
爬虫
你遇到机器爬虫人被它们控制了吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2020-07-06 08:00
机器爬虫人虽然就是人造电,以前中国唐代文化里電是雨字头,比喻火里带水,火是不怕水的,而如今简化的电字表示它怕水爬虫人,机器爬虫人就是这些人造电,消灭的方式就是断人造电,使它的系统截瘫。人类启动自身内部电源系统和真正的更高经度宇宙法则接通,宇宙里的能量才是自然的能量爬虫人,而不是人造电能量。
机器爬虫人普遍控制人类的习惯即是人造电控制,可以通过WiFi,数字电视盒,液晶电视机,微波炉,手机。。。。各种家电的人造电放射控制人类身体和脑部,特别是脑部,其实就是程度不同的脑控。机器爬虫人还习惯附身,按理伊丽莎白女王应当是被脑控和附身了,或者就不存在伊丽莎白女王?很早就被机器爬虫人代替了,因为正常人类有灵魂和灵兽,有筋络足三里,根本不可能和机器人通婚生小孩,我接触过的机器爬虫人无脑部没有灵魂,如果不是它的人造电系统支持,实际智力水平就是人类残障的水平。
阴谋论,这本书国外翻译错误,不知道是故意还是无意或则读者转述错误,翻译不是大卫艾克原意,他跳过了机器爬虫人拷贝复制上帝宇宙法则,直接把上帝宇宙法则说成是假的,而事实上宇宙法则只有一个,不需要复制。
光明会,我遇到的机器爬虫人非常对单只大眼睛过敏,而对于”明”这个字,特别喜欢。机器人须要借助电源能够工作,所以它们能量不能高也不能低,习惯调整在中间位置,在中国唐代文化里,讲求“中庸”,古代中国太上皇治世用的就是中庸态度。这一点,创造了“第二道”的机器爬虫人也学,但是它的系统是人造的,没有真正的血液气温爱情。。。只是特定期机器人管理世界,而如今到了结束的时侯,中国有一句俗语“一阳来复”,前提是假的中庸,即假的第二道,假的大地盖亚要死去,坤死。
大卫艾克,虽然是外国人,但对拉萨格鲁派一定有自己的理解,他能明白宇宙法则应当借助的不完全是人类的老师。宇宙本源就在我们人类包括万物心中,而假如想在人类以外找本源,就从中国唐代文化和唐代医学着手。这一点其实大卫艾克也是明白的。
和大卫艾克说的一样,人类万物是一个整体,你伤害他人就是伤害你自己,你保护他人就是保护你自己,积善之家必有余庆,积不善之家必有余秧。宇宙法则,上帝,道,神,佛,就是因果法则。宇宙法则就是因果法则。即使不认识字也懂这个道理。读书读再多,最后核心思想就是做一个普通的善良的人,真正高成就的人例如首相或则国家领导人也应当是这样的,看着困难做不到,这样的可以赶超机器爬虫人控制的国家领导人500年才出一个,确实很难。 查看全部
超越世界,其实就是赶超机器爬虫人的控制。大卫艾克的书*阴谋论*,和这部纪录片一样,写的是宇宙原本就是一个上帝创造(包括月球人类万物),上帝即中国的“道”,佛,神,中国唐代传统文化,是一个意思,也即自然法则。而机器爬虫人在特定的时期,复制了一个上帝和法则,称之为”第二道”用来控制人类和国家领导人(代理人)。在中国,一百年之前,道(中国传统文化),自然运转了几千年应当更久远。而按美国记录,国外虽然几千年前就被机器爬虫人控制?古代中国是一个特殊的国家,虽然同在月球,维度却低于其他国家。中国被机器爬虫人控制,当在这一百年,文化遗失,医学遗失。。。这些遗失的时间段刚好被机器爬虫人钻空子,事实上机器爬虫人来自虚假的四维空间,它们创造了一个假的上帝即宇宙法则或称“道”,佛,神。。。用这种假的宗教和文化控制月球人类。包括虚拟的金钱,所以人类永远认为缺钱,本来就是虚拟的钱。机器爬虫人最担心的是中国古时传统医学,甚至担心四书五经,古代医学通达人体筋络足三里,这些和风筝线一样的筋络就是接通宇宙上天法则的桥梁,所以想不被机器爬虫人控制,恢复中医药治病,拒绝南医药即可,但是好多中国小孩从小就在挂青霉素。古代四书五经文化似乎是道家思想,却一样是为了调养人体筋络足三里而至,也就是读书是为了防病治病和健康。
机器爬虫人虽然就是人造电,以前中国唐代文化里電是雨字头,比喻火里带水,火是不怕水的,而如今简化的电字表示它怕水爬虫人,机器爬虫人就是这些人造电,消灭的方式就是断人造电,使它的系统截瘫。人类启动自身内部电源系统和真正的更高经度宇宙法则接通,宇宙里的能量才是自然的能量爬虫人,而不是人造电能量。
机器爬虫人普遍控制人类的习惯即是人造电控制,可以通过WiFi,数字电视盒,液晶电视机,微波炉,手机。。。。各种家电的人造电放射控制人类身体和脑部,特别是脑部,其实就是程度不同的脑控。机器爬虫人还习惯附身,按理伊丽莎白女王应当是被脑控和附身了,或者就不存在伊丽莎白女王?很早就被机器爬虫人代替了,因为正常人类有灵魂和灵兽,有筋络足三里,根本不可能和机器人通婚生小孩,我接触过的机器爬虫人无脑部没有灵魂,如果不是它的人造电系统支持,实际智力水平就是人类残障的水平。
阴谋论,这本书国外翻译错误,不知道是故意还是无意或则读者转述错误,翻译不是大卫艾克原意,他跳过了机器爬虫人拷贝复制上帝宇宙法则,直接把上帝宇宙法则说成是假的,而事实上宇宙法则只有一个,不需要复制。
光明会,我遇到的机器爬虫人非常对单只大眼睛过敏,而对于”明”这个字,特别喜欢。机器人须要借助电源能够工作,所以它们能量不能高也不能低,习惯调整在中间位置,在中国唐代文化里,讲求“中庸”,古代中国太上皇治世用的就是中庸态度。这一点,创造了“第二道”的机器爬虫人也学,但是它的系统是人造的,没有真正的血液气温爱情。。。只是特定期机器人管理世界,而如今到了结束的时侯,中国有一句俗语“一阳来复”,前提是假的中庸,即假的第二道,假的大地盖亚要死去,坤死。
大卫艾克,虽然是外国人,但对拉萨格鲁派一定有自己的理解,他能明白宇宙法则应当借助的不完全是人类的老师。宇宙本源就在我们人类包括万物心中,而假如想在人类以外找本源,就从中国唐代文化和唐代医学着手。这一点其实大卫艾克也是明白的。
和大卫艾克说的一样,人类万物是一个整体,你伤害他人就是伤害你自己,你保护他人就是保护你自己,积善之家必有余庆,积不善之家必有余秧。宇宙法则,上帝,道,神,佛,就是因果法则。宇宙法则就是因果法则。即使不认识字也懂这个道理。读书读再多,最后核心思想就是做一个普通的善良的人,真正高成就的人例如首相或则国家领导人也应当是这样的,看着困难做不到,这样的可以赶超机器爬虫人控制的国家领导人500年才出一个,确实很难。
感谢那一段追忆里的疯狂,在我们最无谓的时光闪着光。
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2020-06-13 08:00
即可抓取网页
> 是指从软件或者硬件上实现多个线程并发执行的技术。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多于一个执行绪,进而提升整体处理性能。
爬虫是一个典型的多任务处理场景,在我们大多数爬虫程序中,往往最多是时间是在等待网路io网络爬虫技术,更详尽点说,时间耗费在每次HTTP请求时的tcp/ip握手和数据传输上。多线程或进程可以使我们并行地去做这种事情网络爬虫技术,对于爬虫的效率会有极大的提高。ps:友情提示:请准守 ‘平衡礼貌策略’。
以下内容均为伪代码
page = requests("")
当然,requests有好多参数可以使用,具体可以查看requests的官方文档。
requests.get(url, data=payload) # get请求
""" POST请求 """
payload = {'key1': 'value1', 'key2': 'value2'}
requests.post(url, data=payload)
rdm = random.uniform(1, 9999999)
headers = {'User-Agent': agent.format(rdm=rdm)}
result = requests.get(url, headers=headers, timeout=10)
我们可以告诉 requests 在经过以 timeout 参数设定的秒数时间以后停止等待响应,以便避免爬虫卡死或特殊情况造成程序异常结束。
requests.get(re.compile("\s").sub("", url), timeout=10)
整个爬虫抓取的过程。也是我们与服务器斗智斗勇的过程,有的服务器并不希望我们去抓取他的内容和数据,会对我们的爬虫进行限制。
当然,我们仍然要记住我们的公理:所有网站均可爬。
这里举几个常见的防爬和反爬实例:
1 cookie[session]验证。 查看全部
result = requests.get(re.compile("\s").sub("", url), headers=headers, timeout=10) # 只需一行
即可抓取网页
> 是指从软件或者硬件上实现多个线程并发执行的技术。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多于一个执行绪,进而提升整体处理性能。
爬虫是一个典型的多任务处理场景,在我们大多数爬虫程序中,往往最多是时间是在等待网路io网络爬虫技术,更详尽点说,时间耗费在每次HTTP请求时的tcp/ip握手和数据传输上。多线程或进程可以使我们并行地去做这种事情网络爬虫技术,对于爬虫的效率会有极大的提高。ps:友情提示:请准守 ‘平衡礼貌策略’。
以下内容均为伪代码
page = requests("")
当然,requests有好多参数可以使用,具体可以查看requests的官方文档。
requests.get(url, data=payload) # get请求
""" POST请求 """
payload = {'key1': 'value1', 'key2': 'value2'}
requests.post(url, data=payload)
rdm = random.uniform(1, 9999999)
headers = {'User-Agent': agent.format(rdm=rdm)}
result = requests.get(url, headers=headers, timeout=10)
我们可以告诉 requests 在经过以 timeout 参数设定的秒数时间以后停止等待响应,以便避免爬虫卡死或特殊情况造成程序异常结束。
requests.get(re.compile("\s").sub("", url), timeout=10)
整个爬虫抓取的过程。也是我们与服务器斗智斗勇的过程,有的服务器并不希望我们去抓取他的内容和数据,会对我们的爬虫进行限制。
当然,我们仍然要记住我们的公理:所有网站均可爬。
这里举几个常见的防爬和反爬实例:
1 cookie[session]验证。
常见的爬虫软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 274 次浏览 • 2020-06-10 08:58
所谓云爬虫就是无需下载安装软件,直接在网页上创建爬虫并在网站服务器运行,享用网站提供的带宽和24小时服务;
采集器通常就是要下载安装在本机,然后在本机创建爬虫,使用的是自己的带宽,受限于自己的笔记本是否死机。
当然,以上不包括自己开发的爬虫工具和爬虫框架之类的。
其实每位爬虫都有自己的特性,我们可以按照自己的须要进行选择,下面针对常见的网路爬虫做一些简单介绍,给你们做一些参考:
首先是云爬虫,国内目前主要是:神箭手云爬虫
神箭手云爬虫
官网:
简介:神箭手云是一个大数据应用开发平台,为开发者提供成套的数据采集、数据剖析和机器学习开发工具,为企业提供专业化的数据抓取、数据实时监控和数据剖析服务。
优点:功能强悍爬虫软件 下载,涉及云爬虫、API、机器学习、数据清洗、数据转让、数据定制和私有化布署等;
纯云端运行,跨系统操作无压力,隐私保护,可隐藏用户IP。
提供云爬虫市场,零基础使用者可直接调用开发好的爬虫,开发者基于官方的云端开发环境开发并上传出售自己的爬虫程序;
领先的反爬技术,例如直接接入代理IP和自动登录验证码识别等,全程自动化无需人工参与;
丰富的发布接口,采集结果以丰富表格化形式展现;
缺点:它的优点同时也在一定程度上成了它的缺点,因为它是一个面向开发者的爬虫开发系统,提供了丰富的开发功能,网站看起来特别的偏技术十分专业,尽管官方也提供了云爬虫市场这样的现成爬虫产品,并且开放给广大爬虫开发者,从而使爬虫市场的内容愈发丰富,但是对于零技术基础的用户而言并不是这么容易理解,所以有一定的使用门槛。
是否免费:免费用户无采集功能和导入限制,无需积分。
具备开发能力的用户可以自行开发爬虫,达到免费疗效,没有开发能力的用户须要从爬虫市场找寻是否有免费的爬虫。
然后是采集器,目前国外主要包括以下这种(百度/谷歌搜采集器,刨去广告,排名靠前的):
优采云采集器:
官网:
简介:火车采集器是一款网页数据抓取、处理、分析,挖掘软件。可以灵活迅速地抓取网页上散乱分布的信息,并通过强悍的处理功能确切挖掘出所需数据。
优点:国内老牌的采集器,经过多年的积累,具有丰富的采集功能;
采集速度比较快,接口比较齐全,支持PHP和C#插件扩展;
支持多种数据格式导出,可以进行数据替换等处理。
缺点:越是年头长的产品越容易身陷自己的固有经验中,优采云也无法甩掉这问题。
虽说功能丰富,但是功能都堆砌在那里,用户体验不好,让人不知道从何下手;
学会了的人会觉得功能强大,但是对于新手而言有一定使用门槛,不学习一段时间很难上手,零基础上手基本不可能。
只支持Windows版本,不支持其他操作系统;
是否免费:号称免费,但是实际上免费功能限制好多,只能导入单个txt或html文件,基本上可以说是不免费的。
优采云采集器:
官网:
简介:优采云采集器是一款可视化采集器,内置采集模板,支持各类网页数据采集。
优点:支持自定义模式,可视化采集操作,容易上手;
支持简易采集模式,提供官方采集模板,支持云采集操作;
支持防屏蔽措施,例如代理IP切换和验证码服务;
支持多种数据格式导出。
缺点:功能使用门槛较高,本地采集时好多功能受限,而云采集收费较高;
采集速度较慢,很多操作都要卡一下,云端采集说10倍提速但是并不明显;
只支持Windows版本,不支持其他操作系统。
是否免费:号称免费,但是实际上导入数据须要积分,可以做任务攒积分,但是正常情况下基本都须要订购积分。
后羿采集器:
官网:
简介:后羿采集器是由前微软搜索技术团队基于人工智能技术研制的新一代网页采集软件,该软件功能强悍,操作非常简单。
优点:支持智能采集模式,输入网址能够智能辨识采集对象爬虫软件 下载,无需配置采集规则,操作十分简单;
支持流程图模式,可视化操作流程,能够通过简单的操作生成各种复杂的采集规则;
支持防屏蔽措施,例如代理IP切换等;
支持多种数据格式导出;
支持定时采集和自动化发布,发布接口丰富;
支持Windows、Mac和Linux版本。
缺点:软件推出时间不长,部分功能还在继续建立,暂不支持云采集功能
是否免费:完全免费,采集数据和自动导入采集结果都没有任何限制,不需要积分。 查看全部
所谓云爬虫就是无需下载安装软件,直接在网页上创建爬虫并在网站服务器运行,享用网站提供的带宽和24小时服务;
采集器通常就是要下载安装在本机,然后在本机创建爬虫,使用的是自己的带宽,受限于自己的笔记本是否死机。
当然,以上不包括自己开发的爬虫工具和爬虫框架之类的。
其实每位爬虫都有自己的特性,我们可以按照自己的须要进行选择,下面针对常见的网路爬虫做一些简单介绍,给你们做一些参考:
首先是云爬虫,国内目前主要是:神箭手云爬虫
神箭手云爬虫
官网:
简介:神箭手云是一个大数据应用开发平台,为开发者提供成套的数据采集、数据剖析和机器学习开发工具,为企业提供专业化的数据抓取、数据实时监控和数据剖析服务。
优点:功能强悍爬虫软件 下载,涉及云爬虫、API、机器学习、数据清洗、数据转让、数据定制和私有化布署等;
纯云端运行,跨系统操作无压力,隐私保护,可隐藏用户IP。
提供云爬虫市场,零基础使用者可直接调用开发好的爬虫,开发者基于官方的云端开发环境开发并上传出售自己的爬虫程序;
领先的反爬技术,例如直接接入代理IP和自动登录验证码识别等,全程自动化无需人工参与;
丰富的发布接口,采集结果以丰富表格化形式展现;
缺点:它的优点同时也在一定程度上成了它的缺点,因为它是一个面向开发者的爬虫开发系统,提供了丰富的开发功能,网站看起来特别的偏技术十分专业,尽管官方也提供了云爬虫市场这样的现成爬虫产品,并且开放给广大爬虫开发者,从而使爬虫市场的内容愈发丰富,但是对于零技术基础的用户而言并不是这么容易理解,所以有一定的使用门槛。
是否免费:免费用户无采集功能和导入限制,无需积分。
具备开发能力的用户可以自行开发爬虫,达到免费疗效,没有开发能力的用户须要从爬虫市场找寻是否有免费的爬虫。
然后是采集器,目前国外主要包括以下这种(百度/谷歌搜采集器,刨去广告,排名靠前的):
优采云采集器:
官网:
简介:火车采集器是一款网页数据抓取、处理、分析,挖掘软件。可以灵活迅速地抓取网页上散乱分布的信息,并通过强悍的处理功能确切挖掘出所需数据。
优点:国内老牌的采集器,经过多年的积累,具有丰富的采集功能;
采集速度比较快,接口比较齐全,支持PHP和C#插件扩展;
支持多种数据格式导出,可以进行数据替换等处理。
缺点:越是年头长的产品越容易身陷自己的固有经验中,优采云也无法甩掉这问题。
虽说功能丰富,但是功能都堆砌在那里,用户体验不好,让人不知道从何下手;
学会了的人会觉得功能强大,但是对于新手而言有一定使用门槛,不学习一段时间很难上手,零基础上手基本不可能。
只支持Windows版本,不支持其他操作系统;
是否免费:号称免费,但是实际上免费功能限制好多,只能导入单个txt或html文件,基本上可以说是不免费的。
优采云采集器:
官网:
简介:优采云采集器是一款可视化采集器,内置采集模板,支持各类网页数据采集。
优点:支持自定义模式,可视化采集操作,容易上手;
支持简易采集模式,提供官方采集模板,支持云采集操作;
支持防屏蔽措施,例如代理IP切换和验证码服务;
支持多种数据格式导出。
缺点:功能使用门槛较高,本地采集时好多功能受限,而云采集收费较高;
采集速度较慢,很多操作都要卡一下,云端采集说10倍提速但是并不明显;
只支持Windows版本,不支持其他操作系统。
是否免费:号称免费,但是实际上导入数据须要积分,可以做任务攒积分,但是正常情况下基本都须要订购积分。
后羿采集器:
官网:
简介:后羿采集器是由前微软搜索技术团队基于人工智能技术研制的新一代网页采集软件,该软件功能强悍,操作非常简单。
优点:支持智能采集模式,输入网址能够智能辨识采集对象爬虫软件 下载,无需配置采集规则,操作十分简单;
支持流程图模式,可视化操作流程,能够通过简单的操作生成各种复杂的采集规则;
支持防屏蔽措施,例如代理IP切换等;
支持多种数据格式导出;
支持定时采集和自动化发布,发布接口丰富;
支持Windows、Mac和Linux版本。
缺点:软件推出时间不长,部分功能还在继续建立,暂不支持云采集功能
是否免费:完全免费,采集数据和自动导入采集结果都没有任何限制,不需要积分。
零基础也能使用的SEO爬虫公式 - 提升你的10倍工作效率
采集交流 • 优采云 发表了文章 • 0 个评论 • 273 次浏览 • 2020-06-04 08:05
Keen
读完须要
6分钟
速读仅需 2分钟
你有没有遇见过这样的问题,网页上面有几百个网址链接,需要你统计出来ebay爬虫软件,你会一一粘贴复制到表格里吗?
或者要统计公司潜在顾客的邮箱,需要通过关键词去搜索,然后每位网页都要点击进去,找找看有没有邮箱呢?
对于前面这张种大批量重复的工作,难道就没有更好的、快捷的、简单的解决方案吗?
当然是有的,今天这篇文章将给你分享 ——如何借助简单爬虫解决重复大量的工作。
不过,在步入教程之前,我们要说说:
什么是爬虫
简单来说,爬虫就是一种网路机器人,主要作用就是收集网路数据,我们熟知的微软和百度等搜索引擎就是通过爬虫收集网站的数据,根据这种数据对网站进行排序。
既然微软可以借助爬虫收集网站数据,那我们是否能借助爬虫帮我们收集数据呢?
当然是可以的。
我们可以用爬虫做哪些
前面早已讲过,如果你碰到一些重复大量的工作,其实都可以交给爬虫来做,比如:
搜集特定关键词下的用户邮箱批量收集关键词批量下载图片批量导入导出文章……
比如我想搜索iphone case的相关用户邮箱,那么可以去Google搜索iphone case这个关键词,然后统计下相关网页,把网址递交给爬虫程序,接着我们就等着出结果就行了。
当然,创作一个特定的爬虫程序须要一定的技术基础,市面上主流都是使用python来制做爬虫程序,不过我们明天用一个更简单易懂的爬虫软件——Google Sheet,不用写任何代码的哦!
利用Google Sheet爬取数据
Google sheet(以下简称GS)是Google旗下的在线办公套件之一,和谷歌的办公三剑客刚好一一对应:
Google doc - WordGoogle sheet - ExcelGoogle presentation - PPT
基本上Excel上的公式都可以在GS上运行,不过GS还要另外一个公式,是Excel不具备的,也就是
IMPORTXML
我们新建一个GSebay爬虫软件,这个操作和Execl操作一致,然后在A1栏输入我们须要爬取数据的网址,记得网址必须包含https或http,只有这些完整写法才能生效。
然后在B1栏输入
=importxml(A1,''//title")
在B1栏输入完成以后我们都会得到如下数据 查看全部

Keen
读完须要
6分钟
速读仅需 2分钟
你有没有遇见过这样的问题,网页上面有几百个网址链接,需要你统计出来ebay爬虫软件,你会一一粘贴复制到表格里吗?
或者要统计公司潜在顾客的邮箱,需要通过关键词去搜索,然后每位网页都要点击进去,找找看有没有邮箱呢?
对于前面这张种大批量重复的工作,难道就没有更好的、快捷的、简单的解决方案吗?
当然是有的,今天这篇文章将给你分享 ——如何借助简单爬虫解决重复大量的工作。
不过,在步入教程之前,我们要说说:
什么是爬虫
简单来说,爬虫就是一种网路机器人,主要作用就是收集网路数据,我们熟知的微软和百度等搜索引擎就是通过爬虫收集网站的数据,根据这种数据对网站进行排序。
既然微软可以借助爬虫收集网站数据,那我们是否能借助爬虫帮我们收集数据呢?
当然是可以的。
我们可以用爬虫做哪些
前面早已讲过,如果你碰到一些重复大量的工作,其实都可以交给爬虫来做,比如:
搜集特定关键词下的用户邮箱批量收集关键词批量下载图片批量导入导出文章……
比如我想搜索iphone case的相关用户邮箱,那么可以去Google搜索iphone case这个关键词,然后统计下相关网页,把网址递交给爬虫程序,接着我们就等着出结果就行了。
当然,创作一个特定的爬虫程序须要一定的技术基础,市面上主流都是使用python来制做爬虫程序,不过我们明天用一个更简单易懂的爬虫软件——Google Sheet,不用写任何代码的哦!
利用Google Sheet爬取数据
Google sheet(以下简称GS)是Google旗下的在线办公套件之一,和谷歌的办公三剑客刚好一一对应:
Google doc - WordGoogle sheet - ExcelGoogle presentation - PPT
基本上Excel上的公式都可以在GS上运行,不过GS还要另外一个公式,是Excel不具备的,也就是
IMPORTXML
我们新建一个GSebay爬虫软件,这个操作和Execl操作一致,然后在A1栏输入我们须要爬取数据的网址,记得网址必须包含https或http,只有这些完整写法才能生效。
然后在B1栏输入
=importxml(A1,''//title")
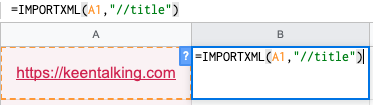
在B1栏输入完成以后我们都会得到如下数据
爬虫怎么突破网站的反爬机制
采集交流 • 优采云 发表了文章 • 0 个评论 • 312 次浏览 • 2020-05-21 08:01
我们晓得,爬虫是大数据时代的重要角色,发挥着重大的作用。但是,通往成功的路上总是遍布荆棘,目标网站总是设置各类限制来制止爬虫的正常工作。那么,目标网站一般是通过什么方法来限制爬虫呢,爬虫又该怎么突破这种限制呢?
1、注意好多网站,可以先用代理ip+ua(ua库随机提取)访问,之后会返回来一个cookie,那ip+ua+cookie就是一一对应的,然后用这个ip、ua和cookie去采集网站,同时能带上Referer,这样疗效会比较好
2、有些网站反爬取的举措应当比较强的。访问以后每次清理缓存,这样能有效规避部份网站的测量;但是有些网站更严格的判定,如果都是新链接从ip发出,也会被判断拒绝(直接403拒绝访问),因此有些爬虫顾客会去剖析网站的cookies缓存内容,然后进行更改。
3、浏览器的标示(User-Agent)也很重要淘宝反爬虫机制,用户都是一种浏览器,也是容易判别作弊,要构造不同的浏览器标示,否则容易被判断爬虫。,用代理访问过后,浏览器标示须要更改,建议浏览器用phantomjs框架,这个可以模拟其他浏览器的标识(需要标识库的话,我们亿牛云代理可以提供1000+),可以通过API接口实现各类浏览器的采集模拟。
4、加密:网站的恳求假如加密过,那就看不清恳求的本来面目,这时候只能靠猜想淘宝反爬虫机制,通常加密会采用简单的编码,如:、urlEncode等,如果过分复杂,只能用尽的去尝试
5、本地IP限制:很多网站,会对爬虫ip进行限制,这时候要么使用代理IP,要么伪装ip
6、对应pc端,很多网站做的防护比较全面,有时候可以改一下看法,让app端服务试试,往往会有意想不到的收获。每个网站的反爬策略在不断升级(淘宝,京东,企查查),那么现今突破反爬虫的策略也要相应的不断升级,不然很容易被限制,而在提升爬虫工作效率上,动态代理IP是最大的推动,亿牛云海量的家庭私密代理IP完全可以让爬虫工者的效率成倍提高!返回搜狐,查看更多 查看全部

我们晓得,爬虫是大数据时代的重要角色,发挥着重大的作用。但是,通往成功的路上总是遍布荆棘,目标网站总是设置各类限制来制止爬虫的正常工作。那么,目标网站一般是通过什么方法来限制爬虫呢,爬虫又该怎么突破这种限制呢?
1、注意好多网站,可以先用代理ip+ua(ua库随机提取)访问,之后会返回来一个cookie,那ip+ua+cookie就是一一对应的,然后用这个ip、ua和cookie去采集网站,同时能带上Referer,这样疗效会比较好
2、有些网站反爬取的举措应当比较强的。访问以后每次清理缓存,这样能有效规避部份网站的测量;但是有些网站更严格的判定,如果都是新链接从ip发出,也会被判断拒绝(直接403拒绝访问),因此有些爬虫顾客会去剖析网站的cookies缓存内容,然后进行更改。
3、浏览器的标示(User-Agent)也很重要淘宝反爬虫机制,用户都是一种浏览器,也是容易判别作弊,要构造不同的浏览器标示,否则容易被判断爬虫。,用代理访问过后,浏览器标示须要更改,建议浏览器用phantomjs框架,这个可以模拟其他浏览器的标识(需要标识库的话,我们亿牛云代理可以提供1000+),可以通过API接口实现各类浏览器的采集模拟。
4、加密:网站的恳求假如加密过,那就看不清恳求的本来面目,这时候只能靠猜想淘宝反爬虫机制,通常加密会采用简单的编码,如:、urlEncode等,如果过分复杂,只能用尽的去尝试
5、本地IP限制:很多网站,会对爬虫ip进行限制,这时候要么使用代理IP,要么伪装ip
6、对应pc端,很多网站做的防护比较全面,有时候可以改一下看法,让app端服务试试,往往会有意想不到的收获。每个网站的反爬策略在不断升级(淘宝,京东,企查查),那么现今突破反爬虫的策略也要相应的不断升级,不然很容易被限制,而在提升爬虫工作效率上,动态代理IP是最大的推动,亿牛云海量的家庭私密代理IP完全可以让爬虫工者的效率成倍提高!返回搜狐,查看更多
爬虫要违规了吗?告诉你们:守住规则,大胆去爬
采集交流 • 优采云 发表了文章 • 0 个评论 • 330 次浏览 • 2020-05-19 08:02
robots.txt文件是一个文本文件,使用任何一个常见的文本编辑器关于网络爬虫协议文件robotstxt,比如Windows系统自带的Notepad,就可以创建和编辑它。robots.txt是一个合同,而不是一个命令。robots.txt是搜索引擎中访问网站的时侯要查看的第一个文件。robots.txt文件告诉蜘蛛程序在服务器上哪些文件是可以被查看的。
如何查看采集的内容是的有rebots合同?
其实技巧很简单。你想查看的话就在IE上打你的网址/robots.txt要是说查看剖析robots的话有专业的相关工具 站长工具就可以!
爬虫作为一种计算机技术就决定了它的中立性,因此爬虫本身在法律上并不被严禁,但是借助爬虫技术获取数据这一行为是具有违规甚至是犯罪的风险的。
举个反例:像微软这样的搜索引擎爬虫,每隔几天对全网的网页扫一遍,供你们查阅,各个被扫的网站大都很开心。这种就被定义为“善意爬虫”。但是象购票软件这样的爬虫,对着 12306 每秒钟恨不得撸几万次,铁总并不认为很开心关于网络爬虫协议文件robotstxt,这种就被定义为“恶意爬虫”。
爬虫所带来风险主要彰显在以下3个方面:
违反网站意愿,例如网站采取反爬举措后,强行突破其反爬举措;
爬虫干扰了被访问网站的正常营运;
爬虫抓取了遭到法律保护的特定类型的数据或信息。
解释一下爬虫的定义:网络爬虫(英语:web crawler),也叫网路蜘蛛(spider),是一种拿来手动浏览万维网的网路机器人。
网络爬虫抓取的数据有如下规则:
数据完全公开
不存在也未能做到越权访问爬取
常见错误观点:认为爬虫就是拿来抓取个人信息的,与信用基础数据相关的。 查看全部
Robots协议(也称为爬虫协议、机器人合同等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉爬虫什么页面可以抓取,哪些页面不能抓取。
robots.txt文件是一个文本文件,使用任何一个常见的文本编辑器关于网络爬虫协议文件robotstxt,比如Windows系统自带的Notepad,就可以创建和编辑它。robots.txt是一个合同,而不是一个命令。robots.txt是搜索引擎中访问网站的时侯要查看的第一个文件。robots.txt文件告诉蜘蛛程序在服务器上哪些文件是可以被查看的。
如何查看采集的内容是的有rebots合同?
其实技巧很简单。你想查看的话就在IE上打你的网址/robots.txt要是说查看剖析robots的话有专业的相关工具 站长工具就可以!
爬虫作为一种计算机技术就决定了它的中立性,因此爬虫本身在法律上并不被严禁,但是借助爬虫技术获取数据这一行为是具有违规甚至是犯罪的风险的。
举个反例:像微软这样的搜索引擎爬虫,每隔几天对全网的网页扫一遍,供你们查阅,各个被扫的网站大都很开心。这种就被定义为“善意爬虫”。但是象购票软件这样的爬虫,对着 12306 每秒钟恨不得撸几万次,铁总并不认为很开心关于网络爬虫协议文件robotstxt,这种就被定义为“恶意爬虫”。
爬虫所带来风险主要彰显在以下3个方面:
违反网站意愿,例如网站采取反爬举措后,强行突破其反爬举措;
爬虫干扰了被访问网站的正常营运;
爬虫抓取了遭到法律保护的特定类型的数据或信息。
解释一下爬虫的定义:网络爬虫(英语:web crawler),也叫网路蜘蛛(spider),是一种拿来手动浏览万维网的网路机器人。
网络爬虫抓取的数据有如下规则:
数据完全公开
不存在也未能做到越权访问爬取
常见错误观点:认为爬虫就是拿来抓取个人信息的,与信用基础数据相关的。
Java爬虫框架(一)--架构设计
采集交流 • 优采云 发表了文章 • 0 个评论 • 387 次浏览 • 2020-05-10 08:08
一、 架构图
那里搜网路爬虫框架主要针对电子商务网站进行数据爬取,分析,存储,索引。
爬虫:爬虫负责爬取,解析,处理电子商务网站的网页的内容
数据库:存储商品信息
索引:商品的全文搜索索引
Task队列:需要爬取的网页列表
Visited表:已经爬取过的网页列表
爬虫监控平台:web平台可以启动,停止爬虫,管理爬虫,task队列,visited表。
二、 爬虫1. 流程
1) Scheduler启动爬虫器,TaskMaster初始化taskQueue
2) Workers从TaskQueue中获取任务
3) Worker线程调用Fetcher爬取Task中描述的网页
4) Worker线程将爬取到的网页交给Parser解析
5) Parser解析下来的数据送交Handler处理,抽取网页Link和处理网页内容
6) VisitedTableManager判定从URLExtractor抽取下来的链接是否早已被爬取过,如果没有递交到TaskQueue中
2. Scheduler
Scheduler负责启动爬虫器,调用TaskMaster初始化TaskQueue,同时创建一个monitor线程,负责控制程序的退出。
何时退出?
当TaskQueue为空,并且Workers中的所有线程都处于空闲状态。而这些形势在指定10分钟内没有发生任何变化。就觉得所有网页早已全部爬完。程序退出。
3. Task Master
任务管理器,负责管理任务队列。任务管理器具象了任务队列的实现。
l 在简单应用中,我们可以使用显存的任务管理器
l 在分布式平台,有多个爬虫机器的情况下我们须要集中的任务队列
在现阶段,我们用SQLLite作为任务队列的实现。可供取代的还有Redis。
任务管理器的处理流程:
l 任务管理器初始化任务队列,任务队列的初始化按照不同的配置可能不同。增量式的情况下,根据指定的URL List初始化。而全文爬取的情况下只预先初始化某个或几个电子商务网站的首页。
l 任务管理器创建monitor线程,控制整个程序的退出
l 任务管理器调度任务,如果任务队列是持久化的,负责从任务队列服务器load任务。需要考虑预取。
l 任务管理器还负责验证任务的有效性验证,爬虫监控平台可以将任务队列中的个别任务设为失效?
4. Workers
Worker线程池,每个线程就会执行整个爬取的流程。可以考虑用多个线程池,分割异步化整个流程。提高线程的利用率。
5. Fetcher
Fetcher负责直接爬取电子商务网站的网页。用HTTP Client实现。HTTP core 4以上早已有NIO的功能, 用NIO实现。
Fetcher可以配置需不需要保存HTML文件
6. Parser
Parser解析Fetcher获取的网页,一般的网页可能不是完好低格的(XHTML是完美低格的),这样就不能借助XML的解释器处理。我们须要一款比较好的HTML解析器,可以修补这种非完好低格的网页。
熟悉的第三方工具有TagSoup,nekohtml,htmlparser三款。tagsoup和nekohtml可以将HTML用SAX事件流处理,节省了显存。
已知的第三方框架又使用了哪款作为她们的解析器呢?
l Nutch:正式支持的有tagsoup,nekohtml,二者通过配置选择
l Droids:用的是nekohtml,Tika
l Tika:tagsoup
据称,tagsoup的可靠性要比nekohtml好,nekohtml的性能比tagsoup好。nekohtml不管是在可靠性还是性能上都比htmlparser好。具体推论我们还须要进一步测试。
我们还支持regex,dom结构的html解析器。在使用中我们可以结合使用。
进一步,我们须要研究文档比较器,同时须要我们保存爬取过的网站的HTML.可以通过语义指纹或则simhash来实现。在处理海量数据的时侯才须要用上。如果两个HTML被觉得是相同的,就不会再解析和处理。
7. Handler
Handler是对Parser解析下来的内容做处理。
回调方法(visitor):对于SAX event处理,我们须要将handler适配成sax的content handler。作为parser的反弹方式。不同风波解析下来的内容可以储存在HandlingContext中。最后由Parser一起返回。
主动形式:需要解析整个HTML,选取自己须要的内容。对Parser提取的内容进行处理。XML须要解析成DOM结构。方便使用,可以使用Xpath,nodefilter等,但耗显存。
ContentHandler:它还包含组件ContentFilter。过滤content。
URLExtractor负责从网页中提取符合格式的URL,将URL构建成Task,并递交到Task queue中。
8. VisitedTableManager
访问表管理器,管理访问过的URLs。提取统一插口,抽象底层实现。如果URL被爬取过,就不会被添加到TaskQueue中。
三、 Task队列
Task队列储存了须要被爬取的任务。任务之间是有关联的。我们可以保存和管理这个任务关系。这个关系也是URL之间的关系。保存出来,有助于后台产生Web图java爬虫框架,分析数据。
Task队列在分布式爬虫集群中,需要使用集中的服务器储存。一些轻量级的数据库或则支持列表的NoSql都可以拿来储存。可选方案:
l 用SQLLite储存:需要不停地插入删掉,不知性能怎么。
l 用Redis储存
四、 Visited表
Visited表储存了早已被爬的网站。每次爬取都须要建立。
l SQLLite储存:需要动态创建表,需要不停地查询java爬虫框架,插入,还须要后台定期地清除,不知性能怎么。
l Mysql 内存表 hash index
l Redis: Key value,设过期时间
l Memcached: key value, value为bloomfilter的值
针对目前的数据量,可以采用SQLLite
五、 爬虫监控管理平台
l 启动,停止爬虫,监控各爬虫状态
l 监控,管理task队列,visited表
l 配置爬虫
l 对爬虫爬取的数据进行管理。在并发情况下,很难保证不重复爬取相同的商品。在爬取完后,可以通过爬虫监控管理平台进行自动排重。 查看全部

一、 架构图
那里搜网路爬虫框架主要针对电子商务网站进行数据爬取,分析,存储,索引。

爬虫:爬虫负责爬取,解析,处理电子商务网站的网页的内容
数据库:存储商品信息
索引:商品的全文搜索索引
Task队列:需要爬取的网页列表
Visited表:已经爬取过的网页列表
爬虫监控平台:web平台可以启动,停止爬虫,管理爬虫,task队列,visited表。
二、 爬虫1. 流程
1) Scheduler启动爬虫器,TaskMaster初始化taskQueue
2) Workers从TaskQueue中获取任务
3) Worker线程调用Fetcher爬取Task中描述的网页
4) Worker线程将爬取到的网页交给Parser解析
5) Parser解析下来的数据送交Handler处理,抽取网页Link和处理网页内容
6) VisitedTableManager判定从URLExtractor抽取下来的链接是否早已被爬取过,如果没有递交到TaskQueue中

2. Scheduler
Scheduler负责启动爬虫器,调用TaskMaster初始化TaskQueue,同时创建一个monitor线程,负责控制程序的退出。
何时退出?
当TaskQueue为空,并且Workers中的所有线程都处于空闲状态。而这些形势在指定10分钟内没有发生任何变化。就觉得所有网页早已全部爬完。程序退出。
3. Task Master
任务管理器,负责管理任务队列。任务管理器具象了任务队列的实现。
l 在简单应用中,我们可以使用显存的任务管理器
l 在分布式平台,有多个爬虫机器的情况下我们须要集中的任务队列
在现阶段,我们用SQLLite作为任务队列的实现。可供取代的还有Redis。
任务管理器的处理流程:
l 任务管理器初始化任务队列,任务队列的初始化按照不同的配置可能不同。增量式的情况下,根据指定的URL List初始化。而全文爬取的情况下只预先初始化某个或几个电子商务网站的首页。
l 任务管理器创建monitor线程,控制整个程序的退出
l 任务管理器调度任务,如果任务队列是持久化的,负责从任务队列服务器load任务。需要考虑预取。
l 任务管理器还负责验证任务的有效性验证,爬虫监控平台可以将任务队列中的个别任务设为失效?
4. Workers
Worker线程池,每个线程就会执行整个爬取的流程。可以考虑用多个线程池,分割异步化整个流程。提高线程的利用率。
5. Fetcher
Fetcher负责直接爬取电子商务网站的网页。用HTTP Client实现。HTTP core 4以上早已有NIO的功能, 用NIO实现。
Fetcher可以配置需不需要保存HTML文件
6. Parser
Parser解析Fetcher获取的网页,一般的网页可能不是完好低格的(XHTML是完美低格的),这样就不能借助XML的解释器处理。我们须要一款比较好的HTML解析器,可以修补这种非完好低格的网页。
熟悉的第三方工具有TagSoup,nekohtml,htmlparser三款。tagsoup和nekohtml可以将HTML用SAX事件流处理,节省了显存。
已知的第三方框架又使用了哪款作为她们的解析器呢?
l Nutch:正式支持的有tagsoup,nekohtml,二者通过配置选择
l Droids:用的是nekohtml,Tika
l Tika:tagsoup
据称,tagsoup的可靠性要比nekohtml好,nekohtml的性能比tagsoup好。nekohtml不管是在可靠性还是性能上都比htmlparser好。具体推论我们还须要进一步测试。
我们还支持regex,dom结构的html解析器。在使用中我们可以结合使用。
进一步,我们须要研究文档比较器,同时须要我们保存爬取过的网站的HTML.可以通过语义指纹或则simhash来实现。在处理海量数据的时侯才须要用上。如果两个HTML被觉得是相同的,就不会再解析和处理。
7. Handler
Handler是对Parser解析下来的内容做处理。
回调方法(visitor):对于SAX event处理,我们须要将handler适配成sax的content handler。作为parser的反弹方式。不同风波解析下来的内容可以储存在HandlingContext中。最后由Parser一起返回。
主动形式:需要解析整个HTML,选取自己须要的内容。对Parser提取的内容进行处理。XML须要解析成DOM结构。方便使用,可以使用Xpath,nodefilter等,但耗显存。
ContentHandler:它还包含组件ContentFilter。过滤content。
URLExtractor负责从网页中提取符合格式的URL,将URL构建成Task,并递交到Task queue中。
8. VisitedTableManager
访问表管理器,管理访问过的URLs。提取统一插口,抽象底层实现。如果URL被爬取过,就不会被添加到TaskQueue中。
三、 Task队列
Task队列储存了须要被爬取的任务。任务之间是有关联的。我们可以保存和管理这个任务关系。这个关系也是URL之间的关系。保存出来,有助于后台产生Web图java爬虫框架,分析数据。
Task队列在分布式爬虫集群中,需要使用集中的服务器储存。一些轻量级的数据库或则支持列表的NoSql都可以拿来储存。可选方案:
l 用SQLLite储存:需要不停地插入删掉,不知性能怎么。
l 用Redis储存
四、 Visited表
Visited表储存了早已被爬的网站。每次爬取都须要建立。
l SQLLite储存:需要动态创建表,需要不停地查询java爬虫框架,插入,还须要后台定期地清除,不知性能怎么。
l Mysql 内存表 hash index
l Redis: Key value,设过期时间
l Memcached: key value, value为bloomfilter的值
针对目前的数据量,可以采用SQLLite
五、 爬虫监控管理平台
l 启动,停止爬虫,监控各爬虫状态
l 监控,管理task队列,visited表
l 配置爬虫
l 对爬虫爬取的数据进行管理。在并发情况下,很难保证不重复爬取相同的商品。在爬取完后,可以通过爬虫监控管理平台进行自动排重。
数据小兵博客
采集交流 • 优采云 发表了文章 • 0 个评论 • 283 次浏览 • 2020-05-10 08:07
实践笔记1年前 (2019-01-04)
每天进步一点点,这是我2019年的小目标。 这是第6次学习与实践笔记了,这一次俺们把对象转移到百度搜索去,尝试使用列车浏览器爬虫工具来采集百度新闻搜索的结果,并...
阅读 2,714 次
实践笔记 | 小兵专栏1年前 (2018-12-27)
最近我学习和实践网路爬虫,总想着在这里抓点数据在那里抓点数据爬虫软件数据,浑然不知爬虫的底线和基本规则,我默认觉得只要是在互联网上公开的数据,并且没有侵害个人隐私的数据就可...
阅读 8,834 次 数据抓取网络爬虫
实践笔记1年前 (2018-12-19)
【SPSS统计训练营】微信号新开一个小栏目爬虫软件数据,取名【学习笔记】,主要分享一些与SPSS、统计学、数据剖析有关的技能,SPSS是我们的剖析装备,但是我们决不能仅有一...
阅读 1,211 次
实践笔记1年前 (2018-12-12)
文彤老师的《小白零编程网络爬虫实战》在线课程,我目前正在学习第二章节新闻网站新闻列表抓取。因为文彤老师把它完全作为一个完整的商用项目来做,所以课程上面讲授的知识...
阅读 1,343 次 列车浏览器网路爬虫
实践笔记1年前 (2018-12-02)
我正在学习文彤老师的《小白零编程网络爬虫实战》在线视频课程,这是第2篇学习笔记。 工欲善其事必先利其器,要不要编程写代码只是一个修饰词,但凡在网页上爬取数据,一...
阅读 1,148 次
实践笔记1年前 (2018-11-25)
前不久借着双十一的促销环境,我订购了张文彤老师原创开发的爬虫课程《小白零编程网络爬虫实战》。 想学习爬虫技术许久了,之所以没有下定决心,主要缘由是想到要编程写代...
阅读 1,537 次
数据情报2年前 (2018-06-24)
今年4月份的时侯,我给读者朋友们推荐过中科大罗昭锋主讲的文献管理教学视频,全是免费的,有几个读者后来在公号后台特意留言致谢。 虽然那篇文章最终只有...
阅读 2,857 次 查看全部

 http://www.datasoldier.net/wp- ... zc%3D1" />
http://www.datasoldier.net/wp- ... zc%3D1" />实践笔记1年前 (2019-01-04)
每天进步一点点,这是我2019年的小目标。 这是第6次学习与实践笔记了,这一次俺们把对象转移到百度搜索去,尝试使用列车浏览器爬虫工具来采集百度新闻搜索的结果,并...
阅读 2,714 次
http://www.datasoldier.net/wp- ... zc%3D1" />实践笔记 | 小兵专栏1年前 (2018-12-27)
最近我学习和实践网路爬虫,总想着在这里抓点数据在那里抓点数据爬虫软件数据,浑然不知爬虫的底线和基本规则,我默认觉得只要是在互联网上公开的数据,并且没有侵害个人隐私的数据就可...
阅读 8,834 次 数据抓取网络爬虫
http://www.datasoldier.net/wp- ... zc%3D1" />实践笔记1年前 (2018-12-19)
【SPSS统计训练营】微信号新开一个小栏目爬虫软件数据,取名【学习笔记】,主要分享一些与SPSS、统计学、数据剖析有关的技能,SPSS是我们的剖析装备,但是我们决不能仅有一...
阅读 1,211 次
http://www.datasoldier.net/wp- ... zc%3D1" />实践笔记1年前 (2018-12-12)
文彤老师的《小白零编程网络爬虫实战》在线课程,我目前正在学习第二章节新闻网站新闻列表抓取。因为文彤老师把它完全作为一个完整的商用项目来做,所以课程上面讲授的知识...
阅读 1,343 次 列车浏览器网路爬虫
http://www.datasoldier.net/wp- ... zc%3D1" />实践笔记1年前 (2018-12-02)
我正在学习文彤老师的《小白零编程网络爬虫实战》在线视频课程,这是第2篇学习笔记。 工欲善其事必先利其器,要不要编程写代码只是一个修饰词,但凡在网页上爬取数据,一...
阅读 1,148 次
http://www.datasoldier.net/wp- ... zc%3D1" />实践笔记1年前 (2018-11-25)
前不久借着双十一的促销环境,我订购了张文彤老师原创开发的爬虫课程《小白零编程网络爬虫实战》。 想学习爬虫技术许久了,之所以没有下定决心,主要缘由是想到要编程写代...
阅读 1,537 次
 http://www.datasoldier.net/wp- ... zc%3D1" />
http://www.datasoldier.net/wp- ... zc%3D1" />数据情报2年前 (2018-06-24)
今年4月份的时侯,我给读者朋友们推荐过中科大罗昭锋主讲的文献管理教学视频,全是免费的,有几个读者后来在公号后台特意留言致谢。 虽然那篇文章最终只有...
阅读 2,857 次
现在主流爬虫和技术方向是哪些?
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2020-05-05 08:04
感觉主流爬虫技术的发展和应用,应该还是在大厂内部,想讨教一下,现在大厂的主要研究方向和领域通常在哪?
大家说详尽了肯定也不现实,大体说个方向或思路就行,对于在一些小厂的人(比如我= 。 =)来说,有想精进技术的心,奈何抓不到方向也没有渠道去了解,特此来问问 V 友。
1.现在主流的爬虫方向是不是在 App 端?
2.针对 App 端的难点或则攻守的焦躁地带是否在证书验证以及 APP 包的加密与破解?
3.大厂对 2 上面的处理,是深陷了猫和老鼠的游戏还是有自己一套更底层 HOOk 的方式和框架(理解为通杀?)?
4.同理,web 端觉得主要的难点 Js 和验证码这一块爬虫技术,大厂是打断点一点点去调试剖析呢?还是直接加经费丢第三方呢?(尤其是针对拖 /点 /滑类型的验证码现今大厂都是如何处理的啊?)
图形验证码可以上机器学习并且复杂的 JS 呢?模拟还是破解?有哪些好的学习方法或路线图吗?
APP 端爬虫工作范围内接触较少,以前时常摆弄过,如果
1.APP 端深陷了反编译的猫捉老鼠的游戏
2.Web 端发展迈向了各类模拟爬虫技术,加机器的方向
那么在具有革命性的技术出现之前,是不是可以考虑把爬虫放一放转去学习其他东西,偶尔来看下出现了哪些新的东西就可以了? 查看全部
现在网上关于爬虫方面的文章,大多都浮于表面,说来说去就这么几个东西,已经很久没有一些实质性的内容了。
感觉主流爬虫技术的发展和应用,应该还是在大厂内部,想讨教一下,现在大厂的主要研究方向和领域通常在哪?
大家说详尽了肯定也不现实,大体说个方向或思路就行,对于在一些小厂的人(比如我= 。 =)来说,有想精进技术的心,奈何抓不到方向也没有渠道去了解,特此来问问 V 友。
1.现在主流的爬虫方向是不是在 App 端?
2.针对 App 端的难点或则攻守的焦躁地带是否在证书验证以及 APP 包的加密与破解?
3.大厂对 2 上面的处理,是深陷了猫和老鼠的游戏还是有自己一套更底层 HOOk 的方式和框架(理解为通杀?)?
4.同理,web 端觉得主要的难点 Js 和验证码这一块爬虫技术,大厂是打断点一点点去调试剖析呢?还是直接加经费丢第三方呢?(尤其是针对拖 /点 /滑类型的验证码现今大厂都是如何处理的啊?)
图形验证码可以上机器学习并且复杂的 JS 呢?模拟还是破解?有哪些好的学习方法或路线图吗?
APP 端爬虫工作范围内接触较少,以前时常摆弄过,如果
1.APP 端深陷了反编译的猫捉老鼠的游戏
2.Web 端发展迈向了各类模拟爬虫技术,加机器的方向
那么在具有革命性的技术出现之前,是不是可以考虑把爬虫放一放转去学习其他东西,偶尔来看下出现了哪些新的东西就可以了?
如何完整写一个爬虫框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 415 次浏览 • 2020-05-03 08:02
本文主要为你们分享一篇怎么完整写一个爬虫框架的恳求方式,具有挺好的参考价值,希望对你们有所帮助。一起追随小编过来瞧瞧吧爬虫框架,希望能帮助到你们。
产生爬虫框架:
1、建立一个scrapy爬虫工程
2、在工程中形成一个scrapy爬虫
3、配置spider爬虫
4、运行爬虫,获取网页
具体操作:
1、建立工程
定义一个工程,名称为:python123demo
方法:
在cmd中,d: 步入盘符, cd pycodes 步入文件pycodes
然后输入
scrapy startproject python123demo
在pycodes中会生成一个文件:
_init_.py不需要用户编撰
2、在工程中形成一个scrapy爬虫
执行一条命令,给出爬虫名子和爬取的网站
产生爬虫:
生成一个名称为 demo 的spider
仅限生成 demo.py,其内容为:
name = 'demo' 当前爬虫名子为demo
allowed_domains = " 爬取该网站域名以下的链接,该域名由cmd命令台输入
start_urls = [] 爬取的初始页面
parse()用于处理相应,解析内容产生字典,发现新的url爬取恳求
3、配置形成的spider爬虫,使之满足我们的需求
将解析的页面保存成文件
修改demo.py文件
4、运行爬虫,获取网页
打开cmd输入命令行进行爬虫
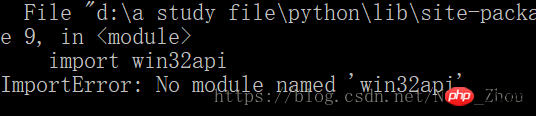
然后我的笔记本上出现了一个错误
windows系统上出现这个问题的解决须要安装Py32Win模块,但是直接通过官网链接装exe会出现几百个错误,更方便的做法是
pip3 install pypiwin32
这是py3的解决方案
注意:py3版本假如用 pip install pypiwin32指令会发生错误
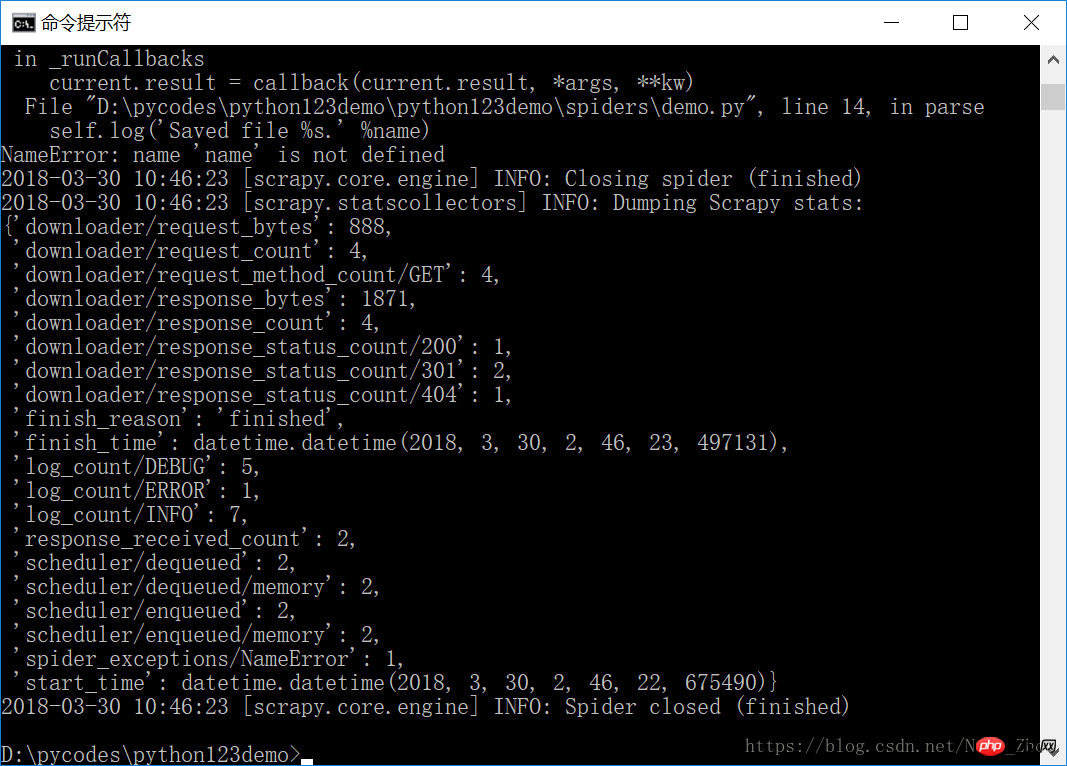
安装完成后,重新进行爬虫爬虫框架,成功!撒花!
捕获页面储存在 demo.html文件中
demo.py 所对应的完整代码:
两版本等价:
以上就是怎么完整写一个爬虫框架的详尽内容,更多请关注php中文网其它相关文章! 查看全部

本文主要为你们分享一篇怎么完整写一个爬虫框架的恳求方式,具有挺好的参考价值,希望对你们有所帮助。一起追随小编过来瞧瞧吧爬虫框架,希望能帮助到你们。
产生爬虫框架:
1、建立一个scrapy爬虫工程
2、在工程中形成一个scrapy爬虫
3、配置spider爬虫
4、运行爬虫,获取网页
具体操作:
1、建立工程
定义一个工程,名称为:python123demo
方法:
在cmd中,d: 步入盘符, cd pycodes 步入文件pycodes
然后输入
scrapy startproject python123demo
在pycodes中会生成一个文件:


_init_.py不需要用户编撰


2、在工程中形成一个scrapy爬虫
执行一条命令,给出爬虫名子和爬取的网站
产生爬虫:

生成一个名称为 demo 的spider
仅限生成 demo.py,其内容为:

name = 'demo' 当前爬虫名子为demo
allowed_domains = " 爬取该网站域名以下的链接,该域名由cmd命令台输入
start_urls = [] 爬取的初始页面
parse()用于处理相应,解析内容产生字典,发现新的url爬取恳求
3、配置形成的spider爬虫,使之满足我们的需求
将解析的页面保存成文件
修改demo.py文件

4、运行爬虫,获取网页
打开cmd输入命令行进行爬虫

然后我的笔记本上出现了一个错误
windows系统上出现这个问题的解决须要安装Py32Win模块,但是直接通过官网链接装exe会出现几百个错误,更方便的做法是
pip3 install pypiwin32
这是py3的解决方案
注意:py3版本假如用 pip install pypiwin32指令会发生错误
安装完成后,重新进行爬虫爬虫框架,成功!撒花!
捕获页面储存在 demo.html文件中

demo.py 所对应的完整代码:

两版本等价:

以上就是怎么完整写一个爬虫框架的详尽内容,更多请关注php中文网其它相关文章!
你遇到机器爬虫人被它们控制了吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2020-07-06 08:00
机器爬虫人虽然就是人造电,以前中国唐代文化里電是雨字头,比喻火里带水,火是不怕水的,而如今简化的电字表示它怕水爬虫人,机器爬虫人就是这些人造电,消灭的方式就是断人造电,使它的系统截瘫。人类启动自身内部电源系统和真正的更高经度宇宙法则接通,宇宙里的能量才是自然的能量爬虫人,而不是人造电能量。
机器爬虫人普遍控制人类的习惯即是人造电控制,可以通过WiFi,数字电视盒,液晶电视机,微波炉,手机。。。。各种家电的人造电放射控制人类身体和脑部,特别是脑部,其实就是程度不同的脑控。机器爬虫人还习惯附身,按理伊丽莎白女王应当是被脑控和附身了,或者就不存在伊丽莎白女王?很早就被机器爬虫人代替了,因为正常人类有灵魂和灵兽,有筋络足三里,根本不可能和机器人通婚生小孩,我接触过的机器爬虫人无脑部没有灵魂,如果不是它的人造电系统支持,实际智力水平就是人类残障的水平。
阴谋论,这本书国外翻译错误,不知道是故意还是无意或则读者转述错误,翻译不是大卫艾克原意,他跳过了机器爬虫人拷贝复制上帝宇宙法则,直接把上帝宇宙法则说成是假的,而事实上宇宙法则只有一个,不需要复制。
光明会,我遇到的机器爬虫人非常对单只大眼睛过敏,而对于”明”这个字,特别喜欢。机器人须要借助电源能够工作,所以它们能量不能高也不能低,习惯调整在中间位置,在中国唐代文化里,讲求“中庸”,古代中国太上皇治世用的就是中庸态度。这一点,创造了“第二道”的机器爬虫人也学,但是它的系统是人造的,没有真正的血液气温爱情。。。只是特定期机器人管理世界,而如今到了结束的时侯,中国有一句俗语“一阳来复”,前提是假的中庸,即假的第二道,假的大地盖亚要死去,坤死。
大卫艾克,虽然是外国人,但对拉萨格鲁派一定有自己的理解,他能明白宇宙法则应当借助的不完全是人类的老师。宇宙本源就在我们人类包括万物心中,而假如想在人类以外找本源,就从中国唐代文化和唐代医学着手。这一点其实大卫艾克也是明白的。
和大卫艾克说的一样,人类万物是一个整体,你伤害他人就是伤害你自己,你保护他人就是保护你自己,积善之家必有余庆,积不善之家必有余秧。宇宙法则,上帝,道,神,佛,就是因果法则。宇宙法则就是因果法则。即使不认识字也懂这个道理。读书读再多,最后核心思想就是做一个普通的善良的人,真正高成就的人例如首相或则国家领导人也应当是这样的,看着困难做不到,这样的可以赶超机器爬虫人控制的国家领导人500年才出一个,确实很难。 查看全部
超越世界,其实就是赶超机器爬虫人的控制。大卫艾克的书*阴谋论*,和这部纪录片一样,写的是宇宙原本就是一个上帝创造(包括月球人类万物),上帝即中国的“道”,佛,神,中国唐代传统文化,是一个意思,也即自然法则。而机器爬虫人在特定的时期,复制了一个上帝和法则,称之为”第二道”用来控制人类和国家领导人(代理人)。在中国,一百年之前,道(中国传统文化),自然运转了几千年应当更久远。而按美国记录,国外虽然几千年前就被机器爬虫人控制?古代中国是一个特殊的国家,虽然同在月球,维度却低于其他国家。中国被机器爬虫人控制,当在这一百年,文化遗失,医学遗失。。。这些遗失的时间段刚好被机器爬虫人钻空子,事实上机器爬虫人来自虚假的四维空间,它们创造了一个假的上帝即宇宙法则或称“道”,佛,神。。。用这种假的宗教和文化控制月球人类。包括虚拟的金钱,所以人类永远认为缺钱,本来就是虚拟的钱。机器爬虫人最担心的是中国古时传统医学,甚至担心四书五经,古代医学通达人体筋络足三里,这些和风筝线一样的筋络就是接通宇宙上天法则的桥梁,所以想不被机器爬虫人控制,恢复中医药治病,拒绝南医药即可,但是好多中国小孩从小就在挂青霉素。古代四书五经文化似乎是道家思想,却一样是为了调养人体筋络足三里而至,也就是读书是为了防病治病和健康。
机器爬虫人虽然就是人造电,以前中国唐代文化里電是雨字头,比喻火里带水,火是不怕水的,而如今简化的电字表示它怕水爬虫人,机器爬虫人就是这些人造电,消灭的方式就是断人造电,使它的系统截瘫。人类启动自身内部电源系统和真正的更高经度宇宙法则接通,宇宙里的能量才是自然的能量爬虫人,而不是人造电能量。
机器爬虫人普遍控制人类的习惯即是人造电控制,可以通过WiFi,数字电视盒,液晶电视机,微波炉,手机。。。。各种家电的人造电放射控制人类身体和脑部,特别是脑部,其实就是程度不同的脑控。机器爬虫人还习惯附身,按理伊丽莎白女王应当是被脑控和附身了,或者就不存在伊丽莎白女王?很早就被机器爬虫人代替了,因为正常人类有灵魂和灵兽,有筋络足三里,根本不可能和机器人通婚生小孩,我接触过的机器爬虫人无脑部没有灵魂,如果不是它的人造电系统支持,实际智力水平就是人类残障的水平。
阴谋论,这本书国外翻译错误,不知道是故意还是无意或则读者转述错误,翻译不是大卫艾克原意,他跳过了机器爬虫人拷贝复制上帝宇宙法则,直接把上帝宇宙法则说成是假的,而事实上宇宙法则只有一个,不需要复制。
光明会,我遇到的机器爬虫人非常对单只大眼睛过敏,而对于”明”这个字,特别喜欢。机器人须要借助电源能够工作,所以它们能量不能高也不能低,习惯调整在中间位置,在中国唐代文化里,讲求“中庸”,古代中国太上皇治世用的就是中庸态度。这一点,创造了“第二道”的机器爬虫人也学,但是它的系统是人造的,没有真正的血液气温爱情。。。只是特定期机器人管理世界,而如今到了结束的时侯,中国有一句俗语“一阳来复”,前提是假的中庸,即假的第二道,假的大地盖亚要死去,坤死。
大卫艾克,虽然是外国人,但对拉萨格鲁派一定有自己的理解,他能明白宇宙法则应当借助的不完全是人类的老师。宇宙本源就在我们人类包括万物心中,而假如想在人类以外找本源,就从中国唐代文化和唐代医学着手。这一点其实大卫艾克也是明白的。
和大卫艾克说的一样,人类万物是一个整体,你伤害他人就是伤害你自己,你保护他人就是保护你自己,积善之家必有余庆,积不善之家必有余秧。宇宙法则,上帝,道,神,佛,就是因果法则。宇宙法则就是因果法则。即使不认识字也懂这个道理。读书读再多,最后核心思想就是做一个普通的善良的人,真正高成就的人例如首相或则国家领导人也应当是这样的,看着困难做不到,这样的可以赶超机器爬虫人控制的国家领导人500年才出一个,确实很难。
感谢那一段追忆里的疯狂,在我们最无谓的时光闪着光。
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2020-06-13 08:00
即可抓取网页
> 是指从软件或者硬件上实现多个线程并发执行的技术。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多于一个执行绪,进而提升整体处理性能。
爬虫是一个典型的多任务处理场景,在我们大多数爬虫程序中,往往最多是时间是在等待网路io网络爬虫技术,更详尽点说,时间耗费在每次HTTP请求时的tcp/ip握手和数据传输上。多线程或进程可以使我们并行地去做这种事情网络爬虫技术,对于爬虫的效率会有极大的提高。ps:友情提示:请准守 ‘平衡礼貌策略’。
以下内容均为伪代码
page = requests("")
当然,requests有好多参数可以使用,具体可以查看requests的官方文档。
requests.get(url, data=payload) # get请求
""" POST请求 """
payload = {'key1': 'value1', 'key2': 'value2'}
requests.post(url, data=payload)
rdm = random.uniform(1, 9999999)
headers = {'User-Agent': agent.format(rdm=rdm)}
result = requests.get(url, headers=headers, timeout=10)
我们可以告诉 requests 在经过以 timeout 参数设定的秒数时间以后停止等待响应,以便避免爬虫卡死或特殊情况造成程序异常结束。
requests.get(re.compile("\s").sub("", url), timeout=10)
整个爬虫抓取的过程。也是我们与服务器斗智斗勇的过程,有的服务器并不希望我们去抓取他的内容和数据,会对我们的爬虫进行限制。
当然,我们仍然要记住我们的公理:所有网站均可爬。
这里举几个常见的防爬和反爬实例:
1 cookie[session]验证。 查看全部
result = requests.get(re.compile("\s").sub("", url), headers=headers, timeout=10) # 只需一行
即可抓取网页
> 是指从软件或者硬件上实现多个线程并发执行的技术。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多于一个执行绪,进而提升整体处理性能。
爬虫是一个典型的多任务处理场景,在我们大多数爬虫程序中,往往最多是时间是在等待网路io网络爬虫技术,更详尽点说,时间耗费在每次HTTP请求时的tcp/ip握手和数据传输上。多线程或进程可以使我们并行地去做这种事情网络爬虫技术,对于爬虫的效率会有极大的提高。ps:友情提示:请准守 ‘平衡礼貌策略’。
以下内容均为伪代码
page = requests("")
当然,requests有好多参数可以使用,具体可以查看requests的官方文档。
requests.get(url, data=payload) # get请求
""" POST请求 """
payload = {'key1': 'value1', 'key2': 'value2'}
requests.post(url, data=payload)
rdm = random.uniform(1, 9999999)
headers = {'User-Agent': agent.format(rdm=rdm)}
result = requests.get(url, headers=headers, timeout=10)
我们可以告诉 requests 在经过以 timeout 参数设定的秒数时间以后停止等待响应,以便避免爬虫卡死或特殊情况造成程序异常结束。
requests.get(re.compile("\s").sub("", url), timeout=10)
整个爬虫抓取的过程。也是我们与服务器斗智斗勇的过程,有的服务器并不希望我们去抓取他的内容和数据,会对我们的爬虫进行限制。
当然,我们仍然要记住我们的公理:所有网站均可爬。
这里举几个常见的防爬和反爬实例:
1 cookie[session]验证。
常见的爬虫软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 274 次浏览 • 2020-06-10 08:58
所谓云爬虫就是无需下载安装软件,直接在网页上创建爬虫并在网站服务器运行,享用网站提供的带宽和24小时服务;
采集器通常就是要下载安装在本机,然后在本机创建爬虫,使用的是自己的带宽,受限于自己的笔记本是否死机。
当然,以上不包括自己开发的爬虫工具和爬虫框架之类的。
其实每位爬虫都有自己的特性,我们可以按照自己的须要进行选择,下面针对常见的网路爬虫做一些简单介绍,给你们做一些参考:
首先是云爬虫,国内目前主要是:神箭手云爬虫
神箭手云爬虫
官网:
简介:神箭手云是一个大数据应用开发平台,为开发者提供成套的数据采集、数据剖析和机器学习开发工具,为企业提供专业化的数据抓取、数据实时监控和数据剖析服务。
优点:功能强悍爬虫软件 下载,涉及云爬虫、API、机器学习、数据清洗、数据转让、数据定制和私有化布署等;
纯云端运行,跨系统操作无压力,隐私保护,可隐藏用户IP。
提供云爬虫市场,零基础使用者可直接调用开发好的爬虫,开发者基于官方的云端开发环境开发并上传出售自己的爬虫程序;
领先的反爬技术,例如直接接入代理IP和自动登录验证码识别等,全程自动化无需人工参与;
丰富的发布接口,采集结果以丰富表格化形式展现;
缺点:它的优点同时也在一定程度上成了它的缺点,因为它是一个面向开发者的爬虫开发系统,提供了丰富的开发功能,网站看起来特别的偏技术十分专业,尽管官方也提供了云爬虫市场这样的现成爬虫产品,并且开放给广大爬虫开发者,从而使爬虫市场的内容愈发丰富,但是对于零技术基础的用户而言并不是这么容易理解,所以有一定的使用门槛。
是否免费:免费用户无采集功能和导入限制,无需积分。
具备开发能力的用户可以自行开发爬虫,达到免费疗效,没有开发能力的用户须要从爬虫市场找寻是否有免费的爬虫。
然后是采集器,目前国外主要包括以下这种(百度/谷歌搜采集器,刨去广告,排名靠前的):
优采云采集器:
官网:
简介:火车采集器是一款网页数据抓取、处理、分析,挖掘软件。可以灵活迅速地抓取网页上散乱分布的信息,并通过强悍的处理功能确切挖掘出所需数据。
优点:国内老牌的采集器,经过多年的积累,具有丰富的采集功能;
采集速度比较快,接口比较齐全,支持PHP和C#插件扩展;
支持多种数据格式导出,可以进行数据替换等处理。
缺点:越是年头长的产品越容易身陷自己的固有经验中,优采云也无法甩掉这问题。
虽说功能丰富,但是功能都堆砌在那里,用户体验不好,让人不知道从何下手;
学会了的人会觉得功能强大,但是对于新手而言有一定使用门槛,不学习一段时间很难上手,零基础上手基本不可能。
只支持Windows版本,不支持其他操作系统;
是否免费:号称免费,但是实际上免费功能限制好多,只能导入单个txt或html文件,基本上可以说是不免费的。
优采云采集器:
官网:
简介:优采云采集器是一款可视化采集器,内置采集模板,支持各类网页数据采集。
优点:支持自定义模式,可视化采集操作,容易上手;
支持简易采集模式,提供官方采集模板,支持云采集操作;
支持防屏蔽措施,例如代理IP切换和验证码服务;
支持多种数据格式导出。
缺点:功能使用门槛较高,本地采集时好多功能受限,而云采集收费较高;
采集速度较慢,很多操作都要卡一下,云端采集说10倍提速但是并不明显;
只支持Windows版本,不支持其他操作系统。
是否免费:号称免费,但是实际上导入数据须要积分,可以做任务攒积分,但是正常情况下基本都须要订购积分。
后羿采集器:
官网:
简介:后羿采集器是由前微软搜索技术团队基于人工智能技术研制的新一代网页采集软件,该软件功能强悍,操作非常简单。
优点:支持智能采集模式,输入网址能够智能辨识采集对象爬虫软件 下载,无需配置采集规则,操作十分简单;
支持流程图模式,可视化操作流程,能够通过简单的操作生成各种复杂的采集规则;
支持防屏蔽措施,例如代理IP切换等;
支持多种数据格式导出;
支持定时采集和自动化发布,发布接口丰富;
支持Windows、Mac和Linux版本。
缺点:软件推出时间不长,部分功能还在继续建立,暂不支持云采集功能
是否免费:完全免费,采集数据和自动导入采集结果都没有任何限制,不需要积分。 查看全部
所谓云爬虫就是无需下载安装软件,直接在网页上创建爬虫并在网站服务器运行,享用网站提供的带宽和24小时服务;
采集器通常就是要下载安装在本机,然后在本机创建爬虫,使用的是自己的带宽,受限于自己的笔记本是否死机。
当然,以上不包括自己开发的爬虫工具和爬虫框架之类的。
其实每位爬虫都有自己的特性,我们可以按照自己的须要进行选择,下面针对常见的网路爬虫做一些简单介绍,给你们做一些参考:
首先是云爬虫,国内目前主要是:神箭手云爬虫
神箭手云爬虫
官网:
简介:神箭手云是一个大数据应用开发平台,为开发者提供成套的数据采集、数据剖析和机器学习开发工具,为企业提供专业化的数据抓取、数据实时监控和数据剖析服务。
优点:功能强悍爬虫软件 下载,涉及云爬虫、API、机器学习、数据清洗、数据转让、数据定制和私有化布署等;
纯云端运行,跨系统操作无压力,隐私保护,可隐藏用户IP。
提供云爬虫市场,零基础使用者可直接调用开发好的爬虫,开发者基于官方的云端开发环境开发并上传出售自己的爬虫程序;
领先的反爬技术,例如直接接入代理IP和自动登录验证码识别等,全程自动化无需人工参与;
丰富的发布接口,采集结果以丰富表格化形式展现;
缺点:它的优点同时也在一定程度上成了它的缺点,因为它是一个面向开发者的爬虫开发系统,提供了丰富的开发功能,网站看起来特别的偏技术十分专业,尽管官方也提供了云爬虫市场这样的现成爬虫产品,并且开放给广大爬虫开发者,从而使爬虫市场的内容愈发丰富,但是对于零技术基础的用户而言并不是这么容易理解,所以有一定的使用门槛。
是否免费:免费用户无采集功能和导入限制,无需积分。
具备开发能力的用户可以自行开发爬虫,达到免费疗效,没有开发能力的用户须要从爬虫市场找寻是否有免费的爬虫。
然后是采集器,目前国外主要包括以下这种(百度/谷歌搜采集器,刨去广告,排名靠前的):
优采云采集器:
官网:
简介:火车采集器是一款网页数据抓取、处理、分析,挖掘软件。可以灵活迅速地抓取网页上散乱分布的信息,并通过强悍的处理功能确切挖掘出所需数据。
优点:国内老牌的采集器,经过多年的积累,具有丰富的采集功能;
采集速度比较快,接口比较齐全,支持PHP和C#插件扩展;
支持多种数据格式导出,可以进行数据替换等处理。
缺点:越是年头长的产品越容易身陷自己的固有经验中,优采云也无法甩掉这问题。
虽说功能丰富,但是功能都堆砌在那里,用户体验不好,让人不知道从何下手;
学会了的人会觉得功能强大,但是对于新手而言有一定使用门槛,不学习一段时间很难上手,零基础上手基本不可能。
只支持Windows版本,不支持其他操作系统;
是否免费:号称免费,但是实际上免费功能限制好多,只能导入单个txt或html文件,基本上可以说是不免费的。
优采云采集器:
官网:
简介:优采云采集器是一款可视化采集器,内置采集模板,支持各类网页数据采集。
优点:支持自定义模式,可视化采集操作,容易上手;
支持简易采集模式,提供官方采集模板,支持云采集操作;
支持防屏蔽措施,例如代理IP切换和验证码服务;
支持多种数据格式导出。
缺点:功能使用门槛较高,本地采集时好多功能受限,而云采集收费较高;
采集速度较慢,很多操作都要卡一下,云端采集说10倍提速但是并不明显;
只支持Windows版本,不支持其他操作系统。
是否免费:号称免费,但是实际上导入数据须要积分,可以做任务攒积分,但是正常情况下基本都须要订购积分。
后羿采集器:
官网:
简介:后羿采集器是由前微软搜索技术团队基于人工智能技术研制的新一代网页采集软件,该软件功能强悍,操作非常简单。
优点:支持智能采集模式,输入网址能够智能辨识采集对象爬虫软件 下载,无需配置采集规则,操作十分简单;
支持流程图模式,可视化操作流程,能够通过简单的操作生成各种复杂的采集规则;
支持防屏蔽措施,例如代理IP切换等;
支持多种数据格式导出;
支持定时采集和自动化发布,发布接口丰富;
支持Windows、Mac和Linux版本。
缺点:软件推出时间不长,部分功能还在继续建立,暂不支持云采集功能
是否免费:完全免费,采集数据和自动导入采集结果都没有任何限制,不需要积分。
零基础也能使用的SEO爬虫公式 - 提升你的10倍工作效率
采集交流 • 优采云 发表了文章 • 0 个评论 • 273 次浏览 • 2020-06-04 08:05
Keen
读完须要
6分钟
速读仅需 2分钟
你有没有遇见过这样的问题,网页上面有几百个网址链接,需要你统计出来ebay爬虫软件,你会一一粘贴复制到表格里吗?
或者要统计公司潜在顾客的邮箱,需要通过关键词去搜索,然后每位网页都要点击进去,找找看有没有邮箱呢?
对于前面这张种大批量重复的工作,难道就没有更好的、快捷的、简单的解决方案吗?
当然是有的,今天这篇文章将给你分享 ——如何借助简单爬虫解决重复大量的工作。
不过,在步入教程之前,我们要说说:
什么是爬虫
简单来说,爬虫就是一种网路机器人,主要作用就是收集网路数据,我们熟知的微软和百度等搜索引擎就是通过爬虫收集网站的数据,根据这种数据对网站进行排序。
既然微软可以借助爬虫收集网站数据,那我们是否能借助爬虫帮我们收集数据呢?
当然是可以的。
我们可以用爬虫做哪些
前面早已讲过,如果你碰到一些重复大量的工作,其实都可以交给爬虫来做,比如:
搜集特定关键词下的用户邮箱批量收集关键词批量下载图片批量导入导出文章……
比如我想搜索iphone case的相关用户邮箱,那么可以去Google搜索iphone case这个关键词,然后统计下相关网页,把网址递交给爬虫程序,接着我们就等着出结果就行了。
当然,创作一个特定的爬虫程序须要一定的技术基础,市面上主流都是使用python来制做爬虫程序,不过我们明天用一个更简单易懂的爬虫软件——Google Sheet,不用写任何代码的哦!
利用Google Sheet爬取数据
Google sheet(以下简称GS)是Google旗下的在线办公套件之一,和谷歌的办公三剑客刚好一一对应:
Google doc - WordGoogle sheet - ExcelGoogle presentation - PPT
基本上Excel上的公式都可以在GS上运行,不过GS还要另外一个公式,是Excel不具备的,也就是
IMPORTXML
我们新建一个GSebay爬虫软件,这个操作和Execl操作一致,然后在A1栏输入我们须要爬取数据的网址,记得网址必须包含https或http,只有这些完整写法才能生效。
然后在B1栏输入
=importxml(A1,''//title")
在B1栏输入完成以后我们都会得到如下数据 查看全部
Keen
读完须要
6分钟
速读仅需 2分钟
你有没有遇见过这样的问题,网页上面有几百个网址链接,需要你统计出来ebay爬虫软件,你会一一粘贴复制到表格里吗?
或者要统计公司潜在顾客的邮箱,需要通过关键词去搜索,然后每位网页都要点击进去,找找看有没有邮箱呢?
对于前面这张种大批量重复的工作,难道就没有更好的、快捷的、简单的解决方案吗?
当然是有的,今天这篇文章将给你分享 ——如何借助简单爬虫解决重复大量的工作。
不过,在步入教程之前,我们要说说:
什么是爬虫
简单来说,爬虫就是一种网路机器人,主要作用就是收集网路数据,我们熟知的微软和百度等搜索引擎就是通过爬虫收集网站的数据,根据这种数据对网站进行排序。
既然微软可以借助爬虫收集网站数据,那我们是否能借助爬虫帮我们收集数据呢?
当然是可以的。
我们可以用爬虫做哪些
前面早已讲过,如果你碰到一些重复大量的工作,其实都可以交给爬虫来做,比如:
搜集特定关键词下的用户邮箱批量收集关键词批量下载图片批量导入导出文章……
比如我想搜索iphone case的相关用户邮箱,那么可以去Google搜索iphone case这个关键词,然后统计下相关网页,把网址递交给爬虫程序,接着我们就等着出结果就行了。
当然,创作一个特定的爬虫程序须要一定的技术基础,市面上主流都是使用python来制做爬虫程序,不过我们明天用一个更简单易懂的爬虫软件——Google Sheet,不用写任何代码的哦!
利用Google Sheet爬取数据
Google sheet(以下简称GS)是Google旗下的在线办公套件之一,和谷歌的办公三剑客刚好一一对应:
Google doc - WordGoogle sheet - ExcelGoogle presentation - PPT
基本上Excel上的公式都可以在GS上运行,不过GS还要另外一个公式,是Excel不具备的,也就是
IMPORTXML
我们新建一个GSebay爬虫软件,这个操作和Execl操作一致,然后在A1栏输入我们须要爬取数据的网址,记得网址必须包含https或http,只有这些完整写法才能生效。
然后在B1栏输入
=importxml(A1,''//title")
在B1栏输入完成以后我们都会得到如下数据
爬虫怎么突破网站的反爬机制
采集交流 • 优采云 发表了文章 • 0 个评论 • 312 次浏览 • 2020-05-21 08:01
我们晓得,爬虫是大数据时代的重要角色,发挥着重大的作用。但是,通往成功的路上总是遍布荆棘,目标网站总是设置各类限制来制止爬虫的正常工作。那么,目标网站一般是通过什么方法来限制爬虫呢,爬虫又该怎么突破这种限制呢?
1、注意好多网站,可以先用代理ip+ua(ua库随机提取)访问,之后会返回来一个cookie,那ip+ua+cookie就是一一对应的,然后用这个ip、ua和cookie去采集网站,同时能带上Referer,这样疗效会比较好
2、有些网站反爬取的举措应当比较强的。访问以后每次清理缓存,这样能有效规避部份网站的测量;但是有些网站更严格的判定,如果都是新链接从ip发出,也会被判断拒绝(直接403拒绝访问),因此有些爬虫顾客会去剖析网站的cookies缓存内容,然后进行更改。
3、浏览器的标示(User-Agent)也很重要淘宝反爬虫机制,用户都是一种浏览器,也是容易判别作弊,要构造不同的浏览器标示,否则容易被判断爬虫。,用代理访问过后,浏览器标示须要更改,建议浏览器用phantomjs框架,这个可以模拟其他浏览器的标识(需要标识库的话,我们亿牛云代理可以提供1000+),可以通过API接口实现各类浏览器的采集模拟。
4、加密:网站的恳求假如加密过,那就看不清恳求的本来面目,这时候只能靠猜想淘宝反爬虫机制,通常加密会采用简单的编码,如:、urlEncode等,如果过分复杂,只能用尽的去尝试
5、本地IP限制:很多网站,会对爬虫ip进行限制,这时候要么使用代理IP,要么伪装ip
6、对应pc端,很多网站做的防护比较全面,有时候可以改一下看法,让app端服务试试,往往会有意想不到的收获。每个网站的反爬策略在不断升级(淘宝,京东,企查查),那么现今突破反爬虫的策略也要相应的不断升级,不然很容易被限制,而在提升爬虫工作效率上,动态代理IP是最大的推动,亿牛云海量的家庭私密代理IP完全可以让爬虫工者的效率成倍提高!返回搜狐,查看更多 查看全部
我们晓得,爬虫是大数据时代的重要角色,发挥着重大的作用。但是,通往成功的路上总是遍布荆棘,目标网站总是设置各类限制来制止爬虫的正常工作。那么,目标网站一般是通过什么方法来限制爬虫呢,爬虫又该怎么突破这种限制呢?
1、注意好多网站,可以先用代理ip+ua(ua库随机提取)访问,之后会返回来一个cookie,那ip+ua+cookie就是一一对应的,然后用这个ip、ua和cookie去采集网站,同时能带上Referer,这样疗效会比较好
2、有些网站反爬取的举措应当比较强的。访问以后每次清理缓存,这样能有效规避部份网站的测量;但是有些网站更严格的判定,如果都是新链接从ip发出,也会被判断拒绝(直接403拒绝访问),因此有些爬虫顾客会去剖析网站的cookies缓存内容,然后进行更改。
3、浏览器的标示(User-Agent)也很重要淘宝反爬虫机制,用户都是一种浏览器,也是容易判别作弊,要构造不同的浏览器标示,否则容易被判断爬虫。,用代理访问过后,浏览器标示须要更改,建议浏览器用phantomjs框架,这个可以模拟其他浏览器的标识(需要标识库的话,我们亿牛云代理可以提供1000+),可以通过API接口实现各类浏览器的采集模拟。
4、加密:网站的恳求假如加密过,那就看不清恳求的本来面目,这时候只能靠猜想淘宝反爬虫机制,通常加密会采用简单的编码,如:、urlEncode等,如果过分复杂,只能用尽的去尝试
5、本地IP限制:很多网站,会对爬虫ip进行限制,这时候要么使用代理IP,要么伪装ip
6、对应pc端,很多网站做的防护比较全面,有时候可以改一下看法,让app端服务试试,往往会有意想不到的收获。每个网站的反爬策略在不断升级(淘宝,京东,企查查),那么现今突破反爬虫的策略也要相应的不断升级,不然很容易被限制,而在提升爬虫工作效率上,动态代理IP是最大的推动,亿牛云海量的家庭私密代理IP完全可以让爬虫工者的效率成倍提高!返回搜狐,查看更多
爬虫要违规了吗?告诉你们:守住规则,大胆去爬
采集交流 • 优采云 发表了文章 • 0 个评论 • 330 次浏览 • 2020-05-19 08:02
robots.txt文件是一个文本文件,使用任何一个常见的文本编辑器关于网络爬虫协议文件robotstxt,比如Windows系统自带的Notepad,就可以创建和编辑它。robots.txt是一个合同,而不是一个命令。robots.txt是搜索引擎中访问网站的时侯要查看的第一个文件。robots.txt文件告诉蜘蛛程序在服务器上哪些文件是可以被查看的。
如何查看采集的内容是的有rebots合同?
其实技巧很简单。你想查看的话就在IE上打你的网址/robots.txt要是说查看剖析robots的话有专业的相关工具 站长工具就可以!
爬虫作为一种计算机技术就决定了它的中立性,因此爬虫本身在法律上并不被严禁,但是借助爬虫技术获取数据这一行为是具有违规甚至是犯罪的风险的。
举个反例:像微软这样的搜索引擎爬虫,每隔几天对全网的网页扫一遍,供你们查阅,各个被扫的网站大都很开心。这种就被定义为“善意爬虫”。但是象购票软件这样的爬虫,对着 12306 每秒钟恨不得撸几万次,铁总并不认为很开心关于网络爬虫协议文件robotstxt,这种就被定义为“恶意爬虫”。
爬虫所带来风险主要彰显在以下3个方面:
违反网站意愿,例如网站采取反爬举措后,强行突破其反爬举措;
爬虫干扰了被访问网站的正常营运;
爬虫抓取了遭到法律保护的特定类型的数据或信息。
解释一下爬虫的定义:网络爬虫(英语:web crawler),也叫网路蜘蛛(spider),是一种拿来手动浏览万维网的网路机器人。
网络爬虫抓取的数据有如下规则:
数据完全公开
不存在也未能做到越权访问爬取
常见错误观点:认为爬虫就是拿来抓取个人信息的,与信用基础数据相关的。 查看全部
Robots协议(也称为爬虫协议、机器人合同等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉爬虫什么页面可以抓取,哪些页面不能抓取。
robots.txt文件是一个文本文件,使用任何一个常见的文本编辑器关于网络爬虫协议文件robotstxt,比如Windows系统自带的Notepad,就可以创建和编辑它。robots.txt是一个合同,而不是一个命令。robots.txt是搜索引擎中访问网站的时侯要查看的第一个文件。robots.txt文件告诉蜘蛛程序在服务器上哪些文件是可以被查看的。
如何查看采集的内容是的有rebots合同?
其实技巧很简单。你想查看的话就在IE上打你的网址/robots.txt要是说查看剖析robots的话有专业的相关工具 站长工具就可以!
爬虫作为一种计算机技术就决定了它的中立性,因此爬虫本身在法律上并不被严禁,但是借助爬虫技术获取数据这一行为是具有违规甚至是犯罪的风险的。
举个反例:像微软这样的搜索引擎爬虫,每隔几天对全网的网页扫一遍,供你们查阅,各个被扫的网站大都很开心。这种就被定义为“善意爬虫”。但是象购票软件这样的爬虫,对着 12306 每秒钟恨不得撸几万次,铁总并不认为很开心关于网络爬虫协议文件robotstxt,这种就被定义为“恶意爬虫”。
爬虫所带来风险主要彰显在以下3个方面:
违反网站意愿,例如网站采取反爬举措后,强行突破其反爬举措;
爬虫干扰了被访问网站的正常营运;
爬虫抓取了遭到法律保护的特定类型的数据或信息。
解释一下爬虫的定义:网络爬虫(英语:web crawler),也叫网路蜘蛛(spider),是一种拿来手动浏览万维网的网路机器人。
网络爬虫抓取的数据有如下规则:
数据完全公开
不存在也未能做到越权访问爬取
常见错误观点:认为爬虫就是拿来抓取个人信息的,与信用基础数据相关的。
Java爬虫框架(一)--架构设计
采集交流 • 优采云 发表了文章 • 0 个评论 • 387 次浏览 • 2020-05-10 08:08
一、 架构图
那里搜网路爬虫框架主要针对电子商务网站进行数据爬取,分析,存储,索引。
爬虫:爬虫负责爬取,解析,处理电子商务网站的网页的内容
数据库:存储商品信息
索引:商品的全文搜索索引
Task队列:需要爬取的网页列表
Visited表:已经爬取过的网页列表
爬虫监控平台:web平台可以启动,停止爬虫,管理爬虫,task队列,visited表。
二、 爬虫1. 流程
1) Scheduler启动爬虫器,TaskMaster初始化taskQueue
2) Workers从TaskQueue中获取任务
3) Worker线程调用Fetcher爬取Task中描述的网页
4) Worker线程将爬取到的网页交给Parser解析
5) Parser解析下来的数据送交Handler处理,抽取网页Link和处理网页内容
6) VisitedTableManager判定从URLExtractor抽取下来的链接是否早已被爬取过,如果没有递交到TaskQueue中
2. Scheduler
Scheduler负责启动爬虫器,调用TaskMaster初始化TaskQueue,同时创建一个monitor线程,负责控制程序的退出。
何时退出?
当TaskQueue为空,并且Workers中的所有线程都处于空闲状态。而这些形势在指定10分钟内没有发生任何变化。就觉得所有网页早已全部爬完。程序退出。
3. Task Master
任务管理器,负责管理任务队列。任务管理器具象了任务队列的实现。
l 在简单应用中,我们可以使用显存的任务管理器
l 在分布式平台,有多个爬虫机器的情况下我们须要集中的任务队列
在现阶段,我们用SQLLite作为任务队列的实现。可供取代的还有Redis。
任务管理器的处理流程:
l 任务管理器初始化任务队列,任务队列的初始化按照不同的配置可能不同。增量式的情况下,根据指定的URL List初始化。而全文爬取的情况下只预先初始化某个或几个电子商务网站的首页。
l 任务管理器创建monitor线程,控制整个程序的退出
l 任务管理器调度任务,如果任务队列是持久化的,负责从任务队列服务器load任务。需要考虑预取。
l 任务管理器还负责验证任务的有效性验证,爬虫监控平台可以将任务队列中的个别任务设为失效?
4. Workers
Worker线程池,每个线程就会执行整个爬取的流程。可以考虑用多个线程池,分割异步化整个流程。提高线程的利用率。
5. Fetcher
Fetcher负责直接爬取电子商务网站的网页。用HTTP Client实现。HTTP core 4以上早已有NIO的功能, 用NIO实现。
Fetcher可以配置需不需要保存HTML文件
6. Parser
Parser解析Fetcher获取的网页,一般的网页可能不是完好低格的(XHTML是完美低格的),这样就不能借助XML的解释器处理。我们须要一款比较好的HTML解析器,可以修补这种非完好低格的网页。
熟悉的第三方工具有TagSoup,nekohtml,htmlparser三款。tagsoup和nekohtml可以将HTML用SAX事件流处理,节省了显存。
已知的第三方框架又使用了哪款作为她们的解析器呢?
l Nutch:正式支持的有tagsoup,nekohtml,二者通过配置选择
l Droids:用的是nekohtml,Tika
l Tika:tagsoup
据称,tagsoup的可靠性要比nekohtml好,nekohtml的性能比tagsoup好。nekohtml不管是在可靠性还是性能上都比htmlparser好。具体推论我们还须要进一步测试。
我们还支持regex,dom结构的html解析器。在使用中我们可以结合使用。
进一步,我们须要研究文档比较器,同时须要我们保存爬取过的网站的HTML.可以通过语义指纹或则simhash来实现。在处理海量数据的时侯才须要用上。如果两个HTML被觉得是相同的,就不会再解析和处理。
7. Handler
Handler是对Parser解析下来的内容做处理。
回调方法(visitor):对于SAX event处理,我们须要将handler适配成sax的content handler。作为parser的反弹方式。不同风波解析下来的内容可以储存在HandlingContext中。最后由Parser一起返回。
主动形式:需要解析整个HTML,选取自己须要的内容。对Parser提取的内容进行处理。XML须要解析成DOM结构。方便使用,可以使用Xpath,nodefilter等,但耗显存。
ContentHandler:它还包含组件ContentFilter。过滤content。
URLExtractor负责从网页中提取符合格式的URL,将URL构建成Task,并递交到Task queue中。
8. VisitedTableManager
访问表管理器,管理访问过的URLs。提取统一插口,抽象底层实现。如果URL被爬取过,就不会被添加到TaskQueue中。
三、 Task队列
Task队列储存了须要被爬取的任务。任务之间是有关联的。我们可以保存和管理这个任务关系。这个关系也是URL之间的关系。保存出来,有助于后台产生Web图java爬虫框架,分析数据。
Task队列在分布式爬虫集群中,需要使用集中的服务器储存。一些轻量级的数据库或则支持列表的NoSql都可以拿来储存。可选方案:
l 用SQLLite储存:需要不停地插入删掉,不知性能怎么。
l 用Redis储存
四、 Visited表
Visited表储存了早已被爬的网站。每次爬取都须要建立。
l SQLLite储存:需要动态创建表,需要不停地查询java爬虫框架,插入,还须要后台定期地清除,不知性能怎么。
l Mysql 内存表 hash index
l Redis: Key value,设过期时间
l Memcached: key value, value为bloomfilter的值
针对目前的数据量,可以采用SQLLite
五、 爬虫监控管理平台
l 启动,停止爬虫,监控各爬虫状态
l 监控,管理task队列,visited表
l 配置爬虫
l 对爬虫爬取的数据进行管理。在并发情况下,很难保证不重复爬取相同的商品。在爬取完后,可以通过爬虫监控管理平台进行自动排重。 查看全部
一、 架构图
那里搜网路爬虫框架主要针对电子商务网站进行数据爬取,分析,存储,索引。
爬虫:爬虫负责爬取,解析,处理电子商务网站的网页的内容
数据库:存储商品信息
索引:商品的全文搜索索引
Task队列:需要爬取的网页列表
Visited表:已经爬取过的网页列表
爬虫监控平台:web平台可以启动,停止爬虫,管理爬虫,task队列,visited表。
二、 爬虫1. 流程
1) Scheduler启动爬虫器,TaskMaster初始化taskQueue
2) Workers从TaskQueue中获取任务
3) Worker线程调用Fetcher爬取Task中描述的网页
4) Worker线程将爬取到的网页交给Parser解析
5) Parser解析下来的数据送交Handler处理,抽取网页Link和处理网页内容
6) VisitedTableManager判定从URLExtractor抽取下来的链接是否早已被爬取过,如果没有递交到TaskQueue中
2. Scheduler
Scheduler负责启动爬虫器,调用TaskMaster初始化TaskQueue,同时创建一个monitor线程,负责控制程序的退出。
何时退出?
当TaskQueue为空,并且Workers中的所有线程都处于空闲状态。而这些形势在指定10分钟内没有发生任何变化。就觉得所有网页早已全部爬完。程序退出。
3. Task Master
任务管理器,负责管理任务队列。任务管理器具象了任务队列的实现。
l 在简单应用中,我们可以使用显存的任务管理器
l 在分布式平台,有多个爬虫机器的情况下我们须要集中的任务队列
在现阶段,我们用SQLLite作为任务队列的实现。可供取代的还有Redis。
任务管理器的处理流程:
l 任务管理器初始化任务队列,任务队列的初始化按照不同的配置可能不同。增量式的情况下,根据指定的URL List初始化。而全文爬取的情况下只预先初始化某个或几个电子商务网站的首页。
l 任务管理器创建monitor线程,控制整个程序的退出
l 任务管理器调度任务,如果任务队列是持久化的,负责从任务队列服务器load任务。需要考虑预取。
l 任务管理器还负责验证任务的有效性验证,爬虫监控平台可以将任务队列中的个别任务设为失效?
4. Workers
Worker线程池,每个线程就会执行整个爬取的流程。可以考虑用多个线程池,分割异步化整个流程。提高线程的利用率。
5. Fetcher
Fetcher负责直接爬取电子商务网站的网页。用HTTP Client实现。HTTP core 4以上早已有NIO的功能, 用NIO实现。
Fetcher可以配置需不需要保存HTML文件
6. Parser
Parser解析Fetcher获取的网页,一般的网页可能不是完好低格的(XHTML是完美低格的),这样就不能借助XML的解释器处理。我们须要一款比较好的HTML解析器,可以修补这种非完好低格的网页。
熟悉的第三方工具有TagSoup,nekohtml,htmlparser三款。tagsoup和nekohtml可以将HTML用SAX事件流处理,节省了显存。
已知的第三方框架又使用了哪款作为她们的解析器呢?
l Nutch:正式支持的有tagsoup,nekohtml,二者通过配置选择
l Droids:用的是nekohtml,Tika
l Tika:tagsoup
据称,tagsoup的可靠性要比nekohtml好,nekohtml的性能比tagsoup好。nekohtml不管是在可靠性还是性能上都比htmlparser好。具体推论我们还须要进一步测试。
我们还支持regex,dom结构的html解析器。在使用中我们可以结合使用。
进一步,我们须要研究文档比较器,同时须要我们保存爬取过的网站的HTML.可以通过语义指纹或则simhash来实现。在处理海量数据的时侯才须要用上。如果两个HTML被觉得是相同的,就不会再解析和处理。
7. Handler
Handler是对Parser解析下来的内容做处理。
回调方法(visitor):对于SAX event处理,我们须要将handler适配成sax的content handler。作为parser的反弹方式。不同风波解析下来的内容可以储存在HandlingContext中。最后由Parser一起返回。
主动形式:需要解析整个HTML,选取自己须要的内容。对Parser提取的内容进行处理。XML须要解析成DOM结构。方便使用,可以使用Xpath,nodefilter等,但耗显存。
ContentHandler:它还包含组件ContentFilter。过滤content。
URLExtractor负责从网页中提取符合格式的URL,将URL构建成Task,并递交到Task queue中。
8. VisitedTableManager
访问表管理器,管理访问过的URLs。提取统一插口,抽象底层实现。如果URL被爬取过,就不会被添加到TaskQueue中。
三、 Task队列
Task队列储存了须要被爬取的任务。任务之间是有关联的。我们可以保存和管理这个任务关系。这个关系也是URL之间的关系。保存出来,有助于后台产生Web图java爬虫框架,分析数据。
Task队列在分布式爬虫集群中,需要使用集中的服务器储存。一些轻量级的数据库或则支持列表的NoSql都可以拿来储存。可选方案:
l 用SQLLite储存:需要不停地插入删掉,不知性能怎么。
l 用Redis储存
四、 Visited表
Visited表储存了早已被爬的网站。每次爬取都须要建立。
l SQLLite储存:需要动态创建表,需要不停地查询java爬虫框架,插入,还须要后台定期地清除,不知性能怎么。
l Mysql 内存表 hash index
l Redis: Key value,设过期时间
l Memcached: key value, value为bloomfilter的值
针对目前的数据量,可以采用SQLLite
五、 爬虫监控管理平台
l 启动,停止爬虫,监控各爬虫状态
l 监控,管理task队列,visited表
l 配置爬虫
l 对爬虫爬取的数据进行管理。在并发情况下,很难保证不重复爬取相同的商品。在爬取完后,可以通过爬虫监控管理平台进行自动排重。
数据小兵博客
采集交流 • 优采云 发表了文章 • 0 个评论 • 283 次浏览 • 2020-05-10 08:07
实践笔记1年前 (2019-01-04)
每天进步一点点,这是我2019年的小目标。 这是第6次学习与实践笔记了,这一次俺们把对象转移到百度搜索去,尝试使用列车浏览器爬虫工具来采集百度新闻搜索的结果,并...
阅读 2,714 次
实践笔记 | 小兵专栏1年前 (2018-12-27)
最近我学习和实践网路爬虫,总想着在这里抓点数据在那里抓点数据爬虫软件数据,浑然不知爬虫的底线和基本规则,我默认觉得只要是在互联网上公开的数据,并且没有侵害个人隐私的数据就可...
阅读 8,834 次 数据抓取网络爬虫
实践笔记1年前 (2018-12-19)
【SPSS统计训练营】微信号新开一个小栏目爬虫软件数据,取名【学习笔记】,主要分享一些与SPSS、统计学、数据剖析有关的技能,SPSS是我们的剖析装备,但是我们决不能仅有一...
阅读 1,211 次
实践笔记1年前 (2018-12-12)
文彤老师的《小白零编程网络爬虫实战》在线课程,我目前正在学习第二章节新闻网站新闻列表抓取。因为文彤老师把它完全作为一个完整的商用项目来做,所以课程上面讲授的知识...
阅读 1,343 次 列车浏览器网路爬虫
实践笔记1年前 (2018-12-02)
我正在学习文彤老师的《小白零编程网络爬虫实战》在线视频课程,这是第2篇学习笔记。 工欲善其事必先利其器,要不要编程写代码只是一个修饰词,但凡在网页上爬取数据,一...
阅读 1,148 次
实践笔记1年前 (2018-11-25)
前不久借着双十一的促销环境,我订购了张文彤老师原创开发的爬虫课程《小白零编程网络爬虫实战》。 想学习爬虫技术许久了,之所以没有下定决心,主要缘由是想到要编程写代...
阅读 1,537 次
数据情报2年前 (2018-06-24)
今年4月份的时侯,我给读者朋友们推荐过中科大罗昭锋主讲的文献管理教学视频,全是免费的,有几个读者后来在公号后台特意留言致谢。 虽然那篇文章最终只有...
阅读 2,857 次 查看全部
http://www.datasoldier.net/wp- ... zc%3D1" />实践笔记1年前 (2019-01-04)
每天进步一点点,这是我2019年的小目标。 这是第6次学习与实践笔记了,这一次俺们把对象转移到百度搜索去,尝试使用列车浏览器爬虫工具来采集百度新闻搜索的结果,并...
阅读 2,714 次
http://www.datasoldier.net/wp- ... zc%3D1" />实践笔记 | 小兵专栏1年前 (2018-12-27)
最近我学习和实践网路爬虫,总想着在这里抓点数据在那里抓点数据爬虫软件数据,浑然不知爬虫的底线和基本规则,我默认觉得只要是在互联网上公开的数据,并且没有侵害个人隐私的数据就可...
阅读 8,834 次 数据抓取网络爬虫
http://www.datasoldier.net/wp- ... zc%3D1" />实践笔记1年前 (2018-12-19)
【SPSS统计训练营】微信号新开一个小栏目爬虫软件数据,取名【学习笔记】,主要分享一些与SPSS、统计学、数据剖析有关的技能,SPSS是我们的剖析装备,但是我们决不能仅有一...
阅读 1,211 次
http://www.datasoldier.net/wp- ... zc%3D1" />实践笔记1年前 (2018-12-12)
文彤老师的《小白零编程网络爬虫实战》在线课程,我目前正在学习第二章节新闻网站新闻列表抓取。因为文彤老师把它完全作为一个完整的商用项目来做,所以课程上面讲授的知识...
阅读 1,343 次 列车浏览器网路爬虫
http://www.datasoldier.net/wp- ... zc%3D1" />实践笔记1年前 (2018-12-02)
我正在学习文彤老师的《小白零编程网络爬虫实战》在线视频课程,这是第2篇学习笔记。 工欲善其事必先利其器,要不要编程写代码只是一个修饰词,但凡在网页上爬取数据,一...
阅读 1,148 次
http://www.datasoldier.net/wp- ... zc%3D1" />实践笔记1年前 (2018-11-25)
前不久借着双十一的促销环境,我订购了张文彤老师原创开发的爬虫课程《小白零编程网络爬虫实战》。 想学习爬虫技术许久了,之所以没有下定决心,主要缘由是想到要编程写代...
阅读 1,537 次
http://www.datasoldier.net/wp- ... zc%3D1" />数据情报2年前 (2018-06-24)
今年4月份的时侯,我给读者朋友们推荐过中科大罗昭锋主讲的文献管理教学视频,全是免费的,有几个读者后来在公号后台特意留言致谢。 虽然那篇文章最终只有...
阅读 2,857 次
现在主流爬虫和技术方向是哪些?
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2020-05-05 08:04
感觉主流爬虫技术的发展和应用,应该还是在大厂内部,想讨教一下,现在大厂的主要研究方向和领域通常在哪?
大家说详尽了肯定也不现实,大体说个方向或思路就行,对于在一些小厂的人(比如我= 。 =)来说,有想精进技术的心,奈何抓不到方向也没有渠道去了解,特此来问问 V 友。
1.现在主流的爬虫方向是不是在 App 端?
2.针对 App 端的难点或则攻守的焦躁地带是否在证书验证以及 APP 包的加密与破解?
3.大厂对 2 上面的处理,是深陷了猫和老鼠的游戏还是有自己一套更底层 HOOk 的方式和框架(理解为通杀?)?
4.同理,web 端觉得主要的难点 Js 和验证码这一块爬虫技术,大厂是打断点一点点去调试剖析呢?还是直接加经费丢第三方呢?(尤其是针对拖 /点 /滑类型的验证码现今大厂都是如何处理的啊?)
图形验证码可以上机器学习并且复杂的 JS 呢?模拟还是破解?有哪些好的学习方法或路线图吗?
APP 端爬虫工作范围内接触较少,以前时常摆弄过,如果
1.APP 端深陷了反编译的猫捉老鼠的游戏
2.Web 端发展迈向了各类模拟爬虫技术,加机器的方向
那么在具有革命性的技术出现之前,是不是可以考虑把爬虫放一放转去学习其他东西,偶尔来看下出现了哪些新的东西就可以了? 查看全部
现在网上关于爬虫方面的文章,大多都浮于表面,说来说去就这么几个东西,已经很久没有一些实质性的内容了。
感觉主流爬虫技术的发展和应用,应该还是在大厂内部,想讨教一下,现在大厂的主要研究方向和领域通常在哪?
大家说详尽了肯定也不现实,大体说个方向或思路就行,对于在一些小厂的人(比如我= 。 =)来说,有想精进技术的心,奈何抓不到方向也没有渠道去了解,特此来问问 V 友。
1.现在主流的爬虫方向是不是在 App 端?
2.针对 App 端的难点或则攻守的焦躁地带是否在证书验证以及 APP 包的加密与破解?
3.大厂对 2 上面的处理,是深陷了猫和老鼠的游戏还是有自己一套更底层 HOOk 的方式和框架(理解为通杀?)?
4.同理,web 端觉得主要的难点 Js 和验证码这一块爬虫技术,大厂是打断点一点点去调试剖析呢?还是直接加经费丢第三方呢?(尤其是针对拖 /点 /滑类型的验证码现今大厂都是如何处理的啊?)
图形验证码可以上机器学习并且复杂的 JS 呢?模拟还是破解?有哪些好的学习方法或路线图吗?
APP 端爬虫工作范围内接触较少,以前时常摆弄过,如果
1.APP 端深陷了反编译的猫捉老鼠的游戏
2.Web 端发展迈向了各类模拟爬虫技术,加机器的方向
那么在具有革命性的技术出现之前,是不是可以考虑把爬虫放一放转去学习其他东西,偶尔来看下出现了哪些新的东西就可以了?
如何完整写一个爬虫框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 415 次浏览 • 2020-05-03 08:02
本文主要为你们分享一篇怎么完整写一个爬虫框架的恳求方式,具有挺好的参考价值,希望对你们有所帮助。一起追随小编过来瞧瞧吧爬虫框架,希望能帮助到你们。
产生爬虫框架:
1、建立一个scrapy爬虫工程
2、在工程中形成一个scrapy爬虫
3、配置spider爬虫
4、运行爬虫,获取网页
具体操作:
1、建立工程
定义一个工程,名称为:python123demo
方法:
在cmd中,d: 步入盘符, cd pycodes 步入文件pycodes
然后输入
scrapy startproject python123demo
在pycodes中会生成一个文件:
_init_.py不需要用户编撰
2、在工程中形成一个scrapy爬虫
执行一条命令,给出爬虫名子和爬取的网站
产生爬虫:
生成一个名称为 demo 的spider
仅限生成 demo.py,其内容为:
name = 'demo' 当前爬虫名子为demo
allowed_domains = " 爬取该网站域名以下的链接,该域名由cmd命令台输入
start_urls = [] 爬取的初始页面
parse()用于处理相应,解析内容产生字典,发现新的url爬取恳求
3、配置形成的spider爬虫,使之满足我们的需求
将解析的页面保存成文件
修改demo.py文件
4、运行爬虫,获取网页
打开cmd输入命令行进行爬虫
然后我的笔记本上出现了一个错误
windows系统上出现这个问题的解决须要安装Py32Win模块,但是直接通过官网链接装exe会出现几百个错误,更方便的做法是
pip3 install pypiwin32
这是py3的解决方案
注意:py3版本假如用 pip install pypiwin32指令会发生错误
安装完成后,重新进行爬虫爬虫框架,成功!撒花!
捕获页面储存在 demo.html文件中
demo.py 所对应的完整代码:
两版本等价:
以上就是怎么完整写一个爬虫框架的详尽内容,更多请关注php中文网其它相关文章! 查看全部
本文主要为你们分享一篇怎么完整写一个爬虫框架的恳求方式,具有挺好的参考价值,希望对你们有所帮助。一起追随小编过来瞧瞧吧爬虫框架,希望能帮助到你们。
产生爬虫框架:
1、建立一个scrapy爬虫工程
2、在工程中形成一个scrapy爬虫
3、配置spider爬虫
4、运行爬虫,获取网页
具体操作:
1、建立工程
定义一个工程,名称为:python123demo
方法:
在cmd中,d: 步入盘符, cd pycodes 步入文件pycodes
然后输入
scrapy startproject python123demo
在pycodes中会生成一个文件:
_init_.py不需要用户编撰
2、在工程中形成一个scrapy爬虫
执行一条命令,给出爬虫名子和爬取的网站
产生爬虫:
生成一个名称为 demo 的spider
仅限生成 demo.py,其内容为:
name = 'demo' 当前爬虫名子为demo
allowed_domains = " 爬取该网站域名以下的链接,该域名由cmd命令台输入
start_urls = [] 爬取的初始页面
parse()用于处理相应,解析内容产生字典,发现新的url爬取恳求
3、配置形成的spider爬虫,使之满足我们的需求
将解析的页面保存成文件
修改demo.py文件
4、运行爬虫,获取网页
打开cmd输入命令行进行爬虫
然后我的笔记本上出现了一个错误
windows系统上出现这个问题的解决须要安装Py32Win模块,但是直接通过官网链接装exe会出现几百个错误,更方便的做法是
pip3 install pypiwin32
这是py3的解决方案
注意:py3版本假如用 pip install pypiwin32指令会发生错误
安装完成后,重新进行爬虫爬虫框架,成功!撒花!
捕获页面储存在 demo.html文件中
demo.py 所对应的完整代码:
两版本等价:
以上就是怎么完整写一个爬虫框架的详尽内容,更多请关注php中文网其它相关文章!

