
过滤
第一步、我们打开织梦后台点击采集——采集节点管理——增加新节点
采集交流 • 优采云 发表了文章 • 0 个评论 • 426 次浏览 • 2020-08-03 15:02
第一步、我们打开织梦后台点击采集——采集节点管理——增加新节点
第二步、新增节点-配置网址索引
填写要采集的网站的列表相关规则,
查看采集站点的编码和网站源码
我们右键单击,点击查看源码,在源码的开头位置,找到一个写有charset=某一编码的meta标签,比如charset="gb2312",这个就是所说的网站编码了
选择采集站点的编码
第三步、新增节点-配置文章网址匹配规则
我们查看采集站点的列表页源码,找到文章列表开始html和结束html标签,分别把它们复制到降低采集节点->文章网址匹配规则的"区域开始的HTML"和“区域结束的HTML”输入框中。你不一定选择右键查看源码来找到文章列表开始标签,你可以在文章开始的地方右键单击,审查元素(chrome浏览器,firefox是查看元素),这样就更方便的找到文章列表开始和结束的标签了。
设置以后我们点击"保存信息并步入下一步设置"
第四步:网址获取规则测试
如果在测试结果发觉有无关的网址信息,说明的第五步中的网址过滤规则有误或则没有填写过滤规则。如果发觉采集有误,你可以返回上一次更改,没有就点击“保存信息并步入下一步设置”。
第五步:内容数组获取规则
我们查看采集站点的文章源码,找到相关选项的开始和结束html标签网站程序自带的采集器采集文章,填写入指定位置,开始和结束标签以"[内容]"分格。
设置完毕,我们点击"保存配置并预览"
第六步:过滤规则
在第七步中的匹配规则前面,都 有一个过滤规则,这个过滤规则是拿来过滤无需采集的内容。
比如,网易整篇文章都有一个放置广告的iframe标签,我们要采集网易的文章,不可能采集回来以后,一篇一篇得去删掉这个广告。但是怎样消除呢?去除方式就是那种过滤规则,我们点击常用规则网站程序自带的采集器采集文章,就会弹出一个小窗口,列出了常用的过滤规则,我们只需点击要们要过滤的规则即可,要过滤网易文章中的iframe标签,我们就点击iframe即可。
测试内容数组设置
因为网易有的文章开头是
,有的文章开头是
,所以会出现采集出错的情况。
如果你如今就要采集,你可以点击保存并采集。这里我选择仅保存
采集内容(一)
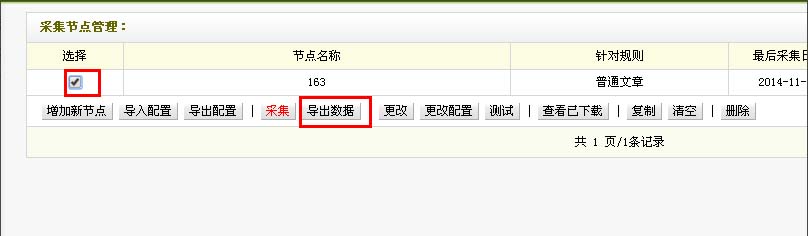
回到采集节点管理的界面,也就是第一步中的界面,我们选择节点,点击采集
采集内容(二)
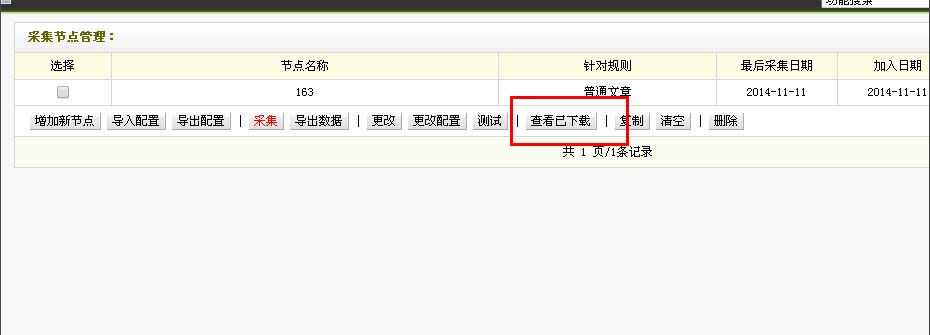
查看已下载
可以在采集界面(即第十步中的界面)的右上角,点击“查看已下载”。也可以在“采集节点管理”的界面里点击“查看已下载”。这里以第二个方式为例。
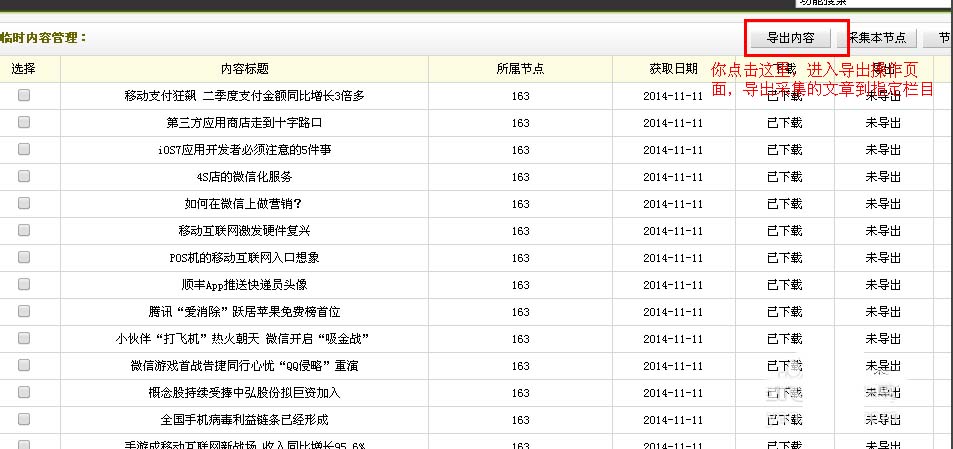
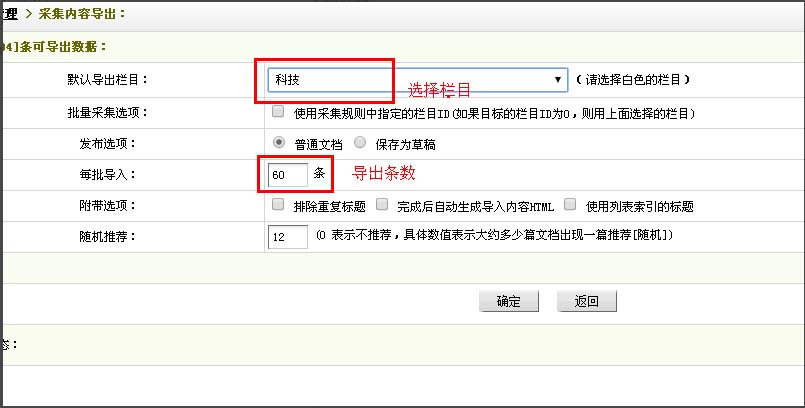
导出内容
选择要导出到的栏目,数据量,是否生成html文件 ,随机推荐数目
最终结果 查看全部
第二步、新增节点-配置网址索引
填写要采集的网站的列表相关规则,
查看采集站点的编码和网站源码
我们右键单击,点击查看源码,在源码的开头位置,找到一个写有charset=某一编码的meta标签,比如charset="gb2312",这个就是所说的网站编码了
选择采集站点的编码
第三步、新增节点-配置文章网址匹配规则
我们查看采集站点的列表页源码,找到文章列表开始html和结束html标签,分别把它们复制到降低采集节点->文章网址匹配规则的"区域开始的HTML"和“区域结束的HTML”输入框中。你不一定选择右键查看源码来找到文章列表开始标签,你可以在文章开始的地方右键单击,审查元素(chrome浏览器,firefox是查看元素),这样就更方便的找到文章列表开始和结束的标签了。
设置以后我们点击"保存信息并步入下一步设置"
第四步:网址获取规则测试
如果在测试结果发觉有无关的网址信息,说明的第五步中的网址过滤规则有误或则没有填写过滤规则。如果发觉采集有误,你可以返回上一次更改,没有就点击“保存信息并步入下一步设置”。
第五步:内容数组获取规则
我们查看采集站点的文章源码,找到相关选项的开始和结束html标签网站程序自带的采集器采集文章,填写入指定位置,开始和结束标签以"[内容]"分格。
设置完毕,我们点击"保存配置并预览"
第六步:过滤规则
在第七步中的匹配规则前面,都 有一个过滤规则,这个过滤规则是拿来过滤无需采集的内容。
比如,网易整篇文章都有一个放置广告的iframe标签,我们要采集网易的文章,不可能采集回来以后,一篇一篇得去删掉这个广告。但是怎样消除呢?去除方式就是那种过滤规则,我们点击常用规则网站程序自带的采集器采集文章,就会弹出一个小窗口,列出了常用的过滤规则,我们只需点击要们要过滤的规则即可,要过滤网易文章中的iframe标签,我们就点击iframe即可。
测试内容数组设置
因为网易有的文章开头是
,有的文章开头是
,所以会出现采集出错的情况。
如果你如今就要采集,你可以点击保存并采集。这里我选择仅保存
采集内容(一)
回到采集节点管理的界面,也就是第一步中的界面,我们选择节点,点击采集
采集内容(二)
查看已下载
可以在采集界面(即第十步中的界面)的右上角,点击“查看已下载”。也可以在“采集节点管理”的界面里点击“查看已下载”。这里以第二个方式为例。
导出内容
选择要导出到的栏目,数据量,是否生成html文件 ,随机推荐数目
最终结果 查看全部
第一步、我们打开织梦后台点击采集——采集节点管理——增加新节点
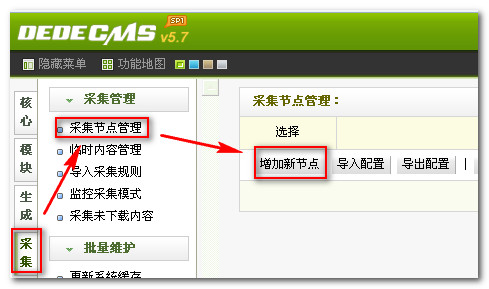
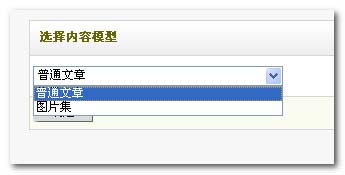
第二步、新增节点-配置网址索引
填写要采集的网站的列表相关规则,
查看采集站点的编码和网站源码
我们右键单击,点击查看源码,在源码的开头位置,找到一个写有charset=某一编码的meta标签,比如charset="gb2312",这个就是所说的网站编码了
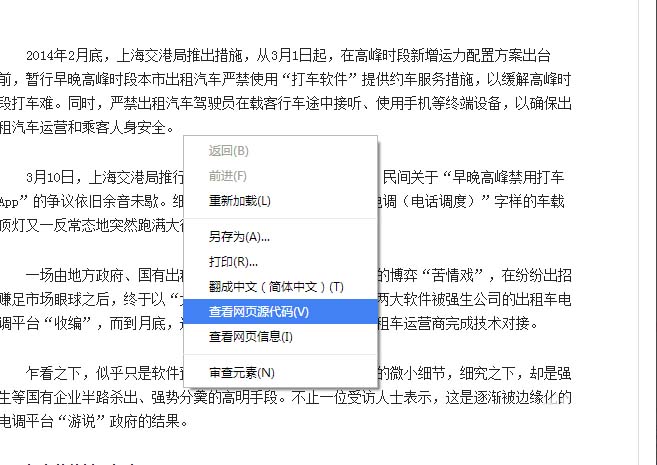
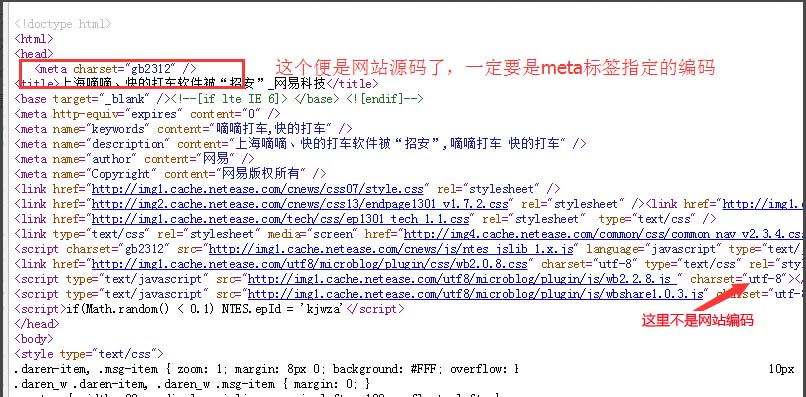
选择采集站点的编码
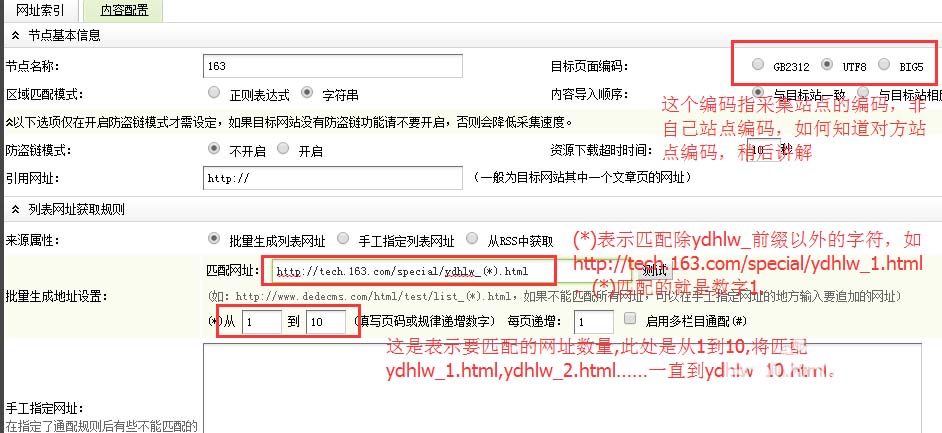
第三步、新增节点-配置文章网址匹配规则
我们查看采集站点的列表页源码,找到文章列表开始html和结束html标签,分别把它们复制到降低采集节点->文章网址匹配规则的"区域开始的HTML"和“区域结束的HTML”输入框中。你不一定选择右键查看源码来找到文章列表开始标签,你可以在文章开始的地方右键单击,审查元素(chrome浏览器,firefox是查看元素),这样就更方便的找到文章列表开始和结束的标签了。
设置以后我们点击"保存信息并步入下一步设置"
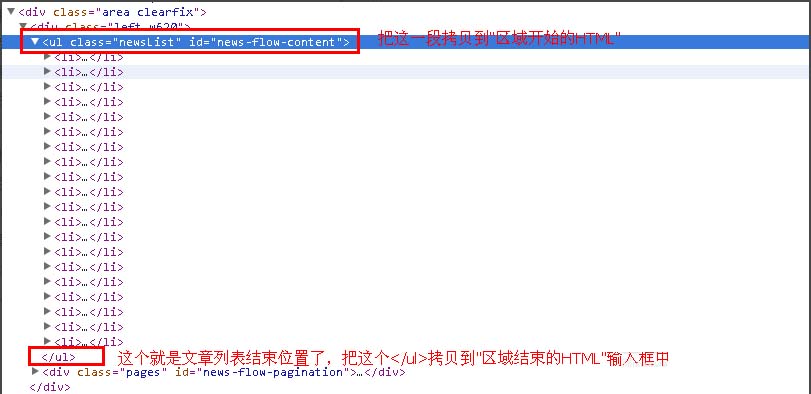

第四步:网址获取规则测试
如果在测试结果发觉有无关的网址信息,说明的第五步中的网址过滤规则有误或则没有填写过滤规则。如果发觉采集有误,你可以返回上一次更改,没有就点击“保存信息并步入下一步设置”。

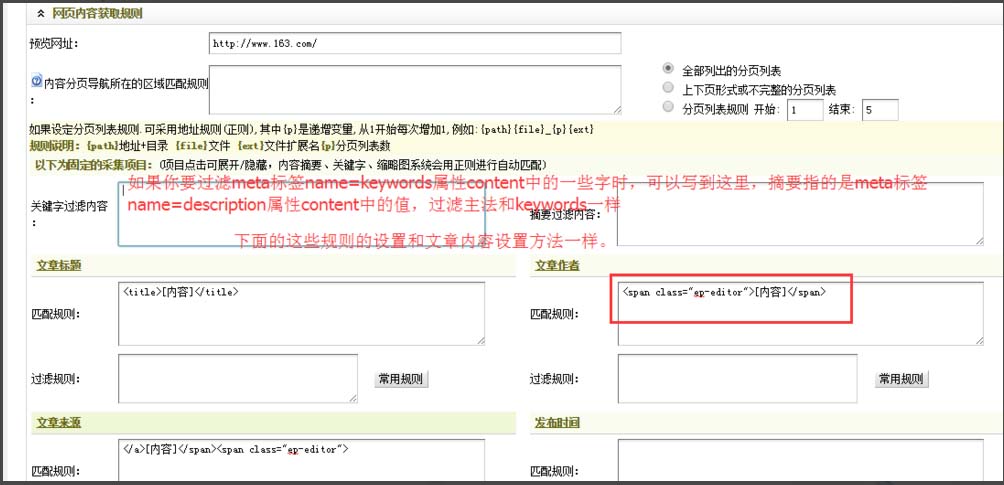
第五步:内容数组获取规则
我们查看采集站点的文章源码,找到相关选项的开始和结束html标签网站程序自带的采集器采集文章,填写入指定位置,开始和结束标签以"[内容]"分格。
设置完毕,我们点击"保存配置并预览"
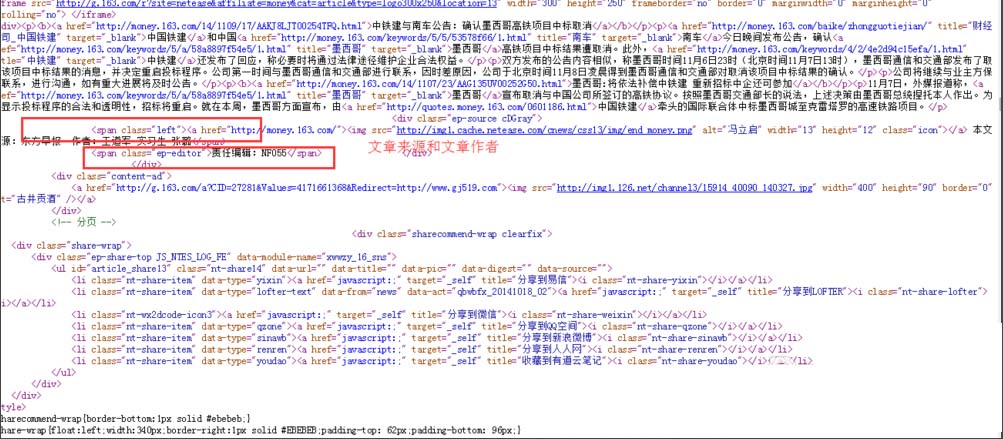
第六步:过滤规则
在第七步中的匹配规则前面,都 有一个过滤规则,这个过滤规则是拿来过滤无需采集的内容。
比如,网易整篇文章都有一个放置广告的iframe标签,我们要采集网易的文章,不可能采集回来以后,一篇一篇得去删掉这个广告。但是怎样消除呢?去除方式就是那种过滤规则,我们点击常用规则网站程序自带的采集器采集文章,就会弹出一个小窗口,列出了常用的过滤规则,我们只需点击要们要过滤的规则即可,要过滤网易文章中的iframe标签,我们就点击iframe即可。
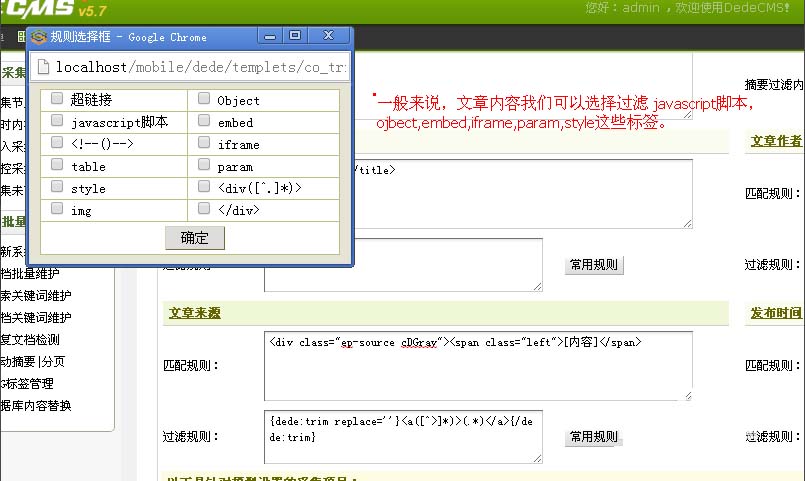
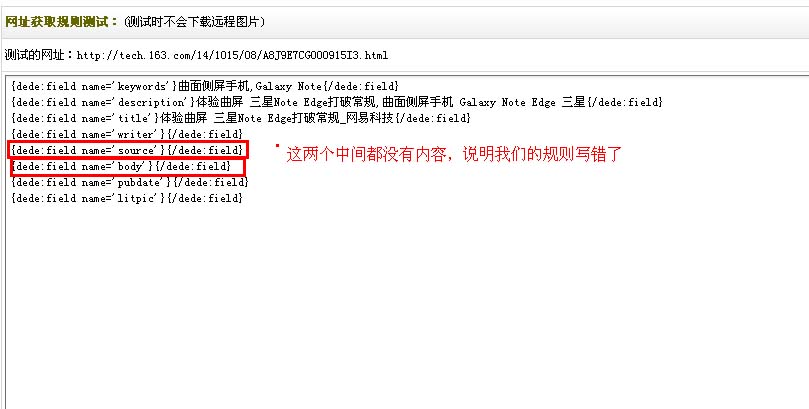
测试内容数组设置
因为网易有的文章开头是
,有的文章开头是
,所以会出现采集出错的情况。
如果你如今就要采集,你可以点击保存并采集。这里我选择仅保存

采集内容(一)
回到采集节点管理的界面,也就是第一步中的界面,我们选择节点,点击采集
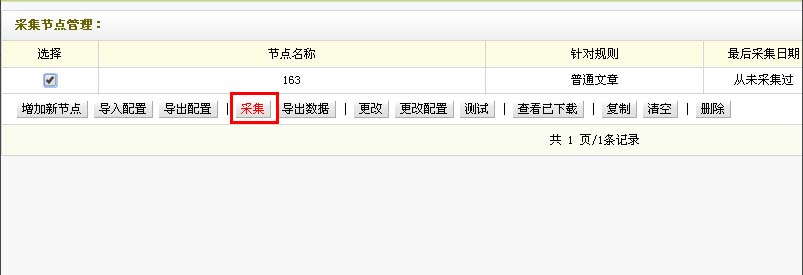
采集内容(二)
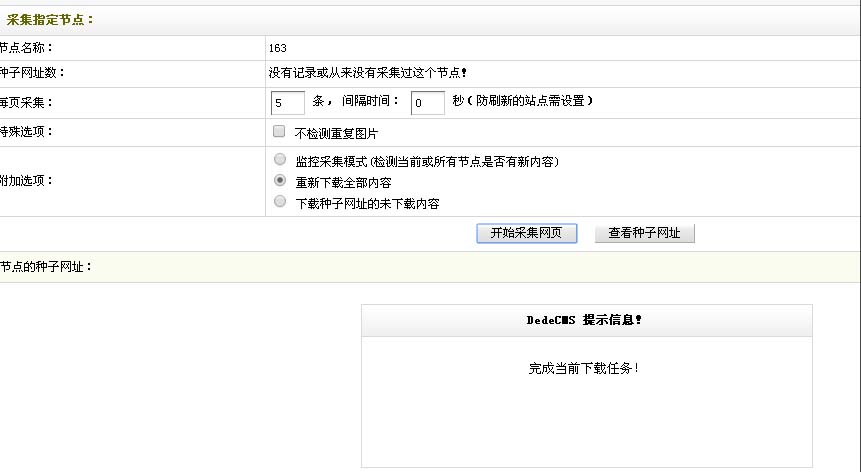
查看已下载
可以在采集界面(即第十步中的界面)的右上角,点击“查看已下载”。也可以在“采集节点管理”的界面里点击“查看已下载”。这里以第二个方式为例。
导出内容
选择要导出到的栏目,数据量,是否生成html文件 ,随机推荐数目
最终结果
老Y文章管理系统采集自动伪原创解读
采集交流 • 优采云 发表了文章 • 0 个评论 • 475 次浏览 • 2020-04-19 11:01
做垃圾站的站长们,最希望的事就是网站可以手动采集、自动完成伪原创、然后手动付钱,这实在是天底下最幸福的事,呵呵。自动采集和手动付钱就不讨论了,我昨天介绍一下怎样借助老Y文章管理系统采集时手动完成伪原创的技巧。
老Y文章管理系统使用简单、方便,虽然功能不如DEDE之类的强悍到几乎变态的程度(当然,老Y文章管理系统是asp语言写的,似乎也没有可比性),但是该有的都有,且相当简单,所以也遭到了不少站长们的欢迎。老Y文章管理系统采集时手动完成伪原创的具体方式还极少有人阐述,在老Y的峰会上,甚至有人在卖这个方式,小小的厌恶一下。
关于采集,我就不多说了,相信你们都可以搞定,我要介绍的是老Y文章管理系统怎样在采集的同时手动完成伪原创工作的具体方式,大体的思路就是借助老Y文章管理系统自带的过滤功能实现反义词的手动替换,从而达到伪原创的目的。比如我想将被采集文章中的所有“网赚博客”字样替换为“网赚日记”。详细步骤如下:
第一步,进入后台。找到“采集管理”-“过滤管理”,添加一个新的过滤项目。
我可以构建一个名为“网赚博客”的项目,具体设置请看图:
“过滤名称”:填入“网赚博客”即可,也可以随便写,但是为了便捷查看,建议与被替换的词句一致。
“所属项目”:请依照自己的网站进行选择一个网站栏目(必须选择一个栏目,否则过滤项目未能保存)
“过滤对象”:可选项有“标题过滤”和“正文过滤”,一般选“正文过滤”即可,如果你连标题都想伪原创一下,可以选择“标题过滤”。
“过滤类型”:可选项有“简单替换”和“高级过滤”,一般选“简单替换”,如果选择了“高级过滤”,需要指定“开始标记”和“结束标记”,这样可对采集来的内容进行代码级的替换。
“使用状态”:可选项有“启用”和“禁用”,不用解释。
“使用范围”:可选项有“公有”和“私有”。选择“私有”,该过滤仅对当前网站栏目有效;选择“公有”,对所有栏目都有效,不管采集任何栏目的任何内容,该过滤均有效。一般选“私有”即可。
“内容”:填入“网赚博客”,将要被替换的熟语。
“替换”:填入“网赚日记”,这样只要被采集的文章中富含“网赚博客”字样,就会被手动替换为“网赚日记”。
第二步,重复第一步的工作,直到添加完所有的反义词。
有网友要问了:我有30000多条反义词,难道要一条一条自动添加?那要到添加什么时候!?不能批量添加吗?
这个问题问得好!手动添加的确几乎是个不可能完成的任务,除非你有超常的毅力,可以手工把这30000多条反义词添加进去。遗憾的是,老Y文章管理系统并没有提供批量导出的功能。但是老y文章管理系统采集功能怎么设置分页,作为真正的、资深的、有思想的懒人,我们要有懒人的觉悟。
要知道,我们刚刚输入的内容,是储存在数据库中的,而老Y文章管理系统是用asp+Access写的,mdb数据库可以很方便的编辑!于是乎,我可以通过直接更改数据库的方式来批量导出伪原创替换规则!
改进的第二步:修改数据库,批量导出规则。
经过查找,我发觉这个数据库坐落“你的管理目录\cai\Database”下。用Access打开这个数据库,找到“Filters”表,你会发觉我们刚刚添加的替换规则就在这里存着呢,根据你的须要,批量添加吧!接下来的工作涉及到Access的操作了,我就不罗嗦了,大家自己可以搞定。
解释一下“Filters”表中的几个数组的涵义:
FilterID:自动生成,无需输入。
ItemID:栏目ID,就是我们自动输入时“所属项目”的内容,不过这儿是个数字ID,注意跟栏目的采集ID做好对应,如果不知道ID,可以重复第一步,测试一下。
FilterName:即“过滤名称”。
FilterObjece:即“过滤对象”,填1为“标题过滤”,填2则是“正文过滤”。
FilterType:即“过滤类型”,填1为“简单替换”,填2为“高级过滤”。
FilterContent:即“内容”。
FisString:即“开始标记”,仅在设置了“高级过滤”时有效,如果设置了“简单过滤”请留空。
FioString:即“结束标记”,仅在设置了“高级过滤”时有效,如果设置了“简单过滤”请留空。
FilterRep:即“替换”。
Flag:即“使用状态”,TRUE为“启用”,FALSE为“禁用”。
PublicTf:即“使用范围”。TRUE为“公有”,FALSE为“私有”。
最后说一点借助过滤功能实现伪原创的使用体会:
老Y文章管理系统的这个功能可以实现采集时手动伪原创,但是功能还不够强悍。比如我站上有“栏目一”、“栏目二”、“栏目三”共三个栏目。我希望“栏目一”对标题和正文都进行伪原创,“栏目二”只对正文进行伪原创,“栏目三”只对标题进行伪原创。
于是老y文章管理系统采集功能怎么设置分页,我只能做如下设置(假设我有30000的反义词规则):
为“栏目一”的标题伪原创创建30000条替换规则;
为“栏目一”的正文伪原创创建30000条替换规则;
为“栏目二”的正文伪原创创建30000条替换规则;
为“栏目三”的标题伪原创创建30000条替换规则。
这样就导致了极大的数据库浪费,如果我的站有几十个栏目,每个栏目的要求都不一样,这个数据库的规格将会非常惊悚。
所以建议老Y文章管理系统下一版本将这个功能做一下改进:
首先添加批量导出功能,毕竟更改数据库有一定的危险性。
其次,过滤规则不再屈从于某个网站栏目,而是将过滤规则独立下来,而在构建新的采集项目的时侯,加入一条是否使用过滤规则的判别。
相信,这样更改以后可以极大地节省数据库储存空间,同时逻辑结构也变得愈发清晰。 查看全部
老Y文章管理系统使用简单、方便,虽然功能不如DEDE之类的强悍到几乎变态的程度(当然,老Y文章管理系统是asp语言写的,似乎也没有可比性),但是该有的都有,且相当简单,所以也遭到了不少站长们的欢迎。老Y文章管理系统采集时手动完成伪原创的具体方式还极少有人阐述,在老Y的峰会上,甚至有人在卖这个方式,小小的厌恶一下。
关于采集,我就不多说了,相信你们都可以搞定,我要介绍的是老Y文章管理系统怎样在采集的同时手动完成伪原创工作的具体方式,大体的思路就是借助老Y文章管理系统自带的过滤功能实现反义词的手动替换,从而达到伪原创的目的。比如我想将被采集文章中的所有“网赚博客”字样替换为“网赚日记”。详细步骤如下:
第一步,进入后台。找到“采集管理”-“过滤管理”,添加一个新的过滤项目。
我可以构建一个名为“网赚博客”的项目,具体设置请看图:
“过滤名称”:填入“网赚博客”即可,也可以随便写,但是为了便捷查看,建议与被替换的词句一致。
“所属项目”:请依照自己的网站进行选择一个网站栏目(必须选择一个栏目,否则过滤项目未能保存)
“过滤对象”:可选项有“标题过滤”和“正文过滤”,一般选“正文过滤”即可,如果你连标题都想伪原创一下,可以选择“标题过滤”。
“过滤类型”:可选项有“简单替换”和“高级过滤”,一般选“简单替换”,如果选择了“高级过滤”,需要指定“开始标记”和“结束标记”,这样可对采集来的内容进行代码级的替换。
“使用状态”:可选项有“启用”和“禁用”,不用解释。
“使用范围”:可选项有“公有”和“私有”。选择“私有”,该过滤仅对当前网站栏目有效;选择“公有”,对所有栏目都有效,不管采集任何栏目的任何内容,该过滤均有效。一般选“私有”即可。
“内容”:填入“网赚博客”,将要被替换的熟语。
“替换”:填入“网赚日记”,这样只要被采集的文章中富含“网赚博客”字样,就会被手动替换为“网赚日记”。
第二步,重复第一步的工作,直到添加完所有的反义词。
有网友要问了:我有30000多条反义词,难道要一条一条自动添加?那要到添加什么时候!?不能批量添加吗?
这个问题问得好!手动添加的确几乎是个不可能完成的任务,除非你有超常的毅力,可以手工把这30000多条反义词添加进去。遗憾的是,老Y文章管理系统并没有提供批量导出的功能。但是老y文章管理系统采集功能怎么设置分页,作为真正的、资深的、有思想的懒人,我们要有懒人的觉悟。
要知道,我们刚刚输入的内容,是储存在数据库中的,而老Y文章管理系统是用asp+Access写的,mdb数据库可以很方便的编辑!于是乎,我可以通过直接更改数据库的方式来批量导出伪原创替换规则!
改进的第二步:修改数据库,批量导出规则。
经过查找,我发觉这个数据库坐落“你的管理目录\cai\Database”下。用Access打开这个数据库,找到“Filters”表,你会发觉我们刚刚添加的替换规则就在这里存着呢,根据你的须要,批量添加吧!接下来的工作涉及到Access的操作了,我就不罗嗦了,大家自己可以搞定。
解释一下“Filters”表中的几个数组的涵义:
FilterID:自动生成,无需输入。
ItemID:栏目ID,就是我们自动输入时“所属项目”的内容,不过这儿是个数字ID,注意跟栏目的采集ID做好对应,如果不知道ID,可以重复第一步,测试一下。
FilterName:即“过滤名称”。
FilterObjece:即“过滤对象”,填1为“标题过滤”,填2则是“正文过滤”。
FilterType:即“过滤类型”,填1为“简单替换”,填2为“高级过滤”。
FilterContent:即“内容”。
FisString:即“开始标记”,仅在设置了“高级过滤”时有效,如果设置了“简单过滤”请留空。
FioString:即“结束标记”,仅在设置了“高级过滤”时有效,如果设置了“简单过滤”请留空。
FilterRep:即“替换”。
Flag:即“使用状态”,TRUE为“启用”,FALSE为“禁用”。
PublicTf:即“使用范围”。TRUE为“公有”,FALSE为“私有”。
最后说一点借助过滤功能实现伪原创的使用体会:
老Y文章管理系统的这个功能可以实现采集时手动伪原创,但是功能还不够强悍。比如我站上有“栏目一”、“栏目二”、“栏目三”共三个栏目。我希望“栏目一”对标题和正文都进行伪原创,“栏目二”只对正文进行伪原创,“栏目三”只对标题进行伪原创。
于是老y文章管理系统采集功能怎么设置分页,我只能做如下设置(假设我有30000的反义词规则):
为“栏目一”的标题伪原创创建30000条替换规则;
为“栏目一”的正文伪原创创建30000条替换规则;
为“栏目二”的正文伪原创创建30000条替换规则;
为“栏目三”的标题伪原创创建30000条替换规则。
这样就导致了极大的数据库浪费,如果我的站有几十个栏目,每个栏目的要求都不一样,这个数据库的规格将会非常惊悚。
所以建议老Y文章管理系统下一版本将这个功能做一下改进:
首先添加批量导出功能,毕竟更改数据库有一定的危险性。
其次,过滤规则不再屈从于某个网站栏目,而是将过滤规则独立下来,而在构建新的采集项目的时侯,加入一条是否使用过滤规则的判别。
相信,这样更改以后可以极大地节省数据库储存空间,同时逻辑结构也变得愈发清晰。 查看全部
做垃圾站的站长们,最希望的事就是网站可以手动采集、自动完成伪原创、然后手动付钱,这实在是天底下最幸福的事,呵呵。自动采集和手动付钱就不讨论了,我昨天介绍一下怎样借助老Y文章管理系统采集时手动完成伪原创的技巧。
老Y文章管理系统使用简单、方便,虽然功能不如DEDE之类的强悍到几乎变态的程度(当然,老Y文章管理系统是asp语言写的,似乎也没有可比性),但是该有的都有,且相当简单,所以也遭到了不少站长们的欢迎。老Y文章管理系统采集时手动完成伪原创的具体方式还极少有人阐述,在老Y的峰会上,甚至有人在卖这个方式,小小的厌恶一下。
关于采集,我就不多说了,相信你们都可以搞定,我要介绍的是老Y文章管理系统怎样在采集的同时手动完成伪原创工作的具体方式,大体的思路就是借助老Y文章管理系统自带的过滤功能实现反义词的手动替换,从而达到伪原创的目的。比如我想将被采集文章中的所有“网赚博客”字样替换为“网赚日记”。详细步骤如下:
第一步,进入后台。找到“采集管理”-“过滤管理”,添加一个新的过滤项目。
我可以构建一个名为“网赚博客”的项目,具体设置请看图:
“过滤名称”:填入“网赚博客”即可,也可以随便写,但是为了便捷查看,建议与被替换的词句一致。
“所属项目”:请依照自己的网站进行选择一个网站栏目(必须选择一个栏目,否则过滤项目未能保存)
“过滤对象”:可选项有“标题过滤”和“正文过滤”,一般选“正文过滤”即可,如果你连标题都想伪原创一下,可以选择“标题过滤”。
“过滤类型”:可选项有“简单替换”和“高级过滤”,一般选“简单替换”,如果选择了“高级过滤”,需要指定“开始标记”和“结束标记”,这样可对采集来的内容进行代码级的替换。
“使用状态”:可选项有“启用”和“禁用”,不用解释。
“使用范围”:可选项有“公有”和“私有”。选择“私有”,该过滤仅对当前网站栏目有效;选择“公有”,对所有栏目都有效,不管采集任何栏目的任何内容,该过滤均有效。一般选“私有”即可。
“内容”:填入“网赚博客”,将要被替换的熟语。
“替换”:填入“网赚日记”,这样只要被采集的文章中富含“网赚博客”字样,就会被手动替换为“网赚日记”。
第二步,重复第一步的工作,直到添加完所有的反义词。
有网友要问了:我有30000多条反义词,难道要一条一条自动添加?那要到添加什么时候!?不能批量添加吗?
这个问题问得好!手动添加的确几乎是个不可能完成的任务,除非你有超常的毅力,可以手工把这30000多条反义词添加进去。遗憾的是,老Y文章管理系统并没有提供批量导出的功能。但是老y文章管理系统采集功能怎么设置分页,作为真正的、资深的、有思想的懒人,我们要有懒人的觉悟。
要知道,我们刚刚输入的内容,是储存在数据库中的,而老Y文章管理系统是用asp+Access写的,mdb数据库可以很方便的编辑!于是乎,我可以通过直接更改数据库的方式来批量导出伪原创替换规则!
改进的第二步:修改数据库,批量导出规则。
经过查找,我发觉这个数据库坐落“你的管理目录\cai\Database”下。用Access打开这个数据库,找到“Filters”表,你会发觉我们刚刚添加的替换规则就在这里存着呢,根据你的须要,批量添加吧!接下来的工作涉及到Access的操作了,我就不罗嗦了,大家自己可以搞定。
解释一下“Filters”表中的几个数组的涵义:
FilterID:自动生成,无需输入。
ItemID:栏目ID,就是我们自动输入时“所属项目”的内容,不过这儿是个数字ID,注意跟栏目的采集ID做好对应,如果不知道ID,可以重复第一步,测试一下。
FilterName:即“过滤名称”。
FilterObjece:即“过滤对象”,填1为“标题过滤”,填2则是“正文过滤”。
FilterType:即“过滤类型”,填1为“简单替换”,填2为“高级过滤”。
FilterContent:即“内容”。
FisString:即“开始标记”,仅在设置了“高级过滤”时有效,如果设置了“简单过滤”请留空。
FioString:即“结束标记”,仅在设置了“高级过滤”时有效,如果设置了“简单过滤”请留空。
FilterRep:即“替换”。
Flag:即“使用状态”,TRUE为“启用”,FALSE为“禁用”。
PublicTf:即“使用范围”。TRUE为“公有”,FALSE为“私有”。
最后说一点借助过滤功能实现伪原创的使用体会:
老Y文章管理系统的这个功能可以实现采集时手动伪原创,但是功能还不够强悍。比如我站上有“栏目一”、“栏目二”、“栏目三”共三个栏目。我希望“栏目一”对标题和正文都进行伪原创,“栏目二”只对正文进行伪原创,“栏目三”只对标题进行伪原创。
于是老y文章管理系统采集功能怎么设置分页,我只能做如下设置(假设我有30000的反义词规则):
为“栏目一”的标题伪原创创建30000条替换规则;
为“栏目一”的正文伪原创创建30000条替换规则;
为“栏目二”的正文伪原创创建30000条替换规则;
为“栏目三”的标题伪原创创建30000条替换规则。
这样就导致了极大的数据库浪费,如果我的站有几十个栏目,每个栏目的要求都不一样,这个数据库的规格将会非常惊悚。
所以建议老Y文章管理系统下一版本将这个功能做一下改进:
首先添加批量导出功能,毕竟更改数据库有一定的危险性。
其次,过滤规则不再屈从于某个网站栏目,而是将过滤规则独立下来,而在构建新的采集项目的时侯,加入一条是否使用过滤规则的判别。
相信,这样更改以后可以极大地节省数据库储存空间,同时逻辑结构也变得愈发清晰。
老Y文章管理系统使用简单、方便,虽然功能不如DEDE之类的强悍到几乎变态的程度(当然,老Y文章管理系统是asp语言写的,似乎也没有可比性),但是该有的都有,且相当简单,所以也遭到了不少站长们的欢迎。老Y文章管理系统采集时手动完成伪原创的具体方式还极少有人阐述,在老Y的峰会上,甚至有人在卖这个方式,小小的厌恶一下。
关于采集,我就不多说了,相信你们都可以搞定,我要介绍的是老Y文章管理系统怎样在采集的同时手动完成伪原创工作的具体方式,大体的思路就是借助老Y文章管理系统自带的过滤功能实现反义词的手动替换,从而达到伪原创的目的。比如我想将被采集文章中的所有“网赚博客”字样替换为“网赚日记”。详细步骤如下:
第一步,进入后台。找到“采集管理”-“过滤管理”,添加一个新的过滤项目。
我可以构建一个名为“网赚博客”的项目,具体设置请看图:
“过滤名称”:填入“网赚博客”即可,也可以随便写,但是为了便捷查看,建议与被替换的词句一致。
“所属项目”:请依照自己的网站进行选择一个网站栏目(必须选择一个栏目,否则过滤项目未能保存)
“过滤对象”:可选项有“标题过滤”和“正文过滤”,一般选“正文过滤”即可,如果你连标题都想伪原创一下,可以选择“标题过滤”。
“过滤类型”:可选项有“简单替换”和“高级过滤”,一般选“简单替换”,如果选择了“高级过滤”,需要指定“开始标记”和“结束标记”,这样可对采集来的内容进行代码级的替换。
“使用状态”:可选项有“启用”和“禁用”,不用解释。
“使用范围”:可选项有“公有”和“私有”。选择“私有”,该过滤仅对当前网站栏目有效;选择“公有”,对所有栏目都有效,不管采集任何栏目的任何内容,该过滤均有效。一般选“私有”即可。
“内容”:填入“网赚博客”,将要被替换的熟语。
“替换”:填入“网赚日记”,这样只要被采集的文章中富含“网赚博客”字样,就会被手动替换为“网赚日记”。
第二步,重复第一步的工作,直到添加完所有的反义词。
有网友要问了:我有30000多条反义词,难道要一条一条自动添加?那要到添加什么时候!?不能批量添加吗?
这个问题问得好!手动添加的确几乎是个不可能完成的任务,除非你有超常的毅力,可以手工把这30000多条反义词添加进去。遗憾的是,老Y文章管理系统并没有提供批量导出的功能。但是老y文章管理系统采集功能怎么设置分页,作为真正的、资深的、有思想的懒人,我们要有懒人的觉悟。
要知道,我们刚刚输入的内容,是储存在数据库中的,而老Y文章管理系统是用asp+Access写的,mdb数据库可以很方便的编辑!于是乎,我可以通过直接更改数据库的方式来批量导出伪原创替换规则!
改进的第二步:修改数据库,批量导出规则。
经过查找,我发觉这个数据库坐落“你的管理目录\cai\Database”下。用Access打开这个数据库,找到“Filters”表,你会发觉我们刚刚添加的替换规则就在这里存着呢,根据你的须要,批量添加吧!接下来的工作涉及到Access的操作了,我就不罗嗦了,大家自己可以搞定。
解释一下“Filters”表中的几个数组的涵义:
FilterID:自动生成,无需输入。
ItemID:栏目ID,就是我们自动输入时“所属项目”的内容,不过这儿是个数字ID,注意跟栏目的采集ID做好对应,如果不知道ID,可以重复第一步,测试一下。
FilterName:即“过滤名称”。
FilterObjece:即“过滤对象”,填1为“标题过滤”,填2则是“正文过滤”。
FilterType:即“过滤类型”,填1为“简单替换”,填2为“高级过滤”。
FilterContent:即“内容”。
FisString:即“开始标记”,仅在设置了“高级过滤”时有效,如果设置了“简单过滤”请留空。
FioString:即“结束标记”,仅在设置了“高级过滤”时有效,如果设置了“简单过滤”请留空。
FilterRep:即“替换”。
Flag:即“使用状态”,TRUE为“启用”,FALSE为“禁用”。
PublicTf:即“使用范围”。TRUE为“公有”,FALSE为“私有”。
最后说一点借助过滤功能实现伪原创的使用体会:
老Y文章管理系统的这个功能可以实现采集时手动伪原创,但是功能还不够强悍。比如我站上有“栏目一”、“栏目二”、“栏目三”共三个栏目。我希望“栏目一”对标题和正文都进行伪原创,“栏目二”只对正文进行伪原创,“栏目三”只对标题进行伪原创。
于是老y文章管理系统采集功能怎么设置分页,我只能做如下设置(假设我有30000的反义词规则):
为“栏目一”的标题伪原创创建30000条替换规则;
为“栏目一”的正文伪原创创建30000条替换规则;
为“栏目二”的正文伪原创创建30000条替换规则;
为“栏目三”的标题伪原创创建30000条替换规则。
这样就导致了极大的数据库浪费,如果我的站有几十个栏目,每个栏目的要求都不一样,这个数据库的规格将会非常惊悚。
所以建议老Y文章管理系统下一版本将这个功能做一下改进:
首先添加批量导出功能,毕竟更改数据库有一定的危险性。
其次,过滤规则不再屈从于某个网站栏目,而是将过滤规则独立下来,而在构建新的采集项目的时侯,加入一条是否使用过滤规则的判别。
相信,这样更改以后可以极大地节省数据库储存空间,同时逻辑结构也变得愈发清晰。
第一步、我们打开织梦后台点击采集——采集节点管理——增加新节点
采集交流 • 优采云 发表了文章 • 0 个评论 • 426 次浏览 • 2020-08-03 15:02
第一步、我们打开织梦后台点击采集——采集节点管理——增加新节点
第二步、新增节点-配置网址索引
填写要采集的网站的列表相关规则,
查看采集站点的编码和网站源码
我们右键单击,点击查看源码,在源码的开头位置,找到一个写有charset=某一编码的meta标签,比如charset="gb2312",这个就是所说的网站编码了
选择采集站点的编码
第三步、新增节点-配置文章网址匹配规则
我们查看采集站点的列表页源码,找到文章列表开始html和结束html标签,分别把它们复制到降低采集节点->文章网址匹配规则的"区域开始的HTML"和“区域结束的HTML”输入框中。你不一定选择右键查看源码来找到文章列表开始标签,你可以在文章开始的地方右键单击,审查元素(chrome浏览器,firefox是查看元素),这样就更方便的找到文章列表开始和结束的标签了。
设置以后我们点击"保存信息并步入下一步设置"
第四步:网址获取规则测试
如果在测试结果发觉有无关的网址信息,说明的第五步中的网址过滤规则有误或则没有填写过滤规则。如果发觉采集有误,你可以返回上一次更改,没有就点击“保存信息并步入下一步设置”。
第五步:内容数组获取规则
我们查看采集站点的文章源码,找到相关选项的开始和结束html标签网站程序自带的采集器采集文章,填写入指定位置,开始和结束标签以"[内容]"分格。
设置完毕,我们点击"保存配置并预览"
第六步:过滤规则
在第七步中的匹配规则前面,都 有一个过滤规则,这个过滤规则是拿来过滤无需采集的内容。
比如,网易整篇文章都有一个放置广告的iframe标签,我们要采集网易的文章,不可能采集回来以后,一篇一篇得去删掉这个广告。但是怎样消除呢?去除方式就是那种过滤规则,我们点击常用规则网站程序自带的采集器采集文章,就会弹出一个小窗口,列出了常用的过滤规则,我们只需点击要们要过滤的规则即可,要过滤网易文章中的iframe标签,我们就点击iframe即可。
测试内容数组设置
因为网易有的文章开头是
,有的文章开头是
,所以会出现采集出错的情况。
如果你如今就要采集,你可以点击保存并采集。这里我选择仅保存
采集内容(一)
回到采集节点管理的界面,也就是第一步中的界面,我们选择节点,点击采集
采集内容(二)
查看已下载
可以在采集界面(即第十步中的界面)的右上角,点击“查看已下载”。也可以在“采集节点管理”的界面里点击“查看已下载”。这里以第二个方式为例。
导出内容
选择要导出到的栏目,数据量,是否生成html文件 ,随机推荐数目
最终结果 查看全部
第二步、新增节点-配置网址索引
填写要采集的网站的列表相关规则,
查看采集站点的编码和网站源码
我们右键单击,点击查看源码,在源码的开头位置,找到一个写有charset=某一编码的meta标签,比如charset="gb2312",这个就是所说的网站编码了
选择采集站点的编码
第三步、新增节点-配置文章网址匹配规则
我们查看采集站点的列表页源码,找到文章列表开始html和结束html标签,分别把它们复制到降低采集节点->文章网址匹配规则的"区域开始的HTML"和“区域结束的HTML”输入框中。你不一定选择右键查看源码来找到文章列表开始标签,你可以在文章开始的地方右键单击,审查元素(chrome浏览器,firefox是查看元素),这样就更方便的找到文章列表开始和结束的标签了。
设置以后我们点击"保存信息并步入下一步设置"
第四步:网址获取规则测试
如果在测试结果发觉有无关的网址信息,说明的第五步中的网址过滤规则有误或则没有填写过滤规则。如果发觉采集有误,你可以返回上一次更改,没有就点击“保存信息并步入下一步设置”。
第五步:内容数组获取规则
我们查看采集站点的文章源码,找到相关选项的开始和结束html标签网站程序自带的采集器采集文章,填写入指定位置,开始和结束标签以"[内容]"分格。
设置完毕,我们点击"保存配置并预览"
第六步:过滤规则
在第七步中的匹配规则前面,都 有一个过滤规则,这个过滤规则是拿来过滤无需采集的内容。
比如,网易整篇文章都有一个放置广告的iframe标签,我们要采集网易的文章,不可能采集回来以后,一篇一篇得去删掉这个广告。但是怎样消除呢?去除方式就是那种过滤规则,我们点击常用规则网站程序自带的采集器采集文章,就会弹出一个小窗口,列出了常用的过滤规则,我们只需点击要们要过滤的规则即可,要过滤网易文章中的iframe标签,我们就点击iframe即可。
测试内容数组设置
因为网易有的文章开头是
,有的文章开头是
,所以会出现采集出错的情况。
如果你如今就要采集,你可以点击保存并采集。这里我选择仅保存
采集内容(一)
回到采集节点管理的界面,也就是第一步中的界面,我们选择节点,点击采集
采集内容(二)
查看已下载
可以在采集界面(即第十步中的界面)的右上角,点击“查看已下载”。也可以在“采集节点管理”的界面里点击“查看已下载”。这里以第二个方式为例。
导出内容
选择要导出到的栏目,数据量,是否生成html文件 ,随机推荐数目
最终结果 查看全部
第一步、我们打开织梦后台点击采集——采集节点管理——增加新节点
第二步、新增节点-配置网址索引
填写要采集的网站的列表相关规则,
查看采集站点的编码和网站源码
我们右键单击,点击查看源码,在源码的开头位置,找到一个写有charset=某一编码的meta标签,比如charset="gb2312",这个就是所说的网站编码了
选择采集站点的编码
第三步、新增节点-配置文章网址匹配规则
我们查看采集站点的列表页源码,找到文章列表开始html和结束html标签,分别把它们复制到降低采集节点->文章网址匹配规则的"区域开始的HTML"和“区域结束的HTML”输入框中。你不一定选择右键查看源码来找到文章列表开始标签,你可以在文章开始的地方右键单击,审查元素(chrome浏览器,firefox是查看元素),这样就更方便的找到文章列表开始和结束的标签了。
设置以后我们点击"保存信息并步入下一步设置"
第四步:网址获取规则测试
如果在测试结果发觉有无关的网址信息,说明的第五步中的网址过滤规则有误或则没有填写过滤规则。如果发觉采集有误,你可以返回上一次更改,没有就点击“保存信息并步入下一步设置”。
第五步:内容数组获取规则
我们查看采集站点的文章源码,找到相关选项的开始和结束html标签网站程序自带的采集器采集文章,填写入指定位置,开始和结束标签以"[内容]"分格。
设置完毕,我们点击"保存配置并预览"
第六步:过滤规则
在第七步中的匹配规则前面,都 有一个过滤规则,这个过滤规则是拿来过滤无需采集的内容。
比如,网易整篇文章都有一个放置广告的iframe标签,我们要采集网易的文章,不可能采集回来以后,一篇一篇得去删掉这个广告。但是怎样消除呢?去除方式就是那种过滤规则,我们点击常用规则网站程序自带的采集器采集文章,就会弹出一个小窗口,列出了常用的过滤规则,我们只需点击要们要过滤的规则即可,要过滤网易文章中的iframe标签,我们就点击iframe即可。
测试内容数组设置
因为网易有的文章开头是
,有的文章开头是
,所以会出现采集出错的情况。
如果你如今就要采集,你可以点击保存并采集。这里我选择仅保存
采集内容(一)
回到采集节点管理的界面,也就是第一步中的界面,我们选择节点,点击采集
采集内容(二)
查看已下载
可以在采集界面(即第十步中的界面)的右上角,点击“查看已下载”。也可以在“采集节点管理”的界面里点击“查看已下载”。这里以第二个方式为例。
导出内容
选择要导出到的栏目,数据量,是否生成html文件 ,随机推荐数目
最终结果
老Y文章管理系统采集自动伪原创解读
采集交流 • 优采云 发表了文章 • 0 个评论 • 475 次浏览 • 2020-04-19 11:01
做垃圾站的站长们,最希望的事就是网站可以手动采集、自动完成伪原创、然后手动付钱,这实在是天底下最幸福的事,呵呵。自动采集和手动付钱就不讨论了,我昨天介绍一下怎样借助老Y文章管理系统采集时手动完成伪原创的技巧。
老Y文章管理系统使用简单、方便,虽然功能不如DEDE之类的强悍到几乎变态的程度(当然,老Y文章管理系统是asp语言写的,似乎也没有可比性),但是该有的都有,且相当简单,所以也遭到了不少站长们的欢迎。老Y文章管理系统采集时手动完成伪原创的具体方式还极少有人阐述,在老Y的峰会上,甚至有人在卖这个方式,小小的厌恶一下。
关于采集,我就不多说了,相信你们都可以搞定,我要介绍的是老Y文章管理系统怎样在采集的同时手动完成伪原创工作的具体方式,大体的思路就是借助老Y文章管理系统自带的过滤功能实现反义词的手动替换,从而达到伪原创的目的。比如我想将被采集文章中的所有“网赚博客”字样替换为“网赚日记”。详细步骤如下:
第一步,进入后台。找到“采集管理”-“过滤管理”,添加一个新的过滤项目。
我可以构建一个名为“网赚博客”的项目,具体设置请看图:
“过滤名称”:填入“网赚博客”即可,也可以随便写,但是为了便捷查看,建议与被替换的词句一致。
“所属项目”:请依照自己的网站进行选择一个网站栏目(必须选择一个栏目,否则过滤项目未能保存)
“过滤对象”:可选项有“标题过滤”和“正文过滤”,一般选“正文过滤”即可,如果你连标题都想伪原创一下,可以选择“标题过滤”。
“过滤类型”:可选项有“简单替换”和“高级过滤”,一般选“简单替换”,如果选择了“高级过滤”,需要指定“开始标记”和“结束标记”,这样可对采集来的内容进行代码级的替换。
“使用状态”:可选项有“启用”和“禁用”,不用解释。
“使用范围”:可选项有“公有”和“私有”。选择“私有”,该过滤仅对当前网站栏目有效;选择“公有”,对所有栏目都有效,不管采集任何栏目的任何内容,该过滤均有效。一般选“私有”即可。
“内容”:填入“网赚博客”,将要被替换的熟语。
“替换”:填入“网赚日记”,这样只要被采集的文章中富含“网赚博客”字样,就会被手动替换为“网赚日记”。
第二步,重复第一步的工作,直到添加完所有的反义词。
有网友要问了:我有30000多条反义词,难道要一条一条自动添加?那要到添加什么时候!?不能批量添加吗?
这个问题问得好!手动添加的确几乎是个不可能完成的任务,除非你有超常的毅力,可以手工把这30000多条反义词添加进去。遗憾的是,老Y文章管理系统并没有提供批量导出的功能。但是老y文章管理系统采集功能怎么设置分页,作为真正的、资深的、有思想的懒人,我们要有懒人的觉悟。
要知道,我们刚刚输入的内容,是储存在数据库中的,而老Y文章管理系统是用asp+Access写的,mdb数据库可以很方便的编辑!于是乎,我可以通过直接更改数据库的方式来批量导出伪原创替换规则!
改进的第二步:修改数据库,批量导出规则。
经过查找,我发觉这个数据库坐落“你的管理目录\cai\Database”下。用Access打开这个数据库,找到“Filters”表,你会发觉我们刚刚添加的替换规则就在这里存着呢,根据你的须要,批量添加吧!接下来的工作涉及到Access的操作了,我就不罗嗦了,大家自己可以搞定。
解释一下“Filters”表中的几个数组的涵义:
FilterID:自动生成,无需输入。
ItemID:栏目ID,就是我们自动输入时“所属项目”的内容,不过这儿是个数字ID,注意跟栏目的采集ID做好对应,如果不知道ID,可以重复第一步,测试一下。
FilterName:即“过滤名称”。
FilterObjece:即“过滤对象”,填1为“标题过滤”,填2则是“正文过滤”。
FilterType:即“过滤类型”,填1为“简单替换”,填2为“高级过滤”。
FilterContent:即“内容”。
FisString:即“开始标记”,仅在设置了“高级过滤”时有效,如果设置了“简单过滤”请留空。
FioString:即“结束标记”,仅在设置了“高级过滤”时有效,如果设置了“简单过滤”请留空。
FilterRep:即“替换”。
Flag:即“使用状态”,TRUE为“启用”,FALSE为“禁用”。
PublicTf:即“使用范围”。TRUE为“公有”,FALSE为“私有”。
最后说一点借助过滤功能实现伪原创的使用体会:
老Y文章管理系统的这个功能可以实现采集时手动伪原创,但是功能还不够强悍。比如我站上有“栏目一”、“栏目二”、“栏目三”共三个栏目。我希望“栏目一”对标题和正文都进行伪原创,“栏目二”只对正文进行伪原创,“栏目三”只对标题进行伪原创。
于是老y文章管理系统采集功能怎么设置分页,我只能做如下设置(假设我有30000的反义词规则):
为“栏目一”的标题伪原创创建30000条替换规则;
为“栏目一”的正文伪原创创建30000条替换规则;
为“栏目二”的正文伪原创创建30000条替换规则;
为“栏目三”的标题伪原创创建30000条替换规则。
这样就导致了极大的数据库浪费,如果我的站有几十个栏目,每个栏目的要求都不一样,这个数据库的规格将会非常惊悚。
所以建议老Y文章管理系统下一版本将这个功能做一下改进:
首先添加批量导出功能,毕竟更改数据库有一定的危险性。
其次,过滤规则不再屈从于某个网站栏目,而是将过滤规则独立下来,而在构建新的采集项目的时侯,加入一条是否使用过滤规则的判别。
相信,这样更改以后可以极大地节省数据库储存空间,同时逻辑结构也变得愈发清晰。 查看全部
老Y文章管理系统使用简单、方便,虽然功能不如DEDE之类的强悍到几乎变态的程度(当然,老Y文章管理系统是asp语言写的,似乎也没有可比性),但是该有的都有,且相当简单,所以也遭到了不少站长们的欢迎。老Y文章管理系统采集时手动完成伪原创的具体方式还极少有人阐述,在老Y的峰会上,甚至有人在卖这个方式,小小的厌恶一下。
关于采集,我就不多说了,相信你们都可以搞定,我要介绍的是老Y文章管理系统怎样在采集的同时手动完成伪原创工作的具体方式,大体的思路就是借助老Y文章管理系统自带的过滤功能实现反义词的手动替换,从而达到伪原创的目的。比如我想将被采集文章中的所有“网赚博客”字样替换为“网赚日记”。详细步骤如下:
第一步,进入后台。找到“采集管理”-“过滤管理”,添加一个新的过滤项目。
我可以构建一个名为“网赚博客”的项目,具体设置请看图:
“过滤名称”:填入“网赚博客”即可,也可以随便写,但是为了便捷查看,建议与被替换的词句一致。
“所属项目”:请依照自己的网站进行选择一个网站栏目(必须选择一个栏目,否则过滤项目未能保存)
“过滤对象”:可选项有“标题过滤”和“正文过滤”,一般选“正文过滤”即可,如果你连标题都想伪原创一下,可以选择“标题过滤”。
“过滤类型”:可选项有“简单替换”和“高级过滤”,一般选“简单替换”,如果选择了“高级过滤”,需要指定“开始标记”和“结束标记”,这样可对采集来的内容进行代码级的替换。
“使用状态”:可选项有“启用”和“禁用”,不用解释。
“使用范围”:可选项有“公有”和“私有”。选择“私有”,该过滤仅对当前网站栏目有效;选择“公有”,对所有栏目都有效,不管采集任何栏目的任何内容,该过滤均有效。一般选“私有”即可。
“内容”:填入“网赚博客”,将要被替换的熟语。
“替换”:填入“网赚日记”,这样只要被采集的文章中富含“网赚博客”字样,就会被手动替换为“网赚日记”。
第二步,重复第一步的工作,直到添加完所有的反义词。
有网友要问了:我有30000多条反义词,难道要一条一条自动添加?那要到添加什么时候!?不能批量添加吗?
这个问题问得好!手动添加的确几乎是个不可能完成的任务,除非你有超常的毅力,可以手工把这30000多条反义词添加进去。遗憾的是,老Y文章管理系统并没有提供批量导出的功能。但是老y文章管理系统采集功能怎么设置分页,作为真正的、资深的、有思想的懒人,我们要有懒人的觉悟。
要知道,我们刚刚输入的内容,是储存在数据库中的,而老Y文章管理系统是用asp+Access写的,mdb数据库可以很方便的编辑!于是乎,我可以通过直接更改数据库的方式来批量导出伪原创替换规则!
改进的第二步:修改数据库,批量导出规则。
经过查找,我发觉这个数据库坐落“你的管理目录\cai\Database”下。用Access打开这个数据库,找到“Filters”表,你会发觉我们刚刚添加的替换规则就在这里存着呢,根据你的须要,批量添加吧!接下来的工作涉及到Access的操作了,我就不罗嗦了,大家自己可以搞定。
解释一下“Filters”表中的几个数组的涵义:
FilterID:自动生成,无需输入。
ItemID:栏目ID,就是我们自动输入时“所属项目”的内容,不过这儿是个数字ID,注意跟栏目的采集ID做好对应,如果不知道ID,可以重复第一步,测试一下。
FilterName:即“过滤名称”。
FilterObjece:即“过滤对象”,填1为“标题过滤”,填2则是“正文过滤”。
FilterType:即“过滤类型”,填1为“简单替换”,填2为“高级过滤”。
FilterContent:即“内容”。
FisString:即“开始标记”,仅在设置了“高级过滤”时有效,如果设置了“简单过滤”请留空。
FioString:即“结束标记”,仅在设置了“高级过滤”时有效,如果设置了“简单过滤”请留空。
FilterRep:即“替换”。
Flag:即“使用状态”,TRUE为“启用”,FALSE为“禁用”。
PublicTf:即“使用范围”。TRUE为“公有”,FALSE为“私有”。
最后说一点借助过滤功能实现伪原创的使用体会:
老Y文章管理系统的这个功能可以实现采集时手动伪原创,但是功能还不够强悍。比如我站上有“栏目一”、“栏目二”、“栏目三”共三个栏目。我希望“栏目一”对标题和正文都进行伪原创,“栏目二”只对正文进行伪原创,“栏目三”只对标题进行伪原创。
于是老y文章管理系统采集功能怎么设置分页,我只能做如下设置(假设我有30000的反义词规则):
为“栏目一”的标题伪原创创建30000条替换规则;
为“栏目一”的正文伪原创创建30000条替换规则;
为“栏目二”的正文伪原创创建30000条替换规则;
为“栏目三”的标题伪原创创建30000条替换规则。
这样就导致了极大的数据库浪费,如果我的站有几十个栏目,每个栏目的要求都不一样,这个数据库的规格将会非常惊悚。
所以建议老Y文章管理系统下一版本将这个功能做一下改进:
首先添加批量导出功能,毕竟更改数据库有一定的危险性。
其次,过滤规则不再屈从于某个网站栏目,而是将过滤规则独立下来,而在构建新的采集项目的时侯,加入一条是否使用过滤规则的判别。
相信,这样更改以后可以极大地节省数据库储存空间,同时逻辑结构也变得愈发清晰。 查看全部
做垃圾站的站长们,最希望的事就是网站可以手动采集、自动完成伪原创、然后手动付钱,这实在是天底下最幸福的事,呵呵。自动采集和手动付钱就不讨论了,我昨天介绍一下怎样借助老Y文章管理系统采集时手动完成伪原创的技巧。
老Y文章管理系统使用简单、方便,虽然功能不如DEDE之类的强悍到几乎变态的程度(当然,老Y文章管理系统是asp语言写的,似乎也没有可比性),但是该有的都有,且相当简单,所以也遭到了不少站长们的欢迎。老Y文章管理系统采集时手动完成伪原创的具体方式还极少有人阐述,在老Y的峰会上,甚至有人在卖这个方式,小小的厌恶一下。
关于采集,我就不多说了,相信你们都可以搞定,我要介绍的是老Y文章管理系统怎样在采集的同时手动完成伪原创工作的具体方式,大体的思路就是借助老Y文章管理系统自带的过滤功能实现反义词的手动替换,从而达到伪原创的目的。比如我想将被采集文章中的所有“网赚博客”字样替换为“网赚日记”。详细步骤如下:
第一步,进入后台。找到“采集管理”-“过滤管理”,添加一个新的过滤项目。
我可以构建一个名为“网赚博客”的项目,具体设置请看图:
“过滤名称”:填入“网赚博客”即可,也可以随便写,但是为了便捷查看,建议与被替换的词句一致。
“所属项目”:请依照自己的网站进行选择一个网站栏目(必须选择一个栏目,否则过滤项目未能保存)
“过滤对象”:可选项有“标题过滤”和“正文过滤”,一般选“正文过滤”即可,如果你连标题都想伪原创一下,可以选择“标题过滤”。
“过滤类型”:可选项有“简单替换”和“高级过滤”,一般选“简单替换”,如果选择了“高级过滤”,需要指定“开始标记”和“结束标记”,这样可对采集来的内容进行代码级的替换。
“使用状态”:可选项有“启用”和“禁用”,不用解释。
“使用范围”:可选项有“公有”和“私有”。选择“私有”,该过滤仅对当前网站栏目有效;选择“公有”,对所有栏目都有效,不管采集任何栏目的任何内容,该过滤均有效。一般选“私有”即可。
“内容”:填入“网赚博客”,将要被替换的熟语。
“替换”:填入“网赚日记”,这样只要被采集的文章中富含“网赚博客”字样,就会被手动替换为“网赚日记”。
第二步,重复第一步的工作,直到添加完所有的反义词。
有网友要问了:我有30000多条反义词,难道要一条一条自动添加?那要到添加什么时候!?不能批量添加吗?
这个问题问得好!手动添加的确几乎是个不可能完成的任务,除非你有超常的毅力,可以手工把这30000多条反义词添加进去。遗憾的是,老Y文章管理系统并没有提供批量导出的功能。但是老y文章管理系统采集功能怎么设置分页,作为真正的、资深的、有思想的懒人,我们要有懒人的觉悟。
要知道,我们刚刚输入的内容,是储存在数据库中的,而老Y文章管理系统是用asp+Access写的,mdb数据库可以很方便的编辑!于是乎,我可以通过直接更改数据库的方式来批量导出伪原创替换规则!
改进的第二步:修改数据库,批量导出规则。
经过查找,我发觉这个数据库坐落“你的管理目录\cai\Database”下。用Access打开这个数据库,找到“Filters”表,你会发觉我们刚刚添加的替换规则就在这里存着呢,根据你的须要,批量添加吧!接下来的工作涉及到Access的操作了,我就不罗嗦了,大家自己可以搞定。
解释一下“Filters”表中的几个数组的涵义:
FilterID:自动生成,无需输入。
ItemID:栏目ID,就是我们自动输入时“所属项目”的内容,不过这儿是个数字ID,注意跟栏目的采集ID做好对应,如果不知道ID,可以重复第一步,测试一下。
FilterName:即“过滤名称”。
FilterObjece:即“过滤对象”,填1为“标题过滤”,填2则是“正文过滤”。
FilterType:即“过滤类型”,填1为“简单替换”,填2为“高级过滤”。
FilterContent:即“内容”。
FisString:即“开始标记”,仅在设置了“高级过滤”时有效,如果设置了“简单过滤”请留空。
FioString:即“结束标记”,仅在设置了“高级过滤”时有效,如果设置了“简单过滤”请留空。
FilterRep:即“替换”。
Flag:即“使用状态”,TRUE为“启用”,FALSE为“禁用”。
PublicTf:即“使用范围”。TRUE为“公有”,FALSE为“私有”。
最后说一点借助过滤功能实现伪原创的使用体会:
老Y文章管理系统的这个功能可以实现采集时手动伪原创,但是功能还不够强悍。比如我站上有“栏目一”、“栏目二”、“栏目三”共三个栏目。我希望“栏目一”对标题和正文都进行伪原创,“栏目二”只对正文进行伪原创,“栏目三”只对标题进行伪原创。
于是老y文章管理系统采集功能怎么设置分页,我只能做如下设置(假设我有30000的反义词规则):
为“栏目一”的标题伪原创创建30000条替换规则;
为“栏目一”的正文伪原创创建30000条替换规则;
为“栏目二”的正文伪原创创建30000条替换规则;
为“栏目三”的标题伪原创创建30000条替换规则。
这样就导致了极大的数据库浪费,如果我的站有几十个栏目,每个栏目的要求都不一样,这个数据库的规格将会非常惊悚。
所以建议老Y文章管理系统下一版本将这个功能做一下改进:
首先添加批量导出功能,毕竟更改数据库有一定的危险性。
其次,过滤规则不再屈从于某个网站栏目,而是将过滤规则独立下来,而在构建新的采集项目的时侯,加入一条是否使用过滤规则的判别。
相信,这样更改以后可以极大地节省数据库储存空间,同时逻辑结构也变得愈发清晰。
老Y文章管理系统使用简单、方便,虽然功能不如DEDE之类的强悍到几乎变态的程度(当然,老Y文章管理系统是asp语言写的,似乎也没有可比性),但是该有的都有,且相当简单,所以也遭到了不少站长们的欢迎。老Y文章管理系统采集时手动完成伪原创的具体方式还极少有人阐述,在老Y的峰会上,甚至有人在卖这个方式,小小的厌恶一下。
关于采集,我就不多说了,相信你们都可以搞定,我要介绍的是老Y文章管理系统怎样在采集的同时手动完成伪原创工作的具体方式,大体的思路就是借助老Y文章管理系统自带的过滤功能实现反义词的手动替换,从而达到伪原创的目的。比如我想将被采集文章中的所有“网赚博客”字样替换为“网赚日记”。详细步骤如下:
第一步,进入后台。找到“采集管理”-“过滤管理”,添加一个新的过滤项目。
我可以构建一个名为“网赚博客”的项目,具体设置请看图:
“过滤名称”:填入“网赚博客”即可,也可以随便写,但是为了便捷查看,建议与被替换的词句一致。
“所属项目”:请依照自己的网站进行选择一个网站栏目(必须选择一个栏目,否则过滤项目未能保存)
“过滤对象”:可选项有“标题过滤”和“正文过滤”,一般选“正文过滤”即可,如果你连标题都想伪原创一下,可以选择“标题过滤”。
“过滤类型”:可选项有“简单替换”和“高级过滤”,一般选“简单替换”,如果选择了“高级过滤”,需要指定“开始标记”和“结束标记”,这样可对采集来的内容进行代码级的替换。
“使用状态”:可选项有“启用”和“禁用”,不用解释。
“使用范围”:可选项有“公有”和“私有”。选择“私有”,该过滤仅对当前网站栏目有效;选择“公有”,对所有栏目都有效,不管采集任何栏目的任何内容,该过滤均有效。一般选“私有”即可。
“内容”:填入“网赚博客”,将要被替换的熟语。
“替换”:填入“网赚日记”,这样只要被采集的文章中富含“网赚博客”字样,就会被手动替换为“网赚日记”。
第二步,重复第一步的工作,直到添加完所有的反义词。
有网友要问了:我有30000多条反义词,难道要一条一条自动添加?那要到添加什么时候!?不能批量添加吗?
这个问题问得好!手动添加的确几乎是个不可能完成的任务,除非你有超常的毅力,可以手工把这30000多条反义词添加进去。遗憾的是,老Y文章管理系统并没有提供批量导出的功能。但是老y文章管理系统采集功能怎么设置分页,作为真正的、资深的、有思想的懒人,我们要有懒人的觉悟。
要知道,我们刚刚输入的内容,是储存在数据库中的,而老Y文章管理系统是用asp+Access写的,mdb数据库可以很方便的编辑!于是乎,我可以通过直接更改数据库的方式来批量导出伪原创替换规则!
改进的第二步:修改数据库,批量导出规则。
经过查找,我发觉这个数据库坐落“你的管理目录\cai\Database”下。用Access打开这个数据库,找到“Filters”表,你会发觉我们刚刚添加的替换规则就在这里存着呢,根据你的须要,批量添加吧!接下来的工作涉及到Access的操作了,我就不罗嗦了,大家自己可以搞定。
解释一下“Filters”表中的几个数组的涵义:
FilterID:自动生成,无需输入。
ItemID:栏目ID,就是我们自动输入时“所属项目”的内容,不过这儿是个数字ID,注意跟栏目的采集ID做好对应,如果不知道ID,可以重复第一步,测试一下。
FilterName:即“过滤名称”。
FilterObjece:即“过滤对象”,填1为“标题过滤”,填2则是“正文过滤”。
FilterType:即“过滤类型”,填1为“简单替换”,填2为“高级过滤”。
FilterContent:即“内容”。
FisString:即“开始标记”,仅在设置了“高级过滤”时有效,如果设置了“简单过滤”请留空。
FioString:即“结束标记”,仅在设置了“高级过滤”时有效,如果设置了“简单过滤”请留空。
FilterRep:即“替换”。
Flag:即“使用状态”,TRUE为“启用”,FALSE为“禁用”。
PublicTf:即“使用范围”。TRUE为“公有”,FALSE为“私有”。
最后说一点借助过滤功能实现伪原创的使用体会:
老Y文章管理系统的这个功能可以实现采集时手动伪原创,但是功能还不够强悍。比如我站上有“栏目一”、“栏目二”、“栏目三”共三个栏目。我希望“栏目一”对标题和正文都进行伪原创,“栏目二”只对正文进行伪原创,“栏目三”只对标题进行伪原创。
于是老y文章管理系统采集功能怎么设置分页,我只能做如下设置(假设我有30000的反义词规则):
为“栏目一”的标题伪原创创建30000条替换规则;
为“栏目一”的正文伪原创创建30000条替换规则;
为“栏目二”的正文伪原创创建30000条替换规则;
为“栏目三”的标题伪原创创建30000条替换规则。
这样就导致了极大的数据库浪费,如果我的站有几十个栏目,每个栏目的要求都不一样,这个数据库的规格将会非常惊悚。
所以建议老Y文章管理系统下一版本将这个功能做一下改进:
首先添加批量导出功能,毕竟更改数据库有一定的危险性。
其次,过滤规则不再屈从于某个网站栏目,而是将过滤规则独立下来,而在构建新的采集项目的时侯,加入一条是否使用过滤规则的判别。
相信,这样更改以后可以极大地节省数据库储存空间,同时逻辑结构也变得愈发清晰。

