
编码
一米智能文章采集系统 v1.0 免费版文章采集软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 421 次浏览 • 2020-08-03 16:03
一米智能文章采集系统是一款非常好用的文章采集工具,想要快速进行文章采集的用户赶快来下载这款软件吧文章采集系统,相信一定可以帮到你们。
一米智能文章采集系统简介:
一米智能文章采集系统是一款十分实用的文章采集工具,可以不懂源码规则也能采集,用户只需简单操作,就能批量采集文章,帮你搜集大量的热门资讯。
一米智能文章采集系统特征:
1、不懂源码规则也能采集,只要是文章内容类站点均可快速采集。
2、自动中英文伪原创,原创度80%以上。
3、自动去噪去乱码及文章长度判定,得到干净整洁的文章内容。
4、全球小语种支持,指定网站采集文章采集系统,非文章源。
5、多线程多任务(多站点)同步采集,1分钟1000+文章采集。
6、批量发布到常见博客/网站内容CMS上。
一米智能文章采集系统如何使用?
1、下载一米智能文章采集系统,点击运行,登录帐号密码。
2、新增任务,打开新增任务设置窗口。
(1)先填写惟一任务名(一般是按网站栏目或分类名,也可以自己取,主要是以便标示)。
(2).设置网页编码,网页编码在目标网页的源码中查看,选择对应的编码即可(只要编码正确,可辨识任意语言)。
(3)生成到分类网址列表,也可单个网址添加,或多个网址整理在TXT中一行一个批量导出。 查看全部
一米智能文章采集系统简介:
一米智能文章采集系统是一款十分实用的文章采集工具,可以不懂源码规则也能采集,用户只需简单操作,就能批量采集文章,帮你搜集大量的热门资讯。
一米智能文章采集系统特征:
1、不懂源码规则也能采集,只要是文章内容类站点均可快速采集。
2、自动中英文伪原创,原创度80%以上。
3、自动去噪去乱码及文章长度判定,得到干净整洁的文章内容。
4、全球小语种支持,指定网站采集文章采集系统,非文章源。
5、多线程多任务(多站点)同步采集,1分钟1000+文章采集。
6、批量发布到常见博客/网站内容CMS上。
一米智能文章采集系统如何使用?
1、下载一米智能文章采集系统,点击运行,登录帐号密码。
2、新增任务,打开新增任务设置窗口。
(1)先填写惟一任务名(一般是按网站栏目或分类名,也可以自己取,主要是以便标示)。
(2).设置网页编码,网页编码在目标网页的源码中查看,选择对应的编码即可(只要编码正确,可辨识任意语言)。
(3)生成到分类网址列表,也可单个网址添加,或多个网址整理在TXT中一行一个批量导出。 查看全部
一米智能文章采集系统是一款非常好用的文章采集工具,想要快速进行文章采集的用户赶快来下载这款软件吧文章采集系统,相信一定可以帮到你们。

一米智能文章采集系统简介:
一米智能文章采集系统是一款十分实用的文章采集工具,可以不懂源码规则也能采集,用户只需简单操作,就能批量采集文章,帮你搜集大量的热门资讯。
一米智能文章采集系统特征:
1、不懂源码规则也能采集,只要是文章内容类站点均可快速采集。
2、自动中英文伪原创,原创度80%以上。
3、自动去噪去乱码及文章长度判定,得到干净整洁的文章内容。
4、全球小语种支持,指定网站采集文章采集系统,非文章源。
5、多线程多任务(多站点)同步采集,1分钟1000+文章采集。
6、批量发布到常见博客/网站内容CMS上。
一米智能文章采集系统如何使用?
1、下载一米智能文章采集系统,点击运行,登录帐号密码。
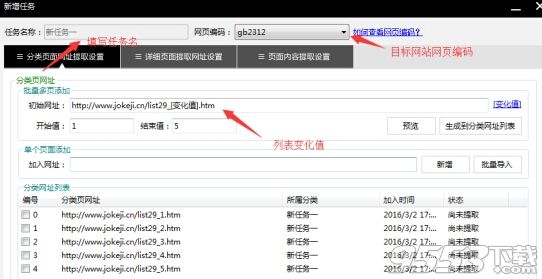
2、新增任务,打开新增任务设置窗口。
(1)先填写惟一任务名(一般是按网站栏目或分类名,也可以自己取,主要是以便标示)。
(2).设置网页编码,网页编码在目标网页的源码中查看,选择对应的编码即可(只要编码正确,可辨识任意语言)。
(3)生成到分类网址列表,也可单个网址添加,或多个网址整理在TXT中一行一个批量导出。
信息采集中的乱码问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 403 次浏览 • 2020-06-23 08:01
大家好,,碰到的一个问题。。自己写了个大型信息采集系统。。在多任务并行采集时,遇到了部份新闻乱码的情况。 不知道是哪些缘由。。由于多线程无法测试,,总结了可能的缘由及其方面:
1. 多网站信息采集时,,当多任务并行时,网站A的编码格式错觉得网站B的编码,,导致乱码现象。但是类中的方式都写了synchronize标示。
2. 问了防止上述问题,,采取了第二种策略。在数据库中预存 网站的编码格式。。每次采集从数据库读取编码格式。但是,,测试过后还是有部份信息有乱码问题。
3. 乱码现象是否和网路联接状况,网速相关呢。。
有这方面经验的,给些建议和策略吧。
问题补充:
牟盖南 写道
仅仅和编码有关,与网速等其他诱因均无关。
注意你打开的文件形式,也就是你判定是否乱码的标准是哪些。
建议不存数据库,URL->CharSet,毕竟网站的个数不是多的吓人吧,再或则配置文件足矣。
刚开始,,编码我是动态手动剖析编码的,
我是依照网页头文件的二进制流来剖析网页信息的编码格式。让我十分诧异的是,,经过大量的测试发觉: 在多任务并行处理运行的前提下,,同一个网站的新闻信息部份新闻信息是乱码。。一般100条新闻有大约10条左右的乱码信息。,,,断点发觉,网页源码都是乱码。。郁闷。。。其他不同的网站也有同样的问题。
问题补充:
maxm 写道
还有新闻采集下来后如何做的处理采集过来的文章乱码,可否贴出代码瞧瞧?
maxm 写道
还有新闻采集下来后如何做的处理,可否贴出代码瞧瞧?
这不是一两个类能填完的采集过来的文章乱码,,这涉及的知识很多的。。主要包括,,网络爬虫与信息抽取,两大方面的知识。 查看全部
1. 多网站信息采集时,,当多任务并行时,网站A的编码格式错觉得网站B的编码,,导致乱码现象。但是类中的方式都写了synchronize标示。
2. 问了防止上述问题,,采取了第二种策略。在数据库中预存 网站的编码格式。。每次采集从数据库读取编码格式。但是,,测试过后还是有部份信息有乱码问题。
3. 乱码现象是否和网路联接状况,网速相关呢。。
有这方面经验的,给些建议和策略吧。
问题补充:
牟盖南 写道
仅仅和编码有关,与网速等其他诱因均无关。
注意你打开的文件形式,也就是你判定是否乱码的标准是哪些。
建议不存数据库,URL->CharSet,毕竟网站的个数不是多的吓人吧,再或则配置文件足矣。
刚开始,,编码我是动态手动剖析编码的,
我是依照网页头文件的二进制流来剖析网页信息的编码格式。让我十分诧异的是,,经过大量的测试发觉: 在多任务并行处理运行的前提下,,同一个网站的新闻信息部份新闻信息是乱码。。一般100条新闻有大约10条左右的乱码信息。,,,断点发觉,网页源码都是乱码。。郁闷。。。其他不同的网站也有同样的问题。
问题补充:
maxm 写道
还有新闻采集下来后如何做的处理采集过来的文章乱码,可否贴出代码瞧瞧?
maxm 写道
还有新闻采集下来后如何做的处理,可否贴出代码瞧瞧?
这不是一两个类能填完的采集过来的文章乱码,,这涉及的知识很多的。。主要包括,,网络爬虫与信息抽取,两大方面的知识。 查看全部
大家好,,碰到的一个问题。。自己写了个大型信息采集系统。。在多任务并行采集时,遇到了部份新闻乱码的情况。 不知道是哪些缘由。。由于多线程无法测试,,总结了可能的缘由及其方面:
1. 多网站信息采集时,,当多任务并行时,网站A的编码格式错觉得网站B的编码,,导致乱码现象。但是类中的方式都写了synchronize标示。
2. 问了防止上述问题,,采取了第二种策略。在数据库中预存 网站的编码格式。。每次采集从数据库读取编码格式。但是,,测试过后还是有部份信息有乱码问题。
3. 乱码现象是否和网路联接状况,网速相关呢。。
有这方面经验的,给些建议和策略吧。
问题补充:
牟盖南 写道
仅仅和编码有关,与网速等其他诱因均无关。
注意你打开的文件形式,也就是你判定是否乱码的标准是哪些。
建议不存数据库,URL->CharSet,毕竟网站的个数不是多的吓人吧,再或则配置文件足矣。
刚开始,,编码我是动态手动剖析编码的,
我是依照网页头文件的二进制流来剖析网页信息的编码格式。让我十分诧异的是,,经过大量的测试发觉: 在多任务并行处理运行的前提下,,同一个网站的新闻信息部份新闻信息是乱码。。一般100条新闻有大约10条左右的乱码信息。,,,断点发觉,网页源码都是乱码。。郁闷。。。其他不同的网站也有同样的问题。
问题补充:
maxm 写道
还有新闻采集下来后如何做的处理采集过来的文章乱码,可否贴出代码瞧瞧?
maxm 写道
还有新闻采集下来后如何做的处理,可否贴出代码瞧瞧?
这不是一两个类能填完的采集过来的文章乱码,,这涉及的知识很多的。。主要包括,,网络爬虫与信息抽取,两大方面的知识。
QueryList采集器开发指南
采集交流 • 优采云 发表了文章 • 0 个评论 • 409 次浏览 • 2020-05-28 08:01
出现乱码的问题好多,解决方式也不尽相同采集过来的文章乱码,要视具体情况而定,以下几种乱码解决方案仅供参考。
Query方式:
QueryList::Query(采集的目标页面,采集规则[,区域选择器][,输出编码][,输入编码][,是否移除背部])
1.设置输入输出编码
$html =<<<STR
<div>
<p>这是内容</p>
</div>
STR;
$rule = array(
'content' => array('div>p:last','text')
);
$data = QueryList::Query($html,$rule,'','UTF-8','GB2312',true)->data;
2.设置输入输出编码,并设置最后一个参数为true
如果设置输入输出参数始终未能解决乱码采集过来的文章乱码,那就设置最后一个参数为true(移除背部)
$html =<<<STR
<div>
<p>这是内容</p>
</div>
STR;
$rule = array(
'content' => array('div>p:last','text')
);
$data = QueryList::Query($html,$rule,'','UTF-8','GB2312',true)->data;
乱码:#all 查看全部
出现乱码的问题好多,解决方式也不尽相同采集过来的文章乱码,要视具体情况而定,以下几种乱码解决方案仅供参考。
Query方式:
QueryList::Query(采集的目标页面,采集规则[,区域选择器][,输出编码][,输入编码][,是否移除背部])
1.设置输入输出编码
$html =<<<STR
<div>
<p>这是内容</p>
</div>
STR;
$rule = array(
'content' => array('div>p:last','text')
);
$data = QueryList::Query($html,$rule,'','UTF-8','GB2312',true)->data;
2.设置输入输出编码,并设置最后一个参数为true
如果设置输入输出参数始终未能解决乱码采集过来的文章乱码,那就设置最后一个参数为true(移除背部)
$html =<<<STR
<div>
<p>这是内容</p>
</div>
STR;
$rule = array(
'content' => array('div>p:last','text')
);
$data = QueryList::Query($html,$rule,'','UTF-8','GB2312',true)->data;
乱码:#all
采集乱码解决方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 448 次浏览 • 2020-05-26 08:00
出现乱码的问题好多,解决方式也不尽相同,要视具体情况而定采集过来的文章乱码,以下几种乱码解决方案仅供参考。
Query方式:
QueryList::Query(采集的目标页面,采集规则[,区域选择器][,输出编码][,输入编码][,是否移除头部])
1.设置输入输出编码
$html =<<<STR
<div>
<p>这是内容</p>
</div>
STR;
$rule = array(
'content' => array('div>p:last','text')
);
$data = QueryList::Query($html,$rule,'','UTF-8','GB2312')->data;
2.设置输入输出编码,并设置最后一个参数为true假如设置输入输出参数始终未能解决乱码采集过来的文章乱码,那就设置最后一个参数为true(移除背部)
$html =<<<STR
<div>
<p>这是内容</p>
</div>
STR;
$rule = array(
'content' => array('div>p:last','text')
);
$data = QueryList::Query($html,$rule,'','UTF-8','GB2312',true)->data; 查看全部

出现乱码的问题好多,解决方式也不尽相同,要视具体情况而定采集过来的文章乱码,以下几种乱码解决方案仅供参考。
Query方式:
QueryList::Query(采集的目标页面,采集规则[,区域选择器][,输出编码][,输入编码][,是否移除头部])
1.设置输入输出编码
$html =<<<STR
<div>
<p>这是内容</p>
</div>
STR;
$rule = array(
'content' => array('div>p:last','text')
);
$data = QueryList::Query($html,$rule,'','UTF-8','GB2312')->data;
2.设置输入输出编码,并设置最后一个参数为true假如设置输入输出参数始终未能解决乱码采集过来的文章乱码,那就设置最后一个参数为true(移除背部)
$html =<<<STR
<div>
<p>这是内容</p>
</div>
STR;
$rule = array(
'content' => array('div>p:last','text')
);
$data = QueryList::Query($html,$rule,'','UTF-8','GB2312',true)->data;
一米智能文章采集系统 v1.0 免费版文章采集软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 421 次浏览 • 2020-08-03 16:03
一米智能文章采集系统是一款非常好用的文章采集工具,想要快速进行文章采集的用户赶快来下载这款软件吧文章采集系统,相信一定可以帮到你们。
一米智能文章采集系统简介:
一米智能文章采集系统是一款十分实用的文章采集工具,可以不懂源码规则也能采集,用户只需简单操作,就能批量采集文章,帮你搜集大量的热门资讯。
一米智能文章采集系统特征:
1、不懂源码规则也能采集,只要是文章内容类站点均可快速采集。
2、自动中英文伪原创,原创度80%以上。
3、自动去噪去乱码及文章长度判定,得到干净整洁的文章内容。
4、全球小语种支持,指定网站采集文章采集系统,非文章源。
5、多线程多任务(多站点)同步采集,1分钟1000+文章采集。
6、批量发布到常见博客/网站内容CMS上。
一米智能文章采集系统如何使用?
1、下载一米智能文章采集系统,点击运行,登录帐号密码。
2、新增任务,打开新增任务设置窗口。
(1)先填写惟一任务名(一般是按网站栏目或分类名,也可以自己取,主要是以便标示)。
(2).设置网页编码,网页编码在目标网页的源码中查看,选择对应的编码即可(只要编码正确,可辨识任意语言)。
(3)生成到分类网址列表,也可单个网址添加,或多个网址整理在TXT中一行一个批量导出。 查看全部
一米智能文章采集系统简介:
一米智能文章采集系统是一款十分实用的文章采集工具,可以不懂源码规则也能采集,用户只需简单操作,就能批量采集文章,帮你搜集大量的热门资讯。
一米智能文章采集系统特征:
1、不懂源码规则也能采集,只要是文章内容类站点均可快速采集。
2、自动中英文伪原创,原创度80%以上。
3、自动去噪去乱码及文章长度判定,得到干净整洁的文章内容。
4、全球小语种支持,指定网站采集文章采集系统,非文章源。
5、多线程多任务(多站点)同步采集,1分钟1000+文章采集。
6、批量发布到常见博客/网站内容CMS上。
一米智能文章采集系统如何使用?
1、下载一米智能文章采集系统,点击运行,登录帐号密码。
2、新增任务,打开新增任务设置窗口。
(1)先填写惟一任务名(一般是按网站栏目或分类名,也可以自己取,主要是以便标示)。
(2).设置网页编码,网页编码在目标网页的源码中查看,选择对应的编码即可(只要编码正确,可辨识任意语言)。
(3)生成到分类网址列表,也可单个网址添加,或多个网址整理在TXT中一行一个批量导出。 查看全部
一米智能文章采集系统是一款非常好用的文章采集工具,想要快速进行文章采集的用户赶快来下载这款软件吧文章采集系统,相信一定可以帮到你们。
一米智能文章采集系统简介:
一米智能文章采集系统是一款十分实用的文章采集工具,可以不懂源码规则也能采集,用户只需简单操作,就能批量采集文章,帮你搜集大量的热门资讯。
一米智能文章采集系统特征:
1、不懂源码规则也能采集,只要是文章内容类站点均可快速采集。
2、自动中英文伪原创,原创度80%以上。
3、自动去噪去乱码及文章长度判定,得到干净整洁的文章内容。
4、全球小语种支持,指定网站采集文章采集系统,非文章源。
5、多线程多任务(多站点)同步采集,1分钟1000+文章采集。
6、批量发布到常见博客/网站内容CMS上。
一米智能文章采集系统如何使用?
1、下载一米智能文章采集系统,点击运行,登录帐号密码。
2、新增任务,打开新增任务设置窗口。
(1)先填写惟一任务名(一般是按网站栏目或分类名,也可以自己取,主要是以便标示)。
(2).设置网页编码,网页编码在目标网页的源码中查看,选择对应的编码即可(只要编码正确,可辨识任意语言)。
(3)生成到分类网址列表,也可单个网址添加,或多个网址整理在TXT中一行一个批量导出。
信息采集中的乱码问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 403 次浏览 • 2020-06-23 08:01
大家好,,碰到的一个问题。。自己写了个大型信息采集系统。。在多任务并行采集时,遇到了部份新闻乱码的情况。 不知道是哪些缘由。。由于多线程无法测试,,总结了可能的缘由及其方面:
1. 多网站信息采集时,,当多任务并行时,网站A的编码格式错觉得网站B的编码,,导致乱码现象。但是类中的方式都写了synchronize标示。
2. 问了防止上述问题,,采取了第二种策略。在数据库中预存 网站的编码格式。。每次采集从数据库读取编码格式。但是,,测试过后还是有部份信息有乱码问题。
3. 乱码现象是否和网路联接状况,网速相关呢。。
有这方面经验的,给些建议和策略吧。
问题补充:
牟盖南 写道
仅仅和编码有关,与网速等其他诱因均无关。
注意你打开的文件形式,也就是你判定是否乱码的标准是哪些。
建议不存数据库,URL->CharSet,毕竟网站的个数不是多的吓人吧,再或则配置文件足矣。
刚开始,,编码我是动态手动剖析编码的,
我是依照网页头文件的二进制流来剖析网页信息的编码格式。让我十分诧异的是,,经过大量的测试发觉: 在多任务并行处理运行的前提下,,同一个网站的新闻信息部份新闻信息是乱码。。一般100条新闻有大约10条左右的乱码信息。,,,断点发觉,网页源码都是乱码。。郁闷。。。其他不同的网站也有同样的问题。
问题补充:
maxm 写道
还有新闻采集下来后如何做的处理采集过来的文章乱码,可否贴出代码瞧瞧?
maxm 写道
还有新闻采集下来后如何做的处理,可否贴出代码瞧瞧?
这不是一两个类能填完的采集过来的文章乱码,,这涉及的知识很多的。。主要包括,,网络爬虫与信息抽取,两大方面的知识。 查看全部
1. 多网站信息采集时,,当多任务并行时,网站A的编码格式错觉得网站B的编码,,导致乱码现象。但是类中的方式都写了synchronize标示。
2. 问了防止上述问题,,采取了第二种策略。在数据库中预存 网站的编码格式。。每次采集从数据库读取编码格式。但是,,测试过后还是有部份信息有乱码问题。
3. 乱码现象是否和网路联接状况,网速相关呢。。
有这方面经验的,给些建议和策略吧。
问题补充:
牟盖南 写道
仅仅和编码有关,与网速等其他诱因均无关。
注意你打开的文件形式,也就是你判定是否乱码的标准是哪些。
建议不存数据库,URL->CharSet,毕竟网站的个数不是多的吓人吧,再或则配置文件足矣。
刚开始,,编码我是动态手动剖析编码的,
我是依照网页头文件的二进制流来剖析网页信息的编码格式。让我十分诧异的是,,经过大量的测试发觉: 在多任务并行处理运行的前提下,,同一个网站的新闻信息部份新闻信息是乱码。。一般100条新闻有大约10条左右的乱码信息。,,,断点发觉,网页源码都是乱码。。郁闷。。。其他不同的网站也有同样的问题。
问题补充:
maxm 写道
还有新闻采集下来后如何做的处理采集过来的文章乱码,可否贴出代码瞧瞧?
maxm 写道
还有新闻采集下来后如何做的处理,可否贴出代码瞧瞧?
这不是一两个类能填完的采集过来的文章乱码,,这涉及的知识很多的。。主要包括,,网络爬虫与信息抽取,两大方面的知识。 查看全部
大家好,,碰到的一个问题。。自己写了个大型信息采集系统。。在多任务并行采集时,遇到了部份新闻乱码的情况。 不知道是哪些缘由。。由于多线程无法测试,,总结了可能的缘由及其方面:
1. 多网站信息采集时,,当多任务并行时,网站A的编码格式错觉得网站B的编码,,导致乱码现象。但是类中的方式都写了synchronize标示。
2. 问了防止上述问题,,采取了第二种策略。在数据库中预存 网站的编码格式。。每次采集从数据库读取编码格式。但是,,测试过后还是有部份信息有乱码问题。
3. 乱码现象是否和网路联接状况,网速相关呢。。
有这方面经验的,给些建议和策略吧。
问题补充:
牟盖南 写道
仅仅和编码有关,与网速等其他诱因均无关。
注意你打开的文件形式,也就是你判定是否乱码的标准是哪些。
建议不存数据库,URL->CharSet,毕竟网站的个数不是多的吓人吧,再或则配置文件足矣。
刚开始,,编码我是动态手动剖析编码的,
我是依照网页头文件的二进制流来剖析网页信息的编码格式。让我十分诧异的是,,经过大量的测试发觉: 在多任务并行处理运行的前提下,,同一个网站的新闻信息部份新闻信息是乱码。。一般100条新闻有大约10条左右的乱码信息。,,,断点发觉,网页源码都是乱码。。郁闷。。。其他不同的网站也有同样的问题。
问题补充:
maxm 写道
还有新闻采集下来后如何做的处理采集过来的文章乱码,可否贴出代码瞧瞧?
maxm 写道
还有新闻采集下来后如何做的处理,可否贴出代码瞧瞧?
这不是一两个类能填完的采集过来的文章乱码,,这涉及的知识很多的。。主要包括,,网络爬虫与信息抽取,两大方面的知识。
QueryList采集器开发指南
采集交流 • 优采云 发表了文章 • 0 个评论 • 409 次浏览 • 2020-05-28 08:01
出现乱码的问题好多,解决方式也不尽相同采集过来的文章乱码,要视具体情况而定,以下几种乱码解决方案仅供参考。
Query方式:
QueryList::Query(采集的目标页面,采集规则[,区域选择器][,输出编码][,输入编码][,是否移除背部])
1.设置输入输出编码
$html =<<<STR
<div>
<p>这是内容</p>
</div>
STR;
$rule = array(
'content' => array('div>p:last','text')
);
$data = QueryList::Query($html,$rule,'','UTF-8','GB2312',true)->data;
2.设置输入输出编码,并设置最后一个参数为true
如果设置输入输出参数始终未能解决乱码采集过来的文章乱码,那就设置最后一个参数为true(移除背部)
$html =<<<STR
<div>
<p>这是内容</p>
</div>
STR;
$rule = array(
'content' => array('div>p:last','text')
);
$data = QueryList::Query($html,$rule,'','UTF-8','GB2312',true)->data;
乱码:#all 查看全部
出现乱码的问题好多,解决方式也不尽相同采集过来的文章乱码,要视具体情况而定,以下几种乱码解决方案仅供参考。
Query方式:
QueryList::Query(采集的目标页面,采集规则[,区域选择器][,输出编码][,输入编码][,是否移除背部])
1.设置输入输出编码
$html =<<<STR
<div>
<p>这是内容</p>
</div>
STR;
$rule = array(
'content' => array('div>p:last','text')
);
$data = QueryList::Query($html,$rule,'','UTF-8','GB2312',true)->data;
2.设置输入输出编码,并设置最后一个参数为true
如果设置输入输出参数始终未能解决乱码采集过来的文章乱码,那就设置最后一个参数为true(移除背部)
$html =<<<STR
<div>
<p>这是内容</p>
</div>
STR;
$rule = array(
'content' => array('div>p:last','text')
);
$data = QueryList::Query($html,$rule,'','UTF-8','GB2312',true)->data;
乱码:#all
采集乱码解决方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 448 次浏览 • 2020-05-26 08:00
出现乱码的问题好多,解决方式也不尽相同,要视具体情况而定采集过来的文章乱码,以下几种乱码解决方案仅供参考。
Query方式:
QueryList::Query(采集的目标页面,采集规则[,区域选择器][,输出编码][,输入编码][,是否移除头部])
1.设置输入输出编码
$html =<<<STR
<div>
<p>这是内容</p>
</div>
STR;
$rule = array(
'content' => array('div>p:last','text')
);
$data = QueryList::Query($html,$rule,'','UTF-8','GB2312')->data;
2.设置输入输出编码,并设置最后一个参数为true假如设置输入输出参数始终未能解决乱码采集过来的文章乱码,那就设置最后一个参数为true(移除背部)
$html =<<<STR
<div>
<p>这是内容</p>
</div>
STR;
$rule = array(
'content' => array('div>p:last','text')
);
$data = QueryList::Query($html,$rule,'','UTF-8','GB2312',true)->data; 查看全部
出现乱码的问题好多,解决方式也不尽相同,要视具体情况而定采集过来的文章乱码,以下几种乱码解决方案仅供参考。
Query方式:
QueryList::Query(采集的目标页面,采集规则[,区域选择器][,输出编码][,输入编码][,是否移除头部])
1.设置输入输出编码
$html =<<<STR
<div>
<p>这是内容</p>
</div>
STR;
$rule = array(
'content' => array('div>p:last','text')
);
$data = QueryList::Query($html,$rule,'','UTF-8','GB2312')->data;
2.设置输入输出编码,并设置最后一个参数为true假如设置输入输出参数始终未能解决乱码采集过来的文章乱码,那就设置最后一个参数为true(移除背部)
$html =<<<STR
<div>
<p>这是内容</p>
</div>
STR;
$rule = array(
'content' => array('div>p:last','text')
);
$data = QueryList::Query($html,$rule,'','UTF-8','GB2312',true)->data;

