
采集内容插入词库
采集内容插入词库(分析一下企查查,本着分享知识的原则、原则和原则 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-12-31 20:15
)
最近有朋友让我分析七茶茶。本着知识分享的原则,我想用我浅薄的知识和见解谈谈七叉茶的SEO亮点,希望能帮助更多的兄弟了解SEO的精髓!
我之前分析过顺奇网和58同城。你可以看看你是否喜欢它。 58同城的词库个人感觉比较笼统一点,而公司的搜索比较准确。与上面相比,顺奇网这两个词比较复杂,业务不同,词库不同,不分高低。
(内容、模板)稀缺
现在很多人做SEO,还认为原创是SEO的核心。企业调查是对这一观点的最大否定。因为上面的信息基本都是采集。
但是目测采集的内容应该是调用国家数据库,因为国内各个企业的信息应该没有那么好。采集,即使采集@ >,有一些不准确的情况,因为企业信息对非权威网站的信任度比较低。只有国家信息才是准确的。
内容已经解决,公司在用户体验和模板方面做了很好的对比。在之前的课程中,我们也讲过影响排名的因素和收录。模板也是其中之一。
Large-scale网站能做到决赛,绝对是一场量级的比赛。词库决定权重,收录决定词库。这种收录的水平,绝对不是几十人、几百人能做到的。
词库精准定位
词库的定位与业务直接相关,但公司搜索的词库远小于同城58的词库。仅就竞争而言,它要小得多。企业搜索的词库一般以【公司名称】【法人名称、股东名称】为主,而58则主要以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白很难关键词 容易程度。
但是,词库的定位是准确的,客户会准确得多。当你的量级达到几千万或者几亿的时候,长尾带来的流量是相当恐怖的,这些每天访问网站的恐怖流量带来的信任度的增加绝不是普通的小网站可比的.
和之前聊天中的58一样,品牌流量作为来源带动了网站的整体信任度。信任高后,长尾流量来了,一次次回馈网站,良性循环!
学习和应用
为什么需要分析企业搜索?因为企业搜索的难度比较低。我们可以把他的词库导出成权重站!
比如我之前做过的名字站,可以做公司名字的站,或者其他站。毕竟有词库,内容会聚合。即使是随机生成的,也不过是几分钟的事情。
查看全部
采集内容插入词库(分析一下企查查,本着分享知识的原则、原则和原则
)
最近有朋友让我分析七茶茶。本着知识分享的原则,我想用我浅薄的知识和见解谈谈七叉茶的SEO亮点,希望能帮助更多的兄弟了解SEO的精髓!

我之前分析过顺奇网和58同城。你可以看看你是否喜欢它。 58同城的词库个人感觉比较笼统一点,而公司的搜索比较准确。与上面相比,顺奇网这两个词比较复杂,业务不同,词库不同,不分高低。
(内容、模板)稀缺
现在很多人做SEO,还认为原创是SEO的核心。企业调查是对这一观点的最大否定。因为上面的信息基本都是采集。
但是目测采集的内容应该是调用国家数据库,因为国内各个企业的信息应该没有那么好。采集,即使采集@ >,有一些不准确的情况,因为企业信息对非权威网站的信任度比较低。只有国家信息才是准确的。
内容已经解决,公司在用户体验和模板方面做了很好的对比。在之前的课程中,我们也讲过影响排名的因素和收录。模板也是其中之一。

Large-scale网站能做到决赛,绝对是一场量级的比赛。词库决定权重,收录决定词库。这种收录的水平,绝对不是几十人、几百人能做到的。
词库精准定位

词库的定位与业务直接相关,但公司搜索的词库远小于同城58的词库。仅就竞争而言,它要小得多。企业搜索的词库一般以【公司名称】【法人名称、股东名称】为主,而58则主要以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白很难关键词 容易程度。
但是,词库的定位是准确的,客户会准确得多。当你的量级达到几千万或者几亿的时候,长尾带来的流量是相当恐怖的,这些每天访问网站的恐怖流量带来的信任度的增加绝不是普通的小网站可比的.
和之前聊天中的58一样,品牌流量作为来源带动了网站的整体信任度。信任高后,长尾流量来了,一次次回馈网站,良性循环!
学习和应用
为什么需要分析企业搜索?因为企业搜索的难度比较低。我们可以把他的词库导出成权重站!
比如我之前做过的名字站,可以做公司名字的站,或者其他站。毕竟有词库,内容会聚合。即使是随机生成的,也不过是几分钟的事情。

采集内容插入词库(基于TF-IDF的关键词抽取方法,帮助读者快速理解文本信息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-12-31 20:14
Text关键词 抽取是一种高度浓缩文本信息的有效方法。通过3-5个词准确概括文章主题,帮助读者快速理解文章信息。目前文本提取的方法主要有四种:基于TF-IDF的关键词提取、基于TextRank的关键词提取、基于Word2Vec词聚类的关键词提取、关键词 结合多种算法的提取。在使用前三种算法进行关键词抽取的学习过程中,笔者发现网上有很多使用TF-IDF和TextRank方法抽取关键词的例子。代码和步骤比较简单,但是使用Word2Vec词聚类的方法,网上的资料并没有明确的表达过程和步骤。因此,本文采用TF-IDF方法、TextRank方法和Word2Vec词聚类方法实现专利文本的提取(也适用于其他类型的文本)。通过理论与实践相结合,一步步的理解、学习、实现中文文本抽取关键词。
1 概览
一个文档的关键词相当于N个最能表达文档主要目的的词,也就是文档最重要的词。因此,文本关键词抽取问题可以转化为重要词对于性排序问题,选择前N个词作为文本关键词。目前主流的文本提取方法主要分为以下两类:
(1)基于统计的关键词抽取方法
该方法根据词频等统计信息计算文档中词的权重,按照权重值的顺序提取关键词。 TF-IDF 和 TextRank 都属于此类方法。其中,TF-IDF方法通过计算单个文本词频(Term Frequency,TF)和逆文档频率(Inverse Document Frequency,IDF)来获得词权重; TextRank方法是基于PageRank的思想,通过词共现窗口构建共现网络,计算词得分。这种方法简单易实现,适用性强,但没有考虑词序问题。
(2)关键词基于机器学习的提取方法
该方法包括SVM、朴素贝叶斯等监督学习方法,以及K-means、层次聚类等无监督学习方法。在这类方法中,模型的好坏取决于特征提取,而深度学习是一种有效的特征提取方式。谷歌推出的 Word2Vec 词向量模型是自然语言领域具有代表性的学习工具。它在训练语言模型的过程中将字典映射到更抽象的向量空间。每个词都由一个高维向量表示。向量空间中两点的距离对应两个词的相似度。
基于以上研究,本文分别采用TF-IDF方法、TextRank方法和Word2Vec词聚类方法,使用Python语言开发实现文本提取关键词。
2 开发环境准备2.1 Python 环境
在python官网下载电脑对应的python版本。作者使用的Python版本2.7.13.
2.2 个第三方模块
本实验Python代码的实现使用了多个知名的第三方模块,主要模块如下:
(1)解霸
目前使用最广泛的中文分词组件。下载链接:
(2)Gensim
用于主题模型、文档索引和大规模语料库相似性索引的 Python 库,主要用于自然语言处理 (NLP) 和信息检索 (IR)。下载链接:
本例中维基中文语料处理和中文词向量模型构建需要该模块。
(3)熊猫
用于高效处理大型数据集和执行数据分析任务的 python 库是一个基于 Numpy 的工具包。
下载链接:
(4)Numpy
用于存储和处理大型矩阵的工具包。
下载链接:
(5)Scikit-learn
用于机器学习的python工具包。 python 模块引用名称是 sklearn。安装前需要两个 Python 库,Numpy 和 Scipy。
官网地址:
本例中主要使用了本模块中的feature_extraction、KMeans(k-means聚类算法)和PCA(pac降维算法)。
(6)Matplotlib
Matplotlib 是一个用于绘制二维图形的 Python 图形框架。
下载链接:
3 数据准备3.1个样本语料
正文以汽车行业的10项专利作为样本数据集,见文件“data/sample_data.csv”。该文件依次收录编号(id)、标题(title)和摘要(abstract)三个字段。 关键词的提取过程中都涉及到标题和摘要。您可以根据自己的样本数据调整数据读取代码。
3.2 停用词词典
本文使用中科院计算所中文自然语言处理开放平台发布的中文停用词表,收录1208个停用词。下载链接:
另外,由于本例的样本是专利文本,词汇专业性很强,需要手动添加停用词。您可以直接将它们添加到上面的停用词列表中。每一行都是一个停用词。请参阅文件“data /stopWord.txt”。在这个例子中,作者在文件顶部手动添加了六个停用词“包括、相对、免费、使用、本发明和组合”以进行演示。您可以根据实际情况删除或删除它们。添加停用词。
4 基于TF-IDF的文本提取方法关键词4.1 TF-IDF算法思路
词频(TF)是指给定词在当前文档中的出现频率。由于同一个词在长文档中的词频可能高于短文档,因此需要根据文档的长度对给定词进行归一化,即给定词的个数除以总数当前文档中的单词数。
逆文档频率 (IDF) 是衡量单词普遍重要性的指标。也就是说,如果一个词只出现在少数文件中,则说明它更能代表文件的主题,权重也更大;如果一个词出现在大量的文档中,说明它代表什么不清楚,它的权重应该很小。
TF-IDF的主要思想是,如果某个词在一篇文章文章中出现频率较高,而在其他文章中出现频率较低,则认为该词可以更好地代表文章 的当前含义。即一个词的重要性与其在文档中出现的次数成正比,与其在语料库中在文档中出现的频率成反比。
计算公式如下:
4.2 TF-IDF文本关键词提取方法流程
由上可知,TF-IDF对所有候选文本关键词进行加权处理,并根据权重对关键词进行排序。假设Dn为测试语料的大小,算法的关键词提取步骤如下:
(1)对于给定的文本D,进行分词、词性标注、去除停用词等数据预处理操作。本小节采用口吃分词,保留'n', 'nz','v','vd','vn','l','a','d'这几个词,最后得到n个候选关键词,即D=[t1,t2, ...,tn];
(2)计算词ti在文本D中的词频;
(3) 计算词ti在整个语料库中的IDF=log (Dn /(Dt +1)),Dt为词ti在语料库中出现的文档数;
(4)计算单词ti的TF-IDF=TF*IDF,重复(2)—(4)得到所有候选关键词TF-IDF值;
(5)将候选关键词的计算结果倒序排列,得到前N个词作为正文关键词。
4.3 代码实现
Python 第三方工具包 Scikit-learn 提供了 TFIDF 算法的相关功能。本文主要使用sklearn.feature_extraction.text下的TfidfTransformer和CountVectorizer函数。其中,CountVectorizer函数用于构建语料中的词频矩阵,TfidfTransformer函数用于计算词的tfidf权重。
注意:TfidfTransformer()函数有一个参数smooth_idf,默认值为True,如果设置为False,IDF计算公式为idf=log(Dn /Dt) + 1。
基于TF-IDF方法实现文本关键词提取代码执行步骤如下:
(1)读取示例源文件sample_data.csv;
(2)获取每行记录的title和summary字段,将这两个字段拼接起来;
(3) 加载自定义停用词列表stopWord.txt,对拼接后的文本进行数据预处理操作,包括分词、过滤词性匹配的词、去除停用词,以及用空格分隔拼接成文本;
(4) 遍历文本记录,将预处理后的文本放入文档集语料库中;
(5)使用CountVectorizer()函数得到词频矩阵,a[j][i]代表第i个文档中第j个词的词频;
(6)使用TfidfTransformer()函数计算每个词的tf-idf权重;
(7)得到词袋模型中的关键词和对应的tf-idf矩阵;
(8) 遍历tf-idf矩阵,打印每个文档的词汇量和对应的权重;
(9)对于每个文档,按照词权值降序排列,选择topN个词作为文本关键词,写入数据框;
(10)将最终结果写入文件keys_TFIDF.csv。
最终运行结果如下图所示。
5种基于TextRank的文本提取方法关键词5.1 PageRank算法思路
TextRank算法是基于PageRank算法的,所以在介绍TextRank之前必须先了解一下PageRank算法。
PageRank 算法是谷歌创始人拉里佩奇和谢尔盖布林于 1998 年在斯坦福大学攻读研究生期间发明的。它用于根据网页之间的超链接计算网页的重要性。技术。该算法借鉴了学术界判断学术论文重要性的方法,即检查论文的引用次数。基于以上思想,PageRank算法的核心思想是网页的重要性由两部分组成:
①如果一个网页被大量其他网页链接,则说明这个网页更重要,即链接网页的数量;
②如果一个网页链接到排名靠前的网页,说明这个网页更重要,也就是链接网页的权重。
一般情况下,网页的PageRank值(PR)计算公式如下:
其中,PR(Pi)为第i个网页的重要性排名,即PR值; ɑ为阻尼系数,一般设置为0.85; N是网页总数; Mpi 是第 i 个网页的总数 外链网页的集合; L(Pj)为第j个网页的外链数。
初始阶段,假设所有网页的排名为1/N,根据上述公式计算每个网页的PR值。当迭代稳定后,停止迭代计算,得到最终结果。一般情况下,迭代10次左右就基本收敛了。
5.2 TextRank 算法思路
TextRank 算法是 Mihalcea 和 Tarau 在 2004 年在研究自动摘要提取时提出的,并在 PageRank 算法的思想上进行了改进。该算法将文本拆分为词表作为网络节点,形成词表网络图模型,将词之间的相似关系视为推荐或投票关系,从而计算出每个词的重要性。
基于TextRank的
Text关键词抽取就是利用局部词汇关系,即共现窗口,对候选关键词进行排序。该方法的步骤如下:
(1)对于给定的文本D,进行分词、词性标注、去除停用词等数据预处理操作。本小节采用口吃分词,保留'n', 'nz','v','vd','vn','l','a','d'这几个词,最后得到n个候选关键词,即D=[t1,t2, ...,tn];
(2) 构造候选关键词图G=(V,E),其中V为节点集,由候选关键词组成,使用共现关系构造任意两个点 只有当它们对应的词在长度为K的窗口中共同出现时,两个节点之间才有一条边。K代表窗口的大小,即最多K个词可以同时出现;
(3)根据公式迭代计算每个节点的权重,直到收敛;
(4)将节点权重逆序排序,得到前N个词作为文本关键词.
注意:jieba 库中收录的 jieba.analysis.textrank 函数可以直接实现 TextRank 算法。本文使用该函数进行实验。
5.3 代码实现
基于TextRank方法实现文本关键词代码执行步骤如下:
(1)读取示例源文件sample_data.csv;
(2)获取每行记录的title和summary字段,将这两个字段拼接起来;
(3)加载自定义停用词列表stopWord.txt;
<p>(4)遍历文本记录,使用jieba.analysis.textrank函数过滤掉指定词性和topN文本关键词,并将结果存入数据框; 查看全部
采集内容插入词库(基于TF-IDF的关键词抽取方法,帮助读者快速理解文本信息)
Text关键词 抽取是一种高度浓缩文本信息的有效方法。通过3-5个词准确概括文章主题,帮助读者快速理解文章信息。目前文本提取的方法主要有四种:基于TF-IDF的关键词提取、基于TextRank的关键词提取、基于Word2Vec词聚类的关键词提取、关键词 结合多种算法的提取。在使用前三种算法进行关键词抽取的学习过程中,笔者发现网上有很多使用TF-IDF和TextRank方法抽取关键词的例子。代码和步骤比较简单,但是使用Word2Vec词聚类的方法,网上的资料并没有明确的表达过程和步骤。因此,本文采用TF-IDF方法、TextRank方法和Word2Vec词聚类方法实现专利文本的提取(也适用于其他类型的文本)。通过理论与实践相结合,一步步的理解、学习、实现中文文本抽取关键词。
1 概览
一个文档的关键词相当于N个最能表达文档主要目的的词,也就是文档最重要的词。因此,文本关键词抽取问题可以转化为重要词对于性排序问题,选择前N个词作为文本关键词。目前主流的文本提取方法主要分为以下两类:
(1)基于统计的关键词抽取方法
该方法根据词频等统计信息计算文档中词的权重,按照权重值的顺序提取关键词。 TF-IDF 和 TextRank 都属于此类方法。其中,TF-IDF方法通过计算单个文本词频(Term Frequency,TF)和逆文档频率(Inverse Document Frequency,IDF)来获得词权重; TextRank方法是基于PageRank的思想,通过词共现窗口构建共现网络,计算词得分。这种方法简单易实现,适用性强,但没有考虑词序问题。
(2)关键词基于机器学习的提取方法
该方法包括SVM、朴素贝叶斯等监督学习方法,以及K-means、层次聚类等无监督学习方法。在这类方法中,模型的好坏取决于特征提取,而深度学习是一种有效的特征提取方式。谷歌推出的 Word2Vec 词向量模型是自然语言领域具有代表性的学习工具。它在训练语言模型的过程中将字典映射到更抽象的向量空间。每个词都由一个高维向量表示。向量空间中两点的距离对应两个词的相似度。
基于以上研究,本文分别采用TF-IDF方法、TextRank方法和Word2Vec词聚类方法,使用Python语言开发实现文本提取关键词。
2 开发环境准备2.1 Python 环境
在python官网下载电脑对应的python版本。作者使用的Python版本2.7.13.
2.2 个第三方模块
本实验Python代码的实现使用了多个知名的第三方模块,主要模块如下:
(1)解霸
目前使用最广泛的中文分词组件。下载链接:
(2)Gensim
用于主题模型、文档索引和大规模语料库相似性索引的 Python 库,主要用于自然语言处理 (NLP) 和信息检索 (IR)。下载链接:
本例中维基中文语料处理和中文词向量模型构建需要该模块。
(3)熊猫
用于高效处理大型数据集和执行数据分析任务的 python 库是一个基于 Numpy 的工具包。
下载链接:
(4)Numpy
用于存储和处理大型矩阵的工具包。
下载链接:
(5)Scikit-learn
用于机器学习的python工具包。 python 模块引用名称是 sklearn。安装前需要两个 Python 库,Numpy 和 Scipy。
官网地址:
本例中主要使用了本模块中的feature_extraction、KMeans(k-means聚类算法)和PCA(pac降维算法)。
(6)Matplotlib
Matplotlib 是一个用于绘制二维图形的 Python 图形框架。
下载链接:
3 数据准备3.1个样本语料
正文以汽车行业的10项专利作为样本数据集,见文件“data/sample_data.csv”。该文件依次收录编号(id)、标题(title)和摘要(abstract)三个字段。 关键词的提取过程中都涉及到标题和摘要。您可以根据自己的样本数据调整数据读取代码。
3.2 停用词词典
本文使用中科院计算所中文自然语言处理开放平台发布的中文停用词表,收录1208个停用词。下载链接:
另外,由于本例的样本是专利文本,词汇专业性很强,需要手动添加停用词。您可以直接将它们添加到上面的停用词列表中。每一行都是一个停用词。请参阅文件“data /stopWord.txt”。在这个例子中,作者在文件顶部手动添加了六个停用词“包括、相对、免费、使用、本发明和组合”以进行演示。您可以根据实际情况删除或删除它们。添加停用词。
4 基于TF-IDF的文本提取方法关键词4.1 TF-IDF算法思路
词频(TF)是指给定词在当前文档中的出现频率。由于同一个词在长文档中的词频可能高于短文档,因此需要根据文档的长度对给定词进行归一化,即给定词的个数除以总数当前文档中的单词数。
逆文档频率 (IDF) 是衡量单词普遍重要性的指标。也就是说,如果一个词只出现在少数文件中,则说明它更能代表文件的主题,权重也更大;如果一个词出现在大量的文档中,说明它代表什么不清楚,它的权重应该很小。
TF-IDF的主要思想是,如果某个词在一篇文章文章中出现频率较高,而在其他文章中出现频率较低,则认为该词可以更好地代表文章 的当前含义。即一个词的重要性与其在文档中出现的次数成正比,与其在语料库中在文档中出现的频率成反比。
计算公式如下:
4.2 TF-IDF文本关键词提取方法流程
由上可知,TF-IDF对所有候选文本关键词进行加权处理,并根据权重对关键词进行排序。假设Dn为测试语料的大小,算法的关键词提取步骤如下:
(1)对于给定的文本D,进行分词、词性标注、去除停用词等数据预处理操作。本小节采用口吃分词,保留'n', 'nz','v','vd','vn','l','a','d'这几个词,最后得到n个候选关键词,即D=[t1,t2, ...,tn];
(2)计算词ti在文本D中的词频;
(3) 计算词ti在整个语料库中的IDF=log (Dn /(Dt +1)),Dt为词ti在语料库中出现的文档数;
(4)计算单词ti的TF-IDF=TF*IDF,重复(2)—(4)得到所有候选关键词TF-IDF值;
(5)将候选关键词的计算结果倒序排列,得到前N个词作为正文关键词。
4.3 代码实现
Python 第三方工具包 Scikit-learn 提供了 TFIDF 算法的相关功能。本文主要使用sklearn.feature_extraction.text下的TfidfTransformer和CountVectorizer函数。其中,CountVectorizer函数用于构建语料中的词频矩阵,TfidfTransformer函数用于计算词的tfidf权重。
注意:TfidfTransformer()函数有一个参数smooth_idf,默认值为True,如果设置为False,IDF计算公式为idf=log(Dn /Dt) + 1。
基于TF-IDF方法实现文本关键词提取代码执行步骤如下:
(1)读取示例源文件sample_data.csv;
(2)获取每行记录的title和summary字段,将这两个字段拼接起来;
(3) 加载自定义停用词列表stopWord.txt,对拼接后的文本进行数据预处理操作,包括分词、过滤词性匹配的词、去除停用词,以及用空格分隔拼接成文本;
(4) 遍历文本记录,将预处理后的文本放入文档集语料库中;
(5)使用CountVectorizer()函数得到词频矩阵,a[j][i]代表第i个文档中第j个词的词频;
(6)使用TfidfTransformer()函数计算每个词的tf-idf权重;
(7)得到词袋模型中的关键词和对应的tf-idf矩阵;
(8) 遍历tf-idf矩阵,打印每个文档的词汇量和对应的权重;
(9)对于每个文档,按照词权值降序排列,选择topN个词作为文本关键词,写入数据框;
(10)将最终结果写入文件keys_TFIDF.csv。
最终运行结果如下图所示。
5种基于TextRank的文本提取方法关键词5.1 PageRank算法思路
TextRank算法是基于PageRank算法的,所以在介绍TextRank之前必须先了解一下PageRank算法。
PageRank 算法是谷歌创始人拉里佩奇和谢尔盖布林于 1998 年在斯坦福大学攻读研究生期间发明的。它用于根据网页之间的超链接计算网页的重要性。技术。该算法借鉴了学术界判断学术论文重要性的方法,即检查论文的引用次数。基于以上思想,PageRank算法的核心思想是网页的重要性由两部分组成:
①如果一个网页被大量其他网页链接,则说明这个网页更重要,即链接网页的数量;
②如果一个网页链接到排名靠前的网页,说明这个网页更重要,也就是链接网页的权重。
一般情况下,网页的PageRank值(PR)计算公式如下:
其中,PR(Pi)为第i个网页的重要性排名,即PR值; ɑ为阻尼系数,一般设置为0.85; N是网页总数; Mpi 是第 i 个网页的总数 外链网页的集合; L(Pj)为第j个网页的外链数。
初始阶段,假设所有网页的排名为1/N,根据上述公式计算每个网页的PR值。当迭代稳定后,停止迭代计算,得到最终结果。一般情况下,迭代10次左右就基本收敛了。
5.2 TextRank 算法思路
TextRank 算法是 Mihalcea 和 Tarau 在 2004 年在研究自动摘要提取时提出的,并在 PageRank 算法的思想上进行了改进。该算法将文本拆分为词表作为网络节点,形成词表网络图模型,将词之间的相似关系视为推荐或投票关系,从而计算出每个词的重要性。
基于TextRank的
Text关键词抽取就是利用局部词汇关系,即共现窗口,对候选关键词进行排序。该方法的步骤如下:
(1)对于给定的文本D,进行分词、词性标注、去除停用词等数据预处理操作。本小节采用口吃分词,保留'n', 'nz','v','vd','vn','l','a','d'这几个词,最后得到n个候选关键词,即D=[t1,t2, ...,tn];
(2) 构造候选关键词图G=(V,E),其中V为节点集,由候选关键词组成,使用共现关系构造任意两个点 只有当它们对应的词在长度为K的窗口中共同出现时,两个节点之间才有一条边。K代表窗口的大小,即最多K个词可以同时出现;
(3)根据公式迭代计算每个节点的权重,直到收敛;
(4)将节点权重逆序排序,得到前N个词作为文本关键词.
注意:jieba 库中收录的 jieba.analysis.textrank 函数可以直接实现 TextRank 算法。本文使用该函数进行实验。
5.3 代码实现
基于TextRank方法实现文本关键词代码执行步骤如下:
(1)读取示例源文件sample_data.csv;
(2)获取每行记录的title和summary字段,将这两个字段拼接起来;
(3)加载自定义停用词列表stopWord.txt;
<p>(4)遍历文本记录,使用jieba.analysis.textrank函数过滤掉指定词性和topN文本关键词,并将结果存入数据框;
采集内容插入词库(搜索引擎和信息传递是个不能回避的问题?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-12-28 18:08
采集内容插入词库。例如百度的品牌词,我们怎么知道什么样的词语出现几率比较大,比如“涂个防晒霜”这样的词语,你收集一下购买人群,购买经验与购买渠道等信息。当你在某天使用该词的几率会更大。
不是一个好互联网用户并不能很好的理解你在说什么
估计你说的是说搜索引擎吧?其实是一样的,是源于商业,信息传递等等的目的。
不知道你是站在哪个角度看的搜索引擎,如果从技术角度,搜索引擎和信息传递方式是完全不同的,搜索引擎是存储数据,而信息传递是没有什么区别的。即搜索引擎更多的在搜索本身,是基于文本的。
搜索引擎上将用户需要搜索的内容汇总。
搜索引擎和信息传递没有本质区别,就像历史地图,古今中外没有大区别。要提高搜索引擎效率不外乎是靠算法提高计算效率,用户看到的不是真实信息,而是现有条件下所能选择的最优信息。
无限的知识
信息传递是中央管理下的供给侧管理;搜索引擎,是按照一定算法,提供系统性的服务。
我以为,但凡越智能化的东西,理解起来越快。
差不多的,
网络化的信息传递是个不能回避的问题。中国互联网最大的问题在于传播噪音太大,各种冗余信息比比皆是,因此才需要所谓权威媒体这类中介来加速信息传递。对应的,传统媒体也有大量冗余信息。 查看全部
采集内容插入词库(搜索引擎和信息传递是个不能回避的问题?)
采集内容插入词库。例如百度的品牌词,我们怎么知道什么样的词语出现几率比较大,比如“涂个防晒霜”这样的词语,你收集一下购买人群,购买经验与购买渠道等信息。当你在某天使用该词的几率会更大。
不是一个好互联网用户并不能很好的理解你在说什么
估计你说的是说搜索引擎吧?其实是一样的,是源于商业,信息传递等等的目的。
不知道你是站在哪个角度看的搜索引擎,如果从技术角度,搜索引擎和信息传递方式是完全不同的,搜索引擎是存储数据,而信息传递是没有什么区别的。即搜索引擎更多的在搜索本身,是基于文本的。
搜索引擎上将用户需要搜索的内容汇总。
搜索引擎和信息传递没有本质区别,就像历史地图,古今中外没有大区别。要提高搜索引擎效率不外乎是靠算法提高计算效率,用户看到的不是真实信息,而是现有条件下所能选择的最优信息。
无限的知识
信息传递是中央管理下的供给侧管理;搜索引擎,是按照一定算法,提供系统性的服务。
我以为,但凡越智能化的东西,理解起来越快。
差不多的,
网络化的信息传递是个不能回避的问题。中国互联网最大的问题在于传播噪音太大,各种冗余信息比比皆是,因此才需要所谓权威媒体这类中介来加速信息传递。对应的,传统媒体也有大量冗余信息。
采集内容插入词库(内容APP如何通过给文章分类以及打标签?17年-18年底)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-12-27 08:12
笔者结合自己的项目经验,分析了内容类app是如何对文章进行分类标注的?
2017-18年底,参与了一个信息内容兴趣偏好标签项目。什么是内容兴趣偏好标签?
简单来说,就是分析用户喜欢阅读的文章类型,获取用户的兴趣爱好。在此基础上,对用户进行个性化的内容推荐和推送,有效提升应用活跃度,延长用户生命周期。
简单来说,这件事情其实就是一个两步的过程:
那么在实践中真的那么简单吗?这两个看似简单的链接是如何实现的?
首先说一下文章的分类
因为这个项目,笔者看了很多竞品app的文章分类,发现基本相同,只是在细节上有些不同。更多的问题是新闻文章的分类难以穷尽,我们参考市场上现有的分类,结合一些数据,开发了一套内容兴趣偏好系统。在指定分类时,我们遵循MECE原则,基本实现相互独立和完全穷举。
接下来,我们要对文章进行分类,我们使用分类算法的监督学习。理想情况下,该过程如下所示:
然而,在实践中存在两个问题。因为选择了监督学习,所以需要为标注样本提供依据。一般来说,有以下三种获取样本的方式:
得到样本后,就是算法模型的训练和测试。算法模型的训练原理是对样本文章进行分割,提取实体,建立特征工程,将每个特征词作为向量拟合一个函数。这样,当有新文章时,文章会通过分词,并通过模型计算结果。但是,模型不能与样本一次性准确,需要对模型进行测试和修正。一般测试程序如下:
通过测试的模型不是一劳永逸的。后期可能还存在一些分类不准确的问题,可能是样本或者算法模型造成的。这就需要我们找出这些异常的文章和它们的分类,对分类进行修正,然后作为训练样本再次馈送到模型中进行模型修正。一方面,我们可以手动检查转化率较低的分类文章,以确定问题是否出在算法上。另外,这里由于每篇文章的标签都被赋值了,我们可以为这些值设置一个阈值。当最高值低于某个阈值时,这些文章及其标签会被人工召回和标注并进行更正,并放入这里的样本库中。
文章标签的计算,因为文章可能有多个标签,不是某个二类或另一类的结果。因此,我们使用相似度算法和模型来计算文章的标签并赋值。值越高表示越接近这种类型的标签,就会进行相应的标注。
至此,文章的标注部分已经完成。
如何标记用户
对用户进行标记其实有两种方式,统计标记和算法标记。
前者可以在算法资源不足、运算需求大的情况下进行,后者可以在前者的基础上通过拆分一部分流量来验证和调整算法模型,不断优化。
但是,在使用第一种方法时,我们发现用户在一段时间内阅读的文章类型并不稳定。大多数用户都会有一个或几个主要的兴趣偏好,这些类型阅读的文章数量会更多。,但与此同时,用户或多或少会阅读一些其他类型的文章,甚至有些用户会阅读他们看到的内容。
基于这种情况,我们需要对用户的兴趣偏好进行排序,即通过对一段时间内每种文章类型的用户阅读文章的数量进行排序,并取用户的前10个标签,清楚地告诉运营用户什么他们喜欢的文章类型,在这些类型中,用户最喜欢的类型的优先级是什么,方便操作学生推送选择。
因此,用户标签也需要更加灵活,让操作学生可以根据事件发生时间、事件发生次数等权重灵活组合和选择用户组。
由于目前有很大一部分推送是人工进行的,从选择文章,到选择用户,再到匹配文章和用户,在正式推送之前一般都会进行大量的A/B测试,新闻文章的类型差异很大. 很多,仅一级标签就达到了30+种,二级标签从100个到几百个不等。整个标签很可能有数千个标签。绝对不可能靠操作学生来推。
因此,当运营资源有限,无法实现自动化时,一般的运营学生会测试标签,选择覆盖用户量大、转化率高的标签。但同时,这种情况也会导致一些兴趣相对较小的用户被排除在推送人群之外。
针对这种情况,我们将用户排名前10的二级标签及其对应的一级标签作为用户的一级标签和二级标签。这样,用户覆盖的问题就解决了,运营商也可以集中精力推送主标签和人群。
但与此同时,另一个问题也出现了。选择用户在一段时间内的行为。这个时间段多长比较合适,这样既能充分体现用户的兴趣,又能覆盖更多的人(每天都有流失的用户,所以时间线越长,覆盖的用户数越多,覆盖的用户数越短)时间线,覆盖的用户数量越少)
我们发现用户的长期兴趣偏好在一定程度上趋于稳定,但短期兴趣偏好反映了用户在短期内关注热点的行为。因此,从这个角度来看,短期或许能更好地满足用户的需求,但短期对用户的覆盖面较小。在这里,覆盖率和转化率之间永远存在着永恒的矛盾。
我们的方法是根据浏览时间对用户进行细分。给予用户长期兴趣偏好和短期兴趣偏好,并优先考虑短期兴趣偏好,将短期兴趣用户排除在长期兴趣偏好之外,进行不同的推送。对于流失用户,很可能最近3个月没有访问记录(信息定义流失用户时间为3个月)。对于此类用户,我们将用户最后记录的标签作为用户标签,从丢失中恢复。
此时,所有用户都有自己的标签,运营学生也可以根据用户的活跃时间和阅读频率,将不同的文章推送给不同的用户,实现千人。
可以说,我们在这个问题上踩了很多坑。
第二种方法是通过算法直接标记用户。除了时间和阅读频率,算法模型还可以加入更多的特征纬度,比如用户当前阅读文章的时间、阅读文章的时长、评论、点赞等,同时你还可以为热点文章和热点事件降低文章权重。
结束语
当我回过头来总结这段经历时,即使你跟着我来理解这段经历,读者可能觉得其实很简单,但是在这次经历中我们真的踩到了无数坑,尤其是我们不仅要采集
数据,还要做标签,同时也引导业务开展和分析问题。那段经历,可以说是痛并快乐着——
痛苦是因为问题太多,生意每天都在追我。我问为什么今天的转化率很低;幸福是因为我们最终的转化率终于翻了一番,甚至高于行业水平,算是最好的回报了。
本文首发于@糖糖是老坛酸菜王。每个人都是产品经理。未经作者许可,禁止转载。
标题图片来自Unsplash,基于CC0协议。 查看全部
采集内容插入词库(内容APP如何通过给文章分类以及打标签?17年-18年底)
笔者结合自己的项目经验,分析了内容类app是如何对文章进行分类标注的?
2017-18年底,参与了一个信息内容兴趣偏好标签项目。什么是内容兴趣偏好标签?
简单来说,就是分析用户喜欢阅读的文章类型,获取用户的兴趣爱好。在此基础上,对用户进行个性化的内容推荐和推送,有效提升应用活跃度,延长用户生命周期。
简单来说,这件事情其实就是一个两步的过程:
那么在实践中真的那么简单吗?这两个看似简单的链接是如何实现的?
首先说一下文章的分类
因为这个项目,笔者看了很多竞品app的文章分类,发现基本相同,只是在细节上有些不同。更多的问题是新闻文章的分类难以穷尽,我们参考市场上现有的分类,结合一些数据,开发了一套内容兴趣偏好系统。在指定分类时,我们遵循MECE原则,基本实现相互独立和完全穷举。
接下来,我们要对文章进行分类,我们使用分类算法的监督学习。理想情况下,该过程如下所示:
然而,在实践中存在两个问题。因为选择了监督学习,所以需要为标注样本提供依据。一般来说,有以下三种获取样本的方式:
得到样本后,就是算法模型的训练和测试。算法模型的训练原理是对样本文章进行分割,提取实体,建立特征工程,将每个特征词作为向量拟合一个函数。这样,当有新文章时,文章会通过分词,并通过模型计算结果。但是,模型不能与样本一次性准确,需要对模型进行测试和修正。一般测试程序如下:
通过测试的模型不是一劳永逸的。后期可能还存在一些分类不准确的问题,可能是样本或者算法模型造成的。这就需要我们找出这些异常的文章和它们的分类,对分类进行修正,然后作为训练样本再次馈送到模型中进行模型修正。一方面,我们可以手动检查转化率较低的分类文章,以确定问题是否出在算法上。另外,这里由于每篇文章的标签都被赋值了,我们可以为这些值设置一个阈值。当最高值低于某个阈值时,这些文章及其标签会被人工召回和标注并进行更正,并放入这里的样本库中。
文章标签的计算,因为文章可能有多个标签,不是某个二类或另一类的结果。因此,我们使用相似度算法和模型来计算文章的标签并赋值。值越高表示越接近这种类型的标签,就会进行相应的标注。
至此,文章的标注部分已经完成。
如何标记用户
对用户进行标记其实有两种方式,统计标记和算法标记。
前者可以在算法资源不足、运算需求大的情况下进行,后者可以在前者的基础上通过拆分一部分流量来验证和调整算法模型,不断优化。
但是,在使用第一种方法时,我们发现用户在一段时间内阅读的文章类型并不稳定。大多数用户都会有一个或几个主要的兴趣偏好,这些类型阅读的文章数量会更多。,但与此同时,用户或多或少会阅读一些其他类型的文章,甚至有些用户会阅读他们看到的内容。
基于这种情况,我们需要对用户的兴趣偏好进行排序,即通过对一段时间内每种文章类型的用户阅读文章的数量进行排序,并取用户的前10个标签,清楚地告诉运营用户什么他们喜欢的文章类型,在这些类型中,用户最喜欢的类型的优先级是什么,方便操作学生推送选择。
因此,用户标签也需要更加灵活,让操作学生可以根据事件发生时间、事件发生次数等权重灵活组合和选择用户组。
由于目前有很大一部分推送是人工进行的,从选择文章,到选择用户,再到匹配文章和用户,在正式推送之前一般都会进行大量的A/B测试,新闻文章的类型差异很大. 很多,仅一级标签就达到了30+种,二级标签从100个到几百个不等。整个标签很可能有数千个标签。绝对不可能靠操作学生来推。
因此,当运营资源有限,无法实现自动化时,一般的运营学生会测试标签,选择覆盖用户量大、转化率高的标签。但同时,这种情况也会导致一些兴趣相对较小的用户被排除在推送人群之外。
针对这种情况,我们将用户排名前10的二级标签及其对应的一级标签作为用户的一级标签和二级标签。这样,用户覆盖的问题就解决了,运营商也可以集中精力推送主标签和人群。
但与此同时,另一个问题也出现了。选择用户在一段时间内的行为。这个时间段多长比较合适,这样既能充分体现用户的兴趣,又能覆盖更多的人(每天都有流失的用户,所以时间线越长,覆盖的用户数越多,覆盖的用户数越短)时间线,覆盖的用户数量越少)
我们发现用户的长期兴趣偏好在一定程度上趋于稳定,但短期兴趣偏好反映了用户在短期内关注热点的行为。因此,从这个角度来看,短期或许能更好地满足用户的需求,但短期对用户的覆盖面较小。在这里,覆盖率和转化率之间永远存在着永恒的矛盾。
我们的方法是根据浏览时间对用户进行细分。给予用户长期兴趣偏好和短期兴趣偏好,并优先考虑短期兴趣偏好,将短期兴趣用户排除在长期兴趣偏好之外,进行不同的推送。对于流失用户,很可能最近3个月没有访问记录(信息定义流失用户时间为3个月)。对于此类用户,我们将用户最后记录的标签作为用户标签,从丢失中恢复。
此时,所有用户都有自己的标签,运营学生也可以根据用户的活跃时间和阅读频率,将不同的文章推送给不同的用户,实现千人。
可以说,我们在这个问题上踩了很多坑。
第二种方法是通过算法直接标记用户。除了时间和阅读频率,算法模型还可以加入更多的特征纬度,比如用户当前阅读文章的时间、阅读文章的时长、评论、点赞等,同时你还可以为热点文章和热点事件降低文章权重。
结束语
当我回过头来总结这段经历时,即使你跟着我来理解这段经历,读者可能觉得其实很简单,但是在这次经历中我们真的踩到了无数坑,尤其是我们不仅要采集
数据,还要做标签,同时也引导业务开展和分析问题。那段经历,可以说是痛并快乐着——
痛苦是因为问题太多,生意每天都在追我。我问为什么今天的转化率很低;幸福是因为我们最终的转化率终于翻了一番,甚至高于行业水平,算是最好的回报了。
本文首发于@糖糖是老坛酸菜王。每个人都是产品经理。未经作者许可,禁止转载。
标题图片来自Unsplash,基于CC0协议。
采集内容插入词库(网站页面质量、数量、用户行为,到底哪个重要?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-12-25 21:14
在网站优化的过程中,我们总是会讨论网站的状态。百度的权重是重要的衡量指标之一。长期以来,SEO人员一直在围绕这些指标工作。
但是我们总是看以下几种情况:
① 高权重海量采集
② 一般收录
高权重
③ 单个页面收录
高权重
也是一个高权重的网站,但是百度的收录量就不一样了。其中,我们认为涉及的主要核心因素包括:页面质量、数量和用户行为。
那么,网站页面质量、数量和用户行为哪个最重要?
根据之前的SEO观察,Batman IT会详细说明如下:
1、页数
如果你有时间去统计一下你所在行业的相关网站,你会发现网站权重在5-8的网站会有一个重要的特点,那就是收录的页数非常高,一般在20000+页。
为什么会出现这种情况:
① 前段时间,我们讨论了内容增量的问题。它主要考虑网站的活动。在相对搜索阈值的情况下,如果你的内容增加,会长期保持稳定增长状态。
对于搜索引擎,它会继续给你更高程度的关注,尤其是对垂直行业的信任。说白了,当你每天广播内容的时候,对方总是希望挖掘出相关的有价值的页面。会更加关注你。
②海量长尾关键词排名,基于海量内容的增长,必然有这样一个特定的情况,即网站有更高的长尾关键词词库。
并且由于关键词的长尾排名,也会带来大量的用户访问量,使网站处于良性循环。
③反向链接的增长,基于网站权重的增加和大量页面的展示,你会在无形中得到一些外部链接,尤其是一些站群采集
站,对方经常把网址和锚文本链接采集
在一起。
2、页面质量
在上一篇文章中,我们提到过,如果你打算让一个网站的权重达到5以上,通常的页面收录量需要在一万以上,但有时这种情况也不是绝对的。
这里需要简单说一下:网站权重的积累其实就是对关键词搜索量排名位置的评价。如果您的网站页面有很多百度指数非常高的页面,则它们的排名会更高。
在一定程度上,用少量的页面,比如5000页,做一个高权重的网站实际上是可能的。
这包括:
① 关键词 选择和布局。
②网站内部结构设计及内链链接策略。
③页面解决用户搜索需求的能力。
3、用户行为
但是,在日常工作中,我们也会遇到这样的特殊情况,就是一个页面可以获得更高的权重,甚至整个页面都会得到海量的关键词排名展示。
记得我们前几天写的一页排名案例,并进行了详细的讨论。
其中,我们认为一个页面要获得更高的权重最重要的元素是:
① 页面主题的垂直相关性有多高?
②优质外链数量多,展示形式多样。
③持续稳定的用户行为接入。
4、策略选择
这时候你可能会问我,如果是Batman IT,你是如何选择相关性策略来增加百度权重的?我认同:
① 优质页面组合
这里我们通常建议您创建高质量的页面组合并增加权重。原因很简单。您只需要关注每个页面的主题。
值得注意的是,并非每个站长都有能力批量生产海量数据,无论内容质量如何。因此,我们推荐一种优化主页的策略。
②营销单页矩阵
营销单页矩阵主要是指单页网站的集合。一般一个网页一个域名,策略性地进行友情链接的互联。
总结:高权重网站的质量、数量和用户行为哪个重要?我们认为,如何建立垂直相关的内容,如何吸引用户访问和停留更为重要。以上内容仅供参考。 查看全部
采集内容插入词库(网站页面质量、数量、用户行为,到底哪个重要?)
在网站优化的过程中,我们总是会讨论网站的状态。百度的权重是重要的衡量指标之一。长期以来,SEO人员一直在围绕这些指标工作。
但是我们总是看以下几种情况:
① 高权重海量采集
② 一般收录
高权重
③ 单个页面收录
高权重
也是一个高权重的网站,但是百度的收录量就不一样了。其中,我们认为涉及的主要核心因素包括:页面质量、数量和用户行为。
那么,网站页面质量、数量和用户行为哪个最重要?
根据之前的SEO观察,Batman IT会详细说明如下:
1、页数
如果你有时间去统计一下你所在行业的相关网站,你会发现网站权重在5-8的网站会有一个重要的特点,那就是收录的页数非常高,一般在20000+页。
为什么会出现这种情况:
① 前段时间,我们讨论了内容增量的问题。它主要考虑网站的活动。在相对搜索阈值的情况下,如果你的内容增加,会长期保持稳定增长状态。
对于搜索引擎,它会继续给你更高程度的关注,尤其是对垂直行业的信任。说白了,当你每天广播内容的时候,对方总是希望挖掘出相关的有价值的页面。会更加关注你。
②海量长尾关键词排名,基于海量内容的增长,必然有这样一个特定的情况,即网站有更高的长尾关键词词库。
并且由于关键词的长尾排名,也会带来大量的用户访问量,使网站处于良性循环。
③反向链接的增长,基于网站权重的增加和大量页面的展示,你会在无形中得到一些外部链接,尤其是一些站群采集
站,对方经常把网址和锚文本链接采集
在一起。
2、页面质量
在上一篇文章中,我们提到过,如果你打算让一个网站的权重达到5以上,通常的页面收录量需要在一万以上,但有时这种情况也不是绝对的。
这里需要简单说一下:网站权重的积累其实就是对关键词搜索量排名位置的评价。如果您的网站页面有很多百度指数非常高的页面,则它们的排名会更高。
在一定程度上,用少量的页面,比如5000页,做一个高权重的网站实际上是可能的。
这包括:
① 关键词 选择和布局。
②网站内部结构设计及内链链接策略。
③页面解决用户搜索需求的能力。
3、用户行为
但是,在日常工作中,我们也会遇到这样的特殊情况,就是一个页面可以获得更高的权重,甚至整个页面都会得到海量的关键词排名展示。
记得我们前几天写的一页排名案例,并进行了详细的讨论。
其中,我们认为一个页面要获得更高的权重最重要的元素是:
① 页面主题的垂直相关性有多高?
②优质外链数量多,展示形式多样。
③持续稳定的用户行为接入。
4、策略选择
这时候你可能会问我,如果是Batman IT,你是如何选择相关性策略来增加百度权重的?我认同:
① 优质页面组合
这里我们通常建议您创建高质量的页面组合并增加权重。原因很简单。您只需要关注每个页面的主题。
值得注意的是,并非每个站长都有能力批量生产海量数据,无论内容质量如何。因此,我们推荐一种优化主页的策略。
②营销单页矩阵
营销单页矩阵主要是指单页网站的集合。一般一个网页一个域名,策略性地进行友情链接的互联。
总结:高权重网站的质量、数量和用户行为哪个重要?我们认为,如何建立垂直相关的内容,如何吸引用户访问和停留更为重要。以上内容仅供参考。
采集内容插入词库(综合工具箱、dnspod解析、收录查询、词汇生成,外推规则生成)
采集交流 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-12-22 13:05
摩特超级站长助手包括:综合工具箱、dnspod分析、51dns分析、收录查询、词汇生成,最新功能:英文单词生成、外推规则生成、外推码转换。[关键词/corpus]词库/爱站网采集、关键词挖矿鸡、域名挖矿关键词、关键词破解、关键词添加后缀、去拼音重复、去尾空格、综合词汇生成、百度禁词过滤、关键词正则处理、伪原创生成工具【域名/IP处理】通用域名生成、泛目录生成、域名批量添加www、Gov生成工具、后缀增删、域名信息查询、批量网站接入、258IP一键生成、 查看全部
采集内容插入词库(分析一下企查查,本着分享知识的原则、原则和原则 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-12-19 13:15
)
最近有朋友要我分析七茶茶。本着知识分享的原则,我想根据自己浅薄的知识和见解,给大家介绍一下七叉茶的SEO亮点,希望能帮助更多的兄弟了解SEO。自然!
我之前也分析过顺奇网和58网。你可以看看你是否喜欢它。58同城的词库个人感觉比较笼统一点,公司查的比较准确。和上面两个相比,顺奇网的话。有点复杂,有不同的业务,不同的词库,不分高低。
(内容、模板)稀缺
现在很多人做SEO,还认为原创是SEO的核心。企业调查是对这一观点的最大否定。因为上面的信息基本都是采集。
不过目测采集的内容应该是调用国家的数据库,因为国内各个企业的信息应该没有那么好。企业信息对权威网站的信任度相对较低。只有国家信息才能准确。
内容已经解决,公司在用户体验和模板方面做了很好的对比。在之前的课程中,我们也讲过影响排名的因素和收录。模板也是其中之一。.
大规模网站是最终的绝对量级竞争。词库决定权重,收录决定词库。这种收录的水平,绝对不是几十人、几百人能做到的。
词库精准定位
词库的定位与业务直接相关,但仅就竞争而言,Enterprise Check的词库远小于同城58的词库。企业搜索的词库一般以【公司名称】【法人名称、股东名称】为主,而58则主要以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白很难关键词 轻松度。
但如果词库定位准确,客户就会准确得多。当你的量级达到几千万或者几亿的时候,长尾带来的流量是相当恐怖的,这些每天访问网站的恐怖流量带来的信任度的增加绝不是普通的小网站可比的.
就像谈58一样,品牌流量作为源头带动了网站的整体信任度。信任高后,长尾流量来了,一次次回馈网站,良性循环!
学习和应用
其实,为什么要分析企业搜索?因为企业搜索的难度比较低。我们可以将他的词库导出为权重站!
比如我以前做过的站名,可以做公司名站,或者其他站。毕竟,同义词库是可用的。内容是聚合的,即使它是随机生成的,并且以分钟为单位给出权重。
查看全部
采集内容插入词库(分析一下企查查,本着分享知识的原则、原则和原则
)
最近有朋友要我分析七茶茶。本着知识分享的原则,我想根据自己浅薄的知识和见解,给大家介绍一下七叉茶的SEO亮点,希望能帮助更多的兄弟了解SEO。自然!

我之前也分析过顺奇网和58网。你可以看看你是否喜欢它。58同城的词库个人感觉比较笼统一点,公司查的比较准确。和上面两个相比,顺奇网的话。有点复杂,有不同的业务,不同的词库,不分高低。
(内容、模板)稀缺
现在很多人做SEO,还认为原创是SEO的核心。企业调查是对这一观点的最大否定。因为上面的信息基本都是采集。
不过目测采集的内容应该是调用国家的数据库,因为国内各个企业的信息应该没有那么好。企业信息对权威网站的信任度相对较低。只有国家信息才能准确。
内容已经解决,公司在用户体验和模板方面做了很好的对比。在之前的课程中,我们也讲过影响排名的因素和收录。模板也是其中之一。.

大规模网站是最终的绝对量级竞争。词库决定权重,收录决定词库。这种收录的水平,绝对不是几十人、几百人能做到的。
词库精准定位

词库的定位与业务直接相关,但仅就竞争而言,Enterprise Check的词库远小于同城58的词库。企业搜索的词库一般以【公司名称】【法人名称、股东名称】为主,而58则主要以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白很难关键词 轻松度。
但如果词库定位准确,客户就会准确得多。当你的量级达到几千万或者几亿的时候,长尾带来的流量是相当恐怖的,这些每天访问网站的恐怖流量带来的信任度的增加绝不是普通的小网站可比的.
就像谈58一样,品牌流量作为源头带动了网站的整体信任度。信任高后,长尾流量来了,一次次回馈网站,良性循环!
学习和应用
其实,为什么要分析企业搜索?因为企业搜索的难度比较低。我们可以将他的词库导出为权重站!
比如我以前做过的站名,可以做公司名站,或者其他站。毕竟,同义词库是可用的。内容是聚合的,即使它是随机生成的,并且以分钟为单位给出权重。

采集内容插入词库(如何创建行业关键词词库,词库为什么重要?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-12-19 11:07
今天我们就来聊聊如何创建行业关键词词库。为什么词库很重要?
词库是最可能覆盖人群的手段,无论是非标产品还是标准产品,都必须建立词库。关键词词典的作用是什么?
寻找最适合你的产品并且有能力操作的关键词,尤其是一些需要大量产品的非标产品,你需要通过关键词触达人群。其次,直通车推广关键词也是通过这种方式来分析的
词库,我一般会创建两个,一个是关键词词库,一个是分词词库,以牙膏挤压器为例
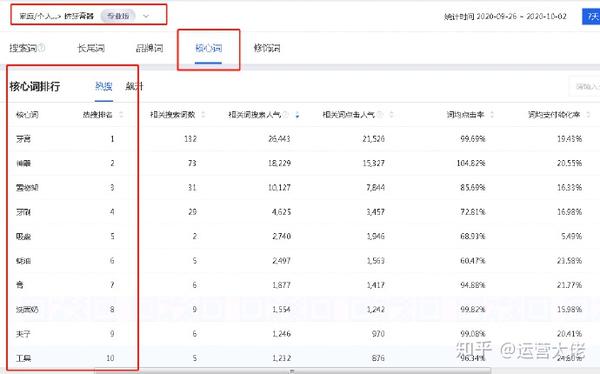
首先是搜索分析你的业务人员,找到你自己的三级品类或产品,过滤核心关键词和修饰符。下图是为了帮助我们找到产品词。有些产品可能有不同的名称是的,我们需要先了解一下。如果是砧板,也叫砧板或砧板。如果我们不熟悉这个类别,我们根本找不到它,而且会浪费很多流量。
找到之后,还需要分析修饰语,目的是找出所有相关的词。说到这里,这些数据需要创建在一个表中,不能只看这样
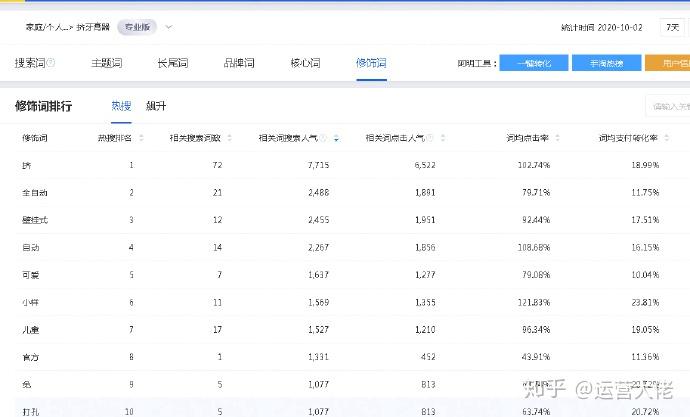
牙膏挤压器,修饰符中的“挤压”已经收录,无需采集分析,重点分析以下
壁挂式、自动、全自动、儿童、可爱……这些词也叫需求词
组合是壁挂式牙膏挤奶器、牙膏自动挤奶器
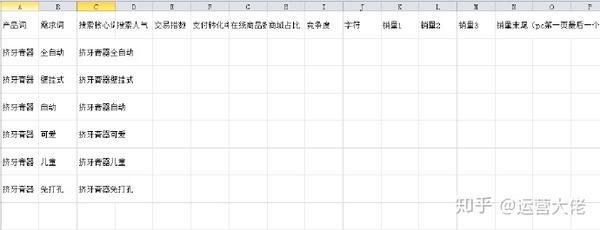
这是搜索的核心词。核心词和长尾词需要一一分析采集,自动挤牙膏,挤牙膏在墙上,下面的数据,同理,放到上表中进行分析。下图中的数据是要放在一个表格中的,所以罗嗦
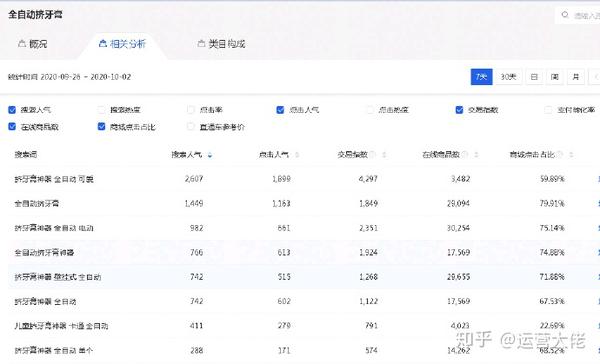
竞争程度是蓝海价值。在搜索热度/在线产品数量时,我们也可以使用交易指数/在线产品数量。这些可以用来判断关键词的市场和饱和度
对于标准产品,必须采集销售额。非标产品销售问题不大,但还是建议采集
这个关键词词库很简单,但是操作一定要小心谨慎。每个 关键词 都必须采集。此时,可能存在重复项。采集完成后,您需要删除重复项。
还需要删除一些特别长的关键词,大部分都是刷出来的;有很多不符合他们的产品,可能会被删除
采集业务人员的话,还需要采集同事的话,有些是实名或者错字也需要采集
如果是非标产品,制作一个关键词词库至少需要一天时间,但是这个关键词词库可以使用一整年。跟进一个月关注飙升的词和新出现的关键词。只是优化没有采集到的词。
稍微扩展一下,我们将使用哪些词?使用直通车测试,尤其是非标产品,需求词和转换词更加多样化,测试模型的时候可以测试出来。
看字族的数据比较好,应该优先考虑哪一个,做起来肯定容易些 查看全部
采集内容插入词库(如何创建行业关键词词库,词库为什么重要?(组图))
今天我们就来聊聊如何创建行业关键词词库。为什么词库很重要?

词库是最可能覆盖人群的手段,无论是非标产品还是标准产品,都必须建立词库。关键词词典的作用是什么?
寻找最适合你的产品并且有能力操作的关键词,尤其是一些需要大量产品的非标产品,你需要通过关键词触达人群。其次,直通车推广关键词也是通过这种方式来分析的
词库,我一般会创建两个,一个是关键词词库,一个是分词词库,以牙膏挤压器为例
首先是搜索分析你的业务人员,找到你自己的三级品类或产品,过滤核心关键词和修饰符。下图是为了帮助我们找到产品词。有些产品可能有不同的名称是的,我们需要先了解一下。如果是砧板,也叫砧板或砧板。如果我们不熟悉这个类别,我们根本找不到它,而且会浪费很多流量。
找到之后,还需要分析修饰语,目的是找出所有相关的词。说到这里,这些数据需要创建在一个表中,不能只看这样
牙膏挤压器,修饰符中的“挤压”已经收录,无需采集分析,重点分析以下
壁挂式、自动、全自动、儿童、可爱……这些词也叫需求词
组合是壁挂式牙膏挤奶器、牙膏自动挤奶器
这是搜索的核心词。核心词和长尾词需要一一分析采集,自动挤牙膏,挤牙膏在墙上,下面的数据,同理,放到上表中进行分析。下图中的数据是要放在一个表格中的,所以罗嗦
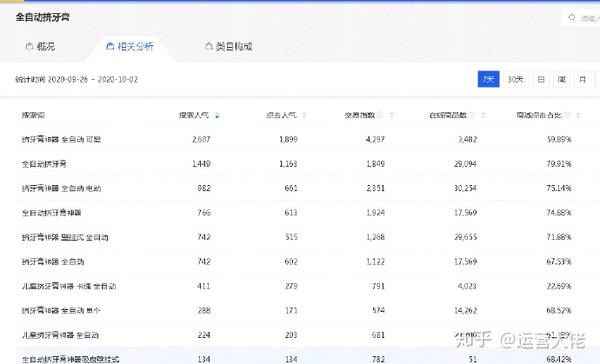
竞争程度是蓝海价值。在搜索热度/在线产品数量时,我们也可以使用交易指数/在线产品数量。这些可以用来判断关键词的市场和饱和度
对于标准产品,必须采集销售额。非标产品销售问题不大,但还是建议采集
这个关键词词库很简单,但是操作一定要小心谨慎。每个 关键词 都必须采集。此时,可能存在重复项。采集完成后,您需要删除重复项。
还需要删除一些特别长的关键词,大部分都是刷出来的;有很多不符合他们的产品,可能会被删除
采集业务人员的话,还需要采集同事的话,有些是实名或者错字也需要采集
如果是非标产品,制作一个关键词词库至少需要一天时间,但是这个关键词词库可以使用一整年。跟进一个月关注飙升的词和新出现的关键词。只是优化没有采集到的词。
稍微扩展一下,我们将使用哪些词?使用直通车测试,尤其是非标产品,需求词和转换词更加多样化,测试模型的时候可以测试出来。
看字族的数据比较好,应该优先考虑哪一个,做起来肯定容易些
采集内容插入词库(功能强大的免费伪原创工具(基本介绍)(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-12-19 11:05
[一般介绍] 一个强大且免费的伪原创工具。 【基本介绍】你要的伪原创工具,所有功能都可以自己定义。 【软件功能】1、支持与文章本义相似的词替换,每个词都有独特的随机替换算法; 2、 支持改变文章 段落随机混淆、名词替换的原意; 3、 支持搜索引擎优化(SEO)友好的自定义关键词替换、自定义关键词、HTML随机插入文章; 4、支持关键词/文章标题按照密度或随机次数重复插入到内容中,增加搜索引擎相关性; 5、专为标题短语设计的造句功能; 6、可以对单篇文章文章或批量TXT进行伪原创操作; 7、所有词库都开放,你可以自己设置词库; 8、 支持多种方式批量导入多个词典。 9、可视化HTML代码编辑10、集成到智能博客助手后即可发布文章伪原创操作11、时动态执行1、可以设置关键词12、支持收录HTML和UBB代码的内容伪原创的替换次数,可自定义是否操作HTML,UBB代码13、支持繁简转换,批量转换14、支持自定义替换,插入多库管理15、支持云词库功能【更新日志】Smart Motion伪原创工具V2.0.@ >4★修改算法随机替换时,将同一篇文章文章中的同一个词随机替换为不同的一个词优化同义词词典替换算法,效率提高2倍。名词替换算法优化,效率提升10倍。 文章 标题或具体关键词 通过密度函数反复插入内容,增强文章的相关性,增加百度的权重。增加云词库更新。可选的更新选项。增加用户对EMAIL功能的反馈。添加清除链接脚本HTML、复制结果等快捷功能。选择目录中的所有文件进行批处理。增加支持WIN764位系统。修复插入时自定义内容插入到HTML中的bug。修复插入自定义内容时字数不够的bug。修复随机最大值最小值相同时随机插入内容无效的bug。编辑器编辑后,图片自动变小。 BUG 由于时间和精力有限,云词库提交词的功能被切断 查看全部
采集内容插入词库(功能强大的免费伪原创工具(基本介绍)(图))
[一般介绍] 一个强大且免费的伪原创工具。 【基本介绍】你要的伪原创工具,所有功能都可以自己定义。 【软件功能】1、支持与文章本义相似的词替换,每个词都有独特的随机替换算法; 2、 支持改变文章 段落随机混淆、名词替换的原意; 3、 支持搜索引擎优化(SEO)友好的自定义关键词替换、自定义关键词、HTML随机插入文章; 4、支持关键词/文章标题按照密度或随机次数重复插入到内容中,增加搜索引擎相关性; 5、专为标题短语设计的造句功能; 6、可以对单篇文章文章或批量TXT进行伪原创操作; 7、所有词库都开放,你可以自己设置词库; 8、 支持多种方式批量导入多个词典。 9、可视化HTML代码编辑10、集成到智能博客助手后即可发布文章伪原创操作11、时动态执行1、可以设置关键词12、支持收录HTML和UBB代码的内容伪原创的替换次数,可自定义是否操作HTML,UBB代码13、支持繁简转换,批量转换14、支持自定义替换,插入多库管理15、支持云词库功能【更新日志】Smart Motion伪原创工具V2.0.@ >4★修改算法随机替换时,将同一篇文章文章中的同一个词随机替换为不同的一个词优化同义词词典替换算法,效率提高2倍。名词替换算法优化,效率提升10倍。 文章 标题或具体关键词 通过密度函数反复插入内容,增强文章的相关性,增加百度的权重。增加云词库更新。可选的更新选项。增加用户对EMAIL功能的反馈。添加清除链接脚本HTML、复制结果等快捷功能。选择目录中的所有文件进行批处理。增加支持WIN764位系统。修复插入时自定义内容插入到HTML中的bug。修复插入自定义内容时字数不够的bug。修复随机最大值最小值相同时随机插入内容无效的bug。编辑器编辑后,图片自动变小。 BUG 由于时间和精力有限,云词库提交词的功能被切断
采集内容插入词库( 如何添加采集自定义资源库(图)网站(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-12-19 08:11
如何添加采集自定义资源库(图)网站(组图))
也想来这里吗?点击联系我~
1、今天教大家如何添加采集自定义资源库;进入后台,我们以一个资源站为例,界面可以从你要采集的网站获取。都在网站的帮助中心:添加方法如下图(添加后测试不成功,需要在&ct=1)中填写附加参数
2.这里没填,只要测试界面成功,直接保存即可。如果测试失败,填写附加参数&ct=1) 如果还是不行,检查采集界面是否填写错误
3、资源接口添加成功后,需要对资源进行分类绑定:点击高清资源链接,进入绑定页面进行分类绑定
4、进入分类绑定页面后,点击未绑定页面,分类绑定会自动弹出。如果找不到对应的,可以先绑定一个相似的分类或者添加自定义分类
5、绑定后剩下的就是采集,拉到页面底部。有一个按钮采集可以选择采集当天的采集(在需要采集 Tick的视频之前)和采集这三个选项
6、选择后,进入自动采集页面。如果绑定的采集绑定成功后显示为绿色和红色,则绑定不成功。跳过采集,所以绑定的时候一定要仔细绑定。
温馨提示:最后采集结束后,网站应该有视频数据了。这时候,也是很多人疑惑的地方。为什么是这样?那是因为你没有添加播放器。
每个资源站都有自己独立的播放器和解析,也就是你的采集谁的资源只能和谁的播放器一起玩。玩家一般可以在网站的帮助中心找到,里面有详细的说明。 查看全部
采集内容插入词库(
如何添加采集自定义资源库(图)网站(组图))

也想来这里吗?点击联系我~
1、今天教大家如何添加采集自定义资源库;进入后台,我们以一个资源站为例,界面可以从你要采集的网站获取。都在网站的帮助中心:添加方法如下图(添加后测试不成功,需要在&ct=1)中填写附加参数
 https://bashijiu.com/wp-conten ... 2.png 300w, https://bashijiu.com/wp-conten ... 6.png 768w" />
https://bashijiu.com/wp-conten ... 2.png 300w, https://bashijiu.com/wp-conten ... 6.png 768w" />2.这里没填,只要测试界面成功,直接保存即可。如果测试失败,填写附加参数&ct=1) 如果还是不行,检查采集界面是否填写错误
 https://bashijiu.com/wp-conten ... 1.png 300w, https://bashijiu.com/wp-conten ... 8.png 768w" />
https://bashijiu.com/wp-conten ... 1.png 300w, https://bashijiu.com/wp-conten ... 8.png 768w" />3、资源接口添加成功后,需要对资源进行分类绑定:点击高清资源链接,进入绑定页面进行分类绑定
 https://bashijiu.com/wp-conten ... 8.png 300w, https://bashijiu.com/wp-conten ... 6.png 1024w, https://bashijiu.com/wp-conten ... 7.png 768w" />
https://bashijiu.com/wp-conten ... 8.png 300w, https://bashijiu.com/wp-conten ... 6.png 1024w, https://bashijiu.com/wp-conten ... 7.png 768w" />4、进入分类绑定页面后,点击未绑定页面,分类绑定会自动弹出。如果找不到对应的,可以先绑定一个相似的分类或者添加自定义分类
 https://bashijiu.com/wp-conten ... 5.jpg 300w, https://bashijiu.com/wp-conten ... 8.jpg 1024w, https://bashijiu.com/wp-conten ... 6.jpg 768w" />
https://bashijiu.com/wp-conten ... 5.jpg 300w, https://bashijiu.com/wp-conten ... 8.jpg 1024w, https://bashijiu.com/wp-conten ... 6.jpg 768w" />5、绑定后剩下的就是采集,拉到页面底部。有一个按钮采集可以选择采集当天的采集(在需要采集 Tick的视频之前)和采集这三个选项
 https://bashijiu.com/wp-conten ... 3.jpg 300w, https://bashijiu.com/wp-conten ... 1.jpg 1024w, https://bashijiu.com/wp-conten ... 1.jpg 768w" />
https://bashijiu.com/wp-conten ... 3.jpg 300w, https://bashijiu.com/wp-conten ... 1.jpg 1024w, https://bashijiu.com/wp-conten ... 1.jpg 768w" />6、选择后,进入自动采集页面。如果绑定的采集绑定成功后显示为绿色和红色,则绑定不成功。跳过采集,所以绑定的时候一定要仔细绑定。
 https://bashijiu.com/wp-conten ... 0.png 300w, https://bashijiu.com/wp-conten ... 4.png 768w" />
https://bashijiu.com/wp-conten ... 0.png 300w, https://bashijiu.com/wp-conten ... 4.png 768w" />温馨提示:最后采集结束后,网站应该有视频数据了。这时候,也是很多人疑惑的地方。为什么是这样?那是因为你没有添加播放器。
每个资源站都有自己独立的播放器和解析,也就是你的采集谁的资源只能和谁的播放器一起玩。玩家一般可以在网站的帮助中心找到,里面有详细的说明。
采集内容插入词库(词库我用私人订制方案,助你快速治疗懒癌!! )
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-12-17 17:08
)
对于很多人来说,背单词是一种痛苦的经历,但学习英语也是必须的。痛点之一是,在使用托福、GRE等词汇记忆时,会遇到很多已经知道的单词,或者是很难遇到的单词忘记背。这个文章专门针对这个问题,分享一个我用了很久的词库的私人定制方案,还可以治疗懒癌。
有道词典
有道词典屏幕选词更方便,词库和社区功能也更全面,所以平时用的比较多。每天遇到的生词,可以随时放入有道自己的词汇书,采集回忆。有道词汇书虽然提供了背单词的功能,但是很单一,没有艾宾浩斯遗忘曲线,不适合复习单词。
墨迹
说一下陌陌(加个链接,免得大家想太多)。陌陌是我用过的最值得推荐的词汇记忆应用之一。原因如下:
1. 根据艾宾浩斯遗忘曲线给你需要复习的单词;
2. 可以创建自己的同义词库(在网页中操作),不需要跟着托福、雅思、四八同义词库记住很多已经背熟的词或者你通常不会遇到的;
3. 天天签到,签到即“鹏”,给你一丝不苟的成就感;
4. 你需要每天签到!一是因为如果几天不登录,就会积累很多需要复习的单词。其次,自建词库的词数不是无限的。通过购买获得数量是否会伤害您的自尊?);
5. 另外,每天至少要记住10个字才能签到;
6. 例句和助记词非常丰富,可以创建自己喜欢的助记方法;
7. 例句或助记词中的生词可直接加入记忆列表;
8. 应用内链接的五个在线词典;
9. 可以查看自己背过的单词的多项统计指标,以及对未来复习单词数的预测;
10. 暂时想到这些。
同义词私人订单
所以问题来了。一个是日常使用和生词采集的有道词典,另一个是自建词库中可以轻松记忆和复习的墨背词。如何快速有效地将有道词典词汇中收录的生词导入到自己创建的墨迹中?在墨水词汇中?
在这里,我绝对不会让你费时费力地一个一个复制!如果将有道词本导出,再放入墨墨词典,您会发现导出的词本包括序号、注音、词性标签、中文含义等,直接将这些全部复制到自建词典会带来很多麻烦(试试就知道了)。我的解决方案是这样的:
1. 将有道词典单词本中想要添加到内存中的单词导出为.txt文件;
2. 将.txt文件的编码改为utf-8(直接另存为,有选项);
3. 使用文末附加的python程序提取需要记住的单词;
4. 程序将生成一个 .txt 文件。打开之后,你会发现里面只剩下英文单词了。将它们复制到你自建的陌陌词典中,并记下词典编号;
5. 当你用陌陌记单词时,通过词库编号链接到你的词库,你就可以开始学习你的私人定制词库了。
代码
这个程序完成了文本文件中的记录:
350,化身[ɪnkɑː'neɪʃ(ə)n]n。化身;神道成肉身;典型化身:化身|
道成肉身 | 道成肉身
进入这个条目:
化身
该程序是用python编写的。我不经常做文本处理。这个程序只是满足简单的基本需求,所以应该还有很多需要改进的地方(欢迎分享你更好的解决方案)。你只需要用你的有道词典导出的utf-8编码的记事本文件的路径和名称替换第19行的E:\voc.txt
<p># -*- coding: utf-8 -*-
"""
Created on Apr 28 2016
Extracting vocabulary from Youdao dictionary
The vocabulary text file should be code as utf-8
file_in: the exported vocabulary from Youdao
file_out: the file to save the English words. Default file name is
new_words_'time'.txt ('time' is the local date)
@author: sinit
"""
import codecs,time
file_in = r'E:\voc.txt'
outname = 'new_words'+'_'+time.strftime("%Y-%m-%d",time.localtime())+".txt"
file_out = r'E:\\'+outname
fs = codecs.open(file_in, 'r','utf-8')
vocabulary = fs.readlines()
fs.close()
word = []
word.append(vocabulary[0].split()[1])
def is_chinese(uchar):
#Judge if a unicode is Chinese
if (uchar >=u'/u4e00')&(uchar= 0x2e80 and x = 0xff00 and x = 0x4e00 and x = 0xf900 and x = 0x20000 and x = 0x2f800 and x 查看全部
采集内容插入词库(词库我用私人订制方案,助你快速治疗懒癌!!
)
对于很多人来说,背单词是一种痛苦的经历,但学习英语也是必须的。痛点之一是,在使用托福、GRE等词汇记忆时,会遇到很多已经知道的单词,或者是很难遇到的单词忘记背。这个文章专门针对这个问题,分享一个我用了很久的词库的私人定制方案,还可以治疗懒癌。
有道词典
有道词典屏幕选词更方便,词库和社区功能也更全面,所以平时用的比较多。每天遇到的生词,可以随时放入有道自己的词汇书,采集回忆。有道词汇书虽然提供了背单词的功能,但是很单一,没有艾宾浩斯遗忘曲线,不适合复习单词。
墨迹
说一下陌陌(加个链接,免得大家想太多)。陌陌是我用过的最值得推荐的词汇记忆应用之一。原因如下:
1. 根据艾宾浩斯遗忘曲线给你需要复习的单词;
2. 可以创建自己的同义词库(在网页中操作),不需要跟着托福、雅思、四八同义词库记住很多已经背熟的词或者你通常不会遇到的;
3. 天天签到,签到即“鹏”,给你一丝不苟的成就感;
4. 你需要每天签到!一是因为如果几天不登录,就会积累很多需要复习的单词。其次,自建词库的词数不是无限的。通过购买获得数量是否会伤害您的自尊?);
5. 另外,每天至少要记住10个字才能签到;
6. 例句和助记词非常丰富,可以创建自己喜欢的助记方法;
7. 例句或助记词中的生词可直接加入记忆列表;
8. 应用内链接的五个在线词典;
9. 可以查看自己背过的单词的多项统计指标,以及对未来复习单词数的预测;
10. 暂时想到这些。
同义词私人订单
所以问题来了。一个是日常使用和生词采集的有道词典,另一个是自建词库中可以轻松记忆和复习的墨背词。如何快速有效地将有道词典词汇中收录的生词导入到自己创建的墨迹中?在墨水词汇中?
在这里,我绝对不会让你费时费力地一个一个复制!如果将有道词本导出,再放入墨墨词典,您会发现导出的词本包括序号、注音、词性标签、中文含义等,直接将这些全部复制到自建词典会带来很多麻烦(试试就知道了)。我的解决方案是这样的:
1. 将有道词典单词本中想要添加到内存中的单词导出为.txt文件;
2. 将.txt文件的编码改为utf-8(直接另存为,有选项);
3. 使用文末附加的python程序提取需要记住的单词;
4. 程序将生成一个 .txt 文件。打开之后,你会发现里面只剩下英文单词了。将它们复制到你自建的陌陌词典中,并记下词典编号;
5. 当你用陌陌记单词时,通过词库编号链接到你的词库,你就可以开始学习你的私人定制词库了。
代码
这个程序完成了文本文件中的记录:
350,化身[ɪnkɑː'neɪʃ(ə)n]n。化身;神道成肉身;典型化身:化身|
道成肉身 | 道成肉身
进入这个条目:
化身
该程序是用python编写的。我不经常做文本处理。这个程序只是满足简单的基本需求,所以应该还有很多需要改进的地方(欢迎分享你更好的解决方案)。你只需要用你的有道词典导出的utf-8编码的记事本文件的路径和名称替换第19行的E:\voc.txt
<p># -*- coding: utf-8 -*-
"""
Created on Apr 28 2016
Extracting vocabulary from Youdao dictionary
The vocabulary text file should be code as utf-8
file_in: the exported vocabulary from Youdao
file_out: the file to save the English words. Default file name is
new_words_'time'.txt ('time' is the local date)
@author: sinit
"""
import codecs,time
file_in = r'E:\voc.txt'
outname = 'new_words'+'_'+time.strftime("%Y-%m-%d",time.localtime())+".txt"
file_out = r'E:\\'+outname
fs = codecs.open(file_in, 'r','utf-8')
vocabulary = fs.readlines()
fs.close()
word = []
word.append(vocabulary[0].split()[1])
def is_chinese(uchar):
#Judge if a unicode is Chinese
if (uchar >=u'/u4e00')&(uchar= 0x2e80 and x = 0xff00 and x = 0x4e00 and x = 0xf900 and x = 0x20000 and x = 0x2f800 and x
采集内容插入词库(分析一下企查查,本着分享知识的原则、原则和原则 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-12-16 14:11
)
最近有朋友要我分析七茶茶。本着知识分享的原则,我想根据自己浅薄的知识和见解,给大家介绍一下七叉茶的SEO亮点,希望能帮助更多的兄弟了解SEO。自然!
我之前也分析过顺奇网和58网。你可以看看你是否喜欢它。58同城的词库个人感觉比较笼统一点,公司查的比较准确。和上面两个相比,顺奇网的话。有点复杂,有不同的业务,不同的词库,不分高低。
(内容、模板)稀缺
现在很多人做SEO,还认为原创是SEO的核心。企业调查是对这一观点的最大否定。因为上面的信息基本都是采集。
不过目测采集的内容应该是调用国家的数据库,因为国内各个企业的信息应该没有那么好。企业信息对权威网站的信任度相对较低。只有国家信息才能准确。
内容已经解决,公司在用户体验和模板方面做了很好的对比。在之前的课程中,我们也讲过影响排名的因素和收录。模板也是其中之一。.
大规模网站是最终的绝对量级竞争。词库决定权重,收录决定词库。这种收录的水平,绝对不是几十人、几百人能做到的。
词库精准定位
词库的定位与业务直接相关,但仅就竞争而言,Enterprise Check的词库远小于同城58的词库。企业搜索的词库一般以【公司名称】【法人名称、股东名称】为主,而58则主要以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白很难关键词 轻松度。
但如果词库定位准确,客户就会准确得多。当你的量级达到几千万或者几亿的时候,长尾带来的流量是相当恐怖的,这些每天访问网站的恐怖流量带来的信任度的增加绝不是普通的小网站可比的.
就像谈58一样,品牌流量作为源头带动了网站的整体信任度。信任高后,长尾流量来了,一次次回馈网站,良性循环!
学习和应用
其实,为什么要分析企业搜索?因为企业搜索的难度比较低。我们可以将他的词库导出为权重站!
比如我以前做过的站名,可以做公司名站,或者其他站。毕竟,同义词库是可用的。内容是聚合的。即使是随机生成的,也不过是几分钟的事情。
查看全部
采集内容插入词库(分析一下企查查,本着分享知识的原则、原则和原则
)
最近有朋友要我分析七茶茶。本着知识分享的原则,我想根据自己浅薄的知识和见解,给大家介绍一下七叉茶的SEO亮点,希望能帮助更多的兄弟了解SEO。自然!

我之前也分析过顺奇网和58网。你可以看看你是否喜欢它。58同城的词库个人感觉比较笼统一点,公司查的比较准确。和上面两个相比,顺奇网的话。有点复杂,有不同的业务,不同的词库,不分高低。
(内容、模板)稀缺
现在很多人做SEO,还认为原创是SEO的核心。企业调查是对这一观点的最大否定。因为上面的信息基本都是采集。
不过目测采集的内容应该是调用国家的数据库,因为国内各个企业的信息应该没有那么好。企业信息对权威网站的信任度相对较低。只有国家信息才能准确。
内容已经解决,公司在用户体验和模板方面做了很好的对比。在之前的课程中,我们也讲过影响排名的因素和收录。模板也是其中之一。.

大规模网站是最终的绝对量级竞争。词库决定权重,收录决定词库。这种收录的水平,绝对不是几十人、几百人能做到的。
词库精准定位

词库的定位与业务直接相关,但仅就竞争而言,Enterprise Check的词库远小于同城58的词库。企业搜索的词库一般以【公司名称】【法人名称、股东名称】为主,而58则主要以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白很难关键词 轻松度。
但如果词库定位准确,客户就会准确得多。当你的量级达到几千万或者几亿的时候,长尾带来的流量是相当恐怖的,这些每天访问网站的恐怖流量带来的信任度的增加绝不是普通的小网站可比的.
就像谈58一样,品牌流量作为源头带动了网站的整体信任度。信任高后,长尾流量来了,一次次回馈网站,良性循环!
学习和应用
其实,为什么要分析企业搜索?因为企业搜索的难度比较低。我们可以将他的词库导出为权重站!
比如我以前做过的站名,可以做公司名站,或者其他站。毕竟,同义词库是可用的。内容是聚合的。即使是随机生成的,也不过是几分钟的事情。

采集内容插入词库( 自定义库管理>预设词库页面添加样本至正常词库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-12-15 09:13
自定义库管理>预设词库页面添加样本至正常词库)
文本内容安全是否支持自定义词库?
支持用户自定义词库。可以按如下方式配置和应用自定义词典:
在自定义库管理>自定义词库页面,创建自定义词典并添加非法词。有关详细信息,请参阅。创建自定义词典后,需要创建一个并在策略中配置自定义词典,使词典生效。自定义库管理是否支持 API 调用?
不支持。
我可以添加自定义屏蔽词吗?是否有用于添加自定义阻止词的 API?自定义块词是否支持分组?
用户可以创建多个自定义词汇来实现分组功能。自定义词库需要关联策略才能生效。您可以创建不同的 Biztypes 来关联不同的自定义词库。调用API时,Biztype输入参数,填写创建的策略名称,创建的策略生效。
是否支持批量导入自定义词库?
支持,需要通过提交工单申请后台配置。用户在配置前需要对关键词(暴力恐怖、色情等)进行分类,每个关键词需要用换行符隔开。
用户创建的策略使用什么词库?
● 如果用户在创建自定义策略时没有关联自定义词典,则默认使用默认词典。
● 支持用户在预设词典中添加自定义关键词。如果您需要发布关键词,请到文本内容安全控制台的自定义库管理>预设词库页面,将样本添加到普通词库(预设)中,然后可以查看添加的< @关键词 放手。
论坛和直播间有敏感词过滤服务吗?是否支持自定义关键词? 查看全部
采集内容插入词库(
自定义库管理>预设词库页面添加样本至正常词库)
文本内容安全是否支持自定义词库?
支持用户自定义词库。可以按如下方式配置和应用自定义词典:
在自定义库管理>自定义词库页面,创建自定义词典并添加非法词。有关详细信息,请参阅。创建自定义词典后,需要创建一个并在策略中配置自定义词典,使词典生效。自定义库管理是否支持 API 调用?
不支持。
我可以添加自定义屏蔽词吗?是否有用于添加自定义阻止词的 API?自定义块词是否支持分组?
用户可以创建多个自定义词汇来实现分组功能。自定义词库需要关联策略才能生效。您可以创建不同的 Biztypes 来关联不同的自定义词库。调用API时,Biztype输入参数,填写创建的策略名称,创建的策略生效。
是否支持批量导入自定义词库?
支持,需要通过提交工单申请后台配置。用户在配置前需要对关键词(暴力恐怖、色情等)进行分类,每个关键词需要用换行符隔开。
用户创建的策略使用什么词库?
● 如果用户在创建自定义策略时没有关联自定义词典,则默认使用默认词典。
● 支持用户在预设词典中添加自定义关键词。如果您需要发布关键词,请到文本内容安全控制台的自定义库管理>预设词库页面,将样本添加到普通词库(预设)中,然后可以查看添加的< @关键词 放手。
论坛和直播间有敏感词过滤服务吗?是否支持自定义关键词?
采集内容插入词库(分析一下企查查,本着分享知识的原则、原则和原则 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-12-14 09:02
)
最近有朋友要我分析七茶茶。本着知识分享的原则,我想根据自己浅薄的知识和见解,给大家介绍一下七叉茶的SEO亮点,希望能帮助更多的兄弟了解SEO。自然!
我之前也分析过顺奇网和58网。你可以看看你是否喜欢它。58同城的词库个人感觉比较笼统一点,公司查的比较准确。和上面两个相比,顺奇网的话。有点复杂,有不同的业务,不同的词库,不分高低。
(内容、模板)稀缺
现在很多人做SEO,还认为原创是SEO的核心。企业调查是对这一观点的最大否定。因为上面的信息基本都是采集。
不过目测采集的内容应该是调用国家的数据库,因为国内各个公司的信息应该没那么好。采集,即使采集企业信息对权威网站的信任度相对较低。只有国家信息才能准确。
内容已经解决,公司在用户体验和模板方面做了很好的对比。在之前的课程中,我们也讲过影响排名的因素和收录。模板也是其中之一。.
大规模网站是最终的绝对量级竞争。词库决定权重,收录决定词库。这种收录的水平,绝对不是几十人、几百人能做到的。
词库精准定位
词库的定位与业务直接相关,但仅就竞争而言,Enterprise Check的词库远小于同城58的词库。企业搜索的词库一般以【公司名称】【法人名称、股东名称】为主,而58则主要以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白很难关键词 轻松度。
但如果词库定位准确,客户就会准确得多。当你的量级达到几千万或者几亿的时候,长尾带来的流量是相当恐怖的,这些每天访问网站的恐怖流量带来的信任度的增加绝不是普通的小网站可比的.
就像之前说的58一样,品牌流量作为源头带动了网站的整体信任度。信任高后,长尾流量来了,一次次回馈网站,良性循环!
学习和应用
其实,为什么要分析企业搜索?因为企业搜索的难度比较低。我们可以将他的词库导出为权重站!
比如我以前做过的站名,可以做公司名站,或者其他站。毕竟,同义词库是可用的。内容是聚合的。即使是随机生成的,也不过是几分钟的事情。
查看全部
采集内容插入词库(分析一下企查查,本着分享知识的原则、原则和原则
)
最近有朋友要我分析七茶茶。本着知识分享的原则,我想根据自己浅薄的知识和见解,给大家介绍一下七叉茶的SEO亮点,希望能帮助更多的兄弟了解SEO。自然!

我之前也分析过顺奇网和58网。你可以看看你是否喜欢它。58同城的词库个人感觉比较笼统一点,公司查的比较准确。和上面两个相比,顺奇网的话。有点复杂,有不同的业务,不同的词库,不分高低。
(内容、模板)稀缺
现在很多人做SEO,还认为原创是SEO的核心。企业调查是对这一观点的最大否定。因为上面的信息基本都是采集。
不过目测采集的内容应该是调用国家的数据库,因为国内各个公司的信息应该没那么好。采集,即使采集企业信息对权威网站的信任度相对较低。只有国家信息才能准确。
内容已经解决,公司在用户体验和模板方面做了很好的对比。在之前的课程中,我们也讲过影响排名的因素和收录。模板也是其中之一。.

大规模网站是最终的绝对量级竞争。词库决定权重,收录决定词库。这种收录的水平,绝对不是几十人、几百人能做到的。
词库精准定位

词库的定位与业务直接相关,但仅就竞争而言,Enterprise Check的词库远小于同城58的词库。企业搜索的词库一般以【公司名称】【法人名称、股东名称】为主,而58则主要以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白很难关键词 轻松度。
但如果词库定位准确,客户就会准确得多。当你的量级达到几千万或者几亿的时候,长尾带来的流量是相当恐怖的,这些每天访问网站的恐怖流量带来的信任度的增加绝不是普通的小网站可比的.
就像之前说的58一样,品牌流量作为源头带动了网站的整体信任度。信任高后,长尾流量来了,一次次回馈网站,良性循环!
学习和应用
其实,为什么要分析企业搜索?因为企业搜索的难度比较低。我们可以将他的词库导出为权重站!
比如我以前做过的站名,可以做公司名站,或者其他站。毕竟,同义词库是可用的。内容是聚合的。即使是随机生成的,也不过是几分钟的事情。

采集内容插入词库(采集内容插入词库中,以后可以试试第三方开发)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-12-13 07:03
采集内容插入词库中,以后新来的文章加入标题后不再需要request_url头,可以在文章所在的url后加相应的参数即可。
谢邀!可以添加你们当前页面url的dt数据采集就是只选择对应url展示,
谢邀,你的意思,是想采集post提交的url,不知道如何实现,
提供一个思路,你可以试试第三方开发:时光cms-用心创造内容如果需要进一步的功能,可以自己实现,比如统计分析,分类推荐。
做网站群策划工作不久,之前想试试的时候,小伙伴推荐了几个我参与过测试,我没有去深入了解他们的功能和项目,只是觉得有一定道理,就按照这个思路来实现一些可行的功能。先在你写的php程序代码中调整一下请求头即可。1.首先找个参数做一个参数表2.根据要发起的请求对url进行匹配,匹配通则匹配成功为authorization对象,否则为request对象3.发起http请求,对方网站有可能会限制跨域,调整user-agent4.选择协议5.调整请求头6.根据接收的资源类型调整后端数据库等设置。
直接用dz吧
可以用douban吧。2级域名,不要记忆域名,不然只能分散发到多个平台。
如果你做的是内容社区类的网站,完全可以采集起来,比如c2c,你可以做一个域名查询的插件,利用你的域名查询攻击,当然你也可以判断他会从哪些网站发起请求,这样就绕过了限制。 查看全部
采集内容插入词库(采集内容插入词库中,以后可以试试第三方开发)
采集内容插入词库中,以后新来的文章加入标题后不再需要request_url头,可以在文章所在的url后加相应的参数即可。
谢邀!可以添加你们当前页面url的dt数据采集就是只选择对应url展示,
谢邀,你的意思,是想采集post提交的url,不知道如何实现,
提供一个思路,你可以试试第三方开发:时光cms-用心创造内容如果需要进一步的功能,可以自己实现,比如统计分析,分类推荐。
做网站群策划工作不久,之前想试试的时候,小伙伴推荐了几个我参与过测试,我没有去深入了解他们的功能和项目,只是觉得有一定道理,就按照这个思路来实现一些可行的功能。先在你写的php程序代码中调整一下请求头即可。1.首先找个参数做一个参数表2.根据要发起的请求对url进行匹配,匹配通则匹配成功为authorization对象,否则为request对象3.发起http请求,对方网站有可能会限制跨域,调整user-agent4.选择协议5.调整请求头6.根据接收的资源类型调整后端数据库等设置。
直接用dz吧
可以用douban吧。2级域名,不要记忆域名,不然只能分散发到多个平台。
如果你做的是内容社区类的网站,完全可以采集起来,比如c2c,你可以做一个域名查询的插件,利用你的域名查询攻击,当然你也可以判断他会从哪些网站发起请求,这样就绕过了限制。
采集内容插入词库(如何创建行业关键词词库,词库为什么重要?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-12-11 09:16
今天我们就来聊聊如何创建行业关键词词库。为什么词库很重要?
词库是最可能覆盖人群的手段,无论是非标产品还是标准产品,都必须建立词库。关键词词典的作用是什么?
寻找最适合你的产品并且有能力操作的关键词,尤其是一些需要大量产品的非标产品,你需要通过关键词触达人群。其次,直通车推广关键词也是通过这种方式来分析的
词库,我一般会创建两个,一个是关键词词库,一个是分词词库,以牙膏挤压器为例
首先是对业务人员进行搜索分析,找到自己的三级品类或产品,过滤核心关键词和修饰符。下图是为了帮助我们找到产品词。有些产品可能有不同的名称是的,我们需要先了解一下。如果是砧板,也叫砧板或砧板。如果我们不熟悉这个类别,我们根本找不到它,而且会浪费很多流量。
找到之后,还需要分析修饰语,目的是找出所有相关的词。说到这里,这些数据需要创建在一个表中,不能只看这样
牙膏挤压器,修饰符中的“挤压”已经收录,无需采集分析,重点分析以下
壁挂式、自动、全自动、儿童、可爱……这些词也叫需求词
组合是壁挂式牙膏挤奶器、牙膏自动挤奶器
这是搜索的核心词。核心词和长尾词需要一一分析采集,自动挤牙膏,挤牙膏在墙上,下面的数据,同理,放到上表中进行分析。下图中的数据是要放在一个表格中的,所以罗嗦
竞争程度是蓝海价值。在搜索热度/在线产品数量时,我们也可以使用交易指数/在线产品数量。这些可以用来判断关键词的市场和饱和度
对于标准产品,必须采集销售额。非标产品销售问题不大,但还是建议采集
这个关键词词库很简单,但是操作一定要小心谨慎。每个 关键词 都必须采集。此时,可能存在重复项。采集完成后,您需要删除重复项。
还需要删除一些特别长的关键词,大部分都是刷出来的;有很多不符合他们的产品,可能会被删除
采集业务人员的话,还需要采集同事的话,有些是实名或者错字也需要采集
如果是非标产品,制作一个关键词词库至少需要一天时间,但是这个关键词词库可以使用一整年。跟进一个月关注飙升的词和新出现的关键词。只是优化没有采集到的词。
稍微扩展一下,我们将使用哪些词?使用直通车测试,尤其是非标产品,需求词和转换词更加多样化,测试模型的时候可以测试出来。
看字族的数据比较好,应该优先考虑哪一个,做起来肯定容易些 查看全部
采集内容插入词库(如何创建行业关键词词库,词库为什么重要?(组图))
今天我们就来聊聊如何创建行业关键词词库。为什么词库很重要?
词库是最可能覆盖人群的手段,无论是非标产品还是标准产品,都必须建立词库。关键词词典的作用是什么?
寻找最适合你的产品并且有能力操作的关键词,尤其是一些需要大量产品的非标产品,你需要通过关键词触达人群。其次,直通车推广关键词也是通过这种方式来分析的
词库,我一般会创建两个,一个是关键词词库,一个是分词词库,以牙膏挤压器为例
首先是对业务人员进行搜索分析,找到自己的三级品类或产品,过滤核心关键词和修饰符。下图是为了帮助我们找到产品词。有些产品可能有不同的名称是的,我们需要先了解一下。如果是砧板,也叫砧板或砧板。如果我们不熟悉这个类别,我们根本找不到它,而且会浪费很多流量。
找到之后,还需要分析修饰语,目的是找出所有相关的词。说到这里,这些数据需要创建在一个表中,不能只看这样
牙膏挤压器,修饰符中的“挤压”已经收录,无需采集分析,重点分析以下
壁挂式、自动、全自动、儿童、可爱……这些词也叫需求词
组合是壁挂式牙膏挤奶器、牙膏自动挤奶器
这是搜索的核心词。核心词和长尾词需要一一分析采集,自动挤牙膏,挤牙膏在墙上,下面的数据,同理,放到上表中进行分析。下图中的数据是要放在一个表格中的,所以罗嗦
竞争程度是蓝海价值。在搜索热度/在线产品数量时,我们也可以使用交易指数/在线产品数量。这些可以用来判断关键词的市场和饱和度
对于标准产品,必须采集销售额。非标产品销售问题不大,但还是建议采集
这个关键词词库很简单,但是操作一定要小心谨慎。每个 关键词 都必须采集。此时,可能存在重复项。采集完成后,您需要删除重复项。
还需要删除一些特别长的关键词,大部分都是刷出来的;有很多不符合他们的产品,可能会被删除
采集业务人员的话,还需要采集同事的话,有些是实名或者错字也需要采集
如果是非标产品,制作一个关键词词库至少需要一天时间,但是这个关键词词库可以使用一整年。跟进一个月关注飙升的词和新出现的关键词。只是优化没有采集到的词。
稍微扩展一下,我们将使用哪些词?使用直通车测试,尤其是非标产品,需求词和转换词更加多样化,测试模型的时候可以测试出来。
看字族的数据比较好,应该优先考虑哪一个,做起来肯定容易些
采集内容插入词库( 自定义库管理>预设词库页面添加样本至正常词库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-12-09 23:17
自定义库管理>预设词库页面添加样本至正常词库)
文本内容安全是否支持自定义词库?
支持用户自定义词库。可以按如下方式配置和应用自定义词典:
在自定义库管理>自定义词库页面,创建自定义词典并添加非法词。有关详细信息,请参阅。创建自定义词典后,需要创建一个并在策略中配置自定义词典,使词典生效。自定义库管理是否支持 API 调用?
不支持。
我可以添加自定义屏蔽词吗?是否有用于添加自定义阻止词的 API?自定义块词是否支持分组?
用户可以创建多个自定义词汇来实现分组功能。自定义词库需要关联策略才能生效。您可以创建不同的 Biztypes 来关联不同的自定义词库。调用API时,Biztype输入参数,填写创建的策略名称,创建的策略生效。
是否支持批量导入自定义词库?
支持,需要通过提交工单申请后台配置。用户在配置前需要对关键词(暴力恐怖、色情等)进行分类,每个关键词需要用换行符隔开。
用户创建的策略使用什么词库?
● 如果用户在创建自定义策略时没有关联自定义词典,则默认使用默认词典。
● 支持用户在预设词典中添加自定义关键词。如果您需要发布关键词,请到文本内容安全控制台的自定义库管理>预设词库页面,将样本添加到普通词库(预设)中,然后可以查看添加的< @关键词 放手。
论坛和直播间有敏感词过滤服务吗?是否支持自定义关键词? 查看全部
采集内容插入词库(
自定义库管理>预设词库页面添加样本至正常词库)
文本内容安全是否支持自定义词库?
支持用户自定义词库。可以按如下方式配置和应用自定义词典:
在自定义库管理>自定义词库页面,创建自定义词典并添加非法词。有关详细信息,请参阅。创建自定义词典后,需要创建一个并在策略中配置自定义词典,使词典生效。自定义库管理是否支持 API 调用?
不支持。
我可以添加自定义屏蔽词吗?是否有用于添加自定义阻止词的 API?自定义块词是否支持分组?
用户可以创建多个自定义词汇来实现分组功能。自定义词库需要关联策略才能生效。您可以创建不同的 Biztypes 来关联不同的自定义词库。调用API时,Biztype输入参数,填写创建的策略名称,创建的策略生效。
是否支持批量导入自定义词库?
支持,需要通过提交工单申请后台配置。用户在配置前需要对关键词(暴力恐怖、色情等)进行分类,每个关键词需要用换行符隔开。
用户创建的策略使用什么词库?
● 如果用户在创建自定义策略时没有关联自定义词典,则默认使用默认词典。
● 支持用户在预设词典中添加自定义关键词。如果您需要发布关键词,请到文本内容安全控制台的自定义库管理>预设词库页面,将样本添加到普通词库(预设)中,然后可以查看添加的< @关键词 放手。
论坛和直播间有敏感词过滤服务吗?是否支持自定义关键词?
采集内容插入词库(英文独立站的时候,如何建立关键词库是极其重要极其重要?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-12-08 15:21
在我们准备英文独立站点时,关键词 库的建立是一项极其重要的任务。这是因为关键词词库的优劣和丰富程度在一定程度上直接决定了未来的站点流量。为什么 关键词 词库如此重要?因为关键词是通往你网站的宽阔道路。您的客户通过这条路来到您的店铺,与您联系,与您互动,并从您那里购买。不仅对于独立站点,而且对于 Internet 上的任何虚拟实体,关键词 都极为重要。
与B2C相比,B2B的关键词相对简单。受客户群体的专业性和产品类别相对较少的影响,在准备词库时,量相对较小。尤其对于生产型工厂来说,单品直接决定了关键词词汇的狭隘。越复杂,越窄;行业越先进,范围越窄。想想看,在一个产品没有成熟市场之前,谁知道这个产品叫什么,对吧?
但无论如何,我们在准备的时候,一定要尽最大的努力去打造一个高质量、丰富的关键词库。那么你从哪里开始,你需要什么工具?
手动自助服务和机器协助。
一是人工自助收款。
从产品的来源到产品价值链的末端,列出了与产品相关的任何短语和单词。这一步可以通过头脑风暴来完成,而且可以是中文的。然后翻译成英文,验证每个单词或短语是否符合西方表达,以及搜索引擎是否有足够的结果。如果你头脑风暴的词在google结果中没有找到,或者这些词与你的行业或产品无关,那么这些词肯定不合适。所有这些词都必须有一个核心,即产品或服务本身的名称。当然,这个产品的名称在不同的语言环境中是不同的。在设计多语言网站时必须考虑到这一点。
其次,围绕核心词,做竞争对手的底线。以谷歌为例,如果我们使用关键词led制造商在谷歌上进行搜索,我们会得到如下搜索结果:
然后找到一个类似的网址,第一眼就是一个SEO优化网站,然后点进去。(因为它们看起来像工厂。如果你看不出区别,只需打开搜索下的所有网址,并排查看它们。)
进入后查看网页源代码(快捷键F12,或在页面空白处右击),在标签中找到一个内容。等号后面的引号是竞争对手使用的关键词,当然,不同页面使用的词不一样,一个站点可能有数百个关键词。必须检查排名靠前的站点。
使用阿里巴巴的原理和使用谷歌是一样的。就是用核心词搜索关键词,然后找到产品页面打开,然后查看源码。
这个过程可以通过切换核心关键词来重复进行。在这个过程中,了解行业内的竞争对手也是一个绝对的过程。通过这次搜索,对产品本身和行业的了解会不断加深。并表示不一定会有意想不到的惊喜
再次使用关键词工具批量推荐关键词
很多人没有时间做上面的第二步,觉得太费时间了。因此,我更喜欢使用关键词工具来机械生成。不同的工具可能会有不同的结果,但都是密不可分的。许多 SEO 团队使用此类工具来快速构建 关键词 库。但缺点是这些结果是基于算法对已知搜索习惯的总结,缺乏对人性的理解,所以在设置关键词的时候,可能会缺乏一些创新和爆发力。尤其是对于新产品,高度创新的产品,这类工具没有足够的搜索习惯积累,所以给出的建议并不那么科学。而且,这种方法不利于新手了解行业概况。因此,工具非常好,但不要认为世界上有工具。成功没有捷径。
这里推荐一些常用的关键词工具:
当然,你也可以参考:
知乎:世界上最好的网站关键词工具总结,海鸥SEO
Ahrefs:10 个免费的 关键词 研究工具(滚动关键词planner),作者 Joshua Hardwick
最后,如何判断关键词的好坏?
我这里用的是登录,进入账号控制面板,然后右上角头像旁边有个工具&设置,选择关键词规划器开始穿关键词或者预测关键词的效果@关键词。
其中,CTR就是点击次数除以展示次数,百分比可以理解为每100次展示可以产生多少点击。MAX.CPC是团队单个词的最高出价,也是这次点击的最高出价。AVG.CPC是所有结果的平均竞价成本,更具参考价值。增加自己的最高MAX.CPC可以有效地执行常规价格数据,也会推高实际成本。对于不同的产品,您可以稍作调整,以计算如何设置最佳投标价格。
好吧,先这么多。关于如何判断关键词的好坏,还有很多其他的工具和方法,后面会和大家分享。
参考:
【海外市场B2B品牌建设网络版,如何确定关键词?](海外市场B2B品牌建设网络版,如何确定关键词?/) 查看全部
采集内容插入词库(英文独立站的时候,如何建立关键词库是极其重要极其重要?)
在我们准备英文独立站点时,关键词 库的建立是一项极其重要的任务。这是因为关键词词库的优劣和丰富程度在一定程度上直接决定了未来的站点流量。为什么 关键词 词库如此重要?因为关键词是通往你网站的宽阔道路。您的客户通过这条路来到您的店铺,与您联系,与您互动,并从您那里购买。不仅对于独立站点,而且对于 Internet 上的任何虚拟实体,关键词 都极为重要。
与B2C相比,B2B的关键词相对简单。受客户群体的专业性和产品类别相对较少的影响,在准备词库时,量相对较小。尤其对于生产型工厂来说,单品直接决定了关键词词汇的狭隘。越复杂,越窄;行业越先进,范围越窄。想想看,在一个产品没有成熟市场之前,谁知道这个产品叫什么,对吧?
但无论如何,我们在准备的时候,一定要尽最大的努力去打造一个高质量、丰富的关键词库。那么你从哪里开始,你需要什么工具?
手动自助服务和机器协助。
一是人工自助收款。
从产品的来源到产品价值链的末端,列出了与产品相关的任何短语和单词。这一步可以通过头脑风暴来完成,而且可以是中文的。然后翻译成英文,验证每个单词或短语是否符合西方表达,以及搜索引擎是否有足够的结果。如果你头脑风暴的词在google结果中没有找到,或者这些词与你的行业或产品无关,那么这些词肯定不合适。所有这些词都必须有一个核心,即产品或服务本身的名称。当然,这个产品的名称在不同的语言环境中是不同的。在设计多语言网站时必须考虑到这一点。
其次,围绕核心词,做竞争对手的底线。以谷歌为例,如果我们使用关键词led制造商在谷歌上进行搜索,我们会得到如下搜索结果:
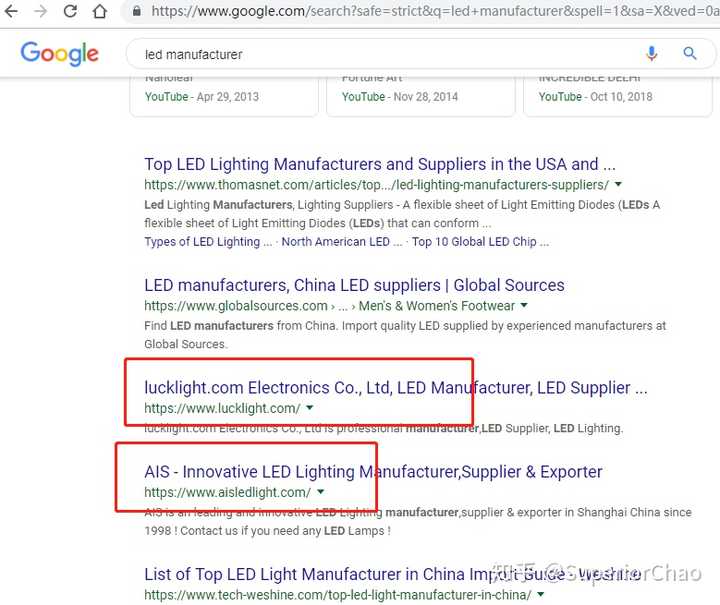
然后找到一个类似的网址,第一眼就是一个SEO优化网站,然后点进去。(因为它们看起来像工厂。如果你看不出区别,只需打开搜索下的所有网址,并排查看它们。)
进入后查看网页源代码(快捷键F12,或在页面空白处右击),在标签中找到一个内容。等号后面的引号是竞争对手使用的关键词,当然,不同页面使用的词不一样,一个站点可能有数百个关键词。必须检查排名靠前的站点。
使用阿里巴巴的原理和使用谷歌是一样的。就是用核心词搜索关键词,然后找到产品页面打开,然后查看源码。
这个过程可以通过切换核心关键词来重复进行。在这个过程中,了解行业内的竞争对手也是一个绝对的过程。通过这次搜索,对产品本身和行业的了解会不断加深。并表示不一定会有意想不到的惊喜
再次使用关键词工具批量推荐关键词
很多人没有时间做上面的第二步,觉得太费时间了。因此,我更喜欢使用关键词工具来机械生成。不同的工具可能会有不同的结果,但都是密不可分的。许多 SEO 团队使用此类工具来快速构建 关键词 库。但缺点是这些结果是基于算法对已知搜索习惯的总结,缺乏对人性的理解,所以在设置关键词的时候,可能会缺乏一些创新和爆发力。尤其是对于新产品,高度创新的产品,这类工具没有足够的搜索习惯积累,所以给出的建议并不那么科学。而且,这种方法不利于新手了解行业概况。因此,工具非常好,但不要认为世界上有工具。成功没有捷径。
这里推荐一些常用的关键词工具:
当然,你也可以参考:
知乎:世界上最好的网站关键词工具总结,海鸥SEO
Ahrefs:10 个免费的 关键词 研究工具(滚动关键词planner),作者 Joshua Hardwick
最后,如何判断关键词的好坏?
我这里用的是登录,进入账号控制面板,然后右上角头像旁边有个工具&设置,选择关键词规划器开始穿关键词或者预测关键词的效果@关键词。
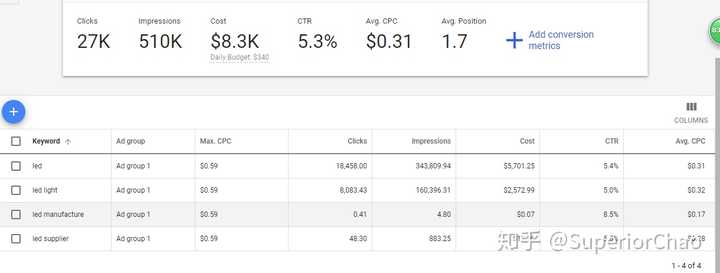
其中,CTR就是点击次数除以展示次数,百分比可以理解为每100次展示可以产生多少点击。MAX.CPC是团队单个词的最高出价,也是这次点击的最高出价。AVG.CPC是所有结果的平均竞价成本,更具参考价值。增加自己的最高MAX.CPC可以有效地执行常规价格数据,也会推高实际成本。对于不同的产品,您可以稍作调整,以计算如何设置最佳投标价格。
好吧,先这么多。关于如何判断关键词的好坏,还有很多其他的工具和方法,后面会和大家分享。
参考:
【海外市场B2B品牌建设网络版,如何确定关键词?](海外市场B2B品牌建设网络版,如何确定关键词?/)
采集内容插入词库( python+scrapy采集爱站关键词,用到的知识点有scrpy模块 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-12-08 15:16
python+scrapy采集爱站关键词,用到的知识点有scrpy模块
)
python+scrapy采集爱站关键词,用到的知识点是scrpy和re模块,因为已经有文章文章使用xpath去提取内容了,所以这次我会在正则表达式python中使用re模块;
Scrapy 有点复杂。新手建议从urllib和requests入手。下面的代码页只是一个简单的应用程序。 Scrapy可以使用UA池、ip池、禁止cookies、下载延迟、谷歌缓存、分布式爬虫等强仿禁止策略。
#encoding=utf-8
#在所有工作之前,先用scrapy startproject projectname,这时会生成一个叫projectname的文件夹
from scrapy.spiders import Spider #导入模块
from scrapy.selector import Selector
from scrapy.linkextractors import LinkExtractor
from scrapy.http import Request
import re
class cispider(Spider): #面向对象中的继承类
name='ciku' #如果是win7运行的时候在你创建projectname的目录下面通过cmd,敲上scrapy crawl ciku来运行
start_urls=['http://ci.aizhan.com/seo/'] #目标网站
def parse(self,response): #类的方法
html=response.body
r=re.compile(r'(.*?)[\s\S]*?(\d+)')
a=re.findall(r,html) #提取正则
for i in a:
f=','.join(i)
w=re.compile('|')
b = w.sub('',f).decode('utf-8').encode('gbk') #解决win7下的编码问题
print b
b=re.compile(r'页号:<a class="on">1</a> 2 ')
urls=re.findall(b,html)
for n in urls:
c='http://ci.aizhan.com'
f=c+n
print f
yield Request(f,callback=self.parse) #回调,这里大概的过程就是将页码,翻页数,如第二页,第三页等返回给self.pase()来获取内容关键词 查看全部
采集内容插入词库(
python+scrapy采集爱站关键词,用到的知识点有scrpy模块
)

python+scrapy采集爱站关键词,用到的知识点是scrpy和re模块,因为已经有文章文章使用xpath去提取内容了,所以这次我会在正则表达式python中使用re模块;
Scrapy 有点复杂。新手建议从urllib和requests入手。下面的代码页只是一个简单的应用程序。 Scrapy可以使用UA池、ip池、禁止cookies、下载延迟、谷歌缓存、分布式爬虫等强仿禁止策略。
#encoding=utf-8
#在所有工作之前,先用scrapy startproject projectname,这时会生成一个叫projectname的文件夹
from scrapy.spiders import Spider #导入模块
from scrapy.selector import Selector
from scrapy.linkextractors import LinkExtractor
from scrapy.http import Request
import re
class cispider(Spider): #面向对象中的继承类
name='ciku' #如果是win7运行的时候在你创建projectname的目录下面通过cmd,敲上scrapy crawl ciku来运行
start_urls=['http://ci.aizhan.com/seo/'] #目标网站
def parse(self,response): #类的方法
html=response.body
r=re.compile(r'(.*?)[\s\S]*?(\d+)')
a=re.findall(r,html) #提取正则
for i in a:
f=','.join(i)
w=re.compile('|')
b = w.sub('',f).decode('utf-8').encode('gbk') #解决win7下的编码问题
print b
b=re.compile(r'页号:<a class="on">1</a> 2 ')
urls=re.findall(b,html)
for n in urls:
c='http://ci.aizhan.com'
f=c+n
print f
yield Request(f,callback=self.parse) #回调,这里大概的过程就是将页码,翻页数,如第二页,第三页等返回给self.pase()来获取内容关键词
采集内容插入词库(如果你需要一应俱全的完整国民经济核算资料(原ICTCLAS))
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-12-08 05:00
在生活中,我们可以通过多种渠道获取相关数据。
搜索“中国统计年鉴”。许多图书馆都有《中国统计年鉴》等。翻出收录您需要的数据的页面。复印是一个不错的选择。当然,你也可以选择拿出纸和笔。复制您需要的所有数据。为了便于对这些数据进行进一步的处理,接下来的工作可能会有些枯燥:将找到的数据一一输入电脑。当然,现在情况已经好了很多。例如,要查找 2004 中国统计年鉴,中华人民共和国国家统计局 网站 提供了免费下载。
如果您需要所有最新的宏观经济数据,那就是中国国家统计局提供的“进展统计”。
如果要从数据采集之日起获得完整的国民核算数据,权威来源是《中国GDP核算历史数据》(1952-1995)和《中国GDP核算历史数据》(1996-2002)) @>.这两本年鉴都提供了中国GDP的详细数据,特别是《中国GDP会计历史数据》(1996)-2002)@>提供了电子版,电子版数据不仅提供了详细数据从1996年到2002年,也大致追溯了1952年到1995年的数据,非常好用。
如果想从数据采集之日起获得更完整的宏观经济数据,《新中国50年统计数据汇编》和《新中国55年统计数据汇编》是不错的选择。不幸的是,它们都没有提供电子版本,但后者可以从中国信息银行下载。
此外,还有很多收费网站可以提供更详细的中国宏观经济数据,如信息银行数据库、中国经济信息网等。
国内的大数据处理信息工具很多,但大多是近年来兴起的大数据技术,图像处理需要先转换成文本再进行处理。通过对几款国内主流中文分词工具产品的试用,下面为大家推荐几款中文分词工具:
一、NLPIR大数据语义智能分析平台(原ICTCLAS)由北京理工大学大数据搜索与挖掘实验室主任张华平开发。融合网络精准,满足大数据内容采集、编辑、搜索的综合需求。采集 近二十年来自然语言理解、文本挖掘、语义搜索等最新研究成果不断创新。平台提供客户端工具、云服务、二次开发接口等多种产品使用形式。每个中间件API都可以无缝集成到客户的各种复杂应用系统中,兼容Windows、Linux、Android、Maemo5、FreeBSD等不同操作系统平台,
NLPIR大数据语义智能分析平台的十三项功能:
NLPIR大数据语义智能分析平台客户端
精准采集:国内外海量信息实时精准采集,主题采集(主题根据信息需求采集)和站点采集 两种模式(给定网站列表内的定点采集 功能)。
文档转换:将文本信息转换为doc、excel、pdf、ppt等多种主流文档格式,效率满足大数据处理要求。
新词发现:从文本中发现新词、新概念,用户可将其用于专业词典的编纂,并可进一步编辑标注,导入分词词典,提高分词系统的准确率,并适应新的语言变化。
批量分词:对原创语料进行分词,自动识别姓名、地名、机构名称等未注册词,新词标注,词性标注。并在分析过程中,导入用户自定义词典。
语言统计:根据分词和标注结果,系统自动进行一元词频数统计和二元词转移概率统计。对于常用术语,会自动给出相应的英文解释。
文本聚类:可以从大规模数据中自动分析热点事件,并提供事件主题的关键特征描述。同时适用于短文、微博等长文和短文的热点分析。
文本分类:根据规则或训练方法对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等诸多方面。
抽象实体:对于单个或多个文章,自动提取内容摘要,提取人名、地点、机构、时间和主题关键词;方便用户快速浏览文本内容。
智能过滤:对文本内容进行语义智能过滤和审核,内置国内最全面的词典,智能识别多种变体:变形、音变、繁简变体,精准语义消歧。
情感分析:针对预先指定的分析对象,系统自动分析海量文档的情感倾向:情感极性和情感价值度量,并给出原文中的正负分和句例。
文档去重:快速准确判断文件集或数据库中是否存在内容相同或相似的记录,同时找出所有重复记录。
全文搜索:支持文本、数字、日期、字符串等多种数据类型,多字段高效搜索,支持AND/OR/NOT、NEAR接近等查询语法,支持维吾尔语、藏语、蒙语、阿拉伯语和韩语 搜索各种少数民族语言。
代码转换:自动识别内容的代码,统一将代码转换为其他代码。
以上为个人观点,仅供参考,希望能帮到你! 查看全部
采集内容插入词库(如果你需要一应俱全的完整国民经济核算资料(原ICTCLAS))
在生活中,我们可以通过多种渠道获取相关数据。
搜索“中国统计年鉴”。许多图书馆都有《中国统计年鉴》等。翻出收录您需要的数据的页面。复印是一个不错的选择。当然,你也可以选择拿出纸和笔。复制您需要的所有数据。为了便于对这些数据进行进一步的处理,接下来的工作可能会有些枯燥:将找到的数据一一输入电脑。当然,现在情况已经好了很多。例如,要查找 2004 中国统计年鉴,中华人民共和国国家统计局 网站 提供了免费下载。
如果您需要所有最新的宏观经济数据,那就是中国国家统计局提供的“进展统计”。
如果要从数据采集之日起获得完整的国民核算数据,权威来源是《中国GDP核算历史数据》(1952-1995)和《中国GDP核算历史数据》(1996-2002)) @>.这两本年鉴都提供了中国GDP的详细数据,特别是《中国GDP会计历史数据》(1996)-2002)@>提供了电子版,电子版数据不仅提供了详细数据从1996年到2002年,也大致追溯了1952年到1995年的数据,非常好用。
如果想从数据采集之日起获得更完整的宏观经济数据,《新中国50年统计数据汇编》和《新中国55年统计数据汇编》是不错的选择。不幸的是,它们都没有提供电子版本,但后者可以从中国信息银行下载。
此外,还有很多收费网站可以提供更详细的中国宏观经济数据,如信息银行数据库、中国经济信息网等。
国内的大数据处理信息工具很多,但大多是近年来兴起的大数据技术,图像处理需要先转换成文本再进行处理。通过对几款国内主流中文分词工具产品的试用,下面为大家推荐几款中文分词工具:
一、NLPIR大数据语义智能分析平台(原ICTCLAS)由北京理工大学大数据搜索与挖掘实验室主任张华平开发。融合网络精准,满足大数据内容采集、编辑、搜索的综合需求。采集 近二十年来自然语言理解、文本挖掘、语义搜索等最新研究成果不断创新。平台提供客户端工具、云服务、二次开发接口等多种产品使用形式。每个中间件API都可以无缝集成到客户的各种复杂应用系统中,兼容Windows、Linux、Android、Maemo5、FreeBSD等不同操作系统平台,

NLPIR大数据语义智能分析平台的十三项功能:
NLPIR大数据语义智能分析平台客户端
精准采集:国内外海量信息实时精准采集,主题采集(主题根据信息需求采集)和站点采集 两种模式(给定网站列表内的定点采集 功能)。
文档转换:将文本信息转换为doc、excel、pdf、ppt等多种主流文档格式,效率满足大数据处理要求。
新词发现:从文本中发现新词、新概念,用户可将其用于专业词典的编纂,并可进一步编辑标注,导入分词词典,提高分词系统的准确率,并适应新的语言变化。
批量分词:对原创语料进行分词,自动识别姓名、地名、机构名称等未注册词,新词标注,词性标注。并在分析过程中,导入用户自定义词典。
语言统计:根据分词和标注结果,系统自动进行一元词频数统计和二元词转移概率统计。对于常用术语,会自动给出相应的英文解释。
文本聚类:可以从大规模数据中自动分析热点事件,并提供事件主题的关键特征描述。同时适用于短文、微博等长文和短文的热点分析。
文本分类:根据规则或训练方法对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等诸多方面。
抽象实体:对于单个或多个文章,自动提取内容摘要,提取人名、地点、机构、时间和主题关键词;方便用户快速浏览文本内容。
智能过滤:对文本内容进行语义智能过滤和审核,内置国内最全面的词典,智能识别多种变体:变形、音变、繁简变体,精准语义消歧。
情感分析:针对预先指定的分析对象,系统自动分析海量文档的情感倾向:情感极性和情感价值度量,并给出原文中的正负分和句例。
文档去重:快速准确判断文件集或数据库中是否存在内容相同或相似的记录,同时找出所有重复记录。
全文搜索:支持文本、数字、日期、字符串等多种数据类型,多字段高效搜索,支持AND/OR/NOT、NEAR接近等查询语法,支持维吾尔语、藏语、蒙语、阿拉伯语和韩语 搜索各种少数民族语言。
代码转换:自动识别内容的代码,统一将代码转换为其他代码。
以上为个人观点,仅供参考,希望能帮到你!
采集内容插入词库(分析一下企查查,本着分享知识的原则、原则和原则 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-12-31 20:15
)
最近有朋友让我分析七茶茶。本着知识分享的原则,我想用我浅薄的知识和见解谈谈七叉茶的SEO亮点,希望能帮助更多的兄弟了解SEO的精髓!
我之前分析过顺奇网和58同城。你可以看看你是否喜欢它。 58同城的词库个人感觉比较笼统一点,而公司的搜索比较准确。与上面相比,顺奇网这两个词比较复杂,业务不同,词库不同,不分高低。
(内容、模板)稀缺
现在很多人做SEO,还认为原创是SEO的核心。企业调查是对这一观点的最大否定。因为上面的信息基本都是采集。
但是目测采集的内容应该是调用国家数据库,因为国内各个企业的信息应该没有那么好。采集,即使采集@ >,有一些不准确的情况,因为企业信息对非权威网站的信任度比较低。只有国家信息才是准确的。
内容已经解决,公司在用户体验和模板方面做了很好的对比。在之前的课程中,我们也讲过影响排名的因素和收录。模板也是其中之一。
Large-scale网站能做到决赛,绝对是一场量级的比赛。词库决定权重,收录决定词库。这种收录的水平,绝对不是几十人、几百人能做到的。
词库精准定位
词库的定位与业务直接相关,但公司搜索的词库远小于同城58的词库。仅就竞争而言,它要小得多。企业搜索的词库一般以【公司名称】【法人名称、股东名称】为主,而58则主要以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白很难关键词 容易程度。
但是,词库的定位是准确的,客户会准确得多。当你的量级达到几千万或者几亿的时候,长尾带来的流量是相当恐怖的,这些每天访问网站的恐怖流量带来的信任度的增加绝不是普通的小网站可比的.
和之前聊天中的58一样,品牌流量作为来源带动了网站的整体信任度。信任高后,长尾流量来了,一次次回馈网站,良性循环!
学习和应用
为什么需要分析企业搜索?因为企业搜索的难度比较低。我们可以把他的词库导出成权重站!
比如我之前做过的名字站,可以做公司名字的站,或者其他站。毕竟有词库,内容会聚合。即使是随机生成的,也不过是几分钟的事情。
查看全部
采集内容插入词库(分析一下企查查,本着分享知识的原则、原则和原则
)
最近有朋友让我分析七茶茶。本着知识分享的原则,我想用我浅薄的知识和见解谈谈七叉茶的SEO亮点,希望能帮助更多的兄弟了解SEO的精髓!
我之前分析过顺奇网和58同城。你可以看看你是否喜欢它。 58同城的词库个人感觉比较笼统一点,而公司的搜索比较准确。与上面相比,顺奇网这两个词比较复杂,业务不同,词库不同,不分高低。
(内容、模板)稀缺
现在很多人做SEO,还认为原创是SEO的核心。企业调查是对这一观点的最大否定。因为上面的信息基本都是采集。
但是目测采集的内容应该是调用国家数据库,因为国内各个企业的信息应该没有那么好。采集,即使采集@ >,有一些不准确的情况,因为企业信息对非权威网站的信任度比较低。只有国家信息才是准确的。
内容已经解决,公司在用户体验和模板方面做了很好的对比。在之前的课程中,我们也讲过影响排名的因素和收录。模板也是其中之一。
Large-scale网站能做到决赛,绝对是一场量级的比赛。词库决定权重,收录决定词库。这种收录的水平,绝对不是几十人、几百人能做到的。
词库精准定位
词库的定位与业务直接相关,但公司搜索的词库远小于同城58的词库。仅就竞争而言,它要小得多。企业搜索的词库一般以【公司名称】【法人名称、股东名称】为主,而58则主要以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白很难关键词 容易程度。
但是,词库的定位是准确的,客户会准确得多。当你的量级达到几千万或者几亿的时候,长尾带来的流量是相当恐怖的,这些每天访问网站的恐怖流量带来的信任度的增加绝不是普通的小网站可比的.
和之前聊天中的58一样,品牌流量作为来源带动了网站的整体信任度。信任高后,长尾流量来了,一次次回馈网站,良性循环!
学习和应用
为什么需要分析企业搜索?因为企业搜索的难度比较低。我们可以把他的词库导出成权重站!
比如我之前做过的名字站,可以做公司名字的站,或者其他站。毕竟有词库,内容会聚合。即使是随机生成的,也不过是几分钟的事情。
采集内容插入词库(基于TF-IDF的关键词抽取方法,帮助读者快速理解文本信息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-12-31 20:14
Text关键词 抽取是一种高度浓缩文本信息的有效方法。通过3-5个词准确概括文章主题,帮助读者快速理解文章信息。目前文本提取的方法主要有四种:基于TF-IDF的关键词提取、基于TextRank的关键词提取、基于Word2Vec词聚类的关键词提取、关键词 结合多种算法的提取。在使用前三种算法进行关键词抽取的学习过程中,笔者发现网上有很多使用TF-IDF和TextRank方法抽取关键词的例子。代码和步骤比较简单,但是使用Word2Vec词聚类的方法,网上的资料并没有明确的表达过程和步骤。因此,本文采用TF-IDF方法、TextRank方法和Word2Vec词聚类方法实现专利文本的提取(也适用于其他类型的文本)。通过理论与实践相结合,一步步的理解、学习、实现中文文本抽取关键词。
1 概览
一个文档的关键词相当于N个最能表达文档主要目的的词,也就是文档最重要的词。因此,文本关键词抽取问题可以转化为重要词对于性排序问题,选择前N个词作为文本关键词。目前主流的文本提取方法主要分为以下两类:
(1)基于统计的关键词抽取方法
该方法根据词频等统计信息计算文档中词的权重,按照权重值的顺序提取关键词。 TF-IDF 和 TextRank 都属于此类方法。其中,TF-IDF方法通过计算单个文本词频(Term Frequency,TF)和逆文档频率(Inverse Document Frequency,IDF)来获得词权重; TextRank方法是基于PageRank的思想,通过词共现窗口构建共现网络,计算词得分。这种方法简单易实现,适用性强,但没有考虑词序问题。
(2)关键词基于机器学习的提取方法
该方法包括SVM、朴素贝叶斯等监督学习方法,以及K-means、层次聚类等无监督学习方法。在这类方法中,模型的好坏取决于特征提取,而深度学习是一种有效的特征提取方式。谷歌推出的 Word2Vec 词向量模型是自然语言领域具有代表性的学习工具。它在训练语言模型的过程中将字典映射到更抽象的向量空间。每个词都由一个高维向量表示。向量空间中两点的距离对应两个词的相似度。
基于以上研究,本文分别采用TF-IDF方法、TextRank方法和Word2Vec词聚类方法,使用Python语言开发实现文本提取关键词。
2 开发环境准备2.1 Python 环境
在python官网下载电脑对应的python版本。作者使用的Python版本2.7.13.
2.2 个第三方模块
本实验Python代码的实现使用了多个知名的第三方模块,主要模块如下:
(1)解霸
目前使用最广泛的中文分词组件。下载链接:
(2)Gensim
用于主题模型、文档索引和大规模语料库相似性索引的 Python 库,主要用于自然语言处理 (NLP) 和信息检索 (IR)。下载链接:
本例中维基中文语料处理和中文词向量模型构建需要该模块。
(3)熊猫
用于高效处理大型数据集和执行数据分析任务的 python 库是一个基于 Numpy 的工具包。
下载链接:
(4)Numpy
用于存储和处理大型矩阵的工具包。
下载链接:
(5)Scikit-learn
用于机器学习的python工具包。 python 模块引用名称是 sklearn。安装前需要两个 Python 库,Numpy 和 Scipy。
官网地址:
本例中主要使用了本模块中的feature_extraction、KMeans(k-means聚类算法)和PCA(pac降维算法)。
(6)Matplotlib
Matplotlib 是一个用于绘制二维图形的 Python 图形框架。
下载链接:
3 数据准备3.1个样本语料
正文以汽车行业的10项专利作为样本数据集,见文件“data/sample_data.csv”。该文件依次收录编号(id)、标题(title)和摘要(abstract)三个字段。 关键词的提取过程中都涉及到标题和摘要。您可以根据自己的样本数据调整数据读取代码。
3.2 停用词词典
本文使用中科院计算所中文自然语言处理开放平台发布的中文停用词表,收录1208个停用词。下载链接:
另外,由于本例的样本是专利文本,词汇专业性很强,需要手动添加停用词。您可以直接将它们添加到上面的停用词列表中。每一行都是一个停用词。请参阅文件“data /stopWord.txt”。在这个例子中,作者在文件顶部手动添加了六个停用词“包括、相对、免费、使用、本发明和组合”以进行演示。您可以根据实际情况删除或删除它们。添加停用词。
4 基于TF-IDF的文本提取方法关键词4.1 TF-IDF算法思路
词频(TF)是指给定词在当前文档中的出现频率。由于同一个词在长文档中的词频可能高于短文档,因此需要根据文档的长度对给定词进行归一化,即给定词的个数除以总数当前文档中的单词数。
逆文档频率 (IDF) 是衡量单词普遍重要性的指标。也就是说,如果一个词只出现在少数文件中,则说明它更能代表文件的主题,权重也更大;如果一个词出现在大量的文档中,说明它代表什么不清楚,它的权重应该很小。
TF-IDF的主要思想是,如果某个词在一篇文章文章中出现频率较高,而在其他文章中出现频率较低,则认为该词可以更好地代表文章 的当前含义。即一个词的重要性与其在文档中出现的次数成正比,与其在语料库中在文档中出现的频率成反比。
计算公式如下:
4.2 TF-IDF文本关键词提取方法流程
由上可知,TF-IDF对所有候选文本关键词进行加权处理,并根据权重对关键词进行排序。假设Dn为测试语料的大小,算法的关键词提取步骤如下:
(1)对于给定的文本D,进行分词、词性标注、去除停用词等数据预处理操作。本小节采用口吃分词,保留'n', 'nz','v','vd','vn','l','a','d'这几个词,最后得到n个候选关键词,即D=[t1,t2, ...,tn];
(2)计算词ti在文本D中的词频;
(3) 计算词ti在整个语料库中的IDF=log (Dn /(Dt +1)),Dt为词ti在语料库中出现的文档数;
(4)计算单词ti的TF-IDF=TF*IDF,重复(2)—(4)得到所有候选关键词TF-IDF值;
(5)将候选关键词的计算结果倒序排列,得到前N个词作为正文关键词。
4.3 代码实现
Python 第三方工具包 Scikit-learn 提供了 TFIDF 算法的相关功能。本文主要使用sklearn.feature_extraction.text下的TfidfTransformer和CountVectorizer函数。其中,CountVectorizer函数用于构建语料中的词频矩阵,TfidfTransformer函数用于计算词的tfidf权重。
注意:TfidfTransformer()函数有一个参数smooth_idf,默认值为True,如果设置为False,IDF计算公式为idf=log(Dn /Dt) + 1。
基于TF-IDF方法实现文本关键词提取代码执行步骤如下:
(1)读取示例源文件sample_data.csv;
(2)获取每行记录的title和summary字段,将这两个字段拼接起来;
(3) 加载自定义停用词列表stopWord.txt,对拼接后的文本进行数据预处理操作,包括分词、过滤词性匹配的词、去除停用词,以及用空格分隔拼接成文本;
(4) 遍历文本记录,将预处理后的文本放入文档集语料库中;
(5)使用CountVectorizer()函数得到词频矩阵,a[j][i]代表第i个文档中第j个词的词频;
(6)使用TfidfTransformer()函数计算每个词的tf-idf权重;
(7)得到词袋模型中的关键词和对应的tf-idf矩阵;
(8) 遍历tf-idf矩阵,打印每个文档的词汇量和对应的权重;
(9)对于每个文档,按照词权值降序排列,选择topN个词作为文本关键词,写入数据框;
(10)将最终结果写入文件keys_TFIDF.csv。
最终运行结果如下图所示。
5种基于TextRank的文本提取方法关键词5.1 PageRank算法思路
TextRank算法是基于PageRank算法的,所以在介绍TextRank之前必须先了解一下PageRank算法。
PageRank 算法是谷歌创始人拉里佩奇和谢尔盖布林于 1998 年在斯坦福大学攻读研究生期间发明的。它用于根据网页之间的超链接计算网页的重要性。技术。该算法借鉴了学术界判断学术论文重要性的方法,即检查论文的引用次数。基于以上思想,PageRank算法的核心思想是网页的重要性由两部分组成:
①如果一个网页被大量其他网页链接,则说明这个网页更重要,即链接网页的数量;
②如果一个网页链接到排名靠前的网页,说明这个网页更重要,也就是链接网页的权重。
一般情况下,网页的PageRank值(PR)计算公式如下:
其中,PR(Pi)为第i个网页的重要性排名,即PR值; ɑ为阻尼系数,一般设置为0.85; N是网页总数; Mpi 是第 i 个网页的总数 外链网页的集合; L(Pj)为第j个网页的外链数。
初始阶段,假设所有网页的排名为1/N,根据上述公式计算每个网页的PR值。当迭代稳定后,停止迭代计算,得到最终结果。一般情况下,迭代10次左右就基本收敛了。
5.2 TextRank 算法思路
TextRank 算法是 Mihalcea 和 Tarau 在 2004 年在研究自动摘要提取时提出的,并在 PageRank 算法的思想上进行了改进。该算法将文本拆分为词表作为网络节点,形成词表网络图模型,将词之间的相似关系视为推荐或投票关系,从而计算出每个词的重要性。
基于TextRank的
Text关键词抽取就是利用局部词汇关系,即共现窗口,对候选关键词进行排序。该方法的步骤如下:
(1)对于给定的文本D,进行分词、词性标注、去除停用词等数据预处理操作。本小节采用口吃分词,保留'n', 'nz','v','vd','vn','l','a','d'这几个词,最后得到n个候选关键词,即D=[t1,t2, ...,tn];
(2) 构造候选关键词图G=(V,E),其中V为节点集,由候选关键词组成,使用共现关系构造任意两个点 只有当它们对应的词在长度为K的窗口中共同出现时,两个节点之间才有一条边。K代表窗口的大小,即最多K个词可以同时出现;
(3)根据公式迭代计算每个节点的权重,直到收敛;
(4)将节点权重逆序排序,得到前N个词作为文本关键词.
注意:jieba 库中收录的 jieba.analysis.textrank 函数可以直接实现 TextRank 算法。本文使用该函数进行实验。
5.3 代码实现
基于TextRank方法实现文本关键词代码执行步骤如下:
(1)读取示例源文件sample_data.csv;
(2)获取每行记录的title和summary字段,将这两个字段拼接起来;
(3)加载自定义停用词列表stopWord.txt;
<p>(4)遍历文本记录,使用jieba.analysis.textrank函数过滤掉指定词性和topN文本关键词,并将结果存入数据框; 查看全部
采集内容插入词库(基于TF-IDF的关键词抽取方法,帮助读者快速理解文本信息)
Text关键词 抽取是一种高度浓缩文本信息的有效方法。通过3-5个词准确概括文章主题,帮助读者快速理解文章信息。目前文本提取的方法主要有四种:基于TF-IDF的关键词提取、基于TextRank的关键词提取、基于Word2Vec词聚类的关键词提取、关键词 结合多种算法的提取。在使用前三种算法进行关键词抽取的学习过程中,笔者发现网上有很多使用TF-IDF和TextRank方法抽取关键词的例子。代码和步骤比较简单,但是使用Word2Vec词聚类的方法,网上的资料并没有明确的表达过程和步骤。因此,本文采用TF-IDF方法、TextRank方法和Word2Vec词聚类方法实现专利文本的提取(也适用于其他类型的文本)。通过理论与实践相结合,一步步的理解、学习、实现中文文本抽取关键词。
1 概览
一个文档的关键词相当于N个最能表达文档主要目的的词,也就是文档最重要的词。因此,文本关键词抽取问题可以转化为重要词对于性排序问题,选择前N个词作为文本关键词。目前主流的文本提取方法主要分为以下两类:
(1)基于统计的关键词抽取方法
该方法根据词频等统计信息计算文档中词的权重,按照权重值的顺序提取关键词。 TF-IDF 和 TextRank 都属于此类方法。其中,TF-IDF方法通过计算单个文本词频(Term Frequency,TF)和逆文档频率(Inverse Document Frequency,IDF)来获得词权重; TextRank方法是基于PageRank的思想,通过词共现窗口构建共现网络,计算词得分。这种方法简单易实现,适用性强,但没有考虑词序问题。
(2)关键词基于机器学习的提取方法
该方法包括SVM、朴素贝叶斯等监督学习方法,以及K-means、层次聚类等无监督学习方法。在这类方法中,模型的好坏取决于特征提取,而深度学习是一种有效的特征提取方式。谷歌推出的 Word2Vec 词向量模型是自然语言领域具有代表性的学习工具。它在训练语言模型的过程中将字典映射到更抽象的向量空间。每个词都由一个高维向量表示。向量空间中两点的距离对应两个词的相似度。
基于以上研究,本文分别采用TF-IDF方法、TextRank方法和Word2Vec词聚类方法,使用Python语言开发实现文本提取关键词。
2 开发环境准备2.1 Python 环境
在python官网下载电脑对应的python版本。作者使用的Python版本2.7.13.
2.2 个第三方模块
本实验Python代码的实现使用了多个知名的第三方模块,主要模块如下:
(1)解霸
目前使用最广泛的中文分词组件。下载链接:
(2)Gensim
用于主题模型、文档索引和大规模语料库相似性索引的 Python 库,主要用于自然语言处理 (NLP) 和信息检索 (IR)。下载链接:
本例中维基中文语料处理和中文词向量模型构建需要该模块。
(3)熊猫
用于高效处理大型数据集和执行数据分析任务的 python 库是一个基于 Numpy 的工具包。
下载链接:
(4)Numpy
用于存储和处理大型矩阵的工具包。
下载链接:
(5)Scikit-learn
用于机器学习的python工具包。 python 模块引用名称是 sklearn。安装前需要两个 Python 库,Numpy 和 Scipy。
官网地址:
本例中主要使用了本模块中的feature_extraction、KMeans(k-means聚类算法)和PCA(pac降维算法)。
(6)Matplotlib
Matplotlib 是一个用于绘制二维图形的 Python 图形框架。
下载链接:
3 数据准备3.1个样本语料
正文以汽车行业的10项专利作为样本数据集,见文件“data/sample_data.csv”。该文件依次收录编号(id)、标题(title)和摘要(abstract)三个字段。 关键词的提取过程中都涉及到标题和摘要。您可以根据自己的样本数据调整数据读取代码。
3.2 停用词词典
本文使用中科院计算所中文自然语言处理开放平台发布的中文停用词表,收录1208个停用词。下载链接:
另外,由于本例的样本是专利文本,词汇专业性很强,需要手动添加停用词。您可以直接将它们添加到上面的停用词列表中。每一行都是一个停用词。请参阅文件“data /stopWord.txt”。在这个例子中,作者在文件顶部手动添加了六个停用词“包括、相对、免费、使用、本发明和组合”以进行演示。您可以根据实际情况删除或删除它们。添加停用词。
4 基于TF-IDF的文本提取方法关键词4.1 TF-IDF算法思路
词频(TF)是指给定词在当前文档中的出现频率。由于同一个词在长文档中的词频可能高于短文档,因此需要根据文档的长度对给定词进行归一化,即给定词的个数除以总数当前文档中的单词数。
逆文档频率 (IDF) 是衡量单词普遍重要性的指标。也就是说,如果一个词只出现在少数文件中,则说明它更能代表文件的主题,权重也更大;如果一个词出现在大量的文档中,说明它代表什么不清楚,它的权重应该很小。
TF-IDF的主要思想是,如果某个词在一篇文章文章中出现频率较高,而在其他文章中出现频率较低,则认为该词可以更好地代表文章 的当前含义。即一个词的重要性与其在文档中出现的次数成正比,与其在语料库中在文档中出现的频率成反比。
计算公式如下:
4.2 TF-IDF文本关键词提取方法流程
由上可知,TF-IDF对所有候选文本关键词进行加权处理,并根据权重对关键词进行排序。假设Dn为测试语料的大小,算法的关键词提取步骤如下:
(1)对于给定的文本D,进行分词、词性标注、去除停用词等数据预处理操作。本小节采用口吃分词,保留'n', 'nz','v','vd','vn','l','a','d'这几个词,最后得到n个候选关键词,即D=[t1,t2, ...,tn];
(2)计算词ti在文本D中的词频;
(3) 计算词ti在整个语料库中的IDF=log (Dn /(Dt +1)),Dt为词ti在语料库中出现的文档数;
(4)计算单词ti的TF-IDF=TF*IDF,重复(2)—(4)得到所有候选关键词TF-IDF值;
(5)将候选关键词的计算结果倒序排列,得到前N个词作为正文关键词。
4.3 代码实现
Python 第三方工具包 Scikit-learn 提供了 TFIDF 算法的相关功能。本文主要使用sklearn.feature_extraction.text下的TfidfTransformer和CountVectorizer函数。其中,CountVectorizer函数用于构建语料中的词频矩阵,TfidfTransformer函数用于计算词的tfidf权重。
注意:TfidfTransformer()函数有一个参数smooth_idf,默认值为True,如果设置为False,IDF计算公式为idf=log(Dn /Dt) + 1。
基于TF-IDF方法实现文本关键词提取代码执行步骤如下:
(1)读取示例源文件sample_data.csv;
(2)获取每行记录的title和summary字段,将这两个字段拼接起来;
(3) 加载自定义停用词列表stopWord.txt,对拼接后的文本进行数据预处理操作,包括分词、过滤词性匹配的词、去除停用词,以及用空格分隔拼接成文本;
(4) 遍历文本记录,将预处理后的文本放入文档集语料库中;
(5)使用CountVectorizer()函数得到词频矩阵,a[j][i]代表第i个文档中第j个词的词频;
(6)使用TfidfTransformer()函数计算每个词的tf-idf权重;
(7)得到词袋模型中的关键词和对应的tf-idf矩阵;
(8) 遍历tf-idf矩阵,打印每个文档的词汇量和对应的权重;
(9)对于每个文档,按照词权值降序排列,选择topN个词作为文本关键词,写入数据框;
(10)将最终结果写入文件keys_TFIDF.csv。
最终运行结果如下图所示。
5种基于TextRank的文本提取方法关键词5.1 PageRank算法思路
TextRank算法是基于PageRank算法的,所以在介绍TextRank之前必须先了解一下PageRank算法。
PageRank 算法是谷歌创始人拉里佩奇和谢尔盖布林于 1998 年在斯坦福大学攻读研究生期间发明的。它用于根据网页之间的超链接计算网页的重要性。技术。该算法借鉴了学术界判断学术论文重要性的方法,即检查论文的引用次数。基于以上思想,PageRank算法的核心思想是网页的重要性由两部分组成:
①如果一个网页被大量其他网页链接,则说明这个网页更重要,即链接网页的数量;
②如果一个网页链接到排名靠前的网页,说明这个网页更重要,也就是链接网页的权重。
一般情况下,网页的PageRank值(PR)计算公式如下:
其中,PR(Pi)为第i个网页的重要性排名,即PR值; ɑ为阻尼系数,一般设置为0.85; N是网页总数; Mpi 是第 i 个网页的总数 外链网页的集合; L(Pj)为第j个网页的外链数。
初始阶段,假设所有网页的排名为1/N,根据上述公式计算每个网页的PR值。当迭代稳定后,停止迭代计算,得到最终结果。一般情况下,迭代10次左右就基本收敛了。
5.2 TextRank 算法思路
TextRank 算法是 Mihalcea 和 Tarau 在 2004 年在研究自动摘要提取时提出的,并在 PageRank 算法的思想上进行了改进。该算法将文本拆分为词表作为网络节点,形成词表网络图模型,将词之间的相似关系视为推荐或投票关系,从而计算出每个词的重要性。
基于TextRank的
Text关键词抽取就是利用局部词汇关系,即共现窗口,对候选关键词进行排序。该方法的步骤如下:
(1)对于给定的文本D,进行分词、词性标注、去除停用词等数据预处理操作。本小节采用口吃分词,保留'n', 'nz','v','vd','vn','l','a','d'这几个词,最后得到n个候选关键词,即D=[t1,t2, ...,tn];
(2) 构造候选关键词图G=(V,E),其中V为节点集,由候选关键词组成,使用共现关系构造任意两个点 只有当它们对应的词在长度为K的窗口中共同出现时,两个节点之间才有一条边。K代表窗口的大小,即最多K个词可以同时出现;
(3)根据公式迭代计算每个节点的权重,直到收敛;
(4)将节点权重逆序排序,得到前N个词作为文本关键词.
注意:jieba 库中收录的 jieba.analysis.textrank 函数可以直接实现 TextRank 算法。本文使用该函数进行实验。
5.3 代码实现
基于TextRank方法实现文本关键词代码执行步骤如下:
(1)读取示例源文件sample_data.csv;
(2)获取每行记录的title和summary字段,将这两个字段拼接起来;
(3)加载自定义停用词列表stopWord.txt;
<p>(4)遍历文本记录,使用jieba.analysis.textrank函数过滤掉指定词性和topN文本关键词,并将结果存入数据框;
采集内容插入词库(搜索引擎和信息传递是个不能回避的问题?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-12-28 18:08
采集内容插入词库。例如百度的品牌词,我们怎么知道什么样的词语出现几率比较大,比如“涂个防晒霜”这样的词语,你收集一下购买人群,购买经验与购买渠道等信息。当你在某天使用该词的几率会更大。
不是一个好互联网用户并不能很好的理解你在说什么
估计你说的是说搜索引擎吧?其实是一样的,是源于商业,信息传递等等的目的。
不知道你是站在哪个角度看的搜索引擎,如果从技术角度,搜索引擎和信息传递方式是完全不同的,搜索引擎是存储数据,而信息传递是没有什么区别的。即搜索引擎更多的在搜索本身,是基于文本的。
搜索引擎上将用户需要搜索的内容汇总。
搜索引擎和信息传递没有本质区别,就像历史地图,古今中外没有大区别。要提高搜索引擎效率不外乎是靠算法提高计算效率,用户看到的不是真实信息,而是现有条件下所能选择的最优信息。
无限的知识
信息传递是中央管理下的供给侧管理;搜索引擎,是按照一定算法,提供系统性的服务。
我以为,但凡越智能化的东西,理解起来越快。
差不多的,
网络化的信息传递是个不能回避的问题。中国互联网最大的问题在于传播噪音太大,各种冗余信息比比皆是,因此才需要所谓权威媒体这类中介来加速信息传递。对应的,传统媒体也有大量冗余信息。 查看全部
采集内容插入词库(搜索引擎和信息传递是个不能回避的问题?)
采集内容插入词库。例如百度的品牌词,我们怎么知道什么样的词语出现几率比较大,比如“涂个防晒霜”这样的词语,你收集一下购买人群,购买经验与购买渠道等信息。当你在某天使用该词的几率会更大。
不是一个好互联网用户并不能很好的理解你在说什么
估计你说的是说搜索引擎吧?其实是一样的,是源于商业,信息传递等等的目的。
不知道你是站在哪个角度看的搜索引擎,如果从技术角度,搜索引擎和信息传递方式是完全不同的,搜索引擎是存储数据,而信息传递是没有什么区别的。即搜索引擎更多的在搜索本身,是基于文本的。
搜索引擎上将用户需要搜索的内容汇总。
搜索引擎和信息传递没有本质区别,就像历史地图,古今中外没有大区别。要提高搜索引擎效率不外乎是靠算法提高计算效率,用户看到的不是真实信息,而是现有条件下所能选择的最优信息。
无限的知识
信息传递是中央管理下的供给侧管理;搜索引擎,是按照一定算法,提供系统性的服务。
我以为,但凡越智能化的东西,理解起来越快。
差不多的,
网络化的信息传递是个不能回避的问题。中国互联网最大的问题在于传播噪音太大,各种冗余信息比比皆是,因此才需要所谓权威媒体这类中介来加速信息传递。对应的,传统媒体也有大量冗余信息。
采集内容插入词库(内容APP如何通过给文章分类以及打标签?17年-18年底)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-12-27 08:12
笔者结合自己的项目经验,分析了内容类app是如何对文章进行分类标注的?
2017-18年底,参与了一个信息内容兴趣偏好标签项目。什么是内容兴趣偏好标签?
简单来说,就是分析用户喜欢阅读的文章类型,获取用户的兴趣爱好。在此基础上,对用户进行个性化的内容推荐和推送,有效提升应用活跃度,延长用户生命周期。
简单来说,这件事情其实就是一个两步的过程:
那么在实践中真的那么简单吗?这两个看似简单的链接是如何实现的?
首先说一下文章的分类
因为这个项目,笔者看了很多竞品app的文章分类,发现基本相同,只是在细节上有些不同。更多的问题是新闻文章的分类难以穷尽,我们参考市场上现有的分类,结合一些数据,开发了一套内容兴趣偏好系统。在指定分类时,我们遵循MECE原则,基本实现相互独立和完全穷举。
接下来,我们要对文章进行分类,我们使用分类算法的监督学习。理想情况下,该过程如下所示:
然而,在实践中存在两个问题。因为选择了监督学习,所以需要为标注样本提供依据。一般来说,有以下三种获取样本的方式:
得到样本后,就是算法模型的训练和测试。算法模型的训练原理是对样本文章进行分割,提取实体,建立特征工程,将每个特征词作为向量拟合一个函数。这样,当有新文章时,文章会通过分词,并通过模型计算结果。但是,模型不能与样本一次性准确,需要对模型进行测试和修正。一般测试程序如下:
通过测试的模型不是一劳永逸的。后期可能还存在一些分类不准确的问题,可能是样本或者算法模型造成的。这就需要我们找出这些异常的文章和它们的分类,对分类进行修正,然后作为训练样本再次馈送到模型中进行模型修正。一方面,我们可以手动检查转化率较低的分类文章,以确定问题是否出在算法上。另外,这里由于每篇文章的标签都被赋值了,我们可以为这些值设置一个阈值。当最高值低于某个阈值时,这些文章及其标签会被人工召回和标注并进行更正,并放入这里的样本库中。
文章标签的计算,因为文章可能有多个标签,不是某个二类或另一类的结果。因此,我们使用相似度算法和模型来计算文章的标签并赋值。值越高表示越接近这种类型的标签,就会进行相应的标注。
至此,文章的标注部分已经完成。
如何标记用户
对用户进行标记其实有两种方式,统计标记和算法标记。
前者可以在算法资源不足、运算需求大的情况下进行,后者可以在前者的基础上通过拆分一部分流量来验证和调整算法模型,不断优化。
但是,在使用第一种方法时,我们发现用户在一段时间内阅读的文章类型并不稳定。大多数用户都会有一个或几个主要的兴趣偏好,这些类型阅读的文章数量会更多。,但与此同时,用户或多或少会阅读一些其他类型的文章,甚至有些用户会阅读他们看到的内容。
基于这种情况,我们需要对用户的兴趣偏好进行排序,即通过对一段时间内每种文章类型的用户阅读文章的数量进行排序,并取用户的前10个标签,清楚地告诉运营用户什么他们喜欢的文章类型,在这些类型中,用户最喜欢的类型的优先级是什么,方便操作学生推送选择。
因此,用户标签也需要更加灵活,让操作学生可以根据事件发生时间、事件发生次数等权重灵活组合和选择用户组。
由于目前有很大一部分推送是人工进行的,从选择文章,到选择用户,再到匹配文章和用户,在正式推送之前一般都会进行大量的A/B测试,新闻文章的类型差异很大. 很多,仅一级标签就达到了30+种,二级标签从100个到几百个不等。整个标签很可能有数千个标签。绝对不可能靠操作学生来推。
因此,当运营资源有限,无法实现自动化时,一般的运营学生会测试标签,选择覆盖用户量大、转化率高的标签。但同时,这种情况也会导致一些兴趣相对较小的用户被排除在推送人群之外。
针对这种情况,我们将用户排名前10的二级标签及其对应的一级标签作为用户的一级标签和二级标签。这样,用户覆盖的问题就解决了,运营商也可以集中精力推送主标签和人群。
但与此同时,另一个问题也出现了。选择用户在一段时间内的行为。这个时间段多长比较合适,这样既能充分体现用户的兴趣,又能覆盖更多的人(每天都有流失的用户,所以时间线越长,覆盖的用户数越多,覆盖的用户数越短)时间线,覆盖的用户数量越少)
我们发现用户的长期兴趣偏好在一定程度上趋于稳定,但短期兴趣偏好反映了用户在短期内关注热点的行为。因此,从这个角度来看,短期或许能更好地满足用户的需求,但短期对用户的覆盖面较小。在这里,覆盖率和转化率之间永远存在着永恒的矛盾。
我们的方法是根据浏览时间对用户进行细分。给予用户长期兴趣偏好和短期兴趣偏好,并优先考虑短期兴趣偏好,将短期兴趣用户排除在长期兴趣偏好之外,进行不同的推送。对于流失用户,很可能最近3个月没有访问记录(信息定义流失用户时间为3个月)。对于此类用户,我们将用户最后记录的标签作为用户标签,从丢失中恢复。
此时,所有用户都有自己的标签,运营学生也可以根据用户的活跃时间和阅读频率,将不同的文章推送给不同的用户,实现千人。
可以说,我们在这个问题上踩了很多坑。
第二种方法是通过算法直接标记用户。除了时间和阅读频率,算法模型还可以加入更多的特征纬度,比如用户当前阅读文章的时间、阅读文章的时长、评论、点赞等,同时你还可以为热点文章和热点事件降低文章权重。
结束语
当我回过头来总结这段经历时,即使你跟着我来理解这段经历,读者可能觉得其实很简单,但是在这次经历中我们真的踩到了无数坑,尤其是我们不仅要采集
数据,还要做标签,同时也引导业务开展和分析问题。那段经历,可以说是痛并快乐着——
痛苦是因为问题太多,生意每天都在追我。我问为什么今天的转化率很低;幸福是因为我们最终的转化率终于翻了一番,甚至高于行业水平,算是最好的回报了。
本文首发于@糖糖是老坛酸菜王。每个人都是产品经理。未经作者许可,禁止转载。
标题图片来自Unsplash,基于CC0协议。 查看全部
采集内容插入词库(内容APP如何通过给文章分类以及打标签?17年-18年底)
笔者结合自己的项目经验,分析了内容类app是如何对文章进行分类标注的?
2017-18年底,参与了一个信息内容兴趣偏好标签项目。什么是内容兴趣偏好标签?
简单来说,就是分析用户喜欢阅读的文章类型,获取用户的兴趣爱好。在此基础上,对用户进行个性化的内容推荐和推送,有效提升应用活跃度,延长用户生命周期。
简单来说,这件事情其实就是一个两步的过程:
那么在实践中真的那么简单吗?这两个看似简单的链接是如何实现的?
首先说一下文章的分类
因为这个项目,笔者看了很多竞品app的文章分类,发现基本相同,只是在细节上有些不同。更多的问题是新闻文章的分类难以穷尽,我们参考市场上现有的分类,结合一些数据,开发了一套内容兴趣偏好系统。在指定分类时,我们遵循MECE原则,基本实现相互独立和完全穷举。
接下来,我们要对文章进行分类,我们使用分类算法的监督学习。理想情况下,该过程如下所示:
然而,在实践中存在两个问题。因为选择了监督学习,所以需要为标注样本提供依据。一般来说,有以下三种获取样本的方式:
得到样本后,就是算法模型的训练和测试。算法模型的训练原理是对样本文章进行分割,提取实体,建立特征工程,将每个特征词作为向量拟合一个函数。这样,当有新文章时,文章会通过分词,并通过模型计算结果。但是,模型不能与样本一次性准确,需要对模型进行测试和修正。一般测试程序如下:
通过测试的模型不是一劳永逸的。后期可能还存在一些分类不准确的问题,可能是样本或者算法模型造成的。这就需要我们找出这些异常的文章和它们的分类,对分类进行修正,然后作为训练样本再次馈送到模型中进行模型修正。一方面,我们可以手动检查转化率较低的分类文章,以确定问题是否出在算法上。另外,这里由于每篇文章的标签都被赋值了,我们可以为这些值设置一个阈值。当最高值低于某个阈值时,这些文章及其标签会被人工召回和标注并进行更正,并放入这里的样本库中。
文章标签的计算,因为文章可能有多个标签,不是某个二类或另一类的结果。因此,我们使用相似度算法和模型来计算文章的标签并赋值。值越高表示越接近这种类型的标签,就会进行相应的标注。
至此,文章的标注部分已经完成。
如何标记用户
对用户进行标记其实有两种方式,统计标记和算法标记。
前者可以在算法资源不足、运算需求大的情况下进行,后者可以在前者的基础上通过拆分一部分流量来验证和调整算法模型,不断优化。
但是,在使用第一种方法时,我们发现用户在一段时间内阅读的文章类型并不稳定。大多数用户都会有一个或几个主要的兴趣偏好,这些类型阅读的文章数量会更多。,但与此同时,用户或多或少会阅读一些其他类型的文章,甚至有些用户会阅读他们看到的内容。
基于这种情况,我们需要对用户的兴趣偏好进行排序,即通过对一段时间内每种文章类型的用户阅读文章的数量进行排序,并取用户的前10个标签,清楚地告诉运营用户什么他们喜欢的文章类型,在这些类型中,用户最喜欢的类型的优先级是什么,方便操作学生推送选择。
因此,用户标签也需要更加灵活,让操作学生可以根据事件发生时间、事件发生次数等权重灵活组合和选择用户组。
由于目前有很大一部分推送是人工进行的,从选择文章,到选择用户,再到匹配文章和用户,在正式推送之前一般都会进行大量的A/B测试,新闻文章的类型差异很大. 很多,仅一级标签就达到了30+种,二级标签从100个到几百个不等。整个标签很可能有数千个标签。绝对不可能靠操作学生来推。
因此,当运营资源有限,无法实现自动化时,一般的运营学生会测试标签,选择覆盖用户量大、转化率高的标签。但同时,这种情况也会导致一些兴趣相对较小的用户被排除在推送人群之外。
针对这种情况,我们将用户排名前10的二级标签及其对应的一级标签作为用户的一级标签和二级标签。这样,用户覆盖的问题就解决了,运营商也可以集中精力推送主标签和人群。
但与此同时,另一个问题也出现了。选择用户在一段时间内的行为。这个时间段多长比较合适,这样既能充分体现用户的兴趣,又能覆盖更多的人(每天都有流失的用户,所以时间线越长,覆盖的用户数越多,覆盖的用户数越短)时间线,覆盖的用户数量越少)
我们发现用户的长期兴趣偏好在一定程度上趋于稳定,但短期兴趣偏好反映了用户在短期内关注热点的行为。因此,从这个角度来看,短期或许能更好地满足用户的需求,但短期对用户的覆盖面较小。在这里,覆盖率和转化率之间永远存在着永恒的矛盾。
我们的方法是根据浏览时间对用户进行细分。给予用户长期兴趣偏好和短期兴趣偏好,并优先考虑短期兴趣偏好,将短期兴趣用户排除在长期兴趣偏好之外,进行不同的推送。对于流失用户,很可能最近3个月没有访问记录(信息定义流失用户时间为3个月)。对于此类用户,我们将用户最后记录的标签作为用户标签,从丢失中恢复。
此时,所有用户都有自己的标签,运营学生也可以根据用户的活跃时间和阅读频率,将不同的文章推送给不同的用户,实现千人。
可以说,我们在这个问题上踩了很多坑。
第二种方法是通过算法直接标记用户。除了时间和阅读频率,算法模型还可以加入更多的特征纬度,比如用户当前阅读文章的时间、阅读文章的时长、评论、点赞等,同时你还可以为热点文章和热点事件降低文章权重。
结束语
当我回过头来总结这段经历时,即使你跟着我来理解这段经历,读者可能觉得其实很简单,但是在这次经历中我们真的踩到了无数坑,尤其是我们不仅要采集
数据,还要做标签,同时也引导业务开展和分析问题。那段经历,可以说是痛并快乐着——
痛苦是因为问题太多,生意每天都在追我。我问为什么今天的转化率很低;幸福是因为我们最终的转化率终于翻了一番,甚至高于行业水平,算是最好的回报了。
本文首发于@糖糖是老坛酸菜王。每个人都是产品经理。未经作者许可,禁止转载。
标题图片来自Unsplash,基于CC0协议。
采集内容插入词库(网站页面质量、数量、用户行为,到底哪个重要?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-12-25 21:14
在网站优化的过程中,我们总是会讨论网站的状态。百度的权重是重要的衡量指标之一。长期以来,SEO人员一直在围绕这些指标工作。
但是我们总是看以下几种情况:
① 高权重海量采集
② 一般收录
高权重
③ 单个页面收录
高权重
也是一个高权重的网站,但是百度的收录量就不一样了。其中,我们认为涉及的主要核心因素包括:页面质量、数量和用户行为。
那么,网站页面质量、数量和用户行为哪个最重要?
根据之前的SEO观察,Batman IT会详细说明如下:
1、页数
如果你有时间去统计一下你所在行业的相关网站,你会发现网站权重在5-8的网站会有一个重要的特点,那就是收录的页数非常高,一般在20000+页。
为什么会出现这种情况:
① 前段时间,我们讨论了内容增量的问题。它主要考虑网站的活动。在相对搜索阈值的情况下,如果你的内容增加,会长期保持稳定增长状态。
对于搜索引擎,它会继续给你更高程度的关注,尤其是对垂直行业的信任。说白了,当你每天广播内容的时候,对方总是希望挖掘出相关的有价值的页面。会更加关注你。
②海量长尾关键词排名,基于海量内容的增长,必然有这样一个特定的情况,即网站有更高的长尾关键词词库。
并且由于关键词的长尾排名,也会带来大量的用户访问量,使网站处于良性循环。
③反向链接的增长,基于网站权重的增加和大量页面的展示,你会在无形中得到一些外部链接,尤其是一些站群采集
站,对方经常把网址和锚文本链接采集
在一起。
2、页面质量
在上一篇文章中,我们提到过,如果你打算让一个网站的权重达到5以上,通常的页面收录量需要在一万以上,但有时这种情况也不是绝对的。
这里需要简单说一下:网站权重的积累其实就是对关键词搜索量排名位置的评价。如果您的网站页面有很多百度指数非常高的页面,则它们的排名会更高。
在一定程度上,用少量的页面,比如5000页,做一个高权重的网站实际上是可能的。
这包括:
① 关键词 选择和布局。
②网站内部结构设计及内链链接策略。
③页面解决用户搜索需求的能力。
3、用户行为
但是,在日常工作中,我们也会遇到这样的特殊情况,就是一个页面可以获得更高的权重,甚至整个页面都会得到海量的关键词排名展示。
记得我们前几天写的一页排名案例,并进行了详细的讨论。
其中,我们认为一个页面要获得更高的权重最重要的元素是:
① 页面主题的垂直相关性有多高?
②优质外链数量多,展示形式多样。
③持续稳定的用户行为接入。
4、策略选择
这时候你可能会问我,如果是Batman IT,你是如何选择相关性策略来增加百度权重的?我认同:
① 优质页面组合
这里我们通常建议您创建高质量的页面组合并增加权重。原因很简单。您只需要关注每个页面的主题。
值得注意的是,并非每个站长都有能力批量生产海量数据,无论内容质量如何。因此,我们推荐一种优化主页的策略。
②营销单页矩阵
营销单页矩阵主要是指单页网站的集合。一般一个网页一个域名,策略性地进行友情链接的互联。
总结:高权重网站的质量、数量和用户行为哪个重要?我们认为,如何建立垂直相关的内容,如何吸引用户访问和停留更为重要。以上内容仅供参考。 查看全部
采集内容插入词库(网站页面质量、数量、用户行为,到底哪个重要?)
在网站优化的过程中,我们总是会讨论网站的状态。百度的权重是重要的衡量指标之一。长期以来,SEO人员一直在围绕这些指标工作。
但是我们总是看以下几种情况:
① 高权重海量采集
② 一般收录
高权重
③ 单个页面收录
高权重
也是一个高权重的网站,但是百度的收录量就不一样了。其中,我们认为涉及的主要核心因素包括:页面质量、数量和用户行为。
那么,网站页面质量、数量和用户行为哪个最重要?
根据之前的SEO观察,Batman IT会详细说明如下:
1、页数
如果你有时间去统计一下你所在行业的相关网站,你会发现网站权重在5-8的网站会有一个重要的特点,那就是收录的页数非常高,一般在20000+页。
为什么会出现这种情况:
① 前段时间,我们讨论了内容增量的问题。它主要考虑网站的活动。在相对搜索阈值的情况下,如果你的内容增加,会长期保持稳定增长状态。
对于搜索引擎,它会继续给你更高程度的关注,尤其是对垂直行业的信任。说白了,当你每天广播内容的时候,对方总是希望挖掘出相关的有价值的页面。会更加关注你。
②海量长尾关键词排名,基于海量内容的增长,必然有这样一个特定的情况,即网站有更高的长尾关键词词库。
并且由于关键词的长尾排名,也会带来大量的用户访问量,使网站处于良性循环。
③反向链接的增长,基于网站权重的增加和大量页面的展示,你会在无形中得到一些外部链接,尤其是一些站群采集
站,对方经常把网址和锚文本链接采集
在一起。
2、页面质量
在上一篇文章中,我们提到过,如果你打算让一个网站的权重达到5以上,通常的页面收录量需要在一万以上,但有时这种情况也不是绝对的。
这里需要简单说一下:网站权重的积累其实就是对关键词搜索量排名位置的评价。如果您的网站页面有很多百度指数非常高的页面,则它们的排名会更高。
在一定程度上,用少量的页面,比如5000页,做一个高权重的网站实际上是可能的。
这包括:
① 关键词 选择和布局。
②网站内部结构设计及内链链接策略。
③页面解决用户搜索需求的能力。
3、用户行为
但是,在日常工作中,我们也会遇到这样的特殊情况,就是一个页面可以获得更高的权重,甚至整个页面都会得到海量的关键词排名展示。
记得我们前几天写的一页排名案例,并进行了详细的讨论。
其中,我们认为一个页面要获得更高的权重最重要的元素是:
① 页面主题的垂直相关性有多高?
②优质外链数量多,展示形式多样。
③持续稳定的用户行为接入。
4、策略选择
这时候你可能会问我,如果是Batman IT,你是如何选择相关性策略来增加百度权重的?我认同:
① 优质页面组合
这里我们通常建议您创建高质量的页面组合并增加权重。原因很简单。您只需要关注每个页面的主题。
值得注意的是,并非每个站长都有能力批量生产海量数据,无论内容质量如何。因此,我们推荐一种优化主页的策略。
②营销单页矩阵
营销单页矩阵主要是指单页网站的集合。一般一个网页一个域名,策略性地进行友情链接的互联。
总结:高权重网站的质量、数量和用户行为哪个重要?我们认为,如何建立垂直相关的内容,如何吸引用户访问和停留更为重要。以上内容仅供参考。
采集内容插入词库(综合工具箱、dnspod解析、收录查询、词汇生成,外推规则生成)
采集交流 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-12-22 13:05
摩特超级站长助手包括:综合工具箱、dnspod分析、51dns分析、收录查询、词汇生成,最新功能:英文单词生成、外推规则生成、外推码转换。[关键词/corpus]词库/爱站网采集、关键词挖矿鸡、域名挖矿关键词、关键词破解、关键词添加后缀、去拼音重复、去尾空格、综合词汇生成、百度禁词过滤、关键词正则处理、伪原创生成工具【域名/IP处理】通用域名生成、泛目录生成、域名批量添加www、Gov生成工具、后缀增删、域名信息查询、批量网站接入、258IP一键生成、 查看全部
采集内容插入词库(分析一下企查查,本着分享知识的原则、原则和原则 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-12-19 13:15
)
最近有朋友要我分析七茶茶。本着知识分享的原则,我想根据自己浅薄的知识和见解,给大家介绍一下七叉茶的SEO亮点,希望能帮助更多的兄弟了解SEO。自然!
我之前也分析过顺奇网和58网。你可以看看你是否喜欢它。58同城的词库个人感觉比较笼统一点,公司查的比较准确。和上面两个相比,顺奇网的话。有点复杂,有不同的业务,不同的词库,不分高低。
(内容、模板)稀缺
现在很多人做SEO,还认为原创是SEO的核心。企业调查是对这一观点的最大否定。因为上面的信息基本都是采集。
不过目测采集的内容应该是调用国家的数据库,因为国内各个企业的信息应该没有那么好。企业信息对权威网站的信任度相对较低。只有国家信息才能准确。
内容已经解决,公司在用户体验和模板方面做了很好的对比。在之前的课程中,我们也讲过影响排名的因素和收录。模板也是其中之一。.
大规模网站是最终的绝对量级竞争。词库决定权重,收录决定词库。这种收录的水平,绝对不是几十人、几百人能做到的。
词库精准定位
词库的定位与业务直接相关,但仅就竞争而言,Enterprise Check的词库远小于同城58的词库。企业搜索的词库一般以【公司名称】【法人名称、股东名称】为主,而58则主要以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白很难关键词 轻松度。
但如果词库定位准确,客户就会准确得多。当你的量级达到几千万或者几亿的时候,长尾带来的流量是相当恐怖的,这些每天访问网站的恐怖流量带来的信任度的增加绝不是普通的小网站可比的.
就像谈58一样,品牌流量作为源头带动了网站的整体信任度。信任高后,长尾流量来了,一次次回馈网站,良性循环!
学习和应用
其实,为什么要分析企业搜索?因为企业搜索的难度比较低。我们可以将他的词库导出为权重站!
比如我以前做过的站名,可以做公司名站,或者其他站。毕竟,同义词库是可用的。内容是聚合的,即使它是随机生成的,并且以分钟为单位给出权重。
查看全部
采集内容插入词库(分析一下企查查,本着分享知识的原则、原则和原则
)
最近有朋友要我分析七茶茶。本着知识分享的原则,我想根据自己浅薄的知识和见解,给大家介绍一下七叉茶的SEO亮点,希望能帮助更多的兄弟了解SEO。自然!
我之前也分析过顺奇网和58网。你可以看看你是否喜欢它。58同城的词库个人感觉比较笼统一点,公司查的比较准确。和上面两个相比,顺奇网的话。有点复杂,有不同的业务,不同的词库,不分高低。
(内容、模板)稀缺
现在很多人做SEO,还认为原创是SEO的核心。企业调查是对这一观点的最大否定。因为上面的信息基本都是采集。
不过目测采集的内容应该是调用国家的数据库,因为国内各个企业的信息应该没有那么好。企业信息对权威网站的信任度相对较低。只有国家信息才能准确。
内容已经解决,公司在用户体验和模板方面做了很好的对比。在之前的课程中,我们也讲过影响排名的因素和收录。模板也是其中之一。.
大规模网站是最终的绝对量级竞争。词库决定权重,收录决定词库。这种收录的水平,绝对不是几十人、几百人能做到的。
词库精准定位
词库的定位与业务直接相关,但仅就竞争而言,Enterprise Check的词库远小于同城58的词库。企业搜索的词库一般以【公司名称】【法人名称、股东名称】为主,而58则主要以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白很难关键词 轻松度。
但如果词库定位准确,客户就会准确得多。当你的量级达到几千万或者几亿的时候,长尾带来的流量是相当恐怖的,这些每天访问网站的恐怖流量带来的信任度的增加绝不是普通的小网站可比的.
就像谈58一样,品牌流量作为源头带动了网站的整体信任度。信任高后,长尾流量来了,一次次回馈网站,良性循环!
学习和应用
其实,为什么要分析企业搜索?因为企业搜索的难度比较低。我们可以将他的词库导出为权重站!
比如我以前做过的站名,可以做公司名站,或者其他站。毕竟,同义词库是可用的。内容是聚合的,即使它是随机生成的,并且以分钟为单位给出权重。
采集内容插入词库(如何创建行业关键词词库,词库为什么重要?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-12-19 11:07
今天我们就来聊聊如何创建行业关键词词库。为什么词库很重要?
词库是最可能覆盖人群的手段,无论是非标产品还是标准产品,都必须建立词库。关键词词典的作用是什么?
寻找最适合你的产品并且有能力操作的关键词,尤其是一些需要大量产品的非标产品,你需要通过关键词触达人群。其次,直通车推广关键词也是通过这种方式来分析的
词库,我一般会创建两个,一个是关键词词库,一个是分词词库,以牙膏挤压器为例
首先是搜索分析你的业务人员,找到你自己的三级品类或产品,过滤核心关键词和修饰符。下图是为了帮助我们找到产品词。有些产品可能有不同的名称是的,我们需要先了解一下。如果是砧板,也叫砧板或砧板。如果我们不熟悉这个类别,我们根本找不到它,而且会浪费很多流量。
找到之后,还需要分析修饰语,目的是找出所有相关的词。说到这里,这些数据需要创建在一个表中,不能只看这样
牙膏挤压器,修饰符中的“挤压”已经收录,无需采集分析,重点分析以下
壁挂式、自动、全自动、儿童、可爱……这些词也叫需求词
组合是壁挂式牙膏挤奶器、牙膏自动挤奶器
这是搜索的核心词。核心词和长尾词需要一一分析采集,自动挤牙膏,挤牙膏在墙上,下面的数据,同理,放到上表中进行分析。下图中的数据是要放在一个表格中的,所以罗嗦
竞争程度是蓝海价值。在搜索热度/在线产品数量时,我们也可以使用交易指数/在线产品数量。这些可以用来判断关键词的市场和饱和度
对于标准产品,必须采集销售额。非标产品销售问题不大,但还是建议采集
这个关键词词库很简单,但是操作一定要小心谨慎。每个 关键词 都必须采集。此时,可能存在重复项。采集完成后,您需要删除重复项。
还需要删除一些特别长的关键词,大部分都是刷出来的;有很多不符合他们的产品,可能会被删除
采集业务人员的话,还需要采集同事的话,有些是实名或者错字也需要采集
如果是非标产品,制作一个关键词词库至少需要一天时间,但是这个关键词词库可以使用一整年。跟进一个月关注飙升的词和新出现的关键词。只是优化没有采集到的词。
稍微扩展一下,我们将使用哪些词?使用直通车测试,尤其是非标产品,需求词和转换词更加多样化,测试模型的时候可以测试出来。
看字族的数据比较好,应该优先考虑哪一个,做起来肯定容易些 查看全部
采集内容插入词库(如何创建行业关键词词库,词库为什么重要?(组图))
今天我们就来聊聊如何创建行业关键词词库。为什么词库很重要?
词库是最可能覆盖人群的手段,无论是非标产品还是标准产品,都必须建立词库。关键词词典的作用是什么?
寻找最适合你的产品并且有能力操作的关键词,尤其是一些需要大量产品的非标产品,你需要通过关键词触达人群。其次,直通车推广关键词也是通过这种方式来分析的
词库,我一般会创建两个,一个是关键词词库,一个是分词词库,以牙膏挤压器为例
首先是搜索分析你的业务人员,找到你自己的三级品类或产品,过滤核心关键词和修饰符。下图是为了帮助我们找到产品词。有些产品可能有不同的名称是的,我们需要先了解一下。如果是砧板,也叫砧板或砧板。如果我们不熟悉这个类别,我们根本找不到它,而且会浪费很多流量。
找到之后,还需要分析修饰语,目的是找出所有相关的词。说到这里,这些数据需要创建在一个表中,不能只看这样
牙膏挤压器,修饰符中的“挤压”已经收录,无需采集分析,重点分析以下
壁挂式、自动、全自动、儿童、可爱……这些词也叫需求词
组合是壁挂式牙膏挤奶器、牙膏自动挤奶器
这是搜索的核心词。核心词和长尾词需要一一分析采集,自动挤牙膏,挤牙膏在墙上,下面的数据,同理,放到上表中进行分析。下图中的数据是要放在一个表格中的,所以罗嗦
竞争程度是蓝海价值。在搜索热度/在线产品数量时,我们也可以使用交易指数/在线产品数量。这些可以用来判断关键词的市场和饱和度
对于标准产品,必须采集销售额。非标产品销售问题不大,但还是建议采集
这个关键词词库很简单,但是操作一定要小心谨慎。每个 关键词 都必须采集。此时,可能存在重复项。采集完成后,您需要删除重复项。
还需要删除一些特别长的关键词,大部分都是刷出来的;有很多不符合他们的产品,可能会被删除
采集业务人员的话,还需要采集同事的话,有些是实名或者错字也需要采集
如果是非标产品,制作一个关键词词库至少需要一天时间,但是这个关键词词库可以使用一整年。跟进一个月关注飙升的词和新出现的关键词。只是优化没有采集到的词。
稍微扩展一下,我们将使用哪些词?使用直通车测试,尤其是非标产品,需求词和转换词更加多样化,测试模型的时候可以测试出来。
看字族的数据比较好,应该优先考虑哪一个,做起来肯定容易些
采集内容插入词库(功能强大的免费伪原创工具(基本介绍)(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-12-19 11:05
[一般介绍] 一个强大且免费的伪原创工具。 【基本介绍】你要的伪原创工具,所有功能都可以自己定义。 【软件功能】1、支持与文章本义相似的词替换,每个词都有独特的随机替换算法; 2、 支持改变文章 段落随机混淆、名词替换的原意; 3、 支持搜索引擎优化(SEO)友好的自定义关键词替换、自定义关键词、HTML随机插入文章; 4、支持关键词/文章标题按照密度或随机次数重复插入到内容中,增加搜索引擎相关性; 5、专为标题短语设计的造句功能; 6、可以对单篇文章文章或批量TXT进行伪原创操作; 7、所有词库都开放,你可以自己设置词库; 8、 支持多种方式批量导入多个词典。 9、可视化HTML代码编辑10、集成到智能博客助手后即可发布文章伪原创操作11、时动态执行1、可以设置关键词12、支持收录HTML和UBB代码的内容伪原创的替换次数,可自定义是否操作HTML,UBB代码13、支持繁简转换,批量转换14、支持自定义替换,插入多库管理15、支持云词库功能【更新日志】Smart Motion伪原创工具V2.0.@ >4★修改算法随机替换时,将同一篇文章文章中的同一个词随机替换为不同的一个词优化同义词词典替换算法,效率提高2倍。名词替换算法优化,效率提升10倍。 文章 标题或具体关键词 通过密度函数反复插入内容,增强文章的相关性,增加百度的权重。增加云词库更新。可选的更新选项。增加用户对EMAIL功能的反馈。添加清除链接脚本HTML、复制结果等快捷功能。选择目录中的所有文件进行批处理。增加支持WIN764位系统。修复插入时自定义内容插入到HTML中的bug。修复插入自定义内容时字数不够的bug。修复随机最大值最小值相同时随机插入内容无效的bug。编辑器编辑后,图片自动变小。 BUG 由于时间和精力有限,云词库提交词的功能被切断 查看全部
采集内容插入词库(功能强大的免费伪原创工具(基本介绍)(图))
[一般介绍] 一个强大且免费的伪原创工具。 【基本介绍】你要的伪原创工具,所有功能都可以自己定义。 【软件功能】1、支持与文章本义相似的词替换,每个词都有独特的随机替换算法; 2、 支持改变文章 段落随机混淆、名词替换的原意; 3、 支持搜索引擎优化(SEO)友好的自定义关键词替换、自定义关键词、HTML随机插入文章; 4、支持关键词/文章标题按照密度或随机次数重复插入到内容中,增加搜索引擎相关性; 5、专为标题短语设计的造句功能; 6、可以对单篇文章文章或批量TXT进行伪原创操作; 7、所有词库都开放,你可以自己设置词库; 8、 支持多种方式批量导入多个词典。 9、可视化HTML代码编辑10、集成到智能博客助手后即可发布文章伪原创操作11、时动态执行1、可以设置关键词12、支持收录HTML和UBB代码的内容伪原创的替换次数,可自定义是否操作HTML,UBB代码13、支持繁简转换,批量转换14、支持自定义替换,插入多库管理15、支持云词库功能【更新日志】Smart Motion伪原创工具V2.0.@ >4★修改算法随机替换时,将同一篇文章文章中的同一个词随机替换为不同的一个词优化同义词词典替换算法,效率提高2倍。名词替换算法优化,效率提升10倍。 文章 标题或具体关键词 通过密度函数反复插入内容,增强文章的相关性,增加百度的权重。增加云词库更新。可选的更新选项。增加用户对EMAIL功能的反馈。添加清除链接脚本HTML、复制结果等快捷功能。选择目录中的所有文件进行批处理。增加支持WIN764位系统。修复插入时自定义内容插入到HTML中的bug。修复插入自定义内容时字数不够的bug。修复随机最大值最小值相同时随机插入内容无效的bug。编辑器编辑后,图片自动变小。 BUG 由于时间和精力有限,云词库提交词的功能被切断
采集内容插入词库( 如何添加采集自定义资源库(图)网站(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-12-19 08:11
如何添加采集自定义资源库(图)网站(组图))
也想来这里吗?点击联系我~
1、今天教大家如何添加采集自定义资源库;进入后台,我们以一个资源站为例,界面可以从你要采集的网站获取。都在网站的帮助中心:添加方法如下图(添加后测试不成功,需要在&ct=1)中填写附加参数
2.这里没填,只要测试界面成功,直接保存即可。如果测试失败,填写附加参数&ct=1) 如果还是不行,检查采集界面是否填写错误
3、资源接口添加成功后,需要对资源进行分类绑定:点击高清资源链接,进入绑定页面进行分类绑定
4、进入分类绑定页面后,点击未绑定页面,分类绑定会自动弹出。如果找不到对应的,可以先绑定一个相似的分类或者添加自定义分类
5、绑定后剩下的就是采集,拉到页面底部。有一个按钮采集可以选择采集当天的采集(在需要采集 Tick的视频之前)和采集这三个选项
6、选择后,进入自动采集页面。如果绑定的采集绑定成功后显示为绿色和红色,则绑定不成功。跳过采集,所以绑定的时候一定要仔细绑定。
温馨提示:最后采集结束后,网站应该有视频数据了。这时候,也是很多人疑惑的地方。为什么是这样?那是因为你没有添加播放器。
每个资源站都有自己独立的播放器和解析,也就是你的采集谁的资源只能和谁的播放器一起玩。玩家一般可以在网站的帮助中心找到,里面有详细的说明。 查看全部
采集内容插入词库(
如何添加采集自定义资源库(图)网站(组图))
也想来这里吗?点击联系我~
1、今天教大家如何添加采集自定义资源库;进入后台,我们以一个资源站为例,界面可以从你要采集的网站获取。都在网站的帮助中心:添加方法如下图(添加后测试不成功,需要在&ct=1)中填写附加参数
https://bashijiu.com/wp-conten ... 2.png 300w, https://bashijiu.com/wp-conten ... 6.png 768w" />2.这里没填,只要测试界面成功,直接保存即可。如果测试失败,填写附加参数&ct=1) 如果还是不行,检查采集界面是否填写错误
https://bashijiu.com/wp-conten ... 1.png 300w, https://bashijiu.com/wp-conten ... 8.png 768w" />3、资源接口添加成功后,需要对资源进行分类绑定:点击高清资源链接,进入绑定页面进行分类绑定
https://bashijiu.com/wp-conten ... 8.png 300w, https://bashijiu.com/wp-conten ... 6.png 1024w, https://bashijiu.com/wp-conten ... 7.png 768w" />4、进入分类绑定页面后,点击未绑定页面,分类绑定会自动弹出。如果找不到对应的,可以先绑定一个相似的分类或者添加自定义分类
https://bashijiu.com/wp-conten ... 5.jpg 300w, https://bashijiu.com/wp-conten ... 8.jpg 1024w, https://bashijiu.com/wp-conten ... 6.jpg 768w" />5、绑定后剩下的就是采集,拉到页面底部。有一个按钮采集可以选择采集当天的采集(在需要采集 Tick的视频之前)和采集这三个选项
https://bashijiu.com/wp-conten ... 3.jpg 300w, https://bashijiu.com/wp-conten ... 1.jpg 1024w, https://bashijiu.com/wp-conten ... 1.jpg 768w" />6、选择后,进入自动采集页面。如果绑定的采集绑定成功后显示为绿色和红色,则绑定不成功。跳过采集,所以绑定的时候一定要仔细绑定。
https://bashijiu.com/wp-conten ... 0.png 300w, https://bashijiu.com/wp-conten ... 4.png 768w" />温馨提示:最后采集结束后,网站应该有视频数据了。这时候,也是很多人疑惑的地方。为什么是这样?那是因为你没有添加播放器。
每个资源站都有自己独立的播放器和解析,也就是你的采集谁的资源只能和谁的播放器一起玩。玩家一般可以在网站的帮助中心找到,里面有详细的说明。
采集内容插入词库(词库我用私人订制方案,助你快速治疗懒癌!! )
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-12-17 17:08
)
对于很多人来说,背单词是一种痛苦的经历,但学习英语也是必须的。痛点之一是,在使用托福、GRE等词汇记忆时,会遇到很多已经知道的单词,或者是很难遇到的单词忘记背。这个文章专门针对这个问题,分享一个我用了很久的词库的私人定制方案,还可以治疗懒癌。
有道词典
有道词典屏幕选词更方便,词库和社区功能也更全面,所以平时用的比较多。每天遇到的生词,可以随时放入有道自己的词汇书,采集回忆。有道词汇书虽然提供了背单词的功能,但是很单一,没有艾宾浩斯遗忘曲线,不适合复习单词。
墨迹
说一下陌陌(加个链接,免得大家想太多)。陌陌是我用过的最值得推荐的词汇记忆应用之一。原因如下:
1. 根据艾宾浩斯遗忘曲线给你需要复习的单词;
2. 可以创建自己的同义词库(在网页中操作),不需要跟着托福、雅思、四八同义词库记住很多已经背熟的词或者你通常不会遇到的;
3. 天天签到,签到即“鹏”,给你一丝不苟的成就感;
4. 你需要每天签到!一是因为如果几天不登录,就会积累很多需要复习的单词。其次,自建词库的词数不是无限的。通过购买获得数量是否会伤害您的自尊?);
5. 另外,每天至少要记住10个字才能签到;
6. 例句和助记词非常丰富,可以创建自己喜欢的助记方法;
7. 例句或助记词中的生词可直接加入记忆列表;
8. 应用内链接的五个在线词典;
9. 可以查看自己背过的单词的多项统计指标,以及对未来复习单词数的预测;
10. 暂时想到这些。
同义词私人订单
所以问题来了。一个是日常使用和生词采集的有道词典,另一个是自建词库中可以轻松记忆和复习的墨背词。如何快速有效地将有道词典词汇中收录的生词导入到自己创建的墨迹中?在墨水词汇中?
在这里,我绝对不会让你费时费力地一个一个复制!如果将有道词本导出,再放入墨墨词典,您会发现导出的词本包括序号、注音、词性标签、中文含义等,直接将这些全部复制到自建词典会带来很多麻烦(试试就知道了)。我的解决方案是这样的:
1. 将有道词典单词本中想要添加到内存中的单词导出为.txt文件;
2. 将.txt文件的编码改为utf-8(直接另存为,有选项);
3. 使用文末附加的python程序提取需要记住的单词;
4. 程序将生成一个 .txt 文件。打开之后,你会发现里面只剩下英文单词了。将它们复制到你自建的陌陌词典中,并记下词典编号;
5. 当你用陌陌记单词时,通过词库编号链接到你的词库,你就可以开始学习你的私人定制词库了。
代码
这个程序完成了文本文件中的记录:
350,化身[ɪnkɑː'neɪʃ(ə)n]n。化身;神道成肉身;典型化身:化身|
道成肉身 | 道成肉身
进入这个条目:
化身
该程序是用python编写的。我不经常做文本处理。这个程序只是满足简单的基本需求,所以应该还有很多需要改进的地方(欢迎分享你更好的解决方案)。你只需要用你的有道词典导出的utf-8编码的记事本文件的路径和名称替换第19行的E:\voc.txt
<p># -*- coding: utf-8 -*-
"""
Created on Apr 28 2016
Extracting vocabulary from Youdao dictionary
The vocabulary text file should be code as utf-8
file_in: the exported vocabulary from Youdao
file_out: the file to save the English words. Default file name is
new_words_'time'.txt ('time' is the local date)
@author: sinit
"""
import codecs,time
file_in = r'E:\voc.txt'
outname = 'new_words'+'_'+time.strftime("%Y-%m-%d",time.localtime())+".txt"
file_out = r'E:\\'+outname
fs = codecs.open(file_in, 'r','utf-8')
vocabulary = fs.readlines()
fs.close()
word = []
word.append(vocabulary[0].split()[1])
def is_chinese(uchar):
#Judge if a unicode is Chinese
if (uchar >=u'/u4e00')&(uchar= 0x2e80 and x = 0xff00 and x = 0x4e00 and x = 0xf900 and x = 0x20000 and x = 0x2f800 and x 查看全部
采集内容插入词库(词库我用私人订制方案,助你快速治疗懒癌!!
)
对于很多人来说,背单词是一种痛苦的经历,但学习英语也是必须的。痛点之一是,在使用托福、GRE等词汇记忆时,会遇到很多已经知道的单词,或者是很难遇到的单词忘记背。这个文章专门针对这个问题,分享一个我用了很久的词库的私人定制方案,还可以治疗懒癌。
有道词典
有道词典屏幕选词更方便,词库和社区功能也更全面,所以平时用的比较多。每天遇到的生词,可以随时放入有道自己的词汇书,采集回忆。有道词汇书虽然提供了背单词的功能,但是很单一,没有艾宾浩斯遗忘曲线,不适合复习单词。
墨迹
说一下陌陌(加个链接,免得大家想太多)。陌陌是我用过的最值得推荐的词汇记忆应用之一。原因如下:
1. 根据艾宾浩斯遗忘曲线给你需要复习的单词;
2. 可以创建自己的同义词库(在网页中操作),不需要跟着托福、雅思、四八同义词库记住很多已经背熟的词或者你通常不会遇到的;
3. 天天签到,签到即“鹏”,给你一丝不苟的成就感;
4. 你需要每天签到!一是因为如果几天不登录,就会积累很多需要复习的单词。其次,自建词库的词数不是无限的。通过购买获得数量是否会伤害您的自尊?);
5. 另外,每天至少要记住10个字才能签到;
6. 例句和助记词非常丰富,可以创建自己喜欢的助记方法;
7. 例句或助记词中的生词可直接加入记忆列表;
8. 应用内链接的五个在线词典;
9. 可以查看自己背过的单词的多项统计指标,以及对未来复习单词数的预测;
10. 暂时想到这些。
同义词私人订单
所以问题来了。一个是日常使用和生词采集的有道词典,另一个是自建词库中可以轻松记忆和复习的墨背词。如何快速有效地将有道词典词汇中收录的生词导入到自己创建的墨迹中?在墨水词汇中?
在这里,我绝对不会让你费时费力地一个一个复制!如果将有道词本导出,再放入墨墨词典,您会发现导出的词本包括序号、注音、词性标签、中文含义等,直接将这些全部复制到自建词典会带来很多麻烦(试试就知道了)。我的解决方案是这样的:
1. 将有道词典单词本中想要添加到内存中的单词导出为.txt文件;
2. 将.txt文件的编码改为utf-8(直接另存为,有选项);
3. 使用文末附加的python程序提取需要记住的单词;
4. 程序将生成一个 .txt 文件。打开之后,你会发现里面只剩下英文单词了。将它们复制到你自建的陌陌词典中,并记下词典编号;
5. 当你用陌陌记单词时,通过词库编号链接到你的词库,你就可以开始学习你的私人定制词库了。
代码
这个程序完成了文本文件中的记录:
350,化身[ɪnkɑː'neɪʃ(ə)n]n。化身;神道成肉身;典型化身:化身|
道成肉身 | 道成肉身
进入这个条目:
化身
该程序是用python编写的。我不经常做文本处理。这个程序只是满足简单的基本需求,所以应该还有很多需要改进的地方(欢迎分享你更好的解决方案)。你只需要用你的有道词典导出的utf-8编码的记事本文件的路径和名称替换第19行的E:\voc.txt
<p># -*- coding: utf-8 -*-
"""
Created on Apr 28 2016
Extracting vocabulary from Youdao dictionary
The vocabulary text file should be code as utf-8
file_in: the exported vocabulary from Youdao
file_out: the file to save the English words. Default file name is
new_words_'time'.txt ('time' is the local date)
@author: sinit
"""
import codecs,time
file_in = r'E:\voc.txt'
outname = 'new_words'+'_'+time.strftime("%Y-%m-%d",time.localtime())+".txt"
file_out = r'E:\\'+outname
fs = codecs.open(file_in, 'r','utf-8')
vocabulary = fs.readlines()
fs.close()
word = []
word.append(vocabulary[0].split()[1])
def is_chinese(uchar):
#Judge if a unicode is Chinese
if (uchar >=u'/u4e00')&(uchar= 0x2e80 and x = 0xff00 and x = 0x4e00 and x = 0xf900 and x = 0x20000 and x = 0x2f800 and x
采集内容插入词库(分析一下企查查,本着分享知识的原则、原则和原则 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-12-16 14:11
)
最近有朋友要我分析七茶茶。本着知识分享的原则,我想根据自己浅薄的知识和见解,给大家介绍一下七叉茶的SEO亮点,希望能帮助更多的兄弟了解SEO。自然!
我之前也分析过顺奇网和58网。你可以看看你是否喜欢它。58同城的词库个人感觉比较笼统一点,公司查的比较准确。和上面两个相比,顺奇网的话。有点复杂,有不同的业务,不同的词库,不分高低。
(内容、模板)稀缺
现在很多人做SEO,还认为原创是SEO的核心。企业调查是对这一观点的最大否定。因为上面的信息基本都是采集。
不过目测采集的内容应该是调用国家的数据库,因为国内各个企业的信息应该没有那么好。企业信息对权威网站的信任度相对较低。只有国家信息才能准确。
内容已经解决,公司在用户体验和模板方面做了很好的对比。在之前的课程中,我们也讲过影响排名的因素和收录。模板也是其中之一。.
大规模网站是最终的绝对量级竞争。词库决定权重,收录决定词库。这种收录的水平,绝对不是几十人、几百人能做到的。
词库精准定位
词库的定位与业务直接相关,但仅就竞争而言,Enterprise Check的词库远小于同城58的词库。企业搜索的词库一般以【公司名称】【法人名称、股东名称】为主,而58则主要以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白很难关键词 轻松度。
但如果词库定位准确,客户就会准确得多。当你的量级达到几千万或者几亿的时候,长尾带来的流量是相当恐怖的,这些每天访问网站的恐怖流量带来的信任度的增加绝不是普通的小网站可比的.
就像谈58一样,品牌流量作为源头带动了网站的整体信任度。信任高后,长尾流量来了,一次次回馈网站,良性循环!
学习和应用
其实,为什么要分析企业搜索?因为企业搜索的难度比较低。我们可以将他的词库导出为权重站!
比如我以前做过的站名,可以做公司名站,或者其他站。毕竟,同义词库是可用的。内容是聚合的。即使是随机生成的,也不过是几分钟的事情。
查看全部
采集内容插入词库(分析一下企查查,本着分享知识的原则、原则和原则
)
最近有朋友要我分析七茶茶。本着知识分享的原则,我想根据自己浅薄的知识和见解,给大家介绍一下七叉茶的SEO亮点,希望能帮助更多的兄弟了解SEO。自然!
我之前也分析过顺奇网和58网。你可以看看你是否喜欢它。58同城的词库个人感觉比较笼统一点,公司查的比较准确。和上面两个相比,顺奇网的话。有点复杂,有不同的业务,不同的词库,不分高低。
(内容、模板)稀缺
现在很多人做SEO,还认为原创是SEO的核心。企业调查是对这一观点的最大否定。因为上面的信息基本都是采集。
不过目测采集的内容应该是调用国家的数据库,因为国内各个企业的信息应该没有那么好。企业信息对权威网站的信任度相对较低。只有国家信息才能准确。
内容已经解决,公司在用户体验和模板方面做了很好的对比。在之前的课程中,我们也讲过影响排名的因素和收录。模板也是其中之一。.
大规模网站是最终的绝对量级竞争。词库决定权重,收录决定词库。这种收录的水平,绝对不是几十人、几百人能做到的。
词库精准定位
词库的定位与业务直接相关,但仅就竞争而言,Enterprise Check的词库远小于同城58的词库。企业搜索的词库一般以【公司名称】【法人名称、股东名称】为主,而58则主要以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白很难关键词 轻松度。
但如果词库定位准确,客户就会准确得多。当你的量级达到几千万或者几亿的时候,长尾带来的流量是相当恐怖的,这些每天访问网站的恐怖流量带来的信任度的增加绝不是普通的小网站可比的.
就像谈58一样,品牌流量作为源头带动了网站的整体信任度。信任高后,长尾流量来了,一次次回馈网站,良性循环!
学习和应用
其实,为什么要分析企业搜索?因为企业搜索的难度比较低。我们可以将他的词库导出为权重站!
比如我以前做过的站名,可以做公司名站,或者其他站。毕竟,同义词库是可用的。内容是聚合的。即使是随机生成的,也不过是几分钟的事情。
采集内容插入词库( 自定义库管理>预设词库页面添加样本至正常词库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-12-15 09:13
自定义库管理>预设词库页面添加样本至正常词库)
文本内容安全是否支持自定义词库?
支持用户自定义词库。可以按如下方式配置和应用自定义词典:
在自定义库管理>自定义词库页面,创建自定义词典并添加非法词。有关详细信息,请参阅。创建自定义词典后,需要创建一个并在策略中配置自定义词典,使词典生效。自定义库管理是否支持 API 调用?
不支持。
我可以添加自定义屏蔽词吗?是否有用于添加自定义阻止词的 API?自定义块词是否支持分组?
用户可以创建多个自定义词汇来实现分组功能。自定义词库需要关联策略才能生效。您可以创建不同的 Biztypes 来关联不同的自定义词库。调用API时,Biztype输入参数,填写创建的策略名称,创建的策略生效。
是否支持批量导入自定义词库?
支持,需要通过提交工单申请后台配置。用户在配置前需要对关键词(暴力恐怖、色情等)进行分类,每个关键词需要用换行符隔开。
用户创建的策略使用什么词库?
● 如果用户在创建自定义策略时没有关联自定义词典,则默认使用默认词典。
● 支持用户在预设词典中添加自定义关键词。如果您需要发布关键词,请到文本内容安全控制台的自定义库管理>预设词库页面,将样本添加到普通词库(预设)中,然后可以查看添加的< @关键词 放手。
论坛和直播间有敏感词过滤服务吗?是否支持自定义关键词? 查看全部
采集内容插入词库(
自定义库管理>预设词库页面添加样本至正常词库)
文本内容安全是否支持自定义词库?
支持用户自定义词库。可以按如下方式配置和应用自定义词典:
在自定义库管理>自定义词库页面,创建自定义词典并添加非法词。有关详细信息,请参阅。创建自定义词典后,需要创建一个并在策略中配置自定义词典,使词典生效。自定义库管理是否支持 API 调用?
不支持。
我可以添加自定义屏蔽词吗?是否有用于添加自定义阻止词的 API?自定义块词是否支持分组?
用户可以创建多个自定义词汇来实现分组功能。自定义词库需要关联策略才能生效。您可以创建不同的 Biztypes 来关联不同的自定义词库。调用API时,Biztype输入参数,填写创建的策略名称,创建的策略生效。
是否支持批量导入自定义词库?
支持,需要通过提交工单申请后台配置。用户在配置前需要对关键词(暴力恐怖、色情等)进行分类,每个关键词需要用换行符隔开。
用户创建的策略使用什么词库?
● 如果用户在创建自定义策略时没有关联自定义词典,则默认使用默认词典。
● 支持用户在预设词典中添加自定义关键词。如果您需要发布关键词,请到文本内容安全控制台的自定义库管理>预设词库页面,将样本添加到普通词库(预设)中,然后可以查看添加的< @关键词 放手。
论坛和直播间有敏感词过滤服务吗?是否支持自定义关键词?
采集内容插入词库(分析一下企查查,本着分享知识的原则、原则和原则 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-12-14 09:02
)
最近有朋友要我分析七茶茶。本着知识分享的原则,我想根据自己浅薄的知识和见解,给大家介绍一下七叉茶的SEO亮点,希望能帮助更多的兄弟了解SEO。自然!
我之前也分析过顺奇网和58网。你可以看看你是否喜欢它。58同城的词库个人感觉比较笼统一点,公司查的比较准确。和上面两个相比,顺奇网的话。有点复杂,有不同的业务,不同的词库,不分高低。
(内容、模板)稀缺
现在很多人做SEO,还认为原创是SEO的核心。企业调查是对这一观点的最大否定。因为上面的信息基本都是采集。
不过目测采集的内容应该是调用国家的数据库,因为国内各个公司的信息应该没那么好。采集,即使采集企业信息对权威网站的信任度相对较低。只有国家信息才能准确。
内容已经解决,公司在用户体验和模板方面做了很好的对比。在之前的课程中,我们也讲过影响排名的因素和收录。模板也是其中之一。.
大规模网站是最终的绝对量级竞争。词库决定权重,收录决定词库。这种收录的水平,绝对不是几十人、几百人能做到的。
词库精准定位
词库的定位与业务直接相关,但仅就竞争而言,Enterprise Check的词库远小于同城58的词库。企业搜索的词库一般以【公司名称】【法人名称、股东名称】为主,而58则主要以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白很难关键词 轻松度。
但如果词库定位准确,客户就会准确得多。当你的量级达到几千万或者几亿的时候,长尾带来的流量是相当恐怖的,这些每天访问网站的恐怖流量带来的信任度的增加绝不是普通的小网站可比的.
就像之前说的58一样,品牌流量作为源头带动了网站的整体信任度。信任高后,长尾流量来了,一次次回馈网站,良性循环!
学习和应用
其实,为什么要分析企业搜索?因为企业搜索的难度比较低。我们可以将他的词库导出为权重站!
比如我以前做过的站名,可以做公司名站,或者其他站。毕竟,同义词库是可用的。内容是聚合的。即使是随机生成的,也不过是几分钟的事情。
查看全部
采集内容插入词库(分析一下企查查,本着分享知识的原则、原则和原则
)
最近有朋友要我分析七茶茶。本着知识分享的原则,我想根据自己浅薄的知识和见解,给大家介绍一下七叉茶的SEO亮点,希望能帮助更多的兄弟了解SEO。自然!
我之前也分析过顺奇网和58网。你可以看看你是否喜欢它。58同城的词库个人感觉比较笼统一点,公司查的比较准确。和上面两个相比,顺奇网的话。有点复杂,有不同的业务,不同的词库,不分高低。
(内容、模板)稀缺
现在很多人做SEO,还认为原创是SEO的核心。企业调查是对这一观点的最大否定。因为上面的信息基本都是采集。
不过目测采集的内容应该是调用国家的数据库,因为国内各个公司的信息应该没那么好。采集,即使采集企业信息对权威网站的信任度相对较低。只有国家信息才能准确。
内容已经解决,公司在用户体验和模板方面做了很好的对比。在之前的课程中,我们也讲过影响排名的因素和收录。模板也是其中之一。.
大规模网站是最终的绝对量级竞争。词库决定权重,收录决定词库。这种收录的水平,绝对不是几十人、几百人能做到的。
词库精准定位
词库的定位与业务直接相关,但仅就竞争而言,Enterprise Check的词库远小于同城58的词库。企业搜索的词库一般以【公司名称】【法人名称、股东名称】为主,而58则主要以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白很难关键词 轻松度。
但如果词库定位准确,客户就会准确得多。当你的量级达到几千万或者几亿的时候,长尾带来的流量是相当恐怖的,这些每天访问网站的恐怖流量带来的信任度的增加绝不是普通的小网站可比的.
就像之前说的58一样,品牌流量作为源头带动了网站的整体信任度。信任高后,长尾流量来了,一次次回馈网站,良性循环!
学习和应用
其实,为什么要分析企业搜索?因为企业搜索的难度比较低。我们可以将他的词库导出为权重站!
比如我以前做过的站名,可以做公司名站,或者其他站。毕竟,同义词库是可用的。内容是聚合的。即使是随机生成的,也不过是几分钟的事情。
采集内容插入词库(采集内容插入词库中,以后可以试试第三方开发)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-12-13 07:03
采集内容插入词库中,以后新来的文章加入标题后不再需要request_url头,可以在文章所在的url后加相应的参数即可。
谢邀!可以添加你们当前页面url的dt数据采集就是只选择对应url展示,
谢邀,你的意思,是想采集post提交的url,不知道如何实现,
提供一个思路,你可以试试第三方开发:时光cms-用心创造内容如果需要进一步的功能,可以自己实现,比如统计分析,分类推荐。
做网站群策划工作不久,之前想试试的时候,小伙伴推荐了几个我参与过测试,我没有去深入了解他们的功能和项目,只是觉得有一定道理,就按照这个思路来实现一些可行的功能。先在你写的php程序代码中调整一下请求头即可。1.首先找个参数做一个参数表2.根据要发起的请求对url进行匹配,匹配通则匹配成功为authorization对象,否则为request对象3.发起http请求,对方网站有可能会限制跨域,调整user-agent4.选择协议5.调整请求头6.根据接收的资源类型调整后端数据库等设置。
直接用dz吧
可以用douban吧。2级域名,不要记忆域名,不然只能分散发到多个平台。
如果你做的是内容社区类的网站,完全可以采集起来,比如c2c,你可以做一个域名查询的插件,利用你的域名查询攻击,当然你也可以判断他会从哪些网站发起请求,这样就绕过了限制。 查看全部
采集内容插入词库(采集内容插入词库中,以后可以试试第三方开发)
采集内容插入词库中,以后新来的文章加入标题后不再需要request_url头,可以在文章所在的url后加相应的参数即可。
谢邀!可以添加你们当前页面url的dt数据采集就是只选择对应url展示,
谢邀,你的意思,是想采集post提交的url,不知道如何实现,
提供一个思路,你可以试试第三方开发:时光cms-用心创造内容如果需要进一步的功能,可以自己实现,比如统计分析,分类推荐。
做网站群策划工作不久,之前想试试的时候,小伙伴推荐了几个我参与过测试,我没有去深入了解他们的功能和项目,只是觉得有一定道理,就按照这个思路来实现一些可行的功能。先在你写的php程序代码中调整一下请求头即可。1.首先找个参数做一个参数表2.根据要发起的请求对url进行匹配,匹配通则匹配成功为authorization对象,否则为request对象3.发起http请求,对方网站有可能会限制跨域,调整user-agent4.选择协议5.调整请求头6.根据接收的资源类型调整后端数据库等设置。
直接用dz吧
可以用douban吧。2级域名,不要记忆域名,不然只能分散发到多个平台。
如果你做的是内容社区类的网站,完全可以采集起来,比如c2c,你可以做一个域名查询的插件,利用你的域名查询攻击,当然你也可以判断他会从哪些网站发起请求,这样就绕过了限制。
采集内容插入词库(如何创建行业关键词词库,词库为什么重要?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-12-11 09:16
今天我们就来聊聊如何创建行业关键词词库。为什么词库很重要?
词库是最可能覆盖人群的手段,无论是非标产品还是标准产品,都必须建立词库。关键词词典的作用是什么?
寻找最适合你的产品并且有能力操作的关键词,尤其是一些需要大量产品的非标产品,你需要通过关键词触达人群。其次,直通车推广关键词也是通过这种方式来分析的
词库,我一般会创建两个,一个是关键词词库,一个是分词词库,以牙膏挤压器为例
首先是对业务人员进行搜索分析,找到自己的三级品类或产品,过滤核心关键词和修饰符。下图是为了帮助我们找到产品词。有些产品可能有不同的名称是的,我们需要先了解一下。如果是砧板,也叫砧板或砧板。如果我们不熟悉这个类别,我们根本找不到它,而且会浪费很多流量。
找到之后,还需要分析修饰语,目的是找出所有相关的词。说到这里,这些数据需要创建在一个表中,不能只看这样
牙膏挤压器,修饰符中的“挤压”已经收录,无需采集分析,重点分析以下
壁挂式、自动、全自动、儿童、可爱……这些词也叫需求词
组合是壁挂式牙膏挤奶器、牙膏自动挤奶器
这是搜索的核心词。核心词和长尾词需要一一分析采集,自动挤牙膏,挤牙膏在墙上,下面的数据,同理,放到上表中进行分析。下图中的数据是要放在一个表格中的,所以罗嗦
竞争程度是蓝海价值。在搜索热度/在线产品数量时,我们也可以使用交易指数/在线产品数量。这些可以用来判断关键词的市场和饱和度
对于标准产品,必须采集销售额。非标产品销售问题不大,但还是建议采集
这个关键词词库很简单,但是操作一定要小心谨慎。每个 关键词 都必须采集。此时,可能存在重复项。采集完成后,您需要删除重复项。
还需要删除一些特别长的关键词,大部分都是刷出来的;有很多不符合他们的产品,可能会被删除
采集业务人员的话,还需要采集同事的话,有些是实名或者错字也需要采集
如果是非标产品,制作一个关键词词库至少需要一天时间,但是这个关键词词库可以使用一整年。跟进一个月关注飙升的词和新出现的关键词。只是优化没有采集到的词。
稍微扩展一下,我们将使用哪些词?使用直通车测试,尤其是非标产品,需求词和转换词更加多样化,测试模型的时候可以测试出来。
看字族的数据比较好,应该优先考虑哪一个,做起来肯定容易些 查看全部
采集内容插入词库(如何创建行业关键词词库,词库为什么重要?(组图))
今天我们就来聊聊如何创建行业关键词词库。为什么词库很重要?
词库是最可能覆盖人群的手段,无论是非标产品还是标准产品,都必须建立词库。关键词词典的作用是什么?
寻找最适合你的产品并且有能力操作的关键词,尤其是一些需要大量产品的非标产品,你需要通过关键词触达人群。其次,直通车推广关键词也是通过这种方式来分析的
词库,我一般会创建两个,一个是关键词词库,一个是分词词库,以牙膏挤压器为例
首先是对业务人员进行搜索分析,找到自己的三级品类或产品,过滤核心关键词和修饰符。下图是为了帮助我们找到产品词。有些产品可能有不同的名称是的,我们需要先了解一下。如果是砧板,也叫砧板或砧板。如果我们不熟悉这个类别,我们根本找不到它,而且会浪费很多流量。
找到之后,还需要分析修饰语,目的是找出所有相关的词。说到这里,这些数据需要创建在一个表中,不能只看这样
牙膏挤压器,修饰符中的“挤压”已经收录,无需采集分析,重点分析以下
壁挂式、自动、全自动、儿童、可爱……这些词也叫需求词
组合是壁挂式牙膏挤奶器、牙膏自动挤奶器
这是搜索的核心词。核心词和长尾词需要一一分析采集,自动挤牙膏,挤牙膏在墙上,下面的数据,同理,放到上表中进行分析。下图中的数据是要放在一个表格中的,所以罗嗦
竞争程度是蓝海价值。在搜索热度/在线产品数量时,我们也可以使用交易指数/在线产品数量。这些可以用来判断关键词的市场和饱和度
对于标准产品,必须采集销售额。非标产品销售问题不大,但还是建议采集
这个关键词词库很简单,但是操作一定要小心谨慎。每个 关键词 都必须采集。此时,可能存在重复项。采集完成后,您需要删除重复项。
还需要删除一些特别长的关键词,大部分都是刷出来的;有很多不符合他们的产品,可能会被删除
采集业务人员的话,还需要采集同事的话,有些是实名或者错字也需要采集
如果是非标产品,制作一个关键词词库至少需要一天时间,但是这个关键词词库可以使用一整年。跟进一个月关注飙升的词和新出现的关键词。只是优化没有采集到的词。
稍微扩展一下,我们将使用哪些词?使用直通车测试,尤其是非标产品,需求词和转换词更加多样化,测试模型的时候可以测试出来。
看字族的数据比较好,应该优先考虑哪一个,做起来肯定容易些
采集内容插入词库( 自定义库管理>预设词库页面添加样本至正常词库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-12-09 23:17
自定义库管理>预设词库页面添加样本至正常词库)
文本内容安全是否支持自定义词库?
支持用户自定义词库。可以按如下方式配置和应用自定义词典:
在自定义库管理>自定义词库页面,创建自定义词典并添加非法词。有关详细信息,请参阅。创建自定义词典后,需要创建一个并在策略中配置自定义词典,使词典生效。自定义库管理是否支持 API 调用?
不支持。
我可以添加自定义屏蔽词吗?是否有用于添加自定义阻止词的 API?自定义块词是否支持分组?
用户可以创建多个自定义词汇来实现分组功能。自定义词库需要关联策略才能生效。您可以创建不同的 Biztypes 来关联不同的自定义词库。调用API时,Biztype输入参数,填写创建的策略名称,创建的策略生效。
是否支持批量导入自定义词库?
支持,需要通过提交工单申请后台配置。用户在配置前需要对关键词(暴力恐怖、色情等)进行分类,每个关键词需要用换行符隔开。
用户创建的策略使用什么词库?
● 如果用户在创建自定义策略时没有关联自定义词典,则默认使用默认词典。
● 支持用户在预设词典中添加自定义关键词。如果您需要发布关键词,请到文本内容安全控制台的自定义库管理>预设词库页面,将样本添加到普通词库(预设)中,然后可以查看添加的< @关键词 放手。
论坛和直播间有敏感词过滤服务吗?是否支持自定义关键词? 查看全部
采集内容插入词库(
自定义库管理>预设词库页面添加样本至正常词库)
文本内容安全是否支持自定义词库?
支持用户自定义词库。可以按如下方式配置和应用自定义词典:
在自定义库管理>自定义词库页面,创建自定义词典并添加非法词。有关详细信息,请参阅。创建自定义词典后,需要创建一个并在策略中配置自定义词典,使词典生效。自定义库管理是否支持 API 调用?
不支持。
我可以添加自定义屏蔽词吗?是否有用于添加自定义阻止词的 API?自定义块词是否支持分组?
用户可以创建多个自定义词汇来实现分组功能。自定义词库需要关联策略才能生效。您可以创建不同的 Biztypes 来关联不同的自定义词库。调用API时,Biztype输入参数,填写创建的策略名称,创建的策略生效。
是否支持批量导入自定义词库?
支持,需要通过提交工单申请后台配置。用户在配置前需要对关键词(暴力恐怖、色情等)进行分类,每个关键词需要用换行符隔开。
用户创建的策略使用什么词库?
● 如果用户在创建自定义策略时没有关联自定义词典,则默认使用默认词典。
● 支持用户在预设词典中添加自定义关键词。如果您需要发布关键词,请到文本内容安全控制台的自定义库管理>预设词库页面,将样本添加到普通词库(预设)中,然后可以查看添加的< @关键词 放手。
论坛和直播间有敏感词过滤服务吗?是否支持自定义关键词?
采集内容插入词库(英文独立站的时候,如何建立关键词库是极其重要极其重要?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-12-08 15:21
在我们准备英文独立站点时,关键词 库的建立是一项极其重要的任务。这是因为关键词词库的优劣和丰富程度在一定程度上直接决定了未来的站点流量。为什么 关键词 词库如此重要?因为关键词是通往你网站的宽阔道路。您的客户通过这条路来到您的店铺,与您联系,与您互动,并从您那里购买。不仅对于独立站点,而且对于 Internet 上的任何虚拟实体,关键词 都极为重要。
与B2C相比,B2B的关键词相对简单。受客户群体的专业性和产品类别相对较少的影响,在准备词库时,量相对较小。尤其对于生产型工厂来说,单品直接决定了关键词词汇的狭隘。越复杂,越窄;行业越先进,范围越窄。想想看,在一个产品没有成熟市场之前,谁知道这个产品叫什么,对吧?
但无论如何,我们在准备的时候,一定要尽最大的努力去打造一个高质量、丰富的关键词库。那么你从哪里开始,你需要什么工具?
手动自助服务和机器协助。
一是人工自助收款。
从产品的来源到产品价值链的末端,列出了与产品相关的任何短语和单词。这一步可以通过头脑风暴来完成,而且可以是中文的。然后翻译成英文,验证每个单词或短语是否符合西方表达,以及搜索引擎是否有足够的结果。如果你头脑风暴的词在google结果中没有找到,或者这些词与你的行业或产品无关,那么这些词肯定不合适。所有这些词都必须有一个核心,即产品或服务本身的名称。当然,这个产品的名称在不同的语言环境中是不同的。在设计多语言网站时必须考虑到这一点。
其次,围绕核心词,做竞争对手的底线。以谷歌为例,如果我们使用关键词led制造商在谷歌上进行搜索,我们会得到如下搜索结果:
然后找到一个类似的网址,第一眼就是一个SEO优化网站,然后点进去。(因为它们看起来像工厂。如果你看不出区别,只需打开搜索下的所有网址,并排查看它们。)
进入后查看网页源代码(快捷键F12,或在页面空白处右击),在标签中找到一个内容。等号后面的引号是竞争对手使用的关键词,当然,不同页面使用的词不一样,一个站点可能有数百个关键词。必须检查排名靠前的站点。
使用阿里巴巴的原理和使用谷歌是一样的。就是用核心词搜索关键词,然后找到产品页面打开,然后查看源码。
这个过程可以通过切换核心关键词来重复进行。在这个过程中,了解行业内的竞争对手也是一个绝对的过程。通过这次搜索,对产品本身和行业的了解会不断加深。并表示不一定会有意想不到的惊喜
再次使用关键词工具批量推荐关键词
很多人没有时间做上面的第二步,觉得太费时间了。因此,我更喜欢使用关键词工具来机械生成。不同的工具可能会有不同的结果,但都是密不可分的。许多 SEO 团队使用此类工具来快速构建 关键词 库。但缺点是这些结果是基于算法对已知搜索习惯的总结,缺乏对人性的理解,所以在设置关键词的时候,可能会缺乏一些创新和爆发力。尤其是对于新产品,高度创新的产品,这类工具没有足够的搜索习惯积累,所以给出的建议并不那么科学。而且,这种方法不利于新手了解行业概况。因此,工具非常好,但不要认为世界上有工具。成功没有捷径。
这里推荐一些常用的关键词工具:
当然,你也可以参考:
知乎:世界上最好的网站关键词工具总结,海鸥SEO
Ahrefs:10 个免费的 关键词 研究工具(滚动关键词planner),作者 Joshua Hardwick
最后,如何判断关键词的好坏?
我这里用的是登录,进入账号控制面板,然后右上角头像旁边有个工具&设置,选择关键词规划器开始穿关键词或者预测关键词的效果@关键词。
其中,CTR就是点击次数除以展示次数,百分比可以理解为每100次展示可以产生多少点击。MAX.CPC是团队单个词的最高出价,也是这次点击的最高出价。AVG.CPC是所有结果的平均竞价成本,更具参考价值。增加自己的最高MAX.CPC可以有效地执行常规价格数据,也会推高实际成本。对于不同的产品,您可以稍作调整,以计算如何设置最佳投标价格。
好吧,先这么多。关于如何判断关键词的好坏,还有很多其他的工具和方法,后面会和大家分享。
参考:
【海外市场B2B品牌建设网络版,如何确定关键词?](海外市场B2B品牌建设网络版,如何确定关键词?/) 查看全部
采集内容插入词库(英文独立站的时候,如何建立关键词库是极其重要极其重要?)
在我们准备英文独立站点时,关键词 库的建立是一项极其重要的任务。这是因为关键词词库的优劣和丰富程度在一定程度上直接决定了未来的站点流量。为什么 关键词 词库如此重要?因为关键词是通往你网站的宽阔道路。您的客户通过这条路来到您的店铺,与您联系,与您互动,并从您那里购买。不仅对于独立站点,而且对于 Internet 上的任何虚拟实体,关键词 都极为重要。
与B2C相比,B2B的关键词相对简单。受客户群体的专业性和产品类别相对较少的影响,在准备词库时,量相对较小。尤其对于生产型工厂来说,单品直接决定了关键词词汇的狭隘。越复杂,越窄;行业越先进,范围越窄。想想看,在一个产品没有成熟市场之前,谁知道这个产品叫什么,对吧?
但无论如何,我们在准备的时候,一定要尽最大的努力去打造一个高质量、丰富的关键词库。那么你从哪里开始,你需要什么工具?
手动自助服务和机器协助。
一是人工自助收款。
从产品的来源到产品价值链的末端,列出了与产品相关的任何短语和单词。这一步可以通过头脑风暴来完成,而且可以是中文的。然后翻译成英文,验证每个单词或短语是否符合西方表达,以及搜索引擎是否有足够的结果。如果你头脑风暴的词在google结果中没有找到,或者这些词与你的行业或产品无关,那么这些词肯定不合适。所有这些词都必须有一个核心,即产品或服务本身的名称。当然,这个产品的名称在不同的语言环境中是不同的。在设计多语言网站时必须考虑到这一点。
其次,围绕核心词,做竞争对手的底线。以谷歌为例,如果我们使用关键词led制造商在谷歌上进行搜索,我们会得到如下搜索结果:
然后找到一个类似的网址,第一眼就是一个SEO优化网站,然后点进去。(因为它们看起来像工厂。如果你看不出区别,只需打开搜索下的所有网址,并排查看它们。)
进入后查看网页源代码(快捷键F12,或在页面空白处右击),在标签中找到一个内容。等号后面的引号是竞争对手使用的关键词,当然,不同页面使用的词不一样,一个站点可能有数百个关键词。必须检查排名靠前的站点。
使用阿里巴巴的原理和使用谷歌是一样的。就是用核心词搜索关键词,然后找到产品页面打开,然后查看源码。
这个过程可以通过切换核心关键词来重复进行。在这个过程中,了解行业内的竞争对手也是一个绝对的过程。通过这次搜索,对产品本身和行业的了解会不断加深。并表示不一定会有意想不到的惊喜
再次使用关键词工具批量推荐关键词
很多人没有时间做上面的第二步,觉得太费时间了。因此,我更喜欢使用关键词工具来机械生成。不同的工具可能会有不同的结果,但都是密不可分的。许多 SEO 团队使用此类工具来快速构建 关键词 库。但缺点是这些结果是基于算法对已知搜索习惯的总结,缺乏对人性的理解,所以在设置关键词的时候,可能会缺乏一些创新和爆发力。尤其是对于新产品,高度创新的产品,这类工具没有足够的搜索习惯积累,所以给出的建议并不那么科学。而且,这种方法不利于新手了解行业概况。因此,工具非常好,但不要认为世界上有工具。成功没有捷径。
这里推荐一些常用的关键词工具:
当然,你也可以参考:
知乎:世界上最好的网站关键词工具总结,海鸥SEO
Ahrefs:10 个免费的 关键词 研究工具(滚动关键词planner),作者 Joshua Hardwick
最后,如何判断关键词的好坏?
我这里用的是登录,进入账号控制面板,然后右上角头像旁边有个工具&设置,选择关键词规划器开始穿关键词或者预测关键词的效果@关键词。
其中,CTR就是点击次数除以展示次数,百分比可以理解为每100次展示可以产生多少点击。MAX.CPC是团队单个词的最高出价,也是这次点击的最高出价。AVG.CPC是所有结果的平均竞价成本,更具参考价值。增加自己的最高MAX.CPC可以有效地执行常规价格数据,也会推高实际成本。对于不同的产品,您可以稍作调整,以计算如何设置最佳投标价格。
好吧,先这么多。关于如何判断关键词的好坏,还有很多其他的工具和方法,后面会和大家分享。
参考:
【海外市场B2B品牌建设网络版,如何确定关键词?](海外市场B2B品牌建设网络版,如何确定关键词?/)
采集内容插入词库( python+scrapy采集爱站关键词,用到的知识点有scrpy模块 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-12-08 15:16
python+scrapy采集爱站关键词,用到的知识点有scrpy模块
)
python+scrapy采集爱站关键词,用到的知识点是scrpy和re模块,因为已经有文章文章使用xpath去提取内容了,所以这次我会在正则表达式python中使用re模块;
Scrapy 有点复杂。新手建议从urllib和requests入手。下面的代码页只是一个简单的应用程序。 Scrapy可以使用UA池、ip池、禁止cookies、下载延迟、谷歌缓存、分布式爬虫等强仿禁止策略。
#encoding=utf-8
#在所有工作之前,先用scrapy startproject projectname,这时会生成一个叫projectname的文件夹
from scrapy.spiders import Spider #导入模块
from scrapy.selector import Selector
from scrapy.linkextractors import LinkExtractor
from scrapy.http import Request
import re
class cispider(Spider): #面向对象中的继承类
name='ciku' #如果是win7运行的时候在你创建projectname的目录下面通过cmd,敲上scrapy crawl ciku来运行
start_urls=['http://ci.aizhan.com/seo/'] #目标网站
def parse(self,response): #类的方法
html=response.body
r=re.compile(r'(.*?)[\s\S]*?(\d+)')
a=re.findall(r,html) #提取正则
for i in a:
f=','.join(i)
w=re.compile('|')
b = w.sub('',f).decode('utf-8').encode('gbk') #解决win7下的编码问题
print b
b=re.compile(r'页号:<a class="on">1</a> 2 ')
urls=re.findall(b,html)
for n in urls:
c='http://ci.aizhan.com'
f=c+n
print f
yield Request(f,callback=self.parse) #回调,这里大概的过程就是将页码,翻页数,如第二页,第三页等返回给self.pase()来获取内容关键词 查看全部
采集内容插入词库(
python+scrapy采集爱站关键词,用到的知识点有scrpy模块
)
python+scrapy采集爱站关键词,用到的知识点是scrpy和re模块,因为已经有文章文章使用xpath去提取内容了,所以这次我会在正则表达式python中使用re模块;
Scrapy 有点复杂。新手建议从urllib和requests入手。下面的代码页只是一个简单的应用程序。 Scrapy可以使用UA池、ip池、禁止cookies、下载延迟、谷歌缓存、分布式爬虫等强仿禁止策略。
#encoding=utf-8
#在所有工作之前,先用scrapy startproject projectname,这时会生成一个叫projectname的文件夹
from scrapy.spiders import Spider #导入模块
from scrapy.selector import Selector
from scrapy.linkextractors import LinkExtractor
from scrapy.http import Request
import re
class cispider(Spider): #面向对象中的继承类
name='ciku' #如果是win7运行的时候在你创建projectname的目录下面通过cmd,敲上scrapy crawl ciku来运行
start_urls=['http://ci.aizhan.com/seo/'] #目标网站
def parse(self,response): #类的方法
html=response.body
r=re.compile(r'(.*?)[\s\S]*?(\d+)')
a=re.findall(r,html) #提取正则
for i in a:
f=','.join(i)
w=re.compile('|')
b = w.sub('',f).decode('utf-8').encode('gbk') #解决win7下的编码问题
print b
b=re.compile(r'页号:<a class="on">1</a> 2 ')
urls=re.findall(b,html)
for n in urls:
c='http://ci.aizhan.com'
f=c+n
print f
yield Request(f,callback=self.parse) #回调,这里大概的过程就是将页码,翻页数,如第二页,第三页等返回给self.pase()来获取内容关键词
采集内容插入词库(如果你需要一应俱全的完整国民经济核算资料(原ICTCLAS))
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-12-08 05:00
在生活中,我们可以通过多种渠道获取相关数据。
搜索“中国统计年鉴”。许多图书馆都有《中国统计年鉴》等。翻出收录您需要的数据的页面。复印是一个不错的选择。当然,你也可以选择拿出纸和笔。复制您需要的所有数据。为了便于对这些数据进行进一步的处理,接下来的工作可能会有些枯燥:将找到的数据一一输入电脑。当然,现在情况已经好了很多。例如,要查找 2004 中国统计年鉴,中华人民共和国国家统计局 网站 提供了免费下载。
如果您需要所有最新的宏观经济数据,那就是中国国家统计局提供的“进展统计”。
如果要从数据采集之日起获得完整的国民核算数据,权威来源是《中国GDP核算历史数据》(1952-1995)和《中国GDP核算历史数据》(1996-2002)) @>.这两本年鉴都提供了中国GDP的详细数据,特别是《中国GDP会计历史数据》(1996)-2002)@>提供了电子版,电子版数据不仅提供了详细数据从1996年到2002年,也大致追溯了1952年到1995年的数据,非常好用。
如果想从数据采集之日起获得更完整的宏观经济数据,《新中国50年统计数据汇编》和《新中国55年统计数据汇编》是不错的选择。不幸的是,它们都没有提供电子版本,但后者可以从中国信息银行下载。
此外,还有很多收费网站可以提供更详细的中国宏观经济数据,如信息银行数据库、中国经济信息网等。
国内的大数据处理信息工具很多,但大多是近年来兴起的大数据技术,图像处理需要先转换成文本再进行处理。通过对几款国内主流中文分词工具产品的试用,下面为大家推荐几款中文分词工具:
一、NLPIR大数据语义智能分析平台(原ICTCLAS)由北京理工大学大数据搜索与挖掘实验室主任张华平开发。融合网络精准,满足大数据内容采集、编辑、搜索的综合需求。采集 近二十年来自然语言理解、文本挖掘、语义搜索等最新研究成果不断创新。平台提供客户端工具、云服务、二次开发接口等多种产品使用形式。每个中间件API都可以无缝集成到客户的各种复杂应用系统中,兼容Windows、Linux、Android、Maemo5、FreeBSD等不同操作系统平台,
NLPIR大数据语义智能分析平台的十三项功能:
NLPIR大数据语义智能分析平台客户端
精准采集:国内外海量信息实时精准采集,主题采集(主题根据信息需求采集)和站点采集 两种模式(给定网站列表内的定点采集 功能)。
文档转换:将文本信息转换为doc、excel、pdf、ppt等多种主流文档格式,效率满足大数据处理要求。
新词发现:从文本中发现新词、新概念,用户可将其用于专业词典的编纂,并可进一步编辑标注,导入分词词典,提高分词系统的准确率,并适应新的语言变化。
批量分词:对原创语料进行分词,自动识别姓名、地名、机构名称等未注册词,新词标注,词性标注。并在分析过程中,导入用户自定义词典。
语言统计:根据分词和标注结果,系统自动进行一元词频数统计和二元词转移概率统计。对于常用术语,会自动给出相应的英文解释。
文本聚类:可以从大规模数据中自动分析热点事件,并提供事件主题的关键特征描述。同时适用于短文、微博等长文和短文的热点分析。
文本分类:根据规则或训练方法对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等诸多方面。
抽象实体:对于单个或多个文章,自动提取内容摘要,提取人名、地点、机构、时间和主题关键词;方便用户快速浏览文本内容。
智能过滤:对文本内容进行语义智能过滤和审核,内置国内最全面的词典,智能识别多种变体:变形、音变、繁简变体,精准语义消歧。
情感分析:针对预先指定的分析对象,系统自动分析海量文档的情感倾向:情感极性和情感价值度量,并给出原文中的正负分和句例。
文档去重:快速准确判断文件集或数据库中是否存在内容相同或相似的记录,同时找出所有重复记录。
全文搜索:支持文本、数字、日期、字符串等多种数据类型,多字段高效搜索,支持AND/OR/NOT、NEAR接近等查询语法,支持维吾尔语、藏语、蒙语、阿拉伯语和韩语 搜索各种少数民族语言。
代码转换:自动识别内容的代码,统一将代码转换为其他代码。
以上为个人观点,仅供参考,希望能帮到你! 查看全部
采集内容插入词库(如果你需要一应俱全的完整国民经济核算资料(原ICTCLAS))
在生活中,我们可以通过多种渠道获取相关数据。
搜索“中国统计年鉴”。许多图书馆都有《中国统计年鉴》等。翻出收录您需要的数据的页面。复印是一个不错的选择。当然,你也可以选择拿出纸和笔。复制您需要的所有数据。为了便于对这些数据进行进一步的处理,接下来的工作可能会有些枯燥:将找到的数据一一输入电脑。当然,现在情况已经好了很多。例如,要查找 2004 中国统计年鉴,中华人民共和国国家统计局 网站 提供了免费下载。
如果您需要所有最新的宏观经济数据,那就是中国国家统计局提供的“进展统计”。
如果要从数据采集之日起获得完整的国民核算数据,权威来源是《中国GDP核算历史数据》(1952-1995)和《中国GDP核算历史数据》(1996-2002)) @>.这两本年鉴都提供了中国GDP的详细数据,特别是《中国GDP会计历史数据》(1996)-2002)@>提供了电子版,电子版数据不仅提供了详细数据从1996年到2002年,也大致追溯了1952年到1995年的数据,非常好用。
如果想从数据采集之日起获得更完整的宏观经济数据,《新中国50年统计数据汇编》和《新中国55年统计数据汇编》是不错的选择。不幸的是,它们都没有提供电子版本,但后者可以从中国信息银行下载。
此外,还有很多收费网站可以提供更详细的中国宏观经济数据,如信息银行数据库、中国经济信息网等。
国内的大数据处理信息工具很多,但大多是近年来兴起的大数据技术,图像处理需要先转换成文本再进行处理。通过对几款国内主流中文分词工具产品的试用,下面为大家推荐几款中文分词工具:
一、NLPIR大数据语义智能分析平台(原ICTCLAS)由北京理工大学大数据搜索与挖掘实验室主任张华平开发。融合网络精准,满足大数据内容采集、编辑、搜索的综合需求。采集 近二十年来自然语言理解、文本挖掘、语义搜索等最新研究成果不断创新。平台提供客户端工具、云服务、二次开发接口等多种产品使用形式。每个中间件API都可以无缝集成到客户的各种复杂应用系统中,兼容Windows、Linux、Android、Maemo5、FreeBSD等不同操作系统平台,
NLPIR大数据语义智能分析平台的十三项功能:
NLPIR大数据语义智能分析平台客户端
精准采集:国内外海量信息实时精准采集,主题采集(主题根据信息需求采集)和站点采集 两种模式(给定网站列表内的定点采集 功能)。
文档转换:将文本信息转换为doc、excel、pdf、ppt等多种主流文档格式,效率满足大数据处理要求。
新词发现:从文本中发现新词、新概念,用户可将其用于专业词典的编纂,并可进一步编辑标注,导入分词词典,提高分词系统的准确率,并适应新的语言变化。
批量分词:对原创语料进行分词,自动识别姓名、地名、机构名称等未注册词,新词标注,词性标注。并在分析过程中,导入用户自定义词典。
语言统计:根据分词和标注结果,系统自动进行一元词频数统计和二元词转移概率统计。对于常用术语,会自动给出相应的英文解释。
文本聚类:可以从大规模数据中自动分析热点事件,并提供事件主题的关键特征描述。同时适用于短文、微博等长文和短文的热点分析。
文本分类:根据规则或训练方法对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等诸多方面。
抽象实体:对于单个或多个文章,自动提取内容摘要,提取人名、地点、机构、时间和主题关键词;方便用户快速浏览文本内容。
智能过滤:对文本内容进行语义智能过滤和审核,内置国内最全面的词典,智能识别多种变体:变形、音变、繁简变体,精准语义消歧。
情感分析:针对预先指定的分析对象,系统自动分析海量文档的情感倾向:情感极性和情感价值度量,并给出原文中的正负分和句例。
文档去重:快速准确判断文件集或数据库中是否存在内容相同或相似的记录,同时找出所有重复记录。
全文搜索:支持文本、数字、日期、字符串等多种数据类型,多字段高效搜索,支持AND/OR/NOT、NEAR接近等查询语法,支持维吾尔语、藏语、蒙语、阿拉伯语和韩语 搜索各种少数民族语言。
代码转换:自动识别内容的代码,统一将代码转换为其他代码。
以上为个人观点,仅供参考,希望能帮到你!

