
脚本
海洋cms怎么设置宝塔手动采集?
采集交流 • 优采云 发表了文章 • 0 个评论 • 746 次浏览 • 2020-07-25 08:01
海洋cms宝塔手动采集教程
海洋cms怎么设置宝塔手动采集海洋cms采集文章,由于很多人在问这个问题所以就有了这个教程,海洋cms虽然给了脚本代码,对于刚接触海洋cms的用户们理解上去并不是这么容易了,今天就深入的细化下海洋cms利用宝塔现实手动采集的具体步骤。
海洋cms怎么设置宝塔手动采集第一步:获取脚本代码。
【1】下面是海洋cms官网提供的手动采集脚本代码,我们须要更改代码上面的3项后才可以使用。
#!/bin/bash
########################################################
# 程序名称: 海洋CMS自动采集脚本
# 版本信息:seacmsbot/ v2.0
# 发布链接: https://www.seacms.net/post-update-92579.htm
# 使用方法:直接复制代码到宝塔计划任务shell脚本内容里添加每小时任务使用
# 更新时间:2019.9.26
##########################################################
#①请修改下面的网站域名及管理目录
web_site="http://网站域名/管理目录/admin_reslib2.php"
#②请修改下面项内容为"admin_reslib2.php"里设置的访问密码(默认为系统设置的cookie密码)
web_pwd="8888e82e85bd4540f0defa3fb7a8e888"
#③下面项内容为资源站每日采集链接地址列表,请自行修改,每行一条,可添加多个,前后需添加引号。
#每日采集链接获取方法:选择"后台-采集-资源库列表",复制资源站右边的"采集每天"的链接地址,去掉?前面的内容。
web_api=(
'?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_ ... 39%3B
'?ac=day&rid=2&url=http://www.zdziyuan.com/inc/s_ ... 39%3B
)
#模拟用户浏览器ua,请勿随意修改,以免被目标防火墙拦截!
web_ua="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/76.0.3809.100 Safari/537.36 seacmsbot/1.2;"
#采集单页
function get_content() {
echo "正在采集第$page页..."
#echo " get_content: --->url:--->$1"
cResult=$(curl --connect-timeout 10 -m 20 -k -s -L -A "$web_ua" "$1" )
echo $cResult | grep -q "采集"
#echo -e "$1\n$cResult"
if [ "$?" = "0" ]; then
next_content "$cResult"
else
echo -e "采集失败,请检查设置!\n失败链接-->$1\n返回信息-->$cResult\n采集结束,共0页"
fi
}
#采集下页
function next_content() {
#统计数据
Result=$(echo "$1" | tr "<br>" "\n")
a=$(echo "$Result" | grep -c "采集成功")
b=$(echo "$Result" | grep -c "更新数据")
c=$(echo "$Result" | grep -c "无需更新")
d=$(echo "$Result" | grep -c "跳过")
echo "采集成功-->已更$c部,新增$a部,更新$b部,跳过$d部"
let add+=$a
let update+=$b
let none+=$c
let jmp+=$d
#检测并采集下页
next_url=${1##*location.href=\'}
next_url=${next_url%%\'*}
#echo $next_url
if [ "${next_url:0:1}" = "?" ]
then
let page++
get_content "$web_site$next_url"
else
echo "采集结束,共$page页"
fi
}
#脚本入口
echo "海洋CMS自动采集脚本开始执行 版本:v1.2"
starttime=$(date +%s)
update=0 #更新
add=0 #新增
none=0 #无变化
jmp=0 # 跳过
for url in ${web_api[@]};
do
if [[ ! -z $url ]]
then
web_param="$web_site$url&password=$web_pwd"
page=1
echo "开始采集:$url"
get_content $web_param
fi
done
endtime=$(date +%s)
echo "============================"
echo "入库-->$add部"
echo "更新-->$update部"
echo "跳过-->$jmp部(未绑定分类或链接错误)"
echo "今日-->$[none+add+update]部"
echo "============================"
echo "全部采集结束,耗时$[endtime - starttime]秒"
海洋cms怎么设置宝塔手动采集第二步:修改脚本
【2】具体更改脚本上面的哪3项呢?下面为你一一说来。(根据前面提供的代码内容复制到记事本或是其他html编辑器来对应更改)
#①请修改下面的网站域名及管理目录
web_site="http://网站域名/管理目录/admin_reslib2.php"
这个是须要更改成你的“网站域名”和“海洋cms后台的管理目录”。域名你们都能理解,后台的管理目录这个对于菜鸟来说须要多讲两句,首先你要能登入你的后台才可以晓得你的后台目录。举例说明:假如我的后台登陆地址是 /article/那么这儿的“article”就是后台的管理目录,得到了管理目录我们直接填写到代码里即可。
#②请修改下面项内容为"admin_reslib2.php"里设置的访问密码(默认为系统设置的cookie密码)
web_pwd="8888e82e85bd4540f0defa3fb7a8e888"
这个更改须要到海洋cms系统后台得到我们的cookie密码进行替换才可以,具体步骤如下图。得到自己网站的cookie密码后替换即可。
#③下面项内容为资源站每日采集链接地址列表,请自行修改,每行一条,可添加多个,前后需添加引号。
#每日采集链接获取方法:选择"后台-采集-资源库列表",复制资源站右边的"采集每天"的链接地址,去掉?前面的内容。
web_api=(
'?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_ ... 39%3B
'?ac=day&rid=2&url=http://www.zdziyuan.com/inc/s_ ... 39%3B
)
这个是代码里须要更改的最后一项,里面是代码里默认提供的2个采集链接地址,我们须要获取自己的采集链接地址添加到上面,具体获取链接地址看下边截图的步骤操作。如果你还没添加或是不懂如何添加采集可以参考帮助文档-海洋cms如何添加资源库采集接口
选择"后台-采集-资源库列表",根据自己的选择去复制资源站一侧的"采集当天"“采集本周” “采集所有”的链接地址,去掉?前面的内容。(鼠标置于采集当天或是本周、所有上键盘右击复制链接即可获取采集链接)
比如这儿是:
1
http://127.0.0.1/admin/admin_r ... s.php
第二步:去掉上一步复制到的内容"?"前面的内容,结果如下:
2
?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_seackm3u8s.php
这样就得到了最终的采集网址
海洋cms怎么设置宝塔手动采集第三步:宝塔定时任务设置。
【3】直接复制代码到宝塔计划任务shell脚本,内容里添加每小时任务使用。具体操作步骤如下截图。第⑤步是把我们更改好的脚本复制粘贴到脚本内容框里即可。
【4】总结
总的来说就是把脚本上面须要更改的几项更改完后海洋cms采集文章,复制更改好的脚本到宝塔的计划任务设置下定时采集任务就可以了,任务类型不要选错。如果你对本教程不理解或是疑问的地方可以加入社群进行讨论和寻问。加入社群 查看全部

海洋cms宝塔手动采集教程
海洋cms怎么设置宝塔手动采集海洋cms采集文章,由于很多人在问这个问题所以就有了这个教程,海洋cms虽然给了脚本代码,对于刚接触海洋cms的用户们理解上去并不是这么容易了,今天就深入的细化下海洋cms利用宝塔现实手动采集的具体步骤。
海洋cms怎么设置宝塔手动采集第一步:获取脚本代码。
【1】下面是海洋cms官网提供的手动采集脚本代码,我们须要更改代码上面的3项后才可以使用。
#!/bin/bash
########################################################
# 程序名称: 海洋CMS自动采集脚本
# 版本信息:seacmsbot/ v2.0
# 发布链接: https://www.seacms.net/post-update-92579.htm
# 使用方法:直接复制代码到宝塔计划任务shell脚本内容里添加每小时任务使用
# 更新时间:2019.9.26
##########################################################
#①请修改下面的网站域名及管理目录
web_site="http://网站域名/管理目录/admin_reslib2.php"
#②请修改下面项内容为"admin_reslib2.php"里设置的访问密码(默认为系统设置的cookie密码)
web_pwd="8888e82e85bd4540f0defa3fb7a8e888"
#③下面项内容为资源站每日采集链接地址列表,请自行修改,每行一条,可添加多个,前后需添加引号。
#每日采集链接获取方法:选择"后台-采集-资源库列表",复制资源站右边的"采集每天"的链接地址,去掉?前面的内容。
web_api=(
'?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_ ... 39%3B
'?ac=day&rid=2&url=http://www.zdziyuan.com/inc/s_ ... 39%3B
)
#模拟用户浏览器ua,请勿随意修改,以免被目标防火墙拦截!
web_ua="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/76.0.3809.100 Safari/537.36 seacmsbot/1.2;"
#采集单页
function get_content() {
echo "正在采集第$page页..."
#echo " get_content: --->url:--->$1"
cResult=$(curl --connect-timeout 10 -m 20 -k -s -L -A "$web_ua" "$1" )
echo $cResult | grep -q "采集"
#echo -e "$1\n$cResult"
if [ "$?" = "0" ]; then
next_content "$cResult"
else
echo -e "采集失败,请检查设置!\n失败链接-->$1\n返回信息-->$cResult\n采集结束,共0页"
fi
}
#采集下页
function next_content() {
#统计数据
Result=$(echo "$1" | tr "<br>" "\n")
a=$(echo "$Result" | grep -c "采集成功")
b=$(echo "$Result" | grep -c "更新数据")
c=$(echo "$Result" | grep -c "无需更新")
d=$(echo "$Result" | grep -c "跳过")
echo "采集成功-->已更$c部,新增$a部,更新$b部,跳过$d部"
let add+=$a
let update+=$b
let none+=$c
let jmp+=$d
#检测并采集下页
next_url=${1##*location.href=\'}
next_url=${next_url%%\'*}
#echo $next_url
if [ "${next_url:0:1}" = "?" ]
then
let page++
get_content "$web_site$next_url"
else
echo "采集结束,共$page页"
fi
}
#脚本入口
echo "海洋CMS自动采集脚本开始执行 版本:v1.2"
starttime=$(date +%s)
update=0 #更新
add=0 #新增
none=0 #无变化
jmp=0 # 跳过
for url in ${web_api[@]};
do
if [[ ! -z $url ]]
then
web_param="$web_site$url&password=$web_pwd"
page=1
echo "开始采集:$url"
get_content $web_param
fi
done
endtime=$(date +%s)
echo "============================"
echo "入库-->$add部"
echo "更新-->$update部"
echo "跳过-->$jmp部(未绑定分类或链接错误)"
echo "今日-->$[none+add+update]部"
echo "============================"
echo "全部采集结束,耗时$[endtime - starttime]秒"
海洋cms怎么设置宝塔手动采集第二步:修改脚本
【2】具体更改脚本上面的哪3项呢?下面为你一一说来。(根据前面提供的代码内容复制到记事本或是其他html编辑器来对应更改)
#①请修改下面的网站域名及管理目录
web_site="http://网站域名/管理目录/admin_reslib2.php"
这个是须要更改成你的“网站域名”和“海洋cms后台的管理目录”。域名你们都能理解,后台的管理目录这个对于菜鸟来说须要多讲两句,首先你要能登入你的后台才可以晓得你的后台目录。举例说明:假如我的后台登陆地址是 /article/那么这儿的“article”就是后台的管理目录,得到了管理目录我们直接填写到代码里即可。
#②请修改下面项内容为"admin_reslib2.php"里设置的访问密码(默认为系统设置的cookie密码)
web_pwd="8888e82e85bd4540f0defa3fb7a8e888"
这个更改须要到海洋cms系统后台得到我们的cookie密码进行替换才可以,具体步骤如下图。得到自己网站的cookie密码后替换即可。
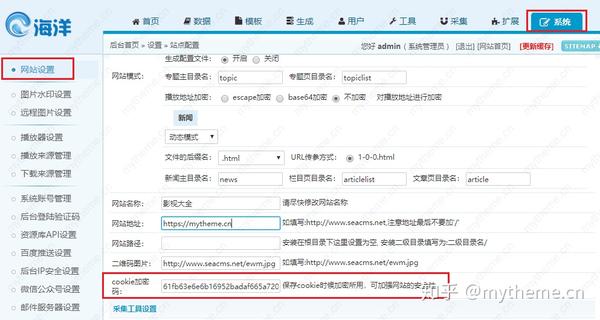
#③下面项内容为资源站每日采集链接地址列表,请自行修改,每行一条,可添加多个,前后需添加引号。
#每日采集链接获取方法:选择"后台-采集-资源库列表",复制资源站右边的"采集每天"的链接地址,去掉?前面的内容。
web_api=(
'?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_ ... 39%3B
'?ac=day&rid=2&url=http://www.zdziyuan.com/inc/s_ ... 39%3B
)
这个是代码里须要更改的最后一项,里面是代码里默认提供的2个采集链接地址,我们须要获取自己的采集链接地址添加到上面,具体获取链接地址看下边截图的步骤操作。如果你还没添加或是不懂如何添加采集可以参考帮助文档-海洋cms如何添加资源库采集接口
选择"后台-采集-资源库列表",根据自己的选择去复制资源站一侧的"采集当天"“采集本周” “采集所有”的链接地址,去掉?前面的内容。(鼠标置于采集当天或是本周、所有上键盘右击复制链接即可获取采集链接)
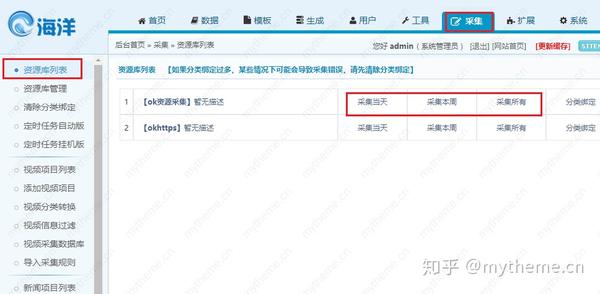
比如这儿是:
1
http://127.0.0.1/admin/admin_r ... s.php
第二步:去掉上一步复制到的内容"?"前面的内容,结果如下:
2
?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_seackm3u8s.php
这样就得到了最终的采集网址
海洋cms怎么设置宝塔手动采集第三步:宝塔定时任务设置。
【3】直接复制代码到宝塔计划任务shell脚本,内容里添加每小时任务使用。具体操作步骤如下截图。第⑤步是把我们更改好的脚本复制粘贴到脚本内容框里即可。
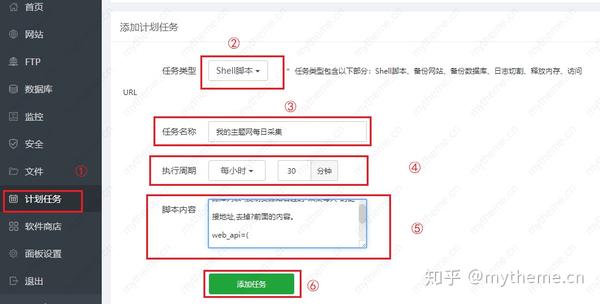
【4】总结
总的来说就是把脚本上面须要更改的几项更改完后海洋cms采集文章,复制更改好的脚本到宝塔的计划任务设置下定时采集任务就可以了,任务类型不要选错。如果你对本教程不理解或是疑问的地方可以加入社群进行讨论和寻问。加入社群
防止网站被爬虫爬取的几种解决办法
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2020-06-02 08:00
#! /bin/bash
LOGFILE=/var/log/nginx/access.log
PREFIX=/etc/spiders
#日志中大部分蜘蛛都有spider的关键字,但是百度的不能封,所以过滤掉百度
grep 'spider' $LOGFILE |grep -v 'Baidu' |awk '{print $1}' >$PREFIX/ip1.txt
# 封掉网易的有道
grep 'YoudaoBot' $LOGFILE | awk '{print $1}' >>$PREFIX/ip1.txt
#封掉雅虎
grep 'Yahoo!' $LOGFILE | awk '{print $1}' >>$PREFIX/ip1.txt
# 过滤掉信任IP
sort -n $PREFIX/ip1.txt |uniq |sort |grep -v '192.168.0.' |grep -v '127.0.0.1'>$PREFIX/ip2.txt
# 如果一小时内,发包不超过30个就要解封
/sbin/iptables -nvL |awk '$1 <= 30 {print $8}' >$PREFIX/ip3.txt
for ip in `cat $PREFIX/ip3.txt`; do /sbin/iptables -D INPUT -s $ip -j DROP ; done
/sbin/iptables -Z // 将iptables计数器置为0
for ip in `cat $PREFIX/ip2.txt`; do /sbin/iptables -I INPUT -s $ip -j DROP ; done
3.使用robots.txt文件:例如阻止所有的爬虫爬取,但是这种效果不是很明显。
User-agent: *
Disallow: /
4.使用nginx的自带功能:通过对httpuseragent阻塞来实现,包括GET/POST方式的请求,以nginx为例,具体步骤如下:
编辑nginx.conf
#vim /usr/local/nginx/conf/nginx.conf
拒绝以wget方式的httpuseragent,增加如下内容
## Block http user agent - wget ##
if ($http_user_agent ~* (Wget) ) {
return 403;
}
## Block Software download user agents ##
if ($http_user_agent ~* LWP::Simple|BBBike|wget) {
return 403;
}
平滑启动
# /usr/local/nginx/sbin/nginx -s reload
如何拒绝多种httpuseragent,内容如下:
if ($http_user_agent ~ (agent1|agent2|Foo|Wget|Catall Spider|AcoiRobot) ) {
return 403;
}
大小写敏感匹配
### 大小写敏感http user agent拒绝###
if ($http_user_agent ~ (Catall Spider|AcoiRobot) ) {
return 403;
}
### 大小写不敏感http user agent拒绝###
if ($http_user_agent ~* (foo|bar) ) {
return 403;
}
以上是脚本之家(jb51.cc)为你搜集整理的全部代码内容,希望文章能够帮你解决所遇见的程序开发问题。
如果认为脚本之家网站内容还不错网页如何防止爬虫,欢迎将脚本之家网站推荐给程序员好友。
以上是脚本之家为你搜集整理的避免网站被爬虫爬取的几种解决办法全部内容,希望文章能够帮你解决避免网站被爬虫爬取的几种解决办法所遇见的程序开发问题。
如果认为脚本之家网站内容还不错网页如何防止爬虫,欢迎将脚本之家网站推荐给程序员好友。 查看全部
LOGFILE=/var/log/nginx/access.log
PREFIX=/etc/spiders
#日志中大部分蜘蛛都有spider的关键字,但是百度的不能封,所以过滤掉百度
grep 'spider' $LOGFILE |grep -v 'Baidu' |awk '{print $1}' >$PREFIX/ip1.txt
# 封掉网易的有道
grep 'YoudaoBot' $LOGFILE | awk '{print $1}' >>$PREFIX/ip1.txt
#封掉雅虎
grep 'Yahoo!' $LOGFILE | awk '{print $1}' >>$PREFIX/ip1.txt
# 过滤掉信任IP
sort -n $PREFIX/ip1.txt |uniq |sort |grep -v '192.168.0.' |grep -v '127.0.0.1'>$PREFIX/ip2.txt
# 如果一小时内,发包不超过30个就要解封
/sbin/iptables -nvL |awk '$1 <= 30 {print $8}' >$PREFIX/ip3.txt
for ip in `cat $PREFIX/ip3.txt`; do /sbin/iptables -D INPUT -s $ip -j DROP ; done
/sbin/iptables -Z // 将iptables计数器置为0
for ip in `cat $PREFIX/ip2.txt`; do /sbin/iptables -I INPUT -s $ip -j DROP ; done
3.使用robots.txt文件:例如阻止所有的爬虫爬取,但是这种效果不是很明显。
User-agent: *
Disallow: /
4.使用nginx的自带功能:通过对httpuseragent阻塞来实现,包括GET/POST方式的请求,以nginx为例,具体步骤如下:
编辑nginx.conf
#vim /usr/local/nginx/conf/nginx.conf
拒绝以wget方式的httpuseragent,增加如下内容
## Block http user agent - wget ##
if ($http_user_agent ~* (Wget) ) {
return 403;
}
## Block Software download user agents ##
if ($http_user_agent ~* LWP::Simple|BBBike|wget) {
return 403;
}
平滑启动
# /usr/local/nginx/sbin/nginx -s reload
如何拒绝多种httpuseragent,内容如下:
if ($http_user_agent ~ (agent1|agent2|Foo|Wget|Catall Spider|AcoiRobot) ) {
return 403;
}
大小写敏感匹配
### 大小写敏感http user agent拒绝###
if ($http_user_agent ~ (Catall Spider|AcoiRobot) ) {
return 403;
}
### 大小写不敏感http user agent拒绝###
if ($http_user_agent ~* (foo|bar) ) {
return 403;
}
以上是脚本之家(jb51.cc)为你搜集整理的全部代码内容,希望文章能够帮你解决所遇见的程序开发问题。
如果认为脚本之家网站内容还不错网页如何防止爬虫,欢迎将脚本之家网站推荐给程序员好友。
以上是脚本之家为你搜集整理的避免网站被爬虫爬取的几种解决办法全部内容,希望文章能够帮你解决避免网站被爬虫爬取的几种解决办法所遇见的程序开发问题。
如果认为脚本之家网站内容还不错网页如何防止爬虫,欢迎将脚本之家网站推荐给程序员好友。 查看全部
#! /bin/bash
LOGFILE=/var/log/nginx/access.log
PREFIX=/etc/spiders
#日志中大部分蜘蛛都有spider的关键字,但是百度的不能封,所以过滤掉百度
grep 'spider' $LOGFILE |grep -v 'Baidu' |awk '{print $1}' >$PREFIX/ip1.txt
# 封掉网易的有道
grep 'YoudaoBot' $LOGFILE | awk '{print $1}' >>$PREFIX/ip1.txt
#封掉雅虎
grep 'Yahoo!' $LOGFILE | awk '{print $1}' >>$PREFIX/ip1.txt
# 过滤掉信任IP
sort -n $PREFIX/ip1.txt |uniq |sort |grep -v '192.168.0.' |grep -v '127.0.0.1'>$PREFIX/ip2.txt
# 如果一小时内,发包不超过30个就要解封
/sbin/iptables -nvL |awk '$1 <= 30 {print $8}' >$PREFIX/ip3.txt
for ip in `cat $PREFIX/ip3.txt`; do /sbin/iptables -D INPUT -s $ip -j DROP ; done
/sbin/iptables -Z // 将iptables计数器置为0
for ip in `cat $PREFIX/ip2.txt`; do /sbin/iptables -I INPUT -s $ip -j DROP ; done
3.使用robots.txt文件:例如阻止所有的爬虫爬取,但是这种效果不是很明显。
User-agent: *
Disallow: /
4.使用nginx的自带功能:通过对httpuseragent阻塞来实现,包括GET/POST方式的请求,以nginx为例,具体步骤如下:
编辑nginx.conf
#vim /usr/local/nginx/conf/nginx.conf
拒绝以wget方式的httpuseragent,增加如下内容
## Block http user agent - wget ##
if ($http_user_agent ~* (Wget) ) {
return 403;
}
## Block Software download user agents ##
if ($http_user_agent ~* LWP::Simple|BBBike|wget) {
return 403;
}
平滑启动
# /usr/local/nginx/sbin/nginx -s reload
如何拒绝多种httpuseragent,内容如下:
if ($http_user_agent ~ (agent1|agent2|Foo|Wget|Catall Spider|AcoiRobot) ) {
return 403;
}
大小写敏感匹配
### 大小写敏感http user agent拒绝###
if ($http_user_agent ~ (Catall Spider|AcoiRobot) ) {
return 403;
}
### 大小写不敏感http user agent拒绝###
if ($http_user_agent ~* (foo|bar) ) {
return 403;
}
以上是脚本之家(jb51.cc)为你搜集整理的全部代码内容,希望文章能够帮你解决所遇见的程序开发问题。
如果认为脚本之家网站内容还不错网页如何防止爬虫,欢迎将脚本之家网站推荐给程序员好友。
以上是脚本之家为你搜集整理的避免网站被爬虫爬取的几种解决办法全部内容,希望文章能够帮你解决避免网站被爬虫爬取的几种解决办法所遇见的程序开发问题。
如果认为脚本之家网站内容还不错网页如何防止爬虫,欢迎将脚本之家网站推荐给程序员好友。
海洋cms怎么设置宝塔手动采集?
采集交流 • 优采云 发表了文章 • 0 个评论 • 746 次浏览 • 2020-07-25 08:01
海洋cms宝塔手动采集教程
海洋cms怎么设置宝塔手动采集海洋cms采集文章,由于很多人在问这个问题所以就有了这个教程,海洋cms虽然给了脚本代码,对于刚接触海洋cms的用户们理解上去并不是这么容易了,今天就深入的细化下海洋cms利用宝塔现实手动采集的具体步骤。
海洋cms怎么设置宝塔手动采集第一步:获取脚本代码。
【1】下面是海洋cms官网提供的手动采集脚本代码,我们须要更改代码上面的3项后才可以使用。
#!/bin/bash
########################################################
# 程序名称: 海洋CMS自动采集脚本
# 版本信息:seacmsbot/ v2.0
# 发布链接: https://www.seacms.net/post-update-92579.htm
# 使用方法:直接复制代码到宝塔计划任务shell脚本内容里添加每小时任务使用
# 更新时间:2019.9.26
##########################################################
#①请修改下面的网站域名及管理目录
web_site="http://网站域名/管理目录/admin_reslib2.php"
#②请修改下面项内容为"admin_reslib2.php"里设置的访问密码(默认为系统设置的cookie密码)
web_pwd="8888e82e85bd4540f0defa3fb7a8e888"
#③下面项内容为资源站每日采集链接地址列表,请自行修改,每行一条,可添加多个,前后需添加引号。
#每日采集链接获取方法:选择"后台-采集-资源库列表",复制资源站右边的"采集每天"的链接地址,去掉?前面的内容。
web_api=(
'?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_ ... 39%3B
'?ac=day&rid=2&url=http://www.zdziyuan.com/inc/s_ ... 39%3B
)
#模拟用户浏览器ua,请勿随意修改,以免被目标防火墙拦截!
web_ua="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/76.0.3809.100 Safari/537.36 seacmsbot/1.2;"
#采集单页
function get_content() {
echo "正在采集第$page页..."
#echo " get_content: --->url:--->$1"
cResult=$(curl --connect-timeout 10 -m 20 -k -s -L -A "$web_ua" "$1" )
echo $cResult | grep -q "采集"
#echo -e "$1\n$cResult"
if [ "$?" = "0" ]; then
next_content "$cResult"
else
echo -e "采集失败,请检查设置!\n失败链接-->$1\n返回信息-->$cResult\n采集结束,共0页"
fi
}
#采集下页
function next_content() {
#统计数据
Result=$(echo "$1" | tr "<br>" "\n")
a=$(echo "$Result" | grep -c "采集成功")
b=$(echo "$Result" | grep -c "更新数据")
c=$(echo "$Result" | grep -c "无需更新")
d=$(echo "$Result" | grep -c "跳过")
echo "采集成功-->已更$c部,新增$a部,更新$b部,跳过$d部"
let add+=$a
let update+=$b
let none+=$c
let jmp+=$d
#检测并采集下页
next_url=${1##*location.href=\'}
next_url=${next_url%%\'*}
#echo $next_url
if [ "${next_url:0:1}" = "?" ]
then
let page++
get_content "$web_site$next_url"
else
echo "采集结束,共$page页"
fi
}
#脚本入口
echo "海洋CMS自动采集脚本开始执行 版本:v1.2"
starttime=$(date +%s)
update=0 #更新
add=0 #新增
none=0 #无变化
jmp=0 # 跳过
for url in ${web_api[@]};
do
if [[ ! -z $url ]]
then
web_param="$web_site$url&password=$web_pwd"
page=1
echo "开始采集:$url"
get_content $web_param
fi
done
endtime=$(date +%s)
echo "============================"
echo "入库-->$add部"
echo "更新-->$update部"
echo "跳过-->$jmp部(未绑定分类或链接错误)"
echo "今日-->$[none+add+update]部"
echo "============================"
echo "全部采集结束,耗时$[endtime - starttime]秒"
海洋cms怎么设置宝塔手动采集第二步:修改脚本
【2】具体更改脚本上面的哪3项呢?下面为你一一说来。(根据前面提供的代码内容复制到记事本或是其他html编辑器来对应更改)
#①请修改下面的网站域名及管理目录
web_site="http://网站域名/管理目录/admin_reslib2.php"
这个是须要更改成你的“网站域名”和“海洋cms后台的管理目录”。域名你们都能理解,后台的管理目录这个对于菜鸟来说须要多讲两句,首先你要能登入你的后台才可以晓得你的后台目录。举例说明:假如我的后台登陆地址是 /article/那么这儿的“article”就是后台的管理目录,得到了管理目录我们直接填写到代码里即可。
#②请修改下面项内容为"admin_reslib2.php"里设置的访问密码(默认为系统设置的cookie密码)
web_pwd="8888e82e85bd4540f0defa3fb7a8e888"
这个更改须要到海洋cms系统后台得到我们的cookie密码进行替换才可以,具体步骤如下图。得到自己网站的cookie密码后替换即可。
#③下面项内容为资源站每日采集链接地址列表,请自行修改,每行一条,可添加多个,前后需添加引号。
#每日采集链接获取方法:选择"后台-采集-资源库列表",复制资源站右边的"采集每天"的链接地址,去掉?前面的内容。
web_api=(
'?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_ ... 39%3B
'?ac=day&rid=2&url=http://www.zdziyuan.com/inc/s_ ... 39%3B
)
这个是代码里须要更改的最后一项,里面是代码里默认提供的2个采集链接地址,我们须要获取自己的采集链接地址添加到上面,具体获取链接地址看下边截图的步骤操作。如果你还没添加或是不懂如何添加采集可以参考帮助文档-海洋cms如何添加资源库采集接口
选择"后台-采集-资源库列表",根据自己的选择去复制资源站一侧的"采集当天"“采集本周” “采集所有”的链接地址,去掉?前面的内容。(鼠标置于采集当天或是本周、所有上键盘右击复制链接即可获取采集链接)
比如这儿是:
1
http://127.0.0.1/admin/admin_r ... s.php
第二步:去掉上一步复制到的内容"?"前面的内容,结果如下:
2
?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_seackm3u8s.php
这样就得到了最终的采集网址
海洋cms怎么设置宝塔手动采集第三步:宝塔定时任务设置。
【3】直接复制代码到宝塔计划任务shell脚本,内容里添加每小时任务使用。具体操作步骤如下截图。第⑤步是把我们更改好的脚本复制粘贴到脚本内容框里即可。
【4】总结
总的来说就是把脚本上面须要更改的几项更改完后海洋cms采集文章,复制更改好的脚本到宝塔的计划任务设置下定时采集任务就可以了,任务类型不要选错。如果你对本教程不理解或是疑问的地方可以加入社群进行讨论和寻问。加入社群 查看全部
海洋cms宝塔手动采集教程
海洋cms怎么设置宝塔手动采集海洋cms采集文章,由于很多人在问这个问题所以就有了这个教程,海洋cms虽然给了脚本代码,对于刚接触海洋cms的用户们理解上去并不是这么容易了,今天就深入的细化下海洋cms利用宝塔现实手动采集的具体步骤。
海洋cms怎么设置宝塔手动采集第一步:获取脚本代码。
【1】下面是海洋cms官网提供的手动采集脚本代码,我们须要更改代码上面的3项后才可以使用。
#!/bin/bash
########################################################
# 程序名称: 海洋CMS自动采集脚本
# 版本信息:seacmsbot/ v2.0
# 发布链接: https://www.seacms.net/post-update-92579.htm
# 使用方法:直接复制代码到宝塔计划任务shell脚本内容里添加每小时任务使用
# 更新时间:2019.9.26
##########################################################
#①请修改下面的网站域名及管理目录
web_site="http://网站域名/管理目录/admin_reslib2.php"
#②请修改下面项内容为"admin_reslib2.php"里设置的访问密码(默认为系统设置的cookie密码)
web_pwd="8888e82e85bd4540f0defa3fb7a8e888"
#③下面项内容为资源站每日采集链接地址列表,请自行修改,每行一条,可添加多个,前后需添加引号。
#每日采集链接获取方法:选择"后台-采集-资源库列表",复制资源站右边的"采集每天"的链接地址,去掉?前面的内容。
web_api=(
'?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_ ... 39%3B
'?ac=day&rid=2&url=http://www.zdziyuan.com/inc/s_ ... 39%3B
)
#模拟用户浏览器ua,请勿随意修改,以免被目标防火墙拦截!
web_ua="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/76.0.3809.100 Safari/537.36 seacmsbot/1.2;"
#采集单页
function get_content() {
echo "正在采集第$page页..."
#echo " get_content: --->url:--->$1"
cResult=$(curl --connect-timeout 10 -m 20 -k -s -L -A "$web_ua" "$1" )
echo $cResult | grep -q "采集"
#echo -e "$1\n$cResult"
if [ "$?" = "0" ]; then
next_content "$cResult"
else
echo -e "采集失败,请检查设置!\n失败链接-->$1\n返回信息-->$cResult\n采集结束,共0页"
fi
}
#采集下页
function next_content() {
#统计数据
Result=$(echo "$1" | tr "<br>" "\n")
a=$(echo "$Result" | grep -c "采集成功")
b=$(echo "$Result" | grep -c "更新数据")
c=$(echo "$Result" | grep -c "无需更新")
d=$(echo "$Result" | grep -c "跳过")
echo "采集成功-->已更$c部,新增$a部,更新$b部,跳过$d部"
let add+=$a
let update+=$b
let none+=$c
let jmp+=$d
#检测并采集下页
next_url=${1##*location.href=\'}
next_url=${next_url%%\'*}
#echo $next_url
if [ "${next_url:0:1}" = "?" ]
then
let page++
get_content "$web_site$next_url"
else
echo "采集结束,共$page页"
fi
}
#脚本入口
echo "海洋CMS自动采集脚本开始执行 版本:v1.2"
starttime=$(date +%s)
update=0 #更新
add=0 #新增
none=0 #无变化
jmp=0 # 跳过
for url in ${web_api[@]};
do
if [[ ! -z $url ]]
then
web_param="$web_site$url&password=$web_pwd"
page=1
echo "开始采集:$url"
get_content $web_param
fi
done
endtime=$(date +%s)
echo "============================"
echo "入库-->$add部"
echo "更新-->$update部"
echo "跳过-->$jmp部(未绑定分类或链接错误)"
echo "今日-->$[none+add+update]部"
echo "============================"
echo "全部采集结束,耗时$[endtime - starttime]秒"
海洋cms怎么设置宝塔手动采集第二步:修改脚本
【2】具体更改脚本上面的哪3项呢?下面为你一一说来。(根据前面提供的代码内容复制到记事本或是其他html编辑器来对应更改)
#①请修改下面的网站域名及管理目录
web_site="http://网站域名/管理目录/admin_reslib2.php"
这个是须要更改成你的“网站域名”和“海洋cms后台的管理目录”。域名你们都能理解,后台的管理目录这个对于菜鸟来说须要多讲两句,首先你要能登入你的后台才可以晓得你的后台目录。举例说明:假如我的后台登陆地址是 /article/那么这儿的“article”就是后台的管理目录,得到了管理目录我们直接填写到代码里即可。
#②请修改下面项内容为"admin_reslib2.php"里设置的访问密码(默认为系统设置的cookie密码)
web_pwd="8888e82e85bd4540f0defa3fb7a8e888"
这个更改须要到海洋cms系统后台得到我们的cookie密码进行替换才可以,具体步骤如下图。得到自己网站的cookie密码后替换即可。
#③下面项内容为资源站每日采集链接地址列表,请自行修改,每行一条,可添加多个,前后需添加引号。
#每日采集链接获取方法:选择"后台-采集-资源库列表",复制资源站右边的"采集每天"的链接地址,去掉?前面的内容。
web_api=(
'?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_ ... 39%3B
'?ac=day&rid=2&url=http://www.zdziyuan.com/inc/s_ ... 39%3B
)
这个是代码里须要更改的最后一项,里面是代码里默认提供的2个采集链接地址,我们须要获取自己的采集链接地址添加到上面,具体获取链接地址看下边截图的步骤操作。如果你还没添加或是不懂如何添加采集可以参考帮助文档-海洋cms如何添加资源库采集接口
选择"后台-采集-资源库列表",根据自己的选择去复制资源站一侧的"采集当天"“采集本周” “采集所有”的链接地址,去掉?前面的内容。(鼠标置于采集当天或是本周、所有上键盘右击复制链接即可获取采集链接)
比如这儿是:
1
http://127.0.0.1/admin/admin_r ... s.php
第二步:去掉上一步复制到的内容"?"前面的内容,结果如下:
2
?ac=day&rid=1&url=https://api.iokzy.com/inc/ldg_seackm3u8s.php
这样就得到了最终的采集网址
海洋cms怎么设置宝塔手动采集第三步:宝塔定时任务设置。
【3】直接复制代码到宝塔计划任务shell脚本,内容里添加每小时任务使用。具体操作步骤如下截图。第⑤步是把我们更改好的脚本复制粘贴到脚本内容框里即可。
【4】总结
总的来说就是把脚本上面须要更改的几项更改完后海洋cms采集文章,复制更改好的脚本到宝塔的计划任务设置下定时采集任务就可以了,任务类型不要选错。如果你对本教程不理解或是疑问的地方可以加入社群进行讨论和寻问。加入社群
防止网站被爬虫爬取的几种解决办法
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2020-06-02 08:00
#! /bin/bash
LOGFILE=/var/log/nginx/access.log
PREFIX=/etc/spiders
#日志中大部分蜘蛛都有spider的关键字,但是百度的不能封,所以过滤掉百度
grep 'spider' $LOGFILE |grep -v 'Baidu' |awk '{print $1}' >$PREFIX/ip1.txt
# 封掉网易的有道
grep 'YoudaoBot' $LOGFILE | awk '{print $1}' >>$PREFIX/ip1.txt
#封掉雅虎
grep 'Yahoo!' $LOGFILE | awk '{print $1}' >>$PREFIX/ip1.txt
# 过滤掉信任IP
sort -n $PREFIX/ip1.txt |uniq |sort |grep -v '192.168.0.' |grep -v '127.0.0.1'>$PREFIX/ip2.txt
# 如果一小时内,发包不超过30个就要解封
/sbin/iptables -nvL |awk '$1 <= 30 {print $8}' >$PREFIX/ip3.txt
for ip in `cat $PREFIX/ip3.txt`; do /sbin/iptables -D INPUT -s $ip -j DROP ; done
/sbin/iptables -Z // 将iptables计数器置为0
for ip in `cat $PREFIX/ip2.txt`; do /sbin/iptables -I INPUT -s $ip -j DROP ; done
3.使用robots.txt文件:例如阻止所有的爬虫爬取,但是这种效果不是很明显。
User-agent: *
Disallow: /
4.使用nginx的自带功能:通过对httpuseragent阻塞来实现,包括GET/POST方式的请求,以nginx为例,具体步骤如下:
编辑nginx.conf
#vim /usr/local/nginx/conf/nginx.conf
拒绝以wget方式的httpuseragent,增加如下内容
## Block http user agent - wget ##
if ($http_user_agent ~* (Wget) ) {
return 403;
}
## Block Software download user agents ##
if ($http_user_agent ~* LWP::Simple|BBBike|wget) {
return 403;
}
平滑启动
# /usr/local/nginx/sbin/nginx -s reload
如何拒绝多种httpuseragent,内容如下:
if ($http_user_agent ~ (agent1|agent2|Foo|Wget|Catall Spider|AcoiRobot) ) {
return 403;
}
大小写敏感匹配
### 大小写敏感http user agent拒绝###
if ($http_user_agent ~ (Catall Spider|AcoiRobot) ) {
return 403;
}
### 大小写不敏感http user agent拒绝###
if ($http_user_agent ~* (foo|bar) ) {
return 403;
}
以上是脚本之家(jb51.cc)为你搜集整理的全部代码内容,希望文章能够帮你解决所遇见的程序开发问题。
如果认为脚本之家网站内容还不错网页如何防止爬虫,欢迎将脚本之家网站推荐给程序员好友。
以上是脚本之家为你搜集整理的避免网站被爬虫爬取的几种解决办法全部内容,希望文章能够帮你解决避免网站被爬虫爬取的几种解决办法所遇见的程序开发问题。
如果认为脚本之家网站内容还不错网页如何防止爬虫,欢迎将脚本之家网站推荐给程序员好友。 查看全部
LOGFILE=/var/log/nginx/access.log
PREFIX=/etc/spiders
#日志中大部分蜘蛛都有spider的关键字,但是百度的不能封,所以过滤掉百度
grep 'spider' $LOGFILE |grep -v 'Baidu' |awk '{print $1}' >$PREFIX/ip1.txt
# 封掉网易的有道
grep 'YoudaoBot' $LOGFILE | awk '{print $1}' >>$PREFIX/ip1.txt
#封掉雅虎
grep 'Yahoo!' $LOGFILE | awk '{print $1}' >>$PREFIX/ip1.txt
# 过滤掉信任IP
sort -n $PREFIX/ip1.txt |uniq |sort |grep -v '192.168.0.' |grep -v '127.0.0.1'>$PREFIX/ip2.txt
# 如果一小时内,发包不超过30个就要解封
/sbin/iptables -nvL |awk '$1 <= 30 {print $8}' >$PREFIX/ip3.txt
for ip in `cat $PREFIX/ip3.txt`; do /sbin/iptables -D INPUT -s $ip -j DROP ; done
/sbin/iptables -Z // 将iptables计数器置为0
for ip in `cat $PREFIX/ip2.txt`; do /sbin/iptables -I INPUT -s $ip -j DROP ; done
3.使用robots.txt文件:例如阻止所有的爬虫爬取,但是这种效果不是很明显。
User-agent: *
Disallow: /
4.使用nginx的自带功能:通过对httpuseragent阻塞来实现,包括GET/POST方式的请求,以nginx为例,具体步骤如下:
编辑nginx.conf
#vim /usr/local/nginx/conf/nginx.conf
拒绝以wget方式的httpuseragent,增加如下内容
## Block http user agent - wget ##
if ($http_user_agent ~* (Wget) ) {
return 403;
}
## Block Software download user agents ##
if ($http_user_agent ~* LWP::Simple|BBBike|wget) {
return 403;
}
平滑启动
# /usr/local/nginx/sbin/nginx -s reload
如何拒绝多种httpuseragent,内容如下:
if ($http_user_agent ~ (agent1|agent2|Foo|Wget|Catall Spider|AcoiRobot) ) {
return 403;
}
大小写敏感匹配
### 大小写敏感http user agent拒绝###
if ($http_user_agent ~ (Catall Spider|AcoiRobot) ) {
return 403;
}
### 大小写不敏感http user agent拒绝###
if ($http_user_agent ~* (foo|bar) ) {
return 403;
}
以上是脚本之家(jb51.cc)为你搜集整理的全部代码内容,希望文章能够帮你解决所遇见的程序开发问题。
如果认为脚本之家网站内容还不错网页如何防止爬虫,欢迎将脚本之家网站推荐给程序员好友。
以上是脚本之家为你搜集整理的避免网站被爬虫爬取的几种解决办法全部内容,希望文章能够帮你解决避免网站被爬虫爬取的几种解决办法所遇见的程序开发问题。
如果认为脚本之家网站内容还不错网页如何防止爬虫,欢迎将脚本之家网站推荐给程序员好友。 查看全部
#! /bin/bash
LOGFILE=/var/log/nginx/access.log
PREFIX=/etc/spiders
#日志中大部分蜘蛛都有spider的关键字,但是百度的不能封,所以过滤掉百度
grep 'spider' $LOGFILE |grep -v 'Baidu' |awk '{print $1}' >$PREFIX/ip1.txt
# 封掉网易的有道
grep 'YoudaoBot' $LOGFILE | awk '{print $1}' >>$PREFIX/ip1.txt
#封掉雅虎
grep 'Yahoo!' $LOGFILE | awk '{print $1}' >>$PREFIX/ip1.txt
# 过滤掉信任IP
sort -n $PREFIX/ip1.txt |uniq |sort |grep -v '192.168.0.' |grep -v '127.0.0.1'>$PREFIX/ip2.txt
# 如果一小时内,发包不超过30个就要解封
/sbin/iptables -nvL |awk '$1 <= 30 {print $8}' >$PREFIX/ip3.txt
for ip in `cat $PREFIX/ip3.txt`; do /sbin/iptables -D INPUT -s $ip -j DROP ; done
/sbin/iptables -Z // 将iptables计数器置为0
for ip in `cat $PREFIX/ip2.txt`; do /sbin/iptables -I INPUT -s $ip -j DROP ; done
3.使用robots.txt文件:例如阻止所有的爬虫爬取,但是这种效果不是很明显。
User-agent: *
Disallow: /
4.使用nginx的自带功能:通过对httpuseragent阻塞来实现,包括GET/POST方式的请求,以nginx为例,具体步骤如下:
编辑nginx.conf
#vim /usr/local/nginx/conf/nginx.conf
拒绝以wget方式的httpuseragent,增加如下内容
## Block http user agent - wget ##
if ($http_user_agent ~* (Wget) ) {
return 403;
}
## Block Software download user agents ##
if ($http_user_agent ~* LWP::Simple|BBBike|wget) {
return 403;
}
平滑启动
# /usr/local/nginx/sbin/nginx -s reload
如何拒绝多种httpuseragent,内容如下:
if ($http_user_agent ~ (agent1|agent2|Foo|Wget|Catall Spider|AcoiRobot) ) {
return 403;
}
大小写敏感匹配
### 大小写敏感http user agent拒绝###
if ($http_user_agent ~ (Catall Spider|AcoiRobot) ) {
return 403;
}
### 大小写不敏感http user agent拒绝###
if ($http_user_agent ~* (foo|bar) ) {
return 403;
}
以上是脚本之家(jb51.cc)为你搜集整理的全部代码内容,希望文章能够帮你解决所遇见的程序开发问题。
如果认为脚本之家网站内容还不错网页如何防止爬虫,欢迎将脚本之家网站推荐给程序员好友。
以上是脚本之家为你搜集整理的避免网站被爬虫爬取的几种解决办法全部内容,希望文章能够帮你解决避免网站被爬虫爬取的几种解决办法所遇见的程序开发问题。
如果认为脚本之家网站内容还不错网页如何防止爬虫,欢迎将脚本之家网站推荐给程序员好友。

