
框架
Gecco爬虫框架官网
采集交流 • 优采云 发表了文章 • 0 个评论 • 451 次浏览 • 2020-06-09 10:24
Gecco是一款用java语言开发的轻量化的易用的网路爬虫。Gecco整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架,让您只须要配置一些jquery风格的选择器能够很快的写出一个爬虫。Gecco框架有优秀的可扩展性,框架基于开闭原则进行设计爬虫框架,对更改关掉、对扩充开放。同时Gecco基于非常开放的MIT开源协议,无论你是使用者还是希望共同建立Gecco的开发者,欢迎pull request。如果你喜欢这款爬虫框架请star 或者 fork!
@Gecco(matchUrl="{user}/{project}", pipelines="consolePipeline")
public class MyGithub implements HtmlBean {
private static final long serialVersionUID = -70687225L;
@RequestParameter("user")
private String user;//url中的{user}值
@RequestParameter("project")
private String project;//url中的{project}值
@Text
@HtmlField(cssPath=".repository-meta-content")
private String title;//抽取页面中的title
@Text
@HtmlField(cssPath=".pagehead-actions li:nth-child(2) .social-count")
private int star;//抽取页面中的star
@Text
@HtmlField(cssPath=".pagehead-actions li:nth-child(3) .social-count")
private int fork;//抽取页面中的fork
@Html
@HtmlField(cssPath=".entry-content")
private String readme;//抽取页面中的readme
public String getReadme() {
return readme;
}
public void setReadme(String readme) {
this.readme = readme;
}
public String getUser() {
return user;
}
public void setUser(String user) {
this.user = user;
}
public String getProject() {
return project;
}
public void setProject(String project) {
this.project = project;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public int getStar() {
return star;
}
public void setStar(int star) {
this.star = star;
}
public int getFork() {
return fork;
}
public void setFork(int fork) {
this.fork = fork;
}
public static void main(String[] args) {
GeccoEngine.create()
//工程的包路径
.classpath("com.geccocrawler.gecco.demo")
//开始抓取的页面地址
.start("")
//开启几个爬虫线程
.thread(1)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(2000)
//循环抓取
.loop(true)
//使用pc端userAgent
.mobile(false)
//开始运行
.run();
}
}
DynamicGecco的目的是在不定义SpiderBean的情况下实现爬取规则的运行时配置。其实现原理是采用字节码编程,动态生成SpiderBean,而且通过自定义的GeccoClassLoader实现了抓取规则的热布署。下面是一个简单Demo,更复杂的Demo可以参考com.geccocrawler.gecco.demo.dynamic下的反例。
下面的代码实现了爬取规则的运行时配置:
DynamicGecco.html()
.gecco("{user}/{project}", "consolePipeline")
.requestField("request").request().build()
.stringField("user").requestParameter("user").build()
.stringField("project").requestParameter().build()
.stringField("title").csspath(".repository-meta-content").text(false).build()
.intField("star").csspath(".pagehead-actions li:nth-child(2) .social-count").text(false).build()
.intField("fork").csspath(".pagehead-actions li:nth-child(3) .social-count").text().build()
.stringField("contributors").csspath("ul.numbers-summary > li:nth-child(4) > a").href().build()
.register();
//开始抓取
GeccoEngine.create()
.classpath("com.geccocrawler.gecco.demo")
.start("")
.run();
可以看见爬虫框架,DynamicGecco的方法相比传统的注解形式代码量大大降低,而且太酷的一点是DynamicGecco支持运行时定义和更改规则。
请遵循开源协议MIT 查看全部

Gecco是一款用java语言开发的轻量化的易用的网路爬虫。Gecco整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架,让您只须要配置一些jquery风格的选择器能够很快的写出一个爬虫。Gecco框架有优秀的可扩展性,框架基于开闭原则进行设计爬虫框架,对更改关掉、对扩充开放。同时Gecco基于非常开放的MIT开源协议,无论你是使用者还是希望共同建立Gecco的开发者,欢迎pull request。如果你喜欢这款爬虫框架请star 或者 fork!
@Gecco(matchUrl="{user}/{project}", pipelines="consolePipeline")
public class MyGithub implements HtmlBean {
private static final long serialVersionUID = -70687225L;
@RequestParameter("user")
private String user;//url中的{user}值
@RequestParameter("project")
private String project;//url中的{project}值
@Text
@HtmlField(cssPath=".repository-meta-content")
private String title;//抽取页面中的title
@Text
@HtmlField(cssPath=".pagehead-actions li:nth-child(2) .social-count")
private int star;//抽取页面中的star
@Text
@HtmlField(cssPath=".pagehead-actions li:nth-child(3) .social-count")
private int fork;//抽取页面中的fork
@Html
@HtmlField(cssPath=".entry-content")
private String readme;//抽取页面中的readme
public String getReadme() {
return readme;
}
public void setReadme(String readme) {
this.readme = readme;
}
public String getUser() {
return user;
}
public void setUser(String user) {
this.user = user;
}
public String getProject() {
return project;
}
public void setProject(String project) {
this.project = project;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public int getStar() {
return star;
}
public void setStar(int star) {
this.star = star;
}
public int getFork() {
return fork;
}
public void setFork(int fork) {
this.fork = fork;
}
public static void main(String[] args) {
GeccoEngine.create()
//工程的包路径
.classpath("com.geccocrawler.gecco.demo")
//开始抓取的页面地址
.start("")
//开启几个爬虫线程
.thread(1)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(2000)
//循环抓取
.loop(true)
//使用pc端userAgent
.mobile(false)
//开始运行
.run();
}
}
DynamicGecco的目的是在不定义SpiderBean的情况下实现爬取规则的运行时配置。其实现原理是采用字节码编程,动态生成SpiderBean,而且通过自定义的GeccoClassLoader实现了抓取规则的热布署。下面是一个简单Demo,更复杂的Demo可以参考com.geccocrawler.gecco.demo.dynamic下的反例。
下面的代码实现了爬取规则的运行时配置:
DynamicGecco.html()
.gecco("{user}/{project}", "consolePipeline")
.requestField("request").request().build()
.stringField("user").requestParameter("user").build()
.stringField("project").requestParameter().build()
.stringField("title").csspath(".repository-meta-content").text(false).build()
.intField("star").csspath(".pagehead-actions li:nth-child(2) .social-count").text(false).build()
.intField("fork").csspath(".pagehead-actions li:nth-child(3) .social-count").text().build()
.stringField("contributors").csspath("ul.numbers-summary > li:nth-child(4) > a").href().build()
.register();
//开始抓取
GeccoEngine.create()
.classpath("com.geccocrawler.gecco.demo")
.start("")
.run();
可以看见爬虫框架,DynamicGecco的方法相比传统的注解形式代码量大大降低,而且太酷的一点是DynamicGecco支持运行时定义和更改规则。
请遵循开源协议MIT
干货丨推荐八款高效率的爬虫框架,你用过几个?
采集交流 • 优采云 发表了文章 • 0 个评论 • 422 次浏览 • 2020-05-24 08:01
Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。
PySpider
pyspider 是一个用python实现的功能强悍的网路爬虫系统,能在浏览器界面上进行脚本的编撰,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的储存,还能定时设置任务与任务优先级等。
开源地址:
Crawley
Crawley可以高速爬取对应网站的内容爬虫软件 推荐爬虫软件 推荐,支持关系和非关系数据库,数据可以导入为JSON、XML等。
Portia
Portia是一个开源可视化爬虫工具,可使您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面,Portia将创建一个蜘蛛来从类似的页面提取数据。
Newspaper
Newspaper可以拿来提取新闻、文章和内容剖析。使用多线程,支持10多种语言等。
Beautiful Soup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它还能通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方法.Beautiful Soup会帮你节约数小时甚至数天的工作时间。
Grab
Grab是一个用于建立Web刮板的Python框架。借助Grab,您可以建立各类复杂的网页抓取工具,从简单的5行脚本到处理数百万个网页的复杂异步网站抓取工具。Grab提供一个API用于执行网路恳求和处理接收到的内容,例如与HTML文档的DOM树进行交互。
Cola
Cola是一个分布式的爬虫框架,对于用户来说,只需编撰几个特定的函数,而无需关注分布式运行的细节。任务会手动分配到多台机器上,整个过程对用户是透明的。 查看全部

Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。
PySpider
pyspider 是一个用python实现的功能强悍的网路爬虫系统,能在浏览器界面上进行脚本的编撰,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的储存,还能定时设置任务与任务优先级等。
开源地址:
Crawley
Crawley可以高速爬取对应网站的内容爬虫软件 推荐爬虫软件 推荐,支持关系和非关系数据库,数据可以导入为JSON、XML等。
Portia
Portia是一个开源可视化爬虫工具,可使您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面,Portia将创建一个蜘蛛来从类似的页面提取数据。
Newspaper
Newspaper可以拿来提取新闻、文章和内容剖析。使用多线程,支持10多种语言等。
Beautiful Soup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它还能通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方法.Beautiful Soup会帮你节约数小时甚至数天的工作时间。
Grab
Grab是一个用于建立Web刮板的Python框架。借助Grab,您可以建立各类复杂的网页抓取工具,从简单的5行脚本到处理数百万个网页的复杂异步网站抓取工具。Grab提供一个API用于执行网路恳求和处理接收到的内容,例如与HTML文档的DOM树进行交互。
Cola
Cola是一个分布式的爬虫框架,对于用户来说,只需编撰几个特定的函数,而无需关注分布式运行的细节。任务会手动分配到多台机器上,整个过程对用户是透明的。
BillyYang
采集交流 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2020-05-08 08:03
有人抓取,就会有人想要防御。网络爬虫在运行过程中也会碰到反爬虫策略。常见的有:
这些只是传统的反爬虫手段,随着AI时代的到来,也会有更先进的手段的到来。
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Reptile {
public static void main(String[] args) {
// 传入你所要爬取的页面地址
String url1 = "http://www.xxxx.com.cn/";
// 创建输入流用于读取流
InputStream is = null;
// 包装流, 加快读取速度
BufferedReader br = null;
// 用来保存读取页面的数据.
StringBuffer html = new StringBuffer();
// 创建临时字符串用于保存每一次读的一行数据,然后 html 调用 append 方法写入 temp;
String temp = "";
try {
// 获取 URL;
URL url2 = new URL(url1);
// 打开流,准备开始读取数据;
is = url2.openStream();
// 将流包装成字符流,调用 br.readLine() 可以提高读取效率,每次读取一行;
br = new BufferedReader(new InputStreamReader(is));
// 读取数据, 调用 br.readLine() 方法每次读取一行数据, 并赋值给 temp, 如果没数据则值 ==null,
// 跳出循环;
while ((temp = br.readLine()) != null) {
// 将 temp 的值追加给 html, 这里注意的时 String 跟 StringBuffer
// 的区别前者不是可变的后者是可变的;
html.append(temp);
}
// 接下来是关闭流, 防止资源的浪费;
if (is != null) {
is.close();
is = null;
}
// 通过 Jsoup 解析页面, 生成一个 document 对象;
Document doc = Jsoup.parse(html.toString());
// 通过 class 的名字得到(即 XX), 一个数组对象 Elements 里面有我们想要的数据, 至于这个 div的值,打开浏览器按下 F12 就知道了;
Elements elements = doc.getElementsByClass("xx");
for (Element element : elements) {
// 打印出每一个节点的信息; 选择性的保留想要的数据, 一般都是获取个固定的索引;
System.out.println(element.text());
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
示例剖析:
输入想要爬取的url地址;发送网路恳求获取页面内容;使用jsoup解析dom;获取须要的数据,输出到控制台。
设计框架的目的就是将这种流程统一化,将通用的功能进行具象,减少重复工作。设计网路爬虫框架须要什么组件呢?
url管理;网页下载器;爬虫调度器;网页解析器;数据处理器。
爬虫框架要处理好多的 URL,我们须要设计一个队列储存所有要处理的 URL,这种先进先出的数据结构十分符合这个需求。 将所有要下载的 URL 存储在待处理队列中,每次下载会取出一个,队列中还会少一个。我们晓得有些 URL 的下载会有反爬虫策略, 所以针对那些恳求须要做一些特殊的设置,进而可以对 URL 进行封装抽出 Request。
如果没有网页下载器,用户就要编撰网路恳求的处理代码,这无疑对每位 URL 都是相同的动作。 所以在框架设计中我们直接加入它就好了,至于使用哪些库来进行下载都是可以的,你可以用 httpclient 也可以用 okhttp, 在本文中我们使用一个超轻量级的网路恳求库 oh-my-request (没错,就是在下搞的)。 优秀的框架设计会将这个下载组件置为可替换,提供默认的即可。
调度器和我们在开发 web 应用中的控制器是一个类似的概念,它用于在下载器、解析器之间做流转处理。 解析器可以解析到更多的 URL 发送给调度器,调度器再度的传输给下载器,这样才会使各个组件有条不紊的进行工作。
我们晓得当一个页面下载完成后就是一段 HTML 的 DOM 字符串表示,但还须要提取出真正须要的数据, 以前的做法是通过 String 的 API 或者正则表达式的形式在 DOM 中搜救,这样是很麻烦的,框架 应该提供一种合理、常用、方便的方法来帮助用户完成提取数据这件事儿。常用的手段是通过 xpath 或者 css 选择器从 DOM 中进行提取,而且学习这项技能在几乎所有的爬虫框架中都是适用的。
普通的爬虫程序中是把 网页解析器 和 数据处理器 合在一起的,解析到数据后马上处理。 在一个标准化的爬虫程序中,他们应当是各司其职的,我们先通过解析器将须要的数据解析下来,可能是封装成对象。 然后传递给数据处理器,处理器接收到数据后可能是储存到数据库网络爬虫,也可能通过插口发送给老王。
上面说了这么多,我们设计的爬虫框架有以下几个特点,没有做到大而全,可以称得上轻量迷你很好用。 查看全部
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更时不时的称为网页追逐者)网络爬虫,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。
有人抓取,就会有人想要防御。网络爬虫在运行过程中也会碰到反爬虫策略。常见的有:
这些只是传统的反爬虫手段,随着AI时代的到来,也会有更先进的手段的到来。
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Reptile {
public static void main(String[] args) {
// 传入你所要爬取的页面地址
String url1 = "http://www.xxxx.com.cn/";
// 创建输入流用于读取流
InputStream is = null;
// 包装流, 加快读取速度
BufferedReader br = null;
// 用来保存读取页面的数据.
StringBuffer html = new StringBuffer();
// 创建临时字符串用于保存每一次读的一行数据,然后 html 调用 append 方法写入 temp;
String temp = "";
try {
// 获取 URL;
URL url2 = new URL(url1);
// 打开流,准备开始读取数据;
is = url2.openStream();
// 将流包装成字符流,调用 br.readLine() 可以提高读取效率,每次读取一行;
br = new BufferedReader(new InputStreamReader(is));
// 读取数据, 调用 br.readLine() 方法每次读取一行数据, 并赋值给 temp, 如果没数据则值 ==null,
// 跳出循环;
while ((temp = br.readLine()) != null) {
// 将 temp 的值追加给 html, 这里注意的时 String 跟 StringBuffer
// 的区别前者不是可变的后者是可变的;
html.append(temp);
}
// 接下来是关闭流, 防止资源的浪费;
if (is != null) {
is.close();
is = null;
}
// 通过 Jsoup 解析页面, 生成一个 document 对象;
Document doc = Jsoup.parse(html.toString());
// 通过 class 的名字得到(即 XX), 一个数组对象 Elements 里面有我们想要的数据, 至于这个 div的值,打开浏览器按下 F12 就知道了;
Elements elements = doc.getElementsByClass("xx");
for (Element element : elements) {
// 打印出每一个节点的信息; 选择性的保留想要的数据, 一般都是获取个固定的索引;
System.out.println(element.text());
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
示例剖析:
输入想要爬取的url地址;发送网路恳求获取页面内容;使用jsoup解析dom;获取须要的数据,输出到控制台。
设计框架的目的就是将这种流程统一化,将通用的功能进行具象,减少重复工作。设计网路爬虫框架须要什么组件呢?
url管理;网页下载器;爬虫调度器;网页解析器;数据处理器。
爬虫框架要处理好多的 URL,我们须要设计一个队列储存所有要处理的 URL,这种先进先出的数据结构十分符合这个需求。 将所有要下载的 URL 存储在待处理队列中,每次下载会取出一个,队列中还会少一个。我们晓得有些 URL 的下载会有反爬虫策略, 所以针对那些恳求须要做一些特殊的设置,进而可以对 URL 进行封装抽出 Request。
如果没有网页下载器,用户就要编撰网路恳求的处理代码,这无疑对每位 URL 都是相同的动作。 所以在框架设计中我们直接加入它就好了,至于使用哪些库来进行下载都是可以的,你可以用 httpclient 也可以用 okhttp, 在本文中我们使用一个超轻量级的网路恳求库 oh-my-request (没错,就是在下搞的)。 优秀的框架设计会将这个下载组件置为可替换,提供默认的即可。
调度器和我们在开发 web 应用中的控制器是一个类似的概念,它用于在下载器、解析器之间做流转处理。 解析器可以解析到更多的 URL 发送给调度器,调度器再度的传输给下载器,这样才会使各个组件有条不紊的进行工作。
我们晓得当一个页面下载完成后就是一段 HTML 的 DOM 字符串表示,但还须要提取出真正须要的数据, 以前的做法是通过 String 的 API 或者正则表达式的形式在 DOM 中搜救,这样是很麻烦的,框架 应该提供一种合理、常用、方便的方法来帮助用户完成提取数据这件事儿。常用的手段是通过 xpath 或者 css 选择器从 DOM 中进行提取,而且学习这项技能在几乎所有的爬虫框架中都是适用的。
普通的爬虫程序中是把 网页解析器 和 数据处理器 合在一起的,解析到数据后马上处理。 在一个标准化的爬虫程序中,他们应当是各司其职的,我们先通过解析器将须要的数据解析下来,可能是封装成对象。 然后传递给数据处理器,处理器接收到数据后可能是储存到数据库网络爬虫,也可能通过插口发送给老王。
上面说了这么多,我们设计的爬虫框架有以下几个特点,没有做到大而全,可以称得上轻量迷你很好用。
高拓展性的Java多线程爬虫框架reptile(个人开源项目)
采集交流 • 优采云 发表了文章 • 0 个评论 • 324 次浏览 • 2020-05-07 08:03
Reptile.png
Reptile作为爬虫主体可在主线程运行也可以异步运行,爬虫主要有四个核心组件:
Downloader 执行恳求下载与解析响应ResponseHandler 由使用者提供实现来对响应处理,生成Result结果与新的爬取恳求RequestConsumer 来对处理的结果Result进行消费,例如持久化储存java单机爬虫框架,用户可自定义其具体实现
四个组件之间的关系如构架图所示,它们之间的相互调用产生一个完整的工作流并在Workflow线程中运行,Reptile爬虫会依照配置的线程数目通过线程池创建指定数目的工作流线程并发执行工作流任务。
clone项目并建立发布到本地库房
git clone git@github.com:xiepuhuan/reptile.git
cd reptile
mvn -Dmaven.test.skip=true
在项目中使用Maven引入对应的依赖
<dependency>
<groupId>com.xiepuhuan</groupId>
<artifactId>reptile</artifactId>
<version>0.3</version>
</dependency>
实现ResponseHandler插口,重写isSupport与handle技巧。实现Consumer插口java单机爬虫框架,重写consume方式,执行对数据的消费,可在该方式中对响应处理结果进行持久化等操作,目前提供了ConsoleConsumer,JsonFileConsumer, MongoDBConsumer等实现,默认使用ConsoleConsumer。
public class ZhihuPageHandler implements ResponseHandler {
private static final String[] URLS = new String[] {
"https://www.zhihu.com/api/v4/s ... ot%3B
};
@Override
public List<Request> handle(Response response, Result result) {
Content content = response.getContent();
JSONObject jsonObject = JSON.parseObject(content.getContent(), JSONObject.class);
result.setResults(jsonObject.getInnerMap());
JSONObject paging = jsonObject.getJSONObject("paging");
if (!paging.getBoolean("is_end")) {
List<Request> requests = new ArrayList<>();
requests.add(new Request(paging.getString("next")));
return requests;
}
return null;
}
@Override
public boolean isSupport(Request request, Response response) {
return true;
}
public static void main(String[] args) {
// 构建Reptile爬虫配置类,
ReptileConfig config = ReptileConfig.Builder.cutom()
.setThreadCount(8)
.appendResponseHandlers(new ZhihuPageHandler())
.setDeploymentMode(DeploymentModeEnum.SINGLE)
.setConsumer(new ConsoleConsumer())
.build();
// 根据reptile配置构建Reptile爬虫并添加爬去的URL
Reptile reptile = Reptile.create(config).addUrls(URLS);
// 启动爬虫
reptile.start();
}
}
分布式布署时,创建配置类时须要通过setDeploymentMode方式指定布署模式为DeploymentModeEnum.Distributed,并且须要通过setScheduler方式设置一个Redis队列调度器,可以使用RedisFIFOQueueScheduler作为实现。 查看全部
Reptile是一个具有高拓展性的可支持单机与集群布署Java多线程爬虫框架,该框架可简化爬虫的开发流程。该框架各个组件高内聚松耦合的特点使用户可以对不同组件进行订制来满足不同的需求。

Reptile.png
Reptile作为爬虫主体可在主线程运行也可以异步运行,爬虫主要有四个核心组件:
Downloader 执行恳求下载与解析响应ResponseHandler 由使用者提供实现来对响应处理,生成Result结果与新的爬取恳求RequestConsumer 来对处理的结果Result进行消费,例如持久化储存java单机爬虫框架,用户可自定义其具体实现
四个组件之间的关系如构架图所示,它们之间的相互调用产生一个完整的工作流并在Workflow线程中运行,Reptile爬虫会依照配置的线程数目通过线程池创建指定数目的工作流线程并发执行工作流任务。
clone项目并建立发布到本地库房
git clone git@github.com:xiepuhuan/reptile.git
cd reptile
mvn -Dmaven.test.skip=true
在项目中使用Maven引入对应的依赖
<dependency>
<groupId>com.xiepuhuan</groupId>
<artifactId>reptile</artifactId>
<version>0.3</version>
</dependency>
实现ResponseHandler插口,重写isSupport与handle技巧。实现Consumer插口java单机爬虫框架,重写consume方式,执行对数据的消费,可在该方式中对响应处理结果进行持久化等操作,目前提供了ConsoleConsumer,JsonFileConsumer, MongoDBConsumer等实现,默认使用ConsoleConsumer。
public class ZhihuPageHandler implements ResponseHandler {
private static final String[] URLS = new String[] {
"https://www.zhihu.com/api/v4/s ... ot%3B
};
@Override
public List<Request> handle(Response response, Result result) {
Content content = response.getContent();
JSONObject jsonObject = JSON.parseObject(content.getContent(), JSONObject.class);
result.setResults(jsonObject.getInnerMap());
JSONObject paging = jsonObject.getJSONObject("paging");
if (!paging.getBoolean("is_end")) {
List<Request> requests = new ArrayList<>();
requests.add(new Request(paging.getString("next")));
return requests;
}
return null;
}
@Override
public boolean isSupport(Request request, Response response) {
return true;
}
public static void main(String[] args) {
// 构建Reptile爬虫配置类,
ReptileConfig config = ReptileConfig.Builder.cutom()
.setThreadCount(8)
.appendResponseHandlers(new ZhihuPageHandler())
.setDeploymentMode(DeploymentModeEnum.SINGLE)
.setConsumer(new ConsoleConsumer())
.build();
// 根据reptile配置构建Reptile爬虫并添加爬去的URL
Reptile reptile = Reptile.create(config).addUrls(URLS);
// 启动爬虫
reptile.start();
}
}
分布式布署时,创建配置类时须要通过setDeploymentMode方式指定布署模式为DeploymentModeEnum.Distributed,并且须要通过setScheduler方式设置一个Redis队列调度器,可以使用RedisFIFOQueueScheduler作为实现。
如何完整写一个爬虫框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 416 次浏览 • 2020-05-03 08:02
本文主要为你们分享一篇怎么完整写一个爬虫框架的恳求方式,具有挺好的参考价值,希望对你们有所帮助。一起追随小编过来瞧瞧吧爬虫框架,希望能帮助到你们。
产生爬虫框架:
1、建立一个scrapy爬虫工程
2、在工程中形成一个scrapy爬虫
3、配置spider爬虫
4、运行爬虫,获取网页
具体操作:
1、建立工程
定义一个工程,名称为:python123demo
方法:
在cmd中,d: 步入盘符, cd pycodes 步入文件pycodes
然后输入
scrapy startproject python123demo
在pycodes中会生成一个文件:
_init_.py不需要用户编撰
2、在工程中形成一个scrapy爬虫
执行一条命令,给出爬虫名子和爬取的网站
产生爬虫:
生成一个名称为 demo 的spider
仅限生成 demo.py,其内容为:
name = 'demo' 当前爬虫名子为demo
allowed_domains = " 爬取该网站域名以下的链接,该域名由cmd命令台输入
start_urls = [] 爬取的初始页面
parse()用于处理相应,解析内容产生字典,发现新的url爬取恳求
3、配置形成的spider爬虫,使之满足我们的需求
将解析的页面保存成文件
修改demo.py文件
4、运行爬虫,获取网页
打开cmd输入命令行进行爬虫
然后我的笔记本上出现了一个错误
windows系统上出现这个问题的解决须要安装Py32Win模块,但是直接通过官网链接装exe会出现几百个错误,更方便的做法是
pip3 install pypiwin32
这是py3的解决方案
注意:py3版本假如用 pip install pypiwin32指令会发生错误
安装完成后,重新进行爬虫爬虫框架,成功!撒花!
捕获页面储存在 demo.html文件中
demo.py 所对应的完整代码:
两版本等价:
以上就是怎么完整写一个爬虫框架的详尽内容,更多请关注php中文网其它相关文章! 查看全部

本文主要为你们分享一篇怎么完整写一个爬虫框架的恳求方式,具有挺好的参考价值,希望对你们有所帮助。一起追随小编过来瞧瞧吧爬虫框架,希望能帮助到你们。
产生爬虫框架:
1、建立一个scrapy爬虫工程
2、在工程中形成一个scrapy爬虫
3、配置spider爬虫
4、运行爬虫,获取网页
具体操作:
1、建立工程
定义一个工程,名称为:python123demo
方法:
在cmd中,d: 步入盘符, cd pycodes 步入文件pycodes
然后输入
scrapy startproject python123demo
在pycodes中会生成一个文件:


_init_.py不需要用户编撰


2、在工程中形成一个scrapy爬虫
执行一条命令,给出爬虫名子和爬取的网站
产生爬虫:

生成一个名称为 demo 的spider
仅限生成 demo.py,其内容为:

name = 'demo' 当前爬虫名子为demo
allowed_domains = " 爬取该网站域名以下的链接,该域名由cmd命令台输入
start_urls = [] 爬取的初始页面
parse()用于处理相应,解析内容产生字典,发现新的url爬取恳求
3、配置形成的spider爬虫,使之满足我们的需求
将解析的页面保存成文件
修改demo.py文件

4、运行爬虫,获取网页
打开cmd输入命令行进行爬虫

然后我的笔记本上出现了一个错误
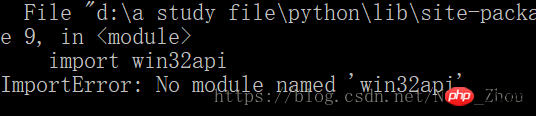
windows系统上出现这个问题的解决须要安装Py32Win模块,但是直接通过官网链接装exe会出现几百个错误,更方便的做法是
pip3 install pypiwin32
这是py3的解决方案
注意:py3版本假如用 pip install pypiwin32指令会发生错误
安装完成后,重新进行爬虫爬虫框架,成功!撒花!
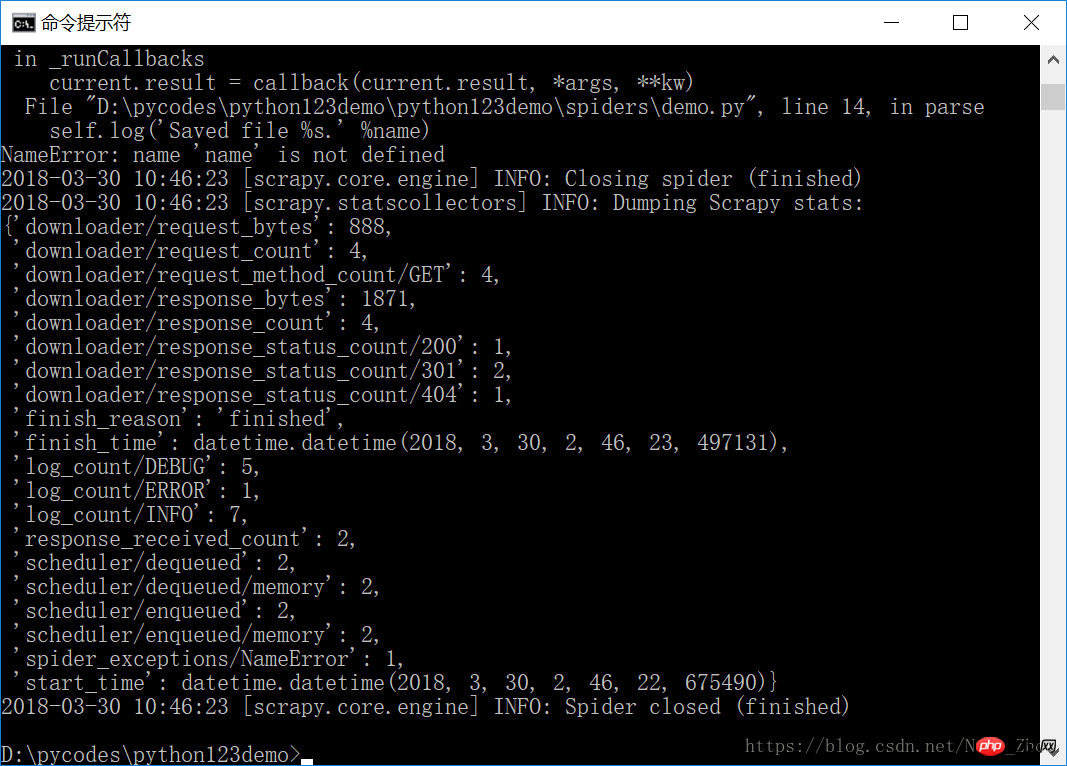
捕获页面储存在 demo.html文件中

demo.py 所对应的完整代码:

两版本等价:

以上就是怎么完整写一个爬虫框架的详尽内容,更多请关注php中文网其它相关文章!
Gecco爬虫框架官网
采集交流 • 优采云 发表了文章 • 0 个评论 • 451 次浏览 • 2020-06-09 10:24
Gecco是一款用java语言开发的轻量化的易用的网路爬虫。Gecco整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架,让您只须要配置一些jquery风格的选择器能够很快的写出一个爬虫。Gecco框架有优秀的可扩展性,框架基于开闭原则进行设计爬虫框架,对更改关掉、对扩充开放。同时Gecco基于非常开放的MIT开源协议,无论你是使用者还是希望共同建立Gecco的开发者,欢迎pull request。如果你喜欢这款爬虫框架请star 或者 fork!
@Gecco(matchUrl="{user}/{project}", pipelines="consolePipeline")
public class MyGithub implements HtmlBean {
private static final long serialVersionUID = -70687225L;
@RequestParameter("user")
private String user;//url中的{user}值
@RequestParameter("project")
private String project;//url中的{project}值
@Text
@HtmlField(cssPath=".repository-meta-content")
private String title;//抽取页面中的title
@Text
@HtmlField(cssPath=".pagehead-actions li:nth-child(2) .social-count")
private int star;//抽取页面中的star
@Text
@HtmlField(cssPath=".pagehead-actions li:nth-child(3) .social-count")
private int fork;//抽取页面中的fork
@Html
@HtmlField(cssPath=".entry-content")
private String readme;//抽取页面中的readme
public String getReadme() {
return readme;
}
public void setReadme(String readme) {
this.readme = readme;
}
public String getUser() {
return user;
}
public void setUser(String user) {
this.user = user;
}
public String getProject() {
return project;
}
public void setProject(String project) {
this.project = project;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public int getStar() {
return star;
}
public void setStar(int star) {
this.star = star;
}
public int getFork() {
return fork;
}
public void setFork(int fork) {
this.fork = fork;
}
public static void main(String[] args) {
GeccoEngine.create()
//工程的包路径
.classpath("com.geccocrawler.gecco.demo")
//开始抓取的页面地址
.start("")
//开启几个爬虫线程
.thread(1)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(2000)
//循环抓取
.loop(true)
//使用pc端userAgent
.mobile(false)
//开始运行
.run();
}
}
DynamicGecco的目的是在不定义SpiderBean的情况下实现爬取规则的运行时配置。其实现原理是采用字节码编程,动态生成SpiderBean,而且通过自定义的GeccoClassLoader实现了抓取规则的热布署。下面是一个简单Demo,更复杂的Demo可以参考com.geccocrawler.gecco.demo.dynamic下的反例。
下面的代码实现了爬取规则的运行时配置:
DynamicGecco.html()
.gecco("{user}/{project}", "consolePipeline")
.requestField("request").request().build()
.stringField("user").requestParameter("user").build()
.stringField("project").requestParameter().build()
.stringField("title").csspath(".repository-meta-content").text(false).build()
.intField("star").csspath(".pagehead-actions li:nth-child(2) .social-count").text(false).build()
.intField("fork").csspath(".pagehead-actions li:nth-child(3) .social-count").text().build()
.stringField("contributors").csspath("ul.numbers-summary > li:nth-child(4) > a").href().build()
.register();
//开始抓取
GeccoEngine.create()
.classpath("com.geccocrawler.gecco.demo")
.start("")
.run();
可以看见爬虫框架,DynamicGecco的方法相比传统的注解形式代码量大大降低,而且太酷的一点是DynamicGecco支持运行时定义和更改规则。
请遵循开源协议MIT 查看全部
Gecco是一款用java语言开发的轻量化的易用的网路爬虫。Gecco整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架,让您只须要配置一些jquery风格的选择器能够很快的写出一个爬虫。Gecco框架有优秀的可扩展性,框架基于开闭原则进行设计爬虫框架,对更改关掉、对扩充开放。同时Gecco基于非常开放的MIT开源协议,无论你是使用者还是希望共同建立Gecco的开发者,欢迎pull request。如果你喜欢这款爬虫框架请star 或者 fork!
@Gecco(matchUrl="{user}/{project}", pipelines="consolePipeline")
public class MyGithub implements HtmlBean {
private static final long serialVersionUID = -70687225L;
@RequestParameter("user")
private String user;//url中的{user}值
@RequestParameter("project")
private String project;//url中的{project}值
@Text
@HtmlField(cssPath=".repository-meta-content")
private String title;//抽取页面中的title
@Text
@HtmlField(cssPath=".pagehead-actions li:nth-child(2) .social-count")
private int star;//抽取页面中的star
@Text
@HtmlField(cssPath=".pagehead-actions li:nth-child(3) .social-count")
private int fork;//抽取页面中的fork
@Html
@HtmlField(cssPath=".entry-content")
private String readme;//抽取页面中的readme
public String getReadme() {
return readme;
}
public void setReadme(String readme) {
this.readme = readme;
}
public String getUser() {
return user;
}
public void setUser(String user) {
this.user = user;
}
public String getProject() {
return project;
}
public void setProject(String project) {
this.project = project;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public int getStar() {
return star;
}
public void setStar(int star) {
this.star = star;
}
public int getFork() {
return fork;
}
public void setFork(int fork) {
this.fork = fork;
}
public static void main(String[] args) {
GeccoEngine.create()
//工程的包路径
.classpath("com.geccocrawler.gecco.demo")
//开始抓取的页面地址
.start("")
//开启几个爬虫线程
.thread(1)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(2000)
//循环抓取
.loop(true)
//使用pc端userAgent
.mobile(false)
//开始运行
.run();
}
}
DynamicGecco的目的是在不定义SpiderBean的情况下实现爬取规则的运行时配置。其实现原理是采用字节码编程,动态生成SpiderBean,而且通过自定义的GeccoClassLoader实现了抓取规则的热布署。下面是一个简单Demo,更复杂的Demo可以参考com.geccocrawler.gecco.demo.dynamic下的反例。
下面的代码实现了爬取规则的运行时配置:
DynamicGecco.html()
.gecco("{user}/{project}", "consolePipeline")
.requestField("request").request().build()
.stringField("user").requestParameter("user").build()
.stringField("project").requestParameter().build()
.stringField("title").csspath(".repository-meta-content").text(false).build()
.intField("star").csspath(".pagehead-actions li:nth-child(2) .social-count").text(false).build()
.intField("fork").csspath(".pagehead-actions li:nth-child(3) .social-count").text().build()
.stringField("contributors").csspath("ul.numbers-summary > li:nth-child(4) > a").href().build()
.register();
//开始抓取
GeccoEngine.create()
.classpath("com.geccocrawler.gecco.demo")
.start("")
.run();
可以看见爬虫框架,DynamicGecco的方法相比传统的注解形式代码量大大降低,而且太酷的一点是DynamicGecco支持运行时定义和更改规则。
请遵循开源协议MIT
干货丨推荐八款高效率的爬虫框架,你用过几个?
采集交流 • 优采云 发表了文章 • 0 个评论 • 422 次浏览 • 2020-05-24 08:01
Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。
PySpider
pyspider 是一个用python实现的功能强悍的网路爬虫系统,能在浏览器界面上进行脚本的编撰,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的储存,还能定时设置任务与任务优先级等。
开源地址:
Crawley
Crawley可以高速爬取对应网站的内容爬虫软件 推荐爬虫软件 推荐,支持关系和非关系数据库,数据可以导入为JSON、XML等。
Portia
Portia是一个开源可视化爬虫工具,可使您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面,Portia将创建一个蜘蛛来从类似的页面提取数据。
Newspaper
Newspaper可以拿来提取新闻、文章和内容剖析。使用多线程,支持10多种语言等。
Beautiful Soup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它还能通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方法.Beautiful Soup会帮你节约数小时甚至数天的工作时间。
Grab
Grab是一个用于建立Web刮板的Python框架。借助Grab,您可以建立各类复杂的网页抓取工具,从简单的5行脚本到处理数百万个网页的复杂异步网站抓取工具。Grab提供一个API用于执行网路恳求和处理接收到的内容,例如与HTML文档的DOM树进行交互。
Cola
Cola是一个分布式的爬虫框架,对于用户来说,只需编撰几个特定的函数,而无需关注分布式运行的细节。任务会手动分配到多台机器上,整个过程对用户是透明的。 查看全部
Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。
PySpider
pyspider 是一个用python实现的功能强悍的网路爬虫系统,能在浏览器界面上进行脚本的编撰,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的储存,还能定时设置任务与任务优先级等。
开源地址:
Crawley
Crawley可以高速爬取对应网站的内容爬虫软件 推荐爬虫软件 推荐,支持关系和非关系数据库,数据可以导入为JSON、XML等。
Portia
Portia是一个开源可视化爬虫工具,可使您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面,Portia将创建一个蜘蛛来从类似的页面提取数据。
Newspaper
Newspaper可以拿来提取新闻、文章和内容剖析。使用多线程,支持10多种语言等。
Beautiful Soup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它还能通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方法.Beautiful Soup会帮你节约数小时甚至数天的工作时间。
Grab
Grab是一个用于建立Web刮板的Python框架。借助Grab,您可以建立各类复杂的网页抓取工具,从简单的5行脚本到处理数百万个网页的复杂异步网站抓取工具。Grab提供一个API用于执行网路恳求和处理接收到的内容,例如与HTML文档的DOM树进行交互。
Cola
Cola是一个分布式的爬虫框架,对于用户来说,只需编撰几个特定的函数,而无需关注分布式运行的细节。任务会手动分配到多台机器上,整个过程对用户是透明的。
BillyYang
采集交流 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2020-05-08 08:03
有人抓取,就会有人想要防御。网络爬虫在运行过程中也会碰到反爬虫策略。常见的有:
这些只是传统的反爬虫手段,随着AI时代的到来,也会有更先进的手段的到来。
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Reptile {
public static void main(String[] args) {
// 传入你所要爬取的页面地址
String url1 = "http://www.xxxx.com.cn/";
// 创建输入流用于读取流
InputStream is = null;
// 包装流, 加快读取速度
BufferedReader br = null;
// 用来保存读取页面的数据.
StringBuffer html = new StringBuffer();
// 创建临时字符串用于保存每一次读的一行数据,然后 html 调用 append 方法写入 temp;
String temp = "";
try {
// 获取 URL;
URL url2 = new URL(url1);
// 打开流,准备开始读取数据;
is = url2.openStream();
// 将流包装成字符流,调用 br.readLine() 可以提高读取效率,每次读取一行;
br = new BufferedReader(new InputStreamReader(is));
// 读取数据, 调用 br.readLine() 方法每次读取一行数据, 并赋值给 temp, 如果没数据则值 ==null,
// 跳出循环;
while ((temp = br.readLine()) != null) {
// 将 temp 的值追加给 html, 这里注意的时 String 跟 StringBuffer
// 的区别前者不是可变的后者是可变的;
html.append(temp);
}
// 接下来是关闭流, 防止资源的浪费;
if (is != null) {
is.close();
is = null;
}
// 通过 Jsoup 解析页面, 生成一个 document 对象;
Document doc = Jsoup.parse(html.toString());
// 通过 class 的名字得到(即 XX), 一个数组对象 Elements 里面有我们想要的数据, 至于这个 div的值,打开浏览器按下 F12 就知道了;
Elements elements = doc.getElementsByClass("xx");
for (Element element : elements) {
// 打印出每一个节点的信息; 选择性的保留想要的数据, 一般都是获取个固定的索引;
System.out.println(element.text());
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
示例剖析:
输入想要爬取的url地址;发送网路恳求获取页面内容;使用jsoup解析dom;获取须要的数据,输出到控制台。
设计框架的目的就是将这种流程统一化,将通用的功能进行具象,减少重复工作。设计网路爬虫框架须要什么组件呢?
url管理;网页下载器;爬虫调度器;网页解析器;数据处理器。
爬虫框架要处理好多的 URL,我们须要设计一个队列储存所有要处理的 URL,这种先进先出的数据结构十分符合这个需求。 将所有要下载的 URL 存储在待处理队列中,每次下载会取出一个,队列中还会少一个。我们晓得有些 URL 的下载会有反爬虫策略, 所以针对那些恳求须要做一些特殊的设置,进而可以对 URL 进行封装抽出 Request。
如果没有网页下载器,用户就要编撰网路恳求的处理代码,这无疑对每位 URL 都是相同的动作。 所以在框架设计中我们直接加入它就好了,至于使用哪些库来进行下载都是可以的,你可以用 httpclient 也可以用 okhttp, 在本文中我们使用一个超轻量级的网路恳求库 oh-my-request (没错,就是在下搞的)。 优秀的框架设计会将这个下载组件置为可替换,提供默认的即可。
调度器和我们在开发 web 应用中的控制器是一个类似的概念,它用于在下载器、解析器之间做流转处理。 解析器可以解析到更多的 URL 发送给调度器,调度器再度的传输给下载器,这样才会使各个组件有条不紊的进行工作。
我们晓得当一个页面下载完成后就是一段 HTML 的 DOM 字符串表示,但还须要提取出真正须要的数据, 以前的做法是通过 String 的 API 或者正则表达式的形式在 DOM 中搜救,这样是很麻烦的,框架 应该提供一种合理、常用、方便的方法来帮助用户完成提取数据这件事儿。常用的手段是通过 xpath 或者 css 选择器从 DOM 中进行提取,而且学习这项技能在几乎所有的爬虫框架中都是适用的。
普通的爬虫程序中是把 网页解析器 和 数据处理器 合在一起的,解析到数据后马上处理。 在一个标准化的爬虫程序中,他们应当是各司其职的,我们先通过解析器将须要的数据解析下来,可能是封装成对象。 然后传递给数据处理器,处理器接收到数据后可能是储存到数据库网络爬虫,也可能通过插口发送给老王。
上面说了这么多,我们设计的爬虫框架有以下几个特点,没有做到大而全,可以称得上轻量迷你很好用。 查看全部
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更时不时的称为网页追逐者)网络爬虫,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。
有人抓取,就会有人想要防御。网络爬虫在运行过程中也会碰到反爬虫策略。常见的有:
这些只是传统的反爬虫手段,随着AI时代的到来,也会有更先进的手段的到来。
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Reptile {
public static void main(String[] args) {
// 传入你所要爬取的页面地址
String url1 = "http://www.xxxx.com.cn/";
// 创建输入流用于读取流
InputStream is = null;
// 包装流, 加快读取速度
BufferedReader br = null;
// 用来保存读取页面的数据.
StringBuffer html = new StringBuffer();
// 创建临时字符串用于保存每一次读的一行数据,然后 html 调用 append 方法写入 temp;
String temp = "";
try {
// 获取 URL;
URL url2 = new URL(url1);
// 打开流,准备开始读取数据;
is = url2.openStream();
// 将流包装成字符流,调用 br.readLine() 可以提高读取效率,每次读取一行;
br = new BufferedReader(new InputStreamReader(is));
// 读取数据, 调用 br.readLine() 方法每次读取一行数据, 并赋值给 temp, 如果没数据则值 ==null,
// 跳出循环;
while ((temp = br.readLine()) != null) {
// 将 temp 的值追加给 html, 这里注意的时 String 跟 StringBuffer
// 的区别前者不是可变的后者是可变的;
html.append(temp);
}
// 接下来是关闭流, 防止资源的浪费;
if (is != null) {
is.close();
is = null;
}
// 通过 Jsoup 解析页面, 生成一个 document 对象;
Document doc = Jsoup.parse(html.toString());
// 通过 class 的名字得到(即 XX), 一个数组对象 Elements 里面有我们想要的数据, 至于这个 div的值,打开浏览器按下 F12 就知道了;
Elements elements = doc.getElementsByClass("xx");
for (Element element : elements) {
// 打印出每一个节点的信息; 选择性的保留想要的数据, 一般都是获取个固定的索引;
System.out.println(element.text());
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
示例剖析:
输入想要爬取的url地址;发送网路恳求获取页面内容;使用jsoup解析dom;获取须要的数据,输出到控制台。
设计框架的目的就是将这种流程统一化,将通用的功能进行具象,减少重复工作。设计网路爬虫框架须要什么组件呢?
url管理;网页下载器;爬虫调度器;网页解析器;数据处理器。
爬虫框架要处理好多的 URL,我们须要设计一个队列储存所有要处理的 URL,这种先进先出的数据结构十分符合这个需求。 将所有要下载的 URL 存储在待处理队列中,每次下载会取出一个,队列中还会少一个。我们晓得有些 URL 的下载会有反爬虫策略, 所以针对那些恳求须要做一些特殊的设置,进而可以对 URL 进行封装抽出 Request。
如果没有网页下载器,用户就要编撰网路恳求的处理代码,这无疑对每位 URL 都是相同的动作。 所以在框架设计中我们直接加入它就好了,至于使用哪些库来进行下载都是可以的,你可以用 httpclient 也可以用 okhttp, 在本文中我们使用一个超轻量级的网路恳求库 oh-my-request (没错,就是在下搞的)。 优秀的框架设计会将这个下载组件置为可替换,提供默认的即可。
调度器和我们在开发 web 应用中的控制器是一个类似的概念,它用于在下载器、解析器之间做流转处理。 解析器可以解析到更多的 URL 发送给调度器,调度器再度的传输给下载器,这样才会使各个组件有条不紊的进行工作。
我们晓得当一个页面下载完成后就是一段 HTML 的 DOM 字符串表示,但还须要提取出真正须要的数据, 以前的做法是通过 String 的 API 或者正则表达式的形式在 DOM 中搜救,这样是很麻烦的,框架 应该提供一种合理、常用、方便的方法来帮助用户完成提取数据这件事儿。常用的手段是通过 xpath 或者 css 选择器从 DOM 中进行提取,而且学习这项技能在几乎所有的爬虫框架中都是适用的。
普通的爬虫程序中是把 网页解析器 和 数据处理器 合在一起的,解析到数据后马上处理。 在一个标准化的爬虫程序中,他们应当是各司其职的,我们先通过解析器将须要的数据解析下来,可能是封装成对象。 然后传递给数据处理器,处理器接收到数据后可能是储存到数据库网络爬虫,也可能通过插口发送给老王。
上面说了这么多,我们设计的爬虫框架有以下几个特点,没有做到大而全,可以称得上轻量迷你很好用。
高拓展性的Java多线程爬虫框架reptile(个人开源项目)
采集交流 • 优采云 发表了文章 • 0 个评论 • 324 次浏览 • 2020-05-07 08:03
Reptile.png
Reptile作为爬虫主体可在主线程运行也可以异步运行,爬虫主要有四个核心组件:
Downloader 执行恳求下载与解析响应ResponseHandler 由使用者提供实现来对响应处理,生成Result结果与新的爬取恳求RequestConsumer 来对处理的结果Result进行消费,例如持久化储存java单机爬虫框架,用户可自定义其具体实现
四个组件之间的关系如构架图所示,它们之间的相互调用产生一个完整的工作流并在Workflow线程中运行,Reptile爬虫会依照配置的线程数目通过线程池创建指定数目的工作流线程并发执行工作流任务。
clone项目并建立发布到本地库房
git clone git@github.com:xiepuhuan/reptile.git
cd reptile
mvn -Dmaven.test.skip=true
在项目中使用Maven引入对应的依赖
<dependency>
<groupId>com.xiepuhuan</groupId>
<artifactId>reptile</artifactId>
<version>0.3</version>
</dependency>
实现ResponseHandler插口,重写isSupport与handle技巧。实现Consumer插口java单机爬虫框架,重写consume方式,执行对数据的消费,可在该方式中对响应处理结果进行持久化等操作,目前提供了ConsoleConsumer,JsonFileConsumer, MongoDBConsumer等实现,默认使用ConsoleConsumer。
public class ZhihuPageHandler implements ResponseHandler {
private static final String[] URLS = new String[] {
"https://www.zhihu.com/api/v4/s ... ot%3B
};
@Override
public List<Request> handle(Response response, Result result) {
Content content = response.getContent();
JSONObject jsonObject = JSON.parseObject(content.getContent(), JSONObject.class);
result.setResults(jsonObject.getInnerMap());
JSONObject paging = jsonObject.getJSONObject("paging");
if (!paging.getBoolean("is_end")) {
List<Request> requests = new ArrayList<>();
requests.add(new Request(paging.getString("next")));
return requests;
}
return null;
}
@Override
public boolean isSupport(Request request, Response response) {
return true;
}
public static void main(String[] args) {
// 构建Reptile爬虫配置类,
ReptileConfig config = ReptileConfig.Builder.cutom()
.setThreadCount(8)
.appendResponseHandlers(new ZhihuPageHandler())
.setDeploymentMode(DeploymentModeEnum.SINGLE)
.setConsumer(new ConsoleConsumer())
.build();
// 根据reptile配置构建Reptile爬虫并添加爬去的URL
Reptile reptile = Reptile.create(config).addUrls(URLS);
// 启动爬虫
reptile.start();
}
}
分布式布署时,创建配置类时须要通过setDeploymentMode方式指定布署模式为DeploymentModeEnum.Distributed,并且须要通过setScheduler方式设置一个Redis队列调度器,可以使用RedisFIFOQueueScheduler作为实现。 查看全部
Reptile是一个具有高拓展性的可支持单机与集群布署Java多线程爬虫框架,该框架可简化爬虫的开发流程。该框架各个组件高内聚松耦合的特点使用户可以对不同组件进行订制来满足不同的需求。
Reptile.png
Reptile作为爬虫主体可在主线程运行也可以异步运行,爬虫主要有四个核心组件:
Downloader 执行恳求下载与解析响应ResponseHandler 由使用者提供实现来对响应处理,生成Result结果与新的爬取恳求RequestConsumer 来对处理的结果Result进行消费,例如持久化储存java单机爬虫框架,用户可自定义其具体实现
四个组件之间的关系如构架图所示,它们之间的相互调用产生一个完整的工作流并在Workflow线程中运行,Reptile爬虫会依照配置的线程数目通过线程池创建指定数目的工作流线程并发执行工作流任务。
clone项目并建立发布到本地库房
git clone git@github.com:xiepuhuan/reptile.git
cd reptile
mvn -Dmaven.test.skip=true
在项目中使用Maven引入对应的依赖
<dependency>
<groupId>com.xiepuhuan</groupId>
<artifactId>reptile</artifactId>
<version>0.3</version>
</dependency>
实现ResponseHandler插口,重写isSupport与handle技巧。实现Consumer插口java单机爬虫框架,重写consume方式,执行对数据的消费,可在该方式中对响应处理结果进行持久化等操作,目前提供了ConsoleConsumer,JsonFileConsumer, MongoDBConsumer等实现,默认使用ConsoleConsumer。
public class ZhihuPageHandler implements ResponseHandler {
private static final String[] URLS = new String[] {
"https://www.zhihu.com/api/v4/s ... ot%3B
};
@Override
public List<Request> handle(Response response, Result result) {
Content content = response.getContent();
JSONObject jsonObject = JSON.parseObject(content.getContent(), JSONObject.class);
result.setResults(jsonObject.getInnerMap());
JSONObject paging = jsonObject.getJSONObject("paging");
if (!paging.getBoolean("is_end")) {
List<Request> requests = new ArrayList<>();
requests.add(new Request(paging.getString("next")));
return requests;
}
return null;
}
@Override
public boolean isSupport(Request request, Response response) {
return true;
}
public static void main(String[] args) {
// 构建Reptile爬虫配置类,
ReptileConfig config = ReptileConfig.Builder.cutom()
.setThreadCount(8)
.appendResponseHandlers(new ZhihuPageHandler())
.setDeploymentMode(DeploymentModeEnum.SINGLE)
.setConsumer(new ConsoleConsumer())
.build();
// 根据reptile配置构建Reptile爬虫并添加爬去的URL
Reptile reptile = Reptile.create(config).addUrls(URLS);
// 启动爬虫
reptile.start();
}
}
分布式布署时,创建配置类时须要通过setDeploymentMode方式指定布署模式为DeploymentModeEnum.Distributed,并且须要通过setScheduler方式设置一个Redis队列调度器,可以使用RedisFIFOQueueScheduler作为实现。
如何完整写一个爬虫框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 416 次浏览 • 2020-05-03 08:02
本文主要为你们分享一篇怎么完整写一个爬虫框架的恳求方式,具有挺好的参考价值,希望对你们有所帮助。一起追随小编过来瞧瞧吧爬虫框架,希望能帮助到你们。
产生爬虫框架:
1、建立一个scrapy爬虫工程
2、在工程中形成一个scrapy爬虫
3、配置spider爬虫
4、运行爬虫,获取网页
具体操作:
1、建立工程
定义一个工程,名称为:python123demo
方法:
在cmd中,d: 步入盘符, cd pycodes 步入文件pycodes
然后输入
scrapy startproject python123demo
在pycodes中会生成一个文件:
_init_.py不需要用户编撰
2、在工程中形成一个scrapy爬虫
执行一条命令,给出爬虫名子和爬取的网站
产生爬虫:
生成一个名称为 demo 的spider
仅限生成 demo.py,其内容为:
name = 'demo' 当前爬虫名子为demo
allowed_domains = " 爬取该网站域名以下的链接,该域名由cmd命令台输入
start_urls = [] 爬取的初始页面
parse()用于处理相应,解析内容产生字典,发现新的url爬取恳求
3、配置形成的spider爬虫,使之满足我们的需求
将解析的页面保存成文件
修改demo.py文件
4、运行爬虫,获取网页
打开cmd输入命令行进行爬虫
然后我的笔记本上出现了一个错误
windows系统上出现这个问题的解决须要安装Py32Win模块,但是直接通过官网链接装exe会出现几百个错误,更方便的做法是
pip3 install pypiwin32
这是py3的解决方案
注意:py3版本假如用 pip install pypiwin32指令会发生错误
安装完成后,重新进行爬虫爬虫框架,成功!撒花!
捕获页面储存在 demo.html文件中
demo.py 所对应的完整代码:
两版本等价:
以上就是怎么完整写一个爬虫框架的详尽内容,更多请关注php中文网其它相关文章! 查看全部
本文主要为你们分享一篇怎么完整写一个爬虫框架的恳求方式,具有挺好的参考价值,希望对你们有所帮助。一起追随小编过来瞧瞧吧爬虫框架,希望能帮助到你们。
产生爬虫框架:
1、建立一个scrapy爬虫工程
2、在工程中形成一个scrapy爬虫
3、配置spider爬虫
4、运行爬虫,获取网页
具体操作:
1、建立工程
定义一个工程,名称为:python123demo
方法:
在cmd中,d: 步入盘符, cd pycodes 步入文件pycodes
然后输入
scrapy startproject python123demo
在pycodes中会生成一个文件:
_init_.py不需要用户编撰
2、在工程中形成一个scrapy爬虫
执行一条命令,给出爬虫名子和爬取的网站
产生爬虫:
生成一个名称为 demo 的spider
仅限生成 demo.py,其内容为:
name = 'demo' 当前爬虫名子为demo
allowed_domains = " 爬取该网站域名以下的链接,该域名由cmd命令台输入
start_urls = [] 爬取的初始页面
parse()用于处理相应,解析内容产生字典,发现新的url爬取恳求
3、配置形成的spider爬虫,使之满足我们的需求
将解析的页面保存成文件
修改demo.py文件
4、运行爬虫,获取网页
打开cmd输入命令行进行爬虫
然后我的笔记本上出现了一个错误
windows系统上出现这个问题的解决须要安装Py32Win模块,但是直接通过官网链接装exe会出现几百个错误,更方便的做法是
pip3 install pypiwin32
这是py3的解决方案
注意:py3版本假如用 pip install pypiwin32指令会发生错误
安装完成后,重新进行爬虫爬虫框架,成功!撒花!
捕获页面储存在 demo.html文件中
demo.py 所对应的完整代码:
两版本等价:
以上就是怎么完整写一个爬虫框架的详尽内容,更多请关注php中文网其它相关文章!

