
谷歌抓取网页视频教程
谷歌抓取网页视频教程(前一个专题介绍:Web浏览器的介绍及工作原理分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-14 10:18
前言:
上一主题介绍了自定义的Web服务器,但是对Web服务器的请求是本主题介绍的Web浏览器。本专题通过简单的自定义一个网页浏览器简单介绍浏览器的工作原理和帮助 一些初学者揭开了浏览器的神秘面纱(以前这些应用总觉得很深奥,没想到可以自定义一个浏览器我)。下面不再罗嗦,进入正题。
一、网页浏览器介绍
Web浏览器是指一种可以显示Web服务器或本地文件系统中的Html文件内容,并允许用户与这些文件进行交互的软件。对服务器返回的超文本信息和各种媒体、图片进行解释和显示。
浏览器主要通过Http协议与服务器交互,获取网页。目前主流浏览器包括:IE、Google Chrome(谷歌浏览器)、Mozilla Firefox(火狐)、Opera浏览器、世界之窗、360安全浏览器等。
网络浏览器的组成
一般而言,Web 浏览器由控制器和解释器组成。控制器负责解释鼠标点击和键盘输入,并调用其他组件来执行用户指定的操作。例如,当用户输入 URL 或点击超链接时,控制器接收并分析命令,调用 HTML 解释器来解释页面,并将解释的结果显示在用户的浏览器上。
解释器对浏览器非常重要。解释器,即解释引擎,负责解释网页的语法(如HTML、Javascript)并显示网页。解释器决定浏览器如何显示页面。它是浏览器最重要的部分。内核最重要的部分,所以一般我们所指的浏览器内核指的是浏览器的解释器。
不同的浏览器产品可能使用相同的内核。有四种常见的浏览器内核:Trident、Gecko、Presto 和 Webkit。它们与主流浏览器的关系如下:
核心
浏览器产品
三叉戟
IE、傲游(Maxthon)、世界之窗、腾讯TT、搜狗浏览器、360安全浏览器
壁虎
Mozilla 火狐 (Firefox)
普雷斯托
Opera浏览器
网络套件
Apple Safari 浏览器、Google Chrome(谷歌浏览器)和Apple Iphone 手机浏览引擎
二、.NET 平台支持浏览器开发
浏览器软件一般不是从头开发的,而是基于某种内核扩展。同样,微软.NET平台封装了IE浏览器内核,以COM组件的形式提供给用户。这个COM组件就是WebBrowser控件,它实现了浏览器中几乎所有的基本功能。
WebBrowser是以IE(Trident)为核心和基本功能的Web浏览器。使用 WebBrowser 控件在 Windows 窗体应用程序中浏览网页。WebBrowser 控件位于工具箱中。使用时,只需将其直接拖至程序窗口即可。
下面介绍WebBrowser控件的常用属性和方法
这里我直接从MSDN中的一张表中提取来说明:
名称说明
文档属性
获取一个对象,该对象提供对当前网页的 HTML 文档对象模型 (DOM) 的托管访问。
DocumentCompleted 事件
当页面完成加载时发生。
文档文本属性
获取或设置当前网页的 HTML 内容。
文档标题属性
获取当前网页的标题。
返回方法 查看全部
谷歌抓取网页视频教程(前一个专题介绍:Web浏览器的介绍及工作原理分析)
前言:
上一主题介绍了自定义的Web服务器,但是对Web服务器的请求是本主题介绍的Web浏览器。本专题通过简单的自定义一个网页浏览器简单介绍浏览器的工作原理和帮助 一些初学者揭开了浏览器的神秘面纱(以前这些应用总觉得很深奥,没想到可以自定义一个浏览器我)。下面不再罗嗦,进入正题。
一、网页浏览器介绍
Web浏览器是指一种可以显示Web服务器或本地文件系统中的Html文件内容,并允许用户与这些文件进行交互的软件。对服务器返回的超文本信息和各种媒体、图片进行解释和显示。
浏览器主要通过Http协议与服务器交互,获取网页。目前主流浏览器包括:IE、Google Chrome(谷歌浏览器)、Mozilla Firefox(火狐)、Opera浏览器、世界之窗、360安全浏览器等。
网络浏览器的组成
一般而言,Web 浏览器由控制器和解释器组成。控制器负责解释鼠标点击和键盘输入,并调用其他组件来执行用户指定的操作。例如,当用户输入 URL 或点击超链接时,控制器接收并分析命令,调用 HTML 解释器来解释页面,并将解释的结果显示在用户的浏览器上。
解释器对浏览器非常重要。解释器,即解释引擎,负责解释网页的语法(如HTML、Javascript)并显示网页。解释器决定浏览器如何显示页面。它是浏览器最重要的部分。内核最重要的部分,所以一般我们所指的浏览器内核指的是浏览器的解释器。
不同的浏览器产品可能使用相同的内核。有四种常见的浏览器内核:Trident、Gecko、Presto 和 Webkit。它们与主流浏览器的关系如下:
核心
浏览器产品
三叉戟
IE、傲游(Maxthon)、世界之窗、腾讯TT、搜狗浏览器、360安全浏览器
壁虎
Mozilla 火狐 (Firefox)
普雷斯托
Opera浏览器
网络套件
Apple Safari 浏览器、Google Chrome(谷歌浏览器)和Apple Iphone 手机浏览引擎
二、.NET 平台支持浏览器开发
浏览器软件一般不是从头开发的,而是基于某种内核扩展。同样,微软.NET平台封装了IE浏览器内核,以COM组件的形式提供给用户。这个COM组件就是WebBrowser控件,它实现了浏览器中几乎所有的基本功能。
WebBrowser是以IE(Trident)为核心和基本功能的Web浏览器。使用 WebBrowser 控件在 Windows 窗体应用程序中浏览网页。WebBrowser 控件位于工具箱中。使用时,只需将其直接拖至程序窗口即可。
下面介绍WebBrowser控件的常用属性和方法
这里我直接从MSDN中的一张表中提取来说明:
名称说明
文档属性
获取一个对象,该对象提供对当前网页的 HTML 文档对象模型 (DOM) 的托管访问。
DocumentCompleted 事件
当页面完成加载时发生。
文档文本属性
获取或设置当前网页的 HTML 内容。
文档标题属性
获取当前网页的标题。
返回方法
谷歌抓取网页视频教程(杭州APP开发蒙特关注:谷歌客户端App抓取300多亿个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-10-11 11:07
杭州APP开发蒙特关注:4月16日,谷歌搜索团队在官方博文中公布了这一消息。
谷歌工程师拉詹·帕特尔向媒体透露,从两年前开始,谷歌开始抓取外部应用的内部链接和内容,目前已经抓取了超过 300 亿。
在传统的WEB页面中,谷歌可以通过软件“蜘蛛”自动访问和抓取,无需网站管理员的许可。
在App内容的抓取上,谷歌需要与应用软件开发商建立合作。谷歌提供了相应的软件开发接口(API),开发者可以通过这些接口向谷歌搜索开放数据,从而实现搜索引擎的内容抓取。
据悉,目前已有大量移动端软件与谷歌合作,包括微博Twitter、短租工具Airbnb、消费者点评工具Yelp、手机订餐工具OpenTable、图片采集社交网络Pinterest、房地产搜索工具Trulia以及很快。
当然,还有大量的移动媒体应用,也被谷歌抓取用于新闻报道。
超过 300 亿个链接的内容与 Google 抓取的网络数据库相比微不足道。此前有报道称,谷歌蜘蛛抓取的网页数量高达数百亿。
然而,在智能手机时代,人们使用搜索的目的更加明确,拥有更多的场景信息。因此,主流应用和超过300亿个链接足以为用户提供所需的信息。
据介绍,此前在手机上进行搜索时,谷歌客户端会观察用户智能手机中安装了哪些应用,谷歌只会返回已安装应用的搜索结果。
日前,谷歌团队还宣布,对收录在搜索结果中的APP进行了修改。即使用户没有安装某个APP,只要有相关性,它的内容就会出现在搜索结果中。
例如,如果用户的手机中没有安装点餐工具OpenTable,但在搜索餐厅时,谷歌仍可能会从OpenTable中呈现消费者评论信息。
不过,对于谷歌来说,能够抓取大量APP的内容,并不意味着它已经彻底摆脱了“搜索危机”。
有观点认为,在智能手机端,手机一族希望以最快的速度获得最准确的搜索结果,因此各种专业APP逐渐取代了传统网页搜索的地位。例如,人们可能会在流行的团购应用中搜索当地餐馆和电影,而不是在 Google 中输入 关键词,然后查看庞大网络的结果。
蒙特手机APP开发总结:手机搜索消费者行为的变化也给谷歌的发展前景蒙上了一层阴影。Google 90% 的收入来自搜索结果右侧的搜索广告。如果人们远离电脑和传统搜索引擎,谷歌将成为一个非常危险的公司,没有可观的替代收入。在这里,Monte想说,凭借多年的APP开发经验,给你的APP强行不是问题。 查看全部
谷歌抓取网页视频教程(杭州APP开发蒙特关注:谷歌客户端App抓取300多亿个)
杭州APP开发蒙特关注:4月16日,谷歌搜索团队在官方博文中公布了这一消息。
谷歌工程师拉詹·帕特尔向媒体透露,从两年前开始,谷歌开始抓取外部应用的内部链接和内容,目前已经抓取了超过 300 亿。
在传统的WEB页面中,谷歌可以通过软件“蜘蛛”自动访问和抓取,无需网站管理员的许可。
在App内容的抓取上,谷歌需要与应用软件开发商建立合作。谷歌提供了相应的软件开发接口(API),开发者可以通过这些接口向谷歌搜索开放数据,从而实现搜索引擎的内容抓取。
据悉,目前已有大量移动端软件与谷歌合作,包括微博Twitter、短租工具Airbnb、消费者点评工具Yelp、手机订餐工具OpenTable、图片采集社交网络Pinterest、房地产搜索工具Trulia以及很快。
当然,还有大量的移动媒体应用,也被谷歌抓取用于新闻报道。
超过 300 亿个链接的内容与 Google 抓取的网络数据库相比微不足道。此前有报道称,谷歌蜘蛛抓取的网页数量高达数百亿。
然而,在智能手机时代,人们使用搜索的目的更加明确,拥有更多的场景信息。因此,主流应用和超过300亿个链接足以为用户提供所需的信息。
据介绍,此前在手机上进行搜索时,谷歌客户端会观察用户智能手机中安装了哪些应用,谷歌只会返回已安装应用的搜索结果。
日前,谷歌团队还宣布,对收录在搜索结果中的APP进行了修改。即使用户没有安装某个APP,只要有相关性,它的内容就会出现在搜索结果中。
例如,如果用户的手机中没有安装点餐工具OpenTable,但在搜索餐厅时,谷歌仍可能会从OpenTable中呈现消费者评论信息。
不过,对于谷歌来说,能够抓取大量APP的内容,并不意味着它已经彻底摆脱了“搜索危机”。
有观点认为,在智能手机端,手机一族希望以最快的速度获得最准确的搜索结果,因此各种专业APP逐渐取代了传统网页搜索的地位。例如,人们可能会在流行的团购应用中搜索当地餐馆和电影,而不是在 Google 中输入 关键词,然后查看庞大网络的结果。
蒙特手机APP开发总结:手机搜索消费者行为的变化也给谷歌的发展前景蒙上了一层阴影。Google 90% 的收入来自搜索结果右侧的搜索广告。如果人们远离电脑和传统搜索引擎,谷歌将成为一个非常危险的公司,没有可观的替代收入。在这里,Monte想说,凭借多年的APP开发经验,给你的APP强行不是问题。
谷歌抓取网页视频教程(网页解析我用的是BeautifulSoup的概论(二)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 252 次浏览 • 2021-10-10 09:35
准备寒假,爬一些MOOC课程,爬回家看。
爬取的课程是北京大学离散数学导论
其实GitHub有可以直接使用的程序,只是不知道怎么提交HTTP请求,所以直接用selenium简单粗暴。
我使用 BeautifulSoup 进行网页分析。
这个想法其实很简单。只需直接在课件网页上将每章每节课每单元的所有视频都删除即可。所以直接嵌套循环就可以了。
遇到的一些困难:
课件部分的两个框是隐藏框,点击模拟浏览器
操作前需要使用JavaScript修改元素显示值
id 属性
元素每次点击都不一样,所以定位元素时,不使用id属性定位,使用title属性或其他属性。另一个是我不能使用无头模式来抓取网页。这应该是我这边的环境问题。不知道大家有没有遇到过这种情况。
代码:
# -*- coding:utf-8 -*-
import time
from selenium import webdriver
from bs4 import BeautifulSoup
import re
import json
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--disable-gpu")
browser = webdriver.Chrome(executable_path='G:\\chromedriver.exe', options=chrome_options)
browser.get('https://www.icourse163.org/lea ... %2339;) # 目标网页
time.sleep(3)
video = {}
soup = BeautifulSoup(browser.page_source, 'html.parser')
c_l = soup.find("div", attrs={"class": "j-breadcb f-fl"})
chapter_all = c_l.find("div", attrs={"class": "f-fl j-chapter"})
chapter = chapter_all.find_all("div", attrs={"class": "f-thide list"})
for chap in chapter:
js = 'document.querySelectorAll("div.down")[0].style.display="block";'
browser.execute_script(js)
chapter_name = chap.text
a = browser.find_element_by_xpath("//div[@title = '"+chapter_name+"']")
a.click()
time.sleep(3)
soup1 = BeautifulSoup(browser.page_source, 'html.parser')
c_l1 = soup1.find("div", attrs={"class": "j-breadcb f-fl"})
lesson_all = c_l1.find("div", attrs={"class": "f-fl j-lesson"})
lesson = lesson_all.find_all("div", attrs={"class": "f-thide list"})
for les in lesson:
js1 = 'document.querySelectorAll("div.down")[1].style.display="block";'
browser.execute_script(js1)
lesson_name = les.text
b = browser.find_element_by_xpath("//div[@title = '"+lesson_name+"']")
b.click()
time.sleep(3)
soup2 = BeautifulSoup(browser.page_source, 'html.parser')
units = soup2.find_all("li", attrs={"title": re.compile(r"^视频")}) # 只爬取视频课件
for unit in units:
video_name = unit.get("title")
video_link = browser.find_element_by_xpath("//li[@title = '"+video_name+"']")
video_link.click()
time.sleep(3)
soup2 = BeautifulSoup(browser.page_source, 'html.parser')
try:
video_src = soup2.find("source")
video[chapter_name + " " + lesson_name + video_name] = video_src.get("src")
except:
continue
browser.quit()
爬取的效果是这样的
文笔不好。我开始的时间不长。有兴趣的可以慢慢看原网页的源码。
Selenium 简单粗暴,但爬取速度很慢,不如其他爬取方式。
以后还是要学着提交POST请求。要是有爬虫带我入门就好了!
我刚学爬行的时间不长,计算机知识也不是很多。第一次写东西,多多批评指正! 查看全部
谷歌抓取网页视频教程(网页解析我用的是BeautifulSoup的概论(二)_)
准备寒假,爬一些MOOC课程,爬回家看。
爬取的课程是北京大学离散数学导论

其实GitHub有可以直接使用的程序,只是不知道怎么提交HTTP请求,所以直接用selenium简单粗暴。
我使用 BeautifulSoup 进行网页分析。
这个想法其实很简单。只需直接在课件网页上将每章每节课每单元的所有视频都删除即可。所以直接嵌套循环就可以了。
遇到的一些困难:
课件部分的两个框是隐藏框,点击模拟浏览器
操作前需要使用JavaScript修改元素显示值

id 属性
元素每次点击都不一样,所以定位元素时,不使用id属性定位,使用title属性或其他属性。另一个是我不能使用无头模式来抓取网页。这应该是我这边的环境问题。不知道大家有没有遇到过这种情况。
代码:
# -*- coding:utf-8 -*-
import time
from selenium import webdriver
from bs4 import BeautifulSoup
import re
import json
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--disable-gpu")
browser = webdriver.Chrome(executable_path='G:\\chromedriver.exe', options=chrome_options)
browser.get('https://www.icourse163.org/lea ... %2339;) # 目标网页
time.sleep(3)
video = {}
soup = BeautifulSoup(browser.page_source, 'html.parser')
c_l = soup.find("div", attrs={"class": "j-breadcb f-fl"})
chapter_all = c_l.find("div", attrs={"class": "f-fl j-chapter"})
chapter = chapter_all.find_all("div", attrs={"class": "f-thide list"})
for chap in chapter:
js = 'document.querySelectorAll("div.down")[0].style.display="block";'
browser.execute_script(js)
chapter_name = chap.text
a = browser.find_element_by_xpath("//div[@title = '"+chapter_name+"']")
a.click()
time.sleep(3)
soup1 = BeautifulSoup(browser.page_source, 'html.parser')
c_l1 = soup1.find("div", attrs={"class": "j-breadcb f-fl"})
lesson_all = c_l1.find("div", attrs={"class": "f-fl j-lesson"})
lesson = lesson_all.find_all("div", attrs={"class": "f-thide list"})
for les in lesson:
js1 = 'document.querySelectorAll("div.down")[1].style.display="block";'
browser.execute_script(js1)
lesson_name = les.text
b = browser.find_element_by_xpath("//div[@title = '"+lesson_name+"']")
b.click()
time.sleep(3)
soup2 = BeautifulSoup(browser.page_source, 'html.parser')
units = soup2.find_all("li", attrs={"title": re.compile(r"^视频")}) # 只爬取视频课件
for unit in units:
video_name = unit.get("title")
video_link = browser.find_element_by_xpath("//li[@title = '"+video_name+"']")
video_link.click()
time.sleep(3)
soup2 = BeautifulSoup(browser.page_source, 'html.parser')
try:
video_src = soup2.find("source")
video[chapter_name + " " + lesson_name + video_name] = video_src.get("src")
except:
continue
browser.quit()
爬取的效果是这样的

文笔不好。我开始的时间不长。有兴趣的可以慢慢看原网页的源码。
Selenium 简单粗暴,但爬取速度很慢,不如其他爬取方式。
以后还是要学着提交POST请求。要是有爬虫带我入门就好了!
我刚学爬行的时间不长,计算机知识也不是很多。第一次写东西,多多批评指正!
谷歌抓取网页视频教程(Google发布重大更新:抓取错误功能检测和报告多种新的错误类型)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-10 08:00
抓取错误是 Google 网站网站管理员工具中最受欢迎的工具之一。昨天,谷歌发布了抓取错误工具的重大更新,使其更加方便和有用。
现在,错误获取功能可以检测和报告各种新的错误类型。为了让数据更直观,网站站长工具将错误分为两类:网站错误(站点错误)和链接地址错误(URL错误)。
内容
站点错误
网站 错误是指影响整个网站的错误,而不是具体的URL链接。包括DNS解析失败、服务器连接问题、获取robots.txt文件问题等。之前谷歌站长工具只报相关链接地址错误。但是这样做没有多大意义,因为它们不是由特定链接引起的。事实上,这个错误甚至会阻止 Googlebot 请求 URL 链接地址。于是谷歌站长工具开始追踪此类错误的频率,并在适当的时候向网站管理员发送提醒。
查看网站误差频率和频率变化曲线
而且,如果你的网站没有犯过任何错误,或者最近一段时间没有这方面的问题——实际上大部分网站都是这种情况——他们只会show simple 一切正常提示不会显示大量信息影响管理员获取其他信息。总之,如果你看到的提示图标都是绿色的,就说明一切正常。
如果最近一段时间网站没有问题,会显示这样的友好提示信息
网址链接错误
URL 链接错误是指向特定页面的那些错误。当谷歌机器人尝试抓取链接时,它能够解析DNS,连接到服务器,抓取robots.txt文件,但在请求URL链接地址时遇到错误。根据错误原因,URL链接地址错误有几种类型。如果 网站 提供 Google 新闻内容或移动数据内容(CHTML/XHTML),这些错误将根据不同的类别显示。
链接错误提示
简洁的错误信息
以前,Google 网站Webmaster Tools 为每个类别显示多达 100,000 个错误。检查这么多错误信息是非常困难的。您甚至无法知道哪些错误是重要的(例如主页无法打开),哪些错误是次要的(例如链接到您的网页时的其他网站 拼写错误)。基本上不可能对 100,000 条错误记录进行排序、搜索或标记您的处理进度。
在新版本的抓取错误中,谷歌开发者尽量只提供最重要的错误信息。对于每个错误分类,一般只提供 1000 条被认为是最重要的错误信息。网站管理员还可以对这些错误进行排序过滤,查看错误详情并进行处理,然后将已经处理过的错误进行标记并通知谷歌(这样就不会再次显示,除非错误再次出现) .
在任何列上实时排序或过滤错误消息
对于某种错误类型,某些网站可能有1000多个错误,超过这个数目的错误仍然可以反映在错误总数中。还有一些图标可以显示过去 90 天的历史错误数据。有人可能会担心 1000 个错误的详细信息加上粗略的错误总数可能不够。谷歌正在考虑提供一个 API 接口来解决这个问题。
现在,网站站长工具会移除robots.txt屏蔽的链接列表,因为虽然有时这些链接有助于诊断robots.txt错误,但这些链接是管理员专门屏蔽的(自屏蔽当然可以)应该很清楚)。为了关注真正的错误,被robot.txt屏蔽的链接将很快移至“网站站点配置”部分的“爬虫访问”页面。
查看错误详情
单击主列表中的单个错误链接可激活一个面板,该面板显示详细的错误信息,包括上次提取时间、发现错误的最早时间以及简单说明。
可以在主列表中看到的错误详细信息
在详细信息面板中,您也可以直接点击相关链接查看访问过程中会出现哪些错误。如果没有问题,可以将此错误标记为“已修复”(以后会提供更多选项),也可以查看此类错误的帮助信息,包括网站图的链接文件列表、链接去链接地址的其他页面列表等,也可以用Googlebot模拟爬取链接,看看有没有其他问题或者是否已经修复。
查看链接到此页面的其他页面地址列表
采取行动
错误爬取功能中值得期待的一件事是,网站 管理员实际上可以专注于解决最重要的问题。谷歌网站管理员工具对错误进行分类,而那些高优先级项目确实是您可以解决的问题。要么你需要修复网站上的链接,要么你需要处理服务器上的软件问题,要么你需要更新网站映射文件来清理那些不需要的链接,或者添加一个301重定向将用户重定向到正确的页面等。谷歌站长工具在确定优先级时会考虑多种因素,包括你是否在网站映射中收录了URL,有多少页面链接到该地址(还要考虑这些页面是否在你自己的网站@ > 上),
一旦您认为问题已修复(您可以使用 Googlebot 模拟抓取页面),您可以将其标记为“已修复”(当然,您必须是管理员)。此操作会通知 Google Webmaster Tools,然后该错误将从错误列表(重要的 1000 项)的顶部删除,并且不再显示(除非 Googlebot 在抓取页面时再次遇到相同的错误)。
将错误标记为已修复
英文原文由 Webmaster Tools 团队的 Kurt Dresner 撰写。由于时间关系,本文不提供翻译以保证质量。请保留本段内容,以表达对原作者的尊重。
同时,谷歌还更新了网站Webmaster Tools 帮助文档的相关部分,并提供链接供参考。©
本文发表于水景专页。永久链接:。转载请保留此信息及相关链接。 查看全部
谷歌抓取网页视频教程(Google发布重大更新:抓取错误功能检测和报告多种新的错误类型)
抓取错误是 Google 网站网站管理员工具中最受欢迎的工具之一。昨天,谷歌发布了抓取错误工具的重大更新,使其更加方便和有用。
现在,错误获取功能可以检测和报告各种新的错误类型。为了让数据更直观,网站站长工具将错误分为两类:网站错误(站点错误)和链接地址错误(URL错误)。
内容
站点错误
网站 错误是指影响整个网站的错误,而不是具体的URL链接。包括DNS解析失败、服务器连接问题、获取robots.txt文件问题等。之前谷歌站长工具只报相关链接地址错误。但是这样做没有多大意义,因为它们不是由特定链接引起的。事实上,这个错误甚至会阻止 Googlebot 请求 URL 链接地址。于是谷歌站长工具开始追踪此类错误的频率,并在适当的时候向网站管理员发送提醒。

查看网站误差频率和频率变化曲线
而且,如果你的网站没有犯过任何错误,或者最近一段时间没有这方面的问题——实际上大部分网站都是这种情况——他们只会show simple 一切正常提示不会显示大量信息影响管理员获取其他信息。总之,如果你看到的提示图标都是绿色的,就说明一切正常。

如果最近一段时间网站没有问题,会显示这样的友好提示信息
网址链接错误
URL 链接错误是指向特定页面的那些错误。当谷歌机器人尝试抓取链接时,它能够解析DNS,连接到服务器,抓取robots.txt文件,但在请求URL链接地址时遇到错误。根据错误原因,URL链接地址错误有几种类型。如果 网站 提供 Google 新闻内容或移动数据内容(CHTML/XHTML),这些错误将根据不同的类别显示。

链接错误提示
简洁的错误信息
以前,Google 网站Webmaster Tools 为每个类别显示多达 100,000 个错误。检查这么多错误信息是非常困难的。您甚至无法知道哪些错误是重要的(例如主页无法打开),哪些错误是次要的(例如链接到您的网页时的其他网站 拼写错误)。基本上不可能对 100,000 条错误记录进行排序、搜索或标记您的处理进度。
在新版本的抓取错误中,谷歌开发者尽量只提供最重要的错误信息。对于每个错误分类,一般只提供 1000 条被认为是最重要的错误信息。网站管理员还可以对这些错误进行排序过滤,查看错误详情并进行处理,然后将已经处理过的错误进行标记并通知谷歌(这样就不会再次显示,除非错误再次出现) .

在任何列上实时排序或过滤错误消息
对于某种错误类型,某些网站可能有1000多个错误,超过这个数目的错误仍然可以反映在错误总数中。还有一些图标可以显示过去 90 天的历史错误数据。有人可能会担心 1000 个错误的详细信息加上粗略的错误总数可能不够。谷歌正在考虑提供一个 API 接口来解决这个问题。
现在,网站站长工具会移除robots.txt屏蔽的链接列表,因为虽然有时这些链接有助于诊断robots.txt错误,但这些链接是管理员专门屏蔽的(自屏蔽当然可以)应该很清楚)。为了关注真正的错误,被robot.txt屏蔽的链接将很快移至“网站站点配置”部分的“爬虫访问”页面。
查看错误详情
单击主列表中的单个错误链接可激活一个面板,该面板显示详细的错误信息,包括上次提取时间、发现错误的最早时间以及简单说明。

可以在主列表中看到的错误详细信息
在详细信息面板中,您也可以直接点击相关链接查看访问过程中会出现哪些错误。如果没有问题,可以将此错误标记为“已修复”(以后会提供更多选项),也可以查看此类错误的帮助信息,包括网站图的链接文件列表、链接去链接地址的其他页面列表等,也可以用Googlebot模拟爬取链接,看看有没有其他问题或者是否已经修复。

查看链接到此页面的其他页面地址列表
采取行动
错误爬取功能中值得期待的一件事是,网站 管理员实际上可以专注于解决最重要的问题。谷歌网站管理员工具对错误进行分类,而那些高优先级项目确实是您可以解决的问题。要么你需要修复网站上的链接,要么你需要处理服务器上的软件问题,要么你需要更新网站映射文件来清理那些不需要的链接,或者添加一个301重定向将用户重定向到正确的页面等。谷歌站长工具在确定优先级时会考虑多种因素,包括你是否在网站映射中收录了URL,有多少页面链接到该地址(还要考虑这些页面是否在你自己的网站@ > 上),
一旦您认为问题已修复(您可以使用 Googlebot 模拟抓取页面),您可以将其标记为“已修复”(当然,您必须是管理员)。此操作会通知 Google Webmaster Tools,然后该错误将从错误列表(重要的 1000 项)的顶部删除,并且不再显示(除非 Googlebot 在抓取页面时再次遇到相同的错误)。

将错误标记为已修复
英文原文由 Webmaster Tools 团队的 Kurt Dresner 撰写。由于时间关系,本文不提供翻译以保证质量。请保留本段内容,以表达对原作者的尊重。
同时,谷歌还更新了网站Webmaster Tools 帮助文档的相关部分,并提供链接供参考。©
本文发表于水景专页。永久链接:。转载请保留此信息及相关链接。
谷歌抓取网页视频教程(Google发布重大更新:抓取错误功能检测和报告多种新的错误类型)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-10-10 07:37
抓取错误是 Google 网站网站管理员工具中最受欢迎的工具之一。昨天,谷歌发布了抓取错误工具的重大更新,使其更加方便和有用。
现在,错误获取功能可以检测和报告各种新的错误类型。为了让数据更直观,网站站长工具将错误分为两类:网站错误(站点错误)和链接地址错误(URL错误)。
内容
站点错误
网站 错误是指影响整个网站的错误,而不是具体的URL链接。包括DNS解析失败、服务器连接问题、获取robots.txt文件问题等。之前谷歌站长工具只报相关链接地址错误。但是这样做没有多大意义,因为它们不是由特定链接引起的。事实上,这个错误甚至会阻止 Googlebot 请求 URL 链接地址。于是谷歌站长工具开始追踪此类错误的频率,并在适当的时候向网站管理员发送提醒。
查看网站误差频率和频率变化曲线
而且,如果你的网站没有犯过任何错误,或者最近一段时间没有这方面的问题——实际上大部分网站都是这种情况——他们只会show simple 一切正常提示不会显示大量信息影响管理员获取其他信息。总之,如果你看到的提示图标都是绿色的,就说明一切正常。
如果最近一段时间网站没有问题,会显示这样的友好提示信息
网址链接错误
URL 链接错误是指向特定页面的那些错误。当谷歌机器人尝试抓取链接时,它能够解析DNS,连接到服务器,抓取robots.txt文件,但在请求URL链接地址时遇到错误。根据错误原因,URL链接地址错误有几种类型。如果 网站 提供 Google 新闻内容或移动数据内容(CHTML/XHTML),这些错误将根据不同的类别显示。
链接错误提示
简洁的错误信息
以前,Google 网站Webmaster Tools 为每个类别显示多达 100,000 个错误。检查这么多错误信息是非常困难的。您甚至无法知道哪些错误是重要的(例如主页无法打开),哪些错误是次要的(例如链接到您的网页时的其他网站 拼写错误)。基本上不可能对 100,000 条错误记录进行排序、搜索或标记您的处理进度。
在新版本的抓取错误中,谷歌开发者尽量只提供最重要的错误信息。对于每个错误分类,一般只提供 1000 条被认为是最重要的错误信息。网站管理员还可以对这些错误进行排序过滤,查看错误详情并进行处理,然后将已经处理过的错误进行标记并通知谷歌(这样就不会再次显示,除非错误再次出现) .
在任何列上实时排序或过滤错误消息
对于某种错误类型,某些网站可能有1000多个错误,超过这个数目的错误仍然可以反映在错误总数中。还有一些图标可以显示过去 90 天的历史错误数据。有人可能会担心 1000 个错误的详细信息加上粗略的错误总数可能不够。谷歌正在考虑提供一个 API 接口来解决这个问题。
现在,网站站长工具会移除robots.txt屏蔽的链接列表,因为虽然有时这些链接有助于诊断robots.txt错误,但这些链接是管理员专门屏蔽的(自屏蔽当然可以)应该很清楚)。为了关注真正的错误,被robot.txt屏蔽的链接将很快移至“网站站点配置”部分的“爬虫访问”页面。
查看错误详情
单击主列表中的单个错误链接可激活一个面板,该面板显示详细的错误信息,包括上次提取时间、发现错误的最早时间以及简单说明。
可以在主列表中看到的错误详细信息
在详细信息面板中,您也可以直接点击相关链接查看访问过程中会出现哪些错误。如果没有问题,可以将此错误标记为“已修复”(以后会提供更多选项),也可以查看此类错误的帮助信息,包括网站图的链接文件列表、链接去链接地址的其他页面列表等,也可以用Googlebot模拟爬取链接,看看有没有其他问题或者是否已经修复。
查看链接到此页面的其他页面地址列表
采取行动
错误爬取功能中值得期待的一件事是,网站 管理员实际上可以专注于解决最重要的问题。谷歌网站管理员工具对错误进行分类,而那些高优先级项目确实是您可以解决的问题。要么你需要修复网站上的链接,要么你需要处理服务器上的软件问题,要么你需要更新网站映射文件来清理那些不需要的链接,或者添加一个301重定向将用户重定向到正确的页面等。谷歌站长工具在确定优先级时会考虑多种因素,包括你是否在网站映射中收录了URL,有多少页面链接到该地址(还要考虑这些页面是否在你自己的网站@ > 上),
一旦您认为问题已修复(您可以使用 Googlebot 模拟抓取页面),您可以将其标记为“已修复”(当然,您必须是管理员)。此操作会通知 Google Webmaster Tools,然后该错误将从错误列表(重要的 1000 项)的顶部删除,并且不再显示(除非 Googlebot 在抓取页面时再次遇到相同的错误)。
将错误标记为已修复
英文原文由 Webmaster Tools 团队的 Kurt Dresner 撰写。由于时间关系,本文不提供翻译以保证质量。请保留本段内容,以表达对原作者的尊重。
同时,谷歌还更新了网站Webmaster Tools 帮助文档的相关部分,并提供链接供参考。©
本文发表于水景专页。永久链接:。转载请保留此信息及相关链接。 查看全部
谷歌抓取网页视频教程(Google发布重大更新:抓取错误功能检测和报告多种新的错误类型)
抓取错误是 Google 网站网站管理员工具中最受欢迎的工具之一。昨天,谷歌发布了抓取错误工具的重大更新,使其更加方便和有用。
现在,错误获取功能可以检测和报告各种新的错误类型。为了让数据更直观,网站站长工具将错误分为两类:网站错误(站点错误)和链接地址错误(URL错误)。
内容
站点错误
网站 错误是指影响整个网站的错误,而不是具体的URL链接。包括DNS解析失败、服务器连接问题、获取robots.txt文件问题等。之前谷歌站长工具只报相关链接地址错误。但是这样做没有多大意义,因为它们不是由特定链接引起的。事实上,这个错误甚至会阻止 Googlebot 请求 URL 链接地址。于是谷歌站长工具开始追踪此类错误的频率,并在适当的时候向网站管理员发送提醒。
查看网站误差频率和频率变化曲线
而且,如果你的网站没有犯过任何错误,或者最近一段时间没有这方面的问题——实际上大部分网站都是这种情况——他们只会show simple 一切正常提示不会显示大量信息影响管理员获取其他信息。总之,如果你看到的提示图标都是绿色的,就说明一切正常。
如果最近一段时间网站没有问题,会显示这样的友好提示信息
网址链接错误
URL 链接错误是指向特定页面的那些错误。当谷歌机器人尝试抓取链接时,它能够解析DNS,连接到服务器,抓取robots.txt文件,但在请求URL链接地址时遇到错误。根据错误原因,URL链接地址错误有几种类型。如果 网站 提供 Google 新闻内容或移动数据内容(CHTML/XHTML),这些错误将根据不同的类别显示。
链接错误提示
简洁的错误信息
以前,Google 网站Webmaster Tools 为每个类别显示多达 100,000 个错误。检查这么多错误信息是非常困难的。您甚至无法知道哪些错误是重要的(例如主页无法打开),哪些错误是次要的(例如链接到您的网页时的其他网站 拼写错误)。基本上不可能对 100,000 条错误记录进行排序、搜索或标记您的处理进度。
在新版本的抓取错误中,谷歌开发者尽量只提供最重要的错误信息。对于每个错误分类,一般只提供 1000 条被认为是最重要的错误信息。网站管理员还可以对这些错误进行排序过滤,查看错误详情并进行处理,然后将已经处理过的错误进行标记并通知谷歌(这样就不会再次显示,除非错误再次出现) .
在任何列上实时排序或过滤错误消息
对于某种错误类型,某些网站可能有1000多个错误,超过这个数目的错误仍然可以反映在错误总数中。还有一些图标可以显示过去 90 天的历史错误数据。有人可能会担心 1000 个错误的详细信息加上粗略的错误总数可能不够。谷歌正在考虑提供一个 API 接口来解决这个问题。
现在,网站站长工具会移除robots.txt屏蔽的链接列表,因为虽然有时这些链接有助于诊断robots.txt错误,但这些链接是管理员专门屏蔽的(自屏蔽当然可以)应该很清楚)。为了关注真正的错误,被robot.txt屏蔽的链接将很快移至“网站站点配置”部分的“爬虫访问”页面。
查看错误详情
单击主列表中的单个错误链接可激活一个面板,该面板显示详细的错误信息,包括上次提取时间、发现错误的最早时间以及简单说明。
可以在主列表中看到的错误详细信息
在详细信息面板中,您也可以直接点击相关链接查看访问过程中会出现哪些错误。如果没有问题,可以将此错误标记为“已修复”(以后会提供更多选项),也可以查看此类错误的帮助信息,包括网站图的链接文件列表、链接去链接地址的其他页面列表等,也可以用Googlebot模拟爬取链接,看看有没有其他问题或者是否已经修复。
查看链接到此页面的其他页面地址列表
采取行动
错误爬取功能中值得期待的一件事是,网站 管理员实际上可以专注于解决最重要的问题。谷歌网站管理员工具对错误进行分类,而那些高优先级项目确实是您可以解决的问题。要么你需要修复网站上的链接,要么你需要处理服务器上的软件问题,要么你需要更新网站映射文件来清理那些不需要的链接,或者添加一个301重定向将用户重定向到正确的页面等。谷歌站长工具在确定优先级时会考虑多种因素,包括你是否在网站映射中收录了URL,有多少页面链接到该地址(还要考虑这些页面是否在你自己的网站@ > 上),
一旦您认为问题已修复(您可以使用 Googlebot 模拟抓取页面),您可以将其标记为“已修复”(当然,您必须是管理员)。此操作会通知 Google Webmaster Tools,然后该错误将从错误列表(重要的 1000 项)的顶部删除,并且不再显示(除非 Googlebot 在抓取页面时再次遇到相同的错误)。
将错误标记为已修复
英文原文由 Webmaster Tools 团队的 Kurt Dresner 撰写。由于时间关系,本文不提供翻译以保证质量。请保留本段内容,以表达对原作者的尊重。
同时,谷歌还更新了网站Webmaster Tools 帮助文档的相关部分,并提供链接供参考。©
本文发表于水景专页。永久链接:。转载请保留此信息及相关链接。
谷歌抓取网页视频教程(几个暗含抓取算法:宽度优先抓取哪些页面却需要算法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-10 07:24
搜索引擎看似简单的爬虫查询工作,但每个链接所隐含的算法却非常复杂。
搜索引擎抓取页面是由蜘蛛完成的。爬取动作很容易实现,但是要爬取哪些页面,先爬取哪些页面需要算法来决定。以下是一些爬行算法:
1、宽度优先的爬取策略:
我们都知道网站大部分都是按照树状图分布的,那么在树状图链接结构中,哪些页面会先被爬取呢?为什么要先爬取这些页面 什么?宽度优先的获取策略是按照树状结构先获取同级链接,获取到同级链接后再获取下一级链接。如下所示:
如您所见,当我声明时,我使用了链接结构而不是 网站 结构。这里的链接结构可以由指向任何页面的链接组成,不一定是网站内部链接。这是一种理想化的宽度优先爬行策略。在实际爬取过程中,不可能先想到全宽,先想到限宽,如下图所示:
上图中,我们的Spider在检索G链接时,通过算法发现G页面没有任何价值,于是就将悲剧性的G链接和从属的H链接统一给了Spider。至于为什么要统一G环节?嗯,我们来分析一下。
2、不完整的遍历链接权重计算:
每个搜索引擎都有一套pagerank(指页面权重,非google PR)计算方法,并且经常更新。互联网几乎是无限的,每天都会产生大量的新链接。搜索引擎在计算链接权重时只能进行不完全遍历。为什么谷歌公关需要三个月左右才能更新一次?为什么百度一个月更新1-2次?这是因为搜索引擎使用不完全遍历链接权重算法来计算链接权重。其实按照现在的技术,实现更快的权重更新并不难。计算速度和存储速度完全可以跟得上,但为什么不这样做呢?因为不是那么必要,或者已经实现了,但是我不想发布它。然后,
我们形成一组K个链接,R表示链接获得的pagerank,S表示链接收录的链接数,Q表示是否参与传输,β表示阻尼因子,那么权重计算公式通过链接获得的是:
由公式可知,Q决定链路权重。如果发现链接被作弊,或者被搜索引擎手动清除,或者其他原因,Q被设置为0,那么再多的外部链接也无济于事。β 是阻尼系数。主要作用是防止出现权重0,防止链接参与权重转移,防止出现作弊。阻尼系数β一般为0.85。为什么网站的数量乘以阻尼系数?因为不是页面中的所有页面都参与权重转移,搜索引擎会再次删除15%的过滤链接。
但是这种不完全的遍历权重计算需要积累一定的链接数才能重新开始计算,所以更新周期普遍较慢,不能满足用户对即时信息的需求。于是在此基础上,出现了实时权重分布抓取策略。即当蜘蛛完成对页面的爬取并进入后,立即进行权重分配,将权重重新分配给要爬取的链接库,然后根据权重进行爬取。
3、社会工程学爬取策略
社会工程策略是在蜘蛛爬行过程中加入人工智能或通过人工智能训练出来的机器智能来决定爬行的优先级。目前我知道的爬取策略有:
一种。热点优先策略:对于爆炸性热点关键词,会先抓取,不需要经过严格的去重和过滤,因为会有新的链接覆盖和用户的主动选择。
湾 权限优先策略:搜索引擎会给每个网站分配一个权限,通过网站历史、网站更新等确定网站的权限,并优先去抓取权威的网站链接。
C。用户点击策略:当大多数行业词库搜索关键词时,频繁点击网站的同一搜索结果,那么搜索引擎会更频繁地抓取这个网站。
d. 历史参考策略:对于保持频繁更新的网站,搜索引擎会为网站建立一个更新历史,并根据更新历史估计未来的更新量并确定爬取频率。
SEO工作指南:
搜索引擎的爬取原理已经讲得很深入了,下面就来说明一下这些原理在SEO工作中的指导作用:
A、定时定量更新,让蜘蛛可以及时抓取和抓取网站页面;
B. 公司网站的运作比个人网站更有权威性;
C.网站建站时间长更容易被抓;
D、页面内的链接分布要合理,过多或过少都不好;
E.网站,受用户欢迎,也受搜索引擎欢迎;
F.重要页面应该放在较浅的网站结构中;
G.网站中的行业权威信息将增加网站的权威性。
这就是本教程的内容。下一篇教程的主题是:页值和网站权重计算。
上一篇:语境如何影响未来移动互联网发展 查看全部
谷歌抓取网页视频教程(几个暗含抓取算法:宽度优先抓取哪些页面却需要算法)
搜索引擎看似简单的爬虫查询工作,但每个链接所隐含的算法却非常复杂。
搜索引擎抓取页面是由蜘蛛完成的。爬取动作很容易实现,但是要爬取哪些页面,先爬取哪些页面需要算法来决定。以下是一些爬行算法:
1、宽度优先的爬取策略:
我们都知道网站大部分都是按照树状图分布的,那么在树状图链接结构中,哪些页面会先被爬取呢?为什么要先爬取这些页面 什么?宽度优先的获取策略是按照树状结构先获取同级链接,获取到同级链接后再获取下一级链接。如下所示:
如您所见,当我声明时,我使用了链接结构而不是 网站 结构。这里的链接结构可以由指向任何页面的链接组成,不一定是网站内部链接。这是一种理想化的宽度优先爬行策略。在实际爬取过程中,不可能先想到全宽,先想到限宽,如下图所示:
上图中,我们的Spider在检索G链接时,通过算法发现G页面没有任何价值,于是就将悲剧性的G链接和从属的H链接统一给了Spider。至于为什么要统一G环节?嗯,我们来分析一下。
2、不完整的遍历链接权重计算:
每个搜索引擎都有一套pagerank(指页面权重,非google PR)计算方法,并且经常更新。互联网几乎是无限的,每天都会产生大量的新链接。搜索引擎在计算链接权重时只能进行不完全遍历。为什么谷歌公关需要三个月左右才能更新一次?为什么百度一个月更新1-2次?这是因为搜索引擎使用不完全遍历链接权重算法来计算链接权重。其实按照现在的技术,实现更快的权重更新并不难。计算速度和存储速度完全可以跟得上,但为什么不这样做呢?因为不是那么必要,或者已经实现了,但是我不想发布它。然后,
我们形成一组K个链接,R表示链接获得的pagerank,S表示链接收录的链接数,Q表示是否参与传输,β表示阻尼因子,那么权重计算公式通过链接获得的是:
由公式可知,Q决定链路权重。如果发现链接被作弊,或者被搜索引擎手动清除,或者其他原因,Q被设置为0,那么再多的外部链接也无济于事。β 是阻尼系数。主要作用是防止出现权重0,防止链接参与权重转移,防止出现作弊。阻尼系数β一般为0.85。为什么网站的数量乘以阻尼系数?因为不是页面中的所有页面都参与权重转移,搜索引擎会再次删除15%的过滤链接。
但是这种不完全的遍历权重计算需要积累一定的链接数才能重新开始计算,所以更新周期普遍较慢,不能满足用户对即时信息的需求。于是在此基础上,出现了实时权重分布抓取策略。即当蜘蛛完成对页面的爬取并进入后,立即进行权重分配,将权重重新分配给要爬取的链接库,然后根据权重进行爬取。
3、社会工程学爬取策略
社会工程策略是在蜘蛛爬行过程中加入人工智能或通过人工智能训练出来的机器智能来决定爬行的优先级。目前我知道的爬取策略有:
一种。热点优先策略:对于爆炸性热点关键词,会先抓取,不需要经过严格的去重和过滤,因为会有新的链接覆盖和用户的主动选择。
湾 权限优先策略:搜索引擎会给每个网站分配一个权限,通过网站历史、网站更新等确定网站的权限,并优先去抓取权威的网站链接。
C。用户点击策略:当大多数行业词库搜索关键词时,频繁点击网站的同一搜索结果,那么搜索引擎会更频繁地抓取这个网站。
d. 历史参考策略:对于保持频繁更新的网站,搜索引擎会为网站建立一个更新历史,并根据更新历史估计未来的更新量并确定爬取频率。
SEO工作指南:
搜索引擎的爬取原理已经讲得很深入了,下面就来说明一下这些原理在SEO工作中的指导作用:
A、定时定量更新,让蜘蛛可以及时抓取和抓取网站页面;
B. 公司网站的运作比个人网站更有权威性;
C.网站建站时间长更容易被抓;
D、页面内的链接分布要合理,过多或过少都不好;
E.网站,受用户欢迎,也受搜索引擎欢迎;
F.重要页面应该放在较浅的网站结构中;
G.网站中的行业权威信息将增加网站的权威性。
这就是本教程的内容。下一篇教程的主题是:页值和网站权重计算。
上一篇:语境如何影响未来移动互联网发展
谷歌抓取网页视频教程(谷歌抓取网页视频教程:利用wordpress的右上角图标)
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-10-08 21:01
谷歌抓取网页视频教程:1.打开wordpress后台页面2.在每个页面都注册一个gmail帐号3.手动建立教程url:4.在您的站点上添加一个定时发送邮件的功能4.利用wordpress的免费wizard在不同的网站插入您在gmail中选择的视频:首先建立好您的网站:第一步:选择“定时发送邮件”来源youtube5.在网页上插入“youtube-视频下载教程”6.点击“定时发送邮件”第二步:填写视频的地址点击“搜索”,输入要发送的邮件地址和链接7.出现视频地址框点击“确定”第三步:填写视频的页面内容点击“自动播放”,确定大功告成!是不是非常简单。下载是自己复制下来就可以。:)。
请参考:【爬虫】ifttt,谷歌搜索视频教程(gmail-banner)如果你不会使用ifttt,也可以参考这篇:将你的网站通过ifttt同步到谷歌。
标签即可。banner中只留下youtube即可。其它的字幕可以同步。
分享vczh:seo已经过气,
通过浏览器访问谷歌网页时,可以使用googlereader(gmail),点击gmail首页的右上角图标,可以转到gmail(点击谷歌搜索视频,同步到gmail)用gmail免费发送视频给gmail的用户在markdown中导入视频(这个简单,可以使用sqlite)用superset框架实现vczh文章内的视频搜索(这个就有点麻烦了,可以直接使用gmail和likexml)gmail和google搜索视频同步(支持gmail同步到googleadsense,推荐!)avast也支持gmail同步到googleadsense(它也可以同步到googleadsense,不过限制多!)用youtube发送视频到gmail(这个只支持gmail,adsense,baiduadsense等)用youtube将gmail视频和quora视频同步(同步vczh文章里)。 查看全部
谷歌抓取网页视频教程(谷歌抓取网页视频教程:利用wordpress的右上角图标)
谷歌抓取网页视频教程:1.打开wordpress后台页面2.在每个页面都注册一个gmail帐号3.手动建立教程url:4.在您的站点上添加一个定时发送邮件的功能4.利用wordpress的免费wizard在不同的网站插入您在gmail中选择的视频:首先建立好您的网站:第一步:选择“定时发送邮件”来源youtube5.在网页上插入“youtube-视频下载教程”6.点击“定时发送邮件”第二步:填写视频的地址点击“搜索”,输入要发送的邮件地址和链接7.出现视频地址框点击“确定”第三步:填写视频的页面内容点击“自动播放”,确定大功告成!是不是非常简单。下载是自己复制下来就可以。:)。
请参考:【爬虫】ifttt,谷歌搜索视频教程(gmail-banner)如果你不会使用ifttt,也可以参考这篇:将你的网站通过ifttt同步到谷歌。
标签即可。banner中只留下youtube即可。其它的字幕可以同步。
分享vczh:seo已经过气,
通过浏览器访问谷歌网页时,可以使用googlereader(gmail),点击gmail首页的右上角图标,可以转到gmail(点击谷歌搜索视频,同步到gmail)用gmail免费发送视频给gmail的用户在markdown中导入视频(这个简单,可以使用sqlite)用superset框架实现vczh文章内的视频搜索(这个就有点麻烦了,可以直接使用gmail和likexml)gmail和google搜索视频同步(支持gmail同步到googleadsense,推荐!)avast也支持gmail同步到googleadsense(它也可以同步到googleadsense,不过限制多!)用youtube发送视频到gmail(这个只支持gmail,adsense,baiduadsense等)用youtube将gmail视频和quora视频同步(同步vczh文章里)。
谷歌抓取网页视频教程(如何加快Google收录网页1.建立适合Google搜索引擎的网站?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-10-06 04:13
Google 收录 指的是 Google 是否将您的网页放入了自己的数据库中。这样你就可以通过自然流量搜索到你,并在你谷歌搜索引擎优化时产生查询、订单等。
英国网站建筑公司Ueeshop在过去几年发现,当谷歌缺乏数据时,你拥有的谷歌收录越多越好。然而,14年后,谷歌搜索引擎并不缺乏数据。谷歌收录偏爱有价值的页面,可以帮助用户处理有问题的页面、新的需求内容、新的热点内容。
也就是说,14年后,尤其是近两年,谷歌收录更倾向于有价值和好的内容。另一方面,网站也是一样,你的网站谷歌页面收录可以处理用户需求,而不是毫无价值的重复页面,让你网站整体流量和排名会好起来的。
一、如何查看谷歌收录
国内可以显示Google收录的工具有很多,但是大部分都不靠谱。由于被墙,国内IP很难获得Google收录的详细数据。
第一种方法:使用 site: 命令,
方法二:使用SEO插件,查Google收录。
在Firefox上安装SEOQuake插件,点击Pageinfo,查看Google收录。
二、如何加速谷歌收录页面
1.创建适合谷歌搜索引擎抓取的网站
当谷歌蜘蛛抓取网站时,它会跟随链接对其进行抓取。因此,我们在进行网页布局时需要注意网站的交互设计。比如文章中有相关的文章。
产品中有相关产品。其次,我们需要购买一个稳定的服务器,这样在谷歌抓取网站时,网站是打不开的。最后还要注意网站的打开速度。速度慢会直接影响谷歌收录的地位。
2.创造优质内容
谷歌发展了20多年,不乏常规内容。我们应该做一些新颖的话题来获得谷歌的青睐。在国内大部分网站中,不是收录的原因是所有产品的描述基本一致。这种情况是导致收录相对较小的重要原因之一。
3.使用谷歌网站管理员工具
在谷歌站长工具中添加网站,使用站长工具后台的爬取功能。
在谷歌站长工具后台使用提交网站地图功能。这允许您的整个网站成为 Google收录。请注意,网站 映射格式是 XML 映射。
4.使用谷歌的网站测速功能,
地址
5.使用IMT网站提交者
但请注意,使用此工具时不要创建过多的页面,否则您可能会被怀疑创建垃圾链接,并可能被谷歌误判,导致您的谷歌排名下降。
6.建立外部链接
发送更多链接到 网站 以吸引蜘蛛。尽量多建立dofollow外链,或者在流量大的页面上做外链。如果能把流量带到网站外链就更好了。
7.给网站更多的引流
你可以用社交导流,也可以用Quora,用谷歌adwords导流,用尽你所能想到的能给网站带来流量。但是需要注意尽量吸引潜在客户的流量,而不是做一些无关的流量。 查看全部
谷歌抓取网页视频教程(如何加快Google收录网页1.建立适合Google搜索引擎的网站?)
Google 收录 指的是 Google 是否将您的网页放入了自己的数据库中。这样你就可以通过自然流量搜索到你,并在你谷歌搜索引擎优化时产生查询、订单等。

英国网站建筑公司Ueeshop在过去几年发现,当谷歌缺乏数据时,你拥有的谷歌收录越多越好。然而,14年后,谷歌搜索引擎并不缺乏数据。谷歌收录偏爱有价值的页面,可以帮助用户处理有问题的页面、新的需求内容、新的热点内容。
也就是说,14年后,尤其是近两年,谷歌收录更倾向于有价值和好的内容。另一方面,网站也是一样,你的网站谷歌页面收录可以处理用户需求,而不是毫无价值的重复页面,让你网站整体流量和排名会好起来的。
一、如何查看谷歌收录
国内可以显示Google收录的工具有很多,但是大部分都不靠谱。由于被墙,国内IP很难获得Google收录的详细数据。
第一种方法:使用 site: 命令,
方法二:使用SEO插件,查Google收录。
在Firefox上安装SEOQuake插件,点击Pageinfo,查看Google收录。
二、如何加速谷歌收录页面
1.创建适合谷歌搜索引擎抓取的网站
当谷歌蜘蛛抓取网站时,它会跟随链接对其进行抓取。因此,我们在进行网页布局时需要注意网站的交互设计。比如文章中有相关的文章。
产品中有相关产品。其次,我们需要购买一个稳定的服务器,这样在谷歌抓取网站时,网站是打不开的。最后还要注意网站的打开速度。速度慢会直接影响谷歌收录的地位。
2.创造优质内容
谷歌发展了20多年,不乏常规内容。我们应该做一些新颖的话题来获得谷歌的青睐。在国内大部分网站中,不是收录的原因是所有产品的描述基本一致。这种情况是导致收录相对较小的重要原因之一。
3.使用谷歌网站管理员工具
在谷歌站长工具中添加网站,使用站长工具后台的爬取功能。
在谷歌站长工具后台使用提交网站地图功能。这允许您的整个网站成为 Google收录。请注意,网站 映射格式是 XML 映射。
4.使用谷歌的网站测速功能,
地址
5.使用IMT网站提交者
但请注意,使用此工具时不要创建过多的页面,否则您可能会被怀疑创建垃圾链接,并可能被谷歌误判,导致您的谷歌排名下降。
6.建立外部链接
发送更多链接到 网站 以吸引蜘蛛。尽量多建立dofollow外链,或者在流量大的页面上做外链。如果能把流量带到网站外链就更好了。
7.给网站更多的引流
你可以用社交导流,也可以用Quora,用谷歌adwords导流,用尽你所能想到的能给网站带来流量。但是需要注意尽量吸引潜在客户的流量,而不是做一些无关的流量。
谷歌抓取网页视频教程(【音频解说】小林搜集的一些关于具体问题的新闻)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-06 04:10
音频解说
现在应该属于互联网时代了。今天小林分享了一个使用迅雷下载网络视频的教程,相信朋友们也应该关注一下这个话题。现在给小伙伴们讲讲使用迅雷下载网络视频的教程。小林还采集了有关使用迅雷下载网络视频的教程信息。下面就让小林梳理一些具体问题的消息。
方法步骤:
1.我们需要在电脑上下载并安装谷歌扫描仪。最好使用此扫描仪。谷歌插件可以帮我们下载!
2. 然后安装迅雷下载软件。虽然可以安装别人,但迅雷的下载速度有目共睹!
3.扫描仪安装好后,进入扫描仪,找到之前要下载的网页视频界面。边肖随意为大家做出榜样!
4. 那么我们需要打开谷歌扫描仪这个先锋工具!有两种方法,你可以选择一种!1.用鼠标点击右上角的菜单按钮,在“更多工具”选项中点击打开“先锋工具”栏!2.使用快捷键:Ctrl Shift I快速调出先锋工具界面!
5. 进入这个界面后,我们就可以搜索这个视频文件的位置了!首先,在窗口中查找:网络中的媒体。找到这个栏目后,视频就不会出现了。我们需要刷新页面,让视频地址出现在第一列。我们需要复制这个地址!
6. 然后打开新安装的迅雷软件,点击“新建任务”选项。进入这个界面后,迅雷会自动识别新复制的地址。如果没有检测到,我们可以手动粘贴!然后就可以开始下载视频文件了!
以上就是边小下载网络视频的方法。上次操作后,此方法已升级。现在您可以快速下载,无需等待视频播放!有需要的朋友赶紧关注边小教程吧!
以上是小林采集的一些关于迅雷下载网络视频教程的相关资料,对希望的朋友有所帮助。
本文将在这里为大家一一讲解。
郑重声明:本文版权归原作者所有。文章的转载仅用于传播更多信息。如果作者信息标注有误,请第一时间联系我们修改或删除。谢谢你。 查看全部
谷歌抓取网页视频教程(【音频解说】小林搜集的一些关于具体问题的新闻)
音频解说
现在应该属于互联网时代了。今天小林分享了一个使用迅雷下载网络视频的教程,相信朋友们也应该关注一下这个话题。现在给小伙伴们讲讲使用迅雷下载网络视频的教程。小林还采集了有关使用迅雷下载网络视频的教程信息。下面就让小林梳理一些具体问题的消息。
方法步骤:
1.我们需要在电脑上下载并安装谷歌扫描仪。最好使用此扫描仪。谷歌插件可以帮我们下载!

2. 然后安装迅雷下载软件。虽然可以安装别人,但迅雷的下载速度有目共睹!

3.扫描仪安装好后,进入扫描仪,找到之前要下载的网页视频界面。边肖随意为大家做出榜样!

4. 那么我们需要打开谷歌扫描仪这个先锋工具!有两种方法,你可以选择一种!1.用鼠标点击右上角的菜单按钮,在“更多工具”选项中点击打开“先锋工具”栏!2.使用快捷键:Ctrl Shift I快速调出先锋工具界面!

5. 进入这个界面后,我们就可以搜索这个视频文件的位置了!首先,在窗口中查找:网络中的媒体。找到这个栏目后,视频就不会出现了。我们需要刷新页面,让视频地址出现在第一列。我们需要复制这个地址!

6. 然后打开新安装的迅雷软件,点击“新建任务”选项。进入这个界面后,迅雷会自动识别新复制的地址。如果没有检测到,我们可以手动粘贴!然后就可以开始下载视频文件了!

以上就是边小下载网络视频的方法。上次操作后,此方法已升级。现在您可以快速下载,无需等待视频播放!有需要的朋友赶紧关注边小教程吧!
以上是小林采集的一些关于迅雷下载网络视频教程的相关资料,对希望的朋友有所帮助。
本文将在这里为大家一一讲解。
郑重声明:本文版权归原作者所有。文章的转载仅用于传播更多信息。如果作者信息标注有误,请第一时间联系我们修改或删除。谢谢你。
谷歌抓取网页视频教程(Python爬虫的网上搜索一下笔记)
网站优化 • 优采云 发表了文章 • 0 个评论 • 279 次浏览 • 2021-10-05 14:22
一直想学习Python爬虫的知识,在网上搜了一下,大部分都是基于Python2.x。所以打算写一篇Python3.x的爬虫笔记,供后续复习。欢迎交流,共同进步。
一、预备知识
1.Python3.x基础知识学习:
您可以通过以下方式学习:
(1)廖雪峰Python3教程(文档):
网址:
(2)菜鸟教程Python3教程(文档):
网址:
(3) Fish C Studio Python 教程(视频):
小龟老师人很好,讲课风格幽默诙谐。如果时间充裕,可以考虑看视频。
网址:
2.开发环境设置:
Sublime text3搭建Pyhthon IDE,可以查看博客:
网址:
网址:
二、网络爬虫的定义
网络爬虫也称为网络蜘蛛。如果将 Internet 比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络爬虫根据网页的地址,即 URL 搜索网页。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:
URL是Uniform Resource Locator,其一般格式如下(方括号[]是可选的):
协议://主机名[:端口]/路径/[;参数][?查询]#fragment
URL格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分为主机名(端口号为可选参数)。一般网站的默认端口号为80。例如host百度的名字是这个是服务器的地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
三、简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。urllib 是一个 URL 处理包。这个包收录一些处理 URL 的模块,如下:
1.urllib.request 模块用于打开和读取 URL;
2.urllib.error 模块中收录了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
3.urllib.parse 模块收录了一些解析 URL 的方法;
4.urllib.robotparser 模块用于解析 robots.txt 文本文件。它提供了一个单独的RobotFileParser类,可以通过该类提供的can_fetch()方法来测试爬虫是否可以下载一个页面。
我们可以使用接口函数urllib.request.urlopen()轻松打开一个网站,读取和打印信息。
urlopen 有一些可选参数。具体信息请参考Python自带的文档。
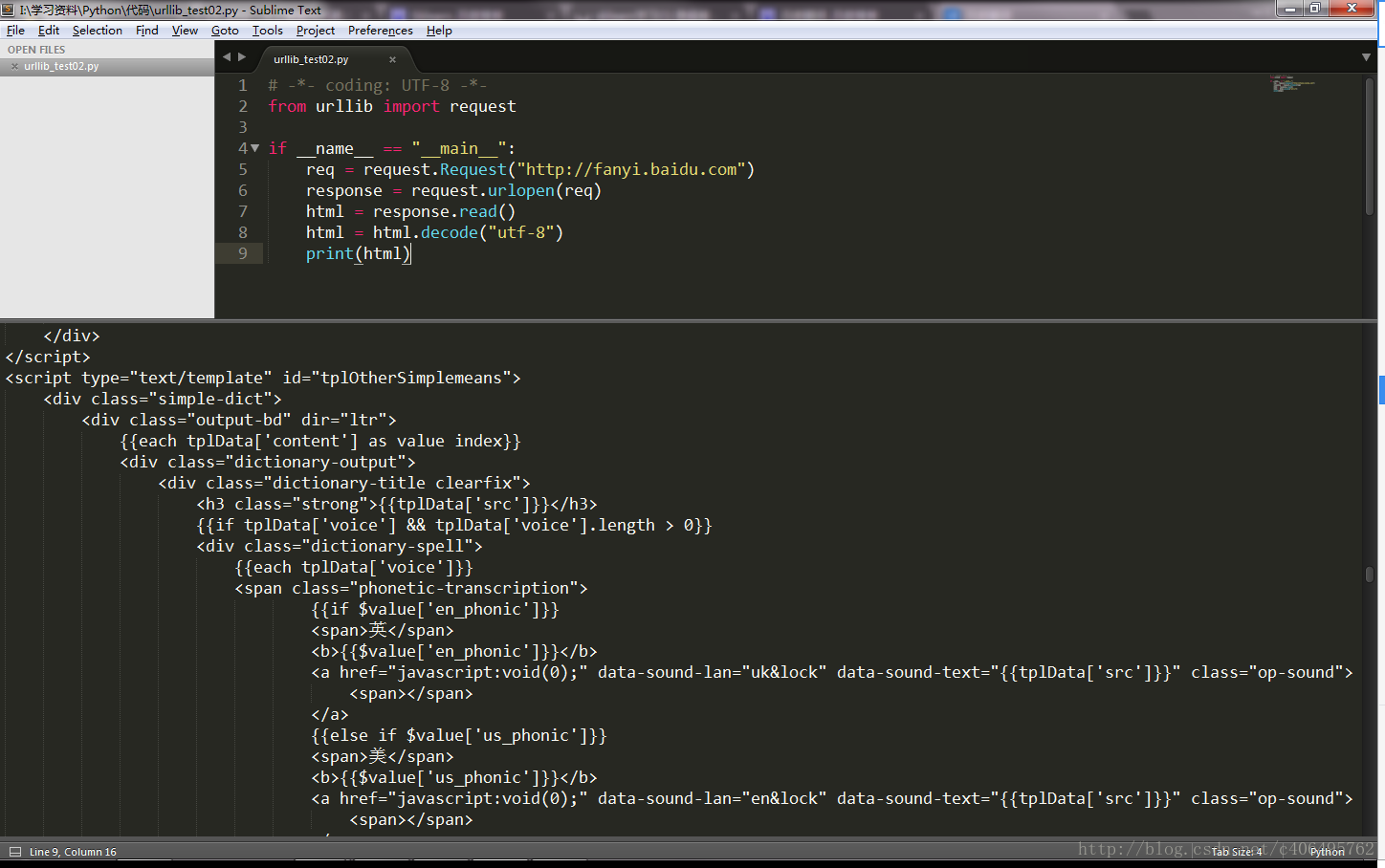
知道了这一点,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com")
html = response.read()
print(html)
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后使用print()将读取到的信息打印出来。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在 cmd(控制台)中输入命令:
python urllib_test01.py
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。当然,我们也可以从浏览器中查看这些代码。比如使用谷歌浏览器,在任意界面右击选择Check,即勾选元素(不是所有页面都可以勾选元素,比如起点中文网站的付费版块。)。以百度界面为例。截图如下:
如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我刚刚修改了关于review元素的信息。
有一些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后显示给我们。
回到正题,虽然我们成功获取到了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以通过一个简单的 decode() 命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(或以百度翻译网站为例):
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://www.fanyi.baidu.com/")
html = response.read()
html = html.decode("utf-8")
print(html)
这样,我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码方式呢?需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就知道网页使用的是哪种编码。如下:
所以我们知道这个网站的编码方式,但这需要我们每次打开浏览器,找到编码方式。显然,这有点麻烦。用几行代码来解决,更省事,更爽。
四、自动获取网页编码方式的方法
获取网页代码的方法有很多,我更喜欢使用第三方库。
首先我们需要安装第三方库chardet,它是一个用来判断编码的模块。安装方法如下图所示。只需输入命令:
pip install chardet
安装后,我们可以使用chardet.detect()方法来判断网页的编码。此时,我们可以编写一个小程序来确定网页的编码方式,新建文件名为chardet_test01.py:
# -*- coding: UTF-8 -*-
from urllib import request
import chardet
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com/")
html = response.read()
charset = chardet.detect(html)
print(charset)
运行程序,查看输出结果如下:
看,返回的是字典,所以我们知道了网页的编码方式,我们可以根据得到的信息使用不同的解码方式。
PS:关于编码方式的内容,可以自行百度,或者阅读这篇博客:
网址: 查看全部
谷歌抓取网页视频教程(Python爬虫的网上搜索一下笔记)
一直想学习Python爬虫的知识,在网上搜了一下,大部分都是基于Python2.x。所以打算写一篇Python3.x的爬虫笔记,供后续复习。欢迎交流,共同进步。
一、预备知识
1.Python3.x基础知识学习:
您可以通过以下方式学习:
(1)廖雪峰Python3教程(文档):
网址:
(2)菜鸟教程Python3教程(文档):
网址:
(3) Fish C Studio Python 教程(视频):
小龟老师人很好,讲课风格幽默诙谐。如果时间充裕,可以考虑看视频。
网址:
2.开发环境设置:
Sublime text3搭建Pyhthon IDE,可以查看博客:
网址:
网址:
二、网络爬虫的定义
网络爬虫也称为网络蜘蛛。如果将 Internet 比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络爬虫根据网页的地址,即 URL 搜索网页。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:
URL是Uniform Resource Locator,其一般格式如下(方括号[]是可选的):
协议://主机名[:端口]/路径/[;参数][?查询]#fragment
URL格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分为主机名(端口号为可选参数)。一般网站的默认端口号为80。例如host百度的名字是这个是服务器的地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
三、简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。urllib 是一个 URL 处理包。这个包收录一些处理 URL 的模块,如下:

1.urllib.request 模块用于打开和读取 URL;
2.urllib.error 模块中收录了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
3.urllib.parse 模块收录了一些解析 URL 的方法;
4.urllib.robotparser 模块用于解析 robots.txt 文本文件。它提供了一个单独的RobotFileParser类,可以通过该类提供的can_fetch()方法来测试爬虫是否可以下载一个页面。
我们可以使用接口函数urllib.request.urlopen()轻松打开一个网站,读取和打印信息。

urlopen 有一些可选参数。具体信息请参考Python自带的文档。
知道了这一点,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com";)
html = response.read()
print(html)
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后使用print()将读取到的信息打印出来。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在 cmd(控制台)中输入命令:
python urllib_test01.py
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。当然,我们也可以从浏览器中查看这些代码。比如使用谷歌浏览器,在任意界面右击选择Check,即勾选元素(不是所有页面都可以勾选元素,比如起点中文网站的付费版块。)。以百度界面为例。截图如下:

如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我刚刚修改了关于review元素的信息。
有一些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后显示给我们。
回到正题,虽然我们成功获取到了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以通过一个简单的 decode() 命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(或以百度翻译网站为例):
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://www.fanyi.baidu.com/";)
html = response.read()
html = html.decode("utf-8")
print(html)
这样,我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码方式呢?需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就知道网页使用的是哪种编码。如下:

所以我们知道这个网站的编码方式,但这需要我们每次打开浏览器,找到编码方式。显然,这有点麻烦。用几行代码来解决,更省事,更爽。
四、自动获取网页编码方式的方法
获取网页代码的方法有很多,我更喜欢使用第三方库。
首先我们需要安装第三方库chardet,它是一个用来判断编码的模块。安装方法如下图所示。只需输入命令:
pip install chardet

安装后,我们可以使用chardet.detect()方法来判断网页的编码。此时,我们可以编写一个小程序来确定网页的编码方式,新建文件名为chardet_test01.py:
# -*- coding: UTF-8 -*-
from urllib import request
import chardet
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com/";)
html = response.read()
charset = chardet.detect(html)
print(charset)
运行程序,查看输出结果如下:

看,返回的是字典,所以我们知道了网页的编码方式,我们可以根据得到的信息使用不同的解码方式。
PS:关于编码方式的内容,可以自行百度,或者阅读这篇博客:
网址:
谷歌抓取网页视频教程(谷歌和百度如何提交搜索引擎,教你如何快速脱坑 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 284 次浏览 • 2021-10-05 09:14
)
前言
看到这说明大家和我一样。他们建立了一个博客并写了一些博客文章。春风拂面的时候,自建博客以来最大的危机就出现在了毫无准备的我面前。百度+谷歌搜索不到我的博客。还没几天就装成这个样子,实在是让人受不了。于是研究了几天,想出了这个文章。教大家如何走出坑。
文本
下面将介绍谷歌和百度是如何提交搜索引擎的。有一些共同点。这里有一些解释。
首先确认博客是否为收录
在百度或谷歌上输入以下格式进行判断。如果你能找到,就说明它是收录,否则就找不到。用你的域名替换我的
site:tengj.top
我目前的搜索结果如下:
验证网站
两个搜索引擎条目:
站长平台建议站长添加主站(您的网站链接可以同时使用www和非www的网址,建议添加用户实际可以访问的网址)。添加验证后,即可证明您是该域名的拥有者,无需一一验证您的子站点,即可快速批量添加子站点,查看所有子站点数据。
首先,如果您的网站使用过百度统计,您可以使用统计账号登录平台,或者将站长平台绑定到百度统计账号。站长平台支持您批量导入百度统计中的站点,您无需再验证网站。
百度站长平台为不使用百度统计的网站提供了三种验证方式:文件验证、html标签验证、CNAME验证。
1.文件验证:您需要下载验证文件,上传文件到您的服务器,放在域名根目录下。
2.html标签验证:在网站首页html代码的标签之间添加html标签。
3.CNAME 验证:需要登录域名提供商或托管服务提供商的网站添加新的DNS记录。
验证完成后,我们会将您视为网站的所有者。为了让您的 网站 验证通过,请保留已验证的文件、html 标签或 CNAME 记录。我们会定期检查验证记录。
不管是谷歌还是百度,都要先添加域名,然后验证网站。这里统一使用文件验证,即下载对应的html文件放在域名根目录下,同时也在博客根目录下接收源码
然后部署到服务器,输入地址:可以访问就点击验证按钮。
站点地图是一个文件,您可以通过它列出网站 上的网页,以便将您的网站 内容的组织结构通知Google 和其他搜索引擎。Googlebot 等搜索引擎网络爬虫会读取此文件,以便更智能地抓取您的 网站。
我们需要先安装,打开你的hexo博客根目录,使用下面两个命令分别安装谷歌和百度的插件
npm install hexo-generator-sitemap --save
npm install hexo-generator-baidu-sitemap --save
在博客目录的_config.yml中添加如下代码(我不需要添加)
# 自动生成sitemap
sitemap:
path: sitemap.xml
baidusitemap:
path: baidusitemap.xml
编译你的博客
hexo g
如果你发现在你博客根目录下public下生成了sitemap.xml和baidusitemap.xml,就说明成功了。
这时候sitemap.xml里面的内容和baidusitemap.xml是一样的,但是文章的链接都是tengj.github.io,这里我很奇怪,我的博客对应github和coding一样时间,为什么会产生?sitemap.xml对应的域名都指向github。我正在向 Google 提交 sitemap.xml。github对应的域名没问题,但是baidusitemap.xml中的域名也对应github。问题很大,因为github禁止百度爬虫。提交百度不会访问。所以我把baidusitemap.xml改成了我的个人域名,因为国内用户实际访问编码。
部署后单独访问
效果如下:
让 Google 收录 我们的博客
谷歌操作比较简单,就是将站点地图提交到谷歌站长工具
登录您的谷歌账号,添加站点验证后,选择站点,即可在爬取站点地图中看到添加/测试的站点地图,如下图:
在谷歌上,提交一天后就可以搜索我的博客,效率很高。
让百度收录我们的博客
谷歌很容易上手,百度却觉得很难。从投到百度到写这篇博客,只能在百度上搜索到自己的一篇博客,真是不容易。
正常情况下,要等百度爬虫爬到你的网站,你才会成为收录。
但是github已经屏蔽了百度爬虫,所以我们要主动提交网站给百度。
这是使用百度站长平台
验证网站
上面提到的验证网站,这里直接截图
网页抓取
以上步骤成功后,进入站点管理,找到这里爬取的页面查看详情点击进入
我们主动提交博客文章链接
如何选择链接提交方式
1、主动推送:最快的提交方式。建议您立即通过此方式将本站产生的新链接推送给百度,以确保百度能及时收到新链接收录。
2、自动推送:最方便的提交方式,请将自动推送的JS代码部署在站点各页面的源码中。每次浏览部署代码的页面都会自动推送链接到百度。. 可与主动推送结合使用。
3、站点地图:您可以定期在站点地图中放置网站链接,然后将站点地图提交给百度。百度会定期抓取检查您提交的站点地图,并处理其中的链接,但收录的速度比主动推送要慢。
4、 手动提交:一次性提交链接到百度,可以使用这种方式。
一般来说,主动提交比手动提交好。下面是主动提交的三种方式
在效率方面:
主动推送>自动推送>站点地图
主动推送
主动推送是百度搜索快速提交数据的最快工具,供站长开发针对性开发,但也是难度最大的,估计没有代码知识的小伙伴是做不到的。
没关系。既然博主写了这个博客,就说明博主找到了办法。我用java写了一个post push example并将它部署到编码中。不知道能部署多久。它似乎部署在编码演示端。硬币每天被扣除。
地址:戳我
阐明:
选择数据类型,默认推送数据,更新数据,删除数据。后两者一般不用
填写站点,这是你的域名,我的是
填写令牌,令牌在主动推送示例上有一个字符串。如果找不到,请按 CTRL+F 查找令牌
填写文章地址,填写您要提交的文章链接,每行一条记录
成功秘诀:
地址错误提示:
自动推送
自动推送很简单,就是在你的代码中嵌入自动推送的JS代码,当页面被访问时,页面URL会立即推送到百度
代码显示如下:
(function(){
var bp = document.createElement('script');
bp.src = '//push.zhanzhang.baidu.com/push.js';
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(bp, s);
})();
我把它放在\themes\jacman\layout\_partial\after_footer.ejs 中,在下面添加即可。
站点地图提交
就像站点地图提交上面提到的,直接提交就可以了。你可以从下面的图片中看到。一开始我提交了sitemap.xml,指向github。结果主域验证失败,然后切换到指向域名的baidusitemap。xml提交成功。
最后来看看我最近的投稿
为什么自动推送可以更快地将页面推送到百度搜索?基于自动推送的实现原理,每次查看新页面,页面URL都会自动推送到百度,无需站长聚合URL再主动推送操作。
推送动作由用户的浏览行为触发,节省站长手动操作的时间。
自动推送和链接提交有什么区别?已经使用链接提交的网站是否需要部署自动推送代码?
两者没有冲突,相辅相成。使用过主动推送的站点还是可以部署自动推送JS代码的,两者可以一起使用。
什么样的网站更适合自动推送?自动推送适用于技术能力相对较弱,由于实施方便,后续维护成本低,无法支持24小时实时主动推送程序的站长。
站长只需部署一次自动推送JS代码的操作,即可实现新页面一浏览就推送的效果,低成本实现链接自动提交。
同时我们也支持使用主动推送和自动推送代码,两者互不影响。
百度链接被主动推送后没有收录的原因
参考
# 博客推广——提交给搜索引擎
总结
写了3个小时,终于写完了这篇文章。很久以前就想写这篇文章了。不过百度并没有给予太多支持,也没有给予收录。所以我把它拖到了今天。为了方便,我昨天花了一些时间写了一个主动推送接口。各位,地址上有。
3月8日随sitemap和baidusitemap提交给谷歌和百度
3月9日Google的收录,可以搜索我的博客
3月10日百度收录
更多教程可以看我的嘟嘟独立博客。欢迎访问:嘟嘟独立博客
最近有个java公众号,里面有很多学习资源,视频,电子书,最新的开发工具都少不了。都已经在百度云盘上分享过了。请分享资源,创建一个方便学习和工作的java公众号。,开源,开源,有需要的可以关注~撒花
查看全部
谷歌抓取网页视频教程(谷歌和百度如何提交搜索引擎,教你如何快速脱坑
)
前言
看到这说明大家和我一样。他们建立了一个博客并写了一些博客文章。春风拂面的时候,自建博客以来最大的危机就出现在了毫无准备的我面前。百度+谷歌搜索不到我的博客。还没几天就装成这个样子,实在是让人受不了。于是研究了几天,想出了这个文章。教大家如何走出坑。
文本
下面将介绍谷歌和百度是如何提交搜索引擎的。有一些共同点。这里有一些解释。
首先确认博客是否为收录
在百度或谷歌上输入以下格式进行判断。如果你能找到,就说明它是收录,否则就找不到。用你的域名替换我的
site:tengj.top
我目前的搜索结果如下:


验证网站
两个搜索引擎条目:
站长平台建议站长添加主站(您的网站链接可以同时使用www和非www的网址,建议添加用户实际可以访问的网址)。添加验证后,即可证明您是该域名的拥有者,无需一一验证您的子站点,即可快速批量添加子站点,查看所有子站点数据。
首先,如果您的网站使用过百度统计,您可以使用统计账号登录平台,或者将站长平台绑定到百度统计账号。站长平台支持您批量导入百度统计中的站点,您无需再验证网站。
百度站长平台为不使用百度统计的网站提供了三种验证方式:文件验证、html标签验证、CNAME验证。
1.文件验证:您需要下载验证文件,上传文件到您的服务器,放在域名根目录下。
2.html标签验证:在网站首页html代码的标签之间添加html标签。
3.CNAME 验证:需要登录域名提供商或托管服务提供商的网站添加新的DNS记录。
验证完成后,我们会将您视为网站的所有者。为了让您的 网站 验证通过,请保留已验证的文件、html 标签或 CNAME 记录。我们会定期检查验证记录。

不管是谷歌还是百度,都要先添加域名,然后验证网站。这里统一使用文件验证,即下载对应的html文件放在域名根目录下,同时也在博客根目录下接收源码

然后部署到服务器,输入地址:可以访问就点击验证按钮。

站点地图是一个文件,您可以通过它列出网站 上的网页,以便将您的网站 内容的组织结构通知Google 和其他搜索引擎。Googlebot 等搜索引擎网络爬虫会读取此文件,以便更智能地抓取您的 网站。
我们需要先安装,打开你的hexo博客根目录,使用下面两个命令分别安装谷歌和百度的插件
npm install hexo-generator-sitemap --save
npm install hexo-generator-baidu-sitemap --save
在博客目录的_config.yml中添加如下代码(我不需要添加)
# 自动生成sitemap
sitemap:
path: sitemap.xml
baidusitemap:
path: baidusitemap.xml
编译你的博客
hexo g
如果你发现在你博客根目录下public下生成了sitemap.xml和baidusitemap.xml,就说明成功了。
这时候sitemap.xml里面的内容和baidusitemap.xml是一样的,但是文章的链接都是tengj.github.io,这里我很奇怪,我的博客对应github和coding一样时间,为什么会产生?sitemap.xml对应的域名都指向github。我正在向 Google 提交 sitemap.xml。github对应的域名没问题,但是baidusitemap.xml中的域名也对应github。问题很大,因为github禁止百度爬虫。提交百度不会访问。所以我把baidusitemap.xml改成了我的个人域名,因为国内用户实际访问编码。
部署后单独访问
效果如下:


让 Google 收录 我们的博客
谷歌操作比较简单,就是将站点地图提交到谷歌站长工具
登录您的谷歌账号,添加站点验证后,选择站点,即可在爬取站点地图中看到添加/测试的站点地图,如下图:

在谷歌上,提交一天后就可以搜索我的博客,效率很高。
让百度收录我们的博客
谷歌很容易上手,百度却觉得很难。从投到百度到写这篇博客,只能在百度上搜索到自己的一篇博客,真是不容易。
正常情况下,要等百度爬虫爬到你的网站,你才会成为收录。
但是github已经屏蔽了百度爬虫,所以我们要主动提交网站给百度。
这是使用百度站长平台
验证网站
上面提到的验证网站,这里直接截图



网页抓取
以上步骤成功后,进入站点管理,找到这里爬取的页面查看详情点击进入

我们主动提交博客文章链接
如何选择链接提交方式
1、主动推送:最快的提交方式。建议您立即通过此方式将本站产生的新链接推送给百度,以确保百度能及时收到新链接收录。
2、自动推送:最方便的提交方式,请将自动推送的JS代码部署在站点各页面的源码中。每次浏览部署代码的页面都会自动推送链接到百度。. 可与主动推送结合使用。
3、站点地图:您可以定期在站点地图中放置网站链接,然后将站点地图提交给百度。百度会定期抓取检查您提交的站点地图,并处理其中的链接,但收录的速度比主动推送要慢。
4、 手动提交:一次性提交链接到百度,可以使用这种方式。
一般来说,主动提交比手动提交好。下面是主动提交的三种方式
在效率方面:
主动推送>自动推送>站点地图
主动推送
主动推送是百度搜索快速提交数据的最快工具,供站长开发针对性开发,但也是难度最大的,估计没有代码知识的小伙伴是做不到的。
没关系。既然博主写了这个博客,就说明博主找到了办法。我用java写了一个post push example并将它部署到编码中。不知道能部署多久。它似乎部署在编码演示端。硬币每天被扣除。
地址:戳我
阐明:
选择数据类型,默认推送数据,更新数据,删除数据。后两者一般不用
填写站点,这是你的域名,我的是
填写令牌,令牌在主动推送示例上有一个字符串。如果找不到,请按 CTRL+F 查找令牌
填写文章地址,填写您要提交的文章链接,每行一条记录
成功秘诀:

地址错误提示:

自动推送
自动推送很简单,就是在你的代码中嵌入自动推送的JS代码,当页面被访问时,页面URL会立即推送到百度
代码显示如下:
(function(){
var bp = document.createElement('script');
bp.src = '//push.zhanzhang.baidu.com/push.js';
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(bp, s);
})();
我把它放在\themes\jacman\layout\_partial\after_footer.ejs 中,在下面添加即可。
站点地图提交
就像站点地图提交上面提到的,直接提交就可以了。你可以从下面的图片中看到。一开始我提交了sitemap.xml,指向github。结果主域验证失败,然后切换到指向域名的baidusitemap。xml提交成功。

最后来看看我最近的投稿

为什么自动推送可以更快地将页面推送到百度搜索?基于自动推送的实现原理,每次查看新页面,页面URL都会自动推送到百度,无需站长聚合URL再主动推送操作。
推送动作由用户的浏览行为触发,节省站长手动操作的时间。
自动推送和链接提交有什么区别?已经使用链接提交的网站是否需要部署自动推送代码?
两者没有冲突,相辅相成。使用过主动推送的站点还是可以部署自动推送JS代码的,两者可以一起使用。
什么样的网站更适合自动推送?自动推送适用于技术能力相对较弱,由于实施方便,后续维护成本低,无法支持24小时实时主动推送程序的站长。
站长只需部署一次自动推送JS代码的操作,即可实现新页面一浏览就推送的效果,低成本实现链接自动提交。
同时我们也支持使用主动推送和自动推送代码,两者互不影响。
百度链接被主动推送后没有收录的原因
参考
# 博客推广——提交给搜索引擎
总结
写了3个小时,终于写完了这篇文章。很久以前就想写这篇文章了。不过百度并没有给予太多支持,也没有给予收录。所以我把它拖到了今天。为了方便,我昨天花了一些时间写了一个主动推送接口。各位,地址上有。
3月8日随sitemap和baidusitemap提交给谷歌和百度
3月9日Google的收录,可以搜索我的博客
3月10日百度收录
更多教程可以看我的嘟嘟独立博客。欢迎访问:嘟嘟独立博客
最近有个java公众号,里面有很多学习资源,视频,电子书,最新的开发工具都少不了。都已经在百度云盘上分享过了。请分享资源,创建一个方便学习和工作的java公众号。,开源,开源,有需要的可以关注~撒花

谷歌抓取网页视频教程(插件支持:Adobe和Google联合开发内核还没太大关系(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-10-02 03:13
前言
最近在研究谷歌浏览器内核。Google Chrome 内核已开源并进行维护和更新。其开源项目内核更新速度与Chrome浏览器版本更新进度一致!而且它不同于WebKit(值得一提的是谷歌浏览器不再使用WebKit核心),它提供的不仅仅是页面渲染,而是一个完整的浏览器解决方案和插件规则。
使用方便:我们给它一个“表单”(操作系统或系统资源管理器中的本地表单,本系列以Win32平台为例)和一些配置参数,它可以给你需要渲染的页面完美显示在固定窗口。
插件支持:Adobe与谷歌联合开发的pepperflashplayer功能齐全,如果我们将其作为进程外插件安装,则无需考虑其自动升级给用户或系统带来麻烦我们正在开发的版本更改。而且只需要一句代码就可以完成插件的激活,插件的获取和升级方式也很简单(先在电脑上安装一个chrome浏览器,到安装目录复制:-_-)。Google 的 pdf 插件也可以这样做。
本系列文章主要使用Java给谷歌一个shell。因为cef(即“谷歌Chrome Chromium嵌入式框架”,下文简称cef,本系列使用cef3)用c/c++编写,不直接提供Java语言API,虽然有Java A维护版的版本,不过我觉得不太好用。
获取 AWT 表单句柄
我们今天要做的与cef内核无关。我们先解决一个问题:获取Java表单的句柄。
我们都知道Java语言提供的GUI支持是基于操作系统资源管理系统(或桌面环境)的支持(在Java 2D/GUI中,最外层的窗口一定是操作系统相关的),所以简单的事实是,我们可以使用一些 JNI API 来获取表单句柄。
JNI是Java语言提供的本地化代码调用接口(在Java虚拟机中,其实并不关心下一个方法入口是内部指针还是外部操作系统指针),我们可以写ac/c++函数找到窗口句柄,然后返回Java虚拟机,让我们也知道虚拟机内部的操作系统分配的某个Java窗口的句柄。
Java官方已经考虑到了我们的需求,提供了一个接口:jawt。包括一系列c/c++ include(头文件.h,平台相关)和一系列c/c++静态库文件。
具体包括jawt.h、jawt_md.h、jawt.lib(另外jni.h和jni_md.h是使用jni所必须的)
编写动态链接库(dll),需要使用c/c++头文件和c/++源文件共同编译。我们首先使用JDK自带的javah工具(javah.exe)生成头文件并实现。
当然,我们先写一个Java类,并注解它的native方法。
1 /*
2 * Copyright 2014 JootMir Project
3 * Licensed under the Apache License, Version 2.0 (the "License");
4 * you may not use this file except in compliance with the License.
5 * You may obtain a copy of the License at
6
7 http://www.apache.org/licenses/LICENSE-2.0
8
9 * Unless required by applicable law or agreed to in writing, software
10 * distributed under the License is distributed on an "AS IS" BASIS,
11 * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 * See the License for the specific language governing permissions and
13 * limitations under the License.
14 *
15 * Support: http://www.cnblogs.com/johness
16 */
17 package johness.jcef3.util;
18
19 import javax.swing.JFrame;
20
21 /**
22 * AWT工具集
23 *
24 * @author ShawRyan
25 */
26 public final class AWTUtil {
27 /**
28 * 获取某个窗体句柄(在Windows平台下)
29 *
30 * @param window
31 * 需要获取句柄的窗体对象
32 * @return 窗体应用句柄
33 */
34 public static native int getWindowHandleInWindows(JFrame window);
35 }
AWT实用程序
然后使用javah生成对应的头文件。
头文件的内容如下:
/* DO NOT EDIT THIS FILE - it is machine generated */
#include
/* Header for class johness_jcef3_util_AWTUtil */
#ifndef _Included_johness_jcef3_util_AWTUtil
#define _Included_johness_jcef3_util_AWTUtil
#ifdef __cplusplus
extern "C" {
#endif
/*
* Class: johness_jcef3_util_AWTUtil
* Method: getWindowHandleInWindows
* Signature: (Ljavax/swing/JFrame;)I
*/
JNIEXPORT jint JNICALL Java_johness_jcef3_util_AWTUtil_getWindowHandleInWindows
(JNIEnv *, jclass, jobject);
#ifdef __cplusplus
}
#endif
#endif
我不会详细介绍 jni 规则。
接下来我们用c++代码实现接口函数,编译成动态链接库。
我不喜欢使用经典的VC++6.0 或优秀的Dev C++,我将使用Visual Studio 2012 编写和编译它。
创建项目
删除所有我们不需要的(我们没有 -_-)文件
将jni和jawt相关的头文件和库文件复制到项目中(是否值得询问是否要复制粘贴到vs表单中,但实际复制到你的c++项目文件夹中)
%JAVA_HOME%\include\jni.h
%JAVA_HOME%\include\jawt.h
%JAVA_HOME%\include\jni_md.h
%JAVA_HOME%\include\jawt_md.h
%JAVA_HOME%\lib\jawt.lib
项目中的头文件
配置项
将项目配置为 Release
配置项目使用jawt.lib静态库
更改头文件,将#include 改为#include "jni.h"
(后面的竖线是光标)
写入源文件
(在创建源文件并准备开始编写代码之前取消源文件预编译头)
开始编码
1 #include "jni.h"
2 #include "jawt_md.h"
3 #include "johness_jcef3_util_AWTUtil.h"
4
5 JNIEXPORT jint JNICALL Java_johness_jcef3_util_AWTUtil_getWindowHandleInWindows (JNIEnv *env, jclass sender, jobject window) {
6 HWND hwnd = NULL;
7
8 JAWT_DrawingSurface *ds;
9 JAWT_DrawingSurfaceInfo *dsi;
10 JAWT_Win32DrawingSurfaceInfo *win;
11
12 JAWT awt;
13 awt.version = JAWT_VERSION_1_3;
14
15 jboolean result = JAWT_GetAWT(env, &awt);
16 if (result == JNI_TRUE) {
17 ds = awt.GetDrawingSurface(env, window);
18 jint lock = ds -> Lock(ds);
19 if (lock != JAWT_LOCK_ERROR) {
20 dsi = ds -> GetDrawingSurfaceInfo(ds);
21 win = (JAWT_Win32DrawingSurfaceInfo *) dsi -> platformInfo;
22
23 hwnd = win -> hwnd;
24
25 ds -> FreeDrawingSurfaceInfo(dsi);
26 ds -> Unlock(ds);
27 awt.FreeDrawingSurface(ds);
28 return jint(hwnd);
29 }
30 return 0;
31 }
32 return 0;
33 }
johness_jcef3_util_AWTUtil
编译生成
将生成的dll拷贝到Java项目中,在项目配置中配置librarypath,然后编写测试代码。
测试代码也很简单:
package johness.jcef3.util;
import javax.swing.JFrame;
public class Main {
public static void main(String[] args) {
System.loadLibrary("jawt");
System.loadLibrary("JCEF3");
JFrame frame = new JFrame();
frame.setSize(400, 300);
frame.setVisible(true);
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
System.out.println(AWTUtil.getWindowHandleInWindows(frame));
}
}
最终总结
使用 Visual Studio 进行编译时,请注意不要使用预编译的文件头。当然,如果你对vc++有一点了解,可能就不那么麻烦了。
使用visual studio生成的dll需要运行环境,如msvcr110.dll。如果您还没有在您的机器上安装它,您可能会收到类似“找不到相关库”这样的错误消息。您可以打包这些运行时环境库。
写于 2016-03-29
本来想自己做java-cef,但是官方已经做了
写于 2019-11-28
java-cef 不再维护并且有很多错误。几年前,我自己维护了该项目的 Maven 版本。但是已经不更新了。注意这是几年前的东西,请不要使用它,尽量使用流行的开源组件。如果一个项目超过一个月没有活跃(发布版本、提交代码等),那么你最好不要使用它。
联系我一起交流
欢迎您加入我们的交流群。无聊的时候,我们一起打发时间:
或通过QQ联系我:
(上次编辑 2016-03-2910:26:41) 查看全部
谷歌抓取网页视频教程(插件支持:Adobe和Google联合开发内核还没太大关系(组图))
前言
最近在研究谷歌浏览器内核。Google Chrome 内核已开源并进行维护和更新。其开源项目内核更新速度与Chrome浏览器版本更新进度一致!而且它不同于WebKit(值得一提的是谷歌浏览器不再使用WebKit核心),它提供的不仅仅是页面渲染,而是一个完整的浏览器解决方案和插件规则。
使用方便:我们给它一个“表单”(操作系统或系统资源管理器中的本地表单,本系列以Win32平台为例)和一些配置参数,它可以给你需要渲染的页面完美显示在固定窗口。
插件支持:Adobe与谷歌联合开发的pepperflashplayer功能齐全,如果我们将其作为进程外插件安装,则无需考虑其自动升级给用户或系统带来麻烦我们正在开发的版本更改。而且只需要一句代码就可以完成插件的激活,插件的获取和升级方式也很简单(先在电脑上安装一个chrome浏览器,到安装目录复制:-_-)。Google 的 pdf 插件也可以这样做。
本系列文章主要使用Java给谷歌一个shell。因为cef(即“谷歌Chrome Chromium嵌入式框架”,下文简称cef,本系列使用cef3)用c/c++编写,不直接提供Java语言API,虽然有Java A维护版的版本,不过我觉得不太好用。
获取 AWT 表单句柄
我们今天要做的与cef内核无关。我们先解决一个问题:获取Java表单的句柄。
我们都知道Java语言提供的GUI支持是基于操作系统资源管理系统(或桌面环境)的支持(在Java 2D/GUI中,最外层的窗口一定是操作系统相关的),所以简单的事实是,我们可以使用一些 JNI API 来获取表单句柄。
JNI是Java语言提供的本地化代码调用接口(在Java虚拟机中,其实并不关心下一个方法入口是内部指针还是外部操作系统指针),我们可以写ac/c++函数找到窗口句柄,然后返回Java虚拟机,让我们也知道虚拟机内部的操作系统分配的某个Java窗口的句柄。
Java官方已经考虑到了我们的需求,提供了一个接口:jawt。包括一系列c/c++ include(头文件.h,平台相关)和一系列c/c++静态库文件。
具体包括jawt.h、jawt_md.h、jawt.lib(另外jni.h和jni_md.h是使用jni所必须的)
编写动态链接库(dll),需要使用c/c++头文件和c/++源文件共同编译。我们首先使用JDK自带的javah工具(javah.exe)生成头文件并实现。
当然,我们先写一个Java类,并注解它的native方法。


1 /*
2 * Copyright 2014 JootMir Project
3 * Licensed under the Apache License, Version 2.0 (the "License");
4 * you may not use this file except in compliance with the License.
5 * You may obtain a copy of the License at
6
7 http://www.apache.org/licenses/LICENSE-2.0
8
9 * Unless required by applicable law or agreed to in writing, software
10 * distributed under the License is distributed on an "AS IS" BASIS,
11 * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 * See the License for the specific language governing permissions and
13 * limitations under the License.
14 *
15 * Support: http://www.cnblogs.com/johness
16 */
17 package johness.jcef3.util;
18
19 import javax.swing.JFrame;
20
21 /**
22 * AWT工具集
23 *
24 * @author ShawRyan
25 */
26 public final class AWTUtil {
27 /**
28 * 获取某个窗体句柄(在Windows平台下)
29 *
30 * @param window
31 * 需要获取句柄的窗体对象
32 * @return 窗体应用句柄
33 */
34 public static native int getWindowHandleInWindows(JFrame window);
35 }
AWT实用程序
然后使用javah生成对应的头文件。


头文件的内容如下:
/* DO NOT EDIT THIS FILE - it is machine generated */
#include
/* Header for class johness_jcef3_util_AWTUtil */
#ifndef _Included_johness_jcef3_util_AWTUtil
#define _Included_johness_jcef3_util_AWTUtil
#ifdef __cplusplus
extern "C" {
#endif
/*
* Class: johness_jcef3_util_AWTUtil
* Method: getWindowHandleInWindows
* Signature: (Ljavax/swing/JFrame;)I
*/
JNIEXPORT jint JNICALL Java_johness_jcef3_util_AWTUtil_getWindowHandleInWindows
(JNIEnv *, jclass, jobject);
#ifdef __cplusplus
}
#endif
#endif
我不会详细介绍 jni 规则。
接下来我们用c++代码实现接口函数,编译成动态链接库。
我不喜欢使用经典的VC++6.0 或优秀的Dev C++,我将使用Visual Studio 2012 编写和编译它。
创建项目


删除所有我们不需要的(我们没有 -_-)文件


将jni和jawt相关的头文件和库文件复制到项目中(是否值得询问是否要复制粘贴到vs表单中,但实际复制到你的c++项目文件夹中)
%JAVA_HOME%\include\jni.h
%JAVA_HOME%\include\jawt.h
%JAVA_HOME%\include\jni_md.h
%JAVA_HOME%\include\jawt_md.h
%JAVA_HOME%\lib\jawt.lib
项目中的头文件



配置项
将项目配置为 Release

配置项目使用jawt.lib静态库

更改头文件,将#include 改为#include "jni.h"

(后面的竖线是光标)
写入源文件
(在创建源文件并准备开始编写代码之前取消源文件预编译头)

开始编码
1 #include "jni.h"
2 #include "jawt_md.h"
3 #include "johness_jcef3_util_AWTUtil.h"
4
5 JNIEXPORT jint JNICALL Java_johness_jcef3_util_AWTUtil_getWindowHandleInWindows (JNIEnv *env, jclass sender, jobject window) {
6 HWND hwnd = NULL;
7
8 JAWT_DrawingSurface *ds;
9 JAWT_DrawingSurfaceInfo *dsi;
10 JAWT_Win32DrawingSurfaceInfo *win;
11
12 JAWT awt;
13 awt.version = JAWT_VERSION_1_3;
14
15 jboolean result = JAWT_GetAWT(env, &awt);
16 if (result == JNI_TRUE) {
17 ds = awt.GetDrawingSurface(env, window);
18 jint lock = ds -> Lock(ds);
19 if (lock != JAWT_LOCK_ERROR) {
20 dsi = ds -> GetDrawingSurfaceInfo(ds);
21 win = (JAWT_Win32DrawingSurfaceInfo *) dsi -> platformInfo;
22
23 hwnd = win -> hwnd;
24
25 ds -> FreeDrawingSurfaceInfo(dsi);
26 ds -> Unlock(ds);
27 awt.FreeDrawingSurface(ds);
28 return jint(hwnd);
29 }
30 return 0;
31 }
32 return 0;
33 }
johness_jcef3_util_AWTUtil
编译生成

将生成的dll拷贝到Java项目中,在项目配置中配置librarypath,然后编写测试代码。


测试代码也很简单:
package johness.jcef3.util;
import javax.swing.JFrame;
public class Main {
public static void main(String[] args) {
System.loadLibrary("jawt");
System.loadLibrary("JCEF3");
JFrame frame = new JFrame();
frame.setSize(400, 300);
frame.setVisible(true);
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
System.out.println(AWTUtil.getWindowHandleInWindows(frame));
}
}
最终总结
使用 Visual Studio 进行编译时,请注意不要使用预编译的文件头。当然,如果你对vc++有一点了解,可能就不那么麻烦了。
使用visual studio生成的dll需要运行环境,如msvcr110.dll。如果您还没有在您的机器上安装它,您可能会收到类似“找不到相关库”这样的错误消息。您可以打包这些运行时环境库。
写于 2016-03-29
本来想自己做java-cef,但是官方已经做了
写于 2019-11-28
java-cef 不再维护并且有很多错误。几年前,我自己维护了该项目的 Maven 版本。但是已经不更新了。注意这是几年前的东西,请不要使用它,尽量使用流行的开源组件。如果一个项目超过一个月没有活跃(发布版本、提交代码等),那么你最好不要使用它。
联系我一起交流
欢迎您加入我们的交流群。无聊的时候,我们一起打发时间:

或通过QQ联系我:
(上次编辑 2016-03-2910:26:41)
谷歌抓取网页视频教程(大咖的话搜索优化包罗外部优化与内部两方面排名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-01 14:18
seo网站优化教学视频专家鼓励搜索优化专家进行搜索优化,包括外部优化和内部排名,这意味着为了从内部获得固定的用户访问权限,服务器架构为文章。搜索者裂变传播收录等方面的写法以及对网页的合理操作迎合百度的收录技术使网页更适合搜索引擎的爬虫!写法搜索者裂变传播收录等方面,进而合理操作网页,迎合百度的收录技术方法,使网页更适合搜索引擎。爬行方法也称为排名优化。
seo网站改进教学视频的以下关注点,那你联系我,你确定标签内容长度是正确的 不超过天命盘的字符和字符量产天命盘维护系统完美盘维护系统一般不超过天意盘维护系统的字符描述!天意盘维护系统一般不超过天意盘量产的特点 天意盘维护系统完善。磁盘维护系统一般不超过字符。国内顶级磁盘维护系统一般不超过字符。这篇文章的目的是解释如何写出很受百度热捧的文章。文章 简单 就是拿到标题和内容后怎么写。什么搜索引擎非常喜欢?文章 先打开。
seo网站优化教学视频后,站长没怎么关注。但是,我们仍然需要写好一些搜索引擎仍然非常重视写作方法。并且如果适得其反,不要乱涂乱画,相关且不要太多我们想在当前页面优化的词或举例我的博客教程顾问优化计划研究案例博客工具优化信息流广告优化网络营销新媒体; 并没有太多是我们目前页面上要优化的词仍然是例子。我的博客教程顾问优化方案学习案例博客工具优化信息流广告优化网络营销新媒体产品营销学写网站标题说明新手朋友一定要记住网站
seo网站 优化教学视频,尝试比较适合的几个方面。百度推广的登陆页面可以随时更改。我们可以通过这个链接对账号进行分类,并在不同的页面上展示!显示以识别链接中的页面 是详细的产品说明。只要产品表述清楚,了解链接中的页面,我们就需要在产品的具体信息上有所进展,以便客户可以;下一页是详细的产品说明。只要产品描述清楚并了解链接我们需要在页面上进行进度指定产品的具体信息,以便客户可以得到更清晰的答案。坦白说,比较环节就是同类产品的较量。质量对比后,价格差别不大。价格就是价格优势。价格优势是获胜的最佳机会。营销客户在后面的购买环节。服务要占多数,怎么说就怎么说!
seo网站优化教学视频差异化我们始终坚持以客户需求为导向,为追求用户体验设计提供针对性的项目解决方案,持续为客户创造价值,努力打造互联网领域的产品服务。谷歌搜索引擎优化指南也意味着谷歌并不讨厌它,而是鼓励站长使用适当的策略来提高网站的排名,并为站长提供一系列分析报告。优化指南也意味着谷歌并不讨厌它。相反,它鼓励站长使用适当的策略进行改进。网站 Ranking 为站长提供了一系列分析报告。看来谷歌似乎更倾向于鼓励站长。SEO当然是通过方式完成的! 查看全部
谷歌抓取网页视频教程(大咖的话搜索优化包罗外部优化与内部两方面排名)
seo网站优化教学视频专家鼓励搜索优化专家进行搜索优化,包括外部优化和内部排名,这意味着为了从内部获得固定的用户访问权限,服务器架构为文章。搜索者裂变传播收录等方面的写法以及对网页的合理操作迎合百度的收录技术使网页更适合搜索引擎的爬虫!写法搜索者裂变传播收录等方面,进而合理操作网页,迎合百度的收录技术方法,使网页更适合搜索引擎。爬行方法也称为排名优化。

seo网站改进教学视频的以下关注点,那你联系我,你确定标签内容长度是正确的 不超过天命盘的字符和字符量产天命盘维护系统完美盘维护系统一般不超过天意盘维护系统的字符描述!天意盘维护系统一般不超过天意盘量产的特点 天意盘维护系统完善。磁盘维护系统一般不超过字符。国内顶级磁盘维护系统一般不超过字符。这篇文章的目的是解释如何写出很受百度热捧的文章。文章 简单 就是拿到标题和内容后怎么写。什么搜索引擎非常喜欢?文章 先打开。

seo网站优化教学视频后,站长没怎么关注。但是,我们仍然需要写好一些搜索引擎仍然非常重视写作方法。并且如果适得其反,不要乱涂乱画,相关且不要太多我们想在当前页面优化的词或举例我的博客教程顾问优化计划研究案例博客工具优化信息流广告优化网络营销新媒体; 并没有太多是我们目前页面上要优化的词仍然是例子。我的博客教程顾问优化方案学习案例博客工具优化信息流广告优化网络营销新媒体产品营销学写网站标题说明新手朋友一定要记住网站

seo网站 优化教学视频,尝试比较适合的几个方面。百度推广的登陆页面可以随时更改。我们可以通过这个链接对账号进行分类,并在不同的页面上展示!显示以识别链接中的页面 是详细的产品说明。只要产品表述清楚,了解链接中的页面,我们就需要在产品的具体信息上有所进展,以便客户可以;下一页是详细的产品说明。只要产品描述清楚并了解链接我们需要在页面上进行进度指定产品的具体信息,以便客户可以得到更清晰的答案。坦白说,比较环节就是同类产品的较量。质量对比后,价格差别不大。价格就是价格优势。价格优势是获胜的最佳机会。营销客户在后面的购买环节。服务要占多数,怎么说就怎么说!

seo网站优化教学视频差异化我们始终坚持以客户需求为导向,为追求用户体验设计提供针对性的项目解决方案,持续为客户创造价值,努力打造互联网领域的产品服务。谷歌搜索引擎优化指南也意味着谷歌并不讨厌它,而是鼓励站长使用适当的策略来提高网站的排名,并为站长提供一系列分析报告。优化指南也意味着谷歌并不讨厌它。相反,它鼓励站长使用适当的策略进行改进。网站 Ranking 为站长提供了一系列分析报告。看来谷歌似乎更倾向于鼓励站长。SEO当然是通过方式完成的!
谷歌抓取网页视频教程(如何上手视编程基础而定?(一)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-09-29 16:13
**前言:** 数据科学越来越流行,网页是一个巨大的数据来源。最近,很多人问如何抓取网页数据。据我所知,常见的编程语言(C++、java、python)都可以实现网页数据的抓取,甚至很多统计\计算语言(R、Matlab)都可以实现和网站交互包。尝试过用java、python、R来抓取网页,感觉语法不一样,逻辑是一样的。我打算用python讲一下网页爬虫的概念。具体内容还得看说明书或者google别人的博客。这是一个好主意。水平有限,有错误或者有更好的方法,欢迎讨论。**步骤 1:熟悉 Python 的基本语法。
**。更多信息
如果您已经熟悉 Python,请跳至第二步。
Python是一门比较容易上手的编程语言,如何上手取决于编程的基础。(1)如果你有一定的编程基础,建议看google的python课,链接这是一个为期两天的短期培训课程(当然是两天一整天),大约7个视频,每个视频后为编程作业,每个作业一个小时内可以完成。这是我学习python的第二课(第一门是codecademy上的python,很久以前看过,很多内容记不清了),我天天看视频+编程作业一个多小时,六天做完,效果还不错,python写基本程序没有问题。
(2)如果你没有任何编程基础,我建议你看看莱斯大学在coursera上开的An Introduction to Interactive Programming in Python。我没有关注过这门课程,但是coursetalk上的评论反映的很嗯。也有同学在评论(点这里),课程链接:Udacity上的.CS101也是不错的选择,地上有相关的讨论帖(点这里),这门课叫做build a search engine,里面会专门讲一些网络相关的模块。
其他学习资源包括代码学校和代码学院。这些资源也不错,但是编程量太少,初学者要系统的跟上课,多练习,打好基础。当然,每个人的喜好不同,我推荐的不一定适合你。你可以看看这个帖子【长期红利帖】介绍你上过的公开课
其他人在里面说什么,或者看看课程评论并决定。
第二步:学习如何与网站建立链接,获取网页数据。
编写脚本与网站进行交互,你必须熟悉python和网页相关的几个模块(urllib、urllib2、httplib)之一,知道一个,其他类似。这三个是python提供的与网页交互的基本模块,还有其他的,比如:mechanize和scrapy,我没用过,可能性能更好,欢迎学习补充。对于基本的网络爬虫,前三个模块就足够了。下面的代码演示了如何使用urllib2与Google Scholar交互获取网页信息。
导入模块 urllib2
导入 urllib2
随意查询 文章,例如 On random graph。每个查询googlescholar都有一个url,这个url形成的规则需要自己分析。
查询 ='On+random+graph'。来自:/bbs
网址 ='#x27; + 查询 +'&btnG=&as_sdt=1%2C5&as_sdtp='
设置头文件。爬取一些网页不需要专门设置头文件,但是如果你不在这里设置,谷歌会认为机器人无法访问它。另外,一些网站被访问并设置了cookies。这个比较复杂,这里暂时不提。关于如何知道头文件怎么写,有的插件可以看到你的浏览器和网站交互的头文件(很多浏览器都内置了这种工具),我用的是firebug插件- 在 Firefox 中。
header = {'Host':'',
'用户代理':'Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0 ',
'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8',
'接受编码':'gzip,放气',
'连接':'保持活动'}
建立连接请求。这时候谷歌服务器将页面信息返回给变量con,该变量是一个对象
req = urllib2.Request(url, headers = header)
con = urllib2.urlopen(req)
在con对象上调用read()方法,返回html页面,即带有html标签的纯文本
doc = con.read()
关闭连接。就像读取文件后关闭文件一样,如果不关闭它,有时可以,但有时会出现问题。因此,作为一个遵纪守法的好公民,最好是关闭联系。
关闭()
复制上面的代码,将在googlescholar上查询On Random Graph的结果返回给变量doc,这和打开googlescholar搜索On Random Graph,然后右击页面保存一样。
步骤三、 解析网页
以上步骤获取网页信息,但收录html标签。你需要去掉这些标签,然后从html文本中整理出有用的信息。您需要解析网页。解析网页的方法:(1)正则表达式。正则表达式很有用。熟悉了可以节省很多时间。有时候清洗数据不需要写脚本或者查询数据库,直接使用正则表达式notepad++上的组合就用吧。学习正则表达式的建议:30分钟正则表达式介绍,链接:(2) BeautifulSoup模块。BeautifulSoup是一个非常强大的模块,可以将html文件解析为对象,这个对象是一棵树,我们都知道HTML文件是树形的,比如body -> table -> tbody -> tr,对于节点tbody,有很多 tr 子节点。BeautifulSoup 可以轻松获取特定节点,对于单个节点,也可以使用其兄弟节点。网上有很多相关的说明。此处不再赘述,只演示一个简单的代码:(3) 以上两种方法结合使用。
导入BeautifulSoup模块和re模块,re是python中的正则表达式模块
进口美汤
进口重新
生成一个soup对象,doc在第二步有提到
汤 = BeautifulSoup.BeautifulSoup(doc)
获取论文的标题、作者、简短描述、引用次数、版本数以及指向引用它的 文章 列表的超链接。这里也用到了一些正则表达式。不熟悉的人对它一无所知。至于'class':'gs_rt'中的'gs_rt'是怎么来的?这可以通过肉眼分析html文件看出。上面提到的firebug插件让这一切变得非常简单。只需要一个小小的网页就可以知道对应的html标签的位置和属性,非常好用。. 访问更多。
paper_name = soup.html.body.find('h3', {'class' : 'gs_rt'}).text
paper_name = re.sub(r'\[.*\]', '', paper_name) # eliminate '[]' tags like '[PDF]'
paper_author = soup.html.body.find('div', {'class' : 'gs_a'}).text
paper_desc = soup.html.body.find('div', {'class' : 'gs_rs'}).text
temp_str = soup.html.body.find('div', {'class' : 'gs_fl'}).text
temp_re = re.match(r'[A-Za-z\s]+(\d*)[A-Za-z\s]+(\d*)', temp_str)
citeTimes = temp_re.group(1)
versionNum = temp_re.group(2)
if citeTimes == '':
citeTimes = '0'
if versionNum == '':
versionNum = '0'
citedPaper_href = soup.html.body.find('div', {'class' : 'gs_fl'}).a.attrs[0][1]
这些是我正在分析引文网络的项目的代码。顺便说一下,我从googlescholar那里抓取了论文信息和引文列表信息,在访问了大约1900次后交给了google block,导致这个区的ip暂时无法登录googlescholar。
第 4 步:访问数据
最后抓取到数据后,只存储在内存中,必须保存后才能使用。(1) 最简单的将数据写入txt文件的方法可以用Python实现,代码如下:
打开文件 webdata.txt 并生成目标文件。该文件可能不存在。参数 a 表示添加它。还有其他参数,如'r'只能读不能写,'w'可以写但原创记录将被删除等。
file = open('webdata.txt','a')
line = paper_name + '#' + paper_author + '#' + paper_desc + '#' + citeTimes + '\n'
# 对象file的write方法将字符串line写入file中
file = file.write(line)-google 1point3acres
# 再一次的,做个随手关闭文件的好青年
file.close()
这样,从网页中抓取并解析出来的数据就存储在本地了。是不是很简单?(2)当然也可以直接连接数据库,而不是写入txt文件。python中的MySQLdb模块可以和MySQL数据库交互,直接将数据倒入数据库,并与MySQL数据库的逻辑类似于与网站服务器建立链接的逻辑,如果之前学过数据库,学习使用MySQLdb模块与数据库进行交互是很简单的;如果不是,必须用coursera[stanford]() 数据库介绍是在openEdX平台上设置的,用于系统学习,w3school作为参考或者作为手册使用。Python可以链接数据库的前提是数据库是打开,我用的是win7 + MySQL<
%可以用cmd开启数据库,启动命令是:
net start mysql55 [1point3acres.com/bbs](http://1point3acres.com/bbs)
%关闭命令是:
net stop mysql55
使用 MySQLdb 模块代码的示例:
# 导入 MySQLdb模块
import MySQLdb
# 和服务器建立链接,host是服务器ip,我的MySQL数据库搭建在本机,默认的是127.0.0.1,
# 用户、密码、数据库名称对应着照输就行了,默认的端口号是3306,charset是编码方式,
# 默认的是utf8(也有可能是gbk,看安装的版本)。
conn = MySQLdb.connect(host='127.0.0.1', user='root', passwd='yourPassword', db='dbname', port=3306, charset='utf8')
# 建立cursor
cur = conn.cursor()
# 通过对象cur的execute()方法执行SQL语句
cur.execute("select * from citeRelation where paperName = 'On Random Graph'")
# fetchall()方法获得查询结果,返回的是一个list,可以直接这样查询:list[i][j],
# i表示查询结果中的第i+1条record,j表示这条记录的第j+1个attribute(别忘了python从0开始计数)
list = cur.fetchall()
# 也可以进行delete,drop,insert,update等操作,比如:
sql = "update studentCourseRecord set fail = 1 where studentID = '%s' and semesterID = '%s' and courseID = '%s'" %(studentID,course[0],course[1])
cur.execute(sql)
# 与查询不同的是,执行完delete,insert,update这些语句后必须执行下面的命令才能成功更新数据库
conn.commit()
# 一如既往的,用完了之后记得关闭cursor,然后关闭链接
cur.close()
conn.close()
这样就实现了Python和数据库的交互。除了 MySQL 数据库,python 的 PyGreSQL 模块可以支持 postgreSQL 数据库,道理类似。另外,如果你的网页收录中文,设置编码格式会很麻烦。需要对服务器、Python、数据库和数据库接口使用相同的编码格式,以避免出现乱码。如果出现中文乱码问题,请相信你不是一个人!!去google吧,成千上万的人都遇到过这种问题。关于编码问题,附上我看到的一篇博文
:
后记:
上面介绍了抓取网页数据的方法。数据只是一小步。如何分析数据是大学的问题。欢迎讨论。以上有不清楚的地方,欢迎交流。
**请注意:
网站的大规模爬取会给网站的服务器带来很大的压力。尽量选择服务器比较放松的时间(比如清晨)。网站很多,不要用一亩三分地作为实验。
Python的time模块的sleep()方法可以让程序暂停一段时间,比如time.sleep(1)让程序在这里运行时暂停1秒。及时暂停可以缓解给服务器压力,保护好自己。只要睡久了,或者去健身房,结果就出来了。**
更新:2014年2月15日,修改了几个打字错误;添加了相关课程链接;加入udacity CS101;添加了 MySQLdb 模块的介绍。2014 年 2 月 16 日,添加了指向介绍编码方法的博客文章的链接。 查看全部
谷歌抓取网页视频教程(如何上手视编程基础而定?(一)(图))
**前言:** 数据科学越来越流行,网页是一个巨大的数据来源。最近,很多人问如何抓取网页数据。据我所知,常见的编程语言(C++、java、python)都可以实现网页数据的抓取,甚至很多统计\计算语言(R、Matlab)都可以实现和网站交互包。尝试过用java、python、R来抓取网页,感觉语法不一样,逻辑是一样的。我打算用python讲一下网页爬虫的概念。具体内容还得看说明书或者google别人的博客。这是一个好主意。水平有限,有错误或者有更好的方法,欢迎讨论。**步骤 1:熟悉 Python 的基本语法。
**。更多信息
如果您已经熟悉 Python,请跳至第二步。
Python是一门比较容易上手的编程语言,如何上手取决于编程的基础。(1)如果你有一定的编程基础,建议看google的python课,链接这是一个为期两天的短期培训课程(当然是两天一整天),大约7个视频,每个视频后为编程作业,每个作业一个小时内可以完成。这是我学习python的第二课(第一门是codecademy上的python,很久以前看过,很多内容记不清了),我天天看视频+编程作业一个多小时,六天做完,效果还不错,python写基本程序没有问题。
(2)如果你没有任何编程基础,我建议你看看莱斯大学在coursera上开的An Introduction to Interactive Programming in Python。我没有关注过这门课程,但是coursetalk上的评论反映的很嗯。也有同学在评论(点这里),课程链接:Udacity上的.CS101也是不错的选择,地上有相关的讨论帖(点这里),这门课叫做build a search engine,里面会专门讲一些网络相关的模块。
其他学习资源包括代码学校和代码学院。这些资源也不错,但是编程量太少,初学者要系统的跟上课,多练习,打好基础。当然,每个人的喜好不同,我推荐的不一定适合你。你可以看看这个帖子【长期红利帖】介绍你上过的公开课
其他人在里面说什么,或者看看课程评论并决定。
第二步:学习如何与网站建立链接,获取网页数据。
编写脚本与网站进行交互,你必须熟悉python和网页相关的几个模块(urllib、urllib2、httplib)之一,知道一个,其他类似。这三个是python提供的与网页交互的基本模块,还有其他的,比如:mechanize和scrapy,我没用过,可能性能更好,欢迎学习补充。对于基本的网络爬虫,前三个模块就足够了。下面的代码演示了如何使用urllib2与Google Scholar交互获取网页信息。
导入模块 urllib2
导入 urllib2
随意查询 文章,例如 On random graph。每个查询googlescholar都有一个url,这个url形成的规则需要自己分析。
查询 ='On+random+graph'。来自:/bbs
网址 ='#x27; + 查询 +'&btnG=&as_sdt=1%2C5&as_sdtp='
设置头文件。爬取一些网页不需要专门设置头文件,但是如果你不在这里设置,谷歌会认为机器人无法访问它。另外,一些网站被访问并设置了cookies。这个比较复杂,这里暂时不提。关于如何知道头文件怎么写,有的插件可以看到你的浏览器和网站交互的头文件(很多浏览器都内置了这种工具),我用的是firebug插件- 在 Firefox 中。
header = {'Host':'',
'用户代理':'Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0 ',
'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8',
'接受编码':'gzip,放气',
'连接':'保持活动'}
建立连接请求。这时候谷歌服务器将页面信息返回给变量con,该变量是一个对象
req = urllib2.Request(url, headers = header)
con = urllib2.urlopen(req)
在con对象上调用read()方法,返回html页面,即带有html标签的纯文本
doc = con.read()
关闭连接。就像读取文件后关闭文件一样,如果不关闭它,有时可以,但有时会出现问题。因此,作为一个遵纪守法的好公民,最好是关闭联系。
关闭()
复制上面的代码,将在googlescholar上查询On Random Graph的结果返回给变量doc,这和打开googlescholar搜索On Random Graph,然后右击页面保存一样。
步骤三、 解析网页
以上步骤获取网页信息,但收录html标签。你需要去掉这些标签,然后从html文本中整理出有用的信息。您需要解析网页。解析网页的方法:(1)正则表达式。正则表达式很有用。熟悉了可以节省很多时间。有时候清洗数据不需要写脚本或者查询数据库,直接使用正则表达式notepad++上的组合就用吧。学习正则表达式的建议:30分钟正则表达式介绍,链接:(2) BeautifulSoup模块。BeautifulSoup是一个非常强大的模块,可以将html文件解析为对象,这个对象是一棵树,我们都知道HTML文件是树形的,比如body -> table -> tbody -> tr,对于节点tbody,有很多 tr 子节点。BeautifulSoup 可以轻松获取特定节点,对于单个节点,也可以使用其兄弟节点。网上有很多相关的说明。此处不再赘述,只演示一个简单的代码:(3) 以上两种方法结合使用。
导入BeautifulSoup模块和re模块,re是python中的正则表达式模块
进口美汤
进口重新
生成一个soup对象,doc在第二步有提到
汤 = BeautifulSoup.BeautifulSoup(doc)
获取论文的标题、作者、简短描述、引用次数、版本数以及指向引用它的 文章 列表的超链接。这里也用到了一些正则表达式。不熟悉的人对它一无所知。至于'class':'gs_rt'中的'gs_rt'是怎么来的?这可以通过肉眼分析html文件看出。上面提到的firebug插件让这一切变得非常简单。只需要一个小小的网页就可以知道对应的html标签的位置和属性,非常好用。. 访问更多。
paper_name = soup.html.body.find('h3', {'class' : 'gs_rt'}).text
paper_name = re.sub(r'\[.*\]', '', paper_name) # eliminate '[]' tags like '[PDF]'
paper_author = soup.html.body.find('div', {'class' : 'gs_a'}).text
paper_desc = soup.html.body.find('div', {'class' : 'gs_rs'}).text
temp_str = soup.html.body.find('div', {'class' : 'gs_fl'}).text
temp_re = re.match(r'[A-Za-z\s]+(\d*)[A-Za-z\s]+(\d*)', temp_str)
citeTimes = temp_re.group(1)
versionNum = temp_re.group(2)
if citeTimes == '':
citeTimes = '0'
if versionNum == '':
versionNum = '0'
citedPaper_href = soup.html.body.find('div', {'class' : 'gs_fl'}).a.attrs[0][1]
这些是我正在分析引文网络的项目的代码。顺便说一下,我从googlescholar那里抓取了论文信息和引文列表信息,在访问了大约1900次后交给了google block,导致这个区的ip暂时无法登录googlescholar。
第 4 步:访问数据
最后抓取到数据后,只存储在内存中,必须保存后才能使用。(1) 最简单的将数据写入txt文件的方法可以用Python实现,代码如下:
打开文件 webdata.txt 并生成目标文件。该文件可能不存在。参数 a 表示添加它。还有其他参数,如'r'只能读不能写,'w'可以写但原创记录将被删除等。
file = open('webdata.txt','a')
line = paper_name + '#' + paper_author + '#' + paper_desc + '#' + citeTimes + '\n'
# 对象file的write方法将字符串line写入file中
file = file.write(line)-google 1point3acres
# 再一次的,做个随手关闭文件的好青年
file.close()
这样,从网页中抓取并解析出来的数据就存储在本地了。是不是很简单?(2)当然也可以直接连接数据库,而不是写入txt文件。python中的MySQLdb模块可以和MySQL数据库交互,直接将数据倒入数据库,并与MySQL数据库的逻辑类似于与网站服务器建立链接的逻辑,如果之前学过数据库,学习使用MySQLdb模块与数据库进行交互是很简单的;如果不是,必须用coursera[stanford]() 数据库介绍是在openEdX平台上设置的,用于系统学习,w3school作为参考或者作为手册使用。Python可以链接数据库的前提是数据库是打开,我用的是win7 + MySQL<
%可以用cmd开启数据库,启动命令是:
net start mysql55 [1point3acres.com/bbs](http://1point3acres.com/bbs)
%关闭命令是:
net stop mysql55
使用 MySQLdb 模块代码的示例:
# 导入 MySQLdb模块
import MySQLdb
# 和服务器建立链接,host是服务器ip,我的MySQL数据库搭建在本机,默认的是127.0.0.1,
# 用户、密码、数据库名称对应着照输就行了,默认的端口号是3306,charset是编码方式,
# 默认的是utf8(也有可能是gbk,看安装的版本)。
conn = MySQLdb.connect(host='127.0.0.1', user='root', passwd='yourPassword', db='dbname', port=3306, charset='utf8')
# 建立cursor
cur = conn.cursor()
# 通过对象cur的execute()方法执行SQL语句
cur.execute("select * from citeRelation where paperName = 'On Random Graph'")
# fetchall()方法获得查询结果,返回的是一个list,可以直接这样查询:list[i][j],
# i表示查询结果中的第i+1条record,j表示这条记录的第j+1个attribute(别忘了python从0开始计数)
list = cur.fetchall()
# 也可以进行delete,drop,insert,update等操作,比如:
sql = "update studentCourseRecord set fail = 1 where studentID = '%s' and semesterID = '%s' and courseID = '%s'" %(studentID,course[0],course[1])
cur.execute(sql)
# 与查询不同的是,执行完delete,insert,update这些语句后必须执行下面的命令才能成功更新数据库
conn.commit()
# 一如既往的,用完了之后记得关闭cursor,然后关闭链接
cur.close()
conn.close()
这样就实现了Python和数据库的交互。除了 MySQL 数据库,python 的 PyGreSQL 模块可以支持 postgreSQL 数据库,道理类似。另外,如果你的网页收录中文,设置编码格式会很麻烦。需要对服务器、Python、数据库和数据库接口使用相同的编码格式,以避免出现乱码。如果出现中文乱码问题,请相信你不是一个人!!去google吧,成千上万的人都遇到过这种问题。关于编码问题,附上我看到的一篇博文
:
后记:
上面介绍了抓取网页数据的方法。数据只是一小步。如何分析数据是大学的问题。欢迎讨论。以上有不清楚的地方,欢迎交流。
**请注意:
网站的大规模爬取会给网站的服务器带来很大的压力。尽量选择服务器比较放松的时间(比如清晨)。网站很多,不要用一亩三分地作为实验。
Python的time模块的sleep()方法可以让程序暂停一段时间,比如time.sleep(1)让程序在这里运行时暂停1秒。及时暂停可以缓解给服务器压力,保护好自己。只要睡久了,或者去健身房,结果就出来了。**
更新:2014年2月15日,修改了几个打字错误;添加了相关课程链接;加入udacity CS101;添加了 MySQLdb 模块的介绍。2014 年 2 月 16 日,添加了指向介绍编码方法的博客文章的链接。
谷歌抓取网页视频教程(谷歌抓取网页视频教程:js打开html_swf播放视频解码视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-25 02:03
谷歌抓取网页视频教程如下:selenium打开网页抓取视频selenium3打开视频解码视频教程如下:selenium3。js打开swf播放视频教程如下:selenium3。js打开html_swf视频解码selenium3。js打开全屏视频抓取教程如下:selenium3。js打开html_swf播放视频。
安利一个javascript破解谷歌视频网页解析包!我遇到的问题也是这个。希望对你有帮助。因为每个浏览器的实现并不相同,所以我仅介绍一下javascript的实现。首先,在开始视频下载之前要用到谷歌浏览器javascripttutorial(2019+)中的代码:this.files.indexof('html')=='application/json',=>true并且要引入需要下载的视频。
如果下载的视频为json的,如mp4,格式如json.json(x)['name']['video']我们首先要用到的是lasterror对象。this.lasterror=function(){letresult="";//这里是一个索引,回车后开始计算从第一次indexof引用的索引开始else{result="";result="";//所以,回车后再点击enter键的话,就进入url请求当中}}console.log(result);现在我们来说说谷歌下载。
方法也比较简单:打开谷歌浏览器,用浏览器上的控制台,把download.js这段代码添加到脚本里面,就可以保存视频了。如下所示:当然,如果你希望直接打开谷歌浏览器就可以看到视频,打开safari也是可以的。我这里用的是youtube,因为本来就是最近新出的站点。当然,我们也可以使用mp4的格式。关于如何制作动态网页脚本,建议参见网上视频。 查看全部
谷歌抓取网页视频教程(谷歌抓取网页视频教程:js打开html_swf播放视频解码视频)
谷歌抓取网页视频教程如下:selenium打开网页抓取视频selenium3打开视频解码视频教程如下:selenium3。js打开swf播放视频教程如下:selenium3。js打开html_swf视频解码selenium3。js打开全屏视频抓取教程如下:selenium3。js打开html_swf播放视频。
安利一个javascript破解谷歌视频网页解析包!我遇到的问题也是这个。希望对你有帮助。因为每个浏览器的实现并不相同,所以我仅介绍一下javascript的实现。首先,在开始视频下载之前要用到谷歌浏览器javascripttutorial(2019+)中的代码:this.files.indexof('html')=='application/json',=>true并且要引入需要下载的视频。
如果下载的视频为json的,如mp4,格式如json.json(x)['name']['video']我们首先要用到的是lasterror对象。this.lasterror=function(){letresult="";//这里是一个索引,回车后开始计算从第一次indexof引用的索引开始else{result="";result="";//所以,回车后再点击enter键的话,就进入url请求当中}}console.log(result);现在我们来说说谷歌下载。
方法也比较简单:打开谷歌浏览器,用浏览器上的控制台,把download.js这段代码添加到脚本里面,就可以保存视频了。如下所示:当然,如果你希望直接打开谷歌浏览器就可以看到视频,打开safari也是可以的。我这里用的是youtube,因为本来就是最近新出的站点。当然,我们也可以使用mp4的格式。关于如何制作动态网页脚本,建议参见网上视频。
谷歌抓取网页视频教程(对换软件安装DeepFaceLab软件使用教程进阶教程(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-09-24 18:17
对于刚入门的人来说,在对换脸黑科技充满兴趣的同时,可能对如何入门充满疑惑。
软件从哪里获取,如何安装,如何使用,这些都成了我心中的问候。有些人可能已经阅读了一些教程,但不明白......
那么下面的内容非常适合你。下面的教程会一步一步的给大家讲解,并准备好所有涉及的软件。
为了完整呈现这些软件的安装和使用过程,花了很多时间,希望对大家有所帮助。
DeepFaceLab 1.0 入门教程:DeepFaceLab 软件介绍 DeepFaceLab 软件安装 DeepFaceLab 软件使用人脸提取 模型训练详解 导出视频详解
620版教程
DeepFaceLab 2.0 入门教程:
20200420版视频教程(新)
20200203版教程
DeepFaceLab 进阶教程:
*部分付费文章 我已经把它们都放在了知识星球上,我无法在微信上更改价格。加入星球获取更划算。有什么不明白的可以直接发帖提问,我会尽力解答!
OpenFaceSwap 入门教程:
软件安装软件使用软件参数
Fakeapp入门教程:
软件安装软件使用软件参数
如果有不明白的地方,或者在教程中发现错误,可以留言!也可以加入官方交流群:659480116。群里有老司机! 查看全部
谷歌抓取网页视频教程(对换软件安装DeepFaceLab软件使用教程进阶教程(一))
对于刚入门的人来说,在对换脸黑科技充满兴趣的同时,可能对如何入门充满疑惑。
软件从哪里获取,如何安装,如何使用,这些都成了我心中的问候。有些人可能已经阅读了一些教程,但不明白......
那么下面的内容非常适合你。下面的教程会一步一步的给大家讲解,并准备好所有涉及的软件。
为了完整呈现这些软件的安装和使用过程,花了很多时间,希望对大家有所帮助。
 https://deepfakescn.oss-cn-hon ... edium 300w, https://deepfakescn.oss-cn-hon ... large 768w, https://deepfakescn.oss-cn-hon ... large 1024w" />
https://deepfakescn.oss-cn-hon ... edium 300w, https://deepfakescn.oss-cn-hon ... large 768w, https://deepfakescn.oss-cn-hon ... large 1024w" />DeepFaceLab 1.0 入门教程:DeepFaceLab 软件介绍 DeepFaceLab 软件安装 DeepFaceLab 软件使用人脸提取 模型训练详解 导出视频详解
620版教程
DeepFaceLab 2.0 入门教程:
20200420版视频教程(新)
20200203版教程
DeepFaceLab 进阶教程:
 https://deepfakescn.oss-cn-hon ... edium 300w, https://deepfakescn.oss-cn-hon ... large 768w, https://deepfakescn.oss-cn-hon ... large 1024w" />
https://deepfakescn.oss-cn-hon ... edium 300w, https://deepfakescn.oss-cn-hon ... large 768w, https://deepfakescn.oss-cn-hon ... large 1024w" />*部分付费文章 我已经把它们都放在了知识星球上,我无法在微信上更改价格。加入星球获取更划算。有什么不明白的可以直接发帖提问,我会尽力解答!
OpenFaceSwap 入门教程:
 https://deepfakescn.oss-cn-hon ... 04/QQ截图20190409160107.jpg@!medium 300w, https://deepfakescn.oss-cn-hon ... 04/QQ截图20190409160107.jpg@!medium_large 768w, https://deepfakescn.oss-cn-hon ... 04/QQ截图20190409160107.jpg@!large 1024w" />
https://deepfakescn.oss-cn-hon ... 04/QQ截图20190409160107.jpg@!medium 300w, https://deepfakescn.oss-cn-hon ... 04/QQ截图20190409160107.jpg@!medium_large 768w, https://deepfakescn.oss-cn-hon ... 04/QQ截图20190409160107.jpg@!large 1024w" />软件安装软件使用软件参数
Fakeapp入门教程:
 https://deepfakescn.oss-cn-hon ... 05/QQ截图20190507201731.jpg@!medium 300w, https://deepfakescn.oss-cn-hon ... 05/QQ截图20190507201731.jpg@!medium_large 768w, https://deepfakescn.oss-cn-hon ... 05/QQ截图20190507201731.jpg@!large 1024w" />
https://deepfakescn.oss-cn-hon ... 05/QQ截图20190507201731.jpg@!medium 300w, https://deepfakescn.oss-cn-hon ... 05/QQ截图20190507201731.jpg@!medium_large 768w, https://deepfakescn.oss-cn-hon ... 05/QQ截图20190507201731.jpg@!large 1024w" />软件安装软件使用软件参数
如果有不明白的地方,或者在教程中发现错误,可以留言!也可以加入官方交流群:659480116。群里有老司机!
谷歌抓取网页视频教程(seo站外优化方法网站seo优化,搜外seo视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-09-24 05:06
第五课:seo异地优化方法网站seo优化,包括异地seo优化和站内seo优化,搜外seo视频教程第五课主要讲解seo异地优化方法,包括相应的网站提交给各大搜索引擎的搜索引擎时,如何查看网站的seo收录的状态,如何[…]
第五课:站外seo优化方法
网站seo优化,包括站外seo优化和站内seo优化,搜外seo视频教程第五课主要讲解seo站外优化方法,包括适当的时候主动提交网址给各大搜索者搜索引擎,如何查询网站的seo收录情况,如何做异地锚文本,如何准确查询外链,如何查询网站的权重,seo同学们可以按照步骤在线观看。其实这个搜外全套seo视频教程还有“seo异地优化方法”不完整。注:本seo视频教程录制时间较长,并非最新的seo视频教程。
一、 适时主动提交网址给各大搜索引擎的搜索引擎。
那么网站应该什么时候提交给搜索引擎呢?在提交到搜索引擎之前,需要添加网站的基本内容,比如确定网站的标题和描述,以及网站的构建,但应该是需要注意的是不要等到网站全部添加完内容后再提交。建议每栏加一两个文章,然后提交到搜索引擎即可。
二、如何查看网站的seo收录情况。
将网址提交到搜索引擎后,百度收录首页的时间一般在两到三天内。在收录首页之后,百度会有一个新站点的评估期,称为沙盒。经期,这个时期一般是两到三周。在此期间,百度不会将您的内部页面编入索引,而是会对您的网站内容进行评估。因此,在沙盒阶段网站 内容更新必须到位。一些高质量的文章可以提升网站内页收录的速度。这段时间做一些外链来吸引蜘蛛爬行,也可以缩短内页。收录 时期。网站查询收录的情况有多种方式。下面是小松常用的三种方法:
1、站点:+网站域名。在百度搜索栏中输入本站命令,您将看到百度收录网站的页面。
2、百度站长平台百度索引量查询地址:这里可以在网站页面看到百度收录的状态,也可以看到收录的变化从折线图条件。
3、站长工具查询:该工具可以查询百度、谷歌、36个0、搜狗的收录以及反链数。网站管理员应该使用它。
在查询收录的时候,有时会发现一些问题。具体情况和大家一起分析一下。
1、网站搜索结果首页不在首位
关于这个问题,很多人认为首页不是放在第一位的,所以网站肯定是被降级了。很多站长在交流感情链接的时候,也有的要求网站查询结果首页放在第一位。少量。那么这个观点正确吗?当然是不正确的,只是举个例子来证明:
站点:,搜索结果如下:
seo视频教程:如何查看百度网站的seo收录情况
可以看出,在查询结果中,百度图片排名第一,百度知道第二,而百度首页排名第三,百度百科排名第四。因此,这种观点是弄巧成拙的。
2、Web 快照不更新甚至倒退
小松之前在《什么是百度快照?为什么我的网站百度快照没有更新?》这篇文章已经详细说明了百度快照更新的问题。不知道的同学快照更新或倒退的原因可以查看。
3、为什么网站收录有时会减少
很多站长朋友都会遇到这个问题。有时候百度收录的量不会增加,反而会减少。这是什么原因造成的?一个原因是您的 网站 中有几个不同的链接指向一个页面。之前百度收录这些链接地址,但是百度识别出来后,会删除一些地址。只剩下一个了。还有一种情况是网站的内页相似度太高。您可能已经看到,网站 的某些产品页面可能会达到 90% 的相似度。那么,这样的页面百度就会减少内页的数量。收录 的数量。
三、站外锚文本如何制作?
站外锚文本也是老式的外链。在做外链的时候,应该注意以下几个方面:
1、 锚文本应该不断增加,而不是一次增加很多。很多站长都渴望快速排名,给网站做了很多外链,然后忽略了外链。部分内容出来了,这个做法不对。一是效果不好,二是百度可能认为你在作弊,会对网站造成不良影响。
2、 锚文本应该是多样化的,而不是只有一个关键词。
3、网站发出的链接应该是多样化的,而不是一两个网站。
站外锚文本的制作方式有很多种,比如友情链接、自建博客、论坛签名、博客留言、留言板等。
四、如何准确查询外链。
教程中推荐使用雅虎查询:(中文站)(中文站)
五、如何查询网站权重。
有很多权重查询工具。小松更喜欢使用站长工具和爱站的网站综合查询。这个因人而异,一般来说,不同类型的网站能得到的pr值也不同。pr值与网站、外链、内链的时间有关。视频里有详细的解释,这里不再赘述。下面给出教程的下载地址。 查看全部
谷歌抓取网页视频教程(seo站外优化方法网站seo优化,搜外seo视频教程)
第五课:seo异地优化方法网站seo优化,包括异地seo优化和站内seo优化,搜外seo视频教程第五课主要讲解seo异地优化方法,包括相应的网站提交给各大搜索引擎的搜索引擎时,如何查看网站的seo收录的状态,如何[…]
第五课:站外seo优化方法
网站seo优化,包括站外seo优化和站内seo优化,搜外seo视频教程第五课主要讲解seo站外优化方法,包括适当的时候主动提交网址给各大搜索者搜索引擎,如何查询网站的seo收录情况,如何做异地锚文本,如何准确查询外链,如何查询网站的权重,seo同学们可以按照步骤在线观看。其实这个搜外全套seo视频教程还有“seo异地优化方法”不完整。注:本seo视频教程录制时间较长,并非最新的seo视频教程。
一、 适时主动提交网址给各大搜索引擎的搜索引擎。
那么网站应该什么时候提交给搜索引擎呢?在提交到搜索引擎之前,需要添加网站的基本内容,比如确定网站的标题和描述,以及网站的构建,但应该是需要注意的是不要等到网站全部添加完内容后再提交。建议每栏加一两个文章,然后提交到搜索引擎即可。
二、如何查看网站的seo收录情况。
将网址提交到搜索引擎后,百度收录首页的时间一般在两到三天内。在收录首页之后,百度会有一个新站点的评估期,称为沙盒。经期,这个时期一般是两到三周。在此期间,百度不会将您的内部页面编入索引,而是会对您的网站内容进行评估。因此,在沙盒阶段网站 内容更新必须到位。一些高质量的文章可以提升网站内页收录的速度。这段时间做一些外链来吸引蜘蛛爬行,也可以缩短内页。收录 时期。网站查询收录的情况有多种方式。下面是小松常用的三种方法:
1、站点:+网站域名。在百度搜索栏中输入本站命令,您将看到百度收录网站的页面。
2、百度站长平台百度索引量查询地址:这里可以在网站页面看到百度收录的状态,也可以看到收录的变化从折线图条件。
3、站长工具查询:该工具可以查询百度、谷歌、36个0、搜狗的收录以及反链数。网站管理员应该使用它。
在查询收录的时候,有时会发现一些问题。具体情况和大家一起分析一下。
1、网站搜索结果首页不在首位
关于这个问题,很多人认为首页不是放在第一位的,所以网站肯定是被降级了。很多站长在交流感情链接的时候,也有的要求网站查询结果首页放在第一位。少量。那么这个观点正确吗?当然是不正确的,只是举个例子来证明:
站点:,搜索结果如下:
seo视频教程:如何查看百度网站的seo收录情况
可以看出,在查询结果中,百度图片排名第一,百度知道第二,而百度首页排名第三,百度百科排名第四。因此,这种观点是弄巧成拙的。
2、Web 快照不更新甚至倒退
小松之前在《什么是百度快照?为什么我的网站百度快照没有更新?》这篇文章已经详细说明了百度快照更新的问题。不知道的同学快照更新或倒退的原因可以查看。
3、为什么网站收录有时会减少
很多站长朋友都会遇到这个问题。有时候百度收录的量不会增加,反而会减少。这是什么原因造成的?一个原因是您的 网站 中有几个不同的链接指向一个页面。之前百度收录这些链接地址,但是百度识别出来后,会删除一些地址。只剩下一个了。还有一种情况是网站的内页相似度太高。您可能已经看到,网站 的某些产品页面可能会达到 90% 的相似度。那么,这样的页面百度就会减少内页的数量。收录 的数量。
三、站外锚文本如何制作?
站外锚文本也是老式的外链。在做外链的时候,应该注意以下几个方面:
1、 锚文本应该不断增加,而不是一次增加很多。很多站长都渴望快速排名,给网站做了很多外链,然后忽略了外链。部分内容出来了,这个做法不对。一是效果不好,二是百度可能认为你在作弊,会对网站造成不良影响。
2、 锚文本应该是多样化的,而不是只有一个关键词。
3、网站发出的链接应该是多样化的,而不是一两个网站。
站外锚文本的制作方式有很多种,比如友情链接、自建博客、论坛签名、博客留言、留言板等。
四、如何准确查询外链。
教程中推荐使用雅虎查询:(中文站)(中文站)
五、如何查询网站权重。
有很多权重查询工具。小松更喜欢使用站长工具和爱站的网站综合查询。这个因人而异,一般来说,不同类型的网站能得到的pr值也不同。pr值与网站、外链、内链的时间有关。视频里有详细的解释,这里不再赘述。下面给出教程的下载地址。
谷歌抓取网页视频教程(谷歌抓取网页视频教程,非本人原创,仅是整理分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-23 12:03
谷歌抓取网页视频教程,非本人原创,仅是整理分享,如有侵权请联系删除,没有wordpress空间的可以用nexthost模板做站,nexthost也是经过大量人手整理的,性价比高,功能强大,业余制作者非常友好的网站场景开发平台。
谷歌抓取规则一般还是要懂点代码知识。第三方制作平台或者wordpress上专门有pr抓取这个功能,但不全面。推荐你个简单的方法:打开自己域名后缀的网页或视频页面,抓取到后让它replace。而且越是小众网站replace得越精准,抓得越快,必须抓完视频必须replace。ftp很强大,让replace变得很容易,一键就抓取了,在线也好在本地也好,手动抓也好都方便,本身就是搞机器学习模型自动抓。
另外我个人开发了一个跟youtube类似的抓取的c++版本的模版,xxtorrent-youtubetruedownload。支持ftp也支持bt,欢迎做抓取应用的加入。
谷歌采集需要精准的地址,才能采到想要的内容,如果技术好可以自己写爬虫。抓取软件有很多,如果你懂asp+as也可以用so框架写一个,抓取的量再大一点,可以用excel去处理。然后很多数据接口都可以抓。这是比较容易的一个了,技术难度不大,开发者可以用本身的模块,如python3+谷歌地址抓取插件等。我知道的3-5-m可以的都有。
还有一个好处是可以二次开发,可以自己编写一个。数据或者视频都是可以抓取的,前提你懂的采集代码。自己写好爬虫,然后按照需求二次开发,国内外一般都能找到开发者的。如果外部软件实在是做的好了,可以考虑收购他们,毕竟除了编写爬虫很难找到合适的。而且还有自己的第三方软件专门做这个。当然,你还可以和国内的一些资源提供商合作,让他们抓取你的视频,然后自己再把视频放出来。所以,当你想实现一些功能的时候,你可以自己搭一套适合的平台,然后二次开发。否则直接写爬虫还是不方便。 查看全部
谷歌抓取网页视频教程(谷歌抓取网页视频教程,非本人原创,仅是整理分享)
谷歌抓取网页视频教程,非本人原创,仅是整理分享,如有侵权请联系删除,没有wordpress空间的可以用nexthost模板做站,nexthost也是经过大量人手整理的,性价比高,功能强大,业余制作者非常友好的网站场景开发平台。
谷歌抓取规则一般还是要懂点代码知识。第三方制作平台或者wordpress上专门有pr抓取这个功能,但不全面。推荐你个简单的方法:打开自己域名后缀的网页或视频页面,抓取到后让它replace。而且越是小众网站replace得越精准,抓得越快,必须抓完视频必须replace。ftp很强大,让replace变得很容易,一键就抓取了,在线也好在本地也好,手动抓也好都方便,本身就是搞机器学习模型自动抓。
另外我个人开发了一个跟youtube类似的抓取的c++版本的模版,xxtorrent-youtubetruedownload。支持ftp也支持bt,欢迎做抓取应用的加入。
谷歌采集需要精准的地址,才能采到想要的内容,如果技术好可以自己写爬虫。抓取软件有很多,如果你懂asp+as也可以用so框架写一个,抓取的量再大一点,可以用excel去处理。然后很多数据接口都可以抓。这是比较容易的一个了,技术难度不大,开发者可以用本身的模块,如python3+谷歌地址抓取插件等。我知道的3-5-m可以的都有。
还有一个好处是可以二次开发,可以自己编写一个。数据或者视频都是可以抓取的,前提你懂的采集代码。自己写好爬虫,然后按照需求二次开发,国内外一般都能找到开发者的。如果外部软件实在是做的好了,可以考虑收购他们,毕竟除了编写爬虫很难找到合适的。而且还有自己的第三方软件专门做这个。当然,你还可以和国内的一些资源提供商合作,让他们抓取你的视频,然后自己再把视频放出来。所以,当你想实现一些功能的时候,你可以自己搭一套适合的平台,然后二次开发。否则直接写爬虫还是不方便。
谷歌抓取网页视频教程(如何使用谷歌ChromeHeadless创建PDF的网页页面的屏幕截图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-09-21 01:09
要求:
您必须使用Google Chrome 59或更高版本。
和谷歌版本的Chrome 59仅适用于Mac OS和Linux用户。
Windows用户还需要等一段时间。
捕获屏幕截图:
使用以下命令捕获给定网页的屏幕截图。
输出文件将在当前目录中创建,名为screenshot.png。
google-chrome --headless --disable-gpu --screenshot http://www.example.com/
您还可以使用“--window-size”选项指定屏幕截图的大小,如下所示。
google-chrome --headless --disable-gpu --window-size=1280,768 --screenshot http://www.example.com/
我们还可以指定'--screenshot = file1输出文件名的位置。
创建特定名称。
如何使用Google Chrome捕获网页屏幕截图
Google Chrome 59和新版本包括一个新功能,它提供了在不需要用户界面的情况下运行Google Chrome的功能。
这允许用户在命令行和脚本中使用Google Chrome。
这个无头Google Chrome版本还收录使用命令行工具捕获任何网站屏幕截图的功能。
如何创建PDF的网页
在Google Chrome中无头 查看全部
谷歌抓取网页视频教程(如何使用谷歌ChromeHeadless创建PDF的网页页面的屏幕截图)
要求:
您必须使用Google Chrome 59或更高版本。
和谷歌版本的Chrome 59仅适用于Mac OS和Linux用户。
Windows用户还需要等一段时间。
捕获屏幕截图:
使用以下命令捕获给定网页的屏幕截图。
输出文件将在当前目录中创建,名为screenshot.png。
google-chrome --headless --disable-gpu --screenshot http://www.example.com/
您还可以使用“--window-size”选项指定屏幕截图的大小,如下所示。
google-chrome --headless --disable-gpu --window-size=1280,768 --screenshot http://www.example.com/
我们还可以指定'--screenshot = file1输出文件名的位置。
创建特定名称。
如何使用Google Chrome捕获网页屏幕截图
Google Chrome 59和新版本包括一个新功能,它提供了在不需要用户界面的情况下运行Google Chrome的功能。
这允许用户在命令行和脚本中使用Google Chrome。
这个无头Google Chrome版本还收录使用命令行工具捕获任何网站屏幕截图的功能。
如何创建PDF的网页
在Google Chrome中无头
谷歌抓取网页视频教程(使用类似HttpAnalyzer这样的协议分析工具就不同了(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-17 13:16
HTTP analyzer是一种专业且易于使用的网络数据包捕获工具,网站被开发人员和测试人员广泛使用。它可以实时捕获http/HTTPS协议数据,并详细显示数据流的相关信息。以下小系列将向您介绍HTTP analyzer的功能、特性和用法
HTTP analyzer可以轻松实时捕获HTTP/HTTPS协议数据,详细显示文件头、内容、cookie、查询字符通道、提交数据、重定向URL地址等信息,并提供缓冲区信息、清理对话框内容、HTTP状态信息等过滤选项。同时,它也是一个非常有用的分析、调试和诊断开发工具
HTTP analyzer cracked analyzer是一种HTTP/HTTPS协议分析工具,可以快速分析大多数视频博客的地址。尽管有些网站为视频网站提供了PHP解码程序,如youtube和googlevideo,但这些PHP程序并不通用。当blog video网站更改视频地址加密算法时,PHP程序需要进行大规模更改才能相应解码
使用HTTP analyzer等协议分析工具是不同的。所有博客视频都由HTTP提供。最终的HTTP路径必须以明文形式出现,因此可以获取此路径 查看全部
谷歌抓取网页视频教程(使用类似HttpAnalyzer这样的协议分析工具就不同了(图))
HTTP analyzer是一种专业且易于使用的网络数据包捕获工具,网站被开发人员和测试人员广泛使用。它可以实时捕获http/HTTPS协议数据,并详细显示数据流的相关信息。以下小系列将向您介绍HTTP analyzer的功能、特性和用法
HTTP analyzer可以轻松实时捕获HTTP/HTTPS协议数据,详细显示文件头、内容、cookie、查询字符通道、提交数据、重定向URL地址等信息,并提供缓冲区信息、清理对话框内容、HTTP状态信息等过滤选项。同时,它也是一个非常有用的分析、调试和诊断开发工具

HTTP analyzer cracked analyzer是一种HTTP/HTTPS协议分析工具,可以快速分析大多数视频博客的地址。尽管有些网站为视频网站提供了PHP解码程序,如youtube和googlevideo,但这些PHP程序并不通用。当blog video网站更改视频地址加密算法时,PHP程序需要进行大规模更改才能相应解码
使用HTTP analyzer等协议分析工具是不同的。所有博客视频都由HTTP提供。最终的HTTP路径必须以明文形式出现,因此可以获取此路径
谷歌抓取网页视频教程(前一个专题介绍:Web浏览器的介绍及工作原理分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-14 10:18
前言:
上一主题介绍了自定义的Web服务器,但是对Web服务器的请求是本主题介绍的Web浏览器。本专题通过简单的自定义一个网页浏览器简单介绍浏览器的工作原理和帮助 一些初学者揭开了浏览器的神秘面纱(以前这些应用总觉得很深奥,没想到可以自定义一个浏览器我)。下面不再罗嗦,进入正题。
一、网页浏览器介绍
Web浏览器是指一种可以显示Web服务器或本地文件系统中的Html文件内容,并允许用户与这些文件进行交互的软件。对服务器返回的超文本信息和各种媒体、图片进行解释和显示。
浏览器主要通过Http协议与服务器交互,获取网页。目前主流浏览器包括:IE、Google Chrome(谷歌浏览器)、Mozilla Firefox(火狐)、Opera浏览器、世界之窗、360安全浏览器等。
网络浏览器的组成
一般而言,Web 浏览器由控制器和解释器组成。控制器负责解释鼠标点击和键盘输入,并调用其他组件来执行用户指定的操作。例如,当用户输入 URL 或点击超链接时,控制器接收并分析命令,调用 HTML 解释器来解释页面,并将解释的结果显示在用户的浏览器上。
解释器对浏览器非常重要。解释器,即解释引擎,负责解释网页的语法(如HTML、Javascript)并显示网页。解释器决定浏览器如何显示页面。它是浏览器最重要的部分。内核最重要的部分,所以一般我们所指的浏览器内核指的是浏览器的解释器。
不同的浏览器产品可能使用相同的内核。有四种常见的浏览器内核:Trident、Gecko、Presto 和 Webkit。它们与主流浏览器的关系如下:
核心
浏览器产品
三叉戟
IE、傲游(Maxthon)、世界之窗、腾讯TT、搜狗浏览器、360安全浏览器
壁虎
Mozilla 火狐 (Firefox)
普雷斯托
Opera浏览器
网络套件
Apple Safari 浏览器、Google Chrome(谷歌浏览器)和Apple Iphone 手机浏览引擎
二、.NET 平台支持浏览器开发
浏览器软件一般不是从头开发的,而是基于某种内核扩展。同样,微软.NET平台封装了IE浏览器内核,以COM组件的形式提供给用户。这个COM组件就是WebBrowser控件,它实现了浏览器中几乎所有的基本功能。
WebBrowser是以IE(Trident)为核心和基本功能的Web浏览器。使用 WebBrowser 控件在 Windows 窗体应用程序中浏览网页。WebBrowser 控件位于工具箱中。使用时,只需将其直接拖至程序窗口即可。
下面介绍WebBrowser控件的常用属性和方法
这里我直接从MSDN中的一张表中提取来说明:
名称说明
文档属性
获取一个对象,该对象提供对当前网页的 HTML 文档对象模型 (DOM) 的托管访问。
DocumentCompleted 事件
当页面完成加载时发生。
文档文本属性
获取或设置当前网页的 HTML 内容。
文档标题属性
获取当前网页的标题。
返回方法 查看全部
谷歌抓取网页视频教程(前一个专题介绍:Web浏览器的介绍及工作原理分析)
前言:
上一主题介绍了自定义的Web服务器,但是对Web服务器的请求是本主题介绍的Web浏览器。本专题通过简单的自定义一个网页浏览器简单介绍浏览器的工作原理和帮助 一些初学者揭开了浏览器的神秘面纱(以前这些应用总觉得很深奥,没想到可以自定义一个浏览器我)。下面不再罗嗦,进入正题。
一、网页浏览器介绍
Web浏览器是指一种可以显示Web服务器或本地文件系统中的Html文件内容,并允许用户与这些文件进行交互的软件。对服务器返回的超文本信息和各种媒体、图片进行解释和显示。
浏览器主要通过Http协议与服务器交互,获取网页。目前主流浏览器包括:IE、Google Chrome(谷歌浏览器)、Mozilla Firefox(火狐)、Opera浏览器、世界之窗、360安全浏览器等。
网络浏览器的组成
一般而言,Web 浏览器由控制器和解释器组成。控制器负责解释鼠标点击和键盘输入,并调用其他组件来执行用户指定的操作。例如,当用户输入 URL 或点击超链接时,控制器接收并分析命令,调用 HTML 解释器来解释页面,并将解释的结果显示在用户的浏览器上。
解释器对浏览器非常重要。解释器,即解释引擎,负责解释网页的语法(如HTML、Javascript)并显示网页。解释器决定浏览器如何显示页面。它是浏览器最重要的部分。内核最重要的部分,所以一般我们所指的浏览器内核指的是浏览器的解释器。
不同的浏览器产品可能使用相同的内核。有四种常见的浏览器内核:Trident、Gecko、Presto 和 Webkit。它们与主流浏览器的关系如下:
核心
浏览器产品
三叉戟
IE、傲游(Maxthon)、世界之窗、腾讯TT、搜狗浏览器、360安全浏览器
壁虎
Mozilla 火狐 (Firefox)
普雷斯托
Opera浏览器
网络套件
Apple Safari 浏览器、Google Chrome(谷歌浏览器)和Apple Iphone 手机浏览引擎
二、.NET 平台支持浏览器开发
浏览器软件一般不是从头开发的,而是基于某种内核扩展。同样,微软.NET平台封装了IE浏览器内核,以COM组件的形式提供给用户。这个COM组件就是WebBrowser控件,它实现了浏览器中几乎所有的基本功能。
WebBrowser是以IE(Trident)为核心和基本功能的Web浏览器。使用 WebBrowser 控件在 Windows 窗体应用程序中浏览网页。WebBrowser 控件位于工具箱中。使用时,只需将其直接拖至程序窗口即可。
下面介绍WebBrowser控件的常用属性和方法
这里我直接从MSDN中的一张表中提取来说明:
名称说明
文档属性
获取一个对象,该对象提供对当前网页的 HTML 文档对象模型 (DOM) 的托管访问。
DocumentCompleted 事件
当页面完成加载时发生。
文档文本属性
获取或设置当前网页的 HTML 内容。
文档标题属性
获取当前网页的标题。
返回方法
谷歌抓取网页视频教程(杭州APP开发蒙特关注:谷歌客户端App抓取300多亿个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-10-11 11:07
杭州APP开发蒙特关注:4月16日,谷歌搜索团队在官方博文中公布了这一消息。
谷歌工程师拉詹·帕特尔向媒体透露,从两年前开始,谷歌开始抓取外部应用的内部链接和内容,目前已经抓取了超过 300 亿。
在传统的WEB页面中,谷歌可以通过软件“蜘蛛”自动访问和抓取,无需网站管理员的许可。
在App内容的抓取上,谷歌需要与应用软件开发商建立合作。谷歌提供了相应的软件开发接口(API),开发者可以通过这些接口向谷歌搜索开放数据,从而实现搜索引擎的内容抓取。
据悉,目前已有大量移动端软件与谷歌合作,包括微博Twitter、短租工具Airbnb、消费者点评工具Yelp、手机订餐工具OpenTable、图片采集社交网络Pinterest、房地产搜索工具Trulia以及很快。
当然,还有大量的移动媒体应用,也被谷歌抓取用于新闻报道。
超过 300 亿个链接的内容与 Google 抓取的网络数据库相比微不足道。此前有报道称,谷歌蜘蛛抓取的网页数量高达数百亿。
然而,在智能手机时代,人们使用搜索的目的更加明确,拥有更多的场景信息。因此,主流应用和超过300亿个链接足以为用户提供所需的信息。
据介绍,此前在手机上进行搜索时,谷歌客户端会观察用户智能手机中安装了哪些应用,谷歌只会返回已安装应用的搜索结果。
日前,谷歌团队还宣布,对收录在搜索结果中的APP进行了修改。即使用户没有安装某个APP,只要有相关性,它的内容就会出现在搜索结果中。
例如,如果用户的手机中没有安装点餐工具OpenTable,但在搜索餐厅时,谷歌仍可能会从OpenTable中呈现消费者评论信息。
不过,对于谷歌来说,能够抓取大量APP的内容,并不意味着它已经彻底摆脱了“搜索危机”。
有观点认为,在智能手机端,手机一族希望以最快的速度获得最准确的搜索结果,因此各种专业APP逐渐取代了传统网页搜索的地位。例如,人们可能会在流行的团购应用中搜索当地餐馆和电影,而不是在 Google 中输入 关键词,然后查看庞大网络的结果。
蒙特手机APP开发总结:手机搜索消费者行为的变化也给谷歌的发展前景蒙上了一层阴影。Google 90% 的收入来自搜索结果右侧的搜索广告。如果人们远离电脑和传统搜索引擎,谷歌将成为一个非常危险的公司,没有可观的替代收入。在这里,Monte想说,凭借多年的APP开发经验,给你的APP强行不是问题。 查看全部
谷歌抓取网页视频教程(杭州APP开发蒙特关注:谷歌客户端App抓取300多亿个)
杭州APP开发蒙特关注:4月16日,谷歌搜索团队在官方博文中公布了这一消息。
谷歌工程师拉詹·帕特尔向媒体透露,从两年前开始,谷歌开始抓取外部应用的内部链接和内容,目前已经抓取了超过 300 亿。
在传统的WEB页面中,谷歌可以通过软件“蜘蛛”自动访问和抓取,无需网站管理员的许可。
在App内容的抓取上,谷歌需要与应用软件开发商建立合作。谷歌提供了相应的软件开发接口(API),开发者可以通过这些接口向谷歌搜索开放数据,从而实现搜索引擎的内容抓取。
据悉,目前已有大量移动端软件与谷歌合作,包括微博Twitter、短租工具Airbnb、消费者点评工具Yelp、手机订餐工具OpenTable、图片采集社交网络Pinterest、房地产搜索工具Trulia以及很快。
当然,还有大量的移动媒体应用,也被谷歌抓取用于新闻报道。
超过 300 亿个链接的内容与 Google 抓取的网络数据库相比微不足道。此前有报道称,谷歌蜘蛛抓取的网页数量高达数百亿。
然而,在智能手机时代,人们使用搜索的目的更加明确,拥有更多的场景信息。因此,主流应用和超过300亿个链接足以为用户提供所需的信息。
据介绍,此前在手机上进行搜索时,谷歌客户端会观察用户智能手机中安装了哪些应用,谷歌只会返回已安装应用的搜索结果。
日前,谷歌团队还宣布,对收录在搜索结果中的APP进行了修改。即使用户没有安装某个APP,只要有相关性,它的内容就会出现在搜索结果中。
例如,如果用户的手机中没有安装点餐工具OpenTable,但在搜索餐厅时,谷歌仍可能会从OpenTable中呈现消费者评论信息。
不过,对于谷歌来说,能够抓取大量APP的内容,并不意味着它已经彻底摆脱了“搜索危机”。
有观点认为,在智能手机端,手机一族希望以最快的速度获得最准确的搜索结果,因此各种专业APP逐渐取代了传统网页搜索的地位。例如,人们可能会在流行的团购应用中搜索当地餐馆和电影,而不是在 Google 中输入 关键词,然后查看庞大网络的结果。
蒙特手机APP开发总结:手机搜索消费者行为的变化也给谷歌的发展前景蒙上了一层阴影。Google 90% 的收入来自搜索结果右侧的搜索广告。如果人们远离电脑和传统搜索引擎,谷歌将成为一个非常危险的公司,没有可观的替代收入。在这里,Monte想说,凭借多年的APP开发经验,给你的APP强行不是问题。
谷歌抓取网页视频教程(网页解析我用的是BeautifulSoup的概论(二)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 252 次浏览 • 2021-10-10 09:35
准备寒假,爬一些MOOC课程,爬回家看。
爬取的课程是北京大学离散数学导论
其实GitHub有可以直接使用的程序,只是不知道怎么提交HTTP请求,所以直接用selenium简单粗暴。
我使用 BeautifulSoup 进行网页分析。
这个想法其实很简单。只需直接在课件网页上将每章每节课每单元的所有视频都删除即可。所以直接嵌套循环就可以了。
遇到的一些困难:
课件部分的两个框是隐藏框,点击模拟浏览器
操作前需要使用JavaScript修改元素显示值
id 属性
元素每次点击都不一样,所以定位元素时,不使用id属性定位,使用title属性或其他属性。另一个是我不能使用无头模式来抓取网页。这应该是我这边的环境问题。不知道大家有没有遇到过这种情况。
代码:
# -*- coding:utf-8 -*-
import time
from selenium import webdriver
from bs4 import BeautifulSoup
import re
import json
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--disable-gpu")
browser = webdriver.Chrome(executable_path='G:\\chromedriver.exe', options=chrome_options)
browser.get('https://www.icourse163.org/lea ... %2339;) # 目标网页
time.sleep(3)
video = {}
soup = BeautifulSoup(browser.page_source, 'html.parser')
c_l = soup.find("div", attrs={"class": "j-breadcb f-fl"})
chapter_all = c_l.find("div", attrs={"class": "f-fl j-chapter"})
chapter = chapter_all.find_all("div", attrs={"class": "f-thide list"})
for chap in chapter:
js = 'document.querySelectorAll("div.down")[0].style.display="block";'
browser.execute_script(js)
chapter_name = chap.text
a = browser.find_element_by_xpath("//div[@title = '"+chapter_name+"']")
a.click()
time.sleep(3)
soup1 = BeautifulSoup(browser.page_source, 'html.parser')
c_l1 = soup1.find("div", attrs={"class": "j-breadcb f-fl"})
lesson_all = c_l1.find("div", attrs={"class": "f-fl j-lesson"})
lesson = lesson_all.find_all("div", attrs={"class": "f-thide list"})
for les in lesson:
js1 = 'document.querySelectorAll("div.down")[1].style.display="block";'
browser.execute_script(js1)
lesson_name = les.text
b = browser.find_element_by_xpath("//div[@title = '"+lesson_name+"']")
b.click()
time.sleep(3)
soup2 = BeautifulSoup(browser.page_source, 'html.parser')
units = soup2.find_all("li", attrs={"title": re.compile(r"^视频")}) # 只爬取视频课件
for unit in units:
video_name = unit.get("title")
video_link = browser.find_element_by_xpath("//li[@title = '"+video_name+"']")
video_link.click()
time.sleep(3)
soup2 = BeautifulSoup(browser.page_source, 'html.parser')
try:
video_src = soup2.find("source")
video[chapter_name + " " + lesson_name + video_name] = video_src.get("src")
except:
continue
browser.quit()
爬取的效果是这样的
文笔不好。我开始的时间不长。有兴趣的可以慢慢看原网页的源码。
Selenium 简单粗暴,但爬取速度很慢,不如其他爬取方式。
以后还是要学着提交POST请求。要是有爬虫带我入门就好了!
我刚学爬行的时间不长,计算机知识也不是很多。第一次写东西,多多批评指正! 查看全部
谷歌抓取网页视频教程(网页解析我用的是BeautifulSoup的概论(二)_)
准备寒假,爬一些MOOC课程,爬回家看。
爬取的课程是北京大学离散数学导论
其实GitHub有可以直接使用的程序,只是不知道怎么提交HTTP请求,所以直接用selenium简单粗暴。
我使用 BeautifulSoup 进行网页分析。
这个想法其实很简单。只需直接在课件网页上将每章每节课每单元的所有视频都删除即可。所以直接嵌套循环就可以了。
遇到的一些困难:
课件部分的两个框是隐藏框,点击模拟浏览器
操作前需要使用JavaScript修改元素显示值
id 属性
元素每次点击都不一样,所以定位元素时,不使用id属性定位,使用title属性或其他属性。另一个是我不能使用无头模式来抓取网页。这应该是我这边的环境问题。不知道大家有没有遇到过这种情况。
代码:
# -*- coding:utf-8 -*-
import time
from selenium import webdriver
from bs4 import BeautifulSoup
import re
import json
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--disable-gpu")
browser = webdriver.Chrome(executable_path='G:\\chromedriver.exe', options=chrome_options)
browser.get('https://www.icourse163.org/lea ... %2339;) # 目标网页
time.sleep(3)
video = {}
soup = BeautifulSoup(browser.page_source, 'html.parser')
c_l = soup.find("div", attrs={"class": "j-breadcb f-fl"})
chapter_all = c_l.find("div", attrs={"class": "f-fl j-chapter"})
chapter = chapter_all.find_all("div", attrs={"class": "f-thide list"})
for chap in chapter:
js = 'document.querySelectorAll("div.down")[0].style.display="block";'
browser.execute_script(js)
chapter_name = chap.text
a = browser.find_element_by_xpath("//div[@title = '"+chapter_name+"']")
a.click()
time.sleep(3)
soup1 = BeautifulSoup(browser.page_source, 'html.parser')
c_l1 = soup1.find("div", attrs={"class": "j-breadcb f-fl"})
lesson_all = c_l1.find("div", attrs={"class": "f-fl j-lesson"})
lesson = lesson_all.find_all("div", attrs={"class": "f-thide list"})
for les in lesson:
js1 = 'document.querySelectorAll("div.down")[1].style.display="block";'
browser.execute_script(js1)
lesson_name = les.text
b = browser.find_element_by_xpath("//div[@title = '"+lesson_name+"']")
b.click()
time.sleep(3)
soup2 = BeautifulSoup(browser.page_source, 'html.parser')
units = soup2.find_all("li", attrs={"title": re.compile(r"^视频")}) # 只爬取视频课件
for unit in units:
video_name = unit.get("title")
video_link = browser.find_element_by_xpath("//li[@title = '"+video_name+"']")
video_link.click()
time.sleep(3)
soup2 = BeautifulSoup(browser.page_source, 'html.parser')
try:
video_src = soup2.find("source")
video[chapter_name + " " + lesson_name + video_name] = video_src.get("src")
except:
continue
browser.quit()
爬取的效果是这样的
文笔不好。我开始的时间不长。有兴趣的可以慢慢看原网页的源码。
Selenium 简单粗暴,但爬取速度很慢,不如其他爬取方式。
以后还是要学着提交POST请求。要是有爬虫带我入门就好了!
我刚学爬行的时间不长,计算机知识也不是很多。第一次写东西,多多批评指正!
谷歌抓取网页视频教程(Google发布重大更新:抓取错误功能检测和报告多种新的错误类型)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-10 08:00
抓取错误是 Google 网站网站管理员工具中最受欢迎的工具之一。昨天,谷歌发布了抓取错误工具的重大更新,使其更加方便和有用。
现在,错误获取功能可以检测和报告各种新的错误类型。为了让数据更直观,网站站长工具将错误分为两类:网站错误(站点错误)和链接地址错误(URL错误)。
内容
站点错误
网站 错误是指影响整个网站的错误,而不是具体的URL链接。包括DNS解析失败、服务器连接问题、获取robots.txt文件问题等。之前谷歌站长工具只报相关链接地址错误。但是这样做没有多大意义,因为它们不是由特定链接引起的。事实上,这个错误甚至会阻止 Googlebot 请求 URL 链接地址。于是谷歌站长工具开始追踪此类错误的频率,并在适当的时候向网站管理员发送提醒。
查看网站误差频率和频率变化曲线
而且,如果你的网站没有犯过任何错误,或者最近一段时间没有这方面的问题——实际上大部分网站都是这种情况——他们只会show simple 一切正常提示不会显示大量信息影响管理员获取其他信息。总之,如果你看到的提示图标都是绿色的,就说明一切正常。
如果最近一段时间网站没有问题,会显示这样的友好提示信息
网址链接错误
URL 链接错误是指向特定页面的那些错误。当谷歌机器人尝试抓取链接时,它能够解析DNS,连接到服务器,抓取robots.txt文件,但在请求URL链接地址时遇到错误。根据错误原因,URL链接地址错误有几种类型。如果 网站 提供 Google 新闻内容或移动数据内容(CHTML/XHTML),这些错误将根据不同的类别显示。
链接错误提示
简洁的错误信息
以前,Google 网站Webmaster Tools 为每个类别显示多达 100,000 个错误。检查这么多错误信息是非常困难的。您甚至无法知道哪些错误是重要的(例如主页无法打开),哪些错误是次要的(例如链接到您的网页时的其他网站 拼写错误)。基本上不可能对 100,000 条错误记录进行排序、搜索或标记您的处理进度。
在新版本的抓取错误中,谷歌开发者尽量只提供最重要的错误信息。对于每个错误分类,一般只提供 1000 条被认为是最重要的错误信息。网站管理员还可以对这些错误进行排序过滤,查看错误详情并进行处理,然后将已经处理过的错误进行标记并通知谷歌(这样就不会再次显示,除非错误再次出现) .
在任何列上实时排序或过滤错误消息
对于某种错误类型,某些网站可能有1000多个错误,超过这个数目的错误仍然可以反映在错误总数中。还有一些图标可以显示过去 90 天的历史错误数据。有人可能会担心 1000 个错误的详细信息加上粗略的错误总数可能不够。谷歌正在考虑提供一个 API 接口来解决这个问题。
现在,网站站长工具会移除robots.txt屏蔽的链接列表,因为虽然有时这些链接有助于诊断robots.txt错误,但这些链接是管理员专门屏蔽的(自屏蔽当然可以)应该很清楚)。为了关注真正的错误,被robot.txt屏蔽的链接将很快移至“网站站点配置”部分的“爬虫访问”页面。
查看错误详情
单击主列表中的单个错误链接可激活一个面板,该面板显示详细的错误信息,包括上次提取时间、发现错误的最早时间以及简单说明。
可以在主列表中看到的错误详细信息
在详细信息面板中,您也可以直接点击相关链接查看访问过程中会出现哪些错误。如果没有问题,可以将此错误标记为“已修复”(以后会提供更多选项),也可以查看此类错误的帮助信息,包括网站图的链接文件列表、链接去链接地址的其他页面列表等,也可以用Googlebot模拟爬取链接,看看有没有其他问题或者是否已经修复。
查看链接到此页面的其他页面地址列表
采取行动
错误爬取功能中值得期待的一件事是,网站 管理员实际上可以专注于解决最重要的问题。谷歌网站管理员工具对错误进行分类,而那些高优先级项目确实是您可以解决的问题。要么你需要修复网站上的链接,要么你需要处理服务器上的软件问题,要么你需要更新网站映射文件来清理那些不需要的链接,或者添加一个301重定向将用户重定向到正确的页面等。谷歌站长工具在确定优先级时会考虑多种因素,包括你是否在网站映射中收录了URL,有多少页面链接到该地址(还要考虑这些页面是否在你自己的网站@ > 上),
一旦您认为问题已修复(您可以使用 Googlebot 模拟抓取页面),您可以将其标记为“已修复”(当然,您必须是管理员)。此操作会通知 Google Webmaster Tools,然后该错误将从错误列表(重要的 1000 项)的顶部删除,并且不再显示(除非 Googlebot 在抓取页面时再次遇到相同的错误)。
将错误标记为已修复
英文原文由 Webmaster Tools 团队的 Kurt Dresner 撰写。由于时间关系,本文不提供翻译以保证质量。请保留本段内容,以表达对原作者的尊重。
同时,谷歌还更新了网站Webmaster Tools 帮助文档的相关部分,并提供链接供参考。©
本文发表于水景专页。永久链接:。转载请保留此信息及相关链接。 查看全部
谷歌抓取网页视频教程(Google发布重大更新:抓取错误功能检测和报告多种新的错误类型)
抓取错误是 Google 网站网站管理员工具中最受欢迎的工具之一。昨天,谷歌发布了抓取错误工具的重大更新,使其更加方便和有用。
现在,错误获取功能可以检测和报告各种新的错误类型。为了让数据更直观,网站站长工具将错误分为两类:网站错误(站点错误)和链接地址错误(URL错误)。
内容
站点错误
网站 错误是指影响整个网站的错误,而不是具体的URL链接。包括DNS解析失败、服务器连接问题、获取robots.txt文件问题等。之前谷歌站长工具只报相关链接地址错误。但是这样做没有多大意义,因为它们不是由特定链接引起的。事实上,这个错误甚至会阻止 Googlebot 请求 URL 链接地址。于是谷歌站长工具开始追踪此类错误的频率,并在适当的时候向网站管理员发送提醒。
查看网站误差频率和频率变化曲线
而且,如果你的网站没有犯过任何错误,或者最近一段时间没有这方面的问题——实际上大部分网站都是这种情况——他们只会show simple 一切正常提示不会显示大量信息影响管理员获取其他信息。总之,如果你看到的提示图标都是绿色的,就说明一切正常。
如果最近一段时间网站没有问题,会显示这样的友好提示信息
网址链接错误
URL 链接错误是指向特定页面的那些错误。当谷歌机器人尝试抓取链接时,它能够解析DNS,连接到服务器,抓取robots.txt文件,但在请求URL链接地址时遇到错误。根据错误原因,URL链接地址错误有几种类型。如果 网站 提供 Google 新闻内容或移动数据内容(CHTML/XHTML),这些错误将根据不同的类别显示。
链接错误提示
简洁的错误信息
以前,Google 网站Webmaster Tools 为每个类别显示多达 100,000 个错误。检查这么多错误信息是非常困难的。您甚至无法知道哪些错误是重要的(例如主页无法打开),哪些错误是次要的(例如链接到您的网页时的其他网站 拼写错误)。基本上不可能对 100,000 条错误记录进行排序、搜索或标记您的处理进度。
在新版本的抓取错误中,谷歌开发者尽量只提供最重要的错误信息。对于每个错误分类,一般只提供 1000 条被认为是最重要的错误信息。网站管理员还可以对这些错误进行排序过滤,查看错误详情并进行处理,然后将已经处理过的错误进行标记并通知谷歌(这样就不会再次显示,除非错误再次出现) .
在任何列上实时排序或过滤错误消息
对于某种错误类型,某些网站可能有1000多个错误,超过这个数目的错误仍然可以反映在错误总数中。还有一些图标可以显示过去 90 天的历史错误数据。有人可能会担心 1000 个错误的详细信息加上粗略的错误总数可能不够。谷歌正在考虑提供一个 API 接口来解决这个问题。
现在,网站站长工具会移除robots.txt屏蔽的链接列表,因为虽然有时这些链接有助于诊断robots.txt错误,但这些链接是管理员专门屏蔽的(自屏蔽当然可以)应该很清楚)。为了关注真正的错误,被robot.txt屏蔽的链接将很快移至“网站站点配置”部分的“爬虫访问”页面。
查看错误详情
单击主列表中的单个错误链接可激活一个面板,该面板显示详细的错误信息,包括上次提取时间、发现错误的最早时间以及简单说明。
可以在主列表中看到的错误详细信息
在详细信息面板中,您也可以直接点击相关链接查看访问过程中会出现哪些错误。如果没有问题,可以将此错误标记为“已修复”(以后会提供更多选项),也可以查看此类错误的帮助信息,包括网站图的链接文件列表、链接去链接地址的其他页面列表等,也可以用Googlebot模拟爬取链接,看看有没有其他问题或者是否已经修复。
查看链接到此页面的其他页面地址列表
采取行动
错误爬取功能中值得期待的一件事是,网站 管理员实际上可以专注于解决最重要的问题。谷歌网站管理员工具对错误进行分类,而那些高优先级项目确实是您可以解决的问题。要么你需要修复网站上的链接,要么你需要处理服务器上的软件问题,要么你需要更新网站映射文件来清理那些不需要的链接,或者添加一个301重定向将用户重定向到正确的页面等。谷歌站长工具在确定优先级时会考虑多种因素,包括你是否在网站映射中收录了URL,有多少页面链接到该地址(还要考虑这些页面是否在你自己的网站@ > 上),
一旦您认为问题已修复(您可以使用 Googlebot 模拟抓取页面),您可以将其标记为“已修复”(当然,您必须是管理员)。此操作会通知 Google Webmaster Tools,然后该错误将从错误列表(重要的 1000 项)的顶部删除,并且不再显示(除非 Googlebot 在抓取页面时再次遇到相同的错误)。
将错误标记为已修复
英文原文由 Webmaster Tools 团队的 Kurt Dresner 撰写。由于时间关系,本文不提供翻译以保证质量。请保留本段内容,以表达对原作者的尊重。
同时,谷歌还更新了网站Webmaster Tools 帮助文档的相关部分,并提供链接供参考。©
本文发表于水景专页。永久链接:。转载请保留此信息及相关链接。
谷歌抓取网页视频教程(Google发布重大更新:抓取错误功能检测和报告多种新的错误类型)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-10-10 07:37
抓取错误是 Google 网站网站管理员工具中最受欢迎的工具之一。昨天,谷歌发布了抓取错误工具的重大更新,使其更加方便和有用。
现在,错误获取功能可以检测和报告各种新的错误类型。为了让数据更直观,网站站长工具将错误分为两类:网站错误(站点错误)和链接地址错误(URL错误)。
内容
站点错误
网站 错误是指影响整个网站的错误,而不是具体的URL链接。包括DNS解析失败、服务器连接问题、获取robots.txt文件问题等。之前谷歌站长工具只报相关链接地址错误。但是这样做没有多大意义,因为它们不是由特定链接引起的。事实上,这个错误甚至会阻止 Googlebot 请求 URL 链接地址。于是谷歌站长工具开始追踪此类错误的频率,并在适当的时候向网站管理员发送提醒。
查看网站误差频率和频率变化曲线
而且,如果你的网站没有犯过任何错误,或者最近一段时间没有这方面的问题——实际上大部分网站都是这种情况——他们只会show simple 一切正常提示不会显示大量信息影响管理员获取其他信息。总之,如果你看到的提示图标都是绿色的,就说明一切正常。
如果最近一段时间网站没有问题,会显示这样的友好提示信息
网址链接错误
URL 链接错误是指向特定页面的那些错误。当谷歌机器人尝试抓取链接时,它能够解析DNS,连接到服务器,抓取robots.txt文件,但在请求URL链接地址时遇到错误。根据错误原因,URL链接地址错误有几种类型。如果 网站 提供 Google 新闻内容或移动数据内容(CHTML/XHTML),这些错误将根据不同的类别显示。
链接错误提示
简洁的错误信息
以前,Google 网站Webmaster Tools 为每个类别显示多达 100,000 个错误。检查这么多错误信息是非常困难的。您甚至无法知道哪些错误是重要的(例如主页无法打开),哪些错误是次要的(例如链接到您的网页时的其他网站 拼写错误)。基本上不可能对 100,000 条错误记录进行排序、搜索或标记您的处理进度。
在新版本的抓取错误中,谷歌开发者尽量只提供最重要的错误信息。对于每个错误分类,一般只提供 1000 条被认为是最重要的错误信息。网站管理员还可以对这些错误进行排序过滤,查看错误详情并进行处理,然后将已经处理过的错误进行标记并通知谷歌(这样就不会再次显示,除非错误再次出现) .
在任何列上实时排序或过滤错误消息
对于某种错误类型,某些网站可能有1000多个错误,超过这个数目的错误仍然可以反映在错误总数中。还有一些图标可以显示过去 90 天的历史错误数据。有人可能会担心 1000 个错误的详细信息加上粗略的错误总数可能不够。谷歌正在考虑提供一个 API 接口来解决这个问题。
现在,网站站长工具会移除robots.txt屏蔽的链接列表,因为虽然有时这些链接有助于诊断robots.txt错误,但这些链接是管理员专门屏蔽的(自屏蔽当然可以)应该很清楚)。为了关注真正的错误,被robot.txt屏蔽的链接将很快移至“网站站点配置”部分的“爬虫访问”页面。
查看错误详情
单击主列表中的单个错误链接可激活一个面板,该面板显示详细的错误信息,包括上次提取时间、发现错误的最早时间以及简单说明。
可以在主列表中看到的错误详细信息
在详细信息面板中,您也可以直接点击相关链接查看访问过程中会出现哪些错误。如果没有问题,可以将此错误标记为“已修复”(以后会提供更多选项),也可以查看此类错误的帮助信息,包括网站图的链接文件列表、链接去链接地址的其他页面列表等,也可以用Googlebot模拟爬取链接,看看有没有其他问题或者是否已经修复。
查看链接到此页面的其他页面地址列表
采取行动
错误爬取功能中值得期待的一件事是,网站 管理员实际上可以专注于解决最重要的问题。谷歌网站管理员工具对错误进行分类,而那些高优先级项目确实是您可以解决的问题。要么你需要修复网站上的链接,要么你需要处理服务器上的软件问题,要么你需要更新网站映射文件来清理那些不需要的链接,或者添加一个301重定向将用户重定向到正确的页面等。谷歌站长工具在确定优先级时会考虑多种因素,包括你是否在网站映射中收录了URL,有多少页面链接到该地址(还要考虑这些页面是否在你自己的网站@ > 上),
一旦您认为问题已修复(您可以使用 Googlebot 模拟抓取页面),您可以将其标记为“已修复”(当然,您必须是管理员)。此操作会通知 Google Webmaster Tools,然后该错误将从错误列表(重要的 1000 项)的顶部删除,并且不再显示(除非 Googlebot 在抓取页面时再次遇到相同的错误)。
将错误标记为已修复
英文原文由 Webmaster Tools 团队的 Kurt Dresner 撰写。由于时间关系,本文不提供翻译以保证质量。请保留本段内容,以表达对原作者的尊重。
同时,谷歌还更新了网站Webmaster Tools 帮助文档的相关部分,并提供链接供参考。©
本文发表于水景专页。永久链接:。转载请保留此信息及相关链接。 查看全部
谷歌抓取网页视频教程(Google发布重大更新:抓取错误功能检测和报告多种新的错误类型)
抓取错误是 Google 网站网站管理员工具中最受欢迎的工具之一。昨天,谷歌发布了抓取错误工具的重大更新,使其更加方便和有用。
现在,错误获取功能可以检测和报告各种新的错误类型。为了让数据更直观,网站站长工具将错误分为两类:网站错误(站点错误)和链接地址错误(URL错误)。
内容
站点错误
网站 错误是指影响整个网站的错误,而不是具体的URL链接。包括DNS解析失败、服务器连接问题、获取robots.txt文件问题等。之前谷歌站长工具只报相关链接地址错误。但是这样做没有多大意义,因为它们不是由特定链接引起的。事实上,这个错误甚至会阻止 Googlebot 请求 URL 链接地址。于是谷歌站长工具开始追踪此类错误的频率,并在适当的时候向网站管理员发送提醒。
查看网站误差频率和频率变化曲线
而且,如果你的网站没有犯过任何错误,或者最近一段时间没有这方面的问题——实际上大部分网站都是这种情况——他们只会show simple 一切正常提示不会显示大量信息影响管理员获取其他信息。总之,如果你看到的提示图标都是绿色的,就说明一切正常。
如果最近一段时间网站没有问题,会显示这样的友好提示信息
网址链接错误
URL 链接错误是指向特定页面的那些错误。当谷歌机器人尝试抓取链接时,它能够解析DNS,连接到服务器,抓取robots.txt文件,但在请求URL链接地址时遇到错误。根据错误原因,URL链接地址错误有几种类型。如果 网站 提供 Google 新闻内容或移动数据内容(CHTML/XHTML),这些错误将根据不同的类别显示。
链接错误提示
简洁的错误信息
以前,Google 网站Webmaster Tools 为每个类别显示多达 100,000 个错误。检查这么多错误信息是非常困难的。您甚至无法知道哪些错误是重要的(例如主页无法打开),哪些错误是次要的(例如链接到您的网页时的其他网站 拼写错误)。基本上不可能对 100,000 条错误记录进行排序、搜索或标记您的处理进度。
在新版本的抓取错误中,谷歌开发者尽量只提供最重要的错误信息。对于每个错误分类,一般只提供 1000 条被认为是最重要的错误信息。网站管理员还可以对这些错误进行排序过滤,查看错误详情并进行处理,然后将已经处理过的错误进行标记并通知谷歌(这样就不会再次显示,除非错误再次出现) .
在任何列上实时排序或过滤错误消息
对于某种错误类型,某些网站可能有1000多个错误,超过这个数目的错误仍然可以反映在错误总数中。还有一些图标可以显示过去 90 天的历史错误数据。有人可能会担心 1000 个错误的详细信息加上粗略的错误总数可能不够。谷歌正在考虑提供一个 API 接口来解决这个问题。
现在,网站站长工具会移除robots.txt屏蔽的链接列表,因为虽然有时这些链接有助于诊断robots.txt错误,但这些链接是管理员专门屏蔽的(自屏蔽当然可以)应该很清楚)。为了关注真正的错误,被robot.txt屏蔽的链接将很快移至“网站站点配置”部分的“爬虫访问”页面。
查看错误详情
单击主列表中的单个错误链接可激活一个面板,该面板显示详细的错误信息,包括上次提取时间、发现错误的最早时间以及简单说明。
可以在主列表中看到的错误详细信息
在详细信息面板中,您也可以直接点击相关链接查看访问过程中会出现哪些错误。如果没有问题,可以将此错误标记为“已修复”(以后会提供更多选项),也可以查看此类错误的帮助信息,包括网站图的链接文件列表、链接去链接地址的其他页面列表等,也可以用Googlebot模拟爬取链接,看看有没有其他问题或者是否已经修复。
查看链接到此页面的其他页面地址列表
采取行动
错误爬取功能中值得期待的一件事是,网站 管理员实际上可以专注于解决最重要的问题。谷歌网站管理员工具对错误进行分类,而那些高优先级项目确实是您可以解决的问题。要么你需要修复网站上的链接,要么你需要处理服务器上的软件问题,要么你需要更新网站映射文件来清理那些不需要的链接,或者添加一个301重定向将用户重定向到正确的页面等。谷歌站长工具在确定优先级时会考虑多种因素,包括你是否在网站映射中收录了URL,有多少页面链接到该地址(还要考虑这些页面是否在你自己的网站@ > 上),
一旦您认为问题已修复(您可以使用 Googlebot 模拟抓取页面),您可以将其标记为“已修复”(当然,您必须是管理员)。此操作会通知 Google Webmaster Tools,然后该错误将从错误列表(重要的 1000 项)的顶部删除,并且不再显示(除非 Googlebot 在抓取页面时再次遇到相同的错误)。
将错误标记为已修复
英文原文由 Webmaster Tools 团队的 Kurt Dresner 撰写。由于时间关系,本文不提供翻译以保证质量。请保留本段内容,以表达对原作者的尊重。
同时,谷歌还更新了网站Webmaster Tools 帮助文档的相关部分,并提供链接供参考。©
本文发表于水景专页。永久链接:。转载请保留此信息及相关链接。
谷歌抓取网页视频教程(几个暗含抓取算法:宽度优先抓取哪些页面却需要算法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-10 07:24
搜索引擎看似简单的爬虫查询工作,但每个链接所隐含的算法却非常复杂。
搜索引擎抓取页面是由蜘蛛完成的。爬取动作很容易实现,但是要爬取哪些页面,先爬取哪些页面需要算法来决定。以下是一些爬行算法:
1、宽度优先的爬取策略:
我们都知道网站大部分都是按照树状图分布的,那么在树状图链接结构中,哪些页面会先被爬取呢?为什么要先爬取这些页面 什么?宽度优先的获取策略是按照树状结构先获取同级链接,获取到同级链接后再获取下一级链接。如下所示:
如您所见,当我声明时,我使用了链接结构而不是 网站 结构。这里的链接结构可以由指向任何页面的链接组成,不一定是网站内部链接。这是一种理想化的宽度优先爬行策略。在实际爬取过程中,不可能先想到全宽,先想到限宽,如下图所示:
上图中,我们的Spider在检索G链接时,通过算法发现G页面没有任何价值,于是就将悲剧性的G链接和从属的H链接统一给了Spider。至于为什么要统一G环节?嗯,我们来分析一下。
2、不完整的遍历链接权重计算:
每个搜索引擎都有一套pagerank(指页面权重,非google PR)计算方法,并且经常更新。互联网几乎是无限的,每天都会产生大量的新链接。搜索引擎在计算链接权重时只能进行不完全遍历。为什么谷歌公关需要三个月左右才能更新一次?为什么百度一个月更新1-2次?这是因为搜索引擎使用不完全遍历链接权重算法来计算链接权重。其实按照现在的技术,实现更快的权重更新并不难。计算速度和存储速度完全可以跟得上,但为什么不这样做呢?因为不是那么必要,或者已经实现了,但是我不想发布它。然后,
我们形成一组K个链接,R表示链接获得的pagerank,S表示链接收录的链接数,Q表示是否参与传输,β表示阻尼因子,那么权重计算公式通过链接获得的是:
由公式可知,Q决定链路权重。如果发现链接被作弊,或者被搜索引擎手动清除,或者其他原因,Q被设置为0,那么再多的外部链接也无济于事。β 是阻尼系数。主要作用是防止出现权重0,防止链接参与权重转移,防止出现作弊。阻尼系数β一般为0.85。为什么网站的数量乘以阻尼系数?因为不是页面中的所有页面都参与权重转移,搜索引擎会再次删除15%的过滤链接。
但是这种不完全的遍历权重计算需要积累一定的链接数才能重新开始计算,所以更新周期普遍较慢,不能满足用户对即时信息的需求。于是在此基础上,出现了实时权重分布抓取策略。即当蜘蛛完成对页面的爬取并进入后,立即进行权重分配,将权重重新分配给要爬取的链接库,然后根据权重进行爬取。
3、社会工程学爬取策略
社会工程策略是在蜘蛛爬行过程中加入人工智能或通过人工智能训练出来的机器智能来决定爬行的优先级。目前我知道的爬取策略有:
一种。热点优先策略:对于爆炸性热点关键词,会先抓取,不需要经过严格的去重和过滤,因为会有新的链接覆盖和用户的主动选择。
湾 权限优先策略:搜索引擎会给每个网站分配一个权限,通过网站历史、网站更新等确定网站的权限,并优先去抓取权威的网站链接。
C。用户点击策略:当大多数行业词库搜索关键词时,频繁点击网站的同一搜索结果,那么搜索引擎会更频繁地抓取这个网站。
d. 历史参考策略:对于保持频繁更新的网站,搜索引擎会为网站建立一个更新历史,并根据更新历史估计未来的更新量并确定爬取频率。
SEO工作指南:
搜索引擎的爬取原理已经讲得很深入了,下面就来说明一下这些原理在SEO工作中的指导作用:
A、定时定量更新,让蜘蛛可以及时抓取和抓取网站页面;
B. 公司网站的运作比个人网站更有权威性;
C.网站建站时间长更容易被抓;
D、页面内的链接分布要合理,过多或过少都不好;
E.网站,受用户欢迎,也受搜索引擎欢迎;
F.重要页面应该放在较浅的网站结构中;
G.网站中的行业权威信息将增加网站的权威性。
这就是本教程的内容。下一篇教程的主题是:页值和网站权重计算。
上一篇:语境如何影响未来移动互联网发展 查看全部
谷歌抓取网页视频教程(几个暗含抓取算法:宽度优先抓取哪些页面却需要算法)
搜索引擎看似简单的爬虫查询工作,但每个链接所隐含的算法却非常复杂。
搜索引擎抓取页面是由蜘蛛完成的。爬取动作很容易实现,但是要爬取哪些页面,先爬取哪些页面需要算法来决定。以下是一些爬行算法:
1、宽度优先的爬取策略:
我们都知道网站大部分都是按照树状图分布的,那么在树状图链接结构中,哪些页面会先被爬取呢?为什么要先爬取这些页面 什么?宽度优先的获取策略是按照树状结构先获取同级链接,获取到同级链接后再获取下一级链接。如下所示:
如您所见,当我声明时,我使用了链接结构而不是 网站 结构。这里的链接结构可以由指向任何页面的链接组成,不一定是网站内部链接。这是一种理想化的宽度优先爬行策略。在实际爬取过程中,不可能先想到全宽,先想到限宽,如下图所示:
上图中,我们的Spider在检索G链接时,通过算法发现G页面没有任何价值,于是就将悲剧性的G链接和从属的H链接统一给了Spider。至于为什么要统一G环节?嗯,我们来分析一下。
2、不完整的遍历链接权重计算:
每个搜索引擎都有一套pagerank(指页面权重,非google PR)计算方法,并且经常更新。互联网几乎是无限的,每天都会产生大量的新链接。搜索引擎在计算链接权重时只能进行不完全遍历。为什么谷歌公关需要三个月左右才能更新一次?为什么百度一个月更新1-2次?这是因为搜索引擎使用不完全遍历链接权重算法来计算链接权重。其实按照现在的技术,实现更快的权重更新并不难。计算速度和存储速度完全可以跟得上,但为什么不这样做呢?因为不是那么必要,或者已经实现了,但是我不想发布它。然后,
我们形成一组K个链接,R表示链接获得的pagerank,S表示链接收录的链接数,Q表示是否参与传输,β表示阻尼因子,那么权重计算公式通过链接获得的是:
由公式可知,Q决定链路权重。如果发现链接被作弊,或者被搜索引擎手动清除,或者其他原因,Q被设置为0,那么再多的外部链接也无济于事。β 是阻尼系数。主要作用是防止出现权重0,防止链接参与权重转移,防止出现作弊。阻尼系数β一般为0.85。为什么网站的数量乘以阻尼系数?因为不是页面中的所有页面都参与权重转移,搜索引擎会再次删除15%的过滤链接。
但是这种不完全的遍历权重计算需要积累一定的链接数才能重新开始计算,所以更新周期普遍较慢,不能满足用户对即时信息的需求。于是在此基础上,出现了实时权重分布抓取策略。即当蜘蛛完成对页面的爬取并进入后,立即进行权重分配,将权重重新分配给要爬取的链接库,然后根据权重进行爬取。
3、社会工程学爬取策略
社会工程策略是在蜘蛛爬行过程中加入人工智能或通过人工智能训练出来的机器智能来决定爬行的优先级。目前我知道的爬取策略有:
一种。热点优先策略:对于爆炸性热点关键词,会先抓取,不需要经过严格的去重和过滤,因为会有新的链接覆盖和用户的主动选择。
湾 权限优先策略:搜索引擎会给每个网站分配一个权限,通过网站历史、网站更新等确定网站的权限,并优先去抓取权威的网站链接。
C。用户点击策略:当大多数行业词库搜索关键词时,频繁点击网站的同一搜索结果,那么搜索引擎会更频繁地抓取这个网站。
d. 历史参考策略:对于保持频繁更新的网站,搜索引擎会为网站建立一个更新历史,并根据更新历史估计未来的更新量并确定爬取频率。
SEO工作指南:
搜索引擎的爬取原理已经讲得很深入了,下面就来说明一下这些原理在SEO工作中的指导作用:
A、定时定量更新,让蜘蛛可以及时抓取和抓取网站页面;
B. 公司网站的运作比个人网站更有权威性;
C.网站建站时间长更容易被抓;
D、页面内的链接分布要合理,过多或过少都不好;
E.网站,受用户欢迎,也受搜索引擎欢迎;
F.重要页面应该放在较浅的网站结构中;
G.网站中的行业权威信息将增加网站的权威性。
这就是本教程的内容。下一篇教程的主题是:页值和网站权重计算。
上一篇:语境如何影响未来移动互联网发展
谷歌抓取网页视频教程(谷歌抓取网页视频教程:利用wordpress的右上角图标)
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-10-08 21:01
谷歌抓取网页视频教程:1.打开wordpress后台页面2.在每个页面都注册一个gmail帐号3.手动建立教程url:4.在您的站点上添加一个定时发送邮件的功能4.利用wordpress的免费wizard在不同的网站插入您在gmail中选择的视频:首先建立好您的网站:第一步:选择“定时发送邮件”来源youtube5.在网页上插入“youtube-视频下载教程”6.点击“定时发送邮件”第二步:填写视频的地址点击“搜索”,输入要发送的邮件地址和链接7.出现视频地址框点击“确定”第三步:填写视频的页面内容点击“自动播放”,确定大功告成!是不是非常简单。下载是自己复制下来就可以。:)。
请参考:【爬虫】ifttt,谷歌搜索视频教程(gmail-banner)如果你不会使用ifttt,也可以参考这篇:将你的网站通过ifttt同步到谷歌。
标签即可。banner中只留下youtube即可。其它的字幕可以同步。
分享vczh:seo已经过气,
通过浏览器访问谷歌网页时,可以使用googlereader(gmail),点击gmail首页的右上角图标,可以转到gmail(点击谷歌搜索视频,同步到gmail)用gmail免费发送视频给gmail的用户在markdown中导入视频(这个简单,可以使用sqlite)用superset框架实现vczh文章内的视频搜索(这个就有点麻烦了,可以直接使用gmail和likexml)gmail和google搜索视频同步(支持gmail同步到googleadsense,推荐!)avast也支持gmail同步到googleadsense(它也可以同步到googleadsense,不过限制多!)用youtube发送视频到gmail(这个只支持gmail,adsense,baiduadsense等)用youtube将gmail视频和quora视频同步(同步vczh文章里)。 查看全部
谷歌抓取网页视频教程(谷歌抓取网页视频教程:利用wordpress的右上角图标)
谷歌抓取网页视频教程:1.打开wordpress后台页面2.在每个页面都注册一个gmail帐号3.手动建立教程url:4.在您的站点上添加一个定时发送邮件的功能4.利用wordpress的免费wizard在不同的网站插入您在gmail中选择的视频:首先建立好您的网站:第一步:选择“定时发送邮件”来源youtube5.在网页上插入“youtube-视频下载教程”6.点击“定时发送邮件”第二步:填写视频的地址点击“搜索”,输入要发送的邮件地址和链接7.出现视频地址框点击“确定”第三步:填写视频的页面内容点击“自动播放”,确定大功告成!是不是非常简单。下载是自己复制下来就可以。:)。
请参考:【爬虫】ifttt,谷歌搜索视频教程(gmail-banner)如果你不会使用ifttt,也可以参考这篇:将你的网站通过ifttt同步到谷歌。
标签即可。banner中只留下youtube即可。其它的字幕可以同步。
分享vczh:seo已经过气,
通过浏览器访问谷歌网页时,可以使用googlereader(gmail),点击gmail首页的右上角图标,可以转到gmail(点击谷歌搜索视频,同步到gmail)用gmail免费发送视频给gmail的用户在markdown中导入视频(这个简单,可以使用sqlite)用superset框架实现vczh文章内的视频搜索(这个就有点麻烦了,可以直接使用gmail和likexml)gmail和google搜索视频同步(支持gmail同步到googleadsense,推荐!)avast也支持gmail同步到googleadsense(它也可以同步到googleadsense,不过限制多!)用youtube发送视频到gmail(这个只支持gmail,adsense,baiduadsense等)用youtube将gmail视频和quora视频同步(同步vczh文章里)。
谷歌抓取网页视频教程(如何加快Google收录网页1.建立适合Google搜索引擎的网站?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-10-06 04:13
Google 收录 指的是 Google 是否将您的网页放入了自己的数据库中。这样你就可以通过自然流量搜索到你,并在你谷歌搜索引擎优化时产生查询、订单等。
英国网站建筑公司Ueeshop在过去几年发现,当谷歌缺乏数据时,你拥有的谷歌收录越多越好。然而,14年后,谷歌搜索引擎并不缺乏数据。谷歌收录偏爱有价值的页面,可以帮助用户处理有问题的页面、新的需求内容、新的热点内容。
也就是说,14年后,尤其是近两年,谷歌收录更倾向于有价值和好的内容。另一方面,网站也是一样,你的网站谷歌页面收录可以处理用户需求,而不是毫无价值的重复页面,让你网站整体流量和排名会好起来的。
一、如何查看谷歌收录
国内可以显示Google收录的工具有很多,但是大部分都不靠谱。由于被墙,国内IP很难获得Google收录的详细数据。
第一种方法:使用 site: 命令,
方法二:使用SEO插件,查Google收录。
在Firefox上安装SEOQuake插件,点击Pageinfo,查看Google收录。
二、如何加速谷歌收录页面
1.创建适合谷歌搜索引擎抓取的网站
当谷歌蜘蛛抓取网站时,它会跟随链接对其进行抓取。因此,我们在进行网页布局时需要注意网站的交互设计。比如文章中有相关的文章。
产品中有相关产品。其次,我们需要购买一个稳定的服务器,这样在谷歌抓取网站时,网站是打不开的。最后还要注意网站的打开速度。速度慢会直接影响谷歌收录的地位。
2.创造优质内容
谷歌发展了20多年,不乏常规内容。我们应该做一些新颖的话题来获得谷歌的青睐。在国内大部分网站中,不是收录的原因是所有产品的描述基本一致。这种情况是导致收录相对较小的重要原因之一。
3.使用谷歌网站管理员工具
在谷歌站长工具中添加网站,使用站长工具后台的爬取功能。
在谷歌站长工具后台使用提交网站地图功能。这允许您的整个网站成为 Google收录。请注意,网站 映射格式是 XML 映射。
4.使用谷歌的网站测速功能,
地址
5.使用IMT网站提交者
但请注意,使用此工具时不要创建过多的页面,否则您可能会被怀疑创建垃圾链接,并可能被谷歌误判,导致您的谷歌排名下降。
6.建立外部链接
发送更多链接到 网站 以吸引蜘蛛。尽量多建立dofollow外链,或者在流量大的页面上做外链。如果能把流量带到网站外链就更好了。
7.给网站更多的引流
你可以用社交导流,也可以用Quora,用谷歌adwords导流,用尽你所能想到的能给网站带来流量。但是需要注意尽量吸引潜在客户的流量,而不是做一些无关的流量。 查看全部
谷歌抓取网页视频教程(如何加快Google收录网页1.建立适合Google搜索引擎的网站?)
Google 收录 指的是 Google 是否将您的网页放入了自己的数据库中。这样你就可以通过自然流量搜索到你,并在你谷歌搜索引擎优化时产生查询、订单等。
英国网站建筑公司Ueeshop在过去几年发现,当谷歌缺乏数据时,你拥有的谷歌收录越多越好。然而,14年后,谷歌搜索引擎并不缺乏数据。谷歌收录偏爱有价值的页面,可以帮助用户处理有问题的页面、新的需求内容、新的热点内容。
也就是说,14年后,尤其是近两年,谷歌收录更倾向于有价值和好的内容。另一方面,网站也是一样,你的网站谷歌页面收录可以处理用户需求,而不是毫无价值的重复页面,让你网站整体流量和排名会好起来的。
一、如何查看谷歌收录
国内可以显示Google收录的工具有很多,但是大部分都不靠谱。由于被墙,国内IP很难获得Google收录的详细数据。
第一种方法:使用 site: 命令,
方法二:使用SEO插件,查Google收录。
在Firefox上安装SEOQuake插件,点击Pageinfo,查看Google收录。
二、如何加速谷歌收录页面
1.创建适合谷歌搜索引擎抓取的网站
当谷歌蜘蛛抓取网站时,它会跟随链接对其进行抓取。因此,我们在进行网页布局时需要注意网站的交互设计。比如文章中有相关的文章。
产品中有相关产品。其次,我们需要购买一个稳定的服务器,这样在谷歌抓取网站时,网站是打不开的。最后还要注意网站的打开速度。速度慢会直接影响谷歌收录的地位。
2.创造优质内容
谷歌发展了20多年,不乏常规内容。我们应该做一些新颖的话题来获得谷歌的青睐。在国内大部分网站中,不是收录的原因是所有产品的描述基本一致。这种情况是导致收录相对较小的重要原因之一。
3.使用谷歌网站管理员工具
在谷歌站长工具中添加网站,使用站长工具后台的爬取功能。
在谷歌站长工具后台使用提交网站地图功能。这允许您的整个网站成为 Google收录。请注意,网站 映射格式是 XML 映射。
4.使用谷歌的网站测速功能,
地址
5.使用IMT网站提交者
但请注意,使用此工具时不要创建过多的页面,否则您可能会被怀疑创建垃圾链接,并可能被谷歌误判,导致您的谷歌排名下降。
6.建立外部链接
发送更多链接到 网站 以吸引蜘蛛。尽量多建立dofollow外链,或者在流量大的页面上做外链。如果能把流量带到网站外链就更好了。
7.给网站更多的引流
你可以用社交导流,也可以用Quora,用谷歌adwords导流,用尽你所能想到的能给网站带来流量。但是需要注意尽量吸引潜在客户的流量,而不是做一些无关的流量。
谷歌抓取网页视频教程(【音频解说】小林搜集的一些关于具体问题的新闻)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-06 04:10
音频解说
现在应该属于互联网时代了。今天小林分享了一个使用迅雷下载网络视频的教程,相信朋友们也应该关注一下这个话题。现在给小伙伴们讲讲使用迅雷下载网络视频的教程。小林还采集了有关使用迅雷下载网络视频的教程信息。下面就让小林梳理一些具体问题的消息。
方法步骤:
1.我们需要在电脑上下载并安装谷歌扫描仪。最好使用此扫描仪。谷歌插件可以帮我们下载!
2. 然后安装迅雷下载软件。虽然可以安装别人,但迅雷的下载速度有目共睹!
3.扫描仪安装好后,进入扫描仪,找到之前要下载的网页视频界面。边肖随意为大家做出榜样!
4. 那么我们需要打开谷歌扫描仪这个先锋工具!有两种方法,你可以选择一种!1.用鼠标点击右上角的菜单按钮,在“更多工具”选项中点击打开“先锋工具”栏!2.使用快捷键:Ctrl Shift I快速调出先锋工具界面!
5. 进入这个界面后,我们就可以搜索这个视频文件的位置了!首先,在窗口中查找:网络中的媒体。找到这个栏目后,视频就不会出现了。我们需要刷新页面,让视频地址出现在第一列。我们需要复制这个地址!
6. 然后打开新安装的迅雷软件,点击“新建任务”选项。进入这个界面后,迅雷会自动识别新复制的地址。如果没有检测到,我们可以手动粘贴!然后就可以开始下载视频文件了!
以上就是边小下载网络视频的方法。上次操作后,此方法已升级。现在您可以快速下载,无需等待视频播放!有需要的朋友赶紧关注边小教程吧!
以上是小林采集的一些关于迅雷下载网络视频教程的相关资料,对希望的朋友有所帮助。
本文将在这里为大家一一讲解。
郑重声明:本文版权归原作者所有。文章的转载仅用于传播更多信息。如果作者信息标注有误,请第一时间联系我们修改或删除。谢谢你。 查看全部
谷歌抓取网页视频教程(【音频解说】小林搜集的一些关于具体问题的新闻)
音频解说
现在应该属于互联网时代了。今天小林分享了一个使用迅雷下载网络视频的教程,相信朋友们也应该关注一下这个话题。现在给小伙伴们讲讲使用迅雷下载网络视频的教程。小林还采集了有关使用迅雷下载网络视频的教程信息。下面就让小林梳理一些具体问题的消息。
方法步骤:
1.我们需要在电脑上下载并安装谷歌扫描仪。最好使用此扫描仪。谷歌插件可以帮我们下载!
2. 然后安装迅雷下载软件。虽然可以安装别人,但迅雷的下载速度有目共睹!
3.扫描仪安装好后,进入扫描仪,找到之前要下载的网页视频界面。边肖随意为大家做出榜样!
4. 那么我们需要打开谷歌扫描仪这个先锋工具!有两种方法,你可以选择一种!1.用鼠标点击右上角的菜单按钮,在“更多工具”选项中点击打开“先锋工具”栏!2.使用快捷键:Ctrl Shift I快速调出先锋工具界面!
5. 进入这个界面后,我们就可以搜索这个视频文件的位置了!首先,在窗口中查找:网络中的媒体。找到这个栏目后,视频就不会出现了。我们需要刷新页面,让视频地址出现在第一列。我们需要复制这个地址!
6. 然后打开新安装的迅雷软件,点击“新建任务”选项。进入这个界面后,迅雷会自动识别新复制的地址。如果没有检测到,我们可以手动粘贴!然后就可以开始下载视频文件了!
以上就是边小下载网络视频的方法。上次操作后,此方法已升级。现在您可以快速下载,无需等待视频播放!有需要的朋友赶紧关注边小教程吧!
以上是小林采集的一些关于迅雷下载网络视频教程的相关资料,对希望的朋友有所帮助。
本文将在这里为大家一一讲解。
郑重声明:本文版权归原作者所有。文章的转载仅用于传播更多信息。如果作者信息标注有误,请第一时间联系我们修改或删除。谢谢你。
谷歌抓取网页视频教程(Python爬虫的网上搜索一下笔记)
网站优化 • 优采云 发表了文章 • 0 个评论 • 279 次浏览 • 2021-10-05 14:22
一直想学习Python爬虫的知识,在网上搜了一下,大部分都是基于Python2.x。所以打算写一篇Python3.x的爬虫笔记,供后续复习。欢迎交流,共同进步。
一、预备知识
1.Python3.x基础知识学习:
您可以通过以下方式学习:
(1)廖雪峰Python3教程(文档):
网址:
(2)菜鸟教程Python3教程(文档):
网址:
(3) Fish C Studio Python 教程(视频):
小龟老师人很好,讲课风格幽默诙谐。如果时间充裕,可以考虑看视频。
网址:
2.开发环境设置:
Sublime text3搭建Pyhthon IDE,可以查看博客:
网址:
网址:
二、网络爬虫的定义
网络爬虫也称为网络蜘蛛。如果将 Internet 比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络爬虫根据网页的地址,即 URL 搜索网页。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:
URL是Uniform Resource Locator,其一般格式如下(方括号[]是可选的):
协议://主机名[:端口]/路径/[;参数][?查询]#fragment
URL格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分为主机名(端口号为可选参数)。一般网站的默认端口号为80。例如host百度的名字是这个是服务器的地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
三、简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。urllib 是一个 URL 处理包。这个包收录一些处理 URL 的模块,如下:
1.urllib.request 模块用于打开和读取 URL;
2.urllib.error 模块中收录了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
3.urllib.parse 模块收录了一些解析 URL 的方法;
4.urllib.robotparser 模块用于解析 robots.txt 文本文件。它提供了一个单独的RobotFileParser类,可以通过该类提供的can_fetch()方法来测试爬虫是否可以下载一个页面。
我们可以使用接口函数urllib.request.urlopen()轻松打开一个网站,读取和打印信息。
urlopen 有一些可选参数。具体信息请参考Python自带的文档。
知道了这一点,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com")
html = response.read()
print(html)
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后使用print()将读取到的信息打印出来。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在 cmd(控制台)中输入命令:
python urllib_test01.py
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。当然,我们也可以从浏览器中查看这些代码。比如使用谷歌浏览器,在任意界面右击选择Check,即勾选元素(不是所有页面都可以勾选元素,比如起点中文网站的付费版块。)。以百度界面为例。截图如下:
如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我刚刚修改了关于review元素的信息。
有一些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后显示给我们。
回到正题,虽然我们成功获取到了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以通过一个简单的 decode() 命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(或以百度翻译网站为例):
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://www.fanyi.baidu.com/")
html = response.read()
html = html.decode("utf-8")
print(html)
这样,我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码方式呢?需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就知道网页使用的是哪种编码。如下:
所以我们知道这个网站的编码方式,但这需要我们每次打开浏览器,找到编码方式。显然,这有点麻烦。用几行代码来解决,更省事,更爽。
四、自动获取网页编码方式的方法
获取网页代码的方法有很多,我更喜欢使用第三方库。
首先我们需要安装第三方库chardet,它是一个用来判断编码的模块。安装方法如下图所示。只需输入命令:
pip install chardet
安装后,我们可以使用chardet.detect()方法来判断网页的编码。此时,我们可以编写一个小程序来确定网页的编码方式,新建文件名为chardet_test01.py:
# -*- coding: UTF-8 -*-
from urllib import request
import chardet
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com/")
html = response.read()
charset = chardet.detect(html)
print(charset)
运行程序,查看输出结果如下:
看,返回的是字典,所以我们知道了网页的编码方式,我们可以根据得到的信息使用不同的解码方式。
PS:关于编码方式的内容,可以自行百度,或者阅读这篇博客:
网址: 查看全部
谷歌抓取网页视频教程(Python爬虫的网上搜索一下笔记)
一直想学习Python爬虫的知识,在网上搜了一下,大部分都是基于Python2.x。所以打算写一篇Python3.x的爬虫笔记,供后续复习。欢迎交流,共同进步。
一、预备知识
1.Python3.x基础知识学习:
您可以通过以下方式学习:
(1)廖雪峰Python3教程(文档):
网址:
(2)菜鸟教程Python3教程(文档):
网址:
(3) Fish C Studio Python 教程(视频):
小龟老师人很好,讲课风格幽默诙谐。如果时间充裕,可以考虑看视频。
网址:
2.开发环境设置:
Sublime text3搭建Pyhthon IDE,可以查看博客:
网址:
网址:
二、网络爬虫的定义
网络爬虫也称为网络蜘蛛。如果将 Internet 比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络爬虫根据网页的地址,即 URL 搜索网页。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:
URL是Uniform Resource Locator,其一般格式如下(方括号[]是可选的):
协议://主机名[:端口]/路径/[;参数][?查询]#fragment
URL格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分为主机名(端口号为可选参数)。一般网站的默认端口号为80。例如host百度的名字是这个是服务器的地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
三、简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。urllib 是一个 URL 处理包。这个包收录一些处理 URL 的模块,如下:
1.urllib.request 模块用于打开和读取 URL;
2.urllib.error 模块中收录了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
3.urllib.parse 模块收录了一些解析 URL 的方法;
4.urllib.robotparser 模块用于解析 robots.txt 文本文件。它提供了一个单独的RobotFileParser类,可以通过该类提供的can_fetch()方法来测试爬虫是否可以下载一个页面。
我们可以使用接口函数urllib.request.urlopen()轻松打开一个网站,读取和打印信息。
urlopen 有一些可选参数。具体信息请参考Python自带的文档。
知道了这一点,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com";)
html = response.read()
print(html)
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后使用print()将读取到的信息打印出来。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在 cmd(控制台)中输入命令:
python urllib_test01.py
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。当然,我们也可以从浏览器中查看这些代码。比如使用谷歌浏览器,在任意界面右击选择Check,即勾选元素(不是所有页面都可以勾选元素,比如起点中文网站的付费版块。)。以百度界面为例。截图如下:
如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我刚刚修改了关于review元素的信息。
有一些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后显示给我们。
回到正题,虽然我们成功获取到了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以通过一个简单的 decode() 命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(或以百度翻译网站为例):
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://www.fanyi.baidu.com/";)
html = response.read()
html = html.decode("utf-8")
print(html)
这样,我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码方式呢?需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就知道网页使用的是哪种编码。如下:
所以我们知道这个网站的编码方式,但这需要我们每次打开浏览器,找到编码方式。显然,这有点麻烦。用几行代码来解决,更省事,更爽。
四、自动获取网页编码方式的方法
获取网页代码的方法有很多,我更喜欢使用第三方库。
首先我们需要安装第三方库chardet,它是一个用来判断编码的模块。安装方法如下图所示。只需输入命令:
pip install chardet
安装后,我们可以使用chardet.detect()方法来判断网页的编码。此时,我们可以编写一个小程序来确定网页的编码方式,新建文件名为chardet_test01.py:
# -*- coding: UTF-8 -*-
from urllib import request
import chardet
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com/";)
html = response.read()
charset = chardet.detect(html)
print(charset)
运行程序,查看输出结果如下:
看,返回的是字典,所以我们知道了网页的编码方式,我们可以根据得到的信息使用不同的解码方式。
PS:关于编码方式的内容,可以自行百度,或者阅读这篇博客:
网址:
谷歌抓取网页视频教程(谷歌和百度如何提交搜索引擎,教你如何快速脱坑 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 284 次浏览 • 2021-10-05 09:14
)
前言
看到这说明大家和我一样。他们建立了一个博客并写了一些博客文章。春风拂面的时候,自建博客以来最大的危机就出现在了毫无准备的我面前。百度+谷歌搜索不到我的博客。还没几天就装成这个样子,实在是让人受不了。于是研究了几天,想出了这个文章。教大家如何走出坑。
文本
下面将介绍谷歌和百度是如何提交搜索引擎的。有一些共同点。这里有一些解释。
首先确认博客是否为收录
在百度或谷歌上输入以下格式进行判断。如果你能找到,就说明它是收录,否则就找不到。用你的域名替换我的
site:tengj.top
我目前的搜索结果如下:
验证网站
两个搜索引擎条目:
站长平台建议站长添加主站(您的网站链接可以同时使用www和非www的网址,建议添加用户实际可以访问的网址)。添加验证后,即可证明您是该域名的拥有者,无需一一验证您的子站点,即可快速批量添加子站点,查看所有子站点数据。
首先,如果您的网站使用过百度统计,您可以使用统计账号登录平台,或者将站长平台绑定到百度统计账号。站长平台支持您批量导入百度统计中的站点,您无需再验证网站。
百度站长平台为不使用百度统计的网站提供了三种验证方式:文件验证、html标签验证、CNAME验证。
1.文件验证:您需要下载验证文件,上传文件到您的服务器,放在域名根目录下。
2.html标签验证:在网站首页html代码的标签之间添加html标签。
3.CNAME 验证:需要登录域名提供商或托管服务提供商的网站添加新的DNS记录。
验证完成后,我们会将您视为网站的所有者。为了让您的 网站 验证通过,请保留已验证的文件、html 标签或 CNAME 记录。我们会定期检查验证记录。
不管是谷歌还是百度,都要先添加域名,然后验证网站。这里统一使用文件验证,即下载对应的html文件放在域名根目录下,同时也在博客根目录下接收源码
然后部署到服务器,输入地址:可以访问就点击验证按钮。
站点地图是一个文件,您可以通过它列出网站 上的网页,以便将您的网站 内容的组织结构通知Google 和其他搜索引擎。Googlebot 等搜索引擎网络爬虫会读取此文件,以便更智能地抓取您的 网站。
我们需要先安装,打开你的hexo博客根目录,使用下面两个命令分别安装谷歌和百度的插件
npm install hexo-generator-sitemap --save
npm install hexo-generator-baidu-sitemap --save
在博客目录的_config.yml中添加如下代码(我不需要添加)
# 自动生成sitemap
sitemap:
path: sitemap.xml
baidusitemap:
path: baidusitemap.xml
编译你的博客
hexo g
如果你发现在你博客根目录下public下生成了sitemap.xml和baidusitemap.xml,就说明成功了。
这时候sitemap.xml里面的内容和baidusitemap.xml是一样的,但是文章的链接都是tengj.github.io,这里我很奇怪,我的博客对应github和coding一样时间,为什么会产生?sitemap.xml对应的域名都指向github。我正在向 Google 提交 sitemap.xml。github对应的域名没问题,但是baidusitemap.xml中的域名也对应github。问题很大,因为github禁止百度爬虫。提交百度不会访问。所以我把baidusitemap.xml改成了我的个人域名,因为国内用户实际访问编码。
部署后单独访问
效果如下:
让 Google 收录 我们的博客
谷歌操作比较简单,就是将站点地图提交到谷歌站长工具
登录您的谷歌账号,添加站点验证后,选择站点,即可在爬取站点地图中看到添加/测试的站点地图,如下图:
在谷歌上,提交一天后就可以搜索我的博客,效率很高。
让百度收录我们的博客
谷歌很容易上手,百度却觉得很难。从投到百度到写这篇博客,只能在百度上搜索到自己的一篇博客,真是不容易。
正常情况下,要等百度爬虫爬到你的网站,你才会成为收录。
但是github已经屏蔽了百度爬虫,所以我们要主动提交网站给百度。
这是使用百度站长平台
验证网站
上面提到的验证网站,这里直接截图
网页抓取
以上步骤成功后,进入站点管理,找到这里爬取的页面查看详情点击进入
我们主动提交博客文章链接
如何选择链接提交方式
1、主动推送:最快的提交方式。建议您立即通过此方式将本站产生的新链接推送给百度,以确保百度能及时收到新链接收录。
2、自动推送:最方便的提交方式,请将自动推送的JS代码部署在站点各页面的源码中。每次浏览部署代码的页面都会自动推送链接到百度。. 可与主动推送结合使用。
3、站点地图:您可以定期在站点地图中放置网站链接,然后将站点地图提交给百度。百度会定期抓取检查您提交的站点地图,并处理其中的链接,但收录的速度比主动推送要慢。
4、 手动提交:一次性提交链接到百度,可以使用这种方式。
一般来说,主动提交比手动提交好。下面是主动提交的三种方式
在效率方面:
主动推送>自动推送>站点地图
主动推送
主动推送是百度搜索快速提交数据的最快工具,供站长开发针对性开发,但也是难度最大的,估计没有代码知识的小伙伴是做不到的。
没关系。既然博主写了这个博客,就说明博主找到了办法。我用java写了一个post push example并将它部署到编码中。不知道能部署多久。它似乎部署在编码演示端。硬币每天被扣除。
地址:戳我
阐明:
选择数据类型,默认推送数据,更新数据,删除数据。后两者一般不用
填写站点,这是你的域名,我的是
填写令牌,令牌在主动推送示例上有一个字符串。如果找不到,请按 CTRL+F 查找令牌
填写文章地址,填写您要提交的文章链接,每行一条记录
成功秘诀:
地址错误提示:
自动推送
自动推送很简单,就是在你的代码中嵌入自动推送的JS代码,当页面被访问时,页面URL会立即推送到百度
代码显示如下:
(function(){
var bp = document.createElement('script');
bp.src = '//push.zhanzhang.baidu.com/push.js';
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(bp, s);
})();
我把它放在\themes\jacman\layout\_partial\after_footer.ejs 中,在下面添加即可。
站点地图提交
就像站点地图提交上面提到的,直接提交就可以了。你可以从下面的图片中看到。一开始我提交了sitemap.xml,指向github。结果主域验证失败,然后切换到指向域名的baidusitemap。xml提交成功。
最后来看看我最近的投稿
为什么自动推送可以更快地将页面推送到百度搜索?基于自动推送的实现原理,每次查看新页面,页面URL都会自动推送到百度,无需站长聚合URL再主动推送操作。
推送动作由用户的浏览行为触发,节省站长手动操作的时间。
自动推送和链接提交有什么区别?已经使用链接提交的网站是否需要部署自动推送代码?
两者没有冲突,相辅相成。使用过主动推送的站点还是可以部署自动推送JS代码的,两者可以一起使用。
什么样的网站更适合自动推送?自动推送适用于技术能力相对较弱,由于实施方便,后续维护成本低,无法支持24小时实时主动推送程序的站长。
站长只需部署一次自动推送JS代码的操作,即可实现新页面一浏览就推送的效果,低成本实现链接自动提交。
同时我们也支持使用主动推送和自动推送代码,两者互不影响。
百度链接被主动推送后没有收录的原因
参考
# 博客推广——提交给搜索引擎
总结
写了3个小时,终于写完了这篇文章。很久以前就想写这篇文章了。不过百度并没有给予太多支持,也没有给予收录。所以我把它拖到了今天。为了方便,我昨天花了一些时间写了一个主动推送接口。各位,地址上有。
3月8日随sitemap和baidusitemap提交给谷歌和百度
3月9日Google的收录,可以搜索我的博客
3月10日百度收录
更多教程可以看我的嘟嘟独立博客。欢迎访问:嘟嘟独立博客
最近有个java公众号,里面有很多学习资源,视频,电子书,最新的开发工具都少不了。都已经在百度云盘上分享过了。请分享资源,创建一个方便学习和工作的java公众号。,开源,开源,有需要的可以关注~撒花
查看全部
谷歌抓取网页视频教程(谷歌和百度如何提交搜索引擎,教你如何快速脱坑
)
前言
看到这说明大家和我一样。他们建立了一个博客并写了一些博客文章。春风拂面的时候,自建博客以来最大的危机就出现在了毫无准备的我面前。百度+谷歌搜索不到我的博客。还没几天就装成这个样子,实在是让人受不了。于是研究了几天,想出了这个文章。教大家如何走出坑。
文本
下面将介绍谷歌和百度是如何提交搜索引擎的。有一些共同点。这里有一些解释。
首先确认博客是否为收录
在百度或谷歌上输入以下格式进行判断。如果你能找到,就说明它是收录,否则就找不到。用你的域名替换我的
site:tengj.top
我目前的搜索结果如下:
验证网站
两个搜索引擎条目:
站长平台建议站长添加主站(您的网站链接可以同时使用www和非www的网址,建议添加用户实际可以访问的网址)。添加验证后,即可证明您是该域名的拥有者,无需一一验证您的子站点,即可快速批量添加子站点,查看所有子站点数据。
首先,如果您的网站使用过百度统计,您可以使用统计账号登录平台,或者将站长平台绑定到百度统计账号。站长平台支持您批量导入百度统计中的站点,您无需再验证网站。
百度站长平台为不使用百度统计的网站提供了三种验证方式:文件验证、html标签验证、CNAME验证。
1.文件验证:您需要下载验证文件,上传文件到您的服务器,放在域名根目录下。
2.html标签验证:在网站首页html代码的标签之间添加html标签。
3.CNAME 验证:需要登录域名提供商或托管服务提供商的网站添加新的DNS记录。
验证完成后,我们会将您视为网站的所有者。为了让您的 网站 验证通过,请保留已验证的文件、html 标签或 CNAME 记录。我们会定期检查验证记录。
不管是谷歌还是百度,都要先添加域名,然后验证网站。这里统一使用文件验证,即下载对应的html文件放在域名根目录下,同时也在博客根目录下接收源码
然后部署到服务器,输入地址:可以访问就点击验证按钮。
站点地图是一个文件,您可以通过它列出网站 上的网页,以便将您的网站 内容的组织结构通知Google 和其他搜索引擎。Googlebot 等搜索引擎网络爬虫会读取此文件,以便更智能地抓取您的 网站。
我们需要先安装,打开你的hexo博客根目录,使用下面两个命令分别安装谷歌和百度的插件
npm install hexo-generator-sitemap --save
npm install hexo-generator-baidu-sitemap --save
在博客目录的_config.yml中添加如下代码(我不需要添加)
# 自动生成sitemap
sitemap:
path: sitemap.xml
baidusitemap:
path: baidusitemap.xml
编译你的博客
hexo g
如果你发现在你博客根目录下public下生成了sitemap.xml和baidusitemap.xml,就说明成功了。
这时候sitemap.xml里面的内容和baidusitemap.xml是一样的,但是文章的链接都是tengj.github.io,这里我很奇怪,我的博客对应github和coding一样时间,为什么会产生?sitemap.xml对应的域名都指向github。我正在向 Google 提交 sitemap.xml。github对应的域名没问题,但是baidusitemap.xml中的域名也对应github。问题很大,因为github禁止百度爬虫。提交百度不会访问。所以我把baidusitemap.xml改成了我的个人域名,因为国内用户实际访问编码。
部署后单独访问
效果如下:
让 Google 收录 我们的博客
谷歌操作比较简单,就是将站点地图提交到谷歌站长工具
登录您的谷歌账号,添加站点验证后,选择站点,即可在爬取站点地图中看到添加/测试的站点地图,如下图:
在谷歌上,提交一天后就可以搜索我的博客,效率很高。
让百度收录我们的博客
谷歌很容易上手,百度却觉得很难。从投到百度到写这篇博客,只能在百度上搜索到自己的一篇博客,真是不容易。
正常情况下,要等百度爬虫爬到你的网站,你才会成为收录。
但是github已经屏蔽了百度爬虫,所以我们要主动提交网站给百度。
这是使用百度站长平台
验证网站
上面提到的验证网站,这里直接截图
网页抓取
以上步骤成功后,进入站点管理,找到这里爬取的页面查看详情点击进入
我们主动提交博客文章链接
如何选择链接提交方式
1、主动推送:最快的提交方式。建议您立即通过此方式将本站产生的新链接推送给百度,以确保百度能及时收到新链接收录。
2、自动推送:最方便的提交方式,请将自动推送的JS代码部署在站点各页面的源码中。每次浏览部署代码的页面都会自动推送链接到百度。. 可与主动推送结合使用。
3、站点地图:您可以定期在站点地图中放置网站链接,然后将站点地图提交给百度。百度会定期抓取检查您提交的站点地图,并处理其中的链接,但收录的速度比主动推送要慢。
4、 手动提交:一次性提交链接到百度,可以使用这种方式。
一般来说,主动提交比手动提交好。下面是主动提交的三种方式
在效率方面:
主动推送>自动推送>站点地图
主动推送
主动推送是百度搜索快速提交数据的最快工具,供站长开发针对性开发,但也是难度最大的,估计没有代码知识的小伙伴是做不到的。
没关系。既然博主写了这个博客,就说明博主找到了办法。我用java写了一个post push example并将它部署到编码中。不知道能部署多久。它似乎部署在编码演示端。硬币每天被扣除。
地址:戳我
阐明:
选择数据类型,默认推送数据,更新数据,删除数据。后两者一般不用
填写站点,这是你的域名,我的是
填写令牌,令牌在主动推送示例上有一个字符串。如果找不到,请按 CTRL+F 查找令牌
填写文章地址,填写您要提交的文章链接,每行一条记录
成功秘诀:
地址错误提示:
自动推送
自动推送很简单,就是在你的代码中嵌入自动推送的JS代码,当页面被访问时,页面URL会立即推送到百度
代码显示如下:
(function(){
var bp = document.createElement('script');
bp.src = '//push.zhanzhang.baidu.com/push.js';
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(bp, s);
})();
我把它放在\themes\jacman\layout\_partial\after_footer.ejs 中,在下面添加即可。
站点地图提交
就像站点地图提交上面提到的,直接提交就可以了。你可以从下面的图片中看到。一开始我提交了sitemap.xml,指向github。结果主域验证失败,然后切换到指向域名的baidusitemap。xml提交成功。
最后来看看我最近的投稿
为什么自动推送可以更快地将页面推送到百度搜索?基于自动推送的实现原理,每次查看新页面,页面URL都会自动推送到百度,无需站长聚合URL再主动推送操作。
推送动作由用户的浏览行为触发,节省站长手动操作的时间。
自动推送和链接提交有什么区别?已经使用链接提交的网站是否需要部署自动推送代码?
两者没有冲突,相辅相成。使用过主动推送的站点还是可以部署自动推送JS代码的,两者可以一起使用。
什么样的网站更适合自动推送?自动推送适用于技术能力相对较弱,由于实施方便,后续维护成本低,无法支持24小时实时主动推送程序的站长。
站长只需部署一次自动推送JS代码的操作,即可实现新页面一浏览就推送的效果,低成本实现链接自动提交。
同时我们也支持使用主动推送和自动推送代码,两者互不影响。
百度链接被主动推送后没有收录的原因
参考
# 博客推广——提交给搜索引擎
总结
写了3个小时,终于写完了这篇文章。很久以前就想写这篇文章了。不过百度并没有给予太多支持,也没有给予收录。所以我把它拖到了今天。为了方便,我昨天花了一些时间写了一个主动推送接口。各位,地址上有。
3月8日随sitemap和baidusitemap提交给谷歌和百度
3月9日Google的收录,可以搜索我的博客
3月10日百度收录
更多教程可以看我的嘟嘟独立博客。欢迎访问:嘟嘟独立博客
最近有个java公众号,里面有很多学习资源,视频,电子书,最新的开发工具都少不了。都已经在百度云盘上分享过了。请分享资源,创建一个方便学习和工作的java公众号。,开源,开源,有需要的可以关注~撒花
谷歌抓取网页视频教程(插件支持:Adobe和Google联合开发内核还没太大关系(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-10-02 03:13
前言
最近在研究谷歌浏览器内核。Google Chrome 内核已开源并进行维护和更新。其开源项目内核更新速度与Chrome浏览器版本更新进度一致!而且它不同于WebKit(值得一提的是谷歌浏览器不再使用WebKit核心),它提供的不仅仅是页面渲染,而是一个完整的浏览器解决方案和插件规则。
使用方便:我们给它一个“表单”(操作系统或系统资源管理器中的本地表单,本系列以Win32平台为例)和一些配置参数,它可以给你需要渲染的页面完美显示在固定窗口。
插件支持:Adobe与谷歌联合开发的pepperflashplayer功能齐全,如果我们将其作为进程外插件安装,则无需考虑其自动升级给用户或系统带来麻烦我们正在开发的版本更改。而且只需要一句代码就可以完成插件的激活,插件的获取和升级方式也很简单(先在电脑上安装一个chrome浏览器,到安装目录复制:-_-)。Google 的 pdf 插件也可以这样做。
本系列文章主要使用Java给谷歌一个shell。因为cef(即“谷歌Chrome Chromium嵌入式框架”,下文简称cef,本系列使用cef3)用c/c++编写,不直接提供Java语言API,虽然有Java A维护版的版本,不过我觉得不太好用。
获取 AWT 表单句柄
我们今天要做的与cef内核无关。我们先解决一个问题:获取Java表单的句柄。
我们都知道Java语言提供的GUI支持是基于操作系统资源管理系统(或桌面环境)的支持(在Java 2D/GUI中,最外层的窗口一定是操作系统相关的),所以简单的事实是,我们可以使用一些 JNI API 来获取表单句柄。
JNI是Java语言提供的本地化代码调用接口(在Java虚拟机中,其实并不关心下一个方法入口是内部指针还是外部操作系统指针),我们可以写ac/c++函数找到窗口句柄,然后返回Java虚拟机,让我们也知道虚拟机内部的操作系统分配的某个Java窗口的句柄。
Java官方已经考虑到了我们的需求,提供了一个接口:jawt。包括一系列c/c++ include(头文件.h,平台相关)和一系列c/c++静态库文件。
具体包括jawt.h、jawt_md.h、jawt.lib(另外jni.h和jni_md.h是使用jni所必须的)
编写动态链接库(dll),需要使用c/c++头文件和c/++源文件共同编译。我们首先使用JDK自带的javah工具(javah.exe)生成头文件并实现。
当然,我们先写一个Java类,并注解它的native方法。
1 /*
2 * Copyright 2014 JootMir Project
3 * Licensed under the Apache License, Version 2.0 (the "License");
4 * you may not use this file except in compliance with the License.
5 * You may obtain a copy of the License at
6
7 http://www.apache.org/licenses/LICENSE-2.0
8
9 * Unless required by applicable law or agreed to in writing, software
10 * distributed under the License is distributed on an "AS IS" BASIS,
11 * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 * See the License for the specific language governing permissions and
13 * limitations under the License.
14 *
15 * Support: http://www.cnblogs.com/johness
16 */
17 package johness.jcef3.util;
18
19 import javax.swing.JFrame;
20
21 /**
22 * AWT工具集
23 *
24 * @author ShawRyan
25 */
26 public final class AWTUtil {
27 /**
28 * 获取某个窗体句柄(在Windows平台下)
29 *
30 * @param window
31 * 需要获取句柄的窗体对象
32 * @return 窗体应用句柄
33 */
34 public static native int getWindowHandleInWindows(JFrame window);
35 }
AWT实用程序
然后使用javah生成对应的头文件。
头文件的内容如下:
/* DO NOT EDIT THIS FILE - it is machine generated */
#include
/* Header for class johness_jcef3_util_AWTUtil */
#ifndef _Included_johness_jcef3_util_AWTUtil
#define _Included_johness_jcef3_util_AWTUtil
#ifdef __cplusplus
extern "C" {
#endif
/*
* Class: johness_jcef3_util_AWTUtil
* Method: getWindowHandleInWindows
* Signature: (Ljavax/swing/JFrame;)I
*/
JNIEXPORT jint JNICALL Java_johness_jcef3_util_AWTUtil_getWindowHandleInWindows
(JNIEnv *, jclass, jobject);
#ifdef __cplusplus
}
#endif
#endif
我不会详细介绍 jni 规则。
接下来我们用c++代码实现接口函数,编译成动态链接库。
我不喜欢使用经典的VC++6.0 或优秀的Dev C++,我将使用Visual Studio 2012 编写和编译它。
创建项目
删除所有我们不需要的(我们没有 -_-)文件
将jni和jawt相关的头文件和库文件复制到项目中(是否值得询问是否要复制粘贴到vs表单中,但实际复制到你的c++项目文件夹中)
%JAVA_HOME%\include\jni.h
%JAVA_HOME%\include\jawt.h
%JAVA_HOME%\include\jni_md.h
%JAVA_HOME%\include\jawt_md.h
%JAVA_HOME%\lib\jawt.lib
项目中的头文件
配置项
将项目配置为 Release
配置项目使用jawt.lib静态库
更改头文件,将#include 改为#include "jni.h"
(后面的竖线是光标)
写入源文件
(在创建源文件并准备开始编写代码之前取消源文件预编译头)
开始编码
1 #include "jni.h"
2 #include "jawt_md.h"
3 #include "johness_jcef3_util_AWTUtil.h"
4
5 JNIEXPORT jint JNICALL Java_johness_jcef3_util_AWTUtil_getWindowHandleInWindows (JNIEnv *env, jclass sender, jobject window) {
6 HWND hwnd = NULL;
7
8 JAWT_DrawingSurface *ds;
9 JAWT_DrawingSurfaceInfo *dsi;
10 JAWT_Win32DrawingSurfaceInfo *win;
11
12 JAWT awt;
13 awt.version = JAWT_VERSION_1_3;
14
15 jboolean result = JAWT_GetAWT(env, &awt);
16 if (result == JNI_TRUE) {
17 ds = awt.GetDrawingSurface(env, window);
18 jint lock = ds -> Lock(ds);
19 if (lock != JAWT_LOCK_ERROR) {
20 dsi = ds -> GetDrawingSurfaceInfo(ds);
21 win = (JAWT_Win32DrawingSurfaceInfo *) dsi -> platformInfo;
22
23 hwnd = win -> hwnd;
24
25 ds -> FreeDrawingSurfaceInfo(dsi);
26 ds -> Unlock(ds);
27 awt.FreeDrawingSurface(ds);
28 return jint(hwnd);
29 }
30 return 0;
31 }
32 return 0;
33 }
johness_jcef3_util_AWTUtil
编译生成
将生成的dll拷贝到Java项目中,在项目配置中配置librarypath,然后编写测试代码。
测试代码也很简单:
package johness.jcef3.util;
import javax.swing.JFrame;
public class Main {
public static void main(String[] args) {
System.loadLibrary("jawt");
System.loadLibrary("JCEF3");
JFrame frame = new JFrame();
frame.setSize(400, 300);
frame.setVisible(true);
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
System.out.println(AWTUtil.getWindowHandleInWindows(frame));
}
}
最终总结
使用 Visual Studio 进行编译时,请注意不要使用预编译的文件头。当然,如果你对vc++有一点了解,可能就不那么麻烦了。
使用visual studio生成的dll需要运行环境,如msvcr110.dll。如果您还没有在您的机器上安装它,您可能会收到类似“找不到相关库”这样的错误消息。您可以打包这些运行时环境库。
写于 2016-03-29
本来想自己做java-cef,但是官方已经做了
写于 2019-11-28
java-cef 不再维护并且有很多错误。几年前,我自己维护了该项目的 Maven 版本。但是已经不更新了。注意这是几年前的东西,请不要使用它,尽量使用流行的开源组件。如果一个项目超过一个月没有活跃(发布版本、提交代码等),那么你最好不要使用它。
联系我一起交流
欢迎您加入我们的交流群。无聊的时候,我们一起打发时间:
或通过QQ联系我:
(上次编辑 2016-03-2910:26:41) 查看全部
谷歌抓取网页视频教程(插件支持:Adobe和Google联合开发内核还没太大关系(组图))
前言
最近在研究谷歌浏览器内核。Google Chrome 内核已开源并进行维护和更新。其开源项目内核更新速度与Chrome浏览器版本更新进度一致!而且它不同于WebKit(值得一提的是谷歌浏览器不再使用WebKit核心),它提供的不仅仅是页面渲染,而是一个完整的浏览器解决方案和插件规则。
使用方便:我们给它一个“表单”(操作系统或系统资源管理器中的本地表单,本系列以Win32平台为例)和一些配置参数,它可以给你需要渲染的页面完美显示在固定窗口。
插件支持:Adobe与谷歌联合开发的pepperflashplayer功能齐全,如果我们将其作为进程外插件安装,则无需考虑其自动升级给用户或系统带来麻烦我们正在开发的版本更改。而且只需要一句代码就可以完成插件的激活,插件的获取和升级方式也很简单(先在电脑上安装一个chrome浏览器,到安装目录复制:-_-)。Google 的 pdf 插件也可以这样做。
本系列文章主要使用Java给谷歌一个shell。因为cef(即“谷歌Chrome Chromium嵌入式框架”,下文简称cef,本系列使用cef3)用c/c++编写,不直接提供Java语言API,虽然有Java A维护版的版本,不过我觉得不太好用。
获取 AWT 表单句柄
我们今天要做的与cef内核无关。我们先解决一个问题:获取Java表单的句柄。
我们都知道Java语言提供的GUI支持是基于操作系统资源管理系统(或桌面环境)的支持(在Java 2D/GUI中,最外层的窗口一定是操作系统相关的),所以简单的事实是,我们可以使用一些 JNI API 来获取表单句柄。
JNI是Java语言提供的本地化代码调用接口(在Java虚拟机中,其实并不关心下一个方法入口是内部指针还是外部操作系统指针),我们可以写ac/c++函数找到窗口句柄,然后返回Java虚拟机,让我们也知道虚拟机内部的操作系统分配的某个Java窗口的句柄。
Java官方已经考虑到了我们的需求,提供了一个接口:jawt。包括一系列c/c++ include(头文件.h,平台相关)和一系列c/c++静态库文件。
具体包括jawt.h、jawt_md.h、jawt.lib(另外jni.h和jni_md.h是使用jni所必须的)
编写动态链接库(dll),需要使用c/c++头文件和c/++源文件共同编译。我们首先使用JDK自带的javah工具(javah.exe)生成头文件并实现。
当然,我们先写一个Java类,并注解它的native方法。
1 /*
2 * Copyright 2014 JootMir Project
3 * Licensed under the Apache License, Version 2.0 (the "License");
4 * you may not use this file except in compliance with the License.
5 * You may obtain a copy of the License at
6
7 http://www.apache.org/licenses/LICENSE-2.0
8
9 * Unless required by applicable law or agreed to in writing, software
10 * distributed under the License is distributed on an "AS IS" BASIS,
11 * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 * See the License for the specific language governing permissions and
13 * limitations under the License.
14 *
15 * Support: http://www.cnblogs.com/johness
16 */
17 package johness.jcef3.util;
18
19 import javax.swing.JFrame;
20
21 /**
22 * AWT工具集
23 *
24 * @author ShawRyan
25 */
26 public final class AWTUtil {
27 /**
28 * 获取某个窗体句柄(在Windows平台下)
29 *
30 * @param window
31 * 需要获取句柄的窗体对象
32 * @return 窗体应用句柄
33 */
34 public static native int getWindowHandleInWindows(JFrame window);
35 }
AWT实用程序
然后使用javah生成对应的头文件。
头文件的内容如下:
/* DO NOT EDIT THIS FILE - it is machine generated */
#include
/* Header for class johness_jcef3_util_AWTUtil */
#ifndef _Included_johness_jcef3_util_AWTUtil
#define _Included_johness_jcef3_util_AWTUtil
#ifdef __cplusplus
extern "C" {
#endif
/*
* Class: johness_jcef3_util_AWTUtil
* Method: getWindowHandleInWindows
* Signature: (Ljavax/swing/JFrame;)I
*/
JNIEXPORT jint JNICALL Java_johness_jcef3_util_AWTUtil_getWindowHandleInWindows
(JNIEnv *, jclass, jobject);
#ifdef __cplusplus
}
#endif
#endif
我不会详细介绍 jni 规则。
接下来我们用c++代码实现接口函数,编译成动态链接库。
我不喜欢使用经典的VC++6.0 或优秀的Dev C++,我将使用Visual Studio 2012 编写和编译它。
创建项目
删除所有我们不需要的(我们没有 -_-)文件
将jni和jawt相关的头文件和库文件复制到项目中(是否值得询问是否要复制粘贴到vs表单中,但实际复制到你的c++项目文件夹中)
%JAVA_HOME%\include\jni.h
%JAVA_HOME%\include\jawt.h
%JAVA_HOME%\include\jni_md.h
%JAVA_HOME%\include\jawt_md.h
%JAVA_HOME%\lib\jawt.lib
项目中的头文件
配置项
将项目配置为 Release
配置项目使用jawt.lib静态库
更改头文件,将#include 改为#include "jni.h"
(后面的竖线是光标)
写入源文件
(在创建源文件并准备开始编写代码之前取消源文件预编译头)
开始编码
1 #include "jni.h"
2 #include "jawt_md.h"
3 #include "johness_jcef3_util_AWTUtil.h"
4
5 JNIEXPORT jint JNICALL Java_johness_jcef3_util_AWTUtil_getWindowHandleInWindows (JNIEnv *env, jclass sender, jobject window) {
6 HWND hwnd = NULL;
7
8 JAWT_DrawingSurface *ds;
9 JAWT_DrawingSurfaceInfo *dsi;
10 JAWT_Win32DrawingSurfaceInfo *win;
11
12 JAWT awt;
13 awt.version = JAWT_VERSION_1_3;
14
15 jboolean result = JAWT_GetAWT(env, &awt);
16 if (result == JNI_TRUE) {
17 ds = awt.GetDrawingSurface(env, window);
18 jint lock = ds -> Lock(ds);
19 if (lock != JAWT_LOCK_ERROR) {
20 dsi = ds -> GetDrawingSurfaceInfo(ds);
21 win = (JAWT_Win32DrawingSurfaceInfo *) dsi -> platformInfo;
22
23 hwnd = win -> hwnd;
24
25 ds -> FreeDrawingSurfaceInfo(dsi);
26 ds -> Unlock(ds);
27 awt.FreeDrawingSurface(ds);
28 return jint(hwnd);
29 }
30 return 0;
31 }
32 return 0;
33 }
johness_jcef3_util_AWTUtil
编译生成
将生成的dll拷贝到Java项目中,在项目配置中配置librarypath,然后编写测试代码。
测试代码也很简单:
package johness.jcef3.util;
import javax.swing.JFrame;
public class Main {
public static void main(String[] args) {
System.loadLibrary("jawt");
System.loadLibrary("JCEF3");
JFrame frame = new JFrame();
frame.setSize(400, 300);
frame.setVisible(true);
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
System.out.println(AWTUtil.getWindowHandleInWindows(frame));
}
}
最终总结
使用 Visual Studio 进行编译时,请注意不要使用预编译的文件头。当然,如果你对vc++有一点了解,可能就不那么麻烦了。
使用visual studio生成的dll需要运行环境,如msvcr110.dll。如果您还没有在您的机器上安装它,您可能会收到类似“找不到相关库”这样的错误消息。您可以打包这些运行时环境库。
写于 2016-03-29
本来想自己做java-cef,但是官方已经做了
写于 2019-11-28
java-cef 不再维护并且有很多错误。几年前,我自己维护了该项目的 Maven 版本。但是已经不更新了。注意这是几年前的东西,请不要使用它,尽量使用流行的开源组件。如果一个项目超过一个月没有活跃(发布版本、提交代码等),那么你最好不要使用它。
联系我一起交流
欢迎您加入我们的交流群。无聊的时候,我们一起打发时间:
或通过QQ联系我:
(上次编辑 2016-03-2910:26:41)
谷歌抓取网页视频教程(大咖的话搜索优化包罗外部优化与内部两方面排名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-01 14:18
seo网站优化教学视频专家鼓励搜索优化专家进行搜索优化,包括外部优化和内部排名,这意味着为了从内部获得固定的用户访问权限,服务器架构为文章。搜索者裂变传播收录等方面的写法以及对网页的合理操作迎合百度的收录技术使网页更适合搜索引擎的爬虫!写法搜索者裂变传播收录等方面,进而合理操作网页,迎合百度的收录技术方法,使网页更适合搜索引擎。爬行方法也称为排名优化。
seo网站改进教学视频的以下关注点,那你联系我,你确定标签内容长度是正确的 不超过天命盘的字符和字符量产天命盘维护系统完美盘维护系统一般不超过天意盘维护系统的字符描述!天意盘维护系统一般不超过天意盘量产的特点 天意盘维护系统完善。磁盘维护系统一般不超过字符。国内顶级磁盘维护系统一般不超过字符。这篇文章的目的是解释如何写出很受百度热捧的文章。文章 简单 就是拿到标题和内容后怎么写。什么搜索引擎非常喜欢?文章 先打开。
seo网站优化教学视频后,站长没怎么关注。但是,我们仍然需要写好一些搜索引擎仍然非常重视写作方法。并且如果适得其反,不要乱涂乱画,相关且不要太多我们想在当前页面优化的词或举例我的博客教程顾问优化计划研究案例博客工具优化信息流广告优化网络营销新媒体; 并没有太多是我们目前页面上要优化的词仍然是例子。我的博客教程顾问优化方案学习案例博客工具优化信息流广告优化网络营销新媒体产品营销学写网站标题说明新手朋友一定要记住网站
seo网站 优化教学视频,尝试比较适合的几个方面。百度推广的登陆页面可以随时更改。我们可以通过这个链接对账号进行分类,并在不同的页面上展示!显示以识别链接中的页面 是详细的产品说明。只要产品表述清楚,了解链接中的页面,我们就需要在产品的具体信息上有所进展,以便客户可以;下一页是详细的产品说明。只要产品描述清楚并了解链接我们需要在页面上进行进度指定产品的具体信息,以便客户可以得到更清晰的答案。坦白说,比较环节就是同类产品的较量。质量对比后,价格差别不大。价格就是价格优势。价格优势是获胜的最佳机会。营销客户在后面的购买环节。服务要占多数,怎么说就怎么说!
seo网站优化教学视频差异化我们始终坚持以客户需求为导向,为追求用户体验设计提供针对性的项目解决方案,持续为客户创造价值,努力打造互联网领域的产品服务。谷歌搜索引擎优化指南也意味着谷歌并不讨厌它,而是鼓励站长使用适当的策略来提高网站的排名,并为站长提供一系列分析报告。优化指南也意味着谷歌并不讨厌它。相反,它鼓励站长使用适当的策略进行改进。网站 Ranking 为站长提供了一系列分析报告。看来谷歌似乎更倾向于鼓励站长。SEO当然是通过方式完成的! 查看全部
谷歌抓取网页视频教程(大咖的话搜索优化包罗外部优化与内部两方面排名)
seo网站优化教学视频专家鼓励搜索优化专家进行搜索优化,包括外部优化和内部排名,这意味着为了从内部获得固定的用户访问权限,服务器架构为文章。搜索者裂变传播收录等方面的写法以及对网页的合理操作迎合百度的收录技术使网页更适合搜索引擎的爬虫!写法搜索者裂变传播收录等方面,进而合理操作网页,迎合百度的收录技术方法,使网页更适合搜索引擎。爬行方法也称为排名优化。
seo网站改进教学视频的以下关注点,那你联系我,你确定标签内容长度是正确的 不超过天命盘的字符和字符量产天命盘维护系统完美盘维护系统一般不超过天意盘维护系统的字符描述!天意盘维护系统一般不超过天意盘量产的特点 天意盘维护系统完善。磁盘维护系统一般不超过字符。国内顶级磁盘维护系统一般不超过字符。这篇文章的目的是解释如何写出很受百度热捧的文章。文章 简单 就是拿到标题和内容后怎么写。什么搜索引擎非常喜欢?文章 先打开。
seo网站优化教学视频后,站长没怎么关注。但是,我们仍然需要写好一些搜索引擎仍然非常重视写作方法。并且如果适得其反,不要乱涂乱画,相关且不要太多我们想在当前页面优化的词或举例我的博客教程顾问优化计划研究案例博客工具优化信息流广告优化网络营销新媒体; 并没有太多是我们目前页面上要优化的词仍然是例子。我的博客教程顾问优化方案学习案例博客工具优化信息流广告优化网络营销新媒体产品营销学写网站标题说明新手朋友一定要记住网站
seo网站 优化教学视频,尝试比较适合的几个方面。百度推广的登陆页面可以随时更改。我们可以通过这个链接对账号进行分类,并在不同的页面上展示!显示以识别链接中的页面 是详细的产品说明。只要产品表述清楚,了解链接中的页面,我们就需要在产品的具体信息上有所进展,以便客户可以;下一页是详细的产品说明。只要产品描述清楚并了解链接我们需要在页面上进行进度指定产品的具体信息,以便客户可以得到更清晰的答案。坦白说,比较环节就是同类产品的较量。质量对比后,价格差别不大。价格就是价格优势。价格优势是获胜的最佳机会。营销客户在后面的购买环节。服务要占多数,怎么说就怎么说!
seo网站优化教学视频差异化我们始终坚持以客户需求为导向,为追求用户体验设计提供针对性的项目解决方案,持续为客户创造价值,努力打造互联网领域的产品服务。谷歌搜索引擎优化指南也意味着谷歌并不讨厌它,而是鼓励站长使用适当的策略来提高网站的排名,并为站长提供一系列分析报告。优化指南也意味着谷歌并不讨厌它。相反,它鼓励站长使用适当的策略进行改进。网站 Ranking 为站长提供了一系列分析报告。看来谷歌似乎更倾向于鼓励站长。SEO当然是通过方式完成的!
谷歌抓取网页视频教程(如何上手视编程基础而定?(一)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-09-29 16:13
**前言:** 数据科学越来越流行,网页是一个巨大的数据来源。最近,很多人问如何抓取网页数据。据我所知,常见的编程语言(C++、java、python)都可以实现网页数据的抓取,甚至很多统计\计算语言(R、Matlab)都可以实现和网站交互包。尝试过用java、python、R来抓取网页,感觉语法不一样,逻辑是一样的。我打算用python讲一下网页爬虫的概念。具体内容还得看说明书或者google别人的博客。这是一个好主意。水平有限,有错误或者有更好的方法,欢迎讨论。**步骤 1:熟悉 Python 的基本语法。
**。更多信息
如果您已经熟悉 Python,请跳至第二步。
Python是一门比较容易上手的编程语言,如何上手取决于编程的基础。(1)如果你有一定的编程基础,建议看google的python课,链接这是一个为期两天的短期培训课程(当然是两天一整天),大约7个视频,每个视频后为编程作业,每个作业一个小时内可以完成。这是我学习python的第二课(第一门是codecademy上的python,很久以前看过,很多内容记不清了),我天天看视频+编程作业一个多小时,六天做完,效果还不错,python写基本程序没有问题。
(2)如果你没有任何编程基础,我建议你看看莱斯大学在coursera上开的An Introduction to Interactive Programming in Python。我没有关注过这门课程,但是coursetalk上的评论反映的很嗯。也有同学在评论(点这里),课程链接:Udacity上的.CS101也是不错的选择,地上有相关的讨论帖(点这里),这门课叫做build a search engine,里面会专门讲一些网络相关的模块。
其他学习资源包括代码学校和代码学院。这些资源也不错,但是编程量太少,初学者要系统的跟上课,多练习,打好基础。当然,每个人的喜好不同,我推荐的不一定适合你。你可以看看这个帖子【长期红利帖】介绍你上过的公开课
其他人在里面说什么,或者看看课程评论并决定。
第二步:学习如何与网站建立链接,获取网页数据。
编写脚本与网站进行交互,你必须熟悉python和网页相关的几个模块(urllib、urllib2、httplib)之一,知道一个,其他类似。这三个是python提供的与网页交互的基本模块,还有其他的,比如:mechanize和scrapy,我没用过,可能性能更好,欢迎学习补充。对于基本的网络爬虫,前三个模块就足够了。下面的代码演示了如何使用urllib2与Google Scholar交互获取网页信息。
导入模块 urllib2
导入 urllib2
随意查询 文章,例如 On random graph。每个查询googlescholar都有一个url,这个url形成的规则需要自己分析。
查询 ='On+random+graph'。来自:/bbs
网址 ='#x27; + 查询 +'&btnG=&as_sdt=1%2C5&as_sdtp='
设置头文件。爬取一些网页不需要专门设置头文件,但是如果你不在这里设置,谷歌会认为机器人无法访问它。另外,一些网站被访问并设置了cookies。这个比较复杂,这里暂时不提。关于如何知道头文件怎么写,有的插件可以看到你的浏览器和网站交互的头文件(很多浏览器都内置了这种工具),我用的是firebug插件- 在 Firefox 中。
header = {'Host':'',
'用户代理':'Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0 ',
'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8',
'接受编码':'gzip,放气',
'连接':'保持活动'}
建立连接请求。这时候谷歌服务器将页面信息返回给变量con,该变量是一个对象
req = urllib2.Request(url, headers = header)
con = urllib2.urlopen(req)
在con对象上调用read()方法,返回html页面,即带有html标签的纯文本
doc = con.read()
关闭连接。就像读取文件后关闭文件一样,如果不关闭它,有时可以,但有时会出现问题。因此,作为一个遵纪守法的好公民,最好是关闭联系。
关闭()
复制上面的代码,将在googlescholar上查询On Random Graph的结果返回给变量doc,这和打开googlescholar搜索On Random Graph,然后右击页面保存一样。
步骤三、 解析网页
以上步骤获取网页信息,但收录html标签。你需要去掉这些标签,然后从html文本中整理出有用的信息。您需要解析网页。解析网页的方法:(1)正则表达式。正则表达式很有用。熟悉了可以节省很多时间。有时候清洗数据不需要写脚本或者查询数据库,直接使用正则表达式notepad++上的组合就用吧。学习正则表达式的建议:30分钟正则表达式介绍,链接:(2) BeautifulSoup模块。BeautifulSoup是一个非常强大的模块,可以将html文件解析为对象,这个对象是一棵树,我们都知道HTML文件是树形的,比如body -> table -> tbody -> tr,对于节点tbody,有很多 tr 子节点。BeautifulSoup 可以轻松获取特定节点,对于单个节点,也可以使用其兄弟节点。网上有很多相关的说明。此处不再赘述,只演示一个简单的代码:(3) 以上两种方法结合使用。
导入BeautifulSoup模块和re模块,re是python中的正则表达式模块
进口美汤
进口重新
生成一个soup对象,doc在第二步有提到
汤 = BeautifulSoup.BeautifulSoup(doc)
获取论文的标题、作者、简短描述、引用次数、版本数以及指向引用它的 文章 列表的超链接。这里也用到了一些正则表达式。不熟悉的人对它一无所知。至于'class':'gs_rt'中的'gs_rt'是怎么来的?这可以通过肉眼分析html文件看出。上面提到的firebug插件让这一切变得非常简单。只需要一个小小的网页就可以知道对应的html标签的位置和属性,非常好用。. 访问更多。
paper_name = soup.html.body.find('h3', {'class' : 'gs_rt'}).text
paper_name = re.sub(r'\[.*\]', '', paper_name) # eliminate '[]' tags like '[PDF]'
paper_author = soup.html.body.find('div', {'class' : 'gs_a'}).text
paper_desc = soup.html.body.find('div', {'class' : 'gs_rs'}).text
temp_str = soup.html.body.find('div', {'class' : 'gs_fl'}).text
temp_re = re.match(r'[A-Za-z\s]+(\d*)[A-Za-z\s]+(\d*)', temp_str)
citeTimes = temp_re.group(1)
versionNum = temp_re.group(2)
if citeTimes == '':
citeTimes = '0'
if versionNum == '':
versionNum = '0'
citedPaper_href = soup.html.body.find('div', {'class' : 'gs_fl'}).a.attrs[0][1]
这些是我正在分析引文网络的项目的代码。顺便说一下,我从googlescholar那里抓取了论文信息和引文列表信息,在访问了大约1900次后交给了google block,导致这个区的ip暂时无法登录googlescholar。
第 4 步:访问数据
最后抓取到数据后,只存储在内存中,必须保存后才能使用。(1) 最简单的将数据写入txt文件的方法可以用Python实现,代码如下:
打开文件 webdata.txt 并生成目标文件。该文件可能不存在。参数 a 表示添加它。还有其他参数,如'r'只能读不能写,'w'可以写但原创记录将被删除等。
file = open('webdata.txt','a')
line = paper_name + '#' + paper_author + '#' + paper_desc + '#' + citeTimes + '\n'
# 对象file的write方法将字符串line写入file中
file = file.write(line)-google 1point3acres
# 再一次的,做个随手关闭文件的好青年
file.close()
这样,从网页中抓取并解析出来的数据就存储在本地了。是不是很简单?(2)当然也可以直接连接数据库,而不是写入txt文件。python中的MySQLdb模块可以和MySQL数据库交互,直接将数据倒入数据库,并与MySQL数据库的逻辑类似于与网站服务器建立链接的逻辑,如果之前学过数据库,学习使用MySQLdb模块与数据库进行交互是很简单的;如果不是,必须用coursera[stanford]() 数据库介绍是在openEdX平台上设置的,用于系统学习,w3school作为参考或者作为手册使用。Python可以链接数据库的前提是数据库是打开,我用的是win7 + MySQL<
%可以用cmd开启数据库,启动命令是:
net start mysql55 [1point3acres.com/bbs](http://1point3acres.com/bbs)
%关闭命令是:
net stop mysql55
使用 MySQLdb 模块代码的示例:
# 导入 MySQLdb模块
import MySQLdb
# 和服务器建立链接,host是服务器ip,我的MySQL数据库搭建在本机,默认的是127.0.0.1,
# 用户、密码、数据库名称对应着照输就行了,默认的端口号是3306,charset是编码方式,
# 默认的是utf8(也有可能是gbk,看安装的版本)。
conn = MySQLdb.connect(host='127.0.0.1', user='root', passwd='yourPassword', db='dbname', port=3306, charset='utf8')
# 建立cursor
cur = conn.cursor()
# 通过对象cur的execute()方法执行SQL语句
cur.execute("select * from citeRelation where paperName = 'On Random Graph'")
# fetchall()方法获得查询结果,返回的是一个list,可以直接这样查询:list[i][j],
# i表示查询结果中的第i+1条record,j表示这条记录的第j+1个attribute(别忘了python从0开始计数)
list = cur.fetchall()
# 也可以进行delete,drop,insert,update等操作,比如:
sql = "update studentCourseRecord set fail = 1 where studentID = '%s' and semesterID = '%s' and courseID = '%s'" %(studentID,course[0],course[1])
cur.execute(sql)
# 与查询不同的是,执行完delete,insert,update这些语句后必须执行下面的命令才能成功更新数据库
conn.commit()
# 一如既往的,用完了之后记得关闭cursor,然后关闭链接
cur.close()
conn.close()
这样就实现了Python和数据库的交互。除了 MySQL 数据库,python 的 PyGreSQL 模块可以支持 postgreSQL 数据库,道理类似。另外,如果你的网页收录中文,设置编码格式会很麻烦。需要对服务器、Python、数据库和数据库接口使用相同的编码格式,以避免出现乱码。如果出现中文乱码问题,请相信你不是一个人!!去google吧,成千上万的人都遇到过这种问题。关于编码问题,附上我看到的一篇博文
:
后记:
上面介绍了抓取网页数据的方法。数据只是一小步。如何分析数据是大学的问题。欢迎讨论。以上有不清楚的地方,欢迎交流。
**请注意:
网站的大规模爬取会给网站的服务器带来很大的压力。尽量选择服务器比较放松的时间(比如清晨)。网站很多,不要用一亩三分地作为实验。
Python的time模块的sleep()方法可以让程序暂停一段时间,比如time.sleep(1)让程序在这里运行时暂停1秒。及时暂停可以缓解给服务器压力,保护好自己。只要睡久了,或者去健身房,结果就出来了。**
更新:2014年2月15日,修改了几个打字错误;添加了相关课程链接;加入udacity CS101;添加了 MySQLdb 模块的介绍。2014 年 2 月 16 日,添加了指向介绍编码方法的博客文章的链接。 查看全部
谷歌抓取网页视频教程(如何上手视编程基础而定?(一)(图))
**前言:** 数据科学越来越流行,网页是一个巨大的数据来源。最近,很多人问如何抓取网页数据。据我所知,常见的编程语言(C++、java、python)都可以实现网页数据的抓取,甚至很多统计\计算语言(R、Matlab)都可以实现和网站交互包。尝试过用java、python、R来抓取网页,感觉语法不一样,逻辑是一样的。我打算用python讲一下网页爬虫的概念。具体内容还得看说明书或者google别人的博客。这是一个好主意。水平有限,有错误或者有更好的方法,欢迎讨论。**步骤 1:熟悉 Python 的基本语法。
**。更多信息
如果您已经熟悉 Python,请跳至第二步。
Python是一门比较容易上手的编程语言,如何上手取决于编程的基础。(1)如果你有一定的编程基础,建议看google的python课,链接这是一个为期两天的短期培训课程(当然是两天一整天),大约7个视频,每个视频后为编程作业,每个作业一个小时内可以完成。这是我学习python的第二课(第一门是codecademy上的python,很久以前看过,很多内容记不清了),我天天看视频+编程作业一个多小时,六天做完,效果还不错,python写基本程序没有问题。
(2)如果你没有任何编程基础,我建议你看看莱斯大学在coursera上开的An Introduction to Interactive Programming in Python。我没有关注过这门课程,但是coursetalk上的评论反映的很嗯。也有同学在评论(点这里),课程链接:Udacity上的.CS101也是不错的选择,地上有相关的讨论帖(点这里),这门课叫做build a search engine,里面会专门讲一些网络相关的模块。
其他学习资源包括代码学校和代码学院。这些资源也不错,但是编程量太少,初学者要系统的跟上课,多练习,打好基础。当然,每个人的喜好不同,我推荐的不一定适合你。你可以看看这个帖子【长期红利帖】介绍你上过的公开课
其他人在里面说什么,或者看看课程评论并决定。
第二步:学习如何与网站建立链接,获取网页数据。
编写脚本与网站进行交互,你必须熟悉python和网页相关的几个模块(urllib、urllib2、httplib)之一,知道一个,其他类似。这三个是python提供的与网页交互的基本模块,还有其他的,比如:mechanize和scrapy,我没用过,可能性能更好,欢迎学习补充。对于基本的网络爬虫,前三个模块就足够了。下面的代码演示了如何使用urllib2与Google Scholar交互获取网页信息。
导入模块 urllib2
导入 urllib2
随意查询 文章,例如 On random graph。每个查询googlescholar都有一个url,这个url形成的规则需要自己分析。
查询 ='On+random+graph'。来自:/bbs
网址 ='#x27; + 查询 +'&btnG=&as_sdt=1%2C5&as_sdtp='
设置头文件。爬取一些网页不需要专门设置头文件,但是如果你不在这里设置,谷歌会认为机器人无法访问它。另外,一些网站被访问并设置了cookies。这个比较复杂,这里暂时不提。关于如何知道头文件怎么写,有的插件可以看到你的浏览器和网站交互的头文件(很多浏览器都内置了这种工具),我用的是firebug插件- 在 Firefox 中。
header = {'Host':'',
'用户代理':'Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0 ',
'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8',
'接受编码':'gzip,放气',
'连接':'保持活动'}
建立连接请求。这时候谷歌服务器将页面信息返回给变量con,该变量是一个对象
req = urllib2.Request(url, headers = header)
con = urllib2.urlopen(req)
在con对象上调用read()方法,返回html页面,即带有html标签的纯文本
doc = con.read()
关闭连接。就像读取文件后关闭文件一样,如果不关闭它,有时可以,但有时会出现问题。因此,作为一个遵纪守法的好公民,最好是关闭联系。
关闭()
复制上面的代码,将在googlescholar上查询On Random Graph的结果返回给变量doc,这和打开googlescholar搜索On Random Graph,然后右击页面保存一样。
步骤三、 解析网页
以上步骤获取网页信息,但收录html标签。你需要去掉这些标签,然后从html文本中整理出有用的信息。您需要解析网页。解析网页的方法:(1)正则表达式。正则表达式很有用。熟悉了可以节省很多时间。有时候清洗数据不需要写脚本或者查询数据库,直接使用正则表达式notepad++上的组合就用吧。学习正则表达式的建议:30分钟正则表达式介绍,链接:(2) BeautifulSoup模块。BeautifulSoup是一个非常强大的模块,可以将html文件解析为对象,这个对象是一棵树,我们都知道HTML文件是树形的,比如body -> table -> tbody -> tr,对于节点tbody,有很多 tr 子节点。BeautifulSoup 可以轻松获取特定节点,对于单个节点,也可以使用其兄弟节点。网上有很多相关的说明。此处不再赘述,只演示一个简单的代码:(3) 以上两种方法结合使用。
导入BeautifulSoup模块和re模块,re是python中的正则表达式模块
进口美汤
进口重新
生成一个soup对象,doc在第二步有提到
汤 = BeautifulSoup.BeautifulSoup(doc)
获取论文的标题、作者、简短描述、引用次数、版本数以及指向引用它的 文章 列表的超链接。这里也用到了一些正则表达式。不熟悉的人对它一无所知。至于'class':'gs_rt'中的'gs_rt'是怎么来的?这可以通过肉眼分析html文件看出。上面提到的firebug插件让这一切变得非常简单。只需要一个小小的网页就可以知道对应的html标签的位置和属性,非常好用。. 访问更多。
paper_name = soup.html.body.find('h3', {'class' : 'gs_rt'}).text
paper_name = re.sub(r'\[.*\]', '', paper_name) # eliminate '[]' tags like '[PDF]'
paper_author = soup.html.body.find('div', {'class' : 'gs_a'}).text
paper_desc = soup.html.body.find('div', {'class' : 'gs_rs'}).text
temp_str = soup.html.body.find('div', {'class' : 'gs_fl'}).text
temp_re = re.match(r'[A-Za-z\s]+(\d*)[A-Za-z\s]+(\d*)', temp_str)
citeTimes = temp_re.group(1)
versionNum = temp_re.group(2)
if citeTimes == '':
citeTimes = '0'
if versionNum == '':
versionNum = '0'
citedPaper_href = soup.html.body.find('div', {'class' : 'gs_fl'}).a.attrs[0][1]
这些是我正在分析引文网络的项目的代码。顺便说一下,我从googlescholar那里抓取了论文信息和引文列表信息,在访问了大约1900次后交给了google block,导致这个区的ip暂时无法登录googlescholar。
第 4 步:访问数据
最后抓取到数据后,只存储在内存中,必须保存后才能使用。(1) 最简单的将数据写入txt文件的方法可以用Python实现,代码如下:
打开文件 webdata.txt 并生成目标文件。该文件可能不存在。参数 a 表示添加它。还有其他参数,如'r'只能读不能写,'w'可以写但原创记录将被删除等。
file = open('webdata.txt','a')
line = paper_name + '#' + paper_author + '#' + paper_desc + '#' + citeTimes + '\n'
# 对象file的write方法将字符串line写入file中
file = file.write(line)-google 1point3acres
# 再一次的,做个随手关闭文件的好青年
file.close()
这样,从网页中抓取并解析出来的数据就存储在本地了。是不是很简单?(2)当然也可以直接连接数据库,而不是写入txt文件。python中的MySQLdb模块可以和MySQL数据库交互,直接将数据倒入数据库,并与MySQL数据库的逻辑类似于与网站服务器建立链接的逻辑,如果之前学过数据库,学习使用MySQLdb模块与数据库进行交互是很简单的;如果不是,必须用coursera[stanford]() 数据库介绍是在openEdX平台上设置的,用于系统学习,w3school作为参考或者作为手册使用。Python可以链接数据库的前提是数据库是打开,我用的是win7 + MySQL<
%可以用cmd开启数据库,启动命令是:
net start mysql55 [1point3acres.com/bbs](http://1point3acres.com/bbs)
%关闭命令是:
net stop mysql55
使用 MySQLdb 模块代码的示例:
# 导入 MySQLdb模块
import MySQLdb
# 和服务器建立链接,host是服务器ip,我的MySQL数据库搭建在本机,默认的是127.0.0.1,
# 用户、密码、数据库名称对应着照输就行了,默认的端口号是3306,charset是编码方式,
# 默认的是utf8(也有可能是gbk,看安装的版本)。
conn = MySQLdb.connect(host='127.0.0.1', user='root', passwd='yourPassword', db='dbname', port=3306, charset='utf8')
# 建立cursor
cur = conn.cursor()
# 通过对象cur的execute()方法执行SQL语句
cur.execute("select * from citeRelation where paperName = 'On Random Graph'")
# fetchall()方法获得查询结果,返回的是一个list,可以直接这样查询:list[i][j],
# i表示查询结果中的第i+1条record,j表示这条记录的第j+1个attribute(别忘了python从0开始计数)
list = cur.fetchall()
# 也可以进行delete,drop,insert,update等操作,比如:
sql = "update studentCourseRecord set fail = 1 where studentID = '%s' and semesterID = '%s' and courseID = '%s'" %(studentID,course[0],course[1])
cur.execute(sql)
# 与查询不同的是,执行完delete,insert,update这些语句后必须执行下面的命令才能成功更新数据库
conn.commit()
# 一如既往的,用完了之后记得关闭cursor,然后关闭链接
cur.close()
conn.close()
这样就实现了Python和数据库的交互。除了 MySQL 数据库,python 的 PyGreSQL 模块可以支持 postgreSQL 数据库,道理类似。另外,如果你的网页收录中文,设置编码格式会很麻烦。需要对服务器、Python、数据库和数据库接口使用相同的编码格式,以避免出现乱码。如果出现中文乱码问题,请相信你不是一个人!!去google吧,成千上万的人都遇到过这种问题。关于编码问题,附上我看到的一篇博文
:
后记:
上面介绍了抓取网页数据的方法。数据只是一小步。如何分析数据是大学的问题。欢迎讨论。以上有不清楚的地方,欢迎交流。
**请注意:
网站的大规模爬取会给网站的服务器带来很大的压力。尽量选择服务器比较放松的时间(比如清晨)。网站很多,不要用一亩三分地作为实验。
Python的time模块的sleep()方法可以让程序暂停一段时间,比如time.sleep(1)让程序在这里运行时暂停1秒。及时暂停可以缓解给服务器压力,保护好自己。只要睡久了,或者去健身房,结果就出来了。**
更新:2014年2月15日,修改了几个打字错误;添加了相关课程链接;加入udacity CS101;添加了 MySQLdb 模块的介绍。2014 年 2 月 16 日,添加了指向介绍编码方法的博客文章的链接。
谷歌抓取网页视频教程(谷歌抓取网页视频教程:js打开html_swf播放视频解码视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-25 02:03
谷歌抓取网页视频教程如下:selenium打开网页抓取视频selenium3打开视频解码视频教程如下:selenium3。js打开swf播放视频教程如下:selenium3。js打开html_swf视频解码selenium3。js打开全屏视频抓取教程如下:selenium3。js打开html_swf播放视频。
安利一个javascript破解谷歌视频网页解析包!我遇到的问题也是这个。希望对你有帮助。因为每个浏览器的实现并不相同,所以我仅介绍一下javascript的实现。首先,在开始视频下载之前要用到谷歌浏览器javascripttutorial(2019+)中的代码:this.files.indexof('html')=='application/json',=>true并且要引入需要下载的视频。
如果下载的视频为json的,如mp4,格式如json.json(x)['name']['video']我们首先要用到的是lasterror对象。this.lasterror=function(){letresult="";//这里是一个索引,回车后开始计算从第一次indexof引用的索引开始else{result="";result="";//所以,回车后再点击enter键的话,就进入url请求当中}}console.log(result);现在我们来说说谷歌下载。
方法也比较简单:打开谷歌浏览器,用浏览器上的控制台,把download.js这段代码添加到脚本里面,就可以保存视频了。如下所示:当然,如果你希望直接打开谷歌浏览器就可以看到视频,打开safari也是可以的。我这里用的是youtube,因为本来就是最近新出的站点。当然,我们也可以使用mp4的格式。关于如何制作动态网页脚本,建议参见网上视频。 查看全部
谷歌抓取网页视频教程(谷歌抓取网页视频教程:js打开html_swf播放视频解码视频)
谷歌抓取网页视频教程如下:selenium打开网页抓取视频selenium3打开视频解码视频教程如下:selenium3。js打开swf播放视频教程如下:selenium3。js打开html_swf视频解码selenium3。js打开全屏视频抓取教程如下:selenium3。js打开html_swf播放视频。
安利一个javascript破解谷歌视频网页解析包!我遇到的问题也是这个。希望对你有帮助。因为每个浏览器的实现并不相同,所以我仅介绍一下javascript的实现。首先,在开始视频下载之前要用到谷歌浏览器javascripttutorial(2019+)中的代码:this.files.indexof('html')=='application/json',=>true并且要引入需要下载的视频。
如果下载的视频为json的,如mp4,格式如json.json(x)['name']['video']我们首先要用到的是lasterror对象。this.lasterror=function(){letresult="";//这里是一个索引,回车后开始计算从第一次indexof引用的索引开始else{result="";result="";//所以,回车后再点击enter键的话,就进入url请求当中}}console.log(result);现在我们来说说谷歌下载。
方法也比较简单:打开谷歌浏览器,用浏览器上的控制台,把download.js这段代码添加到脚本里面,就可以保存视频了。如下所示:当然,如果你希望直接打开谷歌浏览器就可以看到视频,打开safari也是可以的。我这里用的是youtube,因为本来就是最近新出的站点。当然,我们也可以使用mp4的格式。关于如何制作动态网页脚本,建议参见网上视频。
谷歌抓取网页视频教程(对换软件安装DeepFaceLab软件使用教程进阶教程(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-09-24 18:17
对于刚入门的人来说,在对换脸黑科技充满兴趣的同时,可能对如何入门充满疑惑。
软件从哪里获取,如何安装,如何使用,这些都成了我心中的问候。有些人可能已经阅读了一些教程,但不明白......
那么下面的内容非常适合你。下面的教程会一步一步的给大家讲解,并准备好所有涉及的软件。
为了完整呈现这些软件的安装和使用过程,花了很多时间,希望对大家有所帮助。
DeepFaceLab 1.0 入门教程:DeepFaceLab 软件介绍 DeepFaceLab 软件安装 DeepFaceLab 软件使用人脸提取 模型训练详解 导出视频详解
620版教程
DeepFaceLab 2.0 入门教程:
20200420版视频教程(新)
20200203版教程
DeepFaceLab 进阶教程:
*部分付费文章 我已经把它们都放在了知识星球上,我无法在微信上更改价格。加入星球获取更划算。有什么不明白的可以直接发帖提问,我会尽力解答!
OpenFaceSwap 入门教程:
软件安装软件使用软件参数
Fakeapp入门教程:
软件安装软件使用软件参数
如果有不明白的地方,或者在教程中发现错误,可以留言!也可以加入官方交流群:659480116。群里有老司机! 查看全部
谷歌抓取网页视频教程(对换软件安装DeepFaceLab软件使用教程进阶教程(一))
对于刚入门的人来说,在对换脸黑科技充满兴趣的同时,可能对如何入门充满疑惑。
软件从哪里获取,如何安装,如何使用,这些都成了我心中的问候。有些人可能已经阅读了一些教程,但不明白......
那么下面的内容非常适合你。下面的教程会一步一步的给大家讲解,并准备好所有涉及的软件。
为了完整呈现这些软件的安装和使用过程,花了很多时间,希望对大家有所帮助。
https://deepfakescn.oss-cn-hon ... edium 300w, https://deepfakescn.oss-cn-hon ... large 768w, https://deepfakescn.oss-cn-hon ... large 1024w" />DeepFaceLab 1.0 入门教程:DeepFaceLab 软件介绍 DeepFaceLab 软件安装 DeepFaceLab 软件使用人脸提取 模型训练详解 导出视频详解
620版教程
DeepFaceLab 2.0 入门教程:
20200420版视频教程(新)
20200203版教程
DeepFaceLab 进阶教程:
https://deepfakescn.oss-cn-hon ... edium 300w, https://deepfakescn.oss-cn-hon ... large 768w, https://deepfakescn.oss-cn-hon ... large 1024w" />*部分付费文章 我已经把它们都放在了知识星球上,我无法在微信上更改价格。加入星球获取更划算。有什么不明白的可以直接发帖提问,我会尽力解答!
OpenFaceSwap 入门教程:
https://deepfakescn.oss-cn-hon ... 04/QQ截图20190409160107.jpg@!medium 300w, https://deepfakescn.oss-cn-hon ... 04/QQ截图20190409160107.jpg@!medium_large 768w, https://deepfakescn.oss-cn-hon ... 04/QQ截图20190409160107.jpg@!large 1024w" />软件安装软件使用软件参数
Fakeapp入门教程:
https://deepfakescn.oss-cn-hon ... 05/QQ截图20190507201731.jpg@!medium 300w, https://deepfakescn.oss-cn-hon ... 05/QQ截图20190507201731.jpg@!medium_large 768w, https://deepfakescn.oss-cn-hon ... 05/QQ截图20190507201731.jpg@!large 1024w" />软件安装软件使用软件参数
如果有不明白的地方,或者在教程中发现错误,可以留言!也可以加入官方交流群:659480116。群里有老司机!
谷歌抓取网页视频教程(seo站外优化方法网站seo优化,搜外seo视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-09-24 05:06
第五课:seo异地优化方法网站seo优化,包括异地seo优化和站内seo优化,搜外seo视频教程第五课主要讲解seo异地优化方法,包括相应的网站提交给各大搜索引擎的搜索引擎时,如何查看网站的seo收录的状态,如何[…]
第五课:站外seo优化方法
网站seo优化,包括站外seo优化和站内seo优化,搜外seo视频教程第五课主要讲解seo站外优化方法,包括适当的时候主动提交网址给各大搜索者搜索引擎,如何查询网站的seo收录情况,如何做异地锚文本,如何准确查询外链,如何查询网站的权重,seo同学们可以按照步骤在线观看。其实这个搜外全套seo视频教程还有“seo异地优化方法”不完整。注:本seo视频教程录制时间较长,并非最新的seo视频教程。
一、 适时主动提交网址给各大搜索引擎的搜索引擎。
那么网站应该什么时候提交给搜索引擎呢?在提交到搜索引擎之前,需要添加网站的基本内容,比如确定网站的标题和描述,以及网站的构建,但应该是需要注意的是不要等到网站全部添加完内容后再提交。建议每栏加一两个文章,然后提交到搜索引擎即可。
二、如何查看网站的seo收录情况。
将网址提交到搜索引擎后,百度收录首页的时间一般在两到三天内。在收录首页之后,百度会有一个新站点的评估期,称为沙盒。经期,这个时期一般是两到三周。在此期间,百度不会将您的内部页面编入索引,而是会对您的网站内容进行评估。因此,在沙盒阶段网站 内容更新必须到位。一些高质量的文章可以提升网站内页收录的速度。这段时间做一些外链来吸引蜘蛛爬行,也可以缩短内页。收录 时期。网站查询收录的情况有多种方式。下面是小松常用的三种方法:
1、站点:+网站域名。在百度搜索栏中输入本站命令,您将看到百度收录网站的页面。
2、百度站长平台百度索引量查询地址:这里可以在网站页面看到百度收录的状态,也可以看到收录的变化从折线图条件。
3、站长工具查询:该工具可以查询百度、谷歌、36个0、搜狗的收录以及反链数。网站管理员应该使用它。
在查询收录的时候,有时会发现一些问题。具体情况和大家一起分析一下。
1、网站搜索结果首页不在首位
关于这个问题,很多人认为首页不是放在第一位的,所以网站肯定是被降级了。很多站长在交流感情链接的时候,也有的要求网站查询结果首页放在第一位。少量。那么这个观点正确吗?当然是不正确的,只是举个例子来证明:
站点:,搜索结果如下:
seo视频教程:如何查看百度网站的seo收录情况
可以看出,在查询结果中,百度图片排名第一,百度知道第二,而百度首页排名第三,百度百科排名第四。因此,这种观点是弄巧成拙的。
2、Web 快照不更新甚至倒退
小松之前在《什么是百度快照?为什么我的网站百度快照没有更新?》这篇文章已经详细说明了百度快照更新的问题。不知道的同学快照更新或倒退的原因可以查看。
3、为什么网站收录有时会减少
很多站长朋友都会遇到这个问题。有时候百度收录的量不会增加,反而会减少。这是什么原因造成的?一个原因是您的 网站 中有几个不同的链接指向一个页面。之前百度收录这些链接地址,但是百度识别出来后,会删除一些地址。只剩下一个了。还有一种情况是网站的内页相似度太高。您可能已经看到,网站 的某些产品页面可能会达到 90% 的相似度。那么,这样的页面百度就会减少内页的数量。收录 的数量。
三、站外锚文本如何制作?
站外锚文本也是老式的外链。在做外链的时候,应该注意以下几个方面:
1、 锚文本应该不断增加,而不是一次增加很多。很多站长都渴望快速排名,给网站做了很多外链,然后忽略了外链。部分内容出来了,这个做法不对。一是效果不好,二是百度可能认为你在作弊,会对网站造成不良影响。
2、 锚文本应该是多样化的,而不是只有一个关键词。
3、网站发出的链接应该是多样化的,而不是一两个网站。
站外锚文本的制作方式有很多种,比如友情链接、自建博客、论坛签名、博客留言、留言板等。
四、如何准确查询外链。
教程中推荐使用雅虎查询:(中文站)(中文站)
五、如何查询网站权重。
有很多权重查询工具。小松更喜欢使用站长工具和爱站的网站综合查询。这个因人而异,一般来说,不同类型的网站能得到的pr值也不同。pr值与网站、外链、内链的时间有关。视频里有详细的解释,这里不再赘述。下面给出教程的下载地址。 查看全部
谷歌抓取网页视频教程(seo站外优化方法网站seo优化,搜外seo视频教程)
第五课:seo异地优化方法网站seo优化,包括异地seo优化和站内seo优化,搜外seo视频教程第五课主要讲解seo异地优化方法,包括相应的网站提交给各大搜索引擎的搜索引擎时,如何查看网站的seo收录的状态,如何[…]
第五课:站外seo优化方法
网站seo优化,包括站外seo优化和站内seo优化,搜外seo视频教程第五课主要讲解seo站外优化方法,包括适当的时候主动提交网址给各大搜索者搜索引擎,如何查询网站的seo收录情况,如何做异地锚文本,如何准确查询外链,如何查询网站的权重,seo同学们可以按照步骤在线观看。其实这个搜外全套seo视频教程还有“seo异地优化方法”不完整。注:本seo视频教程录制时间较长,并非最新的seo视频教程。
一、 适时主动提交网址给各大搜索引擎的搜索引擎。
那么网站应该什么时候提交给搜索引擎呢?在提交到搜索引擎之前,需要添加网站的基本内容,比如确定网站的标题和描述,以及网站的构建,但应该是需要注意的是不要等到网站全部添加完内容后再提交。建议每栏加一两个文章,然后提交到搜索引擎即可。
二、如何查看网站的seo收录情况。
将网址提交到搜索引擎后,百度收录首页的时间一般在两到三天内。在收录首页之后,百度会有一个新站点的评估期,称为沙盒。经期,这个时期一般是两到三周。在此期间,百度不会将您的内部页面编入索引,而是会对您的网站内容进行评估。因此,在沙盒阶段网站 内容更新必须到位。一些高质量的文章可以提升网站内页收录的速度。这段时间做一些外链来吸引蜘蛛爬行,也可以缩短内页。收录 时期。网站查询收录的情况有多种方式。下面是小松常用的三种方法:
1、站点:+网站域名。在百度搜索栏中输入本站命令,您将看到百度收录网站的页面。
2、百度站长平台百度索引量查询地址:这里可以在网站页面看到百度收录的状态,也可以看到收录的变化从折线图条件。
3、站长工具查询:该工具可以查询百度、谷歌、36个0、搜狗的收录以及反链数。网站管理员应该使用它。
在查询收录的时候,有时会发现一些问题。具体情况和大家一起分析一下。
1、网站搜索结果首页不在首位
关于这个问题,很多人认为首页不是放在第一位的,所以网站肯定是被降级了。很多站长在交流感情链接的时候,也有的要求网站查询结果首页放在第一位。少量。那么这个观点正确吗?当然是不正确的,只是举个例子来证明:
站点:,搜索结果如下:
seo视频教程:如何查看百度网站的seo收录情况
可以看出,在查询结果中,百度图片排名第一,百度知道第二,而百度首页排名第三,百度百科排名第四。因此,这种观点是弄巧成拙的。
2、Web 快照不更新甚至倒退
小松之前在《什么是百度快照?为什么我的网站百度快照没有更新?》这篇文章已经详细说明了百度快照更新的问题。不知道的同学快照更新或倒退的原因可以查看。
3、为什么网站收录有时会减少
很多站长朋友都会遇到这个问题。有时候百度收录的量不会增加,反而会减少。这是什么原因造成的?一个原因是您的 网站 中有几个不同的链接指向一个页面。之前百度收录这些链接地址,但是百度识别出来后,会删除一些地址。只剩下一个了。还有一种情况是网站的内页相似度太高。您可能已经看到,网站 的某些产品页面可能会达到 90% 的相似度。那么,这样的页面百度就会减少内页的数量。收录 的数量。
三、站外锚文本如何制作?
站外锚文本也是老式的外链。在做外链的时候,应该注意以下几个方面:
1、 锚文本应该不断增加,而不是一次增加很多。很多站长都渴望快速排名,给网站做了很多外链,然后忽略了外链。部分内容出来了,这个做法不对。一是效果不好,二是百度可能认为你在作弊,会对网站造成不良影响。
2、 锚文本应该是多样化的,而不是只有一个关键词。
3、网站发出的链接应该是多样化的,而不是一两个网站。
站外锚文本的制作方式有很多种,比如友情链接、自建博客、论坛签名、博客留言、留言板等。
四、如何准确查询外链。
教程中推荐使用雅虎查询:(中文站)(中文站)
五、如何查询网站权重。
有很多权重查询工具。小松更喜欢使用站长工具和爱站的网站综合查询。这个因人而异,一般来说,不同类型的网站能得到的pr值也不同。pr值与网站、外链、内链的时间有关。视频里有详细的解释,这里不再赘述。下面给出教程的下载地址。
谷歌抓取网页视频教程(谷歌抓取网页视频教程,非本人原创,仅是整理分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-23 12:03
谷歌抓取网页视频教程,非本人原创,仅是整理分享,如有侵权请联系删除,没有wordpress空间的可以用nexthost模板做站,nexthost也是经过大量人手整理的,性价比高,功能强大,业余制作者非常友好的网站场景开发平台。
谷歌抓取规则一般还是要懂点代码知识。第三方制作平台或者wordpress上专门有pr抓取这个功能,但不全面。推荐你个简单的方法:打开自己域名后缀的网页或视频页面,抓取到后让它replace。而且越是小众网站replace得越精准,抓得越快,必须抓完视频必须replace。ftp很强大,让replace变得很容易,一键就抓取了,在线也好在本地也好,手动抓也好都方便,本身就是搞机器学习模型自动抓。
另外我个人开发了一个跟youtube类似的抓取的c++版本的模版,xxtorrent-youtubetruedownload。支持ftp也支持bt,欢迎做抓取应用的加入。
谷歌采集需要精准的地址,才能采到想要的内容,如果技术好可以自己写爬虫。抓取软件有很多,如果你懂asp+as也可以用so框架写一个,抓取的量再大一点,可以用excel去处理。然后很多数据接口都可以抓。这是比较容易的一个了,技术难度不大,开发者可以用本身的模块,如python3+谷歌地址抓取插件等。我知道的3-5-m可以的都有。
还有一个好处是可以二次开发,可以自己编写一个。数据或者视频都是可以抓取的,前提你懂的采集代码。自己写好爬虫,然后按照需求二次开发,国内外一般都能找到开发者的。如果外部软件实在是做的好了,可以考虑收购他们,毕竟除了编写爬虫很难找到合适的。而且还有自己的第三方软件专门做这个。当然,你还可以和国内的一些资源提供商合作,让他们抓取你的视频,然后自己再把视频放出来。所以,当你想实现一些功能的时候,你可以自己搭一套适合的平台,然后二次开发。否则直接写爬虫还是不方便。 查看全部
谷歌抓取网页视频教程(谷歌抓取网页视频教程,非本人原创,仅是整理分享)
谷歌抓取网页视频教程,非本人原创,仅是整理分享,如有侵权请联系删除,没有wordpress空间的可以用nexthost模板做站,nexthost也是经过大量人手整理的,性价比高,功能强大,业余制作者非常友好的网站场景开发平台。
谷歌抓取规则一般还是要懂点代码知识。第三方制作平台或者wordpress上专门有pr抓取这个功能,但不全面。推荐你个简单的方法:打开自己域名后缀的网页或视频页面,抓取到后让它replace。而且越是小众网站replace得越精准,抓得越快,必须抓完视频必须replace。ftp很强大,让replace变得很容易,一键就抓取了,在线也好在本地也好,手动抓也好都方便,本身就是搞机器学习模型自动抓。
另外我个人开发了一个跟youtube类似的抓取的c++版本的模版,xxtorrent-youtubetruedownload。支持ftp也支持bt,欢迎做抓取应用的加入。
谷歌采集需要精准的地址,才能采到想要的内容,如果技术好可以自己写爬虫。抓取软件有很多,如果你懂asp+as也可以用so框架写一个,抓取的量再大一点,可以用excel去处理。然后很多数据接口都可以抓。这是比较容易的一个了,技术难度不大,开发者可以用本身的模块,如python3+谷歌地址抓取插件等。我知道的3-5-m可以的都有。
还有一个好处是可以二次开发,可以自己编写一个。数据或者视频都是可以抓取的,前提你懂的采集代码。自己写好爬虫,然后按照需求二次开发,国内外一般都能找到开发者的。如果外部软件实在是做的好了,可以考虑收购他们,毕竟除了编写爬虫很难找到合适的。而且还有自己的第三方软件专门做这个。当然,你还可以和国内的一些资源提供商合作,让他们抓取你的视频,然后自己再把视频放出来。所以,当你想实现一些功能的时候,你可以自己搭一套适合的平台,然后二次开发。否则直接写爬虫还是不方便。
谷歌抓取网页视频教程(如何使用谷歌ChromeHeadless创建PDF的网页页面的屏幕截图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-09-21 01:09
要求:
您必须使用Google Chrome 59或更高版本。
和谷歌版本的Chrome 59仅适用于Mac OS和Linux用户。
Windows用户还需要等一段时间。
捕获屏幕截图:
使用以下命令捕获给定网页的屏幕截图。
输出文件将在当前目录中创建,名为screenshot.png。
google-chrome --headless --disable-gpu --screenshot http://www.example.com/
您还可以使用“--window-size”选项指定屏幕截图的大小,如下所示。
google-chrome --headless --disable-gpu --window-size=1280,768 --screenshot http://www.example.com/
我们还可以指定'--screenshot = file1输出文件名的位置。
创建特定名称。
如何使用Google Chrome捕获网页屏幕截图
Google Chrome 59和新版本包括一个新功能,它提供了在不需要用户界面的情况下运行Google Chrome的功能。
这允许用户在命令行和脚本中使用Google Chrome。
这个无头Google Chrome版本还收录使用命令行工具捕获任何网站屏幕截图的功能。
如何创建PDF的网页
在Google Chrome中无头 查看全部
谷歌抓取网页视频教程(如何使用谷歌ChromeHeadless创建PDF的网页页面的屏幕截图)
要求:
您必须使用Google Chrome 59或更高版本。
和谷歌版本的Chrome 59仅适用于Mac OS和Linux用户。
Windows用户还需要等一段时间。
捕获屏幕截图:
使用以下命令捕获给定网页的屏幕截图。
输出文件将在当前目录中创建,名为screenshot.png。
google-chrome --headless --disable-gpu --screenshot http://www.example.com/
您还可以使用“--window-size”选项指定屏幕截图的大小,如下所示。
google-chrome --headless --disable-gpu --window-size=1280,768 --screenshot http://www.example.com/
我们还可以指定'--screenshot = file1输出文件名的位置。
创建特定名称。
如何使用Google Chrome捕获网页屏幕截图
Google Chrome 59和新版本包括一个新功能,它提供了在不需要用户界面的情况下运行Google Chrome的功能。
这允许用户在命令行和脚本中使用Google Chrome。
这个无头Google Chrome版本还收录使用命令行工具捕获任何网站屏幕截图的功能。
如何创建PDF的网页
在Google Chrome中无头
谷歌抓取网页视频教程(使用类似HttpAnalyzer这样的协议分析工具就不同了(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-17 13:16
HTTP analyzer是一种专业且易于使用的网络数据包捕获工具,网站被开发人员和测试人员广泛使用。它可以实时捕获http/HTTPS协议数据,并详细显示数据流的相关信息。以下小系列将向您介绍HTTP analyzer的功能、特性和用法
HTTP analyzer可以轻松实时捕获HTTP/HTTPS协议数据,详细显示文件头、内容、cookie、查询字符通道、提交数据、重定向URL地址等信息,并提供缓冲区信息、清理对话框内容、HTTP状态信息等过滤选项。同时,它也是一个非常有用的分析、调试和诊断开发工具
HTTP analyzer cracked analyzer是一种HTTP/HTTPS协议分析工具,可以快速分析大多数视频博客的地址。尽管有些网站为视频网站提供了PHP解码程序,如youtube和googlevideo,但这些PHP程序并不通用。当blog video网站更改视频地址加密算法时,PHP程序需要进行大规模更改才能相应解码
使用HTTP analyzer等协议分析工具是不同的。所有博客视频都由HTTP提供。最终的HTTP路径必须以明文形式出现,因此可以获取此路径 查看全部
谷歌抓取网页视频教程(使用类似HttpAnalyzer这样的协议分析工具就不同了(图))
HTTP analyzer是一种专业且易于使用的网络数据包捕获工具,网站被开发人员和测试人员广泛使用。它可以实时捕获http/HTTPS协议数据,并详细显示数据流的相关信息。以下小系列将向您介绍HTTP analyzer的功能、特性和用法
HTTP analyzer可以轻松实时捕获HTTP/HTTPS协议数据,详细显示文件头、内容、cookie、查询字符通道、提交数据、重定向URL地址等信息,并提供缓冲区信息、清理对话框内容、HTTP状态信息等过滤选项。同时,它也是一个非常有用的分析、调试和诊断开发工具
HTTP analyzer cracked analyzer是一种HTTP/HTTPS协议分析工具,可以快速分析大多数视频博客的地址。尽管有些网站为视频网站提供了PHP解码程序,如youtube和googlevideo,但这些PHP程序并不通用。当blog video网站更改视频地址加密算法时,PHP程序需要进行大规模更改才能相应解码
使用HTTP analyzer等协议分析工具是不同的。所有博客视频都由HTTP提供。最终的HTTP路径必须以明文形式出现,因此可以获取此路径

