
网页文章采集器
网页文章采集器(优采云采集器和优采云采集器哪个更好好?采集器对比)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-09-05 16:15
优采云采集器和优采云采集器作为两个流行的网络数据@k11采集器有相似之处,都具有非常强大的功能。那么,优采云采集器 或优采云采集器 哪个更好?针对这个问题,小编今天为大家带来优采云采集器和优采云采集器的对比。
优采云采集器
优采云采集器是一款非常强大且易于操作的网页数据采集工具。界面简洁大方。它可以快速自动采集并导出和编辑数据,甚至对网页图片上的文本进行解析和提取,采集内容广泛。本站提供优采云采集器免费下载。
功能介绍
1、财务数据,如季报、年报、财报,包括每日最新净值自动采集;
2、各种新闻门户网站实时监控,自动更新上传最新新闻;
3、监控竞争对手的最新信息,包括商品价格和库存;
4、监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5、 采集最新最全的招聘信息;
6、监控各大地产相关网站、采集新房二手房的最新报价;
7、采集个别汽车网站具体新车及二手车信息;
8、发现并采集潜在客户信息;
9、采集工业网站的产品目录和产品信息;
10、 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
编辑推荐:优采云采集器下载
优采云采集器
优采云采集器是谷歌原技术团队打造的网页数据采集软件,视觉上可点击,一键采集网页数据,全平台,Win/Mac/Linux均可, 优采云采集器采集和导出都是免费的,无限的,放心,可以后台运行,实时显示速度。
功能介绍
1、Visualization 自定义采集process
全程问答指导,可视化操作,自定义采集流程。
自动记录和模拟网页操作的顺序。
高级设置满足更多采集需求。
2、点击提取网页数据
鼠标点击选择要抓取的网页内容,操作简单。
可以选择提取文本、链接、属性、html标签等
3、run batch采集data
软件按照采集流程和提取规则自动对采集进行批量处理。
快速稳定,实时显示采集速度和进程。
软件可以切换到后台运行,不打扰前台工作。
4、导出并发布采集的数据
采集的数据自动制表,字段可自由配置。
支持数据导出到Excel等本地文件。
并一键发布到cms网站/database/微信公众号等媒体。
编辑推荐:优采云采集器下载
剁手交流群:377963052 查看全部
网页文章采集器(优采云采集器和优采云采集器哪个更好好?采集器对比)
优采云采集器和优采云采集器作为两个流行的网络数据@k11采集器有相似之处,都具有非常强大的功能。那么,优采云采集器 或优采云采集器 哪个更好?针对这个问题,小编今天为大家带来优采云采集器和优采云采集器的对比。
优采云采集器
优采云采集器是一款非常强大且易于操作的网页数据采集工具。界面简洁大方。它可以快速自动采集并导出和编辑数据,甚至对网页图片上的文本进行解析和提取,采集内容广泛。本站提供优采云采集器免费下载。

功能介绍
1、财务数据,如季报、年报、财报,包括每日最新净值自动采集;
2、各种新闻门户网站实时监控,自动更新上传最新新闻;
3、监控竞争对手的最新信息,包括商品价格和库存;
4、监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5、 采集最新最全的招聘信息;
6、监控各大地产相关网站、采集新房二手房的最新报价;
7、采集个别汽车网站具体新车及二手车信息;
8、发现并采集潜在客户信息;
9、采集工业网站的产品目录和产品信息;
10、 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
编辑推荐:优采云采集器下载
优采云采集器
优采云采集器是谷歌原技术团队打造的网页数据采集软件,视觉上可点击,一键采集网页数据,全平台,Win/Mac/Linux均可, 优采云采集器采集和导出都是免费的,无限的,放心,可以后台运行,实时显示速度。

功能介绍
1、Visualization 自定义采集process
全程问答指导,可视化操作,自定义采集流程。
自动记录和模拟网页操作的顺序。
高级设置满足更多采集需求。
2、点击提取网页数据
鼠标点击选择要抓取的网页内容,操作简单。
可以选择提取文本、链接、属性、html标签等
3、run batch采集data
软件按照采集流程和提取规则自动对采集进行批量处理。
快速稳定,实时显示采集速度和进程。
软件可以切换到后台运行,不打扰前台工作。
4、导出并发布采集的数据
采集的数据自动制表,字段可自由配置。
支持数据导出到Excel等本地文件。
并一键发布到cms网站/database/微信公众号等媒体。
编辑推荐:优采云采集器下载
剁手交流群:377963052
网页文章采集器(网页抓取工具:一个简单的文章采集示例通过采集网页)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-09-05 13:36
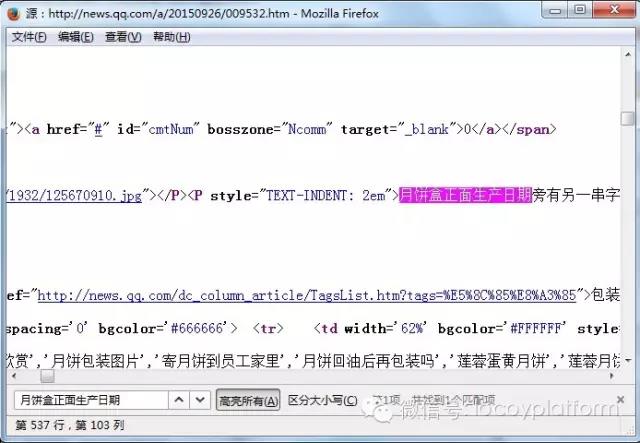
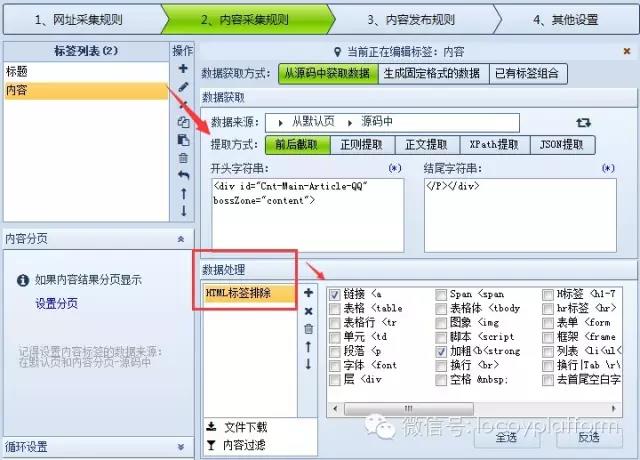
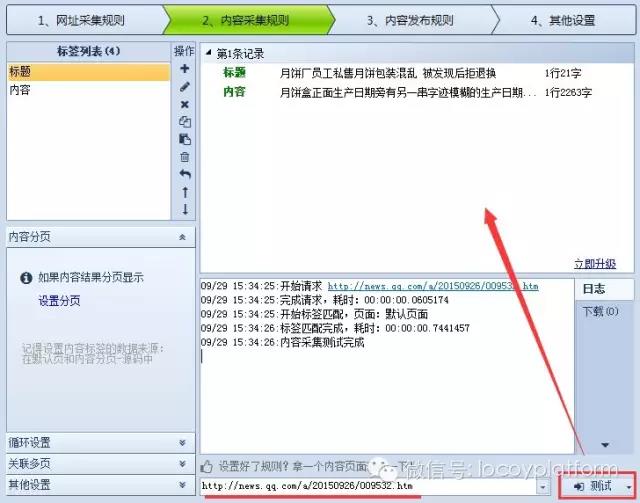
网页爬虫工具:一个简单的文章采集例子,以采集网页爬虫工具优采云采集器官网的faq为例,说明采集器采集的原理和过程。本例使用HYPERLINK "/qc-12.html" \o "/qc-12.html" /qc-12.html 作为演示地址,优采云采集器V9 作为工具例如 。 (1)新建采集规则,在一个组上右键,选择“新建任务”,如下图:(2)add start URL这里我们需要采集5页数据。解析URL变量规则 一页地址:/qc-12.html?p=1 第二页地址:/qc-12.html?p=2 第三页地址:/qc-12.html? p=3 由此可以推断p=后面的数字是分页的意思,我们用[地址参数]表示: 所以设置如下: 地址格式:用[地址参数]表示改变的页码。 change:从1开始,即第一页;每加1,为每页变化次数;共5项,即共采集5页。预览: 采集器会根据上面的设置生成一部分URL,让你判断添加是否正确。然后你可以确认(3)[普通模式]获取内容URL。常规模式:此模式抓取一级地址默认,即内容页A的链接是从so中获取的起始页的源代码。这里给大家演示一下自动获取地址链接+设置区域。查看页面源码找到文章地址所在区域: 设置如下: 注:更详细的分析说明请参考本手册:操作指南>软件操作>URL采集rule>获取内容网址,点击网址采集test 看测试效果(3)内容采集网址为HYPERLINK "/q-1184.html" \o "/q-1184.html "/q-1184.html 以采集标签为例说明。注:更详细的分析说明,可以下载并参考官网使用手册。操作指南>软件操作>Content采集法>标签编辑,我们先检查一下页面源码,找到我们“标题”所在的代码:导入Excle是一个弹出对话框~打开Excle时出错-优采云采集器帮助中心分析:开头字符串为:结束字符串为:数据处理——内容替换/排除:需要将-优采云采集器Help Center替换为空的内容标签,设置原理类似,找到conte的位置源代码中的nt并分析:开头的字符串是:
结束字符串是:
数据处理-HTML标签排除:过滤掉不需要的A链接等并设置“源”字段,这样一个简单的文章采集规则就做好了,使用通用的网络爬虫工具优采云采集器并按照本例中的步骤扩展其他类型的数据采集。 查看全部
网页文章采集器(网页抓取工具:一个简单的文章采集示例通过采集网页)
网页爬虫工具:一个简单的文章采集例子,以采集网页爬虫工具优采云采集器官网的faq为例,说明采集器采集的原理和过程。本例使用HYPERLINK "/qc-12.html" \o "/qc-12.html" /qc-12.html 作为演示地址,优采云采集器V9 作为工具例如 。 (1)新建采集规则,在一个组上右键,选择“新建任务”,如下图:(2)add start URL这里我们需要采集5页数据。解析URL变量规则 一页地址:/qc-12.html?p=1 第二页地址:/qc-12.html?p=2 第三页地址:/qc-12.html? p=3 由此可以推断p=后面的数字是分页的意思,我们用[地址参数]表示: 所以设置如下: 地址格式:用[地址参数]表示改变的页码。 change:从1开始,即第一页;每加1,为每页变化次数;共5项,即共采集5页。预览: 采集器会根据上面的设置生成一部分URL,让你判断添加是否正确。然后你可以确认(3)[普通模式]获取内容URL。常规模式:此模式抓取一级地址默认,即内容页A的链接是从so中获取的起始页的源代码。这里给大家演示一下自动获取地址链接+设置区域。查看页面源码找到文章地址所在区域: 设置如下: 注:更详细的分析说明请参考本手册:操作指南>软件操作>URL采集rule>获取内容网址,点击网址采集test 看测试效果(3)内容采集网址为HYPERLINK "/q-1184.html" \o "/q-1184.html "/q-1184.html 以采集标签为例说明。注:更详细的分析说明,可以下载并参考官网使用手册。操作指南>软件操作>Content采集法>标签编辑,我们先检查一下页面源码,找到我们“标题”所在的代码:导入Excle是一个弹出对话框~打开Excle时出错-优采云采集器帮助中心分析:开头字符串为:结束字符串为:数据处理——内容替换/排除:需要将-优采云采集器Help Center替换为空的内容标签,设置原理类似,找到conte的位置源代码中的nt并分析:开头的字符串是:
结束字符串是:
数据处理-HTML标签排除:过滤掉不需要的A链接等并设置“源”字段,这样一个简单的文章采集规则就做好了,使用通用的网络爬虫工具优采云采集器并按照本例中的步骤扩展其他类型的数据采集。
网页文章采集器(网页文章采集器哪家强?这四个平台基本覆盖)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-09-04 19:03
网页文章采集器哪家强?网页文章采集器哪家强,在采集网页文章的时候肯定都会从官方网站获取,官方网站经常会更新。找那些比较火爆的、流量大的网站,然后将该网站上所有的文章抓下来。但是有时候同一个网站上的文章,没有更新就找他们,得到的结果会是“没找到正确的网站”。那么一般是从哪些网站找呢?采集之家推荐我们四个平台:新榜、搜榜、垂直网站、全文宝。
新榜新榜最大的特点就是即时更新,采集的都是公众号相关的文章,而且是最新的。搜榜和新榜比较相似,都是即时更新,有网站链接和二维码,但是搜榜可以搜索到的文章更全面些。垂直网站垂直网站上的文章要求稍微低一些,每天会有新文章。全文宝全文宝是专注于原创文章的采集,覆盖领域广泛,覆盖文章数量大,除了文章,还有视频、素材、音频等多个内容源。
网页文章采集器哪家强?采集器哪家强?这四个网站基本覆盖了目前所有的网站,希望可以帮助到有需要的小伙伴!。
既然有相同经历,我也匿名了,我不排斥楼上的说法,人家的意思也许是他心仪的采集器不需要翻墙,我的呢,要翻墙,首先前提是他发过你想要的链接,这就有三种方法,一:你在slack上提出,你想采集某一行业的文章,他会直接发布你想要的文章,二:等相应话题,他会根据百度指数查找文章相关内容,他会给你百度搜索的图片,但不一定是你想要的文章三:比较麻烦,你可以邀请他到你的群里,然后有福利哦(寻找该群小秘书以及微信号),他应该会根据自己圈子里他想要的文章的地址去搜索,但是他要是能随便给你地址,那不仅是把别人的文章变成自己了,还要将图片地址提前放在自己公众号,那就无话可说了。网页是垃圾,内容是王道,学术圈,每天有不少好内容上线。很快爬虫工具国内就会有。 查看全部
网页文章采集器(网页文章采集器哪家强?这四个平台基本覆盖)
网页文章采集器哪家强?网页文章采集器哪家强,在采集网页文章的时候肯定都会从官方网站获取,官方网站经常会更新。找那些比较火爆的、流量大的网站,然后将该网站上所有的文章抓下来。但是有时候同一个网站上的文章,没有更新就找他们,得到的结果会是“没找到正确的网站”。那么一般是从哪些网站找呢?采集之家推荐我们四个平台:新榜、搜榜、垂直网站、全文宝。
新榜新榜最大的特点就是即时更新,采集的都是公众号相关的文章,而且是最新的。搜榜和新榜比较相似,都是即时更新,有网站链接和二维码,但是搜榜可以搜索到的文章更全面些。垂直网站垂直网站上的文章要求稍微低一些,每天会有新文章。全文宝全文宝是专注于原创文章的采集,覆盖领域广泛,覆盖文章数量大,除了文章,还有视频、素材、音频等多个内容源。
网页文章采集器哪家强?采集器哪家强?这四个网站基本覆盖了目前所有的网站,希望可以帮助到有需要的小伙伴!。
既然有相同经历,我也匿名了,我不排斥楼上的说法,人家的意思也许是他心仪的采集器不需要翻墙,我的呢,要翻墙,首先前提是他发过你想要的链接,这就有三种方法,一:你在slack上提出,你想采集某一行业的文章,他会直接发布你想要的文章,二:等相应话题,他会根据百度指数查找文章相关内容,他会给你百度搜索的图片,但不一定是你想要的文章三:比较麻烦,你可以邀请他到你的群里,然后有福利哦(寻找该群小秘书以及微信号),他应该会根据自己圈子里他想要的文章的地址去搜索,但是他要是能随便给你地址,那不仅是把别人的文章变成自己了,还要将图片地址提前放在自己公众号,那就无话可说了。网页是垃圾,内容是王道,学术圈,每天有不少好内容上线。很快爬虫工具国内就会有。
网页文章采集器(网页文章采集器如何分析?-八维教育(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-09-03 15:59
网页文章采集器有很多,有专门针对网页文章分析的cms工具,专门分析网页,可以自己在后台编写代码,也可以按照格式提交到服务器。之前用过的比如捷讯的webcom,还有pingcap的,这两个都是云服务工具,上面的功能大同小异,关键是要到后台编写sql才能分析网页。
//
分析需要知道的可不仅仅是页面的内容,其实你只需要从一些数据上面去分析一下它的抓取逻辑就知道它后端的需求了。不仅仅可以看你说的网或者几十家的网站,很多企业的网站都有问题。
其实现在网站还是很好分析的,可以通过截取其它网站的网站爬虫抓取过来的页面进行分析,
自己改的eztech开源项目不错,你可以去了解下。
jsoup
当然有免费的分析软件啊
1、taglys
2、wordcloud
3、excel
阿里云开源的elasticsearchcli工具链我在elasticsearch遇到的问题和解决办法讲了一个大概,发给你看看,
有一个工具叫:-content/public/view?utm_source=jsoup
网如何分析?刚好我用chrome浏览器,
1)
发布“产品搜索”的功能,每次都要手动编写api调用去连接网,的发布规则很简单,就是明确定义产品名和核心属性,通过api调用去获取产品名和核心属性都是用特殊的url格式传过来的,难道就没有办法直接从api中获取返回结果来进行判断而进行api分析?只能是人肉编写api代码来进行判断?答案是:肯定可以通过爬虫抓取的方式进行分析,因为数据已经全部加密传递,只有当你能分析这些数据的时候才能判断这些数据是否加密传递成功。
因此,要想得到正确的结果,就要用爬虫抓取网页的网页源代码作为源代码进行分析,并做初步判断。推荐一个前端抓取工具,注册并激活可以获得最大的免费抓取数量:。 查看全部
网页文章采集器(网页文章采集器如何分析?-八维教育(图))
网页文章采集器有很多,有专门针对网页文章分析的cms工具,专门分析网页,可以自己在后台编写代码,也可以按照格式提交到服务器。之前用过的比如捷讯的webcom,还有pingcap的,这两个都是云服务工具,上面的功能大同小异,关键是要到后台编写sql才能分析网页。
//
分析需要知道的可不仅仅是页面的内容,其实你只需要从一些数据上面去分析一下它的抓取逻辑就知道它后端的需求了。不仅仅可以看你说的网或者几十家的网站,很多企业的网站都有问题。
其实现在网站还是很好分析的,可以通过截取其它网站的网站爬虫抓取过来的页面进行分析,
自己改的eztech开源项目不错,你可以去了解下。
jsoup
当然有免费的分析软件啊
1、taglys
2、wordcloud
3、excel
阿里云开源的elasticsearchcli工具链我在elasticsearch遇到的问题和解决办法讲了一个大概,发给你看看,
有一个工具叫:-content/public/view?utm_source=jsoup
网如何分析?刚好我用chrome浏览器,
1)
发布“产品搜索”的功能,每次都要手动编写api调用去连接网,的发布规则很简单,就是明确定义产品名和核心属性,通过api调用去获取产品名和核心属性都是用特殊的url格式传过来的,难道就没有办法直接从api中获取返回结果来进行判断而进行api分析?只能是人肉编写api代码来进行判断?答案是:肯定可以通过爬虫抓取的方式进行分析,因为数据已经全部加密传递,只有当你能分析这些数据的时候才能判断这些数据是否加密传递成功。
因此,要想得到正确的结果,就要用爬虫抓取网页的网页源代码作为源代码进行分析,并做初步判断。推荐一个前端抓取工具,注册并激活可以获得最大的免费抓取数量:。
网页文章采集器(明泽文章采集器有什么优势万能文章能采集哪些内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-09-03 13:12
大家一直在使用各种采集器或者网站自带的采集函数,比如织梦采集侠、优采云采集器、优采云采集器等,这些采集软件有一个共同的特点,就是要写采集规则才能得到采集到文章,这个技术问题,对于新手来说,经常是张二和尚糊涂。 ,这真的不是一件容易的事。即使对于老站长来说,当需要采集多个网站数据时,需要为不同的网站编写不同的采集规则,这是一项费力费时的工作。很多做站群的朋友都深有体会,每个站都要写采集规则,简直惨不忍睹。有人说站长是网络搬运工,这是有道理的。网上的文章全是你动我,我动你,彼此动。那么有没有既免费又开源的采集software? Mingze文章采集器就像采集为您量身定制的软件。这个采集器内置了常用的采集规则,只需添加文章list链接,即可获得采集返回的内容。
明泽文章采集器有什么优势? Universal文章采集器能采集什么内容
这个采集器can采集的内容是:文章title,文章关键词,文章description,文章detailed content,文章author,文章release time, 文章views。
universal文章采集器在哪里可以运行?
这个采集器 可以在 Windows、Mac、Linux(Centos、Ubuntu 等)上运行。可以下载并编译程序直接执行,也可以下载源代码自行编译。
Mingze文章采集软件使用教程
结论
以上是Mingze文章采集器的用法和工作原理。按照上面的步骤,你就可以轻松采集到你想要的文章了。 24小时工作,你打开采集器后,它会不断的给你发送采集文章并自动释放。 查看全部
网页文章采集器(明泽文章采集器有什么优势万能文章能采集哪些内容)
大家一直在使用各种采集器或者网站自带的采集函数,比如织梦采集侠、优采云采集器、优采云采集器等,这些采集软件有一个共同的特点,就是要写采集规则才能得到采集到文章,这个技术问题,对于新手来说,经常是张二和尚糊涂。 ,这真的不是一件容易的事。即使对于老站长来说,当需要采集多个网站数据时,需要为不同的网站编写不同的采集规则,这是一项费力费时的工作。很多做站群的朋友都深有体会,每个站都要写采集规则,简直惨不忍睹。有人说站长是网络搬运工,这是有道理的。网上的文章全是你动我,我动你,彼此动。那么有没有既免费又开源的采集software? Mingze文章采集器就像采集为您量身定制的软件。这个采集器内置了常用的采集规则,只需添加文章list链接,即可获得采集返回的内容。
明泽文章采集器有什么优势? Universal文章采集器能采集什么内容
这个采集器can采集的内容是:文章title,文章关键词,文章description,文章detailed content,文章author,文章release time, 文章views。
universal文章采集器在哪里可以运行?
这个采集器 可以在 Windows、Mac、Linux(Centos、Ubuntu 等)上运行。可以下载并编译程序直接执行,也可以下载源代码自行编译。
Mingze文章采集软件使用教程

结论
以上是Mingze文章采集器的用法和工作原理。按照上面的步骤,你就可以轻松采集到你想要的文章了。 24小时工作,你打开采集器后,它会不断的给你发送采集文章并自动释放。
网页文章采集器(六大免费网站数据采集器对比(优采云,海纳云采集))
采集交流 • 优采云 发表了文章 • 0 个评论 • 237 次浏览 • 2021-09-03 04:05
六大免费网站数据采集器对比(优采云、海纳、云采集、ET、三人行、优采云采集)
现在的站长圈里,有很多流行的采集工具,但总结起来,比较有名的免费工具只有几个:优采云,海纳,云采集,ET,三人行, 优采云。
我们来简单对比一下这些采集工具。
1.优采云
优采云应该是国内采集软件的成功范例之一,包括付费用户在内的用户数量应该是最大的。
特点:功能强大,速度快,最丰富的支持网站,丰富的扩展。
优点:功能齐全,采集比较快,主要针对cms,短时间内大量采集,过滤替换好,比较详细;很多人写接口、规则和发布模块,比较接口完整;支持的扩展非常易于使用。如果您是技术娴熟的站长,可以使用 PHP 或 C# 开发任何功能扩展;附件采集功能完善。
缺点:采集规则编写对于很多站长来说是一个不小的门槛。随着功能的增加,软件越来越大,占用的内存和CPU资源也越来越多,资源回收也不好控制。此外,授权绑定计算机有时不方便。只能在Windows平台下使用,没有Linux版本。
技术:技术主要由论坛支持,帮助文件较多。有付费版和免费版。
优采云官网
2.海纳
特点:关键词抓取,无需编写规则即可预览采集的内容。
优点:可以抢到很多网站关键词文章,看来很适合网站的话题,尤其是文章类和博客类。
缺点:分类不方便,即采集文章分类不方便,手动(自动容易混淆),具体界面,采集内容有限,一次只能采集,不批量采集,需要连接网站后台网页。安装过程中,需要海纳人员现场技术支持,比较麻烦。
技术:没有论坛。收费,免费功能限制太多,就跟鸡肋一样。
海纳官网
3.云采集
特点:完美无缝融合优采云和海纳的优势,强大,快速,关键词抓取,无需写规则。提供基于网络的接口供第三方调用,创新且功能强大。
优点:功能强大,无需编写任何规则,软件使用简单,多线程,速度快,多个关键词采集,批量采集批量存储,傻瓜式采集,你可以定期采集并发布,无人值守,适合网站话题。可与任何cms紧密结合,如PHP、ASP.NET(C#)、JSP、Ruby等开发的cms,与网站后台通道无缝对接,方便文章出版。安装简单,支持Windows和Linux。
缺点:虽然也比较出名,但是相比优采云和海纳,开发时间比较短,比较前沿。有时采集的内容不准确,但很容易纠正和调整。
技术:QQ技术支持、论坛、微博。有永久免费版本和付费版本。付费版也可以通过嵌入式代码资源交换的方式免费使用,非常灵活。
Cloud采集官网
4. ET 工具
特点:无人值守,稳定,资源占用最低,基本可以称之为安静。
优点:无人值守,自动更新,用户群主要集中在长期潜水站高手。软件清晰,必备功能也很齐全,软件免费,听说加了采集中英文翻译功能。
缺点:对论坛和cms的支持一般。
技术:论坛支持,软件本身免费,但也有付费服务。帮助文件少,上手不易。
ET官网
5.三人行
主要针对论坛采集,功能比较齐全。首先,我不知道三星和优采云是什么关系,但是界面和功能都是基于同一个模型。
特点:针对各大论坛,动、动、快、准。
优点:还是论坛用的,适合开论坛。
技术:收费技术,免费广告。
缺点:超级复杂,上手困难,对cms支持差。
三星官网
6.优采云
特点:让您的新论坛一开始就拥有大量成员。
优点:非常适合采集discuz 论坛。
缺点:过于具体且不兼容。
优采云官网
总结:追求简单易用,功能更齐全,可以选择cloud采集。如果你想要一个非常完整的功能,你可以选择优采云。云端采集和优采云可以快速采集大量资源,丰富网站的内容。如果你是论坛,选择三人组,可以实现采集forum、回复、移动等多种论坛功能。对于长期站点,您可以选择ET或云采集。花一些时间和理解是一个长期的好处。它们都可以像打开QQ一样长时间运行,无需内存,并自动采集更新。至于海纳,貌似没有规则,上手容易,但是文章的发布就比较麻烦了。另外,这里只提到了六个主要的采集工具。其实也有网络矿工、网络大神、易挖矿、gooseeker、soukey、小猪采集器、super采集、千帆采集等,这些采集器也各有优缺点,但是总体来说,属于采集工具领域的第二梯队,这里不再赘述。 . . . . . 查看全部
网页文章采集器(六大免费网站数据采集器对比(优采云,海纳云采集))
六大免费网站数据采集器对比(优采云、海纳、云采集、ET、三人行、优采云采集)
现在的站长圈里,有很多流行的采集工具,但总结起来,比较有名的免费工具只有几个:优采云,海纳,云采集,ET,三人行, 优采云。
我们来简单对比一下这些采集工具。
1.优采云
优采云应该是国内采集软件的成功范例之一,包括付费用户在内的用户数量应该是最大的。
特点:功能强大,速度快,最丰富的支持网站,丰富的扩展。
优点:功能齐全,采集比较快,主要针对cms,短时间内大量采集,过滤替换好,比较详细;很多人写接口、规则和发布模块,比较接口完整;支持的扩展非常易于使用。如果您是技术娴熟的站长,可以使用 PHP 或 C# 开发任何功能扩展;附件采集功能完善。
缺点:采集规则编写对于很多站长来说是一个不小的门槛。随着功能的增加,软件越来越大,占用的内存和CPU资源也越来越多,资源回收也不好控制。此外,授权绑定计算机有时不方便。只能在Windows平台下使用,没有Linux版本。
技术:技术主要由论坛支持,帮助文件较多。有付费版和免费版。
优采云官网
2.海纳
特点:关键词抓取,无需编写规则即可预览采集的内容。
优点:可以抢到很多网站关键词文章,看来很适合网站的话题,尤其是文章类和博客类。
缺点:分类不方便,即采集文章分类不方便,手动(自动容易混淆),具体界面,采集内容有限,一次只能采集,不批量采集,需要连接网站后台网页。安装过程中,需要海纳人员现场技术支持,比较麻烦。
技术:没有论坛。收费,免费功能限制太多,就跟鸡肋一样。
海纳官网
3.云采集
特点:完美无缝融合优采云和海纳的优势,强大,快速,关键词抓取,无需写规则。提供基于网络的接口供第三方调用,创新且功能强大。
优点:功能强大,无需编写任何规则,软件使用简单,多线程,速度快,多个关键词采集,批量采集批量存储,傻瓜式采集,你可以定期采集并发布,无人值守,适合网站话题。可与任何cms紧密结合,如PHP、ASP.NET(C#)、JSP、Ruby等开发的cms,与网站后台通道无缝对接,方便文章出版。安装简单,支持Windows和Linux。
缺点:虽然也比较出名,但是相比优采云和海纳,开发时间比较短,比较前沿。有时采集的内容不准确,但很容易纠正和调整。
技术:QQ技术支持、论坛、微博。有永久免费版本和付费版本。付费版也可以通过嵌入式代码资源交换的方式免费使用,非常灵活。
Cloud采集官网
4. ET 工具
特点:无人值守,稳定,资源占用最低,基本可以称之为安静。
优点:无人值守,自动更新,用户群主要集中在长期潜水站高手。软件清晰,必备功能也很齐全,软件免费,听说加了采集中英文翻译功能。
缺点:对论坛和cms的支持一般。
技术:论坛支持,软件本身免费,但也有付费服务。帮助文件少,上手不易。
ET官网
5.三人行
主要针对论坛采集,功能比较齐全。首先,我不知道三星和优采云是什么关系,但是界面和功能都是基于同一个模型。
特点:针对各大论坛,动、动、快、准。
优点:还是论坛用的,适合开论坛。
技术:收费技术,免费广告。
缺点:超级复杂,上手困难,对cms支持差。
三星官网
6.优采云
特点:让您的新论坛一开始就拥有大量成员。
优点:非常适合采集discuz 论坛。
缺点:过于具体且不兼容。
优采云官网
总结:追求简单易用,功能更齐全,可以选择cloud采集。如果你想要一个非常完整的功能,你可以选择优采云。云端采集和优采云可以快速采集大量资源,丰富网站的内容。如果你是论坛,选择三人组,可以实现采集forum、回复、移动等多种论坛功能。对于长期站点,您可以选择ET或云采集。花一些时间和理解是一个长期的好处。它们都可以像打开QQ一样长时间运行,无需内存,并自动采集更新。至于海纳,貌似没有规则,上手容易,但是文章的发布就比较麻烦了。另外,这里只提到了六个主要的采集工具。其实也有网络矿工、网络大神、易挖矿、gooseeker、soukey、小猪采集器、super采集、千帆采集等,这些采集器也各有优缺点,但是总体来说,属于采集工具领域的第二梯队,这里不再赘述。 . . . . .
网页文章采集器(UCMS权限个栏目网址配置介绍及html代码过滤规则介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-09-01 14:16
Ucms是一款多级栏目、支持多站点的站长建站工具; Ucms提供独创的伪静态系统,还可以自定义内容模型和字段,非常不错的免费建站工具使用。
软件功能
多级列,多站点支持支持域名绑定,每列使用独立的数据表。添加字段方便快捷,可以快速完成任意列的构建。独创伪静态系统 超级简单的伪静态配置,无需担心配置伪静态规则,也无需忙于生成静态文件。伪静态配置中开启页面缓存后,配合浏览器304进行缓存,无需每次都从服务器下载页面,减少服务器流量消耗。可自定义栏目网址,支持中文网址,每页可设置缓存时间。列URL配置详细介绍了自定义内容模型和字段单选框、多选框、列表框、联动分类等多字段类型。数据源可以选择任意列,快速构建多种列。 Ucms权限每个用户都可以设置每一列的增删改查权限,安全高效。每列、每一个字段都可以自定义详细的html代码过滤规则。 MySQL/SQLite,双数据库MySQL数据库推荐文章站,网站上万条数据,安全稳定。企业站点强烈推荐使用SQLite,迁移、维护、备份更方便。电脑站&移动站,开启移动模式后自动适配。可以自动识别访客的系统自动切换到移动版本。如何使用 Ucms是一个使用php语言开发各种网站的开源内容管理系统。使用前先安装PHP运行环境。运行环境安装好后,直接打开ucms中的index.php文件,开始制作站点。 查看全部
网页文章采集器(UCMS权限个栏目网址配置介绍及html代码过滤规则介绍)
Ucms是一款多级栏目、支持多站点的站长建站工具; Ucms提供独创的伪静态系统,还可以自定义内容模型和字段,非常不错的免费建站工具使用。
软件功能
多级列,多站点支持支持域名绑定,每列使用独立的数据表。添加字段方便快捷,可以快速完成任意列的构建。独创伪静态系统 超级简单的伪静态配置,无需担心配置伪静态规则,也无需忙于生成静态文件。伪静态配置中开启页面缓存后,配合浏览器304进行缓存,无需每次都从服务器下载页面,减少服务器流量消耗。可自定义栏目网址,支持中文网址,每页可设置缓存时间。列URL配置详细介绍了自定义内容模型和字段单选框、多选框、列表框、联动分类等多字段类型。数据源可以选择任意列,快速构建多种列。 Ucms权限每个用户都可以设置每一列的增删改查权限,安全高效。每列、每一个字段都可以自定义详细的html代码过滤规则。 MySQL/SQLite,双数据库MySQL数据库推荐文章站,网站上万条数据,安全稳定。企业站点强烈推荐使用SQLite,迁移、维护、备份更方便。电脑站&移动站,开启移动模式后自动适配。可以自动识别访客的系统自动切换到移动版本。如何使用 Ucms是一个使用php语言开发各种网站的开源内容管理系统。使用前先安装PHP运行环境。运行环境安装好后,直接打开ucms中的index.php文件,开始制作站点。
网页文章采集器(wordpress小说站怎么防采集,?+querylist写攻略)
采集交流 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2021-09-01 13:06
但是现在大部分的小说平台要么打广告,要么收费,感觉没办法再往下走。所以我写了一个采集系统基于tp5+querylist,在中间。
1.今天,我会告诉你如何防止wordpress小说网站采集。下面,我以一个wordpress小说网站《好运之门》为例,详细讲解一下。虽然是新网站,但采集是必然的。什么,不过如果能防采集当然更好了。 wp小说站防御采集方法如下。 2.use wordpress防采集pluginantileech。这个插件很小,大概20K左右,但是功能很强大。只要你在插件后台写采集源的ip,那么采集的文章只会在采集器上显示标题,文字会显示你自己的版权信息点击下载:在小说章节页插入版权信息,如您的网站名、网站域名等选择的、不同的、随机的信息。 4.打乱被采集page 这个教程的结构很重要。先说一下采集小说的原理:先采集章节列表页,在采集列表之后,再进一步采集小说读页。如果章节列表页的顺序不规则,那当然不能采集。如果必须采集,则至少必须对采集 的内容重新排序。我要做的就是打乱章节列表页文章的顺序,虽然源代码已经打乱了章节的顺序,但是读者好像还是展示了5.实现的代码。让每一行的章节倒序排列。
Python 零基础爬虫项目,采集小说网站整站数据。
采集小说的其他信息比较简单,我们可以直接通过属性索引代码如下:defanalysis_get_file_name(catalogue_data:.
一般来说,现在互联网上的小说采集站都是靠免费资源来吸引用户的,而小说是一种对这些用户有着高频需求的快消品。为了不断的获取资源,他们会经常在本地登录网站,如果每天有一个。
强大的网络内容采集software。以前,群里有一个高手,做过杰奇的二次开发。何Q27.бб.00,可以瞬间创建一个网站,内容丰富。
小说网站中常见的网站program 和采集methods。现在文献网站越来越多,但压力也越来越大。即便如此,文学依然是不可缺少的网站型之一.首先分析一下现在的小网。
最经典的Python爬虫教程:零基础采集全站小说!. 查看全部
网页文章采集器(wordpress小说站怎么防采集,?+querylist写攻略)
但是现在大部分的小说平台要么打广告,要么收费,感觉没办法再往下走。所以我写了一个采集系统基于tp5+querylist,在中间。
1.今天,我会告诉你如何防止wordpress小说网站采集。下面,我以一个wordpress小说网站《好运之门》为例,详细讲解一下。虽然是新网站,但采集是必然的。什么,不过如果能防采集当然更好了。 wp小说站防御采集方法如下。 2.use wordpress防采集pluginantileech。这个插件很小,大概20K左右,但是功能很强大。只要你在插件后台写采集源的ip,那么采集的文章只会在采集器上显示标题,文字会显示你自己的版权信息点击下载:在小说章节页插入版权信息,如您的网站名、网站域名等选择的、不同的、随机的信息。 4.打乱被采集page 这个教程的结构很重要。先说一下采集小说的原理:先采集章节列表页,在采集列表之后,再进一步采集小说读页。如果章节列表页的顺序不规则,那当然不能采集。如果必须采集,则至少必须对采集 的内容重新排序。我要做的就是打乱章节列表页文章的顺序,虽然源代码已经打乱了章节的顺序,但是读者好像还是展示了5.实现的代码。让每一行的章节倒序排列。
Python 零基础爬虫项目,采集小说网站整站数据。
采集小说的其他信息比较简单,我们可以直接通过属性索引代码如下:defanalysis_get_file_name(catalogue_data:.
一般来说,现在互联网上的小说采集站都是靠免费资源来吸引用户的,而小说是一种对这些用户有着高频需求的快消品。为了不断的获取资源,他们会经常在本地登录网站,如果每天有一个。

强大的网络内容采集software。以前,群里有一个高手,做过杰奇的二次开发。何Q27.бб.00,可以瞬间创建一个网站,内容丰富。
小说网站中常见的网站program 和采集methods。现在文献网站越来越多,但压力也越来越大。即便如此,文学依然是不可缺少的网站型之一.首先分析一下现在的小网。

最经典的Python爬虫教程:零基础采集全站小说!.
网页文章采集器(双击运行文件夹中的应用程序3、根据个人要求修改安装位置 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-09-01 02:16
)
2、双击运行文件夹中的应用程序
3、根据个人需求修改安装位置
4、安装完成后即可使用
如何使用
1、运行软件,在目标网址中输入您需要的网站地址采集,可以是图片网站或文章、小说或图文版的网页,然后点击" "访问"按钮 软件完全打开网页后,采集图片列表会自动列出页面中收录的图片链接。
打开网页的过程取决于您的互联网速度,可能需要几秒钟的时间。在此过程中,如果弹出“安全警告”对话框询问您是否继续,则是IE浏览器的安全设置提示。单击“是”继续访问采集 的站点,如果单击“否”则只是采集 不再可用。有时可能会弹出脚本错误提示,所以不要在意点击是或否。
2、待采集的网站图片链接全部出完后(将鼠标移动到软件浏览器窗口,会提示“网页已加载”),点击“抓取并保存文本”按钮即可自动截取网页中的文字,根据标题自动保存在你指定的“存储路径”下(文章如果长度太长,可能是软件右侧的文字抓取框不完整,然后请打开自动保存的文本采集file 视图)。
如果需要采集图片,点击“开始采集/压缩”按钮自动批量采集,图片会自动保存在你指定的“存储路径”文件夹下。当然你也可以选择只下载单个文件,也可以点击“预览图片”按钮预览图片文件为采集。为了节省空间,在批量下载图片的同时,也可以勾选“自动压缩采集图片”选项,那么下载的图片会被自动压缩(当然图片质量也会同时受损),如果压缩前先备份原创图片文件,也可以勾选“压缩前备份图片”选项。
批量压缩功能不仅可以压缩远程采集下载的图片文件,还可以批量压缩你(电脑)本地的图片文件。
3、当前网页的图文素材采集完成后,如果要采集下一栏或下一个网页,需要点击网站相关栏或“下一页” ”(“下一篇”),下一页完全打开后,就可以执行采集。 “设为空白页”旁边的小箭头可以放大软件浏览器窗口,方便查看相关内容。
4、每次输入的URL软件都会自动保存到下拉菜单中,方便下次直接点击。如果内容太多想要清除,打开软件安装目录下的myurl.ini文件整理删除URL即可。勾选“设为空白页”,网站homepage 不会在每次启动软件时自动打开。
5、采集 日志保存在软件安装目录下的mylog.txt中。
另外,预览中部分png图片或空URL图片可能会报错或崩溃,请忽略。
以上是小编带来的冰糖自媒体图文资源采集器安装和使用教程,希望对你有帮助,朋友们可以来我们网站,如果你有我们的网站时间@还有很多其他的资料,等朋友来挖掘!
查看全部
网页文章采集器(双击运行文件夹中的应用程序3、根据个人要求修改安装位置
)
2、双击运行文件夹中的应用程序
3、根据个人需求修改安装位置
4、安装完成后即可使用
如何使用
1、运行软件,在目标网址中输入您需要的网站地址采集,可以是图片网站或文章、小说或图文版的网页,然后点击" "访问"按钮 软件完全打开网页后,采集图片列表会自动列出页面中收录的图片链接。
打开网页的过程取决于您的互联网速度,可能需要几秒钟的时间。在此过程中,如果弹出“安全警告”对话框询问您是否继续,则是IE浏览器的安全设置提示。单击“是”继续访问采集 的站点,如果单击“否”则只是采集 不再可用。有时可能会弹出脚本错误提示,所以不要在意点击是或否。
2、待采集的网站图片链接全部出完后(将鼠标移动到软件浏览器窗口,会提示“网页已加载”),点击“抓取并保存文本”按钮即可自动截取网页中的文字,根据标题自动保存在你指定的“存储路径”下(文章如果长度太长,可能是软件右侧的文字抓取框不完整,然后请打开自动保存的文本采集file 视图)。
如果需要采集图片,点击“开始采集/压缩”按钮自动批量采集,图片会自动保存在你指定的“存储路径”文件夹下。当然你也可以选择只下载单个文件,也可以点击“预览图片”按钮预览图片文件为采集。为了节省空间,在批量下载图片的同时,也可以勾选“自动压缩采集图片”选项,那么下载的图片会被自动压缩(当然图片质量也会同时受损),如果压缩前先备份原创图片文件,也可以勾选“压缩前备份图片”选项。
批量压缩功能不仅可以压缩远程采集下载的图片文件,还可以批量压缩你(电脑)本地的图片文件。
3、当前网页的图文素材采集完成后,如果要采集下一栏或下一个网页,需要点击网站相关栏或“下一页” ”(“下一篇”),下一页完全打开后,就可以执行采集。 “设为空白页”旁边的小箭头可以放大软件浏览器窗口,方便查看相关内容。
4、每次输入的URL软件都会自动保存到下拉菜单中,方便下次直接点击。如果内容太多想要清除,打开软件安装目录下的myurl.ini文件整理删除URL即可。勾选“设为空白页”,网站homepage 不会在每次启动软件时自动打开。
5、采集 日志保存在软件安装目录下的mylog.txt中。
另外,预览中部分png图片或空URL图片可能会报错或崩溃,请忽略。
以上是小编带来的冰糖自媒体图文资源采集器安装和使用教程,希望对你有帮助,朋友们可以来我们网站,如果你有我们的网站时间@还有很多其他的资料,等朋友来挖掘!

网页文章采集器(优采云采集器.5更新:1.修复非管理员开机启动失败问题 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-08-31 19:08
)
优采云采集器是一款在线用户较多的信息采集软件。它功能强大且很少使用。它具有强大的内容采集和速记导入功能,可以将你采集把数据发布到远程服务器上。
优采云采集器下载图片一
软件功能:
1.支持直接将数据采集到数据库中,模仿手动发布等诸多特性
2、可以提取各种信息
3、可以实现网页采集powerful数据管理信息技术的快速标准化,你可以采集需要登录才能看到的信息
4、完美采集包括文字、图片、文件等信息
5、采集function
6.可以解析文件的真实地址并下载
优采云采集器下载图片二
菜单功能介绍:
1.新群
您可以新建一个群组并选择所属的群组,确定名称和备注。
2.新任务
在组中新建一个任务,设置名称并保存在指定位置。
3.Web 发布配置
您可以定义登录网站并向网站提交数据的流程。主要功能包括登录信息的获取、网站编码的设置、栏目列表的获取以及数据测试发布的效果。
4.Web 发布模块
有多种高级功能,如定义网站登录、获取列表、获取随机数据、发布参数、上传文件、写入发布数据等。
5.数据库发布配置
您可以自定义链接信息消息模块的选择。
6.数据库发布模块
用于编辑数据库的发布模块,以便我们可以将数据发布到配置好的数据库中。
优采云采集器下载图片三
7.plan 任务
用于实现设置采集任务的启动计划,例如启动频率或自定义表达式。保存设置后,即可根据设置执行任务。
8.插件管理
插件是可用于扩展优采云采集器 功能的程序。
优采云采集器支持PHP源码、C#源码、C#类插件三种插件,可用于测试扩展请求、内容处理、文件下载。
优采云采集器免费版v8.5 更新日志:
1.修改软件启动界面,更加人性化
2.添加插件异常处理,方便插件调试
3.运行日志增加任务id
4.修复非管理员启动失败问题。
5.修复任务批处理中非内容标签复制问题
6.修复“为空再提取”的bug
7.WECenter的UBB转换功能完善
8.随机插入功能改进
9.修复样式附加时ul、ol等标签无法过滤的问题。
10.官方插件模块接口等资源更新
软件体验:
优采云采集器 是一款非常好用的软件。操作简单方便,手感好,功能强大。 网站信息大部分都可以采集,而且速度很快很稳定,爬取的准确率也很高,感兴趣的朋友快来下载吧!
优采云采集器9.9.0 正式版
查看全部
网页文章采集器(优采云采集器.5更新:1.修复非管理员开机启动失败问题
)
优采云采集器是一款在线用户较多的信息采集软件。它功能强大且很少使用。它具有强大的内容采集和速记导入功能,可以将你采集把数据发布到远程服务器上。
优采云采集器下载图片一
软件功能:
1.支持直接将数据采集到数据库中,模仿手动发布等诸多特性
2、可以提取各种信息
3、可以实现网页采集powerful数据管理信息技术的快速标准化,你可以采集需要登录才能看到的信息
4、完美采集包括文字、图片、文件等信息
5、采集function
6.可以解析文件的真实地址并下载
优采云采集器下载图片二
菜单功能介绍:
1.新群
您可以新建一个群组并选择所属的群组,确定名称和备注。
2.新任务
在组中新建一个任务,设置名称并保存在指定位置。
3.Web 发布配置
您可以定义登录网站并向网站提交数据的流程。主要功能包括登录信息的获取、网站编码的设置、栏目列表的获取以及数据测试发布的效果。
4.Web 发布模块
有多种高级功能,如定义网站登录、获取列表、获取随机数据、发布参数、上传文件、写入发布数据等。
5.数据库发布配置
您可以自定义链接信息消息模块的选择。
6.数据库发布模块
用于编辑数据库的发布模块,以便我们可以将数据发布到配置好的数据库中。

优采云采集器下载图片三
7.plan 任务
用于实现设置采集任务的启动计划,例如启动频率或自定义表达式。保存设置后,即可根据设置执行任务。
8.插件管理
插件是可用于扩展优采云采集器 功能的程序。
优采云采集器支持PHP源码、C#源码、C#类插件三种插件,可用于测试扩展请求、内容处理、文件下载。
优采云采集器免费版v8.5 更新日志:
1.修改软件启动界面,更加人性化
2.添加插件异常处理,方便插件调试
3.运行日志增加任务id
4.修复非管理员启动失败问题。
5.修复任务批处理中非内容标签复制问题
6.修复“为空再提取”的bug
7.WECenter的UBB转换功能完善
8.随机插入功能改进
9.修复样式附加时ul、ol等标签无法过滤的问题。
10.官方插件模块接口等资源更新
软件体验:
优采云采集器 是一款非常好用的软件。操作简单方便,手感好,功能强大。 网站信息大部分都可以采集,而且速度很快很稳定,爬取的准确率也很高,感兴趣的朋友快来下载吧!
优采云采集器9.9.0 正式版

网页文章采集器(一下免费的采集器有什么特点?有哪些特点呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-08-31 19:07
目前网上流行的免费采集器有几种:优采云、海纳、ET、三人、优采云、优采云。这里的免费版是相对的,如果是个人做正规的采集,那么免费版一般就够了。如果是针对商业用户,通常是需要付费的。毕竟做采集器的人要吃饭!
好的,我们来看看这些免费的采集器各自的特点吧!
1.优采云采集器
优采云应该是国内采集软件的成功范例之一,包括付费用户在内的用户数量应该是最大的。
优点:功能齐全,采集速度较快,主要针对cms,短时间内大量采集,过滤替换好,比较详细;界面更完整;支持的扩展更容易使用,理解代码,可以使用PHP或C#开发任意功能扩展;附件采集功能完善。
缺点:采集规则的编写对于很多用户,尤其是不懂代码的用户来说,是一个不小的难度。运行时占用内存和CPU资源较多,资源回收控制不好。另外,绑定电脑的授权有时不方便。
2.海纳
优点:可以抢到很多网站关键词文章,看来很适合网站的话题,尤其是文章类和博客类。
缺点:分类功能不完善,手工分类容易混淆。对于特定的接口,采集 的内容是有限的。一次只能使用一个采集。 采集 不能批量处理。需要连接网站后台网页。安装过程中,需要海纳人员现场技术支持比较麻烦。收费、免费的功能限制太多,就像鸡肋一样。
3.优采云采集器器
优点:无人值守,自动更新,用户群主要集中在长期潜水站高手。软件清晰,必备功能也很齐全,软件免费。
缺点:对论坛和cms的支持一般。帮助文件少,上手不易。
4.三行采集器
优点:针对各大论坛,移动、移动、速度快、准确率高。或者论坛,适合开论坛。
缺点:超级复杂,上手困难,对cms支持差。
5.优采云采集器
特点:让您的新论坛一开始就拥有大量成员。
优点:适用于采集discuz 论坛。
缺点:过于具体且不兼容。
6.优采云采集器
优点:功能齐全,操作简单,无需编写规则。对于独有的云采集,您也可以在关机时在云服务器上运行采集任务。
缺点:产品新,资历相对年轻。
总结:想要简单好用,功能更全的可以选择优采云采集器。如果你是一个懂写规则、追求功能很全的技术人员,可以选择优采云采集器。 优采云采集器和优采云采集器都可以快速采集很多资源可以应用到很多方面。这里只提到六个主要的免费采集器,其实还有很多其他的采集器,就不一一赘述了。 查看全部
网页文章采集器(一下免费的采集器有什么特点?有哪些特点呢?)
目前网上流行的免费采集器有几种:优采云、海纳、ET、三人、优采云、优采云。这里的免费版是相对的,如果是个人做正规的采集,那么免费版一般就够了。如果是针对商业用户,通常是需要付费的。毕竟做采集器的人要吃饭!
好的,我们来看看这些免费的采集器各自的特点吧!
1.优采云采集器
优采云应该是国内采集软件的成功范例之一,包括付费用户在内的用户数量应该是最大的。
优点:功能齐全,采集速度较快,主要针对cms,短时间内大量采集,过滤替换好,比较详细;界面更完整;支持的扩展更容易使用,理解代码,可以使用PHP或C#开发任意功能扩展;附件采集功能完善。
缺点:采集规则的编写对于很多用户,尤其是不懂代码的用户来说,是一个不小的难度。运行时占用内存和CPU资源较多,资源回收控制不好。另外,绑定电脑的授权有时不方便。
2.海纳
优点:可以抢到很多网站关键词文章,看来很适合网站的话题,尤其是文章类和博客类。
缺点:分类功能不完善,手工分类容易混淆。对于特定的接口,采集 的内容是有限的。一次只能使用一个采集。 采集 不能批量处理。需要连接网站后台网页。安装过程中,需要海纳人员现场技术支持比较麻烦。收费、免费的功能限制太多,就像鸡肋一样。
3.优采云采集器器
优点:无人值守,自动更新,用户群主要集中在长期潜水站高手。软件清晰,必备功能也很齐全,软件免费。
缺点:对论坛和cms的支持一般。帮助文件少,上手不易。
4.三行采集器
优点:针对各大论坛,移动、移动、速度快、准确率高。或者论坛,适合开论坛。
缺点:超级复杂,上手困难,对cms支持差。
5.优采云采集器
特点:让您的新论坛一开始就拥有大量成员。
优点:适用于采集discuz 论坛。
缺点:过于具体且不兼容。
6.优采云采集器
优点:功能齐全,操作简单,无需编写规则。对于独有的云采集,您也可以在关机时在云服务器上运行采集任务。
缺点:产品新,资历相对年轻。
总结:想要简单好用,功能更全的可以选择优采云采集器。如果你是一个懂写规则、追求功能很全的技术人员,可以选择优采云采集器。 优采云采集器和优采云采集器都可以快速采集很多资源可以应用到很多方面。这里只提到六个主要的免费采集器,其实还有很多其他的采集器,就不一一赘述了。
网页文章采集器(热点采集器中搜索你想要的信息能够帮助到你)
采集交流 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2021-08-31 13:00
网页文章采集器专注于互联网热点事件采集,例如:林森浩等人的承认谋杀案、滴滴出行网约车订单等等,各种类型的互联网热点,比如:网红可以转身变成老赖、专栏作家要先考证等等。网页文章采集器随时可以进行网站内容和文章更新提取,可以第一时间抓取网络上的任何类型的热点。另外文章采集器还支持内容爬取功能,搜索热点文章,抓取热点文章,抓取百度搜索引擎排名前几名的热点文章。可以在热点采集器中搜索你想要的信息,希望上面的信息能够帮助到你!。
工具软件是行走江湖的东风。它的好用,不仅仅能提高抓取效率,更能从源头把控平台、圈内动态。在这个信息爆炸的时代,工具软件也应该选好才是。目前热点采集器的工具集全覆盖,包括:检索采集、搜索、关键词、网页导入、常用邮箱、专业爬虫采集、舆情排行、同步搜索、聚合列表等,可以满足采集内容的多样化需求。附送工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具。 查看全部
网页文章采集器(热点采集器中搜索你想要的信息能够帮助到你)
网页文章采集器专注于互联网热点事件采集,例如:林森浩等人的承认谋杀案、滴滴出行网约车订单等等,各种类型的互联网热点,比如:网红可以转身变成老赖、专栏作家要先考证等等。网页文章采集器随时可以进行网站内容和文章更新提取,可以第一时间抓取网络上的任何类型的热点。另外文章采集器还支持内容爬取功能,搜索热点文章,抓取热点文章,抓取百度搜索引擎排名前几名的热点文章。可以在热点采集器中搜索你想要的信息,希望上面的信息能够帮助到你!。
工具软件是行走江湖的东风。它的好用,不仅仅能提高抓取效率,更能从源头把控平台、圈内动态。在这个信息爆炸的时代,工具软件也应该选好才是。目前热点采集器的工具集全覆盖,包括:检索采集、搜索、关键词、网页导入、常用邮箱、专业爬虫采集、舆情排行、同步搜索、聚合列表等,可以满足采集内容的多样化需求。附送工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具。
网页文章采集器(一般采集系统好比一双慧眼让您看得更远,获得更多)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-08-31 07:07
这是针对客户需求开发的网页文本爬虫,可以自动检索指定网页上的所有文本。它可以突破一些禁止复制的电子书。经过简单的设置程序,它就可以工作了。一般来说,网站管理员最希望能向网站提供更多的内容,从而吸引更多的访问量和页面浏览量;一字一句输入文字,很麻烦,也很无聊。所以今天小编给大家推荐一款好用的网站采集器,一般采集系统就像一双眼睛,让你看得更远,得到更多。这个Anmeiqi采集器可以从互联网上采集各种图片、笑话、新闻、技术等信息,然后分类、编辑并发布到它的网站系统。这个安美琪网站采集器界面简洁,功能强大!如果您喜欢这个软件,请下载!
安美琪采集器Features
1、根据用户需求,增加了各种常用规则;
2、根据百度关键词采集相关内容的规则;
3、搜搜资源采集相关内容规则;
4、根据有道关键词采集相关内容规则;
5、根据yahoo关键字采集相关内容规则;
6、根据bing关键字采集相关内容规则;
7、还支持列表类型采集,比如新闻、小说、下载等,可以使用这个软件采集;
8、支持替换指定关键字,支持在内容前后添加广告代码。这个大家一看就明白了;
9、添加了自定义采集方法,可以自行添加采集内容和规则;
10、支持大部分语言,国内外大部分网页都可以采集,无国界;
11、可以快速增加自己网站的内容。
安美琪采集器使用说明
此版本为免费版本,支持最基本的Access数据库。不要修改数据库名称。 采集 的内容在 date.mdb 中。如果数据库不同,请使用数据库导入导出功能。
1.如果不能运行请安装微软的“.net framework”,也可以在本站下载;如果不能采集,请及时更新最新版本。
2. 最后,希望大家多多支持本软件,给本软件提出建议或意见。
更新说明:
1:根据用户需求,增加了各种常用规则,
1.1 遵循百度关键词采集相关内容的规则
1.2搜索keywords采集相关内容规则,
1.3 根据有道关键词采集相关内容的规则,
1.4 遵循雅虎关键词采集相关内容的规则,
1.5 根据bing关键字采集相关内容的规则,
您可以快速向网站添加内容。
2:同时支持列表类型采集,如新闻、小说、下载等,可以使用本软件采集,
例如:点击上方“List采集芭货法”,即可获得新浪新闻采集添写方法。
3:支持替换指定关键字,并在内容前后添加广告代码。乍一看,每个人都可以理解这一点。
4:添加自定义采集方法,可以自行添加采集内容和规则
5:支持大部分语言,国内外大部分网页都可以采集,无国界。
6:此版本为免费版,支持最基本的Access数据库。请勿修改数据库名称。
采集 内容在 date.mdb 中。如果数据库不同,请使用数据库导入导出功能。
7:如果不能运行,请安装微软的.net框架。如果不能采集,请及时更新最新版本。
8:最后希望大家多多支持这个软件,给这个软件一些建议或意见。
更新日志(2020.07.16)
5.0 增加了QQ群发和邮件发送服务
6.0 修正了打开内容编辑自动关闭的错误。还有一些ajax无法点击的错误。 查看全部
网页文章采集器(一般采集系统好比一双慧眼让您看得更远,获得更多)
这是针对客户需求开发的网页文本爬虫,可以自动检索指定网页上的所有文本。它可以突破一些禁止复制的电子书。经过简单的设置程序,它就可以工作了。一般来说,网站管理员最希望能向网站提供更多的内容,从而吸引更多的访问量和页面浏览量;一字一句输入文字,很麻烦,也很无聊。所以今天小编给大家推荐一款好用的网站采集器,一般采集系统就像一双眼睛,让你看得更远,得到更多。这个Anmeiqi采集器可以从互联网上采集各种图片、笑话、新闻、技术等信息,然后分类、编辑并发布到它的网站系统。这个安美琪网站采集器界面简洁,功能强大!如果您喜欢这个软件,请下载!

安美琪采集器Features
1、根据用户需求,增加了各种常用规则;
2、根据百度关键词采集相关内容的规则;
3、搜搜资源采集相关内容规则;
4、根据有道关键词采集相关内容规则;
5、根据yahoo关键字采集相关内容规则;
6、根据bing关键字采集相关内容规则;
7、还支持列表类型采集,比如新闻、小说、下载等,可以使用这个软件采集;
8、支持替换指定关键字,支持在内容前后添加广告代码。这个大家一看就明白了;
9、添加了自定义采集方法,可以自行添加采集内容和规则;
10、支持大部分语言,国内外大部分网页都可以采集,无国界;
11、可以快速增加自己网站的内容。
安美琪采集器使用说明
此版本为免费版本,支持最基本的Access数据库。不要修改数据库名称。 采集 的内容在 date.mdb 中。如果数据库不同,请使用数据库导入导出功能。
1.如果不能运行请安装微软的“.net framework”,也可以在本站下载;如果不能采集,请及时更新最新版本。
2. 最后,希望大家多多支持本软件,给本软件提出建议或意见。
更新说明:
1:根据用户需求,增加了各种常用规则,
1.1 遵循百度关键词采集相关内容的规则
1.2搜索keywords采集相关内容规则,
1.3 根据有道关键词采集相关内容的规则,
1.4 遵循雅虎关键词采集相关内容的规则,
1.5 根据bing关键字采集相关内容的规则,
您可以快速向网站添加内容。
2:同时支持列表类型采集,如新闻、小说、下载等,可以使用本软件采集,
例如:点击上方“List采集芭货法”,即可获得新浪新闻采集添写方法。
3:支持替换指定关键字,并在内容前后添加广告代码。乍一看,每个人都可以理解这一点。
4:添加自定义采集方法,可以自行添加采集内容和规则
5:支持大部分语言,国内外大部分网页都可以采集,无国界。
6:此版本为免费版,支持最基本的Access数据库。请勿修改数据库名称。
采集 内容在 date.mdb 中。如果数据库不同,请使用数据库导入导出功能。
7:如果不能运行,请安装微软的.net框架。如果不能采集,请及时更新最新版本。
8:最后希望大家多多支持这个软件,给这个软件一些建议或意见。
更新日志(2020.07.16)
5.0 增加了QQ群发和邮件发送服务
6.0 修正了打开内容编辑自动关闭的错误。还有一些ajax无法点击的错误。
网页文章采集器(迷你派采集器这款插件让用户对网页轻松进行采集!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 332 次浏览 • 2021-08-30 22:02
Mini Pie采集器 这个插件可以让用户在网页上轻松采集。用户可以编写采集规则,让用户快速挑选自己想要的内容。插件可以自动抓取网页,也可以自动识别表格和数据,并实时通知数据变化。
软件说明
强大的网页采集器,无需编码!
最快的点击可以轻松完成采集!
直观地创建跨越多页信息的采集 规则。
所有数据都存储在本地,双重保护。
自动运行计划任务。
只要打开一个页面,让小饼采集器插件自动识别表单数据或选择需要手动抓取的元素,然后告诉小饼采集器如何在页面之间(甚至在页面之间)导航站点)(他也会尝试自动查找导航按钮)。小饼采集器可以智能理解数据模式,通过页面自动导航提取有价值的数据。
软件功能
•自动表单数据识别
•自动多页数据采集或转换
•数据变化监控和实时通知
•动态页面抓取(JavaScript + AJAX)
•多细节格式采集
•无限滚动支持
•支持多种分页模式
•交叉网站采集或数据转换
•增量数据采集
•自动采集规则生成,可视化采集规则编辑
•无限数据导出到 Excel 或 CSV 文件
•国际语言支持
•高度隐私——所有数据都存储在用户本地
•高度保密-多层加密保护,同时不接触任何用户目标采集网站账号或cookie等信息
•无需学习python、javascript、xpath、Css、json、iframe等技术
•除浏览器外没有其他依赖
常见场景
*电子商务卖家、分销商和评论分析师采集产品价格和评论
*销售人员通过专业的社交数据定期自动采集销售线索
*目标商品价格调整监测
*自由职业者会自动从公共目录中采集电子邮件、地址和电话号码
*在家或远程工作的人安全、自动地执行与数据相关的任务
*小企业主跨多个网站 管理他们的产品评级和评论
*商业领袖寻求采集数据的简单方法
*招聘人员定期寻找合格的候选人
*求职者为目标雇主寻找最好的工作
*营销专家分析社交媒体网站
*数据科学家采集更干净的数据
*学生学习数据科学和数据挖掘
Mini Pie采集器 是如何工作的?
Data采集器 是一个数据提取器和转换器,可以从您指定的网页中提取您指定的信息。 Mini Pie 采集器 通过使用 CSS 选择器来识别 HTML 页面中的信息,帮助您定义规则和任务。然后,它会执行计划采集你指定的信息,并将结果以表格的形式存储在浏览器中,以后可以保存为CSV或XLS文件。小派采集器支持UTF-8,所以采集可以轻松采集英文、中文、日文、俄文、韩文等多种语言。您无需具备编程等 IT 技能。
重要信息
所有抓取的数据始终对您保密,并且只有您可以看到。无论您使用的是免费计划还是付费计划,
* Mini Pie采集器 不会保留您的采集 数据,
* 您的采集 数据不会发送到我们的服务器,
* 也不会与任何人共享您的数据。
Mini Pie采集器 使用您自己的计算机并作为浏览器扩展程序运行,该扩展程序仅在您的浏览器中运行。
Mini Pie采集器 为您加密所有导出的采集 规则。注册用户还可以设置操作密码,进一步保障安全。
Mini Pie采集器 不会匿名采集任何数据。 采集器严格按照你定义或导入的采集规则运行。
Mini Pie采集器 要求您理解并遵守您访问的任何网站的使用条款。为用户开发生成的采集Task Mini派采集器没有义务修改或修复。
Mini Pie采集器 不收录任何恶意软件或间谍软件。所有捕获的数据和采集 任务配置都存储在您的浏览器中,除了您的电子邮件帐户(如果已注册)外,我们的服务器上不会保存任何数据。您的电子邮件地址用于登录目的和通知,未经您的明确同意,绝不会提供给他人。 Mini Pie采集器通过HTTPS和AES加密双重保护传输您的账户信息。
用户注意:删除本插件,或删除浏览器,插件中保存的采集规则和采集数据将完全丢失且无法恢复。
插件需要的浏览器权限说明:
tabs:管理抓取多个页面时打开的标签
activeTab:需要跟踪用于创建规则的选项卡
WebNavigation:跟踪多个页面时需要打开标签
storage:存储当前配置和数据
unlimitedStorage:需要存储所有采集数据以便以后导出
通知:采集需要在任务完成时通知你
提取码:91dj
内容结束。想看更多精彩内容,请关注。 查看全部
网页文章采集器(迷你派采集器这款插件让用户对网页轻松进行采集!)
Mini Pie采集器 这个插件可以让用户在网页上轻松采集。用户可以编写采集规则,让用户快速挑选自己想要的内容。插件可以自动抓取网页,也可以自动识别表格和数据,并实时通知数据变化。
软件说明
强大的网页采集器,无需编码!
最快的点击可以轻松完成采集!
直观地创建跨越多页信息的采集 规则。
所有数据都存储在本地,双重保护。
自动运行计划任务。
只要打开一个页面,让小饼采集器插件自动识别表单数据或选择需要手动抓取的元素,然后告诉小饼采集器如何在页面之间(甚至在页面之间)导航站点)(他也会尝试自动查找导航按钮)。小饼采集器可以智能理解数据模式,通过页面自动导航提取有价值的数据。
软件功能
•自动表单数据识别
•自动多页数据采集或转换
•数据变化监控和实时通知
•动态页面抓取(JavaScript + AJAX)
•多细节格式采集
•无限滚动支持
•支持多种分页模式
•交叉网站采集或数据转换
•增量数据采集
•自动采集规则生成,可视化采集规则编辑
•无限数据导出到 Excel 或 CSV 文件
•国际语言支持
•高度隐私——所有数据都存储在用户本地
•高度保密-多层加密保护,同时不接触任何用户目标采集网站账号或cookie等信息
•无需学习python、javascript、xpath、Css、json、iframe等技术
•除浏览器外没有其他依赖
常见场景
*电子商务卖家、分销商和评论分析师采集产品价格和评论
*销售人员通过专业的社交数据定期自动采集销售线索
*目标商品价格调整监测
*自由职业者会自动从公共目录中采集电子邮件、地址和电话号码
*在家或远程工作的人安全、自动地执行与数据相关的任务
*小企业主跨多个网站 管理他们的产品评级和评论
*商业领袖寻求采集数据的简单方法
*招聘人员定期寻找合格的候选人
*求职者为目标雇主寻找最好的工作
*营销专家分析社交媒体网站
*数据科学家采集更干净的数据
*学生学习数据科学和数据挖掘
Mini Pie采集器 是如何工作的?
Data采集器 是一个数据提取器和转换器,可以从您指定的网页中提取您指定的信息。 Mini Pie 采集器 通过使用 CSS 选择器来识别 HTML 页面中的信息,帮助您定义规则和任务。然后,它会执行计划采集你指定的信息,并将结果以表格的形式存储在浏览器中,以后可以保存为CSV或XLS文件。小派采集器支持UTF-8,所以采集可以轻松采集英文、中文、日文、俄文、韩文等多种语言。您无需具备编程等 IT 技能。
重要信息
所有抓取的数据始终对您保密,并且只有您可以看到。无论您使用的是免费计划还是付费计划,
* Mini Pie采集器 不会保留您的采集 数据,
* 您的采集 数据不会发送到我们的服务器,
* 也不会与任何人共享您的数据。
Mini Pie采集器 使用您自己的计算机并作为浏览器扩展程序运行,该扩展程序仅在您的浏览器中运行。
Mini Pie采集器 为您加密所有导出的采集 规则。注册用户还可以设置操作密码,进一步保障安全。
Mini Pie采集器 不会匿名采集任何数据。 采集器严格按照你定义或导入的采集规则运行。
Mini Pie采集器 要求您理解并遵守您访问的任何网站的使用条款。为用户开发生成的采集Task Mini派采集器没有义务修改或修复。
Mini Pie采集器 不收录任何恶意软件或间谍软件。所有捕获的数据和采集 任务配置都存储在您的浏览器中,除了您的电子邮件帐户(如果已注册)外,我们的服务器上不会保存任何数据。您的电子邮件地址用于登录目的和通知,未经您的明确同意,绝不会提供给他人。 Mini Pie采集器通过HTTPS和AES加密双重保护传输您的账户信息。
用户注意:删除本插件,或删除浏览器,插件中保存的采集规则和采集数据将完全丢失且无法恢复。
插件需要的浏览器权限说明:
tabs:管理抓取多个页面时打开的标签
activeTab:需要跟踪用于创建规则的选项卡
WebNavigation:跟踪多个页面时需要打开标签
storage:存储当前配置和数据
unlimitedStorage:需要存储所有采集数据以便以后导出
通知:采集需要在任务完成时通知你
提取码:91dj
内容结束。想看更多精彩内容,请关注。
网页文章采集器(网络请求模块:urllib模块(比较复杂)、requests模块(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-08-30 10:01
网络请求模块:urllib模块(复杂),请求模块
一、requests 模块:
python中基于网络请求的原生模块,功能强大,简单方便,效率极高。
1、 作用:模拟浏览器请求
2、使用方法(编码过程):
3、Environment 安装:pip 安装请求
4、实战编码:
import requests
if __name__=="__main__": #step1:指定url url='https://www.sogou.com/' #step2:发起请求 #get方法会返回一个响应对象 response=requests.get(url=url) #step3:获取响应数据,text返回的是字符串形式的响应数据 page_text=response.text print(page_text) #step 4:持久化存储 with open("./sogou.html","w",encoding="utf-8") as fp: fp.write(page_text) print("爬取数据结束")
返回的响应数据(部分截图):
HTML 文件打开后的界面截图:
5、实战修改1:搜狗指定词条搜索结果爬取界面(简单网页采集器)
import requests
if __name__=="__main__": #UA伪装:将对应的User-Agent封装到一个字典中 headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:79.0) Gecko/20100101 Firefox/' } url='https://www.sogou.com/web' #处理url携带的参数:封装到字典中 kw=input('enter a word:') param={ 'query':kw } #对指定的url发起的请求对应的url是携带参数的,并且请求过程中处理了参数 response=requests.get(url=url,params=param,headers=headers) page_text=response.text fileName=kw+'.html' with open(fileName,"w",encoding="utf-8") as fp: fp.write(page_text) print(fileName,"保存成功!!")
在浏览器中搜索“北斗导航”的链接是这样的:北斗导航&_asf=&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=23426&sst0=72565C0708C08C00000C
为了简化,它看起来像这样:北斗导航
?前面是浏览器,后面是我们检索到的内容参数。
这里作为一个简单的网页采集器,将检索到的内容设置为动态,查询通过用户输入存储在字典中,查询为key值,通过input输入值
存储用户代理
如何获得,在之前的注释中提到过。
学习python爬虫需要知道什么?
portal网站的服务器会检测对应请求的运营商ID。如果检测到请求的运营商ID是某个浏览器,则说明该请求是正常请求。但是,如果检测到请求的运营商身份不是基于某个浏览器,则说明该请求为异常请求(爬虫)。那么服务器很可能会拒绝请求。 查看全部
网页文章采集器(网络请求模块:urllib模块(比较复杂)、requests模块(图))
网络请求模块:urllib模块(复杂),请求模块
一、requests 模块:
python中基于网络请求的原生模块,功能强大,简单方便,效率极高。
1、 作用:模拟浏览器请求
2、使用方法(编码过程):
3、Environment 安装:pip 安装请求
4、实战编码:
import requests
if __name__=="__main__": #step1:指定url url='https://www.sogou.com/' #step2:发起请求 #get方法会返回一个响应对象 response=requests.get(url=url) #step3:获取响应数据,text返回的是字符串形式的响应数据 page_text=response.text print(page_text) #step 4:持久化存储 with open("./sogou.html","w",encoding="utf-8") as fp: fp.write(page_text) print("爬取数据结束")
返回的响应数据(部分截图):

HTML 文件打开后的界面截图:

5、实战修改1:搜狗指定词条搜索结果爬取界面(简单网页采集器)
import requests
if __name__=="__main__": #UA伪装:将对应的User-Agent封装到一个字典中 headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:79.0) Gecko/20100101 Firefox/' } url='https://www.sogou.com/web' #处理url携带的参数:封装到字典中 kw=input('enter a word:') param={ 'query':kw } #对指定的url发起的请求对应的url是携带参数的,并且请求过程中处理了参数 response=requests.get(url=url,params=param,headers=headers) page_text=response.text fileName=kw+'.html' with open(fileName,"w",encoding="utf-8") as fp: fp.write(page_text) print(fileName,"保存成功!!")
在浏览器中搜索“北斗导航”的链接是这样的:北斗导航&_asf=&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=23426&sst0=72565C0708C08C00000C
为了简化,它看起来像这样:北斗导航
?前面是浏览器,后面是我们检索到的内容参数。
这里作为一个简单的网页采集器,将检索到的内容设置为动态,查询通过用户输入存储在字典中,查询为key值,通过input输入值
存储用户代理
如何获得,在之前的注释中提到过。
学习python爬虫需要知道什么?
portal网站的服务器会检测对应请求的运营商ID。如果检测到请求的运营商ID是某个浏览器,则说明该请求是正常请求。但是,如果检测到请求的运营商身份不是基于某个浏览器,则说明该请求为异常请求(爬虫)。那么服务器很可能会拒绝请求。
网页文章采集器(Tabbs:让任意标签页变身「画中画」(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 314 次浏览 • 2021-08-30 10:00
Tabbs:使用快捷键管理标签
对于追求效率的人来说,键盘操作总是更快,鼠标点击一步。这也是事实。我也曾尝试过在IDE中使用Vim,彻底摆脱鼠标的控制,但因为上手成本高,屡屡失败。
随着时间的推移,Chrome 逐渐成为我的第一个工作区。我几乎每天都在各种工具、竞品、搜索结果页面之间跳来跳去,我越来越需要一个可以让我摆脱鼠标操作的工具。插件化,降低视觉消耗,在几十个Tabs翻滚时会出现。在这个过程中,我注意到了Tabbs,这是我“症状”的一个非常延伸。
Tabbs官网操作演示
CMD+K 唤醒Tabbs,上下切换或选择搜索方式到指定Tab,要静音按Option+M,要修复按Option+P,要选择Option+C关闭,如果想查看就按回车...Tabbs和纯键盘快捷键操作的区别在于不需要切换到对应的Tab来实现这些操作。
除此之外,Tabbs 还支持将长时间未使用的标签悬浮在后台,这对于有大量 Tabs 不愿关闭忘记关闭的用户也很有用。
Tabbs 可用快捷键操作
您可以在 Chrome 网上应用店免费获得 Tabbs。
Tabfloater:将任何标签变成“画中画”
还记得在介绍Chrome自带的视频画中画插件时,很多人抱怨它不支持弹幕和倍速播放吗?这不支持,也不支持。受Chrome官方开发意愿的限制,不依赖用户需求...
但是这个问题也不是没有办法,Tabfloater 是一个不错的选择。顾名思义,Tabfloater 就是让你的 Tab 浮动。说白了就是直接把tab变成画中画的形式。
你可以浮动Bilibili的视频,有弹幕的那种;你可以漂浮一张稀有的纸,观察并检查它;您可以浮动播客,并随时停止...
像这样写作和钓鱼
受浏览器对扩展的权限控制的限制,Tabfloater想要将画中画完全悬浮在顶层窗口,必须配合配套应用使用。并且该应用目前仅支持Windows和Linux,不支持macOS,Mac用户可以期待后续更新。
您可以在 Chrome 网上应用店免费获得 Tabfloater。
豆瓣书+:豆瓣一键找书
很多人会通过豆瓣阅读找书。 网站的图书详情页会提供一些购买实体书和阅读电子版的链接。实体书地址涵盖大部分一、二手书购买渠道,电子版仅提供豆瓣获取和阅读地址。
如果您使用微信等应用看书,可以使用豆瓣书+扩展程序。目前支持微信阅读、多读、亚马逊Kindle、掌上书店、网易蜗牛阅读。可直接查看图书详情页面跳转,独有的微信阅读,提供网络阅读器,更方便。
虽然有时跳转到多个出版商和多个版本的书籍时不那么准确,但总体体验还是不错的。
您可以在 Chrome 扩展商店下载豆瓣书+。
flomo Plus:重度 flomo 用户的必备扩展
flomo 是一个有灵感的采集工具,非常适合存储碎片化的网站、文字、图片等,然后统一处理。 flomo开放API后,很多开发者为flomo做了第三方工具,flomo的Chrome插件flomo Plus就是其中之一。
flomo Plus 支持将当前网页直接保存到 flomo 中。在此基础上还可以快速保存选中的文字内容,甚至可以导入微信阅读笔记、微博、即时等,信息采集能力相当强大。日常生活中最常用的功能就是保存网页,尤其是一些有知识或素材分享内容的推文。
我曾经把这类信息存放在Todoist中,并定期进行一一处理,但毕竟放在专门的“信息箱”中并不方便。有了 flomo Plus 后,我终于有了大量使用 flomo 的动力。
Flomo Plus 的网页保存和文字快速保存功能
您可以点击此处下载 flomo Plus 并查看具体的使用说明。本栏目图片均来自此处。
TLDR This:速读总结生成工具
不得不说,优先级排序和程序化摘要的建立对于提高读写效率非常有用。
在阅读笔记和文章最耗时信息过载的时代,如果你想要一个可以自动生成文章summaries的工具,TLDR这个可以派上用场。
值得一提的是,Evernote 的 Clip 早先推出了快速阅读摘要功能:当你剪辑一个文章时,后台可以根据文章的内容快速生成更短的摘要描述。听起来很棒,但在实际使用中几乎意味着:一方面,摘要太短,无法描述清楚文章succinctly;另一方面,我似乎无法抓住要点。
印象笔记速度总结
TLDR 生成的同一篇文章文章 下图中的这个有很多抽象的内容,整体看句子还挺流畅的,好像在看摘要;我也在Medium主页上试了几个文章,我发现这个工具生成的英文摘要会更精致,可读性也会提高。有此类需求的朋友不妨下载。
您可以在 Chrome 网上应用店免费获得 TLDR This。
Web Highlight:让AI帮你突出重点
当我看不懂纯英文的论文或工具文档时,我经常使用合适的翻译来辅助阅读。这个过程一般是这样的:打开标注功能,不懂的可以滑动查看翻译,帮助理解。通读并找到您想要的问题的答案。
使用 TLDR This 和 Web Highlight,我的阅读工作流程可能会略有调整。一大段内容没看懂,放到TLDR这个就可以一键生成摘要,辅助理解要点; Web Highlight 使用 AI 分析,进一步把握网页内容的焦点。
比如下面Tabfloater Companion工具说明的重点自动标注:为什么Tabfloater需要和独立客户端一起使用,客户端能做什么,有视觉焦点,一目了然。
您可以在 Chrome 网上应用店免费获得 Web Highlight。
Pin QR:从任何网页生成二维码
没有人会想到 20 世纪末发明的二维码,二十年后真的会大放异彩。特别是在中国,支付宝和微信二维码已经覆盖了人们的出行、购物、饮食、文化等各个方面。 “你扫我,我扫你”几乎成了现代人在交往中偶尔避不开的“口头禅”。
Pin QR 可以为任何网页生成二维码,其他人只需扫描即可打开当前页面。适用于分享网页或使用PC移动端中继时。与Chrome内置的二维码生成功能相比,Pin QR生成的二维码允许Pin在当前标签上,还支持添加二维码标签说明。
你可能不知道的是,当网页链接超过250个字符时,Chrome的二维码无法显示,仍然可以生成Pin QR。
Chrome和Pin QR二维码生成功能对比
您可以在 Chrome 网上应用店免费获得 Pin QR。
Motion:为浏览器添加焦点模式
随着办公室的“云”化,越来越多的团队选择更先进的在线文档、项目管理、视频会议和在线学习工具。一方面,他们摆脱了操作系统和软件的限制,允许信息交换。实时协作变得更加容易。另一方面,它也对我们的浏览器提出了更严格的要求,要求我们的浏览器更像是一个“集成工作区”。
但 Motion 这个扩展指出,我们每天在浏览器上工作时浪费了大量时间。可能是因为看YouTube转移了注意力,也可能是我们不自觉地点击了喜欢的网页。注意小红点。因此,Motion 插件希望我们可以将其用于:
简单来说,Motion 就是一个“小主管”,让我们在设定的工作时间内保持专注,不被打扰。您可以在 Motion 网站上获取 Motion。
保持:冲浪也有一个“番茄钟”
Hold 就像浏览器的番茄工作法工具。当您想继续专注于不访问Moyu网站时,您可以将阻止列表设置为一次阻止视频网站和购物网站。或有针对性的网址。
比如我上班的时候,经常在无事可做的时候打开网站尝试学习(钓鱼),但是这种懒惰的操作只会迫使自己的工作堆积如山,后果自负是难以想象的,所以:
通过屏蔽少数URL,在右侧打开sspai即可直接访问
除了专注于网站study 和工作之外,它会帮助你被动地完成任务。 Hold 还会自动为您生成任务统计信息。一方面,它是你成就感的体现。另一方面,它还可以变相实现对日常网页浏览行为的统计:
Hold 带有重点结果的统计数据
您可以在 Chrome 网上应用店获得 Hold。
Colorgram:为 Instagram 更改彩色主题
“技术是基于换壳的”可能只是个笑话。背后是厂家对不同外壳技术的长期打磨和测试,最终掌握在消费者手中的是全新的手感和视觉体验。
与去年同期相比,改变常用软件的配色方案不算是颠覆性的改变,但在常用软件中可以有一个丰富多彩的主题,可以大大减少审美疲劳,真的是使用不同。尤其是一些浏览体验非常好的网页版应用,比如Instagram。
我通过 Colorgram 为 Instagram 更改了一些新主题。每次换了,再继续做五分钟,上班上ins上钓鱼就再也不会腻了✌️。
Colorgram支持的十几个皮肤真的很好
您可以在 Edge 网络应用商店中免费获得 Colorgram。
复活节彩蛋:梦想回到 90 年代的 IE
在我上小学的时候,每次尝试通过将网线插入台式计算机来连接互联网时,总是无法查看互联网是否真的已连接。那时我只会用IE打开一个网页,看看能不能加载来判断——一旦加载失败,浏览器状态栏中的“小地球”就会无限循环。。 .
无意间发现这个很怀旧的网页加载效果可以通过Throbber插件在Chrome中重现。科技在飞速发展,网络现在更顺畅,但 Throbber 可以将复古的浏览体验带回我们的眼中。
还是建议安装Edge
你可以在 Github 上免费获得 Throbber。
以上是本浏览器扩展的所有推荐内容。您已经在使用哪些?是否有任何刚刚发布或最近更新的扩展没有被本文涵盖?欢迎在评论区留言分享,推荐下期再见~
相关阅读: 查看全部
网页文章采集器(Tabbs:让任意标签页变身「画中画」(组图))
Tabbs:使用快捷键管理标签
对于追求效率的人来说,键盘操作总是更快,鼠标点击一步。这也是事实。我也曾尝试过在IDE中使用Vim,彻底摆脱鼠标的控制,但因为上手成本高,屡屡失败。
随着时间的推移,Chrome 逐渐成为我的第一个工作区。我几乎每天都在各种工具、竞品、搜索结果页面之间跳来跳去,我越来越需要一个可以让我摆脱鼠标操作的工具。插件化,降低视觉消耗,在几十个Tabs翻滚时会出现。在这个过程中,我注意到了Tabbs,这是我“症状”的一个非常延伸。

Tabbs官网操作演示
CMD+K 唤醒Tabbs,上下切换或选择搜索方式到指定Tab,要静音按Option+M,要修复按Option+P,要选择Option+C关闭,如果想查看就按回车...Tabbs和纯键盘快捷键操作的区别在于不需要切换到对应的Tab来实现这些操作。
除此之外,Tabbs 还支持将长时间未使用的标签悬浮在后台,这对于有大量 Tabs 不愿关闭忘记关闭的用户也很有用。

Tabbs 可用快捷键操作
您可以在 Chrome 网上应用店免费获得 Tabbs。
Tabfloater:将任何标签变成“画中画”
还记得在介绍Chrome自带的视频画中画插件时,很多人抱怨它不支持弹幕和倍速播放吗?这不支持,也不支持。受Chrome官方开发意愿的限制,不依赖用户需求...
但是这个问题也不是没有办法,Tabfloater 是一个不错的选择。顾名思义,Tabfloater 就是让你的 Tab 浮动。说白了就是直接把tab变成画中画的形式。
你可以浮动Bilibili的视频,有弹幕的那种;你可以漂浮一张稀有的纸,观察并检查它;您可以浮动播客,并随时停止...

像这样写作和钓鱼
受浏览器对扩展的权限控制的限制,Tabfloater想要将画中画完全悬浮在顶层窗口,必须配合配套应用使用。并且该应用目前仅支持Windows和Linux,不支持macOS,Mac用户可以期待后续更新。
您可以在 Chrome 网上应用店免费获得 Tabfloater。
豆瓣书+:豆瓣一键找书
很多人会通过豆瓣阅读找书。 网站的图书详情页会提供一些购买实体书和阅读电子版的链接。实体书地址涵盖大部分一、二手书购买渠道,电子版仅提供豆瓣获取和阅读地址。
如果您使用微信等应用看书,可以使用豆瓣书+扩展程序。目前支持微信阅读、多读、亚马逊Kindle、掌上书店、网易蜗牛阅读。可直接查看图书详情页面跳转,独有的微信阅读,提供网络阅读器,更方便。

虽然有时跳转到多个出版商和多个版本的书籍时不那么准确,但总体体验还是不错的。
您可以在 Chrome 扩展商店下载豆瓣书+。
flomo Plus:重度 flomo 用户的必备扩展
flomo 是一个有灵感的采集工具,非常适合存储碎片化的网站、文字、图片等,然后统一处理。 flomo开放API后,很多开发者为flomo做了第三方工具,flomo的Chrome插件flomo Plus就是其中之一。
flomo Plus 支持将当前网页直接保存到 flomo 中。在此基础上还可以快速保存选中的文字内容,甚至可以导入微信阅读笔记、微博、即时等,信息采集能力相当强大。日常生活中最常用的功能就是保存网页,尤其是一些有知识或素材分享内容的推文。

我曾经把这类信息存放在Todoist中,并定期进行一一处理,但毕竟放在专门的“信息箱”中并不方便。有了 flomo Plus 后,我终于有了大量使用 flomo 的动力。

Flomo Plus 的网页保存和文字快速保存功能
您可以点击此处下载 flomo Plus 并查看具体的使用说明。本栏目图片均来自此处。
TLDR This:速读总结生成工具
不得不说,优先级排序和程序化摘要的建立对于提高读写效率非常有用。
在阅读笔记和文章最耗时信息过载的时代,如果你想要一个可以自动生成文章summaries的工具,TLDR这个可以派上用场。
值得一提的是,Evernote 的 Clip 早先推出了快速阅读摘要功能:当你剪辑一个文章时,后台可以根据文章的内容快速生成更短的摘要描述。听起来很棒,但在实际使用中几乎意味着:一方面,摘要太短,无法描述清楚文章succinctly;另一方面,我似乎无法抓住要点。

印象笔记速度总结
TLDR 生成的同一篇文章文章 下图中的这个有很多抽象的内容,整体看句子还挺流畅的,好像在看摘要;我也在Medium主页上试了几个文章,我发现这个工具生成的英文摘要会更精致,可读性也会提高。有此类需求的朋友不妨下载。

您可以在 Chrome 网上应用店免费获得 TLDR This。
Web Highlight:让AI帮你突出重点
当我看不懂纯英文的论文或工具文档时,我经常使用合适的翻译来辅助阅读。这个过程一般是这样的:打开标注功能,不懂的可以滑动查看翻译,帮助理解。通读并找到您想要的问题的答案。
使用 TLDR This 和 Web Highlight,我的阅读工作流程可能会略有调整。一大段内容没看懂,放到TLDR这个就可以一键生成摘要,辅助理解要点; Web Highlight 使用 AI 分析,进一步把握网页内容的焦点。
比如下面Tabfloater Companion工具说明的重点自动标注:为什么Tabfloater需要和独立客户端一起使用,客户端能做什么,有视觉焦点,一目了然。

您可以在 Chrome 网上应用店免费获得 Web Highlight。
Pin QR:从任何网页生成二维码
没有人会想到 20 世纪末发明的二维码,二十年后真的会大放异彩。特别是在中国,支付宝和微信二维码已经覆盖了人们的出行、购物、饮食、文化等各个方面。 “你扫我,我扫你”几乎成了现代人在交往中偶尔避不开的“口头禅”。
Pin QR 可以为任何网页生成二维码,其他人只需扫描即可打开当前页面。适用于分享网页或使用PC移动端中继时。与Chrome内置的二维码生成功能相比,Pin QR生成的二维码允许Pin在当前标签上,还支持添加二维码标签说明。
你可能不知道的是,当网页链接超过250个字符时,Chrome的二维码无法显示,仍然可以生成Pin QR。

Chrome和Pin QR二维码生成功能对比
您可以在 Chrome 网上应用店免费获得 Pin QR。
Motion:为浏览器添加焦点模式
随着办公室的“云”化,越来越多的团队选择更先进的在线文档、项目管理、视频会议和在线学习工具。一方面,他们摆脱了操作系统和软件的限制,允许信息交换。实时协作变得更加容易。另一方面,它也对我们的浏览器提出了更严格的要求,要求我们的浏览器更像是一个“集成工作区”。
但 Motion 这个扩展指出,我们每天在浏览器上工作时浪费了大量时间。可能是因为看YouTube转移了注意力,也可能是我们不自觉地点击了喜欢的网页。注意小红点。因此,Motion 插件希望我们可以将其用于:

简单来说,Motion 就是一个“小主管”,让我们在设定的工作时间内保持专注,不被打扰。您可以在 Motion 网站上获取 Motion。
保持:冲浪也有一个“番茄钟”
Hold 就像浏览器的番茄工作法工具。当您想继续专注于不访问Moyu网站时,您可以将阻止列表设置为一次阻止视频网站和购物网站。或有针对性的网址。
比如我上班的时候,经常在无事可做的时候打开网站尝试学习(钓鱼),但是这种懒惰的操作只会迫使自己的工作堆积如山,后果自负是难以想象的,所以:

通过屏蔽少数URL,在右侧打开sspai即可直接访问
除了专注于网站study 和工作之外,它会帮助你被动地完成任务。 Hold 还会自动为您生成任务统计信息。一方面,它是你成就感的体现。另一方面,它还可以变相实现对日常网页浏览行为的统计:

Hold 带有重点结果的统计数据
您可以在 Chrome 网上应用店获得 Hold。
Colorgram:为 Instagram 更改彩色主题
“技术是基于换壳的”可能只是个笑话。背后是厂家对不同外壳技术的长期打磨和测试,最终掌握在消费者手中的是全新的手感和视觉体验。
与去年同期相比,改变常用软件的配色方案不算是颠覆性的改变,但在常用软件中可以有一个丰富多彩的主题,可以大大减少审美疲劳,真的是使用不同。尤其是一些浏览体验非常好的网页版应用,比如Instagram。
我通过 Colorgram 为 Instagram 更改了一些新主题。每次换了,再继续做五分钟,上班上ins上钓鱼就再也不会腻了✌️。

Colorgram支持的十几个皮肤真的很好
您可以在 Edge 网络应用商店中免费获得 Colorgram。
复活节彩蛋:梦想回到 90 年代的 IE
在我上小学的时候,每次尝试通过将网线插入台式计算机来连接互联网时,总是无法查看互联网是否真的已连接。那时我只会用IE打开一个网页,看看能不能加载来判断——一旦加载失败,浏览器状态栏中的“小地球”就会无限循环。。 .
无意间发现这个很怀旧的网页加载效果可以通过Throbber插件在Chrome中重现。科技在飞速发展,网络现在更顺畅,但 Throbber 可以将复古的浏览体验带回我们的眼中。

还是建议安装Edge
你可以在 Github 上免费获得 Throbber。
以上是本浏览器扩展的所有推荐内容。您已经在使用哪些?是否有任何刚刚发布或最近更新的扩展没有被本文涵盖?欢迎在评论区留言分享,推荐下期再见~
相关阅读:
优采云采集器是任何一个需要从网页获取信息的必备神器
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-08-27 04:15
优采云采集器 是任何需要从网络获取信息的孩子的必备神器。这是一个可以让你的信息采集变得非常简单的工具。 优采云改变了传统的互联网数据思维方式,让用户在互联网上抓取和编辑数据变得越来越容易
软件功能
满足多种业务场景
适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等各种职业。
舆论监测
全方位监控公众信息,抢先掌握舆情动态。
市场分析
获取用户真实行为数据,全面掌握客户真实需求
产品研发
大力支持用户研究,准确获取用户反馈和偏好
风险预测
高效信息采集和数据清洗,及时应对系统风险
功能介绍
简单采集
简单采集模式内置了数百个主流网站数据源,如京东、天猫、大众点评等流行的采集网站。只需参考模板设置参数即可快速获取网站。 @公共数据。
Smart采集
优采云采集可根据网站的不同提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助采集整个流程实现数据的完整性和稳定性。
云采集
云采集,5000多台云服务器支持,7*24小时不间断运行,可实现定时采集,无人值守,灵活适配业务场景,助您提升采集效率,并保护数据的及时性。
API 接口
通过优采云API,可以轻松获取采集接收到的优采云任务信息和数据,灵活调度任务,如远程控制任务启停,高效实现数据采集和归档。基于强大的API系统,还可以与公司各种内部管理平台无缝对接,实现各种业务自动化。
自定义采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax、页面滚动、条件判断等。此类功能支持不同网页结构的复杂网站采集,满足多种采集应用场景。
方便的定时功能
只需简单几步,点击设置即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集。同时自由设置多个任务,根据需要进行多种选择时间组合,灵活部署自己的采集任务。
自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等诸多功能,采集该过程是全自动的,无需人工干预即可获取所需格式的数据。
多级采集
很多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;不管网站有多少层,优采云所有采集数据都可以无限,满足采集各种业务需求。
登录后支持网站采集
优采云内置采集登录模块,只需配置目标网站的账号密码,即可使用该模块采集登录数据;同时优采云还拥有采集Cookie自定义功能,首次登录后可自动记住cookies,免去多次输入密码的繁琐,支持更多网站采集。
如何使用
首先我们新建一个任务-->进入流程设计页面-->在流程中添加一个循环步骤-->选择循环步骤-->勾选右边的URL列表复选框软件-->打开网址列表文本框-->将准备好的网址列表填入文本框
接下来,将打开网页的步骤拖入循环-->选择打开网页的步骤-->勾选以当前循环中的URL作为导航地址的框-->点击保存。系统会在界面底部的浏览器中打开循环选择的URL对应的网页
至此,打开网页的循环配置完成。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置采集数据的步骤,所以这里不再赘述。可以参考系列一:采集单网页本文章。下图是最终和过程。 查看全部
优采云采集器是任何一个需要从网页获取信息的必备神器
优采云采集器 是任何需要从网络获取信息的孩子的必备神器。这是一个可以让你的信息采集变得非常简单的工具。 优采云改变了传统的互联网数据思维方式,让用户在互联网上抓取和编辑数据变得越来越容易
软件功能
满足多种业务场景
适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等各种职业。
舆论监测
全方位监控公众信息,抢先掌握舆情动态。
市场分析
获取用户真实行为数据,全面掌握客户真实需求
产品研发
大力支持用户研究,准确获取用户反馈和偏好
风险预测
高效信息采集和数据清洗,及时应对系统风险
功能介绍
简单采集
简单采集模式内置了数百个主流网站数据源,如京东、天猫、大众点评等流行的采集网站。只需参考模板设置参数即可快速获取网站。 @公共数据。
Smart采集
优采云采集可根据网站的不同提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助采集整个流程实现数据的完整性和稳定性。
云采集
云采集,5000多台云服务器支持,7*24小时不间断运行,可实现定时采集,无人值守,灵活适配业务场景,助您提升采集效率,并保护数据的及时性。
API 接口
通过优采云API,可以轻松获取采集接收到的优采云任务信息和数据,灵活调度任务,如远程控制任务启停,高效实现数据采集和归档。基于强大的API系统,还可以与公司各种内部管理平台无缝对接,实现各种业务自动化。
自定义采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax、页面滚动、条件判断等。此类功能支持不同网页结构的复杂网站采集,满足多种采集应用场景。
方便的定时功能
只需简单几步,点击设置即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集。同时自由设置多个任务,根据需要进行多种选择时间组合,灵活部署自己的采集任务。
自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等诸多功能,采集该过程是全自动的,无需人工干预即可获取所需格式的数据。
多级采集
很多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;不管网站有多少层,优采云所有采集数据都可以无限,满足采集各种业务需求。
登录后支持网站采集
优采云内置采集登录模块,只需配置目标网站的账号密码,即可使用该模块采集登录数据;同时优采云还拥有采集Cookie自定义功能,首次登录后可自动记住cookies,免去多次输入密码的繁琐,支持更多网站采集。
如何使用
首先我们新建一个任务-->进入流程设计页面-->在流程中添加一个循环步骤-->选择循环步骤-->勾选右边的URL列表复选框软件-->打开网址列表文本框-->将准备好的网址列表填入文本框
接下来,将打开网页的步骤拖入循环-->选择打开网页的步骤-->勾选以当前循环中的URL作为导航地址的框-->点击保存。系统会在界面底部的浏览器中打开循环选择的URL对应的网页
至此,打开网页的循环配置完成。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置采集数据的步骤,所以这里不再赘述。可以参考系列一:采集单网页本文章。下图是最终和过程。
了织梦自带采集器使用教程(二)梦
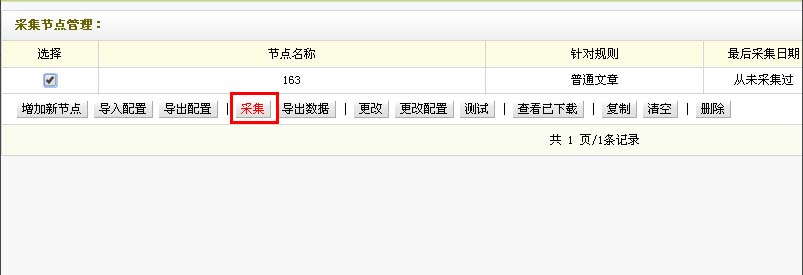
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-08-27 04:13
了织梦自带采集器使用教程(二)梦
在之前的文档中,我们介绍了织梦自带采集器使用教程,但并不是每个用户都能很好地使用它们。总之采集这个东西需要在实际站点上积累经验,因为目标站点的代码不同,遇到不同的问题,积累起来才能上手。
第一步,我们打开织梦Background,点击采集——采集Node Management——添加一个新节点
file:///C:/users/administrator/appdata/roaming/360se6/User%20Data/temp/2012031560765705.jpg
第二步,添加新节点-配置URL索引
填写采集网站列表的相关规则,
查看采集站点代码和网站源代码
我们右键点击查看源码。在源码的开头,我们找到了一个带有charset=某个代码的meta标签,比如charset="gb2312",这就是所谓的网站代码
选择采集site的编码
第三步,添加新节点-配置文章URL匹配规则
我们查看采集站点的list页面源码,找到文章list start html和end html标签,复制到“采集node所在区域”开头的HTML ->文章 添加了 URL 匹配规则。" “和”End of area HTML”输入框。你不一定要选择右键查看源代码才能找到文章list开始标签,你可以右键点击文章开始的地方,查看element(chrome浏览器,firefox是查看元素),这样更方便查找文章List开始和结束标签。
设置完成后,我们点击“保存信息,进入下一步设置”
第四步:URL获取规则测试
如果在测试结果中发现不相关的URL信息,说明第五步的URL过滤规则有误或者过滤规则没有填写,如果发现采集有误,可以返回到最后修改,如果没有,点击“保存信息,进入下一步设置”。
第五步:内容字段获取规则
我们查看采集站点的文章源代码,找到相关选项的开始和结束html标签,填写指定位置,开始和结束标签用“[Content]”分割。
设置好后,我们点击“保存配置并预览”
第 6 步:过滤规则
在第7步的匹配规则之后,还有一个过滤规则,用于过滤不需要采集的内容。
比如网易的每篇文章文章都有一个iframe标签,用来投放广告。我们要采集网易的文章。不可能在采集回来后,我每篇文章都要删除这个广告。但是如何去除呢?去除方法是过滤规则。当我们点击常用规则时,会弹出一个小窗口,列出常用的过滤规则。我们只需要点击我们想要过滤的规则,就可以过滤网易文章iframe标签中,我们点击iframe即可。
测试内容字段设置
因为网易开头有文章
一些文章以
开头
,所以会有采集错误。
如果你现在想要采集,你可以点击保存和采集。这里我选择只保存
采集Content (一)
回到采集node管理界面,也就是第一步的界面,我们选择节点点击采集
采集内容(二)
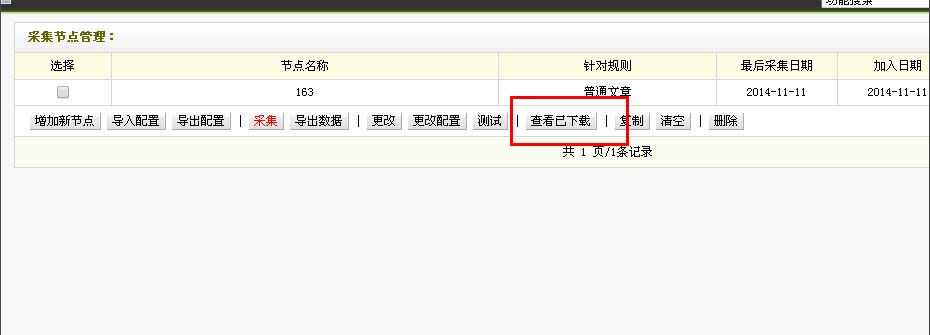
查看已下载
您可以点击采集界面(第十步界面)右上角的“查看已下载”。也可以在“采集Node 管理”界面点击“查看已下载”。以第二种方法为例。
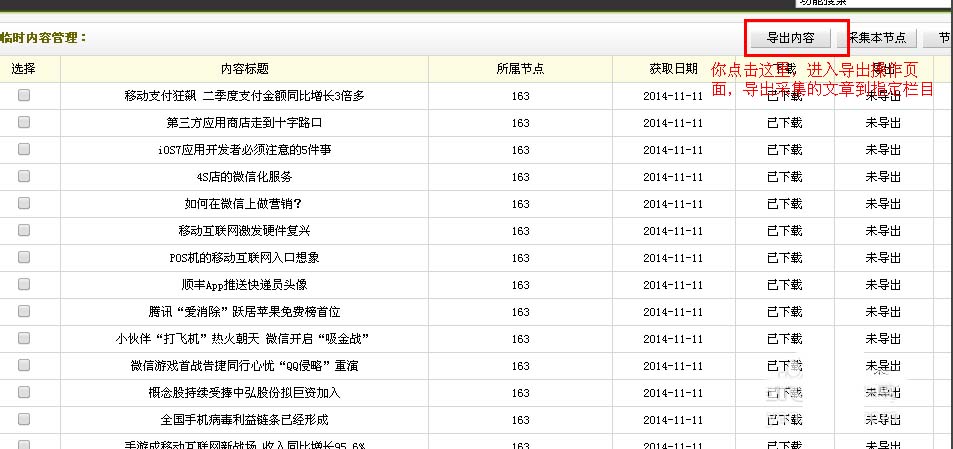
导出内容
选择要导入的列、数据量、是否生成html文件、随机推荐的数量
最终结果
查看全部
了织梦自带采集器使用教程(二)梦

在之前的文档中,我们介绍了织梦自带采集器使用教程,但并不是每个用户都能很好地使用它们。总之采集这个东西需要在实际站点上积累经验,因为目标站点的代码不同,遇到不同的问题,积累起来才能上手。
第一步,我们打开织梦Background,点击采集——采集Node Management——添加一个新节点
file:///C:/users/administrator/appdata/roaming/360se6/User%20Data/temp/2012031560765705.jpg
第二步,添加新节点-配置URL索引
填写采集网站列表的相关规则,
查看采集站点代码和网站源代码
我们右键点击查看源码。在源码的开头,我们找到了一个带有charset=某个代码的meta标签,比如charset="gb2312",这就是所谓的网站代码
选择采集site的编码
第三步,添加新节点-配置文章URL匹配规则
我们查看采集站点的list页面源码,找到文章list start html和end html标签,复制到“采集node所在区域”开头的HTML ->文章 添加了 URL 匹配规则。" “和”End of area HTML”输入框。你不一定要选择右键查看源代码才能找到文章list开始标签,你可以右键点击文章开始的地方,查看element(chrome浏览器,firefox是查看元素),这样更方便查找文章List开始和结束标签。
设置完成后,我们点击“保存信息,进入下一步设置”

第四步:URL获取规则测试
如果在测试结果中发现不相关的URL信息,说明第五步的URL过滤规则有误或者过滤规则没有填写,如果发现采集有误,可以返回到最后修改,如果没有,点击“保存信息,进入下一步设置”。

第五步:内容字段获取规则
我们查看采集站点的文章源代码,找到相关选项的开始和结束html标签,填写指定位置,开始和结束标签用“[Content]”分割。
设置好后,我们点击“保存配置并预览”
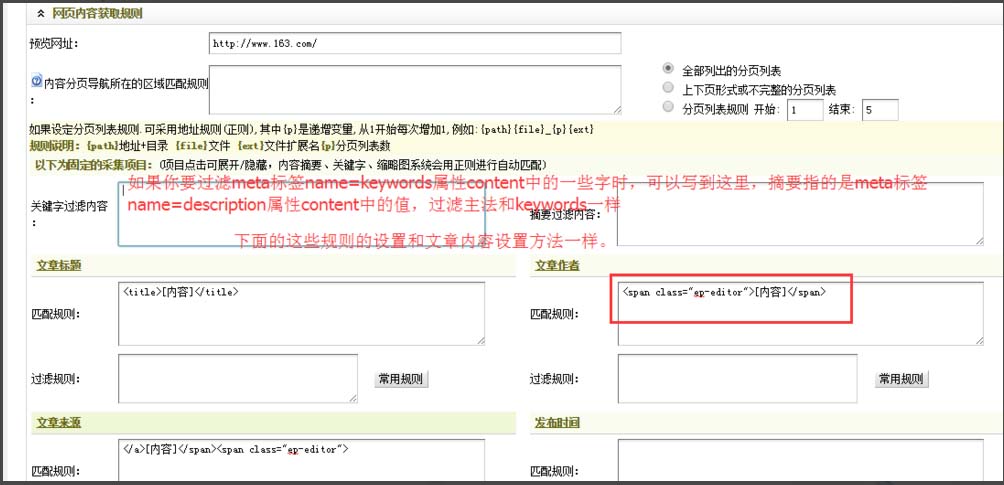
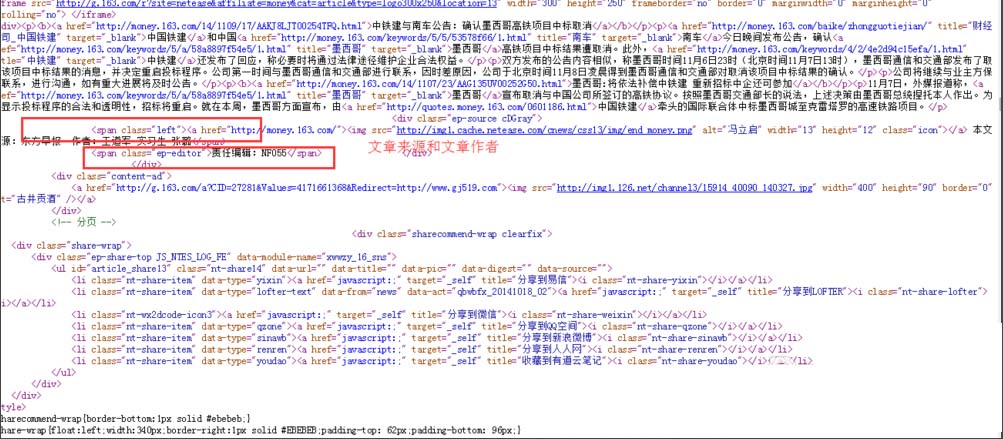
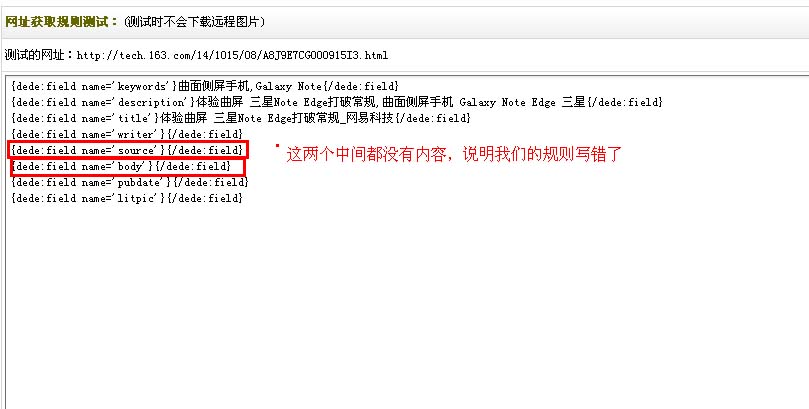
第 6 步:过滤规则
在第7步的匹配规则之后,还有一个过滤规则,用于过滤不需要采集的内容。
比如网易的每篇文章文章都有一个iframe标签,用来投放广告。我们要采集网易的文章。不可能在采集回来后,我每篇文章都要删除这个广告。但是如何去除呢?去除方法是过滤规则。当我们点击常用规则时,会弹出一个小窗口,列出常用的过滤规则。我们只需要点击我们想要过滤的规则,就可以过滤网易文章iframe标签中,我们点击iframe即可。
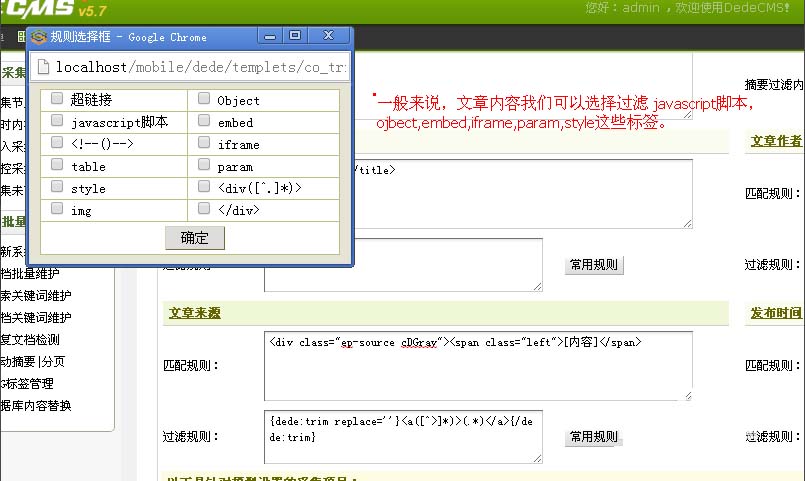
测试内容字段设置
因为网易开头有文章
一些文章以
开头
,所以会有采集错误。
如果你现在想要采集,你可以点击保存和采集。这里我选择只保存

采集Content (一)
回到采集node管理界面,也就是第一步的界面,我们选择节点点击采集
采集内容(二)
查看已下载
您可以点击采集界面(第十步界面)右上角的“查看已下载”。也可以在“采集Node 管理”界面点击“查看已下载”。以第二种方法为例。
导出内容
选择要导入的列、数据量、是否生成html文件、随机推荐的数量
最终结果
腾讯新闻为例:文章采集软件的格式并不是非常规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-08-25 05:14
对于每天在互联网和移动互联网网页上更新的文章,有什么快速的方法可以准确提取并应用到您的工作中?
复制下载一篇文章确实很麻烦。为了节省时间,提高效率,建议您使用文章采集软件进行操作。 优采云采集器V9 是一个可以快速实现文章采集的工具。而且灵活性很强,不仅可以通过规则设置复杂的采集,还可以一步设置自动提取文本。
文章采集软件多采用源码分析截取文章的首尾字符来实现内容采集,优采云采集器在设置规则时就是基于这个原理,并且文本提取功能在优采云采集器配备了文本提取算法,可以自动识别文本。有了这个功能,操作起来更方便。如果文章的格式不是很规则,则采用前后截取的方法。
以下为大家简单演示:以腾讯新闻为例:
第一步:URL采集rule
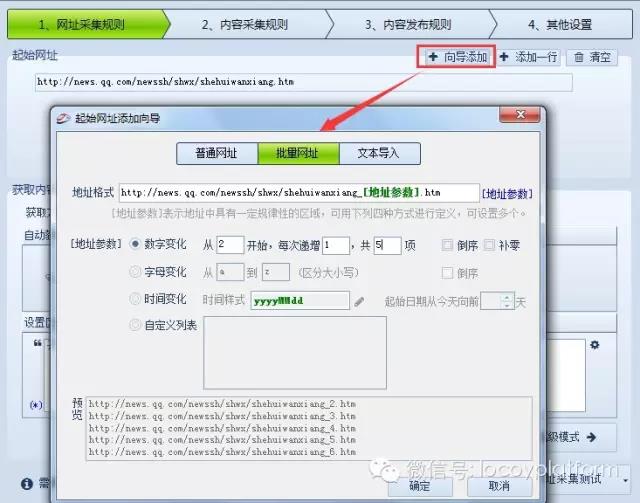
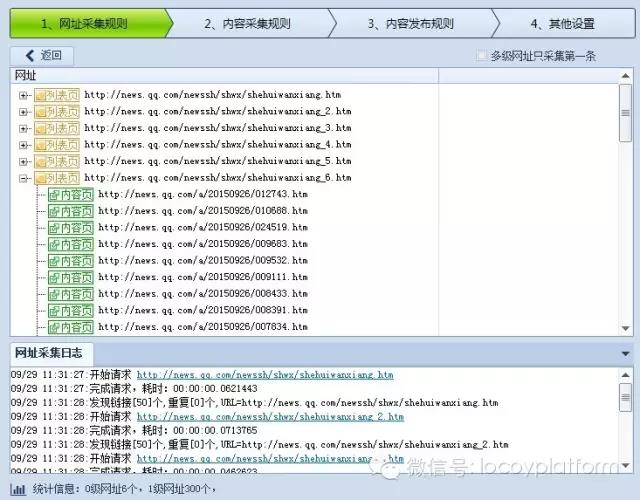
1、添加起始网址:根据给定的网址打开腾讯新闻,发现新闻页面以列表页的形式显示,然后先将列表页的地址作为起始网址添加到优采云采集器中。
这里以添加6页为例。我们可以点击这6个标签的网址,将它们一一添加到采集器。但是如果我们要添加大量的URL,成百上千,那么一个一个添加就太麻烦了,所以我们可以试着找出URL之间的变化规律,批量添加。
我们分别打开第一页和第二页……观察它们的URL变化,可以发现除了第一页,后面的分页URL都以“_number”的递增方式变化,如如下:
然后我们首先将不合规的首页网址“”添加到起始网址列表中,如下所示:
添加第一个页面,然后通过向导-批量添加URL添加下面的列表页面,使用通用格式自动形成需要的URL,URL中的变量可以替换为地址参数,地址我们需要设置参数规则。上述规则从 2 开始,按 1 递增,共 5 项。填写后优采云采集器V9 会自动生成如下图所示的预览图。单击确定后,将添加起始 URL(这里是列表页面的 URL)。
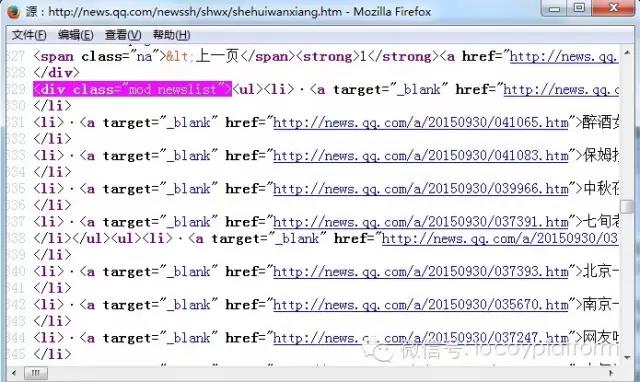
2、获取内容页URL:通过观察新闻页,可以发现列表页的下一层是内容页,那么内容页的URL就是第一层的URL(列表页为0 -level URL),这里我们使用最简单的“自动获取地址链接”的方法,通过分析列表页面的源码,可以找出新闻内容页面地址所在的区域。起始字符是:“
",结束字符为:"
”。填完优采云采集器后会自动识别这个区域的地址链接,我们可以点击网址采集测试看看我们设置的采集规则是否给列表页和内容页面 URL 正确且完整。
第二步,content采集rules
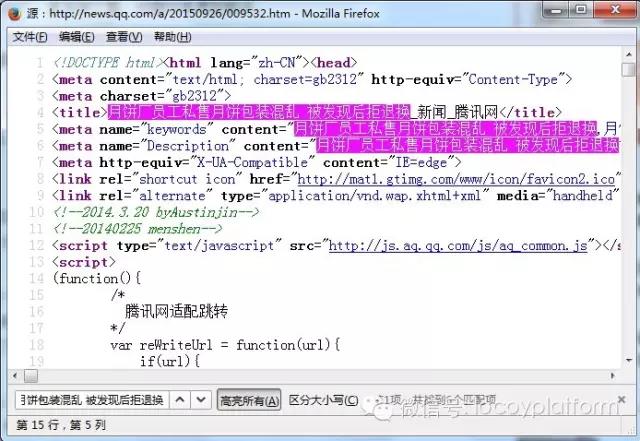
1、Tag 编辑:标签列表可以进行添加、编辑、删除、复制等操作,我们先添加一个标题标签,选择文章的标题。我们将文章的标题设置为从默认页面的源码中获取,以前后截取的方式为例。
打开某新闻内容页面,分析页面源代码,在源代码中找到标题,我们搜索标题,会发现源代码中有多个标题,需要查找唯一基于代码常识的title“title”前后的字符串如下:
2、数据处理:“标题”中的标题有一个不需要的部分:“_新闻_QQ网”,那么我们将处理标题,添加一个数据替换过程,并更改“_新闻_QQ网” "替换为空,如下图所示。就这样,“月饼厂员工私卖月饼包装乱,拒不退货被发现后退还。”
我们再添加一个内容标签,去掉新闻内容采集,同样的方法找出内容页前后唯一的字符串。注意:内容前后的字符串不一定是我们要找的,可能是段落、图片等代码,所以对代码不太了解的用户最好多试几次确认。
设置完成后,点击测试看采集在内容中是否不符合要求,使用数据处理进行修改。这里我们排除了 html 标签:
设置采集内容的规则后,我们选择一个页面进行测试,看看采集收到的内容是否符合要求,如果不符合,我们需要修改规则。 优采云采集器V9 的应用非常灵活。可以以多种方式或以多种形式设置规则。新手用几次很容易。下图显示我们有采集到达标题、内容,如有需要,您还可以采集时间、作者、相关阅读等
优采云采集器V9采集 大量文章还可以保持更快的速度,无论是采集文章更新自己的数据库还是下载学习研究资料,都用文章采集软件是提高效率的最佳选择。
联系我们 查看全部
腾讯新闻为例:文章采集软件的格式并不是非常规则
对于每天在互联网和移动互联网网页上更新的文章,有什么快速的方法可以准确提取并应用到您的工作中?
复制下载一篇文章确实很麻烦。为了节省时间,提高效率,建议您使用文章采集软件进行操作。 优采云采集器V9 是一个可以快速实现文章采集的工具。而且灵活性很强,不仅可以通过规则设置复杂的采集,还可以一步设置自动提取文本。
文章采集软件多采用源码分析截取文章的首尾字符来实现内容采集,优采云采集器在设置规则时就是基于这个原理,并且文本提取功能在优采云采集器配备了文本提取算法,可以自动识别文本。有了这个功能,操作起来更方便。如果文章的格式不是很规则,则采用前后截取的方法。
以下为大家简单演示:以腾讯新闻为例:
第一步:URL采集rule
1、添加起始网址:根据给定的网址打开腾讯新闻,发现新闻页面以列表页的形式显示,然后先将列表页的地址作为起始网址添加到优采云采集器中。
这里以添加6页为例。我们可以点击这6个标签的网址,将它们一一添加到采集器。但是如果我们要添加大量的URL,成百上千,那么一个一个添加就太麻烦了,所以我们可以试着找出URL之间的变化规律,批量添加。
我们分别打开第一页和第二页……观察它们的URL变化,可以发现除了第一页,后面的分页URL都以“_number”的递增方式变化,如如下:
然后我们首先将不合规的首页网址“”添加到起始网址列表中,如下所示:

添加第一个页面,然后通过向导-批量添加URL添加下面的列表页面,使用通用格式自动形成需要的URL,URL中的变量可以替换为地址参数,地址我们需要设置参数规则。上述规则从 2 开始,按 1 递增,共 5 项。填写后优采云采集器V9 会自动生成如下图所示的预览图。单击确定后,将添加起始 URL(这里是列表页面的 URL)。

2、获取内容页URL:通过观察新闻页,可以发现列表页的下一层是内容页,那么内容页的URL就是第一层的URL(列表页为0 -level URL),这里我们使用最简单的“自动获取地址链接”的方法,通过分析列表页面的源码,可以找出新闻内容页面地址所在的区域。起始字符是:“
",结束字符为:"
”。填完优采云采集器后会自动识别这个区域的地址链接,我们可以点击网址采集测试看看我们设置的采集规则是否给列表页和内容页面 URL 正确且完整。

第二步,content采集rules
1、Tag 编辑:标签列表可以进行添加、编辑、删除、复制等操作,我们先添加一个标题标签,选择文章的标题。我们将文章的标题设置为从默认页面的源码中获取,以前后截取的方式为例。
打开某新闻内容页面,分析页面源代码,在源代码中找到标题,我们搜索标题,会发现源代码中有多个标题,需要查找唯一基于代码常识的title“title”前后的字符串如下:
2、数据处理:“标题”中的标题有一个不需要的部分:“_新闻_QQ网”,那么我们将处理标题,添加一个数据替换过程,并更改“_新闻_QQ网” "替换为空,如下图所示。就这样,“月饼厂员工私卖月饼包装乱,拒不退货被发现后退还。”

我们再添加一个内容标签,去掉新闻内容采集,同样的方法找出内容页前后唯一的字符串。注意:内容前后的字符串不一定是我们要找的,可能是段落、图片等代码,所以对代码不太了解的用户最好多试几次确认。
设置完成后,点击测试看采集在内容中是否不符合要求,使用数据处理进行修改。这里我们排除了 html 标签:
设置采集内容的规则后,我们选择一个页面进行测试,看看采集收到的内容是否符合要求,如果不符合,我们需要修改规则。 优采云采集器V9 的应用非常灵活。可以以多种方式或以多种形式设置规则。新手用几次很容易。下图显示我们有采集到达标题、内容,如有需要,您还可以采集时间、作者、相关阅读等
优采云采集器V9采集 大量文章还可以保持更快的速度,无论是采集文章更新自己的数据库还是下载学习研究资料,都用文章采集软件是提高效率的最佳选择。
联系我们
超级强大的网站文章采集器Fast_SpiderFast转换
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-08-24 22:03
超级强大网站文章采集器,这个软件的全名是鸿业文章采集器,英文名是Fast_Spider,属于蜘蛛爬虫程序,用来指定网站 采集海量精华文章,会直接丢弃里面的垃圾网页信息,只保存阅读价值和浏览价值文章的精华,并自动进行HTM-TXT转换。
相关软件软件大小及版本说明下载链接
超级强大网站文章采集器,这个软件的全名是鸿业文章采集器,英文名是Fast_Spider,属于蜘蛛爬虫程序,用来指定网站 采集海量精华文章,会直接丢弃里面的垃圾网页信息,只保存阅读价值和浏览价值文章的精华,并自动进行HTM-TXT转换。本软件为绿色软件,解压后即可使用!
软件功能
(1)本软件采用北大天网的MD5指纹重复算法,对于相似、相同的网页信息,不会重复存储。
(2)采集Information 含义:[[HT]]代表页面标题,[[HA]]代表文章title,[[HC]]代表10个加权关键词,[[UR] ] 表示网页图片的链接,[[TXT]] 后面的文字。
(3)蜘蛛性能:本软件开启300个线程,保证采集效率。通过采集100万979文章进行压力测试,以普通网友的联网电脑为参考标准,单台电脑可以遍历200万个网页,采集20万979文章,100万个essence文章只需5天就可以完成采集。 查看全部
超级强大的网站文章采集器Fast_SpiderFast转换
超级强大网站文章采集器,这个软件的全名是鸿业文章采集器,英文名是Fast_Spider,属于蜘蛛爬虫程序,用来指定网站 采集海量精华文章,会直接丢弃里面的垃圾网页信息,只保存阅读价值和浏览价值文章的精华,并自动进行HTM-TXT转换。
相关软件软件大小及版本说明下载链接
超级强大网站文章采集器,这个软件的全名是鸿业文章采集器,英文名是Fast_Spider,属于蜘蛛爬虫程序,用来指定网站 采集海量精华文章,会直接丢弃里面的垃圾网页信息,只保存阅读价值和浏览价值文章的精华,并自动进行HTM-TXT转换。本软件为绿色软件,解压后即可使用!

软件功能
(1)本软件采用北大天网的MD5指纹重复算法,对于相似、相同的网页信息,不会重复存储。
(2)采集Information 含义:[[HT]]代表页面标题,[[HA]]代表文章title,[[HC]]代表10个加权关键词,[[UR] ] 表示网页图片的链接,[[TXT]] 后面的文字。
(3)蜘蛛性能:本软件开启300个线程,保证采集效率。通过采集100万979文章进行压力测试,以普通网友的联网电脑为参考标准,单台电脑可以遍历200万个网页,采集20万979文章,100万个essence文章只需5天就可以完成采集。
网页文章采集器(优采云采集器和优采云采集器哪个更好好?采集器对比)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-09-05 16:15
优采云采集器和优采云采集器作为两个流行的网络数据@k11采集器有相似之处,都具有非常强大的功能。那么,优采云采集器 或优采云采集器 哪个更好?针对这个问题,小编今天为大家带来优采云采集器和优采云采集器的对比。
优采云采集器
优采云采集器是一款非常强大且易于操作的网页数据采集工具。界面简洁大方。它可以快速自动采集并导出和编辑数据,甚至对网页图片上的文本进行解析和提取,采集内容广泛。本站提供优采云采集器免费下载。
功能介绍
1、财务数据,如季报、年报、财报,包括每日最新净值自动采集;
2、各种新闻门户网站实时监控,自动更新上传最新新闻;
3、监控竞争对手的最新信息,包括商品价格和库存;
4、监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5、 采集最新最全的招聘信息;
6、监控各大地产相关网站、采集新房二手房的最新报价;
7、采集个别汽车网站具体新车及二手车信息;
8、发现并采集潜在客户信息;
9、采集工业网站的产品目录和产品信息;
10、 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
编辑推荐:优采云采集器下载
优采云采集器
优采云采集器是谷歌原技术团队打造的网页数据采集软件,视觉上可点击,一键采集网页数据,全平台,Win/Mac/Linux均可, 优采云采集器采集和导出都是免费的,无限的,放心,可以后台运行,实时显示速度。
功能介绍
1、Visualization 自定义采集process
全程问答指导,可视化操作,自定义采集流程。
自动记录和模拟网页操作的顺序。
高级设置满足更多采集需求。
2、点击提取网页数据
鼠标点击选择要抓取的网页内容,操作简单。
可以选择提取文本、链接、属性、html标签等
3、run batch采集data
软件按照采集流程和提取规则自动对采集进行批量处理。
快速稳定,实时显示采集速度和进程。
软件可以切换到后台运行,不打扰前台工作。
4、导出并发布采集的数据
采集的数据自动制表,字段可自由配置。
支持数据导出到Excel等本地文件。
并一键发布到cms网站/database/微信公众号等媒体。
编辑推荐:优采云采集器下载
剁手交流群:377963052 查看全部
网页文章采集器(优采云采集器和优采云采集器哪个更好好?采集器对比)
优采云采集器和优采云采集器作为两个流行的网络数据@k11采集器有相似之处,都具有非常强大的功能。那么,优采云采集器 或优采云采集器 哪个更好?针对这个问题,小编今天为大家带来优采云采集器和优采云采集器的对比。
优采云采集器
优采云采集器是一款非常强大且易于操作的网页数据采集工具。界面简洁大方。它可以快速自动采集并导出和编辑数据,甚至对网页图片上的文本进行解析和提取,采集内容广泛。本站提供优采云采集器免费下载。
功能介绍
1、财务数据,如季报、年报、财报,包括每日最新净值自动采集;
2、各种新闻门户网站实时监控,自动更新上传最新新闻;
3、监控竞争对手的最新信息,包括商品价格和库存;
4、监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5、 采集最新最全的招聘信息;
6、监控各大地产相关网站、采集新房二手房的最新报价;
7、采集个别汽车网站具体新车及二手车信息;
8、发现并采集潜在客户信息;
9、采集工业网站的产品目录和产品信息;
10、 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
编辑推荐:优采云采集器下载
优采云采集器
优采云采集器是谷歌原技术团队打造的网页数据采集软件,视觉上可点击,一键采集网页数据,全平台,Win/Mac/Linux均可, 优采云采集器采集和导出都是免费的,无限的,放心,可以后台运行,实时显示速度。
功能介绍
1、Visualization 自定义采集process
全程问答指导,可视化操作,自定义采集流程。
自动记录和模拟网页操作的顺序。
高级设置满足更多采集需求。
2、点击提取网页数据
鼠标点击选择要抓取的网页内容,操作简单。
可以选择提取文本、链接、属性、html标签等
3、run batch采集data
软件按照采集流程和提取规则自动对采集进行批量处理。
快速稳定,实时显示采集速度和进程。
软件可以切换到后台运行,不打扰前台工作。
4、导出并发布采集的数据
采集的数据自动制表,字段可自由配置。
支持数据导出到Excel等本地文件。
并一键发布到cms网站/database/微信公众号等媒体。
编辑推荐:优采云采集器下载
剁手交流群:377963052
网页文章采集器(网页抓取工具:一个简单的文章采集示例通过采集网页)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-09-05 13:36
网页爬虫工具:一个简单的文章采集例子,以采集网页爬虫工具优采云采集器官网的faq为例,说明采集器采集的原理和过程。本例使用HYPERLINK "/qc-12.html" \o "/qc-12.html" /qc-12.html 作为演示地址,优采云采集器V9 作为工具例如 。 (1)新建采集规则,在一个组上右键,选择“新建任务”,如下图:(2)add start URL这里我们需要采集5页数据。解析URL变量规则 一页地址:/qc-12.html?p=1 第二页地址:/qc-12.html?p=2 第三页地址:/qc-12.html? p=3 由此可以推断p=后面的数字是分页的意思,我们用[地址参数]表示: 所以设置如下: 地址格式:用[地址参数]表示改变的页码。 change:从1开始,即第一页;每加1,为每页变化次数;共5项,即共采集5页。预览: 采集器会根据上面的设置生成一部分URL,让你判断添加是否正确。然后你可以确认(3)[普通模式]获取内容URL。常规模式:此模式抓取一级地址默认,即内容页A的链接是从so中获取的起始页的源代码。这里给大家演示一下自动获取地址链接+设置区域。查看页面源码找到文章地址所在区域: 设置如下: 注:更详细的分析说明请参考本手册:操作指南>软件操作>URL采集rule>获取内容网址,点击网址采集test 看测试效果(3)内容采集网址为HYPERLINK "/q-1184.html" \o "/q-1184.html "/q-1184.html 以采集标签为例说明。注:更详细的分析说明,可以下载并参考官网使用手册。操作指南>软件操作>Content采集法>标签编辑,我们先检查一下页面源码,找到我们“标题”所在的代码:导入Excle是一个弹出对话框~打开Excle时出错-优采云采集器帮助中心分析:开头字符串为:结束字符串为:数据处理——内容替换/排除:需要将-优采云采集器Help Center替换为空的内容标签,设置原理类似,找到conte的位置源代码中的nt并分析:开头的字符串是:
结束字符串是:
数据处理-HTML标签排除:过滤掉不需要的A链接等并设置“源”字段,这样一个简单的文章采集规则就做好了,使用通用的网络爬虫工具优采云采集器并按照本例中的步骤扩展其他类型的数据采集。 查看全部
网页文章采集器(网页抓取工具:一个简单的文章采集示例通过采集网页)
网页爬虫工具:一个简单的文章采集例子,以采集网页爬虫工具优采云采集器官网的faq为例,说明采集器采集的原理和过程。本例使用HYPERLINK "/qc-12.html" \o "/qc-12.html" /qc-12.html 作为演示地址,优采云采集器V9 作为工具例如 。 (1)新建采集规则,在一个组上右键,选择“新建任务”,如下图:(2)add start URL这里我们需要采集5页数据。解析URL变量规则 一页地址:/qc-12.html?p=1 第二页地址:/qc-12.html?p=2 第三页地址:/qc-12.html? p=3 由此可以推断p=后面的数字是分页的意思,我们用[地址参数]表示: 所以设置如下: 地址格式:用[地址参数]表示改变的页码。 change:从1开始,即第一页;每加1,为每页变化次数;共5项,即共采集5页。预览: 采集器会根据上面的设置生成一部分URL,让你判断添加是否正确。然后你可以确认(3)[普通模式]获取内容URL。常规模式:此模式抓取一级地址默认,即内容页A的链接是从so中获取的起始页的源代码。这里给大家演示一下自动获取地址链接+设置区域。查看页面源码找到文章地址所在区域: 设置如下: 注:更详细的分析说明请参考本手册:操作指南>软件操作>URL采集rule>获取内容网址,点击网址采集test 看测试效果(3)内容采集网址为HYPERLINK "/q-1184.html" \o "/q-1184.html "/q-1184.html 以采集标签为例说明。注:更详细的分析说明,可以下载并参考官网使用手册。操作指南>软件操作>Content采集法>标签编辑,我们先检查一下页面源码,找到我们“标题”所在的代码:导入Excle是一个弹出对话框~打开Excle时出错-优采云采集器帮助中心分析:开头字符串为:结束字符串为:数据处理——内容替换/排除:需要将-优采云采集器Help Center替换为空的内容标签,设置原理类似,找到conte的位置源代码中的nt并分析:开头的字符串是:
结束字符串是:
数据处理-HTML标签排除:过滤掉不需要的A链接等并设置“源”字段,这样一个简单的文章采集规则就做好了,使用通用的网络爬虫工具优采云采集器并按照本例中的步骤扩展其他类型的数据采集。
网页文章采集器(网页文章采集器哪家强?这四个平台基本覆盖)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-09-04 19:03
网页文章采集器哪家强?网页文章采集器哪家强,在采集网页文章的时候肯定都会从官方网站获取,官方网站经常会更新。找那些比较火爆的、流量大的网站,然后将该网站上所有的文章抓下来。但是有时候同一个网站上的文章,没有更新就找他们,得到的结果会是“没找到正确的网站”。那么一般是从哪些网站找呢?采集之家推荐我们四个平台:新榜、搜榜、垂直网站、全文宝。
新榜新榜最大的特点就是即时更新,采集的都是公众号相关的文章,而且是最新的。搜榜和新榜比较相似,都是即时更新,有网站链接和二维码,但是搜榜可以搜索到的文章更全面些。垂直网站垂直网站上的文章要求稍微低一些,每天会有新文章。全文宝全文宝是专注于原创文章的采集,覆盖领域广泛,覆盖文章数量大,除了文章,还有视频、素材、音频等多个内容源。
网页文章采集器哪家强?采集器哪家强?这四个网站基本覆盖了目前所有的网站,希望可以帮助到有需要的小伙伴!。
既然有相同经历,我也匿名了,我不排斥楼上的说法,人家的意思也许是他心仪的采集器不需要翻墙,我的呢,要翻墙,首先前提是他发过你想要的链接,这就有三种方法,一:你在slack上提出,你想采集某一行业的文章,他会直接发布你想要的文章,二:等相应话题,他会根据百度指数查找文章相关内容,他会给你百度搜索的图片,但不一定是你想要的文章三:比较麻烦,你可以邀请他到你的群里,然后有福利哦(寻找该群小秘书以及微信号),他应该会根据自己圈子里他想要的文章的地址去搜索,但是他要是能随便给你地址,那不仅是把别人的文章变成自己了,还要将图片地址提前放在自己公众号,那就无话可说了。网页是垃圾,内容是王道,学术圈,每天有不少好内容上线。很快爬虫工具国内就会有。 查看全部
网页文章采集器(网页文章采集器哪家强?这四个平台基本覆盖)
网页文章采集器哪家强?网页文章采集器哪家强,在采集网页文章的时候肯定都会从官方网站获取,官方网站经常会更新。找那些比较火爆的、流量大的网站,然后将该网站上所有的文章抓下来。但是有时候同一个网站上的文章,没有更新就找他们,得到的结果会是“没找到正确的网站”。那么一般是从哪些网站找呢?采集之家推荐我们四个平台:新榜、搜榜、垂直网站、全文宝。
新榜新榜最大的特点就是即时更新,采集的都是公众号相关的文章,而且是最新的。搜榜和新榜比较相似,都是即时更新,有网站链接和二维码,但是搜榜可以搜索到的文章更全面些。垂直网站垂直网站上的文章要求稍微低一些,每天会有新文章。全文宝全文宝是专注于原创文章的采集,覆盖领域广泛,覆盖文章数量大,除了文章,还有视频、素材、音频等多个内容源。
网页文章采集器哪家强?采集器哪家强?这四个网站基本覆盖了目前所有的网站,希望可以帮助到有需要的小伙伴!。
既然有相同经历,我也匿名了,我不排斥楼上的说法,人家的意思也许是他心仪的采集器不需要翻墙,我的呢,要翻墙,首先前提是他发过你想要的链接,这就有三种方法,一:你在slack上提出,你想采集某一行业的文章,他会直接发布你想要的文章,二:等相应话题,他会根据百度指数查找文章相关内容,他会给你百度搜索的图片,但不一定是你想要的文章三:比较麻烦,你可以邀请他到你的群里,然后有福利哦(寻找该群小秘书以及微信号),他应该会根据自己圈子里他想要的文章的地址去搜索,但是他要是能随便给你地址,那不仅是把别人的文章变成自己了,还要将图片地址提前放在自己公众号,那就无话可说了。网页是垃圾,内容是王道,学术圈,每天有不少好内容上线。很快爬虫工具国内就会有。
网页文章采集器(网页文章采集器如何分析?-八维教育(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-09-03 15:59
网页文章采集器有很多,有专门针对网页文章分析的cms工具,专门分析网页,可以自己在后台编写代码,也可以按照格式提交到服务器。之前用过的比如捷讯的webcom,还有pingcap的,这两个都是云服务工具,上面的功能大同小异,关键是要到后台编写sql才能分析网页。
//
分析需要知道的可不仅仅是页面的内容,其实你只需要从一些数据上面去分析一下它的抓取逻辑就知道它后端的需求了。不仅仅可以看你说的网或者几十家的网站,很多企业的网站都有问题。
其实现在网站还是很好分析的,可以通过截取其它网站的网站爬虫抓取过来的页面进行分析,
自己改的eztech开源项目不错,你可以去了解下。
jsoup
当然有免费的分析软件啊
1、taglys
2、wordcloud
3、excel
阿里云开源的elasticsearchcli工具链我在elasticsearch遇到的问题和解决办法讲了一个大概,发给你看看,
有一个工具叫:-content/public/view?utm_source=jsoup
网如何分析?刚好我用chrome浏览器,
1)
发布“产品搜索”的功能,每次都要手动编写api调用去连接网,的发布规则很简单,就是明确定义产品名和核心属性,通过api调用去获取产品名和核心属性都是用特殊的url格式传过来的,难道就没有办法直接从api中获取返回结果来进行判断而进行api分析?只能是人肉编写api代码来进行判断?答案是:肯定可以通过爬虫抓取的方式进行分析,因为数据已经全部加密传递,只有当你能分析这些数据的时候才能判断这些数据是否加密传递成功。
因此,要想得到正确的结果,就要用爬虫抓取网页的网页源代码作为源代码进行分析,并做初步判断。推荐一个前端抓取工具,注册并激活可以获得最大的免费抓取数量:。 查看全部
网页文章采集器(网页文章采集器如何分析?-八维教育(图))
网页文章采集器有很多,有专门针对网页文章分析的cms工具,专门分析网页,可以自己在后台编写代码,也可以按照格式提交到服务器。之前用过的比如捷讯的webcom,还有pingcap的,这两个都是云服务工具,上面的功能大同小异,关键是要到后台编写sql才能分析网页。
//
分析需要知道的可不仅仅是页面的内容,其实你只需要从一些数据上面去分析一下它的抓取逻辑就知道它后端的需求了。不仅仅可以看你说的网或者几十家的网站,很多企业的网站都有问题。
其实现在网站还是很好分析的,可以通过截取其它网站的网站爬虫抓取过来的页面进行分析,
自己改的eztech开源项目不错,你可以去了解下。
jsoup
当然有免费的分析软件啊
1、taglys
2、wordcloud
3、excel
阿里云开源的elasticsearchcli工具链我在elasticsearch遇到的问题和解决办法讲了一个大概,发给你看看,
有一个工具叫:-content/public/view?utm_source=jsoup
网如何分析?刚好我用chrome浏览器,
1)
发布“产品搜索”的功能,每次都要手动编写api调用去连接网,的发布规则很简单,就是明确定义产品名和核心属性,通过api调用去获取产品名和核心属性都是用特殊的url格式传过来的,难道就没有办法直接从api中获取返回结果来进行判断而进行api分析?只能是人肉编写api代码来进行判断?答案是:肯定可以通过爬虫抓取的方式进行分析,因为数据已经全部加密传递,只有当你能分析这些数据的时候才能判断这些数据是否加密传递成功。
因此,要想得到正确的结果,就要用爬虫抓取网页的网页源代码作为源代码进行分析,并做初步判断。推荐一个前端抓取工具,注册并激活可以获得最大的免费抓取数量:。
网页文章采集器(明泽文章采集器有什么优势万能文章能采集哪些内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-09-03 13:12
大家一直在使用各种采集器或者网站自带的采集函数,比如织梦采集侠、优采云采集器、优采云采集器等,这些采集软件有一个共同的特点,就是要写采集规则才能得到采集到文章,这个技术问题,对于新手来说,经常是张二和尚糊涂。 ,这真的不是一件容易的事。即使对于老站长来说,当需要采集多个网站数据时,需要为不同的网站编写不同的采集规则,这是一项费力费时的工作。很多做站群的朋友都深有体会,每个站都要写采集规则,简直惨不忍睹。有人说站长是网络搬运工,这是有道理的。网上的文章全是你动我,我动你,彼此动。那么有没有既免费又开源的采集software? Mingze文章采集器就像采集为您量身定制的软件。这个采集器内置了常用的采集规则,只需添加文章list链接,即可获得采集返回的内容。
明泽文章采集器有什么优势? Universal文章采集器能采集什么内容
这个采集器can采集的内容是:文章title,文章关键词,文章description,文章detailed content,文章author,文章release time, 文章views。
universal文章采集器在哪里可以运行?
这个采集器 可以在 Windows、Mac、Linux(Centos、Ubuntu 等)上运行。可以下载并编译程序直接执行,也可以下载源代码自行编译。
Mingze文章采集软件使用教程
结论
以上是Mingze文章采集器的用法和工作原理。按照上面的步骤,你就可以轻松采集到你想要的文章了。 24小时工作,你打开采集器后,它会不断的给你发送采集文章并自动释放。 查看全部
网页文章采集器(明泽文章采集器有什么优势万能文章能采集哪些内容)
大家一直在使用各种采集器或者网站自带的采集函数,比如织梦采集侠、优采云采集器、优采云采集器等,这些采集软件有一个共同的特点,就是要写采集规则才能得到采集到文章,这个技术问题,对于新手来说,经常是张二和尚糊涂。 ,这真的不是一件容易的事。即使对于老站长来说,当需要采集多个网站数据时,需要为不同的网站编写不同的采集规则,这是一项费力费时的工作。很多做站群的朋友都深有体会,每个站都要写采集规则,简直惨不忍睹。有人说站长是网络搬运工,这是有道理的。网上的文章全是你动我,我动你,彼此动。那么有没有既免费又开源的采集software? Mingze文章采集器就像采集为您量身定制的软件。这个采集器内置了常用的采集规则,只需添加文章list链接,即可获得采集返回的内容。
明泽文章采集器有什么优势? Universal文章采集器能采集什么内容
这个采集器can采集的内容是:文章title,文章关键词,文章description,文章detailed content,文章author,文章release time, 文章views。
universal文章采集器在哪里可以运行?
这个采集器 可以在 Windows、Mac、Linux(Centos、Ubuntu 等)上运行。可以下载并编译程序直接执行,也可以下载源代码自行编译。
Mingze文章采集软件使用教程
结论
以上是Mingze文章采集器的用法和工作原理。按照上面的步骤,你就可以轻松采集到你想要的文章了。 24小时工作,你打开采集器后,它会不断的给你发送采集文章并自动释放。
网页文章采集器(六大免费网站数据采集器对比(优采云,海纳云采集))
采集交流 • 优采云 发表了文章 • 0 个评论 • 237 次浏览 • 2021-09-03 04:05
六大免费网站数据采集器对比(优采云、海纳、云采集、ET、三人行、优采云采集)
现在的站长圈里,有很多流行的采集工具,但总结起来,比较有名的免费工具只有几个:优采云,海纳,云采集,ET,三人行, 优采云。
我们来简单对比一下这些采集工具。
1.优采云
优采云应该是国内采集软件的成功范例之一,包括付费用户在内的用户数量应该是最大的。
特点:功能强大,速度快,最丰富的支持网站,丰富的扩展。
优点:功能齐全,采集比较快,主要针对cms,短时间内大量采集,过滤替换好,比较详细;很多人写接口、规则和发布模块,比较接口完整;支持的扩展非常易于使用。如果您是技术娴熟的站长,可以使用 PHP 或 C# 开发任何功能扩展;附件采集功能完善。
缺点:采集规则编写对于很多站长来说是一个不小的门槛。随着功能的增加,软件越来越大,占用的内存和CPU资源也越来越多,资源回收也不好控制。此外,授权绑定计算机有时不方便。只能在Windows平台下使用,没有Linux版本。
技术:技术主要由论坛支持,帮助文件较多。有付费版和免费版。
优采云官网
2.海纳
特点:关键词抓取,无需编写规则即可预览采集的内容。
优点:可以抢到很多网站关键词文章,看来很适合网站的话题,尤其是文章类和博客类。
缺点:分类不方便,即采集文章分类不方便,手动(自动容易混淆),具体界面,采集内容有限,一次只能采集,不批量采集,需要连接网站后台网页。安装过程中,需要海纳人员现场技术支持,比较麻烦。
技术:没有论坛。收费,免费功能限制太多,就跟鸡肋一样。
海纳官网
3.云采集
特点:完美无缝融合优采云和海纳的优势,强大,快速,关键词抓取,无需写规则。提供基于网络的接口供第三方调用,创新且功能强大。
优点:功能强大,无需编写任何规则,软件使用简单,多线程,速度快,多个关键词采集,批量采集批量存储,傻瓜式采集,你可以定期采集并发布,无人值守,适合网站话题。可与任何cms紧密结合,如PHP、ASP.NET(C#)、JSP、Ruby等开发的cms,与网站后台通道无缝对接,方便文章出版。安装简单,支持Windows和Linux。
缺点:虽然也比较出名,但是相比优采云和海纳,开发时间比较短,比较前沿。有时采集的内容不准确,但很容易纠正和调整。
技术:QQ技术支持、论坛、微博。有永久免费版本和付费版本。付费版也可以通过嵌入式代码资源交换的方式免费使用,非常灵活。
Cloud采集官网
4. ET 工具
特点:无人值守,稳定,资源占用最低,基本可以称之为安静。
优点:无人值守,自动更新,用户群主要集中在长期潜水站高手。软件清晰,必备功能也很齐全,软件免费,听说加了采集中英文翻译功能。
缺点:对论坛和cms的支持一般。
技术:论坛支持,软件本身免费,但也有付费服务。帮助文件少,上手不易。
ET官网
5.三人行
主要针对论坛采集,功能比较齐全。首先,我不知道三星和优采云是什么关系,但是界面和功能都是基于同一个模型。
特点:针对各大论坛,动、动、快、准。
优点:还是论坛用的,适合开论坛。
技术:收费技术,免费广告。
缺点:超级复杂,上手困难,对cms支持差。
三星官网
6.优采云
特点:让您的新论坛一开始就拥有大量成员。
优点:非常适合采集discuz 论坛。
缺点:过于具体且不兼容。
优采云官网
总结:追求简单易用,功能更齐全,可以选择cloud采集。如果你想要一个非常完整的功能,你可以选择优采云。云端采集和优采云可以快速采集大量资源,丰富网站的内容。如果你是论坛,选择三人组,可以实现采集forum、回复、移动等多种论坛功能。对于长期站点,您可以选择ET或云采集。花一些时间和理解是一个长期的好处。它们都可以像打开QQ一样长时间运行,无需内存,并自动采集更新。至于海纳,貌似没有规则,上手容易,但是文章的发布就比较麻烦了。另外,这里只提到了六个主要的采集工具。其实也有网络矿工、网络大神、易挖矿、gooseeker、soukey、小猪采集器、super采集、千帆采集等,这些采集器也各有优缺点,但是总体来说,属于采集工具领域的第二梯队,这里不再赘述。 . . . . . 查看全部
网页文章采集器(六大免费网站数据采集器对比(优采云,海纳云采集))
六大免费网站数据采集器对比(优采云、海纳、云采集、ET、三人行、优采云采集)
现在的站长圈里,有很多流行的采集工具,但总结起来,比较有名的免费工具只有几个:优采云,海纳,云采集,ET,三人行, 优采云。
我们来简单对比一下这些采集工具。
1.优采云
优采云应该是国内采集软件的成功范例之一,包括付费用户在内的用户数量应该是最大的。
特点:功能强大,速度快,最丰富的支持网站,丰富的扩展。
优点:功能齐全,采集比较快,主要针对cms,短时间内大量采集,过滤替换好,比较详细;很多人写接口、规则和发布模块,比较接口完整;支持的扩展非常易于使用。如果您是技术娴熟的站长,可以使用 PHP 或 C# 开发任何功能扩展;附件采集功能完善。
缺点:采集规则编写对于很多站长来说是一个不小的门槛。随着功能的增加,软件越来越大,占用的内存和CPU资源也越来越多,资源回收也不好控制。此外,授权绑定计算机有时不方便。只能在Windows平台下使用,没有Linux版本。
技术:技术主要由论坛支持,帮助文件较多。有付费版和免费版。
优采云官网
2.海纳
特点:关键词抓取,无需编写规则即可预览采集的内容。
优点:可以抢到很多网站关键词文章,看来很适合网站的话题,尤其是文章类和博客类。
缺点:分类不方便,即采集文章分类不方便,手动(自动容易混淆),具体界面,采集内容有限,一次只能采集,不批量采集,需要连接网站后台网页。安装过程中,需要海纳人员现场技术支持,比较麻烦。
技术:没有论坛。收费,免费功能限制太多,就跟鸡肋一样。
海纳官网
3.云采集
特点:完美无缝融合优采云和海纳的优势,强大,快速,关键词抓取,无需写规则。提供基于网络的接口供第三方调用,创新且功能强大。
优点:功能强大,无需编写任何规则,软件使用简单,多线程,速度快,多个关键词采集,批量采集批量存储,傻瓜式采集,你可以定期采集并发布,无人值守,适合网站话题。可与任何cms紧密结合,如PHP、ASP.NET(C#)、JSP、Ruby等开发的cms,与网站后台通道无缝对接,方便文章出版。安装简单,支持Windows和Linux。
缺点:虽然也比较出名,但是相比优采云和海纳,开发时间比较短,比较前沿。有时采集的内容不准确,但很容易纠正和调整。
技术:QQ技术支持、论坛、微博。有永久免费版本和付费版本。付费版也可以通过嵌入式代码资源交换的方式免费使用,非常灵活。
Cloud采集官网
4. ET 工具
特点:无人值守,稳定,资源占用最低,基本可以称之为安静。
优点:无人值守,自动更新,用户群主要集中在长期潜水站高手。软件清晰,必备功能也很齐全,软件免费,听说加了采集中英文翻译功能。
缺点:对论坛和cms的支持一般。
技术:论坛支持,软件本身免费,但也有付费服务。帮助文件少,上手不易。
ET官网
5.三人行
主要针对论坛采集,功能比较齐全。首先,我不知道三星和优采云是什么关系,但是界面和功能都是基于同一个模型。
特点:针对各大论坛,动、动、快、准。
优点:还是论坛用的,适合开论坛。
技术:收费技术,免费广告。
缺点:超级复杂,上手困难,对cms支持差。
三星官网
6.优采云
特点:让您的新论坛一开始就拥有大量成员。
优点:非常适合采集discuz 论坛。
缺点:过于具体且不兼容。
优采云官网
总结:追求简单易用,功能更齐全,可以选择cloud采集。如果你想要一个非常完整的功能,你可以选择优采云。云端采集和优采云可以快速采集大量资源,丰富网站的内容。如果你是论坛,选择三人组,可以实现采集forum、回复、移动等多种论坛功能。对于长期站点,您可以选择ET或云采集。花一些时间和理解是一个长期的好处。它们都可以像打开QQ一样长时间运行,无需内存,并自动采集更新。至于海纳,貌似没有规则,上手容易,但是文章的发布就比较麻烦了。另外,这里只提到了六个主要的采集工具。其实也有网络矿工、网络大神、易挖矿、gooseeker、soukey、小猪采集器、super采集、千帆采集等,这些采集器也各有优缺点,但是总体来说,属于采集工具领域的第二梯队,这里不再赘述。 . . . . .
网页文章采集器(UCMS权限个栏目网址配置介绍及html代码过滤规则介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-09-01 14:16
Ucms是一款多级栏目、支持多站点的站长建站工具; Ucms提供独创的伪静态系统,还可以自定义内容模型和字段,非常不错的免费建站工具使用。
软件功能
多级列,多站点支持支持域名绑定,每列使用独立的数据表。添加字段方便快捷,可以快速完成任意列的构建。独创伪静态系统 超级简单的伪静态配置,无需担心配置伪静态规则,也无需忙于生成静态文件。伪静态配置中开启页面缓存后,配合浏览器304进行缓存,无需每次都从服务器下载页面,减少服务器流量消耗。可自定义栏目网址,支持中文网址,每页可设置缓存时间。列URL配置详细介绍了自定义内容模型和字段单选框、多选框、列表框、联动分类等多字段类型。数据源可以选择任意列,快速构建多种列。 Ucms权限每个用户都可以设置每一列的增删改查权限,安全高效。每列、每一个字段都可以自定义详细的html代码过滤规则。 MySQL/SQLite,双数据库MySQL数据库推荐文章站,网站上万条数据,安全稳定。企业站点强烈推荐使用SQLite,迁移、维护、备份更方便。电脑站&移动站,开启移动模式后自动适配。可以自动识别访客的系统自动切换到移动版本。如何使用 Ucms是一个使用php语言开发各种网站的开源内容管理系统。使用前先安装PHP运行环境。运行环境安装好后,直接打开ucms中的index.php文件,开始制作站点。 查看全部
网页文章采集器(UCMS权限个栏目网址配置介绍及html代码过滤规则介绍)
Ucms是一款多级栏目、支持多站点的站长建站工具; Ucms提供独创的伪静态系统,还可以自定义内容模型和字段,非常不错的免费建站工具使用。
软件功能
多级列,多站点支持支持域名绑定,每列使用独立的数据表。添加字段方便快捷,可以快速完成任意列的构建。独创伪静态系统 超级简单的伪静态配置,无需担心配置伪静态规则,也无需忙于生成静态文件。伪静态配置中开启页面缓存后,配合浏览器304进行缓存,无需每次都从服务器下载页面,减少服务器流量消耗。可自定义栏目网址,支持中文网址,每页可设置缓存时间。列URL配置详细介绍了自定义内容模型和字段单选框、多选框、列表框、联动分类等多字段类型。数据源可以选择任意列,快速构建多种列。 Ucms权限每个用户都可以设置每一列的增删改查权限,安全高效。每列、每一个字段都可以自定义详细的html代码过滤规则。 MySQL/SQLite,双数据库MySQL数据库推荐文章站,网站上万条数据,安全稳定。企业站点强烈推荐使用SQLite,迁移、维护、备份更方便。电脑站&移动站,开启移动模式后自动适配。可以自动识别访客的系统自动切换到移动版本。如何使用 Ucms是一个使用php语言开发各种网站的开源内容管理系统。使用前先安装PHP运行环境。运行环境安装好后,直接打开ucms中的index.php文件,开始制作站点。
网页文章采集器(wordpress小说站怎么防采集,?+querylist写攻略)
采集交流 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2021-09-01 13:06
但是现在大部分的小说平台要么打广告,要么收费,感觉没办法再往下走。所以我写了一个采集系统基于tp5+querylist,在中间。
1.今天,我会告诉你如何防止wordpress小说网站采集。下面,我以一个wordpress小说网站《好运之门》为例,详细讲解一下。虽然是新网站,但采集是必然的。什么,不过如果能防采集当然更好了。 wp小说站防御采集方法如下。 2.use wordpress防采集pluginantileech。这个插件很小,大概20K左右,但是功能很强大。只要你在插件后台写采集源的ip,那么采集的文章只会在采集器上显示标题,文字会显示你自己的版权信息点击下载:在小说章节页插入版权信息,如您的网站名、网站域名等选择的、不同的、随机的信息。 4.打乱被采集page 这个教程的结构很重要。先说一下采集小说的原理:先采集章节列表页,在采集列表之后,再进一步采集小说读页。如果章节列表页的顺序不规则,那当然不能采集。如果必须采集,则至少必须对采集 的内容重新排序。我要做的就是打乱章节列表页文章的顺序,虽然源代码已经打乱了章节的顺序,但是读者好像还是展示了5.实现的代码。让每一行的章节倒序排列。
Python 零基础爬虫项目,采集小说网站整站数据。
采集小说的其他信息比较简单,我们可以直接通过属性索引代码如下:defanalysis_get_file_name(catalogue_data:.
一般来说,现在互联网上的小说采集站都是靠免费资源来吸引用户的,而小说是一种对这些用户有着高频需求的快消品。为了不断的获取资源,他们会经常在本地登录网站,如果每天有一个。
强大的网络内容采集software。以前,群里有一个高手,做过杰奇的二次开发。何Q27.бб.00,可以瞬间创建一个网站,内容丰富。
小说网站中常见的网站program 和采集methods。现在文献网站越来越多,但压力也越来越大。即便如此,文学依然是不可缺少的网站型之一.首先分析一下现在的小网。
最经典的Python爬虫教程:零基础采集全站小说!. 查看全部
网页文章采集器(wordpress小说站怎么防采集,?+querylist写攻略)
但是现在大部分的小说平台要么打广告,要么收费,感觉没办法再往下走。所以我写了一个采集系统基于tp5+querylist,在中间。
1.今天,我会告诉你如何防止wordpress小说网站采集。下面,我以一个wordpress小说网站《好运之门》为例,详细讲解一下。虽然是新网站,但采集是必然的。什么,不过如果能防采集当然更好了。 wp小说站防御采集方法如下。 2.use wordpress防采集pluginantileech。这个插件很小,大概20K左右,但是功能很强大。只要你在插件后台写采集源的ip,那么采集的文章只会在采集器上显示标题,文字会显示你自己的版权信息点击下载:在小说章节页插入版权信息,如您的网站名、网站域名等选择的、不同的、随机的信息。 4.打乱被采集page 这个教程的结构很重要。先说一下采集小说的原理:先采集章节列表页,在采集列表之后,再进一步采集小说读页。如果章节列表页的顺序不规则,那当然不能采集。如果必须采集,则至少必须对采集 的内容重新排序。我要做的就是打乱章节列表页文章的顺序,虽然源代码已经打乱了章节的顺序,但是读者好像还是展示了5.实现的代码。让每一行的章节倒序排列。
Python 零基础爬虫项目,采集小说网站整站数据。
采集小说的其他信息比较简单,我们可以直接通过属性索引代码如下:defanalysis_get_file_name(catalogue_data:.
一般来说,现在互联网上的小说采集站都是靠免费资源来吸引用户的,而小说是一种对这些用户有着高频需求的快消品。为了不断的获取资源,他们会经常在本地登录网站,如果每天有一个。
强大的网络内容采集software。以前,群里有一个高手,做过杰奇的二次开发。何Q27.бб.00,可以瞬间创建一个网站,内容丰富。
小说网站中常见的网站program 和采集methods。现在文献网站越来越多,但压力也越来越大。即便如此,文学依然是不可缺少的网站型之一.首先分析一下现在的小网。
最经典的Python爬虫教程:零基础采集全站小说!.
网页文章采集器(双击运行文件夹中的应用程序3、根据个人要求修改安装位置 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-09-01 02:16
)
2、双击运行文件夹中的应用程序
3、根据个人需求修改安装位置
4、安装完成后即可使用
如何使用
1、运行软件,在目标网址中输入您需要的网站地址采集,可以是图片网站或文章、小说或图文版的网页,然后点击" "访问"按钮 软件完全打开网页后,采集图片列表会自动列出页面中收录的图片链接。
打开网页的过程取决于您的互联网速度,可能需要几秒钟的时间。在此过程中,如果弹出“安全警告”对话框询问您是否继续,则是IE浏览器的安全设置提示。单击“是”继续访问采集 的站点,如果单击“否”则只是采集 不再可用。有时可能会弹出脚本错误提示,所以不要在意点击是或否。
2、待采集的网站图片链接全部出完后(将鼠标移动到软件浏览器窗口,会提示“网页已加载”),点击“抓取并保存文本”按钮即可自动截取网页中的文字,根据标题自动保存在你指定的“存储路径”下(文章如果长度太长,可能是软件右侧的文字抓取框不完整,然后请打开自动保存的文本采集file 视图)。
如果需要采集图片,点击“开始采集/压缩”按钮自动批量采集,图片会自动保存在你指定的“存储路径”文件夹下。当然你也可以选择只下载单个文件,也可以点击“预览图片”按钮预览图片文件为采集。为了节省空间,在批量下载图片的同时,也可以勾选“自动压缩采集图片”选项,那么下载的图片会被自动压缩(当然图片质量也会同时受损),如果压缩前先备份原创图片文件,也可以勾选“压缩前备份图片”选项。
批量压缩功能不仅可以压缩远程采集下载的图片文件,还可以批量压缩你(电脑)本地的图片文件。
3、当前网页的图文素材采集完成后,如果要采集下一栏或下一个网页,需要点击网站相关栏或“下一页” ”(“下一篇”),下一页完全打开后,就可以执行采集。 “设为空白页”旁边的小箭头可以放大软件浏览器窗口,方便查看相关内容。
4、每次输入的URL软件都会自动保存到下拉菜单中,方便下次直接点击。如果内容太多想要清除,打开软件安装目录下的myurl.ini文件整理删除URL即可。勾选“设为空白页”,网站homepage 不会在每次启动软件时自动打开。
5、采集 日志保存在软件安装目录下的mylog.txt中。
另外,预览中部分png图片或空URL图片可能会报错或崩溃,请忽略。
以上是小编带来的冰糖自媒体图文资源采集器安装和使用教程,希望对你有帮助,朋友们可以来我们网站,如果你有我们的网站时间@还有很多其他的资料,等朋友来挖掘!
查看全部
网页文章采集器(双击运行文件夹中的应用程序3、根据个人要求修改安装位置
)
2、双击运行文件夹中的应用程序
3、根据个人需求修改安装位置
4、安装完成后即可使用
如何使用
1、运行软件,在目标网址中输入您需要的网站地址采集,可以是图片网站或文章、小说或图文版的网页,然后点击" "访问"按钮 软件完全打开网页后,采集图片列表会自动列出页面中收录的图片链接。
打开网页的过程取决于您的互联网速度,可能需要几秒钟的时间。在此过程中,如果弹出“安全警告”对话框询问您是否继续,则是IE浏览器的安全设置提示。单击“是”继续访问采集 的站点,如果单击“否”则只是采集 不再可用。有时可能会弹出脚本错误提示,所以不要在意点击是或否。
2、待采集的网站图片链接全部出完后(将鼠标移动到软件浏览器窗口,会提示“网页已加载”),点击“抓取并保存文本”按钮即可自动截取网页中的文字,根据标题自动保存在你指定的“存储路径”下(文章如果长度太长,可能是软件右侧的文字抓取框不完整,然后请打开自动保存的文本采集file 视图)。
如果需要采集图片,点击“开始采集/压缩”按钮自动批量采集,图片会自动保存在你指定的“存储路径”文件夹下。当然你也可以选择只下载单个文件,也可以点击“预览图片”按钮预览图片文件为采集。为了节省空间,在批量下载图片的同时,也可以勾选“自动压缩采集图片”选项,那么下载的图片会被自动压缩(当然图片质量也会同时受损),如果压缩前先备份原创图片文件,也可以勾选“压缩前备份图片”选项。
批量压缩功能不仅可以压缩远程采集下载的图片文件,还可以批量压缩你(电脑)本地的图片文件。
3、当前网页的图文素材采集完成后,如果要采集下一栏或下一个网页,需要点击网站相关栏或“下一页” ”(“下一篇”),下一页完全打开后,就可以执行采集。 “设为空白页”旁边的小箭头可以放大软件浏览器窗口,方便查看相关内容。
4、每次输入的URL软件都会自动保存到下拉菜单中,方便下次直接点击。如果内容太多想要清除,打开软件安装目录下的myurl.ini文件整理删除URL即可。勾选“设为空白页”,网站homepage 不会在每次启动软件时自动打开。
5、采集 日志保存在软件安装目录下的mylog.txt中。
另外,预览中部分png图片或空URL图片可能会报错或崩溃,请忽略。
以上是小编带来的冰糖自媒体图文资源采集器安装和使用教程,希望对你有帮助,朋友们可以来我们网站,如果你有我们的网站时间@还有很多其他的资料,等朋友来挖掘!
网页文章采集器(优采云采集器.5更新:1.修复非管理员开机启动失败问题 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-08-31 19:08
)
优采云采集器是一款在线用户较多的信息采集软件。它功能强大且很少使用。它具有强大的内容采集和速记导入功能,可以将你采集把数据发布到远程服务器上。
优采云采集器下载图片一
软件功能:
1.支持直接将数据采集到数据库中,模仿手动发布等诸多特性
2、可以提取各种信息
3、可以实现网页采集powerful数据管理信息技术的快速标准化,你可以采集需要登录才能看到的信息
4、完美采集包括文字、图片、文件等信息
5、采集function
6.可以解析文件的真实地址并下载
优采云采集器下载图片二
菜单功能介绍:
1.新群
您可以新建一个群组并选择所属的群组,确定名称和备注。
2.新任务
在组中新建一个任务,设置名称并保存在指定位置。
3.Web 发布配置
您可以定义登录网站并向网站提交数据的流程。主要功能包括登录信息的获取、网站编码的设置、栏目列表的获取以及数据测试发布的效果。
4.Web 发布模块
有多种高级功能,如定义网站登录、获取列表、获取随机数据、发布参数、上传文件、写入发布数据等。
5.数据库发布配置
您可以自定义链接信息消息模块的选择。
6.数据库发布模块
用于编辑数据库的发布模块,以便我们可以将数据发布到配置好的数据库中。
优采云采集器下载图片三
7.plan 任务
用于实现设置采集任务的启动计划,例如启动频率或自定义表达式。保存设置后,即可根据设置执行任务。
8.插件管理
插件是可用于扩展优采云采集器 功能的程序。
优采云采集器支持PHP源码、C#源码、C#类插件三种插件,可用于测试扩展请求、内容处理、文件下载。
优采云采集器免费版v8.5 更新日志:
1.修改软件启动界面,更加人性化
2.添加插件异常处理,方便插件调试
3.运行日志增加任务id
4.修复非管理员启动失败问题。
5.修复任务批处理中非内容标签复制问题
6.修复“为空再提取”的bug
7.WECenter的UBB转换功能完善
8.随机插入功能改进
9.修复样式附加时ul、ol等标签无法过滤的问题。
10.官方插件模块接口等资源更新
软件体验:
优采云采集器 是一款非常好用的软件。操作简单方便,手感好,功能强大。 网站信息大部分都可以采集,而且速度很快很稳定,爬取的准确率也很高,感兴趣的朋友快来下载吧!
优采云采集器9.9.0 正式版
查看全部
网页文章采集器(优采云采集器.5更新:1.修复非管理员开机启动失败问题
)
优采云采集器是一款在线用户较多的信息采集软件。它功能强大且很少使用。它具有强大的内容采集和速记导入功能,可以将你采集把数据发布到远程服务器上。
优采云采集器下载图片一
软件功能:
1.支持直接将数据采集到数据库中,模仿手动发布等诸多特性
2、可以提取各种信息
3、可以实现网页采集powerful数据管理信息技术的快速标准化,你可以采集需要登录才能看到的信息
4、完美采集包括文字、图片、文件等信息
5、采集function
6.可以解析文件的真实地址并下载
优采云采集器下载图片二
菜单功能介绍:
1.新群
您可以新建一个群组并选择所属的群组,确定名称和备注。
2.新任务
在组中新建一个任务,设置名称并保存在指定位置。
3.Web 发布配置
您可以定义登录网站并向网站提交数据的流程。主要功能包括登录信息的获取、网站编码的设置、栏目列表的获取以及数据测试发布的效果。
4.Web 发布模块
有多种高级功能,如定义网站登录、获取列表、获取随机数据、发布参数、上传文件、写入发布数据等。
5.数据库发布配置
您可以自定义链接信息消息模块的选择。
6.数据库发布模块
用于编辑数据库的发布模块,以便我们可以将数据发布到配置好的数据库中。
优采云采集器下载图片三
7.plan 任务
用于实现设置采集任务的启动计划,例如启动频率或自定义表达式。保存设置后,即可根据设置执行任务。
8.插件管理
插件是可用于扩展优采云采集器 功能的程序。
优采云采集器支持PHP源码、C#源码、C#类插件三种插件,可用于测试扩展请求、内容处理、文件下载。
优采云采集器免费版v8.5 更新日志:
1.修改软件启动界面,更加人性化
2.添加插件异常处理,方便插件调试
3.运行日志增加任务id
4.修复非管理员启动失败问题。
5.修复任务批处理中非内容标签复制问题
6.修复“为空再提取”的bug
7.WECenter的UBB转换功能完善
8.随机插入功能改进
9.修复样式附加时ul、ol等标签无法过滤的问题。
10.官方插件模块接口等资源更新
软件体验:
优采云采集器 是一款非常好用的软件。操作简单方便,手感好,功能强大。 网站信息大部分都可以采集,而且速度很快很稳定,爬取的准确率也很高,感兴趣的朋友快来下载吧!
优采云采集器9.9.0 正式版
网页文章采集器(一下免费的采集器有什么特点?有哪些特点呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-08-31 19:07
目前网上流行的免费采集器有几种:优采云、海纳、ET、三人、优采云、优采云。这里的免费版是相对的,如果是个人做正规的采集,那么免费版一般就够了。如果是针对商业用户,通常是需要付费的。毕竟做采集器的人要吃饭!
好的,我们来看看这些免费的采集器各自的特点吧!
1.优采云采集器
优采云应该是国内采集软件的成功范例之一,包括付费用户在内的用户数量应该是最大的。
优点:功能齐全,采集速度较快,主要针对cms,短时间内大量采集,过滤替换好,比较详细;界面更完整;支持的扩展更容易使用,理解代码,可以使用PHP或C#开发任意功能扩展;附件采集功能完善。
缺点:采集规则的编写对于很多用户,尤其是不懂代码的用户来说,是一个不小的难度。运行时占用内存和CPU资源较多,资源回收控制不好。另外,绑定电脑的授权有时不方便。
2.海纳
优点:可以抢到很多网站关键词文章,看来很适合网站的话题,尤其是文章类和博客类。
缺点:分类功能不完善,手工分类容易混淆。对于特定的接口,采集 的内容是有限的。一次只能使用一个采集。 采集 不能批量处理。需要连接网站后台网页。安装过程中,需要海纳人员现场技术支持比较麻烦。收费、免费的功能限制太多,就像鸡肋一样。
3.优采云采集器器
优点:无人值守,自动更新,用户群主要集中在长期潜水站高手。软件清晰,必备功能也很齐全,软件免费。
缺点:对论坛和cms的支持一般。帮助文件少,上手不易。
4.三行采集器
优点:针对各大论坛,移动、移动、速度快、准确率高。或者论坛,适合开论坛。
缺点:超级复杂,上手困难,对cms支持差。
5.优采云采集器
特点:让您的新论坛一开始就拥有大量成员。
优点:适用于采集discuz 论坛。
缺点:过于具体且不兼容。
6.优采云采集器
优点:功能齐全,操作简单,无需编写规则。对于独有的云采集,您也可以在关机时在云服务器上运行采集任务。
缺点:产品新,资历相对年轻。
总结:想要简单好用,功能更全的可以选择优采云采集器。如果你是一个懂写规则、追求功能很全的技术人员,可以选择优采云采集器。 优采云采集器和优采云采集器都可以快速采集很多资源可以应用到很多方面。这里只提到六个主要的免费采集器,其实还有很多其他的采集器,就不一一赘述了。 查看全部
网页文章采集器(一下免费的采集器有什么特点?有哪些特点呢?)
目前网上流行的免费采集器有几种:优采云、海纳、ET、三人、优采云、优采云。这里的免费版是相对的,如果是个人做正规的采集,那么免费版一般就够了。如果是针对商业用户,通常是需要付费的。毕竟做采集器的人要吃饭!
好的,我们来看看这些免费的采集器各自的特点吧!
1.优采云采集器
优采云应该是国内采集软件的成功范例之一,包括付费用户在内的用户数量应该是最大的。
优点:功能齐全,采集速度较快,主要针对cms,短时间内大量采集,过滤替换好,比较详细;界面更完整;支持的扩展更容易使用,理解代码,可以使用PHP或C#开发任意功能扩展;附件采集功能完善。
缺点:采集规则的编写对于很多用户,尤其是不懂代码的用户来说,是一个不小的难度。运行时占用内存和CPU资源较多,资源回收控制不好。另外,绑定电脑的授权有时不方便。
2.海纳
优点:可以抢到很多网站关键词文章,看来很适合网站的话题,尤其是文章类和博客类。
缺点:分类功能不完善,手工分类容易混淆。对于特定的接口,采集 的内容是有限的。一次只能使用一个采集。 采集 不能批量处理。需要连接网站后台网页。安装过程中,需要海纳人员现场技术支持比较麻烦。收费、免费的功能限制太多,就像鸡肋一样。
3.优采云采集器器
优点:无人值守,自动更新,用户群主要集中在长期潜水站高手。软件清晰,必备功能也很齐全,软件免费。
缺点:对论坛和cms的支持一般。帮助文件少,上手不易。
4.三行采集器
优点:针对各大论坛,移动、移动、速度快、准确率高。或者论坛,适合开论坛。
缺点:超级复杂,上手困难,对cms支持差。
5.优采云采集器
特点:让您的新论坛一开始就拥有大量成员。
优点:适用于采集discuz 论坛。
缺点:过于具体且不兼容。
6.优采云采集器
优点:功能齐全,操作简单,无需编写规则。对于独有的云采集,您也可以在关机时在云服务器上运行采集任务。
缺点:产品新,资历相对年轻。
总结:想要简单好用,功能更全的可以选择优采云采集器。如果你是一个懂写规则、追求功能很全的技术人员,可以选择优采云采集器。 优采云采集器和优采云采集器都可以快速采集很多资源可以应用到很多方面。这里只提到六个主要的免费采集器,其实还有很多其他的采集器,就不一一赘述了。
网页文章采集器(热点采集器中搜索你想要的信息能够帮助到你)
采集交流 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2021-08-31 13:00
网页文章采集器专注于互联网热点事件采集,例如:林森浩等人的承认谋杀案、滴滴出行网约车订单等等,各种类型的互联网热点,比如:网红可以转身变成老赖、专栏作家要先考证等等。网页文章采集器随时可以进行网站内容和文章更新提取,可以第一时间抓取网络上的任何类型的热点。另外文章采集器还支持内容爬取功能,搜索热点文章,抓取热点文章,抓取百度搜索引擎排名前几名的热点文章。可以在热点采集器中搜索你想要的信息,希望上面的信息能够帮助到你!。
工具软件是行走江湖的东风。它的好用,不仅仅能提高抓取效率,更能从源头把控平台、圈内动态。在这个信息爆炸的时代,工具软件也应该选好才是。目前热点采集器的工具集全覆盖,包括:检索采集、搜索、关键词、网页导入、常用邮箱、专业爬虫采集、舆情排行、同步搜索、聚合列表等,可以满足采集内容的多样化需求。附送工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具。 查看全部
网页文章采集器(热点采集器中搜索你想要的信息能够帮助到你)
网页文章采集器专注于互联网热点事件采集,例如:林森浩等人的承认谋杀案、滴滴出行网约车订单等等,各种类型的互联网热点,比如:网红可以转身变成老赖、专栏作家要先考证等等。网页文章采集器随时可以进行网站内容和文章更新提取,可以第一时间抓取网络上的任何类型的热点。另外文章采集器还支持内容爬取功能,搜索热点文章,抓取热点文章,抓取百度搜索引擎排名前几名的热点文章。可以在热点采集器中搜索你想要的信息,希望上面的信息能够帮助到你!。
工具软件是行走江湖的东风。它的好用,不仅仅能提高抓取效率,更能从源头把控平台、圈内动态。在这个信息爆炸的时代,工具软件也应该选好才是。目前热点采集器的工具集全覆盖,包括:检索采集、搜索、关键词、网页导入、常用邮箱、专业爬虫采集、舆情排行、同步搜索、聚合列表等,可以满足采集内容的多样化需求。附送工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具采集工具。
网页文章采集器(一般采集系统好比一双慧眼让您看得更远,获得更多)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-08-31 07:07
这是针对客户需求开发的网页文本爬虫,可以自动检索指定网页上的所有文本。它可以突破一些禁止复制的电子书。经过简单的设置程序,它就可以工作了。一般来说,网站管理员最希望能向网站提供更多的内容,从而吸引更多的访问量和页面浏览量;一字一句输入文字,很麻烦,也很无聊。所以今天小编给大家推荐一款好用的网站采集器,一般采集系统就像一双眼睛,让你看得更远,得到更多。这个Anmeiqi采集器可以从互联网上采集各种图片、笑话、新闻、技术等信息,然后分类、编辑并发布到它的网站系统。这个安美琪网站采集器界面简洁,功能强大!如果您喜欢这个软件,请下载!
安美琪采集器Features
1、根据用户需求,增加了各种常用规则;
2、根据百度关键词采集相关内容的规则;
3、搜搜资源采集相关内容规则;
4、根据有道关键词采集相关内容规则;
5、根据yahoo关键字采集相关内容规则;
6、根据bing关键字采集相关内容规则;
7、还支持列表类型采集,比如新闻、小说、下载等,可以使用这个软件采集;
8、支持替换指定关键字,支持在内容前后添加广告代码。这个大家一看就明白了;
9、添加了自定义采集方法,可以自行添加采集内容和规则;
10、支持大部分语言,国内外大部分网页都可以采集,无国界;
11、可以快速增加自己网站的内容。
安美琪采集器使用说明
此版本为免费版本,支持最基本的Access数据库。不要修改数据库名称。 采集 的内容在 date.mdb 中。如果数据库不同,请使用数据库导入导出功能。
1.如果不能运行请安装微软的“.net framework”,也可以在本站下载;如果不能采集,请及时更新最新版本。
2. 最后,希望大家多多支持本软件,给本软件提出建议或意见。
更新说明:
1:根据用户需求,增加了各种常用规则,
1.1 遵循百度关键词采集相关内容的规则
1.2搜索keywords采集相关内容规则,
1.3 根据有道关键词采集相关内容的规则,
1.4 遵循雅虎关键词采集相关内容的规则,
1.5 根据bing关键字采集相关内容的规则,
您可以快速向网站添加内容。
2:同时支持列表类型采集,如新闻、小说、下载等,可以使用本软件采集,
例如:点击上方“List采集芭货法”,即可获得新浪新闻采集添写方法。
3:支持替换指定关键字,并在内容前后添加广告代码。乍一看,每个人都可以理解这一点。
4:添加自定义采集方法,可以自行添加采集内容和规则
5:支持大部分语言,国内外大部分网页都可以采集,无国界。
6:此版本为免费版,支持最基本的Access数据库。请勿修改数据库名称。
采集 内容在 date.mdb 中。如果数据库不同,请使用数据库导入导出功能。
7:如果不能运行,请安装微软的.net框架。如果不能采集,请及时更新最新版本。
8:最后希望大家多多支持这个软件,给这个软件一些建议或意见。
更新日志(2020.07.16)
5.0 增加了QQ群发和邮件发送服务
6.0 修正了打开内容编辑自动关闭的错误。还有一些ajax无法点击的错误。 查看全部
网页文章采集器(一般采集系统好比一双慧眼让您看得更远,获得更多)
这是针对客户需求开发的网页文本爬虫,可以自动检索指定网页上的所有文本。它可以突破一些禁止复制的电子书。经过简单的设置程序,它就可以工作了。一般来说,网站管理员最希望能向网站提供更多的内容,从而吸引更多的访问量和页面浏览量;一字一句输入文字,很麻烦,也很无聊。所以今天小编给大家推荐一款好用的网站采集器,一般采集系统就像一双眼睛,让你看得更远,得到更多。这个Anmeiqi采集器可以从互联网上采集各种图片、笑话、新闻、技术等信息,然后分类、编辑并发布到它的网站系统。这个安美琪网站采集器界面简洁,功能强大!如果您喜欢这个软件,请下载!
安美琪采集器Features
1、根据用户需求,增加了各种常用规则;
2、根据百度关键词采集相关内容的规则;
3、搜搜资源采集相关内容规则;
4、根据有道关键词采集相关内容规则;
5、根据yahoo关键字采集相关内容规则;
6、根据bing关键字采集相关内容规则;
7、还支持列表类型采集,比如新闻、小说、下载等,可以使用这个软件采集;
8、支持替换指定关键字,支持在内容前后添加广告代码。这个大家一看就明白了;
9、添加了自定义采集方法,可以自行添加采集内容和规则;
10、支持大部分语言,国内外大部分网页都可以采集,无国界;
11、可以快速增加自己网站的内容。
安美琪采集器使用说明
此版本为免费版本,支持最基本的Access数据库。不要修改数据库名称。 采集 的内容在 date.mdb 中。如果数据库不同,请使用数据库导入导出功能。
1.如果不能运行请安装微软的“.net framework”,也可以在本站下载;如果不能采集,请及时更新最新版本。
2. 最后,希望大家多多支持本软件,给本软件提出建议或意见。
更新说明:
1:根据用户需求,增加了各种常用规则,
1.1 遵循百度关键词采集相关内容的规则
1.2搜索keywords采集相关内容规则,
1.3 根据有道关键词采集相关内容的规则,
1.4 遵循雅虎关键词采集相关内容的规则,
1.5 根据bing关键字采集相关内容的规则,
您可以快速向网站添加内容。
2:同时支持列表类型采集,如新闻、小说、下载等,可以使用本软件采集,
例如:点击上方“List采集芭货法”,即可获得新浪新闻采集添写方法。
3:支持替换指定关键字,并在内容前后添加广告代码。乍一看,每个人都可以理解这一点。
4:添加自定义采集方法,可以自行添加采集内容和规则
5:支持大部分语言,国内外大部分网页都可以采集,无国界。
6:此版本为免费版,支持最基本的Access数据库。请勿修改数据库名称。
采集 内容在 date.mdb 中。如果数据库不同,请使用数据库导入导出功能。
7:如果不能运行,请安装微软的.net框架。如果不能采集,请及时更新最新版本。
8:最后希望大家多多支持这个软件,给这个软件一些建议或意见。
更新日志(2020.07.16)
5.0 增加了QQ群发和邮件发送服务
6.0 修正了打开内容编辑自动关闭的错误。还有一些ajax无法点击的错误。
网页文章采集器(迷你派采集器这款插件让用户对网页轻松进行采集!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 332 次浏览 • 2021-08-30 22:02
Mini Pie采集器 这个插件可以让用户在网页上轻松采集。用户可以编写采集规则,让用户快速挑选自己想要的内容。插件可以自动抓取网页,也可以自动识别表格和数据,并实时通知数据变化。
软件说明
强大的网页采集器,无需编码!
最快的点击可以轻松完成采集!
直观地创建跨越多页信息的采集 规则。
所有数据都存储在本地,双重保护。
自动运行计划任务。
只要打开一个页面,让小饼采集器插件自动识别表单数据或选择需要手动抓取的元素,然后告诉小饼采集器如何在页面之间(甚至在页面之间)导航站点)(他也会尝试自动查找导航按钮)。小饼采集器可以智能理解数据模式,通过页面自动导航提取有价值的数据。
软件功能
•自动表单数据识别
•自动多页数据采集或转换
•数据变化监控和实时通知
•动态页面抓取(JavaScript + AJAX)
•多细节格式采集
•无限滚动支持
•支持多种分页模式
•交叉网站采集或数据转换
•增量数据采集
•自动采集规则生成,可视化采集规则编辑
•无限数据导出到 Excel 或 CSV 文件
•国际语言支持
•高度隐私——所有数据都存储在用户本地
•高度保密-多层加密保护,同时不接触任何用户目标采集网站账号或cookie等信息
•无需学习python、javascript、xpath、Css、json、iframe等技术
•除浏览器外没有其他依赖
常见场景
*电子商务卖家、分销商和评论分析师采集产品价格和评论
*销售人员通过专业的社交数据定期自动采集销售线索
*目标商品价格调整监测
*自由职业者会自动从公共目录中采集电子邮件、地址和电话号码
*在家或远程工作的人安全、自动地执行与数据相关的任务
*小企业主跨多个网站 管理他们的产品评级和评论
*商业领袖寻求采集数据的简单方法
*招聘人员定期寻找合格的候选人
*求职者为目标雇主寻找最好的工作
*营销专家分析社交媒体网站
*数据科学家采集更干净的数据
*学生学习数据科学和数据挖掘
Mini Pie采集器 是如何工作的?
Data采集器 是一个数据提取器和转换器,可以从您指定的网页中提取您指定的信息。 Mini Pie 采集器 通过使用 CSS 选择器来识别 HTML 页面中的信息,帮助您定义规则和任务。然后,它会执行计划采集你指定的信息,并将结果以表格的形式存储在浏览器中,以后可以保存为CSV或XLS文件。小派采集器支持UTF-8,所以采集可以轻松采集英文、中文、日文、俄文、韩文等多种语言。您无需具备编程等 IT 技能。
重要信息
所有抓取的数据始终对您保密,并且只有您可以看到。无论您使用的是免费计划还是付费计划,
* Mini Pie采集器 不会保留您的采集 数据,
* 您的采集 数据不会发送到我们的服务器,
* 也不会与任何人共享您的数据。
Mini Pie采集器 使用您自己的计算机并作为浏览器扩展程序运行,该扩展程序仅在您的浏览器中运行。
Mini Pie采集器 为您加密所有导出的采集 规则。注册用户还可以设置操作密码,进一步保障安全。
Mini Pie采集器 不会匿名采集任何数据。 采集器严格按照你定义或导入的采集规则运行。
Mini Pie采集器 要求您理解并遵守您访问的任何网站的使用条款。为用户开发生成的采集Task Mini派采集器没有义务修改或修复。
Mini Pie采集器 不收录任何恶意软件或间谍软件。所有捕获的数据和采集 任务配置都存储在您的浏览器中,除了您的电子邮件帐户(如果已注册)外,我们的服务器上不会保存任何数据。您的电子邮件地址用于登录目的和通知,未经您的明确同意,绝不会提供给他人。 Mini Pie采集器通过HTTPS和AES加密双重保护传输您的账户信息。
用户注意:删除本插件,或删除浏览器,插件中保存的采集规则和采集数据将完全丢失且无法恢复。
插件需要的浏览器权限说明:
tabs:管理抓取多个页面时打开的标签
activeTab:需要跟踪用于创建规则的选项卡
WebNavigation:跟踪多个页面时需要打开标签
storage:存储当前配置和数据
unlimitedStorage:需要存储所有采集数据以便以后导出
通知:采集需要在任务完成时通知你
提取码:91dj
内容结束。想看更多精彩内容,请关注。 查看全部
网页文章采集器(迷你派采集器这款插件让用户对网页轻松进行采集!)
Mini Pie采集器 这个插件可以让用户在网页上轻松采集。用户可以编写采集规则,让用户快速挑选自己想要的内容。插件可以自动抓取网页,也可以自动识别表格和数据,并实时通知数据变化。
软件说明
强大的网页采集器,无需编码!
最快的点击可以轻松完成采集!
直观地创建跨越多页信息的采集 规则。
所有数据都存储在本地,双重保护。
自动运行计划任务。
只要打开一个页面,让小饼采集器插件自动识别表单数据或选择需要手动抓取的元素,然后告诉小饼采集器如何在页面之间(甚至在页面之间)导航站点)(他也会尝试自动查找导航按钮)。小饼采集器可以智能理解数据模式,通过页面自动导航提取有价值的数据。
软件功能
•自动表单数据识别
•自动多页数据采集或转换
•数据变化监控和实时通知
•动态页面抓取(JavaScript + AJAX)
•多细节格式采集
•无限滚动支持
•支持多种分页模式
•交叉网站采集或数据转换
•增量数据采集
•自动采集规则生成,可视化采集规则编辑
•无限数据导出到 Excel 或 CSV 文件
•国际语言支持
•高度隐私——所有数据都存储在用户本地
•高度保密-多层加密保护,同时不接触任何用户目标采集网站账号或cookie等信息
•无需学习python、javascript、xpath、Css、json、iframe等技术
•除浏览器外没有其他依赖
常见场景
*电子商务卖家、分销商和评论分析师采集产品价格和评论
*销售人员通过专业的社交数据定期自动采集销售线索
*目标商品价格调整监测
*自由职业者会自动从公共目录中采集电子邮件、地址和电话号码
*在家或远程工作的人安全、自动地执行与数据相关的任务
*小企业主跨多个网站 管理他们的产品评级和评论
*商业领袖寻求采集数据的简单方法
*招聘人员定期寻找合格的候选人
*求职者为目标雇主寻找最好的工作
*营销专家分析社交媒体网站
*数据科学家采集更干净的数据
*学生学习数据科学和数据挖掘
Mini Pie采集器 是如何工作的?
Data采集器 是一个数据提取器和转换器,可以从您指定的网页中提取您指定的信息。 Mini Pie 采集器 通过使用 CSS 选择器来识别 HTML 页面中的信息,帮助您定义规则和任务。然后,它会执行计划采集你指定的信息,并将结果以表格的形式存储在浏览器中,以后可以保存为CSV或XLS文件。小派采集器支持UTF-8,所以采集可以轻松采集英文、中文、日文、俄文、韩文等多种语言。您无需具备编程等 IT 技能。
重要信息
所有抓取的数据始终对您保密,并且只有您可以看到。无论您使用的是免费计划还是付费计划,
* Mini Pie采集器 不会保留您的采集 数据,
* 您的采集 数据不会发送到我们的服务器,
* 也不会与任何人共享您的数据。
Mini Pie采集器 使用您自己的计算机并作为浏览器扩展程序运行,该扩展程序仅在您的浏览器中运行。
Mini Pie采集器 为您加密所有导出的采集 规则。注册用户还可以设置操作密码,进一步保障安全。
Mini Pie采集器 不会匿名采集任何数据。 采集器严格按照你定义或导入的采集规则运行。
Mini Pie采集器 要求您理解并遵守您访问的任何网站的使用条款。为用户开发生成的采集Task Mini派采集器没有义务修改或修复。
Mini Pie采集器 不收录任何恶意软件或间谍软件。所有捕获的数据和采集 任务配置都存储在您的浏览器中,除了您的电子邮件帐户(如果已注册)外,我们的服务器上不会保存任何数据。您的电子邮件地址用于登录目的和通知,未经您的明确同意,绝不会提供给他人。 Mini Pie采集器通过HTTPS和AES加密双重保护传输您的账户信息。
用户注意:删除本插件,或删除浏览器,插件中保存的采集规则和采集数据将完全丢失且无法恢复。
插件需要的浏览器权限说明:
tabs:管理抓取多个页面时打开的标签
activeTab:需要跟踪用于创建规则的选项卡
WebNavigation:跟踪多个页面时需要打开标签
storage:存储当前配置和数据
unlimitedStorage:需要存储所有采集数据以便以后导出
通知:采集需要在任务完成时通知你
提取码:91dj
内容结束。想看更多精彩内容,请关注。
网页文章采集器(网络请求模块:urllib模块(比较复杂)、requests模块(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-08-30 10:01
网络请求模块:urllib模块(复杂),请求模块
一、requests 模块:
python中基于网络请求的原生模块,功能强大,简单方便,效率极高。
1、 作用:模拟浏览器请求
2、使用方法(编码过程):
3、Environment 安装:pip 安装请求
4、实战编码:
import requests
if __name__=="__main__": #step1:指定url url='https://www.sogou.com/' #step2:发起请求 #get方法会返回一个响应对象 response=requests.get(url=url) #step3:获取响应数据,text返回的是字符串形式的响应数据 page_text=response.text print(page_text) #step 4:持久化存储 with open("./sogou.html","w",encoding="utf-8") as fp: fp.write(page_text) print("爬取数据结束")
返回的响应数据(部分截图):
HTML 文件打开后的界面截图:
5、实战修改1:搜狗指定词条搜索结果爬取界面(简单网页采集器)
import requests
if __name__=="__main__": #UA伪装:将对应的User-Agent封装到一个字典中 headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:79.0) Gecko/20100101 Firefox/' } url='https://www.sogou.com/web' #处理url携带的参数:封装到字典中 kw=input('enter a word:') param={ 'query':kw } #对指定的url发起的请求对应的url是携带参数的,并且请求过程中处理了参数 response=requests.get(url=url,params=param,headers=headers) page_text=response.text fileName=kw+'.html' with open(fileName,"w",encoding="utf-8") as fp: fp.write(page_text) print(fileName,"保存成功!!")
在浏览器中搜索“北斗导航”的链接是这样的:北斗导航&_asf=&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=23426&sst0=72565C0708C08C00000C
为了简化,它看起来像这样:北斗导航
?前面是浏览器,后面是我们检索到的内容参数。
这里作为一个简单的网页采集器,将检索到的内容设置为动态,查询通过用户输入存储在字典中,查询为key值,通过input输入值
存储用户代理
如何获得,在之前的注释中提到过。
学习python爬虫需要知道什么?
portal网站的服务器会检测对应请求的运营商ID。如果检测到请求的运营商ID是某个浏览器,则说明该请求是正常请求。但是,如果检测到请求的运营商身份不是基于某个浏览器,则说明该请求为异常请求(爬虫)。那么服务器很可能会拒绝请求。 查看全部
网页文章采集器(网络请求模块:urllib模块(比较复杂)、requests模块(图))
网络请求模块:urllib模块(复杂),请求模块
一、requests 模块:
python中基于网络请求的原生模块,功能强大,简单方便,效率极高。
1、 作用:模拟浏览器请求
2、使用方法(编码过程):
3、Environment 安装:pip 安装请求
4、实战编码:
import requests
if __name__=="__main__": #step1:指定url url='https://www.sogou.com/' #step2:发起请求 #get方法会返回一个响应对象 response=requests.get(url=url) #step3:获取响应数据,text返回的是字符串形式的响应数据 page_text=response.text print(page_text) #step 4:持久化存储 with open("./sogou.html","w",encoding="utf-8") as fp: fp.write(page_text) print("爬取数据结束")
返回的响应数据(部分截图):
HTML 文件打开后的界面截图:
5、实战修改1:搜狗指定词条搜索结果爬取界面(简单网页采集器)
import requests
if __name__=="__main__": #UA伪装:将对应的User-Agent封装到一个字典中 headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:79.0) Gecko/20100101 Firefox/' } url='https://www.sogou.com/web' #处理url携带的参数:封装到字典中 kw=input('enter a word:') param={ 'query':kw } #对指定的url发起的请求对应的url是携带参数的,并且请求过程中处理了参数 response=requests.get(url=url,params=param,headers=headers) page_text=response.text fileName=kw+'.html' with open(fileName,"w",encoding="utf-8") as fp: fp.write(page_text) print(fileName,"保存成功!!")
在浏览器中搜索“北斗导航”的链接是这样的:北斗导航&_asf=&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=23426&sst0=72565C0708C08C00000C
为了简化,它看起来像这样:北斗导航
?前面是浏览器,后面是我们检索到的内容参数。
这里作为一个简单的网页采集器,将检索到的内容设置为动态,查询通过用户输入存储在字典中,查询为key值,通过input输入值
存储用户代理
如何获得,在之前的注释中提到过。
学习python爬虫需要知道什么?
portal网站的服务器会检测对应请求的运营商ID。如果检测到请求的运营商ID是某个浏览器,则说明该请求是正常请求。但是,如果检测到请求的运营商身份不是基于某个浏览器,则说明该请求为异常请求(爬虫)。那么服务器很可能会拒绝请求。
网页文章采集器(Tabbs:让任意标签页变身「画中画」(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 314 次浏览 • 2021-08-30 10:00
Tabbs:使用快捷键管理标签
对于追求效率的人来说,键盘操作总是更快,鼠标点击一步。这也是事实。我也曾尝试过在IDE中使用Vim,彻底摆脱鼠标的控制,但因为上手成本高,屡屡失败。
随着时间的推移,Chrome 逐渐成为我的第一个工作区。我几乎每天都在各种工具、竞品、搜索结果页面之间跳来跳去,我越来越需要一个可以让我摆脱鼠标操作的工具。插件化,降低视觉消耗,在几十个Tabs翻滚时会出现。在这个过程中,我注意到了Tabbs,这是我“症状”的一个非常延伸。
Tabbs官网操作演示
CMD+K 唤醒Tabbs,上下切换或选择搜索方式到指定Tab,要静音按Option+M,要修复按Option+P,要选择Option+C关闭,如果想查看就按回车...Tabbs和纯键盘快捷键操作的区别在于不需要切换到对应的Tab来实现这些操作。
除此之外,Tabbs 还支持将长时间未使用的标签悬浮在后台,这对于有大量 Tabs 不愿关闭忘记关闭的用户也很有用。
Tabbs 可用快捷键操作
您可以在 Chrome 网上应用店免费获得 Tabbs。
Tabfloater:将任何标签变成“画中画”
还记得在介绍Chrome自带的视频画中画插件时,很多人抱怨它不支持弹幕和倍速播放吗?这不支持,也不支持。受Chrome官方开发意愿的限制,不依赖用户需求...
但是这个问题也不是没有办法,Tabfloater 是一个不错的选择。顾名思义,Tabfloater 就是让你的 Tab 浮动。说白了就是直接把tab变成画中画的形式。
你可以浮动Bilibili的视频,有弹幕的那种;你可以漂浮一张稀有的纸,观察并检查它;您可以浮动播客,并随时停止...
像这样写作和钓鱼
受浏览器对扩展的权限控制的限制,Tabfloater想要将画中画完全悬浮在顶层窗口,必须配合配套应用使用。并且该应用目前仅支持Windows和Linux,不支持macOS,Mac用户可以期待后续更新。
您可以在 Chrome 网上应用店免费获得 Tabfloater。
豆瓣书+:豆瓣一键找书
很多人会通过豆瓣阅读找书。 网站的图书详情页会提供一些购买实体书和阅读电子版的链接。实体书地址涵盖大部分一、二手书购买渠道,电子版仅提供豆瓣获取和阅读地址。
如果您使用微信等应用看书,可以使用豆瓣书+扩展程序。目前支持微信阅读、多读、亚马逊Kindle、掌上书店、网易蜗牛阅读。可直接查看图书详情页面跳转,独有的微信阅读,提供网络阅读器,更方便。
虽然有时跳转到多个出版商和多个版本的书籍时不那么准确,但总体体验还是不错的。
您可以在 Chrome 扩展商店下载豆瓣书+。
flomo Plus:重度 flomo 用户的必备扩展
flomo 是一个有灵感的采集工具,非常适合存储碎片化的网站、文字、图片等,然后统一处理。 flomo开放API后,很多开发者为flomo做了第三方工具,flomo的Chrome插件flomo Plus就是其中之一。
flomo Plus 支持将当前网页直接保存到 flomo 中。在此基础上还可以快速保存选中的文字内容,甚至可以导入微信阅读笔记、微博、即时等,信息采集能力相当强大。日常生活中最常用的功能就是保存网页,尤其是一些有知识或素材分享内容的推文。
我曾经把这类信息存放在Todoist中,并定期进行一一处理,但毕竟放在专门的“信息箱”中并不方便。有了 flomo Plus 后,我终于有了大量使用 flomo 的动力。
Flomo Plus 的网页保存和文字快速保存功能
您可以点击此处下载 flomo Plus 并查看具体的使用说明。本栏目图片均来自此处。
TLDR This:速读总结生成工具
不得不说,优先级排序和程序化摘要的建立对于提高读写效率非常有用。
在阅读笔记和文章最耗时信息过载的时代,如果你想要一个可以自动生成文章summaries的工具,TLDR这个可以派上用场。
值得一提的是,Evernote 的 Clip 早先推出了快速阅读摘要功能:当你剪辑一个文章时,后台可以根据文章的内容快速生成更短的摘要描述。听起来很棒,但在实际使用中几乎意味着:一方面,摘要太短,无法描述清楚文章succinctly;另一方面,我似乎无法抓住要点。
印象笔记速度总结
TLDR 生成的同一篇文章文章 下图中的这个有很多抽象的内容,整体看句子还挺流畅的,好像在看摘要;我也在Medium主页上试了几个文章,我发现这个工具生成的英文摘要会更精致,可读性也会提高。有此类需求的朋友不妨下载。
您可以在 Chrome 网上应用店免费获得 TLDR This。
Web Highlight:让AI帮你突出重点
当我看不懂纯英文的论文或工具文档时,我经常使用合适的翻译来辅助阅读。这个过程一般是这样的:打开标注功能,不懂的可以滑动查看翻译,帮助理解。通读并找到您想要的问题的答案。
使用 TLDR This 和 Web Highlight,我的阅读工作流程可能会略有调整。一大段内容没看懂,放到TLDR这个就可以一键生成摘要,辅助理解要点; Web Highlight 使用 AI 分析,进一步把握网页内容的焦点。
比如下面Tabfloater Companion工具说明的重点自动标注:为什么Tabfloater需要和独立客户端一起使用,客户端能做什么,有视觉焦点,一目了然。
您可以在 Chrome 网上应用店免费获得 Web Highlight。
Pin QR:从任何网页生成二维码
没有人会想到 20 世纪末发明的二维码,二十年后真的会大放异彩。特别是在中国,支付宝和微信二维码已经覆盖了人们的出行、购物、饮食、文化等各个方面。 “你扫我,我扫你”几乎成了现代人在交往中偶尔避不开的“口头禅”。
Pin QR 可以为任何网页生成二维码,其他人只需扫描即可打开当前页面。适用于分享网页或使用PC移动端中继时。与Chrome内置的二维码生成功能相比,Pin QR生成的二维码允许Pin在当前标签上,还支持添加二维码标签说明。
你可能不知道的是,当网页链接超过250个字符时,Chrome的二维码无法显示,仍然可以生成Pin QR。
Chrome和Pin QR二维码生成功能对比
您可以在 Chrome 网上应用店免费获得 Pin QR。
Motion:为浏览器添加焦点模式
随着办公室的“云”化,越来越多的团队选择更先进的在线文档、项目管理、视频会议和在线学习工具。一方面,他们摆脱了操作系统和软件的限制,允许信息交换。实时协作变得更加容易。另一方面,它也对我们的浏览器提出了更严格的要求,要求我们的浏览器更像是一个“集成工作区”。
但 Motion 这个扩展指出,我们每天在浏览器上工作时浪费了大量时间。可能是因为看YouTube转移了注意力,也可能是我们不自觉地点击了喜欢的网页。注意小红点。因此,Motion 插件希望我们可以将其用于:
简单来说,Motion 就是一个“小主管”,让我们在设定的工作时间内保持专注,不被打扰。您可以在 Motion 网站上获取 Motion。
保持:冲浪也有一个“番茄钟”
Hold 就像浏览器的番茄工作法工具。当您想继续专注于不访问Moyu网站时,您可以将阻止列表设置为一次阻止视频网站和购物网站。或有针对性的网址。
比如我上班的时候,经常在无事可做的时候打开网站尝试学习(钓鱼),但是这种懒惰的操作只会迫使自己的工作堆积如山,后果自负是难以想象的,所以:
通过屏蔽少数URL,在右侧打开sspai即可直接访问
除了专注于网站study 和工作之外,它会帮助你被动地完成任务。 Hold 还会自动为您生成任务统计信息。一方面,它是你成就感的体现。另一方面,它还可以变相实现对日常网页浏览行为的统计:
Hold 带有重点结果的统计数据
您可以在 Chrome 网上应用店获得 Hold。
Colorgram:为 Instagram 更改彩色主题
“技术是基于换壳的”可能只是个笑话。背后是厂家对不同外壳技术的长期打磨和测试,最终掌握在消费者手中的是全新的手感和视觉体验。
与去年同期相比,改变常用软件的配色方案不算是颠覆性的改变,但在常用软件中可以有一个丰富多彩的主题,可以大大减少审美疲劳,真的是使用不同。尤其是一些浏览体验非常好的网页版应用,比如Instagram。
我通过 Colorgram 为 Instagram 更改了一些新主题。每次换了,再继续做五分钟,上班上ins上钓鱼就再也不会腻了✌️。
Colorgram支持的十几个皮肤真的很好
您可以在 Edge 网络应用商店中免费获得 Colorgram。
复活节彩蛋:梦想回到 90 年代的 IE
在我上小学的时候,每次尝试通过将网线插入台式计算机来连接互联网时,总是无法查看互联网是否真的已连接。那时我只会用IE打开一个网页,看看能不能加载来判断——一旦加载失败,浏览器状态栏中的“小地球”就会无限循环。。 .
无意间发现这个很怀旧的网页加载效果可以通过Throbber插件在Chrome中重现。科技在飞速发展,网络现在更顺畅,但 Throbber 可以将复古的浏览体验带回我们的眼中。
还是建议安装Edge
你可以在 Github 上免费获得 Throbber。
以上是本浏览器扩展的所有推荐内容。您已经在使用哪些?是否有任何刚刚发布或最近更新的扩展没有被本文涵盖?欢迎在评论区留言分享,推荐下期再见~
相关阅读: 查看全部
网页文章采集器(Tabbs:让任意标签页变身「画中画」(组图))
Tabbs:使用快捷键管理标签
对于追求效率的人来说,键盘操作总是更快,鼠标点击一步。这也是事实。我也曾尝试过在IDE中使用Vim,彻底摆脱鼠标的控制,但因为上手成本高,屡屡失败。
随着时间的推移,Chrome 逐渐成为我的第一个工作区。我几乎每天都在各种工具、竞品、搜索结果页面之间跳来跳去,我越来越需要一个可以让我摆脱鼠标操作的工具。插件化,降低视觉消耗,在几十个Tabs翻滚时会出现。在这个过程中,我注意到了Tabbs,这是我“症状”的一个非常延伸。
Tabbs官网操作演示
CMD+K 唤醒Tabbs,上下切换或选择搜索方式到指定Tab,要静音按Option+M,要修复按Option+P,要选择Option+C关闭,如果想查看就按回车...Tabbs和纯键盘快捷键操作的区别在于不需要切换到对应的Tab来实现这些操作。
除此之外,Tabbs 还支持将长时间未使用的标签悬浮在后台,这对于有大量 Tabs 不愿关闭忘记关闭的用户也很有用。
Tabbs 可用快捷键操作
您可以在 Chrome 网上应用店免费获得 Tabbs。
Tabfloater:将任何标签变成“画中画”
还记得在介绍Chrome自带的视频画中画插件时,很多人抱怨它不支持弹幕和倍速播放吗?这不支持,也不支持。受Chrome官方开发意愿的限制,不依赖用户需求...
但是这个问题也不是没有办法,Tabfloater 是一个不错的选择。顾名思义,Tabfloater 就是让你的 Tab 浮动。说白了就是直接把tab变成画中画的形式。
你可以浮动Bilibili的视频,有弹幕的那种;你可以漂浮一张稀有的纸,观察并检查它;您可以浮动播客,并随时停止...
像这样写作和钓鱼
受浏览器对扩展的权限控制的限制,Tabfloater想要将画中画完全悬浮在顶层窗口,必须配合配套应用使用。并且该应用目前仅支持Windows和Linux,不支持macOS,Mac用户可以期待后续更新。
您可以在 Chrome 网上应用店免费获得 Tabfloater。
豆瓣书+:豆瓣一键找书
很多人会通过豆瓣阅读找书。 网站的图书详情页会提供一些购买实体书和阅读电子版的链接。实体书地址涵盖大部分一、二手书购买渠道,电子版仅提供豆瓣获取和阅读地址。
如果您使用微信等应用看书,可以使用豆瓣书+扩展程序。目前支持微信阅读、多读、亚马逊Kindle、掌上书店、网易蜗牛阅读。可直接查看图书详情页面跳转,独有的微信阅读,提供网络阅读器,更方便。
虽然有时跳转到多个出版商和多个版本的书籍时不那么准确,但总体体验还是不错的。
您可以在 Chrome 扩展商店下载豆瓣书+。
flomo Plus:重度 flomo 用户的必备扩展
flomo 是一个有灵感的采集工具,非常适合存储碎片化的网站、文字、图片等,然后统一处理。 flomo开放API后,很多开发者为flomo做了第三方工具,flomo的Chrome插件flomo Plus就是其中之一。
flomo Plus 支持将当前网页直接保存到 flomo 中。在此基础上还可以快速保存选中的文字内容,甚至可以导入微信阅读笔记、微博、即时等,信息采集能力相当强大。日常生活中最常用的功能就是保存网页,尤其是一些有知识或素材分享内容的推文。
我曾经把这类信息存放在Todoist中,并定期进行一一处理,但毕竟放在专门的“信息箱”中并不方便。有了 flomo Plus 后,我终于有了大量使用 flomo 的动力。
Flomo Plus 的网页保存和文字快速保存功能
您可以点击此处下载 flomo Plus 并查看具体的使用说明。本栏目图片均来自此处。
TLDR This:速读总结生成工具
不得不说,优先级排序和程序化摘要的建立对于提高读写效率非常有用。
在阅读笔记和文章最耗时信息过载的时代,如果你想要一个可以自动生成文章summaries的工具,TLDR这个可以派上用场。
值得一提的是,Evernote 的 Clip 早先推出了快速阅读摘要功能:当你剪辑一个文章时,后台可以根据文章的内容快速生成更短的摘要描述。听起来很棒,但在实际使用中几乎意味着:一方面,摘要太短,无法描述清楚文章succinctly;另一方面,我似乎无法抓住要点。
印象笔记速度总结
TLDR 生成的同一篇文章文章 下图中的这个有很多抽象的内容,整体看句子还挺流畅的,好像在看摘要;我也在Medium主页上试了几个文章,我发现这个工具生成的英文摘要会更精致,可读性也会提高。有此类需求的朋友不妨下载。
您可以在 Chrome 网上应用店免费获得 TLDR This。
Web Highlight:让AI帮你突出重点
当我看不懂纯英文的论文或工具文档时,我经常使用合适的翻译来辅助阅读。这个过程一般是这样的:打开标注功能,不懂的可以滑动查看翻译,帮助理解。通读并找到您想要的问题的答案。
使用 TLDR This 和 Web Highlight,我的阅读工作流程可能会略有调整。一大段内容没看懂,放到TLDR这个就可以一键生成摘要,辅助理解要点; Web Highlight 使用 AI 分析,进一步把握网页内容的焦点。
比如下面Tabfloater Companion工具说明的重点自动标注:为什么Tabfloater需要和独立客户端一起使用,客户端能做什么,有视觉焦点,一目了然。
您可以在 Chrome 网上应用店免费获得 Web Highlight。
Pin QR:从任何网页生成二维码
没有人会想到 20 世纪末发明的二维码,二十年后真的会大放异彩。特别是在中国,支付宝和微信二维码已经覆盖了人们的出行、购物、饮食、文化等各个方面。 “你扫我,我扫你”几乎成了现代人在交往中偶尔避不开的“口头禅”。
Pin QR 可以为任何网页生成二维码,其他人只需扫描即可打开当前页面。适用于分享网页或使用PC移动端中继时。与Chrome内置的二维码生成功能相比,Pin QR生成的二维码允许Pin在当前标签上,还支持添加二维码标签说明。
你可能不知道的是,当网页链接超过250个字符时,Chrome的二维码无法显示,仍然可以生成Pin QR。
Chrome和Pin QR二维码生成功能对比
您可以在 Chrome 网上应用店免费获得 Pin QR。
Motion:为浏览器添加焦点模式
随着办公室的“云”化,越来越多的团队选择更先进的在线文档、项目管理、视频会议和在线学习工具。一方面,他们摆脱了操作系统和软件的限制,允许信息交换。实时协作变得更加容易。另一方面,它也对我们的浏览器提出了更严格的要求,要求我们的浏览器更像是一个“集成工作区”。
但 Motion 这个扩展指出,我们每天在浏览器上工作时浪费了大量时间。可能是因为看YouTube转移了注意力,也可能是我们不自觉地点击了喜欢的网页。注意小红点。因此,Motion 插件希望我们可以将其用于:
简单来说,Motion 就是一个“小主管”,让我们在设定的工作时间内保持专注,不被打扰。您可以在 Motion 网站上获取 Motion。
保持:冲浪也有一个“番茄钟”
Hold 就像浏览器的番茄工作法工具。当您想继续专注于不访问Moyu网站时,您可以将阻止列表设置为一次阻止视频网站和购物网站。或有针对性的网址。
比如我上班的时候,经常在无事可做的时候打开网站尝试学习(钓鱼),但是这种懒惰的操作只会迫使自己的工作堆积如山,后果自负是难以想象的,所以:
通过屏蔽少数URL,在右侧打开sspai即可直接访问
除了专注于网站study 和工作之外,它会帮助你被动地完成任务。 Hold 还会自动为您生成任务统计信息。一方面,它是你成就感的体现。另一方面,它还可以变相实现对日常网页浏览行为的统计:
Hold 带有重点结果的统计数据
您可以在 Chrome 网上应用店获得 Hold。
Colorgram:为 Instagram 更改彩色主题
“技术是基于换壳的”可能只是个笑话。背后是厂家对不同外壳技术的长期打磨和测试,最终掌握在消费者手中的是全新的手感和视觉体验。
与去年同期相比,改变常用软件的配色方案不算是颠覆性的改变,但在常用软件中可以有一个丰富多彩的主题,可以大大减少审美疲劳,真的是使用不同。尤其是一些浏览体验非常好的网页版应用,比如Instagram。
我通过 Colorgram 为 Instagram 更改了一些新主题。每次换了,再继续做五分钟,上班上ins上钓鱼就再也不会腻了✌️。
Colorgram支持的十几个皮肤真的很好
您可以在 Edge 网络应用商店中免费获得 Colorgram。
复活节彩蛋:梦想回到 90 年代的 IE
在我上小学的时候,每次尝试通过将网线插入台式计算机来连接互联网时,总是无法查看互联网是否真的已连接。那时我只会用IE打开一个网页,看看能不能加载来判断——一旦加载失败,浏览器状态栏中的“小地球”就会无限循环。。 .
无意间发现这个很怀旧的网页加载效果可以通过Throbber插件在Chrome中重现。科技在飞速发展,网络现在更顺畅,但 Throbber 可以将复古的浏览体验带回我们的眼中。
还是建议安装Edge
你可以在 Github 上免费获得 Throbber。
以上是本浏览器扩展的所有推荐内容。您已经在使用哪些?是否有任何刚刚发布或最近更新的扩展没有被本文涵盖?欢迎在评论区留言分享,推荐下期再见~
相关阅读:
优采云采集器是任何一个需要从网页获取信息的必备神器
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-08-27 04:15
优采云采集器 是任何需要从网络获取信息的孩子的必备神器。这是一个可以让你的信息采集变得非常简单的工具。 优采云改变了传统的互联网数据思维方式,让用户在互联网上抓取和编辑数据变得越来越容易
软件功能
满足多种业务场景
适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等各种职业。
舆论监测
全方位监控公众信息,抢先掌握舆情动态。
市场分析
获取用户真实行为数据,全面掌握客户真实需求
产品研发
大力支持用户研究,准确获取用户反馈和偏好
风险预测
高效信息采集和数据清洗,及时应对系统风险
功能介绍
简单采集
简单采集模式内置了数百个主流网站数据源,如京东、天猫、大众点评等流行的采集网站。只需参考模板设置参数即可快速获取网站。 @公共数据。
Smart采集
优采云采集可根据网站的不同提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助采集整个流程实现数据的完整性和稳定性。
云采集
云采集,5000多台云服务器支持,7*24小时不间断运行,可实现定时采集,无人值守,灵活适配业务场景,助您提升采集效率,并保护数据的及时性。
API 接口
通过优采云API,可以轻松获取采集接收到的优采云任务信息和数据,灵活调度任务,如远程控制任务启停,高效实现数据采集和归档。基于强大的API系统,还可以与公司各种内部管理平台无缝对接,实现各种业务自动化。
自定义采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax、页面滚动、条件判断等。此类功能支持不同网页结构的复杂网站采集,满足多种采集应用场景。
方便的定时功能
只需简单几步,点击设置即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集。同时自由设置多个任务,根据需要进行多种选择时间组合,灵活部署自己的采集任务。
自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等诸多功能,采集该过程是全自动的,无需人工干预即可获取所需格式的数据。
多级采集
很多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;不管网站有多少层,优采云所有采集数据都可以无限,满足采集各种业务需求。
登录后支持网站采集
优采云内置采集登录模块,只需配置目标网站的账号密码,即可使用该模块采集登录数据;同时优采云还拥有采集Cookie自定义功能,首次登录后可自动记住cookies,免去多次输入密码的繁琐,支持更多网站采集。
如何使用
首先我们新建一个任务-->进入流程设计页面-->在流程中添加一个循环步骤-->选择循环步骤-->勾选右边的URL列表复选框软件-->打开网址列表文本框-->将准备好的网址列表填入文本框
接下来,将打开网页的步骤拖入循环-->选择打开网页的步骤-->勾选以当前循环中的URL作为导航地址的框-->点击保存。系统会在界面底部的浏览器中打开循环选择的URL对应的网页
至此,打开网页的循环配置完成。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置采集数据的步骤,所以这里不再赘述。可以参考系列一:采集单网页本文章。下图是最终和过程。 查看全部
优采云采集器是任何一个需要从网页获取信息的必备神器
优采云采集器 是任何需要从网络获取信息的孩子的必备神器。这是一个可以让你的信息采集变得非常简单的工具。 优采云改变了传统的互联网数据思维方式,让用户在互联网上抓取和编辑数据变得越来越容易
软件功能
满足多种业务场景
适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等各种职业。
舆论监测
全方位监控公众信息,抢先掌握舆情动态。
市场分析
获取用户真实行为数据,全面掌握客户真实需求
产品研发
大力支持用户研究,准确获取用户反馈和偏好
风险预测
高效信息采集和数据清洗,及时应对系统风险
功能介绍
简单采集
简单采集模式内置了数百个主流网站数据源,如京东、天猫、大众点评等流行的采集网站。只需参考模板设置参数即可快速获取网站。 @公共数据。
Smart采集
优采云采集可根据网站的不同提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助采集整个流程实现数据的完整性和稳定性。
云采集
云采集,5000多台云服务器支持,7*24小时不间断运行,可实现定时采集,无人值守,灵活适配业务场景,助您提升采集效率,并保护数据的及时性。
API 接口
通过优采云API,可以轻松获取采集接收到的优采云任务信息和数据,灵活调度任务,如远程控制任务启停,高效实现数据采集和归档。基于强大的API系统,还可以与公司各种内部管理平台无缝对接,实现各种业务自动化。
自定义采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax、页面滚动、条件判断等。此类功能支持不同网页结构的复杂网站采集,满足多种采集应用场景。
方便的定时功能
只需简单几步,点击设置即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集。同时自由设置多个任务,根据需要进行多种选择时间组合,灵活部署自己的采集任务。
自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等诸多功能,采集该过程是全自动的,无需人工干预即可获取所需格式的数据。
多级采集
很多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;不管网站有多少层,优采云所有采集数据都可以无限,满足采集各种业务需求。
登录后支持网站采集
优采云内置采集登录模块,只需配置目标网站的账号密码,即可使用该模块采集登录数据;同时优采云还拥有采集Cookie自定义功能,首次登录后可自动记住cookies,免去多次输入密码的繁琐,支持更多网站采集。
如何使用
首先我们新建一个任务-->进入流程设计页面-->在流程中添加一个循环步骤-->选择循环步骤-->勾选右边的URL列表复选框软件-->打开网址列表文本框-->将准备好的网址列表填入文本框
接下来,将打开网页的步骤拖入循环-->选择打开网页的步骤-->勾选以当前循环中的URL作为导航地址的框-->点击保存。系统会在界面底部的浏览器中打开循环选择的URL对应的网页
至此,打开网页的循环配置完成。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置采集数据的步骤,所以这里不再赘述。可以参考系列一:采集单网页本文章。下图是最终和过程。
了织梦自带采集器使用教程(二)梦
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-08-27 04:13
了织梦自带采集器使用教程(二)梦
在之前的文档中,我们介绍了织梦自带采集器使用教程,但并不是每个用户都能很好地使用它们。总之采集这个东西需要在实际站点上积累经验,因为目标站点的代码不同,遇到不同的问题,积累起来才能上手。
第一步,我们打开织梦Background,点击采集——采集Node Management——添加一个新节点
file:///C:/users/administrator/appdata/roaming/360se6/User%20Data/temp/2012031560765705.jpg
第二步,添加新节点-配置URL索引
填写采集网站列表的相关规则,
查看采集站点代码和网站源代码
我们右键点击查看源码。在源码的开头,我们找到了一个带有charset=某个代码的meta标签,比如charset="gb2312",这就是所谓的网站代码
选择采集site的编码
第三步,添加新节点-配置文章URL匹配规则
我们查看采集站点的list页面源码,找到文章list start html和end html标签,复制到“采集node所在区域”开头的HTML ->文章 添加了 URL 匹配规则。" “和”End of area HTML”输入框。你不一定要选择右键查看源代码才能找到文章list开始标签,你可以右键点击文章开始的地方,查看element(chrome浏览器,firefox是查看元素),这样更方便查找文章List开始和结束标签。
设置完成后,我们点击“保存信息,进入下一步设置”
第四步:URL获取规则测试
如果在测试结果中发现不相关的URL信息,说明第五步的URL过滤规则有误或者过滤规则没有填写,如果发现采集有误,可以返回到最后修改,如果没有,点击“保存信息,进入下一步设置”。
第五步:内容字段获取规则
我们查看采集站点的文章源代码,找到相关选项的开始和结束html标签,填写指定位置,开始和结束标签用“[Content]”分割。
设置好后,我们点击“保存配置并预览”
第 6 步:过滤规则
在第7步的匹配规则之后,还有一个过滤规则,用于过滤不需要采集的内容。
比如网易的每篇文章文章都有一个iframe标签,用来投放广告。我们要采集网易的文章。不可能在采集回来后,我每篇文章都要删除这个广告。但是如何去除呢?去除方法是过滤规则。当我们点击常用规则时,会弹出一个小窗口,列出常用的过滤规则。我们只需要点击我们想要过滤的规则,就可以过滤网易文章iframe标签中,我们点击iframe即可。
测试内容字段设置
因为网易开头有文章
一些文章以
开头
,所以会有采集错误。
如果你现在想要采集,你可以点击保存和采集。这里我选择只保存
采集Content (一)
回到采集node管理界面,也就是第一步的界面,我们选择节点点击采集
采集内容(二)
查看已下载
您可以点击采集界面(第十步界面)右上角的“查看已下载”。也可以在“采集Node 管理”界面点击“查看已下载”。以第二种方法为例。
导出内容
选择要导入的列、数据量、是否生成html文件、随机推荐的数量
最终结果
查看全部
了织梦自带采集器使用教程(二)梦
在之前的文档中,我们介绍了织梦自带采集器使用教程,但并不是每个用户都能很好地使用它们。总之采集这个东西需要在实际站点上积累经验,因为目标站点的代码不同,遇到不同的问题,积累起来才能上手。
第一步,我们打开织梦Background,点击采集——采集Node Management——添加一个新节点
file:///C:/users/administrator/appdata/roaming/360se6/User%20Data/temp/2012031560765705.jpg
第二步,添加新节点-配置URL索引
填写采集网站列表的相关规则,
查看采集站点代码和网站源代码
我们右键点击查看源码。在源码的开头,我们找到了一个带有charset=某个代码的meta标签,比如charset="gb2312",这就是所谓的网站代码
选择采集site的编码
第三步,添加新节点-配置文章URL匹配规则
我们查看采集站点的list页面源码,找到文章list start html和end html标签,复制到“采集node所在区域”开头的HTML ->文章 添加了 URL 匹配规则。" “和”End of area HTML”输入框。你不一定要选择右键查看源代码才能找到文章list开始标签,你可以右键点击文章开始的地方,查看element(chrome浏览器,firefox是查看元素),这样更方便查找文章List开始和结束标签。
设置完成后,我们点击“保存信息,进入下一步设置”
第四步:URL获取规则测试
如果在测试结果中发现不相关的URL信息,说明第五步的URL过滤规则有误或者过滤规则没有填写,如果发现采集有误,可以返回到最后修改,如果没有,点击“保存信息,进入下一步设置”。
第五步:内容字段获取规则
我们查看采集站点的文章源代码,找到相关选项的开始和结束html标签,填写指定位置,开始和结束标签用“[Content]”分割。
设置好后,我们点击“保存配置并预览”
第 6 步:过滤规则
在第7步的匹配规则之后,还有一个过滤规则,用于过滤不需要采集的内容。
比如网易的每篇文章文章都有一个iframe标签,用来投放广告。我们要采集网易的文章。不可能在采集回来后,我每篇文章都要删除这个广告。但是如何去除呢?去除方法是过滤规则。当我们点击常用规则时,会弹出一个小窗口,列出常用的过滤规则。我们只需要点击我们想要过滤的规则,就可以过滤网易文章iframe标签中,我们点击iframe即可。
测试内容字段设置
因为网易开头有文章
一些文章以
开头
,所以会有采集错误。
如果你现在想要采集,你可以点击保存和采集。这里我选择只保存
采集Content (一)
回到采集node管理界面,也就是第一步的界面,我们选择节点点击采集
采集内容(二)
查看已下载
您可以点击采集界面(第十步界面)右上角的“查看已下载”。也可以在“采集Node 管理”界面点击“查看已下载”。以第二种方法为例。
导出内容
选择要导入的列、数据量、是否生成html文件、随机推荐的数量
最终结果
腾讯新闻为例:文章采集软件的格式并不是非常规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-08-25 05:14
对于每天在互联网和移动互联网网页上更新的文章,有什么快速的方法可以准确提取并应用到您的工作中?
复制下载一篇文章确实很麻烦。为了节省时间,提高效率,建议您使用文章采集软件进行操作。 优采云采集器V9 是一个可以快速实现文章采集的工具。而且灵活性很强,不仅可以通过规则设置复杂的采集,还可以一步设置自动提取文本。
文章采集软件多采用源码分析截取文章的首尾字符来实现内容采集,优采云采集器在设置规则时就是基于这个原理,并且文本提取功能在优采云采集器配备了文本提取算法,可以自动识别文本。有了这个功能,操作起来更方便。如果文章的格式不是很规则,则采用前后截取的方法。
以下为大家简单演示:以腾讯新闻为例:
第一步:URL采集rule
1、添加起始网址:根据给定的网址打开腾讯新闻,发现新闻页面以列表页的形式显示,然后先将列表页的地址作为起始网址添加到优采云采集器中。
这里以添加6页为例。我们可以点击这6个标签的网址,将它们一一添加到采集器。但是如果我们要添加大量的URL,成百上千,那么一个一个添加就太麻烦了,所以我们可以试着找出URL之间的变化规律,批量添加。
我们分别打开第一页和第二页……观察它们的URL变化,可以发现除了第一页,后面的分页URL都以“_number”的递增方式变化,如如下:
然后我们首先将不合规的首页网址“”添加到起始网址列表中,如下所示:
添加第一个页面,然后通过向导-批量添加URL添加下面的列表页面,使用通用格式自动形成需要的URL,URL中的变量可以替换为地址参数,地址我们需要设置参数规则。上述规则从 2 开始,按 1 递增,共 5 项。填写后优采云采集器V9 会自动生成如下图所示的预览图。单击确定后,将添加起始 URL(这里是列表页面的 URL)。
2、获取内容页URL:通过观察新闻页,可以发现列表页的下一层是内容页,那么内容页的URL就是第一层的URL(列表页为0 -level URL),这里我们使用最简单的“自动获取地址链接”的方法,通过分析列表页面的源码,可以找出新闻内容页面地址所在的区域。起始字符是:“
",结束字符为:"
”。填完优采云采集器后会自动识别这个区域的地址链接,我们可以点击网址采集测试看看我们设置的采集规则是否给列表页和内容页面 URL 正确且完整。
第二步,content采集rules
1、Tag 编辑:标签列表可以进行添加、编辑、删除、复制等操作,我们先添加一个标题标签,选择文章的标题。我们将文章的标题设置为从默认页面的源码中获取,以前后截取的方式为例。
打开某新闻内容页面,分析页面源代码,在源代码中找到标题,我们搜索标题,会发现源代码中有多个标题,需要查找唯一基于代码常识的title“title”前后的字符串如下:
2、数据处理:“标题”中的标题有一个不需要的部分:“_新闻_QQ网”,那么我们将处理标题,添加一个数据替换过程,并更改“_新闻_QQ网” "替换为空,如下图所示。就这样,“月饼厂员工私卖月饼包装乱,拒不退货被发现后退还。”
我们再添加一个内容标签,去掉新闻内容采集,同样的方法找出内容页前后唯一的字符串。注意:内容前后的字符串不一定是我们要找的,可能是段落、图片等代码,所以对代码不太了解的用户最好多试几次确认。
设置完成后,点击测试看采集在内容中是否不符合要求,使用数据处理进行修改。这里我们排除了 html 标签:
设置采集内容的规则后,我们选择一个页面进行测试,看看采集收到的内容是否符合要求,如果不符合,我们需要修改规则。 优采云采集器V9 的应用非常灵活。可以以多种方式或以多种形式设置规则。新手用几次很容易。下图显示我们有采集到达标题、内容,如有需要,您还可以采集时间、作者、相关阅读等
优采云采集器V9采集 大量文章还可以保持更快的速度,无论是采集文章更新自己的数据库还是下载学习研究资料,都用文章采集软件是提高效率的最佳选择。
联系我们 查看全部
腾讯新闻为例:文章采集软件的格式并不是非常规则
对于每天在互联网和移动互联网网页上更新的文章,有什么快速的方法可以准确提取并应用到您的工作中?
复制下载一篇文章确实很麻烦。为了节省时间,提高效率,建议您使用文章采集软件进行操作。 优采云采集器V9 是一个可以快速实现文章采集的工具。而且灵活性很强,不仅可以通过规则设置复杂的采集,还可以一步设置自动提取文本。
文章采集软件多采用源码分析截取文章的首尾字符来实现内容采集,优采云采集器在设置规则时就是基于这个原理,并且文本提取功能在优采云采集器配备了文本提取算法,可以自动识别文本。有了这个功能,操作起来更方便。如果文章的格式不是很规则,则采用前后截取的方法。
以下为大家简单演示:以腾讯新闻为例:
第一步:URL采集rule
1、添加起始网址:根据给定的网址打开腾讯新闻,发现新闻页面以列表页的形式显示,然后先将列表页的地址作为起始网址添加到优采云采集器中。
这里以添加6页为例。我们可以点击这6个标签的网址,将它们一一添加到采集器。但是如果我们要添加大量的URL,成百上千,那么一个一个添加就太麻烦了,所以我们可以试着找出URL之间的变化规律,批量添加。
我们分别打开第一页和第二页……观察它们的URL变化,可以发现除了第一页,后面的分页URL都以“_number”的递增方式变化,如如下:
然后我们首先将不合规的首页网址“”添加到起始网址列表中,如下所示:
添加第一个页面,然后通过向导-批量添加URL添加下面的列表页面,使用通用格式自动形成需要的URL,URL中的变量可以替换为地址参数,地址我们需要设置参数规则。上述规则从 2 开始,按 1 递增,共 5 项。填写后优采云采集器V9 会自动生成如下图所示的预览图。单击确定后,将添加起始 URL(这里是列表页面的 URL)。
2、获取内容页URL:通过观察新闻页,可以发现列表页的下一层是内容页,那么内容页的URL就是第一层的URL(列表页为0 -level URL),这里我们使用最简单的“自动获取地址链接”的方法,通过分析列表页面的源码,可以找出新闻内容页面地址所在的区域。起始字符是:“
",结束字符为:"
”。填完优采云采集器后会自动识别这个区域的地址链接,我们可以点击网址采集测试看看我们设置的采集规则是否给列表页和内容页面 URL 正确且完整。
第二步,content采集rules
1、Tag 编辑:标签列表可以进行添加、编辑、删除、复制等操作,我们先添加一个标题标签,选择文章的标题。我们将文章的标题设置为从默认页面的源码中获取,以前后截取的方式为例。
打开某新闻内容页面,分析页面源代码,在源代码中找到标题,我们搜索标题,会发现源代码中有多个标题,需要查找唯一基于代码常识的title“title”前后的字符串如下:
2、数据处理:“标题”中的标题有一个不需要的部分:“_新闻_QQ网”,那么我们将处理标题,添加一个数据替换过程,并更改“_新闻_QQ网” "替换为空,如下图所示。就这样,“月饼厂员工私卖月饼包装乱,拒不退货被发现后退还。”
我们再添加一个内容标签,去掉新闻内容采集,同样的方法找出内容页前后唯一的字符串。注意:内容前后的字符串不一定是我们要找的,可能是段落、图片等代码,所以对代码不太了解的用户最好多试几次确认。
设置完成后,点击测试看采集在内容中是否不符合要求,使用数据处理进行修改。这里我们排除了 html 标签:
设置采集内容的规则后,我们选择一个页面进行测试,看看采集收到的内容是否符合要求,如果不符合,我们需要修改规则。 优采云采集器V9 的应用非常灵活。可以以多种方式或以多种形式设置规则。新手用几次很容易。下图显示我们有采集到达标题、内容,如有需要,您还可以采集时间、作者、相关阅读等
优采云采集器V9采集 大量文章还可以保持更快的速度,无论是采集文章更新自己的数据库还是下载学习研究资料,都用文章采集软件是提高效率的最佳选择。
联系我们
超级强大的网站文章采集器Fast_SpiderFast转换
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-08-24 22:03
超级强大网站文章采集器,这个软件的全名是鸿业文章采集器,英文名是Fast_Spider,属于蜘蛛爬虫程序,用来指定网站 采集海量精华文章,会直接丢弃里面的垃圾网页信息,只保存阅读价值和浏览价值文章的精华,并自动进行HTM-TXT转换。
相关软件软件大小及版本说明下载链接
超级强大网站文章采集器,这个软件的全名是鸿业文章采集器,英文名是Fast_Spider,属于蜘蛛爬虫程序,用来指定网站 采集海量精华文章,会直接丢弃里面的垃圾网页信息,只保存阅读价值和浏览价值文章的精华,并自动进行HTM-TXT转换。本软件为绿色软件,解压后即可使用!
软件功能
(1)本软件采用北大天网的MD5指纹重复算法,对于相似、相同的网页信息,不会重复存储。
(2)采集Information 含义:[[HT]]代表页面标题,[[HA]]代表文章title,[[HC]]代表10个加权关键词,[[UR] ] 表示网页图片的链接,[[TXT]] 后面的文字。
(3)蜘蛛性能:本软件开启300个线程,保证采集效率。通过采集100万979文章进行压力测试,以普通网友的联网电脑为参考标准,单台电脑可以遍历200万个网页,采集20万979文章,100万个essence文章只需5天就可以完成采集。 查看全部
超级强大的网站文章采集器Fast_SpiderFast转换
超级强大网站文章采集器,这个软件的全名是鸿业文章采集器,英文名是Fast_Spider,属于蜘蛛爬虫程序,用来指定网站 采集海量精华文章,会直接丢弃里面的垃圾网页信息,只保存阅读价值和浏览价值文章的精华,并自动进行HTM-TXT转换。
相关软件软件大小及版本说明下载链接
超级强大网站文章采集器,这个软件的全名是鸿业文章采集器,英文名是Fast_Spider,属于蜘蛛爬虫程序,用来指定网站 采集海量精华文章,会直接丢弃里面的垃圾网页信息,只保存阅读价值和浏览价值文章的精华,并自动进行HTM-TXT转换。本软件为绿色软件,解压后即可使用!
软件功能
(1)本软件采用北大天网的MD5指纹重复算法,对于相似、相同的网页信息,不会重复存储。
(2)采集Information 含义:[[HT]]代表页面标题,[[HA]]代表文章title,[[HC]]代表10个加权关键词,[[UR] ] 表示网页图片的链接,[[TXT]] 后面的文字。
(3)蜘蛛性能:本软件开启300个线程,保证采集效率。通过采集100万979文章进行压力测试,以普通网友的联网电脑为参考标准,单台电脑可以遍历200万个网页,采集20万979文章,100万个essence文章只需5天就可以完成采集。

