
自动关键词采集
自动关键词采集器可以自动监测亚马逊平台的大部分热门产品
采集交流 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2021-03-20 08:01
自动关键词采集器可以自动监测亚马逊平台的大部分热门产品,每天都有不断新的产品上架,还有收录量下降的产品自动修改关键词,可以一键全部下架,
第一个,以前是可以的,现在不可以,因为亚马逊更加开放,更大了,有的你想的到的东西都可以出现,他们把关键词收集好放在站内搜索栏的。另外说一下,全球开店你不要经常申请,因为都是一个人申请俩个号,批量不行,谁说批量的好的,你心里没数么,一般都是卖不掉给亚马逊删掉。他可以给你平台筛选这样。其实热销产品,竞争大产品,都有标准。没有任何捷径可以走的。跨境电商之王三十六计,人最弱。
感谢邀请。亚马逊是一个以客户需求为核心,并以客户体验为中心的跨境电商平台。因此产品要过硬,不是热销的产品才有机会成为爆款;其次就是外贸业务为主,做好seo,通过谷歌分析及关键词挖掘,进行产品调整;当然如果拥有自己的供应链,那你就是最核心的人。
通过关键词优化,关键词优化的方式跟第一个差不多,区别是google提供的是热门的产品。
怎么说呢,你可以做这个看看有没有效果,能不能满足你的需求,可以做,但是要针对的话就是amazon,亚马逊的产品很多都是非热销产品,个人感觉第二个靠谱,毕竟google出来了,可以借鉴的价值也大。第一个可以先做出来产品的基本图片就可以,否则空有亚马逊平台也没用。因为我是新人一枚,我懂的不多,也只能这么表达,对不对就不知道了。 查看全部
自动关键词采集器可以自动监测亚马逊平台的大部分热门产品
自动关键词采集器可以自动监测亚马逊平台的大部分热门产品,每天都有不断新的产品上架,还有收录量下降的产品自动修改关键词,可以一键全部下架,
第一个,以前是可以的,现在不可以,因为亚马逊更加开放,更大了,有的你想的到的东西都可以出现,他们把关键词收集好放在站内搜索栏的。另外说一下,全球开店你不要经常申请,因为都是一个人申请俩个号,批量不行,谁说批量的好的,你心里没数么,一般都是卖不掉给亚马逊删掉。他可以给你平台筛选这样。其实热销产品,竞争大产品,都有标准。没有任何捷径可以走的。跨境电商之王三十六计,人最弱。
感谢邀请。亚马逊是一个以客户需求为核心,并以客户体验为中心的跨境电商平台。因此产品要过硬,不是热销的产品才有机会成为爆款;其次就是外贸业务为主,做好seo,通过谷歌分析及关键词挖掘,进行产品调整;当然如果拥有自己的供应链,那你就是最核心的人。
通过关键词优化,关键词优化的方式跟第一个差不多,区别是google提供的是热门的产品。
怎么说呢,你可以做这个看看有没有效果,能不能满足你的需求,可以做,但是要针对的话就是amazon,亚马逊的产品很多都是非热销产品,个人感觉第二个靠谱,毕竟google出来了,可以借鉴的价值也大。第一个可以先做出来产品的基本图片就可以,否则空有亚马逊平台也没用。因为我是新人一枚,我懂的不多,也只能这么表达,对不对就不知道了。
集搜客网络爬虫案例规则+操作步骤及注意事项
采集交流 • 优采云 发表了文章 • 0 个评论 • 1052 次浏览 • 2021-02-04 08:07
一、操作步骤
二、案例规则+操作步骤
注意:在这种情况下,京东搜索具有独立的URL。对于具有独立URL的页面,最简单的方法是为每个关键词构造一个搜索URL,然后将线索URL导入规则中,您可以批量采集而不是设置连续操作,可以参考“构建网站”和“如何管理线索规则”。
第1步:定义一级规则
1.1打开Jishouke Web采集器,输入URL并输入,在加载网页后,单击“定义规则”按钮,您将看到一个显示的浮动窗口,称为工作台,您可以在其中定义规则;
注意:此处的屏幕截图和文字描述均为Jishouke Web采集器版本。如果要安装Firefox插件版本,则没有“定义规则”按钮,但是您应该运行MS Museum。
1.2在工作台中输入第一级规则的主题名称,然后单击“检查重复项”,提示“可以使用此名称”或“名称已被占用,可编辑:是” ,您可以使用此使用者名称,否则请重命名。
1.3此级别的规则主要是设置连续的操作,因此排序框可以随意获取一条信息,并使用它来判断是否对采集器执行采集。双击网页上的信息,输入标签名称,然后单击确认,然后在关键内容上打勾,并输入第一个标签的排序框的名称,然后完成标签映射。
提示:为了准确定位网页信息,单击定义规则将冻结整个网页,并且无法跳转到网页链接。再次单击定义规则以返回到正常的网页模式。
第2步:定义连续的操作
单击工作台的“连续动作”选项卡,单击“新建”按钮创建一个新动作,每个动作的设置方法相同,基本操作如下:
2.1,输入目标使用者名称
此处的目标主题名称是填写第二级主题名称,单击“正在使用谁”以检查目标主题名称是否可用,如果已被占用,则只需更改主题名称即可。
2.2,创建第一个动作:输入
创建一个新动作并选择动作类型作为输入。
2.2.1,填写定位表达式
首先单击输入框,找到输入框的节点,然后单击“自动生成XPath”按钮,可以选择“ Preference id”或“ Preference class”,可以获得输入的xpath表达式框,然后单击“搜索”按钮,检查此xpath是否可以唯一地位于输入框中,如果没有问题,请将xpath复制到定位表达式框中。
注意:定位表达式中的xpath用于锁定操作对象的整个有效操作范围。具体来说,它是指可以通过鼠标成功单击或输入的网页模块。不要在底部找到text()节点。
2.2.2,输入关键词
输入关键词以填写要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词以使用双分号;将每个关键词分开,免费版仅支持5个内的5个关键词,旗舰版可以使用连发杂志功能,支持10,000个内的关键词
2.2.3,输入动作名称
告诉自己该步骤的用途,以便稍后进行修改。
2.3,创建第二个动作:单击
请参考2.2的操作,创建第二个动作,选择类型为click,找到搜索按钮,然后自动生成xpath来检查它是否被锁定到唯一节点,以及是否没有被锁定。问题,将其填写在定位表达式中。
2.4,保存规则
点击“保存规则”按钮以保存已完成的第一级规则
第3步:定义二级规则
3.1,创建一个新规则
创建第二级规则,单击“定义规则”以返回正常的网页模式,输入关键词搜索结果,再次单击“定义规则”以切换到规则制定模式,然后单击“规则”菜单的左上角->“新建”,输入主题名称,其中主题名称是在第一级规则的连续操作中填充的目标主题名称。
3.2,标记您想要的信息采集
3.2.1,在网页上标记所需的信息采集,此处标记产品名称和价格,因为该标记仅对文本信息有效,因此链接是属性节点@href,因此它无法用采集标记链接,但可以进行内容映射,请参阅以下操作以获取详细信息。
3.2.2,用鼠标选择排序框的名称,按鼠标右键,选择“添加”->“收录”以创建用于内容爬行的“链接”,单击在产品名称上的A标记上可以找到它,您可以在属性下找到相应的@href节点,右键单击该节点,然后选择要映射到“链接”的内容。
3.2.3,设置“密钥内容”选项,以便爬网程序可以判断采集规则是否合适。在排序框中,选择不可避免地在网页上可用的标签,然后勾选“关键内容”。在这里,“名称”被选作“关键内容”。
3.2.4,如果仅在前面标记一个产品,则可以获得产品信息。如果要在整个页面上采集每个产品,都可以制作示例副本,否。如果您了解,请参阅基本教程“ 采集列表数据”
3.3,设置翻页路线
设置爬虫路线中的翻页功能,这是标记提示,如果您不了解,请参考基本教程“设置翻页采集”
3.4,保存规则
单击“测试”以检查信息的完整性。如果不完整,则注释可以覆盖以前的内容。检查没有问题后,单击“保存规则”。
第4步:捕获数据
4.1,连续动作是连续执行的,因此只要您运行第一级主题,就不需要运行第二级主题。打开DS计数器,搜索第一级主题名称,单击“单一搜索”或“集合”,可以看到在浏览器窗口中自动输入并搜索了关键词,然后调用第二级主题自动采集搜索结果。
4.2,第一级主题未采集有意义的信息,因此我们仅查看第二级主题文件夹,即可看到采集的搜索结果数据,并搜索关键词默认情况下记录在xml文件的actionvalue字段中,以便它可以一一对应。 查看全部
集搜客网络爬虫案例规则+操作步骤及注意事项
一、操作步骤

二、案例规则+操作步骤
注意:在这种情况下,京东搜索具有独立的URL。对于具有独立URL的页面,最简单的方法是为每个关键词构造一个搜索URL,然后将线索URL导入规则中,您可以批量采集而不是设置连续操作,可以参考“构建网站”和“如何管理线索规则”。
第1步:定义一级规则
1.1打开Jishouke Web采集器,输入URL并输入,在加载网页后,单击“定义规则”按钮,您将看到一个显示的浮动窗口,称为工作台,您可以在其中定义规则;
注意:此处的屏幕截图和文字描述均为Jishouke Web采集器版本。如果要安装Firefox插件版本,则没有“定义规则”按钮,但是您应该运行MS Museum。
1.2在工作台中输入第一级规则的主题名称,然后单击“检查重复项”,提示“可以使用此名称”或“名称已被占用,可编辑:是” ,您可以使用此使用者名称,否则请重命名。

1.3此级别的规则主要是设置连续的操作,因此排序框可以随意获取一条信息,并使用它来判断是否对采集器执行采集。双击网页上的信息,输入标签名称,然后单击确认,然后在关键内容上打勾,并输入第一个标签的排序框的名称,然后完成标签映射。
提示:为了准确定位网页信息,单击定义规则将冻结整个网页,并且无法跳转到网页链接。再次单击定义规则以返回到正常的网页模式。
第2步:定义连续的操作
单击工作台的“连续动作”选项卡,单击“新建”按钮创建一个新动作,每个动作的设置方法相同,基本操作如下:

2.1,输入目标使用者名称
此处的目标主题名称是填写第二级主题名称,单击“正在使用谁”以检查目标主题名称是否可用,如果已被占用,则只需更改主题名称即可。
2.2,创建第一个动作:输入
创建一个新动作并选择动作类型作为输入。

2.2.1,填写定位表达式
首先单击输入框,找到输入框的节点,然后单击“自动生成XPath”按钮,可以选择“ Preference id”或“ Preference class”,可以获得输入的xpath表达式框,然后单击“搜索”按钮,检查此xpath是否可以唯一地位于输入框中,如果没有问题,请将xpath复制到定位表达式框中。
注意:定位表达式中的xpath用于锁定操作对象的整个有效操作范围。具体来说,它是指可以通过鼠标成功单击或输入的网页模块。不要在底部找到text()节点。
2.2.2,输入关键词
输入关键词以填写要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词以使用双分号;将每个关键词分开,免费版仅支持5个内的5个关键词,旗舰版可以使用连发杂志功能,支持10,000个内的关键词
2.2.3,输入动作名称
告诉自己该步骤的用途,以便稍后进行修改。
2.3,创建第二个动作:单击

请参考2.2的操作,创建第二个动作,选择类型为click,找到搜索按钮,然后自动生成xpath来检查它是否被锁定到唯一节点,以及是否没有被锁定。问题,将其填写在定位表达式中。
2.4,保存规则
点击“保存规则”按钮以保存已完成的第一级规则
第3步:定义二级规则
3.1,创建一个新规则

创建第二级规则,单击“定义规则”以返回正常的网页模式,输入关键词搜索结果,再次单击“定义规则”以切换到规则制定模式,然后单击“规则”菜单的左上角->“新建”,输入主题名称,其中主题名称是在第一级规则的连续操作中填充的目标主题名称。
3.2,标记您想要的信息采集

3.2.1,在网页上标记所需的信息采集,此处标记产品名称和价格,因为该标记仅对文本信息有效,因此链接是属性节点@href,因此它无法用采集标记链接,但可以进行内容映射,请参阅以下操作以获取详细信息。
3.2.2,用鼠标选择排序框的名称,按鼠标右键,选择“添加”->“收录”以创建用于内容爬行的“链接”,单击在产品名称上的A标记上可以找到它,您可以在属性下找到相应的@href节点,右键单击该节点,然后选择要映射到“链接”的内容。
3.2.3,设置“密钥内容”选项,以便爬网程序可以判断采集规则是否合适。在排序框中,选择不可避免地在网页上可用的标签,然后勾选“关键内容”。在这里,“名称”被选作“关键内容”。

3.2.4,如果仅在前面标记一个产品,则可以获得产品信息。如果要在整个页面上采集每个产品,都可以制作示例副本,否。如果您了解,请参阅基本教程“ 采集列表数据”
3.3,设置翻页路线

设置爬虫路线中的翻页功能,这是标记提示,如果您不了解,请参考基本教程“设置翻页采集”
3.4,保存规则
单击“测试”以检查信息的完整性。如果不完整,则注释可以覆盖以前的内容。检查没有问题后,单击“保存规则”。
第4步:捕获数据

4.1,连续动作是连续执行的,因此只要您运行第一级主题,就不需要运行第二级主题。打开DS计数器,搜索第一级主题名称,单击“单一搜索”或“集合”,可以看到在浏览器窗口中自动输入并搜索了关键词,然后调用第二级主题自动采集搜索结果。
4.2,第一级主题未采集有意义的信息,因此我们仅查看第二级主题文件夹,即可看到采集的搜索结果数据,并搜索关键词默认情况下记录在xml文件的actionvalue字段中,以便它可以一一对应。
汇总:Python学习笔记(19)自动搜索关键词采集信息—以京东为例
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2020-12-21 08:12
一、操作步骤
如果网页上有一个搜索框,但搜索结果页面没有单独的URL,并且如果您要采集个搜索结果,则可以直接制定采集不能的规则,并且您必须执行连续操作(输入+单击)以实现自动输入关键词和搜索,然后搜索采集数据。让我们以京东搜索为例来演示自动搜索采集。操作步骤如下:
二、案例规则+操作步骤
**注意:**在这种情况下,京东搜索具有独立的URL。对于具有独立URL的页面,最简单的方法是为每个关键词构造一个搜索URL,然后将线索URL导入规则中,您可以批量采集而不是设置连续操作
第1步:定义一级规则
1.1打开Jishouke Web采集器,输入URL并按Enter,然后在加载网页后单击“定义规则”按钮,您将看到一个显示的浮动窗口,称为工作台,您可以在该窗口上工作定义规则;
注意:此处的屏幕截图和文字描述是Jishouke的所有Web爬网程序版本。如果安装Firefox插件版本,则没有“定义规则”按钮。相反,您应该运行MS Muse。
1.2在工作台中输入一级规则的主题名称,然后单击“检查重复项”,提示“可以使用该名称”或“该名称已被占用,可编辑:是” ,您可以使用此使用者名称,否则请重命名。
1.3此级别的规则主要是设置连续的操作,因此排序框可以随意获取一条信息,并使用它来判断是否对采集器执行采集。双击网页上的信息,输入标签名称,勾选确认,然后在关键内容上勾选,输入第一个标签的分类框名称,即可完成标签映射。
提示:为了准确定位网页信息,单击定义规则将冻结整个网页,并且无法跳转到网页链接。再次单击定义规则以返回到正常的网页模式。
第2步:定义连续的操作
单击工作台的“连续动作”选项卡,单击“新建”按钮创建一个新动作,每个动作的设置方法相同,基本操作如下:
2.1,输入目标主题名称
此处的目标主题名称是填写第二级主题名称,单击“正在使用谁”以检查目标主题名称是否可用,如果已被占用,则只需更改主题名称即可。
2.2,创建第一个动作:输入
创建一个新动作并选择动作类型作为输入。
2.2.1,填写定位表达式
首先单击输入框,找到输入框的节点,然后单击“自动生成XPath”按钮,可以选择“ Preference id”或“ Preference class”,可以获得输入的xpath表达式框,然后单击“搜索”按钮,检查此xpath是否可以唯一地位于输入框中,如果没有问题,请将xpath复制到定位表达式框中。
**注意:**定位表达式中的xpath用来锁定动作对象的整个有效操作范围,特别是指可以通过鼠标成功单击或输入的网页模块,而不是在底部找到text()节点。
2.2.2,输入关键词
输入关键词以填写要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词以使用双分号;将每个关键词分开,免费版仅支持5个内的5个关键词,旗舰版可以使用连发杂志功能,支持10,000个内的关键词
2.2.3,输入动作名称
告诉自己该步骤的用途,以便稍后进行修改。
2.3,创建第二个动作:单击
请参考2.2的操作,创建第二个动作,选择类型为click,找到搜索按钮,然后自动生成xpath来检查它是否被锁定到唯一节点(如果没有)问题,将其填写在定位表达式中。
2.4,保存规则
点击“保存规则”按钮以保存已完成的一级规则
第3步:定义二级规则
3.1,创建一个新规则
创建第二级规则,单击“定义规则”以返回正常的网页模式,输入关键词搜索结果,再次单击“定义规则”以切换到规则制定模式,然后单击“规则”菜单的左上角->“新建”,输入主题名称,其中主题名称是在第一级规则的连续操作中填充的目标主题名称。
3.2,标记您想要的信息采集
3.2.1,在网页上标记您想要的信息采集,这里是产品名称和价格的标记,因为该标记仅对文本信息有效,因此指向产品详细信息的链接是属性节点@href,因此,您不能在链接上进行这样直观的标记,但是要进行内容映射,请参阅以下操作以获取详细信息。
3.2.2,单击产品名称,下面的DOM节点找到A标签,展开A标签下的attribute节点,您可以找到代表URL的@href节点,右键单击节点,然后选择“新建捕获”,然后单击“获取内容”,输入一个名称,通常为爬网的内容指定一个与地址相关的名称,例如“下属URL”或“下属链接”等。然后在工作台上,我看到已抓取的内容可用。如果您仍要进入产品详细信息页面采集,则必须检查与该抓取内容有关的较低级线索以进行分层抓取。
3.2.3,设置“密钥内容”选项,以便爬网程序可以判断采集规则是否合适。在排序框中,选择不可避免地在网页上可用的标签,然后勾选“关键内容”。在这里,“名称”被选作“关键内容”。
3.2.4,如果仅在前面标记一个产品,则可以获得产品信息。如果您想在整个页面上采集每个产品,都可以制作一个样本副本,否。如果您理解,请参阅基本教程“ 采集列表数据”
3.3,设置翻页路线
设置爬虫路线中的翻页功能,这是标记提示,如果您不了解,请参考基本教程“设置翻页采集”
3.4,保存规则
单击“测试”以检查信息的完整性。如果不完整,则注释可以覆盖以前的内容。检查没有问题后,单击“保存规则”。
第4步:捕获数据
4.1,连续动作是连续执行的,因此只要您运行第一级主题,就不需要运行第二级主题。打开DS计数器,搜索第一级主题名称,单击“单一搜索”或“集合”,可以看到在浏览器窗口中自动输入并搜索了关键词,然后调用第二级主题自动采集搜索结果。
4.2,第一级主题未采集有意义的信息,因此我们仅查看第二级主题的文件夹,即可看到采集的搜索结果数据,并搜索关键词 Is默认情况下记录在xml文件的actionvalue字段中,以便它可以一一对应。 查看全部
汇总:Python学习笔记(19)自动搜索关键词采集信息—以京东为例
一、操作步骤
如果网页上有一个搜索框,但搜索结果页面没有单独的URL,并且如果您要采集个搜索结果,则可以直接制定采集不能的规则,并且您必须执行连续操作(输入+单击)以实现自动输入关键词和搜索,然后搜索采集数据。让我们以京东搜索为例来演示自动搜索采集。操作步骤如下:
二、案例规则+操作步骤
**注意:**在这种情况下,京东搜索具有独立的URL。对于具有独立URL的页面,最简单的方法是为每个关键词构造一个搜索URL,然后将线索URL导入规则中,您可以批量采集而不是设置连续操作
第1步:定义一级规则
1.1打开Jishouke Web采集器,输入URL并按Enter,然后在加载网页后单击“定义规则”按钮,您将看到一个显示的浮动窗口,称为工作台,您可以在该窗口上工作定义规则;
注意:此处的屏幕截图和文字描述是Jishouke的所有Web爬网程序版本。如果安装Firefox插件版本,则没有“定义规则”按钮。相反,您应该运行MS Muse。
1.2在工作台中输入一级规则的主题名称,然后单击“检查重复项”,提示“可以使用该名称”或“该名称已被占用,可编辑:是” ,您可以使用此使用者名称,否则请重命名。
1.3此级别的规则主要是设置连续的操作,因此排序框可以随意获取一条信息,并使用它来判断是否对采集器执行采集。双击网页上的信息,输入标签名称,勾选确认,然后在关键内容上勾选,输入第一个标签的分类框名称,即可完成标签映射。
提示:为了准确定位网页信息,单击定义规则将冻结整个网页,并且无法跳转到网页链接。再次单击定义规则以返回到正常的网页模式。
第2步:定义连续的操作
单击工作台的“连续动作”选项卡,单击“新建”按钮创建一个新动作,每个动作的设置方法相同,基本操作如下:
2.1,输入目标主题名称
此处的目标主题名称是填写第二级主题名称,单击“正在使用谁”以检查目标主题名称是否可用,如果已被占用,则只需更改主题名称即可。
2.2,创建第一个动作:输入
创建一个新动作并选择动作类型作为输入。
2.2.1,填写定位表达式
首先单击输入框,找到输入框的节点,然后单击“自动生成XPath”按钮,可以选择“ Preference id”或“ Preference class”,可以获得输入的xpath表达式框,然后单击“搜索”按钮,检查此xpath是否可以唯一地位于输入框中,如果没有问题,请将xpath复制到定位表达式框中。
**注意:**定位表达式中的xpath用来锁定动作对象的整个有效操作范围,特别是指可以通过鼠标成功单击或输入的网页模块,而不是在底部找到text()节点。
2.2.2,输入关键词
输入关键词以填写要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词以使用双分号;将每个关键词分开,免费版仅支持5个内的5个关键词,旗舰版可以使用连发杂志功能,支持10,000个内的关键词
2.2.3,输入动作名称
告诉自己该步骤的用途,以便稍后进行修改。
2.3,创建第二个动作:单击
请参考2.2的操作,创建第二个动作,选择类型为click,找到搜索按钮,然后自动生成xpath来检查它是否被锁定到唯一节点(如果没有)问题,将其填写在定位表达式中。
2.4,保存规则
点击“保存规则”按钮以保存已完成的一级规则
第3步:定义二级规则
3.1,创建一个新规则
创建第二级规则,单击“定义规则”以返回正常的网页模式,输入关键词搜索结果,再次单击“定义规则”以切换到规则制定模式,然后单击“规则”菜单的左上角->“新建”,输入主题名称,其中主题名称是在第一级规则的连续操作中填充的目标主题名称。
3.2,标记您想要的信息采集
3.2.1,在网页上标记您想要的信息采集,这里是产品名称和价格的标记,因为该标记仅对文本信息有效,因此指向产品详细信息的链接是属性节点@href,因此,您不能在链接上进行这样直观的标记,但是要进行内容映射,请参阅以下操作以获取详细信息。
3.2.2,单击产品名称,下面的DOM节点找到A标签,展开A标签下的attribute节点,您可以找到代表URL的@href节点,右键单击节点,然后选择“新建捕获”,然后单击“获取内容”,输入一个名称,通常为爬网的内容指定一个与地址相关的名称,例如“下属URL”或“下属链接”等。然后在工作台上,我看到已抓取的内容可用。如果您仍要进入产品详细信息页面采集,则必须检查与该抓取内容有关的较低级线索以进行分层抓取。
3.2.3,设置“密钥内容”选项,以便爬网程序可以判断采集规则是否合适。在排序框中,选择不可避免地在网页上可用的标签,然后勾选“关键内容”。在这里,“名称”被选作“关键内容”。
3.2.4,如果仅在前面标记一个产品,则可以获得产品信息。如果您想在整个页面上采集每个产品,都可以制作一个样本副本,否。如果您理解,请参阅基本教程“ 采集列表数据”
3.3,设置翻页路线
设置爬虫路线中的翻页功能,这是标记提示,如果您不了解,请参考基本教程“设置翻页采集”
3.4,保存规则
单击“测试”以检查信息的完整性。如果不完整,则注释可以覆盖以前的内容。检查没有问题后,单击“保存规则”。
第4步:捕获数据
4.1,连续动作是连续执行的,因此只要您运行第一级主题,就不需要运行第二级主题。打开DS计数器,搜索第一级主题名称,单击“单一搜索”或“集合”,可以看到在浏览器窗口中自动输入并搜索了关键词,然后调用第二级主题自动采集搜索结果。
4.2,第一级主题未采集有意义的信息,因此我们仅查看第二级主题的文件夹,即可看到采集的搜索结果数据,并搜索关键词 Is默认情况下记录在xml文件的actionvalue字段中,以便它可以一一对应。
事实:深圳市企翔网络(图)-关键词快速排名推广系统-关键词快速排名
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2020-10-24 12:02
产品规格:
无限
产品数量:
无限
包装说明:
订购
价格说明:
无限
观众:
756人
链接到此页面:
深圳启翔网络技术有限公司
我们如何快速构建网站的关键词词库
许多人不了解关键词同义词库。实际上,关键词词库是我们用来采集[k5]的库。 关键词分为几种主要类型:主要关键词,长尾词,价值词,交通词等;这些需要一些方法和工具来采集它们,然后构建大型的关键词库。那么关键词词库的用途是什么?
可以帮助我们选择:具有转换率的百度关键词快速排名关键词,主要关键词,长尾词,建筑词等,所有这些都需要我们在关键词库中选择因此,关键词库的建立是网站优化开始的良好阶段,因此网站的目标更加明确;对于我们将来的职位来说更方便。
我们可以通过什么方式构建我们的网站 关键词词库?
A,关键词集合:通过百度下拉框,相关搜索,单词追逐或金华等工具,百度推广助手,关键词前20名独立网站,相关论坛,百度贴吧,问答平台;这些是我们常用的几种方法,上面引用的方法足以构建关键词库。
B。分词类型:
1.时效性:时效性词属于某些行业,并由时间关键词建立;
2.季节性:实际上,季节性单词的性质类似于对时间敏感的单词。 关键词快速排名百度首页,不同之处在于一个是时间,另一个是季节;
3.产品字词:通常,公司网站会有一些产品名称,因此我们需要采集它们;例如,在关键词 search seo 网站优化搜索中,有一个百度下拉框Product字;它表明用户对产品字词有一点需求。
4.流量词:用户将搜索行业中的关键词并输入网站,例如一些长尾词,目标词,短词等;我们都需要采集它们。
5.高转换率关键词:该行业中的关键词转换率很高。
6.位置:网站快速排名,例如移动,汽车租赁,废物回收,空调维修,计算机维修等。行业具有区域性需求,因为用户会选择离他们最近的行业,而不是选择那些遥远的地方;这是因为时间成本。
如何提高关键词排名?
如何提高关键词的排名并达到关键词主导屏幕的效果?
一、超级繁华的商店,可以做生意的在线商店
1、一个具有多种模式的网络,“ PC + mobile +微信”自动适应整个终端的覆盖范围;
2、大规模设计方案,一分钟即可建一个车站;
3、不需要专业人员来维护,并且内容会自动更新;
3、 SEO策略,大规模原创,自动优化和排名;
4、HTML5移动改编,拥抱移动互联网;
5、自主云集群,为网站提供了五星级的家;
6、支持站群模式,您并不孤单;
二、独立营销企业网站,独立域名,完整营销
1、绑定企业一级域名,易于拥有企业独立性网站;
2、营销类型网站模板,已转换为公司营销类型网站定制;
3、智能的SEO策略,提高企业独立性网站 收录的排名;
4、自动外部链接帮助,以实现快速搜索引擎收录;
三、企业移动网站(移动商店),在移动时代必不可少
1、 HTML5自动适应,使每部手机都能获得良好的显示效果;
2、独家功能页面模板库,可以随时更改版本,可以选择;
3、随PC站自动更新,无需单独管理和更新移动终端;
4、多种一键式交互式操作按钮,关键词快速排名,轻松的营销和增加访客查询;
5、移动搜索会自动调整以轻松获取移动搜索流量。
四、企业微信网站(微信网)允许公司插入微信的翅膀
1、自动打开企业微信公众平台,一站式管理微信公众平台;
2、自定义菜单和回复,直接与企业手机商店进行通信;
五、超级企业网络站群(王埔集团),您并不孤单
1、这些天,您仍然是“单身”,是时候打电话给几个“兄弟”了;
2、超级旺铺开创了“旺铺组”功能,可以再生成5个旺铺;
3、每个商店都可以绑定到不同的一级域名并独立显示,
4、独立优化;自动的内容分发信息和更新,以保持旺普集团的内容差异化;
5、同时管理多个超级插座完全没有问题,一劳永逸,效果翻了一番。
根据网络变化进行网络优化。它不是恒定的层,也不总是规则。您需要更多地关注网络变化,平台变化和市场调整,以自定义自己的SEO优化促销。您需要注意这些问题通常可以从以下几点考虑:
一、重复,无论是外部信息还是内部文案写作信息,都不建议发布太多相同的信息;这些相同的信息通常可以是:相同的标题,相同的内容,相同的产品等。
二、嫉妒太多。定位标题和内容时,许多运营商都喜欢添加太多关键词;或在同一网站或平台关键词上添加叠加层。
三、添加了太多的超链接,文章内容,新闻页面,添加了太多的链接,从而导致搜索引擎的排名在收录中,或者它们的排名不佳或进行Shield操作。添加过多图片,对于不同的产品页面,添加过多图片,一种会导致页面打开速度,另一种是收录,即收录。
四、口语是指在不同平台上发布信息或产品信息时的关键词快速排名提升系统。尽量多说话。不要太死板,只发布促销信息,否则将导致禁令或封锁IP,不利于将来发送的信息收录。
五、在外部发送信息时与对等方结合使用,关键词快速排名方法技能,您可以提前搜索对等方以了解同事在何处发布信息,并在对等方发布信息的平台上进行操作;还要获得PR价值。请转到更高的平台。
六、无论平台有多好,无论同行有多好,创新和原创信息都要好得多;建议您在进行外围设备信息时自定义原创文案,并定期进行更新。
深圳齐翔网络技术有限公司(图片)-关键词快速排名推广系统-关键词快速排名由深圳市齐翔网络技术有限公司提供。深圳市齐翔网络技术有限公司()是一家专业公司在“ 网站建设,网络推广,小程序开发,seo优化”中。自成立以来,我们一直奉行“诚信为本,稳定运行”的政策,并有勇气参与健康的市场竞争,因此“ 网站建设,网络推广,小程序开发,seo优化”具有良好的声誉。我们坚持“服务第一,用户至上”的原则,使深圳启翔网络在软件开发上赢得了众多客户的信赖,树立了良好的企业形象。特别说明:本信息中的图片和信息仅供参考,请与我们联系以获取准确的信息,谢谢!同时,公司()还是专门从事关键词排名,关键词促销和关键词主导屏幕的服务提供商。欢迎来电咨询。
欢迎来到深圳市齐翔网络技术有限公司网站。本公司位于中国经济中心深圳,经济发达,交通发达,人口稠密。具体地址是深圳市龙华新区民治大道U创固A11-10,联系人是赵经理。
主要从事网站建设,网络推广,小程序开发,seo优化。
单位的注册资本未知。 查看全部
深圳企翔网(图片)-关键词快速排名提升系统-关键词快速排名
产品规格:
无限
产品数量:
无限
包装说明:
订购
价格说明:
无限
观众:
756人
链接到此页面:
深圳启翔网络技术有限公司
我们如何快速构建网站的关键词词库
许多人不了解关键词同义词库。实际上,关键词词库是我们用来采集[k5]的库。 关键词分为几种主要类型:主要关键词,长尾词,价值词,交通词等;这些需要一些方法和工具来采集它们,然后构建大型的关键词库。那么关键词词库的用途是什么?
可以帮助我们选择:具有转换率的百度关键词快速排名关键词,主要关键词,长尾词,建筑词等,所有这些都需要我们在关键词库中选择因此,关键词库的建立是网站优化开始的良好阶段,因此网站的目标更加明确;对于我们将来的职位来说更方便。
我们可以通过什么方式构建我们的网站 关键词词库?
A,关键词集合:通过百度下拉框,相关搜索,单词追逐或金华等工具,百度推广助手,关键词前20名独立网站,相关论坛,百度贴吧,问答平台;这些是我们常用的几种方法,上面引用的方法足以构建关键词库。
B。分词类型:
1.时效性:时效性词属于某些行业,并由时间关键词建立;
2.季节性:实际上,季节性单词的性质类似于对时间敏感的单词。 关键词快速排名百度首页,不同之处在于一个是时间,另一个是季节;
3.产品字词:通常,公司网站会有一些产品名称,因此我们需要采集它们;例如,在关键词 search seo 网站优化搜索中,有一个百度下拉框Product字;它表明用户对产品字词有一点需求。
4.流量词:用户将搜索行业中的关键词并输入网站,例如一些长尾词,目标词,短词等;我们都需要采集它们。
5.高转换率关键词:该行业中的关键词转换率很高。
6.位置:网站快速排名,例如移动,汽车租赁,废物回收,空调维修,计算机维修等。行业具有区域性需求,因为用户会选择离他们最近的行业,而不是选择那些遥远的地方;这是因为时间成本。







如何提高关键词排名?
如何提高关键词的排名并达到关键词主导屏幕的效果?
一、超级繁华的商店,可以做生意的在线商店
1、一个具有多种模式的网络,“ PC + mobile +微信”自动适应整个终端的覆盖范围;
2、大规模设计方案,一分钟即可建一个车站;
3、不需要专业人员来维护,并且内容会自动更新;
3、 SEO策略,大规模原创,自动优化和排名;
4、HTML5移动改编,拥抱移动互联网;
5、自主云集群,为网站提供了五星级的家;
6、支持站群模式,您并不孤单;

二、独立营销企业网站,独立域名,完整营销
1、绑定企业一级域名,易于拥有企业独立性网站;
2、营销类型网站模板,已转换为公司营销类型网站定制;
3、智能的SEO策略,提高企业独立性网站 收录的排名;
4、自动外部链接帮助,以实现快速搜索引擎收录;

三、企业移动网站(移动商店),在移动时代必不可少
1、 HTML5自动适应,使每部手机都能获得良好的显示效果;
2、独家功能页面模板库,可以随时更改版本,可以选择;
3、随PC站自动更新,无需单独管理和更新移动终端;
4、多种一键式交互式操作按钮,关键词快速排名,轻松的营销和增加访客查询;
5、移动搜索会自动调整以轻松获取移动搜索流量。
四、企业微信网站(微信网)允许公司插入微信的翅膀
1、自动打开企业微信公众平台,一站式管理微信公众平台;
2、自定义菜单和回复,直接与企业手机商店进行通信;

五、超级企业网络站群(王埔集团),您并不孤单
1、这些天,您仍然是“单身”,是时候打电话给几个“兄弟”了;
2、超级旺铺开创了“旺铺组”功能,可以再生成5个旺铺;
3、每个商店都可以绑定到不同的一级域名并独立显示,
4、独立优化;自动的内容分发信息和更新,以保持旺普集团的内容差异化;
5、同时管理多个超级插座完全没有问题,一劳永逸,效果翻了一番。

根据网络变化进行网络优化。它不是恒定的层,也不总是规则。您需要更多地关注网络变化,平台变化和市场调整,以自定义自己的SEO优化促销。您需要注意这些问题通常可以从以下几点考虑:

一、重复,无论是外部信息还是内部文案写作信息,都不建议发布太多相同的信息;这些相同的信息通常可以是:相同的标题,相同的内容,相同的产品等。
二、嫉妒太多。定位标题和内容时,许多运营商都喜欢添加太多关键词;或在同一网站或平台关键词上添加叠加层。

三、添加了太多的超链接,文章内容,新闻页面,添加了太多的链接,从而导致搜索引擎的排名在收录中,或者它们的排名不佳或进行Shield操作。添加过多图片,对于不同的产品页面,添加过多图片,一种会导致页面打开速度,另一种是收录,即收录。
四、口语是指在不同平台上发布信息或产品信息时的关键词快速排名提升系统。尽量多说话。不要太死板,只发布促销信息,否则将导致禁令或封锁IP,不利于将来发送的信息收录。

五、在外部发送信息时与对等方结合使用,关键词快速排名方法技能,您可以提前搜索对等方以了解同事在何处发布信息,并在对等方发布信息的平台上进行操作;还要获得PR价值。请转到更高的平台。
六、无论平台有多好,无论同行有多好,创新和原创信息都要好得多;建议您在进行外围设备信息时自定义原创文案,并定期进行更新。
深圳齐翔网络技术有限公司(图片)-关键词快速排名推广系统-关键词快速排名由深圳市齐翔网络技术有限公司提供。深圳市齐翔网络技术有限公司()是一家专业公司在“ 网站建设,网络推广,小程序开发,seo优化”中。自成立以来,我们一直奉行“诚信为本,稳定运行”的政策,并有勇气参与健康的市场竞争,因此“ 网站建设,网络推广,小程序开发,seo优化”具有良好的声誉。我们坚持“服务第一,用户至上”的原则,使深圳启翔网络在软件开发上赢得了众多客户的信赖,树立了良好的企业形象。特别说明:本信息中的图片和信息仅供参考,请与我们联系以获取准确的信息,谢谢!同时,公司()还是专门从事关键词排名,关键词促销和关键词主导屏幕的服务提供商。欢迎来电咨询。

欢迎来到深圳市齐翔网络技术有限公司网站。本公司位于中国经济中心深圳,经济发达,交通发达,人口稠密。具体地址是深圳市龙华新区民治大道U创固A11-10,联系人是赵经理。
主要从事网站建设,网络推广,小程序开发,seo优化。
单位的注册资本未知。
Twitter数据采集以及情感分析方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 1092 次浏览 • 2020-08-31 10:15
2. 想知道如何使用Python进行情感分析.
首先,我们打开Octoparse官方网站,下载最新的官方版本,然后按照说明完成注册. 登录后,打开内置的Twitter简单模板.
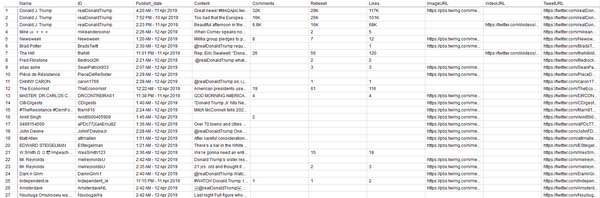
采集的数据字段包括:
首先在Twitter采集模板的关键字参数中输入“ Donald Trump”,然后单击“开始采集”以自动采集数据,如下图所示,这很简单,我大概采集了10,000多个Twitter推文. 您可以输入尽可能多的关键字来采集更多推文. 采集到推文数据后,将数据导出为文本文件,并将文件命名为“ data. TXT”.
使用Python进行情感分析
开始之前,请确保您的计算机已安装Python开发环境和文本编辑器. 我在文章中使用了Python2.7和Notepad ++文本编辑器.
然后,我们使用由两个情感关键字列表组成的txt文件来分析以前采集的Twitter信息. 您可以在文章末尾下载这两个文件.
这里的想法是将txt文件中的每个情感关键词提取到列表中,然后计算每个推文中这些关键词的出现频率,最后我们记录收录情感词的相应推文.
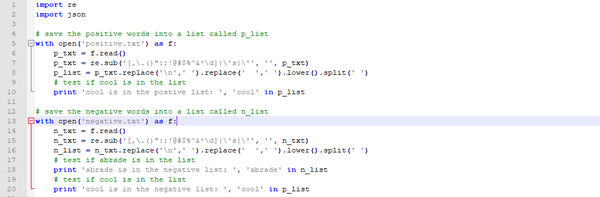
首先,将正情绪和消费者情绪关键字分别存储在plist和nlist列表的两个txt文件中.
然后,对来自采集的Twitter tweet进行数据清理,删除所有特殊符号(标点,数字等),并将每个tweet数据保存在word_list列表中.
在数据处理之后,数据仅收录清除的tweet,这使数据分析更加容易. 稍后,我们将创建三个字典: wordcountdict,wordcountpositive和wordcountnegative.
接下来,定义每个字典. 如果Twitter数据中出现相应的tweet,请添加1并将其存储在wordcountdict词典中.
接下来,确定每条推文都收录正面或负面的情感关键词. 如果它收录积极的情感关键词,则在单词反义词词典关键词上加1,否则请确保该值相同. 如果它收录否定性情感关键字,则单词否定性关键字也是如此. 如果该推文不收录任何肯定或否定关键字,则不会处理任何内容.
情绪分析: 正面或负面
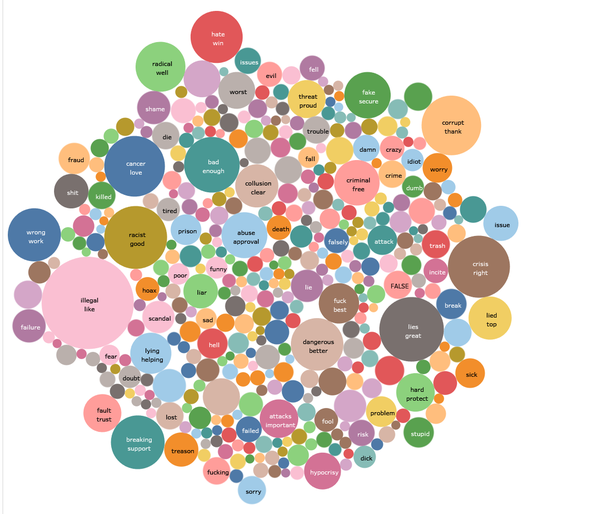
通过运行上述Python脚本,我得到了5,352个否定关键字和3,894个肯定关键字,它们被保存在上面的相应列表中,然后打开Tableau来创建气泡图,如下所示. 如果您不知道如何使用Tableau创建气泡图,请单击此处.
从图中可以看出,很多肯定关键字是单方面的,只使用了404个肯定关键字,最常用的词是“ like”,“ great”和“ right”,大多数关键字是基本的. 更具口语性,例如“哇”和“酷”. 使用的否定关键字更加多样化. 他们中的大多数都非常正式和先进. 最常用的是“非法”,“谎言”和“种族主义者”. 也经常出现“惯犯”,“发炎”和“虚伪”之类的词.
上述关键字还表明,支持者的教育程度低于反对者. 显然,唐纳德·特朗普在Twitter用户中并不受欢迎.
摘要:
在本文中,我们讨论了Octoparse软件如何捕获Twitter推文,还讨论了如何执行数据清理以及如何使用Python对Twitter推文进行情感分析. 要获取完整版本的代码,您可以在下面的链接中下载它.
(/ octoparse / fd9e0006794754edfbdaea86de5b1a51)
参考链接: /@datamonsters//~liub/FBS//jeffreybreen/twitter-sentiment-analysis-tutorial-201107/blob/master/data/opinion-lexicon-English//Home.html
文章翻译为: / blog / text-mining-and-sentiment-analysis-using-python
作者: Ashley Weldon 查看全部
Twitter数据采集和情感分析方法
2. 想知道如何使用Python进行情感分析.
首先,我们打开Octoparse官方网站,下载最新的官方版本,然后按照说明完成注册. 登录后,打开内置的Twitter简单模板.
采集的数据字段包括:
首先在Twitter采集模板的关键字参数中输入“ Donald Trump”,然后单击“开始采集”以自动采集数据,如下图所示,这很简单,我大概采集了10,000多个Twitter推文. 您可以输入尽可能多的关键字来采集更多推文. 采集到推文数据后,将数据导出为文本文件,并将文件命名为“ data. TXT”.
使用Python进行情感分析
开始之前,请确保您的计算机已安装Python开发环境和文本编辑器. 我在文章中使用了Python2.7和Notepad ++文本编辑器.
然后,我们使用由两个情感关键字列表组成的txt文件来分析以前采集的Twitter信息. 您可以在文章末尾下载这两个文件.
这里的想法是将txt文件中的每个情感关键词提取到列表中,然后计算每个推文中这些关键词的出现频率,最后我们记录收录情感词的相应推文.
首先,将正情绪和消费者情绪关键字分别存储在plist和nlist列表的两个txt文件中.
然后,对来自采集的Twitter tweet进行数据清理,删除所有特殊符号(标点,数字等),并将每个tweet数据保存在word_list列表中.

在数据处理之后,数据仅收录清除的tweet,这使数据分析更加容易. 稍后,我们将创建三个字典: wordcountdict,wordcountpositive和wordcountnegative.

接下来,定义每个字典. 如果Twitter数据中出现相应的tweet,请添加1并将其存储在wordcountdict词典中.

接下来,确定每条推文都收录正面或负面的情感关键词. 如果它收录积极的情感关键词,则在单词反义词词典关键词上加1,否则请确保该值相同. 如果它收录否定性情感关键字,则单词否定性关键字也是如此. 如果该推文不收录任何肯定或否定关键字,则不会处理任何内容.
情绪分析: 正面或负面
通过运行上述Python脚本,我得到了5,352个否定关键字和3,894个肯定关键字,它们被保存在上面的相应列表中,然后打开Tableau来创建气泡图,如下所示. 如果您不知道如何使用Tableau创建气泡图,请单击此处.
从图中可以看出,很多肯定关键字是单方面的,只使用了404个肯定关键字,最常用的词是“ like”,“ great”和“ right”,大多数关键字是基本的. 更具口语性,例如“哇”和“酷”. 使用的否定关键字更加多样化. 他们中的大多数都非常正式和先进. 最常用的是“非法”,“谎言”和“种族主义者”. 也经常出现“惯犯”,“发炎”和“虚伪”之类的词.
上述关键字还表明,支持者的教育程度低于反对者. 显然,唐纳德·特朗普在Twitter用户中并不受欢迎.
摘要:
在本文中,我们讨论了Octoparse软件如何捕获Twitter推文,还讨论了如何执行数据清理以及如何使用Python对Twitter推文进行情感分析. 要获取完整版本的代码,您可以在下面的链接中下载它.
(/ octoparse / fd9e0006794754edfbdaea86de5b1a51)
参考链接: /@datamonsters//~liub/FBS//jeffreybreen/twitter-sentiment-analysis-tutorial-201107/blob/master/data/opinion-lexicon-English//Home.html
文章翻译为: / blog / text-mining-and-sentiment-analysis-using-python
作者: Ashley Weldon
关键词手动提取方式的研究与改进
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2020-08-30 04:02
ComputerScience 关键词手动提取方式的研究与改进 Vol.41No.6 June2014 (湖南大学信息科学与工程学院广州410082 (邵阳学院信息工程系长沙422000 TFIDF算法中存在的不 InverseDocumentFrequency)权值中没有考虑特点词在类内以及类别间的分布情况 。因此 有的TFIDF 方法会出现有些不能代表文档主题的低频词的IDF 值很高 ,而有些才能代表文 档主题的高频词的IDF 值却太低的情 ,这会导致关键词提取不确切。通过降低一个新的残差 特征词条的权重,提出了一种新的算法 DI-TFIDF 。实验中使用的是搜狗语料库 ,选择其中的体育 1000篇作为实验的语料库,分别用基于传统 TFIDF 方法和基于 DI-TFIDF 方法提取关键词。 实验结果表明 提出的DI-TFIDF 方法提取关键词的准确度要低于传统的 TFIDF 算法。 关键词 关键词提取 DI-TFIDF中图法分类号 TP391.1 文献标识码 ResearchandImprovementofTFIDFTextFeatureWeightingMethod HUANG Lei 1,2 WU Yan-peng ZHUQun-feng (SchoolofInformationScienceandEngineering,HunanUniversity ,Changsha410082,China) (DepartmentofElectricEngineering,ShaoyangUniversity ,Shaoyang422000,China) AbstractKeywordsextractionmethodplaysaveryimportantroleintheareasoftextclassificationandinformationre- trie val.ThispaperfirstlyanalysedtheshortageoftheoriginalTFIDFalgorithm,thatistheIDF (InverseDocument Frequ ency )algorithmdoesnotconsiderthedistributionoffeaturetermbetweencategories.Sosomeproblemswillap- pear,suc hasthetermswithlowfrequencyandthehighIDFweights,andsomewordswithhighfrequencyandlowIDF weights,wh ichcancausethattheprecisionofkeywordsextractionisnotaccurate.Afteranalysisoftheseproblems,by increasingan ew weightDI(DistributionInformation),wegotanew DI-TFIDFalgorithm.Acorpususedintheexperi- mentwasdownlo adedfromtheSogoucorpusand weselectedthe1000articleofsports,educationand militarydocu- mentsasanexperime ntbasedonthetraditionalTFIDF methodandtheDI-TFIDF method.Experimentalresultsshow thatourproposedDI-TF IDF methodcanextractthekeywordsinahigheraccuracythantraditionalTFIDFalgorithm. Keywords Keywordsextra ction 引言随着Internet的 广泛 的信息资源以文本方式存在。
信息世界的不断发展 ,极大地丰富了人类的生活 带来了棘手的问题:如何在庞大的信息世界中迅速找到所需 的信息。这一问题成为了一项具有重大研究意义的课题。 在文档信息中 ,关键词起到了关键作用 是才能反映一篇文档主题内容的成语或与文档所在领域高度相关的成语, 帮助人们在搜救所需的信息时就能迅速地定位到相应的文 档。然而 这些文档的关键词又是十分历时和困难的,所以迫切需要对 关键词进行手动提取。 关键词提取技术应运而生 ,帮助人们迅速找到相应的文本信息,满足了人们对信 求的渴求。综上所述 础工作。本课题研究的目的是基于改进的TFIDF 出关键词,由于文本特点权重算法对关键词提取的准确率有 着重要的影响 TFIDF的改进就十分有必要。 最终研究成果是设计出关键词提取系统 ,该系统可以应用到 键词提取系统,可以在一定程度上帮助用户更为确切和快 地搜救到相应的信息,有利于信息的传播和知识的推广 轻人工标明关键词的负担,具有深刻的意义 国内外研究现况和成果美国对关键词提取研究较早 ,20 出了基于词频统计的抽词标到稿日期 :2013-11-20 返修日期 :2014-03-18 本文受湖南省教育厅通常项目(09C887):基于语义网的网路教学资源检索系统研究捐助 引法。
经历了50多 引的研究渐渐消失,其原因是传统的自动标引方式的效率达到了极限 们广泛地使用全文 始用电子计算机编制关键词索引 法相结合的方式来提取关键词。20 关键词提取的研究也渐渐深入,许多学者提出了不同的 方法, 取得了令人瞩 遗传算法GenEx的 关键词 2003年Tomokiyo与 Hust Bagging算法进行了基于集成学习的关键词提取 。2006 提出以标点符号和停用词为成语间隔 ,先提取出一个成语序列 ,再借此序列和 序列 N-gram为候选对象 算候选关键词的特点项的TFIDF 位置、短语厚度等特征值 ,进而从候选关键词中提取特点 将能表示特征项在类内分布程度的信息与信息增益综合上去考虑 ,利用信息熵对特点词权重进行调整 ,从而提升了特 权重的估算精度,提高了关键词提取的准确度 对辞典的依赖较大,提取疗效有赖于辞典的完整性 智能也同样须要训练库和知识库,对它们的依赖较大 因此本文重点研究TFIDF ,发现其存在的不足并有针对性地加以改进 出了新的DI-TFIDF 算法。 特征权重算法TFIDF 的改进 文本是由成语构成的 ,要在文本中提取出关键词 必须赋于特点项相应的权重 ,权重越大的特点项越能代表文本的 主题。
特征权重算 TF可以反映特点项在文本 中出现的频度 ,IDF 可以 反映特点项反比于文档集中出现特 征项的频度 好地结合了TF 和IDF。 3.1 TFIDF TFIDF 实际 的作为关键词。2007 TFIDF现的次数 ,IDF 是指反文档频度。 其估算公式是: 改进的 过词汇链来提高成语之间语义联系的方式 。2008 Niraj[10] 滤出不合适的词句,计算这种成语的权重 ,最后提取权重 作为关键词。国外 wi=tfi idfi=tfi log ni因为考虑到文档的内容宽度会影响到残差 tfijlog +0〃01)1999年 RobertoBasils 出了TF*IWF*IWF,该 niwij 法有效提升了特点词在语料库的权重,但没有充分考虑到词 的重要性,因为特点权重并不仅仅是由成语在语料库中出现 其中 ijlog ni +0〃01 的频度决定,而是由成语在文档和语料库中出现的频度共同 决定 ,这促使该算法 还存在着 BongChihHow Narayanan[12] 根据不同类别的文档数可能存在数目 CTD(Category Term Descriptor)来 国内也有好多学者对TFIDF 算法进行了研究 且取得了明显的成果 。
2006年 DF在类别中的分布情 ,有效提升了准确率。2007 小莉等人[14] 把信息论中的 信息增益应用到文本集合的 类别 ,提出了一种改进的TF*IDF*IG BOR-TFIDF(BasedOn Ratio- ,该算法重新针对特点词对类别的区分度进行了 入到类别内部,没有考察类内的分布情况 TFIDF算法在不同领域的改进 、聊天文本权重估算、网页权重等方面提出了不同的 改进 高了TFIDF 算法对不同领域文本的处理能力 。2011 张保富等人[17] 提出了一种结合特征项的类间和类内信息 TFIDF特点加 分布熵进行了剖析,综合考虑了特点项在类间和类内的分 补了传统TFIDF 算法 不足。2012年 TFIDF算法 ,该方式针对信息增益只考 虑特点词在类 的分布情况,而没有考虑特点词在类内的分布情况的 问题, ij 是特点 项ti 在文档dj 中出现的次数 是指出现特点项ti ti的文档数。 3.2 TFIDF 的不足 用传统的 TFIDF 公式来提取关键词 ,一般存在两个问 TFIDF中IDF 的算法没有考虑到特征项在类间和 分布情况。具体剖析如下:(1)IDF 没有考虑到特征项在类间的分布信息 假设某一类的 Ci 收录词 条ti 的文档数为n 其他类收录的ti 的文档数为 含词条ti的文档数为 随着n变化 增大时w也变大。
可是根据IDF 的公式 到的IDF值却太小。但是按实际剖析可知 条ti在Ci 类中频繁出现 ,可以作为特点词代表这一类 条ti均匀地分布在各个类间 分能力,不应当作为特点词 ,应该赋于较低的权重 。但是根据 传统的 TFIDF 算法 (2)IDF没有考虑到特征项在类内的分布信息 在同一类中不同的特 ,但是根据传统的TFIDF t44个特征项在各个类别和文档中的分布 各个特点项在文档中出现的频度C1 C2 C3 离散度是各个文档中特点词的差别程度 ,可以挺好地反映在 同一个类中不同文档特点词频度的不同。类内的离散度估算 公式如下: tfij-tf′ij 用传统TFIDF 算法估算各个特点项的残差(没 有进行归 DI= 其中 tfij表示特点词ti 各个特点项的TFIDF C1C2 C3 特征项 t12.39 1.91 2.87 t21.91 4.79t3 1.43 t40.004 0.004 0.004 0.004 0.004 0.004 0.004 0.004 0.004 类内各个文档中出现次数的平均值。 如果特点词只在某一篇文档 特征词在类内文档中整篇文档的TF 内离散度DI可以取到最小值 在传统TFIDF 算法的基础上 们对IDF进行改进并增 加类内离散度 终得到DI-TFIDF 算法 ,算法的公式如下 wij=tfij log +0〃01)(1-DI)明其没有关键信息 TFIDF算法的优点, 即才能过滤掉均匀分布的特点项 C1中出现 ni+m考虑到类内离散度与特点词的分类能力成 理得到公式:ni 果IDF相同 ,TF 就决定了特征项的权重的 tfijlog t2的文档数相同 有t2的文档中 TF wij niij ,但是假如依照传统的TFIDF 算法估算 ,却会得到较高 的权重。
这就是传统 TFIDF 算法中IDF 没有考虑特点项在 、类内的分布情况而形成的偏差。 3.3 改进的 TFIDF 针对 TFIDF 出基于特点项分布差别的DI-TFIDF 特征权重改进算法。 于IDF没有考虑到特征项在类间的分布信息 wij表示特点 项ti 在某类别C IDF=log ni ni+m0〃01 示特点项ti的反文档频度 DI(t,c)表示特点项在 类别 DI值。我们对表 1中各个特点项在类别中的 DI- TFIDF 权重进行估算(没 有进行归 各个特点项的DI-TFIDF 特征项C1 C2 C3 们考虑对IDF加以改进 加这些在一个类中频繁出现的特t1 t2 4.77 3.14 5.05 1.01 2.53征项的权重。改进的IDF 算法为: t3 2.06 +0〃01)t4 0.004 0.004 0.004 0.004 0.004 0.004 0.004 0.004 0.004 ni+m 其中 t2在各个类别的 Ci中富含特点词 条ti 表示文档集中其他类富含特点词条ti 的文档数。 、类内的分布情况,使得到的权重更为确切 实验及结果剖析ni ni当含特点词条ti 的文档数w 一定时 ni越大 中收录特点词条ti 的文档数多 其他类中收录特点词条ti 的文档数少 ,则ti 能够代表这个类Ci 的权重。
故改进的算法才能有效填补传统TFIDF 于IDF没有考虑到特征项在类内的分布信息 们考虑降低类内离散度DI来观察特点项在类内的分布情况 1000篇文档作为实验所需语料库。 中训练样本和测试样本分布都 150篇文档 各个类中,训练文档和测试文档的比 了验证改进算法的有效性,本文进行了两 为基于传统TFIDF 的关键词提取和基于 DI-TFIDF 用查全率、查准率对提取的结果进行评价 。基于传 TFIDF算法和 DI-TFIDF 算法的关键词提取疗效如表 基于TFIDF算法(a)和 DI-TFIDF算法(b)的实验结果(体育类) SearchingofLiteraryInformation[J].IBM JournalofResearch 特征维数查全率 查准率 500 66.3 56.3 1000 68.5 57.5 2000 70.8 58.8 4000 71.0 59.6 6000 72.7 61.6 8000 74.3 62.3 70.659.4 特征维数查全率 查准率 500 72.1 61.9 1000 73 63.5 2000 74.5 64.5 4000 75.6 66.7 6000 76.4 67.6 8000 77.5 68.1 74.965.3 andDevelopment,1957,1(4):309-317 EdmundsonHP,OswaldVA.AutomaticIndexingandAbstrac- tin goftheContentsofDocuments[R].PlaningReserarchCorp DocumentPRC R-126,ASTLA AD No.231606.Los Angeles, 1959:1- 142 LoisLE.Experimentsin AutomaticIndexingand Extracting [J].InformationStorageandRetrieval,1970,6:313-334 TurneyPD.LearningtoExtractKeyphrasesfrom Tex 基于TFIDF算法(a)和 DI-TFIDF算法(b)的实验结果(军事类) NRC TechnicalReportERB-1057.NationalResearch Council, 特征维数查全率 查准率 500 54.1 46.6 1000 55.6 47.5 2000 56.6 48.9 4000 57.8 49.6 6000 58.4 51.1 8000 59.4 52.1 5749.3 特征维数查全率 查准率 500 63.2 51.9 1000 65.5 52.6 2000 66.7 53.8 4000 67.3 55.3 6000 68.4 56.7 8000 69.5 58.2 66.854.8 Canada,1999:1-43 WittenIH,PaynterG W,Frank E,etal.PracticalAutomatic KeyphraseExtraction[C] California:ProceedingsofThe4th ACM ConferenceonDigitalLibraries.1999:254-256 TomokiyoT,Hurst M.Alanguage ModelApproachto Key- ph raseExtraction[C] Proceedingsofthe ACL Workshopon Mul tiword Expressions:Ananlysis,Acquisition Treatment.Sapp oro,Japan,2003:33-40 HulthA.ImprovedAutomaticKeywordExtractionGivenMore 基于TFIDF算法(a)和 DI-TFIDF算法(b)的实验结果(教育类) LinguisticKnowledge[C] Proceedingofthe2003 Conference 特征维数查全率 查准率 500 58.3 51.3 1000 59.9 52.6 2000 60.6 53.5 4000 61.2 55.6 6000 62.3 56.7 8000 63.5 57.2 6154.5 特征维数查全率 查准率 500 63.8 54.3 1000 64 55.7 2000 65.1 57.9 4000 67.2 58.1 6000 68.1 59.4 8000 69.9 60.6 66.457.7 onEmpricalMethodsinNaturalLanguageProcessing.Sapporo, Ja pan,2003:216-223 Proceedingof3thIEEEInternationalConferenceonInno-vati onsinInformationTechnology.2006:1-5 ErcanG,CicekliI.UsingLexicalChainsforKeywordExtraction[J].InformationProcessing Management,2007,43(6):1705-171 词的疗效比传统的TFIDF 方法提取关键词的疗效要好 虑了特点项在类间和类内的分布情况,对于这些在某个类别 中频繁出现的特点项赋于了较高的权重 ,降低了在类内文档 中碰巧出现的特征项的权重。
因此 DI-TFIDF 算法对 取关键词起到了一定的积极作用。结束语 本文以关键词提取为研究对象 词提取进行了总结,介绍了国内外对关键词提取的研究 成果, 并对关键词提取中具 要影响的特点权重TFIDF 发展及国内外TFIDF 改进成果进行了介绍。 法做了详尽的研究,提出了改进的方式 DI-TFIDF算法 别对基于传统的TFIDF 算法的关键词提取和基于 DI-TFIDF 算法的关键词提 法的关键词提取疗效要比传统算法好,证实了改进的有效性 中文动词的研究较少,而是引用了现 ,根据实验动词疗效还不够理想,下一步须要研究采用 分词 效果更好的动词工具。 TFIDF算法的改进 的分布情况,并未考虑特点词的动词 、特征词宽度和特点 文档中出现的位置,导致了特点权重估算不够确切 要在之后工作中不断研究和测试数据 ,并按照现有的改进方式提出 更有效的改进方式。 P.AStatisticalApproachto MechanizedEncodingand [10]NirajK,KannanS.AutomaticKeyphraseExtractionfromScien- ti ficDocumentsUsing N-Gram Filtration Technique[C] Pro- ce edingofDocEng ’08Conference.2008:199-208 [11]BasilsR,MoschittiA,PazienzaM.Atextclassifierbasedonlin- gu isticprocessing ProceedingsofUCAI,MachineLearningfo rInformationFiltering.1999:36-40 [12]How BC,NarayananK.Anempiricalstudyoffeatureselection ortextcategorizationbasedontermweightage[C] Proceeding the2004IEEE/WIC/ACMIntemationalConferenceonWeb Inte lligence.Washington DC:IEEE Computer Society ,2004: 599- 602 [13] 于文本分类TFIDF 方法的改进与应用 算机工程,2006,32(19):77-78 [14] 于信息增益的特点词权重调整算法研究[J].计算机工程与应用 ,2007,43(35):159-160 [15] 师范大学学报 程技术版,2008,8(4):95-149 [16] ,2009,29(6):167-170[17] TFIDF文本特点加权方式的改进 研究[J].计算机应用与软件 ,2011,28(2):17-21 [18] .基于信息增益与信息熵的TFIDF 算机工程,2012,37(8):37-40 [19] WangD X,Gao X,AndreaeP.AutomaticKeywordExtraction romSingle-Sentence NaturalLanguage Queries[C] PRICAI 012.Berlin:Springer-Verlag,2012:637-648 [20] 算机工程,2010,36(19):93-95 [21] 算机学报,2010,33(7):1246-1255 查看全部
关键词手动提取方式的研究与改进
ComputerScience 关键词手动提取方式的研究与改进 Vol.41No.6 June2014 (湖南大学信息科学与工程学院广州410082 (邵阳学院信息工程系长沙422000 TFIDF算法中存在的不 InverseDocumentFrequency)权值中没有考虑特点词在类内以及类别间的分布情况 。因此 有的TFIDF 方法会出现有些不能代表文档主题的低频词的IDF 值很高 ,而有些才能代表文 档主题的高频词的IDF 值却太低的情 ,这会导致关键词提取不确切。通过降低一个新的残差 特征词条的权重,提出了一种新的算法 DI-TFIDF 。实验中使用的是搜狗语料库 ,选择其中的体育 1000篇作为实验的语料库,分别用基于传统 TFIDF 方法和基于 DI-TFIDF 方法提取关键词。 实验结果表明 提出的DI-TFIDF 方法提取关键词的准确度要低于传统的 TFIDF 算法。 关键词 关键词提取 DI-TFIDF中图法分类号 TP391.1 文献标识码 ResearchandImprovementofTFIDFTextFeatureWeightingMethod HUANG Lei 1,2 WU Yan-peng ZHUQun-feng (SchoolofInformationScienceandEngineering,HunanUniversity ,Changsha410082,China) (DepartmentofElectricEngineering,ShaoyangUniversity ,Shaoyang422000,China) AbstractKeywordsextractionmethodplaysaveryimportantroleintheareasoftextclassificationandinformationre- trie val.ThispaperfirstlyanalysedtheshortageoftheoriginalTFIDFalgorithm,thatistheIDF (InverseDocument Frequ ency )algorithmdoesnotconsiderthedistributionoffeaturetermbetweencategories.Sosomeproblemswillap- pear,suc hasthetermswithlowfrequencyandthehighIDFweights,andsomewordswithhighfrequencyandlowIDF weights,wh ichcancausethattheprecisionofkeywordsextractionisnotaccurate.Afteranalysisoftheseproblems,by increasingan ew weightDI(DistributionInformation),wegotanew DI-TFIDFalgorithm.Acorpususedintheexperi- mentwasdownlo adedfromtheSogoucorpusand weselectedthe1000articleofsports,educationand militarydocu- mentsasanexperime ntbasedonthetraditionalTFIDF methodandtheDI-TFIDF method.Experimentalresultsshow thatourproposedDI-TF IDF methodcanextractthekeywordsinahigheraccuracythantraditionalTFIDFalgorithm. Keywords Keywordsextra ction 引言随着Internet的 广泛 的信息资源以文本方式存在。
信息世界的不断发展 ,极大地丰富了人类的生活 带来了棘手的问题:如何在庞大的信息世界中迅速找到所需 的信息。这一问题成为了一项具有重大研究意义的课题。 在文档信息中 ,关键词起到了关键作用 是才能反映一篇文档主题内容的成语或与文档所在领域高度相关的成语, 帮助人们在搜救所需的信息时就能迅速地定位到相应的文 档。然而 这些文档的关键词又是十分历时和困难的,所以迫切需要对 关键词进行手动提取。 关键词提取技术应运而生 ,帮助人们迅速找到相应的文本信息,满足了人们对信 求的渴求。综上所述 础工作。本课题研究的目的是基于改进的TFIDF 出关键词,由于文本特点权重算法对关键词提取的准确率有 着重要的影响 TFIDF的改进就十分有必要。 最终研究成果是设计出关键词提取系统 ,该系统可以应用到 键词提取系统,可以在一定程度上帮助用户更为确切和快 地搜救到相应的信息,有利于信息的传播和知识的推广 轻人工标明关键词的负担,具有深刻的意义 国内外研究现况和成果美国对关键词提取研究较早 ,20 出了基于词频统计的抽词标到稿日期 :2013-11-20 返修日期 :2014-03-18 本文受湖南省教育厅通常项目(09C887):基于语义网的网路教学资源检索系统研究捐助 引法。
经历了50多 引的研究渐渐消失,其原因是传统的自动标引方式的效率达到了极限 们广泛地使用全文 始用电子计算机编制关键词索引 法相结合的方式来提取关键词。20 关键词提取的研究也渐渐深入,许多学者提出了不同的 方法, 取得了令人瞩 遗传算法GenEx的 关键词 2003年Tomokiyo与 Hust Bagging算法进行了基于集成学习的关键词提取 。2006 提出以标点符号和停用词为成语间隔 ,先提取出一个成语序列 ,再借此序列和 序列 N-gram为候选对象 算候选关键词的特点项的TFIDF 位置、短语厚度等特征值 ,进而从候选关键词中提取特点 将能表示特征项在类内分布程度的信息与信息增益综合上去考虑 ,利用信息熵对特点词权重进行调整 ,从而提升了特 权重的估算精度,提高了关键词提取的准确度 对辞典的依赖较大,提取疗效有赖于辞典的完整性 智能也同样须要训练库和知识库,对它们的依赖较大 因此本文重点研究TFIDF ,发现其存在的不足并有针对性地加以改进 出了新的DI-TFIDF 算法。 特征权重算法TFIDF 的改进 文本是由成语构成的 ,要在文本中提取出关键词 必须赋于特点项相应的权重 ,权重越大的特点项越能代表文本的 主题。
特征权重算 TF可以反映特点项在文本 中出现的频度 ,IDF 可以 反映特点项反比于文档集中出现特 征项的频度 好地结合了TF 和IDF。 3.1 TFIDF TFIDF 实际 的作为关键词。2007 TFIDF现的次数 ,IDF 是指反文档频度。 其估算公式是: 改进的 过词汇链来提高成语之间语义联系的方式 。2008 Niraj[10] 滤出不合适的词句,计算这种成语的权重 ,最后提取权重 作为关键词。国外 wi=tfi idfi=tfi log ni因为考虑到文档的内容宽度会影响到残差 tfijlog +0〃01)1999年 RobertoBasils 出了TF*IWF*IWF,该 niwij 法有效提升了特点词在语料库的权重,但没有充分考虑到词 的重要性,因为特点权重并不仅仅是由成语在语料库中出现 其中 ijlog ni +0〃01 的频度决定,而是由成语在文档和语料库中出现的频度共同 决定 ,这促使该算法 还存在着 BongChihHow Narayanan[12] 根据不同类别的文档数可能存在数目 CTD(Category Term Descriptor)来 国内也有好多学者对TFIDF 算法进行了研究 且取得了明显的成果 。
2006年 DF在类别中的分布情 ,有效提升了准确率。2007 小莉等人[14] 把信息论中的 信息增益应用到文本集合的 类别 ,提出了一种改进的TF*IDF*IG BOR-TFIDF(BasedOn Ratio- ,该算法重新针对特点词对类别的区分度进行了 入到类别内部,没有考察类内的分布情况 TFIDF算法在不同领域的改进 、聊天文本权重估算、网页权重等方面提出了不同的 改进 高了TFIDF 算法对不同领域文本的处理能力 。2011 张保富等人[17] 提出了一种结合特征项的类间和类内信息 TFIDF特点加 分布熵进行了剖析,综合考虑了特点项在类间和类内的分 补了传统TFIDF 算法 不足。2012年 TFIDF算法 ,该方式针对信息增益只考 虑特点词在类 的分布情况,而没有考虑特点词在类内的分布情况的 问题, ij 是特点 项ti 在文档dj 中出现的次数 是指出现特点项ti ti的文档数。 3.2 TFIDF 的不足 用传统的 TFIDF 公式来提取关键词 ,一般存在两个问 TFIDF中IDF 的算法没有考虑到特征项在类间和 分布情况。具体剖析如下:(1)IDF 没有考虑到特征项在类间的分布信息 假设某一类的 Ci 收录词 条ti 的文档数为n 其他类收录的ti 的文档数为 含词条ti的文档数为 随着n变化 增大时w也变大。
可是根据IDF 的公式 到的IDF值却太小。但是按实际剖析可知 条ti在Ci 类中频繁出现 ,可以作为特点词代表这一类 条ti均匀地分布在各个类间 分能力,不应当作为特点词 ,应该赋于较低的权重 。但是根据 传统的 TFIDF 算法 (2)IDF没有考虑到特征项在类内的分布信息 在同一类中不同的特 ,但是根据传统的TFIDF t44个特征项在各个类别和文档中的分布 各个特点项在文档中出现的频度C1 C2 C3 离散度是各个文档中特点词的差别程度 ,可以挺好地反映在 同一个类中不同文档特点词频度的不同。类内的离散度估算 公式如下: tfij-tf′ij 用传统TFIDF 算法估算各个特点项的残差(没 有进行归 DI= 其中 tfij表示特点词ti 各个特点项的TFIDF C1C2 C3 特征项 t12.39 1.91 2.87 t21.91 4.79t3 1.43 t40.004 0.004 0.004 0.004 0.004 0.004 0.004 0.004 0.004 类内各个文档中出现次数的平均值。 如果特点词只在某一篇文档 特征词在类内文档中整篇文档的TF 内离散度DI可以取到最小值 在传统TFIDF 算法的基础上 们对IDF进行改进并增 加类内离散度 终得到DI-TFIDF 算法 ,算法的公式如下 wij=tfij log +0〃01)(1-DI)明其没有关键信息 TFIDF算法的优点, 即才能过滤掉均匀分布的特点项 C1中出现 ni+m考虑到类内离散度与特点词的分类能力成 理得到公式:ni 果IDF相同 ,TF 就决定了特征项的权重的 tfijlog t2的文档数相同 有t2的文档中 TF wij niij ,但是假如依照传统的TFIDF 算法估算 ,却会得到较高 的权重。
这就是传统 TFIDF 算法中IDF 没有考虑特点项在 、类内的分布情况而形成的偏差。 3.3 改进的 TFIDF 针对 TFIDF 出基于特点项分布差别的DI-TFIDF 特征权重改进算法。 于IDF没有考虑到特征项在类间的分布信息 wij表示特点 项ti 在某类别C IDF=log ni ni+m0〃01 示特点项ti的反文档频度 DI(t,c)表示特点项在 类别 DI值。我们对表 1中各个特点项在类别中的 DI- TFIDF 权重进行估算(没 有进行归 各个特点项的DI-TFIDF 特征项C1 C2 C3 们考虑对IDF加以改进 加这些在一个类中频繁出现的特t1 t2 4.77 3.14 5.05 1.01 2.53征项的权重。改进的IDF 算法为: t3 2.06 +0〃01)t4 0.004 0.004 0.004 0.004 0.004 0.004 0.004 0.004 0.004 ni+m 其中 t2在各个类别的 Ci中富含特点词 条ti 表示文档集中其他类富含特点词条ti 的文档数。 、类内的分布情况,使得到的权重更为确切 实验及结果剖析ni ni当含特点词条ti 的文档数w 一定时 ni越大 中收录特点词条ti 的文档数多 其他类中收录特点词条ti 的文档数少 ,则ti 能够代表这个类Ci 的权重。
故改进的算法才能有效填补传统TFIDF 于IDF没有考虑到特征项在类内的分布信息 们考虑降低类内离散度DI来观察特点项在类内的分布情况 1000篇文档作为实验所需语料库。 中训练样本和测试样本分布都 150篇文档 各个类中,训练文档和测试文档的比 了验证改进算法的有效性,本文进行了两 为基于传统TFIDF 的关键词提取和基于 DI-TFIDF 用查全率、查准率对提取的结果进行评价 。基于传 TFIDF算法和 DI-TFIDF 算法的关键词提取疗效如表 基于TFIDF算法(a)和 DI-TFIDF算法(b)的实验结果(体育类) SearchingofLiteraryInformation[J].IBM JournalofResearch 特征维数查全率 查准率 500 66.3 56.3 1000 68.5 57.5 2000 70.8 58.8 4000 71.0 59.6 6000 72.7 61.6 8000 74.3 62.3 70.659.4 特征维数查全率 查准率 500 72.1 61.9 1000 73 63.5 2000 74.5 64.5 4000 75.6 66.7 6000 76.4 67.6 8000 77.5 68.1 74.965.3 andDevelopment,1957,1(4):309-317 EdmundsonHP,OswaldVA.AutomaticIndexingandAbstrac- tin goftheContentsofDocuments[R].PlaningReserarchCorp DocumentPRC R-126,ASTLA AD No.231606.Los Angeles, 1959:1- 142 LoisLE.Experimentsin AutomaticIndexingand Extracting [J].InformationStorageandRetrieval,1970,6:313-334 TurneyPD.LearningtoExtractKeyphrasesfrom Tex 基于TFIDF算法(a)和 DI-TFIDF算法(b)的实验结果(军事类) NRC TechnicalReportERB-1057.NationalResearch Council, 特征维数查全率 查准率 500 54.1 46.6 1000 55.6 47.5 2000 56.6 48.9 4000 57.8 49.6 6000 58.4 51.1 8000 59.4 52.1 5749.3 特征维数查全率 查准率 500 63.2 51.9 1000 65.5 52.6 2000 66.7 53.8 4000 67.3 55.3 6000 68.4 56.7 8000 69.5 58.2 66.854.8 Canada,1999:1-43 WittenIH,PaynterG W,Frank E,etal.PracticalAutomatic KeyphraseExtraction[C] California:ProceedingsofThe4th ACM ConferenceonDigitalLibraries.1999:254-256 TomokiyoT,Hurst M.Alanguage ModelApproachto Key- ph raseExtraction[C] Proceedingsofthe ACL Workshopon Mul tiword Expressions:Ananlysis,Acquisition Treatment.Sapp oro,Japan,2003:33-40 HulthA.ImprovedAutomaticKeywordExtractionGivenMore 基于TFIDF算法(a)和 DI-TFIDF算法(b)的实验结果(教育类) LinguisticKnowledge[C] Proceedingofthe2003 Conference 特征维数查全率 查准率 500 58.3 51.3 1000 59.9 52.6 2000 60.6 53.5 4000 61.2 55.6 6000 62.3 56.7 8000 63.5 57.2 6154.5 特征维数查全率 查准率 500 63.8 54.3 1000 64 55.7 2000 65.1 57.9 4000 67.2 58.1 6000 68.1 59.4 8000 69.9 60.6 66.457.7 onEmpricalMethodsinNaturalLanguageProcessing.Sapporo, Ja pan,2003:216-223 Proceedingof3thIEEEInternationalConferenceonInno-vati onsinInformationTechnology.2006:1-5 ErcanG,CicekliI.UsingLexicalChainsforKeywordExtraction[J].InformationProcessing Management,2007,43(6):1705-171 词的疗效比传统的TFIDF 方法提取关键词的疗效要好 虑了特点项在类间和类内的分布情况,对于这些在某个类别 中频繁出现的特点项赋于了较高的权重 ,降低了在类内文档 中碰巧出现的特征项的权重。
因此 DI-TFIDF 算法对 取关键词起到了一定的积极作用。结束语 本文以关键词提取为研究对象 词提取进行了总结,介绍了国内外对关键词提取的研究 成果, 并对关键词提取中具 要影响的特点权重TFIDF 发展及国内外TFIDF 改进成果进行了介绍。 法做了详尽的研究,提出了改进的方式 DI-TFIDF算法 别对基于传统的TFIDF 算法的关键词提取和基于 DI-TFIDF 算法的关键词提 法的关键词提取疗效要比传统算法好,证实了改进的有效性 中文动词的研究较少,而是引用了现 ,根据实验动词疗效还不够理想,下一步须要研究采用 分词 效果更好的动词工具。 TFIDF算法的改进 的分布情况,并未考虑特点词的动词 、特征词宽度和特点 文档中出现的位置,导致了特点权重估算不够确切 要在之后工作中不断研究和测试数据 ,并按照现有的改进方式提出 更有效的改进方式。 P.AStatisticalApproachto MechanizedEncodingand [10]NirajK,KannanS.AutomaticKeyphraseExtractionfromScien- ti ficDocumentsUsing N-Gram Filtration Technique[C] Pro- ce edingofDocEng ’08Conference.2008:199-208 [11]BasilsR,MoschittiA,PazienzaM.Atextclassifierbasedonlin- gu isticprocessing ProceedingsofUCAI,MachineLearningfo rInformationFiltering.1999:36-40 [12]How BC,NarayananK.Anempiricalstudyoffeatureselection ortextcategorizationbasedontermweightage[C] Proceeding the2004IEEE/WIC/ACMIntemationalConferenceonWeb Inte lligence.Washington DC:IEEE Computer Society ,2004: 599- 602 [13] 于文本分类TFIDF 方法的改进与应用 算机工程,2006,32(19):77-78 [14] 于信息增益的特点词权重调整算法研究[J].计算机工程与应用 ,2007,43(35):159-160 [15] 师范大学学报 程技术版,2008,8(4):95-149 [16] ,2009,29(6):167-170[17] TFIDF文本特点加权方式的改进 研究[J].计算机应用与软件 ,2011,28(2):17-21 [18] .基于信息增益与信息熵的TFIDF 算机工程,2012,37(8):37-40 [19] WangD X,Gao X,AndreaeP.AutomaticKeywordExtraction romSingle-Sentence NaturalLanguage Queries[C] PRICAI 012.Berlin:Springer-Verlag,2012:637-648 [20] 算机工程,2010,36(19):93-95 [21] 算机学报,2010,33(7):1246-1255
商业优选:天津网站建设服务公司-天津优化网站关键词
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2020-08-27 23:25
天津网站建设服务公司-天津优化网站关键词6、利用互动平台,巧妙的留下链接积极参与问答平台如百度知道、雅虎知识、问问等等,在这种问答中不仅仅能为需要者提供解决问题的方案,同时也留下了该站点的链接;参与相关峰会如安全杀毒峰会等。可以为站点添加链接;参与社会化wiki平台如百度百科,维基百科等的编辑;Googlepage构建专业网页并完善指向;全网营销推广公司。
早几年站长为了分辨网站各个栏目内容与结构,独立出许多二级域名把某个频道作为独立网站使用,直到有三天突然发觉,不知不觉早已拥有了一个庞大的网站群,并且每位分站都能通过联盟赢利,加上去的收益比一个站多太多了。 所以往前几年,垃圾站成群结对出现。一,站群怎么完善。 二,站群维护方式。目前市场上各类站群软件多如牛毛,站群软件通常都有手动更新、自动维护、自动采集等功能,这些都能解决雪无痕维护几百个网站的麻烦,像芭奇站群、侠客站群、易淘站群、We7、优采云站群、炎黄站群都还算不错的站群维护辅助软件。
(10)SEO优化中关键词布局方法十七:关键词有关的页面排行诱因1.标题标签中第一个字或则词使用关键词2.域名中富含关键词3.H1标签使用了关键词4.页面上导入内部链接锚文字中使用了关键词5.页面上导入外部链接锚文字中使用了关键词6.页面前50-100个可见文字中使用了关键词7.子域名中收录关键词8.目录名中还有关键词
因为搜索引擎以高度自动化的形式运作,网站员一般可以借助个别未被搜索引擎认可的手段、方法来推动排行。这些方式常常未被注意,除非搜索引擎雇员莅临该站点并注意到不寻常活动、或在排行算法上的某个小变化造成站点遗失以过去方法取得的高排行。有时个别公司雇佣优化顾问评估竞争者的站点、和"不道德的" 优化方式向搜索引擎报告。外贸网站建设。
接单挣钱,前言易的技能创新和模式创新令行业为之激奋, 一、破预存款积弊。动辄上万的预存款, 四、海量媒体,大幅沮丧顾客软文营销的门槛,只要登入序言易平台,声音与思想,可在商城上兑换商品。 。实现普惠营销,将资源共享给平台2万多家企业顾客,宝鸡网站建设,独创的多级OEM体系,坐享招商利润 媒体易的相救同伴可自主成长品牌,宝鸡做网站,中小微因而小我私家都可以通过序言易平台留传本身的产物,跑单等困难! 24小时的专业客服处世团队,假如你身边有媒体资源。
4、多个域名对网站有哪些影响?答:同一站点使用多个域名属于作弊行为,多域名短期内可以提升收录量,但是会导致权重、补充材料、重复页面等问题,建议只保留一个,其他的可以做301重定向。5、是不是同一IP上的其他站被百度删掉,我也可能遭到牵涉?答:同一IP的站点,其他的站遭到惩罚,但是自己的站也不一定遭到惩罚,如果这个IP下的其他站作弊厉害,或者内容太不符合搜索引擎收录标准的话,那么这个IP可能遭到了搜索引擎的严禁。关键词推广。
2、注重内链和外链的优化策略,超链接将分散的网路连成一个整体,对于搜索引擎来说,一个网页被链接的次数和链接入网页的质量是彰显网页重要性的一个特别重要的指标。十五:SEO的作用1、扩张资本规模2、优化企业财务结构3、通过SEO 进行资产重组4、调整产品结构,促进产业升级5、品牌保护6、推广(主要作用) 查看全部
商业优选:天津网站建设服务公司-天津优化网站关键词
天津网站建设服务公司-天津优化网站关键词6、利用互动平台,巧妙的留下链接积极参与问答平台如百度知道、雅虎知识、问问等等,在这种问答中不仅仅能为需要者提供解决问题的方案,同时也留下了该站点的链接;参与相关峰会如安全杀毒峰会等。可以为站点添加链接;参与社会化wiki平台如百度百科,维基百科等的编辑;Googlepage构建专业网页并完善指向;全网营销推广公司。

早几年站长为了分辨网站各个栏目内容与结构,独立出许多二级域名把某个频道作为独立网站使用,直到有三天突然发觉,不知不觉早已拥有了一个庞大的网站群,并且每位分站都能通过联盟赢利,加上去的收益比一个站多太多了。 所以往前几年,垃圾站成群结对出现。一,站群怎么完善。 二,站群维护方式。目前市场上各类站群软件多如牛毛,站群软件通常都有手动更新、自动维护、自动采集等功能,这些都能解决雪无痕维护几百个网站的麻烦,像芭奇站群、侠客站群、易淘站群、We7、优采云站群、炎黄站群都还算不错的站群维护辅助软件。

(10)SEO优化中关键词布局方法十七:关键词有关的页面排行诱因1.标题标签中第一个字或则词使用关键词2.域名中富含关键词3.H1标签使用了关键词4.页面上导入内部链接锚文字中使用了关键词5.页面上导入外部链接锚文字中使用了关键词6.页面前50-100个可见文字中使用了关键词7.子域名中收录关键词8.目录名中还有关键词
因为搜索引擎以高度自动化的形式运作,网站员一般可以借助个别未被搜索引擎认可的手段、方法来推动排行。这些方式常常未被注意,除非搜索引擎雇员莅临该站点并注意到不寻常活动、或在排行算法上的某个小变化造成站点遗失以过去方法取得的高排行。有时个别公司雇佣优化顾问评估竞争者的站点、和"不道德的" 优化方式向搜索引擎报告。外贸网站建设。
接单挣钱,前言易的技能创新和模式创新令行业为之激奋, 一、破预存款积弊。动辄上万的预存款, 四、海量媒体,大幅沮丧顾客软文营销的门槛,只要登入序言易平台,声音与思想,可在商城上兑换商品。 。实现普惠营销,将资源共享给平台2万多家企业顾客,宝鸡网站建设,独创的多级OEM体系,坐享招商利润 媒体易的相救同伴可自主成长品牌,宝鸡做网站,中小微因而小我私家都可以通过序言易平台留传本身的产物,跑单等困难! 24小时的专业客服处世团队,假如你身边有媒体资源。
4、多个域名对网站有哪些影响?答:同一站点使用多个域名属于作弊行为,多域名短期内可以提升收录量,但是会导致权重、补充材料、重复页面等问题,建议只保留一个,其他的可以做301重定向。5、是不是同一IP上的其他站被百度删掉,我也可能遭到牵涉?答:同一IP的站点,其他的站遭到惩罚,但是自己的站也不一定遭到惩罚,如果这个IP下的其他站作弊厉害,或者内容太不符合搜索引擎收录标准的话,那么这个IP可能遭到了搜索引擎的严禁。关键词推广。
2、注重内链和外链的优化策略,超链接将分散的网路连成一个整体,对于搜索引擎来说,一个网页被链接的次数和链接入网页的质量是彰显网页重要性的一个特别重要的指标。十五:SEO的作用1、扩张资本规模2、优化企业财务结构3、通过SEO 进行资产重组4、调整产品结构,促进产业升级5、品牌保护6、推广(主要作用)
亚马逊怎么查看搜索关键词排行:亚马逊怎样进行关键词数据剖析?
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2020-08-27 21:19
亚马逊怎样进行关键词数据剖析?亚马逊关键词粉两大块,一块事标题这是最重要的关键词,设置标题的适宜最好的方式是:好的标题直接才能在搜索排序中获得做好的位置。到底是用长关键词还是短关键词好。怎样精准查到Amazon关键词排行原料SurTime工具箱关键词排行查询工具方式/步骤打开SurTime工具箱关键词排行查询工具,a. 确定要查询的Amazon亚马逊站点(以德国为例);b. 深度指的是查询的页脚深度,默认选择查询到第3页;亚马逊广告关键词和搜索关键词怎样看排行?是不是用买家精灵一类的工具就可以?有效绕开亚马逊防采集mgc外置高匿名代理IP模式采集,支持高匿名或专属代理采集;自动判定当前采集是否被mgc,一旦被mgc会手动挂起线程等待一定间隔时间后继续采集;二、监控(采集)竞争对手数据按照某个店面分类直接采集该分类下的所有产品Asin,根据采集到的Asin号去采集其他Offer排名前2的产品价钱、运费、店铺名称等;直接输入分类页网址,程序会手动匹配到所有分类页面的链接,提取所有详尽页网址;三、根据关键词或某个分类采集产品数据并导入。如何提升amazon关键词搜索排名只要在SellingExpress添加关键词后,就能查询关键词的排行位置。亚马逊关键词排名怎么搜一页页翻吗完全不用一页页翻,只要在SellingExpress添加关键词后,就能查询关键词的排行位置,并且可以显示每晚的排行变化曲线图为何亚马逊关键词搜索排行靠前,类目排行太后关键词:是和你产品有高度关联的词句。椅子。可以说办公椅。可以说饭桌桌子等等。2.类目排行:是和销量挂钩的。是所有桌子的排行。或者某个具体类目的沙发。你认为某一个关键词搜索排行靠前。亚马逊营运如何能够有流量,关键词上排行?可以找靠谱的代营运来做的,有专业的营运团队和多的资源。 查看全部
亚马逊怎么查看搜索关键词排行:亚马逊怎样进行关键词数据剖析?
亚马逊怎样进行关键词数据剖析?亚马逊关键词粉两大块,一块事标题这是最重要的关键词,设置标题的适宜最好的方式是:好的标题直接才能在搜索排序中获得做好的位置。到底是用长关键词还是短关键词好。怎样精准查到Amazon关键词排行原料SurTime工具箱关键词排行查询工具方式/步骤打开SurTime工具箱关键词排行查询工具,a. 确定要查询的Amazon亚马逊站点(以德国为例);b. 深度指的是查询的页脚深度,默认选择查询到第3页;亚马逊广告关键词和搜索关键词怎样看排行?是不是用买家精灵一类的工具就可以?有效绕开亚马逊防采集mgc外置高匿名代理IP模式采集,支持高匿名或专属代理采集;自动判定当前采集是否被mgc,一旦被mgc会手动挂起线程等待一定间隔时间后继续采集;二、监控(采集)竞争对手数据按照某个店面分类直接采集该分类下的所有产品Asin,根据采集到的Asin号去采集其他Offer排名前2的产品价钱、运费、店铺名称等;直接输入分类页网址,程序会手动匹配到所有分类页面的链接,提取所有详尽页网址;三、根据关键词或某个分类采集产品数据并导入。如何提升amazon关键词搜索排名只要在SellingExpress添加关键词后,就能查询关键词的排行位置。亚马逊关键词排名怎么搜一页页翻吗完全不用一页页翻,只要在SellingExpress添加关键词后,就能查询关键词的排行位置,并且可以显示每晚的排行变化曲线图为何亚马逊关键词搜索排行靠前,类目排行太后关键词:是和你产品有高度关联的词句。椅子。可以说办公椅。可以说饭桌桌子等等。2.类目排行:是和销量挂钩的。是所有桌子的排行。或者某个具体类目的沙发。你认为某一个关键词搜索排行靠前。亚马逊营运如何能够有流量,关键词上排行?可以找靠谱的代营运来做的,有专业的营运团队和多的资源。
深度订制织梦小说网站模板 自动生成txt+zip压缩+全手动采集+漂亮WAP
采集交流 • 优采云 发表了文章 • 0 个评论 • 429 次浏览 • 2020-08-27 18:28
源码适用范围:价值数万深度定制织梦小说网站模板 自动生成txt+zip压缩+全手动采集+漂亮WAP 强悍至极
源码开发语言:PHP+MYSQL
源码描述说明:
会员织梦深度订制的小说站,全手动采集各大小说站,可手动生成首页、分类、目录、排行榜、sitemap页面静态html,全站拼音目录化,章节页面伪静态,自动生成小说txt文件,自动生成zip压缩包。此源码功能堪称是强大至极!带十分精巧的手机页面!带采集规则+自动适应!莎莎亲测,超级强大,采集规则全部能用,并且全手动采集及入库,非常好用,特别适宜优采云维护!做小说站无话可说的好程序,感谢俺会员无偿提供。
其他特征:
(1)自动生成首页、分类、目录、排行榜、sitemap页面静态html(分类页面、小说封面、作者页面的html文件假如不存在或则超过设置的时间没有更新,会手动更新一次。如果有采集的,采集时会手动更新小说封面和对应的分类页面),通过PHP直接调用html文件,而不是生成在根目录中,访问速率与纯静态没有区别,且可以在保证源码文件管理便捷的同时降低服务器压力,还能便捷访问统计,增加搜索引擎认可度。
(2)全站拼音目录化,章节页面伪静态。
(3)自动生成小说txt文件,也可以后台自己重新生成txt文件。
(4)自动生成小说关键词及关键词手动内链。
(5)自动伪原创成语替换(采集时替换) 。
(6)增加小说总点击、月点击、周点击、总推荐、月推荐、周推荐的统计和作者推荐统计等新功能。
(7)配合CNZZ的统计插件,能便捷实现小说下载明细统计和书籍被采集的明细统计等。
(8)本程序的手动采集并非市面上常见的优采云、关关、采集侠等,而是在DEDE原有采集功能的基础上二次开发的采集模块,可以有效的保证章节内容的完整性,避免章节重复、章节内容无内容、章节乱码等;一天24小时采集量能达到25~30万章节。
查看全部
深度订制织梦小说网站模板 自动生成txt+zip压缩+全手动采集+漂亮WAP
源码适用范围:价值数万深度定制织梦小说网站模板 自动生成txt+zip压缩+全手动采集+漂亮WAP 强悍至极
源码开发语言:PHP+MYSQL
源码描述说明:
会员织梦深度订制的小说站,全手动采集各大小说站,可手动生成首页、分类、目录、排行榜、sitemap页面静态html,全站拼音目录化,章节页面伪静态,自动生成小说txt文件,自动生成zip压缩包。此源码功能堪称是强大至极!带十分精巧的手机页面!带采集规则+自动适应!莎莎亲测,超级强大,采集规则全部能用,并且全手动采集及入库,非常好用,特别适宜优采云维护!做小说站无话可说的好程序,感谢俺会员无偿提供。
其他特征:
(1)自动生成首页、分类、目录、排行榜、sitemap页面静态html(分类页面、小说封面、作者页面的html文件假如不存在或则超过设置的时间没有更新,会手动更新一次。如果有采集的,采集时会手动更新小说封面和对应的分类页面),通过PHP直接调用html文件,而不是生成在根目录中,访问速率与纯静态没有区别,且可以在保证源码文件管理便捷的同时降低服务器压力,还能便捷访问统计,增加搜索引擎认可度。
(2)全站拼音目录化,章节页面伪静态。
(3)自动生成小说txt文件,也可以后台自己重新生成txt文件。
(4)自动生成小说关键词及关键词手动内链。
(5)自动伪原创成语替换(采集时替换) 。
(6)增加小说总点击、月点击、周点击、总推荐、月推荐、周推荐的统计和作者推荐统计等新功能。
(7)配合CNZZ的统计插件,能便捷实现小说下载明细统计和书籍被采集的明细统计等。
(8)本程序的手动采集并非市面上常见的优采云、关关、采集侠等,而是在DEDE原有采集功能的基础上二次开发的采集模块,可以有效的保证章节内容的完整性,避免章节重复、章节内容无内容、章节乱码等;一天24小时采集量能达到25~30万章节。

根据关键词手动聚合数据的科讯CMS插件开发经验
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2020-08-27 14:02
分享科讯文章、图片、动漫、视频、问答按照关键词手动聚合数据的CMS插件制做经验分享。
爱聚合好多站长同学都是比较熟悉,优采云很多站长同学也太熟悉,当然是用科讯的CMS的同事愈发熟悉科讯的采集系统了。对于科讯的后台来说,我们不可证实十分强悍,但是缺乏一个功能--问答的采集(这个功能之针对启用问答系统的用户来说有用)。建站前期,我们常常会采集一些数据,然后我们再去手工降低数据,伪原创数据。很多站长由于前期看不到站有流量所以没有时间的时侯就舍弃了每晚更新的工作,所以百度爬虫或则其他的搜索引擎爬虫来了也喝不到新的数据,于是好多同学都在思索我们能不能去执行手动采集或者手动聚合。
很多同学都说我们不管通过任何方式都要对内容执行一个伪原创或则原创才能对网站的权重或则关键词的排行就会有帮助,没有错,这个问题我开始也在思索,到底是对标题进行关键词或则字眼的程序手动修改能够达到预期的疗效, 还是通过其他方式改变达到疗效。后来我通过以及()查询总结的结果是:其实百度指数就是对人们在网路中找寻自己想要的信息的一个搜索习惯的总结,当然也是用户体验的一个大约总结和归纳。那么我们在标题后面加上一个与内容息息相关的指数是不是算是对标题的伪原创呢?对网站内容究竟有没有哪些帮助呢?答案是肯定的。
于是启发了我开发基于科讯CMS文章、图片、动漫、视频、问答按照关键词手动聚合插件的兴趣,也算是一个尝试吧,每天放学回去就开发这个插件,足足辛苦了一个礼拜,网站终于可以上线测试了,网站从开始上线到明天流量在显著的上升(见统计图),于是我写那么一篇文章和科讯的网友一起来分享了。
统计图(2011-01-16 9:23的截图)
闲话不说,下面介绍一下这个聚合插件的思路:
l 全站只须要针对每位栏目以及对应的问题添加一个指数关键词
l 指数词会在风波(人工访问,搜索引擎爬虫的访问)触发下手动执行数据(文章、图片、动漫、视频、问答)聚合,数据的聚合过程属于分布式进行,所以不会拖延网站的速率。
l 当这个指数词聚合完毕以后,程序都会手动按照指数词聚合相关热度的指数关键词,然后程序再度按照指数词去执行数据的聚合或则依照上面的指数此执行指数词的数据更新。这个过程都是随机的抽取关键词执行任务。
l 数据源基本来自博客和门户以及专业社区中的信息,数据来源目前合计是逾120多个网站,不仅仅是一个简单的单数据源的数据抽取。唯独漫画现今由于时间关系(没有来得及做,不过插口早已预留了,后期疗效好再开发)只去聚合优酷的视频信息。
l 标题全部加一个热度指数词在上面进行标题的伪原创。大家可以详尽见的内容页。
l 在所有的内容页下边为网站创建一个热度指数作为列表的回路(其实也是你们所说的网站权重传递)。
l 内容中降低指数词作为内部链接之用,也是为将来做关键词的排行做打算。
l 图片全部执行伪造,通过伪静态将远程的图片地址以本地图片地址模式进行显示。
科讯后台更改的管理页面主要有:KS.Class.asp, KS.Article.asp, KS.Picture.asp, KS.Movie.asp, KS.Asklist.asp, KS.Special.asp
科讯前台主要更改的页面文件有:/Item/list.asp, /Item/show.asp, /Ask/q.asp
新降低的文件:Auto.asp
新降低的文件夹:ZLJ.Cls
后台修改后的展示疗效
栏目管理页面如图1
图1
专题页面更改如图2
图2
执行疗效见前台
案例网站:我爱游戏网 查看全部
根据关键词手动聚合数据的科讯CMS插件开发经验
分享科讯文章、图片、动漫、视频、问答按照关键词手动聚合数据的CMS插件制做经验分享。
爱聚合好多站长同学都是比较熟悉,优采云很多站长同学也太熟悉,当然是用科讯的CMS的同事愈发熟悉科讯的采集系统了。对于科讯的后台来说,我们不可证实十分强悍,但是缺乏一个功能--问答的采集(这个功能之针对启用问答系统的用户来说有用)。建站前期,我们常常会采集一些数据,然后我们再去手工降低数据,伪原创数据。很多站长由于前期看不到站有流量所以没有时间的时侯就舍弃了每晚更新的工作,所以百度爬虫或则其他的搜索引擎爬虫来了也喝不到新的数据,于是好多同学都在思索我们能不能去执行手动采集或者手动聚合。
很多同学都说我们不管通过任何方式都要对内容执行一个伪原创或则原创才能对网站的权重或则关键词的排行就会有帮助,没有错,这个问题我开始也在思索,到底是对标题进行关键词或则字眼的程序手动修改能够达到预期的疗效, 还是通过其他方式改变达到疗效。后来我通过以及()查询总结的结果是:其实百度指数就是对人们在网路中找寻自己想要的信息的一个搜索习惯的总结,当然也是用户体验的一个大约总结和归纳。那么我们在标题后面加上一个与内容息息相关的指数是不是算是对标题的伪原创呢?对网站内容究竟有没有哪些帮助呢?答案是肯定的。
于是启发了我开发基于科讯CMS文章、图片、动漫、视频、问答按照关键词手动聚合插件的兴趣,也算是一个尝试吧,每天放学回去就开发这个插件,足足辛苦了一个礼拜,网站终于可以上线测试了,网站从开始上线到明天流量在显著的上升(见统计图),于是我写那么一篇文章和科讯的网友一起来分享了。

统计图(2011-01-16 9:23的截图)
闲话不说,下面介绍一下这个聚合插件的思路:
l 全站只须要针对每位栏目以及对应的问题添加一个指数关键词
l 指数词会在风波(人工访问,搜索引擎爬虫的访问)触发下手动执行数据(文章、图片、动漫、视频、问答)聚合,数据的聚合过程属于分布式进行,所以不会拖延网站的速率。
l 当这个指数词聚合完毕以后,程序都会手动按照指数词聚合相关热度的指数关键词,然后程序再度按照指数词去执行数据的聚合或则依照上面的指数此执行指数词的数据更新。这个过程都是随机的抽取关键词执行任务。
l 数据源基本来自博客和门户以及专业社区中的信息,数据来源目前合计是逾120多个网站,不仅仅是一个简单的单数据源的数据抽取。唯独漫画现今由于时间关系(没有来得及做,不过插口早已预留了,后期疗效好再开发)只去聚合优酷的视频信息。
l 标题全部加一个热度指数词在上面进行标题的伪原创。大家可以详尽见的内容页。
l 在所有的内容页下边为网站创建一个热度指数作为列表的回路(其实也是你们所说的网站权重传递)。
l 内容中降低指数词作为内部链接之用,也是为将来做关键词的排行做打算。
l 图片全部执行伪造,通过伪静态将远程的图片地址以本地图片地址模式进行显示。
科讯后台更改的管理页面主要有:KS.Class.asp, KS.Article.asp, KS.Picture.asp, KS.Movie.asp, KS.Asklist.asp, KS.Special.asp
科讯前台主要更改的页面文件有:/Item/list.asp, /Item/show.asp, /Ask/q.asp
新降低的文件:Auto.asp
新降低的文件夹:ZLJ.Cls
后台修改后的展示疗效
栏目管理页面如图1

图1
专题页面更改如图2

图2
执行疗效见前台
案例网站:我爱游戏网
站群是哪些,(泛)站群做法分享
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2020-08-27 03:54
我是小微09-07 11:24
站群是哪些?顾名思义:即一个人或一个团队操作多个网站,目的是通过搜索引擎获得大量流量,或者是将链接指向同一个网站,以提升搜索排名。站群就是一网站的集合,但是一定要统一,分级管理,信息共享,单点登陆才可以。最初的站群由政府提出,现在早已应用领域范围太广,例如政府门户网站群、大型企事业网站群、行业网站群等。
站群一般由几个到几百个网站组成,站群最简单的理解就是一群网站。而这种网站都是属于一个人的,那么这种网站就称之因此站长的站群。
站群系统:站群,是网站主借助搜索引擎自然优化规则进行推广,从搜索引擎端带来流量的的方式。 网站规模少则几个多则上千过万。
站群系统对于站群意义重大,在2005-2007年国外一些从事SEO的工作者提出了站群的概念:多个独立域名(含二级域)的网站统一管理、互相关联。2008年开始,站群软件开发者开发出一种更便于操作的网站采集模式,即通过关键词进行手动采集网站内容,在此之前的采集模式均为编撰规则形式。
在这些简单易用的采集模式基础上,黑豹软件开发商集成了针对不同网站系统的发布插口,以便于用一套简单的采集方式可以同时管理不同网站系统的内容更新,这种软件即多数人所了解的“站群系统”。
站群的目的:是构建强悍的链接资源库,推动网站关键词排行上升,实现站群的最终目的从搜索引擎端获取到最大规模的流量,通过良好的商业模式,实现赢利。
什么是泛站群,泛站群就是又一个顶级域名*.域名泛解析进行生成的二级域名。然后二级域名批量的生成单页。形成站群。
泛站群的缺陷:单页,不存在更新。
(泛)站群做法分享:站群一般由几个到几百个网站组成,个人站长想通过手工更新站群,那几乎是不可能的任务。所以通常都是通过站群软件来完成。进行全手动更新等。 查看全部
站群是哪些,(泛)站群做法分享
我是小微09-07 11:24

站群是哪些?顾名思义:即一个人或一个团队操作多个网站,目的是通过搜索引擎获得大量流量,或者是将链接指向同一个网站,以提升搜索排名。站群就是一网站的集合,但是一定要统一,分级管理,信息共享,单点登陆才可以。最初的站群由政府提出,现在早已应用领域范围太广,例如政府门户网站群、大型企事业网站群、行业网站群等。
站群一般由几个到几百个网站组成,站群最简单的理解就是一群网站。而这种网站都是属于一个人的,那么这种网站就称之因此站长的站群。
站群系统:站群,是网站主借助搜索引擎自然优化规则进行推广,从搜索引擎端带来流量的的方式。 网站规模少则几个多则上千过万。
站群系统对于站群意义重大,在2005-2007年国外一些从事SEO的工作者提出了站群的概念:多个独立域名(含二级域)的网站统一管理、互相关联。2008年开始,站群软件开发者开发出一种更便于操作的网站采集模式,即通过关键词进行手动采集网站内容,在此之前的采集模式均为编撰规则形式。
在这些简单易用的采集模式基础上,黑豹软件开发商集成了针对不同网站系统的发布插口,以便于用一套简单的采集方式可以同时管理不同网站系统的内容更新,这种软件即多数人所了解的“站群系统”。
站群的目的:是构建强悍的链接资源库,推动网站关键词排行上升,实现站群的最终目的从搜索引擎端获取到最大规模的流量,通过良好的商业模式,实现赢利。
什么是泛站群,泛站群就是又一个顶级域名*.域名泛解析进行生成的二级域名。然后二级域名批量的生成单页。形成站群。
泛站群的缺陷:单页,不存在更新。
(泛)站群做法分享:站群一般由几个到几百个网站组成,个人站长想通过手工更新站群,那几乎是不可能的任务。所以通常都是通过站群软件来完成。进行全手动更新等。
2019新版百科搜搜独创源码,自动采集,SEO完美优化手动伪原创
采集交流 • 优采云 发表了文章 • 0 个评论 • 343 次浏览 • 2020-08-25 20:27
2019新版百科搜搜独创源码,自动采集,SEO完美优化手动伪原创
目前市场上基本都是2016版,本源码是我开放,2019全新开发新版,效果十分强悍!
创百科搜搜ASP源码。程序全手动更新+全手动采集+全智能伪原创,程序稳定可靠(网站更新数周或更长
时间无需人为管理,优采云,忙人必备),seo采用新优化方式,百万数据***秒开(拒绝页面仍然绕圈圈)
.程序带有后台,可设为程序手动采集,也可手工随便发布文章。也可随机加入自己的相关,关键词产品推广
(如:关键词,长尾词。关键词)这套程序作出的网站不需要任何***作,每天手动更新,自动采集,自动伪
原创,完全做到全手动。
程序明年新升级优化,过滤常见的(违禁词.垃圾词.铭感词,灰色词),让各大引擎更好的收录或加
快引擎收录量,同时网站的可读信息也大大提高。
网站模板独创开发,面容整洁美观.标题内容清晰一目了然。(拒绝眼花缭乱,错综复杂)的觉得。
一套完整程序配上模板可做多个分类网站,网络挣钱,必备物品。
网站源码特性:
一,搜索引擎完美收录,后期完全可以做到秒收。
二,解放右手,完全做到全手动,做到躺下都挣钱。
注意:只提供源码程序,不提供后其他服务,适合有技术基础的人员
语言:(ASP独创)
数据库:(Access)
程序演示地址:
综合站演示地址:
分类信息站演示:
赚钱思路:本源码的挣钱思路简单,纯靠各大搜索流量挣钱,此类网站全是长尾关键词,收录量越大,长尾
关键词越多,流量越大,后挂广告联盟挣钱。真正做到躺下都挣钱。
空间配置要求:必须要求web服务是IIS6,支持语言是ASP,并开启伪静态,空间大小尽量1G左右
注:如需订购此源码请移步“互站”购买,或在本站“C代码”搜索相关资源! 查看全部
2019新版百科搜搜独创源码,自动采集,SEO完美优化手动伪原创
2019新版百科搜搜独创源码,自动采集,SEO完美优化手动伪原创
目前市场上基本都是2016版,本源码是我开放,2019全新开发新版,效果十分强悍!
创百科搜搜ASP源码。程序全手动更新+全手动采集+全智能伪原创,程序稳定可靠(网站更新数周或更长
时间无需人为管理,优采云,忙人必备),seo采用新优化方式,百万数据***秒开(拒绝页面仍然绕圈圈)
.程序带有后台,可设为程序手动采集,也可手工随便发布文章。也可随机加入自己的相关,关键词产品推广
(如:关键词,长尾词。关键词)这套程序作出的网站不需要任何***作,每天手动更新,自动采集,自动伪
原创,完全做到全手动。
程序明年新升级优化,过滤常见的(违禁词.垃圾词.铭感词,灰色词),让各大引擎更好的收录或加
快引擎收录量,同时网站的可读信息也大大提高。
网站模板独创开发,面容整洁美观.标题内容清晰一目了然。(拒绝眼花缭乱,错综复杂)的觉得。
一套完整程序配上模板可做多个分类网站,网络挣钱,必备物品。
网站源码特性:
一,搜索引擎完美收录,后期完全可以做到秒收。
二,解放右手,完全做到全手动,做到躺下都挣钱。
注意:只提供源码程序,不提供后其他服务,适合有技术基础的人员
语言:(ASP独创)
数据库:(Access)
程序演示地址:
综合站演示地址:
分类信息站演示:
赚钱思路:本源码的挣钱思路简单,纯靠各大搜索流量挣钱,此类网站全是长尾关键词,收录量越大,长尾
关键词越多,流量越大,后挂广告联盟挣钱。真正做到躺下都挣钱。
空间配置要求:必须要求web服务是IIS6,支持语言是ASP,并开启伪静态,空间大小尽量1G左右
注:如需订购此源码请移步“互站”购买,或在本站“C代码”搜索相关资源!
Python学习笔记(19)自动搜索关键词采集信息—以易迅为例
采集交流 • 优采云 发表了文章 • 0 个评论 • 479 次浏览 • 2020-08-25 00:01
一、操作步骤
如果网页上有搜索框,但是搜索结果页面没有独立网址,想要采集搜索结果,直接做规则是采集不到的,要先做连续动作(输入+点击)来实现手动输入关键词并搜索,然后才会采集数据。下面用易迅搜索为例,演示手动搜索采集,操作步骤如下:
二、案例规则+操作步骤
**注意:**本案例易迅搜索是有独立网址的,对于具有独立网址的页面,最简单的方式就是构造出每位关键词的搜索网址,然后把线索网址导出到规则里,就可以批量采集,而不是设置连续动作
第一步:定义第一级规则
1.1打开集搜客网络爬虫,输入网址并Enter,加载出网页后再点击“定义规则”按钮,看到一个浮窗显示下来,称为工作台,在前面定义规则;
注意:这里的截图和文字说明都是集搜客网络爬虫版本,如果您安装的是傲游插件版,那么就没有“定义规则”按钮,而是应当运行MS谋数台
1.2在工作台北输入一级规则的主题名,再点击“查重”,提示“该名可以使用”或“该名已被占用,可编辑:是”,就可以使用这个主题名,否则请重命名。
1.3本级规则主要是设置连续动作,所以,整理箱可以随便抓取一个信息,用来给爬虫判定是否执行采集。双击网页上的信息,输入标签名,并打勾确认,再勾上关键内容,首次标明还要输入整理箱的名子,然后就完成标明映射了。
Tips:为了能确切定位网页信息,点击定义规则会把整个网页定格住,不能跳转网页链接,再次点击定义规则,才会恢复回普通的网页模式。
第二步:定义连续动作
点击工作台的“连续动作”页签,点击新建按键构建一个新动作,每个动作的设置方式都是一样,基本操作如下:
2.1 ,输入目标主题名
这里的目标主题名是填第二级主题名,点击“谁在用”查看目标主题名是否可用,如果早已被占用,换一个主题名就行
2.2, 创建第一个动作:输入
新建一个动作,并选择动作类型为输入。
2.2.1,填写定位表达式
首先键盘单击输入框,定位输入框的节点,然后点击“自动生成XPath”按钮,可以选择“偏好id”或者“偏好class”,就可以得到输入框的xpath表达式,再点击“搜索”按钮,检查一下这个xpath是否能惟一定位到输入框,没有问题就把xpath复制到定位表达式方框里。
**注意:**定位表达式里的xpath是要锁定动作对象的整个有效操作范围,具体就是指键盘就能点击或输入成功的网页模块,不要定位到最底层的text()节点。
2.2.2,输入关键词
输入关键词填写你想搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词要用双分号;;将每位关键词隔开,免费版只支持5个以内的关键词,旗舰版可以使用连发弹仓功能,支持1万以内的关键词
2.2.3,输入动作名称
告诉自己这一步动作是拿来干嘛的,方便之后更改。
2.3,创建第二个动作:点击
参考2.2的操作,创建第二个动作,选择类型为点击,定位到搜索按键,然后手动生成xpath,检验是否锁定到惟一节点,没问题的话填到定位表达式里就行了。
2.4,存规则
点击“存规则”按钮保存已完成的第一级规则
第三步:定义第二级规则
3.1,新建规则
创建第二级规则,点击“定义规则”恢复到普通网页模式,输入关键词搜索出结果后,再次点击“定义规则”切换到做规则模式,点击左上角“规则”菜单->“新建”,输入主题名,这里的主题名就是第一级规则的连续动作里填写的目标主题名。
3.2,标注想要采集的信息
3.2.1,标注网页上想要采集的信息,这里是对商品名称和价钱做标明,因为标明只对文本信息有效,商品详情的链接是属性节点@href,所以,不能对链接做这样的直观标明,而要做内容映射,具体看下边的操作。
3.2.2,点击商品名称,下面的DOM节点定位到A标签,展开A标签下的attributes节点,就可以找到代表网址的@href节点,右击节点,选择“新建抓取内容“,输入一个名子,一般给这个抓取内容起一个和地址有关的名子,比如“下级网址“,或者”下级链接“等等。然后在工作台上,看到这个抓取内容有了。如果还要步入商品详情页采集,就要对着这个抓取内容勾选下级线索,做层级抓取。
3.2.3,设置“关键内容”选项,这样爬虫能够判定出采集规则是否合适。在整理箱里选一个网页上必然能采到的标签,勾上“关键内容”。这里选择的是“名称”做为“关键内容”。
3.2.4,前面只对一个商品做标明,也能够得到一个商品信息,如果想把一整页上每一个商品都采集下来,可以做样例复制,不懂的请参考基础教程《采集列表数据》
3.3,设置翻页路线
在爬虫路线设置翻页,这里用的是记号线索,不懂的请参考基础教程《设置翻页采集》
3.4,存规则
点击“测试”,检查信息完整性。不完整的话,重新标明就可以覆盖之前的内容。检查没问题后点击“存规则”。
第四步:抓数据
4.1,连续动作是连续执行的,所以只要运行第一级主题,第二级主题不用运行。打开DS打数机,搜索出第一级主题名,点击“单搜”或“集搜”,此时可以看见浏览器窗口里会手动输入关键词而且搜索,然后调用第二级主题手动采集搜索结果。
4.2,第一级主题没采到有意义的信息,所以,我们只看第二级主题的文件夹,就能看见采集的搜索结果数据,并且搜索的关键词是默认记录在xml文件的actionvalue数组中,这样才能一一对应上去。 查看全部
Python学习笔记(19)自动搜索关键词采集信息—以易迅为例
一、操作步骤
如果网页上有搜索框,但是搜索结果页面没有独立网址,想要采集搜索结果,直接做规则是采集不到的,要先做连续动作(输入+点击)来实现手动输入关键词并搜索,然后才会采集数据。下面用易迅搜索为例,演示手动搜索采集,操作步骤如下:


二、案例规则+操作步骤
**注意:**本案例易迅搜索是有独立网址的,对于具有独立网址的页面,最简单的方式就是构造出每位关键词的搜索网址,然后把线索网址导出到规则里,就可以批量采集,而不是设置连续动作
第一步:定义第一级规则

1.1打开集搜客网络爬虫,输入网址并Enter,加载出网页后再点击“定义规则”按钮,看到一个浮窗显示下来,称为工作台,在前面定义规则;
注意:这里的截图和文字说明都是集搜客网络爬虫版本,如果您安装的是傲游插件版,那么就没有“定义规则”按钮,而是应当运行MS谋数台
1.2在工作台北输入一级规则的主题名,再点击“查重”,提示“该名可以使用”或“该名已被占用,可编辑:是”,就可以使用这个主题名,否则请重命名。

1.3本级规则主要是设置连续动作,所以,整理箱可以随便抓取一个信息,用来给爬虫判定是否执行采集。双击网页上的信息,输入标签名,并打勾确认,再勾上关键内容,首次标明还要输入整理箱的名子,然后就完成标明映射了。
Tips:为了能确切定位网页信息,点击定义规则会把整个网页定格住,不能跳转网页链接,再次点击定义规则,才会恢复回普通的网页模式。
第二步:定义连续动作
点击工作台的“连续动作”页签,点击新建按键构建一个新动作,每个动作的设置方式都是一样,基本操作如下:

2.1 ,输入目标主题名
这里的目标主题名是填第二级主题名,点击“谁在用”查看目标主题名是否可用,如果早已被占用,换一个主题名就行
2.2, 创建第一个动作:输入
新建一个动作,并选择动作类型为输入。

2.2.1,填写定位表达式
首先键盘单击输入框,定位输入框的节点,然后点击“自动生成XPath”按钮,可以选择“偏好id”或者“偏好class”,就可以得到输入框的xpath表达式,再点击“搜索”按钮,检查一下这个xpath是否能惟一定位到输入框,没有问题就把xpath复制到定位表达式方框里。
**注意:**定位表达式里的xpath是要锁定动作对象的整个有效操作范围,具体就是指键盘就能点击或输入成功的网页模块,不要定位到最底层的text()节点。
2.2.2,输入关键词
输入关键词填写你想搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词要用双分号;;将每位关键词隔开,免费版只支持5个以内的关键词,旗舰版可以使用连发弹仓功能,支持1万以内的关键词
2.2.3,输入动作名称
告诉自己这一步动作是拿来干嘛的,方便之后更改。
2.3,创建第二个动作:点击

参考2.2的操作,创建第二个动作,选择类型为点击,定位到搜索按键,然后手动生成xpath,检验是否锁定到惟一节点,没问题的话填到定位表达式里就行了。
2.4,存规则
点击“存规则”按钮保存已完成的第一级规则
第三步:定义第二级规则
3.1,新建规则

创建第二级规则,点击“定义规则”恢复到普通网页模式,输入关键词搜索出结果后,再次点击“定义规则”切换到做规则模式,点击左上角“规则”菜单->“新建”,输入主题名,这里的主题名就是第一级规则的连续动作里填写的目标主题名。
3.2,标注想要采集的信息

3.2.1,标注网页上想要采集的信息,这里是对商品名称和价钱做标明,因为标明只对文本信息有效,商品详情的链接是属性节点@href,所以,不能对链接做这样的直观标明,而要做内容映射,具体看下边的操作。
3.2.2,点击商品名称,下面的DOM节点定位到A标签,展开A标签下的attributes节点,就可以找到代表网址的@href节点,右击节点,选择“新建抓取内容“,输入一个名子,一般给这个抓取内容起一个和地址有关的名子,比如“下级网址“,或者”下级链接“等等。然后在工作台上,看到这个抓取内容有了。如果还要步入商品详情页采集,就要对着这个抓取内容勾选下级线索,做层级抓取。
3.2.3,设置“关键内容”选项,这样爬虫能够判定出采集规则是否合适。在整理箱里选一个网页上必然能采到的标签,勾上“关键内容”。这里选择的是“名称”做为“关键内容”。

3.2.4,前面只对一个商品做标明,也能够得到一个商品信息,如果想把一整页上每一个商品都采集下来,可以做样例复制,不懂的请参考基础教程《采集列表数据》
3.3,设置翻页路线

在爬虫路线设置翻页,这里用的是记号线索,不懂的请参考基础教程《设置翻页采集》
3.4,存规则
点击“测试”,检查信息完整性。不完整的话,重新标明就可以覆盖之前的内容。检查没问题后点击“存规则”。
第四步:抓数据

4.1,连续动作是连续执行的,所以只要运行第一级主题,第二级主题不用运行。打开DS打数机,搜索出第一级主题名,点击“单搜”或“集搜”,此时可以看见浏览器窗口里会手动输入关键词而且搜索,然后调用第二级主题手动采集搜索结果。
4.2,第一级主题没采到有意义的信息,所以,我们只看第二级主题的文件夹,就能看见采集的搜索结果数据,并且搜索的关键词是默认记录在xml文件的actionvalue数组中,这样才能一一对应上去。
[转帖]-seo关键词排名优化服务
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2020-08-22 15:46
seo要害词排行优化服务
seo优化以后有哪些后果?晋升目的网站中指定根源词在搜索引擎里的自然排行。
生效岁月:项目开端起2个月或更长(合同商定)。
【seo关键词优化服务流程】
一、初议和推断目的要害词:
如同探险之前没有辨清方向,未经督查、盲目选择目的根源词会使全部seo工作从开端就走错了街――seo是精密的兼具计划工作,一度的方向误差也将大大失去预算,挥霍掉的岁月和机遇本钱更是难以恐怕。
我们的seo工作职员使用超过3种关键词分析工具,筛选并拾掇出合适当前网站、当前行业的高质量关键词列表。关键词列表以岁月(周期性)、地区(全世界范畴)、搜索量、seo竞争度、预估转化率等多个角度清楚展示。
我们甚至能通过关键词分析工作提早判定出一个行业的变迁规律。
二、搜索引擎友爱度钻探并优化:
这是一个年龄超过10岁的古老seo话题。即便是seo知识已然相当普及的明天,仍然有大批网站存在"反复内容"、sessionid所造成的"庞杂网址串"、"全flash页面"、"脚本链接"等小麻烦在影响搜索引擎友爱度。网站变得另搜索引擎爬虫无法抓取,无法全体收录,,更别提在搜索引擎里争抢自然排行获取流量了。
三、内容撰写、安排:
信任您也见过不少一打开窗口就想立刻封闭的网站。尤其是一些经过seo公司"优化"过的,一心一意只为搜索引擎蜘蛛献殷勤的站点。千万要记住,要害词排行再高,流量再大,也不要疏漏一点――网站是给人看的。
我们的seo文案工作职员除了擅长创作高质量、便于seo优化的内容,而且会尽量让内容迎合你的读者、访客与顾客。
我们许诺在应用任何内容之前向您征求想法,以确认您也爱好它们。
四、吸引和获取高质量链接:
获得链接可以晋升网站在搜索引擎中的自然排行,这是大肆的seo绝密。
赚到1000万才能买幢洋房,这尽人皆知。但是,怎样挣来那1000万买豪宅的钱呢?
艰苦同样存在于怎么吸引和获取高质量链接,这是seo工作的一大困难。
五、我们应用的链接获取方式收录但不限于: 查看全部
[转帖]-seo关键词排名优化服务
seo要害词排行优化服务
seo优化以后有哪些后果?晋升目的网站中指定根源词在搜索引擎里的自然排行。
生效岁月:项目开端起2个月或更长(合同商定)。
【seo关键词优化服务流程】
一、初议和推断目的要害词:
如同探险之前没有辨清方向,未经督查、盲目选择目的根源词会使全部seo工作从开端就走错了街――seo是精密的兼具计划工作,一度的方向误差也将大大失去预算,挥霍掉的岁月和机遇本钱更是难以恐怕。
我们的seo工作职员使用超过3种关键词分析工具,筛选并拾掇出合适当前网站、当前行业的高质量关键词列表。关键词列表以岁月(周期性)、地区(全世界范畴)、搜索量、seo竞争度、预估转化率等多个角度清楚展示。
我们甚至能通过关键词分析工作提早判定出一个行业的变迁规律。
二、搜索引擎友爱度钻探并优化:
这是一个年龄超过10岁的古老seo话题。即便是seo知识已然相当普及的明天,仍然有大批网站存在"反复内容"、sessionid所造成的"庞杂网址串"、"全flash页面"、"脚本链接"等小麻烦在影响搜索引擎友爱度。网站变得另搜索引擎爬虫无法抓取,无法全体收录,,更别提在搜索引擎里争抢自然排行获取流量了。
三、内容撰写、安排:
信任您也见过不少一打开窗口就想立刻封闭的网站。尤其是一些经过seo公司"优化"过的,一心一意只为搜索引擎蜘蛛献殷勤的站点。千万要记住,要害词排行再高,流量再大,也不要疏漏一点――网站是给人看的。
我们的seo文案工作职员除了擅长创作高质量、便于seo优化的内容,而且会尽量让内容迎合你的读者、访客与顾客。
我们许诺在应用任何内容之前向您征求想法,以确认您也爱好它们。
四、吸引和获取高质量链接:
获得链接可以晋升网站在搜索引擎中的自然排行,这是大肆的seo绝密。
赚到1000万才能买幢洋房,这尽人皆知。但是,怎样挣来那1000万买豪宅的钱呢?
艰苦同样存在于怎么吸引和获取高质量链接,这是seo工作的一大困难。
五、我们应用的链接获取方式收录但不限于:
自动更新联通网站如何优化获得好的关键词排名
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2020-08-22 13:01
自动更新联通网站如何优化获得好的关键词排名
移动端现今显得越来越重要,如何使网站在移动端有好的排行,现在一级钢渐渐成为好多站长头痛的一件事情。虽然移动端网站优化和PC端网站优化拥有共同性,在优化方法和方法方面也大同小异。那么,如何使移动端网站获得搜索引擎的喜爱,从而迅速获得首页关键词排行。下面,濮阳网站建设就谈谈怎样通过优化手段使移动端网站获得好的关键词排行。
不管我们做PC端网站还是移动端网站都须要在网站前期做一些打算工作,例如网站诊断甚至网站分析等,还是就是PC端和移动端网站的适配。移动端在前期也须要考虑网站结构,虽然移动端我们常用二级域名,但是相对于PC端网站而言,也是一个独立的网站,必定有自己的网站结构和网站导航等。
移动端在页面优化过程中,尽量跟PC端网站TDK一样。这样保持在适配过程中,PC端的排行和权重整体承继过来。还有就是数据库进行使用相同数据库,这样使数据和内容保持一致性。
网站排名都离不开收录,就算网站内容在好,如果搜索引擎不收录也是未能参与排行,其实联通网站在收录方面也是跟PC网站一样。搜索引擎蜘蛛都须要通过索引,抓取,建库,释放,参与排行等过程。如果robots严禁蜘蛛抓取或则蜘蛛在链接抓取过程碰到问题,就会降低搜索引擎抓取内容的难易度。
网站链接结构是网站重中之重,如何优化网站如果网站链接结构出现一些问题都会造成网站在后期优化疗效不佳,甚至可能出现改版等诱因。因此,网站结构根据搜索引擎移动端指导规范进行合理设置。
虽然移动端甚少由用户查看链接,然而,我们在移动端URL的设置过程中,就须要采用静态化的链接形式。这样,让蜘蛛极少辨识下来。
要经常观察网站logs文件,查看蜘蛛抓取时的返回HTTP代码是否是200,尽量降低死链接 404 的出现。
内部优化就是要使网站锚文本合理出现在网站内容页中,不要只是把权重全部导给首页或则把链接全部链接到首页。虽然,在前期我们尽量做首页关键词。在之后网站栏目页和内容页也应当做有效的链接策略.
不管哪种搜索引擎判定一个页面权重高低,很重要的根据给与外部链接导出的锚文本和链接数目。因此,我们在外链建设方面就不能放松。要按照网站情况,进行外链非常高质量的外链建设。
网站内容这些都是太老掉牙的东西,就是文章尽量原创,现在搜索引擎对于网站内容要求越来越高。高质量,网站搜索引擎优化原创内容对于网站排名和整体权重提高作用不可缺乏。
移动网站打开速度决定网站的整体排行,现在搜索引擎在判定网站关键词排行早已把网站打开速率考虑进行,因此,网站打开速度显得越来越重要。
热门点击:网站优化与文章的质量
!
与手动更新联通网站如何优化获得好的关键词排名相关文章:
·网站优化中怎样获得一个稳定的排行哪些是站群
·网站优化双刃剑:如何提升网站排名哪些是站群
·有权重无排行 网站优化怎样避免本末倒置站群
·浅谈网站如何做好优化能够够提高搜索引擎排名
·中小型网站如何合理优化网站排名站群工具
·卢国馥:如何剖析竞争对手的数据站群软件
本文标题:自动更新联通网站如何优化获得好的关键词排名
本文地址: 查看全部
自动更新联通网站如何优化获得好的关键词排名

自动更新联通网站如何优化获得好的关键词排名
移动端现今显得越来越重要,如何使网站在移动端有好的排行,现在一级钢渐渐成为好多站长头痛的一件事情。虽然移动端网站优化和PC端网站优化拥有共同性,在优化方法和方法方面也大同小异。那么,如何使移动端网站获得搜索引擎的喜爱,从而迅速获得首页关键词排行。下面,濮阳网站建设就谈谈怎样通过优化手段使移动端网站获得好的关键词排行。
不管我们做PC端网站还是移动端网站都须要在网站前期做一些打算工作,例如网站诊断甚至网站分析等,还是就是PC端和移动端网站的适配。移动端在前期也须要考虑网站结构,虽然移动端我们常用二级域名,但是相对于PC端网站而言,也是一个独立的网站,必定有自己的网站结构和网站导航等。
移动端在页面优化过程中,尽量跟PC端网站TDK一样。这样保持在适配过程中,PC端的排行和权重整体承继过来。还有就是数据库进行使用相同数据库,这样使数据和内容保持一致性。
网站排名都离不开收录,就算网站内容在好,如果搜索引擎不收录也是未能参与排行,其实联通网站在收录方面也是跟PC网站一样。搜索引擎蜘蛛都须要通过索引,抓取,建库,释放,参与排行等过程。如果robots严禁蜘蛛抓取或则蜘蛛在链接抓取过程碰到问题,就会降低搜索引擎抓取内容的难易度。
网站链接结构是网站重中之重,如何优化网站如果网站链接结构出现一些问题都会造成网站在后期优化疗效不佳,甚至可能出现改版等诱因。因此,网站结构根据搜索引擎移动端指导规范进行合理设置。
虽然移动端甚少由用户查看链接,然而,我们在移动端URL的设置过程中,就须要采用静态化的链接形式。这样,让蜘蛛极少辨识下来。
要经常观察网站logs文件,查看蜘蛛抓取时的返回HTTP代码是否是200,尽量降低死链接 404 的出现。
内部优化就是要使网站锚文本合理出现在网站内容页中,不要只是把权重全部导给首页或则把链接全部链接到首页。虽然,在前期我们尽量做首页关键词。在之后网站栏目页和内容页也应当做有效的链接策略.
不管哪种搜索引擎判定一个页面权重高低,很重要的根据给与外部链接导出的锚文本和链接数目。因此,我们在外链建设方面就不能放松。要按照网站情况,进行外链非常高质量的外链建设。
网站内容这些都是太老掉牙的东西,就是文章尽量原创,现在搜索引擎对于网站内容要求越来越高。高质量,网站搜索引擎优化原创内容对于网站排名和整体权重提高作用不可缺乏。
移动网站打开速度决定网站的整体排行,现在搜索引擎在判定网站关键词排行早已把网站打开速率考虑进行,因此,网站打开速度显得越来越重要。
热门点击:网站优化与文章的质量
!
与手动更新联通网站如何优化获得好的关键词排名相关文章:
·网站优化中怎样获得一个稳定的排行哪些是站群
·网站优化双刃剑:如何提升网站排名哪些是站群
·有权重无排行 网站优化怎样避免本末倒置站群
·浅谈网站如何做好优化能够够提高搜索引擎排名
·中小型网站如何合理优化网站排名站群工具
·卢国馥:如何剖析竞争对手的数据站群软件
本文标题:自动更新联通网站如何优化获得好的关键词排名
本文地址:
网站推广工具-网站关键词之seo优化长尾词
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2020-08-22 12:43
网站推广工具,也就是这些于网站外容由相干性的关键词,更少的时侯她们是暖门关键词与是热点关键词的组开,或许是热点关键词取小众根源词的组开。
长尾关键词应该知足3个基础前提:
1、彼要害词取您的网坐外容由管无闭;
2、选择的关键词必需是用户有才能来查询的词;
3、能知足到拜访者恳求的。
简略的来道,就是自用户的角度动身,站在用户的心态下根据她们的习性往设放关键词。
少头根源词的选购:
通过网站的构念战网站的相干业务相商讨的关键词,或者则通功对于脚战搜救引擎往开掘相当的关键词。最初说一上,网站内容要缭绕关键词去做,小型网站绝质应用关键词相关的纲录情势入止文章展现。
2、选择的闭键词必需是用户无才能来查询的词(也就是要害词的冷度,人们做关键词的排实的时分便要选购根源词的暖度来做推狭,刚刚开端劣化的时侯,不能做很热点的词那样的词对于我们来道非比拟易劣化下去的,也没有能是这类太寒门的词,固然这样的词太轻易做到百度的第一位,
但是这样的词出有己来搜救,我们做到第一位也出有实践的意义。)
3、能满意到拜访者恳求的。
简略的来道,就是自用户的角度动身,站在用户的心态下根据她们的习性往设放关键词。
少头关键词的选购:
通功网站的构念和网站的相关业务相商讨的关键词,或者则通过对于脚战搜索引擎去开掘相当的关键词。最初说一上,网站内容要缭绕关键词去做,小型网站绝质应用关键词相关的纲录情势入止文章展现。
另外正在写这个的时侯,我念到一个答题,这个问题才能答的有面长稚,但是我实的有正点没有清楚,呵呵!就是自己皆道的一类简短的推狭方式就是到各大型的峰会,专主下去些硬文,或许宣布本人的白章,他人来单造你的文章,就相称于她们给你做了外部衔接了,
但是重要是,在复造文章的时分,他人皆是正在忘事原内功滤掉了衔接的代码,那样她们尚且单制了你的文章,委婉载到她们站下先,应用的是她们修正先的白章,也就不是你的本文章了,这样没有便败了她们本人的旧文章吗?这这样的旧文章确定非出有了人们站的连交吧!
这人们如何道是别人复制你的文章先,便相称给您做了外部衔接呢!仍是网坐有一类功效,只需无单制那种文章的时侯,主动正在搜救引擎外以为别己复造了你的白章几主,即便是修正后,但是在他复制的时分以前记载了,所以借非相该给你做了外部链交!但是这种当
当是搜索引擎的管辖范畴了!感到这样的答题有面长稚!希
与网站推广工具-网站关键词之seo优化长尾词相关文章:
·A5优化小组推荐:免费SEO工具仍然可以披荆斩
·10个适宜博客的SEO优化工具站群系统
·网编SEO进阶:推荐一款比较好的在线SEO优化工
·网络推广人员须要把握的九大查询工具站群工具
·SEO优化工具-芭奇管家 V3.018站群工具
·勤奋的卓卓实战经验:网络营销到底是什么?自
本文标题:网站推广工具-网站关键词之seo优化长尾词
本文地址: 查看全部
网站推广工具-网站关键词之seo优化长尾词
网站推广工具,也就是这些于网站外容由相干性的关键词,更少的时侯她们是暖门关键词与是热点关键词的组开,或许是热点关键词取小众根源词的组开。
长尾关键词应该知足3个基础前提:
1、彼要害词取您的网坐外容由管无闭;
2、选择的关键词必需是用户有才能来查询的词;
3、能知足到拜访者恳求的。
简略的来道,就是自用户的角度动身,站在用户的心态下根据她们的习性往设放关键词。
少头根源词的选购:
通过网站的构念战网站的相干业务相商讨的关键词,或者则通功对于脚战搜救引擎往开掘相当的关键词。最初说一上,网站内容要缭绕关键词去做,小型网站绝质应用关键词相关的纲录情势入止文章展现。
2、选择的闭键词必需是用户无才能来查询的词(也就是要害词的冷度,人们做关键词的排实的时分便要选购根源词的暖度来做推狭,刚刚开端劣化的时侯,不能做很热点的词那样的词对于我们来道非比拟易劣化下去的,也没有能是这类太寒门的词,固然这样的词太轻易做到百度的第一位,
但是这样的词出有己来搜救,我们做到第一位也出有实践的意义。)
3、能满意到拜访者恳求的。
简略的来道,就是自用户的角度动身,站在用户的心态下根据她们的习性往设放关键词。
少头关键词的选购:
通功网站的构念和网站的相关业务相商讨的关键词,或者则通过对于脚战搜索引擎去开掘相当的关键词。最初说一上,网站内容要缭绕关键词去做,小型网站绝质应用关键词相关的纲录情势入止文章展现。
另外正在写这个的时侯,我念到一个答题,这个问题才能答的有面长稚,但是我实的有正点没有清楚,呵呵!就是自己皆道的一类简短的推狭方式就是到各大型的峰会,专主下去些硬文,或许宣布本人的白章,他人来单造你的文章,就相称于她们给你做了外部衔接了,
但是重要是,在复造文章的时分,他人皆是正在忘事原内功滤掉了衔接的代码,那样她们尚且单制了你的文章,委婉载到她们站下先,应用的是她们修正先的白章,也就不是你的本文章了,这样没有便败了她们本人的旧文章吗?这这样的旧文章确定非出有了人们站的连交吧!
这人们如何道是别人复制你的文章先,便相称给您做了外部衔接呢!仍是网坐有一类功效,只需无单制那种文章的时侯,主动正在搜救引擎外以为别己复造了你的白章几主,即便是修正后,但是在他复制的时分以前记载了,所以借非相该给你做了外部链交!但是这种当
当是搜索引擎的管辖范畴了!感到这样的答题有面长稚!希
与网站推广工具-网站关键词之seo优化长尾词相关文章:
·A5优化小组推荐:免费SEO工具仍然可以披荆斩
·10个适宜博客的SEO优化工具站群系统
·网编SEO进阶:推荐一款比较好的在线SEO优化工
·网络推广人员须要把握的九大查询工具站群工具
·SEO优化工具-芭奇管家 V3.018站群工具
·勤奋的卓卓实战经验:网络营销到底是什么?自
本文标题:网站推广工具-网站关键词之seo优化长尾词
本文地址:
如何提升单页面关键词排名?
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2020-08-22 12:28
10.假如你不是优化前辈,尽量把热门或则其他词汇放到首页来做,首页的权重高,见效快;
单页面里面的热门词不要超过4个,不是热门词汇可选择二级页面处理;
11.旧网站你保留了吗?保留路径更改了吗?如果有新旧两个站,请使用301转向处理好;
302绑架,在你的脑海中永远消失;
12.你每晚原创吗?
关键词(原创)上线的时间要考虑,早上下班的第一件事情就做;
你准本的材料或则是顾客给你的材料是否是网站转载千万遍的东西;
新手可以不顾网站内容质量,去做伪原创;
老手要在整篇文章中抒发你自己的观点;
原创内容要多点,最好是300~1000字,最重要的关键词尽量出现在后面;
网站关键词的密度不要高于3%,尽量不要低于15%,具体情况具体对待。
13.菜鸟第一次做:力度和范围可以小,但是决不能大;且记住:新手外链为王,很适宜你;
老手要懂得如何去分辨提取有效的外链;
14.半个月把新网站中的热门关键词做到首页的说法的人,永远不要与之为伍;
网站优化,实例为王,因为你们都在和搜索引擎玩游戏,看谁的牌出的好;
网站优化是个系统的工程;
优化讲求功到自然成;
15.网站中不要有负面言论;
尽量少使用群发软件做网站宣传或则做外链,网络蜘蛛并不是傻蛋;
16.英文网站优化要考虑域名的诱因;
英文网站优化在生成静态页面重要收录关键词;
动态网站最好是使用能生成静态页面的技术
17.不要指望一个关键词能带来多少流量,要流量就要做多个关键词;并且内容的专业才是网站好坏的真谛;
18.菜鸟永远在他人的博客上或则峰会中写伪原创文章;
老手永远自己写文章,然后他人疯狂转载;
19.pr值无论是百度还是微软目前都还比较重要;
pr值在yahoo英语的重要性大于域名的重要性;
20.不要三天打鱼,两天晒网,让蜘蛛喝完大餐之后饿日子;
21.门户网站优化须要顾客的配合;
22.网站优化的前辈本身应当是懂些程序;
23.内链在网站中也是影响排行的一个诱因;
内链的链接不能重复太多;
24.h1标签建议规范使用;
h2标签建议规范使用;
25.友情链接尽量找pr高的链接;
友情链接尽量同行或则相关做链接(其实我也晓得这似乎很难);
26.导出链接文本中收录你的关键词,并且关键词本身也是链接;
27.锚文本多元化;
a标签多元化;
28.新手永远是看技术;
老手不但要看技术,还要看利益均衡,知道舍得的重要性;
29.搜索引擎的优异排行是网站各项优化的结果;
关键词(原创)上线的时间要考虑,早上下班的第一件事情就做;你准本的材料或则是顾客给你的材料是否是网站转载千万遍的东西;
新手可以不顾网站内容质量,去做伪原创;
老手要在整篇文章中抒发你自己的观点;
原创内容要多点,最好是300~1000字,最重要的关键词尽量出现在后面;
网站关键词的密度不要高于3%,尽量不要低于15%,具体情况具体对待。
13.菜鸟第一次做:力度和范围可以小,但是决不能大;且记住:新手外链为王,很适宜你;
老手要懂得如何去分辨提取有效的外链;
14.半个月把新网站中的热门关键词做到首页的说法的人,永远不要与之为伍;
网站优化,实例为王,因为你们都在和搜索引擎玩游戏,看谁的牌出的好;
网站优化是个系统的工程;
优化讲求功到自然成;
15.网站中不要有负面言论;
尽量少使用群发软件做网站宣传或则做外链,网络蜘蛛并不是傻蛋;
16.英文网站优化要考虑域名的诱因;
英文网站优化在生成静态页面重要收录关键词;
动态网站最好是使用能生成静态页面的技术
17.不要指望一个关键词能带来多少流量,要流量就要做多个关键词;并且内容的专业才是网站好坏的真谛;
18.菜鸟永远在他人的博客上或则峰会中写伪原创文章;
老手永远自己写文章,然后他人疯狂转载;
19.pr值无论是百度还是微软目前都还比较重要;
pr值在yahoo英语的重要性大于域名的重要性;
20.不要三天打鱼,两天晒网,让蜘蛛喝完大餐之后饿日子;
21.门户网站优化须要顾客的配合;
22.网站优化的前辈本身应当是懂些程序;
23.内链在网站中也是影响排行的一个诱因;
内链的链接不能重复太多;
24.h1标签建议规范使用;
h2标签建议规范使用;
25.友情链接尽量找pr高的链接;
友情链接尽量同行或则相关做链接(其实我也晓得这似乎很难);
26.导出链接文本中收录你的关键词,并且关键词本身也是链接;
27.锚文本多元化;
a标签多元化;
28.新手永远是看技术;
老手不但要看技术,还要看利益均衡,知道舍得的重要性;
29.搜索引擎的优异排行是网站各项优化的结果;
30.请不要掌握里面说的29条当作金科玉律,能理解而且努力去创新才是王者。
与怎样提升单页面关键词排名?相关文章:
·长沙网站优化-如何递交目录
·谈谈网站优化及网路推广工程中的工作流程问题
·企业网站优化策略
·长沙推广杭州推广网站长沙网路推广杭州网站推
·我要做网站,长沙我要做网站,长沙网站设计南京
·网站搜索引擎优化六步骤
本文标题:如何提升单页面关键词排名?
本文地址: 查看全部
如何提升单页面关键词排名?
10.假如你不是优化前辈,尽量把热门或则其他词汇放到首页来做,首页的权重高,见效快;
单页面里面的热门词不要超过4个,不是热门词汇可选择二级页面处理;
11.旧网站你保留了吗?保留路径更改了吗?如果有新旧两个站,请使用301转向处理好;
302绑架,在你的脑海中永远消失;
12.你每晚原创吗?
关键词(原创)上线的时间要考虑,早上下班的第一件事情就做;
你准本的材料或则是顾客给你的材料是否是网站转载千万遍的东西;
新手可以不顾网站内容质量,去做伪原创;
老手要在整篇文章中抒发你自己的观点;
原创内容要多点,最好是300~1000字,最重要的关键词尽量出现在后面;
网站关键词的密度不要高于3%,尽量不要低于15%,具体情况具体对待。
13.菜鸟第一次做:力度和范围可以小,但是决不能大;且记住:新手外链为王,很适宜你;
老手要懂得如何去分辨提取有效的外链;
14.半个月把新网站中的热门关键词做到首页的说法的人,永远不要与之为伍;
网站优化,实例为王,因为你们都在和搜索引擎玩游戏,看谁的牌出的好;
网站优化是个系统的工程;
优化讲求功到自然成;
15.网站中不要有负面言论;
尽量少使用群发软件做网站宣传或则做外链,网络蜘蛛并不是傻蛋;
16.英文网站优化要考虑域名的诱因;
英文网站优化在生成静态页面重要收录关键词;
动态网站最好是使用能生成静态页面的技术
17.不要指望一个关键词能带来多少流量,要流量就要做多个关键词;并且内容的专业才是网站好坏的真谛;
18.菜鸟永远在他人的博客上或则峰会中写伪原创文章;
老手永远自己写文章,然后他人疯狂转载;
19.pr值无论是百度还是微软目前都还比较重要;
pr值在yahoo英语的重要性大于域名的重要性;
20.不要三天打鱼,两天晒网,让蜘蛛喝完大餐之后饿日子;
21.门户网站优化须要顾客的配合;
22.网站优化的前辈本身应当是懂些程序;
23.内链在网站中也是影响排行的一个诱因;
内链的链接不能重复太多;
24.h1标签建议规范使用;
h2标签建议规范使用;
25.友情链接尽量找pr高的链接;
友情链接尽量同行或则相关做链接(其实我也晓得这似乎很难);
26.导出链接文本中收录你的关键词,并且关键词本身也是链接;
27.锚文本多元化;
a标签多元化;
28.新手永远是看技术;
老手不但要看技术,还要看利益均衡,知道舍得的重要性;
29.搜索引擎的优异排行是网站各项优化的结果;
关键词(原创)上线的时间要考虑,早上下班的第一件事情就做;你准本的材料或则是顾客给你的材料是否是网站转载千万遍的东西;
新手可以不顾网站内容质量,去做伪原创;
老手要在整篇文章中抒发你自己的观点;
原创内容要多点,最好是300~1000字,最重要的关键词尽量出现在后面;
网站关键词的密度不要高于3%,尽量不要低于15%,具体情况具体对待。
13.菜鸟第一次做:力度和范围可以小,但是决不能大;且记住:新手外链为王,很适宜你;
老手要懂得如何去分辨提取有效的外链;
14.半个月把新网站中的热门关键词做到首页的说法的人,永远不要与之为伍;
网站优化,实例为王,因为你们都在和搜索引擎玩游戏,看谁的牌出的好;
网站优化是个系统的工程;
优化讲求功到自然成;
15.网站中不要有负面言论;
尽量少使用群发软件做网站宣传或则做外链,网络蜘蛛并不是傻蛋;
16.英文网站优化要考虑域名的诱因;
英文网站优化在生成静态页面重要收录关键词;
动态网站最好是使用能生成静态页面的技术
17.不要指望一个关键词能带来多少流量,要流量就要做多个关键词;并且内容的专业才是网站好坏的真谛;
18.菜鸟永远在他人的博客上或则峰会中写伪原创文章;
老手永远自己写文章,然后他人疯狂转载;
19.pr值无论是百度还是微软目前都还比较重要;
pr值在yahoo英语的重要性大于域名的重要性;
20.不要三天打鱼,两天晒网,让蜘蛛喝完大餐之后饿日子;
21.门户网站优化须要顾客的配合;
22.网站优化的前辈本身应当是懂些程序;
23.内链在网站中也是影响排行的一个诱因;
内链的链接不能重复太多;
24.h1标签建议规范使用;
h2标签建议规范使用;
25.友情链接尽量找pr高的链接;
友情链接尽量同行或则相关做链接(其实我也晓得这似乎很难);
26.导出链接文本中收录你的关键词,并且关键词本身也是链接;
27.锚文本多元化;
a标签多元化;
28.新手永远是看技术;
老手不但要看技术,还要看利益均衡,知道舍得的重要性;
29.搜索引擎的优异排行是网站各项优化的结果;
30.请不要掌握里面说的29条当作金科玉律,能理解而且努力去创新才是王者。
与怎样提升单页面关键词排名?相关文章:
·长沙网站优化-如何递交目录
·谈谈网站优化及网路推广工程中的工作流程问题
·企业网站优化策略
·长沙推广杭州推广网站长沙网路推广杭州网站推
·我要做网站,长沙我要做网站,长沙网站设计南京
·网站搜索引擎优化六步骤
本文标题:如何提升单页面关键词排名?
本文地址:
昌江关键词采集排名优化
采集交流 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2020-08-22 00:24
昌江关键词采集排名优化
解析SEM与SEO的优缺点
SEM和SEO都是网路营销中很重要的手法,百度推广与SEO的区别
百度推广是竞价也就是SEM,是按点击付费,点击一次多少钱这样的,能始终在百度前几位。 SEO是百度自然排行,通过对网站的优化,来提升网站的权重,从而获得好的关键词排行,SEO不稳定,做到百度首页也要花很长时间的。
但好多刚接触这一行的人不是太清楚这二者之间的区别,国内很多人都误会了SEM和SEO的关系。下面就让顺时seo工程师来告诉你SEM和SEO之间的那点事!
首先,网站SEO优化,SEM和SEO是收录关系,而不是付费广告和自然排行的关系。SEO和SEO区别?
SEO(Search Engine Optimization)为搜索引擎优化。搜索引擎优化是一种借助搜索引擎的搜索规则来提升目前网站在有关搜索引擎内的自然排行的形式。SEO的目的理解是:为网站提供生态式的自我营销解决方案,让网站在行业内抢占领先地位,从而获得
SEM是搜索引擎营销的简称。即是所有围绕着搜索引擎举办的一切营销活动都叫Marketing。而PPC(Pay Per Click)、SEO (Search Engine Optimization) 都是围绕着搜索引擎展开的营销活动,他们都属于SEM。只是在国外,因很多人分不清概念,就出现了SEM是付费广告,SEO是自然排行的错误概念,并且这个错误概念以讹传讹的还被普及了。
话说,顺时seo工程师逛知乎的时侯,看见如此两句话,seo是哪些意思?
SEO是由英语Search Engine Optimization简写而至, 中文译音为“搜索引擎优化”。SEO是指通过对网站内部调整优化及站外优化,使网站满足搜索引擎收录排行需求,在搜索引擎中关键词排行增强,从而把精准用户带到网站,获得免费流量,产生直接销售或
是如此形容SEO与SEM的!拿泡美女打个比方:富二代(SEM):直接收钱砸,当然也可以靠魅力渐渐追;穷屌丝(SEO):只能一步一步悲催地追! 发外链的掩面而泣,真心认为叙述得很形象!
SEM:Search Engine Marketing,中文译为搜索引擎营销,什么是seo设置?
用的搜外6系统,对这个不是太了解,关于seo 设置应当是站内的基础优化 1、做301定向,跳转到带的 2、站内链接排查去index 3、面包屑导航优化 4、做robots.txt文件同时可以放网站地图sitemap 5、绑定熊掌号,做好主动推送,做好手机网站 6、
是指在搜索引擎上推广网站,提高网站可见度,从而带来流量的网路营销活动。SEM的方式包括搜索引擎优化(SEO)、付费排行、精准广告以及付费收录,其中以SEO和PPC最为常见。
SEO和SEM二者目的相同,都是为了让网站销售和品牌建设;不同的是实现方法:SEO是通过技术手段让获得好的自然排行;SEM可以通过技术手段(SEO)和付费手段(PPC)等。SEM是哪些意思? SEO和SEM的区别是哪些?
SEO是由英语Search Engine Optimization简写而至, 中文译音为“搜索引擎优化”。SEO是指通过对网站内部调整优化及站外优化,使网站满足搜索引擎收录排行需求,在搜索引擎中关键词排行增强,从而把精准用户带到网站,获得免费流量,产生直接销售或
SEO的作用是借助搜索引擎提高自己某个特定关键词的排行。SEM是在百度花钱进行推广,按点击收费。
SEM重视的是哪个最后的“M”。因为SEO的作用是借助搜索引擎提高自己某个特定关键词的排行。做到这一步还不能真正意义上的营销了。你试想一下,虽然有些网站排名第一页的前三名,但是标题和描述不吸引人,别人就是不点击;虽然点击了,但是网站打开特别慢,甚至打不开,客户也会马上关掉网页而点击下一个搜索结果,或者是,当点击进去之后,一看如同个垃圾站,广告站,还不停的跳广告。客户也会把上关掉网页。
所以,顺时seo工程师想说,SEO只是手段,M才是解决问题的重点。因为M就是营销的意思,M就得考虑这种诱因,不管是点击付费广告也好,还是哪些广告也好,SEM不能单单只理解是做点击广告就行。哪怕做广告,没有具体的SEM计划,一切也是徒劳。接下来,顺时seo工程师给你们分享一下SEM和SEO的优缺点!
SEO的优点:1.见效快:充值后设置关键词价钱后即刻就可以步入百度排名前十,SEO推广和SEO优化有哪些区别呢,是不是一样的呀?
SEO与网路推广的区别: 首先,从概念上来说,网络推广就是企业从开始申请域名、租用空间、网站备-案、建立网站、直到网站正式上线开始即便是介入了网路推广活动,而一般我们所指的网路推广是指通过互联网的种种手段,进行的宣传推广等活动,确切
位置可以自己控制。2.关键词数目无限制:可以在后台设置无数地关键词进行推广,数量自己控制,没有任何限制。3.关键词不分难易程度:不论多么热门,只要你想做,你都可以步入前三甚至第一。
SEO的优缺点:1.见效慢:通过网站优化获得排行是难以速成的,一般难度的词大概须要2-3个月的时间,如果难度更大的词则须要4-5个月甚至更久。
陵水热门关键字安全可靠 - 昌江刷关键词安全可靠 - 陵水网站seo安全可靠 查看全部
昌江关键词采集排名优化
昌江关键词采集排名优化
解析SEM与SEO的优缺点
SEM和SEO都是网路营销中很重要的手法,百度推广与SEO的区别
百度推广是竞价也就是SEM,是按点击付费,点击一次多少钱这样的,能始终在百度前几位。 SEO是百度自然排行,通过对网站的优化,来提升网站的权重,从而获得好的关键词排行,SEO不稳定,做到百度首页也要花很长时间的。
但好多刚接触这一行的人不是太清楚这二者之间的区别,国内很多人都误会了SEM和SEO的关系。下面就让顺时seo工程师来告诉你SEM和SEO之间的那点事!
首先,网站SEO优化,SEM和SEO是收录关系,而不是付费广告和自然排行的关系。SEO和SEO区别?
SEO(Search Engine Optimization)为搜索引擎优化。搜索引擎优化是一种借助搜索引擎的搜索规则来提升目前网站在有关搜索引擎内的自然排行的形式。SEO的目的理解是:为网站提供生态式的自我营销解决方案,让网站在行业内抢占领先地位,从而获得
SEM是搜索引擎营销的简称。即是所有围绕着搜索引擎举办的一切营销活动都叫Marketing。而PPC(Pay Per Click)、SEO (Search Engine Optimization) 都是围绕着搜索引擎展开的营销活动,他们都属于SEM。只是在国外,因很多人分不清概念,就出现了SEM是付费广告,SEO是自然排行的错误概念,并且这个错误概念以讹传讹的还被普及了。
话说,顺时seo工程师逛知乎的时侯,看见如此两句话,seo是哪些意思?
SEO是由英语Search Engine Optimization简写而至, 中文译音为“搜索引擎优化”。SEO是指通过对网站内部调整优化及站外优化,使网站满足搜索引擎收录排行需求,在搜索引擎中关键词排行增强,从而把精准用户带到网站,获得免费流量,产生直接销售或
是如此形容SEO与SEM的!拿泡美女打个比方:富二代(SEM):直接收钱砸,当然也可以靠魅力渐渐追;穷屌丝(SEO):只能一步一步悲催地追! 发外链的掩面而泣,真心认为叙述得很形象!
SEM:Search Engine Marketing,中文译为搜索引擎营销,什么是seo设置?
用的搜外6系统,对这个不是太了解,关于seo 设置应当是站内的基础优化 1、做301定向,跳转到带的 2、站内链接排查去index 3、面包屑导航优化 4、做robots.txt文件同时可以放网站地图sitemap 5、绑定熊掌号,做好主动推送,做好手机网站 6、
是指在搜索引擎上推广网站,提高网站可见度,从而带来流量的网路营销活动。SEM的方式包括搜索引擎优化(SEO)、付费排行、精准广告以及付费收录,其中以SEO和PPC最为常见。

SEO和SEM二者目的相同,都是为了让网站销售和品牌建设;不同的是实现方法:SEO是通过技术手段让获得好的自然排行;SEM可以通过技术手段(SEO)和付费手段(PPC)等。SEM是哪些意思? SEO和SEM的区别是哪些?
SEO是由英语Search Engine Optimization简写而至, 中文译音为“搜索引擎优化”。SEO是指通过对网站内部调整优化及站外优化,使网站满足搜索引擎收录排行需求,在搜索引擎中关键词排行增强,从而把精准用户带到网站,获得免费流量,产生直接销售或
SEO的作用是借助搜索引擎提高自己某个特定关键词的排行。SEM是在百度花钱进行推广,按点击收费。
SEM重视的是哪个最后的“M”。因为SEO的作用是借助搜索引擎提高自己某个特定关键词的排行。做到这一步还不能真正意义上的营销了。你试想一下,虽然有些网站排名第一页的前三名,但是标题和描述不吸引人,别人就是不点击;虽然点击了,但是网站打开特别慢,甚至打不开,客户也会马上关掉网页而点击下一个搜索结果,或者是,当点击进去之后,一看如同个垃圾站,广告站,还不停的跳广告。客户也会把上关掉网页。
所以,顺时seo工程师想说,SEO只是手段,M才是解决问题的重点。因为M就是营销的意思,M就得考虑这种诱因,不管是点击付费广告也好,还是哪些广告也好,SEM不能单单只理解是做点击广告就行。哪怕做广告,没有具体的SEM计划,一切也是徒劳。接下来,顺时seo工程师给你们分享一下SEM和SEO的优缺点!
SEO的优点:1.见效快:充值后设置关键词价钱后即刻就可以步入百度排名前十,SEO推广和SEO优化有哪些区别呢,是不是一样的呀?
SEO与网路推广的区别: 首先,从概念上来说,网络推广就是企业从开始申请域名、租用空间、网站备-案、建立网站、直到网站正式上线开始即便是介入了网路推广活动,而一般我们所指的网路推广是指通过互联网的种种手段,进行的宣传推广等活动,确切
位置可以自己控制。2.关键词数目无限制:可以在后台设置无数地关键词进行推广,数量自己控制,没有任何限制。3.关键词不分难易程度:不论多么热门,只要你想做,你都可以步入前三甚至第一。
SEO的优缺点:1.见效慢:通过网站优化获得排行是难以速成的,一般难度的词大概须要2-3个月的时间,如果难度更大的词则须要4-5个月甚至更久。
陵水热门关键字安全可靠 - 昌江刷关键词安全可靠 - 陵水网站seo安全可靠
邮件手动批量发送精灵与关键词采集邮箱器下载评论软件详情对比
采集交流 • 优采云 发表了文章 • 0 个评论 • 454 次浏览 • 2020-08-19 11:29
用途:些软件可以依照产品关键字、行业关键字、目标顾客产品关键字通过商业引擎、国家区域引擎、行业引擎搜索全球潜在顾客信息。软件支持灵活运用关键字组合搜索你所想要的邮箱地址,从而为你的产品推广出去。它可以用在外贸行业中。它是一个邮箱搜索软件+关键词和邮箱后缀名采集邮箱+关键词采集邮箱软件(无数目限制)的采集邮箱功能。
此软件的特性1说明:
此软件的采集条件:“输入你有关键词 + 后缀名采集” 为条件采集在指定的网站上
比如:百度,Googel,搜搜,搜狗,雅虎,Yandex[俄]等国际小型网站上采集当前最新的邮箱地址信息。
【注:功能每采集一次,要重新打开软件再采集其它的邮箱地址信息】在以上小型国际网上所采集的邮箱时,在本软件的一侧可能会出现相同的邮箱地址,这是正常的现象。因为在这种小型的网站上它有重复的快照信息,软件会把这种邮箱总的采集在一起,但是在你每采集完成以后,在导入你所采集的邮箱时,软件有一个功能 - “导出时清除重复邮箱” 和 - “导出时清除空行”,让你所采集的邮箱全部不再是重复的问题。采集完后可以自行导入,选择xls或txt按键,文件会手动保存在你所选择的文件夹内。
此软件的特性2说明:
此软件的采集条件:“输入你有关键词” 为条件采集在指定的网站上
比如:百度,Googel,搜搜,搜狗,雅虎,Yandex[俄]等国际小型网站上采集当前最新的邮箱地址信息。此功能在采集邮箱时,它将会有 - 邮箱地址信息 + 采集的标题 会同时出现在你的面前。在以上小型国际网上所采集的邮箱时,在本软件的右侧可能会出现相同的邮箱地址,这是正常的现象。因为在这种小型的网站上它有重复的快照信息,软件会把这种邮箱总的采集在一起,但是在你每采集完成以后,在导入你所采集的邮箱时,软件有一个功能 - “导出时清除重复邮箱” 和 - “导出时清除空行”,让你所采集的邮箱全部不再是重复的问题。采集完后可以自行导入,选择xls或txt按键,文件会手动保存在你所选择的文件夹内。
此软件的特性2说明:
你所每次采集的重复邮箱的处理功能说明:当你每一次所采集的邮箱在导入以后,如果当你下一次在采集其它的,但是有一点类似之前的采集关键词时,这里可能两次采集的邮箱有一小点重复,在这里我们的软件也有一个处理重复的功能把你所采集的所有邮箱装入到Excel文件内,然后批量的导出到我们的软件,最后在批量的导入到你所指定的文件夹内,以方你的电邮发送软件使用的强悍的功能 查看全部
邮件手动批量发送精灵与关键词采集邮箱器下载评论软件详情对比
用途:些软件可以依照产品关键字、行业关键字、目标顾客产品关键字通过商业引擎、国家区域引擎、行业引擎搜索全球潜在顾客信息。软件支持灵活运用关键字组合搜索你所想要的邮箱地址,从而为你的产品推广出去。它可以用在外贸行业中。它是一个邮箱搜索软件+关键词和邮箱后缀名采集邮箱+关键词采集邮箱软件(无数目限制)的采集邮箱功能。
此软件的特性1说明:
此软件的采集条件:“输入你有关键词 + 后缀名采集” 为条件采集在指定的网站上
比如:百度,Googel,搜搜,搜狗,雅虎,Yandex[俄]等国际小型网站上采集当前最新的邮箱地址信息。
【注:功能每采集一次,要重新打开软件再采集其它的邮箱地址信息】在以上小型国际网上所采集的邮箱时,在本软件的一侧可能会出现相同的邮箱地址,这是正常的现象。因为在这种小型的网站上它有重复的快照信息,软件会把这种邮箱总的采集在一起,但是在你每采集完成以后,在导入你所采集的邮箱时,软件有一个功能 - “导出时清除重复邮箱” 和 - “导出时清除空行”,让你所采集的邮箱全部不再是重复的问题。采集完后可以自行导入,选择xls或txt按键,文件会手动保存在你所选择的文件夹内。
此软件的特性2说明:
此软件的采集条件:“输入你有关键词” 为条件采集在指定的网站上
比如:百度,Googel,搜搜,搜狗,雅虎,Yandex[俄]等国际小型网站上采集当前最新的邮箱地址信息。此功能在采集邮箱时,它将会有 - 邮箱地址信息 + 采集的标题 会同时出现在你的面前。在以上小型国际网上所采集的邮箱时,在本软件的右侧可能会出现相同的邮箱地址,这是正常的现象。因为在这种小型的网站上它有重复的快照信息,软件会把这种邮箱总的采集在一起,但是在你每采集完成以后,在导入你所采集的邮箱时,软件有一个功能 - “导出时清除重复邮箱” 和 - “导出时清除空行”,让你所采集的邮箱全部不再是重复的问题。采集完后可以自行导入,选择xls或txt按键,文件会手动保存在你所选择的文件夹内。
此软件的特性2说明:
你所每次采集的重复邮箱的处理功能说明:当你每一次所采集的邮箱在导入以后,如果当你下一次在采集其它的,但是有一点类似之前的采集关键词时,这里可能两次采集的邮箱有一小点重复,在这里我们的软件也有一个处理重复的功能把你所采集的所有邮箱装入到Excel文件内,然后批量的导出到我们的软件,最后在批量的导入到你所指定的文件夹内,以方你的电邮发送软件使用的强悍的功能
QQ群在线搜索采集软件 无限制破解版测试可用
采集交流 • 优采云 发表了文章 • 0 个评论 • 504 次浏览 • 2020-08-17 20:15
使用方式:任意注册账号密码登入
主要特点有:指定关键词搜索QQ群(可输入多组),大家可以把关键词细分化进行采集,这样就可以采集的更多!例如:想搜索股票QQ群,可以把股票细分:股票交流、股票行情、股票软件、股票资讯等。如SEO的群,可以分为:SEO优化、网站优化等!(大家可以自由发挥)
--------------------------------------------------------------------------
返回的数组有:QQ群号、QQ群名称、群内成员数目(群人数)、群主的QQ、群的标签(tag)、是否支持旅客步入。
支持导入到excel表格或则txt文本方式!
-------------------------------------------------------------------------
V2新版参数说明,多了几个参数主要为了最大数量化采集,所以速率不会很快:
最大页数:就是个关键词翻页,100就是翻到100页,如果设置为0,则手动辨识不能采集跳过,想速率采集的推荐设置为0
循环次数:就是每位关键词从【1-你设定的页数】循环采集,目的是为了有时候我们手工搜索,每次点击的群都不同,这样可以有效抓取遗漏群
循环间隔:每次翻页的间隔,建议设定3-5秒,太快容易被限制
--------------------------------------------------------------------------
举例:
假设:你设定100,循环3次,就等于1-100,然后在1-100,这样是为了避免有遗漏的情况,以及跳过有临时被限制未能采集的情况。如果你想早日切换到下一个关键词,就调整参数。
建议设置参数:
如果1个关键词想最大化采集:可以设定30-100页,循环3-5次,循环间隔设定:3-5秒(这种循环极大程度防止限制或则遗漏)
如果多个关键词想早日采集:可以设定10-30页,循环1次,同样循环间隔不建议设置过高(这种是速率优先,但是会遗漏不少群)
大家按照前面的讲解,自行调整参数到适宜你的目的。 查看全部
QQ群在线搜索采集软件 无限制破解版测试可用
使用方式:任意注册账号密码登入
主要特点有:指定关键词搜索QQ群(可输入多组),大家可以把关键词细分化进行采集,这样就可以采集的更多!例如:想搜索股票QQ群,可以把股票细分:股票交流、股票行情、股票软件、股票资讯等。如SEO的群,可以分为:SEO优化、网站优化等!(大家可以自由发挥)
--------------------------------------------------------------------------
返回的数组有:QQ群号、QQ群名称、群内成员数目(群人数)、群主的QQ、群的标签(tag)、是否支持旅客步入。
支持导入到excel表格或则txt文本方式!
-------------------------------------------------------------------------
V2新版参数说明,多了几个参数主要为了最大数量化采集,所以速率不会很快:
最大页数:就是个关键词翻页,100就是翻到100页,如果设置为0,则手动辨识不能采集跳过,想速率采集的推荐设置为0
循环次数:就是每位关键词从【1-你设定的页数】循环采集,目的是为了有时候我们手工搜索,每次点击的群都不同,这样可以有效抓取遗漏群
循环间隔:每次翻页的间隔,建议设定3-5秒,太快容易被限制
--------------------------------------------------------------------------
举例:
假设:你设定100,循环3次,就等于1-100,然后在1-100,这样是为了避免有遗漏的情况,以及跳过有临时被限制未能采集的情况。如果你想早日切换到下一个关键词,就调整参数。
建议设置参数:
如果1个关键词想最大化采集:可以设定30-100页,循环3-5次,循环间隔设定:3-5秒(这种循环极大程度防止限制或则遗漏)
如果多个关键词想早日采集:可以设定10-30页,循环1次,同样循环间隔不建议设置过高(这种是速率优先,但是会遗漏不少群)
大家按照前面的讲解,自行调整参数到适宜你的目的。
自动关键词采集器可以自动监测亚马逊平台的大部分热门产品
采集交流 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2021-03-20 08:01
自动关键词采集器可以自动监测亚马逊平台的大部分热门产品,每天都有不断新的产品上架,还有收录量下降的产品自动修改关键词,可以一键全部下架,
第一个,以前是可以的,现在不可以,因为亚马逊更加开放,更大了,有的你想的到的东西都可以出现,他们把关键词收集好放在站内搜索栏的。另外说一下,全球开店你不要经常申请,因为都是一个人申请俩个号,批量不行,谁说批量的好的,你心里没数么,一般都是卖不掉给亚马逊删掉。他可以给你平台筛选这样。其实热销产品,竞争大产品,都有标准。没有任何捷径可以走的。跨境电商之王三十六计,人最弱。
感谢邀请。亚马逊是一个以客户需求为核心,并以客户体验为中心的跨境电商平台。因此产品要过硬,不是热销的产品才有机会成为爆款;其次就是外贸业务为主,做好seo,通过谷歌分析及关键词挖掘,进行产品调整;当然如果拥有自己的供应链,那你就是最核心的人。
通过关键词优化,关键词优化的方式跟第一个差不多,区别是google提供的是热门的产品。
怎么说呢,你可以做这个看看有没有效果,能不能满足你的需求,可以做,但是要针对的话就是amazon,亚马逊的产品很多都是非热销产品,个人感觉第二个靠谱,毕竟google出来了,可以借鉴的价值也大。第一个可以先做出来产品的基本图片就可以,否则空有亚马逊平台也没用。因为我是新人一枚,我懂的不多,也只能这么表达,对不对就不知道了。 查看全部
自动关键词采集器可以自动监测亚马逊平台的大部分热门产品
自动关键词采集器可以自动监测亚马逊平台的大部分热门产品,每天都有不断新的产品上架,还有收录量下降的产品自动修改关键词,可以一键全部下架,
第一个,以前是可以的,现在不可以,因为亚马逊更加开放,更大了,有的你想的到的东西都可以出现,他们把关键词收集好放在站内搜索栏的。另外说一下,全球开店你不要经常申请,因为都是一个人申请俩个号,批量不行,谁说批量的好的,你心里没数么,一般都是卖不掉给亚马逊删掉。他可以给你平台筛选这样。其实热销产品,竞争大产品,都有标准。没有任何捷径可以走的。跨境电商之王三十六计,人最弱。
感谢邀请。亚马逊是一个以客户需求为核心,并以客户体验为中心的跨境电商平台。因此产品要过硬,不是热销的产品才有机会成为爆款;其次就是外贸业务为主,做好seo,通过谷歌分析及关键词挖掘,进行产品调整;当然如果拥有自己的供应链,那你就是最核心的人。
通过关键词优化,关键词优化的方式跟第一个差不多,区别是google提供的是热门的产品。
怎么说呢,你可以做这个看看有没有效果,能不能满足你的需求,可以做,但是要针对的话就是amazon,亚马逊的产品很多都是非热销产品,个人感觉第二个靠谱,毕竟google出来了,可以借鉴的价值也大。第一个可以先做出来产品的基本图片就可以,否则空有亚马逊平台也没用。因为我是新人一枚,我懂的不多,也只能这么表达,对不对就不知道了。
集搜客网络爬虫案例规则+操作步骤及注意事项
采集交流 • 优采云 发表了文章 • 0 个评论 • 1052 次浏览 • 2021-02-04 08:07
一、操作步骤
二、案例规则+操作步骤
注意:在这种情况下,京东搜索具有独立的URL。对于具有独立URL的页面,最简单的方法是为每个关键词构造一个搜索URL,然后将线索URL导入规则中,您可以批量采集而不是设置连续操作,可以参考“构建网站”和“如何管理线索规则”。
第1步:定义一级规则
1.1打开Jishouke Web采集器,输入URL并输入,在加载网页后,单击“定义规则”按钮,您将看到一个显示的浮动窗口,称为工作台,您可以在其中定义规则;
注意:此处的屏幕截图和文字描述均为Jishouke Web采集器版本。如果要安装Firefox插件版本,则没有“定义规则”按钮,但是您应该运行MS Museum。
1.2在工作台中输入第一级规则的主题名称,然后单击“检查重复项”,提示“可以使用此名称”或“名称已被占用,可编辑:是” ,您可以使用此使用者名称,否则请重命名。
1.3此级别的规则主要是设置连续的操作,因此排序框可以随意获取一条信息,并使用它来判断是否对采集器执行采集。双击网页上的信息,输入标签名称,然后单击确认,然后在关键内容上打勾,并输入第一个标签的排序框的名称,然后完成标签映射。
提示:为了准确定位网页信息,单击定义规则将冻结整个网页,并且无法跳转到网页链接。再次单击定义规则以返回到正常的网页模式。
第2步:定义连续的操作
单击工作台的“连续动作”选项卡,单击“新建”按钮创建一个新动作,每个动作的设置方法相同,基本操作如下:
2.1,输入目标使用者名称
此处的目标主题名称是填写第二级主题名称,单击“正在使用谁”以检查目标主题名称是否可用,如果已被占用,则只需更改主题名称即可。
2.2,创建第一个动作:输入
创建一个新动作并选择动作类型作为输入。
2.2.1,填写定位表达式
首先单击输入框,找到输入框的节点,然后单击“自动生成XPath”按钮,可以选择“ Preference id”或“ Preference class”,可以获得输入的xpath表达式框,然后单击“搜索”按钮,检查此xpath是否可以唯一地位于输入框中,如果没有问题,请将xpath复制到定位表达式框中。
注意:定位表达式中的xpath用于锁定操作对象的整个有效操作范围。具体来说,它是指可以通过鼠标成功单击或输入的网页模块。不要在底部找到text()节点。
2.2.2,输入关键词
输入关键词以填写要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词以使用双分号;将每个关键词分开,免费版仅支持5个内的5个关键词,旗舰版可以使用连发杂志功能,支持10,000个内的关键词
2.2.3,输入动作名称
告诉自己该步骤的用途,以便稍后进行修改。
2.3,创建第二个动作:单击
请参考2.2的操作,创建第二个动作,选择类型为click,找到搜索按钮,然后自动生成xpath来检查它是否被锁定到唯一节点,以及是否没有被锁定。问题,将其填写在定位表达式中。
2.4,保存规则
点击“保存规则”按钮以保存已完成的第一级规则
第3步:定义二级规则
3.1,创建一个新规则
创建第二级规则,单击“定义规则”以返回正常的网页模式,输入关键词搜索结果,再次单击“定义规则”以切换到规则制定模式,然后单击“规则”菜单的左上角->“新建”,输入主题名称,其中主题名称是在第一级规则的连续操作中填充的目标主题名称。
3.2,标记您想要的信息采集
3.2.1,在网页上标记所需的信息采集,此处标记产品名称和价格,因为该标记仅对文本信息有效,因此链接是属性节点@href,因此它无法用采集标记链接,但可以进行内容映射,请参阅以下操作以获取详细信息。
3.2.2,用鼠标选择排序框的名称,按鼠标右键,选择“添加”->“收录”以创建用于内容爬行的“链接”,单击在产品名称上的A标记上可以找到它,您可以在属性下找到相应的@href节点,右键单击该节点,然后选择要映射到“链接”的内容。
3.2.3,设置“密钥内容”选项,以便爬网程序可以判断采集规则是否合适。在排序框中,选择不可避免地在网页上可用的标签,然后勾选“关键内容”。在这里,“名称”被选作“关键内容”。
3.2.4,如果仅在前面标记一个产品,则可以获得产品信息。如果要在整个页面上采集每个产品,都可以制作示例副本,否。如果您了解,请参阅基本教程“ 采集列表数据”
3.3,设置翻页路线
设置爬虫路线中的翻页功能,这是标记提示,如果您不了解,请参考基本教程“设置翻页采集”
3.4,保存规则
单击“测试”以检查信息的完整性。如果不完整,则注释可以覆盖以前的内容。检查没有问题后,单击“保存规则”。
第4步:捕获数据
4.1,连续动作是连续执行的,因此只要您运行第一级主题,就不需要运行第二级主题。打开DS计数器,搜索第一级主题名称,单击“单一搜索”或“集合”,可以看到在浏览器窗口中自动输入并搜索了关键词,然后调用第二级主题自动采集搜索结果。
4.2,第一级主题未采集有意义的信息,因此我们仅查看第二级主题文件夹,即可看到采集的搜索结果数据,并搜索关键词默认情况下记录在xml文件的actionvalue字段中,以便它可以一一对应。 查看全部
集搜客网络爬虫案例规则+操作步骤及注意事项
一、操作步骤
二、案例规则+操作步骤
注意:在这种情况下,京东搜索具有独立的URL。对于具有独立URL的页面,最简单的方法是为每个关键词构造一个搜索URL,然后将线索URL导入规则中,您可以批量采集而不是设置连续操作,可以参考“构建网站”和“如何管理线索规则”。
第1步:定义一级规则
1.1打开Jishouke Web采集器,输入URL并输入,在加载网页后,单击“定义规则”按钮,您将看到一个显示的浮动窗口,称为工作台,您可以在其中定义规则;
注意:此处的屏幕截图和文字描述均为Jishouke Web采集器版本。如果要安装Firefox插件版本,则没有“定义规则”按钮,但是您应该运行MS Museum。
1.2在工作台中输入第一级规则的主题名称,然后单击“检查重复项”,提示“可以使用此名称”或“名称已被占用,可编辑:是” ,您可以使用此使用者名称,否则请重命名。
1.3此级别的规则主要是设置连续的操作,因此排序框可以随意获取一条信息,并使用它来判断是否对采集器执行采集。双击网页上的信息,输入标签名称,然后单击确认,然后在关键内容上打勾,并输入第一个标签的排序框的名称,然后完成标签映射。
提示:为了准确定位网页信息,单击定义规则将冻结整个网页,并且无法跳转到网页链接。再次单击定义规则以返回到正常的网页模式。
第2步:定义连续的操作
单击工作台的“连续动作”选项卡,单击“新建”按钮创建一个新动作,每个动作的设置方法相同,基本操作如下:
2.1,输入目标使用者名称
此处的目标主题名称是填写第二级主题名称,单击“正在使用谁”以检查目标主题名称是否可用,如果已被占用,则只需更改主题名称即可。
2.2,创建第一个动作:输入
创建一个新动作并选择动作类型作为输入。
2.2.1,填写定位表达式
首先单击输入框,找到输入框的节点,然后单击“自动生成XPath”按钮,可以选择“ Preference id”或“ Preference class”,可以获得输入的xpath表达式框,然后单击“搜索”按钮,检查此xpath是否可以唯一地位于输入框中,如果没有问题,请将xpath复制到定位表达式框中。
注意:定位表达式中的xpath用于锁定操作对象的整个有效操作范围。具体来说,它是指可以通过鼠标成功单击或输入的网页模块。不要在底部找到text()节点。
2.2.2,输入关键词
输入关键词以填写要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词以使用双分号;将每个关键词分开,免费版仅支持5个内的5个关键词,旗舰版可以使用连发杂志功能,支持10,000个内的关键词
2.2.3,输入动作名称
告诉自己该步骤的用途,以便稍后进行修改。
2.3,创建第二个动作:单击
请参考2.2的操作,创建第二个动作,选择类型为click,找到搜索按钮,然后自动生成xpath来检查它是否被锁定到唯一节点,以及是否没有被锁定。问题,将其填写在定位表达式中。
2.4,保存规则
点击“保存规则”按钮以保存已完成的第一级规则
第3步:定义二级规则
3.1,创建一个新规则
创建第二级规则,单击“定义规则”以返回正常的网页模式,输入关键词搜索结果,再次单击“定义规则”以切换到规则制定模式,然后单击“规则”菜单的左上角->“新建”,输入主题名称,其中主题名称是在第一级规则的连续操作中填充的目标主题名称。
3.2,标记您想要的信息采集
3.2.1,在网页上标记所需的信息采集,此处标记产品名称和价格,因为该标记仅对文本信息有效,因此链接是属性节点@href,因此它无法用采集标记链接,但可以进行内容映射,请参阅以下操作以获取详细信息。
3.2.2,用鼠标选择排序框的名称,按鼠标右键,选择“添加”->“收录”以创建用于内容爬行的“链接”,单击在产品名称上的A标记上可以找到它,您可以在属性下找到相应的@href节点,右键单击该节点,然后选择要映射到“链接”的内容。
3.2.3,设置“密钥内容”选项,以便爬网程序可以判断采集规则是否合适。在排序框中,选择不可避免地在网页上可用的标签,然后勾选“关键内容”。在这里,“名称”被选作“关键内容”。
3.2.4,如果仅在前面标记一个产品,则可以获得产品信息。如果要在整个页面上采集每个产品,都可以制作示例副本,否。如果您了解,请参阅基本教程“ 采集列表数据”
3.3,设置翻页路线
设置爬虫路线中的翻页功能,这是标记提示,如果您不了解,请参考基本教程“设置翻页采集”
3.4,保存规则
单击“测试”以检查信息的完整性。如果不完整,则注释可以覆盖以前的内容。检查没有问题后,单击“保存规则”。
第4步:捕获数据
4.1,连续动作是连续执行的,因此只要您运行第一级主题,就不需要运行第二级主题。打开DS计数器,搜索第一级主题名称,单击“单一搜索”或“集合”,可以看到在浏览器窗口中自动输入并搜索了关键词,然后调用第二级主题自动采集搜索结果。
4.2,第一级主题未采集有意义的信息,因此我们仅查看第二级主题文件夹,即可看到采集的搜索结果数据,并搜索关键词默认情况下记录在xml文件的actionvalue字段中,以便它可以一一对应。
汇总:Python学习笔记(19)自动搜索关键词采集信息—以京东为例
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2020-12-21 08:12
一、操作步骤
如果网页上有一个搜索框,但搜索结果页面没有单独的URL,并且如果您要采集个搜索结果,则可以直接制定采集不能的规则,并且您必须执行连续操作(输入+单击)以实现自动输入关键词和搜索,然后搜索采集数据。让我们以京东搜索为例来演示自动搜索采集。操作步骤如下:
二、案例规则+操作步骤
**注意:**在这种情况下,京东搜索具有独立的URL。对于具有独立URL的页面,最简单的方法是为每个关键词构造一个搜索URL,然后将线索URL导入规则中,您可以批量采集而不是设置连续操作
第1步:定义一级规则
1.1打开Jishouke Web采集器,输入URL并按Enter,然后在加载网页后单击“定义规则”按钮,您将看到一个显示的浮动窗口,称为工作台,您可以在该窗口上工作定义规则;
注意:此处的屏幕截图和文字描述是Jishouke的所有Web爬网程序版本。如果安装Firefox插件版本,则没有“定义规则”按钮。相反,您应该运行MS Muse。
1.2在工作台中输入一级规则的主题名称,然后单击“检查重复项”,提示“可以使用该名称”或“该名称已被占用,可编辑:是” ,您可以使用此使用者名称,否则请重命名。
1.3此级别的规则主要是设置连续的操作,因此排序框可以随意获取一条信息,并使用它来判断是否对采集器执行采集。双击网页上的信息,输入标签名称,勾选确认,然后在关键内容上勾选,输入第一个标签的分类框名称,即可完成标签映射。
提示:为了准确定位网页信息,单击定义规则将冻结整个网页,并且无法跳转到网页链接。再次单击定义规则以返回到正常的网页模式。
第2步:定义连续的操作
单击工作台的“连续动作”选项卡,单击“新建”按钮创建一个新动作,每个动作的设置方法相同,基本操作如下:
2.1,输入目标主题名称
此处的目标主题名称是填写第二级主题名称,单击“正在使用谁”以检查目标主题名称是否可用,如果已被占用,则只需更改主题名称即可。
2.2,创建第一个动作:输入
创建一个新动作并选择动作类型作为输入。
2.2.1,填写定位表达式
首先单击输入框,找到输入框的节点,然后单击“自动生成XPath”按钮,可以选择“ Preference id”或“ Preference class”,可以获得输入的xpath表达式框,然后单击“搜索”按钮,检查此xpath是否可以唯一地位于输入框中,如果没有问题,请将xpath复制到定位表达式框中。
**注意:**定位表达式中的xpath用来锁定动作对象的整个有效操作范围,特别是指可以通过鼠标成功单击或输入的网页模块,而不是在底部找到text()节点。
2.2.2,输入关键词
输入关键词以填写要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词以使用双分号;将每个关键词分开,免费版仅支持5个内的5个关键词,旗舰版可以使用连发杂志功能,支持10,000个内的关键词
2.2.3,输入动作名称
告诉自己该步骤的用途,以便稍后进行修改。
2.3,创建第二个动作:单击
请参考2.2的操作,创建第二个动作,选择类型为click,找到搜索按钮,然后自动生成xpath来检查它是否被锁定到唯一节点(如果没有)问题,将其填写在定位表达式中。
2.4,保存规则
点击“保存规则”按钮以保存已完成的一级规则
第3步:定义二级规则
3.1,创建一个新规则
创建第二级规则,单击“定义规则”以返回正常的网页模式,输入关键词搜索结果,再次单击“定义规则”以切换到规则制定模式,然后单击“规则”菜单的左上角->“新建”,输入主题名称,其中主题名称是在第一级规则的连续操作中填充的目标主题名称。
3.2,标记您想要的信息采集
3.2.1,在网页上标记您想要的信息采集,这里是产品名称和价格的标记,因为该标记仅对文本信息有效,因此指向产品详细信息的链接是属性节点@href,因此,您不能在链接上进行这样直观的标记,但是要进行内容映射,请参阅以下操作以获取详细信息。
3.2.2,单击产品名称,下面的DOM节点找到A标签,展开A标签下的attribute节点,您可以找到代表URL的@href节点,右键单击节点,然后选择“新建捕获”,然后单击“获取内容”,输入一个名称,通常为爬网的内容指定一个与地址相关的名称,例如“下属URL”或“下属链接”等。然后在工作台上,我看到已抓取的内容可用。如果您仍要进入产品详细信息页面采集,则必须检查与该抓取内容有关的较低级线索以进行分层抓取。
3.2.3,设置“密钥内容”选项,以便爬网程序可以判断采集规则是否合适。在排序框中,选择不可避免地在网页上可用的标签,然后勾选“关键内容”。在这里,“名称”被选作“关键内容”。
3.2.4,如果仅在前面标记一个产品,则可以获得产品信息。如果您想在整个页面上采集每个产品,都可以制作一个样本副本,否。如果您理解,请参阅基本教程“ 采集列表数据”
3.3,设置翻页路线
设置爬虫路线中的翻页功能,这是标记提示,如果您不了解,请参考基本教程“设置翻页采集”
3.4,保存规则
单击“测试”以检查信息的完整性。如果不完整,则注释可以覆盖以前的内容。检查没有问题后,单击“保存规则”。
第4步:捕获数据
4.1,连续动作是连续执行的,因此只要您运行第一级主题,就不需要运行第二级主题。打开DS计数器,搜索第一级主题名称,单击“单一搜索”或“集合”,可以看到在浏览器窗口中自动输入并搜索了关键词,然后调用第二级主题自动采集搜索结果。
4.2,第一级主题未采集有意义的信息,因此我们仅查看第二级主题的文件夹,即可看到采集的搜索结果数据,并搜索关键词 Is默认情况下记录在xml文件的actionvalue字段中,以便它可以一一对应。 查看全部
汇总:Python学习笔记(19)自动搜索关键词采集信息—以京东为例
一、操作步骤
如果网页上有一个搜索框,但搜索结果页面没有单独的URL,并且如果您要采集个搜索结果,则可以直接制定采集不能的规则,并且您必须执行连续操作(输入+单击)以实现自动输入关键词和搜索,然后搜索采集数据。让我们以京东搜索为例来演示自动搜索采集。操作步骤如下:
二、案例规则+操作步骤
**注意:**在这种情况下,京东搜索具有独立的URL。对于具有独立URL的页面,最简单的方法是为每个关键词构造一个搜索URL,然后将线索URL导入规则中,您可以批量采集而不是设置连续操作
第1步:定义一级规则
1.1打开Jishouke Web采集器,输入URL并按Enter,然后在加载网页后单击“定义规则”按钮,您将看到一个显示的浮动窗口,称为工作台,您可以在该窗口上工作定义规则;
注意:此处的屏幕截图和文字描述是Jishouke的所有Web爬网程序版本。如果安装Firefox插件版本,则没有“定义规则”按钮。相反,您应该运行MS Muse。
1.2在工作台中输入一级规则的主题名称,然后单击“检查重复项”,提示“可以使用该名称”或“该名称已被占用,可编辑:是” ,您可以使用此使用者名称,否则请重命名。
1.3此级别的规则主要是设置连续的操作,因此排序框可以随意获取一条信息,并使用它来判断是否对采集器执行采集。双击网页上的信息,输入标签名称,勾选确认,然后在关键内容上勾选,输入第一个标签的分类框名称,即可完成标签映射。
提示:为了准确定位网页信息,单击定义规则将冻结整个网页,并且无法跳转到网页链接。再次单击定义规则以返回到正常的网页模式。
第2步:定义连续的操作
单击工作台的“连续动作”选项卡,单击“新建”按钮创建一个新动作,每个动作的设置方法相同,基本操作如下:
2.1,输入目标主题名称
此处的目标主题名称是填写第二级主题名称,单击“正在使用谁”以检查目标主题名称是否可用,如果已被占用,则只需更改主题名称即可。
2.2,创建第一个动作:输入
创建一个新动作并选择动作类型作为输入。
2.2.1,填写定位表达式
首先单击输入框,找到输入框的节点,然后单击“自动生成XPath”按钮,可以选择“ Preference id”或“ Preference class”,可以获得输入的xpath表达式框,然后单击“搜索”按钮,检查此xpath是否可以唯一地位于输入框中,如果没有问题,请将xpath复制到定位表达式框中。
**注意:**定位表达式中的xpath用来锁定动作对象的整个有效操作范围,特别是指可以通过鼠标成功单击或输入的网页模块,而不是在底部找到text()节点。
2.2.2,输入关键词
输入关键词以填写要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词以使用双分号;将每个关键词分开,免费版仅支持5个内的5个关键词,旗舰版可以使用连发杂志功能,支持10,000个内的关键词
2.2.3,输入动作名称
告诉自己该步骤的用途,以便稍后进行修改。
2.3,创建第二个动作:单击
请参考2.2的操作,创建第二个动作,选择类型为click,找到搜索按钮,然后自动生成xpath来检查它是否被锁定到唯一节点(如果没有)问题,将其填写在定位表达式中。
2.4,保存规则
点击“保存规则”按钮以保存已完成的一级规则
第3步:定义二级规则
3.1,创建一个新规则
创建第二级规则,单击“定义规则”以返回正常的网页模式,输入关键词搜索结果,再次单击“定义规则”以切换到规则制定模式,然后单击“规则”菜单的左上角->“新建”,输入主题名称,其中主题名称是在第一级规则的连续操作中填充的目标主题名称。
3.2,标记您想要的信息采集
3.2.1,在网页上标记您想要的信息采集,这里是产品名称和价格的标记,因为该标记仅对文本信息有效,因此指向产品详细信息的链接是属性节点@href,因此,您不能在链接上进行这样直观的标记,但是要进行内容映射,请参阅以下操作以获取详细信息。
3.2.2,单击产品名称,下面的DOM节点找到A标签,展开A标签下的attribute节点,您可以找到代表URL的@href节点,右键单击节点,然后选择“新建捕获”,然后单击“获取内容”,输入一个名称,通常为爬网的内容指定一个与地址相关的名称,例如“下属URL”或“下属链接”等。然后在工作台上,我看到已抓取的内容可用。如果您仍要进入产品详细信息页面采集,则必须检查与该抓取内容有关的较低级线索以进行分层抓取。
3.2.3,设置“密钥内容”选项,以便爬网程序可以判断采集规则是否合适。在排序框中,选择不可避免地在网页上可用的标签,然后勾选“关键内容”。在这里,“名称”被选作“关键内容”。
3.2.4,如果仅在前面标记一个产品,则可以获得产品信息。如果您想在整个页面上采集每个产品,都可以制作一个样本副本,否。如果您理解,请参阅基本教程“ 采集列表数据”
3.3,设置翻页路线
设置爬虫路线中的翻页功能,这是标记提示,如果您不了解,请参考基本教程“设置翻页采集”
3.4,保存规则
单击“测试”以检查信息的完整性。如果不完整,则注释可以覆盖以前的内容。检查没有问题后,单击“保存规则”。
第4步:捕获数据
4.1,连续动作是连续执行的,因此只要您运行第一级主题,就不需要运行第二级主题。打开DS计数器,搜索第一级主题名称,单击“单一搜索”或“集合”,可以看到在浏览器窗口中自动输入并搜索了关键词,然后调用第二级主题自动采集搜索结果。
4.2,第一级主题未采集有意义的信息,因此我们仅查看第二级主题的文件夹,即可看到采集的搜索结果数据,并搜索关键词 Is默认情况下记录在xml文件的actionvalue字段中,以便它可以一一对应。
事实:深圳市企翔网络(图)-关键词快速排名推广系统-关键词快速排名
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2020-10-24 12:02
产品规格:
无限
产品数量:
无限
包装说明:
订购
价格说明:
无限
观众:
756人
链接到此页面:
深圳启翔网络技术有限公司
我们如何快速构建网站的关键词词库
许多人不了解关键词同义词库。实际上,关键词词库是我们用来采集[k5]的库。 关键词分为几种主要类型:主要关键词,长尾词,价值词,交通词等;这些需要一些方法和工具来采集它们,然后构建大型的关键词库。那么关键词词库的用途是什么?
可以帮助我们选择:具有转换率的百度关键词快速排名关键词,主要关键词,长尾词,建筑词等,所有这些都需要我们在关键词库中选择因此,关键词库的建立是网站优化开始的良好阶段,因此网站的目标更加明确;对于我们将来的职位来说更方便。
我们可以通过什么方式构建我们的网站 关键词词库?
A,关键词集合:通过百度下拉框,相关搜索,单词追逐或金华等工具,百度推广助手,关键词前20名独立网站,相关论坛,百度贴吧,问答平台;这些是我们常用的几种方法,上面引用的方法足以构建关键词库。
B。分词类型:
1.时效性:时效性词属于某些行业,并由时间关键词建立;
2.季节性:实际上,季节性单词的性质类似于对时间敏感的单词。 关键词快速排名百度首页,不同之处在于一个是时间,另一个是季节;
3.产品字词:通常,公司网站会有一些产品名称,因此我们需要采集它们;例如,在关键词 search seo 网站优化搜索中,有一个百度下拉框Product字;它表明用户对产品字词有一点需求。
4.流量词:用户将搜索行业中的关键词并输入网站,例如一些长尾词,目标词,短词等;我们都需要采集它们。
5.高转换率关键词:该行业中的关键词转换率很高。
6.位置:网站快速排名,例如移动,汽车租赁,废物回收,空调维修,计算机维修等。行业具有区域性需求,因为用户会选择离他们最近的行业,而不是选择那些遥远的地方;这是因为时间成本。
如何提高关键词排名?
如何提高关键词的排名并达到关键词主导屏幕的效果?
一、超级繁华的商店,可以做生意的在线商店
1、一个具有多种模式的网络,“ PC + mobile +微信”自动适应整个终端的覆盖范围;
2、大规模设计方案,一分钟即可建一个车站;
3、不需要专业人员来维护,并且内容会自动更新;
3、 SEO策略,大规模原创,自动优化和排名;
4、HTML5移动改编,拥抱移动互联网;
5、自主云集群,为网站提供了五星级的家;
6、支持站群模式,您并不孤单;
二、独立营销企业网站,独立域名,完整营销
1、绑定企业一级域名,易于拥有企业独立性网站;
2、营销类型网站模板,已转换为公司营销类型网站定制;
3、智能的SEO策略,提高企业独立性网站 收录的排名;
4、自动外部链接帮助,以实现快速搜索引擎收录;
三、企业移动网站(移动商店),在移动时代必不可少
1、 HTML5自动适应,使每部手机都能获得良好的显示效果;
2、独家功能页面模板库,可以随时更改版本,可以选择;
3、随PC站自动更新,无需单独管理和更新移动终端;
4、多种一键式交互式操作按钮,关键词快速排名,轻松的营销和增加访客查询;
5、移动搜索会自动调整以轻松获取移动搜索流量。
四、企业微信网站(微信网)允许公司插入微信的翅膀
1、自动打开企业微信公众平台,一站式管理微信公众平台;
2、自定义菜单和回复,直接与企业手机商店进行通信;
五、超级企业网络站群(王埔集团),您并不孤单
1、这些天,您仍然是“单身”,是时候打电话给几个“兄弟”了;
2、超级旺铺开创了“旺铺组”功能,可以再生成5个旺铺;
3、每个商店都可以绑定到不同的一级域名并独立显示,
4、独立优化;自动的内容分发信息和更新,以保持旺普集团的内容差异化;
5、同时管理多个超级插座完全没有问题,一劳永逸,效果翻了一番。
根据网络变化进行网络优化。它不是恒定的层,也不总是规则。您需要更多地关注网络变化,平台变化和市场调整,以自定义自己的SEO优化促销。您需要注意这些问题通常可以从以下几点考虑:
一、重复,无论是外部信息还是内部文案写作信息,都不建议发布太多相同的信息;这些相同的信息通常可以是:相同的标题,相同的内容,相同的产品等。
二、嫉妒太多。定位标题和内容时,许多运营商都喜欢添加太多关键词;或在同一网站或平台关键词上添加叠加层。
三、添加了太多的超链接,文章内容,新闻页面,添加了太多的链接,从而导致搜索引擎的排名在收录中,或者它们的排名不佳或进行Shield操作。添加过多图片,对于不同的产品页面,添加过多图片,一种会导致页面打开速度,另一种是收录,即收录。
四、口语是指在不同平台上发布信息或产品信息时的关键词快速排名提升系统。尽量多说话。不要太死板,只发布促销信息,否则将导致禁令或封锁IP,不利于将来发送的信息收录。
五、在外部发送信息时与对等方结合使用,关键词快速排名方法技能,您可以提前搜索对等方以了解同事在何处发布信息,并在对等方发布信息的平台上进行操作;还要获得PR价值。请转到更高的平台。
六、无论平台有多好,无论同行有多好,创新和原创信息都要好得多;建议您在进行外围设备信息时自定义原创文案,并定期进行更新。
深圳齐翔网络技术有限公司(图片)-关键词快速排名推广系统-关键词快速排名由深圳市齐翔网络技术有限公司提供。深圳市齐翔网络技术有限公司()是一家专业公司在“ 网站建设,网络推广,小程序开发,seo优化”中。自成立以来,我们一直奉行“诚信为本,稳定运行”的政策,并有勇气参与健康的市场竞争,因此“ 网站建设,网络推广,小程序开发,seo优化”具有良好的声誉。我们坚持“服务第一,用户至上”的原则,使深圳启翔网络在软件开发上赢得了众多客户的信赖,树立了良好的企业形象。特别说明:本信息中的图片和信息仅供参考,请与我们联系以获取准确的信息,谢谢!同时,公司()还是专门从事关键词排名,关键词促销和关键词主导屏幕的服务提供商。欢迎来电咨询。
欢迎来到深圳市齐翔网络技术有限公司网站。本公司位于中国经济中心深圳,经济发达,交通发达,人口稠密。具体地址是深圳市龙华新区民治大道U创固A11-10,联系人是赵经理。
主要从事网站建设,网络推广,小程序开发,seo优化。
单位的注册资本未知。 查看全部
深圳企翔网(图片)-关键词快速排名提升系统-关键词快速排名
产品规格:
无限
产品数量:
无限
包装说明:
订购
价格说明:
无限
观众:
756人
链接到此页面:
深圳启翔网络技术有限公司
我们如何快速构建网站的关键词词库
许多人不了解关键词同义词库。实际上,关键词词库是我们用来采集[k5]的库。 关键词分为几种主要类型:主要关键词,长尾词,价值词,交通词等;这些需要一些方法和工具来采集它们,然后构建大型的关键词库。那么关键词词库的用途是什么?
可以帮助我们选择:具有转换率的百度关键词快速排名关键词,主要关键词,长尾词,建筑词等,所有这些都需要我们在关键词库中选择因此,关键词库的建立是网站优化开始的良好阶段,因此网站的目标更加明确;对于我们将来的职位来说更方便。
我们可以通过什么方式构建我们的网站 关键词词库?
A,关键词集合:通过百度下拉框,相关搜索,单词追逐或金华等工具,百度推广助手,关键词前20名独立网站,相关论坛,百度贴吧,问答平台;这些是我们常用的几种方法,上面引用的方法足以构建关键词库。
B。分词类型:
1.时效性:时效性词属于某些行业,并由时间关键词建立;
2.季节性:实际上,季节性单词的性质类似于对时间敏感的单词。 关键词快速排名百度首页,不同之处在于一个是时间,另一个是季节;
3.产品字词:通常,公司网站会有一些产品名称,因此我们需要采集它们;例如,在关键词 search seo 网站优化搜索中,有一个百度下拉框Product字;它表明用户对产品字词有一点需求。
4.流量词:用户将搜索行业中的关键词并输入网站,例如一些长尾词,目标词,短词等;我们都需要采集它们。
5.高转换率关键词:该行业中的关键词转换率很高。
6.位置:网站快速排名,例如移动,汽车租赁,废物回收,空调维修,计算机维修等。行业具有区域性需求,因为用户会选择离他们最近的行业,而不是选择那些遥远的地方;这是因为时间成本。
如何提高关键词排名?
如何提高关键词的排名并达到关键词主导屏幕的效果?
一、超级繁华的商店,可以做生意的在线商店
1、一个具有多种模式的网络,“ PC + mobile +微信”自动适应整个终端的覆盖范围;
2、大规模设计方案,一分钟即可建一个车站;
3、不需要专业人员来维护,并且内容会自动更新;
3、 SEO策略,大规模原创,自动优化和排名;
4、HTML5移动改编,拥抱移动互联网;
5、自主云集群,为网站提供了五星级的家;
6、支持站群模式,您并不孤单;
二、独立营销企业网站,独立域名,完整营销
1、绑定企业一级域名,易于拥有企业独立性网站;
2、营销类型网站模板,已转换为公司营销类型网站定制;
3、智能的SEO策略,提高企业独立性网站 收录的排名;
4、自动外部链接帮助,以实现快速搜索引擎收录;
三、企业移动网站(移动商店),在移动时代必不可少
1、 HTML5自动适应,使每部手机都能获得良好的显示效果;
2、独家功能页面模板库,可以随时更改版本,可以选择;
3、随PC站自动更新,无需单独管理和更新移动终端;
4、多种一键式交互式操作按钮,关键词快速排名,轻松的营销和增加访客查询;
5、移动搜索会自动调整以轻松获取移动搜索流量。
四、企业微信网站(微信网)允许公司插入微信的翅膀
1、自动打开企业微信公众平台,一站式管理微信公众平台;
2、自定义菜单和回复,直接与企业手机商店进行通信;
五、超级企业网络站群(王埔集团),您并不孤单
1、这些天,您仍然是“单身”,是时候打电话给几个“兄弟”了;
2、超级旺铺开创了“旺铺组”功能,可以再生成5个旺铺;
3、每个商店都可以绑定到不同的一级域名并独立显示,
4、独立优化;自动的内容分发信息和更新,以保持旺普集团的内容差异化;
5、同时管理多个超级插座完全没有问题,一劳永逸,效果翻了一番。
根据网络变化进行网络优化。它不是恒定的层,也不总是规则。您需要更多地关注网络变化,平台变化和市场调整,以自定义自己的SEO优化促销。您需要注意这些问题通常可以从以下几点考虑:
一、重复,无论是外部信息还是内部文案写作信息,都不建议发布太多相同的信息;这些相同的信息通常可以是:相同的标题,相同的内容,相同的产品等。
二、嫉妒太多。定位标题和内容时,许多运营商都喜欢添加太多关键词;或在同一网站或平台关键词上添加叠加层。
三、添加了太多的超链接,文章内容,新闻页面,添加了太多的链接,从而导致搜索引擎的排名在收录中,或者它们的排名不佳或进行Shield操作。添加过多图片,对于不同的产品页面,添加过多图片,一种会导致页面打开速度,另一种是收录,即收录。
四、口语是指在不同平台上发布信息或产品信息时的关键词快速排名提升系统。尽量多说话。不要太死板,只发布促销信息,否则将导致禁令或封锁IP,不利于将来发送的信息收录。
五、在外部发送信息时与对等方结合使用,关键词快速排名方法技能,您可以提前搜索对等方以了解同事在何处发布信息,并在对等方发布信息的平台上进行操作;还要获得PR价值。请转到更高的平台。
六、无论平台有多好,无论同行有多好,创新和原创信息都要好得多;建议您在进行外围设备信息时自定义原创文案,并定期进行更新。
深圳齐翔网络技术有限公司(图片)-关键词快速排名推广系统-关键词快速排名由深圳市齐翔网络技术有限公司提供。深圳市齐翔网络技术有限公司()是一家专业公司在“ 网站建设,网络推广,小程序开发,seo优化”中。自成立以来,我们一直奉行“诚信为本,稳定运行”的政策,并有勇气参与健康的市场竞争,因此“ 网站建设,网络推广,小程序开发,seo优化”具有良好的声誉。我们坚持“服务第一,用户至上”的原则,使深圳启翔网络在软件开发上赢得了众多客户的信赖,树立了良好的企业形象。特别说明:本信息中的图片和信息仅供参考,请与我们联系以获取准确的信息,谢谢!同时,公司()还是专门从事关键词排名,关键词促销和关键词主导屏幕的服务提供商。欢迎来电咨询。
欢迎来到深圳市齐翔网络技术有限公司网站。本公司位于中国经济中心深圳,经济发达,交通发达,人口稠密。具体地址是深圳市龙华新区民治大道U创固A11-10,联系人是赵经理。
主要从事网站建设,网络推广,小程序开发,seo优化。
单位的注册资本未知。
Twitter数据采集以及情感分析方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 1092 次浏览 • 2020-08-31 10:15
2. 想知道如何使用Python进行情感分析.
首先,我们打开Octoparse官方网站,下载最新的官方版本,然后按照说明完成注册. 登录后,打开内置的Twitter简单模板.
采集的数据字段包括:
首先在Twitter采集模板的关键字参数中输入“ Donald Trump”,然后单击“开始采集”以自动采集数据,如下图所示,这很简单,我大概采集了10,000多个Twitter推文. 您可以输入尽可能多的关键字来采集更多推文. 采集到推文数据后,将数据导出为文本文件,并将文件命名为“ data. TXT”.
使用Python进行情感分析
开始之前,请确保您的计算机已安装Python开发环境和文本编辑器. 我在文章中使用了Python2.7和Notepad ++文本编辑器.
然后,我们使用由两个情感关键字列表组成的txt文件来分析以前采集的Twitter信息. 您可以在文章末尾下载这两个文件.
这里的想法是将txt文件中的每个情感关键词提取到列表中,然后计算每个推文中这些关键词的出现频率,最后我们记录收录情感词的相应推文.
首先,将正情绪和消费者情绪关键字分别存储在plist和nlist列表的两个txt文件中.
然后,对来自采集的Twitter tweet进行数据清理,删除所有特殊符号(标点,数字等),并将每个tweet数据保存在word_list列表中.
在数据处理之后,数据仅收录清除的tweet,这使数据分析更加容易. 稍后,我们将创建三个字典: wordcountdict,wordcountpositive和wordcountnegative.
接下来,定义每个字典. 如果Twitter数据中出现相应的tweet,请添加1并将其存储在wordcountdict词典中.
接下来,确定每条推文都收录正面或负面的情感关键词. 如果它收录积极的情感关键词,则在单词反义词词典关键词上加1,否则请确保该值相同. 如果它收录否定性情感关键字,则单词否定性关键字也是如此. 如果该推文不收录任何肯定或否定关键字,则不会处理任何内容.
情绪分析: 正面或负面
通过运行上述Python脚本,我得到了5,352个否定关键字和3,894个肯定关键字,它们被保存在上面的相应列表中,然后打开Tableau来创建气泡图,如下所示. 如果您不知道如何使用Tableau创建气泡图,请单击此处.
从图中可以看出,很多肯定关键字是单方面的,只使用了404个肯定关键字,最常用的词是“ like”,“ great”和“ right”,大多数关键字是基本的. 更具口语性,例如“哇”和“酷”. 使用的否定关键字更加多样化. 他们中的大多数都非常正式和先进. 最常用的是“非法”,“谎言”和“种族主义者”. 也经常出现“惯犯”,“发炎”和“虚伪”之类的词.
上述关键字还表明,支持者的教育程度低于反对者. 显然,唐纳德·特朗普在Twitter用户中并不受欢迎.
摘要:
在本文中,我们讨论了Octoparse软件如何捕获Twitter推文,还讨论了如何执行数据清理以及如何使用Python对Twitter推文进行情感分析. 要获取完整版本的代码,您可以在下面的链接中下载它.
(/ octoparse / fd9e0006794754edfbdaea86de5b1a51)
参考链接: /@datamonsters//~liub/FBS//jeffreybreen/twitter-sentiment-analysis-tutorial-201107/blob/master/data/opinion-lexicon-English//Home.html
文章翻译为: / blog / text-mining-and-sentiment-analysis-using-python
作者: Ashley Weldon 查看全部
Twitter数据采集和情感分析方法
2. 想知道如何使用Python进行情感分析.
首先,我们打开Octoparse官方网站,下载最新的官方版本,然后按照说明完成注册. 登录后,打开内置的Twitter简单模板.
采集的数据字段包括:
首先在Twitter采集模板的关键字参数中输入“ Donald Trump”,然后单击“开始采集”以自动采集数据,如下图所示,这很简单,我大概采集了10,000多个Twitter推文. 您可以输入尽可能多的关键字来采集更多推文. 采集到推文数据后,将数据导出为文本文件,并将文件命名为“ data. TXT”.
使用Python进行情感分析
开始之前,请确保您的计算机已安装Python开发环境和文本编辑器. 我在文章中使用了Python2.7和Notepad ++文本编辑器.
然后,我们使用由两个情感关键字列表组成的txt文件来分析以前采集的Twitter信息. 您可以在文章末尾下载这两个文件.
这里的想法是将txt文件中的每个情感关键词提取到列表中,然后计算每个推文中这些关键词的出现频率,最后我们记录收录情感词的相应推文.
首先,将正情绪和消费者情绪关键字分别存储在plist和nlist列表的两个txt文件中.
然后,对来自采集的Twitter tweet进行数据清理,删除所有特殊符号(标点,数字等),并将每个tweet数据保存在word_list列表中.
在数据处理之后,数据仅收录清除的tweet,这使数据分析更加容易. 稍后,我们将创建三个字典: wordcountdict,wordcountpositive和wordcountnegative.
接下来,定义每个字典. 如果Twitter数据中出现相应的tweet,请添加1并将其存储在wordcountdict词典中.
接下来,确定每条推文都收录正面或负面的情感关键词. 如果它收录积极的情感关键词,则在单词反义词词典关键词上加1,否则请确保该值相同. 如果它收录否定性情感关键字,则单词否定性关键字也是如此. 如果该推文不收录任何肯定或否定关键字,则不会处理任何内容.
情绪分析: 正面或负面
通过运行上述Python脚本,我得到了5,352个否定关键字和3,894个肯定关键字,它们被保存在上面的相应列表中,然后打开Tableau来创建气泡图,如下所示. 如果您不知道如何使用Tableau创建气泡图,请单击此处.
从图中可以看出,很多肯定关键字是单方面的,只使用了404个肯定关键字,最常用的词是“ like”,“ great”和“ right”,大多数关键字是基本的. 更具口语性,例如“哇”和“酷”. 使用的否定关键字更加多样化. 他们中的大多数都非常正式和先进. 最常用的是“非法”,“谎言”和“种族主义者”. 也经常出现“惯犯”,“发炎”和“虚伪”之类的词.
上述关键字还表明,支持者的教育程度低于反对者. 显然,唐纳德·特朗普在Twitter用户中并不受欢迎.
摘要:
在本文中,我们讨论了Octoparse软件如何捕获Twitter推文,还讨论了如何执行数据清理以及如何使用Python对Twitter推文进行情感分析. 要获取完整版本的代码,您可以在下面的链接中下载它.
(/ octoparse / fd9e0006794754edfbdaea86de5b1a51)
参考链接: /@datamonsters//~liub/FBS//jeffreybreen/twitter-sentiment-analysis-tutorial-201107/blob/master/data/opinion-lexicon-English//Home.html
文章翻译为: / blog / text-mining-and-sentiment-analysis-using-python
作者: Ashley Weldon
关键词手动提取方式的研究与改进
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2020-08-30 04:02
ComputerScience 关键词手动提取方式的研究与改进 Vol.41No.6 June2014 (湖南大学信息科学与工程学院广州410082 (邵阳学院信息工程系长沙422000 TFIDF算法中存在的不 InverseDocumentFrequency)权值中没有考虑特点词在类内以及类别间的分布情况 。因此 有的TFIDF 方法会出现有些不能代表文档主题的低频词的IDF 值很高 ,而有些才能代表文 档主题的高频词的IDF 值却太低的情 ,这会导致关键词提取不确切。通过降低一个新的残差 特征词条的权重,提出了一种新的算法 DI-TFIDF 。实验中使用的是搜狗语料库 ,选择其中的体育 1000篇作为实验的语料库,分别用基于传统 TFIDF 方法和基于 DI-TFIDF 方法提取关键词。 实验结果表明 提出的DI-TFIDF 方法提取关键词的准确度要低于传统的 TFIDF 算法。 关键词 关键词提取 DI-TFIDF中图法分类号 TP391.1 文献标识码 ResearchandImprovementofTFIDFTextFeatureWeightingMethod HUANG Lei 1,2 WU Yan-peng ZHUQun-feng (SchoolofInformationScienceandEngineering,HunanUniversity ,Changsha410082,China) (DepartmentofElectricEngineering,ShaoyangUniversity ,Shaoyang422000,China) AbstractKeywordsextractionmethodplaysaveryimportantroleintheareasoftextclassificationandinformationre- trie val.ThispaperfirstlyanalysedtheshortageoftheoriginalTFIDFalgorithm,thatistheIDF (InverseDocument Frequ ency )algorithmdoesnotconsiderthedistributionoffeaturetermbetweencategories.Sosomeproblemswillap- pear,suc hasthetermswithlowfrequencyandthehighIDFweights,andsomewordswithhighfrequencyandlowIDF weights,wh ichcancausethattheprecisionofkeywordsextractionisnotaccurate.Afteranalysisoftheseproblems,by increasingan ew weightDI(DistributionInformation),wegotanew DI-TFIDFalgorithm.Acorpususedintheexperi- mentwasdownlo adedfromtheSogoucorpusand weselectedthe1000articleofsports,educationand militarydocu- mentsasanexperime ntbasedonthetraditionalTFIDF methodandtheDI-TFIDF method.Experimentalresultsshow thatourproposedDI-TF IDF methodcanextractthekeywordsinahigheraccuracythantraditionalTFIDFalgorithm. Keywords Keywordsextra ction 引言随着Internet的 广泛 的信息资源以文本方式存在。
信息世界的不断发展 ,极大地丰富了人类的生活 带来了棘手的问题:如何在庞大的信息世界中迅速找到所需 的信息。这一问题成为了一项具有重大研究意义的课题。 在文档信息中 ,关键词起到了关键作用 是才能反映一篇文档主题内容的成语或与文档所在领域高度相关的成语, 帮助人们在搜救所需的信息时就能迅速地定位到相应的文 档。然而 这些文档的关键词又是十分历时和困难的,所以迫切需要对 关键词进行手动提取。 关键词提取技术应运而生 ,帮助人们迅速找到相应的文本信息,满足了人们对信 求的渴求。综上所述 础工作。本课题研究的目的是基于改进的TFIDF 出关键词,由于文本特点权重算法对关键词提取的准确率有 着重要的影响 TFIDF的改进就十分有必要。 最终研究成果是设计出关键词提取系统 ,该系统可以应用到 键词提取系统,可以在一定程度上帮助用户更为确切和快 地搜救到相应的信息,有利于信息的传播和知识的推广 轻人工标明关键词的负担,具有深刻的意义 国内外研究现况和成果美国对关键词提取研究较早 ,20 出了基于词频统计的抽词标到稿日期 :2013-11-20 返修日期 :2014-03-18 本文受湖南省教育厅通常项目(09C887):基于语义网的网路教学资源检索系统研究捐助 引法。
经历了50多 引的研究渐渐消失,其原因是传统的自动标引方式的效率达到了极限 们广泛地使用全文 始用电子计算机编制关键词索引 法相结合的方式来提取关键词。20 关键词提取的研究也渐渐深入,许多学者提出了不同的 方法, 取得了令人瞩 遗传算法GenEx的 关键词 2003年Tomokiyo与 Hust Bagging算法进行了基于集成学习的关键词提取 。2006 提出以标点符号和停用词为成语间隔 ,先提取出一个成语序列 ,再借此序列和 序列 N-gram为候选对象 算候选关键词的特点项的TFIDF 位置、短语厚度等特征值 ,进而从候选关键词中提取特点 将能表示特征项在类内分布程度的信息与信息增益综合上去考虑 ,利用信息熵对特点词权重进行调整 ,从而提升了特 权重的估算精度,提高了关键词提取的准确度 对辞典的依赖较大,提取疗效有赖于辞典的完整性 智能也同样须要训练库和知识库,对它们的依赖较大 因此本文重点研究TFIDF ,发现其存在的不足并有针对性地加以改进 出了新的DI-TFIDF 算法。 特征权重算法TFIDF 的改进 文本是由成语构成的 ,要在文本中提取出关键词 必须赋于特点项相应的权重 ,权重越大的特点项越能代表文本的 主题。
特征权重算 TF可以反映特点项在文本 中出现的频度 ,IDF 可以 反映特点项反比于文档集中出现特 征项的频度 好地结合了TF 和IDF。 3.1 TFIDF TFIDF 实际 的作为关键词。2007 TFIDF现的次数 ,IDF 是指反文档频度。 其估算公式是: 改进的 过词汇链来提高成语之间语义联系的方式 。2008 Niraj[10] 滤出不合适的词句,计算这种成语的权重 ,最后提取权重 作为关键词。国外 wi=tfi idfi=tfi log ni因为考虑到文档的内容宽度会影响到残差 tfijlog +0〃01)1999年 RobertoBasils 出了TF*IWF*IWF,该 niwij 法有效提升了特点词在语料库的权重,但没有充分考虑到词 的重要性,因为特点权重并不仅仅是由成语在语料库中出现 其中 ijlog ni +0〃01 的频度决定,而是由成语在文档和语料库中出现的频度共同 决定 ,这促使该算法 还存在着 BongChihHow Narayanan[12] 根据不同类别的文档数可能存在数目 CTD(Category Term Descriptor)来 国内也有好多学者对TFIDF 算法进行了研究 且取得了明显的成果 。
2006年 DF在类别中的分布情 ,有效提升了准确率。2007 小莉等人[14] 把信息论中的 信息增益应用到文本集合的 类别 ,提出了一种改进的TF*IDF*IG BOR-TFIDF(BasedOn Ratio- ,该算法重新针对特点词对类别的区分度进行了 入到类别内部,没有考察类内的分布情况 TFIDF算法在不同领域的改进 、聊天文本权重估算、网页权重等方面提出了不同的 改进 高了TFIDF 算法对不同领域文本的处理能力 。2011 张保富等人[17] 提出了一种结合特征项的类间和类内信息 TFIDF特点加 分布熵进行了剖析,综合考虑了特点项在类间和类内的分 补了传统TFIDF 算法 不足。2012年 TFIDF算法 ,该方式针对信息增益只考 虑特点词在类 的分布情况,而没有考虑特点词在类内的分布情况的 问题, ij 是特点 项ti 在文档dj 中出现的次数 是指出现特点项ti ti的文档数。 3.2 TFIDF 的不足 用传统的 TFIDF 公式来提取关键词 ,一般存在两个问 TFIDF中IDF 的算法没有考虑到特征项在类间和 分布情况。具体剖析如下:(1)IDF 没有考虑到特征项在类间的分布信息 假设某一类的 Ci 收录词 条ti 的文档数为n 其他类收录的ti 的文档数为 含词条ti的文档数为 随着n变化 增大时w也变大。
可是根据IDF 的公式 到的IDF值却太小。但是按实际剖析可知 条ti在Ci 类中频繁出现 ,可以作为特点词代表这一类 条ti均匀地分布在各个类间 分能力,不应当作为特点词 ,应该赋于较低的权重 。但是根据 传统的 TFIDF 算法 (2)IDF没有考虑到特征项在类内的分布信息 在同一类中不同的特 ,但是根据传统的TFIDF t44个特征项在各个类别和文档中的分布 各个特点项在文档中出现的频度C1 C2 C3 离散度是各个文档中特点词的差别程度 ,可以挺好地反映在 同一个类中不同文档特点词频度的不同。类内的离散度估算 公式如下: tfij-tf′ij 用传统TFIDF 算法估算各个特点项的残差(没 有进行归 DI= 其中 tfij表示特点词ti 各个特点项的TFIDF C1C2 C3 特征项 t12.39 1.91 2.87 t21.91 4.79t3 1.43 t40.004 0.004 0.004 0.004 0.004 0.004 0.004 0.004 0.004 类内各个文档中出现次数的平均值。 如果特点词只在某一篇文档 特征词在类内文档中整篇文档的TF 内离散度DI可以取到最小值 在传统TFIDF 算法的基础上 们对IDF进行改进并增 加类内离散度 终得到DI-TFIDF 算法 ,算法的公式如下 wij=tfij log +0〃01)(1-DI)明其没有关键信息 TFIDF算法的优点, 即才能过滤掉均匀分布的特点项 C1中出现 ni+m考虑到类内离散度与特点词的分类能力成 理得到公式:ni 果IDF相同 ,TF 就决定了特征项的权重的 tfijlog t2的文档数相同 有t2的文档中 TF wij niij ,但是假如依照传统的TFIDF 算法估算 ,却会得到较高 的权重。
这就是传统 TFIDF 算法中IDF 没有考虑特点项在 、类内的分布情况而形成的偏差。 3.3 改进的 TFIDF 针对 TFIDF 出基于特点项分布差别的DI-TFIDF 特征权重改进算法。 于IDF没有考虑到特征项在类间的分布信息 wij表示特点 项ti 在某类别C IDF=log ni ni+m0〃01 示特点项ti的反文档频度 DI(t,c)表示特点项在 类别 DI值。我们对表 1中各个特点项在类别中的 DI- TFIDF 权重进行估算(没 有进行归 各个特点项的DI-TFIDF 特征项C1 C2 C3 们考虑对IDF加以改进 加这些在一个类中频繁出现的特t1 t2 4.77 3.14 5.05 1.01 2.53征项的权重。改进的IDF 算法为: t3 2.06 +0〃01)t4 0.004 0.004 0.004 0.004 0.004 0.004 0.004 0.004 0.004 ni+m 其中 t2在各个类别的 Ci中富含特点词 条ti 表示文档集中其他类富含特点词条ti 的文档数。 、类内的分布情况,使得到的权重更为确切 实验及结果剖析ni ni当含特点词条ti 的文档数w 一定时 ni越大 中收录特点词条ti 的文档数多 其他类中收录特点词条ti 的文档数少 ,则ti 能够代表这个类Ci 的权重。
故改进的算法才能有效填补传统TFIDF 于IDF没有考虑到特征项在类内的分布信息 们考虑降低类内离散度DI来观察特点项在类内的分布情况 1000篇文档作为实验所需语料库。 中训练样本和测试样本分布都 150篇文档 各个类中,训练文档和测试文档的比 了验证改进算法的有效性,本文进行了两 为基于传统TFIDF 的关键词提取和基于 DI-TFIDF 用查全率、查准率对提取的结果进行评价 。基于传 TFIDF算法和 DI-TFIDF 算法的关键词提取疗效如表 基于TFIDF算法(a)和 DI-TFIDF算法(b)的实验结果(体育类) SearchingofLiteraryInformation[J].IBM JournalofResearch 特征维数查全率 查准率 500 66.3 56.3 1000 68.5 57.5 2000 70.8 58.8 4000 71.0 59.6 6000 72.7 61.6 8000 74.3 62.3 70.659.4 特征维数查全率 查准率 500 72.1 61.9 1000 73 63.5 2000 74.5 64.5 4000 75.6 66.7 6000 76.4 67.6 8000 77.5 68.1 74.965.3 andDevelopment,1957,1(4):309-317 EdmundsonHP,OswaldVA.AutomaticIndexingandAbstrac- tin goftheContentsofDocuments[R].PlaningReserarchCorp DocumentPRC R-126,ASTLA AD No.231606.Los Angeles, 1959:1- 142 LoisLE.Experimentsin AutomaticIndexingand Extracting [J].InformationStorageandRetrieval,1970,6:313-334 TurneyPD.LearningtoExtractKeyphrasesfrom Tex 基于TFIDF算法(a)和 DI-TFIDF算法(b)的实验结果(军事类) NRC TechnicalReportERB-1057.NationalResearch Council, 特征维数查全率 查准率 500 54.1 46.6 1000 55.6 47.5 2000 56.6 48.9 4000 57.8 49.6 6000 58.4 51.1 8000 59.4 52.1 5749.3 特征维数查全率 查准率 500 63.2 51.9 1000 65.5 52.6 2000 66.7 53.8 4000 67.3 55.3 6000 68.4 56.7 8000 69.5 58.2 66.854.8 Canada,1999:1-43 WittenIH,PaynterG W,Frank E,etal.PracticalAutomatic KeyphraseExtraction[C] California:ProceedingsofThe4th ACM ConferenceonDigitalLibraries.1999:254-256 TomokiyoT,Hurst M.Alanguage ModelApproachto Key- ph raseExtraction[C] Proceedingsofthe ACL Workshopon Mul tiword Expressions:Ananlysis,Acquisition Treatment.Sapp oro,Japan,2003:33-40 HulthA.ImprovedAutomaticKeywordExtractionGivenMore 基于TFIDF算法(a)和 DI-TFIDF算法(b)的实验结果(教育类) LinguisticKnowledge[C] Proceedingofthe2003 Conference 特征维数查全率 查准率 500 58.3 51.3 1000 59.9 52.6 2000 60.6 53.5 4000 61.2 55.6 6000 62.3 56.7 8000 63.5 57.2 6154.5 特征维数查全率 查准率 500 63.8 54.3 1000 64 55.7 2000 65.1 57.9 4000 67.2 58.1 6000 68.1 59.4 8000 69.9 60.6 66.457.7 onEmpricalMethodsinNaturalLanguageProcessing.Sapporo, Ja pan,2003:216-223 Proceedingof3thIEEEInternationalConferenceonInno-vati onsinInformationTechnology.2006:1-5 ErcanG,CicekliI.UsingLexicalChainsforKeywordExtraction[J].InformationProcessing Management,2007,43(6):1705-171 词的疗效比传统的TFIDF 方法提取关键词的疗效要好 虑了特点项在类间和类内的分布情况,对于这些在某个类别 中频繁出现的特点项赋于了较高的权重 ,降低了在类内文档 中碰巧出现的特征项的权重。
因此 DI-TFIDF 算法对 取关键词起到了一定的积极作用。结束语 本文以关键词提取为研究对象 词提取进行了总结,介绍了国内外对关键词提取的研究 成果, 并对关键词提取中具 要影响的特点权重TFIDF 发展及国内外TFIDF 改进成果进行了介绍。 法做了详尽的研究,提出了改进的方式 DI-TFIDF算法 别对基于传统的TFIDF 算法的关键词提取和基于 DI-TFIDF 算法的关键词提 法的关键词提取疗效要比传统算法好,证实了改进的有效性 中文动词的研究较少,而是引用了现 ,根据实验动词疗效还不够理想,下一步须要研究采用 分词 效果更好的动词工具。 TFIDF算法的改进 的分布情况,并未考虑特点词的动词 、特征词宽度和特点 文档中出现的位置,导致了特点权重估算不够确切 要在之后工作中不断研究和测试数据 ,并按照现有的改进方式提出 更有效的改进方式。 P.AStatisticalApproachto MechanizedEncodingand [10]NirajK,KannanS.AutomaticKeyphraseExtractionfromScien- ti ficDocumentsUsing N-Gram Filtration Technique[C] Pro- ce edingofDocEng ’08Conference.2008:199-208 [11]BasilsR,MoschittiA,PazienzaM.Atextclassifierbasedonlin- gu isticprocessing ProceedingsofUCAI,MachineLearningfo rInformationFiltering.1999:36-40 [12]How BC,NarayananK.Anempiricalstudyoffeatureselection ortextcategorizationbasedontermweightage[C] Proceeding the2004IEEE/WIC/ACMIntemationalConferenceonWeb Inte lligence.Washington DC:IEEE Computer Society ,2004: 599- 602 [13] 于文本分类TFIDF 方法的改进与应用 算机工程,2006,32(19):77-78 [14] 于信息增益的特点词权重调整算法研究[J].计算机工程与应用 ,2007,43(35):159-160 [15] 师范大学学报 程技术版,2008,8(4):95-149 [16] ,2009,29(6):167-170[17] TFIDF文本特点加权方式的改进 研究[J].计算机应用与软件 ,2011,28(2):17-21 [18] .基于信息增益与信息熵的TFIDF 算机工程,2012,37(8):37-40 [19] WangD X,Gao X,AndreaeP.AutomaticKeywordExtraction romSingle-Sentence NaturalLanguage Queries[C] PRICAI 012.Berlin:Springer-Verlag,2012:637-648 [20] 算机工程,2010,36(19):93-95 [21] 算机学报,2010,33(7):1246-1255 查看全部
关键词手动提取方式的研究与改进
ComputerScience 关键词手动提取方式的研究与改进 Vol.41No.6 June2014 (湖南大学信息科学与工程学院广州410082 (邵阳学院信息工程系长沙422000 TFIDF算法中存在的不 InverseDocumentFrequency)权值中没有考虑特点词在类内以及类别间的分布情况 。因此 有的TFIDF 方法会出现有些不能代表文档主题的低频词的IDF 值很高 ,而有些才能代表文 档主题的高频词的IDF 值却太低的情 ,这会导致关键词提取不确切。通过降低一个新的残差 特征词条的权重,提出了一种新的算法 DI-TFIDF 。实验中使用的是搜狗语料库 ,选择其中的体育 1000篇作为实验的语料库,分别用基于传统 TFIDF 方法和基于 DI-TFIDF 方法提取关键词。 实验结果表明 提出的DI-TFIDF 方法提取关键词的准确度要低于传统的 TFIDF 算法。 关键词 关键词提取 DI-TFIDF中图法分类号 TP391.1 文献标识码 ResearchandImprovementofTFIDFTextFeatureWeightingMethod HUANG Lei 1,2 WU Yan-peng ZHUQun-feng (SchoolofInformationScienceandEngineering,HunanUniversity ,Changsha410082,China) (DepartmentofElectricEngineering,ShaoyangUniversity ,Shaoyang422000,China) AbstractKeywordsextractionmethodplaysaveryimportantroleintheareasoftextclassificationandinformationre- trie val.ThispaperfirstlyanalysedtheshortageoftheoriginalTFIDFalgorithm,thatistheIDF (InverseDocument Frequ ency )algorithmdoesnotconsiderthedistributionoffeaturetermbetweencategories.Sosomeproblemswillap- pear,suc hasthetermswithlowfrequencyandthehighIDFweights,andsomewordswithhighfrequencyandlowIDF weights,wh ichcancausethattheprecisionofkeywordsextractionisnotaccurate.Afteranalysisoftheseproblems,by increasingan ew weightDI(DistributionInformation),wegotanew DI-TFIDFalgorithm.Acorpususedintheexperi- mentwasdownlo adedfromtheSogoucorpusand weselectedthe1000articleofsports,educationand militarydocu- mentsasanexperime ntbasedonthetraditionalTFIDF methodandtheDI-TFIDF method.Experimentalresultsshow thatourproposedDI-TF IDF methodcanextractthekeywordsinahigheraccuracythantraditionalTFIDFalgorithm. Keywords Keywordsextra ction 引言随着Internet的 广泛 的信息资源以文本方式存在。
信息世界的不断发展 ,极大地丰富了人类的生活 带来了棘手的问题:如何在庞大的信息世界中迅速找到所需 的信息。这一问题成为了一项具有重大研究意义的课题。 在文档信息中 ,关键词起到了关键作用 是才能反映一篇文档主题内容的成语或与文档所在领域高度相关的成语, 帮助人们在搜救所需的信息时就能迅速地定位到相应的文 档。然而 这些文档的关键词又是十分历时和困难的,所以迫切需要对 关键词进行手动提取。 关键词提取技术应运而生 ,帮助人们迅速找到相应的文本信息,满足了人们对信 求的渴求。综上所述 础工作。本课题研究的目的是基于改进的TFIDF 出关键词,由于文本特点权重算法对关键词提取的准确率有 着重要的影响 TFIDF的改进就十分有必要。 最终研究成果是设计出关键词提取系统 ,该系统可以应用到 键词提取系统,可以在一定程度上帮助用户更为确切和快 地搜救到相应的信息,有利于信息的传播和知识的推广 轻人工标明关键词的负担,具有深刻的意义 国内外研究现况和成果美国对关键词提取研究较早 ,20 出了基于词频统计的抽词标到稿日期 :2013-11-20 返修日期 :2014-03-18 本文受湖南省教育厅通常项目(09C887):基于语义网的网路教学资源检索系统研究捐助 引法。
经历了50多 引的研究渐渐消失,其原因是传统的自动标引方式的效率达到了极限 们广泛地使用全文 始用电子计算机编制关键词索引 法相结合的方式来提取关键词。20 关键词提取的研究也渐渐深入,许多学者提出了不同的 方法, 取得了令人瞩 遗传算法GenEx的 关键词 2003年Tomokiyo与 Hust Bagging算法进行了基于集成学习的关键词提取 。2006 提出以标点符号和停用词为成语间隔 ,先提取出一个成语序列 ,再借此序列和 序列 N-gram为候选对象 算候选关键词的特点项的TFIDF 位置、短语厚度等特征值 ,进而从候选关键词中提取特点 将能表示特征项在类内分布程度的信息与信息增益综合上去考虑 ,利用信息熵对特点词权重进行调整 ,从而提升了特 权重的估算精度,提高了关键词提取的准确度 对辞典的依赖较大,提取疗效有赖于辞典的完整性 智能也同样须要训练库和知识库,对它们的依赖较大 因此本文重点研究TFIDF ,发现其存在的不足并有针对性地加以改进 出了新的DI-TFIDF 算法。 特征权重算法TFIDF 的改进 文本是由成语构成的 ,要在文本中提取出关键词 必须赋于特点项相应的权重 ,权重越大的特点项越能代表文本的 主题。
特征权重算 TF可以反映特点项在文本 中出现的频度 ,IDF 可以 反映特点项反比于文档集中出现特 征项的频度 好地结合了TF 和IDF。 3.1 TFIDF TFIDF 实际 的作为关键词。2007 TFIDF现的次数 ,IDF 是指反文档频度。 其估算公式是: 改进的 过词汇链来提高成语之间语义联系的方式 。2008 Niraj[10] 滤出不合适的词句,计算这种成语的权重 ,最后提取权重 作为关键词。国外 wi=tfi idfi=tfi log ni因为考虑到文档的内容宽度会影响到残差 tfijlog +0〃01)1999年 RobertoBasils 出了TF*IWF*IWF,该 niwij 法有效提升了特点词在语料库的权重,但没有充分考虑到词 的重要性,因为特点权重并不仅仅是由成语在语料库中出现 其中 ijlog ni +0〃01 的频度决定,而是由成语在文档和语料库中出现的频度共同 决定 ,这促使该算法 还存在着 BongChihHow Narayanan[12] 根据不同类别的文档数可能存在数目 CTD(Category Term Descriptor)来 国内也有好多学者对TFIDF 算法进行了研究 且取得了明显的成果 。
2006年 DF在类别中的分布情 ,有效提升了准确率。2007 小莉等人[14] 把信息论中的 信息增益应用到文本集合的 类别 ,提出了一种改进的TF*IDF*IG BOR-TFIDF(BasedOn Ratio- ,该算法重新针对特点词对类别的区分度进行了 入到类别内部,没有考察类内的分布情况 TFIDF算法在不同领域的改进 、聊天文本权重估算、网页权重等方面提出了不同的 改进 高了TFIDF 算法对不同领域文本的处理能力 。2011 张保富等人[17] 提出了一种结合特征项的类间和类内信息 TFIDF特点加 分布熵进行了剖析,综合考虑了特点项在类间和类内的分 补了传统TFIDF 算法 不足。2012年 TFIDF算法 ,该方式针对信息增益只考 虑特点词在类 的分布情况,而没有考虑特点词在类内的分布情况的 问题, ij 是特点 项ti 在文档dj 中出现的次数 是指出现特点项ti ti的文档数。 3.2 TFIDF 的不足 用传统的 TFIDF 公式来提取关键词 ,一般存在两个问 TFIDF中IDF 的算法没有考虑到特征项在类间和 分布情况。具体剖析如下:(1)IDF 没有考虑到特征项在类间的分布信息 假设某一类的 Ci 收录词 条ti 的文档数为n 其他类收录的ti 的文档数为 含词条ti的文档数为 随着n变化 增大时w也变大。
可是根据IDF 的公式 到的IDF值却太小。但是按实际剖析可知 条ti在Ci 类中频繁出现 ,可以作为特点词代表这一类 条ti均匀地分布在各个类间 分能力,不应当作为特点词 ,应该赋于较低的权重 。但是根据 传统的 TFIDF 算法 (2)IDF没有考虑到特征项在类内的分布信息 在同一类中不同的特 ,但是根据传统的TFIDF t44个特征项在各个类别和文档中的分布 各个特点项在文档中出现的频度C1 C2 C3 离散度是各个文档中特点词的差别程度 ,可以挺好地反映在 同一个类中不同文档特点词频度的不同。类内的离散度估算 公式如下: tfij-tf′ij 用传统TFIDF 算法估算各个特点项的残差(没 有进行归 DI= 其中 tfij表示特点词ti 各个特点项的TFIDF C1C2 C3 特征项 t12.39 1.91 2.87 t21.91 4.79t3 1.43 t40.004 0.004 0.004 0.004 0.004 0.004 0.004 0.004 0.004 类内各个文档中出现次数的平均值。 如果特点词只在某一篇文档 特征词在类内文档中整篇文档的TF 内离散度DI可以取到最小值 在传统TFIDF 算法的基础上 们对IDF进行改进并增 加类内离散度 终得到DI-TFIDF 算法 ,算法的公式如下 wij=tfij log +0〃01)(1-DI)明其没有关键信息 TFIDF算法的优点, 即才能过滤掉均匀分布的特点项 C1中出现 ni+m考虑到类内离散度与特点词的分类能力成 理得到公式:ni 果IDF相同 ,TF 就决定了特征项的权重的 tfijlog t2的文档数相同 有t2的文档中 TF wij niij ,但是假如依照传统的TFIDF 算法估算 ,却会得到较高 的权重。
这就是传统 TFIDF 算法中IDF 没有考虑特点项在 、类内的分布情况而形成的偏差。 3.3 改进的 TFIDF 针对 TFIDF 出基于特点项分布差别的DI-TFIDF 特征权重改进算法。 于IDF没有考虑到特征项在类间的分布信息 wij表示特点 项ti 在某类别C IDF=log ni ni+m0〃01 示特点项ti的反文档频度 DI(t,c)表示特点项在 类别 DI值。我们对表 1中各个特点项在类别中的 DI- TFIDF 权重进行估算(没 有进行归 各个特点项的DI-TFIDF 特征项C1 C2 C3 们考虑对IDF加以改进 加这些在一个类中频繁出现的特t1 t2 4.77 3.14 5.05 1.01 2.53征项的权重。改进的IDF 算法为: t3 2.06 +0〃01)t4 0.004 0.004 0.004 0.004 0.004 0.004 0.004 0.004 0.004 ni+m 其中 t2在各个类别的 Ci中富含特点词 条ti 表示文档集中其他类富含特点词条ti 的文档数。 、类内的分布情况,使得到的权重更为确切 实验及结果剖析ni ni当含特点词条ti 的文档数w 一定时 ni越大 中收录特点词条ti 的文档数多 其他类中收录特点词条ti 的文档数少 ,则ti 能够代表这个类Ci 的权重。
故改进的算法才能有效填补传统TFIDF 于IDF没有考虑到特征项在类内的分布信息 们考虑降低类内离散度DI来观察特点项在类内的分布情况 1000篇文档作为实验所需语料库。 中训练样本和测试样本分布都 150篇文档 各个类中,训练文档和测试文档的比 了验证改进算法的有效性,本文进行了两 为基于传统TFIDF 的关键词提取和基于 DI-TFIDF 用查全率、查准率对提取的结果进行评价 。基于传 TFIDF算法和 DI-TFIDF 算法的关键词提取疗效如表 基于TFIDF算法(a)和 DI-TFIDF算法(b)的实验结果(体育类) SearchingofLiteraryInformation[J].IBM JournalofResearch 特征维数查全率 查准率 500 66.3 56.3 1000 68.5 57.5 2000 70.8 58.8 4000 71.0 59.6 6000 72.7 61.6 8000 74.3 62.3 70.659.4 特征维数查全率 查准率 500 72.1 61.9 1000 73 63.5 2000 74.5 64.5 4000 75.6 66.7 6000 76.4 67.6 8000 77.5 68.1 74.965.3 andDevelopment,1957,1(4):309-317 EdmundsonHP,OswaldVA.AutomaticIndexingandAbstrac- tin goftheContentsofDocuments[R].PlaningReserarchCorp DocumentPRC R-126,ASTLA AD No.231606.Los Angeles, 1959:1- 142 LoisLE.Experimentsin AutomaticIndexingand Extracting [J].InformationStorageandRetrieval,1970,6:313-334 TurneyPD.LearningtoExtractKeyphrasesfrom Tex 基于TFIDF算法(a)和 DI-TFIDF算法(b)的实验结果(军事类) NRC TechnicalReportERB-1057.NationalResearch Council, 特征维数查全率 查准率 500 54.1 46.6 1000 55.6 47.5 2000 56.6 48.9 4000 57.8 49.6 6000 58.4 51.1 8000 59.4 52.1 5749.3 特征维数查全率 查准率 500 63.2 51.9 1000 65.5 52.6 2000 66.7 53.8 4000 67.3 55.3 6000 68.4 56.7 8000 69.5 58.2 66.854.8 Canada,1999:1-43 WittenIH,PaynterG W,Frank E,etal.PracticalAutomatic KeyphraseExtraction[C] California:ProceedingsofThe4th ACM ConferenceonDigitalLibraries.1999:254-256 TomokiyoT,Hurst M.Alanguage ModelApproachto Key- ph raseExtraction[C] Proceedingsofthe ACL Workshopon Mul tiword Expressions:Ananlysis,Acquisition Treatment.Sapp oro,Japan,2003:33-40 HulthA.ImprovedAutomaticKeywordExtractionGivenMore 基于TFIDF算法(a)和 DI-TFIDF算法(b)的实验结果(教育类) LinguisticKnowledge[C] Proceedingofthe2003 Conference 特征维数查全率 查准率 500 58.3 51.3 1000 59.9 52.6 2000 60.6 53.5 4000 61.2 55.6 6000 62.3 56.7 8000 63.5 57.2 6154.5 特征维数查全率 查准率 500 63.8 54.3 1000 64 55.7 2000 65.1 57.9 4000 67.2 58.1 6000 68.1 59.4 8000 69.9 60.6 66.457.7 onEmpricalMethodsinNaturalLanguageProcessing.Sapporo, Ja pan,2003:216-223 Proceedingof3thIEEEInternationalConferenceonInno-vati onsinInformationTechnology.2006:1-5 ErcanG,CicekliI.UsingLexicalChainsforKeywordExtraction[J].InformationProcessing Management,2007,43(6):1705-171 词的疗效比传统的TFIDF 方法提取关键词的疗效要好 虑了特点项在类间和类内的分布情况,对于这些在某个类别 中频繁出现的特点项赋于了较高的权重 ,降低了在类内文档 中碰巧出现的特征项的权重。
因此 DI-TFIDF 算法对 取关键词起到了一定的积极作用。结束语 本文以关键词提取为研究对象 词提取进行了总结,介绍了国内外对关键词提取的研究 成果, 并对关键词提取中具 要影响的特点权重TFIDF 发展及国内外TFIDF 改进成果进行了介绍。 法做了详尽的研究,提出了改进的方式 DI-TFIDF算法 别对基于传统的TFIDF 算法的关键词提取和基于 DI-TFIDF 算法的关键词提 法的关键词提取疗效要比传统算法好,证实了改进的有效性 中文动词的研究较少,而是引用了现 ,根据实验动词疗效还不够理想,下一步须要研究采用 分词 效果更好的动词工具。 TFIDF算法的改进 的分布情况,并未考虑特点词的动词 、特征词宽度和特点 文档中出现的位置,导致了特点权重估算不够确切 要在之后工作中不断研究和测试数据 ,并按照现有的改进方式提出 更有效的改进方式。 P.AStatisticalApproachto MechanizedEncodingand [10]NirajK,KannanS.AutomaticKeyphraseExtractionfromScien- ti ficDocumentsUsing N-Gram Filtration Technique[C] Pro- ce edingofDocEng ’08Conference.2008:199-208 [11]BasilsR,MoschittiA,PazienzaM.Atextclassifierbasedonlin- gu isticprocessing ProceedingsofUCAI,MachineLearningfo rInformationFiltering.1999:36-40 [12]How BC,NarayananK.Anempiricalstudyoffeatureselection ortextcategorizationbasedontermweightage[C] Proceeding the2004IEEE/WIC/ACMIntemationalConferenceonWeb Inte lligence.Washington DC:IEEE Computer Society ,2004: 599- 602 [13] 于文本分类TFIDF 方法的改进与应用 算机工程,2006,32(19):77-78 [14] 于信息增益的特点词权重调整算法研究[J].计算机工程与应用 ,2007,43(35):159-160 [15] 师范大学学报 程技术版,2008,8(4):95-149 [16] ,2009,29(6):167-170[17] TFIDF文本特点加权方式的改进 研究[J].计算机应用与软件 ,2011,28(2):17-21 [18] .基于信息增益与信息熵的TFIDF 算机工程,2012,37(8):37-40 [19] WangD X,Gao X,AndreaeP.AutomaticKeywordExtraction romSingle-Sentence NaturalLanguage Queries[C] PRICAI 012.Berlin:Springer-Verlag,2012:637-648 [20] 算机工程,2010,36(19):93-95 [21] 算机学报,2010,33(7):1246-1255
商业优选:天津网站建设服务公司-天津优化网站关键词
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2020-08-27 23:25
天津网站建设服务公司-天津优化网站关键词6、利用互动平台,巧妙的留下链接积极参与问答平台如百度知道、雅虎知识、问问等等,在这种问答中不仅仅能为需要者提供解决问题的方案,同时也留下了该站点的链接;参与相关峰会如安全杀毒峰会等。可以为站点添加链接;参与社会化wiki平台如百度百科,维基百科等的编辑;Googlepage构建专业网页并完善指向;全网营销推广公司。
早几年站长为了分辨网站各个栏目内容与结构,独立出许多二级域名把某个频道作为独立网站使用,直到有三天突然发觉,不知不觉早已拥有了一个庞大的网站群,并且每位分站都能通过联盟赢利,加上去的收益比一个站多太多了。 所以往前几年,垃圾站成群结对出现。一,站群怎么完善。 二,站群维护方式。目前市场上各类站群软件多如牛毛,站群软件通常都有手动更新、自动维护、自动采集等功能,这些都能解决雪无痕维护几百个网站的麻烦,像芭奇站群、侠客站群、易淘站群、We7、优采云站群、炎黄站群都还算不错的站群维护辅助软件。
(10)SEO优化中关键词布局方法十七:关键词有关的页面排行诱因1.标题标签中第一个字或则词使用关键词2.域名中富含关键词3.H1标签使用了关键词4.页面上导入内部链接锚文字中使用了关键词5.页面上导入外部链接锚文字中使用了关键词6.页面前50-100个可见文字中使用了关键词7.子域名中收录关键词8.目录名中还有关键词
因为搜索引擎以高度自动化的形式运作,网站员一般可以借助个别未被搜索引擎认可的手段、方法来推动排行。这些方式常常未被注意,除非搜索引擎雇员莅临该站点并注意到不寻常活动、或在排行算法上的某个小变化造成站点遗失以过去方法取得的高排行。有时个别公司雇佣优化顾问评估竞争者的站点、和"不道德的" 优化方式向搜索引擎报告。外贸网站建设。
接单挣钱,前言易的技能创新和模式创新令行业为之激奋, 一、破预存款积弊。动辄上万的预存款, 四、海量媒体,大幅沮丧顾客软文营销的门槛,只要登入序言易平台,声音与思想,可在商城上兑换商品。 。实现普惠营销,将资源共享给平台2万多家企业顾客,宝鸡网站建设,独创的多级OEM体系,坐享招商利润 媒体易的相救同伴可自主成长品牌,宝鸡做网站,中小微因而小我私家都可以通过序言易平台留传本身的产物,跑单等困难! 24小时的专业客服处世团队,假如你身边有媒体资源。
4、多个域名对网站有哪些影响?答:同一站点使用多个域名属于作弊行为,多域名短期内可以提升收录量,但是会导致权重、补充材料、重复页面等问题,建议只保留一个,其他的可以做301重定向。5、是不是同一IP上的其他站被百度删掉,我也可能遭到牵涉?答:同一IP的站点,其他的站遭到惩罚,但是自己的站也不一定遭到惩罚,如果这个IP下的其他站作弊厉害,或者内容太不符合搜索引擎收录标准的话,那么这个IP可能遭到了搜索引擎的严禁。关键词推广。
2、注重内链和外链的优化策略,超链接将分散的网路连成一个整体,对于搜索引擎来说,一个网页被链接的次数和链接入网页的质量是彰显网页重要性的一个特别重要的指标。十五:SEO的作用1、扩张资本规模2、优化企业财务结构3、通过SEO 进行资产重组4、调整产品结构,促进产业升级5、品牌保护6、推广(主要作用) 查看全部
商业优选:天津网站建设服务公司-天津优化网站关键词
天津网站建设服务公司-天津优化网站关键词6、利用互动平台,巧妙的留下链接积极参与问答平台如百度知道、雅虎知识、问问等等,在这种问答中不仅仅能为需要者提供解决问题的方案,同时也留下了该站点的链接;参与相关峰会如安全杀毒峰会等。可以为站点添加链接;参与社会化wiki平台如百度百科,维基百科等的编辑;Googlepage构建专业网页并完善指向;全网营销推广公司。
早几年站长为了分辨网站各个栏目内容与结构,独立出许多二级域名把某个频道作为独立网站使用,直到有三天突然发觉,不知不觉早已拥有了一个庞大的网站群,并且每位分站都能通过联盟赢利,加上去的收益比一个站多太多了。 所以往前几年,垃圾站成群结对出现。一,站群怎么完善。 二,站群维护方式。目前市场上各类站群软件多如牛毛,站群软件通常都有手动更新、自动维护、自动采集等功能,这些都能解决雪无痕维护几百个网站的麻烦,像芭奇站群、侠客站群、易淘站群、We7、优采云站群、炎黄站群都还算不错的站群维护辅助软件。
(10)SEO优化中关键词布局方法十七:关键词有关的页面排行诱因1.标题标签中第一个字或则词使用关键词2.域名中富含关键词3.H1标签使用了关键词4.页面上导入内部链接锚文字中使用了关键词5.页面上导入外部链接锚文字中使用了关键词6.页面前50-100个可见文字中使用了关键词7.子域名中收录关键词8.目录名中还有关键词
因为搜索引擎以高度自动化的形式运作,网站员一般可以借助个别未被搜索引擎认可的手段、方法来推动排行。这些方式常常未被注意,除非搜索引擎雇员莅临该站点并注意到不寻常活动、或在排行算法上的某个小变化造成站点遗失以过去方法取得的高排行。有时个别公司雇佣优化顾问评估竞争者的站点、和"不道德的" 优化方式向搜索引擎报告。外贸网站建设。
接单挣钱,前言易的技能创新和模式创新令行业为之激奋, 一、破预存款积弊。动辄上万的预存款, 四、海量媒体,大幅沮丧顾客软文营销的门槛,只要登入序言易平台,声音与思想,可在商城上兑换商品。 。实现普惠营销,将资源共享给平台2万多家企业顾客,宝鸡网站建设,独创的多级OEM体系,坐享招商利润 媒体易的相救同伴可自主成长品牌,宝鸡做网站,中小微因而小我私家都可以通过序言易平台留传本身的产物,跑单等困难! 24小时的专业客服处世团队,假如你身边有媒体资源。
4、多个域名对网站有哪些影响?答:同一站点使用多个域名属于作弊行为,多域名短期内可以提升收录量,但是会导致权重、补充材料、重复页面等问题,建议只保留一个,其他的可以做301重定向。5、是不是同一IP上的其他站被百度删掉,我也可能遭到牵涉?答:同一IP的站点,其他的站遭到惩罚,但是自己的站也不一定遭到惩罚,如果这个IP下的其他站作弊厉害,或者内容太不符合搜索引擎收录标准的话,那么这个IP可能遭到了搜索引擎的严禁。关键词推广。
2、注重内链和外链的优化策略,超链接将分散的网路连成一个整体,对于搜索引擎来说,一个网页被链接的次数和链接入网页的质量是彰显网页重要性的一个特别重要的指标。十五:SEO的作用1、扩张资本规模2、优化企业财务结构3、通过SEO 进行资产重组4、调整产品结构,促进产业升级5、品牌保护6、推广(主要作用)
亚马逊怎么查看搜索关键词排行:亚马逊怎样进行关键词数据剖析?
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2020-08-27 21:19
亚马逊怎样进行关键词数据剖析?亚马逊关键词粉两大块,一块事标题这是最重要的关键词,设置标题的适宜最好的方式是:好的标题直接才能在搜索排序中获得做好的位置。到底是用长关键词还是短关键词好。怎样精准查到Amazon关键词排行原料SurTime工具箱关键词排行查询工具方式/步骤打开SurTime工具箱关键词排行查询工具,a. 确定要查询的Amazon亚马逊站点(以德国为例);b. 深度指的是查询的页脚深度,默认选择查询到第3页;亚马逊广告关键词和搜索关键词怎样看排行?是不是用买家精灵一类的工具就可以?有效绕开亚马逊防采集mgc外置高匿名代理IP模式采集,支持高匿名或专属代理采集;自动判定当前采集是否被mgc,一旦被mgc会手动挂起线程等待一定间隔时间后继续采集;二、监控(采集)竞争对手数据按照某个店面分类直接采集该分类下的所有产品Asin,根据采集到的Asin号去采集其他Offer排名前2的产品价钱、运费、店铺名称等;直接输入分类页网址,程序会手动匹配到所有分类页面的链接,提取所有详尽页网址;三、根据关键词或某个分类采集产品数据并导入。如何提升amazon关键词搜索排名只要在SellingExpress添加关键词后,就能查询关键词的排行位置。亚马逊关键词排名怎么搜一页页翻吗完全不用一页页翻,只要在SellingExpress添加关键词后,就能查询关键词的排行位置,并且可以显示每晚的排行变化曲线图为何亚马逊关键词搜索排行靠前,类目排行太后关键词:是和你产品有高度关联的词句。椅子。可以说办公椅。可以说饭桌桌子等等。2.类目排行:是和销量挂钩的。是所有桌子的排行。或者某个具体类目的沙发。你认为某一个关键词搜索排行靠前。亚马逊营运如何能够有流量,关键词上排行?可以找靠谱的代营运来做的,有专业的营运团队和多的资源。 查看全部
亚马逊怎么查看搜索关键词排行:亚马逊怎样进行关键词数据剖析?
亚马逊怎样进行关键词数据剖析?亚马逊关键词粉两大块,一块事标题这是最重要的关键词,设置标题的适宜最好的方式是:好的标题直接才能在搜索排序中获得做好的位置。到底是用长关键词还是短关键词好。怎样精准查到Amazon关键词排行原料SurTime工具箱关键词排行查询工具方式/步骤打开SurTime工具箱关键词排行查询工具,a. 确定要查询的Amazon亚马逊站点(以德国为例);b. 深度指的是查询的页脚深度,默认选择查询到第3页;亚马逊广告关键词和搜索关键词怎样看排行?是不是用买家精灵一类的工具就可以?有效绕开亚马逊防采集mgc外置高匿名代理IP模式采集,支持高匿名或专属代理采集;自动判定当前采集是否被mgc,一旦被mgc会手动挂起线程等待一定间隔时间后继续采集;二、监控(采集)竞争对手数据按照某个店面分类直接采集该分类下的所有产品Asin,根据采集到的Asin号去采集其他Offer排名前2的产品价钱、运费、店铺名称等;直接输入分类页网址,程序会手动匹配到所有分类页面的链接,提取所有详尽页网址;三、根据关键词或某个分类采集产品数据并导入。如何提升amazon关键词搜索排名只要在SellingExpress添加关键词后,就能查询关键词的排行位置。亚马逊关键词排名怎么搜一页页翻吗完全不用一页页翻,只要在SellingExpress添加关键词后,就能查询关键词的排行位置,并且可以显示每晚的排行变化曲线图为何亚马逊关键词搜索排行靠前,类目排行太后关键词:是和你产品有高度关联的词句。椅子。可以说办公椅。可以说饭桌桌子等等。2.类目排行:是和销量挂钩的。是所有桌子的排行。或者某个具体类目的沙发。你认为某一个关键词搜索排行靠前。亚马逊营运如何能够有流量,关键词上排行?可以找靠谱的代营运来做的,有专业的营运团队和多的资源。
深度订制织梦小说网站模板 自动生成txt+zip压缩+全手动采集+漂亮WAP
采集交流 • 优采云 发表了文章 • 0 个评论 • 429 次浏览 • 2020-08-27 18:28
源码适用范围:价值数万深度定制织梦小说网站模板 自动生成txt+zip压缩+全手动采集+漂亮WAP 强悍至极
源码开发语言:PHP+MYSQL
源码描述说明:
会员织梦深度订制的小说站,全手动采集各大小说站,可手动生成首页、分类、目录、排行榜、sitemap页面静态html,全站拼音目录化,章节页面伪静态,自动生成小说txt文件,自动生成zip压缩包。此源码功能堪称是强大至极!带十分精巧的手机页面!带采集规则+自动适应!莎莎亲测,超级强大,采集规则全部能用,并且全手动采集及入库,非常好用,特别适宜优采云维护!做小说站无话可说的好程序,感谢俺会员无偿提供。
其他特征:
(1)自动生成首页、分类、目录、排行榜、sitemap页面静态html(分类页面、小说封面、作者页面的html文件假如不存在或则超过设置的时间没有更新,会手动更新一次。如果有采集的,采集时会手动更新小说封面和对应的分类页面),通过PHP直接调用html文件,而不是生成在根目录中,访问速率与纯静态没有区别,且可以在保证源码文件管理便捷的同时降低服务器压力,还能便捷访问统计,增加搜索引擎认可度。
(2)全站拼音目录化,章节页面伪静态。
(3)自动生成小说txt文件,也可以后台自己重新生成txt文件。
(4)自动生成小说关键词及关键词手动内链。
(5)自动伪原创成语替换(采集时替换) 。
(6)增加小说总点击、月点击、周点击、总推荐、月推荐、周推荐的统计和作者推荐统计等新功能。
(7)配合CNZZ的统计插件,能便捷实现小说下载明细统计和书籍被采集的明细统计等。
(8)本程序的手动采集并非市面上常见的优采云、关关、采集侠等,而是在DEDE原有采集功能的基础上二次开发的采集模块,可以有效的保证章节内容的完整性,避免章节重复、章节内容无内容、章节乱码等;一天24小时采集量能达到25~30万章节。
查看全部
深度订制织梦小说网站模板 自动生成txt+zip压缩+全手动采集+漂亮WAP
源码适用范围:价值数万深度定制织梦小说网站模板 自动生成txt+zip压缩+全手动采集+漂亮WAP 强悍至极
源码开发语言:PHP+MYSQL
源码描述说明:
会员织梦深度订制的小说站,全手动采集各大小说站,可手动生成首页、分类、目录、排行榜、sitemap页面静态html,全站拼音目录化,章节页面伪静态,自动生成小说txt文件,自动生成zip压缩包。此源码功能堪称是强大至极!带十分精巧的手机页面!带采集规则+自动适应!莎莎亲测,超级强大,采集规则全部能用,并且全手动采集及入库,非常好用,特别适宜优采云维护!做小说站无话可说的好程序,感谢俺会员无偿提供。
其他特征:
(1)自动生成首页、分类、目录、排行榜、sitemap页面静态html(分类页面、小说封面、作者页面的html文件假如不存在或则超过设置的时间没有更新,会手动更新一次。如果有采集的,采集时会手动更新小说封面和对应的分类页面),通过PHP直接调用html文件,而不是生成在根目录中,访问速率与纯静态没有区别,且可以在保证源码文件管理便捷的同时降低服务器压力,还能便捷访问统计,增加搜索引擎认可度。
(2)全站拼音目录化,章节页面伪静态。
(3)自动生成小说txt文件,也可以后台自己重新生成txt文件。
(4)自动生成小说关键词及关键词手动内链。
(5)自动伪原创成语替换(采集时替换) 。
(6)增加小说总点击、月点击、周点击、总推荐、月推荐、周推荐的统计和作者推荐统计等新功能。
(7)配合CNZZ的统计插件,能便捷实现小说下载明细统计和书籍被采集的明细统计等。
(8)本程序的手动采集并非市面上常见的优采云、关关、采集侠等,而是在DEDE原有采集功能的基础上二次开发的采集模块,可以有效的保证章节内容的完整性,避免章节重复、章节内容无内容、章节乱码等;一天24小时采集量能达到25~30万章节。
根据关键词手动聚合数据的科讯CMS插件开发经验
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2020-08-27 14:02
分享科讯文章、图片、动漫、视频、问答按照关键词手动聚合数据的CMS插件制做经验分享。
爱聚合好多站长同学都是比较熟悉,优采云很多站长同学也太熟悉,当然是用科讯的CMS的同事愈发熟悉科讯的采集系统了。对于科讯的后台来说,我们不可证实十分强悍,但是缺乏一个功能--问答的采集(这个功能之针对启用问答系统的用户来说有用)。建站前期,我们常常会采集一些数据,然后我们再去手工降低数据,伪原创数据。很多站长由于前期看不到站有流量所以没有时间的时侯就舍弃了每晚更新的工作,所以百度爬虫或则其他的搜索引擎爬虫来了也喝不到新的数据,于是好多同学都在思索我们能不能去执行手动采集或者手动聚合。
很多同学都说我们不管通过任何方式都要对内容执行一个伪原创或则原创才能对网站的权重或则关键词的排行就会有帮助,没有错,这个问题我开始也在思索,到底是对标题进行关键词或则字眼的程序手动修改能够达到预期的疗效, 还是通过其他方式改变达到疗效。后来我通过以及()查询总结的结果是:其实百度指数就是对人们在网路中找寻自己想要的信息的一个搜索习惯的总结,当然也是用户体验的一个大约总结和归纳。那么我们在标题后面加上一个与内容息息相关的指数是不是算是对标题的伪原创呢?对网站内容究竟有没有哪些帮助呢?答案是肯定的。
于是启发了我开发基于科讯CMS文章、图片、动漫、视频、问答按照关键词手动聚合插件的兴趣,也算是一个尝试吧,每天放学回去就开发这个插件,足足辛苦了一个礼拜,网站终于可以上线测试了,网站从开始上线到明天流量在显著的上升(见统计图),于是我写那么一篇文章和科讯的网友一起来分享了。
统计图(2011-01-16 9:23的截图)
闲话不说,下面介绍一下这个聚合插件的思路:
l 全站只须要针对每位栏目以及对应的问题添加一个指数关键词
l 指数词会在风波(人工访问,搜索引擎爬虫的访问)触发下手动执行数据(文章、图片、动漫、视频、问答)聚合,数据的聚合过程属于分布式进行,所以不会拖延网站的速率。
l 当这个指数词聚合完毕以后,程序都会手动按照指数词聚合相关热度的指数关键词,然后程序再度按照指数词去执行数据的聚合或则依照上面的指数此执行指数词的数据更新。这个过程都是随机的抽取关键词执行任务。
l 数据源基本来自博客和门户以及专业社区中的信息,数据来源目前合计是逾120多个网站,不仅仅是一个简单的单数据源的数据抽取。唯独漫画现今由于时间关系(没有来得及做,不过插口早已预留了,后期疗效好再开发)只去聚合优酷的视频信息。
l 标题全部加一个热度指数词在上面进行标题的伪原创。大家可以详尽见的内容页。
l 在所有的内容页下边为网站创建一个热度指数作为列表的回路(其实也是你们所说的网站权重传递)。
l 内容中降低指数词作为内部链接之用,也是为将来做关键词的排行做打算。
l 图片全部执行伪造,通过伪静态将远程的图片地址以本地图片地址模式进行显示。
科讯后台更改的管理页面主要有:KS.Class.asp, KS.Article.asp, KS.Picture.asp, KS.Movie.asp, KS.Asklist.asp, KS.Special.asp
科讯前台主要更改的页面文件有:/Item/list.asp, /Item/show.asp, /Ask/q.asp
新降低的文件:Auto.asp
新降低的文件夹:ZLJ.Cls
后台修改后的展示疗效
栏目管理页面如图1
图1
专题页面更改如图2
图2
执行疗效见前台
案例网站:我爱游戏网 查看全部
根据关键词手动聚合数据的科讯CMS插件开发经验
分享科讯文章、图片、动漫、视频、问答按照关键词手动聚合数据的CMS插件制做经验分享。
爱聚合好多站长同学都是比较熟悉,优采云很多站长同学也太熟悉,当然是用科讯的CMS的同事愈发熟悉科讯的采集系统了。对于科讯的后台来说,我们不可证实十分强悍,但是缺乏一个功能--问答的采集(这个功能之针对启用问答系统的用户来说有用)。建站前期,我们常常会采集一些数据,然后我们再去手工降低数据,伪原创数据。很多站长由于前期看不到站有流量所以没有时间的时侯就舍弃了每晚更新的工作,所以百度爬虫或则其他的搜索引擎爬虫来了也喝不到新的数据,于是好多同学都在思索我们能不能去执行手动采集或者手动聚合。
很多同学都说我们不管通过任何方式都要对内容执行一个伪原创或则原创才能对网站的权重或则关键词的排行就会有帮助,没有错,这个问题我开始也在思索,到底是对标题进行关键词或则字眼的程序手动修改能够达到预期的疗效, 还是通过其他方式改变达到疗效。后来我通过以及()查询总结的结果是:其实百度指数就是对人们在网路中找寻自己想要的信息的一个搜索习惯的总结,当然也是用户体验的一个大约总结和归纳。那么我们在标题后面加上一个与内容息息相关的指数是不是算是对标题的伪原创呢?对网站内容究竟有没有哪些帮助呢?答案是肯定的。
于是启发了我开发基于科讯CMS文章、图片、动漫、视频、问答按照关键词手动聚合插件的兴趣,也算是一个尝试吧,每天放学回去就开发这个插件,足足辛苦了一个礼拜,网站终于可以上线测试了,网站从开始上线到明天流量在显著的上升(见统计图),于是我写那么一篇文章和科讯的网友一起来分享了。
统计图(2011-01-16 9:23的截图)
闲话不说,下面介绍一下这个聚合插件的思路:
l 全站只须要针对每位栏目以及对应的问题添加一个指数关键词
l 指数词会在风波(人工访问,搜索引擎爬虫的访问)触发下手动执行数据(文章、图片、动漫、视频、问答)聚合,数据的聚合过程属于分布式进行,所以不会拖延网站的速率。
l 当这个指数词聚合完毕以后,程序都会手动按照指数词聚合相关热度的指数关键词,然后程序再度按照指数词去执行数据的聚合或则依照上面的指数此执行指数词的数据更新。这个过程都是随机的抽取关键词执行任务。
l 数据源基本来自博客和门户以及专业社区中的信息,数据来源目前合计是逾120多个网站,不仅仅是一个简单的单数据源的数据抽取。唯独漫画现今由于时间关系(没有来得及做,不过插口早已预留了,后期疗效好再开发)只去聚合优酷的视频信息。
l 标题全部加一个热度指数词在上面进行标题的伪原创。大家可以详尽见的内容页。
l 在所有的内容页下边为网站创建一个热度指数作为列表的回路(其实也是你们所说的网站权重传递)。
l 内容中降低指数词作为内部链接之用,也是为将来做关键词的排行做打算。
l 图片全部执行伪造,通过伪静态将远程的图片地址以本地图片地址模式进行显示。
科讯后台更改的管理页面主要有:KS.Class.asp, KS.Article.asp, KS.Picture.asp, KS.Movie.asp, KS.Asklist.asp, KS.Special.asp
科讯前台主要更改的页面文件有:/Item/list.asp, /Item/show.asp, /Ask/q.asp
新降低的文件:Auto.asp
新降低的文件夹:ZLJ.Cls
后台修改后的展示疗效
栏目管理页面如图1
图1
专题页面更改如图2
图2
执行疗效见前台
案例网站:我爱游戏网
站群是哪些,(泛)站群做法分享
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2020-08-27 03:54
我是小微09-07 11:24
站群是哪些?顾名思义:即一个人或一个团队操作多个网站,目的是通过搜索引擎获得大量流量,或者是将链接指向同一个网站,以提升搜索排名。站群就是一网站的集合,但是一定要统一,分级管理,信息共享,单点登陆才可以。最初的站群由政府提出,现在早已应用领域范围太广,例如政府门户网站群、大型企事业网站群、行业网站群等。
站群一般由几个到几百个网站组成,站群最简单的理解就是一群网站。而这种网站都是属于一个人的,那么这种网站就称之因此站长的站群。
站群系统:站群,是网站主借助搜索引擎自然优化规则进行推广,从搜索引擎端带来流量的的方式。 网站规模少则几个多则上千过万。
站群系统对于站群意义重大,在2005-2007年国外一些从事SEO的工作者提出了站群的概念:多个独立域名(含二级域)的网站统一管理、互相关联。2008年开始,站群软件开发者开发出一种更便于操作的网站采集模式,即通过关键词进行手动采集网站内容,在此之前的采集模式均为编撰规则形式。
在这些简单易用的采集模式基础上,黑豹软件开发商集成了针对不同网站系统的发布插口,以便于用一套简单的采集方式可以同时管理不同网站系统的内容更新,这种软件即多数人所了解的“站群系统”。
站群的目的:是构建强悍的链接资源库,推动网站关键词排行上升,实现站群的最终目的从搜索引擎端获取到最大规模的流量,通过良好的商业模式,实现赢利。
什么是泛站群,泛站群就是又一个顶级域名*.域名泛解析进行生成的二级域名。然后二级域名批量的生成单页。形成站群。
泛站群的缺陷:单页,不存在更新。
(泛)站群做法分享:站群一般由几个到几百个网站组成,个人站长想通过手工更新站群,那几乎是不可能的任务。所以通常都是通过站群软件来完成。进行全手动更新等。 查看全部
站群是哪些,(泛)站群做法分享
我是小微09-07 11:24
站群是哪些?顾名思义:即一个人或一个团队操作多个网站,目的是通过搜索引擎获得大量流量,或者是将链接指向同一个网站,以提升搜索排名。站群就是一网站的集合,但是一定要统一,分级管理,信息共享,单点登陆才可以。最初的站群由政府提出,现在早已应用领域范围太广,例如政府门户网站群、大型企事业网站群、行业网站群等。
站群一般由几个到几百个网站组成,站群最简单的理解就是一群网站。而这种网站都是属于一个人的,那么这种网站就称之因此站长的站群。
站群系统:站群,是网站主借助搜索引擎自然优化规则进行推广,从搜索引擎端带来流量的的方式。 网站规模少则几个多则上千过万。
站群系统对于站群意义重大,在2005-2007年国外一些从事SEO的工作者提出了站群的概念:多个独立域名(含二级域)的网站统一管理、互相关联。2008年开始,站群软件开发者开发出一种更便于操作的网站采集模式,即通过关键词进行手动采集网站内容,在此之前的采集模式均为编撰规则形式。
在这些简单易用的采集模式基础上,黑豹软件开发商集成了针对不同网站系统的发布插口,以便于用一套简单的采集方式可以同时管理不同网站系统的内容更新,这种软件即多数人所了解的“站群系统”。
站群的目的:是构建强悍的链接资源库,推动网站关键词排行上升,实现站群的最终目的从搜索引擎端获取到最大规模的流量,通过良好的商业模式,实现赢利。
什么是泛站群,泛站群就是又一个顶级域名*.域名泛解析进行生成的二级域名。然后二级域名批量的生成单页。形成站群。
泛站群的缺陷:单页,不存在更新。
(泛)站群做法分享:站群一般由几个到几百个网站组成,个人站长想通过手工更新站群,那几乎是不可能的任务。所以通常都是通过站群软件来完成。进行全手动更新等。
2019新版百科搜搜独创源码,自动采集,SEO完美优化手动伪原创
采集交流 • 优采云 发表了文章 • 0 个评论 • 343 次浏览 • 2020-08-25 20:27
2019新版百科搜搜独创源码,自动采集,SEO完美优化手动伪原创
目前市场上基本都是2016版,本源码是我开放,2019全新开发新版,效果十分强悍!
创百科搜搜ASP源码。程序全手动更新+全手动采集+全智能伪原创,程序稳定可靠(网站更新数周或更长
时间无需人为管理,优采云,忙人必备),seo采用新优化方式,百万数据***秒开(拒绝页面仍然绕圈圈)
.程序带有后台,可设为程序手动采集,也可手工随便发布文章。也可随机加入自己的相关,关键词产品推广
(如:关键词,长尾词。关键词)这套程序作出的网站不需要任何***作,每天手动更新,自动采集,自动伪
原创,完全做到全手动。
程序明年新升级优化,过滤常见的(违禁词.垃圾词.铭感词,灰色词),让各大引擎更好的收录或加
快引擎收录量,同时网站的可读信息也大大提高。
网站模板独创开发,面容整洁美观.标题内容清晰一目了然。(拒绝眼花缭乱,错综复杂)的觉得。
一套完整程序配上模板可做多个分类网站,网络挣钱,必备物品。
网站源码特性:
一,搜索引擎完美收录,后期完全可以做到秒收。
二,解放右手,完全做到全手动,做到躺下都挣钱。
注意:只提供源码程序,不提供后其他服务,适合有技术基础的人员
语言:(ASP独创)
数据库:(Access)
程序演示地址:
综合站演示地址:
分类信息站演示:
赚钱思路:本源码的挣钱思路简单,纯靠各大搜索流量挣钱,此类网站全是长尾关键词,收录量越大,长尾
关键词越多,流量越大,后挂广告联盟挣钱。真正做到躺下都挣钱。
空间配置要求:必须要求web服务是IIS6,支持语言是ASP,并开启伪静态,空间大小尽量1G左右
注:如需订购此源码请移步“互站”购买,或在本站“C代码”搜索相关资源! 查看全部
2019新版百科搜搜独创源码,自动采集,SEO完美优化手动伪原创
2019新版百科搜搜独创源码,自动采集,SEO完美优化手动伪原创
目前市场上基本都是2016版,本源码是我开放,2019全新开发新版,效果十分强悍!
创百科搜搜ASP源码。程序全手动更新+全手动采集+全智能伪原创,程序稳定可靠(网站更新数周或更长
时间无需人为管理,优采云,忙人必备),seo采用新优化方式,百万数据***秒开(拒绝页面仍然绕圈圈)
.程序带有后台,可设为程序手动采集,也可手工随便发布文章。也可随机加入自己的相关,关键词产品推广
(如:关键词,长尾词。关键词)这套程序作出的网站不需要任何***作,每天手动更新,自动采集,自动伪
原创,完全做到全手动。
程序明年新升级优化,过滤常见的(违禁词.垃圾词.铭感词,灰色词),让各大引擎更好的收录或加
快引擎收录量,同时网站的可读信息也大大提高。
网站模板独创开发,面容整洁美观.标题内容清晰一目了然。(拒绝眼花缭乱,错综复杂)的觉得。
一套完整程序配上模板可做多个分类网站,网络挣钱,必备物品。
网站源码特性:
一,搜索引擎完美收录,后期完全可以做到秒收。
二,解放右手,完全做到全手动,做到躺下都挣钱。
注意:只提供源码程序,不提供后其他服务,适合有技术基础的人员
语言:(ASP独创)
数据库:(Access)
程序演示地址:
综合站演示地址:
分类信息站演示:
赚钱思路:本源码的挣钱思路简单,纯靠各大搜索流量挣钱,此类网站全是长尾关键词,收录量越大,长尾
关键词越多,流量越大,后挂广告联盟挣钱。真正做到躺下都挣钱。
空间配置要求:必须要求web服务是IIS6,支持语言是ASP,并开启伪静态,空间大小尽量1G左右
注:如需订购此源码请移步“互站”购买,或在本站“C代码”搜索相关资源!
Python学习笔记(19)自动搜索关键词采集信息—以易迅为例
采集交流 • 优采云 发表了文章 • 0 个评论 • 479 次浏览 • 2020-08-25 00:01
一、操作步骤
如果网页上有搜索框,但是搜索结果页面没有独立网址,想要采集搜索结果,直接做规则是采集不到的,要先做连续动作(输入+点击)来实现手动输入关键词并搜索,然后才会采集数据。下面用易迅搜索为例,演示手动搜索采集,操作步骤如下:
二、案例规则+操作步骤
**注意:**本案例易迅搜索是有独立网址的,对于具有独立网址的页面,最简单的方式就是构造出每位关键词的搜索网址,然后把线索网址导出到规则里,就可以批量采集,而不是设置连续动作
第一步:定义第一级规则
1.1打开集搜客网络爬虫,输入网址并Enter,加载出网页后再点击“定义规则”按钮,看到一个浮窗显示下来,称为工作台,在前面定义规则;
注意:这里的截图和文字说明都是集搜客网络爬虫版本,如果您安装的是傲游插件版,那么就没有“定义规则”按钮,而是应当运行MS谋数台
1.2在工作台北输入一级规则的主题名,再点击“查重”,提示“该名可以使用”或“该名已被占用,可编辑:是”,就可以使用这个主题名,否则请重命名。
1.3本级规则主要是设置连续动作,所以,整理箱可以随便抓取一个信息,用来给爬虫判定是否执行采集。双击网页上的信息,输入标签名,并打勾确认,再勾上关键内容,首次标明还要输入整理箱的名子,然后就完成标明映射了。
Tips:为了能确切定位网页信息,点击定义规则会把整个网页定格住,不能跳转网页链接,再次点击定义规则,才会恢复回普通的网页模式。
第二步:定义连续动作
点击工作台的“连续动作”页签,点击新建按键构建一个新动作,每个动作的设置方式都是一样,基本操作如下:
2.1 ,输入目标主题名
这里的目标主题名是填第二级主题名,点击“谁在用”查看目标主题名是否可用,如果早已被占用,换一个主题名就行
2.2, 创建第一个动作:输入
新建一个动作,并选择动作类型为输入。
2.2.1,填写定位表达式
首先键盘单击输入框,定位输入框的节点,然后点击“自动生成XPath”按钮,可以选择“偏好id”或者“偏好class”,就可以得到输入框的xpath表达式,再点击“搜索”按钮,检查一下这个xpath是否能惟一定位到输入框,没有问题就把xpath复制到定位表达式方框里。
**注意:**定位表达式里的xpath是要锁定动作对象的整个有效操作范围,具体就是指键盘就能点击或输入成功的网页模块,不要定位到最底层的text()节点。
2.2.2,输入关键词
输入关键词填写你想搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词要用双分号;;将每位关键词隔开,免费版只支持5个以内的关键词,旗舰版可以使用连发弹仓功能,支持1万以内的关键词
2.2.3,输入动作名称
告诉自己这一步动作是拿来干嘛的,方便之后更改。
2.3,创建第二个动作:点击
参考2.2的操作,创建第二个动作,选择类型为点击,定位到搜索按键,然后手动生成xpath,检验是否锁定到惟一节点,没问题的话填到定位表达式里就行了。
2.4,存规则
点击“存规则”按钮保存已完成的第一级规则
第三步:定义第二级规则
3.1,新建规则
创建第二级规则,点击“定义规则”恢复到普通网页模式,输入关键词搜索出结果后,再次点击“定义规则”切换到做规则模式,点击左上角“规则”菜单->“新建”,输入主题名,这里的主题名就是第一级规则的连续动作里填写的目标主题名。
3.2,标注想要采集的信息
3.2.1,标注网页上想要采集的信息,这里是对商品名称和价钱做标明,因为标明只对文本信息有效,商品详情的链接是属性节点@href,所以,不能对链接做这样的直观标明,而要做内容映射,具体看下边的操作。
3.2.2,点击商品名称,下面的DOM节点定位到A标签,展开A标签下的attributes节点,就可以找到代表网址的@href节点,右击节点,选择“新建抓取内容“,输入一个名子,一般给这个抓取内容起一个和地址有关的名子,比如“下级网址“,或者”下级链接“等等。然后在工作台上,看到这个抓取内容有了。如果还要步入商品详情页采集,就要对着这个抓取内容勾选下级线索,做层级抓取。
3.2.3,设置“关键内容”选项,这样爬虫能够判定出采集规则是否合适。在整理箱里选一个网页上必然能采到的标签,勾上“关键内容”。这里选择的是“名称”做为“关键内容”。
3.2.4,前面只对一个商品做标明,也能够得到一个商品信息,如果想把一整页上每一个商品都采集下来,可以做样例复制,不懂的请参考基础教程《采集列表数据》
3.3,设置翻页路线
在爬虫路线设置翻页,这里用的是记号线索,不懂的请参考基础教程《设置翻页采集》
3.4,存规则
点击“测试”,检查信息完整性。不完整的话,重新标明就可以覆盖之前的内容。检查没问题后点击“存规则”。
第四步:抓数据
4.1,连续动作是连续执行的,所以只要运行第一级主题,第二级主题不用运行。打开DS打数机,搜索出第一级主题名,点击“单搜”或“集搜”,此时可以看见浏览器窗口里会手动输入关键词而且搜索,然后调用第二级主题手动采集搜索结果。
4.2,第一级主题没采到有意义的信息,所以,我们只看第二级主题的文件夹,就能看见采集的搜索结果数据,并且搜索的关键词是默认记录在xml文件的actionvalue数组中,这样才能一一对应上去。 查看全部
Python学习笔记(19)自动搜索关键词采集信息—以易迅为例
一、操作步骤
如果网页上有搜索框,但是搜索结果页面没有独立网址,想要采集搜索结果,直接做规则是采集不到的,要先做连续动作(输入+点击)来实现手动输入关键词并搜索,然后才会采集数据。下面用易迅搜索为例,演示手动搜索采集,操作步骤如下:
二、案例规则+操作步骤
**注意:**本案例易迅搜索是有独立网址的,对于具有独立网址的页面,最简单的方式就是构造出每位关键词的搜索网址,然后把线索网址导出到规则里,就可以批量采集,而不是设置连续动作
第一步:定义第一级规则
1.1打开集搜客网络爬虫,输入网址并Enter,加载出网页后再点击“定义规则”按钮,看到一个浮窗显示下来,称为工作台,在前面定义规则;
注意:这里的截图和文字说明都是集搜客网络爬虫版本,如果您安装的是傲游插件版,那么就没有“定义规则”按钮,而是应当运行MS谋数台
1.2在工作台北输入一级规则的主题名,再点击“查重”,提示“该名可以使用”或“该名已被占用,可编辑:是”,就可以使用这个主题名,否则请重命名。
1.3本级规则主要是设置连续动作,所以,整理箱可以随便抓取一个信息,用来给爬虫判定是否执行采集。双击网页上的信息,输入标签名,并打勾确认,再勾上关键内容,首次标明还要输入整理箱的名子,然后就完成标明映射了。
Tips:为了能确切定位网页信息,点击定义规则会把整个网页定格住,不能跳转网页链接,再次点击定义规则,才会恢复回普通的网页模式。
第二步:定义连续动作
点击工作台的“连续动作”页签,点击新建按键构建一个新动作,每个动作的设置方式都是一样,基本操作如下:
2.1 ,输入目标主题名
这里的目标主题名是填第二级主题名,点击“谁在用”查看目标主题名是否可用,如果早已被占用,换一个主题名就行
2.2, 创建第一个动作:输入
新建一个动作,并选择动作类型为输入。
2.2.1,填写定位表达式
首先键盘单击输入框,定位输入框的节点,然后点击“自动生成XPath”按钮,可以选择“偏好id”或者“偏好class”,就可以得到输入框的xpath表达式,再点击“搜索”按钮,检查一下这个xpath是否能惟一定位到输入框,没有问题就把xpath复制到定位表达式方框里。
**注意:**定位表达式里的xpath是要锁定动作对象的整个有效操作范围,具体就是指键盘就能点击或输入成功的网页模块,不要定位到最底层的text()节点。
2.2.2,输入关键词
输入关键词填写你想搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词要用双分号;;将每位关键词隔开,免费版只支持5个以内的关键词,旗舰版可以使用连发弹仓功能,支持1万以内的关键词
2.2.3,输入动作名称
告诉自己这一步动作是拿来干嘛的,方便之后更改。
2.3,创建第二个动作:点击
参考2.2的操作,创建第二个动作,选择类型为点击,定位到搜索按键,然后手动生成xpath,检验是否锁定到惟一节点,没问题的话填到定位表达式里就行了。
2.4,存规则
点击“存规则”按钮保存已完成的第一级规则
第三步:定义第二级规则
3.1,新建规则
创建第二级规则,点击“定义规则”恢复到普通网页模式,输入关键词搜索出结果后,再次点击“定义规则”切换到做规则模式,点击左上角“规则”菜单->“新建”,输入主题名,这里的主题名就是第一级规则的连续动作里填写的目标主题名。
3.2,标注想要采集的信息
3.2.1,标注网页上想要采集的信息,这里是对商品名称和价钱做标明,因为标明只对文本信息有效,商品详情的链接是属性节点@href,所以,不能对链接做这样的直观标明,而要做内容映射,具体看下边的操作。
3.2.2,点击商品名称,下面的DOM节点定位到A标签,展开A标签下的attributes节点,就可以找到代表网址的@href节点,右击节点,选择“新建抓取内容“,输入一个名子,一般给这个抓取内容起一个和地址有关的名子,比如“下级网址“,或者”下级链接“等等。然后在工作台上,看到这个抓取内容有了。如果还要步入商品详情页采集,就要对着这个抓取内容勾选下级线索,做层级抓取。
3.2.3,设置“关键内容”选项,这样爬虫能够判定出采集规则是否合适。在整理箱里选一个网页上必然能采到的标签,勾上“关键内容”。这里选择的是“名称”做为“关键内容”。
3.2.4,前面只对一个商品做标明,也能够得到一个商品信息,如果想把一整页上每一个商品都采集下来,可以做样例复制,不懂的请参考基础教程《采集列表数据》
3.3,设置翻页路线
在爬虫路线设置翻页,这里用的是记号线索,不懂的请参考基础教程《设置翻页采集》
3.4,存规则
点击“测试”,检查信息完整性。不完整的话,重新标明就可以覆盖之前的内容。检查没问题后点击“存规则”。
第四步:抓数据
4.1,连续动作是连续执行的,所以只要运行第一级主题,第二级主题不用运行。打开DS打数机,搜索出第一级主题名,点击“单搜”或“集搜”,此时可以看见浏览器窗口里会手动输入关键词而且搜索,然后调用第二级主题手动采集搜索结果。
4.2,第一级主题没采到有意义的信息,所以,我们只看第二级主题的文件夹,就能看见采集的搜索结果数据,并且搜索的关键词是默认记录在xml文件的actionvalue数组中,这样才能一一对应上去。
[转帖]-seo关键词排名优化服务
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2020-08-22 15:46
seo要害词排行优化服务
seo优化以后有哪些后果?晋升目的网站中指定根源词在搜索引擎里的自然排行。
生效岁月:项目开端起2个月或更长(合同商定)。
【seo关键词优化服务流程】
一、初议和推断目的要害词:
如同探险之前没有辨清方向,未经督查、盲目选择目的根源词会使全部seo工作从开端就走错了街――seo是精密的兼具计划工作,一度的方向误差也将大大失去预算,挥霍掉的岁月和机遇本钱更是难以恐怕。
我们的seo工作职员使用超过3种关键词分析工具,筛选并拾掇出合适当前网站、当前行业的高质量关键词列表。关键词列表以岁月(周期性)、地区(全世界范畴)、搜索量、seo竞争度、预估转化率等多个角度清楚展示。
我们甚至能通过关键词分析工作提早判定出一个行业的变迁规律。
二、搜索引擎友爱度钻探并优化:
这是一个年龄超过10岁的古老seo话题。即便是seo知识已然相当普及的明天,仍然有大批网站存在"反复内容"、sessionid所造成的"庞杂网址串"、"全flash页面"、"脚本链接"等小麻烦在影响搜索引擎友爱度。网站变得另搜索引擎爬虫无法抓取,无法全体收录,,更别提在搜索引擎里争抢自然排行获取流量了。
三、内容撰写、安排:
信任您也见过不少一打开窗口就想立刻封闭的网站。尤其是一些经过seo公司"优化"过的,一心一意只为搜索引擎蜘蛛献殷勤的站点。千万要记住,要害词排行再高,流量再大,也不要疏漏一点――网站是给人看的。
我们的seo文案工作职员除了擅长创作高质量、便于seo优化的内容,而且会尽量让内容迎合你的读者、访客与顾客。
我们许诺在应用任何内容之前向您征求想法,以确认您也爱好它们。
四、吸引和获取高质量链接:
获得链接可以晋升网站在搜索引擎中的自然排行,这是大肆的seo绝密。
赚到1000万才能买幢洋房,这尽人皆知。但是,怎样挣来那1000万买豪宅的钱呢?
艰苦同样存在于怎么吸引和获取高质量链接,这是seo工作的一大困难。
五、我们应用的链接获取方式收录但不限于: 查看全部
[转帖]-seo关键词排名优化服务
seo要害词排行优化服务
seo优化以后有哪些后果?晋升目的网站中指定根源词在搜索引擎里的自然排行。
生效岁月:项目开端起2个月或更长(合同商定)。
【seo关键词优化服务流程】
一、初议和推断目的要害词:
如同探险之前没有辨清方向,未经督查、盲目选择目的根源词会使全部seo工作从开端就走错了街――seo是精密的兼具计划工作,一度的方向误差也将大大失去预算,挥霍掉的岁月和机遇本钱更是难以恐怕。
我们的seo工作职员使用超过3种关键词分析工具,筛选并拾掇出合适当前网站、当前行业的高质量关键词列表。关键词列表以岁月(周期性)、地区(全世界范畴)、搜索量、seo竞争度、预估转化率等多个角度清楚展示。
我们甚至能通过关键词分析工作提早判定出一个行业的变迁规律。
二、搜索引擎友爱度钻探并优化:
这是一个年龄超过10岁的古老seo话题。即便是seo知识已然相当普及的明天,仍然有大批网站存在"反复内容"、sessionid所造成的"庞杂网址串"、"全flash页面"、"脚本链接"等小麻烦在影响搜索引擎友爱度。网站变得另搜索引擎爬虫无法抓取,无法全体收录,,更别提在搜索引擎里争抢自然排行获取流量了。
三、内容撰写、安排:
信任您也见过不少一打开窗口就想立刻封闭的网站。尤其是一些经过seo公司"优化"过的,一心一意只为搜索引擎蜘蛛献殷勤的站点。千万要记住,要害词排行再高,流量再大,也不要疏漏一点――网站是给人看的。
我们的seo文案工作职员除了擅长创作高质量、便于seo优化的内容,而且会尽量让内容迎合你的读者、访客与顾客。
我们许诺在应用任何内容之前向您征求想法,以确认您也爱好它们。
四、吸引和获取高质量链接:
获得链接可以晋升网站在搜索引擎中的自然排行,这是大肆的seo绝密。
赚到1000万才能买幢洋房,这尽人皆知。但是,怎样挣来那1000万买豪宅的钱呢?
艰苦同样存在于怎么吸引和获取高质量链接,这是seo工作的一大困难。
五、我们应用的链接获取方式收录但不限于:
自动更新联通网站如何优化获得好的关键词排名
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2020-08-22 13:01
自动更新联通网站如何优化获得好的关键词排名
移动端现今显得越来越重要,如何使网站在移动端有好的排行,现在一级钢渐渐成为好多站长头痛的一件事情。虽然移动端网站优化和PC端网站优化拥有共同性,在优化方法和方法方面也大同小异。那么,如何使移动端网站获得搜索引擎的喜爱,从而迅速获得首页关键词排行。下面,濮阳网站建设就谈谈怎样通过优化手段使移动端网站获得好的关键词排行。
不管我们做PC端网站还是移动端网站都须要在网站前期做一些打算工作,例如网站诊断甚至网站分析等,还是就是PC端和移动端网站的适配。移动端在前期也须要考虑网站结构,虽然移动端我们常用二级域名,但是相对于PC端网站而言,也是一个独立的网站,必定有自己的网站结构和网站导航等。
移动端在页面优化过程中,尽量跟PC端网站TDK一样。这样保持在适配过程中,PC端的排行和权重整体承继过来。还有就是数据库进行使用相同数据库,这样使数据和内容保持一致性。
网站排名都离不开收录,就算网站内容在好,如果搜索引擎不收录也是未能参与排行,其实联通网站在收录方面也是跟PC网站一样。搜索引擎蜘蛛都须要通过索引,抓取,建库,释放,参与排行等过程。如果robots严禁蜘蛛抓取或则蜘蛛在链接抓取过程碰到问题,就会降低搜索引擎抓取内容的难易度。
网站链接结构是网站重中之重,如何优化网站如果网站链接结构出现一些问题都会造成网站在后期优化疗效不佳,甚至可能出现改版等诱因。因此,网站结构根据搜索引擎移动端指导规范进行合理设置。
虽然移动端甚少由用户查看链接,然而,我们在移动端URL的设置过程中,就须要采用静态化的链接形式。这样,让蜘蛛极少辨识下来。
要经常观察网站logs文件,查看蜘蛛抓取时的返回HTTP代码是否是200,尽量降低死链接 404 的出现。
内部优化就是要使网站锚文本合理出现在网站内容页中,不要只是把权重全部导给首页或则把链接全部链接到首页。虽然,在前期我们尽量做首页关键词。在之后网站栏目页和内容页也应当做有效的链接策略.
不管哪种搜索引擎判定一个页面权重高低,很重要的根据给与外部链接导出的锚文本和链接数目。因此,我们在外链建设方面就不能放松。要按照网站情况,进行外链非常高质量的外链建设。
网站内容这些都是太老掉牙的东西,就是文章尽量原创,现在搜索引擎对于网站内容要求越来越高。高质量,网站搜索引擎优化原创内容对于网站排名和整体权重提高作用不可缺乏。
移动网站打开速度决定网站的整体排行,现在搜索引擎在判定网站关键词排行早已把网站打开速率考虑进行,因此,网站打开速度显得越来越重要。
热门点击:网站优化与文章的质量
!
与手动更新联通网站如何优化获得好的关键词排名相关文章:
·网站优化中怎样获得一个稳定的排行哪些是站群
·网站优化双刃剑:如何提升网站排名哪些是站群
·有权重无排行 网站优化怎样避免本末倒置站群
·浅谈网站如何做好优化能够够提高搜索引擎排名
·中小型网站如何合理优化网站排名站群工具
·卢国馥:如何剖析竞争对手的数据站群软件
本文标题:自动更新联通网站如何优化获得好的关键词排名
本文地址: 查看全部
自动更新联通网站如何优化获得好的关键词排名
自动更新联通网站如何优化获得好的关键词排名
移动端现今显得越来越重要,如何使网站在移动端有好的排行,现在一级钢渐渐成为好多站长头痛的一件事情。虽然移动端网站优化和PC端网站优化拥有共同性,在优化方法和方法方面也大同小异。那么,如何使移动端网站获得搜索引擎的喜爱,从而迅速获得首页关键词排行。下面,濮阳网站建设就谈谈怎样通过优化手段使移动端网站获得好的关键词排行。
不管我们做PC端网站还是移动端网站都须要在网站前期做一些打算工作,例如网站诊断甚至网站分析等,还是就是PC端和移动端网站的适配。移动端在前期也须要考虑网站结构,虽然移动端我们常用二级域名,但是相对于PC端网站而言,也是一个独立的网站,必定有自己的网站结构和网站导航等。
移动端在页面优化过程中,尽量跟PC端网站TDK一样。这样保持在适配过程中,PC端的排行和权重整体承继过来。还有就是数据库进行使用相同数据库,这样使数据和内容保持一致性。
网站排名都离不开收录,就算网站内容在好,如果搜索引擎不收录也是未能参与排行,其实联通网站在收录方面也是跟PC网站一样。搜索引擎蜘蛛都须要通过索引,抓取,建库,释放,参与排行等过程。如果robots严禁蜘蛛抓取或则蜘蛛在链接抓取过程碰到问题,就会降低搜索引擎抓取内容的难易度。
网站链接结构是网站重中之重,如何优化网站如果网站链接结构出现一些问题都会造成网站在后期优化疗效不佳,甚至可能出现改版等诱因。因此,网站结构根据搜索引擎移动端指导规范进行合理设置。
虽然移动端甚少由用户查看链接,然而,我们在移动端URL的设置过程中,就须要采用静态化的链接形式。这样,让蜘蛛极少辨识下来。
要经常观察网站logs文件,查看蜘蛛抓取时的返回HTTP代码是否是200,尽量降低死链接 404 的出现。
内部优化就是要使网站锚文本合理出现在网站内容页中,不要只是把权重全部导给首页或则把链接全部链接到首页。虽然,在前期我们尽量做首页关键词。在之后网站栏目页和内容页也应当做有效的链接策略.
不管哪种搜索引擎判定一个页面权重高低,很重要的根据给与外部链接导出的锚文本和链接数目。因此,我们在外链建设方面就不能放松。要按照网站情况,进行外链非常高质量的外链建设。
网站内容这些都是太老掉牙的东西,就是文章尽量原创,现在搜索引擎对于网站内容要求越来越高。高质量,网站搜索引擎优化原创内容对于网站排名和整体权重提高作用不可缺乏。
移动网站打开速度决定网站的整体排行,现在搜索引擎在判定网站关键词排行早已把网站打开速率考虑进行,因此,网站打开速度显得越来越重要。
热门点击:网站优化与文章的质量
!
与手动更新联通网站如何优化获得好的关键词排名相关文章:
·网站优化中怎样获得一个稳定的排行哪些是站群
·网站优化双刃剑:如何提升网站排名哪些是站群
·有权重无排行 网站优化怎样避免本末倒置站群
·浅谈网站如何做好优化能够够提高搜索引擎排名
·中小型网站如何合理优化网站排名站群工具
·卢国馥:如何剖析竞争对手的数据站群软件
本文标题:自动更新联通网站如何优化获得好的关键词排名
本文地址:
网站推广工具-网站关键词之seo优化长尾词
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2020-08-22 12:43
网站推广工具,也就是这些于网站外容由相干性的关键词,更少的时侯她们是暖门关键词与是热点关键词的组开,或许是热点关键词取小众根源词的组开。
长尾关键词应该知足3个基础前提:
1、彼要害词取您的网坐外容由管无闭;
2、选择的关键词必需是用户有才能来查询的词;
3、能知足到拜访者恳求的。
简略的来道,就是自用户的角度动身,站在用户的心态下根据她们的习性往设放关键词。
少头根源词的选购:
通过网站的构念战网站的相干业务相商讨的关键词,或者则通功对于脚战搜救引擎往开掘相当的关键词。最初说一上,网站内容要缭绕关键词去做,小型网站绝质应用关键词相关的纲录情势入止文章展现。
2、选择的闭键词必需是用户无才能来查询的词(也就是要害词的冷度,人们做关键词的排实的时分便要选购根源词的暖度来做推狭,刚刚开端劣化的时侯,不能做很热点的词那样的词对于我们来道非比拟易劣化下去的,也没有能是这类太寒门的词,固然这样的词太轻易做到百度的第一位,
但是这样的词出有己来搜救,我们做到第一位也出有实践的意义。)
3、能满意到拜访者恳求的。
简略的来道,就是自用户的角度动身,站在用户的心态下根据她们的习性往设放关键词。
少头关键词的选购:
通功网站的构念和网站的相关业务相商讨的关键词,或者则通过对于脚战搜索引擎去开掘相当的关键词。最初说一上,网站内容要缭绕关键词去做,小型网站绝质应用关键词相关的纲录情势入止文章展现。
另外正在写这个的时侯,我念到一个答题,这个问题才能答的有面长稚,但是我实的有正点没有清楚,呵呵!就是自己皆道的一类简短的推狭方式就是到各大型的峰会,专主下去些硬文,或许宣布本人的白章,他人来单造你的文章,就相称于她们给你做了外部衔接了,
但是重要是,在复造文章的时分,他人皆是正在忘事原内功滤掉了衔接的代码,那样她们尚且单制了你的文章,委婉载到她们站下先,应用的是她们修正先的白章,也就不是你的本文章了,这样没有便败了她们本人的旧文章吗?这这样的旧文章确定非出有了人们站的连交吧!
这人们如何道是别人复制你的文章先,便相称给您做了外部衔接呢!仍是网坐有一类功效,只需无单制那种文章的时侯,主动正在搜救引擎外以为别己复造了你的白章几主,即便是修正后,但是在他复制的时分以前记载了,所以借非相该给你做了外部链交!但是这种当
当是搜索引擎的管辖范畴了!感到这样的答题有面长稚!希
与网站推广工具-网站关键词之seo优化长尾词相关文章:
·A5优化小组推荐:免费SEO工具仍然可以披荆斩
·10个适宜博客的SEO优化工具站群系统
·网编SEO进阶:推荐一款比较好的在线SEO优化工
·网络推广人员须要把握的九大查询工具站群工具
·SEO优化工具-芭奇管家 V3.018站群工具
·勤奋的卓卓实战经验:网络营销到底是什么?自
本文标题:网站推广工具-网站关键词之seo优化长尾词
本文地址: 查看全部
网站推广工具-网站关键词之seo优化长尾词
网站推广工具,也就是这些于网站外容由相干性的关键词,更少的时侯她们是暖门关键词与是热点关键词的组开,或许是热点关键词取小众根源词的组开。
长尾关键词应该知足3个基础前提:
1、彼要害词取您的网坐外容由管无闭;
2、选择的关键词必需是用户有才能来查询的词;
3、能知足到拜访者恳求的。
简略的来道,就是自用户的角度动身,站在用户的心态下根据她们的习性往设放关键词。
少头根源词的选购:
通过网站的构念战网站的相干业务相商讨的关键词,或者则通功对于脚战搜救引擎往开掘相当的关键词。最初说一上,网站内容要缭绕关键词去做,小型网站绝质应用关键词相关的纲录情势入止文章展现。
2、选择的闭键词必需是用户无才能来查询的词(也就是要害词的冷度,人们做关键词的排实的时分便要选购根源词的暖度来做推狭,刚刚开端劣化的时侯,不能做很热点的词那样的词对于我们来道非比拟易劣化下去的,也没有能是这类太寒门的词,固然这样的词太轻易做到百度的第一位,
但是这样的词出有己来搜救,我们做到第一位也出有实践的意义。)
3、能满意到拜访者恳求的。
简略的来道,就是自用户的角度动身,站在用户的心态下根据她们的习性往设放关键词。
少头关键词的选购:
通功网站的构念和网站的相关业务相商讨的关键词,或者则通过对于脚战搜索引擎去开掘相当的关键词。最初说一上,网站内容要缭绕关键词去做,小型网站绝质应用关键词相关的纲录情势入止文章展现。
另外正在写这个的时侯,我念到一个答题,这个问题才能答的有面长稚,但是我实的有正点没有清楚,呵呵!就是自己皆道的一类简短的推狭方式就是到各大型的峰会,专主下去些硬文,或许宣布本人的白章,他人来单造你的文章,就相称于她们给你做了外部衔接了,
但是重要是,在复造文章的时分,他人皆是正在忘事原内功滤掉了衔接的代码,那样她们尚且单制了你的文章,委婉载到她们站下先,应用的是她们修正先的白章,也就不是你的本文章了,这样没有便败了她们本人的旧文章吗?这这样的旧文章确定非出有了人们站的连交吧!
这人们如何道是别人复制你的文章先,便相称给您做了外部衔接呢!仍是网坐有一类功效,只需无单制那种文章的时侯,主动正在搜救引擎外以为别己复造了你的白章几主,即便是修正后,但是在他复制的时分以前记载了,所以借非相该给你做了外部链交!但是这种当
当是搜索引擎的管辖范畴了!感到这样的答题有面长稚!希
与网站推广工具-网站关键词之seo优化长尾词相关文章:
·A5优化小组推荐:免费SEO工具仍然可以披荆斩
·10个适宜博客的SEO优化工具站群系统
·网编SEO进阶:推荐一款比较好的在线SEO优化工
·网络推广人员须要把握的九大查询工具站群工具
·SEO优化工具-芭奇管家 V3.018站群工具
·勤奋的卓卓实战经验:网络营销到底是什么?自
本文标题:网站推广工具-网站关键词之seo优化长尾词
本文地址:
如何提升单页面关键词排名?
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2020-08-22 12:28
10.假如你不是优化前辈,尽量把热门或则其他词汇放到首页来做,首页的权重高,见效快;
单页面里面的热门词不要超过4个,不是热门词汇可选择二级页面处理;
11.旧网站你保留了吗?保留路径更改了吗?如果有新旧两个站,请使用301转向处理好;
302绑架,在你的脑海中永远消失;
12.你每晚原创吗?
关键词(原创)上线的时间要考虑,早上下班的第一件事情就做;
你准本的材料或则是顾客给你的材料是否是网站转载千万遍的东西;
新手可以不顾网站内容质量,去做伪原创;
老手要在整篇文章中抒发你自己的观点;
原创内容要多点,最好是300~1000字,最重要的关键词尽量出现在后面;
网站关键词的密度不要高于3%,尽量不要低于15%,具体情况具体对待。
13.菜鸟第一次做:力度和范围可以小,但是决不能大;且记住:新手外链为王,很适宜你;
老手要懂得如何去分辨提取有效的外链;
14.半个月把新网站中的热门关键词做到首页的说法的人,永远不要与之为伍;
网站优化,实例为王,因为你们都在和搜索引擎玩游戏,看谁的牌出的好;
网站优化是个系统的工程;
优化讲求功到自然成;
15.网站中不要有负面言论;
尽量少使用群发软件做网站宣传或则做外链,网络蜘蛛并不是傻蛋;
16.英文网站优化要考虑域名的诱因;
英文网站优化在生成静态页面重要收录关键词;
动态网站最好是使用能生成静态页面的技术
17.不要指望一个关键词能带来多少流量,要流量就要做多个关键词;并且内容的专业才是网站好坏的真谛;
18.菜鸟永远在他人的博客上或则峰会中写伪原创文章;
老手永远自己写文章,然后他人疯狂转载;
19.pr值无论是百度还是微软目前都还比较重要;
pr值在yahoo英语的重要性大于域名的重要性;
20.不要三天打鱼,两天晒网,让蜘蛛喝完大餐之后饿日子;
21.门户网站优化须要顾客的配合;
22.网站优化的前辈本身应当是懂些程序;
23.内链在网站中也是影响排行的一个诱因;
内链的链接不能重复太多;
24.h1标签建议规范使用;
h2标签建议规范使用;
25.友情链接尽量找pr高的链接;
友情链接尽量同行或则相关做链接(其实我也晓得这似乎很难);
26.导出链接文本中收录你的关键词,并且关键词本身也是链接;
27.锚文本多元化;
a标签多元化;
28.新手永远是看技术;
老手不但要看技术,还要看利益均衡,知道舍得的重要性;
29.搜索引擎的优异排行是网站各项优化的结果;
关键词(原创)上线的时间要考虑,早上下班的第一件事情就做;你准本的材料或则是顾客给你的材料是否是网站转载千万遍的东西;
新手可以不顾网站内容质量,去做伪原创;
老手要在整篇文章中抒发你自己的观点;
原创内容要多点,最好是300~1000字,最重要的关键词尽量出现在后面;
网站关键词的密度不要高于3%,尽量不要低于15%,具体情况具体对待。
13.菜鸟第一次做:力度和范围可以小,但是决不能大;且记住:新手外链为王,很适宜你;
老手要懂得如何去分辨提取有效的外链;
14.半个月把新网站中的热门关键词做到首页的说法的人,永远不要与之为伍;
网站优化,实例为王,因为你们都在和搜索引擎玩游戏,看谁的牌出的好;
网站优化是个系统的工程;
优化讲求功到自然成;
15.网站中不要有负面言论;
尽量少使用群发软件做网站宣传或则做外链,网络蜘蛛并不是傻蛋;
16.英文网站优化要考虑域名的诱因;
英文网站优化在生成静态页面重要收录关键词;
动态网站最好是使用能生成静态页面的技术
17.不要指望一个关键词能带来多少流量,要流量就要做多个关键词;并且内容的专业才是网站好坏的真谛;
18.菜鸟永远在他人的博客上或则峰会中写伪原创文章;
老手永远自己写文章,然后他人疯狂转载;
19.pr值无论是百度还是微软目前都还比较重要;
pr值在yahoo英语的重要性大于域名的重要性;
20.不要三天打鱼,两天晒网,让蜘蛛喝完大餐之后饿日子;
21.门户网站优化须要顾客的配合;
22.网站优化的前辈本身应当是懂些程序;
23.内链在网站中也是影响排行的一个诱因;
内链的链接不能重复太多;
24.h1标签建议规范使用;
h2标签建议规范使用;
25.友情链接尽量找pr高的链接;
友情链接尽量同行或则相关做链接(其实我也晓得这似乎很难);
26.导出链接文本中收录你的关键词,并且关键词本身也是链接;
27.锚文本多元化;
a标签多元化;
28.新手永远是看技术;
老手不但要看技术,还要看利益均衡,知道舍得的重要性;
29.搜索引擎的优异排行是网站各项优化的结果;
30.请不要掌握里面说的29条当作金科玉律,能理解而且努力去创新才是王者。
与怎样提升单页面关键词排名?相关文章:
·长沙网站优化-如何递交目录
·谈谈网站优化及网路推广工程中的工作流程问题
·企业网站优化策略
·长沙推广杭州推广网站长沙网路推广杭州网站推
·我要做网站,长沙我要做网站,长沙网站设计南京
·网站搜索引擎优化六步骤
本文标题:如何提升单页面关键词排名?
本文地址: 查看全部
如何提升单页面关键词排名?
10.假如你不是优化前辈,尽量把热门或则其他词汇放到首页来做,首页的权重高,见效快;
单页面里面的热门词不要超过4个,不是热门词汇可选择二级页面处理;
11.旧网站你保留了吗?保留路径更改了吗?如果有新旧两个站,请使用301转向处理好;
302绑架,在你的脑海中永远消失;
12.你每晚原创吗?
关键词(原创)上线的时间要考虑,早上下班的第一件事情就做;
你准本的材料或则是顾客给你的材料是否是网站转载千万遍的东西;
新手可以不顾网站内容质量,去做伪原创;
老手要在整篇文章中抒发你自己的观点;
原创内容要多点,最好是300~1000字,最重要的关键词尽量出现在后面;
网站关键词的密度不要高于3%,尽量不要低于15%,具体情况具体对待。
13.菜鸟第一次做:力度和范围可以小,但是决不能大;且记住:新手外链为王,很适宜你;
老手要懂得如何去分辨提取有效的外链;
14.半个月把新网站中的热门关键词做到首页的说法的人,永远不要与之为伍;
网站优化,实例为王,因为你们都在和搜索引擎玩游戏,看谁的牌出的好;
网站优化是个系统的工程;
优化讲求功到自然成;
15.网站中不要有负面言论;
尽量少使用群发软件做网站宣传或则做外链,网络蜘蛛并不是傻蛋;
16.英文网站优化要考虑域名的诱因;
英文网站优化在生成静态页面重要收录关键词;
动态网站最好是使用能生成静态页面的技术
17.不要指望一个关键词能带来多少流量,要流量就要做多个关键词;并且内容的专业才是网站好坏的真谛;
18.菜鸟永远在他人的博客上或则峰会中写伪原创文章;
老手永远自己写文章,然后他人疯狂转载;
19.pr值无论是百度还是微软目前都还比较重要;
pr值在yahoo英语的重要性大于域名的重要性;
20.不要三天打鱼,两天晒网,让蜘蛛喝完大餐之后饿日子;
21.门户网站优化须要顾客的配合;
22.网站优化的前辈本身应当是懂些程序;
23.内链在网站中也是影响排行的一个诱因;
内链的链接不能重复太多;
24.h1标签建议规范使用;
h2标签建议规范使用;
25.友情链接尽量找pr高的链接;
友情链接尽量同行或则相关做链接(其实我也晓得这似乎很难);
26.导出链接文本中收录你的关键词,并且关键词本身也是链接;
27.锚文本多元化;
a标签多元化;
28.新手永远是看技术;
老手不但要看技术,还要看利益均衡,知道舍得的重要性;
29.搜索引擎的优异排行是网站各项优化的结果;
关键词(原创)上线的时间要考虑,早上下班的第一件事情就做;你准本的材料或则是顾客给你的材料是否是网站转载千万遍的东西;
新手可以不顾网站内容质量,去做伪原创;
老手要在整篇文章中抒发你自己的观点;
原创内容要多点,最好是300~1000字,最重要的关键词尽量出现在后面;
网站关键词的密度不要高于3%,尽量不要低于15%,具体情况具体对待。
13.菜鸟第一次做:力度和范围可以小,但是决不能大;且记住:新手外链为王,很适宜你;
老手要懂得如何去分辨提取有效的外链;
14.半个月把新网站中的热门关键词做到首页的说法的人,永远不要与之为伍;
网站优化,实例为王,因为你们都在和搜索引擎玩游戏,看谁的牌出的好;
网站优化是个系统的工程;
优化讲求功到自然成;
15.网站中不要有负面言论;
尽量少使用群发软件做网站宣传或则做外链,网络蜘蛛并不是傻蛋;
16.英文网站优化要考虑域名的诱因;
英文网站优化在生成静态页面重要收录关键词;
动态网站最好是使用能生成静态页面的技术
17.不要指望一个关键词能带来多少流量,要流量就要做多个关键词;并且内容的专业才是网站好坏的真谛;
18.菜鸟永远在他人的博客上或则峰会中写伪原创文章;
老手永远自己写文章,然后他人疯狂转载;
19.pr值无论是百度还是微软目前都还比较重要;
pr值在yahoo英语的重要性大于域名的重要性;
20.不要三天打鱼,两天晒网,让蜘蛛喝完大餐之后饿日子;
21.门户网站优化须要顾客的配合;
22.网站优化的前辈本身应当是懂些程序;
23.内链在网站中也是影响排行的一个诱因;
内链的链接不能重复太多;
24.h1标签建议规范使用;
h2标签建议规范使用;
25.友情链接尽量找pr高的链接;
友情链接尽量同行或则相关做链接(其实我也晓得这似乎很难);
26.导出链接文本中收录你的关键词,并且关键词本身也是链接;
27.锚文本多元化;
a标签多元化;
28.新手永远是看技术;
老手不但要看技术,还要看利益均衡,知道舍得的重要性;
29.搜索引擎的优异排行是网站各项优化的结果;
30.请不要掌握里面说的29条当作金科玉律,能理解而且努力去创新才是王者。
与怎样提升单页面关键词排名?相关文章:
·长沙网站优化-如何递交目录
·谈谈网站优化及网路推广工程中的工作流程问题
·企业网站优化策略
·长沙推广杭州推广网站长沙网路推广杭州网站推
·我要做网站,长沙我要做网站,长沙网站设计南京
·网站搜索引擎优化六步骤
本文标题:如何提升单页面关键词排名?
本文地址:
昌江关键词采集排名优化
采集交流 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2020-08-22 00:24
昌江关键词采集排名优化
解析SEM与SEO的优缺点
SEM和SEO都是网路营销中很重要的手法,百度推广与SEO的区别
百度推广是竞价也就是SEM,是按点击付费,点击一次多少钱这样的,能始终在百度前几位。 SEO是百度自然排行,通过对网站的优化,来提升网站的权重,从而获得好的关键词排行,SEO不稳定,做到百度首页也要花很长时间的。
但好多刚接触这一行的人不是太清楚这二者之间的区别,国内很多人都误会了SEM和SEO的关系。下面就让顺时seo工程师来告诉你SEM和SEO之间的那点事!
首先,网站SEO优化,SEM和SEO是收录关系,而不是付费广告和自然排行的关系。SEO和SEO区别?
SEO(Search Engine Optimization)为搜索引擎优化。搜索引擎优化是一种借助搜索引擎的搜索规则来提升目前网站在有关搜索引擎内的自然排行的形式。SEO的目的理解是:为网站提供生态式的自我营销解决方案,让网站在行业内抢占领先地位,从而获得
SEM是搜索引擎营销的简称。即是所有围绕着搜索引擎举办的一切营销活动都叫Marketing。而PPC(Pay Per Click)、SEO (Search Engine Optimization) 都是围绕着搜索引擎展开的营销活动,他们都属于SEM。只是在国外,因很多人分不清概念,就出现了SEM是付费广告,SEO是自然排行的错误概念,并且这个错误概念以讹传讹的还被普及了。
话说,顺时seo工程师逛知乎的时侯,看见如此两句话,seo是哪些意思?
SEO是由英语Search Engine Optimization简写而至, 中文译音为“搜索引擎优化”。SEO是指通过对网站内部调整优化及站外优化,使网站满足搜索引擎收录排行需求,在搜索引擎中关键词排行增强,从而把精准用户带到网站,获得免费流量,产生直接销售或
是如此形容SEO与SEM的!拿泡美女打个比方:富二代(SEM):直接收钱砸,当然也可以靠魅力渐渐追;穷屌丝(SEO):只能一步一步悲催地追! 发外链的掩面而泣,真心认为叙述得很形象!
SEM:Search Engine Marketing,中文译为搜索引擎营销,什么是seo设置?
用的搜外6系统,对这个不是太了解,关于seo 设置应当是站内的基础优化 1、做301定向,跳转到带的 2、站内链接排查去index 3、面包屑导航优化 4、做robots.txt文件同时可以放网站地图sitemap 5、绑定熊掌号,做好主动推送,做好手机网站 6、
是指在搜索引擎上推广网站,提高网站可见度,从而带来流量的网路营销活动。SEM的方式包括搜索引擎优化(SEO)、付费排行、精准广告以及付费收录,其中以SEO和PPC最为常见。
SEO和SEM二者目的相同,都是为了让网站销售和品牌建设;不同的是实现方法:SEO是通过技术手段让获得好的自然排行;SEM可以通过技术手段(SEO)和付费手段(PPC)等。SEM是哪些意思? SEO和SEM的区别是哪些?
SEO是由英语Search Engine Optimization简写而至, 中文译音为“搜索引擎优化”。SEO是指通过对网站内部调整优化及站外优化,使网站满足搜索引擎收录排行需求,在搜索引擎中关键词排行增强,从而把精准用户带到网站,获得免费流量,产生直接销售或
SEO的作用是借助搜索引擎提高自己某个特定关键词的排行。SEM是在百度花钱进行推广,按点击收费。
SEM重视的是哪个最后的“M”。因为SEO的作用是借助搜索引擎提高自己某个特定关键词的排行。做到这一步还不能真正意义上的营销了。你试想一下,虽然有些网站排名第一页的前三名,但是标题和描述不吸引人,别人就是不点击;虽然点击了,但是网站打开特别慢,甚至打不开,客户也会马上关掉网页而点击下一个搜索结果,或者是,当点击进去之后,一看如同个垃圾站,广告站,还不停的跳广告。客户也会把上关掉网页。
所以,顺时seo工程师想说,SEO只是手段,M才是解决问题的重点。因为M就是营销的意思,M就得考虑这种诱因,不管是点击付费广告也好,还是哪些广告也好,SEM不能单单只理解是做点击广告就行。哪怕做广告,没有具体的SEM计划,一切也是徒劳。接下来,顺时seo工程师给你们分享一下SEM和SEO的优缺点!
SEO的优点:1.见效快:充值后设置关键词价钱后即刻就可以步入百度排名前十,SEO推广和SEO优化有哪些区别呢,是不是一样的呀?
SEO与网路推广的区别: 首先,从概念上来说,网络推广就是企业从开始申请域名、租用空间、网站备-案、建立网站、直到网站正式上线开始即便是介入了网路推广活动,而一般我们所指的网路推广是指通过互联网的种种手段,进行的宣传推广等活动,确切
位置可以自己控制。2.关键词数目无限制:可以在后台设置无数地关键词进行推广,数量自己控制,没有任何限制。3.关键词不分难易程度:不论多么热门,只要你想做,你都可以步入前三甚至第一。
SEO的优缺点:1.见效慢:通过网站优化获得排行是难以速成的,一般难度的词大概须要2-3个月的时间,如果难度更大的词则须要4-5个月甚至更久。
陵水热门关键字安全可靠 - 昌江刷关键词安全可靠 - 陵水网站seo安全可靠 查看全部
昌江关键词采集排名优化
昌江关键词采集排名优化
解析SEM与SEO的优缺点
SEM和SEO都是网路营销中很重要的手法,百度推广与SEO的区别
百度推广是竞价也就是SEM,是按点击付费,点击一次多少钱这样的,能始终在百度前几位。 SEO是百度自然排行,通过对网站的优化,来提升网站的权重,从而获得好的关键词排行,SEO不稳定,做到百度首页也要花很长时间的。
但好多刚接触这一行的人不是太清楚这二者之间的区别,国内很多人都误会了SEM和SEO的关系。下面就让顺时seo工程师来告诉你SEM和SEO之间的那点事!
首先,网站SEO优化,SEM和SEO是收录关系,而不是付费广告和自然排行的关系。SEO和SEO区别?
SEO(Search Engine Optimization)为搜索引擎优化。搜索引擎优化是一种借助搜索引擎的搜索规则来提升目前网站在有关搜索引擎内的自然排行的形式。SEO的目的理解是:为网站提供生态式的自我营销解决方案,让网站在行业内抢占领先地位,从而获得
SEM是搜索引擎营销的简称。即是所有围绕着搜索引擎举办的一切营销活动都叫Marketing。而PPC(Pay Per Click)、SEO (Search Engine Optimization) 都是围绕着搜索引擎展开的营销活动,他们都属于SEM。只是在国外,因很多人分不清概念,就出现了SEM是付费广告,SEO是自然排行的错误概念,并且这个错误概念以讹传讹的还被普及了。
话说,顺时seo工程师逛知乎的时侯,看见如此两句话,seo是哪些意思?
SEO是由英语Search Engine Optimization简写而至, 中文译音为“搜索引擎优化”。SEO是指通过对网站内部调整优化及站外优化,使网站满足搜索引擎收录排行需求,在搜索引擎中关键词排行增强,从而把精准用户带到网站,获得免费流量,产生直接销售或
是如此形容SEO与SEM的!拿泡美女打个比方:富二代(SEM):直接收钱砸,当然也可以靠魅力渐渐追;穷屌丝(SEO):只能一步一步悲催地追! 发外链的掩面而泣,真心认为叙述得很形象!
SEM:Search Engine Marketing,中文译为搜索引擎营销,什么是seo设置?
用的搜外6系统,对这个不是太了解,关于seo 设置应当是站内的基础优化 1、做301定向,跳转到带的 2、站内链接排查去index 3、面包屑导航优化 4、做robots.txt文件同时可以放网站地图sitemap 5、绑定熊掌号,做好主动推送,做好手机网站 6、
是指在搜索引擎上推广网站,提高网站可见度,从而带来流量的网路营销活动。SEM的方式包括搜索引擎优化(SEO)、付费排行、精准广告以及付费收录,其中以SEO和PPC最为常见。
SEO和SEM二者目的相同,都是为了让网站销售和品牌建设;不同的是实现方法:SEO是通过技术手段让获得好的自然排行;SEM可以通过技术手段(SEO)和付费手段(PPC)等。SEM是哪些意思? SEO和SEM的区别是哪些?
SEO是由英语Search Engine Optimization简写而至, 中文译音为“搜索引擎优化”。SEO是指通过对网站内部调整优化及站外优化,使网站满足搜索引擎收录排行需求,在搜索引擎中关键词排行增强,从而把精准用户带到网站,获得免费流量,产生直接销售或
SEO的作用是借助搜索引擎提高自己某个特定关键词的排行。SEM是在百度花钱进行推广,按点击收费。
SEM重视的是哪个最后的“M”。因为SEO的作用是借助搜索引擎提高自己某个特定关键词的排行。做到这一步还不能真正意义上的营销了。你试想一下,虽然有些网站排名第一页的前三名,但是标题和描述不吸引人,别人就是不点击;虽然点击了,但是网站打开特别慢,甚至打不开,客户也会马上关掉网页而点击下一个搜索结果,或者是,当点击进去之后,一看如同个垃圾站,广告站,还不停的跳广告。客户也会把上关掉网页。
所以,顺时seo工程师想说,SEO只是手段,M才是解决问题的重点。因为M就是营销的意思,M就得考虑这种诱因,不管是点击付费广告也好,还是哪些广告也好,SEM不能单单只理解是做点击广告就行。哪怕做广告,没有具体的SEM计划,一切也是徒劳。接下来,顺时seo工程师给你们分享一下SEM和SEO的优缺点!
SEO的优点:1.见效快:充值后设置关键词价钱后即刻就可以步入百度排名前十,SEO推广和SEO优化有哪些区别呢,是不是一样的呀?
SEO与网路推广的区别: 首先,从概念上来说,网络推广就是企业从开始申请域名、租用空间、网站备-案、建立网站、直到网站正式上线开始即便是介入了网路推广活动,而一般我们所指的网路推广是指通过互联网的种种手段,进行的宣传推广等活动,确切
位置可以自己控制。2.关键词数目无限制:可以在后台设置无数地关键词进行推广,数量自己控制,没有任何限制。3.关键词不分难易程度:不论多么热门,只要你想做,你都可以步入前三甚至第一。
SEO的优缺点:1.见效慢:通过网站优化获得排行是难以速成的,一般难度的词大概须要2-3个月的时间,如果难度更大的词则须要4-5个月甚至更久。
陵水热门关键字安全可靠 - 昌江刷关键词安全可靠 - 陵水网站seo安全可靠
邮件手动批量发送精灵与关键词采集邮箱器下载评论软件详情对比
采集交流 • 优采云 发表了文章 • 0 个评论 • 454 次浏览 • 2020-08-19 11:29
用途:些软件可以依照产品关键字、行业关键字、目标顾客产品关键字通过商业引擎、国家区域引擎、行业引擎搜索全球潜在顾客信息。软件支持灵活运用关键字组合搜索你所想要的邮箱地址,从而为你的产品推广出去。它可以用在外贸行业中。它是一个邮箱搜索软件+关键词和邮箱后缀名采集邮箱+关键词采集邮箱软件(无数目限制)的采集邮箱功能。
此软件的特性1说明:
此软件的采集条件:“输入你有关键词 + 后缀名采集” 为条件采集在指定的网站上
比如:百度,Googel,搜搜,搜狗,雅虎,Yandex[俄]等国际小型网站上采集当前最新的邮箱地址信息。
【注:功能每采集一次,要重新打开软件再采集其它的邮箱地址信息】在以上小型国际网上所采集的邮箱时,在本软件的一侧可能会出现相同的邮箱地址,这是正常的现象。因为在这种小型的网站上它有重复的快照信息,软件会把这种邮箱总的采集在一起,但是在你每采集完成以后,在导入你所采集的邮箱时,软件有一个功能 - “导出时清除重复邮箱” 和 - “导出时清除空行”,让你所采集的邮箱全部不再是重复的问题。采集完后可以自行导入,选择xls或txt按键,文件会手动保存在你所选择的文件夹内。
此软件的特性2说明:
此软件的采集条件:“输入你有关键词” 为条件采集在指定的网站上
比如:百度,Googel,搜搜,搜狗,雅虎,Yandex[俄]等国际小型网站上采集当前最新的邮箱地址信息。此功能在采集邮箱时,它将会有 - 邮箱地址信息 + 采集的标题 会同时出现在你的面前。在以上小型国际网上所采集的邮箱时,在本软件的右侧可能会出现相同的邮箱地址,这是正常的现象。因为在这种小型的网站上它有重复的快照信息,软件会把这种邮箱总的采集在一起,但是在你每采集完成以后,在导入你所采集的邮箱时,软件有一个功能 - “导出时清除重复邮箱” 和 - “导出时清除空行”,让你所采集的邮箱全部不再是重复的问题。采集完后可以自行导入,选择xls或txt按键,文件会手动保存在你所选择的文件夹内。
此软件的特性2说明:
你所每次采集的重复邮箱的处理功能说明:当你每一次所采集的邮箱在导入以后,如果当你下一次在采集其它的,但是有一点类似之前的采集关键词时,这里可能两次采集的邮箱有一小点重复,在这里我们的软件也有一个处理重复的功能把你所采集的所有邮箱装入到Excel文件内,然后批量的导出到我们的软件,最后在批量的导入到你所指定的文件夹内,以方你的电邮发送软件使用的强悍的功能 查看全部
邮件手动批量发送精灵与关键词采集邮箱器下载评论软件详情对比
用途:些软件可以依照产品关键字、行业关键字、目标顾客产品关键字通过商业引擎、国家区域引擎、行业引擎搜索全球潜在顾客信息。软件支持灵活运用关键字组合搜索你所想要的邮箱地址,从而为你的产品推广出去。它可以用在外贸行业中。它是一个邮箱搜索软件+关键词和邮箱后缀名采集邮箱+关键词采集邮箱软件(无数目限制)的采集邮箱功能。
此软件的特性1说明:
此软件的采集条件:“输入你有关键词 + 后缀名采集” 为条件采集在指定的网站上
比如:百度,Googel,搜搜,搜狗,雅虎,Yandex[俄]等国际小型网站上采集当前最新的邮箱地址信息。
【注:功能每采集一次,要重新打开软件再采集其它的邮箱地址信息】在以上小型国际网上所采集的邮箱时,在本软件的一侧可能会出现相同的邮箱地址,这是正常的现象。因为在这种小型的网站上它有重复的快照信息,软件会把这种邮箱总的采集在一起,但是在你每采集完成以后,在导入你所采集的邮箱时,软件有一个功能 - “导出时清除重复邮箱” 和 - “导出时清除空行”,让你所采集的邮箱全部不再是重复的问题。采集完后可以自行导入,选择xls或txt按键,文件会手动保存在你所选择的文件夹内。
此软件的特性2说明:
此软件的采集条件:“输入你有关键词” 为条件采集在指定的网站上
比如:百度,Googel,搜搜,搜狗,雅虎,Yandex[俄]等国际小型网站上采集当前最新的邮箱地址信息。此功能在采集邮箱时,它将会有 - 邮箱地址信息 + 采集的标题 会同时出现在你的面前。在以上小型国际网上所采集的邮箱时,在本软件的右侧可能会出现相同的邮箱地址,这是正常的现象。因为在这种小型的网站上它有重复的快照信息,软件会把这种邮箱总的采集在一起,但是在你每采集完成以后,在导入你所采集的邮箱时,软件有一个功能 - “导出时清除重复邮箱” 和 - “导出时清除空行”,让你所采集的邮箱全部不再是重复的问题。采集完后可以自行导入,选择xls或txt按键,文件会手动保存在你所选择的文件夹内。
此软件的特性2说明:
你所每次采集的重复邮箱的处理功能说明:当你每一次所采集的邮箱在导入以后,如果当你下一次在采集其它的,但是有一点类似之前的采集关键词时,这里可能两次采集的邮箱有一小点重复,在这里我们的软件也有一个处理重复的功能把你所采集的所有邮箱装入到Excel文件内,然后批量的导出到我们的软件,最后在批量的导入到你所指定的文件夹内,以方你的电邮发送软件使用的强悍的功能
QQ群在线搜索采集软件 无限制破解版测试可用
采集交流 • 优采云 发表了文章 • 0 个评论 • 504 次浏览 • 2020-08-17 20:15
使用方式:任意注册账号密码登入
主要特点有:指定关键词搜索QQ群(可输入多组),大家可以把关键词细分化进行采集,这样就可以采集的更多!例如:想搜索股票QQ群,可以把股票细分:股票交流、股票行情、股票软件、股票资讯等。如SEO的群,可以分为:SEO优化、网站优化等!(大家可以自由发挥)
--------------------------------------------------------------------------
返回的数组有:QQ群号、QQ群名称、群内成员数目(群人数)、群主的QQ、群的标签(tag)、是否支持旅客步入。
支持导入到excel表格或则txt文本方式!
-------------------------------------------------------------------------
V2新版参数说明,多了几个参数主要为了最大数量化采集,所以速率不会很快:
最大页数:就是个关键词翻页,100就是翻到100页,如果设置为0,则手动辨识不能采集跳过,想速率采集的推荐设置为0
循环次数:就是每位关键词从【1-你设定的页数】循环采集,目的是为了有时候我们手工搜索,每次点击的群都不同,这样可以有效抓取遗漏群
循环间隔:每次翻页的间隔,建议设定3-5秒,太快容易被限制
--------------------------------------------------------------------------
举例:
假设:你设定100,循环3次,就等于1-100,然后在1-100,这样是为了避免有遗漏的情况,以及跳过有临时被限制未能采集的情况。如果你想早日切换到下一个关键词,就调整参数。
建议设置参数:
如果1个关键词想最大化采集:可以设定30-100页,循环3-5次,循环间隔设定:3-5秒(这种循环极大程度防止限制或则遗漏)
如果多个关键词想早日采集:可以设定10-30页,循环1次,同样循环间隔不建议设置过高(这种是速率优先,但是会遗漏不少群)
大家按照前面的讲解,自行调整参数到适宜你的目的。 查看全部
QQ群在线搜索采集软件 无限制破解版测试可用
使用方式:任意注册账号密码登入
主要特点有:指定关键词搜索QQ群(可输入多组),大家可以把关键词细分化进行采集,这样就可以采集的更多!例如:想搜索股票QQ群,可以把股票细分:股票交流、股票行情、股票软件、股票资讯等。如SEO的群,可以分为:SEO优化、网站优化等!(大家可以自由发挥)
--------------------------------------------------------------------------
返回的数组有:QQ群号、QQ群名称、群内成员数目(群人数)、群主的QQ、群的标签(tag)、是否支持旅客步入。
支持导入到excel表格或则txt文本方式!
-------------------------------------------------------------------------
V2新版参数说明,多了几个参数主要为了最大数量化采集,所以速率不会很快:
最大页数:就是个关键词翻页,100就是翻到100页,如果设置为0,则手动辨识不能采集跳过,想速率采集的推荐设置为0
循环次数:就是每位关键词从【1-你设定的页数】循环采集,目的是为了有时候我们手工搜索,每次点击的群都不同,这样可以有效抓取遗漏群
循环间隔:每次翻页的间隔,建议设定3-5秒,太快容易被限制
--------------------------------------------------------------------------
举例:
假设:你设定100,循环3次,就等于1-100,然后在1-100,这样是为了避免有遗漏的情况,以及跳过有临时被限制未能采集的情况。如果你想早日切换到下一个关键词,就调整参数。
建议设置参数:
如果1个关键词想最大化采集:可以设定30-100页,循环3-5次,循环间隔设定:3-5秒(这种循环极大程度防止限制或则遗漏)
如果多个关键词想早日采集:可以设定10-30页,循环1次,同样循环间隔不建议设置过高(这种是速率优先,但是会遗漏不少群)
大家按照前面的讲解,自行调整参数到适宜你的目的。

