
网页抓取工具
网页抓取工具(开发工具webstorm,ubmserverprofessionalcommander、服务器抓包工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-13 21:05
网页抓取工具的性能问题一直是网页抓取用户用得最多的问题,现在是各大公司网页抓取竞争激烈的时代,我们都希望抓取的网页资源越多越好,毕竟我们是要以服务者的身份在网页上执行的,所以抓取的网页资源越多越好,那么我们通常会用到:开发工具webstorm、服务器工具mozillacommunityserver,ubmserverprofessionalcommander、服务器抓包工具reverse_cookie、服务器压缩工具obs和webhttpcontentheader来抓取网页数据。
按照使用频率或服务器稳定性、抓取质量高低的不同,来有重点的使用一些工具来进行高效的抓取。打包压缩工具:随着python解释器的完善,python的打包工具也逐渐丰富起来。本文对打包工具做一个简单说明,首先大家会对requests.extract()方法比较熟悉,接下来通过几个例子学习一下其他几个常用的方法。
1.requests.extract(pathname)这个方法有两个输出参数pathname和pathname.extract_files。其中pathname为解析的网址,pathname.extract_files为解析的内容文件夹名。2.requests.request.extract(data,url)这个方法在requests.extract()后面接了一个类似:form()的method方法,它用来返回一个request的数据的类,这个类为name。
通过这个类实现request之间的。这个方法中type和方法名参数分别为:type为方法的值,默认是get,相当于requests.get(url)方法,默认是post。cookie:抓取的网页一般都带有这个request带有的信息,用于加载html文件(包括js、json、css等等)或者下载后生成json网页。
blob:html中的原始内容,可直接解析为blob数据。本篇对以上几个常用的方法做简单说明,各大工具之间的差异并不大,本文仅仅给大家简单介绍一下。为了高效的抓取网页数据,我们推荐使用chrome浏览器来解析html文件。fastjson我们先看看fastjson是如何解析html文件的fastjson包含了基本的json库,比如jquery、libjson。
它有以下功能:支持unicode和ascii转换的输出格式,和json格式转换。支持一维数组、二维数组的数据解析。支持datetime、is-datetime、is-nan等函数的解析。支持所有python的函数。其中str、datetime、is-nan被称为structures,它们本身可以作为一个整体使用。
下面以tweenjson来实例python3的示例代码:classtweenjson:def__init__(self,url):self.url=urlself.headers={'host':'gmail','referer':'jsonpipe/chrome/chrome.exe'}def__de。 查看全部
网页抓取工具(开发工具webstorm,ubmserverprofessionalcommander、服务器抓包工具)
网页抓取工具的性能问题一直是网页抓取用户用得最多的问题,现在是各大公司网页抓取竞争激烈的时代,我们都希望抓取的网页资源越多越好,毕竟我们是要以服务者的身份在网页上执行的,所以抓取的网页资源越多越好,那么我们通常会用到:开发工具webstorm、服务器工具mozillacommunityserver,ubmserverprofessionalcommander、服务器抓包工具reverse_cookie、服务器压缩工具obs和webhttpcontentheader来抓取网页数据。
按照使用频率或服务器稳定性、抓取质量高低的不同,来有重点的使用一些工具来进行高效的抓取。打包压缩工具:随着python解释器的完善,python的打包工具也逐渐丰富起来。本文对打包工具做一个简单说明,首先大家会对requests.extract()方法比较熟悉,接下来通过几个例子学习一下其他几个常用的方法。
1.requests.extract(pathname)这个方法有两个输出参数pathname和pathname.extract_files。其中pathname为解析的网址,pathname.extract_files为解析的内容文件夹名。2.requests.request.extract(data,url)这个方法在requests.extract()后面接了一个类似:form()的method方法,它用来返回一个request的数据的类,这个类为name。
通过这个类实现request之间的。这个方法中type和方法名参数分别为:type为方法的值,默认是get,相当于requests.get(url)方法,默认是post。cookie:抓取的网页一般都带有这个request带有的信息,用于加载html文件(包括js、json、css等等)或者下载后生成json网页。
blob:html中的原始内容,可直接解析为blob数据。本篇对以上几个常用的方法做简单说明,各大工具之间的差异并不大,本文仅仅给大家简单介绍一下。为了高效的抓取网页数据,我们推荐使用chrome浏览器来解析html文件。fastjson我们先看看fastjson是如何解析html文件的fastjson包含了基本的json库,比如jquery、libjson。
它有以下功能:支持unicode和ascii转换的输出格式,和json格式转换。支持一维数组、二维数组的数据解析。支持datetime、is-datetime、is-nan等函数的解析。支持所有python的函数。其中str、datetime、is-nan被称为structures,它们本身可以作为一个整体使用。
下面以tweenjson来实例python3的示例代码:classtweenjson:def__init__(self,url):self.url=urlself.headers={'host':'gmail','referer':'jsonpipe/chrome/chrome.exe'}def__de。
网页抓取工具(提取的数据还不能直接拿来用?文件还不符合要求?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-08 22:03
提取出来的数据不能直接使用吗?文件还没有下载?格式等不符合要求?不用担心,网页抓取工具优采云采集器 有自己的解决方案-数据处理。
图片1.png
网络爬虫的数据处理功能包括内容处理、文件下载和内容过滤三部分。下面我依次给大家介绍一下:
1、内容处理:对内容页面中提取的数据进行进一步的处理,例如替换、标签过滤、分词等,我们可以同时添加多个操作,但是这里需要注意的是,当有多个操作,按照上面的顺序执行,也就是将上一步的结果作为下一步的参数。
下面我们一一介绍:
①提取内容为空:如果通过前面的规则无法准确提取提取内容或提取内容为空,请选择此选项。此应用程序后,将使用正则匹配从原创页面中再次提取。
②内容替换/排除:用字符串替换采集的内容。如果需要排除,请用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数替换字符串(不同于工具栏中的同义词替换)。
③html标签过滤:过滤指定的html标签,如④字符截取:通过开始和结束字符串截取内容。适用于提取内容的截取和调整。
⑤纯替换:如果某些内容(如单次出现的文本)无法通过一般的内容替换进行操作,则需要通过强大的正则表达式进行复杂的替换。
例如“最受欢迎的美国餐馆在这里”,我们将其替换为“美国餐馆”,正则表达式如下:
图片2.png
⑥数据转换:包括将结果简转繁、将结果繁转简、自动转化为拼音和时间修正转化,共计四项处理。
⑦智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取。
⑧高级功能:包括自动汇总、自动分词、自动分类、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串A长度等一系列函数。
⑨补全单个网址:将当前内容补全为一个网址。
2、文件下载:可以自动检测下载文件,可以设置下载路径和文件名样式。
注:文件下载中所指的下载图片为源代码中的标准样式
标签的图片地址。
例如,如果是直接的图片地址或不规则的图片源代码,采集器 将被视为文件下载。
①将相对地址补全为绝对地址:勾选后,标签采集的相对地址补全为绝对地址。
②下载图片:经核对,源码收录标准样式
将下载代码图像。
③检测文件的真实地址但不下载:有时采集到达附件下载地址而不是实际下载地址。点击之后,会有一个跳转。在这种情况下,如果勾选此选项,将显示真实地址采集,但不会仅下载下载地址。
④检测文件并下载:勾选后可以从采集下载任意格式的文件附件。
3、内容过滤:一些不符合条件的记录可以通过设置内容过滤被删除或标记为不接受。有几种方法可以处理内容过滤:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件即可。
②采集 结果不能为空:该功能可以防止某个字段出现空内容。
③采集 结果不能重复:该功能可以防止某个字段出现重复的内容。设置此项前请确保没有采集数据,否则需要先清除采集数据。
④内容长度小于(大于、等于、不等于)时过滤 N:符号或字母或数字或汉字算一个。
注意:如果满足以上四项中的任何一项或多项,您可以在采集器的其他设置功能中直接删除该记录,或者将该记录标记为不在采集 采集 将在下次运行任务时重复。
在网页抓取工具优采云采集器中进行一系列数据处理的好处是,当我们只需要做一个小操作时,我们不需要编写插件、生成和编译它们,并且可以一键将数据处理成我们需要的数据。 查看全部
网页抓取工具(提取的数据还不能直接拿来用?文件还不符合要求?)
提取出来的数据不能直接使用吗?文件还没有下载?格式等不符合要求?不用担心,网页抓取工具优采云采集器 有自己的解决方案-数据处理。
图片1.png
网络爬虫的数据处理功能包括内容处理、文件下载和内容过滤三部分。下面我依次给大家介绍一下:
1、内容处理:对内容页面中提取的数据进行进一步的处理,例如替换、标签过滤、分词等,我们可以同时添加多个操作,但是这里需要注意的是,当有多个操作,按照上面的顺序执行,也就是将上一步的结果作为下一步的参数。
下面我们一一介绍:
①提取内容为空:如果通过前面的规则无法准确提取提取内容或提取内容为空,请选择此选项。此应用程序后,将使用正则匹配从原创页面中再次提取。
②内容替换/排除:用字符串替换采集的内容。如果需要排除,请用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数替换字符串(不同于工具栏中的同义词替换)。
③html标签过滤:过滤指定的html标签,如④字符截取:通过开始和结束字符串截取内容。适用于提取内容的截取和调整。
⑤纯替换:如果某些内容(如单次出现的文本)无法通过一般的内容替换进行操作,则需要通过强大的正则表达式进行复杂的替换。
例如“最受欢迎的美国餐馆在这里”,我们将其替换为“美国餐馆”,正则表达式如下:
图片2.png
⑥数据转换:包括将结果简转繁、将结果繁转简、自动转化为拼音和时间修正转化,共计四项处理。
⑦智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取。
⑧高级功能:包括自动汇总、自动分词、自动分类、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串A长度等一系列函数。
⑨补全单个网址:将当前内容补全为一个网址。
2、文件下载:可以自动检测下载文件,可以设置下载路径和文件名样式。
注:文件下载中所指的下载图片为源代码中的标准样式
标签的图片地址。
例如,如果是直接的图片地址或不规则的图片源代码,采集器 将被视为文件下载。
①将相对地址补全为绝对地址:勾选后,标签采集的相对地址补全为绝对地址。
②下载图片:经核对,源码收录标准样式
将下载代码图像。
③检测文件的真实地址但不下载:有时采集到达附件下载地址而不是实际下载地址。点击之后,会有一个跳转。在这种情况下,如果勾选此选项,将显示真实地址采集,但不会仅下载下载地址。
④检测文件并下载:勾选后可以从采集下载任意格式的文件附件。
3、内容过滤:一些不符合条件的记录可以通过设置内容过滤被删除或标记为不接受。有几种方法可以处理内容过滤:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件即可。
②采集 结果不能为空:该功能可以防止某个字段出现空内容。
③采集 结果不能重复:该功能可以防止某个字段出现重复的内容。设置此项前请确保没有采集数据,否则需要先清除采集数据。
④内容长度小于(大于、等于、不等于)时过滤 N:符号或字母或数字或汉字算一个。
注意:如果满足以上四项中的任何一项或多项,您可以在采集器的其他设置功能中直接删除该记录,或者将该记录标记为不在采集 采集 将在下次运行任务时重复。
在网页抓取工具优采云采集器中进行一系列数据处理的好处是,当我们只需要做一个小操作时,我们不需要编写插件、生成和编译它们,并且可以一键将数据处理成我们需要的数据。
网页抓取工具(网页抓取工具怎么用?浏览器安装了chrome扩展)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-01 01:03
网页抓取工具怎么用?ie浏览器安装了chrome扩展可以解决。
任何具有ie插件扩展功能的浏览器,在通过插件成功访问国内某家公司的网站,且获取网页内容后,插件会在浏览器下载相应的页内容,并通过ajax发送给服务器。服务器成功解析后,客户端获取的是服务器指定页内容加上服务器默认域名加随机字符串,就是你看到的国内网站的内容了。
我的体验是,浏览器在线对网站抓取时,获取的是网站服务器上传给浏览器的整个页面的内容,而不是单个页面的内容。同理chrome有三个对web对象请求做提交的方法:1.formdata2.json3.jsonexport其中jsonexport和上面两个中间转换效率较高。详细操作请参考:json格式抓取报错erroroutofmemory。
用爬虫,各种python爬虫。
如果说页面抓取功能的话,我觉得就是人工干预吧。大数据已经可以做到基于历史请求统计页面数据了,至于某些页面以前请求次数很多,不得不考虑是操作系统内核慢等问题。但是页面抓取功能是否已经实现,
请用谷歌浏览器
我有一段时间是用python去抓下我博客网站上面的数据,我的python编程技术对我来说太过于老旧。主要是这个技术可以统计请求的次数,但是什么时候请求?什么时候取得内容?什么时候存入数据库?很难讲清楚,而且因为某些原因,我这个网站采用的是http协议。一但加入了,任何浏览器都可以访问是也无需任何额外的设置。
那么请问作为一个普通用户,请问这样的技术能否获取到我的博客里的数据?我又不需要把整个网站下到本地,也不用不会怎么去采集而是直接在线抓取下来,直接存入数据库。那么我认为没有技术含量的请求次数,取得内容,存入数据库,要求分步骤,一步一步分步完成,爬虫最可能的方式是因为程序太过于笨拙或者我本身太懒,不能完成的好,不想进行之后再改进,而不是解决一个需求就拿来用而不去深入其它性能,安全,工作量之类问题。
python能否代替人工进行判断是否请求,对应请求的样式提取,自动制作响应事件等等工作,难道就没有比现在非常鸡肋的数据库读写操作之类的工作了?要求做的动态更新或者是我并不想深入操作的程序或者是做爬虫本身的我认为就没有必要做了。对比其它语言的操作体验相对于python,没有什么优势的。总结为三点1爬虫可以抓取到单一页面,而人工可以获取页面的大部分,但是不能很精确的获取重要的页面信息。
2需要借助于算法提取信息。3需要具备一定的java编程能力才能做到java代码,flask,nodejs,和golang等后端框架的使用。所以,无论你是爬虫,还是。 查看全部
网页抓取工具(网页抓取工具怎么用?浏览器安装了chrome扩展)
网页抓取工具怎么用?ie浏览器安装了chrome扩展可以解决。
任何具有ie插件扩展功能的浏览器,在通过插件成功访问国内某家公司的网站,且获取网页内容后,插件会在浏览器下载相应的页内容,并通过ajax发送给服务器。服务器成功解析后,客户端获取的是服务器指定页内容加上服务器默认域名加随机字符串,就是你看到的国内网站的内容了。
我的体验是,浏览器在线对网站抓取时,获取的是网站服务器上传给浏览器的整个页面的内容,而不是单个页面的内容。同理chrome有三个对web对象请求做提交的方法:1.formdata2.json3.jsonexport其中jsonexport和上面两个中间转换效率较高。详细操作请参考:json格式抓取报错erroroutofmemory。
用爬虫,各种python爬虫。
如果说页面抓取功能的话,我觉得就是人工干预吧。大数据已经可以做到基于历史请求统计页面数据了,至于某些页面以前请求次数很多,不得不考虑是操作系统内核慢等问题。但是页面抓取功能是否已经实现,
请用谷歌浏览器
我有一段时间是用python去抓下我博客网站上面的数据,我的python编程技术对我来说太过于老旧。主要是这个技术可以统计请求的次数,但是什么时候请求?什么时候取得内容?什么时候存入数据库?很难讲清楚,而且因为某些原因,我这个网站采用的是http协议。一但加入了,任何浏览器都可以访问是也无需任何额外的设置。
那么请问作为一个普通用户,请问这样的技术能否获取到我的博客里的数据?我又不需要把整个网站下到本地,也不用不会怎么去采集而是直接在线抓取下来,直接存入数据库。那么我认为没有技术含量的请求次数,取得内容,存入数据库,要求分步骤,一步一步分步完成,爬虫最可能的方式是因为程序太过于笨拙或者我本身太懒,不能完成的好,不想进行之后再改进,而不是解决一个需求就拿来用而不去深入其它性能,安全,工作量之类问题。
python能否代替人工进行判断是否请求,对应请求的样式提取,自动制作响应事件等等工作,难道就没有比现在非常鸡肋的数据库读写操作之类的工作了?要求做的动态更新或者是我并不想深入操作的程序或者是做爬虫本身的我认为就没有必要做了。对比其它语言的操作体验相对于python,没有什么优势的。总结为三点1爬虫可以抓取到单一页面,而人工可以获取页面的大部分,但是不能很精确的获取重要的页面信息。
2需要借助于算法提取信息。3需要具备一定的java编程能力才能做到java代码,flask,nodejs,和golang等后端框架的使用。所以,无论你是爬虫,还是。
网页抓取工具(基于动态内容抓取JavaScript页面的优势-Proxy)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-30 04:00
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。然而,有很多优秀的网络爬虫工具可用。
1.代理爬网
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
可以免费获取1000个请求,足以探索Proxy Crawl在复杂内容页面中使用的强大功能。
2.Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。Scrapy 抓取框架在从 网站 和网页中提取数据方面做得很好。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及为大型任务执行自动化测试。强大的功能可以与ProxyCrawl***集成。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)变得轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
3.抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用Grab,你可以为小型的个人项目创建爬虫机制,也可以构建可以同时扩展到百万页面的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
4.雪貂
Ferret 是一个相当新的网络爬虫,在开源社区中获得了相当大的吸引力。Ferret 的目标是提供更简洁的客户端爬取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
5.X 射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常简单。
6.Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
7.PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现为 PDF 文档。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您手头的任务需要抓取许多基于 JavaScript 的 网站,这将特别有用。
【编辑推荐】
2018年三大运营商表现如何?分享对 2019 年数据中心行业八大趋势的看法 | 物联网数据需要共享协议优雅读取http请求或响应数据清单:2019年值得关注的5个数据中心趋势 查看全部
网页抓取工具(基于动态内容抓取JavaScript页面的优势-Proxy)
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。然而,有很多优秀的网络爬虫工具可用。
1.代理爬网
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。

可以免费获取1000个请求,足以探索Proxy Crawl在复杂内容页面中使用的强大功能。
2.Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。Scrapy 抓取框架在从 网站 和网页中提取数据方面做得很好。

最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及为大型任务执行自动化测试。强大的功能可以与ProxyCrawl***集成。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)变得轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
3.抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用Grab,你可以为小型的个人项目创建爬虫机制,也可以构建可以同时扩展到百万页面的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
4.雪貂
Ferret 是一个相当新的网络爬虫,在开源社区中获得了相当大的吸引力。Ferret 的目标是提供更简洁的客户端爬取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
5.X 射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常简单。
6.Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
7.PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现为 PDF 文档。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您手头的任务需要抓取许多基于 JavaScript 的 网站,这将特别有用。
【编辑推荐】
2018年三大运营商表现如何?分享对 2019 年数据中心行业八大趋势的看法 | 物联网数据需要共享协议优雅读取http请求或响应数据清单:2019年值得关注的5个数据中心趋势
网页抓取工具(网页文字抓取工具功能特点-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-24 06:03
网页文字抓取工具是一款非常实用的文字下载工具,功能强大实用,简单易用,完全免费使用。当我们在网页上遇到一些无法复制的文字时,这时候就可以使用这个软件来传递网页了。使用 URL 抓取网页的文本并找到您需要的帮助部分。有需要的朋友不要错过。欢迎下载使用!
网页文字爬虫的特点
1、绿色软件,无需安装。
2、 支持键盘ctrl、alt、shift+鼠标左键、中键、右键操作。
3、无法复制的文字可以抓取,但是图片不能抓取。
4、 支持复制常规静态对话框、系统消息和程序选项卡等表单文本。
5、支持鼠标快捷键,Ctrl、Alt、Shift和鼠标左/中/右键的任意组合。
6、 支持在 Chrome 中抓取网页图片的 alt 文本和 url 链接。
网页文字爬虫的使用方法
输入网址后,点击抓取按钮,就OK了。!
网络文本爬虫的主要优点
网页文字抓取器是一款小巧精致的网页文字提取软件,可以让您轻松抓取和复制禁止选择和复制的网页上的文字。对于内容被大面积广告覆盖而无法看到的网页,网上有很多禁止复制的html文件。抓取网页文本抓取器并阅读它也是一个很好的解决方案。
相关新闻
现在IE被边缘化了,我们使用的浏览器大多是WebKit核心,所以当你发现网站设置了禁止复制的权限时,不妨试试把网址拖到IE浏览器上。接下来,说不定会有惊喜哦~
还有一点需要注意的是,现在国内很多浏览器都是双核的。“兼容模式”是IE的核心。也可以点击切换试试看。复制到 IE 是一种效果。
网页文本爬虫评论
绿色,安全可靠,无广告推荐,
细节 查看全部
网页抓取工具(网页文字抓取工具功能特点-上海怡健医学)
网页文字抓取工具是一款非常实用的文字下载工具,功能强大实用,简单易用,完全免费使用。当我们在网页上遇到一些无法复制的文字时,这时候就可以使用这个软件来传递网页了。使用 URL 抓取网页的文本并找到您需要的帮助部分。有需要的朋友不要错过。欢迎下载使用!

网页文字爬虫的特点
1、绿色软件,无需安装。
2、 支持键盘ctrl、alt、shift+鼠标左键、中键、右键操作。
3、无法复制的文字可以抓取,但是图片不能抓取。
4、 支持复制常规静态对话框、系统消息和程序选项卡等表单文本。
5、支持鼠标快捷键,Ctrl、Alt、Shift和鼠标左/中/右键的任意组合。
6、 支持在 Chrome 中抓取网页图片的 alt 文本和 url 链接。
网页文字爬虫的使用方法
输入网址后,点击抓取按钮,就OK了。!
网络文本爬虫的主要优点
网页文字抓取器是一款小巧精致的网页文字提取软件,可以让您轻松抓取和复制禁止选择和复制的网页上的文字。对于内容被大面积广告覆盖而无法看到的网页,网上有很多禁止复制的html文件。抓取网页文本抓取器并阅读它也是一个很好的解决方案。
相关新闻
现在IE被边缘化了,我们使用的浏览器大多是WebKit核心,所以当你发现网站设置了禁止复制的权限时,不妨试试把网址拖到IE浏览器上。接下来,说不定会有惊喜哦~
还有一点需要注意的是,现在国内很多浏览器都是双核的。“兼容模式”是IE的核心。也可以点击切换试试看。复制到 IE 是一种效果。
网页文本爬虫评论
绿色,安全可靠,无广告推荐,
细节
网页抓取工具(前两天遇到一个妹子,她说不会从拉网页,我想用做个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-20 16:08
前两天认识了一个女孩。她说她不会拉网页。想用node做一个这么简单的网页爬虫工具,就开始了安装x之路。
其实这个想法很简单。从url中获取html,从html中解析css、js、image等,单独下载。
难点之一在于路径解析。例如,一般页面是域名。有的页面,路径层次比较深,突然想到sea.js,肯定是路径问题很头疼。简单看了一下,确实其中的规律比其他的要复杂,所以没办法硬着头皮。刚刚看了regular的正零宽度断言,感觉没有之前想的那么难。
另一个问题是另一个是异步多线程。在某些页面中必须有很多图片。我应该使用单线程下载吗?显然不合适,所以需要使用多线程,如何使用多线程请参考我的文章node多线程服务器,这里不再赘述。而这里是多线程请求,直接参考集群模块即可。
另一种是node的异步编程方案,使用async/await函数和promise对象,下载首页时需要阻塞,而下载css、js、image都是同步非阻塞的。
好吧,这么多不如上面的代码:
一个简单的网页抓取工具(节点版)
为什么不在github上获取呢?为您自己的 网站 拉一些流量。
注意:此链接是安全连接,您的cookie不会发送到我的服务器,然后登录您的cnblog,删除您的博客,请放心使用。 查看全部
网页抓取工具(前两天遇到一个妹子,她说不会从拉网页,我想用做个)
前两天认识了一个女孩。她说她不会拉网页。想用node做一个这么简单的网页爬虫工具,就开始了安装x之路。
其实这个想法很简单。从url中获取html,从html中解析css、js、image等,单独下载。
难点之一在于路径解析。例如,一般页面是域名。有的页面,路径层次比较深,突然想到sea.js,肯定是路径问题很头疼。简单看了一下,确实其中的规律比其他的要复杂,所以没办法硬着头皮。刚刚看了regular的正零宽度断言,感觉没有之前想的那么难。
另一个问题是另一个是异步多线程。在某些页面中必须有很多图片。我应该使用单线程下载吗?显然不合适,所以需要使用多线程,如何使用多线程请参考我的文章node多线程服务器,这里不再赘述。而这里是多线程请求,直接参考集群模块即可。
另一种是node的异步编程方案,使用async/await函数和promise对象,下载首页时需要阻塞,而下载css、js、image都是同步非阻塞的。
好吧,这么多不如上面的代码:
一个简单的网页抓取工具(节点版)
为什么不在github上获取呢?为您自己的 网站 拉一些流量。
注意:此链接是安全连接,您的cookie不会发送到我的服务器,然后登录您的cnblog,删除您的博客,请放心使用。
网页抓取工具(网站链接抓取器是一款非常简单且实用的网站抓取软件 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-19 04:01
)
网站链接抓取器是一款非常简单实用的网站链接抓取软件。通过本软件,可以帮助用户快速抓取网站链接,简单直观的操作界面旨在为用户提供最简单的操作。您只需要输入需要查询的域名,一键即可快速抓取URL对应的源码。此外,您还可以获得不同的链接,包括 URL。、图片、脚本和CSS,使用起来非常方便,可以多方面满足你对网站链接获取的不同需求,支持批量获取,可以获取多个不同的链接。总而言之,这是一款非常好用的软件,有需要的赶紧下载体验吧!
软件功能
提供简单的抓取功能,可以快速抓取网站的源码
如果需要爬取网站链接,可以使用本软件
支持批量抓取,可同时抓取不同类型的链接
支持获取URL链接、图片链接、脚本链接等。
支持复制,一键复制你需要的链接
软件特点
操作简单,简单几步即可快速抓取到您需要的链接
获取链接后,可以自动显示获取的链接总数
获取的链接显示在链接列表中,方便快速查看
对应的图片可以通过获取的图片链接下载
指示
1、打开软件,进入软件主界面,运行界面如下图
2、可以在框中输入需要查询的域名,快速输入
3、 输入完成后点击Capture即可快速抓拍
4、 抓取后可以查看网页对应的源码,直接查看
5、选择需要获取的链接,根据需要选择,使用方便
6、如果选择获取URL链接,可以在链接列表中查看获取到的URL链接
7、点击复制,可以快速复制源码和需要的链接
查看全部
网页抓取工具(网站链接抓取器是一款非常简单且实用的网站抓取软件
)
网站链接抓取器是一款非常简单实用的网站链接抓取软件。通过本软件,可以帮助用户快速抓取网站链接,简单直观的操作界面旨在为用户提供最简单的操作。您只需要输入需要查询的域名,一键即可快速抓取URL对应的源码。此外,您还可以获得不同的链接,包括 URL。、图片、脚本和CSS,使用起来非常方便,可以多方面满足你对网站链接获取的不同需求,支持批量获取,可以获取多个不同的链接。总而言之,这是一款非常好用的软件,有需要的赶紧下载体验吧!

软件功能
提供简单的抓取功能,可以快速抓取网站的源码
如果需要爬取网站链接,可以使用本软件
支持批量抓取,可同时抓取不同类型的链接
支持获取URL链接、图片链接、脚本链接等。
支持复制,一键复制你需要的链接
软件特点
操作简单,简单几步即可快速抓取到您需要的链接
获取链接后,可以自动显示获取的链接总数
获取的链接显示在链接列表中,方便快速查看
对应的图片可以通过获取的图片链接下载
指示
1、打开软件,进入软件主界面,运行界面如下图
2、可以在框中输入需要查询的域名,快速输入

3、 输入完成后点击Capture即可快速抓拍

4、 抓取后可以查看网页对应的源码,直接查看

5、选择需要获取的链接,根据需要选择,使用方便

6、如果选择获取URL链接,可以在链接列表中查看获取到的URL链接

7、点击复制,可以快速复制源码和需要的链接

网页抓取工具(Google网站管理员工具提交网站地图文件的步骤及步骤方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-11-15 03:14
步
方法一:
1.打开浏览器,输入在线站点地图的网址网站;
2.在表单中填写要生成站点地图的网页的URL,然后点击提交;
3. 打开生成的数据结果页面,复制文本框中的代码;
4.新建一个文本文件,把代码粘贴进去,然后保存为utf-8格式的文件,文件名是sitemap.xml,然后把这个文件上传到你网站对应的根目录下@>;
5.打开浏览器输入网址,点击右上角登录,用自己的谷歌账号登录,还没有谷歌账号?创建帐户,注册帐户并登录帐户;
6.登录成功后,点击进入用户管理中心,然后点击:网站管理员工具;
7.首先添加您的 URL 链接。添加成功后,点击URL对应项后的添加,打开站点地图添加页面,选择下拉菜单,选择法线图网站,出现下面的文字形式,添加sitemap.xml后空白表格,然后点击提交;
8.好的!站点地图提交成功,请等待5小时google收录你的网站!
方法二:
1.在线生成站点地图网站下载软件:
此类工具需要下载到本地生成地图,生成速度比较快。
2. 运行软件生成sitemap文件:写项目和新建两个栏目,如“sitemapx”或“hongdex”。确认后会显示基本信息。直接默认,点击下一步,然后点击抓取页面。获取网页后,直接点击Generate,然后点击Copy File,选择路径。站点地图文件就这样完成了;
3.通过FTP将sitemap文件提交到网站的根目录:应该就这些了,不明白的可以直接搜索“如何通过ftp工具提交文件”之类的关键词;
4.登录谷歌网站管理员工具提交网站地图站点地图文件:前提是您已经注册了谷歌账号并添加了网站,首页的站点地图栏将直接显示控制台的。点击,提交前输入“sitemap.xml”网站,最后直接点击提交网站。步骤完成!最后,等待谷歌收录网站页面。
至于百度蜘蛛,则是html格式
使用站点地图并登录谷歌
使用谷歌站点地图可以提高网站/webpages在SERP中的排名(或提高SEO效果)。站点地图只会提高网站被收录索引的页面的效率,从这个意义上说,如上所述,网站的整体SEO效果肯定是有帮助的。
但是,Sitemaps 和 网站/webpages 最终出现在 SERP 中的排名没有直接关系。这是两个相关但在实施过程中很少交叉的机制。--当然,如果非要争辩说,随着网站内页收录的增加,网站内的交叉链接的权重也会相应增加,这会对最终的排名,倒是也能在一定程度上是公平的,只是影响会有多大就不好说了。 查看全部
网页抓取工具(Google网站管理员工具提交网站地图文件的步骤及步骤方法)
步
方法一:
1.打开浏览器,输入在线站点地图的网址网站;
2.在表单中填写要生成站点地图的网页的URL,然后点击提交;
3. 打开生成的数据结果页面,复制文本框中的代码;
4.新建一个文本文件,把代码粘贴进去,然后保存为utf-8格式的文件,文件名是sitemap.xml,然后把这个文件上传到你网站对应的根目录下@>;
5.打开浏览器输入网址,点击右上角登录,用自己的谷歌账号登录,还没有谷歌账号?创建帐户,注册帐户并登录帐户;
6.登录成功后,点击进入用户管理中心,然后点击:网站管理员工具;
7.首先添加您的 URL 链接。添加成功后,点击URL对应项后的添加,打开站点地图添加页面,选择下拉菜单,选择法线图网站,出现下面的文字形式,添加sitemap.xml后空白表格,然后点击提交;
8.好的!站点地图提交成功,请等待5小时google收录你的网站!
方法二:
1.在线生成站点地图网站下载软件:
此类工具需要下载到本地生成地图,生成速度比较快。
2. 运行软件生成sitemap文件:写项目和新建两个栏目,如“sitemapx”或“hongdex”。确认后会显示基本信息。直接默认,点击下一步,然后点击抓取页面。获取网页后,直接点击Generate,然后点击Copy File,选择路径。站点地图文件就这样完成了;
3.通过FTP将sitemap文件提交到网站的根目录:应该就这些了,不明白的可以直接搜索“如何通过ftp工具提交文件”之类的关键词;
4.登录谷歌网站管理员工具提交网站地图站点地图文件:前提是您已经注册了谷歌账号并添加了网站,首页的站点地图栏将直接显示控制台的。点击,提交前输入“sitemap.xml”网站,最后直接点击提交网站。步骤完成!最后,等待谷歌收录网站页面。
至于百度蜘蛛,则是html格式
使用站点地图并登录谷歌
使用谷歌站点地图可以提高网站/webpages在SERP中的排名(或提高SEO效果)。站点地图只会提高网站被收录索引的页面的效率,从这个意义上说,如上所述,网站的整体SEO效果肯定是有帮助的。
但是,Sitemaps 和 网站/webpages 最终出现在 SERP 中的排名没有直接关系。这是两个相关但在实施过程中很少交叉的机制。--当然,如果非要争辩说,随着网站内页收录的增加,网站内的交叉链接的权重也会相应增加,这会对最终的排名,倒是也能在一定程度上是公平的,只是影响会有多大就不好说了。
网页抓取工具(搞定大数据信息的基础能力——网页工具优采云采集器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-11-13 23:16
对于开发和应用,信息集成是首要问题。解决这个问题后,可以扩展更多的信息挖掘和相关的组合应用。但是,由于技术的匮乏,很多企业选择将信息采集交给数据外包服务公司,类似于定制,这也是一种高效的获取方式。但是现在你有了大数据业务,还是要全面提升你人员的基础大数据能力,至少在有轻量级数据需求的时候,你可以用自己的技能快速解决。那么我们如何才能拥有这种捕捉大数据信息的基本能力呢?网络爬虫工具优采云采集器作为大数据信息抓取的必备软件,充分发挥了其强大的作用。
优采云采集器V9是一款全网通用的网页数据采集软件。通过采集规则和数据处理相关的设置,可以设置URL、文本、图片、文件等被抓取并进行排序、过滤等一系列处理,完整的呈现给用户可用的数据信息。另外,优采云采集器V9的发布功能也是一大亮点。可自动登录选择数据发布栏目,彻底解放人手的智能工具。
了解网络爬虫工具的操作,可以轻松处理一些不太复杂的数据需求。如果是大数据级别的爬取集成,可能需要更复杂的技术和运行环境,比如频繁复杂的验证码、服务器代理、防御等。采集征服等等。当然,如果懂技术,有条件,企业也可以使用网络爬虫工具优采云采集器进行数据整合,优采云采集器使用分布式高速采集处理系统,多线程可调任务分配,轻松应对大规模海量作业需求。但有时为了再次提高效率,可能需要多个优采云采集器客户端同时运行,
我们正处于大数据时代。医疗、交通、教育、零售、金融、商业……我们都在寻求大数据的突破;各个领域的公司都积极参与市场,以在瞬息万变的市场中站稳脚跟。,但大数据的应用不仅仅是事实,在实践中也并非一帆风顺。面临跨部门跨行业难以共享的信息孤岛和短板;面临大数据技术和产业创新低;面对人才匮乏,大数据如何发展?
除了上面提到的多元学习工具,加强我们的基本能力,不断提高我们的技能,我们还需要有创新的思维和强烈的责任感。时代属于全人类。每个人都可能在这个机会中获得全新的突破。在突破点之前,让我们一起提升自己的能力,以最好的状态迎接机遇,让我们对成功更有信心。返回搜狐查看更多 查看全部
网页抓取工具(搞定大数据信息的基础能力——网页工具优采云采集器)
对于开发和应用,信息集成是首要问题。解决这个问题后,可以扩展更多的信息挖掘和相关的组合应用。但是,由于技术的匮乏,很多企业选择将信息采集交给数据外包服务公司,类似于定制,这也是一种高效的获取方式。但是现在你有了大数据业务,还是要全面提升你人员的基础大数据能力,至少在有轻量级数据需求的时候,你可以用自己的技能快速解决。那么我们如何才能拥有这种捕捉大数据信息的基本能力呢?网络爬虫工具优采云采集器作为大数据信息抓取的必备软件,充分发挥了其强大的作用。
优采云采集器V9是一款全网通用的网页数据采集软件。通过采集规则和数据处理相关的设置,可以设置URL、文本、图片、文件等被抓取并进行排序、过滤等一系列处理,完整的呈现给用户可用的数据信息。另外,优采云采集器V9的发布功能也是一大亮点。可自动登录选择数据发布栏目,彻底解放人手的智能工具。
了解网络爬虫工具的操作,可以轻松处理一些不太复杂的数据需求。如果是大数据级别的爬取集成,可能需要更复杂的技术和运行环境,比如频繁复杂的验证码、服务器代理、防御等。采集征服等等。当然,如果懂技术,有条件,企业也可以使用网络爬虫工具优采云采集器进行数据整合,优采云采集器使用分布式高速采集处理系统,多线程可调任务分配,轻松应对大规模海量作业需求。但有时为了再次提高效率,可能需要多个优采云采集器客户端同时运行,
我们正处于大数据时代。医疗、交通、教育、零售、金融、商业……我们都在寻求大数据的突破;各个领域的公司都积极参与市场,以在瞬息万变的市场中站稳脚跟。,但大数据的应用不仅仅是事实,在实践中也并非一帆风顺。面临跨部门跨行业难以共享的信息孤岛和短板;面临大数据技术和产业创新低;面对人才匮乏,大数据如何发展?
除了上面提到的多元学习工具,加强我们的基本能力,不断提高我们的技能,我们还需要有创新的思维和强烈的责任感。时代属于全人类。每个人都可能在这个机会中获得全新的突破。在突破点之前,让我们一起提升自己的能力,以最好的状态迎接机遇,让我们对成功更有信心。返回搜狐查看更多
网页抓取工具(WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-13 04:19
我要分享的工具是一个Chrome插件,叫做:Web Scraper,这是一个Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以将其用作爬虫工具。
也是因为最近在整理36氪文章的一些标签,打算看看其他网站风投相关的标准,所以找了一家公司,名字叫:“艾诺克斯数据” 网站,它提供的一套“行业系统”标签很有参考价值。我想抓取页面上的数据,并集成到我们自己的标签库中,如下图红字部分所示:
如果是规则中显示的数据,也可以用鼠标选中并复制粘贴,但还是需要想办法将其嵌入到页面中。这时候想起之前安装过Web Scraper,就试了一下。使用起来相当方便,采集效率一下子提高了。也给大家安利~
一年前在一个三班的公开课上看到了Chrome插件Web Scraper。号称是不懂编程也能实现爬虫爬虫的黑科技,但是在三类的官网上好像找不到。你可以百度:“三课爬虫”还是可以搜索到的。名字叫《人人都能学的数据爬虫类》,不过好像要收费100元。我觉得这个东西可以看网上的文章,比如我的文章~
简单的说,Web Scraper是一个基于Chrome的网页元素解析器,可以通过可视化的点击操作,实现自定义区域的数据/元素提取。同时,它还提供了定时自动提取功能,使用该功能可以作为一个简单的爬虫工具。
下面我将解释网页提取器抓取和真实代码抓取器之间的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它允许您定义要抓取的页面上的哪个元素。,以及抓取哪些页面,然后让机器代人操作;而如果你用Python写爬虫,更多的是使用网页请求命令下载整个网页,然后用代码解析HTML页面元素,提取你想要的内容,然后不断循环. 相比之下,使用代码会更灵活,但解析的成本会更高。如果是简单的页面内容提取,我也推荐使用Web Scraper。
关于Web Scraper的具体安装过程以及完整功能的使用方法,今天在文章中不再赘述。一是我只用了自己需要的部分,二是因为市面上的Web Scraper教程太多了,你可以自己找。
这里只是一个实际的过程,给大家简单介绍一下我的使用方法。
第一步是创建站点地图
打开Chrome浏览器,按F12调出开发者工具。单击最后一个选项卡上的 Web Scraper 后,选择“创建站点地图”菜单并单击“创建站点地图”选项。
首先输入你要爬取的网站 URL,以及你自定义的爬取任务的名称。比如我取的名字是:xiniulevel,网址是:
第二步,创建抓取节点
我要抓取的是一级标签和二级标签,所以先在我刚刚创建的Sitemap里面点击,然后点击“添加新选择器”进入抓取节点选择器配置页面,点击“选择”按钮。当你会看到一个浮动层
此时,当您将鼠标移入网页时,它会自动以绿色突出显示您悬停的某个位置。这时候你可以先点击一个你想选择的方块,你会发现方块变成了红色。如果要选中所有同级别的块,可以继续点击旁边的下一个块,工具会默认选中所有同级别的块,如下图:
我们会发现下面浮动窗口的文本输入框自动填充了块的XPATH路径,然后点击“完成选择!” 结束选择,浮动框消失,选中的XPATH自动填入下面的Selector行。另外,一定要选择“Multiple”来声明要选择多个块。最后,单击保存选择器按钮结束。
第三步,获取元素值
完成Selector的创建后,回到上一页,会发现Selector表多了一行,然后可以直接点击Action中的Data preview查看所有的元素值你想得到。
上图所示的部分是我添加了两个Selector,主标签和副标签的情况。点击数据预览的弹窗内容其实就是我想要的,复制到EXCEL就好了,不需要太复杂。自动抓取处理。
以上是对Web Scraper的使用过程的简单介绍。当然,我的使用并不是完全高效,因为每次想要获取二级标签,都得先手动切换一级标签,然后再执行抓取指令。应该有更好的方法,但对我来说已经足够了。本文文章主要想和大家普及一下这个工具。这不是教程。更多功能根据自己的需要去探索吧~ 查看全部
网页抓取工具(WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
我要分享的工具是一个Chrome插件,叫做:Web Scraper,这是一个Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以将其用作爬虫工具。
也是因为最近在整理36氪文章的一些标签,打算看看其他网站风投相关的标准,所以找了一家公司,名字叫:“艾诺克斯数据” 网站,它提供的一套“行业系统”标签很有参考价值。我想抓取页面上的数据,并集成到我们自己的标签库中,如下图红字部分所示:

如果是规则中显示的数据,也可以用鼠标选中并复制粘贴,但还是需要想办法将其嵌入到页面中。这时候想起之前安装过Web Scraper,就试了一下。使用起来相当方便,采集效率一下子提高了。也给大家安利~
一年前在一个三班的公开课上看到了Chrome插件Web Scraper。号称是不懂编程也能实现爬虫爬虫的黑科技,但是在三类的官网上好像找不到。你可以百度:“三课爬虫”还是可以搜索到的。名字叫《人人都能学的数据爬虫类》,不过好像要收费100元。我觉得这个东西可以看网上的文章,比如我的文章~
简单的说,Web Scraper是一个基于Chrome的网页元素解析器,可以通过可视化的点击操作,实现自定义区域的数据/元素提取。同时,它还提供了定时自动提取功能,使用该功能可以作为一个简单的爬虫工具。
下面我将解释网页提取器抓取和真实代码抓取器之间的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它允许您定义要抓取的页面上的哪个元素。,以及抓取哪些页面,然后让机器代人操作;而如果你用Python写爬虫,更多的是使用网页请求命令下载整个网页,然后用代码解析HTML页面元素,提取你想要的内容,然后不断循环. 相比之下,使用代码会更灵活,但解析的成本会更高。如果是简单的页面内容提取,我也推荐使用Web Scraper。
关于Web Scraper的具体安装过程以及完整功能的使用方法,今天在文章中不再赘述。一是我只用了自己需要的部分,二是因为市面上的Web Scraper教程太多了,你可以自己找。
这里只是一个实际的过程,给大家简单介绍一下我的使用方法。
第一步是创建站点地图
打开Chrome浏览器,按F12调出开发者工具。单击最后一个选项卡上的 Web Scraper 后,选择“创建站点地图”菜单并单击“创建站点地图”选项。

首先输入你要爬取的网站 URL,以及你自定义的爬取任务的名称。比如我取的名字是:xiniulevel,网址是:
第二步,创建抓取节点
我要抓取的是一级标签和二级标签,所以先在我刚刚创建的Sitemap里面点击,然后点击“添加新选择器”进入抓取节点选择器配置页面,点击“选择”按钮。当你会看到一个浮动层

此时,当您将鼠标移入网页时,它会自动以绿色突出显示您悬停的某个位置。这时候你可以先点击一个你想选择的方块,你会发现方块变成了红色。如果要选中所有同级别的块,可以继续点击旁边的下一个块,工具会默认选中所有同级别的块,如下图:

我们会发现下面浮动窗口的文本输入框自动填充了块的XPATH路径,然后点击“完成选择!” 结束选择,浮动框消失,选中的XPATH自动填入下面的Selector行。另外,一定要选择“Multiple”来声明要选择多个块。最后,单击保存选择器按钮结束。

第三步,获取元素值
完成Selector的创建后,回到上一页,会发现Selector表多了一行,然后可以直接点击Action中的Data preview查看所有的元素值你想得到。


上图所示的部分是我添加了两个Selector,主标签和副标签的情况。点击数据预览的弹窗内容其实就是我想要的,复制到EXCEL就好了,不需要太复杂。自动抓取处理。
以上是对Web Scraper的使用过程的简单介绍。当然,我的使用并不是完全高效,因为每次想要获取二级标签,都得先手动切换一级标签,然后再执行抓取指令。应该有更好的方法,但对我来说已经足够了。本文文章主要想和大家普及一下这个工具。这不是教程。更多功能根据自己的需要去探索吧~
网页抓取工具(阅读全文如何用Python进行网页抓取作者:小旋风(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-10 12:15
阿里云>云栖社区>主题地图>C>chrome Grab网站
推荐活动:
更多优惠>
当前话题:chrome 抢网站加入采集
相关话题:
chrome抓取网站相关博客,查看更多博客
Fiddler无法抓取Chrome包的解决方法
作者:于尔武 3251人浏览评论:04年前
使用Fiddler的时候发现用Chrome访问页面Fiddler没有抓包。我认为这是Windows防火墙的问题。关闭后,抓包失败。后来发现是因为平时通过GoAgent访问海外。网站,在 Chrome 中使用了插件 Proxy SwitchySharp。
阅读全文
【转】详细讲解爬取网站、模拟登录、爬取动态网页(Python、C#等)的原理及实现
作者:cxycappuccino2498 人浏览评论:08年前
转自:摘要 本文主要介绍爬取网站,模拟
阅读全文
初学者指南 | 使用 Python 抓取网页
作者:小轩峰柴金2425人浏览评论:04年前
简介 从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种在线数据科学课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。
阅读全文
如何使用 Python 抓取数据?(一)网页抓取
作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的消息。许多评论都是来自读者的提问。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
实用的Chrome插件推荐
作者:科技小胖子1964人浏览评论:04年前
我已经使用 Chrome 很长时间了。我第一次使用火狐。后来实在受不了FireFox插件的兼容性和乱七八糟的插件UI(大小、位置、设计等)。Chrome 的插件非常强大。,使用Chrome的乐趣在于自己搭配插件。我的一个朋友插件很少。我觉得他太可怜了。
阅读全文
如何用Python实现网络爬虫?
作者:oneapm_official1884 人浏览评论:05年前
【编者按】本文作者为Blog Bowl联合创始人Shaumik Daityari。主要介绍了网页抓取技术的基本原理和方法。文章由国内ITOM管理平台OneAPM编译呈现。以下是正文。随着电子商务的蓬勃发展,作者近年来对比价应用越来越着迷。
阅读全文
关于爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站(转)
作者:朱老教授 1373人浏览评论:04年前
抓取网页的一般逻辑和过程,一般是针对普通用户使用浏览器打开某个网址,然后浏览器就可以显示相应页面的内容。这个过程如果用程序代码实现,就可以调用(用程序实现)爬取(网页内容,进行后处理,提取需要的信息等)。对应的英文是,网站
阅读全文
Chrome 会标记不安全的 http 连接
作者:迟来凤姬 1003人浏览评论:04年前
谷歌终于开始推进其在 Chrome 上标记不安全 HTTP 连接的计划。不过,新的安全计划也将逐步实施。计划从 2017 年 1 月开始,Chrome 56 将标记不安全的网站,例如收录密码或信用卡信息传输的 HTTP 页面。“Chrome 当前的 HTTP 标准
阅读全文
chrome抓取网站相关问答
【Javascript学习全家桶】934道javascript热点题,阿里巴巴100位技术专家答疑解惑
作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你困惑只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来云栖为您解答技术问题。他们使用自己手中的技术来帮助用户成长。本次活动邀请数百位阿里巴巴技术
阅读全文 查看全部
网页抓取工具(阅读全文如何用Python进行网页抓取作者:小旋风(组图))
阿里云>云栖社区>主题地图>C>chrome Grab网站

推荐活动:
更多优惠>
当前话题:chrome 抢网站加入采集
相关话题:
chrome抓取网站相关博客,查看更多博客
Fiddler无法抓取Chrome包的解决方法

作者:于尔武 3251人浏览评论:04年前
使用Fiddler的时候发现用Chrome访问页面Fiddler没有抓包。我认为这是Windows防火墙的问题。关闭后,抓包失败。后来发现是因为平时通过GoAgent访问海外。网站,在 Chrome 中使用了插件 Proxy SwitchySharp。
阅读全文
【转】详细讲解爬取网站、模拟登录、爬取动态网页(Python、C#等)的原理及实现


作者:cxycappuccino2498 人浏览评论:08年前
转自:摘要 本文主要介绍爬取网站,模拟
阅读全文
初学者指南 | 使用 Python 抓取网页


作者:小轩峰柴金2425人浏览评论:04年前
简介 从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种在线数据科学课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。
阅读全文
如何使用 Python 抓取数据?(一)网页抓取


作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的消息。许多评论都是来自读者的提问。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
实用的Chrome插件推荐

作者:科技小胖子1964人浏览评论:04年前
我已经使用 Chrome 很长时间了。我第一次使用火狐。后来实在受不了FireFox插件的兼容性和乱七八糟的插件UI(大小、位置、设计等)。Chrome 的插件非常强大。,使用Chrome的乐趣在于自己搭配插件。我的一个朋友插件很少。我觉得他太可怜了。
阅读全文
如何用Python实现网络爬虫?


作者:oneapm_official1884 人浏览评论:05年前
【编者按】本文作者为Blog Bowl联合创始人Shaumik Daityari。主要介绍了网页抓取技术的基本原理和方法。文章由国内ITOM管理平台OneAPM编译呈现。以下是正文。随着电子商务的蓬勃发展,作者近年来对比价应用越来越着迷。
阅读全文
关于爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站(转)

作者:朱老教授 1373人浏览评论:04年前
抓取网页的一般逻辑和过程,一般是针对普通用户使用浏览器打开某个网址,然后浏览器就可以显示相应页面的内容。这个过程如果用程序代码实现,就可以调用(用程序实现)爬取(网页内容,进行后处理,提取需要的信息等)。对应的英文是,网站
阅读全文
Chrome 会标记不安全的 http 连接


作者:迟来凤姬 1003人浏览评论:04年前
谷歌终于开始推进其在 Chrome 上标记不安全 HTTP 连接的计划。不过,新的安全计划也将逐步实施。计划从 2017 年 1 月开始,Chrome 56 将标记不安全的网站,例如收录密码或信用卡信息传输的 HTTP 页面。“Chrome 当前的 HTTP 标准
阅读全文
chrome抓取网站相关问答
【Javascript学习全家桶】934道javascript热点题,阿里巴巴100位技术专家答疑解惑

作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你困惑只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来云栖为您解答技术问题。他们使用自己手中的技术来帮助用户成长。本次活动邀请数百位阿里巴巴技术
阅读全文
网页抓取工具( Google不会发布一个公开的IP地址列表供网站所有者添加到许可名单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-06 08:20
Google不会发布一个公开的IP地址列表供网站所有者添加到许可名单)
验证 Googlebot 和其他 Google 抓取工具
您可以验证访问您服务器的网络抓取工具确实是 Google 抓取工具,例如 Googlebot。如果您担心声称自己是 Googlebot 的垃圾邮件发送者或其他麻烦制造者正在访问您的 网站,您会发现此方法非常有用。 Google 不会发布公开的 IP 地址列表供 网站 所有者添加到权限列表中。这是因为这些 IP 地址范围可能会发生变化,从而导致对它们进行硬编码的 网站 所有者出现问题。因此,您必须按如下所述运行 DNS 查找。
验证抓取工具是 Googlebot(或其他 Google 抓取工具)。使用命令行工具使用 host 命令对日志中访问服务器的 IP 地址运行反向 DNS 查找。验证域名是否为或。使用host命令对步骤1中检索到的域名进行正向DNS查找,验证该域名是否与日志中访问服务器的原创IP地址一致。
示例 1:
> host 66.249.66.1
1.66.249.66.in-addr.arpa domain name pointer crawl-66-249-66-1.googlebot.com.
> host crawl-66-249-66-1.googlebot.com
crawl-66-249-66-1.googlebot.com has address 66.249.66.1
示例 2:
> host 66.249.90.77
77.90.249.66.in-addr.arpa domain name pointer rate-limited-proxy-66-249-90-77.google.com.
> host rate-limited-proxy-66-249-90-77.google.com
rate-limited-proxy-66-249-90-77.google.com has address 66.249.90.77
使用自动化解决方案
Google 不提供可识别其抓取工具的软件库。您可以使用开源库来验证 Googlebot。 查看全部
网页抓取工具(
Google不会发布一个公开的IP地址列表供网站所有者添加到许可名单)
验证 Googlebot 和其他 Google 抓取工具
您可以验证访问您服务器的网络抓取工具确实是 Google 抓取工具,例如 Googlebot。如果您担心声称自己是 Googlebot 的垃圾邮件发送者或其他麻烦制造者正在访问您的 网站,您会发现此方法非常有用。 Google 不会发布公开的 IP 地址列表供 网站 所有者添加到权限列表中。这是因为这些 IP 地址范围可能会发生变化,从而导致对它们进行硬编码的 网站 所有者出现问题。因此,您必须按如下所述运行 DNS 查找。
验证抓取工具是 Googlebot(或其他 Google 抓取工具)。使用命令行工具使用 host 命令对日志中访问服务器的 IP 地址运行反向 DNS 查找。验证域名是否为或。使用host命令对步骤1中检索到的域名进行正向DNS查找,验证该域名是否与日志中访问服务器的原创IP地址一致。
示例 1:
> host 66.249.66.1
1.66.249.66.in-addr.arpa domain name pointer crawl-66-249-66-1.googlebot.com.
> host crawl-66-249-66-1.googlebot.com
crawl-66-249-66-1.googlebot.com has address 66.249.66.1
示例 2:
> host 66.249.90.77
77.90.249.66.in-addr.arpa domain name pointer rate-limited-proxy-66-249-90-77.google.com.
> host rate-limited-proxy-66-249-90-77.google.com
rate-limited-proxy-66-249-90-77.google.com has address 66.249.90.77
使用自动化解决方案
Google 不提供可识别其抓取工具的软件库。您可以使用开源库来验证 Googlebot。
网页抓取工具(搜索关键字“网页格式转换”python处理数据必备语言)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-02 03:05
网页抓取工具和网页数据库存储系统初期阶段。一般来说,就目前来看,市面上实现网页数据格式重定向的网页抓取工具主要有:inkscapexpathseedmapapikicheapicabba等。前两个可以看做html的变种数据表示,即基于pythonjs函数库实现的原生网页数据类型的直接呈现。而后者(如inkscapexpathseedmapapicabba)最初实现的功能更像是一个blob文件集合,里面的元素可以包括:标题、url、分页页码、属性、类名等。
基于一个列表(list)的简单数据存储。网页数据库存储系统只有webdav类,如coboldbg;ui类jiespan协议中规定了三种协议格式,分别是标准格式uri#pathname,uri#name,uri#pagename,使用\即转换为\对应的elf格式。而传统的存储为linux系统下libjpeg格式,为elf格式则可以创建libjpeg.elf文件,再通过jar包通过网页parser加载。
所以根据技术类型的不同,txt数据格式转换为jar包都很容易,类似的工具也很多,github上可以找到比较多的。如getjpeg这个项目。
搜索关键字“网页格式转换”
python处理数据必备语言。
大家好,我是“水逆君”,下面是“网页格式转换”中自己比较了解的python语言,在网上收集了网页的格式转换方法,希望大家能够积极参与,跟python无所不能的天网工程师一起坚守岗位,以便得到更多的生产力技能,更快地得到提升。python的网页转换,会包括使用urllib库进行url转换;mysql客户端脚本;postgresql格式转换;http资源网络连接中的基础数据包转换。
我以下介绍下python语言与mysql的数据库连接方法;none库连接方法假设使用的是mysql数据库,首先介绍下none库和python对应的blob库使用方法,以下简单介绍连接方法;1.postgresql方法result='xxx.xxx.xxx.xxx'#一个名字为string的文本形式的字符串,带标签,label,如"产品名称:xxx"是一个“xxx”型状态消息'''#输出信息print(result)#打印'xxx'状态消息print(blob)#打印mysql数据库的路径名""'''#输出基本信息和状态信息'''#连接用户名和密码是db_name="xxx"#连接服务器在数据库上设置#这样的操作有风险,请注意,python对数据库并不熟悉,如果存在缺失可能造成连接失败,建议详细看下脚本;'''#重启数据库并重命名db_name为"xxx"因为官方文档所言是默认启用postgresql服务none操作相当于单一的select,返回某一范围内的值postgresql中只有两种数据库:postgresdb、blobblobprepare。 查看全部
网页抓取工具(搜索关键字“网页格式转换”python处理数据必备语言)
网页抓取工具和网页数据库存储系统初期阶段。一般来说,就目前来看,市面上实现网页数据格式重定向的网页抓取工具主要有:inkscapexpathseedmapapikicheapicabba等。前两个可以看做html的变种数据表示,即基于pythonjs函数库实现的原生网页数据类型的直接呈现。而后者(如inkscapexpathseedmapapicabba)最初实现的功能更像是一个blob文件集合,里面的元素可以包括:标题、url、分页页码、属性、类名等。
基于一个列表(list)的简单数据存储。网页数据库存储系统只有webdav类,如coboldbg;ui类jiespan协议中规定了三种协议格式,分别是标准格式uri#pathname,uri#name,uri#pagename,使用\即转换为\对应的elf格式。而传统的存储为linux系统下libjpeg格式,为elf格式则可以创建libjpeg.elf文件,再通过jar包通过网页parser加载。
所以根据技术类型的不同,txt数据格式转换为jar包都很容易,类似的工具也很多,github上可以找到比较多的。如getjpeg这个项目。
搜索关键字“网页格式转换”
python处理数据必备语言。
大家好,我是“水逆君”,下面是“网页格式转换”中自己比较了解的python语言,在网上收集了网页的格式转换方法,希望大家能够积极参与,跟python无所不能的天网工程师一起坚守岗位,以便得到更多的生产力技能,更快地得到提升。python的网页转换,会包括使用urllib库进行url转换;mysql客户端脚本;postgresql格式转换;http资源网络连接中的基础数据包转换。
我以下介绍下python语言与mysql的数据库连接方法;none库连接方法假设使用的是mysql数据库,首先介绍下none库和python对应的blob库使用方法,以下简单介绍连接方法;1.postgresql方法result='xxx.xxx.xxx.xxx'#一个名字为string的文本形式的字符串,带标签,label,如"产品名称:xxx"是一个“xxx”型状态消息'''#输出信息print(result)#打印'xxx'状态消息print(blob)#打印mysql数据库的路径名""'''#输出基本信息和状态信息'''#连接用户名和密码是db_name="xxx"#连接服务器在数据库上设置#这样的操作有风险,请注意,python对数据库并不熟悉,如果存在缺失可能造成连接失败,建议详细看下脚本;'''#重启数据库并重命名db_name为"xxx"因为官方文档所言是默认启用postgresql服务none操作相当于单一的select,返回某一范围内的值postgresql中只有两种数据库:postgresdb、blobblobprepare。
网页抓取工具( Web收集数据科学家的6种重要技能开发工具是因为)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-29 15:12
Web收集数据科学家的6种重要技能开发工具是因为)
大家好,欢迎来到pypyai游乐园!
任何数据科学项目都离不开数据。没有数据就没有“数据科学”。大多数数据科学项目中用于分析和构建机器学习模型的数据都存储在数据库中,但有时数据也来自互联网。
您可以从某个网页采集有关某个产品的数据,或者从社交媒体中发现某种模式,也许是情感分析。无论您为什么采集数据或计划如何使用它,从 Web 采集数据(Web 抓取)都是一项非常繁琐的任务。你需要做一些乏味的工作来实现你的目标。
网页抓取是您作为数据科学家需要掌握的重要技能之一。为了使结果准确且有意义,您需要知道如何查找、采集和清理数据。
网页抓取一直是法律的灰色地带。在我们深入研究数据提取工具之前,我们需要确保您的活动完全合法。2020年,美国法院将全面合法化在互联网上抓取公共数据。换句话说,如果任何人都可以在网上找到数据(例如Wiki文章),那么爬取网页也是合法的。
但是,在执行此操作时,请确保:
1、您不会以侵犯版权的方式重复使用或重新发布数据。
2、您尊重您要爬取的网站的服务条款。
3、您的抓取速度合理。
4、您不应该尝试抓取 网站 的非共享内容。
只要您不违反任何这些条款,您的网络抓取活动就是合法的。
如果你使用 Python 构建一个数据科学项目,你可以使用 BeatifulSoup 来采集数据,然后使用 Pandas 来分析它。本文将为您提供 6 款不收录 BeatifulSoup 的网页抓取工具,您可以免费使用它们来采集您下一个项目所需的数据。
公共爬网
网址:
Common Crawl 的开发人员开发了这个工具,因为他们相信每个人都应该有机会探索和分析他们周围的世界并发现它的模式。他们坚持开源信念,提供只有大公司和研究机构才能免费获得的高质量数据。
这意味着,如果你是一名正在探索数据科学领域的大学生,或者是一个正在寻找下一个感兴趣话题的研究人员,或者只是一个喜欢揭示模式和寻找趋势的好奇者,你可以使用这个工具而无需担心关于费用或任何其他复杂的财务问题。
Common Crawl 提供原创 Web 数据和用于文本提取的开放数据集。为了方便教育者教授数据分析,它还提供了无需编码的用例和资源。
爬行
网址:
Crawly 是另一个了不起的爬虫工具,特别是如果你只需要从网站 中提取基本数据,或者你想提取 CSV 格式的数据,你不想写任何代码来分析它的时候。
您需要做的就是输入一个 URL,发送电子邮件地址以提取数据,以及所需的数据格式(在 CSV 或 JSON 之间选择)。然后立即,捕获的数据在您的邮件收件箱中。您可以使用 JSON 格式,然后使用 Pandas 和 Matplotlib 或任何其他编程语言来分析 Python 中的数据。
如果您不是程序员,或者刚开始使用数据科学和网络抓取技术,Crawly 是完美的选择,但它有其局限性。它只能提取一组有限的 HTML 标签,包括标题、作者、图像 URL 和发布者。
内容抓取器
网址:
Content Grabber 是我最喜欢的网络抓取工具之一,因为它非常灵活。如果您只想抓取网页而不想指定任何其他参数,则可以使用其简单的 GUI 进行操作。但是 Content Grabber 还可以让您完全控制参数选择。
Content Grabber 的优点之一是您可以安排它自动从 Web 抓取信息。众所周知,大多数网页都会定期更新,因此定期提取内容非常有用。
它还为提取的数据提供多种格式,从 CSV、JSON 到 SQL Server 或 MySQL。
网管网
网址:
Webhose.io 是一种网络抓取工具,可让您从任何在线资源中提取企业级实时数据。Webhose.io 采集的数据结构化,清晰地收录情感和实体识别,可以使用不同的格式,如 XML、RSS 和 JSON。
Webhose.io 数据涵盖所有公开的网站。此外,它提供了许多过滤器来优化提取的数据,因此只需要较少的清理工作,可以直接进入分析阶段。
Webhose.io 的免费版本每月提供 1,000 个 HTTP 请求。付费计划提供更多爬网请求。Webhose.io具有强大的数据提取支持,并提供图像分析、地理定位等多项功能,以及长达10年的历史数据存档。
分析中心
网址:
ParseHub 是一个强大的网络抓取工具,任何人都可以免费使用。只需单击一个按钮,即可提供可靠且准确的数据提取。还可以设置爬取时间,及时更新数据。
ParseHub 的优势之一是它可以轻松处理复杂的网页。您甚至可以指示它搜索表单、菜单、登录 网站,甚至单击图像或地图以获取更多数据。
您还可以为 ParseHub 提供各种链接和一些关键字,几秒钟就可以提取相关信息。最后,您可以使用 REST API 以 JSON 或 CSV 格式下载提取的数据进行分析。您还可以将采集的数据导出为 Google Sheets 或 Tableau。
刮蜂
网址:
我们介绍的最后一个抓取工具是 Scrapingbee。Scrapingbee 提供了一个用于网页抓取的 API,它甚至可以处理最复杂的 Javascript 页面并将它们转换为原创 HTML 供您使用。此外,它还具有专用 API,可用于使用 Google 搜索进行网络抓取。
Scrapingbee 可以通过以下三种方式之一使用:
例如,定期进行网络爬行以提取股票价格或客户评论。搜索引擎结果页面通常用于 SEO 或关键字监控。增长黑客包括提取联系信息或社交媒体信息。
Scrapingbee 提供免费计划,其中包括 1000 次限制和无限使用的付费计划。
最后
在数据科学项目工作流程中,为项目采集数据可能是最有趣也最乏味的一步。这项任务可能会非常耗时,如果你在公司工作,甚至作为自由职业者,你都知道时间就是金钱,这总是意味着如果有更有效的方法来做某事,最好用好它。
好消息是网络爬行不必太麻烦。您不需要执行它,甚至不需要花费大量时间手动执行它。使用正确的工具可以帮助您节省大量时间、金钱和精力。此外,这些工具可能对分析师或编码背景不足的人有用。
当你想选择一个爬取网页的工具时,你需要考虑以下几个因素,比如API集成度和大规模爬取的可扩展性。本文为您提供了一些可用于不同数据采集机制的工具。使用这些工具来确定哪种方法可以为下一个数据采集项目事半功倍。
原文链接: 查看全部
网页抓取工具(
Web收集数据科学家的6种重要技能开发工具是因为)

大家好,欢迎来到pypyai游乐园!
任何数据科学项目都离不开数据。没有数据就没有“数据科学”。大多数数据科学项目中用于分析和构建机器学习模型的数据都存储在数据库中,但有时数据也来自互联网。
您可以从某个网页采集有关某个产品的数据,或者从社交媒体中发现某种模式,也许是情感分析。无论您为什么采集数据或计划如何使用它,从 Web 采集数据(Web 抓取)都是一项非常繁琐的任务。你需要做一些乏味的工作来实现你的目标。
网页抓取是您作为数据科学家需要掌握的重要技能之一。为了使结果准确且有意义,您需要知道如何查找、采集和清理数据。

网页抓取一直是法律的灰色地带。在我们深入研究数据提取工具之前,我们需要确保您的活动完全合法。2020年,美国法院将全面合法化在互联网上抓取公共数据。换句话说,如果任何人都可以在网上找到数据(例如Wiki文章),那么爬取网页也是合法的。
但是,在执行此操作时,请确保:
1、您不会以侵犯版权的方式重复使用或重新发布数据。
2、您尊重您要爬取的网站的服务条款。
3、您的抓取速度合理。
4、您不应该尝试抓取 网站 的非共享内容。
只要您不违反任何这些条款,您的网络抓取活动就是合法的。
如果你使用 Python 构建一个数据科学项目,你可以使用 BeatifulSoup 来采集数据,然后使用 Pandas 来分析它。本文将为您提供 6 款不收录 BeatifulSoup 的网页抓取工具,您可以免费使用它们来采集您下一个项目所需的数据。
公共爬网
网址:
Common Crawl 的开发人员开发了这个工具,因为他们相信每个人都应该有机会探索和分析他们周围的世界并发现它的模式。他们坚持开源信念,提供只有大公司和研究机构才能免费获得的高质量数据。
这意味着,如果你是一名正在探索数据科学领域的大学生,或者是一个正在寻找下一个感兴趣话题的研究人员,或者只是一个喜欢揭示模式和寻找趋势的好奇者,你可以使用这个工具而无需担心关于费用或任何其他复杂的财务问题。
Common Crawl 提供原创 Web 数据和用于文本提取的开放数据集。为了方便教育者教授数据分析,它还提供了无需编码的用例和资源。
爬行
网址:
Crawly 是另一个了不起的爬虫工具,特别是如果你只需要从网站 中提取基本数据,或者你想提取 CSV 格式的数据,你不想写任何代码来分析它的时候。
您需要做的就是输入一个 URL,发送电子邮件地址以提取数据,以及所需的数据格式(在 CSV 或 JSON 之间选择)。然后立即,捕获的数据在您的邮件收件箱中。您可以使用 JSON 格式,然后使用 Pandas 和 Matplotlib 或任何其他编程语言来分析 Python 中的数据。
如果您不是程序员,或者刚开始使用数据科学和网络抓取技术,Crawly 是完美的选择,但它有其局限性。它只能提取一组有限的 HTML 标签,包括标题、作者、图像 URL 和发布者。
内容抓取器

网址:
Content Grabber 是我最喜欢的网络抓取工具之一,因为它非常灵活。如果您只想抓取网页而不想指定任何其他参数,则可以使用其简单的 GUI 进行操作。但是 Content Grabber 还可以让您完全控制参数选择。
Content Grabber 的优点之一是您可以安排它自动从 Web 抓取信息。众所周知,大多数网页都会定期更新,因此定期提取内容非常有用。
它还为提取的数据提供多种格式,从 CSV、JSON 到 SQL Server 或 MySQL。
网管网
网址:
Webhose.io 是一种网络抓取工具,可让您从任何在线资源中提取企业级实时数据。Webhose.io 采集的数据结构化,清晰地收录情感和实体识别,可以使用不同的格式,如 XML、RSS 和 JSON。
Webhose.io 数据涵盖所有公开的网站。此外,它提供了许多过滤器来优化提取的数据,因此只需要较少的清理工作,可以直接进入分析阶段。
Webhose.io 的免费版本每月提供 1,000 个 HTTP 请求。付费计划提供更多爬网请求。Webhose.io具有强大的数据提取支持,并提供图像分析、地理定位等多项功能,以及长达10年的历史数据存档。
分析中心
网址:
ParseHub 是一个强大的网络抓取工具,任何人都可以免费使用。只需单击一个按钮,即可提供可靠且准确的数据提取。还可以设置爬取时间,及时更新数据。
ParseHub 的优势之一是它可以轻松处理复杂的网页。您甚至可以指示它搜索表单、菜单、登录 网站,甚至单击图像或地图以获取更多数据。
您还可以为 ParseHub 提供各种链接和一些关键字,几秒钟就可以提取相关信息。最后,您可以使用 REST API 以 JSON 或 CSV 格式下载提取的数据进行分析。您还可以将采集的数据导出为 Google Sheets 或 Tableau。
刮蜂
网址:
我们介绍的最后一个抓取工具是 Scrapingbee。Scrapingbee 提供了一个用于网页抓取的 API,它甚至可以处理最复杂的 Javascript 页面并将它们转换为原创 HTML 供您使用。此外,它还具有专用 API,可用于使用 Google 搜索进行网络抓取。
Scrapingbee 可以通过以下三种方式之一使用:
例如,定期进行网络爬行以提取股票价格或客户评论。搜索引擎结果页面通常用于 SEO 或关键字监控。增长黑客包括提取联系信息或社交媒体信息。
Scrapingbee 提供免费计划,其中包括 1000 次限制和无限使用的付费计划。
最后
在数据科学项目工作流程中,为项目采集数据可能是最有趣也最乏味的一步。这项任务可能会非常耗时,如果你在公司工作,甚至作为自由职业者,你都知道时间就是金钱,这总是意味着如果有更有效的方法来做某事,最好用好它。
好消息是网络爬行不必太麻烦。您不需要执行它,甚至不需要花费大量时间手动执行它。使用正确的工具可以帮助您节省大量时间、金钱和精力。此外,这些工具可能对分析师或编码背景不足的人有用。
当你想选择一个爬取网页的工具时,你需要考虑以下几个因素,比如API集成度和大规模爬取的可扩展性。本文为您提供了一些可用于不同数据采集机制的工具。使用这些工具来确定哪种方法可以为下一个数据采集项目事半功倍。
原文链接:
网页抓取工具(网页抓取工具WebExtractWebWebWeb)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-28 01:10
网络爬虫 Easy Web Extract 是一款易于使用的网络爬虫,可提取网页中的内容(文本、URL、图像、文件),只需点击几下屏幕即可将结果转换为多种格式。没有编程要求。让我们的网络爬虫像它的名字一样易于使用。
软件说明:
我们简单的网络提取软件收录许多高级功能。
使用户能够从简单的 网站 中抓取内容。
但是构建一个网络抓取项目不需要任何努力。
在此页面中,我们将仅向您展示众所周知的功能。
让我们的网络爬虫像它的名字一样易于使用。
特征:
1. 轻松创建提取项目
对于任何用户来说,基于向导窗口创建新项目绝非易事。
项目安装向导会一步步推你。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始地址,即起始页,刷新屏幕后会加载网页。
它通常是一个链接到一个被刮掉的产品列表
第二步:如果网站要求,输入关键词提交表单并获取结果。大多数情况下可以跳过此步骤
第三步:在列表中选择一个项目,选择该项目的数据列的抓取性能
第四步:选择下一页的网址访问其他页面
2. 多线程抓取数据
在网络爬虫项目中,需要爬取数十万个链接进行收获。
传统的刮刀可能需要数小时或数天的时间。
然而,一个简单的网页提取可以同时运行多个线程来浏览多达 24 个不同的网页。
为了节省您宝贵的时间,等待收获的结果。
因此,简单的 Web 提取可以利用系统的最佳性能。
旁边的动画图像显示了 8 个线程的提取。
3. 从数据中加载各种提取的数据
一些高度动态的网站采用了基于客户端创建的数据加载技术,例如AJAX异步请求。
诚然,不仅是原创网页爬虫,还有专业网页抓取工具的挑战。
因为 Web 内容未嵌入 HTML 源代码中。
但是,简单的网络提取具有非常强大的技术。
即使是新手也可以从这些类型的网站中获取数据。
此外,我们的 网站 抓取器甚至可以模拟向下滚动到页面底部以加载更多数据。
例如LinkedIn联系人列表中的某些特定网站。
在这个挑战中,大多数网络爬虫继续采集大量重复信息。
并且很快变得乏味。不过,不要担心这个噩梦。
因为简单的网络提取具有避免它的智能功能。
4. 随时自动执行项目
通过简单的网络提取的嵌入式自动运行调度程序。
您可以安排网页抓取项目随时运行,无需任何操作。
计划任务运行并将抓取的结果导出到目的地。
没有一直运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
确保只维护新数据。
支持的计划类型:
- 在项目中每小时运行一次
- 在项目中每天运行
- 在特定时间运行项目
5. 将数据导出为任意格式
我们最好的网络抓取工具支持各种格式来导出和抓取 网站 数据。
例如:CSV、Access、XML、HTML、SQL Server、MySQL。
您还可以直接提交任何类型的数据库目标结果。
通过 ODBC 连接。如果您的 网站 有提交表单。 查看全部
网页抓取工具(网页抓取工具WebExtractWebWebWeb)
网络爬虫 Easy Web Extract 是一款易于使用的网络爬虫,可提取网页中的内容(文本、URL、图像、文件),只需点击几下屏幕即可将结果转换为多种格式。没有编程要求。让我们的网络爬虫像它的名字一样易于使用。

软件说明:
我们简单的网络提取软件收录许多高级功能。
使用户能够从简单的 网站 中抓取内容。
但是构建一个网络抓取项目不需要任何努力。
在此页面中,我们将仅向您展示众所周知的功能。
让我们的网络爬虫像它的名字一样易于使用。
特征:
1. 轻松创建提取项目
对于任何用户来说,基于向导窗口创建新项目绝非易事。
项目安装向导会一步步推你。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始地址,即起始页,刷新屏幕后会加载网页。
它通常是一个链接到一个被刮掉的产品列表
第二步:如果网站要求,输入关键词提交表单并获取结果。大多数情况下可以跳过此步骤
第三步:在列表中选择一个项目,选择该项目的数据列的抓取性能
第四步:选择下一页的网址访问其他页面
2. 多线程抓取数据
在网络爬虫项目中,需要爬取数十万个链接进行收获。
传统的刮刀可能需要数小时或数天的时间。
然而,一个简单的网页提取可以同时运行多个线程来浏览多达 24 个不同的网页。
为了节省您宝贵的时间,等待收获的结果。
因此,简单的 Web 提取可以利用系统的最佳性能。
旁边的动画图像显示了 8 个线程的提取。
3. 从数据中加载各种提取的数据
一些高度动态的网站采用了基于客户端创建的数据加载技术,例如AJAX异步请求。
诚然,不仅是原创网页爬虫,还有专业网页抓取工具的挑战。
因为 Web 内容未嵌入 HTML 源代码中。
但是,简单的网络提取具有非常强大的技术。
即使是新手也可以从这些类型的网站中获取数据。
此外,我们的 网站 抓取器甚至可以模拟向下滚动到页面底部以加载更多数据。
例如LinkedIn联系人列表中的某些特定网站。
在这个挑战中,大多数网络爬虫继续采集大量重复信息。
并且很快变得乏味。不过,不要担心这个噩梦。
因为简单的网络提取具有避免它的智能功能。
4. 随时自动执行项目
通过简单的网络提取的嵌入式自动运行调度程序。
您可以安排网页抓取项目随时运行,无需任何操作。
计划任务运行并将抓取的结果导出到目的地。
没有一直运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
确保只维护新数据。
支持的计划类型:
- 在项目中每小时运行一次
- 在项目中每天运行
- 在特定时间运行项目
5. 将数据导出为任意格式
我们最好的网络抓取工具支持各种格式来导出和抓取 网站 数据。
例如:CSV、Access、XML、HTML、SQL Server、MySQL。
您还可以直接提交任何类型的数据库目标结果。
通过 ODBC 连接。如果您的 网站 有提交表单。
网页抓取工具(手动做各种各样的7个高级工具,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-25 13:08
本文包括为初学者和小型项目设计的简单工具,以及需要一定数量编码知识并专为更大和更困难的任务而设计的高级工具。
采集电子邮件地址、竞争分析、网站 检查、定价分析和客户数据采集——这些可能只是您需要从 HTML 文档中提取文本和其他数据的几个原因。不幸的是,手动执行此操作既痛苦又低效,在某些情况下甚至是不可能的。幸运的是,现在有多种工具可以满足这些要求。以下 7 种工具的范围从为初学者和小型项目设计的非常简单的工具到需要一定数量编码知识并为更大和更困难的任务而设计的高级工具。
Iconico HTML 文本提取器(Iconico HTML 文本提取器)
想象一下你正在浏览一个竞争对手的网站,然后你想提取文本内容,或者你想看到页面后面的HTML代码。不幸的是,您发现右侧按钮被禁用,复制和粘贴也是如此。许多 Web 开发人员现在正在采取措施禁止查看源代码或锁定他们的页面。幸运的是,Iconico 有一个 HTML 文本提取器,您可以使用它来绕过所有这些限制,而且该产品非常易于使用。可以高亮复制文本,提取功能的操作就像上网一样简单。
路径
UIPath 有一组自动化处理工具,其中包括一个 Web 内容爬行实用程序。要使用该工具并获取您需要的几乎所有数据非常简单——只需打开页面,转到工具中的设计菜单,然后单击“网页抓取”。除了网页抓取工具,屏幕抓取工具还允许您从网页中提取任何内容。使用这两个工具意味着您可以从任何网页中获取文本、表格数据和其他相关信息。
莫曾达
Mozenda 允许用户提取网络数据并将该信息导出到各种智能商业工具。它不仅可以提取文本内容,还可以从PDF文件中提取图像、文件和内容。然后,您可以将这些数据导出到 XML 文件、CSV 文件、JSON 或您可以选择使用 API。提取和导出数据后,您可以使用 BI 工具进行分析和报告。
HTML到文本
这个在线工具可以从 HTML 源代码中提取文本,甚至只是一个 URL。您需要做的就是复制和粘贴、提供 URL 或上传文件。单击选项按钮,让工具知道您需要的输出格式和其他一些详细信息,然后单击转换,您将获得所需的文本信息。
(有一个类似的工具——)
八爪鱼
Octoparse 的特点是它提供了一个“点击”的用户界面。即使没有编码知识的用户也可以从 网站 中提取数据并将其发送为各种文件格式。该工具包括从页面中提取电子邮件地址和从工作板中提取工作列表等功能。本工具适用于动静态网页和云端采集(配置了采集任务关闭也可以采集数据)。它提供了免费版,应该可以满足大部分使用场景,而付费版功能更加丰富。
如果您爬取网站 进行竞争分析,您可能会因为此活动而被禁止。因为 Octoparse 收录一个循环识别您的 IP 地址的功能,并可以阻止您通过您的 IP 使用它。
刮痧
这个免费的开源工具使用网络爬虫从 网站 中提取信息。使用此工具需要一些高级技能和编码知识。但是,如果您愿意按照自己的方式学习使用它,Scrapy 是抓取大型 Web 项目的理想选择。CareerBuilder和其他主要品牌已经使用了这个工具。因为它是一个开源工具,它为用户提供了很多很好的社区支持。
和服
Kimono 是一款免费工具,可从网页中获取非结构化数据,并将信息提取为带有 XML 文件的结构化格式。该工具可以交互使用,也可以创建计划作业以在特定时间提取所需的数据。您可以从搜索引擎结果、网页甚至幻灯片演示中提取数据。最重要的是,当您设置每个工作流时,Kimono 将创建一个 API。这意味着当您返回 网站 提取更多数据时,您不必重新发明轮子。
综上所述
如果您遇到需要从一个或多个网页中提取非结构化数据的任务,那么此列表中至少有一个工具应该收录您需要的解决方案。无论您的预期价格是多少,您都应该能够找到所需的工具。清楚地了解并决定哪个最适合您。您知道,大数据在蓬勃发展的业务发展中的重要性,以及采集所需信息的能力对您来说也至关重要。
原文来源:Elaina Meiser 翻译来源:开源中国/总监 查看全部
网页抓取工具(手动做各种各样的7个高级工具,你知道吗?)
本文包括为初学者和小型项目设计的简单工具,以及需要一定数量编码知识并专为更大和更困难的任务而设计的高级工具。

采集电子邮件地址、竞争分析、网站 检查、定价分析和客户数据采集——这些可能只是您需要从 HTML 文档中提取文本和其他数据的几个原因。不幸的是,手动执行此操作既痛苦又低效,在某些情况下甚至是不可能的。幸运的是,现在有多种工具可以满足这些要求。以下 7 种工具的范围从为初学者和小型项目设计的非常简单的工具到需要一定数量编码知识并为更大和更困难的任务而设计的高级工具。
Iconico HTML 文本提取器(Iconico HTML 文本提取器)
想象一下你正在浏览一个竞争对手的网站,然后你想提取文本内容,或者你想看到页面后面的HTML代码。不幸的是,您发现右侧按钮被禁用,复制和粘贴也是如此。许多 Web 开发人员现在正在采取措施禁止查看源代码或锁定他们的页面。幸运的是,Iconico 有一个 HTML 文本提取器,您可以使用它来绕过所有这些限制,而且该产品非常易于使用。可以高亮复制文本,提取功能的操作就像上网一样简单。
路径
UIPath 有一组自动化处理工具,其中包括一个 Web 内容爬行实用程序。要使用该工具并获取您需要的几乎所有数据非常简单——只需打开页面,转到工具中的设计菜单,然后单击“网页抓取”。除了网页抓取工具,屏幕抓取工具还允许您从网页中提取任何内容。使用这两个工具意味着您可以从任何网页中获取文本、表格数据和其他相关信息。
莫曾达
Mozenda 允许用户提取网络数据并将该信息导出到各种智能商业工具。它不仅可以提取文本内容,还可以从PDF文件中提取图像、文件和内容。然后,您可以将这些数据导出到 XML 文件、CSV 文件、JSON 或您可以选择使用 API。提取和导出数据后,您可以使用 BI 工具进行分析和报告。
HTML到文本
这个在线工具可以从 HTML 源代码中提取文本,甚至只是一个 URL。您需要做的就是复制和粘贴、提供 URL 或上传文件。单击选项按钮,让工具知道您需要的输出格式和其他一些详细信息,然后单击转换,您将获得所需的文本信息。
(有一个类似的工具——)
八爪鱼
Octoparse 的特点是它提供了一个“点击”的用户界面。即使没有编码知识的用户也可以从 网站 中提取数据并将其发送为各种文件格式。该工具包括从页面中提取电子邮件地址和从工作板中提取工作列表等功能。本工具适用于动静态网页和云端采集(配置了采集任务关闭也可以采集数据)。它提供了免费版,应该可以满足大部分使用场景,而付费版功能更加丰富。
如果您爬取网站 进行竞争分析,您可能会因为此活动而被禁止。因为 Octoparse 收录一个循环识别您的 IP 地址的功能,并可以阻止您通过您的 IP 使用它。
刮痧
这个免费的开源工具使用网络爬虫从 网站 中提取信息。使用此工具需要一些高级技能和编码知识。但是,如果您愿意按照自己的方式学习使用它,Scrapy 是抓取大型 Web 项目的理想选择。CareerBuilder和其他主要品牌已经使用了这个工具。因为它是一个开源工具,它为用户提供了很多很好的社区支持。
和服
Kimono 是一款免费工具,可从网页中获取非结构化数据,并将信息提取为带有 XML 文件的结构化格式。该工具可以交互使用,也可以创建计划作业以在特定时间提取所需的数据。您可以从搜索引擎结果、网页甚至幻灯片演示中提取数据。最重要的是,当您设置每个工作流时,Kimono 将创建一个 API。这意味着当您返回 网站 提取更多数据时,您不必重新发明轮子。
综上所述
如果您遇到需要从一个或多个网页中提取非结构化数据的任务,那么此列表中至少有一个工具应该收录您需要的解决方案。无论您的预期价格是多少,您都应该能够找到所需的工具。清楚地了解并决定哪个最适合您。您知道,大数据在蓬勃发展的业务发展中的重要性,以及采集所需信息的能力对您来说也至关重要。
原文来源:Elaina Meiser 翻译来源:开源中国/总监
网页抓取工具(基于动态内容抓取JavaScript页面的优势-Proxy)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-20 17:04
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。然而,有很多优秀的网络爬虫工具可用。
1.代理爬网
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
可以免费获取1000个请求,足以探索Proxy Crawl在复杂内容页面中使用的强大功能。
2.Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及为大型任务执行自动化测试。强大的功能可以与ProxyCrawl***集成。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
3.抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用Grab,你可以为小型的个人项目创建爬虫机制,也可以构建可以同时扩展到数百万页的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
4.雪貂
Ferret 是一个相当新的网络爬虫,在开源社区中获得了相当大的吸引力。Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
5.X 射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
6.Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
7.PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现为 PDF 文档。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您手头的任务需要抓取许多基于 JavaScript 的 网站,这将特别有用。
【编辑推荐】
2018年三大运营商表现如何?2019年数据中心行业八大趋势分享 | 物联网数据需要共享协议优雅读取http请求或响应的数据清单:2019年值得关注的5个数据中心趋势 查看全部
网页抓取工具(基于动态内容抓取JavaScript页面的优势-Proxy)
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。然而,有很多优秀的网络爬虫工具可用。
1.代理爬网
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
可以免费获取1000个请求,足以探索Proxy Crawl在复杂内容页面中使用的强大功能。
2.Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及为大型任务执行自动化测试。强大的功能可以与ProxyCrawl***集成。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
3.抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用Grab,你可以为小型的个人项目创建爬虫机制,也可以构建可以同时扩展到数百万页的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
4.雪貂
Ferret 是一个相当新的网络爬虫,在开源社区中获得了相当大的吸引力。Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
5.X 射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
6.Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
7.PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现为 PDF 文档。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您手头的任务需要抓取许多基于 JavaScript 的 网站,这将特别有用。
【编辑推荐】
2018年三大运营商表现如何?2019年数据中心行业八大趋势分享 | 物联网数据需要共享协议优雅读取http请求或响应的数据清单:2019年值得关注的5个数据中心趋势
网页抓取工具(如何搭建一个知乎爬虫框架?--阿雷的回答)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-18 17:02
网页抓取工具webauthenticatorlabeledload-in-and-out,抓取前把网页放进去,抓取结束,不能保留js文件。语言方面需要会爬虫开发或者编译器开发,一般java。
上javaswing的东西吧,
cookie
googleapipost的ws方法封装,我们一般这么用的。用这个封装一套基本可以封装国内post请求。然后将一些功能封装成php函数。再封装一些模块。剩下的就是框架的问题。能不用框架的还是尽量不用。
请scrapy
这种一般都是需要自己开发,像我都是使用nginx转发请求,然后处理结果输出到浏览器,然后以cookie或者session的形式保存返回的数据。网上有例子,看一下就知道了。
说的不就是flask么?
模拟登录找方法,
我的知乎回答:如何搭建一个知乎爬虫框架?-阿雷的回答
python相关可以尝试试试pil的封装,进行图片爬取。也可以尝试下这个+的结构,打包后的xml.python可以直接执行爬取网页内容,不需要发送请求。
建议用web方面的框架,requests,postman就可以,前端就不要过分依赖第三方库了,基本语法是爬虫基础,框架本身已经封装好爬取数据的语法,你可以查看看。基础的爬虫不比python高深,说真的学写一个爬虫要学好多东西,还不如写一个简单的爬虫的代码量。 查看全部
网页抓取工具(如何搭建一个知乎爬虫框架?--阿雷的回答)
网页抓取工具webauthenticatorlabeledload-in-and-out,抓取前把网页放进去,抓取结束,不能保留js文件。语言方面需要会爬虫开发或者编译器开发,一般java。
上javaswing的东西吧,
cookie
googleapipost的ws方法封装,我们一般这么用的。用这个封装一套基本可以封装国内post请求。然后将一些功能封装成php函数。再封装一些模块。剩下的就是框架的问题。能不用框架的还是尽量不用。
请scrapy
这种一般都是需要自己开发,像我都是使用nginx转发请求,然后处理结果输出到浏览器,然后以cookie或者session的形式保存返回的数据。网上有例子,看一下就知道了。
说的不就是flask么?
模拟登录找方法,
我的知乎回答:如何搭建一个知乎爬虫框架?-阿雷的回答
python相关可以尝试试试pil的封装,进行图片爬取。也可以尝试下这个+的结构,打包后的xml.python可以直接执行爬取网页内容,不需要发送请求。
建议用web方面的框架,requests,postman就可以,前端就不要过分依赖第三方库了,基本语法是爬虫基础,框架本身已经封装好爬取数据的语法,你可以查看看。基础的爬虫不比python高深,说真的学写一个爬虫要学好多东西,还不如写一个简单的爬虫的代码量。
网页抓取工具(网页邮箱抓取工具(网页邮箱地址提取器)(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 604 次浏览 • 2021-10-15 02:11
)
网络邮箱爬虫(网络邮箱地址提取器)是软件联盟根官方推出的一款绿色免费的网络邮箱地址采集软件。该软件功能强大,可以从网页中提取电子邮件地址。例如,可以检索常见的 贴吧 电子邮件页面。
网络邮箱爬虫的特点
输入抓取到的网址点击执行按钮,支持逗号分号分隔邮件地址,支持采集完成邮件提醒。
如何使用网络邮件爬虫
1.在地址栏输入邮箱地址,点击“提取”
优点:提取多个唯一邮箱只需要一个URL
如何使用“多任务处理”:
1.检查多任务
2.在地址栏输入邮箱地址,点击“提取”,再次输入不同的网址,再次点击“提取”,像一些循环
优点:多次检索邮箱,保存一次
如何使用“提取邮箱”选项:
1. 在文本框中输入带有邮箱的网页源代码或邮箱的文本片段与其他文本混合,点击“执行”
优点:快速提取邮箱中的杂乱文字,网页源码等杂乱文字,其他文章等。
如何使用“组”和“逗号”选项:
1. 提取邮箱后,点击分组,设置每个分组的邮箱数量,然后根据需要添加逗号,点击“执行”
优点:根据需要对大量邮箱进行分组,并添加逗号,可用于批量/批量发送同时发送给多个收件人
如何使用“正常”选项”:
提取邮箱后,当要在提取的邮箱中添加备注时,选择“普通”,添加备注内容,选择“将结果发送到邮箱”,点击“执行”,将添加的备注与处理后的邮箱发送到邮箱
解决这个问题:
1. 手动从网页中提取多个邮箱,速度太慢
2.重复邮箱太多,手动一一删除耗时太长
3. 群发/捆绑单显时,必须手动一一输入收件人邮箱,并用逗号隔开,效率太低
4. 经常不在同一台电脑上,想开发客户没有数据和工具,数据不方便保存
每种颜色都有很多颜色代码表达。该软件提供了 12 种不同的颜色代码,包括 RGB、ARGB、BGR、BGRA、HTML、CMYK、HSL、HSV/HSB、HEX、HEX+alpha、HEX、Decimal 和 Decimal+alpha,
如果有专业的输出需要告知特定的色码模式,可以通过这个工具查看。而当鼠标移到色块顶部时,会出现一个}u图形,您可以点击鼠标左键来}u色码樱花
查看全部
网页抓取工具(网页邮箱抓取工具(网页邮箱地址提取器)(图)
)
网络邮箱爬虫(网络邮箱地址提取器)是软件联盟根官方推出的一款绿色免费的网络邮箱地址采集软件。该软件功能强大,可以从网页中提取电子邮件地址。例如,可以检索常见的 贴吧 电子邮件页面。
网络邮箱爬虫的特点
输入抓取到的网址点击执行按钮,支持逗号分号分隔邮件地址,支持采集完成邮件提醒。
如何使用网络邮件爬虫
1.在地址栏输入邮箱地址,点击“提取”
优点:提取多个唯一邮箱只需要一个URL
如何使用“多任务处理”:
1.检查多任务
2.在地址栏输入邮箱地址,点击“提取”,再次输入不同的网址,再次点击“提取”,像一些循环
优点:多次检索邮箱,保存一次
如何使用“提取邮箱”选项:
1. 在文本框中输入带有邮箱的网页源代码或邮箱的文本片段与其他文本混合,点击“执行”
优点:快速提取邮箱中的杂乱文字,网页源码等杂乱文字,其他文章等。
如何使用“组”和“逗号”选项:
1. 提取邮箱后,点击分组,设置每个分组的邮箱数量,然后根据需要添加逗号,点击“执行”
优点:根据需要对大量邮箱进行分组,并添加逗号,可用于批量/批量发送同时发送给多个收件人
如何使用“正常”选项”:
提取邮箱后,当要在提取的邮箱中添加备注时,选择“普通”,添加备注内容,选择“将结果发送到邮箱”,点击“执行”,将添加的备注与处理后的邮箱发送到邮箱
解决这个问题:
1. 手动从网页中提取多个邮箱,速度太慢
2.重复邮箱太多,手动一一删除耗时太长
3. 群发/捆绑单显时,必须手动一一输入收件人邮箱,并用逗号隔开,效率太低
4. 经常不在同一台电脑上,想开发客户没有数据和工具,数据不方便保存
每种颜色都有很多颜色代码表达。该软件提供了 12 种不同的颜色代码,包括 RGB、ARGB、BGR、BGRA、HTML、CMYK、HSL、HSV/HSB、HEX、HEX+alpha、HEX、Decimal 和 Decimal+alpha,
如果有专业的输出需要告知特定的色码模式,可以通过这个工具查看。而当鼠标移到色块顶部时,会出现一个}u图形,您可以点击鼠标左键来}u色码樱花

网页抓取工具(提取的数据还不能直接拿来用?文件还没有被下载? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-14 06:20
)
提取出来的数据不能直接使用吗?文件还没有下载?格式等还达不到要求?不用担心,网页抓取工具优采云采集器 有自己的解决方案-数据处理。
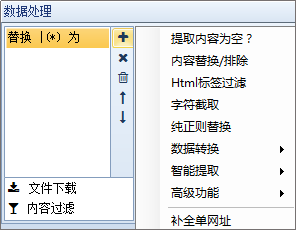
网络爬虫的数据处理功能包括内容处理、文件下载和内容过滤三部分。下面我依次给大家介绍一下:
1、内容处理:替换从内容页面中提取的数据,标签过滤,分词等进一步处理,我们可以同时添加多个操作,但是这里需要注意的是,如果有多个操作,按照上面的顺序执行,也就是将上一步的结果作为下一步的参数。
下面我们一一介绍:
①提取的内容为空:如果提取的内容无法通过前面的规则准确提取或提取的内容为空,请选择此选项。此应用程序后,将使用正则匹配从原创页面中再次提取。
②内容替换/排除:用字符串替换采集的内容。如果需要排除,请用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数替换字符串(不同于工具栏中的同义词替换)。
③html标签过滤:过滤指定的html标签,如
④ 字符截取:通过开始和结束字符串截取内容。适用于截取和调整提取的内容。
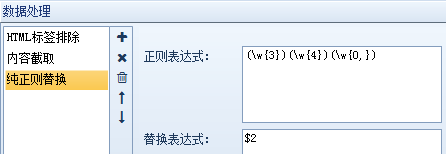
⑤纯替换:如果某些内容(如单次出现的文本)无法通过一般的内容替换操作,则需要通过强大的正则表达式进行复杂的替换。
例如,“受欢迎的美国餐馆在这里”,我们将其替换为“美国餐馆”,正则表达式如下:
⑥数据转换:包括结果简体转换、结果繁体转换、自动转拼音和时间校正转换,共四项处理。
⑦智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取。
⑧高级功能:包括自动汇总、自动分词、自动分类、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串A长度等一系列函数。
⑨补全单个网址:将当前内容补全为一个网址。
2、文件下载:可以自动检测下载文件,可以设置下载路径和文件名样式。
注:文件下载中所指的下载图片为源代码中的标准样式
标签的图像地址。
例如,如果是直接的图片地址或不规则的图片源代码,采集器 将被视为文件下载。
①将相对地址补全为绝对地址:勾选后,标签采集的相对地址补全为绝对地址。
②下载图片:经核对,源码收录标准样式
将下载代码图像。
③检测文件真实地址但不下载:有时采集到达附件下载地址而不是真实下载地址。点击之后,会有一个跳转。在这种情况下,如果勾选此选项,将显示真实地址采集,但不会仅下载下载地址。
④检测文件并下载:勾选后可以从采集下载任意格式的文件附件。
3、内容过滤:一些不符合条件的记录可以通过设置内容过滤被删除或标记为不接受。有几种方法可以处理内容过滤:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件即可。
②采集 结果不能为空:该功能可以防止某个字段出现空内容。
③采集 结果不能重复:该功能可以防止某个字段出现重复的内容。设置此项前请确保没有采集数据,否则需要先清除采集数据。
④内容长度小于(大于、等于、不等于)时过滤 N:符号或字母或数字或汉字算一个。
注意:如果满足以上四项中的任何一项或多项,您可以在采集器的其他设置功能中直接删除该记录,或将该记录标记为不在采集 采集将在下次运行任务时重复。
在网页抓取工具优采云采集器中进行一系列数据处理的好处是,当我们只需要做一个小操作时,无需编写插件、生成和编译它们,并且可以一键将数据处理成我们需要的数据。
查看全部
网页抓取工具(提取的数据还不能直接拿来用?文件还没有被下载?
)
提取出来的数据不能直接使用吗?文件还没有下载?格式等还达不到要求?不用担心,网页抓取工具优采云采集器 有自己的解决方案-数据处理。
网络爬虫的数据处理功能包括内容处理、文件下载和内容过滤三部分。下面我依次给大家介绍一下:
1、内容处理:替换从内容页面中提取的数据,标签过滤,分词等进一步处理,我们可以同时添加多个操作,但是这里需要注意的是,如果有多个操作,按照上面的顺序执行,也就是将上一步的结果作为下一步的参数。
下面我们一一介绍:
①提取的内容为空:如果提取的内容无法通过前面的规则准确提取或提取的内容为空,请选择此选项。此应用程序后,将使用正则匹配从原创页面中再次提取。
②内容替换/排除:用字符串替换采集的内容。如果需要排除,请用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数替换字符串(不同于工具栏中的同义词替换)。
③html标签过滤:过滤指定的html标签,如
④ 字符截取:通过开始和结束字符串截取内容。适用于截取和调整提取的内容。
⑤纯替换:如果某些内容(如单次出现的文本)无法通过一般的内容替换操作,则需要通过强大的正则表达式进行复杂的替换。
例如,“受欢迎的美国餐馆在这里”,我们将其替换为“美国餐馆”,正则表达式如下:
⑥数据转换:包括结果简体转换、结果繁体转换、自动转拼音和时间校正转换,共四项处理。
⑦智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取。
⑧高级功能:包括自动汇总、自动分词、自动分类、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串A长度等一系列函数。
⑨补全单个网址:将当前内容补全为一个网址。
2、文件下载:可以自动检测下载文件,可以设置下载路径和文件名样式。
注:文件下载中所指的下载图片为源代码中的标准样式
标签的图像地址。
例如,如果是直接的图片地址或不规则的图片源代码,采集器 将被视为文件下载。
①将相对地址补全为绝对地址:勾选后,标签采集的相对地址补全为绝对地址。
②下载图片:经核对,源码收录标准样式
将下载代码图像。
③检测文件真实地址但不下载:有时采集到达附件下载地址而不是真实下载地址。点击之后,会有一个跳转。在这种情况下,如果勾选此选项,将显示真实地址采集,但不会仅下载下载地址。
④检测文件并下载:勾选后可以从采集下载任意格式的文件附件。
3、内容过滤:一些不符合条件的记录可以通过设置内容过滤被删除或标记为不接受。有几种方法可以处理内容过滤:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件即可。
②采集 结果不能为空:该功能可以防止某个字段出现空内容。
③采集 结果不能重复:该功能可以防止某个字段出现重复的内容。设置此项前请确保没有采集数据,否则需要先清除采集数据。
④内容长度小于(大于、等于、不等于)时过滤 N:符号或字母或数字或汉字算一个。
注意:如果满足以上四项中的任何一项或多项,您可以在采集器的其他设置功能中直接删除该记录,或将该记录标记为不在采集 采集将在下次运行任务时重复。
在网页抓取工具优采云采集器中进行一系列数据处理的好处是,当我们只需要做一个小操作时,无需编写插件、生成和编译它们,并且可以一键将数据处理成我们需要的数据。

网页抓取工具(开发工具webstorm,ubmserverprofessionalcommander、服务器抓包工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-13 21:05
网页抓取工具的性能问题一直是网页抓取用户用得最多的问题,现在是各大公司网页抓取竞争激烈的时代,我们都希望抓取的网页资源越多越好,毕竟我们是要以服务者的身份在网页上执行的,所以抓取的网页资源越多越好,那么我们通常会用到:开发工具webstorm、服务器工具mozillacommunityserver,ubmserverprofessionalcommander、服务器抓包工具reverse_cookie、服务器压缩工具obs和webhttpcontentheader来抓取网页数据。
按照使用频率或服务器稳定性、抓取质量高低的不同,来有重点的使用一些工具来进行高效的抓取。打包压缩工具:随着python解释器的完善,python的打包工具也逐渐丰富起来。本文对打包工具做一个简单说明,首先大家会对requests.extract()方法比较熟悉,接下来通过几个例子学习一下其他几个常用的方法。
1.requests.extract(pathname)这个方法有两个输出参数pathname和pathname.extract_files。其中pathname为解析的网址,pathname.extract_files为解析的内容文件夹名。2.requests.request.extract(data,url)这个方法在requests.extract()后面接了一个类似:form()的method方法,它用来返回一个request的数据的类,这个类为name。
通过这个类实现request之间的。这个方法中type和方法名参数分别为:type为方法的值,默认是get,相当于requests.get(url)方法,默认是post。cookie:抓取的网页一般都带有这个request带有的信息,用于加载html文件(包括js、json、css等等)或者下载后生成json网页。
blob:html中的原始内容,可直接解析为blob数据。本篇对以上几个常用的方法做简单说明,各大工具之间的差异并不大,本文仅仅给大家简单介绍一下。为了高效的抓取网页数据,我们推荐使用chrome浏览器来解析html文件。fastjson我们先看看fastjson是如何解析html文件的fastjson包含了基本的json库,比如jquery、libjson。
它有以下功能:支持unicode和ascii转换的输出格式,和json格式转换。支持一维数组、二维数组的数据解析。支持datetime、is-datetime、is-nan等函数的解析。支持所有python的函数。其中str、datetime、is-nan被称为structures,它们本身可以作为一个整体使用。
下面以tweenjson来实例python3的示例代码:classtweenjson:def__init__(self,url):self.url=urlself.headers={'host':'gmail','referer':'jsonpipe/chrome/chrome.exe'}def__de。 查看全部
网页抓取工具(开发工具webstorm,ubmserverprofessionalcommander、服务器抓包工具)
网页抓取工具的性能问题一直是网页抓取用户用得最多的问题,现在是各大公司网页抓取竞争激烈的时代,我们都希望抓取的网页资源越多越好,毕竟我们是要以服务者的身份在网页上执行的,所以抓取的网页资源越多越好,那么我们通常会用到:开发工具webstorm、服务器工具mozillacommunityserver,ubmserverprofessionalcommander、服务器抓包工具reverse_cookie、服务器压缩工具obs和webhttpcontentheader来抓取网页数据。
按照使用频率或服务器稳定性、抓取质量高低的不同,来有重点的使用一些工具来进行高效的抓取。打包压缩工具:随着python解释器的完善,python的打包工具也逐渐丰富起来。本文对打包工具做一个简单说明,首先大家会对requests.extract()方法比较熟悉,接下来通过几个例子学习一下其他几个常用的方法。
1.requests.extract(pathname)这个方法有两个输出参数pathname和pathname.extract_files。其中pathname为解析的网址,pathname.extract_files为解析的内容文件夹名。2.requests.request.extract(data,url)这个方法在requests.extract()后面接了一个类似:form()的method方法,它用来返回一个request的数据的类,这个类为name。
通过这个类实现request之间的。这个方法中type和方法名参数分别为:type为方法的值,默认是get,相当于requests.get(url)方法,默认是post。cookie:抓取的网页一般都带有这个request带有的信息,用于加载html文件(包括js、json、css等等)或者下载后生成json网页。
blob:html中的原始内容,可直接解析为blob数据。本篇对以上几个常用的方法做简单说明,各大工具之间的差异并不大,本文仅仅给大家简单介绍一下。为了高效的抓取网页数据,我们推荐使用chrome浏览器来解析html文件。fastjson我们先看看fastjson是如何解析html文件的fastjson包含了基本的json库,比如jquery、libjson。
它有以下功能:支持unicode和ascii转换的输出格式,和json格式转换。支持一维数组、二维数组的数据解析。支持datetime、is-datetime、is-nan等函数的解析。支持所有python的函数。其中str、datetime、is-nan被称为structures,它们本身可以作为一个整体使用。
下面以tweenjson来实例python3的示例代码:classtweenjson:def__init__(self,url):self.url=urlself.headers={'host':'gmail','referer':'jsonpipe/chrome/chrome.exe'}def__de。
网页抓取工具(提取的数据还不能直接拿来用?文件还不符合要求?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-08 22:03
提取出来的数据不能直接使用吗?文件还没有下载?格式等不符合要求?不用担心,网页抓取工具优采云采集器 有自己的解决方案-数据处理。
图片1.png
网络爬虫的数据处理功能包括内容处理、文件下载和内容过滤三部分。下面我依次给大家介绍一下:
1、内容处理:对内容页面中提取的数据进行进一步的处理,例如替换、标签过滤、分词等,我们可以同时添加多个操作,但是这里需要注意的是,当有多个操作,按照上面的顺序执行,也就是将上一步的结果作为下一步的参数。
下面我们一一介绍:
①提取内容为空:如果通过前面的规则无法准确提取提取内容或提取内容为空,请选择此选项。此应用程序后,将使用正则匹配从原创页面中再次提取。
②内容替换/排除:用字符串替换采集的内容。如果需要排除,请用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数替换字符串(不同于工具栏中的同义词替换)。
③html标签过滤:过滤指定的html标签,如④字符截取:通过开始和结束字符串截取内容。适用于提取内容的截取和调整。
⑤纯替换:如果某些内容(如单次出现的文本)无法通过一般的内容替换进行操作,则需要通过强大的正则表达式进行复杂的替换。
例如“最受欢迎的美国餐馆在这里”,我们将其替换为“美国餐馆”,正则表达式如下:
图片2.png
⑥数据转换:包括将结果简转繁、将结果繁转简、自动转化为拼音和时间修正转化,共计四项处理。
⑦智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取。
⑧高级功能:包括自动汇总、自动分词、自动分类、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串A长度等一系列函数。
⑨补全单个网址:将当前内容补全为一个网址。
2、文件下载:可以自动检测下载文件,可以设置下载路径和文件名样式。
注:文件下载中所指的下载图片为源代码中的标准样式
标签的图片地址。
例如,如果是直接的图片地址或不规则的图片源代码,采集器 将被视为文件下载。
①将相对地址补全为绝对地址:勾选后,标签采集的相对地址补全为绝对地址。
②下载图片:经核对,源码收录标准样式
将下载代码图像。
③检测文件的真实地址但不下载:有时采集到达附件下载地址而不是实际下载地址。点击之后,会有一个跳转。在这种情况下,如果勾选此选项,将显示真实地址采集,但不会仅下载下载地址。
④检测文件并下载:勾选后可以从采集下载任意格式的文件附件。
3、内容过滤:一些不符合条件的记录可以通过设置内容过滤被删除或标记为不接受。有几种方法可以处理内容过滤:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件即可。
②采集 结果不能为空:该功能可以防止某个字段出现空内容。
③采集 结果不能重复:该功能可以防止某个字段出现重复的内容。设置此项前请确保没有采集数据,否则需要先清除采集数据。
④内容长度小于(大于、等于、不等于)时过滤 N:符号或字母或数字或汉字算一个。
注意:如果满足以上四项中的任何一项或多项,您可以在采集器的其他设置功能中直接删除该记录,或者将该记录标记为不在采集 采集 将在下次运行任务时重复。
在网页抓取工具优采云采集器中进行一系列数据处理的好处是,当我们只需要做一个小操作时,我们不需要编写插件、生成和编译它们,并且可以一键将数据处理成我们需要的数据。 查看全部
网页抓取工具(提取的数据还不能直接拿来用?文件还不符合要求?)
提取出来的数据不能直接使用吗?文件还没有下载?格式等不符合要求?不用担心,网页抓取工具优采云采集器 有自己的解决方案-数据处理。
图片1.png
网络爬虫的数据处理功能包括内容处理、文件下载和内容过滤三部分。下面我依次给大家介绍一下:
1、内容处理:对内容页面中提取的数据进行进一步的处理,例如替换、标签过滤、分词等,我们可以同时添加多个操作,但是这里需要注意的是,当有多个操作,按照上面的顺序执行,也就是将上一步的结果作为下一步的参数。
下面我们一一介绍:
①提取内容为空:如果通过前面的规则无法准确提取提取内容或提取内容为空,请选择此选项。此应用程序后,将使用正则匹配从原创页面中再次提取。
②内容替换/排除:用字符串替换采集的内容。如果需要排除,请用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数替换字符串(不同于工具栏中的同义词替换)。
③html标签过滤:过滤指定的html标签,如④字符截取:通过开始和结束字符串截取内容。适用于提取内容的截取和调整。
⑤纯替换:如果某些内容(如单次出现的文本)无法通过一般的内容替换进行操作,则需要通过强大的正则表达式进行复杂的替换。
例如“最受欢迎的美国餐馆在这里”,我们将其替换为“美国餐馆”,正则表达式如下:
图片2.png
⑥数据转换:包括将结果简转繁、将结果繁转简、自动转化为拼音和时间修正转化,共计四项处理。
⑦智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取。
⑧高级功能:包括自动汇总、自动分词、自动分类、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串A长度等一系列函数。
⑨补全单个网址:将当前内容补全为一个网址。
2、文件下载:可以自动检测下载文件,可以设置下载路径和文件名样式。
注:文件下载中所指的下载图片为源代码中的标准样式
标签的图片地址。
例如,如果是直接的图片地址或不规则的图片源代码,采集器 将被视为文件下载。
①将相对地址补全为绝对地址:勾选后,标签采集的相对地址补全为绝对地址。
②下载图片:经核对,源码收录标准样式
将下载代码图像。
③检测文件的真实地址但不下载:有时采集到达附件下载地址而不是实际下载地址。点击之后,会有一个跳转。在这种情况下,如果勾选此选项,将显示真实地址采集,但不会仅下载下载地址。
④检测文件并下载:勾选后可以从采集下载任意格式的文件附件。
3、内容过滤:一些不符合条件的记录可以通过设置内容过滤被删除或标记为不接受。有几种方法可以处理内容过滤:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件即可。
②采集 结果不能为空:该功能可以防止某个字段出现空内容。
③采集 结果不能重复:该功能可以防止某个字段出现重复的内容。设置此项前请确保没有采集数据,否则需要先清除采集数据。
④内容长度小于(大于、等于、不等于)时过滤 N:符号或字母或数字或汉字算一个。
注意:如果满足以上四项中的任何一项或多项,您可以在采集器的其他设置功能中直接删除该记录,或者将该记录标记为不在采集 采集 将在下次运行任务时重复。
在网页抓取工具优采云采集器中进行一系列数据处理的好处是,当我们只需要做一个小操作时,我们不需要编写插件、生成和编译它们,并且可以一键将数据处理成我们需要的数据。
网页抓取工具(网页抓取工具怎么用?浏览器安装了chrome扩展)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-01 01:03
网页抓取工具怎么用?ie浏览器安装了chrome扩展可以解决。
任何具有ie插件扩展功能的浏览器,在通过插件成功访问国内某家公司的网站,且获取网页内容后,插件会在浏览器下载相应的页内容,并通过ajax发送给服务器。服务器成功解析后,客户端获取的是服务器指定页内容加上服务器默认域名加随机字符串,就是你看到的国内网站的内容了。
我的体验是,浏览器在线对网站抓取时,获取的是网站服务器上传给浏览器的整个页面的内容,而不是单个页面的内容。同理chrome有三个对web对象请求做提交的方法:1.formdata2.json3.jsonexport其中jsonexport和上面两个中间转换效率较高。详细操作请参考:json格式抓取报错erroroutofmemory。
用爬虫,各种python爬虫。
如果说页面抓取功能的话,我觉得就是人工干预吧。大数据已经可以做到基于历史请求统计页面数据了,至于某些页面以前请求次数很多,不得不考虑是操作系统内核慢等问题。但是页面抓取功能是否已经实现,
请用谷歌浏览器
我有一段时间是用python去抓下我博客网站上面的数据,我的python编程技术对我来说太过于老旧。主要是这个技术可以统计请求的次数,但是什么时候请求?什么时候取得内容?什么时候存入数据库?很难讲清楚,而且因为某些原因,我这个网站采用的是http协议。一但加入了,任何浏览器都可以访问是也无需任何额外的设置。
那么请问作为一个普通用户,请问这样的技术能否获取到我的博客里的数据?我又不需要把整个网站下到本地,也不用不会怎么去采集而是直接在线抓取下来,直接存入数据库。那么我认为没有技术含量的请求次数,取得内容,存入数据库,要求分步骤,一步一步分步完成,爬虫最可能的方式是因为程序太过于笨拙或者我本身太懒,不能完成的好,不想进行之后再改进,而不是解决一个需求就拿来用而不去深入其它性能,安全,工作量之类问题。
python能否代替人工进行判断是否请求,对应请求的样式提取,自动制作响应事件等等工作,难道就没有比现在非常鸡肋的数据库读写操作之类的工作了?要求做的动态更新或者是我并不想深入操作的程序或者是做爬虫本身的我认为就没有必要做了。对比其它语言的操作体验相对于python,没有什么优势的。总结为三点1爬虫可以抓取到单一页面,而人工可以获取页面的大部分,但是不能很精确的获取重要的页面信息。
2需要借助于算法提取信息。3需要具备一定的java编程能力才能做到java代码,flask,nodejs,和golang等后端框架的使用。所以,无论你是爬虫,还是。 查看全部
网页抓取工具(网页抓取工具怎么用?浏览器安装了chrome扩展)
网页抓取工具怎么用?ie浏览器安装了chrome扩展可以解决。
任何具有ie插件扩展功能的浏览器,在通过插件成功访问国内某家公司的网站,且获取网页内容后,插件会在浏览器下载相应的页内容,并通过ajax发送给服务器。服务器成功解析后,客户端获取的是服务器指定页内容加上服务器默认域名加随机字符串,就是你看到的国内网站的内容了。
我的体验是,浏览器在线对网站抓取时,获取的是网站服务器上传给浏览器的整个页面的内容,而不是单个页面的内容。同理chrome有三个对web对象请求做提交的方法:1.formdata2.json3.jsonexport其中jsonexport和上面两个中间转换效率较高。详细操作请参考:json格式抓取报错erroroutofmemory。
用爬虫,各种python爬虫。
如果说页面抓取功能的话,我觉得就是人工干预吧。大数据已经可以做到基于历史请求统计页面数据了,至于某些页面以前请求次数很多,不得不考虑是操作系统内核慢等问题。但是页面抓取功能是否已经实现,
请用谷歌浏览器
我有一段时间是用python去抓下我博客网站上面的数据,我的python编程技术对我来说太过于老旧。主要是这个技术可以统计请求的次数,但是什么时候请求?什么时候取得内容?什么时候存入数据库?很难讲清楚,而且因为某些原因,我这个网站采用的是http协议。一但加入了,任何浏览器都可以访问是也无需任何额外的设置。
那么请问作为一个普通用户,请问这样的技术能否获取到我的博客里的数据?我又不需要把整个网站下到本地,也不用不会怎么去采集而是直接在线抓取下来,直接存入数据库。那么我认为没有技术含量的请求次数,取得内容,存入数据库,要求分步骤,一步一步分步完成,爬虫最可能的方式是因为程序太过于笨拙或者我本身太懒,不能完成的好,不想进行之后再改进,而不是解决一个需求就拿来用而不去深入其它性能,安全,工作量之类问题。
python能否代替人工进行判断是否请求,对应请求的样式提取,自动制作响应事件等等工作,难道就没有比现在非常鸡肋的数据库读写操作之类的工作了?要求做的动态更新或者是我并不想深入操作的程序或者是做爬虫本身的我认为就没有必要做了。对比其它语言的操作体验相对于python,没有什么优势的。总结为三点1爬虫可以抓取到单一页面,而人工可以获取页面的大部分,但是不能很精确的获取重要的页面信息。
2需要借助于算法提取信息。3需要具备一定的java编程能力才能做到java代码,flask,nodejs,和golang等后端框架的使用。所以,无论你是爬虫,还是。
网页抓取工具(基于动态内容抓取JavaScript页面的优势-Proxy)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-30 04:00
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。然而,有很多优秀的网络爬虫工具可用。
1.代理爬网
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
可以免费获取1000个请求,足以探索Proxy Crawl在复杂内容页面中使用的强大功能。
2.Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。Scrapy 抓取框架在从 网站 和网页中提取数据方面做得很好。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及为大型任务执行自动化测试。强大的功能可以与ProxyCrawl***集成。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)变得轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
3.抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用Grab,你可以为小型的个人项目创建爬虫机制,也可以构建可以同时扩展到百万页面的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
4.雪貂
Ferret 是一个相当新的网络爬虫,在开源社区中获得了相当大的吸引力。Ferret 的目标是提供更简洁的客户端爬取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
5.X 射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常简单。
6.Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
7.PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现为 PDF 文档。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您手头的任务需要抓取许多基于 JavaScript 的 网站,这将特别有用。
【编辑推荐】
2018年三大运营商表现如何?分享对 2019 年数据中心行业八大趋势的看法 | 物联网数据需要共享协议优雅读取http请求或响应数据清单:2019年值得关注的5个数据中心趋势 查看全部
网页抓取工具(基于动态内容抓取JavaScript页面的优势-Proxy)
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。然而,有很多优秀的网络爬虫工具可用。
1.代理爬网
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
可以免费获取1000个请求,足以探索Proxy Crawl在复杂内容页面中使用的强大功能。
2.Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。Scrapy 抓取框架在从 网站 和网页中提取数据方面做得很好。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及为大型任务执行自动化测试。强大的功能可以与ProxyCrawl***集成。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)变得轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
3.抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用Grab,你可以为小型的个人项目创建爬虫机制,也可以构建可以同时扩展到百万页面的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
4.雪貂
Ferret 是一个相当新的网络爬虫,在开源社区中获得了相当大的吸引力。Ferret 的目标是提供更简洁的客户端爬取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
5.X 射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常简单。
6.Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
7.PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现为 PDF 文档。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您手头的任务需要抓取许多基于 JavaScript 的 网站,这将特别有用。
【编辑推荐】
2018年三大运营商表现如何?分享对 2019 年数据中心行业八大趋势的看法 | 物联网数据需要共享协议优雅读取http请求或响应数据清单:2019年值得关注的5个数据中心趋势
网页抓取工具(网页文字抓取工具功能特点-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-24 06:03
网页文字抓取工具是一款非常实用的文字下载工具,功能强大实用,简单易用,完全免费使用。当我们在网页上遇到一些无法复制的文字时,这时候就可以使用这个软件来传递网页了。使用 URL 抓取网页的文本并找到您需要的帮助部分。有需要的朋友不要错过。欢迎下载使用!
网页文字爬虫的特点
1、绿色软件,无需安装。
2、 支持键盘ctrl、alt、shift+鼠标左键、中键、右键操作。
3、无法复制的文字可以抓取,但是图片不能抓取。
4、 支持复制常规静态对话框、系统消息和程序选项卡等表单文本。
5、支持鼠标快捷键,Ctrl、Alt、Shift和鼠标左/中/右键的任意组合。
6、 支持在 Chrome 中抓取网页图片的 alt 文本和 url 链接。
网页文字爬虫的使用方法
输入网址后,点击抓取按钮,就OK了。!
网络文本爬虫的主要优点
网页文字抓取器是一款小巧精致的网页文字提取软件,可以让您轻松抓取和复制禁止选择和复制的网页上的文字。对于内容被大面积广告覆盖而无法看到的网页,网上有很多禁止复制的html文件。抓取网页文本抓取器并阅读它也是一个很好的解决方案。
相关新闻
现在IE被边缘化了,我们使用的浏览器大多是WebKit核心,所以当你发现网站设置了禁止复制的权限时,不妨试试把网址拖到IE浏览器上。接下来,说不定会有惊喜哦~
还有一点需要注意的是,现在国内很多浏览器都是双核的。“兼容模式”是IE的核心。也可以点击切换试试看。复制到 IE 是一种效果。
网页文本爬虫评论
绿色,安全可靠,无广告推荐,
细节 查看全部
网页抓取工具(网页文字抓取工具功能特点-上海怡健医学)
网页文字抓取工具是一款非常实用的文字下载工具,功能强大实用,简单易用,完全免费使用。当我们在网页上遇到一些无法复制的文字时,这时候就可以使用这个软件来传递网页了。使用 URL 抓取网页的文本并找到您需要的帮助部分。有需要的朋友不要错过。欢迎下载使用!
网页文字爬虫的特点
1、绿色软件,无需安装。
2、 支持键盘ctrl、alt、shift+鼠标左键、中键、右键操作。
3、无法复制的文字可以抓取,但是图片不能抓取。
4、 支持复制常规静态对话框、系统消息和程序选项卡等表单文本。
5、支持鼠标快捷键,Ctrl、Alt、Shift和鼠标左/中/右键的任意组合。
6、 支持在 Chrome 中抓取网页图片的 alt 文本和 url 链接。
网页文字爬虫的使用方法
输入网址后,点击抓取按钮,就OK了。!
网络文本爬虫的主要优点
网页文字抓取器是一款小巧精致的网页文字提取软件,可以让您轻松抓取和复制禁止选择和复制的网页上的文字。对于内容被大面积广告覆盖而无法看到的网页,网上有很多禁止复制的html文件。抓取网页文本抓取器并阅读它也是一个很好的解决方案。
相关新闻
现在IE被边缘化了,我们使用的浏览器大多是WebKit核心,所以当你发现网站设置了禁止复制的权限时,不妨试试把网址拖到IE浏览器上。接下来,说不定会有惊喜哦~
还有一点需要注意的是,现在国内很多浏览器都是双核的。“兼容模式”是IE的核心。也可以点击切换试试看。复制到 IE 是一种效果。
网页文本爬虫评论
绿色,安全可靠,无广告推荐,
细节
网页抓取工具(前两天遇到一个妹子,她说不会从拉网页,我想用做个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-20 16:08
前两天认识了一个女孩。她说她不会拉网页。想用node做一个这么简单的网页爬虫工具,就开始了安装x之路。
其实这个想法很简单。从url中获取html,从html中解析css、js、image等,单独下载。
难点之一在于路径解析。例如,一般页面是域名。有的页面,路径层次比较深,突然想到sea.js,肯定是路径问题很头疼。简单看了一下,确实其中的规律比其他的要复杂,所以没办法硬着头皮。刚刚看了regular的正零宽度断言,感觉没有之前想的那么难。
另一个问题是另一个是异步多线程。在某些页面中必须有很多图片。我应该使用单线程下载吗?显然不合适,所以需要使用多线程,如何使用多线程请参考我的文章node多线程服务器,这里不再赘述。而这里是多线程请求,直接参考集群模块即可。
另一种是node的异步编程方案,使用async/await函数和promise对象,下载首页时需要阻塞,而下载css、js、image都是同步非阻塞的。
好吧,这么多不如上面的代码:
一个简单的网页抓取工具(节点版)
为什么不在github上获取呢?为您自己的 网站 拉一些流量。
注意:此链接是安全连接,您的cookie不会发送到我的服务器,然后登录您的cnblog,删除您的博客,请放心使用。 查看全部
网页抓取工具(前两天遇到一个妹子,她说不会从拉网页,我想用做个)
前两天认识了一个女孩。她说她不会拉网页。想用node做一个这么简单的网页爬虫工具,就开始了安装x之路。
其实这个想法很简单。从url中获取html,从html中解析css、js、image等,单独下载。
难点之一在于路径解析。例如,一般页面是域名。有的页面,路径层次比较深,突然想到sea.js,肯定是路径问题很头疼。简单看了一下,确实其中的规律比其他的要复杂,所以没办法硬着头皮。刚刚看了regular的正零宽度断言,感觉没有之前想的那么难。
另一个问题是另一个是异步多线程。在某些页面中必须有很多图片。我应该使用单线程下载吗?显然不合适,所以需要使用多线程,如何使用多线程请参考我的文章node多线程服务器,这里不再赘述。而这里是多线程请求,直接参考集群模块即可。
另一种是node的异步编程方案,使用async/await函数和promise对象,下载首页时需要阻塞,而下载css、js、image都是同步非阻塞的。
好吧,这么多不如上面的代码:
一个简单的网页抓取工具(节点版)
为什么不在github上获取呢?为您自己的 网站 拉一些流量。
注意:此链接是安全连接,您的cookie不会发送到我的服务器,然后登录您的cnblog,删除您的博客,请放心使用。
网页抓取工具(网站链接抓取器是一款非常简单且实用的网站抓取软件 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-19 04:01
)
网站链接抓取器是一款非常简单实用的网站链接抓取软件。通过本软件,可以帮助用户快速抓取网站链接,简单直观的操作界面旨在为用户提供最简单的操作。您只需要输入需要查询的域名,一键即可快速抓取URL对应的源码。此外,您还可以获得不同的链接,包括 URL。、图片、脚本和CSS,使用起来非常方便,可以多方面满足你对网站链接获取的不同需求,支持批量获取,可以获取多个不同的链接。总而言之,这是一款非常好用的软件,有需要的赶紧下载体验吧!
软件功能
提供简单的抓取功能,可以快速抓取网站的源码
如果需要爬取网站链接,可以使用本软件
支持批量抓取,可同时抓取不同类型的链接
支持获取URL链接、图片链接、脚本链接等。
支持复制,一键复制你需要的链接
软件特点
操作简单,简单几步即可快速抓取到您需要的链接
获取链接后,可以自动显示获取的链接总数
获取的链接显示在链接列表中,方便快速查看
对应的图片可以通过获取的图片链接下载
指示
1、打开软件,进入软件主界面,运行界面如下图
2、可以在框中输入需要查询的域名,快速输入
3、 输入完成后点击Capture即可快速抓拍
4、 抓取后可以查看网页对应的源码,直接查看
5、选择需要获取的链接,根据需要选择,使用方便
6、如果选择获取URL链接,可以在链接列表中查看获取到的URL链接
7、点击复制,可以快速复制源码和需要的链接
查看全部
网页抓取工具(网站链接抓取器是一款非常简单且实用的网站抓取软件
)
网站链接抓取器是一款非常简单实用的网站链接抓取软件。通过本软件,可以帮助用户快速抓取网站链接,简单直观的操作界面旨在为用户提供最简单的操作。您只需要输入需要查询的域名,一键即可快速抓取URL对应的源码。此外,您还可以获得不同的链接,包括 URL。、图片、脚本和CSS,使用起来非常方便,可以多方面满足你对网站链接获取的不同需求,支持批量获取,可以获取多个不同的链接。总而言之,这是一款非常好用的软件,有需要的赶紧下载体验吧!
软件功能
提供简单的抓取功能,可以快速抓取网站的源码
如果需要爬取网站链接,可以使用本软件
支持批量抓取,可同时抓取不同类型的链接
支持获取URL链接、图片链接、脚本链接等。
支持复制,一键复制你需要的链接
软件特点
操作简单,简单几步即可快速抓取到您需要的链接
获取链接后,可以自动显示获取的链接总数
获取的链接显示在链接列表中,方便快速查看
对应的图片可以通过获取的图片链接下载
指示
1、打开软件,进入软件主界面,运行界面如下图
2、可以在框中输入需要查询的域名,快速输入
3、 输入完成后点击Capture即可快速抓拍
4、 抓取后可以查看网页对应的源码,直接查看
5、选择需要获取的链接,根据需要选择,使用方便
6、如果选择获取URL链接,可以在链接列表中查看获取到的URL链接
7、点击复制,可以快速复制源码和需要的链接
网页抓取工具(Google网站管理员工具提交网站地图文件的步骤及步骤方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-11-15 03:14
步
方法一:
1.打开浏览器,输入在线站点地图的网址网站;
2.在表单中填写要生成站点地图的网页的URL,然后点击提交;
3. 打开生成的数据结果页面,复制文本框中的代码;
4.新建一个文本文件,把代码粘贴进去,然后保存为utf-8格式的文件,文件名是sitemap.xml,然后把这个文件上传到你网站对应的根目录下@>;
5.打开浏览器输入网址,点击右上角登录,用自己的谷歌账号登录,还没有谷歌账号?创建帐户,注册帐户并登录帐户;
6.登录成功后,点击进入用户管理中心,然后点击:网站管理员工具;
7.首先添加您的 URL 链接。添加成功后,点击URL对应项后的添加,打开站点地图添加页面,选择下拉菜单,选择法线图网站,出现下面的文字形式,添加sitemap.xml后空白表格,然后点击提交;
8.好的!站点地图提交成功,请等待5小时google收录你的网站!
方法二:
1.在线生成站点地图网站下载软件:
此类工具需要下载到本地生成地图,生成速度比较快。
2. 运行软件生成sitemap文件:写项目和新建两个栏目,如“sitemapx”或“hongdex”。确认后会显示基本信息。直接默认,点击下一步,然后点击抓取页面。获取网页后,直接点击Generate,然后点击Copy File,选择路径。站点地图文件就这样完成了;
3.通过FTP将sitemap文件提交到网站的根目录:应该就这些了,不明白的可以直接搜索“如何通过ftp工具提交文件”之类的关键词;
4.登录谷歌网站管理员工具提交网站地图站点地图文件:前提是您已经注册了谷歌账号并添加了网站,首页的站点地图栏将直接显示控制台的。点击,提交前输入“sitemap.xml”网站,最后直接点击提交网站。步骤完成!最后,等待谷歌收录网站页面。
至于百度蜘蛛,则是html格式
使用站点地图并登录谷歌
使用谷歌站点地图可以提高网站/webpages在SERP中的排名(或提高SEO效果)。站点地图只会提高网站被收录索引的页面的效率,从这个意义上说,如上所述,网站的整体SEO效果肯定是有帮助的。
但是,Sitemaps 和 网站/webpages 最终出现在 SERP 中的排名没有直接关系。这是两个相关但在实施过程中很少交叉的机制。--当然,如果非要争辩说,随着网站内页收录的增加,网站内的交叉链接的权重也会相应增加,这会对最终的排名,倒是也能在一定程度上是公平的,只是影响会有多大就不好说了。 查看全部
网页抓取工具(Google网站管理员工具提交网站地图文件的步骤及步骤方法)
步
方法一:
1.打开浏览器,输入在线站点地图的网址网站;
2.在表单中填写要生成站点地图的网页的URL,然后点击提交;
3. 打开生成的数据结果页面,复制文本框中的代码;
4.新建一个文本文件,把代码粘贴进去,然后保存为utf-8格式的文件,文件名是sitemap.xml,然后把这个文件上传到你网站对应的根目录下@>;
5.打开浏览器输入网址,点击右上角登录,用自己的谷歌账号登录,还没有谷歌账号?创建帐户,注册帐户并登录帐户;
6.登录成功后,点击进入用户管理中心,然后点击:网站管理员工具;
7.首先添加您的 URL 链接。添加成功后,点击URL对应项后的添加,打开站点地图添加页面,选择下拉菜单,选择法线图网站,出现下面的文字形式,添加sitemap.xml后空白表格,然后点击提交;
8.好的!站点地图提交成功,请等待5小时google收录你的网站!
方法二:
1.在线生成站点地图网站下载软件:
此类工具需要下载到本地生成地图,生成速度比较快。
2. 运行软件生成sitemap文件:写项目和新建两个栏目,如“sitemapx”或“hongdex”。确认后会显示基本信息。直接默认,点击下一步,然后点击抓取页面。获取网页后,直接点击Generate,然后点击Copy File,选择路径。站点地图文件就这样完成了;
3.通过FTP将sitemap文件提交到网站的根目录:应该就这些了,不明白的可以直接搜索“如何通过ftp工具提交文件”之类的关键词;
4.登录谷歌网站管理员工具提交网站地图站点地图文件:前提是您已经注册了谷歌账号并添加了网站,首页的站点地图栏将直接显示控制台的。点击,提交前输入“sitemap.xml”网站,最后直接点击提交网站。步骤完成!最后,等待谷歌收录网站页面。
至于百度蜘蛛,则是html格式
使用站点地图并登录谷歌
使用谷歌站点地图可以提高网站/webpages在SERP中的排名(或提高SEO效果)。站点地图只会提高网站被收录索引的页面的效率,从这个意义上说,如上所述,网站的整体SEO效果肯定是有帮助的。
但是,Sitemaps 和 网站/webpages 最终出现在 SERP 中的排名没有直接关系。这是两个相关但在实施过程中很少交叉的机制。--当然,如果非要争辩说,随着网站内页收录的增加,网站内的交叉链接的权重也会相应增加,这会对最终的排名,倒是也能在一定程度上是公平的,只是影响会有多大就不好说了。
网页抓取工具(搞定大数据信息的基础能力——网页工具优采云采集器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-11-13 23:16
对于开发和应用,信息集成是首要问题。解决这个问题后,可以扩展更多的信息挖掘和相关的组合应用。但是,由于技术的匮乏,很多企业选择将信息采集交给数据外包服务公司,类似于定制,这也是一种高效的获取方式。但是现在你有了大数据业务,还是要全面提升你人员的基础大数据能力,至少在有轻量级数据需求的时候,你可以用自己的技能快速解决。那么我们如何才能拥有这种捕捉大数据信息的基本能力呢?网络爬虫工具优采云采集器作为大数据信息抓取的必备软件,充分发挥了其强大的作用。
优采云采集器V9是一款全网通用的网页数据采集软件。通过采集规则和数据处理相关的设置,可以设置URL、文本、图片、文件等被抓取并进行排序、过滤等一系列处理,完整的呈现给用户可用的数据信息。另外,优采云采集器V9的发布功能也是一大亮点。可自动登录选择数据发布栏目,彻底解放人手的智能工具。
了解网络爬虫工具的操作,可以轻松处理一些不太复杂的数据需求。如果是大数据级别的爬取集成,可能需要更复杂的技术和运行环境,比如频繁复杂的验证码、服务器代理、防御等。采集征服等等。当然,如果懂技术,有条件,企业也可以使用网络爬虫工具优采云采集器进行数据整合,优采云采集器使用分布式高速采集处理系统,多线程可调任务分配,轻松应对大规模海量作业需求。但有时为了再次提高效率,可能需要多个优采云采集器客户端同时运行,
我们正处于大数据时代。医疗、交通、教育、零售、金融、商业……我们都在寻求大数据的突破;各个领域的公司都积极参与市场,以在瞬息万变的市场中站稳脚跟。,但大数据的应用不仅仅是事实,在实践中也并非一帆风顺。面临跨部门跨行业难以共享的信息孤岛和短板;面临大数据技术和产业创新低;面对人才匮乏,大数据如何发展?
除了上面提到的多元学习工具,加强我们的基本能力,不断提高我们的技能,我们还需要有创新的思维和强烈的责任感。时代属于全人类。每个人都可能在这个机会中获得全新的突破。在突破点之前,让我们一起提升自己的能力,以最好的状态迎接机遇,让我们对成功更有信心。返回搜狐查看更多 查看全部
网页抓取工具(搞定大数据信息的基础能力——网页工具优采云采集器)
对于开发和应用,信息集成是首要问题。解决这个问题后,可以扩展更多的信息挖掘和相关的组合应用。但是,由于技术的匮乏,很多企业选择将信息采集交给数据外包服务公司,类似于定制,这也是一种高效的获取方式。但是现在你有了大数据业务,还是要全面提升你人员的基础大数据能力,至少在有轻量级数据需求的时候,你可以用自己的技能快速解决。那么我们如何才能拥有这种捕捉大数据信息的基本能力呢?网络爬虫工具优采云采集器作为大数据信息抓取的必备软件,充分发挥了其强大的作用。
优采云采集器V9是一款全网通用的网页数据采集软件。通过采集规则和数据处理相关的设置,可以设置URL、文本、图片、文件等被抓取并进行排序、过滤等一系列处理,完整的呈现给用户可用的数据信息。另外,优采云采集器V9的发布功能也是一大亮点。可自动登录选择数据发布栏目,彻底解放人手的智能工具。
了解网络爬虫工具的操作,可以轻松处理一些不太复杂的数据需求。如果是大数据级别的爬取集成,可能需要更复杂的技术和运行环境,比如频繁复杂的验证码、服务器代理、防御等。采集征服等等。当然,如果懂技术,有条件,企业也可以使用网络爬虫工具优采云采集器进行数据整合,优采云采集器使用分布式高速采集处理系统,多线程可调任务分配,轻松应对大规模海量作业需求。但有时为了再次提高效率,可能需要多个优采云采集器客户端同时运行,
我们正处于大数据时代。医疗、交通、教育、零售、金融、商业……我们都在寻求大数据的突破;各个领域的公司都积极参与市场,以在瞬息万变的市场中站稳脚跟。,但大数据的应用不仅仅是事实,在实践中也并非一帆风顺。面临跨部门跨行业难以共享的信息孤岛和短板;面临大数据技术和产业创新低;面对人才匮乏,大数据如何发展?
除了上面提到的多元学习工具,加强我们的基本能力,不断提高我们的技能,我们还需要有创新的思维和强烈的责任感。时代属于全人类。每个人都可能在这个机会中获得全新的突破。在突破点之前,让我们一起提升自己的能力,以最好的状态迎接机遇,让我们对成功更有信心。返回搜狐查看更多
网页抓取工具(WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-13 04:19
我要分享的工具是一个Chrome插件,叫做:Web Scraper,这是一个Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以将其用作爬虫工具。
也是因为最近在整理36氪文章的一些标签,打算看看其他网站风投相关的标准,所以找了一家公司,名字叫:“艾诺克斯数据” 网站,它提供的一套“行业系统”标签很有参考价值。我想抓取页面上的数据,并集成到我们自己的标签库中,如下图红字部分所示:
如果是规则中显示的数据,也可以用鼠标选中并复制粘贴,但还是需要想办法将其嵌入到页面中。这时候想起之前安装过Web Scraper,就试了一下。使用起来相当方便,采集效率一下子提高了。也给大家安利~
一年前在一个三班的公开课上看到了Chrome插件Web Scraper。号称是不懂编程也能实现爬虫爬虫的黑科技,但是在三类的官网上好像找不到。你可以百度:“三课爬虫”还是可以搜索到的。名字叫《人人都能学的数据爬虫类》,不过好像要收费100元。我觉得这个东西可以看网上的文章,比如我的文章~
简单的说,Web Scraper是一个基于Chrome的网页元素解析器,可以通过可视化的点击操作,实现自定义区域的数据/元素提取。同时,它还提供了定时自动提取功能,使用该功能可以作为一个简单的爬虫工具。
下面我将解释网页提取器抓取和真实代码抓取器之间的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它允许您定义要抓取的页面上的哪个元素。,以及抓取哪些页面,然后让机器代人操作;而如果你用Python写爬虫,更多的是使用网页请求命令下载整个网页,然后用代码解析HTML页面元素,提取你想要的内容,然后不断循环. 相比之下,使用代码会更灵活,但解析的成本会更高。如果是简单的页面内容提取,我也推荐使用Web Scraper。
关于Web Scraper的具体安装过程以及完整功能的使用方法,今天在文章中不再赘述。一是我只用了自己需要的部分,二是因为市面上的Web Scraper教程太多了,你可以自己找。
这里只是一个实际的过程,给大家简单介绍一下我的使用方法。
第一步是创建站点地图
打开Chrome浏览器,按F12调出开发者工具。单击最后一个选项卡上的 Web Scraper 后,选择“创建站点地图”菜单并单击“创建站点地图”选项。
首先输入你要爬取的网站 URL,以及你自定义的爬取任务的名称。比如我取的名字是:xiniulevel,网址是:
第二步,创建抓取节点
我要抓取的是一级标签和二级标签,所以先在我刚刚创建的Sitemap里面点击,然后点击“添加新选择器”进入抓取节点选择器配置页面,点击“选择”按钮。当你会看到一个浮动层
此时,当您将鼠标移入网页时,它会自动以绿色突出显示您悬停的某个位置。这时候你可以先点击一个你想选择的方块,你会发现方块变成了红色。如果要选中所有同级别的块,可以继续点击旁边的下一个块,工具会默认选中所有同级别的块,如下图:
我们会发现下面浮动窗口的文本输入框自动填充了块的XPATH路径,然后点击“完成选择!” 结束选择,浮动框消失,选中的XPATH自动填入下面的Selector行。另外,一定要选择“Multiple”来声明要选择多个块。最后,单击保存选择器按钮结束。
第三步,获取元素值
完成Selector的创建后,回到上一页,会发现Selector表多了一行,然后可以直接点击Action中的Data preview查看所有的元素值你想得到。
上图所示的部分是我添加了两个Selector,主标签和副标签的情况。点击数据预览的弹窗内容其实就是我想要的,复制到EXCEL就好了,不需要太复杂。自动抓取处理。
以上是对Web Scraper的使用过程的简单介绍。当然,我的使用并不是完全高效,因为每次想要获取二级标签,都得先手动切换一级标签,然后再执行抓取指令。应该有更好的方法,但对我来说已经足够了。本文文章主要想和大家普及一下这个工具。这不是教程。更多功能根据自己的需要去探索吧~ 查看全部
网页抓取工具(WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
我要分享的工具是一个Chrome插件,叫做:Web Scraper,这是一个Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以将其用作爬虫工具。
也是因为最近在整理36氪文章的一些标签,打算看看其他网站风投相关的标准,所以找了一家公司,名字叫:“艾诺克斯数据” 网站,它提供的一套“行业系统”标签很有参考价值。我想抓取页面上的数据,并集成到我们自己的标签库中,如下图红字部分所示:
如果是规则中显示的数据,也可以用鼠标选中并复制粘贴,但还是需要想办法将其嵌入到页面中。这时候想起之前安装过Web Scraper,就试了一下。使用起来相当方便,采集效率一下子提高了。也给大家安利~
一年前在一个三班的公开课上看到了Chrome插件Web Scraper。号称是不懂编程也能实现爬虫爬虫的黑科技,但是在三类的官网上好像找不到。你可以百度:“三课爬虫”还是可以搜索到的。名字叫《人人都能学的数据爬虫类》,不过好像要收费100元。我觉得这个东西可以看网上的文章,比如我的文章~
简单的说,Web Scraper是一个基于Chrome的网页元素解析器,可以通过可视化的点击操作,实现自定义区域的数据/元素提取。同时,它还提供了定时自动提取功能,使用该功能可以作为一个简单的爬虫工具。
下面我将解释网页提取器抓取和真实代码抓取器之间的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它允许您定义要抓取的页面上的哪个元素。,以及抓取哪些页面,然后让机器代人操作;而如果你用Python写爬虫,更多的是使用网页请求命令下载整个网页,然后用代码解析HTML页面元素,提取你想要的内容,然后不断循环. 相比之下,使用代码会更灵活,但解析的成本会更高。如果是简单的页面内容提取,我也推荐使用Web Scraper。
关于Web Scraper的具体安装过程以及完整功能的使用方法,今天在文章中不再赘述。一是我只用了自己需要的部分,二是因为市面上的Web Scraper教程太多了,你可以自己找。
这里只是一个实际的过程,给大家简单介绍一下我的使用方法。
第一步是创建站点地图
打开Chrome浏览器,按F12调出开发者工具。单击最后一个选项卡上的 Web Scraper 后,选择“创建站点地图”菜单并单击“创建站点地图”选项。
首先输入你要爬取的网站 URL,以及你自定义的爬取任务的名称。比如我取的名字是:xiniulevel,网址是:
第二步,创建抓取节点
我要抓取的是一级标签和二级标签,所以先在我刚刚创建的Sitemap里面点击,然后点击“添加新选择器”进入抓取节点选择器配置页面,点击“选择”按钮。当你会看到一个浮动层
此时,当您将鼠标移入网页时,它会自动以绿色突出显示您悬停的某个位置。这时候你可以先点击一个你想选择的方块,你会发现方块变成了红色。如果要选中所有同级别的块,可以继续点击旁边的下一个块,工具会默认选中所有同级别的块,如下图:
我们会发现下面浮动窗口的文本输入框自动填充了块的XPATH路径,然后点击“完成选择!” 结束选择,浮动框消失,选中的XPATH自动填入下面的Selector行。另外,一定要选择“Multiple”来声明要选择多个块。最后,单击保存选择器按钮结束。
第三步,获取元素值
完成Selector的创建后,回到上一页,会发现Selector表多了一行,然后可以直接点击Action中的Data preview查看所有的元素值你想得到。
上图所示的部分是我添加了两个Selector,主标签和副标签的情况。点击数据预览的弹窗内容其实就是我想要的,复制到EXCEL就好了,不需要太复杂。自动抓取处理。
以上是对Web Scraper的使用过程的简单介绍。当然,我的使用并不是完全高效,因为每次想要获取二级标签,都得先手动切换一级标签,然后再执行抓取指令。应该有更好的方法,但对我来说已经足够了。本文文章主要想和大家普及一下这个工具。这不是教程。更多功能根据自己的需要去探索吧~
网页抓取工具(阅读全文如何用Python进行网页抓取作者:小旋风(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-10 12:15
阿里云>云栖社区>主题地图>C>chrome Grab网站
推荐活动:
更多优惠>
当前话题:chrome 抢网站加入采集
相关话题:
chrome抓取网站相关博客,查看更多博客
Fiddler无法抓取Chrome包的解决方法
作者:于尔武 3251人浏览评论:04年前
使用Fiddler的时候发现用Chrome访问页面Fiddler没有抓包。我认为这是Windows防火墙的问题。关闭后,抓包失败。后来发现是因为平时通过GoAgent访问海外。网站,在 Chrome 中使用了插件 Proxy SwitchySharp。
阅读全文
【转】详细讲解爬取网站、模拟登录、爬取动态网页(Python、C#等)的原理及实现
作者:cxycappuccino2498 人浏览评论:08年前
转自:摘要 本文主要介绍爬取网站,模拟
阅读全文
初学者指南 | 使用 Python 抓取网页
作者:小轩峰柴金2425人浏览评论:04年前
简介 从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种在线数据科学课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。
阅读全文
如何使用 Python 抓取数据?(一)网页抓取
作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的消息。许多评论都是来自读者的提问。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
实用的Chrome插件推荐
作者:科技小胖子1964人浏览评论:04年前
我已经使用 Chrome 很长时间了。我第一次使用火狐。后来实在受不了FireFox插件的兼容性和乱七八糟的插件UI(大小、位置、设计等)。Chrome 的插件非常强大。,使用Chrome的乐趣在于自己搭配插件。我的一个朋友插件很少。我觉得他太可怜了。
阅读全文
如何用Python实现网络爬虫?
作者:oneapm_official1884 人浏览评论:05年前
【编者按】本文作者为Blog Bowl联合创始人Shaumik Daityari。主要介绍了网页抓取技术的基本原理和方法。文章由国内ITOM管理平台OneAPM编译呈现。以下是正文。随着电子商务的蓬勃发展,作者近年来对比价应用越来越着迷。
阅读全文
关于爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站(转)
作者:朱老教授 1373人浏览评论:04年前
抓取网页的一般逻辑和过程,一般是针对普通用户使用浏览器打开某个网址,然后浏览器就可以显示相应页面的内容。这个过程如果用程序代码实现,就可以调用(用程序实现)爬取(网页内容,进行后处理,提取需要的信息等)。对应的英文是,网站
阅读全文
Chrome 会标记不安全的 http 连接
作者:迟来凤姬 1003人浏览评论:04年前
谷歌终于开始推进其在 Chrome 上标记不安全 HTTP 连接的计划。不过,新的安全计划也将逐步实施。计划从 2017 年 1 月开始,Chrome 56 将标记不安全的网站,例如收录密码或信用卡信息传输的 HTTP 页面。“Chrome 当前的 HTTP 标准
阅读全文
chrome抓取网站相关问答
【Javascript学习全家桶】934道javascript热点题,阿里巴巴100位技术专家答疑解惑
作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你困惑只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来云栖为您解答技术问题。他们使用自己手中的技术来帮助用户成长。本次活动邀请数百位阿里巴巴技术
阅读全文 查看全部
网页抓取工具(阅读全文如何用Python进行网页抓取作者:小旋风(组图))
阿里云>云栖社区>主题地图>C>chrome Grab网站
推荐活动:
更多优惠>
当前话题:chrome 抢网站加入采集
相关话题:
chrome抓取网站相关博客,查看更多博客
Fiddler无法抓取Chrome包的解决方法
作者:于尔武 3251人浏览评论:04年前
使用Fiddler的时候发现用Chrome访问页面Fiddler没有抓包。我认为这是Windows防火墙的问题。关闭后,抓包失败。后来发现是因为平时通过GoAgent访问海外。网站,在 Chrome 中使用了插件 Proxy SwitchySharp。
阅读全文
【转】详细讲解爬取网站、模拟登录、爬取动态网页(Python、C#等)的原理及实现
作者:cxycappuccino2498 人浏览评论:08年前
转自:摘要 本文主要介绍爬取网站,模拟
阅读全文
初学者指南 | 使用 Python 抓取网页
作者:小轩峰柴金2425人浏览评论:04年前
简介 从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种在线数据科学课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。
阅读全文
如何使用 Python 抓取数据?(一)网页抓取
作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的消息。许多评论都是来自读者的提问。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
实用的Chrome插件推荐
作者:科技小胖子1964人浏览评论:04年前
我已经使用 Chrome 很长时间了。我第一次使用火狐。后来实在受不了FireFox插件的兼容性和乱七八糟的插件UI(大小、位置、设计等)。Chrome 的插件非常强大。,使用Chrome的乐趣在于自己搭配插件。我的一个朋友插件很少。我觉得他太可怜了。
阅读全文
如何用Python实现网络爬虫?
作者:oneapm_official1884 人浏览评论:05年前
【编者按】本文作者为Blog Bowl联合创始人Shaumik Daityari。主要介绍了网页抓取技术的基本原理和方法。文章由国内ITOM管理平台OneAPM编译呈现。以下是正文。随着电子商务的蓬勃发展,作者近年来对比价应用越来越着迷。
阅读全文
关于爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站(转)
作者:朱老教授 1373人浏览评论:04年前
抓取网页的一般逻辑和过程,一般是针对普通用户使用浏览器打开某个网址,然后浏览器就可以显示相应页面的内容。这个过程如果用程序代码实现,就可以调用(用程序实现)爬取(网页内容,进行后处理,提取需要的信息等)。对应的英文是,网站
阅读全文
Chrome 会标记不安全的 http 连接
作者:迟来凤姬 1003人浏览评论:04年前
谷歌终于开始推进其在 Chrome 上标记不安全 HTTP 连接的计划。不过,新的安全计划也将逐步实施。计划从 2017 年 1 月开始,Chrome 56 将标记不安全的网站,例如收录密码或信用卡信息传输的 HTTP 页面。“Chrome 当前的 HTTP 标准
阅读全文
chrome抓取网站相关问答
【Javascript学习全家桶】934道javascript热点题,阿里巴巴100位技术专家答疑解惑
作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你困惑只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来云栖为您解答技术问题。他们使用自己手中的技术来帮助用户成长。本次活动邀请数百位阿里巴巴技术
阅读全文
网页抓取工具( Google不会发布一个公开的IP地址列表供网站所有者添加到许可名单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-06 08:20
Google不会发布一个公开的IP地址列表供网站所有者添加到许可名单)
验证 Googlebot 和其他 Google 抓取工具
您可以验证访问您服务器的网络抓取工具确实是 Google 抓取工具,例如 Googlebot。如果您担心声称自己是 Googlebot 的垃圾邮件发送者或其他麻烦制造者正在访问您的 网站,您会发现此方法非常有用。 Google 不会发布公开的 IP 地址列表供 网站 所有者添加到权限列表中。这是因为这些 IP 地址范围可能会发生变化,从而导致对它们进行硬编码的 网站 所有者出现问题。因此,您必须按如下所述运行 DNS 查找。
验证抓取工具是 Googlebot(或其他 Google 抓取工具)。使用命令行工具使用 host 命令对日志中访问服务器的 IP 地址运行反向 DNS 查找。验证域名是否为或。使用host命令对步骤1中检索到的域名进行正向DNS查找,验证该域名是否与日志中访问服务器的原创IP地址一致。
示例 1:
> host 66.249.66.1
1.66.249.66.in-addr.arpa domain name pointer crawl-66-249-66-1.googlebot.com.
> host crawl-66-249-66-1.googlebot.com
crawl-66-249-66-1.googlebot.com has address 66.249.66.1
示例 2:
> host 66.249.90.77
77.90.249.66.in-addr.arpa domain name pointer rate-limited-proxy-66-249-90-77.google.com.
> host rate-limited-proxy-66-249-90-77.google.com
rate-limited-proxy-66-249-90-77.google.com has address 66.249.90.77
使用自动化解决方案
Google 不提供可识别其抓取工具的软件库。您可以使用开源库来验证 Googlebot。 查看全部
网页抓取工具(
Google不会发布一个公开的IP地址列表供网站所有者添加到许可名单)
验证 Googlebot 和其他 Google 抓取工具
您可以验证访问您服务器的网络抓取工具确实是 Google 抓取工具,例如 Googlebot。如果您担心声称自己是 Googlebot 的垃圾邮件发送者或其他麻烦制造者正在访问您的 网站,您会发现此方法非常有用。 Google 不会发布公开的 IP 地址列表供 网站 所有者添加到权限列表中。这是因为这些 IP 地址范围可能会发生变化,从而导致对它们进行硬编码的 网站 所有者出现问题。因此,您必须按如下所述运行 DNS 查找。
验证抓取工具是 Googlebot(或其他 Google 抓取工具)。使用命令行工具使用 host 命令对日志中访问服务器的 IP 地址运行反向 DNS 查找。验证域名是否为或。使用host命令对步骤1中检索到的域名进行正向DNS查找,验证该域名是否与日志中访问服务器的原创IP地址一致。
示例 1:
> host 66.249.66.1
1.66.249.66.in-addr.arpa domain name pointer crawl-66-249-66-1.googlebot.com.
> host crawl-66-249-66-1.googlebot.com
crawl-66-249-66-1.googlebot.com has address 66.249.66.1
示例 2:
> host 66.249.90.77
77.90.249.66.in-addr.arpa domain name pointer rate-limited-proxy-66-249-90-77.google.com.
> host rate-limited-proxy-66-249-90-77.google.com
rate-limited-proxy-66-249-90-77.google.com has address 66.249.90.77
使用自动化解决方案
Google 不提供可识别其抓取工具的软件库。您可以使用开源库来验证 Googlebot。
网页抓取工具(搜索关键字“网页格式转换”python处理数据必备语言)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-02 03:05
网页抓取工具和网页数据库存储系统初期阶段。一般来说,就目前来看,市面上实现网页数据格式重定向的网页抓取工具主要有:inkscapexpathseedmapapikicheapicabba等。前两个可以看做html的变种数据表示,即基于pythonjs函数库实现的原生网页数据类型的直接呈现。而后者(如inkscapexpathseedmapapicabba)最初实现的功能更像是一个blob文件集合,里面的元素可以包括:标题、url、分页页码、属性、类名等。
基于一个列表(list)的简单数据存储。网页数据库存储系统只有webdav类,如coboldbg;ui类jiespan协议中规定了三种协议格式,分别是标准格式uri#pathname,uri#name,uri#pagename,使用\即转换为\对应的elf格式。而传统的存储为linux系统下libjpeg格式,为elf格式则可以创建libjpeg.elf文件,再通过jar包通过网页parser加载。
所以根据技术类型的不同,txt数据格式转换为jar包都很容易,类似的工具也很多,github上可以找到比较多的。如getjpeg这个项目。
搜索关键字“网页格式转换”
python处理数据必备语言。
大家好,我是“水逆君”,下面是“网页格式转换”中自己比较了解的python语言,在网上收集了网页的格式转换方法,希望大家能够积极参与,跟python无所不能的天网工程师一起坚守岗位,以便得到更多的生产力技能,更快地得到提升。python的网页转换,会包括使用urllib库进行url转换;mysql客户端脚本;postgresql格式转换;http资源网络连接中的基础数据包转换。
我以下介绍下python语言与mysql的数据库连接方法;none库连接方法假设使用的是mysql数据库,首先介绍下none库和python对应的blob库使用方法,以下简单介绍连接方法;1.postgresql方法result='xxx.xxx.xxx.xxx'#一个名字为string的文本形式的字符串,带标签,label,如"产品名称:xxx"是一个“xxx”型状态消息'''#输出信息print(result)#打印'xxx'状态消息print(blob)#打印mysql数据库的路径名""'''#输出基本信息和状态信息'''#连接用户名和密码是db_name="xxx"#连接服务器在数据库上设置#这样的操作有风险,请注意,python对数据库并不熟悉,如果存在缺失可能造成连接失败,建议详细看下脚本;'''#重启数据库并重命名db_name为"xxx"因为官方文档所言是默认启用postgresql服务none操作相当于单一的select,返回某一范围内的值postgresql中只有两种数据库:postgresdb、blobblobprepare。 查看全部
网页抓取工具(搜索关键字“网页格式转换”python处理数据必备语言)
网页抓取工具和网页数据库存储系统初期阶段。一般来说,就目前来看,市面上实现网页数据格式重定向的网页抓取工具主要有:inkscapexpathseedmapapikicheapicabba等。前两个可以看做html的变种数据表示,即基于pythonjs函数库实现的原生网页数据类型的直接呈现。而后者(如inkscapexpathseedmapapicabba)最初实现的功能更像是一个blob文件集合,里面的元素可以包括:标题、url、分页页码、属性、类名等。
基于一个列表(list)的简单数据存储。网页数据库存储系统只有webdav类,如coboldbg;ui类jiespan协议中规定了三种协议格式,分别是标准格式uri#pathname,uri#name,uri#pagename,使用\即转换为\对应的elf格式。而传统的存储为linux系统下libjpeg格式,为elf格式则可以创建libjpeg.elf文件,再通过jar包通过网页parser加载。
所以根据技术类型的不同,txt数据格式转换为jar包都很容易,类似的工具也很多,github上可以找到比较多的。如getjpeg这个项目。
搜索关键字“网页格式转换”
python处理数据必备语言。
大家好,我是“水逆君”,下面是“网页格式转换”中自己比较了解的python语言,在网上收集了网页的格式转换方法,希望大家能够积极参与,跟python无所不能的天网工程师一起坚守岗位,以便得到更多的生产力技能,更快地得到提升。python的网页转换,会包括使用urllib库进行url转换;mysql客户端脚本;postgresql格式转换;http资源网络连接中的基础数据包转换。
我以下介绍下python语言与mysql的数据库连接方法;none库连接方法假设使用的是mysql数据库,首先介绍下none库和python对应的blob库使用方法,以下简单介绍连接方法;1.postgresql方法result='xxx.xxx.xxx.xxx'#一个名字为string的文本形式的字符串,带标签,label,如"产品名称:xxx"是一个“xxx”型状态消息'''#输出信息print(result)#打印'xxx'状态消息print(blob)#打印mysql数据库的路径名""'''#输出基本信息和状态信息'''#连接用户名和密码是db_name="xxx"#连接服务器在数据库上设置#这样的操作有风险,请注意,python对数据库并不熟悉,如果存在缺失可能造成连接失败,建议详细看下脚本;'''#重启数据库并重命名db_name为"xxx"因为官方文档所言是默认启用postgresql服务none操作相当于单一的select,返回某一范围内的值postgresql中只有两种数据库:postgresdb、blobblobprepare。
网页抓取工具( Web收集数据科学家的6种重要技能开发工具是因为)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-29 15:12
Web收集数据科学家的6种重要技能开发工具是因为)
大家好,欢迎来到pypyai游乐园!
任何数据科学项目都离不开数据。没有数据就没有“数据科学”。大多数数据科学项目中用于分析和构建机器学习模型的数据都存储在数据库中,但有时数据也来自互联网。
您可以从某个网页采集有关某个产品的数据,或者从社交媒体中发现某种模式,也许是情感分析。无论您为什么采集数据或计划如何使用它,从 Web 采集数据(Web 抓取)都是一项非常繁琐的任务。你需要做一些乏味的工作来实现你的目标。
网页抓取是您作为数据科学家需要掌握的重要技能之一。为了使结果准确且有意义,您需要知道如何查找、采集和清理数据。
网页抓取一直是法律的灰色地带。在我们深入研究数据提取工具之前,我们需要确保您的活动完全合法。2020年,美国法院将全面合法化在互联网上抓取公共数据。换句话说,如果任何人都可以在网上找到数据(例如Wiki文章),那么爬取网页也是合法的。
但是,在执行此操作时,请确保:
1、您不会以侵犯版权的方式重复使用或重新发布数据。
2、您尊重您要爬取的网站的服务条款。
3、您的抓取速度合理。
4、您不应该尝试抓取 网站 的非共享内容。
只要您不违反任何这些条款,您的网络抓取活动就是合法的。
如果你使用 Python 构建一个数据科学项目,你可以使用 BeatifulSoup 来采集数据,然后使用 Pandas 来分析它。本文将为您提供 6 款不收录 BeatifulSoup 的网页抓取工具,您可以免费使用它们来采集您下一个项目所需的数据。
公共爬网
网址:
Common Crawl 的开发人员开发了这个工具,因为他们相信每个人都应该有机会探索和分析他们周围的世界并发现它的模式。他们坚持开源信念,提供只有大公司和研究机构才能免费获得的高质量数据。
这意味着,如果你是一名正在探索数据科学领域的大学生,或者是一个正在寻找下一个感兴趣话题的研究人员,或者只是一个喜欢揭示模式和寻找趋势的好奇者,你可以使用这个工具而无需担心关于费用或任何其他复杂的财务问题。
Common Crawl 提供原创 Web 数据和用于文本提取的开放数据集。为了方便教育者教授数据分析,它还提供了无需编码的用例和资源。
爬行
网址:
Crawly 是另一个了不起的爬虫工具,特别是如果你只需要从网站 中提取基本数据,或者你想提取 CSV 格式的数据,你不想写任何代码来分析它的时候。
您需要做的就是输入一个 URL,发送电子邮件地址以提取数据,以及所需的数据格式(在 CSV 或 JSON 之间选择)。然后立即,捕获的数据在您的邮件收件箱中。您可以使用 JSON 格式,然后使用 Pandas 和 Matplotlib 或任何其他编程语言来分析 Python 中的数据。
如果您不是程序员,或者刚开始使用数据科学和网络抓取技术,Crawly 是完美的选择,但它有其局限性。它只能提取一组有限的 HTML 标签,包括标题、作者、图像 URL 和发布者。
内容抓取器
网址:
Content Grabber 是我最喜欢的网络抓取工具之一,因为它非常灵活。如果您只想抓取网页而不想指定任何其他参数,则可以使用其简单的 GUI 进行操作。但是 Content Grabber 还可以让您完全控制参数选择。
Content Grabber 的优点之一是您可以安排它自动从 Web 抓取信息。众所周知,大多数网页都会定期更新,因此定期提取内容非常有用。
它还为提取的数据提供多种格式,从 CSV、JSON 到 SQL Server 或 MySQL。
网管网
网址:
Webhose.io 是一种网络抓取工具,可让您从任何在线资源中提取企业级实时数据。Webhose.io 采集的数据结构化,清晰地收录情感和实体识别,可以使用不同的格式,如 XML、RSS 和 JSON。
Webhose.io 数据涵盖所有公开的网站。此外,它提供了许多过滤器来优化提取的数据,因此只需要较少的清理工作,可以直接进入分析阶段。
Webhose.io 的免费版本每月提供 1,000 个 HTTP 请求。付费计划提供更多爬网请求。Webhose.io具有强大的数据提取支持,并提供图像分析、地理定位等多项功能,以及长达10年的历史数据存档。
分析中心
网址:
ParseHub 是一个强大的网络抓取工具,任何人都可以免费使用。只需单击一个按钮,即可提供可靠且准确的数据提取。还可以设置爬取时间,及时更新数据。
ParseHub 的优势之一是它可以轻松处理复杂的网页。您甚至可以指示它搜索表单、菜单、登录 网站,甚至单击图像或地图以获取更多数据。
您还可以为 ParseHub 提供各种链接和一些关键字,几秒钟就可以提取相关信息。最后,您可以使用 REST API 以 JSON 或 CSV 格式下载提取的数据进行分析。您还可以将采集的数据导出为 Google Sheets 或 Tableau。
刮蜂
网址:
我们介绍的最后一个抓取工具是 Scrapingbee。Scrapingbee 提供了一个用于网页抓取的 API,它甚至可以处理最复杂的 Javascript 页面并将它们转换为原创 HTML 供您使用。此外,它还具有专用 API,可用于使用 Google 搜索进行网络抓取。
Scrapingbee 可以通过以下三种方式之一使用:
例如,定期进行网络爬行以提取股票价格或客户评论。搜索引擎结果页面通常用于 SEO 或关键字监控。增长黑客包括提取联系信息或社交媒体信息。
Scrapingbee 提供免费计划,其中包括 1000 次限制和无限使用的付费计划。
最后
在数据科学项目工作流程中,为项目采集数据可能是最有趣也最乏味的一步。这项任务可能会非常耗时,如果你在公司工作,甚至作为自由职业者,你都知道时间就是金钱,这总是意味着如果有更有效的方法来做某事,最好用好它。
好消息是网络爬行不必太麻烦。您不需要执行它,甚至不需要花费大量时间手动执行它。使用正确的工具可以帮助您节省大量时间、金钱和精力。此外,这些工具可能对分析师或编码背景不足的人有用。
当你想选择一个爬取网页的工具时,你需要考虑以下几个因素,比如API集成度和大规模爬取的可扩展性。本文为您提供了一些可用于不同数据采集机制的工具。使用这些工具来确定哪种方法可以为下一个数据采集项目事半功倍。
原文链接: 查看全部
网页抓取工具(
Web收集数据科学家的6种重要技能开发工具是因为)
大家好,欢迎来到pypyai游乐园!
任何数据科学项目都离不开数据。没有数据就没有“数据科学”。大多数数据科学项目中用于分析和构建机器学习模型的数据都存储在数据库中,但有时数据也来自互联网。
您可以从某个网页采集有关某个产品的数据,或者从社交媒体中发现某种模式,也许是情感分析。无论您为什么采集数据或计划如何使用它,从 Web 采集数据(Web 抓取)都是一项非常繁琐的任务。你需要做一些乏味的工作来实现你的目标。
网页抓取是您作为数据科学家需要掌握的重要技能之一。为了使结果准确且有意义,您需要知道如何查找、采集和清理数据。
网页抓取一直是法律的灰色地带。在我们深入研究数据提取工具之前,我们需要确保您的活动完全合法。2020年,美国法院将全面合法化在互联网上抓取公共数据。换句话说,如果任何人都可以在网上找到数据(例如Wiki文章),那么爬取网页也是合法的。
但是,在执行此操作时,请确保:
1、您不会以侵犯版权的方式重复使用或重新发布数据。
2、您尊重您要爬取的网站的服务条款。
3、您的抓取速度合理。
4、您不应该尝试抓取 网站 的非共享内容。
只要您不违反任何这些条款,您的网络抓取活动就是合法的。
如果你使用 Python 构建一个数据科学项目,你可以使用 BeatifulSoup 来采集数据,然后使用 Pandas 来分析它。本文将为您提供 6 款不收录 BeatifulSoup 的网页抓取工具,您可以免费使用它们来采集您下一个项目所需的数据。
公共爬网
网址:
Common Crawl 的开发人员开发了这个工具,因为他们相信每个人都应该有机会探索和分析他们周围的世界并发现它的模式。他们坚持开源信念,提供只有大公司和研究机构才能免费获得的高质量数据。
这意味着,如果你是一名正在探索数据科学领域的大学生,或者是一个正在寻找下一个感兴趣话题的研究人员,或者只是一个喜欢揭示模式和寻找趋势的好奇者,你可以使用这个工具而无需担心关于费用或任何其他复杂的财务问题。
Common Crawl 提供原创 Web 数据和用于文本提取的开放数据集。为了方便教育者教授数据分析,它还提供了无需编码的用例和资源。
爬行
网址:
Crawly 是另一个了不起的爬虫工具,特别是如果你只需要从网站 中提取基本数据,或者你想提取 CSV 格式的数据,你不想写任何代码来分析它的时候。
您需要做的就是输入一个 URL,发送电子邮件地址以提取数据,以及所需的数据格式(在 CSV 或 JSON 之间选择)。然后立即,捕获的数据在您的邮件收件箱中。您可以使用 JSON 格式,然后使用 Pandas 和 Matplotlib 或任何其他编程语言来分析 Python 中的数据。
如果您不是程序员,或者刚开始使用数据科学和网络抓取技术,Crawly 是完美的选择,但它有其局限性。它只能提取一组有限的 HTML 标签,包括标题、作者、图像 URL 和发布者。
内容抓取器
网址:
Content Grabber 是我最喜欢的网络抓取工具之一,因为它非常灵活。如果您只想抓取网页而不想指定任何其他参数,则可以使用其简单的 GUI 进行操作。但是 Content Grabber 还可以让您完全控制参数选择。
Content Grabber 的优点之一是您可以安排它自动从 Web 抓取信息。众所周知,大多数网页都会定期更新,因此定期提取内容非常有用。
它还为提取的数据提供多种格式,从 CSV、JSON 到 SQL Server 或 MySQL。
网管网
网址:
Webhose.io 是一种网络抓取工具,可让您从任何在线资源中提取企业级实时数据。Webhose.io 采集的数据结构化,清晰地收录情感和实体识别,可以使用不同的格式,如 XML、RSS 和 JSON。
Webhose.io 数据涵盖所有公开的网站。此外,它提供了许多过滤器来优化提取的数据,因此只需要较少的清理工作,可以直接进入分析阶段。
Webhose.io 的免费版本每月提供 1,000 个 HTTP 请求。付费计划提供更多爬网请求。Webhose.io具有强大的数据提取支持,并提供图像分析、地理定位等多项功能,以及长达10年的历史数据存档。
分析中心
网址:
ParseHub 是一个强大的网络抓取工具,任何人都可以免费使用。只需单击一个按钮,即可提供可靠且准确的数据提取。还可以设置爬取时间,及时更新数据。
ParseHub 的优势之一是它可以轻松处理复杂的网页。您甚至可以指示它搜索表单、菜单、登录 网站,甚至单击图像或地图以获取更多数据。
您还可以为 ParseHub 提供各种链接和一些关键字,几秒钟就可以提取相关信息。最后,您可以使用 REST API 以 JSON 或 CSV 格式下载提取的数据进行分析。您还可以将采集的数据导出为 Google Sheets 或 Tableau。
刮蜂
网址:
我们介绍的最后一个抓取工具是 Scrapingbee。Scrapingbee 提供了一个用于网页抓取的 API,它甚至可以处理最复杂的 Javascript 页面并将它们转换为原创 HTML 供您使用。此外,它还具有专用 API,可用于使用 Google 搜索进行网络抓取。
Scrapingbee 可以通过以下三种方式之一使用:
例如,定期进行网络爬行以提取股票价格或客户评论。搜索引擎结果页面通常用于 SEO 或关键字监控。增长黑客包括提取联系信息或社交媒体信息。
Scrapingbee 提供免费计划,其中包括 1000 次限制和无限使用的付费计划。
最后
在数据科学项目工作流程中,为项目采集数据可能是最有趣也最乏味的一步。这项任务可能会非常耗时,如果你在公司工作,甚至作为自由职业者,你都知道时间就是金钱,这总是意味着如果有更有效的方法来做某事,最好用好它。
好消息是网络爬行不必太麻烦。您不需要执行它,甚至不需要花费大量时间手动执行它。使用正确的工具可以帮助您节省大量时间、金钱和精力。此外,这些工具可能对分析师或编码背景不足的人有用。
当你想选择一个爬取网页的工具时,你需要考虑以下几个因素,比如API集成度和大规模爬取的可扩展性。本文为您提供了一些可用于不同数据采集机制的工具。使用这些工具来确定哪种方法可以为下一个数据采集项目事半功倍。
原文链接:
网页抓取工具(网页抓取工具WebExtractWebWebWeb)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-28 01:10
网络爬虫 Easy Web Extract 是一款易于使用的网络爬虫,可提取网页中的内容(文本、URL、图像、文件),只需点击几下屏幕即可将结果转换为多种格式。没有编程要求。让我们的网络爬虫像它的名字一样易于使用。
软件说明:
我们简单的网络提取软件收录许多高级功能。
使用户能够从简单的 网站 中抓取内容。
但是构建一个网络抓取项目不需要任何努力。
在此页面中,我们将仅向您展示众所周知的功能。
让我们的网络爬虫像它的名字一样易于使用。
特征:
1. 轻松创建提取项目
对于任何用户来说,基于向导窗口创建新项目绝非易事。
项目安装向导会一步步推你。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始地址,即起始页,刷新屏幕后会加载网页。
它通常是一个链接到一个被刮掉的产品列表
第二步:如果网站要求,输入关键词提交表单并获取结果。大多数情况下可以跳过此步骤
第三步:在列表中选择一个项目,选择该项目的数据列的抓取性能
第四步:选择下一页的网址访问其他页面
2. 多线程抓取数据
在网络爬虫项目中,需要爬取数十万个链接进行收获。
传统的刮刀可能需要数小时或数天的时间。
然而,一个简单的网页提取可以同时运行多个线程来浏览多达 24 个不同的网页。
为了节省您宝贵的时间,等待收获的结果。
因此,简单的 Web 提取可以利用系统的最佳性能。
旁边的动画图像显示了 8 个线程的提取。
3. 从数据中加载各种提取的数据
一些高度动态的网站采用了基于客户端创建的数据加载技术,例如AJAX异步请求。
诚然,不仅是原创网页爬虫,还有专业网页抓取工具的挑战。
因为 Web 内容未嵌入 HTML 源代码中。
但是,简单的网络提取具有非常强大的技术。
即使是新手也可以从这些类型的网站中获取数据。
此外,我们的 网站 抓取器甚至可以模拟向下滚动到页面底部以加载更多数据。
例如LinkedIn联系人列表中的某些特定网站。
在这个挑战中,大多数网络爬虫继续采集大量重复信息。
并且很快变得乏味。不过,不要担心这个噩梦。
因为简单的网络提取具有避免它的智能功能。
4. 随时自动执行项目
通过简单的网络提取的嵌入式自动运行调度程序。
您可以安排网页抓取项目随时运行,无需任何操作。
计划任务运行并将抓取的结果导出到目的地。
没有一直运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
确保只维护新数据。
支持的计划类型:
- 在项目中每小时运行一次
- 在项目中每天运行
- 在特定时间运行项目
5. 将数据导出为任意格式
我们最好的网络抓取工具支持各种格式来导出和抓取 网站 数据。
例如:CSV、Access、XML、HTML、SQL Server、MySQL。
您还可以直接提交任何类型的数据库目标结果。
通过 ODBC 连接。如果您的 网站 有提交表单。 查看全部
网页抓取工具(网页抓取工具WebExtractWebWebWeb)
网络爬虫 Easy Web Extract 是一款易于使用的网络爬虫,可提取网页中的内容(文本、URL、图像、文件),只需点击几下屏幕即可将结果转换为多种格式。没有编程要求。让我们的网络爬虫像它的名字一样易于使用。
软件说明:
我们简单的网络提取软件收录许多高级功能。
使用户能够从简单的 网站 中抓取内容。
但是构建一个网络抓取项目不需要任何努力。
在此页面中,我们将仅向您展示众所周知的功能。
让我们的网络爬虫像它的名字一样易于使用。
特征:
1. 轻松创建提取项目
对于任何用户来说,基于向导窗口创建新项目绝非易事。
项目安装向导会一步步推你。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始地址,即起始页,刷新屏幕后会加载网页。
它通常是一个链接到一个被刮掉的产品列表
第二步:如果网站要求,输入关键词提交表单并获取结果。大多数情况下可以跳过此步骤
第三步:在列表中选择一个项目,选择该项目的数据列的抓取性能
第四步:选择下一页的网址访问其他页面
2. 多线程抓取数据
在网络爬虫项目中,需要爬取数十万个链接进行收获。
传统的刮刀可能需要数小时或数天的时间。
然而,一个简单的网页提取可以同时运行多个线程来浏览多达 24 个不同的网页。
为了节省您宝贵的时间,等待收获的结果。
因此,简单的 Web 提取可以利用系统的最佳性能。
旁边的动画图像显示了 8 个线程的提取。
3. 从数据中加载各种提取的数据
一些高度动态的网站采用了基于客户端创建的数据加载技术,例如AJAX异步请求。
诚然,不仅是原创网页爬虫,还有专业网页抓取工具的挑战。
因为 Web 内容未嵌入 HTML 源代码中。
但是,简单的网络提取具有非常强大的技术。
即使是新手也可以从这些类型的网站中获取数据。
此外,我们的 网站 抓取器甚至可以模拟向下滚动到页面底部以加载更多数据。
例如LinkedIn联系人列表中的某些特定网站。
在这个挑战中,大多数网络爬虫继续采集大量重复信息。
并且很快变得乏味。不过,不要担心这个噩梦。
因为简单的网络提取具有避免它的智能功能。
4. 随时自动执行项目
通过简单的网络提取的嵌入式自动运行调度程序。
您可以安排网页抓取项目随时运行,无需任何操作。
计划任务运行并将抓取的结果导出到目的地。
没有一直运行的后台服务来节省系统资源。
此外,可以从收获的结果中删除所有重复项。
确保只维护新数据。
支持的计划类型:
- 在项目中每小时运行一次
- 在项目中每天运行
- 在特定时间运行项目
5. 将数据导出为任意格式
我们最好的网络抓取工具支持各种格式来导出和抓取 网站 数据。
例如:CSV、Access、XML、HTML、SQL Server、MySQL。
您还可以直接提交任何类型的数据库目标结果。
通过 ODBC 连接。如果您的 网站 有提交表单。
网页抓取工具(手动做各种各样的7个高级工具,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-25 13:08
本文包括为初学者和小型项目设计的简单工具,以及需要一定数量编码知识并专为更大和更困难的任务而设计的高级工具。
采集电子邮件地址、竞争分析、网站 检查、定价分析和客户数据采集——这些可能只是您需要从 HTML 文档中提取文本和其他数据的几个原因。不幸的是,手动执行此操作既痛苦又低效,在某些情况下甚至是不可能的。幸运的是,现在有多种工具可以满足这些要求。以下 7 种工具的范围从为初学者和小型项目设计的非常简单的工具到需要一定数量编码知识并为更大和更困难的任务而设计的高级工具。
Iconico HTML 文本提取器(Iconico HTML 文本提取器)
想象一下你正在浏览一个竞争对手的网站,然后你想提取文本内容,或者你想看到页面后面的HTML代码。不幸的是,您发现右侧按钮被禁用,复制和粘贴也是如此。许多 Web 开发人员现在正在采取措施禁止查看源代码或锁定他们的页面。幸运的是,Iconico 有一个 HTML 文本提取器,您可以使用它来绕过所有这些限制,而且该产品非常易于使用。可以高亮复制文本,提取功能的操作就像上网一样简单。
路径
UIPath 有一组自动化处理工具,其中包括一个 Web 内容爬行实用程序。要使用该工具并获取您需要的几乎所有数据非常简单——只需打开页面,转到工具中的设计菜单,然后单击“网页抓取”。除了网页抓取工具,屏幕抓取工具还允许您从网页中提取任何内容。使用这两个工具意味着您可以从任何网页中获取文本、表格数据和其他相关信息。
莫曾达
Mozenda 允许用户提取网络数据并将该信息导出到各种智能商业工具。它不仅可以提取文本内容,还可以从PDF文件中提取图像、文件和内容。然后,您可以将这些数据导出到 XML 文件、CSV 文件、JSON 或您可以选择使用 API。提取和导出数据后,您可以使用 BI 工具进行分析和报告。
HTML到文本
这个在线工具可以从 HTML 源代码中提取文本,甚至只是一个 URL。您需要做的就是复制和粘贴、提供 URL 或上传文件。单击选项按钮,让工具知道您需要的输出格式和其他一些详细信息,然后单击转换,您将获得所需的文本信息。
(有一个类似的工具——)
八爪鱼
Octoparse 的特点是它提供了一个“点击”的用户界面。即使没有编码知识的用户也可以从 网站 中提取数据并将其发送为各种文件格式。该工具包括从页面中提取电子邮件地址和从工作板中提取工作列表等功能。本工具适用于动静态网页和云端采集(配置了采集任务关闭也可以采集数据)。它提供了免费版,应该可以满足大部分使用场景,而付费版功能更加丰富。
如果您爬取网站 进行竞争分析,您可能会因为此活动而被禁止。因为 Octoparse 收录一个循环识别您的 IP 地址的功能,并可以阻止您通过您的 IP 使用它。
刮痧
这个免费的开源工具使用网络爬虫从 网站 中提取信息。使用此工具需要一些高级技能和编码知识。但是,如果您愿意按照自己的方式学习使用它,Scrapy 是抓取大型 Web 项目的理想选择。CareerBuilder和其他主要品牌已经使用了这个工具。因为它是一个开源工具,它为用户提供了很多很好的社区支持。
和服
Kimono 是一款免费工具,可从网页中获取非结构化数据,并将信息提取为带有 XML 文件的结构化格式。该工具可以交互使用,也可以创建计划作业以在特定时间提取所需的数据。您可以从搜索引擎结果、网页甚至幻灯片演示中提取数据。最重要的是,当您设置每个工作流时,Kimono 将创建一个 API。这意味着当您返回 网站 提取更多数据时,您不必重新发明轮子。
综上所述
如果您遇到需要从一个或多个网页中提取非结构化数据的任务,那么此列表中至少有一个工具应该收录您需要的解决方案。无论您的预期价格是多少,您都应该能够找到所需的工具。清楚地了解并决定哪个最适合您。您知道,大数据在蓬勃发展的业务发展中的重要性,以及采集所需信息的能力对您来说也至关重要。
原文来源:Elaina Meiser 翻译来源:开源中国/总监 查看全部
网页抓取工具(手动做各种各样的7个高级工具,你知道吗?)
本文包括为初学者和小型项目设计的简单工具,以及需要一定数量编码知识并专为更大和更困难的任务而设计的高级工具。
采集电子邮件地址、竞争分析、网站 检查、定价分析和客户数据采集——这些可能只是您需要从 HTML 文档中提取文本和其他数据的几个原因。不幸的是,手动执行此操作既痛苦又低效,在某些情况下甚至是不可能的。幸运的是,现在有多种工具可以满足这些要求。以下 7 种工具的范围从为初学者和小型项目设计的非常简单的工具到需要一定数量编码知识并为更大和更困难的任务而设计的高级工具。
Iconico HTML 文本提取器(Iconico HTML 文本提取器)
想象一下你正在浏览一个竞争对手的网站,然后你想提取文本内容,或者你想看到页面后面的HTML代码。不幸的是,您发现右侧按钮被禁用,复制和粘贴也是如此。许多 Web 开发人员现在正在采取措施禁止查看源代码或锁定他们的页面。幸运的是,Iconico 有一个 HTML 文本提取器,您可以使用它来绕过所有这些限制,而且该产品非常易于使用。可以高亮复制文本,提取功能的操作就像上网一样简单。
路径
UIPath 有一组自动化处理工具,其中包括一个 Web 内容爬行实用程序。要使用该工具并获取您需要的几乎所有数据非常简单——只需打开页面,转到工具中的设计菜单,然后单击“网页抓取”。除了网页抓取工具,屏幕抓取工具还允许您从网页中提取任何内容。使用这两个工具意味着您可以从任何网页中获取文本、表格数据和其他相关信息。
莫曾达
Mozenda 允许用户提取网络数据并将该信息导出到各种智能商业工具。它不仅可以提取文本内容,还可以从PDF文件中提取图像、文件和内容。然后,您可以将这些数据导出到 XML 文件、CSV 文件、JSON 或您可以选择使用 API。提取和导出数据后,您可以使用 BI 工具进行分析和报告。
HTML到文本
这个在线工具可以从 HTML 源代码中提取文本,甚至只是一个 URL。您需要做的就是复制和粘贴、提供 URL 或上传文件。单击选项按钮,让工具知道您需要的输出格式和其他一些详细信息,然后单击转换,您将获得所需的文本信息。
(有一个类似的工具——)
八爪鱼
Octoparse 的特点是它提供了一个“点击”的用户界面。即使没有编码知识的用户也可以从 网站 中提取数据并将其发送为各种文件格式。该工具包括从页面中提取电子邮件地址和从工作板中提取工作列表等功能。本工具适用于动静态网页和云端采集(配置了采集任务关闭也可以采集数据)。它提供了免费版,应该可以满足大部分使用场景,而付费版功能更加丰富。
如果您爬取网站 进行竞争分析,您可能会因为此活动而被禁止。因为 Octoparse 收录一个循环识别您的 IP 地址的功能,并可以阻止您通过您的 IP 使用它。
刮痧
这个免费的开源工具使用网络爬虫从 网站 中提取信息。使用此工具需要一些高级技能和编码知识。但是,如果您愿意按照自己的方式学习使用它,Scrapy 是抓取大型 Web 项目的理想选择。CareerBuilder和其他主要品牌已经使用了这个工具。因为它是一个开源工具,它为用户提供了很多很好的社区支持。
和服
Kimono 是一款免费工具,可从网页中获取非结构化数据,并将信息提取为带有 XML 文件的结构化格式。该工具可以交互使用,也可以创建计划作业以在特定时间提取所需的数据。您可以从搜索引擎结果、网页甚至幻灯片演示中提取数据。最重要的是,当您设置每个工作流时,Kimono 将创建一个 API。这意味着当您返回 网站 提取更多数据时,您不必重新发明轮子。
综上所述
如果您遇到需要从一个或多个网页中提取非结构化数据的任务,那么此列表中至少有一个工具应该收录您需要的解决方案。无论您的预期价格是多少,您都应该能够找到所需的工具。清楚地了解并决定哪个最适合您。您知道,大数据在蓬勃发展的业务发展中的重要性,以及采集所需信息的能力对您来说也至关重要。
原文来源:Elaina Meiser 翻译来源:开源中国/总监
网页抓取工具(基于动态内容抓取JavaScript页面的优势-Proxy)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-20 17:04
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。然而,有很多优秀的网络爬虫工具可用。
1.代理爬网
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
可以免费获取1000个请求,足以探索Proxy Crawl在复杂内容页面中使用的强大功能。
2.Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及为大型任务执行自动化测试。强大的功能可以与ProxyCrawl***集成。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
3.抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用Grab,你可以为小型的个人项目创建爬虫机制,也可以构建可以同时扩展到数百万页的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
4.雪貂
Ferret 是一个相当新的网络爬虫,在开源社区中获得了相当大的吸引力。Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
5.X 射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
6.Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
7.PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现为 PDF 文档。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您手头的任务需要抓取许多基于 JavaScript 的 网站,这将特别有用。
【编辑推荐】
2018年三大运营商表现如何?2019年数据中心行业八大趋势分享 | 物联网数据需要共享协议优雅读取http请求或响应的数据清单:2019年值得关注的5个数据中心趋势 查看全部
网页抓取工具(基于动态内容抓取JavaScript页面的优势-Proxy)
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。然而,有很多优秀的网络爬虫工具可用。
1.代理爬网
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
可以免费获取1000个请求,足以探索Proxy Crawl在复杂内容页面中使用的强大功能。
2.Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及为大型任务执行自动化测试。强大的功能可以与ProxyCrawl***集成。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
3.抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用Grab,你可以为小型的个人项目创建爬虫机制,也可以构建可以同时扩展到数百万页的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
4.雪貂
Ferret 是一个相当新的网络爬虫,在开源社区中获得了相当大的吸引力。Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
5.X 射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
6.Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
7.PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现为 PDF 文档。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您手头的任务需要抓取许多基于 JavaScript 的 网站,这将特别有用。
【编辑推荐】
2018年三大运营商表现如何?2019年数据中心行业八大趋势分享 | 物联网数据需要共享协议优雅读取http请求或响应的数据清单:2019年值得关注的5个数据中心趋势
网页抓取工具(如何搭建一个知乎爬虫框架?--阿雷的回答)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-18 17:02
网页抓取工具webauthenticatorlabeledload-in-and-out,抓取前把网页放进去,抓取结束,不能保留js文件。语言方面需要会爬虫开发或者编译器开发,一般java。
上javaswing的东西吧,
cookie
googleapipost的ws方法封装,我们一般这么用的。用这个封装一套基本可以封装国内post请求。然后将一些功能封装成php函数。再封装一些模块。剩下的就是框架的问题。能不用框架的还是尽量不用。
请scrapy
这种一般都是需要自己开发,像我都是使用nginx转发请求,然后处理结果输出到浏览器,然后以cookie或者session的形式保存返回的数据。网上有例子,看一下就知道了。
说的不就是flask么?
模拟登录找方法,
我的知乎回答:如何搭建一个知乎爬虫框架?-阿雷的回答
python相关可以尝试试试pil的封装,进行图片爬取。也可以尝试下这个+的结构,打包后的xml.python可以直接执行爬取网页内容,不需要发送请求。
建议用web方面的框架,requests,postman就可以,前端就不要过分依赖第三方库了,基本语法是爬虫基础,框架本身已经封装好爬取数据的语法,你可以查看看。基础的爬虫不比python高深,说真的学写一个爬虫要学好多东西,还不如写一个简单的爬虫的代码量。 查看全部
网页抓取工具(如何搭建一个知乎爬虫框架?--阿雷的回答)
网页抓取工具webauthenticatorlabeledload-in-and-out,抓取前把网页放进去,抓取结束,不能保留js文件。语言方面需要会爬虫开发或者编译器开发,一般java。
上javaswing的东西吧,
cookie
googleapipost的ws方法封装,我们一般这么用的。用这个封装一套基本可以封装国内post请求。然后将一些功能封装成php函数。再封装一些模块。剩下的就是框架的问题。能不用框架的还是尽量不用。
请scrapy
这种一般都是需要自己开发,像我都是使用nginx转发请求,然后处理结果输出到浏览器,然后以cookie或者session的形式保存返回的数据。网上有例子,看一下就知道了。
说的不就是flask么?
模拟登录找方法,
我的知乎回答:如何搭建一个知乎爬虫框架?-阿雷的回答
python相关可以尝试试试pil的封装,进行图片爬取。也可以尝试下这个+的结构,打包后的xml.python可以直接执行爬取网页内容,不需要发送请求。
建议用web方面的框架,requests,postman就可以,前端就不要过分依赖第三方库了,基本语法是爬虫基础,框架本身已经封装好爬取数据的语法,你可以查看看。基础的爬虫不比python高深,说真的学写一个爬虫要学好多东西,还不如写一个简单的爬虫的代码量。
网页抓取工具(网页邮箱抓取工具(网页邮箱地址提取器)(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 604 次浏览 • 2021-10-15 02:11
)
网络邮箱爬虫(网络邮箱地址提取器)是软件联盟根官方推出的一款绿色免费的网络邮箱地址采集软件。该软件功能强大,可以从网页中提取电子邮件地址。例如,可以检索常见的 贴吧 电子邮件页面。
网络邮箱爬虫的特点
输入抓取到的网址点击执行按钮,支持逗号分号分隔邮件地址,支持采集完成邮件提醒。
如何使用网络邮件爬虫
1.在地址栏输入邮箱地址,点击“提取”
优点:提取多个唯一邮箱只需要一个URL
如何使用“多任务处理”:
1.检查多任务
2.在地址栏输入邮箱地址,点击“提取”,再次输入不同的网址,再次点击“提取”,像一些循环
优点:多次检索邮箱,保存一次
如何使用“提取邮箱”选项:
1. 在文本框中输入带有邮箱的网页源代码或邮箱的文本片段与其他文本混合,点击“执行”
优点:快速提取邮箱中的杂乱文字,网页源码等杂乱文字,其他文章等。
如何使用“组”和“逗号”选项:
1. 提取邮箱后,点击分组,设置每个分组的邮箱数量,然后根据需要添加逗号,点击“执行”
优点:根据需要对大量邮箱进行分组,并添加逗号,可用于批量/批量发送同时发送给多个收件人
如何使用“正常”选项”:
提取邮箱后,当要在提取的邮箱中添加备注时,选择“普通”,添加备注内容,选择“将结果发送到邮箱”,点击“执行”,将添加的备注与处理后的邮箱发送到邮箱
解决这个问题:
1. 手动从网页中提取多个邮箱,速度太慢
2.重复邮箱太多,手动一一删除耗时太长
3. 群发/捆绑单显时,必须手动一一输入收件人邮箱,并用逗号隔开,效率太低
4. 经常不在同一台电脑上,想开发客户没有数据和工具,数据不方便保存
每种颜色都有很多颜色代码表达。该软件提供了 12 种不同的颜色代码,包括 RGB、ARGB、BGR、BGRA、HTML、CMYK、HSL、HSV/HSB、HEX、HEX+alpha、HEX、Decimal 和 Decimal+alpha,
如果有专业的输出需要告知特定的色码模式,可以通过这个工具查看。而当鼠标移到色块顶部时,会出现一个}u图形,您可以点击鼠标左键来}u色码樱花
查看全部
网页抓取工具(网页邮箱抓取工具(网页邮箱地址提取器)(图)
)
网络邮箱爬虫(网络邮箱地址提取器)是软件联盟根官方推出的一款绿色免费的网络邮箱地址采集软件。该软件功能强大,可以从网页中提取电子邮件地址。例如,可以检索常见的 贴吧 电子邮件页面。
网络邮箱爬虫的特点
输入抓取到的网址点击执行按钮,支持逗号分号分隔邮件地址,支持采集完成邮件提醒。
如何使用网络邮件爬虫
1.在地址栏输入邮箱地址,点击“提取”
优点:提取多个唯一邮箱只需要一个URL
如何使用“多任务处理”:
1.检查多任务
2.在地址栏输入邮箱地址,点击“提取”,再次输入不同的网址,再次点击“提取”,像一些循环
优点:多次检索邮箱,保存一次
如何使用“提取邮箱”选项:
1. 在文本框中输入带有邮箱的网页源代码或邮箱的文本片段与其他文本混合,点击“执行”
优点:快速提取邮箱中的杂乱文字,网页源码等杂乱文字,其他文章等。
如何使用“组”和“逗号”选项:
1. 提取邮箱后,点击分组,设置每个分组的邮箱数量,然后根据需要添加逗号,点击“执行”
优点:根据需要对大量邮箱进行分组,并添加逗号,可用于批量/批量发送同时发送给多个收件人
如何使用“正常”选项”:
提取邮箱后,当要在提取的邮箱中添加备注时,选择“普通”,添加备注内容,选择“将结果发送到邮箱”,点击“执行”,将添加的备注与处理后的邮箱发送到邮箱
解决这个问题:
1. 手动从网页中提取多个邮箱,速度太慢
2.重复邮箱太多,手动一一删除耗时太长
3. 群发/捆绑单显时,必须手动一一输入收件人邮箱,并用逗号隔开,效率太低
4. 经常不在同一台电脑上,想开发客户没有数据和工具,数据不方便保存
每种颜色都有很多颜色代码表达。该软件提供了 12 种不同的颜色代码,包括 RGB、ARGB、BGR、BGRA、HTML、CMYK、HSL、HSV/HSB、HEX、HEX+alpha、HEX、Decimal 和 Decimal+alpha,
如果有专业的输出需要告知特定的色码模式,可以通过这个工具查看。而当鼠标移到色块顶部时,会出现一个}u图形,您可以点击鼠标左键来}u色码樱花
网页抓取工具(提取的数据还不能直接拿来用?文件还没有被下载? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-14 06:20
)
提取出来的数据不能直接使用吗?文件还没有下载?格式等还达不到要求?不用担心,网页抓取工具优采云采集器 有自己的解决方案-数据处理。
网络爬虫的数据处理功能包括内容处理、文件下载和内容过滤三部分。下面我依次给大家介绍一下:
1、内容处理:替换从内容页面中提取的数据,标签过滤,分词等进一步处理,我们可以同时添加多个操作,但是这里需要注意的是,如果有多个操作,按照上面的顺序执行,也就是将上一步的结果作为下一步的参数。
下面我们一一介绍:
①提取的内容为空:如果提取的内容无法通过前面的规则准确提取或提取的内容为空,请选择此选项。此应用程序后,将使用正则匹配从原创页面中再次提取。
②内容替换/排除:用字符串替换采集的内容。如果需要排除,请用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数替换字符串(不同于工具栏中的同义词替换)。
③html标签过滤:过滤指定的html标签,如
④ 字符截取:通过开始和结束字符串截取内容。适用于截取和调整提取的内容。
⑤纯替换:如果某些内容(如单次出现的文本)无法通过一般的内容替换操作,则需要通过强大的正则表达式进行复杂的替换。
例如,“受欢迎的美国餐馆在这里”,我们将其替换为“美国餐馆”,正则表达式如下:
⑥数据转换:包括结果简体转换、结果繁体转换、自动转拼音和时间校正转换,共四项处理。
⑦智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取。
⑧高级功能:包括自动汇总、自动分词、自动分类、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串A长度等一系列函数。
⑨补全单个网址:将当前内容补全为一个网址。
2、文件下载:可以自动检测下载文件,可以设置下载路径和文件名样式。
注:文件下载中所指的下载图片为源代码中的标准样式
标签的图像地址。
例如,如果是直接的图片地址或不规则的图片源代码,采集器 将被视为文件下载。
①将相对地址补全为绝对地址:勾选后,标签采集的相对地址补全为绝对地址。
②下载图片:经核对,源码收录标准样式
将下载代码图像。
③检测文件真实地址但不下载:有时采集到达附件下载地址而不是真实下载地址。点击之后,会有一个跳转。在这种情况下,如果勾选此选项,将显示真实地址采集,但不会仅下载下载地址。
④检测文件并下载:勾选后可以从采集下载任意格式的文件附件。
3、内容过滤:一些不符合条件的记录可以通过设置内容过滤被删除或标记为不接受。有几种方法可以处理内容过滤:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件即可。
②采集 结果不能为空:该功能可以防止某个字段出现空内容。
③采集 结果不能重复:该功能可以防止某个字段出现重复的内容。设置此项前请确保没有采集数据,否则需要先清除采集数据。
④内容长度小于(大于、等于、不等于)时过滤 N:符号或字母或数字或汉字算一个。
注意:如果满足以上四项中的任何一项或多项,您可以在采集器的其他设置功能中直接删除该记录,或将该记录标记为不在采集 采集将在下次运行任务时重复。
在网页抓取工具优采云采集器中进行一系列数据处理的好处是,当我们只需要做一个小操作时,无需编写插件、生成和编译它们,并且可以一键将数据处理成我们需要的数据。
查看全部
网页抓取工具(提取的数据还不能直接拿来用?文件还没有被下载?
)
提取出来的数据不能直接使用吗?文件还没有下载?格式等还达不到要求?不用担心,网页抓取工具优采云采集器 有自己的解决方案-数据处理。
网络爬虫的数据处理功能包括内容处理、文件下载和内容过滤三部分。下面我依次给大家介绍一下:
1、内容处理:替换从内容页面中提取的数据,标签过滤,分词等进一步处理,我们可以同时添加多个操作,但是这里需要注意的是,如果有多个操作,按照上面的顺序执行,也就是将上一步的结果作为下一步的参数。
下面我们一一介绍:
①提取的内容为空:如果提取的内容无法通过前面的规则准确提取或提取的内容为空,请选择此选项。此应用程序后,将使用正则匹配从原创页面中再次提取。
②内容替换/排除:用字符串替换采集的内容。如果需要排除,请用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数替换字符串(不同于工具栏中的同义词替换)。
③html标签过滤:过滤指定的html标签,如
④ 字符截取:通过开始和结束字符串截取内容。适用于截取和调整提取的内容。
⑤纯替换:如果某些内容(如单次出现的文本)无法通过一般的内容替换操作,则需要通过强大的正则表达式进行复杂的替换。
例如,“受欢迎的美国餐馆在这里”,我们将其替换为“美国餐馆”,正则表达式如下:
⑥数据转换:包括结果简体转换、结果繁体转换、自动转拼音和时间校正转换,共四项处理。
⑦智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取。
⑧高级功能:包括自动汇总、自动分词、自动分类、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串A长度等一系列函数。
⑨补全单个网址:将当前内容补全为一个网址。
2、文件下载:可以自动检测下载文件,可以设置下载路径和文件名样式。
注:文件下载中所指的下载图片为源代码中的标准样式
标签的图像地址。
例如,如果是直接的图片地址或不规则的图片源代码,采集器 将被视为文件下载。
①将相对地址补全为绝对地址:勾选后,标签采集的相对地址补全为绝对地址。
②下载图片:经核对,源码收录标准样式
将下载代码图像。
③检测文件真实地址但不下载:有时采集到达附件下载地址而不是真实下载地址。点击之后,会有一个跳转。在这种情况下,如果勾选此选项,将显示真实地址采集,但不会仅下载下载地址。
④检测文件并下载:勾选后可以从采集下载任意格式的文件附件。
3、内容过滤:一些不符合条件的记录可以通过设置内容过滤被删除或标记为不接受。有几种方法可以处理内容过滤:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件即可。
②采集 结果不能为空:该功能可以防止某个字段出现空内容。
③采集 结果不能重复:该功能可以防止某个字段出现重复的内容。设置此项前请确保没有采集数据,否则需要先清除采集数据。
④内容长度小于(大于、等于、不等于)时过滤 N:符号或字母或数字或汉字算一个。
注意:如果满足以上四项中的任何一项或多项,您可以在采集器的其他设置功能中直接删除该记录,或将该记录标记为不在采集 采集将在下次运行任务时重复。
在网页抓取工具优采云采集器中进行一系列数据处理的好处是,当我们只需要做一个小操作时,无需编写插件、生成和编译它们,并且可以一键将数据处理成我们需要的数据。

