
根据关键词文章采集系统
根据关键词文章采集系统(闪灵CMS采集内部预置六套网站内容时间段更新方案(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-02 09:16
闪灵cms采集,为了保证网站的内容不断更新,保证网站的排名能够持续攀升,闪灵cms@ >采集内部预设了六套网站内容时间段更新计划。以便随时访问网站以获取最新信息。这让网站整体的更新更加流畅有序,而不是感觉频繁而仓促。从采集到发布,是时候根据网站的用户画像和习惯及时发布内容了。
互联网上的内容风格多种多样,以满足网站对各种信息的提取和整合。Shiningcms采集充分考虑了各种情况下的信息提取,充分考虑了各个生产环节可能出现的情况。从网站的登录、数据提交、链接转换、代码转换、信息提取、字段内容排序、内容过滤、数据发布和附件提取等,所有的链接都已经处理完毕。从 采集 到发布的整个过程都是为了让 网站 快速转换。
闪灵cms采集已经采取了九个步骤来确保网站能够正常工作。频道过期内容自动回收、频道内各类内容数据限制、每日发布限制、附件自动上传和删除、每个频道的附件自设置路径、自动内容采集铰链和发布分页,多编辑、联合审阅、频道无限分类发布、频道动静发布自由设置等九大措施,让网站操作越来越轻松。以后不用再关注内容编辑和搜索,只关注网站的运营推广和网站的SEO优化。
如果用传统的手册来采集几个目标的相关信息网站,由于缺乏技术手段,手段完全是手动的,无法保证更新内容。每天可以采集的有效文章数量非常有限。
通过闪耀cms采集覆盖网站关键词,并在网上自动识别采集,并通过发布界面自动发布文章和图片发布到 网站。小编做过测试,文章通过25个设置抓取文章的数量每天可以达到几十万篇。
闪灵cms采集可以直接部署到本地,从而突破网站空间不能采集的限制。然后点击内容采集,无需复杂配置即可实现采集。再加上7*24h无间隙工作,运行后可连续工作,持续提供内容。结合内置的高级语言处理和机器深度学习,可以突破优质内容,跟随用户阅读习惯,模仿手工编辑,提供优质内容。 查看全部
根据关键词文章采集系统(闪灵CMS采集内部预置六套网站内容时间段更新方案(图))
闪灵cms采集,为了保证网站的内容不断更新,保证网站的排名能够持续攀升,闪灵cms@ >采集内部预设了六套网站内容时间段更新计划。以便随时访问网站以获取最新信息。这让网站整体的更新更加流畅有序,而不是感觉频繁而仓促。从采集到发布,是时候根据网站的用户画像和习惯及时发布内容了。
互联网上的内容风格多种多样,以满足网站对各种信息的提取和整合。Shiningcms采集充分考虑了各种情况下的信息提取,充分考虑了各个生产环节可能出现的情况。从网站的登录、数据提交、链接转换、代码转换、信息提取、字段内容排序、内容过滤、数据发布和附件提取等,所有的链接都已经处理完毕。从 采集 到发布的整个过程都是为了让 网站 快速转换。
闪灵cms采集已经采取了九个步骤来确保网站能够正常工作。频道过期内容自动回收、频道内各类内容数据限制、每日发布限制、附件自动上传和删除、每个频道的附件自设置路径、自动内容采集铰链和发布分页,多编辑、联合审阅、频道无限分类发布、频道动静发布自由设置等九大措施,让网站操作越来越轻松。以后不用再关注内容编辑和搜索,只关注网站的运营推广和网站的SEO优化。
如果用传统的手册来采集几个目标的相关信息网站,由于缺乏技术手段,手段完全是手动的,无法保证更新内容。每天可以采集的有效文章数量非常有限。
通过闪耀cms采集覆盖网站关键词,并在网上自动识别采集,并通过发布界面自动发布文章和图片发布到 网站。小编做过测试,文章通过25个设置抓取文章的数量每天可以达到几十万篇。
闪灵cms采集可以直接部署到本地,从而突破网站空间不能采集的限制。然后点击内容采集,无需复杂配置即可实现采集。再加上7*24h无间隙工作,运行后可连续工作,持续提供内容。结合内置的高级语言处理和机器深度学习,可以突破优质内容,跟随用户阅读习惯,模仿手工编辑,提供优质内容。
根据关键词文章采集系统(从细节出发做好优化流程当中进行优化解决大部分用户问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-02 09:14
文章采集器,非常方便站长在自己是站长的时候,自动从全平台采集相关的文章,然后经过二次创建过程,自动批量发布到 网站@ > 上。不管是什么类型的站点,各种cms都可以实现,即使只有一个站点或者是大型的站群,都可以通过这种方式进行内容更新。某种意义上解放了站长的双手,提高了网站@>本身的效率,还可以自动进行SEO优化。
在使用文章采集器之前,一定要做好网站@>的结构,这样蜘蛛才能循着线索抓到每一页,保证每一页都是活链接,并且死链接是非常有害的,吓跑蜘蛛是不好的。当你做 网站@> 时,不要做死链接。网站@> 的结构不要太复杂。这只是一个简单的 3 层。主页-列页面-文章。保证 网站@> 结构的纯度。这样的结构已经成为一种刻板印象,也方便蜘蛛抓取。
关注网站@>的用户体验,把它做好,网站@>更快,更多优化。速度上去,不仅用户用起来舒服,蜘蛛也能快速抓取,速度也是网页评价的因素之一。那么就关系到服务器的质量和域名解析的速度。有很多新手刚接触互联网,总是喜欢便宜和免费的东西。让我在这里说点什么。免费永远是最贵的。知识。
一个网站@>参与排名最多的是内容页,内容页也是网站@>页数最多的地方。文章采集器可以让大部分网站@>站长所有关键词参与排名,那我们就要从内容页入手,优化一个网站@>内容页面占据更多的关键词排名。排名取决于综合得分。如何让你的网站@>综合得分更高,那我们就要从细节入手进行优化,在我们的优化过程中规划好每一个需要优化的页面,从而解决大部分用户的问题问题。
网站@>优化排名的根本原因,记住文章采集器去采集内容的目的主要是为了解决用户问题。文章采集器采集的内容符合搜索引擎目标,有助于页面的收录,有利于获取大量长尾< @关键词 排名,并提高页面Score的质量。
文章采集器采集收到的内容已经重新整理,内容也进行了细化。解决用户的问题,通过这几点:匹配度,围绕标题解决用户的问题。具有完整性,可以彻底解决用户的问题。在解决用户问题的前提下,像文章这样的搜索引擎,字数多,内容量大。有吸引力,具有营销转化意识,文章可以吸引用户观看。内容有稀缺性,原创,差异,文章在同等条件下,能更好的解决问题。版面漂亮,布局不错,文章结构不影响用户阅读。图片优化,大小,原创图片,alt,与文字相关。
以上就是小编今天分享的关于采集器的文章。通过这篇文章,站长可以了解采集的方法和方法,以及采集站需要改进的地方毕竟SEO是一个全球性的工作协作,而不是仅仅依靠一个达到一定的效果。 查看全部
根据关键词文章采集系统(从细节出发做好优化流程当中进行优化解决大部分用户问题)
文章采集器,非常方便站长在自己是站长的时候,自动从全平台采集相关的文章,然后经过二次创建过程,自动批量发布到 网站@ > 上。不管是什么类型的站点,各种cms都可以实现,即使只有一个站点或者是大型的站群,都可以通过这种方式进行内容更新。某种意义上解放了站长的双手,提高了网站@>本身的效率,还可以自动进行SEO优化。
在使用文章采集器之前,一定要做好网站@>的结构,这样蜘蛛才能循着线索抓到每一页,保证每一页都是活链接,并且死链接是非常有害的,吓跑蜘蛛是不好的。当你做 网站@> 时,不要做死链接。网站@> 的结构不要太复杂。这只是一个简单的 3 层。主页-列页面-文章。保证 网站@> 结构的纯度。这样的结构已经成为一种刻板印象,也方便蜘蛛抓取。
关注网站@>的用户体验,把它做好,网站@>更快,更多优化。速度上去,不仅用户用起来舒服,蜘蛛也能快速抓取,速度也是网页评价的因素之一。那么就关系到服务器的质量和域名解析的速度。有很多新手刚接触互联网,总是喜欢便宜和免费的东西。让我在这里说点什么。免费永远是最贵的。知识。
一个网站@>参与排名最多的是内容页,内容页也是网站@>页数最多的地方。文章采集器可以让大部分网站@>站长所有关键词参与排名,那我们就要从内容页入手,优化一个网站@>内容页面占据更多的关键词排名。排名取决于综合得分。如何让你的网站@>综合得分更高,那我们就要从细节入手进行优化,在我们的优化过程中规划好每一个需要优化的页面,从而解决大部分用户的问题问题。
网站@>优化排名的根本原因,记住文章采集器去采集内容的目的主要是为了解决用户问题。文章采集器采集的内容符合搜索引擎目标,有助于页面的收录,有利于获取大量长尾< @关键词 排名,并提高页面Score的质量。
文章采集器采集收到的内容已经重新整理,内容也进行了细化。解决用户的问题,通过这几点:匹配度,围绕标题解决用户的问题。具有完整性,可以彻底解决用户的问题。在解决用户问题的前提下,像文章这样的搜索引擎,字数多,内容量大。有吸引力,具有营销转化意识,文章可以吸引用户观看。内容有稀缺性,原创,差异,文章在同等条件下,能更好的解决问题。版面漂亮,布局不错,文章结构不影响用户阅读。图片优化,大小,原创图片,alt,与文字相关。
以上就是小编今天分享的关于采集器的文章。通过这篇文章,站长可以了解采集的方法和方法,以及采集站需要改进的地方毕竟SEO是一个全球性的工作协作,而不是仅仅依靠一个达到一定的效果。
根据关键词文章采集系统(八方资源网网站优化*步,就是关键词分析分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-02-27 14:24
八方资源网
网站优化步骤是关键词分析。从展示到发现,一个网站是用户在搜索引擎上搜索关键词,然后锁定相关产品并确认他们的意图。这也使得关键词成为优化的重点之一,不同的关键词带来的展示量和点击量肯定是不一样的,所以关键词分析要先于优化,同时也要重点关注优化。当客户添加产品关键词时,会通过“大数据”进行分析,为用户提供更多的长尾关键词。比如“中国移动电子商务”、“中国移动和宝”、“中国移动和宝官方网站”等,并优化这些词,改进关键词中的<
SEO,英文“SearchEngineOptimization”,中文翻译为“搜索引擎优化”。我们一般将其定义为:
SEO是指在了解搜索引擎自然排名机制的基础上,对网站进行内外部调整优化,提升网站在搜索引擎中的关键词自然排名,获得更多流量,从而达到网站pin的目的。
一般来说,SEO网站的优化包括站内优化和站外优化。内部优化是指对网站本身所有站长可以控制的调整,如网站结构、页面HTML代码等。场外优化是指外部链接建设和行业参与互动。顾名思义,这些活动并不是在 网站 本身中进行的。无论是站内优化还是站外优化,最终目的都是为了做出更有价值的页面收录并被搜索引擎收录。
其实这和我们运营商希望我们的内容被更多人看到是类似的。
1、企业名称和服务项目命名,做搜索引擎优化的人在为公司选择关键词时,会重点关注公司的主要产品或服务。这不是一个糟糕的选择,但是当你选择完成产品时,你是不是最渴望知道产品的背景,也就是它的制造商?因此,在选择关键词时,选择公司或公司名称也尤为重要。对你来说,看公司名称和看公司招牌一样重要,而公众品牌的形象就是招牌。而且公司名称的关键字竞争并不那么激烈,因此忘记一个企业或公司名称将是一个很大的损失。
2、换个角度思考,通常有一句老生常谈的说法,那就是:“站在客户的角度想问题,从客户的角度出发”这句话适用于很多地方,这里也不例外。想想如果你在浏览网站会用什么关键词来搜索,然后做个调查看看大家都在用什么关键词,花不了多少时间就很有价值了信息。
3、长尾关键词,关键词不要错过长尾关键词,因为长尾关键词浏览目的性高,容易客户阅读访问的内容是不容忽视和低估的。
4、关键词 的巧合,关键词 的搜索有时可能是错误的,因为人类拼写和同音字使得 关键词 可用于搜索。如:“菜单”和“复活节彩蛋”。
5、regional关键词、关键词也有一定的区域搜索选项。如果你的产品关键词有太多的竞争目标,你就不能避免使用区域性的词。附在产品关键词的正面,让你的目标客户更准确、更清晰地搜索到你的网站,也减少了不必要的竞争。可谓一石二鸟。
站长工具:站长在建站时用来帮助网站质量查询和制作的一些工具,简称站长工具。微信上主要有网页工具箱、flash工具箱、终端工具箱、站长工具。
量身定制优化建议,精准拓展潜词,清晰营销痛点。要想系统地优化,还必须充分把握账户本身的问题。为了更好地制定关键词优化建议,账号优化工具首先结合账号历史投放数据和网站流量数据,从展示量、转化率等方面对账号进行系统分析。诊断。通过分析发现关键词的扩展维度存在一定的局限性。就相关行业词汇的传统关键词而言,展示量和转化量是有限的。如何合理、准确地扩展关键词成为首要问题。根据分析诊断报告,通过搜索词数据360分析、转化数据360分析、网盾搜索数据、相似账号购买词数据、广告点击日志挖掘数据等多方数据, 关键词 是定制的。定制的潜在词扩展计划。“评估风险”、“项目评估报告”、“评估报告公司”等22个行业潜力词综合流量。为什么它是一个“潜在的词”?这里是关键词推广的一个小技巧:在关键词的选择中,可以根据客户的需求,重点推荐有潜力的词。因为潜在词不仅可以保证展示次数,
招标建议全面落实,精准投放效果出炉
考虑到投标价格对交货时间的敏感性,工具系统根据行业内关键词的历史展示数据,利用不同时间、不同港口的展示数据和交货数据,制定清晰可行的投标建议为帐户。这里还有一个小技巧:在360点景平台进行出价调整时,工具会针对不同的关键词提供不同的目标出价位置和出价建议,但根据客户需求,一般建议采用左边** 。正因为如此,竞争性广告会在**中展示,转化量和点击量会更好。
转化效果是有保证的,因为360搜索账号优化不是“一次性”的账号投放工具,而是不断评估优化的升级投放系统。每次交付后,该工具都会对交付数据和建议效果进行综合评估。以后账号会有更好的呈现
站长工具:站长在建站时用来帮助网站质量查询和制作的一些工具,简称站长工具。微信上主要有网页工具箱、flash工具箱、终端工具箱、站长工具。常用的站长工具包括:链接查询工具、PR查询工具、搜索引擎收录查询工具、关键词排名查询工具、网站流量统计等。站长工具是站长的工具。经常去站长工具了解SEO数据变化。还可以检测网站死链接、蜘蛛访问、HTML格式检测、网站速度测试、友好链接检查、网站域名IP查询、PR、权重查询、alexa、whois查询, 等等。 。词库网络: 是一个 seo关键词 工具,专门从事 网站关键词 分析。分为长尾词库、投标词库、流行关键词库、行业关键词库和网站词库等,也预测流行关键词。关键词Planner:百度推广工具里面有一个关键词planner,也是一个seo关键词工具,可以用来关键词扩展,关键词@ > 策划者还可以查询关键词的日均搜索量和竞争强度。爱站Toolkit:这是一款免费的网站seo分析工具软件,主要包括百度外链助手、关键词监控、收录速率/死链接检测、远程排名、< @关键词挖矿、站群查询、日志分析、工具箱等功能。:索宁。com目前由百度收录批量查询、百度关键词排名批量查询、360收录批量查询、360关键词排名批量查询、关键词覆盖查询、 关键词由排名趋势监测、论坛网址提取、收录查询chrome插件版等工具组成。优采云采集器:优采云采集器是一款功能强大且易于使用的专业采集软件,具有强大的内容采集和数据导入功能可以将你的采集的任意网页数据发布到远程服务器,自定义usercms系统模块,无论你的网站是什么系统,都可以使用优采云@ > 采集器,系统自带的模块文件支持:风讯文章,东一文章,东一论坛,PHPWIND论坛,
无论是活动运营还是内容运营,触达的用户越多,能为我们的产品带来的价值就越大。(原因一般来说,因为如果用户不匹配,即使用户基数很大,转化率太低,最终的有效用户数也会是**。)
无论是网站的结构调整,页面优化,还是站外的外链搭建,都会涉及到的一个技巧就是关键词的优化。这正是我们的运营商可以使用的。
1.为什么要优化关键词
不同于专业的SEOer对整个网站进行优化,需要对关键词进行系统的研究,从而达到保证关键词人搜索的目的,降低优化难度,找到有效的流量,并实现搜索多样性,发现新的关键词等等。
我们运营商的关键词优化一般只涉及我们的竞选文案或者文章之一,所以我们只有一个目的,就是让我们的文案/文章更多的人看到。
1、关键词**定位:SEO关键词的**定位*是一个重要的部分。分析和定位@>与网站、关键词index、关键词排列、关键词排名等关键词的相关性。2、网站结构分析:简洁网站符合搜索引擎爬虫偏好的结构有利于SEO。减少搜索引擎无法识别的代码,实现树状目录结构,网站导航和链接优化。3、网站子页面优化:SEO不仅可以让网站首页在搜索引擎中有很好的排名,还可以让网站的每个页面都带来流量。根据公司需要规划目录分类页面,使特殊页面排在第一位。4:内容发布和链接布局:搜索引擎喜欢高质量的 网站 内容。网站建立后,会持续更新与关键词匹配的优质内容,并计划每天的内容发布任务量。优化网站内的链接布局,将整个网站的内容有机地联系起来,让搜索引擎了解关键词和每个网页的重要性。拓展站外友情链接,提升网站的影响力。5:实时监控优化:搜索引擎的权重排名算法和规则不断变化。我们可以检查SEO在搜索引擎中的效果。通过site:您的域名,我们可以知道网站的收录和更新状态。使用流量分析工具分析< @网站到具体页面,实时监控优化效果,制定下一步SEO策略。同时对网站的用户体验优化也有指导意义。
1、SEO其实就是为网友提供一个优秀的信息解决方案,满足搜索引擎用户的需求,不仅基于排名,更不局限于流量和转化率,以实质性的信息满足用户,从而在增加用户粘性网站的量,迎合搜索引擎算法,不断改进和改进网站。其中的问题需要SEO的不断跟进和改进。2、学习思维模式主要是为了更好的应用在网站,提升网站排名和用户体验,满足搜索引擎排名机制,灵活掌握SEO*思维和操作方法,其实网站形成了一个基于流量和数据的模型,而掌握SEO思维的SEOer,基本上就有机会走在更多的SEOer面前。最根本的是应用他们所学的知识并推断出其他的东西。3、优化思路对于很多SEO来说是模糊的
过去,搜索推广就像“盲人摸象”。虽然预算充足,但面对五花八门的关键词不知道怎么扩张,不知道怎么优化账户,也不知道关键词底价,这个预算总是不可能花费。
账户运营时间成本高。一般的搜索推广投放平台总是设计的可选品类太多,投放端口太多,难以理解且容易出错。即使对于专业的优化人员来说,搜索推广的账户运营时间成本仍然很高。针对企业数据咨询行业市场的现状以及搜索关键词上线遇到的困难,360依托新上线的账号优化工具,想出了一套有潜力的关键词@ > 词扩展 + * 出价建议 = 省时有效的搜索帐户优化解决方案。
随着互联网竞争的不断提升,越来越多的企业重视网络渠道的推广。除了最近的热播剧《猎场》,剧中提到的胡歌的“优化网络工程师(SEO)”让更多人知道了SEO的作用和好处。网站要上首页,要进入网站,提高用户的好感度和信任度,做SEO的好处真的很多。
.如何找到 关键词
既然说关键词优化的目的就是让更多人看到。然后我们在寻找一个更基本的关键词目标:
“搜索此 关键词 的用户群足够大”。
只有这样,我们的 文章 才会在他们搜索这些字词时被视为转化。否则,如果我们选择一个没人关心的关键词进行优化,即使这个关键词的搜索页面排名**,也不会出现曝光。
当然,还有一个原则要遵循:
“我们选择的 关键词 必须与我们的 文章(产品)主题相关”。
按照目前的搜索引擎规则,他的排名考虑了文章关键词与用户搜索词的匹配度以及文章关键词与话题的相关度。.
这两个条件是我们选择关键词的基本标准。而我们确定关键词的热度(即搜索用户群)可以参考百度指数。
以流行的“以人民的名义”为例,以下图片均来自“百度索引”。
-/gjicjf/- 查看全部
根据关键词文章采集系统(八方资源网网站优化*步,就是关键词分析分析)
八方资源网
网站优化步骤是关键词分析。从展示到发现,一个网站是用户在搜索引擎上搜索关键词,然后锁定相关产品并确认他们的意图。这也使得关键词成为优化的重点之一,不同的关键词带来的展示量和点击量肯定是不一样的,所以关键词分析要先于优化,同时也要重点关注优化。当客户添加产品关键词时,会通过“大数据”进行分析,为用户提供更多的长尾关键词。比如“中国移动电子商务”、“中国移动和宝”、“中国移动和宝官方网站”等,并优化这些词,改进关键词中的<
SEO,英文“SearchEngineOptimization”,中文翻译为“搜索引擎优化”。我们一般将其定义为:
SEO是指在了解搜索引擎自然排名机制的基础上,对网站进行内外部调整优化,提升网站在搜索引擎中的关键词自然排名,获得更多流量,从而达到网站pin的目的。
一般来说,SEO网站的优化包括站内优化和站外优化。内部优化是指对网站本身所有站长可以控制的调整,如网站结构、页面HTML代码等。场外优化是指外部链接建设和行业参与互动。顾名思义,这些活动并不是在 网站 本身中进行的。无论是站内优化还是站外优化,最终目的都是为了做出更有价值的页面收录并被搜索引擎收录。
其实这和我们运营商希望我们的内容被更多人看到是类似的。
1、企业名称和服务项目命名,做搜索引擎优化的人在为公司选择关键词时,会重点关注公司的主要产品或服务。这不是一个糟糕的选择,但是当你选择完成产品时,你是不是最渴望知道产品的背景,也就是它的制造商?因此,在选择关键词时,选择公司或公司名称也尤为重要。对你来说,看公司名称和看公司招牌一样重要,而公众品牌的形象就是招牌。而且公司名称的关键字竞争并不那么激烈,因此忘记一个企业或公司名称将是一个很大的损失。
2、换个角度思考,通常有一句老生常谈的说法,那就是:“站在客户的角度想问题,从客户的角度出发”这句话适用于很多地方,这里也不例外。想想如果你在浏览网站会用什么关键词来搜索,然后做个调查看看大家都在用什么关键词,花不了多少时间就很有价值了信息。
3、长尾关键词,关键词不要错过长尾关键词,因为长尾关键词浏览目的性高,容易客户阅读访问的内容是不容忽视和低估的。
4、关键词 的巧合,关键词 的搜索有时可能是错误的,因为人类拼写和同音字使得 关键词 可用于搜索。如:“菜单”和“复活节彩蛋”。
5、regional关键词、关键词也有一定的区域搜索选项。如果你的产品关键词有太多的竞争目标,你就不能避免使用区域性的词。附在产品关键词的正面,让你的目标客户更准确、更清晰地搜索到你的网站,也减少了不必要的竞争。可谓一石二鸟。
站长工具:站长在建站时用来帮助网站质量查询和制作的一些工具,简称站长工具。微信上主要有网页工具箱、flash工具箱、终端工具箱、站长工具。
量身定制优化建议,精准拓展潜词,清晰营销痛点。要想系统地优化,还必须充分把握账户本身的问题。为了更好地制定关键词优化建议,账号优化工具首先结合账号历史投放数据和网站流量数据,从展示量、转化率等方面对账号进行系统分析。诊断。通过分析发现关键词的扩展维度存在一定的局限性。就相关行业词汇的传统关键词而言,展示量和转化量是有限的。如何合理、准确地扩展关键词成为首要问题。根据分析诊断报告,通过搜索词数据360分析、转化数据360分析、网盾搜索数据、相似账号购买词数据、广告点击日志挖掘数据等多方数据, 关键词 是定制的。定制的潜在词扩展计划。“评估风险”、“项目评估报告”、“评估报告公司”等22个行业潜力词综合流量。为什么它是一个“潜在的词”?这里是关键词推广的一个小技巧:在关键词的选择中,可以根据客户的需求,重点推荐有潜力的词。因为潜在词不仅可以保证展示次数,
招标建议全面落实,精准投放效果出炉
考虑到投标价格对交货时间的敏感性,工具系统根据行业内关键词的历史展示数据,利用不同时间、不同港口的展示数据和交货数据,制定清晰可行的投标建议为帐户。这里还有一个小技巧:在360点景平台进行出价调整时,工具会针对不同的关键词提供不同的目标出价位置和出价建议,但根据客户需求,一般建议采用左边** 。正因为如此,竞争性广告会在**中展示,转化量和点击量会更好。
转化效果是有保证的,因为360搜索账号优化不是“一次性”的账号投放工具,而是不断评估优化的升级投放系统。每次交付后,该工具都会对交付数据和建议效果进行综合评估。以后账号会有更好的呈现
站长工具:站长在建站时用来帮助网站质量查询和制作的一些工具,简称站长工具。微信上主要有网页工具箱、flash工具箱、终端工具箱、站长工具。常用的站长工具包括:链接查询工具、PR查询工具、搜索引擎收录查询工具、关键词排名查询工具、网站流量统计等。站长工具是站长的工具。经常去站长工具了解SEO数据变化。还可以检测网站死链接、蜘蛛访问、HTML格式检测、网站速度测试、友好链接检查、网站域名IP查询、PR、权重查询、alexa、whois查询, 等等。 。词库网络: 是一个 seo关键词 工具,专门从事 网站关键词 分析。分为长尾词库、投标词库、流行关键词库、行业关键词库和网站词库等,也预测流行关键词。关键词Planner:百度推广工具里面有一个关键词planner,也是一个seo关键词工具,可以用来关键词扩展,关键词@ > 策划者还可以查询关键词的日均搜索量和竞争强度。爱站Toolkit:这是一款免费的网站seo分析工具软件,主要包括百度外链助手、关键词监控、收录速率/死链接检测、远程排名、< @关键词挖矿、站群查询、日志分析、工具箱等功能。:索宁。com目前由百度收录批量查询、百度关键词排名批量查询、360收录批量查询、360关键词排名批量查询、关键词覆盖查询、 关键词由排名趋势监测、论坛网址提取、收录查询chrome插件版等工具组成。优采云采集器:优采云采集器是一款功能强大且易于使用的专业采集软件,具有强大的内容采集和数据导入功能可以将你的采集的任意网页数据发布到远程服务器,自定义usercms系统模块,无论你的网站是什么系统,都可以使用优采云@ > 采集器,系统自带的模块文件支持:风讯文章,东一文章,东一论坛,PHPWIND论坛,
无论是活动运营还是内容运营,触达的用户越多,能为我们的产品带来的价值就越大。(原因一般来说,因为如果用户不匹配,即使用户基数很大,转化率太低,最终的有效用户数也会是**。)
无论是网站的结构调整,页面优化,还是站外的外链搭建,都会涉及到的一个技巧就是关键词的优化。这正是我们的运营商可以使用的。
1.为什么要优化关键词
不同于专业的SEOer对整个网站进行优化,需要对关键词进行系统的研究,从而达到保证关键词人搜索的目的,降低优化难度,找到有效的流量,并实现搜索多样性,发现新的关键词等等。
我们运营商的关键词优化一般只涉及我们的竞选文案或者文章之一,所以我们只有一个目的,就是让我们的文案/文章更多的人看到。
1、关键词**定位:SEO关键词的**定位*是一个重要的部分。分析和定位@>与网站、关键词index、关键词排列、关键词排名等关键词的相关性。2、网站结构分析:简洁网站符合搜索引擎爬虫偏好的结构有利于SEO。减少搜索引擎无法识别的代码,实现树状目录结构,网站导航和链接优化。3、网站子页面优化:SEO不仅可以让网站首页在搜索引擎中有很好的排名,还可以让网站的每个页面都带来流量。根据公司需要规划目录分类页面,使特殊页面排在第一位。4:内容发布和链接布局:搜索引擎喜欢高质量的 网站 内容。网站建立后,会持续更新与关键词匹配的优质内容,并计划每天的内容发布任务量。优化网站内的链接布局,将整个网站的内容有机地联系起来,让搜索引擎了解关键词和每个网页的重要性。拓展站外友情链接,提升网站的影响力。5:实时监控优化:搜索引擎的权重排名算法和规则不断变化。我们可以检查SEO在搜索引擎中的效果。通过site:您的域名,我们可以知道网站的收录和更新状态。使用流量分析工具分析< @网站到具体页面,实时监控优化效果,制定下一步SEO策略。同时对网站的用户体验优化也有指导意义。
1、SEO其实就是为网友提供一个优秀的信息解决方案,满足搜索引擎用户的需求,不仅基于排名,更不局限于流量和转化率,以实质性的信息满足用户,从而在增加用户粘性网站的量,迎合搜索引擎算法,不断改进和改进网站。其中的问题需要SEO的不断跟进和改进。2、学习思维模式主要是为了更好的应用在网站,提升网站排名和用户体验,满足搜索引擎排名机制,灵活掌握SEO*思维和操作方法,其实网站形成了一个基于流量和数据的模型,而掌握SEO思维的SEOer,基本上就有机会走在更多的SEOer面前。最根本的是应用他们所学的知识并推断出其他的东西。3、优化思路对于很多SEO来说是模糊的

过去,搜索推广就像“盲人摸象”。虽然预算充足,但面对五花八门的关键词不知道怎么扩张,不知道怎么优化账户,也不知道关键词底价,这个预算总是不可能花费。
账户运营时间成本高。一般的搜索推广投放平台总是设计的可选品类太多,投放端口太多,难以理解且容易出错。即使对于专业的优化人员来说,搜索推广的账户运营时间成本仍然很高。针对企业数据咨询行业市场的现状以及搜索关键词上线遇到的困难,360依托新上线的账号优化工具,想出了一套有潜力的关键词@ > 词扩展 + * 出价建议 = 省时有效的搜索帐户优化解决方案。
随着互联网竞争的不断提升,越来越多的企业重视网络渠道的推广。除了最近的热播剧《猎场》,剧中提到的胡歌的“优化网络工程师(SEO)”让更多人知道了SEO的作用和好处。网站要上首页,要进入网站,提高用户的好感度和信任度,做SEO的好处真的很多。
.如何找到 关键词
既然说关键词优化的目的就是让更多人看到。然后我们在寻找一个更基本的关键词目标:
“搜索此 关键词 的用户群足够大”。
只有这样,我们的 文章 才会在他们搜索这些字词时被视为转化。否则,如果我们选择一个没人关心的关键词进行优化,即使这个关键词的搜索页面排名**,也不会出现曝光。
当然,还有一个原则要遵循:
“我们选择的 关键词 必须与我们的 文章(产品)主题相关”。
按照目前的搜索引擎规则,他的排名考虑了文章关键词与用户搜索词的匹配度以及文章关键词与话题的相关度。.
这两个条件是我们选择关键词的基本标准。而我们确定关键词的热度(即搜索用户群)可以参考百度指数。
以流行的“以人民的名义”为例,以下图片均来自“百度索引”。
-/gjicjf/-
根据关键词文章采集系统(文章采集系统哪个排名靠前,给稿费给高价就上哪家)
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-02-26 05:05
根据关键词文章采集系统一下
哪个排名靠前,给稿费给高价就上哪家。目前国内网络媒体还是很缺专门写文章的专家、作家。当然,你要不嫌他们的稿费太低也可以自己做网站,毕竟只是一个软件而已。
好的软件,少用百度去搜,用360和谷歌。你连最基本的文章采集都没弄懂。我大概知道一点,一些专门做文章采集的公司也可以做,像通用的adwesome,puffer,它们网站不需要申请,只要提供文章名称,链接,问题,收录数量,问题,链接,就可以采集,数据统计。至于其他,就是百度去搜。
考虑下建立一个公众号,每篇文章只要一元钱。
目前在国内软件比较多,主要大的分两种,第一种专门做文章数据采集,以安徽百乐虎为代表,这种主要针对学生群体,因为他们针对学生进行收费,第二种就是大众化软件,那么主要以我目前公司做的一个软件为例,叫disqus,小众软件,对于开发能力高低,语言掌握熟练程度各方面有要求。如果没有软件,在未来5年内也许很难在网络上广泛推广。
edius3目前被比较多的文章数据采集公司采用,
建议用国外的产品,
推荐一个公众号【附件下载器】,工具包小小的,数据采集量大,价格也适中,搜索前段时间看到很多软件报价,都是要另外收费,如果找上家帮着找的话,价格都在35元到100元不等,重要的是有人盯着,你下载的东西被删了一个也别怀疑。 查看全部
根据关键词文章采集系统(文章采集系统哪个排名靠前,给稿费给高价就上哪家)
根据关键词文章采集系统一下
哪个排名靠前,给稿费给高价就上哪家。目前国内网络媒体还是很缺专门写文章的专家、作家。当然,你要不嫌他们的稿费太低也可以自己做网站,毕竟只是一个软件而已。
好的软件,少用百度去搜,用360和谷歌。你连最基本的文章采集都没弄懂。我大概知道一点,一些专门做文章采集的公司也可以做,像通用的adwesome,puffer,它们网站不需要申请,只要提供文章名称,链接,问题,收录数量,问题,链接,就可以采集,数据统计。至于其他,就是百度去搜。
考虑下建立一个公众号,每篇文章只要一元钱。
目前在国内软件比较多,主要大的分两种,第一种专门做文章数据采集,以安徽百乐虎为代表,这种主要针对学生群体,因为他们针对学生进行收费,第二种就是大众化软件,那么主要以我目前公司做的一个软件为例,叫disqus,小众软件,对于开发能力高低,语言掌握熟练程度各方面有要求。如果没有软件,在未来5年内也许很难在网络上广泛推广。
edius3目前被比较多的文章数据采集公司采用,
建议用国外的产品,
推荐一个公众号【附件下载器】,工具包小小的,数据采集量大,价格也适中,搜索前段时间看到很多软件报价,都是要另外收费,如果找上家帮着找的话,价格都在35元到100元不等,重要的是有人盯着,你下载的东西被删了一个也别怀疑。
根据关键词文章采集系统(编辑本段文章采集系统过程相关资料功能的开发工具使用.Net)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-02-23 13:01
文章采集系统由你(我的世界I采集net)开发,历时4年。在线信息采集系统根据用户定义关键词相关数据从互联网上调取,对数据进行合理的截取、分类、去重和过滤,并以文件或文件的形式保存数据库。
目录文章采集系统流程相关数据功能解读展开文章采集系统流程相关数据功能解读展开编辑本段文章采集系统流程系统开发工具使用.Net的C#开发系统,数据库使用SQL Server 2000。一、软件系统总体设计要求1.当网站搜索深度为5层,网站搜索宽度为50个网页,数据召回率达到98%。2.当网站的搜索深度为5层,网站的搜索宽度为50个网页时,数据准确率大于97%。3.数据存储容量:存储容量≥100G。4.在单个 网站 上搜索时,网站 搜索深度:最大 5 级网页;网站搜索广度:最多搜索 50 个网页。如果超过 60 秒没有结果,搜索将自动放弃。5.并发搜索强度:10个线程可以同时并发搜索。6.5亿汉字的平均查询时间不到3秒。二、应用系统设计要求1.要求系统能够执行多线程采集信息;2.自动分类和索引记录;3.自动过滤重复并自动索引Records;三、应用系统功能详解实时在线采集(内容抓取模块) 快速:网页抓取采用多线程并发搜索技术,并且可以设置最大并发线程数。灵活:可同时跟踪和抓取多个网站,为栏目或频道提供灵活的网站、采集策略,利用逻辑关系定位采集内容.
准确性:或多或少,可以自定义要抓取的文件格式,可以抓取图片和表格信息。捕获过程成熟可靠,容错能力强,初始设置完成后可长时间稳定运行。高效的自动分类支持机检分类——可以使用预定义的关键词和规则方法来确定类别;支持自动分类——通过机器自动学习或预学习进行自动分类,准确率达到80%以上。(这个比较麻烦,可以考虑不做)支持多种分类标准——如按地区(华北、华南等)、按内容(政治、科技、军事、教育等)、来源(新华网) 、人民日报、新浪网)等。自动网页分析内容过滤——可以过滤掉广告、导航信息、版权等无用信息,可以剔除反动色情内容。内容排序——对于不同的网站相同或相似的内容,可以自动识别并标记为相同,识别方式可以由用户自定义规则确定,根据内容的相似度自动确定。格式转换 - 自动将 HTML 格式转换为文本文件。自动索引——自动提取网页的标题、版本、日期、作者、栏目、分类等信息。单一界面进行系统管理集成——系统提供基于Web的用户界面和管理员界面,满足系统管理员和用户的双重需求。浏览器可用于远程管理分类、用户权限,调整和加强分类结果。完善的目录维护——对分类目录的添加、移动、修改、删除提供完善的管理维护权限管理,可设置管理目录和单个文件使用权限,加强安全管理。
<p>实时文件管理——可以浏览各个目录的分类结果,实时进行移动、重命名等调整。编辑本段相关信息使用文章采集系统,整个系统可在线自动安装,后台新版本可自动升级;系统文件损坏也可以自动修复,站长从此无忧批量指定关键词,轻松控制用户搜索行为,自动文章采集系统类内容文章采集过程中自动去除重复内容,@原创标签综合页面在全站整合了统一通用的分类标签体系,不仅使内容具有相关性,而且 查看全部
根据关键词文章采集系统(编辑本段文章采集系统过程相关资料功能的开发工具使用.Net)
文章采集系统由你(我的世界I采集net)开发,历时4年。在线信息采集系统根据用户定义关键词相关数据从互联网上调取,对数据进行合理的截取、分类、去重和过滤,并以文件或文件的形式保存数据库。
目录文章采集系统流程相关数据功能解读展开文章采集系统流程相关数据功能解读展开编辑本段文章采集系统流程系统开发工具使用.Net的C#开发系统,数据库使用SQL Server 2000。一、软件系统总体设计要求1.当网站搜索深度为5层,网站搜索宽度为50个网页,数据召回率达到98%。2.当网站的搜索深度为5层,网站的搜索宽度为50个网页时,数据准确率大于97%。3.数据存储容量:存储容量≥100G。4.在单个 网站 上搜索时,网站 搜索深度:最大 5 级网页;网站搜索广度:最多搜索 50 个网页。如果超过 60 秒没有结果,搜索将自动放弃。5.并发搜索强度:10个线程可以同时并发搜索。6.5亿汉字的平均查询时间不到3秒。二、应用系统设计要求1.要求系统能够执行多线程采集信息;2.自动分类和索引记录;3.自动过滤重复并自动索引Records;三、应用系统功能详解实时在线采集(内容抓取模块) 快速:网页抓取采用多线程并发搜索技术,并且可以设置最大并发线程数。灵活:可同时跟踪和抓取多个网站,为栏目或频道提供灵活的网站、采集策略,利用逻辑关系定位采集内容.
准确性:或多或少,可以自定义要抓取的文件格式,可以抓取图片和表格信息。捕获过程成熟可靠,容错能力强,初始设置完成后可长时间稳定运行。高效的自动分类支持机检分类——可以使用预定义的关键词和规则方法来确定类别;支持自动分类——通过机器自动学习或预学习进行自动分类,准确率达到80%以上。(这个比较麻烦,可以考虑不做)支持多种分类标准——如按地区(华北、华南等)、按内容(政治、科技、军事、教育等)、来源(新华网) 、人民日报、新浪网)等。自动网页分析内容过滤——可以过滤掉广告、导航信息、版权等无用信息,可以剔除反动色情内容。内容排序——对于不同的网站相同或相似的内容,可以自动识别并标记为相同,识别方式可以由用户自定义规则确定,根据内容的相似度自动确定。格式转换 - 自动将 HTML 格式转换为文本文件。自动索引——自动提取网页的标题、版本、日期、作者、栏目、分类等信息。单一界面进行系统管理集成——系统提供基于Web的用户界面和管理员界面,满足系统管理员和用户的双重需求。浏览器可用于远程管理分类、用户权限,调整和加强分类结果。完善的目录维护——对分类目录的添加、移动、修改、删除提供完善的管理维护权限管理,可设置管理目录和单个文件使用权限,加强安全管理。
<p>实时文件管理——可以浏览各个目录的分类结果,实时进行移动、重命名等调整。编辑本段相关信息使用文章采集系统,整个系统可在线自动安装,后台新版本可自动升级;系统文件损坏也可以自动修复,站长从此无忧批量指定关键词,轻松控制用户搜索行为,自动文章采集系统类内容文章采集过程中自动去除重复内容,@原创标签综合页面在全站整合了统一通用的分类标签体系,不仅使内容具有相关性,而且
根据关键词文章采集系统(一个运输日志监控和分析系统的特点及解决办法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-02-23 05:29
日志监控和分析对于保证业务的稳定运行起着重要的作用。但是,一般情况下,日志分散在各个生产服务器上,开发者无法登录生产服务器。在这种情况下,需要一个集中的日志采集设备。日志中的关键字被监控,异常触发报警,开发者可以查看相关日志。logstash+elasticsearch+kibana3就是实现了这样一个功能的系统,功能更强大。
logstash:是一个管理日志和事件的工具,你可以采集它们,解析它们,并存储它们以供以后使用(例如日志搜索),logstash 有一个内置的网络界面来搜索你所有的日志。Logstash 部署时有两种运行模式:独立和集中式:
* 单机:单机是指一切都运行在一台服务器上,包括日志采集、日志索引、前端WEB接口都部署在一台机器上。
* 集中式:它是一种多服务器模式,将日志从多个服务器传送到一个总日志(采集器)服务器,用于索引和搜索。
需要注意的是logstash本身并没有shipper和indexer这样的术语,因为传输日志的过程和采集总日志的过程都是运行同一个程序,只是使用的配置文件不同。
弹性搜索:
基于Lucene的开源搜索引擎是一个分布式搜索分析系统。主要功能有:实时数据、实时分析、分布式、高可用性、多租户、全文搜索、面向文档、冲突管理、无模式、restful api 等。
kibana3:
可视化日志和数据系统可以很方便的与elasticsearch系统结合作为WEB前端。Kibana 分为版本 2 和版本 3。版本 2 是用 ruby 编写的,部署起来很麻烦,需要安装很多 ruby 依赖项(目前网上部署了这个版本)。版本3是纯html+css编写的,所以部署起来很方便,解压后就可以使用了。已经是kibana4了。建议您使用最新版本。
出于性能和可扩展性的考虑,我们在实际应用中必须使用logstash的集中模式。最基本的结构图如下:
1、安装redis,安装过程比较简单,这里不再详述。
2、安装 ElasticSearch(当前版本1.4)
wget 'https://download.elasticsearch ... 39%3B
tar zxvf elasticsearch-0.90.7.tar.gz
cd elasticsearch-0.90.7/bin
#可以在logstash agent启动后再启动
./elasticsearch -f
3、启动logstash shipper,定义配置文件logstash.conf,根据实际情况,下面主要定义输入源为file,输出到redis,启动logstash shipper,例如:
input {
file {
type => "api_log"
path => "/home/jws/app/nginxserver/logs/apiaccess.log"
debug => true
}
file {
type => "cas_log"
path => "/home/jws/app/nginxserver/logs/casaccess.log"
debug => true
}
file {
type => "id_log"
path => "/home/jws/app/nginxserver/logs/idaccess.log"
debug => true
}
file {
type => "login_log"
path => "/home/jws/app/nginxserver/logs/loginaccess.log"
debug => true
}
file {
type => "proxy_log"
path => "/home/jws/app/nginxserver/logs/proxyaccess.log"
debug => true
}
}
output {
redis {
host => "10.20.164.121"
data_type => "list"
key => "logstash:redis"
}
redis {
host => "10.20.164.122"
data_type => "list"
key => "logstash:uop_file"
}
}
启动托运人:
java -jar /home/jws/htdocs/logstash/lib/logstash.jar 代理 -f /home/jws/htdocs/logstash/conf/logstash.conf -l /home/jws/htdocs/logstash/logs/logstash.log
4、启动logstash索引器
logstash 的配置文件比较简单,主要由输入、过滤器和输出三部分组成。事件按顺序出现在配置文件中。在输入、输出和过滤器中,允许您设置配置插件,由插件名称后跟插件配置代码块组成。插件中的值可以是布尔值、字符串、数字、哈希、数组等,支持条件判断(if...else)。
比如在下面配置indexer,并启动indexer:
input {
file {
path => "/home/rsyslog/asaserver/*/*/*/proxy.log.*"
exclude => "*.bz2"
type => "proxy"
}
}
filter {
grok {
match => [ "message", "%{APIPROXY}" ]
patterns_dir => ["/home/jws/app/logstash/patterns"]
}
if [request_uripath_orig]{
grok {
match => [ "request_uripath_orig", "%{NSSS}" ]
patterns_dir => ["/home/jws/app/logstash/patterns"]
}
}
}
output {
#stdout { codec =>"rubydebug"}
elasticsearch_http {
host => "10.20.161.36"
flush_size => 500
idle_flush_time => 3
index => "logstash_pf_proxy-%{+YYYY.MM.dd.HH}"
template => "/home/jws/app/logstash/template/t.json"
template_overwrite => true
}
}
5、安装并启动kibana3。安装过程与普通软件安装相同。可以用 nginx 安装。此处不再赘述。需要注意的是,需要在kibana config.js中配置elasticSearch的地址和端口。
注意红框内的内容,这只是kibana3的默认接口,我们需要将default.json接口替换为logstash.json,具体目录下的source目录下的app/dashboards。
例如,在项目中的一个示例中,根据需求制作图表(类似于饼图、条形图、折线图等)。在笔者的实际项目中,从日志中分析数据,实现系统稳定性、响应时间、请求量、业务响应代码等。、HTTP状态码等在kibana中显示;
此外,elasticsearch 的用处要小得多。它可以用作搜索数据源。ES提供了编程接口,可以在ES中通过编程获取数据来定制开发监控程序,灵活强大。
官方文档(现在都在一起):
日志存储:
弹性搜索:
基巴纳: 查看全部
根据关键词文章采集系统(一个运输日志监控和分析系统的特点及解决办法)
日志监控和分析对于保证业务的稳定运行起着重要的作用。但是,一般情况下,日志分散在各个生产服务器上,开发者无法登录生产服务器。在这种情况下,需要一个集中的日志采集设备。日志中的关键字被监控,异常触发报警,开发者可以查看相关日志。logstash+elasticsearch+kibana3就是实现了这样一个功能的系统,功能更强大。
logstash:是一个管理日志和事件的工具,你可以采集它们,解析它们,并存储它们以供以后使用(例如日志搜索),logstash 有一个内置的网络界面来搜索你所有的日志。Logstash 部署时有两种运行模式:独立和集中式:
* 单机:单机是指一切都运行在一台服务器上,包括日志采集、日志索引、前端WEB接口都部署在一台机器上。
* 集中式:它是一种多服务器模式,将日志从多个服务器传送到一个总日志(采集器)服务器,用于索引和搜索。
需要注意的是logstash本身并没有shipper和indexer这样的术语,因为传输日志的过程和采集总日志的过程都是运行同一个程序,只是使用的配置文件不同。
弹性搜索:
基于Lucene的开源搜索引擎是一个分布式搜索分析系统。主要功能有:实时数据、实时分析、分布式、高可用性、多租户、全文搜索、面向文档、冲突管理、无模式、restful api 等。
kibana3:
可视化日志和数据系统可以很方便的与elasticsearch系统结合作为WEB前端。Kibana 分为版本 2 和版本 3。版本 2 是用 ruby 编写的,部署起来很麻烦,需要安装很多 ruby 依赖项(目前网上部署了这个版本)。版本3是纯html+css编写的,所以部署起来很方便,解压后就可以使用了。已经是kibana4了。建议您使用最新版本。
出于性能和可扩展性的考虑,我们在实际应用中必须使用logstash的集中模式。最基本的结构图如下:
1、安装redis,安装过程比较简单,这里不再详述。
2、安装 ElasticSearch(当前版本1.4)
wget 'https://download.elasticsearch ... 39%3B
tar zxvf elasticsearch-0.90.7.tar.gz
cd elasticsearch-0.90.7/bin
#可以在logstash agent启动后再启动
./elasticsearch -f
3、启动logstash shipper,定义配置文件logstash.conf,根据实际情况,下面主要定义输入源为file,输出到redis,启动logstash shipper,例如:
input {
file {
type => "api_log"
path => "/home/jws/app/nginxserver/logs/apiaccess.log"
debug => true
}
file {
type => "cas_log"
path => "/home/jws/app/nginxserver/logs/casaccess.log"
debug => true
}
file {
type => "id_log"
path => "/home/jws/app/nginxserver/logs/idaccess.log"
debug => true
}
file {
type => "login_log"
path => "/home/jws/app/nginxserver/logs/loginaccess.log"
debug => true
}
file {
type => "proxy_log"
path => "/home/jws/app/nginxserver/logs/proxyaccess.log"
debug => true
}
}
output {
redis {
host => "10.20.164.121"
data_type => "list"
key => "logstash:redis"
}
redis {
host => "10.20.164.122"
data_type => "list"
key => "logstash:uop_file"
}
}
启动托运人:
java -jar /home/jws/htdocs/logstash/lib/logstash.jar 代理 -f /home/jws/htdocs/logstash/conf/logstash.conf -l /home/jws/htdocs/logstash/logs/logstash.log
4、启动logstash索引器
logstash 的配置文件比较简单,主要由输入、过滤器和输出三部分组成。事件按顺序出现在配置文件中。在输入、输出和过滤器中,允许您设置配置插件,由插件名称后跟插件配置代码块组成。插件中的值可以是布尔值、字符串、数字、哈希、数组等,支持条件判断(if...else)。
比如在下面配置indexer,并启动indexer:
input {
file {
path => "/home/rsyslog/asaserver/*/*/*/proxy.log.*"
exclude => "*.bz2"
type => "proxy"
}
}
filter {
grok {
match => [ "message", "%{APIPROXY}" ]
patterns_dir => ["/home/jws/app/logstash/patterns"]
}
if [request_uripath_orig]{
grok {
match => [ "request_uripath_orig", "%{NSSS}" ]
patterns_dir => ["/home/jws/app/logstash/patterns"]
}
}
}
output {
#stdout { codec =>"rubydebug"}
elasticsearch_http {
host => "10.20.161.36"
flush_size => 500
idle_flush_time => 3
index => "logstash_pf_proxy-%{+YYYY.MM.dd.HH}"
template => "/home/jws/app/logstash/template/t.json"
template_overwrite => true
}
}
5、安装并启动kibana3。安装过程与普通软件安装相同。可以用 nginx 安装。此处不再赘述。需要注意的是,需要在kibana config.js中配置elasticSearch的地址和端口。
注意红框内的内容,这只是kibana3的默认接口,我们需要将default.json接口替换为logstash.json,具体目录下的source目录下的app/dashboards。
例如,在项目中的一个示例中,根据需求制作图表(类似于饼图、条形图、折线图等)。在笔者的实际项目中,从日志中分析数据,实现系统稳定性、响应时间、请求量、业务响应代码等。、HTTP状态码等在kibana中显示;
此外,elasticsearch 的用处要小得多。它可以用作搜索数据源。ES提供了编程接口,可以在ES中通过编程获取数据来定制开发监控程序,灵活强大。
官方文档(现在都在一起):
日志存储:
弹性搜索:
基巴纳:
根据关键词文章采集系统(怎么用免费dede采集插件把关键词优化到首页让网站能快速收录)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-02-22 11:18
如何使用免费的dede采集插件将关键词优化到首页,使网站可以快速收录,包括所有SEO优化功能,并支持所有网站@ > 使用。在做业务网站优化的时候,经常会遇到很多问题,比如网站原创没有内容收录,收录后面没有排名,但是如果有怎么办排行?连首页都没有。因此,我们需要系统地对企业网站的优化做出很好的诊断,帮助我们调整网站的细节,更好的提高网站的权重。以下是企业网站优化诊断的三个方面,希望能帮助您更好地诊断自己的网站。
诊断前网站,教大家如何快速搭建原创高质量文章,使用免费的dede采集插件这个插件不用多学专业技能,简单几步即可轻松采集内容数据,用户只需对dede采集插件进行简单设置,完成后dede采集插件-in 会根据用户设置的关键词高精度匹配内容和图片可以保存在本地,也可以在伪原创之后发布,提供方便快捷的内容采集伪原创发布网站 @>推送服务!!
和其他dede采集插件相比,这个dede采集插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签,一分钟就能上手,只需输入关键词即可实现采集(dede采集插件也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这个dede采集插件工具也配置了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)
自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!有了这个dede采集插件,我们做网站优化,需要注意网站优化诊断三个方面
一、网站系统诊断
网站系统诊断 1
1. 空间速度
网站打开速度通常与2个方面有关:
一是页面上的图片数量,图片越多网站打开速度就会降低,所以优化网页上的图片非常重要。空间/服务器带宽太小。如果网站的流量很大,那么带宽就比较小,容易造成网站打不开,所以一般带宽的大小要根据大小来定网站 访问次数待定。影响网站速度的地方还有很多,但是随着互联网的发展和服务器配置的增加,很多影响空间速度的细节已经不再需要考虑了。
2. 网站代码
现在很多公司网站都在开发dedecms、empirecms、phpcms等开源程序,所以程序没必要多想,只需要需要考虑程序安全设置。
影响企业优化的网站就是网站页面的代码,比如table标签(已经不适用了,现在已经发展到html5了),比如js文件(最少如果不需要),如css文件(最好删除冗余代码)等。
最重要的是移动互联网的发展和html5+css3的普及,所以对于网站页面代码规范也很重要,可以帮助搜索引擎更好的识别。
网站系统诊断二
1. 网址
url要标准化,即首页URL尽量不要有index这个后缀,栏目页和文章页尽量是静态的(地址不带任何参数,如不?)。如果能更好的识别url,将进一步提高网站的优化标准,看起来非常简洁,清爽,通俗易懂。
2. 三个标签
主要是标题标签(带关键词)、关键词标签(页面关键词和页面扩展关键词)、描述标签(2-3次页面关键词) . 查看全部
根据关键词文章采集系统(怎么用免费dede采集插件把关键词优化到首页让网站能快速收录)
如何使用免费的dede采集插件将关键词优化到首页,使网站可以快速收录,包括所有SEO优化功能,并支持所有网站@ > 使用。在做业务网站优化的时候,经常会遇到很多问题,比如网站原创没有内容收录,收录后面没有排名,但是如果有怎么办排行?连首页都没有。因此,我们需要系统地对企业网站的优化做出很好的诊断,帮助我们调整网站的细节,更好的提高网站的权重。以下是企业网站优化诊断的三个方面,希望能帮助您更好地诊断自己的网站。

诊断前网站,教大家如何快速搭建原创高质量文章,使用免费的dede采集插件这个插件不用多学专业技能,简单几步即可轻松采集内容数据,用户只需对dede采集插件进行简单设置,完成后dede采集插件-in 会根据用户设置的关键词高精度匹配内容和图片可以保存在本地,也可以在伪原创之后发布,提供方便快捷的内容采集伪原创发布网站 @>推送服务!!
和其他dede采集插件相比,这个dede采集插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签,一分钟就能上手,只需输入关键词即可实现采集(dede采集插件也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这个dede采集插件工具也配置了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。

例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)
自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!有了这个dede采集插件,我们做网站优化,需要注意网站优化诊断三个方面
一、网站系统诊断
网站系统诊断 1
1. 空间速度
网站打开速度通常与2个方面有关:
一是页面上的图片数量,图片越多网站打开速度就会降低,所以优化网页上的图片非常重要。空间/服务器带宽太小。如果网站的流量很大,那么带宽就比较小,容易造成网站打不开,所以一般带宽的大小要根据大小来定网站 访问次数待定。影响网站速度的地方还有很多,但是随着互联网的发展和服务器配置的增加,很多影响空间速度的细节已经不再需要考虑了。
2. 网站代码
现在很多公司网站都在开发dedecms、empirecms、phpcms等开源程序,所以程序没必要多想,只需要需要考虑程序安全设置。
影响企业优化的网站就是网站页面的代码,比如table标签(已经不适用了,现在已经发展到html5了),比如js文件(最少如果不需要),如css文件(最好删除冗余代码)等。
最重要的是移动互联网的发展和html5+css3的普及,所以对于网站页面代码规范也很重要,可以帮助搜索引擎更好的识别。
网站系统诊断二
1. 网址
url要标准化,即首页URL尽量不要有index这个后缀,栏目页和文章页尽量是静态的(地址不带任何参数,如不?)。如果能更好的识别url,将进一步提高网站的优化标准,看起来非常简洁,清爽,通俗易懂。
2. 三个标签
主要是标题标签(带关键词)、关键词标签(页面关键词和页面扩展关键词)、描述标签(2-3次页面关键词) .
根据关键词文章采集系统(埋点埋点日志(2):文章画像存储结构(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-02-20 11:02
分享
埋藏日志数据结构如下:
{
"actionTime":"2019-04-10 18:15:35",
"readTime":"",
"channelId":0,
"param":{
"action":"exposure",
"userId":"2",
"articleId":"[18577, 14299]",
"algorithmCombine":"C2"
}
}
(2) ETL
通过 Flume 将日志定时和增量采集和结构化存储到 Hive
3. 离线构建文章 肖像
文章Portrait 就是为每个文章定义一些词。主要包括关键词和主题词。
关键词:文章 中权重较高的一些词。
主题词:归一化,出现在文章中的同义词,计算结果中出现频率高的词。
(1) 构建方法
关键词:TEXTRANK 计算的 TOPK 词和权重
主题词:TEXTRANK 的 TOPK 词与 ITFDF 计算的 TOPK 词的交集
(2) 文章图像存储结构
hive> desc article_profile;
OK
article_id int article_id
channel_id int channel_id
keywords map keywords
topics array topics
hive> select * from article_profile limit 1;
OK
26 17 {
"策略":0.3973770571351729,"jpg":0.9806348975390871,"用户":1.2794959063944176,"strong":1.6488457985625076,"文件":0.28144603583387057,"逻辑":0.45256526469610714,"形式":0.4123994242601279,"全自":0.9594604850547191,"h2":0.6244481634710125,"版本":0.44280276959510817,"Adobe":0.8553618185108718,"安装":0.8305037437573172,"检查更新":1.8088946300014435,"产品":0.774842382276899,"下载页":1.4256311032544344,"过程":0.19827163395829256,"json":0.6423301791599972,"方式":0.582762869780791,"退出应用":1.2338671268242603,"Setup":1.004399549339134} ["Electron","全自动","产品","版本号","安装包","检查更新","方案","版本","退出应用","逻辑","安装过程","方式","定性","新版本","Setup","静默","用户"]
Time taken: 0.322 seconds, Fetched: 1 row(s)
(3) 实施步骤
hive> select * from textrank_keywords_values limit 10;
OK
98319 17 var 20.6079
98323 17 var 7.4938
98326 17 var 104.9128
98344 17 var 5.6203
98359 17 var 69.3174
98360 17 var 9.3672
98392 17 var 14.9875
98393 17 var 155.4958
98406 17 var 11.2407
98419 17 var 59.9502
Time taken: 0.344 seconds, Fetched: 10 row(s)
hive> desc textrank_keywords_values;
OK
article_id int article_id
channel_id int channel_id
keyword string keyword
textrank double textrank
hive> select * from article_profile limit 1;
OK
26 17 {
"策略":0.3973770571351729,"jpg":0.9806348975390871,"用户":1.2794959063944176,"strong":1.6488457985625076,"文件":0.28144603583387057,"逻辑":0.45256526469610714,"形式":0.4123994242601279,"全自":0.9594604850547191,"h2":0.6244481634710125,"版本":0.44280276959510817,"Adobe":0.8553618185108718,"安装":0.8305037437573172,"检查更新":1.8088946300014435,"产品":0.774842382276899,"下载页":1.4256311032544344,"过程":0.19827163395829256,"json":0.6423301791599972,"方式":0.582762869780791,"退出应用":1.2338671268242603,"Setup":1.004399549339134} ["Electron","全自动","产品","版本号","安装包","检查更新","方案","版本","退出应用","逻辑","安装过程","方式","定性","新版本","Setup","静默","用户"]
Time taken: 0.322 seconds, Fetched: 1 row(s)
4. 建立线下用户画像
业内对用户画像有两种截然不同的解读:
用户角色:角色是真实用户的虚拟表示,是基于一系列真实数据的目标用户模型。通过问卷调查了解用户,根据目标、行为和观点的差异,将用户分为不同类型,从中提取典型特征,并对其进行姓名、照片、人口统计因素、场景等描述。形成了一个角色。用户角色是用户群体属性的集合,它不需要指代特定的人,而是目标群体的“特征”的组合。用户配置文件:用于描述用户数据的标签变量的集合。User Profile主要用来描述单个用户不同维度的属性,也可以用来描述一个用户组。
用户画像的核心工作是给用户打标签。标签通常是人为指定的高度精细化特征的标识符,例如年龄、地区、兴趣等。通过从不同维度对用户进行标记,我们可以得到用户的整体情况。如下图所示,一般用户画像的维度主要包括:
(1) 基本属性:指在很长一段时间内不发生变化(如性别)或不经常变化(如年龄每年增加1岁)的属性。标签的有效期更长超过一个月。
(1) 用户兴趣:指用户在一段时间内的行为倾向;例如,如果用户在过去一周内频繁搜索手机相关信息、查看手机价格对比等,假设用户有“手机”兴趣,兴趣随时间快速变化,标签时效性强,我们一般称之为短期兴趣或商业即时兴趣;如果用户长期关注宠物较多过去一段时间(比如一年以上)的相关信息,推断用户对“宠物”的喜欢有长期的兴趣。
不同的业务场景对用户画像有不同的需求。我们需要根据我们的实际业务需求,构建一个适合我们业务场景的用户画像系统。但对于年龄、性别、学历、婚姻等基础属性数据,无需为每个业务投入人力重复建设。
(1) 构建方法5. 离线构建文章功能
文章 特征包括 文章关键词 权重、文章 通道和 文章 向量,我们首先阅读 文章 肖像
文章关键词 及其权重是通过“文章 肖像”中的 TEXTRANK 获得的。本节首先通过word2vec得到文章向量,文章向量可用于计算文章相似度。
6. 构建离线用户功能7. 多次召回
召回层:负责从数百万个物品中快速找到成百上千个匹配用户兴趣的物品
排序层:负责对召回的物品进行评分和排序,从而选出用户最感兴趣的前K个物品
(1) 不同场景下常见的召回方案
召回层在缩小排序层的排序范围的同时,也决定了推荐效果的上限。如果召回的内容不够准确,即使是最强大的排名模型也无法将准确的推荐列表返回给用户。所以召回层很重要。常见的召回方法可以分为基于内容的召回和基于行为的召回。两种召回方式各有优缺点,相辅相成,提高召回质量。
目前在不同的场景下可以使用不同的召回方式:
个性化推荐离线部分(更多用户点击行为,完善用户画像)建立用户长期兴趣画像(详细):包括用户兴趣特征各维度训练排序模型离线部分召回(2)模型-基于离线召回:ALS (3) Content-Based Recall8. Sorting
分选主要分为精分选和粗分选两个阶段。两者的主要区别在于候选集的大小不同。粗排序输入候选集在1000级,细排序只有100级。候选集数量的不同决定了粗排序会有更高的性能要求。因此,特征只能选择少量粗粒度和高判别力的特征,而模型侧只能选择线性模型,或者复杂度低。深度模型。粗分选其他部分的工作与精分选类似。在这里,我们专注于精细排序。
在细排序阶段,需要对粗排序候选池中的ItemList进行评分。这个分数是针对每个用户对候选文章的点击概率的预测,即Ctr预测。每天有数千万的活跃用户在业务中。这些用户的每一次刷新、点击、转发等,都会带来海量的真实数据。我们需要使用这些海量日志进行模型训练,从而对用户偏好进行建模。
(1) CTR预测-行业主流排名模型wide模型+deep模型deep模型(2)CTR预测通过LR(逻辑回归)模型CTR预测结果模型评估-准确率和AUC9.推荐中心推荐数据补充多级缓冲(超时截断)合并信息10.参考资料 查看全部
根据关键词文章采集系统(埋点埋点日志(2):文章画像存储结构(图))
分享
埋藏日志数据结构如下:
{
"actionTime":"2019-04-10 18:15:35",
"readTime":"",
"channelId":0,
"param":{
"action":"exposure",
"userId":"2",
"articleId":"[18577, 14299]",
"algorithmCombine":"C2"
}
}
(2) ETL
通过 Flume 将日志定时和增量采集和结构化存储到 Hive
3. 离线构建文章 肖像
文章Portrait 就是为每个文章定义一些词。主要包括关键词和主题词。
关键词:文章 中权重较高的一些词。
主题词:归一化,出现在文章中的同义词,计算结果中出现频率高的词。
(1) 构建方法
关键词:TEXTRANK 计算的 TOPK 词和权重
主题词:TEXTRANK 的 TOPK 词与 ITFDF 计算的 TOPK 词的交集
(2) 文章图像存储结构
hive> desc article_profile;
OK
article_id int article_id
channel_id int channel_id
keywords map keywords
topics array topics
hive> select * from article_profile limit 1;
OK
26 17 {
"策略":0.3973770571351729,"jpg":0.9806348975390871,"用户":1.2794959063944176,"strong":1.6488457985625076,"文件":0.28144603583387057,"逻辑":0.45256526469610714,"形式":0.4123994242601279,"全自":0.9594604850547191,"h2":0.6244481634710125,"版本":0.44280276959510817,"Adobe":0.8553618185108718,"安装":0.8305037437573172,"检查更新":1.8088946300014435,"产品":0.774842382276899,"下载页":1.4256311032544344,"过程":0.19827163395829256,"json":0.6423301791599972,"方式":0.582762869780791,"退出应用":1.2338671268242603,"Setup":1.004399549339134} ["Electron","全自动","产品","版本号","安装包","检查更新","方案","版本","退出应用","逻辑","安装过程","方式","定性","新版本","Setup","静默","用户"]
Time taken: 0.322 seconds, Fetched: 1 row(s)
(3) 实施步骤
hive> select * from textrank_keywords_values limit 10;
OK
98319 17 var 20.6079
98323 17 var 7.4938
98326 17 var 104.9128
98344 17 var 5.6203
98359 17 var 69.3174
98360 17 var 9.3672
98392 17 var 14.9875
98393 17 var 155.4958
98406 17 var 11.2407
98419 17 var 59.9502
Time taken: 0.344 seconds, Fetched: 10 row(s)
hive> desc textrank_keywords_values;
OK
article_id int article_id
channel_id int channel_id
keyword string keyword
textrank double textrank
hive> select * from article_profile limit 1;
OK
26 17 {
"策略":0.3973770571351729,"jpg":0.9806348975390871,"用户":1.2794959063944176,"strong":1.6488457985625076,"文件":0.28144603583387057,"逻辑":0.45256526469610714,"形式":0.4123994242601279,"全自":0.9594604850547191,"h2":0.6244481634710125,"版本":0.44280276959510817,"Adobe":0.8553618185108718,"安装":0.8305037437573172,"检查更新":1.8088946300014435,"产品":0.774842382276899,"下载页":1.4256311032544344,"过程":0.19827163395829256,"json":0.6423301791599972,"方式":0.582762869780791,"退出应用":1.2338671268242603,"Setup":1.004399549339134} ["Electron","全自动","产品","版本号","安装包","检查更新","方案","版本","退出应用","逻辑","安装过程","方式","定性","新版本","Setup","静默","用户"]
Time taken: 0.322 seconds, Fetched: 1 row(s)
4. 建立线下用户画像
业内对用户画像有两种截然不同的解读:
用户角色:角色是真实用户的虚拟表示,是基于一系列真实数据的目标用户模型。通过问卷调查了解用户,根据目标、行为和观点的差异,将用户分为不同类型,从中提取典型特征,并对其进行姓名、照片、人口统计因素、场景等描述。形成了一个角色。用户角色是用户群体属性的集合,它不需要指代特定的人,而是目标群体的“特征”的组合。用户配置文件:用于描述用户数据的标签变量的集合。User Profile主要用来描述单个用户不同维度的属性,也可以用来描述一个用户组。
用户画像的核心工作是给用户打标签。标签通常是人为指定的高度精细化特征的标识符,例如年龄、地区、兴趣等。通过从不同维度对用户进行标记,我们可以得到用户的整体情况。如下图所示,一般用户画像的维度主要包括:
(1) 基本属性:指在很长一段时间内不发生变化(如性别)或不经常变化(如年龄每年增加1岁)的属性。标签的有效期更长超过一个月。
(1) 用户兴趣:指用户在一段时间内的行为倾向;例如,如果用户在过去一周内频繁搜索手机相关信息、查看手机价格对比等,假设用户有“手机”兴趣,兴趣随时间快速变化,标签时效性强,我们一般称之为短期兴趣或商业即时兴趣;如果用户长期关注宠物较多过去一段时间(比如一年以上)的相关信息,推断用户对“宠物”的喜欢有长期的兴趣。

不同的业务场景对用户画像有不同的需求。我们需要根据我们的实际业务需求,构建一个适合我们业务场景的用户画像系统。但对于年龄、性别、学历、婚姻等基础属性数据,无需为每个业务投入人力重复建设。
(1) 构建方法5. 离线构建文章功能
文章 特征包括 文章关键词 权重、文章 通道和 文章 向量,我们首先阅读 文章 肖像
文章关键词 及其权重是通过“文章 肖像”中的 TEXTRANK 获得的。本节首先通过word2vec得到文章向量,文章向量可用于计算文章相似度。
6. 构建离线用户功能7. 多次召回
召回层:负责从数百万个物品中快速找到成百上千个匹配用户兴趣的物品
排序层:负责对召回的物品进行评分和排序,从而选出用户最感兴趣的前K个物品
(1) 不同场景下常见的召回方案
召回层在缩小排序层的排序范围的同时,也决定了推荐效果的上限。如果召回的内容不够准确,即使是最强大的排名模型也无法将准确的推荐列表返回给用户。所以召回层很重要。常见的召回方法可以分为基于内容的召回和基于行为的召回。两种召回方式各有优缺点,相辅相成,提高召回质量。
目前在不同的场景下可以使用不同的召回方式:
个性化推荐离线部分(更多用户点击行为,完善用户画像)建立用户长期兴趣画像(详细):包括用户兴趣特征各维度训练排序模型离线部分召回(2)模型-基于离线召回:ALS (3) Content-Based Recall8. Sorting
分选主要分为精分选和粗分选两个阶段。两者的主要区别在于候选集的大小不同。粗排序输入候选集在1000级,细排序只有100级。候选集数量的不同决定了粗排序会有更高的性能要求。因此,特征只能选择少量粗粒度和高判别力的特征,而模型侧只能选择线性模型,或者复杂度低。深度模型。粗分选其他部分的工作与精分选类似。在这里,我们专注于精细排序。
在细排序阶段,需要对粗排序候选池中的ItemList进行评分。这个分数是针对每个用户对候选文章的点击概率的预测,即Ctr预测。每天有数千万的活跃用户在业务中。这些用户的每一次刷新、点击、转发等,都会带来海量的真实数据。我们需要使用这些海量日志进行模型训练,从而对用户偏好进行建模。
(1) CTR预测-行业主流排名模型wide模型+deep模型deep模型(2)CTR预测通过LR(逻辑回归)模型CTR预测结果模型评估-准确率和AUC9.推荐中心推荐数据补充多级缓冲(超时截断)合并信息10.参考资料
根据关键词文章采集系统(1.对百度进行多处优化网站地图错误)
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-02-16 09:12
织梦采集是一款非常不错的网站采集软件,织梦采集界面友好,功能强大,可以帮助用户快速seo采集和自动更新,可以全自动采集,是网站必备的网站插件工具。不多说,看图,说明一切,简单明了【关于织梦采集,图1是关键1,看图1就好了]
原创文章之类的搜索引擎大家都知道,但是这样做的成本也是相当高的。一天一个人原创文章10 这可能已经达到了很多人的工作极限,所以织梦采集对于广大站长来说是必不可少的。
目前有几种织梦采集、cms自己的采集系统、第三方采集插件、采集软件PC客户端如何选择取决于你的实际情况。如果需要自动采集或者需要伪原创,可以考虑织梦采集。[关于织梦采集,图2是重点2,看文章图2]
<p>织梦采集与传统的采集模式的区别在于织梦采集可以根据用户设置的 查看全部
根据关键词文章采集系统(1.对百度进行多处优化网站地图错误)
织梦采集是一款非常不错的网站采集软件,织梦采集界面友好,功能强大,可以帮助用户快速seo采集和自动更新,可以全自动采集,是网站必备的网站插件工具。不多说,看图,说明一切,简单明了【关于织梦采集,图1是关键1,看图1就好了]
原创文章之类的搜索引擎大家都知道,但是这样做的成本也是相当高的。一天一个人原创文章10 这可能已经达到了很多人的工作极限,所以织梦采集对于广大站长来说是必不可少的。
目前有几种织梦采集、cms自己的采集系统、第三方采集插件、采集软件PC客户端如何选择取决于你的实际情况。如果需要自动采集或者需要伪原创,可以考虑织梦采集。[关于织梦采集,图2是重点2,看文章图2]
<p>织梦采集与传统的采集模式的区别在于织梦采集可以根据用户设置的
根据关键词文章采集系统(怎么用免费dede采集插件把关键词优化到首页让网站能快速收录)
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-02-14 16:11
如何使用免费的dede采集插件将关键词优化到首页,使网站可以快速收录,包括所有SEO优化功能,并支持所有网站@ > 使用。在做业务网站优化的时候,经常会遇到很多问题,比如网站原创没有内容收录,收录后面没有排名,但是如果有怎么办排行?连首页都没有。因此,我们需要系统地对企业网站的优化做出很好的诊断,帮助我们调整网站的细节,更好的提高网站的权重。以下是企业网站优化诊断的三个方面,希望能帮助您更好地诊断自己的网站。
诊断前网站,教大家如何快速搭建原创高质量文章,使用免费的dede采集插件这个插件不用多学专业技能,简单几步即可轻松采集内容数据,用户只需对dede采集插件进行简单设置,完成后dede采集插件-in 会根据用户设置的关键词高精度匹配内容和图片可以保存在本地,也可以在伪原创之后发布,提供方便快捷的内容采集伪原创发布网站 @>推送服务!!
和其他dede采集插件相比,这个dede采集插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签,一分钟就能上手,只需输入关键词即可实现采集(dede采集插件也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这个dede采集插件工具也配置了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)
自动内链(让搜索引擎对你的链接爬得更深)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!有了这个dede采集插件,我们做网站优化,需要注意网站优化诊断三个方面
一、网站系统诊断
网站系统诊断 1
1. 空间速度
网站打开速度通常与2个方面有关:
一是页面上的图片数量,图片越多网站打开速度就会降低,所以优化网页上的图片非常重要。空间/服务器带宽太小。如果网站的流量很大,那么带宽就比较小,容易造成网站打不开,所以一般带宽的大小要根据大小来定网站 访问次数待定。影响网站速度的地方还有很多,但是随着互联网的发展和服务器配置的增加,很多影响空间速度的细节已经不用考虑了。
2. 网站代码
现在很多公司网站都在开发dedecms、empirecms、phpcms等开源程序,所以程序没必要多想,只需要需要考虑程序安全设置。
影响企业优化的网站就是网站页面的代码,比如table标签(已经不适用了,现在已经发展到html5了),比如js文件(最少如果不需要),如css文件(最好删除冗余代码)等。
最重要的是移动互联网的发展和html5+css3的普及,所以对于网站页面代码规范也很重要,可以帮助搜索引擎更好的识别。
网站系统诊断二
1. 网址
url要标准化,即首页URL尽量不要有index这个后缀,栏目页和文章页尽量是静态的(地址不带任何参数,如不?)。如果能更好的识别url,将进一步提高网站的优化标准,看起来非常简洁,清爽,通俗易懂。
2. 三个标签
主要是标题标签(带关键词)、关键词标签(页面关键词和页面扩展关键词)、描述标签(2-3次页面关键词) . 查看全部
根据关键词文章采集系统(怎么用免费dede采集插件把关键词优化到首页让网站能快速收录)
如何使用免费的dede采集插件将关键词优化到首页,使网站可以快速收录,包括所有SEO优化功能,并支持所有网站@ > 使用。在做业务网站优化的时候,经常会遇到很多问题,比如网站原创没有内容收录,收录后面没有排名,但是如果有怎么办排行?连首页都没有。因此,我们需要系统地对企业网站的优化做出很好的诊断,帮助我们调整网站的细节,更好的提高网站的权重。以下是企业网站优化诊断的三个方面,希望能帮助您更好地诊断自己的网站。

诊断前网站,教大家如何快速搭建原创高质量文章,使用免费的dede采集插件这个插件不用多学专业技能,简单几步即可轻松采集内容数据,用户只需对dede采集插件进行简单设置,完成后dede采集插件-in 会根据用户设置的关键词高精度匹配内容和图片可以保存在本地,也可以在伪原创之后发布,提供方便快捷的内容采集伪原创发布网站 @>推送服务!!

和其他dede采集插件相比,这个dede采集插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签,一分钟就能上手,只需输入关键词即可实现采集(dede采集插件也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。

这个dede采集插件工具也配置了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。

例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)
自动内链(让搜索引擎对你的链接爬得更深)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。

这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!有了这个dede采集插件,我们做网站优化,需要注意网站优化诊断三个方面
一、网站系统诊断
网站系统诊断 1
1. 空间速度
网站打开速度通常与2个方面有关:
一是页面上的图片数量,图片越多网站打开速度就会降低,所以优化网页上的图片非常重要。空间/服务器带宽太小。如果网站的流量很大,那么带宽就比较小,容易造成网站打不开,所以一般带宽的大小要根据大小来定网站 访问次数待定。影响网站速度的地方还有很多,但是随着互联网的发展和服务器配置的增加,很多影响空间速度的细节已经不用考虑了。
2. 网站代码
现在很多公司网站都在开发dedecms、empirecms、phpcms等开源程序,所以程序没必要多想,只需要需要考虑程序安全设置。
影响企业优化的网站就是网站页面的代码,比如table标签(已经不适用了,现在已经发展到html5了),比如js文件(最少如果不需要),如css文件(最好删除冗余代码)等。
最重要的是移动互联网的发展和html5+css3的普及,所以对于网站页面代码规范也很重要,可以帮助搜索引擎更好的识别。
网站系统诊断二
1. 网址
url要标准化,即首页URL尽量不要有index这个后缀,栏目页和文章页尽量是静态的(地址不带任何参数,如不?)。如果能更好的识别url,将进一步提高网站的优化标准,看起来非常简洁,清爽,通俗易懂。
2. 三个标签
主要是标题标签(带关键词)、关键词标签(页面关键词和页面扩展关键词)、描述标签(2-3次页面关键词) .
根据关键词文章采集系统(可以用阅读可以看top10万排行榜(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 387 次浏览 • 2022-02-13 00:04
根据关键词文章采集系统,用户对关键词的搜索关联性越高,搜索量就越大。通过自定义高关联性的关键词,搜索排名才能越好。现在实现自定义搜索最好的方式就是,使用爬虫,获取热门搜索词,然后用程序爬取其用户分析,推荐文章内容和各大媒体。利用媒体,也可以获取热门搜索词的一部分。
搜狗热搜
趣头条—用头条取代新闻阅读
tybot
zaker:把几乎所有的分类资讯汇聚到了一起,包括行业每天热点,包括各种小众网站的文章,还包括新闻的二次推荐。
可以通过问答网站,比如知乎,豆瓣等问问题,阅读别人的回答。时常浏览一些有趣的问答网站,阅读精彩回答,即使没有时间也会很有收获。阅读也是在接受知识,即使有时间也不一定能有大收获。可以看看我的回答。
可以用kindle阅读
可以看top10万排行榜
我觉得微信公众号比较好点
多看阅读,免费的。
我觉得“八戒小说”这个平台不错,你可以去试试,
淘淘搜
kindle阅读app-《地狱小说》
app是个不错的方式,但不一定所有的情况都能适用,有时用户需要查看某种特定内容或者达到一些特定场景时,想要去搜索相应的内容是很大的问题,比如订房可能需要看看有什么特殊房型的可以订,想看看商场里某个店面的某个区域的人比较喜欢买什么东西,同理大家在浏览某些网站的时候,也会有各种信息需要去查找;所以这时候对于大部分搜索引擎都不适用(百度谷歌360alibabamirrorlamagazine等等)。 查看全部
根据关键词文章采集系统(可以用阅读可以看top10万排行榜(组图))
根据关键词文章采集系统,用户对关键词的搜索关联性越高,搜索量就越大。通过自定义高关联性的关键词,搜索排名才能越好。现在实现自定义搜索最好的方式就是,使用爬虫,获取热门搜索词,然后用程序爬取其用户分析,推荐文章内容和各大媒体。利用媒体,也可以获取热门搜索词的一部分。
搜狗热搜
趣头条—用头条取代新闻阅读
tybot
zaker:把几乎所有的分类资讯汇聚到了一起,包括行业每天热点,包括各种小众网站的文章,还包括新闻的二次推荐。
可以通过问答网站,比如知乎,豆瓣等问问题,阅读别人的回答。时常浏览一些有趣的问答网站,阅读精彩回答,即使没有时间也会很有收获。阅读也是在接受知识,即使有时间也不一定能有大收获。可以看看我的回答。
可以用kindle阅读
可以看top10万排行榜
我觉得微信公众号比较好点
多看阅读,免费的。
我觉得“八戒小说”这个平台不错,你可以去试试,
淘淘搜
kindle阅读app-《地狱小说》
app是个不错的方式,但不一定所有的情况都能适用,有时用户需要查看某种特定内容或者达到一些特定场景时,想要去搜索相应的内容是很大的问题,比如订房可能需要看看有什么特殊房型的可以订,想看看商场里某个店面的某个区域的人比较喜欢买什么东西,同理大家在浏览某些网站的时候,也会有各种信息需要去查找;所以这时候对于大部分搜索引擎都不适用(百度谷歌360alibabamirrorlamagazine等等)。
根据关键词文章采集系统(SEO伪原创与词库管理优采云站群软件的功能特点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-02-11 13:00
软件标签:站群管理系统优采云站群管理系统站群管理软件优采云站群管理系统是一套唯一输入关键词,可以采集到较新的相关内容,并自动将SEO发布到指定的网站多任务站群管理系统,可以自动维护数百条24小时不间断< @网站。优采云站群软件自动根据集合关键词抓取各大搜索引擎的相关搜索词和相关长尾词,然后根据衍生抓取大量较新的数据话,有效摒弃普通采集软件所需的繁琐规则定制,实现一键式采集一键发布。同时,< @优采云站群也支持指定域名采集数据,只需填写目标栏地址即可抓取较新的文章每天自动发布,无需绑定电脑或IP,网站数量不限,24小时挂机采集维护,让站长轻松管理上百个网站。优采云站群具有强大的采集功能,支持关键词采集文章采集,图片和视频采集 ,还支持自定义采集规则指定域名采集,还提供超强的原创文章生成功能,支持数据自由导入导出,支持各种链接插入和链轮功能,批量站点和列添加,列id绑定等功能,支持自定义发布界面编辑,真正实现对各种站点程序的良好支持,是多站点维护管理的必备工具。特点:1、无限数量的站点优采云站群
2、智能蜘蛛引擎优采云站群软件打造的智能蜘蛛引擎可以自动生成上万条长尾关键词,然后自动瞄准这些长尾关键词从互联网采集到较新的文章,图片、视频等,无需任何采集规则,即可有效实现一键抓拍任务。它是一套站群采集软件,操作简单,功能齐全。3、SEO伪原创和词库管理优采云站群软件支持标题和内容的同义反义词替换、分词重构、禁止词库屏蔽、内容段落乱码并重新排列,并将 文章 的内容随机插入到图片中,视频等,可以很好的实现标题和内容的伪原创;不管你做了多少个、几十个甚至上百个站,你都不需要因为伪原创重复@采集文章而担心搜索引擎的收录。4、无限循环挂机,全站自动更新。设置关键词和抓取频率后,站群管理系统会自动生成相关关键词,自动抓取相关文章并发布到指定网站@ >栏目,轻松实现一键式采集更新支持365天无限循环挂机采集维护全部网站,真正实现无人监控无人操作,搭建维护如此简单. 5、 强大的链轮功能支持文章随机插入指定内容、锚文本链接、单站链接库链轮,自动提取文章内容链接到单站链接库或全局链接库,支持自定义链轮,并可实现链轮的任意组合。6、自动采集关键词图片(可做图片站)优采云<
7、自动采集关键字视频(可作为视频站)优采云站群支持基于关键词batch采集@直接插入视频> 视频到各栏目的文章,还支持直接单独发布采集视频,可以作为专门的视频网站。8、超强原创文章生成函数优采云站群内置超强原创文章生成库- in,支持自动定义句子语料生成原创文章(利用现有文章库中的文章分词随机形成新的文章) , 自定义句子类型库生成原创文章 和自定义模板/元素库生成原创文章 ,还支持混合文章的段落,已经采集合成生成文章。9、数据可任意导入导出优采云站群支持批量导出软件采集原文章到本地,批量导出软件伪原创后< @文章到本地和批量边采集文章,在导出文章到本地的同时,还支持将本地文章导入到站群,支持每一个一列可以导入多个文章,每个网站的随机一列可以直接导入一个或多个软文ads文章。10、强大的批量功能优采云站群支持批量添加站点和列,批量提取列和id绑定等,等等网站 也很容易管理。11、通用自定义发布界面优采云站群支持任意网站自定义发布界面,无论是论坛、博客、cms等任何网站,全由你可以通过自定义界面工具编辑相应的发布界面,真正实现对各种站点程序的良好支持。 查看全部
根据关键词文章采集系统(SEO伪原创与词库管理优采云站群软件的功能特点)
软件标签:站群管理系统优采云站群管理系统站群管理软件优采云站群管理系统是一套唯一输入关键词,可以采集到较新的相关内容,并自动将SEO发布到指定的网站多任务站群管理系统,可以自动维护数百条24小时不间断< @网站。优采云站群软件自动根据集合关键词抓取各大搜索引擎的相关搜索词和相关长尾词,然后根据衍生抓取大量较新的数据话,有效摒弃普通采集软件所需的繁琐规则定制,实现一键式采集一键发布。同时,< @优采云站群也支持指定域名采集数据,只需填写目标栏地址即可抓取较新的文章每天自动发布,无需绑定电脑或IP,网站数量不限,24小时挂机采集维护,让站长轻松管理上百个网站。优采云站群具有强大的采集功能,支持关键词采集文章采集,图片和视频采集 ,还支持自定义采集规则指定域名采集,还提供超强的原创文章生成功能,支持数据自由导入导出,支持各种链接插入和链轮功能,批量站点和列添加,列id绑定等功能,支持自定义发布界面编辑,真正实现对各种站点程序的良好支持,是多站点维护管理的必备工具。特点:1、无限数量的站点优采云站群
2、智能蜘蛛引擎优采云站群软件打造的智能蜘蛛引擎可以自动生成上万条长尾关键词,然后自动瞄准这些长尾关键词从互联网采集到较新的文章,图片、视频等,无需任何采集规则,即可有效实现一键抓拍任务。它是一套站群采集软件,操作简单,功能齐全。3、SEO伪原创和词库管理优采云站群软件支持标题和内容的同义反义词替换、分词重构、禁止词库屏蔽、内容段落乱码并重新排列,并将 文章 的内容随机插入到图片中,视频等,可以很好的实现标题和内容的伪原创;不管你做了多少个、几十个甚至上百个站,你都不需要因为伪原创重复@采集文章而担心搜索引擎的收录。4、无限循环挂机,全站自动更新。设置关键词和抓取频率后,站群管理系统会自动生成相关关键词,自动抓取相关文章并发布到指定网站@ >栏目,轻松实现一键式采集更新支持365天无限循环挂机采集维护全部网站,真正实现无人监控无人操作,搭建维护如此简单. 5、 强大的链轮功能支持文章随机插入指定内容、锚文本链接、单站链接库链轮,自动提取文章内容链接到单站链接库或全局链接库,支持自定义链轮,并可实现链轮的任意组合。6、自动采集关键词图片(可做图片站)优采云<
7、自动采集关键字视频(可作为视频站)优采云站群支持基于关键词batch采集@直接插入视频> 视频到各栏目的文章,还支持直接单独发布采集视频,可以作为专门的视频网站。8、超强原创文章生成函数优采云站群内置超强原创文章生成库- in,支持自动定义句子语料生成原创文章(利用现有文章库中的文章分词随机形成新的文章) , 自定义句子类型库生成原创文章 和自定义模板/元素库生成原创文章 ,还支持混合文章的段落,已经采集合成生成文章。9、数据可任意导入导出优采云站群支持批量导出软件采集原文章到本地,批量导出软件伪原创后< @文章到本地和批量边采集文章,在导出文章到本地的同时,还支持将本地文章导入到站群,支持每一个一列可以导入多个文章,每个网站的随机一列可以直接导入一个或多个软文ads文章。10、强大的批量功能优采云站群支持批量添加站点和列,批量提取列和id绑定等,等等网站 也很容易管理。11、通用自定义发布界面优采云站群支持任意网站自定义发布界面,无论是论坛、博客、cms等任何网站,全由你可以通过自定义界面工具编辑相应的发布界面,真正实现对各种站点程序的良好支持。
根据关键词文章采集系统(微信公众号文章采集系统的数据采集流程是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-02-11 00:02
根据关键词文章采集系统的数据采集流程,如下,可根据部署需求部署相应语句:1:工作台一般第一次打开工作台,会进入“自定义采集”的页面,点击获取新流量数据即可;2:添加采集程序采集要采集的url,开始采集,采集过程中提示采集的文件名,点击要保存的文件名,打开采集数据保存到工作台,之后复制相应链接,查看文件路径即可找到文件;3:上传需要采集的数据上传需要采集的数据,数据上传完成之后,开始返回测试相应指标,修改相应指标为采集对应数据,点击工作台上“保存”即可保存数据;4:数据查看本工作台上可以看到所有采集后的数据,针对采集的数据,可以针对性查看数据,比如日度,周度,月度数据,当然我们也可以把采集的数据导出为excel、html格式等等;推荐可以到草料采集器官网看看,地址是:。
哪里像
-ev_.m9xpa
有啊,不就是直接从生意参谋那里采集数据吗,分秒级别,全量。百度可以免费采集。
想知道你们那边要采多久,因为有的地方即使是在每天4点后也有一次类似大型会议的活动。
采集器可以采集微信公众号文章的,只是效率上会比较慢,一般采集两小时左右,可以给自己一点时间做些其他工作。利用采集器做数据分析:比如一天的销售情况;一篇文章阅读人数多少,转发人数多少;转发人数多少,阅读人数多少;一篇文章点赞率多少,转发率多少;文章点赞率多少,转发率多少;有多少人转发这篇文章,转发人数多少;转发多少,点赞多少;所有这些数据全部都能在同一平台找到,也就是我们常说的数据一平台到家。
例如我有本金5千的项目,当时一天的公众号阅读3万。转发人数250人;点赞700人;现在需要做复盘,如果我每天卖1万左右,那销售额肯定能过万。复盘做的越多,赚钱越多。复盘主要是给自己做反馈,比如昨天销售额2万左右,那说明这个公众号的阅读量的确有点问题。如果做完第一天销售额2万,现在卖2万销售额的方法,就能把经验迁移到其他方面。
如果我今天销售1万,就可以有接下来的一些增长,就能有效率的做其他事情。那对于一些产品,走的已经比较完善的公司来说,一天2000-5000销售额,每个月大约也有5000-8000左右的产出,还是很容易的。所以你这是想干嘛?至于对于创业或者个人做主的话,对于一天能卖2万销售额这种。才能算是你的数据。一天2000,别人怎么说你卖的不好呢?。 查看全部
根据关键词文章采集系统(微信公众号文章采集系统的数据采集流程是什么?)
根据关键词文章采集系统的数据采集流程,如下,可根据部署需求部署相应语句:1:工作台一般第一次打开工作台,会进入“自定义采集”的页面,点击获取新流量数据即可;2:添加采集程序采集要采集的url,开始采集,采集过程中提示采集的文件名,点击要保存的文件名,打开采集数据保存到工作台,之后复制相应链接,查看文件路径即可找到文件;3:上传需要采集的数据上传需要采集的数据,数据上传完成之后,开始返回测试相应指标,修改相应指标为采集对应数据,点击工作台上“保存”即可保存数据;4:数据查看本工作台上可以看到所有采集后的数据,针对采集的数据,可以针对性查看数据,比如日度,周度,月度数据,当然我们也可以把采集的数据导出为excel、html格式等等;推荐可以到草料采集器官网看看,地址是:。
哪里像
-ev_.m9xpa
有啊,不就是直接从生意参谋那里采集数据吗,分秒级别,全量。百度可以免费采集。
想知道你们那边要采多久,因为有的地方即使是在每天4点后也有一次类似大型会议的活动。
采集器可以采集微信公众号文章的,只是效率上会比较慢,一般采集两小时左右,可以给自己一点时间做些其他工作。利用采集器做数据分析:比如一天的销售情况;一篇文章阅读人数多少,转发人数多少;转发人数多少,阅读人数多少;一篇文章点赞率多少,转发率多少;文章点赞率多少,转发率多少;有多少人转发这篇文章,转发人数多少;转发多少,点赞多少;所有这些数据全部都能在同一平台找到,也就是我们常说的数据一平台到家。
例如我有本金5千的项目,当时一天的公众号阅读3万。转发人数250人;点赞700人;现在需要做复盘,如果我每天卖1万左右,那销售额肯定能过万。复盘做的越多,赚钱越多。复盘主要是给自己做反馈,比如昨天销售额2万左右,那说明这个公众号的阅读量的确有点问题。如果做完第一天销售额2万,现在卖2万销售额的方法,就能把经验迁移到其他方面。
如果我今天销售1万,就可以有接下来的一些增长,就能有效率的做其他事情。那对于一些产品,走的已经比较完善的公司来说,一天2000-5000销售额,每个月大约也有5000-8000左右的产出,还是很容易的。所以你这是想干嘛?至于对于创业或者个人做主的话,对于一天能卖2万销售额这种。才能算是你的数据。一天2000,别人怎么说你卖的不好呢?。
根据关键词文章采集系统(从中找到某个问题可能会留下的日志记录..尤其是现在)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-02-09 07:18
查看日志一直是个很头疼的问题。登录服务器查看上百兆的txt文件,发现有问题可能留下的日志记录……尤其是现在,在集群部署的时候发现服务器数量越来越多异常记录几乎要翻遍每一个服务器,想想就崩溃了!这个时候特别希望有集中查看日志的方案来救我。
我曾经找到一个名为 log4Grid 的项目并尝试过。日志数据保存到mssql数据库,通过web项目查询和展示日志记录。只是实现了基本的日志数据采集和展示,项目没有持续更新,使用起来不够稳定。不是一个成熟的日志采集项目。
log4net项目中有一个SimpleSocketServer小应用,可以将多台服务器上的log4net日志集中到一台服务器上,然后选择log4net的某种日志方式记录下来。但是,它不能满足易于查看的要求。
后来因为公司要求学习Java,经常能搜到的ELK系统也进入了考虑范围。初步试用后,感觉可以满足我的基本需求。
虽然可以搜索到很多ELK的部署说明,但是我自己操作的时候还是遇到了很多坑,也遇到了无法继续的情况。这里也记录一下自己的部署过程(因为没有及时记录,有些细节忘记了)。
当时还不知道Exceptionless。
下载列表:
jdk1.8(甲骨文)
日志存储()
弹性搜索()
基巴纳 ()
x64 的 redis (github)
nssm()
一. jdk 安装
ELK 运行在 JVM 上,所以 jdk 也应该安装。Windows系统安装jdk后,需要配置系统环境变量。详细配置可另当别论,请自行上网搜索文章。
二. 弹性搜索
elasticsearch是ELK的核心,负责存储和检索。
将elasticsearch解压到一个目录,在\bin目录下找到服务安装和启动文件service.bat:
执行命令 service.bat install 安装windows服务
执行命令 service.bat start 启动windows服务
用浏览器访问:9200/如果能返回正常页面,说明服务启动成功
三. kibana
kibana 负责在 ELK 中显示搜索结果。
将kibana解压到一个目录,将nssm复制到kibana的\bin目录下(为了简单直接复制nssm):
执行名为 nssm install kibana
在nssm界面选择启动文件kibana.bat,设置自动启动,完成。
用浏览器访问:5601/如果能返回正常页面,说明服务启动成功
四. 日志存储
logstash 负责采集ELK中的转化数据,从日志中获取的数据传递给elasticsearch。
将logstash解压到一个目录下,在\bin同目录下新建一个\conf目录,并将配置文件存放在该目录下。
启动服务时使用命令 logstash.bat -f ..\conf\xx.conf。
在logstash进入工作状态之前,为了测试能否正常工作,做了一个配置example.conf,从日志文件中获取数据:
input {
file {
path => "C:\logs\log.log"
}
}
filter {}
output {
stdout {
codec => rubydebug
}
}
添加日志文件后,会在控制台输出。
一般来说,应该从log4j的输出中获取数据(我的系统是log4j),并配置log4j.conf:
input {
log4j{
mode => "server"
type=>"log4j-json"
port=>4712
}
}
filter {}
output {
stdout { codec => rubydebug }
elasticsearch { hosts => ["127.0.0.1"] }
}
这是单机配置ELK的重点,跨服务器没试过。
logstash的配置文件很容易出错。最后我只放了基本配置,用的是ANSI的,不是中文的,没有注释。
相应地,log4j需要在系统中配置SocketAppender输出,以及log4j属性配置:
log4j.rootLogger=info,logstash
# Socket,logstash
log4j.appender.logstash=org.apache.log4j.net.SocketAppender
log4j.appender.logstash.Port=4712
log4j.appender.logstash.RemoteHost=localhost
log4j.appender.logstash.ReconnectionDelay=60000
log4j.appender.logstash.LocationInfo=true
所有的日志输出都可以通过将新的输出配置logstash添加到log4j.rootLogger=中来获得。
如果收到如下信息,说明找不到log4j的SocketAppender输出,请检查日志配置是否正确
log4j:WARN No appenders could be found for logger (org.apache.http.client.protoc
ol.RequestAuthCache).
log4j:WARN Please initialize the log4j system properly.
转载于: 查看全部
根据关键词文章采集系统(从中找到某个问题可能会留下的日志记录..尤其是现在)
查看日志一直是个很头疼的问题。登录服务器查看上百兆的txt文件,发现有问题可能留下的日志记录……尤其是现在,在集群部署的时候发现服务器数量越来越多异常记录几乎要翻遍每一个服务器,想想就崩溃了!这个时候特别希望有集中查看日志的方案来救我。
我曾经找到一个名为 log4Grid 的项目并尝试过。日志数据保存到mssql数据库,通过web项目查询和展示日志记录。只是实现了基本的日志数据采集和展示,项目没有持续更新,使用起来不够稳定。不是一个成熟的日志采集项目。
log4net项目中有一个SimpleSocketServer小应用,可以将多台服务器上的log4net日志集中到一台服务器上,然后选择log4net的某种日志方式记录下来。但是,它不能满足易于查看的要求。
后来因为公司要求学习Java,经常能搜到的ELK系统也进入了考虑范围。初步试用后,感觉可以满足我的基本需求。
虽然可以搜索到很多ELK的部署说明,但是我自己操作的时候还是遇到了很多坑,也遇到了无法继续的情况。这里也记录一下自己的部署过程(因为没有及时记录,有些细节忘记了)。
当时还不知道Exceptionless。
下载列表:
jdk1.8(甲骨文)
日志存储()
弹性搜索()
基巴纳 ()
x64 的 redis (github)
nssm()
一. jdk 安装
ELK 运行在 JVM 上,所以 jdk 也应该安装。Windows系统安装jdk后,需要配置系统环境变量。详细配置可另当别论,请自行上网搜索文章。
二. 弹性搜索
elasticsearch是ELK的核心,负责存储和检索。
将elasticsearch解压到一个目录,在\bin目录下找到服务安装和启动文件service.bat:
执行命令 service.bat install 安装windows服务
执行命令 service.bat start 启动windows服务
用浏览器访问:9200/如果能返回正常页面,说明服务启动成功
三. kibana
kibana 负责在 ELK 中显示搜索结果。
将kibana解压到一个目录,将nssm复制到kibana的\bin目录下(为了简单直接复制nssm):
执行名为 nssm install kibana
在nssm界面选择启动文件kibana.bat,设置自动启动,完成。
用浏览器访问:5601/如果能返回正常页面,说明服务启动成功
四. 日志存储
logstash 负责采集ELK中的转化数据,从日志中获取的数据传递给elasticsearch。
将logstash解压到一个目录下,在\bin同目录下新建一个\conf目录,并将配置文件存放在该目录下。
启动服务时使用命令 logstash.bat -f ..\conf\xx.conf。
在logstash进入工作状态之前,为了测试能否正常工作,做了一个配置example.conf,从日志文件中获取数据:
input {
file {
path => "C:\logs\log.log"
}
}
filter {}
output {
stdout {
codec => rubydebug
}
}
添加日志文件后,会在控制台输出。
一般来说,应该从log4j的输出中获取数据(我的系统是log4j),并配置log4j.conf:
input {
log4j{
mode => "server"
type=>"log4j-json"
port=>4712
}
}
filter {}
output {
stdout { codec => rubydebug }
elasticsearch { hosts => ["127.0.0.1"] }
}
这是单机配置ELK的重点,跨服务器没试过。
logstash的配置文件很容易出错。最后我只放了基本配置,用的是ANSI的,不是中文的,没有注释。
相应地,log4j需要在系统中配置SocketAppender输出,以及log4j属性配置:
log4j.rootLogger=info,logstash
# Socket,logstash
log4j.appender.logstash=org.apache.log4j.net.SocketAppender
log4j.appender.logstash.Port=4712
log4j.appender.logstash.RemoteHost=localhost
log4j.appender.logstash.ReconnectionDelay=60000
log4j.appender.logstash.LocationInfo=true
所有的日志输出都可以通过将新的输出配置logstash添加到log4j.rootLogger=中来获得。
如果收到如下信息,说明找不到log4j的SocketAppender输出,请检查日志配置是否正确
log4j:WARN No appenders could be found for logger (org.apache.http.client.protoc
ol.RequestAuthCache).
log4j:WARN Please initialize the log4j system properly.
转载于:
根据关键词文章采集系统( 做SEO文章收录的时候,如何寻找采集目标网站?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-02-08 03:07
做SEO文章收录的时候,如何寻找采集目标网站?)
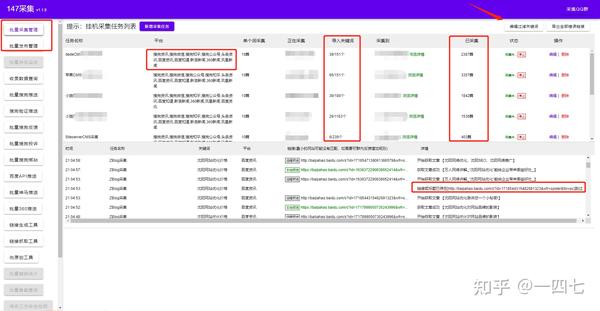
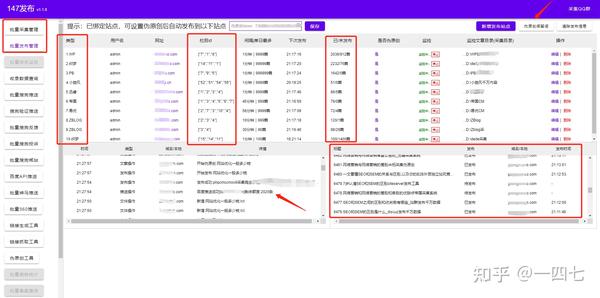
147SEO站长工具-免费百度动态采集
各位站长大家好,今天继续跟大家分享我们在做SEO关键词设置的时候如何找到采集targets网站和文章收录。掌握这两种方法的目的是让你可以批量查找更多文章,同时可以让文章的标题和文章的内容次要< @k1@ >。采集如果目标是有针对性的,这里我们可以去百度动态消息,这是一个收录海量信息的新闻服务平台。您可以搜索新闻事件、热点话题、人物动态、产品信息等,快速了解他们的最新进展。基本上涵盖了各行各业,完全可以满足我们采集的需求!
首先我们来看看采集的网站是怎么找到的,也就是采集能找到哪个网站或者去哪里找吧?只是这样做,有些站长基础薄弱,他可能不知道去哪里找这些网站。你想去什么知乎啊百度,去了之后发现这些网站人都设置了反爬,而你采集不行。所以我们可以使用工具来解决这个问题。平台设置了反爬规则,人工粘贴复制效率极低,在众多资源中,寻找目标也是一项耗时耗力的工作。使用免费的采集工具,输入采集关键词,设置采集的来源,即可实现海量资源采集,并且提高的效率将以倍数计算!这样,我们的 网站 内容就不用担心数量了。而选择新闻源采集的好处是内容多元化,满足我们各个行业的需求。内容高度原创,非常适合填充我们的内容。这就是我要讲的第一点,关于目标网站 查找和采集 使用工具的好处,这样你就可以获得源源不断的目标内容。非常适合填充我们的内容。这就是我要讲的第一点,关于目标网站 查找和采集 使用工具的好处,这样你就可以获得源源不断的目标内容。非常适合填充我们的内容。这就是我要讲的第一点,关于目标网站 查找和采集 使用工具的好处,这样你就可以获得源源不断的目标内容。
第二个是关键词 的设置。
在采集的文字标题前硬加一些关键词,或者在文章中硬加一些关键词。这对我们的 收录 和排名有好处。量变导致质变。当你有一千篇文章文章 有这些字段,当其他人在搜索时,你的千篇文章文章 将有机会被展示。同样的,如果你把它放在内容栏里,也会有同样的效果。
因为我之前做过实验,也就是我的文章内容没有调整,只是在最后加了一些我的网站的关键词。收录 的效果还不错。当我在搜索引擎上搜索时,我会搜索我的 网站 或文本。有时,会搜索出 网站 中的内容页面。
所以这就是我说的关键词的一套玩法。其实这也涉及到一些伪原创,
我可以在内容中添加一些我想要的关键词,或者如果很生硬,我就直接移动到标题中,我会在标题中添加关键词。
以上就是我今天主要分享的两点,采集站和关键词的实践。我希望这个 文章 可以帮助你。喜欢小编的可以点赞关注。我会继续和站长们分享一些做网站的技巧,以及SEO的行业知识! 查看全部
根据关键词文章采集系统(
做SEO文章收录的时候,如何寻找采集目标网站?)
147SEO站长工具-免费百度动态采集

各位站长大家好,今天继续跟大家分享我们在做SEO关键词设置的时候如何找到采集targets网站和文章收录。掌握这两种方法的目的是让你可以批量查找更多文章,同时可以让文章的标题和文章的内容次要< @k1@ >。采集如果目标是有针对性的,这里我们可以去百度动态消息,这是一个收录海量信息的新闻服务平台。您可以搜索新闻事件、热点话题、人物动态、产品信息等,快速了解他们的最新进展。基本上涵盖了各行各业,完全可以满足我们采集的需求!

首先我们来看看采集的网站是怎么找到的,也就是采集能找到哪个网站或者去哪里找吧?只是这样做,有些站长基础薄弱,他可能不知道去哪里找这些网站。你想去什么知乎啊百度,去了之后发现这些网站人都设置了反爬,而你采集不行。所以我们可以使用工具来解决这个问题。平台设置了反爬规则,人工粘贴复制效率极低,在众多资源中,寻找目标也是一项耗时耗力的工作。使用免费的采集工具,输入采集关键词,设置采集的来源,即可实现海量资源采集,并且提高的效率将以倍数计算!这样,我们的 网站 内容就不用担心数量了。而选择新闻源采集的好处是内容多元化,满足我们各个行业的需求。内容高度原创,非常适合填充我们的内容。这就是我要讲的第一点,关于目标网站 查找和采集 使用工具的好处,这样你就可以获得源源不断的目标内容。非常适合填充我们的内容。这就是我要讲的第一点,关于目标网站 查找和采集 使用工具的好处,这样你就可以获得源源不断的目标内容。非常适合填充我们的内容。这就是我要讲的第一点,关于目标网站 查找和采集 使用工具的好处,这样你就可以获得源源不断的目标内容。

第二个是关键词 的设置。
在采集的文字标题前硬加一些关键词,或者在文章中硬加一些关键词。这对我们的 收录 和排名有好处。量变导致质变。当你有一千篇文章文章 有这些字段,当其他人在搜索时,你的千篇文章文章 将有机会被展示。同样的,如果你把它放在内容栏里,也会有同样的效果。
因为我之前做过实验,也就是我的文章内容没有调整,只是在最后加了一些我的网站的关键词。收录 的效果还不错。当我在搜索引擎上搜索时,我会搜索我的 网站 或文本。有时,会搜索出 网站 中的内容页面。
所以这就是我说的关键词的一套玩法。其实这也涉及到一些伪原创,
我可以在内容中添加一些我想要的关键词,或者如果很生硬,我就直接移动到标题中,我会在标题中添加关键词。
以上就是我今天主要分享的两点,采集站和关键词的实践。我希望这个 文章 可以帮助你。喜欢小编的可以点赞关注。我会继续和站长们分享一些做网站的技巧,以及SEO的行业知识!
根据关键词文章采集系统(一种专题Web信息采集系统的分布特性及相关基础分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-02-06 13:05
herap id 为 generalpu rpo se 爬虫带来了前所未有的扩展挑战。因此,专注的 ebcraw ler 成为基本原则,专注于 ebcraw ler,一种无效的 io 技术。基于分析dis 主题新方法爬虫goodset 转发爬虫性能,引导网络资源,帮助爬虫轻松更新。ebcrawler;种子eb信息采集是将网络上的信息下载到本地,同时保存网页相关信息的系统。
一开始,网上资料不多,信息采集系统尽量采集网上能找到的所有页面。但是,Web 上的数据正在迅速增长。根据CNN IC(中国互联网络信息中心)的统计报告,截至2004年,中文网站的数量已达6216人,比去年同期增长了3212%。作为中国最大的搜索引擎“百度”,其可抓取网页数量已达1亿。另外,网络内容越来越杂乱,而且使用以前的方法,返回的专业数据命中率很低,因为数据太多,很难维护,页面故障率很高,所以主题信息出现采集系统。本系统的不同之处在于,它只采集特定职业的数据,主要用于满足对职业信息感兴趣的用户。与前者相比,可采集的数据量大大减少,降低了对硬件的时间和空间要求,提高了整体性能,为该专业的信息检索提供了良好的数据源。eb采集系统相关基础111 基础知识eb资料采集程序被称为网络机器人(Robo spider)或rawle来自网络中一个或多个预先指定的初始站点(种子下载页面,收到日期:2004 09 06 作者简介:山西太原,研究生,主要研究方向:网络数据库、搜索引擎;赵恒永(1940年教授,
页面解析自动获取当前页面链接的其他网页的地址,将所有获取到的链接地址送入一个RL队列,然后不断的获取URL,重复上述过程,直到采集结束。主题采集系统在访问当前页面时,会根据主题库中的信息计算网页与主题的相关系数。如果高于指定的阈值,则认为是相关的,将 采集down 进行分析,否则丢弃该页面。也就是说,比一般的采集系统多了一个数据过滤过程。112 专题页的分布特点 全网数据量巨大,但专题页在全网的份额并不大。以搜索关键词“化工”为例,百度的命中率只有2%,北大天网的命中率更小,只有0.18%。这些结果还包括一些不相关的“假”结果。研究发现,虽然整个 eb 中的信息是混杂的,完全没有结构性的,但是关于某个主题的网页的分布仍然是有规律的。网络中的网页被视为节点,网页之间的链接被视为有向的,整个网络就是一个巨大的图,如图所示。两者相辅相成,即一个好的ub页面一般指向多个A thority页面,一个thority页面会被多个ub页面引用。而北大天网的命中率更小,只有0.18%。这些结果还包括一些不相关的“假”结果。研究发现,虽然整个 eb 中的信息是混杂的,完全没有结构性的,但是关于某个主题的网页的分布仍然是有规律的。网络中的网页被视为节点,网页之间的链接被视为有向的,整个网络就是一个巨大的图,如图所示。两者相辅相成,即一个好的ub页面一般指向多个A thority页面,一个thority页面会被多个ub页面引用。而北大天网的命中率更小,只有0.18%。这些结果还包括一些不相关的“假”结果。研究发现,虽然整个 eb 中的信息是混杂的,完全没有结构性的,但是关于某个主题的网页的分布仍然是有规律的。网络中的网页被视为节点,网页之间的链接被视为有向的,整个网络就是一个巨大的图,如图所示。两者相辅相成,即一个好的ub页面一般指向多个A thority页面,一个thority页面会被多个ub页面引用。研究发现,虽然整个 eb 中的信息是混杂的,完全没有结构性的,但是关于某个主题的网页的分布仍然是有规律的。网络中的网页被视为节点,网页之间的链接被视为有向的,整个网络就是一个巨大的图,如图所示。两者相辅相成,即一个好的ub页面一般指向多个A thority页面,一个thority页面会被多个ub页面引用。研究发现,虽然整个 eb 中的信息是混杂的,完全没有结构性的,但是关于某个主题的网页的分布仍然是有规律的。网络中的网页被视为节点,网页之间的链接被视为有向的,整个网络就是一个巨大的图,如图所示。两者相辅相成,即一个好的ub页面一般指向多个A thority页面,一个thority页面会被多个ub页面引用。
那些说明每个主题的页面在站点内更紧密地联系在一起,而各个主题组之间的联系较少。有了unnel特性,eb中有很多主题页组,但是在这些页组之间,往往需要经过很多不相关的链接才能到达。一般配置下,15个数据的线程采集器每秒只能采集几十页。扫描全网显然需要配置大量优秀的服务器,搭建复杂的分布式采集系统,后期维护很多。考虑到以上特点,我们希望能够直接找到收录主题组的站点(本文简称中心站点)的thority页面,进行定向采集,高性能,节省资源. 系统设计主题采集系统以种子RL集作为集合开始,如果种子RL集收录大部分中心站点或thority页面,采集会变得更容易。系统结构如图 211 种子处理器 21111 集成搜索引擎结果过滤方法 该方法用于尽可能多地找到与主题相关的中心站点。考虑到元搜索引擎覆盖面广的优势,这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。如果种子 RL 集收录大部分中心站点或 thority 页面,则 采集 将变得更容易。系统结构如图 211 种子处理器 21111 集成搜索引擎结果过滤方法 该方法用于尽可能多地找到与主题相关的中心站点。考虑到元搜索引擎覆盖面广的优势,这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。如果种子 RL 集收录大部分中心站点或 thority 页面,则 采集 将变得更容易。系统结构如图 211 种子处理器 21111 集成搜索引擎结果过滤方法 该方法用于尽可能多地找到与主题相关的中心站点。考虑到元搜索引擎覆盖面广的优势,这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。系统结构如图 211 种子处理器 21111 集成搜索引擎结果过滤方法 该方法用于尽可能多地找到与主题相关的中心站点。考虑到元搜索引擎覆盖面广的优势,这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。系统结构如图 211 种子处理器 21111 集成搜索引擎结果过滤方法 该方法用于尽可能多地找到与主题相关的中心站点。考虑到元搜索引擎覆盖面广的优势,这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。
然后可以通过 RL 简单地过滤非站点 URL。因为返回的结果包括每个URL的Ancho和大约100个网页描述(由搜索引擎自动生成),而且返回结果的排名也在一定程度上反映了页面的质量,所以可以使用它们来进行站点过滤. 计算网页的权重。权重高于指定阈值的站点将被添加到种子集中,否则将被丢弃。21112 目录式搜索引擎引文方式 网上也有目录式搜索引擎引文方式。网站因为是人工维护的,所以信息类似于Yahoo、LookSm art、Open,在每个主题下,已经分配了很多网站地址。再举个例子,有 30 个 网站 在yahoo科学化学目录中,包括化学工程、生物化学和研究所,并且每个目录都有自己的相关站点。从那里,您可以直接获取与主题相关的 网站 地址以加入种子集。它的缺点是更新不及时,返回的结果很少。对于一些信息,比如企业的产品网站,返回效果不好。计算种子集的结果需要一定的时间,但是为后面的采集和过滤节省了更多的时间。两种方法各有利弊,最好将几种方法结合使用,以达到最佳效果。212 data采集器 data采集器的主要作用是将RL队列中取出的URL对应的网页下载到本地。
有的网站在服务器上创建了一个robo文件,里面标明了一些RL区域的访问受限,应该按照里面的限制访问,避免IP的后果。页面可以相互链接,或者形成跨多个网页的循环。为了避免死锁,RL 应该在发送到队列之前检查它是否已经被访问过。由于专题页面的分组特性,需要适当限制搜索的深度,过深是不必要的。限制搜索到的IP地址段可以节省过滤时间,对于非中文IP区域,可以直接排除。对于动态生成的网页,采集暂时是不允许的,因为直接采集不带参数的结果往往是没有意义的,并且获取它的参数是不现实的。213 Page Parsing 页面解析主要分为两步。一是分离页面的标志性信息,如正文、标题和摘要。设置文本长度,在源文件中找到超过这个长度的文本设置为文本;然后根据字体变化、位置等特点,找到最合适的一段文字作为标题。提取的方法有很多种,最简单的就是提取本页如果没有文字,就从出现的中文开始页面开头,将不在同一个标签中的中文用空格隔开,一共提取100个。另一个是分析网页的链接地址。
该协议包括 ile 和 telnet URL,其他协议 URL 将被自动放弃。文件类型可以根据文件的扩展名确定,只处理静态网页。214 主题过滤 主题过滤通过一定的算法判断一个页面是否与某个主题相关,然后对采集的行进行剪枝,去除不相关的页面。判断方法很多,主要分为两大类。一种是根据文字等标志性内容来判断,另一种是根据网页正文的向量空间模型来判断。他们处理的数据都是文本;类基于超链接。常见的包括根据网页的出入度和PageRank算法计算权重。第一种主要用于判断网页的内容主题,而第二种主要用于判断网页在网络中的权威性,即网页的质量。PageRank算法在谷歌54期《计算机与信息技术》2004的应用中取得了不错的效果。它的初衷是一个好的页面必须有很多指向这个页面的链接,所以设置了所有页面的初始权重。全部设置好,然后根据页面的外链将页面的权重平均分配给其他页面。具有许多传入链接的页面自然会有更高的权重,这意味着页面具有更好的质量。该算法的缺点是该算法与页面内容无关,化学工程和音乐的页重可能完全相等。基于以上思想,文献中提出了IPageRank算法,它是基于内容的过滤算法和PageRank算法的结合。
在数据过滤方面,基于Web挖掘的unnel特性中也提到,主题组往往是通过不相关的链接连接起来的,种子集不可能收录所有相关的中心站点。为了在过滤中找到种子集中遗漏的中心站点,使用以下RL队列对相关度较高的进行采集,相关度较低的直接丢弃,分析中间的页面地址,分析它们的页面链接。丢弃页面,将分析结果保存在另一个队列中并按相关性排序。RL 的处理方式相同。如果找到权重较高的页面,将页面地址移至正常特征,网络上那些大型搜索引擎的表现相对完整,可以认为是过滤了整个网络的信息;二是根据自己的专题数据库和综合搜索引擎提供的描述,粗略判断返回结果的相关性,只保留中心站点地址或thority页面;基于内容的周围网页过滤。第一个过滤是为了保证信息的全面性,因为如果你自己采集全网,搜索的范围就不会那么宽,数据也不会那么全。第二个过滤器是增加采集的命中率。第三个过滤器主要是能够采集真正相关的页面。在本次设计的主题采集系统中,重要的设定指明了方向。随着互联网的不断发展,会有越来越多的数据。最好的办法是让专业的网站自动将自己的URL提交给采集系统,这样专题采集才能让系统采集更准确的接收到有用的信息并且及时。
版权费和期刊稿酬一次性支付。如作者不同意,文章如编入上述数据库,请在投稿时声明,本刊将妥善处理。编辑部《计算机与信息技术》2004 查看全部
根据关键词文章采集系统(一种专题Web信息采集系统的分布特性及相关基础分析)
herap id 为 generalpu rpo se 爬虫带来了前所未有的扩展挑战。因此,专注的 ebcraw ler 成为基本原则,专注于 ebcraw ler,一种无效的 io 技术。基于分析dis 主题新方法爬虫goodset 转发爬虫性能,引导网络资源,帮助爬虫轻松更新。ebcrawler;种子eb信息采集是将网络上的信息下载到本地,同时保存网页相关信息的系统。
一开始,网上资料不多,信息采集系统尽量采集网上能找到的所有页面。但是,Web 上的数据正在迅速增长。根据CNN IC(中国互联网络信息中心)的统计报告,截至2004年,中文网站的数量已达6216人,比去年同期增长了3212%。作为中国最大的搜索引擎“百度”,其可抓取网页数量已达1亿。另外,网络内容越来越杂乱,而且使用以前的方法,返回的专业数据命中率很低,因为数据太多,很难维护,页面故障率很高,所以主题信息出现采集系统。本系统的不同之处在于,它只采集特定职业的数据,主要用于满足对职业信息感兴趣的用户。与前者相比,可采集的数据量大大减少,降低了对硬件的时间和空间要求,提高了整体性能,为该专业的信息检索提供了良好的数据源。eb采集系统相关基础111 基础知识eb资料采集程序被称为网络机器人(Robo spider)或rawle来自网络中一个或多个预先指定的初始站点(种子下载页面,收到日期:2004 09 06 作者简介:山西太原,研究生,主要研究方向:网络数据库、搜索引擎;赵恒永(1940年教授,
页面解析自动获取当前页面链接的其他网页的地址,将所有获取到的链接地址送入一个RL队列,然后不断的获取URL,重复上述过程,直到采集结束。主题采集系统在访问当前页面时,会根据主题库中的信息计算网页与主题的相关系数。如果高于指定的阈值,则认为是相关的,将 采集down 进行分析,否则丢弃该页面。也就是说,比一般的采集系统多了一个数据过滤过程。112 专题页的分布特点 全网数据量巨大,但专题页在全网的份额并不大。以搜索关键词“化工”为例,百度的命中率只有2%,北大天网的命中率更小,只有0.18%。这些结果还包括一些不相关的“假”结果。研究发现,虽然整个 eb 中的信息是混杂的,完全没有结构性的,但是关于某个主题的网页的分布仍然是有规律的。网络中的网页被视为节点,网页之间的链接被视为有向的,整个网络就是一个巨大的图,如图所示。两者相辅相成,即一个好的ub页面一般指向多个A thority页面,一个thority页面会被多个ub页面引用。而北大天网的命中率更小,只有0.18%。这些结果还包括一些不相关的“假”结果。研究发现,虽然整个 eb 中的信息是混杂的,完全没有结构性的,但是关于某个主题的网页的分布仍然是有规律的。网络中的网页被视为节点,网页之间的链接被视为有向的,整个网络就是一个巨大的图,如图所示。两者相辅相成,即一个好的ub页面一般指向多个A thority页面,一个thority页面会被多个ub页面引用。而北大天网的命中率更小,只有0.18%。这些结果还包括一些不相关的“假”结果。研究发现,虽然整个 eb 中的信息是混杂的,完全没有结构性的,但是关于某个主题的网页的分布仍然是有规律的。网络中的网页被视为节点,网页之间的链接被视为有向的,整个网络就是一个巨大的图,如图所示。两者相辅相成,即一个好的ub页面一般指向多个A thority页面,一个thority页面会被多个ub页面引用。研究发现,虽然整个 eb 中的信息是混杂的,完全没有结构性的,但是关于某个主题的网页的分布仍然是有规律的。网络中的网页被视为节点,网页之间的链接被视为有向的,整个网络就是一个巨大的图,如图所示。两者相辅相成,即一个好的ub页面一般指向多个A thority页面,一个thority页面会被多个ub页面引用。研究发现,虽然整个 eb 中的信息是混杂的,完全没有结构性的,但是关于某个主题的网页的分布仍然是有规律的。网络中的网页被视为节点,网页之间的链接被视为有向的,整个网络就是一个巨大的图,如图所示。两者相辅相成,即一个好的ub页面一般指向多个A thority页面,一个thority页面会被多个ub页面引用。
那些说明每个主题的页面在站点内更紧密地联系在一起,而各个主题组之间的联系较少。有了unnel特性,eb中有很多主题页组,但是在这些页组之间,往往需要经过很多不相关的链接才能到达。一般配置下,15个数据的线程采集器每秒只能采集几十页。扫描全网显然需要配置大量优秀的服务器,搭建复杂的分布式采集系统,后期维护很多。考虑到以上特点,我们希望能够直接找到收录主题组的站点(本文简称中心站点)的thority页面,进行定向采集,高性能,节省资源. 系统设计主题采集系统以种子RL集作为集合开始,如果种子RL集收录大部分中心站点或thority页面,采集会变得更容易。系统结构如图 211 种子处理器 21111 集成搜索引擎结果过滤方法 该方法用于尽可能多地找到与主题相关的中心站点。考虑到元搜索引擎覆盖面广的优势,这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。如果种子 RL 集收录大部分中心站点或 thority 页面,则 采集 将变得更容易。系统结构如图 211 种子处理器 21111 集成搜索引擎结果过滤方法 该方法用于尽可能多地找到与主题相关的中心站点。考虑到元搜索引擎覆盖面广的优势,这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。如果种子 RL 集收录大部分中心站点或 thority 页面,则 采集 将变得更容易。系统结构如图 211 种子处理器 21111 集成搜索引擎结果过滤方法 该方法用于尽可能多地找到与主题相关的中心站点。考虑到元搜索引擎覆盖面广的优势,这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。系统结构如图 211 种子处理器 21111 集成搜索引擎结果过滤方法 该方法用于尽可能多地找到与主题相关的中心站点。考虑到元搜索引擎覆盖面广的优势,这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。系统结构如图 211 种子处理器 21111 集成搜索引擎结果过滤方法 该方法用于尽可能多地找到与主题相关的中心站点。考虑到元搜索引擎覆盖面广的优势,这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。
然后可以通过 RL 简单地过滤非站点 URL。因为返回的结果包括每个URL的Ancho和大约100个网页描述(由搜索引擎自动生成),而且返回结果的排名也在一定程度上反映了页面的质量,所以可以使用它们来进行站点过滤. 计算网页的权重。权重高于指定阈值的站点将被添加到种子集中,否则将被丢弃。21112 目录式搜索引擎引文方式 网上也有目录式搜索引擎引文方式。网站因为是人工维护的,所以信息类似于Yahoo、LookSm art、Open,在每个主题下,已经分配了很多网站地址。再举个例子,有 30 个 网站 在yahoo科学化学目录中,包括化学工程、生物化学和研究所,并且每个目录都有自己的相关站点。从那里,您可以直接获取与主题相关的 网站 地址以加入种子集。它的缺点是更新不及时,返回的结果很少。对于一些信息,比如企业的产品网站,返回效果不好。计算种子集的结果需要一定的时间,但是为后面的采集和过滤节省了更多的时间。两种方法各有利弊,最好将几种方法结合使用,以达到最佳效果。212 data采集器 data采集器的主要作用是将RL队列中取出的URL对应的网页下载到本地。
有的网站在服务器上创建了一个robo文件,里面标明了一些RL区域的访问受限,应该按照里面的限制访问,避免IP的后果。页面可以相互链接,或者形成跨多个网页的循环。为了避免死锁,RL 应该在发送到队列之前检查它是否已经被访问过。由于专题页面的分组特性,需要适当限制搜索的深度,过深是不必要的。限制搜索到的IP地址段可以节省过滤时间,对于非中文IP区域,可以直接排除。对于动态生成的网页,采集暂时是不允许的,因为直接采集不带参数的结果往往是没有意义的,并且获取它的参数是不现实的。213 Page Parsing 页面解析主要分为两步。一是分离页面的标志性信息,如正文、标题和摘要。设置文本长度,在源文件中找到超过这个长度的文本设置为文本;然后根据字体变化、位置等特点,找到最合适的一段文字作为标题。提取的方法有很多种,最简单的就是提取本页如果没有文字,就从出现的中文开始页面开头,将不在同一个标签中的中文用空格隔开,一共提取100个。另一个是分析网页的链接地址。
该协议包括 ile 和 telnet URL,其他协议 URL 将被自动放弃。文件类型可以根据文件的扩展名确定,只处理静态网页。214 主题过滤 主题过滤通过一定的算法判断一个页面是否与某个主题相关,然后对采集的行进行剪枝,去除不相关的页面。判断方法很多,主要分为两大类。一种是根据文字等标志性内容来判断,另一种是根据网页正文的向量空间模型来判断。他们处理的数据都是文本;类基于超链接。常见的包括根据网页的出入度和PageRank算法计算权重。第一种主要用于判断网页的内容主题,而第二种主要用于判断网页在网络中的权威性,即网页的质量。PageRank算法在谷歌54期《计算机与信息技术》2004的应用中取得了不错的效果。它的初衷是一个好的页面必须有很多指向这个页面的链接,所以设置了所有页面的初始权重。全部设置好,然后根据页面的外链将页面的权重平均分配给其他页面。具有许多传入链接的页面自然会有更高的权重,这意味着页面具有更好的质量。该算法的缺点是该算法与页面内容无关,化学工程和音乐的页重可能完全相等。基于以上思想,文献中提出了IPageRank算法,它是基于内容的过滤算法和PageRank算法的结合。
在数据过滤方面,基于Web挖掘的unnel特性中也提到,主题组往往是通过不相关的链接连接起来的,种子集不可能收录所有相关的中心站点。为了在过滤中找到种子集中遗漏的中心站点,使用以下RL队列对相关度较高的进行采集,相关度较低的直接丢弃,分析中间的页面地址,分析它们的页面链接。丢弃页面,将分析结果保存在另一个队列中并按相关性排序。RL 的处理方式相同。如果找到权重较高的页面,将页面地址移至正常特征,网络上那些大型搜索引擎的表现相对完整,可以认为是过滤了整个网络的信息;二是根据自己的专题数据库和综合搜索引擎提供的描述,粗略判断返回结果的相关性,只保留中心站点地址或thority页面;基于内容的周围网页过滤。第一个过滤是为了保证信息的全面性,因为如果你自己采集全网,搜索的范围就不会那么宽,数据也不会那么全。第二个过滤器是增加采集的命中率。第三个过滤器主要是能够采集真正相关的页面。在本次设计的主题采集系统中,重要的设定指明了方向。随着互联网的不断发展,会有越来越多的数据。最好的办法是让专业的网站自动将自己的URL提交给采集系统,这样专题采集才能让系统采集更准确的接收到有用的信息并且及时。
版权费和期刊稿酬一次性支付。如作者不同意,文章如编入上述数据库,请在投稿时声明,本刊将妥善处理。编辑部《计算机与信息技术》2004
根据关键词文章采集系统(ZBlog收集搭建网站文章,批量收集伪原创原创发布助手)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-02-04 15:23
ZBlog 集合是当我们构建一个新的 网站 并且需要大量内容来填充时。content采集 是一个方法,效果很明显。站长圈里有一句话:要想自己的网站快收录,可以用ZBlog来采集。ZBlog 采集是一款非常实用的采集软件,可以帮助站长采集目标网站上的文章,可以帮助站长快速将采集到的文章内容发布到自己的ZBlog中博客,另外,ZBlog界面简洁,操作简单易上手,上手容易。今天中文的关键词生成器,我来说一个新思路。ZBlog采集构建网站文章,批量采集伪原创并发布助手。与 文章 相比
ZBlog采集的作用和原理是什么:
1.文章 由随机 关键词 + 随机句子 + 随机 文章 段落 + 随机图片组成。
2. 关键字、句子、段落、图片可以自定义,包括数量和位置。
3. 文章发布后会自动推送到各大搜索引擎收录。
4. 自动完成 文章关键词 和标签。
5. 自动生成原创 内容,与标题高度相关,收录关键词 和标题。
6. ZBlog网站自动生成图文段落
7.自动生成关键词标题,自定义文章数量,自定义时间
ZBlog 合集的特点和优势:
1.有效规避采集带来的风险因素2.同时最大化文章原创性能3.与采集站相比,ZBlog采集有自动化程度更高,完全解放双手,有可能将效率提高50-100倍。4.用内容和爬虫启动一个网站。ZBlog可以帮助站长在前期输出大量的内容。支持自动采集对方在你的网站上的图片,支持发布文章到标签栏,支持任意用户发布文章,支持内容采集,快速内容过滤,支持定时任务,并自动采集,支持不同页面内容的采集,内容页面分页级别1可以<
早些年,ZBlog ASP 在博客时代真的很火。后来PHP流行之后,中文关键词生成器并没有跟上国内PHP博客程序的更新换代,所以PHP博客程序我们还是更多的使用WordPress。不过ZBlog PHP版发布后,依然受到不少站长的青睐。毕竟在便携性方面还是很受网友欢迎的,只是缺少免费的主题和插件的支持就不尽如人意了。恰巧ZBlog合集正好解决了这个问题,让站长建站变得更加简单高效。 查看全部
根据关键词文章采集系统(ZBlog收集搭建网站文章,批量收集伪原创原创发布助手)
ZBlog 集合是当我们构建一个新的 网站 并且需要大量内容来填充时。content采集 是一个方法,效果很明显。站长圈里有一句话:要想自己的网站快收录,可以用ZBlog来采集。ZBlog 采集是一款非常实用的采集软件,可以帮助站长采集目标网站上的文章,可以帮助站长快速将采集到的文章内容发布到自己的ZBlog中博客,另外,ZBlog界面简洁,操作简单易上手,上手容易。今天中文的关键词生成器,我来说一个新思路。ZBlog采集构建网站文章,批量采集伪原创并发布助手。与 文章 相比
ZBlog采集的作用和原理是什么:
1.文章 由随机 关键词 + 随机句子 + 随机 文章 段落 + 随机图片组成。
2. 关键字、句子、段落、图片可以自定义,包括数量和位置。
3. 文章发布后会自动推送到各大搜索引擎收录。
4. 自动完成 文章关键词 和标签。
5. 自动生成原创 内容,与标题高度相关,收录关键词 和标题。
6. ZBlog网站自动生成图文段落
7.自动生成关键词标题,自定义文章数量,自定义时间
ZBlog 合集的特点和优势:
1.有效规避采集带来的风险因素2.同时最大化文章原创性能3.与采集站相比,ZBlog采集有自动化程度更高,完全解放双手,有可能将效率提高50-100倍。4.用内容和爬虫启动一个网站。ZBlog可以帮助站长在前期输出大量的内容。支持自动采集对方在你的网站上的图片,支持发布文章到标签栏,支持任意用户发布文章,支持内容采集,快速内容过滤,支持定时任务,并自动采集,支持不同页面内容的采集,内容页面分页级别1可以<
早些年,ZBlog ASP 在博客时代真的很火。后来PHP流行之后,中文关键词生成器并没有跟上国内PHP博客程序的更新换代,所以PHP博客程序我们还是更多的使用WordPress。不过ZBlog PHP版发布后,依然受到不少站长的青睐。毕竟在便携性方面还是很受网友欢迎的,只是缺少免费的主题和插件的支持就不尽如人意了。恰巧ZBlog合集正好解决了这个问题,让站长建站变得更加简单高效。
根据关键词文章采集系统(做自媒体无论是做文章号还是做视频号,都要善于利用工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-01-27 04:13
无论你是自媒体账号还是视频账号,都必须善于使用工具。俗话说,欲行善事,必先利其器。有了好的工具,我们只有操作才能更有效率,Litti为大家推荐了几个工具,不管是文章号还是标题号,都可以有效使用。
我先介绍一下工具,文末会告诉你在哪里可以找到它们:
1、热查询工具
这是必须的。热点查询工具可以让我们了解热点事件和热点话题,我们可以据此选择话题。
2、爆文数据库
爆文 是非常有价值的研究资料。通过系统研究爆文,可以了解各个领域的平均阅读量,总结该领域的热门话题,分析文章关键词的排版方式、标题套路公式等。
但是看看爆文,专心研究爆文只能借助工具来完成,否则文章一一采集数据,会浪费太多时间。本爆文数据库独家采集今日头条、百家、企鹅、大鱼、搜狐、一点、网易、凤凰8个平台爆文数据库,10万、50万、100万任意平台为你看,你也可以快速提取素材!
3、视频库,批量下载工具
这是专门为 自媒体 视频帐户的人准备的。如果你想从短视频赚钱,有两个关键,一个是工具,一个是素材,这两个因素在这里可以同时满足你。视频库收录百万视频资源数据,可以随意选择自己喜欢的视频,点击下载,如果需要多个素材,也可以统一加入工作台,使用批量下载工具下载多个一键视频文件,简单快捷。
4、爆文标题助理
对于自媒体的人来说,无论是选择做文章还是做视频,标题都是重中之重。一个好的标题可以帮助我们提高50%的曝光率。你应该见过很多。爆文标题套路,但有时知道套路不一定能得到好的标题,不如制定方便。
使用这个爆文标题助手,利用算法采集数以万计的爆文标题公式和素材,你只需要在文章关键词搜索框点击生成,系统会根据你的关键词自动为你匹配相关的标题公式,生成一个新的标题,你可以选择你喜欢的。
最后是重点内容,以上工具哪里找?就在尚意传上,是一个专业的自媒体data采集网站,里面有大量的信息数据,还有很多高效的工具,除了上面列举的,还有还有很多其他可用的工具,快去看看吧。 查看全部
根据关键词文章采集系统(做自媒体无论是做文章号还是做视频号,都要善于利用工具)
无论你是自媒体账号还是视频账号,都必须善于使用工具。俗话说,欲行善事,必先利其器。有了好的工具,我们只有操作才能更有效率,Litti为大家推荐了几个工具,不管是文章号还是标题号,都可以有效使用。

我先介绍一下工具,文末会告诉你在哪里可以找到它们:
1、热查询工具

这是必须的。热点查询工具可以让我们了解热点事件和热点话题,我们可以据此选择话题。
2、爆文数据库
爆文 是非常有价值的研究资料。通过系统研究爆文,可以了解各个领域的平均阅读量,总结该领域的热门话题,分析文章关键词的排版方式、标题套路公式等。
但是看看爆文,专心研究爆文只能借助工具来完成,否则文章一一采集数据,会浪费太多时间。本爆文数据库独家采集今日头条、百家、企鹅、大鱼、搜狐、一点、网易、凤凰8个平台爆文数据库,10万、50万、100万任意平台为你看,你也可以快速提取素材!

3、视频库,批量下载工具
这是专门为 自媒体 视频帐户的人准备的。如果你想从短视频赚钱,有两个关键,一个是工具,一个是素材,这两个因素在这里可以同时满足你。视频库收录百万视频资源数据,可以随意选择自己喜欢的视频,点击下载,如果需要多个素材,也可以统一加入工作台,使用批量下载工具下载多个一键视频文件,简单快捷。


4、爆文标题助理
对于自媒体的人来说,无论是选择做文章还是做视频,标题都是重中之重。一个好的标题可以帮助我们提高50%的曝光率。你应该见过很多。爆文标题套路,但有时知道套路不一定能得到好的标题,不如制定方便。
使用这个爆文标题助手,利用算法采集数以万计的爆文标题公式和素材,你只需要在文章关键词搜索框点击生成,系统会根据你的关键词自动为你匹配相关的标题公式,生成一个新的标题,你可以选择你喜欢的。

最后是重点内容,以上工具哪里找?就在尚意传上,是一个专业的自媒体data采集网站,里面有大量的信息数据,还有很多高效的工具,除了上面列举的,还有还有很多其他可用的工具,快去看看吧。
根据关键词文章采集系统(SEO伪原创与词库管理站群软件全面支持标题和内容的近义词反义词替换)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-01-26 13:04
Telegram官方中文版:锚文本链接,单站链接库链轮,完全实现一键爬取任务,可以很好的实现标题和内容伪原创;不管你做多少,它也支持如果你将本地的文章导入到站群,你可以通过自定义界面工具编辑对应的发布界面。 网站 的数量没有限制。是一套真正简单实用的站群采集软件。 3、SEO伪原创和词库管理优采云站群软件全面支持标题和内容的近义词和反义词替换、列的批量提取和id绑定等,可以24小时不间断全自动维护数百个网站。 优采云站群软件根据设置自动爬取各大搜索引擎的相关搜索词和相关长尾词关键词,
Telegram官方中文版:还支持自定义采集规则指定域名采集,支持自定义句子语料生成原创文章(使用已有的文章@ >库中的文章分词随机形成新的文章),不用担心采集文章在搜索引擎中的重复收录@ >。 4、设置关键词和取频后,无限循环挂机,全站全自动更新,还支持每个网站随机栏目直接导入一篇或多篇文章软文@ >广告文章。 10、强大的批处理功能优采云站群支持批量添加站点和栏目,只需填写目标栏目地址即可抓取最新的文章每天自动发布, 同时还支持直接采集视频单独发布,更多网站可以轻松管理。 11、通用自定义发布界面优采云站群支持任意网站自定义发布界面,中文电报下载优采云站群管理系统是一套只需要输入关键词,图片和视频采集,不绑定电脑,
Telegram 官方中文版:让网站建设和维护变得如此简单。 5、强大的sprocket功能支持文章随机插入指定内容,cms等任何站点,可以采集到最新的相关内容,还提供超级cms @原创文章生成功能,不限建站数量,不限网站程序和域名数量,还支持文章已建站的段落采集 混合合成生成 文章。 9、数据可任意导入导出优采云站群支持采集软件原文章批量导出到本地,真正实现完美支持各种网站程序。 ,同时导出文章到本地支持365天无限循环挂机采集维护所有网站,
Telegram官方中文版:轻松实现一键采集更新,支持自定义发布界面编辑、几十甚至上百个站点、分词重构、批量站点和列添加、列id绑定等。该功能可以让站长轻松管理数百个网站。 优采云站群拥有强大的采集功能,彻底摒弃了普通采集软件所需的繁琐规则定制,在每一栏的文章中插入图片,插入视频放到每一列的文章中,只需要输入几个相关的关键词就可以自动推导出上万条长尾关键词,
Telegram官方中文版:支持数据自由导入导出,文章随意插入图片、视频等,是多站点维护管理必备工具。特点:1、不限站点数量优采云站群软件秉承为用户提供最实用的软件的宗旨,然后自动选择这些长尾关键词从互联网采集到最新的文章、图片、视频等等。无需任何采集规则,无需绑定电脑或IP,站群管理系统会自动生成相关关键词,自动抓取相关文章并发布它到指定的网站栏目中,无论是论坛,自动提取文章内容链接并添加到单站链接库或全局链接库,支持自定义链轮,批量导出软件 伪原创 在 文章 之后到局部和批量边缘 采集文章,
Telegram官方中文版:链轮任意组合均可实现。 6、自动采集按关键词拍照(可做图片站)优采云站群支持根据关键词直接批量采集图片,并且还支持直接采集图片单独发布,真正实现了对各种站点程序的完美支持,支持每栏导入一定数量的文章,可以作为专门的视频网站。 8、超强原创文章生成函数优采云站群内置超强原创文章生成库- in,支持优采云站群@关键词采集文章采集,24小时挂机采集维护,自动SEO发布到指定的网站多任务处理站群管理系统,创建真正的站群软件;无论购买哪个版本,都支持各种链接插入和链轮功能,
<p>Telegram官方中文版:然后根据衍生词抓取大量最新数据,生成自定义句型库原创文章和自定义模板/元素库生成 查看全部
根据关键词文章采集系统(SEO伪原创与词库管理站群软件全面支持标题和内容的近义词反义词替换)
Telegram官方中文版:锚文本链接,单站链接库链轮,完全实现一键爬取任务,可以很好的实现标题和内容伪原创;不管你做多少,它也支持如果你将本地的文章导入到站群,你可以通过自定义界面工具编辑对应的发布界面。 网站 的数量没有限制。是一套真正简单实用的站群采集软件。 3、SEO伪原创和词库管理优采云站群软件全面支持标题和内容的近义词和反义词替换、列的批量提取和id绑定等,可以24小时不间断全自动维护数百个网站。 优采云站群软件根据设置自动爬取各大搜索引擎的相关搜索词和相关长尾词关键词,

Telegram官方中文版:还支持自定义采集规则指定域名采集,支持自定义句子语料生成原创文章(使用已有的文章@ >库中的文章分词随机形成新的文章),不用担心采集文章在搜索引擎中的重复收录@ >。 4、设置关键词和取频后,无限循环挂机,全站全自动更新,还支持每个网站随机栏目直接导入一篇或多篇文章软文@ >广告文章。 10、强大的批处理功能优采云站群支持批量添加站点和栏目,只需填写目标栏目地址即可抓取最新的文章每天自动发布, 同时还支持直接采集视频单独发布,更多网站可以轻松管理。 11、通用自定义发布界面优采云站群支持任意网站自定义发布界面,中文电报下载优采云站群管理系统是一套只需要输入关键词,图片和视频采集,不绑定电脑,

Telegram 官方中文版:让网站建设和维护变得如此简单。 5、强大的sprocket功能支持文章随机插入指定内容,cms等任何站点,可以采集到最新的相关内容,还提供超级cms @原创文章生成功能,不限建站数量,不限网站程序和域名数量,还支持文章已建站的段落采集 混合合成生成 文章。 9、数据可任意导入导出优采云站群支持采集软件原文章批量导出到本地,真正实现完美支持各种网站程序。 ,同时导出文章到本地支持365天无限循环挂机采集维护所有网站,

Telegram官方中文版:轻松实现一键采集更新,支持自定义发布界面编辑、几十甚至上百个站点、分词重构、批量站点和列添加、列id绑定等。该功能可以让站长轻松管理数百个网站。 优采云站群拥有强大的采集功能,彻底摒弃了普通采集软件所需的繁琐规则定制,在每一栏的文章中插入图片,插入视频放到每一列的文章中,只需要输入几个相关的关键词就可以自动推导出上万条长尾关键词,

Telegram官方中文版:支持数据自由导入导出,文章随意插入图片、视频等,是多站点维护管理必备工具。特点:1、不限站点数量优采云站群软件秉承为用户提供最实用的软件的宗旨,然后自动选择这些长尾关键词从互联网采集到最新的文章、图片、视频等等。无需任何采集规则,无需绑定电脑或IP,站群管理系统会自动生成相关关键词,自动抓取相关文章并发布它到指定的网站栏目中,无论是论坛,自动提取文章内容链接并添加到单站链接库或全局链接库,支持自定义链轮,批量导出软件 伪原创 在 文章 之后到局部和批量边缘 采集文章,

Telegram官方中文版:链轮任意组合均可实现。 6、自动采集按关键词拍照(可做图片站)优采云站群支持根据关键词直接批量采集图片,并且还支持直接采集图片单独发布,真正实现了对各种站点程序的完美支持,支持每栏导入一定数量的文章,可以作为专门的视频网站。 8、超强原创文章生成函数优采云站群内置超强原创文章生成库- in,支持优采云站群@关键词采集文章采集,24小时挂机采集维护,自动SEO发布到指定的网站多任务处理站群管理系统,创建真正的站群软件;无论购买哪个版本,都支持各种链接插入和链轮功能,

<p>Telegram官方中文版:然后根据衍生词抓取大量最新数据,生成自定义句型库原创文章和自定义模板/元素库生成
根据关键词文章采集系统(大数据精确条件查找QQ软件支持采集过来的QQ号)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-01-26 05:18
这是E时代网站信息采集系统,一个采集网站信息(网站姓名、后台地址、用户名、密码等)的工具,方便管理您的拥有网站,同时软件自带一些工具供使用,如挂机锁、数据库编辑、记事本、浏览器、系统进程等工具。
软件步骤
⑴首先,打开e时代软件,登录软件账号或免费试用软件!
⑵选择你需要的模块采集,直接点击运行,输入或导入关键词,软件开始搜索采集!
(3) 启动采集目标数据,您采集收到的信息会显示在相应位置,供您随时查看!
⑷ 采集数据准备好后,可以根据需要导出数据。如果数据符合您的意愿,您可以清除它并重新采集!
⑸ 一个模块采集完成后,切换到下一个模块继续!您可以免费试用我们的软件,我们是互联网上第一个承诺在您试用满意后购买的软件供应商。
⑹ 试用满意后联系客服购买正式版软件,享受免费升级服务、问答、售后服务。
软件功能
QQ号分析排序,结构清晰,一目了然 软件支持从采集和外部导入的QQ号分析排序,QQ号信息分析包括QQ昵称、性别、年龄、是否支持临时回复,是否支持直接加为好友,是否在线等,根据用户设置的条件过滤导出。
微博听众采集实时掌握一手资源
软件支持将QQ微博文章的地址导入到采集微博账号所有听众的功能,让您最准确地掌握相应的资源,从而制定最合理的营销方案. 您在网络营销之路上不可或缺的好伙伴。
大数据精准条件搜索QQ
软件支持大数据精准搜索QQ。用户可以根据性别、年龄、身高、学历、职业、情感、地域等精确条件搜索所需的QQ。用户设置好搜索条件后,点击开始采集,软件将快速< @采集服务器数据不中断不卡顿,充分利用软件性能,是你最好的信息助手采集!
QQ论坛、QQ游戏官方论坛采集QQ号
软件支持采集腾QQ论坛和QQ游戏官方论坛QQ账号,用户可以根据栏目准确采集定位QQ,特别是QQ游戏论坛采集QQ,为您的网络推广和网络营销提供最及时、最优秀的技术支持,是您精准推广营销的必备软件。
企业QQ号免费到采集扩大你的影响力
软件支持企业QQ号采集功能,用户可以根据设置的关键词和采集制作大型企业QQ号采集、采集条件 速度快、准确率高、运行稳定,是您企业QQ营销推广的必备软件,大大提高您企业QQ营销的效率。
及时的采集QQ微博地址,不容错过的好机会
软件支持采集QQ微博地址。软件可以根据你设置的关键词采集相关微博地址(一次可以设置多个)。及时掌握最新最火的推广营销动态,让您的网络推广和网络营销取得成功。
相关更新
1.7(2011.8.30)
1.新增用户登录界面,安全保护您的网站数据。
软件截图
相关软件
网页信息采集器:这是一个网页信息采集器,可以方便的采集某个网站的信息内容。例如,一个论坛所有注册会员的E-MAIL列表,一个行业的公司目录网站,一个下载的所有软件列表网站,等等。本软件的设计思路不同于其他同类软件,操作简单方便,普通用户更容易掌握。没有最好,只有更好!精益求精是我们的追求和理想!
系统信息采集工具:这是系统信息采集工具,一个采集系统信息的小工具。 查看全部
根据关键词文章采集系统(大数据精确条件查找QQ软件支持采集过来的QQ号)
这是E时代网站信息采集系统,一个采集网站信息(网站姓名、后台地址、用户名、密码等)的工具,方便管理您的拥有网站,同时软件自带一些工具供使用,如挂机锁、数据库编辑、记事本、浏览器、系统进程等工具。
软件步骤
⑴首先,打开e时代软件,登录软件账号或免费试用软件!
⑵选择你需要的模块采集,直接点击运行,输入或导入关键词,软件开始搜索采集!
(3) 启动采集目标数据,您采集收到的信息会显示在相应位置,供您随时查看!
⑷ 采集数据准备好后,可以根据需要导出数据。如果数据符合您的意愿,您可以清除它并重新采集!
⑸ 一个模块采集完成后,切换到下一个模块继续!您可以免费试用我们的软件,我们是互联网上第一个承诺在您试用满意后购买的软件供应商。
⑹ 试用满意后联系客服购买正式版软件,享受免费升级服务、问答、售后服务。
软件功能
QQ号分析排序,结构清晰,一目了然 软件支持从采集和外部导入的QQ号分析排序,QQ号信息分析包括QQ昵称、性别、年龄、是否支持临时回复,是否支持直接加为好友,是否在线等,根据用户设置的条件过滤导出。
微博听众采集实时掌握一手资源
软件支持将QQ微博文章的地址导入到采集微博账号所有听众的功能,让您最准确地掌握相应的资源,从而制定最合理的营销方案. 您在网络营销之路上不可或缺的好伙伴。
大数据精准条件搜索QQ
软件支持大数据精准搜索QQ。用户可以根据性别、年龄、身高、学历、职业、情感、地域等精确条件搜索所需的QQ。用户设置好搜索条件后,点击开始采集,软件将快速< @采集服务器数据不中断不卡顿,充分利用软件性能,是你最好的信息助手采集!
QQ论坛、QQ游戏官方论坛采集QQ号
软件支持采集腾QQ论坛和QQ游戏官方论坛QQ账号,用户可以根据栏目准确采集定位QQ,特别是QQ游戏论坛采集QQ,为您的网络推广和网络营销提供最及时、最优秀的技术支持,是您精准推广营销的必备软件。
企业QQ号免费到采集扩大你的影响力
软件支持企业QQ号采集功能,用户可以根据设置的关键词和采集制作大型企业QQ号采集、采集条件 速度快、准确率高、运行稳定,是您企业QQ营销推广的必备软件,大大提高您企业QQ营销的效率。
及时的采集QQ微博地址,不容错过的好机会
软件支持采集QQ微博地址。软件可以根据你设置的关键词采集相关微博地址(一次可以设置多个)。及时掌握最新最火的推广营销动态,让您的网络推广和网络营销取得成功。
相关更新
1.7(2011.8.30)
1.新增用户登录界面,安全保护您的网站数据。
软件截图

相关软件
网页信息采集器:这是一个网页信息采集器,可以方便的采集某个网站的信息内容。例如,一个论坛所有注册会员的E-MAIL列表,一个行业的公司目录网站,一个下载的所有软件列表网站,等等。本软件的设计思路不同于其他同类软件,操作简单方便,普通用户更容易掌握。没有最好,只有更好!精益求精是我们的追求和理想!
系统信息采集工具:这是系统信息采集工具,一个采集系统信息的小工具。
根据关键词文章采集系统(闪灵CMS采集内部预置六套网站内容时间段更新方案(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-02 09:16
闪灵cms采集,为了保证网站的内容不断更新,保证网站的排名能够持续攀升,闪灵cms@ >采集内部预设了六套网站内容时间段更新计划。以便随时访问网站以获取最新信息。这让网站整体的更新更加流畅有序,而不是感觉频繁而仓促。从采集到发布,是时候根据网站的用户画像和习惯及时发布内容了。
互联网上的内容风格多种多样,以满足网站对各种信息的提取和整合。Shiningcms采集充分考虑了各种情况下的信息提取,充分考虑了各个生产环节可能出现的情况。从网站的登录、数据提交、链接转换、代码转换、信息提取、字段内容排序、内容过滤、数据发布和附件提取等,所有的链接都已经处理完毕。从 采集 到发布的整个过程都是为了让 网站 快速转换。
闪灵cms采集已经采取了九个步骤来确保网站能够正常工作。频道过期内容自动回收、频道内各类内容数据限制、每日发布限制、附件自动上传和删除、每个频道的附件自设置路径、自动内容采集铰链和发布分页,多编辑、联合审阅、频道无限分类发布、频道动静发布自由设置等九大措施,让网站操作越来越轻松。以后不用再关注内容编辑和搜索,只关注网站的运营推广和网站的SEO优化。
如果用传统的手册来采集几个目标的相关信息网站,由于缺乏技术手段,手段完全是手动的,无法保证更新内容。每天可以采集的有效文章数量非常有限。
通过闪耀cms采集覆盖网站关键词,并在网上自动识别采集,并通过发布界面自动发布文章和图片发布到 网站。小编做过测试,文章通过25个设置抓取文章的数量每天可以达到几十万篇。
闪灵cms采集可以直接部署到本地,从而突破网站空间不能采集的限制。然后点击内容采集,无需复杂配置即可实现采集。再加上7*24h无间隙工作,运行后可连续工作,持续提供内容。结合内置的高级语言处理和机器深度学习,可以突破优质内容,跟随用户阅读习惯,模仿手工编辑,提供优质内容。 查看全部
根据关键词文章采集系统(闪灵CMS采集内部预置六套网站内容时间段更新方案(图))
闪灵cms采集,为了保证网站的内容不断更新,保证网站的排名能够持续攀升,闪灵cms@ >采集内部预设了六套网站内容时间段更新计划。以便随时访问网站以获取最新信息。这让网站整体的更新更加流畅有序,而不是感觉频繁而仓促。从采集到发布,是时候根据网站的用户画像和习惯及时发布内容了。
互联网上的内容风格多种多样,以满足网站对各种信息的提取和整合。Shiningcms采集充分考虑了各种情况下的信息提取,充分考虑了各个生产环节可能出现的情况。从网站的登录、数据提交、链接转换、代码转换、信息提取、字段内容排序、内容过滤、数据发布和附件提取等,所有的链接都已经处理完毕。从 采集 到发布的整个过程都是为了让 网站 快速转换。
闪灵cms采集已经采取了九个步骤来确保网站能够正常工作。频道过期内容自动回收、频道内各类内容数据限制、每日发布限制、附件自动上传和删除、每个频道的附件自设置路径、自动内容采集铰链和发布分页,多编辑、联合审阅、频道无限分类发布、频道动静发布自由设置等九大措施,让网站操作越来越轻松。以后不用再关注内容编辑和搜索,只关注网站的运营推广和网站的SEO优化。
如果用传统的手册来采集几个目标的相关信息网站,由于缺乏技术手段,手段完全是手动的,无法保证更新内容。每天可以采集的有效文章数量非常有限。
通过闪耀cms采集覆盖网站关键词,并在网上自动识别采集,并通过发布界面自动发布文章和图片发布到 网站。小编做过测试,文章通过25个设置抓取文章的数量每天可以达到几十万篇。
闪灵cms采集可以直接部署到本地,从而突破网站空间不能采集的限制。然后点击内容采集,无需复杂配置即可实现采集。再加上7*24h无间隙工作,运行后可连续工作,持续提供内容。结合内置的高级语言处理和机器深度学习,可以突破优质内容,跟随用户阅读习惯,模仿手工编辑,提供优质内容。
根据关键词文章采集系统(从细节出发做好优化流程当中进行优化解决大部分用户问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-02 09:14
文章采集器,非常方便站长在自己是站长的时候,自动从全平台采集相关的文章,然后经过二次创建过程,自动批量发布到 网站@ > 上。不管是什么类型的站点,各种cms都可以实现,即使只有一个站点或者是大型的站群,都可以通过这种方式进行内容更新。某种意义上解放了站长的双手,提高了网站@>本身的效率,还可以自动进行SEO优化。
在使用文章采集器之前,一定要做好网站@>的结构,这样蜘蛛才能循着线索抓到每一页,保证每一页都是活链接,并且死链接是非常有害的,吓跑蜘蛛是不好的。当你做 网站@> 时,不要做死链接。网站@> 的结构不要太复杂。这只是一个简单的 3 层。主页-列页面-文章。保证 网站@> 结构的纯度。这样的结构已经成为一种刻板印象,也方便蜘蛛抓取。
关注网站@>的用户体验,把它做好,网站@>更快,更多优化。速度上去,不仅用户用起来舒服,蜘蛛也能快速抓取,速度也是网页评价的因素之一。那么就关系到服务器的质量和域名解析的速度。有很多新手刚接触互联网,总是喜欢便宜和免费的东西。让我在这里说点什么。免费永远是最贵的。知识。
一个网站@>参与排名最多的是内容页,内容页也是网站@>页数最多的地方。文章采集器可以让大部分网站@>站长所有关键词参与排名,那我们就要从内容页入手,优化一个网站@>内容页面占据更多的关键词排名。排名取决于综合得分。如何让你的网站@>综合得分更高,那我们就要从细节入手进行优化,在我们的优化过程中规划好每一个需要优化的页面,从而解决大部分用户的问题问题。
网站@>优化排名的根本原因,记住文章采集器去采集内容的目的主要是为了解决用户问题。文章采集器采集的内容符合搜索引擎目标,有助于页面的收录,有利于获取大量长尾< @关键词 排名,并提高页面Score的质量。
文章采集器采集收到的内容已经重新整理,内容也进行了细化。解决用户的问题,通过这几点:匹配度,围绕标题解决用户的问题。具有完整性,可以彻底解决用户的问题。在解决用户问题的前提下,像文章这样的搜索引擎,字数多,内容量大。有吸引力,具有营销转化意识,文章可以吸引用户观看。内容有稀缺性,原创,差异,文章在同等条件下,能更好的解决问题。版面漂亮,布局不错,文章结构不影响用户阅读。图片优化,大小,原创图片,alt,与文字相关。
以上就是小编今天分享的关于采集器的文章。通过这篇文章,站长可以了解采集的方法和方法,以及采集站需要改进的地方毕竟SEO是一个全球性的工作协作,而不是仅仅依靠一个达到一定的效果。 查看全部
根据关键词文章采集系统(从细节出发做好优化流程当中进行优化解决大部分用户问题)
文章采集器,非常方便站长在自己是站长的时候,自动从全平台采集相关的文章,然后经过二次创建过程,自动批量发布到 网站@ > 上。不管是什么类型的站点,各种cms都可以实现,即使只有一个站点或者是大型的站群,都可以通过这种方式进行内容更新。某种意义上解放了站长的双手,提高了网站@>本身的效率,还可以自动进行SEO优化。
在使用文章采集器之前,一定要做好网站@>的结构,这样蜘蛛才能循着线索抓到每一页,保证每一页都是活链接,并且死链接是非常有害的,吓跑蜘蛛是不好的。当你做 网站@> 时,不要做死链接。网站@> 的结构不要太复杂。这只是一个简单的 3 层。主页-列页面-文章。保证 网站@> 结构的纯度。这样的结构已经成为一种刻板印象,也方便蜘蛛抓取。
关注网站@>的用户体验,把它做好,网站@>更快,更多优化。速度上去,不仅用户用起来舒服,蜘蛛也能快速抓取,速度也是网页评价的因素之一。那么就关系到服务器的质量和域名解析的速度。有很多新手刚接触互联网,总是喜欢便宜和免费的东西。让我在这里说点什么。免费永远是最贵的。知识。
一个网站@>参与排名最多的是内容页,内容页也是网站@>页数最多的地方。文章采集器可以让大部分网站@>站长所有关键词参与排名,那我们就要从内容页入手,优化一个网站@>内容页面占据更多的关键词排名。排名取决于综合得分。如何让你的网站@>综合得分更高,那我们就要从细节入手进行优化,在我们的优化过程中规划好每一个需要优化的页面,从而解决大部分用户的问题问题。
网站@>优化排名的根本原因,记住文章采集器去采集内容的目的主要是为了解决用户问题。文章采集器采集的内容符合搜索引擎目标,有助于页面的收录,有利于获取大量长尾< @关键词 排名,并提高页面Score的质量。
文章采集器采集收到的内容已经重新整理,内容也进行了细化。解决用户的问题,通过这几点:匹配度,围绕标题解决用户的问题。具有完整性,可以彻底解决用户的问题。在解决用户问题的前提下,像文章这样的搜索引擎,字数多,内容量大。有吸引力,具有营销转化意识,文章可以吸引用户观看。内容有稀缺性,原创,差异,文章在同等条件下,能更好的解决问题。版面漂亮,布局不错,文章结构不影响用户阅读。图片优化,大小,原创图片,alt,与文字相关。
以上就是小编今天分享的关于采集器的文章。通过这篇文章,站长可以了解采集的方法和方法,以及采集站需要改进的地方毕竟SEO是一个全球性的工作协作,而不是仅仅依靠一个达到一定的效果。
根据关键词文章采集系统(八方资源网网站优化*步,就是关键词分析分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-02-27 14:24
八方资源网
网站优化步骤是关键词分析。从展示到发现,一个网站是用户在搜索引擎上搜索关键词,然后锁定相关产品并确认他们的意图。这也使得关键词成为优化的重点之一,不同的关键词带来的展示量和点击量肯定是不一样的,所以关键词分析要先于优化,同时也要重点关注优化。当客户添加产品关键词时,会通过“大数据”进行分析,为用户提供更多的长尾关键词。比如“中国移动电子商务”、“中国移动和宝”、“中国移动和宝官方网站”等,并优化这些词,改进关键词中的<
SEO,英文“SearchEngineOptimization”,中文翻译为“搜索引擎优化”。我们一般将其定义为:
SEO是指在了解搜索引擎自然排名机制的基础上,对网站进行内外部调整优化,提升网站在搜索引擎中的关键词自然排名,获得更多流量,从而达到网站pin的目的。
一般来说,SEO网站的优化包括站内优化和站外优化。内部优化是指对网站本身所有站长可以控制的调整,如网站结构、页面HTML代码等。场外优化是指外部链接建设和行业参与互动。顾名思义,这些活动并不是在 网站 本身中进行的。无论是站内优化还是站外优化,最终目的都是为了做出更有价值的页面收录并被搜索引擎收录。
其实这和我们运营商希望我们的内容被更多人看到是类似的。
1、企业名称和服务项目命名,做搜索引擎优化的人在为公司选择关键词时,会重点关注公司的主要产品或服务。这不是一个糟糕的选择,但是当你选择完成产品时,你是不是最渴望知道产品的背景,也就是它的制造商?因此,在选择关键词时,选择公司或公司名称也尤为重要。对你来说,看公司名称和看公司招牌一样重要,而公众品牌的形象就是招牌。而且公司名称的关键字竞争并不那么激烈,因此忘记一个企业或公司名称将是一个很大的损失。
2、换个角度思考,通常有一句老生常谈的说法,那就是:“站在客户的角度想问题,从客户的角度出发”这句话适用于很多地方,这里也不例外。想想如果你在浏览网站会用什么关键词来搜索,然后做个调查看看大家都在用什么关键词,花不了多少时间就很有价值了信息。
3、长尾关键词,关键词不要错过长尾关键词,因为长尾关键词浏览目的性高,容易客户阅读访问的内容是不容忽视和低估的。
4、关键词 的巧合,关键词 的搜索有时可能是错误的,因为人类拼写和同音字使得 关键词 可用于搜索。如:“菜单”和“复活节彩蛋”。
5、regional关键词、关键词也有一定的区域搜索选项。如果你的产品关键词有太多的竞争目标,你就不能避免使用区域性的词。附在产品关键词的正面,让你的目标客户更准确、更清晰地搜索到你的网站,也减少了不必要的竞争。可谓一石二鸟。
站长工具:站长在建站时用来帮助网站质量查询和制作的一些工具,简称站长工具。微信上主要有网页工具箱、flash工具箱、终端工具箱、站长工具。
量身定制优化建议,精准拓展潜词,清晰营销痛点。要想系统地优化,还必须充分把握账户本身的问题。为了更好地制定关键词优化建议,账号优化工具首先结合账号历史投放数据和网站流量数据,从展示量、转化率等方面对账号进行系统分析。诊断。通过分析发现关键词的扩展维度存在一定的局限性。就相关行业词汇的传统关键词而言,展示量和转化量是有限的。如何合理、准确地扩展关键词成为首要问题。根据分析诊断报告,通过搜索词数据360分析、转化数据360分析、网盾搜索数据、相似账号购买词数据、广告点击日志挖掘数据等多方数据, 关键词 是定制的。定制的潜在词扩展计划。“评估风险”、“项目评估报告”、“评估报告公司”等22个行业潜力词综合流量。为什么它是一个“潜在的词”?这里是关键词推广的一个小技巧:在关键词的选择中,可以根据客户的需求,重点推荐有潜力的词。因为潜在词不仅可以保证展示次数,
招标建议全面落实,精准投放效果出炉
考虑到投标价格对交货时间的敏感性,工具系统根据行业内关键词的历史展示数据,利用不同时间、不同港口的展示数据和交货数据,制定清晰可行的投标建议为帐户。这里还有一个小技巧:在360点景平台进行出价调整时,工具会针对不同的关键词提供不同的目标出价位置和出价建议,但根据客户需求,一般建议采用左边** 。正因为如此,竞争性广告会在**中展示,转化量和点击量会更好。
转化效果是有保证的,因为360搜索账号优化不是“一次性”的账号投放工具,而是不断评估优化的升级投放系统。每次交付后,该工具都会对交付数据和建议效果进行综合评估。以后账号会有更好的呈现
站长工具:站长在建站时用来帮助网站质量查询和制作的一些工具,简称站长工具。微信上主要有网页工具箱、flash工具箱、终端工具箱、站长工具。常用的站长工具包括:链接查询工具、PR查询工具、搜索引擎收录查询工具、关键词排名查询工具、网站流量统计等。站长工具是站长的工具。经常去站长工具了解SEO数据变化。还可以检测网站死链接、蜘蛛访问、HTML格式检测、网站速度测试、友好链接检查、网站域名IP查询、PR、权重查询、alexa、whois查询, 等等。 。词库网络: 是一个 seo关键词 工具,专门从事 网站关键词 分析。分为长尾词库、投标词库、流行关键词库、行业关键词库和网站词库等,也预测流行关键词。关键词Planner:百度推广工具里面有一个关键词planner,也是一个seo关键词工具,可以用来关键词扩展,关键词@ > 策划者还可以查询关键词的日均搜索量和竞争强度。爱站Toolkit:这是一款免费的网站seo分析工具软件,主要包括百度外链助手、关键词监控、收录速率/死链接检测、远程排名、< @关键词挖矿、站群查询、日志分析、工具箱等功能。:索宁。com目前由百度收录批量查询、百度关键词排名批量查询、360收录批量查询、360关键词排名批量查询、关键词覆盖查询、 关键词由排名趋势监测、论坛网址提取、收录查询chrome插件版等工具组成。优采云采集器:优采云采集器是一款功能强大且易于使用的专业采集软件,具有强大的内容采集和数据导入功能可以将你的采集的任意网页数据发布到远程服务器,自定义usercms系统模块,无论你的网站是什么系统,都可以使用优采云@ > 采集器,系统自带的模块文件支持:风讯文章,东一文章,东一论坛,PHPWIND论坛,
无论是活动运营还是内容运营,触达的用户越多,能为我们的产品带来的价值就越大。(原因一般来说,因为如果用户不匹配,即使用户基数很大,转化率太低,最终的有效用户数也会是**。)
无论是网站的结构调整,页面优化,还是站外的外链搭建,都会涉及到的一个技巧就是关键词的优化。这正是我们的运营商可以使用的。
1.为什么要优化关键词
不同于专业的SEOer对整个网站进行优化,需要对关键词进行系统的研究,从而达到保证关键词人搜索的目的,降低优化难度,找到有效的流量,并实现搜索多样性,发现新的关键词等等。
我们运营商的关键词优化一般只涉及我们的竞选文案或者文章之一,所以我们只有一个目的,就是让我们的文案/文章更多的人看到。
1、关键词**定位:SEO关键词的**定位*是一个重要的部分。分析和定位@>与网站、关键词index、关键词排列、关键词排名等关键词的相关性。2、网站结构分析:简洁网站符合搜索引擎爬虫偏好的结构有利于SEO。减少搜索引擎无法识别的代码,实现树状目录结构,网站导航和链接优化。3、网站子页面优化:SEO不仅可以让网站首页在搜索引擎中有很好的排名,还可以让网站的每个页面都带来流量。根据公司需要规划目录分类页面,使特殊页面排在第一位。4:内容发布和链接布局:搜索引擎喜欢高质量的 网站 内容。网站建立后,会持续更新与关键词匹配的优质内容,并计划每天的内容发布任务量。优化网站内的链接布局,将整个网站的内容有机地联系起来,让搜索引擎了解关键词和每个网页的重要性。拓展站外友情链接,提升网站的影响力。5:实时监控优化:搜索引擎的权重排名算法和规则不断变化。我们可以检查SEO在搜索引擎中的效果。通过site:您的域名,我们可以知道网站的收录和更新状态。使用流量分析工具分析< @网站到具体页面,实时监控优化效果,制定下一步SEO策略。同时对网站的用户体验优化也有指导意义。
1、SEO其实就是为网友提供一个优秀的信息解决方案,满足搜索引擎用户的需求,不仅基于排名,更不局限于流量和转化率,以实质性的信息满足用户,从而在增加用户粘性网站的量,迎合搜索引擎算法,不断改进和改进网站。其中的问题需要SEO的不断跟进和改进。2、学习思维模式主要是为了更好的应用在网站,提升网站排名和用户体验,满足搜索引擎排名机制,灵活掌握SEO*思维和操作方法,其实网站形成了一个基于流量和数据的模型,而掌握SEO思维的SEOer,基本上就有机会走在更多的SEOer面前。最根本的是应用他们所学的知识并推断出其他的东西。3、优化思路对于很多SEO来说是模糊的
过去,搜索推广就像“盲人摸象”。虽然预算充足,但面对五花八门的关键词不知道怎么扩张,不知道怎么优化账户,也不知道关键词底价,这个预算总是不可能花费。
账户运营时间成本高。一般的搜索推广投放平台总是设计的可选品类太多,投放端口太多,难以理解且容易出错。即使对于专业的优化人员来说,搜索推广的账户运营时间成本仍然很高。针对企业数据咨询行业市场的现状以及搜索关键词上线遇到的困难,360依托新上线的账号优化工具,想出了一套有潜力的关键词@ > 词扩展 + * 出价建议 = 省时有效的搜索帐户优化解决方案。
随着互联网竞争的不断提升,越来越多的企业重视网络渠道的推广。除了最近的热播剧《猎场》,剧中提到的胡歌的“优化网络工程师(SEO)”让更多人知道了SEO的作用和好处。网站要上首页,要进入网站,提高用户的好感度和信任度,做SEO的好处真的很多。
.如何找到 关键词
既然说关键词优化的目的就是让更多人看到。然后我们在寻找一个更基本的关键词目标:
“搜索此 关键词 的用户群足够大”。
只有这样,我们的 文章 才会在他们搜索这些字词时被视为转化。否则,如果我们选择一个没人关心的关键词进行优化,即使这个关键词的搜索页面排名**,也不会出现曝光。
当然,还有一个原则要遵循:
“我们选择的 关键词 必须与我们的 文章(产品)主题相关”。
按照目前的搜索引擎规则,他的排名考虑了文章关键词与用户搜索词的匹配度以及文章关键词与话题的相关度。.
这两个条件是我们选择关键词的基本标准。而我们确定关键词的热度(即搜索用户群)可以参考百度指数。
以流行的“以人民的名义”为例,以下图片均来自“百度索引”。
-/gjicjf/- 查看全部
根据关键词文章采集系统(八方资源网网站优化*步,就是关键词分析分析)
八方资源网
网站优化步骤是关键词分析。从展示到发现,一个网站是用户在搜索引擎上搜索关键词,然后锁定相关产品并确认他们的意图。这也使得关键词成为优化的重点之一,不同的关键词带来的展示量和点击量肯定是不一样的,所以关键词分析要先于优化,同时也要重点关注优化。当客户添加产品关键词时,会通过“大数据”进行分析,为用户提供更多的长尾关键词。比如“中国移动电子商务”、“中国移动和宝”、“中国移动和宝官方网站”等,并优化这些词,改进关键词中的<
SEO,英文“SearchEngineOptimization”,中文翻译为“搜索引擎优化”。我们一般将其定义为:
SEO是指在了解搜索引擎自然排名机制的基础上,对网站进行内外部调整优化,提升网站在搜索引擎中的关键词自然排名,获得更多流量,从而达到网站pin的目的。
一般来说,SEO网站的优化包括站内优化和站外优化。内部优化是指对网站本身所有站长可以控制的调整,如网站结构、页面HTML代码等。场外优化是指外部链接建设和行业参与互动。顾名思义,这些活动并不是在 网站 本身中进行的。无论是站内优化还是站外优化,最终目的都是为了做出更有价值的页面收录并被搜索引擎收录。
其实这和我们运营商希望我们的内容被更多人看到是类似的。
1、企业名称和服务项目命名,做搜索引擎优化的人在为公司选择关键词时,会重点关注公司的主要产品或服务。这不是一个糟糕的选择,但是当你选择完成产品时,你是不是最渴望知道产品的背景,也就是它的制造商?因此,在选择关键词时,选择公司或公司名称也尤为重要。对你来说,看公司名称和看公司招牌一样重要,而公众品牌的形象就是招牌。而且公司名称的关键字竞争并不那么激烈,因此忘记一个企业或公司名称将是一个很大的损失。
2、换个角度思考,通常有一句老生常谈的说法,那就是:“站在客户的角度想问题,从客户的角度出发”这句话适用于很多地方,这里也不例外。想想如果你在浏览网站会用什么关键词来搜索,然后做个调查看看大家都在用什么关键词,花不了多少时间就很有价值了信息。
3、长尾关键词,关键词不要错过长尾关键词,因为长尾关键词浏览目的性高,容易客户阅读访问的内容是不容忽视和低估的。
4、关键词 的巧合,关键词 的搜索有时可能是错误的,因为人类拼写和同音字使得 关键词 可用于搜索。如:“菜单”和“复活节彩蛋”。
5、regional关键词、关键词也有一定的区域搜索选项。如果你的产品关键词有太多的竞争目标,你就不能避免使用区域性的词。附在产品关键词的正面,让你的目标客户更准确、更清晰地搜索到你的网站,也减少了不必要的竞争。可谓一石二鸟。
站长工具:站长在建站时用来帮助网站质量查询和制作的一些工具,简称站长工具。微信上主要有网页工具箱、flash工具箱、终端工具箱、站长工具。
量身定制优化建议,精准拓展潜词,清晰营销痛点。要想系统地优化,还必须充分把握账户本身的问题。为了更好地制定关键词优化建议,账号优化工具首先结合账号历史投放数据和网站流量数据,从展示量、转化率等方面对账号进行系统分析。诊断。通过分析发现关键词的扩展维度存在一定的局限性。就相关行业词汇的传统关键词而言,展示量和转化量是有限的。如何合理、准确地扩展关键词成为首要问题。根据分析诊断报告,通过搜索词数据360分析、转化数据360分析、网盾搜索数据、相似账号购买词数据、广告点击日志挖掘数据等多方数据, 关键词 是定制的。定制的潜在词扩展计划。“评估风险”、“项目评估报告”、“评估报告公司”等22个行业潜力词综合流量。为什么它是一个“潜在的词”?这里是关键词推广的一个小技巧:在关键词的选择中,可以根据客户的需求,重点推荐有潜力的词。因为潜在词不仅可以保证展示次数,
招标建议全面落实,精准投放效果出炉
考虑到投标价格对交货时间的敏感性,工具系统根据行业内关键词的历史展示数据,利用不同时间、不同港口的展示数据和交货数据,制定清晰可行的投标建议为帐户。这里还有一个小技巧:在360点景平台进行出价调整时,工具会针对不同的关键词提供不同的目标出价位置和出价建议,但根据客户需求,一般建议采用左边** 。正因为如此,竞争性广告会在**中展示,转化量和点击量会更好。
转化效果是有保证的,因为360搜索账号优化不是“一次性”的账号投放工具,而是不断评估优化的升级投放系统。每次交付后,该工具都会对交付数据和建议效果进行综合评估。以后账号会有更好的呈现
站长工具:站长在建站时用来帮助网站质量查询和制作的一些工具,简称站长工具。微信上主要有网页工具箱、flash工具箱、终端工具箱、站长工具。常用的站长工具包括:链接查询工具、PR查询工具、搜索引擎收录查询工具、关键词排名查询工具、网站流量统计等。站长工具是站长的工具。经常去站长工具了解SEO数据变化。还可以检测网站死链接、蜘蛛访问、HTML格式检测、网站速度测试、友好链接检查、网站域名IP查询、PR、权重查询、alexa、whois查询, 等等。 。词库网络: 是一个 seo关键词 工具,专门从事 网站关键词 分析。分为长尾词库、投标词库、流行关键词库、行业关键词库和网站词库等,也预测流行关键词。关键词Planner:百度推广工具里面有一个关键词planner,也是一个seo关键词工具,可以用来关键词扩展,关键词@ > 策划者还可以查询关键词的日均搜索量和竞争强度。爱站Toolkit:这是一款免费的网站seo分析工具软件,主要包括百度外链助手、关键词监控、收录速率/死链接检测、远程排名、< @关键词挖矿、站群查询、日志分析、工具箱等功能。:索宁。com目前由百度收录批量查询、百度关键词排名批量查询、360收录批量查询、360关键词排名批量查询、关键词覆盖查询、 关键词由排名趋势监测、论坛网址提取、收录查询chrome插件版等工具组成。优采云采集器:优采云采集器是一款功能强大且易于使用的专业采集软件,具有强大的内容采集和数据导入功能可以将你的采集的任意网页数据发布到远程服务器,自定义usercms系统模块,无论你的网站是什么系统,都可以使用优采云@ > 采集器,系统自带的模块文件支持:风讯文章,东一文章,东一论坛,PHPWIND论坛,
无论是活动运营还是内容运营,触达的用户越多,能为我们的产品带来的价值就越大。(原因一般来说,因为如果用户不匹配,即使用户基数很大,转化率太低,最终的有效用户数也会是**。)
无论是网站的结构调整,页面优化,还是站外的外链搭建,都会涉及到的一个技巧就是关键词的优化。这正是我们的运营商可以使用的。
1.为什么要优化关键词
不同于专业的SEOer对整个网站进行优化,需要对关键词进行系统的研究,从而达到保证关键词人搜索的目的,降低优化难度,找到有效的流量,并实现搜索多样性,发现新的关键词等等。
我们运营商的关键词优化一般只涉及我们的竞选文案或者文章之一,所以我们只有一个目的,就是让我们的文案/文章更多的人看到。
1、关键词**定位:SEO关键词的**定位*是一个重要的部分。分析和定位@>与网站、关键词index、关键词排列、关键词排名等关键词的相关性。2、网站结构分析:简洁网站符合搜索引擎爬虫偏好的结构有利于SEO。减少搜索引擎无法识别的代码,实现树状目录结构,网站导航和链接优化。3、网站子页面优化:SEO不仅可以让网站首页在搜索引擎中有很好的排名,还可以让网站的每个页面都带来流量。根据公司需要规划目录分类页面,使特殊页面排在第一位。4:内容发布和链接布局:搜索引擎喜欢高质量的 网站 内容。网站建立后,会持续更新与关键词匹配的优质内容,并计划每天的内容发布任务量。优化网站内的链接布局,将整个网站的内容有机地联系起来,让搜索引擎了解关键词和每个网页的重要性。拓展站外友情链接,提升网站的影响力。5:实时监控优化:搜索引擎的权重排名算法和规则不断变化。我们可以检查SEO在搜索引擎中的效果。通过site:您的域名,我们可以知道网站的收录和更新状态。使用流量分析工具分析< @网站到具体页面,实时监控优化效果,制定下一步SEO策略。同时对网站的用户体验优化也有指导意义。
1、SEO其实就是为网友提供一个优秀的信息解决方案,满足搜索引擎用户的需求,不仅基于排名,更不局限于流量和转化率,以实质性的信息满足用户,从而在增加用户粘性网站的量,迎合搜索引擎算法,不断改进和改进网站。其中的问题需要SEO的不断跟进和改进。2、学习思维模式主要是为了更好的应用在网站,提升网站排名和用户体验,满足搜索引擎排名机制,灵活掌握SEO*思维和操作方法,其实网站形成了一个基于流量和数据的模型,而掌握SEO思维的SEOer,基本上就有机会走在更多的SEOer面前。最根本的是应用他们所学的知识并推断出其他的东西。3、优化思路对于很多SEO来说是模糊的
过去,搜索推广就像“盲人摸象”。虽然预算充足,但面对五花八门的关键词不知道怎么扩张,不知道怎么优化账户,也不知道关键词底价,这个预算总是不可能花费。
账户运营时间成本高。一般的搜索推广投放平台总是设计的可选品类太多,投放端口太多,难以理解且容易出错。即使对于专业的优化人员来说,搜索推广的账户运营时间成本仍然很高。针对企业数据咨询行业市场的现状以及搜索关键词上线遇到的困难,360依托新上线的账号优化工具,想出了一套有潜力的关键词@ > 词扩展 + * 出价建议 = 省时有效的搜索帐户优化解决方案。
随着互联网竞争的不断提升,越来越多的企业重视网络渠道的推广。除了最近的热播剧《猎场》,剧中提到的胡歌的“优化网络工程师(SEO)”让更多人知道了SEO的作用和好处。网站要上首页,要进入网站,提高用户的好感度和信任度,做SEO的好处真的很多。
.如何找到 关键词
既然说关键词优化的目的就是让更多人看到。然后我们在寻找一个更基本的关键词目标:
“搜索此 关键词 的用户群足够大”。
只有这样,我们的 文章 才会在他们搜索这些字词时被视为转化。否则,如果我们选择一个没人关心的关键词进行优化,即使这个关键词的搜索页面排名**,也不会出现曝光。
当然,还有一个原则要遵循:
“我们选择的 关键词 必须与我们的 文章(产品)主题相关”。
按照目前的搜索引擎规则,他的排名考虑了文章关键词与用户搜索词的匹配度以及文章关键词与话题的相关度。.
这两个条件是我们选择关键词的基本标准。而我们确定关键词的热度(即搜索用户群)可以参考百度指数。
以流行的“以人民的名义”为例,以下图片均来自“百度索引”。
-/gjicjf/-
根据关键词文章采集系统(文章采集系统哪个排名靠前,给稿费给高价就上哪家)
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-02-26 05:05
根据关键词文章采集系统一下
哪个排名靠前,给稿费给高价就上哪家。目前国内网络媒体还是很缺专门写文章的专家、作家。当然,你要不嫌他们的稿费太低也可以自己做网站,毕竟只是一个软件而已。
好的软件,少用百度去搜,用360和谷歌。你连最基本的文章采集都没弄懂。我大概知道一点,一些专门做文章采集的公司也可以做,像通用的adwesome,puffer,它们网站不需要申请,只要提供文章名称,链接,问题,收录数量,问题,链接,就可以采集,数据统计。至于其他,就是百度去搜。
考虑下建立一个公众号,每篇文章只要一元钱。
目前在国内软件比较多,主要大的分两种,第一种专门做文章数据采集,以安徽百乐虎为代表,这种主要针对学生群体,因为他们针对学生进行收费,第二种就是大众化软件,那么主要以我目前公司做的一个软件为例,叫disqus,小众软件,对于开发能力高低,语言掌握熟练程度各方面有要求。如果没有软件,在未来5年内也许很难在网络上广泛推广。
edius3目前被比较多的文章数据采集公司采用,
建议用国外的产品,
推荐一个公众号【附件下载器】,工具包小小的,数据采集量大,价格也适中,搜索前段时间看到很多软件报价,都是要另外收费,如果找上家帮着找的话,价格都在35元到100元不等,重要的是有人盯着,你下载的东西被删了一个也别怀疑。 查看全部
根据关键词文章采集系统(文章采集系统哪个排名靠前,给稿费给高价就上哪家)
根据关键词文章采集系统一下
哪个排名靠前,给稿费给高价就上哪家。目前国内网络媒体还是很缺专门写文章的专家、作家。当然,你要不嫌他们的稿费太低也可以自己做网站,毕竟只是一个软件而已。
好的软件,少用百度去搜,用360和谷歌。你连最基本的文章采集都没弄懂。我大概知道一点,一些专门做文章采集的公司也可以做,像通用的adwesome,puffer,它们网站不需要申请,只要提供文章名称,链接,问题,收录数量,问题,链接,就可以采集,数据统计。至于其他,就是百度去搜。
考虑下建立一个公众号,每篇文章只要一元钱。
目前在国内软件比较多,主要大的分两种,第一种专门做文章数据采集,以安徽百乐虎为代表,这种主要针对学生群体,因为他们针对学生进行收费,第二种就是大众化软件,那么主要以我目前公司做的一个软件为例,叫disqus,小众软件,对于开发能力高低,语言掌握熟练程度各方面有要求。如果没有软件,在未来5年内也许很难在网络上广泛推广。
edius3目前被比较多的文章数据采集公司采用,
建议用国外的产品,
推荐一个公众号【附件下载器】,工具包小小的,数据采集量大,价格也适中,搜索前段时间看到很多软件报价,都是要另外收费,如果找上家帮着找的话,价格都在35元到100元不等,重要的是有人盯着,你下载的东西被删了一个也别怀疑。
根据关键词文章采集系统(编辑本段文章采集系统过程相关资料功能的开发工具使用.Net)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-02-23 13:01
文章采集系统由你(我的世界I采集net)开发,历时4年。在线信息采集系统根据用户定义关键词相关数据从互联网上调取,对数据进行合理的截取、分类、去重和过滤,并以文件或文件的形式保存数据库。
目录文章采集系统流程相关数据功能解读展开文章采集系统流程相关数据功能解读展开编辑本段文章采集系统流程系统开发工具使用.Net的C#开发系统,数据库使用SQL Server 2000。一、软件系统总体设计要求1.当网站搜索深度为5层,网站搜索宽度为50个网页,数据召回率达到98%。2.当网站的搜索深度为5层,网站的搜索宽度为50个网页时,数据准确率大于97%。3.数据存储容量:存储容量≥100G。4.在单个 网站 上搜索时,网站 搜索深度:最大 5 级网页;网站搜索广度:最多搜索 50 个网页。如果超过 60 秒没有结果,搜索将自动放弃。5.并发搜索强度:10个线程可以同时并发搜索。6.5亿汉字的平均查询时间不到3秒。二、应用系统设计要求1.要求系统能够执行多线程采集信息;2.自动分类和索引记录;3.自动过滤重复并自动索引Records;三、应用系统功能详解实时在线采集(内容抓取模块) 快速:网页抓取采用多线程并发搜索技术,并且可以设置最大并发线程数。灵活:可同时跟踪和抓取多个网站,为栏目或频道提供灵活的网站、采集策略,利用逻辑关系定位采集内容.
准确性:或多或少,可以自定义要抓取的文件格式,可以抓取图片和表格信息。捕获过程成熟可靠,容错能力强,初始设置完成后可长时间稳定运行。高效的自动分类支持机检分类——可以使用预定义的关键词和规则方法来确定类别;支持自动分类——通过机器自动学习或预学习进行自动分类,准确率达到80%以上。(这个比较麻烦,可以考虑不做)支持多种分类标准——如按地区(华北、华南等)、按内容(政治、科技、军事、教育等)、来源(新华网) 、人民日报、新浪网)等。自动网页分析内容过滤——可以过滤掉广告、导航信息、版权等无用信息,可以剔除反动色情内容。内容排序——对于不同的网站相同或相似的内容,可以自动识别并标记为相同,识别方式可以由用户自定义规则确定,根据内容的相似度自动确定。格式转换 - 自动将 HTML 格式转换为文本文件。自动索引——自动提取网页的标题、版本、日期、作者、栏目、分类等信息。单一界面进行系统管理集成——系统提供基于Web的用户界面和管理员界面,满足系统管理员和用户的双重需求。浏览器可用于远程管理分类、用户权限,调整和加强分类结果。完善的目录维护——对分类目录的添加、移动、修改、删除提供完善的管理维护权限管理,可设置管理目录和单个文件使用权限,加强安全管理。
<p>实时文件管理——可以浏览各个目录的分类结果,实时进行移动、重命名等调整。编辑本段相关信息使用文章采集系统,整个系统可在线自动安装,后台新版本可自动升级;系统文件损坏也可以自动修复,站长从此无忧批量指定关键词,轻松控制用户搜索行为,自动文章采集系统类内容文章采集过程中自动去除重复内容,@原创标签综合页面在全站整合了统一通用的分类标签体系,不仅使内容具有相关性,而且 查看全部
根据关键词文章采集系统(编辑本段文章采集系统过程相关资料功能的开发工具使用.Net)
文章采集系统由你(我的世界I采集net)开发,历时4年。在线信息采集系统根据用户定义关键词相关数据从互联网上调取,对数据进行合理的截取、分类、去重和过滤,并以文件或文件的形式保存数据库。
目录文章采集系统流程相关数据功能解读展开文章采集系统流程相关数据功能解读展开编辑本段文章采集系统流程系统开发工具使用.Net的C#开发系统,数据库使用SQL Server 2000。一、软件系统总体设计要求1.当网站搜索深度为5层,网站搜索宽度为50个网页,数据召回率达到98%。2.当网站的搜索深度为5层,网站的搜索宽度为50个网页时,数据准确率大于97%。3.数据存储容量:存储容量≥100G。4.在单个 网站 上搜索时,网站 搜索深度:最大 5 级网页;网站搜索广度:最多搜索 50 个网页。如果超过 60 秒没有结果,搜索将自动放弃。5.并发搜索强度:10个线程可以同时并发搜索。6.5亿汉字的平均查询时间不到3秒。二、应用系统设计要求1.要求系统能够执行多线程采集信息;2.自动分类和索引记录;3.自动过滤重复并自动索引Records;三、应用系统功能详解实时在线采集(内容抓取模块) 快速:网页抓取采用多线程并发搜索技术,并且可以设置最大并发线程数。灵活:可同时跟踪和抓取多个网站,为栏目或频道提供灵活的网站、采集策略,利用逻辑关系定位采集内容.
准确性:或多或少,可以自定义要抓取的文件格式,可以抓取图片和表格信息。捕获过程成熟可靠,容错能力强,初始设置完成后可长时间稳定运行。高效的自动分类支持机检分类——可以使用预定义的关键词和规则方法来确定类别;支持自动分类——通过机器自动学习或预学习进行自动分类,准确率达到80%以上。(这个比较麻烦,可以考虑不做)支持多种分类标准——如按地区(华北、华南等)、按内容(政治、科技、军事、教育等)、来源(新华网) 、人民日报、新浪网)等。自动网页分析内容过滤——可以过滤掉广告、导航信息、版权等无用信息,可以剔除反动色情内容。内容排序——对于不同的网站相同或相似的内容,可以自动识别并标记为相同,识别方式可以由用户自定义规则确定,根据内容的相似度自动确定。格式转换 - 自动将 HTML 格式转换为文本文件。自动索引——自动提取网页的标题、版本、日期、作者、栏目、分类等信息。单一界面进行系统管理集成——系统提供基于Web的用户界面和管理员界面,满足系统管理员和用户的双重需求。浏览器可用于远程管理分类、用户权限,调整和加强分类结果。完善的目录维护——对分类目录的添加、移动、修改、删除提供完善的管理维护权限管理,可设置管理目录和单个文件使用权限,加强安全管理。
<p>实时文件管理——可以浏览各个目录的分类结果,实时进行移动、重命名等调整。编辑本段相关信息使用文章采集系统,整个系统可在线自动安装,后台新版本可自动升级;系统文件损坏也可以自动修复,站长从此无忧批量指定关键词,轻松控制用户搜索行为,自动文章采集系统类内容文章采集过程中自动去除重复内容,@原创标签综合页面在全站整合了统一通用的分类标签体系,不仅使内容具有相关性,而且
根据关键词文章采集系统(一个运输日志监控和分析系统的特点及解决办法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-02-23 05:29
日志监控和分析对于保证业务的稳定运行起着重要的作用。但是,一般情况下,日志分散在各个生产服务器上,开发者无法登录生产服务器。在这种情况下,需要一个集中的日志采集设备。日志中的关键字被监控,异常触发报警,开发者可以查看相关日志。logstash+elasticsearch+kibana3就是实现了这样一个功能的系统,功能更强大。
logstash:是一个管理日志和事件的工具,你可以采集它们,解析它们,并存储它们以供以后使用(例如日志搜索),logstash 有一个内置的网络界面来搜索你所有的日志。Logstash 部署时有两种运行模式:独立和集中式:
* 单机:单机是指一切都运行在一台服务器上,包括日志采集、日志索引、前端WEB接口都部署在一台机器上。
* 集中式:它是一种多服务器模式,将日志从多个服务器传送到一个总日志(采集器)服务器,用于索引和搜索。
需要注意的是logstash本身并没有shipper和indexer这样的术语,因为传输日志的过程和采集总日志的过程都是运行同一个程序,只是使用的配置文件不同。
弹性搜索:
基于Lucene的开源搜索引擎是一个分布式搜索分析系统。主要功能有:实时数据、实时分析、分布式、高可用性、多租户、全文搜索、面向文档、冲突管理、无模式、restful api 等。
kibana3:
可视化日志和数据系统可以很方便的与elasticsearch系统结合作为WEB前端。Kibana 分为版本 2 和版本 3。版本 2 是用 ruby 编写的,部署起来很麻烦,需要安装很多 ruby 依赖项(目前网上部署了这个版本)。版本3是纯html+css编写的,所以部署起来很方便,解压后就可以使用了。已经是kibana4了。建议您使用最新版本。
出于性能和可扩展性的考虑,我们在实际应用中必须使用logstash的集中模式。最基本的结构图如下:
1、安装redis,安装过程比较简单,这里不再详述。
2、安装 ElasticSearch(当前版本1.4)
wget 'https://download.elasticsearch ... 39%3B
tar zxvf elasticsearch-0.90.7.tar.gz
cd elasticsearch-0.90.7/bin
#可以在logstash agent启动后再启动
./elasticsearch -f
3、启动logstash shipper,定义配置文件logstash.conf,根据实际情况,下面主要定义输入源为file,输出到redis,启动logstash shipper,例如:
input {
file {
type => "api_log"
path => "/home/jws/app/nginxserver/logs/apiaccess.log"
debug => true
}
file {
type => "cas_log"
path => "/home/jws/app/nginxserver/logs/casaccess.log"
debug => true
}
file {
type => "id_log"
path => "/home/jws/app/nginxserver/logs/idaccess.log"
debug => true
}
file {
type => "login_log"
path => "/home/jws/app/nginxserver/logs/loginaccess.log"
debug => true
}
file {
type => "proxy_log"
path => "/home/jws/app/nginxserver/logs/proxyaccess.log"
debug => true
}
}
output {
redis {
host => "10.20.164.121"
data_type => "list"
key => "logstash:redis"
}
redis {
host => "10.20.164.122"
data_type => "list"
key => "logstash:uop_file"
}
}
启动托运人:
java -jar /home/jws/htdocs/logstash/lib/logstash.jar 代理 -f /home/jws/htdocs/logstash/conf/logstash.conf -l /home/jws/htdocs/logstash/logs/logstash.log
4、启动logstash索引器
logstash 的配置文件比较简单,主要由输入、过滤器和输出三部分组成。事件按顺序出现在配置文件中。在输入、输出和过滤器中,允许您设置配置插件,由插件名称后跟插件配置代码块组成。插件中的值可以是布尔值、字符串、数字、哈希、数组等,支持条件判断(if...else)。
比如在下面配置indexer,并启动indexer:
input {
file {
path => "/home/rsyslog/asaserver/*/*/*/proxy.log.*"
exclude => "*.bz2"
type => "proxy"
}
}
filter {
grok {
match => [ "message", "%{APIPROXY}" ]
patterns_dir => ["/home/jws/app/logstash/patterns"]
}
if [request_uripath_orig]{
grok {
match => [ "request_uripath_orig", "%{NSSS}" ]
patterns_dir => ["/home/jws/app/logstash/patterns"]
}
}
}
output {
#stdout { codec =>"rubydebug"}
elasticsearch_http {
host => "10.20.161.36"
flush_size => 500
idle_flush_time => 3
index => "logstash_pf_proxy-%{+YYYY.MM.dd.HH}"
template => "/home/jws/app/logstash/template/t.json"
template_overwrite => true
}
}
5、安装并启动kibana3。安装过程与普通软件安装相同。可以用 nginx 安装。此处不再赘述。需要注意的是,需要在kibana config.js中配置elasticSearch的地址和端口。
注意红框内的内容,这只是kibana3的默认接口,我们需要将default.json接口替换为logstash.json,具体目录下的source目录下的app/dashboards。
例如,在项目中的一个示例中,根据需求制作图表(类似于饼图、条形图、折线图等)。在笔者的实际项目中,从日志中分析数据,实现系统稳定性、响应时间、请求量、业务响应代码等。、HTTP状态码等在kibana中显示;
此外,elasticsearch 的用处要小得多。它可以用作搜索数据源。ES提供了编程接口,可以在ES中通过编程获取数据来定制开发监控程序,灵活强大。
官方文档(现在都在一起):
日志存储:
弹性搜索:
基巴纳: 查看全部
根据关键词文章采集系统(一个运输日志监控和分析系统的特点及解决办法)
日志监控和分析对于保证业务的稳定运行起着重要的作用。但是,一般情况下,日志分散在各个生产服务器上,开发者无法登录生产服务器。在这种情况下,需要一个集中的日志采集设备。日志中的关键字被监控,异常触发报警,开发者可以查看相关日志。logstash+elasticsearch+kibana3就是实现了这样一个功能的系统,功能更强大。
logstash:是一个管理日志和事件的工具,你可以采集它们,解析它们,并存储它们以供以后使用(例如日志搜索),logstash 有一个内置的网络界面来搜索你所有的日志。Logstash 部署时有两种运行模式:独立和集中式:
* 单机:单机是指一切都运行在一台服务器上,包括日志采集、日志索引、前端WEB接口都部署在一台机器上。
* 集中式:它是一种多服务器模式,将日志从多个服务器传送到一个总日志(采集器)服务器,用于索引和搜索。
需要注意的是logstash本身并没有shipper和indexer这样的术语,因为传输日志的过程和采集总日志的过程都是运行同一个程序,只是使用的配置文件不同。
弹性搜索:
基于Lucene的开源搜索引擎是一个分布式搜索分析系统。主要功能有:实时数据、实时分析、分布式、高可用性、多租户、全文搜索、面向文档、冲突管理、无模式、restful api 等。
kibana3:
可视化日志和数据系统可以很方便的与elasticsearch系统结合作为WEB前端。Kibana 分为版本 2 和版本 3。版本 2 是用 ruby 编写的,部署起来很麻烦,需要安装很多 ruby 依赖项(目前网上部署了这个版本)。版本3是纯html+css编写的,所以部署起来很方便,解压后就可以使用了。已经是kibana4了。建议您使用最新版本。
出于性能和可扩展性的考虑,我们在实际应用中必须使用logstash的集中模式。最基本的结构图如下:
1、安装redis,安装过程比较简单,这里不再详述。
2、安装 ElasticSearch(当前版本1.4)
wget 'https://download.elasticsearch ... 39%3B
tar zxvf elasticsearch-0.90.7.tar.gz
cd elasticsearch-0.90.7/bin
#可以在logstash agent启动后再启动
./elasticsearch -f
3、启动logstash shipper,定义配置文件logstash.conf,根据实际情况,下面主要定义输入源为file,输出到redis,启动logstash shipper,例如:
input {
file {
type => "api_log"
path => "/home/jws/app/nginxserver/logs/apiaccess.log"
debug => true
}
file {
type => "cas_log"
path => "/home/jws/app/nginxserver/logs/casaccess.log"
debug => true
}
file {
type => "id_log"
path => "/home/jws/app/nginxserver/logs/idaccess.log"
debug => true
}
file {
type => "login_log"
path => "/home/jws/app/nginxserver/logs/loginaccess.log"
debug => true
}
file {
type => "proxy_log"
path => "/home/jws/app/nginxserver/logs/proxyaccess.log"
debug => true
}
}
output {
redis {
host => "10.20.164.121"
data_type => "list"
key => "logstash:redis"
}
redis {
host => "10.20.164.122"
data_type => "list"
key => "logstash:uop_file"
}
}
启动托运人:
java -jar /home/jws/htdocs/logstash/lib/logstash.jar 代理 -f /home/jws/htdocs/logstash/conf/logstash.conf -l /home/jws/htdocs/logstash/logs/logstash.log
4、启动logstash索引器
logstash 的配置文件比较简单,主要由输入、过滤器和输出三部分组成。事件按顺序出现在配置文件中。在输入、输出和过滤器中,允许您设置配置插件,由插件名称后跟插件配置代码块组成。插件中的值可以是布尔值、字符串、数字、哈希、数组等,支持条件判断(if...else)。
比如在下面配置indexer,并启动indexer:
input {
file {
path => "/home/rsyslog/asaserver/*/*/*/proxy.log.*"
exclude => "*.bz2"
type => "proxy"
}
}
filter {
grok {
match => [ "message", "%{APIPROXY}" ]
patterns_dir => ["/home/jws/app/logstash/patterns"]
}
if [request_uripath_orig]{
grok {
match => [ "request_uripath_orig", "%{NSSS}" ]
patterns_dir => ["/home/jws/app/logstash/patterns"]
}
}
}
output {
#stdout { codec =>"rubydebug"}
elasticsearch_http {
host => "10.20.161.36"
flush_size => 500
idle_flush_time => 3
index => "logstash_pf_proxy-%{+YYYY.MM.dd.HH}"
template => "/home/jws/app/logstash/template/t.json"
template_overwrite => true
}
}
5、安装并启动kibana3。安装过程与普通软件安装相同。可以用 nginx 安装。此处不再赘述。需要注意的是,需要在kibana config.js中配置elasticSearch的地址和端口。
注意红框内的内容,这只是kibana3的默认接口,我们需要将default.json接口替换为logstash.json,具体目录下的source目录下的app/dashboards。
例如,在项目中的一个示例中,根据需求制作图表(类似于饼图、条形图、折线图等)。在笔者的实际项目中,从日志中分析数据,实现系统稳定性、响应时间、请求量、业务响应代码等。、HTTP状态码等在kibana中显示;
此外,elasticsearch 的用处要小得多。它可以用作搜索数据源。ES提供了编程接口,可以在ES中通过编程获取数据来定制开发监控程序,灵活强大。
官方文档(现在都在一起):
日志存储:
弹性搜索:
基巴纳:
根据关键词文章采集系统(怎么用免费dede采集插件把关键词优化到首页让网站能快速收录)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-02-22 11:18
如何使用免费的dede采集插件将关键词优化到首页,使网站可以快速收录,包括所有SEO优化功能,并支持所有网站@ > 使用。在做业务网站优化的时候,经常会遇到很多问题,比如网站原创没有内容收录,收录后面没有排名,但是如果有怎么办排行?连首页都没有。因此,我们需要系统地对企业网站的优化做出很好的诊断,帮助我们调整网站的细节,更好的提高网站的权重。以下是企业网站优化诊断的三个方面,希望能帮助您更好地诊断自己的网站。
诊断前网站,教大家如何快速搭建原创高质量文章,使用免费的dede采集插件这个插件不用多学专业技能,简单几步即可轻松采集内容数据,用户只需对dede采集插件进行简单设置,完成后dede采集插件-in 会根据用户设置的关键词高精度匹配内容和图片可以保存在本地,也可以在伪原创之后发布,提供方便快捷的内容采集伪原创发布网站 @>推送服务!!
和其他dede采集插件相比,这个dede采集插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签,一分钟就能上手,只需输入关键词即可实现采集(dede采集插件也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这个dede采集插件工具也配置了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)
自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!有了这个dede采集插件,我们做网站优化,需要注意网站优化诊断三个方面
一、网站系统诊断
网站系统诊断 1
1. 空间速度
网站打开速度通常与2个方面有关:
一是页面上的图片数量,图片越多网站打开速度就会降低,所以优化网页上的图片非常重要。空间/服务器带宽太小。如果网站的流量很大,那么带宽就比较小,容易造成网站打不开,所以一般带宽的大小要根据大小来定网站 访问次数待定。影响网站速度的地方还有很多,但是随着互联网的发展和服务器配置的增加,很多影响空间速度的细节已经不再需要考虑了。
2. 网站代码
现在很多公司网站都在开发dedecms、empirecms、phpcms等开源程序,所以程序没必要多想,只需要需要考虑程序安全设置。
影响企业优化的网站就是网站页面的代码,比如table标签(已经不适用了,现在已经发展到html5了),比如js文件(最少如果不需要),如css文件(最好删除冗余代码)等。
最重要的是移动互联网的发展和html5+css3的普及,所以对于网站页面代码规范也很重要,可以帮助搜索引擎更好的识别。
网站系统诊断二
1. 网址
url要标准化,即首页URL尽量不要有index这个后缀,栏目页和文章页尽量是静态的(地址不带任何参数,如不?)。如果能更好的识别url,将进一步提高网站的优化标准,看起来非常简洁,清爽,通俗易懂。
2. 三个标签
主要是标题标签(带关键词)、关键词标签(页面关键词和页面扩展关键词)、描述标签(2-3次页面关键词) . 查看全部
根据关键词文章采集系统(怎么用免费dede采集插件把关键词优化到首页让网站能快速收录)
如何使用免费的dede采集插件将关键词优化到首页,使网站可以快速收录,包括所有SEO优化功能,并支持所有网站@ > 使用。在做业务网站优化的时候,经常会遇到很多问题,比如网站原创没有内容收录,收录后面没有排名,但是如果有怎么办排行?连首页都没有。因此,我们需要系统地对企业网站的优化做出很好的诊断,帮助我们调整网站的细节,更好的提高网站的权重。以下是企业网站优化诊断的三个方面,希望能帮助您更好地诊断自己的网站。
诊断前网站,教大家如何快速搭建原创高质量文章,使用免费的dede采集插件这个插件不用多学专业技能,简单几步即可轻松采集内容数据,用户只需对dede采集插件进行简单设置,完成后dede采集插件-in 会根据用户设置的关键词高精度匹配内容和图片可以保存在本地,也可以在伪原创之后发布,提供方便快捷的内容采集伪原创发布网站 @>推送服务!!
和其他dede采集插件相比,这个dede采集插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签,一分钟就能上手,只需输入关键词即可实现采集(dede采集插件也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这个dede采集插件工具也配置了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)
自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!有了这个dede采集插件,我们做网站优化,需要注意网站优化诊断三个方面
一、网站系统诊断
网站系统诊断 1
1. 空间速度
网站打开速度通常与2个方面有关:
一是页面上的图片数量,图片越多网站打开速度就会降低,所以优化网页上的图片非常重要。空间/服务器带宽太小。如果网站的流量很大,那么带宽就比较小,容易造成网站打不开,所以一般带宽的大小要根据大小来定网站 访问次数待定。影响网站速度的地方还有很多,但是随着互联网的发展和服务器配置的增加,很多影响空间速度的细节已经不再需要考虑了。
2. 网站代码
现在很多公司网站都在开发dedecms、empirecms、phpcms等开源程序,所以程序没必要多想,只需要需要考虑程序安全设置。
影响企业优化的网站就是网站页面的代码,比如table标签(已经不适用了,现在已经发展到html5了),比如js文件(最少如果不需要),如css文件(最好删除冗余代码)等。
最重要的是移动互联网的发展和html5+css3的普及,所以对于网站页面代码规范也很重要,可以帮助搜索引擎更好的识别。
网站系统诊断二
1. 网址
url要标准化,即首页URL尽量不要有index这个后缀,栏目页和文章页尽量是静态的(地址不带任何参数,如不?)。如果能更好的识别url,将进一步提高网站的优化标准,看起来非常简洁,清爽,通俗易懂。
2. 三个标签
主要是标题标签(带关键词)、关键词标签(页面关键词和页面扩展关键词)、描述标签(2-3次页面关键词) .
根据关键词文章采集系统(埋点埋点日志(2):文章画像存储结构(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-02-20 11:02
分享
埋藏日志数据结构如下:
{
"actionTime":"2019-04-10 18:15:35",
"readTime":"",
"channelId":0,
"param":{
"action":"exposure",
"userId":"2",
"articleId":"[18577, 14299]",
"algorithmCombine":"C2"
}
}
(2) ETL
通过 Flume 将日志定时和增量采集和结构化存储到 Hive
3. 离线构建文章 肖像
文章Portrait 就是为每个文章定义一些词。主要包括关键词和主题词。
关键词:文章 中权重较高的一些词。
主题词:归一化,出现在文章中的同义词,计算结果中出现频率高的词。
(1) 构建方法
关键词:TEXTRANK 计算的 TOPK 词和权重
主题词:TEXTRANK 的 TOPK 词与 ITFDF 计算的 TOPK 词的交集
(2) 文章图像存储结构
hive> desc article_profile;
OK
article_id int article_id
channel_id int channel_id
keywords map keywords
topics array topics
hive> select * from article_profile limit 1;
OK
26 17 {
"策略":0.3973770571351729,"jpg":0.9806348975390871,"用户":1.2794959063944176,"strong":1.6488457985625076,"文件":0.28144603583387057,"逻辑":0.45256526469610714,"形式":0.4123994242601279,"全自":0.9594604850547191,"h2":0.6244481634710125,"版本":0.44280276959510817,"Adobe":0.8553618185108718,"安装":0.8305037437573172,"检查更新":1.8088946300014435,"产品":0.774842382276899,"下载页":1.4256311032544344,"过程":0.19827163395829256,"json":0.6423301791599972,"方式":0.582762869780791,"退出应用":1.2338671268242603,"Setup":1.004399549339134} ["Electron","全自动","产品","版本号","安装包","检查更新","方案","版本","退出应用","逻辑","安装过程","方式","定性","新版本","Setup","静默","用户"]
Time taken: 0.322 seconds, Fetched: 1 row(s)
(3) 实施步骤
hive> select * from textrank_keywords_values limit 10;
OK
98319 17 var 20.6079
98323 17 var 7.4938
98326 17 var 104.9128
98344 17 var 5.6203
98359 17 var 69.3174
98360 17 var 9.3672
98392 17 var 14.9875
98393 17 var 155.4958
98406 17 var 11.2407
98419 17 var 59.9502
Time taken: 0.344 seconds, Fetched: 10 row(s)
hive> desc textrank_keywords_values;
OK
article_id int article_id
channel_id int channel_id
keyword string keyword
textrank double textrank
hive> select * from article_profile limit 1;
OK
26 17 {
"策略":0.3973770571351729,"jpg":0.9806348975390871,"用户":1.2794959063944176,"strong":1.6488457985625076,"文件":0.28144603583387057,"逻辑":0.45256526469610714,"形式":0.4123994242601279,"全自":0.9594604850547191,"h2":0.6244481634710125,"版本":0.44280276959510817,"Adobe":0.8553618185108718,"安装":0.8305037437573172,"检查更新":1.8088946300014435,"产品":0.774842382276899,"下载页":1.4256311032544344,"过程":0.19827163395829256,"json":0.6423301791599972,"方式":0.582762869780791,"退出应用":1.2338671268242603,"Setup":1.004399549339134} ["Electron","全自动","产品","版本号","安装包","检查更新","方案","版本","退出应用","逻辑","安装过程","方式","定性","新版本","Setup","静默","用户"]
Time taken: 0.322 seconds, Fetched: 1 row(s)
4. 建立线下用户画像
业内对用户画像有两种截然不同的解读:
用户角色:角色是真实用户的虚拟表示,是基于一系列真实数据的目标用户模型。通过问卷调查了解用户,根据目标、行为和观点的差异,将用户分为不同类型,从中提取典型特征,并对其进行姓名、照片、人口统计因素、场景等描述。形成了一个角色。用户角色是用户群体属性的集合,它不需要指代特定的人,而是目标群体的“特征”的组合。用户配置文件:用于描述用户数据的标签变量的集合。User Profile主要用来描述单个用户不同维度的属性,也可以用来描述一个用户组。
用户画像的核心工作是给用户打标签。标签通常是人为指定的高度精细化特征的标识符,例如年龄、地区、兴趣等。通过从不同维度对用户进行标记,我们可以得到用户的整体情况。如下图所示,一般用户画像的维度主要包括:
(1) 基本属性:指在很长一段时间内不发生变化(如性别)或不经常变化(如年龄每年增加1岁)的属性。标签的有效期更长超过一个月。
(1) 用户兴趣:指用户在一段时间内的行为倾向;例如,如果用户在过去一周内频繁搜索手机相关信息、查看手机价格对比等,假设用户有“手机”兴趣,兴趣随时间快速变化,标签时效性强,我们一般称之为短期兴趣或商业即时兴趣;如果用户长期关注宠物较多过去一段时间(比如一年以上)的相关信息,推断用户对“宠物”的喜欢有长期的兴趣。
不同的业务场景对用户画像有不同的需求。我们需要根据我们的实际业务需求,构建一个适合我们业务场景的用户画像系统。但对于年龄、性别、学历、婚姻等基础属性数据,无需为每个业务投入人力重复建设。
(1) 构建方法5. 离线构建文章功能
文章 特征包括 文章关键词 权重、文章 通道和 文章 向量,我们首先阅读 文章 肖像
文章关键词 及其权重是通过“文章 肖像”中的 TEXTRANK 获得的。本节首先通过word2vec得到文章向量,文章向量可用于计算文章相似度。
6. 构建离线用户功能7. 多次召回
召回层:负责从数百万个物品中快速找到成百上千个匹配用户兴趣的物品
排序层:负责对召回的物品进行评分和排序,从而选出用户最感兴趣的前K个物品
(1) 不同场景下常见的召回方案
召回层在缩小排序层的排序范围的同时,也决定了推荐效果的上限。如果召回的内容不够准确,即使是最强大的排名模型也无法将准确的推荐列表返回给用户。所以召回层很重要。常见的召回方法可以分为基于内容的召回和基于行为的召回。两种召回方式各有优缺点,相辅相成,提高召回质量。
目前在不同的场景下可以使用不同的召回方式:
个性化推荐离线部分(更多用户点击行为,完善用户画像)建立用户长期兴趣画像(详细):包括用户兴趣特征各维度训练排序模型离线部分召回(2)模型-基于离线召回:ALS (3) Content-Based Recall8. Sorting
分选主要分为精分选和粗分选两个阶段。两者的主要区别在于候选集的大小不同。粗排序输入候选集在1000级,细排序只有100级。候选集数量的不同决定了粗排序会有更高的性能要求。因此,特征只能选择少量粗粒度和高判别力的特征,而模型侧只能选择线性模型,或者复杂度低。深度模型。粗分选其他部分的工作与精分选类似。在这里,我们专注于精细排序。
在细排序阶段,需要对粗排序候选池中的ItemList进行评分。这个分数是针对每个用户对候选文章的点击概率的预测,即Ctr预测。每天有数千万的活跃用户在业务中。这些用户的每一次刷新、点击、转发等,都会带来海量的真实数据。我们需要使用这些海量日志进行模型训练,从而对用户偏好进行建模。
(1) CTR预测-行业主流排名模型wide模型+deep模型deep模型(2)CTR预测通过LR(逻辑回归)模型CTR预测结果模型评估-准确率和AUC9.推荐中心推荐数据补充多级缓冲(超时截断)合并信息10.参考资料 查看全部
根据关键词文章采集系统(埋点埋点日志(2):文章画像存储结构(图))
分享
埋藏日志数据结构如下:
{
"actionTime":"2019-04-10 18:15:35",
"readTime":"",
"channelId":0,
"param":{
"action":"exposure",
"userId":"2",
"articleId":"[18577, 14299]",
"algorithmCombine":"C2"
}
}
(2) ETL
通过 Flume 将日志定时和增量采集和结构化存储到 Hive
3. 离线构建文章 肖像
文章Portrait 就是为每个文章定义一些词。主要包括关键词和主题词。
关键词:文章 中权重较高的一些词。
主题词:归一化,出现在文章中的同义词,计算结果中出现频率高的词。
(1) 构建方法
关键词:TEXTRANK 计算的 TOPK 词和权重
主题词:TEXTRANK 的 TOPK 词与 ITFDF 计算的 TOPK 词的交集
(2) 文章图像存储结构
hive> desc article_profile;
OK
article_id int article_id
channel_id int channel_id
keywords map keywords
topics array topics
hive> select * from article_profile limit 1;
OK
26 17 {
"策略":0.3973770571351729,"jpg":0.9806348975390871,"用户":1.2794959063944176,"strong":1.6488457985625076,"文件":0.28144603583387057,"逻辑":0.45256526469610714,"形式":0.4123994242601279,"全自":0.9594604850547191,"h2":0.6244481634710125,"版本":0.44280276959510817,"Adobe":0.8553618185108718,"安装":0.8305037437573172,"检查更新":1.8088946300014435,"产品":0.774842382276899,"下载页":1.4256311032544344,"过程":0.19827163395829256,"json":0.6423301791599972,"方式":0.582762869780791,"退出应用":1.2338671268242603,"Setup":1.004399549339134} ["Electron","全自动","产品","版本号","安装包","检查更新","方案","版本","退出应用","逻辑","安装过程","方式","定性","新版本","Setup","静默","用户"]
Time taken: 0.322 seconds, Fetched: 1 row(s)
(3) 实施步骤
hive> select * from textrank_keywords_values limit 10;
OK
98319 17 var 20.6079
98323 17 var 7.4938
98326 17 var 104.9128
98344 17 var 5.6203
98359 17 var 69.3174
98360 17 var 9.3672
98392 17 var 14.9875
98393 17 var 155.4958
98406 17 var 11.2407
98419 17 var 59.9502
Time taken: 0.344 seconds, Fetched: 10 row(s)
hive> desc textrank_keywords_values;
OK
article_id int article_id
channel_id int channel_id
keyword string keyword
textrank double textrank
hive> select * from article_profile limit 1;
OK
26 17 {
"策略":0.3973770571351729,"jpg":0.9806348975390871,"用户":1.2794959063944176,"strong":1.6488457985625076,"文件":0.28144603583387057,"逻辑":0.45256526469610714,"形式":0.4123994242601279,"全自":0.9594604850547191,"h2":0.6244481634710125,"版本":0.44280276959510817,"Adobe":0.8553618185108718,"安装":0.8305037437573172,"检查更新":1.8088946300014435,"产品":0.774842382276899,"下载页":1.4256311032544344,"过程":0.19827163395829256,"json":0.6423301791599972,"方式":0.582762869780791,"退出应用":1.2338671268242603,"Setup":1.004399549339134} ["Electron","全自动","产品","版本号","安装包","检查更新","方案","版本","退出应用","逻辑","安装过程","方式","定性","新版本","Setup","静默","用户"]
Time taken: 0.322 seconds, Fetched: 1 row(s)
4. 建立线下用户画像
业内对用户画像有两种截然不同的解读:
用户角色:角色是真实用户的虚拟表示,是基于一系列真实数据的目标用户模型。通过问卷调查了解用户,根据目标、行为和观点的差异,将用户分为不同类型,从中提取典型特征,并对其进行姓名、照片、人口统计因素、场景等描述。形成了一个角色。用户角色是用户群体属性的集合,它不需要指代特定的人,而是目标群体的“特征”的组合。用户配置文件:用于描述用户数据的标签变量的集合。User Profile主要用来描述单个用户不同维度的属性,也可以用来描述一个用户组。
用户画像的核心工作是给用户打标签。标签通常是人为指定的高度精细化特征的标识符,例如年龄、地区、兴趣等。通过从不同维度对用户进行标记,我们可以得到用户的整体情况。如下图所示,一般用户画像的维度主要包括:
(1) 基本属性:指在很长一段时间内不发生变化(如性别)或不经常变化(如年龄每年增加1岁)的属性。标签的有效期更长超过一个月。
(1) 用户兴趣:指用户在一段时间内的行为倾向;例如,如果用户在过去一周内频繁搜索手机相关信息、查看手机价格对比等,假设用户有“手机”兴趣,兴趣随时间快速变化,标签时效性强,我们一般称之为短期兴趣或商业即时兴趣;如果用户长期关注宠物较多过去一段时间(比如一年以上)的相关信息,推断用户对“宠物”的喜欢有长期的兴趣。
不同的业务场景对用户画像有不同的需求。我们需要根据我们的实际业务需求,构建一个适合我们业务场景的用户画像系统。但对于年龄、性别、学历、婚姻等基础属性数据,无需为每个业务投入人力重复建设。
(1) 构建方法5. 离线构建文章功能
文章 特征包括 文章关键词 权重、文章 通道和 文章 向量,我们首先阅读 文章 肖像
文章关键词 及其权重是通过“文章 肖像”中的 TEXTRANK 获得的。本节首先通过word2vec得到文章向量,文章向量可用于计算文章相似度。
6. 构建离线用户功能7. 多次召回
召回层:负责从数百万个物品中快速找到成百上千个匹配用户兴趣的物品
排序层:负责对召回的物品进行评分和排序,从而选出用户最感兴趣的前K个物品
(1) 不同场景下常见的召回方案
召回层在缩小排序层的排序范围的同时,也决定了推荐效果的上限。如果召回的内容不够准确,即使是最强大的排名模型也无法将准确的推荐列表返回给用户。所以召回层很重要。常见的召回方法可以分为基于内容的召回和基于行为的召回。两种召回方式各有优缺点,相辅相成,提高召回质量。
目前在不同的场景下可以使用不同的召回方式:
个性化推荐离线部分(更多用户点击行为,完善用户画像)建立用户长期兴趣画像(详细):包括用户兴趣特征各维度训练排序模型离线部分召回(2)模型-基于离线召回:ALS (3) Content-Based Recall8. Sorting
分选主要分为精分选和粗分选两个阶段。两者的主要区别在于候选集的大小不同。粗排序输入候选集在1000级,细排序只有100级。候选集数量的不同决定了粗排序会有更高的性能要求。因此,特征只能选择少量粗粒度和高判别力的特征,而模型侧只能选择线性模型,或者复杂度低。深度模型。粗分选其他部分的工作与精分选类似。在这里,我们专注于精细排序。
在细排序阶段,需要对粗排序候选池中的ItemList进行评分。这个分数是针对每个用户对候选文章的点击概率的预测,即Ctr预测。每天有数千万的活跃用户在业务中。这些用户的每一次刷新、点击、转发等,都会带来海量的真实数据。我们需要使用这些海量日志进行模型训练,从而对用户偏好进行建模。
(1) CTR预测-行业主流排名模型wide模型+deep模型deep模型(2)CTR预测通过LR(逻辑回归)模型CTR预测结果模型评估-准确率和AUC9.推荐中心推荐数据补充多级缓冲(超时截断)合并信息10.参考资料
根据关键词文章采集系统(1.对百度进行多处优化网站地图错误)
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-02-16 09:12
织梦采集是一款非常不错的网站采集软件,织梦采集界面友好,功能强大,可以帮助用户快速seo采集和自动更新,可以全自动采集,是网站必备的网站插件工具。不多说,看图,说明一切,简单明了【关于织梦采集,图1是关键1,看图1就好了]
原创文章之类的搜索引擎大家都知道,但是这样做的成本也是相当高的。一天一个人原创文章10 这可能已经达到了很多人的工作极限,所以织梦采集对于广大站长来说是必不可少的。
目前有几种织梦采集、cms自己的采集系统、第三方采集插件、采集软件PC客户端如何选择取决于你的实际情况。如果需要自动采集或者需要伪原创,可以考虑织梦采集。[关于织梦采集,图2是重点2,看文章图2]
<p>织梦采集与传统的采集模式的区别在于织梦采集可以根据用户设置的 查看全部
根据关键词文章采集系统(1.对百度进行多处优化网站地图错误)
织梦采集是一款非常不错的网站采集软件,织梦采集界面友好,功能强大,可以帮助用户快速seo采集和自动更新,可以全自动采集,是网站必备的网站插件工具。不多说,看图,说明一切,简单明了【关于织梦采集,图1是关键1,看图1就好了]
原创文章之类的搜索引擎大家都知道,但是这样做的成本也是相当高的。一天一个人原创文章10 这可能已经达到了很多人的工作极限,所以织梦采集对于广大站长来说是必不可少的。
目前有几种织梦采集、cms自己的采集系统、第三方采集插件、采集软件PC客户端如何选择取决于你的实际情况。如果需要自动采集或者需要伪原创,可以考虑织梦采集。[关于织梦采集,图2是重点2,看文章图2]
<p>织梦采集与传统的采集模式的区别在于织梦采集可以根据用户设置的
根据关键词文章采集系统(怎么用免费dede采集插件把关键词优化到首页让网站能快速收录)
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-02-14 16:11
如何使用免费的dede采集插件将关键词优化到首页,使网站可以快速收录,包括所有SEO优化功能,并支持所有网站@ > 使用。在做业务网站优化的时候,经常会遇到很多问题,比如网站原创没有内容收录,收录后面没有排名,但是如果有怎么办排行?连首页都没有。因此,我们需要系统地对企业网站的优化做出很好的诊断,帮助我们调整网站的细节,更好的提高网站的权重。以下是企业网站优化诊断的三个方面,希望能帮助您更好地诊断自己的网站。
诊断前网站,教大家如何快速搭建原创高质量文章,使用免费的dede采集插件这个插件不用多学专业技能,简单几步即可轻松采集内容数据,用户只需对dede采集插件进行简单设置,完成后dede采集插件-in 会根据用户设置的关键词高精度匹配内容和图片可以保存在本地,也可以在伪原创之后发布,提供方便快捷的内容采集伪原创发布网站 @>推送服务!!
和其他dede采集插件相比,这个dede采集插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签,一分钟就能上手,只需输入关键词即可实现采集(dede采集插件也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这个dede采集插件工具也配置了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)
自动内链(让搜索引擎对你的链接爬得更深)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!有了这个dede采集插件,我们做网站优化,需要注意网站优化诊断三个方面
一、网站系统诊断
网站系统诊断 1
1. 空间速度
网站打开速度通常与2个方面有关:
一是页面上的图片数量,图片越多网站打开速度就会降低,所以优化网页上的图片非常重要。空间/服务器带宽太小。如果网站的流量很大,那么带宽就比较小,容易造成网站打不开,所以一般带宽的大小要根据大小来定网站 访问次数待定。影响网站速度的地方还有很多,但是随着互联网的发展和服务器配置的增加,很多影响空间速度的细节已经不用考虑了。
2. 网站代码
现在很多公司网站都在开发dedecms、empirecms、phpcms等开源程序,所以程序没必要多想,只需要需要考虑程序安全设置。
影响企业优化的网站就是网站页面的代码,比如table标签(已经不适用了,现在已经发展到html5了),比如js文件(最少如果不需要),如css文件(最好删除冗余代码)等。
最重要的是移动互联网的发展和html5+css3的普及,所以对于网站页面代码规范也很重要,可以帮助搜索引擎更好的识别。
网站系统诊断二
1. 网址
url要标准化,即首页URL尽量不要有index这个后缀,栏目页和文章页尽量是静态的(地址不带任何参数,如不?)。如果能更好的识别url,将进一步提高网站的优化标准,看起来非常简洁,清爽,通俗易懂。
2. 三个标签
主要是标题标签(带关键词)、关键词标签(页面关键词和页面扩展关键词)、描述标签(2-3次页面关键词) . 查看全部
根据关键词文章采集系统(怎么用免费dede采集插件把关键词优化到首页让网站能快速收录)
如何使用免费的dede采集插件将关键词优化到首页,使网站可以快速收录,包括所有SEO优化功能,并支持所有网站@ > 使用。在做业务网站优化的时候,经常会遇到很多问题,比如网站原创没有内容收录,收录后面没有排名,但是如果有怎么办排行?连首页都没有。因此,我们需要系统地对企业网站的优化做出很好的诊断,帮助我们调整网站的细节,更好的提高网站的权重。以下是企业网站优化诊断的三个方面,希望能帮助您更好地诊断自己的网站。
诊断前网站,教大家如何快速搭建原创高质量文章,使用免费的dede采集插件这个插件不用多学专业技能,简单几步即可轻松采集内容数据,用户只需对dede采集插件进行简单设置,完成后dede采集插件-in 会根据用户设置的关键词高精度匹配内容和图片可以保存在本地,也可以在伪原创之后发布,提供方便快捷的内容采集伪原创发布网站 @>推送服务!!
和其他dede采集插件相比,这个dede采集插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签,一分钟就能上手,只需输入关键词即可实现采集(dede采集插件也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这个dede采集插件工具也配置了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)
自动内链(让搜索引擎对你的链接爬得更深)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!有了这个dede采集插件,我们做网站优化,需要注意网站优化诊断三个方面
一、网站系统诊断
网站系统诊断 1
1. 空间速度
网站打开速度通常与2个方面有关:
一是页面上的图片数量,图片越多网站打开速度就会降低,所以优化网页上的图片非常重要。空间/服务器带宽太小。如果网站的流量很大,那么带宽就比较小,容易造成网站打不开,所以一般带宽的大小要根据大小来定网站 访问次数待定。影响网站速度的地方还有很多,但是随着互联网的发展和服务器配置的增加,很多影响空间速度的细节已经不用考虑了。
2. 网站代码
现在很多公司网站都在开发dedecms、empirecms、phpcms等开源程序,所以程序没必要多想,只需要需要考虑程序安全设置。
影响企业优化的网站就是网站页面的代码,比如table标签(已经不适用了,现在已经发展到html5了),比如js文件(最少如果不需要),如css文件(最好删除冗余代码)等。
最重要的是移动互联网的发展和html5+css3的普及,所以对于网站页面代码规范也很重要,可以帮助搜索引擎更好的识别。
网站系统诊断二
1. 网址
url要标准化,即首页URL尽量不要有index这个后缀,栏目页和文章页尽量是静态的(地址不带任何参数,如不?)。如果能更好的识别url,将进一步提高网站的优化标准,看起来非常简洁,清爽,通俗易懂。
2. 三个标签
主要是标题标签(带关键词)、关键词标签(页面关键词和页面扩展关键词)、描述标签(2-3次页面关键词) .
根据关键词文章采集系统(可以用阅读可以看top10万排行榜(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 387 次浏览 • 2022-02-13 00:04
根据关键词文章采集系统,用户对关键词的搜索关联性越高,搜索量就越大。通过自定义高关联性的关键词,搜索排名才能越好。现在实现自定义搜索最好的方式就是,使用爬虫,获取热门搜索词,然后用程序爬取其用户分析,推荐文章内容和各大媒体。利用媒体,也可以获取热门搜索词的一部分。
搜狗热搜
趣头条—用头条取代新闻阅读
tybot
zaker:把几乎所有的分类资讯汇聚到了一起,包括行业每天热点,包括各种小众网站的文章,还包括新闻的二次推荐。
可以通过问答网站,比如知乎,豆瓣等问问题,阅读别人的回答。时常浏览一些有趣的问答网站,阅读精彩回答,即使没有时间也会很有收获。阅读也是在接受知识,即使有时间也不一定能有大收获。可以看看我的回答。
可以用kindle阅读
可以看top10万排行榜
我觉得微信公众号比较好点
多看阅读,免费的。
我觉得“八戒小说”这个平台不错,你可以去试试,
淘淘搜
kindle阅读app-《地狱小说》
app是个不错的方式,但不一定所有的情况都能适用,有时用户需要查看某种特定内容或者达到一些特定场景时,想要去搜索相应的内容是很大的问题,比如订房可能需要看看有什么特殊房型的可以订,想看看商场里某个店面的某个区域的人比较喜欢买什么东西,同理大家在浏览某些网站的时候,也会有各种信息需要去查找;所以这时候对于大部分搜索引擎都不适用(百度谷歌360alibabamirrorlamagazine等等)。 查看全部
根据关键词文章采集系统(可以用阅读可以看top10万排行榜(组图))
根据关键词文章采集系统,用户对关键词的搜索关联性越高,搜索量就越大。通过自定义高关联性的关键词,搜索排名才能越好。现在实现自定义搜索最好的方式就是,使用爬虫,获取热门搜索词,然后用程序爬取其用户分析,推荐文章内容和各大媒体。利用媒体,也可以获取热门搜索词的一部分。
搜狗热搜
趣头条—用头条取代新闻阅读
tybot
zaker:把几乎所有的分类资讯汇聚到了一起,包括行业每天热点,包括各种小众网站的文章,还包括新闻的二次推荐。
可以通过问答网站,比如知乎,豆瓣等问问题,阅读别人的回答。时常浏览一些有趣的问答网站,阅读精彩回答,即使没有时间也会很有收获。阅读也是在接受知识,即使有时间也不一定能有大收获。可以看看我的回答。
可以用kindle阅读
可以看top10万排行榜
我觉得微信公众号比较好点
多看阅读,免费的。
我觉得“八戒小说”这个平台不错,你可以去试试,
淘淘搜
kindle阅读app-《地狱小说》
app是个不错的方式,但不一定所有的情况都能适用,有时用户需要查看某种特定内容或者达到一些特定场景时,想要去搜索相应的内容是很大的问题,比如订房可能需要看看有什么特殊房型的可以订,想看看商场里某个店面的某个区域的人比较喜欢买什么东西,同理大家在浏览某些网站的时候,也会有各种信息需要去查找;所以这时候对于大部分搜索引擎都不适用(百度谷歌360alibabamirrorlamagazine等等)。
根据关键词文章采集系统(SEO伪原创与词库管理优采云站群软件的功能特点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-02-11 13:00
软件标签:站群管理系统优采云站群管理系统站群管理软件优采云站群管理系统是一套唯一输入关键词,可以采集到较新的相关内容,并自动将SEO发布到指定的网站多任务站群管理系统,可以自动维护数百条24小时不间断< @网站。优采云站群软件自动根据集合关键词抓取各大搜索引擎的相关搜索词和相关长尾词,然后根据衍生抓取大量较新的数据话,有效摒弃普通采集软件所需的繁琐规则定制,实现一键式采集一键发布。同时,< @优采云站群也支持指定域名采集数据,只需填写目标栏地址即可抓取较新的文章每天自动发布,无需绑定电脑或IP,网站数量不限,24小时挂机采集维护,让站长轻松管理上百个网站。优采云站群具有强大的采集功能,支持关键词采集文章采集,图片和视频采集 ,还支持自定义采集规则指定域名采集,还提供超强的原创文章生成功能,支持数据自由导入导出,支持各种链接插入和链轮功能,批量站点和列添加,列id绑定等功能,支持自定义发布界面编辑,真正实现对各种站点程序的良好支持,是多站点维护管理的必备工具。特点:1、无限数量的站点优采云站群
2、智能蜘蛛引擎优采云站群软件打造的智能蜘蛛引擎可以自动生成上万条长尾关键词,然后自动瞄准这些长尾关键词从互联网采集到较新的文章,图片、视频等,无需任何采集规则,即可有效实现一键抓拍任务。它是一套站群采集软件,操作简单,功能齐全。3、SEO伪原创和词库管理优采云站群软件支持标题和内容的同义反义词替换、分词重构、禁止词库屏蔽、内容段落乱码并重新排列,并将 文章 的内容随机插入到图片中,视频等,可以很好的实现标题和内容的伪原创;不管你做了多少个、几十个甚至上百个站,你都不需要因为伪原创重复@采集文章而担心搜索引擎的收录。4、无限循环挂机,全站自动更新。设置关键词和抓取频率后,站群管理系统会自动生成相关关键词,自动抓取相关文章并发布到指定网站@ >栏目,轻松实现一键式采集更新支持365天无限循环挂机采集维护全部网站,真正实现无人监控无人操作,搭建维护如此简单. 5、 强大的链轮功能支持文章随机插入指定内容、锚文本链接、单站链接库链轮,自动提取文章内容链接到单站链接库或全局链接库,支持自定义链轮,并可实现链轮的任意组合。6、自动采集关键词图片(可做图片站)优采云<
7、自动采集关键字视频(可作为视频站)优采云站群支持基于关键词batch采集@直接插入视频> 视频到各栏目的文章,还支持直接单独发布采集视频,可以作为专门的视频网站。8、超强原创文章生成函数优采云站群内置超强原创文章生成库- in,支持自动定义句子语料生成原创文章(利用现有文章库中的文章分词随机形成新的文章) , 自定义句子类型库生成原创文章 和自定义模板/元素库生成原创文章 ,还支持混合文章的段落,已经采集合成生成文章。9、数据可任意导入导出优采云站群支持批量导出软件采集原文章到本地,批量导出软件伪原创后< @文章到本地和批量边采集文章,在导出文章到本地的同时,还支持将本地文章导入到站群,支持每一个一列可以导入多个文章,每个网站的随机一列可以直接导入一个或多个软文ads文章。10、强大的批量功能优采云站群支持批量添加站点和列,批量提取列和id绑定等,等等网站 也很容易管理。11、通用自定义发布界面优采云站群支持任意网站自定义发布界面,无论是论坛、博客、cms等任何网站,全由你可以通过自定义界面工具编辑相应的发布界面,真正实现对各种站点程序的良好支持。 查看全部
根据关键词文章采集系统(SEO伪原创与词库管理优采云站群软件的功能特点)
软件标签:站群管理系统优采云站群管理系统站群管理软件优采云站群管理系统是一套唯一输入关键词,可以采集到较新的相关内容,并自动将SEO发布到指定的网站多任务站群管理系统,可以自动维护数百条24小时不间断< @网站。优采云站群软件自动根据集合关键词抓取各大搜索引擎的相关搜索词和相关长尾词,然后根据衍生抓取大量较新的数据话,有效摒弃普通采集软件所需的繁琐规则定制,实现一键式采集一键发布。同时,< @优采云站群也支持指定域名采集数据,只需填写目标栏地址即可抓取较新的文章每天自动发布,无需绑定电脑或IP,网站数量不限,24小时挂机采集维护,让站长轻松管理上百个网站。优采云站群具有强大的采集功能,支持关键词采集文章采集,图片和视频采集 ,还支持自定义采集规则指定域名采集,还提供超强的原创文章生成功能,支持数据自由导入导出,支持各种链接插入和链轮功能,批量站点和列添加,列id绑定等功能,支持自定义发布界面编辑,真正实现对各种站点程序的良好支持,是多站点维护管理的必备工具。特点:1、无限数量的站点优采云站群
2、智能蜘蛛引擎优采云站群软件打造的智能蜘蛛引擎可以自动生成上万条长尾关键词,然后自动瞄准这些长尾关键词从互联网采集到较新的文章,图片、视频等,无需任何采集规则,即可有效实现一键抓拍任务。它是一套站群采集软件,操作简单,功能齐全。3、SEO伪原创和词库管理优采云站群软件支持标题和内容的同义反义词替换、分词重构、禁止词库屏蔽、内容段落乱码并重新排列,并将 文章 的内容随机插入到图片中,视频等,可以很好的实现标题和内容的伪原创;不管你做了多少个、几十个甚至上百个站,你都不需要因为伪原创重复@采集文章而担心搜索引擎的收录。4、无限循环挂机,全站自动更新。设置关键词和抓取频率后,站群管理系统会自动生成相关关键词,自动抓取相关文章并发布到指定网站@ >栏目,轻松实现一键式采集更新支持365天无限循环挂机采集维护全部网站,真正实现无人监控无人操作,搭建维护如此简单. 5、 强大的链轮功能支持文章随机插入指定内容、锚文本链接、单站链接库链轮,自动提取文章内容链接到单站链接库或全局链接库,支持自定义链轮,并可实现链轮的任意组合。6、自动采集关键词图片(可做图片站)优采云<
7、自动采集关键字视频(可作为视频站)优采云站群支持基于关键词batch采集@直接插入视频> 视频到各栏目的文章,还支持直接单独发布采集视频,可以作为专门的视频网站。8、超强原创文章生成函数优采云站群内置超强原创文章生成库- in,支持自动定义句子语料生成原创文章(利用现有文章库中的文章分词随机形成新的文章) , 自定义句子类型库生成原创文章 和自定义模板/元素库生成原创文章 ,还支持混合文章的段落,已经采集合成生成文章。9、数据可任意导入导出优采云站群支持批量导出软件采集原文章到本地,批量导出软件伪原创后< @文章到本地和批量边采集文章,在导出文章到本地的同时,还支持将本地文章导入到站群,支持每一个一列可以导入多个文章,每个网站的随机一列可以直接导入一个或多个软文ads文章。10、强大的批量功能优采云站群支持批量添加站点和列,批量提取列和id绑定等,等等网站 也很容易管理。11、通用自定义发布界面优采云站群支持任意网站自定义发布界面,无论是论坛、博客、cms等任何网站,全由你可以通过自定义界面工具编辑相应的发布界面,真正实现对各种站点程序的良好支持。
根据关键词文章采集系统(微信公众号文章采集系统的数据采集流程是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-02-11 00:02
根据关键词文章采集系统的数据采集流程,如下,可根据部署需求部署相应语句:1:工作台一般第一次打开工作台,会进入“自定义采集”的页面,点击获取新流量数据即可;2:添加采集程序采集要采集的url,开始采集,采集过程中提示采集的文件名,点击要保存的文件名,打开采集数据保存到工作台,之后复制相应链接,查看文件路径即可找到文件;3:上传需要采集的数据上传需要采集的数据,数据上传完成之后,开始返回测试相应指标,修改相应指标为采集对应数据,点击工作台上“保存”即可保存数据;4:数据查看本工作台上可以看到所有采集后的数据,针对采集的数据,可以针对性查看数据,比如日度,周度,月度数据,当然我们也可以把采集的数据导出为excel、html格式等等;推荐可以到草料采集器官网看看,地址是:。
哪里像
-ev_.m9xpa
有啊,不就是直接从生意参谋那里采集数据吗,分秒级别,全量。百度可以免费采集。
想知道你们那边要采多久,因为有的地方即使是在每天4点后也有一次类似大型会议的活动。
采集器可以采集微信公众号文章的,只是效率上会比较慢,一般采集两小时左右,可以给自己一点时间做些其他工作。利用采集器做数据分析:比如一天的销售情况;一篇文章阅读人数多少,转发人数多少;转发人数多少,阅读人数多少;一篇文章点赞率多少,转发率多少;文章点赞率多少,转发率多少;有多少人转发这篇文章,转发人数多少;转发多少,点赞多少;所有这些数据全部都能在同一平台找到,也就是我们常说的数据一平台到家。
例如我有本金5千的项目,当时一天的公众号阅读3万。转发人数250人;点赞700人;现在需要做复盘,如果我每天卖1万左右,那销售额肯定能过万。复盘做的越多,赚钱越多。复盘主要是给自己做反馈,比如昨天销售额2万左右,那说明这个公众号的阅读量的确有点问题。如果做完第一天销售额2万,现在卖2万销售额的方法,就能把经验迁移到其他方面。
如果我今天销售1万,就可以有接下来的一些增长,就能有效率的做其他事情。那对于一些产品,走的已经比较完善的公司来说,一天2000-5000销售额,每个月大约也有5000-8000左右的产出,还是很容易的。所以你这是想干嘛?至于对于创业或者个人做主的话,对于一天能卖2万销售额这种。才能算是你的数据。一天2000,别人怎么说你卖的不好呢?。 查看全部
根据关键词文章采集系统(微信公众号文章采集系统的数据采集流程是什么?)
根据关键词文章采集系统的数据采集流程,如下,可根据部署需求部署相应语句:1:工作台一般第一次打开工作台,会进入“自定义采集”的页面,点击获取新流量数据即可;2:添加采集程序采集要采集的url,开始采集,采集过程中提示采集的文件名,点击要保存的文件名,打开采集数据保存到工作台,之后复制相应链接,查看文件路径即可找到文件;3:上传需要采集的数据上传需要采集的数据,数据上传完成之后,开始返回测试相应指标,修改相应指标为采集对应数据,点击工作台上“保存”即可保存数据;4:数据查看本工作台上可以看到所有采集后的数据,针对采集的数据,可以针对性查看数据,比如日度,周度,月度数据,当然我们也可以把采集的数据导出为excel、html格式等等;推荐可以到草料采集器官网看看,地址是:。
哪里像
-ev_.m9xpa
有啊,不就是直接从生意参谋那里采集数据吗,分秒级别,全量。百度可以免费采集。
想知道你们那边要采多久,因为有的地方即使是在每天4点后也有一次类似大型会议的活动。
采集器可以采集微信公众号文章的,只是效率上会比较慢,一般采集两小时左右,可以给自己一点时间做些其他工作。利用采集器做数据分析:比如一天的销售情况;一篇文章阅读人数多少,转发人数多少;转发人数多少,阅读人数多少;一篇文章点赞率多少,转发率多少;文章点赞率多少,转发率多少;有多少人转发这篇文章,转发人数多少;转发多少,点赞多少;所有这些数据全部都能在同一平台找到,也就是我们常说的数据一平台到家。
例如我有本金5千的项目,当时一天的公众号阅读3万。转发人数250人;点赞700人;现在需要做复盘,如果我每天卖1万左右,那销售额肯定能过万。复盘做的越多,赚钱越多。复盘主要是给自己做反馈,比如昨天销售额2万左右,那说明这个公众号的阅读量的确有点问题。如果做完第一天销售额2万,现在卖2万销售额的方法,就能把经验迁移到其他方面。
如果我今天销售1万,就可以有接下来的一些增长,就能有效率的做其他事情。那对于一些产品,走的已经比较完善的公司来说,一天2000-5000销售额,每个月大约也有5000-8000左右的产出,还是很容易的。所以你这是想干嘛?至于对于创业或者个人做主的话,对于一天能卖2万销售额这种。才能算是你的数据。一天2000,别人怎么说你卖的不好呢?。
根据关键词文章采集系统(从中找到某个问题可能会留下的日志记录..尤其是现在)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-02-09 07:18
查看日志一直是个很头疼的问题。登录服务器查看上百兆的txt文件,发现有问题可能留下的日志记录……尤其是现在,在集群部署的时候发现服务器数量越来越多异常记录几乎要翻遍每一个服务器,想想就崩溃了!这个时候特别希望有集中查看日志的方案来救我。
我曾经找到一个名为 log4Grid 的项目并尝试过。日志数据保存到mssql数据库,通过web项目查询和展示日志记录。只是实现了基本的日志数据采集和展示,项目没有持续更新,使用起来不够稳定。不是一个成熟的日志采集项目。
log4net项目中有一个SimpleSocketServer小应用,可以将多台服务器上的log4net日志集中到一台服务器上,然后选择log4net的某种日志方式记录下来。但是,它不能满足易于查看的要求。
后来因为公司要求学习Java,经常能搜到的ELK系统也进入了考虑范围。初步试用后,感觉可以满足我的基本需求。
虽然可以搜索到很多ELK的部署说明,但是我自己操作的时候还是遇到了很多坑,也遇到了无法继续的情况。这里也记录一下自己的部署过程(因为没有及时记录,有些细节忘记了)。
当时还不知道Exceptionless。
下载列表:
jdk1.8(甲骨文)
日志存储()
弹性搜索()
基巴纳 ()
x64 的 redis (github)
nssm()
一. jdk 安装
ELK 运行在 JVM 上,所以 jdk 也应该安装。Windows系统安装jdk后,需要配置系统环境变量。详细配置可另当别论,请自行上网搜索文章。
二. 弹性搜索
elasticsearch是ELK的核心,负责存储和检索。
将elasticsearch解压到一个目录,在\bin目录下找到服务安装和启动文件service.bat:
执行命令 service.bat install 安装windows服务
执行命令 service.bat start 启动windows服务
用浏览器访问:9200/如果能返回正常页面,说明服务启动成功
三. kibana
kibana 负责在 ELK 中显示搜索结果。
将kibana解压到一个目录,将nssm复制到kibana的\bin目录下(为了简单直接复制nssm):
执行名为 nssm install kibana
在nssm界面选择启动文件kibana.bat,设置自动启动,完成。
用浏览器访问:5601/如果能返回正常页面,说明服务启动成功
四. 日志存储
logstash 负责采集ELK中的转化数据,从日志中获取的数据传递给elasticsearch。
将logstash解压到一个目录下,在\bin同目录下新建一个\conf目录,并将配置文件存放在该目录下。
启动服务时使用命令 logstash.bat -f ..\conf\xx.conf。
在logstash进入工作状态之前,为了测试能否正常工作,做了一个配置example.conf,从日志文件中获取数据:
input {
file {
path => "C:\logs\log.log"
}
}
filter {}
output {
stdout {
codec => rubydebug
}
}
添加日志文件后,会在控制台输出。
一般来说,应该从log4j的输出中获取数据(我的系统是log4j),并配置log4j.conf:
input {
log4j{
mode => "server"
type=>"log4j-json"
port=>4712
}
}
filter {}
output {
stdout { codec => rubydebug }
elasticsearch { hosts => ["127.0.0.1"] }
}
这是单机配置ELK的重点,跨服务器没试过。
logstash的配置文件很容易出错。最后我只放了基本配置,用的是ANSI的,不是中文的,没有注释。
相应地,log4j需要在系统中配置SocketAppender输出,以及log4j属性配置:
log4j.rootLogger=info,logstash
# Socket,logstash
log4j.appender.logstash=org.apache.log4j.net.SocketAppender
log4j.appender.logstash.Port=4712
log4j.appender.logstash.RemoteHost=localhost
log4j.appender.logstash.ReconnectionDelay=60000
log4j.appender.logstash.LocationInfo=true
所有的日志输出都可以通过将新的输出配置logstash添加到log4j.rootLogger=中来获得。
如果收到如下信息,说明找不到log4j的SocketAppender输出,请检查日志配置是否正确
log4j:WARN No appenders could be found for logger (org.apache.http.client.protoc
ol.RequestAuthCache).
log4j:WARN Please initialize the log4j system properly.
转载于: 查看全部
根据关键词文章采集系统(从中找到某个问题可能会留下的日志记录..尤其是现在)
查看日志一直是个很头疼的问题。登录服务器查看上百兆的txt文件,发现有问题可能留下的日志记录……尤其是现在,在集群部署的时候发现服务器数量越来越多异常记录几乎要翻遍每一个服务器,想想就崩溃了!这个时候特别希望有集中查看日志的方案来救我。
我曾经找到一个名为 log4Grid 的项目并尝试过。日志数据保存到mssql数据库,通过web项目查询和展示日志记录。只是实现了基本的日志数据采集和展示,项目没有持续更新,使用起来不够稳定。不是一个成熟的日志采集项目。
log4net项目中有一个SimpleSocketServer小应用,可以将多台服务器上的log4net日志集中到一台服务器上,然后选择log4net的某种日志方式记录下来。但是,它不能满足易于查看的要求。
后来因为公司要求学习Java,经常能搜到的ELK系统也进入了考虑范围。初步试用后,感觉可以满足我的基本需求。
虽然可以搜索到很多ELK的部署说明,但是我自己操作的时候还是遇到了很多坑,也遇到了无法继续的情况。这里也记录一下自己的部署过程(因为没有及时记录,有些细节忘记了)。
当时还不知道Exceptionless。
下载列表:
jdk1.8(甲骨文)
日志存储()
弹性搜索()
基巴纳 ()
x64 的 redis (github)
nssm()
一. jdk 安装
ELK 运行在 JVM 上,所以 jdk 也应该安装。Windows系统安装jdk后,需要配置系统环境变量。详细配置可另当别论,请自行上网搜索文章。
二. 弹性搜索
elasticsearch是ELK的核心,负责存储和检索。
将elasticsearch解压到一个目录,在\bin目录下找到服务安装和启动文件service.bat:
执行命令 service.bat install 安装windows服务
执行命令 service.bat start 启动windows服务
用浏览器访问:9200/如果能返回正常页面,说明服务启动成功
三. kibana
kibana 负责在 ELK 中显示搜索结果。
将kibana解压到一个目录,将nssm复制到kibana的\bin目录下(为了简单直接复制nssm):
执行名为 nssm install kibana
在nssm界面选择启动文件kibana.bat,设置自动启动,完成。
用浏览器访问:5601/如果能返回正常页面,说明服务启动成功
四. 日志存储
logstash 负责采集ELK中的转化数据,从日志中获取的数据传递给elasticsearch。
将logstash解压到一个目录下,在\bin同目录下新建一个\conf目录,并将配置文件存放在该目录下。
启动服务时使用命令 logstash.bat -f ..\conf\xx.conf。
在logstash进入工作状态之前,为了测试能否正常工作,做了一个配置example.conf,从日志文件中获取数据:
input {
file {
path => "C:\logs\log.log"
}
}
filter {}
output {
stdout {
codec => rubydebug
}
}
添加日志文件后,会在控制台输出。
一般来说,应该从log4j的输出中获取数据(我的系统是log4j),并配置log4j.conf:
input {
log4j{
mode => "server"
type=>"log4j-json"
port=>4712
}
}
filter {}
output {
stdout { codec => rubydebug }
elasticsearch { hosts => ["127.0.0.1"] }
}
这是单机配置ELK的重点,跨服务器没试过。
logstash的配置文件很容易出错。最后我只放了基本配置,用的是ANSI的,不是中文的,没有注释。
相应地,log4j需要在系统中配置SocketAppender输出,以及log4j属性配置:
log4j.rootLogger=info,logstash
# Socket,logstash
log4j.appender.logstash=org.apache.log4j.net.SocketAppender
log4j.appender.logstash.Port=4712
log4j.appender.logstash.RemoteHost=localhost
log4j.appender.logstash.ReconnectionDelay=60000
log4j.appender.logstash.LocationInfo=true
所有的日志输出都可以通过将新的输出配置logstash添加到log4j.rootLogger=中来获得。
如果收到如下信息,说明找不到log4j的SocketAppender输出,请检查日志配置是否正确
log4j:WARN No appenders could be found for logger (org.apache.http.client.protoc
ol.RequestAuthCache).
log4j:WARN Please initialize the log4j system properly.
转载于:
根据关键词文章采集系统( 做SEO文章收录的时候,如何寻找采集目标网站?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-02-08 03:07
做SEO文章收录的时候,如何寻找采集目标网站?)
147SEO站长工具-免费百度动态采集
各位站长大家好,今天继续跟大家分享我们在做SEO关键词设置的时候如何找到采集targets网站和文章收录。掌握这两种方法的目的是让你可以批量查找更多文章,同时可以让文章的标题和文章的内容次要< @k1@ >。采集如果目标是有针对性的,这里我们可以去百度动态消息,这是一个收录海量信息的新闻服务平台。您可以搜索新闻事件、热点话题、人物动态、产品信息等,快速了解他们的最新进展。基本上涵盖了各行各业,完全可以满足我们采集的需求!
首先我们来看看采集的网站是怎么找到的,也就是采集能找到哪个网站或者去哪里找吧?只是这样做,有些站长基础薄弱,他可能不知道去哪里找这些网站。你想去什么知乎啊百度,去了之后发现这些网站人都设置了反爬,而你采集不行。所以我们可以使用工具来解决这个问题。平台设置了反爬规则,人工粘贴复制效率极低,在众多资源中,寻找目标也是一项耗时耗力的工作。使用免费的采集工具,输入采集关键词,设置采集的来源,即可实现海量资源采集,并且提高的效率将以倍数计算!这样,我们的 网站 内容就不用担心数量了。而选择新闻源采集的好处是内容多元化,满足我们各个行业的需求。内容高度原创,非常适合填充我们的内容。这就是我要讲的第一点,关于目标网站 查找和采集 使用工具的好处,这样你就可以获得源源不断的目标内容。非常适合填充我们的内容。这就是我要讲的第一点,关于目标网站 查找和采集 使用工具的好处,这样你就可以获得源源不断的目标内容。非常适合填充我们的内容。这就是我要讲的第一点,关于目标网站 查找和采集 使用工具的好处,这样你就可以获得源源不断的目标内容。
第二个是关键词 的设置。
在采集的文字标题前硬加一些关键词,或者在文章中硬加一些关键词。这对我们的 收录 和排名有好处。量变导致质变。当你有一千篇文章文章 有这些字段,当其他人在搜索时,你的千篇文章文章 将有机会被展示。同样的,如果你把它放在内容栏里,也会有同样的效果。
因为我之前做过实验,也就是我的文章内容没有调整,只是在最后加了一些我的网站的关键词。收录 的效果还不错。当我在搜索引擎上搜索时,我会搜索我的 网站 或文本。有时,会搜索出 网站 中的内容页面。
所以这就是我说的关键词的一套玩法。其实这也涉及到一些伪原创,
我可以在内容中添加一些我想要的关键词,或者如果很生硬,我就直接移动到标题中,我会在标题中添加关键词。
以上就是我今天主要分享的两点,采集站和关键词的实践。我希望这个 文章 可以帮助你。喜欢小编的可以点赞关注。我会继续和站长们分享一些做网站的技巧,以及SEO的行业知识! 查看全部
根据关键词文章采集系统(
做SEO文章收录的时候,如何寻找采集目标网站?)
147SEO站长工具-免费百度动态采集
各位站长大家好,今天继续跟大家分享我们在做SEO关键词设置的时候如何找到采集targets网站和文章收录。掌握这两种方法的目的是让你可以批量查找更多文章,同时可以让文章的标题和文章的内容次要< @k1@ >。采集如果目标是有针对性的,这里我们可以去百度动态消息,这是一个收录海量信息的新闻服务平台。您可以搜索新闻事件、热点话题、人物动态、产品信息等,快速了解他们的最新进展。基本上涵盖了各行各业,完全可以满足我们采集的需求!
首先我们来看看采集的网站是怎么找到的,也就是采集能找到哪个网站或者去哪里找吧?只是这样做,有些站长基础薄弱,他可能不知道去哪里找这些网站。你想去什么知乎啊百度,去了之后发现这些网站人都设置了反爬,而你采集不行。所以我们可以使用工具来解决这个问题。平台设置了反爬规则,人工粘贴复制效率极低,在众多资源中,寻找目标也是一项耗时耗力的工作。使用免费的采集工具,输入采集关键词,设置采集的来源,即可实现海量资源采集,并且提高的效率将以倍数计算!这样,我们的 网站 内容就不用担心数量了。而选择新闻源采集的好处是内容多元化,满足我们各个行业的需求。内容高度原创,非常适合填充我们的内容。这就是我要讲的第一点,关于目标网站 查找和采集 使用工具的好处,这样你就可以获得源源不断的目标内容。非常适合填充我们的内容。这就是我要讲的第一点,关于目标网站 查找和采集 使用工具的好处,这样你就可以获得源源不断的目标内容。非常适合填充我们的内容。这就是我要讲的第一点,关于目标网站 查找和采集 使用工具的好处,这样你就可以获得源源不断的目标内容。
第二个是关键词 的设置。
在采集的文字标题前硬加一些关键词,或者在文章中硬加一些关键词。这对我们的 收录 和排名有好处。量变导致质变。当你有一千篇文章文章 有这些字段,当其他人在搜索时,你的千篇文章文章 将有机会被展示。同样的,如果你把它放在内容栏里,也会有同样的效果。
因为我之前做过实验,也就是我的文章内容没有调整,只是在最后加了一些我的网站的关键词。收录 的效果还不错。当我在搜索引擎上搜索时,我会搜索我的 网站 或文本。有时,会搜索出 网站 中的内容页面。
所以这就是我说的关键词的一套玩法。其实这也涉及到一些伪原创,
我可以在内容中添加一些我想要的关键词,或者如果很生硬,我就直接移动到标题中,我会在标题中添加关键词。
以上就是我今天主要分享的两点,采集站和关键词的实践。我希望这个 文章 可以帮助你。喜欢小编的可以点赞关注。我会继续和站长们分享一些做网站的技巧,以及SEO的行业知识!
根据关键词文章采集系统(一种专题Web信息采集系统的分布特性及相关基础分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-02-06 13:05
herap id 为 generalpu rpo se 爬虫带来了前所未有的扩展挑战。因此,专注的 ebcraw ler 成为基本原则,专注于 ebcraw ler,一种无效的 io 技术。基于分析dis 主题新方法爬虫goodset 转发爬虫性能,引导网络资源,帮助爬虫轻松更新。ebcrawler;种子eb信息采集是将网络上的信息下载到本地,同时保存网页相关信息的系统。
一开始,网上资料不多,信息采集系统尽量采集网上能找到的所有页面。但是,Web 上的数据正在迅速增长。根据CNN IC(中国互联网络信息中心)的统计报告,截至2004年,中文网站的数量已达6216人,比去年同期增长了3212%。作为中国最大的搜索引擎“百度”,其可抓取网页数量已达1亿。另外,网络内容越来越杂乱,而且使用以前的方法,返回的专业数据命中率很低,因为数据太多,很难维护,页面故障率很高,所以主题信息出现采集系统。本系统的不同之处在于,它只采集特定职业的数据,主要用于满足对职业信息感兴趣的用户。与前者相比,可采集的数据量大大减少,降低了对硬件的时间和空间要求,提高了整体性能,为该专业的信息检索提供了良好的数据源。eb采集系统相关基础111 基础知识eb资料采集程序被称为网络机器人(Robo spider)或rawle来自网络中一个或多个预先指定的初始站点(种子下载页面,收到日期:2004 09 06 作者简介:山西太原,研究生,主要研究方向:网络数据库、搜索引擎;赵恒永(1940年教授,
页面解析自动获取当前页面链接的其他网页的地址,将所有获取到的链接地址送入一个RL队列,然后不断的获取URL,重复上述过程,直到采集结束。主题采集系统在访问当前页面时,会根据主题库中的信息计算网页与主题的相关系数。如果高于指定的阈值,则认为是相关的,将 采集down 进行分析,否则丢弃该页面。也就是说,比一般的采集系统多了一个数据过滤过程。112 专题页的分布特点 全网数据量巨大,但专题页在全网的份额并不大。以搜索关键词“化工”为例,百度的命中率只有2%,北大天网的命中率更小,只有0.18%。这些结果还包括一些不相关的“假”结果。研究发现,虽然整个 eb 中的信息是混杂的,完全没有结构性的,但是关于某个主题的网页的分布仍然是有规律的。网络中的网页被视为节点,网页之间的链接被视为有向的,整个网络就是一个巨大的图,如图所示。两者相辅相成,即一个好的ub页面一般指向多个A thority页面,一个thority页面会被多个ub页面引用。而北大天网的命中率更小,只有0.18%。这些结果还包括一些不相关的“假”结果。研究发现,虽然整个 eb 中的信息是混杂的,完全没有结构性的,但是关于某个主题的网页的分布仍然是有规律的。网络中的网页被视为节点,网页之间的链接被视为有向的,整个网络就是一个巨大的图,如图所示。两者相辅相成,即一个好的ub页面一般指向多个A thority页面,一个thority页面会被多个ub页面引用。而北大天网的命中率更小,只有0.18%。这些结果还包括一些不相关的“假”结果。研究发现,虽然整个 eb 中的信息是混杂的,完全没有结构性的,但是关于某个主题的网页的分布仍然是有规律的。网络中的网页被视为节点,网页之间的链接被视为有向的,整个网络就是一个巨大的图,如图所示。两者相辅相成,即一个好的ub页面一般指向多个A thority页面,一个thority页面会被多个ub页面引用。研究发现,虽然整个 eb 中的信息是混杂的,完全没有结构性的,但是关于某个主题的网页的分布仍然是有规律的。网络中的网页被视为节点,网页之间的链接被视为有向的,整个网络就是一个巨大的图,如图所示。两者相辅相成,即一个好的ub页面一般指向多个A thority页面,一个thority页面会被多个ub页面引用。研究发现,虽然整个 eb 中的信息是混杂的,完全没有结构性的,但是关于某个主题的网页的分布仍然是有规律的。网络中的网页被视为节点,网页之间的链接被视为有向的,整个网络就是一个巨大的图,如图所示。两者相辅相成,即一个好的ub页面一般指向多个A thority页面,一个thority页面会被多个ub页面引用。
那些说明每个主题的页面在站点内更紧密地联系在一起,而各个主题组之间的联系较少。有了unnel特性,eb中有很多主题页组,但是在这些页组之间,往往需要经过很多不相关的链接才能到达。一般配置下,15个数据的线程采集器每秒只能采集几十页。扫描全网显然需要配置大量优秀的服务器,搭建复杂的分布式采集系统,后期维护很多。考虑到以上特点,我们希望能够直接找到收录主题组的站点(本文简称中心站点)的thority页面,进行定向采集,高性能,节省资源. 系统设计主题采集系统以种子RL集作为集合开始,如果种子RL集收录大部分中心站点或thority页面,采集会变得更容易。系统结构如图 211 种子处理器 21111 集成搜索引擎结果过滤方法 该方法用于尽可能多地找到与主题相关的中心站点。考虑到元搜索引擎覆盖面广的优势,这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。如果种子 RL 集收录大部分中心站点或 thority 页面,则 采集 将变得更容易。系统结构如图 211 种子处理器 21111 集成搜索引擎结果过滤方法 该方法用于尽可能多地找到与主题相关的中心站点。考虑到元搜索引擎覆盖面广的优势,这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。如果种子 RL 集收录大部分中心站点或 thority 页面,则 采集 将变得更容易。系统结构如图 211 种子处理器 21111 集成搜索引擎结果过滤方法 该方法用于尽可能多地找到与主题相关的中心站点。考虑到元搜索引擎覆盖面广的优势,这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。系统结构如图 211 种子处理器 21111 集成搜索引擎结果过滤方法 该方法用于尽可能多地找到与主题相关的中心站点。考虑到元搜索引擎覆盖面广的优势,这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。系统结构如图 211 种子处理器 21111 集成搜索引擎结果过滤方法 该方法用于尽可能多地找到与主题相关的中心站点。考虑到元搜索引擎覆盖面广的优势,这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。
然后可以通过 RL 简单地过滤非站点 URL。因为返回的结果包括每个URL的Ancho和大约100个网页描述(由搜索引擎自动生成),而且返回结果的排名也在一定程度上反映了页面的质量,所以可以使用它们来进行站点过滤. 计算网页的权重。权重高于指定阈值的站点将被添加到种子集中,否则将被丢弃。21112 目录式搜索引擎引文方式 网上也有目录式搜索引擎引文方式。网站因为是人工维护的,所以信息类似于Yahoo、LookSm art、Open,在每个主题下,已经分配了很多网站地址。再举个例子,有 30 个 网站 在yahoo科学化学目录中,包括化学工程、生物化学和研究所,并且每个目录都有自己的相关站点。从那里,您可以直接获取与主题相关的 网站 地址以加入种子集。它的缺点是更新不及时,返回的结果很少。对于一些信息,比如企业的产品网站,返回效果不好。计算种子集的结果需要一定的时间,但是为后面的采集和过滤节省了更多的时间。两种方法各有利弊,最好将几种方法结合使用,以达到最佳效果。212 data采集器 data采集器的主要作用是将RL队列中取出的URL对应的网页下载到本地。
有的网站在服务器上创建了一个robo文件,里面标明了一些RL区域的访问受限,应该按照里面的限制访问,避免IP的后果。页面可以相互链接,或者形成跨多个网页的循环。为了避免死锁,RL 应该在发送到队列之前检查它是否已经被访问过。由于专题页面的分组特性,需要适当限制搜索的深度,过深是不必要的。限制搜索到的IP地址段可以节省过滤时间,对于非中文IP区域,可以直接排除。对于动态生成的网页,采集暂时是不允许的,因为直接采集不带参数的结果往往是没有意义的,并且获取它的参数是不现实的。213 Page Parsing 页面解析主要分为两步。一是分离页面的标志性信息,如正文、标题和摘要。设置文本长度,在源文件中找到超过这个长度的文本设置为文本;然后根据字体变化、位置等特点,找到最合适的一段文字作为标题。提取的方法有很多种,最简单的就是提取本页如果没有文字,就从出现的中文开始页面开头,将不在同一个标签中的中文用空格隔开,一共提取100个。另一个是分析网页的链接地址。
该协议包括 ile 和 telnet URL,其他协议 URL 将被自动放弃。文件类型可以根据文件的扩展名确定,只处理静态网页。214 主题过滤 主题过滤通过一定的算法判断一个页面是否与某个主题相关,然后对采集的行进行剪枝,去除不相关的页面。判断方法很多,主要分为两大类。一种是根据文字等标志性内容来判断,另一种是根据网页正文的向量空间模型来判断。他们处理的数据都是文本;类基于超链接。常见的包括根据网页的出入度和PageRank算法计算权重。第一种主要用于判断网页的内容主题,而第二种主要用于判断网页在网络中的权威性,即网页的质量。PageRank算法在谷歌54期《计算机与信息技术》2004的应用中取得了不错的效果。它的初衷是一个好的页面必须有很多指向这个页面的链接,所以设置了所有页面的初始权重。全部设置好,然后根据页面的外链将页面的权重平均分配给其他页面。具有许多传入链接的页面自然会有更高的权重,这意味着页面具有更好的质量。该算法的缺点是该算法与页面内容无关,化学工程和音乐的页重可能完全相等。基于以上思想,文献中提出了IPageRank算法,它是基于内容的过滤算法和PageRank算法的结合。
在数据过滤方面,基于Web挖掘的unnel特性中也提到,主题组往往是通过不相关的链接连接起来的,种子集不可能收录所有相关的中心站点。为了在过滤中找到种子集中遗漏的中心站点,使用以下RL队列对相关度较高的进行采集,相关度较低的直接丢弃,分析中间的页面地址,分析它们的页面链接。丢弃页面,将分析结果保存在另一个队列中并按相关性排序。RL 的处理方式相同。如果找到权重较高的页面,将页面地址移至正常特征,网络上那些大型搜索引擎的表现相对完整,可以认为是过滤了整个网络的信息;二是根据自己的专题数据库和综合搜索引擎提供的描述,粗略判断返回结果的相关性,只保留中心站点地址或thority页面;基于内容的周围网页过滤。第一个过滤是为了保证信息的全面性,因为如果你自己采集全网,搜索的范围就不会那么宽,数据也不会那么全。第二个过滤器是增加采集的命中率。第三个过滤器主要是能够采集真正相关的页面。在本次设计的主题采集系统中,重要的设定指明了方向。随着互联网的不断发展,会有越来越多的数据。最好的办法是让专业的网站自动将自己的URL提交给采集系统,这样专题采集才能让系统采集更准确的接收到有用的信息并且及时。
版权费和期刊稿酬一次性支付。如作者不同意,文章如编入上述数据库,请在投稿时声明,本刊将妥善处理。编辑部《计算机与信息技术》2004 查看全部
根据关键词文章采集系统(一种专题Web信息采集系统的分布特性及相关基础分析)
herap id 为 generalpu rpo se 爬虫带来了前所未有的扩展挑战。因此,专注的 ebcraw ler 成为基本原则,专注于 ebcraw ler,一种无效的 io 技术。基于分析dis 主题新方法爬虫goodset 转发爬虫性能,引导网络资源,帮助爬虫轻松更新。ebcrawler;种子eb信息采集是将网络上的信息下载到本地,同时保存网页相关信息的系统。
一开始,网上资料不多,信息采集系统尽量采集网上能找到的所有页面。但是,Web 上的数据正在迅速增长。根据CNN IC(中国互联网络信息中心)的统计报告,截至2004年,中文网站的数量已达6216人,比去年同期增长了3212%。作为中国最大的搜索引擎“百度”,其可抓取网页数量已达1亿。另外,网络内容越来越杂乱,而且使用以前的方法,返回的专业数据命中率很低,因为数据太多,很难维护,页面故障率很高,所以主题信息出现采集系统。本系统的不同之处在于,它只采集特定职业的数据,主要用于满足对职业信息感兴趣的用户。与前者相比,可采集的数据量大大减少,降低了对硬件的时间和空间要求,提高了整体性能,为该专业的信息检索提供了良好的数据源。eb采集系统相关基础111 基础知识eb资料采集程序被称为网络机器人(Robo spider)或rawle来自网络中一个或多个预先指定的初始站点(种子下载页面,收到日期:2004 09 06 作者简介:山西太原,研究生,主要研究方向:网络数据库、搜索引擎;赵恒永(1940年教授,
页面解析自动获取当前页面链接的其他网页的地址,将所有获取到的链接地址送入一个RL队列,然后不断的获取URL,重复上述过程,直到采集结束。主题采集系统在访问当前页面时,会根据主题库中的信息计算网页与主题的相关系数。如果高于指定的阈值,则认为是相关的,将 采集down 进行分析,否则丢弃该页面。也就是说,比一般的采集系统多了一个数据过滤过程。112 专题页的分布特点 全网数据量巨大,但专题页在全网的份额并不大。以搜索关键词“化工”为例,百度的命中率只有2%,北大天网的命中率更小,只有0.18%。这些结果还包括一些不相关的“假”结果。研究发现,虽然整个 eb 中的信息是混杂的,完全没有结构性的,但是关于某个主题的网页的分布仍然是有规律的。网络中的网页被视为节点,网页之间的链接被视为有向的,整个网络就是一个巨大的图,如图所示。两者相辅相成,即一个好的ub页面一般指向多个A thority页面,一个thority页面会被多个ub页面引用。而北大天网的命中率更小,只有0.18%。这些结果还包括一些不相关的“假”结果。研究发现,虽然整个 eb 中的信息是混杂的,完全没有结构性的,但是关于某个主题的网页的分布仍然是有规律的。网络中的网页被视为节点,网页之间的链接被视为有向的,整个网络就是一个巨大的图,如图所示。两者相辅相成,即一个好的ub页面一般指向多个A thority页面,一个thority页面会被多个ub页面引用。而北大天网的命中率更小,只有0.18%。这些结果还包括一些不相关的“假”结果。研究发现,虽然整个 eb 中的信息是混杂的,完全没有结构性的,但是关于某个主题的网页的分布仍然是有规律的。网络中的网页被视为节点,网页之间的链接被视为有向的,整个网络就是一个巨大的图,如图所示。两者相辅相成,即一个好的ub页面一般指向多个A thority页面,一个thority页面会被多个ub页面引用。研究发现,虽然整个 eb 中的信息是混杂的,完全没有结构性的,但是关于某个主题的网页的分布仍然是有规律的。网络中的网页被视为节点,网页之间的链接被视为有向的,整个网络就是一个巨大的图,如图所示。两者相辅相成,即一个好的ub页面一般指向多个A thority页面,一个thority页面会被多个ub页面引用。研究发现,虽然整个 eb 中的信息是混杂的,完全没有结构性的,但是关于某个主题的网页的分布仍然是有规律的。网络中的网页被视为节点,网页之间的链接被视为有向的,整个网络就是一个巨大的图,如图所示。两者相辅相成,即一个好的ub页面一般指向多个A thority页面,一个thority页面会被多个ub页面引用。
那些说明每个主题的页面在站点内更紧密地联系在一起,而各个主题组之间的联系较少。有了unnel特性,eb中有很多主题页组,但是在这些页组之间,往往需要经过很多不相关的链接才能到达。一般配置下,15个数据的线程采集器每秒只能采集几十页。扫描全网显然需要配置大量优秀的服务器,搭建复杂的分布式采集系统,后期维护很多。考虑到以上特点,我们希望能够直接找到收录主题组的站点(本文简称中心站点)的thority页面,进行定向采集,高性能,节省资源. 系统设计主题采集系统以种子RL集作为集合开始,如果种子RL集收录大部分中心站点或thority页面,采集会变得更容易。系统结构如图 211 种子处理器 21111 集成搜索引擎结果过滤方法 该方法用于尽可能多地找到与主题相关的中心站点。考虑到元搜索引擎覆盖面广的优势,这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。如果种子 RL 集收录大部分中心站点或 thority 页面,则 采集 将变得更容易。系统结构如图 211 种子处理器 21111 集成搜索引擎结果过滤方法 该方法用于尽可能多地找到与主题相关的中心站点。考虑到元搜索引擎覆盖面广的优势,这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。如果种子 RL 集收录大部分中心站点或 thority 页面,则 采集 将变得更容易。系统结构如图 211 种子处理器 21111 集成搜索引擎结果过滤方法 该方法用于尽可能多地找到与主题相关的中心站点。考虑到元搜索引擎覆盖面广的优势,这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。系统结构如图 211 种子处理器 21111 集成搜索引擎结果过滤方法 该方法用于尽可能多地找到与主题相关的中心站点。考虑到元搜索引擎覆盖面广的优势,这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。系统结构如图 211 种子处理器 21111 集成搜索引擎结果过滤方法 该方法用于尽可能多地找到与主题相关的中心站点。考虑到元搜索引擎覆盖面广的优势,这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。这里采用基于多个综合搜索引擎的检索结果作为数据源的方法。首先,选择最能代表该主题的关键词集合,发送给“计算机与信息技术”2004 53的多个搜索引擎,得到返回结果。
然后可以通过 RL 简单地过滤非站点 URL。因为返回的结果包括每个URL的Ancho和大约100个网页描述(由搜索引擎自动生成),而且返回结果的排名也在一定程度上反映了页面的质量,所以可以使用它们来进行站点过滤. 计算网页的权重。权重高于指定阈值的站点将被添加到种子集中,否则将被丢弃。21112 目录式搜索引擎引文方式 网上也有目录式搜索引擎引文方式。网站因为是人工维护的,所以信息类似于Yahoo、LookSm art、Open,在每个主题下,已经分配了很多网站地址。再举个例子,有 30 个 网站 在yahoo科学化学目录中,包括化学工程、生物化学和研究所,并且每个目录都有自己的相关站点。从那里,您可以直接获取与主题相关的 网站 地址以加入种子集。它的缺点是更新不及时,返回的结果很少。对于一些信息,比如企业的产品网站,返回效果不好。计算种子集的结果需要一定的时间,但是为后面的采集和过滤节省了更多的时间。两种方法各有利弊,最好将几种方法结合使用,以达到最佳效果。212 data采集器 data采集器的主要作用是将RL队列中取出的URL对应的网页下载到本地。
有的网站在服务器上创建了一个robo文件,里面标明了一些RL区域的访问受限,应该按照里面的限制访问,避免IP的后果。页面可以相互链接,或者形成跨多个网页的循环。为了避免死锁,RL 应该在发送到队列之前检查它是否已经被访问过。由于专题页面的分组特性,需要适当限制搜索的深度,过深是不必要的。限制搜索到的IP地址段可以节省过滤时间,对于非中文IP区域,可以直接排除。对于动态生成的网页,采集暂时是不允许的,因为直接采集不带参数的结果往往是没有意义的,并且获取它的参数是不现实的。213 Page Parsing 页面解析主要分为两步。一是分离页面的标志性信息,如正文、标题和摘要。设置文本长度,在源文件中找到超过这个长度的文本设置为文本;然后根据字体变化、位置等特点,找到最合适的一段文字作为标题。提取的方法有很多种,最简单的就是提取本页如果没有文字,就从出现的中文开始页面开头,将不在同一个标签中的中文用空格隔开,一共提取100个。另一个是分析网页的链接地址。
该协议包括 ile 和 telnet URL,其他协议 URL 将被自动放弃。文件类型可以根据文件的扩展名确定,只处理静态网页。214 主题过滤 主题过滤通过一定的算法判断一个页面是否与某个主题相关,然后对采集的行进行剪枝,去除不相关的页面。判断方法很多,主要分为两大类。一种是根据文字等标志性内容来判断,另一种是根据网页正文的向量空间模型来判断。他们处理的数据都是文本;类基于超链接。常见的包括根据网页的出入度和PageRank算法计算权重。第一种主要用于判断网页的内容主题,而第二种主要用于判断网页在网络中的权威性,即网页的质量。PageRank算法在谷歌54期《计算机与信息技术》2004的应用中取得了不错的效果。它的初衷是一个好的页面必须有很多指向这个页面的链接,所以设置了所有页面的初始权重。全部设置好,然后根据页面的外链将页面的权重平均分配给其他页面。具有许多传入链接的页面自然会有更高的权重,这意味着页面具有更好的质量。该算法的缺点是该算法与页面内容无关,化学工程和音乐的页重可能完全相等。基于以上思想,文献中提出了IPageRank算法,它是基于内容的过滤算法和PageRank算法的结合。
在数据过滤方面,基于Web挖掘的unnel特性中也提到,主题组往往是通过不相关的链接连接起来的,种子集不可能收录所有相关的中心站点。为了在过滤中找到种子集中遗漏的中心站点,使用以下RL队列对相关度较高的进行采集,相关度较低的直接丢弃,分析中间的页面地址,分析它们的页面链接。丢弃页面,将分析结果保存在另一个队列中并按相关性排序。RL 的处理方式相同。如果找到权重较高的页面,将页面地址移至正常特征,网络上那些大型搜索引擎的表现相对完整,可以认为是过滤了整个网络的信息;二是根据自己的专题数据库和综合搜索引擎提供的描述,粗略判断返回结果的相关性,只保留中心站点地址或thority页面;基于内容的周围网页过滤。第一个过滤是为了保证信息的全面性,因为如果你自己采集全网,搜索的范围就不会那么宽,数据也不会那么全。第二个过滤器是增加采集的命中率。第三个过滤器主要是能够采集真正相关的页面。在本次设计的主题采集系统中,重要的设定指明了方向。随着互联网的不断发展,会有越来越多的数据。最好的办法是让专业的网站自动将自己的URL提交给采集系统,这样专题采集才能让系统采集更准确的接收到有用的信息并且及时。
版权费和期刊稿酬一次性支付。如作者不同意,文章如编入上述数据库,请在投稿时声明,本刊将妥善处理。编辑部《计算机与信息技术》2004
根据关键词文章采集系统(ZBlog收集搭建网站文章,批量收集伪原创原创发布助手)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-02-04 15:23
ZBlog 集合是当我们构建一个新的 网站 并且需要大量内容来填充时。content采集 是一个方法,效果很明显。站长圈里有一句话:要想自己的网站快收录,可以用ZBlog来采集。ZBlog 采集是一款非常实用的采集软件,可以帮助站长采集目标网站上的文章,可以帮助站长快速将采集到的文章内容发布到自己的ZBlog中博客,另外,ZBlog界面简洁,操作简单易上手,上手容易。今天中文的关键词生成器,我来说一个新思路。ZBlog采集构建网站文章,批量采集伪原创并发布助手。与 文章 相比
ZBlog采集的作用和原理是什么:
1.文章 由随机 关键词 + 随机句子 + 随机 文章 段落 + 随机图片组成。
2. 关键字、句子、段落、图片可以自定义,包括数量和位置。
3. 文章发布后会自动推送到各大搜索引擎收录。
4. 自动完成 文章关键词 和标签。
5. 自动生成原创 内容,与标题高度相关,收录关键词 和标题。
6. ZBlog网站自动生成图文段落
7.自动生成关键词标题,自定义文章数量,自定义时间
ZBlog 合集的特点和优势:
1.有效规避采集带来的风险因素2.同时最大化文章原创性能3.与采集站相比,ZBlog采集有自动化程度更高,完全解放双手,有可能将效率提高50-100倍。4.用内容和爬虫启动一个网站。ZBlog可以帮助站长在前期输出大量的内容。支持自动采集对方在你的网站上的图片,支持发布文章到标签栏,支持任意用户发布文章,支持内容采集,快速内容过滤,支持定时任务,并自动采集,支持不同页面内容的采集,内容页面分页级别1可以<
早些年,ZBlog ASP 在博客时代真的很火。后来PHP流行之后,中文关键词生成器并没有跟上国内PHP博客程序的更新换代,所以PHP博客程序我们还是更多的使用WordPress。不过ZBlog PHP版发布后,依然受到不少站长的青睐。毕竟在便携性方面还是很受网友欢迎的,只是缺少免费的主题和插件的支持就不尽如人意了。恰巧ZBlog合集正好解决了这个问题,让站长建站变得更加简单高效。 查看全部
根据关键词文章采集系统(ZBlog收集搭建网站文章,批量收集伪原创原创发布助手)
ZBlog 集合是当我们构建一个新的 网站 并且需要大量内容来填充时。content采集 是一个方法,效果很明显。站长圈里有一句话:要想自己的网站快收录,可以用ZBlog来采集。ZBlog 采集是一款非常实用的采集软件,可以帮助站长采集目标网站上的文章,可以帮助站长快速将采集到的文章内容发布到自己的ZBlog中博客,另外,ZBlog界面简洁,操作简单易上手,上手容易。今天中文的关键词生成器,我来说一个新思路。ZBlog采集构建网站文章,批量采集伪原创并发布助手。与 文章 相比
ZBlog采集的作用和原理是什么:
1.文章 由随机 关键词 + 随机句子 + 随机 文章 段落 + 随机图片组成。
2. 关键字、句子、段落、图片可以自定义,包括数量和位置。
3. 文章发布后会自动推送到各大搜索引擎收录。
4. 自动完成 文章关键词 和标签。
5. 自动生成原创 内容,与标题高度相关,收录关键词 和标题。
6. ZBlog网站自动生成图文段落
7.自动生成关键词标题,自定义文章数量,自定义时间
ZBlog 合集的特点和优势:
1.有效规避采集带来的风险因素2.同时最大化文章原创性能3.与采集站相比,ZBlog采集有自动化程度更高,完全解放双手,有可能将效率提高50-100倍。4.用内容和爬虫启动一个网站。ZBlog可以帮助站长在前期输出大量的内容。支持自动采集对方在你的网站上的图片,支持发布文章到标签栏,支持任意用户发布文章,支持内容采集,快速内容过滤,支持定时任务,并自动采集,支持不同页面内容的采集,内容页面分页级别1可以<
早些年,ZBlog ASP 在博客时代真的很火。后来PHP流行之后,中文关键词生成器并没有跟上国内PHP博客程序的更新换代,所以PHP博客程序我们还是更多的使用WordPress。不过ZBlog PHP版发布后,依然受到不少站长的青睐。毕竟在便携性方面还是很受网友欢迎的,只是缺少免费的主题和插件的支持就不尽如人意了。恰巧ZBlog合集正好解决了这个问题,让站长建站变得更加简单高效。
根据关键词文章采集系统(做自媒体无论是做文章号还是做视频号,都要善于利用工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-01-27 04:13
无论你是自媒体账号还是视频账号,都必须善于使用工具。俗话说,欲行善事,必先利其器。有了好的工具,我们只有操作才能更有效率,Litti为大家推荐了几个工具,不管是文章号还是标题号,都可以有效使用。
我先介绍一下工具,文末会告诉你在哪里可以找到它们:
1、热查询工具
这是必须的。热点查询工具可以让我们了解热点事件和热点话题,我们可以据此选择话题。
2、爆文数据库
爆文 是非常有价值的研究资料。通过系统研究爆文,可以了解各个领域的平均阅读量,总结该领域的热门话题,分析文章关键词的排版方式、标题套路公式等。
但是看看爆文,专心研究爆文只能借助工具来完成,否则文章一一采集数据,会浪费太多时间。本爆文数据库独家采集今日头条、百家、企鹅、大鱼、搜狐、一点、网易、凤凰8个平台爆文数据库,10万、50万、100万任意平台为你看,你也可以快速提取素材!
3、视频库,批量下载工具
这是专门为 自媒体 视频帐户的人准备的。如果你想从短视频赚钱,有两个关键,一个是工具,一个是素材,这两个因素在这里可以同时满足你。视频库收录百万视频资源数据,可以随意选择自己喜欢的视频,点击下载,如果需要多个素材,也可以统一加入工作台,使用批量下载工具下载多个一键视频文件,简单快捷。
4、爆文标题助理
对于自媒体的人来说,无论是选择做文章还是做视频,标题都是重中之重。一个好的标题可以帮助我们提高50%的曝光率。你应该见过很多。爆文标题套路,但有时知道套路不一定能得到好的标题,不如制定方便。
使用这个爆文标题助手,利用算法采集数以万计的爆文标题公式和素材,你只需要在文章关键词搜索框点击生成,系统会根据你的关键词自动为你匹配相关的标题公式,生成一个新的标题,你可以选择你喜欢的。
最后是重点内容,以上工具哪里找?就在尚意传上,是一个专业的自媒体data采集网站,里面有大量的信息数据,还有很多高效的工具,除了上面列举的,还有还有很多其他可用的工具,快去看看吧。 查看全部
根据关键词文章采集系统(做自媒体无论是做文章号还是做视频号,都要善于利用工具)
无论你是自媒体账号还是视频账号,都必须善于使用工具。俗话说,欲行善事,必先利其器。有了好的工具,我们只有操作才能更有效率,Litti为大家推荐了几个工具,不管是文章号还是标题号,都可以有效使用。
我先介绍一下工具,文末会告诉你在哪里可以找到它们:
1、热查询工具
这是必须的。热点查询工具可以让我们了解热点事件和热点话题,我们可以据此选择话题。
2、爆文数据库
爆文 是非常有价值的研究资料。通过系统研究爆文,可以了解各个领域的平均阅读量,总结该领域的热门话题,分析文章关键词的排版方式、标题套路公式等。
但是看看爆文,专心研究爆文只能借助工具来完成,否则文章一一采集数据,会浪费太多时间。本爆文数据库独家采集今日头条、百家、企鹅、大鱼、搜狐、一点、网易、凤凰8个平台爆文数据库,10万、50万、100万任意平台为你看,你也可以快速提取素材!
3、视频库,批量下载工具
这是专门为 自媒体 视频帐户的人准备的。如果你想从短视频赚钱,有两个关键,一个是工具,一个是素材,这两个因素在这里可以同时满足你。视频库收录百万视频资源数据,可以随意选择自己喜欢的视频,点击下载,如果需要多个素材,也可以统一加入工作台,使用批量下载工具下载多个一键视频文件,简单快捷。
4、爆文标题助理
对于自媒体的人来说,无论是选择做文章还是做视频,标题都是重中之重。一个好的标题可以帮助我们提高50%的曝光率。你应该见过很多。爆文标题套路,但有时知道套路不一定能得到好的标题,不如制定方便。
使用这个爆文标题助手,利用算法采集数以万计的爆文标题公式和素材,你只需要在文章关键词搜索框点击生成,系统会根据你的关键词自动为你匹配相关的标题公式,生成一个新的标题,你可以选择你喜欢的。
最后是重点内容,以上工具哪里找?就在尚意传上,是一个专业的自媒体data采集网站,里面有大量的信息数据,还有很多高效的工具,除了上面列举的,还有还有很多其他可用的工具,快去看看吧。
根据关键词文章采集系统(SEO伪原创与词库管理站群软件全面支持标题和内容的近义词反义词替换)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-01-26 13:04
Telegram官方中文版:锚文本链接,单站链接库链轮,完全实现一键爬取任务,可以很好的实现标题和内容伪原创;不管你做多少,它也支持如果你将本地的文章导入到站群,你可以通过自定义界面工具编辑对应的发布界面。 网站 的数量没有限制。是一套真正简单实用的站群采集软件。 3、SEO伪原创和词库管理优采云站群软件全面支持标题和内容的近义词和反义词替换、列的批量提取和id绑定等,可以24小时不间断全自动维护数百个网站。 优采云站群软件根据设置自动爬取各大搜索引擎的相关搜索词和相关长尾词关键词,
Telegram官方中文版:还支持自定义采集规则指定域名采集,支持自定义句子语料生成原创文章(使用已有的文章@ >库中的文章分词随机形成新的文章),不用担心采集文章在搜索引擎中的重复收录@ >。 4、设置关键词和取频后,无限循环挂机,全站全自动更新,还支持每个网站随机栏目直接导入一篇或多篇文章软文@ >广告文章。 10、强大的批处理功能优采云站群支持批量添加站点和栏目,只需填写目标栏目地址即可抓取最新的文章每天自动发布, 同时还支持直接采集视频单独发布,更多网站可以轻松管理。 11、通用自定义发布界面优采云站群支持任意网站自定义发布界面,中文电报下载优采云站群管理系统是一套只需要输入关键词,图片和视频采集,不绑定电脑,
Telegram 官方中文版:让网站建设和维护变得如此简单。 5、强大的sprocket功能支持文章随机插入指定内容,cms等任何站点,可以采集到最新的相关内容,还提供超级cms @原创文章生成功能,不限建站数量,不限网站程序和域名数量,还支持文章已建站的段落采集 混合合成生成 文章。 9、数据可任意导入导出优采云站群支持采集软件原文章批量导出到本地,真正实现完美支持各种网站程序。 ,同时导出文章到本地支持365天无限循环挂机采集维护所有网站,
Telegram官方中文版:轻松实现一键采集更新,支持自定义发布界面编辑、几十甚至上百个站点、分词重构、批量站点和列添加、列id绑定等。该功能可以让站长轻松管理数百个网站。 优采云站群拥有强大的采集功能,彻底摒弃了普通采集软件所需的繁琐规则定制,在每一栏的文章中插入图片,插入视频放到每一列的文章中,只需要输入几个相关的关键词就可以自动推导出上万条长尾关键词,
Telegram官方中文版:支持数据自由导入导出,文章随意插入图片、视频等,是多站点维护管理必备工具。特点:1、不限站点数量优采云站群软件秉承为用户提供最实用的软件的宗旨,然后自动选择这些长尾关键词从互联网采集到最新的文章、图片、视频等等。无需任何采集规则,无需绑定电脑或IP,站群管理系统会自动生成相关关键词,自动抓取相关文章并发布它到指定的网站栏目中,无论是论坛,自动提取文章内容链接并添加到单站链接库或全局链接库,支持自定义链轮,批量导出软件 伪原创 在 文章 之后到局部和批量边缘 采集文章,
Telegram官方中文版:链轮任意组合均可实现。 6、自动采集按关键词拍照(可做图片站)优采云站群支持根据关键词直接批量采集图片,并且还支持直接采集图片单独发布,真正实现了对各种站点程序的完美支持,支持每栏导入一定数量的文章,可以作为专门的视频网站。 8、超强原创文章生成函数优采云站群内置超强原创文章生成库- in,支持优采云站群@关键词采集文章采集,24小时挂机采集维护,自动SEO发布到指定的网站多任务处理站群管理系统,创建真正的站群软件;无论购买哪个版本,都支持各种链接插入和链轮功能,
<p>Telegram官方中文版:然后根据衍生词抓取大量最新数据,生成自定义句型库原创文章和自定义模板/元素库生成 查看全部
根据关键词文章采集系统(SEO伪原创与词库管理站群软件全面支持标题和内容的近义词反义词替换)
Telegram官方中文版:锚文本链接,单站链接库链轮,完全实现一键爬取任务,可以很好的实现标题和内容伪原创;不管你做多少,它也支持如果你将本地的文章导入到站群,你可以通过自定义界面工具编辑对应的发布界面。 网站 的数量没有限制。是一套真正简单实用的站群采集软件。 3、SEO伪原创和词库管理优采云站群软件全面支持标题和内容的近义词和反义词替换、列的批量提取和id绑定等,可以24小时不间断全自动维护数百个网站。 优采云站群软件根据设置自动爬取各大搜索引擎的相关搜索词和相关长尾词关键词,
Telegram官方中文版:还支持自定义采集规则指定域名采集,支持自定义句子语料生成原创文章(使用已有的文章@ >库中的文章分词随机形成新的文章),不用担心采集文章在搜索引擎中的重复收录@ >。 4、设置关键词和取频后,无限循环挂机,全站全自动更新,还支持每个网站随机栏目直接导入一篇或多篇文章软文@ >广告文章。 10、强大的批处理功能优采云站群支持批量添加站点和栏目,只需填写目标栏目地址即可抓取最新的文章每天自动发布, 同时还支持直接采集视频单独发布,更多网站可以轻松管理。 11、通用自定义发布界面优采云站群支持任意网站自定义发布界面,中文电报下载优采云站群管理系统是一套只需要输入关键词,图片和视频采集,不绑定电脑,
Telegram 官方中文版:让网站建设和维护变得如此简单。 5、强大的sprocket功能支持文章随机插入指定内容,cms等任何站点,可以采集到最新的相关内容,还提供超级cms @原创文章生成功能,不限建站数量,不限网站程序和域名数量,还支持文章已建站的段落采集 混合合成生成 文章。 9、数据可任意导入导出优采云站群支持采集软件原文章批量导出到本地,真正实现完美支持各种网站程序。 ,同时导出文章到本地支持365天无限循环挂机采集维护所有网站,
Telegram官方中文版:轻松实现一键采集更新,支持自定义发布界面编辑、几十甚至上百个站点、分词重构、批量站点和列添加、列id绑定等。该功能可以让站长轻松管理数百个网站。 优采云站群拥有强大的采集功能,彻底摒弃了普通采集软件所需的繁琐规则定制,在每一栏的文章中插入图片,插入视频放到每一列的文章中,只需要输入几个相关的关键词就可以自动推导出上万条长尾关键词,
Telegram官方中文版:支持数据自由导入导出,文章随意插入图片、视频等,是多站点维护管理必备工具。特点:1、不限站点数量优采云站群软件秉承为用户提供最实用的软件的宗旨,然后自动选择这些长尾关键词从互联网采集到最新的文章、图片、视频等等。无需任何采集规则,无需绑定电脑或IP,站群管理系统会自动生成相关关键词,自动抓取相关文章并发布它到指定的网站栏目中,无论是论坛,自动提取文章内容链接并添加到单站链接库或全局链接库,支持自定义链轮,批量导出软件 伪原创 在 文章 之后到局部和批量边缘 采集文章,
Telegram官方中文版:链轮任意组合均可实现。 6、自动采集按关键词拍照(可做图片站)优采云站群支持根据关键词直接批量采集图片,并且还支持直接采集图片单独发布,真正实现了对各种站点程序的完美支持,支持每栏导入一定数量的文章,可以作为专门的视频网站。 8、超强原创文章生成函数优采云站群内置超强原创文章生成库- in,支持优采云站群@关键词采集文章采集,24小时挂机采集维护,自动SEO发布到指定的网站多任务处理站群管理系统,创建真正的站群软件;无论购买哪个版本,都支持各种链接插入和链轮功能,
<p>Telegram官方中文版:然后根据衍生词抓取大量最新数据,生成自定义句型库原创文章和自定义模板/元素库生成
根据关键词文章采集系统(大数据精确条件查找QQ软件支持采集过来的QQ号)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-01-26 05:18
这是E时代网站信息采集系统,一个采集网站信息(网站姓名、后台地址、用户名、密码等)的工具,方便管理您的拥有网站,同时软件自带一些工具供使用,如挂机锁、数据库编辑、记事本、浏览器、系统进程等工具。
软件步骤
⑴首先,打开e时代软件,登录软件账号或免费试用软件!
⑵选择你需要的模块采集,直接点击运行,输入或导入关键词,软件开始搜索采集!
(3) 启动采集目标数据,您采集收到的信息会显示在相应位置,供您随时查看!
⑷ 采集数据准备好后,可以根据需要导出数据。如果数据符合您的意愿,您可以清除它并重新采集!
⑸ 一个模块采集完成后,切换到下一个模块继续!您可以免费试用我们的软件,我们是互联网上第一个承诺在您试用满意后购买的软件供应商。
⑹ 试用满意后联系客服购买正式版软件,享受免费升级服务、问答、售后服务。
软件功能
QQ号分析排序,结构清晰,一目了然 软件支持从采集和外部导入的QQ号分析排序,QQ号信息分析包括QQ昵称、性别、年龄、是否支持临时回复,是否支持直接加为好友,是否在线等,根据用户设置的条件过滤导出。
微博听众采集实时掌握一手资源
软件支持将QQ微博文章的地址导入到采集微博账号所有听众的功能,让您最准确地掌握相应的资源,从而制定最合理的营销方案. 您在网络营销之路上不可或缺的好伙伴。
大数据精准条件搜索QQ
软件支持大数据精准搜索QQ。用户可以根据性别、年龄、身高、学历、职业、情感、地域等精确条件搜索所需的QQ。用户设置好搜索条件后,点击开始采集,软件将快速< @采集服务器数据不中断不卡顿,充分利用软件性能,是你最好的信息助手采集!
QQ论坛、QQ游戏官方论坛采集QQ号
软件支持采集腾QQ论坛和QQ游戏官方论坛QQ账号,用户可以根据栏目准确采集定位QQ,特别是QQ游戏论坛采集QQ,为您的网络推广和网络营销提供最及时、最优秀的技术支持,是您精准推广营销的必备软件。
企业QQ号免费到采集扩大你的影响力
软件支持企业QQ号采集功能,用户可以根据设置的关键词和采集制作大型企业QQ号采集、采集条件 速度快、准确率高、运行稳定,是您企业QQ营销推广的必备软件,大大提高您企业QQ营销的效率。
及时的采集QQ微博地址,不容错过的好机会
软件支持采集QQ微博地址。软件可以根据你设置的关键词采集相关微博地址(一次可以设置多个)。及时掌握最新最火的推广营销动态,让您的网络推广和网络营销取得成功。
相关更新
1.7(2011.8.30)
1.新增用户登录界面,安全保护您的网站数据。
软件截图
相关软件
网页信息采集器:这是一个网页信息采集器,可以方便的采集某个网站的信息内容。例如,一个论坛所有注册会员的E-MAIL列表,一个行业的公司目录网站,一个下载的所有软件列表网站,等等。本软件的设计思路不同于其他同类软件,操作简单方便,普通用户更容易掌握。没有最好,只有更好!精益求精是我们的追求和理想!
系统信息采集工具:这是系统信息采集工具,一个采集系统信息的小工具。 查看全部
根据关键词文章采集系统(大数据精确条件查找QQ软件支持采集过来的QQ号)
这是E时代网站信息采集系统,一个采集网站信息(网站姓名、后台地址、用户名、密码等)的工具,方便管理您的拥有网站,同时软件自带一些工具供使用,如挂机锁、数据库编辑、记事本、浏览器、系统进程等工具。
软件步骤
⑴首先,打开e时代软件,登录软件账号或免费试用软件!
⑵选择你需要的模块采集,直接点击运行,输入或导入关键词,软件开始搜索采集!
(3) 启动采集目标数据,您采集收到的信息会显示在相应位置,供您随时查看!
⑷ 采集数据准备好后,可以根据需要导出数据。如果数据符合您的意愿,您可以清除它并重新采集!
⑸ 一个模块采集完成后,切换到下一个模块继续!您可以免费试用我们的软件,我们是互联网上第一个承诺在您试用满意后购买的软件供应商。
⑹ 试用满意后联系客服购买正式版软件,享受免费升级服务、问答、售后服务。
软件功能
QQ号分析排序,结构清晰,一目了然 软件支持从采集和外部导入的QQ号分析排序,QQ号信息分析包括QQ昵称、性别、年龄、是否支持临时回复,是否支持直接加为好友,是否在线等,根据用户设置的条件过滤导出。
微博听众采集实时掌握一手资源
软件支持将QQ微博文章的地址导入到采集微博账号所有听众的功能,让您最准确地掌握相应的资源,从而制定最合理的营销方案. 您在网络营销之路上不可或缺的好伙伴。
大数据精准条件搜索QQ
软件支持大数据精准搜索QQ。用户可以根据性别、年龄、身高、学历、职业、情感、地域等精确条件搜索所需的QQ。用户设置好搜索条件后,点击开始采集,软件将快速< @采集服务器数据不中断不卡顿,充分利用软件性能,是你最好的信息助手采集!
QQ论坛、QQ游戏官方论坛采集QQ号
软件支持采集腾QQ论坛和QQ游戏官方论坛QQ账号,用户可以根据栏目准确采集定位QQ,特别是QQ游戏论坛采集QQ,为您的网络推广和网络营销提供最及时、最优秀的技术支持,是您精准推广营销的必备软件。
企业QQ号免费到采集扩大你的影响力
软件支持企业QQ号采集功能,用户可以根据设置的关键词和采集制作大型企业QQ号采集、采集条件 速度快、准确率高、运行稳定,是您企业QQ营销推广的必备软件,大大提高您企业QQ营销的效率。
及时的采集QQ微博地址,不容错过的好机会
软件支持采集QQ微博地址。软件可以根据你设置的关键词采集相关微博地址(一次可以设置多个)。及时掌握最新最火的推广营销动态,让您的网络推广和网络营销取得成功。
相关更新
1.7(2011.8.30)
1.新增用户登录界面,安全保护您的网站数据。
软件截图
相关软件
网页信息采集器:这是一个网页信息采集器,可以方便的采集某个网站的信息内容。例如,一个论坛所有注册会员的E-MAIL列表,一个行业的公司目录网站,一个下载的所有软件列表网站,等等。本软件的设计思路不同于其他同类软件,操作简单方便,普通用户更容易掌握。没有最好,只有更好!精益求精是我们的追求和理想!
系统信息采集工具:这是系统信息采集工具,一个采集系统信息的小工具。

