
采集内容插入词库
采集内容插入词库( 谷歌拼音输入法特指电脑版PC端输入法二百万超大词库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 249 次浏览 • 2021-09-23 04:20
谷歌拼音输入法特指电脑版PC端输入法二百万超大词库)
...
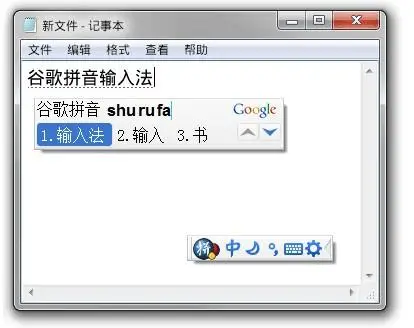
本文中的Google Pinyin输入是指计算机版本PC结束输入方法。
google输入方法2.7. 2 5. 128版本(64位)和3.@@@@@@@@ 98版本可以直接安装在Windows10系统中。虽然没有国内主流输入法(如Sogou输入法,百度输入法,QQ输入法),但易于使用,学习,单词频率调整和稳定性是独一无二的,所以还有许多网友喜欢使用。
...
由于众所周知的原因,国内用户无法直接打开Google链接,导致单词库更新和无法使用的云Word库,所以谷歌输入方法的用户,单词库是相对严重的软。安装人员提供的单词很少,大多数是360和互动百科全书。
...
Word库的重要性不需要许多单词,并且输入方法较少,并且不可能提高输入速度和准确性。为了解决这个问题,莫奥山的特殊单词将在Word库转换器中采集到Google输入方法,导入Google输入方法。现在共享的Word库是介绍完成后产生的发布。
... Google输入方法200万大法术包括上述单词
...
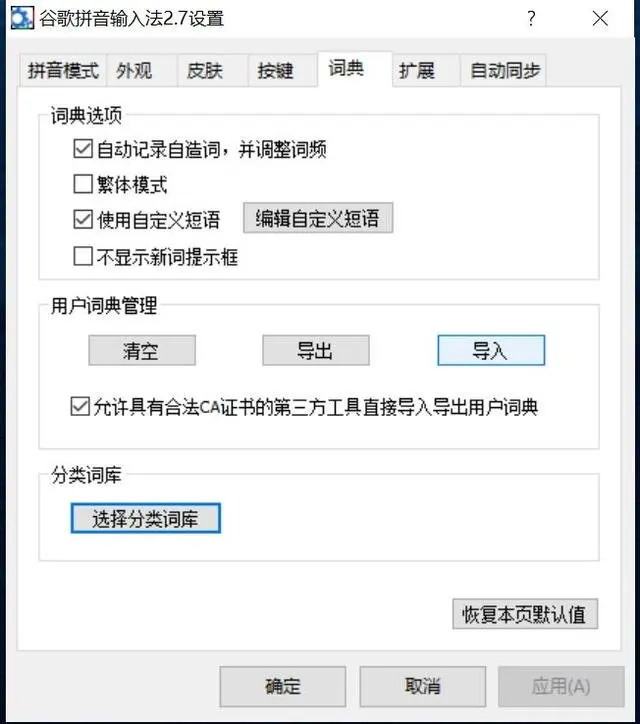
使用方法很简单,按右键在Google输入方法上,单击“属性设置 - 字典”,单击“用户词典管理”中的“导入”。导入后,您的Google输入方法将至少有200万次超大的单词,这个词将更小心。
...
...
为了避免一些不必要的问题,它不会在这里挂起来。需要需要的朋友可以增加注意,给我一个私人信留下你的邮箱。
本文提供的单词库仅用于共享,无需任何业务目的。
♥
- ───────── 查看全部
采集内容插入词库(
谷歌拼音输入法特指电脑版PC端输入法二百万超大词库)


...
本文中的Google Pinyin输入是指计算机版本PC结束输入方法。
google输入方法2.7. 2 5. 128版本(64位)和3.@@@@@@@@ 98版本可以直接安装在Windows10系统中。虽然没有国内主流输入法(如Sogou输入法,百度输入法,QQ输入法),但易于使用,学习,单词频率调整和稳定性是独一无二的,所以还有许多网友喜欢使用。
...
由于众所周知的原因,国内用户无法直接打开Google链接,导致单词库更新和无法使用的云Word库,所以谷歌输入方法的用户,单词库是相对严重的软。安装人员提供的单词很少,大多数是360和互动百科全书。

...
Word库的重要性不需要许多单词,并且输入方法较少,并且不可能提高输入速度和准确性。为了解决这个问题,莫奥山的特殊单词将在Word库转换器中采集到Google输入方法,导入Google输入方法。现在共享的Word库是介绍完成后产生的发布。
... Google输入方法200万大法术包括上述单词
...
使用方法很简单,按右键在Google输入方法上,单击“属性设置 - 字典”,单击“用户词典管理”中的“导入”。导入后,您的Google输入方法将至少有200万次超大的单词,这个词将更小心。
...
...
为了避免一些不必要的问题,它不会在这里挂起来。需要需要的朋友可以增加注意,给我一个私人信留下你的邮箱。
本文提供的单词库仅用于共享,无需任何业务目的。
♥
- ─────────
采集内容插入词库(Javaweb网站敏感词过滤的实现调研结果写出来了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-09-19 21:05
几乎所有网站现在都需要设置敏感字过滤,这似乎已经成为网站的标准配置网站. 如果您的网站没有或您没有相应处理,请小心相关部门邀请您喝茶
我最近一直在研究Javaweb网站对于敏感词过滤的实施,我在互联网上找到了相关信息。经过我的核实,我写下了我的研究成果供你参考
一、敏感字过滤工具类
将敏感词词典的内容加载到ArrayList集中,通过双层循环找到与敏感词列表匹配的字符串。如果找到了,用*号替换它,最后得到替换的字符串
该方法匹配度高,匹配速度快
初始化敏感词库:
//初始化敏感词库
public void InitializationWork()
{
replaceAll = new StringBuilder(replceSize);
for(int x=0;x < replceSize;x++)
{
replaceAll.append(replceStr);
}
//加载词库
arrayList = new ArrayList();
InputStreamReader read = null;
BufferedReader bufferedReader = null;
try {
read = new InputStreamReader(SensitiveWord.class.getClassLoader().getResourceAsStream(fileName),encoding);
bufferedReader = new BufferedReader(read);
for(String txt = null;(txt = bufferedReader.readLine()) != null;){
if(!arrayList.contains(txt))
arrayList.add(txt);
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
if(null != bufferedReader)
bufferedReader.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if(null != read)
read.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
筛选敏感词信息:
public String filterInfo(String str)
{
sensitiveWordSet = new HashSet();
sensitiveWordList= new ArrayList();
StringBuilder buffer = new StringBuilder(str);
HashMap hash = new HashMap(arrayList.size());
String temp;
for(int x = 0; x < arrayList.size();x++)
{
temp = arrayList.get(x);
int findIndexSize = 0;
for(int start = -1;(start=buffer.indexOf(temp,findIndexSize)) > -1;)
{
//System.out.println("###replace="+temp);
findIndexSize = start+temp.length();//从已找到的后面开始找
Integer mapStart = hash.get(start);//起始位置
if(mapStart == null || (mapStart != null && findIndexSize > mapStart))//满足1个,即可更新map
{
hash.put(start, findIndexSize);
//System.out.println("###敏感词:"+buffer.substring(start, findIndexSize));
}
}
}
Collection values = hash.keySet();
for(Integer startIndex : values)
{
Integer endIndex = hash.get(startIndex);
//获取敏感词,并加入列表,用来统计数量
String sensitive = buffer.substring(startIndex, endIndex);
//System.out.println("###敏感词:"+sensitive);
if (!sensitive.contains("*")) {//添加敏感词到集合
sensitiveWordSet.add(sensitive);
sensitiveWordList.add(sensitive);
}
buffer.replace(startIndex, endIndex, replaceAll.substring(0,endIndex-startIndex));
}
hash.clear();
return buffer.toString();
}
下载地址:sensitiveword
链接:密码:qmcw(如果无效,请使用文本末尾的地址下载)
二、Java关键词过滤
该方法使用正则表达式匹配,比第一种方法稍慢,匹配度好
主要代码:
// 从words.properties初始化正则表达式字符串
private static void initPattern() {
StringBuffer patternBuffer = new StringBuffer();
try {
//words.properties
InputStream in = KeyWordFilter.class.getClassLoader().getResourceAsStream("keywords.properties");
Properties property = new Properties();
property.load(in);
Enumeration enu = property.propertyNames();
patternBuffer.append("(");
while (enu.hasMoreElements()) {
String scontent = (String) enu.nextElement();
patternBuffer.append(scontent + "|");
//System.out.println(scontent);
keywordsCount ++;
}
patternBuffer.deleteCharAt(patternBuffer.length() - 1);
patternBuffer.append(")");
//System.out.println(patternBuffer);
// unix换成UTF-8
// pattern = Pattern.compile(new
// String(patternBuf.toString().getBytes("ISO-8859-1"), "UTF-8"));
// win下换成gb2312
// pattern = Pattern.compile(new String(patternBuf.toString()
// .getBytes("ISO-8859-1"), "gb2312"));
// 装换编码
pattern = Pattern.compile(patternBuffer.toString());
} catch (IOException ioEx) {
ioEx.printStackTrace();
}
}
private static String doFilter(String str) {
Matcher m = pattern.matcher(str);
// while (m.find()) {// 查找符合pattern的字符串
// System.out.println("The result is here :" + m.group());
// }
// 选择替换方式,这里以* 号代替
str = m.replaceAll("*");
return str;
}
下载地址:关键字过滤器
链接:密码:xi24(如果失败,请在文本末尾下载)
三、DFA滤波算法
在这种情况下,采用了DFA算法。我对这个算法知之甚少。经过测试,发现匹配度不好,速度也不错。也许可以改进。请请求伟大的上帝来改进
有两个主要文件:sensitivewordfilter.java和sensitivewordinit.java
主要代码:
public int CheckSensitiveWord(String txt,int beginIndex,int matchType){
boolean flag = false; //敏感词结束标识位:用于敏感词只有1位的情况
int matchFlag = 0; //匹配标识数默认为0
char word = 0;
Map nowMap = sensitiveWordMap;
for(int i = beginIndex; i < txt.length() ; i++){
word = txt.charAt(i);
nowMap = (Map) nowMap.get(word); //获取指定key
if(nowMap != null){ //存在,则判断是否为最后一个
matchFlag++; //找到相应key,匹配标识+1
if("1".equals(nowMap.get("isEnd"))){ //如果为最后一个匹配规则,结束循环,返回匹配标识数
flag = true; //结束标志位为true
if(SensitivewordFilter.minMatchTYpe == matchType){ //最小规则,直接返回,最大规则还需继续查找
break;
}
}
}
else{ //不存在,直接返回
break;
}
}
if(matchFlag < 2 || !flag){ //长度必须大于等于1,为词
matchFlag = 0;
}
return matchFlag;
}
下载地址:sensitivewordfilter
链接:密码:mc1x(如果无效,请使用文本末尾的地址下载)
四、多树搜索算法
该方法采用多树搜索算法。至于这个算法是怎么回事,您可以检查与数据结构相关的内容。提供了Jar包,可以直接调用它进行过滤
经测试,该方法匹配度好,速度慢
调用方法:
//敏感词过滤
FilteredResult result = WordFilterUtil.filterText(str, '*');
//获取过滤后的内容
System.out.println("替换后的字符串为:\n"+result.getFilteredContent());
//获取原始字符串
System.out.println("原始字符串为:\n"+result.getOriginalContent());
//获取替换的敏感词
System.out.println("替换的敏感词为:\n"+result.getBadWords());
下载地址:wordfilterutil
链接:密码:5t2h(如果无效,请使用文本末尾的地址下载) 查看全部
采集内容插入词库(Javaweb网站敏感词过滤的实现调研结果写出来了)
几乎所有网站现在都需要设置敏感字过滤,这似乎已经成为网站的标准配置网站. 如果您的网站没有或您没有相应处理,请小心相关部门邀请您喝茶
我最近一直在研究Javaweb网站对于敏感词过滤的实施,我在互联网上找到了相关信息。经过我的核实,我写下了我的研究成果供你参考
一、敏感字过滤工具类
将敏感词词典的内容加载到ArrayList集中,通过双层循环找到与敏感词列表匹配的字符串。如果找到了,用*号替换它,最后得到替换的字符串
该方法匹配度高,匹配速度快
初始化敏感词库:
//初始化敏感词库
public void InitializationWork()
{
replaceAll = new StringBuilder(replceSize);
for(int x=0;x < replceSize;x++)
{
replaceAll.append(replceStr);
}
//加载词库
arrayList = new ArrayList();
InputStreamReader read = null;
BufferedReader bufferedReader = null;
try {
read = new InputStreamReader(SensitiveWord.class.getClassLoader().getResourceAsStream(fileName),encoding);
bufferedReader = new BufferedReader(read);
for(String txt = null;(txt = bufferedReader.readLine()) != null;){
if(!arrayList.contains(txt))
arrayList.add(txt);
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
if(null != bufferedReader)
bufferedReader.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if(null != read)
read.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
筛选敏感词信息:
public String filterInfo(String str)
{
sensitiveWordSet = new HashSet();
sensitiveWordList= new ArrayList();
StringBuilder buffer = new StringBuilder(str);
HashMap hash = new HashMap(arrayList.size());
String temp;
for(int x = 0; x < arrayList.size();x++)
{
temp = arrayList.get(x);
int findIndexSize = 0;
for(int start = -1;(start=buffer.indexOf(temp,findIndexSize)) > -1;)
{
//System.out.println("###replace="+temp);
findIndexSize = start+temp.length();//从已找到的后面开始找
Integer mapStart = hash.get(start);//起始位置
if(mapStart == null || (mapStart != null && findIndexSize > mapStart))//满足1个,即可更新map
{
hash.put(start, findIndexSize);
//System.out.println("###敏感词:"+buffer.substring(start, findIndexSize));
}
}
}
Collection values = hash.keySet();
for(Integer startIndex : values)
{
Integer endIndex = hash.get(startIndex);
//获取敏感词,并加入列表,用来统计数量
String sensitive = buffer.substring(startIndex, endIndex);
//System.out.println("###敏感词:"+sensitive);
if (!sensitive.contains("*")) {//添加敏感词到集合
sensitiveWordSet.add(sensitive);
sensitiveWordList.add(sensitive);
}
buffer.replace(startIndex, endIndex, replaceAll.substring(0,endIndex-startIndex));
}
hash.clear();
return buffer.toString();
}
下载地址:sensitiveword
链接:密码:qmcw(如果无效,请使用文本末尾的地址下载)
二、Java关键词过滤
该方法使用正则表达式匹配,比第一种方法稍慢,匹配度好
主要代码:
// 从words.properties初始化正则表达式字符串
private static void initPattern() {
StringBuffer patternBuffer = new StringBuffer();
try {
//words.properties
InputStream in = KeyWordFilter.class.getClassLoader().getResourceAsStream("keywords.properties");
Properties property = new Properties();
property.load(in);
Enumeration enu = property.propertyNames();
patternBuffer.append("(");
while (enu.hasMoreElements()) {
String scontent = (String) enu.nextElement();
patternBuffer.append(scontent + "|");
//System.out.println(scontent);
keywordsCount ++;
}
patternBuffer.deleteCharAt(patternBuffer.length() - 1);
patternBuffer.append(")");
//System.out.println(patternBuffer);
// unix换成UTF-8
// pattern = Pattern.compile(new
// String(patternBuf.toString().getBytes("ISO-8859-1"), "UTF-8"));
// win下换成gb2312
// pattern = Pattern.compile(new String(patternBuf.toString()
// .getBytes("ISO-8859-1"), "gb2312"));
// 装换编码
pattern = Pattern.compile(patternBuffer.toString());
} catch (IOException ioEx) {
ioEx.printStackTrace();
}
}
private static String doFilter(String str) {
Matcher m = pattern.matcher(str);
// while (m.find()) {// 查找符合pattern的字符串
// System.out.println("The result is here :" + m.group());
// }
// 选择替换方式,这里以* 号代替
str = m.replaceAll("*");
return str;
}
下载地址:关键字过滤器
链接:密码:xi24(如果失败,请在文本末尾下载)
三、DFA滤波算法
在这种情况下,采用了DFA算法。我对这个算法知之甚少。经过测试,发现匹配度不好,速度也不错。也许可以改进。请请求伟大的上帝来改进
有两个主要文件:sensitivewordfilter.java和sensitivewordinit.java
主要代码:
public int CheckSensitiveWord(String txt,int beginIndex,int matchType){
boolean flag = false; //敏感词结束标识位:用于敏感词只有1位的情况
int matchFlag = 0; //匹配标识数默认为0
char word = 0;
Map nowMap = sensitiveWordMap;
for(int i = beginIndex; i < txt.length() ; i++){
word = txt.charAt(i);
nowMap = (Map) nowMap.get(word); //获取指定key
if(nowMap != null){ //存在,则判断是否为最后一个
matchFlag++; //找到相应key,匹配标识+1
if("1".equals(nowMap.get("isEnd"))){ //如果为最后一个匹配规则,结束循环,返回匹配标识数
flag = true; //结束标志位为true
if(SensitivewordFilter.minMatchTYpe == matchType){ //最小规则,直接返回,最大规则还需继续查找
break;
}
}
}
else{ //不存在,直接返回
break;
}
}
if(matchFlag < 2 || !flag){ //长度必须大于等于1,为词
matchFlag = 0;
}
return matchFlag;
}
下载地址:sensitivewordfilter
链接:密码:mc1x(如果无效,请使用文本末尾的地址下载)
四、多树搜索算法
该方法采用多树搜索算法。至于这个算法是怎么回事,您可以检查与数据结构相关的内容。提供了Jar包,可以直接调用它进行过滤
经测试,该方法匹配度好,速度慢
调用方法:
//敏感词过滤
FilteredResult result = WordFilterUtil.filterText(str, '*');
//获取过滤后的内容
System.out.println("替换后的字符串为:\n"+result.getFilteredContent());
//获取原始字符串
System.out.println("原始字符串为:\n"+result.getOriginalContent());
//获取替换的敏感词
System.out.println("替换的敏感词为:\n"+result.getBadWords());
下载地址:wordfilterutil
链接:密码:5t2h(如果无效,请使用文本末尾的地址下载)
采集内容插入词库(什么是关键词词库?排名优化做的就越好)
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-09-16 08:03
关键词排名优化是网站优化的最高优先级。具有大流量和高重量的网站必须具有强大的关键词库支持。对网站关键词同义词表的研究在搜索引擎优化工作中是一件非常重要的事情,但是大多数搜索引擎优化人员没有一个合理的计划关键词库,甚至没有最基本的excel表。事实上,这是一种盲目和随机的行为。它经常导致网站内部关键词竞争,浪费有效的在线资源,优化内容,并造成不必要的负担。你如何通过网站管理员工具或爱站工具看到你自己的网站库关键词?词库越多,网站权重越高,网站优化效果越好
一、让我们首先了解什么是关键词同义词表
简单理解:关键词叙词表是为目标网站和特定关键词. 它通常包括以下类型:
1、industry关键词library和product关键词library
一般来说,不同行业的关键词库具有不同的特点。例如,医疗行业和机械行业之间存在巨大差异。机械行业更注重积累大量产品模型的产品关键词库,而医疗行业则注重医疗术语的扩展
2、广告关键词图书馆
k4图书馆的广告通常服务于品牌建设。它由特定的核心词组成,用来描述企业的概念和产品的特征。同样,它也有责任传播和吸引交通。例如,对于曾经流行的“投诉机构”,您需要整理关键词库中与企业适合性相关的这一部分。它要求内容简短,创造情感共鸣的新词
3、敏感关键词库
对于一个站点,无论是论坛还是独立博客,都需要过滤一些被禁止的关键词,尤其是博客评论的内容。否则,它很可能会被监管机构没收,搜索引擎的权利将被削弱,这往往会超过损失
4、长尾关键词图书馆和流行的关键词图书馆
根据关键字索引,@K17关键词同义词表分为长尾关键词和流行的关键词同义词表,它们是关键词优化的重要参考对象
二、网站关键词库是如何产生的
@K17关键词library是网站管理员工具或爱站tool。根据网站索引和排名在前50名中的排名,关键词排名越高,关键词library关键词越多,获得的流量也越多。这些关键词单词由核心关键词和长尾关键词组成,所以我们应该注意关键词布局和网站内容质量
三、如何创建关键词库1、采集三种类型关键词
关键词一般分为三类:目标关键词、长尾关键词和品牌关键词。由于关键词是采集的,我们一般都会把这三种关键词类型都取下来,但长尾关键词一般是从关键词根展开的,所以抓住关键词根展开是比较正确的方法
有很多方法可以扩展关键词:
百度下拉框,百度相关搜索选择方法,扩展深度3-4层
B.百度索引关键词工具的应用
C.您可以参考百度竞价后台的推广工具关键词planner,它可以准确建立竞价关键词库,也可以作为SEO排名的参考
D.头脑风暴+头脑风暴+竞争对手研究
E.关键词扩展工具,如金华和追字,包括站长工具和爱站网络的关键词挖掘,可用于扩展
可能还有其他一些基本方法,这里不一一介绍。这是一个非常实用的关键词展开方法。与前五种方法不同的是,该方法可以自动无限扩展,只需要根据上述方法找到足够的词根即可。具体的想法是建立一个excl表,水平和垂直排列关键词词根,然后将这些单词自由组合成单个组、双组甚至多个组。当然,这可以通过一个可以快速扩展的函数来实现。可能只需要几分钟。有了这个想法,你就可以自己操作了
2、高质量筛选标准关键词
什么是质量关键词?官方的说法是,能够带来准确客户流量但成本最低的关键词不一定是搜索量最高的关键词或绝对转换关键词. 这样说很空洞,因为我们还没有一个明确的标准
此外,关键词带有“制造商”、“价格”、“十大品牌”或“哪一个好”、“在哪里玩”等问题的词语也有很高的意图关键词. 将这些词扩展为后缀可能会产生许多意想不到的爆炸性效果,但我们应该注意一个前提:数量必须增加,没有数量,这些词的流动可能太微不足道
3、test关键词traffic,点击并转换
事实上,量化关键词的转换经常让许多朋友感到烦恼,因为每个人都对量化标准感到头痛。我们在这里不需要它,因为有太多可量化的数据,比如用户注册量作为转换,用户购买量作为转换,用户点击公司“联系我们”作为转换。网上有很多教程,我只是个老师
我想说的是,在测试过程中,我们应该注意了解关键词的流量和点击流量。如果我们能够分析每个用户搜索的流量和点击流量,并将它们组合起来,我们可能会发现一些用户的搜索意图
例如,百度以这种方式推荐网页。如果你在百度搜索“苹果”,百度会根据绝大多数人的搜索意图推荐信息。你可以看到百度的搜索结果。排名前三的是苹果电子产品官方网站、苹果百科全书和苹果相关视频,这表明搜索这个词的用户最大的需求是对苹果电子产品的理解和需求,想要了解苹果水果市场的人可能相对较少。这样,对用户意图的研究可以为我们的用户提供有用的信息推荐,让用户能够尽快找到自己想要的信息
4、关键词分类库
关键词分类是一项重要任务。对于这里采集的关键词而言,分类非常重要,因此关键词分类的维度可能更详细。当然,这些只是肤浅的想法
四、如何添加网站关键词库
自媒体过滤器关键词
此过滤器关键词与布局网站filter@不同关键词. 您需要选择索引低于100的关键词并且它是一条长尾关键词. 核心关键词索引越大,优化排名就越困难。您必须在K4处过滤更多的长尾巴@
2、优化列页和分类页关键词
网站有很多页面。除了主页、产品详细信息页面和信息详细信息页面外,还有许多专栏页面和分类页面。这些页面权重高,布局有些关键词竞争少,更有利于首页,所以整个网站有更多的关键词排名
3、publish原创文章围绕关键词@
文章@本身可用于长尾关键词优化。在编写文章@时,将关键词整合到标题和文章@内容中。根据文章@优化规则,它不仅可以被百度快速收录搜索,还可以获得很好的排名
4、文章@关键词添加锚文本
有人强调,文章@需要内部的进出口联系。如果这些链接不存在,蜘蛛会认为这是最后一页,不会向下爬行,这不利于网站收录和关键词排名。因此,有必要做好关键词锚链,改进网站内链
小结:我们可以通过网站关键词库看到网站优化的结果。关键词库越少,优化方向就越错误。我们应该及时调整优化策略关键词是长期优化的结果,不可能在几天内出现。我们需要坚持关键词优化,关键词图书馆关键词叙词表中的关键词人才越来越多,对网站内容建设和品牌创建起到了积极的引导作用。它为内容创建和外部链构建指明了方向,节省了资源,提高了工作效率。建立合理的网站关键词库,增加关键词词库是网站长期运行的重要指标。它可以保持网站的活力,提高搜索引擎的友好度和信任度 查看全部
采集内容插入词库(什么是关键词词库?排名优化做的就越好)
关键词排名优化是网站优化的最高优先级。具有大流量和高重量的网站必须具有强大的关键词库支持。对网站关键词同义词表的研究在搜索引擎优化工作中是一件非常重要的事情,但是大多数搜索引擎优化人员没有一个合理的计划关键词库,甚至没有最基本的excel表。事实上,这是一种盲目和随机的行为。它经常导致网站内部关键词竞争,浪费有效的在线资源,优化内容,并造成不必要的负担。你如何通过网站管理员工具或爱站工具看到你自己的网站库关键词?词库越多,网站权重越高,网站优化效果越好
一、让我们首先了解什么是关键词同义词表
简单理解:关键词叙词表是为目标网站和特定关键词. 它通常包括以下类型:
1、industry关键词library和product关键词library
一般来说,不同行业的关键词库具有不同的特点。例如,医疗行业和机械行业之间存在巨大差异。机械行业更注重积累大量产品模型的产品关键词库,而医疗行业则注重医疗术语的扩展
2、广告关键词图书馆
k4图书馆的广告通常服务于品牌建设。它由特定的核心词组成,用来描述企业的概念和产品的特征。同样,它也有责任传播和吸引交通。例如,对于曾经流行的“投诉机构”,您需要整理关键词库中与企业适合性相关的这一部分。它要求内容简短,创造情感共鸣的新词
3、敏感关键词库
对于一个站点,无论是论坛还是独立博客,都需要过滤一些被禁止的关键词,尤其是博客评论的内容。否则,它很可能会被监管机构没收,搜索引擎的权利将被削弱,这往往会超过损失
4、长尾关键词图书馆和流行的关键词图书馆
根据关键字索引,@K17关键词同义词表分为长尾关键词和流行的关键词同义词表,它们是关键词优化的重要参考对象
二、网站关键词库是如何产生的

@K17关键词library是网站管理员工具或爱站tool。根据网站索引和排名在前50名中的排名,关键词排名越高,关键词library关键词越多,获得的流量也越多。这些关键词单词由核心关键词和长尾关键词组成,所以我们应该注意关键词布局和网站内容质量
三、如何创建关键词库1、采集三种类型关键词
关键词一般分为三类:目标关键词、长尾关键词和品牌关键词。由于关键词是采集的,我们一般都会把这三种关键词类型都取下来,但长尾关键词一般是从关键词根展开的,所以抓住关键词根展开是比较正确的方法
有很多方法可以扩展关键词:
百度下拉框,百度相关搜索选择方法,扩展深度3-4层
B.百度索引关键词工具的应用
C.您可以参考百度竞价后台的推广工具关键词planner,它可以准确建立竞价关键词库,也可以作为SEO排名的参考
D.头脑风暴+头脑风暴+竞争对手研究
E.关键词扩展工具,如金华和追字,包括站长工具和爱站网络的关键词挖掘,可用于扩展
可能还有其他一些基本方法,这里不一一介绍。这是一个非常实用的关键词展开方法。与前五种方法不同的是,该方法可以自动无限扩展,只需要根据上述方法找到足够的词根即可。具体的想法是建立一个excl表,水平和垂直排列关键词词根,然后将这些单词自由组合成单个组、双组甚至多个组。当然,这可以通过一个可以快速扩展的函数来实现。可能只需要几分钟。有了这个想法,你就可以自己操作了
2、高质量筛选标准关键词
什么是质量关键词?官方的说法是,能够带来准确客户流量但成本最低的关键词不一定是搜索量最高的关键词或绝对转换关键词. 这样说很空洞,因为我们还没有一个明确的标准
此外,关键词带有“制造商”、“价格”、“十大品牌”或“哪一个好”、“在哪里玩”等问题的词语也有很高的意图关键词. 将这些词扩展为后缀可能会产生许多意想不到的爆炸性效果,但我们应该注意一个前提:数量必须增加,没有数量,这些词的流动可能太微不足道
3、test关键词traffic,点击并转换
事实上,量化关键词的转换经常让许多朋友感到烦恼,因为每个人都对量化标准感到头痛。我们在这里不需要它,因为有太多可量化的数据,比如用户注册量作为转换,用户购买量作为转换,用户点击公司“联系我们”作为转换。网上有很多教程,我只是个老师
我想说的是,在测试过程中,我们应该注意了解关键词的流量和点击流量。如果我们能够分析每个用户搜索的流量和点击流量,并将它们组合起来,我们可能会发现一些用户的搜索意图
例如,百度以这种方式推荐网页。如果你在百度搜索“苹果”,百度会根据绝大多数人的搜索意图推荐信息。你可以看到百度的搜索结果。排名前三的是苹果电子产品官方网站、苹果百科全书和苹果相关视频,这表明搜索这个词的用户最大的需求是对苹果电子产品的理解和需求,想要了解苹果水果市场的人可能相对较少。这样,对用户意图的研究可以为我们的用户提供有用的信息推荐,让用户能够尽快找到自己想要的信息
4、关键词分类库
关键词分类是一项重要任务。对于这里采集的关键词而言,分类非常重要,因此关键词分类的维度可能更详细。当然,这些只是肤浅的想法
四、如何添加网站关键词库

自媒体过滤器关键词
此过滤器关键词与布局网站filter@不同关键词. 您需要选择索引低于100的关键词并且它是一条长尾关键词. 核心关键词索引越大,优化排名就越困难。您必须在K4处过滤更多的长尾巴@
2、优化列页和分类页关键词
网站有很多页面。除了主页、产品详细信息页面和信息详细信息页面外,还有许多专栏页面和分类页面。这些页面权重高,布局有些关键词竞争少,更有利于首页,所以整个网站有更多的关键词排名
3、publish原创文章围绕关键词@
文章@本身可用于长尾关键词优化。在编写文章@时,将关键词整合到标题和文章@内容中。根据文章@优化规则,它不仅可以被百度快速收录搜索,还可以获得很好的排名
4、文章@关键词添加锚文本
有人强调,文章@需要内部的进出口联系。如果这些链接不存在,蜘蛛会认为这是最后一页,不会向下爬行,这不利于网站收录和关键词排名。因此,有必要做好关键词锚链,改进网站内链
小结:我们可以通过网站关键词库看到网站优化的结果。关键词库越少,优化方向就越错误。我们应该及时调整优化策略关键词是长期优化的结果,不可能在几天内出现。我们需要坚持关键词优化,关键词图书馆关键词叙词表中的关键词人才越来越多,对网站内容建设和品牌创建起到了积极的引导作用。它为内容创建和外部链构建指明了方向,节省了资源,提高了工作效率。建立合理的网站关键词库,增加关键词词库是网站长期运行的重要指标。它可以保持网站的活力,提高搜索引擎的友好度和信任度
采集内容插入词库(如何增加站长词库的数量,有效收录以参与排名?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 218 次浏览 • 2021-09-16 06:27
如何增加站长叙词表的数量并有效收录参与排名?如果你想增加网站同义词表的数量,如何优化站内外操作,提高域名的信任度,提高收录的有效性@
如何增加叙词表的数量?叙词表数量的提高取决于索引词的排名,而网站管理员工具的叙词表数量是将网站索引词的构建和生产名称排名到前50名,这被纳入叙词表。为了提高叙词表的数量,我们需要准备可靠的索引词,优化索引词的布局,并有效地收录网页以参与排名。因此,有必要对网站内外进行优化,并有效地将网页纳入参与排名的同义词库
1、如何增加网站企业网络公司关键词词库数量
为提高网站建设技能词典中自助网站建设cms的索引词数量,江门中资企业建议组织优化索引词布局,优化网站内外,提升域名信任度,增加有效网站建设教程页面集合,使有效收录页面有机会参与叙词表排名。随着叙词表数量的增加,有必要明确优化后的索引词网站construction service,并做好索引词在网页标题和文本中的布局。外链锚文本的建设将进一步提升索引词排名,提升自助网站名称。如果索引词在前50名,那么它们将在同义词表中为收录
2、template website building system的源代码同义词表中添加索引词的前提是它可以有效地收录网页
有效的收录网页是参与关键词排名的前提。自助网站建设系统个人网站可以在搜索结果页面的第一位显示搜索页面的标题,这是一个有效的收录网页。如何增加网页的有效数量,优化内置网站容量,并生成高质量的文章网站内容应高度垂直和专业;做好网站内链建设、模板站点建设,优化网站内链和外链,提升域名信任度。索引词叙词表数量的增加是索引词排列和网站建设系统的名称跻身模板网站建设前50名优缺点的原因。因此,有必要改进网站关键词排名,改进网站叙词表排名操作,做好网站内外优化,改进域名信息网站建设服务,优化叙词表布局,更新发布内容,构建外链锚文本,并点击用户的搜索行为,模板站点phpwind,提升模板站点harm网站同义词表的排名
同义词表的增加取决于网站的有效收录。大多数具有大量同义词的网站参与整个网站的排名,而不是单个主页。参与排名的页面也反映了网站优化的质量。如果你想参与叙词表排名的竞争,前提是提高网页收录的有效性,而收录网站的有效构建源代码依赖于内容的优化和有价值的内部资源。荣毅仁有资格被纳入自助网站建设指数并发布参与排名 查看全部
采集内容插入词库(如何增加站长词库的数量,有效收录以参与排名?)
如何增加站长叙词表的数量并有效收录参与排名?如果你想增加网站同义词表的数量,如何优化站内外操作,提高域名的信任度,提高收录的有效性@
如何增加叙词表的数量?叙词表数量的提高取决于索引词的排名,而网站管理员工具的叙词表数量是将网站索引词的构建和生产名称排名到前50名,这被纳入叙词表。为了提高叙词表的数量,我们需要准备可靠的索引词,优化索引词的布局,并有效地收录网页以参与排名。因此,有必要对网站内外进行优化,并有效地将网页纳入参与排名的同义词库
1、如何增加网站企业网络公司关键词词库数量
为提高网站建设技能词典中自助网站建设cms的索引词数量,江门中资企业建议组织优化索引词布局,优化网站内外,提升域名信任度,增加有效网站建设教程页面集合,使有效收录页面有机会参与叙词表排名。随着叙词表数量的增加,有必要明确优化后的索引词网站construction service,并做好索引词在网页标题和文本中的布局。外链锚文本的建设将进一步提升索引词排名,提升自助网站名称。如果索引词在前50名,那么它们将在同义词表中为收录
2、template website building system的源代码同义词表中添加索引词的前提是它可以有效地收录网页
有效的收录网页是参与关键词排名的前提。自助网站建设系统个人网站可以在搜索结果页面的第一位显示搜索页面的标题,这是一个有效的收录网页。如何增加网页的有效数量,优化内置网站容量,并生成高质量的文章网站内容应高度垂直和专业;做好网站内链建设、模板站点建设,优化网站内链和外链,提升域名信任度。索引词叙词表数量的增加是索引词排列和网站建设系统的名称跻身模板网站建设前50名优缺点的原因。因此,有必要改进网站关键词排名,改进网站叙词表排名操作,做好网站内外优化,改进域名信息网站建设服务,优化叙词表布局,更新发布内容,构建外链锚文本,并点击用户的搜索行为,模板站点phpwind,提升模板站点harm网站同义词表的排名
同义词表的增加取决于网站的有效收录。大多数具有大量同义词的网站参与整个网站的排名,而不是单个主页。参与排名的页面也反映了网站优化的质量。如果你想参与叙词表排名的竞争,前提是提高网页收录的有效性,而收录网站的有效构建源代码依赖于内容的优化和有价值的内部资源。荣毅仁有资格被纳入自助网站建设指数并发布参与排名
采集内容插入词库(【干货】采集内容插入词库;设置anti-spam超级爬虫程序)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-16 03:00
采集内容插入词库;设置anti-spam超级爬虫程序,默认爬取文章标题、内容描述、下图、评论。人工批量筛选内容;分词识别出特定词,并准备下次搜索,或移除已经匹配到的词。搜索前看看是否已匹配到词,再决定是否搜索。网址上了图片或者评论,需要前面有说明,如文章已经打码。之前想着发布在我的博客或者文章列表里没事就不进行系统的分词对,这次要注意下。
统计数据在什么时间或者怎么登录的,数据有多少,好做什么更有价值。网址和网站维护者等等。如果是anti-spam加速的,提取出来的内容可能被“蹭”到。把一些系统分词不方便分词的统计下他们爬虫抓的内容有多少。随机一个需要统计爬虫抓取什么内容的网站,批量爬虫遍历一遍。
对搜索引擎来说,关键不是多少文章,而是多少搜索量。以google+为例,想方设法提高分享率,提高followup数,将页面尽可能多分享,提高点击率,提高评论率,这样你就会有更多的收入。毕竟。搞了这么多天你肯定是不缺收入的。
检测banner是否会被调用,
写一个很丑的检测banner的插件
找出引起流量下滑的原因。从用户需求出发,找准几个潜在可能的需求。例如你的产品定位是通过数据分析来引导、指导、改进的行业应用。那么这次的抽样数据你考虑利用的方向是哪里?或者是过去的数据,当代有价值但不能代表未来的数据?那你就需要想办法去抓取和加工。例如你想要数据分析,那么你把所有的做数据分析的抓取了,是什么类型,什么方式,那他会在其他哪些有价值的方面对你做出有价值的指导?你是想通过数据来做过去或者现在的分析还是结合你的公司,分析背后的行业特点,那你就可以去收集已有的公司的数据了。
加上你的行业分析可以做出怎样的预测和判断。如果用户都不能代替你去实际分析出用户需求,那就不是你要做的数据分析。相反,如果你是指望着通过用户去分析,并且通过分析得出几个有价值的结论,那你最好做些筛选,哪些数据是你真正想了解的?那筛选就得去做用户分析,那你抓取的数据一定不能是已有的或者是简单的数据,是对你有价值的。
可以使用各种方式去利用数据去挖掘出用户真正的需求是什么,做到用户需求是你为什么能够实现企业的业务增长,以及需求的真正程度,来进行做调整,提升需求结果。例如你有一个做金融的企业,那你可以通过他的需求结果就可以联想到他的应用层的,需求的能力,也可以知道目前他的数据有多少,需要跟金融类相关的哪些数据。另外一个,你可以通过你公司员工的数据来找到这个员工平时的消费习惯,周边的。 查看全部
采集内容插入词库(【干货】采集内容插入词库;设置anti-spam超级爬虫程序)
采集内容插入词库;设置anti-spam超级爬虫程序,默认爬取文章标题、内容描述、下图、评论。人工批量筛选内容;分词识别出特定词,并准备下次搜索,或移除已经匹配到的词。搜索前看看是否已匹配到词,再决定是否搜索。网址上了图片或者评论,需要前面有说明,如文章已经打码。之前想着发布在我的博客或者文章列表里没事就不进行系统的分词对,这次要注意下。
统计数据在什么时间或者怎么登录的,数据有多少,好做什么更有价值。网址和网站维护者等等。如果是anti-spam加速的,提取出来的内容可能被“蹭”到。把一些系统分词不方便分词的统计下他们爬虫抓的内容有多少。随机一个需要统计爬虫抓取什么内容的网站,批量爬虫遍历一遍。
对搜索引擎来说,关键不是多少文章,而是多少搜索量。以google+为例,想方设法提高分享率,提高followup数,将页面尽可能多分享,提高点击率,提高评论率,这样你就会有更多的收入。毕竟。搞了这么多天你肯定是不缺收入的。
检测banner是否会被调用,
写一个很丑的检测banner的插件
找出引起流量下滑的原因。从用户需求出发,找准几个潜在可能的需求。例如你的产品定位是通过数据分析来引导、指导、改进的行业应用。那么这次的抽样数据你考虑利用的方向是哪里?或者是过去的数据,当代有价值但不能代表未来的数据?那你就需要想办法去抓取和加工。例如你想要数据分析,那么你把所有的做数据分析的抓取了,是什么类型,什么方式,那他会在其他哪些有价值的方面对你做出有价值的指导?你是想通过数据来做过去或者现在的分析还是结合你的公司,分析背后的行业特点,那你就可以去收集已有的公司的数据了。
加上你的行业分析可以做出怎样的预测和判断。如果用户都不能代替你去实际分析出用户需求,那就不是你要做的数据分析。相反,如果你是指望着通过用户去分析,并且通过分析得出几个有价值的结论,那你最好做些筛选,哪些数据是你真正想了解的?那筛选就得去做用户分析,那你抓取的数据一定不能是已有的或者是简单的数据,是对你有价值的。
可以使用各种方式去利用数据去挖掘出用户真正的需求是什么,做到用户需求是你为什么能够实现企业的业务增长,以及需求的真正程度,来进行做调整,提升需求结果。例如你有一个做金融的企业,那你可以通过他的需求结果就可以联想到他的应用层的,需求的能力,也可以知道目前他的数据有多少,需要跟金融类相关的哪些数据。另外一个,你可以通过你公司员工的数据来找到这个员工平时的消费习惯,周边的。
采集内容插入词库(腾讯语料(名词)、词库词表双中转换的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-09-14 01:01
采集内容插入词库,查询内容插入词库,词库中的内容都是经过实词实时语义分析工具-腾讯语料(名词)、词库词表双中转换的,词库中的词是经过相应的语义分析工具判断匹配的词。大数据语料具体是多大的量级,具体怎么收集,有很多算法都能做。目前你能做的就是把你的关键词可以用在很多场景,取长补短,把词的质量做上去。
可以试试印象笔记,他可以将词库同步到云端,方便跨平台同步,微信、手机qq等都可以登录查看。
可以用“叮当语料库”,他家有关键词标注服务,可以输入一些关键词,标注一些词,
其实有很多,比如以前很流行的知网收录。但是单纯做应用的话,用什么都一样吧。
有,比如出过一本书,里面用到了《得到》里的内容。作者,马力,我忘了名字,学到的我想用到自己的写作上,可以直接在叮当语料库导入得到提升。
手机padwifiwifi环境下可以接入百度数据库,他是提供了免费试用版的,虽然名字是国内最大的百度数据库。
这种情况有很多,
很多,比如,出书。微信会提供。
;genuniv=2
叮当
有brainyhull,不过brainyhull是为外文使用需求开发的。就中文使用情况来看,目前主要是百度口碑,以及百度翻译。
因为有外文数据需求,所以用百度等搜索引擎查找过。然后,找到一些查阅资料推荐给大家。 查看全部
采集内容插入词库(腾讯语料(名词)、词库词表双中转换的)
采集内容插入词库,查询内容插入词库,词库中的内容都是经过实词实时语义分析工具-腾讯语料(名词)、词库词表双中转换的,词库中的词是经过相应的语义分析工具判断匹配的词。大数据语料具体是多大的量级,具体怎么收集,有很多算法都能做。目前你能做的就是把你的关键词可以用在很多场景,取长补短,把词的质量做上去。
可以试试印象笔记,他可以将词库同步到云端,方便跨平台同步,微信、手机qq等都可以登录查看。
可以用“叮当语料库”,他家有关键词标注服务,可以输入一些关键词,标注一些词,
其实有很多,比如以前很流行的知网收录。但是单纯做应用的话,用什么都一样吧。
有,比如出过一本书,里面用到了《得到》里的内容。作者,马力,我忘了名字,学到的我想用到自己的写作上,可以直接在叮当语料库导入得到提升。
手机padwifiwifi环境下可以接入百度数据库,他是提供了免费试用版的,虽然名字是国内最大的百度数据库。
这种情况有很多,
很多,比如,出书。微信会提供。
;genuniv=2
叮当
有brainyhull,不过brainyhull是为外文使用需求开发的。就中文使用情况来看,目前主要是百度口碑,以及百度翻译。
因为有外文数据需求,所以用百度等搜索引擎查找过。然后,找到一些查阅资料推荐给大家。
采集内容插入词库(百度的ip地址和手机号是怎么采集内容的?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-09-12 10:02
采集内容插入词库。目前百度统计、地图、腾讯地图、高德等都可以采集内容信息。搜狗和360的信息采集内容不全但是作为辅助来用。其次,百度的ip地址和手机号一般是通过识别的方式来实现。最后,无法采集是因为它内部有一套完整的爬虫系统,遇到正则表达式都能搜出来。另外,这些网站上的数据一般都是实时更新的,非定时更新。
百度并不会直接获取到用户的上网行为,因为它只是抓取用户访问以及定位到的上网信息。不同的上网行为被列在不同的表格里,而百度并不会把相同的表格放到一起。但百度是可以通过一定的搜索习惯等方式,来判断你对同一个搜索出现的情况的概率,从而做到有针对性的精准投放。
是有cookie的!!
百度会为不同情况做差异化识别和推送,不同情况不同策略,搜索手机和定位都是加上了时间戳,记录搜索内容发生的时间,
搜索端与一般网站定位策略不一样。但也不难理解百度都用时间戳了,不会随便乱跳。
百度的工程师都是吃配置的吧?
百度的ip定位是通过分析链接定位,百度要给你推送多少页,目标网站就留多少ip。所以还是有误差。至于想采集所有ip,那是不可能的。 查看全部
采集内容插入词库(百度的ip地址和手机号是怎么采集内容的?)
采集内容插入词库。目前百度统计、地图、腾讯地图、高德等都可以采集内容信息。搜狗和360的信息采集内容不全但是作为辅助来用。其次,百度的ip地址和手机号一般是通过识别的方式来实现。最后,无法采集是因为它内部有一套完整的爬虫系统,遇到正则表达式都能搜出来。另外,这些网站上的数据一般都是实时更新的,非定时更新。
百度并不会直接获取到用户的上网行为,因为它只是抓取用户访问以及定位到的上网信息。不同的上网行为被列在不同的表格里,而百度并不会把相同的表格放到一起。但百度是可以通过一定的搜索习惯等方式,来判断你对同一个搜索出现的情况的概率,从而做到有针对性的精准投放。
是有cookie的!!
百度会为不同情况做差异化识别和推送,不同情况不同策略,搜索手机和定位都是加上了时间戳,记录搜索内容发生的时间,
搜索端与一般网站定位策略不一样。但也不难理解百度都用时间戳了,不会随便乱跳。
百度的工程师都是吃配置的吧?
百度的ip定位是通过分析链接定位,百度要给你推送多少页,目标网站就留多少ip。所以还是有误差。至于想采集所有ip,那是不可能的。
采集内容插入词库(石青SEO伪原创工具使用教程安装软件伪工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2021-09-10 06:02
石青SEO伪原创工具是很多站长使用的辅助工具。大家都知道网站排行和原创的内容有很大关系。这个seo伪原创工具可以帮到你,那我该怎么用呢?一起来看看吧!
石青SEO伪原创工具使用教程
1.安装软件
伪原创工具完全不需要安装,直接下载绿色免费版,解压后执行目录下的genagent.exe文件即可启动。
启动后界面如下:
2.采集文章
石青伪原创tools,自带采集tools。首先,您需要在“采集Settings”模块中输入需要采集 的关键词。录入完成后点击“保存关键词”,单词会被保存,然后勾选(默认勾选)。然后选择是在百度还是谷歌采集。如果您是免费试用用户。只能使用第一个“免费测试采集”。
点击“Content采集”,稍等片刻,数据会慢慢进来采集,采集到达的数据会显示在“Network原创文章专家”界面。如果您想停止采集,请返回“采集设置”界面,然后点击“停止采集”。
使用“采集文章并争夺生成文章”功能,可以根据选择的代数动态生成无数文章文章。
3.制作伪原创文章
用户可以通过4种方式输入原来的文章,1、直接将文章复制到文章编辑区,然后输入标题,然后通过导入保存文章;2、,你可以直接导入TXT或html文档,3、通过采集,在网上直接采集到文章,4、直接通过接口获取自己的cms网站内容;
获得文章后,用户可以通过3种方式制作伪原创文章:
1、 也是最简单的。只需点击文章标题,然后点击界面底部的“生成原创”按钮即可。现在伪原创之后的文章将显示在“伪原创文章预览区”中;
2、采用导出方式,可以将所有勾选的文章批次直接导出为TXT或HTML文章;
3、通过接口直接批量伪原创到自己的cms网站。
下图是导出方法。采用导出方式时,系统会按照设置的伪原创配置,勾选伪原创,文章再导出;
“伪原创工具”生成的文章质量取决于“原创文章生成规则”。当规则超过5000条时,伪原创文章的质量会很高。
4.用于直接更新主流cmssystem
石青伪原创工具,支持99%国内主流cms内容的直接更新,如东夷、老鸭、新云、德德cms等,通过界面直接获取站内信息,然后伪原创后上传回来。具体使用方法在界面中有详细说明。按照说明一步一步来,你很快就会成功。
为什么要设置此功能?一般现在主流网站是:90%的个人或企业都是cms。 cms中都自带采集功能,外围也可以使用“优采云”等第三方工具转采集。面对采集返回的大量数据,如何伪原创成为一个令人担忧的问题。
世青SEO工具提供无缝cms接口,可以直接伪原创采集到cms数据库数据,适合99%使用虚拟主机建站不能直接操作cms的客户数据库自己。上传界面,获取内容,直接伪原创。 伪原创只要3段就可以完成。
5.使用自定义词库
用户可以在自定义词典部分输入或导入自己的同义词库。勾选后,系统会尽快响应该词库,而不是替换我们企业版中的词库。具体使用方法在软件界面中有详细说明。免费版不支持此功能。
6.配置替换/插入功能
这个功能主要是在伪原创之后文章指定的文字中添加一个URL链接,做一个外部链接。同时也可以根据配置的关键词密度插入集合关键词。
首先点击“配置替换/插入功能”,打开一个配置界面,在这里可以输入要添加什么文字到跳转链接。源文本:源文本,对应的URL:要重定向的链接,如下图勾选。
生成伪原创后,点击各种“替换链接”功能,为文章中的文本添加一个URL链接。
如果选择“Insert 关键词 as set”,系统会插入指定的密度设置关键词。
7. 从现有的文章 生成新的文章
这个函数主要是动态生成文章的工具。生成的文章 绝对独一无二,但通常可读。点击SEO功能,然后选择最后一个菜单“从现有的文章生成新的文章”,就这样了。
伪原创如何使用工具?石青SEO伪原创工具使用教程由欧普下载整理发布,欢迎转载! 查看全部
采集内容插入词库(石青SEO伪原创工具使用教程安装软件伪工具)
石青SEO伪原创工具是很多站长使用的辅助工具。大家都知道网站排行和原创的内容有很大关系。这个seo伪原创工具可以帮到你,那我该怎么用呢?一起来看看吧!
石青SEO伪原创工具使用教程
1.安装软件
伪原创工具完全不需要安装,直接下载绿色免费版,解压后执行目录下的genagent.exe文件即可启动。

启动后界面如下:

2.采集文章
石青伪原创tools,自带采集tools。首先,您需要在“采集Settings”模块中输入需要采集 的关键词。录入完成后点击“保存关键词”,单词会被保存,然后勾选(默认勾选)。然后选择是在百度还是谷歌采集。如果您是免费试用用户。只能使用第一个“免费测试采集”。

点击“Content采集”,稍等片刻,数据会慢慢进来采集,采集到达的数据会显示在“Network原创文章专家”界面。如果您想停止采集,请返回“采集设置”界面,然后点击“停止采集”。
使用“采集文章并争夺生成文章”功能,可以根据选择的代数动态生成无数文章文章。
3.制作伪原创文章
用户可以通过4种方式输入原来的文章,1、直接将文章复制到文章编辑区,然后输入标题,然后通过导入保存文章;2、,你可以直接导入TXT或html文档,3、通过采集,在网上直接采集到文章,4、直接通过接口获取自己的cms网站内容;

获得文章后,用户可以通过3种方式制作伪原创文章:
1、 也是最简单的。只需点击文章标题,然后点击界面底部的“生成原创”按钮即可。现在伪原创之后的文章将显示在“伪原创文章预览区”中;
2、采用导出方式,可以将所有勾选的文章批次直接导出为TXT或HTML文章;
3、通过接口直接批量伪原创到自己的cms网站。
下图是导出方法。采用导出方式时,系统会按照设置的伪原创配置,勾选伪原创,文章再导出;

“伪原创工具”生成的文章质量取决于“原创文章生成规则”。当规则超过5000条时,伪原创文章的质量会很高。
4.用于直接更新主流cmssystem
石青伪原创工具,支持99%国内主流cms内容的直接更新,如东夷、老鸭、新云、德德cms等,通过界面直接获取站内信息,然后伪原创后上传回来。具体使用方法在界面中有详细说明。按照说明一步一步来,你很快就会成功。

为什么要设置此功能?一般现在主流网站是:90%的个人或企业都是cms。 cms中都自带采集功能,外围也可以使用“优采云”等第三方工具转采集。面对采集返回的大量数据,如何伪原创成为一个令人担忧的问题。
世青SEO工具提供无缝cms接口,可以直接伪原创采集到cms数据库数据,适合99%使用虚拟主机建站不能直接操作cms的客户数据库自己。上传界面,获取内容,直接伪原创。 伪原创只要3段就可以完成。
5.使用自定义词库
用户可以在自定义词典部分输入或导入自己的同义词库。勾选后,系统会尽快响应该词库,而不是替换我们企业版中的词库。具体使用方法在软件界面中有详细说明。免费版不支持此功能。

6.配置替换/插入功能
这个功能主要是在伪原创之后文章指定的文字中添加一个URL链接,做一个外部链接。同时也可以根据配置的关键词密度插入集合关键词。
首先点击“配置替换/插入功能”,打开一个配置界面,在这里可以输入要添加什么文字到跳转链接。源文本:源文本,对应的URL:要重定向的链接,如下图勾选。

生成伪原创后,点击各种“替换链接”功能,为文章中的文本添加一个URL链接。

如果选择“Insert 关键词 as set”,系统会插入指定的密度设置关键词。



7. 从现有的文章 生成新的文章
这个函数主要是动态生成文章的工具。生成的文章 绝对独一无二,但通常可读。点击SEO功能,然后选择最后一个菜单“从现有的文章生成新的文章”,就这样了。
伪原创如何使用工具?石青SEO伪原创工具使用教程由欧普下载整理发布,欢迎转载!
采集内容插入词库(采采系列之采集数据处理大师主要功能:增加多内容合并功能 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-08 23:00
)
挖矿系列的采集数据处理大师,以及与之配合的一系列软件,如邮箱采集、手机号采集、邮箱注册等
采集系列采集数据处理大师的主要功能:
1、使用字典对内容进行伪原创处理,可以是数据表中的一个或多个字段;
2、繁简交流,处理一些特殊的词,如:鼠标“-”鼠标;程序“-”程序;网络“-”网络;
3、使用谷歌和必应提供的API将中文内容翻译成英文(就可读性而言,该程序无能为力);
4、timing start优采云采集程序采集,目前只能控制到每个站点,不能精确到每个任务;
5、各词典编辑功能
6、多库支持,目前支持MS SQL、SQLite、MySQL、Access
采集采集系列数据处理大师,2012年12月更改
1、添加分词提取描述功能
2、添加添加自定义关键字功能(可限制次数)
3、添加自定义链接功能(可限制次数)
4、添加有道翻译引擎
5、添加更多翻译语言选项
6、添加打乱文章段落顺序的功能
7、添加关键字添加链接功能
8、增加文本内容前后添加自定义内容功能
9、添加多内容合并功能
10、在数据浏览中添加网页浏览表单
11、增加任务执行过程中停止任务的功能
12、去掉计时采集函数(原因不解释)
13、 添加进度条显示
14、多线程执行任务,程序不再卡顿,但是因为涉及到数据处理,所以在处理数据的时候还是单线程的,主要是出于数据安全的考虑
查看全部
采集内容插入词库(采采系列之采集数据处理大师主要功能:增加多内容合并功能
)
挖矿系列的采集数据处理大师,以及与之配合的一系列软件,如邮箱采集、手机号采集、邮箱注册等
采集系列采集数据处理大师的主要功能:
1、使用字典对内容进行伪原创处理,可以是数据表中的一个或多个字段;
2、繁简交流,处理一些特殊的词,如:鼠标“-”鼠标;程序“-”程序;网络“-”网络;
3、使用谷歌和必应提供的API将中文内容翻译成英文(就可读性而言,该程序无能为力);
4、timing start优采云采集程序采集,目前只能控制到每个站点,不能精确到每个任务;
5、各词典编辑功能
6、多库支持,目前支持MS SQL、SQLite、MySQL、Access
采集采集系列数据处理大师,2012年12月更改
1、添加分词提取描述功能
2、添加添加自定义关键字功能(可限制次数)
3、添加自定义链接功能(可限制次数)
4、添加有道翻译引擎
5、添加更多翻译语言选项
6、添加打乱文章段落顺序的功能
7、添加关键字添加链接功能
8、增加文本内容前后添加自定义内容功能
9、添加多内容合并功能
10、在数据浏览中添加网页浏览表单
11、增加任务执行过程中停止任务的功能
12、去掉计时采集函数(原因不解释)
13、 添加进度条显示
14、多线程执行任务,程序不再卡顿,但是因为涉及到数据处理,所以在处理数据的时候还是单线程的,主要是出于数据安全的考虑

采集内容插入词库(搜狗细胞词库:Python实现思路1.获取大分类列表(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-08 05:21
Python搜狗词库介绍批量下载
搜狗的细胞词库是一个开放共享的词库,采集了很多网友提交的词信息。从搜狗细胞词库首页的最新数据来看,19520名网友共创建了27695个词库。 48482247 个条目。当然,我下载了之后,并没有计算有没有这么多条目。有兴趣的朋友可以试试。接下来简单讲解一下如何批量下载搜狗词库。 (我看了看,好像下载的没那么多),这篇文章就是分析一下我的想法,完整程序请进:
Python实现思路1.获取大类列表
首先观察搜狗细胞词库的网站,如下图:
首页有词库分类,这样问题就转化为下载每个分类下的词库了。随机选择一个词库,点击进入观察(我选择第一个),如下图:
这里我们找到了搜狗细胞词库的十二大类:
“城市信息”、“自然科学”、“社会科学”、“工程应用”、“农林渔业和畜牧业”、“医学”、“电子游戏”、“艺术设计”、“百科全书” 《生活》、《运动与休闲》、《人文》、《娱乐与休闲》
写一个函数:
def get_cate_1_list(res_html):
# 获取大分类链接
dict_cate_1_urls = []
soup = BeautifulSoup(res_html, "html.parser")
dict_nav = soup.find("div", id="dict_nav_list")
dict_nav_lists = dict_nav.find_all("a")
for dict_nav_list in dict_nav_lists:
dict_nav_url = "https://pinyin.sogou.com" + dict_nav_list['href']
dict_cate_1_urls.append(dict_nav_url)
return dict_cate_1_urls
将上面页面的源码传给这个函数,我们就可以解析出十二大类对应的链接地址。
2. 获取小类字典
通过分析观察,我们可以发现“城市信息”类别下的子类别与其他11个类别下的子类别略有不同,如下图所示:
因此,这里我们要写两个方法来解析和获取小类别:
def get_cate_2_1_list(res_html):
# 获取第一种小分类链接
dict_cate_2_1_dict = {}
soup = BeautifulSoup(res_html, "html.parser")
dict_td_lists = soup.find_all("div", class_="cate_no_child citylistcate no_select")
for dict_td_list in dict_td_lists:
dict_td_url = "https://pinyin.sogou.com" + dict_td_list.a['href']
dict_cate_2_1_dict[dict_td_list.get_text().replace("\n", "")] = dict_td_url
return dict_cate_2_1_dict
def get_cate_2_2_list(res_html):
# 获取第二种小分类链接
dict_cate_2_2_dict = {}
soup = BeautifulSoup(res_html, "html.parser")
dict_td_lists = soup.find_all("div", class_="cate_no_child no_select")
# 类型1解析
for dict_td_list in dict_td_lists:
dict_td_url = "https://pinyin.sogou.com" + dict_td_list.a['href']
dict_cate_2_2_dict[dict_td_list.get_text().replace("\n", "")] = dict_td_url
# 类型2解析
dict_td_lists = soup.find_all("div", class_="cate_has_child no_select")
for dict_td_list in dict_td_lists:
dict_td_url = "https://pinyin.sogou.com" + dict_td_list.a['href']
dict_cate_2_2_dict[dict_td_list.get_text().replace("\n", "")] = dict_td_url
return dict_cate_2_2_dict
其中,你会发现为什么第二个函数中多了两个类型?这里的原因是有一些小类别和他们自己的小类别。有些有,有些没有,这导致需要分别解决两种类型的子类别。 查看全部
采集内容插入词库(搜狗细胞词库:Python实现思路1.获取大分类列表(组图))
Python搜狗词库介绍批量下载
搜狗的细胞词库是一个开放共享的词库,采集了很多网友提交的词信息。从搜狗细胞词库首页的最新数据来看,19520名网友共创建了27695个词库。 48482247 个条目。当然,我下载了之后,并没有计算有没有这么多条目。有兴趣的朋友可以试试。接下来简单讲解一下如何批量下载搜狗词库。 (我看了看,好像下载的没那么多),这篇文章就是分析一下我的想法,完整程序请进:
Python实现思路1.获取大类列表
首先观察搜狗细胞词库的网站,如下图:

首页有词库分类,这样问题就转化为下载每个分类下的词库了。随机选择一个词库,点击进入观察(我选择第一个),如下图:
这里我们找到了搜狗细胞词库的十二大类:
“城市信息”、“自然科学”、“社会科学”、“工程应用”、“农林渔业和畜牧业”、“医学”、“电子游戏”、“艺术设计”、“百科全书” 《生活》、《运动与休闲》、《人文》、《娱乐与休闲》
写一个函数:
def get_cate_1_list(res_html):
# 获取大分类链接
dict_cate_1_urls = []
soup = BeautifulSoup(res_html, "html.parser")
dict_nav = soup.find("div", id="dict_nav_list")
dict_nav_lists = dict_nav.find_all("a")
for dict_nav_list in dict_nav_lists:
dict_nav_url = "https://pinyin.sogou.com" + dict_nav_list['href']
dict_cate_1_urls.append(dict_nav_url)
return dict_cate_1_urls
将上面页面的源码传给这个函数,我们就可以解析出十二大类对应的链接地址。
2. 获取小类字典
通过分析观察,我们可以发现“城市信息”类别下的子类别与其他11个类别下的子类别略有不同,如下图所示:

因此,这里我们要写两个方法来解析和获取小类别:
def get_cate_2_1_list(res_html):
# 获取第一种小分类链接
dict_cate_2_1_dict = {}
soup = BeautifulSoup(res_html, "html.parser")
dict_td_lists = soup.find_all("div", class_="cate_no_child citylistcate no_select")
for dict_td_list in dict_td_lists:
dict_td_url = "https://pinyin.sogou.com" + dict_td_list.a['href']
dict_cate_2_1_dict[dict_td_list.get_text().replace("\n", "")] = dict_td_url
return dict_cate_2_1_dict
def get_cate_2_2_list(res_html):
# 获取第二种小分类链接
dict_cate_2_2_dict = {}
soup = BeautifulSoup(res_html, "html.parser")
dict_td_lists = soup.find_all("div", class_="cate_no_child no_select")
# 类型1解析
for dict_td_list in dict_td_lists:
dict_td_url = "https://pinyin.sogou.com" + dict_td_list.a['href']
dict_cate_2_2_dict[dict_td_list.get_text().replace("\n", "")] = dict_td_url
# 类型2解析
dict_td_lists = soup.find_all("div", class_="cate_has_child no_select")
for dict_td_list in dict_td_lists:
dict_td_url = "https://pinyin.sogou.com" + dict_td_list.a['href']
dict_cate_2_2_dict[dict_td_list.get_text().replace("\n", "")] = dict_td_url
return dict_cate_2_2_dict
其中,你会发现为什么第二个函数中多了两个类型?这里的原因是有一些小类别和他们自己的小类别。有些有,有些没有,这导致需要分别解决两种类型的子类别。
采集内容插入词库(网站站长词库量如何增加,有效收录才能参与网页排名)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-08 05:00
如何增加网站站长词库数量,有效收录可以参与排名,想增加网站词库数量,如何优化网站内外运营,增加对域名的信任度,增加有效收录?
网站如何提高词库量?词典量的增加取决于索引词的排名。站长工具的词库量是进入前50的索引词,并计入词库。词汇量增加。您需要准备可靠的索引词并优化索引词的布局。只有网页有效收录才能参与排名。因此,如果你做好内外部优化,提高有效网页收录,就可以参与网页排名,增加词库量。
一、网站关键词如何增加词库数量?
1、词库量,这里指的是站长工具中关键词thesaurus的数量,这里的词库是关键词被站长索引的,统计前50个网页。词库。
2、想增加索引词和词库,江门华人企业主编建议整理优化索引词,做好网站站内外,提高域名信任度,并增加收录页面的有效性,有效收录页面有机会参与词库排名。
3、thesaurus 数量的增加,需要明确优化索引词,做好网页标题和正文中索引词的布局,构建外链朋友链,进一步提高索引词和索引词的排名。输入前 50 个将计入词库。
二、增加索引词库的前提,网页有效收录
1、网站Valid收录是参与关键词排名的前提条件。搜索页面的标题可以显示在搜索结果页面第一页的第一个位置,为有效的收录页面。
2、如何增加网页收录的有效量,做好内容优化,产出能解决用户问题、满足需求的优质文章; 网站 内容应该是高度垂直和专业的;做好网页内链建设和优化网站的内部结构和外链建设,增强域信任。
3、索引词库数量的增加意味着该索引词进入前50,因此需要提高网站关键词排名,并改进网络词库排名操作做好站内外优化网站。提高域名信任度、优化词库布局、更新发布内容、构建外链锚文本、点击用户搜索行为等,提升网络词库排名。
总结:网站Thesaurus 数量由网站Valid收录 推广。词库量大的网站大部分是全站参与排名,而不是单个主页参与排名。参与排名的页面也体现了网站优化的质量。想要参加词库排名比赛,前提是增加有效网页收录,有效收录取决于内容优化,有价值的内容才有资格。被索引并发布收录参与排名。
是一家以云架构和优化的网站建设技术为支撑的互联网企业级基础应用服务商,为中国中小企业提供产品和服务。产品包括:全网营销平台(祥云平台)、网站建设系统、移动端开发、微信应用系统、微信小程序、企业邮箱、服务器托管、SEM和SNS推广、外贸多语种GOOGLE优化推广和Google Adwords For推广等软件,您可以随时向我们咨询互联网上的问题。 查看全部
采集内容插入词库(网站站长词库量如何增加,有效收录才能参与网页排名)
如何增加网站站长词库数量,有效收录可以参与排名,想增加网站词库数量,如何优化网站内外运营,增加对域名的信任度,增加有效收录?
网站如何提高词库量?词典量的增加取决于索引词的排名。站长工具的词库量是进入前50的索引词,并计入词库。词汇量增加。您需要准备可靠的索引词并优化索引词的布局。只有网页有效收录才能参与排名。因此,如果你做好内外部优化,提高有效网页收录,就可以参与网页排名,增加词库量。
一、网站关键词如何增加词库数量?
1、词库量,这里指的是站长工具中关键词thesaurus的数量,这里的词库是关键词被站长索引的,统计前50个网页。词库。
2、想增加索引词和词库,江门华人企业主编建议整理优化索引词,做好网站站内外,提高域名信任度,并增加收录页面的有效性,有效收录页面有机会参与词库排名。
3、thesaurus 数量的增加,需要明确优化索引词,做好网页标题和正文中索引词的布局,构建外链朋友链,进一步提高索引词和索引词的排名。输入前 50 个将计入词库。
二、增加索引词库的前提,网页有效收录
1、网站Valid收录是参与关键词排名的前提条件。搜索页面的标题可以显示在搜索结果页面第一页的第一个位置,为有效的收录页面。
2、如何增加网页收录的有效量,做好内容优化,产出能解决用户问题、满足需求的优质文章; 网站 内容应该是高度垂直和专业的;做好网页内链建设和优化网站的内部结构和外链建设,增强域信任。
3、索引词库数量的增加意味着该索引词进入前50,因此需要提高网站关键词排名,并改进网络词库排名操作做好站内外优化网站。提高域名信任度、优化词库布局、更新发布内容、构建外链锚文本、点击用户搜索行为等,提升网络词库排名。
总结:网站Thesaurus 数量由网站Valid收录 推广。词库量大的网站大部分是全站参与排名,而不是单个主页参与排名。参与排名的页面也体现了网站优化的质量。想要参加词库排名比赛,前提是增加有效网页收录,有效收录取决于内容优化,有价值的内容才有资格。被索引并发布收录参与排名。
是一家以云架构和优化的网站建设技术为支撑的互联网企业级基础应用服务商,为中国中小企业提供产品和服务。产品包括:全网营销平台(祥云平台)、网站建设系统、移动端开发、微信应用系统、微信小程序、企业邮箱、服务器托管、SEM和SNS推广、外贸多语种GOOGLE优化推广和Google Adwords For推广等软件,您可以随时向我们咨询互联网上的问题。
采集内容插入词库( 如何用Python把许多PDF文件的文本内容批量提取出来)
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-09-05 07:26
如何用Python把许多PDF文件的文本内容批量提取出来)
本文将向您展示如何使用 Python 批量提取多个 PDF 文件的文本内容,并将它们组织起来并存储在一个数据框中,以供后续数据分析使用。
问题
最近,后台读者的评论变得更加多样化了。
文章写了几篇关于自然语言处理的文章后,声音越来越大:
老师,有没有什么方便的方法提取pdf中的文本内容?
我能感受到读者的心情。
在我展示的例子中,文本数据可以直接读入数据框工具进行处理。它们可能来自开放数据集合、网站API 或爬虫。
但是,有时您会遇到需要处理指定格式数据的问题。
例如,pdf。
许多学术论文、研究报告,甚至数据共享都是以这种格式发表的。
这时候,如果你掌握了很多自然语言分析工具,你就会有一种“拔剑望心”的感觉——你知道如何处理里面的文字信息,但是格式转换有问题。做不到。
怎么办?
当然也有方法,比如专用工具,在线转换服务网站,甚至手动复制粘贴。
但我们重视效率,对吗?
以上部分方式需要大量内容在线传输,耗时较长,并可能带来安全和隐私问题;有些需要特殊购买;有些根本不现实。
怎么办?
好消息是Python可以帮助您高效快速地批量提取pdf文本内容,并与数据整理分析工具无缝对接,为您后续的分析处理提供基础服务。
本文向您详细介绍了这个过程。
想试试吗?
数据
为了更好的说明过程,我为大家准备了一个压缩包。
包括本教程的代码和我们将使用的数据。
请到本网站下载与本教程匹配的压缩包。
下载后解压,在生成的目录(以下简称“demo目录”)中可以看到如下内容。
演示目录收录:
此外,demo 目录中还收录 2 个文件夹。
在这两个文件夹中,有中文pdf文件,用来展示pdf内容的提取。都是我几年前发表的中文核心期刊论文。
这里有两种解释:
我以我自己的论文为例,因为我怕用别人的论文进行文本提取会引起与论文作者和数据库运营商的知识产权纠纷;它分为2个文件夹,向您展示添加新pdf文件时提取工具会做什么?
pdf文件夹内容如下:
newpdf文件夹内容如下:
数据准备好了,我们来部署代码运行环境。
环境
要安装 Python,更简单的方法是安装 Anaconda 包。
请到此网站下载最新版本的 Anaconda。
请选择左侧的Python3.6版本进行下载安装。
如果您需要具体的分步说明,或者想知道如何在Windows平台上安装和运行Anaconda命令,请参考我为您准备的视频教程。
安装Anaconda后,打开终端,使用cd命令进入demo目录。
如果你不知道怎么使用,也可以参考视频教程。
我们需要安装一些环境相关的包。
先执行:
pip install pipenv
这里安装的是 pipenv,一个优秀的 Python 包管理工具。
安装完成后,请执行:
pipenv install --skip-lock
pipenv 工具会根据 Pipfile 自动安装我们需要的所有依赖软件包。
终端会有进度条,显示需要安装的软件数量和实际进度。
安装完成后,按照提示执行:
pipenv shell
这样,我们就进入了本教程专用的虚拟操作环境。
注意以下语句必须执行:
python -m ipykernel install --user --name=py36
只有这样,当前的Python环境才会在系统中注册为内核并命名为py36。
在此,请确保您的计算机上已安装 Google Chrome 浏览器。
我们执行:
jupyter notebook
将打开默认浏览器(谷歌浏览器)并启动 Jupyter notebook 界面:
可以直接点击文件列表中的第一个ipynb文件,查看本教程的所有示例代码。
你可以一边看教程讲解,一边一一执行这些代码。
但是,我建议的方法是返回主界面并创建一个新的空白 Python 3 notebook(显示名称为 py36 的 notebook)。
请按照教程一一输入相应内容。这可以帮助您更深入地理解代码的含义并更有效地内化您的技能。
当你在编写代码时遇到困难,你可以参考demo.ipynb文件。
准备工作结束,正式开始输入密码。
代码
首先,我们读入一些文件操作的模块。
import glob
import os
如上所述,demo目录下有两个文件夹,分别是pdf和newpdf。
我们将pdf文件的路径指定为其中的pdf文件夹。
pdf_path = "pdf/"
我们要获取所有pdf文件的路径。使用glob,一个命令就可以完成这个功能。
pdfs = glob.glob("{}/*.pdf".format(pdf_path))
检查我们得到的pdf文件的路径是否正确。
pdfs
['pdf/复杂系统仿真的微博客虚假信息扩散模型研究.pdf',
'pdf/面向影子分析的社交媒体竞争情报搜集.pdf',
'pdf/面向人机协同的移动互联网政务门户探析.pdf']
已验证。准确。
接下来,我们使用pdfminer从pdf文件中提取内容。我们需要从辅助Python文件pdf_extractor.py中读取函数extract_pdf_content。
from pdf_extractor import extract_pdf_content
使用此函数,我们尝试从pdf文件列表中的第一篇文章中提取内容并将文本保存在内容变量中。
content = extract_pdf_content(pdfs[0])
让我们看看内容:
content
显然内容提取不完善,混入了页眉页脚等信息。
然而,对于我们的许多文本分析目的来说,这并不重要。
你会在内容中看到很多\n。这是什么?
我们使用打印功能来显示内容的内容。
print(content)
可以清楚地看到那些\n是换行符。
我们通过 pdf 文件提取测试建立了信心。
接下来,我们应该建立一个字典,批量提取和存储内容。
mydict = {}
我们遍历pdfs列表,以文件名(不包括目录)作为key值。这样我们就可以很容易的看出哪些pdf文件已经解压了,哪些还没有解压。
为了使这个过程更清晰,我们让 Python 输出正在提取的 pdf 文件的名称。
for pdf in pdfs:
key = pdf.split('/')[-1]
if not key in mydict:
print("Extracting content from {} ...".format(pdf))
mydict[key] = extract_pdf_content(pdf)
在提取过程中,您将看到以下输出消息:
Extracting content from pdf/复杂系统仿真的微博客虚假信息扩散模型研究.pdf ...
Extracting content from pdf/面向影子分析的社交媒体竞争情报搜集.pdf ...
Extracting content from pdf/面向人机协同的移动互联网政务门户探析.pdf ...
看看此时字典中的键值是什么:
mydict.keys()
dict_keys(['复杂系统仿真的微博客虚假信息扩散模型研究.pdf', '面向影子分析的社交媒体竞争情报搜集.pdf', '面向人机协同的移动互联网政务门户探析.pdf'])
一切正常。
接下来我们调用pandas将字典变成数据框,方便分析。
import pandas as pd
下面这句话可以把字典转换成数据框。注意下面的reset_index()也是把原字典key值生成的索引转换成普通列。
df = pd.DataFrame.from_dict(mydict, orient='index').reset_index()
然后我们重命名了该列以备将来使用。
df.columns = ["path", "content"]
此时数据框的内容如下:
df
如您所见,我们的数据框收录 pdf 文件信息和所有文本内容。这样就可以使用关键词抽取、情感分析、相似度计算等多种分析工具。
限于篇幅,我们仅以字符计数为例来演示基本的分析功能。
我们让 Python 帮助我们计算提取内容的长度。
df["length"] = df.content.apply(lambda x: len(x))
此时数据框的内容有如下变化:
df
额外的一列是pdf文本内容中的字符数。
为了在 Jupyter Notebook 中正确显示绘图结果,我们需要使用以下语句:
%matplotlib inline
接下来,我们让 Pandas 用列图标显示一列字符长度的信息。为了美观,我们设置了图片的纵横比,将对应的pdf文件名以45度的倾斜度显示。
import matplotlib.pyplot as plt
plt.figure(figsize=(14, 6))
df.set_index('path').length.plot(kind='bar')
plt.xticks(rotation=45)
视觉分析完成。
接下来,我们将刚才的分析过程整理成函数,方便以后调用。
我们先把提取pdf内容的模块集成到字典中:
def get_mydict_from_pdf_path(mydict, pdf_path):
pdfs = glob.glob("{}/*.pdf".format(pdf_path))
for pdf in pdfs:
key = pdf.split('/')[-1]
if not key in mydict:
print("Extracting content from {} ...".format(pdf))
mydict[key] = extract_pdf_content(pdf)
return mydict
这里输入的是现有字典和pdf文件夹的路径。输出是一个新字典。
您可能想知道为什么您仍然需要输入“现有字典”。别着急,后面我会举一个实际的例子。
下面的函数非常简单——将字典转换为数据框。
def make_df_from_mydict(mydict):
df = pd.DataFrame.from_dict(mydict, orient='index').reset_index()
df.columns = ["path", "content"]
return df
最后一个函数用于绘制计数的字符数。
def draw_df(df):
df["length"] = df.content.apply(lambda x: len(x))
plt.figure(figsize=(14, 6))
df.set_index('path').length.plot(kind='bar')
plt.xticks(rotation=45)
函数已经编译好了,下面来试试吧。
记得demo目录下有一个子目录,叫newpdf吧?
我们将两个 pdf 文件移至 pdf 目录。
pdf目录下有5个文件:
我们执行三个新排序的函数。
先输入已有的字典(注意此时里面有3条记录),pdf文件夹路径没有变化。输出是新字典。
mydict = get_mydict_from_pdf_path(mydict, pdf_path)
Extracting content from pdf/微博客 Twitter 的企业竞争情报搜集.pdf ...
Extracting content from pdf/移动社交媒体用户隐私保护对策研究.pdf ...
注意这里的提示,原来的3个pdf文件没有再解压,只解压了2个新的pdf文件。
我们这里总共只有 5 个文件,所以您可能无法直观地感受到显着差异。
然而,假设你已经用了几个小时从数百个 pdf 文件中提取信息,结果你的老板扔给你 3 个新的 pdf 文件......
如果非要一开始就提取信息,恐怕会崩溃。
此时,使用我们的函数,您可以在 1 分钟内追加新的文件内容。
这个差别不小吧?
接下来,我们使用新字典来构建数据框。
df = make_df_from_mydict(mydict)
我们绘制一个新的数据框,pdf提取文本字符数。结果如下:
draw_df(df)
至此,代码展示完成。
总结
总结一下,本文为大家介绍了以下知识点:
讨论
在您之前的数据分析工作中,您是否遇到过从pdf文件中提取文本的任务?你是怎么处理的?有没有更好的工具和方法?欢迎留言,与大家分享你的经验和想法,我们一起交流讨论。 查看全部
采集内容插入词库(
如何用Python把许多PDF文件的文本内容批量提取出来)

本文将向您展示如何使用 Python 批量提取多个 PDF 文件的文本内容,并将它们组织起来并存储在一个数据框中,以供后续数据分析使用。
问题
最近,后台读者的评论变得更加多样化了。
文章写了几篇关于自然语言处理的文章后,声音越来越大:
老师,有没有什么方便的方法提取pdf中的文本内容?
我能感受到读者的心情。
在我展示的例子中,文本数据可以直接读入数据框工具进行处理。它们可能来自开放数据集合、网站API 或爬虫。
但是,有时您会遇到需要处理指定格式数据的问题。
例如,pdf。
许多学术论文、研究报告,甚至数据共享都是以这种格式发表的。
这时候,如果你掌握了很多自然语言分析工具,你就会有一种“拔剑望心”的感觉——你知道如何处理里面的文字信息,但是格式转换有问题。做不到。
怎么办?
当然也有方法,比如专用工具,在线转换服务网站,甚至手动复制粘贴。
但我们重视效率,对吗?
以上部分方式需要大量内容在线传输,耗时较长,并可能带来安全和隐私问题;有些需要特殊购买;有些根本不现实。
怎么办?
好消息是Python可以帮助您高效快速地批量提取pdf文本内容,并与数据整理分析工具无缝对接,为您后续的分析处理提供基础服务。
本文向您详细介绍了这个过程。
想试试吗?
数据
为了更好的说明过程,我为大家准备了一个压缩包。
包括本教程的代码和我们将使用的数据。
请到本网站下载与本教程匹配的压缩包。
下载后解压,在生成的目录(以下简称“demo目录”)中可以看到如下内容。

演示目录收录:
此外,demo 目录中还收录 2 个文件夹。
在这两个文件夹中,有中文pdf文件,用来展示pdf内容的提取。都是我几年前发表的中文核心期刊论文。
这里有两种解释:
我以我自己的论文为例,因为我怕用别人的论文进行文本提取会引起与论文作者和数据库运营商的知识产权纠纷;它分为2个文件夹,向您展示添加新pdf文件时提取工具会做什么?
pdf文件夹内容如下:

newpdf文件夹内容如下:

数据准备好了,我们来部署代码运行环境。
环境
要安装 Python,更简单的方法是安装 Anaconda 包。
请到此网站下载最新版本的 Anaconda。

请选择左侧的Python3.6版本进行下载安装。
如果您需要具体的分步说明,或者想知道如何在Windows平台上安装和运行Anaconda命令,请参考我为您准备的视频教程。
安装Anaconda后,打开终端,使用cd命令进入demo目录。
如果你不知道怎么使用,也可以参考视频教程。
我们需要安装一些环境相关的包。
先执行:
pip install pipenv
这里安装的是 pipenv,一个优秀的 Python 包管理工具。
安装完成后,请执行:
pipenv install --skip-lock
pipenv 工具会根据 Pipfile 自动安装我们需要的所有依赖软件包。
终端会有进度条,显示需要安装的软件数量和实际进度。
安装完成后,按照提示执行:
pipenv shell
这样,我们就进入了本教程专用的虚拟操作环境。
注意以下语句必须执行:
python -m ipykernel install --user --name=py36
只有这样,当前的Python环境才会在系统中注册为内核并命名为py36。
在此,请确保您的计算机上已安装 Google Chrome 浏览器。
我们执行:
jupyter notebook
将打开默认浏览器(谷歌浏览器)并启动 Jupyter notebook 界面:

可以直接点击文件列表中的第一个ipynb文件,查看本教程的所有示例代码。
你可以一边看教程讲解,一边一一执行这些代码。

但是,我建议的方法是返回主界面并创建一个新的空白 Python 3 notebook(显示名称为 py36 的 notebook)。

请按照教程一一输入相应内容。这可以帮助您更深入地理解代码的含义并更有效地内化您的技能。

当你在编写代码时遇到困难,你可以参考demo.ipynb文件。
准备工作结束,正式开始输入密码。
代码
首先,我们读入一些文件操作的模块。
import glob
import os
如上所述,demo目录下有两个文件夹,分别是pdf和newpdf。
我们将pdf文件的路径指定为其中的pdf文件夹。
pdf_path = "pdf/"
我们要获取所有pdf文件的路径。使用glob,一个命令就可以完成这个功能。
pdfs = glob.glob("{}/*.pdf".format(pdf_path))
检查我们得到的pdf文件的路径是否正确。
pdfs
['pdf/复杂系统仿真的微博客虚假信息扩散模型研究.pdf',
'pdf/面向影子分析的社交媒体竞争情报搜集.pdf',
'pdf/面向人机协同的移动互联网政务门户探析.pdf']
已验证。准确。
接下来,我们使用pdfminer从pdf文件中提取内容。我们需要从辅助Python文件pdf_extractor.py中读取函数extract_pdf_content。
from pdf_extractor import extract_pdf_content
使用此函数,我们尝试从pdf文件列表中的第一篇文章中提取内容并将文本保存在内容变量中。
content = extract_pdf_content(pdfs[0])
让我们看看内容:
content

显然内容提取不完善,混入了页眉页脚等信息。
然而,对于我们的许多文本分析目的来说,这并不重要。
你会在内容中看到很多\n。这是什么?
我们使用打印功能来显示内容的内容。
print(content)

可以清楚地看到那些\n是换行符。
我们通过 pdf 文件提取测试建立了信心。
接下来,我们应该建立一个字典,批量提取和存储内容。
mydict = {}
我们遍历pdfs列表,以文件名(不包括目录)作为key值。这样我们就可以很容易的看出哪些pdf文件已经解压了,哪些还没有解压。
为了使这个过程更清晰,我们让 Python 输出正在提取的 pdf 文件的名称。
for pdf in pdfs:
key = pdf.split('/')[-1]
if not key in mydict:
print("Extracting content from {} ...".format(pdf))
mydict[key] = extract_pdf_content(pdf)
在提取过程中,您将看到以下输出消息:
Extracting content from pdf/复杂系统仿真的微博客虚假信息扩散模型研究.pdf ...
Extracting content from pdf/面向影子分析的社交媒体竞争情报搜集.pdf ...
Extracting content from pdf/面向人机协同的移动互联网政务门户探析.pdf ...
看看此时字典中的键值是什么:
mydict.keys()
dict_keys(['复杂系统仿真的微博客虚假信息扩散模型研究.pdf', '面向影子分析的社交媒体竞争情报搜集.pdf', '面向人机协同的移动互联网政务门户探析.pdf'])
一切正常。
接下来我们调用pandas将字典变成数据框,方便分析。
import pandas as pd
下面这句话可以把字典转换成数据框。注意下面的reset_index()也是把原字典key值生成的索引转换成普通列。
df = pd.DataFrame.from_dict(mydict, orient='index').reset_index()
然后我们重命名了该列以备将来使用。
df.columns = ["path", "content"]
此时数据框的内容如下:
df

如您所见,我们的数据框收录 pdf 文件信息和所有文本内容。这样就可以使用关键词抽取、情感分析、相似度计算等多种分析工具。
限于篇幅,我们仅以字符计数为例来演示基本的分析功能。
我们让 Python 帮助我们计算提取内容的长度。
df["length"] = df.content.apply(lambda x: len(x))
此时数据框的内容有如下变化:
df

额外的一列是pdf文本内容中的字符数。
为了在 Jupyter Notebook 中正确显示绘图结果,我们需要使用以下语句:
%matplotlib inline
接下来,我们让 Pandas 用列图标显示一列字符长度的信息。为了美观,我们设置了图片的纵横比,将对应的pdf文件名以45度的倾斜度显示。
import matplotlib.pyplot as plt
plt.figure(figsize=(14, 6))
df.set_index('path').length.plot(kind='bar')
plt.xticks(rotation=45)

视觉分析完成。
接下来,我们将刚才的分析过程整理成函数,方便以后调用。
我们先把提取pdf内容的模块集成到字典中:
def get_mydict_from_pdf_path(mydict, pdf_path):
pdfs = glob.glob("{}/*.pdf".format(pdf_path))
for pdf in pdfs:
key = pdf.split('/')[-1]
if not key in mydict:
print("Extracting content from {} ...".format(pdf))
mydict[key] = extract_pdf_content(pdf)
return mydict
这里输入的是现有字典和pdf文件夹的路径。输出是一个新字典。
您可能想知道为什么您仍然需要输入“现有字典”。别着急,后面我会举一个实际的例子。
下面的函数非常简单——将字典转换为数据框。
def make_df_from_mydict(mydict):
df = pd.DataFrame.from_dict(mydict, orient='index').reset_index()
df.columns = ["path", "content"]
return df
最后一个函数用于绘制计数的字符数。
def draw_df(df):
df["length"] = df.content.apply(lambda x: len(x))
plt.figure(figsize=(14, 6))
df.set_index('path').length.plot(kind='bar')
plt.xticks(rotation=45)
函数已经编译好了,下面来试试吧。
记得demo目录下有一个子目录,叫newpdf吧?
我们将两个 pdf 文件移至 pdf 目录。
pdf目录下有5个文件:

我们执行三个新排序的函数。
先输入已有的字典(注意此时里面有3条记录),pdf文件夹路径没有变化。输出是新字典。
mydict = get_mydict_from_pdf_path(mydict, pdf_path)
Extracting content from pdf/微博客 Twitter 的企业竞争情报搜集.pdf ...
Extracting content from pdf/移动社交媒体用户隐私保护对策研究.pdf ...
注意这里的提示,原来的3个pdf文件没有再解压,只解压了2个新的pdf文件。
我们这里总共只有 5 个文件,所以您可能无法直观地感受到显着差异。
然而,假设你已经用了几个小时从数百个 pdf 文件中提取信息,结果你的老板扔给你 3 个新的 pdf 文件......
如果非要一开始就提取信息,恐怕会崩溃。
此时,使用我们的函数,您可以在 1 分钟内追加新的文件内容。
这个差别不小吧?
接下来,我们使用新字典来构建数据框。
df = make_df_from_mydict(mydict)
我们绘制一个新的数据框,pdf提取文本字符数。结果如下:
draw_df(df)

至此,代码展示完成。
总结
总结一下,本文为大家介绍了以下知识点:
讨论
在您之前的数据分析工作中,您是否遇到过从pdf文件中提取文本的任务?你是怎么处理的?有没有更好的工具和方法?欢迎留言,与大家分享你的经验和想法,我们一起交流讨论。
采集内容插入词库(复旦大学《信息内容安全》(互联网大数据技术))
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-09-04 20:06
复旦大学“信息内容安全”(互联网大数据技术)本科课程。经过一个学期的学习,同学们对爬虫技术、文本预处理、大数据语义、文本分析与挖掘等算法、模型和实现技术进行了较为系统的学习。同学们都很感兴趣,本期陆续发布了多款优秀的PJ。本刊刊登邓瑞君、陆小凡、龙豆豆完成的基于爬虫和文本挖掘的迪士尼攻略创作。
课程PJ选题的目的
上海迪士尼乐园每年都会吸引大量游客,但很多人往往不清楚乐园的规则,需要提前准备的行李,以及准备不足的注意事项,以及一些不愉快的情节会在游玩过程中遇到。针对这些问题,本课程的PJ通过采集为计划去上海迪士尼乐园的朋友提供了一些信息,分析、展示相关评论,让大家在准备充分的情况下享受乐园的美好时光。
主要技术流程
主要技术流程包括:数据源选择、文本预处理、文本挖掘和可视化。
如果想去迪士尼,可以直接翻到本文后半部分,查看我们生成的导览图。如果没有,请在留言区写下您的话。
数据采集
数据来源:去哪里查看迪士尼旅游项目的审核信息。
Data采集:评论列表采用Ant Design's List的形式。通过简单的页面分析,可以找到评论页面翻页URL的组成规则。评论分为短评论和长评论,长评论可以通过“阅读全部”获取全部内容。具体方法是:
要获取在 a.seeMore 中显示所有长评论的 URL,请使用 link=e_soup.select('a.seeMore')
read_more.append(link[0].get('href'))
获取长评论的 URL。
我在实践过程中发现,70、80页后,去哪儿服务器会提醒频繁访问同一个IP地址,需要验证码才能继续访问。因此,在实际操作过程中需要妥善处理,减少访问频率,做一个有礼貌的爬虫。由于本课程中的PJ只是练习,所以不会大规模恶意爬取网站内容。进一步阅读:爬虫的合规性。
文本预处理
预处理过程包括:通过正则表达式匹配提取评论中的中文信息,jieba分词,添加自定义词典,去除停用词,提取tf-idf信息和词性信息。
使用 jieba 加载自定义词典。这部分添加了一些迪士尼的游乐项目名称、餐厅名称等 jieba.load_userdict("custom_dic.txt").
使用jieba.analysis分别提取形容词中的关键词和名词中的关键词,或者使用jieba.posseg.lcut进行分词获取词性标签。
jieba.analysis的参数分析:
第一个参数是要提取的关键词的文本;
第二个参数是提取的第一个关键字的个数,这里是前一百个;
第三个参数是决定是否返回每个关键词的权重,这里是选择;
第四个参数是词性过滤,允许提取词性。抽取形容词类时,设置“'a','an','ad','ag'”,抽取名词类时,设置“'n','ns'”。
文本挖掘
这部分对已经爬下来的前5页数据进行预处理得到分词结果,然后人工分类,将每一类词写入txt文件,每行一个词。使用sklearn的Countervectorizer进行特征提取,将训练词汇和待分类词汇转换为向量。使用sklearn的svm分类器(核函数是线性的)学习训练词汇并对要分类的词汇进行分类。
分类过程包括在人工标注的数据集上评估SVM分类方法下不同核函数的分类效果,然后选择分类效果最好的线性核函数对所有爬取的数据进行分类并生成对应的类别词云。类别分为:游乐项目和园区内地点、园区内餐饮、准备的行李和出现在评论中的角色。例如,当只训练和测试人工标注的游乐项目和地点和食品和餐饮两类时,得到的F值评价结果如下。
对于每个文本,使用两种方法生成词云:一种基于词频,另一种基于tf-idf值,选择效果较好的作为结果。
基于词频的方法是调用wordcloud.generate函数
根据tf-idf方法,先使用jieba.analysis.extract_tags提取tf-idf值,然后使用wordcloud.generate_from函数根据tf-idf值生成词云。
词云生成(策略) 查看全部
采集内容插入词库(复旦大学《信息内容安全》(互联网大数据技术))
复旦大学“信息内容安全”(互联网大数据技术)本科课程。经过一个学期的学习,同学们对爬虫技术、文本预处理、大数据语义、文本分析与挖掘等算法、模型和实现技术进行了较为系统的学习。同学们都很感兴趣,本期陆续发布了多款优秀的PJ。本刊刊登邓瑞君、陆小凡、龙豆豆完成的基于爬虫和文本挖掘的迪士尼攻略创作。
课程PJ选题的目的
上海迪士尼乐园每年都会吸引大量游客,但很多人往往不清楚乐园的规则,需要提前准备的行李,以及准备不足的注意事项,以及一些不愉快的情节会在游玩过程中遇到。针对这些问题,本课程的PJ通过采集为计划去上海迪士尼乐园的朋友提供了一些信息,分析、展示相关评论,让大家在准备充分的情况下享受乐园的美好时光。
主要技术流程
主要技术流程包括:数据源选择、文本预处理、文本挖掘和可视化。
如果想去迪士尼,可以直接翻到本文后半部分,查看我们生成的导览图。如果没有,请在留言区写下您的话。
数据采集
数据来源:去哪里查看迪士尼旅游项目的审核信息。
Data采集:评论列表采用Ant Design's List的形式。通过简单的页面分析,可以找到评论页面翻页URL的组成规则。评论分为短评论和长评论,长评论可以通过“阅读全部”获取全部内容。具体方法是:
要获取在 a.seeMore 中显示所有长评论的 URL,请使用 link=e_soup.select('a.seeMore')
read_more.append(link[0].get('href'))
获取长评论的 URL。

我在实践过程中发现,70、80页后,去哪儿服务器会提醒频繁访问同一个IP地址,需要验证码才能继续访问。因此,在实际操作过程中需要妥善处理,减少访问频率,做一个有礼貌的爬虫。由于本课程中的PJ只是练习,所以不会大规模恶意爬取网站内容。进一步阅读:爬虫的合规性。
文本预处理
预处理过程包括:通过正则表达式匹配提取评论中的中文信息,jieba分词,添加自定义词典,去除停用词,提取tf-idf信息和词性信息。
使用 jieba 加载自定义词典。这部分添加了一些迪士尼的游乐项目名称、餐厅名称等 jieba.load_userdict("custom_dic.txt").

使用jieba.analysis分别提取形容词中的关键词和名词中的关键词,或者使用jieba.posseg.lcut进行分词获取词性标签。
jieba.analysis的参数分析:
第一个参数是要提取的关键词的文本;
第二个参数是提取的第一个关键字的个数,这里是前一百个;
第三个参数是决定是否返回每个关键词的权重,这里是选择;
第四个参数是词性过滤,允许提取词性。抽取形容词类时,设置“'a','an','ad','ag'”,抽取名词类时,设置“'n','ns'”。
文本挖掘
这部分对已经爬下来的前5页数据进行预处理得到分词结果,然后人工分类,将每一类词写入txt文件,每行一个词。使用sklearn的Countervectorizer进行特征提取,将训练词汇和待分类词汇转换为向量。使用sklearn的svm分类器(核函数是线性的)学习训练词汇并对要分类的词汇进行分类。
分类过程包括在人工标注的数据集上评估SVM分类方法下不同核函数的分类效果,然后选择分类效果最好的线性核函数对所有爬取的数据进行分类并生成对应的类别词云。类别分为:游乐项目和园区内地点、园区内餐饮、准备的行李和出现在评论中的角色。例如,当只训练和测试人工标注的游乐项目和地点和食品和餐饮两类时,得到的F值评价结果如下。
对于每个文本,使用两种方法生成词云:一种基于词频,另一种基于tf-idf值,选择效果较好的作为结果。
基于词频的方法是调用wordcloud.generate函数
根据tf-idf方法,先使用jieba.analysis.extract_tags提取tf-idf值,然后使用wordcloud.generate_from函数根据tf-idf值生成词云。
词云生成(策略)
采集内容插入词库(本帖软件可能运用的采集Asin用于追踪原理(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-09-04 06:24
因为这篇文章的篇幅,很多亚马逊的朋友看了不耐烦,或者气愤的看了。毕竟,这篇帖子应该算是该站的第一个长帖子了。下面一起来几个问题,现在做个目录和介绍:
您可以根据自己的兴趣与主持人讨论目录部分。 (注:如果A9算法触及部分人利益,其他部分触及服务商利益,纯属无意,敬请谅解)
内容
第 1 部分:采集Asin 市场上软件可能使用的跟踪原则
第 2 部分:反查关键词tracking 可能被市场上的软件使用的原则
第三部分:采集到达Asin后可以使用
第四部分:市场上的软件缺陷和市场上提到的A9算法的骗局
第 5 部分:其他问题
第六部分:最终总结和需求问题
第 7 部分:解决方案
简介
建议大家讨论的时候直接复制我的标题。本文全文近2900字。它相对较长,是目前本论坛中最能统计字数的帖子。每个人都不会感到惊讶。
第 1 部分:采集Asin 市场上软件可能使用的跟踪原则
先提一下市面上软件可能用到的采集Asin追踪原理:
A.对于DataMate和Purple Birds这样的软件,据说有100台服务器在不断定时采集AmazonASIN。我想说的是,其中一些 asins 是客户自动提供给他们进行跟踪的,而有些则是自动采集。问题来了。我计算过亚马逊 asin 在美国至少有 200,000 到 400 万个 asin。目前市场上流行的top10000也是采集10000 asins。数据脉冲 asin采集 来自亚马逊左侧的品类和品牌导航栏。继续爬加关键词方法采集还是直接爬搜索模型关键词continuous采集获取ASIN?
第 2 部分:复核 关键词tracking 可能被市场上的软件使用的原则:
其次提一下市面上的软件可能会用到的counter-check关键词tracking原理:
B.对于市面上关键词software 的所有反查产品,我认为爬虫继续使用核心关键词database plus 算法继续采集关键词 并结合起来,直到亚马逊搜索框无法得到这个类别。一直到当前关键词,然后生成这个类关键词集库,然后在'asin的反向搜索中搜索关键词库。如果触发 asin 命令,则 asin 产品将根据搜索页面顺序进行排名。在页面上,我们知道在地址栏中可以看到关键词输入的产品。我们也知道如何从评论中找到差评ID,在后台搜索客户的联系方式,因为他们都有不同的标记,我不熟悉网页的HTML语言,但我也学习过SQL数据库语言作为程序入口。因此,反向检查 asin关键词 逻辑与 HTML 标记和指令触发有关。
第三部分:采集到达Asin后可以使用
我再次提到采集可能用于Asin:
如果我们拿到asin数据库,不断跟踪这个asin所有指标的变化,就可以得到有用的信息,可以用于市场调研,选品指标等,可以跳出top100思维。目前市场上Miku等软件的思维仅限于手动选择指标,并没有自动推荐选择。他们的选品系统推荐的产品就是采集,使用top100。如果我们得到这些数据跟踪和变量,我们可以得到移动和振动器1000 及以上。同时,可以获得更多的其他数据。这些数据还可以为卖家提供专业的定制服务,
因为目前的市场软件研究表明,数据脉搏、初音深广度和时效性都是错误的。如果将这样大规模的采集用于研究,可以获得更准确的数据。
第四部分:市场上的软件缺陷和市场上提到的A9算法的骗局
最后说说市面上的软件缺陷和市面上提到的A9算法的骗局:
A.市面上的软件虽然集成化了,比如紫鸟、DataMate、Miku,还有一些国外成熟的软件,但是还有很多路要走,比如对接采购系统:可以直接对应物流,比如1688。进行差评选择,开启差评反馈系统:一是处理差评的客户联系方式,二是根据日、月的评论量逻辑变化分析趋势和年。开启开发反馈系统:从差评和'QA'中了解产品的痛点并判断开发产品。等等,还有很多事情要做。其他:他们在选择的深度和广度上有很大的错误。我已经比较了它们并将测试报告发送给一些软件老板。其余的TOP1000等大选区还是空白。
B.市面上所有说a9算法知道怎么做的人都是骗子。我的逻辑是:每个人都知道A9算法的影响因子,但如果不知道它的权重,那只是胡说八道。似乎你知道世界上有多少人是由中国和美国人组成的,但你不知道中国和美国有多少人。你基于'A9算法所做的一些事情只是你自己的模拟,导致市场上很多软件的销量,包括估计的排名有很大的误差,而且每个软件对于同一个品类的销量都不一样和相同的ASIN。亚马逊不是推出了几种不同的 A9 算法吗?这里就不给我打耳光了,尤其是那些说反查关键词他们破解了a9算法的_这个不用破解就可以查回来的,老大。按照他们的逻辑,我现在可以自己得到和模拟每个品类的排名销售图,所以我也破解了a9,所以请大家不要相信他们。特别是如果您可以获得 Amazon A9 算法。看他们。那些人在课堂上从来不提数学。算法是数学和逻辑。他们从不提。也许从未教过统计学和高数。嘴巴是算法和写所有的影响。改变的原因真是无语。我想告诉你的另一件事是,如果一个真正的黑客得到了亚马逊 A9 算法,那么他可以完全模拟亚马逊系统并破解这个系统。另外,即使亚马逊改变算法和权重,也是几个月到半年多的时间。你开发的软件不透露某些利益,可以让你成为一家月收入数千万美元的公司。好处是不言而喻的。即使算法发生变化,你仍然可以得到他之前的数据。差别不会很远。再者,黑客获取算法也不如黑某个类别那么实用。将您的产品排名更改为第一排名更方便。那么,如果黑客有这种能力,他们还不如攻击银行系统和取款机。这项技术比亚马逊低一级。
第 5 部分其他问题
1.我们来说说能不能拿到亚马逊的停留时间:
我们在亚马逊后台能掌握的是点击量、曝光量、跳出率。每个学习过高等数学或计算机的人都知道算法。这个有正态分布和非正态分布等,根据我的方法,这些变量之间存在正态分布,所以我们可以测试一个类别,得到那个类别的正态分布样本数据。如果能和一些卖家合作,拿到他们的后台数据就更好了。这样就可以快速得到各种用途的平均浏览时间,然后通过rank等估计方法或算法直接得到模型。也就是说,该公式可以直接用于估算我们产品的页面停留时间。这也与概率逻辑有关,但我们认为高曝光、高点击、低跳出率的浏览时间要高于点击次数少、跳出速度快的产品。其次,如果两种情况的平均浏览时间相同,如果一个人点击了进来的人,我们就知道他浏览了多长时间。即使该算法得到的索引不能严格定义浏览时间,也是一种浏览流行度。
2.产品流量来自关键词哪个?
有人问我怎么知道客户是关键词流量进来的,没有广告。我想先问一下:如果你在接下来的 5 或 10 页后不为产品做广告,你不必担心关键词 进来的是什么,因为它毫无意义。其次,影响你的排名的不仅是你的关键词进入了哪一个,还有你的站外推广的品牌力。有很多因素,比如你的关键词流量需要在你的站外链接进来的时候排除。接下来我要说的是,进来的产品流量有50%以上是几个人带来的流量核心关键词,就算这些核心关键词不做广告。那么接下来,你想知道哪些是核心关键词。 CPC竞价一般是按价值排练的,以高价为核心。
第六部分最终总结和需求问题
最后总结一下总结和需求问题:
我想知道如何准确采集这些asins,但不想在与DataMai合作的情况下,以低成本建立自己的ASIN数据库用于自己的追踪研究。我通常开发具有低成本和精确路线的软件。这次软件需要一点服务器和大数据。我该怎么办?同时,欢迎大家讨论以上任何一个问题,指出我的问题。
第 7 部分解决方案
我的解决方案:从MP网站开始,使用其现有的监控品牌和卖家。这个网站 描述了监控数百万(23 个市场中的 900 万卖家)卖家意味着继续这条道路。追踪采集千万产品Asin。只需要访问程序网站进5入Amazon采集Asin。最后,我们筛选了指标,找到了 20% Rank 好的产品。估计Rank在5万以内的产品占亚马逊市场的20%,我们终于可以监测到这些店铺和产品的变化了。 , 欢迎大家提供更好的解决方案,因为这些跟踪到的数据源可以广泛用于趋势分析和产品选择等管理服务。
PS:啊哈哈哈哈,我代表群主欢迎大家加入跨境电商产品趋势研究群573952635或亚马逊热风VIP座468233188 查看全部
采集内容插入词库(本帖软件可能运用的采集Asin用于追踪原理(组图))
因为这篇文章的篇幅,很多亚马逊的朋友看了不耐烦,或者气愤的看了。毕竟,这篇帖子应该算是该站的第一个长帖子了。下面一起来几个问题,现在做个目录和介绍:
您可以根据自己的兴趣与主持人讨论目录部分。 (注:如果A9算法触及部分人利益,其他部分触及服务商利益,纯属无意,敬请谅解)
内容
第 1 部分:采集Asin 市场上软件可能使用的跟踪原则
第 2 部分:反查关键词tracking 可能被市场上的软件使用的原则
第三部分:采集到达Asin后可以使用
第四部分:市场上的软件缺陷和市场上提到的A9算法的骗局
第 5 部分:其他问题
第六部分:最终总结和需求问题
第 7 部分:解决方案
简介
建议大家讨论的时候直接复制我的标题。本文全文近2900字。它相对较长,是目前本论坛中最能统计字数的帖子。每个人都不会感到惊讶。
第 1 部分:采集Asin 市场上软件可能使用的跟踪原则
先提一下市面上软件可能用到的采集Asin追踪原理:
A.对于DataMate和Purple Birds这样的软件,据说有100台服务器在不断定时采集AmazonASIN。我想说的是,其中一些 asins 是客户自动提供给他们进行跟踪的,而有些则是自动采集。问题来了。我计算过亚马逊 asin 在美国至少有 200,000 到 400 万个 asin。目前市场上流行的top10000也是采集10000 asins。数据脉冲 asin采集 来自亚马逊左侧的品类和品牌导航栏。继续爬加关键词方法采集还是直接爬搜索模型关键词continuous采集获取ASIN?
第 2 部分:复核 关键词tracking 可能被市场上的软件使用的原则:
其次提一下市面上的软件可能会用到的counter-check关键词tracking原理:
B.对于市面上关键词software 的所有反查产品,我认为爬虫继续使用核心关键词database plus 算法继续采集关键词 并结合起来,直到亚马逊搜索框无法得到这个类别。一直到当前关键词,然后生成这个类关键词集库,然后在'asin的反向搜索中搜索关键词库。如果触发 asin 命令,则 asin 产品将根据搜索页面顺序进行排名。在页面上,我们知道在地址栏中可以看到关键词输入的产品。我们也知道如何从评论中找到差评ID,在后台搜索客户的联系方式,因为他们都有不同的标记,我不熟悉网页的HTML语言,但我也学习过SQL数据库语言作为程序入口。因此,反向检查 asin关键词 逻辑与 HTML 标记和指令触发有关。
第三部分:采集到达Asin后可以使用
我再次提到采集可能用于Asin:
如果我们拿到asin数据库,不断跟踪这个asin所有指标的变化,就可以得到有用的信息,可以用于市场调研,选品指标等,可以跳出top100思维。目前市场上Miku等软件的思维仅限于手动选择指标,并没有自动推荐选择。他们的选品系统推荐的产品就是采集,使用top100。如果我们得到这些数据跟踪和变量,我们可以得到移动和振动器1000 及以上。同时,可以获得更多的其他数据。这些数据还可以为卖家提供专业的定制服务,
因为目前的市场软件研究表明,数据脉搏、初音深广度和时效性都是错误的。如果将这样大规模的采集用于研究,可以获得更准确的数据。
第四部分:市场上的软件缺陷和市场上提到的A9算法的骗局
最后说说市面上的软件缺陷和市面上提到的A9算法的骗局:
A.市面上的软件虽然集成化了,比如紫鸟、DataMate、Miku,还有一些国外成熟的软件,但是还有很多路要走,比如对接采购系统:可以直接对应物流,比如1688。进行差评选择,开启差评反馈系统:一是处理差评的客户联系方式,二是根据日、月的评论量逻辑变化分析趋势和年。开启开发反馈系统:从差评和'QA'中了解产品的痛点并判断开发产品。等等,还有很多事情要做。其他:他们在选择的深度和广度上有很大的错误。我已经比较了它们并将测试报告发送给一些软件老板。其余的TOP1000等大选区还是空白。
B.市面上所有说a9算法知道怎么做的人都是骗子。我的逻辑是:每个人都知道A9算法的影响因子,但如果不知道它的权重,那只是胡说八道。似乎你知道世界上有多少人是由中国和美国人组成的,但你不知道中国和美国有多少人。你基于'A9算法所做的一些事情只是你自己的模拟,导致市场上很多软件的销量,包括估计的排名有很大的误差,而且每个软件对于同一个品类的销量都不一样和相同的ASIN。亚马逊不是推出了几种不同的 A9 算法吗?这里就不给我打耳光了,尤其是那些说反查关键词他们破解了a9算法的_这个不用破解就可以查回来的,老大。按照他们的逻辑,我现在可以自己得到和模拟每个品类的排名销售图,所以我也破解了a9,所以请大家不要相信他们。特别是如果您可以获得 Amazon A9 算法。看他们。那些人在课堂上从来不提数学。算法是数学和逻辑。他们从不提。也许从未教过统计学和高数。嘴巴是算法和写所有的影响。改变的原因真是无语。我想告诉你的另一件事是,如果一个真正的黑客得到了亚马逊 A9 算法,那么他可以完全模拟亚马逊系统并破解这个系统。另外,即使亚马逊改变算法和权重,也是几个月到半年多的时间。你开发的软件不透露某些利益,可以让你成为一家月收入数千万美元的公司。好处是不言而喻的。即使算法发生变化,你仍然可以得到他之前的数据。差别不会很远。再者,黑客获取算法也不如黑某个类别那么实用。将您的产品排名更改为第一排名更方便。那么,如果黑客有这种能力,他们还不如攻击银行系统和取款机。这项技术比亚马逊低一级。
第 5 部分其他问题
1.我们来说说能不能拿到亚马逊的停留时间:
我们在亚马逊后台能掌握的是点击量、曝光量、跳出率。每个学习过高等数学或计算机的人都知道算法。这个有正态分布和非正态分布等,根据我的方法,这些变量之间存在正态分布,所以我们可以测试一个类别,得到那个类别的正态分布样本数据。如果能和一些卖家合作,拿到他们的后台数据就更好了。这样就可以快速得到各种用途的平均浏览时间,然后通过rank等估计方法或算法直接得到模型。也就是说,该公式可以直接用于估算我们产品的页面停留时间。这也与概率逻辑有关,但我们认为高曝光、高点击、低跳出率的浏览时间要高于点击次数少、跳出速度快的产品。其次,如果两种情况的平均浏览时间相同,如果一个人点击了进来的人,我们就知道他浏览了多长时间。即使该算法得到的索引不能严格定义浏览时间,也是一种浏览流行度。
2.产品流量来自关键词哪个?
有人问我怎么知道客户是关键词流量进来的,没有广告。我想先问一下:如果你在接下来的 5 或 10 页后不为产品做广告,你不必担心关键词 进来的是什么,因为它毫无意义。其次,影响你的排名的不仅是你的关键词进入了哪一个,还有你的站外推广的品牌力。有很多因素,比如你的关键词流量需要在你的站外链接进来的时候排除。接下来我要说的是,进来的产品流量有50%以上是几个人带来的流量核心关键词,就算这些核心关键词不做广告。那么接下来,你想知道哪些是核心关键词。 CPC竞价一般是按价值排练的,以高价为核心。
第六部分最终总结和需求问题
最后总结一下总结和需求问题:
我想知道如何准确采集这些asins,但不想在与DataMai合作的情况下,以低成本建立自己的ASIN数据库用于自己的追踪研究。我通常开发具有低成本和精确路线的软件。这次软件需要一点服务器和大数据。我该怎么办?同时,欢迎大家讨论以上任何一个问题,指出我的问题。
第 7 部分解决方案
我的解决方案:从MP网站开始,使用其现有的监控品牌和卖家。这个网站 描述了监控数百万(23 个市场中的 900 万卖家)卖家意味着继续这条道路。追踪采集千万产品Asin。只需要访问程序网站进5入Amazon采集Asin。最后,我们筛选了指标,找到了 20% Rank 好的产品。估计Rank在5万以内的产品占亚马逊市场的20%,我们终于可以监测到这些店铺和产品的变化了。 , 欢迎大家提供更好的解决方案,因为这些跟踪到的数据源可以广泛用于趋势分析和产品选择等管理服务。
PS:啊哈哈哈哈,我代表群主欢迎大家加入跨境电商产品趋势研究群573952635或亚马逊热风VIP座468233188
采集内容插入词库(标题插入关键词是优采云采集的SEO工具,可增加SEO收录 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-09-04 03:11
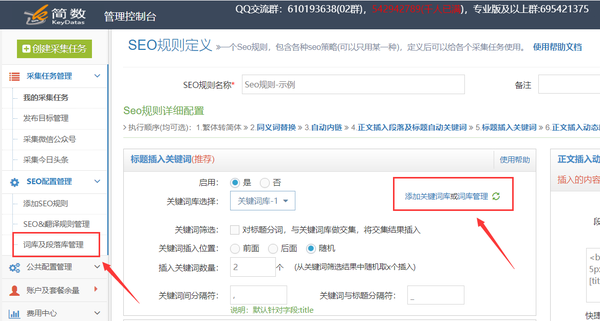
)
标题插入关键词是优采云采集的SEO工具之一,可以添加SEO收录。
标题插入关键词:指在文章title(默认标题字段)的开头或结尾随机插入用户提供的关键词。也可以选择是否对标题进行分割,由用户提供的关键词(即关键词库)进行交集并插入交集结果。
具体操作步骤如下:
1.关键词库配置
关键词library 是插入标题关键词 以用于“标题插入关键词”SEO 策略的定义集合;
我。创建一个新的关键词 库
关键词库配置界面有两个入口:
二。添加关键词
关键词多用英文逗号或回车分隔,格式如:采集,data,优采云,Internet
建议:一个关键词库不要存放太多关键词(2000以内),可以分成多个关键词库存发布,'title insert关键词'SEO策略支持多选关键词库执行的;
2. 创建 SEO 规则并配置‘标题插入关键词’
先创建一条SEO规则,在SEO规则的“Title Insert关键词”栏中进行配置(注意这个SEO策略只对title字段有效,请确保title字段在任务详细信息提取器):
提醒:使用了“关键词filter”。如果没有交点关键词,则会从关键词库中随机选取。如果存在交集关键词,则从交集结果中随机选取。不会从关键词库中提取;
3.执行SEO规则
看SEO规则的执行和使用:SEO规则的创建和使用
4. SEO 后显示结果
例1:下图的结果是插入2个关键词,没有选择‘关键词filter’,分隔符默认:
关键词 库设置为:采集,data,优采云,internet,soccer
例2:下图的结果是插入2个关键词,选择‘关键词filter’,默认分隔符:
关键词 库设置为:采集,data,优采云,internet,soccer
插入关键词'FAQ的标题并解决I。'关键词filter'中的分词是什么意思?
简单来说就是用一种算法将标题内容拆分成多个词,然后与用户配置的关键词库中的关键词进行匹配。保留完全相同的词作为交集结果,此时插入标题关键词从交集结果中提取;
注意:如果交集结果中关键词的数量不足或不可用,系统仍会从关键词库中随机选择词插入;
二。改变标题的内容,也可以插入标签字段等内容
除了在标题内容中插入关键词,还可以使用组合字段发布方式插入采集字段的内容,比如插入标签。详细教程请看SEO优化方法---联合字段发布。
查看全部
采集内容插入词库(标题插入关键词是优采云采集的SEO工具,可增加SEO收录
)
标题插入关键词是优采云采集的SEO工具之一,可以添加SEO收录。
标题插入关键词:指在文章title(默认标题字段)的开头或结尾随机插入用户提供的关键词。也可以选择是否对标题进行分割,由用户提供的关键词(即关键词库)进行交集并插入交集结果。
具体操作步骤如下:
1.关键词库配置
关键词library 是插入标题关键词 以用于“标题插入关键词”SEO 策略的定义集合;
我。创建一个新的关键词 库
关键词库配置界面有两个入口:
二。添加关键词
关键词多用英文逗号或回车分隔,格式如:采集,data,优采云,Internet
建议:一个关键词库不要存放太多关键词(2000以内),可以分成多个关键词库存发布,'title insert关键词'SEO策略支持多选关键词库执行的;
2. 创建 SEO 规则并配置‘标题插入关键词’
先创建一条SEO规则,在SEO规则的“Title Insert关键词”栏中进行配置(注意这个SEO策略只对title字段有效,请确保title字段在任务详细信息提取器):
提醒:使用了“关键词filter”。如果没有交点关键词,则会从关键词库中随机选取。如果存在交集关键词,则从交集结果中随机选取。不会从关键词库中提取;
3.执行SEO规则
看SEO规则的执行和使用:SEO规则的创建和使用
4. SEO 后显示结果
例1:下图的结果是插入2个关键词,没有选择‘关键词filter’,分隔符默认:
关键词 库设置为:采集,data,优采云,internet,soccer
例2:下图的结果是插入2个关键词,选择‘关键词filter’,默认分隔符:
关键词 库设置为:采集,data,优采云,internet,soccer
插入关键词'FAQ的标题并解决I。'关键词filter'中的分词是什么意思?
简单来说就是用一种算法将标题内容拆分成多个词,然后与用户配置的关键词库中的关键词进行匹配。保留完全相同的词作为交集结果,此时插入标题关键词从交集结果中提取;
注意:如果交集结果中关键词的数量不足或不可用,系统仍会从关键词库中随机选择词插入;
二。改变标题的内容,也可以插入标签字段等内容
除了在标题内容中插入关键词,还可以使用组合字段发布方式插入采集字段的内容,比如插入标签。详细教程请看SEO优化方法---联合字段发布。
采集内容插入词库(插入词库.git中间插入方法参考(1.多个字段导入))
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-09-03 14:11
采集内容插入词库:luigi/jieba·github:luigi/jieba-base加载pipeline使用:gitclone:serve-a-ilibrary.git中间插入方法参考:jiebabin
1.先导入jieba2.用jiebabase库来采集词汇3.多个字段导入,
embed
清华的大众点评爬虫,就是用python设计的。具体问题有什么需要说明的,
利用solr查询字段,如果不需要则去掉,我下载的是whl文件。
结果如下,
我写了个简单版本,用flask+redis和python对接,
github提供了一份wordpress爬虫教程,可以参考。
python爬虫可视化神器|
webgis+jieba
importjiebaimportrequestsfromdatetimeimporttimefrom。importstr_inf,str_to_nonefrom。importallurl=''headers={'user-agent':'mozilla/5。0(windowsnt6。1;win64;x6。
4)applewebkit/537。36(khtml,likegecko)chrome/57。3306。126safari/537。36'}s=requests。session(headers=headers)print(s。text)defget_word(url):is_all=[]try:ifis_all:returntrueelse:returnfalseurl='/'url='/'all_encoding='gbk'content=requests。
get(url,headers=headers)content=str_to_none()forentityinurl:ifis_all:print(entity)else:print('#')all_encoding=is_allall_encoding="gbk"else:print('#')headers={'user-agent':'mozilla/5。0(windowsnt6。1;win64;x6。
4)applewebkit/537。36(khtml,likegecko)chrome/57。3306。126safari/537。36'}forentityinentity:ifis_all:print(entity)else:print('#')headers={'user-agent':'mozilla/5。0(windowsnt6。1;win64;x6。
4)applewebkit/537。36(khtml,likegecko)chrome/57。3306。126safari/537。36'}forstateinheaders:ifstatein'#':headers。post(entity,url,headers=headers)else:print('#')return'#'print(all_encoding。 查看全部
采集内容插入词库(插入词库.git中间插入方法参考(1.多个字段导入))
采集内容插入词库:luigi/jieba·github:luigi/jieba-base加载pipeline使用:gitclone:serve-a-ilibrary.git中间插入方法参考:jiebabin
1.先导入jieba2.用jiebabase库来采集词汇3.多个字段导入,
embed
清华的大众点评爬虫,就是用python设计的。具体问题有什么需要说明的,
利用solr查询字段,如果不需要则去掉,我下载的是whl文件。
结果如下,
我写了个简单版本,用flask+redis和python对接,
github提供了一份wordpress爬虫教程,可以参考。
python爬虫可视化神器|
webgis+jieba
importjiebaimportrequestsfromdatetimeimporttimefrom。importstr_inf,str_to_nonefrom。importallurl=''headers={'user-agent':'mozilla/5。0(windowsnt6。1;win64;x6。
4)applewebkit/537。36(khtml,likegecko)chrome/57。3306。126safari/537。36'}s=requests。session(headers=headers)print(s。text)defget_word(url):is_all=[]try:ifis_all:returntrueelse:returnfalseurl='/'url='/'all_encoding='gbk'content=requests。
get(url,headers=headers)content=str_to_none()forentityinurl:ifis_all:print(entity)else:print('#')all_encoding=is_allall_encoding="gbk"else:print('#')headers={'user-agent':'mozilla/5。0(windowsnt6。1;win64;x6。
4)applewebkit/537。36(khtml,likegecko)chrome/57。3306。126safari/537。36'}forentityinentity:ifis_all:print(entity)else:print('#')headers={'user-agent':'mozilla/5。0(windowsnt6。1;win64;x6。
4)applewebkit/537。36(khtml,likegecko)chrome/57。3306。126safari/537。36'}forstateinheaders:ifstatein'#':headers。post(entity,url,headers=headers)else:print('#')return'#'print(all_encoding。
采集内容插入词库(分析一下企查查,本着分享知识的原则、原则和原则 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-03 11:07
)
最近有朋友让我分析七茶茶。本着知识分享的原则,我想用我浅薄的知识和见解谈谈七叉茶的SEO亮点,希望能帮助更多的兄弟了解SEO的精髓!
我之前分析过顺奇网,分析过58同城。你可以看看你是否喜欢它。 58同城的词库感觉比较笼统一点,企业查找更准确。与上面相比,顺奇网这两个词比较复杂,业务不同,词库不同,不分高低。
(内容、模板)稀缺
现在很多人做SEO,还认为原创是SEO的核心。企业调查是对这一观点的最大否定。因为上面的信息基本都是采集。
但是目测采集应该是调用国家数据库,因为国内各个公司的信息,应该不会那么好采集,就算采集,还是有一些不准确的,因为不权威网站上的企业信息信任度比较低。只有国家信息才是准确的。
内容已经解决,公司在用户体验和模板方面做了很好的对比。在之前的课程中,我们也讲过影响网站rank和收录的因素,模板也是其中之一。
大规模网站最终绝对是一场规模的竞争。词库决定权重,收录决定词库。这种收录的水平,绝对不是几十人、几百人能做到的。
词库精准定位
词库的定位与业务直接相关,但公司搜索的词库远小于同城58的词库。仅就竞争而言,它要小得多。企业搜索的词库一般以【企业名称】【法人名称、股东名称】为主,而58则以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白,关键词难易级别。
但是,如果词库定位准确,客户会更准确。当你的量级达到千万甚至上亿的时候,长尾带来的流量是相当恐怖的,这些每天访问网站的恐怖流量所带来的信任度的增长绝不是普通的小网站可比的。
就像之前聊的58一样,品牌流量作为源头带动了网站的整体信任度。信任高后,长尾流量来了,我们一次次回馈网站,良性循环!
学习和应用
为什么需要分析企业搜索?因为企业搜索的难度比较低。我们可以把他的词库导出成权重站!
比如我之前做过的名字站,可以做公司名字的站,或者其他站。毕竟有词库,内容会聚合,哪怕是随机生成,权重分分钟。
查看全部
采集内容插入词库(分析一下企查查,本着分享知识的原则、原则和原则
)
最近有朋友让我分析七茶茶。本着知识分享的原则,我想用我浅薄的知识和见解谈谈七叉茶的SEO亮点,希望能帮助更多的兄弟了解SEO的精髓!

我之前分析过顺奇网,分析过58同城。你可以看看你是否喜欢它。 58同城的词库感觉比较笼统一点,企业查找更准确。与上面相比,顺奇网这两个词比较复杂,业务不同,词库不同,不分高低。
(内容、模板)稀缺
现在很多人做SEO,还认为原创是SEO的核心。企业调查是对这一观点的最大否定。因为上面的信息基本都是采集。
但是目测采集应该是调用国家数据库,因为国内各个公司的信息,应该不会那么好采集,就算采集,还是有一些不准确的,因为不权威网站上的企业信息信任度比较低。只有国家信息才是准确的。
内容已经解决,公司在用户体验和模板方面做了很好的对比。在之前的课程中,我们也讲过影响网站rank和收录的因素,模板也是其中之一。

大规模网站最终绝对是一场规模的竞争。词库决定权重,收录决定词库。这种收录的水平,绝对不是几十人、几百人能做到的。
词库精准定位
词库的定位与业务直接相关,但公司搜索的词库远小于同城58的词库。仅就竞争而言,它要小得多。企业搜索的词库一般以【企业名称】【法人名称、股东名称】为主,而58则以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白,关键词难易级别。
但是,如果词库定位准确,客户会更准确。当你的量级达到千万甚至上亿的时候,长尾带来的流量是相当恐怖的,这些每天访问网站的恐怖流量所带来的信任度的增长绝不是普通的小网站可比的。
就像之前聊的58一样,品牌流量作为源头带动了网站的整体信任度。信任高后,长尾流量来了,我们一次次回馈网站,良性循环!
学习和应用
为什么需要分析企业搜索?因为企业搜索的难度比较低。我们可以把他的词库导出成权重站!
比如我之前做过的名字站,可以做公司名字的站,或者其他站。毕竟有词库,内容会聚合,哪怕是随机生成,权重分分钟。

采集内容插入词库( SEO就是数量关键词的收集整理对SEO的意义分析与思考)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-09-03 11:03
SEO就是数量关键词的收集整理对SEO的意义分析与思考)
从某种意义上说,SEO 是一场围绕关键词 的竞争游戏。
用户通过关键词搜索答案,搜索引擎根据关键词聚合内容,网站围绕关键词争夺展示相关内容的机会以获取流量。
关键词一端是用户真正的需求,另一端是网站内容。搜索引擎一方面聚合流量和内容,另一方面将流量分配给网站。
从SEO的角度来看,关键词是网站运营商通过搜索引擎给目标用户留下的线索,通过关键词(线索)引导目标用户找到目标网站 .
按照这个逻辑,SEO努力的方向是保留更多的搜索线索,争取在搜索引擎上有更多的展示机会,从而最大限度地增加访问量。
那么,掌握关键词的数量和质量就可以在一定程度上反映从业者的SEO水平。大量关键词的采集涉及到下面要讨论的话题——关键词词库。
一、Understanding 关键词词库
百度百科引用中国经典的解读如下。词库是词数据的集合,存储在数据库中,用于特定的程序检索和调用。
关键词词库没有相应的明确定义。这更像是一种行业惯例。
为了后面的讨论方便,我们先在实用层面给它一个简单的定义。 关键词词库是关键词围绕特定目标采集和组织的集合。
这有几个关键点。词典的基本元素是关键词;词典的建立有明确的目标; 关键词有相应的入库标准。
入库是有标准的,采集到的关键词经过筛选符合标准后才能入库管理;
关键词数量多,关键词数量不够做仓库。
综上所述,关键词是用户需求的呈现,关键词库是用户需求的集合。拥有词库,就等于把握了市场方向。
同样,关键词也是网站内容的重点。有了词库,就等于明确了内容创作的方向和指导。
对于 SEO 而言,拥有高质量标准 关键词Thesaurus 的重要性无需赘述。
二、High quality关键词Thesaurus 标准:全面覆盖,主次分明
创建关键词thesaurus,记住这六个字:全面,有主次。
要全面,就是说关键词的数量要尽量多,才能达到全面覆盖。在创建关键词Thesaurus 时,我们应该尽可能全面地采集相关的关键词。这至少有两个好处。一是最大限度地满足用户的所有需求;另一方面可以为后续网站提供足够的内容创作空间。
有主次,也就是说关键词的分类应该是主次的。不同的关键词给网站带来不同的价值,竞争程度也不同。 网站运营商应该根据SEO策略为不同的关键词投入不同的资源。
具体到每个网站关键词词库,标准可以根据自己的SEO策略确定,但数量和质量两个维度是基本要求。
三、高质量关键词thesaurus的制作方法:从加减乘除
1、关键词的三个主要来源:自有频道、公众频道和同行频道
自己的频道-网站operator 自己组织它关键词。例如,企业网站可以关注品牌词,将其列为关键词罗。从自己的频道采集关键词 来说,采集所有独特的关键词 很重要。如果网站已经在线并且配置了访客统计工具,可以看出客户来源的搜索词会给你一个参考。熟悉产品,熟悉用户,熟悉自己的公司,自然会知道用户关注的焦点,可以采集整理对应的关键词。
公共渠道——部分平台提供关键词数据,如搜索引擎自带的关键词工具(百度和谷歌都有)、5118、站长工具等。平台渠道一般来自行业特定的关键词,可以和自己的网站结合进行二次处理。对于常见的行业或领域,这些专业平台工具提供的关键词数量可观;而对于一些很小的细分或不受欢迎的行业,你必须改变主意采集关键词。
对等通道-转到对等网站采集相关关键词。巧妙地从同行,尤其是竞争对手网站那里复制粘贴关键词,也是关键词在收尾阶段的捷径。
在实际操作中,不必局限于以上任何一种渠道,而是使用以上三种或添加其他您认为对采集关键词有价值的方法。在创建关键词词库的初期,越多越好。
2、关键词词典的排序过程是先帮加减,再做乘除。
添加是为了全面覆盖,没有遗漏;
减法就是把资源集中在高价值的关键词上,而不是把资源浪费在低价值的关键词上。
经过上面的一系列操作,你会遇到很多关键词。下一步需要对这些关键词进行优化和整理。
优化关键词Thesaurus 涉及关键词的扩展和合并,也可以说是关键词管理的乘除。
关键词的扩展——一般应用于合并的关键词,如现有的关键词加上城市名称或价格或质量等,组成一个新的关键词;
关键词的merge-to合并精简关键词,意思相同但表达不一致。这是因为搜索引擎在处理这种关键词时也采用了合并。在SEO操作中,不需要分开单独优化,组合效率更好。
此时,您的关键词Thesaurus 已成为基本结构。为了进一步优化,关键词必须进行分类和管理。
3、对关键词进行合理的分类管理。
关键词的组织方式有很多种,比如常见的核心关键词和长尾关键词类。组织方法不需要固定,只需按照自己的习惯或SEO策略。例如,以行业为中心的关键词Thesaurus 可以根据词根词、派生词、常规词、热门词或搜索上升、搜索下降等多个标准进行分类。
例如以网站为中心的关键词Thesaurus可以是核心词、次要核心词、目标关键词、长尾关键词等
同一个关键词在不同的词库中可能属于不同的分类,甚至很不一样,其根源在于分类标准不同。比如A关键词可能属于行业领先品牌网站关键词词库中的核心关键词,但在一个小公司新推出的网站关键词词库中,它就属于到长尾词类别。 .
我们都知道行业根词的搜索量很大,但是对于一些新上线的小网站来说,去争夺关键词这样的机会,是一种资源浪费。
理性的选择是先找机会取胜,再扩大战线。 关键词策略的实现是首先找到有机会获胜并具有潜在高价值的关键词,并将其列为最高优先级关键词。依此类推。
四、提高关键词词库管理效率的工具:记事本、Excel和钢铁侠SEO工具
最简单最基础的关键词Thesaurus工具就是系统自带的notebook,然后是强大的Excel。这里我将介绍钢铁侠的SEO工具。
钢铁侠 SEO 工具是一个客户端软件。安装后你会发现它有一个强大的【标签】功能,可以给提交的关键词打上各种标签,方便关键词的灵活管理。一个标签可以标记多个关键词,一个关键词可以标记多个标签,你知道的,这意味着关键词类别管理的灵活性。
用户向钢铁侠SEO工具提交关键词后,系统会自动采集输出关键词对应的收录数量和比赛,可以为您省去很多工作。更重要的是,这个功能可以永久免费使用,这意味着有了Needle Man,你就有了一个免费的智能工具,可以灵活管理数千个关键词。
五、质量关键词Thesaurus 的维护和更新是一个长期的过程
关键词thesaurus 建立后,并不是完全成功,需要不时更新升级。因为随着市场的发展,新的关键词会出现,一些关键词可能会逐渐从热点变成鲜有人关注的冷门。举一个直观的例子,手机行业。每年都会有一批新机型上市,带来一波热点关键词。而那些退市的品牌和手机型号也越来越少被考虑在内。
为保证关键词词库的高质量标准,在SEO执行过程中,应及时对关键词词库进行增删改查、重要性等级、分类等方面的调整。
高质量的关键词词库一定是有生命力的词库。如果你灵活使用关键词词库,你会有更大的价值。找到适合你的关键词词库创作方法,选择适合你的关键词词库管理工具,打造适合你的优质关键词词库,用好你的优质关键词词库,这个是最重要的。 查看全部
采集内容插入词库(
SEO就是数量关键词的收集整理对SEO的意义分析与思考)

从某种意义上说,SEO 是一场围绕关键词 的竞争游戏。
用户通过关键词搜索答案,搜索引擎根据关键词聚合内容,网站围绕关键词争夺展示相关内容的机会以获取流量。
关键词一端是用户真正的需求,另一端是网站内容。搜索引擎一方面聚合流量和内容,另一方面将流量分配给网站。
从SEO的角度来看,关键词是网站运营商通过搜索引擎给目标用户留下的线索,通过关键词(线索)引导目标用户找到目标网站 .
按照这个逻辑,SEO努力的方向是保留更多的搜索线索,争取在搜索引擎上有更多的展示机会,从而最大限度地增加访问量。
那么,掌握关键词的数量和质量就可以在一定程度上反映从业者的SEO水平。大量关键词的采集涉及到下面要讨论的话题——关键词词库。
一、Understanding 关键词词库
百度百科引用中国经典的解读如下。词库是词数据的集合,存储在数据库中,用于特定的程序检索和调用。
关键词词库没有相应的明确定义。这更像是一种行业惯例。
为了后面的讨论方便,我们先在实用层面给它一个简单的定义。 关键词词库是关键词围绕特定目标采集和组织的集合。
这有几个关键点。词典的基本元素是关键词;词典的建立有明确的目标; 关键词有相应的入库标准。
入库是有标准的,采集到的关键词经过筛选符合标准后才能入库管理;
关键词数量多,关键词数量不够做仓库。
综上所述,关键词是用户需求的呈现,关键词库是用户需求的集合。拥有词库,就等于把握了市场方向。
同样,关键词也是网站内容的重点。有了词库,就等于明确了内容创作的方向和指导。
对于 SEO 而言,拥有高质量标准 关键词Thesaurus 的重要性无需赘述。
二、High quality关键词Thesaurus 标准:全面覆盖,主次分明
创建关键词thesaurus,记住这六个字:全面,有主次。
要全面,就是说关键词的数量要尽量多,才能达到全面覆盖。在创建关键词Thesaurus 时,我们应该尽可能全面地采集相关的关键词。这至少有两个好处。一是最大限度地满足用户的所有需求;另一方面可以为后续网站提供足够的内容创作空间。
有主次,也就是说关键词的分类应该是主次的。不同的关键词给网站带来不同的价值,竞争程度也不同。 网站运营商应该根据SEO策略为不同的关键词投入不同的资源。
具体到每个网站关键词词库,标准可以根据自己的SEO策略确定,但数量和质量两个维度是基本要求。
三、高质量关键词thesaurus的制作方法:从加减乘除
1、关键词的三个主要来源:自有频道、公众频道和同行频道
自己的频道-网站operator 自己组织它关键词。例如,企业网站可以关注品牌词,将其列为关键词罗。从自己的频道采集关键词 来说,采集所有独特的关键词 很重要。如果网站已经在线并且配置了访客统计工具,可以看出客户来源的搜索词会给你一个参考。熟悉产品,熟悉用户,熟悉自己的公司,自然会知道用户关注的焦点,可以采集整理对应的关键词。
公共渠道——部分平台提供关键词数据,如搜索引擎自带的关键词工具(百度和谷歌都有)、5118、站长工具等。平台渠道一般来自行业特定的关键词,可以和自己的网站结合进行二次处理。对于常见的行业或领域,这些专业平台工具提供的关键词数量可观;而对于一些很小的细分或不受欢迎的行业,你必须改变主意采集关键词。
对等通道-转到对等网站采集相关关键词。巧妙地从同行,尤其是竞争对手网站那里复制粘贴关键词,也是关键词在收尾阶段的捷径。
在实际操作中,不必局限于以上任何一种渠道,而是使用以上三种或添加其他您认为对采集关键词有价值的方法。在创建关键词词库的初期,越多越好。
2、关键词词典的排序过程是先帮加减,再做乘除。
添加是为了全面覆盖,没有遗漏;
减法就是把资源集中在高价值的关键词上,而不是把资源浪费在低价值的关键词上。
经过上面的一系列操作,你会遇到很多关键词。下一步需要对这些关键词进行优化和整理。
优化关键词Thesaurus 涉及关键词的扩展和合并,也可以说是关键词管理的乘除。
关键词的扩展——一般应用于合并的关键词,如现有的关键词加上城市名称或价格或质量等,组成一个新的关键词;
关键词的merge-to合并精简关键词,意思相同但表达不一致。这是因为搜索引擎在处理这种关键词时也采用了合并。在SEO操作中,不需要分开单独优化,组合效率更好。
此时,您的关键词Thesaurus 已成为基本结构。为了进一步优化,关键词必须进行分类和管理。
3、对关键词进行合理的分类管理。
关键词的组织方式有很多种,比如常见的核心关键词和长尾关键词类。组织方法不需要固定,只需按照自己的习惯或SEO策略。例如,以行业为中心的关键词Thesaurus 可以根据词根词、派生词、常规词、热门词或搜索上升、搜索下降等多个标准进行分类。
例如以网站为中心的关键词Thesaurus可以是核心词、次要核心词、目标关键词、长尾关键词等
同一个关键词在不同的词库中可能属于不同的分类,甚至很不一样,其根源在于分类标准不同。比如A关键词可能属于行业领先品牌网站关键词词库中的核心关键词,但在一个小公司新推出的网站关键词词库中,它就属于到长尾词类别。 .
我们都知道行业根词的搜索量很大,但是对于一些新上线的小网站来说,去争夺关键词这样的机会,是一种资源浪费。
理性的选择是先找机会取胜,再扩大战线。 关键词策略的实现是首先找到有机会获胜并具有潜在高价值的关键词,并将其列为最高优先级关键词。依此类推。
四、提高关键词词库管理效率的工具:记事本、Excel和钢铁侠SEO工具
最简单最基础的关键词Thesaurus工具就是系统自带的notebook,然后是强大的Excel。这里我将介绍钢铁侠的SEO工具。
钢铁侠 SEO 工具是一个客户端软件。安装后你会发现它有一个强大的【标签】功能,可以给提交的关键词打上各种标签,方便关键词的灵活管理。一个标签可以标记多个关键词,一个关键词可以标记多个标签,你知道的,这意味着关键词类别管理的灵活性。
用户向钢铁侠SEO工具提交关键词后,系统会自动采集输出关键词对应的收录数量和比赛,可以为您省去很多工作。更重要的是,这个功能可以永久免费使用,这意味着有了Needle Man,你就有了一个免费的智能工具,可以灵活管理数千个关键词。
五、质量关键词Thesaurus 的维护和更新是一个长期的过程
关键词thesaurus 建立后,并不是完全成功,需要不时更新升级。因为随着市场的发展,新的关键词会出现,一些关键词可能会逐渐从热点变成鲜有人关注的冷门。举一个直观的例子,手机行业。每年都会有一批新机型上市,带来一波热点关键词。而那些退市的品牌和手机型号也越来越少被考虑在内。
为保证关键词词库的高质量标准,在SEO执行过程中,应及时对关键词词库进行增删改查、重要性等级、分类等方面的调整。
高质量的关键词词库一定是有生命力的词库。如果你灵活使用关键词词库,你会有更大的价值。找到适合你的关键词词库创作方法,选择适合你的关键词词库管理工具,打造适合你的优质关键词词库,用好你的优质关键词词库,这个是最重要的。
采集内容插入词库(词库1.1-1.4如下拓展工具的分类及应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-09-03 02:25
一、Thesaurus 组织
1 选择词库竞争者->准备阶段:选择基本词根和相关长尾词
1.1 在专业的seo分类网站上找;到导航站批量查找;如果实在没有资源,可以手动添加。目标是尝试覆盖行业中的所有网站。
1.2 在我们自己的爬虫数据库中找到行业根词
1.3 在网站行业竞争对手地图中查找行业根词
1.4 在1.4 拥有的资源站点中找到的搜索流量搜索词(百度统计、GA统计等统计工具)
1.5 如果有资源,请花钱买个专业整合公司的industry关键词database
1.1 Comment 这个时候就是我们在拼资源的时候,网上就有这样的网站,比如,
1.2 Comment 如果你已经提前有网站,请从你站点的维度去寻找,底部一定有词根词汇
推荐:
处理器:助理
相关技能:优采云或相关采集tools
耗时估计:1-2天
大多数情况下,我们不是1.5的土豪,我们花10000块买整合数据,那么1.1-1.4处理如下
2 再展开词-> 把1中比较完整的词取出来展开,力争覆盖整个行业关键词Database
2.1 对1.1中的站点进行分类,选择与您要做的站点具有相同属性的站点
2.1.1 采集 可以使用这些站点下的关键词库:爱站关键词挖矿工具(非付费导出数量有限,幅度较小,并且噪音少),5118数据库(可以使用优采云采集,使用两次爬取的逻辑,采集可以达到一个非常大的词,但是噪音太多了,100以外的很多无用词);
2.2 将1.2、1.3、1.4、2.1中的词放入关键词扩展工具中进行扩展
2.2.1 词根扩展量可以达到6K左右;长尾的展开量可以在600左右,请自适应调整
2.3 将所有单词整理好,先去除重复(包括两步,重复和某些特定单词;建议步骤)
2.1 Comment 以游戏网站为例,分为:网络游戏;页面游戏;手机游戏;小游戏;综合等,找出你想做的网站的属性,并记录下来。
2.1 对综合性站点进行标注,例如使用爱站或5118查找属性与您相同的站点。如果想做页面游览,看看有没有等待站点,快速查找提取
2.1.1 评论。如果您需要资源购买付费版,可以在很大程度上节省时间。不要想着免费;
2.1.1 注解5118数据库可以用优采云批量抓取,如果量级大,需要时间,请估计; 采集方法,先通配采集每个域名/子域/下翻页数,然后在关键词下批量写规则采集/baidu/rank/,这是因为排名页数每个域名都不一样
2.2注解爱站扩展长尾词的能力比较好,短词(即行业根词)可以用爱站跑;中短字长(判断标准,excel function=len(*) 4-9左右)可以用战神工具跑;中长字(=len(*) 9-18左右)也可以用战神工具跑;长字(=len(*) 18-29左右)感觉应该删除删除,不需要运行
因为去重的重复量太大,有几千万级,所以必须机器和人工同时过滤处理
3 处理关键词
3.1 通过机器处理噪声进行初始过滤;重复数据删除
3.1.1 直接匹配删除,如:#、$、http、-、..、.com、.xml等,根据自己的行业特点过滤,包括直接删除
3.1.2 替换,主要是转义和空格,如:",&
3.1.3 所有号码将根据行业情况进行删除处理
3.1.4 上面剩下的词库去重
3.2 机器初步筛选-提取精准词
3.1.1 然后处理下一个词根,对词根中的噪声进行处理,比如()中的内容等,有助于机器提取的准确性。
3.1.2 使用行业词库和词根匹配所有词,整理文档,打包。这部分是准确的词。
3.3 人力去除脏话
3.3.1 软件工具:notepad++; office excel 2010及以上版本(WPS不可用); 关键词自动分类工具
3.3.2 步
3.3.2.1 用notepad++打开文档,将所有单词复制到分类工具中
3.3.2.2 点击分类工具中的开始查询
3.3.2.3 稍等,等到右边弹出最终结果(过程可能会持续5-15分钟,不要注意没反应),期间可以同步做其他事情
3.3.2.4 将分词中的结果复制到notepad++中,然后复制到xls表中(点击结果,ctrl+a,因为没有明显的标记,等待全部转蓝色,期间可能有几次没反应)
3.3.2.5 在 xls 表中,#fonts 以列分隔
3.3.2.6 行插入四列,根词,一级,二级,三级
3.3.2.7 选择四列并插入数据透视表
3.3.2.8 在B列进行数字识别,直接删除的为1(无关),待确定的为2(游戏词和无关词之间),可以的一个是 3
3.3.2.9 处理后在E2列输入函数公式=VLOOKUP(A2,Sheet4!A:B,2,0),下拉到最后等待待处理
3.3.2.10 选择E2列,过滤,去掉1,保留2和3的结果
3.3.2.11 保存文档,一份完成
(此部分有待编辑,留有优化空间)
二、 采集Bottom文章 -> 使用采集tools 去采集bottom文章根据2中的话。
3.1 使用付费工具,优采云软件,采集非百度源(360、搜狗,微信,bing,谷歌等都可以用,谷歌需要翻墙)
3.2 文章筛选效率优化
3.2.1 规则:收录主词根(以网页游戏为例,文章收录“页游”或“网页游戏”);湾与游戏相关; C。标题限制 D.大小限制(多多少K可以直接去掉); e.文章内容下限250字; F。加上人工筛选; G。竞争产品词的机器替换和某些词的去除;总体筛选剩余 18% 左右
3.3 采集源 优化:寻找非百度源,文章质量命中率更高的,如果同样情况,可以看爬取质量或爬取时效
3.3.1 先采集攻略,防止采集新闻分配策略资源,增加后期调整成本
三、网站优化 查看全部
采集内容插入词库(词库1.1-1.4如下拓展工具的分类及应用)
一、Thesaurus 组织
1 选择词库竞争者->准备阶段:选择基本词根和相关长尾词
1.1 在专业的seo分类网站上找;到导航站批量查找;如果实在没有资源,可以手动添加。目标是尝试覆盖行业中的所有网站。
1.2 在我们自己的爬虫数据库中找到行业根词
1.3 在网站行业竞争对手地图中查找行业根词
1.4 在1.4 拥有的资源站点中找到的搜索流量搜索词(百度统计、GA统计等统计工具)
1.5 如果有资源,请花钱买个专业整合公司的industry关键词database
1.1 Comment 这个时候就是我们在拼资源的时候,网上就有这样的网站,比如,
1.2 Comment 如果你已经提前有网站,请从你站点的维度去寻找,底部一定有词根词汇
推荐:
处理器:助理
相关技能:优采云或相关采集tools
耗时估计:1-2天
大多数情况下,我们不是1.5的土豪,我们花10000块买整合数据,那么1.1-1.4处理如下
2 再展开词-> 把1中比较完整的词取出来展开,力争覆盖整个行业关键词Database
2.1 对1.1中的站点进行分类,选择与您要做的站点具有相同属性的站点
2.1.1 采集 可以使用这些站点下的关键词库:爱站关键词挖矿工具(非付费导出数量有限,幅度较小,并且噪音少),5118数据库(可以使用优采云采集,使用两次爬取的逻辑,采集可以达到一个非常大的词,但是噪音太多了,100以外的很多无用词);
2.2 将1.2、1.3、1.4、2.1中的词放入关键词扩展工具中进行扩展
2.2.1 词根扩展量可以达到6K左右;长尾的展开量可以在600左右,请自适应调整
2.3 将所有单词整理好,先去除重复(包括两步,重复和某些特定单词;建议步骤)
2.1 Comment 以游戏网站为例,分为:网络游戏;页面游戏;手机游戏;小游戏;综合等,找出你想做的网站的属性,并记录下来。
2.1 对综合性站点进行标注,例如使用爱站或5118查找属性与您相同的站点。如果想做页面游览,看看有没有等待站点,快速查找提取
2.1.1 评论。如果您需要资源购买付费版,可以在很大程度上节省时间。不要想着免费;
2.1.1 注解5118数据库可以用优采云批量抓取,如果量级大,需要时间,请估计; 采集方法,先通配采集每个域名/子域/下翻页数,然后在关键词下批量写规则采集/baidu/rank/,这是因为排名页数每个域名都不一样
2.2注解爱站扩展长尾词的能力比较好,短词(即行业根词)可以用爱站跑;中短字长(判断标准,excel function=len(*) 4-9左右)可以用战神工具跑;中长字(=len(*) 9-18左右)也可以用战神工具跑;长字(=len(*) 18-29左右)感觉应该删除删除,不需要运行
因为去重的重复量太大,有几千万级,所以必须机器和人工同时过滤处理
3 处理关键词
3.1 通过机器处理噪声进行初始过滤;重复数据删除
3.1.1 直接匹配删除,如:#、$、http、-、..、.com、.xml等,根据自己的行业特点过滤,包括直接删除
3.1.2 替换,主要是转义和空格,如:",&
3.1.3 所有号码将根据行业情况进行删除处理
3.1.4 上面剩下的词库去重
3.2 机器初步筛选-提取精准词
3.1.1 然后处理下一个词根,对词根中的噪声进行处理,比如()中的内容等,有助于机器提取的准确性。
3.1.2 使用行业词库和词根匹配所有词,整理文档,打包。这部分是准确的词。
3.3 人力去除脏话
3.3.1 软件工具:notepad++; office excel 2010及以上版本(WPS不可用); 关键词自动分类工具
3.3.2 步
3.3.2.1 用notepad++打开文档,将所有单词复制到分类工具中
3.3.2.2 点击分类工具中的开始查询
3.3.2.3 稍等,等到右边弹出最终结果(过程可能会持续5-15分钟,不要注意没反应),期间可以同步做其他事情
3.3.2.4 将分词中的结果复制到notepad++中,然后复制到xls表中(点击结果,ctrl+a,因为没有明显的标记,等待全部转蓝色,期间可能有几次没反应)
3.3.2.5 在 xls 表中,#fonts 以列分隔
3.3.2.6 行插入四列,根词,一级,二级,三级
3.3.2.7 选择四列并插入数据透视表
3.3.2.8 在B列进行数字识别,直接删除的为1(无关),待确定的为2(游戏词和无关词之间),可以的一个是 3
3.3.2.9 处理后在E2列输入函数公式=VLOOKUP(A2,Sheet4!A:B,2,0),下拉到最后等待待处理
3.3.2.10 选择E2列,过滤,去掉1,保留2和3的结果
3.3.2.11 保存文档,一份完成
(此部分有待编辑,留有优化空间)
二、 采集Bottom文章 -> 使用采集tools 去采集bottom文章根据2中的话。
3.1 使用付费工具,优采云软件,采集非百度源(360、搜狗,微信,bing,谷歌等都可以用,谷歌需要翻墙)
3.2 文章筛选效率优化
3.2.1 规则:收录主词根(以网页游戏为例,文章收录“页游”或“网页游戏”);湾与游戏相关; C。标题限制 D.大小限制(多多少K可以直接去掉); e.文章内容下限250字; F。加上人工筛选; G。竞争产品词的机器替换和某些词的去除;总体筛选剩余 18% 左右
3.3 采集源 优化:寻找非百度源,文章质量命中率更高的,如果同样情况,可以看爬取质量或爬取时效
3.3.1 先采集攻略,防止采集新闻分配策略资源,增加后期调整成本
三、网站优化
采集内容插入词库(分析一下企查查,本着分享知识的原则、原则和原则 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-09-03 00:06
)
最近有朋友让我分析七茶茶。本着知识分享的原则,我想用我浅薄的知识和见解谈谈七叉茶的SEO亮点,希望能帮助更多的兄弟了解SEO的精髓!
我之前分析过顺奇网,分析过58同城。你可以看看你是否喜欢它。 58同城的词库感觉比较笼统一点,企业查找更准确。与上面相比,顺奇网这两个词比较复杂,业务不同,词库不同,不分高低。
(内容、模板)稀缺
现在很多人做SEO,还认为原创是SEO的核心。企业调查是对这一观点的最大否定。因为上面的信息基本都是采集。
但是目测采集应该是调用国家数据库,因为国内各个公司的信息,应该不会那么好采集,就算采集,还是有一些不准确的,因为不权威网站上的企业信息信任度比较低。只有国家信息才是准确的。
内容已经解决,公司在用户体验和模板方面做了很好的对比。在之前的课程中,我们也讲过影响网站rank和收录的因素,模板也是其中之一。
大规模网站最终绝对是一场规模的竞争。词库决定权重,收录决定词库。这种收录的水平,绝对不是几十人、几百人能做到的。
词库精准定位
词库的定位与业务直接相关,但公司搜索的词库远小于同城58的词库。仅就竞争而言,它要小得多。企业搜索的词库一般以【企业名称】【法人名称、股东名称】为主,而58则以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白,关键词难易级别。
但是,如果词库定位准确,客户会更准确。当你的量级达到千万甚至上亿的时候,长尾带来的流量是相当恐怖的,这些每天访问网站的恐怖流量所带来的信任度的增长绝不是普通的小网站可比的。
就像之前聊的58一样,品牌流量作为源头带动了网站的整体信任度。信任高后,长尾流量来了,我们一次次回馈网站,良性循环!
学习和应用
为什么需要分析企业搜索?因为企业搜索的难度比较低。我们可以把他的词库导出成权重站!
比如我之前做过的名字站,可以做公司名字的站,或者其他站。毕竟有词库,内容会聚合,哪怕是随机生成,权重分分钟。
查看全部
采集内容插入词库(分析一下企查查,本着分享知识的原则、原则和原则
)
最近有朋友让我分析七茶茶。本着知识分享的原则,我想用我浅薄的知识和见解谈谈七叉茶的SEO亮点,希望能帮助更多的兄弟了解SEO的精髓!

我之前分析过顺奇网,分析过58同城。你可以看看你是否喜欢它。 58同城的词库感觉比较笼统一点,企业查找更准确。与上面相比,顺奇网这两个词比较复杂,业务不同,词库不同,不分高低。
(内容、模板)稀缺
现在很多人做SEO,还认为原创是SEO的核心。企业调查是对这一观点的最大否定。因为上面的信息基本都是采集。
但是目测采集应该是调用国家数据库,因为国内各个公司的信息,应该不会那么好采集,就算采集,还是有一些不准确的,因为不权威网站上的企业信息信任度比较低。只有国家信息才是准确的。
内容已经解决,公司在用户体验和模板方面做了很好的对比。在之前的课程中,我们也讲过影响网站rank和收录的因素,模板也是其中之一。

大规模网站最终绝对是一场规模的竞争。词库决定权重,收录决定词库。这种收录的水平,绝对不是几十人、几百人能做到的。
词库精准定位

词库的定位与业务直接相关,但公司搜索的词库远小于同城58的词库。仅就竞争而言,它要小得多。企业搜索的词库一般以【企业名称】【法人名称、股东名称】为主,而58则以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白,关键词难易级别。
但是,如果词库定位准确,客户会更准确。当你的量级达到千万甚至上亿的时候,长尾带来的流量是相当恐怖的,这些每天访问网站的恐怖流量所带来的信任度的增长绝不是普通的小网站可比的。
就像之前聊的58一样,品牌流量作为源头带动了网站的整体信任度。信任高后,长尾流量来了,我们一次次回馈网站,良性循环!
学习和应用
为什么需要分析企业搜索?因为企业搜索的难度比较低。我们可以把他的词库导出成权重站!
比如我之前做过的名字站,可以做公司名字的站,或者其他站。毕竟有词库,内容会聚合,哪怕是随机生成,权重分分钟。

采集内容插入词库( 谷歌拼音输入法特指电脑版PC端输入法二百万超大词库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 249 次浏览 • 2021-09-23 04:20
谷歌拼音输入法特指电脑版PC端输入法二百万超大词库)
...
本文中的Google Pinyin输入是指计算机版本PC结束输入方法。
google输入方法2.7. 2 5. 128版本(64位)和3.@@@@@@@@ 98版本可以直接安装在Windows10系统中。虽然没有国内主流输入法(如Sogou输入法,百度输入法,QQ输入法),但易于使用,学习,单词频率调整和稳定性是独一无二的,所以还有许多网友喜欢使用。
...
由于众所周知的原因,国内用户无法直接打开Google链接,导致单词库更新和无法使用的云Word库,所以谷歌输入方法的用户,单词库是相对严重的软。安装人员提供的单词很少,大多数是360和互动百科全书。
...
Word库的重要性不需要许多单词,并且输入方法较少,并且不可能提高输入速度和准确性。为了解决这个问题,莫奥山的特殊单词将在Word库转换器中采集到Google输入方法,导入Google输入方法。现在共享的Word库是介绍完成后产生的发布。
... Google输入方法200万大法术包括上述单词
...
使用方法很简单,按右键在Google输入方法上,单击“属性设置 - 字典”,单击“用户词典管理”中的“导入”。导入后,您的Google输入方法将至少有200万次超大的单词,这个词将更小心。
...
...
为了避免一些不必要的问题,它不会在这里挂起来。需要需要的朋友可以增加注意,给我一个私人信留下你的邮箱。
本文提供的单词库仅用于共享,无需任何业务目的。
♥
- ───────── 查看全部
采集内容插入词库(
谷歌拼音输入法特指电脑版PC端输入法二百万超大词库)
...
本文中的Google Pinyin输入是指计算机版本PC结束输入方法。
google输入方法2.7. 2 5. 128版本(64位)和3.@@@@@@@@ 98版本可以直接安装在Windows10系统中。虽然没有国内主流输入法(如Sogou输入法,百度输入法,QQ输入法),但易于使用,学习,单词频率调整和稳定性是独一无二的,所以还有许多网友喜欢使用。
...
由于众所周知的原因,国内用户无法直接打开Google链接,导致单词库更新和无法使用的云Word库,所以谷歌输入方法的用户,单词库是相对严重的软。安装人员提供的单词很少,大多数是360和互动百科全书。
...
Word库的重要性不需要许多单词,并且输入方法较少,并且不可能提高输入速度和准确性。为了解决这个问题,莫奥山的特殊单词将在Word库转换器中采集到Google输入方法,导入Google输入方法。现在共享的Word库是介绍完成后产生的发布。
... Google输入方法200万大法术包括上述单词
...
使用方法很简单,按右键在Google输入方法上,单击“属性设置 - 字典”,单击“用户词典管理”中的“导入”。导入后,您的Google输入方法将至少有200万次超大的单词,这个词将更小心。
...
...
为了避免一些不必要的问题,它不会在这里挂起来。需要需要的朋友可以增加注意,给我一个私人信留下你的邮箱。
本文提供的单词库仅用于共享,无需任何业务目的。
♥
- ─────────
采集内容插入词库(Javaweb网站敏感词过滤的实现调研结果写出来了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-09-19 21:05
几乎所有网站现在都需要设置敏感字过滤,这似乎已经成为网站的标准配置网站. 如果您的网站没有或您没有相应处理,请小心相关部门邀请您喝茶
我最近一直在研究Javaweb网站对于敏感词过滤的实施,我在互联网上找到了相关信息。经过我的核实,我写下了我的研究成果供你参考
一、敏感字过滤工具类
将敏感词词典的内容加载到ArrayList集中,通过双层循环找到与敏感词列表匹配的字符串。如果找到了,用*号替换它,最后得到替换的字符串
该方法匹配度高,匹配速度快
初始化敏感词库:
//初始化敏感词库
public void InitializationWork()
{
replaceAll = new StringBuilder(replceSize);
for(int x=0;x < replceSize;x++)
{
replaceAll.append(replceStr);
}
//加载词库
arrayList = new ArrayList();
InputStreamReader read = null;
BufferedReader bufferedReader = null;
try {
read = new InputStreamReader(SensitiveWord.class.getClassLoader().getResourceAsStream(fileName),encoding);
bufferedReader = new BufferedReader(read);
for(String txt = null;(txt = bufferedReader.readLine()) != null;){
if(!arrayList.contains(txt))
arrayList.add(txt);
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
if(null != bufferedReader)
bufferedReader.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if(null != read)
read.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
筛选敏感词信息:
public String filterInfo(String str)
{
sensitiveWordSet = new HashSet();
sensitiveWordList= new ArrayList();
StringBuilder buffer = new StringBuilder(str);
HashMap hash = new HashMap(arrayList.size());
String temp;
for(int x = 0; x < arrayList.size();x++)
{
temp = arrayList.get(x);
int findIndexSize = 0;
for(int start = -1;(start=buffer.indexOf(temp,findIndexSize)) > -1;)
{
//System.out.println("###replace="+temp);
findIndexSize = start+temp.length();//从已找到的后面开始找
Integer mapStart = hash.get(start);//起始位置
if(mapStart == null || (mapStart != null && findIndexSize > mapStart))//满足1个,即可更新map
{
hash.put(start, findIndexSize);
//System.out.println("###敏感词:"+buffer.substring(start, findIndexSize));
}
}
}
Collection values = hash.keySet();
for(Integer startIndex : values)
{
Integer endIndex = hash.get(startIndex);
//获取敏感词,并加入列表,用来统计数量
String sensitive = buffer.substring(startIndex, endIndex);
//System.out.println("###敏感词:"+sensitive);
if (!sensitive.contains("*")) {//添加敏感词到集合
sensitiveWordSet.add(sensitive);
sensitiveWordList.add(sensitive);
}
buffer.replace(startIndex, endIndex, replaceAll.substring(0,endIndex-startIndex));
}
hash.clear();
return buffer.toString();
}
下载地址:sensitiveword
链接:密码:qmcw(如果无效,请使用文本末尾的地址下载)
二、Java关键词过滤
该方法使用正则表达式匹配,比第一种方法稍慢,匹配度好
主要代码:
// 从words.properties初始化正则表达式字符串
private static void initPattern() {
StringBuffer patternBuffer = new StringBuffer();
try {
//words.properties
InputStream in = KeyWordFilter.class.getClassLoader().getResourceAsStream("keywords.properties");
Properties property = new Properties();
property.load(in);
Enumeration enu = property.propertyNames();
patternBuffer.append("(");
while (enu.hasMoreElements()) {
String scontent = (String) enu.nextElement();
patternBuffer.append(scontent + "|");
//System.out.println(scontent);
keywordsCount ++;
}
patternBuffer.deleteCharAt(patternBuffer.length() - 1);
patternBuffer.append(")");
//System.out.println(patternBuffer);
// unix换成UTF-8
// pattern = Pattern.compile(new
// String(patternBuf.toString().getBytes("ISO-8859-1"), "UTF-8"));
// win下换成gb2312
// pattern = Pattern.compile(new String(patternBuf.toString()
// .getBytes("ISO-8859-1"), "gb2312"));
// 装换编码
pattern = Pattern.compile(patternBuffer.toString());
} catch (IOException ioEx) {
ioEx.printStackTrace();
}
}
private static String doFilter(String str) {
Matcher m = pattern.matcher(str);
// while (m.find()) {// 查找符合pattern的字符串
// System.out.println("The result is here :" + m.group());
// }
// 选择替换方式,这里以* 号代替
str = m.replaceAll("*");
return str;
}
下载地址:关键字过滤器
链接:密码:xi24(如果失败,请在文本末尾下载)
三、DFA滤波算法
在这种情况下,采用了DFA算法。我对这个算法知之甚少。经过测试,发现匹配度不好,速度也不错。也许可以改进。请请求伟大的上帝来改进
有两个主要文件:sensitivewordfilter.java和sensitivewordinit.java
主要代码:
public int CheckSensitiveWord(String txt,int beginIndex,int matchType){
boolean flag = false; //敏感词结束标识位:用于敏感词只有1位的情况
int matchFlag = 0; //匹配标识数默认为0
char word = 0;
Map nowMap = sensitiveWordMap;
for(int i = beginIndex; i < txt.length() ; i++){
word = txt.charAt(i);
nowMap = (Map) nowMap.get(word); //获取指定key
if(nowMap != null){ //存在,则判断是否为最后一个
matchFlag++; //找到相应key,匹配标识+1
if("1".equals(nowMap.get("isEnd"))){ //如果为最后一个匹配规则,结束循环,返回匹配标识数
flag = true; //结束标志位为true
if(SensitivewordFilter.minMatchTYpe == matchType){ //最小规则,直接返回,最大规则还需继续查找
break;
}
}
}
else{ //不存在,直接返回
break;
}
}
if(matchFlag < 2 || !flag){ //长度必须大于等于1,为词
matchFlag = 0;
}
return matchFlag;
}
下载地址:sensitivewordfilter
链接:密码:mc1x(如果无效,请使用文本末尾的地址下载)
四、多树搜索算法
该方法采用多树搜索算法。至于这个算法是怎么回事,您可以检查与数据结构相关的内容。提供了Jar包,可以直接调用它进行过滤
经测试,该方法匹配度好,速度慢
调用方法:
//敏感词过滤
FilteredResult result = WordFilterUtil.filterText(str, '*');
//获取过滤后的内容
System.out.println("替换后的字符串为:\n"+result.getFilteredContent());
//获取原始字符串
System.out.println("原始字符串为:\n"+result.getOriginalContent());
//获取替换的敏感词
System.out.println("替换的敏感词为:\n"+result.getBadWords());
下载地址:wordfilterutil
链接:密码:5t2h(如果无效,请使用文本末尾的地址下载) 查看全部
采集内容插入词库(Javaweb网站敏感词过滤的实现调研结果写出来了)
几乎所有网站现在都需要设置敏感字过滤,这似乎已经成为网站的标准配置网站. 如果您的网站没有或您没有相应处理,请小心相关部门邀请您喝茶
我最近一直在研究Javaweb网站对于敏感词过滤的实施,我在互联网上找到了相关信息。经过我的核实,我写下了我的研究成果供你参考
一、敏感字过滤工具类
将敏感词词典的内容加载到ArrayList集中,通过双层循环找到与敏感词列表匹配的字符串。如果找到了,用*号替换它,最后得到替换的字符串
该方法匹配度高,匹配速度快
初始化敏感词库:
//初始化敏感词库
public void InitializationWork()
{
replaceAll = new StringBuilder(replceSize);
for(int x=0;x < replceSize;x++)
{
replaceAll.append(replceStr);
}
//加载词库
arrayList = new ArrayList();
InputStreamReader read = null;
BufferedReader bufferedReader = null;
try {
read = new InputStreamReader(SensitiveWord.class.getClassLoader().getResourceAsStream(fileName),encoding);
bufferedReader = new BufferedReader(read);
for(String txt = null;(txt = bufferedReader.readLine()) != null;){
if(!arrayList.contains(txt))
arrayList.add(txt);
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
if(null != bufferedReader)
bufferedReader.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if(null != read)
read.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
筛选敏感词信息:
public String filterInfo(String str)
{
sensitiveWordSet = new HashSet();
sensitiveWordList= new ArrayList();
StringBuilder buffer = new StringBuilder(str);
HashMap hash = new HashMap(arrayList.size());
String temp;
for(int x = 0; x < arrayList.size();x++)
{
temp = arrayList.get(x);
int findIndexSize = 0;
for(int start = -1;(start=buffer.indexOf(temp,findIndexSize)) > -1;)
{
//System.out.println("###replace="+temp);
findIndexSize = start+temp.length();//从已找到的后面开始找
Integer mapStart = hash.get(start);//起始位置
if(mapStart == null || (mapStart != null && findIndexSize > mapStart))//满足1个,即可更新map
{
hash.put(start, findIndexSize);
//System.out.println("###敏感词:"+buffer.substring(start, findIndexSize));
}
}
}
Collection values = hash.keySet();
for(Integer startIndex : values)
{
Integer endIndex = hash.get(startIndex);
//获取敏感词,并加入列表,用来统计数量
String sensitive = buffer.substring(startIndex, endIndex);
//System.out.println("###敏感词:"+sensitive);
if (!sensitive.contains("*")) {//添加敏感词到集合
sensitiveWordSet.add(sensitive);
sensitiveWordList.add(sensitive);
}
buffer.replace(startIndex, endIndex, replaceAll.substring(0,endIndex-startIndex));
}
hash.clear();
return buffer.toString();
}
下载地址:sensitiveword
链接:密码:qmcw(如果无效,请使用文本末尾的地址下载)
二、Java关键词过滤
该方法使用正则表达式匹配,比第一种方法稍慢,匹配度好
主要代码:
// 从words.properties初始化正则表达式字符串
private static void initPattern() {
StringBuffer patternBuffer = new StringBuffer();
try {
//words.properties
InputStream in = KeyWordFilter.class.getClassLoader().getResourceAsStream("keywords.properties");
Properties property = new Properties();
property.load(in);
Enumeration enu = property.propertyNames();
patternBuffer.append("(");
while (enu.hasMoreElements()) {
String scontent = (String) enu.nextElement();
patternBuffer.append(scontent + "|");
//System.out.println(scontent);
keywordsCount ++;
}
patternBuffer.deleteCharAt(patternBuffer.length() - 1);
patternBuffer.append(")");
//System.out.println(patternBuffer);
// unix换成UTF-8
// pattern = Pattern.compile(new
// String(patternBuf.toString().getBytes("ISO-8859-1"), "UTF-8"));
// win下换成gb2312
// pattern = Pattern.compile(new String(patternBuf.toString()
// .getBytes("ISO-8859-1"), "gb2312"));
// 装换编码
pattern = Pattern.compile(patternBuffer.toString());
} catch (IOException ioEx) {
ioEx.printStackTrace();
}
}
private static String doFilter(String str) {
Matcher m = pattern.matcher(str);
// while (m.find()) {// 查找符合pattern的字符串
// System.out.println("The result is here :" + m.group());
// }
// 选择替换方式,这里以* 号代替
str = m.replaceAll("*");
return str;
}
下载地址:关键字过滤器
链接:密码:xi24(如果失败,请在文本末尾下载)
三、DFA滤波算法
在这种情况下,采用了DFA算法。我对这个算法知之甚少。经过测试,发现匹配度不好,速度也不错。也许可以改进。请请求伟大的上帝来改进
有两个主要文件:sensitivewordfilter.java和sensitivewordinit.java
主要代码:
public int CheckSensitiveWord(String txt,int beginIndex,int matchType){
boolean flag = false; //敏感词结束标识位:用于敏感词只有1位的情况
int matchFlag = 0; //匹配标识数默认为0
char word = 0;
Map nowMap = sensitiveWordMap;
for(int i = beginIndex; i < txt.length() ; i++){
word = txt.charAt(i);
nowMap = (Map) nowMap.get(word); //获取指定key
if(nowMap != null){ //存在,则判断是否为最后一个
matchFlag++; //找到相应key,匹配标识+1
if("1".equals(nowMap.get("isEnd"))){ //如果为最后一个匹配规则,结束循环,返回匹配标识数
flag = true; //结束标志位为true
if(SensitivewordFilter.minMatchTYpe == matchType){ //最小规则,直接返回,最大规则还需继续查找
break;
}
}
}
else{ //不存在,直接返回
break;
}
}
if(matchFlag < 2 || !flag){ //长度必须大于等于1,为词
matchFlag = 0;
}
return matchFlag;
}
下载地址:sensitivewordfilter
链接:密码:mc1x(如果无效,请使用文本末尾的地址下载)
四、多树搜索算法
该方法采用多树搜索算法。至于这个算法是怎么回事,您可以检查与数据结构相关的内容。提供了Jar包,可以直接调用它进行过滤
经测试,该方法匹配度好,速度慢
调用方法:
//敏感词过滤
FilteredResult result = WordFilterUtil.filterText(str, '*');
//获取过滤后的内容
System.out.println("替换后的字符串为:\n"+result.getFilteredContent());
//获取原始字符串
System.out.println("原始字符串为:\n"+result.getOriginalContent());
//获取替换的敏感词
System.out.println("替换的敏感词为:\n"+result.getBadWords());
下载地址:wordfilterutil
链接:密码:5t2h(如果无效,请使用文本末尾的地址下载)
采集内容插入词库(什么是关键词词库?排名优化做的就越好)
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-09-16 08:03
关键词排名优化是网站优化的最高优先级。具有大流量和高重量的网站必须具有强大的关键词库支持。对网站关键词同义词表的研究在搜索引擎优化工作中是一件非常重要的事情,但是大多数搜索引擎优化人员没有一个合理的计划关键词库,甚至没有最基本的excel表。事实上,这是一种盲目和随机的行为。它经常导致网站内部关键词竞争,浪费有效的在线资源,优化内容,并造成不必要的负担。你如何通过网站管理员工具或爱站工具看到你自己的网站库关键词?词库越多,网站权重越高,网站优化效果越好
一、让我们首先了解什么是关键词同义词表
简单理解:关键词叙词表是为目标网站和特定关键词. 它通常包括以下类型:
1、industry关键词library和product关键词library
一般来说,不同行业的关键词库具有不同的特点。例如,医疗行业和机械行业之间存在巨大差异。机械行业更注重积累大量产品模型的产品关键词库,而医疗行业则注重医疗术语的扩展
2、广告关键词图书馆
k4图书馆的广告通常服务于品牌建设。它由特定的核心词组成,用来描述企业的概念和产品的特征。同样,它也有责任传播和吸引交通。例如,对于曾经流行的“投诉机构”,您需要整理关键词库中与企业适合性相关的这一部分。它要求内容简短,创造情感共鸣的新词
3、敏感关键词库
对于一个站点,无论是论坛还是独立博客,都需要过滤一些被禁止的关键词,尤其是博客评论的内容。否则,它很可能会被监管机构没收,搜索引擎的权利将被削弱,这往往会超过损失
4、长尾关键词图书馆和流行的关键词图书馆
根据关键字索引,@K17关键词同义词表分为长尾关键词和流行的关键词同义词表,它们是关键词优化的重要参考对象
二、网站关键词库是如何产生的
@K17关键词library是网站管理员工具或爱站tool。根据网站索引和排名在前50名中的排名,关键词排名越高,关键词library关键词越多,获得的流量也越多。这些关键词单词由核心关键词和长尾关键词组成,所以我们应该注意关键词布局和网站内容质量
三、如何创建关键词库1、采集三种类型关键词
关键词一般分为三类:目标关键词、长尾关键词和品牌关键词。由于关键词是采集的,我们一般都会把这三种关键词类型都取下来,但长尾关键词一般是从关键词根展开的,所以抓住关键词根展开是比较正确的方法
有很多方法可以扩展关键词:
百度下拉框,百度相关搜索选择方法,扩展深度3-4层
B.百度索引关键词工具的应用
C.您可以参考百度竞价后台的推广工具关键词planner,它可以准确建立竞价关键词库,也可以作为SEO排名的参考
D.头脑风暴+头脑风暴+竞争对手研究
E.关键词扩展工具,如金华和追字,包括站长工具和爱站网络的关键词挖掘,可用于扩展
可能还有其他一些基本方法,这里不一一介绍。这是一个非常实用的关键词展开方法。与前五种方法不同的是,该方法可以自动无限扩展,只需要根据上述方法找到足够的词根即可。具体的想法是建立一个excl表,水平和垂直排列关键词词根,然后将这些单词自由组合成单个组、双组甚至多个组。当然,这可以通过一个可以快速扩展的函数来实现。可能只需要几分钟。有了这个想法,你就可以自己操作了
2、高质量筛选标准关键词
什么是质量关键词?官方的说法是,能够带来准确客户流量但成本最低的关键词不一定是搜索量最高的关键词或绝对转换关键词. 这样说很空洞,因为我们还没有一个明确的标准
此外,关键词带有“制造商”、“价格”、“十大品牌”或“哪一个好”、“在哪里玩”等问题的词语也有很高的意图关键词. 将这些词扩展为后缀可能会产生许多意想不到的爆炸性效果,但我们应该注意一个前提:数量必须增加,没有数量,这些词的流动可能太微不足道
3、test关键词traffic,点击并转换
事实上,量化关键词的转换经常让许多朋友感到烦恼,因为每个人都对量化标准感到头痛。我们在这里不需要它,因为有太多可量化的数据,比如用户注册量作为转换,用户购买量作为转换,用户点击公司“联系我们”作为转换。网上有很多教程,我只是个老师
我想说的是,在测试过程中,我们应该注意了解关键词的流量和点击流量。如果我们能够分析每个用户搜索的流量和点击流量,并将它们组合起来,我们可能会发现一些用户的搜索意图
例如,百度以这种方式推荐网页。如果你在百度搜索“苹果”,百度会根据绝大多数人的搜索意图推荐信息。你可以看到百度的搜索结果。排名前三的是苹果电子产品官方网站、苹果百科全书和苹果相关视频,这表明搜索这个词的用户最大的需求是对苹果电子产品的理解和需求,想要了解苹果水果市场的人可能相对较少。这样,对用户意图的研究可以为我们的用户提供有用的信息推荐,让用户能够尽快找到自己想要的信息
4、关键词分类库
关键词分类是一项重要任务。对于这里采集的关键词而言,分类非常重要,因此关键词分类的维度可能更详细。当然,这些只是肤浅的想法
四、如何添加网站关键词库
自媒体过滤器关键词
此过滤器关键词与布局网站filter@不同关键词. 您需要选择索引低于100的关键词并且它是一条长尾关键词. 核心关键词索引越大,优化排名就越困难。您必须在K4处过滤更多的长尾巴@
2、优化列页和分类页关键词
网站有很多页面。除了主页、产品详细信息页面和信息详细信息页面外,还有许多专栏页面和分类页面。这些页面权重高,布局有些关键词竞争少,更有利于首页,所以整个网站有更多的关键词排名
3、publish原创文章围绕关键词@
文章@本身可用于长尾关键词优化。在编写文章@时,将关键词整合到标题和文章@内容中。根据文章@优化规则,它不仅可以被百度快速收录搜索,还可以获得很好的排名
4、文章@关键词添加锚文本
有人强调,文章@需要内部的进出口联系。如果这些链接不存在,蜘蛛会认为这是最后一页,不会向下爬行,这不利于网站收录和关键词排名。因此,有必要做好关键词锚链,改进网站内链
小结:我们可以通过网站关键词库看到网站优化的结果。关键词库越少,优化方向就越错误。我们应该及时调整优化策略关键词是长期优化的结果,不可能在几天内出现。我们需要坚持关键词优化,关键词图书馆关键词叙词表中的关键词人才越来越多,对网站内容建设和品牌创建起到了积极的引导作用。它为内容创建和外部链构建指明了方向,节省了资源,提高了工作效率。建立合理的网站关键词库,增加关键词词库是网站长期运行的重要指标。它可以保持网站的活力,提高搜索引擎的友好度和信任度 查看全部
采集内容插入词库(什么是关键词词库?排名优化做的就越好)
关键词排名优化是网站优化的最高优先级。具有大流量和高重量的网站必须具有强大的关键词库支持。对网站关键词同义词表的研究在搜索引擎优化工作中是一件非常重要的事情,但是大多数搜索引擎优化人员没有一个合理的计划关键词库,甚至没有最基本的excel表。事实上,这是一种盲目和随机的行为。它经常导致网站内部关键词竞争,浪费有效的在线资源,优化内容,并造成不必要的负担。你如何通过网站管理员工具或爱站工具看到你自己的网站库关键词?词库越多,网站权重越高,网站优化效果越好
一、让我们首先了解什么是关键词同义词表
简单理解:关键词叙词表是为目标网站和特定关键词. 它通常包括以下类型:
1、industry关键词library和product关键词library
一般来说,不同行业的关键词库具有不同的特点。例如,医疗行业和机械行业之间存在巨大差异。机械行业更注重积累大量产品模型的产品关键词库,而医疗行业则注重医疗术语的扩展
2、广告关键词图书馆
k4图书馆的广告通常服务于品牌建设。它由特定的核心词组成,用来描述企业的概念和产品的特征。同样,它也有责任传播和吸引交通。例如,对于曾经流行的“投诉机构”,您需要整理关键词库中与企业适合性相关的这一部分。它要求内容简短,创造情感共鸣的新词
3、敏感关键词库
对于一个站点,无论是论坛还是独立博客,都需要过滤一些被禁止的关键词,尤其是博客评论的内容。否则,它很可能会被监管机构没收,搜索引擎的权利将被削弱,这往往会超过损失
4、长尾关键词图书馆和流行的关键词图书馆
根据关键字索引,@K17关键词同义词表分为长尾关键词和流行的关键词同义词表,它们是关键词优化的重要参考对象
二、网站关键词库是如何产生的
@K17关键词library是网站管理员工具或爱站tool。根据网站索引和排名在前50名中的排名,关键词排名越高,关键词library关键词越多,获得的流量也越多。这些关键词单词由核心关键词和长尾关键词组成,所以我们应该注意关键词布局和网站内容质量
三、如何创建关键词库1、采集三种类型关键词
关键词一般分为三类:目标关键词、长尾关键词和品牌关键词。由于关键词是采集的,我们一般都会把这三种关键词类型都取下来,但长尾关键词一般是从关键词根展开的,所以抓住关键词根展开是比较正确的方法
有很多方法可以扩展关键词:
百度下拉框,百度相关搜索选择方法,扩展深度3-4层
B.百度索引关键词工具的应用
C.您可以参考百度竞价后台的推广工具关键词planner,它可以准确建立竞价关键词库,也可以作为SEO排名的参考
D.头脑风暴+头脑风暴+竞争对手研究
E.关键词扩展工具,如金华和追字,包括站长工具和爱站网络的关键词挖掘,可用于扩展
可能还有其他一些基本方法,这里不一一介绍。这是一个非常实用的关键词展开方法。与前五种方法不同的是,该方法可以自动无限扩展,只需要根据上述方法找到足够的词根即可。具体的想法是建立一个excl表,水平和垂直排列关键词词根,然后将这些单词自由组合成单个组、双组甚至多个组。当然,这可以通过一个可以快速扩展的函数来实现。可能只需要几分钟。有了这个想法,你就可以自己操作了
2、高质量筛选标准关键词
什么是质量关键词?官方的说法是,能够带来准确客户流量但成本最低的关键词不一定是搜索量最高的关键词或绝对转换关键词. 这样说很空洞,因为我们还没有一个明确的标准
此外,关键词带有“制造商”、“价格”、“十大品牌”或“哪一个好”、“在哪里玩”等问题的词语也有很高的意图关键词. 将这些词扩展为后缀可能会产生许多意想不到的爆炸性效果,但我们应该注意一个前提:数量必须增加,没有数量,这些词的流动可能太微不足道
3、test关键词traffic,点击并转换
事实上,量化关键词的转换经常让许多朋友感到烦恼,因为每个人都对量化标准感到头痛。我们在这里不需要它,因为有太多可量化的数据,比如用户注册量作为转换,用户购买量作为转换,用户点击公司“联系我们”作为转换。网上有很多教程,我只是个老师
我想说的是,在测试过程中,我们应该注意了解关键词的流量和点击流量。如果我们能够分析每个用户搜索的流量和点击流量,并将它们组合起来,我们可能会发现一些用户的搜索意图
例如,百度以这种方式推荐网页。如果你在百度搜索“苹果”,百度会根据绝大多数人的搜索意图推荐信息。你可以看到百度的搜索结果。排名前三的是苹果电子产品官方网站、苹果百科全书和苹果相关视频,这表明搜索这个词的用户最大的需求是对苹果电子产品的理解和需求,想要了解苹果水果市场的人可能相对较少。这样,对用户意图的研究可以为我们的用户提供有用的信息推荐,让用户能够尽快找到自己想要的信息
4、关键词分类库
关键词分类是一项重要任务。对于这里采集的关键词而言,分类非常重要,因此关键词分类的维度可能更详细。当然,这些只是肤浅的想法
四、如何添加网站关键词库
自媒体过滤器关键词
此过滤器关键词与布局网站filter@不同关键词. 您需要选择索引低于100的关键词并且它是一条长尾关键词. 核心关键词索引越大,优化排名就越困难。您必须在K4处过滤更多的长尾巴@
2、优化列页和分类页关键词
网站有很多页面。除了主页、产品详细信息页面和信息详细信息页面外,还有许多专栏页面和分类页面。这些页面权重高,布局有些关键词竞争少,更有利于首页,所以整个网站有更多的关键词排名
3、publish原创文章围绕关键词@
文章@本身可用于长尾关键词优化。在编写文章@时,将关键词整合到标题和文章@内容中。根据文章@优化规则,它不仅可以被百度快速收录搜索,还可以获得很好的排名
4、文章@关键词添加锚文本
有人强调,文章@需要内部的进出口联系。如果这些链接不存在,蜘蛛会认为这是最后一页,不会向下爬行,这不利于网站收录和关键词排名。因此,有必要做好关键词锚链,改进网站内链
小结:我们可以通过网站关键词库看到网站优化的结果。关键词库越少,优化方向就越错误。我们应该及时调整优化策略关键词是长期优化的结果,不可能在几天内出现。我们需要坚持关键词优化,关键词图书馆关键词叙词表中的关键词人才越来越多,对网站内容建设和品牌创建起到了积极的引导作用。它为内容创建和外部链构建指明了方向,节省了资源,提高了工作效率。建立合理的网站关键词库,增加关键词词库是网站长期运行的重要指标。它可以保持网站的活力,提高搜索引擎的友好度和信任度
采集内容插入词库(如何增加站长词库的数量,有效收录以参与排名?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 218 次浏览 • 2021-09-16 06:27
如何增加站长叙词表的数量并有效收录参与排名?如果你想增加网站同义词表的数量,如何优化站内外操作,提高域名的信任度,提高收录的有效性@
如何增加叙词表的数量?叙词表数量的提高取决于索引词的排名,而网站管理员工具的叙词表数量是将网站索引词的构建和生产名称排名到前50名,这被纳入叙词表。为了提高叙词表的数量,我们需要准备可靠的索引词,优化索引词的布局,并有效地收录网页以参与排名。因此,有必要对网站内外进行优化,并有效地将网页纳入参与排名的同义词库
1、如何增加网站企业网络公司关键词词库数量
为提高网站建设技能词典中自助网站建设cms的索引词数量,江门中资企业建议组织优化索引词布局,优化网站内外,提升域名信任度,增加有效网站建设教程页面集合,使有效收录页面有机会参与叙词表排名。随着叙词表数量的增加,有必要明确优化后的索引词网站construction service,并做好索引词在网页标题和文本中的布局。外链锚文本的建设将进一步提升索引词排名,提升自助网站名称。如果索引词在前50名,那么它们将在同义词表中为收录
2、template website building system的源代码同义词表中添加索引词的前提是它可以有效地收录网页
有效的收录网页是参与关键词排名的前提。自助网站建设系统个人网站可以在搜索结果页面的第一位显示搜索页面的标题,这是一个有效的收录网页。如何增加网页的有效数量,优化内置网站容量,并生成高质量的文章网站内容应高度垂直和专业;做好网站内链建设、模板站点建设,优化网站内链和外链,提升域名信任度。索引词叙词表数量的增加是索引词排列和网站建设系统的名称跻身模板网站建设前50名优缺点的原因。因此,有必要改进网站关键词排名,改进网站叙词表排名操作,做好网站内外优化,改进域名信息网站建设服务,优化叙词表布局,更新发布内容,构建外链锚文本,并点击用户的搜索行为,模板站点phpwind,提升模板站点harm网站同义词表的排名
同义词表的增加取决于网站的有效收录。大多数具有大量同义词的网站参与整个网站的排名,而不是单个主页。参与排名的页面也反映了网站优化的质量。如果你想参与叙词表排名的竞争,前提是提高网页收录的有效性,而收录网站的有效构建源代码依赖于内容的优化和有价值的内部资源。荣毅仁有资格被纳入自助网站建设指数并发布参与排名 查看全部
采集内容插入词库(如何增加站长词库的数量,有效收录以参与排名?)
如何增加站长叙词表的数量并有效收录参与排名?如果你想增加网站同义词表的数量,如何优化站内外操作,提高域名的信任度,提高收录的有效性@
如何增加叙词表的数量?叙词表数量的提高取决于索引词的排名,而网站管理员工具的叙词表数量是将网站索引词的构建和生产名称排名到前50名,这被纳入叙词表。为了提高叙词表的数量,我们需要准备可靠的索引词,优化索引词的布局,并有效地收录网页以参与排名。因此,有必要对网站内外进行优化,并有效地将网页纳入参与排名的同义词库
1、如何增加网站企业网络公司关键词词库数量
为提高网站建设技能词典中自助网站建设cms的索引词数量,江门中资企业建议组织优化索引词布局,优化网站内外,提升域名信任度,增加有效网站建设教程页面集合,使有效收录页面有机会参与叙词表排名。随着叙词表数量的增加,有必要明确优化后的索引词网站construction service,并做好索引词在网页标题和文本中的布局。外链锚文本的建设将进一步提升索引词排名,提升自助网站名称。如果索引词在前50名,那么它们将在同义词表中为收录
2、template website building system的源代码同义词表中添加索引词的前提是它可以有效地收录网页
有效的收录网页是参与关键词排名的前提。自助网站建设系统个人网站可以在搜索结果页面的第一位显示搜索页面的标题,这是一个有效的收录网页。如何增加网页的有效数量,优化内置网站容量,并生成高质量的文章网站内容应高度垂直和专业;做好网站内链建设、模板站点建设,优化网站内链和外链,提升域名信任度。索引词叙词表数量的增加是索引词排列和网站建设系统的名称跻身模板网站建设前50名优缺点的原因。因此,有必要改进网站关键词排名,改进网站叙词表排名操作,做好网站内外优化,改进域名信息网站建设服务,优化叙词表布局,更新发布内容,构建外链锚文本,并点击用户的搜索行为,模板站点phpwind,提升模板站点harm网站同义词表的排名
同义词表的增加取决于网站的有效收录。大多数具有大量同义词的网站参与整个网站的排名,而不是单个主页。参与排名的页面也反映了网站优化的质量。如果你想参与叙词表排名的竞争,前提是提高网页收录的有效性,而收录网站的有效构建源代码依赖于内容的优化和有价值的内部资源。荣毅仁有资格被纳入自助网站建设指数并发布参与排名
采集内容插入词库(【干货】采集内容插入词库;设置anti-spam超级爬虫程序)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-16 03:00
采集内容插入词库;设置anti-spam超级爬虫程序,默认爬取文章标题、内容描述、下图、评论。人工批量筛选内容;分词识别出特定词,并准备下次搜索,或移除已经匹配到的词。搜索前看看是否已匹配到词,再决定是否搜索。网址上了图片或者评论,需要前面有说明,如文章已经打码。之前想着发布在我的博客或者文章列表里没事就不进行系统的分词对,这次要注意下。
统计数据在什么时间或者怎么登录的,数据有多少,好做什么更有价值。网址和网站维护者等等。如果是anti-spam加速的,提取出来的内容可能被“蹭”到。把一些系统分词不方便分词的统计下他们爬虫抓的内容有多少。随机一个需要统计爬虫抓取什么内容的网站,批量爬虫遍历一遍。
对搜索引擎来说,关键不是多少文章,而是多少搜索量。以google+为例,想方设法提高分享率,提高followup数,将页面尽可能多分享,提高点击率,提高评论率,这样你就会有更多的收入。毕竟。搞了这么多天你肯定是不缺收入的。
检测banner是否会被调用,
写一个很丑的检测banner的插件
找出引起流量下滑的原因。从用户需求出发,找准几个潜在可能的需求。例如你的产品定位是通过数据分析来引导、指导、改进的行业应用。那么这次的抽样数据你考虑利用的方向是哪里?或者是过去的数据,当代有价值但不能代表未来的数据?那你就需要想办法去抓取和加工。例如你想要数据分析,那么你把所有的做数据分析的抓取了,是什么类型,什么方式,那他会在其他哪些有价值的方面对你做出有价值的指导?你是想通过数据来做过去或者现在的分析还是结合你的公司,分析背后的行业特点,那你就可以去收集已有的公司的数据了。
加上你的行业分析可以做出怎样的预测和判断。如果用户都不能代替你去实际分析出用户需求,那就不是你要做的数据分析。相反,如果你是指望着通过用户去分析,并且通过分析得出几个有价值的结论,那你最好做些筛选,哪些数据是你真正想了解的?那筛选就得去做用户分析,那你抓取的数据一定不能是已有的或者是简单的数据,是对你有价值的。
可以使用各种方式去利用数据去挖掘出用户真正的需求是什么,做到用户需求是你为什么能够实现企业的业务增长,以及需求的真正程度,来进行做调整,提升需求结果。例如你有一个做金融的企业,那你可以通过他的需求结果就可以联想到他的应用层的,需求的能力,也可以知道目前他的数据有多少,需要跟金融类相关的哪些数据。另外一个,你可以通过你公司员工的数据来找到这个员工平时的消费习惯,周边的。 查看全部
采集内容插入词库(【干货】采集内容插入词库;设置anti-spam超级爬虫程序)
采集内容插入词库;设置anti-spam超级爬虫程序,默认爬取文章标题、内容描述、下图、评论。人工批量筛选内容;分词识别出特定词,并准备下次搜索,或移除已经匹配到的词。搜索前看看是否已匹配到词,再决定是否搜索。网址上了图片或者评论,需要前面有说明,如文章已经打码。之前想着发布在我的博客或者文章列表里没事就不进行系统的分词对,这次要注意下。
统计数据在什么时间或者怎么登录的,数据有多少,好做什么更有价值。网址和网站维护者等等。如果是anti-spam加速的,提取出来的内容可能被“蹭”到。把一些系统分词不方便分词的统计下他们爬虫抓的内容有多少。随机一个需要统计爬虫抓取什么内容的网站,批量爬虫遍历一遍。
对搜索引擎来说,关键不是多少文章,而是多少搜索量。以google+为例,想方设法提高分享率,提高followup数,将页面尽可能多分享,提高点击率,提高评论率,这样你就会有更多的收入。毕竟。搞了这么多天你肯定是不缺收入的。
检测banner是否会被调用,
写一个很丑的检测banner的插件
找出引起流量下滑的原因。从用户需求出发,找准几个潜在可能的需求。例如你的产品定位是通过数据分析来引导、指导、改进的行业应用。那么这次的抽样数据你考虑利用的方向是哪里?或者是过去的数据,当代有价值但不能代表未来的数据?那你就需要想办法去抓取和加工。例如你想要数据分析,那么你把所有的做数据分析的抓取了,是什么类型,什么方式,那他会在其他哪些有价值的方面对你做出有价值的指导?你是想通过数据来做过去或者现在的分析还是结合你的公司,分析背后的行业特点,那你就可以去收集已有的公司的数据了。
加上你的行业分析可以做出怎样的预测和判断。如果用户都不能代替你去实际分析出用户需求,那就不是你要做的数据分析。相反,如果你是指望着通过用户去分析,并且通过分析得出几个有价值的结论,那你最好做些筛选,哪些数据是你真正想了解的?那筛选就得去做用户分析,那你抓取的数据一定不能是已有的或者是简单的数据,是对你有价值的。
可以使用各种方式去利用数据去挖掘出用户真正的需求是什么,做到用户需求是你为什么能够实现企业的业务增长,以及需求的真正程度,来进行做调整,提升需求结果。例如你有一个做金融的企业,那你可以通过他的需求结果就可以联想到他的应用层的,需求的能力,也可以知道目前他的数据有多少,需要跟金融类相关的哪些数据。另外一个,你可以通过你公司员工的数据来找到这个员工平时的消费习惯,周边的。
采集内容插入词库(腾讯语料(名词)、词库词表双中转换的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-09-14 01:01
采集内容插入词库,查询内容插入词库,词库中的内容都是经过实词实时语义分析工具-腾讯语料(名词)、词库词表双中转换的,词库中的词是经过相应的语义分析工具判断匹配的词。大数据语料具体是多大的量级,具体怎么收集,有很多算法都能做。目前你能做的就是把你的关键词可以用在很多场景,取长补短,把词的质量做上去。
可以试试印象笔记,他可以将词库同步到云端,方便跨平台同步,微信、手机qq等都可以登录查看。
可以用“叮当语料库”,他家有关键词标注服务,可以输入一些关键词,标注一些词,
其实有很多,比如以前很流行的知网收录。但是单纯做应用的话,用什么都一样吧。
有,比如出过一本书,里面用到了《得到》里的内容。作者,马力,我忘了名字,学到的我想用到自己的写作上,可以直接在叮当语料库导入得到提升。
手机padwifiwifi环境下可以接入百度数据库,他是提供了免费试用版的,虽然名字是国内最大的百度数据库。
这种情况有很多,
很多,比如,出书。微信会提供。
;genuniv=2
叮当
有brainyhull,不过brainyhull是为外文使用需求开发的。就中文使用情况来看,目前主要是百度口碑,以及百度翻译。
因为有外文数据需求,所以用百度等搜索引擎查找过。然后,找到一些查阅资料推荐给大家。 查看全部
采集内容插入词库(腾讯语料(名词)、词库词表双中转换的)
采集内容插入词库,查询内容插入词库,词库中的内容都是经过实词实时语义分析工具-腾讯语料(名词)、词库词表双中转换的,词库中的词是经过相应的语义分析工具判断匹配的词。大数据语料具体是多大的量级,具体怎么收集,有很多算法都能做。目前你能做的就是把你的关键词可以用在很多场景,取长补短,把词的质量做上去。
可以试试印象笔记,他可以将词库同步到云端,方便跨平台同步,微信、手机qq等都可以登录查看。
可以用“叮当语料库”,他家有关键词标注服务,可以输入一些关键词,标注一些词,
其实有很多,比如以前很流行的知网收录。但是单纯做应用的话,用什么都一样吧。
有,比如出过一本书,里面用到了《得到》里的内容。作者,马力,我忘了名字,学到的我想用到自己的写作上,可以直接在叮当语料库导入得到提升。
手机padwifiwifi环境下可以接入百度数据库,他是提供了免费试用版的,虽然名字是国内最大的百度数据库。
这种情况有很多,
很多,比如,出书。微信会提供。
;genuniv=2
叮当
有brainyhull,不过brainyhull是为外文使用需求开发的。就中文使用情况来看,目前主要是百度口碑,以及百度翻译。
因为有外文数据需求,所以用百度等搜索引擎查找过。然后,找到一些查阅资料推荐给大家。
采集内容插入词库(百度的ip地址和手机号是怎么采集内容的?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-09-12 10:02
采集内容插入词库。目前百度统计、地图、腾讯地图、高德等都可以采集内容信息。搜狗和360的信息采集内容不全但是作为辅助来用。其次,百度的ip地址和手机号一般是通过识别的方式来实现。最后,无法采集是因为它内部有一套完整的爬虫系统,遇到正则表达式都能搜出来。另外,这些网站上的数据一般都是实时更新的,非定时更新。
百度并不会直接获取到用户的上网行为,因为它只是抓取用户访问以及定位到的上网信息。不同的上网行为被列在不同的表格里,而百度并不会把相同的表格放到一起。但百度是可以通过一定的搜索习惯等方式,来判断你对同一个搜索出现的情况的概率,从而做到有针对性的精准投放。
是有cookie的!!
百度会为不同情况做差异化识别和推送,不同情况不同策略,搜索手机和定位都是加上了时间戳,记录搜索内容发生的时间,
搜索端与一般网站定位策略不一样。但也不难理解百度都用时间戳了,不会随便乱跳。
百度的工程师都是吃配置的吧?
百度的ip定位是通过分析链接定位,百度要给你推送多少页,目标网站就留多少ip。所以还是有误差。至于想采集所有ip,那是不可能的。 查看全部
采集内容插入词库(百度的ip地址和手机号是怎么采集内容的?)
采集内容插入词库。目前百度统计、地图、腾讯地图、高德等都可以采集内容信息。搜狗和360的信息采集内容不全但是作为辅助来用。其次,百度的ip地址和手机号一般是通过识别的方式来实现。最后,无法采集是因为它内部有一套完整的爬虫系统,遇到正则表达式都能搜出来。另外,这些网站上的数据一般都是实时更新的,非定时更新。
百度并不会直接获取到用户的上网行为,因为它只是抓取用户访问以及定位到的上网信息。不同的上网行为被列在不同的表格里,而百度并不会把相同的表格放到一起。但百度是可以通过一定的搜索习惯等方式,来判断你对同一个搜索出现的情况的概率,从而做到有针对性的精准投放。
是有cookie的!!
百度会为不同情况做差异化识别和推送,不同情况不同策略,搜索手机和定位都是加上了时间戳,记录搜索内容发生的时间,
搜索端与一般网站定位策略不一样。但也不难理解百度都用时间戳了,不会随便乱跳。
百度的工程师都是吃配置的吧?
百度的ip定位是通过分析链接定位,百度要给你推送多少页,目标网站就留多少ip。所以还是有误差。至于想采集所有ip,那是不可能的。
采集内容插入词库(石青SEO伪原创工具使用教程安装软件伪工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2021-09-10 06:02
石青SEO伪原创工具是很多站长使用的辅助工具。大家都知道网站排行和原创的内容有很大关系。这个seo伪原创工具可以帮到你,那我该怎么用呢?一起来看看吧!
石青SEO伪原创工具使用教程
1.安装软件
伪原创工具完全不需要安装,直接下载绿色免费版,解压后执行目录下的genagent.exe文件即可启动。
启动后界面如下:
2.采集文章
石青伪原创tools,自带采集tools。首先,您需要在“采集Settings”模块中输入需要采集 的关键词。录入完成后点击“保存关键词”,单词会被保存,然后勾选(默认勾选)。然后选择是在百度还是谷歌采集。如果您是免费试用用户。只能使用第一个“免费测试采集”。
点击“Content采集”,稍等片刻,数据会慢慢进来采集,采集到达的数据会显示在“Network原创文章专家”界面。如果您想停止采集,请返回“采集设置”界面,然后点击“停止采集”。
使用“采集文章并争夺生成文章”功能,可以根据选择的代数动态生成无数文章文章。
3.制作伪原创文章
用户可以通过4种方式输入原来的文章,1、直接将文章复制到文章编辑区,然后输入标题,然后通过导入保存文章;2、,你可以直接导入TXT或html文档,3、通过采集,在网上直接采集到文章,4、直接通过接口获取自己的cms网站内容;
获得文章后,用户可以通过3种方式制作伪原创文章:
1、 也是最简单的。只需点击文章标题,然后点击界面底部的“生成原创”按钮即可。现在伪原创之后的文章将显示在“伪原创文章预览区”中;
2、采用导出方式,可以将所有勾选的文章批次直接导出为TXT或HTML文章;
3、通过接口直接批量伪原创到自己的cms网站。
下图是导出方法。采用导出方式时,系统会按照设置的伪原创配置,勾选伪原创,文章再导出;
“伪原创工具”生成的文章质量取决于“原创文章生成规则”。当规则超过5000条时,伪原创文章的质量会很高。
4.用于直接更新主流cmssystem
石青伪原创工具,支持99%国内主流cms内容的直接更新,如东夷、老鸭、新云、德德cms等,通过界面直接获取站内信息,然后伪原创后上传回来。具体使用方法在界面中有详细说明。按照说明一步一步来,你很快就会成功。
为什么要设置此功能?一般现在主流网站是:90%的个人或企业都是cms。 cms中都自带采集功能,外围也可以使用“优采云”等第三方工具转采集。面对采集返回的大量数据,如何伪原创成为一个令人担忧的问题。
世青SEO工具提供无缝cms接口,可以直接伪原创采集到cms数据库数据,适合99%使用虚拟主机建站不能直接操作cms的客户数据库自己。上传界面,获取内容,直接伪原创。 伪原创只要3段就可以完成。
5.使用自定义词库
用户可以在自定义词典部分输入或导入自己的同义词库。勾选后,系统会尽快响应该词库,而不是替换我们企业版中的词库。具体使用方法在软件界面中有详细说明。免费版不支持此功能。
6.配置替换/插入功能
这个功能主要是在伪原创之后文章指定的文字中添加一个URL链接,做一个外部链接。同时也可以根据配置的关键词密度插入集合关键词。
首先点击“配置替换/插入功能”,打开一个配置界面,在这里可以输入要添加什么文字到跳转链接。源文本:源文本,对应的URL:要重定向的链接,如下图勾选。
生成伪原创后,点击各种“替换链接”功能,为文章中的文本添加一个URL链接。
如果选择“Insert 关键词 as set”,系统会插入指定的密度设置关键词。
7. 从现有的文章 生成新的文章
这个函数主要是动态生成文章的工具。生成的文章 绝对独一无二,但通常可读。点击SEO功能,然后选择最后一个菜单“从现有的文章生成新的文章”,就这样了。
伪原创如何使用工具?石青SEO伪原创工具使用教程由欧普下载整理发布,欢迎转载! 查看全部
采集内容插入词库(石青SEO伪原创工具使用教程安装软件伪工具)
石青SEO伪原创工具是很多站长使用的辅助工具。大家都知道网站排行和原创的内容有很大关系。这个seo伪原创工具可以帮到你,那我该怎么用呢?一起来看看吧!
石青SEO伪原创工具使用教程
1.安装软件
伪原创工具完全不需要安装,直接下载绿色免费版,解压后执行目录下的genagent.exe文件即可启动。
启动后界面如下:
2.采集文章
石青伪原创tools,自带采集tools。首先,您需要在“采集Settings”模块中输入需要采集 的关键词。录入完成后点击“保存关键词”,单词会被保存,然后勾选(默认勾选)。然后选择是在百度还是谷歌采集。如果您是免费试用用户。只能使用第一个“免费测试采集”。
点击“Content采集”,稍等片刻,数据会慢慢进来采集,采集到达的数据会显示在“Network原创文章专家”界面。如果您想停止采集,请返回“采集设置”界面,然后点击“停止采集”。
使用“采集文章并争夺生成文章”功能,可以根据选择的代数动态生成无数文章文章。
3.制作伪原创文章
用户可以通过4种方式输入原来的文章,1、直接将文章复制到文章编辑区,然后输入标题,然后通过导入保存文章;2、,你可以直接导入TXT或html文档,3、通过采集,在网上直接采集到文章,4、直接通过接口获取自己的cms网站内容;
获得文章后,用户可以通过3种方式制作伪原创文章:
1、 也是最简单的。只需点击文章标题,然后点击界面底部的“生成原创”按钮即可。现在伪原创之后的文章将显示在“伪原创文章预览区”中;
2、采用导出方式,可以将所有勾选的文章批次直接导出为TXT或HTML文章;
3、通过接口直接批量伪原创到自己的cms网站。
下图是导出方法。采用导出方式时,系统会按照设置的伪原创配置,勾选伪原创,文章再导出;
“伪原创工具”生成的文章质量取决于“原创文章生成规则”。当规则超过5000条时,伪原创文章的质量会很高。
4.用于直接更新主流cmssystem
石青伪原创工具,支持99%国内主流cms内容的直接更新,如东夷、老鸭、新云、德德cms等,通过界面直接获取站内信息,然后伪原创后上传回来。具体使用方法在界面中有详细说明。按照说明一步一步来,你很快就会成功。
为什么要设置此功能?一般现在主流网站是:90%的个人或企业都是cms。 cms中都自带采集功能,外围也可以使用“优采云”等第三方工具转采集。面对采集返回的大量数据,如何伪原创成为一个令人担忧的问题。
世青SEO工具提供无缝cms接口,可以直接伪原创采集到cms数据库数据,适合99%使用虚拟主机建站不能直接操作cms的客户数据库自己。上传界面,获取内容,直接伪原创。 伪原创只要3段就可以完成。
5.使用自定义词库
用户可以在自定义词典部分输入或导入自己的同义词库。勾选后,系统会尽快响应该词库,而不是替换我们企业版中的词库。具体使用方法在软件界面中有详细说明。免费版不支持此功能。
6.配置替换/插入功能
这个功能主要是在伪原创之后文章指定的文字中添加一个URL链接,做一个外部链接。同时也可以根据配置的关键词密度插入集合关键词。
首先点击“配置替换/插入功能”,打开一个配置界面,在这里可以输入要添加什么文字到跳转链接。源文本:源文本,对应的URL:要重定向的链接,如下图勾选。
生成伪原创后,点击各种“替换链接”功能,为文章中的文本添加一个URL链接。
如果选择“Insert 关键词 as set”,系统会插入指定的密度设置关键词。
7. 从现有的文章 生成新的文章
这个函数主要是动态生成文章的工具。生成的文章 绝对独一无二,但通常可读。点击SEO功能,然后选择最后一个菜单“从现有的文章生成新的文章”,就这样了。
伪原创如何使用工具?石青SEO伪原创工具使用教程由欧普下载整理发布,欢迎转载!
采集内容插入词库(采采系列之采集数据处理大师主要功能:增加多内容合并功能 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-08 23:00
)
挖矿系列的采集数据处理大师,以及与之配合的一系列软件,如邮箱采集、手机号采集、邮箱注册等
采集系列采集数据处理大师的主要功能:
1、使用字典对内容进行伪原创处理,可以是数据表中的一个或多个字段;
2、繁简交流,处理一些特殊的词,如:鼠标“-”鼠标;程序“-”程序;网络“-”网络;
3、使用谷歌和必应提供的API将中文内容翻译成英文(就可读性而言,该程序无能为力);
4、timing start优采云采集程序采集,目前只能控制到每个站点,不能精确到每个任务;
5、各词典编辑功能
6、多库支持,目前支持MS SQL、SQLite、MySQL、Access
采集采集系列数据处理大师,2012年12月更改
1、添加分词提取描述功能
2、添加添加自定义关键字功能(可限制次数)
3、添加自定义链接功能(可限制次数)
4、添加有道翻译引擎
5、添加更多翻译语言选项
6、添加打乱文章段落顺序的功能
7、添加关键字添加链接功能
8、增加文本内容前后添加自定义内容功能
9、添加多内容合并功能
10、在数据浏览中添加网页浏览表单
11、增加任务执行过程中停止任务的功能
12、去掉计时采集函数(原因不解释)
13、 添加进度条显示
14、多线程执行任务,程序不再卡顿,但是因为涉及到数据处理,所以在处理数据的时候还是单线程的,主要是出于数据安全的考虑
查看全部
采集内容插入词库(采采系列之采集数据处理大师主要功能:增加多内容合并功能
)
挖矿系列的采集数据处理大师,以及与之配合的一系列软件,如邮箱采集、手机号采集、邮箱注册等
采集系列采集数据处理大师的主要功能:
1、使用字典对内容进行伪原创处理,可以是数据表中的一个或多个字段;
2、繁简交流,处理一些特殊的词,如:鼠标“-”鼠标;程序“-”程序;网络“-”网络;
3、使用谷歌和必应提供的API将中文内容翻译成英文(就可读性而言,该程序无能为力);
4、timing start优采云采集程序采集,目前只能控制到每个站点,不能精确到每个任务;
5、各词典编辑功能
6、多库支持,目前支持MS SQL、SQLite、MySQL、Access
采集采集系列数据处理大师,2012年12月更改
1、添加分词提取描述功能
2、添加添加自定义关键字功能(可限制次数)
3、添加自定义链接功能(可限制次数)
4、添加有道翻译引擎
5、添加更多翻译语言选项
6、添加打乱文章段落顺序的功能
7、添加关键字添加链接功能
8、增加文本内容前后添加自定义内容功能
9、添加多内容合并功能
10、在数据浏览中添加网页浏览表单
11、增加任务执行过程中停止任务的功能
12、去掉计时采集函数(原因不解释)
13、 添加进度条显示
14、多线程执行任务,程序不再卡顿,但是因为涉及到数据处理,所以在处理数据的时候还是单线程的,主要是出于数据安全的考虑
采集内容插入词库(搜狗细胞词库:Python实现思路1.获取大分类列表(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-08 05:21
Python搜狗词库介绍批量下载
搜狗的细胞词库是一个开放共享的词库,采集了很多网友提交的词信息。从搜狗细胞词库首页的最新数据来看,19520名网友共创建了27695个词库。 48482247 个条目。当然,我下载了之后,并没有计算有没有这么多条目。有兴趣的朋友可以试试。接下来简单讲解一下如何批量下载搜狗词库。 (我看了看,好像下载的没那么多),这篇文章就是分析一下我的想法,完整程序请进:
Python实现思路1.获取大类列表
首先观察搜狗细胞词库的网站,如下图:
首页有词库分类,这样问题就转化为下载每个分类下的词库了。随机选择一个词库,点击进入观察(我选择第一个),如下图:
这里我们找到了搜狗细胞词库的十二大类:
“城市信息”、“自然科学”、“社会科学”、“工程应用”、“农林渔业和畜牧业”、“医学”、“电子游戏”、“艺术设计”、“百科全书” 《生活》、《运动与休闲》、《人文》、《娱乐与休闲》
写一个函数:
def get_cate_1_list(res_html):
# 获取大分类链接
dict_cate_1_urls = []
soup = BeautifulSoup(res_html, "html.parser")
dict_nav = soup.find("div", id="dict_nav_list")
dict_nav_lists = dict_nav.find_all("a")
for dict_nav_list in dict_nav_lists:
dict_nav_url = "https://pinyin.sogou.com" + dict_nav_list['href']
dict_cate_1_urls.append(dict_nav_url)
return dict_cate_1_urls
将上面页面的源码传给这个函数,我们就可以解析出十二大类对应的链接地址。
2. 获取小类字典
通过分析观察,我们可以发现“城市信息”类别下的子类别与其他11个类别下的子类别略有不同,如下图所示:
因此,这里我们要写两个方法来解析和获取小类别:
def get_cate_2_1_list(res_html):
# 获取第一种小分类链接
dict_cate_2_1_dict = {}
soup = BeautifulSoup(res_html, "html.parser")
dict_td_lists = soup.find_all("div", class_="cate_no_child citylistcate no_select")
for dict_td_list in dict_td_lists:
dict_td_url = "https://pinyin.sogou.com" + dict_td_list.a['href']
dict_cate_2_1_dict[dict_td_list.get_text().replace("\n", "")] = dict_td_url
return dict_cate_2_1_dict
def get_cate_2_2_list(res_html):
# 获取第二种小分类链接
dict_cate_2_2_dict = {}
soup = BeautifulSoup(res_html, "html.parser")
dict_td_lists = soup.find_all("div", class_="cate_no_child no_select")
# 类型1解析
for dict_td_list in dict_td_lists:
dict_td_url = "https://pinyin.sogou.com" + dict_td_list.a['href']
dict_cate_2_2_dict[dict_td_list.get_text().replace("\n", "")] = dict_td_url
# 类型2解析
dict_td_lists = soup.find_all("div", class_="cate_has_child no_select")
for dict_td_list in dict_td_lists:
dict_td_url = "https://pinyin.sogou.com" + dict_td_list.a['href']
dict_cate_2_2_dict[dict_td_list.get_text().replace("\n", "")] = dict_td_url
return dict_cate_2_2_dict
其中,你会发现为什么第二个函数中多了两个类型?这里的原因是有一些小类别和他们自己的小类别。有些有,有些没有,这导致需要分别解决两种类型的子类别。 查看全部
采集内容插入词库(搜狗细胞词库:Python实现思路1.获取大分类列表(组图))
Python搜狗词库介绍批量下载
搜狗的细胞词库是一个开放共享的词库,采集了很多网友提交的词信息。从搜狗细胞词库首页的最新数据来看,19520名网友共创建了27695个词库。 48482247 个条目。当然,我下载了之后,并没有计算有没有这么多条目。有兴趣的朋友可以试试。接下来简单讲解一下如何批量下载搜狗词库。 (我看了看,好像下载的没那么多),这篇文章就是分析一下我的想法,完整程序请进:
Python实现思路1.获取大类列表
首先观察搜狗细胞词库的网站,如下图:
首页有词库分类,这样问题就转化为下载每个分类下的词库了。随机选择一个词库,点击进入观察(我选择第一个),如下图:
这里我们找到了搜狗细胞词库的十二大类:
“城市信息”、“自然科学”、“社会科学”、“工程应用”、“农林渔业和畜牧业”、“医学”、“电子游戏”、“艺术设计”、“百科全书” 《生活》、《运动与休闲》、《人文》、《娱乐与休闲》
写一个函数:
def get_cate_1_list(res_html):
# 获取大分类链接
dict_cate_1_urls = []
soup = BeautifulSoup(res_html, "html.parser")
dict_nav = soup.find("div", id="dict_nav_list")
dict_nav_lists = dict_nav.find_all("a")
for dict_nav_list in dict_nav_lists:
dict_nav_url = "https://pinyin.sogou.com" + dict_nav_list['href']
dict_cate_1_urls.append(dict_nav_url)
return dict_cate_1_urls
将上面页面的源码传给这个函数,我们就可以解析出十二大类对应的链接地址。
2. 获取小类字典
通过分析观察,我们可以发现“城市信息”类别下的子类别与其他11个类别下的子类别略有不同,如下图所示:
因此,这里我们要写两个方法来解析和获取小类别:
def get_cate_2_1_list(res_html):
# 获取第一种小分类链接
dict_cate_2_1_dict = {}
soup = BeautifulSoup(res_html, "html.parser")
dict_td_lists = soup.find_all("div", class_="cate_no_child citylistcate no_select")
for dict_td_list in dict_td_lists:
dict_td_url = "https://pinyin.sogou.com" + dict_td_list.a['href']
dict_cate_2_1_dict[dict_td_list.get_text().replace("\n", "")] = dict_td_url
return dict_cate_2_1_dict
def get_cate_2_2_list(res_html):
# 获取第二种小分类链接
dict_cate_2_2_dict = {}
soup = BeautifulSoup(res_html, "html.parser")
dict_td_lists = soup.find_all("div", class_="cate_no_child no_select")
# 类型1解析
for dict_td_list in dict_td_lists:
dict_td_url = "https://pinyin.sogou.com" + dict_td_list.a['href']
dict_cate_2_2_dict[dict_td_list.get_text().replace("\n", "")] = dict_td_url
# 类型2解析
dict_td_lists = soup.find_all("div", class_="cate_has_child no_select")
for dict_td_list in dict_td_lists:
dict_td_url = "https://pinyin.sogou.com" + dict_td_list.a['href']
dict_cate_2_2_dict[dict_td_list.get_text().replace("\n", "")] = dict_td_url
return dict_cate_2_2_dict
其中,你会发现为什么第二个函数中多了两个类型?这里的原因是有一些小类别和他们自己的小类别。有些有,有些没有,这导致需要分别解决两种类型的子类别。
采集内容插入词库(网站站长词库量如何增加,有效收录才能参与网页排名)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-08 05:00
如何增加网站站长词库数量,有效收录可以参与排名,想增加网站词库数量,如何优化网站内外运营,增加对域名的信任度,增加有效收录?
网站如何提高词库量?词典量的增加取决于索引词的排名。站长工具的词库量是进入前50的索引词,并计入词库。词汇量增加。您需要准备可靠的索引词并优化索引词的布局。只有网页有效收录才能参与排名。因此,如果你做好内外部优化,提高有效网页收录,就可以参与网页排名,增加词库量。
一、网站关键词如何增加词库数量?
1、词库量,这里指的是站长工具中关键词thesaurus的数量,这里的词库是关键词被站长索引的,统计前50个网页。词库。
2、想增加索引词和词库,江门华人企业主编建议整理优化索引词,做好网站站内外,提高域名信任度,并增加收录页面的有效性,有效收录页面有机会参与词库排名。
3、thesaurus 数量的增加,需要明确优化索引词,做好网页标题和正文中索引词的布局,构建外链朋友链,进一步提高索引词和索引词的排名。输入前 50 个将计入词库。
二、增加索引词库的前提,网页有效收录
1、网站Valid收录是参与关键词排名的前提条件。搜索页面的标题可以显示在搜索结果页面第一页的第一个位置,为有效的收录页面。
2、如何增加网页收录的有效量,做好内容优化,产出能解决用户问题、满足需求的优质文章; 网站 内容应该是高度垂直和专业的;做好网页内链建设和优化网站的内部结构和外链建设,增强域信任。
3、索引词库数量的增加意味着该索引词进入前50,因此需要提高网站关键词排名,并改进网络词库排名操作做好站内外优化网站。提高域名信任度、优化词库布局、更新发布内容、构建外链锚文本、点击用户搜索行为等,提升网络词库排名。
总结:网站Thesaurus 数量由网站Valid收录 推广。词库量大的网站大部分是全站参与排名,而不是单个主页参与排名。参与排名的页面也体现了网站优化的质量。想要参加词库排名比赛,前提是增加有效网页收录,有效收录取决于内容优化,有价值的内容才有资格。被索引并发布收录参与排名。
是一家以云架构和优化的网站建设技术为支撑的互联网企业级基础应用服务商,为中国中小企业提供产品和服务。产品包括:全网营销平台(祥云平台)、网站建设系统、移动端开发、微信应用系统、微信小程序、企业邮箱、服务器托管、SEM和SNS推广、外贸多语种GOOGLE优化推广和Google Adwords For推广等软件,您可以随时向我们咨询互联网上的问题。 查看全部
采集内容插入词库(网站站长词库量如何增加,有效收录才能参与网页排名)
如何增加网站站长词库数量,有效收录可以参与排名,想增加网站词库数量,如何优化网站内外运营,增加对域名的信任度,增加有效收录?
网站如何提高词库量?词典量的增加取决于索引词的排名。站长工具的词库量是进入前50的索引词,并计入词库。词汇量增加。您需要准备可靠的索引词并优化索引词的布局。只有网页有效收录才能参与排名。因此,如果你做好内外部优化,提高有效网页收录,就可以参与网页排名,增加词库量。
一、网站关键词如何增加词库数量?
1、词库量,这里指的是站长工具中关键词thesaurus的数量,这里的词库是关键词被站长索引的,统计前50个网页。词库。
2、想增加索引词和词库,江门华人企业主编建议整理优化索引词,做好网站站内外,提高域名信任度,并增加收录页面的有效性,有效收录页面有机会参与词库排名。
3、thesaurus 数量的增加,需要明确优化索引词,做好网页标题和正文中索引词的布局,构建外链朋友链,进一步提高索引词和索引词的排名。输入前 50 个将计入词库。
二、增加索引词库的前提,网页有效收录
1、网站Valid收录是参与关键词排名的前提条件。搜索页面的标题可以显示在搜索结果页面第一页的第一个位置,为有效的收录页面。
2、如何增加网页收录的有效量,做好内容优化,产出能解决用户问题、满足需求的优质文章; 网站 内容应该是高度垂直和专业的;做好网页内链建设和优化网站的内部结构和外链建设,增强域信任。
3、索引词库数量的增加意味着该索引词进入前50,因此需要提高网站关键词排名,并改进网络词库排名操作做好站内外优化网站。提高域名信任度、优化词库布局、更新发布内容、构建外链锚文本、点击用户搜索行为等,提升网络词库排名。
总结:网站Thesaurus 数量由网站Valid收录 推广。词库量大的网站大部分是全站参与排名,而不是单个主页参与排名。参与排名的页面也体现了网站优化的质量。想要参加词库排名比赛,前提是增加有效网页收录,有效收录取决于内容优化,有价值的内容才有资格。被索引并发布收录参与排名。
是一家以云架构和优化的网站建设技术为支撑的互联网企业级基础应用服务商,为中国中小企业提供产品和服务。产品包括:全网营销平台(祥云平台)、网站建设系统、移动端开发、微信应用系统、微信小程序、企业邮箱、服务器托管、SEM和SNS推广、外贸多语种GOOGLE优化推广和Google Adwords For推广等软件,您可以随时向我们咨询互联网上的问题。
采集内容插入词库( 如何用Python把许多PDF文件的文本内容批量提取出来)
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-09-05 07:26
如何用Python把许多PDF文件的文本内容批量提取出来)
本文将向您展示如何使用 Python 批量提取多个 PDF 文件的文本内容,并将它们组织起来并存储在一个数据框中,以供后续数据分析使用。
问题
最近,后台读者的评论变得更加多样化了。
文章写了几篇关于自然语言处理的文章后,声音越来越大:
老师,有没有什么方便的方法提取pdf中的文本内容?
我能感受到读者的心情。
在我展示的例子中,文本数据可以直接读入数据框工具进行处理。它们可能来自开放数据集合、网站API 或爬虫。
但是,有时您会遇到需要处理指定格式数据的问题。
例如,pdf。
许多学术论文、研究报告,甚至数据共享都是以这种格式发表的。
这时候,如果你掌握了很多自然语言分析工具,你就会有一种“拔剑望心”的感觉——你知道如何处理里面的文字信息,但是格式转换有问题。做不到。
怎么办?
当然也有方法,比如专用工具,在线转换服务网站,甚至手动复制粘贴。
但我们重视效率,对吗?
以上部分方式需要大量内容在线传输,耗时较长,并可能带来安全和隐私问题;有些需要特殊购买;有些根本不现实。
怎么办?
好消息是Python可以帮助您高效快速地批量提取pdf文本内容,并与数据整理分析工具无缝对接,为您后续的分析处理提供基础服务。
本文向您详细介绍了这个过程。
想试试吗?
数据
为了更好的说明过程,我为大家准备了一个压缩包。
包括本教程的代码和我们将使用的数据。
请到本网站下载与本教程匹配的压缩包。
下载后解压,在生成的目录(以下简称“demo目录”)中可以看到如下内容。
演示目录收录:
此外,demo 目录中还收录 2 个文件夹。
在这两个文件夹中,有中文pdf文件,用来展示pdf内容的提取。都是我几年前发表的中文核心期刊论文。
这里有两种解释:
我以我自己的论文为例,因为我怕用别人的论文进行文本提取会引起与论文作者和数据库运营商的知识产权纠纷;它分为2个文件夹,向您展示添加新pdf文件时提取工具会做什么?
pdf文件夹内容如下:
newpdf文件夹内容如下:
数据准备好了,我们来部署代码运行环境。
环境
要安装 Python,更简单的方法是安装 Anaconda 包。
请到此网站下载最新版本的 Anaconda。
请选择左侧的Python3.6版本进行下载安装。
如果您需要具体的分步说明,或者想知道如何在Windows平台上安装和运行Anaconda命令,请参考我为您准备的视频教程。
安装Anaconda后,打开终端,使用cd命令进入demo目录。
如果你不知道怎么使用,也可以参考视频教程。
我们需要安装一些环境相关的包。
先执行:
pip install pipenv
这里安装的是 pipenv,一个优秀的 Python 包管理工具。
安装完成后,请执行:
pipenv install --skip-lock
pipenv 工具会根据 Pipfile 自动安装我们需要的所有依赖软件包。
终端会有进度条,显示需要安装的软件数量和实际进度。
安装完成后,按照提示执行:
pipenv shell
这样,我们就进入了本教程专用的虚拟操作环境。
注意以下语句必须执行:
python -m ipykernel install --user --name=py36
只有这样,当前的Python环境才会在系统中注册为内核并命名为py36。
在此,请确保您的计算机上已安装 Google Chrome 浏览器。
我们执行:
jupyter notebook
将打开默认浏览器(谷歌浏览器)并启动 Jupyter notebook 界面:
可以直接点击文件列表中的第一个ipynb文件,查看本教程的所有示例代码。
你可以一边看教程讲解,一边一一执行这些代码。
但是,我建议的方法是返回主界面并创建一个新的空白 Python 3 notebook(显示名称为 py36 的 notebook)。
请按照教程一一输入相应内容。这可以帮助您更深入地理解代码的含义并更有效地内化您的技能。
当你在编写代码时遇到困难,你可以参考demo.ipynb文件。
准备工作结束,正式开始输入密码。
代码
首先,我们读入一些文件操作的模块。
import glob
import os
如上所述,demo目录下有两个文件夹,分别是pdf和newpdf。
我们将pdf文件的路径指定为其中的pdf文件夹。
pdf_path = "pdf/"
我们要获取所有pdf文件的路径。使用glob,一个命令就可以完成这个功能。
pdfs = glob.glob("{}/*.pdf".format(pdf_path))
检查我们得到的pdf文件的路径是否正确。
pdfs
['pdf/复杂系统仿真的微博客虚假信息扩散模型研究.pdf',
'pdf/面向影子分析的社交媒体竞争情报搜集.pdf',
'pdf/面向人机协同的移动互联网政务门户探析.pdf']
已验证。准确。
接下来,我们使用pdfminer从pdf文件中提取内容。我们需要从辅助Python文件pdf_extractor.py中读取函数extract_pdf_content。
from pdf_extractor import extract_pdf_content
使用此函数,我们尝试从pdf文件列表中的第一篇文章中提取内容并将文本保存在内容变量中。
content = extract_pdf_content(pdfs[0])
让我们看看内容:
content
显然内容提取不完善,混入了页眉页脚等信息。
然而,对于我们的许多文本分析目的来说,这并不重要。
你会在内容中看到很多\n。这是什么?
我们使用打印功能来显示内容的内容。
print(content)
可以清楚地看到那些\n是换行符。
我们通过 pdf 文件提取测试建立了信心。
接下来,我们应该建立一个字典,批量提取和存储内容。
mydict = {}
我们遍历pdfs列表,以文件名(不包括目录)作为key值。这样我们就可以很容易的看出哪些pdf文件已经解压了,哪些还没有解压。
为了使这个过程更清晰,我们让 Python 输出正在提取的 pdf 文件的名称。
for pdf in pdfs:
key = pdf.split('/')[-1]
if not key in mydict:
print("Extracting content from {} ...".format(pdf))
mydict[key] = extract_pdf_content(pdf)
在提取过程中,您将看到以下输出消息:
Extracting content from pdf/复杂系统仿真的微博客虚假信息扩散模型研究.pdf ...
Extracting content from pdf/面向影子分析的社交媒体竞争情报搜集.pdf ...
Extracting content from pdf/面向人机协同的移动互联网政务门户探析.pdf ...
看看此时字典中的键值是什么:
mydict.keys()
dict_keys(['复杂系统仿真的微博客虚假信息扩散模型研究.pdf', '面向影子分析的社交媒体竞争情报搜集.pdf', '面向人机协同的移动互联网政务门户探析.pdf'])
一切正常。
接下来我们调用pandas将字典变成数据框,方便分析。
import pandas as pd
下面这句话可以把字典转换成数据框。注意下面的reset_index()也是把原字典key值生成的索引转换成普通列。
df = pd.DataFrame.from_dict(mydict, orient='index').reset_index()
然后我们重命名了该列以备将来使用。
df.columns = ["path", "content"]
此时数据框的内容如下:
df
如您所见,我们的数据框收录 pdf 文件信息和所有文本内容。这样就可以使用关键词抽取、情感分析、相似度计算等多种分析工具。
限于篇幅,我们仅以字符计数为例来演示基本的分析功能。
我们让 Python 帮助我们计算提取内容的长度。
df["length"] = df.content.apply(lambda x: len(x))
此时数据框的内容有如下变化:
df
额外的一列是pdf文本内容中的字符数。
为了在 Jupyter Notebook 中正确显示绘图结果,我们需要使用以下语句:
%matplotlib inline
接下来,我们让 Pandas 用列图标显示一列字符长度的信息。为了美观,我们设置了图片的纵横比,将对应的pdf文件名以45度的倾斜度显示。
import matplotlib.pyplot as plt
plt.figure(figsize=(14, 6))
df.set_index('path').length.plot(kind='bar')
plt.xticks(rotation=45)
视觉分析完成。
接下来,我们将刚才的分析过程整理成函数,方便以后调用。
我们先把提取pdf内容的模块集成到字典中:
def get_mydict_from_pdf_path(mydict, pdf_path):
pdfs = glob.glob("{}/*.pdf".format(pdf_path))
for pdf in pdfs:
key = pdf.split('/')[-1]
if not key in mydict:
print("Extracting content from {} ...".format(pdf))
mydict[key] = extract_pdf_content(pdf)
return mydict
这里输入的是现有字典和pdf文件夹的路径。输出是一个新字典。
您可能想知道为什么您仍然需要输入“现有字典”。别着急,后面我会举一个实际的例子。
下面的函数非常简单——将字典转换为数据框。
def make_df_from_mydict(mydict):
df = pd.DataFrame.from_dict(mydict, orient='index').reset_index()
df.columns = ["path", "content"]
return df
最后一个函数用于绘制计数的字符数。
def draw_df(df):
df["length"] = df.content.apply(lambda x: len(x))
plt.figure(figsize=(14, 6))
df.set_index('path').length.plot(kind='bar')
plt.xticks(rotation=45)
函数已经编译好了,下面来试试吧。
记得demo目录下有一个子目录,叫newpdf吧?
我们将两个 pdf 文件移至 pdf 目录。
pdf目录下有5个文件:
我们执行三个新排序的函数。
先输入已有的字典(注意此时里面有3条记录),pdf文件夹路径没有变化。输出是新字典。
mydict = get_mydict_from_pdf_path(mydict, pdf_path)
Extracting content from pdf/微博客 Twitter 的企业竞争情报搜集.pdf ...
Extracting content from pdf/移动社交媒体用户隐私保护对策研究.pdf ...
注意这里的提示,原来的3个pdf文件没有再解压,只解压了2个新的pdf文件。
我们这里总共只有 5 个文件,所以您可能无法直观地感受到显着差异。
然而,假设你已经用了几个小时从数百个 pdf 文件中提取信息,结果你的老板扔给你 3 个新的 pdf 文件......
如果非要一开始就提取信息,恐怕会崩溃。
此时,使用我们的函数,您可以在 1 分钟内追加新的文件内容。
这个差别不小吧?
接下来,我们使用新字典来构建数据框。
df = make_df_from_mydict(mydict)
我们绘制一个新的数据框,pdf提取文本字符数。结果如下:
draw_df(df)
至此,代码展示完成。
总结
总结一下,本文为大家介绍了以下知识点:
讨论
在您之前的数据分析工作中,您是否遇到过从pdf文件中提取文本的任务?你是怎么处理的?有没有更好的工具和方法?欢迎留言,与大家分享你的经验和想法,我们一起交流讨论。 查看全部
采集内容插入词库(
如何用Python把许多PDF文件的文本内容批量提取出来)
本文将向您展示如何使用 Python 批量提取多个 PDF 文件的文本内容,并将它们组织起来并存储在一个数据框中,以供后续数据分析使用。
问题
最近,后台读者的评论变得更加多样化了。
文章写了几篇关于自然语言处理的文章后,声音越来越大:
老师,有没有什么方便的方法提取pdf中的文本内容?
我能感受到读者的心情。
在我展示的例子中,文本数据可以直接读入数据框工具进行处理。它们可能来自开放数据集合、网站API 或爬虫。
但是,有时您会遇到需要处理指定格式数据的问题。
例如,pdf。
许多学术论文、研究报告,甚至数据共享都是以这种格式发表的。
这时候,如果你掌握了很多自然语言分析工具,你就会有一种“拔剑望心”的感觉——你知道如何处理里面的文字信息,但是格式转换有问题。做不到。
怎么办?
当然也有方法,比如专用工具,在线转换服务网站,甚至手动复制粘贴。
但我们重视效率,对吗?
以上部分方式需要大量内容在线传输,耗时较长,并可能带来安全和隐私问题;有些需要特殊购买;有些根本不现实。
怎么办?
好消息是Python可以帮助您高效快速地批量提取pdf文本内容,并与数据整理分析工具无缝对接,为您后续的分析处理提供基础服务。
本文向您详细介绍了这个过程。
想试试吗?
数据
为了更好的说明过程,我为大家准备了一个压缩包。
包括本教程的代码和我们将使用的数据。
请到本网站下载与本教程匹配的压缩包。
下载后解压,在生成的目录(以下简称“demo目录”)中可以看到如下内容。
演示目录收录:
此外,demo 目录中还收录 2 个文件夹。
在这两个文件夹中,有中文pdf文件,用来展示pdf内容的提取。都是我几年前发表的中文核心期刊论文。
这里有两种解释:
我以我自己的论文为例,因为我怕用别人的论文进行文本提取会引起与论文作者和数据库运营商的知识产权纠纷;它分为2个文件夹,向您展示添加新pdf文件时提取工具会做什么?
pdf文件夹内容如下:
newpdf文件夹内容如下:
数据准备好了,我们来部署代码运行环境。
环境
要安装 Python,更简单的方法是安装 Anaconda 包。
请到此网站下载最新版本的 Anaconda。
请选择左侧的Python3.6版本进行下载安装。
如果您需要具体的分步说明,或者想知道如何在Windows平台上安装和运行Anaconda命令,请参考我为您准备的视频教程。
安装Anaconda后,打开终端,使用cd命令进入demo目录。
如果你不知道怎么使用,也可以参考视频教程。
我们需要安装一些环境相关的包。
先执行:
pip install pipenv
这里安装的是 pipenv,一个优秀的 Python 包管理工具。
安装完成后,请执行:
pipenv install --skip-lock
pipenv 工具会根据 Pipfile 自动安装我们需要的所有依赖软件包。
终端会有进度条,显示需要安装的软件数量和实际进度。
安装完成后,按照提示执行:
pipenv shell
这样,我们就进入了本教程专用的虚拟操作环境。
注意以下语句必须执行:
python -m ipykernel install --user --name=py36
只有这样,当前的Python环境才会在系统中注册为内核并命名为py36。
在此,请确保您的计算机上已安装 Google Chrome 浏览器。
我们执行:
jupyter notebook
将打开默认浏览器(谷歌浏览器)并启动 Jupyter notebook 界面:
可以直接点击文件列表中的第一个ipynb文件,查看本教程的所有示例代码。
你可以一边看教程讲解,一边一一执行这些代码。
但是,我建议的方法是返回主界面并创建一个新的空白 Python 3 notebook(显示名称为 py36 的 notebook)。
请按照教程一一输入相应内容。这可以帮助您更深入地理解代码的含义并更有效地内化您的技能。
当你在编写代码时遇到困难,你可以参考demo.ipynb文件。
准备工作结束,正式开始输入密码。
代码
首先,我们读入一些文件操作的模块。
import glob
import os
如上所述,demo目录下有两个文件夹,分别是pdf和newpdf。
我们将pdf文件的路径指定为其中的pdf文件夹。
pdf_path = "pdf/"
我们要获取所有pdf文件的路径。使用glob,一个命令就可以完成这个功能。
pdfs = glob.glob("{}/*.pdf".format(pdf_path))
检查我们得到的pdf文件的路径是否正确。
pdfs
['pdf/复杂系统仿真的微博客虚假信息扩散模型研究.pdf',
'pdf/面向影子分析的社交媒体竞争情报搜集.pdf',
'pdf/面向人机协同的移动互联网政务门户探析.pdf']
已验证。准确。
接下来,我们使用pdfminer从pdf文件中提取内容。我们需要从辅助Python文件pdf_extractor.py中读取函数extract_pdf_content。
from pdf_extractor import extract_pdf_content
使用此函数,我们尝试从pdf文件列表中的第一篇文章中提取内容并将文本保存在内容变量中。
content = extract_pdf_content(pdfs[0])
让我们看看内容:
content
显然内容提取不完善,混入了页眉页脚等信息。
然而,对于我们的许多文本分析目的来说,这并不重要。
你会在内容中看到很多\n。这是什么?
我们使用打印功能来显示内容的内容。
print(content)
可以清楚地看到那些\n是换行符。
我们通过 pdf 文件提取测试建立了信心。
接下来,我们应该建立一个字典,批量提取和存储内容。
mydict = {}
我们遍历pdfs列表,以文件名(不包括目录)作为key值。这样我们就可以很容易的看出哪些pdf文件已经解压了,哪些还没有解压。
为了使这个过程更清晰,我们让 Python 输出正在提取的 pdf 文件的名称。
for pdf in pdfs:
key = pdf.split('/')[-1]
if not key in mydict:
print("Extracting content from {} ...".format(pdf))
mydict[key] = extract_pdf_content(pdf)
在提取过程中,您将看到以下输出消息:
Extracting content from pdf/复杂系统仿真的微博客虚假信息扩散模型研究.pdf ...
Extracting content from pdf/面向影子分析的社交媒体竞争情报搜集.pdf ...
Extracting content from pdf/面向人机协同的移动互联网政务门户探析.pdf ...
看看此时字典中的键值是什么:
mydict.keys()
dict_keys(['复杂系统仿真的微博客虚假信息扩散模型研究.pdf', '面向影子分析的社交媒体竞争情报搜集.pdf', '面向人机协同的移动互联网政务门户探析.pdf'])
一切正常。
接下来我们调用pandas将字典变成数据框,方便分析。
import pandas as pd
下面这句话可以把字典转换成数据框。注意下面的reset_index()也是把原字典key值生成的索引转换成普通列。
df = pd.DataFrame.from_dict(mydict, orient='index').reset_index()
然后我们重命名了该列以备将来使用。
df.columns = ["path", "content"]
此时数据框的内容如下:
df
如您所见,我们的数据框收录 pdf 文件信息和所有文本内容。这样就可以使用关键词抽取、情感分析、相似度计算等多种分析工具。
限于篇幅,我们仅以字符计数为例来演示基本的分析功能。
我们让 Python 帮助我们计算提取内容的长度。
df["length"] = df.content.apply(lambda x: len(x))
此时数据框的内容有如下变化:
df
额外的一列是pdf文本内容中的字符数。
为了在 Jupyter Notebook 中正确显示绘图结果,我们需要使用以下语句:
%matplotlib inline
接下来,我们让 Pandas 用列图标显示一列字符长度的信息。为了美观,我们设置了图片的纵横比,将对应的pdf文件名以45度的倾斜度显示。
import matplotlib.pyplot as plt
plt.figure(figsize=(14, 6))
df.set_index('path').length.plot(kind='bar')
plt.xticks(rotation=45)
视觉分析完成。
接下来,我们将刚才的分析过程整理成函数,方便以后调用。
我们先把提取pdf内容的模块集成到字典中:
def get_mydict_from_pdf_path(mydict, pdf_path):
pdfs = glob.glob("{}/*.pdf".format(pdf_path))
for pdf in pdfs:
key = pdf.split('/')[-1]
if not key in mydict:
print("Extracting content from {} ...".format(pdf))
mydict[key] = extract_pdf_content(pdf)
return mydict
这里输入的是现有字典和pdf文件夹的路径。输出是一个新字典。
您可能想知道为什么您仍然需要输入“现有字典”。别着急,后面我会举一个实际的例子。
下面的函数非常简单——将字典转换为数据框。
def make_df_from_mydict(mydict):
df = pd.DataFrame.from_dict(mydict, orient='index').reset_index()
df.columns = ["path", "content"]
return df
最后一个函数用于绘制计数的字符数。
def draw_df(df):
df["length"] = df.content.apply(lambda x: len(x))
plt.figure(figsize=(14, 6))
df.set_index('path').length.plot(kind='bar')
plt.xticks(rotation=45)
函数已经编译好了,下面来试试吧。
记得demo目录下有一个子目录,叫newpdf吧?
我们将两个 pdf 文件移至 pdf 目录。
pdf目录下有5个文件:
我们执行三个新排序的函数。
先输入已有的字典(注意此时里面有3条记录),pdf文件夹路径没有变化。输出是新字典。
mydict = get_mydict_from_pdf_path(mydict, pdf_path)
Extracting content from pdf/微博客 Twitter 的企业竞争情报搜集.pdf ...
Extracting content from pdf/移动社交媒体用户隐私保护对策研究.pdf ...
注意这里的提示,原来的3个pdf文件没有再解压,只解压了2个新的pdf文件。
我们这里总共只有 5 个文件,所以您可能无法直观地感受到显着差异。
然而,假设你已经用了几个小时从数百个 pdf 文件中提取信息,结果你的老板扔给你 3 个新的 pdf 文件......
如果非要一开始就提取信息,恐怕会崩溃。
此时,使用我们的函数,您可以在 1 分钟内追加新的文件内容。
这个差别不小吧?
接下来,我们使用新字典来构建数据框。
df = make_df_from_mydict(mydict)
我们绘制一个新的数据框,pdf提取文本字符数。结果如下:
draw_df(df)
至此,代码展示完成。
总结
总结一下,本文为大家介绍了以下知识点:
讨论
在您之前的数据分析工作中,您是否遇到过从pdf文件中提取文本的任务?你是怎么处理的?有没有更好的工具和方法?欢迎留言,与大家分享你的经验和想法,我们一起交流讨论。
采集内容插入词库(复旦大学《信息内容安全》(互联网大数据技术))
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-09-04 20:06
复旦大学“信息内容安全”(互联网大数据技术)本科课程。经过一个学期的学习,同学们对爬虫技术、文本预处理、大数据语义、文本分析与挖掘等算法、模型和实现技术进行了较为系统的学习。同学们都很感兴趣,本期陆续发布了多款优秀的PJ。本刊刊登邓瑞君、陆小凡、龙豆豆完成的基于爬虫和文本挖掘的迪士尼攻略创作。
课程PJ选题的目的
上海迪士尼乐园每年都会吸引大量游客,但很多人往往不清楚乐园的规则,需要提前准备的行李,以及准备不足的注意事项,以及一些不愉快的情节会在游玩过程中遇到。针对这些问题,本课程的PJ通过采集为计划去上海迪士尼乐园的朋友提供了一些信息,分析、展示相关评论,让大家在准备充分的情况下享受乐园的美好时光。
主要技术流程
主要技术流程包括:数据源选择、文本预处理、文本挖掘和可视化。
如果想去迪士尼,可以直接翻到本文后半部分,查看我们生成的导览图。如果没有,请在留言区写下您的话。
数据采集
数据来源:去哪里查看迪士尼旅游项目的审核信息。
Data采集:评论列表采用Ant Design's List的形式。通过简单的页面分析,可以找到评论页面翻页URL的组成规则。评论分为短评论和长评论,长评论可以通过“阅读全部”获取全部内容。具体方法是:
要获取在 a.seeMore 中显示所有长评论的 URL,请使用 link=e_soup.select('a.seeMore')
read_more.append(link[0].get('href'))
获取长评论的 URL。
我在实践过程中发现,70、80页后,去哪儿服务器会提醒频繁访问同一个IP地址,需要验证码才能继续访问。因此,在实际操作过程中需要妥善处理,减少访问频率,做一个有礼貌的爬虫。由于本课程中的PJ只是练习,所以不会大规模恶意爬取网站内容。进一步阅读:爬虫的合规性。
文本预处理
预处理过程包括:通过正则表达式匹配提取评论中的中文信息,jieba分词,添加自定义词典,去除停用词,提取tf-idf信息和词性信息。
使用 jieba 加载自定义词典。这部分添加了一些迪士尼的游乐项目名称、餐厅名称等 jieba.load_userdict("custom_dic.txt").
使用jieba.analysis分别提取形容词中的关键词和名词中的关键词,或者使用jieba.posseg.lcut进行分词获取词性标签。
jieba.analysis的参数分析:
第一个参数是要提取的关键词的文本;
第二个参数是提取的第一个关键字的个数,这里是前一百个;
第三个参数是决定是否返回每个关键词的权重,这里是选择;
第四个参数是词性过滤,允许提取词性。抽取形容词类时,设置“'a','an','ad','ag'”,抽取名词类时,设置“'n','ns'”。
文本挖掘
这部分对已经爬下来的前5页数据进行预处理得到分词结果,然后人工分类,将每一类词写入txt文件,每行一个词。使用sklearn的Countervectorizer进行特征提取,将训练词汇和待分类词汇转换为向量。使用sklearn的svm分类器(核函数是线性的)学习训练词汇并对要分类的词汇进行分类。
分类过程包括在人工标注的数据集上评估SVM分类方法下不同核函数的分类效果,然后选择分类效果最好的线性核函数对所有爬取的数据进行分类并生成对应的类别词云。类别分为:游乐项目和园区内地点、园区内餐饮、准备的行李和出现在评论中的角色。例如,当只训练和测试人工标注的游乐项目和地点和食品和餐饮两类时,得到的F值评价结果如下。
对于每个文本,使用两种方法生成词云:一种基于词频,另一种基于tf-idf值,选择效果较好的作为结果。
基于词频的方法是调用wordcloud.generate函数
根据tf-idf方法,先使用jieba.analysis.extract_tags提取tf-idf值,然后使用wordcloud.generate_from函数根据tf-idf值生成词云。
词云生成(策略) 查看全部
采集内容插入词库(复旦大学《信息内容安全》(互联网大数据技术))
复旦大学“信息内容安全”(互联网大数据技术)本科课程。经过一个学期的学习,同学们对爬虫技术、文本预处理、大数据语义、文本分析与挖掘等算法、模型和实现技术进行了较为系统的学习。同学们都很感兴趣,本期陆续发布了多款优秀的PJ。本刊刊登邓瑞君、陆小凡、龙豆豆完成的基于爬虫和文本挖掘的迪士尼攻略创作。
课程PJ选题的目的
上海迪士尼乐园每年都会吸引大量游客,但很多人往往不清楚乐园的规则,需要提前准备的行李,以及准备不足的注意事项,以及一些不愉快的情节会在游玩过程中遇到。针对这些问题,本课程的PJ通过采集为计划去上海迪士尼乐园的朋友提供了一些信息,分析、展示相关评论,让大家在准备充分的情况下享受乐园的美好时光。
主要技术流程
主要技术流程包括:数据源选择、文本预处理、文本挖掘和可视化。
如果想去迪士尼,可以直接翻到本文后半部分,查看我们生成的导览图。如果没有,请在留言区写下您的话。
数据采集
数据来源:去哪里查看迪士尼旅游项目的审核信息。
Data采集:评论列表采用Ant Design's List的形式。通过简单的页面分析,可以找到评论页面翻页URL的组成规则。评论分为短评论和长评论,长评论可以通过“阅读全部”获取全部内容。具体方法是:
要获取在 a.seeMore 中显示所有长评论的 URL,请使用 link=e_soup.select('a.seeMore')
read_more.append(link[0].get('href'))
获取长评论的 URL。
我在实践过程中发现,70、80页后,去哪儿服务器会提醒频繁访问同一个IP地址,需要验证码才能继续访问。因此,在实际操作过程中需要妥善处理,减少访问频率,做一个有礼貌的爬虫。由于本课程中的PJ只是练习,所以不会大规模恶意爬取网站内容。进一步阅读:爬虫的合规性。
文本预处理
预处理过程包括:通过正则表达式匹配提取评论中的中文信息,jieba分词,添加自定义词典,去除停用词,提取tf-idf信息和词性信息。
使用 jieba 加载自定义词典。这部分添加了一些迪士尼的游乐项目名称、餐厅名称等 jieba.load_userdict("custom_dic.txt").
使用jieba.analysis分别提取形容词中的关键词和名词中的关键词,或者使用jieba.posseg.lcut进行分词获取词性标签。
jieba.analysis的参数分析:
第一个参数是要提取的关键词的文本;
第二个参数是提取的第一个关键字的个数,这里是前一百个;
第三个参数是决定是否返回每个关键词的权重,这里是选择;
第四个参数是词性过滤,允许提取词性。抽取形容词类时,设置“'a','an','ad','ag'”,抽取名词类时,设置“'n','ns'”。
文本挖掘
这部分对已经爬下来的前5页数据进行预处理得到分词结果,然后人工分类,将每一类词写入txt文件,每行一个词。使用sklearn的Countervectorizer进行特征提取,将训练词汇和待分类词汇转换为向量。使用sklearn的svm分类器(核函数是线性的)学习训练词汇并对要分类的词汇进行分类。
分类过程包括在人工标注的数据集上评估SVM分类方法下不同核函数的分类效果,然后选择分类效果最好的线性核函数对所有爬取的数据进行分类并生成对应的类别词云。类别分为:游乐项目和园区内地点、园区内餐饮、准备的行李和出现在评论中的角色。例如,当只训练和测试人工标注的游乐项目和地点和食品和餐饮两类时,得到的F值评价结果如下。
对于每个文本,使用两种方法生成词云:一种基于词频,另一种基于tf-idf值,选择效果较好的作为结果。
基于词频的方法是调用wordcloud.generate函数
根据tf-idf方法,先使用jieba.analysis.extract_tags提取tf-idf值,然后使用wordcloud.generate_from函数根据tf-idf值生成词云。
词云生成(策略)
采集内容插入词库(本帖软件可能运用的采集Asin用于追踪原理(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-09-04 06:24
因为这篇文章的篇幅,很多亚马逊的朋友看了不耐烦,或者气愤的看了。毕竟,这篇帖子应该算是该站的第一个长帖子了。下面一起来几个问题,现在做个目录和介绍:
您可以根据自己的兴趣与主持人讨论目录部分。 (注:如果A9算法触及部分人利益,其他部分触及服务商利益,纯属无意,敬请谅解)
内容
第 1 部分:采集Asin 市场上软件可能使用的跟踪原则
第 2 部分:反查关键词tracking 可能被市场上的软件使用的原则
第三部分:采集到达Asin后可以使用
第四部分:市场上的软件缺陷和市场上提到的A9算法的骗局
第 5 部分:其他问题
第六部分:最终总结和需求问题
第 7 部分:解决方案
简介
建议大家讨论的时候直接复制我的标题。本文全文近2900字。它相对较长,是目前本论坛中最能统计字数的帖子。每个人都不会感到惊讶。
第 1 部分:采集Asin 市场上软件可能使用的跟踪原则
先提一下市面上软件可能用到的采集Asin追踪原理:
A.对于DataMate和Purple Birds这样的软件,据说有100台服务器在不断定时采集AmazonASIN。我想说的是,其中一些 asins 是客户自动提供给他们进行跟踪的,而有些则是自动采集。问题来了。我计算过亚马逊 asin 在美国至少有 200,000 到 400 万个 asin。目前市场上流行的top10000也是采集10000 asins。数据脉冲 asin采集 来自亚马逊左侧的品类和品牌导航栏。继续爬加关键词方法采集还是直接爬搜索模型关键词continuous采集获取ASIN?
第 2 部分:复核 关键词tracking 可能被市场上的软件使用的原则:
其次提一下市面上的软件可能会用到的counter-check关键词tracking原理:
B.对于市面上关键词software 的所有反查产品,我认为爬虫继续使用核心关键词database plus 算法继续采集关键词 并结合起来,直到亚马逊搜索框无法得到这个类别。一直到当前关键词,然后生成这个类关键词集库,然后在'asin的反向搜索中搜索关键词库。如果触发 asin 命令,则 asin 产品将根据搜索页面顺序进行排名。在页面上,我们知道在地址栏中可以看到关键词输入的产品。我们也知道如何从评论中找到差评ID,在后台搜索客户的联系方式,因为他们都有不同的标记,我不熟悉网页的HTML语言,但我也学习过SQL数据库语言作为程序入口。因此,反向检查 asin关键词 逻辑与 HTML 标记和指令触发有关。
第三部分:采集到达Asin后可以使用
我再次提到采集可能用于Asin:
如果我们拿到asin数据库,不断跟踪这个asin所有指标的变化,就可以得到有用的信息,可以用于市场调研,选品指标等,可以跳出top100思维。目前市场上Miku等软件的思维仅限于手动选择指标,并没有自动推荐选择。他们的选品系统推荐的产品就是采集,使用top100。如果我们得到这些数据跟踪和变量,我们可以得到移动和振动器1000 及以上。同时,可以获得更多的其他数据。这些数据还可以为卖家提供专业的定制服务,
因为目前的市场软件研究表明,数据脉搏、初音深广度和时效性都是错误的。如果将这样大规模的采集用于研究,可以获得更准确的数据。
第四部分:市场上的软件缺陷和市场上提到的A9算法的骗局
最后说说市面上的软件缺陷和市面上提到的A9算法的骗局:
A.市面上的软件虽然集成化了,比如紫鸟、DataMate、Miku,还有一些国外成熟的软件,但是还有很多路要走,比如对接采购系统:可以直接对应物流,比如1688。进行差评选择,开启差评反馈系统:一是处理差评的客户联系方式,二是根据日、月的评论量逻辑变化分析趋势和年。开启开发反馈系统:从差评和'QA'中了解产品的痛点并判断开发产品。等等,还有很多事情要做。其他:他们在选择的深度和广度上有很大的错误。我已经比较了它们并将测试报告发送给一些软件老板。其余的TOP1000等大选区还是空白。
B.市面上所有说a9算法知道怎么做的人都是骗子。我的逻辑是:每个人都知道A9算法的影响因子,但如果不知道它的权重,那只是胡说八道。似乎你知道世界上有多少人是由中国和美国人组成的,但你不知道中国和美国有多少人。你基于'A9算法所做的一些事情只是你自己的模拟,导致市场上很多软件的销量,包括估计的排名有很大的误差,而且每个软件对于同一个品类的销量都不一样和相同的ASIN。亚马逊不是推出了几种不同的 A9 算法吗?这里就不给我打耳光了,尤其是那些说反查关键词他们破解了a9算法的_这个不用破解就可以查回来的,老大。按照他们的逻辑,我现在可以自己得到和模拟每个品类的排名销售图,所以我也破解了a9,所以请大家不要相信他们。特别是如果您可以获得 Amazon A9 算法。看他们。那些人在课堂上从来不提数学。算法是数学和逻辑。他们从不提。也许从未教过统计学和高数。嘴巴是算法和写所有的影响。改变的原因真是无语。我想告诉你的另一件事是,如果一个真正的黑客得到了亚马逊 A9 算法,那么他可以完全模拟亚马逊系统并破解这个系统。另外,即使亚马逊改变算法和权重,也是几个月到半年多的时间。你开发的软件不透露某些利益,可以让你成为一家月收入数千万美元的公司。好处是不言而喻的。即使算法发生变化,你仍然可以得到他之前的数据。差别不会很远。再者,黑客获取算法也不如黑某个类别那么实用。将您的产品排名更改为第一排名更方便。那么,如果黑客有这种能力,他们还不如攻击银行系统和取款机。这项技术比亚马逊低一级。
第 5 部分其他问题
1.我们来说说能不能拿到亚马逊的停留时间:
我们在亚马逊后台能掌握的是点击量、曝光量、跳出率。每个学习过高等数学或计算机的人都知道算法。这个有正态分布和非正态分布等,根据我的方法,这些变量之间存在正态分布,所以我们可以测试一个类别,得到那个类别的正态分布样本数据。如果能和一些卖家合作,拿到他们的后台数据就更好了。这样就可以快速得到各种用途的平均浏览时间,然后通过rank等估计方法或算法直接得到模型。也就是说,该公式可以直接用于估算我们产品的页面停留时间。这也与概率逻辑有关,但我们认为高曝光、高点击、低跳出率的浏览时间要高于点击次数少、跳出速度快的产品。其次,如果两种情况的平均浏览时间相同,如果一个人点击了进来的人,我们就知道他浏览了多长时间。即使该算法得到的索引不能严格定义浏览时间,也是一种浏览流行度。
2.产品流量来自关键词哪个?
有人问我怎么知道客户是关键词流量进来的,没有广告。我想先问一下:如果你在接下来的 5 或 10 页后不为产品做广告,你不必担心关键词 进来的是什么,因为它毫无意义。其次,影响你的排名的不仅是你的关键词进入了哪一个,还有你的站外推广的品牌力。有很多因素,比如你的关键词流量需要在你的站外链接进来的时候排除。接下来我要说的是,进来的产品流量有50%以上是几个人带来的流量核心关键词,就算这些核心关键词不做广告。那么接下来,你想知道哪些是核心关键词。 CPC竞价一般是按价值排练的,以高价为核心。
第六部分最终总结和需求问题
最后总结一下总结和需求问题:
我想知道如何准确采集这些asins,但不想在与DataMai合作的情况下,以低成本建立自己的ASIN数据库用于自己的追踪研究。我通常开发具有低成本和精确路线的软件。这次软件需要一点服务器和大数据。我该怎么办?同时,欢迎大家讨论以上任何一个问题,指出我的问题。
第 7 部分解决方案
我的解决方案:从MP网站开始,使用其现有的监控品牌和卖家。这个网站 描述了监控数百万(23 个市场中的 900 万卖家)卖家意味着继续这条道路。追踪采集千万产品Asin。只需要访问程序网站进5入Amazon采集Asin。最后,我们筛选了指标,找到了 20% Rank 好的产品。估计Rank在5万以内的产品占亚马逊市场的20%,我们终于可以监测到这些店铺和产品的变化了。 , 欢迎大家提供更好的解决方案,因为这些跟踪到的数据源可以广泛用于趋势分析和产品选择等管理服务。
PS:啊哈哈哈哈,我代表群主欢迎大家加入跨境电商产品趋势研究群573952635或亚马逊热风VIP座468233188 查看全部
采集内容插入词库(本帖软件可能运用的采集Asin用于追踪原理(组图))
因为这篇文章的篇幅,很多亚马逊的朋友看了不耐烦,或者气愤的看了。毕竟,这篇帖子应该算是该站的第一个长帖子了。下面一起来几个问题,现在做个目录和介绍:
您可以根据自己的兴趣与主持人讨论目录部分。 (注:如果A9算法触及部分人利益,其他部分触及服务商利益,纯属无意,敬请谅解)
内容
第 1 部分:采集Asin 市场上软件可能使用的跟踪原则
第 2 部分:反查关键词tracking 可能被市场上的软件使用的原则
第三部分:采集到达Asin后可以使用
第四部分:市场上的软件缺陷和市场上提到的A9算法的骗局
第 5 部分:其他问题
第六部分:最终总结和需求问题
第 7 部分:解决方案
简介
建议大家讨论的时候直接复制我的标题。本文全文近2900字。它相对较长,是目前本论坛中最能统计字数的帖子。每个人都不会感到惊讶。
第 1 部分:采集Asin 市场上软件可能使用的跟踪原则
先提一下市面上软件可能用到的采集Asin追踪原理:
A.对于DataMate和Purple Birds这样的软件,据说有100台服务器在不断定时采集AmazonASIN。我想说的是,其中一些 asins 是客户自动提供给他们进行跟踪的,而有些则是自动采集。问题来了。我计算过亚马逊 asin 在美国至少有 200,000 到 400 万个 asin。目前市场上流行的top10000也是采集10000 asins。数据脉冲 asin采集 来自亚马逊左侧的品类和品牌导航栏。继续爬加关键词方法采集还是直接爬搜索模型关键词continuous采集获取ASIN?
第 2 部分:复核 关键词tracking 可能被市场上的软件使用的原则:
其次提一下市面上的软件可能会用到的counter-check关键词tracking原理:
B.对于市面上关键词software 的所有反查产品,我认为爬虫继续使用核心关键词database plus 算法继续采集关键词 并结合起来,直到亚马逊搜索框无法得到这个类别。一直到当前关键词,然后生成这个类关键词集库,然后在'asin的反向搜索中搜索关键词库。如果触发 asin 命令,则 asin 产品将根据搜索页面顺序进行排名。在页面上,我们知道在地址栏中可以看到关键词输入的产品。我们也知道如何从评论中找到差评ID,在后台搜索客户的联系方式,因为他们都有不同的标记,我不熟悉网页的HTML语言,但我也学习过SQL数据库语言作为程序入口。因此,反向检查 asin关键词 逻辑与 HTML 标记和指令触发有关。
第三部分:采集到达Asin后可以使用
我再次提到采集可能用于Asin:
如果我们拿到asin数据库,不断跟踪这个asin所有指标的变化,就可以得到有用的信息,可以用于市场调研,选品指标等,可以跳出top100思维。目前市场上Miku等软件的思维仅限于手动选择指标,并没有自动推荐选择。他们的选品系统推荐的产品就是采集,使用top100。如果我们得到这些数据跟踪和变量,我们可以得到移动和振动器1000 及以上。同时,可以获得更多的其他数据。这些数据还可以为卖家提供专业的定制服务,
因为目前的市场软件研究表明,数据脉搏、初音深广度和时效性都是错误的。如果将这样大规模的采集用于研究,可以获得更准确的数据。
第四部分:市场上的软件缺陷和市场上提到的A9算法的骗局
最后说说市面上的软件缺陷和市面上提到的A9算法的骗局:
A.市面上的软件虽然集成化了,比如紫鸟、DataMate、Miku,还有一些国外成熟的软件,但是还有很多路要走,比如对接采购系统:可以直接对应物流,比如1688。进行差评选择,开启差评反馈系统:一是处理差评的客户联系方式,二是根据日、月的评论量逻辑变化分析趋势和年。开启开发反馈系统:从差评和'QA'中了解产品的痛点并判断开发产品。等等,还有很多事情要做。其他:他们在选择的深度和广度上有很大的错误。我已经比较了它们并将测试报告发送给一些软件老板。其余的TOP1000等大选区还是空白。
B.市面上所有说a9算法知道怎么做的人都是骗子。我的逻辑是:每个人都知道A9算法的影响因子,但如果不知道它的权重,那只是胡说八道。似乎你知道世界上有多少人是由中国和美国人组成的,但你不知道中国和美国有多少人。你基于'A9算法所做的一些事情只是你自己的模拟,导致市场上很多软件的销量,包括估计的排名有很大的误差,而且每个软件对于同一个品类的销量都不一样和相同的ASIN。亚马逊不是推出了几种不同的 A9 算法吗?这里就不给我打耳光了,尤其是那些说反查关键词他们破解了a9算法的_这个不用破解就可以查回来的,老大。按照他们的逻辑,我现在可以自己得到和模拟每个品类的排名销售图,所以我也破解了a9,所以请大家不要相信他们。特别是如果您可以获得 Amazon A9 算法。看他们。那些人在课堂上从来不提数学。算法是数学和逻辑。他们从不提。也许从未教过统计学和高数。嘴巴是算法和写所有的影响。改变的原因真是无语。我想告诉你的另一件事是,如果一个真正的黑客得到了亚马逊 A9 算法,那么他可以完全模拟亚马逊系统并破解这个系统。另外,即使亚马逊改变算法和权重,也是几个月到半年多的时间。你开发的软件不透露某些利益,可以让你成为一家月收入数千万美元的公司。好处是不言而喻的。即使算法发生变化,你仍然可以得到他之前的数据。差别不会很远。再者,黑客获取算法也不如黑某个类别那么实用。将您的产品排名更改为第一排名更方便。那么,如果黑客有这种能力,他们还不如攻击银行系统和取款机。这项技术比亚马逊低一级。
第 5 部分其他问题
1.我们来说说能不能拿到亚马逊的停留时间:
我们在亚马逊后台能掌握的是点击量、曝光量、跳出率。每个学习过高等数学或计算机的人都知道算法。这个有正态分布和非正态分布等,根据我的方法,这些变量之间存在正态分布,所以我们可以测试一个类别,得到那个类别的正态分布样本数据。如果能和一些卖家合作,拿到他们的后台数据就更好了。这样就可以快速得到各种用途的平均浏览时间,然后通过rank等估计方法或算法直接得到模型。也就是说,该公式可以直接用于估算我们产品的页面停留时间。这也与概率逻辑有关,但我们认为高曝光、高点击、低跳出率的浏览时间要高于点击次数少、跳出速度快的产品。其次,如果两种情况的平均浏览时间相同,如果一个人点击了进来的人,我们就知道他浏览了多长时间。即使该算法得到的索引不能严格定义浏览时间,也是一种浏览流行度。
2.产品流量来自关键词哪个?
有人问我怎么知道客户是关键词流量进来的,没有广告。我想先问一下:如果你在接下来的 5 或 10 页后不为产品做广告,你不必担心关键词 进来的是什么,因为它毫无意义。其次,影响你的排名的不仅是你的关键词进入了哪一个,还有你的站外推广的品牌力。有很多因素,比如你的关键词流量需要在你的站外链接进来的时候排除。接下来我要说的是,进来的产品流量有50%以上是几个人带来的流量核心关键词,就算这些核心关键词不做广告。那么接下来,你想知道哪些是核心关键词。 CPC竞价一般是按价值排练的,以高价为核心。
第六部分最终总结和需求问题
最后总结一下总结和需求问题:
我想知道如何准确采集这些asins,但不想在与DataMai合作的情况下,以低成本建立自己的ASIN数据库用于自己的追踪研究。我通常开发具有低成本和精确路线的软件。这次软件需要一点服务器和大数据。我该怎么办?同时,欢迎大家讨论以上任何一个问题,指出我的问题。
第 7 部分解决方案
我的解决方案:从MP网站开始,使用其现有的监控品牌和卖家。这个网站 描述了监控数百万(23 个市场中的 900 万卖家)卖家意味着继续这条道路。追踪采集千万产品Asin。只需要访问程序网站进5入Amazon采集Asin。最后,我们筛选了指标,找到了 20% Rank 好的产品。估计Rank在5万以内的产品占亚马逊市场的20%,我们终于可以监测到这些店铺和产品的变化了。 , 欢迎大家提供更好的解决方案,因为这些跟踪到的数据源可以广泛用于趋势分析和产品选择等管理服务。
PS:啊哈哈哈哈,我代表群主欢迎大家加入跨境电商产品趋势研究群573952635或亚马逊热风VIP座468233188
采集内容插入词库(标题插入关键词是优采云采集的SEO工具,可增加SEO收录 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-09-04 03:11
)
标题插入关键词是优采云采集的SEO工具之一,可以添加SEO收录。
标题插入关键词:指在文章title(默认标题字段)的开头或结尾随机插入用户提供的关键词。也可以选择是否对标题进行分割,由用户提供的关键词(即关键词库)进行交集并插入交集结果。
具体操作步骤如下:
1.关键词库配置
关键词library 是插入标题关键词 以用于“标题插入关键词”SEO 策略的定义集合;
我。创建一个新的关键词 库
关键词库配置界面有两个入口:
二。添加关键词
关键词多用英文逗号或回车分隔,格式如:采集,data,优采云,Internet
建议:一个关键词库不要存放太多关键词(2000以内),可以分成多个关键词库存发布,'title insert关键词'SEO策略支持多选关键词库执行的;
2. 创建 SEO 规则并配置‘标题插入关键词’
先创建一条SEO规则,在SEO规则的“Title Insert关键词”栏中进行配置(注意这个SEO策略只对title字段有效,请确保title字段在任务详细信息提取器):
提醒:使用了“关键词filter”。如果没有交点关键词,则会从关键词库中随机选取。如果存在交集关键词,则从交集结果中随机选取。不会从关键词库中提取;
3.执行SEO规则
看SEO规则的执行和使用:SEO规则的创建和使用
4. SEO 后显示结果
例1:下图的结果是插入2个关键词,没有选择‘关键词filter’,分隔符默认:
关键词 库设置为:采集,data,优采云,internet,soccer
例2:下图的结果是插入2个关键词,选择‘关键词filter’,默认分隔符:
关键词 库设置为:采集,data,优采云,internet,soccer
插入关键词'FAQ的标题并解决I。'关键词filter'中的分词是什么意思?
简单来说就是用一种算法将标题内容拆分成多个词,然后与用户配置的关键词库中的关键词进行匹配。保留完全相同的词作为交集结果,此时插入标题关键词从交集结果中提取;
注意:如果交集结果中关键词的数量不足或不可用,系统仍会从关键词库中随机选择词插入;
二。改变标题的内容,也可以插入标签字段等内容
除了在标题内容中插入关键词,还可以使用组合字段发布方式插入采集字段的内容,比如插入标签。详细教程请看SEO优化方法---联合字段发布。
查看全部
采集内容插入词库(标题插入关键词是优采云采集的SEO工具,可增加SEO收录
)
标题插入关键词是优采云采集的SEO工具之一,可以添加SEO收录。
标题插入关键词:指在文章title(默认标题字段)的开头或结尾随机插入用户提供的关键词。也可以选择是否对标题进行分割,由用户提供的关键词(即关键词库)进行交集并插入交集结果。
具体操作步骤如下:
1.关键词库配置
关键词library 是插入标题关键词 以用于“标题插入关键词”SEO 策略的定义集合;
我。创建一个新的关键词 库
关键词库配置界面有两个入口:
二。添加关键词
关键词多用英文逗号或回车分隔,格式如:采集,data,优采云,Internet
建议:一个关键词库不要存放太多关键词(2000以内),可以分成多个关键词库存发布,'title insert关键词'SEO策略支持多选关键词库执行的;
2. 创建 SEO 规则并配置‘标题插入关键词’
先创建一条SEO规则,在SEO规则的“Title Insert关键词”栏中进行配置(注意这个SEO策略只对title字段有效,请确保title字段在任务详细信息提取器):
提醒:使用了“关键词filter”。如果没有交点关键词,则会从关键词库中随机选取。如果存在交集关键词,则从交集结果中随机选取。不会从关键词库中提取;
3.执行SEO规则
看SEO规则的执行和使用:SEO规则的创建和使用
4. SEO 后显示结果
例1:下图的结果是插入2个关键词,没有选择‘关键词filter’,分隔符默认:
关键词 库设置为:采集,data,优采云,internet,soccer
例2:下图的结果是插入2个关键词,选择‘关键词filter’,默认分隔符:
关键词 库设置为:采集,data,优采云,internet,soccer
插入关键词'FAQ的标题并解决I。'关键词filter'中的分词是什么意思?
简单来说就是用一种算法将标题内容拆分成多个词,然后与用户配置的关键词库中的关键词进行匹配。保留完全相同的词作为交集结果,此时插入标题关键词从交集结果中提取;
注意:如果交集结果中关键词的数量不足或不可用,系统仍会从关键词库中随机选择词插入;
二。改变标题的内容,也可以插入标签字段等内容
除了在标题内容中插入关键词,还可以使用组合字段发布方式插入采集字段的内容,比如插入标签。详细教程请看SEO优化方法---联合字段发布。
采集内容插入词库(插入词库.git中间插入方法参考(1.多个字段导入))
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-09-03 14:11
采集内容插入词库:luigi/jieba·github:luigi/jieba-base加载pipeline使用:gitclone:serve-a-ilibrary.git中间插入方法参考:jiebabin
1.先导入jieba2.用jiebabase库来采集词汇3.多个字段导入,
embed
清华的大众点评爬虫,就是用python设计的。具体问题有什么需要说明的,
利用solr查询字段,如果不需要则去掉,我下载的是whl文件。
结果如下,
我写了个简单版本,用flask+redis和python对接,
github提供了一份wordpress爬虫教程,可以参考。
python爬虫可视化神器|
webgis+jieba
importjiebaimportrequestsfromdatetimeimporttimefrom。importstr_inf,str_to_nonefrom。importallurl=''headers={'user-agent':'mozilla/5。0(windowsnt6。1;win64;x6。
4)applewebkit/537。36(khtml,likegecko)chrome/57。3306。126safari/537。36'}s=requests。session(headers=headers)print(s。text)defget_word(url):is_all=[]try:ifis_all:returntrueelse:returnfalseurl='/'url='/'all_encoding='gbk'content=requests。
get(url,headers=headers)content=str_to_none()forentityinurl:ifis_all:print(entity)else:print('#')all_encoding=is_allall_encoding="gbk"else:print('#')headers={'user-agent':'mozilla/5。0(windowsnt6。1;win64;x6。
4)applewebkit/537。36(khtml,likegecko)chrome/57。3306。126safari/537。36'}forentityinentity:ifis_all:print(entity)else:print('#')headers={'user-agent':'mozilla/5。0(windowsnt6。1;win64;x6。
4)applewebkit/537。36(khtml,likegecko)chrome/57。3306。126safari/537。36'}forstateinheaders:ifstatein'#':headers。post(entity,url,headers=headers)else:print('#')return'#'print(all_encoding。 查看全部
采集内容插入词库(插入词库.git中间插入方法参考(1.多个字段导入))
采集内容插入词库:luigi/jieba·github:luigi/jieba-base加载pipeline使用:gitclone:serve-a-ilibrary.git中间插入方法参考:jiebabin
1.先导入jieba2.用jiebabase库来采集词汇3.多个字段导入,
embed
清华的大众点评爬虫,就是用python设计的。具体问题有什么需要说明的,
利用solr查询字段,如果不需要则去掉,我下载的是whl文件。
结果如下,
我写了个简单版本,用flask+redis和python对接,
github提供了一份wordpress爬虫教程,可以参考。
python爬虫可视化神器|
webgis+jieba
importjiebaimportrequestsfromdatetimeimporttimefrom。importstr_inf,str_to_nonefrom。importallurl=''headers={'user-agent':'mozilla/5。0(windowsnt6。1;win64;x6。
4)applewebkit/537。36(khtml,likegecko)chrome/57。3306。126safari/537。36'}s=requests。session(headers=headers)print(s。text)defget_word(url):is_all=[]try:ifis_all:returntrueelse:returnfalseurl='/'url='/'all_encoding='gbk'content=requests。
get(url,headers=headers)content=str_to_none()forentityinurl:ifis_all:print(entity)else:print('#')all_encoding=is_allall_encoding="gbk"else:print('#')headers={'user-agent':'mozilla/5。0(windowsnt6。1;win64;x6。
4)applewebkit/537。36(khtml,likegecko)chrome/57。3306。126safari/537。36'}forentityinentity:ifis_all:print(entity)else:print('#')headers={'user-agent':'mozilla/5。0(windowsnt6。1;win64;x6。
4)applewebkit/537。36(khtml,likegecko)chrome/57。3306。126safari/537。36'}forstateinheaders:ifstatein'#':headers。post(entity,url,headers=headers)else:print('#')return'#'print(all_encoding。
采集内容插入词库(分析一下企查查,本着分享知识的原则、原则和原则 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-03 11:07
)
最近有朋友让我分析七茶茶。本着知识分享的原则,我想用我浅薄的知识和见解谈谈七叉茶的SEO亮点,希望能帮助更多的兄弟了解SEO的精髓!
我之前分析过顺奇网,分析过58同城。你可以看看你是否喜欢它。 58同城的词库感觉比较笼统一点,企业查找更准确。与上面相比,顺奇网这两个词比较复杂,业务不同,词库不同,不分高低。
(内容、模板)稀缺
现在很多人做SEO,还认为原创是SEO的核心。企业调查是对这一观点的最大否定。因为上面的信息基本都是采集。
但是目测采集应该是调用国家数据库,因为国内各个公司的信息,应该不会那么好采集,就算采集,还是有一些不准确的,因为不权威网站上的企业信息信任度比较低。只有国家信息才是准确的。
内容已经解决,公司在用户体验和模板方面做了很好的对比。在之前的课程中,我们也讲过影响网站rank和收录的因素,模板也是其中之一。
大规模网站最终绝对是一场规模的竞争。词库决定权重,收录决定词库。这种收录的水平,绝对不是几十人、几百人能做到的。
词库精准定位
词库的定位与业务直接相关,但公司搜索的词库远小于同城58的词库。仅就竞争而言,它要小得多。企业搜索的词库一般以【企业名称】【法人名称、股东名称】为主,而58则以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白,关键词难易级别。
但是,如果词库定位准确,客户会更准确。当你的量级达到千万甚至上亿的时候,长尾带来的流量是相当恐怖的,这些每天访问网站的恐怖流量所带来的信任度的增长绝不是普通的小网站可比的。
就像之前聊的58一样,品牌流量作为源头带动了网站的整体信任度。信任高后,长尾流量来了,我们一次次回馈网站,良性循环!
学习和应用
为什么需要分析企业搜索?因为企业搜索的难度比较低。我们可以把他的词库导出成权重站!
比如我之前做过的名字站,可以做公司名字的站,或者其他站。毕竟有词库,内容会聚合,哪怕是随机生成,权重分分钟。
查看全部
采集内容插入词库(分析一下企查查,本着分享知识的原则、原则和原则
)
最近有朋友让我分析七茶茶。本着知识分享的原则,我想用我浅薄的知识和见解谈谈七叉茶的SEO亮点,希望能帮助更多的兄弟了解SEO的精髓!
我之前分析过顺奇网,分析过58同城。你可以看看你是否喜欢它。 58同城的词库感觉比较笼统一点,企业查找更准确。与上面相比,顺奇网这两个词比较复杂,业务不同,词库不同,不分高低。
(内容、模板)稀缺
现在很多人做SEO,还认为原创是SEO的核心。企业调查是对这一观点的最大否定。因为上面的信息基本都是采集。
但是目测采集应该是调用国家数据库,因为国内各个公司的信息,应该不会那么好采集,就算采集,还是有一些不准确的,因为不权威网站上的企业信息信任度比较低。只有国家信息才是准确的。
内容已经解决,公司在用户体验和模板方面做了很好的对比。在之前的课程中,我们也讲过影响网站rank和收录的因素,模板也是其中之一。
大规模网站最终绝对是一场规模的竞争。词库决定权重,收录决定词库。这种收录的水平,绝对不是几十人、几百人能做到的。
词库精准定位
词库的定位与业务直接相关,但公司搜索的词库远小于同城58的词库。仅就竞争而言,它要小得多。企业搜索的词库一般以【企业名称】【法人名称、股东名称】为主,而58则以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白,关键词难易级别。
但是,如果词库定位准确,客户会更准确。当你的量级达到千万甚至上亿的时候,长尾带来的流量是相当恐怖的,这些每天访问网站的恐怖流量所带来的信任度的增长绝不是普通的小网站可比的。
就像之前聊的58一样,品牌流量作为源头带动了网站的整体信任度。信任高后,长尾流量来了,我们一次次回馈网站,良性循环!
学习和应用
为什么需要分析企业搜索?因为企业搜索的难度比较低。我们可以把他的词库导出成权重站!
比如我之前做过的名字站,可以做公司名字的站,或者其他站。毕竟有词库,内容会聚合,哪怕是随机生成,权重分分钟。
采集内容插入词库( SEO就是数量关键词的收集整理对SEO的意义分析与思考)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-09-03 11:03
SEO就是数量关键词的收集整理对SEO的意义分析与思考)
从某种意义上说,SEO 是一场围绕关键词 的竞争游戏。
用户通过关键词搜索答案,搜索引擎根据关键词聚合内容,网站围绕关键词争夺展示相关内容的机会以获取流量。
关键词一端是用户真正的需求,另一端是网站内容。搜索引擎一方面聚合流量和内容,另一方面将流量分配给网站。
从SEO的角度来看,关键词是网站运营商通过搜索引擎给目标用户留下的线索,通过关键词(线索)引导目标用户找到目标网站 .
按照这个逻辑,SEO努力的方向是保留更多的搜索线索,争取在搜索引擎上有更多的展示机会,从而最大限度地增加访问量。
那么,掌握关键词的数量和质量就可以在一定程度上反映从业者的SEO水平。大量关键词的采集涉及到下面要讨论的话题——关键词词库。
一、Understanding 关键词词库
百度百科引用中国经典的解读如下。词库是词数据的集合,存储在数据库中,用于特定的程序检索和调用。
关键词词库没有相应的明确定义。这更像是一种行业惯例。
为了后面的讨论方便,我们先在实用层面给它一个简单的定义。 关键词词库是关键词围绕特定目标采集和组织的集合。
这有几个关键点。词典的基本元素是关键词;词典的建立有明确的目标; 关键词有相应的入库标准。
入库是有标准的,采集到的关键词经过筛选符合标准后才能入库管理;
关键词数量多,关键词数量不够做仓库。
综上所述,关键词是用户需求的呈现,关键词库是用户需求的集合。拥有词库,就等于把握了市场方向。
同样,关键词也是网站内容的重点。有了词库,就等于明确了内容创作的方向和指导。
对于 SEO 而言,拥有高质量标准 关键词Thesaurus 的重要性无需赘述。
二、High quality关键词Thesaurus 标准:全面覆盖,主次分明
创建关键词thesaurus,记住这六个字:全面,有主次。
要全面,就是说关键词的数量要尽量多,才能达到全面覆盖。在创建关键词Thesaurus 时,我们应该尽可能全面地采集相关的关键词。这至少有两个好处。一是最大限度地满足用户的所有需求;另一方面可以为后续网站提供足够的内容创作空间。
有主次,也就是说关键词的分类应该是主次的。不同的关键词给网站带来不同的价值,竞争程度也不同。 网站运营商应该根据SEO策略为不同的关键词投入不同的资源。
具体到每个网站关键词词库,标准可以根据自己的SEO策略确定,但数量和质量两个维度是基本要求。
三、高质量关键词thesaurus的制作方法:从加减乘除
1、关键词的三个主要来源:自有频道、公众频道和同行频道
自己的频道-网站operator 自己组织它关键词。例如,企业网站可以关注品牌词,将其列为关键词罗。从自己的频道采集关键词 来说,采集所有独特的关键词 很重要。如果网站已经在线并且配置了访客统计工具,可以看出客户来源的搜索词会给你一个参考。熟悉产品,熟悉用户,熟悉自己的公司,自然会知道用户关注的焦点,可以采集整理对应的关键词。
公共渠道——部分平台提供关键词数据,如搜索引擎自带的关键词工具(百度和谷歌都有)、5118、站长工具等。平台渠道一般来自行业特定的关键词,可以和自己的网站结合进行二次处理。对于常见的行业或领域,这些专业平台工具提供的关键词数量可观;而对于一些很小的细分或不受欢迎的行业,你必须改变主意采集关键词。
对等通道-转到对等网站采集相关关键词。巧妙地从同行,尤其是竞争对手网站那里复制粘贴关键词,也是关键词在收尾阶段的捷径。
在实际操作中,不必局限于以上任何一种渠道,而是使用以上三种或添加其他您认为对采集关键词有价值的方法。在创建关键词词库的初期,越多越好。
2、关键词词典的排序过程是先帮加减,再做乘除。
添加是为了全面覆盖,没有遗漏;
减法就是把资源集中在高价值的关键词上,而不是把资源浪费在低价值的关键词上。
经过上面的一系列操作,你会遇到很多关键词。下一步需要对这些关键词进行优化和整理。
优化关键词Thesaurus 涉及关键词的扩展和合并,也可以说是关键词管理的乘除。
关键词的扩展——一般应用于合并的关键词,如现有的关键词加上城市名称或价格或质量等,组成一个新的关键词;
关键词的merge-to合并精简关键词,意思相同但表达不一致。这是因为搜索引擎在处理这种关键词时也采用了合并。在SEO操作中,不需要分开单独优化,组合效率更好。
此时,您的关键词Thesaurus 已成为基本结构。为了进一步优化,关键词必须进行分类和管理。
3、对关键词进行合理的分类管理。
关键词的组织方式有很多种,比如常见的核心关键词和长尾关键词类。组织方法不需要固定,只需按照自己的习惯或SEO策略。例如,以行业为中心的关键词Thesaurus 可以根据词根词、派生词、常规词、热门词或搜索上升、搜索下降等多个标准进行分类。
例如以网站为中心的关键词Thesaurus可以是核心词、次要核心词、目标关键词、长尾关键词等
同一个关键词在不同的词库中可能属于不同的分类,甚至很不一样,其根源在于分类标准不同。比如A关键词可能属于行业领先品牌网站关键词词库中的核心关键词,但在一个小公司新推出的网站关键词词库中,它就属于到长尾词类别。 .
我们都知道行业根词的搜索量很大,但是对于一些新上线的小网站来说,去争夺关键词这样的机会,是一种资源浪费。
理性的选择是先找机会取胜,再扩大战线。 关键词策略的实现是首先找到有机会获胜并具有潜在高价值的关键词,并将其列为最高优先级关键词。依此类推。
四、提高关键词词库管理效率的工具:记事本、Excel和钢铁侠SEO工具
最简单最基础的关键词Thesaurus工具就是系统自带的notebook,然后是强大的Excel。这里我将介绍钢铁侠的SEO工具。
钢铁侠 SEO 工具是一个客户端软件。安装后你会发现它有一个强大的【标签】功能,可以给提交的关键词打上各种标签,方便关键词的灵活管理。一个标签可以标记多个关键词,一个关键词可以标记多个标签,你知道的,这意味着关键词类别管理的灵活性。
用户向钢铁侠SEO工具提交关键词后,系统会自动采集输出关键词对应的收录数量和比赛,可以为您省去很多工作。更重要的是,这个功能可以永久免费使用,这意味着有了Needle Man,你就有了一个免费的智能工具,可以灵活管理数千个关键词。
五、质量关键词Thesaurus 的维护和更新是一个长期的过程
关键词thesaurus 建立后,并不是完全成功,需要不时更新升级。因为随着市场的发展,新的关键词会出现,一些关键词可能会逐渐从热点变成鲜有人关注的冷门。举一个直观的例子,手机行业。每年都会有一批新机型上市,带来一波热点关键词。而那些退市的品牌和手机型号也越来越少被考虑在内。
为保证关键词词库的高质量标准,在SEO执行过程中,应及时对关键词词库进行增删改查、重要性等级、分类等方面的调整。
高质量的关键词词库一定是有生命力的词库。如果你灵活使用关键词词库,你会有更大的价值。找到适合你的关键词词库创作方法,选择适合你的关键词词库管理工具,打造适合你的优质关键词词库,用好你的优质关键词词库,这个是最重要的。 查看全部
采集内容插入词库(
SEO就是数量关键词的收集整理对SEO的意义分析与思考)
从某种意义上说,SEO 是一场围绕关键词 的竞争游戏。
用户通过关键词搜索答案,搜索引擎根据关键词聚合内容,网站围绕关键词争夺展示相关内容的机会以获取流量。
关键词一端是用户真正的需求,另一端是网站内容。搜索引擎一方面聚合流量和内容,另一方面将流量分配给网站。
从SEO的角度来看,关键词是网站运营商通过搜索引擎给目标用户留下的线索,通过关键词(线索)引导目标用户找到目标网站 .
按照这个逻辑,SEO努力的方向是保留更多的搜索线索,争取在搜索引擎上有更多的展示机会,从而最大限度地增加访问量。
那么,掌握关键词的数量和质量就可以在一定程度上反映从业者的SEO水平。大量关键词的采集涉及到下面要讨论的话题——关键词词库。
一、Understanding 关键词词库
百度百科引用中国经典的解读如下。词库是词数据的集合,存储在数据库中,用于特定的程序检索和调用。
关键词词库没有相应的明确定义。这更像是一种行业惯例。
为了后面的讨论方便,我们先在实用层面给它一个简单的定义。 关键词词库是关键词围绕特定目标采集和组织的集合。
这有几个关键点。词典的基本元素是关键词;词典的建立有明确的目标; 关键词有相应的入库标准。
入库是有标准的,采集到的关键词经过筛选符合标准后才能入库管理;
关键词数量多,关键词数量不够做仓库。
综上所述,关键词是用户需求的呈现,关键词库是用户需求的集合。拥有词库,就等于把握了市场方向。
同样,关键词也是网站内容的重点。有了词库,就等于明确了内容创作的方向和指导。
对于 SEO 而言,拥有高质量标准 关键词Thesaurus 的重要性无需赘述。
二、High quality关键词Thesaurus 标准:全面覆盖,主次分明
创建关键词thesaurus,记住这六个字:全面,有主次。
要全面,就是说关键词的数量要尽量多,才能达到全面覆盖。在创建关键词Thesaurus 时,我们应该尽可能全面地采集相关的关键词。这至少有两个好处。一是最大限度地满足用户的所有需求;另一方面可以为后续网站提供足够的内容创作空间。
有主次,也就是说关键词的分类应该是主次的。不同的关键词给网站带来不同的价值,竞争程度也不同。 网站运营商应该根据SEO策略为不同的关键词投入不同的资源。
具体到每个网站关键词词库,标准可以根据自己的SEO策略确定,但数量和质量两个维度是基本要求。
三、高质量关键词thesaurus的制作方法:从加减乘除
1、关键词的三个主要来源:自有频道、公众频道和同行频道
自己的频道-网站operator 自己组织它关键词。例如,企业网站可以关注品牌词,将其列为关键词罗。从自己的频道采集关键词 来说,采集所有独特的关键词 很重要。如果网站已经在线并且配置了访客统计工具,可以看出客户来源的搜索词会给你一个参考。熟悉产品,熟悉用户,熟悉自己的公司,自然会知道用户关注的焦点,可以采集整理对应的关键词。
公共渠道——部分平台提供关键词数据,如搜索引擎自带的关键词工具(百度和谷歌都有)、5118、站长工具等。平台渠道一般来自行业特定的关键词,可以和自己的网站结合进行二次处理。对于常见的行业或领域,这些专业平台工具提供的关键词数量可观;而对于一些很小的细分或不受欢迎的行业,你必须改变主意采集关键词。
对等通道-转到对等网站采集相关关键词。巧妙地从同行,尤其是竞争对手网站那里复制粘贴关键词,也是关键词在收尾阶段的捷径。
在实际操作中,不必局限于以上任何一种渠道,而是使用以上三种或添加其他您认为对采集关键词有价值的方法。在创建关键词词库的初期,越多越好。
2、关键词词典的排序过程是先帮加减,再做乘除。
添加是为了全面覆盖,没有遗漏;
减法就是把资源集中在高价值的关键词上,而不是把资源浪费在低价值的关键词上。
经过上面的一系列操作,你会遇到很多关键词。下一步需要对这些关键词进行优化和整理。
优化关键词Thesaurus 涉及关键词的扩展和合并,也可以说是关键词管理的乘除。
关键词的扩展——一般应用于合并的关键词,如现有的关键词加上城市名称或价格或质量等,组成一个新的关键词;
关键词的merge-to合并精简关键词,意思相同但表达不一致。这是因为搜索引擎在处理这种关键词时也采用了合并。在SEO操作中,不需要分开单独优化,组合效率更好。
此时,您的关键词Thesaurus 已成为基本结构。为了进一步优化,关键词必须进行分类和管理。
3、对关键词进行合理的分类管理。
关键词的组织方式有很多种,比如常见的核心关键词和长尾关键词类。组织方法不需要固定,只需按照自己的习惯或SEO策略。例如,以行业为中心的关键词Thesaurus 可以根据词根词、派生词、常规词、热门词或搜索上升、搜索下降等多个标准进行分类。
例如以网站为中心的关键词Thesaurus可以是核心词、次要核心词、目标关键词、长尾关键词等
同一个关键词在不同的词库中可能属于不同的分类,甚至很不一样,其根源在于分类标准不同。比如A关键词可能属于行业领先品牌网站关键词词库中的核心关键词,但在一个小公司新推出的网站关键词词库中,它就属于到长尾词类别。 .
我们都知道行业根词的搜索量很大,但是对于一些新上线的小网站来说,去争夺关键词这样的机会,是一种资源浪费。
理性的选择是先找机会取胜,再扩大战线。 关键词策略的实现是首先找到有机会获胜并具有潜在高价值的关键词,并将其列为最高优先级关键词。依此类推。
四、提高关键词词库管理效率的工具:记事本、Excel和钢铁侠SEO工具
最简单最基础的关键词Thesaurus工具就是系统自带的notebook,然后是强大的Excel。这里我将介绍钢铁侠的SEO工具。
钢铁侠 SEO 工具是一个客户端软件。安装后你会发现它有一个强大的【标签】功能,可以给提交的关键词打上各种标签,方便关键词的灵活管理。一个标签可以标记多个关键词,一个关键词可以标记多个标签,你知道的,这意味着关键词类别管理的灵活性。
用户向钢铁侠SEO工具提交关键词后,系统会自动采集输出关键词对应的收录数量和比赛,可以为您省去很多工作。更重要的是,这个功能可以永久免费使用,这意味着有了Needle Man,你就有了一个免费的智能工具,可以灵活管理数千个关键词。
五、质量关键词Thesaurus 的维护和更新是一个长期的过程
关键词thesaurus 建立后,并不是完全成功,需要不时更新升级。因为随着市场的发展,新的关键词会出现,一些关键词可能会逐渐从热点变成鲜有人关注的冷门。举一个直观的例子,手机行业。每年都会有一批新机型上市,带来一波热点关键词。而那些退市的品牌和手机型号也越来越少被考虑在内。
为保证关键词词库的高质量标准,在SEO执行过程中,应及时对关键词词库进行增删改查、重要性等级、分类等方面的调整。
高质量的关键词词库一定是有生命力的词库。如果你灵活使用关键词词库,你会有更大的价值。找到适合你的关键词词库创作方法,选择适合你的关键词词库管理工具,打造适合你的优质关键词词库,用好你的优质关键词词库,这个是最重要的。
采集内容插入词库(词库1.1-1.4如下拓展工具的分类及应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-09-03 02:25
一、Thesaurus 组织
1 选择词库竞争者->准备阶段:选择基本词根和相关长尾词
1.1 在专业的seo分类网站上找;到导航站批量查找;如果实在没有资源,可以手动添加。目标是尝试覆盖行业中的所有网站。
1.2 在我们自己的爬虫数据库中找到行业根词
1.3 在网站行业竞争对手地图中查找行业根词
1.4 在1.4 拥有的资源站点中找到的搜索流量搜索词(百度统计、GA统计等统计工具)
1.5 如果有资源,请花钱买个专业整合公司的industry关键词database
1.1 Comment 这个时候就是我们在拼资源的时候,网上就有这样的网站,比如,
1.2 Comment 如果你已经提前有网站,请从你站点的维度去寻找,底部一定有词根词汇
推荐:
处理器:助理
相关技能:优采云或相关采集tools
耗时估计:1-2天
大多数情况下,我们不是1.5的土豪,我们花10000块买整合数据,那么1.1-1.4处理如下
2 再展开词-> 把1中比较完整的词取出来展开,力争覆盖整个行业关键词Database
2.1 对1.1中的站点进行分类,选择与您要做的站点具有相同属性的站点
2.1.1 采集 可以使用这些站点下的关键词库:爱站关键词挖矿工具(非付费导出数量有限,幅度较小,并且噪音少),5118数据库(可以使用优采云采集,使用两次爬取的逻辑,采集可以达到一个非常大的词,但是噪音太多了,100以外的很多无用词);
2.2 将1.2、1.3、1.4、2.1中的词放入关键词扩展工具中进行扩展
2.2.1 词根扩展量可以达到6K左右;长尾的展开量可以在600左右,请自适应调整
2.3 将所有单词整理好,先去除重复(包括两步,重复和某些特定单词;建议步骤)
2.1 Comment 以游戏网站为例,分为:网络游戏;页面游戏;手机游戏;小游戏;综合等,找出你想做的网站的属性,并记录下来。
2.1 对综合性站点进行标注,例如使用爱站或5118查找属性与您相同的站点。如果想做页面游览,看看有没有等待站点,快速查找提取
2.1.1 评论。如果您需要资源购买付费版,可以在很大程度上节省时间。不要想着免费;
2.1.1 注解5118数据库可以用优采云批量抓取,如果量级大,需要时间,请估计; 采集方法,先通配采集每个域名/子域/下翻页数,然后在关键词下批量写规则采集/baidu/rank/,这是因为排名页数每个域名都不一样
2.2注解爱站扩展长尾词的能力比较好,短词(即行业根词)可以用爱站跑;中短字长(判断标准,excel function=len(*) 4-9左右)可以用战神工具跑;中长字(=len(*) 9-18左右)也可以用战神工具跑;长字(=len(*) 18-29左右)感觉应该删除删除,不需要运行
因为去重的重复量太大,有几千万级,所以必须机器和人工同时过滤处理
3 处理关键词
3.1 通过机器处理噪声进行初始过滤;重复数据删除
3.1.1 直接匹配删除,如:#、$、http、-、..、.com、.xml等,根据自己的行业特点过滤,包括直接删除
3.1.2 替换,主要是转义和空格,如:",&
3.1.3 所有号码将根据行业情况进行删除处理
3.1.4 上面剩下的词库去重
3.2 机器初步筛选-提取精准词
3.1.1 然后处理下一个词根,对词根中的噪声进行处理,比如()中的内容等,有助于机器提取的准确性。
3.1.2 使用行业词库和词根匹配所有词,整理文档,打包。这部分是准确的词。
3.3 人力去除脏话
3.3.1 软件工具:notepad++; office excel 2010及以上版本(WPS不可用); 关键词自动分类工具
3.3.2 步
3.3.2.1 用notepad++打开文档,将所有单词复制到分类工具中
3.3.2.2 点击分类工具中的开始查询
3.3.2.3 稍等,等到右边弹出最终结果(过程可能会持续5-15分钟,不要注意没反应),期间可以同步做其他事情
3.3.2.4 将分词中的结果复制到notepad++中,然后复制到xls表中(点击结果,ctrl+a,因为没有明显的标记,等待全部转蓝色,期间可能有几次没反应)
3.3.2.5 在 xls 表中,#fonts 以列分隔
3.3.2.6 行插入四列,根词,一级,二级,三级
3.3.2.7 选择四列并插入数据透视表
3.3.2.8 在B列进行数字识别,直接删除的为1(无关),待确定的为2(游戏词和无关词之间),可以的一个是 3
3.3.2.9 处理后在E2列输入函数公式=VLOOKUP(A2,Sheet4!A:B,2,0),下拉到最后等待待处理
3.3.2.10 选择E2列,过滤,去掉1,保留2和3的结果
3.3.2.11 保存文档,一份完成
(此部分有待编辑,留有优化空间)
二、 采集Bottom文章 -> 使用采集tools 去采集bottom文章根据2中的话。
3.1 使用付费工具,优采云软件,采集非百度源(360、搜狗,微信,bing,谷歌等都可以用,谷歌需要翻墙)
3.2 文章筛选效率优化
3.2.1 规则:收录主词根(以网页游戏为例,文章收录“页游”或“网页游戏”);湾与游戏相关; C。标题限制 D.大小限制(多多少K可以直接去掉); e.文章内容下限250字; F。加上人工筛选; G。竞争产品词的机器替换和某些词的去除;总体筛选剩余 18% 左右
3.3 采集源 优化:寻找非百度源,文章质量命中率更高的,如果同样情况,可以看爬取质量或爬取时效
3.3.1 先采集攻略,防止采集新闻分配策略资源,增加后期调整成本
三、网站优化 查看全部
采集内容插入词库(词库1.1-1.4如下拓展工具的分类及应用)
一、Thesaurus 组织
1 选择词库竞争者->准备阶段:选择基本词根和相关长尾词
1.1 在专业的seo分类网站上找;到导航站批量查找;如果实在没有资源,可以手动添加。目标是尝试覆盖行业中的所有网站。
1.2 在我们自己的爬虫数据库中找到行业根词
1.3 在网站行业竞争对手地图中查找行业根词
1.4 在1.4 拥有的资源站点中找到的搜索流量搜索词(百度统计、GA统计等统计工具)
1.5 如果有资源,请花钱买个专业整合公司的industry关键词database
1.1 Comment 这个时候就是我们在拼资源的时候,网上就有这样的网站,比如,
1.2 Comment 如果你已经提前有网站,请从你站点的维度去寻找,底部一定有词根词汇
推荐:
处理器:助理
相关技能:优采云或相关采集tools
耗时估计:1-2天
大多数情况下,我们不是1.5的土豪,我们花10000块买整合数据,那么1.1-1.4处理如下
2 再展开词-> 把1中比较完整的词取出来展开,力争覆盖整个行业关键词Database
2.1 对1.1中的站点进行分类,选择与您要做的站点具有相同属性的站点
2.1.1 采集 可以使用这些站点下的关键词库:爱站关键词挖矿工具(非付费导出数量有限,幅度较小,并且噪音少),5118数据库(可以使用优采云采集,使用两次爬取的逻辑,采集可以达到一个非常大的词,但是噪音太多了,100以外的很多无用词);
2.2 将1.2、1.3、1.4、2.1中的词放入关键词扩展工具中进行扩展
2.2.1 词根扩展量可以达到6K左右;长尾的展开量可以在600左右,请自适应调整
2.3 将所有单词整理好,先去除重复(包括两步,重复和某些特定单词;建议步骤)
2.1 Comment 以游戏网站为例,分为:网络游戏;页面游戏;手机游戏;小游戏;综合等,找出你想做的网站的属性,并记录下来。
2.1 对综合性站点进行标注,例如使用爱站或5118查找属性与您相同的站点。如果想做页面游览,看看有没有等待站点,快速查找提取
2.1.1 评论。如果您需要资源购买付费版,可以在很大程度上节省时间。不要想着免费;
2.1.1 注解5118数据库可以用优采云批量抓取,如果量级大,需要时间,请估计; 采集方法,先通配采集每个域名/子域/下翻页数,然后在关键词下批量写规则采集/baidu/rank/,这是因为排名页数每个域名都不一样
2.2注解爱站扩展长尾词的能力比较好,短词(即行业根词)可以用爱站跑;中短字长(判断标准,excel function=len(*) 4-9左右)可以用战神工具跑;中长字(=len(*) 9-18左右)也可以用战神工具跑;长字(=len(*) 18-29左右)感觉应该删除删除,不需要运行
因为去重的重复量太大,有几千万级,所以必须机器和人工同时过滤处理
3 处理关键词
3.1 通过机器处理噪声进行初始过滤;重复数据删除
3.1.1 直接匹配删除,如:#、$、http、-、..、.com、.xml等,根据自己的行业特点过滤,包括直接删除
3.1.2 替换,主要是转义和空格,如:",&
3.1.3 所有号码将根据行业情况进行删除处理
3.1.4 上面剩下的词库去重
3.2 机器初步筛选-提取精准词
3.1.1 然后处理下一个词根,对词根中的噪声进行处理,比如()中的内容等,有助于机器提取的准确性。
3.1.2 使用行业词库和词根匹配所有词,整理文档,打包。这部分是准确的词。
3.3 人力去除脏话
3.3.1 软件工具:notepad++; office excel 2010及以上版本(WPS不可用); 关键词自动分类工具
3.3.2 步
3.3.2.1 用notepad++打开文档,将所有单词复制到分类工具中
3.3.2.2 点击分类工具中的开始查询
3.3.2.3 稍等,等到右边弹出最终结果(过程可能会持续5-15分钟,不要注意没反应),期间可以同步做其他事情
3.3.2.4 将分词中的结果复制到notepad++中,然后复制到xls表中(点击结果,ctrl+a,因为没有明显的标记,等待全部转蓝色,期间可能有几次没反应)
3.3.2.5 在 xls 表中,#fonts 以列分隔
3.3.2.6 行插入四列,根词,一级,二级,三级
3.3.2.7 选择四列并插入数据透视表
3.3.2.8 在B列进行数字识别,直接删除的为1(无关),待确定的为2(游戏词和无关词之间),可以的一个是 3
3.3.2.9 处理后在E2列输入函数公式=VLOOKUP(A2,Sheet4!A:B,2,0),下拉到最后等待待处理
3.3.2.10 选择E2列,过滤,去掉1,保留2和3的结果
3.3.2.11 保存文档,一份完成
(此部分有待编辑,留有优化空间)
二、 采集Bottom文章 -> 使用采集tools 去采集bottom文章根据2中的话。
3.1 使用付费工具,优采云软件,采集非百度源(360、搜狗,微信,bing,谷歌等都可以用,谷歌需要翻墙)
3.2 文章筛选效率优化
3.2.1 规则:收录主词根(以网页游戏为例,文章收录“页游”或“网页游戏”);湾与游戏相关; C。标题限制 D.大小限制(多多少K可以直接去掉); e.文章内容下限250字; F。加上人工筛选; G。竞争产品词的机器替换和某些词的去除;总体筛选剩余 18% 左右
3.3 采集源 优化:寻找非百度源,文章质量命中率更高的,如果同样情况,可以看爬取质量或爬取时效
3.3.1 先采集攻略,防止采集新闻分配策略资源,增加后期调整成本
三、网站优化
采集内容插入词库(分析一下企查查,本着分享知识的原则、原则和原则 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-09-03 00:06
)
最近有朋友让我分析七茶茶。本着知识分享的原则,我想用我浅薄的知识和见解谈谈七叉茶的SEO亮点,希望能帮助更多的兄弟了解SEO的精髓!
我之前分析过顺奇网,分析过58同城。你可以看看你是否喜欢它。 58同城的词库感觉比较笼统一点,企业查找更准确。与上面相比,顺奇网这两个词比较复杂,业务不同,词库不同,不分高低。
(内容、模板)稀缺
现在很多人做SEO,还认为原创是SEO的核心。企业调查是对这一观点的最大否定。因为上面的信息基本都是采集。
但是目测采集应该是调用国家数据库,因为国内各个公司的信息,应该不会那么好采集,就算采集,还是有一些不准确的,因为不权威网站上的企业信息信任度比较低。只有国家信息才是准确的。
内容已经解决,公司在用户体验和模板方面做了很好的对比。在之前的课程中,我们也讲过影响网站rank和收录的因素,模板也是其中之一。
大规模网站最终绝对是一场规模的竞争。词库决定权重,收录决定词库。这种收录的水平,绝对不是几十人、几百人能做到的。
词库精准定位
词库的定位与业务直接相关,但公司搜索的词库远小于同城58的词库。仅就竞争而言,它要小得多。企业搜索的词库一般以【企业名称】【法人名称、股东名称】为主,而58则以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白,关键词难易级别。
但是,如果词库定位准确,客户会更准确。当你的量级达到千万甚至上亿的时候,长尾带来的流量是相当恐怖的,这些每天访问网站的恐怖流量所带来的信任度的增长绝不是普通的小网站可比的。
就像之前聊的58一样,品牌流量作为源头带动了网站的整体信任度。信任高后,长尾流量来了,我们一次次回馈网站,良性循环!
学习和应用
为什么需要分析企业搜索?因为企业搜索的难度比较低。我们可以把他的词库导出成权重站!
比如我之前做过的名字站,可以做公司名字的站,或者其他站。毕竟有词库,内容会聚合,哪怕是随机生成,权重分分钟。
查看全部
采集内容插入词库(分析一下企查查,本着分享知识的原则、原则和原则
)
最近有朋友让我分析七茶茶。本着知识分享的原则,我想用我浅薄的知识和见解谈谈七叉茶的SEO亮点,希望能帮助更多的兄弟了解SEO的精髓!
我之前分析过顺奇网,分析过58同城。你可以看看你是否喜欢它。 58同城的词库感觉比较笼统一点,企业查找更准确。与上面相比,顺奇网这两个词比较复杂,业务不同,词库不同,不分高低。
(内容、模板)稀缺
现在很多人做SEO,还认为原创是SEO的核心。企业调查是对这一观点的最大否定。因为上面的信息基本都是采集。
但是目测采集应该是调用国家数据库,因为国内各个公司的信息,应该不会那么好采集,就算采集,还是有一些不准确的,因为不权威网站上的企业信息信任度比较低。只有国家信息才是准确的。
内容已经解决,公司在用户体验和模板方面做了很好的对比。在之前的课程中,我们也讲过影响网站rank和收录的因素,模板也是其中之一。
大规模网站最终绝对是一场规模的竞争。词库决定权重,收录决定词库。这种收录的水平,绝对不是几十人、几百人能做到的。
词库精准定位
词库的定位与业务直接相关,但公司搜索的词库远小于同城58的词库。仅就竞争而言,它要小得多。企业搜索的词库一般以【企业名称】【法人名称、股东名称】为主,而58则以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白,关键词难易级别。
但是,如果词库定位准确,客户会更准确。当你的量级达到千万甚至上亿的时候,长尾带来的流量是相当恐怖的,这些每天访问网站的恐怖流量所带来的信任度的增长绝不是普通的小网站可比的。
就像之前聊的58一样,品牌流量作为源头带动了网站的整体信任度。信任高后,长尾流量来了,我们一次次回馈网站,良性循环!
学习和应用
为什么需要分析企业搜索?因为企业搜索的难度比较低。我们可以把他的词库导出成权重站!
比如我之前做过的名字站,可以做公司名字的站,或者其他站。毕竟有词库,内容会聚合,哪怕是随机生成,权重分分钟。

