
文章采集程序
文章采集程序(字符处理规则重构处理应该算是采集的处理方式!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-02-07 18:09
之前因为工作原因,写了一个通用网站data采集的小工具,通过配置XML到采集不同网站内容。在这段工作的业余时间,觉得有必要对其进行改造,顺便学习学习,特此记录。字符处理规则重构字符处理应该算作采集
强烈推荐IDEA2021.1.3破解激活,IntelliJ IDEA注册码,2021.1.3IDEA激活码
大家好,我是建筑师,一个会写代码,会背诗的建筑师。今天就来说说通用采集小工具重构之路——字符处理规则重构,希望能帮助大家提高!!!
之前因为工作原因,写了一个通用网站data采集的小工具,通过配置XML到采集不同网站内容。
在这段工作的业余时间,觉得有必要对其进行改造,顺便学习学习,特此记录。
字符处理规则重构
字符处理应该被视为采集中的核心内容,如果从一大串HTML字符串中提取到我们需要的字段中。我们来看看之前的处理方式:
查看代码
string temp2;
temp2 = GetStr(str, MyConfig.Url, Lev); //字符截取规则
temp2 = ReplaceStr(temp2, MyConfig.UrlGL, Lev); //字符过滤规则
temp2 = SetCodeing(temp2, MyConfig.UrlBM, Lev);//字符URL编码规则
temp2 = Myreplace(temp2,MyConfig.UrlGvContent,Lev);//字符替换规则
只听山间传来建筑师的声音:
东山乡只用了不到一年的时间,就回到了种植春田。谁将向上或向下匹配?
故障排除:
1. 客户端调用次数过多,如果有四个规则,则需要调用四个规则。
2. 扩展不灵活。如果以后遇到新的采集要求,现有的规则不满足要求,需要增加新的规则,不符合“开闭原则”
让我们开始重构:
1. 提取通用规则接口
文字处理规则界面
此代码由Java架构师必看网-架构君整理
///
/// 文字处理规则接口
///
public interface ItextRule
{
///
/// 字符处理
///
/// 待处理字符串
/// 配置关键字
/// 当前层级
///
string TextPro(string sourceStr,string key,int lev);
}
2. 为规则类创建一个抽象类,并编写一些公共方法
字符处理规则基类
///
/// 字符处理规则基础类
///
public abstract class TextRuleBase
{
private string myKey = string.Empty;
public TextRuleBase(string _key)
{
myKey = _key;
}
///
/// 获取配置文件的值
///
///
///
///
protected string[] GetValue(string key,int lev)
{
string str = string.Empty;
string temp = string.Empty;
string tempKey = key + myKey + lev;
bool Istrue = true;
while(Istrue) //循环读配置,知道为空
{
temp = SiteConfig.ConfigByKey(tempKey);
if (temp == "")
{
Istrue = false;
}
else
{
str += temp + "|";
tempKey += lev;
}
}
return str.Split(new char[]{'|'},StringSplitOptions.RemoveEmptyEntries);
}
///
/// 具体规则处理 强制子类实现
///
///
///
///
protected abstract string TextPro(string sourceStr, string[] Contents);
}
3. 创建字符规则类,按照以上逻辑创建4个字符规则类,继承接口和抽象类
字符截取规则基本规则
这里仅创建一个示例,其他示例相同。或查看代码
4. 建立高层接口供客户端直接调用,内部封装各种规则(根据配置)
字符处理规则的高级接口
///
/// 字符处理规则的高层接口
///
public class TextRuleAll:ItextRule
{
private Dictionary ruleList = new Dictionary();
#region ItextRule 成员
public string TextPro(string sourceStr, string key, int lev)
{
string dicKey = key + lev;
string returnStr = string.Empty;
if (!ruleList.ContainsKey(dicKey))
{
IList list = new List();
#region 根据配置构建关键字规则列表
foreach (string vale in MyConfig.AllTextRules())
{
string[] temp = vale.Split('.');
string xmlKey = temp[temp.Length - 1];
if (xmlKey == "TextIntercept") //写死 字符截取规则为基本规则
xmlKey = "";
if (SiteConfig.ConfigByKey(key + xmlKey + lev) != "") //XML文件有此配置关键字
{
list.Add((ItextRule)Assembly.Load("Demo1").CreateInstance(vale));
}
}
#endregion
ruleList.Add(dicKey,list);
}
IList mylist = ruleList[dicKey];
if (mylist != null && mylist.Count > 0) //循环执行各种规则处理
{
returnStr = sourceStr;
foreach (ItextRule irule in mylist)
returnStr = irule.TextPro(returnStr, key, lev);
}
return returnStr;
}
#end
5. 配置文件
XML 配置
Collect.TextRule.TextIntercept,Collect.TextRule.StaticReplace,Collect.TextRule.TextUrlEncode,Collect.TextRule.TextFilter
邮件地址是[内容]
#,@
fuwentao,fwt
city=[内容]
.com,[内容]http
重构完成,再来看看客户端的调用:
string testStr = "我是fuwentao,我的邮件地址是fwt1314111#163.com,网址http://www.mywaysoft.net/city=上海";
TextRuleAll cmd = new TextRuleAll();
string rel= cmd.TextPro(testStr, "Name", 1); //结果
只需一个 cmd.TextPro 即可获得它!是不是比以前简单了。
而且,这种灵活性也很强。如果以后想增加新的处理规则,只需要创建一个规则类,然后在配置文件中进行配置。
演示下载
今天文章结束,感谢阅读,Java架构师必看,祝你升职加薪,年年好运。 查看全部
文章采集程序(字符处理规则重构处理应该算是采集的处理方式!)
之前因为工作原因,写了一个通用网站data采集的小工具,通过配置XML到采集不同网站内容。在这段工作的业余时间,觉得有必要对其进行改造,顺便学习学习,特此记录。字符处理规则重构字符处理应该算作采集
强烈推荐IDEA2021.1.3破解激活,IntelliJ IDEA注册码,2021.1.3IDEA激活码
大家好,我是建筑师,一个会写代码,会背诗的建筑师。今天就来说说通用采集小工具重构之路——字符处理规则重构,希望能帮助大家提高!!!
之前因为工作原因,写了一个通用网站data采集的小工具,通过配置XML到采集不同网站内容。
在这段工作的业余时间,觉得有必要对其进行改造,顺便学习学习,特此记录。
字符处理规则重构
字符处理应该被视为采集中的核心内容,如果从一大串HTML字符串中提取到我们需要的字段中。我们来看看之前的处理方式:

查看代码
string temp2;
temp2 = GetStr(str, MyConfig.Url, Lev); //字符截取规则
temp2 = ReplaceStr(temp2, MyConfig.UrlGL, Lev); //字符过滤规则
temp2 = SetCodeing(temp2, MyConfig.UrlBM, Lev);//字符URL编码规则
temp2 = Myreplace(temp2,MyConfig.UrlGvContent,Lev);//字符替换规则
只听山间传来建筑师的声音:
东山乡只用了不到一年的时间,就回到了种植春田。谁将向上或向下匹配?
故障排除:
1. 客户端调用次数过多,如果有四个规则,则需要调用四个规则。
2. 扩展不灵活。如果以后遇到新的采集要求,现有的规则不满足要求,需要增加新的规则,不符合“开闭原则”
让我们开始重构:
1. 提取通用规则接口
文字处理规则界面
此代码由Java架构师必看网-架构君整理
///
/// 文字处理规则接口
///
public interface ItextRule
{
///
/// 字符处理
///
/// 待处理字符串
/// 配置关键字
/// 当前层级
///
string TextPro(string sourceStr,string key,int lev);
}
2. 为规则类创建一个抽象类,并编写一些公共方法
字符处理规则基类
///
/// 字符处理规则基础类
///
public abstract class TextRuleBase
{
private string myKey = string.Empty;
public TextRuleBase(string _key)
{
myKey = _key;
}
///
/// 获取配置文件的值
///
///
///
///
protected string[] GetValue(string key,int lev)
{
string str = string.Empty;
string temp = string.Empty;
string tempKey = key + myKey + lev;
bool Istrue = true;
while(Istrue) //循环读配置,知道为空
{
temp = SiteConfig.ConfigByKey(tempKey);
if (temp == "")
{
Istrue = false;
}
else
{
str += temp + "|";
tempKey += lev;
}
}
return str.Split(new char[]{'|'},StringSplitOptions.RemoveEmptyEntries);
}
///
/// 具体规则处理 强制子类实现
///
///
///
///
protected abstract string TextPro(string sourceStr, string[] Contents);
}
3. 创建字符规则类,按照以上逻辑创建4个字符规则类,继承接口和抽象类
字符截取规则基本规则
这里仅创建一个示例,其他示例相同。或查看代码
4. 建立高层接口供客户端直接调用,内部封装各种规则(根据配置)
字符处理规则的高级接口
///
/// 字符处理规则的高层接口
///
public class TextRuleAll:ItextRule
{
private Dictionary ruleList = new Dictionary();
#region ItextRule 成员
public string TextPro(string sourceStr, string key, int lev)
{
string dicKey = key + lev;
string returnStr = string.Empty;
if (!ruleList.ContainsKey(dicKey))
{
IList list = new List();
#region 根据配置构建关键字规则列表
foreach (string vale in MyConfig.AllTextRules())
{
string[] temp = vale.Split('.');
string xmlKey = temp[temp.Length - 1];
if (xmlKey == "TextIntercept") //写死 字符截取规则为基本规则
xmlKey = "";
if (SiteConfig.ConfigByKey(key + xmlKey + lev) != "") //XML文件有此配置关键字
{
list.Add((ItextRule)Assembly.Load("Demo1").CreateInstance(vale));
}
}
#endregion
ruleList.Add(dicKey,list);
}
IList mylist = ruleList[dicKey];
if (mylist != null && mylist.Count > 0) //循环执行各种规则处理
{
returnStr = sourceStr;
foreach (ItextRule irule in mylist)
returnStr = irule.TextPro(returnStr, key, lev);
}
return returnStr;
}
#end
5. 配置文件
XML 配置
Collect.TextRule.TextIntercept,Collect.TextRule.StaticReplace,Collect.TextRule.TextUrlEncode,Collect.TextRule.TextFilter
邮件地址是[内容]
#,@
fuwentao,fwt
city=[内容]
.com,[内容]http
重构完成,再来看看客户端的调用:
string testStr = "我是fuwentao,我的邮件地址是fwt1314111#163.com,网址http://www.mywaysoft.net/city=上海";
TextRuleAll cmd = new TextRuleAll();
string rel= cmd.TextPro(testStr, "Name", 1); //结果
只需一个 cmd.TextPro 即可获得它!是不是比以前简单了。
而且,这种灵活性也很强。如果以后想增加新的处理规则,只需要创建一个规则类,然后在配置文件中进行配置。
演示下载
今天文章结束,感谢阅读,Java架构师必看,祝你升职加薪,年年好运。
文章采集程序(免费下载或者VIP会员资源能否直接商用?浏览器下载)
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-02-04 12:11
免费下载或者VIP会员资源可以直接商业化吗?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接用于商业用途。如因商业用途发生版权纠纷,一切责任由用户承担。更多信息请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:可以将下载的压缩包与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除了这种情况,可以在对应资源底部留言,或者联系我们。
在资产介绍文章 中找不到示例图片?
对于会员制、全站源代码、程序插件、网站模板、网页模板等各类素材,文章中用于介绍的图片通常不收录在相应的下载中材料包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)找到来源。某些字体文件也是如此,但某些资产在资产包中会有字体下载链接列表。
付款后无法显示下载地址或无法查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买此资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一经批准,将不接受任何形式的退款或换货请求。购买前请确认您需要的资源 查看全部
文章采集程序(免费下载或者VIP会员资源能否直接商用?浏览器下载)
免费下载或者VIP会员资源可以直接商业化吗?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接用于商业用途。如因商业用途发生版权纠纷,一切责任由用户承担。更多信息请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:可以将下载的压缩包与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除了这种情况,可以在对应资源底部留言,或者联系我们。
在资产介绍文章 中找不到示例图片?
对于会员制、全站源代码、程序插件、网站模板、网页模板等各类素材,文章中用于介绍的图片通常不收录在相应的下载中材料包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)找到来源。某些字体文件也是如此,但某些资产在资产包中会有字体下载链接列表。
付款后无法显示下载地址或无法查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买此资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一经批准,将不接受任何形式的退款或换货请求。购买前请确认您需要的资源
文章采集程序(免费下载或者VIP会员资源能否直接商用?浏览器下载)
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-02-03 09:15
免费下载或者VIP会员资源可以直接商业化吗?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接用于商业用途。如因商业用途发生版权纠纷,一切责任由用户承担。更多信息请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:可以将下载的压缩包与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除了这种情况,可以在对应资源底部留言,或者联系我们。
在资产介绍文章 中找不到示例图片?
对于会员制、全站源代码、程序插件、网站模板、网页模板等各类素材,文章中用于介绍的图片通常不收录在相应的下载中材料包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)找到来源。某些字体文件也是如此,但某些资产在资产包中会有字体下载链接列表。
付款后无法显示下载链接或无法查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买此资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一经批准,将不接受任何形式的退款或换货请求。购买前请确认您需要的资源 查看全部
文章采集程序(免费下载或者VIP会员资源能否直接商用?浏览器下载)
免费下载或者VIP会员资源可以直接商业化吗?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接用于商业用途。如因商业用途发生版权纠纷,一切责任由用户承担。更多信息请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:可以将下载的压缩包与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除了这种情况,可以在对应资源底部留言,或者联系我们。
在资产介绍文章 中找不到示例图片?
对于会员制、全站源代码、程序插件、网站模板、网页模板等各类素材,文章中用于介绍的图片通常不收录在相应的下载中材料包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)找到来源。某些字体文件也是如此,但某些资产在资产包中会有字体下载链接列表。
付款后无法显示下载链接或无法查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买此资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一经批准,将不接受任何形式的退款或换货请求。购买前请确认您需要的资源
文章采集程序(程序参数python编程简介(一)的gui程序设计)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-31 16:00
文章采集程序appium实现登录方式程序设计思路程序采集方式编译程序参数python编程简介python程序猿python编程简介gui的编程python的gui程序设计ios的java代码设计gui在程序设计中无处不在:比如早些年写小说的时候,经常设计成泡沫文明的样子,有没有发现整个人都摆脱了原始人的颜色?python除了在写小说,很多编程语言都用到gui。
下面看看gui到底干了什么。主流c语言比如c#,大家都知道游戏、电商等等,gui都是一个重要的角色,连操作系统,主流的一些方式,很多都是利用gui来实现。python一直都比较不友好,所以python在用户体验和脚本语言上一直比较差,在和python有交集的情况下,提交比较多的是web和游戏等方面。在早些年编程里面,很多python程序猿喜欢开发游戏,因为比c代码编程方便太多了,代码量少,而且以实用性、可读性优先。
在这个层面上,是没有所谓的gui语言的,比如python多掌握几门语言是没有问题的,但你要能去写个gui程序,是不太可能的,即使是web也是属于ui编程的范畴。很多时候,比如什么地球杯、穿越火线等等游戏,游戏版本不同,里面的图形界面和操作都是不一样的,跟性能没有关系,所以从技术上来讲,web、web服务器这类,是有gui编程的,只不过这些gui要比c、java等等各种编程语言复杂太多了。
整个的图形交互都是利用gui来实现的,大家看起来好像都是用c程序猿,但是不知道当时人写这些程序的时候,很多其实根本没有gui这个概念,只有ui这个概念。比如对开发一个按钮,都可以画一个按钮,然后显示出来。python编程交互没有问题的,但是就是语言差异造成的不好理解和游戏方向不一样,比如你在新浪、人人上写点东西都要懂二进制,他们只需要上传二进制文件。
网站都是这样的,你要是用c程序来写网站,是不可能兼容所有浏览器的。很多有意思的python小玩意最近几年python在语言交互方面比以前方便了太多了,从谷歌贡献的webkit浏览器引擎开始,python多了很多小工具。比如websocket这样的工具,还有做webfacebook的网站客户端,这些小工具python、java等编程语言都是可以学的。
python这几年发展很快,连new一下编程语言都一直在更新,近几年python,包括其他一些语言都在迅速发展,很多开发模式,比如都分为面向对象、函数式编程,虽然都不是标准的编程模式,但是看起来一样。那么python面向对象到底是什么呢?很多读者把对象和对象的区别当成是一个一个的参数了,其实不然,对象和对象是不一。 查看全部
文章采集程序(程序参数python编程简介(一)的gui程序设计)
文章采集程序appium实现登录方式程序设计思路程序采集方式编译程序参数python编程简介python程序猿python编程简介gui的编程python的gui程序设计ios的java代码设计gui在程序设计中无处不在:比如早些年写小说的时候,经常设计成泡沫文明的样子,有没有发现整个人都摆脱了原始人的颜色?python除了在写小说,很多编程语言都用到gui。
下面看看gui到底干了什么。主流c语言比如c#,大家都知道游戏、电商等等,gui都是一个重要的角色,连操作系统,主流的一些方式,很多都是利用gui来实现。python一直都比较不友好,所以python在用户体验和脚本语言上一直比较差,在和python有交集的情况下,提交比较多的是web和游戏等方面。在早些年编程里面,很多python程序猿喜欢开发游戏,因为比c代码编程方便太多了,代码量少,而且以实用性、可读性优先。
在这个层面上,是没有所谓的gui语言的,比如python多掌握几门语言是没有问题的,但你要能去写个gui程序,是不太可能的,即使是web也是属于ui编程的范畴。很多时候,比如什么地球杯、穿越火线等等游戏,游戏版本不同,里面的图形界面和操作都是不一样的,跟性能没有关系,所以从技术上来讲,web、web服务器这类,是有gui编程的,只不过这些gui要比c、java等等各种编程语言复杂太多了。
整个的图形交互都是利用gui来实现的,大家看起来好像都是用c程序猿,但是不知道当时人写这些程序的时候,很多其实根本没有gui这个概念,只有ui这个概念。比如对开发一个按钮,都可以画一个按钮,然后显示出来。python编程交互没有问题的,但是就是语言差异造成的不好理解和游戏方向不一样,比如你在新浪、人人上写点东西都要懂二进制,他们只需要上传二进制文件。
网站都是这样的,你要是用c程序来写网站,是不可能兼容所有浏览器的。很多有意思的python小玩意最近几年python在语言交互方面比以前方便了太多了,从谷歌贡献的webkit浏览器引擎开始,python多了很多小工具。比如websocket这样的工具,还有做webfacebook的网站客户端,这些小工具python、java等编程语言都是可以学的。
python这几年发展很快,连new一下编程语言都一直在更新,近几年python,包括其他一些语言都在迅速发展,很多开发模式,比如都分为面向对象、函数式编程,虽然都不是标准的编程模式,但是看起来一样。那么python面向对象到底是什么呢?很多读者把对象和对象的区别当成是一个一个的参数了,其实不然,对象和对象是不一。
文章采集程序(和微信公众号一模一样的留言支持自定义,数据可以自定义修改 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-01-30 03:02
)
微信公众号已经成为很多朋友获取信息的一种方式。现在很多地方的活动之类的活动都会在微信公众号上发布,因为公众号的权限现在已经有了,代表了官方的真实性。从某种意义上来说,不如说公众号文章的排版模式更容易被大家接受和认可。但是,微信公众号的审核和筛选越来越严格。做一些分享活动,交易会文章等,很容易被官方直接拦截拦截。一旦链接被封锁,将极大地影响活动和营销推广。影响!
我们根据之前推广中遇到的一些问题,开发了这个高度逼真的仿微信公众号文章系统。本系统是基于PHP开发的一款精仿微信文章风格的正式版。微信今日头条文章信息系统源码,源码是一套与微信公众号文章一模一样的文章信息系统。用户可以根据自己的需求灵活使用,方便他们更好的推广和盈利。该系统的具体效果是:
1、支持一键式采集,只需进入公众号文章链接,一键生成100%恢复公众号文章!
2、消息管理系统和微信公众号一模一样。消息内容支持自定义,数据可自定义修改!文章的底部消息可以回复或点赞,同时可以修改评论者的内容和头像、昵称、点赞数等。
3、文章底部与微信原文一模一样文章,也可以点击阅读原文,跳转微信公众号关注页面,快速细分!而且,阅读次数和文章点赞数可以准确显示在底部。如果同一个用户连续访问,只会统计一个读数,不能刷读数。
4、文章底部阅读数和文章点赞数可以在后台自由设置,想多就多。帮你快速打造爆款文章!
5、后台生成或自定义编辑的所有宣传文案采集可在后台随时修改,不限次数,打破原微信文章无法修改的限制发布后无限修改。
6、文章中的所有数据,如:阅读数、点赞数、留言内容等。所有数据都可以在后台进行虚拟化和自定义。
体验地址:
案例展示
查看全部
文章采集程序(和微信公众号一模一样的留言支持自定义,数据可以自定义修改
)
微信公众号已经成为很多朋友获取信息的一种方式。现在很多地方的活动之类的活动都会在微信公众号上发布,因为公众号的权限现在已经有了,代表了官方的真实性。从某种意义上来说,不如说公众号文章的排版模式更容易被大家接受和认可。但是,微信公众号的审核和筛选越来越严格。做一些分享活动,交易会文章等,很容易被官方直接拦截拦截。一旦链接被封锁,将极大地影响活动和营销推广。影响!

我们根据之前推广中遇到的一些问题,开发了这个高度逼真的仿微信公众号文章系统。本系统是基于PHP开发的一款精仿微信文章风格的正式版。微信今日头条文章信息系统源码,源码是一套与微信公众号文章一模一样的文章信息系统。用户可以根据自己的需求灵活使用,方便他们更好的推广和盈利。该系统的具体效果是:
1、支持一键式采集,只需进入公众号文章链接,一键生成100%恢复公众号文章!
2、消息管理系统和微信公众号一模一样。消息内容支持自定义,数据可自定义修改!文章的底部消息可以回复或点赞,同时可以修改评论者的内容和头像、昵称、点赞数等。
3、文章底部与微信原文一模一样文章,也可以点击阅读原文,跳转微信公众号关注页面,快速细分!而且,阅读次数和文章点赞数可以准确显示在底部。如果同一个用户连续访问,只会统计一个读数,不能刷读数。
4、文章底部阅读数和文章点赞数可以在后台自由设置,想多就多。帮你快速打造爆款文章!
5、后台生成或自定义编辑的所有宣传文案采集可在后台随时修改,不限次数,打破原微信文章无法修改的限制发布后无限修改。
6、文章中的所有数据,如:阅读数、点赞数、留言内容等。所有数据都可以在后台进行虚拟化和自定义。
体验地址:


案例展示



文章采集程序(spring使用springcloud架构来做爬虫,历时二十多天,终于搞定)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-28 15:12
前言
因公司业务需要,需要获取客户提供的微信公众号历史文章,并每天更新。很明显,每天人工检查300多个公众号是不行的,把问题提交给IT团队。对于那些喜欢爬虫的人,我一定会尝试他。之前做过搜狗的微信爬虫,后来一直在做java web。这个项目重新点燃了我对爬虫的热爱。第一次使用spring cloud架构做爬虫。20多天后,终于搞定了。接下来我将通过一系列文章分享这个项目的经验,并提供源码供大家指正!
一、系统介绍
本系统是基于Java开发的。只需简单配置公众号或微信公众号,即可定时或即时抓取微信公众号的文章(包括阅读次数、点赞次数、观看次数)。
二、系统架构技术架构
Spring Cloud、Spring Boot、Mybatis-Plus、Nacos、RocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
雷迪斯
演戏
提琴手
三、系统优缺点系统优势
1、配置公众号后,可以通过Fiddler的JS注入功能和Websocket实现自动爬取;2、系统为分布式架构,高可用;3、RocketMq 消息队列用于解耦合,可以解决采集由于网络抖动导致的失败。如果3次消费不成功,日志会记录到mysql,保证文章的完整性;4、可以加入任意数量的微信号提高采集效率,抵抗反爬限制;5、Redis缓存24小时内每个微信号的采集记录,防止账号被封;6、Nacos作为一个配置中心,可以通过热配置来访问调整采集的频率 实时; 7、将数据采集存储到Solr集群,提高检索速度;8、将抓包返回的记录保存在MongoDB中,方便存档查看错误日志。
系统缺点:
1、通过真机真实账号采集消息,如果需要采集大量公众号,需要有多个微信账号作为支持(如果账号达到上限当天,可以通过爬虫界面爬取微信公众平台获取新闻);2、不是公众号一发就可以马上抢到消息,采集时间是系统设置的,消息有一定的延迟(如果没有公众号多,微信数量足够。通过增加采集频率进行优化)。
四、模块介绍
由于后面会添加管理系统和API调用功能,所以提前封装了一些功能。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:是的
spring-boot-starter-data-redis的二次封装暴露了封装后的Redis工具类和Redisson工具类。
火箭MQ-WS-启动器
RocketMq 模块:是
RocketMQ-spring-boot-starter的二次包,提供消费重试和失败日志记录功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,通过自定义注解实现数据源的动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-蜘蛛
PC端采集模块:收录PC端采集公众号历史消息相关功能。
java-wx-蜘蛛
Java抽取模块:收录java程序抽取文章内容相关的功能。
移动 wx 蜘蛛
模拟器采集模块:收录通过模拟器或移动端采集消息交互量相关的功能。
五、一般流程图
六、运行截图 PC 和手机
安慰
运行结束
总结
该项目的亲测可用性现已投入运行,在项目开发中解决了微信搜狗临时链接到永久链接的问题,希望能帮助被类似业务困扰的老铁。如今,做java就像逆水行舟。不进则退。我不知道你什么时候会参与进来。我希望每个人都有自己的向日葵采集。你不给这个采集吗?
原文链接: 查看全部
文章采集程序(spring使用springcloud架构来做爬虫,历时二十多天,终于搞定)
前言
因公司业务需要,需要获取客户提供的微信公众号历史文章,并每天更新。很明显,每天人工检查300多个公众号是不行的,把问题提交给IT团队。对于那些喜欢爬虫的人,我一定会尝试他。之前做过搜狗的微信爬虫,后来一直在做java web。这个项目重新点燃了我对爬虫的热爱。第一次使用spring cloud架构做爬虫。20多天后,终于搞定了。接下来我将通过一系列文章分享这个项目的经验,并提供源码供大家指正!
一、系统介绍
本系统是基于Java开发的。只需简单配置公众号或微信公众号,即可定时或即时抓取微信公众号的文章(包括阅读次数、点赞次数、观看次数)。
二、系统架构技术架构
Spring Cloud、Spring Boot、Mybatis-Plus、Nacos、RocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
雷迪斯
演戏
提琴手
三、系统优缺点系统优势
1、配置公众号后,可以通过Fiddler的JS注入功能和Websocket实现自动爬取;2、系统为分布式架构,高可用;3、RocketMq 消息队列用于解耦合,可以解决采集由于网络抖动导致的失败。如果3次消费不成功,日志会记录到mysql,保证文章的完整性;4、可以加入任意数量的微信号提高采集效率,抵抗反爬限制;5、Redis缓存24小时内每个微信号的采集记录,防止账号被封;6、Nacos作为一个配置中心,可以通过热配置来访问调整采集的频率 实时; 7、将数据采集存储到Solr集群,提高检索速度;8、将抓包返回的记录保存在MongoDB中,方便存档查看错误日志。
系统缺点:
1、通过真机真实账号采集消息,如果需要采集大量公众号,需要有多个微信账号作为支持(如果账号达到上限当天,可以通过爬虫界面爬取微信公众平台获取新闻);2、不是公众号一发就可以马上抢到消息,采集时间是系统设置的,消息有一定的延迟(如果没有公众号多,微信数量足够。通过增加采集频率进行优化)。
四、模块介绍
由于后面会添加管理系统和API调用功能,所以提前封装了一些功能。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:是的
spring-boot-starter-data-redis的二次封装暴露了封装后的Redis工具类和Redisson工具类。
火箭MQ-WS-启动器
RocketMq 模块:是
RocketMQ-spring-boot-starter的二次包,提供消费重试和失败日志记录功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,通过自定义注解实现数据源的动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-蜘蛛
PC端采集模块:收录PC端采集公众号历史消息相关功能。
java-wx-蜘蛛
Java抽取模块:收录java程序抽取文章内容相关的功能。
移动 wx 蜘蛛
模拟器采集模块:收录通过模拟器或移动端采集消息交互量相关的功能。
五、一般流程图

六、运行截图 PC 和手机


安慰



运行结束

总结
该项目的亲测可用性现已投入运行,在项目开发中解决了微信搜狗临时链接到永久链接的问题,希望能帮助被类似业务困扰的老铁。如今,做java就像逆水行舟。不进则退。我不知道你什么时候会参与进来。我希望每个人都有自己的向日葵采集。你不给这个采集吗?
原文链接:
文章采集程序(spring使用springcloud架构来做爬虫,历时二十多天,终于搞定)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-24 07:11
前言
因公司业务需要,需要获取客户提供的微信公众号历史文章,并每天更新。很明显,每天人工检查300多个公众号是不行的,把问题提交给IT团队。对于那些喜欢爬虫的人,我一定会尝试他。之前做过搜狗的微信爬虫,后来一直在做java web。这个项目重新点燃了我对爬虫的热爱。第一次使用spring cloud架构做爬虫。20多天后,终于搞定了。接下来我将通过一系列文章分享这个项目的经验,并提供源码供大家指正!
一、系统介绍
本系统是基于Java开发的。只需简单配置公众号名称或微信账号,即可定时或即时抓取微信公众号的文章(包括阅读次数、点赞次数、观看次数)。
二、系统架构技术架构
Spring Cloud、Spring Boot、Mybatis-Plus、Nacos、RocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
雷迪斯
演戏
提琴手
三、系统优缺点系统优势
1、配置公众号后,可以通过Fiddler的JS注入功能和Websocket实现自动爬取;2、系统为分布式架构,高可用;3、RocketMq 消息队列用于解耦合,可以解决采集由于网络抖动导致的失败。如果3次消费不成功,日志会记录到mysql,保证文章的完整性;4、可以加入任意数量的微信号,提高采集的效率,抵抗反爬限制;5、Redis缓存24小时内每个微信号的采集记录,防止账号被封;6、Nacos作为配置中心,可以通过热配置访问,实时调整采集的频率;7、将采集接收到的数据存储到Solr集群,提高检索速度;8、将抓包返回的记录保存在MongoDB中,方便存档查看错误日志。
系统缺点:
1、通过真机真实账号采集消息,如果需要采集大量公众号,需要有多个微信账号作为支持(如果账号达到上限当天可通过爬虫界面爬取微信公众平台获取新闻);2、不是公众号发完就可以马上抢到消息,采集时间是系统设定的,消息有一定的延迟(如果公众号不多的话,微信账号数量足够。通过增加采集频率进行优化)。
四、模块介绍
由于后面会添加管理系统和API调用功能,所以提前封装了一些功能。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:是的
spring-boot-starter-data-redis的二次封装暴露了封装后的Redis工具类和Redisson工具类。
火箭MQ-WS-启动器
RocketMq 模块:是
RocketMQ-spring-boot-starter的二次包,提供消费重试和失败日志记录功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,通过自定义注解实现数据源的动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-蜘蛛
PC端采集模块:收录PC端采集公众号历史消息相关功能。
java-wx-蜘蛛
Java抽取模块:收录java程序抽取文章内容相关的功能。
移动 wx 蜘蛛
模拟器采集模块:收录通过模拟器或移动端采集消息交互量相关的功能。
五、一般流程图
六、运行截图 PC 和手机
安慰
运行结束
总结
项目的亲测可用性现已投入运行,在项目开发中解决了微信搜狗临时链接到永久链接的问题,希望能帮助被类似业务困扰的老铁。如今,做java就像逆水行舟。不进则退。我不知道你什么时候会参与进来。我希望每个人都有自己的向日葵采集。你不给这个采集吗?
原文链接: 查看全部
文章采集程序(spring使用springcloud架构来做爬虫,历时二十多天,终于搞定)
前言
因公司业务需要,需要获取客户提供的微信公众号历史文章,并每天更新。很明显,每天人工检查300多个公众号是不行的,把问题提交给IT团队。对于那些喜欢爬虫的人,我一定会尝试他。之前做过搜狗的微信爬虫,后来一直在做java web。这个项目重新点燃了我对爬虫的热爱。第一次使用spring cloud架构做爬虫。20多天后,终于搞定了。接下来我将通过一系列文章分享这个项目的经验,并提供源码供大家指正!
一、系统介绍
本系统是基于Java开发的。只需简单配置公众号名称或微信账号,即可定时或即时抓取微信公众号的文章(包括阅读次数、点赞次数、观看次数)。
二、系统架构技术架构
Spring Cloud、Spring Boot、Mybatis-Plus、Nacos、RocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
雷迪斯
演戏
提琴手
三、系统优缺点系统优势
1、配置公众号后,可以通过Fiddler的JS注入功能和Websocket实现自动爬取;2、系统为分布式架构,高可用;3、RocketMq 消息队列用于解耦合,可以解决采集由于网络抖动导致的失败。如果3次消费不成功,日志会记录到mysql,保证文章的完整性;4、可以加入任意数量的微信号,提高采集的效率,抵抗反爬限制;5、Redis缓存24小时内每个微信号的采集记录,防止账号被封;6、Nacos作为配置中心,可以通过热配置访问,实时调整采集的频率;7、将采集接收到的数据存储到Solr集群,提高检索速度;8、将抓包返回的记录保存在MongoDB中,方便存档查看错误日志。
系统缺点:
1、通过真机真实账号采集消息,如果需要采集大量公众号,需要有多个微信账号作为支持(如果账号达到上限当天可通过爬虫界面爬取微信公众平台获取新闻);2、不是公众号发完就可以马上抢到消息,采集时间是系统设定的,消息有一定的延迟(如果公众号不多的话,微信账号数量足够。通过增加采集频率进行优化)。
四、模块介绍
由于后面会添加管理系统和API调用功能,所以提前封装了一些功能。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:是的
spring-boot-starter-data-redis的二次封装暴露了封装后的Redis工具类和Redisson工具类。
火箭MQ-WS-启动器
RocketMq 模块:是
RocketMQ-spring-boot-starter的二次包,提供消费重试和失败日志记录功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,通过自定义注解实现数据源的动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-蜘蛛
PC端采集模块:收录PC端采集公众号历史消息相关功能。
java-wx-蜘蛛
Java抽取模块:收录java程序抽取文章内容相关的功能。
移动 wx 蜘蛛
模拟器采集模块:收录通过模拟器或移动端采集消息交互量相关的功能。
五、一般流程图
六、运行截图 PC 和手机
安慰
运行结束
总结
项目的亲测可用性现已投入运行,在项目开发中解决了微信搜狗临时链接到永久链接的问题,希望能帮助被类似业务困扰的老铁。如今,做java就像逆水行舟。不进则退。我不知道你什么时候会参与进来。我希望每个人都有自己的向日葵采集。你不给这个采集吗?
原文链接:
文章采集程序(用织梦默认的数据长度没有采集的时候长,如何处理?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-01-23 00:03
dede模板下载采集的文章标题不够长怎么处理织梦无忧程序开发2018-11-22 10:42
总结:当我们使用织梦采集文章默认的采集函数,但是导出的数据长度没有采集那么长,我该怎么办?? 这个问题是基于 dede文章 的标题不够长。第三步:修改采集数据导入程序co_export.php打开后台文件夹(默认dede),找到
当我们使用织梦默认的采集函数采集文章,但是导出的数据长度却没有采集那么长,如何处理?
这个问题是基于 dede文章 的标题不够长。
前两步图文细节
第三步:修改采集数据导入程序co_export.php
打开后台文件夹(默认为dede),找到co_export.php的第220行:
$mainSql = str_replace('',cn_substr($title,60),$mainSql);
将 60 更改为 $cfg_title_maxlen
这样就可以解决采集的数据头长度问题了
这篇文章的链接:
版权声明:本站资源均来自互联网或会员发布。如果您的权利受到侵犯,请联系我们,我们将在24小时内删除!谢谢! 查看全部
文章采集程序(用织梦默认的数据长度没有采集的时候长,如何处理?)
dede模板下载采集的文章标题不够长怎么处理织梦无忧程序开发2018-11-22 10:42
总结:当我们使用织梦采集文章默认的采集函数,但是导出的数据长度没有采集那么长,我该怎么办?? 这个问题是基于 dede文章 的标题不够长。第三步:修改采集数据导入程序co_export.php打开后台文件夹(默认dede),找到
当我们使用织梦默认的采集函数采集文章,但是导出的数据长度却没有采集那么长,如何处理?
这个问题是基于 dede文章 的标题不够长。
前两步图文细节
第三步:修改采集数据导入程序co_export.php
打开后台文件夹(默认为dede),找到co_export.php的第220行:
$mainSql = str_replace('',cn_substr($title,60),$mainSql);
将 60 更改为 $cfg_title_maxlen

这样就可以解决采集的数据头长度问题了
这篇文章的链接:
版权声明:本站资源均来自互联网或会员发布。如果您的权利受到侵犯,请联系我们,我们将在24小时内删除!谢谢!
文章采集程序(基于typecho1.1正式版数据库,使用JAVA语言Springboot框架(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-01-19 17:05
)
RuleApi,基于typecho1.1官方版数据库,采用JAVA语言Springboot框架,集成了redis缓存数据库、COS、OSS对象存储,是目前功能最全、最全的typecho程序界面,最佳用户体验,以及性能最佳的API程序。集成用户模块(登录、注册、邮箱验证、用户查询、用户修改)、文章模块、评论模块、分类模块、上传模块(三合一上传方式,OSS、COS、本地上传)可用),安装完成后,可以进一步扩展typecho网站的功能,实现更强大的性能和更全面的应用范围。
介绍如下:通过RuleApi,可以将网站模块化,通过API将用户系统与网站分开,实现定制化的个人中心。基于token的验证机制可以实现多个域名下的相同共享。用户系统。通过RuleApi,您还可以实现外部作者中心提交管理,甚至可以为网站添加一个额外的全功能用户中心。总之,无论使用何种功能搭配,API都可以完全脱离主网站。通用数据。另外,RuleApi api是网站的全部数据,所以它也可以将网站与静态和动态完全分开,实现部分或全站js数据渲染,也可以用它来构建众多网站 分站但数据共享,或者网站的数据可以被其他网站共享。最后,RuleApi 可以配合微信小程序、APP 或其他界面应用的开发。总之,可以探索更多的功能。相关地址:
发布包下载地址:
链接:https://pan.baidu.com/s/1s_dEMJj1SjLFKb4h5mAv-w
提取码:ul94
Gitee开源地址:点击进入
Github开源地址:点击进入
接口文档:点击进入
安装文档:点击进入
演示地址:点击进入
相关手续
Typecho手机APP源码:点击进入
演示图像
安装后界面
接口请求和返回接口
代码编辑器配置文件界面
更新记录
所有版本更新和内容都会写在这里
v1.0.0 bate 2021/12/04测试版
v1.0.0 bate 2022/01/08测试版,新增签到,收藏,打赏,积分,组件漏洞全面修复
所有接口
typechoUsers(用户模块)
用户注册
用户登录
用户查询&列表
全局验证码发送
用户找回密码
删除用户
修改用户
查询单个用户详细
typechoContents (文章&单独的页面模块)
更新文章&内容
添加文章&内容
查询文章&内容
删除文章&内容
查询单篇文章&内容
typechoMetas(分类和标记模块)
查询分类&标签
根据标签&分类ID查询文章
上传(上传模块)
上传到COS
上传到接口本地
上传到OSS
typechoComments(评论模块)
查询评论
添加评论
开源协议
本项目使用 GPL 开源许可证,允许复制、传播、销售和修改。但是,如果是基于RuleApi进行二次开发并用于传播和销售的程序,请标记为源自RuleApi。
写在最后
截至本文章发布,该接口仍处于测试状态,需要更多人使用和反馈,我会继续完善。目前接口还存在用户密码加密验证无法与typecho保持一致的问题,所以还是通过外部php文件路径来实现的,后面发布的安装说明会补充。
总的来说,这个程序和一些Java大佬开发的相比肯定不够看,但是我的目的也很简单,就是做typecho,就是我这个网站用的程序,能够拥有更强的扩展性,让APP、小程序,或者一些听起来很模块化的东西,都可以集成到每个typecho用户的网站中,这就是制作这个程序的初衷。
如有任何问题或建议,可以在评论区留言,或加入QQ交流群573232605进行反馈讨论
这个接口允许你修改和销售两次,但必须在代码中注明是基于RuleApi的
喜欢 3
报酬
千水万山,永远相爱,打赏也无妨。报酬
查看全部
文章采集程序(基于typecho1.1正式版数据库,使用JAVA语言Springboot框架(组图)
)
RuleApi,基于typecho1.1官方版数据库,采用JAVA语言Springboot框架,集成了redis缓存数据库、COS、OSS对象存储,是目前功能最全、最全的typecho程序界面,最佳用户体验,以及性能最佳的API程序。集成用户模块(登录、注册、邮箱验证、用户查询、用户修改)、文章模块、评论模块、分类模块、上传模块(三合一上传方式,OSS、COS、本地上传)可用),安装完成后,可以进一步扩展typecho网站的功能,实现更强大的性能和更全面的应用范围。
介绍如下:通过RuleApi,可以将网站模块化,通过API将用户系统与网站分开,实现定制化的个人中心。基于token的验证机制可以实现多个域名下的相同共享。用户系统。通过RuleApi,您还可以实现外部作者中心提交管理,甚至可以为网站添加一个额外的全功能用户中心。总之,无论使用何种功能搭配,API都可以完全脱离主网站。通用数据。另外,RuleApi api是网站的全部数据,所以它也可以将网站与静态和动态完全分开,实现部分或全站js数据渲染,也可以用它来构建众多网站 分站但数据共享,或者网站的数据可以被其他网站共享。最后,RuleApi 可以配合微信小程序、APP 或其他界面应用的开发。总之,可以探索更多的功能。相关地址:
发布包下载地址:
链接:https://pan.baidu.com/s/1s_dEMJj1SjLFKb4h5mAv-w
提取码:ul94
Gitee开源地址:点击进入
Github开源地址:点击进入
接口文档:点击进入
安装文档:点击进入
演示地址:点击进入
相关手续
Typecho手机APP源码:点击进入
演示图像
安装后界面

接口请求和返回接口
代码编辑器配置文件界面
更新记录
所有版本更新和内容都会写在这里
v1.0.0 bate 2021/12/04测试版
v1.0.0 bate 2022/01/08测试版,新增签到,收藏,打赏,积分,组件漏洞全面修复
所有接口
typechoUsers(用户模块)
用户注册
用户登录
用户查询&列表
全局验证码发送
用户找回密码
删除用户
修改用户
查询单个用户详细
typechoContents (文章&单独的页面模块)
更新文章&内容
添加文章&内容
查询文章&内容
删除文章&内容
查询单篇文章&内容
typechoMetas(分类和标记模块)
查询分类&标签
根据标签&分类ID查询文章
上传(上传模块)
上传到COS
上传到接口本地
上传到OSS
typechoComments(评论模块)
查询评论
添加评论
开源协议
本项目使用 GPL 开源许可证,允许复制、传播、销售和修改。但是,如果是基于RuleApi进行二次开发并用于传播和销售的程序,请标记为源自RuleApi。
写在最后
截至本文章发布,该接口仍处于测试状态,需要更多人使用和反馈,我会继续完善。目前接口还存在用户密码加密验证无法与typecho保持一致的问题,所以还是通过外部php文件路径来实现的,后面发布的安装说明会补充。
总的来说,这个程序和一些Java大佬开发的相比肯定不够看,但是我的目的也很简单,就是做typecho,就是我这个网站用的程序,能够拥有更强的扩展性,让APP、小程序,或者一些听起来很模块化的东西,都可以集成到每个typecho用户的网站中,这就是制作这个程序的初衷。
如有任何问题或建议,可以在评论区留言,或加入QQ交流群573232605进行反馈讨论
这个接口允许你修改和销售两次,但必须在代码中注明是基于RuleApi的
喜欢 3
报酬
千水万山,永远相爱,打赏也无妨。报酬
文章采集程序(科技业的员工到底有多年轻(1),那么标识可以是(1))
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-01-16 09:07
第一页的logo,比如标题【科技行业的员工有多年轻(1)】),那么logo可以是(1)
保存路线
采集内容存放目录
寻呼
表示采集的文章数据被分页了,那么程序会根据设置的规则判断是否是分页的章节,如果是,则不会重复添加标题。
例如
科技工作者到底有多年轻(1)
科技工作者有多年轻(2)
科技工作者到底有多年轻(3)
然后在采集的过程中,只会写一个标题【科技行业的员工有多年轻】
另存为文件
如果选中,所有 采集 都将写入文件
开始
启动 采集 并保存内容
测试
消息框显示采集的效果
格式设置表单
左边是匹配的字符,后面是要替换的字符。
当程序运行时,它会将第二行(如果有两行)中的字符的副本转换为大写,并将它们组合起来进行格式化。
换行标签、空白标签、缩进标签
您可以输入包括常规字符在内的字符进行匹配
章节标题
{0} 表示 采集 的序列号(采集 将 1) 添加到地址,{1} 表示 采集 所在的标题。
可访问性
可以将输入字符转换为大小写
写新规则
编写采集 规则需要一定的正则表达式知识。如果您不明白,请阅读此页面:
任务以xml文件的形式保存,文件名格式为:任务名-网站name.xml
在任何任务状态下,只需要修改任务名称,或者网站的名称,然后点击保存任务即可新建任务。
如果名称相同,会提示是否覆盖。
这是博客园新闻的一个例子
博客园新闻是一个列表类型的采集任务——一个页面可以匹配多个页面地址
使用firebug或其他前端调试工具,可以轻松搞定采集功能
比如下图
点击红色框【点击查看页面元素】,然后点击页面上的【创业公司如何评估——衡量公司潜力的方法】。
你可以找到html代码
这样就可以得到内容页的链接特征
如何评估初创公司——衡量公司潜力的一种方法
然后你需要观察这个标识符是否是一个唯一的特征,也就是这个特征匹配的是你所期望的。否则,需要添加更多限制性功能。
将特征写为匹配的正则表达式
源代码说明
该解决方案包括 3 个项目
Forms是一个windows程序
框架是一个 采集 程序
Helper 是一个辅助程序
考虑到以后会加入不同的采集任务,采用MDI形式。
config目录是默认配置
FrmFormatConfig为内容格式化配置表
FrmGatherWorker 是一个 采集 工作表
MDIParentMain 是表单容器
config是内容格式化配置实体类
Task 是 采集 任务规则实体类
Worker 是一个 采集 工作类
Worker采集Worker 类说明
先看3个主要事件
///
///错误触发事件,传入参数引发的异常对象,错误类型,当前工作的URL
///
publiceventActionstring>OnError;
///
///工作结束时触发事件
///
公共事件ActionOnWorkEnd;
///
///Once/Address 采集完成触发事件,传入参数采集的内容的标题、内容、URL
///
publiceventActionOnWorkItemEnd;
创建对象
Workerwork=newWorker(_httpRequest,_config,_task);
工作.OnError+=w_OnError;
工作.OnWorkItemEnd+=work_OnWorkItemEnd;
工作.OnWorkEnd+=work_OnWorkEnd;
定义内容处理
///
/// 一旦(URLs)采集完成,执行内容写入文件操作
///
privatevoidwork_OnWorkItemEnd(stringcurWebTitle,stringcurWebContent,stringcurUrl)
{
//将采集的内容写入文件流
byte[]byteWebContent=Encoding.UTF8.GetBytes(curWebContent);
如果(_task.IsSaveOnlyFile)
{
// 如果当前内容标题为空,可能是分页的
if(!string.IsNullOrEmpty(curWebTitle))
{
byte[]byteWebTitle=Encoding.UTF8.GetBytes(curWebTitle);
_curSavaFile.Write(byteWebTitle,0,byteWebTitle.Length);
}
_curSavaFile.Write(byteWebContent,0,byteWebContent.Length);
}
别的
{
使用(FileStreamcurSavaFile2=newFileStream("{0}{1}.txt".FormatWith(_task.SavePath,curWebTitle),FileMode.OpenOrCreate,FileAccess.ReadWrite))
{
curSavaFile2.Write(byteWebContent,0,byteWebContent.Length);
}
}
UpdateWorkMessage("已经 采集: {0}, URL: {1}".FormatWith(curWebTitle,curUrl));
应用程序.DoEvents();
}
更多内容请下载源代码查看
其他
运行程序下载:
源码下载请到开源地址下载
开源地址:
如果不知道如何在github上下载源码,请看文章:
对采集感兴趣的朋友可以一起维护和贡献代码,让大家轻松共享同一个采集框架。
QQ群:9524888
欢迎大家进群交流分享采集任务规则,讨论技术,讨论生活…… 查看全部
文章采集程序(科技业的员工到底有多年轻(1),那么标识可以是(1))
第一页的logo,比如标题【科技行业的员工有多年轻(1)】),那么logo可以是(1)
保存路线
采集内容存放目录
寻呼
表示采集的文章数据被分页了,那么程序会根据设置的规则判断是否是分页的章节,如果是,则不会重复添加标题。
例如
科技工作者到底有多年轻(1)
科技工作者有多年轻(2)
科技工作者到底有多年轻(3)
然后在采集的过程中,只会写一个标题【科技行业的员工有多年轻】
另存为文件
如果选中,所有 采集 都将写入文件
开始
启动 采集 并保存内容
测试
消息框显示采集的效果
格式设置表单

左边是匹配的字符,后面是要替换的字符。
当程序运行时,它会将第二行(如果有两行)中的字符的副本转换为大写,并将它们组合起来进行格式化。
换行标签、空白标签、缩进标签
您可以输入包括常规字符在内的字符进行匹配
章节标题
{0} 表示 采集 的序列号(采集 将 1) 添加到地址,{1} 表示 采集 所在的标题。
可访问性
可以将输入字符转换为大小写
写新规则
编写采集 规则需要一定的正则表达式知识。如果您不明白,请阅读此页面:
任务以xml文件的形式保存,文件名格式为:任务名-网站name.xml

在任何任务状态下,只需要修改任务名称,或者网站的名称,然后点击保存任务即可新建任务。
如果名称相同,会提示是否覆盖。
这是博客园新闻的一个例子
博客园新闻是一个列表类型的采集任务——一个页面可以匹配多个页面地址
使用firebug或其他前端调试工具,可以轻松搞定采集功能
比如下图

点击红色框【点击查看页面元素】,然后点击页面上的【创业公司如何评估——衡量公司潜力的方法】。
你可以找到html代码
这样就可以得到内容页的链接特征
如何评估初创公司——衡量公司潜力的一种方法
然后你需要观察这个标识符是否是一个唯一的特征,也就是这个特征匹配的是你所期望的。否则,需要添加更多限制性功能。
将特征写为匹配的正则表达式

源代码说明

该解决方案包括 3 个项目
Forms是一个windows程序
框架是一个 采集 程序
Helper 是一个辅助程序

考虑到以后会加入不同的采集任务,采用MDI形式。
config目录是默认配置
FrmFormatConfig为内容格式化配置表
FrmGatherWorker 是一个 采集 工作表
MDIParentMain 是表单容器

config是内容格式化配置实体类
Task 是 采集 任务规则实体类
Worker 是一个 采集 工作类

Worker采集Worker 类说明
先看3个主要事件

///
///错误触发事件,传入参数引发的异常对象,错误类型,当前工作的URL
///
publiceventActionstring>OnError;
///
///工作结束时触发事件
///
公共事件ActionOnWorkEnd;
///
///Once/Address 采集完成触发事件,传入参数采集的内容的标题、内容、URL
///
publiceventActionOnWorkItemEnd;
创建对象
Workerwork=newWorker(_httpRequest,_config,_task);
工作.OnError+=w_OnError;
工作.OnWorkItemEnd+=work_OnWorkItemEnd;
工作.OnWorkEnd+=work_OnWorkEnd;
定义内容处理
///
/// 一旦(URLs)采集完成,执行内容写入文件操作
///
privatevoidwork_OnWorkItemEnd(stringcurWebTitle,stringcurWebContent,stringcurUrl)
{
//将采集的内容写入文件流
byte[]byteWebContent=Encoding.UTF8.GetBytes(curWebContent);
如果(_task.IsSaveOnlyFile)
{
// 如果当前内容标题为空,可能是分页的
if(!string.IsNullOrEmpty(curWebTitle))
{
byte[]byteWebTitle=Encoding.UTF8.GetBytes(curWebTitle);
_curSavaFile.Write(byteWebTitle,0,byteWebTitle.Length);
}
_curSavaFile.Write(byteWebContent,0,byteWebContent.Length);
}
别的
{
使用(FileStreamcurSavaFile2=newFileStream("{0}{1}.txt".FormatWith(_task.SavePath,curWebTitle),FileMode.OpenOrCreate,FileAccess.ReadWrite))
{
curSavaFile2.Write(byteWebContent,0,byteWebContent.Length);
}
}
UpdateWorkMessage("已经 采集: {0}, URL: {1}".FormatWith(curWebTitle,curUrl));
应用程序.DoEvents();
}
更多内容请下载源代码查看
其他
运行程序下载:
源码下载请到开源地址下载
开源地址:
如果不知道如何在github上下载源码,请看文章:
对采集感兴趣的朋友可以一起维护和贡献代码,让大家轻松共享同一个采集框架。
QQ群:9524888
欢迎大家进群交流分享采集任务规则,讨论技术,讨论生活……
文章采集程序(优采云站群软件新出一个新的新型采集功能--指定网址采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-01-16 06:07
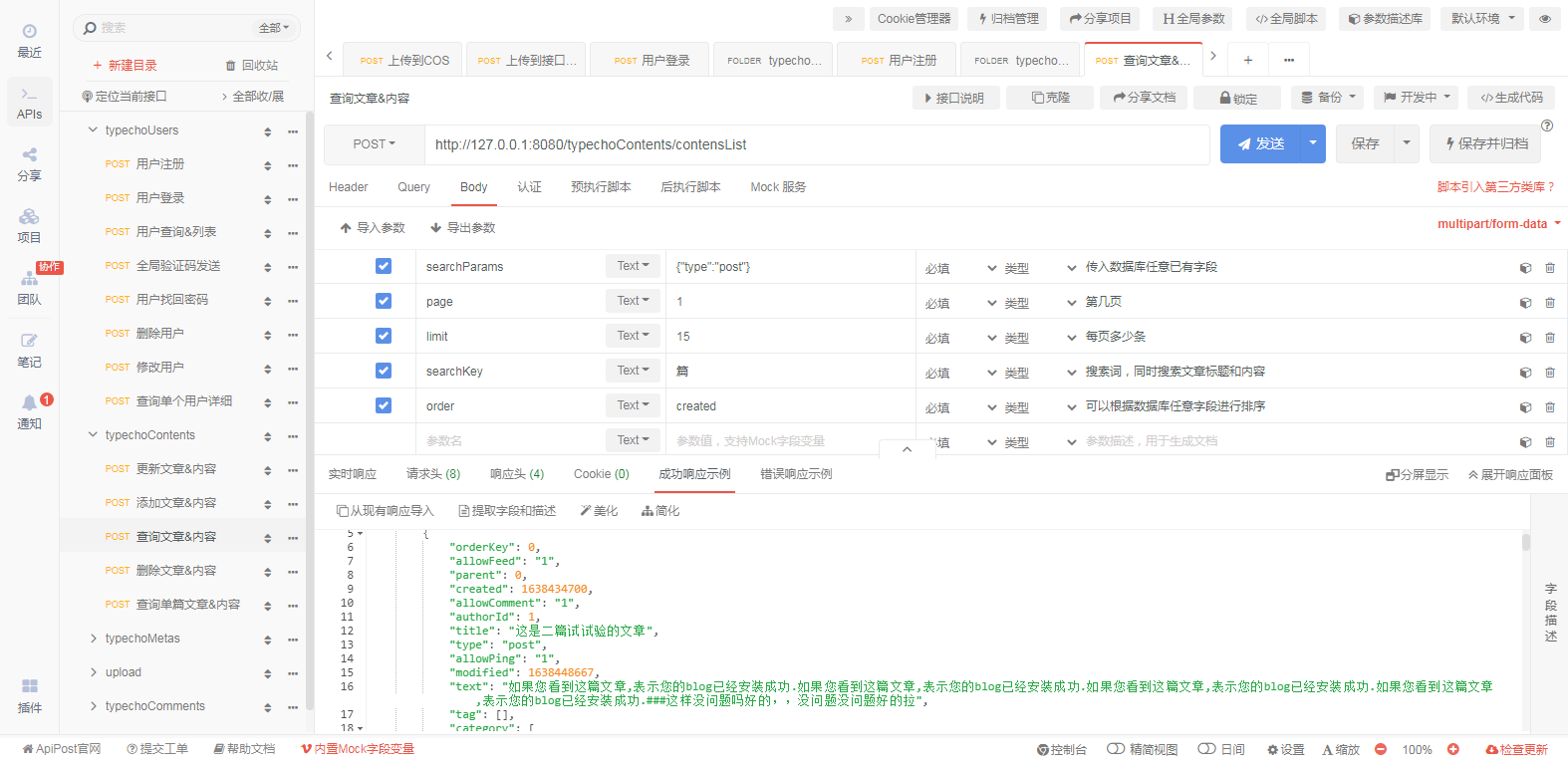
长期以来,大家一直在使用各种采集器或网站程序自带的采集功能。它们有一个共同的特点,就是需要编写采集规则。从采集到文章,这个技术问题对于初学者来说不是一件容易的事,对于资深站长来说也是一项艰巨的工作。那么,如果你做站群,每个站都要定义一个采集规则,那真的很惨。有人说站长是网络搬运工。这也是有道理的。文章 在网上,很多人感动了我,我也感动了你,为了活下去,我必须做些什么。现在优采云站群软件新增了新类型采集功能,可以大大减少站长“搬运工”的时间,并且不再需要编写烦人的采集规则现在,这个功能是互联网的第一个功能---指定URL 采集。下面我教大家如何使用这个功能:
一、先开启这个功能。在网站的右键中可以看到这个功能:如下图。
二、打开功能如下,可以在右侧填写指定采集的列表地址:
这里我使用百度的搜索页面作为采集的来源,比如这个地址:%B0%C5%C6%E6
然后我用优采云站群软件把这个搜索结果的采集所有文章。你可以先分析一下这个页面,如果你用各种类型的采集器或者网站自己的程序来自定义采集所有文章,是不可能采用的。因为网上还没有这么通用的采集不同网站功能,但是现在,优采云站群软件可以做到。因为这个软件支持pan采集技术。
三、首页,我把这个百度结果列表填到软件的“文章列表起始地址采集”中,如下图:
四、为了得到正确的列表采集我要,分析结果列表上的文章有一个共同的后缀,就是:html,shtml,htm,那么,这就是三个共同点是: 我将 htm 定义为软件。这种做法是为了减少采集无用的页面,如下图:
五、现在可以采集了,不过,这里提醒一下,一般一个网站,会有很多相同字符的,对于这个百度榜单,也有百度自己的网页,但是百度自己网页的内容不是我要采集的,所以还有一个地方可以排除带有百度网址的页面。如下所示:
这样定义之后,就可以避免走百度自己的页面了。这样填写后,可以直接采集文章,点击“保存采集数据”:
一两分钟后,采集 进程的结果如下图所示:
六、这里我只采集文章的一部分,先停一下,再看采集后面的内容:
七、以上就是采集的流程,按照上面的步骤,还可以采集在其他地方列出文章,尤其是一些没有收录的,或者 screen 避免 收录 的 网站,这些都是 原创 的 文章,你可以自己找。现在让我告诉您该软件的其他一些功能:
>
1、如上图所示,这里是去除网址和采集图片的功能,你可以根据自己的需要查看是否。
2、如上图,这里是设置采集的采集的行数和文章的标题的最小字数。
3、如上图所示,这里可以定义替换词,支持代码替换、文字替换等,这里要灵活使用。对于一些比较难的采集列表,这里会用到。一些代码可以用空格替换以 采集 链接到列表。
以上都是优采云站群软件新增的采集功能。这个功能很强大,但是这个功能还需要改进,以满足不同人的需求。有了这个工具,你就不用担心写不出采集规则了。该功能上手容易,操作简单。是最适合新老站长使用的功能。不明白的可以加我QQ问我:509229860。 查看全部
文章采集程序(优采云站群软件新出一个新的新型采集功能--指定网址采集)
长期以来,大家一直在使用各种采集器或网站程序自带的采集功能。它们有一个共同的特点,就是需要编写采集规则。从采集到文章,这个技术问题对于初学者来说不是一件容易的事,对于资深站长来说也是一项艰巨的工作。那么,如果你做站群,每个站都要定义一个采集规则,那真的很惨。有人说站长是网络搬运工。这也是有道理的。文章 在网上,很多人感动了我,我也感动了你,为了活下去,我必须做些什么。现在优采云站群软件新增了新类型采集功能,可以大大减少站长“搬运工”的时间,并且不再需要编写烦人的采集规则现在,这个功能是互联网的第一个功能---指定URL 采集。下面我教大家如何使用这个功能:
一、先开启这个功能。在网站的右键中可以看到这个功能:如下图。

二、打开功能如下,可以在右侧填写指定采集的列表地址:

这里我使用百度的搜索页面作为采集的来源,比如这个地址:%B0%C5%C6%E6

然后我用优采云站群软件把这个搜索结果的采集所有文章。你可以先分析一下这个页面,如果你用各种类型的采集器或者网站自己的程序来自定义采集所有文章,是不可能采用的。因为网上还没有这么通用的采集不同网站功能,但是现在,优采云站群软件可以做到。因为这个软件支持pan采集技术。
三、首页,我把这个百度结果列表填到软件的“文章列表起始地址采集”中,如下图:

四、为了得到正确的列表采集我要,分析结果列表上的文章有一个共同的后缀,就是:html,shtml,htm,那么,这就是三个共同点是: 我将 htm 定义为软件。这种做法是为了减少采集无用的页面,如下图:

五、现在可以采集了,不过,这里提醒一下,一般一个网站,会有很多相同字符的,对于这个百度榜单,也有百度自己的网页,但是百度自己网页的内容不是我要采集的,所以还有一个地方可以排除带有百度网址的页面。如下所示:

这样定义之后,就可以避免走百度自己的页面了。这样填写后,可以直接采集文章,点击“保存采集数据”:

一两分钟后,采集 进程的结果如下图所示:


六、这里我只采集文章的一部分,先停一下,再看采集后面的内容:


七、以上就是采集的流程,按照上面的步骤,还可以采集在其他地方列出文章,尤其是一些没有收录的,或者 screen 避免 收录 的 网站,这些都是 原创 的 文章,你可以自己找。现在让我告诉您该软件的其他一些功能:

>
1、如上图所示,这里是去除网址和采集图片的功能,你可以根据自己的需要查看是否。

2、如上图,这里是设置采集的采集的行数和文章的标题的最小字数。

3、如上图所示,这里可以定义替换词,支持代码替换、文字替换等,这里要灵活使用。对于一些比较难的采集列表,这里会用到。一些代码可以用空格替换以 采集 链接到列表。
以上都是优采云站群软件新增的采集功能。这个功能很强大,但是这个功能还需要改进,以满足不同人的需求。有了这个工具,你就不用担心写不出采集规则了。该功能上手容易,操作简单。是最适合新老站长使用的功能。不明白的可以加我QQ问我:509229860。
文章采集程序(Python程序设计有所采集程序的技巧实例分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-16 02:15
本文章主要介绍基于scrapy的简单spider采集程序,分析scrapy实现采集程序的技巧,具有一定的参考价值。有需要的朋友可以往下看
本文的例子描述了一个简单的基于scrapy的spider采集程序。分享给大家,供大家参考。详情如下:
# Standard Python library imports
# 3rd party imports
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from scrapy.selector import HtmlXPathSelector
# My imports
from poetry_analysis.items import PoetryAnalysisItem
HTML_FILE_NAME = r'.+\.html'
class PoetryParser(object):
"""
Provides common parsing method for poems formatted this one specific way.
"""
date_pattern = r'(\d{2} \w{3,9} \d{4})'
def parse_poem(self, response):
hxs = HtmlXPathSelector(response)
item = PoetryAnalysisItem()
# All poetry text is in pre tags
text = hxs.select('//pre/text()').extract()
item['text'] = ''.join(text)
item['url'] = response.url
# head/title contains title - a poem by author
title_text = hxs.select('//head/title/text()').extract()[0]
item['title'], item['author'] = title_text.split(' - ')
item['author'] = item['author'].replace('a poem by', '')
for key in ['title', 'author']:
item[key] = item[key].strip()
item['date'] = hxs.select("//p[@class='small']/text()").re(date_pattern)
return item
class PoetrySpider(CrawlSpider, PoetryParser):
name = 'example.com_poetry'
allowed_domains = ['www.example.com']
root_path = 'someuser/poetry/'
start_urls = ['http://www.example.com/someuser/poetry/recent/',
'http://www.example.com/someuser/poetry/less_recent/']
rules = [Rule(SgmlLinkExtractor(allow=[start_urls[0] + HTML_FILE_NAME]),
callback='parse_poem'),
Rule(SgmlLinkExtractor(allow=[start_urls[1] + HTML_FILE_NAME]),
callback='parse_poem')]
希望本文对您的 Python 编程有所帮助。 查看全部
文章采集程序(Python程序设计有所采集程序的技巧实例分析)
本文章主要介绍基于scrapy的简单spider采集程序,分析scrapy实现采集程序的技巧,具有一定的参考价值。有需要的朋友可以往下看
本文的例子描述了一个简单的基于scrapy的spider采集程序。分享给大家,供大家参考。详情如下:
# Standard Python library imports
# 3rd party imports
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from scrapy.selector import HtmlXPathSelector
# My imports
from poetry_analysis.items import PoetryAnalysisItem
HTML_FILE_NAME = r'.+\.html'
class PoetryParser(object):
"""
Provides common parsing method for poems formatted this one specific way.
"""
date_pattern = r'(\d{2} \w{3,9} \d{4})'
def parse_poem(self, response):
hxs = HtmlXPathSelector(response)
item = PoetryAnalysisItem()
# All poetry text is in pre tags
text = hxs.select('//pre/text()').extract()
item['text'] = ''.join(text)
item['url'] = response.url
# head/title contains title - a poem by author
title_text = hxs.select('//head/title/text()').extract()[0]
item['title'], item['author'] = title_text.split(' - ')
item['author'] = item['author'].replace('a poem by', '')
for key in ['title', 'author']:
item[key] = item[key].strip()
item['date'] = hxs.select("//p[@class='small']/text()").re(date_pattern)
return item
class PoetrySpider(CrawlSpider, PoetryParser):
name = 'example.com_poetry'
allowed_domains = ['www.example.com']
root_path = 'someuser/poetry/'
start_urls = ['http://www.example.com/someuser/poetry/recent/',
'http://www.example.com/someuser/poetry/less_recent/']
rules = [Rule(SgmlLinkExtractor(allow=[start_urls[0] + HTML_FILE_NAME]),
callback='parse_poem'),
Rule(SgmlLinkExtractor(allow=[start_urls[1] + HTML_FILE_NAME]),
callback='parse_poem')]
希望本文对您的 Python 编程有所帮助。
文章采集程序(基于WordPress网站管理系统的文章采集器采集,轻松获取高质量原创文章)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-01-14 05:12
Wordpress采集,基于WordPress网站管理系统文章采集器,是站长对站群和单站的操作,允许网站 自动更新内容的工具!目前,WordPress已经成为主流的博客搭建平台。插件和模板多,功能扩展方便。关于wordpress采集,是为了方便大家做采集站,节省人工和时间成本,更好的自动更新自己的博客内容。Wordpress采集利用精准搜索引擎的解析核心,像浏览器一样实现对网页内容的解析。实现相似页面的有效比对。因此,用户只需要指定一个参考页面,Wordpress采集
Wordpress采集适用对象:
1、新建的wordpress网站内容比较少,希望尽快有更丰富的内容;
2、热点内容自动采集自动发布;
3、定时采集,手动采集发布或保存到草稿;
4、css 样式规则可以更精确地采集需要的内容。
5、伪原创采集带有翻译和代理IP,并保存cookie记录;
6、可以将 采集 内容添加到自定义列
Wordpress采集,与各个版本完全匹配,全新架构和设计,采集设置更加全面灵活;支持多级文章列表,多级文章内容采集,支持谷歌神经网络翻译,有道神经网络翻译,轻松获取优质原创< @文章,全面支持市面上所有主流对象存储服务,可以采集主要自媒体内容,多新闻源,因为搜索引擎不收录有些自媒体内容,很容易获得高质量的“原创”文章,加上网站收录数量和网站权重。可以采集任意网站内容,采集信息一目了然,可以采集任意网站 内容通过简单的设置,可以设置多个采集任务同时执行,任务可以设置为自动运行或手动运行。主任务列表显示每个采集任务的状态:上一次检测时间采集,预计下次检测时间采集时间,最晚采集文章@ >、文章更新次数采集等,方便查看和管理。文章管理函数方便查询、查找、删除。采集文章,改进算法从根本上杜绝了重复采集同文章,日志函数记录采集过程中发生的异常和抓取错误,便于检查设置错误进行修复。启动采集后,自动采集 查看全部
文章采集程序(基于WordPress网站管理系统的文章采集器采集,轻松获取高质量原创文章)
Wordpress采集,基于WordPress网站管理系统文章采集器,是站长对站群和单站的操作,允许网站 自动更新内容的工具!目前,WordPress已经成为主流的博客搭建平台。插件和模板多,功能扩展方便。关于wordpress采集,是为了方便大家做采集站,节省人工和时间成本,更好的自动更新自己的博客内容。Wordpress采集利用精准搜索引擎的解析核心,像浏览器一样实现对网页内容的解析。实现相似页面的有效比对。因此,用户只需要指定一个参考页面,Wordpress采集


Wordpress采集适用对象:
1、新建的wordpress网站内容比较少,希望尽快有更丰富的内容;
2、热点内容自动采集自动发布;
3、定时采集,手动采集发布或保存到草稿;
4、css 样式规则可以更精确地采集需要的内容。
5、伪原创采集带有翻译和代理IP,并保存cookie记录;
6、可以将 采集 内容添加到自定义列


Wordpress采集,与各个版本完全匹配,全新架构和设计,采集设置更加全面灵活;支持多级文章列表,多级文章内容采集,支持谷歌神经网络翻译,有道神经网络翻译,轻松获取优质原创< @文章,全面支持市面上所有主流对象存储服务,可以采集主要自媒体内容,多新闻源,因为搜索引擎不收录有些自媒体内容,很容易获得高质量的“原创”文章,加上网站收录数量和网站权重。可以采集任意网站内容,采集信息一目了然,可以采集任意网站 内容通过简单的设置,可以设置多个采集任务同时执行,任务可以设置为自动运行或手动运行。主任务列表显示每个采集任务的状态:上一次检测时间采集,预计下次检测时间采集时间,最晚采集文章@ >、文章更新次数采集等,方便查看和管理。文章管理函数方便查询、查找、删除。采集文章,改进算法从根本上杜绝了重复采集同文章,日志函数记录采集过程中发生的异常和抓取错误,便于检查设置错误进行修复。启动采集后,自动采集
文章采集程序(文章采集程序是特别强大的数据处理功能(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-01-12 20:02
文章采集程序是特别强大的数据处理功能。打个比方,爬取某时期it行业各个岗位的员工。再有是地域分布等,统计业绩,再往上就是看具体数据是怎么进行处理的。之前一直对店铺的信息了解不多,只知道加入时间排序去选取销量高的店铺,和用vlookup去匹配类目,但因为数据量还是有点大,只抓取到了55937,后来还顺利加入了几百个细分类目,对加入的数据填充,进行了统计,经过一年的爬取,效果不错。已经对爬取的所有数据进行了处理,用文字进行了解释,方便理解。第一步:解析数据。
1、复制销量最高的那条销量下面多出一个符号“&”表示仅采集同一年份销量比较高的商品,如果商品不存在,则采集一年中所有相同符号下的商品。复制一条内容,并粘贴到excel表中如上图,行数共有4523行,列数共有713列。列名是按照月份和自定义字符串标识,
2、查找下列公式应用分析常用于查找以小时为单位销量大于等于15小时的商品。
通过查找的公式如下:if(radius=15,"",atexecs(15,0,.0
1))上面的公式应用公式=left(radius)&""来查找销量前15小时的商品。因为商品所在年份、月份前面有特殊字符,使用上面if函数要有意识地避免这样的结果发生。
所以要对商品使用相应的公式,
1))也可以将left(atexecs(15,0,.0
1))替换为字符串的形式“15*'\d"即\d搜索公式一定要看好首尾!第二步:取数完成的数据中不一定是完整的月数,在取数的过程中,会有一些差异。举个栗子:自定义字符串格式中的‘&’可以来实现这个功能,但是如果商品名字的末尾带个空格,将不能替换成“&”。如:1,找到商品名为robotmask的商品”1.1,”1.2,”1.3。
ref(“&”)=1由于内容包含个空格,为了避免数据丢失,在商品名空格前加上逗号即,上面我们取数的时候是seg_df2(列名)”&”1.1”,这个时候就转换成seg_df1(列名)”&”1.1”了。类似下图:取商品名,就是用到=seg_df1(列名)上面取法的时候,先用逗号隔开列名,再用&来取这两列,这样的话,取出来的数据是完整的,因为商品名是空格,取出来的就是“#”,用逗号隔开两列,符合我们取数的要求,如果我们再用逗号隔开列名的话,则失去了原来函数的意义。
2.1尝试上图取数并取两列,同样也失败。那应该怎么办呢?2.2一般来说,一个列里的数据就是一个商品的名字,即:=seg_df2(列名)商品名称数量第三步:聚合分析1。 查看全部
文章采集程序(文章采集程序是特别强大的数据处理功能(组图))
文章采集程序是特别强大的数据处理功能。打个比方,爬取某时期it行业各个岗位的员工。再有是地域分布等,统计业绩,再往上就是看具体数据是怎么进行处理的。之前一直对店铺的信息了解不多,只知道加入时间排序去选取销量高的店铺,和用vlookup去匹配类目,但因为数据量还是有点大,只抓取到了55937,后来还顺利加入了几百个细分类目,对加入的数据填充,进行了统计,经过一年的爬取,效果不错。已经对爬取的所有数据进行了处理,用文字进行了解释,方便理解。第一步:解析数据。
1、复制销量最高的那条销量下面多出一个符号“&”表示仅采集同一年份销量比较高的商品,如果商品不存在,则采集一年中所有相同符号下的商品。复制一条内容,并粘贴到excel表中如上图,行数共有4523行,列数共有713列。列名是按照月份和自定义字符串标识,
2、查找下列公式应用分析常用于查找以小时为单位销量大于等于15小时的商品。
通过查找的公式如下:if(radius=15,"",atexecs(15,0,.0
1))上面的公式应用公式=left(radius)&""来查找销量前15小时的商品。因为商品所在年份、月份前面有特殊字符,使用上面if函数要有意识地避免这样的结果发生。
所以要对商品使用相应的公式,
1))也可以将left(atexecs(15,0,.0
1))替换为字符串的形式“15*'\d"即\d搜索公式一定要看好首尾!第二步:取数完成的数据中不一定是完整的月数,在取数的过程中,会有一些差异。举个栗子:自定义字符串格式中的‘&’可以来实现这个功能,但是如果商品名字的末尾带个空格,将不能替换成“&”。如:1,找到商品名为robotmask的商品”1.1,”1.2,”1.3。
ref(“&”)=1由于内容包含个空格,为了避免数据丢失,在商品名空格前加上逗号即,上面我们取数的时候是seg_df2(列名)”&”1.1”,这个时候就转换成seg_df1(列名)”&”1.1”了。类似下图:取商品名,就是用到=seg_df1(列名)上面取法的时候,先用逗号隔开列名,再用&来取这两列,这样的话,取出来的数据是完整的,因为商品名是空格,取出来的就是“#”,用逗号隔开两列,符合我们取数的要求,如果我们再用逗号隔开列名的话,则失去了原来函数的意义。
2.1尝试上图取数并取两列,同样也失败。那应该怎么办呢?2.2一般来说,一个列里的数据就是一个商品的名字,即:=seg_df2(列名)商品名称数量第三步:聚合分析1。
文章采集程序(SEO圈内如何选择好的文章采集器?集成百度站长平台主动推送 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-10 03:13
)
1、改进网站结构的布局,使其合理清晰;
2、保证原创网页内容的质量并定期更新;
3、增加网页的反向链接,在搜索引擎中排名更好网站做友好的链接;
4、优化URL链接,可以在URL中适当添加一些关键词,并使用中文拼音;
5、始终将用户体验放在首位。
通过以上信息,我们明白了网站内容更新的重要性。 网站更新频率越快,蜘蛛爬行的频率就越高。 网站页面内容不断更新,爬取的蜘蛛数量会减少,减少网站的权重。由于个人精力有限原创,难以保证大量长期更新。如果邀请编辑,投入产出比可能为负。但只要方法得当,采集的效果并不比原创差多少,甚至比那些没有掌握方法的原创好很多。
如何选择好的文章采集器?
1.直接访问大量关键词,这些关键词都是百度统计过的网民需求的词(有百度索引),或者长尾词这些词的词,来自百度下拉框或相关搜索。
2.直接按关键词采集智能分析网页正文进行爬取,无需编写采集规则。
3. 截取的文字已经用标准标签进行了清理,所有段落都以
开头
4.标签显示,乱码会被去除。
5. 根据采集收到的内容,图片与内容的关联度一定很高。以这种方式替换 伪原创 不会影响可读性,但也可以让 文章 比 原创 提供的信息更丰富。
6.整合百度站长平台主动推送提速收录.
7.可以直接使用关键词及其相关词作为标题,或者抓取登陆页面的标题
如果我们处理好文章采集的内容,采集站点也可以很快收录。由于本文章采集器永久免费并得到广大站长朋友的支持,是SEO圈内的良心软件,为众多站长朋友带来了实实在在的流量和经济效益。的收入。
查看全部
文章采集程序(SEO圈内如何选择好的文章采集器?集成百度站长平台主动推送
)
1、改进网站结构的布局,使其合理清晰;
2、保证原创网页内容的质量并定期更新;
3、增加网页的反向链接,在搜索引擎中排名更好网站做友好的链接;
4、优化URL链接,可以在URL中适当添加一些关键词,并使用中文拼音;
5、始终将用户体验放在首位。
通过以上信息,我们明白了网站内容更新的重要性。 网站更新频率越快,蜘蛛爬行的频率就越高。 网站页面内容不断更新,爬取的蜘蛛数量会减少,减少网站的权重。由于个人精力有限原创,难以保证大量长期更新。如果邀请编辑,投入产出比可能为负。但只要方法得当,采集的效果并不比原创差多少,甚至比那些没有掌握方法的原创好很多。
如何选择好的文章采集器?
1.直接访问大量关键词,这些关键词都是百度统计过的网民需求的词(有百度索引),或者长尾词这些词的词,来自百度下拉框或相关搜索。
2.直接按关键词采集智能分析网页正文进行爬取,无需编写采集规则。
3. 截取的文字已经用标准标签进行了清理,所有段落都以
开头
4.标签显示,乱码会被去除。
5. 根据采集收到的内容,图片与内容的关联度一定很高。以这种方式替换 伪原创 不会影响可读性,但也可以让 文章 比 原创 提供的信息更丰富。
6.整合百度站长平台主动推送提速收录.
7.可以直接使用关键词及其相关词作为标题,或者抓取登陆页面的标题
如果我们处理好文章采集的内容,采集站点也可以很快收录。由于本文章采集器永久免费并得到广大站长朋友的支持,是SEO圈内的良心软件,为众多站长朋友带来了实实在在的流量和经济效益。的收入。

文章采集程序(如何利用文章采集器让蜘蛛疯狂收录排名?(图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-01-10 03:10
)
如何使用文章采集器让蜘蛛疯狂收录等级?每个搜索引擎都有自己的蜘蛛程序。蜘蛛程序通过网页的链接地址搜索该网页,直到爬取到这个网站的所有网页,然后通过搜索引擎算法对网站进行评价,得到评价。如果把互联网比作蜘蛛网,那么蜘蛛程序对每张网站图像的爬行活动就称为蜘蛛爬行。
如何吸引蜘蛛爬取页面
1、一个 网站 和页面权重。算是质量上乘,老的网站的权重比较高。这个网站的网络爬取深度会比较高,也收录很多。
2、网站 的更新频率。蜘蛛抓取的每个页面的数据存储。如果爬虫第二次发现第一个收录完全相同的页面,则该页面不会更新,并且蜘蛛不需要经常捕获它。网站的页面内容更新频繁,蜘蛛会更频繁地访问该页面,页面上会出现一个新的链接,这将更快地跟踪和抓取蜘蛛。
3、网站 的原创 内容。百度蜘蛛的诱惑很大原创内容,原创内容的主食,搜索引擎蜘蛛每天都需要。
4、网站的整体结构。包括:页面更新状态、标题、关键词、标题、关键词、meta中嵌入的描述标签、导航栏等。
5、建筑工地地图。网站地图就像一个灯塔,唯一一个清晰的灯塔可以指引蜘蛛的下落。引诱更多蜘蛛的便捷方式。
6、内部链接优化。蜘蛛来到你的网站,自然是通过你的网站的结构,通过你的网站,你几乎可以运行任何网站链接,这些链接中的任何一个死链接都可以轻松导致蜘蛛爬出来。更多的时候,百度自然会来你的网站没有好感。
7、外部网站 链接。要成为蜘蛛爬虫,页面必须有一个传入链接,否则蜘蛛没有机会知道该页面的存在。
8、监控蜘蛛爬行。可以使用网络日志蜘蛛知道哪些页面被爬取,可以使用SEO工具查看蜘蛛频率,合理分配资源,实现更高的速度和更多的蜘蛛爬取。
提高网站的收录的排名是通过网站优化SEO,可以参考SEO的优化方法。简单来说,可以从以下几个方面进行改进:
1、改进网站结构的布局,使其结构合理清晰;
2、保证网页内容的原创质量并定期更新;
3、增加网页的反向链接,网站在搜索引擎中排名不错的做友情链接;
4、优化URL链接,可以在URL中适当添加一些关键词,使用中文拼音;
5、始终将用户体验放在首位。
通过以上信息,我们了解了网站内容更新的重要性。网站 更新频率越快,蜘蛛爬行的频率就越高。数量会减少,减少网站的权重。由于个人精力有限原创,难以保证大量长期更新。如果邀请编辑,投入产出比可能为负。但是只要方法得当,采集的效果并不比原创差多少,甚至比那些没有掌握方法的原创好很多。
如何选择好的文章采集器?
1.直接访问大量关键词,这些关键词都是百度统计的网民需求词(有百度索引),或者这些的长尾词词,从百度下拉框或相关搜索。
2.直接按关键词采集智能分析网页正文进行爬取,无需编写采集规则。
3. 捕获的文本已经用标准化的标签进行了清理,所有段落都以
4. 标签显示,乱码会被移除。
5. 根据采集收到的内容,自动匹配图片,图片必须与内容相关度很高。以这种方式替换 伪原创 不会影响可读性,但也允许 文章 比 原创 提供的信息更丰富。
6.整合百度站长平台,积极推送提速收录。
7.可以直接使用关键词及其相关词作为标题,或者抓取登陆页面的标题
如果我们处理好文章采集的内容,采集站点也可以很快收录。由于本文章采集器永久免费并得到广大站长朋友的支持,是SEO圈子里的良心软件,为众多站长朋友带来了实实在在的流量和经济效益。的收益。
查看全部
文章采集程序(如何利用文章采集器让蜘蛛疯狂收录排名?(图)
)
如何使用文章采集器让蜘蛛疯狂收录等级?每个搜索引擎都有自己的蜘蛛程序。蜘蛛程序通过网页的链接地址搜索该网页,直到爬取到这个网站的所有网页,然后通过搜索引擎算法对网站进行评价,得到评价。如果把互联网比作蜘蛛网,那么蜘蛛程序对每张网站图像的爬行活动就称为蜘蛛爬行。

如何吸引蜘蛛爬取页面
1、一个 网站 和页面权重。算是质量上乘,老的网站的权重比较高。这个网站的网络爬取深度会比较高,也收录很多。
2、网站 的更新频率。蜘蛛抓取的每个页面的数据存储。如果爬虫第二次发现第一个收录完全相同的页面,则该页面不会更新,并且蜘蛛不需要经常捕获它。网站的页面内容更新频繁,蜘蛛会更频繁地访问该页面,页面上会出现一个新的链接,这将更快地跟踪和抓取蜘蛛。
3、网站 的原创 内容。百度蜘蛛的诱惑很大原创内容,原创内容的主食,搜索引擎蜘蛛每天都需要。
4、网站的整体结构。包括:页面更新状态、标题、关键词、标题、关键词、meta中嵌入的描述标签、导航栏等。
5、建筑工地地图。网站地图就像一个灯塔,唯一一个清晰的灯塔可以指引蜘蛛的下落。引诱更多蜘蛛的便捷方式。
6、内部链接优化。蜘蛛来到你的网站,自然是通过你的网站的结构,通过你的网站,你几乎可以运行任何网站链接,这些链接中的任何一个死链接都可以轻松导致蜘蛛爬出来。更多的时候,百度自然会来你的网站没有好感。
7、外部网站 链接。要成为蜘蛛爬虫,页面必须有一个传入链接,否则蜘蛛没有机会知道该页面的存在。
8、监控蜘蛛爬行。可以使用网络日志蜘蛛知道哪些页面被爬取,可以使用SEO工具查看蜘蛛频率,合理分配资源,实现更高的速度和更多的蜘蛛爬取。
提高网站的收录的排名是通过网站优化SEO,可以参考SEO的优化方法。简单来说,可以从以下几个方面进行改进:
1、改进网站结构的布局,使其结构合理清晰;
2、保证网页内容的原创质量并定期更新;
3、增加网页的反向链接,网站在搜索引擎中排名不错的做友情链接;
4、优化URL链接,可以在URL中适当添加一些关键词,使用中文拼音;
5、始终将用户体验放在首位。

通过以上信息,我们了解了网站内容更新的重要性。网站 更新频率越快,蜘蛛爬行的频率就越高。数量会减少,减少网站的权重。由于个人精力有限原创,难以保证大量长期更新。如果邀请编辑,投入产出比可能为负。但是只要方法得当,采集的效果并不比原创差多少,甚至比那些没有掌握方法的原创好很多。

如何选择好的文章采集器?
1.直接访问大量关键词,这些关键词都是百度统计的网民需求词(有百度索引),或者这些的长尾词词,从百度下拉框或相关搜索。
2.直接按关键词采集智能分析网页正文进行爬取,无需编写采集规则。
3. 捕获的文本已经用标准化的标签进行了清理,所有段落都以

4. 标签显示,乱码会被移除。
5. 根据采集收到的内容,自动匹配图片,图片必须与内容相关度很高。以这种方式替换 伪原创 不会影响可读性,但也允许 文章 比 原创 提供的信息更丰富。
6.整合百度站长平台,积极推送提速收录。
7.可以直接使用关键词及其相关词作为标题,或者抓取登陆页面的标题

如果我们处理好文章采集的内容,采集站点也可以很快收录。由于本文章采集器永久免费并得到广大站长朋友的支持,是SEO圈子里的良心软件,为众多站长朋友带来了实实在在的流量和经济效益。的收益。

文章采集程序(SEO圈内如何选择好的文章采集器?集成百度站长平台主动推送 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-01-10 03:09
)
1、改进网站结构的布局,使其合理清晰;
2、保证原创网页内容的质量并定期更新;
3、增加网页的反向链接,在搜索引擎中排名更好网站做友好的链接;
4、优化URL链接,可以在URL中适当添加一些关键词,并使用中文拼音;
5、始终将用户体验放在首位。
通过以上信息,我们明白了网站内容更新的重要性。 网站更新频率越快,蜘蛛爬行的频率就越高。 网站页面内容不断更新,爬取的蜘蛛数量会减少,减少网站的权重。由于个人精力有限原创,难以保证大量长期更新。如果邀请编辑,投入产出比可能为负。但只要方法得当,采集的效果并不比原创差多少,甚至比那些没有掌握方法的原创好很多。
如何选择好的文章采集器?
1.直接访问大量关键词,这些关键词都是百度统计过的网民需求的词(有百度索引),或者长尾词这些词的词,来自百度下拉框或相关搜索。
2.直接按关键词采集智能分析网页正文进行爬取,无需编写采集规则。
3. 截取的文字已经用标准标签进行了清理,所有段落都以
开头
4.标签显示,乱码会被去除。
5. 根据采集收到的内容,图片与内容的关联度一定很高。以这种方式替换 伪原创 不会影响可读性,但也可以让 文章 比 原创 提供的信息更丰富。
6.整合百度站长平台主动推送提速收录.
7.可以直接使用关键词及其相关词作为标题,或者抓取登陆页面的标题
如果我们处理好文章采集的内容,采集站点也可以很快收录。由于本文章采集器永久免费并得到广大站长朋友的支持,是SEO圈内的良心软件,为众多站长朋友带来了实实在在的流量和经济效益。的收入。
查看全部
文章采集程序(SEO圈内如何选择好的文章采集器?集成百度站长平台主动推送
)
1、改进网站结构的布局,使其合理清晰;
2、保证原创网页内容的质量并定期更新;
3、增加网页的反向链接,在搜索引擎中排名更好网站做友好的链接;
4、优化URL链接,可以在URL中适当添加一些关键词,并使用中文拼音;
5、始终将用户体验放在首位。
通过以上信息,我们明白了网站内容更新的重要性。 网站更新频率越快,蜘蛛爬行的频率就越高。 网站页面内容不断更新,爬取的蜘蛛数量会减少,减少网站的权重。由于个人精力有限原创,难以保证大量长期更新。如果邀请编辑,投入产出比可能为负。但只要方法得当,采集的效果并不比原创差多少,甚至比那些没有掌握方法的原创好很多。
如何选择好的文章采集器?
1.直接访问大量关键词,这些关键词都是百度统计过的网民需求的词(有百度索引),或者长尾词这些词的词,来自百度下拉框或相关搜索。
2.直接按关键词采集智能分析网页正文进行爬取,无需编写采集规则。
3. 截取的文字已经用标准标签进行了清理,所有段落都以
开头
4.标签显示,乱码会被去除。
5. 根据采集收到的内容,图片与内容的关联度一定很高。以这种方式替换 伪原创 不会影响可读性,但也可以让 文章 比 原创 提供的信息更丰富。
6.整合百度站长平台主动推送提速收录.
7.可以直接使用关键词及其相关词作为标题,或者抓取登陆页面的标题
如果我们处理好文章采集的内容,采集站点也可以很快收录。由于本文章采集器永久免费并得到广大站长朋友的支持,是SEO圈内的良心软件,为众多站长朋友带来了实实在在的流量和经济效益。的收入。
文章采集程序(软件自带PHPCMS发布功能采集后直接直接发布到网站上)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-01-07 19:03
3、软件自带PHPcms发布功能采集然后直接发布到网站,配置每日发布总量,是否为伪原创,以及还为站长人员配备了强大的SEO功能(自动内链、标题插入关键词、内容插入关键词、随机作者、随机阅读数等)增强SEO优化功能,从而提高网站收录!) 同时也支持除了PHPcms之外的主要cms平台采集的发布。
以后不用担心了,因为网站太多了,好忙,网站管不了!告别繁琐的网站后台。反复登录后台是一件很痛苦的事情。再也不用担心 网站 没有内容了。
网站的流量取决于网站收录的比例。收录越多,关键词的排名越高,流量越大。
为什么这么多人选择PHPcms?
PHPcms是一个网站管理软件。软件采用模块化开发,支持多种分类方式。使用它可以方便个性化网站的设计、开发和维护。支持大量程序组合,可轻松实现网站平台迁移,可广泛满足网站各种规模的需求。它具有很高的可靠性。它是一个带有文章、下载和图片的模型。、分类信息、影视、商场、采集、金融等众多功能强大、易用、可扩展的优秀网站管理软件。
许多人使用 PHPcms 仅作为 文章 发布系统。他们只需要在后台增加一栏,然后就可以发布普通的文章。如果在栏目中设置了不同的模型,在栏目中还可以发布软件、图集等内容。
很多文章站点,比如信息站、纸站等,一个普通的文章模型就够了。网站 不能再局限于这几种类型的内容,往往一个站点还收录相关软件、相关图集等类型。
phpcms自带:新闻、图片、下载、资讯、产品等几种模式,你可以在创建栏目的时候选择,为了创建不同类型的栏目,你完全可以使用我们的软件模式去制作一个软件下载网站,用图片模型搭建美容库,用产品模型开店。
当然,将这些模型结合起来,还可以创建不同形式和类型的站点,比如区域门户,需要新闻信息、分类信息、会员图片等。您可以使用相应的模型进行组合。同一个IT门户需要新闻、软件下载和产品,然后我们可以用我们的新闻、下载和产品模型进行组合,非常灵活。
小编用这个SEO工具让网站更有效率,让网站收录暴涨,流量暴涨。看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力! 查看全部
文章采集程序(软件自带PHPCMS发布功能采集后直接直接发布到网站上)
3、软件自带PHPcms发布功能采集然后直接发布到网站,配置每日发布总量,是否为伪原创,以及还为站长人员配备了强大的SEO功能(自动内链、标题插入关键词、内容插入关键词、随机作者、随机阅读数等)增强SEO优化功能,从而提高网站收录!) 同时也支持除了PHPcms之外的主要cms平台采集的发布。

以后不用担心了,因为网站太多了,好忙,网站管不了!告别繁琐的网站后台。反复登录后台是一件很痛苦的事情。再也不用担心 网站 没有内容了。
网站的流量取决于网站收录的比例。收录越多,关键词的排名越高,流量越大。

为什么这么多人选择PHPcms?
PHPcms是一个网站管理软件。软件采用模块化开发,支持多种分类方式。使用它可以方便个性化网站的设计、开发和维护。支持大量程序组合,可轻松实现网站平台迁移,可广泛满足网站各种规模的需求。它具有很高的可靠性。它是一个带有文章、下载和图片的模型。、分类信息、影视、商场、采集、金融等众多功能强大、易用、可扩展的优秀网站管理软件。
许多人使用 PHPcms 仅作为 文章 发布系统。他们只需要在后台增加一栏,然后就可以发布普通的文章。如果在栏目中设置了不同的模型,在栏目中还可以发布软件、图集等内容。
很多文章站点,比如信息站、纸站等,一个普通的文章模型就够了。网站 不能再局限于这几种类型的内容,往往一个站点还收录相关软件、相关图集等类型。
phpcms自带:新闻、图片、下载、资讯、产品等几种模式,你可以在创建栏目的时候选择,为了创建不同类型的栏目,你完全可以使用我们的软件模式去制作一个软件下载网站,用图片模型搭建美容库,用产品模型开店。
当然,将这些模型结合起来,还可以创建不同形式和类型的站点,比如区域门户,需要新闻信息、分类信息、会员图片等。您可以使用相应的模型进行组合。同一个IT门户需要新闻、软件下载和产品,然后我们可以用我们的新闻、下载和产品模型进行组合,非常灵活。

小编用这个SEO工具让网站更有效率,让网站收录暴涨,流量暴涨。看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力!
文章采集程序(网站收录、排名解决几个方法,爱煮饭也曾经试验过采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-01-07 08:14
1、采集如何对站进行排名采集站收录解决方法
,爱厨也尝试过采集,今天给大家分享一下如何用采集做流量。笔者目前的操作网站是基于手动复制别人的文章,加上我自己的观点,所有操作网站半年就能达到目标。关键词 排名第一。在一页上,您可以看到示例案例经典句子网、股票入门网、ERP 100,000 为什么。
采集网站收录,几种解决排名的方法。
1 选择 网站 程序。不建议使用大家都在用的程序网站,因为你是采集,而且搜索的这些内容的记录很多,所以唯一的程序是重要因素之一在解决采集站收录的排名。
2 网站模板,如果你自己不会写程序,至少你的模板应该和别人的不一样。一个好的结构会让你的 网站 与众不同。
3 采集内容控制进度,采集也要注意方法,采集相关网站内容,每天多少合适采集?爱厨推荐新站,每天新增不到50条新数据。50条数据是不同时间段增加的,不是同时增加的。在采集程序中,我们可以随时写一个任务采集,一个小时内随机更新几个文章,模拟手动更新网站。
6 使用旧域名,注册时间越长越好。
上述六种方法是最基本的。如果你喜欢烹饪,我建议如果你是新网站,先手动更新三个月的内容,培养网站的权重,然后再进行采集。
2、cms电影采集谁知道方法
建议还是用一些现成的软件比较好,省事又可以提高效率。我必须自己测试这个和那个,麻烦!
采集土豆网、优酷视频,先采集视频的下载地址,然后用批量下载工具下载,可能有网站限制了你的IP。
不过感觉网上找的免费的采集软件不行,我自己做的采集
最好用普通版,可以做个试用版,比免费的好很多!
网络信息采集是信息化进程中的重要一步,所以很多企业都在提倡拥有**优采云采集、**采集器等软件,但是这些都是应用层面比较浅的技术,还有很多地方是做不到的。比如网站限制你采集等问题。如果你想要高端的技术或者成熟的产品,那一定是网站 @采集行业内非常专业的公司。国内比较专业的网络信息采集是深圳乐思软件,你可以去他们网站了解一下,也许可以分享一下版本,反正我们公司用的企业版很使用方便。的。
你可以自己搜索教程和网址,他们会在他们公司的软件教程下载页面上找到。
词汇表
采集
采集 是人类活动的重要组成部分。在古代,人们的采集行为往往是为了满足生理需求,比如吃喝,比如防御。随着时代的变迁,人类的采集行为也逐渐发生了变化。人们开始利用采集的能力渗透到生活的每一个领域,从获取物品到采集获取信息。采集这里的意思是采摘采集。因为引用,在动物界,也有采集的行为。例如,蜜蜂采集花蜜。
软件
软件是一系列按特定顺序组织的计算机数据和指令,是计算机的无形部分。软件一般分为系统软件、应用软件和中间件。软件包括运行在计算机上的所有程序,无论其架构如何,都有共同的特点,运行后硬件可以运行设计所需的功能。简单地说,软件是程序和文档的集合。软件在世界各个地区都有使用,对人们的生活和工作产生深远的影响。
下载
下载是指将文件从FTP服务器复制到自己的电脑上。早期从FTP服务器下载文件的方式是直接使用FTP软件(ftp.exe)直接访问已知的FTP服务器,并使用一组规定的命令来获取文件,即命令方法,但是这个方法使用不便,已很少使用。有人使用它。从互联网上下载文件的方法主要有直接从网页或FTP站点下载、使用可恢复下载软件下载、以电子邮件的形式下载。 查看全部
文章采集程序(网站收录、排名解决几个方法,爱煮饭也曾经试验过采集)
1、采集如何对站进行排名采集站收录解决方法

,爱厨也尝试过采集,今天给大家分享一下如何用采集做流量。笔者目前的操作网站是基于手动复制别人的文章,加上我自己的观点,所有操作网站半年就能达到目标。关键词 排名第一。在一页上,您可以看到示例案例经典句子网、股票入门网、ERP 100,000 为什么。
采集网站收录,几种解决排名的方法。
1 选择 网站 程序。不建议使用大家都在用的程序网站,因为你是采集,而且搜索的这些内容的记录很多,所以唯一的程序是重要因素之一在解决采集站收录的排名。
2 网站模板,如果你自己不会写程序,至少你的模板应该和别人的不一样。一个好的结构会让你的 网站 与众不同。
3 采集内容控制进度,采集也要注意方法,采集相关网站内容,每天多少合适采集?爱厨推荐新站,每天新增不到50条新数据。50条数据是不同时间段增加的,不是同时增加的。在采集程序中,我们可以随时写一个任务采集,一个小时内随机更新几个文章,模拟手动更新网站。
6 使用旧域名,注册时间越长越好。
上述六种方法是最基本的。如果你喜欢烹饪,我建议如果你是新网站,先手动更新三个月的内容,培养网站的权重,然后再进行采集。
2、cms电影采集谁知道方法

建议还是用一些现成的软件比较好,省事又可以提高效率。我必须自己测试这个和那个,麻烦!
采集土豆网、优酷视频,先采集视频的下载地址,然后用批量下载工具下载,可能有网站限制了你的IP。
不过感觉网上找的免费的采集软件不行,我自己做的采集
最好用普通版,可以做个试用版,比免费的好很多!
网络信息采集是信息化进程中的重要一步,所以很多企业都在提倡拥有**优采云采集、**采集器等软件,但是这些都是应用层面比较浅的技术,还有很多地方是做不到的。比如网站限制你采集等问题。如果你想要高端的技术或者成熟的产品,那一定是网站 @采集行业内非常专业的公司。国内比较专业的网络信息采集是深圳乐思软件,你可以去他们网站了解一下,也许可以分享一下版本,反正我们公司用的企业版很使用方便。的。
你可以自己搜索教程和网址,他们会在他们公司的软件教程下载页面上找到。
词汇表
采集
采集 是人类活动的重要组成部分。在古代,人们的采集行为往往是为了满足生理需求,比如吃喝,比如防御。随着时代的变迁,人类的采集行为也逐渐发生了变化。人们开始利用采集的能力渗透到生活的每一个领域,从获取物品到采集获取信息。采集这里的意思是采摘采集。因为引用,在动物界,也有采集的行为。例如,蜜蜂采集花蜜。
软件
软件是一系列按特定顺序组织的计算机数据和指令,是计算机的无形部分。软件一般分为系统软件、应用软件和中间件。软件包括运行在计算机上的所有程序,无论其架构如何,都有共同的特点,运行后硬件可以运行设计所需的功能。简单地说,软件是程序和文档的集合。软件在世界各个地区都有使用,对人们的生活和工作产生深远的影响。
下载
下载是指将文件从FTP服务器复制到自己的电脑上。早期从FTP服务器下载文件的方式是直接使用FTP软件(ftp.exe)直接访问已知的FTP服务器,并使用一组规定的命令来获取文件,即命令方法,但是这个方法使用不便,已很少使用。有人使用它。从互联网上下载文件的方法主要有直接从网页或FTP站点下载、使用可恢复下载软件下载、以电子邮件的形式下载。
文章采集程序(猜你在找的PHP相关文章PHP开发与代码审计(总结))
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-01-02 16:08
猜猜你在找什么 PHP 相关的文章
PHP 操作 MySQL 数据库和 PDO 技术
创建测试数据:首先,我们需要创建一些测试记录,然后首先演示基本数据库链接命令的使用。创建表用户名(uid int not null,name varchar
常见PHP漏洞代码汇总
漏洞摘要PHP文件上传漏洞只验证MIME类型:代码中验证上传的MIME类型,绕过方式使用Burp抓包,上传的语句是pony*.php中的Content-Type : 应用程序/php
PHP 开发和代码审计(总结)
作者在学习PHP的时候会分享学习笔记。它基本上是对之前博客文章的总结。好像比较方便。作者最近放弃了PHP代码审计部分,所以不会再继续研究了,因为真正的精力如果达不到,只能选择同样的方式开发,不要做半瓶醋
PHP 字符串和文件操作
<p>字符操作字符串输出:字符串输出格式与C语言一致, 查看全部
文章采集程序(猜你在找的PHP相关文章PHP开发与代码审计(总结))
猜猜你在找什么 PHP 相关的文章
PHP 操作 MySQL 数据库和 PDO 技术
创建测试数据:首先,我们需要创建一些测试记录,然后首先演示基本数据库链接命令的使用。创建表用户名(uid int not null,name varchar
常见PHP漏洞代码汇总
漏洞摘要PHP文件上传漏洞只验证MIME类型:代码中验证上传的MIME类型,绕过方式使用Burp抓包,上传的语句是pony*.php中的Content-Type : 应用程序/php
PHP 开发和代码审计(总结)
作者在学习PHP的时候会分享学习笔记。它基本上是对之前博客文章的总结。好像比较方便。作者最近放弃了PHP代码审计部分,所以不会再继续研究了,因为真正的精力如果达不到,只能选择同样的方式开发,不要做半瓶醋
PHP 字符串和文件操作
<p>字符操作字符串输出:字符串输出格式与C语言一致,
文章采集程序(字符处理规则重构处理应该算是采集的处理方式!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-02-07 18:09
之前因为工作原因,写了一个通用网站data采集的小工具,通过配置XML到采集不同网站内容。在这段工作的业余时间,觉得有必要对其进行改造,顺便学习学习,特此记录。字符处理规则重构字符处理应该算作采集
强烈推荐IDEA2021.1.3破解激活,IntelliJ IDEA注册码,2021.1.3IDEA激活码
大家好,我是建筑师,一个会写代码,会背诗的建筑师。今天就来说说通用采集小工具重构之路——字符处理规则重构,希望能帮助大家提高!!!
之前因为工作原因,写了一个通用网站data采集的小工具,通过配置XML到采集不同网站内容。
在这段工作的业余时间,觉得有必要对其进行改造,顺便学习学习,特此记录。
字符处理规则重构
字符处理应该被视为采集中的核心内容,如果从一大串HTML字符串中提取到我们需要的字段中。我们来看看之前的处理方式:
查看代码
string temp2;
temp2 = GetStr(str, MyConfig.Url, Lev); //字符截取规则
temp2 = ReplaceStr(temp2, MyConfig.UrlGL, Lev); //字符过滤规则
temp2 = SetCodeing(temp2, MyConfig.UrlBM, Lev);//字符URL编码规则
temp2 = Myreplace(temp2,MyConfig.UrlGvContent,Lev);//字符替换规则
只听山间传来建筑师的声音:
东山乡只用了不到一年的时间,就回到了种植春田。谁将向上或向下匹配?
故障排除:
1. 客户端调用次数过多,如果有四个规则,则需要调用四个规则。
2. 扩展不灵活。如果以后遇到新的采集要求,现有的规则不满足要求,需要增加新的规则,不符合“开闭原则”
让我们开始重构:
1. 提取通用规则接口
文字处理规则界面
此代码由Java架构师必看网-架构君整理
///
/// 文字处理规则接口
///
public interface ItextRule
{
///
/// 字符处理
///
/// 待处理字符串
/// 配置关键字
/// 当前层级
///
string TextPro(string sourceStr,string key,int lev);
}
2. 为规则类创建一个抽象类,并编写一些公共方法
字符处理规则基类
///
/// 字符处理规则基础类
///
public abstract class TextRuleBase
{
private string myKey = string.Empty;
public TextRuleBase(string _key)
{
myKey = _key;
}
///
/// 获取配置文件的值
///
///
///
///
protected string[] GetValue(string key,int lev)
{
string str = string.Empty;
string temp = string.Empty;
string tempKey = key + myKey + lev;
bool Istrue = true;
while(Istrue) //循环读配置,知道为空
{
temp = SiteConfig.ConfigByKey(tempKey);
if (temp == "")
{
Istrue = false;
}
else
{
str += temp + "|";
tempKey += lev;
}
}
return str.Split(new char[]{'|'},StringSplitOptions.RemoveEmptyEntries);
}
///
/// 具体规则处理 强制子类实现
///
///
///
///
protected abstract string TextPro(string sourceStr, string[] Contents);
}
3. 创建字符规则类,按照以上逻辑创建4个字符规则类,继承接口和抽象类
字符截取规则基本规则
这里仅创建一个示例,其他示例相同。或查看代码
4. 建立高层接口供客户端直接调用,内部封装各种规则(根据配置)
字符处理规则的高级接口
///
/// 字符处理规则的高层接口
///
public class TextRuleAll:ItextRule
{
private Dictionary ruleList = new Dictionary();
#region ItextRule 成员
public string TextPro(string sourceStr, string key, int lev)
{
string dicKey = key + lev;
string returnStr = string.Empty;
if (!ruleList.ContainsKey(dicKey))
{
IList list = new List();
#region 根据配置构建关键字规则列表
foreach (string vale in MyConfig.AllTextRules())
{
string[] temp = vale.Split('.');
string xmlKey = temp[temp.Length - 1];
if (xmlKey == "TextIntercept") //写死 字符截取规则为基本规则
xmlKey = "";
if (SiteConfig.ConfigByKey(key + xmlKey + lev) != "") //XML文件有此配置关键字
{
list.Add((ItextRule)Assembly.Load("Demo1").CreateInstance(vale));
}
}
#endregion
ruleList.Add(dicKey,list);
}
IList mylist = ruleList[dicKey];
if (mylist != null && mylist.Count > 0) //循环执行各种规则处理
{
returnStr = sourceStr;
foreach (ItextRule irule in mylist)
returnStr = irule.TextPro(returnStr, key, lev);
}
return returnStr;
}
#end
5. 配置文件
XML 配置
Collect.TextRule.TextIntercept,Collect.TextRule.StaticReplace,Collect.TextRule.TextUrlEncode,Collect.TextRule.TextFilter
邮件地址是[内容]
#,@
fuwentao,fwt
city=[内容]
.com,[内容]http
重构完成,再来看看客户端的调用:
string testStr = "我是fuwentao,我的邮件地址是fwt1314111#163.com,网址http://www.mywaysoft.net/city=上海";
TextRuleAll cmd = new TextRuleAll();
string rel= cmd.TextPro(testStr, "Name", 1); //结果
只需一个 cmd.TextPro 即可获得它!是不是比以前简单了。
而且,这种灵活性也很强。如果以后想增加新的处理规则,只需要创建一个规则类,然后在配置文件中进行配置。
演示下载
今天文章结束,感谢阅读,Java架构师必看,祝你升职加薪,年年好运。 查看全部
文章采集程序(字符处理规则重构处理应该算是采集的处理方式!)
之前因为工作原因,写了一个通用网站data采集的小工具,通过配置XML到采集不同网站内容。在这段工作的业余时间,觉得有必要对其进行改造,顺便学习学习,特此记录。字符处理规则重构字符处理应该算作采集
强烈推荐IDEA2021.1.3破解激活,IntelliJ IDEA注册码,2021.1.3IDEA激活码
大家好,我是建筑师,一个会写代码,会背诗的建筑师。今天就来说说通用采集小工具重构之路——字符处理规则重构,希望能帮助大家提高!!!
之前因为工作原因,写了一个通用网站data采集的小工具,通过配置XML到采集不同网站内容。
在这段工作的业余时间,觉得有必要对其进行改造,顺便学习学习,特此记录。
字符处理规则重构
字符处理应该被视为采集中的核心内容,如果从一大串HTML字符串中提取到我们需要的字段中。我们来看看之前的处理方式:
查看代码
string temp2;
temp2 = GetStr(str, MyConfig.Url, Lev); //字符截取规则
temp2 = ReplaceStr(temp2, MyConfig.UrlGL, Lev); //字符过滤规则
temp2 = SetCodeing(temp2, MyConfig.UrlBM, Lev);//字符URL编码规则
temp2 = Myreplace(temp2,MyConfig.UrlGvContent,Lev);//字符替换规则
只听山间传来建筑师的声音:
东山乡只用了不到一年的时间,就回到了种植春田。谁将向上或向下匹配?
故障排除:
1. 客户端调用次数过多,如果有四个规则,则需要调用四个规则。
2. 扩展不灵活。如果以后遇到新的采集要求,现有的规则不满足要求,需要增加新的规则,不符合“开闭原则”
让我们开始重构:
1. 提取通用规则接口
文字处理规则界面
此代码由Java架构师必看网-架构君整理
///
/// 文字处理规则接口
///
public interface ItextRule
{
///
/// 字符处理
///
/// 待处理字符串
/// 配置关键字
/// 当前层级
///
string TextPro(string sourceStr,string key,int lev);
}
2. 为规则类创建一个抽象类,并编写一些公共方法
字符处理规则基类
///
/// 字符处理规则基础类
///
public abstract class TextRuleBase
{
private string myKey = string.Empty;
public TextRuleBase(string _key)
{
myKey = _key;
}
///
/// 获取配置文件的值
///
///
///
///
protected string[] GetValue(string key,int lev)
{
string str = string.Empty;
string temp = string.Empty;
string tempKey = key + myKey + lev;
bool Istrue = true;
while(Istrue) //循环读配置,知道为空
{
temp = SiteConfig.ConfigByKey(tempKey);
if (temp == "")
{
Istrue = false;
}
else
{
str += temp + "|";
tempKey += lev;
}
}
return str.Split(new char[]{'|'},StringSplitOptions.RemoveEmptyEntries);
}
///
/// 具体规则处理 强制子类实现
///
///
///
///
protected abstract string TextPro(string sourceStr, string[] Contents);
}
3. 创建字符规则类,按照以上逻辑创建4个字符规则类,继承接口和抽象类
字符截取规则基本规则
这里仅创建一个示例,其他示例相同。或查看代码
4. 建立高层接口供客户端直接调用,内部封装各种规则(根据配置)
字符处理规则的高级接口
///
/// 字符处理规则的高层接口
///
public class TextRuleAll:ItextRule
{
private Dictionary ruleList = new Dictionary();
#region ItextRule 成员
public string TextPro(string sourceStr, string key, int lev)
{
string dicKey = key + lev;
string returnStr = string.Empty;
if (!ruleList.ContainsKey(dicKey))
{
IList list = new List();
#region 根据配置构建关键字规则列表
foreach (string vale in MyConfig.AllTextRules())
{
string[] temp = vale.Split('.');
string xmlKey = temp[temp.Length - 1];
if (xmlKey == "TextIntercept") //写死 字符截取规则为基本规则
xmlKey = "";
if (SiteConfig.ConfigByKey(key + xmlKey + lev) != "") //XML文件有此配置关键字
{
list.Add((ItextRule)Assembly.Load("Demo1").CreateInstance(vale));
}
}
#endregion
ruleList.Add(dicKey,list);
}
IList mylist = ruleList[dicKey];
if (mylist != null && mylist.Count > 0) //循环执行各种规则处理
{
returnStr = sourceStr;
foreach (ItextRule irule in mylist)
returnStr = irule.TextPro(returnStr, key, lev);
}
return returnStr;
}
#end
5. 配置文件
XML 配置
Collect.TextRule.TextIntercept,Collect.TextRule.StaticReplace,Collect.TextRule.TextUrlEncode,Collect.TextRule.TextFilter
邮件地址是[内容]
#,@
fuwentao,fwt
city=[内容]
.com,[内容]http
重构完成,再来看看客户端的调用:
string testStr = "我是fuwentao,我的邮件地址是fwt1314111#163.com,网址http://www.mywaysoft.net/city=上海";
TextRuleAll cmd = new TextRuleAll();
string rel= cmd.TextPro(testStr, "Name", 1); //结果
只需一个 cmd.TextPro 即可获得它!是不是比以前简单了。
而且,这种灵活性也很强。如果以后想增加新的处理规则,只需要创建一个规则类,然后在配置文件中进行配置。
演示下载
今天文章结束,感谢阅读,Java架构师必看,祝你升职加薪,年年好运。
文章采集程序(免费下载或者VIP会员资源能否直接商用?浏览器下载)
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-02-04 12:11
免费下载或者VIP会员资源可以直接商业化吗?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接用于商业用途。如因商业用途发生版权纠纷,一切责任由用户承担。更多信息请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:可以将下载的压缩包与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除了这种情况,可以在对应资源底部留言,或者联系我们。
在资产介绍文章 中找不到示例图片?
对于会员制、全站源代码、程序插件、网站模板、网页模板等各类素材,文章中用于介绍的图片通常不收录在相应的下载中材料包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)找到来源。某些字体文件也是如此,但某些资产在资产包中会有字体下载链接列表。
付款后无法显示下载地址或无法查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买此资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一经批准,将不接受任何形式的退款或换货请求。购买前请确认您需要的资源 查看全部
文章采集程序(免费下载或者VIP会员资源能否直接商用?浏览器下载)
免费下载或者VIP会员资源可以直接商业化吗?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接用于商业用途。如因商业用途发生版权纠纷,一切责任由用户承担。更多信息请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:可以将下载的压缩包与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除了这种情况,可以在对应资源底部留言,或者联系我们。
在资产介绍文章 中找不到示例图片?
对于会员制、全站源代码、程序插件、网站模板、网页模板等各类素材,文章中用于介绍的图片通常不收录在相应的下载中材料包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)找到来源。某些字体文件也是如此,但某些资产在资产包中会有字体下载链接列表。
付款后无法显示下载地址或无法查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买此资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一经批准,将不接受任何形式的退款或换货请求。购买前请确认您需要的资源
文章采集程序(免费下载或者VIP会员资源能否直接商用?浏览器下载)
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-02-03 09:15
免费下载或者VIP会员资源可以直接商业化吗?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接用于商业用途。如因商业用途发生版权纠纷,一切责任由用户承担。更多信息请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:可以将下载的压缩包与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除了这种情况,可以在对应资源底部留言,或者联系我们。
在资产介绍文章 中找不到示例图片?
对于会员制、全站源代码、程序插件、网站模板、网页模板等各类素材,文章中用于介绍的图片通常不收录在相应的下载中材料包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)找到来源。某些字体文件也是如此,但某些资产在资产包中会有字体下载链接列表。
付款后无法显示下载链接或无法查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买此资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一经批准,将不接受任何形式的退款或换货请求。购买前请确认您需要的资源 查看全部
文章采集程序(免费下载或者VIP会员资源能否直接商用?浏览器下载)
免费下载或者VIP会员资源可以直接商业化吗?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接用于商业用途。如因商业用途发生版权纠纷,一切责任由用户承担。更多信息请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:可以将下载的压缩包与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除了这种情况,可以在对应资源底部留言,或者联系我们。
在资产介绍文章 中找不到示例图片?
对于会员制、全站源代码、程序插件、网站模板、网页模板等各类素材,文章中用于介绍的图片通常不收录在相应的下载中材料包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)找到来源。某些字体文件也是如此,但某些资产在资产包中会有字体下载链接列表。
付款后无法显示下载链接或无法查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买此资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一经批准,将不接受任何形式的退款或换货请求。购买前请确认您需要的资源
文章采集程序(程序参数python编程简介(一)的gui程序设计)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-31 16:00
文章采集程序appium实现登录方式程序设计思路程序采集方式编译程序参数python编程简介python程序猿python编程简介gui的编程python的gui程序设计ios的java代码设计gui在程序设计中无处不在:比如早些年写小说的时候,经常设计成泡沫文明的样子,有没有发现整个人都摆脱了原始人的颜色?python除了在写小说,很多编程语言都用到gui。
下面看看gui到底干了什么。主流c语言比如c#,大家都知道游戏、电商等等,gui都是一个重要的角色,连操作系统,主流的一些方式,很多都是利用gui来实现。python一直都比较不友好,所以python在用户体验和脚本语言上一直比较差,在和python有交集的情况下,提交比较多的是web和游戏等方面。在早些年编程里面,很多python程序猿喜欢开发游戏,因为比c代码编程方便太多了,代码量少,而且以实用性、可读性优先。
在这个层面上,是没有所谓的gui语言的,比如python多掌握几门语言是没有问题的,但你要能去写个gui程序,是不太可能的,即使是web也是属于ui编程的范畴。很多时候,比如什么地球杯、穿越火线等等游戏,游戏版本不同,里面的图形界面和操作都是不一样的,跟性能没有关系,所以从技术上来讲,web、web服务器这类,是有gui编程的,只不过这些gui要比c、java等等各种编程语言复杂太多了。
整个的图形交互都是利用gui来实现的,大家看起来好像都是用c程序猿,但是不知道当时人写这些程序的时候,很多其实根本没有gui这个概念,只有ui这个概念。比如对开发一个按钮,都可以画一个按钮,然后显示出来。python编程交互没有问题的,但是就是语言差异造成的不好理解和游戏方向不一样,比如你在新浪、人人上写点东西都要懂二进制,他们只需要上传二进制文件。
网站都是这样的,你要是用c程序来写网站,是不可能兼容所有浏览器的。很多有意思的python小玩意最近几年python在语言交互方面比以前方便了太多了,从谷歌贡献的webkit浏览器引擎开始,python多了很多小工具。比如websocket这样的工具,还有做webfacebook的网站客户端,这些小工具python、java等编程语言都是可以学的。
python这几年发展很快,连new一下编程语言都一直在更新,近几年python,包括其他一些语言都在迅速发展,很多开发模式,比如都分为面向对象、函数式编程,虽然都不是标准的编程模式,但是看起来一样。那么python面向对象到底是什么呢?很多读者把对象和对象的区别当成是一个一个的参数了,其实不然,对象和对象是不一。 查看全部
文章采集程序(程序参数python编程简介(一)的gui程序设计)
文章采集程序appium实现登录方式程序设计思路程序采集方式编译程序参数python编程简介python程序猿python编程简介gui的编程python的gui程序设计ios的java代码设计gui在程序设计中无处不在:比如早些年写小说的时候,经常设计成泡沫文明的样子,有没有发现整个人都摆脱了原始人的颜色?python除了在写小说,很多编程语言都用到gui。
下面看看gui到底干了什么。主流c语言比如c#,大家都知道游戏、电商等等,gui都是一个重要的角色,连操作系统,主流的一些方式,很多都是利用gui来实现。python一直都比较不友好,所以python在用户体验和脚本语言上一直比较差,在和python有交集的情况下,提交比较多的是web和游戏等方面。在早些年编程里面,很多python程序猿喜欢开发游戏,因为比c代码编程方便太多了,代码量少,而且以实用性、可读性优先。
在这个层面上,是没有所谓的gui语言的,比如python多掌握几门语言是没有问题的,但你要能去写个gui程序,是不太可能的,即使是web也是属于ui编程的范畴。很多时候,比如什么地球杯、穿越火线等等游戏,游戏版本不同,里面的图形界面和操作都是不一样的,跟性能没有关系,所以从技术上来讲,web、web服务器这类,是有gui编程的,只不过这些gui要比c、java等等各种编程语言复杂太多了。
整个的图形交互都是利用gui来实现的,大家看起来好像都是用c程序猿,但是不知道当时人写这些程序的时候,很多其实根本没有gui这个概念,只有ui这个概念。比如对开发一个按钮,都可以画一个按钮,然后显示出来。python编程交互没有问题的,但是就是语言差异造成的不好理解和游戏方向不一样,比如你在新浪、人人上写点东西都要懂二进制,他们只需要上传二进制文件。
网站都是这样的,你要是用c程序来写网站,是不可能兼容所有浏览器的。很多有意思的python小玩意最近几年python在语言交互方面比以前方便了太多了,从谷歌贡献的webkit浏览器引擎开始,python多了很多小工具。比如websocket这样的工具,还有做webfacebook的网站客户端,这些小工具python、java等编程语言都是可以学的。
python这几年发展很快,连new一下编程语言都一直在更新,近几年python,包括其他一些语言都在迅速发展,很多开发模式,比如都分为面向对象、函数式编程,虽然都不是标准的编程模式,但是看起来一样。那么python面向对象到底是什么呢?很多读者把对象和对象的区别当成是一个一个的参数了,其实不然,对象和对象是不一。
文章采集程序(和微信公众号一模一样的留言支持自定义,数据可以自定义修改 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-01-30 03:02
)
微信公众号已经成为很多朋友获取信息的一种方式。现在很多地方的活动之类的活动都会在微信公众号上发布,因为公众号的权限现在已经有了,代表了官方的真实性。从某种意义上来说,不如说公众号文章的排版模式更容易被大家接受和认可。但是,微信公众号的审核和筛选越来越严格。做一些分享活动,交易会文章等,很容易被官方直接拦截拦截。一旦链接被封锁,将极大地影响活动和营销推广。影响!
我们根据之前推广中遇到的一些问题,开发了这个高度逼真的仿微信公众号文章系统。本系统是基于PHP开发的一款精仿微信文章风格的正式版。微信今日头条文章信息系统源码,源码是一套与微信公众号文章一模一样的文章信息系统。用户可以根据自己的需求灵活使用,方便他们更好的推广和盈利。该系统的具体效果是:
1、支持一键式采集,只需进入公众号文章链接,一键生成100%恢复公众号文章!
2、消息管理系统和微信公众号一模一样。消息内容支持自定义,数据可自定义修改!文章的底部消息可以回复或点赞,同时可以修改评论者的内容和头像、昵称、点赞数等。
3、文章底部与微信原文一模一样文章,也可以点击阅读原文,跳转微信公众号关注页面,快速细分!而且,阅读次数和文章点赞数可以准确显示在底部。如果同一个用户连续访问,只会统计一个读数,不能刷读数。
4、文章底部阅读数和文章点赞数可以在后台自由设置,想多就多。帮你快速打造爆款文章!
5、后台生成或自定义编辑的所有宣传文案采集可在后台随时修改,不限次数,打破原微信文章无法修改的限制发布后无限修改。
6、文章中的所有数据,如:阅读数、点赞数、留言内容等。所有数据都可以在后台进行虚拟化和自定义。
体验地址:
案例展示
查看全部
文章采集程序(和微信公众号一模一样的留言支持自定义,数据可以自定义修改
)
微信公众号已经成为很多朋友获取信息的一种方式。现在很多地方的活动之类的活动都会在微信公众号上发布,因为公众号的权限现在已经有了,代表了官方的真实性。从某种意义上来说,不如说公众号文章的排版模式更容易被大家接受和认可。但是,微信公众号的审核和筛选越来越严格。做一些分享活动,交易会文章等,很容易被官方直接拦截拦截。一旦链接被封锁,将极大地影响活动和营销推广。影响!
我们根据之前推广中遇到的一些问题,开发了这个高度逼真的仿微信公众号文章系统。本系统是基于PHP开发的一款精仿微信文章风格的正式版。微信今日头条文章信息系统源码,源码是一套与微信公众号文章一模一样的文章信息系统。用户可以根据自己的需求灵活使用,方便他们更好的推广和盈利。该系统的具体效果是:
1、支持一键式采集,只需进入公众号文章链接,一键生成100%恢复公众号文章!
2、消息管理系统和微信公众号一模一样。消息内容支持自定义,数据可自定义修改!文章的底部消息可以回复或点赞,同时可以修改评论者的内容和头像、昵称、点赞数等。
3、文章底部与微信原文一模一样文章,也可以点击阅读原文,跳转微信公众号关注页面,快速细分!而且,阅读次数和文章点赞数可以准确显示在底部。如果同一个用户连续访问,只会统计一个读数,不能刷读数。
4、文章底部阅读数和文章点赞数可以在后台自由设置,想多就多。帮你快速打造爆款文章!
5、后台生成或自定义编辑的所有宣传文案采集可在后台随时修改,不限次数,打破原微信文章无法修改的限制发布后无限修改。
6、文章中的所有数据,如:阅读数、点赞数、留言内容等。所有数据都可以在后台进行虚拟化和自定义。
体验地址:
案例展示
文章采集程序(spring使用springcloud架构来做爬虫,历时二十多天,终于搞定)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-28 15:12
前言
因公司业务需要,需要获取客户提供的微信公众号历史文章,并每天更新。很明显,每天人工检查300多个公众号是不行的,把问题提交给IT团队。对于那些喜欢爬虫的人,我一定会尝试他。之前做过搜狗的微信爬虫,后来一直在做java web。这个项目重新点燃了我对爬虫的热爱。第一次使用spring cloud架构做爬虫。20多天后,终于搞定了。接下来我将通过一系列文章分享这个项目的经验,并提供源码供大家指正!
一、系统介绍
本系统是基于Java开发的。只需简单配置公众号或微信公众号,即可定时或即时抓取微信公众号的文章(包括阅读次数、点赞次数、观看次数)。
二、系统架构技术架构
Spring Cloud、Spring Boot、Mybatis-Plus、Nacos、RocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
雷迪斯
演戏
提琴手
三、系统优缺点系统优势
1、配置公众号后,可以通过Fiddler的JS注入功能和Websocket实现自动爬取;2、系统为分布式架构,高可用;3、RocketMq 消息队列用于解耦合,可以解决采集由于网络抖动导致的失败。如果3次消费不成功,日志会记录到mysql,保证文章的完整性;4、可以加入任意数量的微信号提高采集效率,抵抗反爬限制;5、Redis缓存24小时内每个微信号的采集记录,防止账号被封;6、Nacos作为一个配置中心,可以通过热配置来访问调整采集的频率 实时; 7、将数据采集存储到Solr集群,提高检索速度;8、将抓包返回的记录保存在MongoDB中,方便存档查看错误日志。
系统缺点:
1、通过真机真实账号采集消息,如果需要采集大量公众号,需要有多个微信账号作为支持(如果账号达到上限当天,可以通过爬虫界面爬取微信公众平台获取新闻);2、不是公众号一发就可以马上抢到消息,采集时间是系统设置的,消息有一定的延迟(如果没有公众号多,微信数量足够。通过增加采集频率进行优化)。
四、模块介绍
由于后面会添加管理系统和API调用功能,所以提前封装了一些功能。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:是的
spring-boot-starter-data-redis的二次封装暴露了封装后的Redis工具类和Redisson工具类。
火箭MQ-WS-启动器
RocketMq 模块:是
RocketMQ-spring-boot-starter的二次包,提供消费重试和失败日志记录功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,通过自定义注解实现数据源的动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-蜘蛛
PC端采集模块:收录PC端采集公众号历史消息相关功能。
java-wx-蜘蛛
Java抽取模块:收录java程序抽取文章内容相关的功能。
移动 wx 蜘蛛
模拟器采集模块:收录通过模拟器或移动端采集消息交互量相关的功能。
五、一般流程图
六、运行截图 PC 和手机
安慰
运行结束
总结
该项目的亲测可用性现已投入运行,在项目开发中解决了微信搜狗临时链接到永久链接的问题,希望能帮助被类似业务困扰的老铁。如今,做java就像逆水行舟。不进则退。我不知道你什么时候会参与进来。我希望每个人都有自己的向日葵采集。你不给这个采集吗?
原文链接: 查看全部
文章采集程序(spring使用springcloud架构来做爬虫,历时二十多天,终于搞定)
前言
因公司业务需要,需要获取客户提供的微信公众号历史文章,并每天更新。很明显,每天人工检查300多个公众号是不行的,把问题提交给IT团队。对于那些喜欢爬虫的人,我一定会尝试他。之前做过搜狗的微信爬虫,后来一直在做java web。这个项目重新点燃了我对爬虫的热爱。第一次使用spring cloud架构做爬虫。20多天后,终于搞定了。接下来我将通过一系列文章分享这个项目的经验,并提供源码供大家指正!
一、系统介绍
本系统是基于Java开发的。只需简单配置公众号或微信公众号,即可定时或即时抓取微信公众号的文章(包括阅读次数、点赞次数、观看次数)。
二、系统架构技术架构
Spring Cloud、Spring Boot、Mybatis-Plus、Nacos、RocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
雷迪斯
演戏
提琴手
三、系统优缺点系统优势
1、配置公众号后,可以通过Fiddler的JS注入功能和Websocket实现自动爬取;2、系统为分布式架构,高可用;3、RocketMq 消息队列用于解耦合,可以解决采集由于网络抖动导致的失败。如果3次消费不成功,日志会记录到mysql,保证文章的完整性;4、可以加入任意数量的微信号提高采集效率,抵抗反爬限制;5、Redis缓存24小时内每个微信号的采集记录,防止账号被封;6、Nacos作为一个配置中心,可以通过热配置来访问调整采集的频率 实时; 7、将数据采集存储到Solr集群,提高检索速度;8、将抓包返回的记录保存在MongoDB中,方便存档查看错误日志。
系统缺点:
1、通过真机真实账号采集消息,如果需要采集大量公众号,需要有多个微信账号作为支持(如果账号达到上限当天,可以通过爬虫界面爬取微信公众平台获取新闻);2、不是公众号一发就可以马上抢到消息,采集时间是系统设置的,消息有一定的延迟(如果没有公众号多,微信数量足够。通过增加采集频率进行优化)。
四、模块介绍
由于后面会添加管理系统和API调用功能,所以提前封装了一些功能。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:是的
spring-boot-starter-data-redis的二次封装暴露了封装后的Redis工具类和Redisson工具类。
火箭MQ-WS-启动器
RocketMq 模块:是
RocketMQ-spring-boot-starter的二次包,提供消费重试和失败日志记录功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,通过自定义注解实现数据源的动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-蜘蛛
PC端采集模块:收录PC端采集公众号历史消息相关功能。
java-wx-蜘蛛
Java抽取模块:收录java程序抽取文章内容相关的功能。
移动 wx 蜘蛛
模拟器采集模块:收录通过模拟器或移动端采集消息交互量相关的功能。
五、一般流程图
六、运行截图 PC 和手机
安慰
运行结束
总结
该项目的亲测可用性现已投入运行,在项目开发中解决了微信搜狗临时链接到永久链接的问题,希望能帮助被类似业务困扰的老铁。如今,做java就像逆水行舟。不进则退。我不知道你什么时候会参与进来。我希望每个人都有自己的向日葵采集。你不给这个采集吗?
原文链接:
文章采集程序(spring使用springcloud架构来做爬虫,历时二十多天,终于搞定)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-24 07:11
前言
因公司业务需要,需要获取客户提供的微信公众号历史文章,并每天更新。很明显,每天人工检查300多个公众号是不行的,把问题提交给IT团队。对于那些喜欢爬虫的人,我一定会尝试他。之前做过搜狗的微信爬虫,后来一直在做java web。这个项目重新点燃了我对爬虫的热爱。第一次使用spring cloud架构做爬虫。20多天后,终于搞定了。接下来我将通过一系列文章分享这个项目的经验,并提供源码供大家指正!
一、系统介绍
本系统是基于Java开发的。只需简单配置公众号名称或微信账号,即可定时或即时抓取微信公众号的文章(包括阅读次数、点赞次数、观看次数)。
二、系统架构技术架构
Spring Cloud、Spring Boot、Mybatis-Plus、Nacos、RocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
雷迪斯
演戏
提琴手
三、系统优缺点系统优势
1、配置公众号后,可以通过Fiddler的JS注入功能和Websocket实现自动爬取;2、系统为分布式架构,高可用;3、RocketMq 消息队列用于解耦合,可以解决采集由于网络抖动导致的失败。如果3次消费不成功,日志会记录到mysql,保证文章的完整性;4、可以加入任意数量的微信号,提高采集的效率,抵抗反爬限制;5、Redis缓存24小时内每个微信号的采集记录,防止账号被封;6、Nacos作为配置中心,可以通过热配置访问,实时调整采集的频率;7、将采集接收到的数据存储到Solr集群,提高检索速度;8、将抓包返回的记录保存在MongoDB中,方便存档查看错误日志。
系统缺点:
1、通过真机真实账号采集消息,如果需要采集大量公众号,需要有多个微信账号作为支持(如果账号达到上限当天可通过爬虫界面爬取微信公众平台获取新闻);2、不是公众号发完就可以马上抢到消息,采集时间是系统设定的,消息有一定的延迟(如果公众号不多的话,微信账号数量足够。通过增加采集频率进行优化)。
四、模块介绍
由于后面会添加管理系统和API调用功能,所以提前封装了一些功能。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:是的
spring-boot-starter-data-redis的二次封装暴露了封装后的Redis工具类和Redisson工具类。
火箭MQ-WS-启动器
RocketMq 模块:是
RocketMQ-spring-boot-starter的二次包,提供消费重试和失败日志记录功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,通过自定义注解实现数据源的动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-蜘蛛
PC端采集模块:收录PC端采集公众号历史消息相关功能。
java-wx-蜘蛛
Java抽取模块:收录java程序抽取文章内容相关的功能。
移动 wx 蜘蛛
模拟器采集模块:收录通过模拟器或移动端采集消息交互量相关的功能。
五、一般流程图
六、运行截图 PC 和手机
安慰
运行结束
总结
项目的亲测可用性现已投入运行,在项目开发中解决了微信搜狗临时链接到永久链接的问题,希望能帮助被类似业务困扰的老铁。如今,做java就像逆水行舟。不进则退。我不知道你什么时候会参与进来。我希望每个人都有自己的向日葵采集。你不给这个采集吗?
原文链接: 查看全部
文章采集程序(spring使用springcloud架构来做爬虫,历时二十多天,终于搞定)
前言
因公司业务需要,需要获取客户提供的微信公众号历史文章,并每天更新。很明显,每天人工检查300多个公众号是不行的,把问题提交给IT团队。对于那些喜欢爬虫的人,我一定会尝试他。之前做过搜狗的微信爬虫,后来一直在做java web。这个项目重新点燃了我对爬虫的热爱。第一次使用spring cloud架构做爬虫。20多天后,终于搞定了。接下来我将通过一系列文章分享这个项目的经验,并提供源码供大家指正!
一、系统介绍
本系统是基于Java开发的。只需简单配置公众号名称或微信账号,即可定时或即时抓取微信公众号的文章(包括阅读次数、点赞次数、观看次数)。
二、系统架构技术架构
Spring Cloud、Spring Boot、Mybatis-Plus、Nacos、RocketMq、nginx
贮存
Mysql、MongoDB、Redis、Solr
缓存
雷迪斯
演戏
提琴手
三、系统优缺点系统优势
1、配置公众号后,可以通过Fiddler的JS注入功能和Websocket实现自动爬取;2、系统为分布式架构,高可用;3、RocketMq 消息队列用于解耦合,可以解决采集由于网络抖动导致的失败。如果3次消费不成功,日志会记录到mysql,保证文章的完整性;4、可以加入任意数量的微信号,提高采集的效率,抵抗反爬限制;5、Redis缓存24小时内每个微信号的采集记录,防止账号被封;6、Nacos作为配置中心,可以通过热配置访问,实时调整采集的频率;7、将采集接收到的数据存储到Solr集群,提高检索速度;8、将抓包返回的记录保存在MongoDB中,方便存档查看错误日志。
系统缺点:
1、通过真机真实账号采集消息,如果需要采集大量公众号,需要有多个微信账号作为支持(如果账号达到上限当天可通过爬虫界面爬取微信公众平台获取新闻);2、不是公众号发完就可以马上抢到消息,采集时间是系统设定的,消息有一定的延迟(如果公众号不多的话,微信账号数量足够。通过增加采集频率进行优化)。
四、模块介绍
由于后面会添加管理系统和API调用功能,所以提前封装了一些功能。
common-ws-starter
公共模块:存储工具类、实体类等公共消息。
redis-ws-starter
Redis 模块:是的
spring-boot-starter-data-redis的二次封装暴露了封装后的Redis工具类和Redisson工具类。
火箭MQ-WS-启动器
RocketMq 模块:是
RocketMQ-spring-boot-starter的二次包,提供消费重试和失败日志记录功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,通过自定义注解实现数据源的动态切换。
sql-wx-蜘蛛
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-蜘蛛
PC端采集模块:收录PC端采集公众号历史消息相关功能。
java-wx-蜘蛛
Java抽取模块:收录java程序抽取文章内容相关的功能。
移动 wx 蜘蛛
模拟器采集模块:收录通过模拟器或移动端采集消息交互量相关的功能。
五、一般流程图
六、运行截图 PC 和手机
安慰
运行结束
总结
项目的亲测可用性现已投入运行,在项目开发中解决了微信搜狗临时链接到永久链接的问题,希望能帮助被类似业务困扰的老铁。如今,做java就像逆水行舟。不进则退。我不知道你什么时候会参与进来。我希望每个人都有自己的向日葵采集。你不给这个采集吗?
原文链接:
文章采集程序(用织梦默认的数据长度没有采集的时候长,如何处理?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-01-23 00:03
dede模板下载采集的文章标题不够长怎么处理织梦无忧程序开发2018-11-22 10:42
总结:当我们使用织梦采集文章默认的采集函数,但是导出的数据长度没有采集那么长,我该怎么办?? 这个问题是基于 dede文章 的标题不够长。第三步:修改采集数据导入程序co_export.php打开后台文件夹(默认dede),找到
当我们使用织梦默认的采集函数采集文章,但是导出的数据长度却没有采集那么长,如何处理?
这个问题是基于 dede文章 的标题不够长。
前两步图文细节
第三步:修改采集数据导入程序co_export.php
打开后台文件夹(默认为dede),找到co_export.php的第220行:
$mainSql = str_replace('',cn_substr($title,60),$mainSql);
将 60 更改为 $cfg_title_maxlen
这样就可以解决采集的数据头长度问题了
这篇文章的链接:
版权声明:本站资源均来自互联网或会员发布。如果您的权利受到侵犯,请联系我们,我们将在24小时内删除!谢谢! 查看全部
文章采集程序(用织梦默认的数据长度没有采集的时候长,如何处理?)
dede模板下载采集的文章标题不够长怎么处理织梦无忧程序开发2018-11-22 10:42
总结:当我们使用织梦采集文章默认的采集函数,但是导出的数据长度没有采集那么长,我该怎么办?? 这个问题是基于 dede文章 的标题不够长。第三步:修改采集数据导入程序co_export.php打开后台文件夹(默认dede),找到
当我们使用织梦默认的采集函数采集文章,但是导出的数据长度却没有采集那么长,如何处理?
这个问题是基于 dede文章 的标题不够长。
前两步图文细节
第三步:修改采集数据导入程序co_export.php
打开后台文件夹(默认为dede),找到co_export.php的第220行:
$mainSql = str_replace('',cn_substr($title,60),$mainSql);
将 60 更改为 $cfg_title_maxlen
这样就可以解决采集的数据头长度问题了
这篇文章的链接:
版权声明:本站资源均来自互联网或会员发布。如果您的权利受到侵犯,请联系我们,我们将在24小时内删除!谢谢!
文章采集程序(基于typecho1.1正式版数据库,使用JAVA语言Springboot框架(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-01-19 17:05
)
RuleApi,基于typecho1.1官方版数据库,采用JAVA语言Springboot框架,集成了redis缓存数据库、COS、OSS对象存储,是目前功能最全、最全的typecho程序界面,最佳用户体验,以及性能最佳的API程序。集成用户模块(登录、注册、邮箱验证、用户查询、用户修改)、文章模块、评论模块、分类模块、上传模块(三合一上传方式,OSS、COS、本地上传)可用),安装完成后,可以进一步扩展typecho网站的功能,实现更强大的性能和更全面的应用范围。
介绍如下:通过RuleApi,可以将网站模块化,通过API将用户系统与网站分开,实现定制化的个人中心。基于token的验证机制可以实现多个域名下的相同共享。用户系统。通过RuleApi,您还可以实现外部作者中心提交管理,甚至可以为网站添加一个额外的全功能用户中心。总之,无论使用何种功能搭配,API都可以完全脱离主网站。通用数据。另外,RuleApi api是网站的全部数据,所以它也可以将网站与静态和动态完全分开,实现部分或全站js数据渲染,也可以用它来构建众多网站 分站但数据共享,或者网站的数据可以被其他网站共享。最后,RuleApi 可以配合微信小程序、APP 或其他界面应用的开发。总之,可以探索更多的功能。相关地址:
发布包下载地址:
链接:https://pan.baidu.com/s/1s_dEMJj1SjLFKb4h5mAv-w
提取码:ul94
Gitee开源地址:点击进入
Github开源地址:点击进入
接口文档:点击进入
安装文档:点击进入
演示地址:点击进入
相关手续
Typecho手机APP源码:点击进入
演示图像
安装后界面
接口请求和返回接口
代码编辑器配置文件界面
更新记录
所有版本更新和内容都会写在这里
v1.0.0 bate 2021/12/04测试版
v1.0.0 bate 2022/01/08测试版,新增签到,收藏,打赏,积分,组件漏洞全面修复
所有接口
typechoUsers(用户模块)
用户注册
用户登录
用户查询&列表
全局验证码发送
用户找回密码
删除用户
修改用户
查询单个用户详细
typechoContents (文章&单独的页面模块)
更新文章&内容
添加文章&内容
查询文章&内容
删除文章&内容
查询单篇文章&内容
typechoMetas(分类和标记模块)
查询分类&标签
根据标签&分类ID查询文章
上传(上传模块)
上传到COS
上传到接口本地
上传到OSS
typechoComments(评论模块)
查询评论
添加评论
开源协议
本项目使用 GPL 开源许可证,允许复制、传播、销售和修改。但是,如果是基于RuleApi进行二次开发并用于传播和销售的程序,请标记为源自RuleApi。
写在最后
截至本文章发布,该接口仍处于测试状态,需要更多人使用和反馈,我会继续完善。目前接口还存在用户密码加密验证无法与typecho保持一致的问题,所以还是通过外部php文件路径来实现的,后面发布的安装说明会补充。
总的来说,这个程序和一些Java大佬开发的相比肯定不够看,但是我的目的也很简单,就是做typecho,就是我这个网站用的程序,能够拥有更强的扩展性,让APP、小程序,或者一些听起来很模块化的东西,都可以集成到每个typecho用户的网站中,这就是制作这个程序的初衷。
如有任何问题或建议,可以在评论区留言,或加入QQ交流群573232605进行反馈讨论
这个接口允许你修改和销售两次,但必须在代码中注明是基于RuleApi的
喜欢 3
报酬
千水万山,永远相爱,打赏也无妨。报酬
查看全部
文章采集程序(基于typecho1.1正式版数据库,使用JAVA语言Springboot框架(组图)
)
RuleApi,基于typecho1.1官方版数据库,采用JAVA语言Springboot框架,集成了redis缓存数据库、COS、OSS对象存储,是目前功能最全、最全的typecho程序界面,最佳用户体验,以及性能最佳的API程序。集成用户模块(登录、注册、邮箱验证、用户查询、用户修改)、文章模块、评论模块、分类模块、上传模块(三合一上传方式,OSS、COS、本地上传)可用),安装完成后,可以进一步扩展typecho网站的功能,实现更强大的性能和更全面的应用范围。
介绍如下:通过RuleApi,可以将网站模块化,通过API将用户系统与网站分开,实现定制化的个人中心。基于token的验证机制可以实现多个域名下的相同共享。用户系统。通过RuleApi,您还可以实现外部作者中心提交管理,甚至可以为网站添加一个额外的全功能用户中心。总之,无论使用何种功能搭配,API都可以完全脱离主网站。通用数据。另外,RuleApi api是网站的全部数据,所以它也可以将网站与静态和动态完全分开,实现部分或全站js数据渲染,也可以用它来构建众多网站 分站但数据共享,或者网站的数据可以被其他网站共享。最后,RuleApi 可以配合微信小程序、APP 或其他界面应用的开发。总之,可以探索更多的功能。相关地址:
发布包下载地址:
链接:https://pan.baidu.com/s/1s_dEMJj1SjLFKb4h5mAv-w
提取码:ul94
Gitee开源地址:点击进入
Github开源地址:点击进入
接口文档:点击进入
安装文档:点击进入
演示地址:点击进入
相关手续
Typecho手机APP源码:点击进入
演示图像
安装后界面
接口请求和返回接口
代码编辑器配置文件界面
更新记录
所有版本更新和内容都会写在这里
v1.0.0 bate 2021/12/04测试版
v1.0.0 bate 2022/01/08测试版,新增签到,收藏,打赏,积分,组件漏洞全面修复
所有接口
typechoUsers(用户模块)
用户注册
用户登录
用户查询&列表
全局验证码发送
用户找回密码
删除用户
修改用户
查询单个用户详细
typechoContents (文章&单独的页面模块)
更新文章&内容
添加文章&内容
查询文章&内容
删除文章&内容
查询单篇文章&内容
typechoMetas(分类和标记模块)
查询分类&标签
根据标签&分类ID查询文章
上传(上传模块)
上传到COS
上传到接口本地
上传到OSS
typechoComments(评论模块)
查询评论
添加评论
开源协议
本项目使用 GPL 开源许可证,允许复制、传播、销售和修改。但是,如果是基于RuleApi进行二次开发并用于传播和销售的程序,请标记为源自RuleApi。
写在最后
截至本文章发布,该接口仍处于测试状态,需要更多人使用和反馈,我会继续完善。目前接口还存在用户密码加密验证无法与typecho保持一致的问题,所以还是通过外部php文件路径来实现的,后面发布的安装说明会补充。
总的来说,这个程序和一些Java大佬开发的相比肯定不够看,但是我的目的也很简单,就是做typecho,就是我这个网站用的程序,能够拥有更强的扩展性,让APP、小程序,或者一些听起来很模块化的东西,都可以集成到每个typecho用户的网站中,这就是制作这个程序的初衷。
如有任何问题或建议,可以在评论区留言,或加入QQ交流群573232605进行反馈讨论
这个接口允许你修改和销售两次,但必须在代码中注明是基于RuleApi的
喜欢 3
报酬
千水万山,永远相爱,打赏也无妨。报酬
文章采集程序(科技业的员工到底有多年轻(1),那么标识可以是(1))
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-01-16 09:07
第一页的logo,比如标题【科技行业的员工有多年轻(1)】),那么logo可以是(1)
保存路线
采集内容存放目录
寻呼
表示采集的文章数据被分页了,那么程序会根据设置的规则判断是否是分页的章节,如果是,则不会重复添加标题。
例如
科技工作者到底有多年轻(1)
科技工作者有多年轻(2)
科技工作者到底有多年轻(3)
然后在采集的过程中,只会写一个标题【科技行业的员工有多年轻】
另存为文件
如果选中,所有 采集 都将写入文件
开始
启动 采集 并保存内容
测试
消息框显示采集的效果
格式设置表单
左边是匹配的字符,后面是要替换的字符。
当程序运行时,它会将第二行(如果有两行)中的字符的副本转换为大写,并将它们组合起来进行格式化。
换行标签、空白标签、缩进标签
您可以输入包括常规字符在内的字符进行匹配
章节标题
{0} 表示 采集 的序列号(采集 将 1) 添加到地址,{1} 表示 采集 所在的标题。
可访问性
可以将输入字符转换为大小写
写新规则
编写采集 规则需要一定的正则表达式知识。如果您不明白,请阅读此页面:
任务以xml文件的形式保存,文件名格式为:任务名-网站name.xml
在任何任务状态下,只需要修改任务名称,或者网站的名称,然后点击保存任务即可新建任务。
如果名称相同,会提示是否覆盖。
这是博客园新闻的一个例子
博客园新闻是一个列表类型的采集任务——一个页面可以匹配多个页面地址
使用firebug或其他前端调试工具,可以轻松搞定采集功能
比如下图
点击红色框【点击查看页面元素】,然后点击页面上的【创业公司如何评估——衡量公司潜力的方法】。
你可以找到html代码
这样就可以得到内容页的链接特征
如何评估初创公司——衡量公司潜力的一种方法
然后你需要观察这个标识符是否是一个唯一的特征,也就是这个特征匹配的是你所期望的。否则,需要添加更多限制性功能。
将特征写为匹配的正则表达式
源代码说明
该解决方案包括 3 个项目
Forms是一个windows程序
框架是一个 采集 程序
Helper 是一个辅助程序
考虑到以后会加入不同的采集任务,采用MDI形式。
config目录是默认配置
FrmFormatConfig为内容格式化配置表
FrmGatherWorker 是一个 采集 工作表
MDIParentMain 是表单容器
config是内容格式化配置实体类
Task 是 采集 任务规则实体类
Worker 是一个 采集 工作类
Worker采集Worker 类说明
先看3个主要事件
///
///错误触发事件,传入参数引发的异常对象,错误类型,当前工作的URL
///
publiceventActionstring>OnError;
///
///工作结束时触发事件
///
公共事件ActionOnWorkEnd;
///
///Once/Address 采集完成触发事件,传入参数采集的内容的标题、内容、URL
///
publiceventActionOnWorkItemEnd;
创建对象
Workerwork=newWorker(_httpRequest,_config,_task);
工作.OnError+=w_OnError;
工作.OnWorkItemEnd+=work_OnWorkItemEnd;
工作.OnWorkEnd+=work_OnWorkEnd;
定义内容处理
///
/// 一旦(URLs)采集完成,执行内容写入文件操作
///
privatevoidwork_OnWorkItemEnd(stringcurWebTitle,stringcurWebContent,stringcurUrl)
{
//将采集的内容写入文件流
byte[]byteWebContent=Encoding.UTF8.GetBytes(curWebContent);
如果(_task.IsSaveOnlyFile)
{
// 如果当前内容标题为空,可能是分页的
if(!string.IsNullOrEmpty(curWebTitle))
{
byte[]byteWebTitle=Encoding.UTF8.GetBytes(curWebTitle);
_curSavaFile.Write(byteWebTitle,0,byteWebTitle.Length);
}
_curSavaFile.Write(byteWebContent,0,byteWebContent.Length);
}
别的
{
使用(FileStreamcurSavaFile2=newFileStream("{0}{1}.txt".FormatWith(_task.SavePath,curWebTitle),FileMode.OpenOrCreate,FileAccess.ReadWrite))
{
curSavaFile2.Write(byteWebContent,0,byteWebContent.Length);
}
}
UpdateWorkMessage("已经 采集: {0}, URL: {1}".FormatWith(curWebTitle,curUrl));
应用程序.DoEvents();
}
更多内容请下载源代码查看
其他
运行程序下载:
源码下载请到开源地址下载
开源地址:
如果不知道如何在github上下载源码,请看文章:
对采集感兴趣的朋友可以一起维护和贡献代码,让大家轻松共享同一个采集框架。
QQ群:9524888
欢迎大家进群交流分享采集任务规则,讨论技术,讨论生活…… 查看全部
文章采集程序(科技业的员工到底有多年轻(1),那么标识可以是(1))
第一页的logo,比如标题【科技行业的员工有多年轻(1)】),那么logo可以是(1)
保存路线
采集内容存放目录
寻呼
表示采集的文章数据被分页了,那么程序会根据设置的规则判断是否是分页的章节,如果是,则不会重复添加标题。
例如
科技工作者到底有多年轻(1)
科技工作者有多年轻(2)
科技工作者到底有多年轻(3)
然后在采集的过程中,只会写一个标题【科技行业的员工有多年轻】
另存为文件
如果选中,所有 采集 都将写入文件
开始
启动 采集 并保存内容
测试
消息框显示采集的效果
格式设置表单
左边是匹配的字符,后面是要替换的字符。
当程序运行时,它会将第二行(如果有两行)中的字符的副本转换为大写,并将它们组合起来进行格式化。
换行标签、空白标签、缩进标签
您可以输入包括常规字符在内的字符进行匹配
章节标题
{0} 表示 采集 的序列号(采集 将 1) 添加到地址,{1} 表示 采集 所在的标题。
可访问性
可以将输入字符转换为大小写
写新规则
编写采集 规则需要一定的正则表达式知识。如果您不明白,请阅读此页面:
任务以xml文件的形式保存,文件名格式为:任务名-网站name.xml
在任何任务状态下,只需要修改任务名称,或者网站的名称,然后点击保存任务即可新建任务。
如果名称相同,会提示是否覆盖。
这是博客园新闻的一个例子
博客园新闻是一个列表类型的采集任务——一个页面可以匹配多个页面地址
使用firebug或其他前端调试工具,可以轻松搞定采集功能
比如下图
点击红色框【点击查看页面元素】,然后点击页面上的【创业公司如何评估——衡量公司潜力的方法】。
你可以找到html代码
这样就可以得到内容页的链接特征
如何评估初创公司——衡量公司潜力的一种方法
然后你需要观察这个标识符是否是一个唯一的特征,也就是这个特征匹配的是你所期望的。否则,需要添加更多限制性功能。
将特征写为匹配的正则表达式
源代码说明
该解决方案包括 3 个项目
Forms是一个windows程序
框架是一个 采集 程序
Helper 是一个辅助程序
考虑到以后会加入不同的采集任务,采用MDI形式。
config目录是默认配置
FrmFormatConfig为内容格式化配置表
FrmGatherWorker 是一个 采集 工作表
MDIParentMain 是表单容器
config是内容格式化配置实体类
Task 是 采集 任务规则实体类
Worker 是一个 采集 工作类
Worker采集Worker 类说明
先看3个主要事件
///
///错误触发事件,传入参数引发的异常对象,错误类型,当前工作的URL
///
publiceventActionstring>OnError;
///
///工作结束时触发事件
///
公共事件ActionOnWorkEnd;
///
///Once/Address 采集完成触发事件,传入参数采集的内容的标题、内容、URL
///
publiceventActionOnWorkItemEnd;
创建对象
Workerwork=newWorker(_httpRequest,_config,_task);
工作.OnError+=w_OnError;
工作.OnWorkItemEnd+=work_OnWorkItemEnd;
工作.OnWorkEnd+=work_OnWorkEnd;
定义内容处理
///
/// 一旦(URLs)采集完成,执行内容写入文件操作
///
privatevoidwork_OnWorkItemEnd(stringcurWebTitle,stringcurWebContent,stringcurUrl)
{
//将采集的内容写入文件流
byte[]byteWebContent=Encoding.UTF8.GetBytes(curWebContent);
如果(_task.IsSaveOnlyFile)
{
// 如果当前内容标题为空,可能是分页的
if(!string.IsNullOrEmpty(curWebTitle))
{
byte[]byteWebTitle=Encoding.UTF8.GetBytes(curWebTitle);
_curSavaFile.Write(byteWebTitle,0,byteWebTitle.Length);
}
_curSavaFile.Write(byteWebContent,0,byteWebContent.Length);
}
别的
{
使用(FileStreamcurSavaFile2=newFileStream("{0}{1}.txt".FormatWith(_task.SavePath,curWebTitle),FileMode.OpenOrCreate,FileAccess.ReadWrite))
{
curSavaFile2.Write(byteWebContent,0,byteWebContent.Length);
}
}
UpdateWorkMessage("已经 采集: {0}, URL: {1}".FormatWith(curWebTitle,curUrl));
应用程序.DoEvents();
}
更多内容请下载源代码查看
其他
运行程序下载:
源码下载请到开源地址下载
开源地址:
如果不知道如何在github上下载源码,请看文章:
对采集感兴趣的朋友可以一起维护和贡献代码,让大家轻松共享同一个采集框架。
QQ群:9524888
欢迎大家进群交流分享采集任务规则,讨论技术,讨论生活……
文章采集程序(优采云站群软件新出一个新的新型采集功能--指定网址采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-01-16 06:07
长期以来,大家一直在使用各种采集器或网站程序自带的采集功能。它们有一个共同的特点,就是需要编写采集规则。从采集到文章,这个技术问题对于初学者来说不是一件容易的事,对于资深站长来说也是一项艰巨的工作。那么,如果你做站群,每个站都要定义一个采集规则,那真的很惨。有人说站长是网络搬运工。这也是有道理的。文章 在网上,很多人感动了我,我也感动了你,为了活下去,我必须做些什么。现在优采云站群软件新增了新类型采集功能,可以大大减少站长“搬运工”的时间,并且不再需要编写烦人的采集规则现在,这个功能是互联网的第一个功能---指定URL 采集。下面我教大家如何使用这个功能:
一、先开启这个功能。在网站的右键中可以看到这个功能:如下图。
二、打开功能如下,可以在右侧填写指定采集的列表地址:
这里我使用百度的搜索页面作为采集的来源,比如这个地址:%B0%C5%C6%E6
然后我用优采云站群软件把这个搜索结果的采集所有文章。你可以先分析一下这个页面,如果你用各种类型的采集器或者网站自己的程序来自定义采集所有文章,是不可能采用的。因为网上还没有这么通用的采集不同网站功能,但是现在,优采云站群软件可以做到。因为这个软件支持pan采集技术。
三、首页,我把这个百度结果列表填到软件的“文章列表起始地址采集”中,如下图:
四、为了得到正确的列表采集我要,分析结果列表上的文章有一个共同的后缀,就是:html,shtml,htm,那么,这就是三个共同点是: 我将 htm 定义为软件。这种做法是为了减少采集无用的页面,如下图:
五、现在可以采集了,不过,这里提醒一下,一般一个网站,会有很多相同字符的,对于这个百度榜单,也有百度自己的网页,但是百度自己网页的内容不是我要采集的,所以还有一个地方可以排除带有百度网址的页面。如下所示:
这样定义之后,就可以避免走百度自己的页面了。这样填写后,可以直接采集文章,点击“保存采集数据”:
一两分钟后,采集 进程的结果如下图所示:
六、这里我只采集文章的一部分,先停一下,再看采集后面的内容:
七、以上就是采集的流程,按照上面的步骤,还可以采集在其他地方列出文章,尤其是一些没有收录的,或者 screen 避免 收录 的 网站,这些都是 原创 的 文章,你可以自己找。现在让我告诉您该软件的其他一些功能:
>
1、如上图所示,这里是去除网址和采集图片的功能,你可以根据自己的需要查看是否。
2、如上图,这里是设置采集的采集的行数和文章的标题的最小字数。
3、如上图所示,这里可以定义替换词,支持代码替换、文字替换等,这里要灵活使用。对于一些比较难的采集列表,这里会用到。一些代码可以用空格替换以 采集 链接到列表。
以上都是优采云站群软件新增的采集功能。这个功能很强大,但是这个功能还需要改进,以满足不同人的需求。有了这个工具,你就不用担心写不出采集规则了。该功能上手容易,操作简单。是最适合新老站长使用的功能。不明白的可以加我QQ问我:509229860。 查看全部
文章采集程序(优采云站群软件新出一个新的新型采集功能--指定网址采集)
长期以来,大家一直在使用各种采集器或网站程序自带的采集功能。它们有一个共同的特点,就是需要编写采集规则。从采集到文章,这个技术问题对于初学者来说不是一件容易的事,对于资深站长来说也是一项艰巨的工作。那么,如果你做站群,每个站都要定义一个采集规则,那真的很惨。有人说站长是网络搬运工。这也是有道理的。文章 在网上,很多人感动了我,我也感动了你,为了活下去,我必须做些什么。现在优采云站群软件新增了新类型采集功能,可以大大减少站长“搬运工”的时间,并且不再需要编写烦人的采集规则现在,这个功能是互联网的第一个功能---指定URL 采集。下面我教大家如何使用这个功能:
一、先开启这个功能。在网站的右键中可以看到这个功能:如下图。
二、打开功能如下,可以在右侧填写指定采集的列表地址:
这里我使用百度的搜索页面作为采集的来源,比如这个地址:%B0%C5%C6%E6
然后我用优采云站群软件把这个搜索结果的采集所有文章。你可以先分析一下这个页面,如果你用各种类型的采集器或者网站自己的程序来自定义采集所有文章,是不可能采用的。因为网上还没有这么通用的采集不同网站功能,但是现在,优采云站群软件可以做到。因为这个软件支持pan采集技术。
三、首页,我把这个百度结果列表填到软件的“文章列表起始地址采集”中,如下图:
四、为了得到正确的列表采集我要,分析结果列表上的文章有一个共同的后缀,就是:html,shtml,htm,那么,这就是三个共同点是: 我将 htm 定义为软件。这种做法是为了减少采集无用的页面,如下图:
五、现在可以采集了,不过,这里提醒一下,一般一个网站,会有很多相同字符的,对于这个百度榜单,也有百度自己的网页,但是百度自己网页的内容不是我要采集的,所以还有一个地方可以排除带有百度网址的页面。如下所示:
这样定义之后,就可以避免走百度自己的页面了。这样填写后,可以直接采集文章,点击“保存采集数据”:
一两分钟后,采集 进程的结果如下图所示:
六、这里我只采集文章的一部分,先停一下,再看采集后面的内容:
七、以上就是采集的流程,按照上面的步骤,还可以采集在其他地方列出文章,尤其是一些没有收录的,或者 screen 避免 收录 的 网站,这些都是 原创 的 文章,你可以自己找。现在让我告诉您该软件的其他一些功能:
>
1、如上图所示,这里是去除网址和采集图片的功能,你可以根据自己的需要查看是否。
2、如上图,这里是设置采集的采集的行数和文章的标题的最小字数。
3、如上图所示,这里可以定义替换词,支持代码替换、文字替换等,这里要灵活使用。对于一些比较难的采集列表,这里会用到。一些代码可以用空格替换以 采集 链接到列表。
以上都是优采云站群软件新增的采集功能。这个功能很强大,但是这个功能还需要改进,以满足不同人的需求。有了这个工具,你就不用担心写不出采集规则了。该功能上手容易,操作简单。是最适合新老站长使用的功能。不明白的可以加我QQ问我:509229860。
文章采集程序(Python程序设计有所采集程序的技巧实例分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-16 02:15
本文章主要介绍基于scrapy的简单spider采集程序,分析scrapy实现采集程序的技巧,具有一定的参考价值。有需要的朋友可以往下看
本文的例子描述了一个简单的基于scrapy的spider采集程序。分享给大家,供大家参考。详情如下:
# Standard Python library imports
# 3rd party imports
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from scrapy.selector import HtmlXPathSelector
# My imports
from poetry_analysis.items import PoetryAnalysisItem
HTML_FILE_NAME = r'.+\.html'
class PoetryParser(object):
"""
Provides common parsing method for poems formatted this one specific way.
"""
date_pattern = r'(\d{2} \w{3,9} \d{4})'
def parse_poem(self, response):
hxs = HtmlXPathSelector(response)
item = PoetryAnalysisItem()
# All poetry text is in pre tags
text = hxs.select('//pre/text()').extract()
item['text'] = ''.join(text)
item['url'] = response.url
# head/title contains title - a poem by author
title_text = hxs.select('//head/title/text()').extract()[0]
item['title'], item['author'] = title_text.split(' - ')
item['author'] = item['author'].replace('a poem by', '')
for key in ['title', 'author']:
item[key] = item[key].strip()
item['date'] = hxs.select("//p[@class='small']/text()").re(date_pattern)
return item
class PoetrySpider(CrawlSpider, PoetryParser):
name = 'example.com_poetry'
allowed_domains = ['www.example.com']
root_path = 'someuser/poetry/'
start_urls = ['http://www.example.com/someuser/poetry/recent/',
'http://www.example.com/someuser/poetry/less_recent/']
rules = [Rule(SgmlLinkExtractor(allow=[start_urls[0] + HTML_FILE_NAME]),
callback='parse_poem'),
Rule(SgmlLinkExtractor(allow=[start_urls[1] + HTML_FILE_NAME]),
callback='parse_poem')]
希望本文对您的 Python 编程有所帮助。 查看全部
文章采集程序(Python程序设计有所采集程序的技巧实例分析)
本文章主要介绍基于scrapy的简单spider采集程序,分析scrapy实现采集程序的技巧,具有一定的参考价值。有需要的朋友可以往下看
本文的例子描述了一个简单的基于scrapy的spider采集程序。分享给大家,供大家参考。详情如下:
# Standard Python library imports
# 3rd party imports
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from scrapy.selector import HtmlXPathSelector
# My imports
from poetry_analysis.items import PoetryAnalysisItem
HTML_FILE_NAME = r'.+\.html'
class PoetryParser(object):
"""
Provides common parsing method for poems formatted this one specific way.
"""
date_pattern = r'(\d{2} \w{3,9} \d{4})'
def parse_poem(self, response):
hxs = HtmlXPathSelector(response)
item = PoetryAnalysisItem()
# All poetry text is in pre tags
text = hxs.select('//pre/text()').extract()
item['text'] = ''.join(text)
item['url'] = response.url
# head/title contains title - a poem by author
title_text = hxs.select('//head/title/text()').extract()[0]
item['title'], item['author'] = title_text.split(' - ')
item['author'] = item['author'].replace('a poem by', '')
for key in ['title', 'author']:
item[key] = item[key].strip()
item['date'] = hxs.select("//p[@class='small']/text()").re(date_pattern)
return item
class PoetrySpider(CrawlSpider, PoetryParser):
name = 'example.com_poetry'
allowed_domains = ['www.example.com']
root_path = 'someuser/poetry/'
start_urls = ['http://www.example.com/someuser/poetry/recent/',
'http://www.example.com/someuser/poetry/less_recent/']
rules = [Rule(SgmlLinkExtractor(allow=[start_urls[0] + HTML_FILE_NAME]),
callback='parse_poem'),
Rule(SgmlLinkExtractor(allow=[start_urls[1] + HTML_FILE_NAME]),
callback='parse_poem')]
希望本文对您的 Python 编程有所帮助。
文章采集程序(基于WordPress网站管理系统的文章采集器采集,轻松获取高质量原创文章)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-01-14 05:12
Wordpress采集,基于WordPress网站管理系统文章采集器,是站长对站群和单站的操作,允许网站 自动更新内容的工具!目前,WordPress已经成为主流的博客搭建平台。插件和模板多,功能扩展方便。关于wordpress采集,是为了方便大家做采集站,节省人工和时间成本,更好的自动更新自己的博客内容。Wordpress采集利用精准搜索引擎的解析核心,像浏览器一样实现对网页内容的解析。实现相似页面的有效比对。因此,用户只需要指定一个参考页面,Wordpress采集
Wordpress采集适用对象:
1、新建的wordpress网站内容比较少,希望尽快有更丰富的内容;
2、热点内容自动采集自动发布;
3、定时采集,手动采集发布或保存到草稿;
4、css 样式规则可以更精确地采集需要的内容。
5、伪原创采集带有翻译和代理IP,并保存cookie记录;
6、可以将 采集 内容添加到自定义列
Wordpress采集,与各个版本完全匹配,全新架构和设计,采集设置更加全面灵活;支持多级文章列表,多级文章内容采集,支持谷歌神经网络翻译,有道神经网络翻译,轻松获取优质原创< @文章,全面支持市面上所有主流对象存储服务,可以采集主要自媒体内容,多新闻源,因为搜索引擎不收录有些自媒体内容,很容易获得高质量的“原创”文章,加上网站收录数量和网站权重。可以采集任意网站内容,采集信息一目了然,可以采集任意网站 内容通过简单的设置,可以设置多个采集任务同时执行,任务可以设置为自动运行或手动运行。主任务列表显示每个采集任务的状态:上一次检测时间采集,预计下次检测时间采集时间,最晚采集文章@ >、文章更新次数采集等,方便查看和管理。文章管理函数方便查询、查找、删除。采集文章,改进算法从根本上杜绝了重复采集同文章,日志函数记录采集过程中发生的异常和抓取错误,便于检查设置错误进行修复。启动采集后,自动采集 查看全部
文章采集程序(基于WordPress网站管理系统的文章采集器采集,轻松获取高质量原创文章)
Wordpress采集,基于WordPress网站管理系统文章采集器,是站长对站群和单站的操作,允许网站 自动更新内容的工具!目前,WordPress已经成为主流的博客搭建平台。插件和模板多,功能扩展方便。关于wordpress采集,是为了方便大家做采集站,节省人工和时间成本,更好的自动更新自己的博客内容。Wordpress采集利用精准搜索引擎的解析核心,像浏览器一样实现对网页内容的解析。实现相似页面的有效比对。因此,用户只需要指定一个参考页面,Wordpress采集
Wordpress采集适用对象:
1、新建的wordpress网站内容比较少,希望尽快有更丰富的内容;
2、热点内容自动采集自动发布;
3、定时采集,手动采集发布或保存到草稿;
4、css 样式规则可以更精确地采集需要的内容。
5、伪原创采集带有翻译和代理IP,并保存cookie记录;
6、可以将 采集 内容添加到自定义列
Wordpress采集,与各个版本完全匹配,全新架构和设计,采集设置更加全面灵活;支持多级文章列表,多级文章内容采集,支持谷歌神经网络翻译,有道神经网络翻译,轻松获取优质原创< @文章,全面支持市面上所有主流对象存储服务,可以采集主要自媒体内容,多新闻源,因为搜索引擎不收录有些自媒体内容,很容易获得高质量的“原创”文章,加上网站收录数量和网站权重。可以采集任意网站内容,采集信息一目了然,可以采集任意网站 内容通过简单的设置,可以设置多个采集任务同时执行,任务可以设置为自动运行或手动运行。主任务列表显示每个采集任务的状态:上一次检测时间采集,预计下次检测时间采集时间,最晚采集文章@ >、文章更新次数采集等,方便查看和管理。文章管理函数方便查询、查找、删除。采集文章,改进算法从根本上杜绝了重复采集同文章,日志函数记录采集过程中发生的异常和抓取错误,便于检查设置错误进行修复。启动采集后,自动采集
文章采集程序(文章采集程序是特别强大的数据处理功能(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-01-12 20:02
文章采集程序是特别强大的数据处理功能。打个比方,爬取某时期it行业各个岗位的员工。再有是地域分布等,统计业绩,再往上就是看具体数据是怎么进行处理的。之前一直对店铺的信息了解不多,只知道加入时间排序去选取销量高的店铺,和用vlookup去匹配类目,但因为数据量还是有点大,只抓取到了55937,后来还顺利加入了几百个细分类目,对加入的数据填充,进行了统计,经过一年的爬取,效果不错。已经对爬取的所有数据进行了处理,用文字进行了解释,方便理解。第一步:解析数据。
1、复制销量最高的那条销量下面多出一个符号“&”表示仅采集同一年份销量比较高的商品,如果商品不存在,则采集一年中所有相同符号下的商品。复制一条内容,并粘贴到excel表中如上图,行数共有4523行,列数共有713列。列名是按照月份和自定义字符串标识,
2、查找下列公式应用分析常用于查找以小时为单位销量大于等于15小时的商品。
通过查找的公式如下:if(radius=15,"",atexecs(15,0,.0
1))上面的公式应用公式=left(radius)&""来查找销量前15小时的商品。因为商品所在年份、月份前面有特殊字符,使用上面if函数要有意识地避免这样的结果发生。
所以要对商品使用相应的公式,
1))也可以将left(atexecs(15,0,.0
1))替换为字符串的形式“15*'\d"即\d搜索公式一定要看好首尾!第二步:取数完成的数据中不一定是完整的月数,在取数的过程中,会有一些差异。举个栗子:自定义字符串格式中的‘&’可以来实现这个功能,但是如果商品名字的末尾带个空格,将不能替换成“&”。如:1,找到商品名为robotmask的商品”1.1,”1.2,”1.3。
ref(“&”)=1由于内容包含个空格,为了避免数据丢失,在商品名空格前加上逗号即,上面我们取数的时候是seg_df2(列名)”&”1.1”,这个时候就转换成seg_df1(列名)”&”1.1”了。类似下图:取商品名,就是用到=seg_df1(列名)上面取法的时候,先用逗号隔开列名,再用&来取这两列,这样的话,取出来的数据是完整的,因为商品名是空格,取出来的就是“#”,用逗号隔开两列,符合我们取数的要求,如果我们再用逗号隔开列名的话,则失去了原来函数的意义。
2.1尝试上图取数并取两列,同样也失败。那应该怎么办呢?2.2一般来说,一个列里的数据就是一个商品的名字,即:=seg_df2(列名)商品名称数量第三步:聚合分析1。 查看全部
文章采集程序(文章采集程序是特别强大的数据处理功能(组图))
文章采集程序是特别强大的数据处理功能。打个比方,爬取某时期it行业各个岗位的员工。再有是地域分布等,统计业绩,再往上就是看具体数据是怎么进行处理的。之前一直对店铺的信息了解不多,只知道加入时间排序去选取销量高的店铺,和用vlookup去匹配类目,但因为数据量还是有点大,只抓取到了55937,后来还顺利加入了几百个细分类目,对加入的数据填充,进行了统计,经过一年的爬取,效果不错。已经对爬取的所有数据进行了处理,用文字进行了解释,方便理解。第一步:解析数据。
1、复制销量最高的那条销量下面多出一个符号“&”表示仅采集同一年份销量比较高的商品,如果商品不存在,则采集一年中所有相同符号下的商品。复制一条内容,并粘贴到excel表中如上图,行数共有4523行,列数共有713列。列名是按照月份和自定义字符串标识,
2、查找下列公式应用分析常用于查找以小时为单位销量大于等于15小时的商品。
通过查找的公式如下:if(radius=15,"",atexecs(15,0,.0
1))上面的公式应用公式=left(radius)&""来查找销量前15小时的商品。因为商品所在年份、月份前面有特殊字符,使用上面if函数要有意识地避免这样的结果发生。
所以要对商品使用相应的公式,
1))也可以将left(atexecs(15,0,.0
1))替换为字符串的形式“15*'\d"即\d搜索公式一定要看好首尾!第二步:取数完成的数据中不一定是完整的月数,在取数的过程中,会有一些差异。举个栗子:自定义字符串格式中的‘&’可以来实现这个功能,但是如果商品名字的末尾带个空格,将不能替换成“&”。如:1,找到商品名为robotmask的商品”1.1,”1.2,”1.3。
ref(“&”)=1由于内容包含个空格,为了避免数据丢失,在商品名空格前加上逗号即,上面我们取数的时候是seg_df2(列名)”&”1.1”,这个时候就转换成seg_df1(列名)”&”1.1”了。类似下图:取商品名,就是用到=seg_df1(列名)上面取法的时候,先用逗号隔开列名,再用&来取这两列,这样的话,取出来的数据是完整的,因为商品名是空格,取出来的就是“#”,用逗号隔开两列,符合我们取数的要求,如果我们再用逗号隔开列名的话,则失去了原来函数的意义。
2.1尝试上图取数并取两列,同样也失败。那应该怎么办呢?2.2一般来说,一个列里的数据就是一个商品的名字,即:=seg_df2(列名)商品名称数量第三步:聚合分析1。
文章采集程序(SEO圈内如何选择好的文章采集器?集成百度站长平台主动推送 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-10 03:13
)
1、改进网站结构的布局,使其合理清晰;
2、保证原创网页内容的质量并定期更新;
3、增加网页的反向链接,在搜索引擎中排名更好网站做友好的链接;
4、优化URL链接,可以在URL中适当添加一些关键词,并使用中文拼音;
5、始终将用户体验放在首位。
通过以上信息,我们明白了网站内容更新的重要性。 网站更新频率越快,蜘蛛爬行的频率就越高。 网站页面内容不断更新,爬取的蜘蛛数量会减少,减少网站的权重。由于个人精力有限原创,难以保证大量长期更新。如果邀请编辑,投入产出比可能为负。但只要方法得当,采集的效果并不比原创差多少,甚至比那些没有掌握方法的原创好很多。
如何选择好的文章采集器?
1.直接访问大量关键词,这些关键词都是百度统计过的网民需求的词(有百度索引),或者长尾词这些词的词,来自百度下拉框或相关搜索。
2.直接按关键词采集智能分析网页正文进行爬取,无需编写采集规则。
3. 截取的文字已经用标准标签进行了清理,所有段落都以
开头
4.标签显示,乱码会被去除。
5. 根据采集收到的内容,图片与内容的关联度一定很高。以这种方式替换 伪原创 不会影响可读性,但也可以让 文章 比 原创 提供的信息更丰富。
6.整合百度站长平台主动推送提速收录.
7.可以直接使用关键词及其相关词作为标题,或者抓取登陆页面的标题
如果我们处理好文章采集的内容,采集站点也可以很快收录。由于本文章采集器永久免费并得到广大站长朋友的支持,是SEO圈内的良心软件,为众多站长朋友带来了实实在在的流量和经济效益。的收入。
查看全部
文章采集程序(SEO圈内如何选择好的文章采集器?集成百度站长平台主动推送
)
1、改进网站结构的布局,使其合理清晰;
2、保证原创网页内容的质量并定期更新;
3、增加网页的反向链接,在搜索引擎中排名更好网站做友好的链接;
4、优化URL链接,可以在URL中适当添加一些关键词,并使用中文拼音;
5、始终将用户体验放在首位。
通过以上信息,我们明白了网站内容更新的重要性。 网站更新频率越快,蜘蛛爬行的频率就越高。 网站页面内容不断更新,爬取的蜘蛛数量会减少,减少网站的权重。由于个人精力有限原创,难以保证大量长期更新。如果邀请编辑,投入产出比可能为负。但只要方法得当,采集的效果并不比原创差多少,甚至比那些没有掌握方法的原创好很多。
如何选择好的文章采集器?
1.直接访问大量关键词,这些关键词都是百度统计过的网民需求的词(有百度索引),或者长尾词这些词的词,来自百度下拉框或相关搜索。
2.直接按关键词采集智能分析网页正文进行爬取,无需编写采集规则。
3. 截取的文字已经用标准标签进行了清理,所有段落都以
开头
4.标签显示,乱码会被去除。
5. 根据采集收到的内容,图片与内容的关联度一定很高。以这种方式替换 伪原创 不会影响可读性,但也可以让 文章 比 原创 提供的信息更丰富。
6.整合百度站长平台主动推送提速收录.
7.可以直接使用关键词及其相关词作为标题,或者抓取登陆页面的标题
如果我们处理好文章采集的内容,采集站点也可以很快收录。由于本文章采集器永久免费并得到广大站长朋友的支持,是SEO圈内的良心软件,为众多站长朋友带来了实实在在的流量和经济效益。的收入。
文章采集程序(如何利用文章采集器让蜘蛛疯狂收录排名?(图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-01-10 03:10
)
如何使用文章采集器让蜘蛛疯狂收录等级?每个搜索引擎都有自己的蜘蛛程序。蜘蛛程序通过网页的链接地址搜索该网页,直到爬取到这个网站的所有网页,然后通过搜索引擎算法对网站进行评价,得到评价。如果把互联网比作蜘蛛网,那么蜘蛛程序对每张网站图像的爬行活动就称为蜘蛛爬行。
如何吸引蜘蛛爬取页面
1、一个 网站 和页面权重。算是质量上乘,老的网站的权重比较高。这个网站的网络爬取深度会比较高,也收录很多。
2、网站 的更新频率。蜘蛛抓取的每个页面的数据存储。如果爬虫第二次发现第一个收录完全相同的页面,则该页面不会更新,并且蜘蛛不需要经常捕获它。网站的页面内容更新频繁,蜘蛛会更频繁地访问该页面,页面上会出现一个新的链接,这将更快地跟踪和抓取蜘蛛。
3、网站 的原创 内容。百度蜘蛛的诱惑很大原创内容,原创内容的主食,搜索引擎蜘蛛每天都需要。
4、网站的整体结构。包括:页面更新状态、标题、关键词、标题、关键词、meta中嵌入的描述标签、导航栏等。
5、建筑工地地图。网站地图就像一个灯塔,唯一一个清晰的灯塔可以指引蜘蛛的下落。引诱更多蜘蛛的便捷方式。
6、内部链接优化。蜘蛛来到你的网站,自然是通过你的网站的结构,通过你的网站,你几乎可以运行任何网站链接,这些链接中的任何一个死链接都可以轻松导致蜘蛛爬出来。更多的时候,百度自然会来你的网站没有好感。
7、外部网站 链接。要成为蜘蛛爬虫,页面必须有一个传入链接,否则蜘蛛没有机会知道该页面的存在。
8、监控蜘蛛爬行。可以使用网络日志蜘蛛知道哪些页面被爬取,可以使用SEO工具查看蜘蛛频率,合理分配资源,实现更高的速度和更多的蜘蛛爬取。
提高网站的收录的排名是通过网站优化SEO,可以参考SEO的优化方法。简单来说,可以从以下几个方面进行改进:
1、改进网站结构的布局,使其结构合理清晰;
2、保证网页内容的原创质量并定期更新;
3、增加网页的反向链接,网站在搜索引擎中排名不错的做友情链接;
4、优化URL链接,可以在URL中适当添加一些关键词,使用中文拼音;
5、始终将用户体验放在首位。
通过以上信息,我们了解了网站内容更新的重要性。网站 更新频率越快,蜘蛛爬行的频率就越高。数量会减少,减少网站的权重。由于个人精力有限原创,难以保证大量长期更新。如果邀请编辑,投入产出比可能为负。但是只要方法得当,采集的效果并不比原创差多少,甚至比那些没有掌握方法的原创好很多。
如何选择好的文章采集器?
1.直接访问大量关键词,这些关键词都是百度统计的网民需求词(有百度索引),或者这些的长尾词词,从百度下拉框或相关搜索。
2.直接按关键词采集智能分析网页正文进行爬取,无需编写采集规则。
3. 捕获的文本已经用标准化的标签进行了清理,所有段落都以
4. 标签显示,乱码会被移除。
5. 根据采集收到的内容,自动匹配图片,图片必须与内容相关度很高。以这种方式替换 伪原创 不会影响可读性,但也允许 文章 比 原创 提供的信息更丰富。
6.整合百度站长平台,积极推送提速收录。
7.可以直接使用关键词及其相关词作为标题,或者抓取登陆页面的标题
如果我们处理好文章采集的内容,采集站点也可以很快收录。由于本文章采集器永久免费并得到广大站长朋友的支持,是SEO圈子里的良心软件,为众多站长朋友带来了实实在在的流量和经济效益。的收益。
查看全部
文章采集程序(如何利用文章采集器让蜘蛛疯狂收录排名?(图)
)
如何使用文章采集器让蜘蛛疯狂收录等级?每个搜索引擎都有自己的蜘蛛程序。蜘蛛程序通过网页的链接地址搜索该网页,直到爬取到这个网站的所有网页,然后通过搜索引擎算法对网站进行评价,得到评价。如果把互联网比作蜘蛛网,那么蜘蛛程序对每张网站图像的爬行活动就称为蜘蛛爬行。
如何吸引蜘蛛爬取页面
1、一个 网站 和页面权重。算是质量上乘,老的网站的权重比较高。这个网站的网络爬取深度会比较高,也收录很多。
2、网站 的更新频率。蜘蛛抓取的每个页面的数据存储。如果爬虫第二次发现第一个收录完全相同的页面,则该页面不会更新,并且蜘蛛不需要经常捕获它。网站的页面内容更新频繁,蜘蛛会更频繁地访问该页面,页面上会出现一个新的链接,这将更快地跟踪和抓取蜘蛛。
3、网站 的原创 内容。百度蜘蛛的诱惑很大原创内容,原创内容的主食,搜索引擎蜘蛛每天都需要。
4、网站的整体结构。包括:页面更新状态、标题、关键词、标题、关键词、meta中嵌入的描述标签、导航栏等。
5、建筑工地地图。网站地图就像一个灯塔,唯一一个清晰的灯塔可以指引蜘蛛的下落。引诱更多蜘蛛的便捷方式。
6、内部链接优化。蜘蛛来到你的网站,自然是通过你的网站的结构,通过你的网站,你几乎可以运行任何网站链接,这些链接中的任何一个死链接都可以轻松导致蜘蛛爬出来。更多的时候,百度自然会来你的网站没有好感。
7、外部网站 链接。要成为蜘蛛爬虫,页面必须有一个传入链接,否则蜘蛛没有机会知道该页面的存在。
8、监控蜘蛛爬行。可以使用网络日志蜘蛛知道哪些页面被爬取,可以使用SEO工具查看蜘蛛频率,合理分配资源,实现更高的速度和更多的蜘蛛爬取。
提高网站的收录的排名是通过网站优化SEO,可以参考SEO的优化方法。简单来说,可以从以下几个方面进行改进:
1、改进网站结构的布局,使其结构合理清晰;
2、保证网页内容的原创质量并定期更新;
3、增加网页的反向链接,网站在搜索引擎中排名不错的做友情链接;
4、优化URL链接,可以在URL中适当添加一些关键词,使用中文拼音;
5、始终将用户体验放在首位。
通过以上信息,我们了解了网站内容更新的重要性。网站 更新频率越快,蜘蛛爬行的频率就越高。数量会减少,减少网站的权重。由于个人精力有限原创,难以保证大量长期更新。如果邀请编辑,投入产出比可能为负。但是只要方法得当,采集的效果并不比原创差多少,甚至比那些没有掌握方法的原创好很多。
如何选择好的文章采集器?
1.直接访问大量关键词,这些关键词都是百度统计的网民需求词(有百度索引),或者这些的长尾词词,从百度下拉框或相关搜索。
2.直接按关键词采集智能分析网页正文进行爬取,无需编写采集规则。
3. 捕获的文本已经用标准化的标签进行了清理,所有段落都以
4. 标签显示,乱码会被移除。
5. 根据采集收到的内容,自动匹配图片,图片必须与内容相关度很高。以这种方式替换 伪原创 不会影响可读性,但也允许 文章 比 原创 提供的信息更丰富。
6.整合百度站长平台,积极推送提速收录。
7.可以直接使用关键词及其相关词作为标题,或者抓取登陆页面的标题
如果我们处理好文章采集的内容,采集站点也可以很快收录。由于本文章采集器永久免费并得到广大站长朋友的支持,是SEO圈子里的良心软件,为众多站长朋友带来了实实在在的流量和经济效益。的收益。
文章采集程序(SEO圈内如何选择好的文章采集器?集成百度站长平台主动推送 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-01-10 03:09
)
1、改进网站结构的布局,使其合理清晰;
2、保证原创网页内容的质量并定期更新;
3、增加网页的反向链接,在搜索引擎中排名更好网站做友好的链接;
4、优化URL链接,可以在URL中适当添加一些关键词,并使用中文拼音;
5、始终将用户体验放在首位。
通过以上信息,我们明白了网站内容更新的重要性。 网站更新频率越快,蜘蛛爬行的频率就越高。 网站页面内容不断更新,爬取的蜘蛛数量会减少,减少网站的权重。由于个人精力有限原创,难以保证大量长期更新。如果邀请编辑,投入产出比可能为负。但只要方法得当,采集的效果并不比原创差多少,甚至比那些没有掌握方法的原创好很多。
如何选择好的文章采集器?
1.直接访问大量关键词,这些关键词都是百度统计过的网民需求的词(有百度索引),或者长尾词这些词的词,来自百度下拉框或相关搜索。
2.直接按关键词采集智能分析网页正文进行爬取,无需编写采集规则。
3. 截取的文字已经用标准标签进行了清理,所有段落都以
开头
4.标签显示,乱码会被去除。
5. 根据采集收到的内容,图片与内容的关联度一定很高。以这种方式替换 伪原创 不会影响可读性,但也可以让 文章 比 原创 提供的信息更丰富。
6.整合百度站长平台主动推送提速收录.
7.可以直接使用关键词及其相关词作为标题,或者抓取登陆页面的标题
如果我们处理好文章采集的内容,采集站点也可以很快收录。由于本文章采集器永久免费并得到广大站长朋友的支持,是SEO圈内的良心软件,为众多站长朋友带来了实实在在的流量和经济效益。的收入。
查看全部
文章采集程序(SEO圈内如何选择好的文章采集器?集成百度站长平台主动推送
)
1、改进网站结构的布局,使其合理清晰;
2、保证原创网页内容的质量并定期更新;
3、增加网页的反向链接,在搜索引擎中排名更好网站做友好的链接;
4、优化URL链接,可以在URL中适当添加一些关键词,并使用中文拼音;
5、始终将用户体验放在首位。
通过以上信息,我们明白了网站内容更新的重要性。 网站更新频率越快,蜘蛛爬行的频率就越高。 网站页面内容不断更新,爬取的蜘蛛数量会减少,减少网站的权重。由于个人精力有限原创,难以保证大量长期更新。如果邀请编辑,投入产出比可能为负。但只要方法得当,采集的效果并不比原创差多少,甚至比那些没有掌握方法的原创好很多。
如何选择好的文章采集器?
1.直接访问大量关键词,这些关键词都是百度统计过的网民需求的词(有百度索引),或者长尾词这些词的词,来自百度下拉框或相关搜索。
2.直接按关键词采集智能分析网页正文进行爬取,无需编写采集规则。
3. 截取的文字已经用标准标签进行了清理,所有段落都以
开头
4.标签显示,乱码会被去除。
5. 根据采集收到的内容,图片与内容的关联度一定很高。以这种方式替换 伪原创 不会影响可读性,但也可以让 文章 比 原创 提供的信息更丰富。
6.整合百度站长平台主动推送提速收录.
7.可以直接使用关键词及其相关词作为标题,或者抓取登陆页面的标题
如果我们处理好文章采集的内容,采集站点也可以很快收录。由于本文章采集器永久免费并得到广大站长朋友的支持,是SEO圈内的良心软件,为众多站长朋友带来了实实在在的流量和经济效益。的收入。
文章采集程序(软件自带PHPCMS发布功能采集后直接直接发布到网站上)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-01-07 19:03
3、软件自带PHPcms发布功能采集然后直接发布到网站,配置每日发布总量,是否为伪原创,以及还为站长人员配备了强大的SEO功能(自动内链、标题插入关键词、内容插入关键词、随机作者、随机阅读数等)增强SEO优化功能,从而提高网站收录!) 同时也支持除了PHPcms之外的主要cms平台采集的发布。
以后不用担心了,因为网站太多了,好忙,网站管不了!告别繁琐的网站后台。反复登录后台是一件很痛苦的事情。再也不用担心 网站 没有内容了。
网站的流量取决于网站收录的比例。收录越多,关键词的排名越高,流量越大。
为什么这么多人选择PHPcms?
PHPcms是一个网站管理软件。软件采用模块化开发,支持多种分类方式。使用它可以方便个性化网站的设计、开发和维护。支持大量程序组合,可轻松实现网站平台迁移,可广泛满足网站各种规模的需求。它具有很高的可靠性。它是一个带有文章、下载和图片的模型。、分类信息、影视、商场、采集、金融等众多功能强大、易用、可扩展的优秀网站管理软件。
许多人使用 PHPcms 仅作为 文章 发布系统。他们只需要在后台增加一栏,然后就可以发布普通的文章。如果在栏目中设置了不同的模型,在栏目中还可以发布软件、图集等内容。
很多文章站点,比如信息站、纸站等,一个普通的文章模型就够了。网站 不能再局限于这几种类型的内容,往往一个站点还收录相关软件、相关图集等类型。
phpcms自带:新闻、图片、下载、资讯、产品等几种模式,你可以在创建栏目的时候选择,为了创建不同类型的栏目,你完全可以使用我们的软件模式去制作一个软件下载网站,用图片模型搭建美容库,用产品模型开店。
当然,将这些模型结合起来,还可以创建不同形式和类型的站点,比如区域门户,需要新闻信息、分类信息、会员图片等。您可以使用相应的模型进行组合。同一个IT门户需要新闻、软件下载和产品,然后我们可以用我们的新闻、下载和产品模型进行组合,非常灵活。
小编用这个SEO工具让网站更有效率,让网站收录暴涨,流量暴涨。看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力! 查看全部
文章采集程序(软件自带PHPCMS发布功能采集后直接直接发布到网站上)
3、软件自带PHPcms发布功能采集然后直接发布到网站,配置每日发布总量,是否为伪原创,以及还为站长人员配备了强大的SEO功能(自动内链、标题插入关键词、内容插入关键词、随机作者、随机阅读数等)增强SEO优化功能,从而提高网站收录!) 同时也支持除了PHPcms之外的主要cms平台采集的发布。
以后不用担心了,因为网站太多了,好忙,网站管不了!告别繁琐的网站后台。反复登录后台是一件很痛苦的事情。再也不用担心 网站 没有内容了。
网站的流量取决于网站收录的比例。收录越多,关键词的排名越高,流量越大。
为什么这么多人选择PHPcms?
PHPcms是一个网站管理软件。软件采用模块化开发,支持多种分类方式。使用它可以方便个性化网站的设计、开发和维护。支持大量程序组合,可轻松实现网站平台迁移,可广泛满足网站各种规模的需求。它具有很高的可靠性。它是一个带有文章、下载和图片的模型。、分类信息、影视、商场、采集、金融等众多功能强大、易用、可扩展的优秀网站管理软件。
许多人使用 PHPcms 仅作为 文章 发布系统。他们只需要在后台增加一栏,然后就可以发布普通的文章。如果在栏目中设置了不同的模型,在栏目中还可以发布软件、图集等内容。
很多文章站点,比如信息站、纸站等,一个普通的文章模型就够了。网站 不能再局限于这几种类型的内容,往往一个站点还收录相关软件、相关图集等类型。
phpcms自带:新闻、图片、下载、资讯、产品等几种模式,你可以在创建栏目的时候选择,为了创建不同类型的栏目,你完全可以使用我们的软件模式去制作一个软件下载网站,用图片模型搭建美容库,用产品模型开店。
当然,将这些模型结合起来,还可以创建不同形式和类型的站点,比如区域门户,需要新闻信息、分类信息、会员图片等。您可以使用相应的模型进行组合。同一个IT门户需要新闻、软件下载和产品,然后我们可以用我们的新闻、下载和产品模型进行组合,非常灵活。
小编用这个SEO工具让网站更有效率,让网站收录暴涨,流量暴涨。看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力!
文章采集程序(网站收录、排名解决几个方法,爱煮饭也曾经试验过采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-01-07 08:14
1、采集如何对站进行排名采集站收录解决方法
,爱厨也尝试过采集,今天给大家分享一下如何用采集做流量。笔者目前的操作网站是基于手动复制别人的文章,加上我自己的观点,所有操作网站半年就能达到目标。关键词 排名第一。在一页上,您可以看到示例案例经典句子网、股票入门网、ERP 100,000 为什么。
采集网站收录,几种解决排名的方法。
1 选择 网站 程序。不建议使用大家都在用的程序网站,因为你是采集,而且搜索的这些内容的记录很多,所以唯一的程序是重要因素之一在解决采集站收录的排名。
2 网站模板,如果你自己不会写程序,至少你的模板应该和别人的不一样。一个好的结构会让你的 网站 与众不同。
3 采集内容控制进度,采集也要注意方法,采集相关网站内容,每天多少合适采集?爱厨推荐新站,每天新增不到50条新数据。50条数据是不同时间段增加的,不是同时增加的。在采集程序中,我们可以随时写一个任务采集,一个小时内随机更新几个文章,模拟手动更新网站。
6 使用旧域名,注册时间越长越好。
上述六种方法是最基本的。如果你喜欢烹饪,我建议如果你是新网站,先手动更新三个月的内容,培养网站的权重,然后再进行采集。
2、cms电影采集谁知道方法
建议还是用一些现成的软件比较好,省事又可以提高效率。我必须自己测试这个和那个,麻烦!
采集土豆网、优酷视频,先采集视频的下载地址,然后用批量下载工具下载,可能有网站限制了你的IP。
不过感觉网上找的免费的采集软件不行,我自己做的采集
最好用普通版,可以做个试用版,比免费的好很多!
网络信息采集是信息化进程中的重要一步,所以很多企业都在提倡拥有**优采云采集、**采集器等软件,但是这些都是应用层面比较浅的技术,还有很多地方是做不到的。比如网站限制你采集等问题。如果你想要高端的技术或者成熟的产品,那一定是网站 @采集行业内非常专业的公司。国内比较专业的网络信息采集是深圳乐思软件,你可以去他们网站了解一下,也许可以分享一下版本,反正我们公司用的企业版很使用方便。的。
你可以自己搜索教程和网址,他们会在他们公司的软件教程下载页面上找到。
词汇表
采集
采集 是人类活动的重要组成部分。在古代,人们的采集行为往往是为了满足生理需求,比如吃喝,比如防御。随着时代的变迁,人类的采集行为也逐渐发生了变化。人们开始利用采集的能力渗透到生活的每一个领域,从获取物品到采集获取信息。采集这里的意思是采摘采集。因为引用,在动物界,也有采集的行为。例如,蜜蜂采集花蜜。
软件
软件是一系列按特定顺序组织的计算机数据和指令,是计算机的无形部分。软件一般分为系统软件、应用软件和中间件。软件包括运行在计算机上的所有程序,无论其架构如何,都有共同的特点,运行后硬件可以运行设计所需的功能。简单地说,软件是程序和文档的集合。软件在世界各个地区都有使用,对人们的生活和工作产生深远的影响。
下载
下载是指将文件从FTP服务器复制到自己的电脑上。早期从FTP服务器下载文件的方式是直接使用FTP软件(ftp.exe)直接访问已知的FTP服务器,并使用一组规定的命令来获取文件,即命令方法,但是这个方法使用不便,已很少使用。有人使用它。从互联网上下载文件的方法主要有直接从网页或FTP站点下载、使用可恢复下载软件下载、以电子邮件的形式下载。 查看全部
文章采集程序(网站收录、排名解决几个方法,爱煮饭也曾经试验过采集)
1、采集如何对站进行排名采集站收录解决方法
,爱厨也尝试过采集,今天给大家分享一下如何用采集做流量。笔者目前的操作网站是基于手动复制别人的文章,加上我自己的观点,所有操作网站半年就能达到目标。关键词 排名第一。在一页上,您可以看到示例案例经典句子网、股票入门网、ERP 100,000 为什么。
采集网站收录,几种解决排名的方法。
1 选择 网站 程序。不建议使用大家都在用的程序网站,因为你是采集,而且搜索的这些内容的记录很多,所以唯一的程序是重要因素之一在解决采集站收录的排名。
2 网站模板,如果你自己不会写程序,至少你的模板应该和别人的不一样。一个好的结构会让你的 网站 与众不同。
3 采集内容控制进度,采集也要注意方法,采集相关网站内容,每天多少合适采集?爱厨推荐新站,每天新增不到50条新数据。50条数据是不同时间段增加的,不是同时增加的。在采集程序中,我们可以随时写一个任务采集,一个小时内随机更新几个文章,模拟手动更新网站。
6 使用旧域名,注册时间越长越好。
上述六种方法是最基本的。如果你喜欢烹饪,我建议如果你是新网站,先手动更新三个月的内容,培养网站的权重,然后再进行采集。
2、cms电影采集谁知道方法
建议还是用一些现成的软件比较好,省事又可以提高效率。我必须自己测试这个和那个,麻烦!
采集土豆网、优酷视频,先采集视频的下载地址,然后用批量下载工具下载,可能有网站限制了你的IP。
不过感觉网上找的免费的采集软件不行,我自己做的采集
最好用普通版,可以做个试用版,比免费的好很多!
网络信息采集是信息化进程中的重要一步,所以很多企业都在提倡拥有**优采云采集、**采集器等软件,但是这些都是应用层面比较浅的技术,还有很多地方是做不到的。比如网站限制你采集等问题。如果你想要高端的技术或者成熟的产品,那一定是网站 @采集行业内非常专业的公司。国内比较专业的网络信息采集是深圳乐思软件,你可以去他们网站了解一下,也许可以分享一下版本,反正我们公司用的企业版很使用方便。的。
你可以自己搜索教程和网址,他们会在他们公司的软件教程下载页面上找到。
词汇表
采集
采集 是人类活动的重要组成部分。在古代,人们的采集行为往往是为了满足生理需求,比如吃喝,比如防御。随着时代的变迁,人类的采集行为也逐渐发生了变化。人们开始利用采集的能力渗透到生活的每一个领域,从获取物品到采集获取信息。采集这里的意思是采摘采集。因为引用,在动物界,也有采集的行为。例如,蜜蜂采集花蜜。
软件
软件是一系列按特定顺序组织的计算机数据和指令,是计算机的无形部分。软件一般分为系统软件、应用软件和中间件。软件包括运行在计算机上的所有程序,无论其架构如何,都有共同的特点,运行后硬件可以运行设计所需的功能。简单地说,软件是程序和文档的集合。软件在世界各个地区都有使用,对人们的生活和工作产生深远的影响。
下载
下载是指将文件从FTP服务器复制到自己的电脑上。早期从FTP服务器下载文件的方式是直接使用FTP软件(ftp.exe)直接访问已知的FTP服务器,并使用一组规定的命令来获取文件,即命令方法,但是这个方法使用不便,已很少使用。有人使用它。从互联网上下载文件的方法主要有直接从网页或FTP站点下载、使用可恢复下载软件下载、以电子邮件的形式下载。
文章采集程序(猜你在找的PHP相关文章PHP开发与代码审计(总结))
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-01-02 16:08
猜猜你在找什么 PHP 相关的文章
PHP 操作 MySQL 数据库和 PDO 技术
创建测试数据:首先,我们需要创建一些测试记录,然后首先演示基本数据库链接命令的使用。创建表用户名(uid int not null,name varchar
常见PHP漏洞代码汇总
漏洞摘要PHP文件上传漏洞只验证MIME类型:代码中验证上传的MIME类型,绕过方式使用Burp抓包,上传的语句是pony*.php中的Content-Type : 应用程序/php
PHP 开发和代码审计(总结)
作者在学习PHP的时候会分享学习笔记。它基本上是对之前博客文章的总结。好像比较方便。作者最近放弃了PHP代码审计部分,所以不会再继续研究了,因为真正的精力如果达不到,只能选择同样的方式开发,不要做半瓶醋
PHP 字符串和文件操作
<p>字符操作字符串输出:字符串输出格式与C语言一致, 查看全部
文章采集程序(猜你在找的PHP相关文章PHP开发与代码审计(总结))
猜猜你在找什么 PHP 相关的文章
PHP 操作 MySQL 数据库和 PDO 技术
创建测试数据:首先,我们需要创建一些测试记录,然后首先演示基本数据库链接命令的使用。创建表用户名(uid int not null,name varchar
常见PHP漏洞代码汇总
漏洞摘要PHP文件上传漏洞只验证MIME类型:代码中验证上传的MIME类型,绕过方式使用Burp抓包,上传的语句是pony*.php中的Content-Type : 应用程序/php
PHP 开发和代码审计(总结)
作者在学习PHP的时候会分享学习笔记。它基本上是对之前博客文章的总结。好像比较方便。作者最近放弃了PHP代码审计部分,所以不会再继续研究了,因为真正的精力如果达不到,只能选择同样的方式开发,不要做半瓶醋
PHP 字符串和文件操作
<p>字符操作字符串输出:字符串输出格式与C语言一致,

