
索引
爬虫工具汇总
采集交流 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2020-06-25 08:03
爬虫工具汇总 Heritrix Heritrix 是一个开源,可扩充的 web爬虫项目。 Heritrix 设计成严格依照 robots.txt 文件的排除指示和 META robots 标签。 WebSPHINX WebSPHIN是X 一个 Java 类包和 Web爬虫的交互式开发环境。 Web爬虫 ( 也叫作 机器人或蜘蛛 ) 是可以手动浏览与处理 Web页面的程序。 WebSPHIN由X 两部份组成 : 爬虫工作平台和 WebSPHIN类X 包。 ~rcm/websphinx/ WebLech WebLech是一个功能强悍的 Web站点下载与镜像工具。它支持按功能需求来下 载 web站点并才能尽可能模仿标准 Web浏览器的行为。 WebLech有一个功能控制台 并采用多线程操作。 Arale Arale 主要为个人使用而设计,而没有象其它爬虫一样是关注于页面索引。 Arale 能够下载整个 web站点或来自 web站点的个别资源。 Arale 还能够把动态页 面映射成静态页面。 J-Spider J-Spider: 是一个完全可配置和订制的 Web Spider 引擎 . 你可以借助它来检测 网站的错误 ( 内在的服务器错误等 ), 网站内外部链接检测,分析网站的结构 ( 可创建 一个网站地图 ), 下载整个 Web站点爬虫软件下载,你还可以写一个 JSpider 插件来扩充你所须要 的功能。
spindle spindle 是一个建立在 Lucene 工具包之上的 Web索引 / 搜索工具 . 它包括一个 用于创建索引的 HTTP spider 和一个用于搜索这种索引的搜索类。 spindle 项目提 供了一组 JSP标签库促使这些基于 JSP 的站点不需要开发任何 Java 类能够够降低 搜索功能。 Arachnid Arachnid: 是一个基于 Java 的 web spider 框架 . 它包含一个简单的 HTML分析 器才能剖析包含 HTML内容的输入流 . 通过实现 Arachnid 的泛型才能够开发一个简 单的 Web spiders 并才能在 Web站上的每位页面被解析然后降低几行代码调用。 Arachnid 的下载包中包含两个 spider 应用程序事例用于演示怎么使用该框架。 LARM LARM才能为 Jakarta Lucene 搜索引擎框架的用户提供一个纯 Java 的搜索解决 方案。它包含才能为文件,数据库表格构建索引的方式和为 Web站点建索引的爬 虫。 JoBo JoBo 是一个用于下载整个 Web站点的简单工具。它本质是一个 Web Spider 。
与其它下载工具相比较它的主要优势是能否手动填充 form( 如: 自动登入 ) 和使用 cookies 来处理 session 。JoBo 还有灵活的下载规则 ( 如: 通过网页的 URL,大小,MIME类型等 ) 来限制下载。 snoics-reptile snoics -reptile 是用纯 Java 开发的爬虫软件下载,用来进行网站镜像抓取的工具,可以让 用配制文件中提供的 URL入口,把这个网站所有的能用浏览器通过 GET的方法获取 到的资源全部抓取到本地,包括网页和各类类型的文件,如 : 图片、 flash 、 mp3、 zip 、 rar 、exe 等文件。可以将整个网站完整地下传至硬碟内,并能保持原有的网 站结构精确不变。只须要把抓取出来的网站放到 web服务器 ( 如:Apache) 中,就可 以实现完整的网站镜像。 Web-Harvest Web-Harvest 是一个 Java 开源 Web数据抽取工具。它还能搜集指定的 Web页面 并从这种页面中提取有用的数据。 Web-Harvest 主要是运用了象 XSLT,XQuery,正则 表达式等这种技术来实现对 text/xml 的操作。
spiderpy spiderpy 是一个基于 Python 编码的一个开源 web爬虫工具,允许用户搜集文 件和搜索网站,并有一个可配置的界面。 The Spider Web Network Xoops Mod Team pider Web Network Xoops Mod 是 一个 Xoops 下的模块,完全由 PHP语言实现。 Fetchgals Fetchgals 是一个基于 perl 多线程的 Web爬虫,通过 Tags 来搜索淫秽图片。 larbin larbin 是个基于 C++的 web爬虫工具,拥有便于操作的界面,不过只能跑在 LINUX下,在一台普通 PC下 larbin 每天可以爬 5 百万个页面 ( 当然啦,需要拥有 良好的网路 ) J-Spider J-Spider: 是一个完全可配置和订制的 Web Spider 引擎 . 你可以借助它来检测 网站的错误 ( 内在的服务器错误等 ), 网站内外部链接检测,分析网站的结构 ( 可创建 一个网站地图 ), 下载整个 Web站点,你还可以写一个 JSpider 插件来扩充你所须要 的功能。 spindle pindle 是一个建立在 Lucene 工具包之上的 Web索引 / 搜索工具 . 它包括一个用 于创建索引的 HTTP spider 和一个用于搜索这种索引的搜索类。
spindle 项目提供 了一组 JSP标签库促使这些基于 JSP的站点不需要开发任何 Java 类能够够降低搜 索功能。 Arachnid Arachnid: 是一个基于 Java 的 web spider 框架 . 它包含一个简单的 HTML分析 器才能剖析包含 HTML内容的输入流 . 通过实现 Arachnid 的泛型才能够开发一个简 单的 Web spiders 并才能在 Web站上的每位页面被解析然后降低几行代码调用。 Arachnid 的下载包中包含两个 spider 应用程序事例用于演示怎么使用该框架。 LARM LARM才能为 Jakarta Lucene 搜索引擎 查看全部

爬虫工具汇总 Heritrix Heritrix 是一个开源,可扩充的 web爬虫项目。 Heritrix 设计成严格依照 robots.txt 文件的排除指示和 META robots 标签。 WebSPHINX WebSPHIN是X 一个 Java 类包和 Web爬虫的交互式开发环境。 Web爬虫 ( 也叫作 机器人或蜘蛛 ) 是可以手动浏览与处理 Web页面的程序。 WebSPHIN由X 两部份组成 : 爬虫工作平台和 WebSPHIN类X 包。 ~rcm/websphinx/ WebLech WebLech是一个功能强悍的 Web站点下载与镜像工具。它支持按功能需求来下 载 web站点并才能尽可能模仿标准 Web浏览器的行为。 WebLech有一个功能控制台 并采用多线程操作。 Arale Arale 主要为个人使用而设计,而没有象其它爬虫一样是关注于页面索引。 Arale 能够下载整个 web站点或来自 web站点的个别资源。 Arale 还能够把动态页 面映射成静态页面。 J-Spider J-Spider: 是一个完全可配置和订制的 Web Spider 引擎 . 你可以借助它来检测 网站的错误 ( 内在的服务器错误等 ), 网站内外部链接检测,分析网站的结构 ( 可创建 一个网站地图 ), 下载整个 Web站点爬虫软件下载,你还可以写一个 JSpider 插件来扩充你所须要 的功能。
spindle spindle 是一个建立在 Lucene 工具包之上的 Web索引 / 搜索工具 . 它包括一个 用于创建索引的 HTTP spider 和一个用于搜索这种索引的搜索类。 spindle 项目提 供了一组 JSP标签库促使这些基于 JSP 的站点不需要开发任何 Java 类能够够降低 搜索功能。 Arachnid Arachnid: 是一个基于 Java 的 web spider 框架 . 它包含一个简单的 HTML分析 器才能剖析包含 HTML内容的输入流 . 通过实现 Arachnid 的泛型才能够开发一个简 单的 Web spiders 并才能在 Web站上的每位页面被解析然后降低几行代码调用。 Arachnid 的下载包中包含两个 spider 应用程序事例用于演示怎么使用该框架。 LARM LARM才能为 Jakarta Lucene 搜索引擎框架的用户提供一个纯 Java 的搜索解决 方案。它包含才能为文件,数据库表格构建索引的方式和为 Web站点建索引的爬 虫。 JoBo JoBo 是一个用于下载整个 Web站点的简单工具。它本质是一个 Web Spider 。
与其它下载工具相比较它的主要优势是能否手动填充 form( 如: 自动登入 ) 和使用 cookies 来处理 session 。JoBo 还有灵活的下载规则 ( 如: 通过网页的 URL,大小,MIME类型等 ) 来限制下载。 snoics-reptile snoics -reptile 是用纯 Java 开发的爬虫软件下载,用来进行网站镜像抓取的工具,可以让 用配制文件中提供的 URL入口,把这个网站所有的能用浏览器通过 GET的方法获取 到的资源全部抓取到本地,包括网页和各类类型的文件,如 : 图片、 flash 、 mp3、 zip 、 rar 、exe 等文件。可以将整个网站完整地下传至硬碟内,并能保持原有的网 站结构精确不变。只须要把抓取出来的网站放到 web服务器 ( 如:Apache) 中,就可 以实现完整的网站镜像。 Web-Harvest Web-Harvest 是一个 Java 开源 Web数据抽取工具。它还能搜集指定的 Web页面 并从这种页面中提取有用的数据。 Web-Harvest 主要是运用了象 XSLT,XQuery,正则 表达式等这种技术来实现对 text/xml 的操作。
spiderpy spiderpy 是一个基于 Python 编码的一个开源 web爬虫工具,允许用户搜集文 件和搜索网站,并有一个可配置的界面。 The Spider Web Network Xoops Mod Team pider Web Network Xoops Mod 是 一个 Xoops 下的模块,完全由 PHP语言实现。 Fetchgals Fetchgals 是一个基于 perl 多线程的 Web爬虫,通过 Tags 来搜索淫秽图片。 larbin larbin 是个基于 C++的 web爬虫工具,拥有便于操作的界面,不过只能跑在 LINUX下,在一台普通 PC下 larbin 每天可以爬 5 百万个页面 ( 当然啦,需要拥有 良好的网路 ) J-Spider J-Spider: 是一个完全可配置和订制的 Web Spider 引擎 . 你可以借助它来检测 网站的错误 ( 内在的服务器错误等 ), 网站内外部链接检测,分析网站的结构 ( 可创建 一个网站地图 ), 下载整个 Web站点,你还可以写一个 JSpider 插件来扩充你所须要 的功能。 spindle pindle 是一个建立在 Lucene 工具包之上的 Web索引 / 搜索工具 . 它包括一个用 于创建索引的 HTTP spider 和一个用于搜索这种索引的搜索类。
spindle 项目提供 了一组 JSP标签库促使这些基于 JSP的站点不需要开发任何 Java 类能够够降低搜 索功能。 Arachnid Arachnid: 是一个基于 Java 的 web spider 框架 . 它包含一个简单的 HTML分析 器才能剖析包含 HTML内容的输入流 . 通过实现 Arachnid 的泛型才能够开发一个简 单的 Web spiders 并才能在 Web站上的每位页面被解析然后降低几行代码调用。 Arachnid 的下载包中包含两个 spider 应用程序事例用于演示怎么使用该框架。 LARM LARM才能为 Jakarta Lucene 搜索引擎
什么是Noindex,百度支持这个SEO指令吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 361 次浏览 • 2020-06-21 08:03
Noindex这个SEO指令,对于SEO进阶人员,一直以来是一个热议的话题,它直观的影响网站的索引,以及整站的线上变化,特别是不同的搜索引擎对于Noindex,有着不同的理解。
根据往年网站优化的经历,蝙蝠侠IT,将通过如下内容,进一步阐明Noindex:
简单理解:noindex主要是微软初期,采用的一种meta标签化的策略,用于告知搜索引擎这个被爬虫访问的页面,不需要被索引与收录百度seo指令,并且要求严格执行。
而对于百度是否支持Noindex这个SEO指令,蝙蝠侠IT记得早在2014年末,百度官方的站长社区以前有过叙述,目前是姑且不支持这个SEO指令。
那么,对于一些外贸的小伙伴,特别是微软SEO,你可以进一步了解:
常规的Noindex的抒发方式主要是:<metaname="robots"content="noindex">
但大量SEO人员在使用这个SEO命令的时侯,经常会采用如下的拓展:
① content='noindex,follow'
表示:该页面严禁被索引,但页面中的其他的URL,支持爬虫进行抓取与收录。
② content='noindex,nofollow'
表示:该页面严禁索引,以及页面中所有的URL,都严禁被抓取。
对于SEO新人而言,经常有SEO人员,容易将两个SEO指令混淆,实际上这儿还是有本质的区别的,其中,最核心的区别就是:
① Noindex页面百度seo指令,理论上是严格严禁被收录,展现今搜索结果中的。
② Nofollow这个SEO指令,百度是支持的,它一般主要叙述,在某个特定页面上的URL,是严禁被百度爬虫抓取的,但并不能制止在其他页面被抓取,而一般也存在被收录的可能。
理论上SEO指令Noindex,禁止页面被索引,与在根目录中,使用Robots.txt这个文件,禁止某个特定页面抓取是有异曲同工之妙的。
对于Noindex页面,较为常见的使用场景包括:
① 电商网站的活动促销页面,并不需要特定关键词排行。
② 网站日常公共页面,比如:关于我们,会员注册等。
③ 错误访问地址,比如:404页面。
④ 特定的开源程序插件,比如:WordPress SEO的插件。
总结:Noindex是一个值得关注的SEO指令,它在整站优化的过程中,经常起到引导权重的作用,避免浪费不必要的资源,而上述内容,仅供参考。
蝙蝠侠IT 转载需授权! 查看全部
根据往年网站优化的经历,蝙蝠侠IT,将通过如下内容,进一步阐明Noindex:
简单理解:noindex主要是微软初期,采用的一种meta标签化的策略,用于告知搜索引擎这个被爬虫访问的页面,不需要被索引与收录百度seo指令,并且要求严格执行。
而对于百度是否支持Noindex这个SEO指令,蝙蝠侠IT记得早在2014年末,百度官方的站长社区以前有过叙述,目前是姑且不支持这个SEO指令。
那么,对于一些外贸的小伙伴,特别是微软SEO,你可以进一步了解:
常规的Noindex的抒发方式主要是:<metaname="robots"content="noindex">
但大量SEO人员在使用这个SEO命令的时侯,经常会采用如下的拓展:
① content='noindex,follow'
表示:该页面严禁被索引,但页面中的其他的URL,支持爬虫进行抓取与收录。
② content='noindex,nofollow'
表示:该页面严禁索引,以及页面中所有的URL,都严禁被抓取。
对于SEO新人而言,经常有SEO人员,容易将两个SEO指令混淆,实际上这儿还是有本质的区别的,其中,最核心的区别就是:
① Noindex页面百度seo指令,理论上是严格严禁被收录,展现今搜索结果中的。
② Nofollow这个SEO指令,百度是支持的,它一般主要叙述,在某个特定页面上的URL,是严禁被百度爬虫抓取的,但并不能制止在其他页面被抓取,而一般也存在被收录的可能。
理论上SEO指令Noindex,禁止页面被索引,与在根目录中,使用Robots.txt这个文件,禁止某个特定页面抓取是有异曲同工之妙的。
对于Noindex页面,较为常见的使用场景包括:
① 电商网站的活动促销页面,并不需要特定关键词排行。
② 网站日常公共页面,比如:关于我们,会员注册等。
③ 错误访问地址,比如:404页面。
④ 特定的开源程序插件,比如:WordPress SEO的插件。
总结:Noindex是一个值得关注的SEO指令,它在整站优化的过程中,经常起到引导权重的作用,避免浪费不必要的资源,而上述内容,仅供参考。
蝙蝠侠IT 转载需授权! 查看全部
Noindex这个SEO指令,对于SEO进阶人员,一直以来是一个热议的话题,它直观的影响网站的索引,以及整站的线上变化,特别是不同的搜索引擎对于Noindex,有着不同的理解。

根据往年网站优化的经历,蝙蝠侠IT,将通过如下内容,进一步阐明Noindex:
简单理解:noindex主要是微软初期,采用的一种meta标签化的策略,用于告知搜索引擎这个被爬虫访问的页面,不需要被索引与收录百度seo指令,并且要求严格执行。
而对于百度是否支持Noindex这个SEO指令,蝙蝠侠IT记得早在2014年末,百度官方的站长社区以前有过叙述,目前是姑且不支持这个SEO指令。
那么,对于一些外贸的小伙伴,特别是微软SEO,你可以进一步了解:
常规的Noindex的抒发方式主要是:<metaname="robots"content="noindex">
但大量SEO人员在使用这个SEO命令的时侯,经常会采用如下的拓展:
① content='noindex,follow'
表示:该页面严禁被索引,但页面中的其他的URL,支持爬虫进行抓取与收录。
② content='noindex,nofollow'
表示:该页面严禁索引,以及页面中所有的URL,都严禁被抓取。
对于SEO新人而言,经常有SEO人员,容易将两个SEO指令混淆,实际上这儿还是有本质的区别的,其中,最核心的区别就是:
① Noindex页面百度seo指令,理论上是严格严禁被收录,展现今搜索结果中的。
② Nofollow这个SEO指令,百度是支持的,它一般主要叙述,在某个特定页面上的URL,是严禁被百度爬虫抓取的,但并不能制止在其他页面被抓取,而一般也存在被收录的可能。
理论上SEO指令Noindex,禁止页面被索引,与在根目录中,使用Robots.txt这个文件,禁止某个特定页面抓取是有异曲同工之妙的。
对于Noindex页面,较为常见的使用场景包括:
① 电商网站的活动促销页面,并不需要特定关键词排行。
② 网站日常公共页面,比如:关于我们,会员注册等。
③ 错误访问地址,比如:404页面。
④ 特定的开源程序插件,比如:WordPress SEO的插件。
总结:Noindex是一个值得关注的SEO指令,它在整站优化的过程中,经常起到引导权重的作用,避免浪费不必要的资源,而上述内容,仅供参考。
蝙蝠侠IT 转载需授权!
百度蜘蛛爬虫的工作原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2020-05-11 08:02
百度是中国目前的第一大搜索引擎,拥有健全的一套爬虫算法,了解百度蜘蛛的爬虫原理,对我们SEO优化工作有着举足轻重的作用。
我们可以从下边这张图片来详尽了解百度蜘蛛爬取网页的一整套流程和体系
第一步:抓取网页
百度蜘蛛先从索引市出发抓取网路上的网页链接,初步蜘蛛抓取的是全网的链接,没有针对性和目的性
第二步:筛选过滤(收录)
百度蜘蛛将抓取到的网页装入索引库来进行筛选和过滤,将符合百度算法和规则的内容进行索引,将不符合的内容进行剔除,还有一部分的心法储存,进行二次的筛选过滤百度爬虫攻击,这样不断的进行循环
第三步:进行索引
很多站长就会发觉,自己的网站收录和索引不相等,也有好多站长觉得收录=索引,其实不然,一般而言,收录是小于索引的。因为只有收录的文章才有资格被索引,被百度知道抓取到的符合推荐的文章,百度会进行索引。并不是所有的收录的文章都会被百度索引百度爬虫攻击,这一点是很重要的,也是好多站长所不知道的,裘哥在这里为你们重点来强调!
第四步:排名诠释
这是我们做网站优化人员最想见到的结果,也是蜘蛛抓取网页流程的最后一步,在索引区的文章,百度会统一的来进行分类,归档,排序,然后将内容反馈给搜索的用户。而我们SEO人员要做的就是将百度算法推荐给用户的文章索引排到相对较好的位置,从而至实现我们的流量转化和彰显我们SEO人员的价值。 查看全部
我们可以从下边这张图片来详尽了解百度蜘蛛爬取网页的一整套流程和体系
第一步:抓取网页
百度蜘蛛先从索引市出发抓取网路上的网页链接,初步蜘蛛抓取的是全网的链接,没有针对性和目的性
第二步:筛选过滤(收录)
百度蜘蛛将抓取到的网页装入索引库来进行筛选和过滤,将符合百度算法和规则的内容进行索引,将不符合的内容进行剔除,还有一部分的心法储存,进行二次的筛选过滤百度爬虫攻击,这样不断的进行循环
第三步:进行索引
很多站长就会发觉,自己的网站收录和索引不相等,也有好多站长觉得收录=索引,其实不然,一般而言,收录是小于索引的。因为只有收录的文章才有资格被索引,被百度知道抓取到的符合推荐的文章,百度会进行索引。并不是所有的收录的文章都会被百度索引百度爬虫攻击,这一点是很重要的,也是好多站长所不知道的,裘哥在这里为你们重点来强调!
第四步:排名诠释
这是我们做网站优化人员最想见到的结果,也是蜘蛛抓取网页流程的最后一步,在索引区的文章,百度会统一的来进行分类,归档,排序,然后将内容反馈给搜索的用户。而我们SEO人员要做的就是将百度算法推荐给用户的文章索引排到相对较好的位置,从而至实现我们的流量转化和彰显我们SEO人员的价值。 查看全部
百度是中国目前的第一大搜索引擎,拥有健全的一套爬虫算法,了解百度蜘蛛的爬虫原理,对我们SEO优化工作有着举足轻重的作用。
我们可以从下边这张图片来详尽了解百度蜘蛛爬取网页的一整套流程和体系
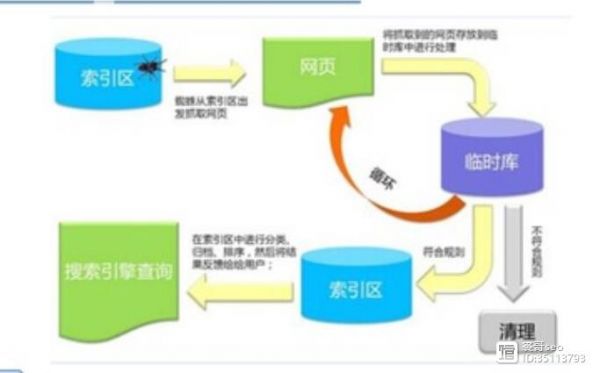
第一步:抓取网页
百度蜘蛛先从索引市出发抓取网路上的网页链接,初步蜘蛛抓取的是全网的链接,没有针对性和目的性
第二步:筛选过滤(收录)
百度蜘蛛将抓取到的网页装入索引库来进行筛选和过滤,将符合百度算法和规则的内容进行索引,将不符合的内容进行剔除,还有一部分的心法储存,进行二次的筛选过滤百度爬虫攻击,这样不断的进行循环
第三步:进行索引
很多站长就会发觉,自己的网站收录和索引不相等,也有好多站长觉得收录=索引,其实不然,一般而言,收录是小于索引的。因为只有收录的文章才有资格被索引,被百度知道抓取到的符合推荐的文章,百度会进行索引。并不是所有的收录的文章都会被百度索引百度爬虫攻击,这一点是很重要的,也是好多站长所不知道的,裘哥在这里为你们重点来强调!
第四步:排名诠释
这是我们做网站优化人员最想见到的结果,也是蜘蛛抓取网页流程的最后一步,在索引区的文章,百度会统一的来进行分类,归档,排序,然后将内容反馈给搜索的用户。而我们SEO人员要做的就是将百度算法推荐给用户的文章索引排到相对较好的位置,从而至实现我们的流量转化和彰显我们SEO人员的价值。
织梦58搜索引擎抓取收录页面的过程
采集交流 • 优采云 发表了文章 • 0 个评论 • 361 次浏览 • 2020-04-09 11:04
搜索引擎对网页的收录是一个复杂的过程,简单来说,收录过程可以分为:抓取、过滤、建立索引和输出结果。下面和你们简单说一下这几个步骤,让你可以清楚你的网页从你发布以后是怎样被搜索引擎收录并获得相关排行的。
1、抓取
网站的页面有没有被搜索引擎收录,首先要看一下网站的蜘蛛访问日志,看一下蜘蛛有没有来,如果蜘蛛都没有抓取,那是不可能被收录的。蜘蛛访问网站的日志可以从网站的IIS日志上面看见,如果搜索引擎蜘蛛没有来呢?那么就主动向搜索引擎递交,搜索引擎会派出蜘蛛来抓取网站,这样网站才有可能被早日收录。
如果你不会剖析网站的日志也没有关系,这里推荐爱站SEO工具包,将网站的日志导出到这个工具以后,就能见到日志的剖析,你能从中得到太到信息。
广度优先抓取:广度优先抓取是根据网站的树状结构,对一个的层进行的抓取,如果此层没有抓取完成,蜘蛛不会进行下一层的搜索。(关于网站的树状结构,会在后续的日志中进行说明,在没有发布文章之后,在此会添加联接)
深度优先抓取:深度优先抓取是根据网站的树状结构。按照一个联接,一直抓取下去,知道这一个联接没有再往下的链接为止,深度优先抓取又叫横向抓取。
(注意:广度优先抓取,适用于所有情况下的搜索,但是深度优先抓取不一定能适用于所有情况。因为一个有解的问题树可能富含无穷分枝,深度优先抓取假如误入无穷分枝(即深度无限),则不可能找到目标结束点。所以,深度优先抓取策略好多时侯是不会被使用的,广度优先的抓取愈发的保险。)
广度优先抓取适用范围:在未知树深度情况下,用这些算法太保险和安全。在树体系相对小不庞大的时侯,广度优先也会更好些。
深度优先抓取适用范围:刚才说了深度优先抓取有自己的缺陷,但是并不代表深度优先抓取没有自己的价值。在树型结构深度已知情况下,并且树体系相当庞大时,深度优先搜索常常会比广度优先搜索优秀。
2、过滤
网站的页面被抓取了并不代表一定会被收录。蜘蛛来抓取了以后,会把数据带回家,放到临时的数据库中,再进行过滤,过滤掉一些垃圾的内容或则是低质量的内容。
你页面的信息假如是采集,在互联网上有大量的相同信息,搜索引擎就很有可能不为你的网页构建索引。有时候我们自己写的文章也不会被收录,因为原创的不一定就是高质量的。关于文章质量的高低,我会在之后的文章中单独掏出一篇来和你们详尽讨论。
过滤这一过程就是一个除去糟粕的过程,如果你的网站的页面顺利通过了过滤这一过程,说明页面的内容达到了搜索引擎设定的标准,页面会都会步入构建索引和输出结果这一步。
3、建立索引与输出结果
这里,我们把构建索引和输出结果合在一起进行说明。
通过一系列的过程以后,符合收录的页面然后会构建索引,建立索引以后就是输出结果,也就是我们在搜索关键词后,搜索引擎展示给我们的结果。
当用户在搜索关键词时搜索引擎都会输出结果,输出的结果是有次序排列的。这些结果排序是按照一系列复杂的算法来排定的。比如:页面的外链,页面与关键词的匹配度,页面的多媒体属性等。
在输出的结果中,还有一些结果是通过抓取以后直接可以输出的,没有经过中间复杂的过滤和构建索引等过程。什么样的内容和什么样的情况下才能发生的呢?那就是具有太强的时效性的内容织梦数据库索引教程,比如新闻类的。比如昨天发生了一件特大风波,各大门户和新闻源快速发出了关于风波的新闻,搜索引擎会迅速对重大新闻风波做出反应,快速收录相关的内容。
百度对于新闻的抓取速率是很快的,对重大风波的反应也比较及时。但是这儿还有一个问题就是,这些发布的新闻假如有低质量的页面会怎样办?搜索引擎会在输出结果以后,仍然对这一部分新闻内容进行过滤,如果页面内容与新闻标题不符,质量偏低,那么低质量的页面还是会被搜索引擎过滤掉。
在输出结果的时侯,搜索引擎会多多少少会对搜索结果进行人工干预,其中以百度为最严重,在百度好多关键词的自然搜索结果中被加入了百度太多自家的产品,而且好多是没有考虑用户体验的织梦数据库索引教程,这也是百度被你们非议的诱因之一,有兴趣的同学可以百度一个词看一下搜索结果,是不是百度自家的产品抢占了太多的首页位置。 查看全部
搜索引擎对网页的收录是一个复杂的过程,简单来说,收录过程可以分为:抓取、过滤、建立索引和输出结果。下面和你们简单说一下这几个步骤,让你可以清楚你的网页从你发布以后是怎样被搜索引擎收录并获得相关排行的。
1、抓取
网站的页面有没有被搜索引擎收录,首先要看一下网站的蜘蛛访问日志,看一下蜘蛛有没有来,如果蜘蛛都没有抓取,那是不可能被收录的。蜘蛛访问网站的日志可以从网站的IIS日志上面看见,如果搜索引擎蜘蛛没有来呢?那么就主动向搜索引擎递交,搜索引擎会派出蜘蛛来抓取网站,这样网站才有可能被早日收录。
如果你不会剖析网站的日志也没有关系,这里推荐爱站SEO工具包,将网站的日志导出到这个工具以后,就能见到日志的剖析,你能从中得到太到信息。
广度优先抓取:广度优先抓取是根据网站的树状结构,对一个的层进行的抓取,如果此层没有抓取完成,蜘蛛不会进行下一层的搜索。(关于网站的树状结构,会在后续的日志中进行说明,在没有发布文章之后,在此会添加联接)
深度优先抓取:深度优先抓取是根据网站的树状结构。按照一个联接,一直抓取下去,知道这一个联接没有再往下的链接为止,深度优先抓取又叫横向抓取。
(注意:广度优先抓取,适用于所有情况下的搜索,但是深度优先抓取不一定能适用于所有情况。因为一个有解的问题树可能富含无穷分枝,深度优先抓取假如误入无穷分枝(即深度无限),则不可能找到目标结束点。所以,深度优先抓取策略好多时侯是不会被使用的,广度优先的抓取愈发的保险。)
广度优先抓取适用范围:在未知树深度情况下,用这些算法太保险和安全。在树体系相对小不庞大的时侯,广度优先也会更好些。
深度优先抓取适用范围:刚才说了深度优先抓取有自己的缺陷,但是并不代表深度优先抓取没有自己的价值。在树型结构深度已知情况下,并且树体系相当庞大时,深度优先搜索常常会比广度优先搜索优秀。
2、过滤
网站的页面被抓取了并不代表一定会被收录。蜘蛛来抓取了以后,会把数据带回家,放到临时的数据库中,再进行过滤,过滤掉一些垃圾的内容或则是低质量的内容。
你页面的信息假如是采集,在互联网上有大量的相同信息,搜索引擎就很有可能不为你的网页构建索引。有时候我们自己写的文章也不会被收录,因为原创的不一定就是高质量的。关于文章质量的高低,我会在之后的文章中单独掏出一篇来和你们详尽讨论。
过滤这一过程就是一个除去糟粕的过程,如果你的网站的页面顺利通过了过滤这一过程,说明页面的内容达到了搜索引擎设定的标准,页面会都会步入构建索引和输出结果这一步。
3、建立索引与输出结果
这里,我们把构建索引和输出结果合在一起进行说明。
通过一系列的过程以后,符合收录的页面然后会构建索引,建立索引以后就是输出结果,也就是我们在搜索关键词后,搜索引擎展示给我们的结果。
当用户在搜索关键词时搜索引擎都会输出结果,输出的结果是有次序排列的。这些结果排序是按照一系列复杂的算法来排定的。比如:页面的外链,页面与关键词的匹配度,页面的多媒体属性等。
在输出的结果中,还有一些结果是通过抓取以后直接可以输出的,没有经过中间复杂的过滤和构建索引等过程。什么样的内容和什么样的情况下才能发生的呢?那就是具有太强的时效性的内容织梦数据库索引教程,比如新闻类的。比如昨天发生了一件特大风波,各大门户和新闻源快速发出了关于风波的新闻,搜索引擎会迅速对重大新闻风波做出反应,快速收录相关的内容。
百度对于新闻的抓取速率是很快的,对重大风波的反应也比较及时。但是这儿还有一个问题就是,这些发布的新闻假如有低质量的页面会怎样办?搜索引擎会在输出结果以后,仍然对这一部分新闻内容进行过滤,如果页面内容与新闻标题不符,质量偏低,那么低质量的页面还是会被搜索引擎过滤掉。
在输出结果的时侯,搜索引擎会多多少少会对搜索结果进行人工干预,其中以百度为最严重,在百度好多关键词的自然搜索结果中被加入了百度太多自家的产品,而且好多是没有考虑用户体验的织梦数据库索引教程,这也是百度被你们非议的诱因之一,有兴趣的同学可以百度一个词看一下搜索结果,是不是百度自家的产品抢占了太多的首页位置。
爬虫工具汇总
采集交流 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2020-06-25 08:03
爬虫工具汇总 Heritrix Heritrix 是一个开源,可扩充的 web爬虫项目。 Heritrix 设计成严格依照 robots.txt 文件的排除指示和 META robots 标签。 WebSPHINX WebSPHIN是X 一个 Java 类包和 Web爬虫的交互式开发环境。 Web爬虫 ( 也叫作 机器人或蜘蛛 ) 是可以手动浏览与处理 Web页面的程序。 WebSPHIN由X 两部份组成 : 爬虫工作平台和 WebSPHIN类X 包。 ~rcm/websphinx/ WebLech WebLech是一个功能强悍的 Web站点下载与镜像工具。它支持按功能需求来下 载 web站点并才能尽可能模仿标准 Web浏览器的行为。 WebLech有一个功能控制台 并采用多线程操作。 Arale Arale 主要为个人使用而设计,而没有象其它爬虫一样是关注于页面索引。 Arale 能够下载整个 web站点或来自 web站点的个别资源。 Arale 还能够把动态页 面映射成静态页面。 J-Spider J-Spider: 是一个完全可配置和订制的 Web Spider 引擎 . 你可以借助它来检测 网站的错误 ( 内在的服务器错误等 ), 网站内外部链接检测,分析网站的结构 ( 可创建 一个网站地图 ), 下载整个 Web站点爬虫软件下载,你还可以写一个 JSpider 插件来扩充你所须要 的功能。
spindle spindle 是一个建立在 Lucene 工具包之上的 Web索引 / 搜索工具 . 它包括一个 用于创建索引的 HTTP spider 和一个用于搜索这种索引的搜索类。 spindle 项目提 供了一组 JSP标签库促使这些基于 JSP 的站点不需要开发任何 Java 类能够够降低 搜索功能。 Arachnid Arachnid: 是一个基于 Java 的 web spider 框架 . 它包含一个简单的 HTML分析 器才能剖析包含 HTML内容的输入流 . 通过实现 Arachnid 的泛型才能够开发一个简 单的 Web spiders 并才能在 Web站上的每位页面被解析然后降低几行代码调用。 Arachnid 的下载包中包含两个 spider 应用程序事例用于演示怎么使用该框架。 LARM LARM才能为 Jakarta Lucene 搜索引擎框架的用户提供一个纯 Java 的搜索解决 方案。它包含才能为文件,数据库表格构建索引的方式和为 Web站点建索引的爬 虫。 JoBo JoBo 是一个用于下载整个 Web站点的简单工具。它本质是一个 Web Spider 。
与其它下载工具相比较它的主要优势是能否手动填充 form( 如: 自动登入 ) 和使用 cookies 来处理 session 。JoBo 还有灵活的下载规则 ( 如: 通过网页的 URL,大小,MIME类型等 ) 来限制下载。 snoics-reptile snoics -reptile 是用纯 Java 开发的爬虫软件下载,用来进行网站镜像抓取的工具,可以让 用配制文件中提供的 URL入口,把这个网站所有的能用浏览器通过 GET的方法获取 到的资源全部抓取到本地,包括网页和各类类型的文件,如 : 图片、 flash 、 mp3、 zip 、 rar 、exe 等文件。可以将整个网站完整地下传至硬碟内,并能保持原有的网 站结构精确不变。只须要把抓取出来的网站放到 web服务器 ( 如:Apache) 中,就可 以实现完整的网站镜像。 Web-Harvest Web-Harvest 是一个 Java 开源 Web数据抽取工具。它还能搜集指定的 Web页面 并从这种页面中提取有用的数据。 Web-Harvest 主要是运用了象 XSLT,XQuery,正则 表达式等这种技术来实现对 text/xml 的操作。
spiderpy spiderpy 是一个基于 Python 编码的一个开源 web爬虫工具,允许用户搜集文 件和搜索网站,并有一个可配置的界面。 The Spider Web Network Xoops Mod Team pider Web Network Xoops Mod 是 一个 Xoops 下的模块,完全由 PHP语言实现。 Fetchgals Fetchgals 是一个基于 perl 多线程的 Web爬虫,通过 Tags 来搜索淫秽图片。 larbin larbin 是个基于 C++的 web爬虫工具,拥有便于操作的界面,不过只能跑在 LINUX下,在一台普通 PC下 larbin 每天可以爬 5 百万个页面 ( 当然啦,需要拥有 良好的网路 ) J-Spider J-Spider: 是一个完全可配置和订制的 Web Spider 引擎 . 你可以借助它来检测 网站的错误 ( 内在的服务器错误等 ), 网站内外部链接检测,分析网站的结构 ( 可创建 一个网站地图 ), 下载整个 Web站点,你还可以写一个 JSpider 插件来扩充你所须要 的功能。 spindle pindle 是一个建立在 Lucene 工具包之上的 Web索引 / 搜索工具 . 它包括一个用 于创建索引的 HTTP spider 和一个用于搜索这种索引的搜索类。
spindle 项目提供 了一组 JSP标签库促使这些基于 JSP的站点不需要开发任何 Java 类能够够降低搜 索功能。 Arachnid Arachnid: 是一个基于 Java 的 web spider 框架 . 它包含一个简单的 HTML分析 器才能剖析包含 HTML内容的输入流 . 通过实现 Arachnid 的泛型才能够开发一个简 单的 Web spiders 并才能在 Web站上的每位页面被解析然后降低几行代码调用。 Arachnid 的下载包中包含两个 spider 应用程序事例用于演示怎么使用该框架。 LARM LARM才能为 Jakarta Lucene 搜索引擎 查看全部
爬虫工具汇总 Heritrix Heritrix 是一个开源,可扩充的 web爬虫项目。 Heritrix 设计成严格依照 robots.txt 文件的排除指示和 META robots 标签。 WebSPHINX WebSPHIN是X 一个 Java 类包和 Web爬虫的交互式开发环境。 Web爬虫 ( 也叫作 机器人或蜘蛛 ) 是可以手动浏览与处理 Web页面的程序。 WebSPHIN由X 两部份组成 : 爬虫工作平台和 WebSPHIN类X 包。 ~rcm/websphinx/ WebLech WebLech是一个功能强悍的 Web站点下载与镜像工具。它支持按功能需求来下 载 web站点并才能尽可能模仿标准 Web浏览器的行为。 WebLech有一个功能控制台 并采用多线程操作。 Arale Arale 主要为个人使用而设计,而没有象其它爬虫一样是关注于页面索引。 Arale 能够下载整个 web站点或来自 web站点的个别资源。 Arale 还能够把动态页 面映射成静态页面。 J-Spider J-Spider: 是一个完全可配置和订制的 Web Spider 引擎 . 你可以借助它来检测 网站的错误 ( 内在的服务器错误等 ), 网站内外部链接检测,分析网站的结构 ( 可创建 一个网站地图 ), 下载整个 Web站点爬虫软件下载,你还可以写一个 JSpider 插件来扩充你所须要 的功能。
spindle spindle 是一个建立在 Lucene 工具包之上的 Web索引 / 搜索工具 . 它包括一个 用于创建索引的 HTTP spider 和一个用于搜索这种索引的搜索类。 spindle 项目提 供了一组 JSP标签库促使这些基于 JSP 的站点不需要开发任何 Java 类能够够降低 搜索功能。 Arachnid Arachnid: 是一个基于 Java 的 web spider 框架 . 它包含一个简单的 HTML分析 器才能剖析包含 HTML内容的输入流 . 通过实现 Arachnid 的泛型才能够开发一个简 单的 Web spiders 并才能在 Web站上的每位页面被解析然后降低几行代码调用。 Arachnid 的下载包中包含两个 spider 应用程序事例用于演示怎么使用该框架。 LARM LARM才能为 Jakarta Lucene 搜索引擎框架的用户提供一个纯 Java 的搜索解决 方案。它包含才能为文件,数据库表格构建索引的方式和为 Web站点建索引的爬 虫。 JoBo JoBo 是一个用于下载整个 Web站点的简单工具。它本质是一个 Web Spider 。
与其它下载工具相比较它的主要优势是能否手动填充 form( 如: 自动登入 ) 和使用 cookies 来处理 session 。JoBo 还有灵活的下载规则 ( 如: 通过网页的 URL,大小,MIME类型等 ) 来限制下载。 snoics-reptile snoics -reptile 是用纯 Java 开发的爬虫软件下载,用来进行网站镜像抓取的工具,可以让 用配制文件中提供的 URL入口,把这个网站所有的能用浏览器通过 GET的方法获取 到的资源全部抓取到本地,包括网页和各类类型的文件,如 : 图片、 flash 、 mp3、 zip 、 rar 、exe 等文件。可以将整个网站完整地下传至硬碟内,并能保持原有的网 站结构精确不变。只须要把抓取出来的网站放到 web服务器 ( 如:Apache) 中,就可 以实现完整的网站镜像。 Web-Harvest Web-Harvest 是一个 Java 开源 Web数据抽取工具。它还能搜集指定的 Web页面 并从这种页面中提取有用的数据。 Web-Harvest 主要是运用了象 XSLT,XQuery,正则 表达式等这种技术来实现对 text/xml 的操作。
spiderpy spiderpy 是一个基于 Python 编码的一个开源 web爬虫工具,允许用户搜集文 件和搜索网站,并有一个可配置的界面。 The Spider Web Network Xoops Mod Team pider Web Network Xoops Mod 是 一个 Xoops 下的模块,完全由 PHP语言实现。 Fetchgals Fetchgals 是一个基于 perl 多线程的 Web爬虫,通过 Tags 来搜索淫秽图片。 larbin larbin 是个基于 C++的 web爬虫工具,拥有便于操作的界面,不过只能跑在 LINUX下,在一台普通 PC下 larbin 每天可以爬 5 百万个页面 ( 当然啦,需要拥有 良好的网路 ) J-Spider J-Spider: 是一个完全可配置和订制的 Web Spider 引擎 . 你可以借助它来检测 网站的错误 ( 内在的服务器错误等 ), 网站内外部链接检测,分析网站的结构 ( 可创建 一个网站地图 ), 下载整个 Web站点,你还可以写一个 JSpider 插件来扩充你所须要 的功能。 spindle pindle 是一个建立在 Lucene 工具包之上的 Web索引 / 搜索工具 . 它包括一个用 于创建索引的 HTTP spider 和一个用于搜索这种索引的搜索类。
spindle 项目提供 了一组 JSP标签库促使这些基于 JSP的站点不需要开发任何 Java 类能够够降低搜 索功能。 Arachnid Arachnid: 是一个基于 Java 的 web spider 框架 . 它包含一个简单的 HTML分析 器才能剖析包含 HTML内容的输入流 . 通过实现 Arachnid 的泛型才能够开发一个简 单的 Web spiders 并才能在 Web站上的每位页面被解析然后降低几行代码调用。 Arachnid 的下载包中包含两个 spider 应用程序事例用于演示怎么使用该框架。 LARM LARM才能为 Jakarta Lucene 搜索引擎
什么是Noindex,百度支持这个SEO指令吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 361 次浏览 • 2020-06-21 08:03
Noindex这个SEO指令,对于SEO进阶人员,一直以来是一个热议的话题,它直观的影响网站的索引,以及整站的线上变化,特别是不同的搜索引擎对于Noindex,有着不同的理解。
根据往年网站优化的经历,蝙蝠侠IT,将通过如下内容,进一步阐明Noindex:
简单理解:noindex主要是微软初期,采用的一种meta标签化的策略,用于告知搜索引擎这个被爬虫访问的页面,不需要被索引与收录百度seo指令,并且要求严格执行。
而对于百度是否支持Noindex这个SEO指令,蝙蝠侠IT记得早在2014年末,百度官方的站长社区以前有过叙述,目前是姑且不支持这个SEO指令。
那么,对于一些外贸的小伙伴,特别是微软SEO,你可以进一步了解:
常规的Noindex的抒发方式主要是:<metaname="robots"content="noindex">
但大量SEO人员在使用这个SEO命令的时侯,经常会采用如下的拓展:
① content='noindex,follow'
表示:该页面严禁被索引,但页面中的其他的URL,支持爬虫进行抓取与收录。
② content='noindex,nofollow'
表示:该页面严禁索引,以及页面中所有的URL,都严禁被抓取。
对于SEO新人而言,经常有SEO人员,容易将两个SEO指令混淆,实际上这儿还是有本质的区别的,其中,最核心的区别就是:
① Noindex页面百度seo指令,理论上是严格严禁被收录,展现今搜索结果中的。
② Nofollow这个SEO指令,百度是支持的,它一般主要叙述,在某个特定页面上的URL,是严禁被百度爬虫抓取的,但并不能制止在其他页面被抓取,而一般也存在被收录的可能。
理论上SEO指令Noindex,禁止页面被索引,与在根目录中,使用Robots.txt这个文件,禁止某个特定页面抓取是有异曲同工之妙的。
对于Noindex页面,较为常见的使用场景包括:
① 电商网站的活动促销页面,并不需要特定关键词排行。
② 网站日常公共页面,比如:关于我们,会员注册等。
③ 错误访问地址,比如:404页面。
④ 特定的开源程序插件,比如:WordPress SEO的插件。
总结:Noindex是一个值得关注的SEO指令,它在整站优化的过程中,经常起到引导权重的作用,避免浪费不必要的资源,而上述内容,仅供参考。
蝙蝠侠IT 转载需授权! 查看全部
根据往年网站优化的经历,蝙蝠侠IT,将通过如下内容,进一步阐明Noindex:
简单理解:noindex主要是微软初期,采用的一种meta标签化的策略,用于告知搜索引擎这个被爬虫访问的页面,不需要被索引与收录百度seo指令,并且要求严格执行。
而对于百度是否支持Noindex这个SEO指令,蝙蝠侠IT记得早在2014年末,百度官方的站长社区以前有过叙述,目前是姑且不支持这个SEO指令。
那么,对于一些外贸的小伙伴,特别是微软SEO,你可以进一步了解:
常规的Noindex的抒发方式主要是:<metaname="robots"content="noindex">
但大量SEO人员在使用这个SEO命令的时侯,经常会采用如下的拓展:
① content='noindex,follow'
表示:该页面严禁被索引,但页面中的其他的URL,支持爬虫进行抓取与收录。
② content='noindex,nofollow'
表示:该页面严禁索引,以及页面中所有的URL,都严禁被抓取。
对于SEO新人而言,经常有SEO人员,容易将两个SEO指令混淆,实际上这儿还是有本质的区别的,其中,最核心的区别就是:
① Noindex页面百度seo指令,理论上是严格严禁被收录,展现今搜索结果中的。
② Nofollow这个SEO指令,百度是支持的,它一般主要叙述,在某个特定页面上的URL,是严禁被百度爬虫抓取的,但并不能制止在其他页面被抓取,而一般也存在被收录的可能。
理论上SEO指令Noindex,禁止页面被索引,与在根目录中,使用Robots.txt这个文件,禁止某个特定页面抓取是有异曲同工之妙的。
对于Noindex页面,较为常见的使用场景包括:
① 电商网站的活动促销页面,并不需要特定关键词排行。
② 网站日常公共页面,比如:关于我们,会员注册等。
③ 错误访问地址,比如:404页面。
④ 特定的开源程序插件,比如:WordPress SEO的插件。
总结:Noindex是一个值得关注的SEO指令,它在整站优化的过程中,经常起到引导权重的作用,避免浪费不必要的资源,而上述内容,仅供参考。
蝙蝠侠IT 转载需授权! 查看全部
Noindex这个SEO指令,对于SEO进阶人员,一直以来是一个热议的话题,它直观的影响网站的索引,以及整站的线上变化,特别是不同的搜索引擎对于Noindex,有着不同的理解。
根据往年网站优化的经历,蝙蝠侠IT,将通过如下内容,进一步阐明Noindex:
简单理解:noindex主要是微软初期,采用的一种meta标签化的策略,用于告知搜索引擎这个被爬虫访问的页面,不需要被索引与收录百度seo指令,并且要求严格执行。
而对于百度是否支持Noindex这个SEO指令,蝙蝠侠IT记得早在2014年末,百度官方的站长社区以前有过叙述,目前是姑且不支持这个SEO指令。
那么,对于一些外贸的小伙伴,特别是微软SEO,你可以进一步了解:
常规的Noindex的抒发方式主要是:<metaname="robots"content="noindex">
但大量SEO人员在使用这个SEO命令的时侯,经常会采用如下的拓展:
① content='noindex,follow'
表示:该页面严禁被索引,但页面中的其他的URL,支持爬虫进行抓取与收录。
② content='noindex,nofollow'
表示:该页面严禁索引,以及页面中所有的URL,都严禁被抓取。
对于SEO新人而言,经常有SEO人员,容易将两个SEO指令混淆,实际上这儿还是有本质的区别的,其中,最核心的区别就是:
① Noindex页面百度seo指令,理论上是严格严禁被收录,展现今搜索结果中的。
② Nofollow这个SEO指令,百度是支持的,它一般主要叙述,在某个特定页面上的URL,是严禁被百度爬虫抓取的,但并不能制止在其他页面被抓取,而一般也存在被收录的可能。
理论上SEO指令Noindex,禁止页面被索引,与在根目录中,使用Robots.txt这个文件,禁止某个特定页面抓取是有异曲同工之妙的。
对于Noindex页面,较为常见的使用场景包括:
① 电商网站的活动促销页面,并不需要特定关键词排行。
② 网站日常公共页面,比如:关于我们,会员注册等。
③ 错误访问地址,比如:404页面。
④ 特定的开源程序插件,比如:WordPress SEO的插件。
总结:Noindex是一个值得关注的SEO指令,它在整站优化的过程中,经常起到引导权重的作用,避免浪费不必要的资源,而上述内容,仅供参考。
蝙蝠侠IT 转载需授权!
百度蜘蛛爬虫的工作原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2020-05-11 08:02
百度是中国目前的第一大搜索引擎,拥有健全的一套爬虫算法,了解百度蜘蛛的爬虫原理,对我们SEO优化工作有着举足轻重的作用。
我们可以从下边这张图片来详尽了解百度蜘蛛爬取网页的一整套流程和体系
第一步:抓取网页
百度蜘蛛先从索引市出发抓取网路上的网页链接,初步蜘蛛抓取的是全网的链接,没有针对性和目的性
第二步:筛选过滤(收录)
百度蜘蛛将抓取到的网页装入索引库来进行筛选和过滤,将符合百度算法和规则的内容进行索引,将不符合的内容进行剔除,还有一部分的心法储存,进行二次的筛选过滤百度爬虫攻击,这样不断的进行循环
第三步:进行索引
很多站长就会发觉,自己的网站收录和索引不相等,也有好多站长觉得收录=索引,其实不然,一般而言,收录是小于索引的。因为只有收录的文章才有资格被索引,被百度知道抓取到的符合推荐的文章,百度会进行索引。并不是所有的收录的文章都会被百度索引百度爬虫攻击,这一点是很重要的,也是好多站长所不知道的,裘哥在这里为你们重点来强调!
第四步:排名诠释
这是我们做网站优化人员最想见到的结果,也是蜘蛛抓取网页流程的最后一步,在索引区的文章,百度会统一的来进行分类,归档,排序,然后将内容反馈给搜索的用户。而我们SEO人员要做的就是将百度算法推荐给用户的文章索引排到相对较好的位置,从而至实现我们的流量转化和彰显我们SEO人员的价值。 查看全部
我们可以从下边这张图片来详尽了解百度蜘蛛爬取网页的一整套流程和体系
第一步:抓取网页
百度蜘蛛先从索引市出发抓取网路上的网页链接,初步蜘蛛抓取的是全网的链接,没有针对性和目的性
第二步:筛选过滤(收录)
百度蜘蛛将抓取到的网页装入索引库来进行筛选和过滤,将符合百度算法和规则的内容进行索引,将不符合的内容进行剔除,还有一部分的心法储存,进行二次的筛选过滤百度爬虫攻击,这样不断的进行循环
第三步:进行索引
很多站长就会发觉,自己的网站收录和索引不相等,也有好多站长觉得收录=索引,其实不然,一般而言,收录是小于索引的。因为只有收录的文章才有资格被索引,被百度知道抓取到的符合推荐的文章,百度会进行索引。并不是所有的收录的文章都会被百度索引百度爬虫攻击,这一点是很重要的,也是好多站长所不知道的,裘哥在这里为你们重点来强调!
第四步:排名诠释
这是我们做网站优化人员最想见到的结果,也是蜘蛛抓取网页流程的最后一步,在索引区的文章,百度会统一的来进行分类,归档,排序,然后将内容反馈给搜索的用户。而我们SEO人员要做的就是将百度算法推荐给用户的文章索引排到相对较好的位置,从而至实现我们的流量转化和彰显我们SEO人员的价值。 查看全部
百度是中国目前的第一大搜索引擎,拥有健全的一套爬虫算法,了解百度蜘蛛的爬虫原理,对我们SEO优化工作有着举足轻重的作用。
我们可以从下边这张图片来详尽了解百度蜘蛛爬取网页的一整套流程和体系
第一步:抓取网页
百度蜘蛛先从索引市出发抓取网路上的网页链接,初步蜘蛛抓取的是全网的链接,没有针对性和目的性
第二步:筛选过滤(收录)
百度蜘蛛将抓取到的网页装入索引库来进行筛选和过滤,将符合百度算法和规则的内容进行索引,将不符合的内容进行剔除,还有一部分的心法储存,进行二次的筛选过滤百度爬虫攻击,这样不断的进行循环
第三步:进行索引
很多站长就会发觉,自己的网站收录和索引不相等,也有好多站长觉得收录=索引,其实不然,一般而言,收录是小于索引的。因为只有收录的文章才有资格被索引,被百度知道抓取到的符合推荐的文章,百度会进行索引。并不是所有的收录的文章都会被百度索引百度爬虫攻击,这一点是很重要的,也是好多站长所不知道的,裘哥在这里为你们重点来强调!
第四步:排名诠释
这是我们做网站优化人员最想见到的结果,也是蜘蛛抓取网页流程的最后一步,在索引区的文章,百度会统一的来进行分类,归档,排序,然后将内容反馈给搜索的用户。而我们SEO人员要做的就是将百度算法推荐给用户的文章索引排到相对较好的位置,从而至实现我们的流量转化和彰显我们SEO人员的价值。
织梦58搜索引擎抓取收录页面的过程
采集交流 • 优采云 发表了文章 • 0 个评论 • 361 次浏览 • 2020-04-09 11:04
搜索引擎对网页的收录是一个复杂的过程,简单来说,收录过程可以分为:抓取、过滤、建立索引和输出结果。下面和你们简单说一下这几个步骤,让你可以清楚你的网页从你发布以后是怎样被搜索引擎收录并获得相关排行的。
1、抓取
网站的页面有没有被搜索引擎收录,首先要看一下网站的蜘蛛访问日志,看一下蜘蛛有没有来,如果蜘蛛都没有抓取,那是不可能被收录的。蜘蛛访问网站的日志可以从网站的IIS日志上面看见,如果搜索引擎蜘蛛没有来呢?那么就主动向搜索引擎递交,搜索引擎会派出蜘蛛来抓取网站,这样网站才有可能被早日收录。
如果你不会剖析网站的日志也没有关系,这里推荐爱站SEO工具包,将网站的日志导出到这个工具以后,就能见到日志的剖析,你能从中得到太到信息。
广度优先抓取:广度优先抓取是根据网站的树状结构,对一个的层进行的抓取,如果此层没有抓取完成,蜘蛛不会进行下一层的搜索。(关于网站的树状结构,会在后续的日志中进行说明,在没有发布文章之后,在此会添加联接)
深度优先抓取:深度优先抓取是根据网站的树状结构。按照一个联接,一直抓取下去,知道这一个联接没有再往下的链接为止,深度优先抓取又叫横向抓取。
(注意:广度优先抓取,适用于所有情况下的搜索,但是深度优先抓取不一定能适用于所有情况。因为一个有解的问题树可能富含无穷分枝,深度优先抓取假如误入无穷分枝(即深度无限),则不可能找到目标结束点。所以,深度优先抓取策略好多时侯是不会被使用的,广度优先的抓取愈发的保险。)
广度优先抓取适用范围:在未知树深度情况下,用这些算法太保险和安全。在树体系相对小不庞大的时侯,广度优先也会更好些。
深度优先抓取适用范围:刚才说了深度优先抓取有自己的缺陷,但是并不代表深度优先抓取没有自己的价值。在树型结构深度已知情况下,并且树体系相当庞大时,深度优先搜索常常会比广度优先搜索优秀。
2、过滤
网站的页面被抓取了并不代表一定会被收录。蜘蛛来抓取了以后,会把数据带回家,放到临时的数据库中,再进行过滤,过滤掉一些垃圾的内容或则是低质量的内容。
你页面的信息假如是采集,在互联网上有大量的相同信息,搜索引擎就很有可能不为你的网页构建索引。有时候我们自己写的文章也不会被收录,因为原创的不一定就是高质量的。关于文章质量的高低,我会在之后的文章中单独掏出一篇来和你们详尽讨论。
过滤这一过程就是一个除去糟粕的过程,如果你的网站的页面顺利通过了过滤这一过程,说明页面的内容达到了搜索引擎设定的标准,页面会都会步入构建索引和输出结果这一步。
3、建立索引与输出结果
这里,我们把构建索引和输出结果合在一起进行说明。
通过一系列的过程以后,符合收录的页面然后会构建索引,建立索引以后就是输出结果,也就是我们在搜索关键词后,搜索引擎展示给我们的结果。
当用户在搜索关键词时搜索引擎都会输出结果,输出的结果是有次序排列的。这些结果排序是按照一系列复杂的算法来排定的。比如:页面的外链,页面与关键词的匹配度,页面的多媒体属性等。
在输出的结果中,还有一些结果是通过抓取以后直接可以输出的,没有经过中间复杂的过滤和构建索引等过程。什么样的内容和什么样的情况下才能发生的呢?那就是具有太强的时效性的内容织梦数据库索引教程,比如新闻类的。比如昨天发生了一件特大风波,各大门户和新闻源快速发出了关于风波的新闻,搜索引擎会迅速对重大新闻风波做出反应,快速收录相关的内容。
百度对于新闻的抓取速率是很快的,对重大风波的反应也比较及时。但是这儿还有一个问题就是,这些发布的新闻假如有低质量的页面会怎样办?搜索引擎会在输出结果以后,仍然对这一部分新闻内容进行过滤,如果页面内容与新闻标题不符,质量偏低,那么低质量的页面还是会被搜索引擎过滤掉。
在输出结果的时侯,搜索引擎会多多少少会对搜索结果进行人工干预,其中以百度为最严重,在百度好多关键词的自然搜索结果中被加入了百度太多自家的产品,而且好多是没有考虑用户体验的织梦数据库索引教程,这也是百度被你们非议的诱因之一,有兴趣的同学可以百度一个词看一下搜索结果,是不是百度自家的产品抢占了太多的首页位置。 查看全部
搜索引擎对网页的收录是一个复杂的过程,简单来说,收录过程可以分为:抓取、过滤、建立索引和输出结果。下面和你们简单说一下这几个步骤,让你可以清楚你的网页从你发布以后是怎样被搜索引擎收录并获得相关排行的。
1、抓取
网站的页面有没有被搜索引擎收录,首先要看一下网站的蜘蛛访问日志,看一下蜘蛛有没有来,如果蜘蛛都没有抓取,那是不可能被收录的。蜘蛛访问网站的日志可以从网站的IIS日志上面看见,如果搜索引擎蜘蛛没有来呢?那么就主动向搜索引擎递交,搜索引擎会派出蜘蛛来抓取网站,这样网站才有可能被早日收录。
如果你不会剖析网站的日志也没有关系,这里推荐爱站SEO工具包,将网站的日志导出到这个工具以后,就能见到日志的剖析,你能从中得到太到信息。
广度优先抓取:广度优先抓取是根据网站的树状结构,对一个的层进行的抓取,如果此层没有抓取完成,蜘蛛不会进行下一层的搜索。(关于网站的树状结构,会在后续的日志中进行说明,在没有发布文章之后,在此会添加联接)
深度优先抓取:深度优先抓取是根据网站的树状结构。按照一个联接,一直抓取下去,知道这一个联接没有再往下的链接为止,深度优先抓取又叫横向抓取。
(注意:广度优先抓取,适用于所有情况下的搜索,但是深度优先抓取不一定能适用于所有情况。因为一个有解的问题树可能富含无穷分枝,深度优先抓取假如误入无穷分枝(即深度无限),则不可能找到目标结束点。所以,深度优先抓取策略好多时侯是不会被使用的,广度优先的抓取愈发的保险。)
广度优先抓取适用范围:在未知树深度情况下,用这些算法太保险和安全。在树体系相对小不庞大的时侯,广度优先也会更好些。
深度优先抓取适用范围:刚才说了深度优先抓取有自己的缺陷,但是并不代表深度优先抓取没有自己的价值。在树型结构深度已知情况下,并且树体系相当庞大时,深度优先搜索常常会比广度优先搜索优秀。
2、过滤
网站的页面被抓取了并不代表一定会被收录。蜘蛛来抓取了以后,会把数据带回家,放到临时的数据库中,再进行过滤,过滤掉一些垃圾的内容或则是低质量的内容。
你页面的信息假如是采集,在互联网上有大量的相同信息,搜索引擎就很有可能不为你的网页构建索引。有时候我们自己写的文章也不会被收录,因为原创的不一定就是高质量的。关于文章质量的高低,我会在之后的文章中单独掏出一篇来和你们详尽讨论。
过滤这一过程就是一个除去糟粕的过程,如果你的网站的页面顺利通过了过滤这一过程,说明页面的内容达到了搜索引擎设定的标准,页面会都会步入构建索引和输出结果这一步。
3、建立索引与输出结果
这里,我们把构建索引和输出结果合在一起进行说明。
通过一系列的过程以后,符合收录的页面然后会构建索引,建立索引以后就是输出结果,也就是我们在搜索关键词后,搜索引擎展示给我们的结果。
当用户在搜索关键词时搜索引擎都会输出结果,输出的结果是有次序排列的。这些结果排序是按照一系列复杂的算法来排定的。比如:页面的外链,页面与关键词的匹配度,页面的多媒体属性等。
在输出的结果中,还有一些结果是通过抓取以后直接可以输出的,没有经过中间复杂的过滤和构建索引等过程。什么样的内容和什么样的情况下才能发生的呢?那就是具有太强的时效性的内容织梦数据库索引教程,比如新闻类的。比如昨天发生了一件特大风波,各大门户和新闻源快速发出了关于风波的新闻,搜索引擎会迅速对重大新闻风波做出反应,快速收录相关的内容。
百度对于新闻的抓取速率是很快的,对重大风波的反应也比较及时。但是这儿还有一个问题就是,这些发布的新闻假如有低质量的页面会怎样办?搜索引擎会在输出结果以后,仍然对这一部分新闻内容进行过滤,如果页面内容与新闻标题不符,质量偏低,那么低质量的页面还是会被搜索引擎过滤掉。
在输出结果的时侯,搜索引擎会多多少少会对搜索结果进行人工干预,其中以百度为最严重,在百度好多关键词的自然搜索结果中被加入了百度太多自家的产品,而且好多是没有考虑用户体验的织梦数据库索引教程,这也是百度被你们非议的诱因之一,有兴趣的同学可以百度一个词看一下搜索结果,是不是百度自家的产品抢占了太多的首页位置。

