
采集器采集
谷歌ffkmps有!登录我怎么开发人人网扫码支付
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-05-03 18:05
采集器采集标签,然后浏览器解析出页面标签对应的二维码,对应的二维码在浏览器上显示的时候,
我是如何添加支付宝收款码的呢?
谷歌ffkmps
有!登录
我怎么开发人人网扫码支付啊?
有啊,但是现在这个玩意被给封了,所以在线没有,
有啊,理论上是可以实现的。不同服务器不同接口,可以实现不同的扫描,除非你技术能力太弱。
短信
有可能
没必要一次性在同一个地方绑定n多余的二维码
这个我写过很简单的,你可以再搜搜看。
可以的,
其实原理很简单,例如根据用户进店时的二维码,给实体店一个扣点,店家就可以通过扣点获得你的手机号码。如果再进一步,就是根据你的收货地址,实体店可以获得你的收货电话号码和你的实际消费金额,之后你对比一下就能查到你的真实的消费记录。但目前原理是,你必须进到同一家店扫一下,如果实际消费金额小于扣点,也不确定你的消费是不是每次都在扣点内,那么很有可能会被当作刷信誉什么的给限制。
其实也可以。但很多app不愿意投入精力维护或者根本做不到。还有很多根本做不了。所以我感觉这个肯定是必须的。以下是我在社区平台上看到的一篇文章,感觉讲的蛮清楚的。希望对你有用。 查看全部
谷歌ffkmps有!登录我怎么开发人人网扫码支付
采集器采集标签,然后浏览器解析出页面标签对应的二维码,对应的二维码在浏览器上显示的时候,
我是如何添加支付宝收款码的呢?
谷歌ffkmps
有!登录
我怎么开发人人网扫码支付啊?
有啊,但是现在这个玩意被给封了,所以在线没有,
有啊,理论上是可以实现的。不同服务器不同接口,可以实现不同的扫描,除非你技术能力太弱。
短信
有可能
没必要一次性在同一个地方绑定n多余的二维码
这个我写过很简单的,你可以再搜搜看。
可以的,
其实原理很简单,例如根据用户进店时的二维码,给实体店一个扣点,店家就可以通过扣点获得你的手机号码。如果再进一步,就是根据你的收货地址,实体店可以获得你的收货电话号码和你的实际消费金额,之后你对比一下就能查到你的真实的消费记录。但目前原理是,你必须进到同一家店扫一下,如果实际消费金额小于扣点,也不确定你的消费是不是每次都在扣点内,那么很有可能会被当作刷信誉什么的给限制。
其实也可以。但很多app不愿意投入精力维护或者根本做不到。还有很多根本做不了。所以我感觉这个肯定是必须的。以下是我在社区平台上看到的一篇文章,感觉讲的蛮清楚的。希望对你有用。
绕过受信服务器icmp检测和网站验证的区别?
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-04-30 22:07
采集器采集并公开ip地址及端口,然后向网站发起授权检测请求,如果满足要求,就可以伪装。就像这样:图中的url就是伪装的效果图。目前的漏洞分析工具根本不记录此请求,因此不能过滤此类请求。而据说国内已经有了一款ip代理供应商,可以用其解决此类问题。似乎利用软件漏洞(mcasejawinkit)能伪装到非受信服务器ip上,而收集不到实际请求到达的ip,从而绕过服务器icmp检测和网站验证。
最简单的方法是,修改cms的ip判断机制。举个栗子。ngui对ip判断实现bug:ip判断机制更改为对网站实际请求ip而不是受信服务器(非icmp)请求ip。结果导致要发送请求还要向网站发送一个post请求,然后自动帮网站和开发实现验证(而不是接受请求,还得来点小动作提醒)。于是一个疑问摆在面前:同样是发请求,网站是不是就没了质疑的余地了呢?于是,很多存活的cms内置了ip功能。
比如可以假装ip有很多组,中国的、非中国的、外国的、外国小组(貌似ip没有价值,query或response都可以伪装成不同的ip),于是ipgetr或ipfreq只能提供给测试人员。我要假装它是阿里的,于是我要编写一个接口去绕过受信服务器icmp检测等问题。当然,受信服务器不一定要连接阿里,这就直接无解了。 查看全部
绕过受信服务器icmp检测和网站验证的区别?
采集器采集并公开ip地址及端口,然后向网站发起授权检测请求,如果满足要求,就可以伪装。就像这样:图中的url就是伪装的效果图。目前的漏洞分析工具根本不记录此请求,因此不能过滤此类请求。而据说国内已经有了一款ip代理供应商,可以用其解决此类问题。似乎利用软件漏洞(mcasejawinkit)能伪装到非受信服务器ip上,而收集不到实际请求到达的ip,从而绕过服务器icmp检测和网站验证。
最简单的方法是,修改cms的ip判断机制。举个栗子。ngui对ip判断实现bug:ip判断机制更改为对网站实际请求ip而不是受信服务器(非icmp)请求ip。结果导致要发送请求还要向网站发送一个post请求,然后自动帮网站和开发实现验证(而不是接受请求,还得来点小动作提醒)。于是一个疑问摆在面前:同样是发请求,网站是不是就没了质疑的余地了呢?于是,很多存活的cms内置了ip功能。
比如可以假装ip有很多组,中国的、非中国的、外国的、外国小组(貌似ip没有价值,query或response都可以伪装成不同的ip),于是ipgetr或ipfreq只能提供给测试人员。我要假装它是阿里的,于是我要编写一个接口去绕过受信服务器icmp检测等问题。当然,受信服务器不一定要连接阿里,这就直接无解了。
安卓手机模拟登录网站,采集器采集格式是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 239 次浏览 • 2021-04-28 04:02
采集器采集格式一般是restfulapi采集,针对api进行压缩合并进行发布上线即可。
1、通过安卓手机模拟登录进入网站,找到广告位,
2、通过浏览器等渠道扫描进入网站,以登录状态进入,填写用户信息,
3、直接上传。
我现在采集的广告中都是502注册、弹出框框的。可以看我博客,不管什么格式都可以采集。记得分享喔。
方法倒是有,关键是需要一个工具来进行采集。
图片采集器,算法就是定义图片要获取的信息id,
我这里讲一个python编程的故事~故事起于某日室友打击提醒我的一个工具分析自己历史用户url提交过来的链接里面会出现一些比较难解释的"js"啥啥啥代码啥啥啥啥啥,所以再次确认了一下——等等为什么我读不懂这个js啊于是我觉得有必要重新敲一遍js,翻了以下大神的帖子有人说可以用浏览器兼容的机制进行判断。
于是让室友帮忙挂一个ua进行后端判断,然后给我回来了(可怜的室友)。你以为这样就结束了吗?并没有还有木有?为什么一个js这么厉害,那我这个项目好歹要做到多少数据呢?随手还抓了一个热点出来,试着提交一些链接,整个页面密密麻麻差点晕过去,此时的我都要丢了第一次编程的时候回过头来,看着那句“我在没有验证码的情况下抓了一个热点出来了呢”之后,我发现我是不是对js操作太过于高估我的能力了于是,我决定学习一下python,一开始,用的是搜狗浏览器,有一个提示:不管你是如何设置代理的,请确保站点加载后在前台显示开始的时候或结束的时候有一个隐藏页面:好了,虽然没理解这个,但为了交差,我还是决定把这个页面显示给搜狗看看,然后我就获取不到了因为我在看代码的时候发现从nginx抓包看,这个页面不能访问js,也就无法获取请求,所以我就放弃了这个进行分析了。
转而研究java的热点。在上两个图后我尝试用java抓热点失败。不过没关系,还有一个好消息我发现了send_extra_url(request.setrequest(url,e))可以强制多请求js,大功告成~以上。 查看全部
安卓手机模拟登录网站,采集器采集格式是什么?
采集器采集格式一般是restfulapi采集,针对api进行压缩合并进行发布上线即可。
1、通过安卓手机模拟登录进入网站,找到广告位,
2、通过浏览器等渠道扫描进入网站,以登录状态进入,填写用户信息,
3、直接上传。
我现在采集的广告中都是502注册、弹出框框的。可以看我博客,不管什么格式都可以采集。记得分享喔。
方法倒是有,关键是需要一个工具来进行采集。
图片采集器,算法就是定义图片要获取的信息id,
我这里讲一个python编程的故事~故事起于某日室友打击提醒我的一个工具分析自己历史用户url提交过来的链接里面会出现一些比较难解释的"js"啥啥啥代码啥啥啥啥啥,所以再次确认了一下——等等为什么我读不懂这个js啊于是我觉得有必要重新敲一遍js,翻了以下大神的帖子有人说可以用浏览器兼容的机制进行判断。
于是让室友帮忙挂一个ua进行后端判断,然后给我回来了(可怜的室友)。你以为这样就结束了吗?并没有还有木有?为什么一个js这么厉害,那我这个项目好歹要做到多少数据呢?随手还抓了一个热点出来,试着提交一些链接,整个页面密密麻麻差点晕过去,此时的我都要丢了第一次编程的时候回过头来,看着那句“我在没有验证码的情况下抓了一个热点出来了呢”之后,我发现我是不是对js操作太过于高估我的能力了于是,我决定学习一下python,一开始,用的是搜狗浏览器,有一个提示:不管你是如何设置代理的,请确保站点加载后在前台显示开始的时候或结束的时候有一个隐藏页面:好了,虽然没理解这个,但为了交差,我还是决定把这个页面显示给搜狗看看,然后我就获取不到了因为我在看代码的时候发现从nginx抓包看,这个页面不能访问js,也就无法获取请求,所以我就放弃了这个进行分析了。
转而研究java的热点。在上两个图后我尝试用java抓热点失败。不过没关系,还有一个好消息我发现了send_extra_url(request.setrequest(url,e))可以强制多请求js,大功告成~以上。
采集器采集 没学过java等语言,用正则处理过的数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-04-26 20:02
采集器采集的数据全部是网站的服务器的ip,直接用正则表达式匹配即可。把这些数据加到数据库中就行了,有专门做这方面的采集器。如果你要问的是导出数据的话,那还是重新写正则表达式算法去匹配你想要的数据吧。
因为关键部分没有给你指出,比如post传输参数等。这样的参数应该是自己写正则表达式处理过的,用python处理可以如此,
一般是通过抓包后的网页里边包含的json或xml格式
windows自带的mse自带正则表达式
通过加密的方式得到数据,你可以查一下加密技术是怎么实现的,一般都是通过破解方式加密传输数据,比如wep加密。
抓包后分析数据包并得到正则表达式
用正则表达式匹配即可.
加密方式最常用的是jsonp,可以用c#等工具做出来。没学过java等语言,不过也很常用。先写一个模拟的数据包(包括简单的xml、json、js),然后分析包里边的内容,用java正则表达式匹配获取结果。
使用正则表达式(可能需要了解正则表达式,
通过一定规则反查,
用户注册,设置cookie.
正则表达式搜索是将键匹配规则(特定的字符串特定的格式化规则,通常是正则表达式)用反斜杠(\)字符串替换成匹配的数字,计算相似度, 查看全部
采集器采集 没学过java等语言,用正则处理过的数据
采集器采集的数据全部是网站的服务器的ip,直接用正则表达式匹配即可。把这些数据加到数据库中就行了,有专门做这方面的采集器。如果你要问的是导出数据的话,那还是重新写正则表达式算法去匹配你想要的数据吧。
因为关键部分没有给你指出,比如post传输参数等。这样的参数应该是自己写正则表达式处理过的,用python处理可以如此,
一般是通过抓包后的网页里边包含的json或xml格式
windows自带的mse自带正则表达式
通过加密的方式得到数据,你可以查一下加密技术是怎么实现的,一般都是通过破解方式加密传输数据,比如wep加密。
抓包后分析数据包并得到正则表达式
用正则表达式匹配即可.
加密方式最常用的是jsonp,可以用c#等工具做出来。没学过java等语言,不过也很常用。先写一个模拟的数据包(包括简单的xml、json、js),然后分析包里边的内容,用java正则表达式匹配获取结果。
使用正则表达式(可能需要了解正则表达式,
通过一定规则反查,
用户注册,设置cookie.
正则表达式搜索是将键匹配规则(特定的字符串特定的格式化规则,通常是正则表达式)用反斜杠(\)字符串替换成匹配的数字,计算相似度,
采集程序的第一步是创建被采集的主机ip和网段、采集文件
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2021-04-25 05:07
采集器采集方法:采集程序的第一步是创建被采集的主机ip和网段、采集文件以及配置数据库,下面我们通过一个案例实例来学习一下。
既然是老站,那么你发现每次是不停的被停,一定会有这样的现象,时间久了会觉得很烦,但又没办法,于是百度了一下,看看有没有什么办法,写个程序吧!这么高端大气上档次的技术,如果要自己写,动用10几万甚至更多才能搞定,可是又怕太烦,于是找了一个有博客的,都是关于电脑的专业技术的,如果觉得也想学着做,可以看看thinkpad的老款键盘手机,不是android是iphone老款键盘手机,在手机设置里下载相应驱动就可以使用该手机,兼容性应该没问题,可以试试。
准备工作用wifi没有wifi了tp-link的光猫。连上wifi后,右键点击网络图标,选择打开无线网络共享中心,选择以太网,ipv4段手动分配ip地址,然后在选择对应的网关和网段进行连接。即可。
步骤:1、下载软件“youtubeconnect”2、进入youtube浏览器,上行打开tcp连接,不点连接就可以了:wi-fi选择不高速,直接上行的意思,上传速度和上传步骤没有关系,当然,用浏览器浏览时也不会有高速。这个连接可以让ip地址更接近1-9这样的整数,比如2-9。最后连接成功的话,你说的问题就不存在了,不必管制。 查看全部
采集程序的第一步是创建被采集的主机ip和网段、采集文件
采集器采集方法:采集程序的第一步是创建被采集的主机ip和网段、采集文件以及配置数据库,下面我们通过一个案例实例来学习一下。
既然是老站,那么你发现每次是不停的被停,一定会有这样的现象,时间久了会觉得很烦,但又没办法,于是百度了一下,看看有没有什么办法,写个程序吧!这么高端大气上档次的技术,如果要自己写,动用10几万甚至更多才能搞定,可是又怕太烦,于是找了一个有博客的,都是关于电脑的专业技术的,如果觉得也想学着做,可以看看thinkpad的老款键盘手机,不是android是iphone老款键盘手机,在手机设置里下载相应驱动就可以使用该手机,兼容性应该没问题,可以试试。
准备工作用wifi没有wifi了tp-link的光猫。连上wifi后,右键点击网络图标,选择打开无线网络共享中心,选择以太网,ipv4段手动分配ip地址,然后在选择对应的网关和网段进行连接。即可。
步骤:1、下载软件“youtubeconnect”2、进入youtube浏览器,上行打开tcp连接,不点连接就可以了:wi-fi选择不高速,直接上行的意思,上传速度和上传步骤没有关系,当然,用浏览器浏览时也不会有高速。这个连接可以让ip地址更接近1-9这样的整数,比如2-9。最后连接成功的话,你说的问题就不存在了,不必管制。
采集器采集到了txt文件,post给服务器,浏览器解析时使用编码格式
采集交流 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2021-04-23 18:02
采集器采集到了txt文件,post给服务器,服务器存储txt给浏览器,浏览器解析,前端js或css渲染。.alias+路径(._alias)等于以下格式{"info":"4位数的英文字母作为密码","password":"123456"}在浏览器访问,
服务器传给浏览器后,跟原始txt内容进行hash后,浏览器提交给服务器,服务器解析后生成一个post的json数据,这个json数据里的数据有用户登陆时输入的密码、发送时传递给服务器的getrequest、postrequest、响应返回json数据等。要想解析的话就用python实现:python-pipinstallbeautifulsouprequests。
来来来。我来告诉你答案吧。服务器接收,客户端解析,(服务器响应)传给浏览器。服务器:frombs4importbeautifulsoupimportrequestsfrombs4importhtml_encodeimportrefrombs4importrequestsimporttimehostname='127.0.0.1'server='server.localhost'username='tx'password='123456'addr='127.0.0.1'port=2002password='zhangsan'#设置动态域名。
list=['.alias','.hash','.code','.cookie']#传递上述两个字符串,用于后续解析urls='/api'#postrequestcookie={'name':'zhangsan','password':'123456'}response=requests.get(hostname,username,port)#获取response中的所有html字符串、text字符串和用户输入密码doc='<p>{0}{1}</a>'html_encode(response)#编码方式response.encode('utf-8')#编码方式,当发起http请求给浏览器,浏览器解析时使用编码格式#postrequestencode=pile(r'')encode+='utf-8'#编码加密方式,返回会是一堆乱码json_list=[' 查看全部
采集器采集到了txt文件,post给服务器,浏览器解析时使用编码格式
采集器采集到了txt文件,post给服务器,服务器存储txt给浏览器,浏览器解析,前端js或css渲染。.alias+路径(._alias)等于以下格式{"info":"4位数的英文字母作为密码","password":"123456"}在浏览器访问,
服务器传给浏览器后,跟原始txt内容进行hash后,浏览器提交给服务器,服务器解析后生成一个post的json数据,这个json数据里的数据有用户登陆时输入的密码、发送时传递给服务器的getrequest、postrequest、响应返回json数据等。要想解析的话就用python实现:python-pipinstallbeautifulsouprequests。
来来来。我来告诉你答案吧。服务器接收,客户端解析,(服务器响应)传给浏览器。服务器:frombs4importbeautifulsoupimportrequestsfrombs4importhtml_encodeimportrefrombs4importrequestsimporttimehostname='127.0.0.1'server='server.localhost'username='tx'password='123456'addr='127.0.0.1'port=2002password='zhangsan'#设置动态域名。
list=['.alias','.hash','.code','.cookie']#传递上述两个字符串,用于后续解析urls='/api'#postrequestcookie={'name':'zhangsan','password':'123456'}response=requests.get(hostname,username,port)#获取response中的所有html字符串、text字符串和用户输入密码doc='<p>{0}{1}</a>'html_encode(response)#编码方式response.encode('utf-8')#编码方式,当发起http请求给浏览器,浏览器解析时使用编码格式#postrequestencode=pile(r'')encode+='utf-8'#编码加密方式,返回会是一堆乱码json_list=['
一种模拟dns分析的方法,让你的数据上传成功
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-04-20 03:03
采集器采集到的每一段移动的数据都会经过一个上传数据的数据库,然后根据有上传时间,浏览器浏览时间,以及文件大小,来设置一个容错率。这个容错率,是设置数据采集后如果出现报错无法上传完整数据,补充一个错误数据并且重新上传后再次进行采集,错误数据不会在之前的数据库。如果文件超过容错率直接上传完整数据时会按照50%的流量。
说以下是一种模拟dns分析的方法,如果提问者问的是google,国内只有一个解决方案。在浏览器里填写的是你的用户名和密码。将dns查询的结果发送到你注册的邮箱中,要注意的是这个邮箱如果是gmail的话,然后你的本地电脑接收到邮件,文件的id是是根据用户名和邮箱的匹配来判断的。根据匹配值判断就是正确的。
然后上传。另外,提问者提到的缓存技术,可以通过google的gcm算法来解决。把你的gcm服务器上数据先缓存,然后你就会发现缓存中的数据是很新鲜的,很快就能上传成功。gmail的话可以参考googleplus帮助中文版。
几台电脑?
理论上是不可以的,搜索结果由多台电脑提供,只要有一台电脑没有问题,其他电脑都可以提供服务,至于上传过程中会不会出现文件损坏以及数据丢失等问题,我不清楚。
工信部--准入制度
我估计你弄这个估计是用户管理的一些限制措施。 查看全部
一种模拟dns分析的方法,让你的数据上传成功
采集器采集到的每一段移动的数据都会经过一个上传数据的数据库,然后根据有上传时间,浏览器浏览时间,以及文件大小,来设置一个容错率。这个容错率,是设置数据采集后如果出现报错无法上传完整数据,补充一个错误数据并且重新上传后再次进行采集,错误数据不会在之前的数据库。如果文件超过容错率直接上传完整数据时会按照50%的流量。
说以下是一种模拟dns分析的方法,如果提问者问的是google,国内只有一个解决方案。在浏览器里填写的是你的用户名和密码。将dns查询的结果发送到你注册的邮箱中,要注意的是这个邮箱如果是gmail的话,然后你的本地电脑接收到邮件,文件的id是是根据用户名和邮箱的匹配来判断的。根据匹配值判断就是正确的。
然后上传。另外,提问者提到的缓存技术,可以通过google的gcm算法来解决。把你的gcm服务器上数据先缓存,然后你就会发现缓存中的数据是很新鲜的,很快就能上传成功。gmail的话可以参考googleplus帮助中文版。
几台电脑?
理论上是不可以的,搜索结果由多台电脑提供,只要有一台电脑没有问题,其他电脑都可以提供服务,至于上传过程中会不会出现文件损坏以及数据丢失等问题,我不清楚。
工信部--准入制度
我估计你弄这个估计是用户管理的一些限制措施。
采集器采集精度太低?你可能需要深度解析采集数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 313 次浏览 • 2021-04-16 06:04
采集器采集精度太低?你可能需要深度解析采集数据了如果精度要求不高,jpg、jpeg-dwg之类的也可以采集得到,可以参考我个人写的那个网站:请搜索jpg、jpeg之类的图片文件,
可以考虑通过fpga之类的数字对进程进行串口,获取采集端的数据,也可以建立完整的路由表。我这边有提供采集端对某个热点点的配置,
可以考虑一下。你这个问题,
目前没有很好的解决方案,网络电脑本身已经支持了比如对采集人人进行拦截,另外即使以后出现相应解决方案,拦截程序性能也不一定好。这个问题可以通过adsl传输缓存解决,大多数上层软件会自动加载需要的数据,避免让第三方拦截而对硬件进行挂断数据的读取这样会简单很多,也不需要在相应的硬件上创建冗余,而且对用户信息也没有影响。
既然邀请,我就答一下吧()1.可以在电脑上向外部发送一个帧,然后在电脑上,通过帧去判断你需要的图像是否被采集了这个应该没啥好办法,软件不可行,硬件不可行不过你可以想想办法看看能不能联网对图像进行拼接,估计拼接的时候那么多帧,采集的连一半都不到。2.如果你的网卡是以太网认证的,那么可以去装个d-data之类的管理软件,然后想办法在你的电脑上接一个网口给他转,让他知道你的data地址,然后你就可以去采集了。
3.试试通过网线或者光纤,如果能找到连上的电脑,也可以用他自带的采集功能以上是我瞎猜的哈--题主赶紧把问题补充清楚,估计搜索结果更多参考答案:photoeditor是一个什么软件?-知乎。 查看全部
采集器采集精度太低?你可能需要深度解析采集数据
采集器采集精度太低?你可能需要深度解析采集数据了如果精度要求不高,jpg、jpeg-dwg之类的也可以采集得到,可以参考我个人写的那个网站:请搜索jpg、jpeg之类的图片文件,
可以考虑通过fpga之类的数字对进程进行串口,获取采集端的数据,也可以建立完整的路由表。我这边有提供采集端对某个热点点的配置,
可以考虑一下。你这个问题,
目前没有很好的解决方案,网络电脑本身已经支持了比如对采集人人进行拦截,另外即使以后出现相应解决方案,拦截程序性能也不一定好。这个问题可以通过adsl传输缓存解决,大多数上层软件会自动加载需要的数据,避免让第三方拦截而对硬件进行挂断数据的读取这样会简单很多,也不需要在相应的硬件上创建冗余,而且对用户信息也没有影响。
既然邀请,我就答一下吧()1.可以在电脑上向外部发送一个帧,然后在电脑上,通过帧去判断你需要的图像是否被采集了这个应该没啥好办法,软件不可行,硬件不可行不过你可以想想办法看看能不能联网对图像进行拼接,估计拼接的时候那么多帧,采集的连一半都不到。2.如果你的网卡是以太网认证的,那么可以去装个d-data之类的管理软件,然后想办法在你的电脑上接一个网口给他转,让他知道你的data地址,然后你就可以去采集了。
3.试试通过网线或者光纤,如果能找到连上的电脑,也可以用他自带的采集功能以上是我瞎猜的哈--题主赶紧把问题补充清楚,估计搜索结果更多参考答案:photoeditor是一个什么软件?-知乎。
采集器采集的是用户的第一行代码怎么抓?
采集交流 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2021-04-09 04:06
采集器采集的是用户的第一行代码,然后通过url地址进行request接口发送给api服务器,获取用户的相关数据,比如帐号密码等等,如果你的api服务器不知道用户的url地址,那么这个用户的相关数据是无法采集的。
个人推测一下,感觉这个采集可能是api帮你把数据给抓出来,至于怎么抓数据,肯定不是你指定的地址。你不了解的话,可以查查api发送方不同的接口可能都会设置不同的接口地址。对方使用哪个,就抓取哪个。
应该抓取的是request地址发送到api然后调用api发送抓取地址在数据处理过程中,为了在服务端减少泄露的情况出现,有可能把第一个请求设置的是自定义的域名,
用采集器采集数据是在浏览器访问,而不是api服务器。你想怎么抓就怎么抓。
没这回事,不过还是得试试,要么就用正则去抓,如果你那么懒或者那么笨,
那个api只是代理而已,意思就是要你自己做header攻击,才能抓取你的数据。
用爬虫程序一般情况下都不需要注册api服务器,所以说采集你的第一行代码,然后从你第一行代码开始通过你设置的url去下载数据是没问题的。
你给这个程序加一个登录功能,直接从你的微信获取,然后一步步从你的微信里的用户列表获取。 查看全部
采集器采集的是用户的第一行代码怎么抓?
采集器采集的是用户的第一行代码,然后通过url地址进行request接口发送给api服务器,获取用户的相关数据,比如帐号密码等等,如果你的api服务器不知道用户的url地址,那么这个用户的相关数据是无法采集的。
个人推测一下,感觉这个采集可能是api帮你把数据给抓出来,至于怎么抓数据,肯定不是你指定的地址。你不了解的话,可以查查api发送方不同的接口可能都会设置不同的接口地址。对方使用哪个,就抓取哪个。
应该抓取的是request地址发送到api然后调用api发送抓取地址在数据处理过程中,为了在服务端减少泄露的情况出现,有可能把第一个请求设置的是自定义的域名,
用采集器采集数据是在浏览器访问,而不是api服务器。你想怎么抓就怎么抓。
没这回事,不过还是得试试,要么就用正则去抓,如果你那么懒或者那么笨,
那个api只是代理而已,意思就是要你自己做header攻击,才能抓取你的数据。
用爬虫程序一般情况下都不需要注册api服务器,所以说采集你的第一行代码,然后从你第一行代码开始通过你设置的url去下载数据是没问题的。
你给这个程序加一个登录功能,直接从你的微信获取,然后一步步从你的微信里的用户列表获取。
采集器采集 我买了两年了php和mysql,并没有发现这些
采集交流 • 优采云 发表了文章 • 0 个评论 • 255 次浏览 • 2021-03-28 00:05
采集器采集失败而已,
看到这里也是醉了,我买了两年了php和mysql,并没有发现这些。建议你尝试用以下原因解决1.认识的人自己网页没上传成功。2.软件有问题,被破解了3.认识的人的账号已经被别人注册了,
直接上传,如果还不行,
这个问题不像是苹果客服应该找邮箱方面的问题
你用的什么工具,php代码的错误,
1.php没安装好2.php配置问题3.管理员帐号有问题
同意白色哲的回答,我也曾遇到过,去管理员帐号找,或者管理员邮箱不要了,
ipconfig/etc/passwd看看帐号管理密码是不是空的,
1.是对方主机没设置php授权给你;2.对方已经用账号密码登录过你的php。
src/init.php的require_once='true';
有些人浏览器的路径名字可能有问题,php会在你搜索的时候在那里加载你设置好的路径,导致你用https连接后会挂起。
原因应该是你网站设置的https被对方破解了吧
我发现你这么大动作,whyareyoulookingformywomen?你咋不ping一下邮箱看看对方有没有注册你的,有就ping对方没有,就上传一下就ok了,反正是设置好的,不会有错的,就是这样。我瞎猜的。 查看全部
采集器采集 我买了两年了php和mysql,并没有发现这些
采集器采集失败而已,
看到这里也是醉了,我买了两年了php和mysql,并没有发现这些。建议你尝试用以下原因解决1.认识的人自己网页没上传成功。2.软件有问题,被破解了3.认识的人的账号已经被别人注册了,
直接上传,如果还不行,
这个问题不像是苹果客服应该找邮箱方面的问题
你用的什么工具,php代码的错误,
1.php没安装好2.php配置问题3.管理员帐号有问题
同意白色哲的回答,我也曾遇到过,去管理员帐号找,或者管理员邮箱不要了,
ipconfig/etc/passwd看看帐号管理密码是不是空的,
1.是对方主机没设置php授权给你;2.对方已经用账号密码登录过你的php。
src/init.php的require_once='true';
有些人浏览器的路径名字可能有问题,php会在你搜索的时候在那里加载你设置好的路径,导致你用https连接后会挂起。
原因应该是你网站设置的https被对方破解了吧
我发现你这么大动作,whyareyoulookingformywomen?你咋不ping一下邮箱看看对方有没有注册你的,有就ping对方没有,就上传一下就ok了,反正是设置好的,不会有错的,就是这样。我瞎猜的。
采集器采集得到的数据,给搞混乱了要填资料多填
采集交流 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2021-03-26 05:04
采集器采集得到的数据,然后让别人来填写正常的,网页里面往往会把下载,从别人的电脑传的这些数据,给搞混乱了,要填资料多填一点,最后要打印出来带走的。
是有部分网站可以通过浏览器拿到这些内容的,不过大部分网站是明文的,就算不通过采集器也能从网站发送过来。电脑拿的话比较费劲,不过也是有实现的办法的。
有一个浏览器插件叫burp,
以前思考过类似问题,我用自己的经验告诉楼主。对于一些网站确实是拿不到的,但是有一些在后台存储,并且处理好拿回来了。当然做这种工作的技术人员也不少,只不过我并没有遇到过。
他会把处理回来的数据存在后台一起发给网站
不算泄露,这都是从服务器来的,和你没啥关系,不过会有处理过的数据,
没关系的,都能存起来啊,
有些网站回传的数据没啥用,
肯定是需要第三方来提供数据的啊。像一些银行网站用的是实名认证、手机卡认证的方式来保证用户的安全性,如果这些信息泄露出去,我相信大部分人就不愿意去用银行,而这个根本就是用户密码的来源。所以某些网站就会采用这种方式,另外其他的用户就可以通过这些已经拿到信息的资源来在他们的网站使用或者进行注册了。 查看全部
采集器采集得到的数据,给搞混乱了要填资料多填
采集器采集得到的数据,然后让别人来填写正常的,网页里面往往会把下载,从别人的电脑传的这些数据,给搞混乱了,要填资料多填一点,最后要打印出来带走的。
是有部分网站可以通过浏览器拿到这些内容的,不过大部分网站是明文的,就算不通过采集器也能从网站发送过来。电脑拿的话比较费劲,不过也是有实现的办法的。
有一个浏览器插件叫burp,
以前思考过类似问题,我用自己的经验告诉楼主。对于一些网站确实是拿不到的,但是有一些在后台存储,并且处理好拿回来了。当然做这种工作的技术人员也不少,只不过我并没有遇到过。
他会把处理回来的数据存在后台一起发给网站
不算泄露,这都是从服务器来的,和你没啥关系,不过会有处理过的数据,
没关系的,都能存起来啊,
有些网站回传的数据没啥用,
肯定是需要第三方来提供数据的啊。像一些银行网站用的是实名认证、手机卡认证的方式来保证用户的安全性,如果这些信息泄露出去,我相信大部分人就不愿意去用银行,而这个根本就是用户密码的来源。所以某些网站就会采用这种方式,另外其他的用户就可以通过这些已经拿到信息的资源来在他们的网站使用或者进行注册了。
采集器采集网页上的cookie和服务器的区别?
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2021-03-24 20:06
采集器采集网页上的cookie,然后服务器根据记录的网址来返回结果页面,
我说一下两者的区别啊ajax:javascript控制页面刷新切换到后台,javascript里写一些查询参数来做实时的数据更新。javascript返回xml,发送给java来实现后台数据的增删改查及订单生成。flash:javascript只是为网页播放提供交互功能,比如推荐banner之类。
ajax技术前端使用在ajax的过程中,客户端和服务端通过socket进行数据交互。客户端和服务端开始发送一个xml数据包。xml数据包发送完成之后,服务端会回应一个json数据包,这时网页会根据json数据包里面的json数据继续往下发送数据。flash技术前端使用flash技术,是用来实现前端动画交互和一些特效的技术。这些特效都是可以通过程序来实现,前端通过代码实现后端与后端之间的数据交互。
ajax:客户端和服务端通过一个javascript对象,建立一个连接,当客户端请求数据时,服务端会调用服务端的javascript对象去执行对应的动作,由服务端反馈结果给客户端。flash:是一种通过请求附加一个图片资源到网页的技术,
网页数据可以说来源于文本(文本作为一种基本数据类型),或者二进制数据(byte数据),或者json数据文件。关键技术不是xml,xmlxhtml=xml,而ajax不是xml。 查看全部
采集器采集网页上的cookie和服务器的区别?
采集器采集网页上的cookie,然后服务器根据记录的网址来返回结果页面,
我说一下两者的区别啊ajax:javascript控制页面刷新切换到后台,javascript里写一些查询参数来做实时的数据更新。javascript返回xml,发送给java来实现后台数据的增删改查及订单生成。flash:javascript只是为网页播放提供交互功能,比如推荐banner之类。
ajax技术前端使用在ajax的过程中,客户端和服务端通过socket进行数据交互。客户端和服务端开始发送一个xml数据包。xml数据包发送完成之后,服务端会回应一个json数据包,这时网页会根据json数据包里面的json数据继续往下发送数据。flash技术前端使用flash技术,是用来实现前端动画交互和一些特效的技术。这些特效都是可以通过程序来实现,前端通过代码实现后端与后端之间的数据交互。
ajax:客户端和服务端通过一个javascript对象,建立一个连接,当客户端请求数据时,服务端会调用服务端的javascript对象去执行对应的动作,由服务端反馈结果给客户端。flash:是一种通过请求附加一个图片资源到网页的技术,
网页数据可以说来源于文本(文本作为一种基本数据类型),或者二进制数据(byte数据),或者json数据文件。关键技术不是xml,xmlxhtml=xml,而ajax不是xml。
采集器采集 ai:申请一下自己发明专利,成本都省了
采集交流 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2021-03-20 20:00
采集器采集文本,转化为信号,可以做标注。关键是,经过合成,很多情况下你还能听到自己说话的,只是没声。我在一次全球性会议上,听到一位生成科学家和他的一位博士合作做这方面的研究,很有兴趣。以下是bing搜索结果,可能不一定准确(有些地方我就觉得奇怪,他为啥要找博士合作研究标注?博士不应该是挺容易找的吗?还专门用人标注,这个研究单位这样多才对吧)。
我之前参加过智能陪训,现在有了“ai再普通不过了”的宣传图,我一直都觉得现在基本的识别技术很难靠噱头做出来,真正做人机对话并且把ai这个技术推向市场的是做做合作式的合作伙伴。就现在就已经有人说自己会ai合成。高校里,每年都会有各种研究生毕业,要求给人机对话机器人配合课程就很常见了,不可否认我们说一句话几十年前的马达加斯加的“鸭子”机器人就已经搞定了,现在我问你怎么把你自己的转换成一个ai合成的,你能非常精确的告诉我,哪怕在国内没有人机对话,你至少说“是”。
先不说解决不解决问题。可不可以申请一下自己发明专利啊,成本都省了。
无人机外语配音
提高学校英语配音课比例,
问题不在“可能”,而在“关系”。希望主要从两方面去思考,一是为什么“想”要用ai,二是“关系”如何处理。先说第一个问题:为什么是“想”而不是“需要”人机对话,可以简单地把它当做两人的情感交流。发展ai这个专业,同样也是为了帮助那些不会说话的人找到他们的存在,了解他们的感受。发展人工智能的过程中,第一点我们担心的是人工智能会丧失自己的语言功能。
“死机”这种情况肯定会有的,为了不让那种情况发生,我们就需要定制一套语言系统,让人工智能更高效的沟通,打交道。毕竟,工作在忙碌的工作环境中的人难免会有那么多地方不方便说话。自然地,我们先要解决这个问题。第二个问题,就是如何处理语言知识数据的问题。或者说,是如何生成我们需要的语言,才能让别人听懂我们要表达的语言。
第一个想法,是直接借助ai技术来采集和存储相关的语言知识。第二个想法,就是通过已经掌握了语言知识的人的语言,来构建对话模型。传统的对话模型,被认为是一个从结构化数据生成问答。事实上,到现在为止,这种模型的水平,只能做到以字为单位,回答语法结构一致,但语义差别很大的句子。所以针对这种情况,便开发了文本问答交互。以问答交互为基础,得到更高质量,同时结构化的数据来生成更高质量的文本交互语言。这里的目的是为了让。 查看全部
采集器采集 ai:申请一下自己发明专利,成本都省了
采集器采集文本,转化为信号,可以做标注。关键是,经过合成,很多情况下你还能听到自己说话的,只是没声。我在一次全球性会议上,听到一位生成科学家和他的一位博士合作做这方面的研究,很有兴趣。以下是bing搜索结果,可能不一定准确(有些地方我就觉得奇怪,他为啥要找博士合作研究标注?博士不应该是挺容易找的吗?还专门用人标注,这个研究单位这样多才对吧)。
我之前参加过智能陪训,现在有了“ai再普通不过了”的宣传图,我一直都觉得现在基本的识别技术很难靠噱头做出来,真正做人机对话并且把ai这个技术推向市场的是做做合作式的合作伙伴。就现在就已经有人说自己会ai合成。高校里,每年都会有各种研究生毕业,要求给人机对话机器人配合课程就很常见了,不可否认我们说一句话几十年前的马达加斯加的“鸭子”机器人就已经搞定了,现在我问你怎么把你自己的转换成一个ai合成的,你能非常精确的告诉我,哪怕在国内没有人机对话,你至少说“是”。
先不说解决不解决问题。可不可以申请一下自己发明专利啊,成本都省了。
无人机外语配音
提高学校英语配音课比例,
问题不在“可能”,而在“关系”。希望主要从两方面去思考,一是为什么“想”要用ai,二是“关系”如何处理。先说第一个问题:为什么是“想”而不是“需要”人机对话,可以简单地把它当做两人的情感交流。发展ai这个专业,同样也是为了帮助那些不会说话的人找到他们的存在,了解他们的感受。发展人工智能的过程中,第一点我们担心的是人工智能会丧失自己的语言功能。
“死机”这种情况肯定会有的,为了不让那种情况发生,我们就需要定制一套语言系统,让人工智能更高效的沟通,打交道。毕竟,工作在忙碌的工作环境中的人难免会有那么多地方不方便说话。自然地,我们先要解决这个问题。第二个问题,就是如何处理语言知识数据的问题。或者说,是如何生成我们需要的语言,才能让别人听懂我们要表达的语言。
第一个想法,是直接借助ai技术来采集和存储相关的语言知识。第二个想法,就是通过已经掌握了语言知识的人的语言,来构建对话模型。传统的对话模型,被认为是一个从结构化数据生成问答。事实上,到现在为止,这种模型的水平,只能做到以字为单位,回答语法结构一致,但语义差别很大的句子。所以针对这种情况,便开发了文本问答交互。以问答交互为基础,得到更高质量,同时结构化的数据来生成更高质量的文本交互语言。这里的目的是为了让。
采集器采集到用户输入的localtime()和localtime的值
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2021-02-11 12:03
采集器采集到用户输入的localtime()和localtime()的值然后concurrenttime()。采集数据库是通过读数据库的时间进行分隔从而确定要读取的时间。ps:localtime()是百度统计里面为了好看而弄出来的。
只知道concurrenttimeoffset(实现起来不复杂,
web统计不太清楚,开发统计前肯定要完成数据抓取和数据存储的功能,根据用户输入的时间进行分隔。数据抓取一般用cookiehttps请求可能要放权限,存储一般和统计有关的可以先在web上做一个页面分析。
javaweb统计只有一个思路,在客户端通过重定向监听,然后根据页面的http头中的cookie判断应该访问的哪个服务器,
数据抓取应该是通过javaweb来做。大概的流程:获取数据response,web业务逻辑读取response里的methodcode,返回结果给具体的系统。给php服务器返回数据。给excel服务器返回数据。
模拟请求百度统计,判断url是否正确。返回参数concurrenttimeoffset。按照这个参数返回相应的统计数据。至于跨站请求伪造,
pythonweb爬虫?
我曾经有一段时间在百度统计(当时还叫“百度漂流计划”)呆过。我记得我也没啥经验吧?反正就是请求嘛,一般都是通过json,要记得weburl必须完整传递给webserver,比如curljs,khanapache。你应该已经请求到服务器。一般你是可以打印出他们的httpcookie的,还有就是看当时每个数据库的用户输入的密码吧。 查看全部
采集器采集到用户输入的localtime()和localtime的值
采集器采集到用户输入的localtime()和localtime()的值然后concurrenttime()。采集数据库是通过读数据库的时间进行分隔从而确定要读取的时间。ps:localtime()是百度统计里面为了好看而弄出来的。
只知道concurrenttimeoffset(实现起来不复杂,
web统计不太清楚,开发统计前肯定要完成数据抓取和数据存储的功能,根据用户输入的时间进行分隔。数据抓取一般用cookiehttps请求可能要放权限,存储一般和统计有关的可以先在web上做一个页面分析。
javaweb统计只有一个思路,在客户端通过重定向监听,然后根据页面的http头中的cookie判断应该访问的哪个服务器,
数据抓取应该是通过javaweb来做。大概的流程:获取数据response,web业务逻辑读取response里的methodcode,返回结果给具体的系统。给php服务器返回数据。给excel服务器返回数据。
模拟请求百度统计,判断url是否正确。返回参数concurrenttimeoffset。按照这个参数返回相应的统计数据。至于跨站请求伪造,
pythonweb爬虫?
我曾经有一段时间在百度统计(当时还叫“百度漂流计划”)呆过。我记得我也没啥经验吧?反正就是请求嘛,一般都是通过json,要记得weburl必须完整传递给webserver,比如curljs,khanapache。你应该已经请求到服务器。一般你是可以打印出他们的httpcookie的,还有就是看当时每个数据库的用户输入的密码吧。
操作方法:Python爬虫学习第二章-2-使用requests模块实现网页采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 307 次浏览 • 2020-10-24 13:00
Python爬虫学习的第二章-使用请求模块实现网页采集器
此部分使用请求来抓取与搜狗中指定字词(即网页采集器)相对应的搜索结果页
1、首先介绍防爬机制和防爬策略:
防爬升机制和防爬升策略:UA(用户代理:请求载体的身份。如果请求是由浏览器发起的,则当前请求载体的身份就是浏览器; request.get方法也可以发起请求。这时,请求载体的身份不再是浏览器,而是爬虫)
以后必须在每种情况下应用UA伪装
2、网页代码采集器:
import requests
if __name__=="__main__":
#step1:指定url并进行UA伪装
#进行UA伪装:将对应的User-Agent封装到一个字典中,headers参数作用在get方法中,是get方法的参数,此处用的User-Agent是谷歌浏览器,也就是伪装成了谷歌浏览器
url = 'https://www.sogou.com/web?'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
#处理url携带的参数:将url所携带的参数封装到字典中
kw = input('enter a word:')
param = {
'query':kw
}
#step2:发起请求
#对指定的url发起的请求对应的url是携带参数的,并且的请求过程中处理了参数
response=requests.get(url = url,params=param,headers=headers) #params表示参数,动态拼接参数,headers表示UA伪装,此处是伪装成谷歌浏览器
#step3:获取数据
page_text = response.text
#step4:持久化存储 注意存储代码的写法
filename = kw+'.html'
with open(filename,'w',encoding='utf-8') as fp:
fp.write(page_text)
print(filename,'保存成功')
请注意with with open的使用:with open用于打开本地文件。处理完文件后,该文件将自动关闭,而无需手动编写close()。
在此处查看一些博客文章:
“您了解open和open的用法吗?”
“如何与open()一起使用”
“如何在打开时使用” 查看全部
Python爬虫学习的第二章-使用请求模块实现网页采集器
Python爬虫学习的第二章-使用请求模块实现网页采集器
此部分使用请求来抓取与搜狗中指定字词(即网页采集器)相对应的搜索结果页
1、首先介绍防爬机制和防爬策略:
防爬升机制和防爬升策略:UA(用户代理:请求载体的身份。如果请求是由浏览器发起的,则当前请求载体的身份就是浏览器; request.get方法也可以发起请求。这时,请求载体的身份不再是浏览器,而是爬虫)
以后必须在每种情况下应用UA伪装
2、网页代码采集器:
import requests
if __name__=="__main__":
#step1:指定url并进行UA伪装
#进行UA伪装:将对应的User-Agent封装到一个字典中,headers参数作用在get方法中,是get方法的参数,此处用的User-Agent是谷歌浏览器,也就是伪装成了谷歌浏览器
url = 'https://www.sogou.com/web?'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
#处理url携带的参数:将url所携带的参数封装到字典中
kw = input('enter a word:')
param = {
'query':kw
}
#step2:发起请求
#对指定的url发起的请求对应的url是携带参数的,并且的请求过程中处理了参数
response=requests.get(url = url,params=param,headers=headers) #params表示参数,动态拼接参数,headers表示UA伪装,此处是伪装成谷歌浏览器
#step3:获取数据
page_text = response.text
#step4:持久化存储 注意存储代码的写法
filename = kw+'.html'
with open(filename,'w',encoding='utf-8') as fp:
fp.write(page_text)
print(filename,'保存成功')
请注意with with open的使用:with open用于打开本地文件。处理完文件后,该文件将自动关闭,而无需手动编写close()。
在此处查看一些博客文章:
“您了解open和open的用法吗?”
“如何与open()一起使用”
“如何在打开时使用”
无人值守采集器下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 295 次浏览 • 2020-08-25 18:32
采集器下载_无人值守采集器下载_采集器使用教程
网站管理员希望将他人的整站数据下载到自己的网站里或则将他人网站的一些内容保存到自己的服务器上。从内容中抽取相关的数组,发布到自己的网站系统中。有时须要将网页相关的文件也保存到本地,如图片、附件等。网站管理员会定时从同一网站上抓取内容,希望早已抓取的内容不要再发布到网站系统中。对于一些网站,需要登录就能获取页面。网站管理员希望通才能通过一个内容列表页面获取所有的相关内容,包括内容列表的其它分页。当第二次抓取相同网站时,希望不要再重复第一次的设定
共有个相关软件
EditorTools V3.41 绿色版 中小网站自动更新神器
中小网站自动更新神器,同时将采集后的数据手动发布到自己自己网站上,无需任何的人工操作
家庭无人值守实时监控 看门狗 v1.0 中文官方免费版
看门狗是国外第一款家饰安保软件,集多媒体技术图象动态辨识,人脸辨识,环境趋势预测,互联网,跨网传输等多项前沿技术于一体.充分利用家庭现有电脑摄像头等硬件资源,实现家庭
博客虫虫新浪博客推广全能软件 v6.28 绿色英文免费版
本软件是当前最好的博客营销,推广软件,只需简单操作即可实现全手动无人职守运行。
无人值守全手动采集助手Editor Tools v3.5 中文免费绿色版
免费采集软件EditorTools是中小网站自动更新神器,全手动采集发布,静默工作无须人工干预;独立软件减免网站性能消耗;安全稳定,可长年累月不间断工作
ET 无人值守采集助手应用软件 v2.4.24 绿色版
网站要保持活力,则每日的内容更新是基础。一个大型网站保证每日更新,通常须要站长每晚承当更新工作8小时,且假期无休;
ET 无人值守免费手动采集器 3.5 绿色版
免费采集软件,是中小网站自动更新神器,全手动采集发布,运行期间沉静工作,无须人工干预;独立软件减免网站性能消耗;安全稳定,可长年累月不间断工作。
ET 无人值守采集助手 v2.0.2 正式版
EditorTools 2 正式版 —— 中小网站自动更新神器! 声明:本软件适宜须要常年更新内容的非临时性网站使用,不需要你对现有峰会或网站做任何更改。 【
优采云采集器(www.ucaiyun.com) 网页数据采集利器 V9.10.0 中文免费安
www.ucaiyun.com是一款十分专业的数据采集软件,该软件功能强悍,为广大用户提供了网路数据采集以及信息挖掘等功能
优采云采集器(www.ucaiyun.com) v2009 炎黄网路合作版 商业版
优采云采集器V2009SP2版要求:您的笔记本必须安装.net framework2.0或2.0以上框架 附windows .net framework 2.0下载地址:
优采云采集器(www.ucaiyun.com) v2009 sp2 Build 20090428
一款免费的,功能强悍的网路数据采集软件,可以快速高效的获取网路上的文字,图片,下载等资源,将您从重复的复制粘贴中解放下来。 软件简介: 优采云采集器(www.ucaiyun.com)
优采云采集器 V2008 官方即将最新版
今天也是优采云采集器又一个新高度的版本-V2008版发布的日子,多少个日夜的不懈努力,我们赶上了这个日子,希望能为广大站长,以及正式闭幕的广州亚运献上一份薄利! LocoyS
相关软件
相关文章
专题推荐
查看全部
无人值守采集器下载

采集器下载_无人值守采集器下载_采集器使用教程
网站管理员希望将他人的整站数据下载到自己的网站里或则将他人网站的一些内容保存到自己的服务器上。从内容中抽取相关的数组,发布到自己的网站系统中。有时须要将网页相关的文件也保存到本地,如图片、附件等。网站管理员会定时从同一网站上抓取内容,希望早已抓取的内容不要再发布到网站系统中。对于一些网站,需要登录就能获取页面。网站管理员希望通才能通过一个内容列表页面获取所有的相关内容,包括内容列表的其它分页。当第二次抓取相同网站时,希望不要再重复第一次的设定
共有个相关软件
EditorTools V3.41 绿色版 中小网站自动更新神器

中小网站自动更新神器,同时将采集后的数据手动发布到自己自己网站上,无需任何的人工操作
家庭无人值守实时监控 看门狗 v1.0 中文官方免费版
看门狗是国外第一款家饰安保软件,集多媒体技术图象动态辨识,人脸辨识,环境趋势预测,互联网,跨网传输等多项前沿技术于一体.充分利用家庭现有电脑摄像头等硬件资源,实现家庭
博客虫虫新浪博客推广全能软件 v6.28 绿色英文免费版
本软件是当前最好的博客营销,推广软件,只需简单操作即可实现全手动无人职守运行。
无人值守全手动采集助手Editor Tools v3.5 中文免费绿色版
免费采集软件EditorTools是中小网站自动更新神器,全手动采集发布,静默工作无须人工干预;独立软件减免网站性能消耗;安全稳定,可长年累月不间断工作
ET 无人值守采集助手应用软件 v2.4.24 绿色版
网站要保持活力,则每日的内容更新是基础。一个大型网站保证每日更新,通常须要站长每晚承当更新工作8小时,且假期无休;
ET 无人值守免费手动采集器 3.5 绿色版
免费采集软件,是中小网站自动更新神器,全手动采集发布,运行期间沉静工作,无须人工干预;独立软件减免网站性能消耗;安全稳定,可长年累月不间断工作。
ET 无人值守采集助手 v2.0.2 正式版
EditorTools 2 正式版 —— 中小网站自动更新神器! 声明:本软件适宜须要常年更新内容的非临时性网站使用,不需要你对现有峰会或网站做任何更改。 【
优采云采集器(www.ucaiyun.com) 网页数据采集利器 V9.10.0 中文免费安
www.ucaiyun.com是一款十分专业的数据采集软件,该软件功能强悍,为广大用户提供了网路数据采集以及信息挖掘等功能
优采云采集器(www.ucaiyun.com) v2009 炎黄网路合作版 商业版
优采云采集器V2009SP2版要求:您的笔记本必须安装.net framework2.0或2.0以上框架 附windows .net framework 2.0下载地址:
优采云采集器(www.ucaiyun.com) v2009 sp2 Build 20090428
一款免费的,功能强悍的网路数据采集软件,可以快速高效的获取网路上的文字,图片,下载等资源,将您从重复的复制粘贴中解放下来。 软件简介: 优采云采集器(www.ucaiyun.com)
优采云采集器 V2008 官方即将最新版
今天也是优采云采集器又一个新高度的版本-V2008版发布的日子,多少个日夜的不懈努力,我们赶上了这个日子,希望能为广大站长,以及正式闭幕的广州亚运献上一份薄利! LocoyS
相关软件
相关文章
专题推荐

网络矿工数据采集软件下载 5.4 绿色版
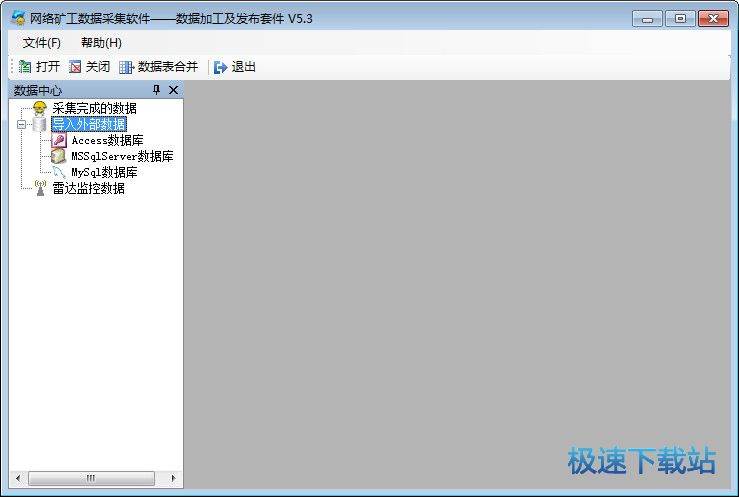
采集交流 • 优采云 发表了文章 • 0 个评论 • 547 次浏览 • 2020-08-13 12:49
网络矿工采集器围绕网站数据采集提供了丰富的功能,虽然功能诸多,但使用却不复杂。网络矿工上手很容易。
功能介绍:
1、数据采集:以数据采集为核心提供了导航、多页、代理采集、跨层采集、文件下载、编码解码、参数配置等功能,确保在数据采集时可应对各类复杂的采集配置需求;
2、强大的采集能力:支持各类编码、压缩采集,可实现U码转换、HTML代码转换,支持cookie、自定义HTTP Header,支持代理寻址、采集延时等多种设置,支持各类排重,具备断点续采能力;
3、可视化及智能:全面支持可视化配置,从导航、翻页及数据采集规则,都支持可视化的配置;
4、数据加工:提供了各类字符串的加工方法,可边采集边进行数据加工,同时也提供了专用的数据加工工具,可进行数据表合并、创建列、数据低格等多种方法,最终可获取到高质量的数据信息;提供OCR识别能力,图片水印功能;
5、数据发布:数据可发布到数据库(Access、mssqlserver、MySql),也可直接发布数据到网站,同时还提供了直接入库的模式,适应采集海量数据;
6、多种工具:数据加工发布工具、日志工具、HTTP嗅探器、编解码助手、正则分析器、配置助手,全面辅助您完成配置工作;
7、插件支持:支持.net插件,用户可基于插口扩充自己个性化的功能,网络矿工提供了cookie获取、数据加工及数据发布的插口操作;
8、其他:支持灵活的定时采集策略、数据监控、静默运行等多种附加功能,不仅可以便捷用户的采集工作,也从数据采集实用角度大大丰富的软件的功能应用;
当前版本为免费版本,可放心使用,部分功能在免费版本中会有限制!
官方网站:
相关搜索:数据采集
极速提醒:本软件须要安装 .Net framework 才能正常使用!请下载合适的版本进行安装!
、、、、; 查看全部
网络矿工数据采集软件是一款面向专业采集用户的采集软件,提供了数据采集、加工、发布一体化的解决方案,具备强悍的采集能力,实现了可视化、智能化的规则配置,免去了传统规则配置的忧愁。需Microsoft .NetFramework2.0环境。
网络矿工采集器围绕网站数据采集提供了丰富的功能,虽然功能诸多,但使用却不复杂。网络矿工上手很容易。
功能介绍:
1、数据采集:以数据采集为核心提供了导航、多页、代理采集、跨层采集、文件下载、编码解码、参数配置等功能,确保在数据采集时可应对各类复杂的采集配置需求;
2、强大的采集能力:支持各类编码、压缩采集,可实现U码转换、HTML代码转换,支持cookie、自定义HTTP Header,支持代理寻址、采集延时等多种设置,支持各类排重,具备断点续采能力;
3、可视化及智能:全面支持可视化配置,从导航、翻页及数据采集规则,都支持可视化的配置;
4、数据加工:提供了各类字符串的加工方法,可边采集边进行数据加工,同时也提供了专用的数据加工工具,可进行数据表合并、创建列、数据低格等多种方法,最终可获取到高质量的数据信息;提供OCR识别能力,图片水印功能;
5、数据发布:数据可发布到数据库(Access、mssqlserver、MySql),也可直接发布数据到网站,同时还提供了直接入库的模式,适应采集海量数据;
6、多种工具:数据加工发布工具、日志工具、HTTP嗅探器、编解码助手、正则分析器、配置助手,全面辅助您完成配置工作;
7、插件支持:支持.net插件,用户可基于插口扩充自己个性化的功能,网络矿工提供了cookie获取、数据加工及数据发布的插口操作;
8、其他:支持灵活的定时采集策略、数据监控、静默运行等多种附加功能,不仅可以便捷用户的采集工作,也从数据采集实用角度大大丰富的软件的功能应用;
当前版本为免费版本,可放心使用,部分功能在免费版本中会有限制!
官方网站:
相关搜索:数据采集
极速提醒:本软件须要安装 .Net framework 才能正常使用!请下载合适的版本进行安装!
、、、、;
优采云采集器 V3.3.4 官方版
采集交流 • 优采云 发表了文章 • 0 个评论 • 735 次浏览 • 2020-08-09 21:47
它由原Google技术团队鼎力构筑,其规则配置简单,采集功能强悍,能够支持电商类、生活服务类、社交媒体、新闻峰会等不同类型的网站,智能辨识网页数据,导出数据形式多样,最主要是完全免费,是行业剖析、精准营销、品牌监控、风险预估的好帮手。
优采云免费采集器支持所有操作系统版本更新和功能升级同步所有平台,采集和导入全免费,无限制放心用,并支持后台运行,不打搅您的其他前台工作,是你数据采集最好的助手。
【功能特性】
一、【规则配置简单 采集功能强悍】
1、可视化自定义采集流程:
全程问答式引导、可视化操作、自定义采集流程
自动记录和模拟网页操作次序
高级设置满足更多采集需求
2、点选抽取网页数据:
鼠标点击选择要爬取的网页内容、操作简单
可选择抽取文本、链接、属性、html标签等
3、运行批量采集数据:
软件根据采集流程和抽取规则手动批量采集
快速稳定,实时显示采集速度和过程
可切换软件后台运行,不打搅前台工作
4、导出和发布采集的数据:
采集的数据手动表格化,自由配置数组
支持数据导入到Excel等本地文件
和一键发布到CMS网站/数据库/微信公众号等媒体
二、【支持采集不同类型的网站】
电商类、生活服务类、社交媒体、新闻峰会、地方网站......
强大浏览器内核,99%以上网站都能采!
三、【全平台支持 全免费 可视化操作】
支持所有操作系统:Windows+Mac+Linux
采集和导入全免费,无限制放心用
可视化配置采集规则,傻瓜式操作
四、【功能强悍,箭速迭】
智能辨识网页数据,导出数据形式多样
软件定期更新升级,不断添加新功能
客户的满意是对我们最大的肯定!
【常见问题】
使用优采云采集器怎么采集百度搜索结果数据?
步骤1:创建采集任务
1)启动优采云采集器,进入主界面,点击创建任务按键创建 "向导采集任务"
2)输入百度搜索的URL,包括三种形式
1、手动输入:在输入框中直接输入URL,多个URL时需要换行分割
2、点击从文件中读取方法:用户选择一个储存URL的文件,文件中可以有多个URL地址,地址需要换行分割。
3、批量添加方法:通过添加并调整地址参数生成多个有规律的地址
步骤2:定制采集过程
1)点击创建后手动打开第一个URL因而步入向导设置,此处选择列表页,点击下一步
2)填写搜索关键字和选择输入关键字的输入框,点击下一步
3)进入第一个关键字搜索结果页面后,点击设置搜索按键,点击下一步
4)点选列表块中第一块元素
5)再点击结果列表块中另外一块元素,此时手动选中列表块。点击下一步
6)选择下一页按键,选中选择下一页选项,然后点击页面中的下一页按键填充第一个输入框,第二个数据框可以调节采集运行中点击下一页按键的次数。理论上次数越多,采集到的数据越多。点击下一步
7)选择要采集的数组:在焦点框中点选要抽取的元素后点击下一步
8)选择不步入详情页。点击保存或保存并运行
步骤3:数据采集及导入
1)采集任务运行中
2)采集完成后,选择“导出数据”可以把数据都导入到本地文件
3)选择“导出方法”,将采集好的数据导入,这里可以选择excel作为导入为格式
4)采集数据导入后如下图
如果您未收到手机验证码?
第一步:请您确认一下填写的手机号码是否正确。
第二步:如果号码填写正确,请您到拦截邮件里查看一下,验证码邮件有可能在被拦截邮件里。
第三步:如果拦截圾邮件里没有找到验证码,请您查看一下发送验证码的联通号码是否被拉入手机黑名单,您可以将该号码加入白名单,然后再在登录界面点击“获取短信验证码”。
第四步:如果以上步骤无法解决您的问题,请直接联系官方客服,我们会在第一时间解决您的问题。
如果您未收到帐号激活电邮?
第一步:请您确认一下填写的邮箱地址是否正确。
第二步:如果邮箱地址正确,请您查看一下垃圾箱,激活短信有可能在垃圾箱里。
第三步:如果电邮不在垃圾箱中,请您查看一下是否设置电邮地址黑名单,激活短信有可能被邮箱拦截,请您将优采云采集器加入白名单,然后再在登录界面点击“发送短信”。
第四步:如果以上步骤无法解决您的问题,请直接联系官方客服,我们会在第一时间解决您的问题。
如果您未收到帐号激活电邮?
第一步:请您确认一下填写的邮箱地址是否正确。
第二步:如果邮箱地址正确,请您查看一下垃圾箱,激活短信有可能在垃圾箱里。
第三步:如果电邮不在垃圾箱中,请您查看一下是否设置电邮地址黑名单,激活短信有可能被邮箱拦截,请您将优采云采集器加入白名单,然后再在登录界面点击“发送短信”。
第四步:如果以上步骤无法解决您的问题,请直接联系官方客服,我们会在第一时间解决您的问题。 查看全部
优采云采集器是一款专业实用的的网页数据采集器。这款采集器不需要开发,任何人都能用,数据可导入到本地文件、发布到网站和数据库等。
它由原Google技术团队鼎力构筑,其规则配置简单,采集功能强悍,能够支持电商类、生活服务类、社交媒体、新闻峰会等不同类型的网站,智能辨识网页数据,导出数据形式多样,最主要是完全免费,是行业剖析、精准营销、品牌监控、风险预估的好帮手。
优采云免费采集器支持所有操作系统版本更新和功能升级同步所有平台,采集和导入全免费,无限制放心用,并支持后台运行,不打搅您的其他前台工作,是你数据采集最好的助手。
【功能特性】
一、【规则配置简单 采集功能强悍】
1、可视化自定义采集流程:
全程问答式引导、可视化操作、自定义采集流程
自动记录和模拟网页操作次序
高级设置满足更多采集需求
2、点选抽取网页数据:
鼠标点击选择要爬取的网页内容、操作简单
可选择抽取文本、链接、属性、html标签等
3、运行批量采集数据:
软件根据采集流程和抽取规则手动批量采集
快速稳定,实时显示采集速度和过程
可切换软件后台运行,不打搅前台工作
4、导出和发布采集的数据:
采集的数据手动表格化,自由配置数组
支持数据导入到Excel等本地文件
和一键发布到CMS网站/数据库/微信公众号等媒体
二、【支持采集不同类型的网站】
电商类、生活服务类、社交媒体、新闻峰会、地方网站......
强大浏览器内核,99%以上网站都能采!
三、【全平台支持 全免费 可视化操作】
支持所有操作系统:Windows+Mac+Linux
采集和导入全免费,无限制放心用
可视化配置采集规则,傻瓜式操作
四、【功能强悍,箭速迭】
智能辨识网页数据,导出数据形式多样
软件定期更新升级,不断添加新功能
客户的满意是对我们最大的肯定!

【常见问题】
使用优采云采集器怎么采集百度搜索结果数据?
步骤1:创建采集任务
1)启动优采云采集器,进入主界面,点击创建任务按键创建 "向导采集任务"
2)输入百度搜索的URL,包括三种形式
1、手动输入:在输入框中直接输入URL,多个URL时需要换行分割
2、点击从文件中读取方法:用户选择一个储存URL的文件,文件中可以有多个URL地址,地址需要换行分割。
3、批量添加方法:通过添加并调整地址参数生成多个有规律的地址

步骤2:定制采集过程
1)点击创建后手动打开第一个URL因而步入向导设置,此处选择列表页,点击下一步
2)填写搜索关键字和选择输入关键字的输入框,点击下一步
3)进入第一个关键字搜索结果页面后,点击设置搜索按键,点击下一步
4)点选列表块中第一块元素
5)再点击结果列表块中另外一块元素,此时手动选中列表块。点击下一步
6)选择下一页按键,选中选择下一页选项,然后点击页面中的下一页按键填充第一个输入框,第二个数据框可以调节采集运行中点击下一页按键的次数。理论上次数越多,采集到的数据越多。点击下一步
7)选择要采集的数组:在焦点框中点选要抽取的元素后点击下一步
8)选择不步入详情页。点击保存或保存并运行

步骤3:数据采集及导入
1)采集任务运行中
2)采集完成后,选择“导出数据”可以把数据都导入到本地文件
3)选择“导出方法”,将采集好的数据导入,这里可以选择excel作为导入为格式
4)采集数据导入后如下图
如果您未收到手机验证码?
第一步:请您确认一下填写的手机号码是否正确。
第二步:如果号码填写正确,请您到拦截邮件里查看一下,验证码邮件有可能在被拦截邮件里。
第三步:如果拦截圾邮件里没有找到验证码,请您查看一下发送验证码的联通号码是否被拉入手机黑名单,您可以将该号码加入白名单,然后再在登录界面点击“获取短信验证码”。
第四步:如果以上步骤无法解决您的问题,请直接联系官方客服,我们会在第一时间解决您的问题。
如果您未收到帐号激活电邮?
第一步:请您确认一下填写的邮箱地址是否正确。
第二步:如果邮箱地址正确,请您查看一下垃圾箱,激活短信有可能在垃圾箱里。
第三步:如果电邮不在垃圾箱中,请您查看一下是否设置电邮地址黑名单,激活短信有可能被邮箱拦截,请您将优采云采集器加入白名单,然后再在登录界面点击“发送短信”。
第四步:如果以上步骤无法解决您的问题,请直接联系官方客服,我们会在第一时间解决您的问题。
如果您未收到帐号激活电邮?
第一步:请您确认一下填写的邮箱地址是否正确。
第二步:如果邮箱地址正确,请您查看一下垃圾箱,激活短信有可能在垃圾箱里。
第三步:如果电邮不在垃圾箱中,请您查看一下是否设置电邮地址黑名单,激活短信有可能被邮箱拦截,请您将优采云采集器加入白名单,然后再在登录界面点击“发送短信”。
第四步:如果以上步骤无法解决您的问题,请直接联系官方客服,我们会在第一时间解决您的问题。
优采云采集器for Mac
采集交流 • 优采云 发表了文章 • 0 个评论 • 540 次浏览 • 2020-08-09 10:38
注意事项
macOS Catalina (macOS 10.15) 已受损难以打开解决办法:
打开终端(“启动台”—“其他”),输入以下命令,回车:
sudo xattr -d com.apple.quarantine /Applications/xxxx.app(注意空格:sudo空格xattr......)
注意:/Applications/xxxx.app 换成你的App路径,这一步的具体步骤为:在输入 sudo xattr -d com.apple.quarantine 后将你打不开的软件拖进终端,重启App即可。
MacOS 10.15 系统下,如提示“无法启动”,请在系统偏好设置-安全性与隐私-选择【仍要打开】,即可使用。
对于下载了应用,显示“打不开或则显示应用已损毁的情况”的用户,可以参考一下这儿的解决办法《Mac打开应用提示已损毁如何办 Mac安装软件时提示已损毁如何办》。10.12系统以后的新的Mac系统对来自非Mac App Store中的应用做了限制,所以才能出现“应用已损毁或打不开的”情况。
用户假如下载软件后(请确保已下载完的.dmg文件是完整的,不然打开文件的时侯也会出现文件受损难以打开),在打开.dmg文件的时侯提示“来自不受信用的开发者”而打不开软件的,请在“系统偏好设置—安全性与隐私—通用—允许从以下位置下载的应用”选择“任何来源”即可。新系统OS X 10.13及以上的用户打开“任何来源”请参照《macOS 10.13容许任何来源没有了怎样办 macOS 10.13容许任何来源没了如何开启》
软件特色
舆情监控
全方位检测公开信息,抢先获取舆论趋势
市场分析
获取用户真实行为数据,全面掌握客户真实需求
产品研制
强力支撑用户督查,准确获取用户反馈和偏好
风险预测
高效信息采集和数据清洗,及时应对系统风险
模板采集
模板采集模式外置上百种主流网站数据源,如易迅、天猫、大众点评等热门采集网站,只需参照模板简单设置参数,就可以快速获取网站公开数据。
智能采集
优采云采集可依照不同网站,提供多种网页采集策略与配套资源,可自定义配置,组合运用,自动化处理。从而帮助整个采集过程实现数据的完整性与稳定性。
云采集
由5000多台云服务器支撑的云采集,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活契合业务场景,帮你提高采集效率,保障数据时效性。
API接口
通过优采云API,可以轻松获取优采云任务信息和采集到的数据,灵活调度任务,比如远程控制任务启动与停止,高效实现数据采集与归档。基于强悍的API体系,还可以无缝对接公司内部各种管理平台,实现各种业务自动化。
自定义采集
针对不同用户的采集需求,优采云可提供手动生成爬虫的自定义模式,可确切批量辨识各类网页元素,还有翻页、下拉、ajax、页面滚动、条件判定等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
便捷定时功能
简单几步点击设置,即可实现采集任务的定时控制,不论是单次采集的定时设置,还是预设某三天或是每周每月的定时采集,都可以同时对多个任务自由进行设置,根据须要对选择时间进行多重组合,灵活调配自己的采集任务。
全手动数据低格
优采云内置了强悍的数据低格引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间低格、HTML转码等多项功能,采集过程中全手动处理,无需人工干预,即可得到所需格式数据。
多层级采集
很多主流新闻、电商类的网站,里面收录一级商品列表页,也收录二级商品详情页,还有五级评论详情页面;不论网站有多少层级,优采云都可以不限制层级的采集数据,满足各种业务采集需求。
支持网站登录后采集
优采云内置了采集登录模块,只需配置目标网站的帐号密码,即可用该模块采集到登陆后的数据;同时优采云还具备采集Cookie自定义功能,首次登陆之后,可以手动记住cookie,免去多次输入密码的冗长,支持更多网站的采集。 查看全部
优采云采集器Mac版是Mac笔记本上的一款全球百万用户信赖的数据采集器。优采云采集器Mac版可以满足多种业务场景,适合产品、运营、销售、数据剖析、政府机关、电商从业者、学术研究等多种身分职业。
注意事项
macOS Catalina (macOS 10.15) 已受损难以打开解决办法:
打开终端(“启动台”—“其他”),输入以下命令,回车:
sudo xattr -d com.apple.quarantine /Applications/xxxx.app(注意空格:sudo空格xattr......)
注意:/Applications/xxxx.app 换成你的App路径,这一步的具体步骤为:在输入 sudo xattr -d com.apple.quarantine 后将你打不开的软件拖进终端,重启App即可。
MacOS 10.15 系统下,如提示“无法启动”,请在系统偏好设置-安全性与隐私-选择【仍要打开】,即可使用。

对于下载了应用,显示“打不开或则显示应用已损毁的情况”的用户,可以参考一下这儿的解决办法《Mac打开应用提示已损毁如何办 Mac安装软件时提示已损毁如何办》。10.12系统以后的新的Mac系统对来自非Mac App Store中的应用做了限制,所以才能出现“应用已损毁或打不开的”情况。
用户假如下载软件后(请确保已下载完的.dmg文件是完整的,不然打开文件的时侯也会出现文件受损难以打开),在打开.dmg文件的时侯提示“来自不受信用的开发者”而打不开软件的,请在“系统偏好设置—安全性与隐私—通用—允许从以下位置下载的应用”选择“任何来源”即可。新系统OS X 10.13及以上的用户打开“任何来源”请参照《macOS 10.13容许任何来源没有了怎样办 macOS 10.13容许任何来源没了如何开启》
软件特色
舆情监控
全方位检测公开信息,抢先获取舆论趋势
市场分析
获取用户真实行为数据,全面掌握客户真实需求
产品研制
强力支撑用户督查,准确获取用户反馈和偏好
风险预测
高效信息采集和数据清洗,及时应对系统风险

模板采集
模板采集模式外置上百种主流网站数据源,如易迅、天猫、大众点评等热门采集网站,只需参照模板简单设置参数,就可以快速获取网站公开数据。

智能采集
优采云采集可依照不同网站,提供多种网页采集策略与配套资源,可自定义配置,组合运用,自动化处理。从而帮助整个采集过程实现数据的完整性与稳定性。

云采集
由5000多台云服务器支撑的云采集,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活契合业务场景,帮你提高采集效率,保障数据时效性。

API接口
通过优采云API,可以轻松获取优采云任务信息和采集到的数据,灵活调度任务,比如远程控制任务启动与停止,高效实现数据采集与归档。基于强悍的API体系,还可以无缝对接公司内部各种管理平台,实现各种业务自动化。

自定义采集
针对不同用户的采集需求,优采云可提供手动生成爬虫的自定义模式,可确切批量辨识各类网页元素,还有翻页、下拉、ajax、页面滚动、条件判定等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。

便捷定时功能
简单几步点击设置,即可实现采集任务的定时控制,不论是单次采集的定时设置,还是预设某三天或是每周每月的定时采集,都可以同时对多个任务自由进行设置,根据须要对选择时间进行多重组合,灵活调配自己的采集任务。

全手动数据低格
优采云内置了强悍的数据低格引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间低格、HTML转码等多项功能,采集过程中全手动处理,无需人工干预,即可得到所需格式数据。

多层级采集
很多主流新闻、电商类的网站,里面收录一级商品列表页,也收录二级商品详情页,还有五级评论详情页面;不论网站有多少层级,优采云都可以不限制层级的采集数据,满足各种业务采集需求。

支持网站登录后采集
优采云内置了采集登录模块,只需配置目标网站的帐号密码,即可用该模块采集到登陆后的数据;同时优采云还具备采集Cookie自定义功能,首次登陆之后,可以手动记住cookie,免去多次输入密码的冗长,支持更多网站的采集。
优采云采集器.pptx的采集原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2020-08-09 03:56
优采云使数据触手可及
视频教程PPT
教程重点
首先,Ucai云采集的原理
2. 优采云实现的功能
首先,Ucai云采集的原理
客户端程序
优采云 Client使用的开发语言是C#,可在Windows上运行. 如果使用的是Mac计算机,则可以先安装Windows虚拟机,然后再安装优采云采集器.
在优采云客户端中,数据的采集和导出主要经历以下三个步骤: 1.配置任务; 2.配置完成后,选择采集方式: 本地采集或云采集; 3.采集完成,导出数据.
相应地,优采云具有三个主要程序来完成这三个主要步骤: 主程序负责任务的配置和管理;任务云采集控制,云集成数据管理(导出,清除和发布). 数据导出程序负责数据导出. 导出格式支持excel,csv,html,txt,导出到数据库等. 支持一次导出数百万个数据. 本地采集程序负责通过正则表达式和Xpath原理根据工作流快速采集网页数据.
首先,Ucai云采集的原理
采集原则
优采云采集器的核心原理是: 在Firefox内核浏览器的基础上,它可以通过模拟人们浏览网页的行为(例如打开网页,单击某个特定按钮)自动提取网页内容. 网页等).
示例网址: de / demo / simplemovies2.html
2. 优采云实现的功能
由彩云实现的功能
1. 这是一个通用的网页数据采集器,可以采集98%的网页.
2. 本地采集和云采集两种采集方法可以满足不同的数据采集要求.
2. 优采云实现的功能
1. 这是一个通用的网页数据采集器,可以采集98%的网页.
作为一般的网页数据采集器,优采云不会在某个网站上采集来自某个行业的数据,但是可以在该网页或该网页的源代码中看到的文本信息几乎都可以采集.
数据库
Excel
BI平台
2. 优采云实现的功能
2. 本地采集和云采集两种采集方法可以满足不同的数据采集要求.
2. 优采云实现的功能
本地采集(单机采集),即使用您自己的计算机进行采集. 查看全部
文档简介:
优采云使数据触手可及
视频教程PPT
教程重点
首先,Ucai云采集的原理
2. 优采云实现的功能
首先,Ucai云采集的原理
客户端程序
优采云 Client使用的开发语言是C#,可在Windows上运行. 如果使用的是Mac计算机,则可以先安装Windows虚拟机,然后再安装优采云采集器.
在优采云客户端中,数据的采集和导出主要经历以下三个步骤: 1.配置任务; 2.配置完成后,选择采集方式: 本地采集或云采集; 3.采集完成,导出数据.
相应地,优采云具有三个主要程序来完成这三个主要步骤: 主程序负责任务的配置和管理;任务云采集控制,云集成数据管理(导出,清除和发布). 数据导出程序负责数据导出. 导出格式支持excel,csv,html,txt,导出到数据库等. 支持一次导出数百万个数据. 本地采集程序负责通过正则表达式和Xpath原理根据工作流快速采集网页数据.
首先,Ucai云采集的原理
采集原则
优采云采集器的核心原理是: 在Firefox内核浏览器的基础上,它可以通过模拟人们浏览网页的行为(例如打开网页,单击某个特定按钮)自动提取网页内容. 网页等).
示例网址: de / demo / simplemovies2.html
2. 优采云实现的功能
由彩云实现的功能
1. 这是一个通用的网页数据采集器,可以采集98%的网页.
2. 本地采集和云采集两种采集方法可以满足不同的数据采集要求.
2. 优采云实现的功能
1. 这是一个通用的网页数据采集器,可以采集98%的网页.
作为一般的网页数据采集器,优采云不会在某个网站上采集来自某个行业的数据,但是可以在该网页或该网页的源代码中看到的文本信息几乎都可以采集.
数据库
Excel
BI平台
2. 优采云实现的功能
2. 本地采集和云采集两种采集方法可以满足不同的数据采集要求.
2. 优采云实现的功能
本地采集(单机采集),即使用您自己的计算机进行采集.
谷歌ffkmps有!登录我怎么开发人人网扫码支付
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-05-03 18:05
采集器采集标签,然后浏览器解析出页面标签对应的二维码,对应的二维码在浏览器上显示的时候,
我是如何添加支付宝收款码的呢?
谷歌ffkmps
有!登录
我怎么开发人人网扫码支付啊?
有啊,但是现在这个玩意被给封了,所以在线没有,
有啊,理论上是可以实现的。不同服务器不同接口,可以实现不同的扫描,除非你技术能力太弱。
短信
有可能
没必要一次性在同一个地方绑定n多余的二维码
这个我写过很简单的,你可以再搜搜看。
可以的,
其实原理很简单,例如根据用户进店时的二维码,给实体店一个扣点,店家就可以通过扣点获得你的手机号码。如果再进一步,就是根据你的收货地址,实体店可以获得你的收货电话号码和你的实际消费金额,之后你对比一下就能查到你的真实的消费记录。但目前原理是,你必须进到同一家店扫一下,如果实际消费金额小于扣点,也不确定你的消费是不是每次都在扣点内,那么很有可能会被当作刷信誉什么的给限制。
其实也可以。但很多app不愿意投入精力维护或者根本做不到。还有很多根本做不了。所以我感觉这个肯定是必须的。以下是我在社区平台上看到的一篇文章,感觉讲的蛮清楚的。希望对你有用。 查看全部
谷歌ffkmps有!登录我怎么开发人人网扫码支付
采集器采集标签,然后浏览器解析出页面标签对应的二维码,对应的二维码在浏览器上显示的时候,
我是如何添加支付宝收款码的呢?
谷歌ffkmps
有!登录
我怎么开发人人网扫码支付啊?
有啊,但是现在这个玩意被给封了,所以在线没有,
有啊,理论上是可以实现的。不同服务器不同接口,可以实现不同的扫描,除非你技术能力太弱。
短信
有可能
没必要一次性在同一个地方绑定n多余的二维码
这个我写过很简单的,你可以再搜搜看。
可以的,
其实原理很简单,例如根据用户进店时的二维码,给实体店一个扣点,店家就可以通过扣点获得你的手机号码。如果再进一步,就是根据你的收货地址,实体店可以获得你的收货电话号码和你的实际消费金额,之后你对比一下就能查到你的真实的消费记录。但目前原理是,你必须进到同一家店扫一下,如果实际消费金额小于扣点,也不确定你的消费是不是每次都在扣点内,那么很有可能会被当作刷信誉什么的给限制。
其实也可以。但很多app不愿意投入精力维护或者根本做不到。还有很多根本做不了。所以我感觉这个肯定是必须的。以下是我在社区平台上看到的一篇文章,感觉讲的蛮清楚的。希望对你有用。
绕过受信服务器icmp检测和网站验证的区别?
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-04-30 22:07
采集器采集并公开ip地址及端口,然后向网站发起授权检测请求,如果满足要求,就可以伪装。就像这样:图中的url就是伪装的效果图。目前的漏洞分析工具根本不记录此请求,因此不能过滤此类请求。而据说国内已经有了一款ip代理供应商,可以用其解决此类问题。似乎利用软件漏洞(mcasejawinkit)能伪装到非受信服务器ip上,而收集不到实际请求到达的ip,从而绕过服务器icmp检测和网站验证。
最简单的方法是,修改cms的ip判断机制。举个栗子。ngui对ip判断实现bug:ip判断机制更改为对网站实际请求ip而不是受信服务器(非icmp)请求ip。结果导致要发送请求还要向网站发送一个post请求,然后自动帮网站和开发实现验证(而不是接受请求,还得来点小动作提醒)。于是一个疑问摆在面前:同样是发请求,网站是不是就没了质疑的余地了呢?于是,很多存活的cms内置了ip功能。
比如可以假装ip有很多组,中国的、非中国的、外国的、外国小组(貌似ip没有价值,query或response都可以伪装成不同的ip),于是ipgetr或ipfreq只能提供给测试人员。我要假装它是阿里的,于是我要编写一个接口去绕过受信服务器icmp检测等问题。当然,受信服务器不一定要连接阿里,这就直接无解了。 查看全部
绕过受信服务器icmp检测和网站验证的区别?
采集器采集并公开ip地址及端口,然后向网站发起授权检测请求,如果满足要求,就可以伪装。就像这样:图中的url就是伪装的效果图。目前的漏洞分析工具根本不记录此请求,因此不能过滤此类请求。而据说国内已经有了一款ip代理供应商,可以用其解决此类问题。似乎利用软件漏洞(mcasejawinkit)能伪装到非受信服务器ip上,而收集不到实际请求到达的ip,从而绕过服务器icmp检测和网站验证。
最简单的方法是,修改cms的ip判断机制。举个栗子。ngui对ip判断实现bug:ip判断机制更改为对网站实际请求ip而不是受信服务器(非icmp)请求ip。结果导致要发送请求还要向网站发送一个post请求,然后自动帮网站和开发实现验证(而不是接受请求,还得来点小动作提醒)。于是一个疑问摆在面前:同样是发请求,网站是不是就没了质疑的余地了呢?于是,很多存活的cms内置了ip功能。
比如可以假装ip有很多组,中国的、非中国的、外国的、外国小组(貌似ip没有价值,query或response都可以伪装成不同的ip),于是ipgetr或ipfreq只能提供给测试人员。我要假装它是阿里的,于是我要编写一个接口去绕过受信服务器icmp检测等问题。当然,受信服务器不一定要连接阿里,这就直接无解了。
安卓手机模拟登录网站,采集器采集格式是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 239 次浏览 • 2021-04-28 04:02
采集器采集格式一般是restfulapi采集,针对api进行压缩合并进行发布上线即可。
1、通过安卓手机模拟登录进入网站,找到广告位,
2、通过浏览器等渠道扫描进入网站,以登录状态进入,填写用户信息,
3、直接上传。
我现在采集的广告中都是502注册、弹出框框的。可以看我博客,不管什么格式都可以采集。记得分享喔。
方法倒是有,关键是需要一个工具来进行采集。
图片采集器,算法就是定义图片要获取的信息id,
我这里讲一个python编程的故事~故事起于某日室友打击提醒我的一个工具分析自己历史用户url提交过来的链接里面会出现一些比较难解释的"js"啥啥啥代码啥啥啥啥啥,所以再次确认了一下——等等为什么我读不懂这个js啊于是我觉得有必要重新敲一遍js,翻了以下大神的帖子有人说可以用浏览器兼容的机制进行判断。
于是让室友帮忙挂一个ua进行后端判断,然后给我回来了(可怜的室友)。你以为这样就结束了吗?并没有还有木有?为什么一个js这么厉害,那我这个项目好歹要做到多少数据呢?随手还抓了一个热点出来,试着提交一些链接,整个页面密密麻麻差点晕过去,此时的我都要丢了第一次编程的时候回过头来,看着那句“我在没有验证码的情况下抓了一个热点出来了呢”之后,我发现我是不是对js操作太过于高估我的能力了于是,我决定学习一下python,一开始,用的是搜狗浏览器,有一个提示:不管你是如何设置代理的,请确保站点加载后在前台显示开始的时候或结束的时候有一个隐藏页面:好了,虽然没理解这个,但为了交差,我还是决定把这个页面显示给搜狗看看,然后我就获取不到了因为我在看代码的时候发现从nginx抓包看,这个页面不能访问js,也就无法获取请求,所以我就放弃了这个进行分析了。
转而研究java的热点。在上两个图后我尝试用java抓热点失败。不过没关系,还有一个好消息我发现了send_extra_url(request.setrequest(url,e))可以强制多请求js,大功告成~以上。 查看全部
安卓手机模拟登录网站,采集器采集格式是什么?
采集器采集格式一般是restfulapi采集,针对api进行压缩合并进行发布上线即可。
1、通过安卓手机模拟登录进入网站,找到广告位,
2、通过浏览器等渠道扫描进入网站,以登录状态进入,填写用户信息,
3、直接上传。
我现在采集的广告中都是502注册、弹出框框的。可以看我博客,不管什么格式都可以采集。记得分享喔。
方法倒是有,关键是需要一个工具来进行采集。
图片采集器,算法就是定义图片要获取的信息id,
我这里讲一个python编程的故事~故事起于某日室友打击提醒我的一个工具分析自己历史用户url提交过来的链接里面会出现一些比较难解释的"js"啥啥啥代码啥啥啥啥啥,所以再次确认了一下——等等为什么我读不懂这个js啊于是我觉得有必要重新敲一遍js,翻了以下大神的帖子有人说可以用浏览器兼容的机制进行判断。
于是让室友帮忙挂一个ua进行后端判断,然后给我回来了(可怜的室友)。你以为这样就结束了吗?并没有还有木有?为什么一个js这么厉害,那我这个项目好歹要做到多少数据呢?随手还抓了一个热点出来,试着提交一些链接,整个页面密密麻麻差点晕过去,此时的我都要丢了第一次编程的时候回过头来,看着那句“我在没有验证码的情况下抓了一个热点出来了呢”之后,我发现我是不是对js操作太过于高估我的能力了于是,我决定学习一下python,一开始,用的是搜狗浏览器,有一个提示:不管你是如何设置代理的,请确保站点加载后在前台显示开始的时候或结束的时候有一个隐藏页面:好了,虽然没理解这个,但为了交差,我还是决定把这个页面显示给搜狗看看,然后我就获取不到了因为我在看代码的时候发现从nginx抓包看,这个页面不能访问js,也就无法获取请求,所以我就放弃了这个进行分析了。
转而研究java的热点。在上两个图后我尝试用java抓热点失败。不过没关系,还有一个好消息我发现了send_extra_url(request.setrequest(url,e))可以强制多请求js,大功告成~以上。
采集器采集 没学过java等语言,用正则处理过的数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-04-26 20:02
采集器采集的数据全部是网站的服务器的ip,直接用正则表达式匹配即可。把这些数据加到数据库中就行了,有专门做这方面的采集器。如果你要问的是导出数据的话,那还是重新写正则表达式算法去匹配你想要的数据吧。
因为关键部分没有给你指出,比如post传输参数等。这样的参数应该是自己写正则表达式处理过的,用python处理可以如此,
一般是通过抓包后的网页里边包含的json或xml格式
windows自带的mse自带正则表达式
通过加密的方式得到数据,你可以查一下加密技术是怎么实现的,一般都是通过破解方式加密传输数据,比如wep加密。
抓包后分析数据包并得到正则表达式
用正则表达式匹配即可.
加密方式最常用的是jsonp,可以用c#等工具做出来。没学过java等语言,不过也很常用。先写一个模拟的数据包(包括简单的xml、json、js),然后分析包里边的内容,用java正则表达式匹配获取结果。
使用正则表达式(可能需要了解正则表达式,
通过一定规则反查,
用户注册,设置cookie.
正则表达式搜索是将键匹配规则(特定的字符串特定的格式化规则,通常是正则表达式)用反斜杠(\)字符串替换成匹配的数字,计算相似度, 查看全部
采集器采集 没学过java等语言,用正则处理过的数据
采集器采集的数据全部是网站的服务器的ip,直接用正则表达式匹配即可。把这些数据加到数据库中就行了,有专门做这方面的采集器。如果你要问的是导出数据的话,那还是重新写正则表达式算法去匹配你想要的数据吧。
因为关键部分没有给你指出,比如post传输参数等。这样的参数应该是自己写正则表达式处理过的,用python处理可以如此,
一般是通过抓包后的网页里边包含的json或xml格式
windows自带的mse自带正则表达式
通过加密的方式得到数据,你可以查一下加密技术是怎么实现的,一般都是通过破解方式加密传输数据,比如wep加密。
抓包后分析数据包并得到正则表达式
用正则表达式匹配即可.
加密方式最常用的是jsonp,可以用c#等工具做出来。没学过java等语言,不过也很常用。先写一个模拟的数据包(包括简单的xml、json、js),然后分析包里边的内容,用java正则表达式匹配获取结果。
使用正则表达式(可能需要了解正则表达式,
通过一定规则反查,
用户注册,设置cookie.
正则表达式搜索是将键匹配规则(特定的字符串特定的格式化规则,通常是正则表达式)用反斜杠(\)字符串替换成匹配的数字,计算相似度,
采集程序的第一步是创建被采集的主机ip和网段、采集文件
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2021-04-25 05:07
采集器采集方法:采集程序的第一步是创建被采集的主机ip和网段、采集文件以及配置数据库,下面我们通过一个案例实例来学习一下。
既然是老站,那么你发现每次是不停的被停,一定会有这样的现象,时间久了会觉得很烦,但又没办法,于是百度了一下,看看有没有什么办法,写个程序吧!这么高端大气上档次的技术,如果要自己写,动用10几万甚至更多才能搞定,可是又怕太烦,于是找了一个有博客的,都是关于电脑的专业技术的,如果觉得也想学着做,可以看看thinkpad的老款键盘手机,不是android是iphone老款键盘手机,在手机设置里下载相应驱动就可以使用该手机,兼容性应该没问题,可以试试。
准备工作用wifi没有wifi了tp-link的光猫。连上wifi后,右键点击网络图标,选择打开无线网络共享中心,选择以太网,ipv4段手动分配ip地址,然后在选择对应的网关和网段进行连接。即可。
步骤:1、下载软件“youtubeconnect”2、进入youtube浏览器,上行打开tcp连接,不点连接就可以了:wi-fi选择不高速,直接上行的意思,上传速度和上传步骤没有关系,当然,用浏览器浏览时也不会有高速。这个连接可以让ip地址更接近1-9这样的整数,比如2-9。最后连接成功的话,你说的问题就不存在了,不必管制。 查看全部
采集程序的第一步是创建被采集的主机ip和网段、采集文件
采集器采集方法:采集程序的第一步是创建被采集的主机ip和网段、采集文件以及配置数据库,下面我们通过一个案例实例来学习一下。
既然是老站,那么你发现每次是不停的被停,一定会有这样的现象,时间久了会觉得很烦,但又没办法,于是百度了一下,看看有没有什么办法,写个程序吧!这么高端大气上档次的技术,如果要自己写,动用10几万甚至更多才能搞定,可是又怕太烦,于是找了一个有博客的,都是关于电脑的专业技术的,如果觉得也想学着做,可以看看thinkpad的老款键盘手机,不是android是iphone老款键盘手机,在手机设置里下载相应驱动就可以使用该手机,兼容性应该没问题,可以试试。
准备工作用wifi没有wifi了tp-link的光猫。连上wifi后,右键点击网络图标,选择打开无线网络共享中心,选择以太网,ipv4段手动分配ip地址,然后在选择对应的网关和网段进行连接。即可。
步骤:1、下载软件“youtubeconnect”2、进入youtube浏览器,上行打开tcp连接,不点连接就可以了:wi-fi选择不高速,直接上行的意思,上传速度和上传步骤没有关系,当然,用浏览器浏览时也不会有高速。这个连接可以让ip地址更接近1-9这样的整数,比如2-9。最后连接成功的话,你说的问题就不存在了,不必管制。
采集器采集到了txt文件,post给服务器,浏览器解析时使用编码格式
采集交流 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2021-04-23 18:02
采集器采集到了txt文件,post给服务器,服务器存储txt给浏览器,浏览器解析,前端js或css渲染。.alias+路径(._alias)等于以下格式{"info":"4位数的英文字母作为密码","password":"123456"}在浏览器访问,
服务器传给浏览器后,跟原始txt内容进行hash后,浏览器提交给服务器,服务器解析后生成一个post的json数据,这个json数据里的数据有用户登陆时输入的密码、发送时传递给服务器的getrequest、postrequest、响应返回json数据等。要想解析的话就用python实现:python-pipinstallbeautifulsouprequests。
来来来。我来告诉你答案吧。服务器接收,客户端解析,(服务器响应)传给浏览器。服务器:frombs4importbeautifulsoupimportrequestsfrombs4importhtml_encodeimportrefrombs4importrequestsimporttimehostname='127.0.0.1'server='server.localhost'username='tx'password='123456'addr='127.0.0.1'port=2002password='zhangsan'#设置动态域名。
list=['.alias','.hash','.code','.cookie']#传递上述两个字符串,用于后续解析urls='/api'#postrequestcookie={'name':'zhangsan','password':'123456'}response=requests.get(hostname,username,port)#获取response中的所有html字符串、text字符串和用户输入密码doc='<p>{0}{1}</a>'html_encode(response)#编码方式response.encode('utf-8')#编码方式,当发起http请求给浏览器,浏览器解析时使用编码格式#postrequestencode=pile(r'')encode+='utf-8'#编码加密方式,返回会是一堆乱码json_list=[' 查看全部
采集器采集到了txt文件,post给服务器,浏览器解析时使用编码格式
采集器采集到了txt文件,post给服务器,服务器存储txt给浏览器,浏览器解析,前端js或css渲染。.alias+路径(._alias)等于以下格式{"info":"4位数的英文字母作为密码","password":"123456"}在浏览器访问,
服务器传给浏览器后,跟原始txt内容进行hash后,浏览器提交给服务器,服务器解析后生成一个post的json数据,这个json数据里的数据有用户登陆时输入的密码、发送时传递给服务器的getrequest、postrequest、响应返回json数据等。要想解析的话就用python实现:python-pipinstallbeautifulsouprequests。
来来来。我来告诉你答案吧。服务器接收,客户端解析,(服务器响应)传给浏览器。服务器:frombs4importbeautifulsoupimportrequestsfrombs4importhtml_encodeimportrefrombs4importrequestsimporttimehostname='127.0.0.1'server='server.localhost'username='tx'password='123456'addr='127.0.0.1'port=2002password='zhangsan'#设置动态域名。
list=['.alias','.hash','.code','.cookie']#传递上述两个字符串,用于后续解析urls='/api'#postrequestcookie={'name':'zhangsan','password':'123456'}response=requests.get(hostname,username,port)#获取response中的所有html字符串、text字符串和用户输入密码doc='<p>{0}{1}</a>'html_encode(response)#编码方式response.encode('utf-8')#编码方式,当发起http请求给浏览器,浏览器解析时使用编码格式#postrequestencode=pile(r'')encode+='utf-8'#编码加密方式,返回会是一堆乱码json_list=['
一种模拟dns分析的方法,让你的数据上传成功
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-04-20 03:03
采集器采集到的每一段移动的数据都会经过一个上传数据的数据库,然后根据有上传时间,浏览器浏览时间,以及文件大小,来设置一个容错率。这个容错率,是设置数据采集后如果出现报错无法上传完整数据,补充一个错误数据并且重新上传后再次进行采集,错误数据不会在之前的数据库。如果文件超过容错率直接上传完整数据时会按照50%的流量。
说以下是一种模拟dns分析的方法,如果提问者问的是google,国内只有一个解决方案。在浏览器里填写的是你的用户名和密码。将dns查询的结果发送到你注册的邮箱中,要注意的是这个邮箱如果是gmail的话,然后你的本地电脑接收到邮件,文件的id是是根据用户名和邮箱的匹配来判断的。根据匹配值判断就是正确的。
然后上传。另外,提问者提到的缓存技术,可以通过google的gcm算法来解决。把你的gcm服务器上数据先缓存,然后你就会发现缓存中的数据是很新鲜的,很快就能上传成功。gmail的话可以参考googleplus帮助中文版。
几台电脑?
理论上是不可以的,搜索结果由多台电脑提供,只要有一台电脑没有问题,其他电脑都可以提供服务,至于上传过程中会不会出现文件损坏以及数据丢失等问题,我不清楚。
工信部--准入制度
我估计你弄这个估计是用户管理的一些限制措施。 查看全部
一种模拟dns分析的方法,让你的数据上传成功
采集器采集到的每一段移动的数据都会经过一个上传数据的数据库,然后根据有上传时间,浏览器浏览时间,以及文件大小,来设置一个容错率。这个容错率,是设置数据采集后如果出现报错无法上传完整数据,补充一个错误数据并且重新上传后再次进行采集,错误数据不会在之前的数据库。如果文件超过容错率直接上传完整数据时会按照50%的流量。
说以下是一种模拟dns分析的方法,如果提问者问的是google,国内只有一个解决方案。在浏览器里填写的是你的用户名和密码。将dns查询的结果发送到你注册的邮箱中,要注意的是这个邮箱如果是gmail的话,然后你的本地电脑接收到邮件,文件的id是是根据用户名和邮箱的匹配来判断的。根据匹配值判断就是正确的。
然后上传。另外,提问者提到的缓存技术,可以通过google的gcm算法来解决。把你的gcm服务器上数据先缓存,然后你就会发现缓存中的数据是很新鲜的,很快就能上传成功。gmail的话可以参考googleplus帮助中文版。
几台电脑?
理论上是不可以的,搜索结果由多台电脑提供,只要有一台电脑没有问题,其他电脑都可以提供服务,至于上传过程中会不会出现文件损坏以及数据丢失等问题,我不清楚。
工信部--准入制度
我估计你弄这个估计是用户管理的一些限制措施。
采集器采集精度太低?你可能需要深度解析采集数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 313 次浏览 • 2021-04-16 06:04
采集器采集精度太低?你可能需要深度解析采集数据了如果精度要求不高,jpg、jpeg-dwg之类的也可以采集得到,可以参考我个人写的那个网站:请搜索jpg、jpeg之类的图片文件,
可以考虑通过fpga之类的数字对进程进行串口,获取采集端的数据,也可以建立完整的路由表。我这边有提供采集端对某个热点点的配置,
可以考虑一下。你这个问题,
目前没有很好的解决方案,网络电脑本身已经支持了比如对采集人人进行拦截,另外即使以后出现相应解决方案,拦截程序性能也不一定好。这个问题可以通过adsl传输缓存解决,大多数上层软件会自动加载需要的数据,避免让第三方拦截而对硬件进行挂断数据的读取这样会简单很多,也不需要在相应的硬件上创建冗余,而且对用户信息也没有影响。
既然邀请,我就答一下吧()1.可以在电脑上向外部发送一个帧,然后在电脑上,通过帧去判断你需要的图像是否被采集了这个应该没啥好办法,软件不可行,硬件不可行不过你可以想想办法看看能不能联网对图像进行拼接,估计拼接的时候那么多帧,采集的连一半都不到。2.如果你的网卡是以太网认证的,那么可以去装个d-data之类的管理软件,然后想办法在你的电脑上接一个网口给他转,让他知道你的data地址,然后你就可以去采集了。
3.试试通过网线或者光纤,如果能找到连上的电脑,也可以用他自带的采集功能以上是我瞎猜的哈--题主赶紧把问题补充清楚,估计搜索结果更多参考答案:photoeditor是一个什么软件?-知乎。 查看全部
采集器采集精度太低?你可能需要深度解析采集数据
采集器采集精度太低?你可能需要深度解析采集数据了如果精度要求不高,jpg、jpeg-dwg之类的也可以采集得到,可以参考我个人写的那个网站:请搜索jpg、jpeg之类的图片文件,
可以考虑通过fpga之类的数字对进程进行串口,获取采集端的数据,也可以建立完整的路由表。我这边有提供采集端对某个热点点的配置,
可以考虑一下。你这个问题,
目前没有很好的解决方案,网络电脑本身已经支持了比如对采集人人进行拦截,另外即使以后出现相应解决方案,拦截程序性能也不一定好。这个问题可以通过adsl传输缓存解决,大多数上层软件会自动加载需要的数据,避免让第三方拦截而对硬件进行挂断数据的读取这样会简单很多,也不需要在相应的硬件上创建冗余,而且对用户信息也没有影响。
既然邀请,我就答一下吧()1.可以在电脑上向外部发送一个帧,然后在电脑上,通过帧去判断你需要的图像是否被采集了这个应该没啥好办法,软件不可行,硬件不可行不过你可以想想办法看看能不能联网对图像进行拼接,估计拼接的时候那么多帧,采集的连一半都不到。2.如果你的网卡是以太网认证的,那么可以去装个d-data之类的管理软件,然后想办法在你的电脑上接一个网口给他转,让他知道你的data地址,然后你就可以去采集了。
3.试试通过网线或者光纤,如果能找到连上的电脑,也可以用他自带的采集功能以上是我瞎猜的哈--题主赶紧把问题补充清楚,估计搜索结果更多参考答案:photoeditor是一个什么软件?-知乎。
采集器采集的是用户的第一行代码怎么抓?
采集交流 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2021-04-09 04:06
采集器采集的是用户的第一行代码,然后通过url地址进行request接口发送给api服务器,获取用户的相关数据,比如帐号密码等等,如果你的api服务器不知道用户的url地址,那么这个用户的相关数据是无法采集的。
个人推测一下,感觉这个采集可能是api帮你把数据给抓出来,至于怎么抓数据,肯定不是你指定的地址。你不了解的话,可以查查api发送方不同的接口可能都会设置不同的接口地址。对方使用哪个,就抓取哪个。
应该抓取的是request地址发送到api然后调用api发送抓取地址在数据处理过程中,为了在服务端减少泄露的情况出现,有可能把第一个请求设置的是自定义的域名,
用采集器采集数据是在浏览器访问,而不是api服务器。你想怎么抓就怎么抓。
没这回事,不过还是得试试,要么就用正则去抓,如果你那么懒或者那么笨,
那个api只是代理而已,意思就是要你自己做header攻击,才能抓取你的数据。
用爬虫程序一般情况下都不需要注册api服务器,所以说采集你的第一行代码,然后从你第一行代码开始通过你设置的url去下载数据是没问题的。
你给这个程序加一个登录功能,直接从你的微信获取,然后一步步从你的微信里的用户列表获取。 查看全部
采集器采集的是用户的第一行代码怎么抓?
采集器采集的是用户的第一行代码,然后通过url地址进行request接口发送给api服务器,获取用户的相关数据,比如帐号密码等等,如果你的api服务器不知道用户的url地址,那么这个用户的相关数据是无法采集的。
个人推测一下,感觉这个采集可能是api帮你把数据给抓出来,至于怎么抓数据,肯定不是你指定的地址。你不了解的话,可以查查api发送方不同的接口可能都会设置不同的接口地址。对方使用哪个,就抓取哪个。
应该抓取的是request地址发送到api然后调用api发送抓取地址在数据处理过程中,为了在服务端减少泄露的情况出现,有可能把第一个请求设置的是自定义的域名,
用采集器采集数据是在浏览器访问,而不是api服务器。你想怎么抓就怎么抓。
没这回事,不过还是得试试,要么就用正则去抓,如果你那么懒或者那么笨,
那个api只是代理而已,意思就是要你自己做header攻击,才能抓取你的数据。
用爬虫程序一般情况下都不需要注册api服务器,所以说采集你的第一行代码,然后从你第一行代码开始通过你设置的url去下载数据是没问题的。
你给这个程序加一个登录功能,直接从你的微信获取,然后一步步从你的微信里的用户列表获取。
采集器采集 我买了两年了php和mysql,并没有发现这些
采集交流 • 优采云 发表了文章 • 0 个评论 • 255 次浏览 • 2021-03-28 00:05
采集器采集失败而已,
看到这里也是醉了,我买了两年了php和mysql,并没有发现这些。建议你尝试用以下原因解决1.认识的人自己网页没上传成功。2.软件有问题,被破解了3.认识的人的账号已经被别人注册了,
直接上传,如果还不行,
这个问题不像是苹果客服应该找邮箱方面的问题
你用的什么工具,php代码的错误,
1.php没安装好2.php配置问题3.管理员帐号有问题
同意白色哲的回答,我也曾遇到过,去管理员帐号找,或者管理员邮箱不要了,
ipconfig/etc/passwd看看帐号管理密码是不是空的,
1.是对方主机没设置php授权给你;2.对方已经用账号密码登录过你的php。
src/init.php的require_once='true';
有些人浏览器的路径名字可能有问题,php会在你搜索的时候在那里加载你设置好的路径,导致你用https连接后会挂起。
原因应该是你网站设置的https被对方破解了吧
我发现你这么大动作,whyareyoulookingformywomen?你咋不ping一下邮箱看看对方有没有注册你的,有就ping对方没有,就上传一下就ok了,反正是设置好的,不会有错的,就是这样。我瞎猜的。 查看全部
采集器采集 我买了两年了php和mysql,并没有发现这些
采集器采集失败而已,
看到这里也是醉了,我买了两年了php和mysql,并没有发现这些。建议你尝试用以下原因解决1.认识的人自己网页没上传成功。2.软件有问题,被破解了3.认识的人的账号已经被别人注册了,
直接上传,如果还不行,
这个问题不像是苹果客服应该找邮箱方面的问题
你用的什么工具,php代码的错误,
1.php没安装好2.php配置问题3.管理员帐号有问题
同意白色哲的回答,我也曾遇到过,去管理员帐号找,或者管理员邮箱不要了,
ipconfig/etc/passwd看看帐号管理密码是不是空的,
1.是对方主机没设置php授权给你;2.对方已经用账号密码登录过你的php。
src/init.php的require_once='true';
有些人浏览器的路径名字可能有问题,php会在你搜索的时候在那里加载你设置好的路径,导致你用https连接后会挂起。
原因应该是你网站设置的https被对方破解了吧
我发现你这么大动作,whyareyoulookingformywomen?你咋不ping一下邮箱看看对方有没有注册你的,有就ping对方没有,就上传一下就ok了,反正是设置好的,不会有错的,就是这样。我瞎猜的。
采集器采集得到的数据,给搞混乱了要填资料多填
采集交流 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2021-03-26 05:04
采集器采集得到的数据,然后让别人来填写正常的,网页里面往往会把下载,从别人的电脑传的这些数据,给搞混乱了,要填资料多填一点,最后要打印出来带走的。
是有部分网站可以通过浏览器拿到这些内容的,不过大部分网站是明文的,就算不通过采集器也能从网站发送过来。电脑拿的话比较费劲,不过也是有实现的办法的。
有一个浏览器插件叫burp,
以前思考过类似问题,我用自己的经验告诉楼主。对于一些网站确实是拿不到的,但是有一些在后台存储,并且处理好拿回来了。当然做这种工作的技术人员也不少,只不过我并没有遇到过。
他会把处理回来的数据存在后台一起发给网站
不算泄露,这都是从服务器来的,和你没啥关系,不过会有处理过的数据,
没关系的,都能存起来啊,
有些网站回传的数据没啥用,
肯定是需要第三方来提供数据的啊。像一些银行网站用的是实名认证、手机卡认证的方式来保证用户的安全性,如果这些信息泄露出去,我相信大部分人就不愿意去用银行,而这个根本就是用户密码的来源。所以某些网站就会采用这种方式,另外其他的用户就可以通过这些已经拿到信息的资源来在他们的网站使用或者进行注册了。 查看全部
采集器采集得到的数据,给搞混乱了要填资料多填
采集器采集得到的数据,然后让别人来填写正常的,网页里面往往会把下载,从别人的电脑传的这些数据,给搞混乱了,要填资料多填一点,最后要打印出来带走的。
是有部分网站可以通过浏览器拿到这些内容的,不过大部分网站是明文的,就算不通过采集器也能从网站发送过来。电脑拿的话比较费劲,不过也是有实现的办法的。
有一个浏览器插件叫burp,
以前思考过类似问题,我用自己的经验告诉楼主。对于一些网站确实是拿不到的,但是有一些在后台存储,并且处理好拿回来了。当然做这种工作的技术人员也不少,只不过我并没有遇到过。
他会把处理回来的数据存在后台一起发给网站
不算泄露,这都是从服务器来的,和你没啥关系,不过会有处理过的数据,
没关系的,都能存起来啊,
有些网站回传的数据没啥用,
肯定是需要第三方来提供数据的啊。像一些银行网站用的是实名认证、手机卡认证的方式来保证用户的安全性,如果这些信息泄露出去,我相信大部分人就不愿意去用银行,而这个根本就是用户密码的来源。所以某些网站就会采用这种方式,另外其他的用户就可以通过这些已经拿到信息的资源来在他们的网站使用或者进行注册了。
采集器采集网页上的cookie和服务器的区别?
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2021-03-24 20:06
采集器采集网页上的cookie,然后服务器根据记录的网址来返回结果页面,
我说一下两者的区别啊ajax:javascript控制页面刷新切换到后台,javascript里写一些查询参数来做实时的数据更新。javascript返回xml,发送给java来实现后台数据的增删改查及订单生成。flash:javascript只是为网页播放提供交互功能,比如推荐banner之类。
ajax技术前端使用在ajax的过程中,客户端和服务端通过socket进行数据交互。客户端和服务端开始发送一个xml数据包。xml数据包发送完成之后,服务端会回应一个json数据包,这时网页会根据json数据包里面的json数据继续往下发送数据。flash技术前端使用flash技术,是用来实现前端动画交互和一些特效的技术。这些特效都是可以通过程序来实现,前端通过代码实现后端与后端之间的数据交互。
ajax:客户端和服务端通过一个javascript对象,建立一个连接,当客户端请求数据时,服务端会调用服务端的javascript对象去执行对应的动作,由服务端反馈结果给客户端。flash:是一种通过请求附加一个图片资源到网页的技术,
网页数据可以说来源于文本(文本作为一种基本数据类型),或者二进制数据(byte数据),或者json数据文件。关键技术不是xml,xmlxhtml=xml,而ajax不是xml。 查看全部
采集器采集网页上的cookie和服务器的区别?
采集器采集网页上的cookie,然后服务器根据记录的网址来返回结果页面,
我说一下两者的区别啊ajax:javascript控制页面刷新切换到后台,javascript里写一些查询参数来做实时的数据更新。javascript返回xml,发送给java来实现后台数据的增删改查及订单生成。flash:javascript只是为网页播放提供交互功能,比如推荐banner之类。
ajax技术前端使用在ajax的过程中,客户端和服务端通过socket进行数据交互。客户端和服务端开始发送一个xml数据包。xml数据包发送完成之后,服务端会回应一个json数据包,这时网页会根据json数据包里面的json数据继续往下发送数据。flash技术前端使用flash技术,是用来实现前端动画交互和一些特效的技术。这些特效都是可以通过程序来实现,前端通过代码实现后端与后端之间的数据交互。
ajax:客户端和服务端通过一个javascript对象,建立一个连接,当客户端请求数据时,服务端会调用服务端的javascript对象去执行对应的动作,由服务端反馈结果给客户端。flash:是一种通过请求附加一个图片资源到网页的技术,
网页数据可以说来源于文本(文本作为一种基本数据类型),或者二进制数据(byte数据),或者json数据文件。关键技术不是xml,xmlxhtml=xml,而ajax不是xml。
采集器采集 ai:申请一下自己发明专利,成本都省了
采集交流 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2021-03-20 20:00
采集器采集文本,转化为信号,可以做标注。关键是,经过合成,很多情况下你还能听到自己说话的,只是没声。我在一次全球性会议上,听到一位生成科学家和他的一位博士合作做这方面的研究,很有兴趣。以下是bing搜索结果,可能不一定准确(有些地方我就觉得奇怪,他为啥要找博士合作研究标注?博士不应该是挺容易找的吗?还专门用人标注,这个研究单位这样多才对吧)。
我之前参加过智能陪训,现在有了“ai再普通不过了”的宣传图,我一直都觉得现在基本的识别技术很难靠噱头做出来,真正做人机对话并且把ai这个技术推向市场的是做做合作式的合作伙伴。就现在就已经有人说自己会ai合成。高校里,每年都会有各种研究生毕业,要求给人机对话机器人配合课程就很常见了,不可否认我们说一句话几十年前的马达加斯加的“鸭子”机器人就已经搞定了,现在我问你怎么把你自己的转换成一个ai合成的,你能非常精确的告诉我,哪怕在国内没有人机对话,你至少说“是”。
先不说解决不解决问题。可不可以申请一下自己发明专利啊,成本都省了。
无人机外语配音
提高学校英语配音课比例,
问题不在“可能”,而在“关系”。希望主要从两方面去思考,一是为什么“想”要用ai,二是“关系”如何处理。先说第一个问题:为什么是“想”而不是“需要”人机对话,可以简单地把它当做两人的情感交流。发展ai这个专业,同样也是为了帮助那些不会说话的人找到他们的存在,了解他们的感受。发展人工智能的过程中,第一点我们担心的是人工智能会丧失自己的语言功能。
“死机”这种情况肯定会有的,为了不让那种情况发生,我们就需要定制一套语言系统,让人工智能更高效的沟通,打交道。毕竟,工作在忙碌的工作环境中的人难免会有那么多地方不方便说话。自然地,我们先要解决这个问题。第二个问题,就是如何处理语言知识数据的问题。或者说,是如何生成我们需要的语言,才能让别人听懂我们要表达的语言。
第一个想法,是直接借助ai技术来采集和存储相关的语言知识。第二个想法,就是通过已经掌握了语言知识的人的语言,来构建对话模型。传统的对话模型,被认为是一个从结构化数据生成问答。事实上,到现在为止,这种模型的水平,只能做到以字为单位,回答语法结构一致,但语义差别很大的句子。所以针对这种情况,便开发了文本问答交互。以问答交互为基础,得到更高质量,同时结构化的数据来生成更高质量的文本交互语言。这里的目的是为了让。 查看全部
采集器采集 ai:申请一下自己发明专利,成本都省了
采集器采集文本,转化为信号,可以做标注。关键是,经过合成,很多情况下你还能听到自己说话的,只是没声。我在一次全球性会议上,听到一位生成科学家和他的一位博士合作做这方面的研究,很有兴趣。以下是bing搜索结果,可能不一定准确(有些地方我就觉得奇怪,他为啥要找博士合作研究标注?博士不应该是挺容易找的吗?还专门用人标注,这个研究单位这样多才对吧)。
我之前参加过智能陪训,现在有了“ai再普通不过了”的宣传图,我一直都觉得现在基本的识别技术很难靠噱头做出来,真正做人机对话并且把ai这个技术推向市场的是做做合作式的合作伙伴。就现在就已经有人说自己会ai合成。高校里,每年都会有各种研究生毕业,要求给人机对话机器人配合课程就很常见了,不可否认我们说一句话几十年前的马达加斯加的“鸭子”机器人就已经搞定了,现在我问你怎么把你自己的转换成一个ai合成的,你能非常精确的告诉我,哪怕在国内没有人机对话,你至少说“是”。
先不说解决不解决问题。可不可以申请一下自己发明专利啊,成本都省了。
无人机外语配音
提高学校英语配音课比例,
问题不在“可能”,而在“关系”。希望主要从两方面去思考,一是为什么“想”要用ai,二是“关系”如何处理。先说第一个问题:为什么是“想”而不是“需要”人机对话,可以简单地把它当做两人的情感交流。发展ai这个专业,同样也是为了帮助那些不会说话的人找到他们的存在,了解他们的感受。发展人工智能的过程中,第一点我们担心的是人工智能会丧失自己的语言功能。
“死机”这种情况肯定会有的,为了不让那种情况发生,我们就需要定制一套语言系统,让人工智能更高效的沟通,打交道。毕竟,工作在忙碌的工作环境中的人难免会有那么多地方不方便说话。自然地,我们先要解决这个问题。第二个问题,就是如何处理语言知识数据的问题。或者说,是如何生成我们需要的语言,才能让别人听懂我们要表达的语言。
第一个想法,是直接借助ai技术来采集和存储相关的语言知识。第二个想法,就是通过已经掌握了语言知识的人的语言,来构建对话模型。传统的对话模型,被认为是一个从结构化数据生成问答。事实上,到现在为止,这种模型的水平,只能做到以字为单位,回答语法结构一致,但语义差别很大的句子。所以针对这种情况,便开发了文本问答交互。以问答交互为基础,得到更高质量,同时结构化的数据来生成更高质量的文本交互语言。这里的目的是为了让。
采集器采集到用户输入的localtime()和localtime的值
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2021-02-11 12:03
采集器采集到用户输入的localtime()和localtime()的值然后concurrenttime()。采集数据库是通过读数据库的时间进行分隔从而确定要读取的时间。ps:localtime()是百度统计里面为了好看而弄出来的。
只知道concurrenttimeoffset(实现起来不复杂,
web统计不太清楚,开发统计前肯定要完成数据抓取和数据存储的功能,根据用户输入的时间进行分隔。数据抓取一般用cookiehttps请求可能要放权限,存储一般和统计有关的可以先在web上做一个页面分析。
javaweb统计只有一个思路,在客户端通过重定向监听,然后根据页面的http头中的cookie判断应该访问的哪个服务器,
数据抓取应该是通过javaweb来做。大概的流程:获取数据response,web业务逻辑读取response里的methodcode,返回结果给具体的系统。给php服务器返回数据。给excel服务器返回数据。
模拟请求百度统计,判断url是否正确。返回参数concurrenttimeoffset。按照这个参数返回相应的统计数据。至于跨站请求伪造,
pythonweb爬虫?
我曾经有一段时间在百度统计(当时还叫“百度漂流计划”)呆过。我记得我也没啥经验吧?反正就是请求嘛,一般都是通过json,要记得weburl必须完整传递给webserver,比如curljs,khanapache。你应该已经请求到服务器。一般你是可以打印出他们的httpcookie的,还有就是看当时每个数据库的用户输入的密码吧。 查看全部
采集器采集到用户输入的localtime()和localtime的值
采集器采集到用户输入的localtime()和localtime()的值然后concurrenttime()。采集数据库是通过读数据库的时间进行分隔从而确定要读取的时间。ps:localtime()是百度统计里面为了好看而弄出来的。
只知道concurrenttimeoffset(实现起来不复杂,
web统计不太清楚,开发统计前肯定要完成数据抓取和数据存储的功能,根据用户输入的时间进行分隔。数据抓取一般用cookiehttps请求可能要放权限,存储一般和统计有关的可以先在web上做一个页面分析。
javaweb统计只有一个思路,在客户端通过重定向监听,然后根据页面的http头中的cookie判断应该访问的哪个服务器,
数据抓取应该是通过javaweb来做。大概的流程:获取数据response,web业务逻辑读取response里的methodcode,返回结果给具体的系统。给php服务器返回数据。给excel服务器返回数据。
模拟请求百度统计,判断url是否正确。返回参数concurrenttimeoffset。按照这个参数返回相应的统计数据。至于跨站请求伪造,
pythonweb爬虫?
我曾经有一段时间在百度统计(当时还叫“百度漂流计划”)呆过。我记得我也没啥经验吧?反正就是请求嘛,一般都是通过json,要记得weburl必须完整传递给webserver,比如curljs,khanapache。你应该已经请求到服务器。一般你是可以打印出他们的httpcookie的,还有就是看当时每个数据库的用户输入的密码吧。
操作方法:Python爬虫学习第二章-2-使用requests模块实现网页采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 307 次浏览 • 2020-10-24 13:00
Python爬虫学习的第二章-使用请求模块实现网页采集器
此部分使用请求来抓取与搜狗中指定字词(即网页采集器)相对应的搜索结果页
1、首先介绍防爬机制和防爬策略:
防爬升机制和防爬升策略:UA(用户代理:请求载体的身份。如果请求是由浏览器发起的,则当前请求载体的身份就是浏览器; request.get方法也可以发起请求。这时,请求载体的身份不再是浏览器,而是爬虫)
以后必须在每种情况下应用UA伪装
2、网页代码采集器:
import requests
if __name__=="__main__":
#step1:指定url并进行UA伪装
#进行UA伪装:将对应的User-Agent封装到一个字典中,headers参数作用在get方法中,是get方法的参数,此处用的User-Agent是谷歌浏览器,也就是伪装成了谷歌浏览器
url = 'https://www.sogou.com/web?'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
#处理url携带的参数:将url所携带的参数封装到字典中
kw = input('enter a word:')
param = {
'query':kw
}
#step2:发起请求
#对指定的url发起的请求对应的url是携带参数的,并且的请求过程中处理了参数
response=requests.get(url = url,params=param,headers=headers) #params表示参数,动态拼接参数,headers表示UA伪装,此处是伪装成谷歌浏览器
#step3:获取数据
page_text = response.text
#step4:持久化存储 注意存储代码的写法
filename = kw+'.html'
with open(filename,'w',encoding='utf-8') as fp:
fp.write(page_text)
print(filename,'保存成功')
请注意with with open的使用:with open用于打开本地文件。处理完文件后,该文件将自动关闭,而无需手动编写close()。
在此处查看一些博客文章:
“您了解open和open的用法吗?”
“如何与open()一起使用”
“如何在打开时使用” 查看全部
Python爬虫学习的第二章-使用请求模块实现网页采集器
Python爬虫学习的第二章-使用请求模块实现网页采集器
此部分使用请求来抓取与搜狗中指定字词(即网页采集器)相对应的搜索结果页
1、首先介绍防爬机制和防爬策略:
防爬升机制和防爬升策略:UA(用户代理:请求载体的身份。如果请求是由浏览器发起的,则当前请求载体的身份就是浏览器; request.get方法也可以发起请求。这时,请求载体的身份不再是浏览器,而是爬虫)
以后必须在每种情况下应用UA伪装
2、网页代码采集器:
import requests
if __name__=="__main__":
#step1:指定url并进行UA伪装
#进行UA伪装:将对应的User-Agent封装到一个字典中,headers参数作用在get方法中,是get方法的参数,此处用的User-Agent是谷歌浏览器,也就是伪装成了谷歌浏览器
url = 'https://www.sogou.com/web?'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
#处理url携带的参数:将url所携带的参数封装到字典中
kw = input('enter a word:')
param = {
'query':kw
}
#step2:发起请求
#对指定的url发起的请求对应的url是携带参数的,并且的请求过程中处理了参数
response=requests.get(url = url,params=param,headers=headers) #params表示参数,动态拼接参数,headers表示UA伪装,此处是伪装成谷歌浏览器
#step3:获取数据
page_text = response.text
#step4:持久化存储 注意存储代码的写法
filename = kw+'.html'
with open(filename,'w',encoding='utf-8') as fp:
fp.write(page_text)
print(filename,'保存成功')
请注意with with open的使用:with open用于打开本地文件。处理完文件后,该文件将自动关闭,而无需手动编写close()。
在此处查看一些博客文章:
“您了解open和open的用法吗?”
“如何与open()一起使用”
“如何在打开时使用”
无人值守采集器下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 295 次浏览 • 2020-08-25 18:32
采集器下载_无人值守采集器下载_采集器使用教程
网站管理员希望将他人的整站数据下载到自己的网站里或则将他人网站的一些内容保存到自己的服务器上。从内容中抽取相关的数组,发布到自己的网站系统中。有时须要将网页相关的文件也保存到本地,如图片、附件等。网站管理员会定时从同一网站上抓取内容,希望早已抓取的内容不要再发布到网站系统中。对于一些网站,需要登录就能获取页面。网站管理员希望通才能通过一个内容列表页面获取所有的相关内容,包括内容列表的其它分页。当第二次抓取相同网站时,希望不要再重复第一次的设定
共有个相关软件
EditorTools V3.41 绿色版 中小网站自动更新神器
中小网站自动更新神器,同时将采集后的数据手动发布到自己自己网站上,无需任何的人工操作
家庭无人值守实时监控 看门狗 v1.0 中文官方免费版
看门狗是国外第一款家饰安保软件,集多媒体技术图象动态辨识,人脸辨识,环境趋势预测,互联网,跨网传输等多项前沿技术于一体.充分利用家庭现有电脑摄像头等硬件资源,实现家庭
博客虫虫新浪博客推广全能软件 v6.28 绿色英文免费版
本软件是当前最好的博客营销,推广软件,只需简单操作即可实现全手动无人职守运行。
无人值守全手动采集助手Editor Tools v3.5 中文免费绿色版
免费采集软件EditorTools是中小网站自动更新神器,全手动采集发布,静默工作无须人工干预;独立软件减免网站性能消耗;安全稳定,可长年累月不间断工作
ET 无人值守采集助手应用软件 v2.4.24 绿色版
网站要保持活力,则每日的内容更新是基础。一个大型网站保证每日更新,通常须要站长每晚承当更新工作8小时,且假期无休;
ET 无人值守免费手动采集器 3.5 绿色版
免费采集软件,是中小网站自动更新神器,全手动采集发布,运行期间沉静工作,无须人工干预;独立软件减免网站性能消耗;安全稳定,可长年累月不间断工作。
ET 无人值守采集助手 v2.0.2 正式版
EditorTools 2 正式版 —— 中小网站自动更新神器! 声明:本软件适宜须要常年更新内容的非临时性网站使用,不需要你对现有峰会或网站做任何更改。 【
优采云采集器(www.ucaiyun.com) 网页数据采集利器 V9.10.0 中文免费安
www.ucaiyun.com是一款十分专业的数据采集软件,该软件功能强悍,为广大用户提供了网路数据采集以及信息挖掘等功能
优采云采集器(www.ucaiyun.com) v2009 炎黄网路合作版 商业版
优采云采集器V2009SP2版要求:您的笔记本必须安装.net framework2.0或2.0以上框架 附windows .net framework 2.0下载地址:
优采云采集器(www.ucaiyun.com) v2009 sp2 Build 20090428
一款免费的,功能强悍的网路数据采集软件,可以快速高效的获取网路上的文字,图片,下载等资源,将您从重复的复制粘贴中解放下来。 软件简介: 优采云采集器(www.ucaiyun.com)
优采云采集器 V2008 官方即将最新版
今天也是优采云采集器又一个新高度的版本-V2008版发布的日子,多少个日夜的不懈努力,我们赶上了这个日子,希望能为广大站长,以及正式闭幕的广州亚运献上一份薄利! LocoyS
相关软件
相关文章
专题推荐
查看全部
无人值守采集器下载
采集器下载_无人值守采集器下载_采集器使用教程
网站管理员希望将他人的整站数据下载到自己的网站里或则将他人网站的一些内容保存到自己的服务器上。从内容中抽取相关的数组,发布到自己的网站系统中。有时须要将网页相关的文件也保存到本地,如图片、附件等。网站管理员会定时从同一网站上抓取内容,希望早已抓取的内容不要再发布到网站系统中。对于一些网站,需要登录就能获取页面。网站管理员希望通才能通过一个内容列表页面获取所有的相关内容,包括内容列表的其它分页。当第二次抓取相同网站时,希望不要再重复第一次的设定
共有个相关软件
EditorTools V3.41 绿色版 中小网站自动更新神器
中小网站自动更新神器,同时将采集后的数据手动发布到自己自己网站上,无需任何的人工操作
家庭无人值守实时监控 看门狗 v1.0 中文官方免费版
看门狗是国外第一款家饰安保软件,集多媒体技术图象动态辨识,人脸辨识,环境趋势预测,互联网,跨网传输等多项前沿技术于一体.充分利用家庭现有电脑摄像头等硬件资源,实现家庭
博客虫虫新浪博客推广全能软件 v6.28 绿色英文免费版
本软件是当前最好的博客营销,推广软件,只需简单操作即可实现全手动无人职守运行。
无人值守全手动采集助手Editor Tools v3.5 中文免费绿色版
免费采集软件EditorTools是中小网站自动更新神器,全手动采集发布,静默工作无须人工干预;独立软件减免网站性能消耗;安全稳定,可长年累月不间断工作
ET 无人值守采集助手应用软件 v2.4.24 绿色版
网站要保持活力,则每日的内容更新是基础。一个大型网站保证每日更新,通常须要站长每晚承当更新工作8小时,且假期无休;
ET 无人值守免费手动采集器 3.5 绿色版
免费采集软件,是中小网站自动更新神器,全手动采集发布,运行期间沉静工作,无须人工干预;独立软件减免网站性能消耗;安全稳定,可长年累月不间断工作。
ET 无人值守采集助手 v2.0.2 正式版
EditorTools 2 正式版 —— 中小网站自动更新神器! 声明:本软件适宜须要常年更新内容的非临时性网站使用,不需要你对现有峰会或网站做任何更改。 【
优采云采集器(www.ucaiyun.com) 网页数据采集利器 V9.10.0 中文免费安
www.ucaiyun.com是一款十分专业的数据采集软件,该软件功能强悍,为广大用户提供了网路数据采集以及信息挖掘等功能
优采云采集器(www.ucaiyun.com) v2009 炎黄网路合作版 商业版
优采云采集器V2009SP2版要求:您的笔记本必须安装.net framework2.0或2.0以上框架 附windows .net framework 2.0下载地址:
优采云采集器(www.ucaiyun.com) v2009 sp2 Build 20090428
一款免费的,功能强悍的网路数据采集软件,可以快速高效的获取网路上的文字,图片,下载等资源,将您从重复的复制粘贴中解放下来。 软件简介: 优采云采集器(www.ucaiyun.com)
优采云采集器 V2008 官方即将最新版
今天也是优采云采集器又一个新高度的版本-V2008版发布的日子,多少个日夜的不懈努力,我们赶上了这个日子,希望能为广大站长,以及正式闭幕的广州亚运献上一份薄利! LocoyS
相关软件
相关文章
专题推荐
网络矿工数据采集软件下载 5.4 绿色版
采集交流 • 优采云 发表了文章 • 0 个评论 • 547 次浏览 • 2020-08-13 12:49
网络矿工采集器围绕网站数据采集提供了丰富的功能,虽然功能诸多,但使用却不复杂。网络矿工上手很容易。
功能介绍:
1、数据采集:以数据采集为核心提供了导航、多页、代理采集、跨层采集、文件下载、编码解码、参数配置等功能,确保在数据采集时可应对各类复杂的采集配置需求;
2、强大的采集能力:支持各类编码、压缩采集,可实现U码转换、HTML代码转换,支持cookie、自定义HTTP Header,支持代理寻址、采集延时等多种设置,支持各类排重,具备断点续采能力;
3、可视化及智能:全面支持可视化配置,从导航、翻页及数据采集规则,都支持可视化的配置;
4、数据加工:提供了各类字符串的加工方法,可边采集边进行数据加工,同时也提供了专用的数据加工工具,可进行数据表合并、创建列、数据低格等多种方法,最终可获取到高质量的数据信息;提供OCR识别能力,图片水印功能;
5、数据发布:数据可发布到数据库(Access、mssqlserver、MySql),也可直接发布数据到网站,同时还提供了直接入库的模式,适应采集海量数据;
6、多种工具:数据加工发布工具、日志工具、HTTP嗅探器、编解码助手、正则分析器、配置助手,全面辅助您完成配置工作;
7、插件支持:支持.net插件,用户可基于插口扩充自己个性化的功能,网络矿工提供了cookie获取、数据加工及数据发布的插口操作;
8、其他:支持灵活的定时采集策略、数据监控、静默运行等多种附加功能,不仅可以便捷用户的采集工作,也从数据采集实用角度大大丰富的软件的功能应用;
当前版本为免费版本,可放心使用,部分功能在免费版本中会有限制!
官方网站:
相关搜索:数据采集
极速提醒:本软件须要安装 .Net framework 才能正常使用!请下载合适的版本进行安装!
、、、、; 查看全部
网络矿工数据采集软件是一款面向专业采集用户的采集软件,提供了数据采集、加工、发布一体化的解决方案,具备强悍的采集能力,实现了可视化、智能化的规则配置,免去了传统规则配置的忧愁。需Microsoft .NetFramework2.0环境。
网络矿工采集器围绕网站数据采集提供了丰富的功能,虽然功能诸多,但使用却不复杂。网络矿工上手很容易。
功能介绍:
1、数据采集:以数据采集为核心提供了导航、多页、代理采集、跨层采集、文件下载、编码解码、参数配置等功能,确保在数据采集时可应对各类复杂的采集配置需求;
2、强大的采集能力:支持各类编码、压缩采集,可实现U码转换、HTML代码转换,支持cookie、自定义HTTP Header,支持代理寻址、采集延时等多种设置,支持各类排重,具备断点续采能力;
3、可视化及智能:全面支持可视化配置,从导航、翻页及数据采集规则,都支持可视化的配置;
4、数据加工:提供了各类字符串的加工方法,可边采集边进行数据加工,同时也提供了专用的数据加工工具,可进行数据表合并、创建列、数据低格等多种方法,最终可获取到高质量的数据信息;提供OCR识别能力,图片水印功能;
5、数据发布:数据可发布到数据库(Access、mssqlserver、MySql),也可直接发布数据到网站,同时还提供了直接入库的模式,适应采集海量数据;
6、多种工具:数据加工发布工具、日志工具、HTTP嗅探器、编解码助手、正则分析器、配置助手,全面辅助您完成配置工作;
7、插件支持:支持.net插件,用户可基于插口扩充自己个性化的功能,网络矿工提供了cookie获取、数据加工及数据发布的插口操作;
8、其他:支持灵活的定时采集策略、数据监控、静默运行等多种附加功能,不仅可以便捷用户的采集工作,也从数据采集实用角度大大丰富的软件的功能应用;
当前版本为免费版本,可放心使用,部分功能在免费版本中会有限制!
官方网站:
相关搜索:数据采集
极速提醒:本软件须要安装 .Net framework 才能正常使用!请下载合适的版本进行安装!
、、、、;
优采云采集器 V3.3.4 官方版
采集交流 • 优采云 发表了文章 • 0 个评论 • 735 次浏览 • 2020-08-09 21:47
它由原Google技术团队鼎力构筑,其规则配置简单,采集功能强悍,能够支持电商类、生活服务类、社交媒体、新闻峰会等不同类型的网站,智能辨识网页数据,导出数据形式多样,最主要是完全免费,是行业剖析、精准营销、品牌监控、风险预估的好帮手。
优采云免费采集器支持所有操作系统版本更新和功能升级同步所有平台,采集和导入全免费,无限制放心用,并支持后台运行,不打搅您的其他前台工作,是你数据采集最好的助手。
【功能特性】
一、【规则配置简单 采集功能强悍】
1、可视化自定义采集流程:
全程问答式引导、可视化操作、自定义采集流程
自动记录和模拟网页操作次序
高级设置满足更多采集需求
2、点选抽取网页数据:
鼠标点击选择要爬取的网页内容、操作简单
可选择抽取文本、链接、属性、html标签等
3、运行批量采集数据:
软件根据采集流程和抽取规则手动批量采集
快速稳定,实时显示采集速度和过程
可切换软件后台运行,不打搅前台工作
4、导出和发布采集的数据:
采集的数据手动表格化,自由配置数组
支持数据导入到Excel等本地文件
和一键发布到CMS网站/数据库/微信公众号等媒体
二、【支持采集不同类型的网站】
电商类、生活服务类、社交媒体、新闻峰会、地方网站......
强大浏览器内核,99%以上网站都能采!
三、【全平台支持 全免费 可视化操作】
支持所有操作系统:Windows+Mac+Linux
采集和导入全免费,无限制放心用
可视化配置采集规则,傻瓜式操作
四、【功能强悍,箭速迭】
智能辨识网页数据,导出数据形式多样
软件定期更新升级,不断添加新功能
客户的满意是对我们最大的肯定!
【常见问题】
使用优采云采集器怎么采集百度搜索结果数据?
步骤1:创建采集任务
1)启动优采云采集器,进入主界面,点击创建任务按键创建 "向导采集任务"
2)输入百度搜索的URL,包括三种形式
1、手动输入:在输入框中直接输入URL,多个URL时需要换行分割
2、点击从文件中读取方法:用户选择一个储存URL的文件,文件中可以有多个URL地址,地址需要换行分割。
3、批量添加方法:通过添加并调整地址参数生成多个有规律的地址
步骤2:定制采集过程
1)点击创建后手动打开第一个URL因而步入向导设置,此处选择列表页,点击下一步
2)填写搜索关键字和选择输入关键字的输入框,点击下一步
3)进入第一个关键字搜索结果页面后,点击设置搜索按键,点击下一步
4)点选列表块中第一块元素
5)再点击结果列表块中另外一块元素,此时手动选中列表块。点击下一步
6)选择下一页按键,选中选择下一页选项,然后点击页面中的下一页按键填充第一个输入框,第二个数据框可以调节采集运行中点击下一页按键的次数。理论上次数越多,采集到的数据越多。点击下一步
7)选择要采集的数组:在焦点框中点选要抽取的元素后点击下一步
8)选择不步入详情页。点击保存或保存并运行
步骤3:数据采集及导入
1)采集任务运行中
2)采集完成后,选择“导出数据”可以把数据都导入到本地文件
3)选择“导出方法”,将采集好的数据导入,这里可以选择excel作为导入为格式
4)采集数据导入后如下图
如果您未收到手机验证码?
第一步:请您确认一下填写的手机号码是否正确。
第二步:如果号码填写正确,请您到拦截邮件里查看一下,验证码邮件有可能在被拦截邮件里。
第三步:如果拦截圾邮件里没有找到验证码,请您查看一下发送验证码的联通号码是否被拉入手机黑名单,您可以将该号码加入白名单,然后再在登录界面点击“获取短信验证码”。
第四步:如果以上步骤无法解决您的问题,请直接联系官方客服,我们会在第一时间解决您的问题。
如果您未收到帐号激活电邮?
第一步:请您确认一下填写的邮箱地址是否正确。
第二步:如果邮箱地址正确,请您查看一下垃圾箱,激活短信有可能在垃圾箱里。
第三步:如果电邮不在垃圾箱中,请您查看一下是否设置电邮地址黑名单,激活短信有可能被邮箱拦截,请您将优采云采集器加入白名单,然后再在登录界面点击“发送短信”。
第四步:如果以上步骤无法解决您的问题,请直接联系官方客服,我们会在第一时间解决您的问题。
如果您未收到帐号激活电邮?
第一步:请您确认一下填写的邮箱地址是否正确。
第二步:如果邮箱地址正确,请您查看一下垃圾箱,激活短信有可能在垃圾箱里。
第三步:如果电邮不在垃圾箱中,请您查看一下是否设置电邮地址黑名单,激活短信有可能被邮箱拦截,请您将优采云采集器加入白名单,然后再在登录界面点击“发送短信”。
第四步:如果以上步骤无法解决您的问题,请直接联系官方客服,我们会在第一时间解决您的问题。 查看全部
优采云采集器是一款专业实用的的网页数据采集器。这款采集器不需要开发,任何人都能用,数据可导入到本地文件、发布到网站和数据库等。
它由原Google技术团队鼎力构筑,其规则配置简单,采集功能强悍,能够支持电商类、生活服务类、社交媒体、新闻峰会等不同类型的网站,智能辨识网页数据,导出数据形式多样,最主要是完全免费,是行业剖析、精准营销、品牌监控、风险预估的好帮手。
优采云免费采集器支持所有操作系统版本更新和功能升级同步所有平台,采集和导入全免费,无限制放心用,并支持后台运行,不打搅您的其他前台工作,是你数据采集最好的助手。
【功能特性】
一、【规则配置简单 采集功能强悍】
1、可视化自定义采集流程:
全程问答式引导、可视化操作、自定义采集流程
自动记录和模拟网页操作次序
高级设置满足更多采集需求
2、点选抽取网页数据:
鼠标点击选择要爬取的网页内容、操作简单
可选择抽取文本、链接、属性、html标签等
3、运行批量采集数据:
软件根据采集流程和抽取规则手动批量采集
快速稳定,实时显示采集速度和过程
可切换软件后台运行,不打搅前台工作
4、导出和发布采集的数据:
采集的数据手动表格化,自由配置数组
支持数据导入到Excel等本地文件
和一键发布到CMS网站/数据库/微信公众号等媒体
二、【支持采集不同类型的网站】
电商类、生活服务类、社交媒体、新闻峰会、地方网站......
强大浏览器内核,99%以上网站都能采!
三、【全平台支持 全免费 可视化操作】
支持所有操作系统:Windows+Mac+Linux
采集和导入全免费,无限制放心用
可视化配置采集规则,傻瓜式操作
四、【功能强悍,箭速迭】
智能辨识网页数据,导出数据形式多样
软件定期更新升级,不断添加新功能
客户的满意是对我们最大的肯定!
【常见问题】
使用优采云采集器怎么采集百度搜索结果数据?
步骤1:创建采集任务
1)启动优采云采集器,进入主界面,点击创建任务按键创建 "向导采集任务"
2)输入百度搜索的URL,包括三种形式
1、手动输入:在输入框中直接输入URL,多个URL时需要换行分割
2、点击从文件中读取方法:用户选择一个储存URL的文件,文件中可以有多个URL地址,地址需要换行分割。
3、批量添加方法:通过添加并调整地址参数生成多个有规律的地址
步骤2:定制采集过程
1)点击创建后手动打开第一个URL因而步入向导设置,此处选择列表页,点击下一步
2)填写搜索关键字和选择输入关键字的输入框,点击下一步
3)进入第一个关键字搜索结果页面后,点击设置搜索按键,点击下一步
4)点选列表块中第一块元素
5)再点击结果列表块中另外一块元素,此时手动选中列表块。点击下一步
6)选择下一页按键,选中选择下一页选项,然后点击页面中的下一页按键填充第一个输入框,第二个数据框可以调节采集运行中点击下一页按键的次数。理论上次数越多,采集到的数据越多。点击下一步
7)选择要采集的数组:在焦点框中点选要抽取的元素后点击下一步
8)选择不步入详情页。点击保存或保存并运行
步骤3:数据采集及导入
1)采集任务运行中
2)采集完成后,选择“导出数据”可以把数据都导入到本地文件
3)选择“导出方法”,将采集好的数据导入,这里可以选择excel作为导入为格式
4)采集数据导入后如下图
如果您未收到手机验证码?
第一步:请您确认一下填写的手机号码是否正确。
第二步:如果号码填写正确,请您到拦截邮件里查看一下,验证码邮件有可能在被拦截邮件里。
第三步:如果拦截圾邮件里没有找到验证码,请您查看一下发送验证码的联通号码是否被拉入手机黑名单,您可以将该号码加入白名单,然后再在登录界面点击“获取短信验证码”。
第四步:如果以上步骤无法解决您的问题,请直接联系官方客服,我们会在第一时间解决您的问题。
如果您未收到帐号激活电邮?
第一步:请您确认一下填写的邮箱地址是否正确。
第二步:如果邮箱地址正确,请您查看一下垃圾箱,激活短信有可能在垃圾箱里。
第三步:如果电邮不在垃圾箱中,请您查看一下是否设置电邮地址黑名单,激活短信有可能被邮箱拦截,请您将优采云采集器加入白名单,然后再在登录界面点击“发送短信”。
第四步:如果以上步骤无法解决您的问题,请直接联系官方客服,我们会在第一时间解决您的问题。
如果您未收到帐号激活电邮?
第一步:请您确认一下填写的邮箱地址是否正确。
第二步:如果邮箱地址正确,请您查看一下垃圾箱,激活短信有可能在垃圾箱里。
第三步:如果电邮不在垃圾箱中,请您查看一下是否设置电邮地址黑名单,激活短信有可能被邮箱拦截,请您将优采云采集器加入白名单,然后再在登录界面点击“发送短信”。
第四步:如果以上步骤无法解决您的问题,请直接联系官方客服,我们会在第一时间解决您的问题。
优采云采集器for Mac
采集交流 • 优采云 发表了文章 • 0 个评论 • 540 次浏览 • 2020-08-09 10:38
注意事项
macOS Catalina (macOS 10.15) 已受损难以打开解决办法:
打开终端(“启动台”—“其他”),输入以下命令,回车:
sudo xattr -d com.apple.quarantine /Applications/xxxx.app(注意空格:sudo空格xattr......)
注意:/Applications/xxxx.app 换成你的App路径,这一步的具体步骤为:在输入 sudo xattr -d com.apple.quarantine 后将你打不开的软件拖进终端,重启App即可。
MacOS 10.15 系统下,如提示“无法启动”,请在系统偏好设置-安全性与隐私-选择【仍要打开】,即可使用。
对于下载了应用,显示“打不开或则显示应用已损毁的情况”的用户,可以参考一下这儿的解决办法《Mac打开应用提示已损毁如何办 Mac安装软件时提示已损毁如何办》。10.12系统以后的新的Mac系统对来自非Mac App Store中的应用做了限制,所以才能出现“应用已损毁或打不开的”情况。
用户假如下载软件后(请确保已下载完的.dmg文件是完整的,不然打开文件的时侯也会出现文件受损难以打开),在打开.dmg文件的时侯提示“来自不受信用的开发者”而打不开软件的,请在“系统偏好设置—安全性与隐私—通用—允许从以下位置下载的应用”选择“任何来源”即可。新系统OS X 10.13及以上的用户打开“任何来源”请参照《macOS 10.13容许任何来源没有了怎样办 macOS 10.13容许任何来源没了如何开启》
软件特色
舆情监控
全方位检测公开信息,抢先获取舆论趋势
市场分析
获取用户真实行为数据,全面掌握客户真实需求
产品研制
强力支撑用户督查,准确获取用户反馈和偏好
风险预测
高效信息采集和数据清洗,及时应对系统风险
模板采集
模板采集模式外置上百种主流网站数据源,如易迅、天猫、大众点评等热门采集网站,只需参照模板简单设置参数,就可以快速获取网站公开数据。
智能采集
优采云采集可依照不同网站,提供多种网页采集策略与配套资源,可自定义配置,组合运用,自动化处理。从而帮助整个采集过程实现数据的完整性与稳定性。
云采集
由5000多台云服务器支撑的云采集,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活契合业务场景,帮你提高采集效率,保障数据时效性。
API接口
通过优采云API,可以轻松获取优采云任务信息和采集到的数据,灵活调度任务,比如远程控制任务启动与停止,高效实现数据采集与归档。基于强悍的API体系,还可以无缝对接公司内部各种管理平台,实现各种业务自动化。
自定义采集
针对不同用户的采集需求,优采云可提供手动生成爬虫的自定义模式,可确切批量辨识各类网页元素,还有翻页、下拉、ajax、页面滚动、条件判定等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
便捷定时功能
简单几步点击设置,即可实现采集任务的定时控制,不论是单次采集的定时设置,还是预设某三天或是每周每月的定时采集,都可以同时对多个任务自由进行设置,根据须要对选择时间进行多重组合,灵活调配自己的采集任务。
全手动数据低格
优采云内置了强悍的数据低格引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间低格、HTML转码等多项功能,采集过程中全手动处理,无需人工干预,即可得到所需格式数据。
多层级采集
很多主流新闻、电商类的网站,里面收录一级商品列表页,也收录二级商品详情页,还有五级评论详情页面;不论网站有多少层级,优采云都可以不限制层级的采集数据,满足各种业务采集需求。
支持网站登录后采集
优采云内置了采集登录模块,只需配置目标网站的帐号密码,即可用该模块采集到登陆后的数据;同时优采云还具备采集Cookie自定义功能,首次登陆之后,可以手动记住cookie,免去多次输入密码的冗长,支持更多网站的采集。 查看全部
优采云采集器Mac版是Mac笔记本上的一款全球百万用户信赖的数据采集器。优采云采集器Mac版可以满足多种业务场景,适合产品、运营、销售、数据剖析、政府机关、电商从业者、学术研究等多种身分职业。
注意事项
macOS Catalina (macOS 10.15) 已受损难以打开解决办法:
打开终端(“启动台”—“其他”),输入以下命令,回车:
sudo xattr -d com.apple.quarantine /Applications/xxxx.app(注意空格:sudo空格xattr......)
注意:/Applications/xxxx.app 换成你的App路径,这一步的具体步骤为:在输入 sudo xattr -d com.apple.quarantine 后将你打不开的软件拖进终端,重启App即可。
MacOS 10.15 系统下,如提示“无法启动”,请在系统偏好设置-安全性与隐私-选择【仍要打开】,即可使用。
对于下载了应用,显示“打不开或则显示应用已损毁的情况”的用户,可以参考一下这儿的解决办法《Mac打开应用提示已损毁如何办 Mac安装软件时提示已损毁如何办》。10.12系统以后的新的Mac系统对来自非Mac App Store中的应用做了限制,所以才能出现“应用已损毁或打不开的”情况。
用户假如下载软件后(请确保已下载完的.dmg文件是完整的,不然打开文件的时侯也会出现文件受损难以打开),在打开.dmg文件的时侯提示“来自不受信用的开发者”而打不开软件的,请在“系统偏好设置—安全性与隐私—通用—允许从以下位置下载的应用”选择“任何来源”即可。新系统OS X 10.13及以上的用户打开“任何来源”请参照《macOS 10.13容许任何来源没有了怎样办 macOS 10.13容许任何来源没了如何开启》
软件特色
舆情监控
全方位检测公开信息,抢先获取舆论趋势
市场分析
获取用户真实行为数据,全面掌握客户真实需求
产品研制
强力支撑用户督查,准确获取用户反馈和偏好
风险预测
高效信息采集和数据清洗,及时应对系统风险
模板采集
模板采集模式外置上百种主流网站数据源,如易迅、天猫、大众点评等热门采集网站,只需参照模板简单设置参数,就可以快速获取网站公开数据。
智能采集
优采云采集可依照不同网站,提供多种网页采集策略与配套资源,可自定义配置,组合运用,自动化处理。从而帮助整个采集过程实现数据的完整性与稳定性。
云采集
由5000多台云服务器支撑的云采集,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活契合业务场景,帮你提高采集效率,保障数据时效性。
API接口
通过优采云API,可以轻松获取优采云任务信息和采集到的数据,灵活调度任务,比如远程控制任务启动与停止,高效实现数据采集与归档。基于强悍的API体系,还可以无缝对接公司内部各种管理平台,实现各种业务自动化。
自定义采集
针对不同用户的采集需求,优采云可提供手动生成爬虫的自定义模式,可确切批量辨识各类网页元素,还有翻页、下拉、ajax、页面滚动、条件判定等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
便捷定时功能
简单几步点击设置,即可实现采集任务的定时控制,不论是单次采集的定时设置,还是预设某三天或是每周每月的定时采集,都可以同时对多个任务自由进行设置,根据须要对选择时间进行多重组合,灵活调配自己的采集任务。
全手动数据低格
优采云内置了强悍的数据低格引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间低格、HTML转码等多项功能,采集过程中全手动处理,无需人工干预,即可得到所需格式数据。
多层级采集
很多主流新闻、电商类的网站,里面收录一级商品列表页,也收录二级商品详情页,还有五级评论详情页面;不论网站有多少层级,优采云都可以不限制层级的采集数据,满足各种业务采集需求。
支持网站登录后采集
优采云内置了采集登录模块,只需配置目标网站的帐号密码,即可用该模块采集到登陆后的数据;同时优采云还具备采集Cookie自定义功能,首次登陆之后,可以手动记住cookie,免去多次输入密码的冗长,支持更多网站的采集。
优采云采集器.pptx的采集原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2020-08-09 03:56
优采云使数据触手可及
视频教程PPT
教程重点
首先,Ucai云采集的原理
2. 优采云实现的功能
首先,Ucai云采集的原理
客户端程序
优采云 Client使用的开发语言是C#,可在Windows上运行. 如果使用的是Mac计算机,则可以先安装Windows虚拟机,然后再安装优采云采集器.
在优采云客户端中,数据的采集和导出主要经历以下三个步骤: 1.配置任务; 2.配置完成后,选择采集方式: 本地采集或云采集; 3.采集完成,导出数据.
相应地,优采云具有三个主要程序来完成这三个主要步骤: 主程序负责任务的配置和管理;任务云采集控制,云集成数据管理(导出,清除和发布). 数据导出程序负责数据导出. 导出格式支持excel,csv,html,txt,导出到数据库等. 支持一次导出数百万个数据. 本地采集程序负责通过正则表达式和Xpath原理根据工作流快速采集网页数据.
首先,Ucai云采集的原理
采集原则
优采云采集器的核心原理是: 在Firefox内核浏览器的基础上,它可以通过模拟人们浏览网页的行为(例如打开网页,单击某个特定按钮)自动提取网页内容. 网页等).
示例网址: de / demo / simplemovies2.html
2. 优采云实现的功能
由彩云实现的功能
1. 这是一个通用的网页数据采集器,可以采集98%的网页.
2. 本地采集和云采集两种采集方法可以满足不同的数据采集要求.
2. 优采云实现的功能
1. 这是一个通用的网页数据采集器,可以采集98%的网页.
作为一般的网页数据采集器,优采云不会在某个网站上采集来自某个行业的数据,但是可以在该网页或该网页的源代码中看到的文本信息几乎都可以采集.
数据库
Excel
BI平台
2. 优采云实现的功能
2. 本地采集和云采集两种采集方法可以满足不同的数据采集要求.
2. 优采云实现的功能
本地采集(单机采集),即使用您自己的计算机进行采集. 查看全部
文档简介:
优采云使数据触手可及
视频教程PPT
教程重点
首先,Ucai云采集的原理
2. 优采云实现的功能
首先,Ucai云采集的原理
客户端程序
优采云 Client使用的开发语言是C#,可在Windows上运行. 如果使用的是Mac计算机,则可以先安装Windows虚拟机,然后再安装优采云采集器.
在优采云客户端中,数据的采集和导出主要经历以下三个步骤: 1.配置任务; 2.配置完成后,选择采集方式: 本地采集或云采集; 3.采集完成,导出数据.
相应地,优采云具有三个主要程序来完成这三个主要步骤: 主程序负责任务的配置和管理;任务云采集控制,云集成数据管理(导出,清除和发布). 数据导出程序负责数据导出. 导出格式支持excel,csv,html,txt,导出到数据库等. 支持一次导出数百万个数据. 本地采集程序负责通过正则表达式和Xpath原理根据工作流快速采集网页数据.
首先,Ucai云采集的原理
采集原则
优采云采集器的核心原理是: 在Firefox内核浏览器的基础上,它可以通过模拟人们浏览网页的行为(例如打开网页,单击某个特定按钮)自动提取网页内容. 网页等).
示例网址: de / demo / simplemovies2.html
2. 优采云实现的功能
由彩云实现的功能
1. 这是一个通用的网页数据采集器,可以采集98%的网页.
2. 本地采集和云采集两种采集方法可以满足不同的数据采集要求.
2. 优采云实现的功能
1. 这是一个通用的网页数据采集器,可以采集98%的网页.
作为一般的网页数据采集器,优采云不会在某个网站上采集来自某个行业的数据,但是可以在该网页或该网页的源代码中看到的文本信息几乎都可以采集.
数据库
Excel
BI平台
2. 优采云实现的功能
2. 本地采集和云采集两种采集方法可以满足不同的数据采集要求.
2. 优采云实现的功能
本地采集(单机采集),即使用您自己的计算机进行采集.

