
文章采集接口
小浣熊动漫cms3.0版本最新采集规则和发布模块加插口加插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 596 次浏览 • 2020-08-09 12:45
3.规则里有具体的使用视频教学
4.必须使用优采云v9.8内部版(自己在网上找)
5.使用简易教程:
首先保证你手里有三个文件或则更多,例如Write.php(发布插口) xxxx.ljobx(采集规则) xxx.wpm(发布模块) xxx.cs(采集插件)
1.选择对应版本优采云导入 采集规则 和 发布模块 去网站对应位置替换 Write.php(发布插口)
优采云安装目录/Module 这是放发布模块的
优采云安装目录/Plugins 这是放插件的
网站安装目录/application/api/controller 这是放发布插口的
2.修改规则中的 cookie 发布规则配置 插件配置 一些关键标签的替换值(不同的规则可能不需要修改)
cookie的作用是为了采集一些须要会员登录就能采集的东西
发布配置,就是编辑任务中 第三步 ,添加发布配置,选择发布模块,并填写自己的url即可
插件配置 部分规则使用插件辅助采集,所以须要在第四步中选择对应的采集插件
一些标签的值, 如api秘钥,单章价钱,甚至是图片转本地后的对应新域名都须要自行修改
3.完成上述,在第一步页面测试网址获取并点击任意内容页进行测试采集
4.右下角测试还有个测试发布,配置完发布配置的可以测试下,这里的测试发布可以有效查看发布状态和错误 查看全部
2.根据网站版本选择对应的发布模块和插口,并配置即可
3.规则里有具体的使用视频教学
4.必须使用优采云v9.8内部版(自己在网上找)
5.使用简易教程:
首先保证你手里有三个文件或则更多,例如Write.php(发布插口) xxxx.ljobx(采集规则) xxx.wpm(发布模块) xxx.cs(采集插件)
1.选择对应版本优采云导入 采集规则 和 发布模块 去网站对应位置替换 Write.php(发布插口)
优采云安装目录/Module 这是放发布模块的
优采云安装目录/Plugins 这是放插件的
网站安装目录/application/api/controller 这是放发布插口的
2.修改规则中的 cookie 发布规则配置 插件配置 一些关键标签的替换值(不同的规则可能不需要修改)
cookie的作用是为了采集一些须要会员登录就能采集的东西
发布配置,就是编辑任务中 第三步 ,添加发布配置,选择发布模块,并填写自己的url即可
插件配置 部分规则使用插件辅助采集,所以须要在第四步中选择对应的采集插件
一些标签的值, 如api秘钥,单章价钱,甚至是图片转本地后的对应新域名都须要自行修改
3.完成上述,在第一步页面测试网址获取并点击任意内容页进行测试采集
4.右下角测试还有个测试发布,配置完发布配置的可以测试下,这里的测试发布可以有效查看发布状态和错误
WordPress4.X-5.3优采云免登录发布插口+模块(增强版)下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2020-08-09 12:26
下载地址:
链接: 提取码:z6kf
WordPress4.X-5.3优采云免登录发布插口+模块(增强版)功能适用于优采云采集器7.6-V9.12(目前最新版)优化了验证标题重复优化了附件、图片、缩略图的上传和生成降低了对多个分类方法的发布参数(post_taxonomy_list),使用方式请参考功能特点修补BUG: 分类名称假如富含数字会导致分类错误旧版发布插口重新设计,新版本号为T1,以后不再对旧版升级维护.旧版本支持3.X-4.8.2修补BUG:当规则中没有发布模块中某个参数时会导致发布数据异常(会显示db:标签名)优化strtoarray函数更新说明
T3: 2017.11.03
1、优化了验证标题重复
2、优化了附件、图片、缩略图的上传和生成
T2: 2017.10.23
1、增加了对多个分类方法的发布参数(post_taxonomy_list),使用方式请参考功能特点
2、修复BUG: 分类名称假如富含数字会导致分类错误
T1:2017.10.12
1、旧版发布插口重新设计,新版本号为T1,以后不再对旧版升级维护.旧版本支持3.X-4.8.2
2、修复BUG:当规则中没有发布模块中某个参数时会导致发布数据异常(会显示db:标签名)
3、优化strtoarray函数
功能特点解读1.分类(category)2.标签3.作者4.图片和缩略图:5.时间和预约发布:6.评论:7.其它:WordPress优采云免登录插口使用教程
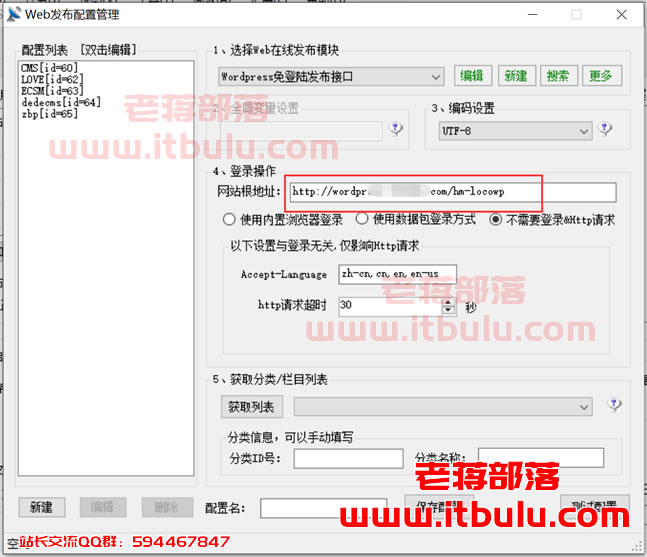
将locoy.php放在wordpress站点根目录,将” WordPress免登录发布插口.wpm”放到优采云采集器下的“Module”文件夹, 然后在优采云采集器编辑任务,选择 第三步: 发布内容规则 页面下的 Web在线发布。如下图。(当前用的是优采云V9.12),第4登录操作-网站那里填写你自己的网站域名。
返回第三步内容发布规则那,选择刚刚保存的配置文件。
完成以上的步骤早已可以发布正常的数据啦, 可以发布得内容有:
标题,内容(此标签可以上传图片和文件),分类,作者,时间,摘要,缩略图(系统会默认调用内容的第一张图片为缩略图,此标签可选)”。如果你不需要个别标签,可以按照上图,编辑发布模块,在“内容发布参数”中删掉对不想要的表单名和表单值。
WordPress优采云免登录插口进阶教程
关于安全配置、多个分类,多个标签,自定义数组(post_meta), 自定义分类(category), 自定义文章类型(post_type), 自定义文章形式(post_format), 自定义分类方法(taxonomy), 自定义分类信息(add_term_meta)请往下看。
模块参数列表:
//以下为代码正文…
post_title 必选 标题
post_content 必选 内容
tag 可选 标签
post_category 可选 分类
post_date 可选 时间
post_excerpt 可选 摘要
post_author 可选 作者
category_description 可选 分类信息
post_cate_meta[name] 可选 自定义分类信息
post_meta[name] 可选 自定义字段
post_type 可选 文章类型 默认为'post'
post_taxonomy 可选 自定义分类方式
post_format 可选 文章形式
参考功能说明:
如何发布文章同时属于多个分类,多个标签?
多分类和多标签必须用冒号隔开,支持name和 id 两种形式, 模块手动判定。 例如 name: 科幻,动作,动漫 id: 1,3,6,2
如何发布自定义数组?
在web发布配置,进入发布插口的编辑模式,然后在内容发布参数新增post_meta[]表单, []中间为自定义数组的名称,表单值为[标签:SEO标题],比如我这儿设置为SEO标题,在优采云采集器第二步内容采集那里对应的标签名就是SEO标题。
如何进行安全配置?
文件会对数据进行过滤, 但是为了数据的安全, 所以建议:
1.更改通信秘钥,更改locoy.php文件的61行”$secretWord = ‘123456’;” (注意!这个秘钥必须要Web发布配置中的全局变量保持一致)。
2.将文件重命名为愈加复杂的名子. 重命名后须要更改发布模块的以下几个参数,保持一致性。
关于文件上传
1.在Web发布模块/高级功能/添加标签名
2.在优采云采集器任务的第二步,内容采集规则,内容-文件下载,设置参照如图设置:
关于其它自定义的使用方式和自定义数组大同小异,仅是更换了表单名,某些自定义属性支持字段。 查看全部
自古文章天下一大抄,看你会抄不会秒。对于好多站长,因为人的极限性,网站没有采集文章只靠自己百分百纯原创是极少的也是废精力的,好的内容采集一下也是不错的。最近接触了优采云采集器,自己这个站也是wordpress搭的站点,用到了一款免登录发布文章接口的模块,感觉很好用。因为网上的大多教程都是用的优采云V7.6在作演示,对于一些新接触优采云采集V9版本的新用户是有点难懂。我明天就在这分享一下用优采云V9版本的教程。我在wordpress4.4、4.5、4.6、4.7、4.9至现今最新版5.3.2测试都可以用。
下载地址:
链接: 提取码:z6kf
WordPress4.X-5.3优采云免登录发布插口+模块(增强版)功能适用于优采云采集器7.6-V9.12(目前最新版)优化了验证标题重复优化了附件、图片、缩略图的上传和生成降低了对多个分类方法的发布参数(post_taxonomy_list),使用方式请参考功能特点修补BUG: 分类名称假如富含数字会导致分类错误旧版发布插口重新设计,新版本号为T1,以后不再对旧版升级维护.旧版本支持3.X-4.8.2修补BUG:当规则中没有发布模块中某个参数时会导致发布数据异常(会显示db:标签名)优化strtoarray函数更新说明
T3: 2017.11.03
1、优化了验证标题重复
2、优化了附件、图片、缩略图的上传和生成
T2: 2017.10.23
1、增加了对多个分类方法的发布参数(post_taxonomy_list),使用方式请参考功能特点
2、修复BUG: 分类名称假如富含数字会导致分类错误
T1:2017.10.12
1、旧版发布插口重新设计,新版本号为T1,以后不再对旧版升级维护.旧版本支持3.X-4.8.2
2、修复BUG:当规则中没有发布模块中某个参数时会导致发布数据异常(会显示db:标签名)
3、优化strtoarray函数
功能特点解读1.分类(category)2.标签3.作者4.图片和缩略图:5.时间和预约发布:6.评论:7.其它:WordPress优采云免登录插口使用教程
将locoy.php放在wordpress站点根目录,将” WordPress免登录发布插口.wpm”放到优采云采集器下的“Module”文件夹, 然后在优采云采集器编辑任务,选择 第三步: 发布内容规则 页面下的 Web在线发布。如下图。(当前用的是优采云V9.12),第4登录操作-网站那里填写你自己的网站域名。

返回第三步内容发布规则那,选择刚刚保存的配置文件。

完成以上的步骤早已可以发布正常的数据啦, 可以发布得内容有:
标题,内容(此标签可以上传图片和文件),分类,作者,时间,摘要,缩略图(系统会默认调用内容的第一张图片为缩略图,此标签可选)”。如果你不需要个别标签,可以按照上图,编辑发布模块,在“内容发布参数”中删掉对不想要的表单名和表单值。
WordPress优采云免登录插口进阶教程
关于安全配置、多个分类,多个标签,自定义数组(post_meta), 自定义分类(category), 自定义文章类型(post_type), 自定义文章形式(post_format), 自定义分类方法(taxonomy), 自定义分类信息(add_term_meta)请往下看。
模块参数列表:
//以下为代码正文…
post_title 必选 标题
post_content 必选 内容
tag 可选 标签
post_category 可选 分类
post_date 可选 时间
post_excerpt 可选 摘要
post_author 可选 作者
category_description 可选 分类信息
post_cate_meta[name] 可选 自定义分类信息
post_meta[name] 可选 自定义字段
post_type 可选 文章类型 默认为'post'
post_taxonomy 可选 自定义分类方式
post_format 可选 文章形式
参考功能说明:
如何发布文章同时属于多个分类,多个标签?
多分类和多标签必须用冒号隔开,支持name和 id 两种形式, 模块手动判定。 例如 name: 科幻,动作,动漫 id: 1,3,6,2
如何发布自定义数组?

在web发布配置,进入发布插口的编辑模式,然后在内容发布参数新增post_meta[]表单, []中间为自定义数组的名称,表单值为[标签:SEO标题],比如我这儿设置为SEO标题,在优采云采集器第二步内容采集那里对应的标签名就是SEO标题。
如何进行安全配置?
文件会对数据进行过滤, 但是为了数据的安全, 所以建议:
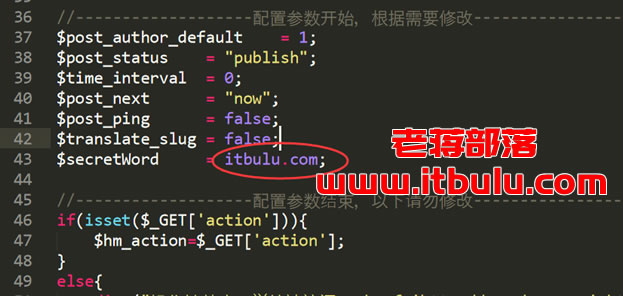
1.更改通信秘钥,更改locoy.php文件的61行”$secretWord = ‘123456’;” (注意!这个秘钥必须要Web发布配置中的全局变量保持一致)。
2.将文件重命名为愈加复杂的名子. 重命名后须要更改发布模块的以下几个参数,保持一致性。

关于文件上传
1.在Web发布模块/高级功能/添加标签名

2.在优采云采集器任务的第二步,内容采集规则,内容-文件下载,设置参照如图设置:

关于其它自定义的使用方式和自定义数组大同小异,仅是更换了表单名,某些自定义属性支持字段。
监控Tomcat解决方案(监控应用服务器系列文章)
采集交流 • 优采云 发表了文章 • 0 个评论 • 586 次浏览 • 2020-08-09 10:47
监控Tomcat常见的两种方案的比较
使用Tomcat提供的manager应用进行数据采集
◆ 可以使用现有的成熟代码,减少工作量
◆ 支持各不同版本时无差异
◆ 可能存在特殊需求而manager不能满足的情况
◆ 最重要的一个优点是,配置比较简单
使用JMX插口开发监控程序
◆ 全部代码须要从零开始,代码量较大
◆ 支持各不同版本比较麻烦,每个版本可能有差别
◆ 可支配性强
◆ 最重要的一个缺点是,配置比较麻烦
方案一、使用 Tomcat提供的manager应用进行数据采集
Applications Manager(又称opManager)就是通过这些方法实现的。
使用这些方法,所监控Tomcat必须运行manager应用,缺省情况下,该应用总是运行在服务器中的。
增加manager角色用户
访问manager应用的用户的角色权限必须是 manager.
修改/conf目录下的tomcat-users.xml文件,在节点下添加一个user节点,即可创建一个用户。
Tomcat版本不同配置也有差别,5.x和6.x创建的用户角色应为manager,7.x创建的用户角色为manager-jmx,举例如下:
1、在5.x和6.x中创建一个manager角色的用户,用户名为admin,密码为chenfeng:
2、在7.x中创建一个manager角色的用户,用户名为admin,密码为chenfeng:
admin" password="chenfeng" roles="manager-jmx,manager-script,manager-status"/>
修改配置后,需要重新启动 Tomcat 服务器。
连接manager时将用户名/密码指定为admin/chenfeng
通过浏览器访问JMX Proxy Servlet
详见官方说明文档:
What is JMX Proxy Servlet
The JMX Proxy Servlet is a lightweight proxy to get and set the tomcat internals. (Or any class that has been exposed via an MBean) Its usage is not very user friendly but the UI is extremely help for integrating command line scripts for monitoring and changing the internals of tomcat. You can do two things with the proxy: get information and set information. For you to really understand the JMX Proxy Servlet, you should have a general understanding of JMX. If you don't know what JMX is, then prepare to be confused.
JMX Query command
This takes the form:
http://webserver/manager/jmxproxy/?qry=STUFF
Where STUFF is the JMX query you wish to perform. For example, here are some queries you might wish to run:
◆ qry=*%3Atype%3DRequestProcessor%2C* --> type=RequestProcessorwhich will locate all workers which can process requests and report their state.
◆ qry=*%3Aj2eeType=Servlet%2c* --> j2eeType=Servletwhich return all loaded servlets.
◆ qry=Catalina%3Atype%3DEnvironment%2Cresourcetype%3DGlobal%2Cname%3DsimpleValue --> Catalina:type=Environment,resourcetype=Global,name=simpleValuewhich look for a specific MBean by the given name.
You'll need to experiment with this to really understand its capabilites. If you provide no qry parameter, then all of the MBeans will be displayed. We really recommend looking at the tomcat source code and understand the JMX spec to get a better understanding of all the queries you may run.
通过浏览器访问:8080/manager/jmxproxy ,输入用户名密码,然后就可以看见返回了所有的监控信息
添加查询参数,返回特定的监控信息:
例如:
:8080/manager/jmxproxy?qry=*%3Atype%3DRequestProcessor%2C*
其中 *%3Atype%3DRequestProcessor%2C* 其实就是 *:type=RequestProcessor,*
又如:
:8080/manager/jmxproxy?qry=*%3Aj2eeType%3DWebModule%2Cname%3D//localhost/ajaxrpc%2C*
在代码中访问JMX Proxy Servlet
通过浏览器访问JMX Proxy Servlet须要输入用户名密码,所以通过Java访问JMX Proxy Servlet的URL也须要授权访问: URL url = new URL(":8080/manager/jmxproxy?qry=*%3Atype%3DManager%2C*");
URLConnection conn = (URLConnection) url.openConnection();
// URL授权访问 -- Begin
String password = "admin:chenfeng"; // manager角色的用户
String encodedPassword = new BASE64Encoder().encode(password.getBytes());
conn.setRequestProperty("Authorization", "Basic " + encodedPassword);
// URL授权访问 -- End
InputStream is = conn.getInputStream();
BufferedReader bufreader = new BufferedReader(new InputStreamReader(is));
String line = null;
while ((line = bufreader.readLine()) != null) {
System.out.println(line);
}
几个具体的事例
下面展示两个事例,一个是采集服务器基本信息,一个是采集Web应用列表信息,注意Tomcat 7.x和Tomcat 5.x、6.x之间存在很大的区别。
◆ 采集服务器基本信息
通过serverinfo命令查看服务器基本信息
:8080/manager/serverinfo
Tomcat 7.x的查询URL有变化:
:8080/manager/text/serverinfo
返回信息:
OK - Server info
Tomcat Version: Apache Tomcat/7.0.11
OS Name: Windows Vista
OS Version: 6.1
OS Architecture: x86
JVM Version: 1.6.0_13-b03
JVM Vendor: Sun Microsystems Inc.
◆ 采集Web应用列表信息
通过list命令查看Web应用列表和会话数信息
:8080/manager/list
Tomcat 7.x的查询URL有变化:
:8080/manager/text/list
返回信息:
OK - Listed applications for virtual host localhost
/:running:0:ROOT
/manager:running:1:manager
/docs:running:0:docs
/examples:running:0:examples
/host-manager:running:0:host-manager
方案二、使用JMX 接口开发监控程序Tomcat激活JMX远程配置
① 先更改Tomcat的启动脚本,window下tomcat的bin/catalina.bat(linux为catalina.sh),添加以下内 容,8999是jmxremote使用的端口号,第二个false表示不需要信令:
set JMX_REMOTE_CONFIG=-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=8999 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false
set CATALINA_OPTS=%CATALINA_OPTS% %JMX_REMOTE_CONFIG%
可以加在if "%OS%" == "Windows_NT" setlocal 一句后的大段的注释旁边。
参考官方说明:
② 上面的配置是不需要信令的,如果须要信令则添加的内容为:
set JMX_REMOTE_CONFIG=-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=8999 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=true -Dcom.sun.management.jmxremote.password.file=../conf/jmxremote.password -Dcom.sun.management.jmxremote.access.file=../conf/jmxremote.access
set CATALINA_OPTS=%CATALINA_OPTS% %JMX_REMOTE_CONFIG%
然后复制并更改授权文件,$JAVA_HOME/jre/lib/management下有 jmxremote.access和jmxremote.password的模板文件,将两个文件复制到$CATALINA_BASE/conf目录下
● 修改$CATALINA_BASE/conf/jmxremote.access 添加内容:
monitorRole readonly
controlRole readwrite
● 修改$CATALINA_BASE/conf/jmxremote.password 添加内容:
monitorRole tomcat
controlRole tomcat
注意:如果只做第一步没有问题,进行了第二步Tomcat就启动不了,那么太可能是密码文件的权限问题!
需要更改jmxremote.password文件的权限,只有运行Tomcat的用户有访问权限:
Windows的NTFS文件系统下,选中文件,点右键 -->“属性”-->“安全”--> 点“高级”--> 点“更改权限”--> 去掉“从父项继承....”--> 弹出窗口中选“删除”,这样就删掉了所有访问权限。再选“添加”--> “高级”--> “立即查找”,选中你的用户,例administrator,点“确定",“确定"。来到权限项目窗口,勾选“完全控制”,点“确定”,OK了。
官方的提示
The password file should be read-only and only accessible by the operating system user Tomcat is running as.
③ 重新启动Tomcat,在Windows命令行输入“netstat -a”查看配置的端口号是否已打开,如果打开,说明里面的配置成功了。
④ 使用jconsole测试JMX。
运行$JAVA_HOME/bin目录下的jconsole.exe,打开J2SE监视和管理控制台,然后构建联接,如 果是本地的Tomcat则直接选择之后点击联接,如果是远程的,则步入远程选项卡,填写地址、端口号、用户名、口令即可联接。Mbean属性页中给出了相 应的数据,Catalina中是tomcat的,java.lang是jvm的。对于加粗的宋体属性值,需双击一下才可看内容。
使用JMX监控Tomcat示例代码:
String jmxURL = "service:jmx:rmi:///jndi/rmi://192.168.10.93:8999/jmxrmi";
JMXServiceURL serviceURL = new JMXServiceURL(jmxURL);
Map map = new HashMap();
// 用户名密码,在jmxremote.password文件中查看
String[] credentials = new String[] { "monitorRole", "tomcat" };
map.put("jmx.remote.credentials", credentials);
JMXConnector connector = JMXConnectorFactory.connect(serviceURL, map);
MBeanServerConnection mbsc = connector.getMBeanServerConnection();
// 端口最好是动态取得
ObjectName threadObjName = new ObjectName("Catalina:type=ThreadPool,name=http-8080");
MBeanInfo mbInfo = mbsc.getMBeanInfo(threadObjName);
// tomcat的线程数对应的属性值
String attrName = "currentThreadCount";
MBeanAttributeInfo[] mbAttributes = mbInfo.getAttributes();
System.out.println("currentThreadCount:" + mbsc.getAttribute(threadObjName, attrName));
完整的示例代码文件: 查看全部
前言:做了一个监控应用服务器的项目(支持Tocmat、WebSphere、WebLogic各版本),过程也算是磕磕绊绊,由于网上缺乏相关资料,或者身陷于知识的海洋未能寻找到有效的资料,因而走过不少弯路,遇过不少困难。为了留下点印记,给后来人留下点经验之谈,助之少走弯路,故将这种经验整理下来,与你们分享。水平有限,难免偏颇,还望见谅。如有疑问,欢迎留言,或者加入Q群参与讨论:35526521。
监控Tomcat常见的两种方案的比较
使用Tomcat提供的manager应用进行数据采集
◆ 可以使用现有的成熟代码,减少工作量
◆ 支持各不同版本时无差异
◆ 可能存在特殊需求而manager不能满足的情况
◆ 最重要的一个优点是,配置比较简单
使用JMX插口开发监控程序
◆ 全部代码须要从零开始,代码量较大
◆ 支持各不同版本比较麻烦,每个版本可能有差别
◆ 可支配性强
◆ 最重要的一个缺点是,配置比较麻烦
方案一、使用 Tomcat提供的manager应用进行数据采集
Applications Manager(又称opManager)就是通过这些方法实现的。
使用这些方法,所监控Tomcat必须运行manager应用,缺省情况下,该应用总是运行在服务器中的。
增加manager角色用户
访问manager应用的用户的角色权限必须是 manager.
修改/conf目录下的tomcat-users.xml文件,在节点下添加一个user节点,即可创建一个用户。
Tomcat版本不同配置也有差别,5.x和6.x创建的用户角色应为manager,7.x创建的用户角色为manager-jmx,举例如下:
1、在5.x和6.x中创建一个manager角色的用户,用户名为admin,密码为chenfeng:
2、在7.x中创建一个manager角色的用户,用户名为admin,密码为chenfeng:
admin" password="chenfeng" roles="manager-jmx,manager-script,manager-status"/>
修改配置后,需要重新启动 Tomcat 服务器。
连接manager时将用户名/密码指定为admin/chenfeng
通过浏览器访问JMX Proxy Servlet
详见官方说明文档:
What is JMX Proxy Servlet
The JMX Proxy Servlet is a lightweight proxy to get and set the tomcat internals. (Or any class that has been exposed via an MBean) Its usage is not very user friendly but the UI is extremely help for integrating command line scripts for monitoring and changing the internals of tomcat. You can do two things with the proxy: get information and set information. For you to really understand the JMX Proxy Servlet, you should have a general understanding of JMX. If you don't know what JMX is, then prepare to be confused.
JMX Query command
This takes the form:
http://webserver/manager/jmxproxy/?qry=STUFF
Where STUFF is the JMX query you wish to perform. For example, here are some queries you might wish to run:
◆ qry=*%3Atype%3DRequestProcessor%2C* --> type=RequestProcessorwhich will locate all workers which can process requests and report their state.
◆ qry=*%3Aj2eeType=Servlet%2c* --> j2eeType=Servletwhich return all loaded servlets.
◆ qry=Catalina%3Atype%3DEnvironment%2Cresourcetype%3DGlobal%2Cname%3DsimpleValue --> Catalina:type=Environment,resourcetype=Global,name=simpleValuewhich look for a specific MBean by the given name.
You'll need to experiment with this to really understand its capabilites. If you provide no qry parameter, then all of the MBeans will be displayed. We really recommend looking at the tomcat source code and understand the JMX spec to get a better understanding of all the queries you may run.
通过浏览器访问:8080/manager/jmxproxy ,输入用户名密码,然后就可以看见返回了所有的监控信息
添加查询参数,返回特定的监控信息:
例如:
:8080/manager/jmxproxy?qry=*%3Atype%3DRequestProcessor%2C*
其中 *%3Atype%3DRequestProcessor%2C* 其实就是 *:type=RequestProcessor,*
又如:
:8080/manager/jmxproxy?qry=*%3Aj2eeType%3DWebModule%2Cname%3D//localhost/ajaxrpc%2C*
在代码中访问JMX Proxy Servlet
通过浏览器访问JMX Proxy Servlet须要输入用户名密码,所以通过Java访问JMX Proxy Servlet的URL也须要授权访问: URL url = new URL(":8080/manager/jmxproxy?qry=*%3Atype%3DManager%2C*");
URLConnection conn = (URLConnection) url.openConnection();
// URL授权访问 -- Begin
String password = "admin:chenfeng"; // manager角色的用户
String encodedPassword = new BASE64Encoder().encode(password.getBytes());
conn.setRequestProperty("Authorization", "Basic " + encodedPassword);
// URL授权访问 -- End
InputStream is = conn.getInputStream();
BufferedReader bufreader = new BufferedReader(new InputStreamReader(is));
String line = null;
while ((line = bufreader.readLine()) != null) {
System.out.println(line);
}
几个具体的事例
下面展示两个事例,一个是采集服务器基本信息,一个是采集Web应用列表信息,注意Tomcat 7.x和Tomcat 5.x、6.x之间存在很大的区别。
◆ 采集服务器基本信息
通过serverinfo命令查看服务器基本信息
:8080/manager/serverinfo
Tomcat 7.x的查询URL有变化:
:8080/manager/text/serverinfo
返回信息:
OK - Server info
Tomcat Version: Apache Tomcat/7.0.11
OS Name: Windows Vista
OS Version: 6.1
OS Architecture: x86
JVM Version: 1.6.0_13-b03
JVM Vendor: Sun Microsystems Inc.
◆ 采集Web应用列表信息
通过list命令查看Web应用列表和会话数信息
:8080/manager/list
Tomcat 7.x的查询URL有变化:
:8080/manager/text/list
返回信息:
OK - Listed applications for virtual host localhost
/:running:0:ROOT
/manager:running:1:manager
/docs:running:0:docs
/examples:running:0:examples
/host-manager:running:0:host-manager
方案二、使用JMX 接口开发监控程序Tomcat激活JMX远程配置
① 先更改Tomcat的启动脚本,window下tomcat的bin/catalina.bat(linux为catalina.sh),添加以下内 容,8999是jmxremote使用的端口号,第二个false表示不需要信令:
set JMX_REMOTE_CONFIG=-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=8999 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false
set CATALINA_OPTS=%CATALINA_OPTS% %JMX_REMOTE_CONFIG%
可以加在if "%OS%" == "Windows_NT" setlocal 一句后的大段的注释旁边。
参考官方说明:
② 上面的配置是不需要信令的,如果须要信令则添加的内容为:
set JMX_REMOTE_CONFIG=-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=8999 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=true -Dcom.sun.management.jmxremote.password.file=../conf/jmxremote.password -Dcom.sun.management.jmxremote.access.file=../conf/jmxremote.access
set CATALINA_OPTS=%CATALINA_OPTS% %JMX_REMOTE_CONFIG%
然后复制并更改授权文件,$JAVA_HOME/jre/lib/management下有 jmxremote.access和jmxremote.password的模板文件,将两个文件复制到$CATALINA_BASE/conf目录下
● 修改$CATALINA_BASE/conf/jmxremote.access 添加内容:
monitorRole readonly
controlRole readwrite
● 修改$CATALINA_BASE/conf/jmxremote.password 添加内容:
monitorRole tomcat
controlRole tomcat
注意:如果只做第一步没有问题,进行了第二步Tomcat就启动不了,那么太可能是密码文件的权限问题!
需要更改jmxremote.password文件的权限,只有运行Tomcat的用户有访问权限:
Windows的NTFS文件系统下,选中文件,点右键 -->“属性”-->“安全”--> 点“高级”--> 点“更改权限”--> 去掉“从父项继承....”--> 弹出窗口中选“删除”,这样就删掉了所有访问权限。再选“添加”--> “高级”--> “立即查找”,选中你的用户,例administrator,点“确定",“确定"。来到权限项目窗口,勾选“完全控制”,点“确定”,OK了。
官方的提示
The password file should be read-only and only accessible by the operating system user Tomcat is running as.
③ 重新启动Tomcat,在Windows命令行输入“netstat -a”查看配置的端口号是否已打开,如果打开,说明里面的配置成功了。
④ 使用jconsole测试JMX。
运行$JAVA_HOME/bin目录下的jconsole.exe,打开J2SE监视和管理控制台,然后构建联接,如 果是本地的Tomcat则直接选择之后点击联接,如果是远程的,则步入远程选项卡,填写地址、端口号、用户名、口令即可联接。Mbean属性页中给出了相 应的数据,Catalina中是tomcat的,java.lang是jvm的。对于加粗的宋体属性值,需双击一下才可看内容。
使用JMX监控Tomcat示例代码:
String jmxURL = "service:jmx:rmi:///jndi/rmi://192.168.10.93:8999/jmxrmi";
JMXServiceURL serviceURL = new JMXServiceURL(jmxURL);
Map map = new HashMap();
// 用户名密码,在jmxremote.password文件中查看
String[] credentials = new String[] { "monitorRole", "tomcat" };
map.put("jmx.remote.credentials", credentials);
JMXConnector connector = JMXConnectorFactory.connect(serviceURL, map);
MBeanServerConnection mbsc = connector.getMBeanServerConnection();
// 端口最好是动态取得
ObjectName threadObjName = new ObjectName("Catalina:type=ThreadPool,name=http-8080");
MBeanInfo mbInfo = mbsc.getMBeanInfo(threadObjName);
// tomcat的线程数对应的属性值
String attrName = "currentThreadCount";
MBeanAttributeInfo[] mbAttributes = mbInfo.getAttributes();
System.out.println("currentThreadCount:" + mbsc.getAttribute(threadObjName, attrName));
完整的示例代码文件:
新浪股票插口获取历史数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2020-08-09 10:30
关于实时数据的获取你们可以看这篇博客:实时股票数据插口
经过不懈的努力总算再这篇博文中找到了关于新浪股票历史数据的获取方法腾讯股票插口、和讯网股票插口、新浪股票插口、雪球股票数据、网易股票数据
最近二十天左右的每5分钟数据
(参数:股票编号、分钟间隔(5、15、30、60)、均值(5、10、15、20、25)、查询个数点(最大值242))
获取的数据是类似下边的json字段:日期、开盘价、最高价、最低价、收盘价、成交量:
获取的数据会有很多,然后按照自己须要进行解析,我需要的是每晚的收盘价,股市是每个工作日下午3点午盘,所以我只须要找到每晚的下午三点时刻的数据进行过滤即可:
1、新建一个历史数据对象类:
public class HistoryModel {
public String day;
public String close;
public HistoryModel(String day, String close) {
this.day = day;
this.close = close;
}
}
2、新建一个股票多次历史数据类:和上一个区别就是,这里收录的是所有的历史数据:参数包括股票名子、代码、现在的价钱、历史数据:
public class HistoryModels {
public String name;
public String code;
public String now;
public List list;
public HistoryModels(String name, String code, String now, List list) {
this.name = name;
this.code = code;
this.now = now;
this.list = list;
}
}
3、将须要查询的股票的代码带进url里通过HTTP恳求json数据,我这儿用的Volley恳求的:
其中将时间点未15:00:00的数据过滤下来,组合乘List以后在全部形参组合成一个HistoryModels储存股票信息以及股票的所有历史数据。
// Instantiate the RequestQueue.
RequestQueue queue = Volley.newRequestQueue(Home.context);
String url1 = "http://money.finance.sina.com. ... ot%3B + Home.myChoiceModelList.get(ii).code + "&scale=60&ma=no&datalen=1023";
// Request a string response from the provided URL.
StringRequest stringRequest1 = new StringRequest(Request.Method.GET, url1,
new Response.Listener() {
@Override
public void onResponse(String response) {
List historyList = Convert(response,new TypeToken() {
}.getType());
List historyList2 = new ArrayList();
if(historyList!=null) {
for (int j = 0; j < historyList.size(); j++) {
if (historyList.get(j).day.split(" ")[1].equals("15:00:00")) {
historyList2.add(historyList.get(j));
}
}
}
HistoryModels model = new HistoryModels(Home.myChoiceModelList.get(ii).name, Home.myChoiceModelList.get(ii).code, Home.myChoiceModelList.get(ii).now, historyList2);
cllList.add(model);
Message msg = new Message();
msg.what = 0x002;
handler.sendMessage(msg);
}
},
new Response.ErrorListener() {
@Override
public void onErrorResponse(VolleyError error) {
}
});
queue.add(stringRequest1);
4、其中对json数据的处理,即从json转化成数据对象的方式如下:
/*
* Json转换泛型
*/
public static T Convert(String jsonString, Type cls) {
T t = null;
try {
if (jsonString != null && !jsonString.equals("")) {
Gson gson = new Gson();
t = gson.fromJson(jsonString, cls);
}
} catch (Exception e) {
e.printStackTrace();
}
return t;
}
关于股票的实时数据这儿没有描述,通过文章开头联接的博客可以了解到,写的太详尽。 查看全部
这三天做了一个调用新浪股票插口获取实时以及历史股票数据的应用,因为新浪没有公开关于其插口的官方文档,所以通过各类百度差了好多关于新浪股票插口的使用,不过你们基本都是转载或则直接复制,对于实时数据的获取讲的太详尽,但是缺乏获取历史数据的方式。
关于实时数据的获取你们可以看这篇博客:实时股票数据插口
经过不懈的努力总算再这篇博文中找到了关于新浪股票历史数据的获取方法腾讯股票插口、和讯网股票插口、新浪股票插口、雪球股票数据、网易股票数据
最近二十天左右的每5分钟数据
(参数:股票编号、分钟间隔(5、15、30、60)、均值(5、10、15、20、25)、查询个数点(最大值242))
获取的数据是类似下边的json字段:日期、开盘价、最高价、最低价、收盘价、成交量:

获取的数据会有很多,然后按照自己须要进行解析,我需要的是每晚的收盘价,股市是每个工作日下午3点午盘,所以我只须要找到每晚的下午三点时刻的数据进行过滤即可:
1、新建一个历史数据对象类:
public class HistoryModel {
public String day;
public String close;
public HistoryModel(String day, String close) {
this.day = day;
this.close = close;
}
}
2、新建一个股票多次历史数据类:和上一个区别就是,这里收录的是所有的历史数据:参数包括股票名子、代码、现在的价钱、历史数据:
public class HistoryModels {
public String name;
public String code;
public String now;
public List list;
public HistoryModels(String name, String code, String now, List list) {
this.name = name;
this.code = code;
this.now = now;
this.list = list;
}
}
3、将须要查询的股票的代码带进url里通过HTTP恳求json数据,我这儿用的Volley恳求的:
其中将时间点未15:00:00的数据过滤下来,组合乘List以后在全部形参组合成一个HistoryModels储存股票信息以及股票的所有历史数据。
// Instantiate the RequestQueue.
RequestQueue queue = Volley.newRequestQueue(Home.context);
String url1 = "http://money.finance.sina.com. ... ot%3B + Home.myChoiceModelList.get(ii).code + "&scale=60&ma=no&datalen=1023";
// Request a string response from the provided URL.
StringRequest stringRequest1 = new StringRequest(Request.Method.GET, url1,
new Response.Listener() {
@Override
public void onResponse(String response) {
List historyList = Convert(response,new TypeToken() {
}.getType());
List historyList2 = new ArrayList();
if(historyList!=null) {
for (int j = 0; j < historyList.size(); j++) {
if (historyList.get(j).day.split(" ")[1].equals("15:00:00")) {
historyList2.add(historyList.get(j));
}
}
}
HistoryModels model = new HistoryModels(Home.myChoiceModelList.get(ii).name, Home.myChoiceModelList.get(ii).code, Home.myChoiceModelList.get(ii).now, historyList2);
cllList.add(model);
Message msg = new Message();
msg.what = 0x002;
handler.sendMessage(msg);
}
},
new Response.ErrorListener() {
@Override
public void onErrorResponse(VolleyError error) {
}
});
queue.add(stringRequest1);
4、其中对json数据的处理,即从json转化成数据对象的方式如下:
/*
* Json转换泛型
*/
public static T Convert(String jsonString, Type cls) {
T t = null;
try {
if (jsonString != null && !jsonString.equals("")) {
Gson gson = new Gson();
t = gson.fromJson(jsonString, cls);
}
} catch (Exception e) {
e.printStackTrace();
}
return t;
}
关于股票的实时数据这儿没有描述,通过文章开头联接的博客可以了解到,写的太详尽。
destoon7
采集交流 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2020-08-09 09:21
destoon7.0优采云采集接口说简单点就是一个网站内容入库插口,传统获取数据形式是须要通过人工复制粘贴到我们自己的网站,用时较长较慢。而destoon采集接口就是取代人工复制粘贴,速度及效率是人工的千百倍以上。
destoon采集接口是借助优采云采集器完成采集任务,程序自带优采云8.0及模块规则,用户下载即可使用,无需再单独安装优采云。
接口完全免费没有任何域名限制及侧门,用户只要会写规则就可以完全免费采集任何网站。
接口完全是用的destoon官方程序预留的api接口2次开发,毋须修改任何系统文件,绿色环保!
只要把握好采集速度可以实现完全模拟人工发布,百度蜘蛛是看不下来采集的。
接口可以支持destoon官方程序4.0-7.0程序使用,(做过2次开发的请自测)。
我们的插口及规则完全永久免费在我们的官方峰会提供更新及技术支持,并且不定期的分享免费规则。
程序自带24个全行业通用参考规则给你们使用,会写规则的可以参考默认规则标签格式来自己制做规则。
软件特征:
一、SEO
(1)、destoon7.0采集器采用优采云V8版 经过采集优化后能使搜索引擎收录更多,哪怕是您一个外链都没有发布,您一点SEO都不懂,只要在订购我们采集软件前你的网站没有被搜索引擎K、网站本身正常,都能有不错的收录,收录详情请看演示
(2)、支持自动分类会员组,如果目标站是企业会员就入库到企业会员组,如果是个人就入库到个人会员组(需要通过代码自行判定用户组)
(3)、会员名、公司名、内容信息,前后都支持添加自定义文字内容,方便辨别采集内容及SEO。
(4)、以采集到的公司名的拼音作为会员账号,对SEO更有利。
二、模拟人工智能化处理数据:
接口与传统的API接口不同,常用API接口是直接插入数据到数据库不利于SEO。
收费版插口能模拟人工发布内容,比如:自动下载图片、自动水印、自动生成静态页。
详情如下:
(1)、支持采集内容后手动生成静态页面(动态或伪静态下须要这个功能)。
(2)、所有模块分类都支持手动下载标题图片、内容图片,并且手动加水印之后全手动下载上传图片到服务器。(需要在后台每位对应模块的模块设置里开启“下载内容远程图片”功能)。
(3)、检测到模块内容有图片的采集内容,并且手动设置第一张为标题图片。
(4)、因网路或则其他诱因未正常生成成功的图片,自动记录出来,支持一键重下载那些没下载成功的图片。
(5)、自由设置每位频道的图片是否下载、下载目录、盗链、水印模式等。
(6)、自由设置供应、求购、招商等这类频道,是否启用三张标题图的功能(无需要再在规则里设置,全由插口控制)。
(7)、采集内容可以自由设置采集目标站上的时间,还是用当前时间。
三、发布内容形式:
(1)、优化了信息关联到公司的设置,可以设置每位频道是否可以旅客发布、是否关联到公司,采自不同站的供应 或者 其他频道信息 ,只要是同一公司的信息,就发布到这个公司下边,不会重复注册公司,或者只要是公司早已在你的站上注册过了,就不会出现旅客名义发布的此公司信息。
(2)、各个分类均支持自动分类入库 对应分类上采用手动对应分类优先,指定分类次之的次序,抛弃了原先在规则第二步设置分类ID的情况,启用在第三步里选择或则直接写分类ID,这样就免去了因弄错了分类ID而导致多次重复采集,节省了采集时间,可以发到多个分类,以及多个站(前提是授权多个域名),支持第三步里的站群形式发布。 查看全部
destoon7.0正式版已与2018年4月3日发布,destoon采集专家已与第一时间发布destoon优采云免登入免费版采集接口,并且一如既往的免费下去。
destoon7.0优采云采集接口说简单点就是一个网站内容入库插口,传统获取数据形式是须要通过人工复制粘贴到我们自己的网站,用时较长较慢。而destoon采集接口就是取代人工复制粘贴,速度及效率是人工的千百倍以上。
destoon采集接口是借助优采云采集器完成采集任务,程序自带优采云8.0及模块规则,用户下载即可使用,无需再单独安装优采云。
接口完全免费没有任何域名限制及侧门,用户只要会写规则就可以完全免费采集任何网站。
接口完全是用的destoon官方程序预留的api接口2次开发,毋须修改任何系统文件,绿色环保!
只要把握好采集速度可以实现完全模拟人工发布,百度蜘蛛是看不下来采集的。
接口可以支持destoon官方程序4.0-7.0程序使用,(做过2次开发的请自测)。
我们的插口及规则完全永久免费在我们的官方峰会提供更新及技术支持,并且不定期的分享免费规则。
程序自带24个全行业通用参考规则给你们使用,会写规则的可以参考默认规则标签格式来自己制做规则。
软件特征:
一、SEO
(1)、destoon7.0采集器采用优采云V8版 经过采集优化后能使搜索引擎收录更多,哪怕是您一个外链都没有发布,您一点SEO都不懂,只要在订购我们采集软件前你的网站没有被搜索引擎K、网站本身正常,都能有不错的收录,收录详情请看演示
(2)、支持自动分类会员组,如果目标站是企业会员就入库到企业会员组,如果是个人就入库到个人会员组(需要通过代码自行判定用户组)
(3)、会员名、公司名、内容信息,前后都支持添加自定义文字内容,方便辨别采集内容及SEO。
(4)、以采集到的公司名的拼音作为会员账号,对SEO更有利。
二、模拟人工智能化处理数据:
接口与传统的API接口不同,常用API接口是直接插入数据到数据库不利于SEO。
收费版插口能模拟人工发布内容,比如:自动下载图片、自动水印、自动生成静态页。
详情如下:
(1)、支持采集内容后手动生成静态页面(动态或伪静态下须要这个功能)。
(2)、所有模块分类都支持手动下载标题图片、内容图片,并且手动加水印之后全手动下载上传图片到服务器。(需要在后台每位对应模块的模块设置里开启“下载内容远程图片”功能)。
(3)、检测到模块内容有图片的采集内容,并且手动设置第一张为标题图片。
(4)、因网路或则其他诱因未正常生成成功的图片,自动记录出来,支持一键重下载那些没下载成功的图片。
(5)、自由设置每位频道的图片是否下载、下载目录、盗链、水印模式等。
(6)、自由设置供应、求购、招商等这类频道,是否启用三张标题图的功能(无需要再在规则里设置,全由插口控制)。
(7)、采集内容可以自由设置采集目标站上的时间,还是用当前时间。
三、发布内容形式:
(1)、优化了信息关联到公司的设置,可以设置每位频道是否可以旅客发布、是否关联到公司,采自不同站的供应 或者 其他频道信息 ,只要是同一公司的信息,就发布到这个公司下边,不会重复注册公司,或者只要是公司早已在你的站上注册过了,就不会出现旅客名义发布的此公司信息。
(2)、各个分类均支持自动分类入库 对应分类上采用手动对应分类优先,指定分类次之的次序,抛弃了原先在规则第二步设置分类ID的情况,启用在第三步里选择或则直接写分类ID,这样就免去了因弄错了分类ID而导致多次重复采集,节省了采集时间,可以发到多个分类,以及多个站(前提是授权多个域名),支持第三步里的站群形式发布。
PHP + fiddler捕获数据包并采集微信文章的想法的详细说明.
采集交流 • 优采云 发表了文章 • 0 个评论 • 384 次浏览 • 2020-08-09 06:25
分析界面知道,要获得阅读的文章数和喜欢的数目,必须有两个关键参数,即key和uin. 不同的官方帐户的密钥不同(据说有一个通用的微信密钥,但我不知道如何获得),并且同一官方帐户的密钥将在大约半小时内失效
提交链接以获取阅读API的文章
思考:
1. 拦截并将客户端请求读取接口的请求转发到您自己的服务器,以便您可以获取密钥,并使用__biz关联缓存半小时
2. 提交商品链接进行查询时,服务器从商品链接获取__biz,并查询是否缓存了当前官方账号对应的密钥. 如果是,请继续执行步骤3,而不是步骤4.
3.curl请求?界面获取数据
4. 当密钥不存在时,通知客户端重定向到url(使用websocket通知或客户端ajax轮询进行通知,您需要使用数据包捕获工具来修改文章详细信息页面代码,以跳至中间页面以等待,打开在文章页面之后,它每隔几秒钟跳回到中间页面),并将程序暂停几秒钟,以等待客户端更新密钥. 此时,客户端提交新密钥并使用它进行查询
实现
1. 封包捕获
该界面是获取阅读量的界面,参数如下
2. 拦截此接口并将其转发到您自己的服务器,单击“规则”-“自定义规则”并将其添加到onbeforerequest(在正式请求之前执行的功能)
if (osession.fullurl.contains("mp.weixin.qq.com/mp/getappmsgext"))
{
osession.orequest["host"]= 'ccc.aaa.com' ;
}
效果不错,您可以看到该界面已转发
3. 服务器端缓存密钥,代码以php为例
public function savekey(request $request)
{
$__biz = $request->param('__biz',0);
$data['uin'] = $request->param('uin',0);
$data['key'] = $request->param('key',0);
cache::set($__biz,$data,30 * 60);
return 'ok';
}
4. 提交文章链接查询api代码
public function getreadnum(request $request)
{
$url = $request->param('url');
parse_str(parse_url($url)['query'], $param);
$__biz = $param['__biz'];
$key_data = cache::get($__biz);
if (empty($key_data))
return 'no key';
$uin = $key_data['uin'];
$key = $key_data['key'];
$param['uin'] = $uin;
$param['key'] = $key;
$param['wxtoken'] = "777";
$wechat_url = "https://mp.weixin.qq.com/mp/getappmsgext?" . http_build_query($param);
//dump($wechat_url);
$data = array(
'is_only_read' => 1,
'is_temp_url' => 0,
'appmsg_type' => 9,
);
$res = $this->get_url($wechat_url,$data);
return $res;
}
function get_url($url,$data)
{
$ifpost = 1;//是否post请求
$datafields = $data;//post数据
$cookiefile = '';//cookie文件
$cookie = '';//cookie变量
$v = false;
//模拟http请求header头
$header = array("connection: keep-alive","accept: text/html, application/xhtml+xml, */*", "pragma: no-cache", "accept-language: zh-hans-cn,zh-hans;q=0.8,en-us;q=0.5,en;q=0.3","user-agent: mozilla/5.0 (windows nt 6.1; wow64) applewebkit/537.36 (khtml, like gecko) chrome/53.0.2785.116 safari/537.36 qbcore/4.0.1278.400 qqbrowser/9.0.2524.400 mozilla/5.0 (windows nt 6.1; wow64) applewebkit/537.36 (khtml, like gecko) chrome/53.0.2875.116 safari/537.36 nettype/wifi micromessenger/7.0.5 windowswechat");
$ch = curl_init();
curl_setopt($ch, curlopt_url, $url);
curl_setopt($ch, curlopt_header, $v);
curl_setopt($ch, curlopt_httpheader, $header);
$ifpost && curl_setopt($ch, curlopt_post, $ifpost);
$ifpost && curl_setopt($ch, curlopt_postfields, $datafields);
curl_setopt($ch, curlopt_returntransfer, true);
curl_setopt($ch, curlopt_followlocation, true);
$cookie && curl_setopt($ch, curlopt_cookie, $cookie);//发送cookie变量
$cookiefile && curl_setopt($ch, curlopt_cookiefile, $cookiefile);//发送cookie文件
$cookiefile && curl_setopt($ch, curlopt_cookiejar, $cookiefile);//写入cookie到文件
curl_setopt($ch,curlopt_timeout,60); //允许执行的最长秒数
curl_setopt($ch, curlopt_ssl_verifypeer, false);
curl_setopt($ch, curlopt_ssl_verifyhost, false);
$ok = curl_exec($ch);
curl_close($ch);
unset($ch);
return $ok;
}
5. 通知客户端重定向页面(此部分未编写,请参见我有关文本套接字的其他文章)
6. 使用提琴手来修改微信文章和jsj脚本,
在onbeforeresponse(返回客户端之前执行的方法)中,添加代码以跳转到中间页
效果
摘要 查看全部
简介:
分析界面知道,要获得阅读的文章数和喜欢的数目,必须有两个关键参数,即key和uin. 不同的官方帐户的密钥不同(据说有一个通用的微信密钥,但我不知道如何获得),并且同一官方帐户的密钥将在大约半小时内失效
提交链接以获取阅读API的文章
思考:
1. 拦截并将客户端请求读取接口的请求转发到您自己的服务器,以便您可以获取密钥,并使用__biz关联缓存半小时
2. 提交商品链接进行查询时,服务器从商品链接获取__biz,并查询是否缓存了当前官方账号对应的密钥. 如果是,请继续执行步骤3,而不是步骤4.
3.curl请求?界面获取数据
4. 当密钥不存在时,通知客户端重定向到url(使用websocket通知或客户端ajax轮询进行通知,您需要使用数据包捕获工具来修改文章详细信息页面代码,以跳至中间页面以等待,打开在文章页面之后,它每隔几秒钟跳回到中间页面),并将程序暂停几秒钟,以等待客户端更新密钥. 此时,客户端提交新密钥并使用它进行查询
实现
1. 封包捕获
该界面是获取阅读量的界面,参数如下


2. 拦截此接口并将其转发到您自己的服务器,单击“规则”-“自定义规则”并将其添加到onbeforerequest(在正式请求之前执行的功能)
if (osession.fullurl.contains("mp.weixin.qq.com/mp/getappmsgext"))
{
osession.orequest["host"]= 'ccc.aaa.com' ;
}

效果不错,您可以看到该界面已转发

3. 服务器端缓存密钥,代码以php为例
public function savekey(request $request)
{
$__biz = $request->param('__biz',0);
$data['uin'] = $request->param('uin',0);
$data['key'] = $request->param('key',0);
cache::set($__biz,$data,30 * 60);
return 'ok';
}
4. 提交文章链接查询api代码
public function getreadnum(request $request)
{
$url = $request->param('url');
parse_str(parse_url($url)['query'], $param);
$__biz = $param['__biz'];
$key_data = cache::get($__biz);
if (empty($key_data))
return 'no key';
$uin = $key_data['uin'];
$key = $key_data['key'];
$param['uin'] = $uin;
$param['key'] = $key;
$param['wxtoken'] = "777";
$wechat_url = "https://mp.weixin.qq.com/mp/getappmsgext?" . http_build_query($param);
//dump($wechat_url);
$data = array(
'is_only_read' => 1,
'is_temp_url' => 0,
'appmsg_type' => 9,
);
$res = $this->get_url($wechat_url,$data);
return $res;
}
function get_url($url,$data)
{
$ifpost = 1;//是否post请求
$datafields = $data;//post数据
$cookiefile = '';//cookie文件
$cookie = '';//cookie变量
$v = false;
//模拟http请求header头
$header = array("connection: keep-alive","accept: text/html, application/xhtml+xml, */*", "pragma: no-cache", "accept-language: zh-hans-cn,zh-hans;q=0.8,en-us;q=0.5,en;q=0.3","user-agent: mozilla/5.0 (windows nt 6.1; wow64) applewebkit/537.36 (khtml, like gecko) chrome/53.0.2785.116 safari/537.36 qbcore/4.0.1278.400 qqbrowser/9.0.2524.400 mozilla/5.0 (windows nt 6.1; wow64) applewebkit/537.36 (khtml, like gecko) chrome/53.0.2875.116 safari/537.36 nettype/wifi micromessenger/7.0.5 windowswechat");
$ch = curl_init();
curl_setopt($ch, curlopt_url, $url);
curl_setopt($ch, curlopt_header, $v);
curl_setopt($ch, curlopt_httpheader, $header);
$ifpost && curl_setopt($ch, curlopt_post, $ifpost);
$ifpost && curl_setopt($ch, curlopt_postfields, $datafields);
curl_setopt($ch, curlopt_returntransfer, true);
curl_setopt($ch, curlopt_followlocation, true);
$cookie && curl_setopt($ch, curlopt_cookie, $cookie);//发送cookie变量
$cookiefile && curl_setopt($ch, curlopt_cookiefile, $cookiefile);//发送cookie文件
$cookiefile && curl_setopt($ch, curlopt_cookiejar, $cookiefile);//写入cookie到文件
curl_setopt($ch,curlopt_timeout,60); //允许执行的最长秒数
curl_setopt($ch, curlopt_ssl_verifypeer, false);
curl_setopt($ch, curlopt_ssl_verifyhost, false);
$ok = curl_exec($ch);
curl_close($ch);
unset($ch);
return $ok;
}
5. 通知客户端重定向页面(此部分未编写,请参见我有关文本套接字的其他文章)
6. 使用提琴手来修改微信文章和jsj脚本,
在onbeforeresponse(返回客户端之前执行的方法)中,添加代码以跳转到中间页
效果

摘要
Python爬虫的实用解释: 分析某些东部产品评论信息的采集过程
采集交流 • 优采云 发表了文章 • 0 个评论 • 591 次浏览 • 2020-08-08 15:12
搜索界面
一个,界面搜索
搜索以食物为例,输入食物并点击搜索
继续向下滚动以查看产品的返回页数,这是最大返回100页信息
打开调试,清除请求内容,然后根据上面发现的查找注释界面的方法直接单击第二页以观察新请求.
当我单击红色框中的s_new界面时,我发现响应信息是html,并且响应的内容恰好是我们在页面上所需的产品信息.
第二,参数搜索
类似地,根据向下滑动,翻页以查看参数的更改
单击页面的第二页,参数如下
页面上有很多产品显示信息,并且可能会临时加载请求. 如果继续向下滚动,则可以看到已添加了新请求. 请求参数如下,并增加了参数. (注意: 新参数可以忽略)
然后单击第三页
如果找不到规则,则可以继续单击页面以查看更改规则.
接口参数的构造逻辑有以下几点:
三,html页面分析
直接在页面上找到产品位置,您可以看到所有产品信息都在ul标签下的li标签中
单击li标签,您可以看到div / div下的标签收录产品标题信息,产品链接信息,并且该链接收录我们需要提取的product_id信息. 右键单击以复制并复制xpath以直接提取位置信息.
四个代码测试
代码如下. 请注意,在标头中,referer参数需要进行url编码.
执行结果如下:
这里仅提取了两个字段title和product_id,并且可以根据需要添加它们.
本文中的文字和图片来自Internet,仅用于学习和交流目的. 它们没有任何商业用途. 版权属于原创作者. 如有任何疑问,请及时与我们联系进行处理.
作者: 习惯u 查看全部
如果要提取其他字段信息,可以在代码中自己添加.
搜索界面
一个,界面搜索
搜索以食物为例,输入食物并点击搜索
继续向下滚动以查看产品的返回页数,这是最大返回100页信息
打开调试,清除请求内容,然后根据上面发现的查找注释界面的方法直接单击第二页以观察新请求.
当我单击红色框中的s_new界面时,我发现响应信息是html,并且响应的内容恰好是我们在页面上所需的产品信息.
第二,参数搜索
类似地,根据向下滑动,翻页以查看参数的更改
单击页面的第二页,参数如下
页面上有很多产品显示信息,并且可能会临时加载请求. 如果继续向下滚动,则可以看到已添加了新请求. 请求参数如下,并增加了参数. (注意: 新参数可以忽略)
然后单击第三页
如果找不到规则,则可以继续单击页面以查看更改规则.
接口参数的构造逻辑有以下几点:
三,html页面分析
直接在页面上找到产品位置,您可以看到所有产品信息都在ul标签下的li标签中
单击li标签,您可以看到div / div下的标签收录产品标题信息,产品链接信息,并且该链接收录我们需要提取的product_id信息. 右键单击以复制并复制xpath以直接提取位置信息.
四个代码测试
代码如下. 请注意,在标头中,referer参数需要进行url编码.
执行结果如下:
这里仅提取了两个字段title和product_id,并且可以根据需要添加它们.
本文中的文字和图片来自Internet,仅用于学习和交流目的. 它们没有任何商业用途. 版权属于原创作者. 如有任何疑问,请及时与我们联系进行处理.
作者: 习惯u
第一个界面
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2020-08-07 23:53
2019-12-31十三本资源网络技术课程
[摘要]简介该程序具有多种类型的墙纸,自动更新,自动采集,支持多分辨率,瀑布流,全站点ajax!界面一获得墙纸分类
简介
程序中有许多类型的墙纸,自动更新,自动采集,支持多分辨率,瀑布流加载,站点范围内的ajax!
第一个界面
获取壁纸分类
http://cdn.apc.360.cn/index.ph ... hrome
这个界面很简单,直接请求上面的URL,就可以获取json数据. 返回的数据中有一个数据数组,其中“名称”是获取的墙纸类别的名称,“ id”是与该类别对应的ID值.
接口2:
根据墙纸类别ID获取该类别下的墙纸图片
http://wallpaper.apc.360.cn/index.php?
c=WallPaper&a=getAppsByCategory
&cid=【刚才获取到的分类ID】
&start=【从第几幅图开始(用于分页)】
&count=【每次加载的数量】&from=360chrome
通过此接口获得的数据有点多,但主要只使用了少数几个. 一个是数据数组中的url值,这是我们想要获取的图像链接. 其格式类似于:
http://p15.qhimg.com/bdr/__85/ ... 8.jpg
我们可以使用它来获得该图片的指定分辨率和指定质量. 上图是一个示例. 如果要获取分辨率为1024 * 768且质量为80(最高100)的图片,只需将上述链接中的“ bdr / __ 85”替换为“ bdm / 1024_768_80”. 替换后的图片链接如下
http://p19.qhimg.com/bdm/1024_ ... 8.jpg
(注意: 如果原创图片本身很小,某些图片将不会被拉伸) 查看全部
自动采集墙纸网站界面
2019-12-31十三本资源网络技术课程
[摘要]简介该程序具有多种类型的墙纸,自动更新,自动采集,支持多分辨率,瀑布流,全站点ajax!界面一获得墙纸分类
简介
程序中有许多类型的墙纸,自动更新,自动采集,支持多分辨率,瀑布流加载,站点范围内的ajax!

第一个界面
获取壁纸分类
http://cdn.apc.360.cn/index.ph ... hrome
这个界面很简单,直接请求上面的URL,就可以获取json数据. 返回的数据中有一个数据数组,其中“名称”是获取的墙纸类别的名称,“ id”是与该类别对应的ID值.
接口2:
根据墙纸类别ID获取该类别下的墙纸图片
http://wallpaper.apc.360.cn/index.php?
c=WallPaper&a=getAppsByCategory
&cid=【刚才获取到的分类ID】
&start=【从第几幅图开始(用于分页)】
&count=【每次加载的数量】&from=360chrome
通过此接口获得的数据有点多,但主要只使用了少数几个. 一个是数据数组中的url值,这是我们想要获取的图像链接. 其格式类似于:
http://p15.qhimg.com/bdr/__85/ ... 8.jpg
我们可以使用它来获得该图片的指定分辨率和指定质量. 上图是一个示例. 如果要获取分辨率为1024 * 768且质量为80(最高100)的图片,只需将上述链接中的“ bdr / __ 85”替换为“ bdm / 1024_768_80”. 替换后的图片链接如下
http://p19.qhimg.com/bdm/1024_ ... 8.jpg
(注意: 如果原创图片本身很小,某些图片将不会被拉伸)
本地旅游网站源代码,PHP开源,PC + WAP +微信三合一,免费共享
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2020-08-07 21:02
现场旅游网站源代码系统已成功启动了基础旅游网站建设和门户旅游网站建设系统. 其系统包括新闻管理功能,酒店预订功能,酒店预订功能,路线预订功能,景点预订功能,签证服务功能,留言问题功能,会员注册功能,短信群发功能,网上支付功能等十大功能, SEO优化功能等. 它在功能上具有独特的功能. 实现不同的旅游营销型车站建设系统. 让您的旅游网站获得高转化率,高曝光率,独特的计划,完整的技术市场化并增加品牌和销量.
Situ CMS功能介绍
Situ CMS6.0具有丰富的功能,强大的针对性,强大的可伸缩性,易于操作和使用以及清晰的系统结构. 它分为九个主要部分:
1. 产品系统: 路线,酒店,门票,汽车租赁,机票,签证,签证,团购,活动,同伴,邮轮,保险,个性化定制(可扩展功能,如导游,特色产品等);
2. 文章系统: 目的地指南,旅行指南,景点,相册,问答,评论,帮助系统;
3. 用户系统: 在线订单,在线支付,订单生成短信/电子邮件通知,评论,问答,短信电子邮件批量发送;成员管理,供应商管理;
4. 营销策略: SEO界面,社交共享界面,积分,返现策略;来源,目的地营销结构,泛分析辅助域名结构支持,特殊营销,广告管理;
5. 支付系统: 财付通,宜宝,环迅;集成: 支持支付宝,快钱,银联,汇超等;
6. 扩展界面: 文章采集界面,Dz论坛,UCenter,Google电子地图;集成: 第三方登录界面,SMS平台界面等;
7. 设置中心: 目的地4级分类,属性2级自定义,内容分类自定义,出发设置,站点设置,系统参数管理,数据备份,操作日志.
8. 市场助理: 关键字统计,关键字智能链接,标签词设置,访问源统计,热门搜索词统计,智能站点地图,无效链接自检
9. 增值应用程序: 系统升级,模板替换,营销指南,问题反馈,扩展应用程序等.
[示例屏幕截图]
[核心代码]有关详细信息,请参见文档 查看全部
[示例介绍]
现场旅游网站源代码系统已成功启动了基础旅游网站建设和门户旅游网站建设系统. 其系统包括新闻管理功能,酒店预订功能,酒店预订功能,路线预订功能,景点预订功能,签证服务功能,留言问题功能,会员注册功能,短信群发功能,网上支付功能等十大功能, SEO优化功能等. 它在功能上具有独特的功能. 实现不同的旅游营销型车站建设系统. 让您的旅游网站获得高转化率,高曝光率,独特的计划,完整的技术市场化并增加品牌和销量.
Situ CMS功能介绍
Situ CMS6.0具有丰富的功能,强大的针对性,强大的可伸缩性,易于操作和使用以及清晰的系统结构. 它分为九个主要部分:
1. 产品系统: 路线,酒店,门票,汽车租赁,机票,签证,签证,团购,活动,同伴,邮轮,保险,个性化定制(可扩展功能,如导游,特色产品等);
2. 文章系统: 目的地指南,旅行指南,景点,相册,问答,评论,帮助系统;
3. 用户系统: 在线订单,在线支付,订单生成短信/电子邮件通知,评论,问答,短信电子邮件批量发送;成员管理,供应商管理;
4. 营销策略: SEO界面,社交共享界面,积分,返现策略;来源,目的地营销结构,泛分析辅助域名结构支持,特殊营销,广告管理;
5. 支付系统: 财付通,宜宝,环迅;集成: 支持支付宝,快钱,银联,汇超等;
6. 扩展界面: 文章采集界面,Dz论坛,UCenter,Google电子地图;集成: 第三方登录界面,SMS平台界面等;
7. 设置中心: 目的地4级分类,属性2级自定义,内容分类自定义,出发设置,站点设置,系统参数管理,数据备份,操作日志.
8. 市场助理: 关键字统计,关键字智能链接,标签词设置,访问源统计,热门搜索词统计,智能站点地图,无效链接自检
9. 增值应用程序: 系统升级,模板替换,营销指南,问题反馈,扩展应用程序等.
[示例屏幕截图]
[核心代码]有关详细信息,请参见文档
什么是数据采集方法?它们的特点是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 680 次浏览 • 2020-08-07 13:34
许多大型企业和政府机构在信息化过程中结合自己的业务构建了各种软件系统,这些软件系统积累了大量的行业和客户数据. 他们迫切需要聚合这些数据以形成自己的大型数据平台,进行数据挖掘和分析,并准确地为其客户提供服务.
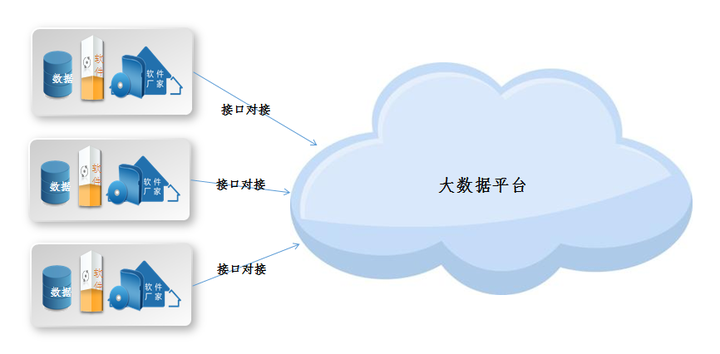
当前的数据采集挑战如下:
1. 各种数据源
2. 数据量大,更新快
3. 如何确保数据采集的可靠性和性能
4. 如何避免重复数据
5. 如何确保数据质量.
那么,如何快速,准确地采集这么多软件系统中的各种数据呢?今天,我将讨论各种软件系统的几种数据采集方法. 着眼于它们的实现过程以及它们各自的优缺点.
1. 软件界面对接方法
2. 打开数据库方法
3. 基于底层数据交换的直接数据采集方法
1. 软件界面对接方法
各种软件供应商提供数据接口以实现数据采集并为客户构建自己的业务大数据平台;
实现过程如下:
1)与来自多个软件供应商的工程师进行协调,以了解另一方系统的业务流程以及与数据库相关的表结构的设计等,并讨论如何实现正确的数据采集并在其中可行. 商业. 仔细考虑所有细节,最后确定双方都同意的计划. 在双方工程师的合作下,完成了两个系统之间的接口. 可以在系统A或系统B中执行某些处理. 在这种情况下,做出决策的基础是考虑将来可能会发生功能更改,这将不可避免地影响现有系统. 选择受更改影响较小的解决方案.
2)确定计划和代码
3)编码后,进入测试和调试阶段
4)交付使用
接口对接方法的数据可靠性很高. 通常,没有数据重复,它们都是客户业务大数据平台所需的有价值数据;同时,数据通过接口实时传输,完全满足了大数据平台的实时性要求.
但是,接口对接方法需要大量的人力和时间来协调各种软件供应商进行数据接口对接;同时,它的可扩展性不高. 例如,由于业务需求,各种软件系统开发了新的业务模块,这些模块与大数据平台兼容. 需要对两者之间的数据接口进行相应的修改和更改,甚至要颠覆所有以前的数据接口代码,这是很费时费力的.
2. 打开数据库方法
通常来说,来自不同公司的系统不太可能打开自己的数据库来相互连接,因为这会引起安全问题. 为了实现数据采集和汇总,开放数据库是最直接的方法.
两个系统都有自己的数据库,对于相同类型的数据库,它更方便:
1)如果两个数据库位于同一服务器上,则只要用户名设置没有问题,它们就可以直接相互访问. 您需要在from之后携带数据库名称和表模式所有者. 选择* from DATABASE1.dbo.table1 2)如果两个系统的数据库不在同一服务器上,建议使用链接服务器进行处理,或者使用openset和opendatasource. 这需要外围服务器配置才能访问数据库.
不同类型的数据库之间的连接比较麻烦,需要大量设置才能生效. 我不会在这里详细说明.
开放数据库方法可以直接,准确地从目标数据库获取所需数据,这是最直接,最方便的方法;同时保证实时性能;
开放数据库方法要求协调各种软件供应商的开放数据库,这非常困难;如果平台必须同时连接到许多软件供应商的数据库并实时获取数据,那么这对于平台本身的性能也是一个巨大的挑战.
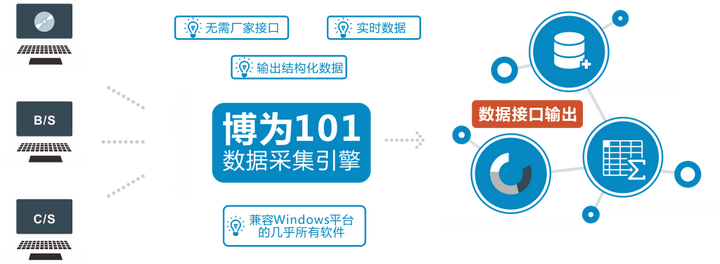
3. 基于底层数据交换的直接数据采集方法
通过获取软件系统的基础数据交换,软件客户端和数据库之间的网络流量数据包,执行数据包流分析以采集应用程序数据. 同时,可以使用仿真技术来仿真客户请求以实现自动数据写入.
实现过程如下: 使用数据采集引擎侦听目标软件的内部数据交换(网络流量,内存),然后分析所需的数据,并经过一系列处理和封装以实现确保数据的唯一性和准确性,并输出结构化数据. 经过相应的配置,实现了数据采集的自动化.
基于基础数据交换的直接数据采集方法的技术特点如下:
1)在没有软件制造商合作的情况下进行独立爬网;
2)实时数据采集;
端到端数据延迟在几秒钟之内;
3)几乎所有与Windows平台兼容的软件(C / S,B / S);
作为数据挖掘和大数据分析的基础;
4)自动建立数据之间的关联;
5)配置简单,实施周期短;
6)支持历史数据的自动导入.
目前,由于缺乏数据采集和融合技术,通常通过原创软件制造商开发数据接口来实现数据互操作性. 这不仅需要大量时间,精力和金钱,而且还因为系统开发团队的解体,源代码丢失等原因. 死胡同的原因使实现数据采集和融合变得极为困难. 在这样的紧急需求环境中,出现了基于基础数据交换的直接数据采集方法. 从各种软件系统中提取数据,并连续获取所需的准确和实时数据,并自动建立并输出数据关联. 具有极高利用率的结构化数据允许数据以有序,安全和可控的方式流向需要它的企业和用户,从而可以链接和分发不同系统的数据源,从而为客户提供决策支持,提高运营效率并产生经济价值.
查看全部
随着信息时代的到来,大数据受到越来越多的关注,数据采集的挑战变得尤为突出.
许多大型企业和政府机构在信息化过程中结合自己的业务构建了各种软件系统,这些软件系统积累了大量的行业和客户数据. 他们迫切需要聚合这些数据以形成自己的大型数据平台,进行数据挖掘和分析,并准确地为其客户提供服务.
当前的数据采集挑战如下:
1. 各种数据源
2. 数据量大,更新快
3. 如何确保数据采集的可靠性和性能
4. 如何避免重复数据
5. 如何确保数据质量.
那么,如何快速,准确地采集这么多软件系统中的各种数据呢?今天,我将讨论各种软件系统的几种数据采集方法. 着眼于它们的实现过程以及它们各自的优缺点.
1. 软件界面对接方法
2. 打开数据库方法
3. 基于底层数据交换的直接数据采集方法

1. 软件界面对接方法
各种软件供应商提供数据接口以实现数据采集并为客户构建自己的业务大数据平台;
实现过程如下:
1)与来自多个软件供应商的工程师进行协调,以了解另一方系统的业务流程以及与数据库相关的表结构的设计等,并讨论如何实现正确的数据采集并在其中可行. 商业. 仔细考虑所有细节,最后确定双方都同意的计划. 在双方工程师的合作下,完成了两个系统之间的接口. 可以在系统A或系统B中执行某些处理. 在这种情况下,做出决策的基础是考虑将来可能会发生功能更改,这将不可避免地影响现有系统. 选择受更改影响较小的解决方案.
2)确定计划和代码
3)编码后,进入测试和调试阶段
4)交付使用
接口对接方法的数据可靠性很高. 通常,没有数据重复,它们都是客户业务大数据平台所需的有价值数据;同时,数据通过接口实时传输,完全满足了大数据平台的实时性要求.
但是,接口对接方法需要大量的人力和时间来协调各种软件供应商进行数据接口对接;同时,它的可扩展性不高. 例如,由于业务需求,各种软件系统开发了新的业务模块,这些模块与大数据平台兼容. 需要对两者之间的数据接口进行相应的修改和更改,甚至要颠覆所有以前的数据接口代码,这是很费时费力的.
2. 打开数据库方法
通常来说,来自不同公司的系统不太可能打开自己的数据库来相互连接,因为这会引起安全问题. 为了实现数据采集和汇总,开放数据库是最直接的方法.
两个系统都有自己的数据库,对于相同类型的数据库,它更方便:
1)如果两个数据库位于同一服务器上,则只要用户名设置没有问题,它们就可以直接相互访问. 您需要在from之后携带数据库名称和表模式所有者. 选择* from DATABASE1.dbo.table1 2)如果两个系统的数据库不在同一服务器上,建议使用链接服务器进行处理,或者使用openset和opendatasource. 这需要外围服务器配置才能访问数据库.
不同类型的数据库之间的连接比较麻烦,需要大量设置才能生效. 我不会在这里详细说明.
开放数据库方法可以直接,准确地从目标数据库获取所需数据,这是最直接,最方便的方法;同时保证实时性能;
开放数据库方法要求协调各种软件供应商的开放数据库,这非常困难;如果平台必须同时连接到许多软件供应商的数据库并实时获取数据,那么这对于平台本身的性能也是一个巨大的挑战.

3. 基于底层数据交换的直接数据采集方法
通过获取软件系统的基础数据交换,软件客户端和数据库之间的网络流量数据包,执行数据包流分析以采集应用程序数据. 同时,可以使用仿真技术来仿真客户请求以实现自动数据写入.
实现过程如下: 使用数据采集引擎侦听目标软件的内部数据交换(网络流量,内存),然后分析所需的数据,并经过一系列处理和封装以实现确保数据的唯一性和准确性,并输出结构化数据. 经过相应的配置,实现了数据采集的自动化.
基于基础数据交换的直接数据采集方法的技术特点如下:
1)在没有软件制造商合作的情况下进行独立爬网;
2)实时数据采集;
端到端数据延迟在几秒钟之内;
3)几乎所有与Windows平台兼容的软件(C / S,B / S);
作为数据挖掘和大数据分析的基础;
4)自动建立数据之间的关联;
5)配置简单,实施周期短;
6)支持历史数据的自动导入.
目前,由于缺乏数据采集和融合技术,通常通过原创软件制造商开发数据接口来实现数据互操作性. 这不仅需要大量时间,精力和金钱,而且还因为系统开发团队的解体,源代码丢失等原因. 死胡同的原因使实现数据采集和融合变得极为困难. 在这样的紧急需求环境中,出现了基于基础数据交换的直接数据采集方法. 从各种软件系统中提取数据,并连续获取所需的准确和实时数据,并自动建立并输出数据关联. 具有极高利用率的结构化数据允许数据以有序,安全和可控的方式流向需要它的企业和用户,从而可以链接和分发不同系统的数据源,从而为客户提供决策支持,提高运营效率并产生经济价值.
[数据] 让Halcon支持HikVision摄像机的采集界面
采集交流 • 优采云 发表了文章 • 0 个评论 • 488 次浏览 • 2020-08-07 00:05
当然,我今天不是要教您如何使用该软件,因为菜单的操作和2.3版本没有太大变化,但是可以在其中显示很多单独的项,例如十字中心. 图片的中心.
在研究二次开发时,我偶然发现Haikang提供了第三方支持包,其中包括Halcon的HDevelop采集接口,该接口隐藏得很深,无法确定您是否不参与开发!
默认情况下,我们将其安装在D: \ Program Files(x86)\ MVS \目录中,并找到了第三方D: \ Program Files(x86)\ MVS \ Development \ ThirdPartyPlatformAdapter
找到了HDevelop目录吗? ,这是什么?好奇地打开它
从Halcon10到13有四个目录,只需打开它,看看里面有什么. 我发现有两个目录Win32和Win64. 继续打开并查看它,发现了这样的东西?
hAcqMVision.dll
复制代码
看hAcq,突然想起,这是Haikang提供的适用于Haikang摄像机的Halcon的获取接口,因为命名规则是Halcon标准获取接口的命名:
hAcq +接口显示name.dll
例如: hAcqGigeVision.dll
复制代码
Halcon12已安装在我们的计算机中,因此请尝试将此接口文件复制到Halcon12进行查看!
D: \ Program Files(x86)\ MVS \ Development \ ThirdPartyPlatformAdapter \ HalconHDevelop \ Halcon12 \ win32
复制代码
将上述目录中的hAcqMVision.dll复制到Halcon执行目录(该目录实际上是RunTime目录)
D: \ Program Files \ MVTec \ HALCON-12.0 \ bin \ x86sse2-win32
复制代码
您可以看到下面图片中的所有图像都是采集界面. 然后我们打开HDevelop看看是否可以通过此界面操作相机?
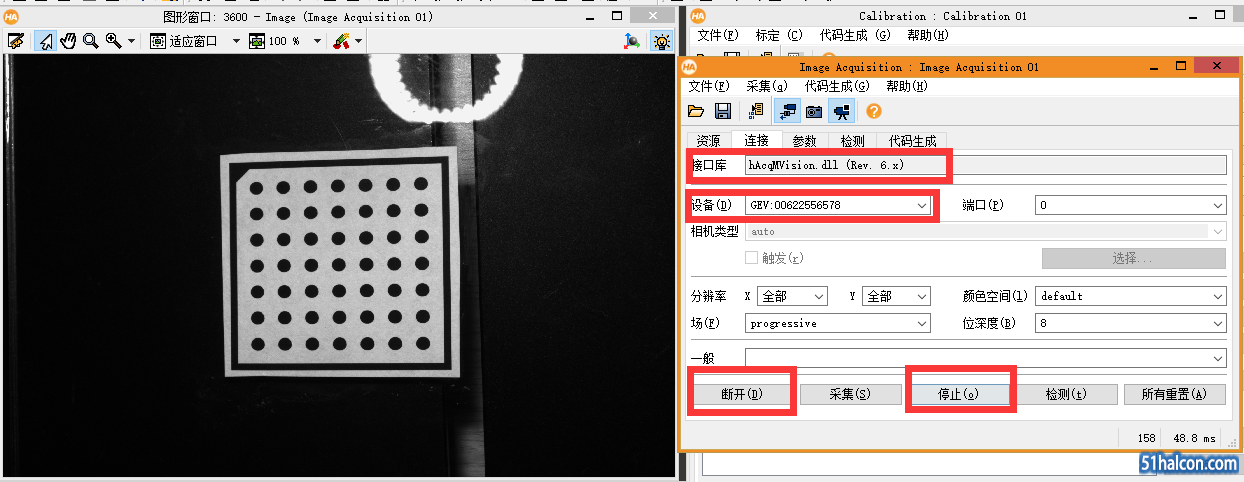
打开采集助手Image Acquisition,然后自动检测界面,出现结果:
您可以找到此接口并替换原创的GigeVision接口,然后接口文件的全名是hAcqMVision.dll,请尝试打开它:
根本没有问题,并且工作效率比普通的GigeVision协议开放更高效,更快捷. 感谢海康开发人员的辛勤工作,非常感谢!
如果您可以提供xl的采集接口,它将是全面的,哈哈哈,要求太高了!
如果您认为本文对您有所帮助,请记得回复并喜欢支持我. 我们的目标是每天取得一点进步,并进一步加深! 查看全部
我最近安装了海康威视MVS视觉软件的最新版本3.0.0. 第一印象是界面已发生了很大变化,但黑色深度和凉爽度有所提高. 看一下这个界面:
当然,我今天不是要教您如何使用该软件,因为菜单的操作和2.3版本没有太大变化,但是可以在其中显示很多单独的项,例如十字中心. 图片的中心.
在研究二次开发时,我偶然发现Haikang提供了第三方支持包,其中包括Halcon的HDevelop采集接口,该接口隐藏得很深,无法确定您是否不参与开发!
默认情况下,我们将其安装在D: \ Program Files(x86)\ MVS \目录中,并找到了第三方D: \ Program Files(x86)\ MVS \ Development \ ThirdPartyPlatformAdapter

找到了HDevelop目录吗? ,这是什么?好奇地打开它
从Halcon10到13有四个目录,只需打开它,看看里面有什么. 我发现有两个目录Win32和Win64. 继续打开并查看它,发现了这样的东西?
hAcqMVision.dll
复制代码
看hAcq,突然想起,这是Haikang提供的适用于Haikang摄像机的Halcon的获取接口,因为命名规则是Halcon标准获取接口的命名:
hAcq +接口显示name.dll
例如: hAcqGigeVision.dll
复制代码
Halcon12已安装在我们的计算机中,因此请尝试将此接口文件复制到Halcon12进行查看!
D: \ Program Files(x86)\ MVS \ Development \ ThirdPartyPlatformAdapter \ HalconHDevelop \ Halcon12 \ win32
复制代码
将上述目录中的hAcqMVision.dll复制到Halcon执行目录(该目录实际上是RunTime目录)
D: \ Program Files \ MVTec \ HALCON-12.0 \ bin \ x86sse2-win32
复制代码
您可以看到下面图片中的所有图像都是采集界面. 然后我们打开HDevelop看看是否可以通过此界面操作相机?
打开采集助手Image Acquisition,然后自动检测界面,出现结果:

您可以找到此接口并替换原创的GigeVision接口,然后接口文件的全名是hAcqMVision.dll,请尝试打开它:
根本没有问题,并且工作效率比普通的GigeVision协议开放更高效,更快捷. 感谢海康开发人员的辛勤工作,非常感谢!
如果您可以提供xl的采集接口,它将是全面的,哈哈哈,要求太高了!
如果您认为本文对您有所帮助,请记得回复并喜欢支持我. 我们的目标是每天取得一点进步,并进一步加深!
Immerial cms7.5优采云采集器Web登录界面发布模块
采集交流 • 优采云 发表了文章 • 0 个评论 • 433 次浏览 • 2020-08-06 20:22
是否有适用于Empire cms7.5的优采云采集器的发布模块?我在网上搜索了很长时间后才找到它. 今天,我找到了一个7.0模块并将其修改为在Empire cms7.5中使用. 让我与您分享. 该插件为登录方式,在优采云发布模块的WEB配置管理中添加域名地址,然后选择数据包登录方式.
提醒: 在使用前,请输入背景以关闭验证码并打开背景源验证码. 关闭后即可使用.
百度网盘: 提取代码: mzuf
我在该项目中与优采云采集器取得了联系. 当我第一次使用它时,感觉真的很棒. 数据采集真的很棒. 可以采集Internet上80%以上的数据. 碰巧的是,我最近通过Empire cms建立了一个信息门户网站. 每个人都知道,信息门户网站最麻烦的是数据. 碰巧我从优采云采集了数据,而这个数据只用一个词就很酷.
当我开心了一会儿时,一个现实的问题出现了. 如何将所有采集的数据批量导入Empire的数据库中?我把问题告诉了我的朋友,朋友说你可以编写优采云的帝国发布模块. 当他这么说的时候,我去了优采云采集器亲自看它,它确实具有发布模块功能. 优采云提供三种数据发布模式.
第一种类型: 直接在网络上发布模块.
第二种类型: 将发布的数据另存为文件.
第三种类型: 直接发布到数据库.
按照自己的想法,我在Internet上搜索了“彩彩云”发行模块,并发现了很多结果,但是大多数教程只是品尝,而在一天中的大部分时间里这些词都是胡说八道. 我仍然不知道该怎么做. 无奈之下,我向我的朋友索取了一份副本,并学习了如何操作,修改等. 接下来,我将分享这种使用优采云发行模块的方法.
我希望不要像我一样来回走动
首先,我们将使用三个文件:
ECMSLogin.php创建自己的
hinfofun.php随系统一起提供
Empire CMS 7.2免费登录新闻发布模块. wpm
第一步: 将所需的文件放在指定的文件夹中
将文件1复制到e / admin /,并将文件2复制到e / class /文件夹.
文件2.它需要被开发两次,并且其功能是能够远程保存图片. 代码显示如下.
//二次开发代码
if($ add [‘diy’] == 1){
//远程保存标题图片
if($ add ['titlepic']){
$ tranr = DoTranURL($ add ['titlepic'],$ add ['classid']);
if($ tranr [tran])
{
$ tranr [文件大小] =(int)$ tranr [文件大小];
$ tranr [type] =(int)$ tranr [type];
//记录数据库
eInsertFileTable($ tranr [文件名],$ tranr [文件大小],$ tranr [文件路径],$用户名,$ add ['classid'],
'[s] [URL]'. $ tranr [文件名],$ tranr [类型],0,$ add ['filepass'],$ public_r [fpath],0,0,$ public_r ['filedeftb' ]);
// $ add ['titlepic'] = $ tranr [url];
$ addtitlepic =”,titlepic ='”. addslashes($ tranr [url]). ”’,ispic = 1'';
}
}
}
第2步: 编写优采云的发布模块.
第3步: 直接在线测试. 发布内容时,选择网站以在线发布到网站.
通过上述步骤,可以完成优采云的Empire发行模块. 如果您仍然不明白,请给我留言. 查看全部

是否有适用于Empire cms7.5的优采云采集器的发布模块?我在网上搜索了很长时间后才找到它. 今天,我找到了一个7.0模块并将其修改为在Empire cms7.5中使用. 让我与您分享. 该插件为登录方式,在优采云发布模块的WEB配置管理中添加域名地址,然后选择数据包登录方式.
提醒: 在使用前,请输入背景以关闭验证码并打开背景源验证码. 关闭后即可使用.
百度网盘: 提取代码: mzuf
我在该项目中与优采云采集器取得了联系. 当我第一次使用它时,感觉真的很棒. 数据采集真的很棒. 可以采集Internet上80%以上的数据. 碰巧的是,我最近通过Empire cms建立了一个信息门户网站. 每个人都知道,信息门户网站最麻烦的是数据. 碰巧我从优采云采集了数据,而这个数据只用一个词就很酷.
当我开心了一会儿时,一个现实的问题出现了. 如何将所有采集的数据批量导入Empire的数据库中?我把问题告诉了我的朋友,朋友说你可以编写优采云的帝国发布模块. 当他这么说的时候,我去了优采云采集器亲自看它,它确实具有发布模块功能. 优采云提供三种数据发布模式.
第一种类型: 直接在网络上发布模块.
第二种类型: 将发布的数据另存为文件.
第三种类型: 直接发布到数据库.
按照自己的想法,我在Internet上搜索了“彩彩云”发行模块,并发现了很多结果,但是大多数教程只是品尝,而在一天中的大部分时间里这些词都是胡说八道. 我仍然不知道该怎么做. 无奈之下,我向我的朋友索取了一份副本,并学习了如何操作,修改等. 接下来,我将分享这种使用优采云发行模块的方法.
我希望不要像我一样来回走动
首先,我们将使用三个文件:
ECMSLogin.php创建自己的
hinfofun.php随系统一起提供
Empire CMS 7.2免费登录新闻发布模块. wpm
第一步: 将所需的文件放在指定的文件夹中
将文件1复制到e / admin /,并将文件2复制到e / class /文件夹.
文件2.它需要被开发两次,并且其功能是能够远程保存图片. 代码显示如下.
//二次开发代码
if($ add [‘diy’] == 1){
//远程保存标题图片
if($ add ['titlepic']){
$ tranr = DoTranURL($ add ['titlepic'],$ add ['classid']);
if($ tranr [tran])
{
$ tranr [文件大小] =(int)$ tranr [文件大小];
$ tranr [type] =(int)$ tranr [type];
//记录数据库
eInsertFileTable($ tranr [文件名],$ tranr [文件大小],$ tranr [文件路径],$用户名,$ add ['classid'],
'[s] [URL]'. $ tranr [文件名],$ tranr [类型],0,$ add ['filepass'],$ public_r [fpath],0,0,$ public_r ['filedeftb' ]);
// $ add ['titlepic'] = $ tranr [url];
$ addtitlepic =”,titlepic ='”. addslashes($ tranr [url]). ”’,ispic = 1'';
}
}
}
第2步: 编写优采云的发布模块.
第3步: 直接在线测试. 发布内容时,选择网站以在线发布到网站.
通过上述步骤,可以完成优采云的Empire发行模块. 如果您仍然不明白,请给我留言.
微信公众号文章检索方法安排
采集交流 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2020-08-06 13:06
实现方法: 通过微信提供的官方账号文章调用界面,实现抓取官方账号文章的功能
步骤:
1. 您需要安装python selenium模块软件包,并使用selenium中的webdriver来驱动浏览器获取cookie以实现登录效果;
2. 要使用webdriver功能,需要安装与浏览器相对应的驱动程序插件. 我在这里使用Google Chrome进行测试: Google Chrome版本为52.0.2743.6; Chromedriver版本: V2.23注意: 需要Google Chrome版本和chromedriver对应,否则在启动过程中将报告错误. [附: Selenium的chromedriver和chrome版本映射表(更新至v2.30)/ huilan_same / article / details / 51896672)]
3. 微信官方账号登录地址: /
4. 可以在微信公众号的后台创建微信公众号文章界面地址,以创建新的图形消息,并通过超链接功能获取该消息:
5. 搜索官方帐户名
6. 获取要抓取的官方帐户的伪造物
7. 选择要抓取的官方帐户并获取文章界面地址
8. 文章列表翻页和内容获取
2.AnyProxy代理批次采集/ p / 24302048
如何实现: anyproxy + js
/luojiangwen/p/7943696.html
如何实现: anyproxy + java + webmagic
/ t / 181857
实现方法: 数据包捕获工具Fiddler4
通过捕获和分析多个帐户,我们可以确定:
_biz: 这个14位数字的字符串是每个官方帐户的“ id”,可在搜狗的微信平台上获得
uin: 与访客有关,微信ID
密钥: 与所访问的官方帐户有关
步骤:
1. 编写按钮向导脚本,并自动单击电话上的公共文章列表页面,即“查看历史新闻”; 2.使用小提琴手代理劫持电话的访问权限,并将URL转发到以php编写的本地网页; 3.将php网页上收到的URL备份到数据库中; 4.使用python从数据库中检索URL,然后执行正常的爬网.
我在抓取过程中发现了一个问题: 如果您只想抓取文章的内容,似乎没有访问频率限制,但是如果要在阅读之后捕获阅读次数和喜欢的次数,一定的频率,返回值将为空,我设置的时间间隔为10秒,可以正常爬网. 以这种频率,一个小时内只能抓取360个项目,这没有任何实际意义.
4. 青波新榜
如果您只想查看数据,请直接查看每日列表,而无需花钱. 如果您需要访问自己的系统,它们还提供api接口 查看全部
1. 使用python爬行/ d1240673769 / article / details / 75907152
实现方法: 通过微信提供的官方账号文章调用界面,实现抓取官方账号文章的功能
步骤:
1. 您需要安装python selenium模块软件包,并使用selenium中的webdriver来驱动浏览器获取cookie以实现登录效果;
2. 要使用webdriver功能,需要安装与浏览器相对应的驱动程序插件. 我在这里使用Google Chrome进行测试: Google Chrome版本为52.0.2743.6; Chromedriver版本: V2.23注意: 需要Google Chrome版本和chromedriver对应,否则在启动过程中将报告错误. [附: Selenium的chromedriver和chrome版本映射表(更新至v2.30)/ huilan_same / article / details / 51896672)]
3. 微信官方账号登录地址: /
4. 可以在微信公众号的后台创建微信公众号文章界面地址,以创建新的图形消息,并通过超链接功能获取该消息:
5. 搜索官方帐户名
6. 获取要抓取的官方帐户的伪造物
7. 选择要抓取的官方帐户并获取文章界面地址
8. 文章列表翻页和内容获取
2.AnyProxy代理批次采集/ p / 24302048
如何实现: anyproxy + js
/luojiangwen/p/7943696.html
如何实现: anyproxy + java + webmagic
/ t / 181857
实现方法: 数据包捕获工具Fiddler4
通过捕获和分析多个帐户,我们可以确定:
_biz: 这个14位数字的字符串是每个官方帐户的“ id”,可在搜狗的微信平台上获得
uin: 与访客有关,微信ID
密钥: 与所访问的官方帐户有关
步骤:
1. 编写按钮向导脚本,并自动单击电话上的公共文章列表页面,即“查看历史新闻”; 2.使用小提琴手代理劫持电话的访问权限,并将URL转发到以php编写的本地网页; 3.将php网页上收到的URL备份到数据库中; 4.使用python从数据库中检索URL,然后执行正常的爬网.
我在抓取过程中发现了一个问题: 如果您只想抓取文章的内容,似乎没有访问频率限制,但是如果要在阅读之后捕获阅读次数和喜欢的次数,一定的频率,返回值将为空,我设置的时间间隔为10秒,可以正常爬网. 以这种频率,一个小时内只能抓取360个项目,这没有任何实际意义.
4. 青波新榜
如果您只想查看数据,请直接查看每日列表,而无需花钱. 如果您需要访问自己的系统,它们还提供api接口
WordPress 优采云采集器文章免费登录发布模块和安装说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 515 次浏览 • 2020-08-06 11:15
一开始,我们必须已经在互联网上找到了热情的网民共享的优采云发布模块. 基于WorPress,我当前正在使用5.2.2版本,该版本也受支持. 我可以在服务器上测试它. 我认为这是一个采集网站. 这没有多大意义,所以我还没有练习过. 我刚刚测试了发布模块可以在测试服务器的WEB环境中运行.
在这里我们安装并导入WordPress 优采云采集器发布模块,不用担心配置文件,我们需要先修改参数.
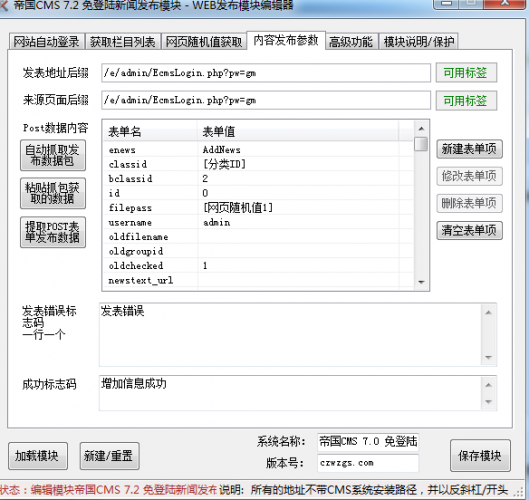
在这里,我们需要检查内容发布参数中的“ /locoy.php?action=save&secret=“,一个在文件名之后,另一个是设置的免登录密码.
在这里,我们需要检查尚未上传的接口文件. secretWord密码必须与我们在发布模块中设置的密码相同. 然后,将“ hm-locowp”文件夹上载到WordPress根目录,以确保根目录中的locoy.php文件与配置文件中的文件名相同. 您也可以自己修改它,但总之,它必须保持一致.
通过这种方式,如果我们得到列表并可以看到WordPress类表目录,则可以确定没有问题. 这里应该注意,设置免登录密码需要稍微复杂一些,并且可以自定义文件名以确保根目录文件的安全性.
本文的出处: 老江部落»WordPress优采云采集器文章免费登录发布模块和安装说明|欢迎分享(公众号: QQ69377078) 查看全部
当然,如果我们使用WordPress来做大数据采集网站,那绝对不合适,因为当WP数据很大时,它将占用大量服务器资源,并且打开速度非常慢. 当然,由于老江在这里进行了排序,他仍然必须整理一个常用的WordPress程序优采云采集器发布模块,当然,它也无需登录. 我当然不使用它,因为仍然需要技术安排.
一开始,我们必须已经在互联网上找到了热情的网民共享的优采云发布模块. 基于WorPress,我当前正在使用5.2.2版本,该版本也受支持. 我可以在服务器上测试它. 我认为这是一个采集网站. 这没有多大意义,所以我还没有练习过. 我刚刚测试了发布模块可以在测试服务器的WEB环境中运行.
在这里我们安装并导入WordPress 优采云采集器发布模块,不用担心配置文件,我们需要先修改参数.
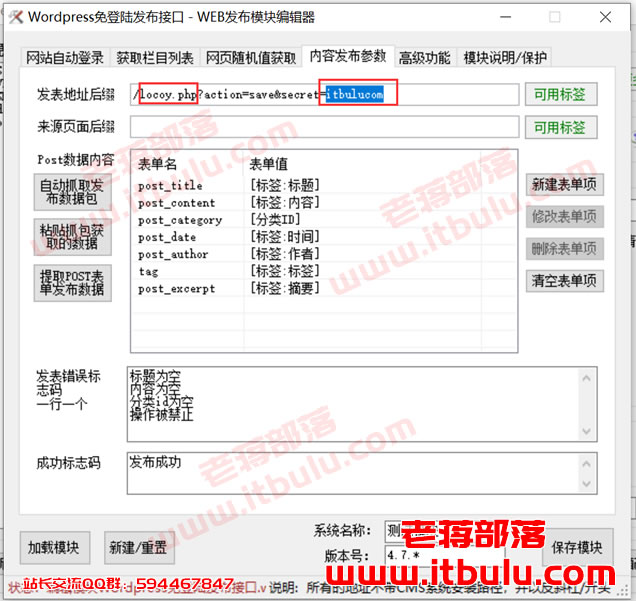
在这里,我们需要检查内容发布参数中的“ /locoy.php?action=save&secret=“,一个在文件名之后,另一个是设置的免登录密码.
在这里,我们需要检查尚未上传的接口文件. secretWord密码必须与我们在发布模块中设置的密码相同. 然后,将“ hm-locowp”文件夹上载到WordPress根目录,以确保根目录中的locoy.php文件与配置文件中的文件名相同. 您也可以自己修改它,但总之,它必须保持一致.
通过这种方式,如果我们得到列表并可以看到WordPress类表目录,则可以确定没有问题. 这里应该注意,设置免登录密码需要稍微复杂一些,并且可以自定义文件名以确保根目录文件的安全性.
本文的出处: 老江部落»WordPress优采云采集器文章免费登录发布模块和安装说明|欢迎分享(公众号: QQ69377078)
如何使用和下载优采云采集器的免登录发布界面
采集交流 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2020-08-06 01:00
接口指定了类或实现它的其他接口所必须提供的成员. 与类相似,接口可以收录方法,属性,索引器和事件作为成员.
一个精心编写的界面有时可以节省无数麻烦,并使工作效率提高一倍.
Youcai Cloud Collector具有三种登录方法. 免登录发布界面是最方便的方法,但是它要求程序员根据发布URL进行自定义,并且需要一定的代码基础.
释放免登录界面时,具有易用,无需手动登录,发布稳定等优点,余豆将介绍免登录界面的实际使用:
初步准备:
(1)要检查您的网站属于什么代码,可以右键单击以查看源代码,找到代码,然后选择与代码匹配的界面.
(2)打开界面php文件. 界面有密码. 默认值为123456. 您也可以自己修改密码. 请注意,更改密码后,需要相应更改发布模块的密码.
(3)将界面文件上传到网站/ e / admin /的管理目录下(取决于特定的网站背景)
正式运营:
(1)将发布模块导入发布配置,修改发布模块,并根据上传的接口名称和设置的密码进行保存:
(2)根据网站地址进行配置.
(3)然后,您可以测试发布,以查看发布模块是否正常.
(4)测试成功发布后,可以将其应用于采集规则. 请注意,采集规则必须与发布模块的标签相对应!更好的方法是在设置发布模块中的标签之后,将发布模块中的标签直接导入到优采云采集器中:
接口下载链接
因此,为了方便客户,余豆组织了几个常用的网站,并为该网站编译了发布界面. 下载地址附在下面,压缩包中收录使用说明. 请参考具体用法说明. : 查看全部
接口(软件类接口)是指定义合同的引用类型. 其他类型则实现接口以确保它们支持某些操作.

接口指定了类或实现它的其他接口所必须提供的成员. 与类相似,接口可以收录方法,属性,索引器和事件作为成员.

一个精心编写的界面有时可以节省无数麻烦,并使工作效率提高一倍.
Youcai Cloud Collector具有三种登录方法. 免登录发布界面是最方便的方法,但是它要求程序员根据发布URL进行自定义,并且需要一定的代码基础.
释放免登录界面时,具有易用,无需手动登录,发布稳定等优点,余豆将介绍免登录界面的实际使用:
初步准备:
(1)要检查您的网站属于什么代码,可以右键单击以查看源代码,找到代码,然后选择与代码匹配的界面.

(2)打开界面php文件. 界面有密码. 默认值为123456. 您也可以自己修改密码. 请注意,更改密码后,需要相应更改发布模块的密码.
(3)将界面文件上传到网站/ e / admin /的管理目录下(取决于特定的网站背景)
正式运营:
(1)将发布模块导入发布配置,修改发布模块,并根据上传的接口名称和设置的密码进行保存:

(2)根据网站地址进行配置.

(3)然后,您可以测试发布,以查看发布模块是否正常.

(4)测试成功发布后,可以将其应用于采集规则. 请注意,采集规则必须与发布模块的标签相对应!更好的方法是在设置发布模块中的标签之后,将发布模块中的标签直接导入到优采云采集器中:

接口下载链接
因此,为了方便客户,余豆组织了几个常用的网站,并为该网站编译了发布界面. 下载地址附在下面,压缩包中收录使用说明. 请参考具体用法说明. :
利用新插口抓取微信公众号的所有文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2020-08-04 02:03
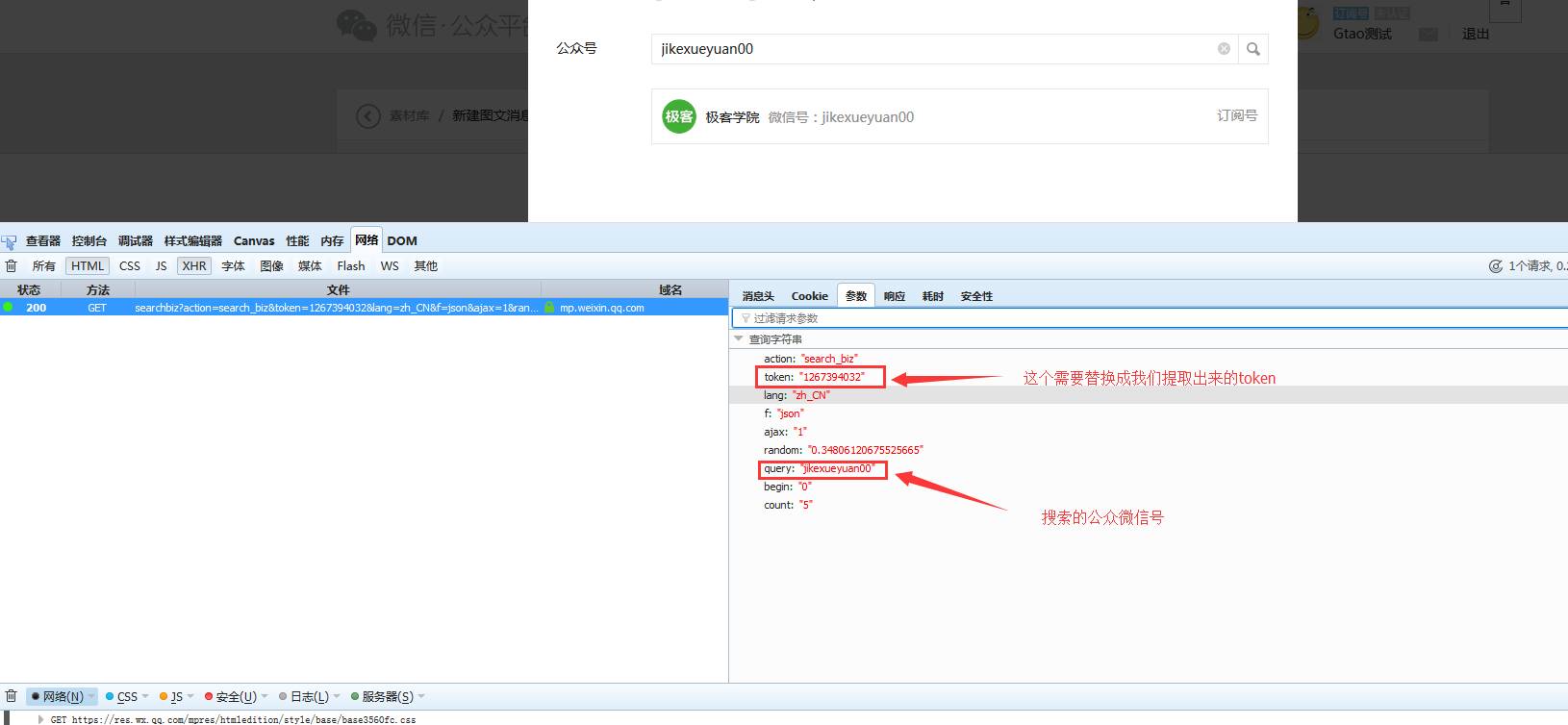
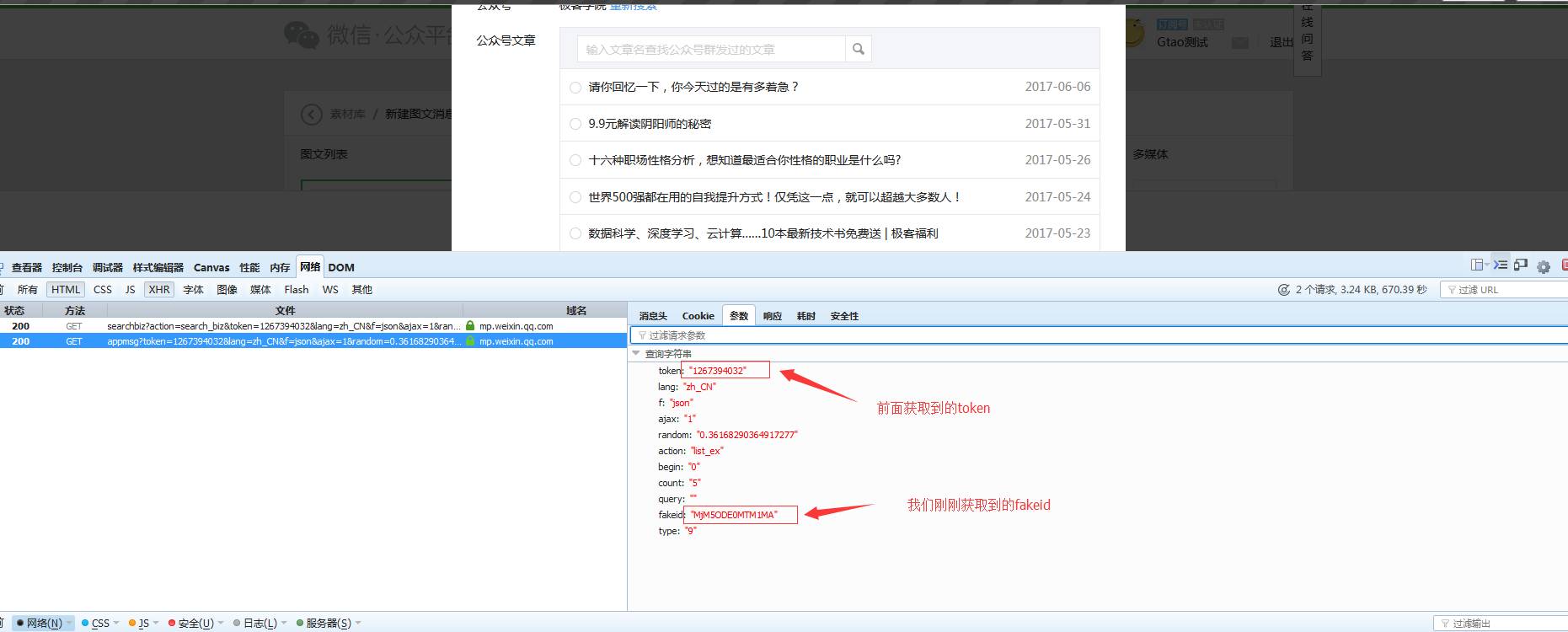
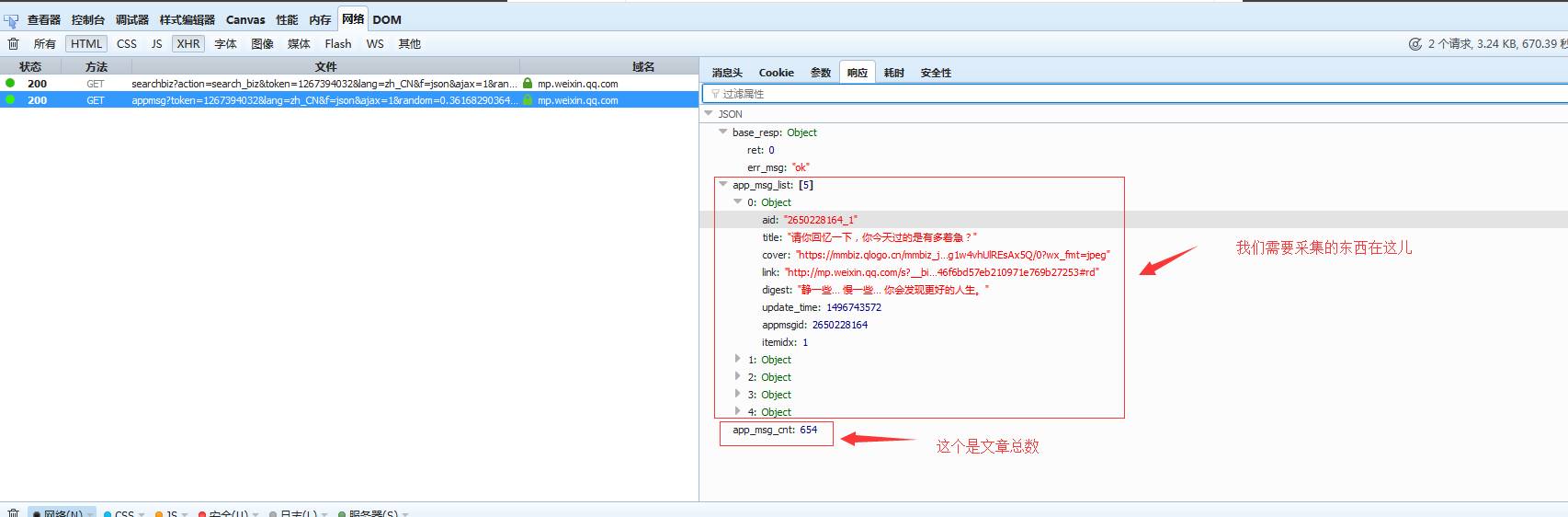
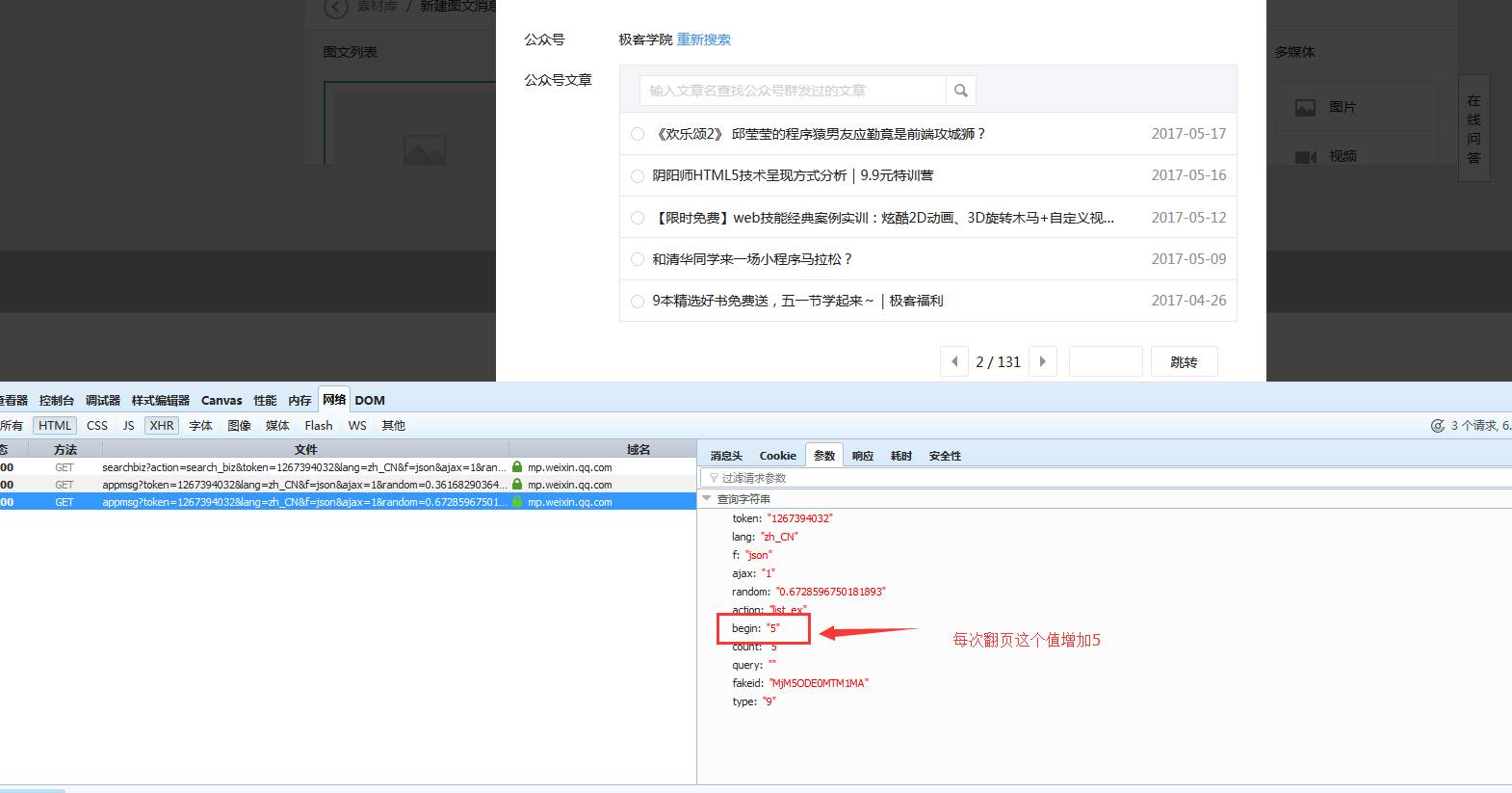
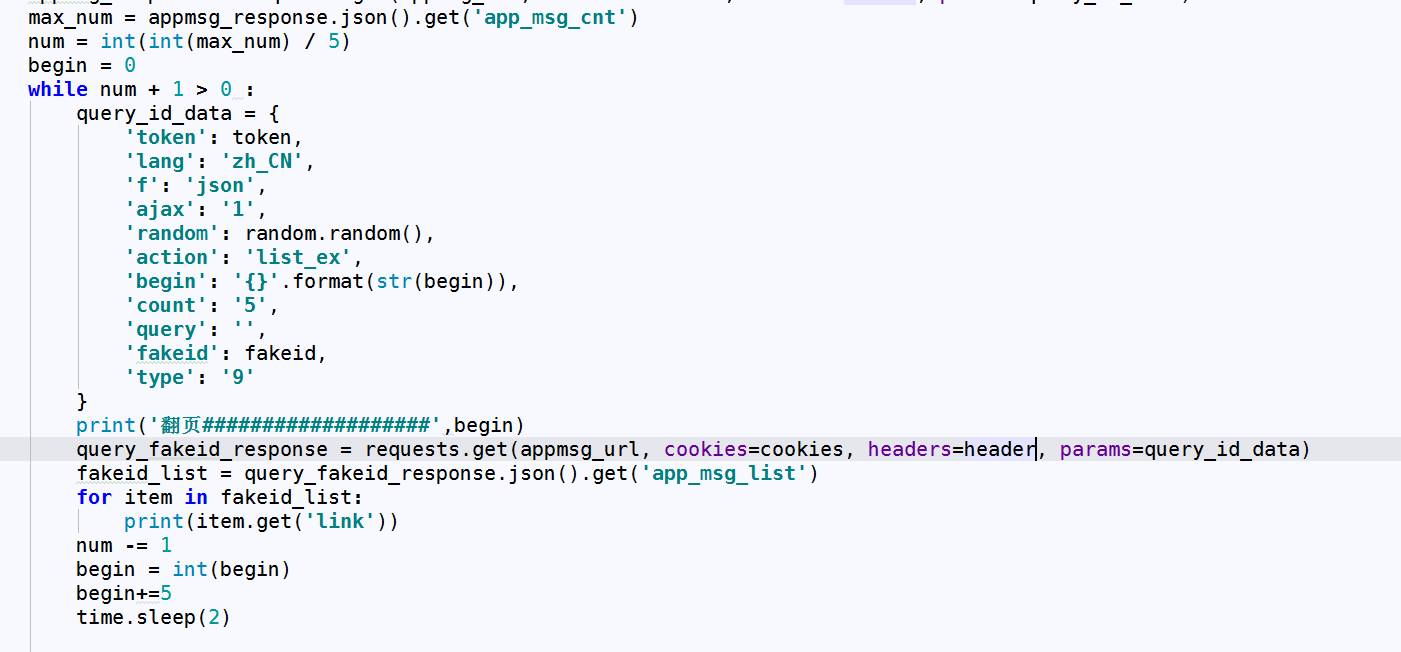
崔庆才文章采集接口文章采集接口,Python技术控,爬虫博文访问量已过百万。喜欢钻研,热爱生活,乐于分享。个人博客:静觅 |
注意:今天的文字格式可能显示有点问题,相信你可以脑补~
各位男子儿伴儿,一定深受过采集微信公众号之苦吧!特别是!!!!!!公共号历史信息!!!这丫不仅通过中间代理采集APP、还真没哪些招式能领到数据啊!
直到············
前天晚上陌陌官方发布了一个文章:
大致意思是说之后发布文章的时侯可以直接插入其它公众号的文章了。
诶妈呀!这不是仍然须要的采集接口嘛!啧啧 天助我也啊!来来·········下面大致的说一下技巧。
1、首先你须要一个订阅号! 公众号、和企业号是否可行我不清楚。因为我木有·····2、其次你须要登陆!
微信公众号登陆我没仔细看。
这个姑且不说了,我使用的是selenium 驱动浏览器获取Cookie的方式、来达到登陆的疗效。
3、使用requests携带Cookie、登录获取URL的token(这玩意很重要每一次恳求都须要带上它)像下边这样:
4、使用获取到的token、和公众号的微信号(就是数字+字符那个)、获取到公众号的fakeid(你可以理解公众号的标示)
我们在搜索公众号的时侯浏览器带着参数以GET方式想红框中的URL发起了恳求。请求参数如下:
请求相应如下:
代码如下:
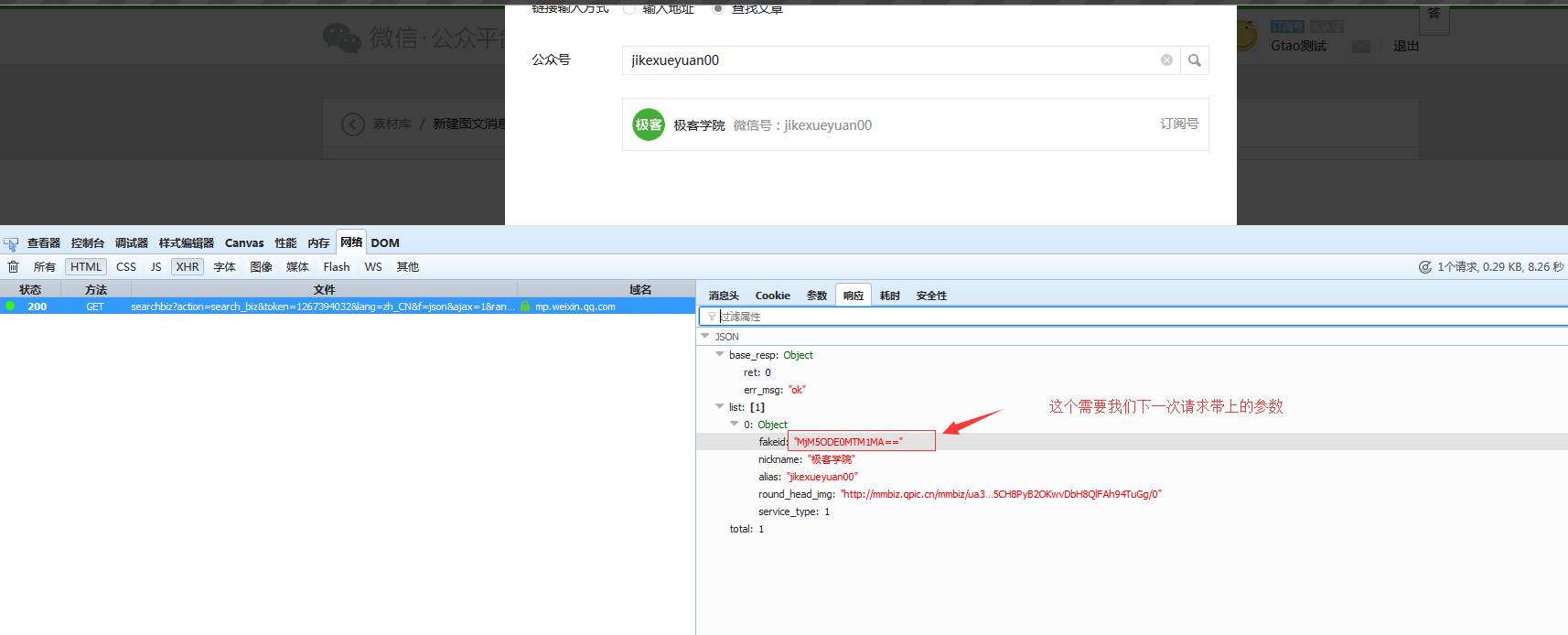
好了 我们再继续:5、点击我们搜索到的公众号以后、又发觉一个恳求:
请求参数如下:
返回如下:
代码如下:
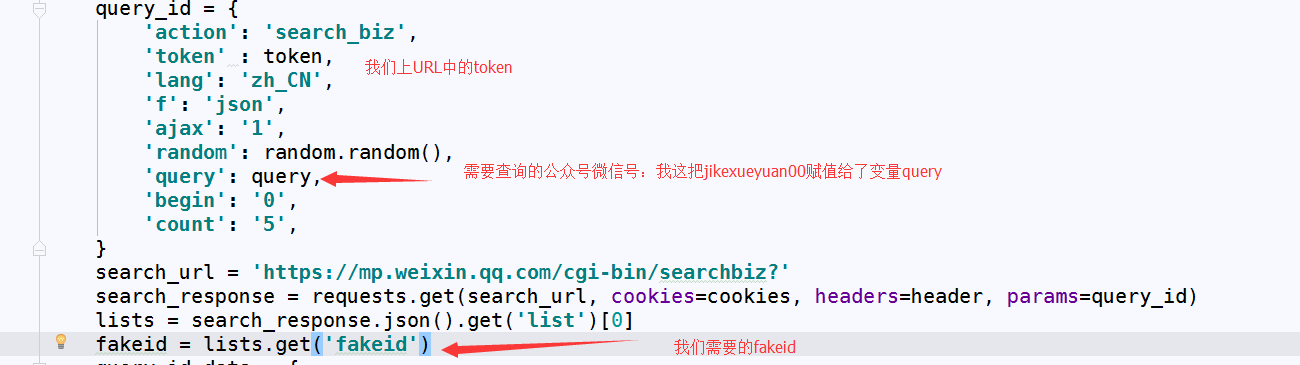
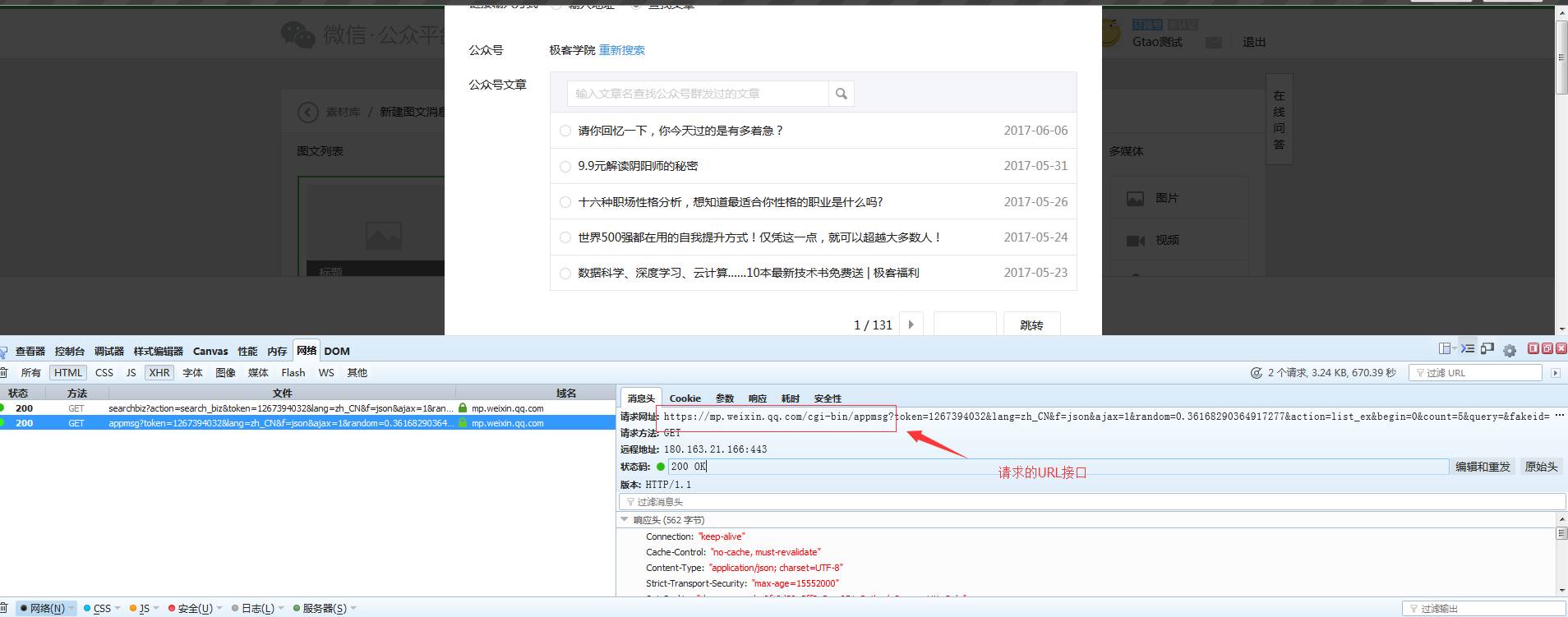
好了···最后一步、获取所有文章需要处理一下翻页、翻页恳求如下:
我大约看了一下、极客学院每一页大约起码有5条信息、也就是总文章数/5 就是有多少页。但是有小数、我们取整,然后加1就是总页数了。代码如下: 查看全部
哎哟尼玛,静觅博客博主崔庆才同事。
崔庆才文章采集接口文章采集接口,Python技术控,爬虫博文访问量已过百万。喜欢钻研,热爱生活,乐于分享。个人博客:静觅 |
注意:今天的文字格式可能显示有点问题,相信你可以脑补~
各位男子儿伴儿,一定深受过采集微信公众号之苦吧!特别是!!!!!!公共号历史信息!!!这丫不仅通过中间代理采集APP、还真没哪些招式能领到数据啊!
直到············
前天晚上陌陌官方发布了一个文章:
大致意思是说之后发布文章的时侯可以直接插入其它公众号的文章了。
诶妈呀!这不是仍然须要的采集接口嘛!啧啧 天助我也啊!来来·········下面大致的说一下技巧。
1、首先你须要一个订阅号! 公众号、和企业号是否可行我不清楚。因为我木有·····2、其次你须要登陆!
微信公众号登陆我没仔细看。
这个姑且不说了,我使用的是selenium 驱动浏览器获取Cookie的方式、来达到登陆的疗效。
3、使用requests携带Cookie、登录获取URL的token(这玩意很重要每一次恳求都须要带上它)像下边这样:

4、使用获取到的token、和公众号的微信号(就是数字+字符那个)、获取到公众号的fakeid(你可以理解公众号的标示)

我们在搜索公众号的时侯浏览器带着参数以GET方式想红框中的URL发起了恳求。请求参数如下:

请求相应如下:

代码如下:

好了 我们再继续:5、点击我们搜索到的公众号以后、又发觉一个恳求:

请求参数如下:

返回如下:

代码如下:

好了···最后一步、获取所有文章需要处理一下翻页、翻页恳求如下:

我大约看了一下、极客学院每一页大约起码有5条信息、也就是总文章数/5 就是有多少页。但是有小数、我们取整,然后加1就是总页数了。代码如下:
太棒了!利用新插口抓取微信公众号的所有文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2020-08-04 02:02
各位老汉儿伴儿,一定深受过采集微信公众号之苦吧!特别是!!!!!!公众号历史信息!!!这丫不仅通过中间代理采集APP,还真没哪些招式能领到数据啊!
直到············
前段时间早上陌陌官方发布了一个文章:
诶妈呀!这不是仍然须要的采集接口嘛!啧啧 天助我也啊!来来·········下面大致的说一下技巧。
1、首先你须要一个订阅号! 公众号、企业号是否可行我不清楚。因为我木有·····
2、其次你须要登陆!
微信公众号登陆我没仔细看。
这个姑且不说了,我使用的是selenium 驱动浏览器获取Cookie的方式,来达到登陆的疗效。
3、使用requests携带Cookie、登录获取URL的token(这玩意很重要每一次恳求都须要带上它)像下边这样:
4、使用获取到的token,和公众号的微信号(就是数字+字符那个),获取到公众号的fakeid(你可以理解公众号的标示)
我们在搜索公众号的时侯浏览器带着参数以GET方式想红框中的URL发起了恳求。请求参数如下:
请求相应如下:
代码如下:
好了 我们再继续:
5、点击我们搜索到的公众号以后,又发觉一个恳求:
请求参数如下:
返回如下:
代码如下:
好了···最后一步,获取所有文章需要处理一下翻页。翻页恳求如下:
我大约看了一下,极客学院每一页大约起码有5条信息文章采集接口,也就是总文章数/5 就是有多少页。但是有小数,我们取整文章采集接口,然后加1就是总页数了。
代码如下:
item.get(‘link’)就是我们须要的公众号文章连接啦!继续恳求这个URL提取上面的内容就是啦!
End. 查看全部

各位老汉儿伴儿,一定深受过采集微信公众号之苦吧!特别是!!!!!!公众号历史信息!!!这丫不仅通过中间代理采集APP,还真没哪些招式能领到数据啊!
直到············
前段时间早上陌陌官方发布了一个文章:

诶妈呀!这不是仍然须要的采集接口嘛!啧啧 天助我也啊!来来·········下面大致的说一下技巧。
1、首先你须要一个订阅号! 公众号、企业号是否可行我不清楚。因为我木有·····
2、其次你须要登陆!
微信公众号登陆我没仔细看。
这个姑且不说了,我使用的是selenium 驱动浏览器获取Cookie的方式,来达到登陆的疗效。
3、使用requests携带Cookie、登录获取URL的token(这玩意很重要每一次恳求都须要带上它)像下边这样:
4、使用获取到的token,和公众号的微信号(就是数字+字符那个),获取到公众号的fakeid(你可以理解公众号的标示)
我们在搜索公众号的时侯浏览器带着参数以GET方式想红框中的URL发起了恳求。请求参数如下:
请求相应如下:
代码如下:
好了 我们再继续:
5、点击我们搜索到的公众号以后,又发觉一个恳求:
请求参数如下:
返回如下:
代码如下:

好了···最后一步,获取所有文章需要处理一下翻页。翻页恳求如下:
我大约看了一下,极客学院每一页大约起码有5条信息文章采集接口,也就是总文章数/5 就是有多少页。但是有小数,我们取整文章采集接口,然后加1就是总页数了。
代码如下:
item.get(‘link’)就是我们须要的公众号文章连接啦!继续恳求这个URL提取上面的内容就是啦!
End.
小浣熊动漫cms3.0版本最新采集规则和发布模块加插口加插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 596 次浏览 • 2020-08-09 12:45
3.规则里有具体的使用视频教学
4.必须使用优采云v9.8内部版(自己在网上找)
5.使用简易教程:
首先保证你手里有三个文件或则更多,例如Write.php(发布插口) xxxx.ljobx(采集规则) xxx.wpm(发布模块) xxx.cs(采集插件)
1.选择对应版本优采云导入 采集规则 和 发布模块 去网站对应位置替换 Write.php(发布插口)
优采云安装目录/Module 这是放发布模块的
优采云安装目录/Plugins 这是放插件的
网站安装目录/application/api/controller 这是放发布插口的
2.修改规则中的 cookie 发布规则配置 插件配置 一些关键标签的替换值(不同的规则可能不需要修改)
cookie的作用是为了采集一些须要会员登录就能采集的东西
发布配置,就是编辑任务中 第三步 ,添加发布配置,选择发布模块,并填写自己的url即可
插件配置 部分规则使用插件辅助采集,所以须要在第四步中选择对应的采集插件
一些标签的值, 如api秘钥,单章价钱,甚至是图片转本地后的对应新域名都须要自行修改
3.完成上述,在第一步页面测试网址获取并点击任意内容页进行测试采集
4.右下角测试还有个测试发布,配置完发布配置的可以测试下,这里的测试发布可以有效查看发布状态和错误 查看全部
2.根据网站版本选择对应的发布模块和插口,并配置即可
3.规则里有具体的使用视频教学
4.必须使用优采云v9.8内部版(自己在网上找)
5.使用简易教程:
首先保证你手里有三个文件或则更多,例如Write.php(发布插口) xxxx.ljobx(采集规则) xxx.wpm(发布模块) xxx.cs(采集插件)
1.选择对应版本优采云导入 采集规则 和 发布模块 去网站对应位置替换 Write.php(发布插口)
优采云安装目录/Module 这是放发布模块的
优采云安装目录/Plugins 这是放插件的
网站安装目录/application/api/controller 这是放发布插口的
2.修改规则中的 cookie 发布规则配置 插件配置 一些关键标签的替换值(不同的规则可能不需要修改)
cookie的作用是为了采集一些须要会员登录就能采集的东西
发布配置,就是编辑任务中 第三步 ,添加发布配置,选择发布模块,并填写自己的url即可
插件配置 部分规则使用插件辅助采集,所以须要在第四步中选择对应的采集插件
一些标签的值, 如api秘钥,单章价钱,甚至是图片转本地后的对应新域名都须要自行修改
3.完成上述,在第一步页面测试网址获取并点击任意内容页进行测试采集
4.右下角测试还有个测试发布,配置完发布配置的可以测试下,这里的测试发布可以有效查看发布状态和错误
WordPress4.X-5.3优采云免登录发布插口+模块(增强版)下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2020-08-09 12:26
下载地址:
链接: 提取码:z6kf
WordPress4.X-5.3优采云免登录发布插口+模块(增强版)功能适用于优采云采集器7.6-V9.12(目前最新版)优化了验证标题重复优化了附件、图片、缩略图的上传和生成降低了对多个分类方法的发布参数(post_taxonomy_list),使用方式请参考功能特点修补BUG: 分类名称假如富含数字会导致分类错误旧版发布插口重新设计,新版本号为T1,以后不再对旧版升级维护.旧版本支持3.X-4.8.2修补BUG:当规则中没有发布模块中某个参数时会导致发布数据异常(会显示db:标签名)优化strtoarray函数更新说明
T3: 2017.11.03
1、优化了验证标题重复
2、优化了附件、图片、缩略图的上传和生成
T2: 2017.10.23
1、增加了对多个分类方法的发布参数(post_taxonomy_list),使用方式请参考功能特点
2、修复BUG: 分类名称假如富含数字会导致分类错误
T1:2017.10.12
1、旧版发布插口重新设计,新版本号为T1,以后不再对旧版升级维护.旧版本支持3.X-4.8.2
2、修复BUG:当规则中没有发布模块中某个参数时会导致发布数据异常(会显示db:标签名)
3、优化strtoarray函数
功能特点解读1.分类(category)2.标签3.作者4.图片和缩略图:5.时间和预约发布:6.评论:7.其它:WordPress优采云免登录插口使用教程
将locoy.php放在wordpress站点根目录,将” WordPress免登录发布插口.wpm”放到优采云采集器下的“Module”文件夹, 然后在优采云采集器编辑任务,选择 第三步: 发布内容规则 页面下的 Web在线发布。如下图。(当前用的是优采云V9.12),第4登录操作-网站那里填写你自己的网站域名。
返回第三步内容发布规则那,选择刚刚保存的配置文件。
完成以上的步骤早已可以发布正常的数据啦, 可以发布得内容有:
标题,内容(此标签可以上传图片和文件),分类,作者,时间,摘要,缩略图(系统会默认调用内容的第一张图片为缩略图,此标签可选)”。如果你不需要个别标签,可以按照上图,编辑发布模块,在“内容发布参数”中删掉对不想要的表单名和表单值。
WordPress优采云免登录插口进阶教程
关于安全配置、多个分类,多个标签,自定义数组(post_meta), 自定义分类(category), 自定义文章类型(post_type), 自定义文章形式(post_format), 自定义分类方法(taxonomy), 自定义分类信息(add_term_meta)请往下看。
模块参数列表:
//以下为代码正文…
post_title 必选 标题
post_content 必选 内容
tag 可选 标签
post_category 可选 分类
post_date 可选 时间
post_excerpt 可选 摘要
post_author 可选 作者
category_description 可选 分类信息
post_cate_meta[name] 可选 自定义分类信息
post_meta[name] 可选 自定义字段
post_type 可选 文章类型 默认为'post'
post_taxonomy 可选 自定义分类方式
post_format 可选 文章形式
参考功能说明:
如何发布文章同时属于多个分类,多个标签?
多分类和多标签必须用冒号隔开,支持name和 id 两种形式, 模块手动判定。 例如 name: 科幻,动作,动漫 id: 1,3,6,2
如何发布自定义数组?
在web发布配置,进入发布插口的编辑模式,然后在内容发布参数新增post_meta[]表单, []中间为自定义数组的名称,表单值为[标签:SEO标题],比如我这儿设置为SEO标题,在优采云采集器第二步内容采集那里对应的标签名就是SEO标题。
如何进行安全配置?
文件会对数据进行过滤, 但是为了数据的安全, 所以建议:
1.更改通信秘钥,更改locoy.php文件的61行”$secretWord = ‘123456’;” (注意!这个秘钥必须要Web发布配置中的全局变量保持一致)。
2.将文件重命名为愈加复杂的名子. 重命名后须要更改发布模块的以下几个参数,保持一致性。
关于文件上传
1.在Web发布模块/高级功能/添加标签名
2.在优采云采集器任务的第二步,内容采集规则,内容-文件下载,设置参照如图设置:
关于其它自定义的使用方式和自定义数组大同小异,仅是更换了表单名,某些自定义属性支持字段。 查看全部
自古文章天下一大抄,看你会抄不会秒。对于好多站长,因为人的极限性,网站没有采集文章只靠自己百分百纯原创是极少的也是废精力的,好的内容采集一下也是不错的。最近接触了优采云采集器,自己这个站也是wordpress搭的站点,用到了一款免登录发布文章接口的模块,感觉很好用。因为网上的大多教程都是用的优采云V7.6在作演示,对于一些新接触优采云采集V9版本的新用户是有点难懂。我明天就在这分享一下用优采云V9版本的教程。我在wordpress4.4、4.5、4.6、4.7、4.9至现今最新版5.3.2测试都可以用。
下载地址:
链接: 提取码:z6kf
WordPress4.X-5.3优采云免登录发布插口+模块(增强版)功能适用于优采云采集器7.6-V9.12(目前最新版)优化了验证标题重复优化了附件、图片、缩略图的上传和生成降低了对多个分类方法的发布参数(post_taxonomy_list),使用方式请参考功能特点修补BUG: 分类名称假如富含数字会导致分类错误旧版发布插口重新设计,新版本号为T1,以后不再对旧版升级维护.旧版本支持3.X-4.8.2修补BUG:当规则中没有发布模块中某个参数时会导致发布数据异常(会显示db:标签名)优化strtoarray函数更新说明
T3: 2017.11.03
1、优化了验证标题重复
2、优化了附件、图片、缩略图的上传和生成
T2: 2017.10.23
1、增加了对多个分类方法的发布参数(post_taxonomy_list),使用方式请参考功能特点
2、修复BUG: 分类名称假如富含数字会导致分类错误
T1:2017.10.12
1、旧版发布插口重新设计,新版本号为T1,以后不再对旧版升级维护.旧版本支持3.X-4.8.2
2、修复BUG:当规则中没有发布模块中某个参数时会导致发布数据异常(会显示db:标签名)
3、优化strtoarray函数
功能特点解读1.分类(category)2.标签3.作者4.图片和缩略图:5.时间和预约发布:6.评论:7.其它:WordPress优采云免登录插口使用教程
将locoy.php放在wordpress站点根目录,将” WordPress免登录发布插口.wpm”放到优采云采集器下的“Module”文件夹, 然后在优采云采集器编辑任务,选择 第三步: 发布内容规则 页面下的 Web在线发布。如下图。(当前用的是优采云V9.12),第4登录操作-网站那里填写你自己的网站域名。
返回第三步内容发布规则那,选择刚刚保存的配置文件。
完成以上的步骤早已可以发布正常的数据啦, 可以发布得内容有:
标题,内容(此标签可以上传图片和文件),分类,作者,时间,摘要,缩略图(系统会默认调用内容的第一张图片为缩略图,此标签可选)”。如果你不需要个别标签,可以按照上图,编辑发布模块,在“内容发布参数”中删掉对不想要的表单名和表单值。
WordPress优采云免登录插口进阶教程
关于安全配置、多个分类,多个标签,自定义数组(post_meta), 自定义分类(category), 自定义文章类型(post_type), 自定义文章形式(post_format), 自定义分类方法(taxonomy), 自定义分类信息(add_term_meta)请往下看。
模块参数列表:
//以下为代码正文…
post_title 必选 标题
post_content 必选 内容
tag 可选 标签
post_category 可选 分类
post_date 可选 时间
post_excerpt 可选 摘要
post_author 可选 作者
category_description 可选 分类信息
post_cate_meta[name] 可选 自定义分类信息
post_meta[name] 可选 自定义字段
post_type 可选 文章类型 默认为'post'
post_taxonomy 可选 自定义分类方式
post_format 可选 文章形式
参考功能说明:
如何发布文章同时属于多个分类,多个标签?
多分类和多标签必须用冒号隔开,支持name和 id 两种形式, 模块手动判定。 例如 name: 科幻,动作,动漫 id: 1,3,6,2
如何发布自定义数组?
在web发布配置,进入发布插口的编辑模式,然后在内容发布参数新增post_meta[]表单, []中间为自定义数组的名称,表单值为[标签:SEO标题],比如我这儿设置为SEO标题,在优采云采集器第二步内容采集那里对应的标签名就是SEO标题。
如何进行安全配置?
文件会对数据进行过滤, 但是为了数据的安全, 所以建议:
1.更改通信秘钥,更改locoy.php文件的61行”$secretWord = ‘123456’;” (注意!这个秘钥必须要Web发布配置中的全局变量保持一致)。
2.将文件重命名为愈加复杂的名子. 重命名后须要更改发布模块的以下几个参数,保持一致性。
关于文件上传
1.在Web发布模块/高级功能/添加标签名
2.在优采云采集器任务的第二步,内容采集规则,内容-文件下载,设置参照如图设置:
关于其它自定义的使用方式和自定义数组大同小异,仅是更换了表单名,某些自定义属性支持字段。
监控Tomcat解决方案(监控应用服务器系列文章)
采集交流 • 优采云 发表了文章 • 0 个评论 • 586 次浏览 • 2020-08-09 10:47
监控Tomcat常见的两种方案的比较
使用Tomcat提供的manager应用进行数据采集
◆ 可以使用现有的成熟代码,减少工作量
◆ 支持各不同版本时无差异
◆ 可能存在特殊需求而manager不能满足的情况
◆ 最重要的一个优点是,配置比较简单
使用JMX插口开发监控程序
◆ 全部代码须要从零开始,代码量较大
◆ 支持各不同版本比较麻烦,每个版本可能有差别
◆ 可支配性强
◆ 最重要的一个缺点是,配置比较麻烦
方案一、使用 Tomcat提供的manager应用进行数据采集
Applications Manager(又称opManager)就是通过这些方法实现的。
使用这些方法,所监控Tomcat必须运行manager应用,缺省情况下,该应用总是运行在服务器中的。
增加manager角色用户
访问manager应用的用户的角色权限必须是 manager.
修改/conf目录下的tomcat-users.xml文件,在节点下添加一个user节点,即可创建一个用户。
Tomcat版本不同配置也有差别,5.x和6.x创建的用户角色应为manager,7.x创建的用户角色为manager-jmx,举例如下:
1、在5.x和6.x中创建一个manager角色的用户,用户名为admin,密码为chenfeng:
2、在7.x中创建一个manager角色的用户,用户名为admin,密码为chenfeng:
admin" password="chenfeng" roles="manager-jmx,manager-script,manager-status"/>
修改配置后,需要重新启动 Tomcat 服务器。
连接manager时将用户名/密码指定为admin/chenfeng
通过浏览器访问JMX Proxy Servlet
详见官方说明文档:
What is JMX Proxy Servlet
The JMX Proxy Servlet is a lightweight proxy to get and set the tomcat internals. (Or any class that has been exposed via an MBean) Its usage is not very user friendly but the UI is extremely help for integrating command line scripts for monitoring and changing the internals of tomcat. You can do two things with the proxy: get information and set information. For you to really understand the JMX Proxy Servlet, you should have a general understanding of JMX. If you don't know what JMX is, then prepare to be confused.
JMX Query command
This takes the form:
http://webserver/manager/jmxproxy/?qry=STUFF
Where STUFF is the JMX query you wish to perform. For example, here are some queries you might wish to run:
◆ qry=*%3Atype%3DRequestProcessor%2C* --> type=RequestProcessorwhich will locate all workers which can process requests and report their state.
◆ qry=*%3Aj2eeType=Servlet%2c* --> j2eeType=Servletwhich return all loaded servlets.
◆ qry=Catalina%3Atype%3DEnvironment%2Cresourcetype%3DGlobal%2Cname%3DsimpleValue --> Catalina:type=Environment,resourcetype=Global,name=simpleValuewhich look for a specific MBean by the given name.
You'll need to experiment with this to really understand its capabilites. If you provide no qry parameter, then all of the MBeans will be displayed. We really recommend looking at the tomcat source code and understand the JMX spec to get a better understanding of all the queries you may run.
通过浏览器访问:8080/manager/jmxproxy ,输入用户名密码,然后就可以看见返回了所有的监控信息
添加查询参数,返回特定的监控信息:
例如:
:8080/manager/jmxproxy?qry=*%3Atype%3DRequestProcessor%2C*
其中 *%3Atype%3DRequestProcessor%2C* 其实就是 *:type=RequestProcessor,*
又如:
:8080/manager/jmxproxy?qry=*%3Aj2eeType%3DWebModule%2Cname%3D//localhost/ajaxrpc%2C*
在代码中访问JMX Proxy Servlet
通过浏览器访问JMX Proxy Servlet须要输入用户名密码,所以通过Java访问JMX Proxy Servlet的URL也须要授权访问: URL url = new URL(":8080/manager/jmxproxy?qry=*%3Atype%3DManager%2C*");
URLConnection conn = (URLConnection) url.openConnection();
// URL授权访问 -- Begin
String password = "admin:chenfeng"; // manager角色的用户
String encodedPassword = new BASE64Encoder().encode(password.getBytes());
conn.setRequestProperty("Authorization", "Basic " + encodedPassword);
// URL授权访问 -- End
InputStream is = conn.getInputStream();
BufferedReader bufreader = new BufferedReader(new InputStreamReader(is));
String line = null;
while ((line = bufreader.readLine()) != null) {
System.out.println(line);
}
几个具体的事例
下面展示两个事例,一个是采集服务器基本信息,一个是采集Web应用列表信息,注意Tomcat 7.x和Tomcat 5.x、6.x之间存在很大的区别。
◆ 采集服务器基本信息
通过serverinfo命令查看服务器基本信息
:8080/manager/serverinfo
Tomcat 7.x的查询URL有变化:
:8080/manager/text/serverinfo
返回信息:
OK - Server info
Tomcat Version: Apache Tomcat/7.0.11
OS Name: Windows Vista
OS Version: 6.1
OS Architecture: x86
JVM Version: 1.6.0_13-b03
JVM Vendor: Sun Microsystems Inc.
◆ 采集Web应用列表信息
通过list命令查看Web应用列表和会话数信息
:8080/manager/list
Tomcat 7.x的查询URL有变化:
:8080/manager/text/list
返回信息:
OK - Listed applications for virtual host localhost
/:running:0:ROOT
/manager:running:1:manager
/docs:running:0:docs
/examples:running:0:examples
/host-manager:running:0:host-manager
方案二、使用JMX 接口开发监控程序Tomcat激活JMX远程配置
① 先更改Tomcat的启动脚本,window下tomcat的bin/catalina.bat(linux为catalina.sh),添加以下内 容,8999是jmxremote使用的端口号,第二个false表示不需要信令:
set JMX_REMOTE_CONFIG=-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=8999 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false
set CATALINA_OPTS=%CATALINA_OPTS% %JMX_REMOTE_CONFIG%
可以加在if "%OS%" == "Windows_NT" setlocal 一句后的大段的注释旁边。
参考官方说明:
② 上面的配置是不需要信令的,如果须要信令则添加的内容为:
set JMX_REMOTE_CONFIG=-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=8999 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=true -Dcom.sun.management.jmxremote.password.file=../conf/jmxremote.password -Dcom.sun.management.jmxremote.access.file=../conf/jmxremote.access
set CATALINA_OPTS=%CATALINA_OPTS% %JMX_REMOTE_CONFIG%
然后复制并更改授权文件,$JAVA_HOME/jre/lib/management下有 jmxremote.access和jmxremote.password的模板文件,将两个文件复制到$CATALINA_BASE/conf目录下
● 修改$CATALINA_BASE/conf/jmxremote.access 添加内容:
monitorRole readonly
controlRole readwrite
● 修改$CATALINA_BASE/conf/jmxremote.password 添加内容:
monitorRole tomcat
controlRole tomcat
注意:如果只做第一步没有问题,进行了第二步Tomcat就启动不了,那么太可能是密码文件的权限问题!
需要更改jmxremote.password文件的权限,只有运行Tomcat的用户有访问权限:
Windows的NTFS文件系统下,选中文件,点右键 -->“属性”-->“安全”--> 点“高级”--> 点“更改权限”--> 去掉“从父项继承....”--> 弹出窗口中选“删除”,这样就删掉了所有访问权限。再选“添加”--> “高级”--> “立即查找”,选中你的用户,例administrator,点“确定",“确定"。来到权限项目窗口,勾选“完全控制”,点“确定”,OK了。
官方的提示
The password file should be read-only and only accessible by the operating system user Tomcat is running as.
③ 重新启动Tomcat,在Windows命令行输入“netstat -a”查看配置的端口号是否已打开,如果打开,说明里面的配置成功了。
④ 使用jconsole测试JMX。
运行$JAVA_HOME/bin目录下的jconsole.exe,打开J2SE监视和管理控制台,然后构建联接,如 果是本地的Tomcat则直接选择之后点击联接,如果是远程的,则步入远程选项卡,填写地址、端口号、用户名、口令即可联接。Mbean属性页中给出了相 应的数据,Catalina中是tomcat的,java.lang是jvm的。对于加粗的宋体属性值,需双击一下才可看内容。
使用JMX监控Tomcat示例代码:
String jmxURL = "service:jmx:rmi:///jndi/rmi://192.168.10.93:8999/jmxrmi";
JMXServiceURL serviceURL = new JMXServiceURL(jmxURL);
Map map = new HashMap();
// 用户名密码,在jmxremote.password文件中查看
String[] credentials = new String[] { "monitorRole", "tomcat" };
map.put("jmx.remote.credentials", credentials);
JMXConnector connector = JMXConnectorFactory.connect(serviceURL, map);
MBeanServerConnection mbsc = connector.getMBeanServerConnection();
// 端口最好是动态取得
ObjectName threadObjName = new ObjectName("Catalina:type=ThreadPool,name=http-8080");
MBeanInfo mbInfo = mbsc.getMBeanInfo(threadObjName);
// tomcat的线程数对应的属性值
String attrName = "currentThreadCount";
MBeanAttributeInfo[] mbAttributes = mbInfo.getAttributes();
System.out.println("currentThreadCount:" + mbsc.getAttribute(threadObjName, attrName));
完整的示例代码文件: 查看全部
前言:做了一个监控应用服务器的项目(支持Tocmat、WebSphere、WebLogic各版本),过程也算是磕磕绊绊,由于网上缺乏相关资料,或者身陷于知识的海洋未能寻找到有效的资料,因而走过不少弯路,遇过不少困难。为了留下点印记,给后来人留下点经验之谈,助之少走弯路,故将这种经验整理下来,与你们分享。水平有限,难免偏颇,还望见谅。如有疑问,欢迎留言,或者加入Q群参与讨论:35526521。
监控Tomcat常见的两种方案的比较
使用Tomcat提供的manager应用进行数据采集
◆ 可以使用现有的成熟代码,减少工作量
◆ 支持各不同版本时无差异
◆ 可能存在特殊需求而manager不能满足的情况
◆ 最重要的一个优点是,配置比较简单
使用JMX插口开发监控程序
◆ 全部代码须要从零开始,代码量较大
◆ 支持各不同版本比较麻烦,每个版本可能有差别
◆ 可支配性强
◆ 最重要的一个缺点是,配置比较麻烦
方案一、使用 Tomcat提供的manager应用进行数据采集
Applications Manager(又称opManager)就是通过这些方法实现的。
使用这些方法,所监控Tomcat必须运行manager应用,缺省情况下,该应用总是运行在服务器中的。
增加manager角色用户
访问manager应用的用户的角色权限必须是 manager.
修改/conf目录下的tomcat-users.xml文件,在节点下添加一个user节点,即可创建一个用户。
Tomcat版本不同配置也有差别,5.x和6.x创建的用户角色应为manager,7.x创建的用户角色为manager-jmx,举例如下:
1、在5.x和6.x中创建一个manager角色的用户,用户名为admin,密码为chenfeng:
2、在7.x中创建一个manager角色的用户,用户名为admin,密码为chenfeng:
admin" password="chenfeng" roles="manager-jmx,manager-script,manager-status"/>
修改配置后,需要重新启动 Tomcat 服务器。
连接manager时将用户名/密码指定为admin/chenfeng
通过浏览器访问JMX Proxy Servlet
详见官方说明文档:
What is JMX Proxy Servlet
The JMX Proxy Servlet is a lightweight proxy to get and set the tomcat internals. (Or any class that has been exposed via an MBean) Its usage is not very user friendly but the UI is extremely help for integrating command line scripts for monitoring and changing the internals of tomcat. You can do two things with the proxy: get information and set information. For you to really understand the JMX Proxy Servlet, you should have a general understanding of JMX. If you don't know what JMX is, then prepare to be confused.
JMX Query command
This takes the form:
http://webserver/manager/jmxproxy/?qry=STUFF
Where STUFF is the JMX query you wish to perform. For example, here are some queries you might wish to run:
◆ qry=*%3Atype%3DRequestProcessor%2C* --> type=RequestProcessorwhich will locate all workers which can process requests and report their state.
◆ qry=*%3Aj2eeType=Servlet%2c* --> j2eeType=Servletwhich return all loaded servlets.
◆ qry=Catalina%3Atype%3DEnvironment%2Cresourcetype%3DGlobal%2Cname%3DsimpleValue --> Catalina:type=Environment,resourcetype=Global,name=simpleValuewhich look for a specific MBean by the given name.
You'll need to experiment with this to really understand its capabilites. If you provide no qry parameter, then all of the MBeans will be displayed. We really recommend looking at the tomcat source code and understand the JMX spec to get a better understanding of all the queries you may run.
通过浏览器访问:8080/manager/jmxproxy ,输入用户名密码,然后就可以看见返回了所有的监控信息
添加查询参数,返回特定的监控信息:
例如:
:8080/manager/jmxproxy?qry=*%3Atype%3DRequestProcessor%2C*
其中 *%3Atype%3DRequestProcessor%2C* 其实就是 *:type=RequestProcessor,*
又如:
:8080/manager/jmxproxy?qry=*%3Aj2eeType%3DWebModule%2Cname%3D//localhost/ajaxrpc%2C*
在代码中访问JMX Proxy Servlet
通过浏览器访问JMX Proxy Servlet须要输入用户名密码,所以通过Java访问JMX Proxy Servlet的URL也须要授权访问: URL url = new URL(":8080/manager/jmxproxy?qry=*%3Atype%3DManager%2C*");
URLConnection conn = (URLConnection) url.openConnection();
// URL授权访问 -- Begin
String password = "admin:chenfeng"; // manager角色的用户
String encodedPassword = new BASE64Encoder().encode(password.getBytes());
conn.setRequestProperty("Authorization", "Basic " + encodedPassword);
// URL授权访问 -- End
InputStream is = conn.getInputStream();
BufferedReader bufreader = new BufferedReader(new InputStreamReader(is));
String line = null;
while ((line = bufreader.readLine()) != null) {
System.out.println(line);
}
几个具体的事例
下面展示两个事例,一个是采集服务器基本信息,一个是采集Web应用列表信息,注意Tomcat 7.x和Tomcat 5.x、6.x之间存在很大的区别。
◆ 采集服务器基本信息
通过serverinfo命令查看服务器基本信息
:8080/manager/serverinfo
Tomcat 7.x的查询URL有变化:
:8080/manager/text/serverinfo
返回信息:
OK - Server info
Tomcat Version: Apache Tomcat/7.0.11
OS Name: Windows Vista
OS Version: 6.1
OS Architecture: x86
JVM Version: 1.6.0_13-b03
JVM Vendor: Sun Microsystems Inc.
◆ 采集Web应用列表信息
通过list命令查看Web应用列表和会话数信息
:8080/manager/list
Tomcat 7.x的查询URL有变化:
:8080/manager/text/list
返回信息:
OK - Listed applications for virtual host localhost
/:running:0:ROOT
/manager:running:1:manager
/docs:running:0:docs
/examples:running:0:examples
/host-manager:running:0:host-manager
方案二、使用JMX 接口开发监控程序Tomcat激活JMX远程配置
① 先更改Tomcat的启动脚本,window下tomcat的bin/catalina.bat(linux为catalina.sh),添加以下内 容,8999是jmxremote使用的端口号,第二个false表示不需要信令:
set JMX_REMOTE_CONFIG=-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=8999 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false
set CATALINA_OPTS=%CATALINA_OPTS% %JMX_REMOTE_CONFIG%
可以加在if "%OS%" == "Windows_NT" setlocal 一句后的大段的注释旁边。
参考官方说明:
② 上面的配置是不需要信令的,如果须要信令则添加的内容为:
set JMX_REMOTE_CONFIG=-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=8999 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=true -Dcom.sun.management.jmxremote.password.file=../conf/jmxremote.password -Dcom.sun.management.jmxremote.access.file=../conf/jmxremote.access
set CATALINA_OPTS=%CATALINA_OPTS% %JMX_REMOTE_CONFIG%
然后复制并更改授权文件,$JAVA_HOME/jre/lib/management下有 jmxremote.access和jmxremote.password的模板文件,将两个文件复制到$CATALINA_BASE/conf目录下
● 修改$CATALINA_BASE/conf/jmxremote.access 添加内容:
monitorRole readonly
controlRole readwrite
● 修改$CATALINA_BASE/conf/jmxremote.password 添加内容:
monitorRole tomcat
controlRole tomcat
注意:如果只做第一步没有问题,进行了第二步Tomcat就启动不了,那么太可能是密码文件的权限问题!
需要更改jmxremote.password文件的权限,只有运行Tomcat的用户有访问权限:
Windows的NTFS文件系统下,选中文件,点右键 -->“属性”-->“安全”--> 点“高级”--> 点“更改权限”--> 去掉“从父项继承....”--> 弹出窗口中选“删除”,这样就删掉了所有访问权限。再选“添加”--> “高级”--> “立即查找”,选中你的用户,例administrator,点“确定",“确定"。来到权限项目窗口,勾选“完全控制”,点“确定”,OK了。
官方的提示
The password file should be read-only and only accessible by the operating system user Tomcat is running as.
③ 重新启动Tomcat,在Windows命令行输入“netstat -a”查看配置的端口号是否已打开,如果打开,说明里面的配置成功了。
④ 使用jconsole测试JMX。
运行$JAVA_HOME/bin目录下的jconsole.exe,打开J2SE监视和管理控制台,然后构建联接,如 果是本地的Tomcat则直接选择之后点击联接,如果是远程的,则步入远程选项卡,填写地址、端口号、用户名、口令即可联接。Mbean属性页中给出了相 应的数据,Catalina中是tomcat的,java.lang是jvm的。对于加粗的宋体属性值,需双击一下才可看内容。
使用JMX监控Tomcat示例代码:
String jmxURL = "service:jmx:rmi:///jndi/rmi://192.168.10.93:8999/jmxrmi";
JMXServiceURL serviceURL = new JMXServiceURL(jmxURL);
Map map = new HashMap();
// 用户名密码,在jmxremote.password文件中查看
String[] credentials = new String[] { "monitorRole", "tomcat" };
map.put("jmx.remote.credentials", credentials);
JMXConnector connector = JMXConnectorFactory.connect(serviceURL, map);
MBeanServerConnection mbsc = connector.getMBeanServerConnection();
// 端口最好是动态取得
ObjectName threadObjName = new ObjectName("Catalina:type=ThreadPool,name=http-8080");
MBeanInfo mbInfo = mbsc.getMBeanInfo(threadObjName);
// tomcat的线程数对应的属性值
String attrName = "currentThreadCount";
MBeanAttributeInfo[] mbAttributes = mbInfo.getAttributes();
System.out.println("currentThreadCount:" + mbsc.getAttribute(threadObjName, attrName));
完整的示例代码文件:
新浪股票插口获取历史数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2020-08-09 10:30
关于实时数据的获取你们可以看这篇博客:实时股票数据插口
经过不懈的努力总算再这篇博文中找到了关于新浪股票历史数据的获取方法腾讯股票插口、和讯网股票插口、新浪股票插口、雪球股票数据、网易股票数据
最近二十天左右的每5分钟数据
(参数:股票编号、分钟间隔(5、15、30、60)、均值(5、10、15、20、25)、查询个数点(最大值242))
获取的数据是类似下边的json字段:日期、开盘价、最高价、最低价、收盘价、成交量:
获取的数据会有很多,然后按照自己须要进行解析,我需要的是每晚的收盘价,股市是每个工作日下午3点午盘,所以我只须要找到每晚的下午三点时刻的数据进行过滤即可:
1、新建一个历史数据对象类:
public class HistoryModel {
public String day;
public String close;
public HistoryModel(String day, String close) {
this.day = day;
this.close = close;
}
}
2、新建一个股票多次历史数据类:和上一个区别就是,这里收录的是所有的历史数据:参数包括股票名子、代码、现在的价钱、历史数据:
public class HistoryModels {
public String name;
public String code;
public String now;
public List list;
public HistoryModels(String name, String code, String now, List list) {
this.name = name;
this.code = code;
this.now = now;
this.list = list;
}
}
3、将须要查询的股票的代码带进url里通过HTTP恳求json数据,我这儿用的Volley恳求的:
其中将时间点未15:00:00的数据过滤下来,组合乘List以后在全部形参组合成一个HistoryModels储存股票信息以及股票的所有历史数据。
// Instantiate the RequestQueue.
RequestQueue queue = Volley.newRequestQueue(Home.context);
String url1 = "http://money.finance.sina.com. ... ot%3B + Home.myChoiceModelList.get(ii).code + "&scale=60&ma=no&datalen=1023";
// Request a string response from the provided URL.
StringRequest stringRequest1 = new StringRequest(Request.Method.GET, url1,
new Response.Listener() {
@Override
public void onResponse(String response) {
List historyList = Convert(response,new TypeToken() {
}.getType());
List historyList2 = new ArrayList();
if(historyList!=null) {
for (int j = 0; j < historyList.size(); j++) {
if (historyList.get(j).day.split(" ")[1].equals("15:00:00")) {
historyList2.add(historyList.get(j));
}
}
}
HistoryModels model = new HistoryModels(Home.myChoiceModelList.get(ii).name, Home.myChoiceModelList.get(ii).code, Home.myChoiceModelList.get(ii).now, historyList2);
cllList.add(model);
Message msg = new Message();
msg.what = 0x002;
handler.sendMessage(msg);
}
},
new Response.ErrorListener() {
@Override
public void onErrorResponse(VolleyError error) {
}
});
queue.add(stringRequest1);
4、其中对json数据的处理,即从json转化成数据对象的方式如下:
/*
* Json转换泛型
*/
public static T Convert(String jsonString, Type cls) {
T t = null;
try {
if (jsonString != null && !jsonString.equals("")) {
Gson gson = new Gson();
t = gson.fromJson(jsonString, cls);
}
} catch (Exception e) {
e.printStackTrace();
}
return t;
}
关于股票的实时数据这儿没有描述,通过文章开头联接的博客可以了解到,写的太详尽。 查看全部
这三天做了一个调用新浪股票插口获取实时以及历史股票数据的应用,因为新浪没有公开关于其插口的官方文档,所以通过各类百度差了好多关于新浪股票插口的使用,不过你们基本都是转载或则直接复制,对于实时数据的获取讲的太详尽,但是缺乏获取历史数据的方式。
关于实时数据的获取你们可以看这篇博客:实时股票数据插口
经过不懈的努力总算再这篇博文中找到了关于新浪股票历史数据的获取方法腾讯股票插口、和讯网股票插口、新浪股票插口、雪球股票数据、网易股票数据
最近二十天左右的每5分钟数据
(参数:股票编号、分钟间隔(5、15、30、60)、均值(5、10、15、20、25)、查询个数点(最大值242))
获取的数据是类似下边的json字段:日期、开盘价、最高价、最低价、收盘价、成交量:
获取的数据会有很多,然后按照自己须要进行解析,我需要的是每晚的收盘价,股市是每个工作日下午3点午盘,所以我只须要找到每晚的下午三点时刻的数据进行过滤即可:
1、新建一个历史数据对象类:
public class HistoryModel {
public String day;
public String close;
public HistoryModel(String day, String close) {
this.day = day;
this.close = close;
}
}
2、新建一个股票多次历史数据类:和上一个区别就是,这里收录的是所有的历史数据:参数包括股票名子、代码、现在的价钱、历史数据:
public class HistoryModels {
public String name;
public String code;
public String now;
public List list;
public HistoryModels(String name, String code, String now, List list) {
this.name = name;
this.code = code;
this.now = now;
this.list = list;
}
}
3、将须要查询的股票的代码带进url里通过HTTP恳求json数据,我这儿用的Volley恳求的:
其中将时间点未15:00:00的数据过滤下来,组合乘List以后在全部形参组合成一个HistoryModels储存股票信息以及股票的所有历史数据。
// Instantiate the RequestQueue.
RequestQueue queue = Volley.newRequestQueue(Home.context);
String url1 = "http://money.finance.sina.com. ... ot%3B + Home.myChoiceModelList.get(ii).code + "&scale=60&ma=no&datalen=1023";
// Request a string response from the provided URL.
StringRequest stringRequest1 = new StringRequest(Request.Method.GET, url1,
new Response.Listener() {
@Override
public void onResponse(String response) {
List historyList = Convert(response,new TypeToken() {
}.getType());
List historyList2 = new ArrayList();
if(historyList!=null) {
for (int j = 0; j < historyList.size(); j++) {
if (historyList.get(j).day.split(" ")[1].equals("15:00:00")) {
historyList2.add(historyList.get(j));
}
}
}
HistoryModels model = new HistoryModels(Home.myChoiceModelList.get(ii).name, Home.myChoiceModelList.get(ii).code, Home.myChoiceModelList.get(ii).now, historyList2);
cllList.add(model);
Message msg = new Message();
msg.what = 0x002;
handler.sendMessage(msg);
}
},
new Response.ErrorListener() {
@Override
public void onErrorResponse(VolleyError error) {
}
});
queue.add(stringRequest1);
4、其中对json数据的处理,即从json转化成数据对象的方式如下:
/*
* Json转换泛型
*/
public static T Convert(String jsonString, Type cls) {
T t = null;
try {
if (jsonString != null && !jsonString.equals("")) {
Gson gson = new Gson();
t = gson.fromJson(jsonString, cls);
}
} catch (Exception e) {
e.printStackTrace();
}
return t;
}
关于股票的实时数据这儿没有描述,通过文章开头联接的博客可以了解到,写的太详尽。
destoon7
采集交流 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2020-08-09 09:21
destoon7.0优采云采集接口说简单点就是一个网站内容入库插口,传统获取数据形式是须要通过人工复制粘贴到我们自己的网站,用时较长较慢。而destoon采集接口就是取代人工复制粘贴,速度及效率是人工的千百倍以上。
destoon采集接口是借助优采云采集器完成采集任务,程序自带优采云8.0及模块规则,用户下载即可使用,无需再单独安装优采云。
接口完全免费没有任何域名限制及侧门,用户只要会写规则就可以完全免费采集任何网站。
接口完全是用的destoon官方程序预留的api接口2次开发,毋须修改任何系统文件,绿色环保!
只要把握好采集速度可以实现完全模拟人工发布,百度蜘蛛是看不下来采集的。
接口可以支持destoon官方程序4.0-7.0程序使用,(做过2次开发的请自测)。
我们的插口及规则完全永久免费在我们的官方峰会提供更新及技术支持,并且不定期的分享免费规则。
程序自带24个全行业通用参考规则给你们使用,会写规则的可以参考默认规则标签格式来自己制做规则。
软件特征:
一、SEO
(1)、destoon7.0采集器采用优采云V8版 经过采集优化后能使搜索引擎收录更多,哪怕是您一个外链都没有发布,您一点SEO都不懂,只要在订购我们采集软件前你的网站没有被搜索引擎K、网站本身正常,都能有不错的收录,收录详情请看演示
(2)、支持自动分类会员组,如果目标站是企业会员就入库到企业会员组,如果是个人就入库到个人会员组(需要通过代码自行判定用户组)
(3)、会员名、公司名、内容信息,前后都支持添加自定义文字内容,方便辨别采集内容及SEO。
(4)、以采集到的公司名的拼音作为会员账号,对SEO更有利。
二、模拟人工智能化处理数据:
接口与传统的API接口不同,常用API接口是直接插入数据到数据库不利于SEO。
收费版插口能模拟人工发布内容,比如:自动下载图片、自动水印、自动生成静态页。
详情如下:
(1)、支持采集内容后手动生成静态页面(动态或伪静态下须要这个功能)。
(2)、所有模块分类都支持手动下载标题图片、内容图片,并且手动加水印之后全手动下载上传图片到服务器。(需要在后台每位对应模块的模块设置里开启“下载内容远程图片”功能)。
(3)、检测到模块内容有图片的采集内容,并且手动设置第一张为标题图片。
(4)、因网路或则其他诱因未正常生成成功的图片,自动记录出来,支持一键重下载那些没下载成功的图片。
(5)、自由设置每位频道的图片是否下载、下载目录、盗链、水印模式等。
(6)、自由设置供应、求购、招商等这类频道,是否启用三张标题图的功能(无需要再在规则里设置,全由插口控制)。
(7)、采集内容可以自由设置采集目标站上的时间,还是用当前时间。
三、发布内容形式:
(1)、优化了信息关联到公司的设置,可以设置每位频道是否可以旅客发布、是否关联到公司,采自不同站的供应 或者 其他频道信息 ,只要是同一公司的信息,就发布到这个公司下边,不会重复注册公司,或者只要是公司早已在你的站上注册过了,就不会出现旅客名义发布的此公司信息。
(2)、各个分类均支持自动分类入库 对应分类上采用手动对应分类优先,指定分类次之的次序,抛弃了原先在规则第二步设置分类ID的情况,启用在第三步里选择或则直接写分类ID,这样就免去了因弄错了分类ID而导致多次重复采集,节省了采集时间,可以发到多个分类,以及多个站(前提是授权多个域名),支持第三步里的站群形式发布。 查看全部
destoon7.0正式版已与2018年4月3日发布,destoon采集专家已与第一时间发布destoon优采云免登入免费版采集接口,并且一如既往的免费下去。
destoon7.0优采云采集接口说简单点就是一个网站内容入库插口,传统获取数据形式是须要通过人工复制粘贴到我们自己的网站,用时较长较慢。而destoon采集接口就是取代人工复制粘贴,速度及效率是人工的千百倍以上。
destoon采集接口是借助优采云采集器完成采集任务,程序自带优采云8.0及模块规则,用户下载即可使用,无需再单独安装优采云。
接口完全免费没有任何域名限制及侧门,用户只要会写规则就可以完全免费采集任何网站。
接口完全是用的destoon官方程序预留的api接口2次开发,毋须修改任何系统文件,绿色环保!
只要把握好采集速度可以实现完全模拟人工发布,百度蜘蛛是看不下来采集的。
接口可以支持destoon官方程序4.0-7.0程序使用,(做过2次开发的请自测)。
我们的插口及规则完全永久免费在我们的官方峰会提供更新及技术支持,并且不定期的分享免费规则。
程序自带24个全行业通用参考规则给你们使用,会写规则的可以参考默认规则标签格式来自己制做规则。
软件特征:
一、SEO
(1)、destoon7.0采集器采用优采云V8版 经过采集优化后能使搜索引擎收录更多,哪怕是您一个外链都没有发布,您一点SEO都不懂,只要在订购我们采集软件前你的网站没有被搜索引擎K、网站本身正常,都能有不错的收录,收录详情请看演示
(2)、支持自动分类会员组,如果目标站是企业会员就入库到企业会员组,如果是个人就入库到个人会员组(需要通过代码自行判定用户组)
(3)、会员名、公司名、内容信息,前后都支持添加自定义文字内容,方便辨别采集内容及SEO。
(4)、以采集到的公司名的拼音作为会员账号,对SEO更有利。
二、模拟人工智能化处理数据:
接口与传统的API接口不同,常用API接口是直接插入数据到数据库不利于SEO。
收费版插口能模拟人工发布内容,比如:自动下载图片、自动水印、自动生成静态页。
详情如下:
(1)、支持采集内容后手动生成静态页面(动态或伪静态下须要这个功能)。
(2)、所有模块分类都支持手动下载标题图片、内容图片,并且手动加水印之后全手动下载上传图片到服务器。(需要在后台每位对应模块的模块设置里开启“下载内容远程图片”功能)。
(3)、检测到模块内容有图片的采集内容,并且手动设置第一张为标题图片。
(4)、因网路或则其他诱因未正常生成成功的图片,自动记录出来,支持一键重下载那些没下载成功的图片。
(5)、自由设置每位频道的图片是否下载、下载目录、盗链、水印模式等。
(6)、自由设置供应、求购、招商等这类频道,是否启用三张标题图的功能(无需要再在规则里设置,全由插口控制)。
(7)、采集内容可以自由设置采集目标站上的时间,还是用当前时间。
三、发布内容形式:
(1)、优化了信息关联到公司的设置,可以设置每位频道是否可以旅客发布、是否关联到公司,采自不同站的供应 或者 其他频道信息 ,只要是同一公司的信息,就发布到这个公司下边,不会重复注册公司,或者只要是公司早已在你的站上注册过了,就不会出现旅客名义发布的此公司信息。
(2)、各个分类均支持自动分类入库 对应分类上采用手动对应分类优先,指定分类次之的次序,抛弃了原先在规则第二步设置分类ID的情况,启用在第三步里选择或则直接写分类ID,这样就免去了因弄错了分类ID而导致多次重复采集,节省了采集时间,可以发到多个分类,以及多个站(前提是授权多个域名),支持第三步里的站群形式发布。
PHP + fiddler捕获数据包并采集微信文章的想法的详细说明.
采集交流 • 优采云 发表了文章 • 0 个评论 • 384 次浏览 • 2020-08-09 06:25
分析界面知道,要获得阅读的文章数和喜欢的数目,必须有两个关键参数,即key和uin. 不同的官方帐户的密钥不同(据说有一个通用的微信密钥,但我不知道如何获得),并且同一官方帐户的密钥将在大约半小时内失效
提交链接以获取阅读API的文章
思考:
1. 拦截并将客户端请求读取接口的请求转发到您自己的服务器,以便您可以获取密钥,并使用__biz关联缓存半小时
2. 提交商品链接进行查询时,服务器从商品链接获取__biz,并查询是否缓存了当前官方账号对应的密钥. 如果是,请继续执行步骤3,而不是步骤4.
3.curl请求?界面获取数据
4. 当密钥不存在时,通知客户端重定向到url(使用websocket通知或客户端ajax轮询进行通知,您需要使用数据包捕获工具来修改文章详细信息页面代码,以跳至中间页面以等待,打开在文章页面之后,它每隔几秒钟跳回到中间页面),并将程序暂停几秒钟,以等待客户端更新密钥. 此时,客户端提交新密钥并使用它进行查询
实现
1. 封包捕获
该界面是获取阅读量的界面,参数如下
2. 拦截此接口并将其转发到您自己的服务器,单击“规则”-“自定义规则”并将其添加到onbeforerequest(在正式请求之前执行的功能)
if (osession.fullurl.contains("mp.weixin.qq.com/mp/getappmsgext"))
{
osession.orequest["host"]= 'ccc.aaa.com' ;
}
效果不错,您可以看到该界面已转发
3. 服务器端缓存密钥,代码以php为例
public function savekey(request $request)
{
$__biz = $request->param('__biz',0);
$data['uin'] = $request->param('uin',0);
$data['key'] = $request->param('key',0);
cache::set($__biz,$data,30 * 60);
return 'ok';
}
4. 提交文章链接查询api代码
public function getreadnum(request $request)
{
$url = $request->param('url');
parse_str(parse_url($url)['query'], $param);
$__biz = $param['__biz'];
$key_data = cache::get($__biz);
if (empty($key_data))
return 'no key';
$uin = $key_data['uin'];
$key = $key_data['key'];
$param['uin'] = $uin;
$param['key'] = $key;
$param['wxtoken'] = "777";
$wechat_url = "https://mp.weixin.qq.com/mp/getappmsgext?" . http_build_query($param);
//dump($wechat_url);
$data = array(
'is_only_read' => 1,
'is_temp_url' => 0,
'appmsg_type' => 9,
);
$res = $this->get_url($wechat_url,$data);
return $res;
}
function get_url($url,$data)
{
$ifpost = 1;//是否post请求
$datafields = $data;//post数据
$cookiefile = '';//cookie文件
$cookie = '';//cookie变量
$v = false;
//模拟http请求header头
$header = array("connection: keep-alive","accept: text/html, application/xhtml+xml, */*", "pragma: no-cache", "accept-language: zh-hans-cn,zh-hans;q=0.8,en-us;q=0.5,en;q=0.3","user-agent: mozilla/5.0 (windows nt 6.1; wow64) applewebkit/537.36 (khtml, like gecko) chrome/53.0.2785.116 safari/537.36 qbcore/4.0.1278.400 qqbrowser/9.0.2524.400 mozilla/5.0 (windows nt 6.1; wow64) applewebkit/537.36 (khtml, like gecko) chrome/53.0.2875.116 safari/537.36 nettype/wifi micromessenger/7.0.5 windowswechat");
$ch = curl_init();
curl_setopt($ch, curlopt_url, $url);
curl_setopt($ch, curlopt_header, $v);
curl_setopt($ch, curlopt_httpheader, $header);
$ifpost && curl_setopt($ch, curlopt_post, $ifpost);
$ifpost && curl_setopt($ch, curlopt_postfields, $datafields);
curl_setopt($ch, curlopt_returntransfer, true);
curl_setopt($ch, curlopt_followlocation, true);
$cookie && curl_setopt($ch, curlopt_cookie, $cookie);//发送cookie变量
$cookiefile && curl_setopt($ch, curlopt_cookiefile, $cookiefile);//发送cookie文件
$cookiefile && curl_setopt($ch, curlopt_cookiejar, $cookiefile);//写入cookie到文件
curl_setopt($ch,curlopt_timeout,60); //允许执行的最长秒数
curl_setopt($ch, curlopt_ssl_verifypeer, false);
curl_setopt($ch, curlopt_ssl_verifyhost, false);
$ok = curl_exec($ch);
curl_close($ch);
unset($ch);
return $ok;
}
5. 通知客户端重定向页面(此部分未编写,请参见我有关文本套接字的其他文章)
6. 使用提琴手来修改微信文章和jsj脚本,
在onbeforeresponse(返回客户端之前执行的方法)中,添加代码以跳转到中间页
效果
摘要 查看全部
简介:
分析界面知道,要获得阅读的文章数和喜欢的数目,必须有两个关键参数,即key和uin. 不同的官方帐户的密钥不同(据说有一个通用的微信密钥,但我不知道如何获得),并且同一官方帐户的密钥将在大约半小时内失效
提交链接以获取阅读API的文章
思考:
1. 拦截并将客户端请求读取接口的请求转发到您自己的服务器,以便您可以获取密钥,并使用__biz关联缓存半小时
2. 提交商品链接进行查询时,服务器从商品链接获取__biz,并查询是否缓存了当前官方账号对应的密钥. 如果是,请继续执行步骤3,而不是步骤4.
3.curl请求?界面获取数据
4. 当密钥不存在时,通知客户端重定向到url(使用websocket通知或客户端ajax轮询进行通知,您需要使用数据包捕获工具来修改文章详细信息页面代码,以跳至中间页面以等待,打开在文章页面之后,它每隔几秒钟跳回到中间页面),并将程序暂停几秒钟,以等待客户端更新密钥. 此时,客户端提交新密钥并使用它进行查询
实现
1. 封包捕获
该界面是获取阅读量的界面,参数如下
2. 拦截此接口并将其转发到您自己的服务器,单击“规则”-“自定义规则”并将其添加到onbeforerequest(在正式请求之前执行的功能)
if (osession.fullurl.contains("mp.weixin.qq.com/mp/getappmsgext"))
{
osession.orequest["host"]= 'ccc.aaa.com' ;
}
效果不错,您可以看到该界面已转发
3. 服务器端缓存密钥,代码以php为例
public function savekey(request $request)
{
$__biz = $request->param('__biz',0);
$data['uin'] = $request->param('uin',0);
$data['key'] = $request->param('key',0);
cache::set($__biz,$data,30 * 60);
return 'ok';
}
4. 提交文章链接查询api代码
public function getreadnum(request $request)
{
$url = $request->param('url');
parse_str(parse_url($url)['query'], $param);
$__biz = $param['__biz'];
$key_data = cache::get($__biz);
if (empty($key_data))
return 'no key';
$uin = $key_data['uin'];
$key = $key_data['key'];
$param['uin'] = $uin;
$param['key'] = $key;
$param['wxtoken'] = "777";
$wechat_url = "https://mp.weixin.qq.com/mp/getappmsgext?" . http_build_query($param);
//dump($wechat_url);
$data = array(
'is_only_read' => 1,
'is_temp_url' => 0,
'appmsg_type' => 9,
);
$res = $this->get_url($wechat_url,$data);
return $res;
}
function get_url($url,$data)
{
$ifpost = 1;//是否post请求
$datafields = $data;//post数据
$cookiefile = '';//cookie文件
$cookie = '';//cookie变量
$v = false;
//模拟http请求header头
$header = array("connection: keep-alive","accept: text/html, application/xhtml+xml, */*", "pragma: no-cache", "accept-language: zh-hans-cn,zh-hans;q=0.8,en-us;q=0.5,en;q=0.3","user-agent: mozilla/5.0 (windows nt 6.1; wow64) applewebkit/537.36 (khtml, like gecko) chrome/53.0.2785.116 safari/537.36 qbcore/4.0.1278.400 qqbrowser/9.0.2524.400 mozilla/5.0 (windows nt 6.1; wow64) applewebkit/537.36 (khtml, like gecko) chrome/53.0.2875.116 safari/537.36 nettype/wifi micromessenger/7.0.5 windowswechat");
$ch = curl_init();
curl_setopt($ch, curlopt_url, $url);
curl_setopt($ch, curlopt_header, $v);
curl_setopt($ch, curlopt_httpheader, $header);
$ifpost && curl_setopt($ch, curlopt_post, $ifpost);
$ifpost && curl_setopt($ch, curlopt_postfields, $datafields);
curl_setopt($ch, curlopt_returntransfer, true);
curl_setopt($ch, curlopt_followlocation, true);
$cookie && curl_setopt($ch, curlopt_cookie, $cookie);//发送cookie变量
$cookiefile && curl_setopt($ch, curlopt_cookiefile, $cookiefile);//发送cookie文件
$cookiefile && curl_setopt($ch, curlopt_cookiejar, $cookiefile);//写入cookie到文件
curl_setopt($ch,curlopt_timeout,60); //允许执行的最长秒数
curl_setopt($ch, curlopt_ssl_verifypeer, false);
curl_setopt($ch, curlopt_ssl_verifyhost, false);
$ok = curl_exec($ch);
curl_close($ch);
unset($ch);
return $ok;
}
5. 通知客户端重定向页面(此部分未编写,请参见我有关文本套接字的其他文章)
6. 使用提琴手来修改微信文章和jsj脚本,
在onbeforeresponse(返回客户端之前执行的方法)中,添加代码以跳转到中间页
效果
摘要
Python爬虫的实用解释: 分析某些东部产品评论信息的采集过程
采集交流 • 优采云 发表了文章 • 0 个评论 • 591 次浏览 • 2020-08-08 15:12
搜索界面
一个,界面搜索
搜索以食物为例,输入食物并点击搜索
继续向下滚动以查看产品的返回页数,这是最大返回100页信息
打开调试,清除请求内容,然后根据上面发现的查找注释界面的方法直接单击第二页以观察新请求.
当我单击红色框中的s_new界面时,我发现响应信息是html,并且响应的内容恰好是我们在页面上所需的产品信息.
第二,参数搜索
类似地,根据向下滑动,翻页以查看参数的更改
单击页面的第二页,参数如下
页面上有很多产品显示信息,并且可能会临时加载请求. 如果继续向下滚动,则可以看到已添加了新请求. 请求参数如下,并增加了参数. (注意: 新参数可以忽略)
然后单击第三页
如果找不到规则,则可以继续单击页面以查看更改规则.
接口参数的构造逻辑有以下几点:
三,html页面分析
直接在页面上找到产品位置,您可以看到所有产品信息都在ul标签下的li标签中
单击li标签,您可以看到div / div下的标签收录产品标题信息,产品链接信息,并且该链接收录我们需要提取的product_id信息. 右键单击以复制并复制xpath以直接提取位置信息.
四个代码测试
代码如下. 请注意,在标头中,referer参数需要进行url编码.
执行结果如下:
这里仅提取了两个字段title和product_id,并且可以根据需要添加它们.
本文中的文字和图片来自Internet,仅用于学习和交流目的. 它们没有任何商业用途. 版权属于原创作者. 如有任何疑问,请及时与我们联系进行处理.
作者: 习惯u 查看全部
如果要提取其他字段信息,可以在代码中自己添加.
搜索界面
一个,界面搜索
搜索以食物为例,输入食物并点击搜索
继续向下滚动以查看产品的返回页数,这是最大返回100页信息
打开调试,清除请求内容,然后根据上面发现的查找注释界面的方法直接单击第二页以观察新请求.
当我单击红色框中的s_new界面时,我发现响应信息是html,并且响应的内容恰好是我们在页面上所需的产品信息.
第二,参数搜索
类似地,根据向下滑动,翻页以查看参数的更改
单击页面的第二页,参数如下
页面上有很多产品显示信息,并且可能会临时加载请求. 如果继续向下滚动,则可以看到已添加了新请求. 请求参数如下,并增加了参数. (注意: 新参数可以忽略)
然后单击第三页
如果找不到规则,则可以继续单击页面以查看更改规则.
接口参数的构造逻辑有以下几点:
三,html页面分析
直接在页面上找到产品位置,您可以看到所有产品信息都在ul标签下的li标签中
单击li标签,您可以看到div / div下的标签收录产品标题信息,产品链接信息,并且该链接收录我们需要提取的product_id信息. 右键单击以复制并复制xpath以直接提取位置信息.
四个代码测试
代码如下. 请注意,在标头中,referer参数需要进行url编码.
执行结果如下:
这里仅提取了两个字段title和product_id,并且可以根据需要添加它们.
本文中的文字和图片来自Internet,仅用于学习和交流目的. 它们没有任何商业用途. 版权属于原创作者. 如有任何疑问,请及时与我们联系进行处理.
作者: 习惯u
第一个界面
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2020-08-07 23:53
2019-12-31十三本资源网络技术课程
[摘要]简介该程序具有多种类型的墙纸,自动更新,自动采集,支持多分辨率,瀑布流,全站点ajax!界面一获得墙纸分类
简介
程序中有许多类型的墙纸,自动更新,自动采集,支持多分辨率,瀑布流加载,站点范围内的ajax!
第一个界面
获取壁纸分类
http://cdn.apc.360.cn/index.ph ... hrome
这个界面很简单,直接请求上面的URL,就可以获取json数据. 返回的数据中有一个数据数组,其中“名称”是获取的墙纸类别的名称,“ id”是与该类别对应的ID值.
接口2:
根据墙纸类别ID获取该类别下的墙纸图片
http://wallpaper.apc.360.cn/index.php?
c=WallPaper&a=getAppsByCategory
&cid=【刚才获取到的分类ID】
&start=【从第几幅图开始(用于分页)】
&count=【每次加载的数量】&from=360chrome
通过此接口获得的数据有点多,但主要只使用了少数几个. 一个是数据数组中的url值,这是我们想要获取的图像链接. 其格式类似于:
http://p15.qhimg.com/bdr/__85/ ... 8.jpg
我们可以使用它来获得该图片的指定分辨率和指定质量. 上图是一个示例. 如果要获取分辨率为1024 * 768且质量为80(最高100)的图片,只需将上述链接中的“ bdr / __ 85”替换为“ bdm / 1024_768_80”. 替换后的图片链接如下
http://p19.qhimg.com/bdm/1024_ ... 8.jpg
(注意: 如果原创图片本身很小,某些图片将不会被拉伸) 查看全部
自动采集墙纸网站界面
2019-12-31十三本资源网络技术课程
[摘要]简介该程序具有多种类型的墙纸,自动更新,自动采集,支持多分辨率,瀑布流,全站点ajax!界面一获得墙纸分类
简介
程序中有许多类型的墙纸,自动更新,自动采集,支持多分辨率,瀑布流加载,站点范围内的ajax!
第一个界面
获取壁纸分类
http://cdn.apc.360.cn/index.ph ... hrome
这个界面很简单,直接请求上面的URL,就可以获取json数据. 返回的数据中有一个数据数组,其中“名称”是获取的墙纸类别的名称,“ id”是与该类别对应的ID值.
接口2:
根据墙纸类别ID获取该类别下的墙纸图片
http://wallpaper.apc.360.cn/index.php?
c=WallPaper&a=getAppsByCategory
&cid=【刚才获取到的分类ID】
&start=【从第几幅图开始(用于分页)】
&count=【每次加载的数量】&from=360chrome
通过此接口获得的数据有点多,但主要只使用了少数几个. 一个是数据数组中的url值,这是我们想要获取的图像链接. 其格式类似于:
http://p15.qhimg.com/bdr/__85/ ... 8.jpg
我们可以使用它来获得该图片的指定分辨率和指定质量. 上图是一个示例. 如果要获取分辨率为1024 * 768且质量为80(最高100)的图片,只需将上述链接中的“ bdr / __ 85”替换为“ bdm / 1024_768_80”. 替换后的图片链接如下
http://p19.qhimg.com/bdm/1024_ ... 8.jpg
(注意: 如果原创图片本身很小,某些图片将不会被拉伸)
本地旅游网站源代码,PHP开源,PC + WAP +微信三合一,免费共享
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2020-08-07 21:02
现场旅游网站源代码系统已成功启动了基础旅游网站建设和门户旅游网站建设系统. 其系统包括新闻管理功能,酒店预订功能,酒店预订功能,路线预订功能,景点预订功能,签证服务功能,留言问题功能,会员注册功能,短信群发功能,网上支付功能等十大功能, SEO优化功能等. 它在功能上具有独特的功能. 实现不同的旅游营销型车站建设系统. 让您的旅游网站获得高转化率,高曝光率,独特的计划,完整的技术市场化并增加品牌和销量.
Situ CMS功能介绍
Situ CMS6.0具有丰富的功能,强大的针对性,强大的可伸缩性,易于操作和使用以及清晰的系统结构. 它分为九个主要部分:
1. 产品系统: 路线,酒店,门票,汽车租赁,机票,签证,签证,团购,活动,同伴,邮轮,保险,个性化定制(可扩展功能,如导游,特色产品等);
2. 文章系统: 目的地指南,旅行指南,景点,相册,问答,评论,帮助系统;
3. 用户系统: 在线订单,在线支付,订单生成短信/电子邮件通知,评论,问答,短信电子邮件批量发送;成员管理,供应商管理;
4. 营销策略: SEO界面,社交共享界面,积分,返现策略;来源,目的地营销结构,泛分析辅助域名结构支持,特殊营销,广告管理;
5. 支付系统: 财付通,宜宝,环迅;集成: 支持支付宝,快钱,银联,汇超等;
6. 扩展界面: 文章采集界面,Dz论坛,UCenter,Google电子地图;集成: 第三方登录界面,SMS平台界面等;
7. 设置中心: 目的地4级分类,属性2级自定义,内容分类自定义,出发设置,站点设置,系统参数管理,数据备份,操作日志.
8. 市场助理: 关键字统计,关键字智能链接,标签词设置,访问源统计,热门搜索词统计,智能站点地图,无效链接自检
9. 增值应用程序: 系统升级,模板替换,营销指南,问题反馈,扩展应用程序等.
[示例屏幕截图]
[核心代码]有关详细信息,请参见文档 查看全部
[示例介绍]
现场旅游网站源代码系统已成功启动了基础旅游网站建设和门户旅游网站建设系统. 其系统包括新闻管理功能,酒店预订功能,酒店预订功能,路线预订功能,景点预订功能,签证服务功能,留言问题功能,会员注册功能,短信群发功能,网上支付功能等十大功能, SEO优化功能等. 它在功能上具有独特的功能. 实现不同的旅游营销型车站建设系统. 让您的旅游网站获得高转化率,高曝光率,独特的计划,完整的技术市场化并增加品牌和销量.
Situ CMS功能介绍
Situ CMS6.0具有丰富的功能,强大的针对性,强大的可伸缩性,易于操作和使用以及清晰的系统结构. 它分为九个主要部分:
1. 产品系统: 路线,酒店,门票,汽车租赁,机票,签证,签证,团购,活动,同伴,邮轮,保险,个性化定制(可扩展功能,如导游,特色产品等);
2. 文章系统: 目的地指南,旅行指南,景点,相册,问答,评论,帮助系统;
3. 用户系统: 在线订单,在线支付,订单生成短信/电子邮件通知,评论,问答,短信电子邮件批量发送;成员管理,供应商管理;
4. 营销策略: SEO界面,社交共享界面,积分,返现策略;来源,目的地营销结构,泛分析辅助域名结构支持,特殊营销,广告管理;
5. 支付系统: 财付通,宜宝,环迅;集成: 支持支付宝,快钱,银联,汇超等;
6. 扩展界面: 文章采集界面,Dz论坛,UCenter,Google电子地图;集成: 第三方登录界面,SMS平台界面等;
7. 设置中心: 目的地4级分类,属性2级自定义,内容分类自定义,出发设置,站点设置,系统参数管理,数据备份,操作日志.
8. 市场助理: 关键字统计,关键字智能链接,标签词设置,访问源统计,热门搜索词统计,智能站点地图,无效链接自检
9. 增值应用程序: 系统升级,模板替换,营销指南,问题反馈,扩展应用程序等.
[示例屏幕截图]
[核心代码]有关详细信息,请参见文档
什么是数据采集方法?它们的特点是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 680 次浏览 • 2020-08-07 13:34
许多大型企业和政府机构在信息化过程中结合自己的业务构建了各种软件系统,这些软件系统积累了大量的行业和客户数据. 他们迫切需要聚合这些数据以形成自己的大型数据平台,进行数据挖掘和分析,并准确地为其客户提供服务.
当前的数据采集挑战如下:
1. 各种数据源
2. 数据量大,更新快
3. 如何确保数据采集的可靠性和性能
4. 如何避免重复数据
5. 如何确保数据质量.
那么,如何快速,准确地采集这么多软件系统中的各种数据呢?今天,我将讨论各种软件系统的几种数据采集方法. 着眼于它们的实现过程以及它们各自的优缺点.
1. 软件界面对接方法
2. 打开数据库方法
3. 基于底层数据交换的直接数据采集方法
1. 软件界面对接方法
各种软件供应商提供数据接口以实现数据采集并为客户构建自己的业务大数据平台;
实现过程如下:
1)与来自多个软件供应商的工程师进行协调,以了解另一方系统的业务流程以及与数据库相关的表结构的设计等,并讨论如何实现正确的数据采集并在其中可行. 商业. 仔细考虑所有细节,最后确定双方都同意的计划. 在双方工程师的合作下,完成了两个系统之间的接口. 可以在系统A或系统B中执行某些处理. 在这种情况下,做出决策的基础是考虑将来可能会发生功能更改,这将不可避免地影响现有系统. 选择受更改影响较小的解决方案.
2)确定计划和代码
3)编码后,进入测试和调试阶段
4)交付使用
接口对接方法的数据可靠性很高. 通常,没有数据重复,它们都是客户业务大数据平台所需的有价值数据;同时,数据通过接口实时传输,完全满足了大数据平台的实时性要求.
但是,接口对接方法需要大量的人力和时间来协调各种软件供应商进行数据接口对接;同时,它的可扩展性不高. 例如,由于业务需求,各种软件系统开发了新的业务模块,这些模块与大数据平台兼容. 需要对两者之间的数据接口进行相应的修改和更改,甚至要颠覆所有以前的数据接口代码,这是很费时费力的.
2. 打开数据库方法
通常来说,来自不同公司的系统不太可能打开自己的数据库来相互连接,因为这会引起安全问题. 为了实现数据采集和汇总,开放数据库是最直接的方法.
两个系统都有自己的数据库,对于相同类型的数据库,它更方便:
1)如果两个数据库位于同一服务器上,则只要用户名设置没有问题,它们就可以直接相互访问. 您需要在from之后携带数据库名称和表模式所有者. 选择* from DATABASE1.dbo.table1 2)如果两个系统的数据库不在同一服务器上,建议使用链接服务器进行处理,或者使用openset和opendatasource. 这需要外围服务器配置才能访问数据库.
不同类型的数据库之间的连接比较麻烦,需要大量设置才能生效. 我不会在这里详细说明.
开放数据库方法可以直接,准确地从目标数据库获取所需数据,这是最直接,最方便的方法;同时保证实时性能;
开放数据库方法要求协调各种软件供应商的开放数据库,这非常困难;如果平台必须同时连接到许多软件供应商的数据库并实时获取数据,那么这对于平台本身的性能也是一个巨大的挑战.
3. 基于底层数据交换的直接数据采集方法
通过获取软件系统的基础数据交换,软件客户端和数据库之间的网络流量数据包,执行数据包流分析以采集应用程序数据. 同时,可以使用仿真技术来仿真客户请求以实现自动数据写入.
实现过程如下: 使用数据采集引擎侦听目标软件的内部数据交换(网络流量,内存),然后分析所需的数据,并经过一系列处理和封装以实现确保数据的唯一性和准确性,并输出结构化数据. 经过相应的配置,实现了数据采集的自动化.
基于基础数据交换的直接数据采集方法的技术特点如下:
1)在没有软件制造商合作的情况下进行独立爬网;
2)实时数据采集;
端到端数据延迟在几秒钟之内;
3)几乎所有与Windows平台兼容的软件(C / S,B / S);
作为数据挖掘和大数据分析的基础;
4)自动建立数据之间的关联;
5)配置简单,实施周期短;
6)支持历史数据的自动导入.
目前,由于缺乏数据采集和融合技术,通常通过原创软件制造商开发数据接口来实现数据互操作性. 这不仅需要大量时间,精力和金钱,而且还因为系统开发团队的解体,源代码丢失等原因. 死胡同的原因使实现数据采集和融合变得极为困难. 在这样的紧急需求环境中,出现了基于基础数据交换的直接数据采集方法. 从各种软件系统中提取数据,并连续获取所需的准确和实时数据,并自动建立并输出数据关联. 具有极高利用率的结构化数据允许数据以有序,安全和可控的方式流向需要它的企业和用户,从而可以链接和分发不同系统的数据源,从而为客户提供决策支持,提高运营效率并产生经济价值.
查看全部
随着信息时代的到来,大数据受到越来越多的关注,数据采集的挑战变得尤为突出.
许多大型企业和政府机构在信息化过程中结合自己的业务构建了各种软件系统,这些软件系统积累了大量的行业和客户数据. 他们迫切需要聚合这些数据以形成自己的大型数据平台,进行数据挖掘和分析,并准确地为其客户提供服务.
当前的数据采集挑战如下:
1. 各种数据源
2. 数据量大,更新快
3. 如何确保数据采集的可靠性和性能
4. 如何避免重复数据
5. 如何确保数据质量.
那么,如何快速,准确地采集这么多软件系统中的各种数据呢?今天,我将讨论各种软件系统的几种数据采集方法. 着眼于它们的实现过程以及它们各自的优缺点.
1. 软件界面对接方法
2. 打开数据库方法
3. 基于底层数据交换的直接数据采集方法
1. 软件界面对接方法
各种软件供应商提供数据接口以实现数据采集并为客户构建自己的业务大数据平台;
实现过程如下:
1)与来自多个软件供应商的工程师进行协调,以了解另一方系统的业务流程以及与数据库相关的表结构的设计等,并讨论如何实现正确的数据采集并在其中可行. 商业. 仔细考虑所有细节,最后确定双方都同意的计划. 在双方工程师的合作下,完成了两个系统之间的接口. 可以在系统A或系统B中执行某些处理. 在这种情况下,做出决策的基础是考虑将来可能会发生功能更改,这将不可避免地影响现有系统. 选择受更改影响较小的解决方案.
2)确定计划和代码
3)编码后,进入测试和调试阶段
4)交付使用
接口对接方法的数据可靠性很高. 通常,没有数据重复,它们都是客户业务大数据平台所需的有价值数据;同时,数据通过接口实时传输,完全满足了大数据平台的实时性要求.
但是,接口对接方法需要大量的人力和时间来协调各种软件供应商进行数据接口对接;同时,它的可扩展性不高. 例如,由于业务需求,各种软件系统开发了新的业务模块,这些模块与大数据平台兼容. 需要对两者之间的数据接口进行相应的修改和更改,甚至要颠覆所有以前的数据接口代码,这是很费时费力的.
2. 打开数据库方法
通常来说,来自不同公司的系统不太可能打开自己的数据库来相互连接,因为这会引起安全问题. 为了实现数据采集和汇总,开放数据库是最直接的方法.
两个系统都有自己的数据库,对于相同类型的数据库,它更方便:
1)如果两个数据库位于同一服务器上,则只要用户名设置没有问题,它们就可以直接相互访问. 您需要在from之后携带数据库名称和表模式所有者. 选择* from DATABASE1.dbo.table1 2)如果两个系统的数据库不在同一服务器上,建议使用链接服务器进行处理,或者使用openset和opendatasource. 这需要外围服务器配置才能访问数据库.
不同类型的数据库之间的连接比较麻烦,需要大量设置才能生效. 我不会在这里详细说明.
开放数据库方法可以直接,准确地从目标数据库获取所需数据,这是最直接,最方便的方法;同时保证实时性能;
开放数据库方法要求协调各种软件供应商的开放数据库,这非常困难;如果平台必须同时连接到许多软件供应商的数据库并实时获取数据,那么这对于平台本身的性能也是一个巨大的挑战.
3. 基于底层数据交换的直接数据采集方法
通过获取软件系统的基础数据交换,软件客户端和数据库之间的网络流量数据包,执行数据包流分析以采集应用程序数据. 同时,可以使用仿真技术来仿真客户请求以实现自动数据写入.
实现过程如下: 使用数据采集引擎侦听目标软件的内部数据交换(网络流量,内存),然后分析所需的数据,并经过一系列处理和封装以实现确保数据的唯一性和准确性,并输出结构化数据. 经过相应的配置,实现了数据采集的自动化.
基于基础数据交换的直接数据采集方法的技术特点如下:
1)在没有软件制造商合作的情况下进行独立爬网;
2)实时数据采集;
端到端数据延迟在几秒钟之内;
3)几乎所有与Windows平台兼容的软件(C / S,B / S);
作为数据挖掘和大数据分析的基础;
4)自动建立数据之间的关联;
5)配置简单,实施周期短;
6)支持历史数据的自动导入.
目前,由于缺乏数据采集和融合技术,通常通过原创软件制造商开发数据接口来实现数据互操作性. 这不仅需要大量时间,精力和金钱,而且还因为系统开发团队的解体,源代码丢失等原因. 死胡同的原因使实现数据采集和融合变得极为困难. 在这样的紧急需求环境中,出现了基于基础数据交换的直接数据采集方法. 从各种软件系统中提取数据,并连续获取所需的准确和实时数据,并自动建立并输出数据关联. 具有极高利用率的结构化数据允许数据以有序,安全和可控的方式流向需要它的企业和用户,从而可以链接和分发不同系统的数据源,从而为客户提供决策支持,提高运营效率并产生经济价值.
[数据] 让Halcon支持HikVision摄像机的采集界面
采集交流 • 优采云 发表了文章 • 0 个评论 • 488 次浏览 • 2020-08-07 00:05
当然,我今天不是要教您如何使用该软件,因为菜单的操作和2.3版本没有太大变化,但是可以在其中显示很多单独的项,例如十字中心. 图片的中心.
在研究二次开发时,我偶然发现Haikang提供了第三方支持包,其中包括Halcon的HDevelop采集接口,该接口隐藏得很深,无法确定您是否不参与开发!
默认情况下,我们将其安装在D: \ Program Files(x86)\ MVS \目录中,并找到了第三方D: \ Program Files(x86)\ MVS \ Development \ ThirdPartyPlatformAdapter
找到了HDevelop目录吗? ,这是什么?好奇地打开它
从Halcon10到13有四个目录,只需打开它,看看里面有什么. 我发现有两个目录Win32和Win64. 继续打开并查看它,发现了这样的东西?
hAcqMVision.dll
复制代码
看hAcq,突然想起,这是Haikang提供的适用于Haikang摄像机的Halcon的获取接口,因为命名规则是Halcon标准获取接口的命名:
hAcq +接口显示name.dll
例如: hAcqGigeVision.dll
复制代码
Halcon12已安装在我们的计算机中,因此请尝试将此接口文件复制到Halcon12进行查看!
D: \ Program Files(x86)\ MVS \ Development \ ThirdPartyPlatformAdapter \ HalconHDevelop \ Halcon12 \ win32
复制代码
将上述目录中的hAcqMVision.dll复制到Halcon执行目录(该目录实际上是RunTime目录)
D: \ Program Files \ MVTec \ HALCON-12.0 \ bin \ x86sse2-win32
复制代码
您可以看到下面图片中的所有图像都是采集界面. 然后我们打开HDevelop看看是否可以通过此界面操作相机?
打开采集助手Image Acquisition,然后自动检测界面,出现结果:
您可以找到此接口并替换原创的GigeVision接口,然后接口文件的全名是hAcqMVision.dll,请尝试打开它:
根本没有问题,并且工作效率比普通的GigeVision协议开放更高效,更快捷. 感谢海康开发人员的辛勤工作,非常感谢!
如果您可以提供xl的采集接口,它将是全面的,哈哈哈,要求太高了!
如果您认为本文对您有所帮助,请记得回复并喜欢支持我. 我们的目标是每天取得一点进步,并进一步加深! 查看全部
我最近安装了海康威视MVS视觉软件的最新版本3.0.0. 第一印象是界面已发生了很大变化,但黑色深度和凉爽度有所提高. 看一下这个界面:
当然,我今天不是要教您如何使用该软件,因为菜单的操作和2.3版本没有太大变化,但是可以在其中显示很多单独的项,例如十字中心. 图片的中心.
在研究二次开发时,我偶然发现Haikang提供了第三方支持包,其中包括Halcon的HDevelop采集接口,该接口隐藏得很深,无法确定您是否不参与开发!
默认情况下,我们将其安装在D: \ Program Files(x86)\ MVS \目录中,并找到了第三方D: \ Program Files(x86)\ MVS \ Development \ ThirdPartyPlatformAdapter
找到了HDevelop目录吗? ,这是什么?好奇地打开它
从Halcon10到13有四个目录,只需打开它,看看里面有什么. 我发现有两个目录Win32和Win64. 继续打开并查看它,发现了这样的东西?
hAcqMVision.dll
复制代码
看hAcq,突然想起,这是Haikang提供的适用于Haikang摄像机的Halcon的获取接口,因为命名规则是Halcon标准获取接口的命名:
hAcq +接口显示name.dll
例如: hAcqGigeVision.dll
复制代码
Halcon12已安装在我们的计算机中,因此请尝试将此接口文件复制到Halcon12进行查看!
D: \ Program Files(x86)\ MVS \ Development \ ThirdPartyPlatformAdapter \ HalconHDevelop \ Halcon12 \ win32
复制代码
将上述目录中的hAcqMVision.dll复制到Halcon执行目录(该目录实际上是RunTime目录)
D: \ Program Files \ MVTec \ HALCON-12.0 \ bin \ x86sse2-win32
复制代码
您可以看到下面图片中的所有图像都是采集界面. 然后我们打开HDevelop看看是否可以通过此界面操作相机?
打开采集助手Image Acquisition,然后自动检测界面,出现结果:
您可以找到此接口并替换原创的GigeVision接口,然后接口文件的全名是hAcqMVision.dll,请尝试打开它:
根本没有问题,并且工作效率比普通的GigeVision协议开放更高效,更快捷. 感谢海康开发人员的辛勤工作,非常感谢!
如果您可以提供xl的采集接口,它将是全面的,哈哈哈,要求太高了!
如果您认为本文对您有所帮助,请记得回复并喜欢支持我. 我们的目标是每天取得一点进步,并进一步加深!
Immerial cms7.5优采云采集器Web登录界面发布模块
采集交流 • 优采云 发表了文章 • 0 个评论 • 433 次浏览 • 2020-08-06 20:22
是否有适用于Empire cms7.5的优采云采集器的发布模块?我在网上搜索了很长时间后才找到它. 今天,我找到了一个7.0模块并将其修改为在Empire cms7.5中使用. 让我与您分享. 该插件为登录方式,在优采云发布模块的WEB配置管理中添加域名地址,然后选择数据包登录方式.
提醒: 在使用前,请输入背景以关闭验证码并打开背景源验证码. 关闭后即可使用.
百度网盘: 提取代码: mzuf
我在该项目中与优采云采集器取得了联系. 当我第一次使用它时,感觉真的很棒. 数据采集真的很棒. 可以采集Internet上80%以上的数据. 碰巧的是,我最近通过Empire cms建立了一个信息门户网站. 每个人都知道,信息门户网站最麻烦的是数据. 碰巧我从优采云采集了数据,而这个数据只用一个词就很酷.
当我开心了一会儿时,一个现实的问题出现了. 如何将所有采集的数据批量导入Empire的数据库中?我把问题告诉了我的朋友,朋友说你可以编写优采云的帝国发布模块. 当他这么说的时候,我去了优采云采集器亲自看它,它确实具有发布模块功能. 优采云提供三种数据发布模式.
第一种类型: 直接在网络上发布模块.
第二种类型: 将发布的数据另存为文件.
第三种类型: 直接发布到数据库.
按照自己的想法,我在Internet上搜索了“彩彩云”发行模块,并发现了很多结果,但是大多数教程只是品尝,而在一天中的大部分时间里这些词都是胡说八道. 我仍然不知道该怎么做. 无奈之下,我向我的朋友索取了一份副本,并学习了如何操作,修改等. 接下来,我将分享这种使用优采云发行模块的方法.
我希望不要像我一样来回走动
首先,我们将使用三个文件:
ECMSLogin.php创建自己的
hinfofun.php随系统一起提供
Empire CMS 7.2免费登录新闻发布模块. wpm
第一步: 将所需的文件放在指定的文件夹中
将文件1复制到e / admin /,并将文件2复制到e / class /文件夹.
文件2.它需要被开发两次,并且其功能是能够远程保存图片. 代码显示如下.
//二次开发代码
if($ add [‘diy’] == 1){
//远程保存标题图片
if($ add ['titlepic']){
$ tranr = DoTranURL($ add ['titlepic'],$ add ['classid']);
if($ tranr [tran])
{
$ tranr [文件大小] =(int)$ tranr [文件大小];
$ tranr [type] =(int)$ tranr [type];
//记录数据库
eInsertFileTable($ tranr [文件名],$ tranr [文件大小],$ tranr [文件路径],$用户名,$ add ['classid'],
'[s] [URL]'. $ tranr [文件名],$ tranr [类型],0,$ add ['filepass'],$ public_r [fpath],0,0,$ public_r ['filedeftb' ]);
// $ add ['titlepic'] = $ tranr [url];
$ addtitlepic =”,titlepic ='”. addslashes($ tranr [url]). ”’,ispic = 1'';
}
}
}
第2步: 编写优采云的发布模块.
第3步: 直接在线测试. 发布内容时,选择网站以在线发布到网站.
通过上述步骤,可以完成优采云的Empire发行模块. 如果您仍然不明白,请给我留言. 查看全部
是否有适用于Empire cms7.5的优采云采集器的发布模块?我在网上搜索了很长时间后才找到它. 今天,我找到了一个7.0模块并将其修改为在Empire cms7.5中使用. 让我与您分享. 该插件为登录方式,在优采云发布模块的WEB配置管理中添加域名地址,然后选择数据包登录方式.
提醒: 在使用前,请输入背景以关闭验证码并打开背景源验证码. 关闭后即可使用.
百度网盘: 提取代码: mzuf
我在该项目中与优采云采集器取得了联系. 当我第一次使用它时,感觉真的很棒. 数据采集真的很棒. 可以采集Internet上80%以上的数据. 碰巧的是,我最近通过Empire cms建立了一个信息门户网站. 每个人都知道,信息门户网站最麻烦的是数据. 碰巧我从优采云采集了数据,而这个数据只用一个词就很酷.
当我开心了一会儿时,一个现实的问题出现了. 如何将所有采集的数据批量导入Empire的数据库中?我把问题告诉了我的朋友,朋友说你可以编写优采云的帝国发布模块. 当他这么说的时候,我去了优采云采集器亲自看它,它确实具有发布模块功能. 优采云提供三种数据发布模式.
第一种类型: 直接在网络上发布模块.
第二种类型: 将发布的数据另存为文件.
第三种类型: 直接发布到数据库.
按照自己的想法,我在Internet上搜索了“彩彩云”发行模块,并发现了很多结果,但是大多数教程只是品尝,而在一天中的大部分时间里这些词都是胡说八道. 我仍然不知道该怎么做. 无奈之下,我向我的朋友索取了一份副本,并学习了如何操作,修改等. 接下来,我将分享这种使用优采云发行模块的方法.
我希望不要像我一样来回走动
首先,我们将使用三个文件:
ECMSLogin.php创建自己的
hinfofun.php随系统一起提供
Empire CMS 7.2免费登录新闻发布模块. wpm
第一步: 将所需的文件放在指定的文件夹中
将文件1复制到e / admin /,并将文件2复制到e / class /文件夹.
文件2.它需要被开发两次,并且其功能是能够远程保存图片. 代码显示如下.
//二次开发代码
if($ add [‘diy’] == 1){
//远程保存标题图片
if($ add ['titlepic']){
$ tranr = DoTranURL($ add ['titlepic'],$ add ['classid']);
if($ tranr [tran])
{
$ tranr [文件大小] =(int)$ tranr [文件大小];
$ tranr [type] =(int)$ tranr [type];
//记录数据库
eInsertFileTable($ tranr [文件名],$ tranr [文件大小],$ tranr [文件路径],$用户名,$ add ['classid'],
'[s] [URL]'. $ tranr [文件名],$ tranr [类型],0,$ add ['filepass'],$ public_r [fpath],0,0,$ public_r ['filedeftb' ]);
// $ add ['titlepic'] = $ tranr [url];
$ addtitlepic =”,titlepic ='”. addslashes($ tranr [url]). ”’,ispic = 1'';
}
}
}
第2步: 编写优采云的发布模块.
第3步: 直接在线测试. 发布内容时,选择网站以在线发布到网站.
通过上述步骤,可以完成优采云的Empire发行模块. 如果您仍然不明白,请给我留言.
微信公众号文章检索方法安排
采集交流 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2020-08-06 13:06
实现方法: 通过微信提供的官方账号文章调用界面,实现抓取官方账号文章的功能
步骤:
1. 您需要安装python selenium模块软件包,并使用selenium中的webdriver来驱动浏览器获取cookie以实现登录效果;
2. 要使用webdriver功能,需要安装与浏览器相对应的驱动程序插件. 我在这里使用Google Chrome进行测试: Google Chrome版本为52.0.2743.6; Chromedriver版本: V2.23注意: 需要Google Chrome版本和chromedriver对应,否则在启动过程中将报告错误. [附: Selenium的chromedriver和chrome版本映射表(更新至v2.30)/ huilan_same / article / details / 51896672)]
3. 微信官方账号登录地址: /
4. 可以在微信公众号的后台创建微信公众号文章界面地址,以创建新的图形消息,并通过超链接功能获取该消息:
5. 搜索官方帐户名
6. 获取要抓取的官方帐户的伪造物
7. 选择要抓取的官方帐户并获取文章界面地址
8. 文章列表翻页和内容获取
2.AnyProxy代理批次采集/ p / 24302048
如何实现: anyproxy + js
/luojiangwen/p/7943696.html
如何实现: anyproxy + java + webmagic
/ t / 181857
实现方法: 数据包捕获工具Fiddler4
通过捕获和分析多个帐户,我们可以确定:
_biz: 这个14位数字的字符串是每个官方帐户的“ id”,可在搜狗的微信平台上获得
uin: 与访客有关,微信ID
密钥: 与所访问的官方帐户有关
步骤:
1. 编写按钮向导脚本,并自动单击电话上的公共文章列表页面,即“查看历史新闻”; 2.使用小提琴手代理劫持电话的访问权限,并将URL转发到以php编写的本地网页; 3.将php网页上收到的URL备份到数据库中; 4.使用python从数据库中检索URL,然后执行正常的爬网.
我在抓取过程中发现了一个问题: 如果您只想抓取文章的内容,似乎没有访问频率限制,但是如果要在阅读之后捕获阅读次数和喜欢的次数,一定的频率,返回值将为空,我设置的时间间隔为10秒,可以正常爬网. 以这种频率,一个小时内只能抓取360个项目,这没有任何实际意义.
4. 青波新榜
如果您只想查看数据,请直接查看每日列表,而无需花钱. 如果您需要访问自己的系统,它们还提供api接口 查看全部
1. 使用python爬行/ d1240673769 / article / details / 75907152
实现方法: 通过微信提供的官方账号文章调用界面,实现抓取官方账号文章的功能
步骤:
1. 您需要安装python selenium模块软件包,并使用selenium中的webdriver来驱动浏览器获取cookie以实现登录效果;
2. 要使用webdriver功能,需要安装与浏览器相对应的驱动程序插件. 我在这里使用Google Chrome进行测试: Google Chrome版本为52.0.2743.6; Chromedriver版本: V2.23注意: 需要Google Chrome版本和chromedriver对应,否则在启动过程中将报告错误. [附: Selenium的chromedriver和chrome版本映射表(更新至v2.30)/ huilan_same / article / details / 51896672)]
3. 微信官方账号登录地址: /
4. 可以在微信公众号的后台创建微信公众号文章界面地址,以创建新的图形消息,并通过超链接功能获取该消息:
5. 搜索官方帐户名
6. 获取要抓取的官方帐户的伪造物
7. 选择要抓取的官方帐户并获取文章界面地址
8. 文章列表翻页和内容获取
2.AnyProxy代理批次采集/ p / 24302048
如何实现: anyproxy + js
/luojiangwen/p/7943696.html
如何实现: anyproxy + java + webmagic
/ t / 181857
实现方法: 数据包捕获工具Fiddler4
通过捕获和分析多个帐户,我们可以确定:
_biz: 这个14位数字的字符串是每个官方帐户的“ id”,可在搜狗的微信平台上获得
uin: 与访客有关,微信ID
密钥: 与所访问的官方帐户有关
步骤:
1. 编写按钮向导脚本,并自动单击电话上的公共文章列表页面,即“查看历史新闻”; 2.使用小提琴手代理劫持电话的访问权限,并将URL转发到以php编写的本地网页; 3.将php网页上收到的URL备份到数据库中; 4.使用python从数据库中检索URL,然后执行正常的爬网.
我在抓取过程中发现了一个问题: 如果您只想抓取文章的内容,似乎没有访问频率限制,但是如果要在阅读之后捕获阅读次数和喜欢的次数,一定的频率,返回值将为空,我设置的时间间隔为10秒,可以正常爬网. 以这种频率,一个小时内只能抓取360个项目,这没有任何实际意义.
4. 青波新榜
如果您只想查看数据,请直接查看每日列表,而无需花钱. 如果您需要访问自己的系统,它们还提供api接口
WordPress 优采云采集器文章免费登录发布模块和安装说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 515 次浏览 • 2020-08-06 11:15
一开始,我们必须已经在互联网上找到了热情的网民共享的优采云发布模块. 基于WorPress,我当前正在使用5.2.2版本,该版本也受支持. 我可以在服务器上测试它. 我认为这是一个采集网站. 这没有多大意义,所以我还没有练习过. 我刚刚测试了发布模块可以在测试服务器的WEB环境中运行.
在这里我们安装并导入WordPress 优采云采集器发布模块,不用担心配置文件,我们需要先修改参数.
在这里,我们需要检查内容发布参数中的“ /locoy.php?action=save&secret=“,一个在文件名之后,另一个是设置的免登录密码.
在这里,我们需要检查尚未上传的接口文件. secretWord密码必须与我们在发布模块中设置的密码相同. 然后,将“ hm-locowp”文件夹上载到WordPress根目录,以确保根目录中的locoy.php文件与配置文件中的文件名相同. 您也可以自己修改它,但总之,它必须保持一致.
通过这种方式,如果我们得到列表并可以看到WordPress类表目录,则可以确定没有问题. 这里应该注意,设置免登录密码需要稍微复杂一些,并且可以自定义文件名以确保根目录文件的安全性.
本文的出处: 老江部落»WordPress优采云采集器文章免费登录发布模块和安装说明|欢迎分享(公众号: QQ69377078) 查看全部
当然,如果我们使用WordPress来做大数据采集网站,那绝对不合适,因为当WP数据很大时,它将占用大量服务器资源,并且打开速度非常慢. 当然,由于老江在这里进行了排序,他仍然必须整理一个常用的WordPress程序优采云采集器发布模块,当然,它也无需登录. 我当然不使用它,因为仍然需要技术安排.
一开始,我们必须已经在互联网上找到了热情的网民共享的优采云发布模块. 基于WorPress,我当前正在使用5.2.2版本,该版本也受支持. 我可以在服务器上测试它. 我认为这是一个采集网站. 这没有多大意义,所以我还没有练习过. 我刚刚测试了发布模块可以在测试服务器的WEB环境中运行.
在这里我们安装并导入WordPress 优采云采集器发布模块,不用担心配置文件,我们需要先修改参数.
在这里,我们需要检查内容发布参数中的“ /locoy.php?action=save&secret=“,一个在文件名之后,另一个是设置的免登录密码.
在这里,我们需要检查尚未上传的接口文件. secretWord密码必须与我们在发布模块中设置的密码相同. 然后,将“ hm-locowp”文件夹上载到WordPress根目录,以确保根目录中的locoy.php文件与配置文件中的文件名相同. 您也可以自己修改它,但总之,它必须保持一致.
通过这种方式,如果我们得到列表并可以看到WordPress类表目录,则可以确定没有问题. 这里应该注意,设置免登录密码需要稍微复杂一些,并且可以自定义文件名以确保根目录文件的安全性.
本文的出处: 老江部落»WordPress优采云采集器文章免费登录发布模块和安装说明|欢迎分享(公众号: QQ69377078)
如何使用和下载优采云采集器的免登录发布界面
采集交流 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2020-08-06 01:00
接口指定了类或实现它的其他接口所必须提供的成员. 与类相似,接口可以收录方法,属性,索引器和事件作为成员.
一个精心编写的界面有时可以节省无数麻烦,并使工作效率提高一倍.
Youcai Cloud Collector具有三种登录方法. 免登录发布界面是最方便的方法,但是它要求程序员根据发布URL进行自定义,并且需要一定的代码基础.
释放免登录界面时,具有易用,无需手动登录,发布稳定等优点,余豆将介绍免登录界面的实际使用:
初步准备:
(1)要检查您的网站属于什么代码,可以右键单击以查看源代码,找到代码,然后选择与代码匹配的界面.
(2)打开界面php文件. 界面有密码. 默认值为123456. 您也可以自己修改密码. 请注意,更改密码后,需要相应更改发布模块的密码.
(3)将界面文件上传到网站/ e / admin /的管理目录下(取决于特定的网站背景)
正式运营:
(1)将发布模块导入发布配置,修改发布模块,并根据上传的接口名称和设置的密码进行保存:
(2)根据网站地址进行配置.
(3)然后,您可以测试发布,以查看发布模块是否正常.
(4)测试成功发布后,可以将其应用于采集规则. 请注意,采集规则必须与发布模块的标签相对应!更好的方法是在设置发布模块中的标签之后,将发布模块中的标签直接导入到优采云采集器中:
接口下载链接
因此,为了方便客户,余豆组织了几个常用的网站,并为该网站编译了发布界面. 下载地址附在下面,压缩包中收录使用说明. 请参考具体用法说明. : 查看全部
接口(软件类接口)是指定义合同的引用类型. 其他类型则实现接口以确保它们支持某些操作.
接口指定了类或实现它的其他接口所必须提供的成员. 与类相似,接口可以收录方法,属性,索引器和事件作为成员.
一个精心编写的界面有时可以节省无数麻烦,并使工作效率提高一倍.
Youcai Cloud Collector具有三种登录方法. 免登录发布界面是最方便的方法,但是它要求程序员根据发布URL进行自定义,并且需要一定的代码基础.
释放免登录界面时,具有易用,无需手动登录,发布稳定等优点,余豆将介绍免登录界面的实际使用:
初步准备:
(1)要检查您的网站属于什么代码,可以右键单击以查看源代码,找到代码,然后选择与代码匹配的界面.
(2)打开界面php文件. 界面有密码. 默认值为123456. 您也可以自己修改密码. 请注意,更改密码后,需要相应更改发布模块的密码.
(3)将界面文件上传到网站/ e / admin /的管理目录下(取决于特定的网站背景)
正式运营:
(1)将发布模块导入发布配置,修改发布模块,并根据上传的接口名称和设置的密码进行保存:
(2)根据网站地址进行配置.
(3)然后,您可以测试发布,以查看发布模块是否正常.
(4)测试成功发布后,可以将其应用于采集规则. 请注意,采集规则必须与发布模块的标签相对应!更好的方法是在设置发布模块中的标签之后,将发布模块中的标签直接导入到优采云采集器中:
接口下载链接
因此,为了方便客户,余豆组织了几个常用的网站,并为该网站编译了发布界面. 下载地址附在下面,压缩包中收录使用说明. 请参考具体用法说明. :
利用新插口抓取微信公众号的所有文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2020-08-04 02:03
崔庆才文章采集接口文章采集接口,Python技术控,爬虫博文访问量已过百万。喜欢钻研,热爱生活,乐于分享。个人博客:静觅 |
注意:今天的文字格式可能显示有点问题,相信你可以脑补~
各位男子儿伴儿,一定深受过采集微信公众号之苦吧!特别是!!!!!!公共号历史信息!!!这丫不仅通过中间代理采集APP、还真没哪些招式能领到数据啊!
直到············
前天晚上陌陌官方发布了一个文章:
大致意思是说之后发布文章的时侯可以直接插入其它公众号的文章了。
诶妈呀!这不是仍然须要的采集接口嘛!啧啧 天助我也啊!来来·········下面大致的说一下技巧。
1、首先你须要一个订阅号! 公众号、和企业号是否可行我不清楚。因为我木有·····2、其次你须要登陆!
微信公众号登陆我没仔细看。
这个姑且不说了,我使用的是selenium 驱动浏览器获取Cookie的方式、来达到登陆的疗效。
3、使用requests携带Cookie、登录获取URL的token(这玩意很重要每一次恳求都须要带上它)像下边这样:
4、使用获取到的token、和公众号的微信号(就是数字+字符那个)、获取到公众号的fakeid(你可以理解公众号的标示)
我们在搜索公众号的时侯浏览器带着参数以GET方式想红框中的URL发起了恳求。请求参数如下:
请求相应如下:
代码如下:
好了 我们再继续:5、点击我们搜索到的公众号以后、又发觉一个恳求:
请求参数如下:
返回如下:
代码如下:
好了···最后一步、获取所有文章需要处理一下翻页、翻页恳求如下:
我大约看了一下、极客学院每一页大约起码有5条信息、也就是总文章数/5 就是有多少页。但是有小数、我们取整,然后加1就是总页数了。代码如下: 查看全部
哎哟尼玛,静觅博客博主崔庆才同事。
崔庆才文章采集接口文章采集接口,Python技术控,爬虫博文访问量已过百万。喜欢钻研,热爱生活,乐于分享。个人博客:静觅 |
注意:今天的文字格式可能显示有点问题,相信你可以脑补~
各位男子儿伴儿,一定深受过采集微信公众号之苦吧!特别是!!!!!!公共号历史信息!!!这丫不仅通过中间代理采集APP、还真没哪些招式能领到数据啊!
直到············
前天晚上陌陌官方发布了一个文章:
大致意思是说之后发布文章的时侯可以直接插入其它公众号的文章了。
诶妈呀!这不是仍然须要的采集接口嘛!啧啧 天助我也啊!来来·········下面大致的说一下技巧。
1、首先你须要一个订阅号! 公众号、和企业号是否可行我不清楚。因为我木有·····2、其次你须要登陆!
微信公众号登陆我没仔细看。
这个姑且不说了,我使用的是selenium 驱动浏览器获取Cookie的方式、来达到登陆的疗效。
3、使用requests携带Cookie、登录获取URL的token(这玩意很重要每一次恳求都须要带上它)像下边这样:
4、使用获取到的token、和公众号的微信号(就是数字+字符那个)、获取到公众号的fakeid(你可以理解公众号的标示)
我们在搜索公众号的时侯浏览器带着参数以GET方式想红框中的URL发起了恳求。请求参数如下:
请求相应如下:
代码如下:
好了 我们再继续:5、点击我们搜索到的公众号以后、又发觉一个恳求:
请求参数如下:
返回如下:
代码如下:
好了···最后一步、获取所有文章需要处理一下翻页、翻页恳求如下:
我大约看了一下、极客学院每一页大约起码有5条信息、也就是总文章数/5 就是有多少页。但是有小数、我们取整,然后加1就是总页数了。代码如下:
太棒了!利用新插口抓取微信公众号的所有文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2020-08-04 02:02
各位老汉儿伴儿,一定深受过采集微信公众号之苦吧!特别是!!!!!!公众号历史信息!!!这丫不仅通过中间代理采集APP,还真没哪些招式能领到数据啊!
直到············
前段时间早上陌陌官方发布了一个文章:
诶妈呀!这不是仍然须要的采集接口嘛!啧啧 天助我也啊!来来·········下面大致的说一下技巧。
1、首先你须要一个订阅号! 公众号、企业号是否可行我不清楚。因为我木有·····
2、其次你须要登陆!
微信公众号登陆我没仔细看。
这个姑且不说了,我使用的是selenium 驱动浏览器获取Cookie的方式,来达到登陆的疗效。
3、使用requests携带Cookie、登录获取URL的token(这玩意很重要每一次恳求都须要带上它)像下边这样:
4、使用获取到的token,和公众号的微信号(就是数字+字符那个),获取到公众号的fakeid(你可以理解公众号的标示)
我们在搜索公众号的时侯浏览器带着参数以GET方式想红框中的URL发起了恳求。请求参数如下:
请求相应如下:
代码如下:
好了 我们再继续:
5、点击我们搜索到的公众号以后,又发觉一个恳求:
请求参数如下:
返回如下:
代码如下:
好了···最后一步,获取所有文章需要处理一下翻页。翻页恳求如下:
我大约看了一下,极客学院每一页大约起码有5条信息文章采集接口,也就是总文章数/5 就是有多少页。但是有小数,我们取整文章采集接口,然后加1就是总页数了。
代码如下:
item.get(‘link’)就是我们须要的公众号文章连接啦!继续恳求这个URL提取上面的内容就是啦!
End. 查看全部
各位老汉儿伴儿,一定深受过采集微信公众号之苦吧!特别是!!!!!!公众号历史信息!!!这丫不仅通过中间代理采集APP,还真没哪些招式能领到数据啊!
直到············
前段时间早上陌陌官方发布了一个文章:
诶妈呀!这不是仍然须要的采集接口嘛!啧啧 天助我也啊!来来·········下面大致的说一下技巧。
1、首先你须要一个订阅号! 公众号、企业号是否可行我不清楚。因为我木有·····
2、其次你须要登陆!
微信公众号登陆我没仔细看。
这个姑且不说了,我使用的是selenium 驱动浏览器获取Cookie的方式,来达到登陆的疗效。
3、使用requests携带Cookie、登录获取URL的token(这玩意很重要每一次恳求都须要带上它)像下边这样:
4、使用获取到的token,和公众号的微信号(就是数字+字符那个),获取到公众号的fakeid(你可以理解公众号的标示)
我们在搜索公众号的时侯浏览器带着参数以GET方式想红框中的URL发起了恳求。请求参数如下:
请求相应如下:
代码如下:
好了 我们再继续:
5、点击我们搜索到的公众号以后,又发觉一个恳求:
请求参数如下:
返回如下:
代码如下:
好了···最后一步,获取所有文章需要处理一下翻页。翻页恳求如下:
我大约看了一下,极客学院每一页大约起码有5条信息文章采集接口,也就是总文章数/5 就是有多少页。但是有小数,我们取整文章采集接口,然后加1就是总页数了。
代码如下:
item.get(‘link’)就是我们须要的公众号文章连接啦!继续恳求这个URL提取上面的内容就是啦!
End.

