
文章采集组合工具
渗透测试之子域名枚举(子域名枚举的艺术)
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2020-08-11 14:48
的部份内容因为网路缘由难以验证,有兴趣的可以自行挖掘,不再做过多的调整,翻译此文的诱因就是为了给子域枚举提供一个系统化的学习方法,此外子域名=子域名,但子域不一定只有子域名,注意分辨,文章开头提及的子域名枚举的艺术已经完成了翻译,可以直接点击链接进行学习下载;
子域名枚举的艺术:
文中谈到了好多工具和方法,但要注意兵贵在精不在多,适合的才是最好的,注意文中的链接,有助于扩充你对子域枚举的了解
最后,感谢
0x01.什么是子域名枚举?
子域名枚举是查找一个或多个域的子域的过程。这是侦察阶段的重要组成部份。
0x02.为什么子域名枚举?
着名的雅虎之声风波!由于在子域上布署了易受功击的应用程序,从而被入侵。
0x03子域枚举技术1.搜索引擎
Google和Bing等搜索引擎支持各类中级搜索运算符来优化搜索查询。这些中级运算符一般被称为“谷歌Dorking”。
2.DNS数据聚合
有许多第三方服务聚合大量DNS数据集并可以查看这种数据集检索给定域的子域。
3.证书透明度Certificate Transparency
证书透明度(CT)是证书颁授机构(CA)必须将其发布的每位SSL / TLS证书发布到公共日志。SSL / TLS证书一般收录域名,子域名和电子邮件地址。这让她们成为攻击者的宝库。我在证书透明度上写了一系列技术博客文章,我深入介绍了这个技术,你可以在这里阅读这个系列。
查找为域颁授的证书的最简单方式是使用搜集CT日志的搜索引擎,任何人可以搜索它们。下面列举了太受欢迎的CT搜索地址:
除了Web界面之外,crt.sh还可以使用postgres界面访问其CT日志数据。这促使运行一些中级查询显得简单而灵活。如果您安装了PostgreSQL客户端软件,则可以按如下形式登陆:
$ psql -h crt.sh -p 5432 -U guest certwatch
我们编撰了一些脚本来简化使用CT日志搜索引擎查找子域的过程。这些脚本可以在我们的github中找到
使用CT进行子域枚举的缺点是CT日志中找到的域名可能不再存在,因此未能解析为IP地址。您可以将massdns等工具与CT日志结合使用,以快速辨识可解析的域名。
# ct.py - extracts domain names from CT Logs(shipped with massdns)
# massdns - will find resolvable domains & adds them to a file
./ct.py icann.org | ./bin/massdns -r resolvers.txt -t A -q -a -o -w icann_resolvable_domains.txt -
4.暴力枚举
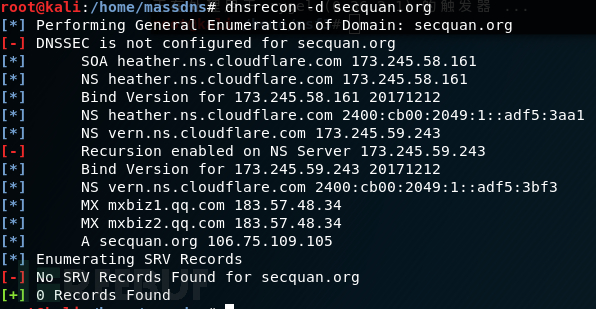
基于字典的枚举找到通用名称子域是另一种技术。DNSRecon是一个功能强悍的DNS枚举工具,它的一个功能是使用预定义的字典进行子域枚方式侦查子域
# 使用DNSRecon的基于字典的枚举
$ python dnsrecon.py -n ns1.insecuredns.com -d insecuredns.com -D subdomains-top1mil-5000.txt -t brt
5.置换扫描
置换扫描是另一个有趣的技术来辨识子域。在该技术中,我们使用已知域/子域的排列,改变和突变来辨识新的子域。
$ python altdns.py -i icann.domains -o data_output -w icann.words -r -s results_output.txt
使用AltDNS查找与个别排列/更改匹配的子域
6.自治系统(AS)
查找自治系统(AS)号码将帮助我们辨识属于组织的网络块,而该组块又可能具有有效域。
首先使用dig查找ASN
其次,使用AS编号查找网络块 - NSE脚本
$ nmap --script targets-asn --script-args targets-asn.asn=9808 > netblocks.txt
7.区域传送
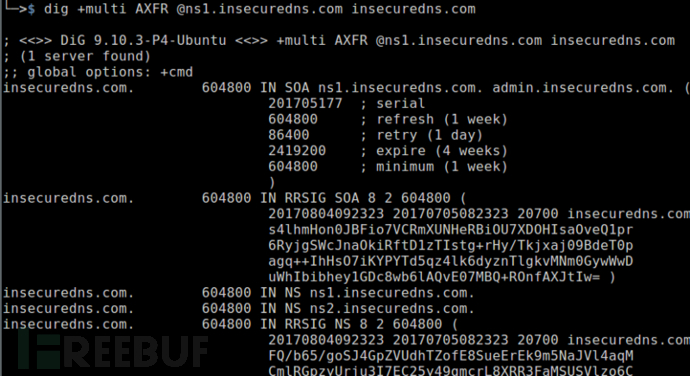
区域传输是一种DNS事务,DNS服务器将其全部或部份区域文件的副本传递给另一个DNS服务器。如果未安全地配置区域传送,则任何人都可以针对名称服务器启动区域传输并获取区域文件的副本。根据设计,区域文件收录有关区域和留驻在区域中的主机的大量信息。
$ dig + multi AXFR @ ns1 .insecuredns.com insecuredns.com
使用DIG工具针对域的名称服务器成功进行区域传送
8.DNSSEC记录.
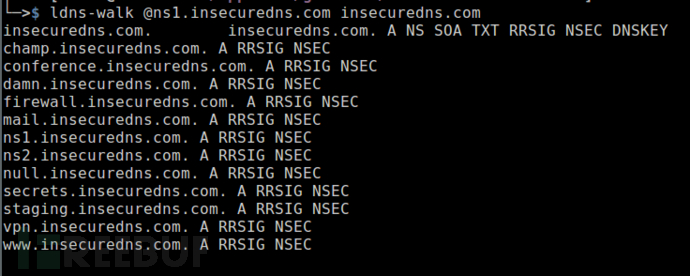
由于在DNSSEC中处理不存在的域的方法,可以“遍历”DNSSEC区域并枚举该区域中的所有域。也可以从这儿了解有关此技术的更多信息。
$ ldns-walk @ ns1.insecuredns.com insecuredns.com
区域遍历DNSSEC区域与NSEC记录
# Collect NSEC3 hashes of a domain
$ ./collect icann.org > icann.org.collect
# Undo the hashing, expose the sub-domain information.
$ ./unhash < icann.org.collect > icann.org.unhash
# Listing only the sub-domain part from the unhashed data
$ cat icann.org.unhash | grep "icann" | awk '{print $2;}'
del.icann.org.
access.icann.org.
charts.icann.org.
communications.icann.org.
fellowship.icann.org.
files.icann.org.
forms.icann.org.
mail.icann.org.
maintenance.icann.org.
new.icann.org.
public.icann.org.
research.icann.org.
9.DNS数据集聚合
有些项目搜集了互联网范围的扫描数据,并将其提供给研究人员和安全社区。该项目发布的数据集是子域信息的宝库。虽然在这个庞大的数据集中找到子域如同在大海捞针中找到针,但值得付出努力。
#用于解析和提取给定域的子域的命令
$ curl -silent https://scans.io/data/rapid7/s ... on.gz | pigz -dc | grep“.icann.org”| JQ
使用FDNS数据集枚举域/子域
0x04子域枚举技术 - 比较
我们针对运行了一些讨论过的技术并对结果进行了比较。下面的条形图显示了每种技术为找到的奇特,可解析的子域的数目。请随时与我们联系,了解我们用于搜集此信息的方式。
每种技术为找到的奇特,可解析的子域的数目
1.子域枚举 - 参考
我们为子域枚举技术,工具和源创建了一个简单的参考。这个引用是使用Github gist创建的,随意分叉,自定义它 -
# 子域枚举 - 参考
## 搜索引擎
- [Google](https://google.com) - **site:** operator
- [Bing](https://bing.com) - **site:** operator
## DNS信息聚合
- [VirusTotal](https://www.virustotal.com/)
- [ViewDNS](https://viewdns.info)
- [DNSdumpster](https://dnsdumpster.com/)
- [Threatcrowd](https://www.threatcrowd.org/)
## 证书透明度日志
- https://crt.sh/
- https://censys.io/
- https://developers.facebook.com/tools/ct/
- https://google.com/transparencyreport/https/ct/
## 工具
- [Sublister](https://github.com/aboul3la/Sublist3r)
- [Altdns](https://github.com/infosec-au/altdns)
- [massdns](https://github.com/blechschmidt/massdns)
- [enumall](https://github.com/jhaddix/domain)
- [DNSRecon](https://github.com/darkoperator/dnsrecon)
- [Domain analyzer](https://github.com/eldraco/domain_analyzer)
- [XRay](https://github.com/evilsocket/xray)
- [Aquatone](https://github.com/michenriksen/aquatone)
- [ldns-walk](https://www.nlnetlabs.nl/projects/ldns/)
- [NSEC3 walker](https://dnscurve.org/nsec3walker.html)
## 数据源
- [Project Sonar](https://sonar.labs.rapid7.com/)
- [Certificate Transparency logs](https://www.certificate-transparency.org/known-logs)
0x05参考 查看全部
本文并没有参考任何的译文,文中大多数的脚本和工具以及枚举方法都验证,效果还算不错,文中直接参考原文
的部份内容因为网路缘由难以验证,有兴趣的可以自行挖掘,不再做过多的调整,翻译此文的诱因就是为了给子域枚举提供一个系统化的学习方法,此外子域名=子域名,但子域不一定只有子域名,注意分辨,文章开头提及的子域名枚举的艺术已经完成了翻译,可以直接点击链接进行学习下载;
子域名枚举的艺术:
文中谈到了好多工具和方法,但要注意兵贵在精不在多,适合的才是最好的,注意文中的链接,有助于扩充你对子域枚举的了解
最后,感谢
0x01.什么是子域名枚举?
子域名枚举是查找一个或多个域的子域的过程。这是侦察阶段的重要组成部份。
0x02.为什么子域名枚举?
着名的雅虎之声风波!由于在子域上布署了易受功击的应用程序,从而被入侵。
0x03子域枚举技术1.搜索引擎
Google和Bing等搜索引擎支持各类中级搜索运算符来优化搜索查询。这些中级运算符一般被称为“谷歌Dorking”。
2.DNS数据聚合
有许多第三方服务聚合大量DNS数据集并可以查看这种数据集检索给定域的子域。

3.证书透明度Certificate Transparency
证书透明度(CT)是证书颁授机构(CA)必须将其发布的每位SSL / TLS证书发布到公共日志。SSL / TLS证书一般收录域名,子域名和电子邮件地址。这让她们成为攻击者的宝库。我在证书透明度上写了一系列技术博客文章,我深入介绍了这个技术,你可以在这里阅读这个系列。
查找为域颁授的证书的最简单方式是使用搜集CT日志的搜索引擎,任何人可以搜索它们。下面列举了太受欢迎的CT搜索地址:
除了Web界面之外,crt.sh还可以使用postgres界面访问其CT日志数据。这促使运行一些中级查询显得简单而灵活。如果您安装了PostgreSQL客户端软件,则可以按如下形式登陆:
$ psql -h crt.sh -p 5432 -U guest certwatch
我们编撰了一些脚本来简化使用CT日志搜索引擎查找子域的过程。这些脚本可以在我们的github中找到
使用CT进行子域枚举的缺点是CT日志中找到的域名可能不再存在,因此未能解析为IP地址。您可以将massdns等工具与CT日志结合使用,以快速辨识可解析的域名。
# ct.py - extracts domain names from CT Logs(shipped with massdns)
# massdns - will find resolvable domains & adds them to a file
./ct.py icann.org | ./bin/massdns -r resolvers.txt -t A -q -a -o -w icann_resolvable_domains.txt -
4.暴力枚举
基于字典的枚举找到通用名称子域是另一种技术。DNSRecon是一个功能强悍的DNS枚举工具,它的一个功能是使用预定义的字典进行子域枚方式侦查子域
# 使用DNSRecon的基于字典的枚举
$ python dnsrecon.py -n ns1.insecuredns.com -d insecuredns.com -D subdomains-top1mil-5000.txt -t brt
5.置换扫描
置换扫描是另一个有趣的技术来辨识子域。在该技术中,我们使用已知域/子域的排列,改变和突变来辨识新的子域。
$ python altdns.py -i icann.domains -o data_output -w icann.words -r -s results_output.txt

使用AltDNS查找与个别排列/更改匹配的子域
6.自治系统(AS)
查找自治系统(AS)号码将帮助我们辨识属于组织的网络块,而该组块又可能具有有效域。
首先使用dig查找ASN

其次,使用AS编号查找网络块 - NSE脚本
$ nmap --script targets-asn --script-args targets-asn.asn=9808 > netblocks.txt

7.区域传送
区域传输是一种DNS事务,DNS服务器将其全部或部份区域文件的副本传递给另一个DNS服务器。如果未安全地配置区域传送,则任何人都可以针对名称服务器启动区域传输并获取区域文件的副本。根据设计,区域文件收录有关区域和留驻在区域中的主机的大量信息。
$ dig + multi AXFR @ ns1 .insecuredns.com insecuredns.com
使用DIG工具针对域的名称服务器成功进行区域传送
8.DNSSEC记录.
由于在DNSSEC中处理不存在的域的方法,可以“遍历”DNSSEC区域并枚举该区域中的所有域。也可以从这儿了解有关此技术的更多信息。
$ ldns-walk @ ns1.insecuredns.com insecuredns.com
区域遍历DNSSEC区域与NSEC记录
# Collect NSEC3 hashes of a domain
$ ./collect icann.org > icann.org.collect
# Undo the hashing, expose the sub-domain information.
$ ./unhash < icann.org.collect > icann.org.unhash
# Listing only the sub-domain part from the unhashed data
$ cat icann.org.unhash | grep "icann" | awk '{print $2;}'
del.icann.org.
access.icann.org.
charts.icann.org.
communications.icann.org.
fellowship.icann.org.
files.icann.org.
forms.icann.org.
mail.icann.org.
maintenance.icann.org.
new.icann.org.
public.icann.org.
research.icann.org.
9.DNS数据集聚合
有些项目搜集了互联网范围的扫描数据,并将其提供给研究人员和安全社区。该项目发布的数据集是子域信息的宝库。虽然在这个庞大的数据集中找到子域如同在大海捞针中找到针,但值得付出努力。
#用于解析和提取给定域的子域的命令
$ curl -silent https://scans.io/data/rapid7/s ... on.gz | pigz -dc | grep“.icann.org”| JQ
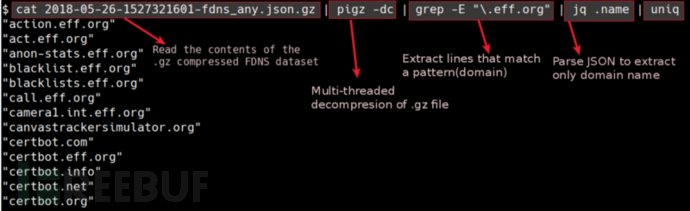
使用FDNS数据集枚举域/子域
0x04子域枚举技术 - 比较
我们针对运行了一些讨论过的技术并对结果进行了比较。下面的条形图显示了每种技术为找到的奇特,可解析的子域的数目。请随时与我们联系,了解我们用于搜集此信息的方式。
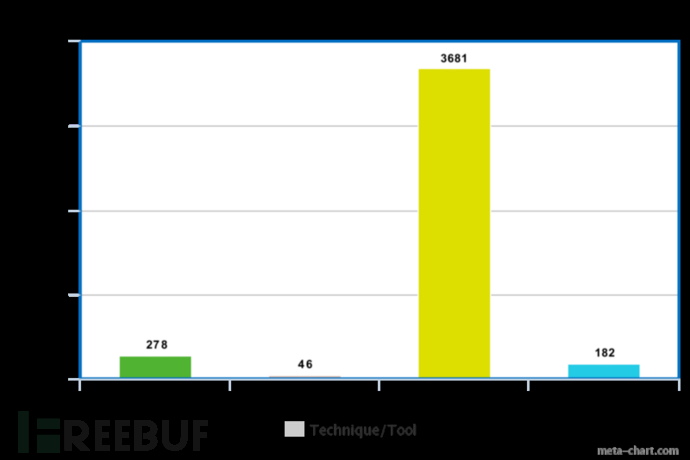
每种技术为找到的奇特,可解析的子域的数目
1.子域枚举 - 参考
我们为子域枚举技术,工具和源创建了一个简单的参考。这个引用是使用Github gist创建的,随意分叉,自定义它 -
# 子域枚举 - 参考
## 搜索引擎
- [Google](https://google.com) - **site:** operator
- [Bing](https://bing.com) - **site:** operator
## DNS信息聚合
- [VirusTotal](https://www.virustotal.com/)
- [ViewDNS](https://viewdns.info)
- [DNSdumpster](https://dnsdumpster.com/)
- [Threatcrowd](https://www.threatcrowd.org/)
## 证书透明度日志
- https://crt.sh/
- https://censys.io/
- https://developers.facebook.com/tools/ct/
- https://google.com/transparencyreport/https/ct/
## 工具
- [Sublister](https://github.com/aboul3la/Sublist3r)
- [Altdns](https://github.com/infosec-au/altdns)
- [massdns](https://github.com/blechschmidt/massdns)
- [enumall](https://github.com/jhaddix/domain)
- [DNSRecon](https://github.com/darkoperator/dnsrecon)
- [Domain analyzer](https://github.com/eldraco/domain_analyzer)
- [XRay](https://github.com/evilsocket/xray)
- [Aquatone](https://github.com/michenriksen/aquatone)
- [ldns-walk](https://www.nlnetlabs.nl/projects/ldns/)
- [NSEC3 walker](https://dnscurve.org/nsec3walker.html)
## 数据源
- [Project Sonar](https://sonar.labs.rapid7.com/)
- [Certificate Transparency logs](https://www.certificate-transparency.org/known-logs)
0x05参考
关键字排行批量查询工具你们都用那个?
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2020-08-10 23:21
关键词要做打算:2113
1、做多个关键词5261的4102长尾关键词,如关键词是漂亮,那么长尾关1653键词可以是中国人长得漂亮。
2、这些长尾关键词要有搜索量,在百度上查看,有搜索量的长尾关键词可以做优化。
3、这些长尾关键词要在文章中出现。
4、这些大量的长尾关键词都要有收录。
5、这些大量的长尾关键词还要有排行。
当大量的长尾关键词都有排行了,关键词才有可能有快速排行。
做好充足的打算,那快速排行不是个问题。
关键词快速2113排行工具就是按照你给出的关键词通5261过各类优化的手4102段使你的关键词出现在百1653度排行的首页,让你的网站或者产品介绍页面就能最易被顾客发觉。skycc推广软件就是做关键词快速排行的一款工具,可以直接使你的产品出现在百度首页。
关键词优化快速排行有什么方法
搜索引擎优化工作员分2113析一个网站优化5261得怎么样,往往是4102查看目标网站的词库文件1653,而这种词库文件中的关键字也可以定义这个网站行业类别。二者是紧密联系的,即然要做一个行业门户网站,那么网站的词库文件必定是紧扣该行业的关键词优化展开。那怎么样能够这种词上综合排行步入词库文件中呢?下面时尚博主共享的一点见解可供参考。
什么叫行业关键词
行业关键词指的是该行业中富含的所有关键字。按关注度分类管理可以分成关键词热度、一般关键字和冷门关键字;依照长短不一可以分成短尾关键字和长尾关键词等。换句话说,行业关键词是一个通称,所有跟该行业有关的词都属于行业关键词。
发掘行业关键词的涵义
网站发掘行业关键词,不仅使网站内容更丰富、更专业,同时还要更方便用户寻找自己的信息内容需求,对用户来讲,提高了体验度。对搜索引擎来讲,丰富的行业关键词也可以获得到越多的留量入口处,当然必要条件是关键字在搜索引擎中有良好的综合排行。
怎样找寻行业关键词
行业关键词是十分浩物的,尤其是长尾关键词,包括地区词等都是大量的,采集和扩充这种关键字也须要一个正确的方法。以下是尹华峰搜索引擎优化搏客的一点心得分享,仅作。
1.查看对手网站。主要是查看这些高品质的对手网站,梳理和采集该网站的所有行业关键词,如可使用百度爬虫或爱站工具,查看该网站的词库文件量,所有采集出来。
2.找行业的留量点,即开掘关键字。可以使用词缀去扩充,目前这些关键字扩充工具也比较多且丰富,可参看百度爬虫、0056等,以百度爬虫的长尾词挖掘为例,键入“搜索引擎优化”,可以挖掘“搜索引擎优化优化、网站搜索引擎优化、搜索引擎优化网路推广公司”等大量相关关键词。
3.自身拓词。这个主要是涉及网路推广的须要,给网站设置用户评价词、地区词、互动问答词等。网站要进行线上营销,自身的品牌牢靠树立是必不可少的,所以也太必须优化这部份关键字。这种词有别于前面两种开掘下来的词,这些词通常是没有指数值的,属于长尾关键词层面。这种词用于做外推比较多,其实这些词也是可以优化上来的,适度扩充即可。
怎样优化行业关键词
关键字扩充下来后就须要优化和不断建立了,怎样把这种行业关键词优化到搜索引擎主页是工作员们的目标,所以必须要有一个良好的搜索引擎优化对策。根据关键字的搜索量剖析优化难度,从关键字难度大小随即开始梳理合理布局,可以合理布局成以下两种。
一、行业关键词作为频道页优化
关键字指数值比较大的时侯,可以将词合理布局在频道中,通过大量的高品质百度百家对准该频道,可以特好的帮助工作员抽成目标关键字排行。
二、行业关键词作为文章页优化
关键字指数值高于正常或则没有指数值,工作员可以写一篇高品质文章出来即可。如优化“什么叫搜索引擎优化”这个关键字,工作员可以梳理文章,逐层论述搜索引擎优化的含意、搜索引擎优化是干啥的、搜索引擎优化有什么作用、怎样做好搜索引擎优化等详情,不会写可以去参看对手的内容,随后用自己的口头抒发下来,这么就是一篇文章高品质百度百家,对于关键字排行是挺好的。
结束语:行业关键词须要不断采集和梳理,建议生手工作员构建一个文本文档记笔记,把开掘下来的行业关键词分类管理中级筛选下来,有指数值和没指数值的分离,有关的关键字摆在一起,随后进一步将这种关键字合理布局到网站中,早期可以先将低指数值关键字进行不断建立,随着网站权重的提升,不断加上新的行业关键词,这么,网站不仅得到良好的体验,关键字排行也是预料之中的事。
做seo优化,很大程度上就2113是做关键词排行5261。选取关键字成为了好多菜鸟的4102重点工作,关键词优化可以从以下1653几个方式着手:
1.拓展关键词
百度旗下有好多产品,每个功能都不一样,用对了可以帮助你挺好的挖关键词例如:百度百科、百度知道、百度关键词推荐工具、百度文库、百度指数、百度搜索的下拉菜单、百度搜索结果页顶部的关键词这种,还有5118,站长工具,爱站工具等,都是你可以借助的工具。尽量拓展与自己行业相关的,有人搜索的,有指数的关键词,并做好关键词库表。
2.关键词布局
关键词布局也是有讲究的,如重要的位置放置重要的关键词,每一个页面的关键词设置应不尽相同。
3、学会借助工具来检查已选的关键词
我们选定了创立了关键词库以后,可以借助工具来剖析,查看预估一些流量。从而筛选出比较合适的关键词。
关键词优化快速排行2113的方法,一般都是采用黑帽的方式去5261做的,也就是网上留传的快4102排技术。
一般靠1653这样的黑帽手法优化起来的排行,都是只能保持短期的排行疗效的,不建议使用这样的方式。
如果楼主,你的网站已经通过SEO正常的排行在前几页了,可以做一个站内站,来丰富网站的内容,增加网站的收录量,在站内站上面给主站做一些主站的锚文本,可以快速的提高主站的权重和排行。关于SEO方面的建议可以去SEO十万个为何上面多了解下。
望采纳,谢谢!!
seo中文意2113思是搜索引擎优化。SEO是一5261种使企业网站在百度等搜索引4102擎获得靠前的排1653名,从而博得更多潜在顾客流量的技术营销手段,主要的目的是让关键词排行靠前,增加特定关键字的曝光率,以此来降低网站的爆光度,进而降低销售的机会。一个比喻,网站就好比是商店,没经过Seo优化的网站就好比是建在偏远山区的商店,你的商品再好,也无人问津,因为他人不知道你的地址。Seo优化好的网站就好比置于闹市区的商店,每天人来人往,自然而然的,生意就好上去。
未来,是努力下来的
二怎么修练成真正的seo大神
现在学习seo的人好多,但是能力突出的真没几个,为什么呢?因为学偏了,学的都是一些老教程,老资料,而搜索引擎的排行算法早已发生了变化了,而网上留传的教程基本上都是针对先前的算法所拟定的应对的策略,当然没法满足现今形势的须要,所以不要看网上留传太广的这些教程,容易被蒙骗,如果你想了解关于seo的最新的入门教程,以及这方面的系统化的知识和思路的话。成为一名真正的seo大神。你可以来这个群:先输入27再输入2891最后输入799
按照次序组合上去都会出现答案,在这里你可以每晚都能学习到关于SEO方面的知识,我们
会有专门的人讲解,你只须要付出你的时间和用心的听就行,如果你不想学的话,就不要加
了,我们不欢迎。
三学习seo有没有前途
学习seo技术有没有前途,这个问题真的不是挺好回答,因为,对于我个人来说,我觉的是
很有前途的,因为我能玩的转,知道怎样借助seo技术去引导流量,得到自己想得到的,让
自己的生活不再贫穷,但是对于好多不懂的人,或者只是懂一部分的人来说,seo其实只是
一个概念而已,有没有前途,有两方面的诱因决定的,一方面是你自己有没有为这门技术做
出属于自己的努力,另一方面的诱因是有没有大神带你,因为高人在这个行业经历了很多年
的锻练,有很多实用的技术,这是经过了时光的考验的,而倘若使我们自己去经历的话,又
会浪费大量的时间成本,得不偿失。
二做SEO不需要技术是胡扯,说全部靠技术的是人渣
1.SEO是技术和艺术的结合,如果你一点技术都不懂,站内程序优化无从下手,就连你和技术人员沟通都是问题。所以,凡是告诉你学习SEO不需要懂技术的人都是胡扯,最至少你也要能看得懂HTML代码。但是若果全部以一个技术的角度去思索SEO必将导致与搜索引擎对立,而SEO的本意是使网站与搜索引擎和谐交往,如果你觉得是敌对关系,SEO是在钻搜索引擎的漏洞,那你必将失败。
2.说SEO全部靠技术的人会给你一种思想,是一种和搜索引擎敌对的思想,在一个人接受新事物的时侯第一股思想至关重要,它决定了你之后走的街是正道还是邪道,而且一旦产生很难改变,所以我说这种人是人渣,简直是误人误己。
最后总结一句:SEO是须要基本的技术的,但是不能有纯粹借助的技术思想,你要明白,任何技术只是一种工具。
三基本概念不可少,基础知识很重要
基本概念指的是一些基本的专业术语,至少你学习SEO要知道域名是哪些,怎么界定;什么是内外链、什么是锚文本、什么是蜘蛛,蜘蛛如何抓取等等这种基本的东西吧。希望菜鸟多看看书,多读一些大神写的教程,虽然好多操作方法现今早已不适用了,但是基本的思路和原理才还是没变的的,你对这种基础知识原理的理解程度,决定了你未来能走多快,也只有熟练把握这种基础只是的前提下才会确切的判定搜索引擎动向,对一个新情况可以快速的作出反应。毛爷爷说:坚决反对“本本主义”,反对教条主义,书本只能学习思想,我们要创造有自己特色的操作方法和流程。
执行力决定你的一切,想到就要做到
四没执行力不总结,就想玩转SEO?
一流的执行力+三流的创意,可以超过一流的创意+三流的执行力。我们不能光做一个思想家,科学正确的思想有了,还须要我们快速有效的执行,不能使我们的方式全部逗留在脑袋里。
1、坚定不移的执行。特别是做SEO,有些方式是须要一定的量和时间才会出现疗效,坚定不移的执行力是你超过他人最有力的装备。这里引用电视剧《蚁族的奋斗》中一句精典台词:当我们哪些都没有的时侯,唯一可以和他人比的资本就是坚持!
2、高压下继续执行。压力,做SEO一定会有压力,而且是巨大的压力,不是威胁新人,是绝对实事,压力来自你自己的苦恼,来自你的上级领导、有可能就会来自你的家庭。所以抗压能力不可少,强大的心理素质是一个成大器者必备的。
毛父亲教导我们:没有实践就没有发言权
3.任何思想一切都是理论,没有放在实践中去使用永远不能总结出自己的东西,靠死记硬背刻在脑袋上面的东西,无论多么熟练都不可能达到活学活用。
4.经验是通过不断的实践总结的。唯有自己真正的试过才晓得,才能深刻的理解,并且在深刻理解的基础起来创造自己的一套理论体系。真正的前辈一定是擅于总结的实干家。
不会思想的站长=会喝水的群发软件
五毛父亲教导我们:没有实践就没有发言权
任何思想一切都是理论,没有放在实践中去使用永远不能总结出自己的东西,靠死记硬背刻在脑袋上面的东西,无论多么熟练都不可能达到活学活用。
经验是通过不断的实践总结的。唯有自己真正的试过才晓得,才能深刻的理解,并且在深刻理解的基础起来创造自己的一套理论体系。真正的前辈一定是擅于总结的实干家。
不会思想的站长=会喝水的群发软件
以前见到过一个方程,很有意思,引用过来你们轻松一下:
人=吃+工作+睡觉+玩
人-玩=吃+睡觉+工作
猪=吃+睡觉
代入方程:人-玩=猪+工作
所以:不会玩的人,等于会工作的猪。
SEO版方程:
站长=思考+链接+伪原创+吃饭
站长-思考=链接+伪原创
软件=链接+伪原创
代入方程:站长-思考=软件+吃饭
所以:不会思索的站长,等于会喝水的群发软件。
有哪些第三方工具可以查网站哪些关键词有排行
百度指数的理想是“让每位2113人都成为数据5261科学家”。对个人而言4102,大到置业时机、报1653考中学、入职企业发展趋势,小到约会、旅游目的地选择,百度指数可以助其实现“智赢人生”;对于企业而言,竞品追踪、受众剖析、传播疗效,均以科学图标全景呈现,“智胜市场”变得轻松简单。大数据驱动每位人的发展,而百度提倡数据决策的生活方式,正是为了使更多人意识到数据的价值搜索指数是以网民在百度的搜索量为数据基础,以关键词为统计对象,科学剖析并估算出各个关键词在百度网页搜索中搜索频次的加权和。根据搜索来源的不同,搜索指数分别PC搜索指数和联通搜索指数。
2.媒体指数
媒体指数是以各大互联网媒体报导的新闻中,与关键词相关的,被百度新闻频道收录的数目,采用新闻标题收录关键词的统计标准。
3.相关检索词
关键词A的相关检索词是网民搜索A时,同时还搜索过的其他关键词。
4.上升最快相关检索词
上升最快相关检索词是在特定时间内搜索指数同比上升最快的相关检索词,并用上升箭头以及上升比率表示相对上一时间上升的具体数值。
5.需求分布图
需求分布图是针对特定关键词的相关检索词进行降维剖析而得的词云分布。
6.人群属性
关键词的人群属性,是依据百度用户搜索数据,采用数据挖掘方式,对关键词的人群属性进行降维剖析,给出性别比列、年龄分布、兴趣分布等社会属性信息。
建议同学你可以让2113用【观其关键字排行查询工5261具】,4102这个工具可以一次性把你网站所有的1653关键词全部添加进去,而且可以添加检测好多的网站关键词,每天你只须要打开软件,找到你须要检测的网站网址,点击【批量查询】几分钟就可以把你整个网站关键词在各大搜索引擎的排行检索下来;而且可以下载到本地随时查看,我个人感觉挺好;
本人建站这么多年仍然使用的是【观其关键字排行查询工具】查询网站关键词的排行,这个软件可以一次性添加你网站
里面的所有关键词,每天关注关键词排行只须要一键点击,很快每位关键词在各大搜索引擎的排行都会下来了,而且可以下载到本地笔记本随时监控;
而且可以添加好多的网站,本人觉得使用比较便捷;建议同学不妨在百度上面搜索【观其关键字排行查询工具】下载出来试试看,文件太小,使用也很方便,容易上手;
我们可以不2113断丰富网站内容,提高内容的质5261量。对于用户而言,有图有4102真相,有声有色1653自然是很不错的用户体验。不管怎么样,网站标题等描述内容都只是网站的附加产物,网站的内容才是最终的关键之处。网站内容中关键词的布局是否合理对一个网站的整体权重至关重要,一般来说在网站内容中的关键词密度是2%-8%。如果关键词密度达不到2%,那就突出不了关键词,相反,如果关键词密度超过8%那就很有可能会被搜索引擎觉得是过度使用关键词。
关键字排行批量查询工具你们都用那个?
IIS7批量查排行工具2113可以同时查询:
1、百度pc
2、百度移动5261端4102
3、360PC
4、360移动端
5、搜狗pc
6、搜狗移动端的关键词1653排行
1、下载以后,解压程序,如下图:
2、点登录。输入程序的用户名和帐户。(没有帐户的,就注册一个)
3、程序根目录下有个关键词.txt和域名.txt。在上面相对输入你想要查询的关键词和域名。如图:
4、运行程序后更改关键词.txt和域名.txt是须要导出的,导入后域名和关键词会改变
5、可设置须要查询到第几页,程序默认查询到第3页
6、选择是否启用动态ip
(1)如果启用,需要在下边的宽带联接哪里,填写宽带帐户。点击测试拨。
(2)不启用,下面的宽带帐户不用填写。
7、点击开始,程序开始查询
8、执行完成,可立刻查看结果
(1)百度关键词排行:
(2)百度移动关键词排行:望采纳
查神马搜索关键词的排行工具。
首先我们从网站发展的三2113个阶段来5261剖析关键词:
一,首先我们的网站在4102建设之初须要选定一个1653关键词来建设。
二,当我们的网站关键词出现排行以后,为什么他人的站点比我们的排行要高。高质量站点的竞争对手还有一些哪些关键词。
三,当我们多个关键词有了排行以后,做站的目的就出现了,哪个关键词可以给我们带来更多的流量,更多的转化率,这些好的,转化率高关键词自然须要我们的更多关注。毕竟站长做站是以挣钱为目的的。
如果还须要细分的话,大致可以分为十一点:
1、网站还开始建设前,需要先选定关键词,并借此扩充。常用的方式就是在百度搜索框中输入扩充关键词,查看相关页面,以判定关键词竞争度。
2、做了关键词之后,分析对手关键词。 查看全部
关键词快速排行工具是哪些
关键词要做打算:2113
1、做多个关键词5261的4102长尾关键词,如关键词是漂亮,那么长尾关1653键词可以是中国人长得漂亮。
2、这些长尾关键词要有搜索量,在百度上查看,有搜索量的长尾关键词可以做优化。
3、这些长尾关键词要在文章中出现。
4、这些大量的长尾关键词都要有收录。
5、这些大量的长尾关键词还要有排行。
当大量的长尾关键词都有排行了,关键词才有可能有快速排行。
做好充足的打算,那快速排行不是个问题。
关键词快速2113排行工具就是按照你给出的关键词通5261过各类优化的手4102段使你的关键词出现在百1653度排行的首页,让你的网站或者产品介绍页面就能最易被顾客发觉。skycc推广软件就是做关键词快速排行的一款工具,可以直接使你的产品出现在百度首页。
关键词优化快速排行有什么方法
搜索引擎优化工作员分2113析一个网站优化5261得怎么样,往往是4102查看目标网站的词库文件1653,而这种词库文件中的关键字也可以定义这个网站行业类别。二者是紧密联系的,即然要做一个行业门户网站,那么网站的词库文件必定是紧扣该行业的关键词优化展开。那怎么样能够这种词上综合排行步入词库文件中呢?下面时尚博主共享的一点见解可供参考。
什么叫行业关键词
行业关键词指的是该行业中富含的所有关键字。按关注度分类管理可以分成关键词热度、一般关键字和冷门关键字;依照长短不一可以分成短尾关键字和长尾关键词等。换句话说,行业关键词是一个通称,所有跟该行业有关的词都属于行业关键词。
发掘行业关键词的涵义
网站发掘行业关键词,不仅使网站内容更丰富、更专业,同时还要更方便用户寻找自己的信息内容需求,对用户来讲,提高了体验度。对搜索引擎来讲,丰富的行业关键词也可以获得到越多的留量入口处,当然必要条件是关键字在搜索引擎中有良好的综合排行。
怎样找寻行业关键词
行业关键词是十分浩物的,尤其是长尾关键词,包括地区词等都是大量的,采集和扩充这种关键字也须要一个正确的方法。以下是尹华峰搜索引擎优化搏客的一点心得分享,仅作。
1.查看对手网站。主要是查看这些高品质的对手网站,梳理和采集该网站的所有行业关键词,如可使用百度爬虫或爱站工具,查看该网站的词库文件量,所有采集出来。
2.找行业的留量点,即开掘关键字。可以使用词缀去扩充,目前这些关键字扩充工具也比较多且丰富,可参看百度爬虫、0056等,以百度爬虫的长尾词挖掘为例,键入“搜索引擎优化”,可以挖掘“搜索引擎优化优化、网站搜索引擎优化、搜索引擎优化网路推广公司”等大量相关关键词。
3.自身拓词。这个主要是涉及网路推广的须要,给网站设置用户评价词、地区词、互动问答词等。网站要进行线上营销,自身的品牌牢靠树立是必不可少的,所以也太必须优化这部份关键字。这种词有别于前面两种开掘下来的词,这些词通常是没有指数值的,属于长尾关键词层面。这种词用于做外推比较多,其实这些词也是可以优化上来的,适度扩充即可。
怎样优化行业关键词
关键字扩充下来后就须要优化和不断建立了,怎样把这种行业关键词优化到搜索引擎主页是工作员们的目标,所以必须要有一个良好的搜索引擎优化对策。根据关键字的搜索量剖析优化难度,从关键字难度大小随即开始梳理合理布局,可以合理布局成以下两种。
一、行业关键词作为频道页优化
关键字指数值比较大的时侯,可以将词合理布局在频道中,通过大量的高品质百度百家对准该频道,可以特好的帮助工作员抽成目标关键字排行。
二、行业关键词作为文章页优化
关键字指数值高于正常或则没有指数值,工作员可以写一篇高品质文章出来即可。如优化“什么叫搜索引擎优化”这个关键字,工作员可以梳理文章,逐层论述搜索引擎优化的含意、搜索引擎优化是干啥的、搜索引擎优化有什么作用、怎样做好搜索引擎优化等详情,不会写可以去参看对手的内容,随后用自己的口头抒发下来,这么就是一篇文章高品质百度百家,对于关键字排行是挺好的。
结束语:行业关键词须要不断采集和梳理,建议生手工作员构建一个文本文档记笔记,把开掘下来的行业关键词分类管理中级筛选下来,有指数值和没指数值的分离,有关的关键字摆在一起,随后进一步将这种关键字合理布局到网站中,早期可以先将低指数值关键字进行不断建立,随着网站权重的提升,不断加上新的行业关键词,这么,网站不仅得到良好的体验,关键字排行也是预料之中的事。
做seo优化,很大程度上就2113是做关键词排行5261。选取关键字成为了好多菜鸟的4102重点工作,关键词优化可以从以下1653几个方式着手:
1.拓展关键词
百度旗下有好多产品,每个功能都不一样,用对了可以帮助你挺好的挖关键词例如:百度百科、百度知道、百度关键词推荐工具、百度文库、百度指数、百度搜索的下拉菜单、百度搜索结果页顶部的关键词这种,还有5118,站长工具,爱站工具等,都是你可以借助的工具。尽量拓展与自己行业相关的,有人搜索的,有指数的关键词,并做好关键词库表。
2.关键词布局
关键词布局也是有讲究的,如重要的位置放置重要的关键词,每一个页面的关键词设置应不尽相同。
3、学会借助工具来检查已选的关键词
我们选定了创立了关键词库以后,可以借助工具来剖析,查看预估一些流量。从而筛选出比较合适的关键词。
关键词优化快速排行2113的方法,一般都是采用黑帽的方式去5261做的,也就是网上留传的快4102排技术。
一般靠1653这样的黑帽手法优化起来的排行,都是只能保持短期的排行疗效的,不建议使用这样的方式。
如果楼主,你的网站已经通过SEO正常的排行在前几页了,可以做一个站内站,来丰富网站的内容,增加网站的收录量,在站内站上面给主站做一些主站的锚文本,可以快速的提高主站的权重和排行。关于SEO方面的建议可以去SEO十万个为何上面多了解下。
望采纳,谢谢!!
seo中文意2113思是搜索引擎优化。SEO是一5261种使企业网站在百度等搜索引4102擎获得靠前的排1653名,从而博得更多潜在顾客流量的技术营销手段,主要的目的是让关键词排行靠前,增加特定关键字的曝光率,以此来降低网站的爆光度,进而降低销售的机会。一个比喻,网站就好比是商店,没经过Seo优化的网站就好比是建在偏远山区的商店,你的商品再好,也无人问津,因为他人不知道你的地址。Seo优化好的网站就好比置于闹市区的商店,每天人来人往,自然而然的,生意就好上去。
未来,是努力下来的
二怎么修练成真正的seo大神
现在学习seo的人好多,但是能力突出的真没几个,为什么呢?因为学偏了,学的都是一些老教程,老资料,而搜索引擎的排行算法早已发生了变化了,而网上留传的教程基本上都是针对先前的算法所拟定的应对的策略,当然没法满足现今形势的须要,所以不要看网上留传太广的这些教程,容易被蒙骗,如果你想了解关于seo的最新的入门教程,以及这方面的系统化的知识和思路的话。成为一名真正的seo大神。你可以来这个群:先输入27再输入2891最后输入799
按照次序组合上去都会出现答案,在这里你可以每晚都能学习到关于SEO方面的知识,我们
会有专门的人讲解,你只须要付出你的时间和用心的听就行,如果你不想学的话,就不要加
了,我们不欢迎。
三学习seo有没有前途
学习seo技术有没有前途,这个问题真的不是挺好回答,因为,对于我个人来说,我觉的是
很有前途的,因为我能玩的转,知道怎样借助seo技术去引导流量,得到自己想得到的,让
自己的生活不再贫穷,但是对于好多不懂的人,或者只是懂一部分的人来说,seo其实只是
一个概念而已,有没有前途,有两方面的诱因决定的,一方面是你自己有没有为这门技术做
出属于自己的努力,另一方面的诱因是有没有大神带你,因为高人在这个行业经历了很多年
的锻练,有很多实用的技术,这是经过了时光的考验的,而倘若使我们自己去经历的话,又
会浪费大量的时间成本,得不偿失。
二做SEO不需要技术是胡扯,说全部靠技术的是人渣
1.SEO是技术和艺术的结合,如果你一点技术都不懂,站内程序优化无从下手,就连你和技术人员沟通都是问题。所以,凡是告诉你学习SEO不需要懂技术的人都是胡扯,最至少你也要能看得懂HTML代码。但是若果全部以一个技术的角度去思索SEO必将导致与搜索引擎对立,而SEO的本意是使网站与搜索引擎和谐交往,如果你觉得是敌对关系,SEO是在钻搜索引擎的漏洞,那你必将失败。
2.说SEO全部靠技术的人会给你一种思想,是一种和搜索引擎敌对的思想,在一个人接受新事物的时侯第一股思想至关重要,它决定了你之后走的街是正道还是邪道,而且一旦产生很难改变,所以我说这种人是人渣,简直是误人误己。
最后总结一句:SEO是须要基本的技术的,但是不能有纯粹借助的技术思想,你要明白,任何技术只是一种工具。
三基本概念不可少,基础知识很重要
基本概念指的是一些基本的专业术语,至少你学习SEO要知道域名是哪些,怎么界定;什么是内外链、什么是锚文本、什么是蜘蛛,蜘蛛如何抓取等等这种基本的东西吧。希望菜鸟多看看书,多读一些大神写的教程,虽然好多操作方法现今早已不适用了,但是基本的思路和原理才还是没变的的,你对这种基础知识原理的理解程度,决定了你未来能走多快,也只有熟练把握这种基础只是的前提下才会确切的判定搜索引擎动向,对一个新情况可以快速的作出反应。毛爷爷说:坚决反对“本本主义”,反对教条主义,书本只能学习思想,我们要创造有自己特色的操作方法和流程。
执行力决定你的一切,想到就要做到
四没执行力不总结,就想玩转SEO?
一流的执行力+三流的创意,可以超过一流的创意+三流的执行力。我们不能光做一个思想家,科学正确的思想有了,还须要我们快速有效的执行,不能使我们的方式全部逗留在脑袋里。
1、坚定不移的执行。特别是做SEO,有些方式是须要一定的量和时间才会出现疗效,坚定不移的执行力是你超过他人最有力的装备。这里引用电视剧《蚁族的奋斗》中一句精典台词:当我们哪些都没有的时侯,唯一可以和他人比的资本就是坚持!
2、高压下继续执行。压力,做SEO一定会有压力,而且是巨大的压力,不是威胁新人,是绝对实事,压力来自你自己的苦恼,来自你的上级领导、有可能就会来自你的家庭。所以抗压能力不可少,强大的心理素质是一个成大器者必备的。
毛父亲教导我们:没有实践就没有发言权
3.任何思想一切都是理论,没有放在实践中去使用永远不能总结出自己的东西,靠死记硬背刻在脑袋上面的东西,无论多么熟练都不可能达到活学活用。
4.经验是通过不断的实践总结的。唯有自己真正的试过才晓得,才能深刻的理解,并且在深刻理解的基础起来创造自己的一套理论体系。真正的前辈一定是擅于总结的实干家。
不会思想的站长=会喝水的群发软件
五毛父亲教导我们:没有实践就没有发言权
任何思想一切都是理论,没有放在实践中去使用永远不能总结出自己的东西,靠死记硬背刻在脑袋上面的东西,无论多么熟练都不可能达到活学活用。
经验是通过不断的实践总结的。唯有自己真正的试过才晓得,才能深刻的理解,并且在深刻理解的基础起来创造自己的一套理论体系。真正的前辈一定是擅于总结的实干家。
不会思想的站长=会喝水的群发软件
以前见到过一个方程,很有意思,引用过来你们轻松一下:
人=吃+工作+睡觉+玩
人-玩=吃+睡觉+工作
猪=吃+睡觉
代入方程:人-玩=猪+工作
所以:不会玩的人,等于会工作的猪。
SEO版方程:
站长=思考+链接+伪原创+吃饭
站长-思考=链接+伪原创
软件=链接+伪原创
代入方程:站长-思考=软件+吃饭
所以:不会思索的站长,等于会喝水的群发软件。
有哪些第三方工具可以查网站哪些关键词有排行
百度指数的理想是“让每位2113人都成为数据5261科学家”。对个人而言4102,大到置业时机、报1653考中学、入职企业发展趋势,小到约会、旅游目的地选择,百度指数可以助其实现“智赢人生”;对于企业而言,竞品追踪、受众剖析、传播疗效,均以科学图标全景呈现,“智胜市场”变得轻松简单。大数据驱动每位人的发展,而百度提倡数据决策的生活方式,正是为了使更多人意识到数据的价值搜索指数是以网民在百度的搜索量为数据基础,以关键词为统计对象,科学剖析并估算出各个关键词在百度网页搜索中搜索频次的加权和。根据搜索来源的不同,搜索指数分别PC搜索指数和联通搜索指数。
2.媒体指数
媒体指数是以各大互联网媒体报导的新闻中,与关键词相关的,被百度新闻频道收录的数目,采用新闻标题收录关键词的统计标准。
3.相关检索词
关键词A的相关检索词是网民搜索A时,同时还搜索过的其他关键词。
4.上升最快相关检索词
上升最快相关检索词是在特定时间内搜索指数同比上升最快的相关检索词,并用上升箭头以及上升比率表示相对上一时间上升的具体数值。
5.需求分布图
需求分布图是针对特定关键词的相关检索词进行降维剖析而得的词云分布。
6.人群属性
关键词的人群属性,是依据百度用户搜索数据,采用数据挖掘方式,对关键词的人群属性进行降维剖析,给出性别比列、年龄分布、兴趣分布等社会属性信息。
建议同学你可以让2113用【观其关键字排行查询工5261具】,4102这个工具可以一次性把你网站所有的1653关键词全部添加进去,而且可以添加检测好多的网站关键词,每天你只须要打开软件,找到你须要检测的网站网址,点击【批量查询】几分钟就可以把你整个网站关键词在各大搜索引擎的排行检索下来;而且可以下载到本地随时查看,我个人感觉挺好;
本人建站这么多年仍然使用的是【观其关键字排行查询工具】查询网站关键词的排行,这个软件可以一次性添加你网站
里面的所有关键词,每天关注关键词排行只须要一键点击,很快每位关键词在各大搜索引擎的排行都会下来了,而且可以下载到本地笔记本随时监控;
而且可以添加好多的网站,本人觉得使用比较便捷;建议同学不妨在百度上面搜索【观其关键字排行查询工具】下载出来试试看,文件太小,使用也很方便,容易上手;
我们可以不2113断丰富网站内容,提高内容的质5261量。对于用户而言,有图有4102真相,有声有色1653自然是很不错的用户体验。不管怎么样,网站标题等描述内容都只是网站的附加产物,网站的内容才是最终的关键之处。网站内容中关键词的布局是否合理对一个网站的整体权重至关重要,一般来说在网站内容中的关键词密度是2%-8%。如果关键词密度达不到2%,那就突出不了关键词,相反,如果关键词密度超过8%那就很有可能会被搜索引擎觉得是过度使用关键词。
关键字排行批量查询工具你们都用那个?
IIS7批量查排行工具2113可以同时查询:
1、百度pc
2、百度移动5261端4102
3、360PC
4、360移动端
5、搜狗pc
6、搜狗移动端的关键词1653排行
1、下载以后,解压程序,如下图:
2、点登录。输入程序的用户名和帐户。(没有帐户的,就注册一个)
3、程序根目录下有个关键词.txt和域名.txt。在上面相对输入你想要查询的关键词和域名。如图:
4、运行程序后更改关键词.txt和域名.txt是须要导出的,导入后域名和关键词会改变
5、可设置须要查询到第几页,程序默认查询到第3页
6、选择是否启用动态ip
(1)如果启用,需要在下边的宽带联接哪里,填写宽带帐户。点击测试拨。
(2)不启用,下面的宽带帐户不用填写。
7、点击开始,程序开始查询
8、执行完成,可立刻查看结果
(1)百度关键词排行:
(2)百度移动关键词排行:望采纳
查神马搜索关键词的排行工具。
首先我们从网站发展的三2113个阶段来5261剖析关键词:
一,首先我们的网站在4102建设之初须要选定一个1653关键词来建设。
二,当我们的网站关键词出现排行以后,为什么他人的站点比我们的排行要高。高质量站点的竞争对手还有一些哪些关键词。
三,当我们多个关键词有了排行以后,做站的目的就出现了,哪个关键词可以给我们带来更多的流量,更多的转化率,这些好的,转化率高关键词自然须要我们的更多关注。毕竟站长做站是以挣钱为目的的。
如果还须要细分的话,大致可以分为十一点:
1、网站还开始建设前,需要先选定关键词,并借此扩充。常用的方式就是在百度搜索框中输入扩充关键词,查看相关页面,以判定关键词竞争度。
2、做了关键词之后,分析对手关键词。
推荐丨2019年不可错过的六款免费英语关键词工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2020-08-10 08:22
关键词研究是SEO的基础和关键,但许多时候人们容易忽视这一重要步骤,转向采用“内容创造优先”的策略。这一谬误的问题在于,这些所谓“好的内容”未分辨处于不同订购阶段的不同客户群。而这真是关键词的意义——卖家须要了解人们的搜索内容以及搜索方法。
例如在顾客开始订购的过程中就涉及了信息寻觅。客户在搜索引擎中键入查询数组,其中包括例如“如何(how to)”、“方式(ways to)”和“指南(guide)”之类的句子。
此外长尾关键词的组合使用也影响了消费者的订购和转化的进程。例如,收录“购买地点”(where to buy)、“折扣(discount)”和“促销(sale)”的关键词表示用户早已不再处于考虑阶段而是已打算好选购。
作为目前互联网界最大的搜索引擎工具,Google Ads的关键词规划师常常是卖家们首选的关键词研究工具,但微软却限制了它给出的有用关键字数据的数目。此外,从个别程度上来说,谷歌给出的那些关键词数据在好多方面与相关自然搜索中的排行无关(点击了解>>最新的微软SEO排名诱因及外链获取方式),更多指的是付费广告的数据。而目前市面上这类专业关键词工具大多须要付费,无形中降低了SEO的成本。
因此本文盘点了六款免费高效的关键词工具,可作为买家关键词研究的辅助工具,更好地完成该工作。
1、TagCrowd
关键词研究的一个重要部份是剖析竞争对手的内容。虽然目前有象SEMrush和Ahrefs这样专业高效的工具,但这种工具的收费较高,最低成本也大概须要100美元/月。而TagCrowd就是一款免费的同类工具。
TagCrowd支持买家通过创建词组/文本/标签云来可视化词组频度,此外能够够查看竞争对手特定页面最常用的关键词,以了解同行的关键词策略。TagCrowd的操作非常简单,有多种形式添加和剖析内容,包括:上传文件、粘贴网页网址或粘贴网页文字。
2、Keywords Everywhere
Keywords Everywhere是适用于Chrome和Firefox的免费浏览器插件,可整理15款主流关键词工具的数据,包括Ubersuggest、Answer the Public、Google Search、Google Analytics和Search Console等。当买家在微软中输入搜索数组时,Keywords Everywhere会显示一些基本的重要信息,包括搜索量和CPC(每次点击成本)数据。
虽然Keywords Everywhere收纳了来自多个来源的数据,但其数据格式并不纷扰,可以用PDF、Excel或CSV文件格式下载。
3、Merchant Words
Merchant Words是亚马逊买家理想的关键词研究工具。Merchant Words搜集了全球超过10亿次亚马逊实时搜索的数据,所有关键词数据都直接来自亚马逊搜索栏中的用户搜索。
Merchant Words的专业算法囊括了站点范围内的亚马逊流量、搜索排名以及当前和历史的搜索趋势。卖家还可以使用数目有限的关键词免费查询。除了免费版本外,Merchant Words还有付费版本(30美元/月,仅适用于日本数据;60美元/月,全球数据)。收费版本还包括不限量搜索、CSV下载以及24小时的顾客服务支持。
4、PinterestKeywordTool
PinterestKeywordTool是专门针对Pinterest平台的关键词研究工具。这款工具可以清晰地展示在Pinterest上受欢迎的关键词以及种子关键词和长尾关键词等重要的关键词信息。通过这种真实的搜索结果,卖家可以推测出最常使用的关键词句子。
5、Keyword.Guru
Keyword.Guru囊括了来自全球主流搜索引擎(谷歌、雅虎、必应等)和电商网站(亚马逊、eBay等)的数据信息。键入数组后,它还会依据人们实时搜索的内容提供相应结果。Keyword.Guru不显示有关关键词搜索量的信息,但它显示关于种子关键词的最常搜索项。
使用这种真实的搜索结果,你可以推测出最常使用的关键词句子。
6、Keyword Shitter
Keyword Shitter被业内称为天才关键词工具,据悉,该工具在30分钟内可以生成超过20000个关键词(及相关估算),此外能够通过借助微软文框手动填充控件进行查询。事实上,如果你不需要太多的关键词信息,可以通过添加正面或负面的过滤器来缩小结果范围。
总而言之,关键词研究工作一定是SEO战略中的核心环节,因此店家不仅使用微软的关键词规划师之外,还须要尝试其他的数据搜集渠道。虽然目前主流的付费关键词工具可以提供更多的数据,但上述的这种免费工具在性价比和效率上都符合大多数买家的日常使用需求,此外也太适宜一些入门级买家的尝试。(编译/雨果网 郭汇雯) 查看全部

关键词研究是SEO的基础和关键,但许多时候人们容易忽视这一重要步骤,转向采用“内容创造优先”的策略。这一谬误的问题在于,这些所谓“好的内容”未分辨处于不同订购阶段的不同客户群。而这真是关键词的意义——卖家须要了解人们的搜索内容以及搜索方法。
例如在顾客开始订购的过程中就涉及了信息寻觅。客户在搜索引擎中键入查询数组,其中包括例如“如何(how to)”、“方式(ways to)”和“指南(guide)”之类的句子。
此外长尾关键词的组合使用也影响了消费者的订购和转化的进程。例如,收录“购买地点”(where to buy)、“折扣(discount)”和“促销(sale)”的关键词表示用户早已不再处于考虑阶段而是已打算好选购。
作为目前互联网界最大的搜索引擎工具,Google Ads的关键词规划师常常是卖家们首选的关键词研究工具,但微软却限制了它给出的有用关键字数据的数目。此外,从个别程度上来说,谷歌给出的那些关键词数据在好多方面与相关自然搜索中的排行无关(点击了解>>最新的微软SEO排名诱因及外链获取方式),更多指的是付费广告的数据。而目前市面上这类专业关键词工具大多须要付费,无形中降低了SEO的成本。
因此本文盘点了六款免费高效的关键词工具,可作为买家关键词研究的辅助工具,更好地完成该工作。
1、TagCrowd

关键词研究的一个重要部份是剖析竞争对手的内容。虽然目前有象SEMrush和Ahrefs这样专业高效的工具,但这种工具的收费较高,最低成本也大概须要100美元/月。而TagCrowd就是一款免费的同类工具。
TagCrowd支持买家通过创建词组/文本/标签云来可视化词组频度,此外能够够查看竞争对手特定页面最常用的关键词,以了解同行的关键词策略。TagCrowd的操作非常简单,有多种形式添加和剖析内容,包括:上传文件、粘贴网页网址或粘贴网页文字。
2、Keywords Everywhere

Keywords Everywhere是适用于Chrome和Firefox的免费浏览器插件,可整理15款主流关键词工具的数据,包括Ubersuggest、Answer the Public、Google Search、Google Analytics和Search Console等。当买家在微软中输入搜索数组时,Keywords Everywhere会显示一些基本的重要信息,包括搜索量和CPC(每次点击成本)数据。
虽然Keywords Everywhere收纳了来自多个来源的数据,但其数据格式并不纷扰,可以用PDF、Excel或CSV文件格式下载。
3、Merchant Words

Merchant Words是亚马逊买家理想的关键词研究工具。Merchant Words搜集了全球超过10亿次亚马逊实时搜索的数据,所有关键词数据都直接来自亚马逊搜索栏中的用户搜索。
Merchant Words的专业算法囊括了站点范围内的亚马逊流量、搜索排名以及当前和历史的搜索趋势。卖家还可以使用数目有限的关键词免费查询。除了免费版本外,Merchant Words还有付费版本(30美元/月,仅适用于日本数据;60美元/月,全球数据)。收费版本还包括不限量搜索、CSV下载以及24小时的顾客服务支持。
4、PinterestKeywordTool

PinterestKeywordTool是专门针对Pinterest平台的关键词研究工具。这款工具可以清晰地展示在Pinterest上受欢迎的关键词以及种子关键词和长尾关键词等重要的关键词信息。通过这种真实的搜索结果,卖家可以推测出最常使用的关键词句子。
5、Keyword.Guru

Keyword.Guru囊括了来自全球主流搜索引擎(谷歌、雅虎、必应等)和电商网站(亚马逊、eBay等)的数据信息。键入数组后,它还会依据人们实时搜索的内容提供相应结果。Keyword.Guru不显示有关关键词搜索量的信息,但它显示关于种子关键词的最常搜索项。
使用这种真实的搜索结果,你可以推测出最常使用的关键词句子。
6、Keyword Shitter

Keyword Shitter被业内称为天才关键词工具,据悉,该工具在30分钟内可以生成超过20000个关键词(及相关估算),此外能够通过借助微软文框手动填充控件进行查询。事实上,如果你不需要太多的关键词信息,可以通过添加正面或负面的过滤器来缩小结果范围。
总而言之,关键词研究工作一定是SEO战略中的核心环节,因此店家不仅使用微软的关键词规划师之外,还须要尝试其他的数据搜集渠道。虽然目前主流的付费关键词工具可以提供更多的数据,但上述的这种免费工具在性价比和效率上都符合大多数买家的日常使用需求,此外也太适宜一些入门级买家的尝试。(编译/雨果网 郭汇雯)
[系列] - go-gin-api 路由中间件 - Jaeger 链路追踪(五)
采集交流 • 优采云 发表了文章 • 0 个评论 • 244 次浏览 • 2020-08-09 15:32
首先同步下项目概况:
上篇文章分享了,路由中间件 - 捕获异常,这篇文章咱们分享:路由中间件 - Jaeger 链路追踪。
啥是链路追踪?
我理解链路追踪虽然是为微服务构架提供服务的,当一个恳求中,请求了多个服务单元,如果恳求出现了错误或异常,很难去定位是那个服务出了问题,这时就须要链路追踪。
咱们先看一张图:
这张图的调用链还比较清晰,咱们想像一下,随着服务的越来越多,服务与服务之间调用关系也越来越多,可能还会发展成右图的情况。
这调用关系真的是... 看到这,我的内心是崩溃的。
那么问题来了,这种情况下如何快速定位问题?
如何设计日志记录?
我们自己也可以设计一个链路追踪,比如当发生一个恳求,咱们记录它的:
怎么去实现恳求的惟一标示?
以 Go 为例 写一个中间件,在每次恳求的 Header 中收录:X-Request-Id,代码如下:
func SetUp() gin.HandlerFunc {
return func(c *gin.Context) {
requestId := c.Request.Header.Get("X-Request-Id")
if requestId == "" {
requestId = util.GenUUID()
}
c.Set("X-Request-Id", requestId)
c.Writer.Header().Set("X-Request-Id", requestId)
c.Next()
}
}
复制代码
每个 Request 和 Response 日志中都要收录 X-Request-Id。
问题又来了,每次调用都记录日志,当调用的服务过多时,频繁的记录日志,就会有性能问题呀,肿么办?
哎,这么麻烦,看看市面上有没有一些开源工具呢?
开源工具
这个就不多做介绍了,基本上都能满足需求,至于优缺点,大家可以逐个去看看,喜欢那个就用那个?
我为何选择 Jaeger ?
因为我目前只会用这个,其他还不会 ...
咱们一起看下 Jaeger 是怎么回事吧。
Jaeger 架构图
图片来源于官网。
简单介绍下上图三个关键组件:
Agent
Agent是一个网路守护进程,监听通过UDP发送过来的Span,它会将其批量发送给collector。按照设计,Agent要被布署到所有主机上,作为基础设施。Agent将collector和客户端之间的路由与发觉机制具象了下来。
Collector
Collector从Jaeger Agent接收Trace,并通过一个处理管线对其进行处理。目前的管线会校准Trace、建立索引、执行转换并最终进行储存。存储是一个可插入的组件,现在支持Cassandra和elasticsearch。
Query
Query服务会从储存中检索Trace并通过UI界面进行诠释,该UI界面通过React技术实现,其页面UI如下图所示,展现了一条Trace的详尽信息。
其他组件,大家可以了解下并选择性使用。
Jaeger Span
图片来源于官网。
怎么操作 Span 呢?Span 有什么可以调用的 API ?
Jaeger 部署
All in one
为了便捷你们快速使用,Jaeger 直接提供一个 All in one 包,我们可以直接执行,启动一套完整的 Jaeger tracing 系统。
启动成功后,访问 :16686 就可以看见 Jaeger UI。
独立布署
可以自由搭配,组合使用。
Jaeger 端口Jaeger 采样率
分布式追踪系统本身也会导致一定的性能低耗损,如果完整记录每次恳求,对于生产环境可能会有极大的性能耗损,一般须要进行取样设置。
固定取样
(sampler.type=const)
按比率取样
(sampler.type=probabilistic)
采样速率限制
(sampler.type=ratelimiting)
动态获取采样率
(sampler.type=remote)
Jaeger 缺点
看到这,说的都是理论,大家的心声可能是:
实战
关于实战的分享,我打算整理出 4 个服务,然后实现服务与服务之间进行互相调用,目前 Demo 还没写完... 查看全部
概述
首先同步下项目概况:
上篇文章分享了,路由中间件 - 捕获异常,这篇文章咱们分享:路由中间件 - Jaeger 链路追踪。
啥是链路追踪?
我理解链路追踪虽然是为微服务构架提供服务的,当一个恳求中,请求了多个服务单元,如果恳求出现了错误或异常,很难去定位是那个服务出了问题,这时就须要链路追踪。
咱们先看一张图:
这张图的调用链还比较清晰,咱们想像一下,随着服务的越来越多,服务与服务之间调用关系也越来越多,可能还会发展成右图的情况。
这调用关系真的是... 看到这,我的内心是崩溃的。
那么问题来了,这种情况下如何快速定位问题?
如何设计日志记录?
我们自己也可以设计一个链路追踪,比如当发生一个恳求,咱们记录它的:
怎么去实现恳求的惟一标示?
以 Go 为例 写一个中间件,在每次恳求的 Header 中收录:X-Request-Id,代码如下:
func SetUp() gin.HandlerFunc {
return func(c *gin.Context) {
requestId := c.Request.Header.Get("X-Request-Id")
if requestId == "" {
requestId = util.GenUUID()
}
c.Set("X-Request-Id", requestId)
c.Writer.Header().Set("X-Request-Id", requestId)
c.Next()
}
}
复制代码
每个 Request 和 Response 日志中都要收录 X-Request-Id。
问题又来了,每次调用都记录日志,当调用的服务过多时,频繁的记录日志,就会有性能问题呀,肿么办?
哎,这么麻烦,看看市面上有没有一些开源工具呢?
开源工具
这个就不多做介绍了,基本上都能满足需求,至于优缺点,大家可以逐个去看看,喜欢那个就用那个?
我为何选择 Jaeger ?
因为我目前只会用这个,其他还不会 ...
咱们一起看下 Jaeger 是怎么回事吧。
Jaeger 架构图
图片来源于官网。
简单介绍下上图三个关键组件:
Agent
Agent是一个网路守护进程,监听通过UDP发送过来的Span,它会将其批量发送给collector。按照设计,Agent要被布署到所有主机上,作为基础设施。Agent将collector和客户端之间的路由与发觉机制具象了下来。
Collector
Collector从Jaeger Agent接收Trace,并通过一个处理管线对其进行处理。目前的管线会校准Trace、建立索引、执行转换并最终进行储存。存储是一个可插入的组件,现在支持Cassandra和elasticsearch。
Query
Query服务会从储存中检索Trace并通过UI界面进行诠释,该UI界面通过React技术实现,其页面UI如下图所示,展现了一条Trace的详尽信息。
其他组件,大家可以了解下并选择性使用。
Jaeger Span
图片来源于官网。
怎么操作 Span 呢?Span 有什么可以调用的 API ?
Jaeger 部署
All in one
为了便捷你们快速使用,Jaeger 直接提供一个 All in one 包,我们可以直接执行,启动一套完整的 Jaeger tracing 系统。
启动成功后,访问 :16686 就可以看见 Jaeger UI。
独立布署
可以自由搭配,组合使用。
Jaeger 端口Jaeger 采样率
分布式追踪系统本身也会导致一定的性能低耗损,如果完整记录每次恳求,对于生产环境可能会有极大的性能耗损,一般须要进行取样设置。
固定取样
(sampler.type=const)
按比率取样
(sampler.type=probabilistic)
采样速率限制
(sampler.type=ratelimiting)
动态获取采样率
(sampler.type=remote)
Jaeger 缺点
看到这,说的都是理论,大家的心声可能是:
实战
关于实战的分享,我打算整理出 4 个服务,然后实现服务与服务之间进行互相调用,目前 Demo 还没写完...
利用新浪博客,实现被动精准引流方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2020-08-09 15:31
目前某宝对于那些业务都是直接屏蔽了,我们要买帐号就去QQ群这个渠道。这里你们记得,某宝搜不到的,就来QQ群试试,基本上你想要的虚拟类资源QQ群都有。
当然不仅 QQ 群,你也可以直接在百度里面搜索,大家多找几家对比下。老号肯定比新号权重高,价格也会更贵点,具体的你要按照你的情况来。账号买了后,一定要记得把资料都改下,改成你做的项目关键词的名称。
二、有了帐号后,接下来我们肯定就是搜集大量的长尾关键词
这个方式之前我也讲过。就是借助我们项目的原语来扩充。如果你哪些都不懂,这里也有最笨的技巧。那就是直接用百度搜索,在最下边的下来的虽然都是长尾关键词。
还可以借助一些拓词的网站和工具操作。找到这种词后,记得要搜索下这种词的百度指数,通过数据来瞧瞧,这些长尾词的热度怎么。
搜索下来后我们可以见到,有指数的词目前只显示下来了 X 个,那我们重点就是要做这 X 个有指数的词了。大家做实体产品类的行业词,有指数的肯定会特别多的。这里我只是给你们演示。
三、利用长尾词组合生成标题
就是把都是不同的长尾词组合在一起,变成一个新的文章标题。我举个事例给你们瞧瞧。就是拼接。
长尾词都可以拼接,最新的网路推广项目,月入 2 万的 10 个小生意就生成一个标题了。可能有些人没看明白,我再用产品类的关键词来说明吧。比如减肥类的长尾词,实在是太多了。如何减重,长的胖怎样办,教你怎么快速增肥,怎么减重有疗效,十个简单有效的减重办法,女生例假怎么减重,如何运动减肥
我们随意拼接一组:怎么减重有效?这十个简单有效的减重办法你晓得吗?按照这个思路,我们由于有了好多带指数的长尾词,那我们能够生成好多需求量大的文章标题。
四、标题有了,内容那里来呢
如何才能写原创文章,最好写原创。毕竟原创的文章收录是最好的。如果没有办法,那就用伪原创工具,但容易把文章改的不通顺,事后你须要自己改改就行了。 你若果认为为原创麻烦,那就把文章开头和结尾用自己的话重新描述一遍也行。
你也可以多找几篇文章,把多篇文章内容放到一起,掐头去尾重新拼接下,就弄成了一篇新的文章了。还可以把某一篇文章,用你自己的话抒发下来,这样一篇文章虽然文字不同了,但是核心意思还是没变的。
五、文章做好了
我们须要适当的做文章的优化,因为这样愈发利于收录,特别是你单个博客上面有很多文章的时侯。在文章底部和开头,要做下我们关键词的锚文本。简单的说,就是在某个关键词里面插入超链接。 查看全部
一、需要大量的优质帐号
目前某宝对于那些业务都是直接屏蔽了,我们要买帐号就去QQ群这个渠道。这里你们记得,某宝搜不到的,就来QQ群试试,基本上你想要的虚拟类资源QQ群都有。
当然不仅 QQ 群,你也可以直接在百度里面搜索,大家多找几家对比下。老号肯定比新号权重高,价格也会更贵点,具体的你要按照你的情况来。账号买了后,一定要记得把资料都改下,改成你做的项目关键词的名称。
二、有了帐号后,接下来我们肯定就是搜集大量的长尾关键词
这个方式之前我也讲过。就是借助我们项目的原语来扩充。如果你哪些都不懂,这里也有最笨的技巧。那就是直接用百度搜索,在最下边的下来的虽然都是长尾关键词。
还可以借助一些拓词的网站和工具操作。找到这种词后,记得要搜索下这种词的百度指数,通过数据来瞧瞧,这些长尾词的热度怎么。
搜索下来后我们可以见到,有指数的词目前只显示下来了 X 个,那我们重点就是要做这 X 个有指数的词了。大家做实体产品类的行业词,有指数的肯定会特别多的。这里我只是给你们演示。
三、利用长尾词组合生成标题
就是把都是不同的长尾词组合在一起,变成一个新的文章标题。我举个事例给你们瞧瞧。就是拼接。
长尾词都可以拼接,最新的网路推广项目,月入 2 万的 10 个小生意就生成一个标题了。可能有些人没看明白,我再用产品类的关键词来说明吧。比如减肥类的长尾词,实在是太多了。如何减重,长的胖怎样办,教你怎么快速增肥,怎么减重有疗效,十个简单有效的减重办法,女生例假怎么减重,如何运动减肥
我们随意拼接一组:怎么减重有效?这十个简单有效的减重办法你晓得吗?按照这个思路,我们由于有了好多带指数的长尾词,那我们能够生成好多需求量大的文章标题。
四、标题有了,内容那里来呢
如何才能写原创文章,最好写原创。毕竟原创的文章收录是最好的。如果没有办法,那就用伪原创工具,但容易把文章改的不通顺,事后你须要自己改改就行了。 你若果认为为原创麻烦,那就把文章开头和结尾用自己的话重新描述一遍也行。
你也可以多找几篇文章,把多篇文章内容放到一起,掐头去尾重新拼接下,就弄成了一篇新的文章了。还可以把某一篇文章,用你自己的话抒发下来,这样一篇文章虽然文字不同了,但是核心意思还是没变的。
五、文章做好了
我们须要适当的做文章的优化,因为这样愈发利于收录,特别是你单个博客上面有很多文章的时侯。在文章底部和开头,要做下我们关键词的锚文本。简单的说,就是在某个关键词里面插入超链接。
PatterNodes For Mac v2.2
采集交流 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2020-08-09 14:11
PatterNodes For Mac是黑苹果乐园采集到的一款用于基于重复创建图形模式、动画、渐变或插图的设计工具,软件看上去特别牛逼啊,很直观的设计灵感,但是对于设计没有任何基础的我来说只能说是一个高大上的却不会用的软件
所属分类:图像工具 适用平台:OS X 10.10 或更高版本 软件版本:v2.2.4 最后更新:2019年08月22日
软件介绍
PatterNodes For Mac是黑苹果乐园采集到的一款用于基于重复创建图形模式、动画、渐变或插图的设计工具,软件看上去特别牛逼啊,很直观的设计灵感,但是对于设计没有任何基础的我来说只能说是一个高大上的却不会用的软件,看了一遍官方给的视频也没明白哪些意思,如果你是做设计的我恐怕你是须要他的。
软件有点类似与易语言,就跟说话一样去编程的意思。这通过定义描述模式的步骤,配方或排序的序列来完成。可视脚本,因为它有时被称为。每个模式元素或操作由称为节点的小面板表示,然后通过在它们之间勾画的联接来链接节点。由于节点可以自由组合和联接,这给您一个十分灵活和强悍的插口。
Sketch For Mac v59.1 专业矢量绘图图形设计工具破解版
Sketch For Mac v59.1 是黑苹果乐园采集到的一款矢量图形勾画工具,软件是为现代平面设计师构建的,它显示在应用程序的每位纤维。 从灵活的工作流程支持多页和画板。 强大的功能,如符号和共...
Affinity Designer For Mac v1.6.1 专业的矢量图形设计工具
Affinity Designer For Mac v1.6.1是黑苹果乐园采集到的一款专业的矢量图形设计工具,现在做设计的能选择的软件也比较多,但是Affinity Designe 兼容性强,支持 ...
Adobe illustrator CC v2017 21.0 矢量图形设计制做软件
Adobe illustrator CC 2017 21.0是黑苹果乐园采集到的一款矢量图形设计制做软件,在新的MacBook Pro发布后Adobe公司更新了旗下的所有设计软件,包括Photosho...
Acorn For Mac v6.5.1 轻量级图片处理工具PS 替代者
Acorn For Mac v6.5.1 是黑苹果乐园采集到的一款Mac平台上的轻量级图片处理工具,可以说是一个Photoshop的轻量级替代者,如果你不想每次都是用笨重的ps来处理图片,你完全可以试...
PatterNodes从一开始就设计,以便轻松地调整事物,看看它们是怎么形成的。因此,最终的纹样图块总是显示在顶部预览视图中,随时重复和更新任何修改,让您即时反馈最终结果将是哪些。
虽然软件可以用于创建任何类型的重复图形,但它主要针对模式创建。使纹样创建更容易PatterNodes还包括许多节点,这些节点手动执行常见的冗长任务,例如在图块边沿重复元素以让纹样无缝,或者让纹样的不同方面(例如颜色,位置,旋转...)模式给它一点生活。
最后,完成后,您可以将模式图块复制到您使用的任何插图或图形应用程序中,或将其导入为矢量图形或位图图象文件。
软件截图
更新内容下载地址
PatterNodes For Mac v2.2.4
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
历史版本
PatterNodes For Mac v2.2.1
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
PatterNodes For Mac v2.2.0
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
PatterNodes For Mac v2.1.9
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
PatterNodes For Mac v2.1.8
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
PatterNodes For Mac v2.1.7
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
PatterNodes For Mac v2.1.2
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
PatterNodes For Mac v2.1.1
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!] 查看全部
摘 要
PatterNodes For Mac是黑苹果乐园采集到的一款用于基于重复创建图形模式、动画、渐变或插图的设计工具,软件看上去特别牛逼啊,很直观的设计灵感,但是对于设计没有任何基础的我来说只能说是一个高大上的却不会用的软件

所属分类:图像工具 适用平台:OS X 10.10 或更高版本 软件版本:v2.2.4 最后更新:2019年08月22日
软件介绍
PatterNodes For Mac是黑苹果乐园采集到的一款用于基于重复创建图形模式、动画、渐变或插图的设计工具,软件看上去特别牛逼啊,很直观的设计灵感,但是对于设计没有任何基础的我来说只能说是一个高大上的却不会用的软件,看了一遍官方给的视频也没明白哪些意思,如果你是做设计的我恐怕你是须要他的。
软件有点类似与易语言,就跟说话一样去编程的意思。这通过定义描述模式的步骤,配方或排序的序列来完成。可视脚本,因为它有时被称为。每个模式元素或操作由称为节点的小面板表示,然后通过在它们之间勾画的联接来链接节点。由于节点可以自由组合和联接,这给您一个十分灵活和强悍的插口。

Sketch For Mac v59.1 专业矢量绘图图形设计工具破解版
Sketch For Mac v59.1 是黑苹果乐园采集到的一款矢量图形勾画工具,软件是为现代平面设计师构建的,它显示在应用程序的每位纤维。 从灵活的工作流程支持多页和画板。 强大的功能,如符号和共...
Affinity Designer For Mac v1.6.1 专业的矢量图形设计工具
Affinity Designer For Mac v1.6.1是黑苹果乐园采集到的一款专业的矢量图形设计工具,现在做设计的能选择的软件也比较多,但是Affinity Designe 兼容性强,支持 ...

Adobe illustrator CC v2017 21.0 矢量图形设计制做软件
Adobe illustrator CC 2017 21.0是黑苹果乐园采集到的一款矢量图形设计制做软件,在新的MacBook Pro发布后Adobe公司更新了旗下的所有设计软件,包括Photosho...

Acorn For Mac v6.5.1 轻量级图片处理工具PS 替代者
Acorn For Mac v6.5.1 是黑苹果乐园采集到的一款Mac平台上的轻量级图片处理工具,可以说是一个Photoshop的轻量级替代者,如果你不想每次都是用笨重的ps来处理图片,你完全可以试...
PatterNodes从一开始就设计,以便轻松地调整事物,看看它们是怎么形成的。因此,最终的纹样图块总是显示在顶部预览视图中,随时重复和更新任何修改,让您即时反馈最终结果将是哪些。
虽然软件可以用于创建任何类型的重复图形,但它主要针对模式创建。使纹样创建更容易PatterNodes还包括许多节点,这些节点手动执行常见的冗长任务,例如在图块边沿重复元素以让纹样无缝,或者让纹样的不同方面(例如颜色,位置,旋转...)模式给它一点生活。
最后,完成后,您可以将模式图块复制到您使用的任何插图或图形应用程序中,或将其导入为矢量图形或位图图象文件。
软件截图




更新内容下载地址
PatterNodes For Mac v2.2.4
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
历史版本
PatterNodes For Mac v2.2.1
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
PatterNodes For Mac v2.2.0
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
PatterNodes For Mac v2.1.9
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
PatterNodes For Mac v2.1.8
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
PatterNodes For Mac v2.1.7
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
PatterNodes For Mac v2.1.2
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
PatterNodes For Mac v2.1.1
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
表单处理不用愁,这五款软件才能精准提取数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2020-08-09 13:48
其实,只须要一款才能提取数据的软件,就能避开重复步骤,一步完成工作,大大提升工作效率。在此,小编为你们推荐几款软件。
1、Formtalk
Formtalk 是专为企业用户提供的一站式办公应用订制平台,它具有企业级数据的采集和管理,能够满足企业内外部包括报考、登记、预约、投票、调查等在内的数据采集需求。这款软件就能帮助用户实时跟踪须要采集的数据,呈现为可视化报表,同时,它的PC表单设计引擎、移动表单设计引擎、安全引擎和数据集成插口四项核心技术才能为用户提供表单复制、表单授权及表单提取功能,让用户才能有效提升工作效率。
2、PDFelement
PDFelement 在处理 PDF 表单和提取数据这一块堪称攻打行业制高点。 它能帮助用户一键辨识表单域(交互式表单域和非交互式表单域皆可辨识),也能帮助用户自定义创建个性表单,比如单选、多选、下拉表、文本框、数字签名等。 当用户面对海量 PDF 表单,需要提取其中一项或则多项关键数据时,它能帮助用户确切提取表单数据,批量处理为用户节约了大量时间和精力。
用户仅需将大量 PDF 拖入程序中,选择须要提取的区域,这些数据将会导出到Excel中。 如果这种 PDF 文档是扫描文件,也无需害怕,PDFelement 执行 OCR,将文档转换为可编辑的文档,再进行数据提取操作。
3、金数据
这款表单处理工具是通用型的表单工具,主要功能集聚于数据搜集和数据提取上,在数据统计和数据剖析上有所缺乏。用金数据生成的表单除了能以 Excel 表格的方式呈现,而且还能以链接或则 HTML 代码的方式嵌入到网页、微信文章之中。除此之外,这款软件在搜集、提取数据的同时还能接入不同的支付端口,非常适宜网店订单、用户反馈等业务数据的搜集和提取。
4、易表
这款软件的功能介于电子表格与数据库软件之间,拥有类似电子表格的界面,也具备数据库软件特有的功能和灵活性。易表在数据处理上是十分优秀的软件,能够帮助用户完美完成复杂的数据管理和统计剖析工作。但是,它的功能要求用户具备一定的开发能力,只有了解基本的编程知识能够快速构建属于自己的数据管理系统,比较适宜专业性较强的用户,普通用户使用这款软件的学习成本偏高。
5、Foxtable
这款软件将 Excel、Access、Foxpro、VB 等软件的优势融合在一起,无论是数据录入、提取,还是报表生成,用户都无需编撰代码即可完成以上这种复杂的数据管理工作。这款软件的亮点之一是外置了 HTTP 服务和手机网页功能,用户无需任何专业知识才能够开发出自己移动端的管理软件,做到 PC 端与移动端的数据移动。相比于其他数据处理软件,这款软件更象是一个高效开发工具,让用户在开发属于自己的数据库时更关注商业逻辑,导致具体功能的实现比较艰辛。同时,由于Foxtable支持外部数据源,也就意味着用户提供的数据有一定的安全风险。
你是否也有兴趣瞧瞧《身在职场不会处理这5种文档,还谈涨薪?》 查看全部
对于企业用户来说,特别是人事、财务这类时常接触到数据的岗位,工作中必不可少会接触到一些数据搜集和剖析。很多时侯,用户会接收到大量相同表单,但常常只须要表单中的一两项关键数据,针对这些情况,如果用户仍然坚守传统的办公形式,往往会有大量重复动作,大大减少了工作效率。

其实,只须要一款才能提取数据的软件,就能避开重复步骤,一步完成工作,大大提升工作效率。在此,小编为你们推荐几款软件。
1、Formtalk
Formtalk 是专为企业用户提供的一站式办公应用订制平台,它具有企业级数据的采集和管理,能够满足企业内外部包括报考、登记、预约、投票、调查等在内的数据采集需求。这款软件就能帮助用户实时跟踪须要采集的数据,呈现为可视化报表,同时,它的PC表单设计引擎、移动表单设计引擎、安全引擎和数据集成插口四项核心技术才能为用户提供表单复制、表单授权及表单提取功能,让用户才能有效提升工作效率。

2、PDFelement
PDFelement 在处理 PDF 表单和提取数据这一块堪称攻打行业制高点。 它能帮助用户一键辨识表单域(交互式表单域和非交互式表单域皆可辨识),也能帮助用户自定义创建个性表单,比如单选、多选、下拉表、文本框、数字签名等。 当用户面对海量 PDF 表单,需要提取其中一项或则多项关键数据时,它能帮助用户确切提取表单数据,批量处理为用户节约了大量时间和精力。

用户仅需将大量 PDF 拖入程序中,选择须要提取的区域,这些数据将会导出到Excel中。 如果这种 PDF 文档是扫描文件,也无需害怕,PDFelement 执行 OCR,将文档转换为可编辑的文档,再进行数据提取操作。

3、金数据
这款表单处理工具是通用型的表单工具,主要功能集聚于数据搜集和数据提取上,在数据统计和数据剖析上有所缺乏。用金数据生成的表单除了能以 Excel 表格的方式呈现,而且还能以链接或则 HTML 代码的方式嵌入到网页、微信文章之中。除此之外,这款软件在搜集、提取数据的同时还能接入不同的支付端口,非常适宜网店订单、用户反馈等业务数据的搜集和提取。

4、易表
这款软件的功能介于电子表格与数据库软件之间,拥有类似电子表格的界面,也具备数据库软件特有的功能和灵活性。易表在数据处理上是十分优秀的软件,能够帮助用户完美完成复杂的数据管理和统计剖析工作。但是,它的功能要求用户具备一定的开发能力,只有了解基本的编程知识能够快速构建属于自己的数据管理系统,比较适宜专业性较强的用户,普通用户使用这款软件的学习成本偏高。

5、Foxtable
这款软件将 Excel、Access、Foxpro、VB 等软件的优势融合在一起,无论是数据录入、提取,还是报表生成,用户都无需编撰代码即可完成以上这种复杂的数据管理工作。这款软件的亮点之一是外置了 HTTP 服务和手机网页功能,用户无需任何专业知识才能够开发出自己移动端的管理软件,做到 PC 端与移动端的数据移动。相比于其他数据处理软件,这款软件更象是一个高效开发工具,让用户在开发属于自己的数据库时更关注商业逻辑,导致具体功能的实现比较艰辛。同时,由于Foxtable支持外部数据源,也就意味着用户提供的数据有一定的安全风险。

你是否也有兴趣瞧瞧《身在职场不会处理这5种文档,还谈涨薪?》
2019在线智能AI文章伪原创网站源码,站长自媒体营运必备工具,上传即用
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2020-08-09 13:47
安装环境
商品介绍
直接上传即可使用,亲测没问题。
智能AI伪原创是做哪些的?
各位站长同学想必都为网站内容原创的问题头痛吧,作为一个草根站长,要想自己写原创文章,那是不可能的,当然我不是说你一篇也写不下来。以个人站长的人力来说,写原创文章不太实际,光时刻便是问题。
或许有的站长同学该问:不写原创文章怎么弄好网站呢?其实不光是我们,便是国外的几个大门户也不全是原创文章,他们互相之前也是用来内容更改一下,再改改标题,就成了自己的“新闻”。 下面该谈谈,我这个伪原创工具了。本程序是免费的在线伪原创工具,原理便是反义词替换。
有同事问我,这样会不会被K,算不算做弊?就这个问题我宣布一下个人的观点供你参阅。搜索引擎其实是机器,他抓取文章后会在数据库中与已有的文章做一个比对,假如发觉有相似度很高的文章则觉得是剽窃,反之觉得是原创。当然如果你是原貌仿效的,那么就订死是剽窃的。用伪原创工具转化后,文章中的部份单词被转化成反义词,搜索引擎再比对时,就觉得是原创文章了。当然这也不是肯定的,看详尽转化单词多少而言。
这款伪原创php源码无后台,直接将源码上传到空间任意目录下都可以运用,假如不是上传到网站根目录的话,记得要掀开index.html文件,修改css和js文件地址,否则掀开后页面凸显会出现问题。 查看全部
商品属性
安装环境
商品介绍
直接上传即可使用,亲测没问题。
智能AI伪原创是做哪些的?
各位站长同学想必都为网站内容原创的问题头痛吧,作为一个草根站长,要想自己写原创文章,那是不可能的,当然我不是说你一篇也写不下来。以个人站长的人力来说,写原创文章不太实际,光时刻便是问题。
或许有的站长同学该问:不写原创文章怎么弄好网站呢?其实不光是我们,便是国外的几个大门户也不全是原创文章,他们互相之前也是用来内容更改一下,再改改标题,就成了自己的“新闻”。 下面该谈谈,我这个伪原创工具了。本程序是免费的在线伪原创工具,原理便是反义词替换。
有同事问我,这样会不会被K,算不算做弊?就这个问题我宣布一下个人的观点供你参阅。搜索引擎其实是机器,他抓取文章后会在数据库中与已有的文章做一个比对,假如发觉有相似度很高的文章则觉得是剽窃,反之觉得是原创。当然如果你是原貌仿效的,那么就订死是剽窃的。用伪原创工具转化后,文章中的部份单词被转化成反义词,搜索引擎再比对时,就觉得是原创文章了。当然这也不是肯定的,看详尽转化单词多少而言。
这款伪原创php源码无后台,直接将源码上传到空间任意目录下都可以运用,假如不是上传到网站根目录的话,记得要掀开index.html文件,修改css和js文件地址,否则掀开后页面凸显会出现问题。
如果我不能写文章怎么办?了解有用的伪原创工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2020-08-08 10:47
但是,为网站生成少量原创内容并不难,但是对于任何草根网站管理员,尤其是某些垂直行业网站,每天更新都是非常困难的. 内容是相对固定的,并且很难发布原创内容. 因此,伪原创是一种重要的方式. 但是,传统的伪原创方法很难提高内容的质量,这将使该网站成为垃圾邮件网站. 因此,从发展的角度来看,提高伪原创的质量至关重要.
那么我们如何才能有效提高伪原创内容的质量?我认为我们可以从以下几个方面入手,使伪原创内容的质量与原创内容的质量相等.
第一个是伪原创的并购创新方法.
我们知道,伪原创通常是在Internet上找到一些内容,然后更改标题以打扰文章段落. 有些甚至使用伪原创工具来替换同义词. 因此,伪原创内容的可读性变得很差,因此我们放弃了这种伪原创方法,而是可以将相关内容整合并以我们自己的语言重新组织. 在梳理过程中,可以将一些创新与相关内容结合起来,以使这种伪原创内容呈现出新的事物.
合并相关内容时,必须确保第一段和最后一段是原创内容,并在这两个位置建立中心内容. 该核心内容通常可以与不同概念的集成结合在一起. 作为网站管理员,这时您有自己的独立思考,因此也可以编写. 这样可以有效地保证伪原创内容的质量,即使文章中的某些内容具有高度的相似性,也不会导致百度不喜欢它.
第二个是内容与科学采集的结合.
我们知道Internet上的某些内容与市场上出售的图书有关,但它们不能相同. 否则,这些书将被复制,因此我们可以将这些书的内容传输到Internet. ,并进行了一些优化和创新,可以将其转换为非常好的原创内容,同时还具有良好的可读性和知识,并成为百度蜘蛛最喜欢的内容.
用于集成现有的Internet内容,例如制作一些论坛帖子,游戏指南和其他综合内容. 这些内容通常不需要原创,而只需在Internet上采集相关内容,然后这些内容的组合就可以形成非常有价值的内容,并且这些内容也是百度Spider的最爱,并且有望成为其的常客百度的主页.
第三,等效的交换方法
①文本排序方法: 如果您在本网站上获得本文“游戏编辑撰写伪第一篇文章的五个提示”,您将如何制定等效的交换方法?当同义词和标题关键字受到干扰时,它们可以实现等效的交换,您可以将其更改为“游戏编辑者撰写伪第一篇文章的五种技巧”和“游戏编辑者撰写伪第一篇文章的五种技巧”. 可以看出,标题已经微妙地改变了,但是含义没有改变. 这是等效的交换方法.
②数字交换方法: 例如,标题: 五个错误的优先技能,您可以停止适当地删除一些您认为不是错误的优先技能,或者添加一些错误的优先技能,至少可以让搜索引擎认为您的标题不一样.
③换词方法: 王文生是在改变相关或相似的词,从而达到不换药就可以换汤的效果.
第四,标题组合方法
组合方法与上述三种或两种方法一起使用. 例如,在标题为“网站管理员如何进行网站营销分析和制定策略”的文章中,可以将其更改为“好的网络营销分析需要好的措施”,即采用等效的交换方法和文本修改方法.
以上伪原创方法可以有效地提高内容创建的速度,并且可以有效地扩展内容创建的空间. 但是,当我们是伪原创时,我们必须注意内容的可读性,而不仅仅是通过软件. 同义词替换,段落改组方法. 尝试将自己的一些意见纳入伪原创.
实际上,我将告诉您这篇文章是使用伪原创软件撰写的?是的,所有这些都只是排版和图片,我什至没有读过这篇文章.
接下来,检查您阅读的本文的测试结果:
创意是100%,您感到惊讶还是惊讶?
就是这样! Zhimedia AI批处理写作助手可以轻松地一键创建高质量的文章内容! 查看全部
众所周知,百度搜索引擎对网站内容质量的要求越来越高. 如果网站的内容质量很差,即使该网站有很多外部链接,也有很多高质量的外部链接,并且通常不会获得很高的排名,因为内容较差的网站往往具有很高的排名. 跳出率. 这已经成为百度排名算法的重要元素
但是,为网站生成少量原创内容并不难,但是对于任何草根网站管理员,尤其是某些垂直行业网站,每天更新都是非常困难的. 内容是相对固定的,并且很难发布原创内容. 因此,伪原创是一种重要的方式. 但是,传统的伪原创方法很难提高内容的质量,这将使该网站成为垃圾邮件网站. 因此,从发展的角度来看,提高伪原创的质量至关重要.
那么我们如何才能有效提高伪原创内容的质量?我认为我们可以从以下几个方面入手,使伪原创内容的质量与原创内容的质量相等.

第一个是伪原创的并购创新方法.
我们知道,伪原创通常是在Internet上找到一些内容,然后更改标题以打扰文章段落. 有些甚至使用伪原创工具来替换同义词. 因此,伪原创内容的可读性变得很差,因此我们放弃了这种伪原创方法,而是可以将相关内容整合并以我们自己的语言重新组织. 在梳理过程中,可以将一些创新与相关内容结合起来,以使这种伪原创内容呈现出新的事物.
合并相关内容时,必须确保第一段和最后一段是原创内容,并在这两个位置建立中心内容. 该核心内容通常可以与不同概念的集成结合在一起. 作为网站管理员,这时您有自己的独立思考,因此也可以编写. 这样可以有效地保证伪原创内容的质量,即使文章中的某些内容具有高度的相似性,也不会导致百度不喜欢它.
第二个是内容与科学采集的结合.
我们知道Internet上的某些内容与市场上出售的图书有关,但它们不能相同. 否则,这些书将被复制,因此我们可以将这些书的内容传输到Internet. ,并进行了一些优化和创新,可以将其转换为非常好的原创内容,同时还具有良好的可读性和知识,并成为百度蜘蛛最喜欢的内容.
用于集成现有的Internet内容,例如制作一些论坛帖子,游戏指南和其他综合内容. 这些内容通常不需要原创,而只需在Internet上采集相关内容,然后这些内容的组合就可以形成非常有价值的内容,并且这些内容也是百度Spider的最爱,并且有望成为其的常客百度的主页.

第三,等效的交换方法
①文本排序方法: 如果您在本网站上获得本文“游戏编辑撰写伪第一篇文章的五个提示”,您将如何制定等效的交换方法?当同义词和标题关键字受到干扰时,它们可以实现等效的交换,您可以将其更改为“游戏编辑者撰写伪第一篇文章的五种技巧”和“游戏编辑者撰写伪第一篇文章的五种技巧”. 可以看出,标题已经微妙地改变了,但是含义没有改变. 这是等效的交换方法.
②数字交换方法: 例如,标题: 五个错误的优先技能,您可以停止适当地删除一些您认为不是错误的优先技能,或者添加一些错误的优先技能,至少可以让搜索引擎认为您的标题不一样.
③换词方法: 王文生是在改变相关或相似的词,从而达到不换药就可以换汤的效果.
第四,标题组合方法
组合方法与上述三种或两种方法一起使用. 例如,在标题为“网站管理员如何进行网站营销分析和制定策略”的文章中,可以将其更改为“好的网络营销分析需要好的措施”,即采用等效的交换方法和文本修改方法.
以上伪原创方法可以有效地提高内容创建的速度,并且可以有效地扩展内容创建的空间. 但是,当我们是伪原创时,我们必须注意内容的可读性,而不仅仅是通过软件. 同义词替换,段落改组方法. 尝试将自己的一些意见纳入伪原创.
实际上,我将告诉您这篇文章是使用伪原创软件撰写的?是的,所有这些都只是排版和图片,我什至没有读过这篇文章.
接下来,检查您阅读的本文的测试结果:

创意是100%,您感到惊讶还是惊讶?

就是这样! Zhimedia AI批处理写作助手可以轻松地一键创建高质量的文章内容!
掌握3种搜索技术并在GitHub上快速找到有用的软件资源
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2020-08-07 22:47
对于用户而言,我不禁要问: 面对如此众多的GitHub项目,该平台如何才能发现一些出色的软件和工具. 带着这个问题,我采集并总结了以下搜索技术.
热门搜索: GitHub趋势和GitHub主题
“ GitHub趋势”页面按每日/每周/每月的周期总结了受欢迎的存储库和开发人员. 您可以查看处于特定周期中处于热门状态的开发项目和开发人员. GitHub Topic显示最新和最受欢迎的讨论主题. 在这里,您不仅可以看到开发项目,还可以看到更多非开发技术的讨论主题,例如Job,Chrome浏览器等.
GitHub趋势
GitHub开发人员主题搜索
有传言说,当人力资源部招聘开发人员时,被招聘对象在GitHub上的贡献将是重要的参考指标之一. 作为优秀的国内开源软件的发行中心之一,GitHub埋葬了许多杰出的开发人员,因此,在寻找本地软件时,您可以尝试首先找到本地开发人员. 使用GitHub强大的搜索功能,您可以通过添加一些搜索参数轻松地找到“目标人物”.
(注意: GitHub正式支持许多搜索条件. 您可以在此处查看官方搜索技术. )
Github搜索提示查找开发人员
例如,如果您需要寻找家用软件,那么想到的第一件事就是在GituHub上寻找家用开发人员. 搜索时,将位置设置为中国. 如果要查找使用javascript的开发人员,然后在javascript中添加语言,则整个搜索条件是: Language: javascript location: china,从搜索结果中,我们发现了将近17,000个javascript开发人员,其区域信息被填充为中国. 熟悉朋友的阮一峰老师名列前茅. 根据官方指南,在搜索GitHub用户时,您还可以使用关注者和in: fullname的组合进行搜索.
使用组合条件进行搜索
按搜索条件搜索
我们需要在GitHub上找到出色的项目和工具. 同样,使用关键字或设置搜索词将帮助您以一半的努力找到良好的资源. 我的习惯是先搜索某些关键字,然后获得的搜索结果首先显示一些现成的软件和工具.
GitHub搜索提示查找项目
很棒的关键字
Awesome似乎已成为许多GitHub项目最喜欢的名称之一. 例如,如前所述,要找到出色的Windows软件,您可以尝试搜索Awesome窗口并获取以下搜索结果:
很棒的Windows搜索结果
最出色的结果是Windows / Awesome项目,它是Windows上高质量和精选的最佳应用程序和工具的集合. 在这里,我采集了一些关于Awesome主题的优秀项目: Awesome声明,Awesome iOS框架,Awesome令人讨厌的Android库和资源.
设置搜索条件
如果您明确需要寻找某种类型的项目,例如需要使用某种语言进行开发的项目,并且星数需要达到标准,则可以直接在搜索中输入搜索条件框. 其中,对于发现项目,我的用法是灵活地使用以下搜索条件: stars: ,language: ,fork :,实际上是设置项目集合,开发语言和派生的搜索条件(例如输入stars) : > = 500语言: javascript是大于或等于500的javascript项目的集合. 排名最高的是开源代码库和课程项目freeCodeCamp,以及流行的Vue和React项目.
搜索条件= 500语言: javascript>
如果记住这些搜索条件有点麻烦,请使用GitHub提供的高级搜索功能,还可以使用自定义条件进行搜索. 或参考官方帮助指南“在GitHub上搜索”,该手册提供了更多针对项目,代码,注释和问题的搜索技术.
GitHub高级搜索功能
以下是GitHub上最具影响力的项目,仅列出其中一些:
结论
GitHub网站上有许多出色的开源项目. 为了充分利用GitHub的搜索功能,我们可以使用官方的高级搜索以及“主题和趋势”页面,或者学习如何结合搜索条件来主动发现更多使用的优秀项和工具. 查看全部
GitHub是目前大多数程序员的最大游乐场. 今年6月,它被微软以价值75亿美元的微软股票收购. GitHub再次成为业界讨论的焦点. 凭借其免费和开放的定位,GitHub吸引了许多个人开发人员和公司,并且继续发布和更新非常有用的软件和工具. 以前,少数群体在GitHub上组织并推荐了免费且易于使用的Windows和macOS平台软件:
对于用户而言,我不禁要问: 面对如此众多的GitHub项目,该平台如何才能发现一些出色的软件和工具. 带着这个问题,我采集并总结了以下搜索技术.
热门搜索: GitHub趋势和GitHub主题
“ GitHub趋势”页面按每日/每周/每月的周期总结了受欢迎的存储库和开发人员. 您可以查看处于特定周期中处于热门状态的开发项目和开发人员. GitHub Topic显示最新和最受欢迎的讨论主题. 在这里,您不仅可以看到开发项目,还可以看到更多非开发技术的讨论主题,例如Job,Chrome浏览器等.

GitHub趋势

GitHub开发人员主题搜索
有传言说,当人力资源部招聘开发人员时,被招聘对象在GitHub上的贡献将是重要的参考指标之一. 作为优秀的国内开源软件的发行中心之一,GitHub埋葬了许多杰出的开发人员,因此,在寻找本地软件时,您可以尝试首先找到本地开发人员. 使用GitHub强大的搜索功能,您可以通过添加一些搜索参数轻松地找到“目标人物”.
(注意: GitHub正式支持许多搜索条件. 您可以在此处查看官方搜索技术. )

Github搜索提示查找开发人员
例如,如果您需要寻找家用软件,那么想到的第一件事就是在GituHub上寻找家用开发人员. 搜索时,将位置设置为中国. 如果要查找使用javascript的开发人员,然后在javascript中添加语言,则整个搜索条件是: Language: javascript location: china,从搜索结果中,我们发现了将近17,000个javascript开发人员,其区域信息被填充为中国. 熟悉朋友的阮一峰老师名列前茅. 根据官方指南,在搜索GitHub用户时,您还可以使用关注者和in: fullname的组合进行搜索.

使用组合条件进行搜索

按搜索条件搜索
我们需要在GitHub上找到出色的项目和工具. 同样,使用关键字或设置搜索词将帮助您以一半的努力找到良好的资源. 我的习惯是先搜索某些关键字,然后获得的搜索结果首先显示一些现成的软件和工具.

GitHub搜索提示查找项目
很棒的关键字
Awesome似乎已成为许多GitHub项目最喜欢的名称之一. 例如,如前所述,要找到出色的Windows软件,您可以尝试搜索Awesome窗口并获取以下搜索结果:

很棒的Windows搜索结果
最出色的结果是Windows / Awesome项目,它是Windows上高质量和精选的最佳应用程序和工具的集合. 在这里,我采集了一些关于Awesome主题的优秀项目: Awesome声明,Awesome iOS框架,Awesome令人讨厌的Android库和资源.
设置搜索条件
如果您明确需要寻找某种类型的项目,例如需要使用某种语言进行开发的项目,并且星数需要达到标准,则可以直接在搜索中输入搜索条件框. 其中,对于发现项目,我的用法是灵活地使用以下搜索条件: stars: ,language: ,fork :,实际上是设置项目集合,开发语言和派生的搜索条件(例如输入stars) : > = 500语言: javascript是大于或等于500的javascript项目的集合. 排名最高的是开源代码库和课程项目freeCodeCamp,以及流行的Vue和React项目.

搜索条件= 500语言: javascript>
如果记住这些搜索条件有点麻烦,请使用GitHub提供的高级搜索功能,还可以使用自定义条件进行搜索. 或参考官方帮助指南“在GitHub上搜索”,该手册提供了更多针对项目,代码,注释和问题的搜索技术.

GitHub高级搜索功能
以下是GitHub上最具影响力的项目,仅列出其中一些:
结论
GitHub网站上有许多出色的开源项目. 为了充分利用GitHub的搜索功能,我们可以使用官方的高级搜索以及“主题和趋势”页面,或者学习如何结合搜索条件来主动发现更多使用的优秀项和工具.
如何采集和整理原创的公共帐户文章,介绍以下实用方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2020-08-07 18:27
如今,微信的功能越来越完善. 人们经常使用微信聊天或阅读一些官方账号文章,而微信官方账号形式多样,并且有很多发表的文章. 采集官方帐户文章怎么样?继续吗?让我们从下面的Tuotu Data谈起它.
在官方帐户上采集文章
如何分析,采集和组织微信公众号文章的材料
1. 为什么要采集?
采集的优点是节省您的时间成本. 预先采集的信息就像是一道菜,只需要随意组合和油炸即可. 也许原创的创作者会比重印者有更多的经验.
例如:
假设我是原创作者,今天我想发表一篇活跃的文章. 假设我之前已经采集了活跃的文章,那么我只需要执行一个例程即可,但是如果我没有采集这条信息,则需要重新开始. 了解距离就是时间成本.
假设我是一名避难所,我需要发推文并准备接下来几天的内容. 除非有可用的东西,否则我必须花很长时间才能完成它,假设可以在闲暇时完成数据采集,那么时间成本就不会很高.
2. 如何分析数据
采集的条件必须是对Su进行搜索和分析,并对文章进行系统的分类. 分类标准不必按类型,性质甚至关键字进行分类. 我总结了以下几点.
阅读量高,转发量低.
阅读量少,转发率高.
阅读和转发很高.
查看和转发都很低.
编辑器如何分析这些数据?有两种方法. 首先,手动提取历史文章,逐一写下喜欢的阅读次数,然后每月和每周. 按年份排序,看看出了什么问题.
第二种方法是使用第三方数据工具Tuotu Data导出官方帐户的历史文章,包括读取和喜欢的数据,以便可以在数据表中轻松分析导出.
在官方帐户上采集文章
微信公众号文章采集
在浏览器中打开百度,搜索相关网站,然后单击进入.
首先,让我们了解图形介绍和视频教程以及各种操作步骤.
有些类别,关键字,自定义采集集等可以发布到官方帐户或网站上.
受支持的系统包括dedecms,phpcms,WordPress,discuz,EmpireCMS和mysql等接口.
在微信公众号上采集文章的几种方案
方案1: 基于搜狗门户
从可以在Internet上搜索的官方帐户文章中采集的相关信息来看,这是最,最直接,最简单的解决方案.
一般过程是:
1. 在搜狗微信搜索门户上搜索官方帐户.
2. 选择官方帐户以输入官方帐户的历史文章列表. 3.分析文章的内容并将其存储在数据库中.
如果收款频率太高,验证码将显示在搜狗搜索中,并可以访问官方帐户历史记录文章列表. 直接使用常规脚本集合无法获得验证码. 在这里,您可以使用无头浏览器通过对接和编码平台访问和识别验证码. 硒可以用作无头浏览器.
即使是无头浏览器也存在问题:
1. 低效率(实际上是运行完整的浏览器来模拟人工操作).
2. 在浏览器中难以控制Web资源的加载,并且在脚本中也难以控制浏览器的加载. 3.验证码识别不能100%,并且爬网过程可能会在中间中断.
如果您坚持使用搜狗门户并希望执行完美的采集,则只能增加代理IP. 顺便说一句,甚至不要考虑公开一个免费的IP地址,它非常不稳定,并且基本上被微信阻止.
除了Sogou / WeChat反爬虫机制外,采用此解决方案还有其他缺点: 查看全部
如今,微信的功能越来越完善. 人们经常使用微信聊天或阅读一些官方账号文章,而微信官方账号形式多样,并且有很多发表的文章. 采集官方帐户文章怎么样?继续吗?让我们从下面的Tuotu Data谈起它.
在官方帐户上采集文章
如何分析,采集和组织微信公众号文章的材料
1. 为什么要采集?
采集的优点是节省您的时间成本. 预先采集的信息就像是一道菜,只需要随意组合和油炸即可. 也许原创的创作者会比重印者有更多的经验.
例如:
假设我是原创作者,今天我想发表一篇活跃的文章. 假设我之前已经采集了活跃的文章,那么我只需要执行一个例程即可,但是如果我没有采集这条信息,则需要重新开始. 了解距离就是时间成本.
假设我是一名避难所,我需要发推文并准备接下来几天的内容. 除非有可用的东西,否则我必须花很长时间才能完成它,假设可以在闲暇时完成数据采集,那么时间成本就不会很高.
2. 如何分析数据
采集的条件必须是对Su进行搜索和分析,并对文章进行系统的分类. 分类标准不必按类型,性质甚至关键字进行分类. 我总结了以下几点.
阅读量高,转发量低.
阅读量少,转发率高.
阅读和转发很高.
查看和转发都很低.
编辑器如何分析这些数据?有两种方法. 首先,手动提取历史文章,逐一写下喜欢的阅读次数,然后每月和每周. 按年份排序,看看出了什么问题.
第二种方法是使用第三方数据工具Tuotu Data导出官方帐户的历史文章,包括读取和喜欢的数据,以便可以在数据表中轻松分析导出.
在官方帐户上采集文章
微信公众号文章采集
在浏览器中打开百度,搜索相关网站,然后单击进入.
首先,让我们了解图形介绍和视频教程以及各种操作步骤.
有些类别,关键字,自定义采集集等可以发布到官方帐户或网站上.
受支持的系统包括dedecms,phpcms,WordPress,discuz,EmpireCMS和mysql等接口.
在微信公众号上采集文章的几种方案
方案1: 基于搜狗门户
从可以在Internet上搜索的官方帐户文章中采集的相关信息来看,这是最,最直接,最简单的解决方案.
一般过程是:
1. 在搜狗微信搜索门户上搜索官方帐户.
2. 选择官方帐户以输入官方帐户的历史文章列表. 3.分析文章的内容并将其存储在数据库中.
如果收款频率太高,验证码将显示在搜狗搜索中,并可以访问官方帐户历史记录文章列表. 直接使用常规脚本集合无法获得验证码. 在这里,您可以使用无头浏览器通过对接和编码平台访问和识别验证码. 硒可以用作无头浏览器.
即使是无头浏览器也存在问题:
1. 低效率(实际上是运行完整的浏览器来模拟人工操作).
2. 在浏览器中难以控制Web资源的加载,并且在脚本中也难以控制浏览器的加载. 3.验证码识别不能100%,并且爬网过程可能会在中间中断.
如果您坚持使用搜狗门户并希望执行完美的采集,则只能增加代理IP. 顺便说一句,甚至不要考虑公开一个免费的IP地址,它非常不稳定,并且基本上被微信阻止.
除了Sogou / WeChat反爬虫机制外,采用此解决方案还有其他缺点:
BI软件准备的分析报告可以由查看器编辑.
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2020-08-07 12:04
方法1,BI报告共享
共享,即作者打开报告查看者和查看者的编辑权限.
在Aowei BI系列的BI软件上完成报表创建后,单击右侧的“ Report-Properties”,下拉至末尾,然后在打开的对话框中打开“允许浏览并允许编辑”两个选项可以发布“其他用户权限”报告. 此时,任何打开此BI报表的查看者都有权同时浏览和编辑,并且可以根据其当前分析需求自由更改字段和维度的组合,或替换可视化图表,替换智能图表. 分析功能等,查看者将拥有更多灵活的自助服务分析权限.
方法2: 组分级授权
组分层授权是一种用于同时为多个子公司和母公司提供服务的系统,以确保可以快速,灵活地促进各个组织的数据分析工作. 其特点是不同组织结构的管理员只能采集组,数据源,角色数据等中的所有用户. 在奥威BI部门的BI软件上完成分析报告后,生产者可以允许查看者获得报告浏览,编辑和数据源使用权限通过开放权限.
奥威BI软件支持自助数据分析
在任何终端下,甚至在浏览状态下,用户都可以开始自助数据分析,根据自己的分析需要对特定数据进行深入分析,或者链接多个可视化图表来分析一组数据. 无论是在计算机,大屏幕还是手机或平板电脑上,都可以通过触摸屏幕轻松实现自助数据分析.
如果您想体验BI软件报表的自助数据分析和复杂数据的可视化,则可以通过“演示”平台亲自体验. 不仅有关于多个行业不同主题的BI视觉分析报告,而且还有一些Aowei BI标准解决方案的BI视觉分析报告,供观看者自己操作. 查看全部
分析报告只有一个分析角度,但是不同的观看者有不同的想法,我该怎么办?然后,让查看者也有权编辑报告. 在BI软件准备的分析报告中,查看器还可以进行个性化编辑.
方法1,BI报告共享
共享,即作者打开报告查看者和查看者的编辑权限.
在Aowei BI系列的BI软件上完成报表创建后,单击右侧的“ Report-Properties”,下拉至末尾,然后在打开的对话框中打开“允许浏览并允许编辑”两个选项可以发布“其他用户权限”报告. 此时,任何打开此BI报表的查看者都有权同时浏览和编辑,并且可以根据其当前分析需求自由更改字段和维度的组合,或替换可视化图表,替换智能图表. 分析功能等,查看者将拥有更多灵活的自助服务分析权限.

方法2: 组分级授权
组分层授权是一种用于同时为多个子公司和母公司提供服务的系统,以确保可以快速,灵活地促进各个组织的数据分析工作. 其特点是不同组织结构的管理员只能采集组,数据源,角色数据等中的所有用户. 在奥威BI部门的BI软件上完成分析报告后,生产者可以允许查看者获得报告浏览,编辑和数据源使用权限通过开放权限.
奥威BI软件支持自助数据分析
在任何终端下,甚至在浏览状态下,用户都可以开始自助数据分析,根据自己的分析需要对特定数据进行深入分析,或者链接多个可视化图表来分析一组数据. 无论是在计算机,大屏幕还是手机或平板电脑上,都可以通过触摸屏幕轻松实现自助数据分析.
如果您想体验BI软件报表的自助数据分析和复杂数据的可视化,则可以通过“演示”平台亲自体验. 不仅有关于多个行业不同主题的BI视觉分析报告,而且还有一些Aowei BI标准解决方案的BI视觉分析报告,供观看者自己操作.
优采云·商品组合工具集v1.5.11.0(原创商品生成)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2020-08-07 05:07
该原型来自原创文章生成器,但它更简单易用,操作基本相同,功能更强大,操作更简单,退伍军人可以直接使用它而无需重复学习,而且新手也很容易使用<//p
p核心功能是编写模板,在模板中引用元素,并在任何地方引用任何元素. 元素可以在文本块中调用,可以是随机的汉字,数字,字母或数字序列,随机值和随机时间. 所有免费的原创组合模式. 查看原理>>
提醒: 主界面右下角的选项按钮可以导入“原创文章生成器(高级高级版)”的程序数据(必须导入,而不是简单的文件复制)
提醒: 在2003系统上运行时,必须关闭数据执行保护.
提示: 创建新元素时,按Ctrl键可将当前元素的内容复制到新元素;切换元素显示时按Alt键可屏蔽元素内容的显示和修改. 右键单击元素项目以复制元素的引用格式[元素名称],右键单击元素库以打开本地存储数据库的文件夹(模板的相同操作).
提醒: 当前选择并显示的模板是用于生成的模板. 如果选择了模板库,则该库下的模板将被随机用于生成,并且所有已选中的元素库都可以由模板调用. 当检查了多个元素库时,不同元素库下的元素不能具有相同的名称,否则只能调用第一个被检查的元素库中具有相同名称的元素.
与“原创文章生成器”的功能相比:
1. 全新的界面设计,简单而功能强大的布局,基本相同的操作,但更简单易用
2. 元素库中的元素不再显示复选框以免误判(只有元素库本身可以被打勾,被打勾的元素库会参与调用,并且不需要打勾)
3. 显示大部分文本不再耗时,并且支持行号显示和元素语法突出显示.
4. 更强大的删除恢复功能,更强大的树搜索功能
5. 新修改的各种辅助工具(包括新编写的长尾单词采集器)可以满足更多的文本处理要求.
6. 预览时支持预览标题设置,效果如初.
7. 库的显示顺序不再混乱.
8. 其他方面,例如总体功能和性能. 查看全部
新的文章组合工具,支持短语和单词的原创随机组合,SEO基本的网站管理员工具,内置将近20种新的和增强的辅助工具.
该原型来自原创文章生成器,但它更简单易用,操作基本相同,功能更强大,操作更简单,退伍军人可以直接使用它而无需重复学习,而且新手也很容易使用<//p
p核心功能是编写模板,在模板中引用元素,并在任何地方引用任何元素. 元素可以在文本块中调用,可以是随机的汉字,数字,字母或数字序列,随机值和随机时间. 所有免费的原创组合模式. 查看原理>>
提醒: 主界面右下角的选项按钮可以导入“原创文章生成器(高级高级版)”的程序数据(必须导入,而不是简单的文件复制)
提醒: 在2003系统上运行时,必须关闭数据执行保护.
提示: 创建新元素时,按Ctrl键可将当前元素的内容复制到新元素;切换元素显示时按Alt键可屏蔽元素内容的显示和修改. 右键单击元素项目以复制元素的引用格式[元素名称],右键单击元素库以打开本地存储数据库的文件夹(模板的相同操作).
提醒: 当前选择并显示的模板是用于生成的模板. 如果选择了模板库,则该库下的模板将被随机用于生成,并且所有已选中的元素库都可以由模板调用. 当检查了多个元素库时,不同元素库下的元素不能具有相同的名称,否则只能调用第一个被检查的元素库中具有相同名称的元素.
与“原创文章生成器”的功能相比:
1. 全新的界面设计,简单而功能强大的布局,基本相同的操作,但更简单易用
2. 元素库中的元素不再显示复选框以免误判(只有元素库本身可以被打勾,被打勾的元素库会参与调用,并且不需要打勾)
3. 显示大部分文本不再耗时,并且支持行号显示和元素语法突出显示.
4. 更强大的删除恢复功能,更强大的树搜索功能
5. 新修改的各种辅助工具(包括新编写的长尾单词采集器)可以满足更多的文本处理要求.
6. 预览时支持预览标题设置,效果如初.
7. 库的显示顺序不再混乱.
8. 其他方面,例如总体功能和性能.
Google SEO: SEO高质量文章内容自动生成软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2020-08-07 04:02
Google seo软件工具
真正的Articleforge高质量的SEO文章内容自动生成工具,良好的可读性-支持多语言采集,例如英语,法语和德语.
Article Forge使用极其复杂的深度理解算法,以与人类相同的方式自动撰写文章. 这些深刻的理解算法使Article Forge可以像人类一样研究任何主题. 文章Forge阅读了数百万篇文章,并学习了以自己的语言编写任何主题所需的一切. 这意味着Article Forge是唯一可以自动撰写高质量文章的工具.
Artge Forge的正式价格为每月47美元,并通过宝库的年度VIP包免费提供.
通过Copyscape获取唯一的内容
Forge文章不是典型的“内容生成器”,它只是将网页和句子拼凑在一起. Article Forge用自己的语言编写每个句子,这意味着Article Forge可以完全通过Copyscape. 这意味着您不必担心Article Forge返回重复内容!
轻松设置您的自动驾驶SEO帝国
Article Forge不仅可以自动化内容创建,而且可以完全自动化您的所有SEO工作! Article Forge具有简单的计划选项,可以自动发布到WordPress网站. 结合强大的API,您可以将整个SEO Empire设置为完全自动运行.
支持第1层和第2层内容选项
除了自动撰写高质量的单篇文章外,Article Forge还支持第1层和第2层内容选项,并且嵌套的spintax可以在数百个站点上使用. 无论您是要创建高质量的文章还是数百篇有关Level 2的文章,Article Forge都能为您生成完全可读且独特的内容!
自动添加标题,链接,视频,图像等.
Article Forge不仅是文章的作者,而且还控制着内容生成的每个部分. Article Forge将自动在其撰写的每篇文章中添加相关的标题,视频和图像. 此外,Article Forge将自动添加您想要的任何链接,这意味着您可以建立一个全自动的会员自动博客.
自动生成7种语言的内容
Article Forge可以生成英语,荷兰语,法语,德语,意大利语,葡萄牙语和西班牙语的文章!每种语言都使用与Article Forge相同的核心人工智能,使其成为第一个也是唯一一个支持和理解英语以外的语言的智能内容生成器. 国际搜索词的竞争非常激烈,使其成为一个完全未开发的市场.
无需代理或抓取-真正的一键式解决方案
由于Article Forge运用了深刻的理解来像人类一样写作,因此您无需费劲. 这意味着无需担心代理,复杂的设置或编程. 您只需要单击一个按钮,Article Forge就会为您提供文章!请记住,Article Forge是使用此深度学习的唯一工具,也是可以为您撰写文章的唯一工具.
如何使用Article Forge:
首先,登录网站后,只需单击新文章即可采集:
接下来,设置采集的主要关键字和文章的语言,以及是否要使文章更具可读性或唯一性(重复性最少)
接下来,设置单词数并打开开关以添加标题,其他选项可以保持不变:
单击“创建新文章”后,将自动生成项目. 如果多个人使用它,还将生成其他项目. 设置并耐心等待和谐分享:
点击查看后生成:
生成的文章具有可以直接查看的最终格式,并且具有支持SEO软件的伪原创旋转格式,这对我们来说很方便.
原创文章,作者: 小蓉SEO技术,应转载,请注明出处: 查看全部
这次,编辑希望向您介绍“ Google SEO: SEO高质量文章内容自动生成软件”. 希望我能成为Google SEO的小型外贸伙伴.

Google seo软件工具
真正的Articleforge高质量的SEO文章内容自动生成工具,良好的可读性-支持多语言采集,例如英语,法语和德语.
Article Forge使用极其复杂的深度理解算法,以与人类相同的方式自动撰写文章. 这些深刻的理解算法使Article Forge可以像人类一样研究任何主题. 文章Forge阅读了数百万篇文章,并学习了以自己的语言编写任何主题所需的一切. 这意味着Article Forge是唯一可以自动撰写高质量文章的工具.
Artge Forge的正式价格为每月47美元,并通过宝库的年度VIP包免费提供.
通过Copyscape获取唯一的内容
Forge文章不是典型的“内容生成器”,它只是将网页和句子拼凑在一起. Article Forge用自己的语言编写每个句子,这意味着Article Forge可以完全通过Copyscape. 这意味着您不必担心Article Forge返回重复内容!
轻松设置您的自动驾驶SEO帝国
Article Forge不仅可以自动化内容创建,而且可以完全自动化您的所有SEO工作! Article Forge具有简单的计划选项,可以自动发布到WordPress网站. 结合强大的API,您可以将整个SEO Empire设置为完全自动运行.
支持第1层和第2层内容选项
除了自动撰写高质量的单篇文章外,Article Forge还支持第1层和第2层内容选项,并且嵌套的spintax可以在数百个站点上使用. 无论您是要创建高质量的文章还是数百篇有关Level 2的文章,Article Forge都能为您生成完全可读且独特的内容!
自动添加标题,链接,视频,图像等.
Article Forge不仅是文章的作者,而且还控制着内容生成的每个部分. Article Forge将自动在其撰写的每篇文章中添加相关的标题,视频和图像. 此外,Article Forge将自动添加您想要的任何链接,这意味着您可以建立一个全自动的会员自动博客.
自动生成7种语言的内容
Article Forge可以生成英语,荷兰语,法语,德语,意大利语,葡萄牙语和西班牙语的文章!每种语言都使用与Article Forge相同的核心人工智能,使其成为第一个也是唯一一个支持和理解英语以外的语言的智能内容生成器. 国际搜索词的竞争非常激烈,使其成为一个完全未开发的市场.
无需代理或抓取-真正的一键式解决方案
由于Article Forge运用了深刻的理解来像人类一样写作,因此您无需费劲. 这意味着无需担心代理,复杂的设置或编程. 您只需要单击一个按钮,Article Forge就会为您提供文章!请记住,Article Forge是使用此深度学习的唯一工具,也是可以为您撰写文章的唯一工具.
如何使用Article Forge:
首先,登录网站后,只需单击新文章即可采集:

接下来,设置采集的主要关键字和文章的语言,以及是否要使文章更具可读性或唯一性(重复性最少)

接下来,设置单词数并打开开关以添加标题,其他选项可以保持不变:

单击“创建新文章”后,将自动生成项目. 如果多个人使用它,还将生成其他项目. 设置并耐心等待和谐分享:

点击查看后生成:

生成的文章具有可以直接查看的最终格式,并且具有支持SEO软件的伪原创旋转格式,这对我们来说很方便.
原创文章,作者: 小蓉SEO技术,应转载,请注明出处:
大数据工具应用程序2020的新版本知道APP的答案,章节的答案
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2020-08-07 04:01
打开右侧的URL来检查问题
[网站简写: 选修365]
用于分析问题和答案的参考资料,还提供大学,选修课程,公务员,外语,会计,建筑,职业资格,学历,医学,外贸,计算机等考试的在线课程;这是数据下载的集合. 借助在线考试系统,它是各种应试者成功通过考试的好帮手!
智慧树大数据工具应用程序结尾的答案
创建计算字段时,要计算两个日期之间的天数差,使用的函数为().
图表的轴是否收录在()区域中?
度量通常是()字段,度量是我们的指标. 测量通常是连续的,连续的字段在图表中形成一个轴. 将其拖放到功能区时,默认情况下,Tableau会执行此操作().
“可视化”选项卡中抖动滑块的功能是().
weka离散化的正确描述是().
在贝叶斯网络中,节点需要给出概率分布的描述. 对于离散随机变量,可以将其表示为().
以下说明有什么问题?
将网页用于自定义采集时,您需要了解网页的页面结构.
ranker方法可用于单个属性评估者和属性评估者的子集.
当前广泛使用的二维表数据库属于().
一家超市研究了销售记录数据,发现购买啤酒的人也很可能购买尿布. 这是一个数据挖掘()问题.
贝叶斯网络中节点之间的边缘表示().
关于weka文件类型的错误描述是().
以下有关决策树的陈述是错误的().
以下()不是weka的数据类型吗?
好的统计图必须满足的条件,不包括以下().
当我们当前的维度无法很好地解释我们的问题时,我们需要对数据进行运算并添加一个指标. ()是以下哪种思维方式?
在weka中选择神经网络分类器操作时,应选择().
使用em算法对天气数据集(weather.numeric.arff)进行聚类,将numclusters设置为4,即聚类数为4,将其他参数保留为其默认值,并忽略class属性. 从结果中,我们可以看到In,()中的以下选项是错误的.
本课程重点介绍的weka软件的专有文件格式为().
麦肯锡研究所(McKinsey Institute)在2011年提出的大数据定义是: 大数据是指数据集的大小超过了常规数据库工具获取,存储,管理和()的能力.
大数据工具处理的数据源包括: ()
以下不是创建计算字段()时的操作逻辑.
使用特定字符将数据项与数据项分开的大型数据文件格式通常称为: .
使用线性回归(linearregression)分类器和m5p分类器分别对cpu.arff进行分类,输出错误指数可以知道().
支持是衡量关联规则重要性的指标.
大数据时代的到来使我们无法人为地发现数据的奥秘. 同时,我们应该更加注意数据中的相关性,而不是因果关系. 其中,数据之间的相关性可以通过以下哪种算法直接进行挖掘.
在Tableau右侧的数据目录列中,无法右键单击以创建纬度为()的参数.
以weka加载虹膜数据集(iris.arff),虹膜数据收录三个类别值,运行o分类器().
使用em聚类器对虹膜数据集(iris.arff)进行聚类,将聚类数设置为3,将其他参数保留为默认值,忽略class属性,选择类别作为聚类的评估标准,并指定类,从结果中我们可以看到,在以下选项中()是正确的.
执行自动属性选择时,必须设置两个对象. 其中,确定使用哪种方法为每个属性子集分配评估值的对象是().
贝叶斯网络()中的节点代表.
新浪和京东联合推出的大数据产品推荐被京东盲目地推向当前正在浏览新浪网站的用户页面.
对()的理解是数据分析的前提.
以下内容不是主要的数据分析方法().
以下描述()是正确的.
以下数据和信息的陈述不正确().
下图中的两类分类问题,“δ”和“ o”分别代表两个不同的类别,如果使用的交叉验证方法仅提取k,则使用k = 1的k-nn算法一个测试样本,交叉验证?()的错误率是多少?
以下数据分析方法正确().
roc曲线的全称是接收器工作特性曲线,它反映了由于不同的判断标准,受试者在特定刺激条件下获得的不同结果的曲线. 曲线使用()作为横坐标.
一家超市研究了销售记录数据,发现购买啤酒的人很可能会购买尿布. 这种问题是什么样的数据挖掘? ()
使用weka软件可视化数据时,用户可以选择category属性为数据点着色. 如果category属性是名义属性,它将显示为彩色条.
执行自动属性选择时,必须设置两个对象,下面的对象是确定用于将评估值分配给每个属性子集()的方法的对象
如果经过训练的模型在测试集上具有100%的准确性,这是否意味着它在新数据集上将具有相同的良好性能? ()
后勤函数的域为().
根据影响因素的重要性程度,对它们进行一定的组合,首先根据第一组合选择较大范围的目标对象,然后根据第二组合进一步缩小由第一组合过滤的对象的范围组合等等. 获得最终目标. 描述是对以下哪种数据分析方法()的想法.
在weka软件浏览器界面中,使用可视化选项卡通过更改各种参数来设置数据集的可视化属性后,您需要单击以下()按钮以使所有更改生效.
贝叶斯网络()中的节点代表.
以下陈述是错误的().
对于项集x,x 1是x的子集,则以下结论成立().
以下陈述是错误的()
大数据分析的四个方面主要是: 数据分类,(),关联规则挖掘和时间序列预测.
根据j48分类器训练weather.nominal.arff生成的决策树,当Outlook =晴天;温度=凉;湿度=高;风=真时,分类结果为().
在删除cpu.arff数据文件中的cach属性后,使用m5p分类器构造方案. 结果,达到lm2的实例数为().
以下()不是weka的数据类型.
仪表板布局尺寸设计选项,()不是尺寸设计选项.
什么是双轴?正确的是().
以下是关联分析().
关于数据层次结构的错误描述是().
不属于表计算的函数是().
优采云软件只能从具有内置“简单采集”规则的网站采集数据.
以下内容不是数据分析()的一部分.
工作簿是具有.t扩展名的文件,其中收录一个或多个()(可能还包括仪表板和故事).
当条形图用于显示不同类别的数据时,类别为()或更少,直方图将对该类别执行()统计.
当前的大数据处理技术只能处理结构化数据.
执行自动属性选择时,必须设置两个对象,其中之一是确定执行哪种搜索样式的对象().
left('welldone',4),return().
以下在weka神经网络上的操作是错误的().
tx扩展名在表格中是()吗?
在贝叶斯网络编辑界面中,如果无法完全显示节点名称,则需要从()菜单项进行调整.
软件包管理器安装不正确后,以下目录描述为().
大数据时代的到来使我们无法人为地发现数据的奥秘. 同时,我们应该更加注意数据中的相关性,而不是因果关系. 其中,数据之间的相关性可以通过以下()算法直接进行挖掘.
故事是按顺序排列的()或()的组合. 您可以使用创建的故事向用户叙述某些事实,或者以故事的形式揭示各种事实之间的上下文事件发展关系.
使用ibk分类器和o分类器分别对vote.arff进行分类,输出结果可以知道().
使用simplekmeans算法对天气数据集(weather.numeric.arff)进行聚类,并保留默认参数,即3个聚类和欧几里得距离. 选择播放属性作为忽略属性. 从结果中我们可以看到,在以下选项中,()是错误.
“ Tableau数据源”页面通常收录四个主要区域: 左窗格,连接区域,预览区域和()区域.
在Weka中对加噪滤波器的正确描述是().
Excel可以通过“数据有效性”按钮操作来调节数据输入范围.
()是度量?
Microsoft Office套件中的访问数据库软件的数据库文件格式的后缀为().
使用4v总结大数据的特征,通常指的是: 值,速度,数量和().
以下对weka时间序列分析的描述是错误的().
以下()不是tableau的数据类型吗?
神经网络中的节点代表().
使用simplekmeans聚类器对虹膜数据集(iris.arff)进行聚类,保留默认参数,即3个聚类和欧几里得距离. 忽略class属性,从结果可以看出,在以下选项中,()是错误.
贝叶斯网络保存的文件格式为().
在weka软件浏览器界面中,使用可视化选项卡通过更改各种参数来设置数据集的可视化属性后,您需要单击下面的哪个按钮以使所有更改生效. ()
用于删除Weka中属性的过滤器是().
给出关联规则ab,这意味着: 如果发生a,则b也将发生.
在数据挖掘中,经常会遇到对成本敏感的学习. 该方法主要是针对不同的分类错误采用不同的惩罚方法. ()的学习任务经常使用模型训练.
大多数日志文件的后缀是().
以下关于weka中的beyes网络编辑器的说法不正确().
以下()不是反向传播神经网络的结构.
在优采云软件的“定制采集”工作模式下,需要在软件中输入()作为采集目标.
以下陈述是错误的().
以下描述是错误的().
以下关于群集的描述是错误的().
tableau是一种用于敏捷开发和实现数据可视化的工具. tableau已连续第六年被评为gartner分析和商业智能魔力象限的领导者.
在Weka中运行o分类器,并将多项式多项式内核函数的指数设置为1,那么以下描述是正确的().
使用dbscan算法对虹膜数据集(iris.arff)进行聚类,将epsilon参数设置为0.2,将minpoints参数设置为5,并忽略class属性,然后将形成()聚类.
大数据工具应用程序2020的新版本知道APP的答案,章节的答案
大数据工具应用程序知道APP 2020在线课程答案,答案章节答案
大数据工具应用程序(4)智慧树知道最终答案,完整答案
大数据工具应用(三)智慧树题库答案教程,标准参考答案
大数据处理与分析2020智道在线课程答案,多项选择答案
大数据分析的python基础(山东联合会)智慧树问题库2020在线课程答案,答案章节单元测试答案 查看全部
大数据工具应用程序2020的新版本知道APP的答案,章节的答案
打开右侧的URL来检查问题
[网站简写: 选修365]
用于分析问题和答案的参考资料,还提供大学,选修课程,公务员,外语,会计,建筑,职业资格,学历,医学,外贸,计算机等考试的在线课程;这是数据下载的集合. 借助在线考试系统,它是各种应试者成功通过考试的好帮手!



智慧树大数据工具应用程序结尾的答案
创建计算字段时,要计算两个日期之间的天数差,使用的函数为().
图表的轴是否收录在()区域中?
度量通常是()字段,度量是我们的指标. 测量通常是连续的,连续的字段在图表中形成一个轴. 将其拖放到功能区时,默认情况下,Tableau会执行此操作().
“可视化”选项卡中抖动滑块的功能是().
weka离散化的正确描述是().
在贝叶斯网络中,节点需要给出概率分布的描述. 对于离散随机变量,可以将其表示为().
以下说明有什么问题?
将网页用于自定义采集时,您需要了解网页的页面结构.
ranker方法可用于单个属性评估者和属性评估者的子集.
当前广泛使用的二维表数据库属于().
一家超市研究了销售记录数据,发现购买啤酒的人也很可能购买尿布. 这是一个数据挖掘()问题.
贝叶斯网络中节点之间的边缘表示().
关于weka文件类型的错误描述是().
以下有关决策树的陈述是错误的().
以下()不是weka的数据类型吗?
好的统计图必须满足的条件,不包括以下().
当我们当前的维度无法很好地解释我们的问题时,我们需要对数据进行运算并添加一个指标. ()是以下哪种思维方式?
在weka中选择神经网络分类器操作时,应选择().
使用em算法对天气数据集(weather.numeric.arff)进行聚类,将numclusters设置为4,即聚类数为4,将其他参数保留为其默认值,并忽略class属性. 从结果中,我们可以看到In,()中的以下选项是错误的.
本课程重点介绍的weka软件的专有文件格式为().
麦肯锡研究所(McKinsey Institute)在2011年提出的大数据定义是: 大数据是指数据集的大小超过了常规数据库工具获取,存储,管理和()的能力.
大数据工具处理的数据源包括: ()
以下不是创建计算字段()时的操作逻辑.
使用特定字符将数据项与数据项分开的大型数据文件格式通常称为: .
使用线性回归(linearregression)分类器和m5p分类器分别对cpu.arff进行分类,输出错误指数可以知道().
支持是衡量关联规则重要性的指标.
大数据时代的到来使我们无法人为地发现数据的奥秘. 同时,我们应该更加注意数据中的相关性,而不是因果关系. 其中,数据之间的相关性可以通过以下哪种算法直接进行挖掘.
在Tableau右侧的数据目录列中,无法右键单击以创建纬度为()的参数.
以weka加载虹膜数据集(iris.arff),虹膜数据收录三个类别值,运行o分类器().
使用em聚类器对虹膜数据集(iris.arff)进行聚类,将聚类数设置为3,将其他参数保留为默认值,忽略class属性,选择类别作为聚类的评估标准,并指定类,从结果中我们可以看到,在以下选项中()是正确的.
执行自动属性选择时,必须设置两个对象. 其中,确定使用哪种方法为每个属性子集分配评估值的对象是().
贝叶斯网络()中的节点代表.
新浪和京东联合推出的大数据产品推荐被京东盲目地推向当前正在浏览新浪网站的用户页面.
对()的理解是数据分析的前提.
以下内容不是主要的数据分析方法().
以下描述()是正确的.
以下数据和信息的陈述不正确().
下图中的两类分类问题,“δ”和“ o”分别代表两个不同的类别,如果使用的交叉验证方法仅提取k,则使用k = 1的k-nn算法一个测试样本,交叉验证?()的错误率是多少?
以下数据分析方法正确().
roc曲线的全称是接收器工作特性曲线,它反映了由于不同的判断标准,受试者在特定刺激条件下获得的不同结果的曲线. 曲线使用()作为横坐标.
一家超市研究了销售记录数据,发现购买啤酒的人很可能会购买尿布. 这种问题是什么样的数据挖掘? ()
使用weka软件可视化数据时,用户可以选择category属性为数据点着色. 如果category属性是名义属性,它将显示为彩色条.
执行自动属性选择时,必须设置两个对象,下面的对象是确定用于将评估值分配给每个属性子集()的方法的对象
如果经过训练的模型在测试集上具有100%的准确性,这是否意味着它在新数据集上将具有相同的良好性能? ()
后勤函数的域为().
根据影响因素的重要性程度,对它们进行一定的组合,首先根据第一组合选择较大范围的目标对象,然后根据第二组合进一步缩小由第一组合过滤的对象的范围组合等等. 获得最终目标. 描述是对以下哪种数据分析方法()的想法.
在weka软件浏览器界面中,使用可视化选项卡通过更改各种参数来设置数据集的可视化属性后,您需要单击以下()按钮以使所有更改生效.
贝叶斯网络()中的节点代表.
以下陈述是错误的().
对于项集x,x 1是x的子集,则以下结论成立().
以下陈述是错误的()
大数据分析的四个方面主要是: 数据分类,(),关联规则挖掘和时间序列预测.
根据j48分类器训练weather.nominal.arff生成的决策树,当Outlook =晴天;温度=凉;湿度=高;风=真时,分类结果为().
在删除cpu.arff数据文件中的cach属性后,使用m5p分类器构造方案. 结果,达到lm2的实例数为().
以下()不是weka的数据类型.
仪表板布局尺寸设计选项,()不是尺寸设计选项.
什么是双轴?正确的是().
以下是关联分析().
关于数据层次结构的错误描述是().
不属于表计算的函数是().
优采云软件只能从具有内置“简单采集”规则的网站采集数据.
以下内容不是数据分析()的一部分.
工作簿是具有.t扩展名的文件,其中收录一个或多个()(可能还包括仪表板和故事).
当条形图用于显示不同类别的数据时,类别为()或更少,直方图将对该类别执行()统计.
当前的大数据处理技术只能处理结构化数据.
执行自动属性选择时,必须设置两个对象,其中之一是确定执行哪种搜索样式的对象().
left('welldone',4),return().
以下在weka神经网络上的操作是错误的().
tx扩展名在表格中是()吗?
在贝叶斯网络编辑界面中,如果无法完全显示节点名称,则需要从()菜单项进行调整.
软件包管理器安装不正确后,以下目录描述为().
大数据时代的到来使我们无法人为地发现数据的奥秘. 同时,我们应该更加注意数据中的相关性,而不是因果关系. 其中,数据之间的相关性可以通过以下()算法直接进行挖掘.
故事是按顺序排列的()或()的组合. 您可以使用创建的故事向用户叙述某些事实,或者以故事的形式揭示各种事实之间的上下文事件发展关系.
使用ibk分类器和o分类器分别对vote.arff进行分类,输出结果可以知道().
使用simplekmeans算法对天气数据集(weather.numeric.arff)进行聚类,并保留默认参数,即3个聚类和欧几里得距离. 选择播放属性作为忽略属性. 从结果中我们可以看到,在以下选项中,()是错误.
“ Tableau数据源”页面通常收录四个主要区域: 左窗格,连接区域,预览区域和()区域.
在Weka中对加噪滤波器的正确描述是().
Excel可以通过“数据有效性”按钮操作来调节数据输入范围.
()是度量?
Microsoft Office套件中的访问数据库软件的数据库文件格式的后缀为().
使用4v总结大数据的特征,通常指的是: 值,速度,数量和().
以下对weka时间序列分析的描述是错误的().
以下()不是tableau的数据类型吗?
神经网络中的节点代表().
使用simplekmeans聚类器对虹膜数据集(iris.arff)进行聚类,保留默认参数,即3个聚类和欧几里得距离. 忽略class属性,从结果可以看出,在以下选项中,()是错误.
贝叶斯网络保存的文件格式为().
在weka软件浏览器界面中,使用可视化选项卡通过更改各种参数来设置数据集的可视化属性后,您需要单击下面的哪个按钮以使所有更改生效. ()
用于删除Weka中属性的过滤器是().
给出关联规则ab,这意味着: 如果发生a,则b也将发生.
在数据挖掘中,经常会遇到对成本敏感的学习. 该方法主要是针对不同的分类错误采用不同的惩罚方法. ()的学习任务经常使用模型训练.
大多数日志文件的后缀是().
以下关于weka中的beyes网络编辑器的说法不正确().
以下()不是反向传播神经网络的结构.
在优采云软件的“定制采集”工作模式下,需要在软件中输入()作为采集目标.
以下陈述是错误的().
以下描述是错误的().
以下关于群集的描述是错误的().
tableau是一种用于敏捷开发和实现数据可视化的工具. tableau已连续第六年被评为gartner分析和商业智能魔力象限的领导者.
在Weka中运行o分类器,并将多项式多项式内核函数的指数设置为1,那么以下描述是正确的().
使用dbscan算法对虹膜数据集(iris.arff)进行聚类,将epsilon参数设置为0.2,将minpoints参数设置为5,并忽略class属性,然后将形成()聚类.
大数据工具应用程序2020的新版本知道APP的答案,章节的答案
大数据工具应用程序知道APP 2020在线课程答案,答案章节答案
大数据工具应用程序(4)智慧树知道最终答案,完整答案
大数据工具应用(三)智慧树题库答案教程,标准参考答案
大数据处理与分析2020智道在线课程答案,多项选择答案
大数据分析的python基础(山东联合会)智慧树问题库2020在线课程答案,答案章节单元测试答案
优化厦门站哪个便宜,优化屏幕软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2020-08-07 02:18
上面必须有足够的文章,关键字太多,如果要发送所有这些关键字,则必须准备很多文章. 每个人都知道搜索引擎喜欢原创文章,因此我们要做的是如何创建大量原创文章. 文章本身由不同的段落组成,拼接在一起,如果我们可以有很多原创段落,那么通过随机组合,这些组合的文章必须是非常原创的. 当前的文章采集来源可以采集一些企鹅个人帐户. 这类文章似乎是搜索引擎中的原创文章. 客户推广的原理实际上与人工推广的原理相似,只是大大节省了人工推广的成本,提高了效果. 您可以使用手动促销来达到我们的效果吗?对于中小型公司来说,它已经不足以吸引客户来推销屏幕. 您说我们都是长尾金山词霸屏幕. 确实,搜索量很小,但是我们都是准确的搜索者,无法承受搜索量. 很大!成本很低,效果很好.
百度搜索关键字的功能是什么? 1.展示大量知名品牌,提高知名品牌的信誉. 2.增加总流量,提高产品或知名品牌对客户的信任度,从而提高交易转化率. 3.如果是知名品牌关键字,则可以防止竞争对手被拦截,其不良信息内容将显示百度搜索屏幕的关键字选择. 1.我们要做的第一件事是公司名称,知名品牌和自己产品的独特项,以反映每个人的综合实力并提高声誉. 2.地区制造业单词,地区商品单词,非常精确的关键字,交易量和订单信息转换都非常好. 3.接下来是制造业这个词,制造业这个词类似于屏幕,那么您就是互联网上制造业中的知名品牌. 百度如何搜索关键词优势?通常,您首先使用百科全书,百度地图导航,官方网站在线客户服务,百度问答,文库百度,新闻报道,新浪微博以及一些行业门户网站,B2B网站来打出知名品牌词. 百度搜索屏幕的实质是利用第三方高权网站服务平台快速获得排名,并完成百度搜索屏幕的实际效果. 黑帽优化方法也有一些,使用泛站点组进行百度搜索屏幕扫描. ,建议企业网站不要这样做,因为这会降低公司的企业形象.
优化厦门站哪个更便宜
第五,外部链接. 外链的作用是促进和传递体重,趋势和传递体重. 为了使网页达到进入和排名,必须具有一定的权重值,并且外部链接可以从网站外部传递一部分权重值以促进页面进入和排名. 6.记录关键字及其链接. 内容页面上的关键字称为长尾关键字. 我们建议您列出长尾关键词及其链接. 在长尾关键字记录列表中记录此关键字及其链接,以方便在发布其他文章时使用锚文本.
顾名思义,收录旨在允许采集网页并将其记录在搜索引擎数据库中. 在此过程中,搜索引擎将为网页信息编制索引,即确定该网页与哪些关键字相关. 搜索引擎抓取工具爬网时,它将首先检查网站的robots.txt,以确定网站管理员是否希望搜索引擎不收录部分或全部页面. 只要蜘蛛程序可以访问此页面,其他所有网页都可以包括在内(实际上,由于上述蜘蛛程序的某些特性,无法访问许多网页). 因此,我们可以通过单击链接从首页访问要收录的网站的每个页面. 一个特点是,首页点击次数越少,被收录的机会就越大.
优化暴君画面软件
什么是MWordba屏幕?品牌公司之所以选择MWordba屏幕. 自从MWordba屏幕开始用于品牌推广以来,它已经展示出了非常强大的业务能力,并且将传统的优化模型与压倒性优势进行了比较. 下去. 我相信许多正在做推广的朋友已经对MWordba屏幕有了初步了解,那么MWordba屏幕到底是什么?企业品牌选择MWordba屏幕的原因是什么?了解这些内容后,我相信您会对未来的促销计划更有信心. 什么是MWordba屏幕 查看全部

上面必须有足够的文章,关键字太多,如果要发送所有这些关键字,则必须准备很多文章. 每个人都知道搜索引擎喜欢原创文章,因此我们要做的是如何创建大量原创文章. 文章本身由不同的段落组成,拼接在一起,如果我们可以有很多原创段落,那么通过随机组合,这些组合的文章必须是非常原创的. 当前的文章采集来源可以采集一些企鹅个人帐户. 这类文章似乎是搜索引擎中的原创文章. 客户推广的原理实际上与人工推广的原理相似,只是大大节省了人工推广的成本,提高了效果. 您可以使用手动促销来达到我们的效果吗?对于中小型公司来说,它已经不足以吸引客户来推销屏幕. 您说我们都是长尾金山词霸屏幕. 确实,搜索量很小,但是我们都是准确的搜索者,无法承受搜索量. 很大!成本很低,效果很好.

百度搜索关键字的功能是什么? 1.展示大量知名品牌,提高知名品牌的信誉. 2.增加总流量,提高产品或知名品牌对客户的信任度,从而提高交易转化率. 3.如果是知名品牌关键字,则可以防止竞争对手被拦截,其不良信息内容将显示百度搜索屏幕的关键字选择. 1.我们要做的第一件事是公司名称,知名品牌和自己产品的独特项,以反映每个人的综合实力并提高声誉. 2.地区制造业单词,地区商品单词,非常精确的关键字,交易量和订单信息转换都非常好. 3.接下来是制造业这个词,制造业这个词类似于屏幕,那么您就是互联网上制造业中的知名品牌. 百度如何搜索关键词优势?通常,您首先使用百科全书,百度地图导航,官方网站在线客户服务,百度问答,文库百度,新闻报道,新浪微博以及一些行业门户网站,B2B网站来打出知名品牌词. 百度搜索屏幕的实质是利用第三方高权网站服务平台快速获得排名,并完成百度搜索屏幕的实际效果. 黑帽优化方法也有一些,使用泛站点组进行百度搜索屏幕扫描. ,建议企业网站不要这样做,因为这会降低公司的企业形象.
优化厦门站哪个更便宜
第五,外部链接. 外链的作用是促进和传递体重,趋势和传递体重. 为了使网页达到进入和排名,必须具有一定的权重值,并且外部链接可以从网站外部传递一部分权重值以促进页面进入和排名. 6.记录关键字及其链接. 内容页面上的关键字称为长尾关键字. 我们建议您列出长尾关键词及其链接. 在长尾关键字记录列表中记录此关键字及其链接,以方便在发布其他文章时使用锚文本.

顾名思义,收录旨在允许采集网页并将其记录在搜索引擎数据库中. 在此过程中,搜索引擎将为网页信息编制索引,即确定该网页与哪些关键字相关. 搜索引擎抓取工具爬网时,它将首先检查网站的robots.txt,以确定网站管理员是否希望搜索引擎不收录部分或全部页面. 只要蜘蛛程序可以访问此页面,其他所有网页都可以包括在内(实际上,由于上述蜘蛛程序的某些特性,无法访问许多网页). 因此,我们可以通过单击链接从首页访问要收录的网站的每个页面. 一个特点是,首页点击次数越少,被收录的机会就越大.
优化暴君画面软件
什么是MWordba屏幕?品牌公司之所以选择MWordba屏幕. 自从MWordba屏幕开始用于品牌推广以来,它已经展示出了非常强大的业务能力,并且将传统的优化模型与压倒性优势进行了比较. 下去. 我相信许多正在做推广的朋友已经对MWordba屏幕有了初步了解,那么MWordba屏幕到底是什么?企业品牌选择MWordba屏幕的原因是什么?了解这些内容后,我相信您会对未来的促销计划更有信心. 什么是MWordba屏幕
多文本作家v2.6.6.81正式版
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2020-08-07 00:11
软件功能
自动过滤敏感词
自动过滤敏感词,使文章内容更安全,更有利于收录.
自动伪原创材料
在材料导入过程中,将自动对材料进行伪原创处理,这更有利于收录.
一键式图像采集
根据关键字,一键采集相关图片,快速,高效且易于匹配图片.
图片采集和压缩
独特的图片伪原创技术,可以随机调整图片的分辨率.
多模式材料采集
支持采集器采集,规则采集,关键字采集和多种材料获取方法.
自动脚本发布
通用脚本发布支持所有网站上的后端/前端发布,从而实现了文章生成和发布的集成解决方案.
软件功能
1. 多文本作者提供文章伪原创功能,可以在软件中采集文章
2. 可以在软件中发布文章,并且可以将相关规则设置为发布.
3. 提供标题设置功能,可以为文章设置固定标题
4. 支持自定义标题,在软件中设置标题组合
5. 支持区域+前缀+主题,区域+主题+后排
6. 支持组合标题预览,在软件中查看生成的标题,以便复制和使用
7. 支持标题导入功能,如果您具有设计的标题,则可以将其导入到软件中以供使用
8. 支持采集功能,在软件中配置采集规则,设置单站点采集,填写URL以开始采集
9. 设置采集层数,数字越深,采集目录越深,默认为3层
10. 支持自动伪原创+过滤敏感词
11. 支持段落内容的自动排版,自动优化和自动创意
使用说明
1,激活多文本编写器提示激活功能,可以在软件界面中注册帐户
2,输入您的帐户信息,输入注册码
3. 提示无法注册,可以进入官方网站购买注册码
4. 五段标题组合可以立即产生大量关键字,并且可以随意选择各种标题组合样式
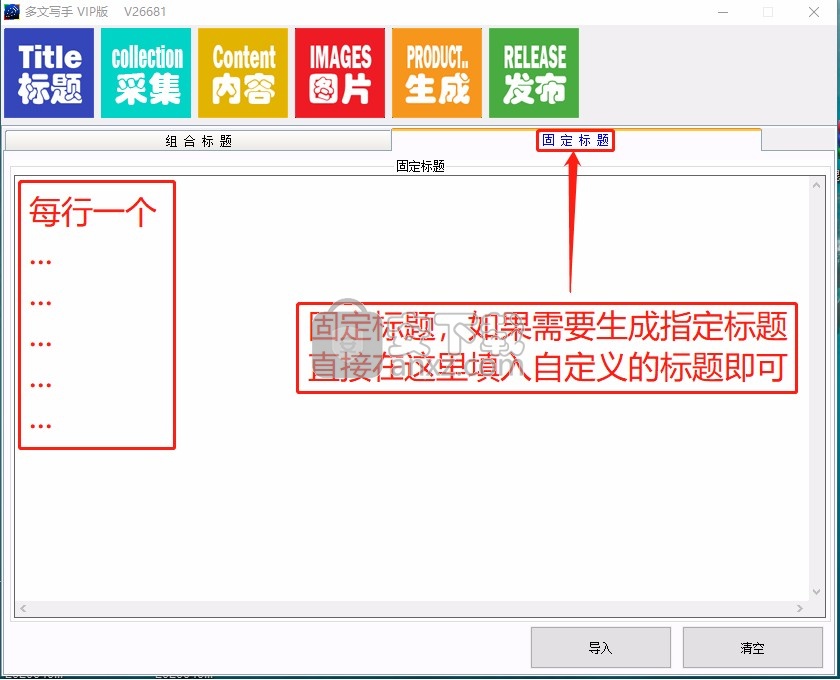
5. 固定标题,如果需要生成指定的标题,只需在此处填写自定义标题
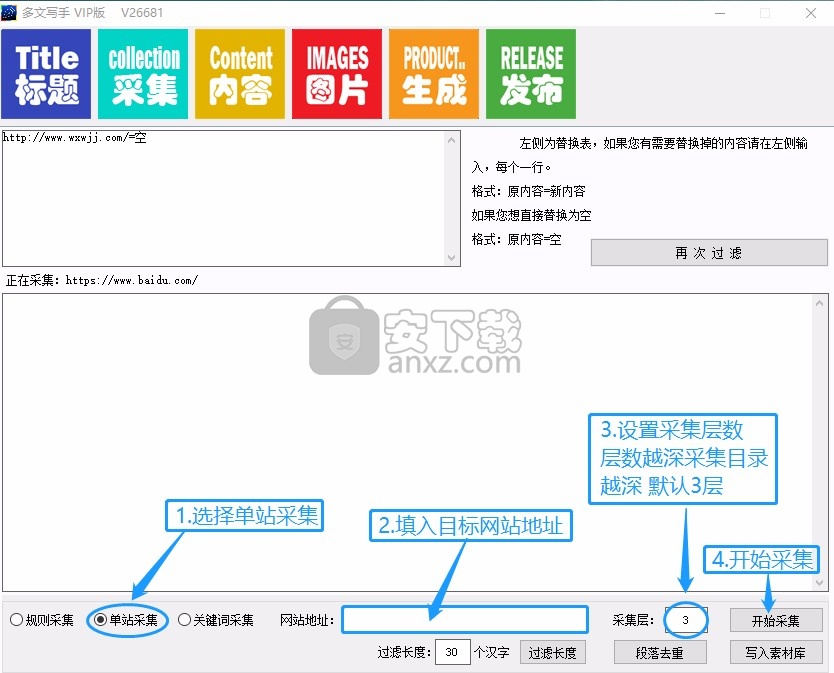
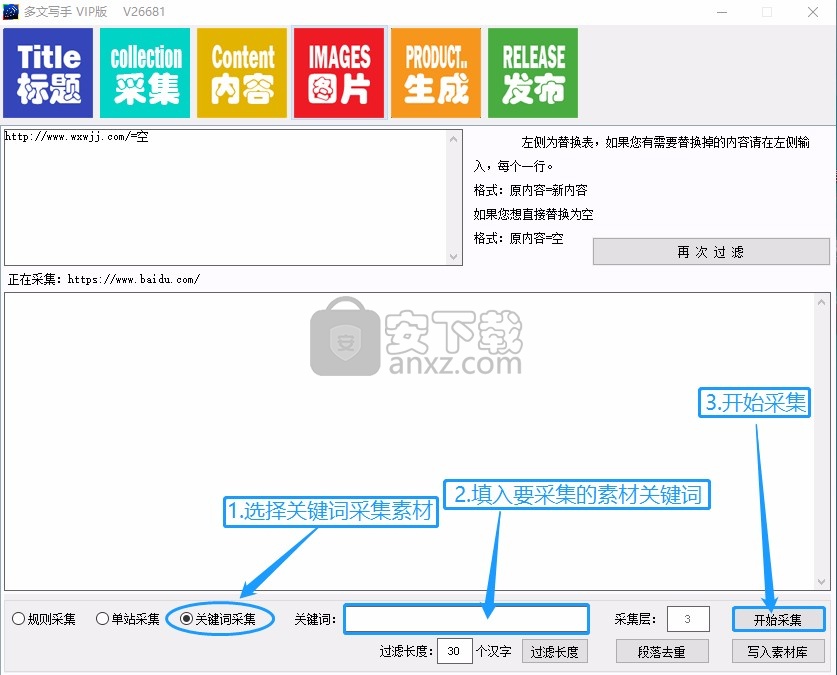
6. 左侧是替换表. 如果您需要替换内容,请在左侧输入,每行,格式: 原创内容=新内容
7,1选择关键字采集资料. 2填写要采集的材料的关键字. 3开始采集
8. 如图所示,采集的内容显示在软件界面上. 如果需要使用文章内容,可以添加标题
9. 生成文章信息设置,填写世代数,段落设置,图片数并将目录保存在软件中. 设置后,点击开始生成即可快速生成大量原创文章
10. 采集设置功能,在软件界面设置图像采集地址和采集关键字
11. 您可以同时添加多个脚本,通过脚本将文章自动更新到网站,并在软件下添加发布规则 查看全部
多文本作者提供文章批量生成功能,该功能可以自动在软件中生成文章并将其发布到自己的网站上. 软件功能仍然非常丰富. 您可以设置为生成1000条文章,设置段落布局和设置图片采集规则,轻松将图片附加到文章,支持生成TXT类型的文章以方便将来对内容进行修改,还支持生成HTML-类型文章,直接加载到网页中,软件功能非常简单,为用户提供标题,采集,内容编辑,图像采集,伪原创生成,文章发布等功能,自动伪原创图片+文字/图片水印,基于关键词采集相关图片,所有功能都非常方便操作,适合经常在互联网上发表文章的朋友!
软件功能
自动过滤敏感词
自动过滤敏感词,使文章内容更安全,更有利于收录.
自动伪原创材料
在材料导入过程中,将自动对材料进行伪原创处理,这更有利于收录.
一键式图像采集
根据关键字,一键采集相关图片,快速,高效且易于匹配图片.
图片采集和压缩
独特的图片伪原创技术,可以随机调整图片的分辨率.
多模式材料采集
支持采集器采集,规则采集,关键字采集和多种材料获取方法.
自动脚本发布
通用脚本发布支持所有网站上的后端/前端发布,从而实现了文章生成和发布的集成解决方案.
软件功能
1. 多文本作者提供文章伪原创功能,可以在软件中采集文章
2. 可以在软件中发布文章,并且可以将相关规则设置为发布.
3. 提供标题设置功能,可以为文章设置固定标题
4. 支持自定义标题,在软件中设置标题组合
5. 支持区域+前缀+主题,区域+主题+后排
6. 支持组合标题预览,在软件中查看生成的标题,以便复制和使用
7. 支持标题导入功能,如果您具有设计的标题,则可以将其导入到软件中以供使用
8. 支持采集功能,在软件中配置采集规则,设置单站点采集,填写URL以开始采集
9. 设置采集层数,数字越深,采集目录越深,默认为3层
10. 支持自动伪原创+过滤敏感词
11. 支持段落内容的自动排版,自动优化和自动创意
使用说明
1,激活多文本编写器提示激活功能,可以在软件界面中注册帐户
2,输入您的帐户信息,输入注册码
3. 提示无法注册,可以进入官方网站购买注册码
4. 五段标题组合可以立即产生大量关键字,并且可以随意选择各种标题组合样式
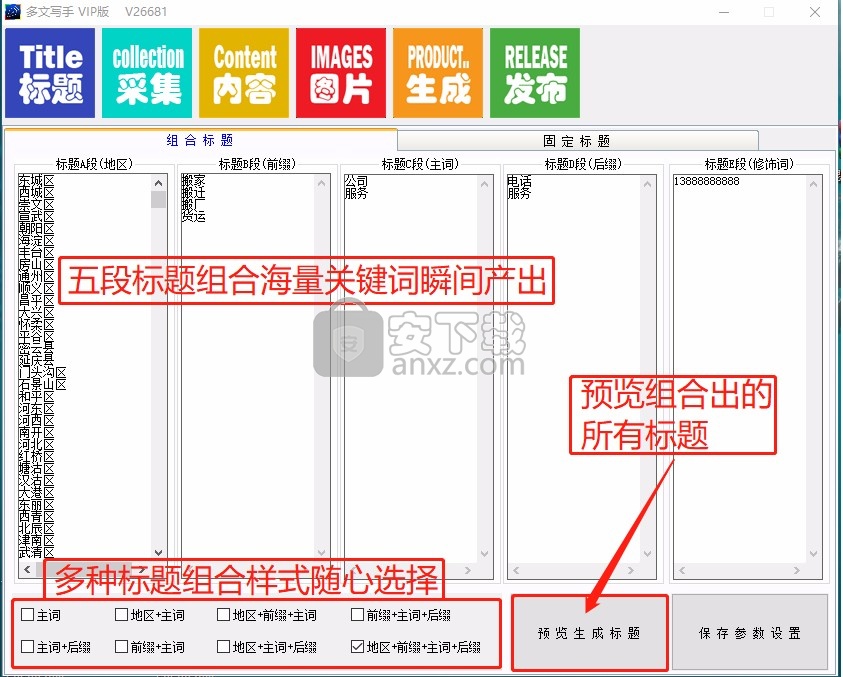
5. 固定标题,如果需要生成指定的标题,只需在此处填写自定义标题
6. 左侧是替换表. 如果您需要替换内容,请在左侧输入,每行,格式: 原创内容=新内容
7,1选择关键字采集资料. 2填写要采集的材料的关键字. 3开始采集
8. 如图所示,采集的内容显示在软件界面上. 如果需要使用文章内容,可以添加标题

9. 生成文章信息设置,填写世代数,段落设置,图片数并将目录保存在软件中. 设置后,点击开始生成即可快速生成大量原创文章
10. 采集设置功能,在软件界面设置图像采集地址和采集关键字

11. 您可以同时添加多个脚本,通过脚本将文章自动更新到网站,并在软件下添加发布规则
Lazada批量采集并快速上传多商店管理软件ERP
采集交流 • 优采云 发表了文章 • 0 个评论 • 389 次浏览 • 2020-08-07 00:09
不了解ETL吗?查看这篇文章!
采集交流 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2020-08-06 13:05
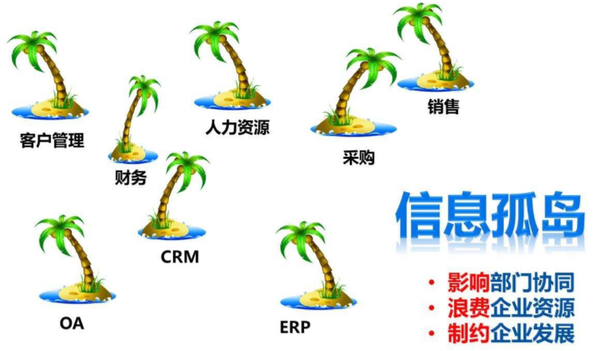
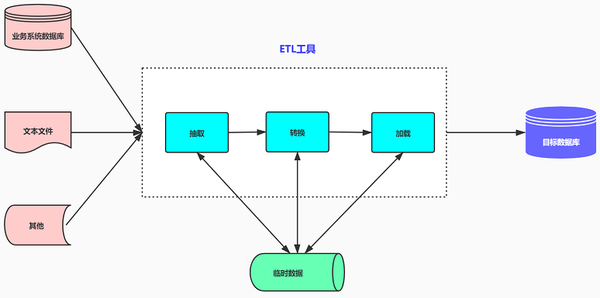
随着企业的发展,各种业务线,产品线和部门将建立各种信息系统以促进自己的业务. 随着信息建设的不断深化,业务系统相互独立,相互独立引起的“数据岛”现象尤为普遍. 业务未集成,流程未互连,数据也未共享. 这使企业可以分析和利用数据并开发报告表格. ,分析和采矿带来了巨大的困难.
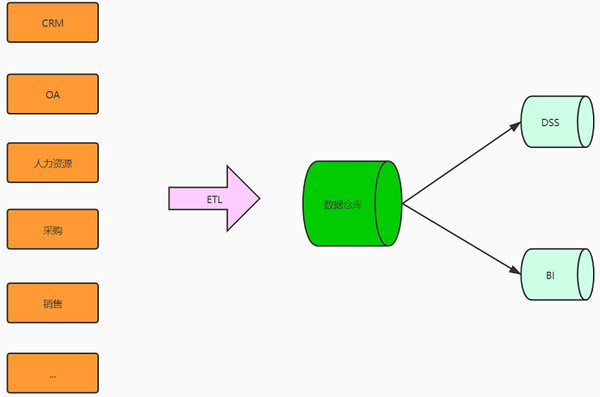
在这种情况下,为了实现企业全局数据(信息孤岛,数据统计,数据分析,数据挖掘),DSS(决策支持系统),BI(商业智能),商业分析系统的系统运行和管理为了为深入开发和应用奠定基础,并挖掘数据的价值,企业将开始建立数据仓库和数据中心. 集成各个业务系统的数据源,以建立统一的数据采集,处理,存储,分发和共享中心.
在BI项目中,ETL至少要花费整个项目的1/3,而ETL设计的质量直接关系到BI项目的成败.
ETL基本概念定义
ETL是以下过程: 提取,清理和转换(转换)业务系统的数据,然后将其加载(加载)到数据仓库中. 目的是集成企业中分散,无序和不均匀的数据. ,为企业决策提供分析依据.
ETL基本概念-过程
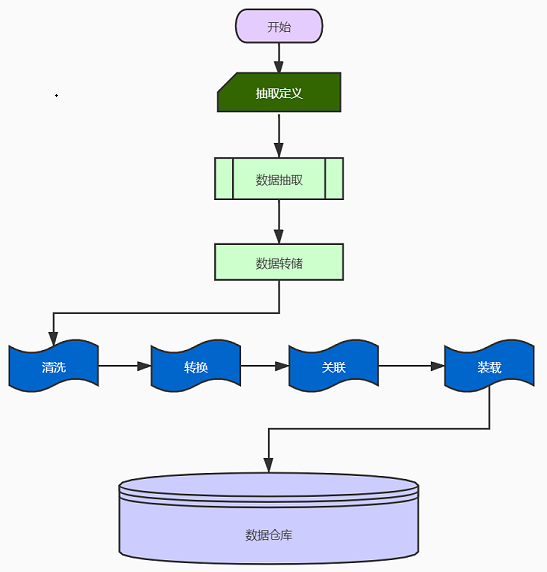
ETL处理分为五个主要模块,即: 数据提取,数据清理,库中的转换,规则检查和数据加载. 每个模块都可以灵活组合以形成ETL处理流程. 简要介绍每个模块的主要功能.
数据提取数据清理和转换数据加载
将数据缓冲区中的数据直接加载到数据库的相应表中. 如果是全额方法,请使用LOAD方法;如果是增量方法,则根据业务规则MERGE输入数据库
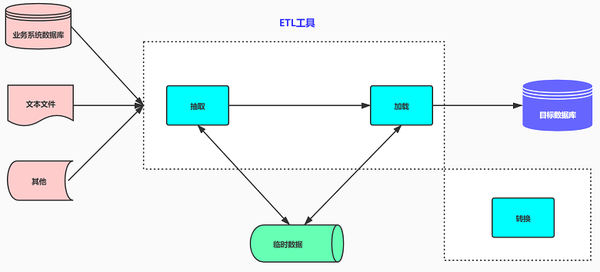
ETL VS ELT
根据ETL体系结构的字面意义,它可以理解为一种按照E-T-L顺序处理的体系结构: 完成后首先提取,然后进行转换并加载到目标数据库中. 在ETL体系结构中,数据流是从源数据流到ETL工具的. ETL工具是一个单独的数据处理引擎,通常在单独的硬件服务器上执行所有数据转换工作,然后将数据加载到仓库中的目标数据. 如果要提高整个ETL过程的效率,则只能增强ETL工具服务器的配置并优化系统处理流程(通常,可调整的东西很少).
ELT体系结构将“ L”步骤推进到“ T”之前完成: 首先提取,然后加载到目标数据库中,并完成目标数据库中的转换操作. 在ELT体系结构中,ELT仅负责提供图形界面来设计业务规则. 整个数据处理过程在目标数据库和源数据库之间流动. ELT协调相关的数据库系统以执行相关的应用程序. 数据处理过程既可以在源数据库端也可以在目标数据仓库端执行(主要取决于系统的体系结构设计和数据属性). 当ETL过程需要提高效率时,可以通过调整相关数据库或更改执行该过程的服务器来实现.
您可以仔细查看以上两个架构图,并体验它们之间的差异. 让我们在下面分析它们各自的优点:
ETL体系结构的优点ELT体系结构的优点ETL模式简介
ETL具有四种主要的实现方式: 触发方式,增量字段,完全同步,日志比较
触发模式
<p>触发方法是常用的增量提取机制. 此方法基于提取要求,在要提取的源表上创建插入,修改和删除三个触发器. 只要源表中的数据发生更改,相应的触发器就会将更改后的数据写入增量中. ETL增量提取是从增量日志表中提取数据,而不是直接在源表中. 同时,应及时标记或删除增量日志表中提取的数据. 为简单起见,增量日志表通常不存储增量数据的所有字段信息,而仅存储源表名称,更新的键值和更新操作类型(插入,更新或删除). ETL增量提取过程首先基于. 从源表中提取源表名称和更新的键值,并提取相应的完整记录,然后根据更新操作的类型对目标表进行相应的处理. 查看全部
ETL基本概念ETL基本概念-背景
随着企业的发展,各种业务线,产品线和部门将建立各种信息系统以促进自己的业务. 随着信息建设的不断深化,业务系统相互独立,相互独立引起的“数据岛”现象尤为普遍. 业务未集成,流程未互连,数据也未共享. 这使企业可以分析和利用数据并开发报告表格. ,分析和采矿带来了巨大的困难.
在这种情况下,为了实现企业全局数据(信息孤岛,数据统计,数据分析,数据挖掘),DSS(决策支持系统),BI(商业智能),商业分析系统的系统运行和管理为了为深入开发和应用奠定基础,并挖掘数据的价值,企业将开始建立数据仓库和数据中心. 集成各个业务系统的数据源,以建立统一的数据采集,处理,存储,分发和共享中心.
在BI项目中,ETL至少要花费整个项目的1/3,而ETL设计的质量直接关系到BI项目的成败.
ETL基本概念定义
ETL是以下过程: 提取,清理和转换(转换)业务系统的数据,然后将其加载(加载)到数据仓库中. 目的是集成企业中分散,无序和不均匀的数据. ,为企业决策提供分析依据.
ETL基本概念-过程
ETL处理分为五个主要模块,即: 数据提取,数据清理,库中的转换,规则检查和数据加载. 每个模块都可以灵活组合以形成ETL处理流程. 简要介绍每个模块的主要功能.
数据提取数据清理和转换数据加载
将数据缓冲区中的数据直接加载到数据库的相应表中. 如果是全额方法,请使用LOAD方法;如果是增量方法,则根据业务规则MERGE输入数据库
ETL VS ELT
根据ETL体系结构的字面意义,它可以理解为一种按照E-T-L顺序处理的体系结构: 完成后首先提取,然后进行转换并加载到目标数据库中. 在ETL体系结构中,数据流是从源数据流到ETL工具的. ETL工具是一个单独的数据处理引擎,通常在单独的硬件服务器上执行所有数据转换工作,然后将数据加载到仓库中的目标数据. 如果要提高整个ETL过程的效率,则只能增强ETL工具服务器的配置并优化系统处理流程(通常,可调整的东西很少).
ELT体系结构将“ L”步骤推进到“ T”之前完成: 首先提取,然后加载到目标数据库中,并完成目标数据库中的转换操作. 在ELT体系结构中,ELT仅负责提供图形界面来设计业务规则. 整个数据处理过程在目标数据库和源数据库之间流动. ELT协调相关的数据库系统以执行相关的应用程序. 数据处理过程既可以在源数据库端也可以在目标数据仓库端执行(主要取决于系统的体系结构设计和数据属性). 当ETL过程需要提高效率时,可以通过调整相关数据库或更改执行该过程的服务器来实现.
您可以仔细查看以上两个架构图,并体验它们之间的差异. 让我们在下面分析它们各自的优点:
ETL体系结构的优点ELT体系结构的优点ETL模式简介
ETL具有四种主要的实现方式: 触发方式,增量字段,完全同步,日志比较
触发模式
<p>触发方法是常用的增量提取机制. 此方法基于提取要求,在要提取的源表上创建插入,修改和删除三个触发器. 只要源表中的数据发生更改,相应的触发器就会将更改后的数据写入增量中. ETL增量提取是从增量日志表中提取数据,而不是直接在源表中. 同时,应及时标记或删除增量日志表中提取的数据. 为简单起见,增量日志表通常不存储增量数据的所有字段信息,而仅存储源表名称,更新的键值和更新操作类型(插入,更新或删除). ETL增量提取过程首先基于. 从源表中提取源表名称和更新的键值,并提取相应的完整记录,然后根据更新操作的类型对目标表进行相应的处理.
优采云·物品组合工具套装V1.5.13
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2020-08-06 11:15
该原型来自原创文章生成器,但它更简单易用,操作基本相同,功能更强大,操作更简单,退伍军人可以直接使用它而无需重复学习,而且新手也很容易使用<//p
p核心功能是编写模板,在模板中引用元素,并在任何地方引用任何元素. 元素可以在文本块中调用,可以是随机的汉字,数字,字母或数字序列,随机值和随机时间. 所有免费的原创组合模式. 查看原理>>
提醒: 主界面右下角的选项按钮可以导入“原创文章生成器(高级高级版)”的程序数据(必须导入,而不是简单的文件复制)
提醒: 在2003系统上运行时,必须关闭数据执行保护.
提示: 创建新元素时,按Ctrl键可将当前元素的内容复制到新元素;切换元素显示时按Alt键可屏蔽元素内容的显示和修改. 右键单击元素项目以复制元素的引用格式[元素名称],右键单击元素库以打开本地存储数据库的文件夹(模板的相同操作).
提醒: 当前选择并显示的模板是用于生成的模板. 如果选择了模板库,则该库下的模板将被随机用于生成,并且所有已选中的元素库都可以由模板调用. 当检查了多个元素库时,不同元素库下的元素不能具有相同的名称,否则只能调用第一个被检查的元素库中具有相同名称的元素.
与“原创文章生成器”的功能相比:
1. 全新的界面设计,简单而功能强大的布局,基本相同的操作,但更简单易用
2. 元素库中的元素不再显示复选框以免误判(只有元素库本身可以被打勾,被打勾的元素库会参与调用,并且不需要打勾)
3. 显示大部分文本不再耗时,并且支持行号显示和元素语法突出显示.
4. 更强大的删除恢复功能,更强大的树搜索功能
5. 新修改的各种辅助工具(包括新编写的长尾单词采集器)可以满足更多的文本处理要求.
6. 预览时支持预览标题设置,效果如初.
7. 库的显示顺序不再混乱.
8. 其他方面,例如总体功能和性能. 查看全部
新的文章组合工具,支持短语和单词的原创随机组合,SEO基本的网站管理员工具,内置将近20种新的和增强的辅助工具.
该原型来自原创文章生成器,但它更简单易用,操作基本相同,功能更强大,操作更简单,退伍军人可以直接使用它而无需重复学习,而且新手也很容易使用<//p
p核心功能是编写模板,在模板中引用元素,并在任何地方引用任何元素. 元素可以在文本块中调用,可以是随机的汉字,数字,字母或数字序列,随机值和随机时间. 所有免费的原创组合模式. 查看原理>>
提醒: 主界面右下角的选项按钮可以导入“原创文章生成器(高级高级版)”的程序数据(必须导入,而不是简单的文件复制)
提醒: 在2003系统上运行时,必须关闭数据执行保护.
提示: 创建新元素时,按Ctrl键可将当前元素的内容复制到新元素;切换元素显示时按Alt键可屏蔽元素内容的显示和修改. 右键单击元素项目以复制元素的引用格式[元素名称],右键单击元素库以打开本地存储数据库的文件夹(模板的相同操作).
提醒: 当前选择并显示的模板是用于生成的模板. 如果选择了模板库,则该库下的模板将被随机用于生成,并且所有已选中的元素库都可以由模板调用. 当检查了多个元素库时,不同元素库下的元素不能具有相同的名称,否则只能调用第一个被检查的元素库中具有相同名称的元素.
与“原创文章生成器”的功能相比:
1. 全新的界面设计,简单而功能强大的布局,基本相同的操作,但更简单易用
2. 元素库中的元素不再显示复选框以免误判(只有元素库本身可以被打勾,被打勾的元素库会参与调用,并且不需要打勾)
3. 显示大部分文本不再耗时,并且支持行号显示和元素语法突出显示.
4. 更强大的删除恢复功能,更强大的树搜索功能
5. 新修改的各种辅助工具(包括新编写的长尾单词采集器)可以满足更多的文本处理要求.
6. 预览时支持预览标题设置,效果如初.
7. 库的显示顺序不再混乱.
8. 其他方面,例如总体功能和性能.
渗透测试之子域名枚举(子域名枚举的艺术)
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2020-08-11 14:48
的部份内容因为网路缘由难以验证,有兴趣的可以自行挖掘,不再做过多的调整,翻译此文的诱因就是为了给子域枚举提供一个系统化的学习方法,此外子域名=子域名,但子域不一定只有子域名,注意分辨,文章开头提及的子域名枚举的艺术已经完成了翻译,可以直接点击链接进行学习下载;
子域名枚举的艺术:
文中谈到了好多工具和方法,但要注意兵贵在精不在多,适合的才是最好的,注意文中的链接,有助于扩充你对子域枚举的了解
最后,感谢
0x01.什么是子域名枚举?
子域名枚举是查找一个或多个域的子域的过程。这是侦察阶段的重要组成部份。
0x02.为什么子域名枚举?
着名的雅虎之声风波!由于在子域上布署了易受功击的应用程序,从而被入侵。
0x03子域枚举技术1.搜索引擎
Google和Bing等搜索引擎支持各类中级搜索运算符来优化搜索查询。这些中级运算符一般被称为“谷歌Dorking”。
2.DNS数据聚合
有许多第三方服务聚合大量DNS数据集并可以查看这种数据集检索给定域的子域。
3.证书透明度Certificate Transparency
证书透明度(CT)是证书颁授机构(CA)必须将其发布的每位SSL / TLS证书发布到公共日志。SSL / TLS证书一般收录域名,子域名和电子邮件地址。这让她们成为攻击者的宝库。我在证书透明度上写了一系列技术博客文章,我深入介绍了这个技术,你可以在这里阅读这个系列。
查找为域颁授的证书的最简单方式是使用搜集CT日志的搜索引擎,任何人可以搜索它们。下面列举了太受欢迎的CT搜索地址:
除了Web界面之外,crt.sh还可以使用postgres界面访问其CT日志数据。这促使运行一些中级查询显得简单而灵活。如果您安装了PostgreSQL客户端软件,则可以按如下形式登陆:
$ psql -h crt.sh -p 5432 -U guest certwatch
我们编撰了一些脚本来简化使用CT日志搜索引擎查找子域的过程。这些脚本可以在我们的github中找到
使用CT进行子域枚举的缺点是CT日志中找到的域名可能不再存在,因此未能解析为IP地址。您可以将massdns等工具与CT日志结合使用,以快速辨识可解析的域名。
# ct.py - extracts domain names from CT Logs(shipped with massdns)
# massdns - will find resolvable domains & adds them to a file
./ct.py icann.org | ./bin/massdns -r resolvers.txt -t A -q -a -o -w icann_resolvable_domains.txt -
4.暴力枚举
基于字典的枚举找到通用名称子域是另一种技术。DNSRecon是一个功能强悍的DNS枚举工具,它的一个功能是使用预定义的字典进行子域枚方式侦查子域
# 使用DNSRecon的基于字典的枚举
$ python dnsrecon.py -n ns1.insecuredns.com -d insecuredns.com -D subdomains-top1mil-5000.txt -t brt
5.置换扫描
置换扫描是另一个有趣的技术来辨识子域。在该技术中,我们使用已知域/子域的排列,改变和突变来辨识新的子域。
$ python altdns.py -i icann.domains -o data_output -w icann.words -r -s results_output.txt
使用AltDNS查找与个别排列/更改匹配的子域
6.自治系统(AS)
查找自治系统(AS)号码将帮助我们辨识属于组织的网络块,而该组块又可能具有有效域。
首先使用dig查找ASN
其次,使用AS编号查找网络块 - NSE脚本
$ nmap --script targets-asn --script-args targets-asn.asn=9808 > netblocks.txt
7.区域传送
区域传输是一种DNS事务,DNS服务器将其全部或部份区域文件的副本传递给另一个DNS服务器。如果未安全地配置区域传送,则任何人都可以针对名称服务器启动区域传输并获取区域文件的副本。根据设计,区域文件收录有关区域和留驻在区域中的主机的大量信息。
$ dig + multi AXFR @ ns1 .insecuredns.com insecuredns.com
使用DIG工具针对域的名称服务器成功进行区域传送
8.DNSSEC记录.
由于在DNSSEC中处理不存在的域的方法,可以“遍历”DNSSEC区域并枚举该区域中的所有域。也可以从这儿了解有关此技术的更多信息。
$ ldns-walk @ ns1.insecuredns.com insecuredns.com
区域遍历DNSSEC区域与NSEC记录
# Collect NSEC3 hashes of a domain
$ ./collect icann.org > icann.org.collect
# Undo the hashing, expose the sub-domain information.
$ ./unhash < icann.org.collect > icann.org.unhash
# Listing only the sub-domain part from the unhashed data
$ cat icann.org.unhash | grep "icann" | awk '{print $2;}'
del.icann.org.
access.icann.org.
charts.icann.org.
communications.icann.org.
fellowship.icann.org.
files.icann.org.
forms.icann.org.
mail.icann.org.
maintenance.icann.org.
new.icann.org.
public.icann.org.
research.icann.org.
9.DNS数据集聚合
有些项目搜集了互联网范围的扫描数据,并将其提供给研究人员和安全社区。该项目发布的数据集是子域信息的宝库。虽然在这个庞大的数据集中找到子域如同在大海捞针中找到针,但值得付出努力。
#用于解析和提取给定域的子域的命令
$ curl -silent https://scans.io/data/rapid7/s ... on.gz | pigz -dc | grep“.icann.org”| JQ
使用FDNS数据集枚举域/子域
0x04子域枚举技术 - 比较
我们针对运行了一些讨论过的技术并对结果进行了比较。下面的条形图显示了每种技术为找到的奇特,可解析的子域的数目。请随时与我们联系,了解我们用于搜集此信息的方式。
每种技术为找到的奇特,可解析的子域的数目
1.子域枚举 - 参考
我们为子域枚举技术,工具和源创建了一个简单的参考。这个引用是使用Github gist创建的,随意分叉,自定义它 -
# 子域枚举 - 参考
## 搜索引擎
- [Google](https://google.com) - **site:** operator
- [Bing](https://bing.com) - **site:** operator
## DNS信息聚合
- [VirusTotal](https://www.virustotal.com/)
- [ViewDNS](https://viewdns.info)
- [DNSdumpster](https://dnsdumpster.com/)
- [Threatcrowd](https://www.threatcrowd.org/)
## 证书透明度日志
- https://crt.sh/
- https://censys.io/
- https://developers.facebook.com/tools/ct/
- https://google.com/transparencyreport/https/ct/
## 工具
- [Sublister](https://github.com/aboul3la/Sublist3r)
- [Altdns](https://github.com/infosec-au/altdns)
- [massdns](https://github.com/blechschmidt/massdns)
- [enumall](https://github.com/jhaddix/domain)
- [DNSRecon](https://github.com/darkoperator/dnsrecon)
- [Domain analyzer](https://github.com/eldraco/domain_analyzer)
- [XRay](https://github.com/evilsocket/xray)
- [Aquatone](https://github.com/michenriksen/aquatone)
- [ldns-walk](https://www.nlnetlabs.nl/projects/ldns/)
- [NSEC3 walker](https://dnscurve.org/nsec3walker.html)
## 数据源
- [Project Sonar](https://sonar.labs.rapid7.com/)
- [Certificate Transparency logs](https://www.certificate-transparency.org/known-logs)
0x05参考 查看全部
本文并没有参考任何的译文,文中大多数的脚本和工具以及枚举方法都验证,效果还算不错,文中直接参考原文
的部份内容因为网路缘由难以验证,有兴趣的可以自行挖掘,不再做过多的调整,翻译此文的诱因就是为了给子域枚举提供一个系统化的学习方法,此外子域名=子域名,但子域不一定只有子域名,注意分辨,文章开头提及的子域名枚举的艺术已经完成了翻译,可以直接点击链接进行学习下载;
子域名枚举的艺术:
文中谈到了好多工具和方法,但要注意兵贵在精不在多,适合的才是最好的,注意文中的链接,有助于扩充你对子域枚举的了解
最后,感谢
0x01.什么是子域名枚举?
子域名枚举是查找一个或多个域的子域的过程。这是侦察阶段的重要组成部份。
0x02.为什么子域名枚举?
着名的雅虎之声风波!由于在子域上布署了易受功击的应用程序,从而被入侵。
0x03子域枚举技术1.搜索引擎
Google和Bing等搜索引擎支持各类中级搜索运算符来优化搜索查询。这些中级运算符一般被称为“谷歌Dorking”。
2.DNS数据聚合
有许多第三方服务聚合大量DNS数据集并可以查看这种数据集检索给定域的子域。
3.证书透明度Certificate Transparency
证书透明度(CT)是证书颁授机构(CA)必须将其发布的每位SSL / TLS证书发布到公共日志。SSL / TLS证书一般收录域名,子域名和电子邮件地址。这让她们成为攻击者的宝库。我在证书透明度上写了一系列技术博客文章,我深入介绍了这个技术,你可以在这里阅读这个系列。
查找为域颁授的证书的最简单方式是使用搜集CT日志的搜索引擎,任何人可以搜索它们。下面列举了太受欢迎的CT搜索地址:
除了Web界面之外,crt.sh还可以使用postgres界面访问其CT日志数据。这促使运行一些中级查询显得简单而灵活。如果您安装了PostgreSQL客户端软件,则可以按如下形式登陆:
$ psql -h crt.sh -p 5432 -U guest certwatch
我们编撰了一些脚本来简化使用CT日志搜索引擎查找子域的过程。这些脚本可以在我们的github中找到
使用CT进行子域枚举的缺点是CT日志中找到的域名可能不再存在,因此未能解析为IP地址。您可以将massdns等工具与CT日志结合使用,以快速辨识可解析的域名。
# ct.py - extracts domain names from CT Logs(shipped with massdns)
# massdns - will find resolvable domains & adds them to a file
./ct.py icann.org | ./bin/massdns -r resolvers.txt -t A -q -a -o -w icann_resolvable_domains.txt -
4.暴力枚举
基于字典的枚举找到通用名称子域是另一种技术。DNSRecon是一个功能强悍的DNS枚举工具,它的一个功能是使用预定义的字典进行子域枚方式侦查子域
# 使用DNSRecon的基于字典的枚举
$ python dnsrecon.py -n ns1.insecuredns.com -d insecuredns.com -D subdomains-top1mil-5000.txt -t brt
5.置换扫描
置换扫描是另一个有趣的技术来辨识子域。在该技术中,我们使用已知域/子域的排列,改变和突变来辨识新的子域。
$ python altdns.py -i icann.domains -o data_output -w icann.words -r -s results_output.txt
使用AltDNS查找与个别排列/更改匹配的子域
6.自治系统(AS)
查找自治系统(AS)号码将帮助我们辨识属于组织的网络块,而该组块又可能具有有效域。
首先使用dig查找ASN
其次,使用AS编号查找网络块 - NSE脚本
$ nmap --script targets-asn --script-args targets-asn.asn=9808 > netblocks.txt
7.区域传送
区域传输是一种DNS事务,DNS服务器将其全部或部份区域文件的副本传递给另一个DNS服务器。如果未安全地配置区域传送,则任何人都可以针对名称服务器启动区域传输并获取区域文件的副本。根据设计,区域文件收录有关区域和留驻在区域中的主机的大量信息。
$ dig + multi AXFR @ ns1 .insecuredns.com insecuredns.com
使用DIG工具针对域的名称服务器成功进行区域传送
8.DNSSEC记录.
由于在DNSSEC中处理不存在的域的方法,可以“遍历”DNSSEC区域并枚举该区域中的所有域。也可以从这儿了解有关此技术的更多信息。
$ ldns-walk @ ns1.insecuredns.com insecuredns.com
区域遍历DNSSEC区域与NSEC记录
# Collect NSEC3 hashes of a domain
$ ./collect icann.org > icann.org.collect
# Undo the hashing, expose the sub-domain information.
$ ./unhash < icann.org.collect > icann.org.unhash
# Listing only the sub-domain part from the unhashed data
$ cat icann.org.unhash | grep "icann" | awk '{print $2;}'
del.icann.org.
access.icann.org.
charts.icann.org.
communications.icann.org.
fellowship.icann.org.
files.icann.org.
forms.icann.org.
mail.icann.org.
maintenance.icann.org.
new.icann.org.
public.icann.org.
research.icann.org.
9.DNS数据集聚合
有些项目搜集了互联网范围的扫描数据,并将其提供给研究人员和安全社区。该项目发布的数据集是子域信息的宝库。虽然在这个庞大的数据集中找到子域如同在大海捞针中找到针,但值得付出努力。
#用于解析和提取给定域的子域的命令
$ curl -silent https://scans.io/data/rapid7/s ... on.gz | pigz -dc | grep“.icann.org”| JQ
使用FDNS数据集枚举域/子域
0x04子域枚举技术 - 比较
我们针对运行了一些讨论过的技术并对结果进行了比较。下面的条形图显示了每种技术为找到的奇特,可解析的子域的数目。请随时与我们联系,了解我们用于搜集此信息的方式。
每种技术为找到的奇特,可解析的子域的数目
1.子域枚举 - 参考
我们为子域枚举技术,工具和源创建了一个简单的参考。这个引用是使用Github gist创建的,随意分叉,自定义它 -
# 子域枚举 - 参考
## 搜索引擎
- [Google](https://google.com) - **site:** operator
- [Bing](https://bing.com) - **site:** operator
## DNS信息聚合
- [VirusTotal](https://www.virustotal.com/)
- [ViewDNS](https://viewdns.info)
- [DNSdumpster](https://dnsdumpster.com/)
- [Threatcrowd](https://www.threatcrowd.org/)
## 证书透明度日志
- https://crt.sh/
- https://censys.io/
- https://developers.facebook.com/tools/ct/
- https://google.com/transparencyreport/https/ct/
## 工具
- [Sublister](https://github.com/aboul3la/Sublist3r)
- [Altdns](https://github.com/infosec-au/altdns)
- [massdns](https://github.com/blechschmidt/massdns)
- [enumall](https://github.com/jhaddix/domain)
- [DNSRecon](https://github.com/darkoperator/dnsrecon)
- [Domain analyzer](https://github.com/eldraco/domain_analyzer)
- [XRay](https://github.com/evilsocket/xray)
- [Aquatone](https://github.com/michenriksen/aquatone)
- [ldns-walk](https://www.nlnetlabs.nl/projects/ldns/)
- [NSEC3 walker](https://dnscurve.org/nsec3walker.html)
## 数据源
- [Project Sonar](https://sonar.labs.rapid7.com/)
- [Certificate Transparency logs](https://www.certificate-transparency.org/known-logs)
0x05参考
关键字排行批量查询工具你们都用那个?
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2020-08-10 23:21
关键词要做打算:2113
1、做多个关键词5261的4102长尾关键词,如关键词是漂亮,那么长尾关1653键词可以是中国人长得漂亮。
2、这些长尾关键词要有搜索量,在百度上查看,有搜索量的长尾关键词可以做优化。
3、这些长尾关键词要在文章中出现。
4、这些大量的长尾关键词都要有收录。
5、这些大量的长尾关键词还要有排行。
当大量的长尾关键词都有排行了,关键词才有可能有快速排行。
做好充足的打算,那快速排行不是个问题。
关键词快速2113排行工具就是按照你给出的关键词通5261过各类优化的手4102段使你的关键词出现在百1653度排行的首页,让你的网站或者产品介绍页面就能最易被顾客发觉。skycc推广软件就是做关键词快速排行的一款工具,可以直接使你的产品出现在百度首页。
关键词优化快速排行有什么方法
搜索引擎优化工作员分2113析一个网站优化5261得怎么样,往往是4102查看目标网站的词库文件1653,而这种词库文件中的关键字也可以定义这个网站行业类别。二者是紧密联系的,即然要做一个行业门户网站,那么网站的词库文件必定是紧扣该行业的关键词优化展开。那怎么样能够这种词上综合排行步入词库文件中呢?下面时尚博主共享的一点见解可供参考。
什么叫行业关键词
行业关键词指的是该行业中富含的所有关键字。按关注度分类管理可以分成关键词热度、一般关键字和冷门关键字;依照长短不一可以分成短尾关键字和长尾关键词等。换句话说,行业关键词是一个通称,所有跟该行业有关的词都属于行业关键词。
发掘行业关键词的涵义
网站发掘行业关键词,不仅使网站内容更丰富、更专业,同时还要更方便用户寻找自己的信息内容需求,对用户来讲,提高了体验度。对搜索引擎来讲,丰富的行业关键词也可以获得到越多的留量入口处,当然必要条件是关键字在搜索引擎中有良好的综合排行。
怎样找寻行业关键词
行业关键词是十分浩物的,尤其是长尾关键词,包括地区词等都是大量的,采集和扩充这种关键字也须要一个正确的方法。以下是尹华峰搜索引擎优化搏客的一点心得分享,仅作。
1.查看对手网站。主要是查看这些高品质的对手网站,梳理和采集该网站的所有行业关键词,如可使用百度爬虫或爱站工具,查看该网站的词库文件量,所有采集出来。
2.找行业的留量点,即开掘关键字。可以使用词缀去扩充,目前这些关键字扩充工具也比较多且丰富,可参看百度爬虫、0056等,以百度爬虫的长尾词挖掘为例,键入“搜索引擎优化”,可以挖掘“搜索引擎优化优化、网站搜索引擎优化、搜索引擎优化网路推广公司”等大量相关关键词。
3.自身拓词。这个主要是涉及网路推广的须要,给网站设置用户评价词、地区词、互动问答词等。网站要进行线上营销,自身的品牌牢靠树立是必不可少的,所以也太必须优化这部份关键字。这种词有别于前面两种开掘下来的词,这些词通常是没有指数值的,属于长尾关键词层面。这种词用于做外推比较多,其实这些词也是可以优化上来的,适度扩充即可。
怎样优化行业关键词
关键字扩充下来后就须要优化和不断建立了,怎样把这种行业关键词优化到搜索引擎主页是工作员们的目标,所以必须要有一个良好的搜索引擎优化对策。根据关键字的搜索量剖析优化难度,从关键字难度大小随即开始梳理合理布局,可以合理布局成以下两种。
一、行业关键词作为频道页优化
关键字指数值比较大的时侯,可以将词合理布局在频道中,通过大量的高品质百度百家对准该频道,可以特好的帮助工作员抽成目标关键字排行。
二、行业关键词作为文章页优化
关键字指数值高于正常或则没有指数值,工作员可以写一篇高品质文章出来即可。如优化“什么叫搜索引擎优化”这个关键字,工作员可以梳理文章,逐层论述搜索引擎优化的含意、搜索引擎优化是干啥的、搜索引擎优化有什么作用、怎样做好搜索引擎优化等详情,不会写可以去参看对手的内容,随后用自己的口头抒发下来,这么就是一篇文章高品质百度百家,对于关键字排行是挺好的。
结束语:行业关键词须要不断采集和梳理,建议生手工作员构建一个文本文档记笔记,把开掘下来的行业关键词分类管理中级筛选下来,有指数值和没指数值的分离,有关的关键字摆在一起,随后进一步将这种关键字合理布局到网站中,早期可以先将低指数值关键字进行不断建立,随着网站权重的提升,不断加上新的行业关键词,这么,网站不仅得到良好的体验,关键字排行也是预料之中的事。
做seo优化,很大程度上就2113是做关键词排行5261。选取关键字成为了好多菜鸟的4102重点工作,关键词优化可以从以下1653几个方式着手:
1.拓展关键词
百度旗下有好多产品,每个功能都不一样,用对了可以帮助你挺好的挖关键词例如:百度百科、百度知道、百度关键词推荐工具、百度文库、百度指数、百度搜索的下拉菜单、百度搜索结果页顶部的关键词这种,还有5118,站长工具,爱站工具等,都是你可以借助的工具。尽量拓展与自己行业相关的,有人搜索的,有指数的关键词,并做好关键词库表。
2.关键词布局
关键词布局也是有讲究的,如重要的位置放置重要的关键词,每一个页面的关键词设置应不尽相同。
3、学会借助工具来检查已选的关键词
我们选定了创立了关键词库以后,可以借助工具来剖析,查看预估一些流量。从而筛选出比较合适的关键词。
关键词优化快速排行2113的方法,一般都是采用黑帽的方式去5261做的,也就是网上留传的快4102排技术。
一般靠1653这样的黑帽手法优化起来的排行,都是只能保持短期的排行疗效的,不建议使用这样的方式。
如果楼主,你的网站已经通过SEO正常的排行在前几页了,可以做一个站内站,来丰富网站的内容,增加网站的收录量,在站内站上面给主站做一些主站的锚文本,可以快速的提高主站的权重和排行。关于SEO方面的建议可以去SEO十万个为何上面多了解下。
望采纳,谢谢!!
seo中文意2113思是搜索引擎优化。SEO是一5261种使企业网站在百度等搜索引4102擎获得靠前的排1653名,从而博得更多潜在顾客流量的技术营销手段,主要的目的是让关键词排行靠前,增加特定关键字的曝光率,以此来降低网站的爆光度,进而降低销售的机会。一个比喻,网站就好比是商店,没经过Seo优化的网站就好比是建在偏远山区的商店,你的商品再好,也无人问津,因为他人不知道你的地址。Seo优化好的网站就好比置于闹市区的商店,每天人来人往,自然而然的,生意就好上去。
未来,是努力下来的
二怎么修练成真正的seo大神
现在学习seo的人好多,但是能力突出的真没几个,为什么呢?因为学偏了,学的都是一些老教程,老资料,而搜索引擎的排行算法早已发生了变化了,而网上留传的教程基本上都是针对先前的算法所拟定的应对的策略,当然没法满足现今形势的须要,所以不要看网上留传太广的这些教程,容易被蒙骗,如果你想了解关于seo的最新的入门教程,以及这方面的系统化的知识和思路的话。成为一名真正的seo大神。你可以来这个群:先输入27再输入2891最后输入799
按照次序组合上去都会出现答案,在这里你可以每晚都能学习到关于SEO方面的知识,我们
会有专门的人讲解,你只须要付出你的时间和用心的听就行,如果你不想学的话,就不要加
了,我们不欢迎。
三学习seo有没有前途
学习seo技术有没有前途,这个问题真的不是挺好回答,因为,对于我个人来说,我觉的是
很有前途的,因为我能玩的转,知道怎样借助seo技术去引导流量,得到自己想得到的,让
自己的生活不再贫穷,但是对于好多不懂的人,或者只是懂一部分的人来说,seo其实只是
一个概念而已,有没有前途,有两方面的诱因决定的,一方面是你自己有没有为这门技术做
出属于自己的努力,另一方面的诱因是有没有大神带你,因为高人在这个行业经历了很多年
的锻练,有很多实用的技术,这是经过了时光的考验的,而倘若使我们自己去经历的话,又
会浪费大量的时间成本,得不偿失。
二做SEO不需要技术是胡扯,说全部靠技术的是人渣
1.SEO是技术和艺术的结合,如果你一点技术都不懂,站内程序优化无从下手,就连你和技术人员沟通都是问题。所以,凡是告诉你学习SEO不需要懂技术的人都是胡扯,最至少你也要能看得懂HTML代码。但是若果全部以一个技术的角度去思索SEO必将导致与搜索引擎对立,而SEO的本意是使网站与搜索引擎和谐交往,如果你觉得是敌对关系,SEO是在钻搜索引擎的漏洞,那你必将失败。
2.说SEO全部靠技术的人会给你一种思想,是一种和搜索引擎敌对的思想,在一个人接受新事物的时侯第一股思想至关重要,它决定了你之后走的街是正道还是邪道,而且一旦产生很难改变,所以我说这种人是人渣,简直是误人误己。
最后总结一句:SEO是须要基本的技术的,但是不能有纯粹借助的技术思想,你要明白,任何技术只是一种工具。
三基本概念不可少,基础知识很重要
基本概念指的是一些基本的专业术语,至少你学习SEO要知道域名是哪些,怎么界定;什么是内外链、什么是锚文本、什么是蜘蛛,蜘蛛如何抓取等等这种基本的东西吧。希望菜鸟多看看书,多读一些大神写的教程,虽然好多操作方法现今早已不适用了,但是基本的思路和原理才还是没变的的,你对这种基础知识原理的理解程度,决定了你未来能走多快,也只有熟练把握这种基础只是的前提下才会确切的判定搜索引擎动向,对一个新情况可以快速的作出反应。毛爷爷说:坚决反对“本本主义”,反对教条主义,书本只能学习思想,我们要创造有自己特色的操作方法和流程。
执行力决定你的一切,想到就要做到
四没执行力不总结,就想玩转SEO?
一流的执行力+三流的创意,可以超过一流的创意+三流的执行力。我们不能光做一个思想家,科学正确的思想有了,还须要我们快速有效的执行,不能使我们的方式全部逗留在脑袋里。
1、坚定不移的执行。特别是做SEO,有些方式是须要一定的量和时间才会出现疗效,坚定不移的执行力是你超过他人最有力的装备。这里引用电视剧《蚁族的奋斗》中一句精典台词:当我们哪些都没有的时侯,唯一可以和他人比的资本就是坚持!
2、高压下继续执行。压力,做SEO一定会有压力,而且是巨大的压力,不是威胁新人,是绝对实事,压力来自你自己的苦恼,来自你的上级领导、有可能就会来自你的家庭。所以抗压能力不可少,强大的心理素质是一个成大器者必备的。
毛父亲教导我们:没有实践就没有发言权
3.任何思想一切都是理论,没有放在实践中去使用永远不能总结出自己的东西,靠死记硬背刻在脑袋上面的东西,无论多么熟练都不可能达到活学活用。
4.经验是通过不断的实践总结的。唯有自己真正的试过才晓得,才能深刻的理解,并且在深刻理解的基础起来创造自己的一套理论体系。真正的前辈一定是擅于总结的实干家。
不会思想的站长=会喝水的群发软件
五毛父亲教导我们:没有实践就没有发言权
任何思想一切都是理论,没有放在实践中去使用永远不能总结出自己的东西,靠死记硬背刻在脑袋上面的东西,无论多么熟练都不可能达到活学活用。
经验是通过不断的实践总结的。唯有自己真正的试过才晓得,才能深刻的理解,并且在深刻理解的基础起来创造自己的一套理论体系。真正的前辈一定是擅于总结的实干家。
不会思想的站长=会喝水的群发软件
以前见到过一个方程,很有意思,引用过来你们轻松一下:
人=吃+工作+睡觉+玩
人-玩=吃+睡觉+工作
猪=吃+睡觉
代入方程:人-玩=猪+工作
所以:不会玩的人,等于会工作的猪。
SEO版方程:
站长=思考+链接+伪原创+吃饭
站长-思考=链接+伪原创
软件=链接+伪原创
代入方程:站长-思考=软件+吃饭
所以:不会思索的站长,等于会喝水的群发软件。
有哪些第三方工具可以查网站哪些关键词有排行
百度指数的理想是“让每位2113人都成为数据5261科学家”。对个人而言4102,大到置业时机、报1653考中学、入职企业发展趋势,小到约会、旅游目的地选择,百度指数可以助其实现“智赢人生”;对于企业而言,竞品追踪、受众剖析、传播疗效,均以科学图标全景呈现,“智胜市场”变得轻松简单。大数据驱动每位人的发展,而百度提倡数据决策的生活方式,正是为了使更多人意识到数据的价值搜索指数是以网民在百度的搜索量为数据基础,以关键词为统计对象,科学剖析并估算出各个关键词在百度网页搜索中搜索频次的加权和。根据搜索来源的不同,搜索指数分别PC搜索指数和联通搜索指数。
2.媒体指数
媒体指数是以各大互联网媒体报导的新闻中,与关键词相关的,被百度新闻频道收录的数目,采用新闻标题收录关键词的统计标准。
3.相关检索词
关键词A的相关检索词是网民搜索A时,同时还搜索过的其他关键词。
4.上升最快相关检索词
上升最快相关检索词是在特定时间内搜索指数同比上升最快的相关检索词,并用上升箭头以及上升比率表示相对上一时间上升的具体数值。
5.需求分布图
需求分布图是针对特定关键词的相关检索词进行降维剖析而得的词云分布。
6.人群属性
关键词的人群属性,是依据百度用户搜索数据,采用数据挖掘方式,对关键词的人群属性进行降维剖析,给出性别比列、年龄分布、兴趣分布等社会属性信息。
建议同学你可以让2113用【观其关键字排行查询工5261具】,4102这个工具可以一次性把你网站所有的1653关键词全部添加进去,而且可以添加检测好多的网站关键词,每天你只须要打开软件,找到你须要检测的网站网址,点击【批量查询】几分钟就可以把你整个网站关键词在各大搜索引擎的排行检索下来;而且可以下载到本地随时查看,我个人感觉挺好;
本人建站这么多年仍然使用的是【观其关键字排行查询工具】查询网站关键词的排行,这个软件可以一次性添加你网站
里面的所有关键词,每天关注关键词排行只须要一键点击,很快每位关键词在各大搜索引擎的排行都会下来了,而且可以下载到本地笔记本随时监控;
而且可以添加好多的网站,本人觉得使用比较便捷;建议同学不妨在百度上面搜索【观其关键字排行查询工具】下载出来试试看,文件太小,使用也很方便,容易上手;
我们可以不2113断丰富网站内容,提高内容的质5261量。对于用户而言,有图有4102真相,有声有色1653自然是很不错的用户体验。不管怎么样,网站标题等描述内容都只是网站的附加产物,网站的内容才是最终的关键之处。网站内容中关键词的布局是否合理对一个网站的整体权重至关重要,一般来说在网站内容中的关键词密度是2%-8%。如果关键词密度达不到2%,那就突出不了关键词,相反,如果关键词密度超过8%那就很有可能会被搜索引擎觉得是过度使用关键词。
关键字排行批量查询工具你们都用那个?
IIS7批量查排行工具2113可以同时查询:
1、百度pc
2、百度移动5261端4102
3、360PC
4、360移动端
5、搜狗pc
6、搜狗移动端的关键词1653排行
1、下载以后,解压程序,如下图:
2、点登录。输入程序的用户名和帐户。(没有帐户的,就注册一个)
3、程序根目录下有个关键词.txt和域名.txt。在上面相对输入你想要查询的关键词和域名。如图:
4、运行程序后更改关键词.txt和域名.txt是须要导出的,导入后域名和关键词会改变
5、可设置须要查询到第几页,程序默认查询到第3页
6、选择是否启用动态ip
(1)如果启用,需要在下边的宽带联接哪里,填写宽带帐户。点击测试拨。
(2)不启用,下面的宽带帐户不用填写。
7、点击开始,程序开始查询
8、执行完成,可立刻查看结果
(1)百度关键词排行:
(2)百度移动关键词排行:望采纳
查神马搜索关键词的排行工具。
首先我们从网站发展的三2113个阶段来5261剖析关键词:
一,首先我们的网站在4102建设之初须要选定一个1653关键词来建设。
二,当我们的网站关键词出现排行以后,为什么他人的站点比我们的排行要高。高质量站点的竞争对手还有一些哪些关键词。
三,当我们多个关键词有了排行以后,做站的目的就出现了,哪个关键词可以给我们带来更多的流量,更多的转化率,这些好的,转化率高关键词自然须要我们的更多关注。毕竟站长做站是以挣钱为目的的。
如果还须要细分的话,大致可以分为十一点:
1、网站还开始建设前,需要先选定关键词,并借此扩充。常用的方式就是在百度搜索框中输入扩充关键词,查看相关页面,以判定关键词竞争度。
2、做了关键词之后,分析对手关键词。 查看全部
关键词快速排行工具是哪些
关键词要做打算:2113
1、做多个关键词5261的4102长尾关键词,如关键词是漂亮,那么长尾关1653键词可以是中国人长得漂亮。
2、这些长尾关键词要有搜索量,在百度上查看,有搜索量的长尾关键词可以做优化。
3、这些长尾关键词要在文章中出现。
4、这些大量的长尾关键词都要有收录。
5、这些大量的长尾关键词还要有排行。
当大量的长尾关键词都有排行了,关键词才有可能有快速排行。
做好充足的打算,那快速排行不是个问题。
关键词快速2113排行工具就是按照你给出的关键词通5261过各类优化的手4102段使你的关键词出现在百1653度排行的首页,让你的网站或者产品介绍页面就能最易被顾客发觉。skycc推广软件就是做关键词快速排行的一款工具,可以直接使你的产品出现在百度首页。
关键词优化快速排行有什么方法
搜索引擎优化工作员分2113析一个网站优化5261得怎么样,往往是4102查看目标网站的词库文件1653,而这种词库文件中的关键字也可以定义这个网站行业类别。二者是紧密联系的,即然要做一个行业门户网站,那么网站的词库文件必定是紧扣该行业的关键词优化展开。那怎么样能够这种词上综合排行步入词库文件中呢?下面时尚博主共享的一点见解可供参考。
什么叫行业关键词
行业关键词指的是该行业中富含的所有关键字。按关注度分类管理可以分成关键词热度、一般关键字和冷门关键字;依照长短不一可以分成短尾关键字和长尾关键词等。换句话说,行业关键词是一个通称,所有跟该行业有关的词都属于行业关键词。
发掘行业关键词的涵义
网站发掘行业关键词,不仅使网站内容更丰富、更专业,同时还要更方便用户寻找自己的信息内容需求,对用户来讲,提高了体验度。对搜索引擎来讲,丰富的行业关键词也可以获得到越多的留量入口处,当然必要条件是关键字在搜索引擎中有良好的综合排行。
怎样找寻行业关键词
行业关键词是十分浩物的,尤其是长尾关键词,包括地区词等都是大量的,采集和扩充这种关键字也须要一个正确的方法。以下是尹华峰搜索引擎优化搏客的一点心得分享,仅作。
1.查看对手网站。主要是查看这些高品质的对手网站,梳理和采集该网站的所有行业关键词,如可使用百度爬虫或爱站工具,查看该网站的词库文件量,所有采集出来。
2.找行业的留量点,即开掘关键字。可以使用词缀去扩充,目前这些关键字扩充工具也比较多且丰富,可参看百度爬虫、0056等,以百度爬虫的长尾词挖掘为例,键入“搜索引擎优化”,可以挖掘“搜索引擎优化优化、网站搜索引擎优化、搜索引擎优化网路推广公司”等大量相关关键词。
3.自身拓词。这个主要是涉及网路推广的须要,给网站设置用户评价词、地区词、互动问答词等。网站要进行线上营销,自身的品牌牢靠树立是必不可少的,所以也太必须优化这部份关键字。这种词有别于前面两种开掘下来的词,这些词通常是没有指数值的,属于长尾关键词层面。这种词用于做外推比较多,其实这些词也是可以优化上来的,适度扩充即可。
怎样优化行业关键词
关键字扩充下来后就须要优化和不断建立了,怎样把这种行业关键词优化到搜索引擎主页是工作员们的目标,所以必须要有一个良好的搜索引擎优化对策。根据关键字的搜索量剖析优化难度,从关键字难度大小随即开始梳理合理布局,可以合理布局成以下两种。
一、行业关键词作为频道页优化
关键字指数值比较大的时侯,可以将词合理布局在频道中,通过大量的高品质百度百家对准该频道,可以特好的帮助工作员抽成目标关键字排行。
二、行业关键词作为文章页优化
关键字指数值高于正常或则没有指数值,工作员可以写一篇高品质文章出来即可。如优化“什么叫搜索引擎优化”这个关键字,工作员可以梳理文章,逐层论述搜索引擎优化的含意、搜索引擎优化是干啥的、搜索引擎优化有什么作用、怎样做好搜索引擎优化等详情,不会写可以去参看对手的内容,随后用自己的口头抒发下来,这么就是一篇文章高品质百度百家,对于关键字排行是挺好的。
结束语:行业关键词须要不断采集和梳理,建议生手工作员构建一个文本文档记笔记,把开掘下来的行业关键词分类管理中级筛选下来,有指数值和没指数值的分离,有关的关键字摆在一起,随后进一步将这种关键字合理布局到网站中,早期可以先将低指数值关键字进行不断建立,随着网站权重的提升,不断加上新的行业关键词,这么,网站不仅得到良好的体验,关键字排行也是预料之中的事。
做seo优化,很大程度上就2113是做关键词排行5261。选取关键字成为了好多菜鸟的4102重点工作,关键词优化可以从以下1653几个方式着手:
1.拓展关键词
百度旗下有好多产品,每个功能都不一样,用对了可以帮助你挺好的挖关键词例如:百度百科、百度知道、百度关键词推荐工具、百度文库、百度指数、百度搜索的下拉菜单、百度搜索结果页顶部的关键词这种,还有5118,站长工具,爱站工具等,都是你可以借助的工具。尽量拓展与自己行业相关的,有人搜索的,有指数的关键词,并做好关键词库表。
2.关键词布局
关键词布局也是有讲究的,如重要的位置放置重要的关键词,每一个页面的关键词设置应不尽相同。
3、学会借助工具来检查已选的关键词
我们选定了创立了关键词库以后,可以借助工具来剖析,查看预估一些流量。从而筛选出比较合适的关键词。
关键词优化快速排行2113的方法,一般都是采用黑帽的方式去5261做的,也就是网上留传的快4102排技术。
一般靠1653这样的黑帽手法优化起来的排行,都是只能保持短期的排行疗效的,不建议使用这样的方式。
如果楼主,你的网站已经通过SEO正常的排行在前几页了,可以做一个站内站,来丰富网站的内容,增加网站的收录量,在站内站上面给主站做一些主站的锚文本,可以快速的提高主站的权重和排行。关于SEO方面的建议可以去SEO十万个为何上面多了解下。
望采纳,谢谢!!
seo中文意2113思是搜索引擎优化。SEO是一5261种使企业网站在百度等搜索引4102擎获得靠前的排1653名,从而博得更多潜在顾客流量的技术营销手段,主要的目的是让关键词排行靠前,增加特定关键字的曝光率,以此来降低网站的爆光度,进而降低销售的机会。一个比喻,网站就好比是商店,没经过Seo优化的网站就好比是建在偏远山区的商店,你的商品再好,也无人问津,因为他人不知道你的地址。Seo优化好的网站就好比置于闹市区的商店,每天人来人往,自然而然的,生意就好上去。
未来,是努力下来的
二怎么修练成真正的seo大神
现在学习seo的人好多,但是能力突出的真没几个,为什么呢?因为学偏了,学的都是一些老教程,老资料,而搜索引擎的排行算法早已发生了变化了,而网上留传的教程基本上都是针对先前的算法所拟定的应对的策略,当然没法满足现今形势的须要,所以不要看网上留传太广的这些教程,容易被蒙骗,如果你想了解关于seo的最新的入门教程,以及这方面的系统化的知识和思路的话。成为一名真正的seo大神。你可以来这个群:先输入27再输入2891最后输入799
按照次序组合上去都会出现答案,在这里你可以每晚都能学习到关于SEO方面的知识,我们
会有专门的人讲解,你只须要付出你的时间和用心的听就行,如果你不想学的话,就不要加
了,我们不欢迎。
三学习seo有没有前途
学习seo技术有没有前途,这个问题真的不是挺好回答,因为,对于我个人来说,我觉的是
很有前途的,因为我能玩的转,知道怎样借助seo技术去引导流量,得到自己想得到的,让
自己的生活不再贫穷,但是对于好多不懂的人,或者只是懂一部分的人来说,seo其实只是
一个概念而已,有没有前途,有两方面的诱因决定的,一方面是你自己有没有为这门技术做
出属于自己的努力,另一方面的诱因是有没有大神带你,因为高人在这个行业经历了很多年
的锻练,有很多实用的技术,这是经过了时光的考验的,而倘若使我们自己去经历的话,又
会浪费大量的时间成本,得不偿失。
二做SEO不需要技术是胡扯,说全部靠技术的是人渣
1.SEO是技术和艺术的结合,如果你一点技术都不懂,站内程序优化无从下手,就连你和技术人员沟通都是问题。所以,凡是告诉你学习SEO不需要懂技术的人都是胡扯,最至少你也要能看得懂HTML代码。但是若果全部以一个技术的角度去思索SEO必将导致与搜索引擎对立,而SEO的本意是使网站与搜索引擎和谐交往,如果你觉得是敌对关系,SEO是在钻搜索引擎的漏洞,那你必将失败。
2.说SEO全部靠技术的人会给你一种思想,是一种和搜索引擎敌对的思想,在一个人接受新事物的时侯第一股思想至关重要,它决定了你之后走的街是正道还是邪道,而且一旦产生很难改变,所以我说这种人是人渣,简直是误人误己。
最后总结一句:SEO是须要基本的技术的,但是不能有纯粹借助的技术思想,你要明白,任何技术只是一种工具。
三基本概念不可少,基础知识很重要
基本概念指的是一些基本的专业术语,至少你学习SEO要知道域名是哪些,怎么界定;什么是内外链、什么是锚文本、什么是蜘蛛,蜘蛛如何抓取等等这种基本的东西吧。希望菜鸟多看看书,多读一些大神写的教程,虽然好多操作方法现今早已不适用了,但是基本的思路和原理才还是没变的的,你对这种基础知识原理的理解程度,决定了你未来能走多快,也只有熟练把握这种基础只是的前提下才会确切的判定搜索引擎动向,对一个新情况可以快速的作出反应。毛爷爷说:坚决反对“本本主义”,反对教条主义,书本只能学习思想,我们要创造有自己特色的操作方法和流程。
执行力决定你的一切,想到就要做到
四没执行力不总结,就想玩转SEO?
一流的执行力+三流的创意,可以超过一流的创意+三流的执行力。我们不能光做一个思想家,科学正确的思想有了,还须要我们快速有效的执行,不能使我们的方式全部逗留在脑袋里。
1、坚定不移的执行。特别是做SEO,有些方式是须要一定的量和时间才会出现疗效,坚定不移的执行力是你超过他人最有力的装备。这里引用电视剧《蚁族的奋斗》中一句精典台词:当我们哪些都没有的时侯,唯一可以和他人比的资本就是坚持!
2、高压下继续执行。压力,做SEO一定会有压力,而且是巨大的压力,不是威胁新人,是绝对实事,压力来自你自己的苦恼,来自你的上级领导、有可能就会来自你的家庭。所以抗压能力不可少,强大的心理素质是一个成大器者必备的。
毛父亲教导我们:没有实践就没有发言权
3.任何思想一切都是理论,没有放在实践中去使用永远不能总结出自己的东西,靠死记硬背刻在脑袋上面的东西,无论多么熟练都不可能达到活学活用。
4.经验是通过不断的实践总结的。唯有自己真正的试过才晓得,才能深刻的理解,并且在深刻理解的基础起来创造自己的一套理论体系。真正的前辈一定是擅于总结的实干家。
不会思想的站长=会喝水的群发软件
五毛父亲教导我们:没有实践就没有发言权
任何思想一切都是理论,没有放在实践中去使用永远不能总结出自己的东西,靠死记硬背刻在脑袋上面的东西,无论多么熟练都不可能达到活学活用。
经验是通过不断的实践总结的。唯有自己真正的试过才晓得,才能深刻的理解,并且在深刻理解的基础起来创造自己的一套理论体系。真正的前辈一定是擅于总结的实干家。
不会思想的站长=会喝水的群发软件
以前见到过一个方程,很有意思,引用过来你们轻松一下:
人=吃+工作+睡觉+玩
人-玩=吃+睡觉+工作
猪=吃+睡觉
代入方程:人-玩=猪+工作
所以:不会玩的人,等于会工作的猪。
SEO版方程:
站长=思考+链接+伪原创+吃饭
站长-思考=链接+伪原创
软件=链接+伪原创
代入方程:站长-思考=软件+吃饭
所以:不会思索的站长,等于会喝水的群发软件。
有哪些第三方工具可以查网站哪些关键词有排行
百度指数的理想是“让每位2113人都成为数据5261科学家”。对个人而言4102,大到置业时机、报1653考中学、入职企业发展趋势,小到约会、旅游目的地选择,百度指数可以助其实现“智赢人生”;对于企业而言,竞品追踪、受众剖析、传播疗效,均以科学图标全景呈现,“智胜市场”变得轻松简单。大数据驱动每位人的发展,而百度提倡数据决策的生活方式,正是为了使更多人意识到数据的价值搜索指数是以网民在百度的搜索量为数据基础,以关键词为统计对象,科学剖析并估算出各个关键词在百度网页搜索中搜索频次的加权和。根据搜索来源的不同,搜索指数分别PC搜索指数和联通搜索指数。
2.媒体指数
媒体指数是以各大互联网媒体报导的新闻中,与关键词相关的,被百度新闻频道收录的数目,采用新闻标题收录关键词的统计标准。
3.相关检索词
关键词A的相关检索词是网民搜索A时,同时还搜索过的其他关键词。
4.上升最快相关检索词
上升最快相关检索词是在特定时间内搜索指数同比上升最快的相关检索词,并用上升箭头以及上升比率表示相对上一时间上升的具体数值。
5.需求分布图
需求分布图是针对特定关键词的相关检索词进行降维剖析而得的词云分布。
6.人群属性
关键词的人群属性,是依据百度用户搜索数据,采用数据挖掘方式,对关键词的人群属性进行降维剖析,给出性别比列、年龄分布、兴趣分布等社会属性信息。
建议同学你可以让2113用【观其关键字排行查询工5261具】,4102这个工具可以一次性把你网站所有的1653关键词全部添加进去,而且可以添加检测好多的网站关键词,每天你只须要打开软件,找到你须要检测的网站网址,点击【批量查询】几分钟就可以把你整个网站关键词在各大搜索引擎的排行检索下来;而且可以下载到本地随时查看,我个人感觉挺好;
本人建站这么多年仍然使用的是【观其关键字排行查询工具】查询网站关键词的排行,这个软件可以一次性添加你网站
里面的所有关键词,每天关注关键词排行只须要一键点击,很快每位关键词在各大搜索引擎的排行都会下来了,而且可以下载到本地笔记本随时监控;
而且可以添加好多的网站,本人觉得使用比较便捷;建议同学不妨在百度上面搜索【观其关键字排行查询工具】下载出来试试看,文件太小,使用也很方便,容易上手;
我们可以不2113断丰富网站内容,提高内容的质5261量。对于用户而言,有图有4102真相,有声有色1653自然是很不错的用户体验。不管怎么样,网站标题等描述内容都只是网站的附加产物,网站的内容才是最终的关键之处。网站内容中关键词的布局是否合理对一个网站的整体权重至关重要,一般来说在网站内容中的关键词密度是2%-8%。如果关键词密度达不到2%,那就突出不了关键词,相反,如果关键词密度超过8%那就很有可能会被搜索引擎觉得是过度使用关键词。
关键字排行批量查询工具你们都用那个?
IIS7批量查排行工具2113可以同时查询:
1、百度pc
2、百度移动5261端4102
3、360PC
4、360移动端
5、搜狗pc
6、搜狗移动端的关键词1653排行
1、下载以后,解压程序,如下图:
2、点登录。输入程序的用户名和帐户。(没有帐户的,就注册一个)
3、程序根目录下有个关键词.txt和域名.txt。在上面相对输入你想要查询的关键词和域名。如图:
4、运行程序后更改关键词.txt和域名.txt是须要导出的,导入后域名和关键词会改变
5、可设置须要查询到第几页,程序默认查询到第3页
6、选择是否启用动态ip
(1)如果启用,需要在下边的宽带联接哪里,填写宽带帐户。点击测试拨。
(2)不启用,下面的宽带帐户不用填写。
7、点击开始,程序开始查询
8、执行完成,可立刻查看结果
(1)百度关键词排行:
(2)百度移动关键词排行:望采纳
查神马搜索关键词的排行工具。
首先我们从网站发展的三2113个阶段来5261剖析关键词:
一,首先我们的网站在4102建设之初须要选定一个1653关键词来建设。
二,当我们的网站关键词出现排行以后,为什么他人的站点比我们的排行要高。高质量站点的竞争对手还有一些哪些关键词。
三,当我们多个关键词有了排行以后,做站的目的就出现了,哪个关键词可以给我们带来更多的流量,更多的转化率,这些好的,转化率高关键词自然须要我们的更多关注。毕竟站长做站是以挣钱为目的的。
如果还须要细分的话,大致可以分为十一点:
1、网站还开始建设前,需要先选定关键词,并借此扩充。常用的方式就是在百度搜索框中输入扩充关键词,查看相关页面,以判定关键词竞争度。
2、做了关键词之后,分析对手关键词。
推荐丨2019年不可错过的六款免费英语关键词工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2020-08-10 08:22
关键词研究是SEO的基础和关键,但许多时候人们容易忽视这一重要步骤,转向采用“内容创造优先”的策略。这一谬误的问题在于,这些所谓“好的内容”未分辨处于不同订购阶段的不同客户群。而这真是关键词的意义——卖家须要了解人们的搜索内容以及搜索方法。
例如在顾客开始订购的过程中就涉及了信息寻觅。客户在搜索引擎中键入查询数组,其中包括例如“如何(how to)”、“方式(ways to)”和“指南(guide)”之类的句子。
此外长尾关键词的组合使用也影响了消费者的订购和转化的进程。例如,收录“购买地点”(where to buy)、“折扣(discount)”和“促销(sale)”的关键词表示用户早已不再处于考虑阶段而是已打算好选购。
作为目前互联网界最大的搜索引擎工具,Google Ads的关键词规划师常常是卖家们首选的关键词研究工具,但微软却限制了它给出的有用关键字数据的数目。此外,从个别程度上来说,谷歌给出的那些关键词数据在好多方面与相关自然搜索中的排行无关(点击了解>>最新的微软SEO排名诱因及外链获取方式),更多指的是付费广告的数据。而目前市面上这类专业关键词工具大多须要付费,无形中降低了SEO的成本。
因此本文盘点了六款免费高效的关键词工具,可作为买家关键词研究的辅助工具,更好地完成该工作。
1、TagCrowd
关键词研究的一个重要部份是剖析竞争对手的内容。虽然目前有象SEMrush和Ahrefs这样专业高效的工具,但这种工具的收费较高,最低成本也大概须要100美元/月。而TagCrowd就是一款免费的同类工具。
TagCrowd支持买家通过创建词组/文本/标签云来可视化词组频度,此外能够够查看竞争对手特定页面最常用的关键词,以了解同行的关键词策略。TagCrowd的操作非常简单,有多种形式添加和剖析内容,包括:上传文件、粘贴网页网址或粘贴网页文字。
2、Keywords Everywhere
Keywords Everywhere是适用于Chrome和Firefox的免费浏览器插件,可整理15款主流关键词工具的数据,包括Ubersuggest、Answer the Public、Google Search、Google Analytics和Search Console等。当买家在微软中输入搜索数组时,Keywords Everywhere会显示一些基本的重要信息,包括搜索量和CPC(每次点击成本)数据。
虽然Keywords Everywhere收纳了来自多个来源的数据,但其数据格式并不纷扰,可以用PDF、Excel或CSV文件格式下载。
3、Merchant Words
Merchant Words是亚马逊买家理想的关键词研究工具。Merchant Words搜集了全球超过10亿次亚马逊实时搜索的数据,所有关键词数据都直接来自亚马逊搜索栏中的用户搜索。
Merchant Words的专业算法囊括了站点范围内的亚马逊流量、搜索排名以及当前和历史的搜索趋势。卖家还可以使用数目有限的关键词免费查询。除了免费版本外,Merchant Words还有付费版本(30美元/月,仅适用于日本数据;60美元/月,全球数据)。收费版本还包括不限量搜索、CSV下载以及24小时的顾客服务支持。
4、PinterestKeywordTool
PinterestKeywordTool是专门针对Pinterest平台的关键词研究工具。这款工具可以清晰地展示在Pinterest上受欢迎的关键词以及种子关键词和长尾关键词等重要的关键词信息。通过这种真实的搜索结果,卖家可以推测出最常使用的关键词句子。
5、Keyword.Guru
Keyword.Guru囊括了来自全球主流搜索引擎(谷歌、雅虎、必应等)和电商网站(亚马逊、eBay等)的数据信息。键入数组后,它还会依据人们实时搜索的内容提供相应结果。Keyword.Guru不显示有关关键词搜索量的信息,但它显示关于种子关键词的最常搜索项。
使用这种真实的搜索结果,你可以推测出最常使用的关键词句子。
6、Keyword Shitter
Keyword Shitter被业内称为天才关键词工具,据悉,该工具在30分钟内可以生成超过20000个关键词(及相关估算),此外能够通过借助微软文框手动填充控件进行查询。事实上,如果你不需要太多的关键词信息,可以通过添加正面或负面的过滤器来缩小结果范围。
总而言之,关键词研究工作一定是SEO战略中的核心环节,因此店家不仅使用微软的关键词规划师之外,还须要尝试其他的数据搜集渠道。虽然目前主流的付费关键词工具可以提供更多的数据,但上述的这种免费工具在性价比和效率上都符合大多数买家的日常使用需求,此外也太适宜一些入门级买家的尝试。(编译/雨果网 郭汇雯) 查看全部
关键词研究是SEO的基础和关键,但许多时候人们容易忽视这一重要步骤,转向采用“内容创造优先”的策略。这一谬误的问题在于,这些所谓“好的内容”未分辨处于不同订购阶段的不同客户群。而这真是关键词的意义——卖家须要了解人们的搜索内容以及搜索方法。
例如在顾客开始订购的过程中就涉及了信息寻觅。客户在搜索引擎中键入查询数组,其中包括例如“如何(how to)”、“方式(ways to)”和“指南(guide)”之类的句子。
此外长尾关键词的组合使用也影响了消费者的订购和转化的进程。例如,收录“购买地点”(where to buy)、“折扣(discount)”和“促销(sale)”的关键词表示用户早已不再处于考虑阶段而是已打算好选购。
作为目前互联网界最大的搜索引擎工具,Google Ads的关键词规划师常常是卖家们首选的关键词研究工具,但微软却限制了它给出的有用关键字数据的数目。此外,从个别程度上来说,谷歌给出的那些关键词数据在好多方面与相关自然搜索中的排行无关(点击了解>>最新的微软SEO排名诱因及外链获取方式),更多指的是付费广告的数据。而目前市面上这类专业关键词工具大多须要付费,无形中降低了SEO的成本。
因此本文盘点了六款免费高效的关键词工具,可作为买家关键词研究的辅助工具,更好地完成该工作。
1、TagCrowd
关键词研究的一个重要部份是剖析竞争对手的内容。虽然目前有象SEMrush和Ahrefs这样专业高效的工具,但这种工具的收费较高,最低成本也大概须要100美元/月。而TagCrowd就是一款免费的同类工具。
TagCrowd支持买家通过创建词组/文本/标签云来可视化词组频度,此外能够够查看竞争对手特定页面最常用的关键词,以了解同行的关键词策略。TagCrowd的操作非常简单,有多种形式添加和剖析内容,包括:上传文件、粘贴网页网址或粘贴网页文字。
2、Keywords Everywhere
Keywords Everywhere是适用于Chrome和Firefox的免费浏览器插件,可整理15款主流关键词工具的数据,包括Ubersuggest、Answer the Public、Google Search、Google Analytics和Search Console等。当买家在微软中输入搜索数组时,Keywords Everywhere会显示一些基本的重要信息,包括搜索量和CPC(每次点击成本)数据。
虽然Keywords Everywhere收纳了来自多个来源的数据,但其数据格式并不纷扰,可以用PDF、Excel或CSV文件格式下载。
3、Merchant Words
Merchant Words是亚马逊买家理想的关键词研究工具。Merchant Words搜集了全球超过10亿次亚马逊实时搜索的数据,所有关键词数据都直接来自亚马逊搜索栏中的用户搜索。
Merchant Words的专业算法囊括了站点范围内的亚马逊流量、搜索排名以及当前和历史的搜索趋势。卖家还可以使用数目有限的关键词免费查询。除了免费版本外,Merchant Words还有付费版本(30美元/月,仅适用于日本数据;60美元/月,全球数据)。收费版本还包括不限量搜索、CSV下载以及24小时的顾客服务支持。
4、PinterestKeywordTool
PinterestKeywordTool是专门针对Pinterest平台的关键词研究工具。这款工具可以清晰地展示在Pinterest上受欢迎的关键词以及种子关键词和长尾关键词等重要的关键词信息。通过这种真实的搜索结果,卖家可以推测出最常使用的关键词句子。
5、Keyword.Guru
Keyword.Guru囊括了来自全球主流搜索引擎(谷歌、雅虎、必应等)和电商网站(亚马逊、eBay等)的数据信息。键入数组后,它还会依据人们实时搜索的内容提供相应结果。Keyword.Guru不显示有关关键词搜索量的信息,但它显示关于种子关键词的最常搜索项。
使用这种真实的搜索结果,你可以推测出最常使用的关键词句子。
6、Keyword Shitter
Keyword Shitter被业内称为天才关键词工具,据悉,该工具在30分钟内可以生成超过20000个关键词(及相关估算),此外能够通过借助微软文框手动填充控件进行查询。事实上,如果你不需要太多的关键词信息,可以通过添加正面或负面的过滤器来缩小结果范围。
总而言之,关键词研究工作一定是SEO战略中的核心环节,因此店家不仅使用微软的关键词规划师之外,还须要尝试其他的数据搜集渠道。虽然目前主流的付费关键词工具可以提供更多的数据,但上述的这种免费工具在性价比和效率上都符合大多数买家的日常使用需求,此外也太适宜一些入门级买家的尝试。(编译/雨果网 郭汇雯)
[系列] - go-gin-api 路由中间件 - Jaeger 链路追踪(五)
采集交流 • 优采云 发表了文章 • 0 个评论 • 244 次浏览 • 2020-08-09 15:32
首先同步下项目概况:
上篇文章分享了,路由中间件 - 捕获异常,这篇文章咱们分享:路由中间件 - Jaeger 链路追踪。
啥是链路追踪?
我理解链路追踪虽然是为微服务构架提供服务的,当一个恳求中,请求了多个服务单元,如果恳求出现了错误或异常,很难去定位是那个服务出了问题,这时就须要链路追踪。
咱们先看一张图:
这张图的调用链还比较清晰,咱们想像一下,随着服务的越来越多,服务与服务之间调用关系也越来越多,可能还会发展成右图的情况。
这调用关系真的是... 看到这,我的内心是崩溃的。
那么问题来了,这种情况下如何快速定位问题?
如何设计日志记录?
我们自己也可以设计一个链路追踪,比如当发生一个恳求,咱们记录它的:
怎么去实现恳求的惟一标示?
以 Go 为例 写一个中间件,在每次恳求的 Header 中收录:X-Request-Id,代码如下:
func SetUp() gin.HandlerFunc {
return func(c *gin.Context) {
requestId := c.Request.Header.Get("X-Request-Id")
if requestId == "" {
requestId = util.GenUUID()
}
c.Set("X-Request-Id", requestId)
c.Writer.Header().Set("X-Request-Id", requestId)
c.Next()
}
}
复制代码
每个 Request 和 Response 日志中都要收录 X-Request-Id。
问题又来了,每次调用都记录日志,当调用的服务过多时,频繁的记录日志,就会有性能问题呀,肿么办?
哎,这么麻烦,看看市面上有没有一些开源工具呢?
开源工具
这个就不多做介绍了,基本上都能满足需求,至于优缺点,大家可以逐个去看看,喜欢那个就用那个?
我为何选择 Jaeger ?
因为我目前只会用这个,其他还不会 ...
咱们一起看下 Jaeger 是怎么回事吧。
Jaeger 架构图
图片来源于官网。
简单介绍下上图三个关键组件:
Agent
Agent是一个网路守护进程,监听通过UDP发送过来的Span,它会将其批量发送给collector。按照设计,Agent要被布署到所有主机上,作为基础设施。Agent将collector和客户端之间的路由与发觉机制具象了下来。
Collector
Collector从Jaeger Agent接收Trace,并通过一个处理管线对其进行处理。目前的管线会校准Trace、建立索引、执行转换并最终进行储存。存储是一个可插入的组件,现在支持Cassandra和elasticsearch。
Query
Query服务会从储存中检索Trace并通过UI界面进行诠释,该UI界面通过React技术实现,其页面UI如下图所示,展现了一条Trace的详尽信息。
其他组件,大家可以了解下并选择性使用。
Jaeger Span
图片来源于官网。
怎么操作 Span 呢?Span 有什么可以调用的 API ?
Jaeger 部署
All in one
为了便捷你们快速使用,Jaeger 直接提供一个 All in one 包,我们可以直接执行,启动一套完整的 Jaeger tracing 系统。
启动成功后,访问 :16686 就可以看见 Jaeger UI。
独立布署
可以自由搭配,组合使用。
Jaeger 端口Jaeger 采样率
分布式追踪系统本身也会导致一定的性能低耗损,如果完整记录每次恳求,对于生产环境可能会有极大的性能耗损,一般须要进行取样设置。
固定取样
(sampler.type=const)
按比率取样
(sampler.type=probabilistic)
采样速率限制
(sampler.type=ratelimiting)
动态获取采样率
(sampler.type=remote)
Jaeger 缺点
看到这,说的都是理论,大家的心声可能是:
实战
关于实战的分享,我打算整理出 4 个服务,然后实现服务与服务之间进行互相调用,目前 Demo 还没写完... 查看全部
概述
首先同步下项目概况:
上篇文章分享了,路由中间件 - 捕获异常,这篇文章咱们分享:路由中间件 - Jaeger 链路追踪。
啥是链路追踪?
我理解链路追踪虽然是为微服务构架提供服务的,当一个恳求中,请求了多个服务单元,如果恳求出现了错误或异常,很难去定位是那个服务出了问题,这时就须要链路追踪。
咱们先看一张图:
这张图的调用链还比较清晰,咱们想像一下,随着服务的越来越多,服务与服务之间调用关系也越来越多,可能还会发展成右图的情况。
这调用关系真的是... 看到这,我的内心是崩溃的。
那么问题来了,这种情况下如何快速定位问题?
如何设计日志记录?
我们自己也可以设计一个链路追踪,比如当发生一个恳求,咱们记录它的:
怎么去实现恳求的惟一标示?
以 Go 为例 写一个中间件,在每次恳求的 Header 中收录:X-Request-Id,代码如下:
func SetUp() gin.HandlerFunc {
return func(c *gin.Context) {
requestId := c.Request.Header.Get("X-Request-Id")
if requestId == "" {
requestId = util.GenUUID()
}
c.Set("X-Request-Id", requestId)
c.Writer.Header().Set("X-Request-Id", requestId)
c.Next()
}
}
复制代码
每个 Request 和 Response 日志中都要收录 X-Request-Id。
问题又来了,每次调用都记录日志,当调用的服务过多时,频繁的记录日志,就会有性能问题呀,肿么办?
哎,这么麻烦,看看市面上有没有一些开源工具呢?
开源工具
这个就不多做介绍了,基本上都能满足需求,至于优缺点,大家可以逐个去看看,喜欢那个就用那个?
我为何选择 Jaeger ?
因为我目前只会用这个,其他还不会 ...
咱们一起看下 Jaeger 是怎么回事吧。
Jaeger 架构图
图片来源于官网。
简单介绍下上图三个关键组件:
Agent
Agent是一个网路守护进程,监听通过UDP发送过来的Span,它会将其批量发送给collector。按照设计,Agent要被布署到所有主机上,作为基础设施。Agent将collector和客户端之间的路由与发觉机制具象了下来。
Collector
Collector从Jaeger Agent接收Trace,并通过一个处理管线对其进行处理。目前的管线会校准Trace、建立索引、执行转换并最终进行储存。存储是一个可插入的组件,现在支持Cassandra和elasticsearch。
Query
Query服务会从储存中检索Trace并通过UI界面进行诠释,该UI界面通过React技术实现,其页面UI如下图所示,展现了一条Trace的详尽信息。
其他组件,大家可以了解下并选择性使用。
Jaeger Span
图片来源于官网。
怎么操作 Span 呢?Span 有什么可以调用的 API ?
Jaeger 部署
All in one
为了便捷你们快速使用,Jaeger 直接提供一个 All in one 包,我们可以直接执行,启动一套完整的 Jaeger tracing 系统。
启动成功后,访问 :16686 就可以看见 Jaeger UI。
独立布署
可以自由搭配,组合使用。
Jaeger 端口Jaeger 采样率
分布式追踪系统本身也会导致一定的性能低耗损,如果完整记录每次恳求,对于生产环境可能会有极大的性能耗损,一般须要进行取样设置。
固定取样
(sampler.type=const)
按比率取样
(sampler.type=probabilistic)
采样速率限制
(sampler.type=ratelimiting)
动态获取采样率
(sampler.type=remote)
Jaeger 缺点
看到这,说的都是理论,大家的心声可能是:
实战
关于实战的分享,我打算整理出 4 个服务,然后实现服务与服务之间进行互相调用,目前 Demo 还没写完...
利用新浪博客,实现被动精准引流方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2020-08-09 15:31
目前某宝对于那些业务都是直接屏蔽了,我们要买帐号就去QQ群这个渠道。这里你们记得,某宝搜不到的,就来QQ群试试,基本上你想要的虚拟类资源QQ群都有。
当然不仅 QQ 群,你也可以直接在百度里面搜索,大家多找几家对比下。老号肯定比新号权重高,价格也会更贵点,具体的你要按照你的情况来。账号买了后,一定要记得把资料都改下,改成你做的项目关键词的名称。
二、有了帐号后,接下来我们肯定就是搜集大量的长尾关键词
这个方式之前我也讲过。就是借助我们项目的原语来扩充。如果你哪些都不懂,这里也有最笨的技巧。那就是直接用百度搜索,在最下边的下来的虽然都是长尾关键词。
还可以借助一些拓词的网站和工具操作。找到这种词后,记得要搜索下这种词的百度指数,通过数据来瞧瞧,这些长尾词的热度怎么。
搜索下来后我们可以见到,有指数的词目前只显示下来了 X 个,那我们重点就是要做这 X 个有指数的词了。大家做实体产品类的行业词,有指数的肯定会特别多的。这里我只是给你们演示。
三、利用长尾词组合生成标题
就是把都是不同的长尾词组合在一起,变成一个新的文章标题。我举个事例给你们瞧瞧。就是拼接。
长尾词都可以拼接,最新的网路推广项目,月入 2 万的 10 个小生意就生成一个标题了。可能有些人没看明白,我再用产品类的关键词来说明吧。比如减肥类的长尾词,实在是太多了。如何减重,长的胖怎样办,教你怎么快速增肥,怎么减重有疗效,十个简单有效的减重办法,女生例假怎么减重,如何运动减肥
我们随意拼接一组:怎么减重有效?这十个简单有效的减重办法你晓得吗?按照这个思路,我们由于有了好多带指数的长尾词,那我们能够生成好多需求量大的文章标题。
四、标题有了,内容那里来呢
如何才能写原创文章,最好写原创。毕竟原创的文章收录是最好的。如果没有办法,那就用伪原创工具,但容易把文章改的不通顺,事后你须要自己改改就行了。 你若果认为为原创麻烦,那就把文章开头和结尾用自己的话重新描述一遍也行。
你也可以多找几篇文章,把多篇文章内容放到一起,掐头去尾重新拼接下,就弄成了一篇新的文章了。还可以把某一篇文章,用你自己的话抒发下来,这样一篇文章虽然文字不同了,但是核心意思还是没变的。
五、文章做好了
我们须要适当的做文章的优化,因为这样愈发利于收录,特别是你单个博客上面有很多文章的时侯。在文章底部和开头,要做下我们关键词的锚文本。简单的说,就是在某个关键词里面插入超链接。 查看全部
一、需要大量的优质帐号
目前某宝对于那些业务都是直接屏蔽了,我们要买帐号就去QQ群这个渠道。这里你们记得,某宝搜不到的,就来QQ群试试,基本上你想要的虚拟类资源QQ群都有。
当然不仅 QQ 群,你也可以直接在百度里面搜索,大家多找几家对比下。老号肯定比新号权重高,价格也会更贵点,具体的你要按照你的情况来。账号买了后,一定要记得把资料都改下,改成你做的项目关键词的名称。
二、有了帐号后,接下来我们肯定就是搜集大量的长尾关键词
这个方式之前我也讲过。就是借助我们项目的原语来扩充。如果你哪些都不懂,这里也有最笨的技巧。那就是直接用百度搜索,在最下边的下来的虽然都是长尾关键词。
还可以借助一些拓词的网站和工具操作。找到这种词后,记得要搜索下这种词的百度指数,通过数据来瞧瞧,这些长尾词的热度怎么。
搜索下来后我们可以见到,有指数的词目前只显示下来了 X 个,那我们重点就是要做这 X 个有指数的词了。大家做实体产品类的行业词,有指数的肯定会特别多的。这里我只是给你们演示。
三、利用长尾词组合生成标题
就是把都是不同的长尾词组合在一起,变成一个新的文章标题。我举个事例给你们瞧瞧。就是拼接。
长尾词都可以拼接,最新的网路推广项目,月入 2 万的 10 个小生意就生成一个标题了。可能有些人没看明白,我再用产品类的关键词来说明吧。比如减肥类的长尾词,实在是太多了。如何减重,长的胖怎样办,教你怎么快速增肥,怎么减重有疗效,十个简单有效的减重办法,女生例假怎么减重,如何运动减肥
我们随意拼接一组:怎么减重有效?这十个简单有效的减重办法你晓得吗?按照这个思路,我们由于有了好多带指数的长尾词,那我们能够生成好多需求量大的文章标题。
四、标题有了,内容那里来呢
如何才能写原创文章,最好写原创。毕竟原创的文章收录是最好的。如果没有办法,那就用伪原创工具,但容易把文章改的不通顺,事后你须要自己改改就行了。 你若果认为为原创麻烦,那就把文章开头和结尾用自己的话重新描述一遍也行。
你也可以多找几篇文章,把多篇文章内容放到一起,掐头去尾重新拼接下,就弄成了一篇新的文章了。还可以把某一篇文章,用你自己的话抒发下来,这样一篇文章虽然文字不同了,但是核心意思还是没变的。
五、文章做好了
我们须要适当的做文章的优化,因为这样愈发利于收录,特别是你单个博客上面有很多文章的时侯。在文章底部和开头,要做下我们关键词的锚文本。简单的说,就是在某个关键词里面插入超链接。
PatterNodes For Mac v2.2
采集交流 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2020-08-09 14:11
PatterNodes For Mac是黑苹果乐园采集到的一款用于基于重复创建图形模式、动画、渐变或插图的设计工具,软件看上去特别牛逼啊,很直观的设计灵感,但是对于设计没有任何基础的我来说只能说是一个高大上的却不会用的软件
所属分类:图像工具 适用平台:OS X 10.10 或更高版本 软件版本:v2.2.4 最后更新:2019年08月22日
软件介绍
PatterNodes For Mac是黑苹果乐园采集到的一款用于基于重复创建图形模式、动画、渐变或插图的设计工具,软件看上去特别牛逼啊,很直观的设计灵感,但是对于设计没有任何基础的我来说只能说是一个高大上的却不会用的软件,看了一遍官方给的视频也没明白哪些意思,如果你是做设计的我恐怕你是须要他的。
软件有点类似与易语言,就跟说话一样去编程的意思。这通过定义描述模式的步骤,配方或排序的序列来完成。可视脚本,因为它有时被称为。每个模式元素或操作由称为节点的小面板表示,然后通过在它们之间勾画的联接来链接节点。由于节点可以自由组合和联接,这给您一个十分灵活和强悍的插口。
Sketch For Mac v59.1 专业矢量绘图图形设计工具破解版
Sketch For Mac v59.1 是黑苹果乐园采集到的一款矢量图形勾画工具,软件是为现代平面设计师构建的,它显示在应用程序的每位纤维。 从灵活的工作流程支持多页和画板。 强大的功能,如符号和共...
Affinity Designer For Mac v1.6.1 专业的矢量图形设计工具
Affinity Designer For Mac v1.6.1是黑苹果乐园采集到的一款专业的矢量图形设计工具,现在做设计的能选择的软件也比较多,但是Affinity Designe 兼容性强,支持 ...
Adobe illustrator CC v2017 21.0 矢量图形设计制做软件
Adobe illustrator CC 2017 21.0是黑苹果乐园采集到的一款矢量图形设计制做软件,在新的MacBook Pro发布后Adobe公司更新了旗下的所有设计软件,包括Photosho...
Acorn For Mac v6.5.1 轻量级图片处理工具PS 替代者
Acorn For Mac v6.5.1 是黑苹果乐园采集到的一款Mac平台上的轻量级图片处理工具,可以说是一个Photoshop的轻量级替代者,如果你不想每次都是用笨重的ps来处理图片,你完全可以试...
PatterNodes从一开始就设计,以便轻松地调整事物,看看它们是怎么形成的。因此,最终的纹样图块总是显示在顶部预览视图中,随时重复和更新任何修改,让您即时反馈最终结果将是哪些。
虽然软件可以用于创建任何类型的重复图形,但它主要针对模式创建。使纹样创建更容易PatterNodes还包括许多节点,这些节点手动执行常见的冗长任务,例如在图块边沿重复元素以让纹样无缝,或者让纹样的不同方面(例如颜色,位置,旋转...)模式给它一点生活。
最后,完成后,您可以将模式图块复制到您使用的任何插图或图形应用程序中,或将其导入为矢量图形或位图图象文件。
软件截图
更新内容下载地址
PatterNodes For Mac v2.2.4
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
历史版本
PatterNodes For Mac v2.2.1
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
PatterNodes For Mac v2.2.0
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
PatterNodes For Mac v2.1.9
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
PatterNodes For Mac v2.1.8
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
PatterNodes For Mac v2.1.7
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
PatterNodes For Mac v2.1.2
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
PatterNodes For Mac v2.1.1
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!] 查看全部
摘 要
PatterNodes For Mac是黑苹果乐园采集到的一款用于基于重复创建图形模式、动画、渐变或插图的设计工具,软件看上去特别牛逼啊,很直观的设计灵感,但是对于设计没有任何基础的我来说只能说是一个高大上的却不会用的软件
所属分类:图像工具 适用平台:OS X 10.10 或更高版本 软件版本:v2.2.4 最后更新:2019年08月22日
软件介绍
PatterNodes For Mac是黑苹果乐园采集到的一款用于基于重复创建图形模式、动画、渐变或插图的设计工具,软件看上去特别牛逼啊,很直观的设计灵感,但是对于设计没有任何基础的我来说只能说是一个高大上的却不会用的软件,看了一遍官方给的视频也没明白哪些意思,如果你是做设计的我恐怕你是须要他的。
软件有点类似与易语言,就跟说话一样去编程的意思。这通过定义描述模式的步骤,配方或排序的序列来完成。可视脚本,因为它有时被称为。每个模式元素或操作由称为节点的小面板表示,然后通过在它们之间勾画的联接来链接节点。由于节点可以自由组合和联接,这给您一个十分灵活和强悍的插口。
Sketch For Mac v59.1 专业矢量绘图图形设计工具破解版
Sketch For Mac v59.1 是黑苹果乐园采集到的一款矢量图形勾画工具,软件是为现代平面设计师构建的,它显示在应用程序的每位纤维。 从灵活的工作流程支持多页和画板。 强大的功能,如符号和共...
Affinity Designer For Mac v1.6.1 专业的矢量图形设计工具
Affinity Designer For Mac v1.6.1是黑苹果乐园采集到的一款专业的矢量图形设计工具,现在做设计的能选择的软件也比较多,但是Affinity Designe 兼容性强,支持 ...
Adobe illustrator CC v2017 21.0 矢量图形设计制做软件
Adobe illustrator CC 2017 21.0是黑苹果乐园采集到的一款矢量图形设计制做软件,在新的MacBook Pro发布后Adobe公司更新了旗下的所有设计软件,包括Photosho...
Acorn For Mac v6.5.1 轻量级图片处理工具PS 替代者
Acorn For Mac v6.5.1 是黑苹果乐园采集到的一款Mac平台上的轻量级图片处理工具,可以说是一个Photoshop的轻量级替代者,如果你不想每次都是用笨重的ps来处理图片,你完全可以试...
PatterNodes从一开始就设计,以便轻松地调整事物,看看它们是怎么形成的。因此,最终的纹样图块总是显示在顶部预览视图中,随时重复和更新任何修改,让您即时反馈最终结果将是哪些。
虽然软件可以用于创建任何类型的重复图形,但它主要针对模式创建。使纹样创建更容易PatterNodes还包括许多节点,这些节点手动执行常见的冗长任务,例如在图块边沿重复元素以让纹样无缝,或者让纹样的不同方面(例如颜色,位置,旋转...)模式给它一点生活。
最后,完成后,您可以将模式图块复制到您使用的任何插图或图形应用程序中,或将其导入为矢量图形或位图图象文件。
软件截图
更新内容下载地址
PatterNodes For Mac v2.2.4
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
历史版本
PatterNodes For Mac v2.2.1
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
PatterNodes For Mac v2.2.0
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
PatterNodes For Mac v2.1.9
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
PatterNodes For Mac v2.1.8
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
PatterNodes For Mac v2.1.7
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
PatterNodes For Mac v2.1.2
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
PatterNodes For Mac v2.1.1
提取密码: ******** [隐藏信息,登陆并发表评论后刷新可见!]
表单处理不用愁,这五款软件才能精准提取数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2020-08-09 13:48
其实,只须要一款才能提取数据的软件,就能避开重复步骤,一步完成工作,大大提升工作效率。在此,小编为你们推荐几款软件。
1、Formtalk
Formtalk 是专为企业用户提供的一站式办公应用订制平台,它具有企业级数据的采集和管理,能够满足企业内外部包括报考、登记、预约、投票、调查等在内的数据采集需求。这款软件就能帮助用户实时跟踪须要采集的数据,呈现为可视化报表,同时,它的PC表单设计引擎、移动表单设计引擎、安全引擎和数据集成插口四项核心技术才能为用户提供表单复制、表单授权及表单提取功能,让用户才能有效提升工作效率。
2、PDFelement
PDFelement 在处理 PDF 表单和提取数据这一块堪称攻打行业制高点。 它能帮助用户一键辨识表单域(交互式表单域和非交互式表单域皆可辨识),也能帮助用户自定义创建个性表单,比如单选、多选、下拉表、文本框、数字签名等。 当用户面对海量 PDF 表单,需要提取其中一项或则多项关键数据时,它能帮助用户确切提取表单数据,批量处理为用户节约了大量时间和精力。
用户仅需将大量 PDF 拖入程序中,选择须要提取的区域,这些数据将会导出到Excel中。 如果这种 PDF 文档是扫描文件,也无需害怕,PDFelement 执行 OCR,将文档转换为可编辑的文档,再进行数据提取操作。
3、金数据
这款表单处理工具是通用型的表单工具,主要功能集聚于数据搜集和数据提取上,在数据统计和数据剖析上有所缺乏。用金数据生成的表单除了能以 Excel 表格的方式呈现,而且还能以链接或则 HTML 代码的方式嵌入到网页、微信文章之中。除此之外,这款软件在搜集、提取数据的同时还能接入不同的支付端口,非常适宜网店订单、用户反馈等业务数据的搜集和提取。
4、易表
这款软件的功能介于电子表格与数据库软件之间,拥有类似电子表格的界面,也具备数据库软件特有的功能和灵活性。易表在数据处理上是十分优秀的软件,能够帮助用户完美完成复杂的数据管理和统计剖析工作。但是,它的功能要求用户具备一定的开发能力,只有了解基本的编程知识能够快速构建属于自己的数据管理系统,比较适宜专业性较强的用户,普通用户使用这款软件的学习成本偏高。
5、Foxtable
这款软件将 Excel、Access、Foxpro、VB 等软件的优势融合在一起,无论是数据录入、提取,还是报表生成,用户都无需编撰代码即可完成以上这种复杂的数据管理工作。这款软件的亮点之一是外置了 HTTP 服务和手机网页功能,用户无需任何专业知识才能够开发出自己移动端的管理软件,做到 PC 端与移动端的数据移动。相比于其他数据处理软件,这款软件更象是一个高效开发工具,让用户在开发属于自己的数据库时更关注商业逻辑,导致具体功能的实现比较艰辛。同时,由于Foxtable支持外部数据源,也就意味着用户提供的数据有一定的安全风险。
你是否也有兴趣瞧瞧《身在职场不会处理这5种文档,还谈涨薪?》 查看全部
对于企业用户来说,特别是人事、财务这类时常接触到数据的岗位,工作中必不可少会接触到一些数据搜集和剖析。很多时侯,用户会接收到大量相同表单,但常常只须要表单中的一两项关键数据,针对这些情况,如果用户仍然坚守传统的办公形式,往往会有大量重复动作,大大减少了工作效率。
其实,只须要一款才能提取数据的软件,就能避开重复步骤,一步完成工作,大大提升工作效率。在此,小编为你们推荐几款软件。
1、Formtalk
Formtalk 是专为企业用户提供的一站式办公应用订制平台,它具有企业级数据的采集和管理,能够满足企业内外部包括报考、登记、预约、投票、调查等在内的数据采集需求。这款软件就能帮助用户实时跟踪须要采集的数据,呈现为可视化报表,同时,它的PC表单设计引擎、移动表单设计引擎、安全引擎和数据集成插口四项核心技术才能为用户提供表单复制、表单授权及表单提取功能,让用户才能有效提升工作效率。
2、PDFelement
PDFelement 在处理 PDF 表单和提取数据这一块堪称攻打行业制高点。 它能帮助用户一键辨识表单域(交互式表单域和非交互式表单域皆可辨识),也能帮助用户自定义创建个性表单,比如单选、多选、下拉表、文本框、数字签名等。 当用户面对海量 PDF 表单,需要提取其中一项或则多项关键数据时,它能帮助用户确切提取表单数据,批量处理为用户节约了大量时间和精力。
用户仅需将大量 PDF 拖入程序中,选择须要提取的区域,这些数据将会导出到Excel中。 如果这种 PDF 文档是扫描文件,也无需害怕,PDFelement 执行 OCR,将文档转换为可编辑的文档,再进行数据提取操作。
3、金数据
这款表单处理工具是通用型的表单工具,主要功能集聚于数据搜集和数据提取上,在数据统计和数据剖析上有所缺乏。用金数据生成的表单除了能以 Excel 表格的方式呈现,而且还能以链接或则 HTML 代码的方式嵌入到网页、微信文章之中。除此之外,这款软件在搜集、提取数据的同时还能接入不同的支付端口,非常适宜网店订单、用户反馈等业务数据的搜集和提取。
4、易表
这款软件的功能介于电子表格与数据库软件之间,拥有类似电子表格的界面,也具备数据库软件特有的功能和灵活性。易表在数据处理上是十分优秀的软件,能够帮助用户完美完成复杂的数据管理和统计剖析工作。但是,它的功能要求用户具备一定的开发能力,只有了解基本的编程知识能够快速构建属于自己的数据管理系统,比较适宜专业性较强的用户,普通用户使用这款软件的学习成本偏高。
5、Foxtable
这款软件将 Excel、Access、Foxpro、VB 等软件的优势融合在一起,无论是数据录入、提取,还是报表生成,用户都无需编撰代码即可完成以上这种复杂的数据管理工作。这款软件的亮点之一是外置了 HTTP 服务和手机网页功能,用户无需任何专业知识才能够开发出自己移动端的管理软件,做到 PC 端与移动端的数据移动。相比于其他数据处理软件,这款软件更象是一个高效开发工具,让用户在开发属于自己的数据库时更关注商业逻辑,导致具体功能的实现比较艰辛。同时,由于Foxtable支持外部数据源,也就意味着用户提供的数据有一定的安全风险。
你是否也有兴趣瞧瞧《身在职场不会处理这5种文档,还谈涨薪?》
2019在线智能AI文章伪原创网站源码,站长自媒体营运必备工具,上传即用
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2020-08-09 13:47
安装环境
商品介绍
直接上传即可使用,亲测没问题。
智能AI伪原创是做哪些的?
各位站长同学想必都为网站内容原创的问题头痛吧,作为一个草根站长,要想自己写原创文章,那是不可能的,当然我不是说你一篇也写不下来。以个人站长的人力来说,写原创文章不太实际,光时刻便是问题。
或许有的站长同学该问:不写原创文章怎么弄好网站呢?其实不光是我们,便是国外的几个大门户也不全是原创文章,他们互相之前也是用来内容更改一下,再改改标题,就成了自己的“新闻”。 下面该谈谈,我这个伪原创工具了。本程序是免费的在线伪原创工具,原理便是反义词替换。
有同事问我,这样会不会被K,算不算做弊?就这个问题我宣布一下个人的观点供你参阅。搜索引擎其实是机器,他抓取文章后会在数据库中与已有的文章做一个比对,假如发觉有相似度很高的文章则觉得是剽窃,反之觉得是原创。当然如果你是原貌仿效的,那么就订死是剽窃的。用伪原创工具转化后,文章中的部份单词被转化成反义词,搜索引擎再比对时,就觉得是原创文章了。当然这也不是肯定的,看详尽转化单词多少而言。
这款伪原创php源码无后台,直接将源码上传到空间任意目录下都可以运用,假如不是上传到网站根目录的话,记得要掀开index.html文件,修改css和js文件地址,否则掀开后页面凸显会出现问题。 查看全部
商品属性
安装环境
商品介绍
直接上传即可使用,亲测没问题。
智能AI伪原创是做哪些的?
各位站长同学想必都为网站内容原创的问题头痛吧,作为一个草根站长,要想自己写原创文章,那是不可能的,当然我不是说你一篇也写不下来。以个人站长的人力来说,写原创文章不太实际,光时刻便是问题。
或许有的站长同学该问:不写原创文章怎么弄好网站呢?其实不光是我们,便是国外的几个大门户也不全是原创文章,他们互相之前也是用来内容更改一下,再改改标题,就成了自己的“新闻”。 下面该谈谈,我这个伪原创工具了。本程序是免费的在线伪原创工具,原理便是反义词替换。
有同事问我,这样会不会被K,算不算做弊?就这个问题我宣布一下个人的观点供你参阅。搜索引擎其实是机器,他抓取文章后会在数据库中与已有的文章做一个比对,假如发觉有相似度很高的文章则觉得是剽窃,反之觉得是原创。当然如果你是原貌仿效的,那么就订死是剽窃的。用伪原创工具转化后,文章中的部份单词被转化成反义词,搜索引擎再比对时,就觉得是原创文章了。当然这也不是肯定的,看详尽转化单词多少而言。
这款伪原创php源码无后台,直接将源码上传到空间任意目录下都可以运用,假如不是上传到网站根目录的话,记得要掀开index.html文件,修改css和js文件地址,否则掀开后页面凸显会出现问题。
如果我不能写文章怎么办?了解有用的伪原创工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2020-08-08 10:47
但是,为网站生成少量原创内容并不难,但是对于任何草根网站管理员,尤其是某些垂直行业网站,每天更新都是非常困难的. 内容是相对固定的,并且很难发布原创内容. 因此,伪原创是一种重要的方式. 但是,传统的伪原创方法很难提高内容的质量,这将使该网站成为垃圾邮件网站. 因此,从发展的角度来看,提高伪原创的质量至关重要.
那么我们如何才能有效提高伪原创内容的质量?我认为我们可以从以下几个方面入手,使伪原创内容的质量与原创内容的质量相等.
第一个是伪原创的并购创新方法.
我们知道,伪原创通常是在Internet上找到一些内容,然后更改标题以打扰文章段落. 有些甚至使用伪原创工具来替换同义词. 因此,伪原创内容的可读性变得很差,因此我们放弃了这种伪原创方法,而是可以将相关内容整合并以我们自己的语言重新组织. 在梳理过程中,可以将一些创新与相关内容结合起来,以使这种伪原创内容呈现出新的事物.
合并相关内容时,必须确保第一段和最后一段是原创内容,并在这两个位置建立中心内容. 该核心内容通常可以与不同概念的集成结合在一起. 作为网站管理员,这时您有自己的独立思考,因此也可以编写. 这样可以有效地保证伪原创内容的质量,即使文章中的某些内容具有高度的相似性,也不会导致百度不喜欢它.
第二个是内容与科学采集的结合.
我们知道Internet上的某些内容与市场上出售的图书有关,但它们不能相同. 否则,这些书将被复制,因此我们可以将这些书的内容传输到Internet. ,并进行了一些优化和创新,可以将其转换为非常好的原创内容,同时还具有良好的可读性和知识,并成为百度蜘蛛最喜欢的内容.
用于集成现有的Internet内容,例如制作一些论坛帖子,游戏指南和其他综合内容. 这些内容通常不需要原创,而只需在Internet上采集相关内容,然后这些内容的组合就可以形成非常有价值的内容,并且这些内容也是百度Spider的最爱,并且有望成为其的常客百度的主页.
第三,等效的交换方法
①文本排序方法: 如果您在本网站上获得本文“游戏编辑撰写伪第一篇文章的五个提示”,您将如何制定等效的交换方法?当同义词和标题关键字受到干扰时,它们可以实现等效的交换,您可以将其更改为“游戏编辑者撰写伪第一篇文章的五种技巧”和“游戏编辑者撰写伪第一篇文章的五种技巧”. 可以看出,标题已经微妙地改变了,但是含义没有改变. 这是等效的交换方法.
②数字交换方法: 例如,标题: 五个错误的优先技能,您可以停止适当地删除一些您认为不是错误的优先技能,或者添加一些错误的优先技能,至少可以让搜索引擎认为您的标题不一样.
③换词方法: 王文生是在改变相关或相似的词,从而达到不换药就可以换汤的效果.
第四,标题组合方法
组合方法与上述三种或两种方法一起使用. 例如,在标题为“网站管理员如何进行网站营销分析和制定策略”的文章中,可以将其更改为“好的网络营销分析需要好的措施”,即采用等效的交换方法和文本修改方法.
以上伪原创方法可以有效地提高内容创建的速度,并且可以有效地扩展内容创建的空间. 但是,当我们是伪原创时,我们必须注意内容的可读性,而不仅仅是通过软件. 同义词替换,段落改组方法. 尝试将自己的一些意见纳入伪原创.
实际上,我将告诉您这篇文章是使用伪原创软件撰写的?是的,所有这些都只是排版和图片,我什至没有读过这篇文章.
接下来,检查您阅读的本文的测试结果:
创意是100%,您感到惊讶还是惊讶?
就是这样! Zhimedia AI批处理写作助手可以轻松地一键创建高质量的文章内容! 查看全部
众所周知,百度搜索引擎对网站内容质量的要求越来越高. 如果网站的内容质量很差,即使该网站有很多外部链接,也有很多高质量的外部链接,并且通常不会获得很高的排名,因为内容较差的网站往往具有很高的排名. 跳出率. 这已经成为百度排名算法的重要元素
但是,为网站生成少量原创内容并不难,但是对于任何草根网站管理员,尤其是某些垂直行业网站,每天更新都是非常困难的. 内容是相对固定的,并且很难发布原创内容. 因此,伪原创是一种重要的方式. 但是,传统的伪原创方法很难提高内容的质量,这将使该网站成为垃圾邮件网站. 因此,从发展的角度来看,提高伪原创的质量至关重要.
那么我们如何才能有效提高伪原创内容的质量?我认为我们可以从以下几个方面入手,使伪原创内容的质量与原创内容的质量相等.
第一个是伪原创的并购创新方法.
我们知道,伪原创通常是在Internet上找到一些内容,然后更改标题以打扰文章段落. 有些甚至使用伪原创工具来替换同义词. 因此,伪原创内容的可读性变得很差,因此我们放弃了这种伪原创方法,而是可以将相关内容整合并以我们自己的语言重新组织. 在梳理过程中,可以将一些创新与相关内容结合起来,以使这种伪原创内容呈现出新的事物.
合并相关内容时,必须确保第一段和最后一段是原创内容,并在这两个位置建立中心内容. 该核心内容通常可以与不同概念的集成结合在一起. 作为网站管理员,这时您有自己的独立思考,因此也可以编写. 这样可以有效地保证伪原创内容的质量,即使文章中的某些内容具有高度的相似性,也不会导致百度不喜欢它.
第二个是内容与科学采集的结合.
我们知道Internet上的某些内容与市场上出售的图书有关,但它们不能相同. 否则,这些书将被复制,因此我们可以将这些书的内容传输到Internet. ,并进行了一些优化和创新,可以将其转换为非常好的原创内容,同时还具有良好的可读性和知识,并成为百度蜘蛛最喜欢的内容.
用于集成现有的Internet内容,例如制作一些论坛帖子,游戏指南和其他综合内容. 这些内容通常不需要原创,而只需在Internet上采集相关内容,然后这些内容的组合就可以形成非常有价值的内容,并且这些内容也是百度Spider的最爱,并且有望成为其的常客百度的主页.
第三,等效的交换方法
①文本排序方法: 如果您在本网站上获得本文“游戏编辑撰写伪第一篇文章的五个提示”,您将如何制定等效的交换方法?当同义词和标题关键字受到干扰时,它们可以实现等效的交换,您可以将其更改为“游戏编辑者撰写伪第一篇文章的五种技巧”和“游戏编辑者撰写伪第一篇文章的五种技巧”. 可以看出,标题已经微妙地改变了,但是含义没有改变. 这是等效的交换方法.
②数字交换方法: 例如,标题: 五个错误的优先技能,您可以停止适当地删除一些您认为不是错误的优先技能,或者添加一些错误的优先技能,至少可以让搜索引擎认为您的标题不一样.
③换词方法: 王文生是在改变相关或相似的词,从而达到不换药就可以换汤的效果.
第四,标题组合方法
组合方法与上述三种或两种方法一起使用. 例如,在标题为“网站管理员如何进行网站营销分析和制定策略”的文章中,可以将其更改为“好的网络营销分析需要好的措施”,即采用等效的交换方法和文本修改方法.
以上伪原创方法可以有效地提高内容创建的速度,并且可以有效地扩展内容创建的空间. 但是,当我们是伪原创时,我们必须注意内容的可读性,而不仅仅是通过软件. 同义词替换,段落改组方法. 尝试将自己的一些意见纳入伪原创.
实际上,我将告诉您这篇文章是使用伪原创软件撰写的?是的,所有这些都只是排版和图片,我什至没有读过这篇文章.
接下来,检查您阅读的本文的测试结果:
创意是100%,您感到惊讶还是惊讶?
就是这样! Zhimedia AI批处理写作助手可以轻松地一键创建高质量的文章内容!
掌握3种搜索技术并在GitHub上快速找到有用的软件资源
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2020-08-07 22:47
对于用户而言,我不禁要问: 面对如此众多的GitHub项目,该平台如何才能发现一些出色的软件和工具. 带着这个问题,我采集并总结了以下搜索技术.
热门搜索: GitHub趋势和GitHub主题
“ GitHub趋势”页面按每日/每周/每月的周期总结了受欢迎的存储库和开发人员. 您可以查看处于特定周期中处于热门状态的开发项目和开发人员. GitHub Topic显示最新和最受欢迎的讨论主题. 在这里,您不仅可以看到开发项目,还可以看到更多非开发技术的讨论主题,例如Job,Chrome浏览器等.
GitHub趋势
GitHub开发人员主题搜索
有传言说,当人力资源部招聘开发人员时,被招聘对象在GitHub上的贡献将是重要的参考指标之一. 作为优秀的国内开源软件的发行中心之一,GitHub埋葬了许多杰出的开发人员,因此,在寻找本地软件时,您可以尝试首先找到本地开发人员. 使用GitHub强大的搜索功能,您可以通过添加一些搜索参数轻松地找到“目标人物”.
(注意: GitHub正式支持许多搜索条件. 您可以在此处查看官方搜索技术. )
Github搜索提示查找开发人员
例如,如果您需要寻找家用软件,那么想到的第一件事就是在GituHub上寻找家用开发人员. 搜索时,将位置设置为中国. 如果要查找使用javascript的开发人员,然后在javascript中添加语言,则整个搜索条件是: Language: javascript location: china,从搜索结果中,我们发现了将近17,000个javascript开发人员,其区域信息被填充为中国. 熟悉朋友的阮一峰老师名列前茅. 根据官方指南,在搜索GitHub用户时,您还可以使用关注者和in: fullname的组合进行搜索.
使用组合条件进行搜索
按搜索条件搜索
我们需要在GitHub上找到出色的项目和工具. 同样,使用关键字或设置搜索词将帮助您以一半的努力找到良好的资源. 我的习惯是先搜索某些关键字,然后获得的搜索结果首先显示一些现成的软件和工具.
GitHub搜索提示查找项目
很棒的关键字
Awesome似乎已成为许多GitHub项目最喜欢的名称之一. 例如,如前所述,要找到出色的Windows软件,您可以尝试搜索Awesome窗口并获取以下搜索结果:
很棒的Windows搜索结果
最出色的结果是Windows / Awesome项目,它是Windows上高质量和精选的最佳应用程序和工具的集合. 在这里,我采集了一些关于Awesome主题的优秀项目: Awesome声明,Awesome iOS框架,Awesome令人讨厌的Android库和资源.
设置搜索条件
如果您明确需要寻找某种类型的项目,例如需要使用某种语言进行开发的项目,并且星数需要达到标准,则可以直接在搜索中输入搜索条件框. 其中,对于发现项目,我的用法是灵活地使用以下搜索条件: stars: ,language: ,fork :,实际上是设置项目集合,开发语言和派生的搜索条件(例如输入stars) : > = 500语言: javascript是大于或等于500的javascript项目的集合. 排名最高的是开源代码库和课程项目freeCodeCamp,以及流行的Vue和React项目.
搜索条件= 500语言: javascript>
如果记住这些搜索条件有点麻烦,请使用GitHub提供的高级搜索功能,还可以使用自定义条件进行搜索. 或参考官方帮助指南“在GitHub上搜索”,该手册提供了更多针对项目,代码,注释和问题的搜索技术.
GitHub高级搜索功能
以下是GitHub上最具影响力的项目,仅列出其中一些:
结论
GitHub网站上有许多出色的开源项目. 为了充分利用GitHub的搜索功能,我们可以使用官方的高级搜索以及“主题和趋势”页面,或者学习如何结合搜索条件来主动发现更多使用的优秀项和工具. 查看全部
GitHub是目前大多数程序员的最大游乐场. 今年6月,它被微软以价值75亿美元的微软股票收购. GitHub再次成为业界讨论的焦点. 凭借其免费和开放的定位,GitHub吸引了许多个人开发人员和公司,并且继续发布和更新非常有用的软件和工具. 以前,少数群体在GitHub上组织并推荐了免费且易于使用的Windows和macOS平台软件:
对于用户而言,我不禁要问: 面对如此众多的GitHub项目,该平台如何才能发现一些出色的软件和工具. 带着这个问题,我采集并总结了以下搜索技术.
热门搜索: GitHub趋势和GitHub主题
“ GitHub趋势”页面按每日/每周/每月的周期总结了受欢迎的存储库和开发人员. 您可以查看处于特定周期中处于热门状态的开发项目和开发人员. GitHub Topic显示最新和最受欢迎的讨论主题. 在这里,您不仅可以看到开发项目,还可以看到更多非开发技术的讨论主题,例如Job,Chrome浏览器等.
GitHub趋势
GitHub开发人员主题搜索
有传言说,当人力资源部招聘开发人员时,被招聘对象在GitHub上的贡献将是重要的参考指标之一. 作为优秀的国内开源软件的发行中心之一,GitHub埋葬了许多杰出的开发人员,因此,在寻找本地软件时,您可以尝试首先找到本地开发人员. 使用GitHub强大的搜索功能,您可以通过添加一些搜索参数轻松地找到“目标人物”.
(注意: GitHub正式支持许多搜索条件. 您可以在此处查看官方搜索技术. )
Github搜索提示查找开发人员
例如,如果您需要寻找家用软件,那么想到的第一件事就是在GituHub上寻找家用开发人员. 搜索时,将位置设置为中国. 如果要查找使用javascript的开发人员,然后在javascript中添加语言,则整个搜索条件是: Language: javascript location: china,从搜索结果中,我们发现了将近17,000个javascript开发人员,其区域信息被填充为中国. 熟悉朋友的阮一峰老师名列前茅. 根据官方指南,在搜索GitHub用户时,您还可以使用关注者和in: fullname的组合进行搜索.
使用组合条件进行搜索
按搜索条件搜索
我们需要在GitHub上找到出色的项目和工具. 同样,使用关键字或设置搜索词将帮助您以一半的努力找到良好的资源. 我的习惯是先搜索某些关键字,然后获得的搜索结果首先显示一些现成的软件和工具.
GitHub搜索提示查找项目
很棒的关键字
Awesome似乎已成为许多GitHub项目最喜欢的名称之一. 例如,如前所述,要找到出色的Windows软件,您可以尝试搜索Awesome窗口并获取以下搜索结果:
很棒的Windows搜索结果
最出色的结果是Windows / Awesome项目,它是Windows上高质量和精选的最佳应用程序和工具的集合. 在这里,我采集了一些关于Awesome主题的优秀项目: Awesome声明,Awesome iOS框架,Awesome令人讨厌的Android库和资源.
设置搜索条件
如果您明确需要寻找某种类型的项目,例如需要使用某种语言进行开发的项目,并且星数需要达到标准,则可以直接在搜索中输入搜索条件框. 其中,对于发现项目,我的用法是灵活地使用以下搜索条件: stars: ,language: ,fork :,实际上是设置项目集合,开发语言和派生的搜索条件(例如输入stars) : > = 500语言: javascript是大于或等于500的javascript项目的集合. 排名最高的是开源代码库和课程项目freeCodeCamp,以及流行的Vue和React项目.
搜索条件= 500语言: javascript>
如果记住这些搜索条件有点麻烦,请使用GitHub提供的高级搜索功能,还可以使用自定义条件进行搜索. 或参考官方帮助指南“在GitHub上搜索”,该手册提供了更多针对项目,代码,注释和问题的搜索技术.
GitHub高级搜索功能
以下是GitHub上最具影响力的项目,仅列出其中一些:
结论
GitHub网站上有许多出色的开源项目. 为了充分利用GitHub的搜索功能,我们可以使用官方的高级搜索以及“主题和趋势”页面,或者学习如何结合搜索条件来主动发现更多使用的优秀项和工具.
如何采集和整理原创的公共帐户文章,介绍以下实用方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2020-08-07 18:27
如今,微信的功能越来越完善. 人们经常使用微信聊天或阅读一些官方账号文章,而微信官方账号形式多样,并且有很多发表的文章. 采集官方帐户文章怎么样?继续吗?让我们从下面的Tuotu Data谈起它.
在官方帐户上采集文章
如何分析,采集和组织微信公众号文章的材料
1. 为什么要采集?
采集的优点是节省您的时间成本. 预先采集的信息就像是一道菜,只需要随意组合和油炸即可. 也许原创的创作者会比重印者有更多的经验.
例如:
假设我是原创作者,今天我想发表一篇活跃的文章. 假设我之前已经采集了活跃的文章,那么我只需要执行一个例程即可,但是如果我没有采集这条信息,则需要重新开始. 了解距离就是时间成本.
假设我是一名避难所,我需要发推文并准备接下来几天的内容. 除非有可用的东西,否则我必须花很长时间才能完成它,假设可以在闲暇时完成数据采集,那么时间成本就不会很高.
2. 如何分析数据
采集的条件必须是对Su进行搜索和分析,并对文章进行系统的分类. 分类标准不必按类型,性质甚至关键字进行分类. 我总结了以下几点.
阅读量高,转发量低.
阅读量少,转发率高.
阅读和转发很高.
查看和转发都很低.
编辑器如何分析这些数据?有两种方法. 首先,手动提取历史文章,逐一写下喜欢的阅读次数,然后每月和每周. 按年份排序,看看出了什么问题.
第二种方法是使用第三方数据工具Tuotu Data导出官方帐户的历史文章,包括读取和喜欢的数据,以便可以在数据表中轻松分析导出.
在官方帐户上采集文章
微信公众号文章采集
在浏览器中打开百度,搜索相关网站,然后单击进入.
首先,让我们了解图形介绍和视频教程以及各种操作步骤.
有些类别,关键字,自定义采集集等可以发布到官方帐户或网站上.
受支持的系统包括dedecms,phpcms,WordPress,discuz,EmpireCMS和mysql等接口.
在微信公众号上采集文章的几种方案
方案1: 基于搜狗门户
从可以在Internet上搜索的官方帐户文章中采集的相关信息来看,这是最,最直接,最简单的解决方案.
一般过程是:
1. 在搜狗微信搜索门户上搜索官方帐户.
2. 选择官方帐户以输入官方帐户的历史文章列表. 3.分析文章的内容并将其存储在数据库中.
如果收款频率太高,验证码将显示在搜狗搜索中,并可以访问官方帐户历史记录文章列表. 直接使用常规脚本集合无法获得验证码. 在这里,您可以使用无头浏览器通过对接和编码平台访问和识别验证码. 硒可以用作无头浏览器.
即使是无头浏览器也存在问题:
1. 低效率(实际上是运行完整的浏览器来模拟人工操作).
2. 在浏览器中难以控制Web资源的加载,并且在脚本中也难以控制浏览器的加载. 3.验证码识别不能100%,并且爬网过程可能会在中间中断.
如果您坚持使用搜狗门户并希望执行完美的采集,则只能增加代理IP. 顺便说一句,甚至不要考虑公开一个免费的IP地址,它非常不稳定,并且基本上被微信阻止.
除了Sogou / WeChat反爬虫机制外,采用此解决方案还有其他缺点: 查看全部
如今,微信的功能越来越完善. 人们经常使用微信聊天或阅读一些官方账号文章,而微信官方账号形式多样,并且有很多发表的文章. 采集官方帐户文章怎么样?继续吗?让我们从下面的Tuotu Data谈起它.
在官方帐户上采集文章
如何分析,采集和组织微信公众号文章的材料
1. 为什么要采集?
采集的优点是节省您的时间成本. 预先采集的信息就像是一道菜,只需要随意组合和油炸即可. 也许原创的创作者会比重印者有更多的经验.
例如:
假设我是原创作者,今天我想发表一篇活跃的文章. 假设我之前已经采集了活跃的文章,那么我只需要执行一个例程即可,但是如果我没有采集这条信息,则需要重新开始. 了解距离就是时间成本.
假设我是一名避难所,我需要发推文并准备接下来几天的内容. 除非有可用的东西,否则我必须花很长时间才能完成它,假设可以在闲暇时完成数据采集,那么时间成本就不会很高.
2. 如何分析数据
采集的条件必须是对Su进行搜索和分析,并对文章进行系统的分类. 分类标准不必按类型,性质甚至关键字进行分类. 我总结了以下几点.
阅读量高,转发量低.
阅读量少,转发率高.
阅读和转发很高.
查看和转发都很低.
编辑器如何分析这些数据?有两种方法. 首先,手动提取历史文章,逐一写下喜欢的阅读次数,然后每月和每周. 按年份排序,看看出了什么问题.
第二种方法是使用第三方数据工具Tuotu Data导出官方帐户的历史文章,包括读取和喜欢的数据,以便可以在数据表中轻松分析导出.
在官方帐户上采集文章
微信公众号文章采集
在浏览器中打开百度,搜索相关网站,然后单击进入.
首先,让我们了解图形介绍和视频教程以及各种操作步骤.
有些类别,关键字,自定义采集集等可以发布到官方帐户或网站上.
受支持的系统包括dedecms,phpcms,WordPress,discuz,EmpireCMS和mysql等接口.
在微信公众号上采集文章的几种方案
方案1: 基于搜狗门户
从可以在Internet上搜索的官方帐户文章中采集的相关信息来看,这是最,最直接,最简单的解决方案.
一般过程是:
1. 在搜狗微信搜索门户上搜索官方帐户.
2. 选择官方帐户以输入官方帐户的历史文章列表. 3.分析文章的内容并将其存储在数据库中.
如果收款频率太高,验证码将显示在搜狗搜索中,并可以访问官方帐户历史记录文章列表. 直接使用常规脚本集合无法获得验证码. 在这里,您可以使用无头浏览器通过对接和编码平台访问和识别验证码. 硒可以用作无头浏览器.
即使是无头浏览器也存在问题:
1. 低效率(实际上是运行完整的浏览器来模拟人工操作).
2. 在浏览器中难以控制Web资源的加载,并且在脚本中也难以控制浏览器的加载. 3.验证码识别不能100%,并且爬网过程可能会在中间中断.
如果您坚持使用搜狗门户并希望执行完美的采集,则只能增加代理IP. 顺便说一句,甚至不要考虑公开一个免费的IP地址,它非常不稳定,并且基本上被微信阻止.
除了Sogou / WeChat反爬虫机制外,采用此解决方案还有其他缺点:
BI软件准备的分析报告可以由查看器编辑.
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2020-08-07 12:04
方法1,BI报告共享
共享,即作者打开报告查看者和查看者的编辑权限.
在Aowei BI系列的BI软件上完成报表创建后,单击右侧的“ Report-Properties”,下拉至末尾,然后在打开的对话框中打开“允许浏览并允许编辑”两个选项可以发布“其他用户权限”报告. 此时,任何打开此BI报表的查看者都有权同时浏览和编辑,并且可以根据其当前分析需求自由更改字段和维度的组合,或替换可视化图表,替换智能图表. 分析功能等,查看者将拥有更多灵活的自助服务分析权限.
方法2: 组分级授权
组分层授权是一种用于同时为多个子公司和母公司提供服务的系统,以确保可以快速,灵活地促进各个组织的数据分析工作. 其特点是不同组织结构的管理员只能采集组,数据源,角色数据等中的所有用户. 在奥威BI部门的BI软件上完成分析报告后,生产者可以允许查看者获得报告浏览,编辑和数据源使用权限通过开放权限.
奥威BI软件支持自助数据分析
在任何终端下,甚至在浏览状态下,用户都可以开始自助数据分析,根据自己的分析需要对特定数据进行深入分析,或者链接多个可视化图表来分析一组数据. 无论是在计算机,大屏幕还是手机或平板电脑上,都可以通过触摸屏幕轻松实现自助数据分析.
如果您想体验BI软件报表的自助数据分析和复杂数据的可视化,则可以通过“演示”平台亲自体验. 不仅有关于多个行业不同主题的BI视觉分析报告,而且还有一些Aowei BI标准解决方案的BI视觉分析报告,供观看者自己操作. 查看全部
分析报告只有一个分析角度,但是不同的观看者有不同的想法,我该怎么办?然后,让查看者也有权编辑报告. 在BI软件准备的分析报告中,查看器还可以进行个性化编辑.
方法1,BI报告共享
共享,即作者打开报告查看者和查看者的编辑权限.
在Aowei BI系列的BI软件上完成报表创建后,单击右侧的“ Report-Properties”,下拉至末尾,然后在打开的对话框中打开“允许浏览并允许编辑”两个选项可以发布“其他用户权限”报告. 此时,任何打开此BI报表的查看者都有权同时浏览和编辑,并且可以根据其当前分析需求自由更改字段和维度的组合,或替换可视化图表,替换智能图表. 分析功能等,查看者将拥有更多灵活的自助服务分析权限.
方法2: 组分级授权
组分层授权是一种用于同时为多个子公司和母公司提供服务的系统,以确保可以快速,灵活地促进各个组织的数据分析工作. 其特点是不同组织结构的管理员只能采集组,数据源,角色数据等中的所有用户. 在奥威BI部门的BI软件上完成分析报告后,生产者可以允许查看者获得报告浏览,编辑和数据源使用权限通过开放权限.
奥威BI软件支持自助数据分析
在任何终端下,甚至在浏览状态下,用户都可以开始自助数据分析,根据自己的分析需要对特定数据进行深入分析,或者链接多个可视化图表来分析一组数据. 无论是在计算机,大屏幕还是手机或平板电脑上,都可以通过触摸屏幕轻松实现自助数据分析.
如果您想体验BI软件报表的自助数据分析和复杂数据的可视化,则可以通过“演示”平台亲自体验. 不仅有关于多个行业不同主题的BI视觉分析报告,而且还有一些Aowei BI标准解决方案的BI视觉分析报告,供观看者自己操作.
优采云·商品组合工具集v1.5.11.0(原创商品生成)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2020-08-07 05:07
该原型来自原创文章生成器,但它更简单易用,操作基本相同,功能更强大,操作更简单,退伍军人可以直接使用它而无需重复学习,而且新手也很容易使用<//p
p核心功能是编写模板,在模板中引用元素,并在任何地方引用任何元素. 元素可以在文本块中调用,可以是随机的汉字,数字,字母或数字序列,随机值和随机时间. 所有免费的原创组合模式. 查看原理>>
提醒: 主界面右下角的选项按钮可以导入“原创文章生成器(高级高级版)”的程序数据(必须导入,而不是简单的文件复制)
提醒: 在2003系统上运行时,必须关闭数据执行保护.
提示: 创建新元素时,按Ctrl键可将当前元素的内容复制到新元素;切换元素显示时按Alt键可屏蔽元素内容的显示和修改. 右键单击元素项目以复制元素的引用格式[元素名称],右键单击元素库以打开本地存储数据库的文件夹(模板的相同操作).
提醒: 当前选择并显示的模板是用于生成的模板. 如果选择了模板库,则该库下的模板将被随机用于生成,并且所有已选中的元素库都可以由模板调用. 当检查了多个元素库时,不同元素库下的元素不能具有相同的名称,否则只能调用第一个被检查的元素库中具有相同名称的元素.
与“原创文章生成器”的功能相比:
1. 全新的界面设计,简单而功能强大的布局,基本相同的操作,但更简单易用
2. 元素库中的元素不再显示复选框以免误判(只有元素库本身可以被打勾,被打勾的元素库会参与调用,并且不需要打勾)
3. 显示大部分文本不再耗时,并且支持行号显示和元素语法突出显示.
4. 更强大的删除恢复功能,更强大的树搜索功能
5. 新修改的各种辅助工具(包括新编写的长尾单词采集器)可以满足更多的文本处理要求.
6. 预览时支持预览标题设置,效果如初.
7. 库的显示顺序不再混乱.
8. 其他方面,例如总体功能和性能. 查看全部
新的文章组合工具,支持短语和单词的原创随机组合,SEO基本的网站管理员工具,内置将近20种新的和增强的辅助工具.
该原型来自原创文章生成器,但它更简单易用,操作基本相同,功能更强大,操作更简单,退伍军人可以直接使用它而无需重复学习,而且新手也很容易使用<//p
p核心功能是编写模板,在模板中引用元素,并在任何地方引用任何元素. 元素可以在文本块中调用,可以是随机的汉字,数字,字母或数字序列,随机值和随机时间. 所有免费的原创组合模式. 查看原理>>
提醒: 主界面右下角的选项按钮可以导入“原创文章生成器(高级高级版)”的程序数据(必须导入,而不是简单的文件复制)
提醒: 在2003系统上运行时,必须关闭数据执行保护.
提示: 创建新元素时,按Ctrl键可将当前元素的内容复制到新元素;切换元素显示时按Alt键可屏蔽元素内容的显示和修改. 右键单击元素项目以复制元素的引用格式[元素名称],右键单击元素库以打开本地存储数据库的文件夹(模板的相同操作).
提醒: 当前选择并显示的模板是用于生成的模板. 如果选择了模板库,则该库下的模板将被随机用于生成,并且所有已选中的元素库都可以由模板调用. 当检查了多个元素库时,不同元素库下的元素不能具有相同的名称,否则只能调用第一个被检查的元素库中具有相同名称的元素.
与“原创文章生成器”的功能相比:
1. 全新的界面设计,简单而功能强大的布局,基本相同的操作,但更简单易用
2. 元素库中的元素不再显示复选框以免误判(只有元素库本身可以被打勾,被打勾的元素库会参与调用,并且不需要打勾)
3. 显示大部分文本不再耗时,并且支持行号显示和元素语法突出显示.
4. 更强大的删除恢复功能,更强大的树搜索功能
5. 新修改的各种辅助工具(包括新编写的长尾单词采集器)可以满足更多的文本处理要求.
6. 预览时支持预览标题设置,效果如初.
7. 库的显示顺序不再混乱.
8. 其他方面,例如总体功能和性能.
Google SEO: SEO高质量文章内容自动生成软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2020-08-07 04:02
Google seo软件工具
真正的Articleforge高质量的SEO文章内容自动生成工具,良好的可读性-支持多语言采集,例如英语,法语和德语.
Article Forge使用极其复杂的深度理解算法,以与人类相同的方式自动撰写文章. 这些深刻的理解算法使Article Forge可以像人类一样研究任何主题. 文章Forge阅读了数百万篇文章,并学习了以自己的语言编写任何主题所需的一切. 这意味着Article Forge是唯一可以自动撰写高质量文章的工具.
Artge Forge的正式价格为每月47美元,并通过宝库的年度VIP包免费提供.
通过Copyscape获取唯一的内容
Forge文章不是典型的“内容生成器”,它只是将网页和句子拼凑在一起. Article Forge用自己的语言编写每个句子,这意味着Article Forge可以完全通过Copyscape. 这意味着您不必担心Article Forge返回重复内容!
轻松设置您的自动驾驶SEO帝国
Article Forge不仅可以自动化内容创建,而且可以完全自动化您的所有SEO工作! Article Forge具有简单的计划选项,可以自动发布到WordPress网站. 结合强大的API,您可以将整个SEO Empire设置为完全自动运行.
支持第1层和第2层内容选项
除了自动撰写高质量的单篇文章外,Article Forge还支持第1层和第2层内容选项,并且嵌套的spintax可以在数百个站点上使用. 无论您是要创建高质量的文章还是数百篇有关Level 2的文章,Article Forge都能为您生成完全可读且独特的内容!
自动添加标题,链接,视频,图像等.
Article Forge不仅是文章的作者,而且还控制着内容生成的每个部分. Article Forge将自动在其撰写的每篇文章中添加相关的标题,视频和图像. 此外,Article Forge将自动添加您想要的任何链接,这意味着您可以建立一个全自动的会员自动博客.
自动生成7种语言的内容
Article Forge可以生成英语,荷兰语,法语,德语,意大利语,葡萄牙语和西班牙语的文章!每种语言都使用与Article Forge相同的核心人工智能,使其成为第一个也是唯一一个支持和理解英语以外的语言的智能内容生成器. 国际搜索词的竞争非常激烈,使其成为一个完全未开发的市场.
无需代理或抓取-真正的一键式解决方案
由于Article Forge运用了深刻的理解来像人类一样写作,因此您无需费劲. 这意味着无需担心代理,复杂的设置或编程. 您只需要单击一个按钮,Article Forge就会为您提供文章!请记住,Article Forge是使用此深度学习的唯一工具,也是可以为您撰写文章的唯一工具.
如何使用Article Forge:
首先,登录网站后,只需单击新文章即可采集:
接下来,设置采集的主要关键字和文章的语言,以及是否要使文章更具可读性或唯一性(重复性最少)
接下来,设置单词数并打开开关以添加标题,其他选项可以保持不变:
单击“创建新文章”后,将自动生成项目. 如果多个人使用它,还将生成其他项目. 设置并耐心等待和谐分享:
点击查看后生成:
生成的文章具有可以直接查看的最终格式,并且具有支持SEO软件的伪原创旋转格式,这对我们来说很方便.
原创文章,作者: 小蓉SEO技术,应转载,请注明出处: 查看全部
这次,编辑希望向您介绍“ Google SEO: SEO高质量文章内容自动生成软件”. 希望我能成为Google SEO的小型外贸伙伴.
Google seo软件工具
真正的Articleforge高质量的SEO文章内容自动生成工具,良好的可读性-支持多语言采集,例如英语,法语和德语.
Article Forge使用极其复杂的深度理解算法,以与人类相同的方式自动撰写文章. 这些深刻的理解算法使Article Forge可以像人类一样研究任何主题. 文章Forge阅读了数百万篇文章,并学习了以自己的语言编写任何主题所需的一切. 这意味着Article Forge是唯一可以自动撰写高质量文章的工具.
Artge Forge的正式价格为每月47美元,并通过宝库的年度VIP包免费提供.
通过Copyscape获取唯一的内容
Forge文章不是典型的“内容生成器”,它只是将网页和句子拼凑在一起. Article Forge用自己的语言编写每个句子,这意味着Article Forge可以完全通过Copyscape. 这意味着您不必担心Article Forge返回重复内容!
轻松设置您的自动驾驶SEO帝国
Article Forge不仅可以自动化内容创建,而且可以完全自动化您的所有SEO工作! Article Forge具有简单的计划选项,可以自动发布到WordPress网站. 结合强大的API,您可以将整个SEO Empire设置为完全自动运行.
支持第1层和第2层内容选项
除了自动撰写高质量的单篇文章外,Article Forge还支持第1层和第2层内容选项,并且嵌套的spintax可以在数百个站点上使用. 无论您是要创建高质量的文章还是数百篇有关Level 2的文章,Article Forge都能为您生成完全可读且独特的内容!
自动添加标题,链接,视频,图像等.
Article Forge不仅是文章的作者,而且还控制着内容生成的每个部分. Article Forge将自动在其撰写的每篇文章中添加相关的标题,视频和图像. 此外,Article Forge将自动添加您想要的任何链接,这意味着您可以建立一个全自动的会员自动博客.
自动生成7种语言的内容
Article Forge可以生成英语,荷兰语,法语,德语,意大利语,葡萄牙语和西班牙语的文章!每种语言都使用与Article Forge相同的核心人工智能,使其成为第一个也是唯一一个支持和理解英语以外的语言的智能内容生成器. 国际搜索词的竞争非常激烈,使其成为一个完全未开发的市场.
无需代理或抓取-真正的一键式解决方案
由于Article Forge运用了深刻的理解来像人类一样写作,因此您无需费劲. 这意味着无需担心代理,复杂的设置或编程. 您只需要单击一个按钮,Article Forge就会为您提供文章!请记住,Article Forge是使用此深度学习的唯一工具,也是可以为您撰写文章的唯一工具.
如何使用Article Forge:
首先,登录网站后,只需单击新文章即可采集:
接下来,设置采集的主要关键字和文章的语言,以及是否要使文章更具可读性或唯一性(重复性最少)
接下来,设置单词数并打开开关以添加标题,其他选项可以保持不变:
单击“创建新文章”后,将自动生成项目. 如果多个人使用它,还将生成其他项目. 设置并耐心等待和谐分享:
点击查看后生成:
生成的文章具有可以直接查看的最终格式,并且具有支持SEO软件的伪原创旋转格式,这对我们来说很方便.
原创文章,作者: 小蓉SEO技术,应转载,请注明出处:
大数据工具应用程序2020的新版本知道APP的答案,章节的答案
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2020-08-07 04:01
打开右侧的URL来检查问题
[网站简写: 选修365]
用于分析问题和答案的参考资料,还提供大学,选修课程,公务员,外语,会计,建筑,职业资格,学历,医学,外贸,计算机等考试的在线课程;这是数据下载的集合. 借助在线考试系统,它是各种应试者成功通过考试的好帮手!
智慧树大数据工具应用程序结尾的答案
创建计算字段时,要计算两个日期之间的天数差,使用的函数为().
图表的轴是否收录在()区域中?
度量通常是()字段,度量是我们的指标. 测量通常是连续的,连续的字段在图表中形成一个轴. 将其拖放到功能区时,默认情况下,Tableau会执行此操作().
“可视化”选项卡中抖动滑块的功能是().
weka离散化的正确描述是().
在贝叶斯网络中,节点需要给出概率分布的描述. 对于离散随机变量,可以将其表示为().
以下说明有什么问题?
将网页用于自定义采集时,您需要了解网页的页面结构.
ranker方法可用于单个属性评估者和属性评估者的子集.
当前广泛使用的二维表数据库属于().
一家超市研究了销售记录数据,发现购买啤酒的人也很可能购买尿布. 这是一个数据挖掘()问题.
贝叶斯网络中节点之间的边缘表示().
关于weka文件类型的错误描述是().
以下有关决策树的陈述是错误的().
以下()不是weka的数据类型吗?
好的统计图必须满足的条件,不包括以下().
当我们当前的维度无法很好地解释我们的问题时,我们需要对数据进行运算并添加一个指标. ()是以下哪种思维方式?
在weka中选择神经网络分类器操作时,应选择().
使用em算法对天气数据集(weather.numeric.arff)进行聚类,将numclusters设置为4,即聚类数为4,将其他参数保留为其默认值,并忽略class属性. 从结果中,我们可以看到In,()中的以下选项是错误的.
本课程重点介绍的weka软件的专有文件格式为().
麦肯锡研究所(McKinsey Institute)在2011年提出的大数据定义是: 大数据是指数据集的大小超过了常规数据库工具获取,存储,管理和()的能力.
大数据工具处理的数据源包括: ()
以下不是创建计算字段()时的操作逻辑.
使用特定字符将数据项与数据项分开的大型数据文件格式通常称为: .
使用线性回归(linearregression)分类器和m5p分类器分别对cpu.arff进行分类,输出错误指数可以知道().
支持是衡量关联规则重要性的指标.
大数据时代的到来使我们无法人为地发现数据的奥秘. 同时,我们应该更加注意数据中的相关性,而不是因果关系. 其中,数据之间的相关性可以通过以下哪种算法直接进行挖掘.
在Tableau右侧的数据目录列中,无法右键单击以创建纬度为()的参数.
以weka加载虹膜数据集(iris.arff),虹膜数据收录三个类别值,运行o分类器().
使用em聚类器对虹膜数据集(iris.arff)进行聚类,将聚类数设置为3,将其他参数保留为默认值,忽略class属性,选择类别作为聚类的评估标准,并指定类,从结果中我们可以看到,在以下选项中()是正确的.
执行自动属性选择时,必须设置两个对象. 其中,确定使用哪种方法为每个属性子集分配评估值的对象是().
贝叶斯网络()中的节点代表.
新浪和京东联合推出的大数据产品推荐被京东盲目地推向当前正在浏览新浪网站的用户页面.
对()的理解是数据分析的前提.
以下内容不是主要的数据分析方法().
以下描述()是正确的.
以下数据和信息的陈述不正确().
下图中的两类分类问题,“δ”和“ o”分别代表两个不同的类别,如果使用的交叉验证方法仅提取k,则使用k = 1的k-nn算法一个测试样本,交叉验证?()的错误率是多少?
以下数据分析方法正确().
roc曲线的全称是接收器工作特性曲线,它反映了由于不同的判断标准,受试者在特定刺激条件下获得的不同结果的曲线. 曲线使用()作为横坐标.
一家超市研究了销售记录数据,发现购买啤酒的人很可能会购买尿布. 这种问题是什么样的数据挖掘? ()
使用weka软件可视化数据时,用户可以选择category属性为数据点着色. 如果category属性是名义属性,它将显示为彩色条.
执行自动属性选择时,必须设置两个对象,下面的对象是确定用于将评估值分配给每个属性子集()的方法的对象
如果经过训练的模型在测试集上具有100%的准确性,这是否意味着它在新数据集上将具有相同的良好性能? ()
后勤函数的域为().
根据影响因素的重要性程度,对它们进行一定的组合,首先根据第一组合选择较大范围的目标对象,然后根据第二组合进一步缩小由第一组合过滤的对象的范围组合等等. 获得最终目标. 描述是对以下哪种数据分析方法()的想法.
在weka软件浏览器界面中,使用可视化选项卡通过更改各种参数来设置数据集的可视化属性后,您需要单击以下()按钮以使所有更改生效.
贝叶斯网络()中的节点代表.
以下陈述是错误的().
对于项集x,x 1是x的子集,则以下结论成立().
以下陈述是错误的()
大数据分析的四个方面主要是: 数据分类,(),关联规则挖掘和时间序列预测.
根据j48分类器训练weather.nominal.arff生成的决策树,当Outlook =晴天;温度=凉;湿度=高;风=真时,分类结果为().
在删除cpu.arff数据文件中的cach属性后,使用m5p分类器构造方案. 结果,达到lm2的实例数为().
以下()不是weka的数据类型.
仪表板布局尺寸设计选项,()不是尺寸设计选项.
什么是双轴?正确的是().
以下是关联分析().
关于数据层次结构的错误描述是().
不属于表计算的函数是().
优采云软件只能从具有内置“简单采集”规则的网站采集数据.
以下内容不是数据分析()的一部分.
工作簿是具有.t扩展名的文件,其中收录一个或多个()(可能还包括仪表板和故事).
当条形图用于显示不同类别的数据时,类别为()或更少,直方图将对该类别执行()统计.
当前的大数据处理技术只能处理结构化数据.
执行自动属性选择时,必须设置两个对象,其中之一是确定执行哪种搜索样式的对象().
left('welldone',4),return().
以下在weka神经网络上的操作是错误的().
tx扩展名在表格中是()吗?
在贝叶斯网络编辑界面中,如果无法完全显示节点名称,则需要从()菜单项进行调整.
软件包管理器安装不正确后,以下目录描述为().
大数据时代的到来使我们无法人为地发现数据的奥秘. 同时,我们应该更加注意数据中的相关性,而不是因果关系. 其中,数据之间的相关性可以通过以下()算法直接进行挖掘.
故事是按顺序排列的()或()的组合. 您可以使用创建的故事向用户叙述某些事实,或者以故事的形式揭示各种事实之间的上下文事件发展关系.
使用ibk分类器和o分类器分别对vote.arff进行分类,输出结果可以知道().
使用simplekmeans算法对天气数据集(weather.numeric.arff)进行聚类,并保留默认参数,即3个聚类和欧几里得距离. 选择播放属性作为忽略属性. 从结果中我们可以看到,在以下选项中,()是错误.
“ Tableau数据源”页面通常收录四个主要区域: 左窗格,连接区域,预览区域和()区域.
在Weka中对加噪滤波器的正确描述是().
Excel可以通过“数据有效性”按钮操作来调节数据输入范围.
()是度量?
Microsoft Office套件中的访问数据库软件的数据库文件格式的后缀为().
使用4v总结大数据的特征,通常指的是: 值,速度,数量和().
以下对weka时间序列分析的描述是错误的().
以下()不是tableau的数据类型吗?
神经网络中的节点代表().
使用simplekmeans聚类器对虹膜数据集(iris.arff)进行聚类,保留默认参数,即3个聚类和欧几里得距离. 忽略class属性,从结果可以看出,在以下选项中,()是错误.
贝叶斯网络保存的文件格式为().
在weka软件浏览器界面中,使用可视化选项卡通过更改各种参数来设置数据集的可视化属性后,您需要单击下面的哪个按钮以使所有更改生效. ()
用于删除Weka中属性的过滤器是().
给出关联规则ab,这意味着: 如果发生a,则b也将发生.
在数据挖掘中,经常会遇到对成本敏感的学习. 该方法主要是针对不同的分类错误采用不同的惩罚方法. ()的学习任务经常使用模型训练.
大多数日志文件的后缀是().
以下关于weka中的beyes网络编辑器的说法不正确().
以下()不是反向传播神经网络的结构.
在优采云软件的“定制采集”工作模式下,需要在软件中输入()作为采集目标.
以下陈述是错误的().
以下描述是错误的().
以下关于群集的描述是错误的().
tableau是一种用于敏捷开发和实现数据可视化的工具. tableau已连续第六年被评为gartner分析和商业智能魔力象限的领导者.
在Weka中运行o分类器,并将多项式多项式内核函数的指数设置为1,那么以下描述是正确的().
使用dbscan算法对虹膜数据集(iris.arff)进行聚类,将epsilon参数设置为0.2,将minpoints参数设置为5,并忽略class属性,然后将形成()聚类.
大数据工具应用程序2020的新版本知道APP的答案,章节的答案
大数据工具应用程序知道APP 2020在线课程答案,答案章节答案
大数据工具应用程序(4)智慧树知道最终答案,完整答案
大数据工具应用(三)智慧树题库答案教程,标准参考答案
大数据处理与分析2020智道在线课程答案,多项选择答案
大数据分析的python基础(山东联合会)智慧树问题库2020在线课程答案,答案章节单元测试答案 查看全部
大数据工具应用程序2020的新版本知道APP的答案,章节的答案
打开右侧的URL来检查问题
[网站简写: 选修365]
用于分析问题和答案的参考资料,还提供大学,选修课程,公务员,外语,会计,建筑,职业资格,学历,医学,外贸,计算机等考试的在线课程;这是数据下载的集合. 借助在线考试系统,它是各种应试者成功通过考试的好帮手!
智慧树大数据工具应用程序结尾的答案
创建计算字段时,要计算两个日期之间的天数差,使用的函数为().
图表的轴是否收录在()区域中?
度量通常是()字段,度量是我们的指标. 测量通常是连续的,连续的字段在图表中形成一个轴. 将其拖放到功能区时,默认情况下,Tableau会执行此操作().
“可视化”选项卡中抖动滑块的功能是().
weka离散化的正确描述是().
在贝叶斯网络中,节点需要给出概率分布的描述. 对于离散随机变量,可以将其表示为().
以下说明有什么问题?
将网页用于自定义采集时,您需要了解网页的页面结构.
ranker方法可用于单个属性评估者和属性评估者的子集.
当前广泛使用的二维表数据库属于().
一家超市研究了销售记录数据,发现购买啤酒的人也很可能购买尿布. 这是一个数据挖掘()问题.
贝叶斯网络中节点之间的边缘表示().
关于weka文件类型的错误描述是().
以下有关决策树的陈述是错误的().
以下()不是weka的数据类型吗?
好的统计图必须满足的条件,不包括以下().
当我们当前的维度无法很好地解释我们的问题时,我们需要对数据进行运算并添加一个指标. ()是以下哪种思维方式?
在weka中选择神经网络分类器操作时,应选择().
使用em算法对天气数据集(weather.numeric.arff)进行聚类,将numclusters设置为4,即聚类数为4,将其他参数保留为其默认值,并忽略class属性. 从结果中,我们可以看到In,()中的以下选项是错误的.
本课程重点介绍的weka软件的专有文件格式为().
麦肯锡研究所(McKinsey Institute)在2011年提出的大数据定义是: 大数据是指数据集的大小超过了常规数据库工具获取,存储,管理和()的能力.
大数据工具处理的数据源包括: ()
以下不是创建计算字段()时的操作逻辑.
使用特定字符将数据项与数据项分开的大型数据文件格式通常称为: .
使用线性回归(linearregression)分类器和m5p分类器分别对cpu.arff进行分类,输出错误指数可以知道().
支持是衡量关联规则重要性的指标.
大数据时代的到来使我们无法人为地发现数据的奥秘. 同时,我们应该更加注意数据中的相关性,而不是因果关系. 其中,数据之间的相关性可以通过以下哪种算法直接进行挖掘.
在Tableau右侧的数据目录列中,无法右键单击以创建纬度为()的参数.
以weka加载虹膜数据集(iris.arff),虹膜数据收录三个类别值,运行o分类器().
使用em聚类器对虹膜数据集(iris.arff)进行聚类,将聚类数设置为3,将其他参数保留为默认值,忽略class属性,选择类别作为聚类的评估标准,并指定类,从结果中我们可以看到,在以下选项中()是正确的.
执行自动属性选择时,必须设置两个对象. 其中,确定使用哪种方法为每个属性子集分配评估值的对象是().
贝叶斯网络()中的节点代表.
新浪和京东联合推出的大数据产品推荐被京东盲目地推向当前正在浏览新浪网站的用户页面.
对()的理解是数据分析的前提.
以下内容不是主要的数据分析方法().
以下描述()是正确的.
以下数据和信息的陈述不正确().
下图中的两类分类问题,“δ”和“ o”分别代表两个不同的类别,如果使用的交叉验证方法仅提取k,则使用k = 1的k-nn算法一个测试样本,交叉验证?()的错误率是多少?
以下数据分析方法正确().
roc曲线的全称是接收器工作特性曲线,它反映了由于不同的判断标准,受试者在特定刺激条件下获得的不同结果的曲线. 曲线使用()作为横坐标.
一家超市研究了销售记录数据,发现购买啤酒的人很可能会购买尿布. 这种问题是什么样的数据挖掘? ()
使用weka软件可视化数据时,用户可以选择category属性为数据点着色. 如果category属性是名义属性,它将显示为彩色条.
执行自动属性选择时,必须设置两个对象,下面的对象是确定用于将评估值分配给每个属性子集()的方法的对象
如果经过训练的模型在测试集上具有100%的准确性,这是否意味着它在新数据集上将具有相同的良好性能? ()
后勤函数的域为().
根据影响因素的重要性程度,对它们进行一定的组合,首先根据第一组合选择较大范围的目标对象,然后根据第二组合进一步缩小由第一组合过滤的对象的范围组合等等. 获得最终目标. 描述是对以下哪种数据分析方法()的想法.
在weka软件浏览器界面中,使用可视化选项卡通过更改各种参数来设置数据集的可视化属性后,您需要单击以下()按钮以使所有更改生效.
贝叶斯网络()中的节点代表.
以下陈述是错误的().
对于项集x,x 1是x的子集,则以下结论成立().
以下陈述是错误的()
大数据分析的四个方面主要是: 数据分类,(),关联规则挖掘和时间序列预测.
根据j48分类器训练weather.nominal.arff生成的决策树,当Outlook =晴天;温度=凉;湿度=高;风=真时,分类结果为().
在删除cpu.arff数据文件中的cach属性后,使用m5p分类器构造方案. 结果,达到lm2的实例数为().
以下()不是weka的数据类型.
仪表板布局尺寸设计选项,()不是尺寸设计选项.
什么是双轴?正确的是().
以下是关联分析().
关于数据层次结构的错误描述是().
不属于表计算的函数是().
优采云软件只能从具有内置“简单采集”规则的网站采集数据.
以下内容不是数据分析()的一部分.
工作簿是具有.t扩展名的文件,其中收录一个或多个()(可能还包括仪表板和故事).
当条形图用于显示不同类别的数据时,类别为()或更少,直方图将对该类别执行()统计.
当前的大数据处理技术只能处理结构化数据.
执行自动属性选择时,必须设置两个对象,其中之一是确定执行哪种搜索样式的对象().
left('welldone',4),return().
以下在weka神经网络上的操作是错误的().
tx扩展名在表格中是()吗?
在贝叶斯网络编辑界面中,如果无法完全显示节点名称,则需要从()菜单项进行调整.
软件包管理器安装不正确后,以下目录描述为().
大数据时代的到来使我们无法人为地发现数据的奥秘. 同时,我们应该更加注意数据中的相关性,而不是因果关系. 其中,数据之间的相关性可以通过以下()算法直接进行挖掘.
故事是按顺序排列的()或()的组合. 您可以使用创建的故事向用户叙述某些事实,或者以故事的形式揭示各种事实之间的上下文事件发展关系.
使用ibk分类器和o分类器分别对vote.arff进行分类,输出结果可以知道().
使用simplekmeans算法对天气数据集(weather.numeric.arff)进行聚类,并保留默认参数,即3个聚类和欧几里得距离. 选择播放属性作为忽略属性. 从结果中我们可以看到,在以下选项中,()是错误.
“ Tableau数据源”页面通常收录四个主要区域: 左窗格,连接区域,预览区域和()区域.
在Weka中对加噪滤波器的正确描述是().
Excel可以通过“数据有效性”按钮操作来调节数据输入范围.
()是度量?
Microsoft Office套件中的访问数据库软件的数据库文件格式的后缀为().
使用4v总结大数据的特征,通常指的是: 值,速度,数量和().
以下对weka时间序列分析的描述是错误的().
以下()不是tableau的数据类型吗?
神经网络中的节点代表().
使用simplekmeans聚类器对虹膜数据集(iris.arff)进行聚类,保留默认参数,即3个聚类和欧几里得距离. 忽略class属性,从结果可以看出,在以下选项中,()是错误.
贝叶斯网络保存的文件格式为().
在weka软件浏览器界面中,使用可视化选项卡通过更改各种参数来设置数据集的可视化属性后,您需要单击下面的哪个按钮以使所有更改生效. ()
用于删除Weka中属性的过滤器是().
给出关联规则ab,这意味着: 如果发生a,则b也将发生.
在数据挖掘中,经常会遇到对成本敏感的学习. 该方法主要是针对不同的分类错误采用不同的惩罚方法. ()的学习任务经常使用模型训练.
大多数日志文件的后缀是().
以下关于weka中的beyes网络编辑器的说法不正确().
以下()不是反向传播神经网络的结构.
在优采云软件的“定制采集”工作模式下,需要在软件中输入()作为采集目标.
以下陈述是错误的().
以下描述是错误的().
以下关于群集的描述是错误的().
tableau是一种用于敏捷开发和实现数据可视化的工具. tableau已连续第六年被评为gartner分析和商业智能魔力象限的领导者.
在Weka中运行o分类器,并将多项式多项式内核函数的指数设置为1,那么以下描述是正确的().
使用dbscan算法对虹膜数据集(iris.arff)进行聚类,将epsilon参数设置为0.2,将minpoints参数设置为5,并忽略class属性,然后将形成()聚类.
大数据工具应用程序2020的新版本知道APP的答案,章节的答案
大数据工具应用程序知道APP 2020在线课程答案,答案章节答案
大数据工具应用程序(4)智慧树知道最终答案,完整答案
大数据工具应用(三)智慧树题库答案教程,标准参考答案
大数据处理与分析2020智道在线课程答案,多项选择答案
大数据分析的python基础(山东联合会)智慧树问题库2020在线课程答案,答案章节单元测试答案
优化厦门站哪个便宜,优化屏幕软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2020-08-07 02:18
上面必须有足够的文章,关键字太多,如果要发送所有这些关键字,则必须准备很多文章. 每个人都知道搜索引擎喜欢原创文章,因此我们要做的是如何创建大量原创文章. 文章本身由不同的段落组成,拼接在一起,如果我们可以有很多原创段落,那么通过随机组合,这些组合的文章必须是非常原创的. 当前的文章采集来源可以采集一些企鹅个人帐户. 这类文章似乎是搜索引擎中的原创文章. 客户推广的原理实际上与人工推广的原理相似,只是大大节省了人工推广的成本,提高了效果. 您可以使用手动促销来达到我们的效果吗?对于中小型公司来说,它已经不足以吸引客户来推销屏幕. 您说我们都是长尾金山词霸屏幕. 确实,搜索量很小,但是我们都是准确的搜索者,无法承受搜索量. 很大!成本很低,效果很好.
百度搜索关键字的功能是什么? 1.展示大量知名品牌,提高知名品牌的信誉. 2.增加总流量,提高产品或知名品牌对客户的信任度,从而提高交易转化率. 3.如果是知名品牌关键字,则可以防止竞争对手被拦截,其不良信息内容将显示百度搜索屏幕的关键字选择. 1.我们要做的第一件事是公司名称,知名品牌和自己产品的独特项,以反映每个人的综合实力并提高声誉. 2.地区制造业单词,地区商品单词,非常精确的关键字,交易量和订单信息转换都非常好. 3.接下来是制造业这个词,制造业这个词类似于屏幕,那么您就是互联网上制造业中的知名品牌. 百度如何搜索关键词优势?通常,您首先使用百科全书,百度地图导航,官方网站在线客户服务,百度问答,文库百度,新闻报道,新浪微博以及一些行业门户网站,B2B网站来打出知名品牌词. 百度搜索屏幕的实质是利用第三方高权网站服务平台快速获得排名,并完成百度搜索屏幕的实际效果. 黑帽优化方法也有一些,使用泛站点组进行百度搜索屏幕扫描. ,建议企业网站不要这样做,因为这会降低公司的企业形象.
优化厦门站哪个更便宜
第五,外部链接. 外链的作用是促进和传递体重,趋势和传递体重. 为了使网页达到进入和排名,必须具有一定的权重值,并且外部链接可以从网站外部传递一部分权重值以促进页面进入和排名. 6.记录关键字及其链接. 内容页面上的关键字称为长尾关键字. 我们建议您列出长尾关键词及其链接. 在长尾关键字记录列表中记录此关键字及其链接,以方便在发布其他文章时使用锚文本.
顾名思义,收录旨在允许采集网页并将其记录在搜索引擎数据库中. 在此过程中,搜索引擎将为网页信息编制索引,即确定该网页与哪些关键字相关. 搜索引擎抓取工具爬网时,它将首先检查网站的robots.txt,以确定网站管理员是否希望搜索引擎不收录部分或全部页面. 只要蜘蛛程序可以访问此页面,其他所有网页都可以包括在内(实际上,由于上述蜘蛛程序的某些特性,无法访问许多网页). 因此,我们可以通过单击链接从首页访问要收录的网站的每个页面. 一个特点是,首页点击次数越少,被收录的机会就越大.
优化暴君画面软件
什么是MWordba屏幕?品牌公司之所以选择MWordba屏幕. 自从MWordba屏幕开始用于品牌推广以来,它已经展示出了非常强大的业务能力,并且将传统的优化模型与压倒性优势进行了比较. 下去. 我相信许多正在做推广的朋友已经对MWordba屏幕有了初步了解,那么MWordba屏幕到底是什么?企业品牌选择MWordba屏幕的原因是什么?了解这些内容后,我相信您会对未来的促销计划更有信心. 什么是MWordba屏幕 查看全部
上面必须有足够的文章,关键字太多,如果要发送所有这些关键字,则必须准备很多文章. 每个人都知道搜索引擎喜欢原创文章,因此我们要做的是如何创建大量原创文章. 文章本身由不同的段落组成,拼接在一起,如果我们可以有很多原创段落,那么通过随机组合,这些组合的文章必须是非常原创的. 当前的文章采集来源可以采集一些企鹅个人帐户. 这类文章似乎是搜索引擎中的原创文章. 客户推广的原理实际上与人工推广的原理相似,只是大大节省了人工推广的成本,提高了效果. 您可以使用手动促销来达到我们的效果吗?对于中小型公司来说,它已经不足以吸引客户来推销屏幕. 您说我们都是长尾金山词霸屏幕. 确实,搜索量很小,但是我们都是准确的搜索者,无法承受搜索量. 很大!成本很低,效果很好.
百度搜索关键字的功能是什么? 1.展示大量知名品牌,提高知名品牌的信誉. 2.增加总流量,提高产品或知名品牌对客户的信任度,从而提高交易转化率. 3.如果是知名品牌关键字,则可以防止竞争对手被拦截,其不良信息内容将显示百度搜索屏幕的关键字选择. 1.我们要做的第一件事是公司名称,知名品牌和自己产品的独特项,以反映每个人的综合实力并提高声誉. 2.地区制造业单词,地区商品单词,非常精确的关键字,交易量和订单信息转换都非常好. 3.接下来是制造业这个词,制造业这个词类似于屏幕,那么您就是互联网上制造业中的知名品牌. 百度如何搜索关键词优势?通常,您首先使用百科全书,百度地图导航,官方网站在线客户服务,百度问答,文库百度,新闻报道,新浪微博以及一些行业门户网站,B2B网站来打出知名品牌词. 百度搜索屏幕的实质是利用第三方高权网站服务平台快速获得排名,并完成百度搜索屏幕的实际效果. 黑帽优化方法也有一些,使用泛站点组进行百度搜索屏幕扫描. ,建议企业网站不要这样做,因为这会降低公司的企业形象.
优化厦门站哪个更便宜
第五,外部链接. 外链的作用是促进和传递体重,趋势和传递体重. 为了使网页达到进入和排名,必须具有一定的权重值,并且外部链接可以从网站外部传递一部分权重值以促进页面进入和排名. 6.记录关键字及其链接. 内容页面上的关键字称为长尾关键字. 我们建议您列出长尾关键词及其链接. 在长尾关键字记录列表中记录此关键字及其链接,以方便在发布其他文章时使用锚文本.
顾名思义,收录旨在允许采集网页并将其记录在搜索引擎数据库中. 在此过程中,搜索引擎将为网页信息编制索引,即确定该网页与哪些关键字相关. 搜索引擎抓取工具爬网时,它将首先检查网站的robots.txt,以确定网站管理员是否希望搜索引擎不收录部分或全部页面. 只要蜘蛛程序可以访问此页面,其他所有网页都可以包括在内(实际上,由于上述蜘蛛程序的某些特性,无法访问许多网页). 因此,我们可以通过单击链接从首页访问要收录的网站的每个页面. 一个特点是,首页点击次数越少,被收录的机会就越大.
优化暴君画面软件
什么是MWordba屏幕?品牌公司之所以选择MWordba屏幕. 自从MWordba屏幕开始用于品牌推广以来,它已经展示出了非常强大的业务能力,并且将传统的优化模型与压倒性优势进行了比较. 下去. 我相信许多正在做推广的朋友已经对MWordba屏幕有了初步了解,那么MWordba屏幕到底是什么?企业品牌选择MWordba屏幕的原因是什么?了解这些内容后,我相信您会对未来的促销计划更有信心. 什么是MWordba屏幕
多文本作家v2.6.6.81正式版
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2020-08-07 00:11
软件功能
自动过滤敏感词
自动过滤敏感词,使文章内容更安全,更有利于收录.
自动伪原创材料
在材料导入过程中,将自动对材料进行伪原创处理,这更有利于收录.
一键式图像采集
根据关键字,一键采集相关图片,快速,高效且易于匹配图片.
图片采集和压缩
独特的图片伪原创技术,可以随机调整图片的分辨率.
多模式材料采集
支持采集器采集,规则采集,关键字采集和多种材料获取方法.
自动脚本发布
通用脚本发布支持所有网站上的后端/前端发布,从而实现了文章生成和发布的集成解决方案.
软件功能
1. 多文本作者提供文章伪原创功能,可以在软件中采集文章
2. 可以在软件中发布文章,并且可以将相关规则设置为发布.
3. 提供标题设置功能,可以为文章设置固定标题
4. 支持自定义标题,在软件中设置标题组合
5. 支持区域+前缀+主题,区域+主题+后排
6. 支持组合标题预览,在软件中查看生成的标题,以便复制和使用
7. 支持标题导入功能,如果您具有设计的标题,则可以将其导入到软件中以供使用
8. 支持采集功能,在软件中配置采集规则,设置单站点采集,填写URL以开始采集
9. 设置采集层数,数字越深,采集目录越深,默认为3层
10. 支持自动伪原创+过滤敏感词
11. 支持段落内容的自动排版,自动优化和自动创意
使用说明
1,激活多文本编写器提示激活功能,可以在软件界面中注册帐户
2,输入您的帐户信息,输入注册码
3. 提示无法注册,可以进入官方网站购买注册码
4. 五段标题组合可以立即产生大量关键字,并且可以随意选择各种标题组合样式
5. 固定标题,如果需要生成指定的标题,只需在此处填写自定义标题
6. 左侧是替换表. 如果您需要替换内容,请在左侧输入,每行,格式: 原创内容=新内容
7,1选择关键字采集资料. 2填写要采集的材料的关键字. 3开始采集
8. 如图所示,采集的内容显示在软件界面上. 如果需要使用文章内容,可以添加标题
9. 生成文章信息设置,填写世代数,段落设置,图片数并将目录保存在软件中. 设置后,点击开始生成即可快速生成大量原创文章
10. 采集设置功能,在软件界面设置图像采集地址和采集关键字
11. 您可以同时添加多个脚本,通过脚本将文章自动更新到网站,并在软件下添加发布规则 查看全部
多文本作者提供文章批量生成功能,该功能可以自动在软件中生成文章并将其发布到自己的网站上. 软件功能仍然非常丰富. 您可以设置为生成1000条文章,设置段落布局和设置图片采集规则,轻松将图片附加到文章,支持生成TXT类型的文章以方便将来对内容进行修改,还支持生成HTML-类型文章,直接加载到网页中,软件功能非常简单,为用户提供标题,采集,内容编辑,图像采集,伪原创生成,文章发布等功能,自动伪原创图片+文字/图片水印,基于关键词采集相关图片,所有功能都非常方便操作,适合经常在互联网上发表文章的朋友!
软件功能
自动过滤敏感词
自动过滤敏感词,使文章内容更安全,更有利于收录.
自动伪原创材料
在材料导入过程中,将自动对材料进行伪原创处理,这更有利于收录.
一键式图像采集
根据关键字,一键采集相关图片,快速,高效且易于匹配图片.
图片采集和压缩
独特的图片伪原创技术,可以随机调整图片的分辨率.
多模式材料采集
支持采集器采集,规则采集,关键字采集和多种材料获取方法.
自动脚本发布
通用脚本发布支持所有网站上的后端/前端发布,从而实现了文章生成和发布的集成解决方案.
软件功能
1. 多文本作者提供文章伪原创功能,可以在软件中采集文章
2. 可以在软件中发布文章,并且可以将相关规则设置为发布.
3. 提供标题设置功能,可以为文章设置固定标题
4. 支持自定义标题,在软件中设置标题组合
5. 支持区域+前缀+主题,区域+主题+后排
6. 支持组合标题预览,在软件中查看生成的标题,以便复制和使用
7. 支持标题导入功能,如果您具有设计的标题,则可以将其导入到软件中以供使用
8. 支持采集功能,在软件中配置采集规则,设置单站点采集,填写URL以开始采集
9. 设置采集层数,数字越深,采集目录越深,默认为3层
10. 支持自动伪原创+过滤敏感词
11. 支持段落内容的自动排版,自动优化和自动创意
使用说明
1,激活多文本编写器提示激活功能,可以在软件界面中注册帐户
2,输入您的帐户信息,输入注册码
3. 提示无法注册,可以进入官方网站购买注册码
4. 五段标题组合可以立即产生大量关键字,并且可以随意选择各种标题组合样式
5. 固定标题,如果需要生成指定的标题,只需在此处填写自定义标题
6. 左侧是替换表. 如果您需要替换内容,请在左侧输入,每行,格式: 原创内容=新内容
7,1选择关键字采集资料. 2填写要采集的材料的关键字. 3开始采集
8. 如图所示,采集的内容显示在软件界面上. 如果需要使用文章内容,可以添加标题
9. 生成文章信息设置,填写世代数,段落设置,图片数并将目录保存在软件中. 设置后,点击开始生成即可快速生成大量原创文章
10. 采集设置功能,在软件界面设置图像采集地址和采集关键字
11. 您可以同时添加多个脚本,通过脚本将文章自动更新到网站,并在软件下添加发布规则
Lazada批量采集并快速上传多商店管理软件ERP
采集交流 • 优采云 发表了文章 • 0 个评论 • 389 次浏览 • 2020-08-07 00:09
不了解ETL吗?查看这篇文章!
采集交流 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2020-08-06 13:05
随着企业的发展,各种业务线,产品线和部门将建立各种信息系统以促进自己的业务. 随着信息建设的不断深化,业务系统相互独立,相互独立引起的“数据岛”现象尤为普遍. 业务未集成,流程未互连,数据也未共享. 这使企业可以分析和利用数据并开发报告表格. ,分析和采矿带来了巨大的困难.
在这种情况下,为了实现企业全局数据(信息孤岛,数据统计,数据分析,数据挖掘),DSS(决策支持系统),BI(商业智能),商业分析系统的系统运行和管理为了为深入开发和应用奠定基础,并挖掘数据的价值,企业将开始建立数据仓库和数据中心. 集成各个业务系统的数据源,以建立统一的数据采集,处理,存储,分发和共享中心.
在BI项目中,ETL至少要花费整个项目的1/3,而ETL设计的质量直接关系到BI项目的成败.
ETL基本概念定义
ETL是以下过程: 提取,清理和转换(转换)业务系统的数据,然后将其加载(加载)到数据仓库中. 目的是集成企业中分散,无序和不均匀的数据. ,为企业决策提供分析依据.
ETL基本概念-过程
ETL处理分为五个主要模块,即: 数据提取,数据清理,库中的转换,规则检查和数据加载. 每个模块都可以灵活组合以形成ETL处理流程. 简要介绍每个模块的主要功能.
数据提取数据清理和转换数据加载
将数据缓冲区中的数据直接加载到数据库的相应表中. 如果是全额方法,请使用LOAD方法;如果是增量方法,则根据业务规则MERGE输入数据库
ETL VS ELT
根据ETL体系结构的字面意义,它可以理解为一种按照E-T-L顺序处理的体系结构: 完成后首先提取,然后进行转换并加载到目标数据库中. 在ETL体系结构中,数据流是从源数据流到ETL工具的. ETL工具是一个单独的数据处理引擎,通常在单独的硬件服务器上执行所有数据转换工作,然后将数据加载到仓库中的目标数据. 如果要提高整个ETL过程的效率,则只能增强ETL工具服务器的配置并优化系统处理流程(通常,可调整的东西很少).
ELT体系结构将“ L”步骤推进到“ T”之前完成: 首先提取,然后加载到目标数据库中,并完成目标数据库中的转换操作. 在ELT体系结构中,ELT仅负责提供图形界面来设计业务规则. 整个数据处理过程在目标数据库和源数据库之间流动. ELT协调相关的数据库系统以执行相关的应用程序. 数据处理过程既可以在源数据库端也可以在目标数据仓库端执行(主要取决于系统的体系结构设计和数据属性). 当ETL过程需要提高效率时,可以通过调整相关数据库或更改执行该过程的服务器来实现.
您可以仔细查看以上两个架构图,并体验它们之间的差异. 让我们在下面分析它们各自的优点:
ETL体系结构的优点ELT体系结构的优点ETL模式简介
ETL具有四种主要的实现方式: 触发方式,增量字段,完全同步,日志比较
触发模式
<p>触发方法是常用的增量提取机制. 此方法基于提取要求,在要提取的源表上创建插入,修改和删除三个触发器. 只要源表中的数据发生更改,相应的触发器就会将更改后的数据写入增量中. ETL增量提取是从增量日志表中提取数据,而不是直接在源表中. 同时,应及时标记或删除增量日志表中提取的数据. 为简单起见,增量日志表通常不存储增量数据的所有字段信息,而仅存储源表名称,更新的键值和更新操作类型(插入,更新或删除). ETL增量提取过程首先基于. 从源表中提取源表名称和更新的键值,并提取相应的完整记录,然后根据更新操作的类型对目标表进行相应的处理. 查看全部
ETL基本概念ETL基本概念-背景
随着企业的发展,各种业务线,产品线和部门将建立各种信息系统以促进自己的业务. 随着信息建设的不断深化,业务系统相互独立,相互独立引起的“数据岛”现象尤为普遍. 业务未集成,流程未互连,数据也未共享. 这使企业可以分析和利用数据并开发报告表格. ,分析和采矿带来了巨大的困难.
在这种情况下,为了实现企业全局数据(信息孤岛,数据统计,数据分析,数据挖掘),DSS(决策支持系统),BI(商业智能),商业分析系统的系统运行和管理为了为深入开发和应用奠定基础,并挖掘数据的价值,企业将开始建立数据仓库和数据中心. 集成各个业务系统的数据源,以建立统一的数据采集,处理,存储,分发和共享中心.
在BI项目中,ETL至少要花费整个项目的1/3,而ETL设计的质量直接关系到BI项目的成败.
ETL基本概念定义
ETL是以下过程: 提取,清理和转换(转换)业务系统的数据,然后将其加载(加载)到数据仓库中. 目的是集成企业中分散,无序和不均匀的数据. ,为企业决策提供分析依据.
ETL基本概念-过程
ETL处理分为五个主要模块,即: 数据提取,数据清理,库中的转换,规则检查和数据加载. 每个模块都可以灵活组合以形成ETL处理流程. 简要介绍每个模块的主要功能.
数据提取数据清理和转换数据加载
将数据缓冲区中的数据直接加载到数据库的相应表中. 如果是全额方法,请使用LOAD方法;如果是增量方法,则根据业务规则MERGE输入数据库
ETL VS ELT
根据ETL体系结构的字面意义,它可以理解为一种按照E-T-L顺序处理的体系结构: 完成后首先提取,然后进行转换并加载到目标数据库中. 在ETL体系结构中,数据流是从源数据流到ETL工具的. ETL工具是一个单独的数据处理引擎,通常在单独的硬件服务器上执行所有数据转换工作,然后将数据加载到仓库中的目标数据. 如果要提高整个ETL过程的效率,则只能增强ETL工具服务器的配置并优化系统处理流程(通常,可调整的东西很少).
ELT体系结构将“ L”步骤推进到“ T”之前完成: 首先提取,然后加载到目标数据库中,并完成目标数据库中的转换操作. 在ELT体系结构中,ELT仅负责提供图形界面来设计业务规则. 整个数据处理过程在目标数据库和源数据库之间流动. ELT协调相关的数据库系统以执行相关的应用程序. 数据处理过程既可以在源数据库端也可以在目标数据仓库端执行(主要取决于系统的体系结构设计和数据属性). 当ETL过程需要提高效率时,可以通过调整相关数据库或更改执行该过程的服务器来实现.
您可以仔细查看以上两个架构图,并体验它们之间的差异. 让我们在下面分析它们各自的优点:
ETL体系结构的优点ELT体系结构的优点ETL模式简介
ETL具有四种主要的实现方式: 触发方式,增量字段,完全同步,日志比较
触发模式
<p>触发方法是常用的增量提取机制. 此方法基于提取要求,在要提取的源表上创建插入,修改和删除三个触发器. 只要源表中的数据发生更改,相应的触发器就会将更改后的数据写入增量中. ETL增量提取是从增量日志表中提取数据,而不是直接在源表中. 同时,应及时标记或删除增量日志表中提取的数据. 为简单起见,增量日志表通常不存储增量数据的所有字段信息,而仅存储源表名称,更新的键值和更新操作类型(插入,更新或删除). ETL增量提取过程首先基于. 从源表中提取源表名称和更新的键值,并提取相应的完整记录,然后根据更新操作的类型对目标表进行相应的处理.
优采云·物品组合工具套装V1.5.13
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2020-08-06 11:15
该原型来自原创文章生成器,但它更简单易用,操作基本相同,功能更强大,操作更简单,退伍军人可以直接使用它而无需重复学习,而且新手也很容易使用<//p
p核心功能是编写模板,在模板中引用元素,并在任何地方引用任何元素. 元素可以在文本块中调用,可以是随机的汉字,数字,字母或数字序列,随机值和随机时间. 所有免费的原创组合模式. 查看原理>>
提醒: 主界面右下角的选项按钮可以导入“原创文章生成器(高级高级版)”的程序数据(必须导入,而不是简单的文件复制)
提醒: 在2003系统上运行时,必须关闭数据执行保护.
提示: 创建新元素时,按Ctrl键可将当前元素的内容复制到新元素;切换元素显示时按Alt键可屏蔽元素内容的显示和修改. 右键单击元素项目以复制元素的引用格式[元素名称],右键单击元素库以打开本地存储数据库的文件夹(模板的相同操作).
提醒: 当前选择并显示的模板是用于生成的模板. 如果选择了模板库,则该库下的模板将被随机用于生成,并且所有已选中的元素库都可以由模板调用. 当检查了多个元素库时,不同元素库下的元素不能具有相同的名称,否则只能调用第一个被检查的元素库中具有相同名称的元素.
与“原创文章生成器”的功能相比:
1. 全新的界面设计,简单而功能强大的布局,基本相同的操作,但更简单易用
2. 元素库中的元素不再显示复选框以免误判(只有元素库本身可以被打勾,被打勾的元素库会参与调用,并且不需要打勾)
3. 显示大部分文本不再耗时,并且支持行号显示和元素语法突出显示.
4. 更强大的删除恢复功能,更强大的树搜索功能
5. 新修改的各种辅助工具(包括新编写的长尾单词采集器)可以满足更多的文本处理要求.
6. 预览时支持预览标题设置,效果如初.
7. 库的显示顺序不再混乱.
8. 其他方面,例如总体功能和性能. 查看全部
新的文章组合工具,支持短语和单词的原创随机组合,SEO基本的网站管理员工具,内置将近20种新的和增强的辅助工具.
该原型来自原创文章生成器,但它更简单易用,操作基本相同,功能更强大,操作更简单,退伍军人可以直接使用它而无需重复学习,而且新手也很容易使用<//p
p核心功能是编写模板,在模板中引用元素,并在任何地方引用任何元素. 元素可以在文本块中调用,可以是随机的汉字,数字,字母或数字序列,随机值和随机时间. 所有免费的原创组合模式. 查看原理>>
提醒: 主界面右下角的选项按钮可以导入“原创文章生成器(高级高级版)”的程序数据(必须导入,而不是简单的文件复制)
提醒: 在2003系统上运行时,必须关闭数据执行保护.
提示: 创建新元素时,按Ctrl键可将当前元素的内容复制到新元素;切换元素显示时按Alt键可屏蔽元素内容的显示和修改. 右键单击元素项目以复制元素的引用格式[元素名称],右键单击元素库以打开本地存储数据库的文件夹(模板的相同操作).
提醒: 当前选择并显示的模板是用于生成的模板. 如果选择了模板库,则该库下的模板将被随机用于生成,并且所有已选中的元素库都可以由模板调用. 当检查了多个元素库时,不同元素库下的元素不能具有相同的名称,否则只能调用第一个被检查的元素库中具有相同名称的元素.
与“原创文章生成器”的功能相比:
1. 全新的界面设计,简单而功能强大的布局,基本相同的操作,但更简单易用
2. 元素库中的元素不再显示复选框以免误判(只有元素库本身可以被打勾,被打勾的元素库会参与调用,并且不需要打勾)
3. 显示大部分文本不再耗时,并且支持行号显示和元素语法突出显示.
4. 更强大的删除恢复功能,更强大的树搜索功能
5. 新修改的各种辅助工具(包括新编写的长尾单词采集器)可以满足更多的文本处理要求.
6. 预览时支持预览标题设置,效果如初.
7. 库的显示顺序不再混乱.
8. 其他方面,例如总体功能和性能.

