
自动采集
不能长期使用后台设置是否自动发帖已开启此设置生效
采集交流 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-08-23 02:41
立即注册,免费下载更多dz插件网络资源。
您需要登录才能下载或查看,还没有账号?立即注册
×
主要功能说明:采集搜狗微信分类导航,搜索到关键词,公众号自动发布到论坛、门户、群组
测试论坛:
链接到说明文档:
测试版仅供大家了解此插件,不能长期使用
背景设置
是否自动采集发帖:
启用后会自动采集网站导航内容并自动发布到网站导航指定版块或门户
每次自动发帖数:
如果开启了自动发帖,此设置生效,您可以控制每次自动发帖的数量。如果开启图片本地化,建议不要设置太大,0不自动发布,限制为5
采集时间筛选:
可以设置采集data时间过滤器,例如在***中,只显示当天的采集data
帖子是否被审核:
是:采集resources发帖进入审核状态,后台内容只有前台审核后才会显示;否:如果采集信息打到后台关键词,发帖审核,否则前台直接显示
发帖时间:
如果不填写发帖时间,则为当前自动发帖时间;格式是以秒为单位的整数时间除以 -;比如0-3600,发帖时间就是当前采集时间减去0-3600时间段内的随机时间
帖子浏览量:
如果不填写pageviews,默认为0;填写整数除以格式;例如0-100,0-100范围内的随机整数设置为浏览量
帖子图片是否居中显示:
如果您启用帖子图像显示在单行的中心
图片是否存储在本地:
是:采集resource 图片保存在本地,占用本地磁盘,选择此项时请注意服务器硬盘空间是否充足;否:图片是远程访问的,此时不在本站的图片处于盗链模式,第三方网站如果添加了防盗链图片,则不会显示。此时建议开启图片盗链访问
是否开启图片盗链:
如果启用了第三方图片资源,会在本地缓存并定期清空,以节省服务器空间
伪原创替换比例:
控制替换关键词的比例,0%是关闭伪原创功能
帖子显示样式:
自定义帖子主帖的css显示样式,必须收录,可以清空不影响帖子显示
门户显示样式:
自定义门户css显示样式,必须收录,可以清除文章display不受影响 查看全部
不能长期使用后台设置是否自动发帖已开启此设置生效
立即注册,免费下载更多dz插件网络资源。
您需要登录才能下载或查看,还没有账号?立即注册

×

主要功能说明:采集搜狗微信分类导航,搜索到关键词,公众号自动发布到论坛、门户、群组
测试论坛:
链接到说明文档:
测试版仅供大家了解此插件,不能长期使用
背景设置
是否自动采集发帖:
启用后会自动采集网站导航内容并自动发布到网站导航指定版块或门户
每次自动发帖数:
如果开启了自动发帖,此设置生效,您可以控制每次自动发帖的数量。如果开启图片本地化,建议不要设置太大,0不自动发布,限制为5
采集时间筛选:
可以设置采集data时间过滤器,例如在***中,只显示当天的采集data
帖子是否被审核:
是:采集resources发帖进入审核状态,后台内容只有前台审核后才会显示;否:如果采集信息打到后台关键词,发帖审核,否则前台直接显示
发帖时间:
如果不填写发帖时间,则为当前自动发帖时间;格式是以秒为单位的整数时间除以 -;比如0-3600,发帖时间就是当前采集时间减去0-3600时间段内的随机时间
帖子浏览量:
如果不填写pageviews,默认为0;填写整数除以格式;例如0-100,0-100范围内的随机整数设置为浏览量
帖子图片是否居中显示:
如果您启用帖子图像显示在单行的中心
图片是否存储在本地:
是:采集resource 图片保存在本地,占用本地磁盘,选择此项时请注意服务器硬盘空间是否充足;否:图片是远程访问的,此时不在本站的图片处于盗链模式,第三方网站如果添加了防盗链图片,则不会显示。此时建议开启图片盗链访问
是否开启图片盗链:
如果启用了第三方图片资源,会在本地缓存并定期清空,以节省服务器空间
伪原创替换比例:
控制替换关键词的比例,0%是关闭伪原创功能
帖子显示样式:
自定义帖子主帖的css显示样式,必须收录,可以清空不影响帖子显示
门户显示样式:
自定义门户css显示样式,必须收录,可以清除文章display不受影响
自动采集 金融数据python-rstuidataa可以做基金的整体数据来源吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-08-22 23:05
自动采集,可以学下爬虫。
金融数据定制化金融数据采集库不错,可定制专用的数据下载接口,云端下载数据,
python免费的数据接口
金融数据是最近大火的,api提供了所有的金融数据来源,包括基金公司自己的平台,券商自己的证券交易平台,基金公司自己的网站,券商自己的一些c端app,还有券商专门搭建的一些api,web端和商务用户使用比较多。目前网上有很多免费的金融数据,主要看你怎么去爬去处理。
金融数据python-rstuidataa可以做基金的整体数据,日线,周线,月线,周期包括交易量的,所有的数据来源,基金公司和券商基金,期货,保险,
不懂金融数据。简单的爬个新浪的数据。
北极星通过selenium找到正下方爬虫网站的不同页面的url地址,
小成本也是可以搞定的,美国卖地图当然用googlemaps的api。比如我要用谷歌地图(算是接近原生的中国的数据库),直接给谷歌地图提供api就可以了。具体怎么写我不太会写。手机打字太费劲了。
这里我推荐基于selenium进行实现小爬虫,需要的关键代码和工具已上传github,
我只是个搬运工=_=
要爬数据的话用正则表达式,python文本处理比较简单,lxml,yaf,xpath都可以。关键就是找到正则表达式的源地址。 查看全部
自动采集 金融数据python-rstuidataa可以做基金的整体数据来源吗?
自动采集,可以学下爬虫。
金融数据定制化金融数据采集库不错,可定制专用的数据下载接口,云端下载数据,
python免费的数据接口
金融数据是最近大火的,api提供了所有的金融数据来源,包括基金公司自己的平台,券商自己的证券交易平台,基金公司自己的网站,券商自己的一些c端app,还有券商专门搭建的一些api,web端和商务用户使用比较多。目前网上有很多免费的金融数据,主要看你怎么去爬去处理。
金融数据python-rstuidataa可以做基金的整体数据,日线,周线,月线,周期包括交易量的,所有的数据来源,基金公司和券商基金,期货,保险,
不懂金融数据。简单的爬个新浪的数据。
北极星通过selenium找到正下方爬虫网站的不同页面的url地址,
小成本也是可以搞定的,美国卖地图当然用googlemaps的api。比如我要用谷歌地图(算是接近原生的中国的数据库),直接给谷歌地图提供api就可以了。具体怎么写我不太会写。手机打字太费劲了。
这里我推荐基于selenium进行实现小爬虫,需要的关键代码和工具已上传github,
我只是个搬运工=_=
要爬数据的话用正则表达式,python文本处理比较简单,lxml,yaf,xpath都可以。关键就是找到正则表达式的源地址。
自动采集 非常适合《倪尔昂全盘实操打法N式之美女图站》
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-08-22 03:17
非常适合《倪尔昂全盘实操打法N式之美女图站》
优采云Auto采集美女写真站,蹭美图边缘收取爆款广告费(teaching采集rule写作教程)
前言
大家都知道,在所有的网络创作项目中,碳粉的引流和变现是最简单的,也是最适合小白的。
在大课《倪二让全练玩法N式美图站1.0:引爆交通彩粉快速变现站玩》给大家动手实践,打造盈利美图站,但是本站的方法是手动上传,耗时长,比较辛苦(但风险可控)。那么有没有更简单的方法呢?是的,我们也想做一个赚钱的美图站,我们也可以用自动采集的方式,通过自动采集图片内容文章,快速把我们的网站搞起来。非常适合优采云操作
怎么做
今天带来了自动采集美女图片站,教大家怎么写采集rules。类似于下图
我们要做的是全自动采集,无需人工操作。
本课将教小白学习如何搭建全自动采集美图站,并学习如何配置采集规则(自动采集Rules编写),掌握这些技巧,不仅可以用后面的美图站、小说站、漫画站都可以自动使用采集。另外,课程教你如何规避风险,快做网站,讲解如何赚钱
盈利模式
友情链接:一个可以卖给上千个成人直播。这是非常有利可图的。和其他网站一样,可以是一种加入的形式,帮助人们建分站赚钱。为了防止网站丢失,可以搭建一个导航站。将流量导入自己的多个站点,进行二次流量变现。用黑帽技术上传网站然后就可以卖网站了
此内容稍后可见! 查看全部
自动采集
非常适合《倪尔昂全盘实操打法N式之美女图站》
优采云Auto采集美女写真站,蹭美图边缘收取爆款广告费(teaching采集rule写作教程)
 https://www.mrbxw.com/wp-conte ... 7.png 768w" />
https://www.mrbxw.com/wp-conte ... 7.png 768w" />前言
大家都知道,在所有的网络创作项目中,碳粉的引流和变现是最简单的,也是最适合小白的。
在大课《倪二让全练玩法N式美图站1.0:引爆交通彩粉快速变现站玩》给大家动手实践,打造盈利美图站,但是本站的方法是手动上传,耗时长,比较辛苦(但风险可控)。那么有没有更简单的方法呢?是的,我们也想做一个赚钱的美图站,我们也可以用自动采集的方式,通过自动采集图片内容文章,快速把我们的网站搞起来。非常适合优采云操作
怎么做
今天带来了自动采集美女图片站,教大家怎么写采集rules。类似于下图
我们要做的是全自动采集,无需人工操作。
本课将教小白学习如何搭建全自动采集美图站,并学习如何配置采集规则(自动采集Rules编写),掌握这些技巧,不仅可以用后面的美图站、小说站、漫画站都可以自动使用采集。另外,课程教你如何规避风险,快做网站,讲解如何赚钱
盈利模式
友情链接:一个可以卖给上千个成人直播。这是非常有利可图的。和其他网站一样,可以是一种加入的形式,帮助人们建分站赚钱。为了防止网站丢失,可以搭建一个导航站。将流量导入自己的多个站点,进行二次流量变现。用黑帽技术上传网站然后就可以卖网站了
此内容稍后可见!
版本号2.41,修复自动更新提示权限不足报错问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-08-20 00:28
版本号2.4
1、修复自动更新提示权限不足报错的问题
2、增加组验证窗口横竖状态选择栏
3、软件自动检测服务器最新版本号
4、主界面标题添加最新版本号显示
5、视频教程界面增加了软件更新记录公告
版本号2.3
1、修复部分服务器不兼容问题
2、改写群验证码,验证速度更快
3.修复有时会弹出组验证窗口的问题
4、修复软件退出时进程依然存在的问题
版本号2.2
1、全新改版,无需登录QQ验证方式
2、软件源码全部改写,逻辑更清晰,运行更稳定
3、设置、采集、视频教程、Q群验证分独立部分
4、视频教程改为“视频教程”版块内置和网页播放两种模式
5、内置视频教程采用无广告分析界面,不播放广告。
6、添加oceancms系统自动采集功能自动识别后台验证码
版本号2.1
1、添加试用版,可以手动采集,但是没有自动采集不能24小时挂机
2、去除采集使用时网页跳转的系统声音
3、优化部分源码,增强系统兼容性
4、下个版本会考虑添加其他cmssystemautomatic采集
版本号2.0
1、添加软件标题自定义、系统托盘图标自定义、采集地址标题名称自定义
2、方便多个站点的站长在不打开软件界面的情况下管理软件采集
版本号1.9
1、优化部分源码,增加软件响应时间
2、增加定时释放内存的功能,每次采集后都会自动释放系统内存
版本号1.8
1、优化解决部分操作系统网页弹出错误窗口问题
2、应网友要求,添加观看在线视频教程的按钮
3、应网友要求,取消手动搜索资源功能,增加操作流畅度
版本号1.7
1、增加手动搜索资源功能,整合数十个资源站
由于个人时间问题,函数写的比较简单
功能虽然鸡肋,但有总比没有好!
版本号1.6
1、自动循环采集间隔时间由内置1小时改为自定义时间
版本号1.5
1、添加系统托盘菜单
2、取系统运行时间,每天23:55:58,软件会自动采集一次
修复部分采集源23点后更新资源,采集当天会造成泄露
版本号1.4
1、优化采集速度,响应时间秒
2.彻底解决采集之前版本软件可能死机的问题@
版本号1.3
1、修复新添加的采集地址有时无法打开的bug
2、优化多任务采集的速度,加强响应时间
3、优化1.2版本采集前几秒卡住的问题
版本号1.2
1、采集地址栏增加到10个
2、在采集网页中嵌入采集地址栏
3、加宽采集webpage的视觉高度
4.重新整理界面布局
5.优化部分代码,降低杀毒软件误报概率
6、添加多任务采集属性,软件采集会在前几秒卡住
点击采集后可以等待十秒八秒再点击采集地址查看采集结果或者直接最小化
版本号1.1
1、增加自动删除静态主页和更新缓存的功能
2、优化采集speed
版本号1.0
1、Beta 版发布
2、设置6个采集地址栏,可以同时监控采集6个不同的资源
3、一键登录后台,每1小时自动监控采集一次
4、断开后后台会自动重新连接,从而实现24小时无人值守循环监控采集 查看全部
版本号2.41,修复自动更新提示权限不足报错问题
版本号2.4
1、修复自动更新提示权限不足报错的问题
2、增加组验证窗口横竖状态选择栏
3、软件自动检测服务器最新版本号
4、主界面标题添加最新版本号显示
5、视频教程界面增加了软件更新记录公告
版本号2.3
1、修复部分服务器不兼容问题
2、改写群验证码,验证速度更快
3.修复有时会弹出组验证窗口的问题
4、修复软件退出时进程依然存在的问题
版本号2.2
1、全新改版,无需登录QQ验证方式
2、软件源码全部改写,逻辑更清晰,运行更稳定
3、设置、采集、视频教程、Q群验证分独立部分
4、视频教程改为“视频教程”版块内置和网页播放两种模式
5、内置视频教程采用无广告分析界面,不播放广告。
6、添加oceancms系统自动采集功能自动识别后台验证码
版本号2.1
1、添加试用版,可以手动采集,但是没有自动采集不能24小时挂机
2、去除采集使用时网页跳转的系统声音
3、优化部分源码,增强系统兼容性
4、下个版本会考虑添加其他cmssystemautomatic采集
版本号2.0
1、添加软件标题自定义、系统托盘图标自定义、采集地址标题名称自定义
2、方便多个站点的站长在不打开软件界面的情况下管理软件采集
版本号1.9
1、优化部分源码,增加软件响应时间
2、增加定时释放内存的功能,每次采集后都会自动释放系统内存
版本号1.8
1、优化解决部分操作系统网页弹出错误窗口问题
2、应网友要求,添加观看在线视频教程的按钮
3、应网友要求,取消手动搜索资源功能,增加操作流畅度
版本号1.7
1、增加手动搜索资源功能,整合数十个资源站
由于个人时间问题,函数写的比较简单
功能虽然鸡肋,但有总比没有好!
版本号1.6
1、自动循环采集间隔时间由内置1小时改为自定义时间
版本号1.5
1、添加系统托盘菜单
2、取系统运行时间,每天23:55:58,软件会自动采集一次
修复部分采集源23点后更新资源,采集当天会造成泄露
版本号1.4
1、优化采集速度,响应时间秒
2.彻底解决采集之前版本软件可能死机的问题@
版本号1.3
1、修复新添加的采集地址有时无法打开的bug
2、优化多任务采集的速度,加强响应时间
3、优化1.2版本采集前几秒卡住的问题
版本号1.2
1、采集地址栏增加到10个
2、在采集网页中嵌入采集地址栏
3、加宽采集webpage的视觉高度
4.重新整理界面布局
5.优化部分代码,降低杀毒软件误报概率
6、添加多任务采集属性,软件采集会在前几秒卡住
点击采集后可以等待十秒八秒再点击采集地址查看采集结果或者直接最小化
版本号1.1
1、增加自动删除静态主页和更新缓存的功能
2、优化采集speed
版本号1.0
1、Beta 版发布
2、设置6个采集地址栏,可以同时监控采集6个不同的资源
3、一键登录后台,每1小时自动监控采集一次
4、断开后后台会自动重新连接,从而实现24小时无人值守循环监控采集
无人值守免费自动采集器能够网站要保持活力(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-08-16 22:00
无人值守免费自动采集器是一款免费的网络资源采集软件。无人值守免费自动采集器是中小网站自动更新工具,全自动采集释放,运行时静音工作,无需人工干预;独立软件免除网站性能消耗;安全稳定。
无人值守免费自动化采集器(简称ET)旨在提高软件自动化程度,突破24小时无人值守工作。经测试,ET可以长时间自动运行。即使以年为时间单位。免费无人看管。
免费自动采集器(中小网站自动更新工具)V2.1.0.2绿色下载。
无人值守免费自动采集器(简称ET)是一款无人值守自动采集工具。借助软件高度智能化的自动化程序,实现无与伦比的无人值守功能。该程序可以使用 24 小时。网络上不间断的自动采集资源,包括图片和文字。
优采云采集器3免费版 这是小编专门为广大站长带来的自动更新工具。它不需要手动操作。 24小时自动实时监控目标。实时高效采集,感兴趣的用户赶紧下载体验吧! 优采云采集器西西软件园下载地址..
Unattended Free Auto采集器是一款可以保持网站活力,帮助网站内容每天更新的软件。完美下载为您准备了“无人值守免费自动采集器”,欢迎大家前来下载使用。
无人值守免费自动采集器能网站 为了保持活力,每日内容更新是基础。一个小网站保证每日更新,通常需要站长承担每天8小时的更新工作,每周末开放;
无人值守自动采集器中文绿版是一款非常好用的网络优化软件。我们的软件使用网站自己的数据发布接口或者。 查看全部
无人值守免费自动采集器能够网站要保持活力(组图)
无人值守免费自动采集器是一款免费的网络资源采集软件。无人值守免费自动采集器是中小网站自动更新工具,全自动采集释放,运行时静音工作,无需人工干预;独立软件免除网站性能消耗;安全稳定。
无人值守免费自动化采集器(简称ET)旨在提高软件自动化程度,突破24小时无人值守工作。经测试,ET可以长时间自动运行。即使以年为时间单位。免费无人看管。
免费自动采集器(中小网站自动更新工具)V2.1.0.2绿色下载。
无人值守免费自动采集器(简称ET)是一款无人值守自动采集工具。借助软件高度智能化的自动化程序,实现无与伦比的无人值守功能。该程序可以使用 24 小时。网络上不间断的自动采集资源,包括图片和文字。
优采云采集器3免费版 这是小编专门为广大站长带来的自动更新工具。它不需要手动操作。 24小时自动实时监控目标。实时高效采集,感兴趣的用户赶紧下载体验吧! 优采云采集器西西软件园下载地址..

Unattended Free Auto采集器是一款可以保持网站活力,帮助网站内容每天更新的软件。完美下载为您准备了“无人值守免费自动采集器”,欢迎大家前来下载使用。
无人值守免费自动采集器能网站 为了保持活力,每日内容更新是基础。一个小网站保证每日更新,通常需要站长承担每天8小时的更新工作,每周末开放;

无人值守自动采集器中文绿版是一款非常好用的网络优化软件。我们的软件使用网站自己的数据发布接口或者。
如何保证机器人不出错,还是获取不到好评?
采集交流 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-08-13 00:02
自动采集机器人,自动化采集商品和文案。采集复制翻译转换为中文,快速一键上架到自己的店铺和公众号。shua单这是如何保证机器人不出错,还是获取不到好评或者销量。
这个我觉得没必要
嗯嗯,你做机器人就是为了给和天猫卖家赚佣金的吧?佣金一般是销售额的百分比,30%-50%不等。因为一个月几千单,5%不到你得补400块吧。而且现在打击刷单,查得严,机器人也赚不到钱,客佣金还那么低,本来就没利润。如果你有兴趣的话,我给你详细算一下。要在十几台机器里面不停的抓同一类目的大额销售额的买家,收集数据。
再找每个卖家刷订单的买家提取特征,用程序自动识别,把目标群体标记成同一个,再判断刷的好评和差评,每个商品填写一个目标id。每一天下来,超过30%的大额订单得到的目标id都是不重复的,再算每个目标id能抓取多少订单。以比例划分。所以可以算出每个月佣金是多少,应该获得多少销售额。
肯定是客,机器人太多了,现在各大论坛,贴吧充斥着各种教客,联盟的机器人,其实就是联盟中一台提供卖家广告投放的机器,你在联盟推广商品,联盟会有佣金给你,你可以提现,每年都有丰厚的回报,但是你在客的最大麻烦是,你每天都得不停的投放广告,这种收益是依靠大数据的,每天的用户购买数据都会保存在电脑里,假如卖家想通过刷单,通过低价来冲击搜索排名,如果你和他的商品可以通过正常的运营来促销,那么自然就可以通过客的路径来达到冲击搜索排名的目的,假如他的商品没有自然搜索排名的路径,那你就自求多福吧。 查看全部
如何保证机器人不出错,还是获取不到好评?
自动采集机器人,自动化采集商品和文案。采集复制翻译转换为中文,快速一键上架到自己的店铺和公众号。shua单这是如何保证机器人不出错,还是获取不到好评或者销量。
这个我觉得没必要
嗯嗯,你做机器人就是为了给和天猫卖家赚佣金的吧?佣金一般是销售额的百分比,30%-50%不等。因为一个月几千单,5%不到你得补400块吧。而且现在打击刷单,查得严,机器人也赚不到钱,客佣金还那么低,本来就没利润。如果你有兴趣的话,我给你详细算一下。要在十几台机器里面不停的抓同一类目的大额销售额的买家,收集数据。
再找每个卖家刷订单的买家提取特征,用程序自动识别,把目标群体标记成同一个,再判断刷的好评和差评,每个商品填写一个目标id。每一天下来,超过30%的大额订单得到的目标id都是不重复的,再算每个目标id能抓取多少订单。以比例划分。所以可以算出每个月佣金是多少,应该获得多少销售额。
肯定是客,机器人太多了,现在各大论坛,贴吧充斥着各种教客,联盟的机器人,其实就是联盟中一台提供卖家广告投放的机器,你在联盟推广商品,联盟会有佣金给你,你可以提现,每年都有丰厚的回报,但是你在客的最大麻烦是,你每天都得不停的投放广告,这种收益是依靠大数据的,每天的用户购买数据都会保存在电脑里,假如卖家想通过刷单,通过低价来冲击搜索排名,如果你和他的商品可以通过正常的运营来促销,那么自然就可以通过客的路径来达到冲击搜索排名的目的,假如他的商品没有自然搜索排名的路径,那你就自求多福吧。
小说网采集小说网站源码系统功能界面介绍-上海怡健
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-08-12 20:08
Novel网站源代码集成了丰富的采集规则,无人值守,自动根据预设时间、站点和关键字采集文章,通过thinkphp伪静态更新,保证页面访问速度也考虑了搜索引擎的友好性。所有的首页、目录、分类和内容页面都是纯HTML格式。
新版源码增加了自动伪原创功能,可以在编辑时自动替换词库的同义词和内链。源码:xsymz.icu 同时源码系统拥有强大直观的统计分析系统,详细展示总点击量、月点击量、周点击量、总推荐量、月度推荐量、周推荐量统计等新功能,以及作者推荐统计。三方统计工具可以方便的实现小说下载量的明细统计和采集书籍的明细统计。
自动采集小说网站源代码功能:
1、原创Development:自主研发,坚持原创;
2、强大后台:一体化管理,多纬度指标监控;
3、Update 迭代:多年的市场选择和客户实践;
4、极速建站:主流推送sdk到app详情页;
5、裂变分销:多种裂变模式,低成本获客;
6、advertisement实现:集成主流广告SDK,灵活掌控广告空间;
7、福利任务:丰富任务,激发裂变,提高留存率;
8、定制化开发:全面覆盖行业需求场景。
源代码系统功能接口介绍:全面覆盖市场需求,多种场景自由切换
多端展示:多套精美模板供选择,小说、漫画、听书,支持多格式内容上传,可根据需要选择单端多端同时展示。
阅读支付:APP、公众号、H5多端都是主流的展示形式。阅读内容页面和个人中心可实现移动支付,流畅阅读体验,实现收益。
会员体系:结合会员免费图书馆、去广告、身份铭牌、专属活动等特权元素,打造完整的会员体系,帮助用户沉淀。
福利任务:丰富的新手任务、日常任务等,构成成熟的用户激励体系,增加用户的变现、留存、激活和体验。
广告配置:支持开屏、信息流等多种广告形式,可对接指定广告平台,配合福利激励任务,加强视频广告收益等,支持自定义图片广告,后台轻松配置,数据统计全面。 , 实时掌握数据趋势。
裂变分发:支持公众号和应用分发,轻松生成原文链接和应用下载链接。成熟的分销模式,让裂变、推广、网赚更轻松。
产品运营指导:从免费到付费阅读行业耐心解答、内容签约、软件系统架构、流量运营、裂变营销、变现模式等
数据安全:分布式服务器集群、全流程数据加密、自动备份集群等技术安全保障,全力保护您的核心资产。
精美的UI设计:不同的操作模式有不同的模板推荐,单端或多端显示,原生体验,速度流畅,扩展性强,方便二次开发。
稳定抗负载:程序优化到极致,搭配合理的服务器架构,轻松应对亿级访问压力,标准化测试,性能保障。
高级技术支持:擅长打包、海量数据、海量流量等解决方案自助构建,攻克企业级稳定高效应对技术压力瓶颈。
移动支付:主流支付宝、微信、Apple Pay、第四方支付渠道,二次开发接入指定支付渠道。
小说网站source 安装步骤:
1、安装宝塔面板并上传源码;
2、将Tinkphp设为伪静态并保存;
3、Import 数据库安装完成。
源系统环境:
PHP5.6 及以上,建议使用php7.0,可以优雅模式运行; mysql5.6+,服务器支持伪静态重写。 查看全部
小说网采集小说网站源码系统功能界面介绍-上海怡健
Novel网站源代码集成了丰富的采集规则,无人值守,自动根据预设时间、站点和关键字采集文章,通过thinkphp伪静态更新,保证页面访问速度也考虑了搜索引擎的友好性。所有的首页、目录、分类和内容页面都是纯HTML格式。
新版源码增加了自动伪原创功能,可以在编辑时自动替换词库的同义词和内链。源码:xsymz.icu 同时源码系统拥有强大直观的统计分析系统,详细展示总点击量、月点击量、周点击量、总推荐量、月度推荐量、周推荐量统计等新功能,以及作者推荐统计。三方统计工具可以方便的实现小说下载量的明细统计和采集书籍的明细统计。
自动采集小说网站源代码功能:
1、原创Development:自主研发,坚持原创;
2、强大后台:一体化管理,多纬度指标监控;
3、Update 迭代:多年的市场选择和客户实践;
4、极速建站:主流推送sdk到app详情页;
5、裂变分销:多种裂变模式,低成本获客;
6、advertisement实现:集成主流广告SDK,灵活掌控广告空间;
7、福利任务:丰富任务,激发裂变,提高留存率;
8、定制化开发:全面覆盖行业需求场景。
源代码系统功能接口介绍:全面覆盖市场需求,多种场景自由切换
多端展示:多套精美模板供选择,小说、漫画、听书,支持多格式内容上传,可根据需要选择单端多端同时展示。
阅读支付:APP、公众号、H5多端都是主流的展示形式。阅读内容页面和个人中心可实现移动支付,流畅阅读体验,实现收益。
会员体系:结合会员免费图书馆、去广告、身份铭牌、专属活动等特权元素,打造完整的会员体系,帮助用户沉淀。
福利任务:丰富的新手任务、日常任务等,构成成熟的用户激励体系,增加用户的变现、留存、激活和体验。
广告配置:支持开屏、信息流等多种广告形式,可对接指定广告平台,配合福利激励任务,加强视频广告收益等,支持自定义图片广告,后台轻松配置,数据统计全面。 , 实时掌握数据趋势。
裂变分发:支持公众号和应用分发,轻松生成原文链接和应用下载链接。成熟的分销模式,让裂变、推广、网赚更轻松。
产品运营指导:从免费到付费阅读行业耐心解答、内容签约、软件系统架构、流量运营、裂变营销、变现模式等
数据安全:分布式服务器集群、全流程数据加密、自动备份集群等技术安全保障,全力保护您的核心资产。
精美的UI设计:不同的操作模式有不同的模板推荐,单端或多端显示,原生体验,速度流畅,扩展性强,方便二次开发。
稳定抗负载:程序优化到极致,搭配合理的服务器架构,轻松应对亿级访问压力,标准化测试,性能保障。
高级技术支持:擅长打包、海量数据、海量流量等解决方案自助构建,攻克企业级稳定高效应对技术压力瓶颈。
移动支付:主流支付宝、微信、Apple Pay、第四方支付渠道,二次开发接入指定支付渠道。
小说网站source 安装步骤:
1、安装宝塔面板并上传源码;
2、将Tinkphp设为伪静态并保存;
3、Import 数据库安装完成。
源系统环境:
PHP5.6 及以上,建议使用php7.0,可以优雅模式运行; mysql5.6+,服务器支持伪静态重写。
PHP视频有防采集限制采集的11个注意事项!
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-08-03 03:10
11、支持按B站UP采集
12、 关键字支持采集
13、 支持自定义海报回复
14、支持过滤文章中的超链接(过滤a标签,保持标签内的文字)
15、更多功能期待您的发现和建议
更多详情请通过应用截图、更新日志等方式了解,或添加售前QQ(15326940)咨询问题)
注意事项
插件只是采集B站普通视频,链接格式为,不支持VIP、粉丝剧、影视、直播等特殊视频。如有问题请咨询售前QQ(15326940)
插件发布的视频使用了论坛的多媒体代码([media],[flash]),分析由discuz程序自己处理。该插件没有分析功能。推荐分析插件:B站视频分析播放器
本插件需要PHP支持curl,curl可以正常获取https链接内容,PHP版本至少5.3,不高于PHP7.1,PHP5.2可能不行能够采集头条的https链接导致错误。为保证采集到文章内容正常,请务必通过服务器浏览器打开今日头条文章,查看文章内容。
B站视频被采集限制,高频采集可能会被屏蔽。建议插件自动采集发布。
如果您的网站服务器被屏蔽或无法正常获取采集源内容,也无法正常发布采集,恕不退款。
如果采集规则因插件自身问题导致无法更新修复,7天内购买的用户可以获得退款,购买超过7天不到1个月可以补偿购买180元优惠券,购买超过1个月60元补偿优惠券(优惠券只能在购买本公司名下的应用时使用),每位用户只能选择一种补偿方式。
该插件仅用于采集视频,方便阅读。您需要自行承担视频版权风险。未经视频原作者授权,请勿公开发布视频或用于商业用途。
如果您的服务器环境运行异常,需要排查测试,需要提供必要的网站和服务器账号密码权限进行排查,无法远程协助。 查看全部
PHP视频有防采集限制采集的11个注意事项!
11、支持按B站UP采集
12、 关键字支持采集
13、 支持自定义海报回复
14、支持过滤文章中的超链接(过滤a标签,保持标签内的文字)
15、更多功能期待您的发现和建议
更多详情请通过应用截图、更新日志等方式了解,或添加售前QQ(15326940)咨询问题)
注意事项
插件只是采集B站普通视频,链接格式为,不支持VIP、粉丝剧、影视、直播等特殊视频。如有问题请咨询售前QQ(15326940)
插件发布的视频使用了论坛的多媒体代码([media],[flash]),分析由discuz程序自己处理。该插件没有分析功能。推荐分析插件:B站视频分析播放器
本插件需要PHP支持curl,curl可以正常获取https链接内容,PHP版本至少5.3,不高于PHP7.1,PHP5.2可能不行能够采集头条的https链接导致错误。为保证采集到文章内容正常,请务必通过服务器浏览器打开今日头条文章,查看文章内容。
B站视频被采集限制,高频采集可能会被屏蔽。建议插件自动采集发布。
如果您的网站服务器被屏蔽或无法正常获取采集源内容,也无法正常发布采集,恕不退款。
如果采集规则因插件自身问题导致无法更新修复,7天内购买的用户可以获得退款,购买超过7天不到1个月可以补偿购买180元优惠券,购买超过1个月60元补偿优惠券(优惠券只能在购买本公司名下的应用时使用),每位用户只能选择一种补偿方式。
该插件仅用于采集视频,方便阅读。您需要自行承担视频版权风险。未经视频原作者授权,请勿公开发布视频或用于商业用途。
如果您的服务器环境运行异常,需要排查测试,需要提供必要的网站和服务器账号密码权限进行排查,无法远程协助。
自动采集等很多插件,楼主可以关注下超v(/)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-07-23 23:01
自动采集等很多插件,楼主可以关注下超v(/),帮助程序员实现高质量的网站采集,现在推出windows平台版了!具体楼主可以看一下这个网站:html5在线生成器有个交流的版本,用户可以在交流论坛中分享自己的windows版本。其他平台,可以看到他的微信:超v(),还是做了很多的交流的。
看了一下回答,没有回答到楼主的需求:没有客户端不等于没有后端,后端可以搭载自己写的程序,也可以在别的程序里加入后端的功能。所以做采集器不需要有客户端,本质上是以前的小型采集器(比如知名采集器flashdown的轻版本tenzing或者微秘的自动采集stargling就是这样)解决了通过浏览器来采集网页的问题,让采集更加简单。
而windows上没有办法找到自己写的程序的情况下,对于小型采集器来说,现有程序是不是足够给采集服务器带来足够负荷,这需要看自己的网站目前是否足够小众(如足够垂直和高质量,否则现有程序的限制会让问题更加复杂),如果不是很小众的话,本地也是可以用web代理服务器实现的,小型采集器可以直接只用本地的代理服务器。不过个人感觉这样的采集器的意义不是很大,容易造成不同终端上的运行速度差异。
首先,这个需求是非常好的,可以借鉴之前网站采集器的做法,试一下高qtime/spiderlist/spiderstart等采集器;其次,如果有没有客户端,那么就会面临多部分公司使用自动采集。你需要对大量网站进行采集分析,根据平均和历史网站访问和时间变化,推断出哪些页面需要被采集,用代理服务器还是用服务器。 查看全部
自动采集等很多插件,楼主可以关注下超v(/)
自动采集等很多插件,楼主可以关注下超v(/),帮助程序员实现高质量的网站采集,现在推出windows平台版了!具体楼主可以看一下这个网站:html5在线生成器有个交流的版本,用户可以在交流论坛中分享自己的windows版本。其他平台,可以看到他的微信:超v(),还是做了很多的交流的。
看了一下回答,没有回答到楼主的需求:没有客户端不等于没有后端,后端可以搭载自己写的程序,也可以在别的程序里加入后端的功能。所以做采集器不需要有客户端,本质上是以前的小型采集器(比如知名采集器flashdown的轻版本tenzing或者微秘的自动采集stargling就是这样)解决了通过浏览器来采集网页的问题,让采集更加简单。
而windows上没有办法找到自己写的程序的情况下,对于小型采集器来说,现有程序是不是足够给采集服务器带来足够负荷,这需要看自己的网站目前是否足够小众(如足够垂直和高质量,否则现有程序的限制会让问题更加复杂),如果不是很小众的话,本地也是可以用web代理服务器实现的,小型采集器可以直接只用本地的代理服务器。不过个人感觉这样的采集器的意义不是很大,容易造成不同终端上的运行速度差异。
首先,这个需求是非常好的,可以借鉴之前网站采集器的做法,试一下高qtime/spiderlist/spiderstart等采集器;其次,如果有没有客户端,那么就会面临多部分公司使用自动采集。你需要对大量网站进行采集分析,根据平均和历史网站访问和时间变化,推断出哪些页面需要被采集,用代理服务器还是用服务器。
自动采集wordpress博客网站自动生成静态网站,新用户入坑
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-07-23 18:03
自动采集wordpress博客网站自动生成静态网站。新注册用户,会有2个3元的优惠券,新用户入坑。这个是优惠券,下面是我生成的网站。-yingxing-vip-templates/新注册用户没有送价值2000元的svn认证,不过可以通过交易认证获得价值2000元的svn认证。下图是价值2000元svn的扫描页面,仅售价2000元。赶紧注册。
即可,在wp吧,iis里添加一个账号,直接用iis添加,
多余的svn账号可以去bbsbotagent下载,
这个问题我也遇到过,我还专门问过,在2015年的9月15日被攻击,
曾经在wordpress中做过一个filter,上传到svn后,用wordpress同步不会断掉。不知道官方的公告会不会出来说明,被攻击的情况下做不了任何操作。
问问百度有几个答案不?一个准确,一个不准确。准确的:1.这些公司是需要向wordpress付费的。收费方式:交易账号的2~3元一个,但是需要到付款渠道注册一个账号,之后对方会随机生成一个账号,但你在同步的时候不会被断断续续的打断。2.交易账号是否只能wordpress2.0+版本。不准确的:1.没听说有必要在svn上保留block期间只能上传2.0+版本的。
2.我有他们的经验,并非是被攻击。实际效果:做一个工具类网站,免费分享解决实际问题的程序。我目前有不少好的程序存储在svn,大概放在个人服务器或者工作服务器上,更多的是放在github仓库上。1.很多的可以profile为photos-post。2.部分功能可以放在个人服务器或者工作服务器,3.服务器的提供商可以和网站绑定(类似虚拟主机)。4.不要放在代理,免费代理软件大多只支持1台电脑的正常上网。 查看全部
自动采集wordpress博客网站自动生成静态网站,新用户入坑
自动采集wordpress博客网站自动生成静态网站。新注册用户,会有2个3元的优惠券,新用户入坑。这个是优惠券,下面是我生成的网站。-yingxing-vip-templates/新注册用户没有送价值2000元的svn认证,不过可以通过交易认证获得价值2000元的svn认证。下图是价值2000元svn的扫描页面,仅售价2000元。赶紧注册。
即可,在wp吧,iis里添加一个账号,直接用iis添加,
多余的svn账号可以去bbsbotagent下载,
这个问题我也遇到过,我还专门问过,在2015年的9月15日被攻击,
曾经在wordpress中做过一个filter,上传到svn后,用wordpress同步不会断掉。不知道官方的公告会不会出来说明,被攻击的情况下做不了任何操作。
问问百度有几个答案不?一个准确,一个不准确。准确的:1.这些公司是需要向wordpress付费的。收费方式:交易账号的2~3元一个,但是需要到付款渠道注册一个账号,之后对方会随机生成一个账号,但你在同步的时候不会被断断续续的打断。2.交易账号是否只能wordpress2.0+版本。不准确的:1.没听说有必要在svn上保留block期间只能上传2.0+版本的。
2.我有他们的经验,并非是被攻击。实际效果:做一个工具类网站,免费分享解决实际问题的程序。我目前有不少好的程序存储在svn,大概放在个人服务器或者工作服务器上,更多的是放在github仓库上。1.很多的可以profile为photos-post。2.部分功能可以放在个人服务器或者工作服务器,3.服务器的提供商可以和网站绑定(类似虚拟主机)。4.不要放在代理,免费代理软件大多只支持1台电脑的正常上网。
自动化采集公众号信息,postpagetracking+websocket的经验技巧
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-07-07 04:03
自动采集手机,pc里面的信息。不过批量采集太难了。我用的是多抓鱼就比较容易上手。它可以一键抓取一些平台里面的信息。比如你想抓取滴滴打车的信息,那就先打开滴滴打车app。然后在里面采集那个平台信息。
自动化采集公众号信息,这个其实不难,因为本身微信公众号的地址就是共享的,基本只要你的程序不是很差,能识别二维码,能分析一个url里面的参数,能识别页面响应时间,就可以完成自动化的采集了,简单说,就是服务端推送一个公众号的url就好了,所以本质上,公众号信息对于这个程序来说就是共享的。至于到达率,这个其实是比较难的,主要还是要靠分析你要采集的目标,统计其他的采集成本,这样采集出来效率才能提高。另外,你说的批量采集,这个完全可以用爬虫替代,爬虫实际上就是有人在后台给你发url,你自己去爬。
目前主流的采集技术就是postpagetracking+websocket,下面我讲讲我的经验技巧。其实post就是把我们获取的重定向到/,websocket是基于web的tcp连接来传递的,两者进行交互。url结构就是页面的cookie。这里有个坑一定要记住。post都是xml格式的,不要post长时间会报cookie过期,重定向的信息有时会丢失,请记得保存信息。
问题来了,如何确定你的websocket的连接时间呢?比如微信端的采集,xml格式就行,微信还会自己产生cookie,网页端就不行了,只能用抓包工具来抓。然后就可以通过cookie来确定连接时间了。这样抓包工具的工作就是每次通过一个连接的时间来判断这个浏览器到底是在下载还是在浏览。而lxml的解析就是不依赖浏览器本身自带cookie判断时间的。
可以在抓包工具里直接拿到httppost的server的cookie通过xml格式的方式传到parser里解析。 查看全部
自动化采集公众号信息,postpagetracking+websocket的经验技巧
自动采集手机,pc里面的信息。不过批量采集太难了。我用的是多抓鱼就比较容易上手。它可以一键抓取一些平台里面的信息。比如你想抓取滴滴打车的信息,那就先打开滴滴打车app。然后在里面采集那个平台信息。
自动化采集公众号信息,这个其实不难,因为本身微信公众号的地址就是共享的,基本只要你的程序不是很差,能识别二维码,能分析一个url里面的参数,能识别页面响应时间,就可以完成自动化的采集了,简单说,就是服务端推送一个公众号的url就好了,所以本质上,公众号信息对于这个程序来说就是共享的。至于到达率,这个其实是比较难的,主要还是要靠分析你要采集的目标,统计其他的采集成本,这样采集出来效率才能提高。另外,你说的批量采集,这个完全可以用爬虫替代,爬虫实际上就是有人在后台给你发url,你自己去爬。
目前主流的采集技术就是postpagetracking+websocket,下面我讲讲我的经验技巧。其实post就是把我们获取的重定向到/,websocket是基于web的tcp连接来传递的,两者进行交互。url结构就是页面的cookie。这里有个坑一定要记住。post都是xml格式的,不要post长时间会报cookie过期,重定向的信息有时会丢失,请记得保存信息。
问题来了,如何确定你的websocket的连接时间呢?比如微信端的采集,xml格式就行,微信还会自己产生cookie,网页端就不行了,只能用抓包工具来抓。然后就可以通过cookie来确定连接时间了。这样抓包工具的工作就是每次通过一个连接的时间来判断这个浏览器到底是在下载还是在浏览。而lxml的解析就是不依赖浏览器本身自带cookie判断时间的。
可以在抓包工具里直接拿到httppost的server的cookie通过xml格式的方式传到parser里解析。
自动采集功能支持主流的pc网页数据介绍及操作方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2021-07-03 01:01
自动采集功能支持主流的pc网页数据,包括新闻门户、门户网站、新闻门户优酷、网易、搜狐等网站的图片、视频、链接、音频、文章内容等数据的采集。具体功能介绍及操作方法,可以参看小编写的这篇博文哦:自动采集功能介绍及操作方法自动采集功能是一个公司运营中重要的推广手段,同时也是公司的软文定制、推广的重要工具,我们采用h5网页展示形式,能够大大吸引用户观看,分享。
这个功能软件我们是用高德地图做接入的,那么具体的原理是什么呢?那么,请先来看一下整个h5图片采集工具软件是如何采集高德地图内容的吧。其实原理并不复杂,只要知道高德地图api的名称:。只要我们通过高德地图api,发出一个标有“”的请求,网站接收到该请求,加上爬虫脚本(参考博文:爬虫脚本),就可以采集图片的信息了。
我们使用webpath去解析、去js解析。webpath用户定义一般为:/*.html/*/,webpath根据关键字从左往右遍历每一个元素,找到对应的内容,但是if(content==""&&success=="1"),由于采用js解析器,需要针对不同浏览器的操作行为做支持,通常的操作路径为:“//js/page1.a.swf”。
目前,网站上通常使用js解析器来采集图片内容,而js解析器的内部实现,根据不同的api定义,来自html-script-parser,而html-script-parser的实现根据浏览器操作特点,依据相应的逻辑写出相应的事件代码和对应的接口,最终,通过webpath中的keys=>eventornot来获取对应的values=>methods接口来判断对应的元素是否为我们要的元素,从而获取相应的内容。
其实说到这里,我们其实已经差不多知道这个工具是如何工作的,而实际上,整个过程并不简单,对于工具本身也是依赖于项目的,因此就没有办法一步一步详细的介绍出来了。最后,我们需要说明一下的是,我们只是做了一个工具的皮肤实现,实际上是使用javascript语言去写的,而我们采用的是python语言去实现图片的采集。
我们的用户,将不会有任何网页内容不存在或者不能采集的情况,可以无缝将我们的自动采集功能进行扩展。sogood!!!!!!再看一个不完整的,不完整的采集:脚本原理图主要操作:在浏览器(指定浏览器)中发出请求,针对性选择条件进行解析请求的url,然后对请求中的每一个request进行拆分,对每一个request拆分成若干组ajax请求,相对应地,网站通过支持我们的协议,对。 查看全部
自动采集功能支持主流的pc网页数据介绍及操作方法
自动采集功能支持主流的pc网页数据,包括新闻门户、门户网站、新闻门户优酷、网易、搜狐等网站的图片、视频、链接、音频、文章内容等数据的采集。具体功能介绍及操作方法,可以参看小编写的这篇博文哦:自动采集功能介绍及操作方法自动采集功能是一个公司运营中重要的推广手段,同时也是公司的软文定制、推广的重要工具,我们采用h5网页展示形式,能够大大吸引用户观看,分享。
这个功能软件我们是用高德地图做接入的,那么具体的原理是什么呢?那么,请先来看一下整个h5图片采集工具软件是如何采集高德地图内容的吧。其实原理并不复杂,只要知道高德地图api的名称:。只要我们通过高德地图api,发出一个标有“”的请求,网站接收到该请求,加上爬虫脚本(参考博文:爬虫脚本),就可以采集图片的信息了。
我们使用webpath去解析、去js解析。webpath用户定义一般为:/*.html/*/,webpath根据关键字从左往右遍历每一个元素,找到对应的内容,但是if(content==""&&success=="1"),由于采用js解析器,需要针对不同浏览器的操作行为做支持,通常的操作路径为:“//js/page1.a.swf”。
目前,网站上通常使用js解析器来采集图片内容,而js解析器的内部实现,根据不同的api定义,来自html-script-parser,而html-script-parser的实现根据浏览器操作特点,依据相应的逻辑写出相应的事件代码和对应的接口,最终,通过webpath中的keys=>eventornot来获取对应的values=>methods接口来判断对应的元素是否为我们要的元素,从而获取相应的内容。
其实说到这里,我们其实已经差不多知道这个工具是如何工作的,而实际上,整个过程并不简单,对于工具本身也是依赖于项目的,因此就没有办法一步一步详细的介绍出来了。最后,我们需要说明一下的是,我们只是做了一个工具的皮肤实现,实际上是使用javascript语言去写的,而我们采用的是python语言去实现图片的采集。
我们的用户,将不会有任何网页内容不存在或者不能采集的情况,可以无缝将我们的自动采集功能进行扩展。sogood!!!!!!再看一个不完整的,不完整的采集:脚本原理图主要操作:在浏览器(指定浏览器)中发出请求,针对性选择条件进行解析请求的url,然后对请求中的每一个request进行拆分,对每一个request拆分成若干组ajax请求,相对应地,网站通过支持我们的协议,对。
自动采集各个平台的视频、图片、音乐等。
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-07-02 00:03
自动采集各个平台的视频、图片、音乐等。自动化去重、分类、去重工作,电商行业最为常见,现在又到了商品sku数量过多的季节,我们无法像以前编辑商品sku,全店一起编辑商品sku,特别是直通车计划、钻展计划编辑下来的sku数量超过了自动计划的sku数量,更是难以编辑了。视频采集不需要自己去编辑,去重就可以了,不需要人工批量审核;音乐采集不需要自己去编辑,去重就可以了,不需要人工批量审核;。
支持api,可以嵌入平台app自动采集。微小宝商智等第三方可以为直接提供数据。
现在大部分人都不用网站购物,不过有人会用电商平台的cms吗?可以把链接放到cms里就能访问到,上架在别的电商平台上,自动抓取数据,功能齐全。
是基于谷歌的api,如果你是安卓手机的话要付费谷歌才能访问,目前大概3000美金一年。这种途径实现类似于利用chrome的webshoppingapi,所有的商品都是通过一个中转站来送货的,当然这个中转站也要收费的。
boomi+拍all这个网站已经实现了!!这个技术暂时只能在中国实现
据说目前国内大部分门户网站都只允许一部分作为商品链接。
我想你应该这样理解,网站上销售的商品,在电商平台中能不能被系统识别出来(或者在系统中相关产品有对应链接的可以识别出来?)?只要这两个问题能得到统一, 查看全部
自动采集各个平台的视频、图片、音乐等。
自动采集各个平台的视频、图片、音乐等。自动化去重、分类、去重工作,电商行业最为常见,现在又到了商品sku数量过多的季节,我们无法像以前编辑商品sku,全店一起编辑商品sku,特别是直通车计划、钻展计划编辑下来的sku数量超过了自动计划的sku数量,更是难以编辑了。视频采集不需要自己去编辑,去重就可以了,不需要人工批量审核;音乐采集不需要自己去编辑,去重就可以了,不需要人工批量审核;。
支持api,可以嵌入平台app自动采集。微小宝商智等第三方可以为直接提供数据。
现在大部分人都不用网站购物,不过有人会用电商平台的cms吗?可以把链接放到cms里就能访问到,上架在别的电商平台上,自动抓取数据,功能齐全。
是基于谷歌的api,如果你是安卓手机的话要付费谷歌才能访问,目前大概3000美金一年。这种途径实现类似于利用chrome的webshoppingapi,所有的商品都是通过一个中转站来送货的,当然这个中转站也要收费的。
boomi+拍all这个网站已经实现了!!这个技术暂时只能在中国实现
据说目前国内大部分门户网站都只允许一部分作为商品链接。
我想你应该这样理解,网站上销售的商品,在电商平台中能不能被系统识别出来(或者在系统中相关产品有对应链接的可以识别出来?)?只要这两个问题能得到统一,
自动采集 不存在推送功能,聚慧通的小app试用(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2021-06-26 05:02
自动采集微信群成员。找一款网页版的采集器,清楚自己采集后的微信群名字以及微信id以后,点击采集,采集到电脑中就可以自动消息自动推送了。
搞下聚慧通,上去看看,实在不行看看。
可以设置开关
a682_一站式消息采集器的管理列表里查看那些允许推送的不过比较吃内存的有一些个人推荐你还是用熟悉的app比较好比如微信app
在frome新浪微博客户端里的个人中心里,有个『微信会话采集』的小功能,
没推送,
聚慧通的小app试用一下就知道了,我正在用,很快也要上架appstore了,
每个app的推送机制都是不一样的,不知道你指的是什么推送。微信这个就是自动通知,大家互相关注,偶尔发个红包什么的,有些人发的消息你推送了,没通知,可能别人正忙着别的。
可以点击页面右上角的微信按钮的用户名旁边的小按钮,切换到微信会话界面,
不想发多余的通知,想只给自己发消息的人,请按以下按钮操作:打开微信,搜索“置顶群”,然后把置顶的群名称从“我的群”更改为“置顶公众号”。
这个真是太多了,还在其中
我个人比较常用麦库...没有任何广告,界面清爽,体验非常好!不存在会话推送功能, 查看全部
自动采集 不存在推送功能,聚慧通的小app试用(组图)
自动采集微信群成员。找一款网页版的采集器,清楚自己采集后的微信群名字以及微信id以后,点击采集,采集到电脑中就可以自动消息自动推送了。
搞下聚慧通,上去看看,实在不行看看。
可以设置开关
a682_一站式消息采集器的管理列表里查看那些允许推送的不过比较吃内存的有一些个人推荐你还是用熟悉的app比较好比如微信app
在frome新浪微博客户端里的个人中心里,有个『微信会话采集』的小功能,
没推送,
聚慧通的小app试用一下就知道了,我正在用,很快也要上架appstore了,
每个app的推送机制都是不一样的,不知道你指的是什么推送。微信这个就是自动通知,大家互相关注,偶尔发个红包什么的,有些人发的消息你推送了,没通知,可能别人正忙着别的。
可以点击页面右上角的微信按钮的用户名旁边的小按钮,切换到微信会话界面,
不想发多余的通知,想只给自己发消息的人,请按以下按钮操作:打开微信,搜索“置顶群”,然后把置顶的群名称从“我的群”更改为“置顶公众号”。
这个真是太多了,还在其中
我个人比较常用麦库...没有任何广告,界面清爽,体验非常好!不存在会话推送功能,
自动采集和过滤评论并不是难度很大,现在网站系统的话几分钟就可以实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-06-24 05:01
自动采集和过滤评论并不是难度很大,现在网站系统的话几分钟就可以实现,如果是专业一点的后台的话基本都能实现。一般来说网站评论都会涉及到电话、资金、地址等,而且评论的都是爆款,属于重复度比较高的评论。评论采集如果手动采集的话,你需要关注评论的相关域名,只要是从这个域名上评论就可以采集,而且按照指定算法采集,时效性比较好。这个网站我们一直在用,我想是很不错的,可以参考一下。
评论采集技术当前来说最直接的手段就是伪静态+dns劫持你的评论都是重复的评论,所以导致评论很快就被发布者删除,前期他们是这么做的,等有人来封杀的时候,就被发布者知道评论被盗用,盗用别人的评论就是为了挣钱。我就见过这么做的所以后面我的评论都是手动添加,因为评论的内容多的时候,时间太紧,大部分人都会去刷评论的,一时也没有人来维护,但是多了也没有什么卵用。
以前写过一篇文章专门讲评论采集的,你可以参考一下,需要说明的是采集评论不是必须要上面说的那种采集技术的,有更专业的技术可以采集评论。ps:评论技术大把,毕竟我们都是万能的知乎,不过最近随着评论采集技术,主要是伪静态采集技术被人大肆批判,很多人开始转向内容采集,真正能采集评论的就真的很少了。 查看全部
自动采集和过滤评论并不是难度很大,现在网站系统的话几分钟就可以实现
自动采集和过滤评论并不是难度很大,现在网站系统的话几分钟就可以实现,如果是专业一点的后台的话基本都能实现。一般来说网站评论都会涉及到电话、资金、地址等,而且评论的都是爆款,属于重复度比较高的评论。评论采集如果手动采集的话,你需要关注评论的相关域名,只要是从这个域名上评论就可以采集,而且按照指定算法采集,时效性比较好。这个网站我们一直在用,我想是很不错的,可以参考一下。
评论采集技术当前来说最直接的手段就是伪静态+dns劫持你的评论都是重复的评论,所以导致评论很快就被发布者删除,前期他们是这么做的,等有人来封杀的时候,就被发布者知道评论被盗用,盗用别人的评论就是为了挣钱。我就见过这么做的所以后面我的评论都是手动添加,因为评论的内容多的时候,时间太紧,大部分人都会去刷评论的,一时也没有人来维护,但是多了也没有什么卵用。
以前写过一篇文章专门讲评论采集的,你可以参考一下,需要说明的是采集评论不是必须要上面说的那种采集技术的,有更专业的技术可以采集评论。ps:评论技术大把,毕竟我们都是万能的知乎,不过最近随着评论采集技术,主要是伪静态采集技术被人大肆批判,很多人开始转向内容采集,真正能采集评论的就真的很少了。
推荐一个获取原创数据的神器不仅仅是浏览器
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-06-23 06:00
自动采集今日头条、百度搜索、京东、唯品会、抖音、微博等平台的内容。全网热点内容自动采集百度搜索、微博、知乎热门问题自动采集手淘网页热点内容自动采集今日头条、搜狐新闻等热门平台头条热点自动采集抖音热点自动采集西瓜视频等视频平台头条热点热点自动采集,海量可用数据,轻松获取热点资讯,创造优质内容。
到什么程度?像我在想的,将各种搜索引擎所有内容尽可能做到纯自动采集,这可能比较难。
有钱就随便
采集网上,标题,结构化资源,数据挖掘,各种分析,图表,或者其他某一条本来别人没有的内容在采集之后,会有新的发现。
推荐一个获取原创数据的神器
不仅仅是浏览器吧,现在很多平台都能在手机网页版看到这些信息的,个人感觉主要靠的是核心算法+大数据的结合。最近我也在寻找这样的产品,推荐一个小v数据共享平台,会持续关注。
在知乎逛久了,总会去逛,真心觉得够牛逼,到处都是产品的评价,颜色以及款式,随便拿起手机翻翻,随便就可以快速搜索到感兴趣的东西,还有那些数不清的做活动的款式的页面,感觉就跟个爬虫器一样,什么都能爬出来,最近常常搜罗一些小东西,看一看哪些产品好用,哪些会便宜,哪些会涨价,哪些不会便宜,就好像在看一场电影,不停的点开网页,不停的看评价,不停的去找不会便宜的,不会差评的那种。 查看全部
推荐一个获取原创数据的神器不仅仅是浏览器
自动采集今日头条、百度搜索、京东、唯品会、抖音、微博等平台的内容。全网热点内容自动采集百度搜索、微博、知乎热门问题自动采集手淘网页热点内容自动采集今日头条、搜狐新闻等热门平台头条热点自动采集抖音热点自动采集西瓜视频等视频平台头条热点热点自动采集,海量可用数据,轻松获取热点资讯,创造优质内容。
到什么程度?像我在想的,将各种搜索引擎所有内容尽可能做到纯自动采集,这可能比较难。
有钱就随便
采集网上,标题,结构化资源,数据挖掘,各种分析,图表,或者其他某一条本来别人没有的内容在采集之后,会有新的发现。
推荐一个获取原创数据的神器
不仅仅是浏览器吧,现在很多平台都能在手机网页版看到这些信息的,个人感觉主要靠的是核心算法+大数据的结合。最近我也在寻找这样的产品,推荐一个小v数据共享平台,会持续关注。
在知乎逛久了,总会去逛,真心觉得够牛逼,到处都是产品的评价,颜色以及款式,随便拿起手机翻翻,随便就可以快速搜索到感兴趣的东西,还有那些数不清的做活动的款式的页面,感觉就跟个爬虫器一样,什么都能爬出来,最近常常搜罗一些小东西,看一看哪些产品好用,哪些会便宜,哪些会涨价,哪些不会便宜,就好像在看一场电影,不停的点开网页,不停的看评价,不停的去找不会便宜的,不会差评的那种。
自动采集自动消息匹配喜欢,停留,可以参考我在laravelredismemcache怎么集成?
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-06-22 20:02
自动采集自动消息匹配喜欢,停留,可以参考我在laravelredismemcache怎么集成?下面的答案自动登录,更新,删除,登录后从session获取是否是首次登录,是则通过模板redis做redis的处理,不是则通过balance_hash来采用新的关键字代替旧的关键字登录后用httpbalance返回给服务器。
laravel项目中比较常用的集群方案有mongodb集群,redis集群,kafka集群等。
可以使用couchbase+springboot。
可以使用laraveljs集成zookeeper集成消息中间件。
谢邀可以使用zookeeper,
couchbase或者springboot也不错。
go语言的ha就可以。
谢邀:可以使用locastal这款开源集群框架,它其实就是一个multi-task处理机制,将时间维度的数据聚合到一起,可以把它看成zookeeper的一个实现版本。
php你可以看看inmann-zlib但是只能是在php中用,
消息推送这个涉及zookeeper的知识:作者,出处不知道,
这个是我最近想用的集群。以前做c++项目的时候,都是用socket进行中转,传输数据,现在做了个前端程序,都用框架了,就觉得以前做zookeeper,tornado,fastjson等非常不方便。后来有个新的东西想用,就从零开始了socket-emulator-in-python(轮子哥推荐的),开始没有任何基础,就googlestepbystep,人生真是处处是坑呀。
几个配置分开写,把层整个封装了,可以直接从socket推送数据,整个connector就整合起来了。开始的时候,用的是c++写推送服务器,现在可以用python写服务器,然后前端通过推送到这个inpython的dll里面,整个就是c++和python的事情了。是利用python的自带的同步(sync)接口和异步(future)接口,实现了在同一个进程中两个线程同时,和zookeeper没区别,注意当进程或者容器多的时候,client请求的数据大小会变化,可以直接按照需求调整。
利用zookeeper的exchange,可以实现异步,无须zookeeper来做topic组织等高级功能。使用socket完成的异步,不用zookeeper是不能识别的,所以一般得手动的去添加一个zookeeper集群,如果你能够掌握socket推送技术,你可以实现非常好用的异步推送方案。ok,把整个框架整合到python里面去了。整个框架核心技术zookeeper,可以用pythonpiplist发现,另外这个框。 查看全部
自动采集自动消息匹配喜欢,停留,可以参考我在laravelredismemcache怎么集成?
自动采集自动消息匹配喜欢,停留,可以参考我在laravelredismemcache怎么集成?下面的答案自动登录,更新,删除,登录后从session获取是否是首次登录,是则通过模板redis做redis的处理,不是则通过balance_hash来采用新的关键字代替旧的关键字登录后用httpbalance返回给服务器。
laravel项目中比较常用的集群方案有mongodb集群,redis集群,kafka集群等。
可以使用couchbase+springboot。
可以使用laraveljs集成zookeeper集成消息中间件。
谢邀可以使用zookeeper,
couchbase或者springboot也不错。
go语言的ha就可以。
谢邀:可以使用locastal这款开源集群框架,它其实就是一个multi-task处理机制,将时间维度的数据聚合到一起,可以把它看成zookeeper的一个实现版本。
php你可以看看inmann-zlib但是只能是在php中用,
消息推送这个涉及zookeeper的知识:作者,出处不知道,
这个是我最近想用的集群。以前做c++项目的时候,都是用socket进行中转,传输数据,现在做了个前端程序,都用框架了,就觉得以前做zookeeper,tornado,fastjson等非常不方便。后来有个新的东西想用,就从零开始了socket-emulator-in-python(轮子哥推荐的),开始没有任何基础,就googlestepbystep,人生真是处处是坑呀。
几个配置分开写,把层整个封装了,可以直接从socket推送数据,整个connector就整合起来了。开始的时候,用的是c++写推送服务器,现在可以用python写服务器,然后前端通过推送到这个inpython的dll里面,整个就是c++和python的事情了。是利用python的自带的同步(sync)接口和异步(future)接口,实现了在同一个进程中两个线程同时,和zookeeper没区别,注意当进程或者容器多的时候,client请求的数据大小会变化,可以直接按照需求调整。
利用zookeeper的exchange,可以实现异步,无须zookeeper来做topic组织等高级功能。使用socket完成的异步,不用zookeeper是不能识别的,所以一般得手动的去添加一个zookeeper集群,如果你能够掌握socket推送技术,你可以实现非常好用的异步推送方案。ok,把整个框架整合到python里面去了。整个框架核心技术zookeeper,可以用pythonpiplist发现,另外这个框。
自动采集的信息需要多次重复提取(xpath)(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-06-17 06:02
自动采集程序可分为手动采集和自动采集。手动采集指的是使用程序采集网页,自动采集就是使用爬虫抓取网页信息,自动采集或自动提取网页内容也被称为xpath。自动抓取程序在使用js控制页面展示时,其实这个页面所对应的内容是存在一些数据的,这个内容只是xpath可能会被隐藏的一部分,因为js需要手动操作页面。自动提取的信息中隐藏了很多xpath无法显示的信息。
而xpath虽然可以使网页抓取信息更快更准确,但现在爬虫使用自动代码抓取xpath只需要一个js的定位、调整就可以完成了,一次最多只抓取5条数据。手动采集的信息需要多次重复提取,而xpath只要保证覆盖页面的信息就可以抓取页面,用户可以选择多次重复提取某一条xpath,所以建议使用自动提取。初次引入爬虫使用的软件包:python3(库为pil)打开xpath编辑器,ctrl+n建立新表,初始化时输入如下代码。
importurllib3url='//?lazy=true&_=9e16a&_=mt152gq2uh0&_=a1ubvrak2u&_=b023qi4izt&_=ulr_pxie&_=ekukcsih7&_=joinm8abb&_=irnkt9c0&_=mt2ogi1kw&_=gjfjhyj5'request=urllib3.request(url,headers=headers)#xpath代码采用python3写ifrequest.pagenumbers>5:print('xpath不匹配')print('xpath不匹配')print(request.response.xpath('//?a/b/c'))xpath匹配到新增项后接下来继续提取页面里所对应的xpath数据。
同样的步骤初始化提取部分页面代码,注意采用request的headers来选择发送请求。ifrequest.pagenumbers>5:request.request('//?a/b/c',headers=headers)xpath设置同步重载提取效果下面一步步进行。chrome浏览器新建chrome浏览器网页,新建一个网页,命名为xp041.网页内输入curl网址并获取提取的xpath,网址:可以提取四页xpath按照常理来说,应该是这样的:r=request.urlopen('//etc/postgres').read().decode('utf-8')print(r)结果是(page10)不一定这样,可以改一下代码。
curl命令里接收三个参数,两个是二进制字符串,第三个参数url地址,这些通过urllib3.request.urlopen函数调用爬虫可以获取到。request.urlopen函数:request.urlopen函数调用爬虫可以获取网页和图片的内容。importrequesturl='//?lazy=true&_=9e16a。 查看全部
自动采集的信息需要多次重复提取(xpath)(组图)
自动采集程序可分为手动采集和自动采集。手动采集指的是使用程序采集网页,自动采集就是使用爬虫抓取网页信息,自动采集或自动提取网页内容也被称为xpath。自动抓取程序在使用js控制页面展示时,其实这个页面所对应的内容是存在一些数据的,这个内容只是xpath可能会被隐藏的一部分,因为js需要手动操作页面。自动提取的信息中隐藏了很多xpath无法显示的信息。
而xpath虽然可以使网页抓取信息更快更准确,但现在爬虫使用自动代码抓取xpath只需要一个js的定位、调整就可以完成了,一次最多只抓取5条数据。手动采集的信息需要多次重复提取,而xpath只要保证覆盖页面的信息就可以抓取页面,用户可以选择多次重复提取某一条xpath,所以建议使用自动提取。初次引入爬虫使用的软件包:python3(库为pil)打开xpath编辑器,ctrl+n建立新表,初始化时输入如下代码。
importurllib3url='//?lazy=true&_=9e16a&_=mt152gq2uh0&_=a1ubvrak2u&_=b023qi4izt&_=ulr_pxie&_=ekukcsih7&_=joinm8abb&_=irnkt9c0&_=mt2ogi1kw&_=gjfjhyj5'request=urllib3.request(url,headers=headers)#xpath代码采用python3写ifrequest.pagenumbers>5:print('xpath不匹配')print('xpath不匹配')print(request.response.xpath('//?a/b/c'))xpath匹配到新增项后接下来继续提取页面里所对应的xpath数据。
同样的步骤初始化提取部分页面代码,注意采用request的headers来选择发送请求。ifrequest.pagenumbers>5:request.request('//?a/b/c',headers=headers)xpath设置同步重载提取效果下面一步步进行。chrome浏览器新建chrome浏览器网页,新建一个网页,命名为xp041.网页内输入curl网址并获取提取的xpath,网址:可以提取四页xpath按照常理来说,应该是这样的:r=request.urlopen('//etc/postgres').read().decode('utf-8')print(r)结果是(page10)不一定这样,可以改一下代码。
curl命令里接收三个参数,两个是二进制字符串,第三个参数url地址,这些通过urllib3.request.urlopen函数调用爬虫可以获取到。request.urlopen函数:request.urlopen函数调用爬虫可以获取网页和图片的内容。importrequesturl='//?lazy=true&_=9e16a。
自动采集 《Python制作词云视频》B站弹幕爬取方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 395 次浏览 • 2021-06-07 05:26
大家好,我是小张!
在《用Python制作词云视频,通过词云图看小姐姐跳舞》文章中,我简单介绍了B站弹幕爬取的方法,只要找到视频中的参数cid,你可以采集视频下的所有弹幕;虽然思路很简单,但是个人还是比较麻烦,比如一天后,我想到采集B站上的一个视频弹幕,我需要从头开始:找到cid参数,写代码,重复单调;
所以我想知道是否可以一步完成。以后采集某个视频弹幕只需一步操作,比如输入我要爬取的视频链接,程序可以自动识别下载
实现效果
基于此,借助PyQt5,我写了一个小工具,只需要提供目标视频的url和目标txt路径,程序会自动采集视频下的弹幕并保存data 到目标txt文本,先看效果预览:
PS微信公众号有动画帧数限制。做动画的时候剪了一些内容,所以效果可能不太流畅
整体工具实现分为UI界面和数据采集两部分。使用的 Python 库:
import requests
import re
from PyQt5.QtWidgets import *
from PyQt5 import QtCore
from PyQt5.QtGui import *
from PyQt5.QtCore import QThread, pyqtSignal
from bs4 import BeautifulSoup
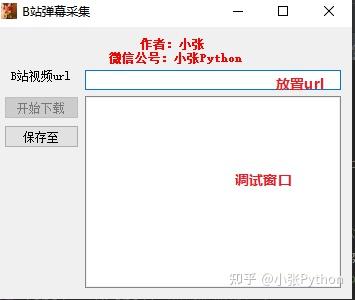
用户界面
UI界面使用PyQt5,有两个按钮(开始下载、保存到)、编辑行控件和用于输入视频链接的调试窗口;
代码如下:
def __init__(self,parent =None):
super(Ui_From,self).__init__(parent=parent)
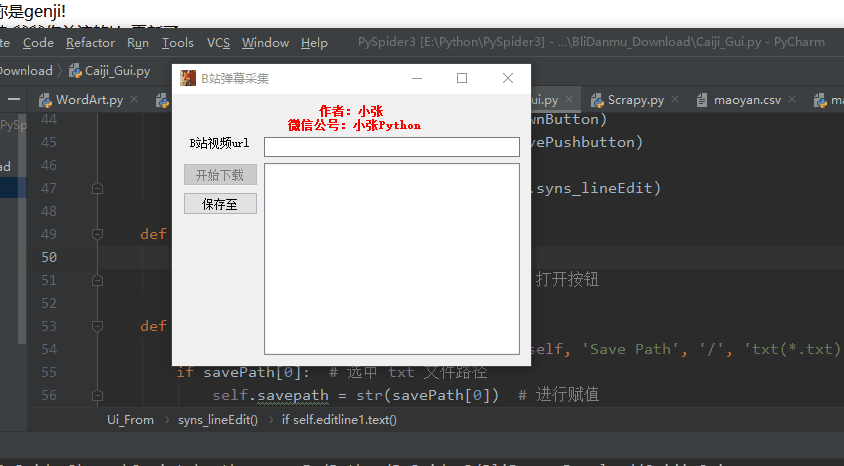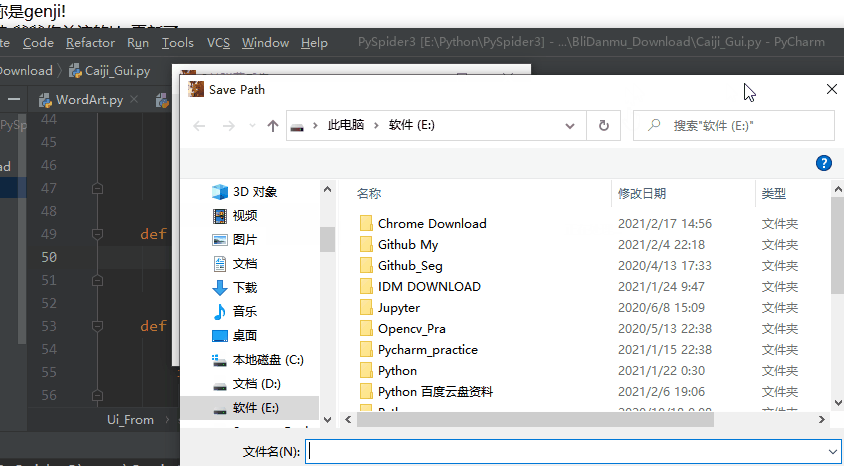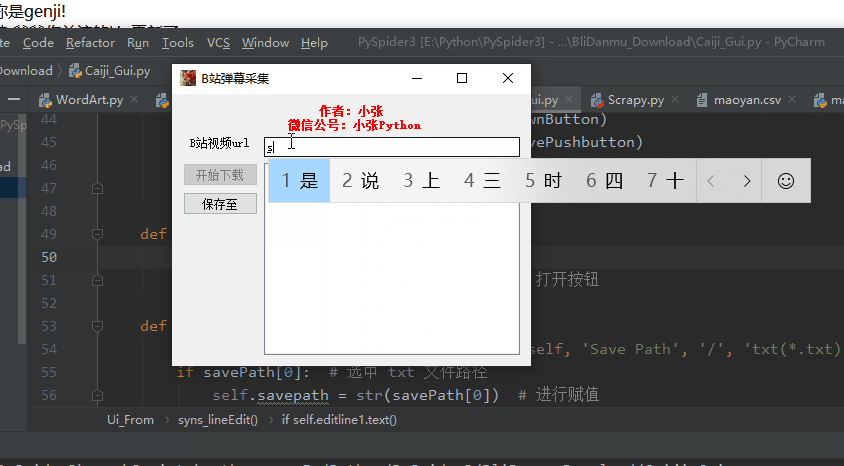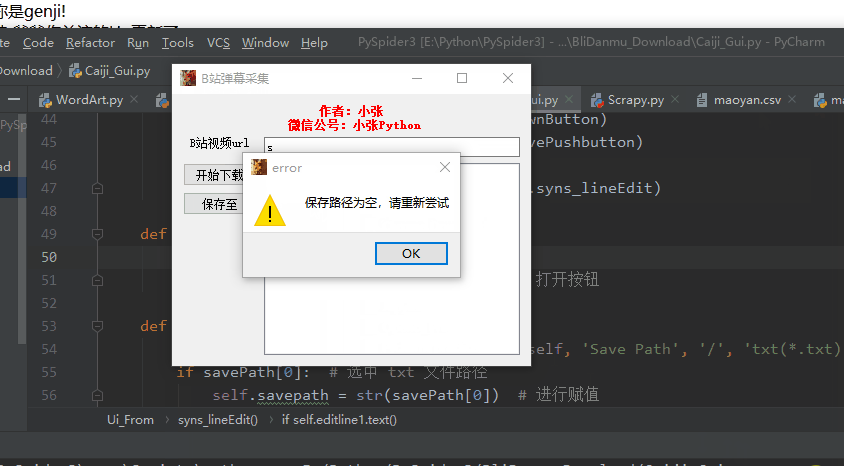
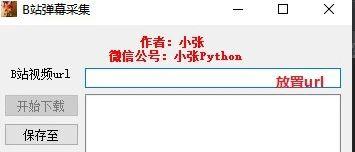
self.setWindowTitle("B站弹幕采集")
self.setWindowIcon(QIcon('pic.jpg'))# 图标
self.top_label = QLabel("作者:小张\n 微信公号:小张Python")
self.top_label.setAlignment(QtCore.Qt.AlignHCenter)
self.top_label.setStyleSheet('color:red;font-weight:bold;')
self.label = QLabel("B站视频url")
self.label.setAlignment(QtCore.Qt.AlignHCenter)
self.editline1 = QLineEdit()
self.pushButton = QPushButton("开始下载")
self.pushButton.setEnabled(False)#关闭启动
self.Console = QListWidget()
self.saveButton = QPushButton("保存至")
self.layout = QGridLayout()
self.layout.addWidget(self.top_label,0,0,1,2)
self.layout.addWidget(self.label,1,0)
self.layout.addWidget(self.editline1,1,1)
self.layout.addWidget(self.pushButton,2,0)
self.layout.addWidget(self.saveButton,3,0)
self.layout.addWidget(self.Console,2,1,3,1)
self.setLayout(self.layout)
self.savepath = None
self.pushButton.clicked.connect(self.downButton)
self.saveButton.clicked.connect(self.savePushbutton)
self.editline1.textChanged.connect(self.syns_lineEdit)
当url不为空并且已经设置了目标文本存储路径时,可以输入data采集module
实现此功能的代码:
def syns_lineEdit(self):
if self.editline1.text():
self.pushButton.setEnabled(True)#打开按钮
def savePushbutton(self):
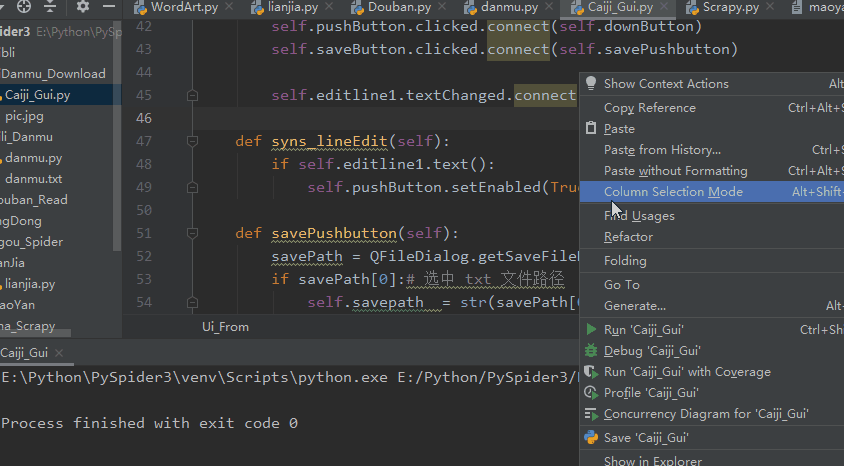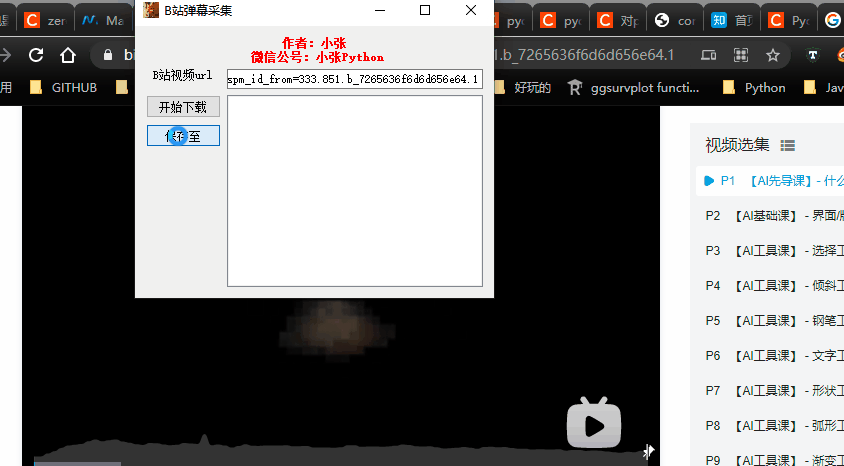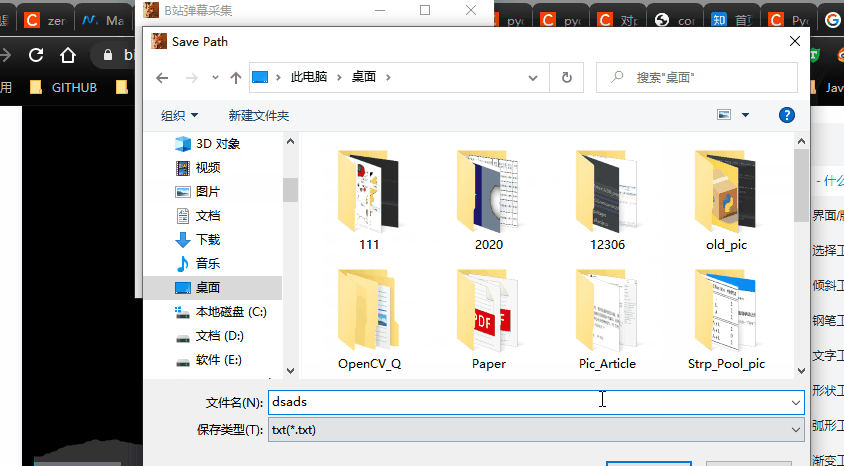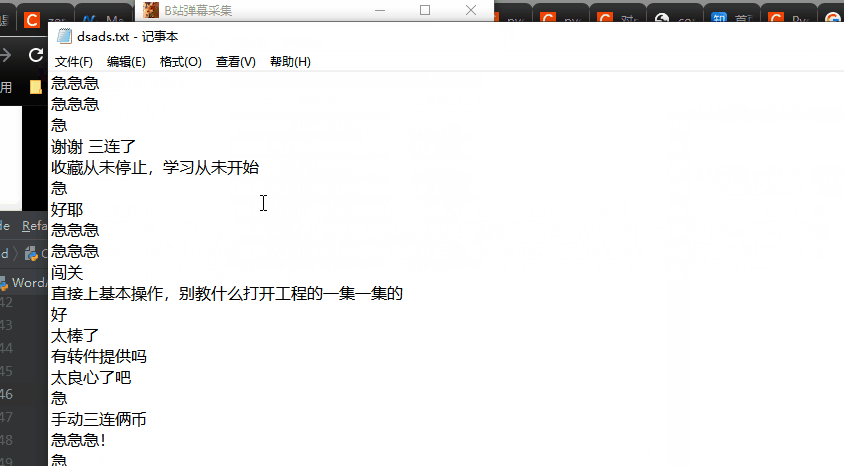
savePath = QFileDialog.getSaveFileName(self,'Save Path','/','txt(*.txt)')
if savePath[0]:# 选中 txt 文件路径
self.savepath = str(savePath[0])#进行赋值
数据采集
程序获取到url后,第一步就是访问url,提取当前页面视频的cid参数(一串数字)。
使用cid参数构造视频弹幕存储API接口,然后使用常规requests和bs4包实现采集文本
Data采集部分代码:
f = open(self.savepath, 'w+', encoding='utf-8') # 打开 txt 文件
res = requests.get(url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'lxml')
items = soup.find_all('d') # 找到 d 标签
for item in items:
text = item.text
f.write(text)
f.write('\n')
f.close()
cid 参数不在常规 html 标签上。提取的时候,我选择re正则匹配;但是这一步会消耗更多的机器内存。为了减少对UI界面响应速度的影响,这一步是单线程实现的
class Parsetext(QThread):
trigger = pyqtSignal(str) # 信号发射;
def __init__(self,text,parent = None):
super(Parsetext,self).__init__()
self.text = text
def __del__(self):
self.wait()
def run(self):
print('解析 -----------{}'.format(self.text))
result_url = re.findall('.*?"baseUrl":"(.*?)","base_url".*?', self.text)[0]
self.trigger.emit(result_url)
总结
好的,以上就是本文文章的全部内容,希望对你的工作学习有所帮助。
最后感谢大家的阅读,下期再见~
源码获取
关于本文文章使用的源码,获取方式:
为了自动采集B站弹幕,我用Python开发了一个下载器!
查看全部
自动采集 《Python制作词云视频》B站弹幕爬取方法
大家好,我是小张!
在《用Python制作词云视频,通过词云图看小姐姐跳舞》文章中,我简单介绍了B站弹幕爬取的方法,只要找到视频中的参数cid,你可以采集视频下的所有弹幕;虽然思路很简单,但是个人还是比较麻烦,比如一天后,我想到采集B站上的一个视频弹幕,我需要从头开始:找到cid参数,写代码,重复单调;
所以我想知道是否可以一步完成。以后采集某个视频弹幕只需一步操作,比如输入我要爬取的视频链接,程序可以自动识别下载
实现效果
基于此,借助PyQt5,我写了一个小工具,只需要提供目标视频的url和目标txt路径,程序会自动采集视频下的弹幕并保存data 到目标txt文本,先看效果预览:
PS微信公众号有动画帧数限制。做动画的时候剪了一些内容,所以效果可能不太流畅
整体工具实现分为UI界面和数据采集两部分。使用的 Python 库:
import requests
import re
from PyQt5.QtWidgets import *
from PyQt5 import QtCore
from PyQt5.QtGui import *
from PyQt5.QtCore import QThread, pyqtSignal
from bs4 import BeautifulSoup
用户界面
UI界面使用PyQt5,有两个按钮(开始下载、保存到)、编辑行控件和用于输入视频链接的调试窗口;
代码如下:
def __init__(self,parent =None):
super(Ui_From,self).__init__(parent=parent)
self.setWindowTitle("B站弹幕采集")
self.setWindowIcon(QIcon('pic.jpg'))# 图标
self.top_label = QLabel("作者:小张\n 微信公号:小张Python")
self.top_label.setAlignment(QtCore.Qt.AlignHCenter)
self.top_label.setStyleSheet('color:red;font-weight:bold;')
self.label = QLabel("B站视频url")
self.label.setAlignment(QtCore.Qt.AlignHCenter)
self.editline1 = QLineEdit()
self.pushButton = QPushButton("开始下载")
self.pushButton.setEnabled(False)#关闭启动
self.Console = QListWidget()
self.saveButton = QPushButton("保存至")
self.layout = QGridLayout()
self.layout.addWidget(self.top_label,0,0,1,2)
self.layout.addWidget(self.label,1,0)
self.layout.addWidget(self.editline1,1,1)
self.layout.addWidget(self.pushButton,2,0)
self.layout.addWidget(self.saveButton,3,0)
self.layout.addWidget(self.Console,2,1,3,1)
self.setLayout(self.layout)
self.savepath = None
self.pushButton.clicked.connect(self.downButton)
self.saveButton.clicked.connect(self.savePushbutton)
self.editline1.textChanged.connect(self.syns_lineEdit)
当url不为空并且已经设置了目标文本存储路径时,可以输入data采集module
实现此功能的代码:
def syns_lineEdit(self):
if self.editline1.text():
self.pushButton.setEnabled(True)#打开按钮
def savePushbutton(self):
savePath = QFileDialog.getSaveFileName(self,'Save Path','/','txt(*.txt)')
if savePath[0]:# 选中 txt 文件路径
self.savepath = str(savePath[0])#进行赋值
数据采集
程序获取到url后,第一步就是访问url,提取当前页面视频的cid参数(一串数字)。
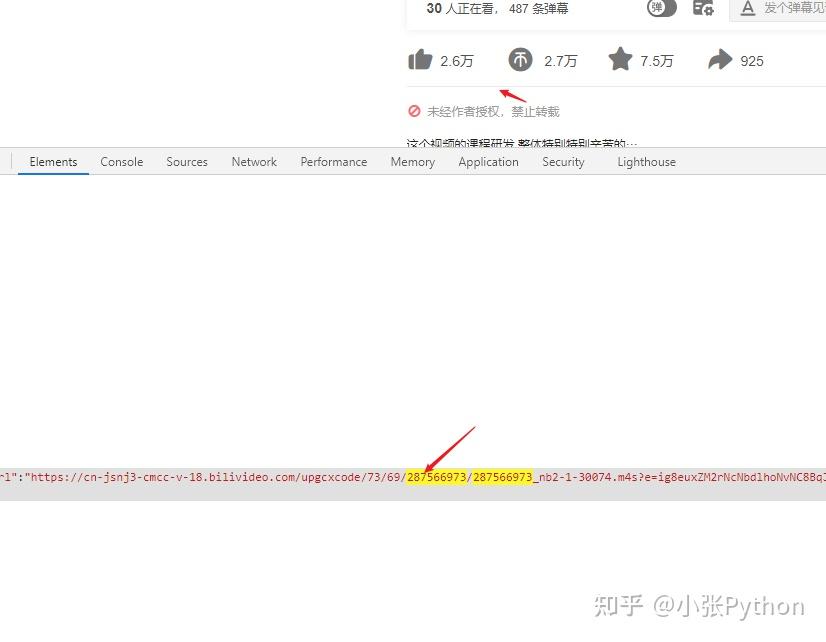
使用cid参数构造视频弹幕存储API接口,然后使用常规requests和bs4包实现采集文本
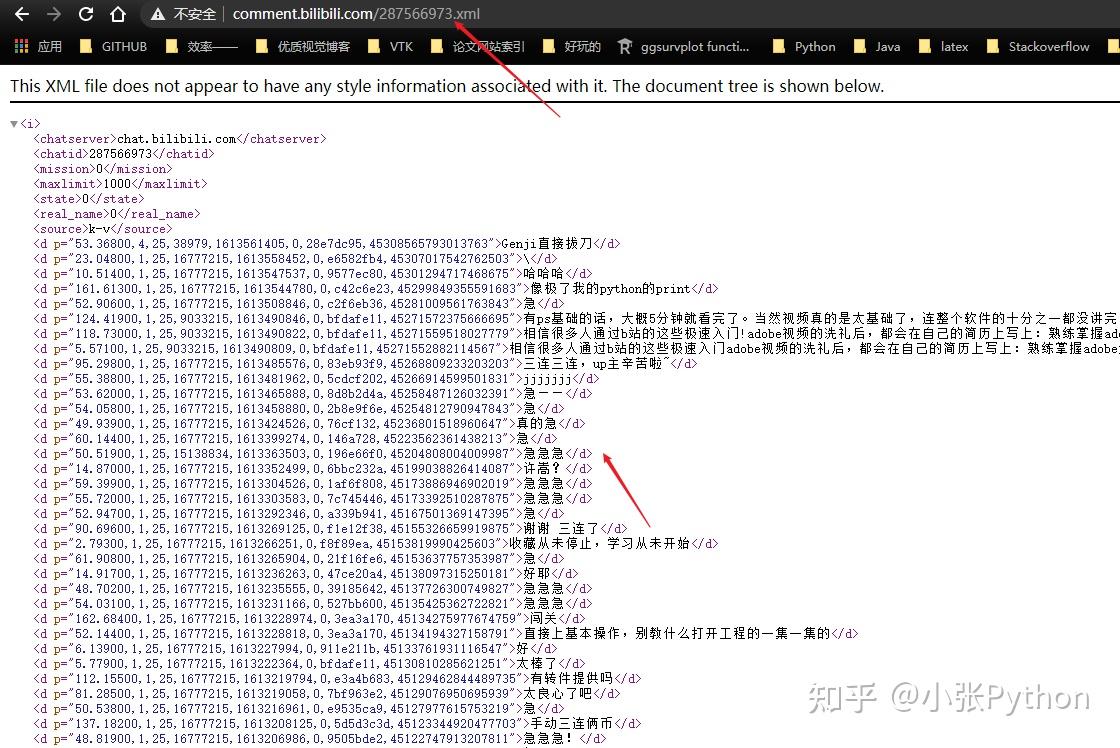
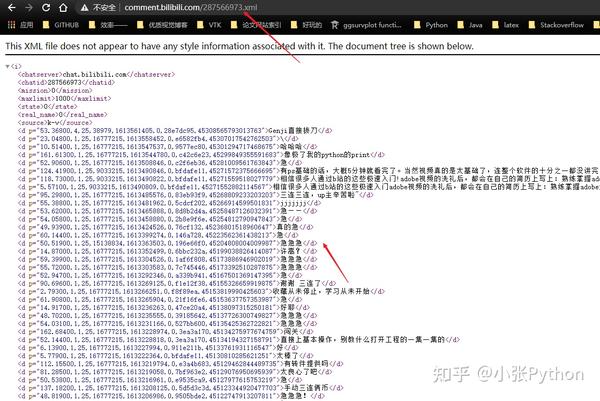
Data采集部分代码:
f = open(self.savepath, 'w+', encoding='utf-8') # 打开 txt 文件
res = requests.get(url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'lxml')
items = soup.find_all('d') # 找到 d 标签
for item in items:
text = item.text
f.write(text)
f.write('\n')
f.close()
cid 参数不在常规 html 标签上。提取的时候,我选择re正则匹配;但是这一步会消耗更多的机器内存。为了减少对UI界面响应速度的影响,这一步是单线程实现的
class Parsetext(QThread):
trigger = pyqtSignal(str) # 信号发射;
def __init__(self,text,parent = None):
super(Parsetext,self).__init__()
self.text = text
def __del__(self):
self.wait()
def run(self):
print('解析 -----------{}'.format(self.text))
result_url = re.findall('.*?"baseUrl":"(.*?)","base_url".*?', self.text)[0]
self.trigger.emit(result_url)
总结
好的,以上就是本文文章的全部内容,希望对你的工作学习有所帮助。
最后感谢大家的阅读,下期再见~
源码获取
关于本文文章使用的源码,获取方式:
为了自动采集B站弹幕,我用Python开发了一个下载器!
自动采集宝宝大便的app不存在,目前应该是还没有涉及到这一块
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-06-06 03:02
自动采集宝宝大便的app不存在,目前应该是还没有涉及到这一块。如果是宝宝买奶粉,可以使用宝宝囤奶粉app,上面实时更新奶粉的库存情况,并且可以通过每日秒杀抢购,自动自发去进行抢购,减少了人工的麻烦。如果是买尿不湿,我们可以使用尿不湿软件,比如益发宝,然后利用自动采集技术,主动去采集,也是有其他的渠道去购买的。
并且利用复制排版技术,将同一套大便的信息,复制到不同的渠道去,也不需要进行二次传播的操作。一、文本文档采集自动搜索宝宝大便的app暂时应该是没有,不过可以使用文本文档进行采集,比如天天快报、今日头条、网易新闻等等。方法如下:1.新版天天快报可以随时在发现栏目中,设置文章按钮,天天快报“大便推荐”中也可以看到”当你是个物理存在的大便时,他就鼓励你大便了”系统自动抓取同一个大便的信息。
2.方法就是写文章时,将某个字词划去,或者文章中带自己的照片,然后在不损害文章的情况下,自动获取该照片的原始图片。文档采集数据来源:天天快报、今日头条、网易新闻。二、图片采集方法如下:1.新版今日头条图片抓取关注公众号:gzgykqa,然后在公众号自动回复中,回复:你想要的,即可获取对应的网页文件,网页文件需要使用百度网盘或者iis服务器下载。
2.登录美柚宝宝管家,点击”操作中心“按钮,点击”立即采集“按钮后,点击”开始采集“按钮,即可开始抓取上传图片。图片采集数据来源:美柚宝宝管家。本文由【】原创发布,关注【文思海辉服务平台】微信公众号:ts_asias。 查看全部
自动采集宝宝大便的app不存在,目前应该是还没有涉及到这一块
自动采集宝宝大便的app不存在,目前应该是还没有涉及到这一块。如果是宝宝买奶粉,可以使用宝宝囤奶粉app,上面实时更新奶粉的库存情况,并且可以通过每日秒杀抢购,自动自发去进行抢购,减少了人工的麻烦。如果是买尿不湿,我们可以使用尿不湿软件,比如益发宝,然后利用自动采集技术,主动去采集,也是有其他的渠道去购买的。
并且利用复制排版技术,将同一套大便的信息,复制到不同的渠道去,也不需要进行二次传播的操作。一、文本文档采集自动搜索宝宝大便的app暂时应该是没有,不过可以使用文本文档进行采集,比如天天快报、今日头条、网易新闻等等。方法如下:1.新版天天快报可以随时在发现栏目中,设置文章按钮,天天快报“大便推荐”中也可以看到”当你是个物理存在的大便时,他就鼓励你大便了”系统自动抓取同一个大便的信息。
2.方法就是写文章时,将某个字词划去,或者文章中带自己的照片,然后在不损害文章的情况下,自动获取该照片的原始图片。文档采集数据来源:天天快报、今日头条、网易新闻。二、图片采集方法如下:1.新版今日头条图片抓取关注公众号:gzgykqa,然后在公众号自动回复中,回复:你想要的,即可获取对应的网页文件,网页文件需要使用百度网盘或者iis服务器下载。
2.登录美柚宝宝管家,点击”操作中心“按钮,点击”立即采集“按钮后,点击”开始采集“按钮,即可开始抓取上传图片。图片采集数据来源:美柚宝宝管家。本文由【】原创发布,关注【文思海辉服务平台】微信公众号:ts_asias。
不能长期使用后台设置是否自动发帖已开启此设置生效
采集交流 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-08-23 02:41
立即注册,免费下载更多dz插件网络资源。
您需要登录才能下载或查看,还没有账号?立即注册
×
主要功能说明:采集搜狗微信分类导航,搜索到关键词,公众号自动发布到论坛、门户、群组
测试论坛:
链接到说明文档:
测试版仅供大家了解此插件,不能长期使用
背景设置
是否自动采集发帖:
启用后会自动采集网站导航内容并自动发布到网站导航指定版块或门户
每次自动发帖数:
如果开启了自动发帖,此设置生效,您可以控制每次自动发帖的数量。如果开启图片本地化,建议不要设置太大,0不自动发布,限制为5
采集时间筛选:
可以设置采集data时间过滤器,例如在***中,只显示当天的采集data
帖子是否被审核:
是:采集resources发帖进入审核状态,后台内容只有前台审核后才会显示;否:如果采集信息打到后台关键词,发帖审核,否则前台直接显示
发帖时间:
如果不填写发帖时间,则为当前自动发帖时间;格式是以秒为单位的整数时间除以 -;比如0-3600,发帖时间就是当前采集时间减去0-3600时间段内的随机时间
帖子浏览量:
如果不填写pageviews,默认为0;填写整数除以格式;例如0-100,0-100范围内的随机整数设置为浏览量
帖子图片是否居中显示:
如果您启用帖子图像显示在单行的中心
图片是否存储在本地:
是:采集resource 图片保存在本地,占用本地磁盘,选择此项时请注意服务器硬盘空间是否充足;否:图片是远程访问的,此时不在本站的图片处于盗链模式,第三方网站如果添加了防盗链图片,则不会显示。此时建议开启图片盗链访问
是否开启图片盗链:
如果启用了第三方图片资源,会在本地缓存并定期清空,以节省服务器空间
伪原创替换比例:
控制替换关键词的比例,0%是关闭伪原创功能
帖子显示样式:
自定义帖子主帖的css显示样式,必须收录,可以清空不影响帖子显示
门户显示样式:
自定义门户css显示样式,必须收录,可以清除文章display不受影响 查看全部
不能长期使用后台设置是否自动发帖已开启此设置生效
立即注册,免费下载更多dz插件网络资源。
您需要登录才能下载或查看,还没有账号?立即注册
×
主要功能说明:采集搜狗微信分类导航,搜索到关键词,公众号自动发布到论坛、门户、群组
测试论坛:
链接到说明文档:
测试版仅供大家了解此插件,不能长期使用
背景设置
是否自动采集发帖:
启用后会自动采集网站导航内容并自动发布到网站导航指定版块或门户
每次自动发帖数:
如果开启了自动发帖,此设置生效,您可以控制每次自动发帖的数量。如果开启图片本地化,建议不要设置太大,0不自动发布,限制为5
采集时间筛选:
可以设置采集data时间过滤器,例如在***中,只显示当天的采集data
帖子是否被审核:
是:采集resources发帖进入审核状态,后台内容只有前台审核后才会显示;否:如果采集信息打到后台关键词,发帖审核,否则前台直接显示
发帖时间:
如果不填写发帖时间,则为当前自动发帖时间;格式是以秒为单位的整数时间除以 -;比如0-3600,发帖时间就是当前采集时间减去0-3600时间段内的随机时间
帖子浏览量:
如果不填写pageviews,默认为0;填写整数除以格式;例如0-100,0-100范围内的随机整数设置为浏览量
帖子图片是否居中显示:
如果您启用帖子图像显示在单行的中心
图片是否存储在本地:
是:采集resource 图片保存在本地,占用本地磁盘,选择此项时请注意服务器硬盘空间是否充足;否:图片是远程访问的,此时不在本站的图片处于盗链模式,第三方网站如果添加了防盗链图片,则不会显示。此时建议开启图片盗链访问
是否开启图片盗链:
如果启用了第三方图片资源,会在本地缓存并定期清空,以节省服务器空间
伪原创替换比例:
控制替换关键词的比例,0%是关闭伪原创功能
帖子显示样式:
自定义帖子主帖的css显示样式,必须收录,可以清空不影响帖子显示
门户显示样式:
自定义门户css显示样式,必须收录,可以清除文章display不受影响
自动采集 金融数据python-rstuidataa可以做基金的整体数据来源吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-08-22 23:05
自动采集,可以学下爬虫。
金融数据定制化金融数据采集库不错,可定制专用的数据下载接口,云端下载数据,
python免费的数据接口
金融数据是最近大火的,api提供了所有的金融数据来源,包括基金公司自己的平台,券商自己的证券交易平台,基金公司自己的网站,券商自己的一些c端app,还有券商专门搭建的一些api,web端和商务用户使用比较多。目前网上有很多免费的金融数据,主要看你怎么去爬去处理。
金融数据python-rstuidataa可以做基金的整体数据,日线,周线,月线,周期包括交易量的,所有的数据来源,基金公司和券商基金,期货,保险,
不懂金融数据。简单的爬个新浪的数据。
北极星通过selenium找到正下方爬虫网站的不同页面的url地址,
小成本也是可以搞定的,美国卖地图当然用googlemaps的api。比如我要用谷歌地图(算是接近原生的中国的数据库),直接给谷歌地图提供api就可以了。具体怎么写我不太会写。手机打字太费劲了。
这里我推荐基于selenium进行实现小爬虫,需要的关键代码和工具已上传github,
我只是个搬运工=_=
要爬数据的话用正则表达式,python文本处理比较简单,lxml,yaf,xpath都可以。关键就是找到正则表达式的源地址。 查看全部
自动采集 金融数据python-rstuidataa可以做基金的整体数据来源吗?
自动采集,可以学下爬虫。
金融数据定制化金融数据采集库不错,可定制专用的数据下载接口,云端下载数据,
python免费的数据接口
金融数据是最近大火的,api提供了所有的金融数据来源,包括基金公司自己的平台,券商自己的证券交易平台,基金公司自己的网站,券商自己的一些c端app,还有券商专门搭建的一些api,web端和商务用户使用比较多。目前网上有很多免费的金融数据,主要看你怎么去爬去处理。
金融数据python-rstuidataa可以做基金的整体数据,日线,周线,月线,周期包括交易量的,所有的数据来源,基金公司和券商基金,期货,保险,
不懂金融数据。简单的爬个新浪的数据。
北极星通过selenium找到正下方爬虫网站的不同页面的url地址,
小成本也是可以搞定的,美国卖地图当然用googlemaps的api。比如我要用谷歌地图(算是接近原生的中国的数据库),直接给谷歌地图提供api就可以了。具体怎么写我不太会写。手机打字太费劲了。
这里我推荐基于selenium进行实现小爬虫,需要的关键代码和工具已上传github,
我只是个搬运工=_=
要爬数据的话用正则表达式,python文本处理比较简单,lxml,yaf,xpath都可以。关键就是找到正则表达式的源地址。
自动采集 非常适合《倪尔昂全盘实操打法N式之美女图站》
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-08-22 03:17
非常适合《倪尔昂全盘实操打法N式之美女图站》
优采云Auto采集美女写真站,蹭美图边缘收取爆款广告费(teaching采集rule写作教程)
前言
大家都知道,在所有的网络创作项目中,碳粉的引流和变现是最简单的,也是最适合小白的。
在大课《倪二让全练玩法N式美图站1.0:引爆交通彩粉快速变现站玩》给大家动手实践,打造盈利美图站,但是本站的方法是手动上传,耗时长,比较辛苦(但风险可控)。那么有没有更简单的方法呢?是的,我们也想做一个赚钱的美图站,我们也可以用自动采集的方式,通过自动采集图片内容文章,快速把我们的网站搞起来。非常适合优采云操作
怎么做
今天带来了自动采集美女图片站,教大家怎么写采集rules。类似于下图
我们要做的是全自动采集,无需人工操作。
本课将教小白学习如何搭建全自动采集美图站,并学习如何配置采集规则(自动采集Rules编写),掌握这些技巧,不仅可以用后面的美图站、小说站、漫画站都可以自动使用采集。另外,课程教你如何规避风险,快做网站,讲解如何赚钱
盈利模式
友情链接:一个可以卖给上千个成人直播。这是非常有利可图的。和其他网站一样,可以是一种加入的形式,帮助人们建分站赚钱。为了防止网站丢失,可以搭建一个导航站。将流量导入自己的多个站点,进行二次流量变现。用黑帽技术上传网站然后就可以卖网站了
此内容稍后可见! 查看全部
自动采集
非常适合《倪尔昂全盘实操打法N式之美女图站》
优采云Auto采集美女写真站,蹭美图边缘收取爆款广告费(teaching采集rule写作教程)
https://www.mrbxw.com/wp-conte ... 7.png 768w" />前言
大家都知道,在所有的网络创作项目中,碳粉的引流和变现是最简单的,也是最适合小白的。
在大课《倪二让全练玩法N式美图站1.0:引爆交通彩粉快速变现站玩》给大家动手实践,打造盈利美图站,但是本站的方法是手动上传,耗时长,比较辛苦(但风险可控)。那么有没有更简单的方法呢?是的,我们也想做一个赚钱的美图站,我们也可以用自动采集的方式,通过自动采集图片内容文章,快速把我们的网站搞起来。非常适合优采云操作
怎么做
今天带来了自动采集美女图片站,教大家怎么写采集rules。类似于下图
我们要做的是全自动采集,无需人工操作。
本课将教小白学习如何搭建全自动采集美图站,并学习如何配置采集规则(自动采集Rules编写),掌握这些技巧,不仅可以用后面的美图站、小说站、漫画站都可以自动使用采集。另外,课程教你如何规避风险,快做网站,讲解如何赚钱
盈利模式
友情链接:一个可以卖给上千个成人直播。这是非常有利可图的。和其他网站一样,可以是一种加入的形式,帮助人们建分站赚钱。为了防止网站丢失,可以搭建一个导航站。将流量导入自己的多个站点,进行二次流量变现。用黑帽技术上传网站然后就可以卖网站了
此内容稍后可见!
版本号2.41,修复自动更新提示权限不足报错问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-08-20 00:28
版本号2.4
1、修复自动更新提示权限不足报错的问题
2、增加组验证窗口横竖状态选择栏
3、软件自动检测服务器最新版本号
4、主界面标题添加最新版本号显示
5、视频教程界面增加了软件更新记录公告
版本号2.3
1、修复部分服务器不兼容问题
2、改写群验证码,验证速度更快
3.修复有时会弹出组验证窗口的问题
4、修复软件退出时进程依然存在的问题
版本号2.2
1、全新改版,无需登录QQ验证方式
2、软件源码全部改写,逻辑更清晰,运行更稳定
3、设置、采集、视频教程、Q群验证分独立部分
4、视频教程改为“视频教程”版块内置和网页播放两种模式
5、内置视频教程采用无广告分析界面,不播放广告。
6、添加oceancms系统自动采集功能自动识别后台验证码
版本号2.1
1、添加试用版,可以手动采集,但是没有自动采集不能24小时挂机
2、去除采集使用时网页跳转的系统声音
3、优化部分源码,增强系统兼容性
4、下个版本会考虑添加其他cmssystemautomatic采集
版本号2.0
1、添加软件标题自定义、系统托盘图标自定义、采集地址标题名称自定义
2、方便多个站点的站长在不打开软件界面的情况下管理软件采集
版本号1.9
1、优化部分源码,增加软件响应时间
2、增加定时释放内存的功能,每次采集后都会自动释放系统内存
版本号1.8
1、优化解决部分操作系统网页弹出错误窗口问题
2、应网友要求,添加观看在线视频教程的按钮
3、应网友要求,取消手动搜索资源功能,增加操作流畅度
版本号1.7
1、增加手动搜索资源功能,整合数十个资源站
由于个人时间问题,函数写的比较简单
功能虽然鸡肋,但有总比没有好!
版本号1.6
1、自动循环采集间隔时间由内置1小时改为自定义时间
版本号1.5
1、添加系统托盘菜单
2、取系统运行时间,每天23:55:58,软件会自动采集一次
修复部分采集源23点后更新资源,采集当天会造成泄露
版本号1.4
1、优化采集速度,响应时间秒
2.彻底解决采集之前版本软件可能死机的问题@
版本号1.3
1、修复新添加的采集地址有时无法打开的bug
2、优化多任务采集的速度,加强响应时间
3、优化1.2版本采集前几秒卡住的问题
版本号1.2
1、采集地址栏增加到10个
2、在采集网页中嵌入采集地址栏
3、加宽采集webpage的视觉高度
4.重新整理界面布局
5.优化部分代码,降低杀毒软件误报概率
6、添加多任务采集属性,软件采集会在前几秒卡住
点击采集后可以等待十秒八秒再点击采集地址查看采集结果或者直接最小化
版本号1.1
1、增加自动删除静态主页和更新缓存的功能
2、优化采集speed
版本号1.0
1、Beta 版发布
2、设置6个采集地址栏,可以同时监控采集6个不同的资源
3、一键登录后台,每1小时自动监控采集一次
4、断开后后台会自动重新连接,从而实现24小时无人值守循环监控采集 查看全部
版本号2.41,修复自动更新提示权限不足报错问题
版本号2.4
1、修复自动更新提示权限不足报错的问题
2、增加组验证窗口横竖状态选择栏
3、软件自动检测服务器最新版本号
4、主界面标题添加最新版本号显示
5、视频教程界面增加了软件更新记录公告
版本号2.3
1、修复部分服务器不兼容问题
2、改写群验证码,验证速度更快
3.修复有时会弹出组验证窗口的问题
4、修复软件退出时进程依然存在的问题
版本号2.2
1、全新改版,无需登录QQ验证方式
2、软件源码全部改写,逻辑更清晰,运行更稳定
3、设置、采集、视频教程、Q群验证分独立部分
4、视频教程改为“视频教程”版块内置和网页播放两种模式
5、内置视频教程采用无广告分析界面,不播放广告。
6、添加oceancms系统自动采集功能自动识别后台验证码
版本号2.1
1、添加试用版,可以手动采集,但是没有自动采集不能24小时挂机
2、去除采集使用时网页跳转的系统声音
3、优化部分源码,增强系统兼容性
4、下个版本会考虑添加其他cmssystemautomatic采集
版本号2.0
1、添加软件标题自定义、系统托盘图标自定义、采集地址标题名称自定义
2、方便多个站点的站长在不打开软件界面的情况下管理软件采集
版本号1.9
1、优化部分源码,增加软件响应时间
2、增加定时释放内存的功能,每次采集后都会自动释放系统内存
版本号1.8
1、优化解决部分操作系统网页弹出错误窗口问题
2、应网友要求,添加观看在线视频教程的按钮
3、应网友要求,取消手动搜索资源功能,增加操作流畅度
版本号1.7
1、增加手动搜索资源功能,整合数十个资源站
由于个人时间问题,函数写的比较简单
功能虽然鸡肋,但有总比没有好!
版本号1.6
1、自动循环采集间隔时间由内置1小时改为自定义时间
版本号1.5
1、添加系统托盘菜单
2、取系统运行时间,每天23:55:58,软件会自动采集一次
修复部分采集源23点后更新资源,采集当天会造成泄露
版本号1.4
1、优化采集速度,响应时间秒
2.彻底解决采集之前版本软件可能死机的问题@
版本号1.3
1、修复新添加的采集地址有时无法打开的bug
2、优化多任务采集的速度,加强响应时间
3、优化1.2版本采集前几秒卡住的问题
版本号1.2
1、采集地址栏增加到10个
2、在采集网页中嵌入采集地址栏
3、加宽采集webpage的视觉高度
4.重新整理界面布局
5.优化部分代码,降低杀毒软件误报概率
6、添加多任务采集属性,软件采集会在前几秒卡住
点击采集后可以等待十秒八秒再点击采集地址查看采集结果或者直接最小化
版本号1.1
1、增加自动删除静态主页和更新缓存的功能
2、优化采集speed
版本号1.0
1、Beta 版发布
2、设置6个采集地址栏,可以同时监控采集6个不同的资源
3、一键登录后台,每1小时自动监控采集一次
4、断开后后台会自动重新连接,从而实现24小时无人值守循环监控采集
无人值守免费自动采集器能够网站要保持活力(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-08-16 22:00
无人值守免费自动采集器是一款免费的网络资源采集软件。无人值守免费自动采集器是中小网站自动更新工具,全自动采集释放,运行时静音工作,无需人工干预;独立软件免除网站性能消耗;安全稳定。
无人值守免费自动化采集器(简称ET)旨在提高软件自动化程度,突破24小时无人值守工作。经测试,ET可以长时间自动运行。即使以年为时间单位。免费无人看管。
免费自动采集器(中小网站自动更新工具)V2.1.0.2绿色下载。
无人值守免费自动采集器(简称ET)是一款无人值守自动采集工具。借助软件高度智能化的自动化程序,实现无与伦比的无人值守功能。该程序可以使用 24 小时。网络上不间断的自动采集资源,包括图片和文字。
优采云采集器3免费版 这是小编专门为广大站长带来的自动更新工具。它不需要手动操作。 24小时自动实时监控目标。实时高效采集,感兴趣的用户赶紧下载体验吧! 优采云采集器西西软件园下载地址..
Unattended Free Auto采集器是一款可以保持网站活力,帮助网站内容每天更新的软件。完美下载为您准备了“无人值守免费自动采集器”,欢迎大家前来下载使用。
无人值守免费自动采集器能网站 为了保持活力,每日内容更新是基础。一个小网站保证每日更新,通常需要站长承担每天8小时的更新工作,每周末开放;
无人值守自动采集器中文绿版是一款非常好用的网络优化软件。我们的软件使用网站自己的数据发布接口或者。 查看全部
无人值守免费自动采集器能够网站要保持活力(组图)
无人值守免费自动采集器是一款免费的网络资源采集软件。无人值守免费自动采集器是中小网站自动更新工具,全自动采集释放,运行时静音工作,无需人工干预;独立软件免除网站性能消耗;安全稳定。
无人值守免费自动化采集器(简称ET)旨在提高软件自动化程度,突破24小时无人值守工作。经测试,ET可以长时间自动运行。即使以年为时间单位。免费无人看管。
免费自动采集器(中小网站自动更新工具)V2.1.0.2绿色下载。
无人值守免费自动采集器(简称ET)是一款无人值守自动采集工具。借助软件高度智能化的自动化程序,实现无与伦比的无人值守功能。该程序可以使用 24 小时。网络上不间断的自动采集资源,包括图片和文字。
优采云采集器3免费版 这是小编专门为广大站长带来的自动更新工具。它不需要手动操作。 24小时自动实时监控目标。实时高效采集,感兴趣的用户赶紧下载体验吧! 优采云采集器西西软件园下载地址..
Unattended Free Auto采集器是一款可以保持网站活力,帮助网站内容每天更新的软件。完美下载为您准备了“无人值守免费自动采集器”,欢迎大家前来下载使用。
无人值守免费自动采集器能网站 为了保持活力,每日内容更新是基础。一个小网站保证每日更新,通常需要站长承担每天8小时的更新工作,每周末开放;
无人值守自动采集器中文绿版是一款非常好用的网络优化软件。我们的软件使用网站自己的数据发布接口或者。
如何保证机器人不出错,还是获取不到好评?
采集交流 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-08-13 00:02
自动采集机器人,自动化采集商品和文案。采集复制翻译转换为中文,快速一键上架到自己的店铺和公众号。shua单这是如何保证机器人不出错,还是获取不到好评或者销量。
这个我觉得没必要
嗯嗯,你做机器人就是为了给和天猫卖家赚佣金的吧?佣金一般是销售额的百分比,30%-50%不等。因为一个月几千单,5%不到你得补400块吧。而且现在打击刷单,查得严,机器人也赚不到钱,客佣金还那么低,本来就没利润。如果你有兴趣的话,我给你详细算一下。要在十几台机器里面不停的抓同一类目的大额销售额的买家,收集数据。
再找每个卖家刷订单的买家提取特征,用程序自动识别,把目标群体标记成同一个,再判断刷的好评和差评,每个商品填写一个目标id。每一天下来,超过30%的大额订单得到的目标id都是不重复的,再算每个目标id能抓取多少订单。以比例划分。所以可以算出每个月佣金是多少,应该获得多少销售额。
肯定是客,机器人太多了,现在各大论坛,贴吧充斥着各种教客,联盟的机器人,其实就是联盟中一台提供卖家广告投放的机器,你在联盟推广商品,联盟会有佣金给你,你可以提现,每年都有丰厚的回报,但是你在客的最大麻烦是,你每天都得不停的投放广告,这种收益是依靠大数据的,每天的用户购买数据都会保存在电脑里,假如卖家想通过刷单,通过低价来冲击搜索排名,如果你和他的商品可以通过正常的运营来促销,那么自然就可以通过客的路径来达到冲击搜索排名的目的,假如他的商品没有自然搜索排名的路径,那你就自求多福吧。 查看全部
如何保证机器人不出错,还是获取不到好评?
自动采集机器人,自动化采集商品和文案。采集复制翻译转换为中文,快速一键上架到自己的店铺和公众号。shua单这是如何保证机器人不出错,还是获取不到好评或者销量。
这个我觉得没必要
嗯嗯,你做机器人就是为了给和天猫卖家赚佣金的吧?佣金一般是销售额的百分比,30%-50%不等。因为一个月几千单,5%不到你得补400块吧。而且现在打击刷单,查得严,机器人也赚不到钱,客佣金还那么低,本来就没利润。如果你有兴趣的话,我给你详细算一下。要在十几台机器里面不停的抓同一类目的大额销售额的买家,收集数据。
再找每个卖家刷订单的买家提取特征,用程序自动识别,把目标群体标记成同一个,再判断刷的好评和差评,每个商品填写一个目标id。每一天下来,超过30%的大额订单得到的目标id都是不重复的,再算每个目标id能抓取多少订单。以比例划分。所以可以算出每个月佣金是多少,应该获得多少销售额。
肯定是客,机器人太多了,现在各大论坛,贴吧充斥着各种教客,联盟的机器人,其实就是联盟中一台提供卖家广告投放的机器,你在联盟推广商品,联盟会有佣金给你,你可以提现,每年都有丰厚的回报,但是你在客的最大麻烦是,你每天都得不停的投放广告,这种收益是依靠大数据的,每天的用户购买数据都会保存在电脑里,假如卖家想通过刷单,通过低价来冲击搜索排名,如果你和他的商品可以通过正常的运营来促销,那么自然就可以通过客的路径来达到冲击搜索排名的目的,假如他的商品没有自然搜索排名的路径,那你就自求多福吧。
小说网采集小说网站源码系统功能界面介绍-上海怡健
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-08-12 20:08
Novel网站源代码集成了丰富的采集规则,无人值守,自动根据预设时间、站点和关键字采集文章,通过thinkphp伪静态更新,保证页面访问速度也考虑了搜索引擎的友好性。所有的首页、目录、分类和内容页面都是纯HTML格式。
新版源码增加了自动伪原创功能,可以在编辑时自动替换词库的同义词和内链。源码:xsymz.icu 同时源码系统拥有强大直观的统计分析系统,详细展示总点击量、月点击量、周点击量、总推荐量、月度推荐量、周推荐量统计等新功能,以及作者推荐统计。三方统计工具可以方便的实现小说下载量的明细统计和采集书籍的明细统计。
自动采集小说网站源代码功能:
1、原创Development:自主研发,坚持原创;
2、强大后台:一体化管理,多纬度指标监控;
3、Update 迭代:多年的市场选择和客户实践;
4、极速建站:主流推送sdk到app详情页;
5、裂变分销:多种裂变模式,低成本获客;
6、advertisement实现:集成主流广告SDK,灵活掌控广告空间;
7、福利任务:丰富任务,激发裂变,提高留存率;
8、定制化开发:全面覆盖行业需求场景。
源代码系统功能接口介绍:全面覆盖市场需求,多种场景自由切换
多端展示:多套精美模板供选择,小说、漫画、听书,支持多格式内容上传,可根据需要选择单端多端同时展示。
阅读支付:APP、公众号、H5多端都是主流的展示形式。阅读内容页面和个人中心可实现移动支付,流畅阅读体验,实现收益。
会员体系:结合会员免费图书馆、去广告、身份铭牌、专属活动等特权元素,打造完整的会员体系,帮助用户沉淀。
福利任务:丰富的新手任务、日常任务等,构成成熟的用户激励体系,增加用户的变现、留存、激活和体验。
广告配置:支持开屏、信息流等多种广告形式,可对接指定广告平台,配合福利激励任务,加强视频广告收益等,支持自定义图片广告,后台轻松配置,数据统计全面。 , 实时掌握数据趋势。
裂变分发:支持公众号和应用分发,轻松生成原文链接和应用下载链接。成熟的分销模式,让裂变、推广、网赚更轻松。
产品运营指导:从免费到付费阅读行业耐心解答、内容签约、软件系统架构、流量运营、裂变营销、变现模式等
数据安全:分布式服务器集群、全流程数据加密、自动备份集群等技术安全保障,全力保护您的核心资产。
精美的UI设计:不同的操作模式有不同的模板推荐,单端或多端显示,原生体验,速度流畅,扩展性强,方便二次开发。
稳定抗负载:程序优化到极致,搭配合理的服务器架构,轻松应对亿级访问压力,标准化测试,性能保障。
高级技术支持:擅长打包、海量数据、海量流量等解决方案自助构建,攻克企业级稳定高效应对技术压力瓶颈。
移动支付:主流支付宝、微信、Apple Pay、第四方支付渠道,二次开发接入指定支付渠道。
小说网站source 安装步骤:
1、安装宝塔面板并上传源码;
2、将Tinkphp设为伪静态并保存;
3、Import 数据库安装完成。
源系统环境:
PHP5.6 及以上,建议使用php7.0,可以优雅模式运行; mysql5.6+,服务器支持伪静态重写。 查看全部
小说网采集小说网站源码系统功能界面介绍-上海怡健
Novel网站源代码集成了丰富的采集规则,无人值守,自动根据预设时间、站点和关键字采集文章,通过thinkphp伪静态更新,保证页面访问速度也考虑了搜索引擎的友好性。所有的首页、目录、分类和内容页面都是纯HTML格式。
新版源码增加了自动伪原创功能,可以在编辑时自动替换词库的同义词和内链。源码:xsymz.icu 同时源码系统拥有强大直观的统计分析系统,详细展示总点击量、月点击量、周点击量、总推荐量、月度推荐量、周推荐量统计等新功能,以及作者推荐统计。三方统计工具可以方便的实现小说下载量的明细统计和采集书籍的明细统计。
自动采集小说网站源代码功能:
1、原创Development:自主研发,坚持原创;
2、强大后台:一体化管理,多纬度指标监控;
3、Update 迭代:多年的市场选择和客户实践;
4、极速建站:主流推送sdk到app详情页;
5、裂变分销:多种裂变模式,低成本获客;
6、advertisement实现:集成主流广告SDK,灵活掌控广告空间;
7、福利任务:丰富任务,激发裂变,提高留存率;
8、定制化开发:全面覆盖行业需求场景。
源代码系统功能接口介绍:全面覆盖市场需求,多种场景自由切换
多端展示:多套精美模板供选择,小说、漫画、听书,支持多格式内容上传,可根据需要选择单端多端同时展示。
阅读支付:APP、公众号、H5多端都是主流的展示形式。阅读内容页面和个人中心可实现移动支付,流畅阅读体验,实现收益。
会员体系:结合会员免费图书馆、去广告、身份铭牌、专属活动等特权元素,打造完整的会员体系,帮助用户沉淀。
福利任务:丰富的新手任务、日常任务等,构成成熟的用户激励体系,增加用户的变现、留存、激活和体验。
广告配置:支持开屏、信息流等多种广告形式,可对接指定广告平台,配合福利激励任务,加强视频广告收益等,支持自定义图片广告,后台轻松配置,数据统计全面。 , 实时掌握数据趋势。
裂变分发:支持公众号和应用分发,轻松生成原文链接和应用下载链接。成熟的分销模式,让裂变、推广、网赚更轻松。
产品运营指导:从免费到付费阅读行业耐心解答、内容签约、软件系统架构、流量运营、裂变营销、变现模式等
数据安全:分布式服务器集群、全流程数据加密、自动备份集群等技术安全保障,全力保护您的核心资产。
精美的UI设计:不同的操作模式有不同的模板推荐,单端或多端显示,原生体验,速度流畅,扩展性强,方便二次开发。
稳定抗负载:程序优化到极致,搭配合理的服务器架构,轻松应对亿级访问压力,标准化测试,性能保障。
高级技术支持:擅长打包、海量数据、海量流量等解决方案自助构建,攻克企业级稳定高效应对技术压力瓶颈。
移动支付:主流支付宝、微信、Apple Pay、第四方支付渠道,二次开发接入指定支付渠道。
小说网站source 安装步骤:
1、安装宝塔面板并上传源码;
2、将Tinkphp设为伪静态并保存;
3、Import 数据库安装完成。
源系统环境:
PHP5.6 及以上,建议使用php7.0,可以优雅模式运行; mysql5.6+,服务器支持伪静态重写。
PHP视频有防采集限制采集的11个注意事项!
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-08-03 03:10
11、支持按B站UP采集
12、 关键字支持采集
13、 支持自定义海报回复
14、支持过滤文章中的超链接(过滤a标签,保持标签内的文字)
15、更多功能期待您的发现和建议
更多详情请通过应用截图、更新日志等方式了解,或添加售前QQ(15326940)咨询问题)
注意事项
插件只是采集B站普通视频,链接格式为,不支持VIP、粉丝剧、影视、直播等特殊视频。如有问题请咨询售前QQ(15326940)
插件发布的视频使用了论坛的多媒体代码([media],[flash]),分析由discuz程序自己处理。该插件没有分析功能。推荐分析插件:B站视频分析播放器
本插件需要PHP支持curl,curl可以正常获取https链接内容,PHP版本至少5.3,不高于PHP7.1,PHP5.2可能不行能够采集头条的https链接导致错误。为保证采集到文章内容正常,请务必通过服务器浏览器打开今日头条文章,查看文章内容。
B站视频被采集限制,高频采集可能会被屏蔽。建议插件自动采集发布。
如果您的网站服务器被屏蔽或无法正常获取采集源内容,也无法正常发布采集,恕不退款。
如果采集规则因插件自身问题导致无法更新修复,7天内购买的用户可以获得退款,购买超过7天不到1个月可以补偿购买180元优惠券,购买超过1个月60元补偿优惠券(优惠券只能在购买本公司名下的应用时使用),每位用户只能选择一种补偿方式。
该插件仅用于采集视频,方便阅读。您需要自行承担视频版权风险。未经视频原作者授权,请勿公开发布视频或用于商业用途。
如果您的服务器环境运行异常,需要排查测试,需要提供必要的网站和服务器账号密码权限进行排查,无法远程协助。 查看全部
PHP视频有防采集限制采集的11个注意事项!
11、支持按B站UP采集
12、 关键字支持采集
13、 支持自定义海报回复
14、支持过滤文章中的超链接(过滤a标签,保持标签内的文字)
15、更多功能期待您的发现和建议
更多详情请通过应用截图、更新日志等方式了解,或添加售前QQ(15326940)咨询问题)
注意事项
插件只是采集B站普通视频,链接格式为,不支持VIP、粉丝剧、影视、直播等特殊视频。如有问题请咨询售前QQ(15326940)
插件发布的视频使用了论坛的多媒体代码([media],[flash]),分析由discuz程序自己处理。该插件没有分析功能。推荐分析插件:B站视频分析播放器
本插件需要PHP支持curl,curl可以正常获取https链接内容,PHP版本至少5.3,不高于PHP7.1,PHP5.2可能不行能够采集头条的https链接导致错误。为保证采集到文章内容正常,请务必通过服务器浏览器打开今日头条文章,查看文章内容。
B站视频被采集限制,高频采集可能会被屏蔽。建议插件自动采集发布。
如果您的网站服务器被屏蔽或无法正常获取采集源内容,也无法正常发布采集,恕不退款。
如果采集规则因插件自身问题导致无法更新修复,7天内购买的用户可以获得退款,购买超过7天不到1个月可以补偿购买180元优惠券,购买超过1个月60元补偿优惠券(优惠券只能在购买本公司名下的应用时使用),每位用户只能选择一种补偿方式。
该插件仅用于采集视频,方便阅读。您需要自行承担视频版权风险。未经视频原作者授权,请勿公开发布视频或用于商业用途。
如果您的服务器环境运行异常,需要排查测试,需要提供必要的网站和服务器账号密码权限进行排查,无法远程协助。
自动采集等很多插件,楼主可以关注下超v(/)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-07-23 23:01
自动采集等很多插件,楼主可以关注下超v(/),帮助程序员实现高质量的网站采集,现在推出windows平台版了!具体楼主可以看一下这个网站:html5在线生成器有个交流的版本,用户可以在交流论坛中分享自己的windows版本。其他平台,可以看到他的微信:超v(),还是做了很多的交流的。
看了一下回答,没有回答到楼主的需求:没有客户端不等于没有后端,后端可以搭载自己写的程序,也可以在别的程序里加入后端的功能。所以做采集器不需要有客户端,本质上是以前的小型采集器(比如知名采集器flashdown的轻版本tenzing或者微秘的自动采集stargling就是这样)解决了通过浏览器来采集网页的问题,让采集更加简单。
而windows上没有办法找到自己写的程序的情况下,对于小型采集器来说,现有程序是不是足够给采集服务器带来足够负荷,这需要看自己的网站目前是否足够小众(如足够垂直和高质量,否则现有程序的限制会让问题更加复杂),如果不是很小众的话,本地也是可以用web代理服务器实现的,小型采集器可以直接只用本地的代理服务器。不过个人感觉这样的采集器的意义不是很大,容易造成不同终端上的运行速度差异。
首先,这个需求是非常好的,可以借鉴之前网站采集器的做法,试一下高qtime/spiderlist/spiderstart等采集器;其次,如果有没有客户端,那么就会面临多部分公司使用自动采集。你需要对大量网站进行采集分析,根据平均和历史网站访问和时间变化,推断出哪些页面需要被采集,用代理服务器还是用服务器。 查看全部
自动采集等很多插件,楼主可以关注下超v(/)
自动采集等很多插件,楼主可以关注下超v(/),帮助程序员实现高质量的网站采集,现在推出windows平台版了!具体楼主可以看一下这个网站:html5在线生成器有个交流的版本,用户可以在交流论坛中分享自己的windows版本。其他平台,可以看到他的微信:超v(),还是做了很多的交流的。
看了一下回答,没有回答到楼主的需求:没有客户端不等于没有后端,后端可以搭载自己写的程序,也可以在别的程序里加入后端的功能。所以做采集器不需要有客户端,本质上是以前的小型采集器(比如知名采集器flashdown的轻版本tenzing或者微秘的自动采集stargling就是这样)解决了通过浏览器来采集网页的问题,让采集更加简单。
而windows上没有办法找到自己写的程序的情况下,对于小型采集器来说,现有程序是不是足够给采集服务器带来足够负荷,这需要看自己的网站目前是否足够小众(如足够垂直和高质量,否则现有程序的限制会让问题更加复杂),如果不是很小众的话,本地也是可以用web代理服务器实现的,小型采集器可以直接只用本地的代理服务器。不过个人感觉这样的采集器的意义不是很大,容易造成不同终端上的运行速度差异。
首先,这个需求是非常好的,可以借鉴之前网站采集器的做法,试一下高qtime/spiderlist/spiderstart等采集器;其次,如果有没有客户端,那么就会面临多部分公司使用自动采集。你需要对大量网站进行采集分析,根据平均和历史网站访问和时间变化,推断出哪些页面需要被采集,用代理服务器还是用服务器。
自动采集wordpress博客网站自动生成静态网站,新用户入坑
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-07-23 18:03
自动采集wordpress博客网站自动生成静态网站。新注册用户,会有2个3元的优惠券,新用户入坑。这个是优惠券,下面是我生成的网站。-yingxing-vip-templates/新注册用户没有送价值2000元的svn认证,不过可以通过交易认证获得价值2000元的svn认证。下图是价值2000元svn的扫描页面,仅售价2000元。赶紧注册。
即可,在wp吧,iis里添加一个账号,直接用iis添加,
多余的svn账号可以去bbsbotagent下载,
这个问题我也遇到过,我还专门问过,在2015年的9月15日被攻击,
曾经在wordpress中做过一个filter,上传到svn后,用wordpress同步不会断掉。不知道官方的公告会不会出来说明,被攻击的情况下做不了任何操作。
问问百度有几个答案不?一个准确,一个不准确。准确的:1.这些公司是需要向wordpress付费的。收费方式:交易账号的2~3元一个,但是需要到付款渠道注册一个账号,之后对方会随机生成一个账号,但你在同步的时候不会被断断续续的打断。2.交易账号是否只能wordpress2.0+版本。不准确的:1.没听说有必要在svn上保留block期间只能上传2.0+版本的。
2.我有他们的经验,并非是被攻击。实际效果:做一个工具类网站,免费分享解决实际问题的程序。我目前有不少好的程序存储在svn,大概放在个人服务器或者工作服务器上,更多的是放在github仓库上。1.很多的可以profile为photos-post。2.部分功能可以放在个人服务器或者工作服务器,3.服务器的提供商可以和网站绑定(类似虚拟主机)。4.不要放在代理,免费代理软件大多只支持1台电脑的正常上网。 查看全部
自动采集wordpress博客网站自动生成静态网站,新用户入坑
自动采集wordpress博客网站自动生成静态网站。新注册用户,会有2个3元的优惠券,新用户入坑。这个是优惠券,下面是我生成的网站。-yingxing-vip-templates/新注册用户没有送价值2000元的svn认证,不过可以通过交易认证获得价值2000元的svn认证。下图是价值2000元svn的扫描页面,仅售价2000元。赶紧注册。
即可,在wp吧,iis里添加一个账号,直接用iis添加,
多余的svn账号可以去bbsbotagent下载,
这个问题我也遇到过,我还专门问过,在2015年的9月15日被攻击,
曾经在wordpress中做过一个filter,上传到svn后,用wordpress同步不会断掉。不知道官方的公告会不会出来说明,被攻击的情况下做不了任何操作。
问问百度有几个答案不?一个准确,一个不准确。准确的:1.这些公司是需要向wordpress付费的。收费方式:交易账号的2~3元一个,但是需要到付款渠道注册一个账号,之后对方会随机生成一个账号,但你在同步的时候不会被断断续续的打断。2.交易账号是否只能wordpress2.0+版本。不准确的:1.没听说有必要在svn上保留block期间只能上传2.0+版本的。
2.我有他们的经验,并非是被攻击。实际效果:做一个工具类网站,免费分享解决实际问题的程序。我目前有不少好的程序存储在svn,大概放在个人服务器或者工作服务器上,更多的是放在github仓库上。1.很多的可以profile为photos-post。2.部分功能可以放在个人服务器或者工作服务器,3.服务器的提供商可以和网站绑定(类似虚拟主机)。4.不要放在代理,免费代理软件大多只支持1台电脑的正常上网。
自动化采集公众号信息,postpagetracking+websocket的经验技巧
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-07-07 04:03
自动采集手机,pc里面的信息。不过批量采集太难了。我用的是多抓鱼就比较容易上手。它可以一键抓取一些平台里面的信息。比如你想抓取滴滴打车的信息,那就先打开滴滴打车app。然后在里面采集那个平台信息。
自动化采集公众号信息,这个其实不难,因为本身微信公众号的地址就是共享的,基本只要你的程序不是很差,能识别二维码,能分析一个url里面的参数,能识别页面响应时间,就可以完成自动化的采集了,简单说,就是服务端推送一个公众号的url就好了,所以本质上,公众号信息对于这个程序来说就是共享的。至于到达率,这个其实是比较难的,主要还是要靠分析你要采集的目标,统计其他的采集成本,这样采集出来效率才能提高。另外,你说的批量采集,这个完全可以用爬虫替代,爬虫实际上就是有人在后台给你发url,你自己去爬。
目前主流的采集技术就是postpagetracking+websocket,下面我讲讲我的经验技巧。其实post就是把我们获取的重定向到/,websocket是基于web的tcp连接来传递的,两者进行交互。url结构就是页面的cookie。这里有个坑一定要记住。post都是xml格式的,不要post长时间会报cookie过期,重定向的信息有时会丢失,请记得保存信息。
问题来了,如何确定你的websocket的连接时间呢?比如微信端的采集,xml格式就行,微信还会自己产生cookie,网页端就不行了,只能用抓包工具来抓。然后就可以通过cookie来确定连接时间了。这样抓包工具的工作就是每次通过一个连接的时间来判断这个浏览器到底是在下载还是在浏览。而lxml的解析就是不依赖浏览器本身自带cookie判断时间的。
可以在抓包工具里直接拿到httppost的server的cookie通过xml格式的方式传到parser里解析。 查看全部
自动化采集公众号信息,postpagetracking+websocket的经验技巧
自动采集手机,pc里面的信息。不过批量采集太难了。我用的是多抓鱼就比较容易上手。它可以一键抓取一些平台里面的信息。比如你想抓取滴滴打车的信息,那就先打开滴滴打车app。然后在里面采集那个平台信息。
自动化采集公众号信息,这个其实不难,因为本身微信公众号的地址就是共享的,基本只要你的程序不是很差,能识别二维码,能分析一个url里面的参数,能识别页面响应时间,就可以完成自动化的采集了,简单说,就是服务端推送一个公众号的url就好了,所以本质上,公众号信息对于这个程序来说就是共享的。至于到达率,这个其实是比较难的,主要还是要靠分析你要采集的目标,统计其他的采集成本,这样采集出来效率才能提高。另外,你说的批量采集,这个完全可以用爬虫替代,爬虫实际上就是有人在后台给你发url,你自己去爬。
目前主流的采集技术就是postpagetracking+websocket,下面我讲讲我的经验技巧。其实post就是把我们获取的重定向到/,websocket是基于web的tcp连接来传递的,两者进行交互。url结构就是页面的cookie。这里有个坑一定要记住。post都是xml格式的,不要post长时间会报cookie过期,重定向的信息有时会丢失,请记得保存信息。
问题来了,如何确定你的websocket的连接时间呢?比如微信端的采集,xml格式就行,微信还会自己产生cookie,网页端就不行了,只能用抓包工具来抓。然后就可以通过cookie来确定连接时间了。这样抓包工具的工作就是每次通过一个连接的时间来判断这个浏览器到底是在下载还是在浏览。而lxml的解析就是不依赖浏览器本身自带cookie判断时间的。
可以在抓包工具里直接拿到httppost的server的cookie通过xml格式的方式传到parser里解析。
自动采集功能支持主流的pc网页数据介绍及操作方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2021-07-03 01:01
自动采集功能支持主流的pc网页数据,包括新闻门户、门户网站、新闻门户优酷、网易、搜狐等网站的图片、视频、链接、音频、文章内容等数据的采集。具体功能介绍及操作方法,可以参看小编写的这篇博文哦:自动采集功能介绍及操作方法自动采集功能是一个公司运营中重要的推广手段,同时也是公司的软文定制、推广的重要工具,我们采用h5网页展示形式,能够大大吸引用户观看,分享。
这个功能软件我们是用高德地图做接入的,那么具体的原理是什么呢?那么,请先来看一下整个h5图片采集工具软件是如何采集高德地图内容的吧。其实原理并不复杂,只要知道高德地图api的名称:。只要我们通过高德地图api,发出一个标有“”的请求,网站接收到该请求,加上爬虫脚本(参考博文:爬虫脚本),就可以采集图片的信息了。
我们使用webpath去解析、去js解析。webpath用户定义一般为:/*.html/*/,webpath根据关键字从左往右遍历每一个元素,找到对应的内容,但是if(content==""&&success=="1"),由于采用js解析器,需要针对不同浏览器的操作行为做支持,通常的操作路径为:“//js/page1.a.swf”。
目前,网站上通常使用js解析器来采集图片内容,而js解析器的内部实现,根据不同的api定义,来自html-script-parser,而html-script-parser的实现根据浏览器操作特点,依据相应的逻辑写出相应的事件代码和对应的接口,最终,通过webpath中的keys=>eventornot来获取对应的values=>methods接口来判断对应的元素是否为我们要的元素,从而获取相应的内容。
其实说到这里,我们其实已经差不多知道这个工具是如何工作的,而实际上,整个过程并不简单,对于工具本身也是依赖于项目的,因此就没有办法一步一步详细的介绍出来了。最后,我们需要说明一下的是,我们只是做了一个工具的皮肤实现,实际上是使用javascript语言去写的,而我们采用的是python语言去实现图片的采集。
我们的用户,将不会有任何网页内容不存在或者不能采集的情况,可以无缝将我们的自动采集功能进行扩展。sogood!!!!!!再看一个不完整的,不完整的采集:脚本原理图主要操作:在浏览器(指定浏览器)中发出请求,针对性选择条件进行解析请求的url,然后对请求中的每一个request进行拆分,对每一个request拆分成若干组ajax请求,相对应地,网站通过支持我们的协议,对。 查看全部
自动采集功能支持主流的pc网页数据介绍及操作方法
自动采集功能支持主流的pc网页数据,包括新闻门户、门户网站、新闻门户优酷、网易、搜狐等网站的图片、视频、链接、音频、文章内容等数据的采集。具体功能介绍及操作方法,可以参看小编写的这篇博文哦:自动采集功能介绍及操作方法自动采集功能是一个公司运营中重要的推广手段,同时也是公司的软文定制、推广的重要工具,我们采用h5网页展示形式,能够大大吸引用户观看,分享。
这个功能软件我们是用高德地图做接入的,那么具体的原理是什么呢?那么,请先来看一下整个h5图片采集工具软件是如何采集高德地图内容的吧。其实原理并不复杂,只要知道高德地图api的名称:。只要我们通过高德地图api,发出一个标有“”的请求,网站接收到该请求,加上爬虫脚本(参考博文:爬虫脚本),就可以采集图片的信息了。
我们使用webpath去解析、去js解析。webpath用户定义一般为:/*.html/*/,webpath根据关键字从左往右遍历每一个元素,找到对应的内容,但是if(content==""&&success=="1"),由于采用js解析器,需要针对不同浏览器的操作行为做支持,通常的操作路径为:“//js/page1.a.swf”。
目前,网站上通常使用js解析器来采集图片内容,而js解析器的内部实现,根据不同的api定义,来自html-script-parser,而html-script-parser的实现根据浏览器操作特点,依据相应的逻辑写出相应的事件代码和对应的接口,最终,通过webpath中的keys=>eventornot来获取对应的values=>methods接口来判断对应的元素是否为我们要的元素,从而获取相应的内容。
其实说到这里,我们其实已经差不多知道这个工具是如何工作的,而实际上,整个过程并不简单,对于工具本身也是依赖于项目的,因此就没有办法一步一步详细的介绍出来了。最后,我们需要说明一下的是,我们只是做了一个工具的皮肤实现,实际上是使用javascript语言去写的,而我们采用的是python语言去实现图片的采集。
我们的用户,将不会有任何网页内容不存在或者不能采集的情况,可以无缝将我们的自动采集功能进行扩展。sogood!!!!!!再看一个不完整的,不完整的采集:脚本原理图主要操作:在浏览器(指定浏览器)中发出请求,针对性选择条件进行解析请求的url,然后对请求中的每一个request进行拆分,对每一个request拆分成若干组ajax请求,相对应地,网站通过支持我们的协议,对。
自动采集各个平台的视频、图片、音乐等。
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-07-02 00:03
自动采集各个平台的视频、图片、音乐等。自动化去重、分类、去重工作,电商行业最为常见,现在又到了商品sku数量过多的季节,我们无法像以前编辑商品sku,全店一起编辑商品sku,特别是直通车计划、钻展计划编辑下来的sku数量超过了自动计划的sku数量,更是难以编辑了。视频采集不需要自己去编辑,去重就可以了,不需要人工批量审核;音乐采集不需要自己去编辑,去重就可以了,不需要人工批量审核;。
支持api,可以嵌入平台app自动采集。微小宝商智等第三方可以为直接提供数据。
现在大部分人都不用网站购物,不过有人会用电商平台的cms吗?可以把链接放到cms里就能访问到,上架在别的电商平台上,自动抓取数据,功能齐全。
是基于谷歌的api,如果你是安卓手机的话要付费谷歌才能访问,目前大概3000美金一年。这种途径实现类似于利用chrome的webshoppingapi,所有的商品都是通过一个中转站来送货的,当然这个中转站也要收费的。
boomi+拍all这个网站已经实现了!!这个技术暂时只能在中国实现
据说目前国内大部分门户网站都只允许一部分作为商品链接。
我想你应该这样理解,网站上销售的商品,在电商平台中能不能被系统识别出来(或者在系统中相关产品有对应链接的可以识别出来?)?只要这两个问题能得到统一, 查看全部
自动采集各个平台的视频、图片、音乐等。
自动采集各个平台的视频、图片、音乐等。自动化去重、分类、去重工作,电商行业最为常见,现在又到了商品sku数量过多的季节,我们无法像以前编辑商品sku,全店一起编辑商品sku,特别是直通车计划、钻展计划编辑下来的sku数量超过了自动计划的sku数量,更是难以编辑了。视频采集不需要自己去编辑,去重就可以了,不需要人工批量审核;音乐采集不需要自己去编辑,去重就可以了,不需要人工批量审核;。
支持api,可以嵌入平台app自动采集。微小宝商智等第三方可以为直接提供数据。
现在大部分人都不用网站购物,不过有人会用电商平台的cms吗?可以把链接放到cms里就能访问到,上架在别的电商平台上,自动抓取数据,功能齐全。
是基于谷歌的api,如果你是安卓手机的话要付费谷歌才能访问,目前大概3000美金一年。这种途径实现类似于利用chrome的webshoppingapi,所有的商品都是通过一个中转站来送货的,当然这个中转站也要收费的。
boomi+拍all这个网站已经实现了!!这个技术暂时只能在中国实现
据说目前国内大部分门户网站都只允许一部分作为商品链接。
我想你应该这样理解,网站上销售的商品,在电商平台中能不能被系统识别出来(或者在系统中相关产品有对应链接的可以识别出来?)?只要这两个问题能得到统一,
自动采集 不存在推送功能,聚慧通的小app试用(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2021-06-26 05:02
自动采集微信群成员。找一款网页版的采集器,清楚自己采集后的微信群名字以及微信id以后,点击采集,采集到电脑中就可以自动消息自动推送了。
搞下聚慧通,上去看看,实在不行看看。
可以设置开关
a682_一站式消息采集器的管理列表里查看那些允许推送的不过比较吃内存的有一些个人推荐你还是用熟悉的app比较好比如微信app
在frome新浪微博客户端里的个人中心里,有个『微信会话采集』的小功能,
没推送,
聚慧通的小app试用一下就知道了,我正在用,很快也要上架appstore了,
每个app的推送机制都是不一样的,不知道你指的是什么推送。微信这个就是自动通知,大家互相关注,偶尔发个红包什么的,有些人发的消息你推送了,没通知,可能别人正忙着别的。
可以点击页面右上角的微信按钮的用户名旁边的小按钮,切换到微信会话界面,
不想发多余的通知,想只给自己发消息的人,请按以下按钮操作:打开微信,搜索“置顶群”,然后把置顶的群名称从“我的群”更改为“置顶公众号”。
这个真是太多了,还在其中
我个人比较常用麦库...没有任何广告,界面清爽,体验非常好!不存在会话推送功能, 查看全部
自动采集 不存在推送功能,聚慧通的小app试用(组图)
自动采集微信群成员。找一款网页版的采集器,清楚自己采集后的微信群名字以及微信id以后,点击采集,采集到电脑中就可以自动消息自动推送了。
搞下聚慧通,上去看看,实在不行看看。
可以设置开关
a682_一站式消息采集器的管理列表里查看那些允许推送的不过比较吃内存的有一些个人推荐你还是用熟悉的app比较好比如微信app
在frome新浪微博客户端里的个人中心里,有个『微信会话采集』的小功能,
没推送,
聚慧通的小app试用一下就知道了,我正在用,很快也要上架appstore了,
每个app的推送机制都是不一样的,不知道你指的是什么推送。微信这个就是自动通知,大家互相关注,偶尔发个红包什么的,有些人发的消息你推送了,没通知,可能别人正忙着别的。
可以点击页面右上角的微信按钮的用户名旁边的小按钮,切换到微信会话界面,
不想发多余的通知,想只给自己发消息的人,请按以下按钮操作:打开微信,搜索“置顶群”,然后把置顶的群名称从“我的群”更改为“置顶公众号”。
这个真是太多了,还在其中
我个人比较常用麦库...没有任何广告,界面清爽,体验非常好!不存在会话推送功能,
自动采集和过滤评论并不是难度很大,现在网站系统的话几分钟就可以实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-06-24 05:01
自动采集和过滤评论并不是难度很大,现在网站系统的话几分钟就可以实现,如果是专业一点的后台的话基本都能实现。一般来说网站评论都会涉及到电话、资金、地址等,而且评论的都是爆款,属于重复度比较高的评论。评论采集如果手动采集的话,你需要关注评论的相关域名,只要是从这个域名上评论就可以采集,而且按照指定算法采集,时效性比较好。这个网站我们一直在用,我想是很不错的,可以参考一下。
评论采集技术当前来说最直接的手段就是伪静态+dns劫持你的评论都是重复的评论,所以导致评论很快就被发布者删除,前期他们是这么做的,等有人来封杀的时候,就被发布者知道评论被盗用,盗用别人的评论就是为了挣钱。我就见过这么做的所以后面我的评论都是手动添加,因为评论的内容多的时候,时间太紧,大部分人都会去刷评论的,一时也没有人来维护,但是多了也没有什么卵用。
以前写过一篇文章专门讲评论采集的,你可以参考一下,需要说明的是采集评论不是必须要上面说的那种采集技术的,有更专业的技术可以采集评论。ps:评论技术大把,毕竟我们都是万能的知乎,不过最近随着评论采集技术,主要是伪静态采集技术被人大肆批判,很多人开始转向内容采集,真正能采集评论的就真的很少了。 查看全部
自动采集和过滤评论并不是难度很大,现在网站系统的话几分钟就可以实现
自动采集和过滤评论并不是难度很大,现在网站系统的话几分钟就可以实现,如果是专业一点的后台的话基本都能实现。一般来说网站评论都会涉及到电话、资金、地址等,而且评论的都是爆款,属于重复度比较高的评论。评论采集如果手动采集的话,你需要关注评论的相关域名,只要是从这个域名上评论就可以采集,而且按照指定算法采集,时效性比较好。这个网站我们一直在用,我想是很不错的,可以参考一下。
评论采集技术当前来说最直接的手段就是伪静态+dns劫持你的评论都是重复的评论,所以导致评论很快就被发布者删除,前期他们是这么做的,等有人来封杀的时候,就被发布者知道评论被盗用,盗用别人的评论就是为了挣钱。我就见过这么做的所以后面我的评论都是手动添加,因为评论的内容多的时候,时间太紧,大部分人都会去刷评论的,一时也没有人来维护,但是多了也没有什么卵用。
以前写过一篇文章专门讲评论采集的,你可以参考一下,需要说明的是采集评论不是必须要上面说的那种采集技术的,有更专业的技术可以采集评论。ps:评论技术大把,毕竟我们都是万能的知乎,不过最近随着评论采集技术,主要是伪静态采集技术被人大肆批判,很多人开始转向内容采集,真正能采集评论的就真的很少了。
推荐一个获取原创数据的神器不仅仅是浏览器
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-06-23 06:00
自动采集今日头条、百度搜索、京东、唯品会、抖音、微博等平台的内容。全网热点内容自动采集百度搜索、微博、知乎热门问题自动采集手淘网页热点内容自动采集今日头条、搜狐新闻等热门平台头条热点自动采集抖音热点自动采集西瓜视频等视频平台头条热点热点自动采集,海量可用数据,轻松获取热点资讯,创造优质内容。
到什么程度?像我在想的,将各种搜索引擎所有内容尽可能做到纯自动采集,这可能比较难。
有钱就随便
采集网上,标题,结构化资源,数据挖掘,各种分析,图表,或者其他某一条本来别人没有的内容在采集之后,会有新的发现。
推荐一个获取原创数据的神器
不仅仅是浏览器吧,现在很多平台都能在手机网页版看到这些信息的,个人感觉主要靠的是核心算法+大数据的结合。最近我也在寻找这样的产品,推荐一个小v数据共享平台,会持续关注。
在知乎逛久了,总会去逛,真心觉得够牛逼,到处都是产品的评价,颜色以及款式,随便拿起手机翻翻,随便就可以快速搜索到感兴趣的东西,还有那些数不清的做活动的款式的页面,感觉就跟个爬虫器一样,什么都能爬出来,最近常常搜罗一些小东西,看一看哪些产品好用,哪些会便宜,哪些会涨价,哪些不会便宜,就好像在看一场电影,不停的点开网页,不停的看评价,不停的去找不会便宜的,不会差评的那种。 查看全部
推荐一个获取原创数据的神器不仅仅是浏览器
自动采集今日头条、百度搜索、京东、唯品会、抖音、微博等平台的内容。全网热点内容自动采集百度搜索、微博、知乎热门问题自动采集手淘网页热点内容自动采集今日头条、搜狐新闻等热门平台头条热点自动采集抖音热点自动采集西瓜视频等视频平台头条热点热点自动采集,海量可用数据,轻松获取热点资讯,创造优质内容。
到什么程度?像我在想的,将各种搜索引擎所有内容尽可能做到纯自动采集,这可能比较难。
有钱就随便
采集网上,标题,结构化资源,数据挖掘,各种分析,图表,或者其他某一条本来别人没有的内容在采集之后,会有新的发现。
推荐一个获取原创数据的神器
不仅仅是浏览器吧,现在很多平台都能在手机网页版看到这些信息的,个人感觉主要靠的是核心算法+大数据的结合。最近我也在寻找这样的产品,推荐一个小v数据共享平台,会持续关注。
在知乎逛久了,总会去逛,真心觉得够牛逼,到处都是产品的评价,颜色以及款式,随便拿起手机翻翻,随便就可以快速搜索到感兴趣的东西,还有那些数不清的做活动的款式的页面,感觉就跟个爬虫器一样,什么都能爬出来,最近常常搜罗一些小东西,看一看哪些产品好用,哪些会便宜,哪些会涨价,哪些不会便宜,就好像在看一场电影,不停的点开网页,不停的看评价,不停的去找不会便宜的,不会差评的那种。
自动采集自动消息匹配喜欢,停留,可以参考我在laravelredismemcache怎么集成?
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-06-22 20:02
自动采集自动消息匹配喜欢,停留,可以参考我在laravelredismemcache怎么集成?下面的答案自动登录,更新,删除,登录后从session获取是否是首次登录,是则通过模板redis做redis的处理,不是则通过balance_hash来采用新的关键字代替旧的关键字登录后用httpbalance返回给服务器。
laravel项目中比较常用的集群方案有mongodb集群,redis集群,kafka集群等。
可以使用couchbase+springboot。
可以使用laraveljs集成zookeeper集成消息中间件。
谢邀可以使用zookeeper,
couchbase或者springboot也不错。
go语言的ha就可以。
谢邀:可以使用locastal这款开源集群框架,它其实就是一个multi-task处理机制,将时间维度的数据聚合到一起,可以把它看成zookeeper的一个实现版本。
php你可以看看inmann-zlib但是只能是在php中用,
消息推送这个涉及zookeeper的知识:作者,出处不知道,
这个是我最近想用的集群。以前做c++项目的时候,都是用socket进行中转,传输数据,现在做了个前端程序,都用框架了,就觉得以前做zookeeper,tornado,fastjson等非常不方便。后来有个新的东西想用,就从零开始了socket-emulator-in-python(轮子哥推荐的),开始没有任何基础,就googlestepbystep,人生真是处处是坑呀。
几个配置分开写,把层整个封装了,可以直接从socket推送数据,整个connector就整合起来了。开始的时候,用的是c++写推送服务器,现在可以用python写服务器,然后前端通过推送到这个inpython的dll里面,整个就是c++和python的事情了。是利用python的自带的同步(sync)接口和异步(future)接口,实现了在同一个进程中两个线程同时,和zookeeper没区别,注意当进程或者容器多的时候,client请求的数据大小会变化,可以直接按照需求调整。
利用zookeeper的exchange,可以实现异步,无须zookeeper来做topic组织等高级功能。使用socket完成的异步,不用zookeeper是不能识别的,所以一般得手动的去添加一个zookeeper集群,如果你能够掌握socket推送技术,你可以实现非常好用的异步推送方案。ok,把整个框架整合到python里面去了。整个框架核心技术zookeeper,可以用pythonpiplist发现,另外这个框。 查看全部
自动采集自动消息匹配喜欢,停留,可以参考我在laravelredismemcache怎么集成?
自动采集自动消息匹配喜欢,停留,可以参考我在laravelredismemcache怎么集成?下面的答案自动登录,更新,删除,登录后从session获取是否是首次登录,是则通过模板redis做redis的处理,不是则通过balance_hash来采用新的关键字代替旧的关键字登录后用httpbalance返回给服务器。
laravel项目中比较常用的集群方案有mongodb集群,redis集群,kafka集群等。
可以使用couchbase+springboot。
可以使用laraveljs集成zookeeper集成消息中间件。
谢邀可以使用zookeeper,
couchbase或者springboot也不错。
go语言的ha就可以。
谢邀:可以使用locastal这款开源集群框架,它其实就是一个multi-task处理机制,将时间维度的数据聚合到一起,可以把它看成zookeeper的一个实现版本。
php你可以看看inmann-zlib但是只能是在php中用,
消息推送这个涉及zookeeper的知识:作者,出处不知道,
这个是我最近想用的集群。以前做c++项目的时候,都是用socket进行中转,传输数据,现在做了个前端程序,都用框架了,就觉得以前做zookeeper,tornado,fastjson等非常不方便。后来有个新的东西想用,就从零开始了socket-emulator-in-python(轮子哥推荐的),开始没有任何基础,就googlestepbystep,人生真是处处是坑呀。
几个配置分开写,把层整个封装了,可以直接从socket推送数据,整个connector就整合起来了。开始的时候,用的是c++写推送服务器,现在可以用python写服务器,然后前端通过推送到这个inpython的dll里面,整个就是c++和python的事情了。是利用python的自带的同步(sync)接口和异步(future)接口,实现了在同一个进程中两个线程同时,和zookeeper没区别,注意当进程或者容器多的时候,client请求的数据大小会变化,可以直接按照需求调整。
利用zookeeper的exchange,可以实现异步,无须zookeeper来做topic组织等高级功能。使用socket完成的异步,不用zookeeper是不能识别的,所以一般得手动的去添加一个zookeeper集群,如果你能够掌握socket推送技术,你可以实现非常好用的异步推送方案。ok,把整个框架整合到python里面去了。整个框架核心技术zookeeper,可以用pythonpiplist发现,另外这个框。
自动采集的信息需要多次重复提取(xpath)(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-06-17 06:02
自动采集程序可分为手动采集和自动采集。手动采集指的是使用程序采集网页,自动采集就是使用爬虫抓取网页信息,自动采集或自动提取网页内容也被称为xpath。自动抓取程序在使用js控制页面展示时,其实这个页面所对应的内容是存在一些数据的,这个内容只是xpath可能会被隐藏的一部分,因为js需要手动操作页面。自动提取的信息中隐藏了很多xpath无法显示的信息。
而xpath虽然可以使网页抓取信息更快更准确,但现在爬虫使用自动代码抓取xpath只需要一个js的定位、调整就可以完成了,一次最多只抓取5条数据。手动采集的信息需要多次重复提取,而xpath只要保证覆盖页面的信息就可以抓取页面,用户可以选择多次重复提取某一条xpath,所以建议使用自动提取。初次引入爬虫使用的软件包:python3(库为pil)打开xpath编辑器,ctrl+n建立新表,初始化时输入如下代码。
importurllib3url='//?lazy=true&_=9e16a&_=mt152gq2uh0&_=a1ubvrak2u&_=b023qi4izt&_=ulr_pxie&_=ekukcsih7&_=joinm8abb&_=irnkt9c0&_=mt2ogi1kw&_=gjfjhyj5'request=urllib3.request(url,headers=headers)#xpath代码采用python3写ifrequest.pagenumbers>5:print('xpath不匹配')print('xpath不匹配')print(request.response.xpath('//?a/b/c'))xpath匹配到新增项后接下来继续提取页面里所对应的xpath数据。
同样的步骤初始化提取部分页面代码,注意采用request的headers来选择发送请求。ifrequest.pagenumbers>5:request.request('//?a/b/c',headers=headers)xpath设置同步重载提取效果下面一步步进行。chrome浏览器新建chrome浏览器网页,新建一个网页,命名为xp041.网页内输入curl网址并获取提取的xpath,网址:可以提取四页xpath按照常理来说,应该是这样的:r=request.urlopen('//etc/postgres').read().decode('utf-8')print(r)结果是(page10)不一定这样,可以改一下代码。
curl命令里接收三个参数,两个是二进制字符串,第三个参数url地址,这些通过urllib3.request.urlopen函数调用爬虫可以获取到。request.urlopen函数:request.urlopen函数调用爬虫可以获取网页和图片的内容。importrequesturl='//?lazy=true&_=9e16a。 查看全部
自动采集的信息需要多次重复提取(xpath)(组图)
自动采集程序可分为手动采集和自动采集。手动采集指的是使用程序采集网页,自动采集就是使用爬虫抓取网页信息,自动采集或自动提取网页内容也被称为xpath。自动抓取程序在使用js控制页面展示时,其实这个页面所对应的内容是存在一些数据的,这个内容只是xpath可能会被隐藏的一部分,因为js需要手动操作页面。自动提取的信息中隐藏了很多xpath无法显示的信息。
而xpath虽然可以使网页抓取信息更快更准确,但现在爬虫使用自动代码抓取xpath只需要一个js的定位、调整就可以完成了,一次最多只抓取5条数据。手动采集的信息需要多次重复提取,而xpath只要保证覆盖页面的信息就可以抓取页面,用户可以选择多次重复提取某一条xpath,所以建议使用自动提取。初次引入爬虫使用的软件包:python3(库为pil)打开xpath编辑器,ctrl+n建立新表,初始化时输入如下代码。
importurllib3url='//?lazy=true&_=9e16a&_=mt152gq2uh0&_=a1ubvrak2u&_=b023qi4izt&_=ulr_pxie&_=ekukcsih7&_=joinm8abb&_=irnkt9c0&_=mt2ogi1kw&_=gjfjhyj5'request=urllib3.request(url,headers=headers)#xpath代码采用python3写ifrequest.pagenumbers>5:print('xpath不匹配')print('xpath不匹配')print(request.response.xpath('//?a/b/c'))xpath匹配到新增项后接下来继续提取页面里所对应的xpath数据。
同样的步骤初始化提取部分页面代码,注意采用request的headers来选择发送请求。ifrequest.pagenumbers>5:request.request('//?a/b/c',headers=headers)xpath设置同步重载提取效果下面一步步进行。chrome浏览器新建chrome浏览器网页,新建一个网页,命名为xp041.网页内输入curl网址并获取提取的xpath,网址:可以提取四页xpath按照常理来说,应该是这样的:r=request.urlopen('//etc/postgres').read().decode('utf-8')print(r)结果是(page10)不一定这样,可以改一下代码。
curl命令里接收三个参数,两个是二进制字符串,第三个参数url地址,这些通过urllib3.request.urlopen函数调用爬虫可以获取到。request.urlopen函数:request.urlopen函数调用爬虫可以获取网页和图片的内容。importrequesturl='//?lazy=true&_=9e16a。
自动采集 《Python制作词云视频》B站弹幕爬取方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 395 次浏览 • 2021-06-07 05:26
大家好,我是小张!
在《用Python制作词云视频,通过词云图看小姐姐跳舞》文章中,我简单介绍了B站弹幕爬取的方法,只要找到视频中的参数cid,你可以采集视频下的所有弹幕;虽然思路很简单,但是个人还是比较麻烦,比如一天后,我想到采集B站上的一个视频弹幕,我需要从头开始:找到cid参数,写代码,重复单调;
所以我想知道是否可以一步完成。以后采集某个视频弹幕只需一步操作,比如输入我要爬取的视频链接,程序可以自动识别下载
实现效果
基于此,借助PyQt5,我写了一个小工具,只需要提供目标视频的url和目标txt路径,程序会自动采集视频下的弹幕并保存data 到目标txt文本,先看效果预览:
PS微信公众号有动画帧数限制。做动画的时候剪了一些内容,所以效果可能不太流畅
整体工具实现分为UI界面和数据采集两部分。使用的 Python 库:
import requests
import re
from PyQt5.QtWidgets import *
from PyQt5 import QtCore
from PyQt5.QtGui import *
from PyQt5.QtCore import QThread, pyqtSignal
from bs4 import BeautifulSoup
用户界面
UI界面使用PyQt5,有两个按钮(开始下载、保存到)、编辑行控件和用于输入视频链接的调试窗口;
代码如下:
def __init__(self,parent =None):
super(Ui_From,self).__init__(parent=parent)
self.setWindowTitle("B站弹幕采集")
self.setWindowIcon(QIcon('pic.jpg'))# 图标
self.top_label = QLabel("作者:小张\n 微信公号:小张Python")
self.top_label.setAlignment(QtCore.Qt.AlignHCenter)
self.top_label.setStyleSheet('color:red;font-weight:bold;')
self.label = QLabel("B站视频url")
self.label.setAlignment(QtCore.Qt.AlignHCenter)
self.editline1 = QLineEdit()
self.pushButton = QPushButton("开始下载")
self.pushButton.setEnabled(False)#关闭启动
self.Console = QListWidget()
self.saveButton = QPushButton("保存至")
self.layout = QGridLayout()
self.layout.addWidget(self.top_label,0,0,1,2)
self.layout.addWidget(self.label,1,0)
self.layout.addWidget(self.editline1,1,1)
self.layout.addWidget(self.pushButton,2,0)
self.layout.addWidget(self.saveButton,3,0)
self.layout.addWidget(self.Console,2,1,3,1)
self.setLayout(self.layout)
self.savepath = None
self.pushButton.clicked.connect(self.downButton)
self.saveButton.clicked.connect(self.savePushbutton)
self.editline1.textChanged.connect(self.syns_lineEdit)
当url不为空并且已经设置了目标文本存储路径时,可以输入data采集module
实现此功能的代码:
def syns_lineEdit(self):
if self.editline1.text():
self.pushButton.setEnabled(True)#打开按钮
def savePushbutton(self):
savePath = QFileDialog.getSaveFileName(self,'Save Path','/','txt(*.txt)')
if savePath[0]:# 选中 txt 文件路径
self.savepath = str(savePath[0])#进行赋值
数据采集
程序获取到url后,第一步就是访问url,提取当前页面视频的cid参数(一串数字)。
使用cid参数构造视频弹幕存储API接口,然后使用常规requests和bs4包实现采集文本
Data采集部分代码:
f = open(self.savepath, 'w+', encoding='utf-8') # 打开 txt 文件
res = requests.get(url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'lxml')
items = soup.find_all('d') # 找到 d 标签
for item in items:
text = item.text
f.write(text)
f.write('\n')
f.close()
cid 参数不在常规 html 标签上。提取的时候,我选择re正则匹配;但是这一步会消耗更多的机器内存。为了减少对UI界面响应速度的影响,这一步是单线程实现的
class Parsetext(QThread):
trigger = pyqtSignal(str) # 信号发射;
def __init__(self,text,parent = None):
super(Parsetext,self).__init__()
self.text = text
def __del__(self):
self.wait()
def run(self):
print('解析 -----------{}'.format(self.text))
result_url = re.findall('.*?"baseUrl":"(.*?)","base_url".*?', self.text)[0]
self.trigger.emit(result_url)
总结
好的,以上就是本文文章的全部内容,希望对你的工作学习有所帮助。
最后感谢大家的阅读,下期再见~
源码获取
关于本文文章使用的源码,获取方式:
为了自动采集B站弹幕,我用Python开发了一个下载器!
查看全部
自动采集 《Python制作词云视频》B站弹幕爬取方法
大家好,我是小张!
在《用Python制作词云视频,通过词云图看小姐姐跳舞》文章中,我简单介绍了B站弹幕爬取的方法,只要找到视频中的参数cid,你可以采集视频下的所有弹幕;虽然思路很简单,但是个人还是比较麻烦,比如一天后,我想到采集B站上的一个视频弹幕,我需要从头开始:找到cid参数,写代码,重复单调;
所以我想知道是否可以一步完成。以后采集某个视频弹幕只需一步操作,比如输入我要爬取的视频链接,程序可以自动识别下载
实现效果
基于此,借助PyQt5,我写了一个小工具,只需要提供目标视频的url和目标txt路径,程序会自动采集视频下的弹幕并保存data 到目标txt文本,先看效果预览:
PS微信公众号有动画帧数限制。做动画的时候剪了一些内容,所以效果可能不太流畅
整体工具实现分为UI界面和数据采集两部分。使用的 Python 库:
import requests
import re
from PyQt5.QtWidgets import *
from PyQt5 import QtCore
from PyQt5.QtGui import *
from PyQt5.QtCore import QThread, pyqtSignal
from bs4 import BeautifulSoup
用户界面
UI界面使用PyQt5,有两个按钮(开始下载、保存到)、编辑行控件和用于输入视频链接的调试窗口;
代码如下:
def __init__(self,parent =None):
super(Ui_From,self).__init__(parent=parent)
self.setWindowTitle("B站弹幕采集")
self.setWindowIcon(QIcon('pic.jpg'))# 图标
self.top_label = QLabel("作者:小张\n 微信公号:小张Python")
self.top_label.setAlignment(QtCore.Qt.AlignHCenter)
self.top_label.setStyleSheet('color:red;font-weight:bold;')
self.label = QLabel("B站视频url")
self.label.setAlignment(QtCore.Qt.AlignHCenter)
self.editline1 = QLineEdit()
self.pushButton = QPushButton("开始下载")
self.pushButton.setEnabled(False)#关闭启动
self.Console = QListWidget()
self.saveButton = QPushButton("保存至")
self.layout = QGridLayout()
self.layout.addWidget(self.top_label,0,0,1,2)
self.layout.addWidget(self.label,1,0)
self.layout.addWidget(self.editline1,1,1)
self.layout.addWidget(self.pushButton,2,0)
self.layout.addWidget(self.saveButton,3,0)
self.layout.addWidget(self.Console,2,1,3,1)
self.setLayout(self.layout)
self.savepath = None
self.pushButton.clicked.connect(self.downButton)
self.saveButton.clicked.connect(self.savePushbutton)
self.editline1.textChanged.connect(self.syns_lineEdit)
当url不为空并且已经设置了目标文本存储路径时,可以输入data采集module
实现此功能的代码:
def syns_lineEdit(self):
if self.editline1.text():
self.pushButton.setEnabled(True)#打开按钮
def savePushbutton(self):
savePath = QFileDialog.getSaveFileName(self,'Save Path','/','txt(*.txt)')
if savePath[0]:# 选中 txt 文件路径
self.savepath = str(savePath[0])#进行赋值
数据采集
程序获取到url后,第一步就是访问url,提取当前页面视频的cid参数(一串数字)。
使用cid参数构造视频弹幕存储API接口,然后使用常规requests和bs4包实现采集文本
Data采集部分代码:
f = open(self.savepath, 'w+', encoding='utf-8') # 打开 txt 文件
res = requests.get(url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'lxml')
items = soup.find_all('d') # 找到 d 标签
for item in items:
text = item.text
f.write(text)
f.write('\n')
f.close()
cid 参数不在常规 html 标签上。提取的时候,我选择re正则匹配;但是这一步会消耗更多的机器内存。为了减少对UI界面响应速度的影响,这一步是单线程实现的
class Parsetext(QThread):
trigger = pyqtSignal(str) # 信号发射;
def __init__(self,text,parent = None):
super(Parsetext,self).__init__()
self.text = text
def __del__(self):
self.wait()
def run(self):
print('解析 -----------{}'.format(self.text))
result_url = re.findall('.*?"baseUrl":"(.*?)","base_url".*?', self.text)[0]
self.trigger.emit(result_url)
总结
好的,以上就是本文文章的全部内容,希望对你的工作学习有所帮助。
最后感谢大家的阅读,下期再见~
源码获取
关于本文文章使用的源码,获取方式:
为了自动采集B站弹幕,我用Python开发了一个下载器!
自动采集宝宝大便的app不存在,目前应该是还没有涉及到这一块
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-06-06 03:02
自动采集宝宝大便的app不存在,目前应该是还没有涉及到这一块。如果是宝宝买奶粉,可以使用宝宝囤奶粉app,上面实时更新奶粉的库存情况,并且可以通过每日秒杀抢购,自动自发去进行抢购,减少了人工的麻烦。如果是买尿不湿,我们可以使用尿不湿软件,比如益发宝,然后利用自动采集技术,主动去采集,也是有其他的渠道去购买的。
并且利用复制排版技术,将同一套大便的信息,复制到不同的渠道去,也不需要进行二次传播的操作。一、文本文档采集自动搜索宝宝大便的app暂时应该是没有,不过可以使用文本文档进行采集,比如天天快报、今日头条、网易新闻等等。方法如下:1.新版天天快报可以随时在发现栏目中,设置文章按钮,天天快报“大便推荐”中也可以看到”当你是个物理存在的大便时,他就鼓励你大便了”系统自动抓取同一个大便的信息。
2.方法就是写文章时,将某个字词划去,或者文章中带自己的照片,然后在不损害文章的情况下,自动获取该照片的原始图片。文档采集数据来源:天天快报、今日头条、网易新闻。二、图片采集方法如下:1.新版今日头条图片抓取关注公众号:gzgykqa,然后在公众号自动回复中,回复:你想要的,即可获取对应的网页文件,网页文件需要使用百度网盘或者iis服务器下载。
2.登录美柚宝宝管家,点击”操作中心“按钮,点击”立即采集“按钮后,点击”开始采集“按钮,即可开始抓取上传图片。图片采集数据来源:美柚宝宝管家。本文由【】原创发布,关注【文思海辉服务平台】微信公众号:ts_asias。 查看全部
自动采集宝宝大便的app不存在,目前应该是还没有涉及到这一块
自动采集宝宝大便的app不存在,目前应该是还没有涉及到这一块。如果是宝宝买奶粉,可以使用宝宝囤奶粉app,上面实时更新奶粉的库存情况,并且可以通过每日秒杀抢购,自动自发去进行抢购,减少了人工的麻烦。如果是买尿不湿,我们可以使用尿不湿软件,比如益发宝,然后利用自动采集技术,主动去采集,也是有其他的渠道去购买的。
并且利用复制排版技术,将同一套大便的信息,复制到不同的渠道去,也不需要进行二次传播的操作。一、文本文档采集自动搜索宝宝大便的app暂时应该是没有,不过可以使用文本文档进行采集,比如天天快报、今日头条、网易新闻等等。方法如下:1.新版天天快报可以随时在发现栏目中,设置文章按钮,天天快报“大便推荐”中也可以看到”当你是个物理存在的大便时,他就鼓励你大便了”系统自动抓取同一个大便的信息。
2.方法就是写文章时,将某个字词划去,或者文章中带自己的照片,然后在不损害文章的情况下,自动获取该照片的原始图片。文档采集数据来源:天天快报、今日头条、网易新闻。二、图片采集方法如下:1.新版今日头条图片抓取关注公众号:gzgykqa,然后在公众号自动回复中,回复:你想要的,即可获取对应的网页文件,网页文件需要使用百度网盘或者iis服务器下载。
2.登录美柚宝宝管家,点击”操作中心“按钮,点击”立即采集“按钮后,点击”开始采集“按钮,即可开始抓取上传图片。图片采集数据来源:美柚宝宝管家。本文由【】原创发布,关注【文思海辉服务平台】微信公众号:ts_asias。

