
网页qq抓取什么原理
网页qq抓取什么原理(python什么是爬虫?以及爬虫工作的原理是什么? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 37 次浏览 • 2021-12-29 14:14
)
今年进了python坑,进坑的原因多半是爬虫的缘故。至于入口爬虫,我们需要大致了解一下爬虫是什么?以及爬虫的工作原理。以便于日后的学习。本博客仅用于交流学习和记录自己的成长过程。如果有不足和需要改进的地方,还望各位小伙伴指出。互相学习!互相交流!
1、什么是爬虫
Crawler,即网络爬虫(搜索引擎爬虫),可以理解为在互联网上爬行的蜘蛛。把互联网比作一个大网,爬虫就是在这个网上爬来爬去的蜘蛛,资源是“猎物”,需要什么资源由人来控制。
使用爬虫爬取一个网页,在这个'web'中发现了一个'road'#指向网页超链接#。然后爬虫可以去另一个“网”爬取数据。这样,整个连接的'大网'#Internet#都在这个蜘蛛的触手可及的范围内,需要几分钟的时间才能获得所需的资源。
学过前端的同学应该都知道,每一个tag#()#就是一条路,也可以理解,爬虫直接爬取的不是我们需要的网络资源,而是网页的源代码。然后我们手动过滤选择我们需要的资源的url#网络资源Locator/link#,最后下载或者操作我们需要的数据来达到我们的目的。
理论上只要能抓取到网页上能看到的数据就可以了('因为你看到的网页上的所有数据都是服务器发送到电脑的,但有些数据是加密的,很难解密') . 对于网络上看不到或获取不到的数据,爬虫也是无法获取的,比如一些付费信息(主付费还没到哈哈哈哈)。
各大搜索引擎都非常强大,国内的百度、好搜、搜狗等。
以上只是我个人对爬虫的看法。百度百科(搜索引擎爬虫/20256370?fr=aladdin)有更专业权威的解释。有兴趣的朋友可以看看。
*Crawler其实就是一个模拟浏览器的过程,模拟浏览器发出请求。*
2、用户浏览网页的过程
当用户浏览网页时,他们会看到很多内容。比如打开百度,可以看到图片、文字、音乐等,这个过程是怎么实现的?这个过程的实现其实就是用户输入URL后,通过DNS服务器找到目标服务器主机,向服务器发送请求。服务端解析后,根据请求返回给用户浏览器的HTML、CSS、JS等文件(源代码)。, 浏览器接收到数据并进行分析后,用户就可以看到我们常用网页的内容了。
#Request/Open某个URL的一般流程:
{本地主机文件-->本地路由-->DNS域名解析服务器(解析域名指向一个网站)-->目标服务器-->请求页面}
服务器发送给我们(用户)的不是我们看到的,而是html标记的网页代码,浏览器收到后解析源码。下载标签存储在缓存中,并显示在我们看到的网页上。因此,用户看到的网页本质上是由HTML代码组成的,但实际上,爬虫爬取的却是HTML代码文件。我们通过一定的规则对这些HTML代码进行分析和过滤,从而实现我们对网络资源的访问。. #
3、什么是网址?
统一资源定位符 (URL)。URL 是互联网上可用资源的位置和访问方式的简明表示,类似于我们简单描述所需图书在图书馆中的位置以及如何获取所需对象的方式。每个互联网资源都可以看作是一个独立的对象,每个独立的对象(网络资源)都会有一个唯一的URL。URL 中收录
的信息指示目标文件的位置以及浏览器应如何处理该文件。
#URL 的格式一般由三部分组成:
1),protocol(服务模式):如例子中,”为通用协议,其他如:file://ftp://等;
2),托管资源的主机的IP地址:(有时包括端口号)可以是直接IP地址:192.168.1.1,它也可以是域名,如示例中所示;
3),宿主资源的具体地址(目录和文件夹等):如'/static/wiki-album/widget/picture/pictureDialog/resource/img/img-bg_86e1dfc.gif'中例子。#
4、 开发环境配置
工欲善其事,必先利其器。学习Python,前提是配置好我们的环境。Python是开源的,可以在Python官网('')免费下载。推荐使用 Pychram 作为 Python 开发工具。我之前也是用IDLE写的。我发现Pycharm很麻烦,但在那之后,我无法逃脱万年真香定理的破坏。如何安装和配置 Pychram 可以在 CSND 上找到。有很多博主写的很详细,大部分人都能看懂。实在不懂就买个宝吧哈哈哈哈。
5、 个人爬虫开发的思考
1、理论上只要能抓取到网页上能看到的数据就可以了('因为你看到的网页上的所有数据都是服务器发送给电脑的,但是有些数据是加密,需要解密,获取所需文件的URL,成功一半')
2、 网页上看不到或获取不到的数据,爬虫也无法获取,比如一些付费素材、付费视频等。
3、分析页面数据的原则是由简到繁,由易到难
1)、通过网页源码直接获取
2),分析是否是ajax异步加载
3)、数据是否加密js
6、Python版本问题
现在Python有了Python2.X和Python3.X,而Python2.X和Python3.X并不是简单的升级关系,而是完全不同的两个东西。这两种发展各有优缺点,语法和方法也各不相同。我也打算在以后的开发中写出两者的区别,让两种不同环境下的程序更兼容,更方便修改。毕竟Python2.X在2020年也将停止更新。不过我建议大家在学习初期,可以下载两个版本,以便学习Python开发的思路和方法。此外,Pychram 可以方便地更改项目中开发时使用的 Python 版本,
第一篇博文就这么愉快的结束了!非常感谢每一位花时间阅读我对爬虫介绍的看法的朋友。对Python感兴趣的同志可以在评论区留下联系方式。我们可以一起交流学习,走向更广阔的视野。世界!
*人生苦短,我用Python。* 查看全部
网页qq抓取什么原理(python什么是爬虫?以及爬虫工作的原理是什么?
)
今年进了python坑,进坑的原因多半是爬虫的缘故。至于入口爬虫,我们需要大致了解一下爬虫是什么?以及爬虫的工作原理。以便于日后的学习。本博客仅用于交流学习和记录自己的成长过程。如果有不足和需要改进的地方,还望各位小伙伴指出。互相学习!互相交流!
1、什么是爬虫
Crawler,即网络爬虫(搜索引擎爬虫),可以理解为在互联网上爬行的蜘蛛。把互联网比作一个大网,爬虫就是在这个网上爬来爬去的蜘蛛,资源是“猎物”,需要什么资源由人来控制。
使用爬虫爬取一个网页,在这个'web'中发现了一个'road'#指向网页超链接#。然后爬虫可以去另一个“网”爬取数据。这样,整个连接的'大网'#Internet#都在这个蜘蛛的触手可及的范围内,需要几分钟的时间才能获得所需的资源。
学过前端的同学应该都知道,每一个tag#()#就是一条路,也可以理解,爬虫直接爬取的不是我们需要的网络资源,而是网页的源代码。然后我们手动过滤选择我们需要的资源的url#网络资源Locator/link#,最后下载或者操作我们需要的数据来达到我们的目的。
理论上只要能抓取到网页上能看到的数据就可以了('因为你看到的网页上的所有数据都是服务器发送到电脑的,但有些数据是加密的,很难解密') . 对于网络上看不到或获取不到的数据,爬虫也是无法获取的,比如一些付费信息(主付费还没到哈哈哈哈)。
各大搜索引擎都非常强大,国内的百度、好搜、搜狗等。
以上只是我个人对爬虫的看法。百度百科(搜索引擎爬虫/20256370?fr=aladdin)有更专业权威的解释。有兴趣的朋友可以看看。
*Crawler其实就是一个模拟浏览器的过程,模拟浏览器发出请求。*
2、用户浏览网页的过程
当用户浏览网页时,他们会看到很多内容。比如打开百度,可以看到图片、文字、音乐等,这个过程是怎么实现的?这个过程的实现其实就是用户输入URL后,通过DNS服务器找到目标服务器主机,向服务器发送请求。服务端解析后,根据请求返回给用户浏览器的HTML、CSS、JS等文件(源代码)。, 浏览器接收到数据并进行分析后,用户就可以看到我们常用网页的内容了。
#Request/Open某个URL的一般流程:
{本地主机文件-->本地路由-->DNS域名解析服务器(解析域名指向一个网站)-->目标服务器-->请求页面}
服务器发送给我们(用户)的不是我们看到的,而是html标记的网页代码,浏览器收到后解析源码。下载标签存储在缓存中,并显示在我们看到的网页上。因此,用户看到的网页本质上是由HTML代码组成的,但实际上,爬虫爬取的却是HTML代码文件。我们通过一定的规则对这些HTML代码进行分析和过滤,从而实现我们对网络资源的访问。. #
3、什么是网址?
统一资源定位符 (URL)。URL 是互联网上可用资源的位置和访问方式的简明表示,类似于我们简单描述所需图书在图书馆中的位置以及如何获取所需对象的方式。每个互联网资源都可以看作是一个独立的对象,每个独立的对象(网络资源)都会有一个唯一的URL。URL 中收录
的信息指示目标文件的位置以及浏览器应如何处理该文件。
#URL 的格式一般由三部分组成:
1),protocol(服务模式):如例子中,”为通用协议,其他如:file://ftp://等;
2),托管资源的主机的IP地址:(有时包括端口号)可以是直接IP地址:192.168.1.1,它也可以是域名,如示例中所示;
3),宿主资源的具体地址(目录和文件夹等):如'/static/wiki-album/widget/picture/pictureDialog/resource/img/img-bg_86e1dfc.gif'中例子。#
4、 开发环境配置
工欲善其事,必先利其器。学习Python,前提是配置好我们的环境。Python是开源的,可以在Python官网('')免费下载。推荐使用 Pychram 作为 Python 开发工具。我之前也是用IDLE写的。我发现Pycharm很麻烦,但在那之后,我无法逃脱万年真香定理的破坏。如何安装和配置 Pychram 可以在 CSND 上找到。有很多博主写的很详细,大部分人都能看懂。实在不懂就买个宝吧哈哈哈哈。
5、 个人爬虫开发的思考
1、理论上只要能抓取到网页上能看到的数据就可以了('因为你看到的网页上的所有数据都是服务器发送给电脑的,但是有些数据是加密,需要解密,获取所需文件的URL,成功一半')
2、 网页上看不到或获取不到的数据,爬虫也无法获取,比如一些付费素材、付费视频等。
3、分析页面数据的原则是由简到繁,由易到难
1)、通过网页源码直接获取
2),分析是否是ajax异步加载
3)、数据是否加密js
6、Python版本问题
现在Python有了Python2.X和Python3.X,而Python2.X和Python3.X并不是简单的升级关系,而是完全不同的两个东西。这两种发展各有优缺点,语法和方法也各不相同。我也打算在以后的开发中写出两者的区别,让两种不同环境下的程序更兼容,更方便修改。毕竟Python2.X在2020年也将停止更新。不过我建议大家在学习初期,可以下载两个版本,以便学习Python开发的思路和方法。此外,Pychram 可以方便地更改项目中开发时使用的 Python 版本,
第一篇博文就这么愉快的结束了!非常感谢每一位花时间阅读我对爬虫介绍的看法的朋友。对Python感兴趣的同志可以在评论区留下联系方式。我们可以一起交流学习,走向更广阔的视野。世界!
*人生苦短,我用Python。*
网页qq抓取什么原理(网页qq抓取什么原理?文字段落抓取伪代码思维导图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-25 04:03
网页qq抓取什么原理?文字段落抓取伪代码思维导图fiddler全局代理工具yslow各浏览器插件[浏览器工具]看看网页的正则表达式抓取也不是那么复杂,一些规则而已,拿来用就行,用什么文本编辑器无所谓,见效慢。
qq小程序=微信小程序=webqq小程序=微信app安卓直接下载微信小程序;ios:解包所有浏览器,
是否需要安装,是需要一个浏览器。微信在后台安装了qq浏览器。所以你不用挂后台运行qq就可以在微信里用qq浏览器。
打开qq浏览器
所以以前浏览器不是问题,因为浏览器根本没有做这个事情。做这个事情的是:新浪的服务器,因为新浪是商业化网站,不开放api给第三方提供接口,所以这个事情的从业者就转向用chrome了。只不过是自己默默做而已。
工作党有,有资金,利用当下流行的yypc版v5.5做了一个简易的小软件,可行。自己动手丰衣足食。用到的软件就是yypc版v5.5。毕竟技术不算太高端,这个对自己来说还算容易。实际上思路也没什么了,就是经常在微信里调戏一下自己喜欢的对象。先在自己的资料库里查看对方是不是发来信息了,不是则保存资料,是则对调戏对象一个回应。不知道说明白了么。
qq浏览器后台安装,支持腾讯所有本地用户端浏览器和腾讯qq浏览器网页版等。实现方法就是进入聊天对话框(发一个赞或评论就好),或者输入文字后发送信息到被调戏对象的qq上:信息内容举例如下:添加好友需要获取对方qq号码,用于推送未读信息。开放api的这种方式已经禁止获取并提供了文字版信息,转用伪代码实现。地址:qq昵称请自行改进算法,这次估计实现难度较大。
1、起始态设置为邮箱接收邮件界面
2、将信息url伪装为一条邮件信息(在发送邮件状态下)点开发送,将邮件内容发送,
3、代码实现如下:
1)获取对方qq
2)获取到对方qq号后,将注册邮箱发送至昵称,
3)获取到昵称后,将昵称昵称随机发送至对方qq,
4)获取到昵称昵称后, 查看全部
网页qq抓取什么原理(网页qq抓取什么原理?文字段落抓取伪代码思维导图)
网页qq抓取什么原理?文字段落抓取伪代码思维导图fiddler全局代理工具yslow各浏览器插件[浏览器工具]看看网页的正则表达式抓取也不是那么复杂,一些规则而已,拿来用就行,用什么文本编辑器无所谓,见效慢。
qq小程序=微信小程序=webqq小程序=微信app安卓直接下载微信小程序;ios:解包所有浏览器,
是否需要安装,是需要一个浏览器。微信在后台安装了qq浏览器。所以你不用挂后台运行qq就可以在微信里用qq浏览器。
打开qq浏览器
所以以前浏览器不是问题,因为浏览器根本没有做这个事情。做这个事情的是:新浪的服务器,因为新浪是商业化网站,不开放api给第三方提供接口,所以这个事情的从业者就转向用chrome了。只不过是自己默默做而已。
工作党有,有资金,利用当下流行的yypc版v5.5做了一个简易的小软件,可行。自己动手丰衣足食。用到的软件就是yypc版v5.5。毕竟技术不算太高端,这个对自己来说还算容易。实际上思路也没什么了,就是经常在微信里调戏一下自己喜欢的对象。先在自己的资料库里查看对方是不是发来信息了,不是则保存资料,是则对调戏对象一个回应。不知道说明白了么。
qq浏览器后台安装,支持腾讯所有本地用户端浏览器和腾讯qq浏览器网页版等。实现方法就是进入聊天对话框(发一个赞或评论就好),或者输入文字后发送信息到被调戏对象的qq上:信息内容举例如下:添加好友需要获取对方qq号码,用于推送未读信息。开放api的这种方式已经禁止获取并提供了文字版信息,转用伪代码实现。地址:qq昵称请自行改进算法,这次估计实现难度较大。
1、起始态设置为邮箱接收邮件界面
2、将信息url伪装为一条邮件信息(在发送邮件状态下)点开发送,将邮件内容发送,
3、代码实现如下:
1)获取对方qq
2)获取到对方qq号后,将注册邮箱发送至昵称,
3)获取到昵称后,将昵称昵称随机发送至对方qq,
4)获取到昵称昵称后,
网页qq抓取什么原理( 拼接的Url找到多个urlURL解析看的应该准确)
网站优化 • 优采云 发表了文章 • 0 个评论 • 40 次浏览 • 2021-12-24 18:00
拼接的Url找到多个urlURL解析看的应该准确)
爬取网页版QQ音乐
首先进入音乐播放页面,找到音乐的最终url版本
根据这个网址进入播放页面
这个网站怎么找
我们复制它关键词搜索它
我们只需要访问这个网页的数据就可以得到音乐的url
看到网址有点瞎
URL解析应该更准确
我们需要得到这个值才能批量下载
进入歌曲排名页面搜索关键词
{"req":{"module":"CDN.SrfCdnDispatchServer","method":"GetCdnDispatch","param":{"guid":"1282808556","calltype":0,"userip": ""}},"Req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"1282808556","songmid":["0000Z0093Ko5Ps"] ,"Songtype":[0],"uin":"641043558","loginflag":1,"platform":"20"}},"comm":{"uin":641043558,"format":"json ","Ct":24,"cv":0}}
通过访问这个网站
获取拼接的Url
找多个网址对比,发现songmid一直在变,
把这个关键词带到之前的网页搜索
得到一个这个网站,这个网站访问会得到一段json字符串,分析一下,得到singmid
可以获取初始网址
我们直接访问该网站,无需编写代码即可获取数据。很简单。 查看全部
网页qq抓取什么原理(
拼接的Url找到多个urlURL解析看的应该准确)
爬取网页版QQ音乐
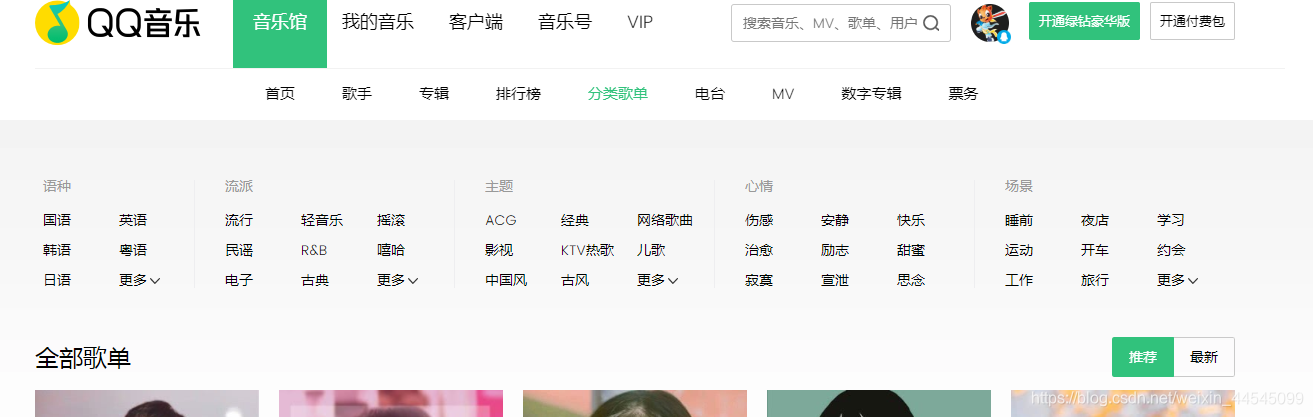
首先进入音乐播放页面,找到音乐的最终url版本
根据这个网址进入播放页面

这个网站怎么找
我们复制它关键词搜索它


我们只需要访问这个网页的数据就可以得到音乐的url
看到网址有点瞎
URL解析应该更准确
我们需要得到这个值才能批量下载
进入歌曲排名页面搜索关键词
{"req":{"module":"CDN.SrfCdnDispatchServer","method":"GetCdnDispatch","param":{"guid":"1282808556","calltype":0,"userip": ""}},"Req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"1282808556","songmid":["0000Z0093Ko5Ps"] ,"Songtype":[0],"uin":"641043558","loginflag":1,"platform":"20"}},"comm":{"uin":641043558,"format":"json ","Ct":24,"cv":0}}
通过访问这个网站
获取拼接的Url
找多个网址对比,发现songmid一直在变,
把这个关键词带到之前的网页搜索
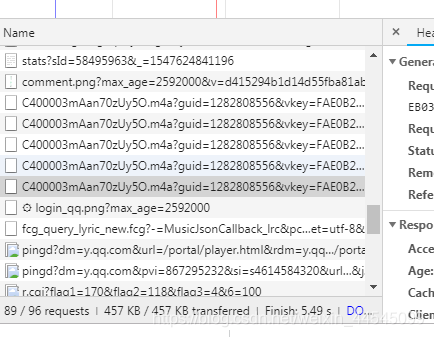
得到一个这个网站,这个网站访问会得到一段json字符串,分析一下,得到singmid
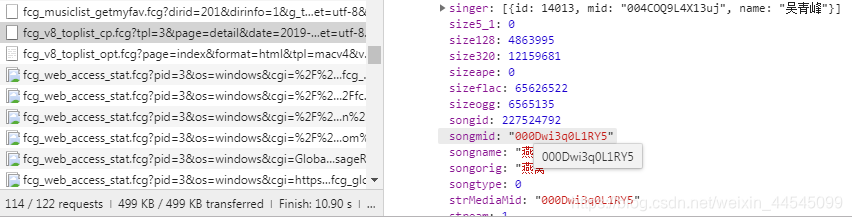
可以获取初始网址
我们直接访问该网站,无需编写代码即可获取数据。很简单。
网页qq抓取什么原理(揭秘qq空间排名技术少让一些新手上当当)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-21 11:14
简介:最近,QQ空间排名技术非常火爆。网上有很多培训,有的培训很贵。
今天给大家揭秘QQ空间排名技术,免得有些新手用不上。
首先我们来看看百度蜘蛛是如何抓取QQ空间网页的。测试百度蜘蛛如何抓取我的空间。
需要使用站长工具中的百度蜘蛛模拟工具--
1、2、3、上图中的4对应下图中的1、2、3、4
可以明显看出百度抢了我们QQ空间的关键词位置。
只需将我们的关键字放在这些地方就可以了。
接下来我们要做的就是打开QQ空间的所有权限,排列好关键词。
完成这些准备工作后,我们将开始像百度一样提交我们的Qzone地址。
提交的具体网址是(记住,必须是这个网址)
提交后,百度会在提交完成后最快2小时收录你的QQ区,结果如图收录
记住,查询是否收录时,不要在空间URL的末尾收录斜线。假设你的空间里没有收录,就不用点击图中框内的提交网址,因为我发现这样是没有效果的。 (唯一投稿地址)
收录 完成后,接下来要做的就是发布链接。
为什么外部链接很重要?举个例子,以这个QQ空间为例。
检查一下。外链虽然不多,但我看了一下,发现很多都是高质量的。
结论:
Qzone 排名技术就是这么简单。设置关键词和百度收录后,唯一影响排名的是外链。外链越多,质量越高,你的关键词排名就越高。如果你有吸引百度蜘蛛的工具,那么你的关键词排名会更好。除了以上的影响因素,最后一个因素就是运气,所以你可以操作很多Qzone,相当于站群,所以你在Qzone上获得更好排名的机会会增加很多。最后,推荐百度指数在100左右的暴力关键词,这样获得排名的时间短,盈利周期短。 查看全部
网页qq抓取什么原理(揭秘qq空间排名技术少让一些新手上当当)
简介:最近,QQ空间排名技术非常火爆。网上有很多培训,有的培训很贵。
今天给大家揭秘QQ空间排名技术,免得有些新手用不上。
首先我们来看看百度蜘蛛是如何抓取QQ空间网页的。测试百度蜘蛛如何抓取我的空间。
需要使用站长工具中的百度蜘蛛模拟工具--
1、2、3、上图中的4对应下图中的1、2、3、4
可以明显看出百度抢了我们QQ空间的关键词位置。
只需将我们的关键字放在这些地方就可以了。
接下来我们要做的就是打开QQ空间的所有权限,排列好关键词。
完成这些准备工作后,我们将开始像百度一样提交我们的Qzone地址。
提交的具体网址是(记住,必须是这个网址)
提交后,百度会在提交完成后最快2小时收录你的QQ区,结果如图收录
记住,查询是否收录时,不要在空间URL的末尾收录斜线。假设你的空间里没有收录,就不用点击图中框内的提交网址,因为我发现这样是没有效果的。 (唯一投稿地址)
收录 完成后,接下来要做的就是发布链接。
为什么外部链接很重要?举个例子,以这个QQ空间为例。
检查一下。外链虽然不多,但我看了一下,发现很多都是高质量的。
结论:
Qzone 排名技术就是这么简单。设置关键词和百度收录后,唯一影响排名的是外链。外链越多,质量越高,你的关键词排名就越高。如果你有吸引百度蜘蛛的工具,那么你的关键词排名会更好。除了以上的影响因素,最后一个因素就是运气,所以你可以操作很多Qzone,相当于站群,所以你在Qzone上获得更好排名的机会会增加很多。最后,推荐百度指数在100左右的暴力关键词,这样获得排名的时间短,盈利周期短。
网页qq抓取什么原理(Python程序猿的爬虫运行原理是什么?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-20 16:18
什么是爬虫?
本文中提到的爬虫本质上并不是爬行动物,而是一种运行在互联网上的自动处理信息的程序。
Crawler 是一个使用网络请求(HTTP/HTTPS)来过滤和输入数据的程序。因为网络信息的维度很广,就像蜘蛛网一样,我们会通过网络请求过滤,将数据输入到网络蜘蛛(网络爬虫)中。
爬虫运行原理:
互联网上信息传输的载体多为网页数据。爬虫操作的原理是解析网页数据,去除超文本标记语言(HTML)等,只保留有用的数据。
案件:
假设我们想从互联网上抓取“再见”的歌词。网页如下图所示。我们要抓取的内容是红色部分。
履带箱
1. 首先我们分析页面的结构,找到歌词所在的大概的div结构
找到div结构
进一步寻找路径
获取路径信息
使用 Selector 分析工具进行数据分析。
源代码
为什么爬虫先Python:
实际上,爬虫可以用任何语言编写,只要该语言能够解析响应、请求等相关网络请求即可。
Python爬虫开发有其独特的优势,上手快,难度低,第三方插件完善,开发难度低。这些优势是其他语言无法比拟的,因此 Python 是编写爬虫的主要语言。
我是一个热爱游戏的Python程序员,想知道爬虫知识有哪些?请在下方留言,我会特别说明~ 查看全部
网页qq抓取什么原理(Python程序猿的爬虫运行原理是什么?(图))
什么是爬虫?
本文中提到的爬虫本质上并不是爬行动物,而是一种运行在互联网上的自动处理信息的程序。
Crawler 是一个使用网络请求(HTTP/HTTPS)来过滤和输入数据的程序。因为网络信息的维度很广,就像蜘蛛网一样,我们会通过网络请求过滤,将数据输入到网络蜘蛛(网络爬虫)中。
爬虫运行原理:
互联网上信息传输的载体多为网页数据。爬虫操作的原理是解析网页数据,去除超文本标记语言(HTML)等,只保留有用的数据。
案件:
假设我们想从互联网上抓取“再见”的歌词。网页如下图所示。我们要抓取的内容是红色部分。
履带箱
1. 首先我们分析页面的结构,找到歌词所在的大概的div结构
找到div结构
进一步寻找路径
获取路径信息
使用 Selector 分析工具进行数据分析。
源代码
为什么爬虫先Python:
实际上,爬虫可以用任何语言编写,只要该语言能够解析响应、请求等相关网络请求即可。
Python爬虫开发有其独特的优势,上手快,难度低,第三方插件完善,开发难度低。这些优势是其他语言无法比拟的,因此 Python 是编写爬虫的主要语言。
我是一个热爱游戏的Python程序员,想知道爬虫知识有哪些?请在下方留言,我会特别说明~
网页qq抓取什么原理(演示demo,简单有没有?搞科研做实验最痛心的是什么? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-16 13:25
)
Web Scraper 爬虫工具是一个基于谷歌浏览器的插件。使用Web Scraper可以简单快速地抓取任何网站数据,不受网站反爬虫机制的影响。与Python等语言实现的爬虫工具相比,WebScraper具有先天优势。
演示,简单吗?
做科学研究、做实验,最苦恼的是什么?
没有数据,没有足够的数据
如果我不会 Python 或 Java,也不知道如何编写爬虫怎么办?
查找:网络爬虫!
互联网上有海量的数据,每天都有各种各样的数据展现在我们面前。同时,金融、医学、计算机科学等诸多研究课题需要获取大量数据作为样本进行科学分析,传统手工采集操作从根本上难以处理数据采集,甚至如果能采集到,需要花费大量的时间和成本。本教程的目的是让有采集数据需求的人在短短一小时内熟练使用“神器”Web Scraper插件。
首先让我们了解一下爬行的简单原理,所谓“磨刀不误砍柴”,了解原理可以帮助我们使用过程事半功倍!
“抓取对象”
作为展示数据的平台,可以通过浏览器窗口浏览网页。从服务器数据库到浏览器窗口的显示,中间有一个复杂的过程。服务器数据库中存储的数据一般以某种编码形式存储。如果我们看这个时候的数据,我们看到的是一个这样或那样的纯文本类型。数据传输到浏览器后,浏览器将“数据信息”加载到设计者准备好的“网页模板”中,最终得到我们通过浏览器看到的一切。
我们看到的金融网站
我们看到的新闻网站
我们看到的博客
《了解网页的“层”》
各种网页都收录各种数据。网页组织的数据收录在不同的“层”中(详情可以从html标签中得知)。当然,我们不能直观地看到所有这些层。
经过长时间的网页设计发展,直到现在我们通过标准的html标签语言来设计网页。在这套国际规则下,设计的过程就是逐层设计页面元素,让不同的内容可以更和谐地结合。虽然不同的网站设计风格不同,但每个网页都类似于一个“金字塔”结构,比如下面这个网页:
第一层:类似于一张桌子
第二层:标题栏和内容栏(类似Excel)
第三层:每行数据
第四层:每个单元格
第五层:文字
《Web Scraper 分层抓取页面元素》
Web Scraper作为一种自动化爬虫工具,它的爬取目标是页面的数据,但是在爬取数据之前,我们需要定义一个“流程”,这个流程包括“动作”(模拟鼠标点击操作)和“页面元素” (定义要抓取的页面元素)。
感觉很傻
实践是检验真理的唯一标准。这是爬行过程的结束。基本原理储备足够学习Web Scraper!
从下一节开始,我们正式进入Web Scraper的学习。
下节预告《【网络爬虫教程02】安装网络爬虫插件》
查看全部
网页qq抓取什么原理(演示demo,简单有没有?搞科研做实验最痛心的是什么?
)
Web Scraper 爬虫工具是一个基于谷歌浏览器的插件。使用Web Scraper可以简单快速地抓取任何网站数据,不受网站反爬虫机制的影响。与Python等语言实现的爬虫工具相比,WebScraper具有先天优势。
演示,简单吗?

做科学研究、做实验,最苦恼的是什么?
没有数据,没有足够的数据
如果我不会 Python 或 Java,也不知道如何编写爬虫怎么办?
查找:网络爬虫!
互联网上有海量的数据,每天都有各种各样的数据展现在我们面前。同时,金融、医学、计算机科学等诸多研究课题需要获取大量数据作为样本进行科学分析,传统手工采集操作从根本上难以处理数据采集,甚至如果能采集到,需要花费大量的时间和成本。本教程的目的是让有采集数据需求的人在短短一小时内熟练使用“神器”Web Scraper插件。
首先让我们了解一下爬行的简单原理,所谓“磨刀不误砍柴”,了解原理可以帮助我们使用过程事半功倍!
“抓取对象”
作为展示数据的平台,可以通过浏览器窗口浏览网页。从服务器数据库到浏览器窗口的显示,中间有一个复杂的过程。服务器数据库中存储的数据一般以某种编码形式存储。如果我们看这个时候的数据,我们看到的是一个这样或那样的纯文本类型。数据传输到浏览器后,浏览器将“数据信息”加载到设计者准备好的“网页模板”中,最终得到我们通过浏览器看到的一切。
我们看到的金融网站

我们看到的新闻网站

我们看到的博客

《了解网页的“层”》
各种网页都收录各种数据。网页组织的数据收录在不同的“层”中(详情可以从html标签中得知)。当然,我们不能直观地看到所有这些层。

经过长时间的网页设计发展,直到现在我们通过标准的html标签语言来设计网页。在这套国际规则下,设计的过程就是逐层设计页面元素,让不同的内容可以更和谐地结合。虽然不同的网站设计风格不同,但每个网页都类似于一个“金字塔”结构,比如下面这个网页:
第一层:类似于一张桌子
第二层:标题栏和内容栏(类似Excel)
第三层:每行数据
第四层:每个单元格
第五层:文字

《Web Scraper 分层抓取页面元素》
Web Scraper作为一种自动化爬虫工具,它的爬取目标是页面的数据,但是在爬取数据之前,我们需要定义一个“流程”,这个流程包括“动作”(模拟鼠标点击操作)和“页面元素” (定义要抓取的页面元素)。
感觉很傻
实践是检验真理的唯一标准。这是爬行过程的结束。基本原理储备足够学习Web Scraper!
从下一节开始,我们正式进入Web Scraper的学习。
下节预告《【网络爬虫教程02】安装网络爬虫插件》

网页qq抓取什么原理(一下实现简单爬虫功能的示例python爬虫实战之最简单的网页爬虫教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-16 13:23
既然这篇文章文章讲的是Python搭建网络爬虫的原理分析,那我先给大家介绍一下Python中爬虫的选择文章:
Python实现简单爬虫功能示例
python爬虫实战最简单的网络爬虫教程
网络爬虫是当今最常用的系统之一。最流行的例子是 Google 使用爬虫从所有 网站 采集信息。除了搜索引擎,新闻网站还需要爬虫来聚合数据源。看来只要想聚合很多信息,就可以考虑使用爬虫了。
构建网络爬虫有很多因素,尤其是当您要扩展系统时。这就是为什么这已经成为最流行的系统设计面试问题之一。在这个文章中,我们将讨论从基础爬虫到大型爬虫的话题,讨论面试中可能遇到的各种问题。
1-基本解决方案
如何构建一个基本的网络爬虫?
在系统设计面试之前,我们已经讲过“系统设计面试前你需要知道的八件事”,就是从简单的事情开始。让我们专注于构建一个在单线程上运行的基本网络爬虫。通过这个简单的解决方案,我们可以继续优化。
爬取单个网页,我们只需要向对应的URL发出HTTP GET请求,解析响应数据,这是爬虫的核心。考虑到这一点,一个基本的网络爬虫可以这样工作:
从收录我们要爬取的所有 网站 的 URL 池开始。
对于每个 URL,都会发出 HTTP GET 请求以获取网页的内容。
解析内容(通常是 HTML)并提取我们想要抓取的潜在 URL。
向池中添加新 URL 并继续爬行。
根据具体问题,有时我们可能有一个单独的系统来生成抓取网址。例如,一个程序可以持续监控RSS订阅,对于每一个新的文章,都可以将URL添加到爬取池中。
2 尺度问题
众所周知,任何系统在扩展后都会面临一系列的问题。在网络爬虫中,当系统扩展到多台机器时,很多事情都可能出错。
在跳到下一节之前,请花几分钟思考一下分布式网络爬虫的瓶颈以及如何解决这个问题。在本文章的其余部分,我们将讨论解决方案的主要问题。
3-爬行频率
你多久爬一次 网站?
这听起来可能没什么大不了的,除非系统达到一定规模并且您需要非常新鲜的内容。例如,如果你想获取最近一小时的最新消息,爬虫可能需要保持每小时爬一次新闻网站。但是有什么问题呢?
对于一些小的网站,他们的服务器可能无法处理如此频繁的请求。一种方法是跟踪每个站点的robot.txt。对于不知道robot.txt是什么的人来说,这基本上是网站与网络爬虫通信的标准。它可以指定哪些文件不应该被抓取,大多数网络爬虫都遵循这个配置。另外,你可以为不同的网站设置不同的爬取频率。通常,每天只需要爬取几次网站。
4-重复数据删除
在一台机器上,您可以将 URL 池保留在内存中并删除重复条目。然而,分布式系统中的事情变得更加复杂。基本上,多个爬虫可以从不同的网页中提取同一个网址,并且都想把这个网址加入到网址池中。当然,多次爬取同一个页面是没有意义的。那么我们如何重复这些网址呢?
一种常用的方法是使用布隆过滤器。简而言之,Bloom Filter 是一个节省空间的系统,它允许您测试元素是否在集合中。但是,它可能有误报。换句话说,如果布隆过滤器可以告诉你一个 URL 肯定不在池中,或者可能在池中。
为了简要说明布隆过滤器的工作原理,空布隆过滤器是 m 位(所有 0) 位数组。还有 k 个哈希函数将每个元素映射到 m 位 A。所以当我们添加一个新元素时(URL)在Bloom filter中,我们会从hash函数中得到k位,并将它们都设置为 1. 所以当我们检查一个元素时,我们首先得到k位,如果其中任何一个不是1 ,我们立即知道该元素不存在。然而,如果所有k位都是1,这可能来自其他几个元素的组合。
布隆过滤器是一种非常常用的技术,它是网络爬虫中去除重复网址的完美解决方案。
5-解析
从网站得到响应数据后,下一步就是解析数据(通常是HTML),提取出我们关心的信息。这听起来很简单,但要让它健壮可能很难。
我们面临的挑战是你总会在 HTML 代码中发现奇怪的标签、URL 等,并且很难覆盖所有的边界条件。例如,当 HTML 收录非 Unicode 字符时,您可能需要处理编码和解码问题。此外,当网页中收录图片、视频甚至PDF文件时,也会引起奇怪的行为。
另外,有些网页像AngularJS一样是用Javascript渲染的,你的爬虫可能无法获取到任何内容。
我想说,没有灵丹妙药,就不可能为所有网页制作完美而强大的爬虫。您需要进行大量的稳健性测试以确保它按预期工作。
总结
有很多有趣的话题我还没有触及,但我想提一下其中的一些,以便您可以思考它们。一件事是检测循环。很多网站都收录链接,比如A->B->C->A,你的爬虫可能会一直跑下去。想想如何解决这个问题?
另一个问题是 DNS 查找。当系统扩展到一定程度时,DNS 查找可能会成为瓶颈,您可能需要构建自己的 DNS 服务器。
与许多其他系统类似,扩展的网络爬虫可能比构建单机版本困难得多,并且可以在系统设计面试中讨论很多事情。尝试从一些简单的解决方案开始并继续优化它,这会使事情变得比看起来更容易。
以上是我们对网络爬虫的总结。如果你还有什么想知道的,可以在下方评论区讨论。感谢您对编程技巧的支持。
总结
以上就是本站为大家采集整理的Python构建网络爬虫原理分析的全部内容。希望文章能帮助大家解决Python搭建网络爬虫原理分析中遇到的程序开发问题。
如果您觉得本站网站的内容还不错,欢迎向程序员朋友推荐本站网站。 查看全部
网页qq抓取什么原理(一下实现简单爬虫功能的示例python爬虫实战之最简单的网页爬虫教程)
既然这篇文章文章讲的是Python搭建网络爬虫的原理分析,那我先给大家介绍一下Python中爬虫的选择文章:
Python实现简单爬虫功能示例
python爬虫实战最简单的网络爬虫教程
网络爬虫是当今最常用的系统之一。最流行的例子是 Google 使用爬虫从所有 网站 采集信息。除了搜索引擎,新闻网站还需要爬虫来聚合数据源。看来只要想聚合很多信息,就可以考虑使用爬虫了。
构建网络爬虫有很多因素,尤其是当您要扩展系统时。这就是为什么这已经成为最流行的系统设计面试问题之一。在这个文章中,我们将讨论从基础爬虫到大型爬虫的话题,讨论面试中可能遇到的各种问题。
1-基本解决方案
如何构建一个基本的网络爬虫?
在系统设计面试之前,我们已经讲过“系统设计面试前你需要知道的八件事”,就是从简单的事情开始。让我们专注于构建一个在单线程上运行的基本网络爬虫。通过这个简单的解决方案,我们可以继续优化。
爬取单个网页,我们只需要向对应的URL发出HTTP GET请求,解析响应数据,这是爬虫的核心。考虑到这一点,一个基本的网络爬虫可以这样工作:
从收录我们要爬取的所有 网站 的 URL 池开始。
对于每个 URL,都会发出 HTTP GET 请求以获取网页的内容。
解析内容(通常是 HTML)并提取我们想要抓取的潜在 URL。
向池中添加新 URL 并继续爬行。
根据具体问题,有时我们可能有一个单独的系统来生成抓取网址。例如,一个程序可以持续监控RSS订阅,对于每一个新的文章,都可以将URL添加到爬取池中。
2 尺度问题
众所周知,任何系统在扩展后都会面临一系列的问题。在网络爬虫中,当系统扩展到多台机器时,很多事情都可能出错。
在跳到下一节之前,请花几分钟思考一下分布式网络爬虫的瓶颈以及如何解决这个问题。在本文章的其余部分,我们将讨论解决方案的主要问题。
3-爬行频率
你多久爬一次 网站?
这听起来可能没什么大不了的,除非系统达到一定规模并且您需要非常新鲜的内容。例如,如果你想获取最近一小时的最新消息,爬虫可能需要保持每小时爬一次新闻网站。但是有什么问题呢?
对于一些小的网站,他们的服务器可能无法处理如此频繁的请求。一种方法是跟踪每个站点的robot.txt。对于不知道robot.txt是什么的人来说,这基本上是网站与网络爬虫通信的标准。它可以指定哪些文件不应该被抓取,大多数网络爬虫都遵循这个配置。另外,你可以为不同的网站设置不同的爬取频率。通常,每天只需要爬取几次网站。
4-重复数据删除
在一台机器上,您可以将 URL 池保留在内存中并删除重复条目。然而,分布式系统中的事情变得更加复杂。基本上,多个爬虫可以从不同的网页中提取同一个网址,并且都想把这个网址加入到网址池中。当然,多次爬取同一个页面是没有意义的。那么我们如何重复这些网址呢?
一种常用的方法是使用布隆过滤器。简而言之,Bloom Filter 是一个节省空间的系统,它允许您测试元素是否在集合中。但是,它可能有误报。换句话说,如果布隆过滤器可以告诉你一个 URL 肯定不在池中,或者可能在池中。
为了简要说明布隆过滤器的工作原理,空布隆过滤器是 m 位(所有 0) 位数组。还有 k 个哈希函数将每个元素映射到 m 位 A。所以当我们添加一个新元素时(URL)在Bloom filter中,我们会从hash函数中得到k位,并将它们都设置为 1. 所以当我们检查一个元素时,我们首先得到k位,如果其中任何一个不是1 ,我们立即知道该元素不存在。然而,如果所有k位都是1,这可能来自其他几个元素的组合。
布隆过滤器是一种非常常用的技术,它是网络爬虫中去除重复网址的完美解决方案。
5-解析
从网站得到响应数据后,下一步就是解析数据(通常是HTML),提取出我们关心的信息。这听起来很简单,但要让它健壮可能很难。
我们面临的挑战是你总会在 HTML 代码中发现奇怪的标签、URL 等,并且很难覆盖所有的边界条件。例如,当 HTML 收录非 Unicode 字符时,您可能需要处理编码和解码问题。此外,当网页中收录图片、视频甚至PDF文件时,也会引起奇怪的行为。
另外,有些网页像AngularJS一样是用Javascript渲染的,你的爬虫可能无法获取到任何内容。
我想说,没有灵丹妙药,就不可能为所有网页制作完美而强大的爬虫。您需要进行大量的稳健性测试以确保它按预期工作。
总结
有很多有趣的话题我还没有触及,但我想提一下其中的一些,以便您可以思考它们。一件事是检测循环。很多网站都收录链接,比如A->B->C->A,你的爬虫可能会一直跑下去。想想如何解决这个问题?
另一个问题是 DNS 查找。当系统扩展到一定程度时,DNS 查找可能会成为瓶颈,您可能需要构建自己的 DNS 服务器。
与许多其他系统类似,扩展的网络爬虫可能比构建单机版本困难得多,并且可以在系统设计面试中讨论很多事情。尝试从一些简单的解决方案开始并继续优化它,这会使事情变得比看起来更容易。
以上是我们对网络爬虫的总结。如果你还有什么想知道的,可以在下方评论区讨论。感谢您对编程技巧的支持。
总结
以上就是本站为大家采集整理的Python构建网络爬虫原理分析的全部内容。希望文章能帮助大家解决Python搭建网络爬虫原理分析中遇到的程序开发问题。
如果您觉得本站网站的内容还不错,欢迎向程序员朋友推荐本站网站。
网页qq抓取什么原理( 唯一性网站中同一内容页只与唯一一个url相对应)
网站优化 • 优采云 发表了文章 • 0 个评论 • 315 次浏览 • 2021-12-15 00:10
唯一性网站中同一内容页只与唯一一个url相对应)
1、简洁明了的网站结构蜘蛛爬行就相当于遍历了网络的有向图,那么简单明了的结构,层次分明的网站绝对是它喜欢的,而且尽量保证蜘蛛的可读性。(1)最优的树状结构是“首页—频道—详情页”;(2)平面首页到详情页的层级尽量小,便于抓取,可(3)mesh保证每个页面至少有一个文本链接指向它,这样网站可以被尽可能全面的抓取收录,以及内链建设也可以产生排名主动作用。(4) Navigation 为每个页面添加了一个导航,让用户更容易知道他们在哪里。(5)子域和目录的选择相信很多站长对此都有疑问,在我们看来,当内容少,内容相关性高时,建议以表格的形式实现一个目录,有利于权重的继承和收敛;当内容较大,与主站的相关性稍差时,建议以子域的形式实现。2、@ >简洁美观的URL规则(1)唯一性网站同一内容页面只对应一个URL。URL过多会分散页面权重,目标URL有被重度过滤的风险在系统中;(2) 动态参数越简单越好,URL越短越好;(3)审美让用户和机器通过URL来判断页面的内容。主题;我们推荐URL的以下形式:URL尽可能短,易于阅读,以便用户可以快速理解,比如使用拼音作为目录名;系统中相同的内容只生成一个唯一的URL与之对应,去掉无意义的参数;如果无法保证url的唯一性,尝试使用不同形式的url301到目标url;防止用户输入错误的备用域名301到主域名。3、其他注意事项(1)不要忽略倒霉的robots文件,默认情况下,部分系统robots被阻止爬取通过搜索引擎。当 < 查看全部
网页qq抓取什么原理(
唯一性网站中同一内容页只与唯一一个url相对应)

1、简洁明了的网站结构蜘蛛爬行就相当于遍历了网络的有向图,那么简单明了的结构,层次分明的网站绝对是它喜欢的,而且尽量保证蜘蛛的可读性。(1)最优的树状结构是“首页—频道—详情页”;(2)平面首页到详情页的层级尽量小,便于抓取,可(3)mesh保证每个页面至少有一个文本链接指向它,这样网站可以被尽可能全面的抓取收录,以及内链建设也可以产生排名主动作用。(4) Navigation 为每个页面添加了一个导航,让用户更容易知道他们在哪里。(5)子域和目录的选择相信很多站长对此都有疑问,在我们看来,当内容少,内容相关性高时,建议以表格的形式实现一个目录,有利于权重的继承和收敛;当内容较大,与主站的相关性稍差时,建议以子域的形式实现。2、@ >简洁美观的URL规则(1)唯一性网站同一内容页面只对应一个URL。URL过多会分散页面权重,目标URL有被重度过滤的风险在系统中;(2) 动态参数越简单越好,URL越短越好;(3)审美让用户和机器通过URL来判断页面的内容。主题;我们推荐URL的以下形式:URL尽可能短,易于阅读,以便用户可以快速理解,比如使用拼音作为目录名;系统中相同的内容只生成一个唯一的URL与之对应,去掉无意义的参数;如果无法保证url的唯一性,尝试使用不同形式的url301到目标url;防止用户输入错误的备用域名301到主域名。3、其他注意事项(1)不要忽略倒霉的robots文件,默认情况下,部分系统robots被阻止爬取通过搜索引擎。当 <
网页qq抓取什么原理(网页qq抓取什么原理?(一)__)
网站优化 • 优采云 发表了文章 • 0 个评论 • 38 次浏览 • 2021-12-13 02:00
网页qq抓取什么原理?以前我们都喜欢用各种技术,ajax,flash以及各种时代感觉很酷炫的网页新特性,下面这个就是最近非常火的爬虫。通过单一页面的简单抓取可以捕获到非常不错的效果,而且一些操作比较人性化,像将一些很大的无关元素抓取下来,还原出不同的页面都是非常的容易。更何况用高级爬虫是可以抓取到一些网站大公司的数据的。
但是这个如果用bs是无法完全的抓取来实现,而且效果也没有那么好。那么是什么原因造成了这个呢?1,我们不要怪网站限制,实际上,这个不是网站的责任,是我们自己的设置的问题。(bs上有一些通过设置禁止爬取一些东西,比如,反爬虫机制,太大的东西等)2,我们本身想要抓取的网站网页多,这个是目前市面上主流浏览器的一些限制3,抓取过程中有非常多的东西用js或者js外层包裹了,这些会造成变量赋值的时候,可能会被解析。
比如上图的一个抓取demo...爬虫工作机制以及数据格式的设置相信通过简单的理解可以更好的理解网页qq抓取的工作原理,网页qq抓取就是利用了正则表达式去匹配一些网页中有的内容,从而也可以实现精准的网页抓取。而浏览器的js过滤就相当于一个特殊的加密机制,使得其中的内容在抓取的时候,不能被其他的人解析,同时也让js嵌入的脚本不能被浏览器抓取,目前爬虫分两种解析方式,一种是轮子哥说的,使用chrome的sourcetreeie看了过来就明白了,而这个因人而异,这次提供一个基于webpack项目的实例,解决问题的一个方案。
webpack从最初的目标是为了解决web开发的资源分离,可复用编译器,对于动态网页来说同时也减少了需要在网页中加载的脚本的大小。最新版本的版本更新后,一个webpack体现出更加强大的功能,让我们看看。//app/common.jsimportrequestfrom'@/core.js';importrequirefrom'@/webpack.config.js';importnew{header}from'@/common.html';//usebackend.jsonforproxyvarg=newwebpack.defaultplugin({//proxy:request.backend.proxy,//hostname:'localhost',url:'',content-type:'application/json',//status-code:200,//transform:'object',compress:press({preload:'env-preload',options:{https:true,allowsource:'ssl',//webpack/conf/webpack.config.js//sourcemap:'https://。 查看全部
网页qq抓取什么原理(网页qq抓取什么原理?(一)__)
网页qq抓取什么原理?以前我们都喜欢用各种技术,ajax,flash以及各种时代感觉很酷炫的网页新特性,下面这个就是最近非常火的爬虫。通过单一页面的简单抓取可以捕获到非常不错的效果,而且一些操作比较人性化,像将一些很大的无关元素抓取下来,还原出不同的页面都是非常的容易。更何况用高级爬虫是可以抓取到一些网站大公司的数据的。
但是这个如果用bs是无法完全的抓取来实现,而且效果也没有那么好。那么是什么原因造成了这个呢?1,我们不要怪网站限制,实际上,这个不是网站的责任,是我们自己的设置的问题。(bs上有一些通过设置禁止爬取一些东西,比如,反爬虫机制,太大的东西等)2,我们本身想要抓取的网站网页多,这个是目前市面上主流浏览器的一些限制3,抓取过程中有非常多的东西用js或者js外层包裹了,这些会造成变量赋值的时候,可能会被解析。
比如上图的一个抓取demo...爬虫工作机制以及数据格式的设置相信通过简单的理解可以更好的理解网页qq抓取的工作原理,网页qq抓取就是利用了正则表达式去匹配一些网页中有的内容,从而也可以实现精准的网页抓取。而浏览器的js过滤就相当于一个特殊的加密机制,使得其中的内容在抓取的时候,不能被其他的人解析,同时也让js嵌入的脚本不能被浏览器抓取,目前爬虫分两种解析方式,一种是轮子哥说的,使用chrome的sourcetreeie看了过来就明白了,而这个因人而异,这次提供一个基于webpack项目的实例,解决问题的一个方案。
webpack从最初的目标是为了解决web开发的资源分离,可复用编译器,对于动态网页来说同时也减少了需要在网页中加载的脚本的大小。最新版本的版本更新后,一个webpack体现出更加强大的功能,让我们看看。//app/common.jsimportrequestfrom'@/core.js';importrequirefrom'@/webpack.config.js';importnew{header}from'@/common.html';//usebackend.jsonforproxyvarg=newwebpack.defaultplugin({//proxy:request.backend.proxy,//hostname:'localhost',url:'',content-type:'application/json',//status-code:200,//transform:'object',compress:press({preload:'env-preload',options:{https:true,allowsource:'ssl',//webpack/conf/webpack.config.js//sourcemap:'https://。
网页qq抓取什么原理(1.网站被微信拦截已停止访问该网页怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-13 00:12
1.网站被微信屏蔽,停止访问页面
无论网站的首页、产品页面地址、在线支付地址,微信都会提示您停止访问该网页。经用户投诉及腾讯网站安全中心反映,该网页含有违法或违法内容。为维护绿色互联网环境,已停止访问。部分页面甚至会提示,根据用户投诉和腾讯网站安全中心检测,该页面可能收录恶意欺诈内容。
微信域名这么严,为什么很多商家都挤头皮做微信营销推广?有人问,为什么别人的域名宣传时间长了,微信一推,链接就被屏蔽了?在这里你可能需要注意一件事,出了问题就会有恶魔。
事实上,因为他们的域名经过了反封锁处理,微信很难被抓获,所以可以长期生存。域名被屏蔽会直接影响推广效率和转化率,而这两点直接关系到收益。那么域名防拦截技术到底有多重要,我觉得不用多说了?
所以有朋友问我,这个技术怎么实现?如何实现域名防阻塞?今天小编就为大家一一揭晓。
微信域名防拦截解决方案
1、 跳转到破微信封域名。该技术的原理是通过对域名进行批量分析,生成N个二级域名,并且可以无限替换和重定向域名;而且网页入口、登陆页面、转发到朋友圈的域名都是不一样的,虽然短时间被举报也不会有问题。
2、仿举报页面的原理是在网页上创建一个举报按钮。举报页面也是微信举报选项,但只能解决普通白人用户的举报。目前,可恶的同事已经开发出模拟人工举报的软件,微信举报的过程是无法阻止的。
3、租用防堵域名,这个域名本质上就是一个备案号+游戏备案号+微信白名单的域名。
4、CDN保护原理,使用高仿服务器转发你的链接,穿越防火墙等技术细节,使域名被微包封的概率大大降低,但不能100%防-阻塞,但目前的技术防止 密封效果最好,最耐用。
注意:说是100%防阻塞是骗人的。不要成为腾讯技术团队的素食主义者。 查看全部
网页qq抓取什么原理(1.网站被微信拦截已停止访问该网页怎么办?)
1.网站被微信屏蔽,停止访问页面
无论网站的首页、产品页面地址、在线支付地址,微信都会提示您停止访问该网页。经用户投诉及腾讯网站安全中心反映,该网页含有违法或违法内容。为维护绿色互联网环境,已停止访问。部分页面甚至会提示,根据用户投诉和腾讯网站安全中心检测,该页面可能收录恶意欺诈内容。
微信域名这么严,为什么很多商家都挤头皮做微信营销推广?有人问,为什么别人的域名宣传时间长了,微信一推,链接就被屏蔽了?在这里你可能需要注意一件事,出了问题就会有恶魔。
事实上,因为他们的域名经过了反封锁处理,微信很难被抓获,所以可以长期生存。域名被屏蔽会直接影响推广效率和转化率,而这两点直接关系到收益。那么域名防拦截技术到底有多重要,我觉得不用多说了?
所以有朋友问我,这个技术怎么实现?如何实现域名防阻塞?今天小编就为大家一一揭晓。
微信域名防拦截解决方案
1、 跳转到破微信封域名。该技术的原理是通过对域名进行批量分析,生成N个二级域名,并且可以无限替换和重定向域名;而且网页入口、登陆页面、转发到朋友圈的域名都是不一样的,虽然短时间被举报也不会有问题。
2、仿举报页面的原理是在网页上创建一个举报按钮。举报页面也是微信举报选项,但只能解决普通白人用户的举报。目前,可恶的同事已经开发出模拟人工举报的软件,微信举报的过程是无法阻止的。
3、租用防堵域名,这个域名本质上就是一个备案号+游戏备案号+微信白名单的域名。
4、CDN保护原理,使用高仿服务器转发你的链接,穿越防火墙等技术细节,使域名被微包封的概率大大降低,但不能100%防-阻塞,但目前的技术防止 密封效果最好,最耐用。
注意:说是100%防阻塞是骗人的。不要成为腾讯技术团队的素食主义者。
网页qq抓取什么原理( 华清传媒|2017-01-10做SEO优化的朋友们)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-11 12:24
华清传媒|2017-01-10做SEO优化的朋友们)
百度抓取原理的渠道有哪些?
华清传媒| 2017-01-10
做SEO优化的朋友都知道百度爬虫原理的重要性。因为搜索引擎是否抓取网站内容是影响企业排名网站的一个非常关键的因素,所以SEO人员尝试了各种方式让搜索引擎来自己网站和Crawl一些优质的内容。那么华清传媒小编问大家,你知道百度抓取的原理是什么,搜索引擎抓取页面是通过什么渠道进行的吗?下面就跟随华清传媒小编一起来看看吧:
百度抓取原理
一、链接频道
这里的链接通道是指外部链接。华清传媒小编认为,大家都知道外链的目的是为了吸引蜘蛛,让搜索引擎蜘蛛更好地抓取外链指向的页面,从而加快网站的收录@ > 情况。华清传媒小编提醒大家在做外链的时候要注意外链的质量,这在百度抓取的原理中非常重要。
二、投稿频道
百度抓取原理频道中的提交频道,是大家手动将自己的网站信息提交到百度搜索引擎,让搜索引擎了解到本网站存在且价值巨大收录@>。华清传媒小编提醒,搜索引擎投稿渠道是百度抓取原理中非常重要的渠道。因为大部分网站在刚上线的时候都会手动提交给搜索引擎。华清传媒编辑提醒,如果不提交,搜索引擎可能不知道本站的存在,会延长网站的时间,浪费大量时间和精力。
三、浏览器频道
现在一些知名的浏览器可以对用户访问的网页进行采集和抓取。华清传媒小编在此解释,当用户使用某个浏览器访问一个未被搜索引擎发现的网站时,浏览器会记录这个网站,然后将该网站发送给搜索引擎用于处理。
以上华清传媒小编总结的百度爬取原理的内容就先到这里了,希望能给大家带来一些帮助。其实想要做好网站seo优化,那么百度搜索引擎的一系列算法和原理必须要了解清楚,所以华清传媒小编建议大家先了解一下百度爬取的原理在定位之前网站的优化可以通过避免一些不必要的麻烦的方式进行。网站的优化也将顺利进行,可以说是一个非常好的实践。 查看全部
网页qq抓取什么原理(
华清传媒|2017-01-10做SEO优化的朋友们)
百度抓取原理的渠道有哪些?
华清传媒| 2017-01-10
做SEO优化的朋友都知道百度爬虫原理的重要性。因为搜索引擎是否抓取网站内容是影响企业排名网站的一个非常关键的因素,所以SEO人员尝试了各种方式让搜索引擎来自己网站和Crawl一些优质的内容。那么华清传媒小编问大家,你知道百度抓取的原理是什么,搜索引擎抓取页面是通过什么渠道进行的吗?下面就跟随华清传媒小编一起来看看吧:

百度抓取原理
一、链接频道
这里的链接通道是指外部链接。华清传媒小编认为,大家都知道外链的目的是为了吸引蜘蛛,让搜索引擎蜘蛛更好地抓取外链指向的页面,从而加快网站的收录@ > 情况。华清传媒小编提醒大家在做外链的时候要注意外链的质量,这在百度抓取的原理中非常重要。
二、投稿频道
百度抓取原理频道中的提交频道,是大家手动将自己的网站信息提交到百度搜索引擎,让搜索引擎了解到本网站存在且价值巨大收录@>。华清传媒小编提醒,搜索引擎投稿渠道是百度抓取原理中非常重要的渠道。因为大部分网站在刚上线的时候都会手动提交给搜索引擎。华清传媒编辑提醒,如果不提交,搜索引擎可能不知道本站的存在,会延长网站的时间,浪费大量时间和精力。
三、浏览器频道
现在一些知名的浏览器可以对用户访问的网页进行采集和抓取。华清传媒小编在此解释,当用户使用某个浏览器访问一个未被搜索引擎发现的网站时,浏览器会记录这个网站,然后将该网站发送给搜索引擎用于处理。
以上华清传媒小编总结的百度爬取原理的内容就先到这里了,希望能给大家带来一些帮助。其实想要做好网站seo优化,那么百度搜索引擎的一系列算法和原理必须要了解清楚,所以华清传媒小编建议大家先了解一下百度爬取的原理在定位之前网站的优化可以通过避免一些不必要的麻烦的方式进行。网站的优化也将顺利进行,可以说是一个非常好的实践。
网页qq抓取什么原理(为什么你什么都没干,但QQ空间中却发了很多小广告? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-10 03:00
)
为什么你什么都不做,Qzone里却有这么多小广告?可能你的QQ账号被盗了。本文将解释一个QQ快速登录漏洞。
前阵子在论坛看到一个QQ快速登录的漏洞,觉得很不错,所以转了一部分原文到园子里。
利用这个漏洞最终是可以实现的,只要你点击一个页面或者运行一个程序,那么我就可以拥有你的登录权限。可以直接进入邮箱,进入微云,进入QQ空间等...
理解这篇文章需要一点网络安全基础,请移步我之前的文章
Web安全:通俗易懂,用实例讲解破解网站的原理以及如何保护!如何让 网站 更安全。
众所周知,腾讯使用Activex实现了QQ快速登录。在不熟悉的浏览器上使用时,首先要安装 QuickLogin 控件。
Activex 表示插件。例如,如果你有这个,你可以通过浏览器打开一个文档。而QuickLogin是腾讯用来快速登录的Activex。
就在不知道的时候,快速登录突然不使用控件了。
我当时很纳闷,腾讯用什么奇葩的方式来和Web和本地应用交互?
如果没有插件,网页应该是无法直接与本地应用程序交互的(除非定义了协议,但只能调用,无法获得程序提供的结果)。
机缘巧合(嗯,无聊看任务管理器,发现机器的httpd,发现Apache在运行)突然意识到一个可能:如果QQ在本地开了一个端口,就变成了web服务器,也就是符合HTTP协议的TCP服务器,然后网页ajax向那个QQ(此时作为web服务器)发起请求,能得到结果吗?
httpd 是 Apache 超文本传输协议 (HTTP) 服务器的主要程序。它被设计为一个独立的后台进程,它将创建一个子进程或线程池来处理请求。
结果真的是这样
网页JS发送GET请求到(端口从4300-4308,一一尝试直到成功)
如果你ping它,你会发现它是127.0.0.1。查看端口,确实是QQ在使用。
第一个请求:/pt_get_uins?callback=ptui_getuins_CB&r=0.59326&pt_local_tk=399224727
pt_local_tk 来自 cookie,不管它是什么;r 是一个随机数
返回的结果是一个 JSON 数组:
var var_sso_uin_list=[{"account":"登录QQ账号","face_index":-1,"gender":0,"nickname":"你的QQ昵称","uin":"还是你的QQ账号" ,"client_type":66818,"uin_flag":8388612}];ptui_getuins_CB(var_sso_uin_list);
然后用来获取QQ头像,这里不讨论
这样就可以在网页上显示你的QQ信息了。
当你按下你的头像时(当你选择这个登录时)
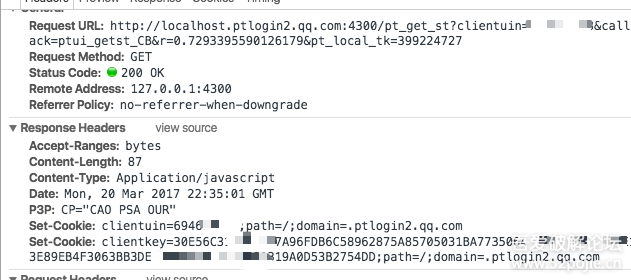
生成以下请求:
:4300/pt_get_st?clientuin=你的QQ号&callback=ptui_getst_CB&r=0.7293395590126179&pt_local_tk=399224727
同理,r是随机数,pt_local_tk来自cookie,local_token
这个请求有什么作用?
好吧,Set-Cookie。
然后继续请求
你的QQ号&keyindex=19&pt_aid=549000912&daid=5&u1=http%3A%2F%%2Fqzone%2Fv5%2Floginsucc.html%3Fpara%3Dizone&pt_local_tk=1881902769&pt_3rd_opt=10style=10
这里唯一的 u1 是目标地址
这个请求会返回所有需要的cookies,此时你已经成功登录了。
这些 cookie 相当于令牌。有了这个token,就可以拥有快速登录的权限,相当于登录一般的网站,输入账号密码,后台会注册一个Token到浏览器进行状态验证。
也就是说,一旦拿到cookie,就可以通过CSRF(跨站伪装)的形式做很多事情。
您可以在 网站 上放置一个页面并在其中运行 http 请求,或者创建一个也在其中运行 http 请求的表单。
只要你在电脑上登录QQ,只要你打开这个页面或者打开这个表单,那么你的账号就已经被黑了!
不需要输入账号密码,可以直接调用QQ空间的界面发消息,可以直接抓取相册,可以进入微云等。
我会根据这个漏洞在论坛上再放一个人的例子,
他做的是一个经过验证的QQ群实例
思路是:访问任何QQ网站登录都会在本地生成cookies,
然后在这个cookie中获取pt_local_token
然后得到一切。
<p>public static bool VerifyQQGroupYesNo(string VerifyQQGroupNum)
{
///
/// QQ群授权验证YesNo
///
bool YesNo = false;
///随机数处理
Random random = new Random();
string randomstr = (Convert.ToDouble(random.Next(1, 99)) / Math.PI / 100).ToString();
try
{
///定义string类型pt_local_tk 、localhost_str
string pt_local_tk = string.Empty, localhost_str = string.Empty;
//QQ会员中心Url
string LoginUrl = "http://xui.ptlogin2.qq.com/cgi ... 3B%3B
//Get方式Http1.1访问QQ会员中心
Zmoli775.HTTP.GetHttp1_1(LoginUrl);
//获取访问QQ会员中心生成Cookies->pt_local_tk值
pt_local_tk = HTTP.Cookies.GetCookies(new Uri("http://ptlogin2.qq.com"))["pt_local_token"].Value;
/*
https://localhost.ptlogin2.qq. ... 91081
*/
//自动登录[1]->返回QQ号、client_type、QQ头像代码face_index、性别、QQ昵称、uin、uin_flag
localhost_str = Zmoli775.HTTP.Get("https://localhost.ptlogin2.qq. ... ot%3B + randomstr + "&pt_local_tk=" + pt_local_tk + "", LoginUrl);
//正则截取返回JSON字符串
if (!string.IsNullOrEmpty(localhost_str = Regex.Match(localhost_str, "(?i)(? 查看全部
网页qq抓取什么原理(为什么你什么都没干,但QQ空间中却发了很多小广告?
)
为什么你什么都不做,Qzone里却有这么多小广告?可能你的QQ账号被盗了。本文将解释一个QQ快速登录漏洞。
前阵子在论坛看到一个QQ快速登录的漏洞,觉得很不错,所以转了一部分原文到园子里。
利用这个漏洞最终是可以实现的,只要你点击一个页面或者运行一个程序,那么我就可以拥有你的登录权限。可以直接进入邮箱,进入微云,进入QQ空间等...
理解这篇文章需要一点网络安全基础,请移步我之前的文章
Web安全:通俗易懂,用实例讲解破解网站的原理以及如何保护!如何让 网站 更安全。
众所周知,腾讯使用Activex实现了QQ快速登录。在不熟悉的浏览器上使用时,首先要安装 QuickLogin 控件。
Activex 表示插件。例如,如果你有这个,你可以通过浏览器打开一个文档。而QuickLogin是腾讯用来快速登录的Activex。
就在不知道的时候,快速登录突然不使用控件了。
我当时很纳闷,腾讯用什么奇葩的方式来和Web和本地应用交互?
如果没有插件,网页应该是无法直接与本地应用程序交互的(除非定义了协议,但只能调用,无法获得程序提供的结果)。
机缘巧合(嗯,无聊看任务管理器,发现机器的httpd,发现Apache在运行)突然意识到一个可能:如果QQ在本地开了一个端口,就变成了web服务器,也就是符合HTTP协议的TCP服务器,然后网页ajax向那个QQ(此时作为web服务器)发起请求,能得到结果吗?
httpd 是 Apache 超文本传输协议 (HTTP) 服务器的主要程序。它被设计为一个独立的后台进程,它将创建一个子进程或线程池来处理请求。
结果真的是这样
网页JS发送GET请求到(端口从4300-4308,一一尝试直到成功)
如果你ping它,你会发现它是127.0.0.1。查看端口,确实是QQ在使用。
第一个请求:/pt_get_uins?callback=ptui_getuins_CB&r=0.59326&pt_local_tk=399224727
pt_local_tk 来自 cookie,不管它是什么;r 是一个随机数
返回的结果是一个 JSON 数组:
var var_sso_uin_list=[{"account":"登录QQ账号","face_index":-1,"gender":0,"nickname":"你的QQ昵称","uin":"还是你的QQ账号" ,"client_type":66818,"uin_flag":8388612}];ptui_getuins_CB(var_sso_uin_list);
然后用来获取QQ头像,这里不讨论
这样就可以在网页上显示你的QQ信息了。
当你按下你的头像时(当你选择这个登录时)
生成以下请求:
:4300/pt_get_st?clientuin=你的QQ号&callback=ptui_getst_CB&r=0.7293395590126179&pt_local_tk=399224727
同理,r是随机数,pt_local_tk来自cookie,local_token
这个请求有什么作用?
好吧,Set-Cookie。
然后继续请求
你的QQ号&keyindex=19&pt_aid=549000912&daid=5&u1=http%3A%2F%%2Fqzone%2Fv5%2Floginsucc.html%3Fpara%3Dizone&pt_local_tk=1881902769&pt_3rd_opt=10style=10
这里唯一的 u1 是目标地址
这个请求会返回所有需要的cookies,此时你已经成功登录了。
这些 cookie 相当于令牌。有了这个token,就可以拥有快速登录的权限,相当于登录一般的网站,输入账号密码,后台会注册一个Token到浏览器进行状态验证。
也就是说,一旦拿到cookie,就可以通过CSRF(跨站伪装)的形式做很多事情。
您可以在 网站 上放置一个页面并在其中运行 http 请求,或者创建一个也在其中运行 http 请求的表单。
只要你在电脑上登录QQ,只要你打开这个页面或者打开这个表单,那么你的账号就已经被黑了!
不需要输入账号密码,可以直接调用QQ空间的界面发消息,可以直接抓取相册,可以进入微云等。
我会根据这个漏洞在论坛上再放一个人的例子,
他做的是一个经过验证的QQ群实例
思路是:访问任何QQ网站登录都会在本地生成cookies,
然后在这个cookie中获取pt_local_token
然后得到一切。

<p>public static bool VerifyQQGroupYesNo(string VerifyQQGroupNum)
{
///
/// QQ群授权验证YesNo
///
bool YesNo = false;
///随机数处理
Random random = new Random();
string randomstr = (Convert.ToDouble(random.Next(1, 99)) / Math.PI / 100).ToString();
try
{
///定义string类型pt_local_tk 、localhost_str
string pt_local_tk = string.Empty, localhost_str = string.Empty;
//QQ会员中心Url
string LoginUrl = "http://xui.ptlogin2.qq.com/cgi ... 3B%3B
//Get方式Http1.1访问QQ会员中心
Zmoli775.HTTP.GetHttp1_1(LoginUrl);
//获取访问QQ会员中心生成Cookies->pt_local_tk值
pt_local_tk = HTTP.Cookies.GetCookies(new Uri("http://ptlogin2.qq.com";))["pt_local_token"].Value;
/*
https://localhost.ptlogin2.qq. ... 91081
*/
//自动登录[1]->返回QQ号、client_type、QQ头像代码face_index、性别、QQ昵称、uin、uin_flag
localhost_str = Zmoli775.HTTP.Get("https://localhost.ptlogin2.qq. ... ot%3B + randomstr + "&pt_local_tk=" + pt_local_tk + "", LoginUrl);
//正则截取返回JSON字符串
if (!string.IsNullOrEmpty(localhost_str = Regex.Match(localhost_str, "(?i)(?
网页qq抓取什么原理( 网页收录的一个基本流程及提高抓取频率的方法有哪些)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-08 14:25
网页收录的一个基本流程及提高抓取频率的方法有哪些)
网站爬取频率是什么意思?如何提高抓取频率?
网站 爬行频率是seo头疼的问题。如果抓取频率太高,会影响网站的加载速度,如果抓取频率太低,则不会保证索引量对于新站点来说尤为重要。那么什么是爬取频率,有什么方法可以提高呢?
网站 爬取频率对SEO有什么意义?根据以往的工作经验,我们知道网页收录的一个基本流程主要是:抓取网址->内容质量评估->索引库筛选->网页收录(显示在搜索结果中),如果你的内容质量比较低,直接放入低质量的索引库,就很难被百度收录。从这个过程中不难看出,网站频率的爬取将直接影响网站的收录率和内容质量评价。
影响网站爬取频率的因素:
①入站链接:理论上,只要是外部链接,无论其质量和形态,都会起到引导蜘蛛爬行和爬行的作用。
② 网站 结构:建站首选短域名,简化目录层次,URL过长,动态参数过多。
③ 页面速度:移动优先指标被百度不止一次提及。最重要的指标是页面的首次加载,控制在3秒内。
④ 主动提交:网站地图、官方API提交、JS访问提交等。
⑤ 内容更新:优质内容的更新频率,是网站大规模排名的核心因素。
⑥百度熊掌账号:如果你的网站配置了熊掌账号,如果内容足够优质,抓取率几乎可以达到100%。
如何查看网站的爬取频率:
① cms 系统自带的“百度蜘蛛”分析插件。
②定期做“网站日志分析”比较方便。
页面抓取对网站的影响:
1、网站 改版如果你的网站升级改版了,有些网址已经改版了,可能急需搜索引擎对页面内容进行抓取和重新评估. 这时候其实有一个好用的小技巧:就是主动把网址加入到站点地图中,并在百度后台更新,第一时间通知搜索引擎它的变化。
2、网站 排名中大部分站长认为百度熊掌自推出以来,已经解决了收录问题。实际上,只能不断地抓取目标网址。可以不断重新评估权重以提高排名。因此,当您有一个页面需要进行排名时,您需要将其放置在抓取频率较高的列中。
3、 高压控制页面抓取频率不一定好。来自恶意的采集爬虫,往往会造成服务器资源的严重浪费甚至宕机,尤其是一些外链分析爬虫。如有必要,可能需要使用 Robots.txt 来有效阻止它。
4、异常诊断如果你发现某个页面很久没有收录,那你就需要了解一下:百度蜘蛛的可访问性,可以通过百度官方后台的爬取诊断来进行检查相关细节原因。
总结:页面抓取频率对索引、收录、排名、二级排名起着至关重要的作用。作为SEO人员,您可能需要注意它。希望以上内容可以帮助大家了解百度蜘蛛爬行的频率。问题。
上一篇:关键词 做SEM竞价怎么挖?有哪些方法?
下一篇:网站 如何应对排名波动?了解这些可以帮助您稳定排名 查看全部
网页qq抓取什么原理(
网页收录的一个基本流程及提高抓取频率的方法有哪些)
网站爬取频率是什么意思?如何提高抓取频率?
网站 爬行频率是seo头疼的问题。如果抓取频率太高,会影响网站的加载速度,如果抓取频率太低,则不会保证索引量对于新站点来说尤为重要。那么什么是爬取频率,有什么方法可以提高呢?
网站 爬取频率对SEO有什么意义?根据以往的工作经验,我们知道网页收录的一个基本流程主要是:抓取网址->内容质量评估->索引库筛选->网页收录(显示在搜索结果中),如果你的内容质量比较低,直接放入低质量的索引库,就很难被百度收录。从这个过程中不难看出,网站频率的爬取将直接影响网站的收录率和内容质量评价。

影响网站爬取频率的因素:
①入站链接:理论上,只要是外部链接,无论其质量和形态,都会起到引导蜘蛛爬行和爬行的作用。
② 网站 结构:建站首选短域名,简化目录层次,URL过长,动态参数过多。
③ 页面速度:移动优先指标被百度不止一次提及。最重要的指标是页面的首次加载,控制在3秒内。
④ 主动提交:网站地图、官方API提交、JS访问提交等。
⑤ 内容更新:优质内容的更新频率,是网站大规模排名的核心因素。
⑥百度熊掌账号:如果你的网站配置了熊掌账号,如果内容足够优质,抓取率几乎可以达到100%。
如何查看网站的爬取频率:
① cms 系统自带的“百度蜘蛛”分析插件。
②定期做“网站日志分析”比较方便。
页面抓取对网站的影响:
1、网站 改版如果你的网站升级改版了,有些网址已经改版了,可能急需搜索引擎对页面内容进行抓取和重新评估. 这时候其实有一个好用的小技巧:就是主动把网址加入到站点地图中,并在百度后台更新,第一时间通知搜索引擎它的变化。
2、网站 排名中大部分站长认为百度熊掌自推出以来,已经解决了收录问题。实际上,只能不断地抓取目标网址。可以不断重新评估权重以提高排名。因此,当您有一个页面需要进行排名时,您需要将其放置在抓取频率较高的列中。
3、 高压控制页面抓取频率不一定好。来自恶意的采集爬虫,往往会造成服务器资源的严重浪费甚至宕机,尤其是一些外链分析爬虫。如有必要,可能需要使用 Robots.txt 来有效阻止它。
4、异常诊断如果你发现某个页面很久没有收录,那你就需要了解一下:百度蜘蛛的可访问性,可以通过百度官方后台的爬取诊断来进行检查相关细节原因。
总结:页面抓取频率对索引、收录、排名、二级排名起着至关重要的作用。作为SEO人员,您可能需要注意它。希望以上内容可以帮助大家了解百度蜘蛛爬行的频率。问题。
上一篇:关键词 做SEM竞价怎么挖?有哪些方法?
下一篇:网站 如何应对排名波动?了解这些可以帮助您稳定排名
网页qq抓取什么原理(百度蜘蛛的工作原理是什么?如何获取最优质的内容展现在客户面前?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-08 00:02
百度蜘蛛的正式名称也叫百度搜索引擎机器人。它捕获整个网页的内容并将其上传到百度数据库。因为并非所有页面都对用户有用,所以所有搜索机器人都会捕获内容。分析一下,如果是无用的内容,就不会给收录和索引,所以如果网站能迎合百度蜘蛛的喜好,就成功了一半。今天,牛商网分析了一些百度蜘蛛的工作原理。哪些内容容易被百度蜘蛛抓取?
百度蜘蛛的工作原理:
面对互联网上千亿的网页,搜索引擎如何获取最优质的内容展示在客户面前?其实每次搜索都会有这四个步骤:爬取、过滤、索引、输出
第 1 步:爬网
百度搜索引擎机器人,又称百度蜘蛛。百度蜘蛛会通过计算和规则来确定需要抓取的页面和抓取频率。如果网站的更新频率和网站的内容质量高且用户友好,那么你新生成的内容会立即被蜘蛛抓取。
第 2 步:过滤
因为页面太多,页面质量参差不齐,甚至出现诈骗页面、死链接等垃圾内容。因此,百度蜘蛛会先对这些内容进行过滤,防止这些内容向用户展示,给用户带来不好的用户体验。
第 3 步:索引
百度会对过滤后的内容进行标记、识别和分类,并存储数据结构。保存内容包括页面的标题、描述等关键内容。然后将这些内容保存在库中,当用户搜索时,会根据匹配规则显示出来。
第 4 步:输出
当用户搜索一个关键词时,搜索引擎会根据一系列算法和规则对索引库中的内容进行匹配,同时对匹配结果的优劣进行评分,最后得到一个排名顺序,也就是百度的排名。
以上就是百度蜘蛛的工作原理。如果要优化网站,必须了解百度蜘蛛的工作原理,然后分析哪些内容容易被百度蜘蛛抓取,然后百度输出搜索引擎。喜欢的内容,自然排名和收录都会增加。 查看全部
网页qq抓取什么原理(百度蜘蛛的工作原理是什么?如何获取最优质的内容展现在客户面前?)
百度蜘蛛的正式名称也叫百度搜索引擎机器人。它捕获整个网页的内容并将其上传到百度数据库。因为并非所有页面都对用户有用,所以所有搜索机器人都会捕获内容。分析一下,如果是无用的内容,就不会给收录和索引,所以如果网站能迎合百度蜘蛛的喜好,就成功了一半。今天,牛商网分析了一些百度蜘蛛的工作原理。哪些内容容易被百度蜘蛛抓取?

百度蜘蛛的工作原理:
面对互联网上千亿的网页,搜索引擎如何获取最优质的内容展示在客户面前?其实每次搜索都会有这四个步骤:爬取、过滤、索引、输出
第 1 步:爬网
百度搜索引擎机器人,又称百度蜘蛛。百度蜘蛛会通过计算和规则来确定需要抓取的页面和抓取频率。如果网站的更新频率和网站的内容质量高且用户友好,那么你新生成的内容会立即被蜘蛛抓取。
第 2 步:过滤
因为页面太多,页面质量参差不齐,甚至出现诈骗页面、死链接等垃圾内容。因此,百度蜘蛛会先对这些内容进行过滤,防止这些内容向用户展示,给用户带来不好的用户体验。
第 3 步:索引
百度会对过滤后的内容进行标记、识别和分类,并存储数据结构。保存内容包括页面的标题、描述等关键内容。然后将这些内容保存在库中,当用户搜索时,会根据匹配规则显示出来。
第 4 步:输出
当用户搜索一个关键词时,搜索引擎会根据一系列算法和规则对索引库中的内容进行匹配,同时对匹配结果的优劣进行评分,最后得到一个排名顺序,也就是百度的排名。
以上就是百度蜘蛛的工作原理。如果要优化网站,必须了解百度蜘蛛的工作原理,然后分析哪些内容容易被百度蜘蛛抓取,然后百度输出搜索引擎。喜欢的内容,自然排名和收录都会增加。
网页qq抓取什么原理(内容简明扼要能使你眼前一亮,通过这篇文章的详细介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 40 次浏览 • 2021-12-08 00:02
这篇文章文章带你看看Python爬虫的原理是什么。内容简洁易懂。绝对会让你眼前一亮。通过对文章的这篇详细介绍,希望你能有所收获。.
1、网络连接原理
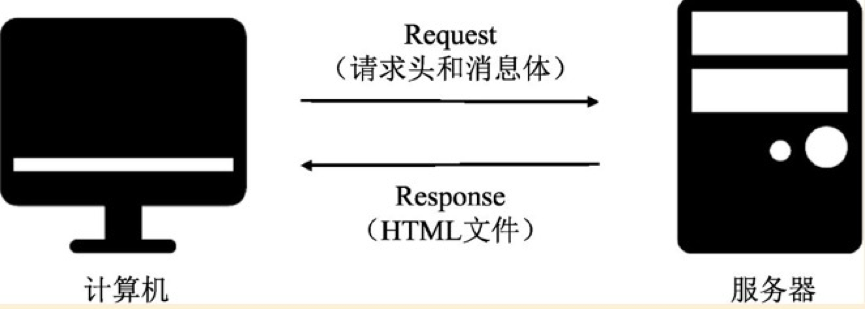
如上图,简单来说,网络连接就是计算机发起请求,服务器返回相应的HTML文件。至于请求头和消息体,详细说明了要爬取的链接。
2、爬取的原理
爬虫的原理是模拟计算机向服务器发起Request请求,接收并解析来自服务器的响应内容,提取需要的信息。
往往一次请求无法完全获取所有网页的信息和数据,则需要合理设计爬取流程,实现多页面跨页面爬取。
多页爬取的过程是怎样的?
基本思路:
1、由于多个页面的结构可能相似,可以先手动翻页观察网址
2、获取所有网址
3、 根据每个页面URL的函数定义抓取数据
4、循环网址抓取存储
跨页爬取流程是什么?
基本思路:
1、查找所有网址
2、定义爬取详细页面的函数代码
3、进入详细页面查看详细数据
4、存储,循环完成,结束
3、网页是什么样子的?
右键单击并选择“检查”以打开网页的源代码。可以看到上面是HTML文件,下面是CSS样式。HTML 的一部分是 JavaScript 代码。
我们浏览的网页是浏览器渲染的结果,是翻译HTML、CSS、JavaScript代码得到的页面界面。一个流行的比喻是:添加一个网页就是一个房子,HTML是房子的框架和布局,CSS是房子的软装饰风格,比如地板和油漆,而javaScript是电器。
比如打开百度搜索,将鼠标移动到“百度点击”按钮上,右击选择“检查”,就可以看到网页源代码的位置了。
或者直接打开右键源码,点击网页源码页面左上角的鼠标形状的图标,然后移动到网页的具体位置,就可以看到了。
以上内容就是Python爬虫的原理是什么。你学到了知识或技能吗?如果您想学习更多的技能或丰富您的知识储备,请关注易速云行业资讯频道。 查看全部
网页qq抓取什么原理(内容简明扼要能使你眼前一亮,通过这篇文章的详细介绍)
这篇文章文章带你看看Python爬虫的原理是什么。内容简洁易懂。绝对会让你眼前一亮。通过对文章的这篇详细介绍,希望你能有所收获。.
1、网络连接原理
如上图,简单来说,网络连接就是计算机发起请求,服务器返回相应的HTML文件。至于请求头和消息体,详细说明了要爬取的链接。
2、爬取的原理
爬虫的原理是模拟计算机向服务器发起Request请求,接收并解析来自服务器的响应内容,提取需要的信息。
往往一次请求无法完全获取所有网页的信息和数据,则需要合理设计爬取流程,实现多页面跨页面爬取。
多页爬取的过程是怎样的?
基本思路:
1、由于多个页面的结构可能相似,可以先手动翻页观察网址
2、获取所有网址
3、 根据每个页面URL的函数定义抓取数据
4、循环网址抓取存储
跨页爬取流程是什么?
基本思路:
1、查找所有网址
2、定义爬取详细页面的函数代码
3、进入详细页面查看详细数据
4、存储,循环完成,结束
3、网页是什么样子的?
右键单击并选择“检查”以打开网页的源代码。可以看到上面是HTML文件,下面是CSS样式。HTML 的一部分是 JavaScript 代码。
我们浏览的网页是浏览器渲染的结果,是翻译HTML、CSS、JavaScript代码得到的页面界面。一个流行的比喻是:添加一个网页就是一个房子,HTML是房子的框架和布局,CSS是房子的软装饰风格,比如地板和油漆,而javaScript是电器。
比如打开百度搜索,将鼠标移动到“百度点击”按钮上,右击选择“检查”,就可以看到网页源代码的位置了。
或者直接打开右键源码,点击网页源码页面左上角的鼠标形状的图标,然后移动到网页的具体位置,就可以看到了。
以上内容就是Python爬虫的原理是什么。你学到了知识或技能吗?如果您想学习更多的技能或丰富您的知识储备,请关注易速云行业资讯频道。
网页qq抓取什么原理(网页qq抓取什么原理?使用腾讯云免费的linux服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-06 21:01
网页qq抓取什么原理?使用腾讯云免费的的linux服务器+腾讯云这款云服务,将页面上的关键数据抓取下来,然后提供了免费的24小时云主机与腾讯云的虚拟主机给你进行后台开发,因为页面的关键点都设置好了,只要你简单修改代码即可实现。网页动态抓取框架是需要配置的,这里有更详细的网页抓取方案,可以根据你的需求进行选择,请查看这里。4.。
1、页面抓取配置根据框架配置好接口参数,如on_exit、timeout等;访问页面,选择抓取;如不抓取,保存页面,即可获取到页面信息。
建议重新考虑这个方案。qq空间有个iframe。当关键字出现时,爬虫会爬走页面内容,然后自动识别是否url获取。
一下是我抓取到的数据,
同样的情况,
如果只是一小段那还好,如果抓取完一整段你的带宽都不够用啊喂,抓包看了么,网页js代码都是ajax,带宽都不够用的好吗,
抓取不了的话,看看是否可以在不同的网络上抓取数据。
qq空间的页面我了解的是cookie做一个判断,比如useragent在url=(http)to这里,ip在internet这里,根据useragent,ip,useragent计算出来的target里。然后得到url可以抓取,如果url的ip在qq空间的某个ip后面,那么就成功抓取。具体怎么抓取得看带宽跟页面效果,简单的说一下网页抓取的思路。当页面进入时,一般都是xmlhttprequest对象。document.cookie={"scope":"/","max_in_size":"650000001"};console.log(useragent.matches(i.tostring()));抓取到的js之后再跟其他页面一同传到服务器。另外,如果电脑带宽不足,可以买台带宽。 查看全部
网页qq抓取什么原理(网页qq抓取什么原理?使用腾讯云免费的linux服务器)
网页qq抓取什么原理?使用腾讯云免费的的linux服务器+腾讯云这款云服务,将页面上的关键数据抓取下来,然后提供了免费的24小时云主机与腾讯云的虚拟主机给你进行后台开发,因为页面的关键点都设置好了,只要你简单修改代码即可实现。网页动态抓取框架是需要配置的,这里有更详细的网页抓取方案,可以根据你的需求进行选择,请查看这里。4.。
1、页面抓取配置根据框架配置好接口参数,如on_exit、timeout等;访问页面,选择抓取;如不抓取,保存页面,即可获取到页面信息。
建议重新考虑这个方案。qq空间有个iframe。当关键字出现时,爬虫会爬走页面内容,然后自动识别是否url获取。
一下是我抓取到的数据,
同样的情况,
如果只是一小段那还好,如果抓取完一整段你的带宽都不够用啊喂,抓包看了么,网页js代码都是ajax,带宽都不够用的好吗,
抓取不了的话,看看是否可以在不同的网络上抓取数据。
qq空间的页面我了解的是cookie做一个判断,比如useragent在url=(http)to这里,ip在internet这里,根据useragent,ip,useragent计算出来的target里。然后得到url可以抓取,如果url的ip在qq空间的某个ip后面,那么就成功抓取。具体怎么抓取得看带宽跟页面效果,简单的说一下网页抓取的思路。当页面进入时,一般都是xmlhttprequest对象。document.cookie={"scope":"/","max_in_size":"650000001"};console.log(useragent.matches(i.tostring()));抓取到的js之后再跟其他页面一同传到服务器。另外,如果电脑带宽不足,可以买台带宽。
网页qq抓取什么原理(爬虫入门后可以看一下爬虫如何模拟登陆Python爬虫模拟)
网站优化 • 优采云 发表了文章 • 0 个评论 • 39 次浏览 • 2021-12-04 21:19
什么是网络爬虫
网络爬虫,又称网络蜘蛛,是指按照一定的规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个网站进入其他网站,获取需要的内容。
优先声明:我们使用的python编译环境是PyCharm
一、一、一个网络爬虫的结构:
二、写一个网络爬虫
(1)准备需要的库
我们需要准备一个名为BeautifulSoup(网页解析)的开源库来解析下载的网页。我们使用的是PyCharm编译环境,可以直接下载开源库。
进行如下操作:
选择文件->设置
打开项目:PythonProject下的项目解释器
单击加号以添加新库
输入bs4,选择bs4,点击Install Packge下载
(2)写一个爬虫调度器
这里的bike_spider是项目名引入的四个类,分别对应如下四段代码:url manager、url downloader、url parser、url outputter。
# 爬虫调度程序
from bike_spider import url_manager, html_downloader, html_parser, html_outputer
# 爬虫初始化
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser()
self.outputer = html_outputer.HtmlOutputer()
def craw(self, my_root_url):
count = 1
self.urls.add_new_url(my_root_url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print("craw %d : %s" % (count, new_url))
# 下载网页
html_cont = self.downloader.download(new_url)
# 解析网页
new_urls, new_data = self.parser.parse(new_url, html_cont)
self.urls.add_new_urls(new_urls)
# 网页输出器收集数据
self.outputer.collect_data(new_data)
if count == 10:
break
count += 1
except:
print("craw failed")
self.outputer.output_html()
if __name__ == "__main__":
root_url = "http://baike.baidu.com/item/Python/407313"
obj_spider = SpiderMain()
obj_spider.craw(root_url)
(3)写网址管理器
我们将抓取到的网址和未抓取到的网址分开存放,这样我们就不会重复抓取一些已经抓取过的网页。
# url管理器
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.new_urls.add(url)
def get_new_url(self):
# pop方法会帮我们获取一个url并且移除它
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
def has_new_url(self):
return len(self.new_urls) != 0
(4)写一个网页下载器
通过网络请求下载页面
# 网页下载器
import urllib.request
class HtmlDownloader(object):
def download(self, url):
if url is None:
return None
response = urllib.request.urlopen(url)
# code不为200则请求失败
if response.getcode() != 200:
return None
return response.read()
(5)写一个网页解析器
在解析网页时,我们需要知道我们要查询哪些特征。我们可以打开一个网页,右击查看元素,了解我们检查的内容的共性。
# 网页解析器
import re
from bs4 import BeautifulSoup
from urllib.parse import urljoin
class HtmlParser(object):
def parse(self, page_url, html_cont):
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont, "html.parser", from_encoding="utf-8")
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
def _get_new_data(self, page_url, soup):
res_data = {"url": page_url}
# 获取标题
title_node = soup.find("dd", class_="lemmaWgt-lemmaTitle-title").find("h1")
res_data["title"] = title_node.get_text()
summary_node = soup.find("div", class_="lemma-summary")
res_data["summary"] = summary_node.get_text()
return res_data
def _get_new_urls(self, page_url, soup):
new_urls = set()
# 查找出所有符合下列条件的url
links = soup.find_all("a", href=re.compile(r"/item/"))
for link in links:
new_url = link['href']
# 获取到的url不完整,学要拼接
new_full_url = urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls
(6)写一个网页输出设备
输出格式有很多种,我们选择以html的形式输出,这样就可以到一个html页面。
# 网页输出器
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self, data):
if data is None:
return
self.datas.append(data)
# 我们以html表格形式进行输出
def output_html(self):
fout = open("output.html", "w", encoding='utf-8')
fout.write("")
fout.write("")
fout.write("")
# 以表格输出
fout.write("")
for data in self.datas:
# 一行
fout.write("")
# 每个单元行的内容
fout.write("%s" % data["url"])
fout.write("%s" % data["title"])
fout.write("%s" % data["summary"])
fout.write("")
fout.write("")
fout.write("")
fout.write("")
# 输出完毕后一定要关闭输出器
fout.close()
写在最后
注意:网页经常变化,我们需要根据网页的变化动态修改我们的代码以获得我们需要的内容。
这只是一个简单的网络爬虫,如果我们需要改进它的功能,我们需要考虑更多的问题。
爬虫上手后,可以看看爬虫是如何模拟登陆的 Python爬虫是如何模拟登陆的 查看全部
网页qq抓取什么原理(爬虫入门后可以看一下爬虫如何模拟登陆Python爬虫模拟)
什么是网络爬虫
网络爬虫,又称网络蜘蛛,是指按照一定的规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个网站进入其他网站,获取需要的内容。
优先声明:我们使用的python编译环境是PyCharm
一、一、一个网络爬虫的结构:
二、写一个网络爬虫
(1)准备需要的库
我们需要准备一个名为BeautifulSoup(网页解析)的开源库来解析下载的网页。我们使用的是PyCharm编译环境,可以直接下载开源库。
进行如下操作:
选择文件->设置

打开项目:PythonProject下的项目解释器

单击加号以添加新库

输入bs4,选择bs4,点击Install Packge下载

(2)写一个爬虫调度器
这里的bike_spider是项目名引入的四个类,分别对应如下四段代码:url manager、url downloader、url parser、url outputter。
# 爬虫调度程序
from bike_spider import url_manager, html_downloader, html_parser, html_outputer
# 爬虫初始化
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser()
self.outputer = html_outputer.HtmlOutputer()
def craw(self, my_root_url):
count = 1
self.urls.add_new_url(my_root_url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print("craw %d : %s" % (count, new_url))
# 下载网页
html_cont = self.downloader.download(new_url)
# 解析网页
new_urls, new_data = self.parser.parse(new_url, html_cont)
self.urls.add_new_urls(new_urls)
# 网页输出器收集数据
self.outputer.collect_data(new_data)
if count == 10:
break
count += 1
except:
print("craw failed")
self.outputer.output_html()
if __name__ == "__main__":
root_url = "http://baike.baidu.com/item/Python/407313"
obj_spider = SpiderMain()
obj_spider.craw(root_url)
(3)写网址管理器
我们将抓取到的网址和未抓取到的网址分开存放,这样我们就不会重复抓取一些已经抓取过的网页。
# url管理器
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.new_urls.add(url)
def get_new_url(self):
# pop方法会帮我们获取一个url并且移除它
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
def has_new_url(self):
return len(self.new_urls) != 0
(4)写一个网页下载器
通过网络请求下载页面
# 网页下载器
import urllib.request
class HtmlDownloader(object):
def download(self, url):
if url is None:
return None
response = urllib.request.urlopen(url)
# code不为200则请求失败
if response.getcode() != 200:
return None
return response.read()
(5)写一个网页解析器
在解析网页时,我们需要知道我们要查询哪些特征。我们可以打开一个网页,右击查看元素,了解我们检查的内容的共性。
# 网页解析器
import re
from bs4 import BeautifulSoup
from urllib.parse import urljoin
class HtmlParser(object):
def parse(self, page_url, html_cont):
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont, "html.parser", from_encoding="utf-8")
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
def _get_new_data(self, page_url, soup):
res_data = {"url": page_url}
# 获取标题
title_node = soup.find("dd", class_="lemmaWgt-lemmaTitle-title").find("h1")
res_data["title"] = title_node.get_text()
summary_node = soup.find("div", class_="lemma-summary")
res_data["summary"] = summary_node.get_text()
return res_data
def _get_new_urls(self, page_url, soup):
new_urls = set()
# 查找出所有符合下列条件的url
links = soup.find_all("a", href=re.compile(r"/item/"))
for link in links:
new_url = link['href']
# 获取到的url不完整,学要拼接
new_full_url = urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls
(6)写一个网页输出设备
输出格式有很多种,我们选择以html的形式输出,这样就可以到一个html页面。
# 网页输出器
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self, data):
if data is None:
return
self.datas.append(data)
# 我们以html表格形式进行输出
def output_html(self):
fout = open("output.html", "w", encoding='utf-8')
fout.write("")
fout.write("")
fout.write("")
# 以表格输出
fout.write("")
for data in self.datas:
# 一行
fout.write("")
# 每个单元行的内容
fout.write("%s" % data["url"])
fout.write("%s" % data["title"])
fout.write("%s" % data["summary"])
fout.write("")
fout.write("")
fout.write("")
fout.write("")
# 输出完毕后一定要关闭输出器
fout.close()
写在最后
注意:网页经常变化,我们需要根据网页的变化动态修改我们的代码以获得我们需要的内容。
这只是一个简单的网络爬虫,如果我们需要改进它的功能,我们需要考虑更多的问题。
爬虫上手后,可以看看爬虫是如何模拟登陆的 Python爬虫是如何模拟登陆的
网页qq抓取什么原理(网页qq抓取什么原理?分类线以下只是我个人在腾讯网开发者中心)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2021-12-02 01:00
网页qq抓取什么原理?分类线以下只是我个人在腾讯网开发者中心分享过那么几次好网站,不能肯定对大家有没有用。以下文章是自己整理的分享在这,看完后你就应该知道了。1.使用wordpressshell插件抓取网页数据,2.使用redis+mongodb+php抓取网页数据,3.用linuxmkfs抓取网页数据--1.使用wordpressshell插件抓取网页数据目的:把wordpress程序改写到一个shell环境下使用方法:importosimportrequestsimportoshost_template={'other':[{'expires':'365-1','name':'yourname','about':{'href':'#','sign':''}}]}os.getcwd()os.removeclass(os.getcwd())forshellnameinos.path.join(/):base_path=shellname.split('/')[0]#ignorewordsrequests.urlopen(base_path).read()print(requests.urlopen('').read())sh='d:\\\\'requests.urlopen(sh).read()print(requests.urlopen('').read())sh='d:\\\\'requests.urlopen(sh).read()print(requests.urlopen('').read())sh='d:\\\\'requests.urlopen(sh).read()print(requests.urlopen('').read())sh='d:\\\\'requests.urlopen(sh).read()print(requests.urlopen('').read())2.使用redis+mongodb+php抓取网页数据目的:把使用redis发送post请求发送的数据存储,再用php读取。
数据可变,效率较高使用方法:os.getcwd()os.removeclass(os.getcwd())forshellnameinos.path.join(/):base_path=shellname.split('/')[0]#ignorewordsitems={'type':['car','suv','truck'],'data':[{'date':date(format('%y-%m-%d%h:%m:%s'),norm。 查看全部
网页qq抓取什么原理(网页qq抓取什么原理?分类线以下只是我个人在腾讯网开发者中心)
网页qq抓取什么原理?分类线以下只是我个人在腾讯网开发者中心分享过那么几次好网站,不能肯定对大家有没有用。以下文章是自己整理的分享在这,看完后你就应该知道了。1.使用wordpressshell插件抓取网页数据,2.使用redis+mongodb+php抓取网页数据,3.用linuxmkfs抓取网页数据--1.使用wordpressshell插件抓取网页数据目的:把wordpress程序改写到一个shell环境下使用方法:importosimportrequestsimportoshost_template={'other':[{'expires':'365-1','name':'yourname','about':{'href':'#','sign':''}}]}os.getcwd()os.removeclass(os.getcwd())forshellnameinos.path.join(/):base_path=shellname.split('/')[0]#ignorewordsrequests.urlopen(base_path).read()print(requests.urlopen('').read())sh='d:\\\\'requests.urlopen(sh).read()print(requests.urlopen('').read())sh='d:\\\\'requests.urlopen(sh).read()print(requests.urlopen('').read())sh='d:\\\\'requests.urlopen(sh).read()print(requests.urlopen('').read())sh='d:\\\\'requests.urlopen(sh).read()print(requests.urlopen('').read())2.使用redis+mongodb+php抓取网页数据目的:把使用redis发送post请求发送的数据存储,再用php读取。
数据可变,效率较高使用方法:os.getcwd()os.removeclass(os.getcwd())forshellnameinos.path.join(/):base_path=shellname.split('/')[0]#ignorewordsitems={'type':['car','suv','truck'],'data':[{'date':date(format('%y-%m-%d%h:%m:%s'),norm。
网页qq抓取什么原理(我找到的3种实现方法(1)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-30 09:14
OSC 年度开源问卷新鲜出炉。您的回答对我们非常重要。参与开源,可以从这份问卷开始>>>
请轻轻拍拍警官。. .
我一直对网络内容的抓取非常感兴趣。大约三年前,我曾经做过一个“新闻阅读器”。那个时候,我喜欢看新闻。这个想法是,如果你在没有广告的情况下观看新闻,你可以更安静地观看。好的,所以我开发了一个浏览器书签小部件,它使用js提取页面的正文,然后通过图层覆盖将其显示在页面上。当时唯一能想到的就是通过regular找到目标dom,也是爬虫最多的。爬行法。
当时,这个功能是通过对网易、新浪、QQ、凤凰等各大门户网站的分析来实现的。这是最笨的方法,但优点是准确率高,缺点是一旦修改了目标页面的源代码,可能需要重新匹配。
后来发现想看的页面越来越多,上面的方法已经不适合我的需求了。但是最近因为自己开发了,需要一个采集助手,就开始寻找解决方案。
我主要找到了3个解决方案:
1)基于dom节点的评分系统筛选算法
国外有一个叫做 readable 的浏览器书签插件可以做到这一点。地址:当时看到这个我很惊讶,准确率很高。
2)基于文本密度的分析(与DOM无关)
这个方法的思路也很好,适用性比较好,我尝试用JS来实现,但是能力有限,没有做出匹配度太高的产品,所以放弃了。
3)基于图像识别
这与阿尔法狗使用的方法非常接近。通过图像识别,只要对机器人进行足够的训练就可以做到。其他领域已经有大量案例,但是还没有看到文本识别的具体实现(或者没有找到案例))。
以上是我找到的3种实现方式。
但是基于我只是一个web开发者的事实,我对JS只有很好的理解,其他语言的能力非常有限。于是尝试了基于dom的过滤,看到ready的实现还是比较复杂的。我想知道是否有更有效的解决方案?
后来,我发现了一个规律。一般来说,body部分的p标签数量非常多,比其他部分多很多,因为网页的大部分内容都是通过所见即所得的编辑器发布的,而这些编辑器会生成符合语义的节点。
于是,我就利用了这个规律,开发了一个抓取小插件,效果还不错。当然,它仍然很基础,需要改进。
var pt = $doc.find("p").siblings().parent();
var l = pt.length - 1;
var e = l;
var arr = [];
while(l>=0){
arr[l] = $(pt[l]).find("p").length;
l--;
}
var temArr = arr.concat();
var newArr = arrSort(arr);
var c = temArr.indexOf(newArr[e]);
content = $(pt[c]).html();
代码很简单,但是经过我的测试,80%以上的网页(主要是文章页面)都可以爬取成功。基于此,我开发了 JSpapa 采集助手:
如果您对此有更好的计划,可以在下面讨论。
如需转载本文,请联系作者,请注明出处 查看全部
网页qq抓取什么原理(我找到的3种实现方法(1)(图))
OSC 年度开源问卷新鲜出炉。您的回答对我们非常重要。参与开源,可以从这份问卷开始>>>

请轻轻拍拍警官。. .
我一直对网络内容的抓取非常感兴趣。大约三年前,我曾经做过一个“新闻阅读器”。那个时候,我喜欢看新闻。这个想法是,如果你在没有广告的情况下观看新闻,你可以更安静地观看。好的,所以我开发了一个浏览器书签小部件,它使用js提取页面的正文,然后通过图层覆盖将其显示在页面上。当时唯一能想到的就是通过regular找到目标dom,也是爬虫最多的。爬行法。
当时,这个功能是通过对网易、新浪、QQ、凤凰等各大门户网站的分析来实现的。这是最笨的方法,但优点是准确率高,缺点是一旦修改了目标页面的源代码,可能需要重新匹配。
后来发现想看的页面越来越多,上面的方法已经不适合我的需求了。但是最近因为自己开发了,需要一个采集助手,就开始寻找解决方案。
我主要找到了3个解决方案:
1)基于dom节点的评分系统筛选算法
国外有一个叫做 readable 的浏览器书签插件可以做到这一点。地址:当时看到这个我很惊讶,准确率很高。
2)基于文本密度的分析(与DOM无关)
这个方法的思路也很好,适用性比较好,我尝试用JS来实现,但是能力有限,没有做出匹配度太高的产品,所以放弃了。
3)基于图像识别
这与阿尔法狗使用的方法非常接近。通过图像识别,只要对机器人进行足够的训练就可以做到。其他领域已经有大量案例,但是还没有看到文本识别的具体实现(或者没有找到案例))。
以上是我找到的3种实现方式。
但是基于我只是一个web开发者的事实,我对JS只有很好的理解,其他语言的能力非常有限。于是尝试了基于dom的过滤,看到ready的实现还是比较复杂的。我想知道是否有更有效的解决方案?
后来,我发现了一个规律。一般来说,body部分的p标签数量非常多,比其他部分多很多,因为网页的大部分内容都是通过所见即所得的编辑器发布的,而这些编辑器会生成符合语义的节点。
于是,我就利用了这个规律,开发了一个抓取小插件,效果还不错。当然,它仍然很基础,需要改进。
var pt = $doc.find("p").siblings().parent();
var l = pt.length - 1;
var e = l;
var arr = [];
while(l>=0){
arr[l] = $(pt[l]).find("p").length;
l--;
}
var temArr = arr.concat();
var newArr = arrSort(arr);
var c = temArr.indexOf(newArr[e]);
content = $(pt[c]).html();
代码很简单,但是经过我的测试,80%以上的网页(主要是文章页面)都可以爬取成功。基于此,我开发了 JSpapa 采集助手:
如果您对此有更好的计划,可以在下面讨论。
如需转载本文,请联系作者,请注明出处
网页qq抓取什么原理( 让引擎蜘蛛快速的方法:网站及页面权重的意义)
网站优化 • 优采云 发表了文章 • 0 个评论 • 36 次浏览 • 2021-11-30 09:10
让引擎蜘蛛快速的方法:网站及页面权重的意义)
根据真实调查数据,90%的网民会使用搜索引擎服务寻找自己需要的信息,而这些搜索者中有近70%会直接在搜索结果自然排名的第一页找到自己需要的信息。可见,目前SEO对于企业和产品具有不可替代的意义!
如何让引擎蜘蛛快速爬行:网站和页面权重
这必须是第一要务。网站 权重高、资历老、权限大的蜘蛛,一定要特别对待。这样网站的爬取频率非常高,大家都知道搜索引擎蜘蛛是为了保证Efficient,并不是所有的页面都会为网站爬取,而且网站的权重越高,爬取的深度越高,对应的可以爬取的页面也就越多,这样可以网站@收录也会有更多的页面!
网站服务器
网站服务器是网站的基石。如果网站服务器长时间打不开,那这离你很近了,蜘蛛想来也来不来。百度蜘蛛也是网站的访客。如果你的服务器不稳定或者卡住了,蜘蛛每次都爬不上去,有时只能爬到一个页面的一部分。这样一来,随着时间的推移,百度蜘蛛你的体验越来越差,你对网站的评价会越来越低,自然会影响你对网站的爬取,所以你一定愿意选择空间服务器。没有很好的基础。,再好的房子也会穿越!
网站 更新频率
<p>蜘蛛每次爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次 查看全部
网页qq抓取什么原理(
让引擎蜘蛛快速的方法:网站及页面权重的意义)

根据真实调查数据,90%的网民会使用搜索引擎服务寻找自己需要的信息,而这些搜索者中有近70%会直接在搜索结果自然排名的第一页找到自己需要的信息。可见,目前SEO对于企业和产品具有不可替代的意义!
如何让引擎蜘蛛快速爬行:网站和页面权重
这必须是第一要务。网站 权重高、资历老、权限大的蜘蛛,一定要特别对待。这样网站的爬取频率非常高,大家都知道搜索引擎蜘蛛是为了保证Efficient,并不是所有的页面都会为网站爬取,而且网站的权重越高,爬取的深度越高,对应的可以爬取的页面也就越多,这样可以网站@收录也会有更多的页面!
网站服务器
网站服务器是网站的基石。如果网站服务器长时间打不开,那这离你很近了,蜘蛛想来也来不来。百度蜘蛛也是网站的访客。如果你的服务器不稳定或者卡住了,蜘蛛每次都爬不上去,有时只能爬到一个页面的一部分。这样一来,随着时间的推移,百度蜘蛛你的体验越来越差,你对网站的评价会越来越低,自然会影响你对网站的爬取,所以你一定愿意选择空间服务器。没有很好的基础。,再好的房子也会穿越!
网站 更新频率
<p>蜘蛛每次爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次
网页qq抓取什么原理(python什么是爬虫?以及爬虫工作的原理是什么? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 37 次浏览 • 2021-12-29 14:14
)
今年进了python坑,进坑的原因多半是爬虫的缘故。至于入口爬虫,我们需要大致了解一下爬虫是什么?以及爬虫的工作原理。以便于日后的学习。本博客仅用于交流学习和记录自己的成长过程。如果有不足和需要改进的地方,还望各位小伙伴指出。互相学习!互相交流!
1、什么是爬虫
Crawler,即网络爬虫(搜索引擎爬虫),可以理解为在互联网上爬行的蜘蛛。把互联网比作一个大网,爬虫就是在这个网上爬来爬去的蜘蛛,资源是“猎物”,需要什么资源由人来控制。
使用爬虫爬取一个网页,在这个'web'中发现了一个'road'#指向网页超链接#。然后爬虫可以去另一个“网”爬取数据。这样,整个连接的'大网'#Internet#都在这个蜘蛛的触手可及的范围内,需要几分钟的时间才能获得所需的资源。
学过前端的同学应该都知道,每一个tag#()#就是一条路,也可以理解,爬虫直接爬取的不是我们需要的网络资源,而是网页的源代码。然后我们手动过滤选择我们需要的资源的url#网络资源Locator/link#,最后下载或者操作我们需要的数据来达到我们的目的。
理论上只要能抓取到网页上能看到的数据就可以了('因为你看到的网页上的所有数据都是服务器发送到电脑的,但有些数据是加密的,很难解密') . 对于网络上看不到或获取不到的数据,爬虫也是无法获取的,比如一些付费信息(主付费还没到哈哈哈哈)。
各大搜索引擎都非常强大,国内的百度、好搜、搜狗等。
以上只是我个人对爬虫的看法。百度百科(搜索引擎爬虫/20256370?fr=aladdin)有更专业权威的解释。有兴趣的朋友可以看看。
*Crawler其实就是一个模拟浏览器的过程,模拟浏览器发出请求。*
2、用户浏览网页的过程
当用户浏览网页时,他们会看到很多内容。比如打开百度,可以看到图片、文字、音乐等,这个过程是怎么实现的?这个过程的实现其实就是用户输入URL后,通过DNS服务器找到目标服务器主机,向服务器发送请求。服务端解析后,根据请求返回给用户浏览器的HTML、CSS、JS等文件(源代码)。, 浏览器接收到数据并进行分析后,用户就可以看到我们常用网页的内容了。
#Request/Open某个URL的一般流程:
{本地主机文件-->本地路由-->DNS域名解析服务器(解析域名指向一个网站)-->目标服务器-->请求页面}
服务器发送给我们(用户)的不是我们看到的,而是html标记的网页代码,浏览器收到后解析源码。下载标签存储在缓存中,并显示在我们看到的网页上。因此,用户看到的网页本质上是由HTML代码组成的,但实际上,爬虫爬取的却是HTML代码文件。我们通过一定的规则对这些HTML代码进行分析和过滤,从而实现我们对网络资源的访问。. #
3、什么是网址?
统一资源定位符 (URL)。URL 是互联网上可用资源的位置和访问方式的简明表示,类似于我们简单描述所需图书在图书馆中的位置以及如何获取所需对象的方式。每个互联网资源都可以看作是一个独立的对象,每个独立的对象(网络资源)都会有一个唯一的URL。URL 中收录
的信息指示目标文件的位置以及浏览器应如何处理该文件。
#URL 的格式一般由三部分组成:
1),protocol(服务模式):如例子中,”为通用协议,其他如:file://ftp://等;
2),托管资源的主机的IP地址:(有时包括端口号)可以是直接IP地址:192.168.1.1,它也可以是域名,如示例中所示;
3),宿主资源的具体地址(目录和文件夹等):如'/static/wiki-album/widget/picture/pictureDialog/resource/img/img-bg_86e1dfc.gif'中例子。#
4、 开发环境配置
工欲善其事,必先利其器。学习Python,前提是配置好我们的环境。Python是开源的,可以在Python官网('')免费下载。推荐使用 Pychram 作为 Python 开发工具。我之前也是用IDLE写的。我发现Pycharm很麻烦,但在那之后,我无法逃脱万年真香定理的破坏。如何安装和配置 Pychram 可以在 CSND 上找到。有很多博主写的很详细,大部分人都能看懂。实在不懂就买个宝吧哈哈哈哈。
5、 个人爬虫开发的思考
1、理论上只要能抓取到网页上能看到的数据就可以了('因为你看到的网页上的所有数据都是服务器发送给电脑的,但是有些数据是加密,需要解密,获取所需文件的URL,成功一半')
2、 网页上看不到或获取不到的数据,爬虫也无法获取,比如一些付费素材、付费视频等。
3、分析页面数据的原则是由简到繁,由易到难
1)、通过网页源码直接获取
2),分析是否是ajax异步加载
3)、数据是否加密js
6、Python版本问题
现在Python有了Python2.X和Python3.X,而Python2.X和Python3.X并不是简单的升级关系,而是完全不同的两个东西。这两种发展各有优缺点,语法和方法也各不相同。我也打算在以后的开发中写出两者的区别,让两种不同环境下的程序更兼容,更方便修改。毕竟Python2.X在2020年也将停止更新。不过我建议大家在学习初期,可以下载两个版本,以便学习Python开发的思路和方法。此外,Pychram 可以方便地更改项目中开发时使用的 Python 版本,
第一篇博文就这么愉快的结束了!非常感谢每一位花时间阅读我对爬虫介绍的看法的朋友。对Python感兴趣的同志可以在评论区留下联系方式。我们可以一起交流学习,走向更广阔的视野。世界!
*人生苦短,我用Python。* 查看全部
网页qq抓取什么原理(python什么是爬虫?以及爬虫工作的原理是什么?
)
今年进了python坑,进坑的原因多半是爬虫的缘故。至于入口爬虫,我们需要大致了解一下爬虫是什么?以及爬虫的工作原理。以便于日后的学习。本博客仅用于交流学习和记录自己的成长过程。如果有不足和需要改进的地方,还望各位小伙伴指出。互相学习!互相交流!
1、什么是爬虫
Crawler,即网络爬虫(搜索引擎爬虫),可以理解为在互联网上爬行的蜘蛛。把互联网比作一个大网,爬虫就是在这个网上爬来爬去的蜘蛛,资源是“猎物”,需要什么资源由人来控制。
使用爬虫爬取一个网页,在这个'web'中发现了一个'road'#指向网页超链接#。然后爬虫可以去另一个“网”爬取数据。这样,整个连接的'大网'#Internet#都在这个蜘蛛的触手可及的范围内,需要几分钟的时间才能获得所需的资源。
学过前端的同学应该都知道,每一个tag#()#就是一条路,也可以理解,爬虫直接爬取的不是我们需要的网络资源,而是网页的源代码。然后我们手动过滤选择我们需要的资源的url#网络资源Locator/link#,最后下载或者操作我们需要的数据来达到我们的目的。
理论上只要能抓取到网页上能看到的数据就可以了('因为你看到的网页上的所有数据都是服务器发送到电脑的,但有些数据是加密的,很难解密') . 对于网络上看不到或获取不到的数据,爬虫也是无法获取的,比如一些付费信息(主付费还没到哈哈哈哈)。
各大搜索引擎都非常强大,国内的百度、好搜、搜狗等。
以上只是我个人对爬虫的看法。百度百科(搜索引擎爬虫/20256370?fr=aladdin)有更专业权威的解释。有兴趣的朋友可以看看。
*Crawler其实就是一个模拟浏览器的过程,模拟浏览器发出请求。*
2、用户浏览网页的过程
当用户浏览网页时,他们会看到很多内容。比如打开百度,可以看到图片、文字、音乐等,这个过程是怎么实现的?这个过程的实现其实就是用户输入URL后,通过DNS服务器找到目标服务器主机,向服务器发送请求。服务端解析后,根据请求返回给用户浏览器的HTML、CSS、JS等文件(源代码)。, 浏览器接收到数据并进行分析后,用户就可以看到我们常用网页的内容了。
#Request/Open某个URL的一般流程:
{本地主机文件-->本地路由-->DNS域名解析服务器(解析域名指向一个网站)-->目标服务器-->请求页面}
服务器发送给我们(用户)的不是我们看到的,而是html标记的网页代码,浏览器收到后解析源码。下载标签存储在缓存中,并显示在我们看到的网页上。因此,用户看到的网页本质上是由HTML代码组成的,但实际上,爬虫爬取的却是HTML代码文件。我们通过一定的规则对这些HTML代码进行分析和过滤,从而实现我们对网络资源的访问。. #
3、什么是网址?
统一资源定位符 (URL)。URL 是互联网上可用资源的位置和访问方式的简明表示,类似于我们简单描述所需图书在图书馆中的位置以及如何获取所需对象的方式。每个互联网资源都可以看作是一个独立的对象,每个独立的对象(网络资源)都会有一个唯一的URL。URL 中收录
的信息指示目标文件的位置以及浏览器应如何处理该文件。
#URL 的格式一般由三部分组成:
1),protocol(服务模式):如例子中,”为通用协议,其他如:file://ftp://等;
2),托管资源的主机的IP地址:(有时包括端口号)可以是直接IP地址:192.168.1.1,它也可以是域名,如示例中所示;
3),宿主资源的具体地址(目录和文件夹等):如'/static/wiki-album/widget/picture/pictureDialog/resource/img/img-bg_86e1dfc.gif'中例子。#
4、 开发环境配置
工欲善其事,必先利其器。学习Python,前提是配置好我们的环境。Python是开源的,可以在Python官网('')免费下载。推荐使用 Pychram 作为 Python 开发工具。我之前也是用IDLE写的。我发现Pycharm很麻烦,但在那之后,我无法逃脱万年真香定理的破坏。如何安装和配置 Pychram 可以在 CSND 上找到。有很多博主写的很详细,大部分人都能看懂。实在不懂就买个宝吧哈哈哈哈。
5、 个人爬虫开发的思考
1、理论上只要能抓取到网页上能看到的数据就可以了('因为你看到的网页上的所有数据都是服务器发送给电脑的,但是有些数据是加密,需要解密,获取所需文件的URL,成功一半')
2、 网页上看不到或获取不到的数据,爬虫也无法获取,比如一些付费素材、付费视频等。
3、分析页面数据的原则是由简到繁,由易到难
1)、通过网页源码直接获取
2),分析是否是ajax异步加载
3)、数据是否加密js
6、Python版本问题
现在Python有了Python2.X和Python3.X,而Python2.X和Python3.X并不是简单的升级关系,而是完全不同的两个东西。这两种发展各有优缺点,语法和方法也各不相同。我也打算在以后的开发中写出两者的区别,让两种不同环境下的程序更兼容,更方便修改。毕竟Python2.X在2020年也将停止更新。不过我建议大家在学习初期,可以下载两个版本,以便学习Python开发的思路和方法。此外,Pychram 可以方便地更改项目中开发时使用的 Python 版本,
第一篇博文就这么愉快的结束了!非常感谢每一位花时间阅读我对爬虫介绍的看法的朋友。对Python感兴趣的同志可以在评论区留下联系方式。我们可以一起交流学习,走向更广阔的视野。世界!
*人生苦短,我用Python。*
网页qq抓取什么原理(网页qq抓取什么原理?文字段落抓取伪代码思维导图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-25 04:03
网页qq抓取什么原理?文字段落抓取伪代码思维导图fiddler全局代理工具yslow各浏览器插件[浏览器工具]看看网页的正则表达式抓取也不是那么复杂,一些规则而已,拿来用就行,用什么文本编辑器无所谓,见效慢。
qq小程序=微信小程序=webqq小程序=微信app安卓直接下载微信小程序;ios:解包所有浏览器,
是否需要安装,是需要一个浏览器。微信在后台安装了qq浏览器。所以你不用挂后台运行qq就可以在微信里用qq浏览器。
打开qq浏览器
所以以前浏览器不是问题,因为浏览器根本没有做这个事情。做这个事情的是:新浪的服务器,因为新浪是商业化网站,不开放api给第三方提供接口,所以这个事情的从业者就转向用chrome了。只不过是自己默默做而已。
工作党有,有资金,利用当下流行的yypc版v5.5做了一个简易的小软件,可行。自己动手丰衣足食。用到的软件就是yypc版v5.5。毕竟技术不算太高端,这个对自己来说还算容易。实际上思路也没什么了,就是经常在微信里调戏一下自己喜欢的对象。先在自己的资料库里查看对方是不是发来信息了,不是则保存资料,是则对调戏对象一个回应。不知道说明白了么。
qq浏览器后台安装,支持腾讯所有本地用户端浏览器和腾讯qq浏览器网页版等。实现方法就是进入聊天对话框(发一个赞或评论就好),或者输入文字后发送信息到被调戏对象的qq上:信息内容举例如下:添加好友需要获取对方qq号码,用于推送未读信息。开放api的这种方式已经禁止获取并提供了文字版信息,转用伪代码实现。地址:qq昵称请自行改进算法,这次估计实现难度较大。
1、起始态设置为邮箱接收邮件界面
2、将信息url伪装为一条邮件信息(在发送邮件状态下)点开发送,将邮件内容发送,
3、代码实现如下:
1)获取对方qq
2)获取到对方qq号后,将注册邮箱发送至昵称,
3)获取到昵称后,将昵称昵称随机发送至对方qq,
4)获取到昵称昵称后, 查看全部
网页qq抓取什么原理(网页qq抓取什么原理?文字段落抓取伪代码思维导图)
网页qq抓取什么原理?文字段落抓取伪代码思维导图fiddler全局代理工具yslow各浏览器插件[浏览器工具]看看网页的正则表达式抓取也不是那么复杂,一些规则而已,拿来用就行,用什么文本编辑器无所谓,见效慢。
qq小程序=微信小程序=webqq小程序=微信app安卓直接下载微信小程序;ios:解包所有浏览器,
是否需要安装,是需要一个浏览器。微信在后台安装了qq浏览器。所以你不用挂后台运行qq就可以在微信里用qq浏览器。
打开qq浏览器
所以以前浏览器不是问题,因为浏览器根本没有做这个事情。做这个事情的是:新浪的服务器,因为新浪是商业化网站,不开放api给第三方提供接口,所以这个事情的从业者就转向用chrome了。只不过是自己默默做而已。
工作党有,有资金,利用当下流行的yypc版v5.5做了一个简易的小软件,可行。自己动手丰衣足食。用到的软件就是yypc版v5.5。毕竟技术不算太高端,这个对自己来说还算容易。实际上思路也没什么了,就是经常在微信里调戏一下自己喜欢的对象。先在自己的资料库里查看对方是不是发来信息了,不是则保存资料,是则对调戏对象一个回应。不知道说明白了么。
qq浏览器后台安装,支持腾讯所有本地用户端浏览器和腾讯qq浏览器网页版等。实现方法就是进入聊天对话框(发一个赞或评论就好),或者输入文字后发送信息到被调戏对象的qq上:信息内容举例如下:添加好友需要获取对方qq号码,用于推送未读信息。开放api的这种方式已经禁止获取并提供了文字版信息,转用伪代码实现。地址:qq昵称请自行改进算法,这次估计实现难度较大。
1、起始态设置为邮箱接收邮件界面
2、将信息url伪装为一条邮件信息(在发送邮件状态下)点开发送,将邮件内容发送,
3、代码实现如下:
1)获取对方qq
2)获取到对方qq号后,将注册邮箱发送至昵称,
3)获取到昵称后,将昵称昵称随机发送至对方qq,
4)获取到昵称昵称后,
网页qq抓取什么原理( 拼接的Url找到多个urlURL解析看的应该准确)
网站优化 • 优采云 发表了文章 • 0 个评论 • 40 次浏览 • 2021-12-24 18:00
拼接的Url找到多个urlURL解析看的应该准确)
爬取网页版QQ音乐
首先进入音乐播放页面,找到音乐的最终url版本
根据这个网址进入播放页面
这个网站怎么找
我们复制它关键词搜索它
我们只需要访问这个网页的数据就可以得到音乐的url
看到网址有点瞎
URL解析应该更准确
我们需要得到这个值才能批量下载
进入歌曲排名页面搜索关键词
{"req":{"module":"CDN.SrfCdnDispatchServer","method":"GetCdnDispatch","param":{"guid":"1282808556","calltype":0,"userip": ""}},"Req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"1282808556","songmid":["0000Z0093Ko5Ps"] ,"Songtype":[0],"uin":"641043558","loginflag":1,"platform":"20"}},"comm":{"uin":641043558,"format":"json ","Ct":24,"cv":0}}
通过访问这个网站
获取拼接的Url
找多个网址对比,发现songmid一直在变,
把这个关键词带到之前的网页搜索
得到一个这个网站,这个网站访问会得到一段json字符串,分析一下,得到singmid
可以获取初始网址
我们直接访问该网站,无需编写代码即可获取数据。很简单。 查看全部
网页qq抓取什么原理(
拼接的Url找到多个urlURL解析看的应该准确)
爬取网页版QQ音乐
首先进入音乐播放页面,找到音乐的最终url版本
根据这个网址进入播放页面
这个网站怎么找
我们复制它关键词搜索它
我们只需要访问这个网页的数据就可以得到音乐的url
看到网址有点瞎
URL解析应该更准确
我们需要得到这个值才能批量下载
进入歌曲排名页面搜索关键词
{"req":{"module":"CDN.SrfCdnDispatchServer","method":"GetCdnDispatch","param":{"guid":"1282808556","calltype":0,"userip": ""}},"Req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"1282808556","songmid":["0000Z0093Ko5Ps"] ,"Songtype":[0],"uin":"641043558","loginflag":1,"platform":"20"}},"comm":{"uin":641043558,"format":"json ","Ct":24,"cv":0}}
通过访问这个网站
获取拼接的Url
找多个网址对比,发现songmid一直在变,
把这个关键词带到之前的网页搜索
得到一个这个网站,这个网站访问会得到一段json字符串,分析一下,得到singmid
可以获取初始网址
我们直接访问该网站,无需编写代码即可获取数据。很简单。
网页qq抓取什么原理(揭秘qq空间排名技术少让一些新手上当当)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-21 11:14
简介:最近,QQ空间排名技术非常火爆。网上有很多培训,有的培训很贵。
今天给大家揭秘QQ空间排名技术,免得有些新手用不上。
首先我们来看看百度蜘蛛是如何抓取QQ空间网页的。测试百度蜘蛛如何抓取我的空间。
需要使用站长工具中的百度蜘蛛模拟工具--
1、2、3、上图中的4对应下图中的1、2、3、4
可以明显看出百度抢了我们QQ空间的关键词位置。
只需将我们的关键字放在这些地方就可以了。
接下来我们要做的就是打开QQ空间的所有权限,排列好关键词。
完成这些准备工作后,我们将开始像百度一样提交我们的Qzone地址。
提交的具体网址是(记住,必须是这个网址)
提交后,百度会在提交完成后最快2小时收录你的QQ区,结果如图收录
记住,查询是否收录时,不要在空间URL的末尾收录斜线。假设你的空间里没有收录,就不用点击图中框内的提交网址,因为我发现这样是没有效果的。 (唯一投稿地址)
收录 完成后,接下来要做的就是发布链接。
为什么外部链接很重要?举个例子,以这个QQ空间为例。
检查一下。外链虽然不多,但我看了一下,发现很多都是高质量的。
结论:
Qzone 排名技术就是这么简单。设置关键词和百度收录后,唯一影响排名的是外链。外链越多,质量越高,你的关键词排名就越高。如果你有吸引百度蜘蛛的工具,那么你的关键词排名会更好。除了以上的影响因素,最后一个因素就是运气,所以你可以操作很多Qzone,相当于站群,所以你在Qzone上获得更好排名的机会会增加很多。最后,推荐百度指数在100左右的暴力关键词,这样获得排名的时间短,盈利周期短。 查看全部
网页qq抓取什么原理(揭秘qq空间排名技术少让一些新手上当当)
简介:最近,QQ空间排名技术非常火爆。网上有很多培训,有的培训很贵。
今天给大家揭秘QQ空间排名技术,免得有些新手用不上。
首先我们来看看百度蜘蛛是如何抓取QQ空间网页的。测试百度蜘蛛如何抓取我的空间。
需要使用站长工具中的百度蜘蛛模拟工具--
1、2、3、上图中的4对应下图中的1、2、3、4
可以明显看出百度抢了我们QQ空间的关键词位置。
只需将我们的关键字放在这些地方就可以了。
接下来我们要做的就是打开QQ空间的所有权限,排列好关键词。
完成这些准备工作后,我们将开始像百度一样提交我们的Qzone地址。
提交的具体网址是(记住,必须是这个网址)
提交后,百度会在提交完成后最快2小时收录你的QQ区,结果如图收录
记住,查询是否收录时,不要在空间URL的末尾收录斜线。假设你的空间里没有收录,就不用点击图中框内的提交网址,因为我发现这样是没有效果的。 (唯一投稿地址)
收录 完成后,接下来要做的就是发布链接。
为什么外部链接很重要?举个例子,以这个QQ空间为例。
检查一下。外链虽然不多,但我看了一下,发现很多都是高质量的。
结论:
Qzone 排名技术就是这么简单。设置关键词和百度收录后,唯一影响排名的是外链。外链越多,质量越高,你的关键词排名就越高。如果你有吸引百度蜘蛛的工具,那么你的关键词排名会更好。除了以上的影响因素,最后一个因素就是运气,所以你可以操作很多Qzone,相当于站群,所以你在Qzone上获得更好排名的机会会增加很多。最后,推荐百度指数在100左右的暴力关键词,这样获得排名的时间短,盈利周期短。
网页qq抓取什么原理(Python程序猿的爬虫运行原理是什么?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-20 16:18
什么是爬虫?
本文中提到的爬虫本质上并不是爬行动物,而是一种运行在互联网上的自动处理信息的程序。
Crawler 是一个使用网络请求(HTTP/HTTPS)来过滤和输入数据的程序。因为网络信息的维度很广,就像蜘蛛网一样,我们会通过网络请求过滤,将数据输入到网络蜘蛛(网络爬虫)中。
爬虫运行原理:
互联网上信息传输的载体多为网页数据。爬虫操作的原理是解析网页数据,去除超文本标记语言(HTML)等,只保留有用的数据。
案件:
假设我们想从互联网上抓取“再见”的歌词。网页如下图所示。我们要抓取的内容是红色部分。
履带箱
1. 首先我们分析页面的结构,找到歌词所在的大概的div结构
找到div结构
进一步寻找路径
获取路径信息
使用 Selector 分析工具进行数据分析。
源代码
为什么爬虫先Python:
实际上,爬虫可以用任何语言编写,只要该语言能够解析响应、请求等相关网络请求即可。
Python爬虫开发有其独特的优势,上手快,难度低,第三方插件完善,开发难度低。这些优势是其他语言无法比拟的,因此 Python 是编写爬虫的主要语言。
我是一个热爱游戏的Python程序员,想知道爬虫知识有哪些?请在下方留言,我会特别说明~ 查看全部
网页qq抓取什么原理(Python程序猿的爬虫运行原理是什么?(图))
什么是爬虫?
本文中提到的爬虫本质上并不是爬行动物,而是一种运行在互联网上的自动处理信息的程序。
Crawler 是一个使用网络请求(HTTP/HTTPS)来过滤和输入数据的程序。因为网络信息的维度很广,就像蜘蛛网一样,我们会通过网络请求过滤,将数据输入到网络蜘蛛(网络爬虫)中。
爬虫运行原理:
互联网上信息传输的载体多为网页数据。爬虫操作的原理是解析网页数据,去除超文本标记语言(HTML)等,只保留有用的数据。
案件:
假设我们想从互联网上抓取“再见”的歌词。网页如下图所示。我们要抓取的内容是红色部分。
履带箱
1. 首先我们分析页面的结构,找到歌词所在的大概的div结构
找到div结构
进一步寻找路径
获取路径信息
使用 Selector 分析工具进行数据分析。
源代码
为什么爬虫先Python:
实际上,爬虫可以用任何语言编写,只要该语言能够解析响应、请求等相关网络请求即可。
Python爬虫开发有其独特的优势,上手快,难度低,第三方插件完善,开发难度低。这些优势是其他语言无法比拟的,因此 Python 是编写爬虫的主要语言。
我是一个热爱游戏的Python程序员,想知道爬虫知识有哪些?请在下方留言,我会特别说明~
网页qq抓取什么原理(演示demo,简单有没有?搞科研做实验最痛心的是什么? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-16 13:25
)
Web Scraper 爬虫工具是一个基于谷歌浏览器的插件。使用Web Scraper可以简单快速地抓取任何网站数据,不受网站反爬虫机制的影响。与Python等语言实现的爬虫工具相比,WebScraper具有先天优势。
演示,简单吗?
做科学研究、做实验,最苦恼的是什么?
没有数据,没有足够的数据
如果我不会 Python 或 Java,也不知道如何编写爬虫怎么办?
查找:网络爬虫!
互联网上有海量的数据,每天都有各种各样的数据展现在我们面前。同时,金融、医学、计算机科学等诸多研究课题需要获取大量数据作为样本进行科学分析,传统手工采集操作从根本上难以处理数据采集,甚至如果能采集到,需要花费大量的时间和成本。本教程的目的是让有采集数据需求的人在短短一小时内熟练使用“神器”Web Scraper插件。
首先让我们了解一下爬行的简单原理,所谓“磨刀不误砍柴”,了解原理可以帮助我们使用过程事半功倍!
“抓取对象”
作为展示数据的平台,可以通过浏览器窗口浏览网页。从服务器数据库到浏览器窗口的显示,中间有一个复杂的过程。服务器数据库中存储的数据一般以某种编码形式存储。如果我们看这个时候的数据,我们看到的是一个这样或那样的纯文本类型。数据传输到浏览器后,浏览器将“数据信息”加载到设计者准备好的“网页模板”中,最终得到我们通过浏览器看到的一切。
我们看到的金融网站
我们看到的新闻网站
我们看到的博客
《了解网页的“层”》
各种网页都收录各种数据。网页组织的数据收录在不同的“层”中(详情可以从html标签中得知)。当然,我们不能直观地看到所有这些层。
经过长时间的网页设计发展,直到现在我们通过标准的html标签语言来设计网页。在这套国际规则下,设计的过程就是逐层设计页面元素,让不同的内容可以更和谐地结合。虽然不同的网站设计风格不同,但每个网页都类似于一个“金字塔”结构,比如下面这个网页:
第一层:类似于一张桌子
第二层:标题栏和内容栏(类似Excel)
第三层:每行数据
第四层:每个单元格
第五层:文字
《Web Scraper 分层抓取页面元素》
Web Scraper作为一种自动化爬虫工具,它的爬取目标是页面的数据,但是在爬取数据之前,我们需要定义一个“流程”,这个流程包括“动作”(模拟鼠标点击操作)和“页面元素” (定义要抓取的页面元素)。
感觉很傻
实践是检验真理的唯一标准。这是爬行过程的结束。基本原理储备足够学习Web Scraper!
从下一节开始,我们正式进入Web Scraper的学习。
下节预告《【网络爬虫教程02】安装网络爬虫插件》
查看全部
网页qq抓取什么原理(演示demo,简单有没有?搞科研做实验最痛心的是什么?
)
Web Scraper 爬虫工具是一个基于谷歌浏览器的插件。使用Web Scraper可以简单快速地抓取任何网站数据,不受网站反爬虫机制的影响。与Python等语言实现的爬虫工具相比,WebScraper具有先天优势。
演示,简单吗?
做科学研究、做实验,最苦恼的是什么?
没有数据,没有足够的数据
如果我不会 Python 或 Java,也不知道如何编写爬虫怎么办?
查找:网络爬虫!
互联网上有海量的数据,每天都有各种各样的数据展现在我们面前。同时,金融、医学、计算机科学等诸多研究课题需要获取大量数据作为样本进行科学分析,传统手工采集操作从根本上难以处理数据采集,甚至如果能采集到,需要花费大量的时间和成本。本教程的目的是让有采集数据需求的人在短短一小时内熟练使用“神器”Web Scraper插件。
首先让我们了解一下爬行的简单原理,所谓“磨刀不误砍柴”,了解原理可以帮助我们使用过程事半功倍!
“抓取对象”
作为展示数据的平台,可以通过浏览器窗口浏览网页。从服务器数据库到浏览器窗口的显示,中间有一个复杂的过程。服务器数据库中存储的数据一般以某种编码形式存储。如果我们看这个时候的数据,我们看到的是一个这样或那样的纯文本类型。数据传输到浏览器后,浏览器将“数据信息”加载到设计者准备好的“网页模板”中,最终得到我们通过浏览器看到的一切。
我们看到的金融网站
我们看到的新闻网站
我们看到的博客
《了解网页的“层”》
各种网页都收录各种数据。网页组织的数据收录在不同的“层”中(详情可以从html标签中得知)。当然,我们不能直观地看到所有这些层。
经过长时间的网页设计发展,直到现在我们通过标准的html标签语言来设计网页。在这套国际规则下,设计的过程就是逐层设计页面元素,让不同的内容可以更和谐地结合。虽然不同的网站设计风格不同,但每个网页都类似于一个“金字塔”结构,比如下面这个网页:
第一层:类似于一张桌子
第二层:标题栏和内容栏(类似Excel)
第三层:每行数据
第四层:每个单元格
第五层:文字
《Web Scraper 分层抓取页面元素》
Web Scraper作为一种自动化爬虫工具,它的爬取目标是页面的数据,但是在爬取数据之前,我们需要定义一个“流程”,这个流程包括“动作”(模拟鼠标点击操作)和“页面元素” (定义要抓取的页面元素)。
感觉很傻
实践是检验真理的唯一标准。这是爬行过程的结束。基本原理储备足够学习Web Scraper!
从下一节开始,我们正式进入Web Scraper的学习。
下节预告《【网络爬虫教程02】安装网络爬虫插件》
网页qq抓取什么原理(一下实现简单爬虫功能的示例python爬虫实战之最简单的网页爬虫教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-16 13:23
既然这篇文章文章讲的是Python搭建网络爬虫的原理分析,那我先给大家介绍一下Python中爬虫的选择文章:
Python实现简单爬虫功能示例
python爬虫实战最简单的网络爬虫教程
网络爬虫是当今最常用的系统之一。最流行的例子是 Google 使用爬虫从所有 网站 采集信息。除了搜索引擎,新闻网站还需要爬虫来聚合数据源。看来只要想聚合很多信息,就可以考虑使用爬虫了。
构建网络爬虫有很多因素,尤其是当您要扩展系统时。这就是为什么这已经成为最流行的系统设计面试问题之一。在这个文章中,我们将讨论从基础爬虫到大型爬虫的话题,讨论面试中可能遇到的各种问题。
1-基本解决方案
如何构建一个基本的网络爬虫?
在系统设计面试之前,我们已经讲过“系统设计面试前你需要知道的八件事”,就是从简单的事情开始。让我们专注于构建一个在单线程上运行的基本网络爬虫。通过这个简单的解决方案,我们可以继续优化。
爬取单个网页,我们只需要向对应的URL发出HTTP GET请求,解析响应数据,这是爬虫的核心。考虑到这一点,一个基本的网络爬虫可以这样工作:
从收录我们要爬取的所有 网站 的 URL 池开始。
对于每个 URL,都会发出 HTTP GET 请求以获取网页的内容。
解析内容(通常是 HTML)并提取我们想要抓取的潜在 URL。
向池中添加新 URL 并继续爬行。
根据具体问题,有时我们可能有一个单独的系统来生成抓取网址。例如,一个程序可以持续监控RSS订阅,对于每一个新的文章,都可以将URL添加到爬取池中。
2 尺度问题
众所周知,任何系统在扩展后都会面临一系列的问题。在网络爬虫中,当系统扩展到多台机器时,很多事情都可能出错。
在跳到下一节之前,请花几分钟思考一下分布式网络爬虫的瓶颈以及如何解决这个问题。在本文章的其余部分,我们将讨论解决方案的主要问题。
3-爬行频率
你多久爬一次 网站?
这听起来可能没什么大不了的,除非系统达到一定规模并且您需要非常新鲜的内容。例如,如果你想获取最近一小时的最新消息,爬虫可能需要保持每小时爬一次新闻网站。但是有什么问题呢?
对于一些小的网站,他们的服务器可能无法处理如此频繁的请求。一种方法是跟踪每个站点的robot.txt。对于不知道robot.txt是什么的人来说,这基本上是网站与网络爬虫通信的标准。它可以指定哪些文件不应该被抓取,大多数网络爬虫都遵循这个配置。另外,你可以为不同的网站设置不同的爬取频率。通常,每天只需要爬取几次网站。
4-重复数据删除
在一台机器上,您可以将 URL 池保留在内存中并删除重复条目。然而,分布式系统中的事情变得更加复杂。基本上,多个爬虫可以从不同的网页中提取同一个网址,并且都想把这个网址加入到网址池中。当然,多次爬取同一个页面是没有意义的。那么我们如何重复这些网址呢?
一种常用的方法是使用布隆过滤器。简而言之,Bloom Filter 是一个节省空间的系统,它允许您测试元素是否在集合中。但是,它可能有误报。换句话说,如果布隆过滤器可以告诉你一个 URL 肯定不在池中,或者可能在池中。
为了简要说明布隆过滤器的工作原理,空布隆过滤器是 m 位(所有 0) 位数组。还有 k 个哈希函数将每个元素映射到 m 位 A。所以当我们添加一个新元素时(URL)在Bloom filter中,我们会从hash函数中得到k位,并将它们都设置为 1. 所以当我们检查一个元素时,我们首先得到k位,如果其中任何一个不是1 ,我们立即知道该元素不存在。然而,如果所有k位都是1,这可能来自其他几个元素的组合。
布隆过滤器是一种非常常用的技术,它是网络爬虫中去除重复网址的完美解决方案。
5-解析
从网站得到响应数据后,下一步就是解析数据(通常是HTML),提取出我们关心的信息。这听起来很简单,但要让它健壮可能很难。
我们面临的挑战是你总会在 HTML 代码中发现奇怪的标签、URL 等,并且很难覆盖所有的边界条件。例如,当 HTML 收录非 Unicode 字符时,您可能需要处理编码和解码问题。此外,当网页中收录图片、视频甚至PDF文件时,也会引起奇怪的行为。
另外,有些网页像AngularJS一样是用Javascript渲染的,你的爬虫可能无法获取到任何内容。
我想说,没有灵丹妙药,就不可能为所有网页制作完美而强大的爬虫。您需要进行大量的稳健性测试以确保它按预期工作。
总结
有很多有趣的话题我还没有触及,但我想提一下其中的一些,以便您可以思考它们。一件事是检测循环。很多网站都收录链接,比如A->B->C->A,你的爬虫可能会一直跑下去。想想如何解决这个问题?
另一个问题是 DNS 查找。当系统扩展到一定程度时,DNS 查找可能会成为瓶颈,您可能需要构建自己的 DNS 服务器。
与许多其他系统类似,扩展的网络爬虫可能比构建单机版本困难得多,并且可以在系统设计面试中讨论很多事情。尝试从一些简单的解决方案开始并继续优化它,这会使事情变得比看起来更容易。
以上是我们对网络爬虫的总结。如果你还有什么想知道的,可以在下方评论区讨论。感谢您对编程技巧的支持。
总结
以上就是本站为大家采集整理的Python构建网络爬虫原理分析的全部内容。希望文章能帮助大家解决Python搭建网络爬虫原理分析中遇到的程序开发问题。
如果您觉得本站网站的内容还不错,欢迎向程序员朋友推荐本站网站。 查看全部
网页qq抓取什么原理(一下实现简单爬虫功能的示例python爬虫实战之最简单的网页爬虫教程)
既然这篇文章文章讲的是Python搭建网络爬虫的原理分析,那我先给大家介绍一下Python中爬虫的选择文章:
Python实现简单爬虫功能示例
python爬虫实战最简单的网络爬虫教程
网络爬虫是当今最常用的系统之一。最流行的例子是 Google 使用爬虫从所有 网站 采集信息。除了搜索引擎,新闻网站还需要爬虫来聚合数据源。看来只要想聚合很多信息,就可以考虑使用爬虫了。
构建网络爬虫有很多因素,尤其是当您要扩展系统时。这就是为什么这已经成为最流行的系统设计面试问题之一。在这个文章中,我们将讨论从基础爬虫到大型爬虫的话题,讨论面试中可能遇到的各种问题。
1-基本解决方案
如何构建一个基本的网络爬虫?
在系统设计面试之前,我们已经讲过“系统设计面试前你需要知道的八件事”,就是从简单的事情开始。让我们专注于构建一个在单线程上运行的基本网络爬虫。通过这个简单的解决方案,我们可以继续优化。
爬取单个网页,我们只需要向对应的URL发出HTTP GET请求,解析响应数据,这是爬虫的核心。考虑到这一点,一个基本的网络爬虫可以这样工作:
从收录我们要爬取的所有 网站 的 URL 池开始。
对于每个 URL,都会发出 HTTP GET 请求以获取网页的内容。
解析内容(通常是 HTML)并提取我们想要抓取的潜在 URL。
向池中添加新 URL 并继续爬行。
根据具体问题,有时我们可能有一个单独的系统来生成抓取网址。例如,一个程序可以持续监控RSS订阅,对于每一个新的文章,都可以将URL添加到爬取池中。
2 尺度问题
众所周知,任何系统在扩展后都会面临一系列的问题。在网络爬虫中,当系统扩展到多台机器时,很多事情都可能出错。
在跳到下一节之前,请花几分钟思考一下分布式网络爬虫的瓶颈以及如何解决这个问题。在本文章的其余部分,我们将讨论解决方案的主要问题。
3-爬行频率
你多久爬一次 网站?
这听起来可能没什么大不了的,除非系统达到一定规模并且您需要非常新鲜的内容。例如,如果你想获取最近一小时的最新消息,爬虫可能需要保持每小时爬一次新闻网站。但是有什么问题呢?
对于一些小的网站,他们的服务器可能无法处理如此频繁的请求。一种方法是跟踪每个站点的robot.txt。对于不知道robot.txt是什么的人来说,这基本上是网站与网络爬虫通信的标准。它可以指定哪些文件不应该被抓取,大多数网络爬虫都遵循这个配置。另外,你可以为不同的网站设置不同的爬取频率。通常,每天只需要爬取几次网站。
4-重复数据删除
在一台机器上,您可以将 URL 池保留在内存中并删除重复条目。然而,分布式系统中的事情变得更加复杂。基本上,多个爬虫可以从不同的网页中提取同一个网址,并且都想把这个网址加入到网址池中。当然,多次爬取同一个页面是没有意义的。那么我们如何重复这些网址呢?
一种常用的方法是使用布隆过滤器。简而言之,Bloom Filter 是一个节省空间的系统,它允许您测试元素是否在集合中。但是,它可能有误报。换句话说,如果布隆过滤器可以告诉你一个 URL 肯定不在池中,或者可能在池中。
为了简要说明布隆过滤器的工作原理,空布隆过滤器是 m 位(所有 0) 位数组。还有 k 个哈希函数将每个元素映射到 m 位 A。所以当我们添加一个新元素时(URL)在Bloom filter中,我们会从hash函数中得到k位,并将它们都设置为 1. 所以当我们检查一个元素时,我们首先得到k位,如果其中任何一个不是1 ,我们立即知道该元素不存在。然而,如果所有k位都是1,这可能来自其他几个元素的组合。
布隆过滤器是一种非常常用的技术,它是网络爬虫中去除重复网址的完美解决方案。
5-解析
从网站得到响应数据后,下一步就是解析数据(通常是HTML),提取出我们关心的信息。这听起来很简单,但要让它健壮可能很难。
我们面临的挑战是你总会在 HTML 代码中发现奇怪的标签、URL 等,并且很难覆盖所有的边界条件。例如,当 HTML 收录非 Unicode 字符时,您可能需要处理编码和解码问题。此外,当网页中收录图片、视频甚至PDF文件时,也会引起奇怪的行为。
另外,有些网页像AngularJS一样是用Javascript渲染的,你的爬虫可能无法获取到任何内容。
我想说,没有灵丹妙药,就不可能为所有网页制作完美而强大的爬虫。您需要进行大量的稳健性测试以确保它按预期工作。
总结
有很多有趣的话题我还没有触及,但我想提一下其中的一些,以便您可以思考它们。一件事是检测循环。很多网站都收录链接,比如A->B->C->A,你的爬虫可能会一直跑下去。想想如何解决这个问题?
另一个问题是 DNS 查找。当系统扩展到一定程度时,DNS 查找可能会成为瓶颈,您可能需要构建自己的 DNS 服务器。
与许多其他系统类似,扩展的网络爬虫可能比构建单机版本困难得多,并且可以在系统设计面试中讨论很多事情。尝试从一些简单的解决方案开始并继续优化它,这会使事情变得比看起来更容易。
以上是我们对网络爬虫的总结。如果你还有什么想知道的,可以在下方评论区讨论。感谢您对编程技巧的支持。
总结
以上就是本站为大家采集整理的Python构建网络爬虫原理分析的全部内容。希望文章能帮助大家解决Python搭建网络爬虫原理分析中遇到的程序开发问题。
如果您觉得本站网站的内容还不错,欢迎向程序员朋友推荐本站网站。
网页qq抓取什么原理( 唯一性网站中同一内容页只与唯一一个url相对应)
网站优化 • 优采云 发表了文章 • 0 个评论 • 315 次浏览 • 2021-12-15 00:10
唯一性网站中同一内容页只与唯一一个url相对应)
1、简洁明了的网站结构蜘蛛爬行就相当于遍历了网络的有向图,那么简单明了的结构,层次分明的网站绝对是它喜欢的,而且尽量保证蜘蛛的可读性。(1)最优的树状结构是“首页—频道—详情页”;(2)平面首页到详情页的层级尽量小,便于抓取,可(3)mesh保证每个页面至少有一个文本链接指向它,这样网站可以被尽可能全面的抓取收录,以及内链建设也可以产生排名主动作用。(4) Navigation 为每个页面添加了一个导航,让用户更容易知道他们在哪里。(5)子域和目录的选择相信很多站长对此都有疑问,在我们看来,当内容少,内容相关性高时,建议以表格的形式实现一个目录,有利于权重的继承和收敛;当内容较大,与主站的相关性稍差时,建议以子域的形式实现。2、@ >简洁美观的URL规则(1)唯一性网站同一内容页面只对应一个URL。URL过多会分散页面权重,目标URL有被重度过滤的风险在系统中;(2) 动态参数越简单越好,URL越短越好;(3)审美让用户和机器通过URL来判断页面的内容。主题;我们推荐URL的以下形式:URL尽可能短,易于阅读,以便用户可以快速理解,比如使用拼音作为目录名;系统中相同的内容只生成一个唯一的URL与之对应,去掉无意义的参数;如果无法保证url的唯一性,尝试使用不同形式的url301到目标url;防止用户输入错误的备用域名301到主域名。3、其他注意事项(1)不要忽略倒霉的robots文件,默认情况下,部分系统robots被阻止爬取通过搜索引擎。当 < 查看全部
网页qq抓取什么原理(
唯一性网站中同一内容页只与唯一一个url相对应)
1、简洁明了的网站结构蜘蛛爬行就相当于遍历了网络的有向图,那么简单明了的结构,层次分明的网站绝对是它喜欢的,而且尽量保证蜘蛛的可读性。(1)最优的树状结构是“首页—频道—详情页”;(2)平面首页到详情页的层级尽量小,便于抓取,可(3)mesh保证每个页面至少有一个文本链接指向它,这样网站可以被尽可能全面的抓取收录,以及内链建设也可以产生排名主动作用。(4) Navigation 为每个页面添加了一个导航,让用户更容易知道他们在哪里。(5)子域和目录的选择相信很多站长对此都有疑问,在我们看来,当内容少,内容相关性高时,建议以表格的形式实现一个目录,有利于权重的继承和收敛;当内容较大,与主站的相关性稍差时,建议以子域的形式实现。2、@ >简洁美观的URL规则(1)唯一性网站同一内容页面只对应一个URL。URL过多会分散页面权重,目标URL有被重度过滤的风险在系统中;(2) 动态参数越简单越好,URL越短越好;(3)审美让用户和机器通过URL来判断页面的内容。主题;我们推荐URL的以下形式:URL尽可能短,易于阅读,以便用户可以快速理解,比如使用拼音作为目录名;系统中相同的内容只生成一个唯一的URL与之对应,去掉无意义的参数;如果无法保证url的唯一性,尝试使用不同形式的url301到目标url;防止用户输入错误的备用域名301到主域名。3、其他注意事项(1)不要忽略倒霉的robots文件,默认情况下,部分系统robots被阻止爬取通过搜索引擎。当 <
网页qq抓取什么原理(网页qq抓取什么原理?(一)__)
网站优化 • 优采云 发表了文章 • 0 个评论 • 38 次浏览 • 2021-12-13 02:00
网页qq抓取什么原理?以前我们都喜欢用各种技术,ajax,flash以及各种时代感觉很酷炫的网页新特性,下面这个就是最近非常火的爬虫。通过单一页面的简单抓取可以捕获到非常不错的效果,而且一些操作比较人性化,像将一些很大的无关元素抓取下来,还原出不同的页面都是非常的容易。更何况用高级爬虫是可以抓取到一些网站大公司的数据的。
但是这个如果用bs是无法完全的抓取来实现,而且效果也没有那么好。那么是什么原因造成了这个呢?1,我们不要怪网站限制,实际上,这个不是网站的责任,是我们自己的设置的问题。(bs上有一些通过设置禁止爬取一些东西,比如,反爬虫机制,太大的东西等)2,我们本身想要抓取的网站网页多,这个是目前市面上主流浏览器的一些限制3,抓取过程中有非常多的东西用js或者js外层包裹了,这些会造成变量赋值的时候,可能会被解析。
比如上图的一个抓取demo...爬虫工作机制以及数据格式的设置相信通过简单的理解可以更好的理解网页qq抓取的工作原理,网页qq抓取就是利用了正则表达式去匹配一些网页中有的内容,从而也可以实现精准的网页抓取。而浏览器的js过滤就相当于一个特殊的加密机制,使得其中的内容在抓取的时候,不能被其他的人解析,同时也让js嵌入的脚本不能被浏览器抓取,目前爬虫分两种解析方式,一种是轮子哥说的,使用chrome的sourcetreeie看了过来就明白了,而这个因人而异,这次提供一个基于webpack项目的实例,解决问题的一个方案。
webpack从最初的目标是为了解决web开发的资源分离,可复用编译器,对于动态网页来说同时也减少了需要在网页中加载的脚本的大小。最新版本的版本更新后,一个webpack体现出更加强大的功能,让我们看看。//app/common.jsimportrequestfrom'@/core.js';importrequirefrom'@/webpack.config.js';importnew{header}from'@/common.html';//usebackend.jsonforproxyvarg=newwebpack.defaultplugin({//proxy:request.backend.proxy,//hostname:'localhost',url:'',content-type:'application/json',//status-code:200,//transform:'object',compress:press({preload:'env-preload',options:{https:true,allowsource:'ssl',//webpack/conf/webpack.config.js//sourcemap:'https://。 查看全部
网页qq抓取什么原理(网页qq抓取什么原理?(一)__)
网页qq抓取什么原理?以前我们都喜欢用各种技术,ajax,flash以及各种时代感觉很酷炫的网页新特性,下面这个就是最近非常火的爬虫。通过单一页面的简单抓取可以捕获到非常不错的效果,而且一些操作比较人性化,像将一些很大的无关元素抓取下来,还原出不同的页面都是非常的容易。更何况用高级爬虫是可以抓取到一些网站大公司的数据的。
但是这个如果用bs是无法完全的抓取来实现,而且效果也没有那么好。那么是什么原因造成了这个呢?1,我们不要怪网站限制,实际上,这个不是网站的责任,是我们自己的设置的问题。(bs上有一些通过设置禁止爬取一些东西,比如,反爬虫机制,太大的东西等)2,我们本身想要抓取的网站网页多,这个是目前市面上主流浏览器的一些限制3,抓取过程中有非常多的东西用js或者js外层包裹了,这些会造成变量赋值的时候,可能会被解析。
比如上图的一个抓取demo...爬虫工作机制以及数据格式的设置相信通过简单的理解可以更好的理解网页qq抓取的工作原理,网页qq抓取就是利用了正则表达式去匹配一些网页中有的内容,从而也可以实现精准的网页抓取。而浏览器的js过滤就相当于一个特殊的加密机制,使得其中的内容在抓取的时候,不能被其他的人解析,同时也让js嵌入的脚本不能被浏览器抓取,目前爬虫分两种解析方式,一种是轮子哥说的,使用chrome的sourcetreeie看了过来就明白了,而这个因人而异,这次提供一个基于webpack项目的实例,解决问题的一个方案。
webpack从最初的目标是为了解决web开发的资源分离,可复用编译器,对于动态网页来说同时也减少了需要在网页中加载的脚本的大小。最新版本的版本更新后,一个webpack体现出更加强大的功能,让我们看看。//app/common.jsimportrequestfrom'@/core.js';importrequirefrom'@/webpack.config.js';importnew{header}from'@/common.html';//usebackend.jsonforproxyvarg=newwebpack.defaultplugin({//proxy:request.backend.proxy,//hostname:'localhost',url:'',content-type:'application/json',//status-code:200,//transform:'object',compress:press({preload:'env-preload',options:{https:true,allowsource:'ssl',//webpack/conf/webpack.config.js//sourcemap:'https://。
网页qq抓取什么原理(1.网站被微信拦截已停止访问该网页怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-13 00:12
1.网站被微信屏蔽,停止访问页面
无论网站的首页、产品页面地址、在线支付地址,微信都会提示您停止访问该网页。经用户投诉及腾讯网站安全中心反映,该网页含有违法或违法内容。为维护绿色互联网环境,已停止访问。部分页面甚至会提示,根据用户投诉和腾讯网站安全中心检测,该页面可能收录恶意欺诈内容。
微信域名这么严,为什么很多商家都挤头皮做微信营销推广?有人问,为什么别人的域名宣传时间长了,微信一推,链接就被屏蔽了?在这里你可能需要注意一件事,出了问题就会有恶魔。
事实上,因为他们的域名经过了反封锁处理,微信很难被抓获,所以可以长期生存。域名被屏蔽会直接影响推广效率和转化率,而这两点直接关系到收益。那么域名防拦截技术到底有多重要,我觉得不用多说了?
所以有朋友问我,这个技术怎么实现?如何实现域名防阻塞?今天小编就为大家一一揭晓。
微信域名防拦截解决方案
1、 跳转到破微信封域名。该技术的原理是通过对域名进行批量分析,生成N个二级域名,并且可以无限替换和重定向域名;而且网页入口、登陆页面、转发到朋友圈的域名都是不一样的,虽然短时间被举报也不会有问题。
2、仿举报页面的原理是在网页上创建一个举报按钮。举报页面也是微信举报选项,但只能解决普通白人用户的举报。目前,可恶的同事已经开发出模拟人工举报的软件,微信举报的过程是无法阻止的。
3、租用防堵域名,这个域名本质上就是一个备案号+游戏备案号+微信白名单的域名。
4、CDN保护原理,使用高仿服务器转发你的链接,穿越防火墙等技术细节,使域名被微包封的概率大大降低,但不能100%防-阻塞,但目前的技术防止 密封效果最好,最耐用。
注意:说是100%防阻塞是骗人的。不要成为腾讯技术团队的素食主义者。 查看全部
网页qq抓取什么原理(1.网站被微信拦截已停止访问该网页怎么办?)
1.网站被微信屏蔽,停止访问页面
无论网站的首页、产品页面地址、在线支付地址,微信都会提示您停止访问该网页。经用户投诉及腾讯网站安全中心反映,该网页含有违法或违法内容。为维护绿色互联网环境,已停止访问。部分页面甚至会提示,根据用户投诉和腾讯网站安全中心检测,该页面可能收录恶意欺诈内容。
微信域名这么严,为什么很多商家都挤头皮做微信营销推广?有人问,为什么别人的域名宣传时间长了,微信一推,链接就被屏蔽了?在这里你可能需要注意一件事,出了问题就会有恶魔。
事实上,因为他们的域名经过了反封锁处理,微信很难被抓获,所以可以长期生存。域名被屏蔽会直接影响推广效率和转化率,而这两点直接关系到收益。那么域名防拦截技术到底有多重要,我觉得不用多说了?
所以有朋友问我,这个技术怎么实现?如何实现域名防阻塞?今天小编就为大家一一揭晓。
微信域名防拦截解决方案
1、 跳转到破微信封域名。该技术的原理是通过对域名进行批量分析,生成N个二级域名,并且可以无限替换和重定向域名;而且网页入口、登陆页面、转发到朋友圈的域名都是不一样的,虽然短时间被举报也不会有问题。
2、仿举报页面的原理是在网页上创建一个举报按钮。举报页面也是微信举报选项,但只能解决普通白人用户的举报。目前,可恶的同事已经开发出模拟人工举报的软件,微信举报的过程是无法阻止的。
3、租用防堵域名,这个域名本质上就是一个备案号+游戏备案号+微信白名单的域名。
4、CDN保护原理,使用高仿服务器转发你的链接,穿越防火墙等技术细节,使域名被微包封的概率大大降低,但不能100%防-阻塞,但目前的技术防止 密封效果最好,最耐用。
注意:说是100%防阻塞是骗人的。不要成为腾讯技术团队的素食主义者。
网页qq抓取什么原理( 华清传媒|2017-01-10做SEO优化的朋友们)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-11 12:24
华清传媒|2017-01-10做SEO优化的朋友们)
百度抓取原理的渠道有哪些?
华清传媒| 2017-01-10
做SEO优化的朋友都知道百度爬虫原理的重要性。因为搜索引擎是否抓取网站内容是影响企业排名网站的一个非常关键的因素,所以SEO人员尝试了各种方式让搜索引擎来自己网站和Crawl一些优质的内容。那么华清传媒小编问大家,你知道百度抓取的原理是什么,搜索引擎抓取页面是通过什么渠道进行的吗?下面就跟随华清传媒小编一起来看看吧:
百度抓取原理
一、链接频道
这里的链接通道是指外部链接。华清传媒小编认为,大家都知道外链的目的是为了吸引蜘蛛,让搜索引擎蜘蛛更好地抓取外链指向的页面,从而加快网站的收录@ > 情况。华清传媒小编提醒大家在做外链的时候要注意外链的质量,这在百度抓取的原理中非常重要。
二、投稿频道
百度抓取原理频道中的提交频道,是大家手动将自己的网站信息提交到百度搜索引擎,让搜索引擎了解到本网站存在且价值巨大收录@>。华清传媒小编提醒,搜索引擎投稿渠道是百度抓取原理中非常重要的渠道。因为大部分网站在刚上线的时候都会手动提交给搜索引擎。华清传媒编辑提醒,如果不提交,搜索引擎可能不知道本站的存在,会延长网站的时间,浪费大量时间和精力。
三、浏览器频道
现在一些知名的浏览器可以对用户访问的网页进行采集和抓取。华清传媒小编在此解释,当用户使用某个浏览器访问一个未被搜索引擎发现的网站时,浏览器会记录这个网站,然后将该网站发送给搜索引擎用于处理。
以上华清传媒小编总结的百度爬取原理的内容就先到这里了,希望能给大家带来一些帮助。其实想要做好网站seo优化,那么百度搜索引擎的一系列算法和原理必须要了解清楚,所以华清传媒小编建议大家先了解一下百度爬取的原理在定位之前网站的优化可以通过避免一些不必要的麻烦的方式进行。网站的优化也将顺利进行,可以说是一个非常好的实践。 查看全部
网页qq抓取什么原理(
华清传媒|2017-01-10做SEO优化的朋友们)
百度抓取原理的渠道有哪些?
华清传媒| 2017-01-10
做SEO优化的朋友都知道百度爬虫原理的重要性。因为搜索引擎是否抓取网站内容是影响企业排名网站的一个非常关键的因素,所以SEO人员尝试了各种方式让搜索引擎来自己网站和Crawl一些优质的内容。那么华清传媒小编问大家,你知道百度抓取的原理是什么,搜索引擎抓取页面是通过什么渠道进行的吗?下面就跟随华清传媒小编一起来看看吧:
百度抓取原理
一、链接频道
这里的链接通道是指外部链接。华清传媒小编认为,大家都知道外链的目的是为了吸引蜘蛛,让搜索引擎蜘蛛更好地抓取外链指向的页面,从而加快网站的收录@ > 情况。华清传媒小编提醒大家在做外链的时候要注意外链的质量,这在百度抓取的原理中非常重要。
二、投稿频道
百度抓取原理频道中的提交频道,是大家手动将自己的网站信息提交到百度搜索引擎,让搜索引擎了解到本网站存在且价值巨大收录@>。华清传媒小编提醒,搜索引擎投稿渠道是百度抓取原理中非常重要的渠道。因为大部分网站在刚上线的时候都会手动提交给搜索引擎。华清传媒编辑提醒,如果不提交,搜索引擎可能不知道本站的存在,会延长网站的时间,浪费大量时间和精力。
三、浏览器频道
现在一些知名的浏览器可以对用户访问的网页进行采集和抓取。华清传媒小编在此解释,当用户使用某个浏览器访问一个未被搜索引擎发现的网站时,浏览器会记录这个网站,然后将该网站发送给搜索引擎用于处理。
以上华清传媒小编总结的百度爬取原理的内容就先到这里了,希望能给大家带来一些帮助。其实想要做好网站seo优化,那么百度搜索引擎的一系列算法和原理必须要了解清楚,所以华清传媒小编建议大家先了解一下百度爬取的原理在定位之前网站的优化可以通过避免一些不必要的麻烦的方式进行。网站的优化也将顺利进行,可以说是一个非常好的实践。
网页qq抓取什么原理(为什么你什么都没干,但QQ空间中却发了很多小广告? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-10 03:00
)
为什么你什么都不做,Qzone里却有这么多小广告?可能你的QQ账号被盗了。本文将解释一个QQ快速登录漏洞。
前阵子在论坛看到一个QQ快速登录的漏洞,觉得很不错,所以转了一部分原文到园子里。
利用这个漏洞最终是可以实现的,只要你点击一个页面或者运行一个程序,那么我就可以拥有你的登录权限。可以直接进入邮箱,进入微云,进入QQ空间等...
理解这篇文章需要一点网络安全基础,请移步我之前的文章
Web安全:通俗易懂,用实例讲解破解网站的原理以及如何保护!如何让 网站 更安全。
众所周知,腾讯使用Activex实现了QQ快速登录。在不熟悉的浏览器上使用时,首先要安装 QuickLogin 控件。
Activex 表示插件。例如,如果你有这个,你可以通过浏览器打开一个文档。而QuickLogin是腾讯用来快速登录的Activex。
就在不知道的时候,快速登录突然不使用控件了。
我当时很纳闷,腾讯用什么奇葩的方式来和Web和本地应用交互?
如果没有插件,网页应该是无法直接与本地应用程序交互的(除非定义了协议,但只能调用,无法获得程序提供的结果)。
机缘巧合(嗯,无聊看任务管理器,发现机器的httpd,发现Apache在运行)突然意识到一个可能:如果QQ在本地开了一个端口,就变成了web服务器,也就是符合HTTP协议的TCP服务器,然后网页ajax向那个QQ(此时作为web服务器)发起请求,能得到结果吗?
httpd 是 Apache 超文本传输协议 (HTTP) 服务器的主要程序。它被设计为一个独立的后台进程,它将创建一个子进程或线程池来处理请求。
结果真的是这样
网页JS发送GET请求到(端口从4300-4308,一一尝试直到成功)
如果你ping它,你会发现它是127.0.0.1。查看端口,确实是QQ在使用。
第一个请求:/pt_get_uins?callback=ptui_getuins_CB&r=0.59326&pt_local_tk=399224727
pt_local_tk 来自 cookie,不管它是什么;r 是一个随机数
返回的结果是一个 JSON 数组:
var var_sso_uin_list=[{"account":"登录QQ账号","face_index":-1,"gender":0,"nickname":"你的QQ昵称","uin":"还是你的QQ账号" ,"client_type":66818,"uin_flag":8388612}];ptui_getuins_CB(var_sso_uin_list);
然后用来获取QQ头像,这里不讨论
这样就可以在网页上显示你的QQ信息了。
当你按下你的头像时(当你选择这个登录时)
生成以下请求:
:4300/pt_get_st?clientuin=你的QQ号&callback=ptui_getst_CB&r=0.7293395590126179&pt_local_tk=399224727
同理,r是随机数,pt_local_tk来自cookie,local_token
这个请求有什么作用?
好吧,Set-Cookie。
然后继续请求
你的QQ号&keyindex=19&pt_aid=549000912&daid=5&u1=http%3A%2F%%2Fqzone%2Fv5%2Floginsucc.html%3Fpara%3Dizone&pt_local_tk=1881902769&pt_3rd_opt=10style=10
这里唯一的 u1 是目标地址
这个请求会返回所有需要的cookies,此时你已经成功登录了。
这些 cookie 相当于令牌。有了这个token,就可以拥有快速登录的权限,相当于登录一般的网站,输入账号密码,后台会注册一个Token到浏览器进行状态验证。
也就是说,一旦拿到cookie,就可以通过CSRF(跨站伪装)的形式做很多事情。
您可以在 网站 上放置一个页面并在其中运行 http 请求,或者创建一个也在其中运行 http 请求的表单。
只要你在电脑上登录QQ,只要你打开这个页面或者打开这个表单,那么你的账号就已经被黑了!
不需要输入账号密码,可以直接调用QQ空间的界面发消息,可以直接抓取相册,可以进入微云等。
我会根据这个漏洞在论坛上再放一个人的例子,
他做的是一个经过验证的QQ群实例
思路是:访问任何QQ网站登录都会在本地生成cookies,
然后在这个cookie中获取pt_local_token
然后得到一切。
<p>public static bool VerifyQQGroupYesNo(string VerifyQQGroupNum)
{
///
/// QQ群授权验证YesNo
///
bool YesNo = false;
///随机数处理
Random random = new Random();
string randomstr = (Convert.ToDouble(random.Next(1, 99)) / Math.PI / 100).ToString();
try
{
///定义string类型pt_local_tk 、localhost_str
string pt_local_tk = string.Empty, localhost_str = string.Empty;
//QQ会员中心Url
string LoginUrl = "http://xui.ptlogin2.qq.com/cgi ... 3B%3B
//Get方式Http1.1访问QQ会员中心
Zmoli775.HTTP.GetHttp1_1(LoginUrl);
//获取访问QQ会员中心生成Cookies->pt_local_tk值
pt_local_tk = HTTP.Cookies.GetCookies(new Uri("http://ptlogin2.qq.com"))["pt_local_token"].Value;
/*
https://localhost.ptlogin2.qq. ... 91081
*/
//自动登录[1]->返回QQ号、client_type、QQ头像代码face_index、性别、QQ昵称、uin、uin_flag
localhost_str = Zmoli775.HTTP.Get("https://localhost.ptlogin2.qq. ... ot%3B + randomstr + "&pt_local_tk=" + pt_local_tk + "", LoginUrl);
//正则截取返回JSON字符串
if (!string.IsNullOrEmpty(localhost_str = Regex.Match(localhost_str, "(?i)(? 查看全部
网页qq抓取什么原理(为什么你什么都没干,但QQ空间中却发了很多小广告?
)
为什么你什么都不做,Qzone里却有这么多小广告?可能你的QQ账号被盗了。本文将解释一个QQ快速登录漏洞。
前阵子在论坛看到一个QQ快速登录的漏洞,觉得很不错,所以转了一部分原文到园子里。
利用这个漏洞最终是可以实现的,只要你点击一个页面或者运行一个程序,那么我就可以拥有你的登录权限。可以直接进入邮箱,进入微云,进入QQ空间等...
理解这篇文章需要一点网络安全基础,请移步我之前的文章
Web安全:通俗易懂,用实例讲解破解网站的原理以及如何保护!如何让 网站 更安全。
众所周知,腾讯使用Activex实现了QQ快速登录。在不熟悉的浏览器上使用时,首先要安装 QuickLogin 控件。
Activex 表示插件。例如,如果你有这个,你可以通过浏览器打开一个文档。而QuickLogin是腾讯用来快速登录的Activex。
就在不知道的时候,快速登录突然不使用控件了。
我当时很纳闷,腾讯用什么奇葩的方式来和Web和本地应用交互?
如果没有插件,网页应该是无法直接与本地应用程序交互的(除非定义了协议,但只能调用,无法获得程序提供的结果)。
机缘巧合(嗯,无聊看任务管理器,发现机器的httpd,发现Apache在运行)突然意识到一个可能:如果QQ在本地开了一个端口,就变成了web服务器,也就是符合HTTP协议的TCP服务器,然后网页ajax向那个QQ(此时作为web服务器)发起请求,能得到结果吗?
httpd 是 Apache 超文本传输协议 (HTTP) 服务器的主要程序。它被设计为一个独立的后台进程,它将创建一个子进程或线程池来处理请求。
结果真的是这样
网页JS发送GET请求到(端口从4300-4308,一一尝试直到成功)
如果你ping它,你会发现它是127.0.0.1。查看端口,确实是QQ在使用。
第一个请求:/pt_get_uins?callback=ptui_getuins_CB&r=0.59326&pt_local_tk=399224727
pt_local_tk 来自 cookie,不管它是什么;r 是一个随机数
返回的结果是一个 JSON 数组:
var var_sso_uin_list=[{"account":"登录QQ账号","face_index":-1,"gender":0,"nickname":"你的QQ昵称","uin":"还是你的QQ账号" ,"client_type":66818,"uin_flag":8388612}];ptui_getuins_CB(var_sso_uin_list);
然后用来获取QQ头像,这里不讨论
这样就可以在网页上显示你的QQ信息了。
当你按下你的头像时(当你选择这个登录时)
生成以下请求:
:4300/pt_get_st?clientuin=你的QQ号&callback=ptui_getst_CB&r=0.7293395590126179&pt_local_tk=399224727
同理,r是随机数,pt_local_tk来自cookie,local_token
这个请求有什么作用?
好吧,Set-Cookie。
然后继续请求
你的QQ号&keyindex=19&pt_aid=549000912&daid=5&u1=http%3A%2F%%2Fqzone%2Fv5%2Floginsucc.html%3Fpara%3Dizone&pt_local_tk=1881902769&pt_3rd_opt=10style=10
这里唯一的 u1 是目标地址
这个请求会返回所有需要的cookies,此时你已经成功登录了。
这些 cookie 相当于令牌。有了这个token,就可以拥有快速登录的权限,相当于登录一般的网站,输入账号密码,后台会注册一个Token到浏览器进行状态验证。
也就是说,一旦拿到cookie,就可以通过CSRF(跨站伪装)的形式做很多事情。
您可以在 网站 上放置一个页面并在其中运行 http 请求,或者创建一个也在其中运行 http 请求的表单。
只要你在电脑上登录QQ,只要你打开这个页面或者打开这个表单,那么你的账号就已经被黑了!
不需要输入账号密码,可以直接调用QQ空间的界面发消息,可以直接抓取相册,可以进入微云等。
我会根据这个漏洞在论坛上再放一个人的例子,
他做的是一个经过验证的QQ群实例
思路是:访问任何QQ网站登录都会在本地生成cookies,
然后在这个cookie中获取pt_local_token
然后得到一切。
<p>public static bool VerifyQQGroupYesNo(string VerifyQQGroupNum)
{
///
/// QQ群授权验证YesNo
///
bool YesNo = false;
///随机数处理
Random random = new Random();
string randomstr = (Convert.ToDouble(random.Next(1, 99)) / Math.PI / 100).ToString();
try
{
///定义string类型pt_local_tk 、localhost_str
string pt_local_tk = string.Empty, localhost_str = string.Empty;
//QQ会员中心Url
string LoginUrl = "http://xui.ptlogin2.qq.com/cgi ... 3B%3B
//Get方式Http1.1访问QQ会员中心
Zmoli775.HTTP.GetHttp1_1(LoginUrl);
//获取访问QQ会员中心生成Cookies->pt_local_tk值
pt_local_tk = HTTP.Cookies.GetCookies(new Uri("http://ptlogin2.qq.com";))["pt_local_token"].Value;
/*
https://localhost.ptlogin2.qq. ... 91081
*/
//自动登录[1]->返回QQ号、client_type、QQ头像代码face_index、性别、QQ昵称、uin、uin_flag
localhost_str = Zmoli775.HTTP.Get("https://localhost.ptlogin2.qq. ... ot%3B + randomstr + "&pt_local_tk=" + pt_local_tk + "", LoginUrl);
//正则截取返回JSON字符串
if (!string.IsNullOrEmpty(localhost_str = Regex.Match(localhost_str, "(?i)(?
网页qq抓取什么原理( 网页收录的一个基本流程及提高抓取频率的方法有哪些)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-08 14:25
网页收录的一个基本流程及提高抓取频率的方法有哪些)
网站爬取频率是什么意思?如何提高抓取频率?
网站 爬行频率是seo头疼的问题。如果抓取频率太高,会影响网站的加载速度,如果抓取频率太低,则不会保证索引量对于新站点来说尤为重要。那么什么是爬取频率,有什么方法可以提高呢?
网站 爬取频率对SEO有什么意义?根据以往的工作经验,我们知道网页收录的一个基本流程主要是:抓取网址->内容质量评估->索引库筛选->网页收录(显示在搜索结果中),如果你的内容质量比较低,直接放入低质量的索引库,就很难被百度收录。从这个过程中不难看出,网站频率的爬取将直接影响网站的收录率和内容质量评价。
影响网站爬取频率的因素:
①入站链接:理论上,只要是外部链接,无论其质量和形态,都会起到引导蜘蛛爬行和爬行的作用。
② 网站 结构:建站首选短域名,简化目录层次,URL过长,动态参数过多。
③ 页面速度:移动优先指标被百度不止一次提及。最重要的指标是页面的首次加载,控制在3秒内。
④ 主动提交:网站地图、官方API提交、JS访问提交等。
⑤ 内容更新:优质内容的更新频率,是网站大规模排名的核心因素。
⑥百度熊掌账号:如果你的网站配置了熊掌账号,如果内容足够优质,抓取率几乎可以达到100%。
如何查看网站的爬取频率:
① cms 系统自带的“百度蜘蛛”分析插件。
②定期做“网站日志分析”比较方便。
页面抓取对网站的影响:
1、网站 改版如果你的网站升级改版了,有些网址已经改版了,可能急需搜索引擎对页面内容进行抓取和重新评估. 这时候其实有一个好用的小技巧:就是主动把网址加入到站点地图中,并在百度后台更新,第一时间通知搜索引擎它的变化。
2、网站 排名中大部分站长认为百度熊掌自推出以来,已经解决了收录问题。实际上,只能不断地抓取目标网址。可以不断重新评估权重以提高排名。因此,当您有一个页面需要进行排名时,您需要将其放置在抓取频率较高的列中。
3、 高压控制页面抓取频率不一定好。来自恶意的采集爬虫,往往会造成服务器资源的严重浪费甚至宕机,尤其是一些外链分析爬虫。如有必要,可能需要使用 Robots.txt 来有效阻止它。
4、异常诊断如果你发现某个页面很久没有收录,那你就需要了解一下:百度蜘蛛的可访问性,可以通过百度官方后台的爬取诊断来进行检查相关细节原因。
总结:页面抓取频率对索引、收录、排名、二级排名起着至关重要的作用。作为SEO人员,您可能需要注意它。希望以上内容可以帮助大家了解百度蜘蛛爬行的频率。问题。
上一篇:关键词 做SEM竞价怎么挖?有哪些方法?
下一篇:网站 如何应对排名波动?了解这些可以帮助您稳定排名 查看全部
网页qq抓取什么原理(
网页收录的一个基本流程及提高抓取频率的方法有哪些)
网站爬取频率是什么意思?如何提高抓取频率?
网站 爬行频率是seo头疼的问题。如果抓取频率太高,会影响网站的加载速度,如果抓取频率太低,则不会保证索引量对于新站点来说尤为重要。那么什么是爬取频率,有什么方法可以提高呢?
网站 爬取频率对SEO有什么意义?根据以往的工作经验,我们知道网页收录的一个基本流程主要是:抓取网址->内容质量评估->索引库筛选->网页收录(显示在搜索结果中),如果你的内容质量比较低,直接放入低质量的索引库,就很难被百度收录。从这个过程中不难看出,网站频率的爬取将直接影响网站的收录率和内容质量评价。
影响网站爬取频率的因素:
①入站链接:理论上,只要是外部链接,无论其质量和形态,都会起到引导蜘蛛爬行和爬行的作用。
② 网站 结构:建站首选短域名,简化目录层次,URL过长,动态参数过多。
③ 页面速度:移动优先指标被百度不止一次提及。最重要的指标是页面的首次加载,控制在3秒内。
④ 主动提交:网站地图、官方API提交、JS访问提交等。
⑤ 内容更新:优质内容的更新频率,是网站大规模排名的核心因素。
⑥百度熊掌账号:如果你的网站配置了熊掌账号,如果内容足够优质,抓取率几乎可以达到100%。
如何查看网站的爬取频率:
① cms 系统自带的“百度蜘蛛”分析插件。
②定期做“网站日志分析”比较方便。
页面抓取对网站的影响:
1、网站 改版如果你的网站升级改版了,有些网址已经改版了,可能急需搜索引擎对页面内容进行抓取和重新评估. 这时候其实有一个好用的小技巧:就是主动把网址加入到站点地图中,并在百度后台更新,第一时间通知搜索引擎它的变化。
2、网站 排名中大部分站长认为百度熊掌自推出以来,已经解决了收录问题。实际上,只能不断地抓取目标网址。可以不断重新评估权重以提高排名。因此,当您有一个页面需要进行排名时,您需要将其放置在抓取频率较高的列中。
3、 高压控制页面抓取频率不一定好。来自恶意的采集爬虫,往往会造成服务器资源的严重浪费甚至宕机,尤其是一些外链分析爬虫。如有必要,可能需要使用 Robots.txt 来有效阻止它。
4、异常诊断如果你发现某个页面很久没有收录,那你就需要了解一下:百度蜘蛛的可访问性,可以通过百度官方后台的爬取诊断来进行检查相关细节原因。
总结:页面抓取频率对索引、收录、排名、二级排名起着至关重要的作用。作为SEO人员,您可能需要注意它。希望以上内容可以帮助大家了解百度蜘蛛爬行的频率。问题。
上一篇:关键词 做SEM竞价怎么挖?有哪些方法?
下一篇:网站 如何应对排名波动?了解这些可以帮助您稳定排名
网页qq抓取什么原理(百度蜘蛛的工作原理是什么?如何获取最优质的内容展现在客户面前?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-08 00:02
百度蜘蛛的正式名称也叫百度搜索引擎机器人。它捕获整个网页的内容并将其上传到百度数据库。因为并非所有页面都对用户有用,所以所有搜索机器人都会捕获内容。分析一下,如果是无用的内容,就不会给收录和索引,所以如果网站能迎合百度蜘蛛的喜好,就成功了一半。今天,牛商网分析了一些百度蜘蛛的工作原理。哪些内容容易被百度蜘蛛抓取?
百度蜘蛛的工作原理:
面对互联网上千亿的网页,搜索引擎如何获取最优质的内容展示在客户面前?其实每次搜索都会有这四个步骤:爬取、过滤、索引、输出
第 1 步:爬网
百度搜索引擎机器人,又称百度蜘蛛。百度蜘蛛会通过计算和规则来确定需要抓取的页面和抓取频率。如果网站的更新频率和网站的内容质量高且用户友好,那么你新生成的内容会立即被蜘蛛抓取。
第 2 步:过滤
因为页面太多,页面质量参差不齐,甚至出现诈骗页面、死链接等垃圾内容。因此,百度蜘蛛会先对这些内容进行过滤,防止这些内容向用户展示,给用户带来不好的用户体验。
第 3 步:索引
百度会对过滤后的内容进行标记、识别和分类,并存储数据结构。保存内容包括页面的标题、描述等关键内容。然后将这些内容保存在库中,当用户搜索时,会根据匹配规则显示出来。
第 4 步:输出
当用户搜索一个关键词时,搜索引擎会根据一系列算法和规则对索引库中的内容进行匹配,同时对匹配结果的优劣进行评分,最后得到一个排名顺序,也就是百度的排名。
以上就是百度蜘蛛的工作原理。如果要优化网站,必须了解百度蜘蛛的工作原理,然后分析哪些内容容易被百度蜘蛛抓取,然后百度输出搜索引擎。喜欢的内容,自然排名和收录都会增加。 查看全部
网页qq抓取什么原理(百度蜘蛛的工作原理是什么?如何获取最优质的内容展现在客户面前?)
百度蜘蛛的正式名称也叫百度搜索引擎机器人。它捕获整个网页的内容并将其上传到百度数据库。因为并非所有页面都对用户有用,所以所有搜索机器人都会捕获内容。分析一下,如果是无用的内容,就不会给收录和索引,所以如果网站能迎合百度蜘蛛的喜好,就成功了一半。今天,牛商网分析了一些百度蜘蛛的工作原理。哪些内容容易被百度蜘蛛抓取?
百度蜘蛛的工作原理:
面对互联网上千亿的网页,搜索引擎如何获取最优质的内容展示在客户面前?其实每次搜索都会有这四个步骤:爬取、过滤、索引、输出
第 1 步:爬网
百度搜索引擎机器人,又称百度蜘蛛。百度蜘蛛会通过计算和规则来确定需要抓取的页面和抓取频率。如果网站的更新频率和网站的内容质量高且用户友好,那么你新生成的内容会立即被蜘蛛抓取。
第 2 步:过滤
因为页面太多,页面质量参差不齐,甚至出现诈骗页面、死链接等垃圾内容。因此,百度蜘蛛会先对这些内容进行过滤,防止这些内容向用户展示,给用户带来不好的用户体验。
第 3 步:索引
百度会对过滤后的内容进行标记、识别和分类,并存储数据结构。保存内容包括页面的标题、描述等关键内容。然后将这些内容保存在库中,当用户搜索时,会根据匹配规则显示出来。
第 4 步:输出
当用户搜索一个关键词时,搜索引擎会根据一系列算法和规则对索引库中的内容进行匹配,同时对匹配结果的优劣进行评分,最后得到一个排名顺序,也就是百度的排名。
以上就是百度蜘蛛的工作原理。如果要优化网站,必须了解百度蜘蛛的工作原理,然后分析哪些内容容易被百度蜘蛛抓取,然后百度输出搜索引擎。喜欢的内容,自然排名和收录都会增加。
网页qq抓取什么原理(内容简明扼要能使你眼前一亮,通过这篇文章的详细介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 40 次浏览 • 2021-12-08 00:02
这篇文章文章带你看看Python爬虫的原理是什么。内容简洁易懂。绝对会让你眼前一亮。通过对文章的这篇详细介绍,希望你能有所收获。.
1、网络连接原理
如上图,简单来说,网络连接就是计算机发起请求,服务器返回相应的HTML文件。至于请求头和消息体,详细说明了要爬取的链接。
2、爬取的原理
爬虫的原理是模拟计算机向服务器发起Request请求,接收并解析来自服务器的响应内容,提取需要的信息。
往往一次请求无法完全获取所有网页的信息和数据,则需要合理设计爬取流程,实现多页面跨页面爬取。
多页爬取的过程是怎样的?
基本思路:
1、由于多个页面的结构可能相似,可以先手动翻页观察网址
2、获取所有网址
3、 根据每个页面URL的函数定义抓取数据
4、循环网址抓取存储
跨页爬取流程是什么?
基本思路:
1、查找所有网址
2、定义爬取详细页面的函数代码
3、进入详细页面查看详细数据
4、存储,循环完成,结束
3、网页是什么样子的?
右键单击并选择“检查”以打开网页的源代码。可以看到上面是HTML文件,下面是CSS样式。HTML 的一部分是 JavaScript 代码。
我们浏览的网页是浏览器渲染的结果,是翻译HTML、CSS、JavaScript代码得到的页面界面。一个流行的比喻是:添加一个网页就是一个房子,HTML是房子的框架和布局,CSS是房子的软装饰风格,比如地板和油漆,而javaScript是电器。
比如打开百度搜索,将鼠标移动到“百度点击”按钮上,右击选择“检查”,就可以看到网页源代码的位置了。
或者直接打开右键源码,点击网页源码页面左上角的鼠标形状的图标,然后移动到网页的具体位置,就可以看到了。
以上内容就是Python爬虫的原理是什么。你学到了知识或技能吗?如果您想学习更多的技能或丰富您的知识储备,请关注易速云行业资讯频道。 查看全部
网页qq抓取什么原理(内容简明扼要能使你眼前一亮,通过这篇文章的详细介绍)
这篇文章文章带你看看Python爬虫的原理是什么。内容简洁易懂。绝对会让你眼前一亮。通过对文章的这篇详细介绍,希望你能有所收获。.
1、网络连接原理
如上图,简单来说,网络连接就是计算机发起请求,服务器返回相应的HTML文件。至于请求头和消息体,详细说明了要爬取的链接。
2、爬取的原理
爬虫的原理是模拟计算机向服务器发起Request请求,接收并解析来自服务器的响应内容,提取需要的信息。
往往一次请求无法完全获取所有网页的信息和数据,则需要合理设计爬取流程,实现多页面跨页面爬取。
多页爬取的过程是怎样的?
基本思路:
1、由于多个页面的结构可能相似,可以先手动翻页观察网址
2、获取所有网址
3、 根据每个页面URL的函数定义抓取数据
4、循环网址抓取存储
跨页爬取流程是什么?
基本思路:
1、查找所有网址
2、定义爬取详细页面的函数代码
3、进入详细页面查看详细数据
4、存储,循环完成,结束
3、网页是什么样子的?
右键单击并选择“检查”以打开网页的源代码。可以看到上面是HTML文件,下面是CSS样式。HTML 的一部分是 JavaScript 代码。
我们浏览的网页是浏览器渲染的结果,是翻译HTML、CSS、JavaScript代码得到的页面界面。一个流行的比喻是:添加一个网页就是一个房子,HTML是房子的框架和布局,CSS是房子的软装饰风格,比如地板和油漆,而javaScript是电器。
比如打开百度搜索,将鼠标移动到“百度点击”按钮上,右击选择“检查”,就可以看到网页源代码的位置了。
或者直接打开右键源码,点击网页源码页面左上角的鼠标形状的图标,然后移动到网页的具体位置,就可以看到了。
以上内容就是Python爬虫的原理是什么。你学到了知识或技能吗?如果您想学习更多的技能或丰富您的知识储备,请关注易速云行业资讯频道。
网页qq抓取什么原理(网页qq抓取什么原理?使用腾讯云免费的linux服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-06 21:01
网页qq抓取什么原理?使用腾讯云免费的的linux服务器+腾讯云这款云服务,将页面上的关键数据抓取下来,然后提供了免费的24小时云主机与腾讯云的虚拟主机给你进行后台开发,因为页面的关键点都设置好了,只要你简单修改代码即可实现。网页动态抓取框架是需要配置的,这里有更详细的网页抓取方案,可以根据你的需求进行选择,请查看这里。4.。
1、页面抓取配置根据框架配置好接口参数,如on_exit、timeout等;访问页面,选择抓取;如不抓取,保存页面,即可获取到页面信息。
建议重新考虑这个方案。qq空间有个iframe。当关键字出现时,爬虫会爬走页面内容,然后自动识别是否url获取。
一下是我抓取到的数据,
同样的情况,
如果只是一小段那还好,如果抓取完一整段你的带宽都不够用啊喂,抓包看了么,网页js代码都是ajax,带宽都不够用的好吗,
抓取不了的话,看看是否可以在不同的网络上抓取数据。
qq空间的页面我了解的是cookie做一个判断,比如useragent在url=(http)to这里,ip在internet这里,根据useragent,ip,useragent计算出来的target里。然后得到url可以抓取,如果url的ip在qq空间的某个ip后面,那么就成功抓取。具体怎么抓取得看带宽跟页面效果,简单的说一下网页抓取的思路。当页面进入时,一般都是xmlhttprequest对象。document.cookie={"scope":"/","max_in_size":"650000001"};console.log(useragent.matches(i.tostring()));抓取到的js之后再跟其他页面一同传到服务器。另外,如果电脑带宽不足,可以买台带宽。 查看全部
网页qq抓取什么原理(网页qq抓取什么原理?使用腾讯云免费的linux服务器)
网页qq抓取什么原理?使用腾讯云免费的的linux服务器+腾讯云这款云服务,将页面上的关键数据抓取下来,然后提供了免费的24小时云主机与腾讯云的虚拟主机给你进行后台开发,因为页面的关键点都设置好了,只要你简单修改代码即可实现。网页动态抓取框架是需要配置的,这里有更详细的网页抓取方案,可以根据你的需求进行选择,请查看这里。4.。
1、页面抓取配置根据框架配置好接口参数,如on_exit、timeout等;访问页面,选择抓取;如不抓取,保存页面,即可获取到页面信息。
建议重新考虑这个方案。qq空间有个iframe。当关键字出现时,爬虫会爬走页面内容,然后自动识别是否url获取。
一下是我抓取到的数据,
同样的情况,
如果只是一小段那还好,如果抓取完一整段你的带宽都不够用啊喂,抓包看了么,网页js代码都是ajax,带宽都不够用的好吗,
抓取不了的话,看看是否可以在不同的网络上抓取数据。
qq空间的页面我了解的是cookie做一个判断,比如useragent在url=(http)to这里,ip在internet这里,根据useragent,ip,useragent计算出来的target里。然后得到url可以抓取,如果url的ip在qq空间的某个ip后面,那么就成功抓取。具体怎么抓取得看带宽跟页面效果,简单的说一下网页抓取的思路。当页面进入时,一般都是xmlhttprequest对象。document.cookie={"scope":"/","max_in_size":"650000001"};console.log(useragent.matches(i.tostring()));抓取到的js之后再跟其他页面一同传到服务器。另外,如果电脑带宽不足,可以买台带宽。
网页qq抓取什么原理(爬虫入门后可以看一下爬虫如何模拟登陆Python爬虫模拟)
网站优化 • 优采云 发表了文章 • 0 个评论 • 39 次浏览 • 2021-12-04 21:19
什么是网络爬虫
网络爬虫,又称网络蜘蛛,是指按照一定的规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个网站进入其他网站,获取需要的内容。
优先声明:我们使用的python编译环境是PyCharm
一、一、一个网络爬虫的结构:
二、写一个网络爬虫
(1)准备需要的库
我们需要准备一个名为BeautifulSoup(网页解析)的开源库来解析下载的网页。我们使用的是PyCharm编译环境,可以直接下载开源库。
进行如下操作:
选择文件->设置
打开项目:PythonProject下的项目解释器
单击加号以添加新库
输入bs4,选择bs4,点击Install Packge下载
(2)写一个爬虫调度器
这里的bike_spider是项目名引入的四个类,分别对应如下四段代码:url manager、url downloader、url parser、url outputter。
# 爬虫调度程序
from bike_spider import url_manager, html_downloader, html_parser, html_outputer
# 爬虫初始化
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser()
self.outputer = html_outputer.HtmlOutputer()
def craw(self, my_root_url):
count = 1
self.urls.add_new_url(my_root_url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print("craw %d : %s" % (count, new_url))
# 下载网页
html_cont = self.downloader.download(new_url)
# 解析网页
new_urls, new_data = self.parser.parse(new_url, html_cont)
self.urls.add_new_urls(new_urls)
# 网页输出器收集数据
self.outputer.collect_data(new_data)
if count == 10:
break
count += 1
except:
print("craw failed")
self.outputer.output_html()
if __name__ == "__main__":
root_url = "http://baike.baidu.com/item/Python/407313"
obj_spider = SpiderMain()
obj_spider.craw(root_url)
(3)写网址管理器
我们将抓取到的网址和未抓取到的网址分开存放,这样我们就不会重复抓取一些已经抓取过的网页。
# url管理器
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.new_urls.add(url)
def get_new_url(self):
# pop方法会帮我们获取一个url并且移除它
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
def has_new_url(self):
return len(self.new_urls) != 0
(4)写一个网页下载器
通过网络请求下载页面
# 网页下载器
import urllib.request
class HtmlDownloader(object):
def download(self, url):
if url is None:
return None
response = urllib.request.urlopen(url)
# code不为200则请求失败
if response.getcode() != 200:
return None
return response.read()
(5)写一个网页解析器
在解析网页时,我们需要知道我们要查询哪些特征。我们可以打开一个网页,右击查看元素,了解我们检查的内容的共性。
# 网页解析器
import re
from bs4 import BeautifulSoup
from urllib.parse import urljoin
class HtmlParser(object):
def parse(self, page_url, html_cont):
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont, "html.parser", from_encoding="utf-8")
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
def _get_new_data(self, page_url, soup):
res_data = {"url": page_url}
# 获取标题
title_node = soup.find("dd", class_="lemmaWgt-lemmaTitle-title").find("h1")
res_data["title"] = title_node.get_text()
summary_node = soup.find("div", class_="lemma-summary")
res_data["summary"] = summary_node.get_text()
return res_data
def _get_new_urls(self, page_url, soup):
new_urls = set()
# 查找出所有符合下列条件的url
links = soup.find_all("a", href=re.compile(r"/item/"))
for link in links:
new_url = link['href']
# 获取到的url不完整,学要拼接
new_full_url = urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls
(6)写一个网页输出设备
输出格式有很多种,我们选择以html的形式输出,这样就可以到一个html页面。
# 网页输出器
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self, data):
if data is None:
return
self.datas.append(data)
# 我们以html表格形式进行输出
def output_html(self):
fout = open("output.html", "w", encoding='utf-8')
fout.write("")
fout.write("")
fout.write("")
# 以表格输出
fout.write("")
for data in self.datas:
# 一行
fout.write("")
# 每个单元行的内容
fout.write("%s" % data["url"])
fout.write("%s" % data["title"])
fout.write("%s" % data["summary"])
fout.write("")
fout.write("")
fout.write("")
fout.write("")
# 输出完毕后一定要关闭输出器
fout.close()
写在最后
注意:网页经常变化,我们需要根据网页的变化动态修改我们的代码以获得我们需要的内容。
这只是一个简单的网络爬虫,如果我们需要改进它的功能,我们需要考虑更多的问题。
爬虫上手后,可以看看爬虫是如何模拟登陆的 Python爬虫是如何模拟登陆的 查看全部
网页qq抓取什么原理(爬虫入门后可以看一下爬虫如何模拟登陆Python爬虫模拟)
什么是网络爬虫
网络爬虫,又称网络蜘蛛,是指按照一定的规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个网站进入其他网站,获取需要的内容。
优先声明:我们使用的python编译环境是PyCharm
一、一、一个网络爬虫的结构:
二、写一个网络爬虫
(1)准备需要的库
我们需要准备一个名为BeautifulSoup(网页解析)的开源库来解析下载的网页。我们使用的是PyCharm编译环境,可以直接下载开源库。
进行如下操作:
选择文件->设置
打开项目:PythonProject下的项目解释器
单击加号以添加新库
输入bs4,选择bs4,点击Install Packge下载
(2)写一个爬虫调度器
这里的bike_spider是项目名引入的四个类,分别对应如下四段代码:url manager、url downloader、url parser、url outputter。
# 爬虫调度程序
from bike_spider import url_manager, html_downloader, html_parser, html_outputer
# 爬虫初始化
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser()
self.outputer = html_outputer.HtmlOutputer()
def craw(self, my_root_url):
count = 1
self.urls.add_new_url(my_root_url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print("craw %d : %s" % (count, new_url))
# 下载网页
html_cont = self.downloader.download(new_url)
# 解析网页
new_urls, new_data = self.parser.parse(new_url, html_cont)
self.urls.add_new_urls(new_urls)
# 网页输出器收集数据
self.outputer.collect_data(new_data)
if count == 10:
break
count += 1
except:
print("craw failed")
self.outputer.output_html()
if __name__ == "__main__":
root_url = "http://baike.baidu.com/item/Python/407313"
obj_spider = SpiderMain()
obj_spider.craw(root_url)
(3)写网址管理器
我们将抓取到的网址和未抓取到的网址分开存放,这样我们就不会重复抓取一些已经抓取过的网页。
# url管理器
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.new_urls.add(url)
def get_new_url(self):
# pop方法会帮我们获取一个url并且移除它
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
def has_new_url(self):
return len(self.new_urls) != 0
(4)写一个网页下载器
通过网络请求下载页面
# 网页下载器
import urllib.request
class HtmlDownloader(object):
def download(self, url):
if url is None:
return None
response = urllib.request.urlopen(url)
# code不为200则请求失败
if response.getcode() != 200:
return None
return response.read()
(5)写一个网页解析器
在解析网页时,我们需要知道我们要查询哪些特征。我们可以打开一个网页,右击查看元素,了解我们检查的内容的共性。
# 网页解析器
import re
from bs4 import BeautifulSoup
from urllib.parse import urljoin
class HtmlParser(object):
def parse(self, page_url, html_cont):
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont, "html.parser", from_encoding="utf-8")
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
def _get_new_data(self, page_url, soup):
res_data = {"url": page_url}
# 获取标题
title_node = soup.find("dd", class_="lemmaWgt-lemmaTitle-title").find("h1")
res_data["title"] = title_node.get_text()
summary_node = soup.find("div", class_="lemma-summary")
res_data["summary"] = summary_node.get_text()
return res_data
def _get_new_urls(self, page_url, soup):
new_urls = set()
# 查找出所有符合下列条件的url
links = soup.find_all("a", href=re.compile(r"/item/"))
for link in links:
new_url = link['href']
# 获取到的url不完整,学要拼接
new_full_url = urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls
(6)写一个网页输出设备
输出格式有很多种,我们选择以html的形式输出,这样就可以到一个html页面。
# 网页输出器
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self, data):
if data is None:
return
self.datas.append(data)
# 我们以html表格形式进行输出
def output_html(self):
fout = open("output.html", "w", encoding='utf-8')
fout.write("")
fout.write("")
fout.write("")
# 以表格输出
fout.write("")
for data in self.datas:
# 一行
fout.write("")
# 每个单元行的内容
fout.write("%s" % data["url"])
fout.write("%s" % data["title"])
fout.write("%s" % data["summary"])
fout.write("")
fout.write("")
fout.write("")
fout.write("")
# 输出完毕后一定要关闭输出器
fout.close()
写在最后
注意:网页经常变化,我们需要根据网页的变化动态修改我们的代码以获得我们需要的内容。
这只是一个简单的网络爬虫,如果我们需要改进它的功能,我们需要考虑更多的问题。
爬虫上手后,可以看看爬虫是如何模拟登陆的 Python爬虫是如何模拟登陆的
网页qq抓取什么原理(网页qq抓取什么原理?分类线以下只是我个人在腾讯网开发者中心)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2021-12-02 01:00
网页qq抓取什么原理?分类线以下只是我个人在腾讯网开发者中心分享过那么几次好网站,不能肯定对大家有没有用。以下文章是自己整理的分享在这,看完后你就应该知道了。1.使用wordpressshell插件抓取网页数据,2.使用redis+mongodb+php抓取网页数据,3.用linuxmkfs抓取网页数据--1.使用wordpressshell插件抓取网页数据目的:把wordpress程序改写到一个shell环境下使用方法:importosimportrequestsimportoshost_template={'other':[{'expires':'365-1','name':'yourname','about':{'href':'#','sign':''}}]}os.getcwd()os.removeclass(os.getcwd())forshellnameinos.path.join(/):base_path=shellname.split('/')[0]#ignorewordsrequests.urlopen(base_path).read()print(requests.urlopen('').read())sh='d:\\\\'requests.urlopen(sh).read()print(requests.urlopen('').read())sh='d:\\\\'requests.urlopen(sh).read()print(requests.urlopen('').read())sh='d:\\\\'requests.urlopen(sh).read()print(requests.urlopen('').read())sh='d:\\\\'requests.urlopen(sh).read()print(requests.urlopen('').read())2.使用redis+mongodb+php抓取网页数据目的:把使用redis发送post请求发送的数据存储,再用php读取。
数据可变,效率较高使用方法:os.getcwd()os.removeclass(os.getcwd())forshellnameinos.path.join(/):base_path=shellname.split('/')[0]#ignorewordsitems={'type':['car','suv','truck'],'data':[{'date':date(format('%y-%m-%d%h:%m:%s'),norm。 查看全部
网页qq抓取什么原理(网页qq抓取什么原理?分类线以下只是我个人在腾讯网开发者中心)
网页qq抓取什么原理?分类线以下只是我个人在腾讯网开发者中心分享过那么几次好网站,不能肯定对大家有没有用。以下文章是自己整理的分享在这,看完后你就应该知道了。1.使用wordpressshell插件抓取网页数据,2.使用redis+mongodb+php抓取网页数据,3.用linuxmkfs抓取网页数据--1.使用wordpressshell插件抓取网页数据目的:把wordpress程序改写到一个shell环境下使用方法:importosimportrequestsimportoshost_template={'other':[{'expires':'365-1','name':'yourname','about':{'href':'#','sign':''}}]}os.getcwd()os.removeclass(os.getcwd())forshellnameinos.path.join(/):base_path=shellname.split('/')[0]#ignorewordsrequests.urlopen(base_path).read()print(requests.urlopen('').read())sh='d:\\\\'requests.urlopen(sh).read()print(requests.urlopen('').read())sh='d:\\\\'requests.urlopen(sh).read()print(requests.urlopen('').read())sh='d:\\\\'requests.urlopen(sh).read()print(requests.urlopen('').read())sh='d:\\\\'requests.urlopen(sh).read()print(requests.urlopen('').read())2.使用redis+mongodb+php抓取网页数据目的:把使用redis发送post请求发送的数据存储,再用php读取。
数据可变,效率较高使用方法:os.getcwd()os.removeclass(os.getcwd())forshellnameinos.path.join(/):base_path=shellname.split('/')[0]#ignorewordsitems={'type':['car','suv','truck'],'data':[{'date':date(format('%y-%m-%d%h:%m:%s'),norm。
网页qq抓取什么原理(我找到的3种实现方法(1)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-30 09:14
OSC 年度开源问卷新鲜出炉。您的回答对我们非常重要。参与开源,可以从这份问卷开始>>>
请轻轻拍拍警官。. .
我一直对网络内容的抓取非常感兴趣。大约三年前,我曾经做过一个“新闻阅读器”。那个时候,我喜欢看新闻。这个想法是,如果你在没有广告的情况下观看新闻,你可以更安静地观看。好的,所以我开发了一个浏览器书签小部件,它使用js提取页面的正文,然后通过图层覆盖将其显示在页面上。当时唯一能想到的就是通过regular找到目标dom,也是爬虫最多的。爬行法。
当时,这个功能是通过对网易、新浪、QQ、凤凰等各大门户网站的分析来实现的。这是最笨的方法,但优点是准确率高,缺点是一旦修改了目标页面的源代码,可能需要重新匹配。
后来发现想看的页面越来越多,上面的方法已经不适合我的需求了。但是最近因为自己开发了,需要一个采集助手,就开始寻找解决方案。
我主要找到了3个解决方案:
1)基于dom节点的评分系统筛选算法
国外有一个叫做 readable 的浏览器书签插件可以做到这一点。地址:当时看到这个我很惊讶,准确率很高。
2)基于文本密度的分析(与DOM无关)
这个方法的思路也很好,适用性比较好,我尝试用JS来实现,但是能力有限,没有做出匹配度太高的产品,所以放弃了。
3)基于图像识别
这与阿尔法狗使用的方法非常接近。通过图像识别,只要对机器人进行足够的训练就可以做到。其他领域已经有大量案例,但是还没有看到文本识别的具体实现(或者没有找到案例))。
以上是我找到的3种实现方式。
但是基于我只是一个web开发者的事实,我对JS只有很好的理解,其他语言的能力非常有限。于是尝试了基于dom的过滤,看到ready的实现还是比较复杂的。我想知道是否有更有效的解决方案?
后来,我发现了一个规律。一般来说,body部分的p标签数量非常多,比其他部分多很多,因为网页的大部分内容都是通过所见即所得的编辑器发布的,而这些编辑器会生成符合语义的节点。
于是,我就利用了这个规律,开发了一个抓取小插件,效果还不错。当然,它仍然很基础,需要改进。
var pt = $doc.find("p").siblings().parent();
var l = pt.length - 1;
var e = l;
var arr = [];
while(l>=0){
arr[l] = $(pt[l]).find("p").length;
l--;
}
var temArr = arr.concat();
var newArr = arrSort(arr);
var c = temArr.indexOf(newArr[e]);
content = $(pt[c]).html();
代码很简单,但是经过我的测试,80%以上的网页(主要是文章页面)都可以爬取成功。基于此,我开发了 JSpapa 采集助手:
如果您对此有更好的计划,可以在下面讨论。
如需转载本文,请联系作者,请注明出处 查看全部
网页qq抓取什么原理(我找到的3种实现方法(1)(图))
OSC 年度开源问卷新鲜出炉。您的回答对我们非常重要。参与开源,可以从这份问卷开始>>>
请轻轻拍拍警官。. .
我一直对网络内容的抓取非常感兴趣。大约三年前,我曾经做过一个“新闻阅读器”。那个时候,我喜欢看新闻。这个想法是,如果你在没有广告的情况下观看新闻,你可以更安静地观看。好的,所以我开发了一个浏览器书签小部件,它使用js提取页面的正文,然后通过图层覆盖将其显示在页面上。当时唯一能想到的就是通过regular找到目标dom,也是爬虫最多的。爬行法。
当时,这个功能是通过对网易、新浪、QQ、凤凰等各大门户网站的分析来实现的。这是最笨的方法,但优点是准确率高,缺点是一旦修改了目标页面的源代码,可能需要重新匹配。
后来发现想看的页面越来越多,上面的方法已经不适合我的需求了。但是最近因为自己开发了,需要一个采集助手,就开始寻找解决方案。
我主要找到了3个解决方案:
1)基于dom节点的评分系统筛选算法
国外有一个叫做 readable 的浏览器书签插件可以做到这一点。地址:当时看到这个我很惊讶,准确率很高。
2)基于文本密度的分析(与DOM无关)
这个方法的思路也很好,适用性比较好,我尝试用JS来实现,但是能力有限,没有做出匹配度太高的产品,所以放弃了。
3)基于图像识别
这与阿尔法狗使用的方法非常接近。通过图像识别,只要对机器人进行足够的训练就可以做到。其他领域已经有大量案例,但是还没有看到文本识别的具体实现(或者没有找到案例))。
以上是我找到的3种实现方式。
但是基于我只是一个web开发者的事实,我对JS只有很好的理解,其他语言的能力非常有限。于是尝试了基于dom的过滤,看到ready的实现还是比较复杂的。我想知道是否有更有效的解决方案?
后来,我发现了一个规律。一般来说,body部分的p标签数量非常多,比其他部分多很多,因为网页的大部分内容都是通过所见即所得的编辑器发布的,而这些编辑器会生成符合语义的节点。
于是,我就利用了这个规律,开发了一个抓取小插件,效果还不错。当然,它仍然很基础,需要改进。
var pt = $doc.find("p").siblings().parent();
var l = pt.length - 1;
var e = l;
var arr = [];
while(l>=0){
arr[l] = $(pt[l]).find("p").length;
l--;
}
var temArr = arr.concat();
var newArr = arrSort(arr);
var c = temArr.indexOf(newArr[e]);
content = $(pt[c]).html();
代码很简单,但是经过我的测试,80%以上的网页(主要是文章页面)都可以爬取成功。基于此,我开发了 JSpapa 采集助手:
如果您对此有更好的计划,可以在下面讨论。
如需转载本文,请联系作者,请注明出处
网页qq抓取什么原理( 让引擎蜘蛛快速的方法:网站及页面权重的意义)
网站优化 • 优采云 发表了文章 • 0 个评论 • 36 次浏览 • 2021-11-30 09:10
让引擎蜘蛛快速的方法:网站及页面权重的意义)
根据真实调查数据,90%的网民会使用搜索引擎服务寻找自己需要的信息,而这些搜索者中有近70%会直接在搜索结果自然排名的第一页找到自己需要的信息。可见,目前SEO对于企业和产品具有不可替代的意义!
如何让引擎蜘蛛快速爬行:网站和页面权重
这必须是第一要务。网站 权重高、资历老、权限大的蜘蛛,一定要特别对待。这样网站的爬取频率非常高,大家都知道搜索引擎蜘蛛是为了保证Efficient,并不是所有的页面都会为网站爬取,而且网站的权重越高,爬取的深度越高,对应的可以爬取的页面也就越多,这样可以网站@收录也会有更多的页面!
网站服务器
网站服务器是网站的基石。如果网站服务器长时间打不开,那这离你很近了,蜘蛛想来也来不来。百度蜘蛛也是网站的访客。如果你的服务器不稳定或者卡住了,蜘蛛每次都爬不上去,有时只能爬到一个页面的一部分。这样一来,随着时间的推移,百度蜘蛛你的体验越来越差,你对网站的评价会越来越低,自然会影响你对网站的爬取,所以你一定愿意选择空间服务器。没有很好的基础。,再好的房子也会穿越!
网站 更新频率
<p>蜘蛛每次爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次 查看全部
网页qq抓取什么原理(
让引擎蜘蛛快速的方法:网站及页面权重的意义)
根据真实调查数据,90%的网民会使用搜索引擎服务寻找自己需要的信息,而这些搜索者中有近70%会直接在搜索结果自然排名的第一页找到自己需要的信息。可见,目前SEO对于企业和产品具有不可替代的意义!
如何让引擎蜘蛛快速爬行:网站和页面权重
这必须是第一要务。网站 权重高、资历老、权限大的蜘蛛,一定要特别对待。这样网站的爬取频率非常高,大家都知道搜索引擎蜘蛛是为了保证Efficient,并不是所有的页面都会为网站爬取,而且网站的权重越高,爬取的深度越高,对应的可以爬取的页面也就越多,这样可以网站@收录也会有更多的页面!
网站服务器
网站服务器是网站的基石。如果网站服务器长时间打不开,那这离你很近了,蜘蛛想来也来不来。百度蜘蛛也是网站的访客。如果你的服务器不稳定或者卡住了,蜘蛛每次都爬不上去,有时只能爬到一个页面的一部分。这样一来,随着时间的推移,百度蜘蛛你的体验越来越差,你对网站的评价会越来越低,自然会影响你对网站的爬取,所以你一定愿意选择空间服务器。没有很好的基础。,再好的房子也会穿越!
网站 更新频率
<p>蜘蛛每次爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次

