO,做网站@采集Station收录效果还是很不错的!
免费文章采集器特点:
精准的文本识别算法,通过网页元素的多次评分,识别出文本概率最高的元素块,然后进行HTML清洗、链接清洗、冗余信息清洗,得到干净整洁的文本内容。并计算关键词与文本内容的特征向量相似度,有效识别率98%以上,无需编写任何采集规则。
方便灵活的关键词库,为了解决大部分站长缺少关键词的积累问题,会按照用户使用的关键词进行存储,并公开一个关键词@ > 数亿已开通。>图书馆,用户可以任意搜索任何内容,作为个人私人词库,也可以直接从采集系统调用。公共词库查询还支持词根自动扩展,方便用户快速查询行业相关关键词。并且搜索引擎的实时下拉词和相关搜索不断更新。
丰富的可选SEO优化选项,系统内置了业界主流的SEO优化方法,包括组合标题、正文长度过滤、标签智能提取、关键词自动加粗、关键词插入、自动内嵌链接、自动配置图片、主动推送等。插入文字和图片的频率根据搜索引擎算法量身定制,主动推送到各个搜索引擎,让收录上线更快。
高度智能化的伪原创系统采用深度学习语言模型(Language Model)自动识别句子的流畅度。学习、人工智能、百度大脑的自然语言分割、词性分析、词法依赖等相关技术,让所有搜索引擎都认为这是一个原创文章。在2500万词库中,智能选择最合适的词汇将原文替换为伪原创,句子可读性强,效果同原创。
采集任务自动运行稳定可靠,采集任务可以自动挂机运行,无需手动持久化,文章采集会自动发布到网站@ > 成功后。只需要设置必要的参数,就可以实现高质量的全托管无人值守自动更新文章。
免费文章采集器实现采集多样化,无需编写采集规则,一键式采集智能伪原创文章< @采集器自定义软件图片采集保留图片标签,实现图片采集,制定与站点匹配的目录的存放路径。免费文章采集器定制软件一键发布,实现文章一键发布功能,将文章直接发布到网站。免费的文章采集器是我们网站建设网站管理网站运营的站长工具。
查看全部
采集文章系统(
免费文章采集器的特色亮点是什么?如何做好采集站收录效果
)
免费文章采集器,深耕采集领域,借助AI领先的智能写作算法,SEO通用智能伪原创采集器。基于高度智能的文本识别算法,按下关键词采集文章,无需编写采集规则。自动全网采集,覆盖六大搜索引擎。自动过滤内容相关度和文章平滑度,只有采集高度相关和平滑度文章。地图自动分配,智能伪原创,定时采集,自动发布,自动提交给搜索引擎,支持各种内容管理系统和建站程序。通过免费的文章采集器、采集上百篇文章文章 全网可即时提供参考写作。当然,这几百个文章也可以拼凑出知识点,进行伪原创也是可以的,效果很好,不用写规则,直接输入关键词@ > 到 采集100 篇文章文章。通过免费的文章采集器,编辑器可以同时批量处理不同cms类型的网站,自动更新网站的内容,自动优化做SEO,做网站@采集Station收录效果还是很不错的!只需输入 关键词 到 采集100 篇文章文章。通过免费的文章采集器,编辑器可以同时批量处理不同cms类型的网站,自动更新网站的内容,自动优化做SEO,做网站@采集Station收录效果还是很不错的!只需输入 关键词 到 采集100 篇文章文章。通过免费的文章采集器,编辑器可以同时批量处理不同cms类型的网站,自动更新网站的内容,自动优化做SEO,做网站@采集Station收录效果还是很不错的!
免费文章采集器特点:
精准的文本识别算法,通过网页元素的多次评分,识别出文本概率最高的元素块,然后进行HTML清洗、链接清洗、冗余信息清洗,得到干净整洁的文本内容。并计算关键词与文本内容的特征向量相似度,有效识别率98%以上,无需编写任何采集规则。
方便灵活的关键词库,为了解决大部分站长缺少关键词的积累问题,会按照用户使用的关键词进行存储,并公开一个关键词@ > 数亿已开通。>图书馆,用户可以任意搜索任何内容,作为个人私人词库,也可以直接从采集系统调用。公共词库查询还支持词根自动扩展,方便用户快速查询行业相关关键词。并且搜索引擎的实时下拉词和相关搜索不断更新。
丰富的可选SEO优化选项,系统内置了业界主流的SEO优化方法,包括组合标题、正文长度过滤、标签智能提取、关键词自动加粗、关键词插入、自动内嵌链接、自动配置图片、主动推送等。插入文字和图片的频率根据搜索引擎算法量身定制,主动推送到各个搜索引擎,让收录上线更快。
高度智能化的伪原创系统采用深度学习语言模型(Language Model)自动识别句子的流畅度。学习、人工智能、百度大脑的自然语言分割、词性分析、词法依赖等相关技术,让所有搜索引擎都认为这是一个原创文章。在2500万词库中,智能选择最合适的词汇将原文替换为伪原创,句子可读性强,效果同原创。
采集任务自动运行稳定可靠,采集任务可以自动挂机运行,无需手动持久化,文章采集会自动发布到网站@ > 成功后。只需要设置必要的参数,就可以实现高质量的全托管无人值守自动更新文章。
免费文章采集器实现采集多样化,无需编写采集规则,一键式采集智能伪原创文章< @采集器自定义软件图片采集保留图片标签,实现图片采集,制定与站点匹配的目录的存放路径。免费文章采集器定制软件一键发布,实现文章一键发布功能,将文章直接发布到网站。免费的文章采集器是我们网站建设网站管理网站运营的站长工具。
采集文章系统(Java实现一个小说采集程序的简单实例的相关内容吗)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-01-03 18:03
想了解一个Java实现的小说采集程序的简单例子的相关内容吗?本文将仔细讲解java小说采集系统的相关知识和一些代码示例。欢迎阅读和纠正我。先划重点:java小说采集系统,一起来学习一下。
被标题吸引的不要骂我。
就是一个简单的实现,只要交给它下载喜欢的小说。例子中的小说只是例子,不是我的菜。
使用Jsoup。一个非常有用的工具。
如有需要,请参考自行更改。很简单,不是吗。
代码如下:
<p>
package com.zhyea.doggie;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class Doggie {
public static void main(String[] args){
try{
File txtFile = new File("D:/无限崩坏.txt");
createTxtDoc(txtFile);
addContent(txtFile);
}catch(Exception e){
e.printStackTrace();
}
}
/**
* 向小说文件中添加内容
* @param txtFile
* 小说文件
* @throws IOException
* @throws InterruptedException
*/
private static void addContent(File txtFile) throws IOException, InterruptedException{
appendTxt(txtFile, getBookInfo("无限崩坏", "啪啪啪狂魔"));
String url = "http://www.83kxs.com/View/12/12653/{pattern}.html";
for(int i=5850686; i 查看全部
采集文章系统(Java实现一个小说采集程序的简单实例的相关内容吗)
想了解一个Java实现的小说采集程序的简单例子的相关内容吗?本文将仔细讲解java小说采集系统的相关知识和一些代码示例。欢迎阅读和纠正我。先划重点:java小说采集系统,一起来学习一下。
被标题吸引的不要骂我。
就是一个简单的实现,只要交给它下载喜欢的小说。例子中的小说只是例子,不是我的菜。
使用Jsoup。一个非常有用的工具。
如有需要,请参考自行更改。很简单,不是吗。
代码如下:
<p>
package com.zhyea.doggie;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class Doggie {
public static void main(String[] args){
try{
File txtFile = new File("D:/无限崩坏.txt");
createTxtDoc(txtFile);
addContent(txtFile);
}catch(Exception e){
e.printStackTrace();
}
}
/**
* 向小说文件中添加内容
* @param txtFile
* 小说文件
* @throws IOException
* @throws InterruptedException
*/
private static void addContent(File txtFile) throws IOException, InterruptedException{
appendTxt(txtFile, getBookInfo("无限崩坏", "啪啪啪狂魔"));
String url = "http://www.83kxs.com/View/12/12653/{pattern}.html";
for(int i=5850686; i
采集文章系统( 自动化消息是什么?区别于运营人员手工创建任务发送的消息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-12-30 16:11
自动化消息是什么?区别于运营人员手工创建任务发送的消息)
一、什么是自动消息?
与操作员手动创建任务发送的消息不同,自动消息是由系统根据既定规则触发的。
自动消息根据内容类型可分为通知消息和营销消息。
1) Notification:个人信息变更通知消息,用于增加用户交互频率和转化概率,主要如下:
2) 营销:活动统一通知,区别于人工消息。自动化消息可根据营销规则自动通知,节省运营商的人工操作,并辅以策略提升效果。
目前常用的主要有:
需要注意的是,本文所讨论的营销通知大多是偏向于自身业务的通知。商户相关规则的设置与自营不同,后面会在其他文章中讨论。
不同的交付方式的服务方式和领域是不同的。比如微信服务号的订阅通知。模板需要在微信提供的固定字段中选择,而push是直接对接的界面。文案可以自己设置,不同的渠道是通知。营销类和营销类的发送限制是有区别的。
以推送为例:小米限制营销总量,但不限制通知总量;和 vivo 都限制了两者。区分营销和通知类别可以在遵守平台使用规范的同时增加覆盖面。另外,请务必遵守各个平台的使用规范,否则严重时可能会导致通道被禁用。
根据触发方式的不同,可分为触发型和定时型:
触发类型:根据用户行为及时触发;定时类型:系统按照一定的规则筛选用户,定时触发。
计时系统和触发系统的实现是有区别的,下面会一一介绍。
二、触发消息的实现
有两种类型的触发消息:
前者系统比较简单,而后者比较复杂。
先介绍第一个。第一个主要需要提供一个通用的发送服务,触发的节点都是由业务系统控制的。符合第一类的主要是通知,比如订单发货通知。这个过程大约需要三个步骤:
1. 申请模板
本步骤中,联系人系统需要提供后台页面功能,模板申请需要手动进行。模板可能需要以下信息:
1)Name:标记模板的主要目的,需要验证唯一性;
2)分发方式:不同的发送方式决定了需要填写的消息内容,比如短信只需要填写消息内容,而推送则需要填写模板、消息内容和跳转链接等;
3)内容类型:短信和推送标签是营销还是通知,此项也将决定短信内容的验证。例如,营销短信必须收录
退订说明,而通知则不需要验证。
4)留言内容:留言内容的设计主要有几点:
5)激活时间:主要决定是否激活模板。生效方式有三种:立即激活生效,设置时间生效(选择精确到分钟)暂时不生效。这三种方法的设计主要体现了商家和供应商使用时的价值。
为什么需要申请模板,而不是直接通过接口传递业务系统需要发送的内容?
这主要是由于:
2. 发送
发送节点由业务系统触发,调用触摸系统提供的通用接口。输入参数的必要字段是:
系统所有权:标记哪个系统被调用;使用模板;发送用户:包括用户ID和手机号码;动态字段内容:如果模板中有动态字段,需要标注每个用户的动态内容是什么。
其他字段可以根据自己的业务添加。
返回的参数需要返回调用的成功和失败,失败需要标注失败的原因和调用的任务id;此时的成功和失败只是接口调用的成功或失败,并不代表已经到达。用户。
由于服务提供者返回结果的时间不同,真正到达用户的结果需要异步获取。
3. 结果收据
收据可以有两种方式:
推荐第二个方案,避免了由于需要多个系统存储报文结果而导致的数据冗余,也节省了开发量。每次连接新系统时,无需触摸系统连接界面。
消息回执需要包括什么?
发送时返回任务ID。如果通过task id查询需要单独存储,也可以通过系统+时间+模板查询。这种类型的查询需要系统进行汇总。
当然,消息接收的接口不是必须的。您也可以通过触摸系统页面查看数据。
三、如何实现定时消息
定时消息一般需要在到达系统中创建规则,然后触发它们。流程大致分为5个步骤:
1. 创建任务
创建任务有点类似于手动。您需要指定任务的基本信息、目标用户规则以及到达信息的配置:
并且这里的任务创建页面不是完全可配置的,因为每个策略针对不同的用户规则;例如,休眠用户可能基于浏览/追加购买等规则,而生日提醒则是基于生日时间的提醒;so new 要添加策略,需要改变目标用户的配置。
一开始不需要做一个对所有策略完全通用的页面,只需要支持每个策略可能改变的配置即可;例如,睡眠用户的定义可能从 30 天变为 15 天。这是一个配置页面,很容易调整。
除了用户的定义,如果是促销通知类型,还需要对产品进行筛选,确认哪些产品是用户筛选匹配的;可以根据品类、品牌、促销类型、价格区间、利润率等配置产品标签。
2. 用户搜索
根据设置的规则进行用户查询。这时候就需要注意搜索时间了。为了在设定的时间发送,您需要提前估计系统的处理时间并搜索用户。
3. 消息组装
之所以特意提到这个链接,是因为有些策略需要算法来匹配。
例如:促销通知。根据今天设置的产品规则和用户规则筛选产品和用户后,我们需要为每个用户触达不同的产品,以增加用户的点击量。消息类似于“您有兴趣[产品名称]正在参与[促销名称],过来看看”
这时候就需要一个算法,将用户池和产品池进行匹配,找到用户最有情感的产品,然后到达系统就会组装起来,到达不同用户的需求。
4. 发送和结果统计
和手动任务类似,还是要注意用户的免打扰等,这里不具体讲了。
四、结论
自动化访问设计的难点在于策略的制定。需要与运营人员密切沟通,根据目标制定策略,并通过关注数据及时分析和调整策略。
此外,需要与算法部门密切沟通合作,推动算法部门改进算法也是重要的工作之一。
本文由@举个栗子原发布 人人都是产品经理,未经许可禁止转载
题图来自Unsplash,基于CC0协议 查看全部
采集文章系统(
自动化消息是什么?区别于运营人员手工创建任务发送的消息)
一、什么是自动消息?
与操作员手动创建任务发送的消息不同,自动消息是由系统根据既定规则触发的。
自动消息根据内容类型可分为通知消息和营销消息。
1) Notification:个人信息变更通知消息,用于增加用户交互频率和转化概率,主要如下:
2) 营销:活动统一通知,区别于人工消息。自动化消息可根据营销规则自动通知,节省运营商的人工操作,并辅以策略提升效果。
目前常用的主要有:
需要注意的是,本文所讨论的营销通知大多是偏向于自身业务的通知。商户相关规则的设置与自营不同,后面会在其他文章中讨论。
不同的交付方式的服务方式和领域是不同的。比如微信服务号的订阅通知。模板需要在微信提供的固定字段中选择,而push是直接对接的界面。文案可以自己设置,不同的渠道是通知。营销类和营销类的发送限制是有区别的。
以推送为例:小米限制营销总量,但不限制通知总量;和 vivo 都限制了两者。区分营销和通知类别可以在遵守平台使用规范的同时增加覆盖面。另外,请务必遵守各个平台的使用规范,否则严重时可能会导致通道被禁用。
根据触发方式的不同,可分为触发型和定时型:
触发类型:根据用户行为及时触发;定时类型:系统按照一定的规则筛选用户,定时触发。
计时系统和触发系统的实现是有区别的,下面会一一介绍。
二、触发消息的实现
有两种类型的触发消息:
前者系统比较简单,而后者比较复杂。
先介绍第一个。第一个主要需要提供一个通用的发送服务,触发的节点都是由业务系统控制的。符合第一类的主要是通知,比如订单发货通知。这个过程大约需要三个步骤:
1. 申请模板
本步骤中,联系人系统需要提供后台页面功能,模板申请需要手动进行。模板可能需要以下信息:
1)Name:标记模板的主要目的,需要验证唯一性;
2)分发方式:不同的发送方式决定了需要填写的消息内容,比如短信只需要填写消息内容,而推送则需要填写模板、消息内容和跳转链接等;
3)内容类型:短信和推送标签是营销还是通知,此项也将决定短信内容的验证。例如,营销短信必须收录
退订说明,而通知则不需要验证。
4)留言内容:留言内容的设计主要有几点:
5)激活时间:主要决定是否激活模板。生效方式有三种:立即激活生效,设置时间生效(选择精确到分钟)暂时不生效。这三种方法的设计主要体现了商家和供应商使用时的价值。
为什么需要申请模板,而不是直接通过接口传递业务系统需要发送的内容?
这主要是由于:
2. 发送
发送节点由业务系统触发,调用触摸系统提供的通用接口。输入参数的必要字段是:
系统所有权:标记哪个系统被调用;使用模板;发送用户:包括用户ID和手机号码;动态字段内容:如果模板中有动态字段,需要标注每个用户的动态内容是什么。
其他字段可以根据自己的业务添加。
返回的参数需要返回调用的成功和失败,失败需要标注失败的原因和调用的任务id;此时的成功和失败只是接口调用的成功或失败,并不代表已经到达。用户。
由于服务提供者返回结果的时间不同,真正到达用户的结果需要异步获取。
3. 结果收据
收据可以有两种方式:
推荐第二个方案,避免了由于需要多个系统存储报文结果而导致的数据冗余,也节省了开发量。每次连接新系统时,无需触摸系统连接界面。
消息回执需要包括什么?
发送时返回任务ID。如果通过task id查询需要单独存储,也可以通过系统+时间+模板查询。这种类型的查询需要系统进行汇总。
当然,消息接收的接口不是必须的。您也可以通过触摸系统页面查看数据。
三、如何实现定时消息
定时消息一般需要在到达系统中创建规则,然后触发它们。流程大致分为5个步骤:
1. 创建任务
创建任务有点类似于手动。您需要指定任务的基本信息、目标用户规则以及到达信息的配置:
并且这里的任务创建页面不是完全可配置的,因为每个策略针对不同的用户规则;例如,休眠用户可能基于浏览/追加购买等规则,而生日提醒则是基于生日时间的提醒;so new 要添加策略,需要改变目标用户的配置。
一开始不需要做一个对所有策略完全通用的页面,只需要支持每个策略可能改变的配置即可;例如,睡眠用户的定义可能从 30 天变为 15 天。这是一个配置页面,很容易调整。
除了用户的定义,如果是促销通知类型,还需要对产品进行筛选,确认哪些产品是用户筛选匹配的;可以根据品类、品牌、促销类型、价格区间、利润率等配置产品标签。
2. 用户搜索
根据设置的规则进行用户查询。这时候就需要注意搜索时间了。为了在设定的时间发送,您需要提前估计系统的处理时间并搜索用户。
3. 消息组装
之所以特意提到这个链接,是因为有些策略需要算法来匹配。
例如:促销通知。根据今天设置的产品规则和用户规则筛选产品和用户后,我们需要为每个用户触达不同的产品,以增加用户的点击量。消息类似于“您有兴趣[产品名称]正在参与[促销名称],过来看看”
这时候就需要一个算法,将用户池和产品池进行匹配,找到用户最有情感的产品,然后到达系统就会组装起来,到达不同用户的需求。
4. 发送和结果统计
和手动任务类似,还是要注意用户的免打扰等,这里不具体讲了。
四、结论
自动化访问设计的难点在于策略的制定。需要与运营人员密切沟通,根据目标制定策略,并通过关注数据及时分析和调整策略。
此外,需要与算法部门密切沟通合作,推动算法部门改进算法也是重要的工作之一。
本文由@举个栗子原发布 人人都是产品经理,未经许可禁止转载
题图来自Unsplash,基于CC0协议
采集文章系统(网站收录与排名的关系有影响吗?如何理解?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-12-29 23:15
一些SEO人员认为一个网站被收录的越多,排名就越好。其实一个网站的收录和排名并没有直接的关系,但是两者之间有一定的联系。那么如何理解网站收录与排名的关系呢?
网站收录是指爬虫抓取网页并将页面内容数据放入搜索引擎数据库。可以通过搜索引擎目标网址检索到相应的内容。所以,一个网站想要被收录,首先需要有内容供爬虫爬取,然后爬虫会一直爬爬爬爬,直到建立索引,完成网页收录。在这个过程中,搜索引擎爬虫会评估内容的质量,只有符合标准的才会被有效收录和排名。
对于网站内容质量的评价,在搜索结果中一般有两种情况:
如果你的内容是优质内容,或者比较优质的内容,那么在搜索结果中,搜索特定的关键词,就会有相应的排名;但是如果你的内容质量不高,任何搜索引擎关键词都不会排名,只有在检索到网址时,才会有一定的收录。
因此,网站收录和排名没有直接关系,并不代表网站收录就意味着会有排名。那么网站收录
的内容多的话,会不会影响排名呢?
网站收录和排名有什么关系?更多的包容是否意味着更高的排名?
快速增加网站收录的方法有很多种,比如建立站群系统,采集
大量文章发表来增加网站的收录,或者利用镜像采集
大量文章的镜像网站。目标网站内容实现内容同步,也可以使得收录大量页面,但是这些低质量的内容或者负面SEO的效果无法有效收录,也就不会有排名。
如果你想真正提高你的网站排名,你必须做高质量的内容。优质内容是能够满足用户需求的原创且有价值的内容。只有收录的此类优质内容越多,排名可能会上升。当然,增加包容性的技术和方法的选择也很重要。我们必须使用正常的优化方法来提高网站的收录,比如外链发布、站点地图、内容和锚文本等。走捷径只能让你获得短期收益,最终会受到搜索引擎的惩罚。如果你想让你的网站有效、稳定和长期发展,那么你应该逐步优化你的网站,并保持它的定期和有规律。高质量的更新是正确的。
以上就是对网站收录与排名关系的分析。一般来说,网站收录的越多,排名越高并不意味着收录的优质内容越多。可以提高网站的排名。 查看全部
采集文章系统(网站收录与排名的关系有影响吗?如何理解?)
一些SEO人员认为一个网站被收录的越多,排名就越好。其实一个网站的收录和排名并没有直接的关系,但是两者之间有一定的联系。那么如何理解网站收录与排名的关系呢?
网站收录是指爬虫抓取网页并将页面内容数据放入搜索引擎数据库。可以通过搜索引擎目标网址检索到相应的内容。所以,一个网站想要被收录,首先需要有内容供爬虫爬取,然后爬虫会一直爬爬爬爬,直到建立索引,完成网页收录。在这个过程中,搜索引擎爬虫会评估内容的质量,只有符合标准的才会被有效收录和排名。
对于网站内容质量的评价,在搜索结果中一般有两种情况:
如果你的内容是优质内容,或者比较优质的内容,那么在搜索结果中,搜索特定的关键词,就会有相应的排名;但是如果你的内容质量不高,任何搜索引擎关键词都不会排名,只有在检索到网址时,才会有一定的收录。
因此,网站收录和排名没有直接关系,并不代表网站收录就意味着会有排名。那么网站收录
的内容多的话,会不会影响排名呢?
网站收录和排名有什么关系?更多的包容是否意味着更高的排名?
快速增加网站收录的方法有很多种,比如建立站群系统,采集
大量文章发表来增加网站的收录,或者利用镜像采集
大量文章的镜像网站。目标网站内容实现内容同步,也可以使得收录大量页面,但是这些低质量的内容或者负面SEO的效果无法有效收录,也就不会有排名。
如果你想真正提高你的网站排名,你必须做高质量的内容。优质内容是能够满足用户需求的原创且有价值的内容。只有收录的此类优质内容越多,排名可能会上升。当然,增加包容性的技术和方法的选择也很重要。我们必须使用正常的优化方法来提高网站的收录,比如外链发布、站点地图、内容和锚文本等。走捷径只能让你获得短期收益,最终会受到搜索引擎的惩罚。如果你想让你的网站有效、稳定和长期发展,那么你应该逐步优化你的网站,并保持它的定期和有规律。高质量的更新是正确的。
以上就是对网站收录与排名关系的分析。一般来说,网站收录的越多,排名越高并不意味着收录的优质内容越多。可以提高网站的排名。
采集文章系统(一下如何利用老Y文章管理系统采集时自动完成伪原创)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-12-27 22:24
垃圾站站长最希望的就是网站可以自动收,自动补伪原创,然后自动收钱。这是世界上最幸福的事情,哈哈。自动收款和自动收款将不再讨论。今天给大家介绍一下如何使用老Y文章管理系统在采集
时自动完成伪原创的方法。文章管理系统简单易用。虽然功能没有DEDE之类的强大,几乎变态(文章管理系统用asp语言写的时候,好像没有可比性),但是都有,而且还挺简单的. 所以也受到了很多站长的欢迎。老Y文章管理系统采集
时自动完成伪原创创作的具体方法,目前还鲜有讨论。在老Y的论坛上,甚至有人在卖这个方法。我有点鄙视它。关于采集
,我就不多说了。我相信每个人都能应付。我想介绍的是旧的Y文章管理系统如何在采集
的同时自动完成伪原创工作。大体思路是使用旧的Y文章管理系统。内置过滤功能,实现同义词自动替换,从而达到伪原创的目的。比如我想把采集
文章中的“网转博客”全部替换成“网转日记”。详细步骤如下:第一步是进入后台。找到“采集
管理”-“过滤管理”,添加一个新的过滤项。我可以创建一个名为“网赚博客”的项目,具体设置请看图片: “过滤器名称”:填写“网赚博客”,也可以随意写,但是为了方便查看,建议和替换的话是一致的。
“主题”:请根据您自己的网站选择网站栏目(一定要选择栏目,否则过滤后的项目无法保存)。“过滤器对象”:可用选项有“标题过滤器”和“文本过滤器”。一般选择“文本过滤器”。如果你想伪原创甚至标题,你可以选择“标题过滤器”。“过滤器类型”:选项为“简单更换”和“高级过滤器”。一般选择“简单替换”。代码级替换的内容。“使用状态”:选项为“启用”和“禁用”,不作解释。“使用范围”:选项为“公共”和“私人”。选择“私人”,过滤器只对当前网站栏目有效;选择“Public”,对所有列都有效,无论哪一列采集什么内容,过滤都有效。一般选择“私人”。“内容”:填写将被替换的“网赚博客”字样。“替换”:填写“网转日记”,只要收录的文章中含有“网转博客”字样,就会自动替换为“网转日记”。第二步,重复第一步的工作,直到添加完所有的同义词。有网友想问:我有3万多个同义词,要不要手动一一添加?我什么时候添加它们?不能批量添加吗?这是一个很好的问题!手动添加确实是一项几乎不可能完成的任务。
遗憾的是,旧的Y文章管理系统没有提供批量导入的功能。但是,作为真实的、有经验的、有思想的优采云
,我们必须有优采云
的意识。要知道,我们刚刚输入的内容是存放在数据库中的,而旧的文章管理系统是用asp+Access编写的,mdb数据库可以很方便的编辑!所以,我可以直接修改数据库批量导入伪原创替换规则!改进的第二步:批量修改数据库和导入规则。经过搜索,我发现这个数据库在“你的管理目录\cai\Database”下。使用 Access 打开此数据库并找到“过滤器”表。你会发现我们刚刚添加的替换规则就存放在这里。根据您的需要分批添加!接下来的工作涉及到Access操作,我就不啰嗦了,大家可以自己做。解释一下“Filters”表中几个字段的含义: FilterID:自动生成,不需要输入。ItemID:列ID是我们手动输入时“item”的内容,但这里是数字ID,注意对应列的集合ID,不知道ID的可以重复第一步,测试一下。过滤器名称:“过滤器名称”。FilterObjece:“过滤对象”,“标题过滤器”填1,“文本过滤器”填2。不需要输入。ItemID:列ID是我们手动输入时“item”的内容,但这里是数字ID,注意对应列的集合ID,不知道ID的可以重复第一步,测试一下。过滤器名称:“过滤器名称”。FilterObjece:“过滤对象”,“标题过滤器”填1,“文本过滤器”填2。不需要输入。ItemID:列ID是我们手动输入时“item”的内容,但这里是数字ID,注意对应列的集合ID,不知道ID的可以重复第一步,测试一下。过滤器名称:“过滤器名称”。FilterObjece:“过滤对象”,“标题过滤器”填1,“文本过滤器”填2。
FilterType:“过滤器类型”,“简单更换”填1,“高级过滤器”填2。FilterContent:“内容”。FisString:“开始标签”,只有在设置了“高级过滤器”时才有效,如果设置了“简单过滤器”,请留空。FioString:“结束标签”,仅在设置了“高级过滤器”时有效,如果设置了“简单过滤器”,请留空。FilterRep:即“替换”。Flag:“使用状态”,TRUE 表示“启用”,FALSE 表示“禁用”。PublicTf:“使用范围”。TRUE 表示“公共”,FALSE 表示“私有”。最后说一下使用过滤功能实现伪原创体验的使用:文章管理系统的这个功能在采集
的时候可以实现自动伪原创,但是功能不够强大。例如,我的站点上有三列:“第一列”、“第二列”和“第三列”。我希望“第一栏”对标题和正文都进行伪原创,“第二栏”只会对文字进行伪原创,“第三栏”只会对标题进行伪原创。因此,我只能做如下设置(假设我有30000个同义词规则): 为“Column 1”的伪原创标题创建30000个替换规则;为“第一栏”的伪原文创建30000条替换规则;为“第2栏”的伪原文创建30000条替换规则;创建 30,
这造成了巨大的数据库浪费。如果我的网站有几十个栏目,每一个栏目的要求都不一样,这个数据库的大小会很吓人。所以建议在老Y文章管理系统下一个版本完善这个功能:首先,增加批量导入功能,毕竟修改数据库有一定的风险。其次,过滤规则不再依附于某个网站栏目,而是独立于过滤规则,并且在新建集合项时,添加是否使用过滤规则的判断。相信经过这样的修改,可以大大节省数据库存储空间,逻辑结构也更加清晰。本文为“我的网赚日记-原创网赚博客”原创,请尊重我的劳动成果,转载请注明出处!另外,我已经很久没有使用旧的Y文章管理系统了,如果文章地方有错误或不当的文章,欢迎大家指正!企业贸易网 查看全部
采集文章系统(一下如何利用老Y文章管理系统采集时自动完成伪原创)
垃圾站站长最希望的就是网站可以自动收,自动补伪原创,然后自动收钱。这是世界上最幸福的事情,哈哈。自动收款和自动收款将不再讨论。今天给大家介绍一下如何使用老Y文章管理系统在采集
时自动完成伪原创的方法。文章管理系统简单易用。虽然功能没有DEDE之类的强大,几乎变态(文章管理系统用asp语言写的时候,好像没有可比性),但是都有,而且还挺简单的. 所以也受到了很多站长的欢迎。老Y文章管理系统采集
时自动完成伪原创创作的具体方法,目前还鲜有讨论。在老Y的论坛上,甚至有人在卖这个方法。我有点鄙视它。关于采集
,我就不多说了。我相信每个人都能应付。我想介绍的是旧的Y文章管理系统如何在采集
的同时自动完成伪原创工作。大体思路是使用旧的Y文章管理系统。内置过滤功能,实现同义词自动替换,从而达到伪原创的目的。比如我想把采集
文章中的“网转博客”全部替换成“网转日记”。详细步骤如下:第一步是进入后台。找到“采集
管理”-“过滤管理”,添加一个新的过滤项。我可以创建一个名为“网赚博客”的项目,具体设置请看图片: “过滤器名称”:填写“网赚博客”,也可以随意写,但是为了方便查看,建议和替换的话是一致的。
“主题”:请根据您自己的网站选择网站栏目(一定要选择栏目,否则过滤后的项目无法保存)。“过滤器对象”:可用选项有“标题过滤器”和“文本过滤器”。一般选择“文本过滤器”。如果你想伪原创甚至标题,你可以选择“标题过滤器”。“过滤器类型”:选项为“简单更换”和“高级过滤器”。一般选择“简单替换”。代码级替换的内容。“使用状态”:选项为“启用”和“禁用”,不作解释。“使用范围”:选项为“公共”和“私人”。选择“私人”,过滤器只对当前网站栏目有效;选择“Public”,对所有列都有效,无论哪一列采集什么内容,过滤都有效。一般选择“私人”。“内容”:填写将被替换的“网赚博客”字样。“替换”:填写“网转日记”,只要收录的文章中含有“网转博客”字样,就会自动替换为“网转日记”。第二步,重复第一步的工作,直到添加完所有的同义词。有网友想问:我有3万多个同义词,要不要手动一一添加?我什么时候添加它们?不能批量添加吗?这是一个很好的问题!手动添加确实是一项几乎不可能完成的任务。
遗憾的是,旧的Y文章管理系统没有提供批量导入的功能。但是,作为真实的、有经验的、有思想的优采云
,我们必须有优采云
的意识。要知道,我们刚刚输入的内容是存放在数据库中的,而旧的文章管理系统是用asp+Access编写的,mdb数据库可以很方便的编辑!所以,我可以直接修改数据库批量导入伪原创替换规则!改进的第二步:批量修改数据库和导入规则。经过搜索,我发现这个数据库在“你的管理目录\cai\Database”下。使用 Access 打开此数据库并找到“过滤器”表。你会发现我们刚刚添加的替换规则就存放在这里。根据您的需要分批添加!接下来的工作涉及到Access操作,我就不啰嗦了,大家可以自己做。解释一下“Filters”表中几个字段的含义: FilterID:自动生成,不需要输入。ItemID:列ID是我们手动输入时“item”的内容,但这里是数字ID,注意对应列的集合ID,不知道ID的可以重复第一步,测试一下。过滤器名称:“过滤器名称”。FilterObjece:“过滤对象”,“标题过滤器”填1,“文本过滤器”填2。不需要输入。ItemID:列ID是我们手动输入时“item”的内容,但这里是数字ID,注意对应列的集合ID,不知道ID的可以重复第一步,测试一下。过滤器名称:“过滤器名称”。FilterObjece:“过滤对象”,“标题过滤器”填1,“文本过滤器”填2。不需要输入。ItemID:列ID是我们手动输入时“item”的内容,但这里是数字ID,注意对应列的集合ID,不知道ID的可以重复第一步,测试一下。过滤器名称:“过滤器名称”。FilterObjece:“过滤对象”,“标题过滤器”填1,“文本过滤器”填2。
FilterType:“过滤器类型”,“简单更换”填1,“高级过滤器”填2。FilterContent:“内容”。FisString:“开始标签”,只有在设置了“高级过滤器”时才有效,如果设置了“简单过滤器”,请留空。FioString:“结束标签”,仅在设置了“高级过滤器”时有效,如果设置了“简单过滤器”,请留空。FilterRep:即“替换”。Flag:“使用状态”,TRUE 表示“启用”,FALSE 表示“禁用”。PublicTf:“使用范围”。TRUE 表示“公共”,FALSE 表示“私有”。最后说一下使用过滤功能实现伪原创体验的使用:文章管理系统的这个功能在采集
的时候可以实现自动伪原创,但是功能不够强大。例如,我的站点上有三列:“第一列”、“第二列”和“第三列”。我希望“第一栏”对标题和正文都进行伪原创,“第二栏”只会对文字进行伪原创,“第三栏”只会对标题进行伪原创。因此,我只能做如下设置(假设我有30000个同义词规则): 为“Column 1”的伪原创标题创建30000个替换规则;为“第一栏”的伪原文创建30000条替换规则;为“第2栏”的伪原文创建30000条替换规则;创建 30,
这造成了巨大的数据库浪费。如果我的网站有几十个栏目,每一个栏目的要求都不一样,这个数据库的大小会很吓人。所以建议在老Y文章管理系统下一个版本完善这个功能:首先,增加批量导入功能,毕竟修改数据库有一定的风险。其次,过滤规则不再依附于某个网站栏目,而是独立于过滤规则,并且在新建集合项时,添加是否使用过滤规则的判断。相信经过这样的修改,可以大大节省数据库存储空间,逻辑结构也更加清晰。本文为“我的网赚日记-原创网赚博客”原创,请尊重我的劳动成果,转载请注明出处!另外,我已经很久没有使用旧的Y文章管理系统了,如果文章地方有错误或不当的文章,欢迎大家指正!企业贸易网
采集文章系统(一个微信公众号历史消息页的采集方法整理之后写)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-12-27 20:20
从2014年开始做微信公众号内容的批量采集,最初的目的是搭建一个html5垃圾网站。当时,垃圾站采集
的微信公众号的内容很容易在公众号传播。那个时候批量采集
特别好做,采集
入口就是公众号的历史新闻页面。这个入口现在还是一样,只是越来越难采集
了。采集
方法也更新了很多版本。后来,2015年html5垃圾站没有做,转而将采集
目标定位在本地新闻信息公众号上,前端展示做成了app。于是,一个可以自动采集
公众号内容的新闻APP就形成了。我曾经担心微信技术升级一天后,无法采集内容,我的新闻应用程序会失败。但是随着微信的不断技术升级,采集
方式也得到了升级,这让我越来越有信心。只要有公众号历史信息页面,就可以批量采集内容。所以今天决定整理一下采集
方法,写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。这让我越来越自信。只要有公众号历史信息页面,就可以批量采集内容。所以今天决定整理一下采集
方法,写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。这让我越来越自信。只要有公众号历史信息页面,就可以批量采集内容。所以今天决定整理一下采集
方法,写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文将持续更新,保证您看到的内容在您看到时可用。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... r%3D1
有几个参数:
__biz;uin=;key=;devicetype=;version=;lang=;nettype=;ascene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这4个参数。
__biz 是公众号的类似id的参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
其余三个参数与用户的id和tokenticket的含义有关。这三个参数的值只能由微信客户端生成。所以,如果我们要采集
公众号,就必须使用微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号时都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集
系统由以下几部分组成:
1、 微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。批量采集测试的ios微信客户端崩溃率高于Android系统。为了降低成本,我使用了Android模拟器。
2、一个微信个人号:要采集
内容,不仅需要一个微信客户端,还需要一个专门用于采集
的微信个人号,因为这个微信号不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体的安装方法后面会详细介绍。
4、 文章列表分析入库系统:本人使用php语言编写,下篇文章将详细介绍如何分析文章列表,建立采集
队列,实现内容的批量采集
。
步
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个我就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、安装NodeJS
2、 在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、 生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
方法一:启动anyproxy,打开浏览器:8002/fetchCr...,即可得到rootCA.crt文件
方法二:启动anyproxy,:8002/qr_root可以获取证书路径的二维码,手机安装会更方便
建议通过二维码将证书安装到手机中。
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意一条公众号历史消息或文章,就可以在终端看到滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址:8002,可以看到anyproxy的web界面。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
如果右侧出现html文件内容,则说明解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成了ca证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,理解后根据自己的情况修改内容):
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
上面的代码就是使用anyproxy修改了返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理,可以批量采集公众号的内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件的末尾添加以下代码:
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统的性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是对anyproxy规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p> 查看全部
采集文章系统(一个微信公众号历史消息页的采集方法整理之后写)
从2014年开始做微信公众号内容的批量采集,最初的目的是搭建一个html5垃圾网站。当时,垃圾站采集
的微信公众号的内容很容易在公众号传播。那个时候批量采集
特别好做,采集
入口就是公众号的历史新闻页面。这个入口现在还是一样,只是越来越难采集
了。采集
方法也更新了很多版本。后来,2015年html5垃圾站没有做,转而将采集
目标定位在本地新闻信息公众号上,前端展示做成了app。于是,一个可以自动采集
公众号内容的新闻APP就形成了。我曾经担心微信技术升级一天后,无法采集内容,我的新闻应用程序会失败。但是随着微信的不断技术升级,采集
方式也得到了升级,这让我越来越有信心。只要有公众号历史信息页面,就可以批量采集内容。所以今天决定整理一下采集
方法,写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。这让我越来越自信。只要有公众号历史信息页面,就可以批量采集内容。所以今天决定整理一下采集
方法,写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。这让我越来越自信。只要有公众号历史信息页面,就可以批量采集内容。所以今天决定整理一下采集
方法,写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文将持续更新,保证您看到的内容在您看到时可用。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... r%3D1
有几个参数:
__biz;uin=;key=;devicetype=;version=;lang=;nettype=;ascene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这4个参数。
__biz 是公众号的类似id的参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
其余三个参数与用户的id和tokenticket的含义有关。这三个参数的值只能由微信客户端生成。所以,如果我们要采集
公众号,就必须使用微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号时都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集
系统由以下几部分组成:
1、 微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。批量采集测试的ios微信客户端崩溃率高于Android系统。为了降低成本,我使用了Android模拟器。
2、一个微信个人号:要采集
内容,不仅需要一个微信客户端,还需要一个专门用于采集
的微信个人号,因为这个微信号不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体的安装方法后面会详细介绍。
4、 文章列表分析入库系统:本人使用php语言编写,下篇文章将详细介绍如何分析文章列表,建立采集
队列,实现内容的批量采集
。
步
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个我就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、安装NodeJS
2、 在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、 生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
方法一:启动anyproxy,打开浏览器:8002/fetchCr...,即可得到rootCA.crt文件
方法二:启动anyproxy,:8002/qr_root可以获取证书路径的二维码,手机安装会更方便
建议通过二维码将证书安装到手机中。
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意一条公众号历史消息或文章,就可以在终端看到滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址:8002,可以看到anyproxy的web界面。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
如果右侧出现html文件内容,则说明解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成了ca证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,理解后根据自己的情况修改内容):
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
上面的代码就是使用anyproxy修改了返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理,可以批量采集公众号的内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件的末尾添加以下代码:
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统的性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是对anyproxy规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p>

