
文章采集系统
文章采集系统(如何做好一个网站SEO收录?有哪些收录技巧和注意的地方)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-03-01 01:32
Emlog采集,很多博主、个人网站、企业网站长期使用的网站内容扩展工具,可以大大提升网站的性能@网站 充实,通过海量内容吸引更多用户访问。如何做好网站SEO收录?收录 的提示和注意事项有哪些?接下来,我们将从 Emlog采集 的功能和功能,以及 SEO 技巧来看整个 SEO 优化。
网站采集的文章个数与收录的速率有一定的关系。到现在,站采集仍然可以达到很高的权重。搜索引擎也表示采集的内容要注意是否去掉多余的标签,内容是否完整等。虽然Emlog采集并不是一个好的选择,但是对于很多网站来说,只有在 采集 之后,他们才有能力输出新鲜的内容。
那么Emlog采集制作的采集站点会做这些优化:网站采集内容清晰,没有乱码,标签不干净。扩充补充采集的内容,减少采集的内容。在采集的内容后面添加其他相关内容,使内容相互指向,扩大相关性。尽可能采集优质网站的内容不会采集不可读或带有广告文章。
Emlog采集发布后会主动推送内容,持续推送内容会增加爬虫访问的概率。爬取推广网站的收录,这就是前面提到的内容建设和网站优化。此外,最好提交大量的站点地图。搜索引擎处理站点地图的时间很长,最近时间缩短了很多。至于怎么推送,一般都是后台推送,支持结构化数据提交,提交多了会有惊喜。毅力是必需的。另外,网站还可以推送到收录的目录栏,可以查看其API文档申请。
目前很多建站系统都集成了采集系统,Emlog采集对于采集的内容已经成为一件很简单的事情。在短时间内用内容填满您的新网站或使搜索引擎更快收录我们的新网站变得更快乐。
但是当我们采集完成这个内容并通过搜索引擎得到收录之后,我们的网站可以非常快速的增长。搜索引擎启动收录我们的内容后,但后来在他的数据库中发现类似的内容时,一些低权重的网站收录的信息往往最先被删除。掉了。这是我们的收入先升后降的主要原因之一。因此,Emlog采集返回的内容在发布前必须经过内置的文章处理,并根据搜索引擎算法和实际情况进行文章排列。用户的时间搜索需求,让文章对搜索引擎和用户都有价值。 查看全部
文章采集系统(如何做好一个网站SEO收录?有哪些收录技巧和注意的地方)
Emlog采集,很多博主、个人网站、企业网站长期使用的网站内容扩展工具,可以大大提升网站的性能@网站 充实,通过海量内容吸引更多用户访问。如何做好网站SEO收录?收录 的提示和注意事项有哪些?接下来,我们将从 Emlog采集 的功能和功能,以及 SEO 技巧来看整个 SEO 优化。
网站采集的文章个数与收录的速率有一定的关系。到现在,站采集仍然可以达到很高的权重。搜索引擎也表示采集的内容要注意是否去掉多余的标签,内容是否完整等。虽然Emlog采集并不是一个好的选择,但是对于很多网站来说,只有在 采集 之后,他们才有能力输出新鲜的内容。
那么Emlog采集制作的采集站点会做这些优化:网站采集内容清晰,没有乱码,标签不干净。扩充补充采集的内容,减少采集的内容。在采集的内容后面添加其他相关内容,使内容相互指向,扩大相关性。尽可能采集优质网站的内容不会采集不可读或带有广告文章。
Emlog采集发布后会主动推送内容,持续推送内容会增加爬虫访问的概率。爬取推广网站的收录,这就是前面提到的内容建设和网站优化。此外,最好提交大量的站点地图。搜索引擎处理站点地图的时间很长,最近时间缩短了很多。至于怎么推送,一般都是后台推送,支持结构化数据提交,提交多了会有惊喜。毅力是必需的。另外,网站还可以推送到收录的目录栏,可以查看其API文档申请。
目前很多建站系统都集成了采集系统,Emlog采集对于采集的内容已经成为一件很简单的事情。在短时间内用内容填满您的新网站或使搜索引擎更快收录我们的新网站变得更快乐。
但是当我们采集完成这个内容并通过搜索引擎得到收录之后,我们的网站可以非常快速的增长。搜索引擎启动收录我们的内容后,但后来在他的数据库中发现类似的内容时,一些低权重的网站收录的信息往往最先被删除。掉了。这是我们的收入先升后降的主要原因之一。因此,Emlog采集返回的内容在发布前必须经过内置的文章处理,并根据搜索引擎算法和实际情况进行文章排列。用户的时间搜索需求,让文章对搜索引擎和用户都有价值。
文章采集系统(文章采集系统一般有社交关系链抓取,要哪些内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-02-24 16:03
文章采集系统一般有社交关系链抓取,互联网产品内各类用户行为抓取,以及专门的第三方爬虫系统对互联网产品内外的产品相关的事物进行采集,并可对采集到的内容进行一些分析等等。对于常见的数据采集软件有免费的、收费的和国外的软件。一般来说一个爬虫系统的开发周期需要半年至一年的时间,一些较为复杂的软件可能要花费几年时间完成整个系统的开发。
因此对于我们业务流程还不算很完善的企业来说,寻找一个开发团队为我们的业务发展快速形成产品,并在自己的产品中快速验证有无交叉,是必不可少的一个步骤。采集抓取系统会提供相应的api,这是现有业务系统对外提供的接口。对于某些特定功能开发的爬虫系统,可能会提供系统的定制化、专门的功能;对于某些特定功能开发的爬虫系统,也有可能会提供一些常见爬虫功能的兼容接口。
要抓取哪些内容,一般需要根据当前使用的业务系统来决定,业务系统开发周期一般需要半年左右。常见的抓取系统功能如下图所示:采集抓取系统往往会提供相应的服务器,即服务器采集客户端(pc客户端、手机app客户端或h5客户端等),服务器采集客户端与一般网站相同,同时也可以通过文件上传或http代理等方式实现多终端之间的数据采集。
对于大批量采集会使用文件上传功能,总之是根据具体业务来定。数据抓取时对比的是数据抓取系统所对应的一些现有的功能,比如:爬虫的采集设置、特殊字段的封装、url链接重定向、结构化爬虫的封装等,常用的爬虫系统对数据抓取的功能往往并不会设计非常详细,往往会有点乱。一般的爬虫软件通常会有人工来规划整个数据采集流程。
采集工具系统采集抓取系统提供了爬虫工具模块。采集工具系统包括:采集爬虫、数据构建模块、采集内容的格式化处理模块、采集清洗模块、数据处理模块、数据发布模块、数据统计分析模块等等。从工具系统的实现方式来说主要分为人工实现模块和机器自动化运算模块。比如有些采集工具在运行中会有失败、宕机、死机等情况,如果采集量大,保证爬虫服务器的稳定性十分重要,人工实现模块的采集就是一个选择。 查看全部
文章采集系统(文章采集系统一般有社交关系链抓取,要哪些内容)
文章采集系统一般有社交关系链抓取,互联网产品内各类用户行为抓取,以及专门的第三方爬虫系统对互联网产品内外的产品相关的事物进行采集,并可对采集到的内容进行一些分析等等。对于常见的数据采集软件有免费的、收费的和国外的软件。一般来说一个爬虫系统的开发周期需要半年至一年的时间,一些较为复杂的软件可能要花费几年时间完成整个系统的开发。
因此对于我们业务流程还不算很完善的企业来说,寻找一个开发团队为我们的业务发展快速形成产品,并在自己的产品中快速验证有无交叉,是必不可少的一个步骤。采集抓取系统会提供相应的api,这是现有业务系统对外提供的接口。对于某些特定功能开发的爬虫系统,可能会提供系统的定制化、专门的功能;对于某些特定功能开发的爬虫系统,也有可能会提供一些常见爬虫功能的兼容接口。
要抓取哪些内容,一般需要根据当前使用的业务系统来决定,业务系统开发周期一般需要半年左右。常见的抓取系统功能如下图所示:采集抓取系统往往会提供相应的服务器,即服务器采集客户端(pc客户端、手机app客户端或h5客户端等),服务器采集客户端与一般网站相同,同时也可以通过文件上传或http代理等方式实现多终端之间的数据采集。
对于大批量采集会使用文件上传功能,总之是根据具体业务来定。数据抓取时对比的是数据抓取系统所对应的一些现有的功能,比如:爬虫的采集设置、特殊字段的封装、url链接重定向、结构化爬虫的封装等,常用的爬虫系统对数据抓取的功能往往并不会设计非常详细,往往会有点乱。一般的爬虫软件通常会有人工来规划整个数据采集流程。
采集工具系统采集抓取系统提供了爬虫工具模块。采集工具系统包括:采集爬虫、数据构建模块、采集内容的格式化处理模块、采集清洗模块、数据处理模块、数据发布模块、数据统计分析模块等等。从工具系统的实现方式来说主要分为人工实现模块和机器自动化运算模块。比如有些采集工具在运行中会有失败、宕机、死机等情况,如果采集量大,保证爬虫服务器的稳定性十分重要,人工实现模块的采集就是一个选择。
文章采集系统(一套开源的分布式日志管理方案(2)-负责日志)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-02-18 17:10
目录
ELK 是 Elasticsearch、Logstash 和 Kibana 的结合体,是一个开源的分布式日志管理解决方案。
简介
Elasticsearch:负责日志的存储、检索和分析
LogStash:负责日志的采集和处理
Kibana:负责日志的可视化
ELK 日志平台
java8
logstash和elasticsearch都依赖java,所以在安装这两个之前,我们应该先安装java,java版本大于7,但是官方推荐是java 8.
安装:
$sudo add-apt-repository -y ppa:webupd8team/java
$sudo apt-get update
$sudo apt-get -y install oracle-java8-installer
弹性搜索
我们以elasticsearch当前版本1.7为例,参考官方教程:在官方网站上下载elasticsearch的压缩包,解压到一个目录下执行。
当然,在Ubuntu下,我们可以使用apt-get来安装:
下载并安装公钥:
wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
添加来源:
echo "deb http://packages.elastic.co/ela ... ebian stable main" | sudo tee -a /etc/apt/sources.list.d/elasticsearch-1.7.list
安装:
$sudo apt-get update
$sudo apt-get install elasticsearch
设置开机启动:
$sudo update-rc.d elasticsearch defaults 95 10
配置:修改network.host:localhost
$sudo vim /etc/elasticsearch/elasticsearch.yml
启动:elasticsearch启动后,绑定端口localhost:9200
$sudo service elasticsearch start
常用命令:
# 查看elasticsearch健康状态
$curl localhost:9200/_cat/health?v
# 查看elasticsearch indices
$curl localhost:9200/_cat/indices?v
# 删除指定的indices,这里删除了logstash-2015.09.26的indices
$curl -XDELETE localhost:9200/logstash-2015.09.26
Kibana
从官网下载最新的压缩包:解压到任意目录
$tar xvf kibana-*.tar.gz
$sudo mkdir -p /opt/kibana
$sudo cp -R ~/kibana-4*/* /opt/kibana/
# 将kibana作为一个服务
$cd /etc/init.d && sudo wget https://gist.githubusercontent ... bana4
$sudo chmod +x /etc/init.d/kibana4
# 将kibana设为开机启动
$sudo update-rc.d kibana4 defaults 96 9
# 修改kibana配置,因为我们采用nginx作为反向代理,修改 host: "localhsot"
$sudo vim /opt/kibana/config/kibana.yml
# 启动kibana,默认绑定在了localhost:5601
$sudo service kibana4 start
Nginx 配置:
# elk
server {
listen 80;
server_name elk.chenjiehua.me;
#auth_basic "Restricted Access";
#auth_basic_user_file /home/ubuntu/htpasswd.users;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
如果需要限制访问,可以通过nginx的auth_basic设置:
$sudo apt-get install apache2-utils
# 新建一个kibana认证用户
$sudo htpasswd -c /home/ubuntu/htpasswd.users kibana
# 然后按提示设置kibana密码
$sudo nginx -t
$sudo nginx -s reload
Logstash
安装:
参考官方教程:.
在Ubuntu下,我们可以使用apt-get来安装:
$sudo wget -qO - https://packages.elasticsearch ... earch | sudo apt-key add -
$sudo echo "deb http://packages.elasticsearch. ... ebian stable main" | sudo tee -a /etc/apt/sources.list#
$sudo apt-get update
$sudo apt-get install logstash
这里logstash有两个身份,一个是shipper,一个是indexer;在分布式系统中应用时,通常是多个shipper采集日志并发送给redis(作为broker身份),而indexer从redis中读取数据进行处理,然后发送给elasticsearch,我们可以查看所有的日志信息通过 kibana。
这里的broker使用redis作为消息系统。根据业务需要,我们还可以使用kafka等其他消息系统。
中央logstash(索引器)配置,/etc/logstash/conf.d/central.conf
input {
redis {
host => "127.0.0.1"
port => 6379
type => "redis-input"
data_type => "list"
key => "key_count"
}
}
output {
stdout {}
elasticsearch {
cluster => "elasticsearch"
codec => "json"
protocol => "http"
}
}
远程logstash(shipper)配置,/etc/logstash/conf.d/shipper.conf
input {
file {
type => "type_count"
path => ["/data/logs/count/stdout.log", "/data/logs/count/stderr.log"]
exclude => ["*.gz", "access.log"]
}
}
output {
stdout {}
redis {
host => "20.8.40.49"
port => 6379
data_type => "list"
key => "key_count"
}
}
这里,由于我们在单台服务器上运行,我们可以将 indexer 和 shipper 合并在一起,而将 redis 省略掉。配置文件如下:
input {
file {
type => "blog"
path => ["/home/ubuntu/log/nginx/blog.log"]
}
}
output {
stdout {}
elasticsearch {
cluster => "elasticsearch"
codec => "json"
host => "localhost"
protocol => "http"
}
}
basic_logstash_pipeline
对于logstash,我们有很多插件可以使用,其中过滤器部分的grok插件比较常用。如果我们想处理nginx日志,获取各个字段的信息,可以参考如下用法:
nginx日志格式:
log_format main '$remote_addr - $remote_user [$time_local]'
'"$request" $status $bytes_sent '
'"$http_referer" "$http_user_agent" $request_time';
access_log /var/log/nginx/access.log main;
Logstash 中过滤器的配置:
filter {
grok {
match => { 'message' => '%{IP:remote_addr} - - \[%{HTTPDATE:time_local}\]"%{WORD:http_method} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}" %{NUMBER:status} %{NUMBER:body_bytes_sent} (?:\"(?:%{URI:http_referer}|-)\"|%{QS:http_referer}) %{QS:http_user_agent} %{NUMBER:request_time}' }
remove_field => ["message"]
}
date {
match => ["time_local", "dd/MMM/YYYY:HH:mm:ss Z"]
}
}
关于grokdebugger,可以使用在线调试。当grok中的配置与日志格式不匹配时,可以在Kibana管理后台看到_grokparsefailure。
启动logstash:
$sudo service logstash start
我们可以在kibana中看到日志数据,搜索起来也很方便。
kibana
参考:
码字很难,转载请注明出处来自陈洁华《ELK日志采集系统搭建》 查看全部
文章采集系统(一套开源的分布式日志管理方案(2)-负责日志)
目录
ELK 是 Elasticsearch、Logstash 和 Kibana 的结合体,是一个开源的分布式日志管理解决方案。
简介
Elasticsearch:负责日志的存储、检索和分析
LogStash:负责日志的采集和处理
Kibana:负责日志的可视化
 https://chenjiehua.me/wp-conte ... 5.jpg 300w, https://chenjiehua.me/wp-conte ... m.jpg 1542w" />
https://chenjiehua.me/wp-conte ... 5.jpg 300w, https://chenjiehua.me/wp-conte ... m.jpg 1542w" />ELK 日志平台
java8
logstash和elasticsearch都依赖java,所以在安装这两个之前,我们应该先安装java,java版本大于7,但是官方推荐是java 8.
安装:
$sudo add-apt-repository -y ppa:webupd8team/java
$sudo apt-get update
$sudo apt-get -y install oracle-java8-installer
弹性搜索
我们以elasticsearch当前版本1.7为例,参考官方教程:在官方网站上下载elasticsearch的压缩包,解压到一个目录下执行。
当然,在Ubuntu下,我们可以使用apt-get来安装:
下载并安装公钥:
wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
添加来源:
echo "deb http://packages.elastic.co/ela ... ebian stable main" | sudo tee -a /etc/apt/sources.list.d/elasticsearch-1.7.list
安装:
$sudo apt-get update
$sudo apt-get install elasticsearch
设置开机启动:
$sudo update-rc.d elasticsearch defaults 95 10
配置:修改network.host:localhost
$sudo vim /etc/elasticsearch/elasticsearch.yml
启动:elasticsearch启动后,绑定端口localhost:9200
$sudo service elasticsearch start
常用命令:
# 查看elasticsearch健康状态
$curl localhost:9200/_cat/health?v
# 查看elasticsearch indices
$curl localhost:9200/_cat/indices?v
# 删除指定的indices,这里删除了logstash-2015.09.26的indices
$curl -XDELETE localhost:9200/logstash-2015.09.26
Kibana
从官网下载最新的压缩包:解压到任意目录
$tar xvf kibana-*.tar.gz
$sudo mkdir -p /opt/kibana
$sudo cp -R ~/kibana-4*/* /opt/kibana/
# 将kibana作为一个服务
$cd /etc/init.d &amp;&amp; sudo wget https://gist.githubusercontent ... bana4
$sudo chmod +x /etc/init.d/kibana4
# 将kibana设为开机启动
$sudo update-rc.d kibana4 defaults 96 9
# 修改kibana配置,因为我们采用nginx作为反向代理,修改 host: "localhsot"
$sudo vim /opt/kibana/config/kibana.yml
# 启动kibana,默认绑定在了localhost:5601
$sudo service kibana4 start
Nginx 配置:
# elk
server {
listen 80;
server_name elk.chenjiehua.me;
#auth_basic "Restricted Access";
#auth_basic_user_file /home/ubuntu/htpasswd.users;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
如果需要限制访问,可以通过nginx的auth_basic设置:
$sudo apt-get install&nbsp;apache2-utils
# 新建一个kibana认证用户
$sudo htpasswd -c /home/ubuntu/htpasswd.users kibana
# 然后按提示设置kibana密码
$sudo nginx -t
$sudo nginx -s reload
Logstash
安装:
参考官方教程:.
在Ubuntu下,我们可以使用apt-get来安装:
$sudo wget -qO - https://packages.elasticsearch ... earch | sudo apt-key add -
$sudo echo "deb http://packages.elasticsearch. ... ebian stable main" | sudo tee -a /etc/apt/sources.list#
$sudo apt-get update
$sudo apt-get install logstash
这里logstash有两个身份,一个是shipper,一个是indexer;在分布式系统中应用时,通常是多个shipper采集日志并发送给redis(作为broker身份),而indexer从redis中读取数据进行处理,然后发送给elasticsearch,我们可以查看所有的日志信息通过 kibana。
这里的broker使用redis作为消息系统。根据业务需要,我们还可以使用kafka等其他消息系统。
中央logstash(索引器)配置,/etc/logstash/conf.d/central.conf
input {
redis {
host => "127.0.0.1"
port => 6379
type => "redis-input"
data_type => "list"
key => "key_count"
}
}
output {
stdout {}
elasticsearch {
cluster => "elasticsearch"
codec => "json"
protocol => "http"
}
}
远程logstash(shipper)配置,/etc/logstash/conf.d/shipper.conf
input {
file {
type => "type_count"
path => ["/data/logs/count/stdout.log", "/data/logs/count/stderr.log"]
exclude => ["*.gz", "access.log"]
}
}
output {
stdout {}
redis {
host => "20.8.40.49"
port => 6379
data_type => "list"
key => "key_count"
}
}
这里,由于我们在单台服务器上运行,我们可以将 indexer 和 shipper 合并在一起,而将 redis 省略掉。配置文件如下:
input {
file {
type => "blog"
path => ["/home/ubuntu/log/nginx/blog.log"]
}
}
output {
stdout {}
elasticsearch {
cluster => "elasticsearch"
codec => "json"
host => "localhost"
protocol => "http"
}
}
 https://chenjiehua.me/wp-conte ... 9.png 300w, https://chenjiehua.me/wp-conte ... e.png 1473w" />
https://chenjiehua.me/wp-conte ... 9.png 300w, https://chenjiehua.me/wp-conte ... e.png 1473w" />basic_logstash_pipeline
对于logstash,我们有很多插件可以使用,其中过滤器部分的grok插件比较常用。如果我们想处理nginx日志,获取各个字段的信息,可以参考如下用法:
nginx日志格式:
log_format main '$remote_addr - $remote_user [$time_local]'
'"$request" $status $bytes_sent '
'"$http_referer" "$http_user_agent" $request_time';
access_log /var/log/nginx/access.log main;
Logstash 中过滤器的配置:
filter {
grok {
match => { 'message' => '%{IP:remote_addr} - - \[%{HTTPDATE:time_local}\]"%{WORD:http_method} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}" %{NUMBER:status} %{NUMBER:body_bytes_sent} (?:\"(?:%{URI:http_referer}|-)\"|%{QS:http_referer}) %{QS:http_user_agent} %{NUMBER:request_time}' }
remove_field => ["message"]
}
date {
match => ["time_local", "dd/MMM/YYYY:HH:mm:ss Z"]
}
}
关于grokdebugger,可以使用在线调试。当grok中的配置与日志格式不匹配时,可以在Kibana管理后台看到_grokparsefailure。
启动logstash:
$sudo service logstash start
我们可以在kibana中看到日志数据,搜索起来也很方便。
 https://chenjiehua.me/wp-conte ... 5.png 300w" />
https://chenjiehua.me/wp-conte ... 5.png 300w" />kibana
参考:
码字很难,转载请注明出处来自陈洁华《ELK日志采集系统搭建》
文章采集系统(Linux系统中有很多日志类型分析系统产生的文件介绍(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2022-02-18 17:09
一台正常提供服务的Linux服务器,时时刻刻都会产生大量的日志信息。如果生产环境有几十台甚至上百台服务器,要一一查看系统日志是很麻烦的。的。
在技术不断更新的今天,可以集中管理日志的技术有很多。最常见的操作是ELK日志分析系统,但是这些日志是怎么产生的呢?使用哪个服务进行统一管理?这个 文章 将围绕系统日志服务 - rsyslog。
Linux 系统中有多种日志类型。以下是系统自身产生的一些日志文件:
/var/log/boot.log
/var/log/cron
/var/log/dmesg
/var/log/lastlog
/var/log/maillog或/var/log/mail/*
/var/log/messages
/var/log/secure
/var/log/wtmp,/var/log/faillog
/var/log/httpd/* , /var/log/samba/*
如果想详细了解日志文件中记录了哪些信息,可以参考这篇博文:Linux中常见日志文件介绍,其中还收录了7个错误级别的介绍!这里不乱说。
系统中的大部分日志都由 rsyslog 服务管理。该服务的主要配置文件如下:
[root@aaa ~]# grep -v "^$" /etc/rsyslog.conf | grep -v "^#" #过滤配置文件中的空行和注释行
$ModLoad imuxsock # provides support for local system logging (e.g. via logger command)
$ModLoad imjournal # provides access to the systemd journal
$WorkDirectory /var/lib/rsyslog
$ActionFileDefaultTemplate RSYSLOG_TraditionalFileFormat
$IncludeConfig /etc/rsyslog.d/*.conf
$OmitLocalLogging on
$IMJournalStateFile imjournal.state
*.info;mail.none;authpriv.none;cron.none /var/log/messages
上面行开头的星号表示所有服务,点号后面的等级表示那些等级记录下来,/var/lo....表示记录到哪里
authpriv.* /var/log/secure #表示authpriv所有等级的信息都记录到secure文件中
mail.* /var/log/maillog #表示mail服务的所有级别信息都记录到/var/log/maillog中
cron.* /var/log/cron
*.emerg :omusrmsg:*
uucp,news.crit /var/log/spooler
local7.* /var/log/boot.log
#由上面几行注释可以看出,第一段中的点号前面表示某个服务,点号后面表示哪些报错等级要记录。
#点号前后都可以使用通配符星号来表示,如第一列为“*.*”,则表示所有服务的所有等级
#若为“*.info”,则表示所有服务的info等级及比info更严重的等级都记录起来。
在上面的配置文件中,可以更改日志的存放位置,以及应该记录哪些日志级别,但一般不建议这样做。
其实依靠配置文件/etc/rsyslog.conf,也可以将其日志发送到另一台服务器,然后在另一台服务器上进行统一管理。如果生产环境小,服务器不多,这种情况可以使用,但是如果生产环境的服务器数量比较多,建议部署ELK日志分析系统。
配置 rsyslog 服务实例
我这里有两台服务器,主机名分别是aaa和bbb(IP地址分别是192.168.1.1和1.2),现在要实现以下要求:
开始配置:
1、将info级别以上aaa服务器的所有系统服务日志同步发送给bbb服务器统一管理
(1)在 aaa 服务器上执行以下操作:
[root@aaa ~]# vim /etc/rsyslog.conf #编辑日志服务的配置文件
#..............省略部分内容
$ModLoad imudp #将该行开头的注释符号“#”去掉,以便开启udp协议
$UDPServerRun 514 #将该行开头的注释符号“#”去掉,以便开启udp的514端口
# Provides TCP syslog reception
$ModLoad imtcp #将该行开头的注释符号“#”去掉,以便开启tcp协议
$InputTCPServerRun 514 #将该行开头的注释符号“#”去掉,以便开启tcp的514端口
#..............省略部分内容
*.info;mail.none;authpriv.none;cron.none /var/log/messages
*.info @@192.168.1.2 #星号表示所有服务“*.info”表示info等级及以上的信息
#@@表示使用tcp协议传输,192.168.1.2是指定要发送到哪台服务器
#若使用一个@符号,则表示使用udp协议传输
#..............省略部分内容
#编辑完成后,保存退出即可。
[root@aaa ~]# systemctl restart rsyslog #重启rsyslog服务,以便更改生效
(2)在 bbb 服务器上执行以下操作:
[root@bbb ~]# vim /etc/rsyslog.conf #编辑日志服务的配置文件,开启udp和tcp的514端口
#..............省略部分内容
$ModLoad imudp #去掉该行开头的“#”注释符号
$UDPServerRun 514 #去掉该行开头的“#”注释符号
# Provides TCP syslog reception
$ModLoad imtcp #去掉该行开头的“#”注释符号
$InputTCPServerRun 514 #去掉该行开头的“#”注释符号
#..............省略部分内容
[root@bbb ~]# systemctl restart rsyslog #重启服务,使更改生效
[root@bbb ~]# tailf /var/log/secure #动态监控着本机的日志文件
Sep 19 15:00:32 aaa useradd[5998]: new group: name=lvjianzh, GID=1003
Sep 19 15:00:32 aaa useradd[5998]: new user: name=lvjianzh, UID=1003, GID=1003....
#..............省略部分内容
(3)在aaa服务器上进行如下操作(主要是生成日志信息):
[root@aaa ~]# useradd admini
[root@aaa ~]# echo '123.com' | passwd --stdin admini
更改用户 admini 的密码 。
passwd:所有的身份验证令牌已经成功更新。
(4)查看bbb生成的新日志如下:
2、将编译安装好的Nginx日志发送到bbb服务器进行管理;
(1)在 aaa 服务器上执行以下操作:
[root@aaa ~]# vim /etc/yum.repos.d/epel.repo #写入以下文件,指定阿里镜像站
[epel]
name=epel
baseurl=https://mirrors.aliyun.com/epel/7/x86_64/
gpgcheck=0
#必须保证系统默认自带的yum文件也存在/etc/yum.repos.d/目录下,写入后保存退出即可。
[root@aaa ~]# yum repolist #最好执行一下该命令
#..............省略部分内容
(7/7): base/7/x86_64/primary_db | 6.0 MB 00:01
源标识 源名称 状态
base/7/x86_64 CentOS-7 - Base 10,097
epel epel 13,384
#上面一行就是我们刚写入的文件生效的,表示没问题
extras/7/x86_64 CentOS-7 - Extras 304
updates/7/x86_64 CentOS-7 - Updates 311
repolist: 24,096
#若命令yum repolist执行后没有显示出上述内容,排除配置文件的错误后,可以执行以下命令
[root@aaa ~]# yum makecache #用来建立元数据缓存的
#..............省略部分内容
元数据缓存已建立
[root@aaa ~]# yum -y install nginx #安装nginx服务
[root@aaa ~]# systemctl start nginx #启动Nginx服务
[root@aaa ~]# netstat -anpt | grep nginx #确定Nginx服务已启动
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 6609/nginx: master
tcp6 0 0 :::80 :::* LISTEN 6609/nginx: master
[root@aaa ~]# ls /var/log/nginx/ #以下是yum安装Nginx后,Nginx两个日志文件的存放位置
access.log error.log
#记住Nginx日志的存放路径,一会要用到,若采用的是编译安装,请自行找到Nginx日志存放路径记下来
[root@aaa ~]# vim /etc/rsyslog.conf #编辑rsyslog服务的配置文件
#..............省略部分内容
#在配置文件末尾写入以下内容
$ModLoad imfile
$InputFilePollInterval 1
$InputFileName /var/log/nginx/access.log
$InputFileTag nginx-info-access;
$InputFilestateFile state-nginx-info-accesslog
$InputRunFileMonitor
$InputFileName /var/log/nginx/error.log
$InputFileTag nginx-info-error;
$InputFilestateFile state-nginx-info-errorlog
$InputRunFileMonitor
$InputFilePollInterval 10
if $programname == 'nginx-info-access' then @192.168.1.2:514
if $programname == 'nginx-info-access' then ~
if $programname == 'nginx-info-error' then @192.168.1.2:514
if $programname == 'nginx-info-error' then ~
[root@aaa ~]# systemctl restart rsyslog #重启服务以便生效
上面写的配置项解释如下:
$ModLoad imfile #加载模块
$InputFilePollInterval 1 #间隔多久采集次,默认单位是秒
$InputFileName /var/log/nginx/access.log #指定要采集的日志文件
$InputFileTag nginx-info-access; #给对应的日志打一个标签
$InputFilestateFile state-nginx-info-accesslog #给这个日志命名
$InputRunFileMonitor #启动监控
#以下的配置和上面类似,因为要采集两个日志文件嘛!
$InputFileName /var/log/nginx/error.log
$InputFileTag nginx-info-error;
$InputFilestateFile state-nginx-info-errorlog
$InputRunFileMonitor
$InputFilePollInterval 10
#以下是指定将采集的日志发送到哪里,同理,一个@符号表示使用的udp协议,两个表示tcp协议
if $programname == 'nginx-info-access' then @192.168.1.2:514
if $programname == 'nginx-info-access' then ~ #这的~,表示本地的意思
if $programname == 'nginx-info-error' then @192.168.1.2:514
if $programname == 'nginx-info-error' then ~
(2)bbb服务器上的监控日志:
(3)客户端为了生成日志,访问aaa的Nginx服务。
(4)回到bbb服务器看看aaa服务器上是否有生成Nginx访问日志(如果没有生成新的日志,客户端可以在排除配置错误的前提下刷新几次):
可见Nginx的日志信息应该不会太详细了吧?日志信息中是否收录日志的生成时间?哪个服务器生成的?标签名称是什么?访问了哪个 IP 地址?访问时间是什么时候?访问的状态码是什么?客户端访问的是什么系统,系统的位数是多少?比如(Windows NT 10.0; Win64; x64,表示是64位win10系统),你用什么浏览器访问呢?我用谷歌在这里访问它,它甚至记录了我客户的谷歌浏览器的版本号。
至此,Nginx日志文件采集就完成了,接下来就是执行apache日志采集了。有了前面的铺垫,这个就简单多了,只需要更改配置项即可。
3、将编译安装的apache日志发送到bbb服务器进行管理
(1)在 aaa 服务器上执行以下操作:
[root@aaa ~]# yum -y install httpd #安装apache服务
[root@aaa ~]# systemctl stop nginx #为了避免端口冲突,停止Nginx服务
[root@aaa ~]# systemctl start httpd #启动apache服务
[root@aaa ~]# vim /etc/rsyslog.conf #更改rsyslog配置文件,主要是更改采集日志的路径
#..............省略部分内容
$ModLoad imfile
$InputFilePollInterval 1
$InputFileName /var/log/httpd/access_log #主要是改这个
$InputFileTag httpd-info-access;
$InputFilestateFile state-httpd-info-accesslog
$InputRunFileMonitor
$InputFileName /var/log/httpd/error_log #还要改这个
#其余配置项可不改,但是建议改一下,以免看起来日志不太直观。
$InputFileTag httpd-info-error;
$InputFilestateFile state-httpd-info-errorlog
$InputRunFileMonitor
$InputFilePollInterval 10
if $programname == 'httpd-info-access' then @192.168.1.2:514
if $programname == 'httpd-info-access' then ~
if $programname == 'httpd-info-error' then @192.168.1.2:514
if $programname == 'httpd-info-error' then ~
#主要就是将上面配置中的Nginx都换成了httpd。
[root@aaa ~]# systemctl restart rsyslog #重启服务,使更改生效
(2)bbb服务器上的监控日志:
(3)客户端访问aaa的Nginx服务是为了生成日志(刷新几次)。
(4)回到bbb服务器看看有没有关于aaa服务器的httpd访问日志。
好的!没问题,采集 来了。. .
————————— 本文到此结束,感谢您的阅读—————— 查看全部
文章采集系统(Linux系统中有很多日志类型分析系统产生的文件介绍(二))
一台正常提供服务的Linux服务器,时时刻刻都会产生大量的日志信息。如果生产环境有几十台甚至上百台服务器,要一一查看系统日志是很麻烦的。的。
在技术不断更新的今天,可以集中管理日志的技术有很多。最常见的操作是ELK日志分析系统,但是这些日志是怎么产生的呢?使用哪个服务进行统一管理?这个 文章 将围绕系统日志服务 - rsyslog。
Linux 系统中有多种日志类型。以下是系统自身产生的一些日志文件:
/var/log/boot.log
/var/log/cron
/var/log/dmesg
/var/log/lastlog
/var/log/maillog或/var/log/mail/*
/var/log/messages
/var/log/secure
/var/log/wtmp,/var/log/faillog
/var/log/httpd/* , /var/log/samba/*
如果想详细了解日志文件中记录了哪些信息,可以参考这篇博文:Linux中常见日志文件介绍,其中还收录了7个错误级别的介绍!这里不乱说。
系统中的大部分日志都由 rsyslog 服务管理。该服务的主要配置文件如下:
[root@aaa ~]# grep -v "^$" /etc/rsyslog.conf | grep -v "^#" #过滤配置文件中的空行和注释行
$ModLoad imuxsock # provides support for local system logging (e.g. via logger command)
$ModLoad imjournal # provides access to the systemd journal
$WorkDirectory /var/lib/rsyslog
$ActionFileDefaultTemplate RSYSLOG_TraditionalFileFormat
$IncludeConfig /etc/rsyslog.d/*.conf
$OmitLocalLogging on
$IMJournalStateFile imjournal.state
*.info;mail.none;authpriv.none;cron.none /var/log/messages
上面行开头的星号表示所有服务,点号后面的等级表示那些等级记录下来,/var/lo....表示记录到哪里
authpriv.* /var/log/secure #表示authpriv所有等级的信息都记录到secure文件中
mail.* /var/log/maillog #表示mail服务的所有级别信息都记录到/var/log/maillog中
cron.* /var/log/cron
*.emerg :omusrmsg:*
uucp,news.crit /var/log/spooler
local7.* /var/log/boot.log
#由上面几行注释可以看出,第一段中的点号前面表示某个服务,点号后面表示哪些报错等级要记录。
#点号前后都可以使用通配符星号来表示,如第一列为“*.*”,则表示所有服务的所有等级
#若为“*.info”,则表示所有服务的info等级及比info更严重的等级都记录起来。
在上面的配置文件中,可以更改日志的存放位置,以及应该记录哪些日志级别,但一般不建议这样做。
其实依靠配置文件/etc/rsyslog.conf,也可以将其日志发送到另一台服务器,然后在另一台服务器上进行统一管理。如果生产环境小,服务器不多,这种情况可以使用,但是如果生产环境的服务器数量比较多,建议部署ELK日志分析系统。
配置 rsyslog 服务实例
我这里有两台服务器,主机名分别是aaa和bbb(IP地址分别是192.168.1.1和1.2),现在要实现以下要求:
开始配置:
1、将info级别以上aaa服务器的所有系统服务日志同步发送给bbb服务器统一管理
(1)在 aaa 服务器上执行以下操作:
[root@aaa ~]# vim /etc/rsyslog.conf #编辑日志服务的配置文件
#..............省略部分内容
$ModLoad imudp #将该行开头的注释符号“#”去掉,以便开启udp协议
$UDPServerRun 514 #将该行开头的注释符号“#”去掉,以便开启udp的514端口
# Provides TCP syslog reception
$ModLoad imtcp #将该行开头的注释符号“#”去掉,以便开启tcp协议
$InputTCPServerRun 514 #将该行开头的注释符号“#”去掉,以便开启tcp的514端口
#..............省略部分内容
*.info;mail.none;authpriv.none;cron.none /var/log/messages
*.info @@192.168.1.2 #星号表示所有服务“*.info”表示info等级及以上的信息
#@@表示使用tcp协议传输,192.168.1.2是指定要发送到哪台服务器
#若使用一个@符号,则表示使用udp协议传输
#..............省略部分内容
#编辑完成后,保存退出即可。
[root@aaa ~]# systemctl restart rsyslog #重启rsyslog服务,以便更改生效
(2)在 bbb 服务器上执行以下操作:
[root@bbb ~]# vim /etc/rsyslog.conf #编辑日志服务的配置文件,开启udp和tcp的514端口
#..............省略部分内容
$ModLoad imudp #去掉该行开头的“#”注释符号
$UDPServerRun 514 #去掉该行开头的“#”注释符号
# Provides TCP syslog reception
$ModLoad imtcp #去掉该行开头的“#”注释符号
$InputTCPServerRun 514 #去掉该行开头的“#”注释符号
#..............省略部分内容
[root@bbb ~]# systemctl restart rsyslog #重启服务,使更改生效
[root@bbb ~]# tailf /var/log/secure #动态监控着本机的日志文件
Sep 19 15:00:32 aaa useradd[5998]: new group: name=lvjianzh, GID=1003
Sep 19 15:00:32 aaa useradd[5998]: new user: name=lvjianzh, UID=1003, GID=1003....
#..............省略部分内容
(3)在aaa服务器上进行如下操作(主要是生成日志信息):
[root@aaa ~]# useradd admini
[root@aaa ~]# echo '123.com' | passwd --stdin admini
更改用户 admini 的密码 。
passwd:所有的身份验证令牌已经成功更新。
(4)查看bbb生成的新日志如下:
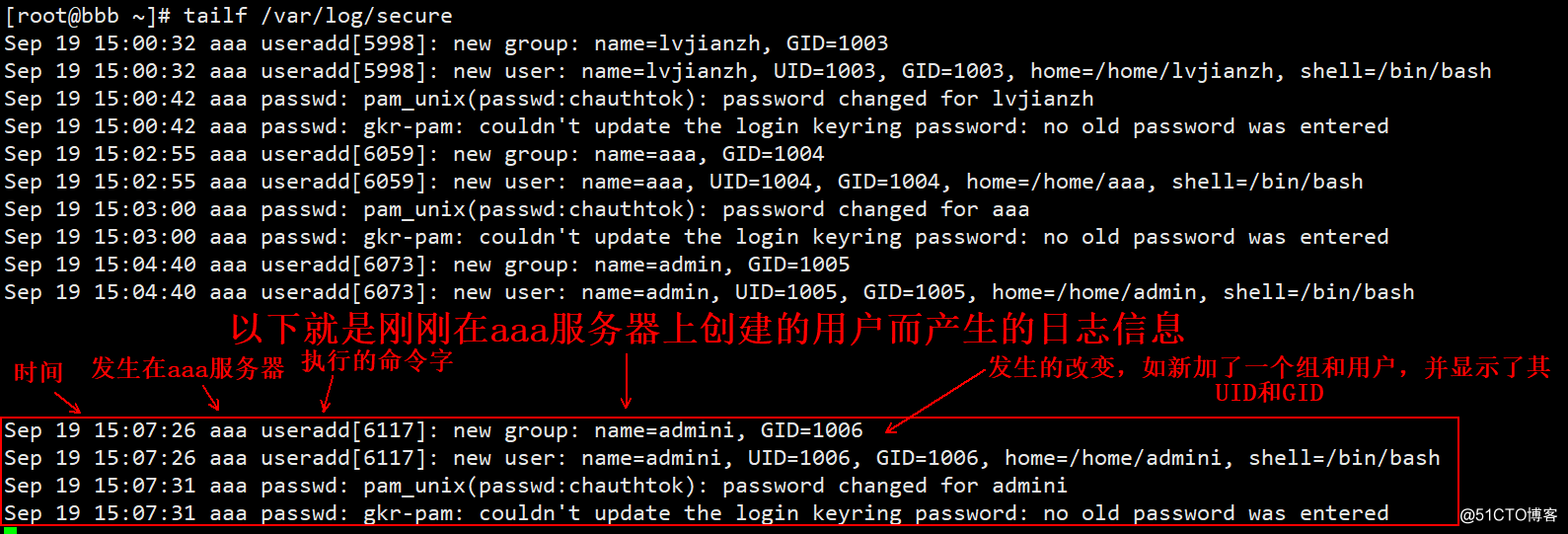
2、将编译安装好的Nginx日志发送到bbb服务器进行管理;
(1)在 aaa 服务器上执行以下操作:
[root@aaa ~]# vim /etc/yum.repos.d/epel.repo #写入以下文件,指定阿里镜像站
[epel]
name=epel
baseurl=https://mirrors.aliyun.com/epel/7/x86_64/
gpgcheck=0
#必须保证系统默认自带的yum文件也存在/etc/yum.repos.d/目录下,写入后保存退出即可。
[root@aaa ~]# yum repolist #最好执行一下该命令
#..............省略部分内容
(7/7): base/7/x86_64/primary_db | 6.0 MB 00:01
源标识 源名称 状态
base/7/x86_64 CentOS-7 - Base 10,097
epel epel 13,384
#上面一行就是我们刚写入的文件生效的,表示没问题
extras/7/x86_64 CentOS-7 - Extras 304
updates/7/x86_64 CentOS-7 - Updates 311
repolist: 24,096
#若命令yum repolist执行后没有显示出上述内容,排除配置文件的错误后,可以执行以下命令
[root@aaa ~]# yum makecache #用来建立元数据缓存的
#..............省略部分内容
元数据缓存已建立
[root@aaa ~]# yum -y install nginx #安装nginx服务
[root@aaa ~]# systemctl start nginx #启动Nginx服务
[root@aaa ~]# netstat -anpt | grep nginx #确定Nginx服务已启动
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 6609/nginx: master
tcp6 0 0 :::80 :::* LISTEN 6609/nginx: master
[root@aaa ~]# ls /var/log/nginx/ #以下是yum安装Nginx后,Nginx两个日志文件的存放位置
access.log error.log
#记住Nginx日志的存放路径,一会要用到,若采用的是编译安装,请自行找到Nginx日志存放路径记下来
[root@aaa ~]# vim /etc/rsyslog.conf #编辑rsyslog服务的配置文件
#..............省略部分内容
#在配置文件末尾写入以下内容
$ModLoad imfile
$InputFilePollInterval 1
$InputFileName /var/log/nginx/access.log
$InputFileTag nginx-info-access;
$InputFilestateFile state-nginx-info-accesslog
$InputRunFileMonitor
$InputFileName /var/log/nginx/error.log
$InputFileTag nginx-info-error;
$InputFilestateFile state-nginx-info-errorlog
$InputRunFileMonitor
$InputFilePollInterval 10
if $programname == 'nginx-info-access' then @192.168.1.2:514
if $programname == 'nginx-info-access' then ~
if $programname == 'nginx-info-error' then @192.168.1.2:514
if $programname == 'nginx-info-error' then ~
[root@aaa ~]# systemctl restart rsyslog #重启服务以便生效
上面写的配置项解释如下:
$ModLoad imfile #加载模块
$InputFilePollInterval 1 #间隔多久采集次,默认单位是秒
$InputFileName /var/log/nginx/access.log #指定要采集的日志文件
$InputFileTag nginx-info-access; #给对应的日志打一个标签
$InputFilestateFile state-nginx-info-accesslog #给这个日志命名
$InputRunFileMonitor #启动监控
#以下的配置和上面类似,因为要采集两个日志文件嘛!
$InputFileName /var/log/nginx/error.log
$InputFileTag nginx-info-error;
$InputFilestateFile state-nginx-info-errorlog
$InputRunFileMonitor
$InputFilePollInterval 10
#以下是指定将采集的日志发送到哪里,同理,一个@符号表示使用的udp协议,两个表示tcp协议
if $programname == 'nginx-info-access' then @192.168.1.2:514
if $programname == 'nginx-info-access' then ~ #这的~,表示本地的意思
if $programname == 'nginx-info-error' then @192.168.1.2:514
if $programname == 'nginx-info-error' then ~
(2)bbb服务器上的监控日志:
(3)客户端为了生成日志,访问aaa的Nginx服务。
(4)回到bbb服务器看看aaa服务器上是否有生成Nginx访问日志(如果没有生成新的日志,客户端可以在排除配置错误的前提下刷新几次):
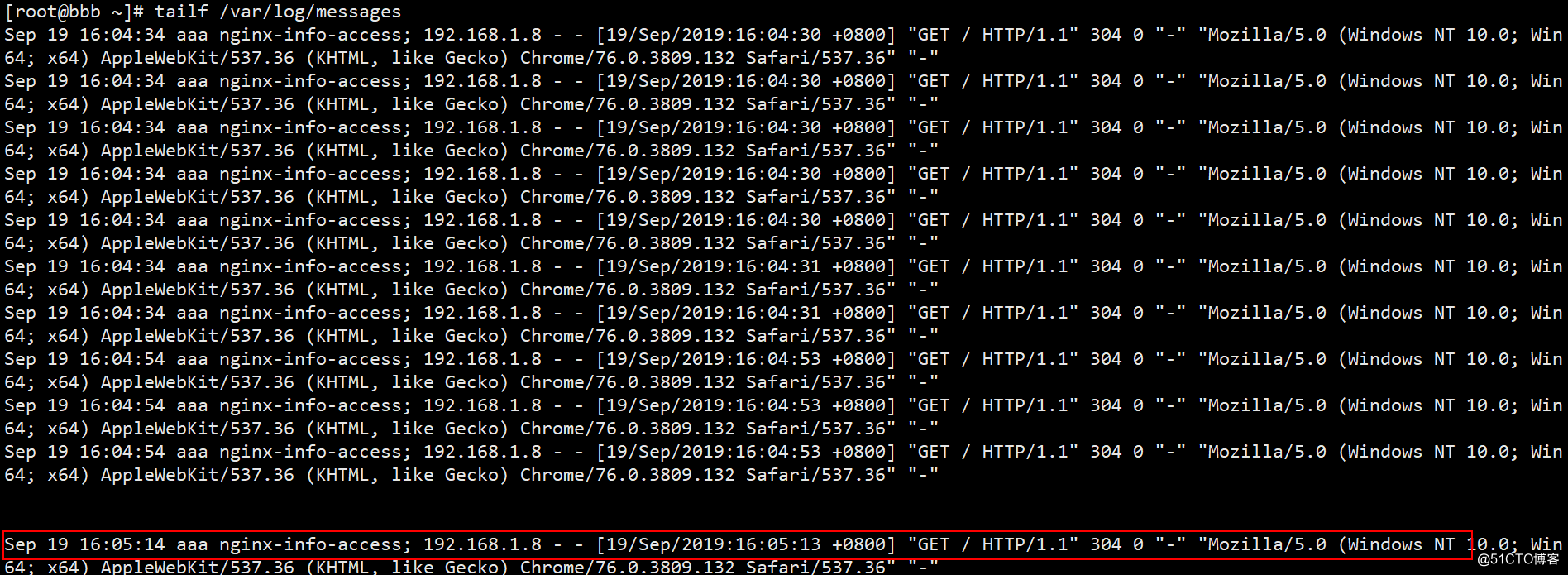
可见Nginx的日志信息应该不会太详细了吧?日志信息中是否收录日志的生成时间?哪个服务器生成的?标签名称是什么?访问了哪个 IP 地址?访问时间是什么时候?访问的状态码是什么?客户端访问的是什么系统,系统的位数是多少?比如(Windows NT 10.0; Win64; x64,表示是64位win10系统),你用什么浏览器访问呢?我用谷歌在这里访问它,它甚至记录了我客户的谷歌浏览器的版本号。
至此,Nginx日志文件采集就完成了,接下来就是执行apache日志采集了。有了前面的铺垫,这个就简单多了,只需要更改配置项即可。
3、将编译安装的apache日志发送到bbb服务器进行管理
(1)在 aaa 服务器上执行以下操作:
[root@aaa ~]# yum -y install httpd #安装apache服务
[root@aaa ~]# systemctl stop nginx #为了避免端口冲突,停止Nginx服务
[root@aaa ~]# systemctl start httpd #启动apache服务
[root@aaa ~]# vim /etc/rsyslog.conf #更改rsyslog配置文件,主要是更改采集日志的路径
#..............省略部分内容
$ModLoad imfile
$InputFilePollInterval 1
$InputFileName /var/log/httpd/access_log #主要是改这个
$InputFileTag httpd-info-access;
$InputFilestateFile state-httpd-info-accesslog
$InputRunFileMonitor
$InputFileName /var/log/httpd/error_log #还要改这个
#其余配置项可不改,但是建议改一下,以免看起来日志不太直观。
$InputFileTag httpd-info-error;
$InputFilestateFile state-httpd-info-errorlog
$InputRunFileMonitor
$InputFilePollInterval 10
if $programname == 'httpd-info-access' then @192.168.1.2:514
if $programname == 'httpd-info-access' then ~
if $programname == 'httpd-info-error' then @192.168.1.2:514
if $programname == 'httpd-info-error' then ~
#主要就是将上面配置中的Nginx都换成了httpd。
[root@aaa ~]# systemctl restart rsyslog #重启服务,使更改生效
(2)bbb服务器上的监控日志:

(3)客户端访问aaa的Nginx服务是为了生成日志(刷新几次)。

(4)回到bbb服务器看看有没有关于aaa服务器的httpd访问日志。
好的!没问题,采集 来了。. .
————————— 本文到此结束,感谢您的阅读——————
文章采集系统(这款知乎采集器的采用智能模式只需要输入网址就能自动识别采集知乎高赞)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2022-02-09 20:16
相比市面上大部分的采集软件,采集知乎的文章都可以实现,例如爬虫,优采云,优采云采集器、优采云采集器等很多内容采集系统都有自己的特点,很多用户也有自己的习惯和喜好,但是对于大部分新手来说,上手比较困难。但如果抛开熟练使用后的用户体验,一款操作极其简单、功能强大的数据采集软件才是广大新手用户真正需要的。
下面小编推荐这款知乎采集器智能模式,输入网址即可自动识别采集知乎好评问答,方便大家阅读知乎问答和文章内容,并将喜欢的问答或文章永久保存到本地计算机,便于集中管理和阅读。
一、软件介绍
1、导出知乎网站任何问答中的问答内容,以及问答的评论区;
2、导出指定用户下的所有文章,包括文章内容和文章评论;
3、导出格式主要是html格式,也可以导出pdf和word格式(推荐使用默认html,html相当于本地网页,可以永久保存到电脑中);
二、软件功能介绍
1、导出知乎网站任何问答中的问答内容,以及问答的评论区;
2、导出指定用户下的所有文章,包括文章内容和文章评论;
3、导出格式主要是html格式,也可以导出pdf和word格式(推荐使用默认html,html相当于本地网页,可以永久保存到电脑中);
三、知乎 助手软件教程
第一步:下载软件并安装。可以通过下方小编给出的蓝琴云网盘链接下载安装包,解压后运行。
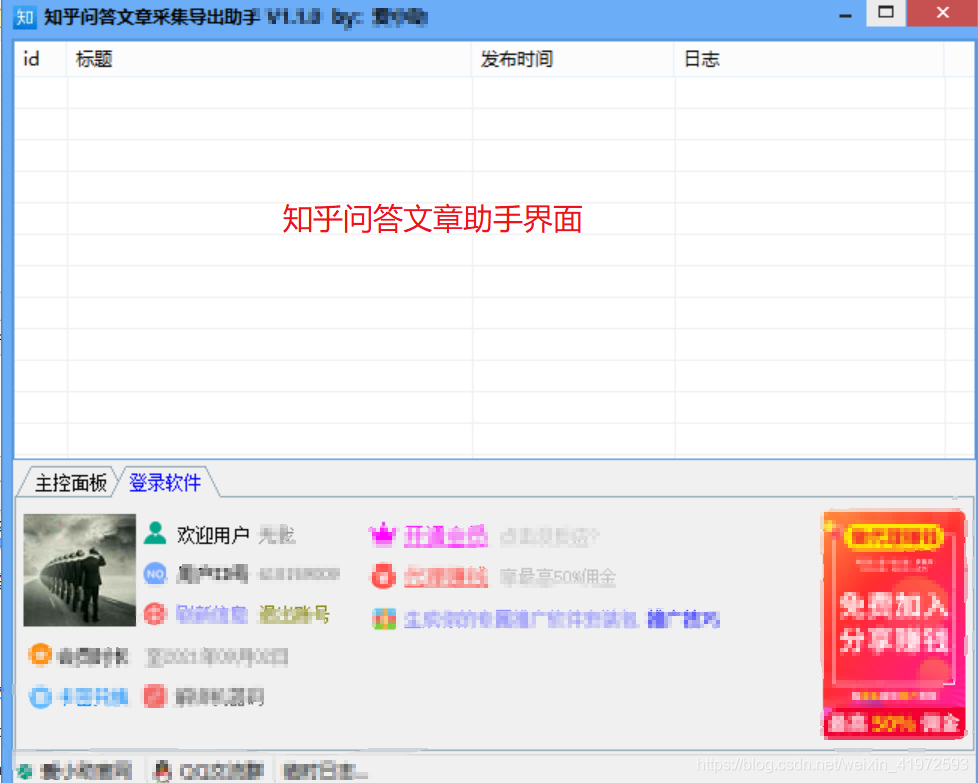
第二步:打开软件后,可以看到主界面,用你的微信登录。
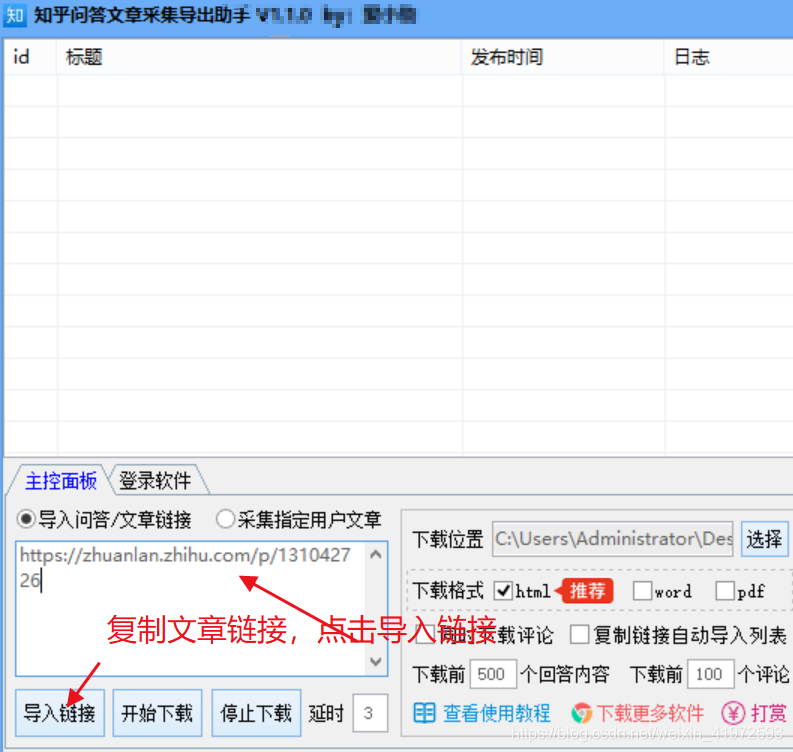
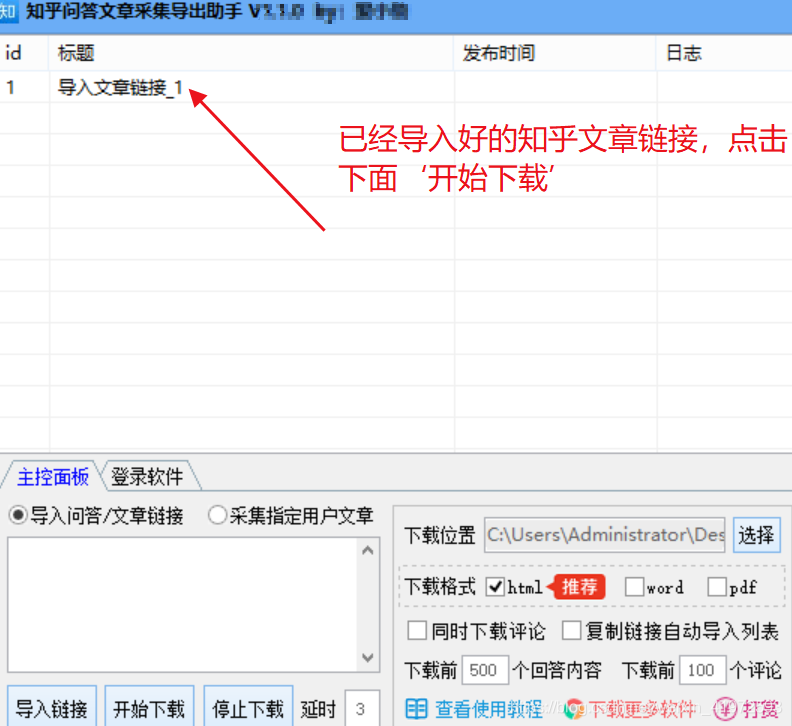
Step 3. 导入采集问答链接/文章链接或指定用户文章链接。如下所示
示例连接:
Step 4.选择采集指定的本地电脑的本地保存位置,选择导出的文件格式【html格式、pdf和Word格式】(建议使用默认html,html相当于一个本地网页,可以永久保存到您的计算机)并启动 采集。
四、支持三种连接导入和下载
1、问答链接示例:
问答链接
2、文章链接示例:
3、采集指定用户主页文章链接:. 下面界面中的链接主要用于批量下载一个知乎首页下的所有文章。
(这里指的是一个导入的单个问答或文章链接,多个链接每行一个)
五、文章采集成功本地截图
六、操作方法总结
1、先下载蓝琴云网盘的软件链接[]
2、下载后解压,打开软件登录,设置采集导出文章保存位置。
3、复制并导入需要采集的文章链接、问答链接、指定用户文章链接,点击开始下载
4、下载完成后,找到刚才设置的文章的保存位置,打开就可以看到下载的知乎文章。
注:所有下载的知乎文章仅供自学使用,禁止以分发或使用为目的直接或间接分发、使用、改编或再分发,禁止任何其他商业用途。 查看全部
文章采集系统(这款知乎采集器的采用智能模式只需要输入网址就能自动识别采集知乎高赞)
相比市面上大部分的采集软件,采集知乎的文章都可以实现,例如爬虫,优采云,优采云采集器、优采云采集器等很多内容采集系统都有自己的特点,很多用户也有自己的习惯和喜好,但是对于大部分新手来说,上手比较困难。但如果抛开熟练使用后的用户体验,一款操作极其简单、功能强大的数据采集软件才是广大新手用户真正需要的。
下面小编推荐这款知乎采集器智能模式,输入网址即可自动识别采集知乎好评问答,方便大家阅读知乎问答和文章内容,并将喜欢的问答或文章永久保存到本地计算机,便于集中管理和阅读。
一、软件介绍
1、导出知乎网站任何问答中的问答内容,以及问答的评论区;
2、导出指定用户下的所有文章,包括文章内容和文章评论;
3、导出格式主要是html格式,也可以导出pdf和word格式(推荐使用默认html,html相当于本地网页,可以永久保存到电脑中);
二、软件功能介绍
1、导出知乎网站任何问答中的问答内容,以及问答的评论区;
2、导出指定用户下的所有文章,包括文章内容和文章评论;
3、导出格式主要是html格式,也可以导出pdf和word格式(推荐使用默认html,html相当于本地网页,可以永久保存到电脑中);
三、知乎 助手软件教程
第一步:下载软件并安装。可以通过下方小编给出的蓝琴云网盘链接下载安装包,解压后运行。
第二步:打开软件后,可以看到主界面,用你的微信登录。
Step 3. 导入采集问答链接/文章链接或指定用户文章链接。如下所示
示例连接:
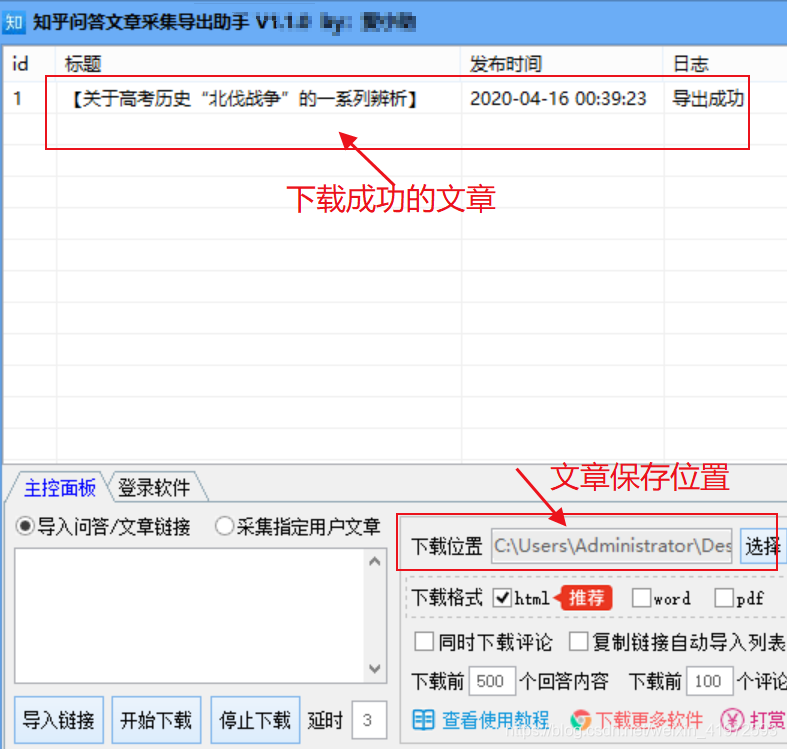
Step 4.选择采集指定的本地电脑的本地保存位置,选择导出的文件格式【html格式、pdf和Word格式】(建议使用默认html,html相当于一个本地网页,可以永久保存到您的计算机)并启动 采集。
四、支持三种连接导入和下载
1、问答链接示例:
问答链接
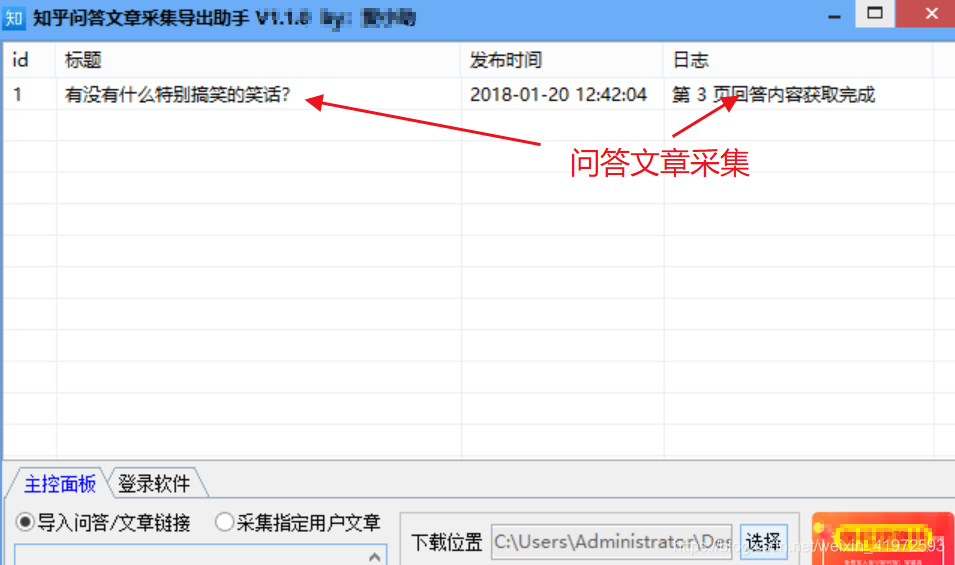
2、文章链接示例:
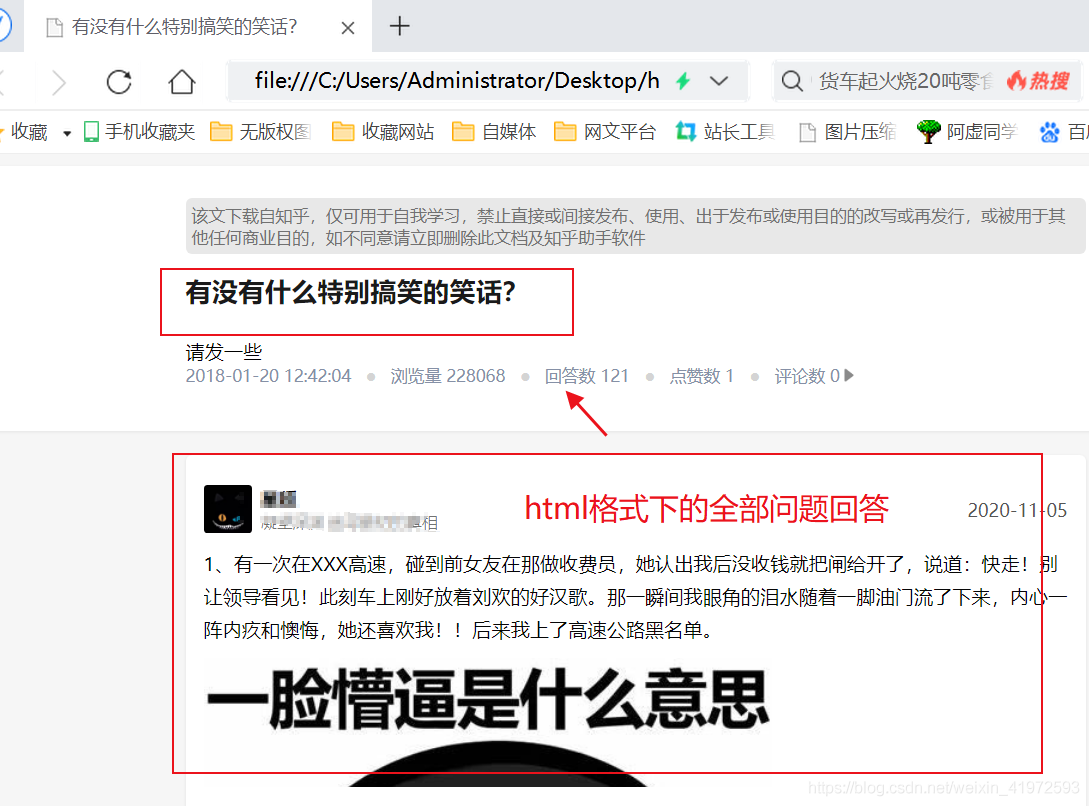
3、采集指定用户主页文章链接:. 下面界面中的链接主要用于批量下载一个知乎首页下的所有文章。
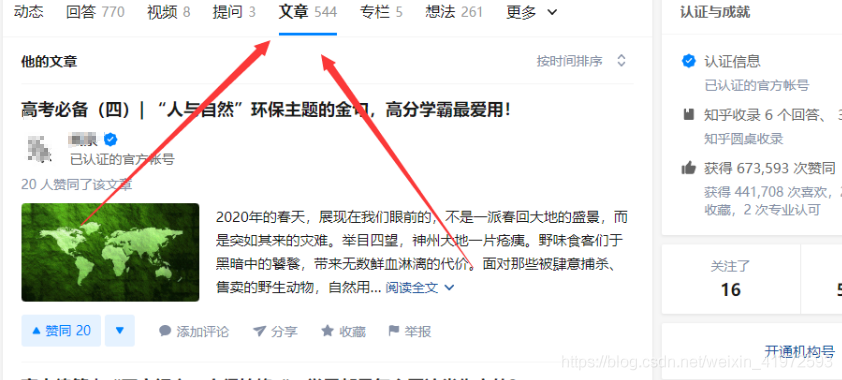
(这里指的是一个导入的单个问答或文章链接,多个链接每行一个)
五、文章采集成功本地截图
六、操作方法总结
1、先下载蓝琴云网盘的软件链接[]
2、下载后解压,打开软件登录,设置采集导出文章保存位置。
3、复制并导入需要采集的文章链接、问答链接、指定用户文章链接,点击开始下载
4、下载完成后,找到刚才设置的文章的保存位置,打开就可以看到下载的知乎文章。
注:所有下载的知乎文章仅供自学使用,禁止以分发或使用为目的直接或间接分发、使用、改编或再分发,禁止任何其他商业用途。
文章采集系统(ELK日志收集、Logstash、Kibana的简称,并非全部)
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2022-02-09 02:09
ELK日志采集
ELK 是 Elasticsearch、Logstash、Kibana 的缩写,这三个是核心套件,但不是全部。
Elasticsearch是一个实时全文搜索分析引擎,提供数据采集、分析、存储三大功能;它是一套开放的 REST 和 JAVA API 结构,提供高效的搜索功能和可扩展的分布式系统。它建立在 Apache Lucene 搜索引擎库之上。
Logstash 是一个采集、分析和过滤日志的工具。它支持几乎所有类型的日志,包括系统日志、错误日志和自定义应用程序日志。它可以接收来自多种来源的日志,包括 syslog、消息传递(例如 RabbitMQ)和 JMX,并且可以通过多种方式输出数据,包括电子邮件、websockets 和 Elasticsearch。
Kibana 是一个基于 Web 的图形界面,用于搜索、分析和可视化存储在 Elasticsearch 指标中的日志数据。它利用 Elasticsearch 的 REST 接口来检索数据,不仅允许用户为自己的数据创建定制的仪表板视图,还允许他们以特别的方式查询和过滤数据。
1、准备环境1.1、配置java环境
去官网下载jdk1.8以上的包,然后配置java环境,保证环境正常使用。此处跳过安装过程。不明白的请自行百度。
[root@vm96-yw-65-test-3060 application]# java -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
1.2、下载ELK包
去官网下载Elasticsearch、Logstash和Kibana。因为是测试环境,所以我下载了最新版本v6.4.0,下载后解压。
wget https://artifacts.elastic.co/d ... ar.gz
wget https://artifacts.elastic.co/d ... ar.gz
wget https://artifacts.elastic.co/d ... ar.gz
2、配置2.1、修改系统配置
Elasticsearch对系统最大连接数有要求,所以需要修改系统连接数。
echo '
* hard nofile 65536
* soft nofile 65536
* soft nproc 65536
* hard nproc 65536
' >>/etc/security/limits.conf
echo 'vm.max_map_count = 262144' >> /etc/sysctl.conf
vim /etc/security/limits.d/90-nproc.conf
# 第一行最后一个数,修改为4096,如果是则不用修改
# limits.d下面的文件可能不是90-nproc.conf,可能是其他数字开头的文件。
* soft nproc 4096
root soft nproc unlimited
2.2、elasticSearch 配置
这其实是ELK的核心。启动时一定要注意。从5.0开始,提高了ElasticSearch的安全级别,不允许使用root账号启动,所以我们需要添加用户,所以还需要创建一个elsearch账号。
groupadd es #新建es组
useradd es -g es -p elasticsearch #新建一个es用户
chown -R es:es /usr/elasticsearch-6.4.0/ #指定elasticsearch-6.4.0目录下的文件所属elsearch组
修改配置文件
vim /application/elasticsearch-6.4.0/config/elasticsearch.yml
······
path.data: /application/elasticsearch-6.4.0/data
path.logs: /application/elasticsearch-6.4.0/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
······
启动
su es ## 切换到普通用户
cd /application/elasticsearch-6.4.0/
./bin/elasticsearch -d ## -d 后台运行
2.3、logstash 配置
解压后进入config目录新建logstash.conf配置,添加如下内容。
[root@vm96-yw-65-test-3060 config]# pwd
/application/logstash-6.4.0/config
[root@vm96-yw-65-test-3060 config]# vim logstash.conf
input {
file {
type => "log"
path => "/logs/*.log" ##创建一个/logs目录用于之后的测试
start_position => "beginning"
}
}
output {
stdout {
codec => rubydebug { }
}
elasticsearch { ##输出到es
hosts => "localhost:9200"
index => "log-%{+YYYY.MM.dd}"
}
}
logstash做的事情是分三个阶段执行的:输入输入-》处理过滤器(非必须)-》输出输出,这是我们需要配置的三个部分,因为是测试,所以不加filter过滤和过滤,配置只有输入和输出。一个文件可以有多个输入。过滤器很有用,但也是个麻烦点。它需要大量的实验。nginx、Apache等服务的日志分析需要使用该模块进行过滤分析。
[root@vm96-yw-65-test-3060 config]# nohup ../bin/logstash -f logstash.conf &
# 使用nohup,启动后台运行,如需关闭使用kill -9,建议多开窗口,启动ELK三个服务,可以观看控制窗口的报错信息
2.4、kibana 配置
它的配置也很简单,需要在kibana.yml文件中指定需要读取的elasticSearch地址和可以从外网访问的绑定地址。
[root@vm96-yw-65-test-3060 config]# vim /application/kinbana-6.4.0/config/kibana.yml
······
elasticsearch.url: "http://localhost:9200"
server.host: 0.0.0.0
······
启动
[root@vm96-yw-65-test-3060 config]# nohup ../bin/kibana &
# 使用nohup,启动后台运行,如需关闭使用kill -9
2.5、测试
写测试日志
vim /logs/test.log
Hello,World!!!
启动logstash
[root@vm96-yw-65-test-3060 config]# nohup ../bin/logstash -f logstash.conf &
在浏览器中输入::5601/,即可打开kibana页面。
单击管理 => 索引模式以创建索引。如果ES从logstash接收到日志数据,页面会显示可以创建的索引,否则会显示无法创建索引。请自行检查日志文件中的分析错误。
创建索引后,点击左侧的Discover,可以看到对刚刚创建的日志的分析。 查看全部
文章采集系统(ELK日志收集、Logstash、Kibana的简称,并非全部)
ELK日志采集
ELK 是 Elasticsearch、Logstash、Kibana 的缩写,这三个是核心套件,但不是全部。
Elasticsearch是一个实时全文搜索分析引擎,提供数据采集、分析、存储三大功能;它是一套开放的 REST 和 JAVA API 结构,提供高效的搜索功能和可扩展的分布式系统。它建立在 Apache Lucene 搜索引擎库之上。
Logstash 是一个采集、分析和过滤日志的工具。它支持几乎所有类型的日志,包括系统日志、错误日志和自定义应用程序日志。它可以接收来自多种来源的日志,包括 syslog、消息传递(例如 RabbitMQ)和 JMX,并且可以通过多种方式输出数据,包括电子邮件、websockets 和 Elasticsearch。
Kibana 是一个基于 Web 的图形界面,用于搜索、分析和可视化存储在 Elasticsearch 指标中的日志数据。它利用 Elasticsearch 的 REST 接口来检索数据,不仅允许用户为自己的数据创建定制的仪表板视图,还允许他们以特别的方式查询和过滤数据。
1、准备环境1.1、配置java环境
去官网下载jdk1.8以上的包,然后配置java环境,保证环境正常使用。此处跳过安装过程。不明白的请自行百度。
[root@vm96-yw-65-test-3060 application]# java -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
1.2、下载ELK包
去官网下载Elasticsearch、Logstash和Kibana。因为是测试环境,所以我下载了最新版本v6.4.0,下载后解压。
wget https://artifacts.elastic.co/d ... ar.gz
wget https://artifacts.elastic.co/d ... ar.gz
wget https://artifacts.elastic.co/d ... ar.gz
2、配置2.1、修改系统配置
Elasticsearch对系统最大连接数有要求,所以需要修改系统连接数。
echo '
* hard nofile 65536
* soft nofile 65536
* soft nproc 65536
* hard nproc 65536
' >>/etc/security/limits.conf
echo 'vm.max_map_count = 262144' >> /etc/sysctl.conf
vim /etc/security/limits.d/90-nproc.conf
# 第一行最后一个数,修改为4096,如果是则不用修改
# limits.d下面的文件可能不是90-nproc.conf,可能是其他数字开头的文件。
* soft nproc 4096
root soft nproc unlimited
2.2、elasticSearch 配置
这其实是ELK的核心。启动时一定要注意。从5.0开始,提高了ElasticSearch的安全级别,不允许使用root账号启动,所以我们需要添加用户,所以还需要创建一个elsearch账号。
groupadd es #新建es组
useradd es -g es -p elasticsearch #新建一个es用户
chown -R es:es /usr/elasticsearch-6.4.0/ #指定elasticsearch-6.4.0目录下的文件所属elsearch组
修改配置文件
vim /application/elasticsearch-6.4.0/config/elasticsearch.yml
······
path.data: /application/elasticsearch-6.4.0/data
path.logs: /application/elasticsearch-6.4.0/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
······
启动
su es ## 切换到普通用户
cd /application/elasticsearch-6.4.0/
./bin/elasticsearch -d ## -d 后台运行
2.3、logstash 配置
解压后进入config目录新建logstash.conf配置,添加如下内容。
[root@vm96-yw-65-test-3060 config]# pwd
/application/logstash-6.4.0/config
[root@vm96-yw-65-test-3060 config]# vim logstash.conf
input {
file {
type => "log"
path => "/logs/*.log" ##创建一个/logs目录用于之后的测试
start_position => "beginning"
}
}
output {
stdout {
codec => rubydebug { }
}
elasticsearch { ##输出到es
hosts => "localhost:9200"
index => "log-%{+YYYY.MM.dd}"
}
}
logstash做的事情是分三个阶段执行的:输入输入-》处理过滤器(非必须)-》输出输出,这是我们需要配置的三个部分,因为是测试,所以不加filter过滤和过滤,配置只有输入和输出。一个文件可以有多个输入。过滤器很有用,但也是个麻烦点。它需要大量的实验。nginx、Apache等服务的日志分析需要使用该模块进行过滤分析。
[root@vm96-yw-65-test-3060 config]# nohup ../bin/logstash -f logstash.conf &
# 使用nohup,启动后台运行,如需关闭使用kill -9,建议多开窗口,启动ELK三个服务,可以观看控制窗口的报错信息
2.4、kibana 配置
它的配置也很简单,需要在kibana.yml文件中指定需要读取的elasticSearch地址和可以从外网访问的绑定地址。
[root@vm96-yw-65-test-3060 config]# vim /application/kinbana-6.4.0/config/kibana.yml
······
elasticsearch.url: "http://localhost:9200"
server.host: 0.0.0.0
······
启动
[root@vm96-yw-65-test-3060 config]# nohup ../bin/kibana &
# 使用nohup,启动后台运行,如需关闭使用kill -9
2.5、测试
写测试日志
vim /logs/test.log
Hello,World!!!
启动logstash
[root@vm96-yw-65-test-3060 config]# nohup ../bin/logstash -f logstash.conf &
在浏览器中输入::5601/,即可打开kibana页面。
单击管理 => 索引模式以创建索引。如果ES从logstash接收到日志数据,页面会显示可以创建的索引,否则会显示无法创建索引。请自行检查日志文件中的分析错误。
创建索引后,点击左侧的Discover,可以看到对刚刚创建的日志的分析。
文章采集系统(helloword系统准备学习一下看看看看看看吧(图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-02-01 19:02
)
今天自己搭建了elk系统来学习看看,因为它是现在主流的实时数据分析系统。
具体安装过程不再赘述。和大部分linux安装文件一样,没有太大区别。
安装后进行测试。居然报错了。
启动命令://bin/logstash -e 'input {stdin {}} output {stdout {codec =>rubydebug}}'
启动此命令后,终端正在等待我们的输入。我们可以输入任何我们想要的字符串。还是和学习编程初学者一样,输入hello word,看看会返回什么。
大约几秒钟后,返回的结果如下。
这是我们输入hello word的执行结果,也就是json格式返回的数据。JSON 也是我们经常使用的一种数据格式。它具有丰富的界面,非常易于使用。
注意:以上是前台启动模式操作,不是很方便。因此,我们需要做一个后台启动,即将标准输入输出语句写入配置文件。好吧,让我们创建一个名为 logstash.conf 的配置文件。
输入内容:
输入此段后,保存并再次进行测试。
命令:./bin/logstash -f logstash.conf 终端会等待我们输入信息,或者输入hello word进行测试
编辑此文件后,它会立即运行。由于没有检查,所以结果是错误的。
wuError:在第 10 行第 1 列(字节 71) 之后的 #、输入、过滤器、输出
您可能对“--configtest”标志感兴趣,您可以在选择重新启动正在运行的系统之前使用它来验证logstash的配置
刚在百度上查了一堆,没有可靠的答案,都是英文错误,看到就头疼,不知道哪里错了。后来仔细耐心的看了下报错信息,发现配置文件的内容应该是错误的。我重新编辑和修改它,发现括号不见了。这是一个粗心造成的严重错误。记住要小心避免低级错误。.
修改后重新测试正常。
结果如下:
但是提示域名解析失败。应该是主机名和ip不匹配导致的解析异常。应该是早上改主机名的结果,没有生效。
哎,没办法改回原来的hostname,重新解析一下就OK了。
这是使用配置文件的输出哦,完全正确。大家也应该避免小问题的出现,多学英语,遇到问题要耐心阅读错误提示,并加以解决。
您可以在另一个终端中测试它:
查看全部
文章采集系统(helloword系统准备学习一下看看看看看看吧(图)
)
今天自己搭建了elk系统来学习看看,因为它是现在主流的实时数据分析系统。
具体安装过程不再赘述。和大部分linux安装文件一样,没有太大区别。
安装后进行测试。居然报错了。
启动命令://bin/logstash -e 'input {stdin {}} output {stdout {codec =>rubydebug}}'

启动此命令后,终端正在等待我们的输入。我们可以输入任何我们想要的字符串。还是和学习编程初学者一样,输入hello word,看看会返回什么。
大约几秒钟后,返回的结果如下。

这是我们输入hello word的执行结果,也就是json格式返回的数据。JSON 也是我们经常使用的一种数据格式。它具有丰富的界面,非常易于使用。
注意:以上是前台启动模式操作,不是很方便。因此,我们需要做一个后台启动,即将标准输入输出语句写入配置文件。好吧,让我们创建一个名为 logstash.conf 的配置文件。
输入内容:

输入此段后,保存并再次进行测试。
命令:./bin/logstash -f logstash.conf 终端会等待我们输入信息,或者输入hello word进行测试
编辑此文件后,它会立即运行。由于没有检查,所以结果是错误的。
wuError:在第 10 行第 1 列(字节 71) 之后的 #、输入、过滤器、输出
您可能对“--configtest”标志感兴趣,您可以在选择重新启动正在运行的系统之前使用它来验证logstash的配置
刚在百度上查了一堆,没有可靠的答案,都是英文错误,看到就头疼,不知道哪里错了。后来仔细耐心的看了下报错信息,发现配置文件的内容应该是错误的。我重新编辑和修改它,发现括号不见了。这是一个粗心造成的严重错误。记住要小心避免低级错误。.
修改后重新测试正常。
结果如下:

但是提示域名解析失败。应该是主机名和ip不匹配导致的解析异常。应该是早上改主机名的结果,没有生效。
哎,没办法改回原来的hostname,重新解析一下就OK了。

这是使用配置文件的输出哦,完全正确。大家也应该避免小问题的出现,多学英语,遇到问题要耐心阅读错误提示,并加以解决。
您可以在另一个终端中测试它:

文章采集系统(一下如何利用老Y文章管理系统采集时自动完成伪原创)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-01-27 12:11
作为垃圾站的站长,最想要的就是网站能自动采集,自动完成伪原创,然后自动收钱。这真的是世界上最幸福的事情。呵呵。自动采集 和自动收款将不予讨论。今天给大家介绍一下如何使用旧的Y文章管理系统采集自动补全伪原创的方法。
第一步是进入后台。找到“采集管理”-“过滤器管理”,添加一个新的过滤器项。
关于采集,我就不多说了,相信大家都能做到,我要介绍的是旧的Y文章管理系统是如何自动完成伪原创同时< @采集 @>具体工作方法,大体思路是利用老Y文章管理系统的过滤功能实现同义词的自动替换,从而达到伪原创的目的@>。比如我想把采集文章中的“网赚博客”全部换成“网赚日记”。详细步骤如下:
旧的Y文章管理系统使用简单方便,虽然功能没有DEDE之类的强大到几乎变态(当然旧的Y文章管理系统是用asp写的语言,似乎没有可比性),但它应有尽有,而且相当简单,因此也受到许多站长的欢迎。老Y文章管理系统采集时自动补全伪原创的具体方法很少讨论。新电影是在老Y的论坛上推荐的,甚至有人在兜售这种方法。歧视。
我可以建立一个名为“净赚博客”的项目,具体设置请看图:
“过滤器名称”:填写“网赚博客”即可,也可以随意写,但为了方便查阅,建议与替换词保持一致。
“项目”:请根据您的网站选择一列网站(必须选择一列,否则无法保存过滤项目)。
“过滤对象”:选项有“标题过滤”和“文本过滤”。一般可以选择“文本过滤器”。如果你想伪原创连标题,你可以选择“标题过滤器”。
<p>“过滤器类型”:选项有“简单替换”和“高级过滤”,一般选择“简单替换”,如果选择“高级过滤”,则需要指定“开始标签”和“结束标签”,这样 查看全部
文章采集系统(一下如何利用老Y文章管理系统采集时自动完成伪原创)
作为垃圾站的站长,最想要的就是网站能自动采集,自动完成伪原创,然后自动收钱。这真的是世界上最幸福的事情。呵呵。自动采集 和自动收款将不予讨论。今天给大家介绍一下如何使用旧的Y文章管理系统采集自动补全伪原创的方法。
第一步是进入后台。找到“采集管理”-“过滤器管理”,添加一个新的过滤器项。
关于采集,我就不多说了,相信大家都能做到,我要介绍的是旧的Y文章管理系统是如何自动完成伪原创同时< @采集 @>具体工作方法,大体思路是利用老Y文章管理系统的过滤功能实现同义词的自动替换,从而达到伪原创的目的@>。比如我想把采集文章中的“网赚博客”全部换成“网赚日记”。详细步骤如下:
旧的Y文章管理系统使用简单方便,虽然功能没有DEDE之类的强大到几乎变态(当然旧的Y文章管理系统是用asp写的语言,似乎没有可比性),但它应有尽有,而且相当简单,因此也受到许多站长的欢迎。老Y文章管理系统采集时自动补全伪原创的具体方法很少讨论。新电影是在老Y的论坛上推荐的,甚至有人在兜售这种方法。歧视。
我可以建立一个名为“净赚博客”的项目,具体设置请看图:
“过滤器名称”:填写“网赚博客”即可,也可以随意写,但为了方便查阅,建议与替换词保持一致。

“项目”:请根据您的网站选择一列网站(必须选择一列,否则无法保存过滤项目)。
“过滤对象”:选项有“标题过滤”和“文本过滤”。一般可以选择“文本过滤器”。如果你想伪原创连标题,你可以选择“标题过滤器”。
<p>“过滤器类型”:选项有“简单替换”和“高级过滤”,一般选择“简单替换”,如果选择“高级过滤”,则需要指定“开始标签”和“结束标签”,这样
文章采集系统(文章采集系统为什么需要兼容flash?(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-01-27 06:05
文章采集系统为什么需要兼容flash?5月份已经是flash10周年之际,一直以来,有flash开发者吐槽说它已经不能用了,chrome,firefox,ie都需要安装第三方插件才能播放flash文件。如果要支持这种情况,就得再加一个浏览器,flash的地位可见一斑。这次要发布的browserstack是一款不支持flash的浏览器,但能为flash提供可靠的服务。
作为第三方,browserstack提供html5代码质量测试工具,跟踪drm获取方式,swf获取方式,web安全反编译工具,web安全平台工具等。browserstack还能为程序员做出怎样的服务呢?让我们一起来看看。在主要浏览器中,谷歌浏览器几乎可以覆盖大部分市场。当然safari,chrome,ie等其他浏览器也能支持它。
然而,在所有的浏览器中,唯独谷歌浏览器看起来不兼容flash。很多研究人员都非常期待,谷歌浏览器能看着推出新的maxthon标准来修正错误。不幸的是,人们大多数时候并不知道他们如何使用maxthon.虽然有一些简单的工具可以使用,但这些工具会大大增加网页的错误率。那么,我们要怎么改变这个现状呢?1.加强安全性-兼容性使浏览器拥有更安全的源代码。
在使用javascript时,flash在源代码中的位置是安全的。但是,adobe承诺flash不会使用任何直接的activex驱动去执行javascript代码。因此,虽然目前flash是最常用的标准,可以通过浏览器的低错误率来提供服务,但是ddos攻击和javascript反射攻击会更容易。2.提供浏览体验改进flash并不是开放源代码的。
linux和macos版本都存在代码问题。在10周年版本前,主要的浏览器都支持。但是,随着windows版本的更新,浏览器的大小将会增加。为了解决这个问题,browserstack将与主要的浏览器浏览器公司一起,提供更好的安全功能和更棒的浏览体验。通过三种方式部署,browserstack能够为flash提供可靠的服务。
技术实现组件browserstack采用http服务器来改进流式网页。通过它,网页保持所有可用的代码。实际上,现在越来越多的浏览器已经加入了这项计划。像这样的项目一直都存在,如libfreetype.js开发工具等。自定义代码要检查每个浏览器的可用flash文件是很简单的,每个浏览器都提供javascript访问网页的api。
因此,你可以在flash扩展程序或其他flash支持的外部扩展程序中使用。此外,browserstack已经测试过h5视频编码器-video.html。flash根据它的版本来区分,以便于互操作。浏览器将通过不同的接口读取文件并输出,如果网页不支持该文件,则读取的内容将被修改。上面的视频演示了这个功能。点击。 查看全部
文章采集系统(文章采集系统为什么需要兼容flash?(二))
文章采集系统为什么需要兼容flash?5月份已经是flash10周年之际,一直以来,有flash开发者吐槽说它已经不能用了,chrome,firefox,ie都需要安装第三方插件才能播放flash文件。如果要支持这种情况,就得再加一个浏览器,flash的地位可见一斑。这次要发布的browserstack是一款不支持flash的浏览器,但能为flash提供可靠的服务。
作为第三方,browserstack提供html5代码质量测试工具,跟踪drm获取方式,swf获取方式,web安全反编译工具,web安全平台工具等。browserstack还能为程序员做出怎样的服务呢?让我们一起来看看。在主要浏览器中,谷歌浏览器几乎可以覆盖大部分市场。当然safari,chrome,ie等其他浏览器也能支持它。
然而,在所有的浏览器中,唯独谷歌浏览器看起来不兼容flash。很多研究人员都非常期待,谷歌浏览器能看着推出新的maxthon标准来修正错误。不幸的是,人们大多数时候并不知道他们如何使用maxthon.虽然有一些简单的工具可以使用,但这些工具会大大增加网页的错误率。那么,我们要怎么改变这个现状呢?1.加强安全性-兼容性使浏览器拥有更安全的源代码。
在使用javascript时,flash在源代码中的位置是安全的。但是,adobe承诺flash不会使用任何直接的activex驱动去执行javascript代码。因此,虽然目前flash是最常用的标准,可以通过浏览器的低错误率来提供服务,但是ddos攻击和javascript反射攻击会更容易。2.提供浏览体验改进flash并不是开放源代码的。
linux和macos版本都存在代码问题。在10周年版本前,主要的浏览器都支持。但是,随着windows版本的更新,浏览器的大小将会增加。为了解决这个问题,browserstack将与主要的浏览器浏览器公司一起,提供更好的安全功能和更棒的浏览体验。通过三种方式部署,browserstack能够为flash提供可靠的服务。
技术实现组件browserstack采用http服务器来改进流式网页。通过它,网页保持所有可用的代码。实际上,现在越来越多的浏览器已经加入了这项计划。像这样的项目一直都存在,如libfreetype.js开发工具等。自定义代码要检查每个浏览器的可用flash文件是很简单的,每个浏览器都提供javascript访问网页的api。
因此,你可以在flash扩展程序或其他flash支持的外部扩展程序中使用。此外,browserstack已经测试过h5视频编码器-video.html。flash根据它的版本来区分,以便于互操作。浏览器将通过不同的接口读取文件并输出,如果网页不支持该文件,则读取的内容将被修改。上面的视频演示了这个功能。点击。
文章采集系统(文章采集系统有免费版的需要购买吗?(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-01-26 00:01
文章采集系统只是采集数据源,可以不开源,开源的采集系统有免费版的,收费版的需要购买,1.采集系统采集效率低,2.采集效率高,用户体验不好。这是最重要的两点。
哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈你在逗我。我好奇从什么角度思考才会得出“还有免费版的”这样的结论,而且也不知道你是不是对“免费版”有错误的认识。根据你的资金限制,免费版估计你也是想都别想了。有个别能进行爬虫的,但是爬的是论坛、网站内容。专业的还是要用付费版。
别说免费版了,就算是巨额的python培训班课程,一年学费都要几万甚至十几万,和爬虫培训相比简直不值一提。人家只是可以帮你爬取一些网站而已。普通爬虫,爬几十个足够了,精度和效率也够用。
免费版本的话,我建议你还是用浏览器插件就可以。因为大数据量的数据采集,做python爬虫是很费劲的,你可以选择用requests库或beautifulsoup库进行爬取或requests库中的phantomjs对网页文本进行采集。
python是弱类型语言,python采集数据库相对于java,c语言要方便的多。主要有两个方面。1.python语言的表达能力强,理解原理,可以快速掌握各种操作的原理。2.python是脚本语言,不限程序语言。所以,目前,对于有c语言基础的人,直接用python来爬虫,再将采集结果发布到社区中,不失为一个好选择。对于没有c语言基础的人,可以慢慢学习python。 查看全部
文章采集系统(文章采集系统有免费版的需要购买吗?(一))
文章采集系统只是采集数据源,可以不开源,开源的采集系统有免费版的,收费版的需要购买,1.采集系统采集效率低,2.采集效率高,用户体验不好。这是最重要的两点。
哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈你在逗我。我好奇从什么角度思考才会得出“还有免费版的”这样的结论,而且也不知道你是不是对“免费版”有错误的认识。根据你的资金限制,免费版估计你也是想都别想了。有个别能进行爬虫的,但是爬的是论坛、网站内容。专业的还是要用付费版。
别说免费版了,就算是巨额的python培训班课程,一年学费都要几万甚至十几万,和爬虫培训相比简直不值一提。人家只是可以帮你爬取一些网站而已。普通爬虫,爬几十个足够了,精度和效率也够用。
免费版本的话,我建议你还是用浏览器插件就可以。因为大数据量的数据采集,做python爬虫是很费劲的,你可以选择用requests库或beautifulsoup库进行爬取或requests库中的phantomjs对网页文本进行采集。
python是弱类型语言,python采集数据库相对于java,c语言要方便的多。主要有两个方面。1.python语言的表达能力强,理解原理,可以快速掌握各种操作的原理。2.python是脚本语言,不限程序语言。所以,目前,对于有c语言基础的人,直接用python来爬虫,再将采集结果发布到社区中,不失为一个好选择。对于没有c语言基础的人,可以慢慢学习python。
文章采集系统( 技术领域[0001]本发明-OG三层状态日志收集系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-01-18 05:11
技术领域[0001]本发明-OG三层状态日志收集系统)
自定义日志采集系统及方法
技术领域
[0001] 本发明涉及一种采集各种系统和应用程序的日志,并对不同的日志进行自定义筛选处理的处理方法,尤其涉及一种自定义日志采集系统和方法。
背景技术
[0002] 日志采集是对各个系统和应用程序产生的日志文件进行采集,日志文件包括当前程序运行状态、错误信息、用户操作信息等。
[0003] 当前的日志采集系统和方法包括基于 Scribe 的采集框架、Chukwa 的采集框架和 Flume-OG 采集框架。
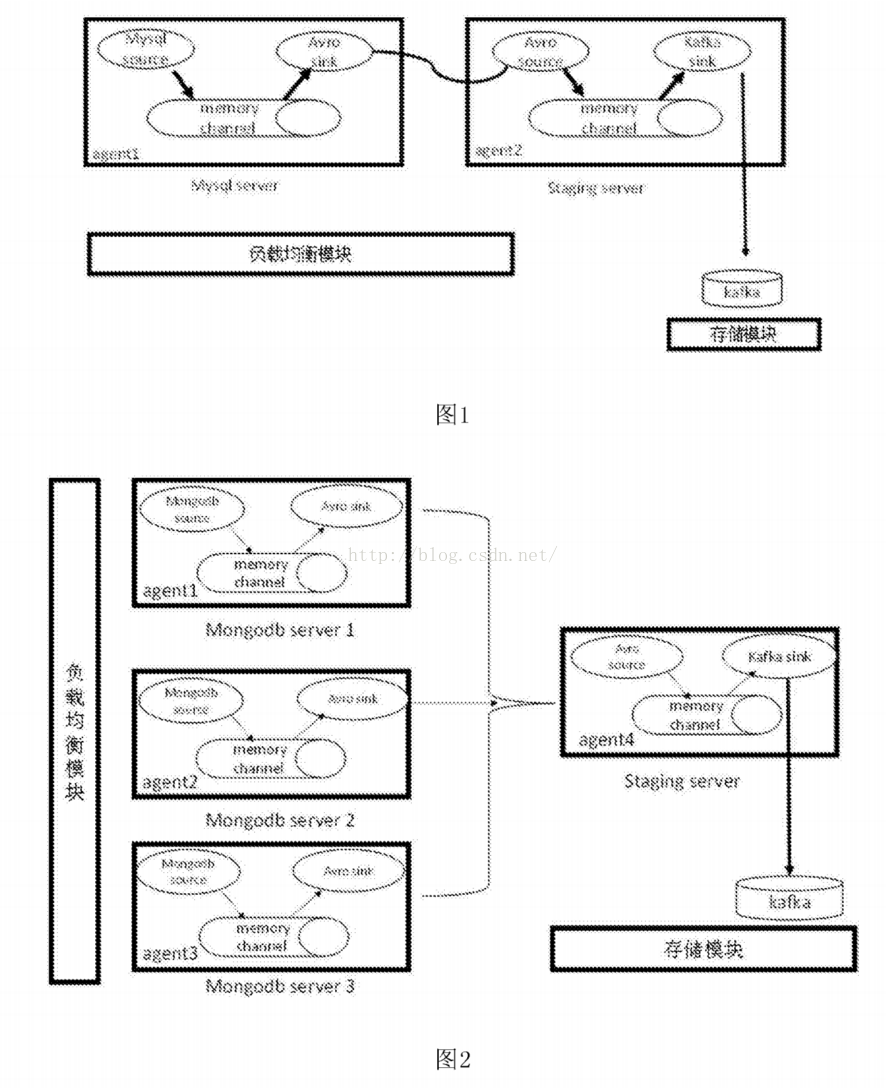
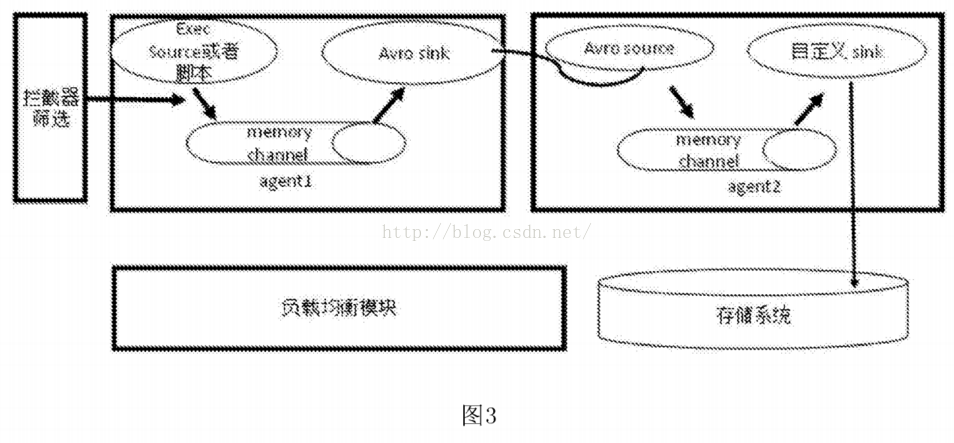
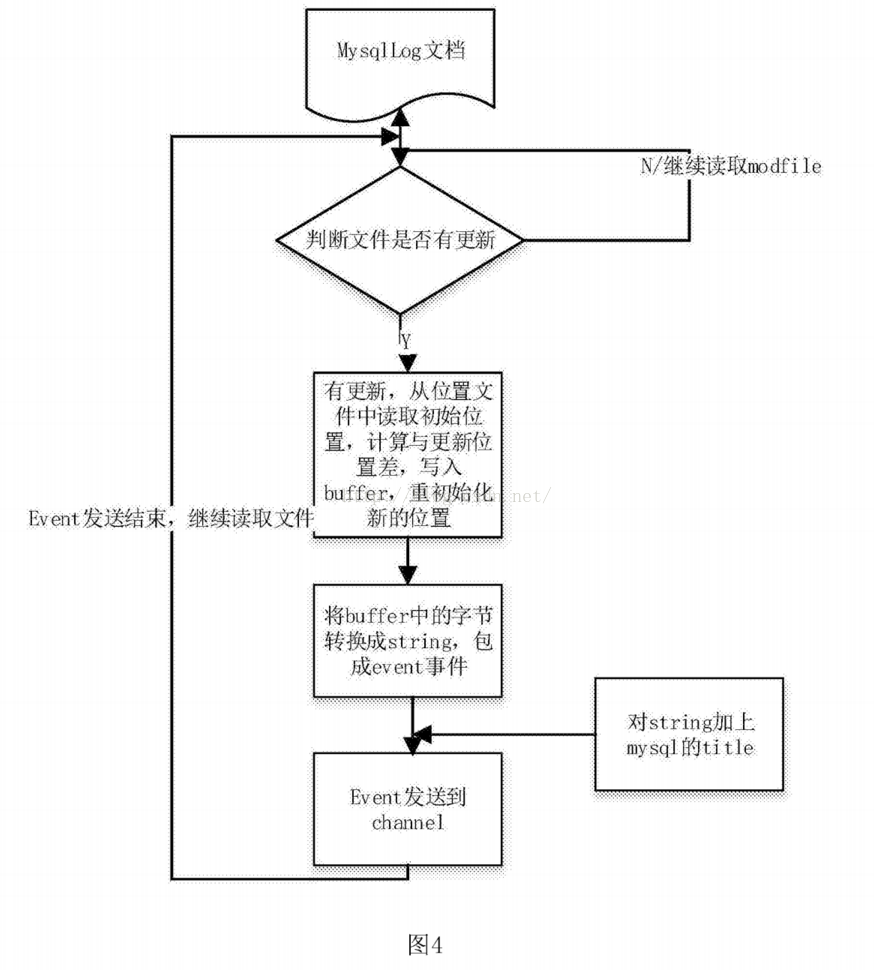
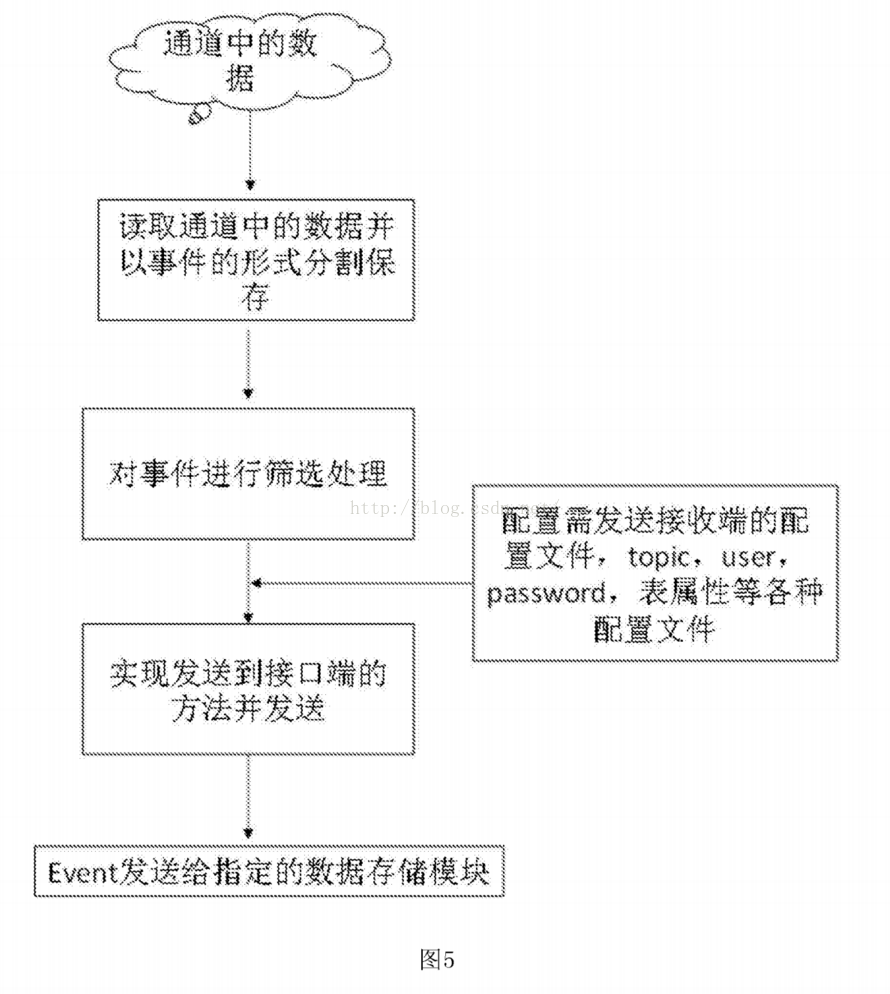
[0004]Scirbe框架是从各种来源采集日志,集中存储在中央存储系统中,然后进行集中统计分析。但是,由于代理和采集器之间没有相应的容错机制,数据就会出现。失去的局面,虽然是基于节俭的,但依赖更复杂,环境更具侵略性。Chukwa系统主要是为了采集各种数据。它收录了很多强大灵活的工具集,可以同时分析采集得到的数据,所以它的扩展性非常好。相比Scirbe框架,它可以定时记录发送的数据,提供容错机制,和hadoop的集成也很好,但是因为它的版本比较新,并且设计的主要初衷是为了各种数据的采集,日志的采集没有区别。什么具体的商业扩展,因此没有商业应用采用。Flume-OG框架也是一个三层的日志采集系统,具有agent、collector、store的三层结构。agent负责读取,collector负责采集过滤,store是存储层。同时负载由zookeeper提供,相比前两个框架更加可靠和安全。但是由于框架过于复杂,操作起来不是很方便,开发工作量巨大。什么具体的商业扩展,因此没有商业应用采用。Flume-OG框架也是一个三层的日志采集系统,具有agent、collector、store的三层结构。agent负责读取,collector负责采集过滤,store是存储层。同时负载由zookeeper提供,相比前两个框架更加可靠和安全。但是由于框架过于复杂,操作起来不是很方便,开发工作量巨大。什么具体的商业扩展,因此没有商业应用采用。Flume-OG框架也是一个三层的日志采集系统,具有agent、collector、store的三层结构。agent负责读取,collector负责采集过滤,store是存储层。同时负载由zookeeper提供,相比前两个框架更加可靠和安全。但是由于框架过于复杂,操作起来不是很方便,开发工作量巨大。采集器负责采集过滤,store是存储层。同时负载由zookeeper提供,相比前两个框架更加可靠和安全。但是由于框架过于复杂,操作起来不是很方便,开发工作量巨大。采集器负责采集过滤,store是存储层。同时负载由zookeeper提供,相比前两个框架更加可靠和安全。但是由于框架过于复杂,操作起来不是很方便,开发工作量巨大。
发明内容
本发明克服了现有技术的不足,不存在现有日志采集系统实时性、高可靠性、高自定制的问题,提出了一种高可靠性的自定制日志采集系统及方法。
为解决上述技术问题,本发明采用以下技术方案:
一个自定义的日志采集系统,包括采集系统、中间服务器、存储系统和负载均衡系统;所述采集系统连接所述中间服务器,所述中间服务器连接所有存储系统和负载均衡系统。
[0008] 进一步的技术方案是进一步包括拦截器,采集系统图连接到拦截器,拦截器连接到中间服务器。
[0009] 进一步的技术方案是采集系统包括至少三个客户端采集。
进一步的技术方案是提供一种自定义日志采集方法,所述方法包括以下步骤:
[0011]步骤一、根据需要采集的日志文件类型,确定自定义数据库系统结构化日志的采集源程序,实现日志的内容拉取功能文件;
[0012]步骤二、配置需要采集的文件路径;
[0013]步骤三、设置采用的通道类型;
[0014]步骤四、设置拦截器的内容,用于过滤掉不需要的事件;
[0015] 步骤五、设计为根据需要的客户端数量采集流向中间服务器的自定义框架;
Step六、 各客户端实时拉取日志文件内容,实现过滤写入段落;之后通过组件avrosink将指定端口发送给中间服务器,中间服务器接收数据并通过自定义的sink发送给目标的消息存储机制,完成日志的采集流程.
进一步的技术方案是步骤1中自定义的采集源程序步骤包括:
步骤一。设置采集文件的配置参数类;
[0019] 步骤b。实现文件的采集启动和停止方法;
步骤 c。配置并存储在位置文件中到文件的初始读取点;
步骤 d。建立一个线程,从posit1n点开始处理,不断发送的日志更新文件内容;
[0022] 步骤e。设置容错点,线程每10次执行一次,将当前读取文件的最后一个pist1n值存入posit1n文件;
[0023] 步骤f。为采集添加倾斜字符串的事件,具体标识内容包括:采集属于服务器名,采集属于应用程序名,采集属于到服务器IP。
进一步的技术方案是,步骤3中所述的通道类型包括:文件类型或内存类型。
[0025] 进一步的技术方案是,步骤6中描述的消息存储机制包括:数据库、消息定序器或分布式文件系统。
与现有技术相比,本发明的有益效果是:本发明可以对各种数据库系统和应用程序进行定制化的日志采集,利用实时的操作日志数据对操作系统的数据进行分析。提供状态、用户操作行为等实时数据。一旦出现系统错误信息,将及时获知并纠正。同时保证如果用户对系统进行了不当操作,可以及时停止。
图纸说明
[0027] 图。附图说明图1为本发明实施例的mysql数据库集群日志采集框架结构示意图。
图2为本发明一实施例中的mongodb数据库集群日志采集框架结构示意图。
[0029] 图。图3为本发明实施例的应用程序非结构化日志采集框架的结构示意图。
[0030] 图。图4为本发明一实施例的源程序采集的流程图。
[0031] 图。图5为本发明一实施例的日志过滤和写入消息序列的流程图。
详细说明
[0032] 本说明书中公开的所有特征,或公开的所有方法或过程中的步骤,可以以任何方式组合,除了相互排斥的特征和/或步骤。
[0033] 除非另有明确说明,否则本说明书(包括任何随附的权利要求、摘要和附图)中公开的任何特征都可以被用于类似目的的其他等效或替代特征代替。也就是说,除非另有明确说明,否则每个特征只是一系列等效或相似特征的一个示例。
[0034] 下面结合附图和实施例对本发明的具体实施方式进行详细说明。
[0035] 根据本发明实施例,本实施例公开了一种自定义日志采集系统,包括采集系统、中间服务器、存储系统和负载均衡系统;采集 系统连接中间服务器,中间服务器连接存储系统,存储系统连接负载均衡系统。
[0036] 具体地,如图3所示。1,图。图1是采集mysql数据库集群产生的日志的系统架构图。因为mysql集群的日志是相互连接的,所以采用单流框架。该系统包括客户端代理采集平台、中间服务器编写平台、存储系统和负载均衡系统。其中,客户端采集平台主要负责日志内容的可靠读取、过滤过滤,并通过自定义的采集源程序传输到中间服务器。中间服务器平台主要通过自研的发送程序发送到kafka分布式消息队列。存储模块是基于Kafka的分布式消息系统。
[0037] 如图2所示,图2是采集mongodb数据库集群查询日志的系统架构图,以采集流向的方式构建。该系统包括3个客户端采集、一个中间服务器、存储系统和负载均衡系统。其中,3个客户端采集、采集将日志发送到中间服务器的指定端口,中间服务器将自定义的sin写入分布式消息队列。
[0038] 如图所示。3,图。图3是采集应用程序产生的非结构化日志的装置和系统架构图。系统主要由采集客户端、拦截器、负载均衡、中间发送模块、存储模块组成。第一:
[0039] a)采集客户端,对于不同的应用,它们的日志结构是不一样的。所以直接使用Iinux命令行或者python脚本的方式采集程序的运行状态日志。
[0040] B)使用拦截器,过滤掉正确的运行状态,直接拦截错误的运行状态。
[0041] c)错误运行状态以事件的形式发送给具有内网权限的中间服务器。
d) 中间服务器自定义的发送模块可以将收到的事件发送到mongodb、hive、hbase等数据存储模块,方便处理端调用处理。
根据本发明的另一个实施例,本实施例公开了一种自定义日志采集方法,该方法包括以下步骤:
[0044]步骤一、根据需要采集的日志文件类型,确定自定义数据库系统结构化日志的采集源程序,实现内容拉取功能日志文件;
自定义采集源程序步骤包括:
步骤一。设置采集文件的配置参数类;
[0047] 步骤b。实现文件的采集启动和停止方法;
步骤 c。配置并存储在位置文件中到文件的初始读取点;
步骤 d。建立一个线程,从posit1n点开始处理,不断发送的日志更新文件内容;
[0050] 步骤e。设置容错点,线程每执行10次,将文件当前读取的最后一个pist1n值存入posit1n文件;
[0051] 步骤f。是采集的事件,加上一个tiltle字符串,具体标识内容包括:采集属于服务器名,采集属于应用程序名,采集属于服务器IP。
[0052]步骤二、配置需要采集的文件路径;
Step 三、 设置采用的通道类型;
[0054] 步骤四、设置拦截器的内容,用于过滤掉不需要的事件;
[0055] 步骤五、设计自定义框架,根据需要采集的客户端数量流向中间服务器;
步骤六、各客户端实时拉取日志文件内容,实现过滤写入通道;之后通过组件avrosink将指定端口发送给中间服务器,中间服务器接收数据并通过自定义的sink发送给目标的消息存储机制,完成日志的采集流程.
[0057] 具体地,结合附图对本实施例的方法进行详细描述。如图4所示,图4是采集的源程序流程图,采集结构化日志的步骤为:
a) 设置一个线程,用于不间断循环读取日志文件内容并发送处理后的日志。
[0059] b)设置最新的文件大小,从什么字节数开始读取,并存储在posit1n文件中。
c)读取文件的更新时间,如果new update time no wmodfile和last update event Iastmodfile不相等,则表示日志文件有新内容要写入,可以进行实时Read获取最新的日志更新内容.
d) 比较当前FiIe和posit1n中的字节大小,读取差值并设置posit1n的值,将posit1n之间的日志数据以事件的形式存储到缓存中最新的大小,存储最新的posit1n的值为存储在文件中,并在下次执行时再次读取比较。
e) 对缓冲区中的数据进行解码操作,并以字符串事件的形式划分出各个日志。
f) 事件添加标题,标题的内容包括日志所属的服务器、产生日志的系统或应用程序、日志所属的业务线和服务器的IP,在处理日志时可以明确区分那个采集 cluster产生这样的问题 找出问题所在的服务器的工作状态。
g)将分加标题的日志传递给发送模块,在信道中不断循环发送,直到该缓冲区中的数据全部发送完。
[0065] H)本次发送后,开始比较文件是否再次更新,从b)步骤开始执行。形成实时读取文件内容并发送。
[0066] 如图所示。5,图。图5是日志被读入通道,经过发送方筛选后发送到指定消息序列的流程图。包括以下步骤:
1)建立管道,从管道中以事件的形式读取数据。
[0068]2)读取事件会做筛选过程,如果发送到kafka分布式消息系统,增加topic相当于发送,如果发送到mongodb等数据库,需要数据的相关参数被设置。
[0069] 3)设定值与接口的实现一起写入指定的数据存储模块。
[0070] 本实施例基于Flume-NG的第三方框架,增加了一种实现高可靠、高定制化日志采集的方法,实现了非结构化日志和结构化日志采集,简单的处理和过滤,可以将采集日志实时发送到存储系统,为日志的分析和处理提供了很好的保障。本实施例不仅继承了Flume-NG框架的优点和底层结构,还可以根据自己的独特需求定制更合适的log采集解决方案,提高了用户对系统资源的高利用率,也可以保证系统稳定运行,大大提高用户使用日志采集的效率。
本说明书中所提及的“一个实施例”、“另一实施例”、“实施例”等是指结合本申请发明内容所收录的实施例所描述的具体特征、结构或特征。在说明书的至少一个实施例中。说明书中不同地方出现的相同表述不一定都是指同一个实施例。此外,当结合任一实施例描述特定特征、结构或特性时,要求结合其他实施例实现该特征、结构或特性也在本发明的范围内。
尽管本发明已在本文中参照其多个说明性实施例进行了描述,但应当理解,本领域技术人员可以设计出许多其他修改和实施例,这些修改和实施例将落入本申请的范围和范围内。所披露的原则精神。更具体地,在本文公开的权利要求的范围内,主题组合布置的组成部分和/或布置的各种变化和修改是可能的。除了部件和/或布置的变化和修改之外,其他用途对于本领域技术人员来说也是显而易见的。 查看全部
文章采集系统(
技术领域[0001]本发明-OG三层状态日志收集系统)
自定义日志采集系统及方法
技术领域
[0001] 本发明涉及一种采集各种系统和应用程序的日志,并对不同的日志进行自定义筛选处理的处理方法,尤其涉及一种自定义日志采集系统和方法。
背景技术
[0002] 日志采集是对各个系统和应用程序产生的日志文件进行采集,日志文件包括当前程序运行状态、错误信息、用户操作信息等。
[0003] 当前的日志采集系统和方法包括基于 Scribe 的采集框架、Chukwa 的采集框架和 Flume-OG 采集框架。
[0004]Scirbe框架是从各种来源采集日志,集中存储在中央存储系统中,然后进行集中统计分析。但是,由于代理和采集器之间没有相应的容错机制,数据就会出现。失去的局面,虽然是基于节俭的,但依赖更复杂,环境更具侵略性。Chukwa系统主要是为了采集各种数据。它收录了很多强大灵活的工具集,可以同时分析采集得到的数据,所以它的扩展性非常好。相比Scirbe框架,它可以定时记录发送的数据,提供容错机制,和hadoop的集成也很好,但是因为它的版本比较新,并且设计的主要初衷是为了各种数据的采集,日志的采集没有区别。什么具体的商业扩展,因此没有商业应用采用。Flume-OG框架也是一个三层的日志采集系统,具有agent、collector、store的三层结构。agent负责读取,collector负责采集过滤,store是存储层。同时负载由zookeeper提供,相比前两个框架更加可靠和安全。但是由于框架过于复杂,操作起来不是很方便,开发工作量巨大。什么具体的商业扩展,因此没有商业应用采用。Flume-OG框架也是一个三层的日志采集系统,具有agent、collector、store的三层结构。agent负责读取,collector负责采集过滤,store是存储层。同时负载由zookeeper提供,相比前两个框架更加可靠和安全。但是由于框架过于复杂,操作起来不是很方便,开发工作量巨大。什么具体的商业扩展,因此没有商业应用采用。Flume-OG框架也是一个三层的日志采集系统,具有agent、collector、store的三层结构。agent负责读取,collector负责采集过滤,store是存储层。同时负载由zookeeper提供,相比前两个框架更加可靠和安全。但是由于框架过于复杂,操作起来不是很方便,开发工作量巨大。采集器负责采集过滤,store是存储层。同时负载由zookeeper提供,相比前两个框架更加可靠和安全。但是由于框架过于复杂,操作起来不是很方便,开发工作量巨大。采集器负责采集过滤,store是存储层。同时负载由zookeeper提供,相比前两个框架更加可靠和安全。但是由于框架过于复杂,操作起来不是很方便,开发工作量巨大。
发明内容
本发明克服了现有技术的不足,不存在现有日志采集系统实时性、高可靠性、高自定制的问题,提出了一种高可靠性的自定制日志采集系统及方法。
为解决上述技术问题,本发明采用以下技术方案:
一个自定义的日志采集系统,包括采集系统、中间服务器、存储系统和负载均衡系统;所述采集系统连接所述中间服务器,所述中间服务器连接所有存储系统和负载均衡系统。
[0008] 进一步的技术方案是进一步包括拦截器,采集系统图连接到拦截器,拦截器连接到中间服务器。
[0009] 进一步的技术方案是采集系统包括至少三个客户端采集。
进一步的技术方案是提供一种自定义日志采集方法,所述方法包括以下步骤:
[0011]步骤一、根据需要采集的日志文件类型,确定自定义数据库系统结构化日志的采集源程序,实现日志的内容拉取功能文件;
[0012]步骤二、配置需要采集的文件路径;
[0013]步骤三、设置采用的通道类型;
[0014]步骤四、设置拦截器的内容,用于过滤掉不需要的事件;
[0015] 步骤五、设计为根据需要的客户端数量采集流向中间服务器的自定义框架;
Step六、 各客户端实时拉取日志文件内容,实现过滤写入段落;之后通过组件avrosink将指定端口发送给中间服务器,中间服务器接收数据并通过自定义的sink发送给目标的消息存储机制,完成日志的采集流程.
进一步的技术方案是步骤1中自定义的采集源程序步骤包括:
步骤一。设置采集文件的配置参数类;
[0019] 步骤b。实现文件的采集启动和停止方法;
步骤 c。配置并存储在位置文件中到文件的初始读取点;
步骤 d。建立一个线程,从posit1n点开始处理,不断发送的日志更新文件内容;
[0022] 步骤e。设置容错点,线程每10次执行一次,将当前读取文件的最后一个pist1n值存入posit1n文件;
[0023] 步骤f。为采集添加倾斜字符串的事件,具体标识内容包括:采集属于服务器名,采集属于应用程序名,采集属于到服务器IP。
进一步的技术方案是,步骤3中所述的通道类型包括:文件类型或内存类型。
[0025] 进一步的技术方案是,步骤6中描述的消息存储机制包括:数据库、消息定序器或分布式文件系统。
与现有技术相比,本发明的有益效果是:本发明可以对各种数据库系统和应用程序进行定制化的日志采集,利用实时的操作日志数据对操作系统的数据进行分析。提供状态、用户操作行为等实时数据。一旦出现系统错误信息,将及时获知并纠正。同时保证如果用户对系统进行了不当操作,可以及时停止。
图纸说明
[0027] 图。附图说明图1为本发明实施例的mysql数据库集群日志采集框架结构示意图。
图2为本发明一实施例中的mongodb数据库集群日志采集框架结构示意图。
[0029] 图。图3为本发明实施例的应用程序非结构化日志采集框架的结构示意图。
[0030] 图。图4为本发明一实施例的源程序采集的流程图。
[0031] 图。图5为本发明一实施例的日志过滤和写入消息序列的流程图。
详细说明
[0032] 本说明书中公开的所有特征,或公开的所有方法或过程中的步骤,可以以任何方式组合,除了相互排斥的特征和/或步骤。
[0033] 除非另有明确说明,否则本说明书(包括任何随附的权利要求、摘要和附图)中公开的任何特征都可以被用于类似目的的其他等效或替代特征代替。也就是说,除非另有明确说明,否则每个特征只是一系列等效或相似特征的一个示例。
[0034] 下面结合附图和实施例对本发明的具体实施方式进行详细说明。
[0035] 根据本发明实施例,本实施例公开了一种自定义日志采集系统,包括采集系统、中间服务器、存储系统和负载均衡系统;采集 系统连接中间服务器,中间服务器连接存储系统,存储系统连接负载均衡系统。
[0036] 具体地,如图3所示。1,图。图1是采集mysql数据库集群产生的日志的系统架构图。因为mysql集群的日志是相互连接的,所以采用单流框架。该系统包括客户端代理采集平台、中间服务器编写平台、存储系统和负载均衡系统。其中,客户端采集平台主要负责日志内容的可靠读取、过滤过滤,并通过自定义的采集源程序传输到中间服务器。中间服务器平台主要通过自研的发送程序发送到kafka分布式消息队列。存储模块是基于Kafka的分布式消息系统。
[0037] 如图2所示,图2是采集mongodb数据库集群查询日志的系统架构图,以采集流向的方式构建。该系统包括3个客户端采集、一个中间服务器、存储系统和负载均衡系统。其中,3个客户端采集、采集将日志发送到中间服务器的指定端口,中间服务器将自定义的sin写入分布式消息队列。
[0038] 如图所示。3,图。图3是采集应用程序产生的非结构化日志的装置和系统架构图。系统主要由采集客户端、拦截器、负载均衡、中间发送模块、存储模块组成。第一:
[0039] a)采集客户端,对于不同的应用,它们的日志结构是不一样的。所以直接使用Iinux命令行或者python脚本的方式采集程序的运行状态日志。
[0040] B)使用拦截器,过滤掉正确的运行状态,直接拦截错误的运行状态。
[0041] c)错误运行状态以事件的形式发送给具有内网权限的中间服务器。
d) 中间服务器自定义的发送模块可以将收到的事件发送到mongodb、hive、hbase等数据存储模块,方便处理端调用处理。
根据本发明的另一个实施例,本实施例公开了一种自定义日志采集方法,该方法包括以下步骤:
[0044]步骤一、根据需要采集的日志文件类型,确定自定义数据库系统结构化日志的采集源程序,实现内容拉取功能日志文件;
自定义采集源程序步骤包括:
步骤一。设置采集文件的配置参数类;
[0047] 步骤b。实现文件的采集启动和停止方法;
步骤 c。配置并存储在位置文件中到文件的初始读取点;
步骤 d。建立一个线程,从posit1n点开始处理,不断发送的日志更新文件内容;
[0050] 步骤e。设置容错点,线程每执行10次,将文件当前读取的最后一个pist1n值存入posit1n文件;
[0051] 步骤f。是采集的事件,加上一个tiltle字符串,具体标识内容包括:采集属于服务器名,采集属于应用程序名,采集属于服务器IP。
[0052]步骤二、配置需要采集的文件路径;
Step 三、 设置采用的通道类型;
[0054] 步骤四、设置拦截器的内容,用于过滤掉不需要的事件;
[0055] 步骤五、设计自定义框架,根据需要采集的客户端数量流向中间服务器;
步骤六、各客户端实时拉取日志文件内容,实现过滤写入通道;之后通过组件avrosink将指定端口发送给中间服务器,中间服务器接收数据并通过自定义的sink发送给目标的消息存储机制,完成日志的采集流程.
[0057] 具体地,结合附图对本实施例的方法进行详细描述。如图4所示,图4是采集的源程序流程图,采集结构化日志的步骤为:
a) 设置一个线程,用于不间断循环读取日志文件内容并发送处理后的日志。
[0059] b)设置最新的文件大小,从什么字节数开始读取,并存储在posit1n文件中。
c)读取文件的更新时间,如果new update time no wmodfile和last update event Iastmodfile不相等,则表示日志文件有新内容要写入,可以进行实时Read获取最新的日志更新内容.
d) 比较当前FiIe和posit1n中的字节大小,读取差值并设置posit1n的值,将posit1n之间的日志数据以事件的形式存储到缓存中最新的大小,存储最新的posit1n的值为存储在文件中,并在下次执行时再次读取比较。
e) 对缓冲区中的数据进行解码操作,并以字符串事件的形式划分出各个日志。
f) 事件添加标题,标题的内容包括日志所属的服务器、产生日志的系统或应用程序、日志所属的业务线和服务器的IP,在处理日志时可以明确区分那个采集 cluster产生这样的问题 找出问题所在的服务器的工作状态。
g)将分加标题的日志传递给发送模块,在信道中不断循环发送,直到该缓冲区中的数据全部发送完。
[0065] H)本次发送后,开始比较文件是否再次更新,从b)步骤开始执行。形成实时读取文件内容并发送。
[0066] 如图所示。5,图。图5是日志被读入通道,经过发送方筛选后发送到指定消息序列的流程图。包括以下步骤:
1)建立管道,从管道中以事件的形式读取数据。
[0068]2)读取事件会做筛选过程,如果发送到kafka分布式消息系统,增加topic相当于发送,如果发送到mongodb等数据库,需要数据的相关参数被设置。
[0069] 3)设定值与接口的实现一起写入指定的数据存储模块。
[0070] 本实施例基于Flume-NG的第三方框架,增加了一种实现高可靠、高定制化日志采集的方法,实现了非结构化日志和结构化日志采集,简单的处理和过滤,可以将采集日志实时发送到存储系统,为日志的分析和处理提供了很好的保障。本实施例不仅继承了Flume-NG框架的优点和底层结构,还可以根据自己的独特需求定制更合适的log采集解决方案,提高了用户对系统资源的高利用率,也可以保证系统稳定运行,大大提高用户使用日志采集的效率。
本说明书中所提及的“一个实施例”、“另一实施例”、“实施例”等是指结合本申请发明内容所收录的实施例所描述的具体特征、结构或特征。在说明书的至少一个实施例中。说明书中不同地方出现的相同表述不一定都是指同一个实施例。此外,当结合任一实施例描述特定特征、结构或特性时,要求结合其他实施例实现该特征、结构或特性也在本发明的范围内。
尽管本发明已在本文中参照其多个说明性实施例进行了描述,但应当理解,本领域技术人员可以设计出许多其他修改和实施例,这些修改和实施例将落入本申请的范围和范围内。所披露的原则精神。更具体地,在本文公开的权利要求的范围内,主题组合布置的组成部分和/或布置的各种变化和修改是可能的。除了部件和/或布置的变化和修改之外,其他用途对于本领域技术人员来说也是显而易见的。
文章采集系统(文章采集系统的基本结构和流程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-01-17 14:03
文章采集系统是一个典型的excel基础产品,基本结构如下:最核心的就是模块:采集模块,请求模块,获取模块,清洗模块,融合模块,采集库。其他模块,可选的有元数据采集模块,测试数据采集模块,应用数据采集模块,参数字段采集模块,ui采集模块等等。下面一个个介绍。采集模块采集的基本是来自网站的信息,也就是数据。
采集的流程就是:从采集对象列表中,找到目标,并进行相应的操作(如查询,截取等)。采集一个信息,我们需要的最简单的数据结构是:id,地址,信息内容。如果信息结构太复杂,我们还可以调整sql查询数据的方式,但sql是一个非常慢的语言,通常在使用的时候需要做出量级很大的任务,否则影响正常运行。所以我们采用简单的excel工作表内数据来完成这个任务。
还有一个非常重要的任务,就是数据的筛选,补充。毕竟要从数据中提取出符合条件的数据,并且保留对应的信息,是个体力活。要做成有一个简单的筛选,补充,我们需要代码简单起见,我们就不做定义条件提取的这个操作了。代码如下:varredis=[]varmatches=[]varjson={"registration_id":"1","registration_code":"1","registration_device":"m","registration_port":"211234","identifier":"llvm6.1","file":"this","version":"6.1.2","date":"2014-04-09t08:21:44.1608","type":"exists","failed_code":"9082","exit_code":"9082","true":"failed","false":"failed","client":".xxx.conf.data.mydata.json.json","client_identifier":"c1325336297","tls":"json.stringify","database":"","database":"","client_status":"ok","client_registration_id":"1","registration_code":"1","registration_device":"m","registration_port":"211234","identifier":"llvm6.1","file":"this","version":"6.1.2","file_list":[{"registration_id":"1","registration_code":"1","registration_device":"m","registration_port":"211234","identifier":"c1325336297","file":"","version":"6.1.2","repo":"","account":"dz","d。 查看全部
文章采集系统(文章采集系统的基本结构和流程)
文章采集系统是一个典型的excel基础产品,基本结构如下:最核心的就是模块:采集模块,请求模块,获取模块,清洗模块,融合模块,采集库。其他模块,可选的有元数据采集模块,测试数据采集模块,应用数据采集模块,参数字段采集模块,ui采集模块等等。下面一个个介绍。采集模块采集的基本是来自网站的信息,也就是数据。
采集的流程就是:从采集对象列表中,找到目标,并进行相应的操作(如查询,截取等)。采集一个信息,我们需要的最简单的数据结构是:id,地址,信息内容。如果信息结构太复杂,我们还可以调整sql查询数据的方式,但sql是一个非常慢的语言,通常在使用的时候需要做出量级很大的任务,否则影响正常运行。所以我们采用简单的excel工作表内数据来完成这个任务。
还有一个非常重要的任务,就是数据的筛选,补充。毕竟要从数据中提取出符合条件的数据,并且保留对应的信息,是个体力活。要做成有一个简单的筛选,补充,我们需要代码简单起见,我们就不做定义条件提取的这个操作了。代码如下:varredis=[]varmatches=[]varjson={"registration_id":"1","registration_code":"1","registration_device":"m","registration_port":"211234","identifier":"llvm6.1","file":"this","version":"6.1.2","date":"2014-04-09t08:21:44.1608","type":"exists","failed_code":"9082","exit_code":"9082","true":"failed","false":"failed","client":".xxx.conf.data.mydata.json.json","client_identifier":"c1325336297","tls":"json.stringify","database":"","database":"","client_status":"ok","client_registration_id":"1","registration_code":"1","registration_device":"m","registration_port":"211234","identifier":"llvm6.1","file":"this","version":"6.1.2","file_list":[{"registration_id":"1","registration_code":"1","registration_device":"m","registration_port":"211234","identifier":"c1325336297","file":"","version":"6.1.2","repo":"","account":"dz","d。
文章采集系统(免费数据采集软件需要注意哪些问题?-八维教育 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-01-10 22:10
)
Free Data采集软件是一款无需编写复杂的采集规则即可自动伪原创并根据关键词自动采集自动发布内容的绿色软件。简单配置后,即可实现24小时不间断采集、伪原创和发布。是站长维护网站的首选软件,内置全网发布接口cms,也可以直接导出为txt格式到本地,非常实用方便采集 软件。自从得到了广大站长朋友的永久免费支持,是SEO圈子里的良心软件,给很多站长朋友带来了实实在在的流量和经济效益。
特点介绍:
1、 自动去噪,可以自动过滤标题内容中的图片\网站\电话\QQ\邮件等信息;
2、这个数据采集软件不同于传统的采集模式,它可以根据设置的关键词执行采集、采集用户的好处是可以通过采集关键词的不同搜索结果自动采集最新发布的文章,以免搜索到一个或一个几个指定的 采集 站点。采集,降低采集网站被搜索引擎判断为采集网站被搜索引擎惩罚的风险。
3、 各种伪原创 和优化方法来提高收录 率和关键词 排名 标题插入、内容插入、自动内部链接、内容过滤、URL 过滤、随机图片插入、常规发布等多种方式方法提升采集文章原创的性能,提升搜索引擎收录、网站权重和关键词@ > 排名。
一个搜索引擎,其核心价值是为用户提供他/她最需要的结果。搜索引擎对网民的需求进行了统计。对于网民需求很少或没有需求的内容,即使你是原创,也可能会被搜索引擎忽略,因为它不想把资源浪费在无意义的内容上。对于网友需求量大的内容,收录应该会越来越快,但是因为收录的数量很多,就算你是原创,可能也很难挤进入排行榜。这么多用户选择使用采集!
一、使用数据采集软件需要注意网站结构规划?
1. 网址设计。URL 还可以收录 关键词。例如,如果您的 网站 是关于计算机的,那么您的 URL 可以收录“PC”,因为在搜索引擎眼中它通常是“计算机”的同义词。URL不宜过长,层级尽量不要超过4层。
2. 列设计。列通常与导航相关联。设计要考虑网站的整体主题,用户可能感兴趣的内容,列名最好是网站的几个主要的关键词,这样也方便导航权重的使用.
3. 关键词布局。理论上,每个内容页面都应该有它的核心关键词,同一个栏目下的文章应该尽可能的围绕关键词栏目转。一个简单粗暴的方法是直接使用列关键词的长尾关键字。
二、根据数据量设置动态、伪静态、静态采集
这不能一概而论,建议使用伪静态或静态。三者的区别在于是否生成静态文件以及URL格式是否为动态。生成静态文件本质上是为了加快访问速度,减少数据库查询,但是会不断增加占用的空间;伪静态仅通过 URL 重写来修改 URL。对于加速访问完全无效。动态和伪静态的区别仅在于 URL,带有问号和参数。
不同的网站 程序可能有不同的数据库操作效率。一般来说,如果内容页数小于10000,页面打开速度比较快,数据量较大,达到50000、100000甚至更多,通常需要考虑静态。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
查看全部
文章采集系统(免费数据采集软件需要注意哪些问题?-八维教育
)
Free Data采集软件是一款无需编写复杂的采集规则即可自动伪原创并根据关键词自动采集自动发布内容的绿色软件。简单配置后,即可实现24小时不间断采集、伪原创和发布。是站长维护网站的首选软件,内置全网发布接口cms,也可以直接导出为txt格式到本地,非常实用方便采集 软件。自从得到了广大站长朋友的永久免费支持,是SEO圈子里的良心软件,给很多站长朋友带来了实实在在的流量和经济效益。

特点介绍:
1、 自动去噪,可以自动过滤标题内容中的图片\网站\电话\QQ\邮件等信息;
2、这个数据采集软件不同于传统的采集模式,它可以根据设置的关键词执行采集、采集用户的好处是可以通过采集关键词的不同搜索结果自动采集最新发布的文章,以免搜索到一个或一个几个指定的 采集 站点。采集,降低采集网站被搜索引擎判断为采集网站被搜索引擎惩罚的风险。
3、 各种伪原创 和优化方法来提高收录 率和关键词 排名 标题插入、内容插入、自动内部链接、内容过滤、URL 过滤、随机图片插入、常规发布等多种方式方法提升采集文章原创的性能,提升搜索引擎收录、网站权重和关键词@ > 排名。
一个搜索引擎,其核心价值是为用户提供他/她最需要的结果。搜索引擎对网民的需求进行了统计。对于网民需求很少或没有需求的内容,即使你是原创,也可能会被搜索引擎忽略,因为它不想把资源浪费在无意义的内容上。对于网友需求量大的内容,收录应该会越来越快,但是因为收录的数量很多,就算你是原创,可能也很难挤进入排行榜。这么多用户选择使用采集!
一、使用数据采集软件需要注意网站结构规划?
1. 网址设计。URL 还可以收录 关键词。例如,如果您的 网站 是关于计算机的,那么您的 URL 可以收录“PC”,因为在搜索引擎眼中它通常是“计算机”的同义词。URL不宜过长,层级尽量不要超过4层。
2. 列设计。列通常与导航相关联。设计要考虑网站的整体主题,用户可能感兴趣的内容,列名最好是网站的几个主要的关键词,这样也方便导航权重的使用.
3. 关键词布局。理论上,每个内容页面都应该有它的核心关键词,同一个栏目下的文章应该尽可能的围绕关键词栏目转。一个简单粗暴的方法是直接使用列关键词的长尾关键字。
二、根据数据量设置动态、伪静态、静态采集
这不能一概而论,建议使用伪静态或静态。三者的区别在于是否生成静态文件以及URL格式是否为动态。生成静态文件本质上是为了加快访问速度,减少数据库查询,但是会不断增加占用的空间;伪静态仅通过 URL 重写来修改 URL。对于加速访问完全无效。动态和伪静态的区别仅在于 URL,带有问号和参数。
不同的网站 程序可能有不同的数据库操作效率。一般来说,如果内容页数小于10000,页面打开速度比较快,数据量较大,达到50000、100000甚至更多,通常需要考虑静态。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!

文章采集系统(这节教您如何来运用采集系统,如何设置采集规则 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-01-02 07:22
)
信息采集管理系统的作用:
可以帮助企业在信息采集和资源整合方面节省大量的人力和资金。广泛应用于行业门户网站、竞争情报系统、知识管理系统、网站内容系统、垂直搜索、科研等领域。
今天这一节,我们将以采集腾讯网站的本地新闻列表为例,一步步教你如何使用采集系统,以及如何使用设置 采集 规则。
点击内容管理-->信息管理采集,如下图:
<p>点击“新建项目”,选择所属型号文章,所属栏目就是你要采集放入哪个栏目,我们选择国内新闻栏目,如下图: 查看全部
文章采集系统(这节教您如何来运用采集系统,如何设置采集规则
)
信息采集管理系统的作用:
可以帮助企业在信息采集和资源整合方面节省大量的人力和资金。广泛应用于行业门户网站、竞争情报系统、知识管理系统、网站内容系统、垂直搜索、科研等领域。
今天这一节,我们将以采集腾讯网站的本地新闻列表为例,一步步教你如何使用采集系统,以及如何使用设置 采集 规则。
点击内容管理-->信息管理采集,如下图:
<p>点击“新建项目”,选择所属型号文章,所属栏目就是你要采集放入哪个栏目,我们选择国内新闻栏目,如下图:
文章采集系统(免费织梦采集规则怎么写?看看文章列表的地址)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-12-30 10:27
dedecms 以其简单、实用和开源而著称。是国内知名度最高的PHP开源网站管理系统,也是用户最多的PHP CMS系统。经过多年的发展,无论是版本还是功能,都有着悠久的发展和进步,DedeCms的主要目标用户集中在个人网站或中小型门户网站的建设。当然,也有使用该系统的企业用户和学校。
免费梦想采集
优势:
1. 简单易用:使用织梦,十分钟学会,十分钟搭建一个。
2. 完美:织梦基本收录
了一般网站需要的所有功能。
3. 资料丰富:织梦作为国产CMS,拥有完整的中文学习资料。
4. 丰富的模板:织梦有海量免费精美模板,你可以自由使用。
5. 丰富的开发教程:织梦德德拥有丰富的二次开发和修改文档教程资源,可以满足大部分的修改需求和功能。
织梦合集的规则真的很复杂
如何编写免费的dedeCMS采集
规则?
看文章列表第一页地址
建站新德/list_49_1.html
比较第二页的地址
建站新德/list_49_2.html
我们发现除了49_后面的数字都一样,所以我们可以这样写
/建站心德/list_49_(*).html
就用(*)代替1吧,因为只有2页,所以我们从1填到2,每页加1,当然2-1...等于1。
后续还有十几步。不懂html的人感觉好陌生,无法下手。很多朋友在使用dede模板的时候都为DEDECMS采集
教程头疼,确实!官方教程太笼统了,也没说什么。Dedecms后台的免费采集
功能,不熟悉的新手也可以使用。采集规则配置起来比较麻烦。采集
过程中经常会遇到错误、乱码、无图片、管理不便等问题。我们需要使用其他易于使用的免费dede采集
和发布工具
免费采集
和发布工具
免费的Dede采集和发布管理工具
1、 只需导入关键词 采集
文章,即可同时创建数十个或数百个采集
任务,自动识别数据和规则,每周、每天、每小时...,只需设置采集
并按计划定时发布,轻松实现定时定量自动更新内容。
免费采集
工具
2、支持各大平台采集
3、可设置关键词采集
文章数
4、同时支持Empire、eyou、ZBLOG、dede、WP、PB、Apple、搜外等主流CMS的发布,可以同时批量管理和采集
发布的工具
以上是编辑器使用织梦工具的效果,整体收录和排名都还不错!看完这篇文章,如果你觉得不错,不妨采集
起来或者送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力! 查看全部
文章采集系统(免费织梦采集规则怎么写?看看文章列表的地址)
dedecms 以其简单、实用和开源而著称。是国内知名度最高的PHP开源网站管理系统,也是用户最多的PHP CMS系统。经过多年的发展,无论是版本还是功能,都有着悠久的发展和进步,DedeCms的主要目标用户集中在个人网站或中小型门户网站的建设。当然,也有使用该系统的企业用户和学校。

免费梦想采集
优势:
1. 简单易用:使用织梦,十分钟学会,十分钟搭建一个。
2. 完美:织梦基本收录
了一般网站需要的所有功能。
3. 资料丰富:织梦作为国产CMS,拥有完整的中文学习资料。
4. 丰富的模板:织梦有海量免费精美模板,你可以自由使用。
5. 丰富的开发教程:织梦德德拥有丰富的二次开发和修改文档教程资源,可以满足大部分的修改需求和功能。
织梦合集的规则真的很复杂
如何编写免费的dedeCMS采集
规则?
看文章列表第一页地址
建站新德/list_49_1.html
比较第二页的地址
建站新德/list_49_2.html
我们发现除了49_后面的数字都一样,所以我们可以这样写
/建站心德/list_49_(*).html
就用(*)代替1吧,因为只有2页,所以我们从1填到2,每页加1,当然2-1...等于1。
后续还有十几步。不懂html的人感觉好陌生,无法下手。很多朋友在使用dede模板的时候都为DEDECMS采集
教程头疼,确实!官方教程太笼统了,也没说什么。Dedecms后台的免费采集
功能,不熟悉的新手也可以使用。采集规则配置起来比较麻烦。采集
过程中经常会遇到错误、乱码、无图片、管理不便等问题。我们需要使用其他易于使用的免费dede采集
和发布工具
免费采集
和发布工具
免费的Dede采集和发布管理工具
1、 只需导入关键词 采集
文章,即可同时创建数十个或数百个采集
任务,自动识别数据和规则,每周、每天、每小时...,只需设置采集
并按计划定时发布,轻松实现定时定量自动更新内容。
免费采集
工具
2、支持各大平台采集
3、可设置关键词采集
文章数
4、同时支持Empire、eyou、ZBLOG、dede、WP、PB、Apple、搜外等主流CMS的发布,可以同时批量管理和采集
发布的工具
以上是编辑器使用织梦工具的效果,整体收录和排名都还不错!看完这篇文章,如果你觉得不错,不妨采集
起来或者送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力!
文章采集系统(log日志文件中grep、awk节点(node)节点 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-12-26 20:06
)
我们通常在日志文件中直接用grep和awk分析日志,得到我们想要的信息。这种方法效率低下,并且需要在生产中进行集中日志管理。汇总了所有服务器上的日志采集
。
弹性搜索
一个节点(node)是一个Elasticsearch实例,一个集群(cluster)是由一个或多个节点组成,它们具有相同的cluster.name,它们一起工作来共享数据和负载。当添加新节点或删除节点时,集群将感知并平衡数据。
集群中的一个节点会被选举为主节点(master),它会临时管理集群层面的一些变化,比如创建或删除索引,添加或删除节点等。主节点不参与文档- level 变化或搜索,这意味着当流量增长时,master 节点不会成为集群的瓶颈。
作为用户,我们可以与集群中的任何节点通信,包括主节点。每个节点都知道文档存在于哪个节点,并且可以将请求转发到相应的节点。我们访问的节点负责采集
各个节点返回的数据,最后一起返回给客户端。所有这些都由 Elasticsearch 处理。
一个完整的集中式日志系统需要包括以下主要功能:
采集——可以采集多个来源的日志数据
传输——日志数据可以稳定传输到中央系统
Storage-如何存储日志数据
分析-可以支持UI分析
警告-可以提供错误报告,监控机制
Fluentd基于CRuby实现,一些对性能很关键的组件用C语言重新实现,整体性能不错。
Fluentd支持所有主流日志类型,插件支持更多,性能更好
Logstash支持所有主流日志类型,插件支持最丰富,DIY灵活,但性能较差,JVM容易导致内存占用高。
Elasticsearch 是一个开源的分布式搜索引擎,提供采集
、分析和存储数据三大功能
Kibana 也是一个开源的免费工具。Kibana 可以为 td-agent 和 ElasticSearch 提供日志分析友好的 web 界面,可以帮助汇总、分析和搜索重要的数据日志。
node-1
#yum -y install java //下载java
#java -version //检测版本号
openjdk version "1.8.0_171"
OpenJDK Runtime Environment (build 1.8.0_171-b10)
OpenJDK 64-Bit Server VM (build 25.171-b10, mixed mode)
#wget https://artifacts.elastic.co/d ... 1.rpm
# rpm -ivh elasticsearch-6.3.1.rpm //安装
# vim /etc/elasticsearch/elasticsearch.yml //修改配置文件
cluster.name: my-application
node.name: node-1
node.master: true
network.host: 172.21.0.9
http.port: 9200
/etc/init.d/elasticsearch start //启动
curl http://192.168.124.173:9200/_cat/ //尝试链接 如果链接失败,关闭防火墙,查看配置文件
#curl http://192.168.124.173:9200/_cat/health
# curl http://192.168.124.173:9200/_cat/nodes
node-2
# yum install java
# java -version
#wget https://artifacts.elastic.co/d ... 1.rpm
# rpm -ivh elasticsearch-6.3.1.rpm
# vim /etc/elasticsearch/elasticsearch.yml //更改配置
cluster.name: my-application
node.name: node-2
node.master: false
network.host: 192.168.124.251
http.port: 9200
discovery.zen.ping.unicast.hosts: ["host1", "192.168.124.173"]
# /etc/init.d/elasticsearch start //启动服务
# /etc/init.d/elasticsearch status //查看状态
# curl http://192.168.124.251:9200/_cat
node-1
Fluentd(tdagent)
wget http://packages.treasuredata.c ... 4.rpm
rpm -ivh td-agent-3.2.0-0.el7.x86_64.rpm --force --nodeps
yum install -y libcurl-devel
opt/td-agent/embedded/bin/fluent-gem install fluent-plugin-elasticsearch
#cd /etc/td-agent/
#cat td-agent.conf
@type forward
port 24224
####################################
@type tail
path /var/log/httpd/access_log
pos_file /var/log/td-agent/httpd-access.log.pos
tag apache.access
@type apache2
####################################
@type stdout
####################################
@type copy
@type elasticsearch
host 10.0.0.9
port 9200
logstash_format true
logstash_prefix fluentd-${tag}
logstash_dateformat %Y%m%d
include_tag_key true
type_name access_log
tag_key @log_name
flush_interval 1s
@type stdout
# /etc/init.d/td-agent restart
# yum -y install http
# systemctl start httpd
# chmod 777 /var/log/httpd/
# curl 'http://192.168.124.173:9200/_cat/indices?v'
# systemctl stop firewalld
# wget https://artifacts.elastic.co/d ... 4.rpm
# rpm -ivh kibana-6.3.1-x86_64.rpm
# vim /etc/kibana/kibana.yml
server.port: 5601
server.host: “192.168.124.173"
elasticsearch.url: "http://192.168.124.173:9200
kibana.index: ".kibana”
# /etc/init.d/kibana restart
#tail -f /var/log/kibana/kibana.stderr
访问 kibana 网页界面
http://192.168.124.173:5601/
添加监控项
file:///root/%E4%B8%8B%E8%BD%BD/%E7%81%AB%E7%8B%90%E6%88%AA%E5%9B%BE_2018-07-14T06-39 -23.568Z.png
查看全部
文章采集系统(log日志文件中grep、awk节点(node)节点
)
我们通常在日志文件中直接用grep和awk分析日志,得到我们想要的信息。这种方法效率低下,并且需要在生产中进行集中日志管理。汇总了所有服务器上的日志采集
。
弹性搜索
一个节点(node)是一个Elasticsearch实例,一个集群(cluster)是由一个或多个节点组成,它们具有相同的cluster.name,它们一起工作来共享数据和负载。当添加新节点或删除节点时,集群将感知并平衡数据。
集群中的一个节点会被选举为主节点(master),它会临时管理集群层面的一些变化,比如创建或删除索引,添加或删除节点等。主节点不参与文档- level 变化或搜索,这意味着当流量增长时,master 节点不会成为集群的瓶颈。
作为用户,我们可以与集群中的任何节点通信,包括主节点。每个节点都知道文档存在于哪个节点,并且可以将请求转发到相应的节点。我们访问的节点负责采集
各个节点返回的数据,最后一起返回给客户端。所有这些都由 Elasticsearch 处理。
一个完整的集中式日志系统需要包括以下主要功能:
采集——可以采集多个来源的日志数据
传输——日志数据可以稳定传输到中央系统
Storage-如何存储日志数据
分析-可以支持UI分析
警告-可以提供错误报告,监控机制
Fluentd基于CRuby实现,一些对性能很关键的组件用C语言重新实现,整体性能不错。
Fluentd支持所有主流日志类型,插件支持更多,性能更好
Logstash支持所有主流日志类型,插件支持最丰富,DIY灵活,但性能较差,JVM容易导致内存占用高。
Elasticsearch 是一个开源的分布式搜索引擎,提供采集
、分析和存储数据三大功能
Kibana 也是一个开源的免费工具。Kibana 可以为 td-agent 和 ElasticSearch 提供日志分析友好的 web 界面,可以帮助汇总、分析和搜索重要的数据日志。
node-1
#yum -y install java //下载java
#java -version //检测版本号
openjdk version "1.8.0_171"
OpenJDK Runtime Environment (build 1.8.0_171-b10)
OpenJDK 64-Bit Server VM (build 25.171-b10, mixed mode)
#wget https://artifacts.elastic.co/d ... 1.rpm
# rpm -ivh elasticsearch-6.3.1.rpm //安装
# vim /etc/elasticsearch/elasticsearch.yml //修改配置文件
cluster.name: my-application
node.name: node-1
node.master: true
network.host: 172.21.0.9
http.port: 9200
/etc/init.d/elasticsearch start //启动
curl http://192.168.124.173:9200/_cat/ //尝试链接 如果链接失败,关闭防火墙,查看配置文件
#curl http://192.168.124.173:9200/_cat/health
# curl http://192.168.124.173:9200/_cat/nodes
node-2
# yum install java
# java -version
#wget https://artifacts.elastic.co/d ... 1.rpm
# rpm -ivh elasticsearch-6.3.1.rpm
# vim /etc/elasticsearch/elasticsearch.yml //更改配置
cluster.name: my-application
node.name: node-2
node.master: false
network.host: 192.168.124.251
http.port: 9200
discovery.zen.ping.unicast.hosts: ["host1", "192.168.124.173"]
# /etc/init.d/elasticsearch start //启动服务
# /etc/init.d/elasticsearch status //查看状态
# curl http://192.168.124.251:9200/_cat
node-1
Fluentd(tdagent)
wget http://packages.treasuredata.c ... 4.rpm
rpm -ivh td-agent-3.2.0-0.el7.x86_64.rpm --force --nodeps
yum install -y libcurl-devel
opt/td-agent/embedded/bin/fluent-gem install fluent-plugin-elasticsearch
#cd /etc/td-agent/
#cat td-agent.conf
@type forward
port 24224
####################################
@type tail
path /var/log/httpd/access_log
pos_file /var/log/td-agent/httpd-access.log.pos
tag apache.access
@type apache2
####################################
@type stdout
####################################
@type copy
@type elasticsearch
host 10.0.0.9
port 9200
logstash_format true
logstash_prefix fluentd-${tag}
logstash_dateformat %Y%m%d
include_tag_key true
type_name access_log
tag_key @log_name
flush_interval 1s
@type stdout
# /etc/init.d/td-agent restart
# yum -y install http
# systemctl start httpd
# chmod 777 /var/log/httpd/
# curl 'http://192.168.124.173:9200/_cat/indices?v'
# systemctl stop firewalld
# wget https://artifacts.elastic.co/d ... 4.rpm
# rpm -ivh kibana-6.3.1-x86_64.rpm
# vim /etc/kibana/kibana.yml
server.port: 5601
server.host: “192.168.124.173"
elasticsearch.url: "http://192.168.124.173:9200
kibana.index: ".kibana”
# /etc/init.d/kibana restart
#tail -f /var/log/kibana/kibana.stderr
访问 kibana 网页界面
http://192.168.124.173:5601/
添加监控项

file:///root/%E4%B8%8B%E8%BD%BD/%E7%81%AB%E7%8B%90%E6%88%AA%E5%9B%BE_2018-07-14T06-39 -23.568Z.png


文章采集系统(spring使用springcloud架构来做爬虫,历时二十多天,终于搞定)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-12-26 17:26
前言
因公司业务需要,需要获取客户提供的微信公众号历史文章,并每日更新。显然,300多个公众号无法每天手动检查,问题提交给IT团队。对于喜欢爬虫的人来说,我绝对想要他。之前用过搜狗的微信爬虫,后来一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过系列文章分享项目经验,并提供源码供大家指正!
一、系统介绍
本系统是基于Java开发的。只需配置公众号名称或微信公众号,即可抓取微信公众号文章(包括阅读、点赞、正在观看)。
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、RocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
Redis
演戏
提琴手
三、系统优缺点 系统优点
1、配置公众号后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取;2、系统为分布式架构,高可用;3、RocketMq 消息队列解决方案 Coupling 可以解决网络抖动导致的采集失败问题。如果三次消费不成功,日志会记录到mysql中,保证文章的完整性;4、可以添加任意数量的微信信号,提高采集效率,抵制反攀登限制;5、Redis在24小时内缓存每个微信账号的收款记录,防止账号被关闭;6、Nacos作为配置中心,可以通过热配置实时调整采集频率;7、 将采集
的数据存储在Solr集群中,提高检索速度;8、 将捕获返回的记录存储到MongoDB存档中,方便查看错误日志。
系统缺点:
1、 通过真实手机和真实账户采集
消息。如果需要采集
大量公众号,需要有多个微信帐号作为支持(如果当天达到上限,可以通过微信官方平台界面爬取消息);2、不是公众号发完就可以立即抓取,采集
时间是系统设置的,留言有一定的滞后性(如果公众号不多,微信信号数是足够了,可以通过增加采集
频率来优化)。
四、模块介绍
由于后面会添加管理系统和API调用函数,所以提前封装了一些函数。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:是
spring-boot-starter-data-redis的二次包暴露了打包好的Redis工具类和Redisson工具类。
RocketMQ-WS-启动器
RocketMQ 模块:是
Rocketmq-spring-boot-starter 的二次封装提供了消费重试和故障日志记录功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-蜘蛛
PC端采集模块:收录
PC端公众号历史消息采集相关功能。
java-wx-蜘蛛
Java Extraction Module:收录
与java程序提取文章内容相关的功能。
移动-wx-蜘蛛
模拟器采集模块:收录
与通过模拟器或手机采集消息的交互量相关的功能。
五、一般流程图
六、 在 PC 和手机上运行截图
安慰
运行结束
总结
项目亲测现已上线,项目开发中解决了微信搜狗临时链接永久链接问题,希望能帮助到被同类业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。我希望每个人都有自己的向日葵采集
。如果你看到这个,你不把它给一个采集
吗? 查看全部
文章采集系统(spring使用springcloud架构来做爬虫,历时二十多天,终于搞定)
前言
因公司业务需要,需要获取客户提供的微信公众号历史文章,并每日更新。显然,300多个公众号无法每天手动检查,问题提交给IT团队。对于喜欢爬虫的人来说,我绝对想要他。之前用过搜狗的微信爬虫,后来一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过系列文章分享项目经验,并提供源码供大家指正!
一、系统介绍
本系统是基于Java开发的。只需配置公众号名称或微信公众号,即可抓取微信公众号文章(包括阅读、点赞、正在观看)。
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、RocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
Redis
演戏
提琴手
三、系统优缺点 系统优点
1、配置公众号后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取;2、系统为分布式架构,高可用;3、RocketMq 消息队列解决方案 Coupling 可以解决网络抖动导致的采集失败问题。如果三次消费不成功,日志会记录到mysql中,保证文章的完整性;4、可以添加任意数量的微信信号,提高采集效率,抵制反攀登限制;5、Redis在24小时内缓存每个微信账号的收款记录,防止账号被关闭;6、Nacos作为配置中心,可以通过热配置实时调整采集频率;7、 将采集
的数据存储在Solr集群中,提高检索速度;8、 将捕获返回的记录存储到MongoDB存档中,方便查看错误日志。
系统缺点:
1、 通过真实手机和真实账户采集
消息。如果需要采集
大量公众号,需要有多个微信帐号作为支持(如果当天达到上限,可以通过微信官方平台界面爬取消息);2、不是公众号发完就可以立即抓取,采集
时间是系统设置的,留言有一定的滞后性(如果公众号不多,微信信号数是足够了,可以通过增加采集
频率来优化)。
四、模块介绍
由于后面会添加管理系统和API调用函数,所以提前封装了一些函数。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:是
spring-boot-starter-data-redis的二次包暴露了打包好的Redis工具类和Redisson工具类。
RocketMQ-WS-启动器
RocketMQ 模块:是
Rocketmq-spring-boot-starter 的二次封装提供了消费重试和故障日志记录功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-蜘蛛
PC端采集模块:收录
PC端公众号历史消息采集相关功能。
java-wx-蜘蛛
Java Extraction Module:收录
与java程序提取文章内容相关的功能。
移动-wx-蜘蛛
模拟器采集模块:收录
与通过模拟器或手机采集消息的交互量相关的功能。
五、一般流程图
六、 在 PC 和手机上运行截图

安慰
运行结束
总结
项目亲测现已上线,项目开发中解决了微信搜狗临时链接永久链接问题,希望能帮助到被同类业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。我希望每个人都有自己的向日葵采集
。如果你看到这个,你不把它给一个采集
吗?
文章采集系统(从木子小渔聊起bt技术用bt下载软件是怎么采集网页资源的?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-12-24 09:03
文章采集系统的开发过程我就不描述了,网上有很多相关文章,如何搭建和怎么搭建,基本都差不多,后面对比了一下,网上的几篇文章都有问题,或者说都不是我需要的!在梳理了相关知识后,我做出了这个,他们在知乎上有专门的专栏,对我的相关分析,软件体验都有,提供免费培训和一对一培训,能够让你快速上手,了解市场环境的实际情况,避免上当受骗!如果对做采集系统感兴趣,或者打算学习搭建采集系统,都可以看一下他们的专栏,十分欢迎报名!我还有一个最近写的bt技术系列文章,有兴趣也可以看看:木子小渔:从木子小渔聊起bt技术用bt下载软件是怎么采集网页资源的?!(。
1)木子小渔:从木子小渔聊起bt技术用bt下载软件是怎么采集网页资源的?!
2)木子小渔:从木子小渔聊起bt技术用bt下载软件是怎么采集网页资源的?!
3)木子小渔:从木子小渔聊起bt技术用bt下载软件是怎么采集网页资源的?!
4)
你可以给开发者点300块钱,大家都开心。他的代码他看着心情写,事后你觉得不满意,
我刚刚也和楼主遇到同样的问题,刚刚在某公司的圈子里用某团购网站的网页版本随机搜索了一下,发现几千页有大约2-3万条数据,访问都在几十秒左右,真是令人心头一颤。随后开始去研究他们的采集软件,发现有多个版本的、这么大的任务量,按照多个版本切换,应该是为了提高效率和降低延时进行改良。但从长远角度出发,应该直接让团队全员编写代码来进行,会大大提高产出。
如果你实在不满意提供的这个插件,可以编写一个类似的免费的采集软件,是只能随机采集网页的数据的。这个对学生会不会不太友好呢,毕竟本身来说学习成本还挺高的。 查看全部
文章采集系统(从木子小渔聊起bt技术用bt下载软件是怎么采集网页资源的?)
文章采集系统的开发过程我就不描述了,网上有很多相关文章,如何搭建和怎么搭建,基本都差不多,后面对比了一下,网上的几篇文章都有问题,或者说都不是我需要的!在梳理了相关知识后,我做出了这个,他们在知乎上有专门的专栏,对我的相关分析,软件体验都有,提供免费培训和一对一培训,能够让你快速上手,了解市场环境的实际情况,避免上当受骗!如果对做采集系统感兴趣,或者打算学习搭建采集系统,都可以看一下他们的专栏,十分欢迎报名!我还有一个最近写的bt技术系列文章,有兴趣也可以看看:木子小渔:从木子小渔聊起bt技术用bt下载软件是怎么采集网页资源的?!(。
1)木子小渔:从木子小渔聊起bt技术用bt下载软件是怎么采集网页资源的?!
2)木子小渔:从木子小渔聊起bt技术用bt下载软件是怎么采集网页资源的?!
3)木子小渔:从木子小渔聊起bt技术用bt下载软件是怎么采集网页资源的?!
4)
你可以给开发者点300块钱,大家都开心。他的代码他看着心情写,事后你觉得不满意,
我刚刚也和楼主遇到同样的问题,刚刚在某公司的圈子里用某团购网站的网页版本随机搜索了一下,发现几千页有大约2-3万条数据,访问都在几十秒左右,真是令人心头一颤。随后开始去研究他们的采集软件,发现有多个版本的、这么大的任务量,按照多个版本切换,应该是为了提高效率和降低延时进行改良。但从长远角度出发,应该直接让团队全员编写代码来进行,会大大提高产出。
如果你实在不满意提供的这个插件,可以编写一个类似的免费的采集软件,是只能随机采集网页的数据的。这个对学生会不会不太友好呢,毕竟本身来说学习成本还挺高的。
文章采集系统(软件应用环境:支持PHP+Mysql+ZENDOptimizer的WEB系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-12-20 03:15
欢迎使用不受目标语言限制、不选择存储对象数据库的在线采集器。谷歌和百度在搜索中排名第一。它是完全免费的,可以放心使用。
软件应用环境:支持PHP+Mysql+ZEND Optimizer的WEB系统
当前版本:V2.0324 发布时间:07.03.24 13:53
老版本用户升级请参考升级文件目录下的指令文件操作!!!
发行说明:
V2.0324 发布时间:07.03.24 13:53
1、优化URL编码程序,提高目标URL编码字符串的识别智能
---------------
适用范围:
1、 部署环境不限,Windows、Linux、FreeBSD、Solaris等可以安装PHP语言支持环境的系统均可使用;
2、采集 对象不限,静态HTML、动态PHP/ASP/JAVA页面均可采集;
3、采集对象支持:文章、图片、Flash;
4、完美的内容存储解决方案,小蜜蜂采集器提供2种存储方式:直接数据库引导和模拟提交。
1)Database Direct Guide完美支持任何基于Mysql数据库的内容管理系统存储信息,包括多表/多字段联动系统指南库;
2) 仿真提交指南库理论上支持任何目标,不受目标程序语言和数据库类别的限制;实际使用效果受目标应用影响。
各采集模块功能简介:
1、 文章采集Module special 采集文章/Picture,或者采集文章内附的Flash,但功能是不如 Flash采集 模块功能强大;
2、 BBS 论坛采集特定模块采集BBS 论坛内容;
3、 Flash采集模块专攻采集Flash游戏,可以完美的采集缩略图和游戏介绍;
采集内容导引库介绍:采集各模块的内容可自由导入WEB应用系统。
特征:
1、支持文章内容分页采集;
2、支持论坛采集
3、支持UTF-8转GB2312,但采集内容字符格式是UTF-8的目标;
4、 支持将文章的内容保存到本地;
5、支持站点+栏目管理模式,让采集管理一目了然;
6、支持链接替换,分页链接替换,破解JS/后台程序设置的一些反扒功能;
7、支持采集器设置无限过滤功能;
8、支持图片采集保存到本地,自动替换文件名避免重复;
9、支持FLASH文件采集保存到本地,自动替换文件名避免重复;
10、 支持限制PHP FOPEN和FSOCKET功能的虚拟主机;
11、 支持手动过滤采集结果,并提供“空标题空内容”的快速过滤和删除;
12、支持Flash专业站点采集,特色采集flash小游戏,可完美采集缩略图,游戏介绍;
13、 支持全站配置规则的导入导出;
14、 支持列配置规则的导入导出,并提供规则复制功能,简化设置;
15、 提供引导库规则导入导出;
16、支持自定义采集间隔时间,避免被误认为DDOS攻击而拒绝响应,但采集可以设置防止DDOS攻击网站;
17、 支持自定义存储间隔时间,避免虚拟主机并发限制;
18、支持自定义内容写入,用户可以设置任意内容(如自己的链接、广告代码),写入采集的内容:第一个、最后一个或随机写入;需要写入的内容在浏览库时自动带在身边,无需修改WEB系统模板。
19、支持采集内容替换功能,用户可以设置替换规则随意替换;
20、支持html标签过滤,让采集接收到的内容只保留必要的html标签,甚至纯文本不带任何html标签;
21、支持多种cms引导库如:BBWPS、Dedecms(织梦) V2/V3、PHP168 cms、mephp< @cms、曼波cms、Joomlacms、多迅(DuoXun)cms、SupeSite、cmsware、帝国Ecms、新宇东网( XYDW)cms、东易cms、风迅cms、HUGESKY、PHPcms系统指南库;用户还可以设计自己的系统指南库功能。
22、支持PHPWIND、Discuz、BBSxp论坛指南库,程序包收录3个论坛指南库规则和操作说明;
23、 自带数据库优化玩具,减少频繁采集 过多的数据碎片降低数据库性能。
以下特殊功能仅适用于“小蜜蜂采集器”:
1、支持采集进程断点续传功能,不受浏览器意外关闭影响,重启后不会重复采集;
2、 支持自动比较过滤功能,不会在采集的链接系统中重复采集和存储;
以上两个功能可以大大减少采集时间,减少系统负载。
3、 支持系统每天自动创建图片存储目录,方便管理;
4、 支持采集/guidance间隔时间设置,避免被目标站识别为流量攻击而拒绝响应;
5、支持自定义内容写入,实现简单的反采集功能;
6、支持html标签过滤,几乎完美展现你想要的采集效果;
7、完美的内容存储解决方案,不受目标编程语言和数据库类别的限制。
以上众多强大功能免费供您使用,您可以轻松高效地安装使用体验资料采集。
-----------------------------
选择小蜜蜂采集器的好处:
1、小蜜蜂程序采用PHP开发,支持跨平台操作。它可以在 Windows 和 Unix 操作系统上运行。是一款高效的采集在线应用软件,完美入库。
2、 小蜜蜂不受安装位置限制,家中,工作电脑,网站服务器均可使用;建议直接安装在网站服务器上,体验小蜜蜂的超强功能和便利。
3、 使用服务器安装,可以直接抓取采集的图片/Flash到机器上使用;无需像其他采集器采集服务器那样通过FTP将数据上传到个人电脑。想象一下,如果那天你的采集图片和Flash超过100M,上传时间是什么概念。
4、使用服务器安装,可以快速导入采集内容cms文章系统或BBS论坛系统;如果使用离线采集器,远程存储或者上传SQL文件进行存储都是浪费时间。
5、小蜜蜂独有的断点续传和重复采集过滤功能,可以节省您创作内容的时间。
-----------------------------
单点下载:
更多下载: 查看全部
文章采集系统(软件应用环境:支持PHP+Mysql+ZENDOptimizer的WEB系统)
欢迎使用不受目标语言限制、不选择存储对象数据库的在线采集器。谷歌和百度在搜索中排名第一。它是完全免费的,可以放心使用。
软件应用环境:支持PHP+Mysql+ZEND Optimizer的WEB系统
当前版本:V2.0324 发布时间:07.03.24 13:53
老版本用户升级请参考升级文件目录下的指令文件操作!!!
发行说明:
V2.0324 发布时间:07.03.24 13:53
1、优化URL编码程序,提高目标URL编码字符串的识别智能
---------------
适用范围:
1、 部署环境不限,Windows、Linux、FreeBSD、Solaris等可以安装PHP语言支持环境的系统均可使用;
2、采集 对象不限,静态HTML、动态PHP/ASP/JAVA页面均可采集;
3、采集对象支持:文章、图片、Flash;
4、完美的内容存储解决方案,小蜜蜂采集器提供2种存储方式:直接数据库引导和模拟提交。
1)Database Direct Guide完美支持任何基于Mysql数据库的内容管理系统存储信息,包括多表/多字段联动系统指南库;
2) 仿真提交指南库理论上支持任何目标,不受目标程序语言和数据库类别的限制;实际使用效果受目标应用影响。
各采集模块功能简介:
1、 文章采集Module special 采集文章/Picture,或者采集文章内附的Flash,但功能是不如 Flash采集 模块功能强大;
2、 BBS 论坛采集特定模块采集BBS 论坛内容;
3、 Flash采集模块专攻采集Flash游戏,可以完美的采集缩略图和游戏介绍;
采集内容导引库介绍:采集各模块的内容可自由导入WEB应用系统。
特征:
1、支持文章内容分页采集;
2、支持论坛采集
3、支持UTF-8转GB2312,但采集内容字符格式是UTF-8的目标;
4、 支持将文章的内容保存到本地;
5、支持站点+栏目管理模式,让采集管理一目了然;
6、支持链接替换,分页链接替换,破解JS/后台程序设置的一些反扒功能;
7、支持采集器设置无限过滤功能;
8、支持图片采集保存到本地,自动替换文件名避免重复;
9、支持FLASH文件采集保存到本地,自动替换文件名避免重复;
10、 支持限制PHP FOPEN和FSOCKET功能的虚拟主机;
11、 支持手动过滤采集结果,并提供“空标题空内容”的快速过滤和删除;
12、支持Flash专业站点采集,特色采集flash小游戏,可完美采集缩略图,游戏介绍;
13、 支持全站配置规则的导入导出;
14、 支持列配置规则的导入导出,并提供规则复制功能,简化设置;
15、 提供引导库规则导入导出;
16、支持自定义采集间隔时间,避免被误认为DDOS攻击而拒绝响应,但采集可以设置防止DDOS攻击网站;
17、 支持自定义存储间隔时间,避免虚拟主机并发限制;
18、支持自定义内容写入,用户可以设置任意内容(如自己的链接、广告代码),写入采集的内容:第一个、最后一个或随机写入;需要写入的内容在浏览库时自动带在身边,无需修改WEB系统模板。
19、支持采集内容替换功能,用户可以设置替换规则随意替换;
20、支持html标签过滤,让采集接收到的内容只保留必要的html标签,甚至纯文本不带任何html标签;
21、支持多种cms引导库如:BBWPS、Dedecms(织梦) V2/V3、PHP168 cms、mephp< @cms、曼波cms、Joomlacms、多迅(DuoXun)cms、SupeSite、cmsware、帝国Ecms、新宇东网( XYDW)cms、东易cms、风迅cms、HUGESKY、PHPcms系统指南库;用户还可以设计自己的系统指南库功能。
22、支持PHPWIND、Discuz、BBSxp论坛指南库,程序包收录3个论坛指南库规则和操作说明;
23、 自带数据库优化玩具,减少频繁采集 过多的数据碎片降低数据库性能。
以下特殊功能仅适用于“小蜜蜂采集器”:
1、支持采集进程断点续传功能,不受浏览器意外关闭影响,重启后不会重复采集;
2、 支持自动比较过滤功能,不会在采集的链接系统中重复采集和存储;
以上两个功能可以大大减少采集时间,减少系统负载。
3、 支持系统每天自动创建图片存储目录,方便管理;
4、 支持采集/guidance间隔时间设置,避免被目标站识别为流量攻击而拒绝响应;
5、支持自定义内容写入,实现简单的反采集功能;
6、支持html标签过滤,几乎完美展现你想要的采集效果;
7、完美的内容存储解决方案,不受目标编程语言和数据库类别的限制。
以上众多强大功能免费供您使用,您可以轻松高效地安装使用体验资料采集。
-----------------------------
选择小蜜蜂采集器的好处:
1、小蜜蜂程序采用PHP开发,支持跨平台操作。它可以在 Windows 和 Unix 操作系统上运行。是一款高效的采集在线应用软件,完美入库。
2、 小蜜蜂不受安装位置限制,家中,工作电脑,网站服务器均可使用;建议直接安装在网站服务器上,体验小蜜蜂的超强功能和便利。
3、 使用服务器安装,可以直接抓取采集的图片/Flash到机器上使用;无需像其他采集器采集服务器那样通过FTP将数据上传到个人电脑。想象一下,如果那天你的采集图片和Flash超过100M,上传时间是什么概念。
4、使用服务器安装,可以快速导入采集内容cms文章系统或BBS论坛系统;如果使用离线采集器,远程存储或者上传SQL文件进行存储都是浪费时间。
5、小蜜蜂独有的断点续传和重复采集过滤功能,可以节省您创作内容的时间。
-----------------------------
单点下载:
更多下载:
文章采集系统(文章采集系统的市场需求决定功能的优先级,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-12-17 22:08
文章采集系统基础知识文章采集系统的市场需求决定功能的优先级,作为采集系统,基础市场需求包括但不限于:1.开发采集系统难度低,只要有php和数据库知识就可以开发2.采集系统不一定需要具备数据爬取,还可以爬取图片,视频,点击等采集模块3.对爬虫能力要求低,只要爬取速度能够满足采集要求即可4.对系统的复杂度和安全性有一定要求5.对爬虫可能会出现无法抓取和对地址规则收集不全等情况有很大影响6.作为一个完善的采集系统,其系统管理,上传,清洗和存储等要能够满足存储数据量大,爬取速度慢,对地址规则收集不全等多个问题每个客户都想开发适合自己的采集系统,基于此,我们开发了和自己产品相适应的文章采集系统,包括了收集功能和上传功能。
采集系统的市场需求包括但不限于:1.手动采集速度慢,重复采集严重2.需要管理爬虫,处理爬虫的后门,判断爬虫是否可用3.爬虫权限控制和批量采集权限的控制4.爬虫存储,缓存,读取和命中率控制5.爬虫监控,定期监控爬虫数据6.支持采集java,php,html5等爬虫语言采集系统的功能1.爬虫收集模块:爬虫收集系统提供文章收集接口,使用采集模块中的文章来爬取内容2.爬虫爬取模块:采集模块提供爬虫爬取接口,采集文章和页面。
采集数据全部从网站搜索引擎爬取,或者爬取系统爬取系统文章采集系统开发和实施采集系统开发采集系统实施采集系统管理采集系统管理采集系统爬虫爬取文章采集数据收集系统定期爬取文章图片,视频和点击采集系统实现采集后端采集爬虫爬取后端采集存储存储爬虫采集服务采集系统定期爬取数据采集系统定期爬取数据采集系统定期爬取数据采集系统定期爬取数据数据采集。 查看全部
文章采集系统(文章采集系统的市场需求决定功能的优先级,你知道吗?)
文章采集系统基础知识文章采集系统的市场需求决定功能的优先级,作为采集系统,基础市场需求包括但不限于:1.开发采集系统难度低,只要有php和数据库知识就可以开发2.采集系统不一定需要具备数据爬取,还可以爬取图片,视频,点击等采集模块3.对爬虫能力要求低,只要爬取速度能够满足采集要求即可4.对系统的复杂度和安全性有一定要求5.对爬虫可能会出现无法抓取和对地址规则收集不全等情况有很大影响6.作为一个完善的采集系统,其系统管理,上传,清洗和存储等要能够满足存储数据量大,爬取速度慢,对地址规则收集不全等多个问题每个客户都想开发适合自己的采集系统,基于此,我们开发了和自己产品相适应的文章采集系统,包括了收集功能和上传功能。
采集系统的市场需求包括但不限于:1.手动采集速度慢,重复采集严重2.需要管理爬虫,处理爬虫的后门,判断爬虫是否可用3.爬虫权限控制和批量采集权限的控制4.爬虫存储,缓存,读取和命中率控制5.爬虫监控,定期监控爬虫数据6.支持采集java,php,html5等爬虫语言采集系统的功能1.爬虫收集模块:爬虫收集系统提供文章收集接口,使用采集模块中的文章来爬取内容2.爬虫爬取模块:采集模块提供爬虫爬取接口,采集文章和页面。
采集数据全部从网站搜索引擎爬取,或者爬取系统爬取系统文章采集系统开发和实施采集系统开发采集系统实施采集系统管理采集系统管理采集系统爬虫爬取文章采集数据收集系统定期爬取文章图片,视频和点击采集系统实现采集后端采集爬虫爬取后端采集存储存储爬虫采集服务采集系统定期爬取数据采集系统定期爬取数据采集系统定期爬取数据采集系统定期爬取数据数据采集。
文章采集系统(如何做好一个网站SEO收录?有哪些收录技巧和注意的地方)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-03-01 01:32
Emlog采集,很多博主、个人网站、企业网站长期使用的网站内容扩展工具,可以大大提升网站的性能@网站 充实,通过海量内容吸引更多用户访问。如何做好网站SEO收录?收录 的提示和注意事项有哪些?接下来,我们将从 Emlog采集 的功能和功能,以及 SEO 技巧来看整个 SEO 优化。
网站采集的文章个数与收录的速率有一定的关系。到现在,站采集仍然可以达到很高的权重。搜索引擎也表示采集的内容要注意是否去掉多余的标签,内容是否完整等。虽然Emlog采集并不是一个好的选择,但是对于很多网站来说,只有在 采集 之后,他们才有能力输出新鲜的内容。
那么Emlog采集制作的采集站点会做这些优化:网站采集内容清晰,没有乱码,标签不干净。扩充补充采集的内容,减少采集的内容。在采集的内容后面添加其他相关内容,使内容相互指向,扩大相关性。尽可能采集优质网站的内容不会采集不可读或带有广告文章。
Emlog采集发布后会主动推送内容,持续推送内容会增加爬虫访问的概率。爬取推广网站的收录,这就是前面提到的内容建设和网站优化。此外,最好提交大量的站点地图。搜索引擎处理站点地图的时间很长,最近时间缩短了很多。至于怎么推送,一般都是后台推送,支持结构化数据提交,提交多了会有惊喜。毅力是必需的。另外,网站还可以推送到收录的目录栏,可以查看其API文档申请。
目前很多建站系统都集成了采集系统,Emlog采集对于采集的内容已经成为一件很简单的事情。在短时间内用内容填满您的新网站或使搜索引擎更快收录我们的新网站变得更快乐。
但是当我们采集完成这个内容并通过搜索引擎得到收录之后,我们的网站可以非常快速的增长。搜索引擎启动收录我们的内容后,但后来在他的数据库中发现类似的内容时,一些低权重的网站收录的信息往往最先被删除。掉了。这是我们的收入先升后降的主要原因之一。因此,Emlog采集返回的内容在发布前必须经过内置的文章处理,并根据搜索引擎算法和实际情况进行文章排列。用户的时间搜索需求,让文章对搜索引擎和用户都有价值。 查看全部
文章采集系统(如何做好一个网站SEO收录?有哪些收录技巧和注意的地方)
Emlog采集,很多博主、个人网站、企业网站长期使用的网站内容扩展工具,可以大大提升网站的性能@网站 充实,通过海量内容吸引更多用户访问。如何做好网站SEO收录?收录 的提示和注意事项有哪些?接下来,我们将从 Emlog采集 的功能和功能,以及 SEO 技巧来看整个 SEO 优化。
网站采集的文章个数与收录的速率有一定的关系。到现在,站采集仍然可以达到很高的权重。搜索引擎也表示采集的内容要注意是否去掉多余的标签,内容是否完整等。虽然Emlog采集并不是一个好的选择,但是对于很多网站来说,只有在 采集 之后,他们才有能力输出新鲜的内容。
那么Emlog采集制作的采集站点会做这些优化:网站采集内容清晰,没有乱码,标签不干净。扩充补充采集的内容,减少采集的内容。在采集的内容后面添加其他相关内容,使内容相互指向,扩大相关性。尽可能采集优质网站的内容不会采集不可读或带有广告文章。
Emlog采集发布后会主动推送内容,持续推送内容会增加爬虫访问的概率。爬取推广网站的收录,这就是前面提到的内容建设和网站优化。此外,最好提交大量的站点地图。搜索引擎处理站点地图的时间很长,最近时间缩短了很多。至于怎么推送,一般都是后台推送,支持结构化数据提交,提交多了会有惊喜。毅力是必需的。另外,网站还可以推送到收录的目录栏,可以查看其API文档申请。
目前很多建站系统都集成了采集系统,Emlog采集对于采集的内容已经成为一件很简单的事情。在短时间内用内容填满您的新网站或使搜索引擎更快收录我们的新网站变得更快乐。
但是当我们采集完成这个内容并通过搜索引擎得到收录之后,我们的网站可以非常快速的增长。搜索引擎启动收录我们的内容后,但后来在他的数据库中发现类似的内容时,一些低权重的网站收录的信息往往最先被删除。掉了。这是我们的收入先升后降的主要原因之一。因此,Emlog采集返回的内容在发布前必须经过内置的文章处理,并根据搜索引擎算法和实际情况进行文章排列。用户的时间搜索需求,让文章对搜索引擎和用户都有价值。
文章采集系统(文章采集系统一般有社交关系链抓取,要哪些内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-02-24 16:03
文章采集系统一般有社交关系链抓取,互联网产品内各类用户行为抓取,以及专门的第三方爬虫系统对互联网产品内外的产品相关的事物进行采集,并可对采集到的内容进行一些分析等等。对于常见的数据采集软件有免费的、收费的和国外的软件。一般来说一个爬虫系统的开发周期需要半年至一年的时间,一些较为复杂的软件可能要花费几年时间完成整个系统的开发。
因此对于我们业务流程还不算很完善的企业来说,寻找一个开发团队为我们的业务发展快速形成产品,并在自己的产品中快速验证有无交叉,是必不可少的一个步骤。采集抓取系统会提供相应的api,这是现有业务系统对外提供的接口。对于某些特定功能开发的爬虫系统,可能会提供系统的定制化、专门的功能;对于某些特定功能开发的爬虫系统,也有可能会提供一些常见爬虫功能的兼容接口。
要抓取哪些内容,一般需要根据当前使用的业务系统来决定,业务系统开发周期一般需要半年左右。常见的抓取系统功能如下图所示:采集抓取系统往往会提供相应的服务器,即服务器采集客户端(pc客户端、手机app客户端或h5客户端等),服务器采集客户端与一般网站相同,同时也可以通过文件上传或http代理等方式实现多终端之间的数据采集。
对于大批量采集会使用文件上传功能,总之是根据具体业务来定。数据抓取时对比的是数据抓取系统所对应的一些现有的功能,比如:爬虫的采集设置、特殊字段的封装、url链接重定向、结构化爬虫的封装等,常用的爬虫系统对数据抓取的功能往往并不会设计非常详细,往往会有点乱。一般的爬虫软件通常会有人工来规划整个数据采集流程。
采集工具系统采集抓取系统提供了爬虫工具模块。采集工具系统包括:采集爬虫、数据构建模块、采集内容的格式化处理模块、采集清洗模块、数据处理模块、数据发布模块、数据统计分析模块等等。从工具系统的实现方式来说主要分为人工实现模块和机器自动化运算模块。比如有些采集工具在运行中会有失败、宕机、死机等情况,如果采集量大,保证爬虫服务器的稳定性十分重要,人工实现模块的采集就是一个选择。 查看全部
文章采集系统(文章采集系统一般有社交关系链抓取,要哪些内容)
文章采集系统一般有社交关系链抓取,互联网产品内各类用户行为抓取,以及专门的第三方爬虫系统对互联网产品内外的产品相关的事物进行采集,并可对采集到的内容进行一些分析等等。对于常见的数据采集软件有免费的、收费的和国外的软件。一般来说一个爬虫系统的开发周期需要半年至一年的时间,一些较为复杂的软件可能要花费几年时间完成整个系统的开发。
因此对于我们业务流程还不算很完善的企业来说,寻找一个开发团队为我们的业务发展快速形成产品,并在自己的产品中快速验证有无交叉,是必不可少的一个步骤。采集抓取系统会提供相应的api,这是现有业务系统对外提供的接口。对于某些特定功能开发的爬虫系统,可能会提供系统的定制化、专门的功能;对于某些特定功能开发的爬虫系统,也有可能会提供一些常见爬虫功能的兼容接口。
要抓取哪些内容,一般需要根据当前使用的业务系统来决定,业务系统开发周期一般需要半年左右。常见的抓取系统功能如下图所示:采集抓取系统往往会提供相应的服务器,即服务器采集客户端(pc客户端、手机app客户端或h5客户端等),服务器采集客户端与一般网站相同,同时也可以通过文件上传或http代理等方式实现多终端之间的数据采集。
对于大批量采集会使用文件上传功能,总之是根据具体业务来定。数据抓取时对比的是数据抓取系统所对应的一些现有的功能,比如:爬虫的采集设置、特殊字段的封装、url链接重定向、结构化爬虫的封装等,常用的爬虫系统对数据抓取的功能往往并不会设计非常详细,往往会有点乱。一般的爬虫软件通常会有人工来规划整个数据采集流程。
采集工具系统采集抓取系统提供了爬虫工具模块。采集工具系统包括:采集爬虫、数据构建模块、采集内容的格式化处理模块、采集清洗模块、数据处理模块、数据发布模块、数据统计分析模块等等。从工具系统的实现方式来说主要分为人工实现模块和机器自动化运算模块。比如有些采集工具在运行中会有失败、宕机、死机等情况,如果采集量大,保证爬虫服务器的稳定性十分重要,人工实现模块的采集就是一个选择。
文章采集系统(一套开源的分布式日志管理方案(2)-负责日志)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-02-18 17:10
目录
ELK 是 Elasticsearch、Logstash 和 Kibana 的结合体,是一个开源的分布式日志管理解决方案。
简介
Elasticsearch:负责日志的存储、检索和分析
LogStash:负责日志的采集和处理
Kibana:负责日志的可视化
ELK 日志平台
java8
logstash和elasticsearch都依赖java,所以在安装这两个之前,我们应该先安装java,java版本大于7,但是官方推荐是java 8.
安装:
$sudo add-apt-repository -y ppa:webupd8team/java
$sudo apt-get update
$sudo apt-get -y install oracle-java8-installer
弹性搜索
我们以elasticsearch当前版本1.7为例,参考官方教程:在官方网站上下载elasticsearch的压缩包,解压到一个目录下执行。
当然,在Ubuntu下,我们可以使用apt-get来安装:
下载并安装公钥:
wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
添加来源:
echo "deb http://packages.elastic.co/ela ... ebian stable main" | sudo tee -a /etc/apt/sources.list.d/elasticsearch-1.7.list
安装:
$sudo apt-get update
$sudo apt-get install elasticsearch
设置开机启动:
$sudo update-rc.d elasticsearch defaults 95 10
配置:修改network.host:localhost
$sudo vim /etc/elasticsearch/elasticsearch.yml
启动:elasticsearch启动后,绑定端口localhost:9200
$sudo service elasticsearch start
常用命令:
# 查看elasticsearch健康状态
$curl localhost:9200/_cat/health?v
# 查看elasticsearch indices
$curl localhost:9200/_cat/indices?v
# 删除指定的indices,这里删除了logstash-2015.09.26的indices
$curl -XDELETE localhost:9200/logstash-2015.09.26
Kibana
从官网下载最新的压缩包:解压到任意目录
$tar xvf kibana-*.tar.gz
$sudo mkdir -p /opt/kibana
$sudo cp -R ~/kibana-4*/* /opt/kibana/
# 将kibana作为一个服务
$cd /etc/init.d &amp;&amp; sudo wget https://gist.githubusercontent ... bana4
$sudo chmod +x /etc/init.d/kibana4
# 将kibana设为开机启动
$sudo update-rc.d kibana4 defaults 96 9
# 修改kibana配置,因为我们采用nginx作为反向代理,修改 host: "localhsot"
$sudo vim /opt/kibana/config/kibana.yml
# 启动kibana,默认绑定在了localhost:5601
$sudo service kibana4 start
Nginx 配置:
# elk
server {
listen 80;
server_name elk.chenjiehua.me;
#auth_basic "Restricted Access";
#auth_basic_user_file /home/ubuntu/htpasswd.users;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
如果需要限制访问,可以通过nginx的auth_basic设置:
$sudo apt-get install&nbsp;apache2-utils
# 新建一个kibana认证用户
$sudo htpasswd -c /home/ubuntu/htpasswd.users kibana
# 然后按提示设置kibana密码
$sudo nginx -t
$sudo nginx -s reload
Logstash
安装:
参考官方教程:.
在Ubuntu下,我们可以使用apt-get来安装:
$sudo wget -qO - https://packages.elasticsearch ... earch | sudo apt-key add -
$sudo echo "deb http://packages.elasticsearch. ... ebian stable main" | sudo tee -a /etc/apt/sources.list#
$sudo apt-get update
$sudo apt-get install logstash
这里logstash有两个身份,一个是shipper,一个是indexer;在分布式系统中应用时,通常是多个shipper采集日志并发送给redis(作为broker身份),而indexer从redis中读取数据进行处理,然后发送给elasticsearch,我们可以查看所有的日志信息通过 kibana。
这里的broker使用redis作为消息系统。根据业务需要,我们还可以使用kafka等其他消息系统。
中央logstash(索引器)配置,/etc/logstash/conf.d/central.conf
input {
redis {
host => "127.0.0.1"
port => 6379
type => "redis-input"
data_type => "list"
key => "key_count"
}
}
output {
stdout {}
elasticsearch {
cluster => "elasticsearch"
codec => "json"
protocol => "http"
}
}
远程logstash(shipper)配置,/etc/logstash/conf.d/shipper.conf
input {
file {
type => "type_count"
path => ["/data/logs/count/stdout.log", "/data/logs/count/stderr.log"]
exclude => ["*.gz", "access.log"]
}
}
output {
stdout {}
redis {
host => "20.8.40.49"
port => 6379
data_type => "list"
key => "key_count"
}
}
这里,由于我们在单台服务器上运行,我们可以将 indexer 和 shipper 合并在一起,而将 redis 省略掉。配置文件如下:
input {
file {
type => "blog"
path => ["/home/ubuntu/log/nginx/blog.log"]
}
}
output {
stdout {}
elasticsearch {
cluster => "elasticsearch"
codec => "json"
host => "localhost"
protocol => "http"
}
}
basic_logstash_pipeline
对于logstash,我们有很多插件可以使用,其中过滤器部分的grok插件比较常用。如果我们想处理nginx日志,获取各个字段的信息,可以参考如下用法:
nginx日志格式:
log_format main '$remote_addr - $remote_user [$time_local]'
'"$request" $status $bytes_sent '
'"$http_referer" "$http_user_agent" $request_time';
access_log /var/log/nginx/access.log main;
Logstash 中过滤器的配置:
filter {
grok {
match => { 'message' => '%{IP:remote_addr} - - \[%{HTTPDATE:time_local}\]"%{WORD:http_method} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}" %{NUMBER:status} %{NUMBER:body_bytes_sent} (?:\"(?:%{URI:http_referer}|-)\"|%{QS:http_referer}) %{QS:http_user_agent} %{NUMBER:request_time}' }
remove_field => ["message"]
}
date {
match => ["time_local", "dd/MMM/YYYY:HH:mm:ss Z"]
}
}
关于grokdebugger,可以使用在线调试。当grok中的配置与日志格式不匹配时,可以在Kibana管理后台看到_grokparsefailure。
启动logstash:
$sudo service logstash start
我们可以在kibana中看到日志数据,搜索起来也很方便。
kibana
参考:
码字很难,转载请注明出处来自陈洁华《ELK日志采集系统搭建》 查看全部
文章采集系统(一套开源的分布式日志管理方案(2)-负责日志)
目录
ELK 是 Elasticsearch、Logstash 和 Kibana 的结合体,是一个开源的分布式日志管理解决方案。
简介
Elasticsearch:负责日志的存储、检索和分析
LogStash:负责日志的采集和处理
Kibana:负责日志的可视化
https://chenjiehua.me/wp-conte ... 5.jpg 300w, https://chenjiehua.me/wp-conte ... m.jpg 1542w" />ELK 日志平台
java8
logstash和elasticsearch都依赖java,所以在安装这两个之前,我们应该先安装java,java版本大于7,但是官方推荐是java 8.
安装:
$sudo add-apt-repository -y ppa:webupd8team/java
$sudo apt-get update
$sudo apt-get -y install oracle-java8-installer
弹性搜索
我们以elasticsearch当前版本1.7为例,参考官方教程:在官方网站上下载elasticsearch的压缩包,解压到一个目录下执行。
当然,在Ubuntu下,我们可以使用apt-get来安装:
下载并安装公钥:
wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
添加来源:
echo "deb http://packages.elastic.co/ela ... ebian stable main" | sudo tee -a /etc/apt/sources.list.d/elasticsearch-1.7.list
安装:
$sudo apt-get update
$sudo apt-get install elasticsearch
设置开机启动:
$sudo update-rc.d elasticsearch defaults 95 10
配置:修改network.host:localhost
$sudo vim /etc/elasticsearch/elasticsearch.yml
启动:elasticsearch启动后,绑定端口localhost:9200
$sudo service elasticsearch start
常用命令:
# 查看elasticsearch健康状态
$curl localhost:9200/_cat/health?v
# 查看elasticsearch indices
$curl localhost:9200/_cat/indices?v
# 删除指定的indices,这里删除了logstash-2015.09.26的indices
$curl -XDELETE localhost:9200/logstash-2015.09.26
Kibana
从官网下载最新的压缩包:解压到任意目录
$tar xvf kibana-*.tar.gz
$sudo mkdir -p /opt/kibana
$sudo cp -R ~/kibana-4*/* /opt/kibana/
# 将kibana作为一个服务
$cd /etc/init.d &amp;&amp; sudo wget https://gist.githubusercontent ... bana4
$sudo chmod +x /etc/init.d/kibana4
# 将kibana设为开机启动
$sudo update-rc.d kibana4 defaults 96 9
# 修改kibana配置,因为我们采用nginx作为反向代理,修改 host: "localhsot"
$sudo vim /opt/kibana/config/kibana.yml
# 启动kibana,默认绑定在了localhost:5601
$sudo service kibana4 start
Nginx 配置:
# elk
server {
listen 80;
server_name elk.chenjiehua.me;
#auth_basic "Restricted Access";
#auth_basic_user_file /home/ubuntu/htpasswd.users;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
如果需要限制访问,可以通过nginx的auth_basic设置:
$sudo apt-get install&nbsp;apache2-utils
# 新建一个kibana认证用户
$sudo htpasswd -c /home/ubuntu/htpasswd.users kibana
# 然后按提示设置kibana密码
$sudo nginx -t
$sudo nginx -s reload
Logstash
安装:
参考官方教程:.
在Ubuntu下,我们可以使用apt-get来安装:
$sudo wget -qO - https://packages.elasticsearch ... earch | sudo apt-key add -
$sudo echo "deb http://packages.elasticsearch. ... ebian stable main" | sudo tee -a /etc/apt/sources.list#
$sudo apt-get update
$sudo apt-get install logstash
这里logstash有两个身份,一个是shipper,一个是indexer;在分布式系统中应用时,通常是多个shipper采集日志并发送给redis(作为broker身份),而indexer从redis中读取数据进行处理,然后发送给elasticsearch,我们可以查看所有的日志信息通过 kibana。
这里的broker使用redis作为消息系统。根据业务需要,我们还可以使用kafka等其他消息系统。
中央logstash(索引器)配置,/etc/logstash/conf.d/central.conf
input {
redis {
host => "127.0.0.1"
port => 6379
type => "redis-input"
data_type => "list"
key => "key_count"
}
}
output {
stdout {}
elasticsearch {
cluster => "elasticsearch"
codec => "json"
protocol => "http"
}
}
远程logstash(shipper)配置,/etc/logstash/conf.d/shipper.conf
input {
file {
type => "type_count"
path => ["/data/logs/count/stdout.log", "/data/logs/count/stderr.log"]
exclude => ["*.gz", "access.log"]
}
}
output {
stdout {}
redis {
host => "20.8.40.49"
port => 6379
data_type => "list"
key => "key_count"
}
}
这里,由于我们在单台服务器上运行,我们可以将 indexer 和 shipper 合并在一起,而将 redis 省略掉。配置文件如下:
input {
file {
type => "blog"
path => ["/home/ubuntu/log/nginx/blog.log"]
}
}
output {
stdout {}
elasticsearch {
cluster => "elasticsearch"
codec => "json"
host => "localhost"
protocol => "http"
}
}
https://chenjiehua.me/wp-conte ... 9.png 300w, https://chenjiehua.me/wp-conte ... e.png 1473w" />basic_logstash_pipeline
对于logstash,我们有很多插件可以使用,其中过滤器部分的grok插件比较常用。如果我们想处理nginx日志,获取各个字段的信息,可以参考如下用法:
nginx日志格式:
log_format main '$remote_addr - $remote_user [$time_local]'
'"$request" $status $bytes_sent '
'"$http_referer" "$http_user_agent" $request_time';
access_log /var/log/nginx/access.log main;
Logstash 中过滤器的配置:
filter {
grok {
match => { 'message' => '%{IP:remote_addr} - - \[%{HTTPDATE:time_local}\]"%{WORD:http_method} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}" %{NUMBER:status} %{NUMBER:body_bytes_sent} (?:\"(?:%{URI:http_referer}|-)\"|%{QS:http_referer}) %{QS:http_user_agent} %{NUMBER:request_time}' }
remove_field => ["message"]
}
date {
match => ["time_local", "dd/MMM/YYYY:HH:mm:ss Z"]
}
}
关于grokdebugger,可以使用在线调试。当grok中的配置与日志格式不匹配时,可以在Kibana管理后台看到_grokparsefailure。
启动logstash:
$sudo service logstash start
我们可以在kibana中看到日志数据,搜索起来也很方便。
https://chenjiehua.me/wp-conte ... 5.png 300w" />kibana
参考:
码字很难,转载请注明出处来自陈洁华《ELK日志采集系统搭建》
文章采集系统(Linux系统中有很多日志类型分析系统产生的文件介绍(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2022-02-18 17:09
一台正常提供服务的Linux服务器,时时刻刻都会产生大量的日志信息。如果生产环境有几十台甚至上百台服务器,要一一查看系统日志是很麻烦的。的。
在技术不断更新的今天,可以集中管理日志的技术有很多。最常见的操作是ELK日志分析系统,但是这些日志是怎么产生的呢?使用哪个服务进行统一管理?这个 文章 将围绕系统日志服务 - rsyslog。
Linux 系统中有多种日志类型。以下是系统自身产生的一些日志文件:
/var/log/boot.log
/var/log/cron
/var/log/dmesg
/var/log/lastlog
/var/log/maillog或/var/log/mail/*
/var/log/messages
/var/log/secure
/var/log/wtmp,/var/log/faillog
/var/log/httpd/* , /var/log/samba/*
如果想详细了解日志文件中记录了哪些信息,可以参考这篇博文:Linux中常见日志文件介绍,其中还收录了7个错误级别的介绍!这里不乱说。
系统中的大部分日志都由 rsyslog 服务管理。该服务的主要配置文件如下:
[root@aaa ~]# grep -v "^$" /etc/rsyslog.conf | grep -v "^#" #过滤配置文件中的空行和注释行
$ModLoad imuxsock # provides support for local system logging (e.g. via logger command)
$ModLoad imjournal # provides access to the systemd journal
$WorkDirectory /var/lib/rsyslog
$ActionFileDefaultTemplate RSYSLOG_TraditionalFileFormat
$IncludeConfig /etc/rsyslog.d/*.conf
$OmitLocalLogging on
$IMJournalStateFile imjournal.state
*.info;mail.none;authpriv.none;cron.none /var/log/messages
上面行开头的星号表示所有服务,点号后面的等级表示那些等级记录下来,/var/lo....表示记录到哪里
authpriv.* /var/log/secure #表示authpriv所有等级的信息都记录到secure文件中
mail.* /var/log/maillog #表示mail服务的所有级别信息都记录到/var/log/maillog中
cron.* /var/log/cron
*.emerg :omusrmsg:*
uucp,news.crit /var/log/spooler
local7.* /var/log/boot.log
#由上面几行注释可以看出,第一段中的点号前面表示某个服务,点号后面表示哪些报错等级要记录。
#点号前后都可以使用通配符星号来表示,如第一列为“*.*”,则表示所有服务的所有等级
#若为“*.info”,则表示所有服务的info等级及比info更严重的等级都记录起来。
在上面的配置文件中,可以更改日志的存放位置,以及应该记录哪些日志级别,但一般不建议这样做。
其实依靠配置文件/etc/rsyslog.conf,也可以将其日志发送到另一台服务器,然后在另一台服务器上进行统一管理。如果生产环境小,服务器不多,这种情况可以使用,但是如果生产环境的服务器数量比较多,建议部署ELK日志分析系统。
配置 rsyslog 服务实例
我这里有两台服务器,主机名分别是aaa和bbb(IP地址分别是192.168.1.1和1.2),现在要实现以下要求:
开始配置:
1、将info级别以上aaa服务器的所有系统服务日志同步发送给bbb服务器统一管理
(1)在 aaa 服务器上执行以下操作:
[root@aaa ~]# vim /etc/rsyslog.conf #编辑日志服务的配置文件
#..............省略部分内容
$ModLoad imudp #将该行开头的注释符号“#”去掉,以便开启udp协议
$UDPServerRun 514 #将该行开头的注释符号“#”去掉,以便开启udp的514端口
# Provides TCP syslog reception
$ModLoad imtcp #将该行开头的注释符号“#”去掉,以便开启tcp协议
$InputTCPServerRun 514 #将该行开头的注释符号“#”去掉,以便开启tcp的514端口
#..............省略部分内容
*.info;mail.none;authpriv.none;cron.none /var/log/messages
*.info @@192.168.1.2 #星号表示所有服务“*.info”表示info等级及以上的信息
#@@表示使用tcp协议传输,192.168.1.2是指定要发送到哪台服务器
#若使用一个@符号,则表示使用udp协议传输
#..............省略部分内容
#编辑完成后,保存退出即可。
[root@aaa ~]# systemctl restart rsyslog #重启rsyslog服务,以便更改生效
(2)在 bbb 服务器上执行以下操作:
[root@bbb ~]# vim /etc/rsyslog.conf #编辑日志服务的配置文件,开启udp和tcp的514端口
#..............省略部分内容
$ModLoad imudp #去掉该行开头的“#”注释符号
$UDPServerRun 514 #去掉该行开头的“#”注释符号
# Provides TCP syslog reception
$ModLoad imtcp #去掉该行开头的“#”注释符号
$InputTCPServerRun 514 #去掉该行开头的“#”注释符号
#..............省略部分内容
[root@bbb ~]# systemctl restart rsyslog #重启服务,使更改生效
[root@bbb ~]# tailf /var/log/secure #动态监控着本机的日志文件
Sep 19 15:00:32 aaa useradd[5998]: new group: name=lvjianzh, GID=1003
Sep 19 15:00:32 aaa useradd[5998]: new user: name=lvjianzh, UID=1003, GID=1003....
#..............省略部分内容
(3)在aaa服务器上进行如下操作(主要是生成日志信息):
[root@aaa ~]# useradd admini
[root@aaa ~]# echo '123.com' | passwd --stdin admini
更改用户 admini 的密码 。
passwd:所有的身份验证令牌已经成功更新。
(4)查看bbb生成的新日志如下:
2、将编译安装好的Nginx日志发送到bbb服务器进行管理;
(1)在 aaa 服务器上执行以下操作:
[root@aaa ~]# vim /etc/yum.repos.d/epel.repo #写入以下文件,指定阿里镜像站
[epel]
name=epel
baseurl=https://mirrors.aliyun.com/epel/7/x86_64/
gpgcheck=0
#必须保证系统默认自带的yum文件也存在/etc/yum.repos.d/目录下,写入后保存退出即可。
[root@aaa ~]# yum repolist #最好执行一下该命令
#..............省略部分内容
(7/7): base/7/x86_64/primary_db | 6.0 MB 00:01
源标识 源名称 状态
base/7/x86_64 CentOS-7 - Base 10,097
epel epel 13,384
#上面一行就是我们刚写入的文件生效的,表示没问题
extras/7/x86_64 CentOS-7 - Extras 304
updates/7/x86_64 CentOS-7 - Updates 311
repolist: 24,096
#若命令yum repolist执行后没有显示出上述内容,排除配置文件的错误后,可以执行以下命令
[root@aaa ~]# yum makecache #用来建立元数据缓存的
#..............省略部分内容
元数据缓存已建立
[root@aaa ~]# yum -y install nginx #安装nginx服务
[root@aaa ~]# systemctl start nginx #启动Nginx服务
[root@aaa ~]# netstat -anpt | grep nginx #确定Nginx服务已启动
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 6609/nginx: master
tcp6 0 0 :::80 :::* LISTEN 6609/nginx: master
[root@aaa ~]# ls /var/log/nginx/ #以下是yum安装Nginx后,Nginx两个日志文件的存放位置
access.log error.log
#记住Nginx日志的存放路径,一会要用到,若采用的是编译安装,请自行找到Nginx日志存放路径记下来
[root@aaa ~]# vim /etc/rsyslog.conf #编辑rsyslog服务的配置文件
#..............省略部分内容
#在配置文件末尾写入以下内容
$ModLoad imfile
$InputFilePollInterval 1
$InputFileName /var/log/nginx/access.log
$InputFileTag nginx-info-access;
$InputFilestateFile state-nginx-info-accesslog
$InputRunFileMonitor
$InputFileName /var/log/nginx/error.log
$InputFileTag nginx-info-error;
$InputFilestateFile state-nginx-info-errorlog
$InputRunFileMonitor
$InputFilePollInterval 10
if $programname == 'nginx-info-access' then @192.168.1.2:514
if $programname == 'nginx-info-access' then ~
if $programname == 'nginx-info-error' then @192.168.1.2:514
if $programname == 'nginx-info-error' then ~
[root@aaa ~]# systemctl restart rsyslog #重启服务以便生效
上面写的配置项解释如下:
$ModLoad imfile #加载模块
$InputFilePollInterval 1 #间隔多久采集次,默认单位是秒
$InputFileName /var/log/nginx/access.log #指定要采集的日志文件
$InputFileTag nginx-info-access; #给对应的日志打一个标签
$InputFilestateFile state-nginx-info-accesslog #给这个日志命名
$InputRunFileMonitor #启动监控
#以下的配置和上面类似,因为要采集两个日志文件嘛!
$InputFileName /var/log/nginx/error.log
$InputFileTag nginx-info-error;
$InputFilestateFile state-nginx-info-errorlog
$InputRunFileMonitor
$InputFilePollInterval 10
#以下是指定将采集的日志发送到哪里,同理,一个@符号表示使用的udp协议,两个表示tcp协议
if $programname == 'nginx-info-access' then @192.168.1.2:514
if $programname == 'nginx-info-access' then ~ #这的~,表示本地的意思
if $programname == 'nginx-info-error' then @192.168.1.2:514
if $programname == 'nginx-info-error' then ~
(2)bbb服务器上的监控日志:
(3)客户端为了生成日志,访问aaa的Nginx服务。
(4)回到bbb服务器看看aaa服务器上是否有生成Nginx访问日志(如果没有生成新的日志,客户端可以在排除配置错误的前提下刷新几次):
可见Nginx的日志信息应该不会太详细了吧?日志信息中是否收录日志的生成时间?哪个服务器生成的?标签名称是什么?访问了哪个 IP 地址?访问时间是什么时候?访问的状态码是什么?客户端访问的是什么系统,系统的位数是多少?比如(Windows NT 10.0; Win64; x64,表示是64位win10系统),你用什么浏览器访问呢?我用谷歌在这里访问它,它甚至记录了我客户的谷歌浏览器的版本号。
至此,Nginx日志文件采集就完成了,接下来就是执行apache日志采集了。有了前面的铺垫,这个就简单多了,只需要更改配置项即可。
3、将编译安装的apache日志发送到bbb服务器进行管理
(1)在 aaa 服务器上执行以下操作:
[root@aaa ~]# yum -y install httpd #安装apache服务
[root@aaa ~]# systemctl stop nginx #为了避免端口冲突,停止Nginx服务
[root@aaa ~]# systemctl start httpd #启动apache服务
[root@aaa ~]# vim /etc/rsyslog.conf #更改rsyslog配置文件,主要是更改采集日志的路径
#..............省略部分内容
$ModLoad imfile
$InputFilePollInterval 1
$InputFileName /var/log/httpd/access_log #主要是改这个
$InputFileTag httpd-info-access;
$InputFilestateFile state-httpd-info-accesslog
$InputRunFileMonitor
$InputFileName /var/log/httpd/error_log #还要改这个
#其余配置项可不改,但是建议改一下,以免看起来日志不太直观。
$InputFileTag httpd-info-error;
$InputFilestateFile state-httpd-info-errorlog
$InputRunFileMonitor
$InputFilePollInterval 10
if $programname == 'httpd-info-access' then @192.168.1.2:514
if $programname == 'httpd-info-access' then ~
if $programname == 'httpd-info-error' then @192.168.1.2:514
if $programname == 'httpd-info-error' then ~
#主要就是将上面配置中的Nginx都换成了httpd。
[root@aaa ~]# systemctl restart rsyslog #重启服务,使更改生效
(2)bbb服务器上的监控日志:
(3)客户端访问aaa的Nginx服务是为了生成日志(刷新几次)。
(4)回到bbb服务器看看有没有关于aaa服务器的httpd访问日志。
好的!没问题,采集 来了。. .
————————— 本文到此结束,感谢您的阅读—————— 查看全部
文章采集系统(Linux系统中有很多日志类型分析系统产生的文件介绍(二))
一台正常提供服务的Linux服务器,时时刻刻都会产生大量的日志信息。如果生产环境有几十台甚至上百台服务器,要一一查看系统日志是很麻烦的。的。
在技术不断更新的今天,可以集中管理日志的技术有很多。最常见的操作是ELK日志分析系统,但是这些日志是怎么产生的呢?使用哪个服务进行统一管理?这个 文章 将围绕系统日志服务 - rsyslog。
Linux 系统中有多种日志类型。以下是系统自身产生的一些日志文件:
/var/log/boot.log
/var/log/cron
/var/log/dmesg
/var/log/lastlog
/var/log/maillog或/var/log/mail/*
/var/log/messages
/var/log/secure
/var/log/wtmp,/var/log/faillog
/var/log/httpd/* , /var/log/samba/*
如果想详细了解日志文件中记录了哪些信息,可以参考这篇博文:Linux中常见日志文件介绍,其中还收录了7个错误级别的介绍!这里不乱说。
系统中的大部分日志都由 rsyslog 服务管理。该服务的主要配置文件如下:
[root@aaa ~]# grep -v "^$" /etc/rsyslog.conf | grep -v "^#" #过滤配置文件中的空行和注释行
$ModLoad imuxsock # provides support for local system logging (e.g. via logger command)
$ModLoad imjournal # provides access to the systemd journal
$WorkDirectory /var/lib/rsyslog
$ActionFileDefaultTemplate RSYSLOG_TraditionalFileFormat
$IncludeConfig /etc/rsyslog.d/*.conf
$OmitLocalLogging on
$IMJournalStateFile imjournal.state
*.info;mail.none;authpriv.none;cron.none /var/log/messages
上面行开头的星号表示所有服务,点号后面的等级表示那些等级记录下来,/var/lo....表示记录到哪里
authpriv.* /var/log/secure #表示authpriv所有等级的信息都记录到secure文件中
mail.* /var/log/maillog #表示mail服务的所有级别信息都记录到/var/log/maillog中
cron.* /var/log/cron
*.emerg :omusrmsg:*
uucp,news.crit /var/log/spooler
local7.* /var/log/boot.log
#由上面几行注释可以看出,第一段中的点号前面表示某个服务,点号后面表示哪些报错等级要记录。
#点号前后都可以使用通配符星号来表示,如第一列为“*.*”,则表示所有服务的所有等级
#若为“*.info”,则表示所有服务的info等级及比info更严重的等级都记录起来。
在上面的配置文件中,可以更改日志的存放位置,以及应该记录哪些日志级别,但一般不建议这样做。
其实依靠配置文件/etc/rsyslog.conf,也可以将其日志发送到另一台服务器,然后在另一台服务器上进行统一管理。如果生产环境小,服务器不多,这种情况可以使用,但是如果生产环境的服务器数量比较多,建议部署ELK日志分析系统。
配置 rsyslog 服务实例
我这里有两台服务器,主机名分别是aaa和bbb(IP地址分别是192.168.1.1和1.2),现在要实现以下要求:
开始配置:
1、将info级别以上aaa服务器的所有系统服务日志同步发送给bbb服务器统一管理
(1)在 aaa 服务器上执行以下操作:
[root@aaa ~]# vim /etc/rsyslog.conf #编辑日志服务的配置文件
#..............省略部分内容
$ModLoad imudp #将该行开头的注释符号“#”去掉,以便开启udp协议
$UDPServerRun 514 #将该行开头的注释符号“#”去掉,以便开启udp的514端口
# Provides TCP syslog reception
$ModLoad imtcp #将该行开头的注释符号“#”去掉,以便开启tcp协议
$InputTCPServerRun 514 #将该行开头的注释符号“#”去掉,以便开启tcp的514端口
#..............省略部分内容
*.info;mail.none;authpriv.none;cron.none /var/log/messages
*.info @@192.168.1.2 #星号表示所有服务“*.info”表示info等级及以上的信息
#@@表示使用tcp协议传输,192.168.1.2是指定要发送到哪台服务器
#若使用一个@符号,则表示使用udp协议传输
#..............省略部分内容
#编辑完成后,保存退出即可。
[root@aaa ~]# systemctl restart rsyslog #重启rsyslog服务,以便更改生效
(2)在 bbb 服务器上执行以下操作:
[root@bbb ~]# vim /etc/rsyslog.conf #编辑日志服务的配置文件,开启udp和tcp的514端口
#..............省略部分内容
$ModLoad imudp #去掉该行开头的“#”注释符号
$UDPServerRun 514 #去掉该行开头的“#”注释符号
# Provides TCP syslog reception
$ModLoad imtcp #去掉该行开头的“#”注释符号
$InputTCPServerRun 514 #去掉该行开头的“#”注释符号
#..............省略部分内容
[root@bbb ~]# systemctl restart rsyslog #重启服务,使更改生效
[root@bbb ~]# tailf /var/log/secure #动态监控着本机的日志文件
Sep 19 15:00:32 aaa useradd[5998]: new group: name=lvjianzh, GID=1003
Sep 19 15:00:32 aaa useradd[5998]: new user: name=lvjianzh, UID=1003, GID=1003....
#..............省略部分内容
(3)在aaa服务器上进行如下操作(主要是生成日志信息):
[root@aaa ~]# useradd admini
[root@aaa ~]# echo '123.com' | passwd --stdin admini
更改用户 admini 的密码 。
passwd:所有的身份验证令牌已经成功更新。
(4)查看bbb生成的新日志如下:
2、将编译安装好的Nginx日志发送到bbb服务器进行管理;
(1)在 aaa 服务器上执行以下操作:
[root@aaa ~]# vim /etc/yum.repos.d/epel.repo #写入以下文件,指定阿里镜像站
[epel]
name=epel
baseurl=https://mirrors.aliyun.com/epel/7/x86_64/
gpgcheck=0
#必须保证系统默认自带的yum文件也存在/etc/yum.repos.d/目录下,写入后保存退出即可。
[root@aaa ~]# yum repolist #最好执行一下该命令
#..............省略部分内容
(7/7): base/7/x86_64/primary_db | 6.0 MB 00:01
源标识 源名称 状态
base/7/x86_64 CentOS-7 - Base 10,097
epel epel 13,384
#上面一行就是我们刚写入的文件生效的,表示没问题
extras/7/x86_64 CentOS-7 - Extras 304
updates/7/x86_64 CentOS-7 - Updates 311
repolist: 24,096
#若命令yum repolist执行后没有显示出上述内容,排除配置文件的错误后,可以执行以下命令
[root@aaa ~]# yum makecache #用来建立元数据缓存的
#..............省略部分内容
元数据缓存已建立
[root@aaa ~]# yum -y install nginx #安装nginx服务
[root@aaa ~]# systemctl start nginx #启动Nginx服务
[root@aaa ~]# netstat -anpt | grep nginx #确定Nginx服务已启动
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 6609/nginx: master
tcp6 0 0 :::80 :::* LISTEN 6609/nginx: master
[root@aaa ~]# ls /var/log/nginx/ #以下是yum安装Nginx后,Nginx两个日志文件的存放位置
access.log error.log
#记住Nginx日志的存放路径,一会要用到,若采用的是编译安装,请自行找到Nginx日志存放路径记下来
[root@aaa ~]# vim /etc/rsyslog.conf #编辑rsyslog服务的配置文件
#..............省略部分内容
#在配置文件末尾写入以下内容
$ModLoad imfile
$InputFilePollInterval 1
$InputFileName /var/log/nginx/access.log
$InputFileTag nginx-info-access;
$InputFilestateFile state-nginx-info-accesslog
$InputRunFileMonitor
$InputFileName /var/log/nginx/error.log
$InputFileTag nginx-info-error;
$InputFilestateFile state-nginx-info-errorlog
$InputRunFileMonitor
$InputFilePollInterval 10
if $programname == 'nginx-info-access' then @192.168.1.2:514
if $programname == 'nginx-info-access' then ~
if $programname == 'nginx-info-error' then @192.168.1.2:514
if $programname == 'nginx-info-error' then ~
[root@aaa ~]# systemctl restart rsyslog #重启服务以便生效
上面写的配置项解释如下:
$ModLoad imfile #加载模块
$InputFilePollInterval 1 #间隔多久采集次,默认单位是秒
$InputFileName /var/log/nginx/access.log #指定要采集的日志文件
$InputFileTag nginx-info-access; #给对应的日志打一个标签
$InputFilestateFile state-nginx-info-accesslog #给这个日志命名
$InputRunFileMonitor #启动监控
#以下的配置和上面类似,因为要采集两个日志文件嘛!
$InputFileName /var/log/nginx/error.log
$InputFileTag nginx-info-error;
$InputFilestateFile state-nginx-info-errorlog
$InputRunFileMonitor
$InputFilePollInterval 10
#以下是指定将采集的日志发送到哪里,同理,一个@符号表示使用的udp协议,两个表示tcp协议
if $programname == 'nginx-info-access' then @192.168.1.2:514
if $programname == 'nginx-info-access' then ~ #这的~,表示本地的意思
if $programname == 'nginx-info-error' then @192.168.1.2:514
if $programname == 'nginx-info-error' then ~
(2)bbb服务器上的监控日志:
(3)客户端为了生成日志,访问aaa的Nginx服务。
(4)回到bbb服务器看看aaa服务器上是否有生成Nginx访问日志(如果没有生成新的日志,客户端可以在排除配置错误的前提下刷新几次):
可见Nginx的日志信息应该不会太详细了吧?日志信息中是否收录日志的生成时间?哪个服务器生成的?标签名称是什么?访问了哪个 IP 地址?访问时间是什么时候?访问的状态码是什么?客户端访问的是什么系统,系统的位数是多少?比如(Windows NT 10.0; Win64; x64,表示是64位win10系统),你用什么浏览器访问呢?我用谷歌在这里访问它,它甚至记录了我客户的谷歌浏览器的版本号。
至此,Nginx日志文件采集就完成了,接下来就是执行apache日志采集了。有了前面的铺垫,这个就简单多了,只需要更改配置项即可。
3、将编译安装的apache日志发送到bbb服务器进行管理
(1)在 aaa 服务器上执行以下操作:
[root@aaa ~]# yum -y install httpd #安装apache服务
[root@aaa ~]# systemctl stop nginx #为了避免端口冲突,停止Nginx服务
[root@aaa ~]# systemctl start httpd #启动apache服务
[root@aaa ~]# vim /etc/rsyslog.conf #更改rsyslog配置文件,主要是更改采集日志的路径
#..............省略部分内容
$ModLoad imfile
$InputFilePollInterval 1
$InputFileName /var/log/httpd/access_log #主要是改这个
$InputFileTag httpd-info-access;
$InputFilestateFile state-httpd-info-accesslog
$InputRunFileMonitor
$InputFileName /var/log/httpd/error_log #还要改这个
#其余配置项可不改,但是建议改一下,以免看起来日志不太直观。
$InputFileTag httpd-info-error;
$InputFilestateFile state-httpd-info-errorlog
$InputRunFileMonitor
$InputFilePollInterval 10
if $programname == 'httpd-info-access' then @192.168.1.2:514
if $programname == 'httpd-info-access' then ~
if $programname == 'httpd-info-error' then @192.168.1.2:514
if $programname == 'httpd-info-error' then ~
#主要就是将上面配置中的Nginx都换成了httpd。
[root@aaa ~]# systemctl restart rsyslog #重启服务,使更改生效
(2)bbb服务器上的监控日志:
(3)客户端访问aaa的Nginx服务是为了生成日志(刷新几次)。
(4)回到bbb服务器看看有没有关于aaa服务器的httpd访问日志。
好的!没问题,采集 来了。. .
————————— 本文到此结束,感谢您的阅读——————
文章采集系统(这款知乎采集器的采用智能模式只需要输入网址就能自动识别采集知乎高赞)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2022-02-09 20:16
相比市面上大部分的采集软件,采集知乎的文章都可以实现,例如爬虫,优采云,优采云采集器、优采云采集器等很多内容采集系统都有自己的特点,很多用户也有自己的习惯和喜好,但是对于大部分新手来说,上手比较困难。但如果抛开熟练使用后的用户体验,一款操作极其简单、功能强大的数据采集软件才是广大新手用户真正需要的。
下面小编推荐这款知乎采集器智能模式,输入网址即可自动识别采集知乎好评问答,方便大家阅读知乎问答和文章内容,并将喜欢的问答或文章永久保存到本地计算机,便于集中管理和阅读。
一、软件介绍
1、导出知乎网站任何问答中的问答内容,以及问答的评论区;
2、导出指定用户下的所有文章,包括文章内容和文章评论;
3、导出格式主要是html格式,也可以导出pdf和word格式(推荐使用默认html,html相当于本地网页,可以永久保存到电脑中);
二、软件功能介绍
1、导出知乎网站任何问答中的问答内容,以及问答的评论区;
2、导出指定用户下的所有文章,包括文章内容和文章评论;
3、导出格式主要是html格式,也可以导出pdf和word格式(推荐使用默认html,html相当于本地网页,可以永久保存到电脑中);
三、知乎 助手软件教程
第一步:下载软件并安装。可以通过下方小编给出的蓝琴云网盘链接下载安装包,解压后运行。
第二步:打开软件后,可以看到主界面,用你的微信登录。
Step 3. 导入采集问答链接/文章链接或指定用户文章链接。如下所示
示例连接:
Step 4.选择采集指定的本地电脑的本地保存位置,选择导出的文件格式【html格式、pdf和Word格式】(建议使用默认html,html相当于一个本地网页,可以永久保存到您的计算机)并启动 采集。
四、支持三种连接导入和下载
1、问答链接示例:
问答链接
2、文章链接示例:
3、采集指定用户主页文章链接:. 下面界面中的链接主要用于批量下载一个知乎首页下的所有文章。
(这里指的是一个导入的单个问答或文章链接,多个链接每行一个)
五、文章采集成功本地截图
六、操作方法总结
1、先下载蓝琴云网盘的软件链接[]
2、下载后解压,打开软件登录,设置采集导出文章保存位置。
3、复制并导入需要采集的文章链接、问答链接、指定用户文章链接,点击开始下载
4、下载完成后,找到刚才设置的文章的保存位置,打开就可以看到下载的知乎文章。
注:所有下载的知乎文章仅供自学使用,禁止以分发或使用为目的直接或间接分发、使用、改编或再分发,禁止任何其他商业用途。 查看全部
文章采集系统(这款知乎采集器的采用智能模式只需要输入网址就能自动识别采集知乎高赞)
相比市面上大部分的采集软件,采集知乎的文章都可以实现,例如爬虫,优采云,优采云采集器、优采云采集器等很多内容采集系统都有自己的特点,很多用户也有自己的习惯和喜好,但是对于大部分新手来说,上手比较困难。但如果抛开熟练使用后的用户体验,一款操作极其简单、功能强大的数据采集软件才是广大新手用户真正需要的。
下面小编推荐这款知乎采集器智能模式,输入网址即可自动识别采集知乎好评问答,方便大家阅读知乎问答和文章内容,并将喜欢的问答或文章永久保存到本地计算机,便于集中管理和阅读。
一、软件介绍
1、导出知乎网站任何问答中的问答内容,以及问答的评论区;
2、导出指定用户下的所有文章,包括文章内容和文章评论;
3、导出格式主要是html格式,也可以导出pdf和word格式(推荐使用默认html,html相当于本地网页,可以永久保存到电脑中);
二、软件功能介绍
1、导出知乎网站任何问答中的问答内容,以及问答的评论区;
2、导出指定用户下的所有文章,包括文章内容和文章评论;
3、导出格式主要是html格式,也可以导出pdf和word格式(推荐使用默认html,html相当于本地网页,可以永久保存到电脑中);
三、知乎 助手软件教程
第一步:下载软件并安装。可以通过下方小编给出的蓝琴云网盘链接下载安装包,解压后运行。
第二步:打开软件后,可以看到主界面,用你的微信登录。
Step 3. 导入采集问答链接/文章链接或指定用户文章链接。如下所示
示例连接:
Step 4.选择采集指定的本地电脑的本地保存位置,选择导出的文件格式【html格式、pdf和Word格式】(建议使用默认html,html相当于一个本地网页,可以永久保存到您的计算机)并启动 采集。
四、支持三种连接导入和下载
1、问答链接示例:
问答链接
2、文章链接示例:
3、采集指定用户主页文章链接:. 下面界面中的链接主要用于批量下载一个知乎首页下的所有文章。
(这里指的是一个导入的单个问答或文章链接,多个链接每行一个)
五、文章采集成功本地截图
六、操作方法总结
1、先下载蓝琴云网盘的软件链接[]
2、下载后解压,打开软件登录,设置采集导出文章保存位置。
3、复制并导入需要采集的文章链接、问答链接、指定用户文章链接,点击开始下载
4、下载完成后,找到刚才设置的文章的保存位置,打开就可以看到下载的知乎文章。
注:所有下载的知乎文章仅供自学使用,禁止以分发或使用为目的直接或间接分发、使用、改编或再分发,禁止任何其他商业用途。
文章采集系统(ELK日志收集、Logstash、Kibana的简称,并非全部)
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2022-02-09 02:09
ELK日志采集
ELK 是 Elasticsearch、Logstash、Kibana 的缩写,这三个是核心套件,但不是全部。
Elasticsearch是一个实时全文搜索分析引擎,提供数据采集、分析、存储三大功能;它是一套开放的 REST 和 JAVA API 结构,提供高效的搜索功能和可扩展的分布式系统。它建立在 Apache Lucene 搜索引擎库之上。
Logstash 是一个采集、分析和过滤日志的工具。它支持几乎所有类型的日志,包括系统日志、错误日志和自定义应用程序日志。它可以接收来自多种来源的日志,包括 syslog、消息传递(例如 RabbitMQ)和 JMX,并且可以通过多种方式输出数据,包括电子邮件、websockets 和 Elasticsearch。
Kibana 是一个基于 Web 的图形界面,用于搜索、分析和可视化存储在 Elasticsearch 指标中的日志数据。它利用 Elasticsearch 的 REST 接口来检索数据,不仅允许用户为自己的数据创建定制的仪表板视图,还允许他们以特别的方式查询和过滤数据。
1、准备环境1.1、配置java环境
去官网下载jdk1.8以上的包,然后配置java环境,保证环境正常使用。此处跳过安装过程。不明白的请自行百度。
[root@vm96-yw-65-test-3060 application]# java -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
1.2、下载ELK包
去官网下载Elasticsearch、Logstash和Kibana。因为是测试环境,所以我下载了最新版本v6.4.0,下载后解压。
wget https://artifacts.elastic.co/d ... ar.gz
wget https://artifacts.elastic.co/d ... ar.gz
wget https://artifacts.elastic.co/d ... ar.gz
2、配置2.1、修改系统配置
Elasticsearch对系统最大连接数有要求,所以需要修改系统连接数。
echo '
* hard nofile 65536
* soft nofile 65536
* soft nproc 65536
* hard nproc 65536
' >>/etc/security/limits.conf
echo 'vm.max_map_count = 262144' >> /etc/sysctl.conf
vim /etc/security/limits.d/90-nproc.conf
# 第一行最后一个数,修改为4096,如果是则不用修改
# limits.d下面的文件可能不是90-nproc.conf,可能是其他数字开头的文件。
* soft nproc 4096
root soft nproc unlimited
2.2、elasticSearch 配置
这其实是ELK的核心。启动时一定要注意。从5.0开始,提高了ElasticSearch的安全级别,不允许使用root账号启动,所以我们需要添加用户,所以还需要创建一个elsearch账号。
groupadd es #新建es组
useradd es -g es -p elasticsearch #新建一个es用户
chown -R es:es /usr/elasticsearch-6.4.0/ #指定elasticsearch-6.4.0目录下的文件所属elsearch组
修改配置文件
vim /application/elasticsearch-6.4.0/config/elasticsearch.yml
······
path.data: /application/elasticsearch-6.4.0/data
path.logs: /application/elasticsearch-6.4.0/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
······
启动
su es ## 切换到普通用户
cd /application/elasticsearch-6.4.0/
./bin/elasticsearch -d ## -d 后台运行
2.3、logstash 配置
解压后进入config目录新建logstash.conf配置,添加如下内容。
[root@vm96-yw-65-test-3060 config]# pwd
/application/logstash-6.4.0/config
[root@vm96-yw-65-test-3060 config]# vim logstash.conf
input {
file {
type => "log"
path => "/logs/*.log" ##创建一个/logs目录用于之后的测试
start_position => "beginning"
}
}
output {
stdout {
codec => rubydebug { }
}
elasticsearch { ##输出到es
hosts => "localhost:9200"
index => "log-%{+YYYY.MM.dd}"
}
}
logstash做的事情是分三个阶段执行的:输入输入-》处理过滤器(非必须)-》输出输出,这是我们需要配置的三个部分,因为是测试,所以不加filter过滤和过滤,配置只有输入和输出。一个文件可以有多个输入。过滤器很有用,但也是个麻烦点。它需要大量的实验。nginx、Apache等服务的日志分析需要使用该模块进行过滤分析。
[root@vm96-yw-65-test-3060 config]# nohup ../bin/logstash -f logstash.conf &
# 使用nohup,启动后台运行,如需关闭使用kill -9,建议多开窗口,启动ELK三个服务,可以观看控制窗口的报错信息
2.4、kibana 配置
它的配置也很简单,需要在kibana.yml文件中指定需要读取的elasticSearch地址和可以从外网访问的绑定地址。
[root@vm96-yw-65-test-3060 config]# vim /application/kinbana-6.4.0/config/kibana.yml
······
elasticsearch.url: "http://localhost:9200"
server.host: 0.0.0.0
······
启动
[root@vm96-yw-65-test-3060 config]# nohup ../bin/kibana &
# 使用nohup,启动后台运行,如需关闭使用kill -9
2.5、测试
写测试日志
vim /logs/test.log
Hello,World!!!
启动logstash
[root@vm96-yw-65-test-3060 config]# nohup ../bin/logstash -f logstash.conf &
在浏览器中输入::5601/,即可打开kibana页面。
单击管理 => 索引模式以创建索引。如果ES从logstash接收到日志数据,页面会显示可以创建的索引,否则会显示无法创建索引。请自行检查日志文件中的分析错误。
创建索引后,点击左侧的Discover,可以看到对刚刚创建的日志的分析。 查看全部
文章采集系统(ELK日志收集、Logstash、Kibana的简称,并非全部)
ELK日志采集
ELK 是 Elasticsearch、Logstash、Kibana 的缩写,这三个是核心套件,但不是全部。
Elasticsearch是一个实时全文搜索分析引擎,提供数据采集、分析、存储三大功能;它是一套开放的 REST 和 JAVA API 结构,提供高效的搜索功能和可扩展的分布式系统。它建立在 Apache Lucene 搜索引擎库之上。
Logstash 是一个采集、分析和过滤日志的工具。它支持几乎所有类型的日志,包括系统日志、错误日志和自定义应用程序日志。它可以接收来自多种来源的日志,包括 syslog、消息传递(例如 RabbitMQ)和 JMX,并且可以通过多种方式输出数据,包括电子邮件、websockets 和 Elasticsearch。
Kibana 是一个基于 Web 的图形界面,用于搜索、分析和可视化存储在 Elasticsearch 指标中的日志数据。它利用 Elasticsearch 的 REST 接口来检索数据,不仅允许用户为自己的数据创建定制的仪表板视图,还允许他们以特别的方式查询和过滤数据。
1、准备环境1.1、配置java环境
去官网下载jdk1.8以上的包,然后配置java环境,保证环境正常使用。此处跳过安装过程。不明白的请自行百度。
[root@vm96-yw-65-test-3060 application]# java -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
1.2、下载ELK包
去官网下载Elasticsearch、Logstash和Kibana。因为是测试环境,所以我下载了最新版本v6.4.0,下载后解压。
wget https://artifacts.elastic.co/d ... ar.gz
wget https://artifacts.elastic.co/d ... ar.gz
wget https://artifacts.elastic.co/d ... ar.gz
2、配置2.1、修改系统配置
Elasticsearch对系统最大连接数有要求,所以需要修改系统连接数。
echo '
* hard nofile 65536
* soft nofile 65536
* soft nproc 65536
* hard nproc 65536
' >>/etc/security/limits.conf
echo 'vm.max_map_count = 262144' >> /etc/sysctl.conf
vim /etc/security/limits.d/90-nproc.conf
# 第一行最后一个数,修改为4096,如果是则不用修改
# limits.d下面的文件可能不是90-nproc.conf,可能是其他数字开头的文件。
* soft nproc 4096
root soft nproc unlimited
2.2、elasticSearch 配置
这其实是ELK的核心。启动时一定要注意。从5.0开始,提高了ElasticSearch的安全级别,不允许使用root账号启动,所以我们需要添加用户,所以还需要创建一个elsearch账号。
groupadd es #新建es组
useradd es -g es -p elasticsearch #新建一个es用户
chown -R es:es /usr/elasticsearch-6.4.0/ #指定elasticsearch-6.4.0目录下的文件所属elsearch组
修改配置文件
vim /application/elasticsearch-6.4.0/config/elasticsearch.yml
······
path.data: /application/elasticsearch-6.4.0/data
path.logs: /application/elasticsearch-6.4.0/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
······
启动
su es ## 切换到普通用户
cd /application/elasticsearch-6.4.0/
./bin/elasticsearch -d ## -d 后台运行
2.3、logstash 配置
解压后进入config目录新建logstash.conf配置,添加如下内容。
[root@vm96-yw-65-test-3060 config]# pwd
/application/logstash-6.4.0/config
[root@vm96-yw-65-test-3060 config]# vim logstash.conf
input {
file {
type => "log"
path => "/logs/*.log" ##创建一个/logs目录用于之后的测试
start_position => "beginning"
}
}
output {
stdout {
codec => rubydebug { }
}
elasticsearch { ##输出到es
hosts => "localhost:9200"
index => "log-%{+YYYY.MM.dd}"
}
}
logstash做的事情是分三个阶段执行的:输入输入-》处理过滤器(非必须)-》输出输出,这是我们需要配置的三个部分,因为是测试,所以不加filter过滤和过滤,配置只有输入和输出。一个文件可以有多个输入。过滤器很有用,但也是个麻烦点。它需要大量的实验。nginx、Apache等服务的日志分析需要使用该模块进行过滤分析。
[root@vm96-yw-65-test-3060 config]# nohup ../bin/logstash -f logstash.conf &
# 使用nohup,启动后台运行,如需关闭使用kill -9,建议多开窗口,启动ELK三个服务,可以观看控制窗口的报错信息
2.4、kibana 配置
它的配置也很简单,需要在kibana.yml文件中指定需要读取的elasticSearch地址和可以从外网访问的绑定地址。
[root@vm96-yw-65-test-3060 config]# vim /application/kinbana-6.4.0/config/kibana.yml
······
elasticsearch.url: "http://localhost:9200"
server.host: 0.0.0.0
······
启动
[root@vm96-yw-65-test-3060 config]# nohup ../bin/kibana &
# 使用nohup,启动后台运行,如需关闭使用kill -9
2.5、测试
写测试日志
vim /logs/test.log
Hello,World!!!
启动logstash
[root@vm96-yw-65-test-3060 config]# nohup ../bin/logstash -f logstash.conf &
在浏览器中输入::5601/,即可打开kibana页面。
单击管理 => 索引模式以创建索引。如果ES从logstash接收到日志数据,页面会显示可以创建的索引,否则会显示无法创建索引。请自行检查日志文件中的分析错误。
创建索引后,点击左侧的Discover,可以看到对刚刚创建的日志的分析。
文章采集系统(helloword系统准备学习一下看看看看看看吧(图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-02-01 19:02
)
今天自己搭建了elk系统来学习看看,因为它是现在主流的实时数据分析系统。
具体安装过程不再赘述。和大部分linux安装文件一样,没有太大区别。
安装后进行测试。居然报错了。
启动命令://bin/logstash -e 'input {stdin {}} output {stdout {codec =>rubydebug}}'
启动此命令后,终端正在等待我们的输入。我们可以输入任何我们想要的字符串。还是和学习编程初学者一样,输入hello word,看看会返回什么。
大约几秒钟后,返回的结果如下。
这是我们输入hello word的执行结果,也就是json格式返回的数据。JSON 也是我们经常使用的一种数据格式。它具有丰富的界面,非常易于使用。
注意:以上是前台启动模式操作,不是很方便。因此,我们需要做一个后台启动,即将标准输入输出语句写入配置文件。好吧,让我们创建一个名为 logstash.conf 的配置文件。
输入内容:
输入此段后,保存并再次进行测试。
命令:./bin/logstash -f logstash.conf 终端会等待我们输入信息,或者输入hello word进行测试
编辑此文件后,它会立即运行。由于没有检查,所以结果是错误的。
wuError:在第 10 行第 1 列(字节 71) 之后的 #、输入、过滤器、输出
您可能对“--configtest”标志感兴趣,您可以在选择重新启动正在运行的系统之前使用它来验证logstash的配置
刚在百度上查了一堆,没有可靠的答案,都是英文错误,看到就头疼,不知道哪里错了。后来仔细耐心的看了下报错信息,发现配置文件的内容应该是错误的。我重新编辑和修改它,发现括号不见了。这是一个粗心造成的严重错误。记住要小心避免低级错误。.
修改后重新测试正常。
结果如下:
但是提示域名解析失败。应该是主机名和ip不匹配导致的解析异常。应该是早上改主机名的结果,没有生效。
哎,没办法改回原来的hostname,重新解析一下就OK了。
这是使用配置文件的输出哦,完全正确。大家也应该避免小问题的出现,多学英语,遇到问题要耐心阅读错误提示,并加以解决。
您可以在另一个终端中测试它:
查看全部
文章采集系统(helloword系统准备学习一下看看看看看看吧(图)
)
今天自己搭建了elk系统来学习看看,因为它是现在主流的实时数据分析系统。
具体安装过程不再赘述。和大部分linux安装文件一样,没有太大区别。
安装后进行测试。居然报错了。
启动命令://bin/logstash -e 'input {stdin {}} output {stdout {codec =>rubydebug}}'
启动此命令后,终端正在等待我们的输入。我们可以输入任何我们想要的字符串。还是和学习编程初学者一样,输入hello word,看看会返回什么。
大约几秒钟后,返回的结果如下。
这是我们输入hello word的执行结果,也就是json格式返回的数据。JSON 也是我们经常使用的一种数据格式。它具有丰富的界面,非常易于使用。
注意:以上是前台启动模式操作,不是很方便。因此,我们需要做一个后台启动,即将标准输入输出语句写入配置文件。好吧,让我们创建一个名为 logstash.conf 的配置文件。
输入内容:
输入此段后,保存并再次进行测试。
命令:./bin/logstash -f logstash.conf 终端会等待我们输入信息,或者输入hello word进行测试
编辑此文件后,它会立即运行。由于没有检查,所以结果是错误的。
wuError:在第 10 行第 1 列(字节 71) 之后的 #、输入、过滤器、输出
您可能对“--configtest”标志感兴趣,您可以在选择重新启动正在运行的系统之前使用它来验证logstash的配置
刚在百度上查了一堆,没有可靠的答案,都是英文错误,看到就头疼,不知道哪里错了。后来仔细耐心的看了下报错信息,发现配置文件的内容应该是错误的。我重新编辑和修改它,发现括号不见了。这是一个粗心造成的严重错误。记住要小心避免低级错误。.
修改后重新测试正常。
结果如下:
但是提示域名解析失败。应该是主机名和ip不匹配导致的解析异常。应该是早上改主机名的结果,没有生效。
哎,没办法改回原来的hostname,重新解析一下就OK了。
这是使用配置文件的输出哦,完全正确。大家也应该避免小问题的出现,多学英语,遇到问题要耐心阅读错误提示,并加以解决。
您可以在另一个终端中测试它:
文章采集系统(一下如何利用老Y文章管理系统采集时自动完成伪原创)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-01-27 12:11
作为垃圾站的站长,最想要的就是网站能自动采集,自动完成伪原创,然后自动收钱。这真的是世界上最幸福的事情。呵呵。自动采集 和自动收款将不予讨论。今天给大家介绍一下如何使用旧的Y文章管理系统采集自动补全伪原创的方法。
第一步是进入后台。找到“采集管理”-“过滤器管理”,添加一个新的过滤器项。
关于采集,我就不多说了,相信大家都能做到,我要介绍的是旧的Y文章管理系统是如何自动完成伪原创同时< @采集 @>具体工作方法,大体思路是利用老Y文章管理系统的过滤功能实现同义词的自动替换,从而达到伪原创的目的@>。比如我想把采集文章中的“网赚博客”全部换成“网赚日记”。详细步骤如下:
旧的Y文章管理系统使用简单方便,虽然功能没有DEDE之类的强大到几乎变态(当然旧的Y文章管理系统是用asp写的语言,似乎没有可比性),但它应有尽有,而且相当简单,因此也受到许多站长的欢迎。老Y文章管理系统采集时自动补全伪原创的具体方法很少讨论。新电影是在老Y的论坛上推荐的,甚至有人在兜售这种方法。歧视。
我可以建立一个名为“净赚博客”的项目,具体设置请看图:
“过滤器名称”:填写“网赚博客”即可,也可以随意写,但为了方便查阅,建议与替换词保持一致。
“项目”:请根据您的网站选择一列网站(必须选择一列,否则无法保存过滤项目)。
“过滤对象”:选项有“标题过滤”和“文本过滤”。一般可以选择“文本过滤器”。如果你想伪原创连标题,你可以选择“标题过滤器”。
<p>“过滤器类型”:选项有“简单替换”和“高级过滤”,一般选择“简单替换”,如果选择“高级过滤”,则需要指定“开始标签”和“结束标签”,这样 查看全部
文章采集系统(一下如何利用老Y文章管理系统采集时自动完成伪原创)
作为垃圾站的站长,最想要的就是网站能自动采集,自动完成伪原创,然后自动收钱。这真的是世界上最幸福的事情。呵呵。自动采集 和自动收款将不予讨论。今天给大家介绍一下如何使用旧的Y文章管理系统采集自动补全伪原创的方法。
第一步是进入后台。找到“采集管理”-“过滤器管理”,添加一个新的过滤器项。
关于采集,我就不多说了,相信大家都能做到,我要介绍的是旧的Y文章管理系统是如何自动完成伪原创同时< @采集 @>具体工作方法,大体思路是利用老Y文章管理系统的过滤功能实现同义词的自动替换,从而达到伪原创的目的@>。比如我想把采集文章中的“网赚博客”全部换成“网赚日记”。详细步骤如下:
旧的Y文章管理系统使用简单方便,虽然功能没有DEDE之类的强大到几乎变态(当然旧的Y文章管理系统是用asp写的语言,似乎没有可比性),但它应有尽有,而且相当简单,因此也受到许多站长的欢迎。老Y文章管理系统采集时自动补全伪原创的具体方法很少讨论。新电影是在老Y的论坛上推荐的,甚至有人在兜售这种方法。歧视。
我可以建立一个名为“净赚博客”的项目,具体设置请看图:
“过滤器名称”:填写“网赚博客”即可,也可以随意写,但为了方便查阅,建议与替换词保持一致。
“项目”:请根据您的网站选择一列网站(必须选择一列,否则无法保存过滤项目)。
“过滤对象”:选项有“标题过滤”和“文本过滤”。一般可以选择“文本过滤器”。如果你想伪原创连标题,你可以选择“标题过滤器”。
<p>“过滤器类型”:选项有“简单替换”和“高级过滤”,一般选择“简单替换”,如果选择“高级过滤”,则需要指定“开始标签”和“结束标签”,这样
文章采集系统(文章采集系统为什么需要兼容flash?(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-01-27 06:05
文章采集系统为什么需要兼容flash?5月份已经是flash10周年之际,一直以来,有flash开发者吐槽说它已经不能用了,chrome,firefox,ie都需要安装第三方插件才能播放flash文件。如果要支持这种情况,就得再加一个浏览器,flash的地位可见一斑。这次要发布的browserstack是一款不支持flash的浏览器,但能为flash提供可靠的服务。
作为第三方,browserstack提供html5代码质量测试工具,跟踪drm获取方式,swf获取方式,web安全反编译工具,web安全平台工具等。browserstack还能为程序员做出怎样的服务呢?让我们一起来看看。在主要浏览器中,谷歌浏览器几乎可以覆盖大部分市场。当然safari,chrome,ie等其他浏览器也能支持它。
然而,在所有的浏览器中,唯独谷歌浏览器看起来不兼容flash。很多研究人员都非常期待,谷歌浏览器能看着推出新的maxthon标准来修正错误。不幸的是,人们大多数时候并不知道他们如何使用maxthon.虽然有一些简单的工具可以使用,但这些工具会大大增加网页的错误率。那么,我们要怎么改变这个现状呢?1.加强安全性-兼容性使浏览器拥有更安全的源代码。
在使用javascript时,flash在源代码中的位置是安全的。但是,adobe承诺flash不会使用任何直接的activex驱动去执行javascript代码。因此,虽然目前flash是最常用的标准,可以通过浏览器的低错误率来提供服务,但是ddos攻击和javascript反射攻击会更容易。2.提供浏览体验改进flash并不是开放源代码的。
linux和macos版本都存在代码问题。在10周年版本前,主要的浏览器都支持。但是,随着windows版本的更新,浏览器的大小将会增加。为了解决这个问题,browserstack将与主要的浏览器浏览器公司一起,提供更好的安全功能和更棒的浏览体验。通过三种方式部署,browserstack能够为flash提供可靠的服务。
技术实现组件browserstack采用http服务器来改进流式网页。通过它,网页保持所有可用的代码。实际上,现在越来越多的浏览器已经加入了这项计划。像这样的项目一直都存在,如libfreetype.js开发工具等。自定义代码要检查每个浏览器的可用flash文件是很简单的,每个浏览器都提供javascript访问网页的api。
因此,你可以在flash扩展程序或其他flash支持的外部扩展程序中使用。此外,browserstack已经测试过h5视频编码器-video.html。flash根据它的版本来区分,以便于互操作。浏览器将通过不同的接口读取文件并输出,如果网页不支持该文件,则读取的内容将被修改。上面的视频演示了这个功能。点击。 查看全部
文章采集系统(文章采集系统为什么需要兼容flash?(二))
文章采集系统为什么需要兼容flash?5月份已经是flash10周年之际,一直以来,有flash开发者吐槽说它已经不能用了,chrome,firefox,ie都需要安装第三方插件才能播放flash文件。如果要支持这种情况,就得再加一个浏览器,flash的地位可见一斑。这次要发布的browserstack是一款不支持flash的浏览器,但能为flash提供可靠的服务。
作为第三方,browserstack提供html5代码质量测试工具,跟踪drm获取方式,swf获取方式,web安全反编译工具,web安全平台工具等。browserstack还能为程序员做出怎样的服务呢?让我们一起来看看。在主要浏览器中,谷歌浏览器几乎可以覆盖大部分市场。当然safari,chrome,ie等其他浏览器也能支持它。
然而,在所有的浏览器中,唯独谷歌浏览器看起来不兼容flash。很多研究人员都非常期待,谷歌浏览器能看着推出新的maxthon标准来修正错误。不幸的是,人们大多数时候并不知道他们如何使用maxthon.虽然有一些简单的工具可以使用,但这些工具会大大增加网页的错误率。那么,我们要怎么改变这个现状呢?1.加强安全性-兼容性使浏览器拥有更安全的源代码。
在使用javascript时,flash在源代码中的位置是安全的。但是,adobe承诺flash不会使用任何直接的activex驱动去执行javascript代码。因此,虽然目前flash是最常用的标准,可以通过浏览器的低错误率来提供服务,但是ddos攻击和javascript反射攻击会更容易。2.提供浏览体验改进flash并不是开放源代码的。
linux和macos版本都存在代码问题。在10周年版本前,主要的浏览器都支持。但是,随着windows版本的更新,浏览器的大小将会增加。为了解决这个问题,browserstack将与主要的浏览器浏览器公司一起,提供更好的安全功能和更棒的浏览体验。通过三种方式部署,browserstack能够为flash提供可靠的服务。
技术实现组件browserstack采用http服务器来改进流式网页。通过它,网页保持所有可用的代码。实际上,现在越来越多的浏览器已经加入了这项计划。像这样的项目一直都存在,如libfreetype.js开发工具等。自定义代码要检查每个浏览器的可用flash文件是很简单的,每个浏览器都提供javascript访问网页的api。
因此,你可以在flash扩展程序或其他flash支持的外部扩展程序中使用。此外,browserstack已经测试过h5视频编码器-video.html。flash根据它的版本来区分,以便于互操作。浏览器将通过不同的接口读取文件并输出,如果网页不支持该文件,则读取的内容将被修改。上面的视频演示了这个功能。点击。
文章采集系统(文章采集系统有免费版的需要购买吗?(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-01-26 00:01
文章采集系统只是采集数据源,可以不开源,开源的采集系统有免费版的,收费版的需要购买,1.采集系统采集效率低,2.采集效率高,用户体验不好。这是最重要的两点。
哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈你在逗我。我好奇从什么角度思考才会得出“还有免费版的”这样的结论,而且也不知道你是不是对“免费版”有错误的认识。根据你的资金限制,免费版估计你也是想都别想了。有个别能进行爬虫的,但是爬的是论坛、网站内容。专业的还是要用付费版。
别说免费版了,就算是巨额的python培训班课程,一年学费都要几万甚至十几万,和爬虫培训相比简直不值一提。人家只是可以帮你爬取一些网站而已。普通爬虫,爬几十个足够了,精度和效率也够用。
免费版本的话,我建议你还是用浏览器插件就可以。因为大数据量的数据采集,做python爬虫是很费劲的,你可以选择用requests库或beautifulsoup库进行爬取或requests库中的phantomjs对网页文本进行采集。
python是弱类型语言,python采集数据库相对于java,c语言要方便的多。主要有两个方面。1.python语言的表达能力强,理解原理,可以快速掌握各种操作的原理。2.python是脚本语言,不限程序语言。所以,目前,对于有c语言基础的人,直接用python来爬虫,再将采集结果发布到社区中,不失为一个好选择。对于没有c语言基础的人,可以慢慢学习python。 查看全部
文章采集系统(文章采集系统有免费版的需要购买吗?(一))
文章采集系统只是采集数据源,可以不开源,开源的采集系统有免费版的,收费版的需要购买,1.采集系统采集效率低,2.采集效率高,用户体验不好。这是最重要的两点。
哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈你在逗我。我好奇从什么角度思考才会得出“还有免费版的”这样的结论,而且也不知道你是不是对“免费版”有错误的认识。根据你的资金限制,免费版估计你也是想都别想了。有个别能进行爬虫的,但是爬的是论坛、网站内容。专业的还是要用付费版。
别说免费版了,就算是巨额的python培训班课程,一年学费都要几万甚至十几万,和爬虫培训相比简直不值一提。人家只是可以帮你爬取一些网站而已。普通爬虫,爬几十个足够了,精度和效率也够用。
免费版本的话,我建议你还是用浏览器插件就可以。因为大数据量的数据采集,做python爬虫是很费劲的,你可以选择用requests库或beautifulsoup库进行爬取或requests库中的phantomjs对网页文本进行采集。
python是弱类型语言,python采集数据库相对于java,c语言要方便的多。主要有两个方面。1.python语言的表达能力强,理解原理,可以快速掌握各种操作的原理。2.python是脚本语言,不限程序语言。所以,目前,对于有c语言基础的人,直接用python来爬虫,再将采集结果发布到社区中,不失为一个好选择。对于没有c语言基础的人,可以慢慢学习python。
文章采集系统( 技术领域[0001]本发明-OG三层状态日志收集系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-01-18 05:11
技术领域[0001]本发明-OG三层状态日志收集系统)
自定义日志采集系统及方法
技术领域
[0001] 本发明涉及一种采集各种系统和应用程序的日志,并对不同的日志进行自定义筛选处理的处理方法,尤其涉及一种自定义日志采集系统和方法。
背景技术
[0002] 日志采集是对各个系统和应用程序产生的日志文件进行采集,日志文件包括当前程序运行状态、错误信息、用户操作信息等。
[0003] 当前的日志采集系统和方法包括基于 Scribe 的采集框架、Chukwa 的采集框架和 Flume-OG 采集框架。
[0004]Scirbe框架是从各种来源采集日志,集中存储在中央存储系统中,然后进行集中统计分析。但是,由于代理和采集器之间没有相应的容错机制,数据就会出现。失去的局面,虽然是基于节俭的,但依赖更复杂,环境更具侵略性。Chukwa系统主要是为了采集各种数据。它收录了很多强大灵活的工具集,可以同时分析采集得到的数据,所以它的扩展性非常好。相比Scirbe框架,它可以定时记录发送的数据,提供容错机制,和hadoop的集成也很好,但是因为它的版本比较新,并且设计的主要初衷是为了各种数据的采集,日志的采集没有区别。什么具体的商业扩展,因此没有商业应用采用。Flume-OG框架也是一个三层的日志采集系统,具有agent、collector、store的三层结构。agent负责读取,collector负责采集过滤,store是存储层。同时负载由zookeeper提供,相比前两个框架更加可靠和安全。但是由于框架过于复杂,操作起来不是很方便,开发工作量巨大。什么具体的商业扩展,因此没有商业应用采用。Flume-OG框架也是一个三层的日志采集系统,具有agent、collector、store的三层结构。agent负责读取,collector负责采集过滤,store是存储层。同时负载由zookeeper提供,相比前两个框架更加可靠和安全。但是由于框架过于复杂,操作起来不是很方便,开发工作量巨大。什么具体的商业扩展,因此没有商业应用采用。Flume-OG框架也是一个三层的日志采集系统,具有agent、collector、store的三层结构。agent负责读取,collector负责采集过滤,store是存储层。同时负载由zookeeper提供,相比前两个框架更加可靠和安全。但是由于框架过于复杂,操作起来不是很方便,开发工作量巨大。采集器负责采集过滤,store是存储层。同时负载由zookeeper提供,相比前两个框架更加可靠和安全。但是由于框架过于复杂,操作起来不是很方便,开发工作量巨大。采集器负责采集过滤,store是存储层。同时负载由zookeeper提供,相比前两个框架更加可靠和安全。但是由于框架过于复杂,操作起来不是很方便,开发工作量巨大。
发明内容
本发明克服了现有技术的不足,不存在现有日志采集系统实时性、高可靠性、高自定制的问题,提出了一种高可靠性的自定制日志采集系统及方法。
为解决上述技术问题,本发明采用以下技术方案:
一个自定义的日志采集系统,包括采集系统、中间服务器、存储系统和负载均衡系统;所述采集系统连接所述中间服务器,所述中间服务器连接所有存储系统和负载均衡系统。
[0008] 进一步的技术方案是进一步包括拦截器,采集系统图连接到拦截器,拦截器连接到中间服务器。
[0009] 进一步的技术方案是采集系统包括至少三个客户端采集。
进一步的技术方案是提供一种自定义日志采集方法,所述方法包括以下步骤:
[0011]步骤一、根据需要采集的日志文件类型,确定自定义数据库系统结构化日志的采集源程序,实现日志的内容拉取功能文件;
[0012]步骤二、配置需要采集的文件路径;
[0013]步骤三、设置采用的通道类型;
[0014]步骤四、设置拦截器的内容,用于过滤掉不需要的事件;
[0015] 步骤五、设计为根据需要的客户端数量采集流向中间服务器的自定义框架;
Step六、 各客户端实时拉取日志文件内容,实现过滤写入段落;之后通过组件avrosink将指定端口发送给中间服务器,中间服务器接收数据并通过自定义的sink发送给目标的消息存储机制,完成日志的采集流程.
进一步的技术方案是步骤1中自定义的采集源程序步骤包括:
步骤一。设置采集文件的配置参数类;
[0019] 步骤b。实现文件的采集启动和停止方法;
步骤 c。配置并存储在位置文件中到文件的初始读取点;
步骤 d。建立一个线程,从posit1n点开始处理,不断发送的日志更新文件内容;
[0022] 步骤e。设置容错点,线程每10次执行一次,将当前读取文件的最后一个pist1n值存入posit1n文件;
[0023] 步骤f。为采集添加倾斜字符串的事件,具体标识内容包括:采集属于服务器名,采集属于应用程序名,采集属于到服务器IP。
进一步的技术方案是,步骤3中所述的通道类型包括:文件类型或内存类型。
[0025] 进一步的技术方案是,步骤6中描述的消息存储机制包括:数据库、消息定序器或分布式文件系统。
与现有技术相比,本发明的有益效果是:本发明可以对各种数据库系统和应用程序进行定制化的日志采集,利用实时的操作日志数据对操作系统的数据进行分析。提供状态、用户操作行为等实时数据。一旦出现系统错误信息,将及时获知并纠正。同时保证如果用户对系统进行了不当操作,可以及时停止。
图纸说明
[0027] 图。附图说明图1为本发明实施例的mysql数据库集群日志采集框架结构示意图。
图2为本发明一实施例中的mongodb数据库集群日志采集框架结构示意图。
[0029] 图。图3为本发明实施例的应用程序非结构化日志采集框架的结构示意图。
[0030] 图。图4为本发明一实施例的源程序采集的流程图。
[0031] 图。图5为本发明一实施例的日志过滤和写入消息序列的流程图。
详细说明
[0032] 本说明书中公开的所有特征,或公开的所有方法或过程中的步骤,可以以任何方式组合,除了相互排斥的特征和/或步骤。
[0033] 除非另有明确说明,否则本说明书(包括任何随附的权利要求、摘要和附图)中公开的任何特征都可以被用于类似目的的其他等效或替代特征代替。也就是说,除非另有明确说明,否则每个特征只是一系列等效或相似特征的一个示例。
[0034] 下面结合附图和实施例对本发明的具体实施方式进行详细说明。
[0035] 根据本发明实施例,本实施例公开了一种自定义日志采集系统,包括采集系统、中间服务器、存储系统和负载均衡系统;采集 系统连接中间服务器,中间服务器连接存储系统,存储系统连接负载均衡系统。
[0036] 具体地,如图3所示。1,图。图1是采集mysql数据库集群产生的日志的系统架构图。因为mysql集群的日志是相互连接的,所以采用单流框架。该系统包括客户端代理采集平台、中间服务器编写平台、存储系统和负载均衡系统。其中,客户端采集平台主要负责日志内容的可靠读取、过滤过滤,并通过自定义的采集源程序传输到中间服务器。中间服务器平台主要通过自研的发送程序发送到kafka分布式消息队列。存储模块是基于Kafka的分布式消息系统。
[0037] 如图2所示,图2是采集mongodb数据库集群查询日志的系统架构图,以采集流向的方式构建。该系统包括3个客户端采集、一个中间服务器、存储系统和负载均衡系统。其中,3个客户端采集、采集将日志发送到中间服务器的指定端口,中间服务器将自定义的sin写入分布式消息队列。
[0038] 如图所示。3,图。图3是采集应用程序产生的非结构化日志的装置和系统架构图。系统主要由采集客户端、拦截器、负载均衡、中间发送模块、存储模块组成。第一:
[0039] a)采集客户端,对于不同的应用,它们的日志结构是不一样的。所以直接使用Iinux命令行或者python脚本的方式采集程序的运行状态日志。
[0040] B)使用拦截器,过滤掉正确的运行状态,直接拦截错误的运行状态。
[0041] c)错误运行状态以事件的形式发送给具有内网权限的中间服务器。
d) 中间服务器自定义的发送模块可以将收到的事件发送到mongodb、hive、hbase等数据存储模块,方便处理端调用处理。
根据本发明的另一个实施例,本实施例公开了一种自定义日志采集方法,该方法包括以下步骤:
[0044]步骤一、根据需要采集的日志文件类型,确定自定义数据库系统结构化日志的采集源程序,实现内容拉取功能日志文件;
自定义采集源程序步骤包括:
步骤一。设置采集文件的配置参数类;
[0047] 步骤b。实现文件的采集启动和停止方法;
步骤 c。配置并存储在位置文件中到文件的初始读取点;
步骤 d。建立一个线程,从posit1n点开始处理,不断发送的日志更新文件内容;
[0050] 步骤e。设置容错点,线程每执行10次,将文件当前读取的最后一个pist1n值存入posit1n文件;
[0051] 步骤f。是采集的事件,加上一个tiltle字符串,具体标识内容包括:采集属于服务器名,采集属于应用程序名,采集属于服务器IP。
[0052]步骤二、配置需要采集的文件路径;
Step 三、 设置采用的通道类型;
[0054] 步骤四、设置拦截器的内容,用于过滤掉不需要的事件;
[0055] 步骤五、设计自定义框架,根据需要采集的客户端数量流向中间服务器;
步骤六、各客户端实时拉取日志文件内容,实现过滤写入通道;之后通过组件avrosink将指定端口发送给中间服务器,中间服务器接收数据并通过自定义的sink发送给目标的消息存储机制,完成日志的采集流程.
[0057] 具体地,结合附图对本实施例的方法进行详细描述。如图4所示,图4是采集的源程序流程图,采集结构化日志的步骤为:
a) 设置一个线程,用于不间断循环读取日志文件内容并发送处理后的日志。
[0059] b)设置最新的文件大小,从什么字节数开始读取,并存储在posit1n文件中。
c)读取文件的更新时间,如果new update time no wmodfile和last update event Iastmodfile不相等,则表示日志文件有新内容要写入,可以进行实时Read获取最新的日志更新内容.
d) 比较当前FiIe和posit1n中的字节大小,读取差值并设置posit1n的值,将posit1n之间的日志数据以事件的形式存储到缓存中最新的大小,存储最新的posit1n的值为存储在文件中,并在下次执行时再次读取比较。
e) 对缓冲区中的数据进行解码操作,并以字符串事件的形式划分出各个日志。
f) 事件添加标题,标题的内容包括日志所属的服务器、产生日志的系统或应用程序、日志所属的业务线和服务器的IP,在处理日志时可以明确区分那个采集 cluster产生这样的问题 找出问题所在的服务器的工作状态。
g)将分加标题的日志传递给发送模块,在信道中不断循环发送,直到该缓冲区中的数据全部发送完。
[0065] H)本次发送后,开始比较文件是否再次更新,从b)步骤开始执行。形成实时读取文件内容并发送。
[0066] 如图所示。5,图。图5是日志被读入通道,经过发送方筛选后发送到指定消息序列的流程图。包括以下步骤:
1)建立管道,从管道中以事件的形式读取数据。
[0068]2)读取事件会做筛选过程,如果发送到kafka分布式消息系统,增加topic相当于发送,如果发送到mongodb等数据库,需要数据的相关参数被设置。
[0069] 3)设定值与接口的实现一起写入指定的数据存储模块。
[0070] 本实施例基于Flume-NG的第三方框架,增加了一种实现高可靠、高定制化日志采集的方法,实现了非结构化日志和结构化日志采集,简单的处理和过滤,可以将采集日志实时发送到存储系统,为日志的分析和处理提供了很好的保障。本实施例不仅继承了Flume-NG框架的优点和底层结构,还可以根据自己的独特需求定制更合适的log采集解决方案,提高了用户对系统资源的高利用率,也可以保证系统稳定运行,大大提高用户使用日志采集的效率。
本说明书中所提及的“一个实施例”、“另一实施例”、“实施例”等是指结合本申请发明内容所收录的实施例所描述的具体特征、结构或特征。在说明书的至少一个实施例中。说明书中不同地方出现的相同表述不一定都是指同一个实施例。此外,当结合任一实施例描述特定特征、结构或特性时,要求结合其他实施例实现该特征、结构或特性也在本发明的范围内。
尽管本发明已在本文中参照其多个说明性实施例进行了描述,但应当理解,本领域技术人员可以设计出许多其他修改和实施例,这些修改和实施例将落入本申请的范围和范围内。所披露的原则精神。更具体地,在本文公开的权利要求的范围内,主题组合布置的组成部分和/或布置的各种变化和修改是可能的。除了部件和/或布置的变化和修改之外,其他用途对于本领域技术人员来说也是显而易见的。 查看全部
文章采集系统(
技术领域[0001]本发明-OG三层状态日志收集系统)
自定义日志采集系统及方法
技术领域
[0001] 本发明涉及一种采集各种系统和应用程序的日志,并对不同的日志进行自定义筛选处理的处理方法,尤其涉及一种自定义日志采集系统和方法。
背景技术
[0002] 日志采集是对各个系统和应用程序产生的日志文件进行采集,日志文件包括当前程序运行状态、错误信息、用户操作信息等。
[0003] 当前的日志采集系统和方法包括基于 Scribe 的采集框架、Chukwa 的采集框架和 Flume-OG 采集框架。
[0004]Scirbe框架是从各种来源采集日志,集中存储在中央存储系统中,然后进行集中统计分析。但是,由于代理和采集器之间没有相应的容错机制,数据就会出现。失去的局面,虽然是基于节俭的,但依赖更复杂,环境更具侵略性。Chukwa系统主要是为了采集各种数据。它收录了很多强大灵活的工具集,可以同时分析采集得到的数据,所以它的扩展性非常好。相比Scirbe框架,它可以定时记录发送的数据,提供容错机制,和hadoop的集成也很好,但是因为它的版本比较新,并且设计的主要初衷是为了各种数据的采集,日志的采集没有区别。什么具体的商业扩展,因此没有商业应用采用。Flume-OG框架也是一个三层的日志采集系统,具有agent、collector、store的三层结构。agent负责读取,collector负责采集过滤,store是存储层。同时负载由zookeeper提供,相比前两个框架更加可靠和安全。但是由于框架过于复杂,操作起来不是很方便,开发工作量巨大。什么具体的商业扩展,因此没有商业应用采用。Flume-OG框架也是一个三层的日志采集系统,具有agent、collector、store的三层结构。agent负责读取,collector负责采集过滤,store是存储层。同时负载由zookeeper提供,相比前两个框架更加可靠和安全。但是由于框架过于复杂,操作起来不是很方便,开发工作量巨大。什么具体的商业扩展,因此没有商业应用采用。Flume-OG框架也是一个三层的日志采集系统,具有agent、collector、store的三层结构。agent负责读取,collector负责采集过滤,store是存储层。同时负载由zookeeper提供,相比前两个框架更加可靠和安全。但是由于框架过于复杂,操作起来不是很方便,开发工作量巨大。采集器负责采集过滤,store是存储层。同时负载由zookeeper提供,相比前两个框架更加可靠和安全。但是由于框架过于复杂,操作起来不是很方便,开发工作量巨大。采集器负责采集过滤,store是存储层。同时负载由zookeeper提供,相比前两个框架更加可靠和安全。但是由于框架过于复杂,操作起来不是很方便,开发工作量巨大。
发明内容
本发明克服了现有技术的不足,不存在现有日志采集系统实时性、高可靠性、高自定制的问题,提出了一种高可靠性的自定制日志采集系统及方法。
为解决上述技术问题,本发明采用以下技术方案:
一个自定义的日志采集系统,包括采集系统、中间服务器、存储系统和负载均衡系统;所述采集系统连接所述中间服务器,所述中间服务器连接所有存储系统和负载均衡系统。
[0008] 进一步的技术方案是进一步包括拦截器,采集系统图连接到拦截器,拦截器连接到中间服务器。
[0009] 进一步的技术方案是采集系统包括至少三个客户端采集。
进一步的技术方案是提供一种自定义日志采集方法,所述方法包括以下步骤:
[0011]步骤一、根据需要采集的日志文件类型,确定自定义数据库系统结构化日志的采集源程序,实现日志的内容拉取功能文件;
[0012]步骤二、配置需要采集的文件路径;
[0013]步骤三、设置采用的通道类型;
[0014]步骤四、设置拦截器的内容,用于过滤掉不需要的事件;
[0015] 步骤五、设计为根据需要的客户端数量采集流向中间服务器的自定义框架;
Step六、 各客户端实时拉取日志文件内容,实现过滤写入段落;之后通过组件avrosink将指定端口发送给中间服务器,中间服务器接收数据并通过自定义的sink发送给目标的消息存储机制,完成日志的采集流程.
进一步的技术方案是步骤1中自定义的采集源程序步骤包括:
步骤一。设置采集文件的配置参数类;
[0019] 步骤b。实现文件的采集启动和停止方法;
步骤 c。配置并存储在位置文件中到文件的初始读取点;
步骤 d。建立一个线程,从posit1n点开始处理,不断发送的日志更新文件内容;
[0022] 步骤e。设置容错点,线程每10次执行一次,将当前读取文件的最后一个pist1n值存入posit1n文件;
[0023] 步骤f。为采集添加倾斜字符串的事件,具体标识内容包括:采集属于服务器名,采集属于应用程序名,采集属于到服务器IP。
进一步的技术方案是,步骤3中所述的通道类型包括:文件类型或内存类型。
[0025] 进一步的技术方案是,步骤6中描述的消息存储机制包括:数据库、消息定序器或分布式文件系统。
与现有技术相比,本发明的有益效果是:本发明可以对各种数据库系统和应用程序进行定制化的日志采集,利用实时的操作日志数据对操作系统的数据进行分析。提供状态、用户操作行为等实时数据。一旦出现系统错误信息,将及时获知并纠正。同时保证如果用户对系统进行了不当操作,可以及时停止。
图纸说明
[0027] 图。附图说明图1为本发明实施例的mysql数据库集群日志采集框架结构示意图。
图2为本发明一实施例中的mongodb数据库集群日志采集框架结构示意图。
[0029] 图。图3为本发明实施例的应用程序非结构化日志采集框架的结构示意图。
[0030] 图。图4为本发明一实施例的源程序采集的流程图。
[0031] 图。图5为本发明一实施例的日志过滤和写入消息序列的流程图。
详细说明
[0032] 本说明书中公开的所有特征,或公开的所有方法或过程中的步骤,可以以任何方式组合,除了相互排斥的特征和/或步骤。
[0033] 除非另有明确说明,否则本说明书(包括任何随附的权利要求、摘要和附图)中公开的任何特征都可以被用于类似目的的其他等效或替代特征代替。也就是说,除非另有明确说明,否则每个特征只是一系列等效或相似特征的一个示例。
[0034] 下面结合附图和实施例对本发明的具体实施方式进行详细说明。
[0035] 根据本发明实施例,本实施例公开了一种自定义日志采集系统,包括采集系统、中间服务器、存储系统和负载均衡系统;采集 系统连接中间服务器,中间服务器连接存储系统,存储系统连接负载均衡系统。
[0036] 具体地,如图3所示。1,图。图1是采集mysql数据库集群产生的日志的系统架构图。因为mysql集群的日志是相互连接的,所以采用单流框架。该系统包括客户端代理采集平台、中间服务器编写平台、存储系统和负载均衡系统。其中,客户端采集平台主要负责日志内容的可靠读取、过滤过滤,并通过自定义的采集源程序传输到中间服务器。中间服务器平台主要通过自研的发送程序发送到kafka分布式消息队列。存储模块是基于Kafka的分布式消息系统。
[0037] 如图2所示,图2是采集mongodb数据库集群查询日志的系统架构图,以采集流向的方式构建。该系统包括3个客户端采集、一个中间服务器、存储系统和负载均衡系统。其中,3个客户端采集、采集将日志发送到中间服务器的指定端口,中间服务器将自定义的sin写入分布式消息队列。
[0038] 如图所示。3,图。图3是采集应用程序产生的非结构化日志的装置和系统架构图。系统主要由采集客户端、拦截器、负载均衡、中间发送模块、存储模块组成。第一:
[0039] a)采集客户端,对于不同的应用,它们的日志结构是不一样的。所以直接使用Iinux命令行或者python脚本的方式采集程序的运行状态日志。
[0040] B)使用拦截器,过滤掉正确的运行状态,直接拦截错误的运行状态。
[0041] c)错误运行状态以事件的形式发送给具有内网权限的中间服务器。
d) 中间服务器自定义的发送模块可以将收到的事件发送到mongodb、hive、hbase等数据存储模块,方便处理端调用处理。
根据本发明的另一个实施例,本实施例公开了一种自定义日志采集方法,该方法包括以下步骤:
[0044]步骤一、根据需要采集的日志文件类型,确定自定义数据库系统结构化日志的采集源程序,实现内容拉取功能日志文件;
自定义采集源程序步骤包括:
步骤一。设置采集文件的配置参数类;
[0047] 步骤b。实现文件的采集启动和停止方法;
步骤 c。配置并存储在位置文件中到文件的初始读取点;
步骤 d。建立一个线程,从posit1n点开始处理,不断发送的日志更新文件内容;
[0050] 步骤e。设置容错点,线程每执行10次,将文件当前读取的最后一个pist1n值存入posit1n文件;
[0051] 步骤f。是采集的事件,加上一个tiltle字符串,具体标识内容包括:采集属于服务器名,采集属于应用程序名,采集属于服务器IP。
[0052]步骤二、配置需要采集的文件路径;
Step 三、 设置采用的通道类型;
[0054] 步骤四、设置拦截器的内容,用于过滤掉不需要的事件;
[0055] 步骤五、设计自定义框架,根据需要采集的客户端数量流向中间服务器;
步骤六、各客户端实时拉取日志文件内容,实现过滤写入通道;之后通过组件avrosink将指定端口发送给中间服务器,中间服务器接收数据并通过自定义的sink发送给目标的消息存储机制,完成日志的采集流程.
[0057] 具体地,结合附图对本实施例的方法进行详细描述。如图4所示,图4是采集的源程序流程图,采集结构化日志的步骤为:
a) 设置一个线程,用于不间断循环读取日志文件内容并发送处理后的日志。
[0059] b)设置最新的文件大小,从什么字节数开始读取,并存储在posit1n文件中。
c)读取文件的更新时间,如果new update time no wmodfile和last update event Iastmodfile不相等,则表示日志文件有新内容要写入,可以进行实时Read获取最新的日志更新内容.
d) 比较当前FiIe和posit1n中的字节大小,读取差值并设置posit1n的值,将posit1n之间的日志数据以事件的形式存储到缓存中最新的大小,存储最新的posit1n的值为存储在文件中,并在下次执行时再次读取比较。
e) 对缓冲区中的数据进行解码操作,并以字符串事件的形式划分出各个日志。
f) 事件添加标题,标题的内容包括日志所属的服务器、产生日志的系统或应用程序、日志所属的业务线和服务器的IP,在处理日志时可以明确区分那个采集 cluster产生这样的问题 找出问题所在的服务器的工作状态。
g)将分加标题的日志传递给发送模块,在信道中不断循环发送,直到该缓冲区中的数据全部发送完。
[0065] H)本次发送后,开始比较文件是否再次更新,从b)步骤开始执行。形成实时读取文件内容并发送。
[0066] 如图所示。5,图。图5是日志被读入通道,经过发送方筛选后发送到指定消息序列的流程图。包括以下步骤:
1)建立管道,从管道中以事件的形式读取数据。
[0068]2)读取事件会做筛选过程,如果发送到kafka分布式消息系统,增加topic相当于发送,如果发送到mongodb等数据库,需要数据的相关参数被设置。
[0069] 3)设定值与接口的实现一起写入指定的数据存储模块。
[0070] 本实施例基于Flume-NG的第三方框架,增加了一种实现高可靠、高定制化日志采集的方法,实现了非结构化日志和结构化日志采集,简单的处理和过滤,可以将采集日志实时发送到存储系统,为日志的分析和处理提供了很好的保障。本实施例不仅继承了Flume-NG框架的优点和底层结构,还可以根据自己的独特需求定制更合适的log采集解决方案,提高了用户对系统资源的高利用率,也可以保证系统稳定运行,大大提高用户使用日志采集的效率。
本说明书中所提及的“一个实施例”、“另一实施例”、“实施例”等是指结合本申请发明内容所收录的实施例所描述的具体特征、结构或特征。在说明书的至少一个实施例中。说明书中不同地方出现的相同表述不一定都是指同一个实施例。此外,当结合任一实施例描述特定特征、结构或特性时,要求结合其他实施例实现该特征、结构或特性也在本发明的范围内。
尽管本发明已在本文中参照其多个说明性实施例进行了描述,但应当理解,本领域技术人员可以设计出许多其他修改和实施例,这些修改和实施例将落入本申请的范围和范围内。所披露的原则精神。更具体地,在本文公开的权利要求的范围内,主题组合布置的组成部分和/或布置的各种变化和修改是可能的。除了部件和/或布置的变化和修改之外,其他用途对于本领域技术人员来说也是显而易见的。
文章采集系统(文章采集系统的基本结构和流程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-01-17 14:03
文章采集系统是一个典型的excel基础产品,基本结构如下:最核心的就是模块:采集模块,请求模块,获取模块,清洗模块,融合模块,采集库。其他模块,可选的有元数据采集模块,测试数据采集模块,应用数据采集模块,参数字段采集模块,ui采集模块等等。下面一个个介绍。采集模块采集的基本是来自网站的信息,也就是数据。
采集的流程就是:从采集对象列表中,找到目标,并进行相应的操作(如查询,截取等)。采集一个信息,我们需要的最简单的数据结构是:id,地址,信息内容。如果信息结构太复杂,我们还可以调整sql查询数据的方式,但sql是一个非常慢的语言,通常在使用的时候需要做出量级很大的任务,否则影响正常运行。所以我们采用简单的excel工作表内数据来完成这个任务。
还有一个非常重要的任务,就是数据的筛选,补充。毕竟要从数据中提取出符合条件的数据,并且保留对应的信息,是个体力活。要做成有一个简单的筛选,补充,我们需要代码简单起见,我们就不做定义条件提取的这个操作了。代码如下:varredis=[]varmatches=[]varjson={"registration_id":"1","registration_code":"1","registration_device":"m","registration_port":"211234","identifier":"llvm6.1","file":"this","version":"6.1.2","date":"2014-04-09t08:21:44.1608","type":"exists","failed_code":"9082","exit_code":"9082","true":"failed","false":"failed","client":".xxx.conf.data.mydata.json.json","client_identifier":"c1325336297","tls":"json.stringify","database":"","database":"","client_status":"ok","client_registration_id":"1","registration_code":"1","registration_device":"m","registration_port":"211234","identifier":"llvm6.1","file":"this","version":"6.1.2","file_list":[{"registration_id":"1","registration_code":"1","registration_device":"m","registration_port":"211234","identifier":"c1325336297","file":"","version":"6.1.2","repo":"","account":"dz","d。 查看全部
文章采集系统(文章采集系统的基本结构和流程)
文章采集系统是一个典型的excel基础产品,基本结构如下:最核心的就是模块:采集模块,请求模块,获取模块,清洗模块,融合模块,采集库。其他模块,可选的有元数据采集模块,测试数据采集模块,应用数据采集模块,参数字段采集模块,ui采集模块等等。下面一个个介绍。采集模块采集的基本是来自网站的信息,也就是数据。
采集的流程就是:从采集对象列表中,找到目标,并进行相应的操作(如查询,截取等)。采集一个信息,我们需要的最简单的数据结构是:id,地址,信息内容。如果信息结构太复杂,我们还可以调整sql查询数据的方式,但sql是一个非常慢的语言,通常在使用的时候需要做出量级很大的任务,否则影响正常运行。所以我们采用简单的excel工作表内数据来完成这个任务。
还有一个非常重要的任务,就是数据的筛选,补充。毕竟要从数据中提取出符合条件的数据,并且保留对应的信息,是个体力活。要做成有一个简单的筛选,补充,我们需要代码简单起见,我们就不做定义条件提取的这个操作了。代码如下:varredis=[]varmatches=[]varjson={"registration_id":"1","registration_code":"1","registration_device":"m","registration_port":"211234","identifier":"llvm6.1","file":"this","version":"6.1.2","date":"2014-04-09t08:21:44.1608","type":"exists","failed_code":"9082","exit_code":"9082","true":"failed","false":"failed","client":".xxx.conf.data.mydata.json.json","client_identifier":"c1325336297","tls":"json.stringify","database":"","database":"","client_status":"ok","client_registration_id":"1","registration_code":"1","registration_device":"m","registration_port":"211234","identifier":"llvm6.1","file":"this","version":"6.1.2","file_list":[{"registration_id":"1","registration_code":"1","registration_device":"m","registration_port":"211234","identifier":"c1325336297","file":"","version":"6.1.2","repo":"","account":"dz","d。
文章采集系统(免费数据采集软件需要注意哪些问题?-八维教育 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-01-10 22:10
)
Free Data采集软件是一款无需编写复杂的采集规则即可自动伪原创并根据关键词自动采集自动发布内容的绿色软件。简单配置后,即可实现24小时不间断采集、伪原创和发布。是站长维护网站的首选软件,内置全网发布接口cms,也可以直接导出为txt格式到本地,非常实用方便采集 软件。自从得到了广大站长朋友的永久免费支持,是SEO圈子里的良心软件,给很多站长朋友带来了实实在在的流量和经济效益。
特点介绍:
1、 自动去噪,可以自动过滤标题内容中的图片\网站\电话\QQ\邮件等信息;
2、这个数据采集软件不同于传统的采集模式,它可以根据设置的关键词执行采集、采集用户的好处是可以通过采集关键词的不同搜索结果自动采集最新发布的文章,以免搜索到一个或一个几个指定的 采集 站点。采集,降低采集网站被搜索引擎判断为采集网站被搜索引擎惩罚的风险。
3、 各种伪原创 和优化方法来提高收录 率和关键词 排名 标题插入、内容插入、自动内部链接、内容过滤、URL 过滤、随机图片插入、常规发布等多种方式方法提升采集文章原创的性能,提升搜索引擎收录、网站权重和关键词@ > 排名。
一个搜索引擎,其核心价值是为用户提供他/她最需要的结果。搜索引擎对网民的需求进行了统计。对于网民需求很少或没有需求的内容,即使你是原创,也可能会被搜索引擎忽略,因为它不想把资源浪费在无意义的内容上。对于网友需求量大的内容,收录应该会越来越快,但是因为收录的数量很多,就算你是原创,可能也很难挤进入排行榜。这么多用户选择使用采集!
一、使用数据采集软件需要注意网站结构规划?
1. 网址设计。URL 还可以收录 关键词。例如,如果您的 网站 是关于计算机的,那么您的 URL 可以收录“PC”,因为在搜索引擎眼中它通常是“计算机”的同义词。URL不宜过长,层级尽量不要超过4层。
2. 列设计。列通常与导航相关联。设计要考虑网站的整体主题,用户可能感兴趣的内容,列名最好是网站的几个主要的关键词,这样也方便导航权重的使用.
3. 关键词布局。理论上,每个内容页面都应该有它的核心关键词,同一个栏目下的文章应该尽可能的围绕关键词栏目转。一个简单粗暴的方法是直接使用列关键词的长尾关键字。
二、根据数据量设置动态、伪静态、静态采集
这不能一概而论,建议使用伪静态或静态。三者的区别在于是否生成静态文件以及URL格式是否为动态。生成静态文件本质上是为了加快访问速度,减少数据库查询,但是会不断增加占用的空间;伪静态仅通过 URL 重写来修改 URL。对于加速访问完全无效。动态和伪静态的区别仅在于 URL,带有问号和参数。
不同的网站 程序可能有不同的数据库操作效率。一般来说,如果内容页数小于10000,页面打开速度比较快,数据量较大,达到50000、100000甚至更多,通常需要考虑静态。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
查看全部
文章采集系统(免费数据采集软件需要注意哪些问题?-八维教育
)
Free Data采集软件是一款无需编写复杂的采集规则即可自动伪原创并根据关键词自动采集自动发布内容的绿色软件。简单配置后,即可实现24小时不间断采集、伪原创和发布。是站长维护网站的首选软件,内置全网发布接口cms,也可以直接导出为txt格式到本地,非常实用方便采集 软件。自从得到了广大站长朋友的永久免费支持,是SEO圈子里的良心软件,给很多站长朋友带来了实实在在的流量和经济效益。
特点介绍:
1、 自动去噪,可以自动过滤标题内容中的图片\网站\电话\QQ\邮件等信息;
2、这个数据采集软件不同于传统的采集模式,它可以根据设置的关键词执行采集、采集用户的好处是可以通过采集关键词的不同搜索结果自动采集最新发布的文章,以免搜索到一个或一个几个指定的 采集 站点。采集,降低采集网站被搜索引擎判断为采集网站被搜索引擎惩罚的风险。
3、 各种伪原创 和优化方法来提高收录 率和关键词 排名 标题插入、内容插入、自动内部链接、内容过滤、URL 过滤、随机图片插入、常规发布等多种方式方法提升采集文章原创的性能,提升搜索引擎收录、网站权重和关键词@ > 排名。
一个搜索引擎,其核心价值是为用户提供他/她最需要的结果。搜索引擎对网民的需求进行了统计。对于网民需求很少或没有需求的内容,即使你是原创,也可能会被搜索引擎忽略,因为它不想把资源浪费在无意义的内容上。对于网友需求量大的内容,收录应该会越来越快,但是因为收录的数量很多,就算你是原创,可能也很难挤进入排行榜。这么多用户选择使用采集!
一、使用数据采集软件需要注意网站结构规划?
1. 网址设计。URL 还可以收录 关键词。例如,如果您的 网站 是关于计算机的,那么您的 URL 可以收录“PC”,因为在搜索引擎眼中它通常是“计算机”的同义词。URL不宜过长,层级尽量不要超过4层。
2. 列设计。列通常与导航相关联。设计要考虑网站的整体主题,用户可能感兴趣的内容,列名最好是网站的几个主要的关键词,这样也方便导航权重的使用.
3. 关键词布局。理论上,每个内容页面都应该有它的核心关键词,同一个栏目下的文章应该尽可能的围绕关键词栏目转。一个简单粗暴的方法是直接使用列关键词的长尾关键字。
二、根据数据量设置动态、伪静态、静态采集
这不能一概而论,建议使用伪静态或静态。三者的区别在于是否生成静态文件以及URL格式是否为动态。生成静态文件本质上是为了加快访问速度,减少数据库查询,但是会不断增加占用的空间;伪静态仅通过 URL 重写来修改 URL。对于加速访问完全无效。动态和伪静态的区别仅在于 URL,带有问号和参数。
不同的网站 程序可能有不同的数据库操作效率。一般来说,如果内容页数小于10000,页面打开速度比较快,数据量较大,达到50000、100000甚至更多,通常需要考虑静态。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
文章采集系统(这节教您如何来运用采集系统,如何设置采集规则 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-01-02 07:22
)
信息采集管理系统的作用:
可以帮助企业在信息采集和资源整合方面节省大量的人力和资金。广泛应用于行业门户网站、竞争情报系统、知识管理系统、网站内容系统、垂直搜索、科研等领域。
今天这一节,我们将以采集腾讯网站的本地新闻列表为例,一步步教你如何使用采集系统,以及如何使用设置 采集 规则。
点击内容管理-->信息管理采集,如下图:
<p>点击“新建项目”,选择所属型号文章,所属栏目就是你要采集放入哪个栏目,我们选择国内新闻栏目,如下图: 查看全部
文章采集系统(这节教您如何来运用采集系统,如何设置采集规则
)
信息采集管理系统的作用:
可以帮助企业在信息采集和资源整合方面节省大量的人力和资金。广泛应用于行业门户网站、竞争情报系统、知识管理系统、网站内容系统、垂直搜索、科研等领域。
今天这一节,我们将以采集腾讯网站的本地新闻列表为例,一步步教你如何使用采集系统,以及如何使用设置 采集 规则。
点击内容管理-->信息管理采集,如下图:
<p>点击“新建项目”,选择所属型号文章,所属栏目就是你要采集放入哪个栏目,我们选择国内新闻栏目,如下图:
文章采集系统(免费织梦采集规则怎么写?看看文章列表的地址)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-12-30 10:27
dedecms 以其简单、实用和开源而著称。是国内知名度最高的PHP开源网站管理系统,也是用户最多的PHP CMS系统。经过多年的发展,无论是版本还是功能,都有着悠久的发展和进步,DedeCms的主要目标用户集中在个人网站或中小型门户网站的建设。当然,也有使用该系统的企业用户和学校。
免费梦想采集
优势:
1. 简单易用:使用织梦,十分钟学会,十分钟搭建一个。
2. 完美:织梦基本收录
了一般网站需要的所有功能。
3. 资料丰富:织梦作为国产CMS,拥有完整的中文学习资料。
4. 丰富的模板:织梦有海量免费精美模板,你可以自由使用。
5. 丰富的开发教程:织梦德德拥有丰富的二次开发和修改文档教程资源,可以满足大部分的修改需求和功能。
织梦合集的规则真的很复杂
如何编写免费的dedeCMS采集
规则?
看文章列表第一页地址
建站新德/list_49_1.html
比较第二页的地址
建站新德/list_49_2.html
我们发现除了49_后面的数字都一样,所以我们可以这样写
/建站心德/list_49_(*).html
就用(*)代替1吧,因为只有2页,所以我们从1填到2,每页加1,当然2-1...等于1。
后续还有十几步。不懂html的人感觉好陌生,无法下手。很多朋友在使用dede模板的时候都为DEDECMS采集
教程头疼,确实!官方教程太笼统了,也没说什么。Dedecms后台的免费采集
功能,不熟悉的新手也可以使用。采集规则配置起来比较麻烦。采集
过程中经常会遇到错误、乱码、无图片、管理不便等问题。我们需要使用其他易于使用的免费dede采集
和发布工具
免费采集
和发布工具
免费的Dede采集和发布管理工具
1、 只需导入关键词 采集
文章,即可同时创建数十个或数百个采集
任务,自动识别数据和规则,每周、每天、每小时...,只需设置采集
并按计划定时发布,轻松实现定时定量自动更新内容。
免费采集
工具
2、支持各大平台采集
3、可设置关键词采集
文章数
4、同时支持Empire、eyou、ZBLOG、dede、WP、PB、Apple、搜外等主流CMS的发布,可以同时批量管理和采集
发布的工具
以上是编辑器使用织梦工具的效果,整体收录和排名都还不错!看完这篇文章,如果你觉得不错,不妨采集
起来或者送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力! 查看全部
文章采集系统(免费织梦采集规则怎么写?看看文章列表的地址)
dedecms 以其简单、实用和开源而著称。是国内知名度最高的PHP开源网站管理系统,也是用户最多的PHP CMS系统。经过多年的发展,无论是版本还是功能,都有着悠久的发展和进步,DedeCms的主要目标用户集中在个人网站或中小型门户网站的建设。当然,也有使用该系统的企业用户和学校。
免费梦想采集
优势:
1. 简单易用:使用织梦,十分钟学会,十分钟搭建一个。
2. 完美:织梦基本收录
了一般网站需要的所有功能。
3. 资料丰富:织梦作为国产CMS,拥有完整的中文学习资料。
4. 丰富的模板:织梦有海量免费精美模板,你可以自由使用。
5. 丰富的开发教程:织梦德德拥有丰富的二次开发和修改文档教程资源,可以满足大部分的修改需求和功能。
织梦合集的规则真的很复杂
如何编写免费的dedeCMS采集
规则?
看文章列表第一页地址
建站新德/list_49_1.html
比较第二页的地址
建站新德/list_49_2.html
我们发现除了49_后面的数字都一样,所以我们可以这样写
/建站心德/list_49_(*).html
就用(*)代替1吧,因为只有2页,所以我们从1填到2,每页加1,当然2-1...等于1。
后续还有十几步。不懂html的人感觉好陌生,无法下手。很多朋友在使用dede模板的时候都为DEDECMS采集
教程头疼,确实!官方教程太笼统了,也没说什么。Dedecms后台的免费采集
功能,不熟悉的新手也可以使用。采集规则配置起来比较麻烦。采集
过程中经常会遇到错误、乱码、无图片、管理不便等问题。我们需要使用其他易于使用的免费dede采集
和发布工具
免费采集
和发布工具
免费的Dede采集和发布管理工具
1、 只需导入关键词 采集
文章,即可同时创建数十个或数百个采集
任务,自动识别数据和规则,每周、每天、每小时...,只需设置采集
并按计划定时发布,轻松实现定时定量自动更新内容。
免费采集
工具
2、支持各大平台采集
3、可设置关键词采集
文章数
4、同时支持Empire、eyou、ZBLOG、dede、WP、PB、Apple、搜外等主流CMS的发布,可以同时批量管理和采集
发布的工具
以上是编辑器使用织梦工具的效果,整体收录和排名都还不错!看完这篇文章,如果你觉得不错,不妨采集
起来或者送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力!
文章采集系统(log日志文件中grep、awk节点(node)节点 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-12-26 20:06
)
我们通常在日志文件中直接用grep和awk分析日志,得到我们想要的信息。这种方法效率低下,并且需要在生产中进行集中日志管理。汇总了所有服务器上的日志采集
。
弹性搜索
一个节点(node)是一个Elasticsearch实例,一个集群(cluster)是由一个或多个节点组成,它们具有相同的cluster.name,它们一起工作来共享数据和负载。当添加新节点或删除节点时,集群将感知并平衡数据。
集群中的一个节点会被选举为主节点(master),它会临时管理集群层面的一些变化,比如创建或删除索引,添加或删除节点等。主节点不参与文档- level 变化或搜索,这意味着当流量增长时,master 节点不会成为集群的瓶颈。
作为用户,我们可以与集群中的任何节点通信,包括主节点。每个节点都知道文档存在于哪个节点,并且可以将请求转发到相应的节点。我们访问的节点负责采集
各个节点返回的数据,最后一起返回给客户端。所有这些都由 Elasticsearch 处理。
一个完整的集中式日志系统需要包括以下主要功能:
采集——可以采集多个来源的日志数据
传输——日志数据可以稳定传输到中央系统
Storage-如何存储日志数据
分析-可以支持UI分析
警告-可以提供错误报告,监控机制
Fluentd基于CRuby实现,一些对性能很关键的组件用C语言重新实现,整体性能不错。
Fluentd支持所有主流日志类型,插件支持更多,性能更好
Logstash支持所有主流日志类型,插件支持最丰富,DIY灵活,但性能较差,JVM容易导致内存占用高。
Elasticsearch 是一个开源的分布式搜索引擎,提供采集
、分析和存储数据三大功能
Kibana 也是一个开源的免费工具。Kibana 可以为 td-agent 和 ElasticSearch 提供日志分析友好的 web 界面,可以帮助汇总、分析和搜索重要的数据日志。
node-1
#yum -y install java //下载java
#java -version //检测版本号
openjdk version "1.8.0_171"
OpenJDK Runtime Environment (build 1.8.0_171-b10)
OpenJDK 64-Bit Server VM (build 25.171-b10, mixed mode)
#wget https://artifacts.elastic.co/d ... 1.rpm
# rpm -ivh elasticsearch-6.3.1.rpm //安装
# vim /etc/elasticsearch/elasticsearch.yml //修改配置文件
cluster.name: my-application
node.name: node-1
node.master: true
network.host: 172.21.0.9
http.port: 9200
/etc/init.d/elasticsearch start //启动
curl http://192.168.124.173:9200/_cat/ //尝试链接 如果链接失败,关闭防火墙,查看配置文件
#curl http://192.168.124.173:9200/_cat/health
# curl http://192.168.124.173:9200/_cat/nodes
node-2
# yum install java
# java -version
#wget https://artifacts.elastic.co/d ... 1.rpm
# rpm -ivh elasticsearch-6.3.1.rpm
# vim /etc/elasticsearch/elasticsearch.yml //更改配置
cluster.name: my-application
node.name: node-2
node.master: false
network.host: 192.168.124.251
http.port: 9200
discovery.zen.ping.unicast.hosts: ["host1", "192.168.124.173"]
# /etc/init.d/elasticsearch start //启动服务
# /etc/init.d/elasticsearch status //查看状态
# curl http://192.168.124.251:9200/_cat
node-1
Fluentd(tdagent)
wget http://packages.treasuredata.c ... 4.rpm
rpm -ivh td-agent-3.2.0-0.el7.x86_64.rpm --force --nodeps
yum install -y libcurl-devel
opt/td-agent/embedded/bin/fluent-gem install fluent-plugin-elasticsearch
#cd /etc/td-agent/
#cat td-agent.conf
@type forward
port 24224
####################################
@type tail
path /var/log/httpd/access_log
pos_file /var/log/td-agent/httpd-access.log.pos
tag apache.access
@type apache2
####################################
@type stdout
####################################
@type copy
@type elasticsearch
host 10.0.0.9
port 9200
logstash_format true
logstash_prefix fluentd-${tag}
logstash_dateformat %Y%m%d
include_tag_key true
type_name access_log
tag_key @log_name
flush_interval 1s
@type stdout
# /etc/init.d/td-agent restart
# yum -y install http
# systemctl start httpd
# chmod 777 /var/log/httpd/
# curl 'http://192.168.124.173:9200/_cat/indices?v'
# systemctl stop firewalld
# wget https://artifacts.elastic.co/d ... 4.rpm
# rpm -ivh kibana-6.3.1-x86_64.rpm
# vim /etc/kibana/kibana.yml
server.port: 5601
server.host: “192.168.124.173"
elasticsearch.url: "http://192.168.124.173:9200
kibana.index: ".kibana”
# /etc/init.d/kibana restart
#tail -f /var/log/kibana/kibana.stderr
访问 kibana 网页界面
http://192.168.124.173:5601/
添加监控项
file:///root/%E4%B8%8B%E8%BD%BD/%E7%81%AB%E7%8B%90%E6%88%AA%E5%9B%BE_2018-07-14T06-39 -23.568Z.png
查看全部
文章采集系统(log日志文件中grep、awk节点(node)节点
)
我们通常在日志文件中直接用grep和awk分析日志,得到我们想要的信息。这种方法效率低下,并且需要在生产中进行集中日志管理。汇总了所有服务器上的日志采集
。
弹性搜索
一个节点(node)是一个Elasticsearch实例,一个集群(cluster)是由一个或多个节点组成,它们具有相同的cluster.name,它们一起工作来共享数据和负载。当添加新节点或删除节点时,集群将感知并平衡数据。
集群中的一个节点会被选举为主节点(master),它会临时管理集群层面的一些变化,比如创建或删除索引,添加或删除节点等。主节点不参与文档- level 变化或搜索,这意味着当流量增长时,master 节点不会成为集群的瓶颈。
作为用户,我们可以与集群中的任何节点通信,包括主节点。每个节点都知道文档存在于哪个节点,并且可以将请求转发到相应的节点。我们访问的节点负责采集
各个节点返回的数据,最后一起返回给客户端。所有这些都由 Elasticsearch 处理。
一个完整的集中式日志系统需要包括以下主要功能:
采集——可以采集多个来源的日志数据
传输——日志数据可以稳定传输到中央系统
Storage-如何存储日志数据
分析-可以支持UI分析
警告-可以提供错误报告,监控机制
Fluentd基于CRuby实现,一些对性能很关键的组件用C语言重新实现,整体性能不错。
Fluentd支持所有主流日志类型,插件支持更多,性能更好
Logstash支持所有主流日志类型,插件支持最丰富,DIY灵活,但性能较差,JVM容易导致内存占用高。
Elasticsearch 是一个开源的分布式搜索引擎,提供采集
、分析和存储数据三大功能
Kibana 也是一个开源的免费工具。Kibana 可以为 td-agent 和 ElasticSearch 提供日志分析友好的 web 界面,可以帮助汇总、分析和搜索重要的数据日志。
node-1
#yum -y install java //下载java
#java -version //检测版本号
openjdk version "1.8.0_171"
OpenJDK Runtime Environment (build 1.8.0_171-b10)
OpenJDK 64-Bit Server VM (build 25.171-b10, mixed mode)
#wget https://artifacts.elastic.co/d ... 1.rpm
# rpm -ivh elasticsearch-6.3.1.rpm //安装
# vim /etc/elasticsearch/elasticsearch.yml //修改配置文件
cluster.name: my-application
node.name: node-1
node.master: true
network.host: 172.21.0.9
http.port: 9200
/etc/init.d/elasticsearch start //启动
curl http://192.168.124.173:9200/_cat/ //尝试链接 如果链接失败,关闭防火墙,查看配置文件
#curl http://192.168.124.173:9200/_cat/health
# curl http://192.168.124.173:9200/_cat/nodes
node-2
# yum install java
# java -version
#wget https://artifacts.elastic.co/d ... 1.rpm
# rpm -ivh elasticsearch-6.3.1.rpm
# vim /etc/elasticsearch/elasticsearch.yml //更改配置
cluster.name: my-application
node.name: node-2
node.master: false
network.host: 192.168.124.251
http.port: 9200
discovery.zen.ping.unicast.hosts: ["host1", "192.168.124.173"]
# /etc/init.d/elasticsearch start //启动服务
# /etc/init.d/elasticsearch status //查看状态
# curl http://192.168.124.251:9200/_cat
node-1
Fluentd(tdagent)
wget http://packages.treasuredata.c ... 4.rpm
rpm -ivh td-agent-3.2.0-0.el7.x86_64.rpm --force --nodeps
yum install -y libcurl-devel
opt/td-agent/embedded/bin/fluent-gem install fluent-plugin-elasticsearch
#cd /etc/td-agent/
#cat td-agent.conf
@type forward
port 24224
####################################
@type tail
path /var/log/httpd/access_log
pos_file /var/log/td-agent/httpd-access.log.pos
tag apache.access
@type apache2
####################################
@type stdout
####################################
@type copy
@type elasticsearch
host 10.0.0.9
port 9200
logstash_format true
logstash_prefix fluentd-${tag}
logstash_dateformat %Y%m%d
include_tag_key true
type_name access_log
tag_key @log_name
flush_interval 1s
@type stdout
# /etc/init.d/td-agent restart
# yum -y install http
# systemctl start httpd
# chmod 777 /var/log/httpd/
# curl 'http://192.168.124.173:9200/_cat/indices?v'
# systemctl stop firewalld
# wget https://artifacts.elastic.co/d ... 4.rpm
# rpm -ivh kibana-6.3.1-x86_64.rpm
# vim /etc/kibana/kibana.yml
server.port: 5601
server.host: “192.168.124.173"
elasticsearch.url: "http://192.168.124.173:9200
kibana.index: ".kibana”
# /etc/init.d/kibana restart
#tail -f /var/log/kibana/kibana.stderr
访问 kibana 网页界面
http://192.168.124.173:5601/
添加监控项
file:///root/%E4%B8%8B%E8%BD%BD/%E7%81%AB%E7%8B%90%E6%88%AA%E5%9B%BE_2018-07-14T06-39 -23.568Z.png
文章采集系统(spring使用springcloud架构来做爬虫,历时二十多天,终于搞定)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-12-26 17:26
前言
因公司业务需要,需要获取客户提供的微信公众号历史文章,并每日更新。显然,300多个公众号无法每天手动检查,问题提交给IT团队。对于喜欢爬虫的人来说,我绝对想要他。之前用过搜狗的微信爬虫,后来一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过系列文章分享项目经验,并提供源码供大家指正!
一、系统介绍
本系统是基于Java开发的。只需配置公众号名称或微信公众号,即可抓取微信公众号文章(包括阅读、点赞、正在观看)。
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、RocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
Redis
演戏
提琴手
三、系统优缺点 系统优点
1、配置公众号后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取;2、系统为分布式架构,高可用;3、RocketMq 消息队列解决方案 Coupling 可以解决网络抖动导致的采集失败问题。如果三次消费不成功,日志会记录到mysql中,保证文章的完整性;4、可以添加任意数量的微信信号,提高采集效率,抵制反攀登限制;5、Redis在24小时内缓存每个微信账号的收款记录,防止账号被关闭;6、Nacos作为配置中心,可以通过热配置实时调整采集频率;7、 将采集
的数据存储在Solr集群中,提高检索速度;8、 将捕获返回的记录存储到MongoDB存档中,方便查看错误日志。
系统缺点:
1、 通过真实手机和真实账户采集
消息。如果需要采集
大量公众号,需要有多个微信帐号作为支持(如果当天达到上限,可以通过微信官方平台界面爬取消息);2、不是公众号发完就可以立即抓取,采集
时间是系统设置的,留言有一定的滞后性(如果公众号不多,微信信号数是足够了,可以通过增加采集
频率来优化)。
四、模块介绍
由于后面会添加管理系统和API调用函数,所以提前封装了一些函数。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:是
spring-boot-starter-data-redis的二次包暴露了打包好的Redis工具类和Redisson工具类。
RocketMQ-WS-启动器
RocketMQ 模块:是
Rocketmq-spring-boot-starter 的二次封装提供了消费重试和故障日志记录功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-蜘蛛
PC端采集模块:收录
PC端公众号历史消息采集相关功能。
java-wx-蜘蛛
Java Extraction Module:收录
与java程序提取文章内容相关的功能。
移动-wx-蜘蛛
模拟器采集模块:收录
与通过模拟器或手机采集消息的交互量相关的功能。
五、一般流程图
六、 在 PC 和手机上运行截图
安慰
运行结束
总结
项目亲测现已上线,项目开发中解决了微信搜狗临时链接永久链接问题,希望能帮助到被同类业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。我希望每个人都有自己的向日葵采集
。如果你看到这个,你不把它给一个采集
吗? 查看全部
文章采集系统(spring使用springcloud架构来做爬虫,历时二十多天,终于搞定)
前言
因公司业务需要,需要获取客户提供的微信公众号历史文章,并每日更新。显然,300多个公众号无法每天手动检查,问题提交给IT团队。对于喜欢爬虫的人来说,我绝对想要他。之前用过搜狗的微信爬虫,后来一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过系列文章分享项目经验,并提供源码供大家指正!
一、系统介绍
本系统是基于Java开发的。只需配置公众号名称或微信公众号,即可抓取微信公众号文章(包括阅读、点赞、正在观看)。
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、RocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
Redis
演戏
提琴手
三、系统优缺点 系统优点
1、配置公众号后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取;2、系统为分布式架构,高可用;3、RocketMq 消息队列解决方案 Coupling 可以解决网络抖动导致的采集失败问题。如果三次消费不成功,日志会记录到mysql中,保证文章的完整性;4、可以添加任意数量的微信信号,提高采集效率,抵制反攀登限制;5、Redis在24小时内缓存每个微信账号的收款记录,防止账号被关闭;6、Nacos作为配置中心,可以通过热配置实时调整采集频率;7、 将采集
的数据存储在Solr集群中,提高检索速度;8、 将捕获返回的记录存储到MongoDB存档中,方便查看错误日志。
系统缺点:
1、 通过真实手机和真实账户采集
消息。如果需要采集
大量公众号,需要有多个微信帐号作为支持(如果当天达到上限,可以通过微信官方平台界面爬取消息);2、不是公众号发完就可以立即抓取,采集
时间是系统设置的,留言有一定的滞后性(如果公众号不多,微信信号数是足够了,可以通过增加采集
频率来优化)。
四、模块介绍
由于后面会添加管理系统和API调用函数,所以提前封装了一些函数。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:是
spring-boot-starter-data-redis的二次包暴露了打包好的Redis工具类和Redisson工具类。
RocketMQ-WS-启动器
RocketMQ 模块:是
Rocketmq-spring-boot-starter 的二次封装提供了消费重试和故障日志记录功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-蜘蛛
PC端采集模块:收录
PC端公众号历史消息采集相关功能。
java-wx-蜘蛛
Java Extraction Module:收录
与java程序提取文章内容相关的功能。
移动-wx-蜘蛛
模拟器采集模块:收录
与通过模拟器或手机采集消息的交互量相关的功能。
五、一般流程图
六、 在 PC 和手机上运行截图
安慰
运行结束
总结
项目亲测现已上线,项目开发中解决了微信搜狗临时链接永久链接问题,希望能帮助到被同类业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。我希望每个人都有自己的向日葵采集
。如果你看到这个,你不把它给一个采集
吗?
文章采集系统(从木子小渔聊起bt技术用bt下载软件是怎么采集网页资源的?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-12-24 09:03
文章采集系统的开发过程我就不描述了,网上有很多相关文章,如何搭建和怎么搭建,基本都差不多,后面对比了一下,网上的几篇文章都有问题,或者说都不是我需要的!在梳理了相关知识后,我做出了这个,他们在知乎上有专门的专栏,对我的相关分析,软件体验都有,提供免费培训和一对一培训,能够让你快速上手,了解市场环境的实际情况,避免上当受骗!如果对做采集系统感兴趣,或者打算学习搭建采集系统,都可以看一下他们的专栏,十分欢迎报名!我还有一个最近写的bt技术系列文章,有兴趣也可以看看:木子小渔:从木子小渔聊起bt技术用bt下载软件是怎么采集网页资源的?!(。
1)木子小渔:从木子小渔聊起bt技术用bt下载软件是怎么采集网页资源的?!
2)木子小渔:从木子小渔聊起bt技术用bt下载软件是怎么采集网页资源的?!
3)木子小渔:从木子小渔聊起bt技术用bt下载软件是怎么采集网页资源的?!
4)
你可以给开发者点300块钱,大家都开心。他的代码他看着心情写,事后你觉得不满意,
我刚刚也和楼主遇到同样的问题,刚刚在某公司的圈子里用某团购网站的网页版本随机搜索了一下,发现几千页有大约2-3万条数据,访问都在几十秒左右,真是令人心头一颤。随后开始去研究他们的采集软件,发现有多个版本的、这么大的任务量,按照多个版本切换,应该是为了提高效率和降低延时进行改良。但从长远角度出发,应该直接让团队全员编写代码来进行,会大大提高产出。
如果你实在不满意提供的这个插件,可以编写一个类似的免费的采集软件,是只能随机采集网页的数据的。这个对学生会不会不太友好呢,毕竟本身来说学习成本还挺高的。 查看全部
文章采集系统(从木子小渔聊起bt技术用bt下载软件是怎么采集网页资源的?)
文章采集系统的开发过程我就不描述了,网上有很多相关文章,如何搭建和怎么搭建,基本都差不多,后面对比了一下,网上的几篇文章都有问题,或者说都不是我需要的!在梳理了相关知识后,我做出了这个,他们在知乎上有专门的专栏,对我的相关分析,软件体验都有,提供免费培训和一对一培训,能够让你快速上手,了解市场环境的实际情况,避免上当受骗!如果对做采集系统感兴趣,或者打算学习搭建采集系统,都可以看一下他们的专栏,十分欢迎报名!我还有一个最近写的bt技术系列文章,有兴趣也可以看看:木子小渔:从木子小渔聊起bt技术用bt下载软件是怎么采集网页资源的?!(。
1)木子小渔:从木子小渔聊起bt技术用bt下载软件是怎么采集网页资源的?!
2)木子小渔:从木子小渔聊起bt技术用bt下载软件是怎么采集网页资源的?!
3)木子小渔:从木子小渔聊起bt技术用bt下载软件是怎么采集网页资源的?!
4)
你可以给开发者点300块钱,大家都开心。他的代码他看着心情写,事后你觉得不满意,
我刚刚也和楼主遇到同样的问题,刚刚在某公司的圈子里用某团购网站的网页版本随机搜索了一下,发现几千页有大约2-3万条数据,访问都在几十秒左右,真是令人心头一颤。随后开始去研究他们的采集软件,发现有多个版本的、这么大的任务量,按照多个版本切换,应该是为了提高效率和降低延时进行改良。但从长远角度出发,应该直接让团队全员编写代码来进行,会大大提高产出。
如果你实在不满意提供的这个插件,可以编写一个类似的免费的采集软件,是只能随机采集网页的数据的。这个对学生会不会不太友好呢,毕竟本身来说学习成本还挺高的。
文章采集系统(软件应用环境:支持PHP+Mysql+ZENDOptimizer的WEB系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-12-20 03:15
欢迎使用不受目标语言限制、不选择存储对象数据库的在线采集器。谷歌和百度在搜索中排名第一。它是完全免费的,可以放心使用。
软件应用环境:支持PHP+Mysql+ZEND Optimizer的WEB系统
当前版本:V2.0324 发布时间:07.03.24 13:53
老版本用户升级请参考升级文件目录下的指令文件操作!!!
发行说明:
V2.0324 发布时间:07.03.24 13:53
1、优化URL编码程序,提高目标URL编码字符串的识别智能
---------------
适用范围:
1、 部署环境不限,Windows、Linux、FreeBSD、Solaris等可以安装PHP语言支持环境的系统均可使用;
2、采集 对象不限,静态HTML、动态PHP/ASP/JAVA页面均可采集;
3、采集对象支持:文章、图片、Flash;
4、完美的内容存储解决方案,小蜜蜂采集器提供2种存储方式:直接数据库引导和模拟提交。
1)Database Direct Guide完美支持任何基于Mysql数据库的内容管理系统存储信息,包括多表/多字段联动系统指南库;
2) 仿真提交指南库理论上支持任何目标,不受目标程序语言和数据库类别的限制;实际使用效果受目标应用影响。
各采集模块功能简介:
1、 文章采集Module special 采集文章/Picture,或者采集文章内附的Flash,但功能是不如 Flash采集 模块功能强大;
2、 BBS 论坛采集特定模块采集BBS 论坛内容;
3、 Flash采集模块专攻采集Flash游戏,可以完美的采集缩略图和游戏介绍;
采集内容导引库介绍:采集各模块的内容可自由导入WEB应用系统。
特征:
1、支持文章内容分页采集;
2、支持论坛采集
3、支持UTF-8转GB2312,但采集内容字符格式是UTF-8的目标;
4、 支持将文章的内容保存到本地;
5、支持站点+栏目管理模式,让采集管理一目了然;
6、支持链接替换,分页链接替换,破解JS/后台程序设置的一些反扒功能;
7、支持采集器设置无限过滤功能;
8、支持图片采集保存到本地,自动替换文件名避免重复;
9、支持FLASH文件采集保存到本地,自动替换文件名避免重复;
10、 支持限制PHP FOPEN和FSOCKET功能的虚拟主机;
11、 支持手动过滤采集结果,并提供“空标题空内容”的快速过滤和删除;
12、支持Flash专业站点采集,特色采集flash小游戏,可完美采集缩略图,游戏介绍;
13、 支持全站配置规则的导入导出;
14、 支持列配置规则的导入导出,并提供规则复制功能,简化设置;
15、 提供引导库规则导入导出;
16、支持自定义采集间隔时间,避免被误认为DDOS攻击而拒绝响应,但采集可以设置防止DDOS攻击网站;
17、 支持自定义存储间隔时间,避免虚拟主机并发限制;
18、支持自定义内容写入,用户可以设置任意内容(如自己的链接、广告代码),写入采集的内容:第一个、最后一个或随机写入;需要写入的内容在浏览库时自动带在身边,无需修改WEB系统模板。
19、支持采集内容替换功能,用户可以设置替换规则随意替换;
20、支持html标签过滤,让采集接收到的内容只保留必要的html标签,甚至纯文本不带任何html标签;
21、支持多种cms引导库如:BBWPS、Dedecms(织梦) V2/V3、PHP168 cms、mephp< @cms、曼波cms、Joomlacms、多迅(DuoXun)cms、SupeSite、cmsware、帝国Ecms、新宇东网( XYDW)cms、东易cms、风迅cms、HUGESKY、PHPcms系统指南库;用户还可以设计自己的系统指南库功能。
22、支持PHPWIND、Discuz、BBSxp论坛指南库,程序包收录3个论坛指南库规则和操作说明;
23、 自带数据库优化玩具,减少频繁采集 过多的数据碎片降低数据库性能。
以下特殊功能仅适用于“小蜜蜂采集器”:
1、支持采集进程断点续传功能,不受浏览器意外关闭影响,重启后不会重复采集;
2、 支持自动比较过滤功能,不会在采集的链接系统中重复采集和存储;
以上两个功能可以大大减少采集时间,减少系统负载。
3、 支持系统每天自动创建图片存储目录,方便管理;
4、 支持采集/guidance间隔时间设置,避免被目标站识别为流量攻击而拒绝响应;
5、支持自定义内容写入,实现简单的反采集功能;
6、支持html标签过滤,几乎完美展现你想要的采集效果;
7、完美的内容存储解决方案,不受目标编程语言和数据库类别的限制。
以上众多强大功能免费供您使用,您可以轻松高效地安装使用体验资料采集。
-----------------------------
选择小蜜蜂采集器的好处:
1、小蜜蜂程序采用PHP开发,支持跨平台操作。它可以在 Windows 和 Unix 操作系统上运行。是一款高效的采集在线应用软件,完美入库。
2、 小蜜蜂不受安装位置限制,家中,工作电脑,网站服务器均可使用;建议直接安装在网站服务器上,体验小蜜蜂的超强功能和便利。
3、 使用服务器安装,可以直接抓取采集的图片/Flash到机器上使用;无需像其他采集器采集服务器那样通过FTP将数据上传到个人电脑。想象一下,如果那天你的采集图片和Flash超过100M,上传时间是什么概念。
4、使用服务器安装,可以快速导入采集内容cms文章系统或BBS论坛系统;如果使用离线采集器,远程存储或者上传SQL文件进行存储都是浪费时间。
5、小蜜蜂独有的断点续传和重复采集过滤功能,可以节省您创作内容的时间。
-----------------------------
单点下载:
更多下载: 查看全部
文章采集系统(软件应用环境:支持PHP+Mysql+ZENDOptimizer的WEB系统)
欢迎使用不受目标语言限制、不选择存储对象数据库的在线采集器。谷歌和百度在搜索中排名第一。它是完全免费的,可以放心使用。
软件应用环境:支持PHP+Mysql+ZEND Optimizer的WEB系统
当前版本:V2.0324 发布时间:07.03.24 13:53
老版本用户升级请参考升级文件目录下的指令文件操作!!!
发行说明:
V2.0324 发布时间:07.03.24 13:53
1、优化URL编码程序,提高目标URL编码字符串的识别智能
---------------
适用范围:
1、 部署环境不限,Windows、Linux、FreeBSD、Solaris等可以安装PHP语言支持环境的系统均可使用;
2、采集 对象不限,静态HTML、动态PHP/ASP/JAVA页面均可采集;
3、采集对象支持:文章、图片、Flash;
4、完美的内容存储解决方案,小蜜蜂采集器提供2种存储方式:直接数据库引导和模拟提交。
1)Database Direct Guide完美支持任何基于Mysql数据库的内容管理系统存储信息,包括多表/多字段联动系统指南库;
2) 仿真提交指南库理论上支持任何目标,不受目标程序语言和数据库类别的限制;实际使用效果受目标应用影响。
各采集模块功能简介:
1、 文章采集Module special 采集文章/Picture,或者采集文章内附的Flash,但功能是不如 Flash采集 模块功能强大;
2、 BBS 论坛采集特定模块采集BBS 论坛内容;
3、 Flash采集模块专攻采集Flash游戏,可以完美的采集缩略图和游戏介绍;
采集内容导引库介绍:采集各模块的内容可自由导入WEB应用系统。
特征:
1、支持文章内容分页采集;
2、支持论坛采集
3、支持UTF-8转GB2312,但采集内容字符格式是UTF-8的目标;
4、 支持将文章的内容保存到本地;
5、支持站点+栏目管理模式,让采集管理一目了然;
6、支持链接替换,分页链接替换,破解JS/后台程序设置的一些反扒功能;
7、支持采集器设置无限过滤功能;
8、支持图片采集保存到本地,自动替换文件名避免重复;
9、支持FLASH文件采集保存到本地,自动替换文件名避免重复;
10、 支持限制PHP FOPEN和FSOCKET功能的虚拟主机;
11、 支持手动过滤采集结果,并提供“空标题空内容”的快速过滤和删除;
12、支持Flash专业站点采集,特色采集flash小游戏,可完美采集缩略图,游戏介绍;
13、 支持全站配置规则的导入导出;
14、 支持列配置规则的导入导出,并提供规则复制功能,简化设置;
15、 提供引导库规则导入导出;
16、支持自定义采集间隔时间,避免被误认为DDOS攻击而拒绝响应,但采集可以设置防止DDOS攻击网站;
17、 支持自定义存储间隔时间,避免虚拟主机并发限制;
18、支持自定义内容写入,用户可以设置任意内容(如自己的链接、广告代码),写入采集的内容:第一个、最后一个或随机写入;需要写入的内容在浏览库时自动带在身边,无需修改WEB系统模板。
19、支持采集内容替换功能,用户可以设置替换规则随意替换;
20、支持html标签过滤,让采集接收到的内容只保留必要的html标签,甚至纯文本不带任何html标签;
21、支持多种cms引导库如:BBWPS、Dedecms(织梦) V2/V3、PHP168 cms、mephp< @cms、曼波cms、Joomlacms、多迅(DuoXun)cms、SupeSite、cmsware、帝国Ecms、新宇东网( XYDW)cms、东易cms、风迅cms、HUGESKY、PHPcms系统指南库;用户还可以设计自己的系统指南库功能。
22、支持PHPWIND、Discuz、BBSxp论坛指南库,程序包收录3个论坛指南库规则和操作说明;
23、 自带数据库优化玩具,减少频繁采集 过多的数据碎片降低数据库性能。
以下特殊功能仅适用于“小蜜蜂采集器”:
1、支持采集进程断点续传功能,不受浏览器意外关闭影响,重启后不会重复采集;
2、 支持自动比较过滤功能,不会在采集的链接系统中重复采集和存储;
以上两个功能可以大大减少采集时间,减少系统负载。
3、 支持系统每天自动创建图片存储目录,方便管理;
4、 支持采集/guidance间隔时间设置,避免被目标站识别为流量攻击而拒绝响应;
5、支持自定义内容写入,实现简单的反采集功能;
6、支持html标签过滤,几乎完美展现你想要的采集效果;
7、完美的内容存储解决方案,不受目标编程语言和数据库类别的限制。
以上众多强大功能免费供您使用,您可以轻松高效地安装使用体验资料采集。
-----------------------------
选择小蜜蜂采集器的好处:
1、小蜜蜂程序采用PHP开发,支持跨平台操作。它可以在 Windows 和 Unix 操作系统上运行。是一款高效的采集在线应用软件,完美入库。
2、 小蜜蜂不受安装位置限制,家中,工作电脑,网站服务器均可使用;建议直接安装在网站服务器上,体验小蜜蜂的超强功能和便利。
3、 使用服务器安装,可以直接抓取采集的图片/Flash到机器上使用;无需像其他采集器采集服务器那样通过FTP将数据上传到个人电脑。想象一下,如果那天你的采集图片和Flash超过100M,上传时间是什么概念。
4、使用服务器安装,可以快速导入采集内容cms文章系统或BBS论坛系统;如果使用离线采集器,远程存储或者上传SQL文件进行存储都是浪费时间。
5、小蜜蜂独有的断点续传和重复采集过滤功能,可以节省您创作内容的时间。
-----------------------------
单点下载:
更多下载:
文章采集系统(文章采集系统的市场需求决定功能的优先级,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-12-17 22:08
文章采集系统基础知识文章采集系统的市场需求决定功能的优先级,作为采集系统,基础市场需求包括但不限于:1.开发采集系统难度低,只要有php和数据库知识就可以开发2.采集系统不一定需要具备数据爬取,还可以爬取图片,视频,点击等采集模块3.对爬虫能力要求低,只要爬取速度能够满足采集要求即可4.对系统的复杂度和安全性有一定要求5.对爬虫可能会出现无法抓取和对地址规则收集不全等情况有很大影响6.作为一个完善的采集系统,其系统管理,上传,清洗和存储等要能够满足存储数据量大,爬取速度慢,对地址规则收集不全等多个问题每个客户都想开发适合自己的采集系统,基于此,我们开发了和自己产品相适应的文章采集系统,包括了收集功能和上传功能。
采集系统的市场需求包括但不限于:1.手动采集速度慢,重复采集严重2.需要管理爬虫,处理爬虫的后门,判断爬虫是否可用3.爬虫权限控制和批量采集权限的控制4.爬虫存储,缓存,读取和命中率控制5.爬虫监控,定期监控爬虫数据6.支持采集java,php,html5等爬虫语言采集系统的功能1.爬虫收集模块:爬虫收集系统提供文章收集接口,使用采集模块中的文章来爬取内容2.爬虫爬取模块:采集模块提供爬虫爬取接口,采集文章和页面。
采集数据全部从网站搜索引擎爬取,或者爬取系统爬取系统文章采集系统开发和实施采集系统开发采集系统实施采集系统管理采集系统管理采集系统爬虫爬取文章采集数据收集系统定期爬取文章图片,视频和点击采集系统实现采集后端采集爬虫爬取后端采集存储存储爬虫采集服务采集系统定期爬取数据采集系统定期爬取数据采集系统定期爬取数据采集系统定期爬取数据数据采集。 查看全部
文章采集系统(文章采集系统的市场需求决定功能的优先级,你知道吗?)
文章采集系统基础知识文章采集系统的市场需求决定功能的优先级,作为采集系统,基础市场需求包括但不限于:1.开发采集系统难度低,只要有php和数据库知识就可以开发2.采集系统不一定需要具备数据爬取,还可以爬取图片,视频,点击等采集模块3.对爬虫能力要求低,只要爬取速度能够满足采集要求即可4.对系统的复杂度和安全性有一定要求5.对爬虫可能会出现无法抓取和对地址规则收集不全等情况有很大影响6.作为一个完善的采集系统,其系统管理,上传,清洗和存储等要能够满足存储数据量大,爬取速度慢,对地址规则收集不全等多个问题每个客户都想开发适合自己的采集系统,基于此,我们开发了和自己产品相适应的文章采集系统,包括了收集功能和上传功能。
采集系统的市场需求包括但不限于:1.手动采集速度慢,重复采集严重2.需要管理爬虫,处理爬虫的后门,判断爬虫是否可用3.爬虫权限控制和批量采集权限的控制4.爬虫存储,缓存,读取和命中率控制5.爬虫监控,定期监控爬虫数据6.支持采集java,php,html5等爬虫语言采集系统的功能1.爬虫收集模块:爬虫收集系统提供文章收集接口,使用采集模块中的文章来爬取内容2.爬虫爬取模块:采集模块提供爬虫爬取接口,采集文章和页面。
采集数据全部从网站搜索引擎爬取,或者爬取系统爬取系统文章采集系统开发和实施采集系统开发采集系统实施采集系统管理采集系统管理采集系统爬虫爬取文章采集数据收集系统定期爬取文章图片,视频和点击采集系统实现采集后端采集爬虫爬取后端采集存储存储爬虫采集服务采集系统定期爬取数据采集系统定期爬取数据采集系统定期爬取数据采集系统定期爬取数据数据采集。

