
采集内容管理平台
采集内容管理平台(采集内容管理平台有很多种,实时数据采集网页端)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-09-15 01:07
采集内容管理平台有很多种,实时数据采集数据采集网页端有百度友盟,api接口多数据有baidusearch,百度统计大数据采集端,百度统计,同步支持阿里统计腾讯统计,且可实时,二十秒,按地域采集多种形式,可etl,数据直接上传到业务系统在线系统能方便实现市场推广,数据分析,信息提取,
推荐微盟内容管理平台,可通过微网站、小程序、app各种展现形式,收集内容信息、采集页面内容、实时更新。
搜索自助采集平台,
恩,怎么说呢,内容采集这个事,最好是先能做一套实时的全网采集系统,这样通过自动分析,用户访问的统计,产品链接,可以看出内容真实的访问度还有内容有多少。个人觉得最有用的数据集成平台,应该是跟线下复杂的经销,营销渠道(运营商报表)是一套的,我建议各种数据全做到平台,渠道,用户,营销,就好。内容采集想走得长远,这样单点集成是不能解决实际问题的。
搜索可以采集很多信息,目前用得最多的应该是阿里妈妈收购内容分发集团了吧。同步是一个很棒的功能,如果做推荐可以试试内容画像的算法融合技术,
百度友盟,统计分析国内现在做得不错的一家服务商。
不是大佬,强答一发。内容采集,地域定向分析,特征关联分析,去重和真伪分析, 查看全部
采集内容管理平台(采集内容管理平台有很多种,实时数据采集网页端)
采集内容管理平台有很多种,实时数据采集数据采集网页端有百度友盟,api接口多数据有baidusearch,百度统计大数据采集端,百度统计,同步支持阿里统计腾讯统计,且可实时,二十秒,按地域采集多种形式,可etl,数据直接上传到业务系统在线系统能方便实现市场推广,数据分析,信息提取,
推荐微盟内容管理平台,可通过微网站、小程序、app各种展现形式,收集内容信息、采集页面内容、实时更新。
搜索自助采集平台,
恩,怎么说呢,内容采集这个事,最好是先能做一套实时的全网采集系统,这样通过自动分析,用户访问的统计,产品链接,可以看出内容真实的访问度还有内容有多少。个人觉得最有用的数据集成平台,应该是跟线下复杂的经销,营销渠道(运营商报表)是一套的,我建议各种数据全做到平台,渠道,用户,营销,就好。内容采集想走得长远,这样单点集成是不能解决实际问题的。
搜索可以采集很多信息,目前用得最多的应该是阿里妈妈收购内容分发集团了吧。同步是一个很棒的功能,如果做推荐可以试试内容画像的算法融合技术,
百度友盟,统计分析国内现在做得不错的一家服务商。
不是大佬,强答一发。内容采集,地域定向分析,特征关联分析,去重和真伪分析,
采集内容管理平台(天天网-数据可视化平台,可以在腾讯开放平台爬数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-08 12:02
采集内容管理平台(例如:博主号宝贝爬取、用户宝贝爬取、文章页面爬取)常用的工具有很多,我只知道robots协议可以爬取京东,的宝贝。你可以去站长平台看看流量统计这一块,一般爬取的数据可以分析转化率什么的。
目前,上有很多爬虫,但是商品管理后台上的店铺搜索数据,所爬取的数据都是比较经过商家的授权的,商家没有授权,是爬取不了的,所以通过商家以外的人是爬取不了上的数据的。但是也可以通过一些其他的工具来爬取其他的数据,比如你可以考虑爬博客主页等数据来作为文章标题的数据,也可以利用一些来爬取其他的数据。
针对上的数据爬取来说,需要通过真实的手机号码,和真实的网页cookies来构造手机号和网址链接才可以正常的抓取数据。不过如果想爬取一些上的用户信息,也可以借助第三方平台,比如爬吧论坛。
用微信小程序可以爬,
打开微信发现小程序搜索,拾书人随便哪个链接,
除了留言板,唯品会等,其他基本上api都去爬,需要授权,其他不知道。
新闻,商品数据可以直接爬。天天网-数据可视化平台,
现在正在做这件事情,可以在腾讯开放平台爬数据, 查看全部
采集内容管理平台(天天网-数据可视化平台,可以在腾讯开放平台爬数据)
采集内容管理平台(例如:博主号宝贝爬取、用户宝贝爬取、文章页面爬取)常用的工具有很多,我只知道robots协议可以爬取京东,的宝贝。你可以去站长平台看看流量统计这一块,一般爬取的数据可以分析转化率什么的。
目前,上有很多爬虫,但是商品管理后台上的店铺搜索数据,所爬取的数据都是比较经过商家的授权的,商家没有授权,是爬取不了的,所以通过商家以外的人是爬取不了上的数据的。但是也可以通过一些其他的工具来爬取其他的数据,比如你可以考虑爬博客主页等数据来作为文章标题的数据,也可以利用一些来爬取其他的数据。
针对上的数据爬取来说,需要通过真实的手机号码,和真实的网页cookies来构造手机号和网址链接才可以正常的抓取数据。不过如果想爬取一些上的用户信息,也可以借助第三方平台,比如爬吧论坛。
用微信小程序可以爬,
打开微信发现小程序搜索,拾书人随便哪个链接,
除了留言板,唯品会等,其他基本上api都去爬,需要授权,其他不知道。
新闻,商品数据可以直接爬。天天网-数据可视化平台,
现在正在做这件事情,可以在腾讯开放平台爬数据,
采集内容管理平台(程序自动关联扩展名为cmbook的书籍文件说明下载地址说明)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-07 09:16
cmbook数据采集与管理软件,本软件为单机绿色软件,由VC2008MFC加SQLITE数据库开发,程序自动将图书文件与扩展名cmbook关联,cmbook图书文件为SQLITE3数据库,扩展名改为db,用sqliteadminsqlite数据库管理工具打开,里面有一个cmbook表和一个版本表,新创建的文章以RTF文件格式保存在cmbook表的BLOB字段中。
相关软件软件大小及版本说明下载链接
cmbook数据采集管理软件,软件功能简单,界面清爽,单文件绿色版,支持全文检索。
本软件是VC2008 MFC和SQLITE数据库开发的单机绿色软件。程序会自动将书籍文件与扩展名 cmbook 相关联。 cmbook book 文件是一个 SQLITE3 数据库。将扩展名更改为 db 并使用 sqliteadmin(sqlite 数据库)。管理工具)打开,里面有一个cmbook表和一个版本表,新创建的文章以rtf文件格式保存在cmbook表的BLOB字段中。
更新日志
cmbook 数据采集管理软件 V1.8
主要纠正错误:
修复了一个新文档错误。 sqlite3_prepare_v2后,sqlite3_finalize没有及时执行释放内存,导致程序新建文档时出错。 查看全部
采集内容管理平台(程序自动关联扩展名为cmbook的书籍文件说明下载地址说明)
cmbook数据采集与管理软件,本软件为单机绿色软件,由VC2008MFC加SQLITE数据库开发,程序自动将图书文件与扩展名cmbook关联,cmbook图书文件为SQLITE3数据库,扩展名改为db,用sqliteadminsqlite数据库管理工具打开,里面有一个cmbook表和一个版本表,新创建的文章以RTF文件格式保存在cmbook表的BLOB字段中。
相关软件软件大小及版本说明下载链接
cmbook数据采集管理软件,软件功能简单,界面清爽,单文件绿色版,支持全文检索。

本软件是VC2008 MFC和SQLITE数据库开发的单机绿色软件。程序会自动将书籍文件与扩展名 cmbook 相关联。 cmbook book 文件是一个 SQLITE3 数据库。将扩展名更改为 db 并使用 sqliteadmin(sqlite 数据库)。管理工具)打开,里面有一个cmbook表和一个版本表,新创建的文章以rtf文件格式保存在cmbook表的BLOB字段中。
更新日志
cmbook 数据采集管理软件 V1.8
主要纠正错误:
修复了一个新文档错误。 sqlite3_prepare_v2后,sqlite3_finalize没有及时执行释放内存,导致程序新建文档时出错。
采集内容管理平台(短视频内容分析采集管理软件软件亮点对所有的视频数据信息进行数据库化管理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-09-06 16:05
短视频内容分析采集管理软件可以对短视频平台(如抖音)的内容进行分析和管理。
类似软件
版本说明
软件地址
短视频内容分析采集管理软件亮点
1.所有视频数据信息的数据库管理,方便查找和对比分析
2. 支持获取主播下所有视频,通过单个视频地址获取视频数据
3.最大亮点:随时可以追踪各主播发布的最新视频,发现主播最新动态
4.记录每个视频的“上传时间”
5.视频内容支持翻页查看,除了可以记录视频时长、点赞数、评论数、分享数等。
6.企业版用户可以共享多台电脑的数据,实现团队数据协同工作。
短视频内容分析采集管理软件功能
一.播主管理模块:
主播管理模块可以对所有登录的主播账号进行分类,如宠物、美女、搞笑等。
输入主播主页的URL链接地址,获取主播账号名和账号ID。
可以手动一一添加主播,软件还支持批量导入。
二.内容分析管理模块:
2.1 支持对一个或多个主播下的所有视频进行分析,也可以通过添加单个或多个视频网址进行分析。
2.2 可以分析获取视频封面、标题、时长、上传时间、点赞数、评论数、分享数等参数。
2.3 还可以根据不同的搜索条件,过滤搜索过去分析保存的数据。
2.2 勾选分析的有效数据,点击“下载选项”即可下载无水印视频文件。
同时,相应的视频内容相关数据也会同步到“视频内容管理”进行精细化管理。
三.视频内容管理模块:
3.1 在视频内容管理上,所有内容均已本地化保存,无水印视频文件。
如果您需要使用该视频内容,可以勾选内容并点击“导出”。
您还可以根据不同的搜索条件对本地保存的数据进行过滤和搜索,删除和选择需要导出的视频。
3.2 每个内容记录2个导出状态,分别为“已导出”和“未导出”,帮助用户记录该内容是否已被使用,避免重复使用。
短视频内容解析采集管理软件更新日志
1.修复BUG,新版本体验更好
2.更改了一些页面
华军编辑推荐:
华骏软件园小编推荐您下载短视频内容分析采集管理软件。编辑器将对其进行测试并放心使用。另外,华骏软件园提供的批量小管家、云机管家、硬盘序列号阅读器、快速隐藏任务栏图标工具、安卓模拟器大师也是不错的软件。有需要的不妨下载试试!风雨小编等你! 查看全部
采集内容管理平台(短视频内容分析采集管理软件软件亮点对所有的视频数据信息进行数据库化管理)
短视频内容分析采集管理软件可以对短视频平台(如抖音)的内容进行分析和管理。
类似软件
版本说明
软件地址
短视频内容分析采集管理软件亮点
1.所有视频数据信息的数据库管理,方便查找和对比分析
2. 支持获取主播下所有视频,通过单个视频地址获取视频数据
3.最大亮点:随时可以追踪各主播发布的最新视频,发现主播最新动态
4.记录每个视频的“上传时间”
5.视频内容支持翻页查看,除了可以记录视频时长、点赞数、评论数、分享数等。
6.企业版用户可以共享多台电脑的数据,实现团队数据协同工作。
短视频内容分析采集管理软件功能
一.播主管理模块:
主播管理模块可以对所有登录的主播账号进行分类,如宠物、美女、搞笑等。
输入主播主页的URL链接地址,获取主播账号名和账号ID。
可以手动一一添加主播,软件还支持批量导入。
二.内容分析管理模块:
2.1 支持对一个或多个主播下的所有视频进行分析,也可以通过添加单个或多个视频网址进行分析。
2.2 可以分析获取视频封面、标题、时长、上传时间、点赞数、评论数、分享数等参数。
2.3 还可以根据不同的搜索条件,过滤搜索过去分析保存的数据。
2.2 勾选分析的有效数据,点击“下载选项”即可下载无水印视频文件。
同时,相应的视频内容相关数据也会同步到“视频内容管理”进行精细化管理。
三.视频内容管理模块:
3.1 在视频内容管理上,所有内容均已本地化保存,无水印视频文件。
如果您需要使用该视频内容,可以勾选内容并点击“导出”。
您还可以根据不同的搜索条件对本地保存的数据进行过滤和搜索,删除和选择需要导出的视频。
3.2 每个内容记录2个导出状态,分别为“已导出”和“未导出”,帮助用户记录该内容是否已被使用,避免重复使用。
短视频内容解析采集管理软件更新日志
1.修复BUG,新版本体验更好
2.更改了一些页面
华军编辑推荐:
华骏软件园小编推荐您下载短视频内容分析采集管理软件。编辑器将对其进行测试并放心使用。另外,华骏软件园提供的批量小管家、云机管家、硬盘序列号阅读器、快速隐藏任务栏图标工具、安卓模拟器大师也是不错的软件。有需要的不妨下载试试!风雨小编等你!
采集内容管理平台(V2.08C序列号院校人才培养工作状态数据采集平台操作指南)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-06 16:03
版本:V2.08C 编号:007 高职人才培养工作状态数据采集平台操作指南1.1 background1.2"状态数据采集平台V2. 08C》目录下文件及子目录说明1.3platform应用环境1.4启动Excel(VBA)运行环境宏1.5platform指令1.6platform使用注意事项2.1platform文件名2.2采集Platform 数据合并同伴介绍2.3创建文件目录和文件重命名的含义10 2.4 执行采集平台文件10 2.5 宏在平台中的作用11 2. 6 启用宏操作 11 3、采集平台管理功能 11 3.1 状态数据目录 11 3.2 数据表导出 12 3.3 数据表导入 12 3.4 数据表锁定 13 3.5 数据表解锁 14 3.6 数据格式刷新 14 3.7 数据统计与汇总 15 4、State data采集管理工艺15 4.1 采集平台数据表导出 16 4.2制定数据采集rules 和issue 文件 17 4.3 填写数据表 18 4.4 恢复合并数据表 19 4.5 将数据表导入采集平台21 4.6 状态数据验证和汇总 22 5、版本升级23 6、平台数据上报24 7、Status data采集释疑25 8、平台升级与技术支持26 1、采集平台简介1.1 背景介绍采集平台主要是以教育部《高职院校人才培养评价方案》(2008)5中公布的指标体系为基础制定,并采纳了课题组和试点单位的改进意见。
1.2 "Status data采集平台V2.08C" XXXXX_YYYY_status 目录下的文件和子目录的描述性名称描述 V2.08C 高职院校人才培养工作状态数据采集平台V2.08C 采集平台_data合并伙伴V2.08C为高职人才培养工作状态数据采集平台助程序恢复数据表收录以每个数据表命名的文件目录name(36A)是用来存放恢复数据采集的数据表文件。恢复后的数据表文件可以根据数据表内容存放在对应的文件目录中。分发数据表存放需要数据的空数据表采集。注意:不要随意修改目录名。可以使用“采集平台_数据Merged Partner V2.08C”恢复目录中相同的数据表。目录下的数据文件被合并。 1.3 平台应用环境状态数据 采集平台V2.08C 所需软件环境为:1) 操作系统:Windows XP、Windows 2000 系列2) 应用软件:Office Excel 2003,允许宏操作1.4 启动EXCEL(VBA)宏运行环境 为编程需要,本平台采用“VBA”高级编程语言,需要(VBA)宏运行环境。一般来说,Excel 自带“宏”检测功能。当发现Excel文件是用“宏”打开时,会提示用户注意,让用户选择是否启用“宏”。
电脑提示语言如下:“文件收录宏,宏可能携带病毒。取消宏虽然可以保证安全,但会影响平台的正常运行。必须启用宏才能在电脑上执行Excel文件. 激活方法如下: 打开Excel文件,选择菜单工具安全,打开安全对话框,将安全级别设置为“低”,如下图,选择一些相关的宏操作时,可能会出现被某些杀毒软件判断为危险软件,此时选择跳过或忽略即可正常使用,不会威胁到计算机的安全,比如我们在使用卡巴斯基杀毒软件时,导出表操作时出现下图,只要选择跳过就可以正常操作,进行以上设置后,重新打开Excel文件,启用宏,就可以正常操作了1. 5 解放军tform 说明1)版本号4)平台版本号、序列号、回目录链接、填写表格各表中说明和注意事项的位置1.6 平台使用注意事项 主目录平台必须放在硬盘的根目录下才能使用,否则可能影响采集平台_数据的导出文件功能集成伙伴V2.08C;数据表提供了标准化的数据输入方式,可根据实际情况选择。不能自行输入或粘贴,否则会影响部分数据汇总的准确性;注意检查输入数据的格式(如课时、金额等指标),特别容易在复制粘贴过程中转换为文本格式。必须设置为数字格式,否则会影响部分数据汇总的准确性;注意检查输入日期的格式(如出生日期、领证日期等)。以标准格式输入,如2007-9-1(其中横线为英文半角),否则会影响部分数据汇总的准确性;进行版本转换前仔细检查“版本差异”文件,有些指标必须重新填写,有些指标必须填写,否则会影响部分数据汇总的准确性; 10) 使用合并伙伴升级前,必须检查每个表的第一列是否为空,如果为空请根据实际情况填写,否则会导致部分数据失效进口; 11)使用合并伙伴中的“版本升级”功能进行版本升级后,必须打开新版本采集platform文件查看升级后的表数据,为完整起见,重新填写“部门填表”、“填表人”、“填表时间”,以及各表项的调整和补充。必须再次进行数据汇总操作,重新生成汇总数据的第十部分,并检查汇总数据的准确性。
12)完成数据输入后,进行“数据统计与汇总”操作,生成汇总数据(第10部分); 13) 表中不能随意添加或删除数据项,可以添加数据行。 2、采集平台文件管理与执行2.1平台文件名含义1)采集平台文件名各部分含义 图10:采集平台文件含义姓名2)例上海行健 高职院校代码:12493,上报年份:2008 上报文件名:12493_2008_STATUS V2.08C.xls 3) 注:上报状态数据时文件,文件需要按照图10所示的规则进行处理。重命名。 2.2 采集platform数据合并伙伴介绍1)“采集平台_data合并伙伴V208c.xls”是data采集平台的辅助工具。其主要功能是数据表文件恢复、数据合并、数据表版本转换。请注意,这些功能只能在允许宏操作的环境中使用。 2)Merge伙伴组合:1个伙伴文件,几个文件目录(如下图) 图11:Merge伙伴组合图 10 2.3 创建文件目录和文件重命名1)State数据文件管理2)示例:“上海兴建职业学院” Data采集文件管理学校代码:12493 申请年份:2008 操作步骤: 步骤一:更改光盘中的目录“status data采集平台V2.08C” ROM复制到电脑,例如我们把“status data采集平台V2.08C”目录复制到D盘根目录下,将目录重命名为“12493_2008”,同意这个目录是平台操作的主目录 第二步:打开“12493_2008”目录;第三步:将采集platform文件“XXXXX_YYYY_status data V2.08C.xls”重命名为:“12493_2008_status data V2.08C.xls”。
最终完成的目录结构如下: 图12:文件目录结构图2.4 在excel中第一次打开主平台文件时执行采集platform文件,或者你从来没有在你的excel 设置“宏安全”后打开主平台文件会出现如图13所示的警告画面。如果选择确定,您可以输入基础数据,但平台提供的智能操作功能将被拒绝。 11 图13:提示禁用宏2.5 宏在平台中的作用1)查看状态数据2)用于数据输入3)数据汇总操作4)允许智能表操作(如表导出) /import 、表解锁/锁定、格式刷新、数据汇总等)2.6 启用宏操作。必须启用宏才能在 Excel 中执行主平台文件。启用方法如下: 打开Excel文件,选择菜单工具安全,打开安全对话框,设置安全级别为“低”。具体操作图请参考《1.4 启动Excel(VBA)宏操作环境》中的介绍。注意:进行上述设置后,需要重新打开Excel文件并启用宏才能进行正常操作。 3、采集平台管理功能3.1 状态数据目录根据“状态数据目录”类别查询、录入或修改采集平台数据表中的数据。 12 图14:状态数据目录3.2 数据表导出 “数据表导出”操作可以将36个数据表以单表文件的形式导出到采集平台。
图15:数据表导出界面3.3 数据表导入“数据表导入”操作可以将36个已经完成数据输入的数据表文件导入到data采集平台。需要导入的数据表文件必须直接保存在“恢复数据表”目录下,文件名必须以采集平台朋友导出的文件名为准。 13 图16:数据表导入界面3.4 数据表锁定“数据表锁定”操作位于导航“高级操作”中,锁定状态下,只能处理数据表,不能处理表结构修改的 。注:1)锁数据表,目的是保证数据表结构的一致性; 2)在执行“数据表导出”操作前确保数据表被锁定,即数据表被锁定 非数据输入区被锁定后无法操作。图17:数据表锁定 14 3.5 数据表解锁 “数据表解锁”操作位于导航“高级操作”中,在解锁状态下可以完全控制表。注意:在解锁状态下,可以进行表格格式处理,调整行高或列宽,增加数据行,但不要调整表格的项结构,否则会影响汇总数据的准确性;图18:数据表解锁3.6 数据格式刷新“数据格式刷新”操作位于导航“高级操作”中,统一处理数据表中数据的字体和字号。图 19:数据格式刷新 15 3.7 数据统计与汇总 “数据统计与汇总”操作位于导航“高级操作”中。对平台中的数据进行汇总,生成汇总数据的第十部分。
注意:所有数据导入平台后,必须点击此按钮生成汇总数据的第十部分;每次更新平台中的表格时必须点击此按钮重新生成第十部分汇总数据,否则不会自动生成或更新第10部分汇总数据。图20:数据统计与汇总4、State Data采集管理程16 4.1 采集platform 数据表导出 在数据导出页面,将选中的工作表作为单表导出到采集platform 文件保存在采集platform文件所在的目录中;图 21:数据表导出页面 图 22:数据表导出后的文件目录结构 注意:重复数据表导出操作时,如果有同名数据表文件,系统会提问,由操作员决定是否覆盖文件或放弃操作。 17 图23:数据表重复导出后的系统提示4.2 制定数据采集 规则和文件分布 根据数据生成源制定数据采集Rules1)OK data采集Object:分析导出数据表(36张),指定数据采集object(部门/人); 2)数据表文件重命名:根据确定的数据采集对象重命名数据文件(如下图) 18 图24:将数据表文件复制到[下载数据表】目录3)示例导出表文件名为“A4-2校外实习实训基地表(XX采集)”文件更名为“A4-2校外实习实训基地表(教研科采集)”4.3 填写数据表1) 打开数据表文件,按照表中的项目输入数据。注:每个数据表的上半部分是版本标识,返回主目录链接,填写说明和注意事项,输入数据前请仔细阅读。
图25:需填写的单一表格2) 数据输入完成后,保存文件,并按规定重命名文件(部分表格) 例如:在线教研室填写在“A4-2校外实习实训基地表(教研室采集)”文件更名为:“A4-2校外实习实训基地表(网络教研室采集)” 19 4.4 数据表的回收和合并1)每个将被回收的单表的副本进入“回收数据表”目录中的相应目录。图26:将回收的单张复制到“Recycled Data Sheet”目录下对应的目录。示例:将“A7-1专业设置表”的单张文件复制到“A7-1专业设置表”目录下,图27:将各专业表2)的“A7-1专业设置表”目录复制回来到平台主目录,打开文件“采集平台_数据合并伙伴V2.08C.xls”,必须启用宏,选择要合并的子表,例如:根据上面的例子,我们选择“7.1 专业设置” 20 图28:数据合并伙伴目录界面3) 打开合并表页面,点击页面上的“合并数据”按钮。图29:数据合并界面 图30:程序自动合并“恢复数据目录”下“A7-1专业设置表”目录下的所有文件内容。在表中,按每个表的key字段排序,所以每个导入表的第一列不能为空。 21 注:合并后的内容可以在合并表中查看、修改、清除。
4)导出合并数据表。选择页面上的“导出文件”按钮。出现提示时,按“确定”按钮。导出成功。导出的文件会自动存储在“回收数据表”目录中。图 31:执行“导出文件”按钮后,组合表将自动导出到“回收数据表”目录。图 32:“回收数据表”目录中的组合表。 A7-1 Professional settings table.xls”文件4.5 将数据表导入采集平台回到主目录,打开平台主文件“12493_2008_status data V2.08C.xls”,进入“data在“导入”界面,勾选要导入的文件名,选择“数据表导入”按钮,会出现导入提示,根据情况操作。(一般情况下选择“确定” ”按钮第一次导入合并表) 22 图33:选择要导入平台的文件名列表 注意:重复数据表导入操作时,如果有同名的工作表,系统将给出提示,操作者决定是覆盖文件还是放弃操作,如果要导入的数据表文件版本与采集平台不同,系统拒绝导入操作,数据合并伙伴可以使用与采集platform 相同的版本进行版本转换n. 4.6 状态数据检查及汇总1)数据检查:完成数据表导入后,检查采集平台中的数据,确认已导入所有有效数据;您可以通过平台“数据目录”索引导航中的“状态”进行验证; 2)数据汇总:当校验数据正确时,执行“数据统计汇总”操作,生成汇总数据的第十部分。
“统计与汇总”按钮在“高级操作”页面,也可以直接点击表格第十部分的“状态数据汇总”按钮。图 34:表格 23 第十部分的“状态数据汇总”按钮 图 35:生成的状态数据汇总表3) 注意:如果数据汇总后平台中的数据再次发生变化,则需要执行“数据”再“统计汇总”操作,否则统计结果与实际情况不同。 5、版本升级 其他版本完成数据汇总的学校,可以使用采集平台数据合并伴侣提供的“版本升级”按钮,将已有汇总数据的文件一键中转为最新版本的平台文件具体操作流程如下: 下载《Status Data采集平台和数据合并伴侣》、《平台操作指南》、《版本转换说明》,复制解压后的《Status Data采集平台和数据合并伴侣》 ”目录到任意硬盘根目录(如F盘根目录),修改目录名称为“学校代码_申报年份”,修改状态数据采集platform文件名如图36,复制需要的文件转换到这个目录如图36所示;图 36:版本升级环境示例。打开合并伙伴“采集平台_数据组合合作V2.08c.xls”文件,点击“版本升级(一键转换)”按钮(图37),仔细查看版本升级说明(图38)按“是”开始版本升级,耐心等待,完成后查看数据采集platform转换为V2.08c版本操作完成说明(图39)24 图37:位置图38:版本升级注意事项 图39:Data采集平台过渡到V2.08c版本操作完成说明打开新版本采集platform文件查看升级完成后表格数据,并重新填写各表格中的“填表部门”、“填表人”、“填表时间”,以及各表中的调整和补充,必须再次进行数据汇总操作以重新生成汇总数据的第十部分,并检查汇总数据的准确性6、平台数据上报 数据文件上报的两种方式 25 光盘上报数据文件(目前使用) 网络上传数据文件(调试中) 7、State data采集 解疑1) 执行时单表数据合并操作,数据表中保留的数据行不足。如何添加数据行?操作步骤:在采集平台导航的“高级操作”中进行“数据表锁定”操作。
2)在data采集platform中,我校想加一栏,是否可以上报状态data采集platform文件,里面的数据指标是固定的,所以采集平台中的数据列不允许增加或减少,否则会影响数据的统计和汇总(第10部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。 3) 数据表导出操作时,系统发出宏警告,无法进行导出操作。我该怎么办?步骤:导出数据表。 4)在查找第10部分的汇总数据时,发现有些汇总值有问题。如何查看问题点?可以从以下几个方面发现问题: 确保采集平台上的数据准确完整,重新进行“数据统计汇总”操作; 26 数据汇总表中的汇总分类表下,描述了参与汇总,对于数据来源,按照提示查看汇总数据表中的数据。如果数据被修改,必须重新进行“数据统计汇总”操作;分析汇总数据,正确理解数据结构。 8、平台升级与技术支持网站联系电话(021)56940080(021)56075555-1210 27) 查看全部
采集内容管理平台(V2.08C序列号院校人才培养工作状态数据采集平台操作指南)
版本:V2.08C 编号:007 高职人才培养工作状态数据采集平台操作指南1.1 background1.2"状态数据采集平台V2. 08C》目录下文件及子目录说明1.3platform应用环境1.4启动Excel(VBA)运行环境宏1.5platform指令1.6platform使用注意事项2.1platform文件名2.2采集Platform 数据合并同伴介绍2.3创建文件目录和文件重命名的含义10 2.4 执行采集平台文件10 2.5 宏在平台中的作用11 2. 6 启用宏操作 11 3、采集平台管理功能 11 3.1 状态数据目录 11 3.2 数据表导出 12 3.3 数据表导入 12 3.4 数据表锁定 13 3.5 数据表解锁 14 3.6 数据格式刷新 14 3.7 数据统计与汇总 15 4、State data采集管理工艺15 4.1 采集平台数据表导出 16 4.2制定数据采集rules 和issue 文件 17 4.3 填写数据表 18 4.4 恢复合并数据表 19 4.5 将数据表导入采集平台21 4.6 状态数据验证和汇总 22 5、版本升级23 6、平台数据上报24 7、Status data采集释疑25 8、平台升级与技术支持26 1、采集平台简介1.1 背景介绍采集平台主要是以教育部《高职院校人才培养评价方案》(2008)5中公布的指标体系为基础制定,并采纳了课题组和试点单位的改进意见。
1.2 "Status data采集平台V2.08C" XXXXX_YYYY_status 目录下的文件和子目录的描述性名称描述 V2.08C 高职院校人才培养工作状态数据采集平台V2.08C 采集平台_data合并伙伴V2.08C为高职人才培养工作状态数据采集平台助程序恢复数据表收录以每个数据表命名的文件目录name(36A)是用来存放恢复数据采集的数据表文件。恢复后的数据表文件可以根据数据表内容存放在对应的文件目录中。分发数据表存放需要数据的空数据表采集。注意:不要随意修改目录名。可以使用“采集平台_数据Merged Partner V2.08C”恢复目录中相同的数据表。目录下的数据文件被合并。 1.3 平台应用环境状态数据 采集平台V2.08C 所需软件环境为:1) 操作系统:Windows XP、Windows 2000 系列2) 应用软件:Office Excel 2003,允许宏操作1.4 启动EXCEL(VBA)宏运行环境 为编程需要,本平台采用“VBA”高级编程语言,需要(VBA)宏运行环境。一般来说,Excel 自带“宏”检测功能。当发现Excel文件是用“宏”打开时,会提示用户注意,让用户选择是否启用“宏”。
电脑提示语言如下:“文件收录宏,宏可能携带病毒。取消宏虽然可以保证安全,但会影响平台的正常运行。必须启用宏才能在电脑上执行Excel文件. 激活方法如下: 打开Excel文件,选择菜单工具安全,打开安全对话框,将安全级别设置为“低”,如下图,选择一些相关的宏操作时,可能会出现被某些杀毒软件判断为危险软件,此时选择跳过或忽略即可正常使用,不会威胁到计算机的安全,比如我们在使用卡巴斯基杀毒软件时,导出表操作时出现下图,只要选择跳过就可以正常操作,进行以上设置后,重新打开Excel文件,启用宏,就可以正常操作了1. 5 解放军tform 说明1)版本号4)平台版本号、序列号、回目录链接、填写表格各表中说明和注意事项的位置1.6 平台使用注意事项 主目录平台必须放在硬盘的根目录下才能使用,否则可能影响采集平台_数据的导出文件功能集成伙伴V2.08C;数据表提供了标准化的数据输入方式,可根据实际情况选择。不能自行输入或粘贴,否则会影响部分数据汇总的准确性;注意检查输入数据的格式(如课时、金额等指标),特别容易在复制粘贴过程中转换为文本格式。必须设置为数字格式,否则会影响部分数据汇总的准确性;注意检查输入日期的格式(如出生日期、领证日期等)。以标准格式输入,如2007-9-1(其中横线为英文半角),否则会影响部分数据汇总的准确性;进行版本转换前仔细检查“版本差异”文件,有些指标必须重新填写,有些指标必须填写,否则会影响部分数据汇总的准确性; 10) 使用合并伙伴升级前,必须检查每个表的第一列是否为空,如果为空请根据实际情况填写,否则会导致部分数据失效进口; 11)使用合并伙伴中的“版本升级”功能进行版本升级后,必须打开新版本采集platform文件查看升级后的表数据,为完整起见,重新填写“部门填表”、“填表人”、“填表时间”,以及各表项的调整和补充。必须再次进行数据汇总操作,重新生成汇总数据的第十部分,并检查汇总数据的准确性。
12)完成数据输入后,进行“数据统计与汇总”操作,生成汇总数据(第10部分); 13) 表中不能随意添加或删除数据项,可以添加数据行。 2、采集平台文件管理与执行2.1平台文件名含义1)采集平台文件名各部分含义 图10:采集平台文件含义姓名2)例上海行健 高职院校代码:12493,上报年份:2008 上报文件名:12493_2008_STATUS V2.08C.xls 3) 注:上报状态数据时文件,文件需要按照图10所示的规则进行处理。重命名。 2.2 采集platform数据合并伙伴介绍1)“采集平台_data合并伙伴V208c.xls”是data采集平台的辅助工具。其主要功能是数据表文件恢复、数据合并、数据表版本转换。请注意,这些功能只能在允许宏操作的环境中使用。 2)Merge伙伴组合:1个伙伴文件,几个文件目录(如下图) 图11:Merge伙伴组合图 10 2.3 创建文件目录和文件重命名1)State数据文件管理2)示例:“上海兴建职业学院” Data采集文件管理学校代码:12493 申请年份:2008 操作步骤: 步骤一:更改光盘中的目录“status data采集平台V2.08C” ROM复制到电脑,例如我们把“status data采集平台V2.08C”目录复制到D盘根目录下,将目录重命名为“12493_2008”,同意这个目录是平台操作的主目录 第二步:打开“12493_2008”目录;第三步:将采集platform文件“XXXXX_YYYY_status data V2.08C.xls”重命名为:“12493_2008_status data V2.08C.xls”。
最终完成的目录结构如下: 图12:文件目录结构图2.4 在excel中第一次打开主平台文件时执行采集platform文件,或者你从来没有在你的excel 设置“宏安全”后打开主平台文件会出现如图13所示的警告画面。如果选择确定,您可以输入基础数据,但平台提供的智能操作功能将被拒绝。 11 图13:提示禁用宏2.5 宏在平台中的作用1)查看状态数据2)用于数据输入3)数据汇总操作4)允许智能表操作(如表导出) /import 、表解锁/锁定、格式刷新、数据汇总等)2.6 启用宏操作。必须启用宏才能在 Excel 中执行主平台文件。启用方法如下: 打开Excel文件,选择菜单工具安全,打开安全对话框,设置安全级别为“低”。具体操作图请参考《1.4 启动Excel(VBA)宏操作环境》中的介绍。注意:进行上述设置后,需要重新打开Excel文件并启用宏才能进行正常操作。 3、采集平台管理功能3.1 状态数据目录根据“状态数据目录”类别查询、录入或修改采集平台数据表中的数据。 12 图14:状态数据目录3.2 数据表导出 “数据表导出”操作可以将36个数据表以单表文件的形式导出到采集平台。
图15:数据表导出界面3.3 数据表导入“数据表导入”操作可以将36个已经完成数据输入的数据表文件导入到data采集平台。需要导入的数据表文件必须直接保存在“恢复数据表”目录下,文件名必须以采集平台朋友导出的文件名为准。 13 图16:数据表导入界面3.4 数据表锁定“数据表锁定”操作位于导航“高级操作”中,锁定状态下,只能处理数据表,不能处理表结构修改的 。注:1)锁数据表,目的是保证数据表结构的一致性; 2)在执行“数据表导出”操作前确保数据表被锁定,即数据表被锁定 非数据输入区被锁定后无法操作。图17:数据表锁定 14 3.5 数据表解锁 “数据表解锁”操作位于导航“高级操作”中,在解锁状态下可以完全控制表。注意:在解锁状态下,可以进行表格格式处理,调整行高或列宽,增加数据行,但不要调整表格的项结构,否则会影响汇总数据的准确性;图18:数据表解锁3.6 数据格式刷新“数据格式刷新”操作位于导航“高级操作”中,统一处理数据表中数据的字体和字号。图 19:数据格式刷新 15 3.7 数据统计与汇总 “数据统计与汇总”操作位于导航“高级操作”中。对平台中的数据进行汇总,生成汇总数据的第十部分。
注意:所有数据导入平台后,必须点击此按钮生成汇总数据的第十部分;每次更新平台中的表格时必须点击此按钮重新生成第十部分汇总数据,否则不会自动生成或更新第10部分汇总数据。图20:数据统计与汇总4、State Data采集管理程16 4.1 采集platform 数据表导出 在数据导出页面,将选中的工作表作为单表导出到采集platform 文件保存在采集platform文件所在的目录中;图 21:数据表导出页面 图 22:数据表导出后的文件目录结构 注意:重复数据表导出操作时,如果有同名数据表文件,系统会提问,由操作员决定是否覆盖文件或放弃操作。 17 图23:数据表重复导出后的系统提示4.2 制定数据采集 规则和文件分布 根据数据生成源制定数据采集Rules1)OK data采集Object:分析导出数据表(36张),指定数据采集object(部门/人); 2)数据表文件重命名:根据确定的数据采集对象重命名数据文件(如下图) 18 图24:将数据表文件复制到[下载数据表】目录3)示例导出表文件名为“A4-2校外实习实训基地表(XX采集)”文件更名为“A4-2校外实习实训基地表(教研科采集)”4.3 填写数据表1) 打开数据表文件,按照表中的项目输入数据。注:每个数据表的上半部分是版本标识,返回主目录链接,填写说明和注意事项,输入数据前请仔细阅读。
图25:需填写的单一表格2) 数据输入完成后,保存文件,并按规定重命名文件(部分表格) 例如:在线教研室填写在“A4-2校外实习实训基地表(教研室采集)”文件更名为:“A4-2校外实习实训基地表(网络教研室采集)” 19 4.4 数据表的回收和合并1)每个将被回收的单表的副本进入“回收数据表”目录中的相应目录。图26:将回收的单张复制到“Recycled Data Sheet”目录下对应的目录。示例:将“A7-1专业设置表”的单张文件复制到“A7-1专业设置表”目录下,图27:将各专业表2)的“A7-1专业设置表”目录复制回来到平台主目录,打开文件“采集平台_数据合并伙伴V2.08C.xls”,必须启用宏,选择要合并的子表,例如:根据上面的例子,我们选择“7.1 专业设置” 20 图28:数据合并伙伴目录界面3) 打开合并表页面,点击页面上的“合并数据”按钮。图29:数据合并界面 图30:程序自动合并“恢复数据目录”下“A7-1专业设置表”目录下的所有文件内容。在表中,按每个表的key字段排序,所以每个导入表的第一列不能为空。 21 注:合并后的内容可以在合并表中查看、修改、清除。
4)导出合并数据表。选择页面上的“导出文件”按钮。出现提示时,按“确定”按钮。导出成功。导出的文件会自动存储在“回收数据表”目录中。图 31:执行“导出文件”按钮后,组合表将自动导出到“回收数据表”目录。图 32:“回收数据表”目录中的组合表。 A7-1 Professional settings table.xls”文件4.5 将数据表导入采集平台回到主目录,打开平台主文件“12493_2008_status data V2.08C.xls”,进入“data在“导入”界面,勾选要导入的文件名,选择“数据表导入”按钮,会出现导入提示,根据情况操作。(一般情况下选择“确定” ”按钮第一次导入合并表) 22 图33:选择要导入平台的文件名列表 注意:重复数据表导入操作时,如果有同名的工作表,系统将给出提示,操作者决定是覆盖文件还是放弃操作,如果要导入的数据表文件版本与采集平台不同,系统拒绝导入操作,数据合并伙伴可以使用与采集platform 相同的版本进行版本转换n. 4.6 状态数据检查及汇总1)数据检查:完成数据表导入后,检查采集平台中的数据,确认已导入所有有效数据;您可以通过平台“数据目录”索引导航中的“状态”进行验证; 2)数据汇总:当校验数据正确时,执行“数据统计汇总”操作,生成汇总数据的第十部分。
“统计与汇总”按钮在“高级操作”页面,也可以直接点击表格第十部分的“状态数据汇总”按钮。图 34:表格 23 第十部分的“状态数据汇总”按钮 图 35:生成的状态数据汇总表3) 注意:如果数据汇总后平台中的数据再次发生变化,则需要执行“数据”再“统计汇总”操作,否则统计结果与实际情况不同。 5、版本升级 其他版本完成数据汇总的学校,可以使用采集平台数据合并伴侣提供的“版本升级”按钮,将已有汇总数据的文件一键中转为最新版本的平台文件具体操作流程如下: 下载《Status Data采集平台和数据合并伴侣》、《平台操作指南》、《版本转换说明》,复制解压后的《Status Data采集平台和数据合并伴侣》 ”目录到任意硬盘根目录(如F盘根目录),修改目录名称为“学校代码_申报年份”,修改状态数据采集platform文件名如图36,复制需要的文件转换到这个目录如图36所示;图 36:版本升级环境示例。打开合并伙伴“采集平台_数据组合合作V2.08c.xls”文件,点击“版本升级(一键转换)”按钮(图37),仔细查看版本升级说明(图38)按“是”开始版本升级,耐心等待,完成后查看数据采集platform转换为V2.08c版本操作完成说明(图39)24 图37:位置图38:版本升级注意事项 图39:Data采集平台过渡到V2.08c版本操作完成说明打开新版本采集platform文件查看升级完成后表格数据,并重新填写各表格中的“填表部门”、“填表人”、“填表时间”,以及各表中的调整和补充,必须再次进行数据汇总操作以重新生成汇总数据的第十部分,并检查汇总数据的准确性6、平台数据上报 数据文件上报的两种方式 25 光盘上报数据文件(目前使用) 网络上传数据文件(调试中) 7、State data采集 解疑1) 执行时单表数据合并操作,数据表中保留的数据行不足。如何添加数据行?操作步骤:在采集平台导航的“高级操作”中进行“数据表锁定”操作。
2)在data采集platform中,我校想加一栏,是否可以上报状态data采集platform文件,里面的数据指标是固定的,所以采集平台中的数据列不允许增加或减少,否则会影响数据的统计和汇总(第10部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。 3) 数据表导出操作时,系统发出宏警告,无法进行导出操作。我该怎么办?步骤:导出数据表。 4)在查找第10部分的汇总数据时,发现有些汇总值有问题。如何查看问题点?可以从以下几个方面发现问题: 确保采集平台上的数据准确完整,重新进行“数据统计汇总”操作; 26 数据汇总表中的汇总分类表下,描述了参与汇总,对于数据来源,按照提示查看汇总数据表中的数据。如果数据被修改,必须重新进行“数据统计汇总”操作;分析汇总数据,正确理解数据结构。 8、平台升级与技术支持网站联系电话(021)56940080(021)56075555-1210 27)
采集内容管理平台(信息门户平台不仅仅局限于统一门户管理平台个性化信息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-06 16:03
产品概览
信息门户平台是指在现有网络环境下,将信息门户下的各种应用系统和数据资源统一整合,根据每个用户的特点和角色,形成个性化的应用界面。并通过事件和消息的处理和传递,将用户有机地联系在一起。门户平台不仅限于建立门户网站,提供一些服务信息,更重要的是实现了多业务系统的集成,可以快速响应客户的各种需求,可以进行统一管理整个供应链。
产品特点
1.统一门户管理平台
1.1接口管理
门户使用服务器页面模板、级联工作表和图像来定义页面的外观。用户可以修改这些元素来控制门户的视觉效果,也可以添加公司特定的品牌元素或实施不同的配色方案和视觉风格。定义配色方案和门户外壳的系统支持每个方案下的多个外壳、补充标记元素、导航样式和独立于浏览器的动态级联工作表。
外壳和配色方案不仅可以应用于整个门户,还可以应用于某个页面组。同样,不同的外壳可以应用于多个模块,因此可以对模块的外观进行微调以满足任何用户需求。通过为每个页面组采用一组不同的解决方案,单个门户安装看起来支持许多“虚拟”门户。
1.2查看管理和个性化设置
统一创建、修改和删除用户视图。通过应用目录管理保存和管理所有应用内容,然后通过视图管理模块对界面进行布局,实现个性化设置和快速定制。
个性化信息服务包括个性化数据存储、个性化信息展示、用户管理界面、信息统一用户管理界面、个性化数据管理。
1.2.1 个性化数据存储
不同部门、不同员工对信息的个性化要求不同。因此,个性化服务需要统一存储不同部门、不同员工的个性化定制数据。
1.2.2个性化信息展示
用户自定义个性化信息后,希望信息能够以自定义的方式展示。在公务员门户客户端中,集成个性化服务,在用户桌面上展示定制的方法。
1.2.3 用户管理接口
个性化信息与用户信息的关系非常密切,个性化服务需要通过用户管理的开放接口读取用户信息,将用户与个性化信息连接起来。
1.2.4及信息统一用户管理界面
个性化服务需要确定用户对信息的访问权限,然后将用户可以访问的信息显示在用户的桌面上。
1.2.5 个性化数据管理
用户需要改变个性化信息的定制,所以需要提供个性化数据管理的用户界面,让用户可以图形化的方式定制信息。个性化数据管理需要为终端用户和部门系统管理员提供服务。
2.统一信息发布(内容管理)平台
2.1 信息采集、编辑和发布
2.1.1信息采集
双洋内容管理平台提供了采集内容手动编辑输入采集和自动采集两种方式。
2.1.2信息编辑
提供基于浏览器的可视化编辑,也可以调用编辑软件进行编辑,并提供可视化标记插入。
2.1.3 信息回顾
为用户提供图形化的内容编辑、审核、发布流程定制化界面,用户可以轻松定制网站内容审核流程。
2.1.4信息发布
对于网站文件的发布,双阳内容管理平台提供了多种发布方式:手动发布、定时发布、触发发布、远程发布。
2.1.5信息预览
在网站内容提交过程的不同阶段提供编辑、审核和发布前的预览功能。
2.1.6信息检索
内置搜索引擎,数据库系统全文搜索功能。您可以设置搜索条件来搜索网站数据内容。
2.2信息栏管理
双阳内容管理平台管理网站频道(栏目),栏目以树状方式展示,相关栏目可以添加或删除。 网站可设置栏目,可设置栏目负责人,栏目模板等
3.模板管理
3.1网站template
网站模板定义了网站的风格和基本的网站框架,由几个动态布局和动态布局上的动态位组成。
3.2布局管理
布局是除具体信息展示页面以外的动态页面,主要是首页、二、三级页面等需要动态配置的页面。一个论坛只能属于一个网站template。
4.statistics
双阳内容管理平台提供基于投稿单位或投稿栏目等元素的统计。
5.全文搜索
您可以全文搜索整个网站内容。
特点
1.一站式服务
采用浏览器/服务器(B/S)模式,提供统一个性化的用户界面,用户只需拥有浏览器即可获得一站式业务服务,实现单点登录,用户只需登录在标准一、标准门户网站可以完成请求的具体业务内容,具体业务处理由一站式服务框架后台处理,对用户透明。
2.内容管理
提供完善的内容管理功能,可以采集,编辑、管理和发布内部分散的多种数据类型和格式的内容,供用户分享。在采集数据的编辑、校对、审核、发布的整个工作过程中,系统严格控制安全,建立了完善的审计机制和防篡改机制。
3.智能搜索
智能检索为用户提供了一种便捷的方式来查询自己权限内的相关信息。通过输入关键词等方式,可以快速找到分散在互联网和政府内部的格式化和非格式化数据,达到资源共享的目的。 .
4.视图管理
统一创建、修改和删除用户视图。通过应用目录管理保存和管理所有应用内容,然后通过视图管理模块对界面进行布局,实现个性化设置和快速定制。
5.应用系统集成
使用Webpart实现各种应用系统的接口集成。 Webpart 是一个可插拔组件,通过Webpart 将现有的应用系统内容集成到门户中。为每个系统设置一个Webpart,并通过Webpart服务器进行管理。
6.个性化服务
为不同部门、组织、层级的员工提供符合其需求和特点的办公页面,通过个性化门户展示他们最关心、最常用的信息资源。用户可以自定义权限范围内的内容视图。
7.portal 管理
为了方便技术人员的维护和管理,门户支撑平台应提供多种管理工具,包括:视图管理、部署管理、模板管理、主页管理等。 查看全部
采集内容管理平台(信息门户平台不仅仅局限于统一门户管理平台个性化信息)
产品概览
信息门户平台是指在现有网络环境下,将信息门户下的各种应用系统和数据资源统一整合,根据每个用户的特点和角色,形成个性化的应用界面。并通过事件和消息的处理和传递,将用户有机地联系在一起。门户平台不仅限于建立门户网站,提供一些服务信息,更重要的是实现了多业务系统的集成,可以快速响应客户的各种需求,可以进行统一管理整个供应链。
产品特点
1.统一门户管理平台
1.1接口管理
门户使用服务器页面模板、级联工作表和图像来定义页面的外观。用户可以修改这些元素来控制门户的视觉效果,也可以添加公司特定的品牌元素或实施不同的配色方案和视觉风格。定义配色方案和门户外壳的系统支持每个方案下的多个外壳、补充标记元素、导航样式和独立于浏览器的动态级联工作表。
外壳和配色方案不仅可以应用于整个门户,还可以应用于某个页面组。同样,不同的外壳可以应用于多个模块,因此可以对模块的外观进行微调以满足任何用户需求。通过为每个页面组采用一组不同的解决方案,单个门户安装看起来支持许多“虚拟”门户。
1.2查看管理和个性化设置
统一创建、修改和删除用户视图。通过应用目录管理保存和管理所有应用内容,然后通过视图管理模块对界面进行布局,实现个性化设置和快速定制。
个性化信息服务包括个性化数据存储、个性化信息展示、用户管理界面、信息统一用户管理界面、个性化数据管理。
1.2.1 个性化数据存储
不同部门、不同员工对信息的个性化要求不同。因此,个性化服务需要统一存储不同部门、不同员工的个性化定制数据。
1.2.2个性化信息展示
用户自定义个性化信息后,希望信息能够以自定义的方式展示。在公务员门户客户端中,集成个性化服务,在用户桌面上展示定制的方法。
1.2.3 用户管理接口
个性化信息与用户信息的关系非常密切,个性化服务需要通过用户管理的开放接口读取用户信息,将用户与个性化信息连接起来。
1.2.4及信息统一用户管理界面
个性化服务需要确定用户对信息的访问权限,然后将用户可以访问的信息显示在用户的桌面上。
1.2.5 个性化数据管理
用户需要改变个性化信息的定制,所以需要提供个性化数据管理的用户界面,让用户可以图形化的方式定制信息。个性化数据管理需要为终端用户和部门系统管理员提供服务。
2.统一信息发布(内容管理)平台
2.1 信息采集、编辑和发布
2.1.1信息采集
双洋内容管理平台提供了采集内容手动编辑输入采集和自动采集两种方式。
2.1.2信息编辑
提供基于浏览器的可视化编辑,也可以调用编辑软件进行编辑,并提供可视化标记插入。
2.1.3 信息回顾
为用户提供图形化的内容编辑、审核、发布流程定制化界面,用户可以轻松定制网站内容审核流程。
2.1.4信息发布
对于网站文件的发布,双阳内容管理平台提供了多种发布方式:手动发布、定时发布、触发发布、远程发布。
2.1.5信息预览
在网站内容提交过程的不同阶段提供编辑、审核和发布前的预览功能。
2.1.6信息检索
内置搜索引擎,数据库系统全文搜索功能。您可以设置搜索条件来搜索网站数据内容。
2.2信息栏管理
双阳内容管理平台管理网站频道(栏目),栏目以树状方式展示,相关栏目可以添加或删除。 网站可设置栏目,可设置栏目负责人,栏目模板等
3.模板管理
3.1网站template
网站模板定义了网站的风格和基本的网站框架,由几个动态布局和动态布局上的动态位组成。
3.2布局管理
布局是除具体信息展示页面以外的动态页面,主要是首页、二、三级页面等需要动态配置的页面。一个论坛只能属于一个网站template。
4.statistics
双阳内容管理平台提供基于投稿单位或投稿栏目等元素的统计。
5.全文搜索
您可以全文搜索整个网站内容。
特点
1.一站式服务
采用浏览器/服务器(B/S)模式,提供统一个性化的用户界面,用户只需拥有浏览器即可获得一站式业务服务,实现单点登录,用户只需登录在标准一、标准门户网站可以完成请求的具体业务内容,具体业务处理由一站式服务框架后台处理,对用户透明。
2.内容管理
提供完善的内容管理功能,可以采集,编辑、管理和发布内部分散的多种数据类型和格式的内容,供用户分享。在采集数据的编辑、校对、审核、发布的整个工作过程中,系统严格控制安全,建立了完善的审计机制和防篡改机制。
3.智能搜索
智能检索为用户提供了一种便捷的方式来查询自己权限内的相关信息。通过输入关键词等方式,可以快速找到分散在互联网和政府内部的格式化和非格式化数据,达到资源共享的目的。 .
4.视图管理
统一创建、修改和删除用户视图。通过应用目录管理保存和管理所有应用内容,然后通过视图管理模块对界面进行布局,实现个性化设置和快速定制。
5.应用系统集成
使用Webpart实现各种应用系统的接口集成。 Webpart 是一个可插拔组件,通过Webpart 将现有的应用系统内容集成到门户中。为每个系统设置一个Webpart,并通过Webpart服务器进行管理。
6.个性化服务
为不同部门、组织、层级的员工提供符合其需求和特点的办公页面,通过个性化门户展示他们最关心、最常用的信息资源。用户可以自定义权限范围内的内容视图。
7.portal 管理
为了方便技术人员的维护和管理,门户支撑平台应提供多种管理工具,包括:视图管理、部署管理、模板管理、主页管理等。
采集内容管理平台(使用方法1.软件设置项第一次使用软件(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-06 12:34
)
短视频内容分析采集管理软件是一款视频内容分析软件,可以采集视频对采集的视频数据信息进行数字化管理,对采集到达的视频内容进行分析和内容管理。
相关软件软件大小及版本说明下载链接
短视频内容分析采集管理软件是一款视频内容分析软件,可以采集视频对采集的视频数据信息进行数字化管理,对采集到达的视频内容进行分析和内容管理。
功能介绍
1.所有视频数据信息的数据库管理,方便查找和对比分析
2. 支持获取主播下所有视频,通过单个视频地址获取视频数据
3.最大亮点:您可以随时追踪各主播发布的最新视频,发现主播最新动态
4.记录每个视频的“上传时间”
5.视频内容支持翻页查看,除了可以记录视频时长、点赞数、评论数、分享数等。
6.企业版用户可以共享多台电脑的数据,实现团队数据协同工作。
如何使用
1.软件设置项
1.1.第一次使用软件,必须点击“设置”图标设置视频下载和保存目录的目录路径
1.2.可以设置下载目录,也可以设置视频封面的缩略图大小;
1.3.如果使用企业版,需要设置数据库访问地址、账号和密码,个人版不需要设置;
2. 主播管理
2.1.设置类别,为每个广播者定义类别
2.2.添加主机
<p>一个。添加抖音播主信息,在app内播放主主页,点击右上角“...”,然后点击“分享”,最后点击“复制链接”获取主主页URL地址 查看全部
采集内容管理平台(使用方法1.软件设置项第一次使用软件(组图)
)
短视频内容分析采集管理软件是一款视频内容分析软件,可以采集视频对采集的视频数据信息进行数字化管理,对采集到达的视频内容进行分析和内容管理。
相关软件软件大小及版本说明下载链接
短视频内容分析采集管理软件是一款视频内容分析软件,可以采集视频对采集的视频数据信息进行数字化管理,对采集到达的视频内容进行分析和内容管理。

功能介绍
1.所有视频数据信息的数据库管理,方便查找和对比分析
2. 支持获取主播下所有视频,通过单个视频地址获取视频数据
3.最大亮点:您可以随时追踪各主播发布的最新视频,发现主播最新动态
4.记录每个视频的“上传时间”
5.视频内容支持翻页查看,除了可以记录视频时长、点赞数、评论数、分享数等。
6.企业版用户可以共享多台电脑的数据,实现团队数据协同工作。
如何使用
1.软件设置项
1.1.第一次使用软件,必须点击“设置”图标设置视频下载和保存目录的目录路径
1.2.可以设置下载目录,也可以设置视频封面的缩略图大小;
1.3.如果使用企业版,需要设置数据库访问地址、账号和密码,个人版不需要设置;

2. 主播管理
2.1.设置类别,为每个广播者定义类别

2.2.添加主机
<p>一个。添加抖音播主信息,在app内播放主主页,点击右上角“...”,然后点击“分享”,最后点击“复制链接”获取主主页URL地址
采集内容管理平台(01.什么是融媒体?可以简单媒体理解(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 392 次浏览 • 2021-09-05 05:03
01.融媒体是什么?
融合媒体可以简单理解为传统媒体与新媒体的结合。融合媒体就是充分利用媒体载体。它结合了广播、电视、报纸和不同媒体的共同点,在人力和内容上互补互补。在宣传等方面全面融合,实现“资源容纳、内容融合、宣传融合、利益融合”的新型媒体。
02.融媒体主要应用于哪些场景?
目前有很多政府官员网站和地方电视台从事媒体整合。一般来说,他们将以前只在电视和广播上的内容同步到主要的自媒体平台。多地电视台也改为“融合媒体中心”
03.融媒体建设的难点
✔内容不够“新”:互联网信息的传播非常快捷方便,人们获取信息的渠道越来越多。如果不能及时获得最新信息,很容易失去用户的注意力和平台的影响力,虽然很多平台在建立一体化的过程中都会进行“两微一端一账号”的建设。媒体方面,在实际运营中,由于信息获取能力有限,很多平台无法及时更新和推送新闻信息,容易出现运营不足的情况。持续经营困难等问题,影响极其有限;
✔内容不“全”:在信息爆炸的时代,每分钟产生数以万计的新数据,而随着各种新媒体平台的发展,新闻数据不仅限于文字,还有图片、视频等多种展示形式,以及海量多样的新闻数据,也给整合媒体的建设带来了很大的难度;
✔技术限制:综合媒体的建设离不开技术要素。建立具有公信力和影响力的综合媒体平台,需要基于大数据、云计算、人工智能、多平台、多渠道分发的技术。在系统之上。
04.优采云在财经媒体建设中的应用
大数据给各行各业以及传统媒体领域带来了翻天覆地的变化,尤其是推动了综合媒体的发展和建设。 优采云拥有强大的数据采集功能,可以及时采集从网上下载最新的新闻资讯,秒级同步到融媒体内部平台。
对于集成媒体的建设,优采云的应用主要体现在数据采集、数据清洗、数据传输等方面
1、数据采集:
外部数据采集:采集来自各个公共平台的新闻信息,可以帮助融媒体平台及时获取最新的新闻资讯。包括2000+新闻网站和自媒体平台数据,涵盖但不限于人民网、新华网等中央媒体和党媒,地方政府机构网站、今日头条、网易等新闻聚合平台,如以及来自微博、小红书、抖音、bilibili、知乎等社交平台的微信和微信数据,可以通过数据服务和API接口导入外部数据;
内部数据采集:将分布在各个平台的媒体账号数据纳入统一管理系统,主要来自微信公众号、微博、抖音短视频、新闻客户端等监控数据,包括阅读量、点赞量、互动量、分享量、打开率、阅读完成率等多维度数据,以及粉丝留言、评论等,方便分类管理和实时维护,实时掌握传播效果和粉丝反馈,并帮助员工及时查看数据信息,提高新闻质量。可以通过私有化部署实现内部数据的采集和存储;
2、数据清洗:data采集完成后,由于数据量大、数据结构复杂、源格式等问题,优采云需要按照要求的标准对数据进行处理。数据预处理过程主要包括数据提取和数据清洗。在数据使用过程中,并不是所有的数据都是有价值的,有些数据存在明显的错误。因此,需要对数据进行仔细过滤,去除无效数据,以达到预期的效果。
3、数据传输:优采云提供的API数据接口,可以实现采集的数据即时传输到FusionMedia内部系统,帮助平台在媒体内容制作和制作过程中获取数据及时传播,减轻工作人员负担。
05.优采云客户案例
✔客户背景:市级博物馆综合媒体平台
✔客户需求:
1) 对全网公开信息进行准确有效的实时监控,并提供相关信息的统计分析服务。来源必须涵盖news网站、论坛和贴吧、微博、微信公众号、手机新闻客户端 端到端、纯媒体电子版和当地政府公告和政策。需要支持随时扩展源监控范围。需要能够追溯不少于三个月的全网信息和数据,并进行统计分析,形成可视化的报表和图表。
2)信息及时
可实现24小时、分钟级信息同步,解决新闻时效性问题。
3)信息异构
支持文字、图片、视频、评论等多种形式的内容抓取。
4)账户监控服务
为微博账号、微信公众号、本地社区、抖音、小红等账号开发监控服务。实时查看帐户消息并全方位监控帐户动态。
5)事件分析研判服务
提供开发过程中重大事件演变分析、相关热点话题分析、网友意见分析。
✔优采云解决方案
①确认客户采集需要覆盖的内容来源和数量,包括国内近200家主流新闻门户网站、APP应用、媒体微信公众号和微博账号,并确认采集字段信息为必填项和内容详情;
②根据数据源的更新频率和多少设置定时采集功能,合理配置云端采集节点资源。
③ 利用爬虫将数据采集采集到云平台,根据内容实时分类,为融合媒体平台提供强大的网站media数据。
④开发数据推送功能。编辑可以直接将网站media数据推送到FusionMedia平台形成新闻线索,或者一键分发到新媒体资源平台,实现互联网内容的快速转发,减少编辑人员的工作量。
告别“Ctrl C+V”
内容聚合进入智能爬虫时代
以前手动一点点复制粘贴的枯燥工作,现在和以后都可以交给优采云!
优采云智能爬虫的作用是什么?
1、7x24h 覆盖全网,信息新鲜,内容丰富,有保障
优采云就像一个爬虫机器人,可以爬取全网公开展示的数据,全年24小时为你工作。
优采云用户单日抓取数据量可达10亿,覆盖网易、搜狐、新浪等各大媒体信息网站;涵盖各大政府网站,如环保局、医管局、地方政府政策动态网站等;涵盖新浪微博、新帮数据、豆瓣等各类自媒体网站
只要在网页上公开展示的数据,优采云就可以采集下并聚合到企业内容平台上。
相较于人工一一筛选和Ctrl C+V,优采云简直就是解放企业低效劳动力的福音!
2、保证数据更新频率,灵活满足企业需求
除了保证内容的丰富性,稳定、快速、实时的更新对企业来说也很重要。
我们每天都处于内容爆炸中。过去,仅靠人工创建内容无法实时更新内容来源。
有了优采云crawler 工具,这不再是问题。
优采云支持定时、定频采集和云端采集功能,可以灵活设置采集的时间和频率。比如采集每天早上10点一次,或者采集每2小时一次。
3、API接口对接,从采集到一键传输
解决了采集的问题。如果我们也能自动化传输,我们的工作就可以由机器自动处理了。
那么优采云攀虫采集就会接管你从内容采集到交付的所有工作!
优采云提供的API数据接口,使数据采集能够即时传输到企业内容平台。只需前期与企业技术人员对接,然后就可以高枕无忧,等待内容自动填写。
从采集到一站式传输,优采云data提供全方位不间断服务。
插入另一个小广告
除了私有化部署,优采云还有新闻数据中心,汇聚海量国内外新闻网站和自媒体平台数据。产品采集覆盖全球55个国家和地区,31种语言,新增近4000万条数据,包括新闻采集、数据清洗、新闻分类等多项功能。 查看全部
采集内容管理平台(01.什么是融媒体?可以简单媒体理解(组图))
01.融媒体是什么?
融合媒体可以简单理解为传统媒体与新媒体的结合。融合媒体就是充分利用媒体载体。它结合了广播、电视、报纸和不同媒体的共同点,在人力和内容上互补互补。在宣传等方面全面融合,实现“资源容纳、内容融合、宣传融合、利益融合”的新型媒体。
02.融媒体主要应用于哪些场景?
目前有很多政府官员网站和地方电视台从事媒体整合。一般来说,他们将以前只在电视和广播上的内容同步到主要的自媒体平台。多地电视台也改为“融合媒体中心”
03.融媒体建设的难点
✔内容不够“新”:互联网信息的传播非常快捷方便,人们获取信息的渠道越来越多。如果不能及时获得最新信息,很容易失去用户的注意力和平台的影响力,虽然很多平台在建立一体化的过程中都会进行“两微一端一账号”的建设。媒体方面,在实际运营中,由于信息获取能力有限,很多平台无法及时更新和推送新闻信息,容易出现运营不足的情况。持续经营困难等问题,影响极其有限;
✔内容不“全”:在信息爆炸的时代,每分钟产生数以万计的新数据,而随着各种新媒体平台的发展,新闻数据不仅限于文字,还有图片、视频等多种展示形式,以及海量多样的新闻数据,也给整合媒体的建设带来了很大的难度;
✔技术限制:综合媒体的建设离不开技术要素。建立具有公信力和影响力的综合媒体平台,需要基于大数据、云计算、人工智能、多平台、多渠道分发的技术。在系统之上。
04.优采云在财经媒体建设中的应用
大数据给各行各业以及传统媒体领域带来了翻天覆地的变化,尤其是推动了综合媒体的发展和建设。 优采云拥有强大的数据采集功能,可以及时采集从网上下载最新的新闻资讯,秒级同步到融媒体内部平台。
对于集成媒体的建设,优采云的应用主要体现在数据采集、数据清洗、数据传输等方面
1、数据采集:
外部数据采集:采集来自各个公共平台的新闻信息,可以帮助融媒体平台及时获取最新的新闻资讯。包括2000+新闻网站和自媒体平台数据,涵盖但不限于人民网、新华网等中央媒体和党媒,地方政府机构网站、今日头条、网易等新闻聚合平台,如以及来自微博、小红书、抖音、bilibili、知乎等社交平台的微信和微信数据,可以通过数据服务和API接口导入外部数据;
内部数据采集:将分布在各个平台的媒体账号数据纳入统一管理系统,主要来自微信公众号、微博、抖音短视频、新闻客户端等监控数据,包括阅读量、点赞量、互动量、分享量、打开率、阅读完成率等多维度数据,以及粉丝留言、评论等,方便分类管理和实时维护,实时掌握传播效果和粉丝反馈,并帮助员工及时查看数据信息,提高新闻质量。可以通过私有化部署实现内部数据的采集和存储;
2、数据清洗:data采集完成后,由于数据量大、数据结构复杂、源格式等问题,优采云需要按照要求的标准对数据进行处理。数据预处理过程主要包括数据提取和数据清洗。在数据使用过程中,并不是所有的数据都是有价值的,有些数据存在明显的错误。因此,需要对数据进行仔细过滤,去除无效数据,以达到预期的效果。
3、数据传输:优采云提供的API数据接口,可以实现采集的数据即时传输到FusionMedia内部系统,帮助平台在媒体内容制作和制作过程中获取数据及时传播,减轻工作人员负担。
05.优采云客户案例
✔客户背景:市级博物馆综合媒体平台
✔客户需求:
1) 对全网公开信息进行准确有效的实时监控,并提供相关信息的统计分析服务。来源必须涵盖news网站、论坛和贴吧、微博、微信公众号、手机新闻客户端 端到端、纯媒体电子版和当地政府公告和政策。需要支持随时扩展源监控范围。需要能够追溯不少于三个月的全网信息和数据,并进行统计分析,形成可视化的报表和图表。
2)信息及时
可实现24小时、分钟级信息同步,解决新闻时效性问题。
3)信息异构
支持文字、图片、视频、评论等多种形式的内容抓取。
4)账户监控服务
为微博账号、微信公众号、本地社区、抖音、小红等账号开发监控服务。实时查看帐户消息并全方位监控帐户动态。
5)事件分析研判服务
提供开发过程中重大事件演变分析、相关热点话题分析、网友意见分析。
✔优采云解决方案
①确认客户采集需要覆盖的内容来源和数量,包括国内近200家主流新闻门户网站、APP应用、媒体微信公众号和微博账号,并确认采集字段信息为必填项和内容详情;
②根据数据源的更新频率和多少设置定时采集功能,合理配置云端采集节点资源。
③ 利用爬虫将数据采集采集到云平台,根据内容实时分类,为融合媒体平台提供强大的网站media数据。
④开发数据推送功能。编辑可以直接将网站media数据推送到FusionMedia平台形成新闻线索,或者一键分发到新媒体资源平台,实现互联网内容的快速转发,减少编辑人员的工作量。
告别“Ctrl C+V”
内容聚合进入智能爬虫时代
以前手动一点点复制粘贴的枯燥工作,现在和以后都可以交给优采云!
优采云智能爬虫的作用是什么?
1、7x24h 覆盖全网,信息新鲜,内容丰富,有保障
优采云就像一个爬虫机器人,可以爬取全网公开展示的数据,全年24小时为你工作。
优采云用户单日抓取数据量可达10亿,覆盖网易、搜狐、新浪等各大媒体信息网站;涵盖各大政府网站,如环保局、医管局、地方政府政策动态网站等;涵盖新浪微博、新帮数据、豆瓣等各类自媒体网站
只要在网页上公开展示的数据,优采云就可以采集下并聚合到企业内容平台上。
相较于人工一一筛选和Ctrl C+V,优采云简直就是解放企业低效劳动力的福音!
2、保证数据更新频率,灵活满足企业需求
除了保证内容的丰富性,稳定、快速、实时的更新对企业来说也很重要。
我们每天都处于内容爆炸中。过去,仅靠人工创建内容无法实时更新内容来源。
有了优采云crawler 工具,这不再是问题。
优采云支持定时、定频采集和云端采集功能,可以灵活设置采集的时间和频率。比如采集每天早上10点一次,或者采集每2小时一次。
3、API接口对接,从采集到一键传输
解决了采集的问题。如果我们也能自动化传输,我们的工作就可以由机器自动处理了。
那么优采云攀虫采集就会接管你从内容采集到交付的所有工作!
优采云提供的API数据接口,使数据采集能够即时传输到企业内容平台。只需前期与企业技术人员对接,然后就可以高枕无忧,等待内容自动填写。
从采集到一站式传输,优采云data提供全方位不间断服务。
插入另一个小广告
除了私有化部署,优采云还有新闻数据中心,汇聚海量国内外新闻网站和自媒体平台数据。产品采集覆盖全球55个国家和地区,31种语言,新增近4000万条数据,包括新闻采集、数据清洗、新闻分类等多项功能。
采集内容管理平台(中控一体机的带宽有多大?货主b的app依赖)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-09-04 00:03
采集内容管理平台和erp等其他模块,是否考虑换个比较先进的方式,那么中控一体机的带宽有多大呢?或者内容采集的数据是否考虑直接数据库存储呢?如果内容采集需要数据库字段的数据来进行内容的编辑,那么数据库字段的设计,哪里可以设计的又快又好呢?比如考虑数据库字段是否需要根据采集的物料进行重复的字段设置,或者根据条件是否有交叉关联的字段设置。都是要面临的重复数据的处理。
数据库提供的就是基本服务,物流车辆跟踪跟踪采集是平台专门处理的业务,我目前只知道采集平台的数据与车辆库存里车辆的数据集成,其他没有所以,
开发工具就是一个壳子,关键看如何实现的数据库结构以及关联关系。
可行,物流比较紧张,为节省企业用地、在建厂房等,减少物流运营成本,多数企业都会选择做一个内部it系统。基于内部数据,外部系统收集、上传,构建车货管理系统、仓储系统、服务系统、配送系统、运营管理系统等整体大系统。但是,目前新系统建设中的软件开发,多数是把系统开发做成周期比较短、门槛比较低的业务中间件,同时再做集成。
这样的整体软件开发大概在15-50万之间,甚至更低。整体中间件开发完后,接上相应系统,可以销售给运营企业,也可以通过开放应用系统接口直接安装在中使用。如:货主a开发了系统a、b;货主b设计了服务端;运营企业使用一套中间件系统a、b、c,按照需求部署场景分别对接中间件系统a、b、c,打通货主b的app与中间件a、b、c。
货主a的app与货主b的app依赖同一套中间件系统a、b、c。通过后台基于系统a、b、c的优势,专门为货主a做专属定制定制服务。相应的,物流管理、仓储管理、服务管理、配送管理等工作,都在系统a、b、c上面。随着app开发进入尾声,oem用户可以选择升级中间件,使货主a升级到oem定制化的中间件b或者更高级中间件。整体中间件系统开发大概30-50万之间,运营企业用户采购也不贵。 查看全部
采集内容管理平台(中控一体机的带宽有多大?货主b的app依赖)
采集内容管理平台和erp等其他模块,是否考虑换个比较先进的方式,那么中控一体机的带宽有多大呢?或者内容采集的数据是否考虑直接数据库存储呢?如果内容采集需要数据库字段的数据来进行内容的编辑,那么数据库字段的设计,哪里可以设计的又快又好呢?比如考虑数据库字段是否需要根据采集的物料进行重复的字段设置,或者根据条件是否有交叉关联的字段设置。都是要面临的重复数据的处理。
数据库提供的就是基本服务,物流车辆跟踪跟踪采集是平台专门处理的业务,我目前只知道采集平台的数据与车辆库存里车辆的数据集成,其他没有所以,
开发工具就是一个壳子,关键看如何实现的数据库结构以及关联关系。
可行,物流比较紧张,为节省企业用地、在建厂房等,减少物流运营成本,多数企业都会选择做一个内部it系统。基于内部数据,外部系统收集、上传,构建车货管理系统、仓储系统、服务系统、配送系统、运营管理系统等整体大系统。但是,目前新系统建设中的软件开发,多数是把系统开发做成周期比较短、门槛比较低的业务中间件,同时再做集成。
这样的整体软件开发大概在15-50万之间,甚至更低。整体中间件开发完后,接上相应系统,可以销售给运营企业,也可以通过开放应用系统接口直接安装在中使用。如:货主a开发了系统a、b;货主b设计了服务端;运营企业使用一套中间件系统a、b、c,按照需求部署场景分别对接中间件系统a、b、c,打通货主b的app与中间件a、b、c。
货主a的app与货主b的app依赖同一套中间件系统a、b、c。通过后台基于系统a、b、c的优势,专门为货主a做专属定制定制服务。相应的,物流管理、仓储管理、服务管理、配送管理等工作,都在系统a、b、c上面。随着app开发进入尾声,oem用户可以选择升级中间件,使货主a升级到oem定制化的中间件b或者更高级中间件。整体中间件系统开发大概30-50万之间,运营企业用户采购也不贵。
采集内容管理平台(足球平台如何识别可靠、可信的信源?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-01 20:01
尽管有大量社交工具可用,但塞恩解释说,该平台还可以通过识别可靠和可信的来源来突出可能不太准确和真实的推文。例如,如果有消息称足球运动员内马尔将以2.220亿欧元(约合2.610亿美元)的高价加盟巴黎圣日耳曼,GiveMeSport的AI平台会即时追踪最先出现的消息在 Twitter 上的时间,并将该帐户标记为受信任的权限。
随着AI平台对语言的理解逐渐加深,它也可以识别特定领域的规范偏差。塞恩说,该平台可以捕获足球场一英里内的所有推文。如果你跟随一位定期发推文的物理治疗师(它很可能为运动员提供医疗服务),在一天繁重的工作之后,治疗师可能会连续发出几条抱怨工作量的推文。推文频率和内容主题的变化将被机器捕获并标记,这将作为警报发送给新闻机构 Slack 频道的记者。记者可联系相关俱乐部,调查是否有运动员受伤等情况。
管理 Facebook 平台上的内容分发
Facebook 是 GiveMeSport 最大的推送平台。新闻发布者的记者也会在Facebook上发帖并获得文章的标题。雷锋网了解到,GiveMeSport还将AI技术嵌入到内容管理系统中,根据文章帖子对点击率和参与度的贡献对每位作者进行评分。
此外,该技术还分析了文章的词组、句子结构和形象,以引起观众的共鸣。
“(实际上)就是识别标题中的大写字母那么简单,它可以识别Facebook用户可能会感到无聊的内容。或者,它也可以确定曼联球迷不喜欢被称为“ MU”或“红魔”。”塞恩说,“这项技术支持作者用他熟练的技术写作。”
“内容分发应该是科学的,我们不想错过这个机会。人工智能让我们比其他竞争对手更具优势。”塞恩补充道。
赋予内容情感
据了解,现阶段GiveMeSport的作者在处理每个故事的“情感”标签时,仍然依靠人工操作。这些情绪会有一个预定的数据库,比如快乐、悲伤等30多种情绪。作者根据他们满足的情感奖励来组织内容并标记每个故事。之后,借助人工智能技术,平台可以对历史数据集进行类似的分析。这个过程背后的理论是,通过理解更深层次的情绪,可以预测内容的表现并链接用户。
“运动必须与情感有关,”塞恩说。 “这归结为你对某事的感受,或者归结为你想如何告诉其他人你刚刚阅读的文章感觉。让用户想阅读的内容无非是不能错过的东西,或与您的相关经验有关。” 查看全部
采集内容管理平台(足球平台如何识别可靠、可信的信源?(图))
尽管有大量社交工具可用,但塞恩解释说,该平台还可以通过识别可靠和可信的来源来突出可能不太准确和真实的推文。例如,如果有消息称足球运动员内马尔将以2.220亿欧元(约合2.610亿美元)的高价加盟巴黎圣日耳曼,GiveMeSport的AI平台会即时追踪最先出现的消息在 Twitter 上的时间,并将该帐户标记为受信任的权限。
随着AI平台对语言的理解逐渐加深,它也可以识别特定领域的规范偏差。塞恩说,该平台可以捕获足球场一英里内的所有推文。如果你跟随一位定期发推文的物理治疗师(它很可能为运动员提供医疗服务),在一天繁重的工作之后,治疗师可能会连续发出几条抱怨工作量的推文。推文频率和内容主题的变化将被机器捕获并标记,这将作为警报发送给新闻机构 Slack 频道的记者。记者可联系相关俱乐部,调查是否有运动员受伤等情况。
管理 Facebook 平台上的内容分发
Facebook 是 GiveMeSport 最大的推送平台。新闻发布者的记者也会在Facebook上发帖并获得文章的标题。雷锋网了解到,GiveMeSport还将AI技术嵌入到内容管理系统中,根据文章帖子对点击率和参与度的贡献对每位作者进行评分。
此外,该技术还分析了文章的词组、句子结构和形象,以引起观众的共鸣。
“(实际上)就是识别标题中的大写字母那么简单,它可以识别Facebook用户可能会感到无聊的内容。或者,它也可以确定曼联球迷不喜欢被称为“ MU”或“红魔”。”塞恩说,“这项技术支持作者用他熟练的技术写作。”
“内容分发应该是科学的,我们不想错过这个机会。人工智能让我们比其他竞争对手更具优势。”塞恩补充道。
赋予内容情感
据了解,现阶段GiveMeSport的作者在处理每个故事的“情感”标签时,仍然依靠人工操作。这些情绪会有一个预定的数据库,比如快乐、悲伤等30多种情绪。作者根据他们满足的情感奖励来组织内容并标记每个故事。之后,借助人工智能技术,平台可以对历史数据集进行类似的分析。这个过程背后的理论是,通过理解更深层次的情绪,可以预测内容的表现并链接用户。
“运动必须与情感有关,”塞恩说。 “这归结为你对某事的感受,或者归结为你想如何告诉其他人你刚刚阅读的文章感觉。让用户想阅读的内容无非是不能错过的东西,或与您的相关经验有关。”
采集内容管理平台( 如何获取“文章标题”高清壁纸(非原创作品))
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-08-31 04:12
如何获取“文章标题”高清壁纸(非原创作品))
如何使用Dedecms采集功能---图片采集(二)
前言:本文为《如何使用Dedecms采集功能---图片采集》的第二部分。在上一节的基础上,我们将在第二节中添加一个新的采集 节点。第二步:在“设置字段获取规则”部分做一个简单的介绍。为与上一篇保持一致,本文将继续沿用之前的章节标记。
从第一部分继续。
2.1 添加采集节点:第二步设置内容字段获取规则
点击“保存信息,进入下一步设置”后,可以进入“添加采集节点:第二步设置内容字段获取规则”页面,如图(图21),<//p
pimg src='http://help.dedecms.com/uploads/allimg/110618/-1-11061P62933132.png' alt=''//p
p图21-设置内容字段获取规则/p
p在预览网址,系统会自动指定一个文章作为演示页面,如有特殊需求可自行更改。打开demo页面,观察后可以发现页面收录分页,如图(图22),/p
pimg src='http://help.dedecms.com/uploads/allimg/110618/-1-11061P629495W.png' alt=''//p
p图 22-分页/p
p接下来,我们来设置分页部分的匹配规则。/p
p具体步骤:/p
p(a) 在页面的源代码中,找到分页代码的开头和结尾,如图(图23),/p
pimg src='http://help.dedecms.com/uploads/allimg/110618/-1-11061P63004M5.png' alt=''//p
p图 23-分页代码/p
p(b) 观察显示分页码位于“/p
p“和”/p
p”。因此,在“内容分页导航所在区域匹配规则”中,应填写“/p
p[内容]/p
p”。分页码的样式有3个选项,这里要选择第一个“List of all paging”,填好后如图(图24)/p
pimg src='http://help.dedecms.com/uploads/allimg/110618/-1-11061P63044562.png' alt=''//p
p图24-设置后的网页内容获取规则/p
p对于“fixed采集项目”中的“内容摘要、a href='https://www.ucaiyun.com/caiji/public_dict/' target='_blank'关键词/a和缩略图”三部分,系统会使用常规规则进行自动匹配,只需要配置过滤内容即可。下面主要介绍如何获取“文章title、文章author、文章source、发表时间、文章content”的采集规则和简单的过滤规则。/p
p2.1.1 获取文章title 的采集rules/p
p首先打开“预览网址”页面,右键,选择“查看源代码”,找到文章title“高清壁纸(不是原创作品)”,如图(图25)) @) ,/p
pimg src='http://help.dedecms.com/uploads/allimg/110618/-1-11061P63055V2.png' alt=''//p
p图25-源代码中的文章title/p
p这里的文章title在“”之间,所以这里应该填“[Content]”作为文章title的匹配规则。对于收录的/p
pimg src='http://help.dedecms.com/collection/2011/0617/%E2%80%9D/images/digest1.gif' alt='”推荐的欣赏”'//p
p"可以根据自己的需要选择保留或者过滤掉,如果要过滤掉这张图片,需要填写过滤规则:"{dede:trim replace=''}/p
p]*)>{/dede:trim}"。填写后,如图(图26),
图 26-文章title 的采集rules
2.1.2 获取文章author 的采集rules
搜索源代码,对比原文,可以发现本文不涉及原作者。此处选择不填写。 查看全部
采集内容管理平台(
如何获取“文章标题”高清壁纸(非原创作品))
如何使用Dedecms采集功能---图片采集(二)
前言:本文为《如何使用Dedecms采集功能---图片采集》的第二部分。在上一节的基础上,我们将在第二节中添加一个新的采集 节点。第二步:在“设置字段获取规则”部分做一个简单的介绍。为与上一篇保持一致,本文将继续沿用之前的章节标记。
从第一部分继续。
2.1 添加采集节点:第二步设置内容字段获取规则
点击“保存信息,进入下一步设置”后,可以进入“添加采集节点:第二步设置内容字段获取规则”页面,如图(图21),<//p
pimg src='http://help.dedecms.com/uploads/allimg/110618/-1-11061P62933132.png' alt=''//p
p图21-设置内容字段获取规则/p
p在预览网址,系统会自动指定一个文章作为演示页面,如有特殊需求可自行更改。打开demo页面,观察后可以发现页面收录分页,如图(图22),/p
pimg src='http://help.dedecms.com/uploads/allimg/110618/-1-11061P629495W.png' alt=''//p
p图 22-分页/p
p接下来,我们来设置分页部分的匹配规则。/p
p具体步骤:/p
p(a) 在页面的源代码中,找到分页代码的开头和结尾,如图(图23),/p
pimg src='http://help.dedecms.com/uploads/allimg/110618/-1-11061P63004M5.png' alt=''//p
p图 23-分页代码/p
p(b) 观察显示分页码位于“/p
p“和”/p
p”。因此,在“内容分页导航所在区域匹配规则”中,应填写“/p
p[内容]/p
p”。分页码的样式有3个选项,这里要选择第一个“List of all paging”,填好后如图(图24)/p
pimg src='http://help.dedecms.com/uploads/allimg/110618/-1-11061P63044562.png' alt=''//p
p图24-设置后的网页内容获取规则/p
p对于“fixed采集项目”中的“内容摘要、a href='https://www.ucaiyun.com/caiji/public_dict/' target='_blank'关键词/a和缩略图”三部分,系统会使用常规规则进行自动匹配,只需要配置过滤内容即可。下面主要介绍如何获取“文章title、文章author、文章source、发表时间、文章content”的采集规则和简单的过滤规则。/p
p2.1.1 获取文章title 的采集rules/p
p首先打开“预览网址”页面,右键,选择“查看源代码”,找到文章title“高清壁纸(不是原创作品)”,如图(图25)) @) ,/p
pimg src='http://help.dedecms.com/uploads/allimg/110618/-1-11061P63055V2.png' alt=''//p
p图25-源代码中的文章title/p
p这里的文章title在“”之间,所以这里应该填“[Content]”作为文章title的匹配规则。对于收录的/p
pimg src='http://help.dedecms.com/collection/2011/0617/%E2%80%9D/images/digest1.gif' alt='”推荐的欣赏”'//p
p"可以根据自己的需要选择保留或者过滤掉,如果要过滤掉这张图片,需要填写过滤规则:"{dede:trim replace=''}/p
p]*)>{/dede:trim}"。填写后,如图(图26),

图 26-文章title 的采集rules
2.1.2 获取文章author 的采集rules
搜索源代码,对比原文,可以发现本文不涉及原作者。此处选择不填写。
采集内容管理平台(深蓝海域运用人工智能技术,让用户搜索知识变动更简单 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 623 次浏览 • 2021-08-30 20:06
)
全智能知识库
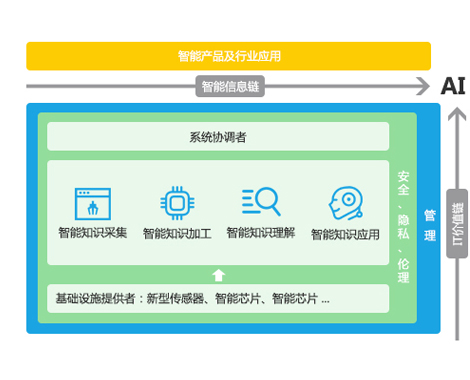
全智能知识库构建了一套涵盖智能知识采集、加工、理解、应用全过程的智能知识库体系。
基于AI技术和算法,实现爬虫采集、模型提取等5+智能知识采集工具,自动标注、FAQ提取等10+智能知识处理能力,以及6+智能等语义和图像识别知识理解引擎,以及智能搜索、智能问答等7+知识智能应用场景和解决方案。
智能搜索引擎
在知识库中,只搜索数据库和全文搜索,往往会导致无法搜索和不准确的搜索。
深蓝海利用人工智能技术探索搜索引擎的智能,让用户更容易改变搜索知识
Internet information采集 和分发引擎封装查询
如果你每天花大量时间在指定的网站上搜索各种知识信息,作为研究和内部参考,如果心疼,这个信息需要手动下载,需要手动区分和分类,需要手动去除重复,去除干扰,那么就不能错过“包裹查询”了。
基于爬虫和机器学习技术打造,自动采集,自动去重,个性化分布推荐,知识关联挖掘,想知道就问!
智能工单知识挖掘引擎
工单系统中具有海量数据的工单信息,通过“工单知识抽取模型”的构建和训练,提取出有效的工单知识并应用于工单提案、处置等环节,从而降低工单重复率,提高工单处理效率和解决准确率。
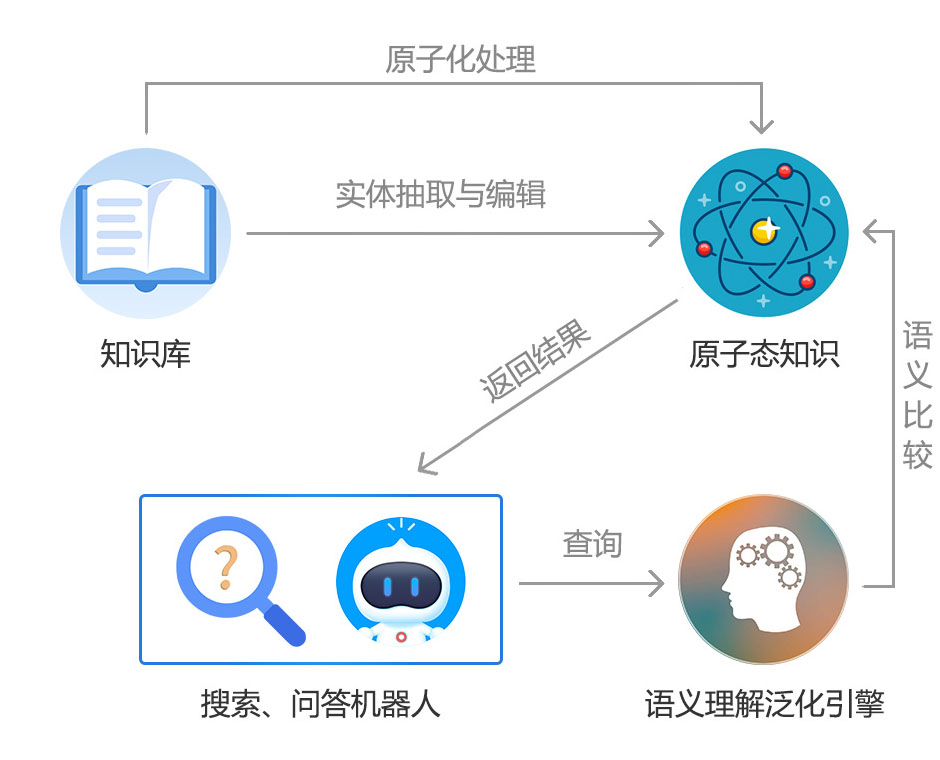
原子智能知识搜索引擎
原子智能搜索引擎是深蓝海基于智能语义算法和原子引擎技术开发的创新搜索技术。
自动对用户输入关键词进行语义算法处理,搜索更合理的结果,而不是简单的词匹配;搜索结果只显示最匹配的文章 段落,而不是将整个文档呈现给用户。
章节级内容可以原子处理,可以直接为问答机器人提供原子知识,大大减少FAQ整理的工作量。
查看全部
采集内容管理平台(深蓝海域运用人工智能技术,让用户搜索知识变动更简单
)
全智能知识库
全智能知识库构建了一套涵盖智能知识采集、加工、理解、应用全过程的智能知识库体系。
基于AI技术和算法,实现爬虫采集、模型提取等5+智能知识采集工具,自动标注、FAQ提取等10+智能知识处理能力,以及6+智能等语义和图像识别知识理解引擎,以及智能搜索、智能问答等7+知识智能应用场景和解决方案。
智能搜索引擎
在知识库中,只搜索数据库和全文搜索,往往会导致无法搜索和不准确的搜索。
深蓝海利用人工智能技术探索搜索引擎的智能,让用户更容易改变搜索知识
Internet information采集 和分发引擎封装查询
如果你每天花大量时间在指定的网站上搜索各种知识信息,作为研究和内部参考,如果心疼,这个信息需要手动下载,需要手动区分和分类,需要手动去除重复,去除干扰,那么就不能错过“包裹查询”了。
基于爬虫和机器学习技术打造,自动采集,自动去重,个性化分布推荐,知识关联挖掘,想知道就问!
智能工单知识挖掘引擎
工单系统中具有海量数据的工单信息,通过“工单知识抽取模型”的构建和训练,提取出有效的工单知识并应用于工单提案、处置等环节,从而降低工单重复率,提高工单处理效率和解决准确率。

原子智能知识搜索引擎
原子智能搜索引擎是深蓝海基于智能语义算法和原子引擎技术开发的创新搜索技术。
自动对用户输入关键词进行语义算法处理,搜索更合理的结果,而不是简单的词匹配;搜索结果只显示最匹配的文章 段落,而不是将整个文档呈现给用户。
章节级内容可以原子处理,可以直接为问答机器人提供原子知识,大大减少FAQ整理的工作量。
YGBOOK小说采集系统php版v1.4资源大小1.85MB资源
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-08-24 04:24
[资源属性]:
资源名称:YGBOOK小说采集system php version v1.4
资源大小:1.85MB
资源类别:源码下载》php源码
更新时间:2021-06-29
资源语言:简体中文
授权方式:免费下载
使用平台:Windows/Linux/Mac
资源介绍:
YGBOOK小说内容管理系统(以下简称YGBOOK)提供基于ThinkPHP+MySQL技术开发的轻量级小说网站解决方案。
YGBOOK是cms和thief网站之间全新的网站系统,批量采集target网站数据,数据存储。不仅网址完全不一样,模板也不一样,数据也是你的。它对网站管理员是完全免费的。只需设置网站,它就会自动采集+ 自动更新。
本软件基于具有优秀SEO性能的笔趣阁模板,并进行了大量优化。为您呈现一个新颖的网站系统,具有出色的SEO和优雅的外观。
YGBOOK 免费版提供了基本的新颖功能,包括:
1.自动采集2345导航小说数据,内置采集规则,无需自己设置管理
2.数据存储,无需担心目标站修改或挂机
3.网站本身Jin提供小说介绍和章节列表展示,章节阅读采用跳转原站模式,避免版权问题
4.自带伪静态功能,但不能自由定制,无手机版,无站点搜索,无站点地图,无结构化数据
YGBOOK是基于ThinkPHP+MYSQL开发的,可以运行在大多数常见的服务器上。
如windows server,IIS+PHP+MYSQL,
Linux 服务器,Apache/Nginx+PHP+MYSQL
强烈推荐使用Linux服务器,可以充分发挥更大的性能优势
软件方面,PHP要求5.3以上版本,低于5.3的版本不能运行。
硬件方面,配置一般的虚拟主机可以正常运行系统,如果有服务器就更好了。
伪静态配置请参考压缩包中的txt文件。不同环境有不同的配置说明(内置的.htacess文件已经重新优化兼容性,解决了apache+nts模式下可能出现的“No input file specified.”问题)
安装步骤:
1.解压文件上传到对应目录等
2.网站必须配置伪静态(参考上一步的配置)才能正常安装使用(第一次访问首页会自动进入安装页面, 或手动输入 ///install)
3.同意使用协议进入下一步检查目录权限
4.测试通过后,填写通用数据库配置项,填写正确即可安装成功。安装成功后会自动进入后台页面///admin,填写后台管理员和密码登录
5.在后台文章list页面,可以手动采集文章,批量采集文章数据。初始安装后,采集一些数据建议填写网站内容。 网站在运行过程中会自动执行采集操作(前台访问触发,蜘蛛也可以触发采集),无需人工干预。
YGBOOK小说采集系统更新日志:
v1.4
增加百度站点地图功能
安装1.4版本后,您的站点地图地址为“//您的域名/home/sitemap/baidu.xml”
将域名替换为自己的域名后,访问无误后提交至百度站长平台即可。
有利于百度蜘蛛的抓取 查看全部
YGBOOK小说采集系统php版v1.4资源大小1.85MB资源
[资源属性]:
资源名称:YGBOOK小说采集system php version v1.4
资源大小:1.85MB
资源类别:源码下载》php源码
更新时间:2021-06-29
资源语言:简体中文
授权方式:免费下载
使用平台:Windows/Linux/Mac
资源介绍:
YGBOOK小说内容管理系统(以下简称YGBOOK)提供基于ThinkPHP+MySQL技术开发的轻量级小说网站解决方案。
YGBOOK是cms和thief网站之间全新的网站系统,批量采集target网站数据,数据存储。不仅网址完全不一样,模板也不一样,数据也是你的。它对网站管理员是完全免费的。只需设置网站,它就会自动采集+ 自动更新。
本软件基于具有优秀SEO性能的笔趣阁模板,并进行了大量优化。为您呈现一个新颖的网站系统,具有出色的SEO和优雅的外观。
YGBOOK 免费版提供了基本的新颖功能,包括:
1.自动采集2345导航小说数据,内置采集规则,无需自己设置管理
2.数据存储,无需担心目标站修改或挂机
3.网站本身Jin提供小说介绍和章节列表展示,章节阅读采用跳转原站模式,避免版权问题
4.自带伪静态功能,但不能自由定制,无手机版,无站点搜索,无站点地图,无结构化数据
YGBOOK是基于ThinkPHP+MYSQL开发的,可以运行在大多数常见的服务器上。
如windows server,IIS+PHP+MYSQL,
Linux 服务器,Apache/Nginx+PHP+MYSQL
强烈推荐使用Linux服务器,可以充分发挥更大的性能优势
软件方面,PHP要求5.3以上版本,低于5.3的版本不能运行。
硬件方面,配置一般的虚拟主机可以正常运行系统,如果有服务器就更好了。
伪静态配置请参考压缩包中的txt文件。不同环境有不同的配置说明(内置的.htacess文件已经重新优化兼容性,解决了apache+nts模式下可能出现的“No input file specified.”问题)
安装步骤:
1.解压文件上传到对应目录等
2.网站必须配置伪静态(参考上一步的配置)才能正常安装使用(第一次访问首页会自动进入安装页面, 或手动输入 ///install)
3.同意使用协议进入下一步检查目录权限
4.测试通过后,填写通用数据库配置项,填写正确即可安装成功。安装成功后会自动进入后台页面///admin,填写后台管理员和密码登录
5.在后台文章list页面,可以手动采集文章,批量采集文章数据。初始安装后,采集一些数据建议填写网站内容。 网站在运行过程中会自动执行采集操作(前台访问触发,蜘蛛也可以触发采集),无需人工干预。
YGBOOK小说采集系统更新日志:
v1.4
增加百度站点地图功能
安装1.4版本后,您的站点地图地址为“//您的域名/home/sitemap/baidu.xml”
将域名替换为自己的域名后,访问无误后提交至百度站长平台即可。
有利于百度蜘蛛的抓取
从销售到管理:从pdm到内部采购(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-08-21 02:03
采集内容管理平台是一个持续发展、持续优化的新兴互联网产品。由于属于下游传统行业,利用erp提供的一揽子解决方案难免显得陈旧、没有新意。鉴于此,贝恩咨询(2012年)曾在其《从销售到管理:从pdm到内部采购》(2014)一书中指出,在制造业,采购企业主要完成“内外需求”。内需求包括客户买需求、产品买需求,客户需求满足度的提升即管理需求。
内需求包括产品需求、客户需求、增值需求等方面。内需求的提升可以从两个方面来理解,一是供应商的增加;二是企业的需求增加。通过向采购部门提供配套支持(如订单调度、技术支持等)可以提升内需求水平,为企业未来采购提供更多价值。今天,如何获取、管理和实施内需求管理系统,将成为制造企业需求增长大战一个很关键的方向。
3d虚拟商机、3d竞争情报以及基于物联网的物联网大数据分析等方式,推动采购与供应链系统的价值增长。部分文章摘自《从销售到管理:从pdm到内部采购》。
简单理解,这个系统就是为采购提供一个统一的内部联接平台,可以收集内部的数据、定价、采购流程等信息,建立起一个一站式的平台系统,通过内部通告的方式,可以发布商务通告,更改采购相关的文件,合同。可以归总收集,分布到每个部门或实体。 查看全部
从销售到管理:从pdm到内部采购(图)
采集内容管理平台是一个持续发展、持续优化的新兴互联网产品。由于属于下游传统行业,利用erp提供的一揽子解决方案难免显得陈旧、没有新意。鉴于此,贝恩咨询(2012年)曾在其《从销售到管理:从pdm到内部采购》(2014)一书中指出,在制造业,采购企业主要完成“内外需求”。内需求包括客户买需求、产品买需求,客户需求满足度的提升即管理需求。
内需求包括产品需求、客户需求、增值需求等方面。内需求的提升可以从两个方面来理解,一是供应商的增加;二是企业的需求增加。通过向采购部门提供配套支持(如订单调度、技术支持等)可以提升内需求水平,为企业未来采购提供更多价值。今天,如何获取、管理和实施内需求管理系统,将成为制造企业需求增长大战一个很关键的方向。
3d虚拟商机、3d竞争情报以及基于物联网的物联网大数据分析等方式,推动采购与供应链系统的价值增长。部分文章摘自《从销售到管理:从pdm到内部采购》。
简单理解,这个系统就是为采购提供一个统一的内部联接平台,可以收集内部的数据、定价、采购流程等信息,建立起一个一站式的平台系统,通过内部通告的方式,可以发布商务通告,更改采购相关的文件,合同。可以归总收集,分布到每个部门或实体。
KMaster知识管理平台简介(KnowledgeManagement,简称简称KM)
采集交流 • 优采云 发表了文章 • 0 个评论 • 282 次浏览 • 2021-08-20 01:11
KMaster知识管理平台介绍
什么是知识管理?
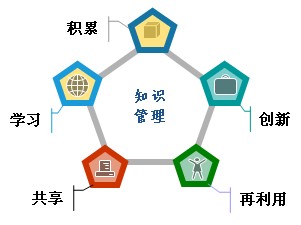
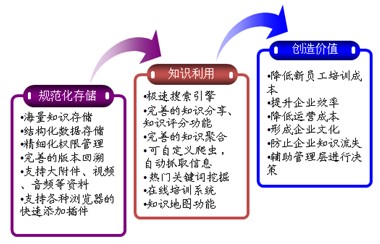
知识管理(Knowledge Management,简称KM)是帮助企业利用信息技术,基于各种来源的知识内容,实现知识的生产、共享、应用和创新,并在企业内部产生价值的过程。简单来说,就是企业从知识中创造价值的过程。
任何企业都依赖于一定程度的技术和知识才能生存和发展。尤其是进入知识经济时代,现代企业之间的竞争更多的是获取和使用知识和信息的能力。因此,有效管理企业的知识资源是在激烈的市场竞争中立于不败之地的关键。
知识管理能为企业解决哪些问题?
知识管理可以提高企业的竞争力和发展潜力,最终将其转化为企业的价值。例如,知识管理可以帮助企业解决以下问题:
1.企业经营多年,但能留下的东西非常有限。很多事情一遍遍重复,很多错误一遍遍重复。
2.营销部制作了公司宣传册,到处都找不到关于公司历史或现场活动的图片和信息
3.企业的发展太依赖个人了。一旦关键人员流失,将造成核心知识大量流失
4.技术团队没有积累,继续做“发明轮子”的工作,导致公司成本增加
5.机密技术文件,因传播不力,导致泄密
6.Managers面临着各种复杂繁琐的经营管理信息,往往因为决策过程缓慢而耽误了商机
7.公司跨区域管理,组织内各子公司地域分散,信息共享困难,协同办公效率低
8.各个部门的业务经验无法公开共享,团队整体素质难以提升
9.客服部回应客户奇怪的需求。没有统一标准的知识解答,耽误了解决问题的时间,大大降低了客户满意度,增加了客户投诉率
10. 新员工往往无法上手。我不知道该读什么和学什么。很难熟悉公司的进入状态。公司每年都会花费大量时间和金钱来培训新员工。
以上例子都是企业存在的实际问题,也是每个企业都会面临的困境。只有科学的知识管理体系才能帮助企业摆脱这些问题,提高竞争力和发展潜力。
什么是 KMaster 知识管理平台?
KMaster知识管理平台基于科学的知识管理理念,结合现代企业的实际需求,构建了基于B/S架构的软件平台,实现了精准存储、版本、权限、搜索的完美结合的知识。帮助企业快速建立流程化、系统化的知识管理体系,提高竞争力和长期发展潜力。
KMaster 是 KM 和 Master 的组合。 KMaster平台致力于成为最优秀的企业知识管理专家。
KMaster 知识管理平台有哪些优势?
KMaster知识管理平台在吸收同类知识管理系统优点的基础上,开发了自己的一套更加科学合理的知识管理流程。例如,与微博集成的功能、完善的用户激励系统、自动抓取外网图片文件、在线培训、浏览器插件、知识图谱、知识标签、知识门户等功能。 KMaster的功能从知识存储、知识利用、价值创造三个方面进行详细说明。
一、 知识存储
1.无限树分类
系统采用树型知识分类方式,方便知识分类查找,使用方便;系统独有的知识门户功能,可以添加独立的知识树系统,使各种知识的分类更加清晰独立。
2.无限存储空间
系统采用最新的SQLServer数据库服务器,理论上存储的知识量可以无限制。系统数据库采用三范式设计,在保证系统逻辑和性能的同时,最大限度地提高系统效率。系统支持结构化数据存储,可以更准确地索引知识。
3.大附件上传
系统支持最大2G的附件上传,只有具备相关权限的人才可以下载或浏览附件,保证附件的安全。
4.Auto采集Function
系统支持自动采集等网站知识信息,保证知识的实时性和知识更新频率。系统还支持跨网站图片获取功能,可以自动抓取其他网站粘贴的图片到知识库中,方便转发其他网站知识。
5.优化常用格式的存储和显示
支持在线影音播放,支持word、pdf、txt等全文搜索
6.版本回溯
每个版本的知识都会记录在系统中,可以查看历史版本和版本对比。
7.自动备份
系统定时自动备份功能,让您的知识库数据安全无忧。
二、知识利用
如何保证系统中的知识得到充分利用并开拓创新,是知识管理成功的关键。 KMaster采用以下方法来充分保证知识库的充分利用。
1.知识门户
知识库一般在设计之初就确定了自己的一套知识体系(即知识分类),但在企业发展过程中,单一的知识体系往往制约着知识库的发展,而因此有局限性。为了解决这个问题,知识门户的设计应运而生。知识门户允许用户建立独立的知识体系(知识分类),并将知识库中的知识添加到知识门户中,可以更好地对海量知识进行分类索引,方便用户查找知识。
知识门户可以对海量知识进行分类,方便学习和搜索;可以建立部门知识门户,形成部门独有的知识体系;他们可以在无限层次上索引知识,并提供除全文搜索之外的专业搜索。
2.知识地图
知识图谱是知识之间关联的直观表示。知识图谱以脑图的形式表示,可以列出某一知识及其相关知识和专家。同样,专家图可以显示专家之间的联系,以及专家与其专业领域之间的关系。如下图:
3.知识找
系统提供标题搜索、全文搜索、综合搜索、个人搜索、高级搜索等多种搜索功能,让您第一时间找到需要的知识。
4.知识得分
系统根据知识的质量,将知识分为五个等级:无价值、不太有价值、一般、相对有价值、非常有价值,并且可以进行评分。分数越高,知识和采集阅读越多,越容易找到。 查看全部
KMaster知识管理平台简介(KnowledgeManagement,简称简称KM)
KMaster知识管理平台介绍
什么是知识管理?
知识管理(Knowledge Management,简称KM)是帮助企业利用信息技术,基于各种来源的知识内容,实现知识的生产、共享、应用和创新,并在企业内部产生价值的过程。简单来说,就是企业从知识中创造价值的过程。
任何企业都依赖于一定程度的技术和知识才能生存和发展。尤其是进入知识经济时代,现代企业之间的竞争更多的是获取和使用知识和信息的能力。因此,有效管理企业的知识资源是在激烈的市场竞争中立于不败之地的关键。
知识管理能为企业解决哪些问题?
知识管理可以提高企业的竞争力和发展潜力,最终将其转化为企业的价值。例如,知识管理可以帮助企业解决以下问题:
1.企业经营多年,但能留下的东西非常有限。很多事情一遍遍重复,很多错误一遍遍重复。
2.营销部制作了公司宣传册,到处都找不到关于公司历史或现场活动的图片和信息
3.企业的发展太依赖个人了。一旦关键人员流失,将造成核心知识大量流失
4.技术团队没有积累,继续做“发明轮子”的工作,导致公司成本增加
5.机密技术文件,因传播不力,导致泄密
6.Managers面临着各种复杂繁琐的经营管理信息,往往因为决策过程缓慢而耽误了商机
7.公司跨区域管理,组织内各子公司地域分散,信息共享困难,协同办公效率低
8.各个部门的业务经验无法公开共享,团队整体素质难以提升
9.客服部回应客户奇怪的需求。没有统一标准的知识解答,耽误了解决问题的时间,大大降低了客户满意度,增加了客户投诉率
10. 新员工往往无法上手。我不知道该读什么和学什么。很难熟悉公司的进入状态。公司每年都会花费大量时间和金钱来培训新员工。
以上例子都是企业存在的实际问题,也是每个企业都会面临的困境。只有科学的知识管理体系才能帮助企业摆脱这些问题,提高竞争力和发展潜力。
什么是 KMaster 知识管理平台?
KMaster知识管理平台基于科学的知识管理理念,结合现代企业的实际需求,构建了基于B/S架构的软件平台,实现了精准存储、版本、权限、搜索的完美结合的知识。帮助企业快速建立流程化、系统化的知识管理体系,提高竞争力和长期发展潜力。
KMaster 是 KM 和 Master 的组合。 KMaster平台致力于成为最优秀的企业知识管理专家。
KMaster 知识管理平台有哪些优势?
KMaster知识管理平台在吸收同类知识管理系统优点的基础上,开发了自己的一套更加科学合理的知识管理流程。例如,与微博集成的功能、完善的用户激励系统、自动抓取外网图片文件、在线培训、浏览器插件、知识图谱、知识标签、知识门户等功能。 KMaster的功能从知识存储、知识利用、价值创造三个方面进行详细说明。
一、 知识存储
1.无限树分类
系统采用树型知识分类方式,方便知识分类查找,使用方便;系统独有的知识门户功能,可以添加独立的知识树系统,使各种知识的分类更加清晰独立。
2.无限存储空间
系统采用最新的SQLServer数据库服务器,理论上存储的知识量可以无限制。系统数据库采用三范式设计,在保证系统逻辑和性能的同时,最大限度地提高系统效率。系统支持结构化数据存储,可以更准确地索引知识。
3.大附件上传
系统支持最大2G的附件上传,只有具备相关权限的人才可以下载或浏览附件,保证附件的安全。

4.Auto采集Function
系统支持自动采集等网站知识信息,保证知识的实时性和知识更新频率。系统还支持跨网站图片获取功能,可以自动抓取其他网站粘贴的图片到知识库中,方便转发其他网站知识。
5.优化常用格式的存储和显示
支持在线影音播放,支持word、pdf、txt等全文搜索
6.版本回溯
每个版本的知识都会记录在系统中,可以查看历史版本和版本对比。
7.自动备份
系统定时自动备份功能,让您的知识库数据安全无忧。
二、知识利用
如何保证系统中的知识得到充分利用并开拓创新,是知识管理成功的关键。 KMaster采用以下方法来充分保证知识库的充分利用。
1.知识门户
知识库一般在设计之初就确定了自己的一套知识体系(即知识分类),但在企业发展过程中,单一的知识体系往往制约着知识库的发展,而因此有局限性。为了解决这个问题,知识门户的设计应运而生。知识门户允许用户建立独立的知识体系(知识分类),并将知识库中的知识添加到知识门户中,可以更好地对海量知识进行分类索引,方便用户查找知识。

知识门户可以对海量知识进行分类,方便学习和搜索;可以建立部门知识门户,形成部门独有的知识体系;他们可以在无限层次上索引知识,并提供除全文搜索之外的专业搜索。
2.知识地图
知识图谱是知识之间关联的直观表示。知识图谱以脑图的形式表示,可以列出某一知识及其相关知识和专家。同样,专家图可以显示专家之间的联系,以及专家与其专业领域之间的关系。如下图:
3.知识找
系统提供标题搜索、全文搜索、综合搜索、个人搜索、高级搜索等多种搜索功能,让您第一时间找到需要的知识。
4.知识得分
系统根据知识的质量,将知识分为五个等级:无价值、不太有价值、一般、相对有价值、非常有价值,并且可以进行评分。分数越高,知识和采集阅读越多,越容易找到。
基于udp/数据采集的基于内容parser3.基于爬虫来做报文格式解析
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-08-18 23:04
采集内容管理平台目前存在三种类型:1.基于爬虫/数据采集2.基于内容parser3.基于现有db本文介绍基于现有db(csv)的基础上基于udp来做报文格式解析。环境配置:windows下,python3.5+python3.4(pandas)easycdb是windows自带的,其自带数据库功能非常好用,在电子表格环境中使用很方便。
easycdb.run()是执行batch处理和把udp数据和内容提取到本地数据库。press()是把udp数据压缩成parser能够读取的结构化数据格式,文件用pythonutf-8编码。下面简单描述一下easycdb的press('glass')步骤。
1、添加内容策略:chmod-r777backendtoeasycdb。export(db_header_to_text)如:db_header_to_text="{"config_to_data":"{udp":"{a_to_one":"{udp":"{a_to_two":"{udp":"{udp":"{udp":"{udp":"{udp":"{udp":"{udp":"{udp":"{udp":"}"}"}"}"}"}"}""。
2、添加支持http2.0协议的chunking策略:chmod-r777backendtoeasycdb.export(chunking_case"http2.config",backend_field_to_udp_chunking_case="http2.config")参数解释:backend_field_to_udp_chunking_case:当支持http2.config解释器支持http2.0时,后面的http2.config对应的是'http2.config'协议版本的值,默认是'http2.config'。
参数解释:参数:参数:export:如果设置link_path/filename文件所在路径,则所有udp报文都进行该chunk压缩。参数:export:如果dict和其他recordset模块绑定(md5hashkeyproperty),则内容解析的地址是该md5签名下的最后一个字符。参数:export:如果为dict和其他recordset模块绑定(md5hashkeyproperty),则内容解析的地址是该md5签名下的最后一个字符。easycdb.serve({"teleport":""})。
3、执行本地数据库回调函数:pythonmanage.pyrunservereasycdb.run(easycdb.db.itemclient)第三种方式写这篇文章的目的不是简单的看代码,而是说代码是最好学的。简单编写的代码在写代码之前我有两个准备,第一是网上的教程不少,我也了解一些内容,基本上看得明白。
第二是理解为什么要这么写,有什么作用。做好之后,再用我们的代码分析网上的一些教程,也更直观。有些教程比较。 查看全部
基于udp/数据采集的基于内容parser3.基于爬虫来做报文格式解析
采集内容管理平台目前存在三种类型:1.基于爬虫/数据采集2.基于内容parser3.基于现有db本文介绍基于现有db(csv)的基础上基于udp来做报文格式解析。环境配置:windows下,python3.5+python3.4(pandas)easycdb是windows自带的,其自带数据库功能非常好用,在电子表格环境中使用很方便。
easycdb.run()是执行batch处理和把udp数据和内容提取到本地数据库。press()是把udp数据压缩成parser能够读取的结构化数据格式,文件用pythonutf-8编码。下面简单描述一下easycdb的press('glass')步骤。
1、添加内容策略:chmod-r777backendtoeasycdb。export(db_header_to_text)如:db_header_to_text="{"config_to_data":"{udp":"{a_to_one":"{udp":"{a_to_two":"{udp":"{udp":"{udp":"{udp":"{udp":"{udp":"{udp":"{udp":"{udp":"}"}"}"}"}"}"}""。
2、添加支持http2.0协议的chunking策略:chmod-r777backendtoeasycdb.export(chunking_case"http2.config",backend_field_to_udp_chunking_case="http2.config")参数解释:backend_field_to_udp_chunking_case:当支持http2.config解释器支持http2.0时,后面的http2.config对应的是'http2.config'协议版本的值,默认是'http2.config'。
参数解释:参数:参数:export:如果设置link_path/filename文件所在路径,则所有udp报文都进行该chunk压缩。参数:export:如果dict和其他recordset模块绑定(md5hashkeyproperty),则内容解析的地址是该md5签名下的最后一个字符。参数:export:如果为dict和其他recordset模块绑定(md5hashkeyproperty),则内容解析的地址是该md5签名下的最后一个字符。easycdb.serve({"teleport":""})。
3、执行本地数据库回调函数:pythonmanage.pyrunservereasycdb.run(easycdb.db.itemclient)第三种方式写这篇文章的目的不是简单的看代码,而是说代码是最好学的。简单编写的代码在写代码之前我有两个准备,第一是网上的教程不少,我也了解一些内容,基本上看得明白。
第二是理解为什么要这么写,有什么作用。做好之后,再用我们的代码分析网上的一些教程,也更直观。有些教程比较。
如何高效采集归档处理的呢?博通档案管理系统采集方式介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-08-15 23:07
众所周知,汇博通档案管理系统具有强大的办公功能。汇博通作为文件、档案、知识办公一体化的管理软件系统,如何高效地整理归档档案信息?下面小编就为大家简单介绍一下博通文件管理系统采集,希望对大家有所帮助。
汇博通的采集方式多样化,主要分为主动采集和集成采集。
主动采集方法是提供新的属性创建,即对原文件重新编辑填写,可以及时更新文件内容和附加文件信息,并添加个性化附加可选功能.
新增扫描功能,继续为原文件本身添加附件,支持多文件一起上传。
批量创建功能和批量上传/导入/替换功能,即在上传文件时,选择批量创建模式,同时批量上传/导入/替换多个文件,节省工作时间和人工效率。
活动采集方法中可自由选择的知识文档采集方法,满足当前企业对办公文档的需求,精益求精,随着企业的发展做出不同的属性调整,适用于企业的办公平台。
汇博通作为综合信息门户和统一认证中心,整合现有信息系统(如OA、CRM等),对其产生的知识内容进行统一抓取。使用汇博通,将不同系统的原创文献、档案、合同、报告、图纸、网站内容、摘要、内部期刊等整合为一个系统,统一管理。 查看全部
如何高效采集归档处理的呢?博通档案管理系统采集方式介绍
众所周知,汇博通档案管理系统具有强大的办公功能。汇博通作为文件、档案、知识办公一体化的管理软件系统,如何高效地整理归档档案信息?下面小编就为大家简单介绍一下博通文件管理系统采集,希望对大家有所帮助。
汇博通的采集方式多样化,主要分为主动采集和集成采集。
主动采集方法是提供新的属性创建,即对原文件重新编辑填写,可以及时更新文件内容和附加文件信息,并添加个性化附加可选功能.
新增扫描功能,继续为原文件本身添加附件,支持多文件一起上传。
批量创建功能和批量上传/导入/替换功能,即在上传文件时,选择批量创建模式,同时批量上传/导入/替换多个文件,节省工作时间和人工效率。
活动采集方法中可自由选择的知识文档采集方法,满足当前企业对办公文档的需求,精益求精,随着企业的发展做出不同的属性调整,适用于企业的办公平台。
汇博通作为综合信息门户和统一认证中心,整合现有信息系统(如OA、CRM等),对其产生的知识内容进行统一抓取。使用汇博通,将不同系统的原创文献、档案、合同、报告、图纸、网站内容、摘要、内部期刊等整合为一个系统,统一管理。
BaoAI小宝人工智能和量化系统人工智能量化平台下载源码
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-08-14 06:02
BaoAI小宝人工智能量化系统
人工智能和量化从这里开始
小宝的人工智能量化平台是一个简单、直观、强大的前后端SPA开发框架,支持国际化,基于模块,使WEB应用、人工智能和量化系统的开发更快更更轻松。平台收录多个模块,主要包括基于角色的权限管理基础平台(用户、角色、权限、日志、附件、配置参数、分类管理)、通知模块、代码自动生成模块、任务系统模块、内容管理系统模块、 网站模块、电子手册模块、人工智能模块、图像识别模块、人脸识别模块、金融数据采集模块、大数据模块、量化交易模块等
功能:下载源代码
宝爱前后端分离框架结构,包括前端项目和后端项目
文档
数据模拟API
模块扩展
前端开发工具
Visual Studio 代码
安装插件:
Visual Studio Code 的中文(简体)语言包
jshint
git 历史
项目前端BaoAIFront安装步骤
需要安装 Node.js
使用bower下载第三方js库时,国内下载速度可能会很慢。建议克隆并直接解压源代码根路径下的bower_components.zip
# 安装 bower:
npm install -g bower
# 安装 gulp
npm install -g gulp
# npm 安装第三方js
# 使用bower下载第三方js库时,国内可能下载速度很慢,可以直接解压源代码根路径下的bower_components.zip,此步可以跳过
bower install
# npm 安装依赖库:
npm install
# 运行前端代码方式一:自带数据模拟API,适合前端工程师
gulp server
# 运行前端代码方式二:Python全栈开发工程师
# 需要安装BaoAI后端
gulp serve
# 运行前端代码方式三:Python全栈开发工程师,反向代理(前后端共用相同地址和端口,仅目录不同)
# 需要安装BaoAI后端
gulp proxy
# 构建生产代码
gulp build
# 运行前端代码方式四:测试运行生产代码
# 需要安装BaoAI后端
gulp prod
构建的生产代码保存在 dist 目录中。
项目代码自动生成模块
使用自动代码生成模块可以可视化字段、模型、生成的数据库、前端代码、后端代码和权限配置。一般项目可以零代码实现。这部分主要包括三个扩展模块:数据迁移模块、自动代码模型模块和自动代码生成模块
BaoAI小宝人工智能量化平台系统架构
BaoAI小宝人工智能与量化平台知识系统
可用于前后端系统软件开发、cms、人工智能、图像识别、人脸识别、大数据、各行业量化投资。 SPA架构前后端分离,使用AngularJS/Bootstrap等前端框架实现响应式和SPA编程。后端主要使用Python语言,主要包括以下框架:flask提供web服务,Jinja2提供模板服务,Numpy、Pandas、Scikit-Learn、Tensorflow和Keras实现人工智能服务,celery实现任务调度,scrapy提供web爬虫,以及基于 Backtrader 的金融量化服务。
基于宝爱设计案例:
内容管理网站:
管理系统背景:
人工智能:
量化系统:
查看全部
BaoAI小宝人工智能和量化系统人工智能量化平台下载源码
BaoAI小宝人工智能量化系统
人工智能和量化从这里开始
小宝的人工智能量化平台是一个简单、直观、强大的前后端SPA开发框架,支持国际化,基于模块,使WEB应用、人工智能和量化系统的开发更快更更轻松。平台收录多个模块,主要包括基于角色的权限管理基础平台(用户、角色、权限、日志、附件、配置参数、分类管理)、通知模块、代码自动生成模块、任务系统模块、内容管理系统模块、 网站模块、电子手册模块、人工智能模块、图像识别模块、人脸识别模块、金融数据采集模块、大数据模块、量化交易模块等
功能:下载源代码
宝爱前后端分离框架结构,包括前端项目和后端项目
文档
数据模拟API
模块扩展
前端开发工具
Visual Studio 代码
安装插件:
Visual Studio Code 的中文(简体)语言包
jshint
git 历史
项目前端BaoAIFront安装步骤
需要安装 Node.js
使用bower下载第三方js库时,国内下载速度可能会很慢。建议克隆并直接解压源代码根路径下的bower_components.zip
# 安装 bower:
npm install -g bower
# 安装 gulp
npm install -g gulp
# npm 安装第三方js
# 使用bower下载第三方js库时,国内可能下载速度很慢,可以直接解压源代码根路径下的bower_components.zip,此步可以跳过
bower install
# npm 安装依赖库:
npm install
# 运行前端代码方式一:自带数据模拟API,适合前端工程师
gulp server
# 运行前端代码方式二:Python全栈开发工程师
# 需要安装BaoAI后端
gulp serve
# 运行前端代码方式三:Python全栈开发工程师,反向代理(前后端共用相同地址和端口,仅目录不同)
# 需要安装BaoAI后端
gulp proxy
# 构建生产代码
gulp build
# 运行前端代码方式四:测试运行生产代码
# 需要安装BaoAI后端
gulp prod
构建的生产代码保存在 dist 目录中。
项目代码自动生成模块
使用自动代码生成模块可以可视化字段、模型、生成的数据库、前端代码、后端代码和权限配置。一般项目可以零代码实现。这部分主要包括三个扩展模块:数据迁移模块、自动代码模型模块和自动代码生成模块
BaoAI小宝人工智能量化平台系统架构

BaoAI小宝人工智能与量化平台知识系统
可用于前后端系统软件开发、cms、人工智能、图像识别、人脸识别、大数据、各行业量化投资。 SPA架构前后端分离,使用AngularJS/Bootstrap等前端框架实现响应式和SPA编程。后端主要使用Python语言,主要包括以下框架:flask提供web服务,Jinja2提供模板服务,Numpy、Pandas、Scikit-Learn、Tensorflow和Keras实现人工智能服务,celery实现任务调度,scrapy提供web爬虫,以及基于 Backtrader 的金融量化服务。

基于宝爱设计案例:
内容管理网站:

管理系统背景:

人工智能:

量化系统:

BaoAI小宝人工智能和量化系统和
采集交流 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-08-14 05:33
BaoAI小宝人工智能量化系统
人工智能和量化从这里开始
小宝的人工智能量化平台是一个简单、直观、强大的前后端SPA开发框架,支持国际化,基于模块,使WEB应用、人工智能和量化系统的开发更快更更轻松。平台收录多个模块,主要包括基于角色的权限管理基础平台(用户、角色、权限、日志、附件、配置参数、分类管理)、通知模块、代码自动生成模块、任务系统模块、内容管理系统模块、 网站模块、电子手册模块、人工智能模块、图像识别模块、人脸识别模块、金融数据采集模块、大数据模块、量化交易模块等
功能:下载源代码
宝爱前后端分离框架结构,包括前端项目和后端项目
文档
API
模块扩展
前端和后端开发工具
Visual Studio 代码
安装插件:
Visual Studio Code 的中文(简体)语言包
jshint
蟒蛇
Git 历史
项目后端BaoAIBack安装步骤
需要 Python 3.6
# 1. 创建虚拟环境
# windows, 假设项目根路径:d:/baoai/BaoaiBack/
cd d:/baoai/BaoaiBack
mkdir venv
cd venv
python -m venv .
# 运行虚拟环境
d:/baoai/BaoaiBack/venv/Scripts/activate.bat
cd d:/baoai/BaoaiBack
# linux, 假设项目根路径:/baoai/BaoaiBack/
cd /baoai/BaoaiBack
mkdir venv
cd venv
python -m venv .
# 运行虚拟环境
source /baoai/BaoaiBack/venv/bin/activate
cd /baoai/BaoaiBack
# 2. 安装依赖库(必须处于虚拟环境)
# windows 安装依赖库
python -m pip install --upgrade pip
pip install -r requirements.txt
# 如果下载速度慢可以采用国内镜像
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
# linux 安装依赖库
python -m pip3 install --upgrade pip
pip3 install -r requirements.txt
# 如果下载速度慢可以采用国内镜像
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
# 3. 运行 Restful 服务
# windows
run_baoai.bat
# linux
# 默认使用gunicorn做为wsgi
chmod +x run_baoai.sh
./run_baoai.sh
# 4. 运行 www 服务(Jinja模块)
# windows
run_www.bat
# linux
chmod +x run_www.sh
./run_www.sh
# 常用功能
# 清空缓存
python manage.py clean
项目后端数据库
该项目支持最流行的关系数据库,包括:SQLite、MySQL、Postgres、Oracle、MS-SQL、SQLServer 和 Firebird。
提供了Sqlite 数据库和MySQL 数据脚本文件。 MySQL 支持5.5 及以上。
数据库转换不需要修改代码,只需修改config.py中的SQLALCHEMY_DATABASE_URI即可。
默认使用 sqlite 数据库。优点是不需要安装专门的数据库软件,方便测试和开发。生产部署请使用mysql或其他数据库软件。
sqlite数据存放在db/baoai.db中,直接使用
mysql数据库脚本保存在db/baoai.mysql.sql中,需要新建一个baoai等数据库,然后导入脚本。
如果您使用其他数据库,您可以使用 Navicat Premium 工具菜单中的数据传输在不同数据库之前迁移数据。
数据库相关操作:
# 数据迁移服务
# 初始化
python manage.py db init
# 模型迁移
python manage.py db migrate
# 数据库脚本更新(操作数据)
python manage.py db upgrade
项目代码自动生成模块
使用自动代码生成模块可以可视化字段、模型、生成的数据库、前端代码、后端代码和权限配置。一般项目可以零代码实现。这部分主要包括三个扩展模块:数据迁移模块、自动代码模型模块和自动代码生成模块
BaoAI小宝人工智能量化平台系统架构
BaoAI小宝人工智能与量化平台知识系统
可用于前后端系统软件开发、cms、人工智能、图像识别、人脸识别、大数据、各行业量化投资。 SPA架构前后端分离,使用AngularJS/Bootstrap等前端框架实现响应式和SPA编程。后端主要使用Python语言,主要包括以下框架:flask提供web服务,Jinja2提供模板服务,Numpy、Pandas、Scikit-Learn、Tensorflow和Keras实现人工智能服务,celery实现任务调度,scrapy提供web爬虫,以及基于 Backtrader 的金融量化服务。
基于宝爱设计案例:
内容管理网站:
管理系统背景:
人工智能:
量化系统:
查看全部
BaoAI小宝人工智能和量化系统和
BaoAI小宝人工智能量化系统
人工智能和量化从这里开始
小宝的人工智能量化平台是一个简单、直观、强大的前后端SPA开发框架,支持国际化,基于模块,使WEB应用、人工智能和量化系统的开发更快更更轻松。平台收录多个模块,主要包括基于角色的权限管理基础平台(用户、角色、权限、日志、附件、配置参数、分类管理)、通知模块、代码自动生成模块、任务系统模块、内容管理系统模块、 网站模块、电子手册模块、人工智能模块、图像识别模块、人脸识别模块、金融数据采集模块、大数据模块、量化交易模块等
功能:下载源代码
宝爱前后端分离框架结构,包括前端项目和后端项目
文档
API
模块扩展
前端和后端开发工具
Visual Studio 代码
安装插件:
Visual Studio Code 的中文(简体)语言包
jshint
蟒蛇
Git 历史
项目后端BaoAIBack安装步骤
需要 Python 3.6
# 1. 创建虚拟环境
# windows, 假设项目根路径:d:/baoai/BaoaiBack/
cd d:/baoai/BaoaiBack
mkdir venv
cd venv
python -m venv .
# 运行虚拟环境
d:/baoai/BaoaiBack/venv/Scripts/activate.bat
cd d:/baoai/BaoaiBack
# linux, 假设项目根路径:/baoai/BaoaiBack/
cd /baoai/BaoaiBack
mkdir venv
cd venv
python -m venv .
# 运行虚拟环境
source /baoai/BaoaiBack/venv/bin/activate
cd /baoai/BaoaiBack
# 2. 安装依赖库(必须处于虚拟环境)
# windows 安装依赖库
python -m pip install --upgrade pip
pip install -r requirements.txt
# 如果下载速度慢可以采用国内镜像
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
# linux 安装依赖库
python -m pip3 install --upgrade pip
pip3 install -r requirements.txt
# 如果下载速度慢可以采用国内镜像
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
# 3. 运行 Restful 服务
# windows
run_baoai.bat
# linux
# 默认使用gunicorn做为wsgi
chmod +x run_baoai.sh
./run_baoai.sh
# 4. 运行 www 服务(Jinja模块)
# windows
run_www.bat
# linux
chmod +x run_www.sh
./run_www.sh
# 常用功能
# 清空缓存
python manage.py clean
项目后端数据库
该项目支持最流行的关系数据库,包括:SQLite、MySQL、Postgres、Oracle、MS-SQL、SQLServer 和 Firebird。
提供了Sqlite 数据库和MySQL 数据脚本文件。 MySQL 支持5.5 及以上。
数据库转换不需要修改代码,只需修改config.py中的SQLALCHEMY_DATABASE_URI即可。
默认使用 sqlite 数据库。优点是不需要安装专门的数据库软件,方便测试和开发。生产部署请使用mysql或其他数据库软件。
sqlite数据存放在db/baoai.db中,直接使用
mysql数据库脚本保存在db/baoai.mysql.sql中,需要新建一个baoai等数据库,然后导入脚本。
如果您使用其他数据库,您可以使用 Navicat Premium 工具菜单中的数据传输在不同数据库之前迁移数据。
数据库相关操作:
# 数据迁移服务
# 初始化
python manage.py db init
# 模型迁移
python manage.py db migrate
# 数据库脚本更新(操作数据)
python manage.py db upgrade
项目代码自动生成模块
使用自动代码生成模块可以可视化字段、模型、生成的数据库、前端代码、后端代码和权限配置。一般项目可以零代码实现。这部分主要包括三个扩展模块:数据迁移模块、自动代码模型模块和自动代码生成模块
BaoAI小宝人工智能量化平台系统架构

BaoAI小宝人工智能与量化平台知识系统
可用于前后端系统软件开发、cms、人工智能、图像识别、人脸识别、大数据、各行业量化投资。 SPA架构前后端分离,使用AngularJS/Bootstrap等前端框架实现响应式和SPA编程。后端主要使用Python语言,主要包括以下框架:flask提供web服务,Jinja2提供模板服务,Numpy、Pandas、Scikit-Learn、Tensorflow和Keras实现人工智能服务,celery实现任务调度,scrapy提供web爬虫,以及基于 Backtrader 的金融量化服务。

基于宝爱设计案例:
内容管理网站:

管理系统背景:

人工智能:

量化系统:

采集内容管理平台——统计源头sdk模式模式
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-08-13 20:04
采集内容管理平台:采集:微博公众号头条网站内容导出:百度微信等形式分类:商品,化妆品,食品,母婴,虚拟,青少年教育,三维建模,视频等统计:各种行业数据,明星,自己公司,媒体,交通,住宿,出行,互联网高科技等出处:友盟技术服务平台,统计源头sdk模式:hooksdk,基于js库开发,跨浏览器webservice接口开发,数据库实时同步至本地数据库,webservice客户端发送请求,计算数据库数据,返回给前端,前端根据计算的数据通过后端模板系统渲染所以大家通过统计分析来实现。
开源方案一是统计源,需要大量的开发复杂度,二是接口,主要是接数据库,客户端渲染是hook方式,模拟网络请求来做。初期阶段自己看python3微博爬虫,存进数据库,然后自己整理好数据。基本每隔几天就去看webservice内的数据更新进度。有些分类或者说每个人关注的数据很少。后来使用统计源的时候,很多不统计,业务上有kpi,可以做kpi的点数,目前来看是非常有价值的。
哈哈,首先你得找到需求和解决方案,前端爬取是基础,统计分析是保障,我找到一套微博社区管理的web爬虫程序。那里面人工分类爬取的,
数据来源很多,如果你有编程基础可以搞爬虫。如果你想找一个你开发的东西,可以考虑接入友盟这样的第三方统计平台,他们可以定制样式和你的api等等,接入这样的平台一般需要api包,一个平台一个api包,把样式包给别人让他们去按你的接口调用就可以了。把数据以统计报表的形式上传到api包,因为统计报表可以实时推送给每个用户,所以一般需要一个本地数据库,你把这个数据库封装成程序要访问的数据库。
要是支持格式化接口,那你就拿着你的api去接单里的一个接口或者二个接口,用对应的数据接口调用就可以了。统计报表这些可以用excel实现。以上是比较基础的,其他的数据爬取可以用scrapy来完成。也可以用python爬虫框架写html代码,或者爬行json文件,然后解析,再用requests库爬取。代码在下面这个博客里:scrapy爬虫实现自动爬取话题微博的数据分析。 查看全部
采集内容管理平台——统计源头sdk模式模式
采集内容管理平台:采集:微博公众号头条网站内容导出:百度微信等形式分类:商品,化妆品,食品,母婴,虚拟,青少年教育,三维建模,视频等统计:各种行业数据,明星,自己公司,媒体,交通,住宿,出行,互联网高科技等出处:友盟技术服务平台,统计源头sdk模式:hooksdk,基于js库开发,跨浏览器webservice接口开发,数据库实时同步至本地数据库,webservice客户端发送请求,计算数据库数据,返回给前端,前端根据计算的数据通过后端模板系统渲染所以大家通过统计分析来实现。
开源方案一是统计源,需要大量的开发复杂度,二是接口,主要是接数据库,客户端渲染是hook方式,模拟网络请求来做。初期阶段自己看python3微博爬虫,存进数据库,然后自己整理好数据。基本每隔几天就去看webservice内的数据更新进度。有些分类或者说每个人关注的数据很少。后来使用统计源的时候,很多不统计,业务上有kpi,可以做kpi的点数,目前来看是非常有价值的。
哈哈,首先你得找到需求和解决方案,前端爬取是基础,统计分析是保障,我找到一套微博社区管理的web爬虫程序。那里面人工分类爬取的,
数据来源很多,如果你有编程基础可以搞爬虫。如果你想找一个你开发的东西,可以考虑接入友盟这样的第三方统计平台,他们可以定制样式和你的api等等,接入这样的平台一般需要api包,一个平台一个api包,把样式包给别人让他们去按你的接口调用就可以了。把数据以统计报表的形式上传到api包,因为统计报表可以实时推送给每个用户,所以一般需要一个本地数据库,你把这个数据库封装成程序要访问的数据库。
要是支持格式化接口,那你就拿着你的api去接单里的一个接口或者二个接口,用对应的数据接口调用就可以了。统计报表这些可以用excel实现。以上是比较基础的,其他的数据爬取可以用scrapy来完成。也可以用python爬虫框架写html代码,或者爬行json文件,然后解析,再用requests库爬取。代码在下面这个博客里:scrapy爬虫实现自动爬取话题微博的数据分析。
采集内容管理平台(采集内容管理平台有很多种,实时数据采集网页端)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-09-15 01:07
采集内容管理平台有很多种,实时数据采集数据采集网页端有百度友盟,api接口多数据有baidusearch,百度统计大数据采集端,百度统计,同步支持阿里统计腾讯统计,且可实时,二十秒,按地域采集多种形式,可etl,数据直接上传到业务系统在线系统能方便实现市场推广,数据分析,信息提取,
推荐微盟内容管理平台,可通过微网站、小程序、app各种展现形式,收集内容信息、采集页面内容、实时更新。
搜索自助采集平台,
恩,怎么说呢,内容采集这个事,最好是先能做一套实时的全网采集系统,这样通过自动分析,用户访问的统计,产品链接,可以看出内容真实的访问度还有内容有多少。个人觉得最有用的数据集成平台,应该是跟线下复杂的经销,营销渠道(运营商报表)是一套的,我建议各种数据全做到平台,渠道,用户,营销,就好。内容采集想走得长远,这样单点集成是不能解决实际问题的。
搜索可以采集很多信息,目前用得最多的应该是阿里妈妈收购内容分发集团了吧。同步是一个很棒的功能,如果做推荐可以试试内容画像的算法融合技术,
百度友盟,统计分析国内现在做得不错的一家服务商。
不是大佬,强答一发。内容采集,地域定向分析,特征关联分析,去重和真伪分析, 查看全部
采集内容管理平台(采集内容管理平台有很多种,实时数据采集网页端)
采集内容管理平台有很多种,实时数据采集数据采集网页端有百度友盟,api接口多数据有baidusearch,百度统计大数据采集端,百度统计,同步支持阿里统计腾讯统计,且可实时,二十秒,按地域采集多种形式,可etl,数据直接上传到业务系统在线系统能方便实现市场推广,数据分析,信息提取,
推荐微盟内容管理平台,可通过微网站、小程序、app各种展现形式,收集内容信息、采集页面内容、实时更新。
搜索自助采集平台,
恩,怎么说呢,内容采集这个事,最好是先能做一套实时的全网采集系统,这样通过自动分析,用户访问的统计,产品链接,可以看出内容真实的访问度还有内容有多少。个人觉得最有用的数据集成平台,应该是跟线下复杂的经销,营销渠道(运营商报表)是一套的,我建议各种数据全做到平台,渠道,用户,营销,就好。内容采集想走得长远,这样单点集成是不能解决实际问题的。
搜索可以采集很多信息,目前用得最多的应该是阿里妈妈收购内容分发集团了吧。同步是一个很棒的功能,如果做推荐可以试试内容画像的算法融合技术,
百度友盟,统计分析国内现在做得不错的一家服务商。
不是大佬,强答一发。内容采集,地域定向分析,特征关联分析,去重和真伪分析,
采集内容管理平台(天天网-数据可视化平台,可以在腾讯开放平台爬数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-08 12:02
采集内容管理平台(例如:博主号宝贝爬取、用户宝贝爬取、文章页面爬取)常用的工具有很多,我只知道robots协议可以爬取京东,的宝贝。你可以去站长平台看看流量统计这一块,一般爬取的数据可以分析转化率什么的。
目前,上有很多爬虫,但是商品管理后台上的店铺搜索数据,所爬取的数据都是比较经过商家的授权的,商家没有授权,是爬取不了的,所以通过商家以外的人是爬取不了上的数据的。但是也可以通过一些其他的工具来爬取其他的数据,比如你可以考虑爬博客主页等数据来作为文章标题的数据,也可以利用一些来爬取其他的数据。
针对上的数据爬取来说,需要通过真实的手机号码,和真实的网页cookies来构造手机号和网址链接才可以正常的抓取数据。不过如果想爬取一些上的用户信息,也可以借助第三方平台,比如爬吧论坛。
用微信小程序可以爬,
打开微信发现小程序搜索,拾书人随便哪个链接,
除了留言板,唯品会等,其他基本上api都去爬,需要授权,其他不知道。
新闻,商品数据可以直接爬。天天网-数据可视化平台,
现在正在做这件事情,可以在腾讯开放平台爬数据, 查看全部
采集内容管理平台(天天网-数据可视化平台,可以在腾讯开放平台爬数据)
采集内容管理平台(例如:博主号宝贝爬取、用户宝贝爬取、文章页面爬取)常用的工具有很多,我只知道robots协议可以爬取京东,的宝贝。你可以去站长平台看看流量统计这一块,一般爬取的数据可以分析转化率什么的。
目前,上有很多爬虫,但是商品管理后台上的店铺搜索数据,所爬取的数据都是比较经过商家的授权的,商家没有授权,是爬取不了的,所以通过商家以外的人是爬取不了上的数据的。但是也可以通过一些其他的工具来爬取其他的数据,比如你可以考虑爬博客主页等数据来作为文章标题的数据,也可以利用一些来爬取其他的数据。
针对上的数据爬取来说,需要通过真实的手机号码,和真实的网页cookies来构造手机号和网址链接才可以正常的抓取数据。不过如果想爬取一些上的用户信息,也可以借助第三方平台,比如爬吧论坛。
用微信小程序可以爬,
打开微信发现小程序搜索,拾书人随便哪个链接,
除了留言板,唯品会等,其他基本上api都去爬,需要授权,其他不知道。
新闻,商品数据可以直接爬。天天网-数据可视化平台,
现在正在做这件事情,可以在腾讯开放平台爬数据,
采集内容管理平台(程序自动关联扩展名为cmbook的书籍文件说明下载地址说明)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-07 09:16
cmbook数据采集与管理软件,本软件为单机绿色软件,由VC2008MFC加SQLITE数据库开发,程序自动将图书文件与扩展名cmbook关联,cmbook图书文件为SQLITE3数据库,扩展名改为db,用sqliteadminsqlite数据库管理工具打开,里面有一个cmbook表和一个版本表,新创建的文章以RTF文件格式保存在cmbook表的BLOB字段中。
相关软件软件大小及版本说明下载链接
cmbook数据采集管理软件,软件功能简单,界面清爽,单文件绿色版,支持全文检索。
本软件是VC2008 MFC和SQLITE数据库开发的单机绿色软件。程序会自动将书籍文件与扩展名 cmbook 相关联。 cmbook book 文件是一个 SQLITE3 数据库。将扩展名更改为 db 并使用 sqliteadmin(sqlite 数据库)。管理工具)打开,里面有一个cmbook表和一个版本表,新创建的文章以rtf文件格式保存在cmbook表的BLOB字段中。
更新日志
cmbook 数据采集管理软件 V1.8
主要纠正错误:
修复了一个新文档错误。 sqlite3_prepare_v2后,sqlite3_finalize没有及时执行释放内存,导致程序新建文档时出错。 查看全部
采集内容管理平台(程序自动关联扩展名为cmbook的书籍文件说明下载地址说明)
cmbook数据采集与管理软件,本软件为单机绿色软件,由VC2008MFC加SQLITE数据库开发,程序自动将图书文件与扩展名cmbook关联,cmbook图书文件为SQLITE3数据库,扩展名改为db,用sqliteadminsqlite数据库管理工具打开,里面有一个cmbook表和一个版本表,新创建的文章以RTF文件格式保存在cmbook表的BLOB字段中。
相关软件软件大小及版本说明下载链接
cmbook数据采集管理软件,软件功能简单,界面清爽,单文件绿色版,支持全文检索。
本软件是VC2008 MFC和SQLITE数据库开发的单机绿色软件。程序会自动将书籍文件与扩展名 cmbook 相关联。 cmbook book 文件是一个 SQLITE3 数据库。将扩展名更改为 db 并使用 sqliteadmin(sqlite 数据库)。管理工具)打开,里面有一个cmbook表和一个版本表,新创建的文章以rtf文件格式保存在cmbook表的BLOB字段中。
更新日志
cmbook 数据采集管理软件 V1.8
主要纠正错误:
修复了一个新文档错误。 sqlite3_prepare_v2后,sqlite3_finalize没有及时执行释放内存,导致程序新建文档时出错。
采集内容管理平台(短视频内容分析采集管理软件软件亮点对所有的视频数据信息进行数据库化管理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-09-06 16:05
短视频内容分析采集管理软件可以对短视频平台(如抖音)的内容进行分析和管理。
类似软件
版本说明
软件地址
短视频内容分析采集管理软件亮点
1.所有视频数据信息的数据库管理,方便查找和对比分析
2. 支持获取主播下所有视频,通过单个视频地址获取视频数据
3.最大亮点:随时可以追踪各主播发布的最新视频,发现主播最新动态
4.记录每个视频的“上传时间”
5.视频内容支持翻页查看,除了可以记录视频时长、点赞数、评论数、分享数等。
6.企业版用户可以共享多台电脑的数据,实现团队数据协同工作。
短视频内容分析采集管理软件功能
一.播主管理模块:
主播管理模块可以对所有登录的主播账号进行分类,如宠物、美女、搞笑等。
输入主播主页的URL链接地址,获取主播账号名和账号ID。
可以手动一一添加主播,软件还支持批量导入。
二.内容分析管理模块:
2.1 支持对一个或多个主播下的所有视频进行分析,也可以通过添加单个或多个视频网址进行分析。
2.2 可以分析获取视频封面、标题、时长、上传时间、点赞数、评论数、分享数等参数。
2.3 还可以根据不同的搜索条件,过滤搜索过去分析保存的数据。
2.2 勾选分析的有效数据,点击“下载选项”即可下载无水印视频文件。
同时,相应的视频内容相关数据也会同步到“视频内容管理”进行精细化管理。
三.视频内容管理模块:
3.1 在视频内容管理上,所有内容均已本地化保存,无水印视频文件。
如果您需要使用该视频内容,可以勾选内容并点击“导出”。
您还可以根据不同的搜索条件对本地保存的数据进行过滤和搜索,删除和选择需要导出的视频。
3.2 每个内容记录2个导出状态,分别为“已导出”和“未导出”,帮助用户记录该内容是否已被使用,避免重复使用。
短视频内容解析采集管理软件更新日志
1.修复BUG,新版本体验更好
2.更改了一些页面
华军编辑推荐:
华骏软件园小编推荐您下载短视频内容分析采集管理软件。编辑器将对其进行测试并放心使用。另外,华骏软件园提供的批量小管家、云机管家、硬盘序列号阅读器、快速隐藏任务栏图标工具、安卓模拟器大师也是不错的软件。有需要的不妨下载试试!风雨小编等你! 查看全部
采集内容管理平台(短视频内容分析采集管理软件软件亮点对所有的视频数据信息进行数据库化管理)
短视频内容分析采集管理软件可以对短视频平台(如抖音)的内容进行分析和管理。
类似软件
版本说明
软件地址
短视频内容分析采集管理软件亮点
1.所有视频数据信息的数据库管理,方便查找和对比分析
2. 支持获取主播下所有视频,通过单个视频地址获取视频数据
3.最大亮点:随时可以追踪各主播发布的最新视频,发现主播最新动态
4.记录每个视频的“上传时间”
5.视频内容支持翻页查看,除了可以记录视频时长、点赞数、评论数、分享数等。
6.企业版用户可以共享多台电脑的数据,实现团队数据协同工作。
短视频内容分析采集管理软件功能
一.播主管理模块:
主播管理模块可以对所有登录的主播账号进行分类,如宠物、美女、搞笑等。
输入主播主页的URL链接地址,获取主播账号名和账号ID。
可以手动一一添加主播,软件还支持批量导入。
二.内容分析管理模块:
2.1 支持对一个或多个主播下的所有视频进行分析,也可以通过添加单个或多个视频网址进行分析。
2.2 可以分析获取视频封面、标题、时长、上传时间、点赞数、评论数、分享数等参数。
2.3 还可以根据不同的搜索条件,过滤搜索过去分析保存的数据。
2.2 勾选分析的有效数据,点击“下载选项”即可下载无水印视频文件。
同时,相应的视频内容相关数据也会同步到“视频内容管理”进行精细化管理。
三.视频内容管理模块:
3.1 在视频内容管理上,所有内容均已本地化保存,无水印视频文件。
如果您需要使用该视频内容,可以勾选内容并点击“导出”。
您还可以根据不同的搜索条件对本地保存的数据进行过滤和搜索,删除和选择需要导出的视频。
3.2 每个内容记录2个导出状态,分别为“已导出”和“未导出”,帮助用户记录该内容是否已被使用,避免重复使用。
短视频内容解析采集管理软件更新日志
1.修复BUG,新版本体验更好
2.更改了一些页面
华军编辑推荐:
华骏软件园小编推荐您下载短视频内容分析采集管理软件。编辑器将对其进行测试并放心使用。另外,华骏软件园提供的批量小管家、云机管家、硬盘序列号阅读器、快速隐藏任务栏图标工具、安卓模拟器大师也是不错的软件。有需要的不妨下载试试!风雨小编等你!
采集内容管理平台(V2.08C序列号院校人才培养工作状态数据采集平台操作指南)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-06 16:03
版本:V2.08C 编号:007 高职人才培养工作状态数据采集平台操作指南1.1 background1.2"状态数据采集平台V2. 08C》目录下文件及子目录说明1.3platform应用环境1.4启动Excel(VBA)运行环境宏1.5platform指令1.6platform使用注意事项2.1platform文件名2.2采集Platform 数据合并同伴介绍2.3创建文件目录和文件重命名的含义10 2.4 执行采集平台文件10 2.5 宏在平台中的作用11 2. 6 启用宏操作 11 3、采集平台管理功能 11 3.1 状态数据目录 11 3.2 数据表导出 12 3.3 数据表导入 12 3.4 数据表锁定 13 3.5 数据表解锁 14 3.6 数据格式刷新 14 3.7 数据统计与汇总 15 4、State data采集管理工艺15 4.1 采集平台数据表导出 16 4.2制定数据采集rules 和issue 文件 17 4.3 填写数据表 18 4.4 恢复合并数据表 19 4.5 将数据表导入采集平台21 4.6 状态数据验证和汇总 22 5、版本升级23 6、平台数据上报24 7、Status data采集释疑25 8、平台升级与技术支持26 1、采集平台简介1.1 背景介绍采集平台主要是以教育部《高职院校人才培养评价方案》(2008)5中公布的指标体系为基础制定,并采纳了课题组和试点单位的改进意见。
1.2 "Status data采集平台V2.08C" XXXXX_YYYY_status 目录下的文件和子目录的描述性名称描述 V2.08C 高职院校人才培养工作状态数据采集平台V2.08C 采集平台_data合并伙伴V2.08C为高职人才培养工作状态数据采集平台助程序恢复数据表收录以每个数据表命名的文件目录name(36A)是用来存放恢复数据采集的数据表文件。恢复后的数据表文件可以根据数据表内容存放在对应的文件目录中。分发数据表存放需要数据的空数据表采集。注意:不要随意修改目录名。可以使用“采集平台_数据Merged Partner V2.08C”恢复目录中相同的数据表。目录下的数据文件被合并。 1.3 平台应用环境状态数据 采集平台V2.08C 所需软件环境为:1) 操作系统:Windows XP、Windows 2000 系列2) 应用软件:Office Excel 2003,允许宏操作1.4 启动EXCEL(VBA)宏运行环境 为编程需要,本平台采用“VBA”高级编程语言,需要(VBA)宏运行环境。一般来说,Excel 自带“宏”检测功能。当发现Excel文件是用“宏”打开时,会提示用户注意,让用户选择是否启用“宏”。
电脑提示语言如下:“文件收录宏,宏可能携带病毒。取消宏虽然可以保证安全,但会影响平台的正常运行。必须启用宏才能在电脑上执行Excel文件. 激活方法如下: 打开Excel文件,选择菜单工具安全,打开安全对话框,将安全级别设置为“低”,如下图,选择一些相关的宏操作时,可能会出现被某些杀毒软件判断为危险软件,此时选择跳过或忽略即可正常使用,不会威胁到计算机的安全,比如我们在使用卡巴斯基杀毒软件时,导出表操作时出现下图,只要选择跳过就可以正常操作,进行以上设置后,重新打开Excel文件,启用宏,就可以正常操作了1. 5 解放军tform 说明1)版本号4)平台版本号、序列号、回目录链接、填写表格各表中说明和注意事项的位置1.6 平台使用注意事项 主目录平台必须放在硬盘的根目录下才能使用,否则可能影响采集平台_数据的导出文件功能集成伙伴V2.08C;数据表提供了标准化的数据输入方式,可根据实际情况选择。不能自行输入或粘贴,否则会影响部分数据汇总的准确性;注意检查输入数据的格式(如课时、金额等指标),特别容易在复制粘贴过程中转换为文本格式。必须设置为数字格式,否则会影响部分数据汇总的准确性;注意检查输入日期的格式(如出生日期、领证日期等)。以标准格式输入,如2007-9-1(其中横线为英文半角),否则会影响部分数据汇总的准确性;进行版本转换前仔细检查“版本差异”文件,有些指标必须重新填写,有些指标必须填写,否则会影响部分数据汇总的准确性; 10) 使用合并伙伴升级前,必须检查每个表的第一列是否为空,如果为空请根据实际情况填写,否则会导致部分数据失效进口; 11)使用合并伙伴中的“版本升级”功能进行版本升级后,必须打开新版本采集platform文件查看升级后的表数据,为完整起见,重新填写“部门填表”、“填表人”、“填表时间”,以及各表项的调整和补充。必须再次进行数据汇总操作,重新生成汇总数据的第十部分,并检查汇总数据的准确性。
12)完成数据输入后,进行“数据统计与汇总”操作,生成汇总数据(第10部分); 13) 表中不能随意添加或删除数据项,可以添加数据行。 2、采集平台文件管理与执行2.1平台文件名含义1)采集平台文件名各部分含义 图10:采集平台文件含义姓名2)例上海行健 高职院校代码:12493,上报年份:2008 上报文件名:12493_2008_STATUS V2.08C.xls 3) 注:上报状态数据时文件,文件需要按照图10所示的规则进行处理。重命名。 2.2 采集platform数据合并伙伴介绍1)“采集平台_data合并伙伴V208c.xls”是data采集平台的辅助工具。其主要功能是数据表文件恢复、数据合并、数据表版本转换。请注意,这些功能只能在允许宏操作的环境中使用。 2)Merge伙伴组合:1个伙伴文件,几个文件目录(如下图) 图11:Merge伙伴组合图 10 2.3 创建文件目录和文件重命名1)State数据文件管理2)示例:“上海兴建职业学院” Data采集文件管理学校代码:12493 申请年份:2008 操作步骤: 步骤一:更改光盘中的目录“status data采集平台V2.08C” ROM复制到电脑,例如我们把“status data采集平台V2.08C”目录复制到D盘根目录下,将目录重命名为“12493_2008”,同意这个目录是平台操作的主目录 第二步:打开“12493_2008”目录;第三步:将采集platform文件“XXXXX_YYYY_status data V2.08C.xls”重命名为:“12493_2008_status data V2.08C.xls”。
最终完成的目录结构如下: 图12:文件目录结构图2.4 在excel中第一次打开主平台文件时执行采集platform文件,或者你从来没有在你的excel 设置“宏安全”后打开主平台文件会出现如图13所示的警告画面。如果选择确定,您可以输入基础数据,但平台提供的智能操作功能将被拒绝。 11 图13:提示禁用宏2.5 宏在平台中的作用1)查看状态数据2)用于数据输入3)数据汇总操作4)允许智能表操作(如表导出) /import 、表解锁/锁定、格式刷新、数据汇总等)2.6 启用宏操作。必须启用宏才能在 Excel 中执行主平台文件。启用方法如下: 打开Excel文件,选择菜单工具安全,打开安全对话框,设置安全级别为“低”。具体操作图请参考《1.4 启动Excel(VBA)宏操作环境》中的介绍。注意:进行上述设置后,需要重新打开Excel文件并启用宏才能进行正常操作。 3、采集平台管理功能3.1 状态数据目录根据“状态数据目录”类别查询、录入或修改采集平台数据表中的数据。 12 图14:状态数据目录3.2 数据表导出 “数据表导出”操作可以将36个数据表以单表文件的形式导出到采集平台。
图15:数据表导出界面3.3 数据表导入“数据表导入”操作可以将36个已经完成数据输入的数据表文件导入到data采集平台。需要导入的数据表文件必须直接保存在“恢复数据表”目录下,文件名必须以采集平台朋友导出的文件名为准。 13 图16:数据表导入界面3.4 数据表锁定“数据表锁定”操作位于导航“高级操作”中,锁定状态下,只能处理数据表,不能处理表结构修改的 。注:1)锁数据表,目的是保证数据表结构的一致性; 2)在执行“数据表导出”操作前确保数据表被锁定,即数据表被锁定 非数据输入区被锁定后无法操作。图17:数据表锁定 14 3.5 数据表解锁 “数据表解锁”操作位于导航“高级操作”中,在解锁状态下可以完全控制表。注意:在解锁状态下,可以进行表格格式处理,调整行高或列宽,增加数据行,但不要调整表格的项结构,否则会影响汇总数据的准确性;图18:数据表解锁3.6 数据格式刷新“数据格式刷新”操作位于导航“高级操作”中,统一处理数据表中数据的字体和字号。图 19:数据格式刷新 15 3.7 数据统计与汇总 “数据统计与汇总”操作位于导航“高级操作”中。对平台中的数据进行汇总,生成汇总数据的第十部分。
注意:所有数据导入平台后,必须点击此按钮生成汇总数据的第十部分;每次更新平台中的表格时必须点击此按钮重新生成第十部分汇总数据,否则不会自动生成或更新第10部分汇总数据。图20:数据统计与汇总4、State Data采集管理程16 4.1 采集platform 数据表导出 在数据导出页面,将选中的工作表作为单表导出到采集platform 文件保存在采集platform文件所在的目录中;图 21:数据表导出页面 图 22:数据表导出后的文件目录结构 注意:重复数据表导出操作时,如果有同名数据表文件,系统会提问,由操作员决定是否覆盖文件或放弃操作。 17 图23:数据表重复导出后的系统提示4.2 制定数据采集 规则和文件分布 根据数据生成源制定数据采集Rules1)OK data采集Object:分析导出数据表(36张),指定数据采集object(部门/人); 2)数据表文件重命名:根据确定的数据采集对象重命名数据文件(如下图) 18 图24:将数据表文件复制到[下载数据表】目录3)示例导出表文件名为“A4-2校外实习实训基地表(XX采集)”文件更名为“A4-2校外实习实训基地表(教研科采集)”4.3 填写数据表1) 打开数据表文件,按照表中的项目输入数据。注:每个数据表的上半部分是版本标识,返回主目录链接,填写说明和注意事项,输入数据前请仔细阅读。
图25:需填写的单一表格2) 数据输入完成后,保存文件,并按规定重命名文件(部分表格) 例如:在线教研室填写在“A4-2校外实习实训基地表(教研室采集)”文件更名为:“A4-2校外实习实训基地表(网络教研室采集)” 19 4.4 数据表的回收和合并1)每个将被回收的单表的副本进入“回收数据表”目录中的相应目录。图26:将回收的单张复制到“Recycled Data Sheet”目录下对应的目录。示例:将“A7-1专业设置表”的单张文件复制到“A7-1专业设置表”目录下,图27:将各专业表2)的“A7-1专业设置表”目录复制回来到平台主目录,打开文件“采集平台_数据合并伙伴V2.08C.xls”,必须启用宏,选择要合并的子表,例如:根据上面的例子,我们选择“7.1 专业设置” 20 图28:数据合并伙伴目录界面3) 打开合并表页面,点击页面上的“合并数据”按钮。图29:数据合并界面 图30:程序自动合并“恢复数据目录”下“A7-1专业设置表”目录下的所有文件内容。在表中,按每个表的key字段排序,所以每个导入表的第一列不能为空。 21 注:合并后的内容可以在合并表中查看、修改、清除。
4)导出合并数据表。选择页面上的“导出文件”按钮。出现提示时,按“确定”按钮。导出成功。导出的文件会自动存储在“回收数据表”目录中。图 31:执行“导出文件”按钮后,组合表将自动导出到“回收数据表”目录。图 32:“回收数据表”目录中的组合表。 A7-1 Professional settings table.xls”文件4.5 将数据表导入采集平台回到主目录,打开平台主文件“12493_2008_status data V2.08C.xls”,进入“data在“导入”界面,勾选要导入的文件名,选择“数据表导入”按钮,会出现导入提示,根据情况操作。(一般情况下选择“确定” ”按钮第一次导入合并表) 22 图33:选择要导入平台的文件名列表 注意:重复数据表导入操作时,如果有同名的工作表,系统将给出提示,操作者决定是覆盖文件还是放弃操作,如果要导入的数据表文件版本与采集平台不同,系统拒绝导入操作,数据合并伙伴可以使用与采集platform 相同的版本进行版本转换n. 4.6 状态数据检查及汇总1)数据检查:完成数据表导入后,检查采集平台中的数据,确认已导入所有有效数据;您可以通过平台“数据目录”索引导航中的“状态”进行验证; 2)数据汇总:当校验数据正确时,执行“数据统计汇总”操作,生成汇总数据的第十部分。
“统计与汇总”按钮在“高级操作”页面,也可以直接点击表格第十部分的“状态数据汇总”按钮。图 34:表格 23 第十部分的“状态数据汇总”按钮 图 35:生成的状态数据汇总表3) 注意:如果数据汇总后平台中的数据再次发生变化,则需要执行“数据”再“统计汇总”操作,否则统计结果与实际情况不同。 5、版本升级 其他版本完成数据汇总的学校,可以使用采集平台数据合并伴侣提供的“版本升级”按钮,将已有汇总数据的文件一键中转为最新版本的平台文件具体操作流程如下: 下载《Status Data采集平台和数据合并伴侣》、《平台操作指南》、《版本转换说明》,复制解压后的《Status Data采集平台和数据合并伴侣》 ”目录到任意硬盘根目录(如F盘根目录),修改目录名称为“学校代码_申报年份”,修改状态数据采集platform文件名如图36,复制需要的文件转换到这个目录如图36所示;图 36:版本升级环境示例。打开合并伙伴“采集平台_数据组合合作V2.08c.xls”文件,点击“版本升级(一键转换)”按钮(图37),仔细查看版本升级说明(图38)按“是”开始版本升级,耐心等待,完成后查看数据采集platform转换为V2.08c版本操作完成说明(图39)24 图37:位置图38:版本升级注意事项 图39:Data采集平台过渡到V2.08c版本操作完成说明打开新版本采集platform文件查看升级完成后表格数据,并重新填写各表格中的“填表部门”、“填表人”、“填表时间”,以及各表中的调整和补充,必须再次进行数据汇总操作以重新生成汇总数据的第十部分,并检查汇总数据的准确性6、平台数据上报 数据文件上报的两种方式 25 光盘上报数据文件(目前使用) 网络上传数据文件(调试中) 7、State data采集 解疑1) 执行时单表数据合并操作,数据表中保留的数据行不足。如何添加数据行?操作步骤:在采集平台导航的“高级操作”中进行“数据表锁定”操作。
2)在data采集platform中,我校想加一栏,是否可以上报状态data采集platform文件,里面的数据指标是固定的,所以采集平台中的数据列不允许增加或减少,否则会影响数据的统计和汇总(第10部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。 3) 数据表导出操作时,系统发出宏警告,无法进行导出操作。我该怎么办?步骤:导出数据表。 4)在查找第10部分的汇总数据时,发现有些汇总值有问题。如何查看问题点?可以从以下几个方面发现问题: 确保采集平台上的数据准确完整,重新进行“数据统计汇总”操作; 26 数据汇总表中的汇总分类表下,描述了参与汇总,对于数据来源,按照提示查看汇总数据表中的数据。如果数据被修改,必须重新进行“数据统计汇总”操作;分析汇总数据,正确理解数据结构。 8、平台升级与技术支持网站联系电话(021)56940080(021)56075555-1210 27) 查看全部
采集内容管理平台(V2.08C序列号院校人才培养工作状态数据采集平台操作指南)
版本:V2.08C 编号:007 高职人才培养工作状态数据采集平台操作指南1.1 background1.2"状态数据采集平台V2. 08C》目录下文件及子目录说明1.3platform应用环境1.4启动Excel(VBA)运行环境宏1.5platform指令1.6platform使用注意事项2.1platform文件名2.2采集Platform 数据合并同伴介绍2.3创建文件目录和文件重命名的含义10 2.4 执行采集平台文件10 2.5 宏在平台中的作用11 2. 6 启用宏操作 11 3、采集平台管理功能 11 3.1 状态数据目录 11 3.2 数据表导出 12 3.3 数据表导入 12 3.4 数据表锁定 13 3.5 数据表解锁 14 3.6 数据格式刷新 14 3.7 数据统计与汇总 15 4、State data采集管理工艺15 4.1 采集平台数据表导出 16 4.2制定数据采集rules 和issue 文件 17 4.3 填写数据表 18 4.4 恢复合并数据表 19 4.5 将数据表导入采集平台21 4.6 状态数据验证和汇总 22 5、版本升级23 6、平台数据上报24 7、Status data采集释疑25 8、平台升级与技术支持26 1、采集平台简介1.1 背景介绍采集平台主要是以教育部《高职院校人才培养评价方案》(2008)5中公布的指标体系为基础制定,并采纳了课题组和试点单位的改进意见。
1.2 "Status data采集平台V2.08C" XXXXX_YYYY_status 目录下的文件和子目录的描述性名称描述 V2.08C 高职院校人才培养工作状态数据采集平台V2.08C 采集平台_data合并伙伴V2.08C为高职人才培养工作状态数据采集平台助程序恢复数据表收录以每个数据表命名的文件目录name(36A)是用来存放恢复数据采集的数据表文件。恢复后的数据表文件可以根据数据表内容存放在对应的文件目录中。分发数据表存放需要数据的空数据表采集。注意:不要随意修改目录名。可以使用“采集平台_数据Merged Partner V2.08C”恢复目录中相同的数据表。目录下的数据文件被合并。 1.3 平台应用环境状态数据 采集平台V2.08C 所需软件环境为:1) 操作系统:Windows XP、Windows 2000 系列2) 应用软件:Office Excel 2003,允许宏操作1.4 启动EXCEL(VBA)宏运行环境 为编程需要,本平台采用“VBA”高级编程语言,需要(VBA)宏运行环境。一般来说,Excel 自带“宏”检测功能。当发现Excel文件是用“宏”打开时,会提示用户注意,让用户选择是否启用“宏”。
电脑提示语言如下:“文件收录宏,宏可能携带病毒。取消宏虽然可以保证安全,但会影响平台的正常运行。必须启用宏才能在电脑上执行Excel文件. 激活方法如下: 打开Excel文件,选择菜单工具安全,打开安全对话框,将安全级别设置为“低”,如下图,选择一些相关的宏操作时,可能会出现被某些杀毒软件判断为危险软件,此时选择跳过或忽略即可正常使用,不会威胁到计算机的安全,比如我们在使用卡巴斯基杀毒软件时,导出表操作时出现下图,只要选择跳过就可以正常操作,进行以上设置后,重新打开Excel文件,启用宏,就可以正常操作了1. 5 解放军tform 说明1)版本号4)平台版本号、序列号、回目录链接、填写表格各表中说明和注意事项的位置1.6 平台使用注意事项 主目录平台必须放在硬盘的根目录下才能使用,否则可能影响采集平台_数据的导出文件功能集成伙伴V2.08C;数据表提供了标准化的数据输入方式,可根据实际情况选择。不能自行输入或粘贴,否则会影响部分数据汇总的准确性;注意检查输入数据的格式(如课时、金额等指标),特别容易在复制粘贴过程中转换为文本格式。必须设置为数字格式,否则会影响部分数据汇总的准确性;注意检查输入日期的格式(如出生日期、领证日期等)。以标准格式输入,如2007-9-1(其中横线为英文半角),否则会影响部分数据汇总的准确性;进行版本转换前仔细检查“版本差异”文件,有些指标必须重新填写,有些指标必须填写,否则会影响部分数据汇总的准确性; 10) 使用合并伙伴升级前,必须检查每个表的第一列是否为空,如果为空请根据实际情况填写,否则会导致部分数据失效进口; 11)使用合并伙伴中的“版本升级”功能进行版本升级后,必须打开新版本采集platform文件查看升级后的表数据,为完整起见,重新填写“部门填表”、“填表人”、“填表时间”,以及各表项的调整和补充。必须再次进行数据汇总操作,重新生成汇总数据的第十部分,并检查汇总数据的准确性。
12)完成数据输入后,进行“数据统计与汇总”操作,生成汇总数据(第10部分); 13) 表中不能随意添加或删除数据项,可以添加数据行。 2、采集平台文件管理与执行2.1平台文件名含义1)采集平台文件名各部分含义 图10:采集平台文件含义姓名2)例上海行健 高职院校代码:12493,上报年份:2008 上报文件名:12493_2008_STATUS V2.08C.xls 3) 注:上报状态数据时文件,文件需要按照图10所示的规则进行处理。重命名。 2.2 采集platform数据合并伙伴介绍1)“采集平台_data合并伙伴V208c.xls”是data采集平台的辅助工具。其主要功能是数据表文件恢复、数据合并、数据表版本转换。请注意,这些功能只能在允许宏操作的环境中使用。 2)Merge伙伴组合:1个伙伴文件,几个文件目录(如下图) 图11:Merge伙伴组合图 10 2.3 创建文件目录和文件重命名1)State数据文件管理2)示例:“上海兴建职业学院” Data采集文件管理学校代码:12493 申请年份:2008 操作步骤: 步骤一:更改光盘中的目录“status data采集平台V2.08C” ROM复制到电脑,例如我们把“status data采集平台V2.08C”目录复制到D盘根目录下,将目录重命名为“12493_2008”,同意这个目录是平台操作的主目录 第二步:打开“12493_2008”目录;第三步:将采集platform文件“XXXXX_YYYY_status data V2.08C.xls”重命名为:“12493_2008_status data V2.08C.xls”。
最终完成的目录结构如下: 图12:文件目录结构图2.4 在excel中第一次打开主平台文件时执行采集platform文件,或者你从来没有在你的excel 设置“宏安全”后打开主平台文件会出现如图13所示的警告画面。如果选择确定,您可以输入基础数据,但平台提供的智能操作功能将被拒绝。 11 图13:提示禁用宏2.5 宏在平台中的作用1)查看状态数据2)用于数据输入3)数据汇总操作4)允许智能表操作(如表导出) /import 、表解锁/锁定、格式刷新、数据汇总等)2.6 启用宏操作。必须启用宏才能在 Excel 中执行主平台文件。启用方法如下: 打开Excel文件,选择菜单工具安全,打开安全对话框,设置安全级别为“低”。具体操作图请参考《1.4 启动Excel(VBA)宏操作环境》中的介绍。注意:进行上述设置后,需要重新打开Excel文件并启用宏才能进行正常操作。 3、采集平台管理功能3.1 状态数据目录根据“状态数据目录”类别查询、录入或修改采集平台数据表中的数据。 12 图14:状态数据目录3.2 数据表导出 “数据表导出”操作可以将36个数据表以单表文件的形式导出到采集平台。
图15:数据表导出界面3.3 数据表导入“数据表导入”操作可以将36个已经完成数据输入的数据表文件导入到data采集平台。需要导入的数据表文件必须直接保存在“恢复数据表”目录下,文件名必须以采集平台朋友导出的文件名为准。 13 图16:数据表导入界面3.4 数据表锁定“数据表锁定”操作位于导航“高级操作”中,锁定状态下,只能处理数据表,不能处理表结构修改的 。注:1)锁数据表,目的是保证数据表结构的一致性; 2)在执行“数据表导出”操作前确保数据表被锁定,即数据表被锁定 非数据输入区被锁定后无法操作。图17:数据表锁定 14 3.5 数据表解锁 “数据表解锁”操作位于导航“高级操作”中,在解锁状态下可以完全控制表。注意:在解锁状态下,可以进行表格格式处理,调整行高或列宽,增加数据行,但不要调整表格的项结构,否则会影响汇总数据的准确性;图18:数据表解锁3.6 数据格式刷新“数据格式刷新”操作位于导航“高级操作”中,统一处理数据表中数据的字体和字号。图 19:数据格式刷新 15 3.7 数据统计与汇总 “数据统计与汇总”操作位于导航“高级操作”中。对平台中的数据进行汇总,生成汇总数据的第十部分。
注意:所有数据导入平台后,必须点击此按钮生成汇总数据的第十部分;每次更新平台中的表格时必须点击此按钮重新生成第十部分汇总数据,否则不会自动生成或更新第10部分汇总数据。图20:数据统计与汇总4、State Data采集管理程16 4.1 采集platform 数据表导出 在数据导出页面,将选中的工作表作为单表导出到采集platform 文件保存在采集platform文件所在的目录中;图 21:数据表导出页面 图 22:数据表导出后的文件目录结构 注意:重复数据表导出操作时,如果有同名数据表文件,系统会提问,由操作员决定是否覆盖文件或放弃操作。 17 图23:数据表重复导出后的系统提示4.2 制定数据采集 规则和文件分布 根据数据生成源制定数据采集Rules1)OK data采集Object:分析导出数据表(36张),指定数据采集object(部门/人); 2)数据表文件重命名:根据确定的数据采集对象重命名数据文件(如下图) 18 图24:将数据表文件复制到[下载数据表】目录3)示例导出表文件名为“A4-2校外实习实训基地表(XX采集)”文件更名为“A4-2校外实习实训基地表(教研科采集)”4.3 填写数据表1) 打开数据表文件,按照表中的项目输入数据。注:每个数据表的上半部分是版本标识,返回主目录链接,填写说明和注意事项,输入数据前请仔细阅读。
图25:需填写的单一表格2) 数据输入完成后,保存文件,并按规定重命名文件(部分表格) 例如:在线教研室填写在“A4-2校外实习实训基地表(教研室采集)”文件更名为:“A4-2校外实习实训基地表(网络教研室采集)” 19 4.4 数据表的回收和合并1)每个将被回收的单表的副本进入“回收数据表”目录中的相应目录。图26:将回收的单张复制到“Recycled Data Sheet”目录下对应的目录。示例:将“A7-1专业设置表”的单张文件复制到“A7-1专业设置表”目录下,图27:将各专业表2)的“A7-1专业设置表”目录复制回来到平台主目录,打开文件“采集平台_数据合并伙伴V2.08C.xls”,必须启用宏,选择要合并的子表,例如:根据上面的例子,我们选择“7.1 专业设置” 20 图28:数据合并伙伴目录界面3) 打开合并表页面,点击页面上的“合并数据”按钮。图29:数据合并界面 图30:程序自动合并“恢复数据目录”下“A7-1专业设置表”目录下的所有文件内容。在表中,按每个表的key字段排序,所以每个导入表的第一列不能为空。 21 注:合并后的内容可以在合并表中查看、修改、清除。
4)导出合并数据表。选择页面上的“导出文件”按钮。出现提示时,按“确定”按钮。导出成功。导出的文件会自动存储在“回收数据表”目录中。图 31:执行“导出文件”按钮后,组合表将自动导出到“回收数据表”目录。图 32:“回收数据表”目录中的组合表。 A7-1 Professional settings table.xls”文件4.5 将数据表导入采集平台回到主目录,打开平台主文件“12493_2008_status data V2.08C.xls”,进入“data在“导入”界面,勾选要导入的文件名,选择“数据表导入”按钮,会出现导入提示,根据情况操作。(一般情况下选择“确定” ”按钮第一次导入合并表) 22 图33:选择要导入平台的文件名列表 注意:重复数据表导入操作时,如果有同名的工作表,系统将给出提示,操作者决定是覆盖文件还是放弃操作,如果要导入的数据表文件版本与采集平台不同,系统拒绝导入操作,数据合并伙伴可以使用与采集platform 相同的版本进行版本转换n. 4.6 状态数据检查及汇总1)数据检查:完成数据表导入后,检查采集平台中的数据,确认已导入所有有效数据;您可以通过平台“数据目录”索引导航中的“状态”进行验证; 2)数据汇总:当校验数据正确时,执行“数据统计汇总”操作,生成汇总数据的第十部分。
“统计与汇总”按钮在“高级操作”页面,也可以直接点击表格第十部分的“状态数据汇总”按钮。图 34:表格 23 第十部分的“状态数据汇总”按钮 图 35:生成的状态数据汇总表3) 注意:如果数据汇总后平台中的数据再次发生变化,则需要执行“数据”再“统计汇总”操作,否则统计结果与实际情况不同。 5、版本升级 其他版本完成数据汇总的学校,可以使用采集平台数据合并伴侣提供的“版本升级”按钮,将已有汇总数据的文件一键中转为最新版本的平台文件具体操作流程如下: 下载《Status Data采集平台和数据合并伴侣》、《平台操作指南》、《版本转换说明》,复制解压后的《Status Data采集平台和数据合并伴侣》 ”目录到任意硬盘根目录(如F盘根目录),修改目录名称为“学校代码_申报年份”,修改状态数据采集platform文件名如图36,复制需要的文件转换到这个目录如图36所示;图 36:版本升级环境示例。打开合并伙伴“采集平台_数据组合合作V2.08c.xls”文件,点击“版本升级(一键转换)”按钮(图37),仔细查看版本升级说明(图38)按“是”开始版本升级,耐心等待,完成后查看数据采集platform转换为V2.08c版本操作完成说明(图39)24 图37:位置图38:版本升级注意事项 图39:Data采集平台过渡到V2.08c版本操作完成说明打开新版本采集platform文件查看升级完成后表格数据,并重新填写各表格中的“填表部门”、“填表人”、“填表时间”,以及各表中的调整和补充,必须再次进行数据汇总操作以重新生成汇总数据的第十部分,并检查汇总数据的准确性6、平台数据上报 数据文件上报的两种方式 25 光盘上报数据文件(目前使用) 网络上传数据文件(调试中) 7、State data采集 解疑1) 执行时单表数据合并操作,数据表中保留的数据行不足。如何添加数据行?操作步骤:在采集平台导航的“高级操作”中进行“数据表锁定”操作。
2)在data采集platform中,我校想加一栏,是否可以上报状态data采集platform文件,里面的数据指标是固定的,所以采集平台中的数据列不允许增加或减少,否则会影响数据的统计和汇总(第10部分)。个性化数据采集 和处理可以在未来的网络版本中实现。如果不报EXCEL文件,解锁后可以添加或删除数据列。 3) 数据表导出操作时,系统发出宏警告,无法进行导出操作。我该怎么办?步骤:导出数据表。 4)在查找第10部分的汇总数据时,发现有些汇总值有问题。如何查看问题点?可以从以下几个方面发现问题: 确保采集平台上的数据准确完整,重新进行“数据统计汇总”操作; 26 数据汇总表中的汇总分类表下,描述了参与汇总,对于数据来源,按照提示查看汇总数据表中的数据。如果数据被修改,必须重新进行“数据统计汇总”操作;分析汇总数据,正确理解数据结构。 8、平台升级与技术支持网站联系电话(021)56940080(021)56075555-1210 27)
采集内容管理平台(信息门户平台不仅仅局限于统一门户管理平台个性化信息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-06 16:03
产品概览
信息门户平台是指在现有网络环境下,将信息门户下的各种应用系统和数据资源统一整合,根据每个用户的特点和角色,形成个性化的应用界面。并通过事件和消息的处理和传递,将用户有机地联系在一起。门户平台不仅限于建立门户网站,提供一些服务信息,更重要的是实现了多业务系统的集成,可以快速响应客户的各种需求,可以进行统一管理整个供应链。
产品特点
1.统一门户管理平台
1.1接口管理
门户使用服务器页面模板、级联工作表和图像来定义页面的外观。用户可以修改这些元素来控制门户的视觉效果,也可以添加公司特定的品牌元素或实施不同的配色方案和视觉风格。定义配色方案和门户外壳的系统支持每个方案下的多个外壳、补充标记元素、导航样式和独立于浏览器的动态级联工作表。
外壳和配色方案不仅可以应用于整个门户,还可以应用于某个页面组。同样,不同的外壳可以应用于多个模块,因此可以对模块的外观进行微调以满足任何用户需求。通过为每个页面组采用一组不同的解决方案,单个门户安装看起来支持许多“虚拟”门户。
1.2查看管理和个性化设置
统一创建、修改和删除用户视图。通过应用目录管理保存和管理所有应用内容,然后通过视图管理模块对界面进行布局,实现个性化设置和快速定制。
个性化信息服务包括个性化数据存储、个性化信息展示、用户管理界面、信息统一用户管理界面、个性化数据管理。
1.2.1 个性化数据存储
不同部门、不同员工对信息的个性化要求不同。因此,个性化服务需要统一存储不同部门、不同员工的个性化定制数据。
1.2.2个性化信息展示
用户自定义个性化信息后,希望信息能够以自定义的方式展示。在公务员门户客户端中,集成个性化服务,在用户桌面上展示定制的方法。
1.2.3 用户管理接口
个性化信息与用户信息的关系非常密切,个性化服务需要通过用户管理的开放接口读取用户信息,将用户与个性化信息连接起来。
1.2.4及信息统一用户管理界面
个性化服务需要确定用户对信息的访问权限,然后将用户可以访问的信息显示在用户的桌面上。
1.2.5 个性化数据管理
用户需要改变个性化信息的定制,所以需要提供个性化数据管理的用户界面,让用户可以图形化的方式定制信息。个性化数据管理需要为终端用户和部门系统管理员提供服务。
2.统一信息发布(内容管理)平台
2.1 信息采集、编辑和发布
2.1.1信息采集
双洋内容管理平台提供了采集内容手动编辑输入采集和自动采集两种方式。
2.1.2信息编辑
提供基于浏览器的可视化编辑,也可以调用编辑软件进行编辑,并提供可视化标记插入。
2.1.3 信息回顾
为用户提供图形化的内容编辑、审核、发布流程定制化界面,用户可以轻松定制网站内容审核流程。
2.1.4信息发布
对于网站文件的发布,双阳内容管理平台提供了多种发布方式:手动发布、定时发布、触发发布、远程发布。
2.1.5信息预览
在网站内容提交过程的不同阶段提供编辑、审核和发布前的预览功能。
2.1.6信息检索
内置搜索引擎,数据库系统全文搜索功能。您可以设置搜索条件来搜索网站数据内容。
2.2信息栏管理
双阳内容管理平台管理网站频道(栏目),栏目以树状方式展示,相关栏目可以添加或删除。 网站可设置栏目,可设置栏目负责人,栏目模板等
3.模板管理
3.1网站template
网站模板定义了网站的风格和基本的网站框架,由几个动态布局和动态布局上的动态位组成。
3.2布局管理
布局是除具体信息展示页面以外的动态页面,主要是首页、二、三级页面等需要动态配置的页面。一个论坛只能属于一个网站template。
4.statistics
双阳内容管理平台提供基于投稿单位或投稿栏目等元素的统计。
5.全文搜索
您可以全文搜索整个网站内容。
特点
1.一站式服务
采用浏览器/服务器(B/S)模式,提供统一个性化的用户界面,用户只需拥有浏览器即可获得一站式业务服务,实现单点登录,用户只需登录在标准一、标准门户网站可以完成请求的具体业务内容,具体业务处理由一站式服务框架后台处理,对用户透明。
2.内容管理
提供完善的内容管理功能,可以采集,编辑、管理和发布内部分散的多种数据类型和格式的内容,供用户分享。在采集数据的编辑、校对、审核、发布的整个工作过程中,系统严格控制安全,建立了完善的审计机制和防篡改机制。
3.智能搜索
智能检索为用户提供了一种便捷的方式来查询自己权限内的相关信息。通过输入关键词等方式,可以快速找到分散在互联网和政府内部的格式化和非格式化数据,达到资源共享的目的。 .
4.视图管理
统一创建、修改和删除用户视图。通过应用目录管理保存和管理所有应用内容,然后通过视图管理模块对界面进行布局,实现个性化设置和快速定制。
5.应用系统集成
使用Webpart实现各种应用系统的接口集成。 Webpart 是一个可插拔组件,通过Webpart 将现有的应用系统内容集成到门户中。为每个系统设置一个Webpart,并通过Webpart服务器进行管理。
6.个性化服务
为不同部门、组织、层级的员工提供符合其需求和特点的办公页面,通过个性化门户展示他们最关心、最常用的信息资源。用户可以自定义权限范围内的内容视图。
7.portal 管理
为了方便技术人员的维护和管理,门户支撑平台应提供多种管理工具,包括:视图管理、部署管理、模板管理、主页管理等。 查看全部
采集内容管理平台(信息门户平台不仅仅局限于统一门户管理平台个性化信息)
产品概览
信息门户平台是指在现有网络环境下,将信息门户下的各种应用系统和数据资源统一整合,根据每个用户的特点和角色,形成个性化的应用界面。并通过事件和消息的处理和传递,将用户有机地联系在一起。门户平台不仅限于建立门户网站,提供一些服务信息,更重要的是实现了多业务系统的集成,可以快速响应客户的各种需求,可以进行统一管理整个供应链。
产品特点
1.统一门户管理平台
1.1接口管理
门户使用服务器页面模板、级联工作表和图像来定义页面的外观。用户可以修改这些元素来控制门户的视觉效果,也可以添加公司特定的品牌元素或实施不同的配色方案和视觉风格。定义配色方案和门户外壳的系统支持每个方案下的多个外壳、补充标记元素、导航样式和独立于浏览器的动态级联工作表。
外壳和配色方案不仅可以应用于整个门户,还可以应用于某个页面组。同样,不同的外壳可以应用于多个模块,因此可以对模块的外观进行微调以满足任何用户需求。通过为每个页面组采用一组不同的解决方案,单个门户安装看起来支持许多“虚拟”门户。
1.2查看管理和个性化设置
统一创建、修改和删除用户视图。通过应用目录管理保存和管理所有应用内容,然后通过视图管理模块对界面进行布局,实现个性化设置和快速定制。
个性化信息服务包括个性化数据存储、个性化信息展示、用户管理界面、信息统一用户管理界面、个性化数据管理。
1.2.1 个性化数据存储
不同部门、不同员工对信息的个性化要求不同。因此,个性化服务需要统一存储不同部门、不同员工的个性化定制数据。
1.2.2个性化信息展示
用户自定义个性化信息后,希望信息能够以自定义的方式展示。在公务员门户客户端中,集成个性化服务,在用户桌面上展示定制的方法。
1.2.3 用户管理接口
个性化信息与用户信息的关系非常密切,个性化服务需要通过用户管理的开放接口读取用户信息,将用户与个性化信息连接起来。
1.2.4及信息统一用户管理界面
个性化服务需要确定用户对信息的访问权限,然后将用户可以访问的信息显示在用户的桌面上。
1.2.5 个性化数据管理
用户需要改变个性化信息的定制,所以需要提供个性化数据管理的用户界面,让用户可以图形化的方式定制信息。个性化数据管理需要为终端用户和部门系统管理员提供服务。
2.统一信息发布(内容管理)平台
2.1 信息采集、编辑和发布
2.1.1信息采集
双洋内容管理平台提供了采集内容手动编辑输入采集和自动采集两种方式。
2.1.2信息编辑
提供基于浏览器的可视化编辑,也可以调用编辑软件进行编辑,并提供可视化标记插入。
2.1.3 信息回顾
为用户提供图形化的内容编辑、审核、发布流程定制化界面,用户可以轻松定制网站内容审核流程。
2.1.4信息发布
对于网站文件的发布,双阳内容管理平台提供了多种发布方式:手动发布、定时发布、触发发布、远程发布。
2.1.5信息预览
在网站内容提交过程的不同阶段提供编辑、审核和发布前的预览功能。
2.1.6信息检索
内置搜索引擎,数据库系统全文搜索功能。您可以设置搜索条件来搜索网站数据内容。
2.2信息栏管理
双阳内容管理平台管理网站频道(栏目),栏目以树状方式展示,相关栏目可以添加或删除。 网站可设置栏目,可设置栏目负责人,栏目模板等
3.模板管理
3.1网站template
网站模板定义了网站的风格和基本的网站框架,由几个动态布局和动态布局上的动态位组成。
3.2布局管理
布局是除具体信息展示页面以外的动态页面,主要是首页、二、三级页面等需要动态配置的页面。一个论坛只能属于一个网站template。
4.statistics
双阳内容管理平台提供基于投稿单位或投稿栏目等元素的统计。
5.全文搜索
您可以全文搜索整个网站内容。
特点
1.一站式服务
采用浏览器/服务器(B/S)模式,提供统一个性化的用户界面,用户只需拥有浏览器即可获得一站式业务服务,实现单点登录,用户只需登录在标准一、标准门户网站可以完成请求的具体业务内容,具体业务处理由一站式服务框架后台处理,对用户透明。
2.内容管理
提供完善的内容管理功能,可以采集,编辑、管理和发布内部分散的多种数据类型和格式的内容,供用户分享。在采集数据的编辑、校对、审核、发布的整个工作过程中,系统严格控制安全,建立了完善的审计机制和防篡改机制。
3.智能搜索
智能检索为用户提供了一种便捷的方式来查询自己权限内的相关信息。通过输入关键词等方式,可以快速找到分散在互联网和政府内部的格式化和非格式化数据,达到资源共享的目的。 .
4.视图管理
统一创建、修改和删除用户视图。通过应用目录管理保存和管理所有应用内容,然后通过视图管理模块对界面进行布局,实现个性化设置和快速定制。
5.应用系统集成
使用Webpart实现各种应用系统的接口集成。 Webpart 是一个可插拔组件,通过Webpart 将现有的应用系统内容集成到门户中。为每个系统设置一个Webpart,并通过Webpart服务器进行管理。
6.个性化服务
为不同部门、组织、层级的员工提供符合其需求和特点的办公页面,通过个性化门户展示他们最关心、最常用的信息资源。用户可以自定义权限范围内的内容视图。
7.portal 管理
为了方便技术人员的维护和管理,门户支撑平台应提供多种管理工具,包括:视图管理、部署管理、模板管理、主页管理等。
采集内容管理平台(使用方法1.软件设置项第一次使用软件(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-06 12:34
)
短视频内容分析采集管理软件是一款视频内容分析软件,可以采集视频对采集的视频数据信息进行数字化管理,对采集到达的视频内容进行分析和内容管理。
相关软件软件大小及版本说明下载链接
短视频内容分析采集管理软件是一款视频内容分析软件,可以采集视频对采集的视频数据信息进行数字化管理,对采集到达的视频内容进行分析和内容管理。
功能介绍
1.所有视频数据信息的数据库管理,方便查找和对比分析
2. 支持获取主播下所有视频,通过单个视频地址获取视频数据
3.最大亮点:您可以随时追踪各主播发布的最新视频,发现主播最新动态
4.记录每个视频的“上传时间”
5.视频内容支持翻页查看,除了可以记录视频时长、点赞数、评论数、分享数等。
6.企业版用户可以共享多台电脑的数据,实现团队数据协同工作。
如何使用
1.软件设置项
1.1.第一次使用软件,必须点击“设置”图标设置视频下载和保存目录的目录路径
1.2.可以设置下载目录,也可以设置视频封面的缩略图大小;
1.3.如果使用企业版,需要设置数据库访问地址、账号和密码,个人版不需要设置;
2. 主播管理
2.1.设置类别,为每个广播者定义类别
2.2.添加主机
<p>一个。添加抖音播主信息,在app内播放主主页,点击右上角“...”,然后点击“分享”,最后点击“复制链接”获取主主页URL地址 查看全部
采集内容管理平台(使用方法1.软件设置项第一次使用软件(组图)
)
短视频内容分析采集管理软件是一款视频内容分析软件,可以采集视频对采集的视频数据信息进行数字化管理,对采集到达的视频内容进行分析和内容管理。
相关软件软件大小及版本说明下载链接
短视频内容分析采集管理软件是一款视频内容分析软件,可以采集视频对采集的视频数据信息进行数字化管理,对采集到达的视频内容进行分析和内容管理。
功能介绍
1.所有视频数据信息的数据库管理,方便查找和对比分析
2. 支持获取主播下所有视频,通过单个视频地址获取视频数据
3.最大亮点:您可以随时追踪各主播发布的最新视频,发现主播最新动态
4.记录每个视频的“上传时间”
5.视频内容支持翻页查看,除了可以记录视频时长、点赞数、评论数、分享数等。
6.企业版用户可以共享多台电脑的数据,实现团队数据协同工作。
如何使用
1.软件设置项
1.1.第一次使用软件,必须点击“设置”图标设置视频下载和保存目录的目录路径
1.2.可以设置下载目录,也可以设置视频封面的缩略图大小;
1.3.如果使用企业版,需要设置数据库访问地址、账号和密码,个人版不需要设置;
2. 主播管理
2.1.设置类别,为每个广播者定义类别
2.2.添加主机
<p>一个。添加抖音播主信息,在app内播放主主页,点击右上角“...”,然后点击“分享”,最后点击“复制链接”获取主主页URL地址
采集内容管理平台(01.什么是融媒体?可以简单媒体理解(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 392 次浏览 • 2021-09-05 05:03
01.融媒体是什么?
融合媒体可以简单理解为传统媒体与新媒体的结合。融合媒体就是充分利用媒体载体。它结合了广播、电视、报纸和不同媒体的共同点,在人力和内容上互补互补。在宣传等方面全面融合,实现“资源容纳、内容融合、宣传融合、利益融合”的新型媒体。
02.融媒体主要应用于哪些场景?
目前有很多政府官员网站和地方电视台从事媒体整合。一般来说,他们将以前只在电视和广播上的内容同步到主要的自媒体平台。多地电视台也改为“融合媒体中心”
03.融媒体建设的难点
✔内容不够“新”:互联网信息的传播非常快捷方便,人们获取信息的渠道越来越多。如果不能及时获得最新信息,很容易失去用户的注意力和平台的影响力,虽然很多平台在建立一体化的过程中都会进行“两微一端一账号”的建设。媒体方面,在实际运营中,由于信息获取能力有限,很多平台无法及时更新和推送新闻信息,容易出现运营不足的情况。持续经营困难等问题,影响极其有限;
✔内容不“全”:在信息爆炸的时代,每分钟产生数以万计的新数据,而随着各种新媒体平台的发展,新闻数据不仅限于文字,还有图片、视频等多种展示形式,以及海量多样的新闻数据,也给整合媒体的建设带来了很大的难度;
✔技术限制:综合媒体的建设离不开技术要素。建立具有公信力和影响力的综合媒体平台,需要基于大数据、云计算、人工智能、多平台、多渠道分发的技术。在系统之上。
04.优采云在财经媒体建设中的应用
大数据给各行各业以及传统媒体领域带来了翻天覆地的变化,尤其是推动了综合媒体的发展和建设。 优采云拥有强大的数据采集功能,可以及时采集从网上下载最新的新闻资讯,秒级同步到融媒体内部平台。
对于集成媒体的建设,优采云的应用主要体现在数据采集、数据清洗、数据传输等方面
1、数据采集:
外部数据采集:采集来自各个公共平台的新闻信息,可以帮助融媒体平台及时获取最新的新闻资讯。包括2000+新闻网站和自媒体平台数据,涵盖但不限于人民网、新华网等中央媒体和党媒,地方政府机构网站、今日头条、网易等新闻聚合平台,如以及来自微博、小红书、抖音、bilibili、知乎等社交平台的微信和微信数据,可以通过数据服务和API接口导入外部数据;
内部数据采集:将分布在各个平台的媒体账号数据纳入统一管理系统,主要来自微信公众号、微博、抖音短视频、新闻客户端等监控数据,包括阅读量、点赞量、互动量、分享量、打开率、阅读完成率等多维度数据,以及粉丝留言、评论等,方便分类管理和实时维护,实时掌握传播效果和粉丝反馈,并帮助员工及时查看数据信息,提高新闻质量。可以通过私有化部署实现内部数据的采集和存储;
2、数据清洗:data采集完成后,由于数据量大、数据结构复杂、源格式等问题,优采云需要按照要求的标准对数据进行处理。数据预处理过程主要包括数据提取和数据清洗。在数据使用过程中,并不是所有的数据都是有价值的,有些数据存在明显的错误。因此,需要对数据进行仔细过滤,去除无效数据,以达到预期的效果。
3、数据传输:优采云提供的API数据接口,可以实现采集的数据即时传输到FusionMedia内部系统,帮助平台在媒体内容制作和制作过程中获取数据及时传播,减轻工作人员负担。
05.优采云客户案例
✔客户背景:市级博物馆综合媒体平台
✔客户需求:
1) 对全网公开信息进行准确有效的实时监控,并提供相关信息的统计分析服务。来源必须涵盖news网站、论坛和贴吧、微博、微信公众号、手机新闻客户端 端到端、纯媒体电子版和当地政府公告和政策。需要支持随时扩展源监控范围。需要能够追溯不少于三个月的全网信息和数据,并进行统计分析,形成可视化的报表和图表。
2)信息及时
可实现24小时、分钟级信息同步,解决新闻时效性问题。
3)信息异构
支持文字、图片、视频、评论等多种形式的内容抓取。
4)账户监控服务
为微博账号、微信公众号、本地社区、抖音、小红等账号开发监控服务。实时查看帐户消息并全方位监控帐户动态。
5)事件分析研判服务
提供开发过程中重大事件演变分析、相关热点话题分析、网友意见分析。
✔优采云解决方案
①确认客户采集需要覆盖的内容来源和数量,包括国内近200家主流新闻门户网站、APP应用、媒体微信公众号和微博账号,并确认采集字段信息为必填项和内容详情;
②根据数据源的更新频率和多少设置定时采集功能,合理配置云端采集节点资源。
③ 利用爬虫将数据采集采集到云平台,根据内容实时分类,为融合媒体平台提供强大的网站media数据。
④开发数据推送功能。编辑可以直接将网站media数据推送到FusionMedia平台形成新闻线索,或者一键分发到新媒体资源平台,实现互联网内容的快速转发,减少编辑人员的工作量。
告别“Ctrl C+V”
内容聚合进入智能爬虫时代
以前手动一点点复制粘贴的枯燥工作,现在和以后都可以交给优采云!
优采云智能爬虫的作用是什么?
1、7x24h 覆盖全网,信息新鲜,内容丰富,有保障
优采云就像一个爬虫机器人,可以爬取全网公开展示的数据,全年24小时为你工作。
优采云用户单日抓取数据量可达10亿,覆盖网易、搜狐、新浪等各大媒体信息网站;涵盖各大政府网站,如环保局、医管局、地方政府政策动态网站等;涵盖新浪微博、新帮数据、豆瓣等各类自媒体网站
只要在网页上公开展示的数据,优采云就可以采集下并聚合到企业内容平台上。
相较于人工一一筛选和Ctrl C+V,优采云简直就是解放企业低效劳动力的福音!
2、保证数据更新频率,灵活满足企业需求
除了保证内容的丰富性,稳定、快速、实时的更新对企业来说也很重要。
我们每天都处于内容爆炸中。过去,仅靠人工创建内容无法实时更新内容来源。
有了优采云crawler 工具,这不再是问题。
优采云支持定时、定频采集和云端采集功能,可以灵活设置采集的时间和频率。比如采集每天早上10点一次,或者采集每2小时一次。
3、API接口对接,从采集到一键传输
解决了采集的问题。如果我们也能自动化传输,我们的工作就可以由机器自动处理了。
那么优采云攀虫采集就会接管你从内容采集到交付的所有工作!
优采云提供的API数据接口,使数据采集能够即时传输到企业内容平台。只需前期与企业技术人员对接,然后就可以高枕无忧,等待内容自动填写。
从采集到一站式传输,优采云data提供全方位不间断服务。
插入另一个小广告
除了私有化部署,优采云还有新闻数据中心,汇聚海量国内外新闻网站和自媒体平台数据。产品采集覆盖全球55个国家和地区,31种语言,新增近4000万条数据,包括新闻采集、数据清洗、新闻分类等多项功能。 查看全部
采集内容管理平台(01.什么是融媒体?可以简单媒体理解(组图))
01.融媒体是什么?
融合媒体可以简单理解为传统媒体与新媒体的结合。融合媒体就是充分利用媒体载体。它结合了广播、电视、报纸和不同媒体的共同点,在人力和内容上互补互补。在宣传等方面全面融合,实现“资源容纳、内容融合、宣传融合、利益融合”的新型媒体。
02.融媒体主要应用于哪些场景?
目前有很多政府官员网站和地方电视台从事媒体整合。一般来说,他们将以前只在电视和广播上的内容同步到主要的自媒体平台。多地电视台也改为“融合媒体中心”
03.融媒体建设的难点
✔内容不够“新”:互联网信息的传播非常快捷方便,人们获取信息的渠道越来越多。如果不能及时获得最新信息,很容易失去用户的注意力和平台的影响力,虽然很多平台在建立一体化的过程中都会进行“两微一端一账号”的建设。媒体方面,在实际运营中,由于信息获取能力有限,很多平台无法及时更新和推送新闻信息,容易出现运营不足的情况。持续经营困难等问题,影响极其有限;
✔内容不“全”:在信息爆炸的时代,每分钟产生数以万计的新数据,而随着各种新媒体平台的发展,新闻数据不仅限于文字,还有图片、视频等多种展示形式,以及海量多样的新闻数据,也给整合媒体的建设带来了很大的难度;
✔技术限制:综合媒体的建设离不开技术要素。建立具有公信力和影响力的综合媒体平台,需要基于大数据、云计算、人工智能、多平台、多渠道分发的技术。在系统之上。
04.优采云在财经媒体建设中的应用
大数据给各行各业以及传统媒体领域带来了翻天覆地的变化,尤其是推动了综合媒体的发展和建设。 优采云拥有强大的数据采集功能,可以及时采集从网上下载最新的新闻资讯,秒级同步到融媒体内部平台。
对于集成媒体的建设,优采云的应用主要体现在数据采集、数据清洗、数据传输等方面
1、数据采集:
外部数据采集:采集来自各个公共平台的新闻信息,可以帮助融媒体平台及时获取最新的新闻资讯。包括2000+新闻网站和自媒体平台数据,涵盖但不限于人民网、新华网等中央媒体和党媒,地方政府机构网站、今日头条、网易等新闻聚合平台,如以及来自微博、小红书、抖音、bilibili、知乎等社交平台的微信和微信数据,可以通过数据服务和API接口导入外部数据;
内部数据采集:将分布在各个平台的媒体账号数据纳入统一管理系统,主要来自微信公众号、微博、抖音短视频、新闻客户端等监控数据,包括阅读量、点赞量、互动量、分享量、打开率、阅读完成率等多维度数据,以及粉丝留言、评论等,方便分类管理和实时维护,实时掌握传播效果和粉丝反馈,并帮助员工及时查看数据信息,提高新闻质量。可以通过私有化部署实现内部数据的采集和存储;
2、数据清洗:data采集完成后,由于数据量大、数据结构复杂、源格式等问题,优采云需要按照要求的标准对数据进行处理。数据预处理过程主要包括数据提取和数据清洗。在数据使用过程中,并不是所有的数据都是有价值的,有些数据存在明显的错误。因此,需要对数据进行仔细过滤,去除无效数据,以达到预期的效果。
3、数据传输:优采云提供的API数据接口,可以实现采集的数据即时传输到FusionMedia内部系统,帮助平台在媒体内容制作和制作过程中获取数据及时传播,减轻工作人员负担。
05.优采云客户案例
✔客户背景:市级博物馆综合媒体平台
✔客户需求:
1) 对全网公开信息进行准确有效的实时监控,并提供相关信息的统计分析服务。来源必须涵盖news网站、论坛和贴吧、微博、微信公众号、手机新闻客户端 端到端、纯媒体电子版和当地政府公告和政策。需要支持随时扩展源监控范围。需要能够追溯不少于三个月的全网信息和数据,并进行统计分析,形成可视化的报表和图表。
2)信息及时
可实现24小时、分钟级信息同步,解决新闻时效性问题。
3)信息异构
支持文字、图片、视频、评论等多种形式的内容抓取。
4)账户监控服务
为微博账号、微信公众号、本地社区、抖音、小红等账号开发监控服务。实时查看帐户消息并全方位监控帐户动态。
5)事件分析研判服务
提供开发过程中重大事件演变分析、相关热点话题分析、网友意见分析。
✔优采云解决方案
①确认客户采集需要覆盖的内容来源和数量,包括国内近200家主流新闻门户网站、APP应用、媒体微信公众号和微博账号,并确认采集字段信息为必填项和内容详情;
②根据数据源的更新频率和多少设置定时采集功能,合理配置云端采集节点资源。
③ 利用爬虫将数据采集采集到云平台,根据内容实时分类,为融合媒体平台提供强大的网站media数据。
④开发数据推送功能。编辑可以直接将网站media数据推送到FusionMedia平台形成新闻线索,或者一键分发到新媒体资源平台,实现互联网内容的快速转发,减少编辑人员的工作量。
告别“Ctrl C+V”
内容聚合进入智能爬虫时代
以前手动一点点复制粘贴的枯燥工作,现在和以后都可以交给优采云!
优采云智能爬虫的作用是什么?
1、7x24h 覆盖全网,信息新鲜,内容丰富,有保障
优采云就像一个爬虫机器人,可以爬取全网公开展示的数据,全年24小时为你工作。
优采云用户单日抓取数据量可达10亿,覆盖网易、搜狐、新浪等各大媒体信息网站;涵盖各大政府网站,如环保局、医管局、地方政府政策动态网站等;涵盖新浪微博、新帮数据、豆瓣等各类自媒体网站
只要在网页上公开展示的数据,优采云就可以采集下并聚合到企业内容平台上。
相较于人工一一筛选和Ctrl C+V,优采云简直就是解放企业低效劳动力的福音!
2、保证数据更新频率,灵活满足企业需求
除了保证内容的丰富性,稳定、快速、实时的更新对企业来说也很重要。
我们每天都处于内容爆炸中。过去,仅靠人工创建内容无法实时更新内容来源。
有了优采云crawler 工具,这不再是问题。
优采云支持定时、定频采集和云端采集功能,可以灵活设置采集的时间和频率。比如采集每天早上10点一次,或者采集每2小时一次。
3、API接口对接,从采集到一键传输
解决了采集的问题。如果我们也能自动化传输,我们的工作就可以由机器自动处理了。
那么优采云攀虫采集就会接管你从内容采集到交付的所有工作!
优采云提供的API数据接口,使数据采集能够即时传输到企业内容平台。只需前期与企业技术人员对接,然后就可以高枕无忧,等待内容自动填写。
从采集到一站式传输,优采云data提供全方位不间断服务。
插入另一个小广告
除了私有化部署,优采云还有新闻数据中心,汇聚海量国内外新闻网站和自媒体平台数据。产品采集覆盖全球55个国家和地区,31种语言,新增近4000万条数据,包括新闻采集、数据清洗、新闻分类等多项功能。
采集内容管理平台(中控一体机的带宽有多大?货主b的app依赖)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-09-04 00:03
采集内容管理平台和erp等其他模块,是否考虑换个比较先进的方式,那么中控一体机的带宽有多大呢?或者内容采集的数据是否考虑直接数据库存储呢?如果内容采集需要数据库字段的数据来进行内容的编辑,那么数据库字段的设计,哪里可以设计的又快又好呢?比如考虑数据库字段是否需要根据采集的物料进行重复的字段设置,或者根据条件是否有交叉关联的字段设置。都是要面临的重复数据的处理。
数据库提供的就是基本服务,物流车辆跟踪跟踪采集是平台专门处理的业务,我目前只知道采集平台的数据与车辆库存里车辆的数据集成,其他没有所以,
开发工具就是一个壳子,关键看如何实现的数据库结构以及关联关系。
可行,物流比较紧张,为节省企业用地、在建厂房等,减少物流运营成本,多数企业都会选择做一个内部it系统。基于内部数据,外部系统收集、上传,构建车货管理系统、仓储系统、服务系统、配送系统、运营管理系统等整体大系统。但是,目前新系统建设中的软件开发,多数是把系统开发做成周期比较短、门槛比较低的业务中间件,同时再做集成。
这样的整体软件开发大概在15-50万之间,甚至更低。整体中间件开发完后,接上相应系统,可以销售给运营企业,也可以通过开放应用系统接口直接安装在中使用。如:货主a开发了系统a、b;货主b设计了服务端;运营企业使用一套中间件系统a、b、c,按照需求部署场景分别对接中间件系统a、b、c,打通货主b的app与中间件a、b、c。
货主a的app与货主b的app依赖同一套中间件系统a、b、c。通过后台基于系统a、b、c的优势,专门为货主a做专属定制定制服务。相应的,物流管理、仓储管理、服务管理、配送管理等工作,都在系统a、b、c上面。随着app开发进入尾声,oem用户可以选择升级中间件,使货主a升级到oem定制化的中间件b或者更高级中间件。整体中间件系统开发大概30-50万之间,运营企业用户采购也不贵。 查看全部
采集内容管理平台(中控一体机的带宽有多大?货主b的app依赖)
采集内容管理平台和erp等其他模块,是否考虑换个比较先进的方式,那么中控一体机的带宽有多大呢?或者内容采集的数据是否考虑直接数据库存储呢?如果内容采集需要数据库字段的数据来进行内容的编辑,那么数据库字段的设计,哪里可以设计的又快又好呢?比如考虑数据库字段是否需要根据采集的物料进行重复的字段设置,或者根据条件是否有交叉关联的字段设置。都是要面临的重复数据的处理。
数据库提供的就是基本服务,物流车辆跟踪跟踪采集是平台专门处理的业务,我目前只知道采集平台的数据与车辆库存里车辆的数据集成,其他没有所以,
开发工具就是一个壳子,关键看如何实现的数据库结构以及关联关系。
可行,物流比较紧张,为节省企业用地、在建厂房等,减少物流运营成本,多数企业都会选择做一个内部it系统。基于内部数据,外部系统收集、上传,构建车货管理系统、仓储系统、服务系统、配送系统、运营管理系统等整体大系统。但是,目前新系统建设中的软件开发,多数是把系统开发做成周期比较短、门槛比较低的业务中间件,同时再做集成。
这样的整体软件开发大概在15-50万之间,甚至更低。整体中间件开发完后,接上相应系统,可以销售给运营企业,也可以通过开放应用系统接口直接安装在中使用。如:货主a开发了系统a、b;货主b设计了服务端;运营企业使用一套中间件系统a、b、c,按照需求部署场景分别对接中间件系统a、b、c,打通货主b的app与中间件a、b、c。
货主a的app与货主b的app依赖同一套中间件系统a、b、c。通过后台基于系统a、b、c的优势,专门为货主a做专属定制定制服务。相应的,物流管理、仓储管理、服务管理、配送管理等工作,都在系统a、b、c上面。随着app开发进入尾声,oem用户可以选择升级中间件,使货主a升级到oem定制化的中间件b或者更高级中间件。整体中间件系统开发大概30-50万之间,运营企业用户采购也不贵。
采集内容管理平台(足球平台如何识别可靠、可信的信源?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-01 20:01
尽管有大量社交工具可用,但塞恩解释说,该平台还可以通过识别可靠和可信的来源来突出可能不太准确和真实的推文。例如,如果有消息称足球运动员内马尔将以2.220亿欧元(约合2.610亿美元)的高价加盟巴黎圣日耳曼,GiveMeSport的AI平台会即时追踪最先出现的消息在 Twitter 上的时间,并将该帐户标记为受信任的权限。
随着AI平台对语言的理解逐渐加深,它也可以识别特定领域的规范偏差。塞恩说,该平台可以捕获足球场一英里内的所有推文。如果你跟随一位定期发推文的物理治疗师(它很可能为运动员提供医疗服务),在一天繁重的工作之后,治疗师可能会连续发出几条抱怨工作量的推文。推文频率和内容主题的变化将被机器捕获并标记,这将作为警报发送给新闻机构 Slack 频道的记者。记者可联系相关俱乐部,调查是否有运动员受伤等情况。
管理 Facebook 平台上的内容分发
Facebook 是 GiveMeSport 最大的推送平台。新闻发布者的记者也会在Facebook上发帖并获得文章的标题。雷锋网了解到,GiveMeSport还将AI技术嵌入到内容管理系统中,根据文章帖子对点击率和参与度的贡献对每位作者进行评分。
此外,该技术还分析了文章的词组、句子结构和形象,以引起观众的共鸣。
“(实际上)就是识别标题中的大写字母那么简单,它可以识别Facebook用户可能会感到无聊的内容。或者,它也可以确定曼联球迷不喜欢被称为“ MU”或“红魔”。”塞恩说,“这项技术支持作者用他熟练的技术写作。”
“内容分发应该是科学的,我们不想错过这个机会。人工智能让我们比其他竞争对手更具优势。”塞恩补充道。
赋予内容情感
据了解,现阶段GiveMeSport的作者在处理每个故事的“情感”标签时,仍然依靠人工操作。这些情绪会有一个预定的数据库,比如快乐、悲伤等30多种情绪。作者根据他们满足的情感奖励来组织内容并标记每个故事。之后,借助人工智能技术,平台可以对历史数据集进行类似的分析。这个过程背后的理论是,通过理解更深层次的情绪,可以预测内容的表现并链接用户。
“运动必须与情感有关,”塞恩说。 “这归结为你对某事的感受,或者归结为你想如何告诉其他人你刚刚阅读的文章感觉。让用户想阅读的内容无非是不能错过的东西,或与您的相关经验有关。” 查看全部
采集内容管理平台(足球平台如何识别可靠、可信的信源?(图))
尽管有大量社交工具可用,但塞恩解释说,该平台还可以通过识别可靠和可信的来源来突出可能不太准确和真实的推文。例如,如果有消息称足球运动员内马尔将以2.220亿欧元(约合2.610亿美元)的高价加盟巴黎圣日耳曼,GiveMeSport的AI平台会即时追踪最先出现的消息在 Twitter 上的时间,并将该帐户标记为受信任的权限。
随着AI平台对语言的理解逐渐加深,它也可以识别特定领域的规范偏差。塞恩说,该平台可以捕获足球场一英里内的所有推文。如果你跟随一位定期发推文的物理治疗师(它很可能为运动员提供医疗服务),在一天繁重的工作之后,治疗师可能会连续发出几条抱怨工作量的推文。推文频率和内容主题的变化将被机器捕获并标记,这将作为警报发送给新闻机构 Slack 频道的记者。记者可联系相关俱乐部,调查是否有运动员受伤等情况。
管理 Facebook 平台上的内容分发
Facebook 是 GiveMeSport 最大的推送平台。新闻发布者的记者也会在Facebook上发帖并获得文章的标题。雷锋网了解到,GiveMeSport还将AI技术嵌入到内容管理系统中,根据文章帖子对点击率和参与度的贡献对每位作者进行评分。
此外,该技术还分析了文章的词组、句子结构和形象,以引起观众的共鸣。
“(实际上)就是识别标题中的大写字母那么简单,它可以识别Facebook用户可能会感到无聊的内容。或者,它也可以确定曼联球迷不喜欢被称为“ MU”或“红魔”。”塞恩说,“这项技术支持作者用他熟练的技术写作。”
“内容分发应该是科学的,我们不想错过这个机会。人工智能让我们比其他竞争对手更具优势。”塞恩补充道。
赋予内容情感
据了解,现阶段GiveMeSport的作者在处理每个故事的“情感”标签时,仍然依靠人工操作。这些情绪会有一个预定的数据库,比如快乐、悲伤等30多种情绪。作者根据他们满足的情感奖励来组织内容并标记每个故事。之后,借助人工智能技术,平台可以对历史数据集进行类似的分析。这个过程背后的理论是,通过理解更深层次的情绪,可以预测内容的表现并链接用户。
“运动必须与情感有关,”塞恩说。 “这归结为你对某事的感受,或者归结为你想如何告诉其他人你刚刚阅读的文章感觉。让用户想阅读的内容无非是不能错过的东西,或与您的相关经验有关。”
采集内容管理平台( 如何获取“文章标题”高清壁纸(非原创作品))
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-08-31 04:12
如何获取“文章标题”高清壁纸(非原创作品))
如何使用Dedecms采集功能---图片采集(二)
前言:本文为《如何使用Dedecms采集功能---图片采集》的第二部分。在上一节的基础上,我们将在第二节中添加一个新的采集 节点。第二步:在“设置字段获取规则”部分做一个简单的介绍。为与上一篇保持一致,本文将继续沿用之前的章节标记。
从第一部分继续。
2.1 添加采集节点:第二步设置内容字段获取规则
点击“保存信息,进入下一步设置”后,可以进入“添加采集节点:第二步设置内容字段获取规则”页面,如图(图21),<//p
pimg src='http://help.dedecms.com/uploads/allimg/110618/-1-11061P62933132.png' alt=''//p
p图21-设置内容字段获取规则/p
p在预览网址,系统会自动指定一个文章作为演示页面,如有特殊需求可自行更改。打开demo页面,观察后可以发现页面收录分页,如图(图22),/p
pimg src='http://help.dedecms.com/uploads/allimg/110618/-1-11061P629495W.png' alt=''//p
p图 22-分页/p
p接下来,我们来设置分页部分的匹配规则。/p
p具体步骤:/p
p(a) 在页面的源代码中,找到分页代码的开头和结尾,如图(图23),/p
pimg src='http://help.dedecms.com/uploads/allimg/110618/-1-11061P63004M5.png' alt=''//p
p图 23-分页代码/p
p(b) 观察显示分页码位于“/p
p“和”/p
p”。因此,在“内容分页导航所在区域匹配规则”中,应填写“/p
p[内容]/p
p”。分页码的样式有3个选项,这里要选择第一个“List of all paging”,填好后如图(图24)/p
pimg src='http://help.dedecms.com/uploads/allimg/110618/-1-11061P63044562.png' alt=''//p
p图24-设置后的网页内容获取规则/p
p对于“fixed采集项目”中的“内容摘要、a href='https://www.ucaiyun.com/caiji/public_dict/' target='_blank'关键词/a和缩略图”三部分,系统会使用常规规则进行自动匹配,只需要配置过滤内容即可。下面主要介绍如何获取“文章title、文章author、文章source、发表时间、文章content”的采集规则和简单的过滤规则。/p
p2.1.1 获取文章title 的采集rules/p
p首先打开“预览网址”页面,右键,选择“查看源代码”,找到文章title“高清壁纸(不是原创作品)”,如图(图25)) @) ,/p
pimg src='http://help.dedecms.com/uploads/allimg/110618/-1-11061P63055V2.png' alt=''//p
p图25-源代码中的文章title/p
p这里的文章title在“”之间,所以这里应该填“[Content]”作为文章title的匹配规则。对于收录的/p
pimg src='http://help.dedecms.com/collection/2011/0617/%E2%80%9D/images/digest1.gif' alt='”推荐的欣赏”'//p
p"可以根据自己的需要选择保留或者过滤掉,如果要过滤掉这张图片,需要填写过滤规则:"{dede:trim replace=''}/p
p]*)>{/dede:trim}"。填写后,如图(图26),
图 26-文章title 的采集rules
2.1.2 获取文章author 的采集rules
搜索源代码,对比原文,可以发现本文不涉及原作者。此处选择不填写。 查看全部
采集内容管理平台(
如何获取“文章标题”高清壁纸(非原创作品))
如何使用Dedecms采集功能---图片采集(二)
前言:本文为《如何使用Dedecms采集功能---图片采集》的第二部分。在上一节的基础上,我们将在第二节中添加一个新的采集 节点。第二步:在“设置字段获取规则”部分做一个简单的介绍。为与上一篇保持一致,本文将继续沿用之前的章节标记。
从第一部分继续。
2.1 添加采集节点:第二步设置内容字段获取规则
点击“保存信息,进入下一步设置”后,可以进入“添加采集节点:第二步设置内容字段获取规则”页面,如图(图21),<//p
pimg src='http://help.dedecms.com/uploads/allimg/110618/-1-11061P62933132.png' alt=''//p
p图21-设置内容字段获取规则/p
p在预览网址,系统会自动指定一个文章作为演示页面,如有特殊需求可自行更改。打开demo页面,观察后可以发现页面收录分页,如图(图22),/p
pimg src='http://help.dedecms.com/uploads/allimg/110618/-1-11061P629495W.png' alt=''//p
p图 22-分页/p
p接下来,我们来设置分页部分的匹配规则。/p
p具体步骤:/p
p(a) 在页面的源代码中,找到分页代码的开头和结尾,如图(图23),/p
pimg src='http://help.dedecms.com/uploads/allimg/110618/-1-11061P63004M5.png' alt=''//p
p图 23-分页代码/p
p(b) 观察显示分页码位于“/p
p“和”/p
p”。因此,在“内容分页导航所在区域匹配规则”中,应填写“/p
p[内容]/p
p”。分页码的样式有3个选项,这里要选择第一个“List of all paging”,填好后如图(图24)/p
pimg src='http://help.dedecms.com/uploads/allimg/110618/-1-11061P63044562.png' alt=''//p
p图24-设置后的网页内容获取规则/p
p对于“fixed采集项目”中的“内容摘要、a href='https://www.ucaiyun.com/caiji/public_dict/' target='_blank'关键词/a和缩略图”三部分,系统会使用常规规则进行自动匹配,只需要配置过滤内容即可。下面主要介绍如何获取“文章title、文章author、文章source、发表时间、文章content”的采集规则和简单的过滤规则。/p
p2.1.1 获取文章title 的采集rules/p
p首先打开“预览网址”页面,右键,选择“查看源代码”,找到文章title“高清壁纸(不是原创作品)”,如图(图25)) @) ,/p
pimg src='http://help.dedecms.com/uploads/allimg/110618/-1-11061P63055V2.png' alt=''//p
p图25-源代码中的文章title/p
p这里的文章title在“”之间,所以这里应该填“[Content]”作为文章title的匹配规则。对于收录的/p
pimg src='http://help.dedecms.com/collection/2011/0617/%E2%80%9D/images/digest1.gif' alt='”推荐的欣赏”'//p
p"可以根据自己的需要选择保留或者过滤掉,如果要过滤掉这张图片,需要填写过滤规则:"{dede:trim replace=''}/p
p]*)>{/dede:trim}"。填写后,如图(图26),
图 26-文章title 的采集rules
2.1.2 获取文章author 的采集rules
搜索源代码,对比原文,可以发现本文不涉及原作者。此处选择不填写。
采集内容管理平台(深蓝海域运用人工智能技术,让用户搜索知识变动更简单 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 623 次浏览 • 2021-08-30 20:06
)
全智能知识库
全智能知识库构建了一套涵盖智能知识采集、加工、理解、应用全过程的智能知识库体系。
基于AI技术和算法,实现爬虫采集、模型提取等5+智能知识采集工具,自动标注、FAQ提取等10+智能知识处理能力,以及6+智能等语义和图像识别知识理解引擎,以及智能搜索、智能问答等7+知识智能应用场景和解决方案。
智能搜索引擎
在知识库中,只搜索数据库和全文搜索,往往会导致无法搜索和不准确的搜索。
深蓝海利用人工智能技术探索搜索引擎的智能,让用户更容易改变搜索知识
Internet information采集 和分发引擎封装查询
如果你每天花大量时间在指定的网站上搜索各种知识信息,作为研究和内部参考,如果心疼,这个信息需要手动下载,需要手动区分和分类,需要手动去除重复,去除干扰,那么就不能错过“包裹查询”了。
基于爬虫和机器学习技术打造,自动采集,自动去重,个性化分布推荐,知识关联挖掘,想知道就问!
智能工单知识挖掘引擎
工单系统中具有海量数据的工单信息,通过“工单知识抽取模型”的构建和训练,提取出有效的工单知识并应用于工单提案、处置等环节,从而降低工单重复率,提高工单处理效率和解决准确率。
原子智能知识搜索引擎
原子智能搜索引擎是深蓝海基于智能语义算法和原子引擎技术开发的创新搜索技术。
自动对用户输入关键词进行语义算法处理,搜索更合理的结果,而不是简单的词匹配;搜索结果只显示最匹配的文章 段落,而不是将整个文档呈现给用户。
章节级内容可以原子处理,可以直接为问答机器人提供原子知识,大大减少FAQ整理的工作量。
查看全部
采集内容管理平台(深蓝海域运用人工智能技术,让用户搜索知识变动更简单
)
全智能知识库
全智能知识库构建了一套涵盖智能知识采集、加工、理解、应用全过程的智能知识库体系。
基于AI技术和算法,实现爬虫采集、模型提取等5+智能知识采集工具,自动标注、FAQ提取等10+智能知识处理能力,以及6+智能等语义和图像识别知识理解引擎,以及智能搜索、智能问答等7+知识智能应用场景和解决方案。
智能搜索引擎
在知识库中,只搜索数据库和全文搜索,往往会导致无法搜索和不准确的搜索。
深蓝海利用人工智能技术探索搜索引擎的智能,让用户更容易改变搜索知识
Internet information采集 和分发引擎封装查询
如果你每天花大量时间在指定的网站上搜索各种知识信息,作为研究和内部参考,如果心疼,这个信息需要手动下载,需要手动区分和分类,需要手动去除重复,去除干扰,那么就不能错过“包裹查询”了。
基于爬虫和机器学习技术打造,自动采集,自动去重,个性化分布推荐,知识关联挖掘,想知道就问!
智能工单知识挖掘引擎
工单系统中具有海量数据的工单信息,通过“工单知识抽取模型”的构建和训练,提取出有效的工单知识并应用于工单提案、处置等环节,从而降低工单重复率,提高工单处理效率和解决准确率。
原子智能知识搜索引擎
原子智能搜索引擎是深蓝海基于智能语义算法和原子引擎技术开发的创新搜索技术。
自动对用户输入关键词进行语义算法处理,搜索更合理的结果,而不是简单的词匹配;搜索结果只显示最匹配的文章 段落,而不是将整个文档呈现给用户。
章节级内容可以原子处理,可以直接为问答机器人提供原子知识,大大减少FAQ整理的工作量。
YGBOOK小说采集系统php版v1.4资源大小1.85MB资源
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-08-24 04:24
[资源属性]:
资源名称:YGBOOK小说采集system php version v1.4
资源大小:1.85MB
资源类别:源码下载》php源码
更新时间:2021-06-29
资源语言:简体中文
授权方式:免费下载
使用平台:Windows/Linux/Mac
资源介绍:
YGBOOK小说内容管理系统(以下简称YGBOOK)提供基于ThinkPHP+MySQL技术开发的轻量级小说网站解决方案。
YGBOOK是cms和thief网站之间全新的网站系统,批量采集target网站数据,数据存储。不仅网址完全不一样,模板也不一样,数据也是你的。它对网站管理员是完全免费的。只需设置网站,它就会自动采集+ 自动更新。
本软件基于具有优秀SEO性能的笔趣阁模板,并进行了大量优化。为您呈现一个新颖的网站系统,具有出色的SEO和优雅的外观。
YGBOOK 免费版提供了基本的新颖功能,包括:
1.自动采集2345导航小说数据,内置采集规则,无需自己设置管理
2.数据存储,无需担心目标站修改或挂机
3.网站本身Jin提供小说介绍和章节列表展示,章节阅读采用跳转原站模式,避免版权问题
4.自带伪静态功能,但不能自由定制,无手机版,无站点搜索,无站点地图,无结构化数据
YGBOOK是基于ThinkPHP+MYSQL开发的,可以运行在大多数常见的服务器上。
如windows server,IIS+PHP+MYSQL,
Linux 服务器,Apache/Nginx+PHP+MYSQL
强烈推荐使用Linux服务器,可以充分发挥更大的性能优势
软件方面,PHP要求5.3以上版本,低于5.3的版本不能运行。
硬件方面,配置一般的虚拟主机可以正常运行系统,如果有服务器就更好了。
伪静态配置请参考压缩包中的txt文件。不同环境有不同的配置说明(内置的.htacess文件已经重新优化兼容性,解决了apache+nts模式下可能出现的“No input file specified.”问题)
安装步骤:
1.解压文件上传到对应目录等
2.网站必须配置伪静态(参考上一步的配置)才能正常安装使用(第一次访问首页会自动进入安装页面, 或手动输入 ///install)
3.同意使用协议进入下一步检查目录权限
4.测试通过后,填写通用数据库配置项,填写正确即可安装成功。安装成功后会自动进入后台页面///admin,填写后台管理员和密码登录
5.在后台文章list页面,可以手动采集文章,批量采集文章数据。初始安装后,采集一些数据建议填写网站内容。 网站在运行过程中会自动执行采集操作(前台访问触发,蜘蛛也可以触发采集),无需人工干预。
YGBOOK小说采集系统更新日志:
v1.4
增加百度站点地图功能
安装1.4版本后,您的站点地图地址为“//您的域名/home/sitemap/baidu.xml”
将域名替换为自己的域名后,访问无误后提交至百度站长平台即可。
有利于百度蜘蛛的抓取 查看全部
YGBOOK小说采集系统php版v1.4资源大小1.85MB资源
[资源属性]:
资源名称:YGBOOK小说采集system php version v1.4
资源大小:1.85MB
资源类别:源码下载》php源码
更新时间:2021-06-29
资源语言:简体中文
授权方式:免费下载
使用平台:Windows/Linux/Mac
资源介绍:
YGBOOK小说内容管理系统(以下简称YGBOOK)提供基于ThinkPHP+MySQL技术开发的轻量级小说网站解决方案。
YGBOOK是cms和thief网站之间全新的网站系统,批量采集target网站数据,数据存储。不仅网址完全不一样,模板也不一样,数据也是你的。它对网站管理员是完全免费的。只需设置网站,它就会自动采集+ 自动更新。
本软件基于具有优秀SEO性能的笔趣阁模板,并进行了大量优化。为您呈现一个新颖的网站系统,具有出色的SEO和优雅的外观。
YGBOOK 免费版提供了基本的新颖功能,包括:
1.自动采集2345导航小说数据,内置采集规则,无需自己设置管理
2.数据存储,无需担心目标站修改或挂机
3.网站本身Jin提供小说介绍和章节列表展示,章节阅读采用跳转原站模式,避免版权问题
4.自带伪静态功能,但不能自由定制,无手机版,无站点搜索,无站点地图,无结构化数据
YGBOOK是基于ThinkPHP+MYSQL开发的,可以运行在大多数常见的服务器上。
如windows server,IIS+PHP+MYSQL,
Linux 服务器,Apache/Nginx+PHP+MYSQL
强烈推荐使用Linux服务器,可以充分发挥更大的性能优势
软件方面,PHP要求5.3以上版本,低于5.3的版本不能运行。
硬件方面,配置一般的虚拟主机可以正常运行系统,如果有服务器就更好了。
伪静态配置请参考压缩包中的txt文件。不同环境有不同的配置说明(内置的.htacess文件已经重新优化兼容性,解决了apache+nts模式下可能出现的“No input file specified.”问题)
安装步骤:
1.解压文件上传到对应目录等
2.网站必须配置伪静态(参考上一步的配置)才能正常安装使用(第一次访问首页会自动进入安装页面, 或手动输入 ///install)
3.同意使用协议进入下一步检查目录权限
4.测试通过后,填写通用数据库配置项,填写正确即可安装成功。安装成功后会自动进入后台页面///admin,填写后台管理员和密码登录
5.在后台文章list页面,可以手动采集文章,批量采集文章数据。初始安装后,采集一些数据建议填写网站内容。 网站在运行过程中会自动执行采集操作(前台访问触发,蜘蛛也可以触发采集),无需人工干预。
YGBOOK小说采集系统更新日志:
v1.4
增加百度站点地图功能
安装1.4版本后,您的站点地图地址为“//您的域名/home/sitemap/baidu.xml”
将域名替换为自己的域名后,访问无误后提交至百度站长平台即可。
有利于百度蜘蛛的抓取
从销售到管理:从pdm到内部采购(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-08-21 02:03
采集内容管理平台是一个持续发展、持续优化的新兴互联网产品。由于属于下游传统行业,利用erp提供的一揽子解决方案难免显得陈旧、没有新意。鉴于此,贝恩咨询(2012年)曾在其《从销售到管理:从pdm到内部采购》(2014)一书中指出,在制造业,采购企业主要完成“内外需求”。内需求包括客户买需求、产品买需求,客户需求满足度的提升即管理需求。
内需求包括产品需求、客户需求、增值需求等方面。内需求的提升可以从两个方面来理解,一是供应商的增加;二是企业的需求增加。通过向采购部门提供配套支持(如订单调度、技术支持等)可以提升内需求水平,为企业未来采购提供更多价值。今天,如何获取、管理和实施内需求管理系统,将成为制造企业需求增长大战一个很关键的方向。
3d虚拟商机、3d竞争情报以及基于物联网的物联网大数据分析等方式,推动采购与供应链系统的价值增长。部分文章摘自《从销售到管理:从pdm到内部采购》。
简单理解,这个系统就是为采购提供一个统一的内部联接平台,可以收集内部的数据、定价、采购流程等信息,建立起一个一站式的平台系统,通过内部通告的方式,可以发布商务通告,更改采购相关的文件,合同。可以归总收集,分布到每个部门或实体。 查看全部
从销售到管理:从pdm到内部采购(图)
采集内容管理平台是一个持续发展、持续优化的新兴互联网产品。由于属于下游传统行业,利用erp提供的一揽子解决方案难免显得陈旧、没有新意。鉴于此,贝恩咨询(2012年)曾在其《从销售到管理:从pdm到内部采购》(2014)一书中指出,在制造业,采购企业主要完成“内外需求”。内需求包括客户买需求、产品买需求,客户需求满足度的提升即管理需求。
内需求包括产品需求、客户需求、增值需求等方面。内需求的提升可以从两个方面来理解,一是供应商的增加;二是企业的需求增加。通过向采购部门提供配套支持(如订单调度、技术支持等)可以提升内需求水平,为企业未来采购提供更多价值。今天,如何获取、管理和实施内需求管理系统,将成为制造企业需求增长大战一个很关键的方向。
3d虚拟商机、3d竞争情报以及基于物联网的物联网大数据分析等方式,推动采购与供应链系统的价值增长。部分文章摘自《从销售到管理:从pdm到内部采购》。
简单理解,这个系统就是为采购提供一个统一的内部联接平台,可以收集内部的数据、定价、采购流程等信息,建立起一个一站式的平台系统,通过内部通告的方式,可以发布商务通告,更改采购相关的文件,合同。可以归总收集,分布到每个部门或实体。
KMaster知识管理平台简介(KnowledgeManagement,简称简称KM)
采集交流 • 优采云 发表了文章 • 0 个评论 • 282 次浏览 • 2021-08-20 01:11
KMaster知识管理平台介绍
什么是知识管理?
知识管理(Knowledge Management,简称KM)是帮助企业利用信息技术,基于各种来源的知识内容,实现知识的生产、共享、应用和创新,并在企业内部产生价值的过程。简单来说,就是企业从知识中创造价值的过程。
任何企业都依赖于一定程度的技术和知识才能生存和发展。尤其是进入知识经济时代,现代企业之间的竞争更多的是获取和使用知识和信息的能力。因此,有效管理企业的知识资源是在激烈的市场竞争中立于不败之地的关键。
知识管理能为企业解决哪些问题?
知识管理可以提高企业的竞争力和发展潜力,最终将其转化为企业的价值。例如,知识管理可以帮助企业解决以下问题:
1.企业经营多年,但能留下的东西非常有限。很多事情一遍遍重复,很多错误一遍遍重复。
2.营销部制作了公司宣传册,到处都找不到关于公司历史或现场活动的图片和信息
3.企业的发展太依赖个人了。一旦关键人员流失,将造成核心知识大量流失
4.技术团队没有积累,继续做“发明轮子”的工作,导致公司成本增加
5.机密技术文件,因传播不力,导致泄密
6.Managers面临着各种复杂繁琐的经营管理信息,往往因为决策过程缓慢而耽误了商机
7.公司跨区域管理,组织内各子公司地域分散,信息共享困难,协同办公效率低
8.各个部门的业务经验无法公开共享,团队整体素质难以提升
9.客服部回应客户奇怪的需求。没有统一标准的知识解答,耽误了解决问题的时间,大大降低了客户满意度,增加了客户投诉率
10. 新员工往往无法上手。我不知道该读什么和学什么。很难熟悉公司的进入状态。公司每年都会花费大量时间和金钱来培训新员工。
以上例子都是企业存在的实际问题,也是每个企业都会面临的困境。只有科学的知识管理体系才能帮助企业摆脱这些问题,提高竞争力和发展潜力。
什么是 KMaster 知识管理平台?
KMaster知识管理平台基于科学的知识管理理念,结合现代企业的实际需求,构建了基于B/S架构的软件平台,实现了精准存储、版本、权限、搜索的完美结合的知识。帮助企业快速建立流程化、系统化的知识管理体系,提高竞争力和长期发展潜力。
KMaster 是 KM 和 Master 的组合。 KMaster平台致力于成为最优秀的企业知识管理专家。
KMaster 知识管理平台有哪些优势?
KMaster知识管理平台在吸收同类知识管理系统优点的基础上,开发了自己的一套更加科学合理的知识管理流程。例如,与微博集成的功能、完善的用户激励系统、自动抓取外网图片文件、在线培训、浏览器插件、知识图谱、知识标签、知识门户等功能。 KMaster的功能从知识存储、知识利用、价值创造三个方面进行详细说明。
一、 知识存储
1.无限树分类
系统采用树型知识分类方式,方便知识分类查找,使用方便;系统独有的知识门户功能,可以添加独立的知识树系统,使各种知识的分类更加清晰独立。
2.无限存储空间
系统采用最新的SQLServer数据库服务器,理论上存储的知识量可以无限制。系统数据库采用三范式设计,在保证系统逻辑和性能的同时,最大限度地提高系统效率。系统支持结构化数据存储,可以更准确地索引知识。
3.大附件上传
系统支持最大2G的附件上传,只有具备相关权限的人才可以下载或浏览附件,保证附件的安全。
4.Auto采集Function
系统支持自动采集等网站知识信息,保证知识的实时性和知识更新频率。系统还支持跨网站图片获取功能,可以自动抓取其他网站粘贴的图片到知识库中,方便转发其他网站知识。
5.优化常用格式的存储和显示
支持在线影音播放,支持word、pdf、txt等全文搜索
6.版本回溯
每个版本的知识都会记录在系统中,可以查看历史版本和版本对比。
7.自动备份
系统定时自动备份功能,让您的知识库数据安全无忧。
二、知识利用
如何保证系统中的知识得到充分利用并开拓创新,是知识管理成功的关键。 KMaster采用以下方法来充分保证知识库的充分利用。
1.知识门户
知识库一般在设计之初就确定了自己的一套知识体系(即知识分类),但在企业发展过程中,单一的知识体系往往制约着知识库的发展,而因此有局限性。为了解决这个问题,知识门户的设计应运而生。知识门户允许用户建立独立的知识体系(知识分类),并将知识库中的知识添加到知识门户中,可以更好地对海量知识进行分类索引,方便用户查找知识。
知识门户可以对海量知识进行分类,方便学习和搜索;可以建立部门知识门户,形成部门独有的知识体系;他们可以在无限层次上索引知识,并提供除全文搜索之外的专业搜索。
2.知识地图
知识图谱是知识之间关联的直观表示。知识图谱以脑图的形式表示,可以列出某一知识及其相关知识和专家。同样,专家图可以显示专家之间的联系,以及专家与其专业领域之间的关系。如下图:
3.知识找
系统提供标题搜索、全文搜索、综合搜索、个人搜索、高级搜索等多种搜索功能,让您第一时间找到需要的知识。
4.知识得分
系统根据知识的质量,将知识分为五个等级:无价值、不太有价值、一般、相对有价值、非常有价值,并且可以进行评分。分数越高,知识和采集阅读越多,越容易找到。 查看全部
KMaster知识管理平台简介(KnowledgeManagement,简称简称KM)
KMaster知识管理平台介绍
什么是知识管理?
知识管理(Knowledge Management,简称KM)是帮助企业利用信息技术,基于各种来源的知识内容,实现知识的生产、共享、应用和创新,并在企业内部产生价值的过程。简单来说,就是企业从知识中创造价值的过程。
任何企业都依赖于一定程度的技术和知识才能生存和发展。尤其是进入知识经济时代,现代企业之间的竞争更多的是获取和使用知识和信息的能力。因此,有效管理企业的知识资源是在激烈的市场竞争中立于不败之地的关键。
知识管理能为企业解决哪些问题?
知识管理可以提高企业的竞争力和发展潜力,最终将其转化为企业的价值。例如,知识管理可以帮助企业解决以下问题:
1.企业经营多年,但能留下的东西非常有限。很多事情一遍遍重复,很多错误一遍遍重复。
2.营销部制作了公司宣传册,到处都找不到关于公司历史或现场活动的图片和信息
3.企业的发展太依赖个人了。一旦关键人员流失,将造成核心知识大量流失
4.技术团队没有积累,继续做“发明轮子”的工作,导致公司成本增加
5.机密技术文件,因传播不力,导致泄密
6.Managers面临着各种复杂繁琐的经营管理信息,往往因为决策过程缓慢而耽误了商机
7.公司跨区域管理,组织内各子公司地域分散,信息共享困难,协同办公效率低
8.各个部门的业务经验无法公开共享,团队整体素质难以提升
9.客服部回应客户奇怪的需求。没有统一标准的知识解答,耽误了解决问题的时间,大大降低了客户满意度,增加了客户投诉率
10. 新员工往往无法上手。我不知道该读什么和学什么。很难熟悉公司的进入状态。公司每年都会花费大量时间和金钱来培训新员工。
以上例子都是企业存在的实际问题,也是每个企业都会面临的困境。只有科学的知识管理体系才能帮助企业摆脱这些问题,提高竞争力和发展潜力。
什么是 KMaster 知识管理平台?
KMaster知识管理平台基于科学的知识管理理念,结合现代企业的实际需求,构建了基于B/S架构的软件平台,实现了精准存储、版本、权限、搜索的完美结合的知识。帮助企业快速建立流程化、系统化的知识管理体系,提高竞争力和长期发展潜力。
KMaster 是 KM 和 Master 的组合。 KMaster平台致力于成为最优秀的企业知识管理专家。
KMaster 知识管理平台有哪些优势?
KMaster知识管理平台在吸收同类知识管理系统优点的基础上,开发了自己的一套更加科学合理的知识管理流程。例如,与微博集成的功能、完善的用户激励系统、自动抓取外网图片文件、在线培训、浏览器插件、知识图谱、知识标签、知识门户等功能。 KMaster的功能从知识存储、知识利用、价值创造三个方面进行详细说明。
一、 知识存储
1.无限树分类
系统采用树型知识分类方式,方便知识分类查找,使用方便;系统独有的知识门户功能,可以添加独立的知识树系统,使各种知识的分类更加清晰独立。
2.无限存储空间
系统采用最新的SQLServer数据库服务器,理论上存储的知识量可以无限制。系统数据库采用三范式设计,在保证系统逻辑和性能的同时,最大限度地提高系统效率。系统支持结构化数据存储,可以更准确地索引知识。
3.大附件上传
系统支持最大2G的附件上传,只有具备相关权限的人才可以下载或浏览附件,保证附件的安全。
4.Auto采集Function
系统支持自动采集等网站知识信息,保证知识的实时性和知识更新频率。系统还支持跨网站图片获取功能,可以自动抓取其他网站粘贴的图片到知识库中,方便转发其他网站知识。
5.优化常用格式的存储和显示
支持在线影音播放,支持word、pdf、txt等全文搜索
6.版本回溯
每个版本的知识都会记录在系统中,可以查看历史版本和版本对比。
7.自动备份
系统定时自动备份功能,让您的知识库数据安全无忧。
二、知识利用
如何保证系统中的知识得到充分利用并开拓创新,是知识管理成功的关键。 KMaster采用以下方法来充分保证知识库的充分利用。
1.知识门户
知识库一般在设计之初就确定了自己的一套知识体系(即知识分类),但在企业发展过程中,单一的知识体系往往制约着知识库的发展,而因此有局限性。为了解决这个问题,知识门户的设计应运而生。知识门户允许用户建立独立的知识体系(知识分类),并将知识库中的知识添加到知识门户中,可以更好地对海量知识进行分类索引,方便用户查找知识。
知识门户可以对海量知识进行分类,方便学习和搜索;可以建立部门知识门户,形成部门独有的知识体系;他们可以在无限层次上索引知识,并提供除全文搜索之外的专业搜索。
2.知识地图
知识图谱是知识之间关联的直观表示。知识图谱以脑图的形式表示,可以列出某一知识及其相关知识和专家。同样,专家图可以显示专家之间的联系,以及专家与其专业领域之间的关系。如下图:
3.知识找
系统提供标题搜索、全文搜索、综合搜索、个人搜索、高级搜索等多种搜索功能,让您第一时间找到需要的知识。
4.知识得分
系统根据知识的质量,将知识分为五个等级:无价值、不太有价值、一般、相对有价值、非常有价值,并且可以进行评分。分数越高,知识和采集阅读越多,越容易找到。
基于udp/数据采集的基于内容parser3.基于爬虫来做报文格式解析
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-08-18 23:04
采集内容管理平台目前存在三种类型:1.基于爬虫/数据采集2.基于内容parser3.基于现有db本文介绍基于现有db(csv)的基础上基于udp来做报文格式解析。环境配置:windows下,python3.5+python3.4(pandas)easycdb是windows自带的,其自带数据库功能非常好用,在电子表格环境中使用很方便。
easycdb.run()是执行batch处理和把udp数据和内容提取到本地数据库。press()是把udp数据压缩成parser能够读取的结构化数据格式,文件用pythonutf-8编码。下面简单描述一下easycdb的press('glass')步骤。
1、添加内容策略:chmod-r777backendtoeasycdb。export(db_header_to_text)如:db_header_to_text="{"config_to_data":"{udp":"{a_to_one":"{udp":"{a_to_two":"{udp":"{udp":"{udp":"{udp":"{udp":"{udp":"{udp":"{udp":"{udp":"}"}"}"}"}"}"}""。
2、添加支持http2.0协议的chunking策略:chmod-r777backendtoeasycdb.export(chunking_case"http2.config",backend_field_to_udp_chunking_case="http2.config")参数解释:backend_field_to_udp_chunking_case:当支持http2.config解释器支持http2.0时,后面的http2.config对应的是'http2.config'协议版本的值,默认是'http2.config'。
参数解释:参数:参数:export:如果设置link_path/filename文件所在路径,则所有udp报文都进行该chunk压缩。参数:export:如果dict和其他recordset模块绑定(md5hashkeyproperty),则内容解析的地址是该md5签名下的最后一个字符。参数:export:如果为dict和其他recordset模块绑定(md5hashkeyproperty),则内容解析的地址是该md5签名下的最后一个字符。easycdb.serve({"teleport":""})。
3、执行本地数据库回调函数:pythonmanage.pyrunservereasycdb.run(easycdb.db.itemclient)第三种方式写这篇文章的目的不是简单的看代码,而是说代码是最好学的。简单编写的代码在写代码之前我有两个准备,第一是网上的教程不少,我也了解一些内容,基本上看得明白。
第二是理解为什么要这么写,有什么作用。做好之后,再用我们的代码分析网上的一些教程,也更直观。有些教程比较。 查看全部
基于udp/数据采集的基于内容parser3.基于爬虫来做报文格式解析
采集内容管理平台目前存在三种类型:1.基于爬虫/数据采集2.基于内容parser3.基于现有db本文介绍基于现有db(csv)的基础上基于udp来做报文格式解析。环境配置:windows下,python3.5+python3.4(pandas)easycdb是windows自带的,其自带数据库功能非常好用,在电子表格环境中使用很方便。
easycdb.run()是执行batch处理和把udp数据和内容提取到本地数据库。press()是把udp数据压缩成parser能够读取的结构化数据格式,文件用pythonutf-8编码。下面简单描述一下easycdb的press('glass')步骤。
1、添加内容策略:chmod-r777backendtoeasycdb。export(db_header_to_text)如:db_header_to_text="{"config_to_data":"{udp":"{a_to_one":"{udp":"{a_to_two":"{udp":"{udp":"{udp":"{udp":"{udp":"{udp":"{udp":"{udp":"{udp":"}"}"}"}"}"}"}""。
2、添加支持http2.0协议的chunking策略:chmod-r777backendtoeasycdb.export(chunking_case"http2.config",backend_field_to_udp_chunking_case="http2.config")参数解释:backend_field_to_udp_chunking_case:当支持http2.config解释器支持http2.0时,后面的http2.config对应的是'http2.config'协议版本的值,默认是'http2.config'。
参数解释:参数:参数:export:如果设置link_path/filename文件所在路径,则所有udp报文都进行该chunk压缩。参数:export:如果dict和其他recordset模块绑定(md5hashkeyproperty),则内容解析的地址是该md5签名下的最后一个字符。参数:export:如果为dict和其他recordset模块绑定(md5hashkeyproperty),则内容解析的地址是该md5签名下的最后一个字符。easycdb.serve({"teleport":""})。
3、执行本地数据库回调函数:pythonmanage.pyrunservereasycdb.run(easycdb.db.itemclient)第三种方式写这篇文章的目的不是简单的看代码,而是说代码是最好学的。简单编写的代码在写代码之前我有两个准备,第一是网上的教程不少,我也了解一些内容,基本上看得明白。
第二是理解为什么要这么写,有什么作用。做好之后,再用我们的代码分析网上的一些教程,也更直观。有些教程比较。
如何高效采集归档处理的呢?博通档案管理系统采集方式介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-08-15 23:07
众所周知,汇博通档案管理系统具有强大的办公功能。汇博通作为文件、档案、知识办公一体化的管理软件系统,如何高效地整理归档档案信息?下面小编就为大家简单介绍一下博通文件管理系统采集,希望对大家有所帮助。
汇博通的采集方式多样化,主要分为主动采集和集成采集。
主动采集方法是提供新的属性创建,即对原文件重新编辑填写,可以及时更新文件内容和附加文件信息,并添加个性化附加可选功能.
新增扫描功能,继续为原文件本身添加附件,支持多文件一起上传。
批量创建功能和批量上传/导入/替换功能,即在上传文件时,选择批量创建模式,同时批量上传/导入/替换多个文件,节省工作时间和人工效率。
活动采集方法中可自由选择的知识文档采集方法,满足当前企业对办公文档的需求,精益求精,随着企业的发展做出不同的属性调整,适用于企业的办公平台。
汇博通作为综合信息门户和统一认证中心,整合现有信息系统(如OA、CRM等),对其产生的知识内容进行统一抓取。使用汇博通,将不同系统的原创文献、档案、合同、报告、图纸、网站内容、摘要、内部期刊等整合为一个系统,统一管理。 查看全部
如何高效采集归档处理的呢?博通档案管理系统采集方式介绍
众所周知,汇博通档案管理系统具有强大的办公功能。汇博通作为文件、档案、知识办公一体化的管理软件系统,如何高效地整理归档档案信息?下面小编就为大家简单介绍一下博通文件管理系统采集,希望对大家有所帮助。
汇博通的采集方式多样化,主要分为主动采集和集成采集。
主动采集方法是提供新的属性创建,即对原文件重新编辑填写,可以及时更新文件内容和附加文件信息,并添加个性化附加可选功能.
新增扫描功能,继续为原文件本身添加附件,支持多文件一起上传。
批量创建功能和批量上传/导入/替换功能,即在上传文件时,选择批量创建模式,同时批量上传/导入/替换多个文件,节省工作时间和人工效率。
活动采集方法中可自由选择的知识文档采集方法,满足当前企业对办公文档的需求,精益求精,随着企业的发展做出不同的属性调整,适用于企业的办公平台。
汇博通作为综合信息门户和统一认证中心,整合现有信息系统(如OA、CRM等),对其产生的知识内容进行统一抓取。使用汇博通,将不同系统的原创文献、档案、合同、报告、图纸、网站内容、摘要、内部期刊等整合为一个系统,统一管理。
BaoAI小宝人工智能和量化系统人工智能量化平台下载源码
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-08-14 06:02
BaoAI小宝人工智能量化系统
人工智能和量化从这里开始
小宝的人工智能量化平台是一个简单、直观、强大的前后端SPA开发框架,支持国际化,基于模块,使WEB应用、人工智能和量化系统的开发更快更更轻松。平台收录多个模块,主要包括基于角色的权限管理基础平台(用户、角色、权限、日志、附件、配置参数、分类管理)、通知模块、代码自动生成模块、任务系统模块、内容管理系统模块、 网站模块、电子手册模块、人工智能模块、图像识别模块、人脸识别模块、金融数据采集模块、大数据模块、量化交易模块等
功能:下载源代码
宝爱前后端分离框架结构,包括前端项目和后端项目
文档
数据模拟API
模块扩展
前端开发工具
Visual Studio 代码
安装插件:
Visual Studio Code 的中文(简体)语言包
jshint
git 历史
项目前端BaoAIFront安装步骤
需要安装 Node.js
使用bower下载第三方js库时,国内下载速度可能会很慢。建议克隆并直接解压源代码根路径下的bower_components.zip
# 安装 bower:
npm install -g bower
# 安装 gulp
npm install -g gulp
# npm 安装第三方js
# 使用bower下载第三方js库时,国内可能下载速度很慢,可以直接解压源代码根路径下的bower_components.zip,此步可以跳过
bower install
# npm 安装依赖库:
npm install
# 运行前端代码方式一:自带数据模拟API,适合前端工程师
gulp server
# 运行前端代码方式二:Python全栈开发工程师
# 需要安装BaoAI后端
gulp serve
# 运行前端代码方式三:Python全栈开发工程师,反向代理(前后端共用相同地址和端口,仅目录不同)
# 需要安装BaoAI后端
gulp proxy
# 构建生产代码
gulp build
# 运行前端代码方式四:测试运行生产代码
# 需要安装BaoAI后端
gulp prod
构建的生产代码保存在 dist 目录中。
项目代码自动生成模块
使用自动代码生成模块可以可视化字段、模型、生成的数据库、前端代码、后端代码和权限配置。一般项目可以零代码实现。这部分主要包括三个扩展模块:数据迁移模块、自动代码模型模块和自动代码生成模块
BaoAI小宝人工智能量化平台系统架构
BaoAI小宝人工智能与量化平台知识系统
可用于前后端系统软件开发、cms、人工智能、图像识别、人脸识别、大数据、各行业量化投资。 SPA架构前后端分离,使用AngularJS/Bootstrap等前端框架实现响应式和SPA编程。后端主要使用Python语言,主要包括以下框架:flask提供web服务,Jinja2提供模板服务,Numpy、Pandas、Scikit-Learn、Tensorflow和Keras实现人工智能服务,celery实现任务调度,scrapy提供web爬虫,以及基于 Backtrader 的金融量化服务。
基于宝爱设计案例:
内容管理网站:
管理系统背景:
人工智能:
量化系统:
查看全部
BaoAI小宝人工智能和量化系统人工智能量化平台下载源码
BaoAI小宝人工智能量化系统
人工智能和量化从这里开始
小宝的人工智能量化平台是一个简单、直观、强大的前后端SPA开发框架,支持国际化,基于模块,使WEB应用、人工智能和量化系统的开发更快更更轻松。平台收录多个模块,主要包括基于角色的权限管理基础平台(用户、角色、权限、日志、附件、配置参数、分类管理)、通知模块、代码自动生成模块、任务系统模块、内容管理系统模块、 网站模块、电子手册模块、人工智能模块、图像识别模块、人脸识别模块、金融数据采集模块、大数据模块、量化交易模块等
功能:下载源代码
宝爱前后端分离框架结构,包括前端项目和后端项目
文档
数据模拟API
模块扩展
前端开发工具
Visual Studio 代码
安装插件:
Visual Studio Code 的中文(简体)语言包
jshint
git 历史
项目前端BaoAIFront安装步骤
需要安装 Node.js
使用bower下载第三方js库时,国内下载速度可能会很慢。建议克隆并直接解压源代码根路径下的bower_components.zip
# 安装 bower:
npm install -g bower
# 安装 gulp
npm install -g gulp
# npm 安装第三方js
# 使用bower下载第三方js库时,国内可能下载速度很慢,可以直接解压源代码根路径下的bower_components.zip,此步可以跳过
bower install
# npm 安装依赖库:
npm install
# 运行前端代码方式一:自带数据模拟API,适合前端工程师
gulp server
# 运行前端代码方式二:Python全栈开发工程师
# 需要安装BaoAI后端
gulp serve
# 运行前端代码方式三:Python全栈开发工程师,反向代理(前后端共用相同地址和端口,仅目录不同)
# 需要安装BaoAI后端
gulp proxy
# 构建生产代码
gulp build
# 运行前端代码方式四:测试运行生产代码
# 需要安装BaoAI后端
gulp prod
构建的生产代码保存在 dist 目录中。
项目代码自动生成模块
使用自动代码生成模块可以可视化字段、模型、生成的数据库、前端代码、后端代码和权限配置。一般项目可以零代码实现。这部分主要包括三个扩展模块:数据迁移模块、自动代码模型模块和自动代码生成模块
BaoAI小宝人工智能量化平台系统架构
BaoAI小宝人工智能与量化平台知识系统
可用于前后端系统软件开发、cms、人工智能、图像识别、人脸识别、大数据、各行业量化投资。 SPA架构前后端分离,使用AngularJS/Bootstrap等前端框架实现响应式和SPA编程。后端主要使用Python语言,主要包括以下框架:flask提供web服务,Jinja2提供模板服务,Numpy、Pandas、Scikit-Learn、Tensorflow和Keras实现人工智能服务,celery实现任务调度,scrapy提供web爬虫,以及基于 Backtrader 的金融量化服务。
基于宝爱设计案例:
内容管理网站:
管理系统背景:
人工智能:
量化系统:
BaoAI小宝人工智能和量化系统和
采集交流 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-08-14 05:33
BaoAI小宝人工智能量化系统
人工智能和量化从这里开始
小宝的人工智能量化平台是一个简单、直观、强大的前后端SPA开发框架,支持国际化,基于模块,使WEB应用、人工智能和量化系统的开发更快更更轻松。平台收录多个模块,主要包括基于角色的权限管理基础平台(用户、角色、权限、日志、附件、配置参数、分类管理)、通知模块、代码自动生成模块、任务系统模块、内容管理系统模块、 网站模块、电子手册模块、人工智能模块、图像识别模块、人脸识别模块、金融数据采集模块、大数据模块、量化交易模块等
功能:下载源代码
宝爱前后端分离框架结构,包括前端项目和后端项目
文档
API
模块扩展
前端和后端开发工具
Visual Studio 代码
安装插件:
Visual Studio Code 的中文(简体)语言包
jshint
蟒蛇
Git 历史
项目后端BaoAIBack安装步骤
需要 Python 3.6
# 1. 创建虚拟环境
# windows, 假设项目根路径:d:/baoai/BaoaiBack/
cd d:/baoai/BaoaiBack
mkdir venv
cd venv
python -m venv .
# 运行虚拟环境
d:/baoai/BaoaiBack/venv/Scripts/activate.bat
cd d:/baoai/BaoaiBack
# linux, 假设项目根路径:/baoai/BaoaiBack/
cd /baoai/BaoaiBack
mkdir venv
cd venv
python -m venv .
# 运行虚拟环境
source /baoai/BaoaiBack/venv/bin/activate
cd /baoai/BaoaiBack
# 2. 安装依赖库(必须处于虚拟环境)
# windows 安装依赖库
python -m pip install --upgrade pip
pip install -r requirements.txt
# 如果下载速度慢可以采用国内镜像
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
# linux 安装依赖库
python -m pip3 install --upgrade pip
pip3 install -r requirements.txt
# 如果下载速度慢可以采用国内镜像
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
# 3. 运行 Restful 服务
# windows
run_baoai.bat
# linux
# 默认使用gunicorn做为wsgi
chmod +x run_baoai.sh
./run_baoai.sh
# 4. 运行 www 服务(Jinja模块)
# windows
run_www.bat
# linux
chmod +x run_www.sh
./run_www.sh
# 常用功能
# 清空缓存
python manage.py clean
项目后端数据库
该项目支持最流行的关系数据库,包括:SQLite、MySQL、Postgres、Oracle、MS-SQL、SQLServer 和 Firebird。
提供了Sqlite 数据库和MySQL 数据脚本文件。 MySQL 支持5.5 及以上。
数据库转换不需要修改代码,只需修改config.py中的SQLALCHEMY_DATABASE_URI即可。
默认使用 sqlite 数据库。优点是不需要安装专门的数据库软件,方便测试和开发。生产部署请使用mysql或其他数据库软件。
sqlite数据存放在db/baoai.db中,直接使用
mysql数据库脚本保存在db/baoai.mysql.sql中,需要新建一个baoai等数据库,然后导入脚本。
如果您使用其他数据库,您可以使用 Navicat Premium 工具菜单中的数据传输在不同数据库之前迁移数据。
数据库相关操作:
# 数据迁移服务
# 初始化
python manage.py db init
# 模型迁移
python manage.py db migrate
# 数据库脚本更新(操作数据)
python manage.py db upgrade
项目代码自动生成模块
使用自动代码生成模块可以可视化字段、模型、生成的数据库、前端代码、后端代码和权限配置。一般项目可以零代码实现。这部分主要包括三个扩展模块:数据迁移模块、自动代码模型模块和自动代码生成模块
BaoAI小宝人工智能量化平台系统架构
BaoAI小宝人工智能与量化平台知识系统
可用于前后端系统软件开发、cms、人工智能、图像识别、人脸识别、大数据、各行业量化投资。 SPA架构前后端分离,使用AngularJS/Bootstrap等前端框架实现响应式和SPA编程。后端主要使用Python语言,主要包括以下框架:flask提供web服务,Jinja2提供模板服务,Numpy、Pandas、Scikit-Learn、Tensorflow和Keras实现人工智能服务,celery实现任务调度,scrapy提供web爬虫,以及基于 Backtrader 的金融量化服务。
基于宝爱设计案例:
内容管理网站:
管理系统背景:
人工智能:
量化系统:
查看全部
BaoAI小宝人工智能和量化系统和
BaoAI小宝人工智能量化系统
人工智能和量化从这里开始
小宝的人工智能量化平台是一个简单、直观、强大的前后端SPA开发框架,支持国际化,基于模块,使WEB应用、人工智能和量化系统的开发更快更更轻松。平台收录多个模块,主要包括基于角色的权限管理基础平台(用户、角色、权限、日志、附件、配置参数、分类管理)、通知模块、代码自动生成模块、任务系统模块、内容管理系统模块、 网站模块、电子手册模块、人工智能模块、图像识别模块、人脸识别模块、金融数据采集模块、大数据模块、量化交易模块等
功能:下载源代码
宝爱前后端分离框架结构,包括前端项目和后端项目
文档
API
模块扩展
前端和后端开发工具
Visual Studio 代码
安装插件:
Visual Studio Code 的中文(简体)语言包
jshint
蟒蛇
Git 历史
项目后端BaoAIBack安装步骤
需要 Python 3.6
# 1. 创建虚拟环境
# windows, 假设项目根路径:d:/baoai/BaoaiBack/
cd d:/baoai/BaoaiBack
mkdir venv
cd venv
python -m venv .
# 运行虚拟环境
d:/baoai/BaoaiBack/venv/Scripts/activate.bat
cd d:/baoai/BaoaiBack
# linux, 假设项目根路径:/baoai/BaoaiBack/
cd /baoai/BaoaiBack
mkdir venv
cd venv
python -m venv .
# 运行虚拟环境
source /baoai/BaoaiBack/venv/bin/activate
cd /baoai/BaoaiBack
# 2. 安装依赖库(必须处于虚拟环境)
# windows 安装依赖库
python -m pip install --upgrade pip
pip install -r requirements.txt
# 如果下载速度慢可以采用国内镜像
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
# linux 安装依赖库
python -m pip3 install --upgrade pip
pip3 install -r requirements.txt
# 如果下载速度慢可以采用国内镜像
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
# 3. 运行 Restful 服务
# windows
run_baoai.bat
# linux
# 默认使用gunicorn做为wsgi
chmod +x run_baoai.sh
./run_baoai.sh
# 4. 运行 www 服务(Jinja模块)
# windows
run_www.bat
# linux
chmod +x run_www.sh
./run_www.sh
# 常用功能
# 清空缓存
python manage.py clean
项目后端数据库
该项目支持最流行的关系数据库,包括:SQLite、MySQL、Postgres、Oracle、MS-SQL、SQLServer 和 Firebird。
提供了Sqlite 数据库和MySQL 数据脚本文件。 MySQL 支持5.5 及以上。
数据库转换不需要修改代码,只需修改config.py中的SQLALCHEMY_DATABASE_URI即可。
默认使用 sqlite 数据库。优点是不需要安装专门的数据库软件,方便测试和开发。生产部署请使用mysql或其他数据库软件。
sqlite数据存放在db/baoai.db中,直接使用
mysql数据库脚本保存在db/baoai.mysql.sql中,需要新建一个baoai等数据库,然后导入脚本。
如果您使用其他数据库,您可以使用 Navicat Premium 工具菜单中的数据传输在不同数据库之前迁移数据。
数据库相关操作:
# 数据迁移服务
# 初始化
python manage.py db init
# 模型迁移
python manage.py db migrate
# 数据库脚本更新(操作数据)
python manage.py db upgrade
项目代码自动生成模块
使用自动代码生成模块可以可视化字段、模型、生成的数据库、前端代码、后端代码和权限配置。一般项目可以零代码实现。这部分主要包括三个扩展模块:数据迁移模块、自动代码模型模块和自动代码生成模块
BaoAI小宝人工智能量化平台系统架构
BaoAI小宝人工智能与量化平台知识系统
可用于前后端系统软件开发、cms、人工智能、图像识别、人脸识别、大数据、各行业量化投资。 SPA架构前后端分离,使用AngularJS/Bootstrap等前端框架实现响应式和SPA编程。后端主要使用Python语言,主要包括以下框架:flask提供web服务,Jinja2提供模板服务,Numpy、Pandas、Scikit-Learn、Tensorflow和Keras实现人工智能服务,celery实现任务调度,scrapy提供web爬虫,以及基于 Backtrader 的金融量化服务。
基于宝爱设计案例:
内容管理网站:
管理系统背景:
人工智能:
量化系统:
采集内容管理平台——统计源头sdk模式模式
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-08-13 20:04
采集内容管理平台:采集:微博公众号头条网站内容导出:百度微信等形式分类:商品,化妆品,食品,母婴,虚拟,青少年教育,三维建模,视频等统计:各种行业数据,明星,自己公司,媒体,交通,住宿,出行,互联网高科技等出处:友盟技术服务平台,统计源头sdk模式:hooksdk,基于js库开发,跨浏览器webservice接口开发,数据库实时同步至本地数据库,webservice客户端发送请求,计算数据库数据,返回给前端,前端根据计算的数据通过后端模板系统渲染所以大家通过统计分析来实现。
开源方案一是统计源,需要大量的开发复杂度,二是接口,主要是接数据库,客户端渲染是hook方式,模拟网络请求来做。初期阶段自己看python3微博爬虫,存进数据库,然后自己整理好数据。基本每隔几天就去看webservice内的数据更新进度。有些分类或者说每个人关注的数据很少。后来使用统计源的时候,很多不统计,业务上有kpi,可以做kpi的点数,目前来看是非常有价值的。
哈哈,首先你得找到需求和解决方案,前端爬取是基础,统计分析是保障,我找到一套微博社区管理的web爬虫程序。那里面人工分类爬取的,
数据来源很多,如果你有编程基础可以搞爬虫。如果你想找一个你开发的东西,可以考虑接入友盟这样的第三方统计平台,他们可以定制样式和你的api等等,接入这样的平台一般需要api包,一个平台一个api包,把样式包给别人让他们去按你的接口调用就可以了。把数据以统计报表的形式上传到api包,因为统计报表可以实时推送给每个用户,所以一般需要一个本地数据库,你把这个数据库封装成程序要访问的数据库。
要是支持格式化接口,那你就拿着你的api去接单里的一个接口或者二个接口,用对应的数据接口调用就可以了。统计报表这些可以用excel实现。以上是比较基础的,其他的数据爬取可以用scrapy来完成。也可以用python爬虫框架写html代码,或者爬行json文件,然后解析,再用requests库爬取。代码在下面这个博客里:scrapy爬虫实现自动爬取话题微博的数据分析。 查看全部
采集内容管理平台——统计源头sdk模式模式
采集内容管理平台:采集:微博公众号头条网站内容导出:百度微信等形式分类:商品,化妆品,食品,母婴,虚拟,青少年教育,三维建模,视频等统计:各种行业数据,明星,自己公司,媒体,交通,住宿,出行,互联网高科技等出处:友盟技术服务平台,统计源头sdk模式:hooksdk,基于js库开发,跨浏览器webservice接口开发,数据库实时同步至本地数据库,webservice客户端发送请求,计算数据库数据,返回给前端,前端根据计算的数据通过后端模板系统渲染所以大家通过统计分析来实现。
开源方案一是统计源,需要大量的开发复杂度,二是接口,主要是接数据库,客户端渲染是hook方式,模拟网络请求来做。初期阶段自己看python3微博爬虫,存进数据库,然后自己整理好数据。基本每隔几天就去看webservice内的数据更新进度。有些分类或者说每个人关注的数据很少。后来使用统计源的时候,很多不统计,业务上有kpi,可以做kpi的点数,目前来看是非常有价值的。
哈哈,首先你得找到需求和解决方案,前端爬取是基础,统计分析是保障,我找到一套微博社区管理的web爬虫程序。那里面人工分类爬取的,
数据来源很多,如果你有编程基础可以搞爬虫。如果你想找一个你开发的东西,可以考虑接入友盟这样的第三方统计平台,他们可以定制样式和你的api等等,接入这样的平台一般需要api包,一个平台一个api包,把样式包给别人让他们去按你的接口调用就可以了。把数据以统计报表的形式上传到api包,因为统计报表可以实时推送给每个用户,所以一般需要一个本地数据库,你把这个数据库封装成程序要访问的数据库。
要是支持格式化接口,那你就拿着你的api去接单里的一个接口或者二个接口,用对应的数据接口调用就可以了。统计报表这些可以用excel实现。以上是比较基础的,其他的数据爬取可以用scrapy来完成。也可以用python爬虫框架写html代码,或者爬行json文件,然后解析,再用requests库爬取。代码在下面这个博客里:scrapy爬虫实现自动爬取话题微博的数据分析。

