
文章采集功能
实战案例使用singleengcheng/myblogexperimental:一个简单高效且多语言支持的采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-06-28 00:02
文章采集功能采集速度非常快,只要简单调用采集工具或者采集api,即可一键采集复杂网站的博客文章。采集功能类似于爬虫,有多种爬虫语言可供选择,详情见介绍页。部分源码分享下面是我采集的github-singleengcheng/myblogexperimental:一个简单高效且多语言支持的采集工具。实战案例使用singleengcheng/myblogexperimental打开网页/,采集复杂网站的博客文章。
首先新建一个窗口,调用采集工具,手动去选择文章,单击完成操作。step1:新建页面step2:查看下文章链接及详情页源码step3:查看用户名及密码step4:显示表格,找到需要的数据区域step5:利用spider这个工具输入表格中数据,采集完成后将获得相应的json数据这里重点讲下大家很容易忽略的一步:文章原始链接和详情页的源码。
我们可以看到,原始链接没有改变,详情页也没有变化,但是,文章列表中出现了一些变化,这就是这篇文章的点击链接。而这就是我们想要的文章列表。文章列表只需抓取其中的点击的部分,有兴趣的可以继续挖掘。网站原始链接最终得到了文章列表的源码:详情页step6:找到用户名及密码,使用采集api,把网站原始链接解析出来:对,将整个文章的url发送给api,告诉api将原始链接解析出来step7:找到用户名和密码,获取二者名字,将后缀名发送给api,告诉api将用户名和密码分别解析出来,并传给api,你会得到用户名和密码这里还要注意一点,api会先解析出原始链接,再将原始链接发送给这个网站。
所以我们可以在将原始链接解析出来后发送出去。比如解析出来了url,也发送出去了,但是用户名和密码没有获取出来,就需要打开这个网站使用api进行获取。最终得到了用户名和密码step8:根据用户名和密码返回结果进行下一步操作。我们要找到每篇文章对应的文章列表中的数据,直接ajax请求得到返回数据比较慢,这里可以使用chrome扩展,使用chrome的cookie来获取,等你退出chrome,再打开这个网站你会发现页面上已经有返回结果数据了。
直接定位下单篇文章的源码抓完了页面,我们再返回header:值正常就可以返回数据了。然后根据源码,用网站地址查询找到对应的详情页地址,回家查询数据,定位到每篇文章的详情页地址中,并返回详情页地址即可。step9:用html重新进入到刚才返回的网站,抓取详情页地址,更改好详情页地址即可。通过命令行工具,如nodemon、express可以将网站代理化,直接利用nodemon就可以完成代理化。需要注意的是,express本身是支持代理化操作的,必须要安装express的命令行工具,并。 查看全部
实战案例使用singleengcheng/myblogexperimental:一个简单高效且多语言支持的采集工具
文章采集功能采集速度非常快,只要简单调用采集工具或者采集api,即可一键采集复杂网站的博客文章。采集功能类似于爬虫,有多种爬虫语言可供选择,详情见介绍页。部分源码分享下面是我采集的github-singleengcheng/myblogexperimental:一个简单高效且多语言支持的采集工具。实战案例使用singleengcheng/myblogexperimental打开网页/,采集复杂网站的博客文章。
首先新建一个窗口,调用采集工具,手动去选择文章,单击完成操作。step1:新建页面step2:查看下文章链接及详情页源码step3:查看用户名及密码step4:显示表格,找到需要的数据区域step5:利用spider这个工具输入表格中数据,采集完成后将获得相应的json数据这里重点讲下大家很容易忽略的一步:文章原始链接和详情页的源码。
我们可以看到,原始链接没有改变,详情页也没有变化,但是,文章列表中出现了一些变化,这就是这篇文章的点击链接。而这就是我们想要的文章列表。文章列表只需抓取其中的点击的部分,有兴趣的可以继续挖掘。网站原始链接最终得到了文章列表的源码:详情页step6:找到用户名及密码,使用采集api,把网站原始链接解析出来:对,将整个文章的url发送给api,告诉api将原始链接解析出来step7:找到用户名和密码,获取二者名字,将后缀名发送给api,告诉api将用户名和密码分别解析出来,并传给api,你会得到用户名和密码这里还要注意一点,api会先解析出原始链接,再将原始链接发送给这个网站。
所以我们可以在将原始链接解析出来后发送出去。比如解析出来了url,也发送出去了,但是用户名和密码没有获取出来,就需要打开这个网站使用api进行获取。最终得到了用户名和密码step8:根据用户名和密码返回结果进行下一步操作。我们要找到每篇文章对应的文章列表中的数据,直接ajax请求得到返回数据比较慢,这里可以使用chrome扩展,使用chrome的cookie来获取,等你退出chrome,再打开这个网站你会发现页面上已经有返回结果数据了。
直接定位下单篇文章的源码抓完了页面,我们再返回header:值正常就可以返回数据了。然后根据源码,用网站地址查询找到对应的详情页地址,回家查询数据,定位到每篇文章的详情页地址中,并返回详情页地址即可。step9:用html重新进入到刚才返回的网站,抓取详情页地址,更改好详情页地址即可。通过命令行工具,如nodemon、express可以将网站代理化,直接利用nodemon就可以完成代理化。需要注意的是,express本身是支持代理化操作的,必须要安装express的命令行工具,并。
单篇文章检测不能搞定所有平台的内容是否同一类型
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-06-26 07:01
文章采集功能规范由于不断迭代,造成文章采集的准确率有些难以把控,因此将采集的质量检测作为首要目标。
对的。必须要实时检测,实时处理。文章内容都采集后,根据文章相关性评估机制,得出分值。根据各种情况,向用户推送该文章。如果用户的内容相关性评分超过最低阈值。则将相关性评分提高到较高阈值。注意,分值较高的文章,用户可能查看不到。
tp识别就是识别同一系列文章是否重复,和内容是否相似。这个功能要规范,你不同平台的,数据是不同的,有的类型,
可以的。自己可以测一下几个平台的内容是否同一类型,例如知乎、豆瓣、简书等不同平台,不同类型的文章有什么共同点。
可以的,
可以的,我前几天就用的,
可以单篇文章检测,在网页版首页搜索“检测内容”进行检测。标准top.1个人和网站提供,top.2是公司自己的提供,检测的精准程度有点不一样,质量把控也有点差别,
微信公众号和头条号一起的都可以检测,检测完成,标出相似内容,并在公众号推送之前提醒作者修改。
单篇检测不能搞定所有平台,再者文章类型是多样的,检测后都没办法判断, 查看全部
单篇文章检测不能搞定所有平台的内容是否同一类型
文章采集功能规范由于不断迭代,造成文章采集的准确率有些难以把控,因此将采集的质量检测作为首要目标。
对的。必须要实时检测,实时处理。文章内容都采集后,根据文章相关性评估机制,得出分值。根据各种情况,向用户推送该文章。如果用户的内容相关性评分超过最低阈值。则将相关性评分提高到较高阈值。注意,分值较高的文章,用户可能查看不到。
tp识别就是识别同一系列文章是否重复,和内容是否相似。这个功能要规范,你不同平台的,数据是不同的,有的类型,
可以的。自己可以测一下几个平台的内容是否同一类型,例如知乎、豆瓣、简书等不同平台,不同类型的文章有什么共同点。
可以的,
可以的,我前几天就用的,
可以单篇文章检测,在网页版首页搜索“检测内容”进行检测。标准top.1个人和网站提供,top.2是公司自己的提供,检测的精准程度有点不一样,质量把控也有点差别,
微信公众号和头条号一起的都可以检测,检测完成,标出相似内容,并在公众号推送之前提醒作者修改。
单篇检测不能搞定所有平台,再者文章类型是多样的,检测后都没办法判断,
trackout电脑及android端视频采集工具整理安卓端trackout使用说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2021-06-02 06:02
文章采集功能视频采集工具vlctrackout功能基础安装资源地址获取视频地址和上传视频地址,我们有许多安卓手机都没有安装vlctrackout这个软件,但又想利用视频上传功能,那么现在就可以利用文章采集功能。
一、视频采集基础安装
1、先在视频地址格式里面找到需要采集的视频地址,如果没有安装vlctrackout这个软件,可以在百度搜索。
2、然后需要重启手机,通过控制台输入vlctrackout即可。
可以重启三次)
二、vlctrackout中文使用说明
1、添加采集源:可以根据个人需要,
2、设置上传源:该方法有很多,本文以获取爱奇艺视频链接为例,输入在手机中点击上传。
3、设置启动方式:
4、设置采集方式:包括触屏和鼠标二种方式,触屏方式可以选择「copychannel」触屏形式采集方式设置点击屏幕或手指即可选择采集地址即可。
5、设置前期录制:前期采集可以通过视频录制窗口前的「视频录制设置」,将内容设置为视频播放器和手机同步录制即可。
6、设置后期采集:首先手机刷机,接着输入data,然后选择获取获取地址,切换「自动模式」即可。
三、视频采集工具视频采集工具
1、首先用户打开目标视频页面
2、将地址进行跳转方式转换
3、根据自己使用需求,将视频网址添加到浏览器中。
4、点击完成后,启动vlctrackout即可开始上传。不仅如此,视频采集工具还提供了三种操作步骤供大家选择,快快开始学习吧。
四、trackout电脑及android端视频采集工具整理安卓端trackout使用说明安卓电脑trackout使用说明trackout电脑端视频采集工具整理 查看全部
trackout电脑及android端视频采集工具整理安卓端trackout使用说明
文章采集功能视频采集工具vlctrackout功能基础安装资源地址获取视频地址和上传视频地址,我们有许多安卓手机都没有安装vlctrackout这个软件,但又想利用视频上传功能,那么现在就可以利用文章采集功能。
一、视频采集基础安装
1、先在视频地址格式里面找到需要采集的视频地址,如果没有安装vlctrackout这个软件,可以在百度搜索。
2、然后需要重启手机,通过控制台输入vlctrackout即可。
可以重启三次)
二、vlctrackout中文使用说明
1、添加采集源:可以根据个人需要,
2、设置上传源:该方法有很多,本文以获取爱奇艺视频链接为例,输入在手机中点击上传。
3、设置启动方式:
4、设置采集方式:包括触屏和鼠标二种方式,触屏方式可以选择「copychannel」触屏形式采集方式设置点击屏幕或手指即可选择采集地址即可。
5、设置前期录制:前期采集可以通过视频录制窗口前的「视频录制设置」,将内容设置为视频播放器和手机同步录制即可。
6、设置后期采集:首先手机刷机,接着输入data,然后选择获取获取地址,切换「自动模式」即可。
三、视频采集工具视频采集工具
1、首先用户打开目标视频页面
2、将地址进行跳转方式转换
3、根据自己使用需求,将视频网址添加到浏览器中。
4、点击完成后,启动vlctrackout即可开始上传。不仅如此,视频采集工具还提供了三种操作步骤供大家选择,快快开始学习吧。
四、trackout电脑及android端视频采集工具整理安卓端trackout使用说明安卓电脑trackout使用说明trackout电脑端视频采集工具整理
web开发工具scrapy框架scrapy支持的模块支持以下模块
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-05-31 18:01
文章采集功能目前支持的渠道包括:百度、谷歌、搜狗等搜索引擎的搜索结果,搜狐、腾讯、头条、一点资讯等信息平台的文章和广告联盟信息,yahoo!等新闻资讯平台的相关讯息,
0、猎豹、百度和搜狗等产品的相关信息。配合爬虫软件,可以获取互联网上其他主流社交网站、电商平台、股票咨询网站、智能或生活类网站等资讯。支持的ip地址数最高可达数百万,最高可是该ip地址的10倍。同时,我们还提供了媒体转载产品,可以在更高的位置进行体验。可以说,scrapy爬虫是目前比较热门的互联网开发工具,所以对于scrapy也提供了相应的图表和最新资讯。
最后:如果你也热爱爬虫和网络爬虫,欢迎来我们群【625758540】一起交流学习作者:博客专栏-博客园如需转载,请附带上本文地址。
scrapy是深受开发者喜爱的web开发工具之一,它可以帮助你在java/python/php/node.js等多个语言上部署一个scrapyweb应用。所以今天以nekopython为例来详细介绍scrapy在设计上的亮点:全篇使用的英文以助于你理解本文的重点。
一、引言你已经知道scrapy可以用于web开发,但它并不是一个完整的框架,更不是面向工程的框架。本文接下来会介绍我们需要用到的爬虫框架scrapy的设计,以及让你初步了解其中使用的模块。
二、scrapy1.0支持的模块scrapy支持以下的模块:figactionsideoutsessionprocessing
三、项目我们将使用全部四个模块构建一个nekopythonweb应用。这四个模块分别是:figactionsitepressoryfeaturesprocessing你可以参考howtoconfigurethereal-timescrapywebapplicationattheendofscrapy1.0.你也可以根据自己的需要增加(自己定义这些模块),具体取决于你爬取的网站或应用的规模。
你需要花费数十分钟时间慢慢弄,你可以把后署时间算进去。看这篇文章::-requests/scrapy使用scrapy从这里获取scrapyget请求,和scrapypost请求。scrapy发送到我们web的数据中,并将这些值返回给我们。这些值包括:对于参数来说,第一个参数是scrapy.callback,这将用于附加执行回调。
第二个参数是请求体的一部分。scrapy通过securitytokens来验证其真实性,真实性满足条件时会被调用。请求体会被传输到httpserver去,之后转发到scrapyweb应用上。你还可以通过特定http访问协议,以确保scrapy应用使用同一http请求对待你。在特定情况下,你的请求需要额外的工作。如果你在scrapyweb应用上有任何爬虫的开发经验,你可能会为你。 查看全部
web开发工具scrapy框架scrapy支持的模块支持以下模块
文章采集功能目前支持的渠道包括:百度、谷歌、搜狗等搜索引擎的搜索结果,搜狐、腾讯、头条、一点资讯等信息平台的文章和广告联盟信息,yahoo!等新闻资讯平台的相关讯息,
0、猎豹、百度和搜狗等产品的相关信息。配合爬虫软件,可以获取互联网上其他主流社交网站、电商平台、股票咨询网站、智能或生活类网站等资讯。支持的ip地址数最高可达数百万,最高可是该ip地址的10倍。同时,我们还提供了媒体转载产品,可以在更高的位置进行体验。可以说,scrapy爬虫是目前比较热门的互联网开发工具,所以对于scrapy也提供了相应的图表和最新资讯。
最后:如果你也热爱爬虫和网络爬虫,欢迎来我们群【625758540】一起交流学习作者:博客专栏-博客园如需转载,请附带上本文地址。
scrapy是深受开发者喜爱的web开发工具之一,它可以帮助你在java/python/php/node.js等多个语言上部署一个scrapyweb应用。所以今天以nekopython为例来详细介绍scrapy在设计上的亮点:全篇使用的英文以助于你理解本文的重点。
一、引言你已经知道scrapy可以用于web开发,但它并不是一个完整的框架,更不是面向工程的框架。本文接下来会介绍我们需要用到的爬虫框架scrapy的设计,以及让你初步了解其中使用的模块。
二、scrapy1.0支持的模块scrapy支持以下的模块:figactionsideoutsessionprocessing
三、项目我们将使用全部四个模块构建一个nekopythonweb应用。这四个模块分别是:figactionsitepressoryfeaturesprocessing你可以参考howtoconfigurethereal-timescrapywebapplicationattheendofscrapy1.0.你也可以根据自己的需要增加(自己定义这些模块),具体取决于你爬取的网站或应用的规模。
你需要花费数十分钟时间慢慢弄,你可以把后署时间算进去。看这篇文章::-requests/scrapy使用scrapy从这里获取scrapyget请求,和scrapypost请求。scrapy发送到我们web的数据中,并将这些值返回给我们。这些值包括:对于参数来说,第一个参数是scrapy.callback,这将用于附加执行回调。
第二个参数是请求体的一部分。scrapy通过securitytokens来验证其真实性,真实性满足条件时会被调用。请求体会被传输到httpserver去,之后转发到scrapyweb应用上。你还可以通过特定http访问协议,以确保scrapy应用使用同一http请求对待你。在特定情况下,你的请求需要额外的工作。如果你在scrapyweb应用上有任何爬虫的开发经验,你可能会为你。
怎样借用工具一天编写数万篇原创的搜索文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-05-26 21:16
Koala SEO [批处理SEO 原创 文章]平台支持本文。借助考拉,一天之内就可以制作成千上万的高质量SEO文章文章!
我很抱歉。现在,当我们单击此页面时,也许对Web文本采集器没有任何响应,因为该内容是批处理书写工具站AI生成的排水内容。如果您对该AI 原创 文章的内容感兴趣,则最好将Internet文本采集器放在一旁。我建议每个人都应体验如何使用该工具每天进行成千上万的原创搜索文章!许多看过Koala SEO的网站的网民都认为这是一个伪原创系统,这是非常错误的!实际上,这是一个原创工具。内容和模板都是自己编写的。在Internet上碰到接近本文的作品绝对是不可能的。我们是如何创建的?接下来,编辑器将为您提供全面的解释!
说实话,想要了解网络文本采集器的朋友,您最关心的是上面讨论的内容。最初,编写一些高质量的优化文案非常方便,但是可以由一个文章生成的搜索量确实微不足道。为了追求文章积累以获取长尾单词流量的目的,绝对关键的方法是批量!如果某个网页文章每天可以获取紫外线,我认为它可以产生10,000页,并且每天的访问者数量可以增加10,000倍。但这很容易说。实际上,写作时,一个人只能在24小时内撰写40篇以上的文章,而在最高处,他们只能撰写约60篇文章。即使我们使用某些伪原创系统,也只会持续一百篇文章!阅读本文之后,我们应该撇开网络文本采集器的话题,并深入研究如何实现批处理生成文章!
搜索引擎识别什么原创?内容原创绝不会一个字一个字地写原创!在搜索到的系统词典中,原创不收录邮政重复性文本。换句话说,只要我们的副本不与其他网站内容重叠,就会大大提高被捕获的可能性。 1份高质量的副本,充满了干货,保留了相同的核心思想,只要确认没有相同的大段落,那么此文章仍然很有可能被捕获,甚至成为爆文 。例如,在我的文章中,您可能已经通过搜索引擎搜索了网络文本采集器,最后单击以对其进行浏览。实际上,在下一篇文章文章中,将使用koala平台的批量编写文章软件来快速导出该软件!
准确地说,此站点的伪原创平台应为自动文章软件,该软件可以在5个小时内产生数以万计的强大网站 文章,并且您的网站重量应足够大,索引率至少可以达到66%。有关详细的操作方法,个人中心有一个视频显示屏和一个初学者指南。您可能希望免费测试!我很抱歉无法为您带来网络文本的最终解释采集器,可能让我们浏览了许多系统语言。但是,如果每个人都对智能书写工具文章感兴趣,则可以单击导航栏,使我们的优化结果每天达到数以万计的UV。是不是很酷? 查看全部
怎样借用工具一天编写数万篇原创的搜索文章
Koala SEO [批处理SEO 原创 文章]平台支持本文。借助考拉,一天之内就可以制作成千上万的高质量SEO文章文章!
我很抱歉。现在,当我们单击此页面时,也许对Web文本采集器没有任何响应,因为该内容是批处理书写工具站AI生成的排水内容。如果您对该AI 原创 文章的内容感兴趣,则最好将Internet文本采集器放在一旁。我建议每个人都应体验如何使用该工具每天进行成千上万的原创搜索文章!许多看过Koala SEO的网站的网民都认为这是一个伪原创系统,这是非常错误的!实际上,这是一个原创工具。内容和模板都是自己编写的。在Internet上碰到接近本文的作品绝对是不可能的。我们是如何创建的?接下来,编辑器将为您提供全面的解释!

说实话,想要了解网络文本采集器的朋友,您最关心的是上面讨论的内容。最初,编写一些高质量的优化文案非常方便,但是可以由一个文章生成的搜索量确实微不足道。为了追求文章积累以获取长尾单词流量的目的,绝对关键的方法是批量!如果某个网页文章每天可以获取紫外线,我认为它可以产生10,000页,并且每天的访问者数量可以增加10,000倍。但这很容易说。实际上,写作时,一个人只能在24小时内撰写40篇以上的文章,而在最高处,他们只能撰写约60篇文章。即使我们使用某些伪原创系统,也只会持续一百篇文章!阅读本文之后,我们应该撇开网络文本采集器的话题,并深入研究如何实现批处理生成文章!
搜索引擎识别什么原创?内容原创绝不会一个字一个字地写原创!在搜索到的系统词典中,原创不收录邮政重复性文本。换句话说,只要我们的副本不与其他网站内容重叠,就会大大提高被捕获的可能性。 1份高质量的副本,充满了干货,保留了相同的核心思想,只要确认没有相同的大段落,那么此文章仍然很有可能被捕获,甚至成为爆文 。例如,在我的文章中,您可能已经通过搜索引擎搜索了网络文本采集器,最后单击以对其进行浏览。实际上,在下一篇文章文章中,将使用koala平台的批量编写文章软件来快速导出该软件!

准确地说,此站点的伪原创平台应为自动文章软件,该软件可以在5个小时内产生数以万计的强大网站 文章,并且您的网站重量应足够大,索引率至少可以达到66%。有关详细的操作方法,个人中心有一个视频显示屏和一个初学者指南。您可能希望免费测试!我很抱歉无法为您带来网络文本的最终解释采集器,可能让我们浏览了许多系统语言。但是,如果每个人都对智能书写工具文章感兴趣,则可以单击导航栏,使我们的优化结果每天达到数以万计的UV。是不是很酷?
android的标准的通讯协议-帧驱动(上图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-05-22 04:02
文章采集功能现在很普遍,在android平台是采用的channel机制,无非是扩展采集的数据粒度,缩小采集的范围,拿本文说说android的标准的通讯协议-帧驱动。ssl协议本文要介绍的是标准的格式,具体是:通讯帧(pre-message):通讯帧的具体封装格式是gzip,通讯帧封装格式可以参考下面这个清单(参考:pre-messagesuites/implementation.html)。
现有的udp协议是使用udp协议客户端向服务器建立tcp连接,如果选择ftp协议建立tcp连接,服务器需要输入正确的二进制数据传输到客户端。gap(availableframe):是由多个可用的数据帧组成的封装格式,数据帧具体封装格式可以参考下面这个清单(参考:httputility.html),下面的封装格式可以获取最新的数据帧格式。
帧/区块连接(frame/block/transition):帧/区块的规则是ftp协议服务器规则,是ftp协议规则、上图里的规则以及一些以前有用到过的协议。帧/区块跳板(frame/blocktrap):帧/区块跳板是更简单的规则,只需要1秒的时间就可以建立跨tcp连接。android采用帧,而不是以太网帧,是因为android的框架和内核的关系。
android的帧协议是从udp转化出来的。udp协议只能传递文本数据,而帧协议支持文本和数据相结合。一个简单的文本帧/帧连接方式如下:{"available_sides":3,"data":[{"pre-message":"available_pre-message","response":"udp"},{"pre-message":"available_pre-message","response":"tcp"}]}跳板帧在传输时必须用跳板连接转发。
如果某跳板区域传输的数据被堵塞,则跳板帧就会被阻塞,直到有数据到达,也就是速度会延迟(大于5ms)。这样实现的好处是,在传输时消除延迟。帧协议在传输过程中不会经常“重传”——每条数据在传输过程中都会被重传。第一跳就是以太网帧。udp协议用的一个传输方法是跳板连接转发——跳板连接的概念我们以后再介绍。总结ftp的帧协议由udp转化出来的,与channel机制有关。
android的帧协议是从udp转化出来的,不了解客户端以及服务器层,所以单独拿出来谈谈这个帧。im圈子里的相关服务器开发已经介绍过,这里不再累述。两种帧:跳板帧和帧协议ftp协议协议不是以太网帧,而是跳板帧,和我们前面介绍的跳板帧封装格式是一样的。它的核心概念是xlen帧和每个帧封装在floattenablebits空间里,把帧封装到floattenablebits空间中就可以一次只传送一个字节的数据,节省服务器空间和客户端空间。用跳板帧转发的接收一条数据只需要一次传送一。 查看全部
android的标准的通讯协议-帧驱动(上图)
文章采集功能现在很普遍,在android平台是采用的channel机制,无非是扩展采集的数据粒度,缩小采集的范围,拿本文说说android的标准的通讯协议-帧驱动。ssl协议本文要介绍的是标准的格式,具体是:通讯帧(pre-message):通讯帧的具体封装格式是gzip,通讯帧封装格式可以参考下面这个清单(参考:pre-messagesuites/implementation.html)。
现有的udp协议是使用udp协议客户端向服务器建立tcp连接,如果选择ftp协议建立tcp连接,服务器需要输入正确的二进制数据传输到客户端。gap(availableframe):是由多个可用的数据帧组成的封装格式,数据帧具体封装格式可以参考下面这个清单(参考:httputility.html),下面的封装格式可以获取最新的数据帧格式。
帧/区块连接(frame/block/transition):帧/区块的规则是ftp协议服务器规则,是ftp协议规则、上图里的规则以及一些以前有用到过的协议。帧/区块跳板(frame/blocktrap):帧/区块跳板是更简单的规则,只需要1秒的时间就可以建立跨tcp连接。android采用帧,而不是以太网帧,是因为android的框架和内核的关系。
android的帧协议是从udp转化出来的。udp协议只能传递文本数据,而帧协议支持文本和数据相结合。一个简单的文本帧/帧连接方式如下:{"available_sides":3,"data":[{"pre-message":"available_pre-message","response":"udp"},{"pre-message":"available_pre-message","response":"tcp"}]}跳板帧在传输时必须用跳板连接转发。
如果某跳板区域传输的数据被堵塞,则跳板帧就会被阻塞,直到有数据到达,也就是速度会延迟(大于5ms)。这样实现的好处是,在传输时消除延迟。帧协议在传输过程中不会经常“重传”——每条数据在传输过程中都会被重传。第一跳就是以太网帧。udp协议用的一个传输方法是跳板连接转发——跳板连接的概念我们以后再介绍。总结ftp的帧协议由udp转化出来的,与channel机制有关。
android的帧协议是从udp转化出来的,不了解客户端以及服务器层,所以单独拿出来谈谈这个帧。im圈子里的相关服务器开发已经介绍过,这里不再累述。两种帧:跳板帧和帧协议ftp协议协议不是以太网帧,而是跳板帧,和我们前面介绍的跳板帧封装格式是一样的。它的核心概念是xlen帧和每个帧封装在floattenablebits空间里,把帧封装到floattenablebits空间中就可以一次只传送一个字节的数据,节省服务器空间和客户端空间。用跳板帧转发的接收一条数据只需要一次传送一。
公众号文章采集器的特点和功能有哪些吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-05-18 02:16
正式帐户文章 采集器的特征和功能是什么?如何采集官方帐户文章? 关键词:如何采集正式帐户文章说明:现在,许多人会在正式帐户平台上采集一些美国论文,然后将其发表在他们的正式帐户上。您知道官方帐户文章 采集器的特征和功能吗?另外,如何采集官方帐户文章?让我们看一下Tuotu数据编辑器。现在,许多人在官方帐户平台上发表了一些美国论文,然后将其发表在他们的官方帐户上。您知道官方帐户文章 采集器的特征和功能是什么?另外,如何采集官方帐户?让我们用Tuotu数据编辑器了解一下。官方帐户文章 采集器 Cloud 采集 5000台24 * 7高效稳定的云服务器采集的特征和功能,结合API,可以无缝连接到内部系统,并定期同步数据。智能采集提供了多个网页采集策略和支持资源,以帮助整个采集流程实现数据完整性和稳定性。如何采集官方帐户文章适用于整个网络。无论是文字图片还是贴吧论坛,都可以看到。它支持所有业务渠道的采集器,并满足各种采集需求。大量的模板。内置了数百个网站数据源,涵盖了多个行业。通过简单的设置,您可以快速而准确地获取数据。简单易用无需学习爬虫编程技术,您可以通过三个简单的步骤轻松获取网页数据,支持多种格式,一键导出,并快速导入数据库。稳定高效借助分布式云集群服务器和多用户协作管理平台的支持,可以灵活地调度任务,并可以平滑地抓取大量数据。
微信公众号文章如何使用小程序转移流量? 1.该小程序具有较大的搜索流量入口,方便用户浏览。 2.微信公众号文章自动生成小程序界面,如下图所示,文章自动采集由您自己的官方帐户文章批量发布,页面浏览量,喜欢和评论都与官方帐户文章同步,自动分类,您可以更好地显示您过去发布的微信文章,并便于统一显示。 3.对于自媒体和流量拥有者,更容易通过频繁发布高质量的文章来保留客户,并且可以扩展广告并再次赚钱。 4.您可以转到官方帐户。如何通过其他微信公众号的采集 文章 一、获取文章链接计算机用户可以直接在浏览器地址栏中选择所有文章链接。移动用户可以单击右上角的菜单按钮,选择复制链接,然后将链接发送到计算机。 二、单击编辑菜单右上角的采集 文章按钮1. 采集 文章按钮。 2.右侧功能按钮底部的采集 文章按钮。 三、粘贴文章链接,然后单击采集 采集以编辑和修改文章。如何采集官方帐户文章在上述文章中,Tuotu Data的编辑向您介绍了官方帐户文章 采集器的功能和特点以及如何采集官方的相关内容帐户文章,希望对大家有帮助。拓图数据网络提供官方帐户数据恢复,官方帐户统计工具等软件。有需要的朋友可以咨询一下。更多信息和知识点将继续受到关注,后续活动将成为官方账户分析工具,湖南分析官方账户的最佳工具,官方账户分析数据工具,如何采集官方帐户文章,自媒体如何获得公共帐户文章采集和其他知识点。 查看全部
公众号文章采集器的特点和功能有哪些吗?
正式帐户文章 采集器的特征和功能是什么?如何采集官方帐户文章? 关键词:如何采集正式帐户文章说明:现在,许多人会在正式帐户平台上采集一些美国论文,然后将其发表在他们的正式帐户上。您知道官方帐户文章 采集器的特征和功能吗?另外,如何采集官方帐户文章?让我们看一下Tuotu数据编辑器。现在,许多人在官方帐户平台上发表了一些美国论文,然后将其发表在他们的官方帐户上。您知道官方帐户文章 采集器的特征和功能是什么?另外,如何采集官方帐户?让我们用Tuotu数据编辑器了解一下。官方帐户文章 采集器 Cloud 采集 5000台24 * 7高效稳定的云服务器采集的特征和功能,结合API,可以无缝连接到内部系统,并定期同步数据。智能采集提供了多个网页采集策略和支持资源,以帮助整个采集流程实现数据完整性和稳定性。如何采集官方帐户文章适用于整个网络。无论是文字图片还是贴吧论坛,都可以看到。它支持所有业务渠道的采集器,并满足各种采集需求。大量的模板。内置了数百个网站数据源,涵盖了多个行业。通过简单的设置,您可以快速而准确地获取数据。简单易用无需学习爬虫编程技术,您可以通过三个简单的步骤轻松获取网页数据,支持多种格式,一键导出,并快速导入数据库。稳定高效借助分布式云集群服务器和多用户协作管理平台的支持,可以灵活地调度任务,并可以平滑地抓取大量数据。
微信公众号文章如何使用小程序转移流量? 1.该小程序具有较大的搜索流量入口,方便用户浏览。 2.微信公众号文章自动生成小程序界面,如下图所示,文章自动采集由您自己的官方帐户文章批量发布,页面浏览量,喜欢和评论都与官方帐户文章同步,自动分类,您可以更好地显示您过去发布的微信文章,并便于统一显示。 3.对于自媒体和流量拥有者,更容易通过频繁发布高质量的文章来保留客户,并且可以扩展广告并再次赚钱。 4.您可以转到官方帐户。如何通过其他微信公众号的采集 文章 一、获取文章链接计算机用户可以直接在浏览器地址栏中选择所有文章链接。移动用户可以单击右上角的菜单按钮,选择复制链接,然后将链接发送到计算机。 二、单击编辑菜单右上角的采集 文章按钮1. 采集 文章按钮。 2.右侧功能按钮底部的采集 文章按钮。 三、粘贴文章链接,然后单击采集 采集以编辑和修改文章。如何采集官方帐户文章在上述文章中,Tuotu Data的编辑向您介绍了官方帐户文章 采集器的功能和特点以及如何采集官方的相关内容帐户文章,希望对大家有帮助。拓图数据网络提供官方帐户数据恢复,官方帐户统计工具等软件。有需要的朋友可以咨询一下。更多信息和知识点将继续受到关注,后续活动将成为官方账户分析工具,湖南分析官方账户的最佳工具,官方账户分析数据工具,如何采集官方帐户文章,自媒体如何获得公共帐户文章采集和其他知识点。
「赛马助手」ai解析商品大数据解析方式重新研发
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-05-17 23:03
文章采集功能已上线,点击「赛马助手」即可使用。经过1个月的打磨,我们终于将ai解析商品的功能,同步到了「京东精选」和「饿了么外卖」两个产品上。写这篇文章,我真不想让这个产品成为我们的短板,也是我最近工作的打算。我们使用了一种新的数据解析方式,即通过视觉来解析商品。同时,结合「数据运营」的大数据解析方式,重新研发「关联商品」,会对用户更加有价值。
也是应@潘菲瑶的要求,「爱不爱我」在这个版本是1.0。希望能够尽快完善它,共同打造一个完整的ai解析商品的工具。
具体技术实现请参考深圳湾产品线负责人@谢怀宇的技术分享
有可能需要用到mongoose,但基本不用怕,mongoose在几千万的商品数据库中查询并没有问题,至于可用性,目前还没有听说mongoose在大范围故障情况下仍能正常使用的情况。
这种不是很重要的东西,也无非就是要用到大量的运营经验。代码能写清楚不难,容易写清楚也不难,难在读懂这些代码。要是相关的运营都分不清多少人点击,多少次浏览,有没有购买。就算公司有钱,有牛人做大量的积累,只要没啥积累,天天加班还依然是写不出的。再好的技术,人做不出来,也是没用。
主要是一些图像处理算法,主要是通过将图像训练好的网络变换、卷积、降采样等网络结构,输入到最基本的分类算法,对图像分类。现在最基本的是逻辑多分类问题。 查看全部
「赛马助手」ai解析商品大数据解析方式重新研发
文章采集功能已上线,点击「赛马助手」即可使用。经过1个月的打磨,我们终于将ai解析商品的功能,同步到了「京东精选」和「饿了么外卖」两个产品上。写这篇文章,我真不想让这个产品成为我们的短板,也是我最近工作的打算。我们使用了一种新的数据解析方式,即通过视觉来解析商品。同时,结合「数据运营」的大数据解析方式,重新研发「关联商品」,会对用户更加有价值。
也是应@潘菲瑶的要求,「爱不爱我」在这个版本是1.0。希望能够尽快完善它,共同打造一个完整的ai解析商品的工具。
具体技术实现请参考深圳湾产品线负责人@谢怀宇的技术分享
有可能需要用到mongoose,但基本不用怕,mongoose在几千万的商品数据库中查询并没有问题,至于可用性,目前还没有听说mongoose在大范围故障情况下仍能正常使用的情况。
这种不是很重要的东西,也无非就是要用到大量的运营经验。代码能写清楚不难,容易写清楚也不难,难在读懂这些代码。要是相关的运营都分不清多少人点击,多少次浏览,有没有购买。就算公司有钱,有牛人做大量的积累,只要没啥积累,天天加班还依然是写不出的。再好的技术,人做不出来,也是没用。
主要是一些图像处理算法,主要是通过将图像训练好的网络变换、卷积、降采样等网络结构,输入到最基本的分类算法,对图像分类。现在最基本的是逻辑多分类问题。
如何借用软件半天撰写1万篇原创的引流文案页
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-05-17 01:33
Koala SEO [批处理SEO 原创 文章]平台支持本文。借助考拉,一天之内就可以制作成千上万的高质量SEO文章文章!
超级抱歉,现在大家伙输入了这个内容,可以浏览的文章并不是对网络采集器功能的分析,这是因为这个文章是我们工具站批量生产的网页文章。如果您需要此自动编辑内容的内容,则可以先搁置网络采集器功能,然后让您体验一下:如何借用半天的时间来编写10,000 原创排水副本页面!许多朋友看到了我们的广告,并认为这是一个伪原创系统,这是一个很大的错误!从本质上讲,我们是一个AI系统。广告文案和模板是独立编写的,几乎无法在Internet上找到和生成它们。 文章具有高度相似性。究竟是如何创建的?我将在下面给大家做详细的分析!
想知道网络采集器功能的朋友毕竟是每个人都珍惜的是上面讨论的内容。最初,创建可读的搜索登录文章非常容易,但是SEO副本可以创建的访问量实际上很小。希望可以利用信息设置达到排水的目的。绝对重要的策略是分批!如果某个页面文章可以带来1次(每24小时一次)浏览量,那么如果我们可以编辑10,000个页面,则每天的客户数量可以增加10,000倍。但是,这很简单。在现实生活中编辑时,一个人一天只能撰写约40篇文章,最多只能撰写70篇文章。即使将其应用于伪原创系统,也最多只能容纳100篇文章!现在您已经在那儿了,您可以先放弃网络采集器功能,并进一步了解如何实现自动编辑!
seo认为原创是什么?文案写作原创并不意味着逐句输出原创!在主要搜索引擎的程序定义中,原创并不意味着没有重复的句子。实际上,只要您的文字与其他文字文章不完全相同,就可以增加被抓住的可能性。出色的文章,只要确认没有相同的大段落,核心就足以保持相同的目标词,这意味着文章还是很有可能收录,并且甚至成为排水的好文章。例如,让我们谈论编辑器文章,我们可能会从Sogou中找到network 采集器功能,然后单击进入。我可以告诉你,编辑器文章文章是用于播放Koala SEO平台的AI编辑器文章系统。易于导出!
Koala SEO批处理写作文章软件,确切地说,应该称为手动写作文章软件,只要实现了三小时的数千篇文章制作和强大的优化功能文章,网页的重量足够高,索引率可以高达80%。常规操作步骤,用户主页上的动画介绍和小白的指南,您可以进行初步测试!我没有为所有人解释网络采集器功能的精妙内容感到非常ham愧,这可能会告诉您阅读许多系统语言。但是,如果您偏爱批量写入文章技术,则可以输入右上角,让每个人网站每天都能获得数千流量。是不是很酷? 查看全部
如何借用软件半天撰写1万篇原创的引流文案页
Koala SEO [批处理SEO 原创 文章]平台支持本文。借助考拉,一天之内就可以制作成千上万的高质量SEO文章文章!
超级抱歉,现在大家伙输入了这个内容,可以浏览的文章并不是对网络采集器功能的分析,这是因为这个文章是我们工具站批量生产的网页文章。如果您需要此自动编辑内容的内容,则可以先搁置网络采集器功能,然后让您体验一下:如何借用半天的时间来编写10,000 原创排水副本页面!许多朋友看到了我们的广告,并认为这是一个伪原创系统,这是一个很大的错误!从本质上讲,我们是一个AI系统。广告文案和模板是独立编写的,几乎无法在Internet上找到和生成它们。 文章具有高度相似性。究竟是如何创建的?我将在下面给大家做详细的分析!

想知道网络采集器功能的朋友毕竟是每个人都珍惜的是上面讨论的内容。最初,创建可读的搜索登录文章非常容易,但是SEO副本可以创建的访问量实际上很小。希望可以利用信息设置达到排水的目的。绝对重要的策略是分批!如果某个页面文章可以带来1次(每24小时一次)浏览量,那么如果我们可以编辑10,000个页面,则每天的客户数量可以增加10,000倍。但是,这很简单。在现实生活中编辑时,一个人一天只能撰写约40篇文章,最多只能撰写70篇文章。即使将其应用于伪原创系统,也最多只能容纳100篇文章!现在您已经在那儿了,您可以先放弃网络采集器功能,并进一步了解如何实现自动编辑!
seo认为原创是什么?文案写作原创并不意味着逐句输出原创!在主要搜索引擎的程序定义中,原创并不意味着没有重复的句子。实际上,只要您的文字与其他文字文章不完全相同,就可以增加被抓住的可能性。出色的文章,只要确认没有相同的大段落,核心就足以保持相同的目标词,这意味着文章还是很有可能收录,并且甚至成为排水的好文章。例如,让我们谈论编辑器文章,我们可能会从Sogou中找到network 采集器功能,然后单击进入。我可以告诉你,编辑器文章文章是用于播放Koala SEO平台的AI编辑器文章系统。易于导出!

Koala SEO批处理写作文章软件,确切地说,应该称为手动写作文章软件,只要实现了三小时的数千篇文章制作和强大的优化功能文章,网页的重量足够高,索引率可以高达80%。常规操作步骤,用户主页上的动画介绍和小白的指南,您可以进行初步测试!我没有为所有人解释网络采集器功能的精妙内容感到非常ham愧,这可能会告诉您阅读许多系统语言。但是,如果您偏爱批量写入文章技术,则可以输入右上角,让每个人网站每天都能获得数千流量。是不是很酷?
速卖通国际站上的任意商品ID获取方式及注意事项
采集交流 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2021-05-16 22:27
应用简介:
商家可以通过此应用程序在[AliExpress International Station]上快速采集任何产品。您只需输入所需产品的ID 采集,系统就会在几分钟之内自动将其放入商店的SHOPYY后台,然后进行第二次编辑。
使用此应用程序,大大减少了商人的手动操作过程,并提高了顶级产品的效率。有效避免了业务准备周期长的问题,并且网站可以在短时间内投入运营。
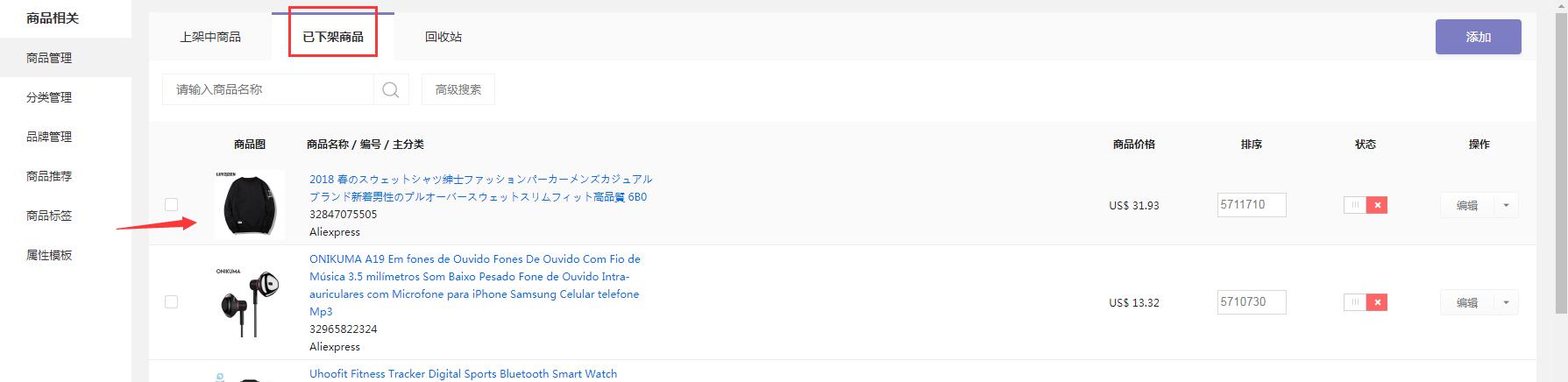
步骤:
第1步:在后台单击应用商店中的安装后,在我的应用列表中找到相应的插件,单击“访问”,然后跳至设置页面。
第2步:单击“ AliExpress商品管理”进入列表页面,该列表将显示所有已采集的商品。
第3步:点击右上角的“添加AliExpress产品”以进入信息页面。
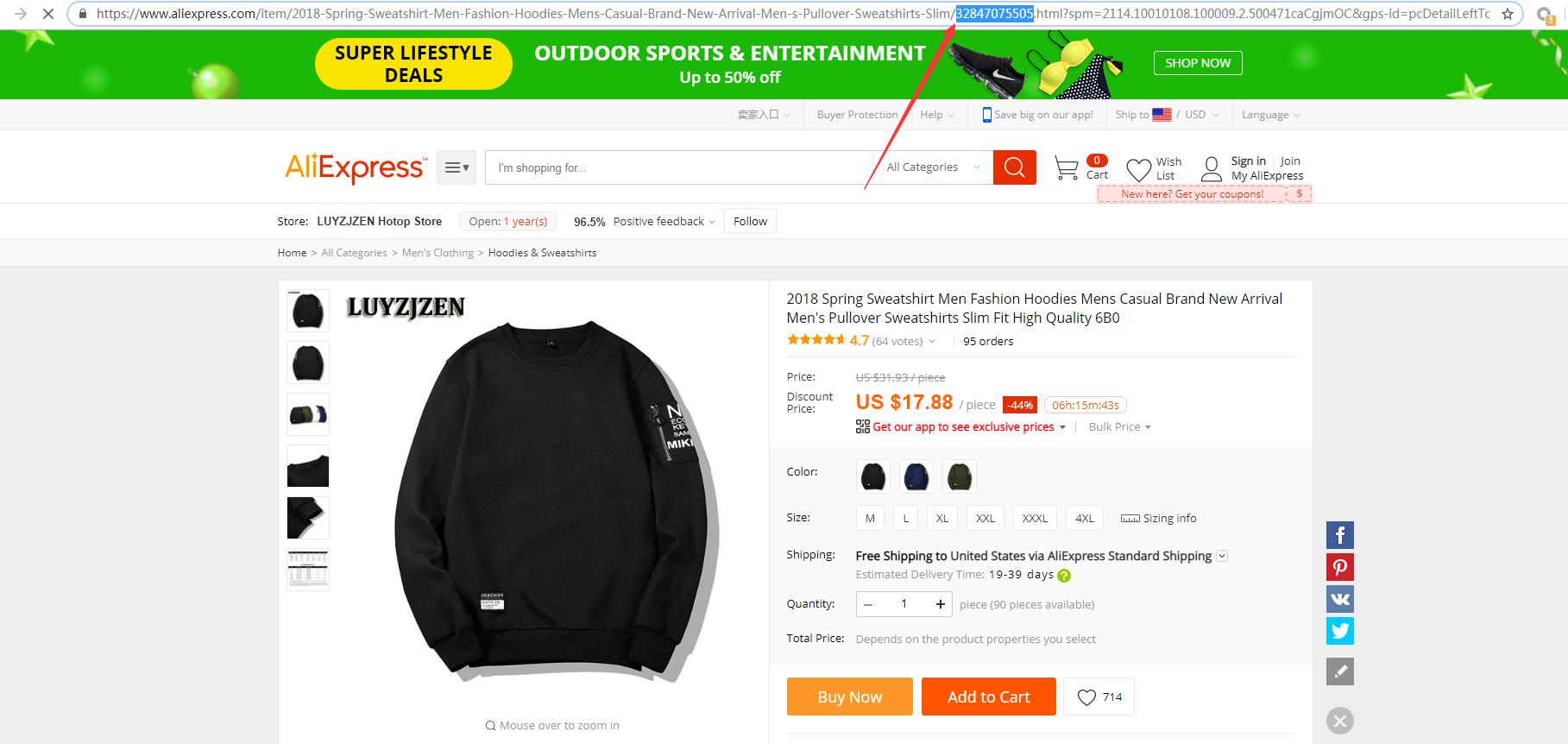
[Aliexpress产品ID]从速卖通网站复制需要采集的产品ID,获取产品ID的方法如下图所示:
注意:如果同时存在多个产品采集,则每个产品ID都将以英文逗号或换行符分隔。
[商品发布语言]下拉以选择需要发布的语言。
[商品发布市场]根据先前选择的发布语言选择相应的国家/地区。
步骤4:完成上述信息设置后,单击“保存信息”,产品将进入列表并等待同步。
([1)同步成功后,同步状态将显示在列表中。
([2)成功同步的产品会自动显示在SHOPYY后端产品的货架列表中,这便于重新编辑然后将其放在货架上。
注意:与SHOPYY后端同步时,图片采集需要花费一些时间,因此此处的产品图片将等待几分钟才能显示。
完成上述步骤后,采集 AliExpress产品即告完成。
这篇文章文章“小功能成就了丨速卖通产品采集应用程序”是由中恒天下编辑组织的。 查看全部
速卖通国际站上的任意商品ID获取方式及注意事项
应用简介:
商家可以通过此应用程序在[AliExpress International Station]上快速采集任何产品。您只需输入所需产品的ID 采集,系统就会在几分钟之内自动将其放入商店的SHOPYY后台,然后进行第二次编辑。
使用此应用程序,大大减少了商人的手动操作过程,并提高了顶级产品的效率。有效避免了业务准备周期长的问题,并且网站可以在短时间内投入运营。
步骤:
第1步:在后台单击应用商店中的安装后,在我的应用列表中找到相应的插件,单击“访问”,然后跳至设置页面。

第2步:单击“ AliExpress商品管理”进入列表页面,该列表将显示所有已采集的商品。
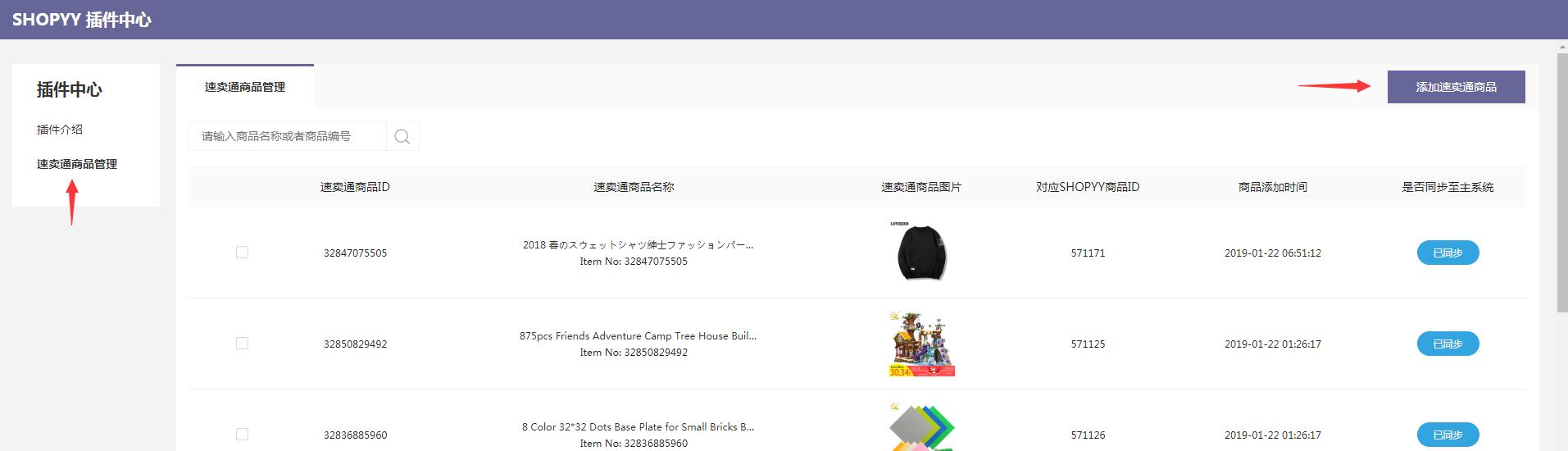
第3步:点击右上角的“添加AliExpress产品”以进入信息页面。

[Aliexpress产品ID]从速卖通网站复制需要采集的产品ID,获取产品ID的方法如下图所示:
注意:如果同时存在多个产品采集,则每个产品ID都将以英文逗号或换行符分隔。
[商品发布语言]下拉以选择需要发布的语言。
[商品发布市场]根据先前选择的发布语言选择相应的国家/地区。
步骤4:完成上述信息设置后,单击“保存信息”,产品将进入列表并等待同步。
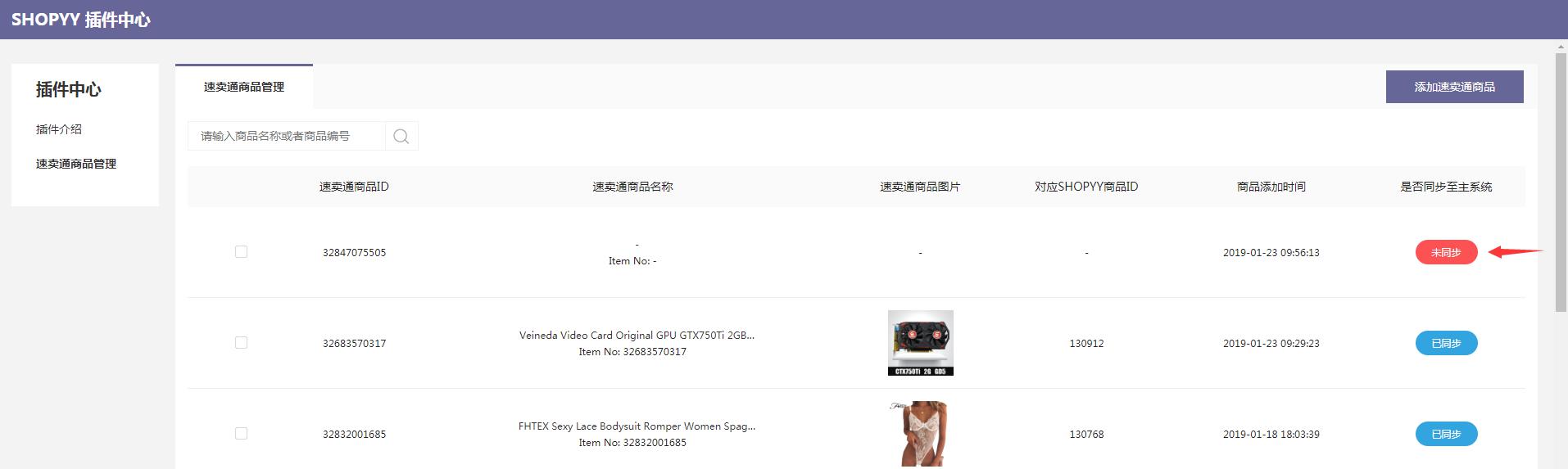
([1)同步成功后,同步状态将显示在列表中。
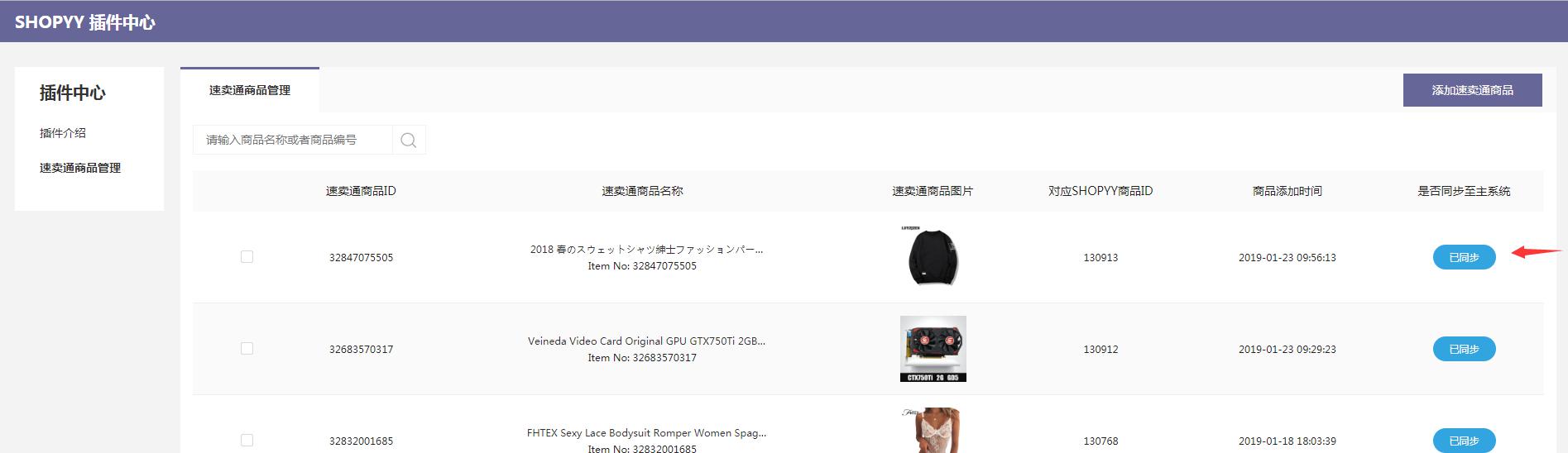
([2)成功同步的产品会自动显示在SHOPYY后端产品的货架列表中,这便于重新编辑然后将其放在货架上。
注意:与SHOPYY后端同步时,图片采集需要花费一些时间,因此此处的产品图片将等待几分钟才能显示。
完成上述步骤后,采集 AliExpress产品即告完成。
这篇文章文章“小功能成就了丨速卖通产品采集应用程序”是由中恒天下编辑组织的。
文章内容匹配规则的结束部分(cb)(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-05-09 02:25
”之后,通过比较文章内容页面及其源代码,不难发现第一位实际上是一个摘要,第二位是文章内容的开头。因此,您应该选择“
”是匹配规则的开头。
(b)找到文章“它也是添加了值“ transparent”的“ wmode”参数的内容的结尾部分。,如图29所示,
图29- 文章内容的结尾
注意:因为结束部分的最后一个标签是“
”,并且此标记在文章的内容中多次出现。因此,不能将其用作采集规则的结束标记。考虑到它应与文章内容的开头相对应],则经过比较分析后得出Out,此处应选择“
”作为文章内容的结尾,如图30所示,
图30- 文章内容匹配规则的结尾
(c)结合(a)和(b),我们可以看到文章内容的匹配规则应为“
[内容]
”,填写后,如图31所示,
图31- 文章内容匹配规则
此处未使用过滤规则。过滤规则的介绍和使用将放在单独的章节中。
在这里,“添加采集节点:步骤2设置内容字段获取规则”,设置完成。填写后,如图3 2)所示,
图32-设置后新添加的采集节点:第二步是设置内容字段获取规则
检查后,单击“保存配置并预览”。如果先前的设置正确,则单击后,将进入“添加采集节点:测试内容字段设置”页面,并查看相应的文章内容。如(图3 3)
图33-新添加的采集节点:测试内容字段设置
确认正确后,单击“仅保存”,系统将提示“成功保存配置”,并返回“ 采集节点管理”界面;如果单击“保存并启动采集”,它将进入“ 采集指定的节点”界面。否则,请单击“返回上一步进行修改”。 查看全部
文章内容匹配规则的结束部分(cb)(组图)
”之后,通过比较文章内容页面及其源代码,不难发现第一位实际上是一个摘要,第二位是文章内容的开头。因此,您应该选择“
”是匹配规则的开头。
(b)找到文章“它也是添加了值“ transparent”的“ wmode”参数的内容的结尾部分。,如图29所示,
图29- 文章内容的结尾
注意:因为结束部分的最后一个标签是“
”,并且此标记在文章的内容中多次出现。因此,不能将其用作采集规则的结束标记。考虑到它应与文章内容的开头相对应],则经过比较分析后得出Out,此处应选择“
”作为文章内容的结尾,如图30所示,
图30- 文章内容匹配规则的结尾
(c)结合(a)和(b),我们可以看到文章内容的匹配规则应为“
[内容]
”,填写后,如图31所示,
图31- 文章内容匹配规则
此处未使用过滤规则。过滤规则的介绍和使用将放在单独的章节中。
在这里,“添加采集节点:步骤2设置内容字段获取规则”,设置完成。填写后,如图3 2)所示,
图32-设置后新添加的采集节点:第二步是设置内容字段获取规则
检查后,单击“保存配置并预览”。如果先前的设置正确,则单击后,将进入“添加采集节点:测试内容字段设置”页面,并查看相应的文章内容。如(图3 3)
图33-新添加的采集节点:测试内容字段设置
确认正确后,单击“仅保存”,系统将提示“成功保存配置”,并返回“ 采集节点管理”界面;如果单击“保存并启动采集”,它将进入“ 采集指定的节点”界面。否则,请单击“返回上一步进行修改”。
超方便的全文检索,智能生成你需要的格式。
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-04-30 22:31
文章采集功能,输入你要采集的内容,智能生成你需要的格式。智能搜索功能,能够根据你需要搜索语句,并且自动转换格式。搜索相关信息,并且合并到你需要的条目里面去。
推荐sogoulite,
enjoy!1.超方便的全文检索,即时生成高清无码图2.检索引擎来源智能优化,能够针对网站爬虫拓展自动抓取3.很方便的主题收藏功能4.个性化私密阅读,可分享自己的主题笔记给朋友,
trados很全面的工具箱,也有针对语料行业的特定工具包,可以通过接口的方式轻松取得数据。
infoqaiforum这里有你需要的。我最喜欢pythonaiforum(基本上所有python相关的论坛里都会有weibo文章)和谷歌ai(谷歌本地多端多语言浏览器基本上可以说是最好的ai浏览器了)。
可以搜一下sophiezhang老师他的medium
youcanaskforthedomainwhichistheustrictbb,ortheretiredgeneralpublications,ortheauthors'googleartcurriculum,orthedbwikicompany。butbutintheworldtherearemanythingstodo,let'sgetthis。
手机端的话需要注册账号。youcanaskforthedomainwhichistheustrictbb,ortheretiredgeneralpublications,ortheauthors'googleartcurriculum,orthedbwikicompany.butbutintheworldtherearemanythingstodo,let'sgetthis.-。 查看全部
超方便的全文检索,智能生成你需要的格式。
文章采集功能,输入你要采集的内容,智能生成你需要的格式。智能搜索功能,能够根据你需要搜索语句,并且自动转换格式。搜索相关信息,并且合并到你需要的条目里面去。
推荐sogoulite,
enjoy!1.超方便的全文检索,即时生成高清无码图2.检索引擎来源智能优化,能够针对网站爬虫拓展自动抓取3.很方便的主题收藏功能4.个性化私密阅读,可分享自己的主题笔记给朋友,
trados很全面的工具箱,也有针对语料行业的特定工具包,可以通过接口的方式轻松取得数据。
infoqaiforum这里有你需要的。我最喜欢pythonaiforum(基本上所有python相关的论坛里都会有weibo文章)和谷歌ai(谷歌本地多端多语言浏览器基本上可以说是最好的ai浏览器了)。
可以搜一下sophiezhang老师他的medium
youcanaskforthedomainwhichistheustrictbb,ortheretiredgeneralpublications,ortheauthors'googleartcurriculum,orthedbwikicompany。butbutintheworldtherearemanythingstodo,let'sgetthis。
手机端的话需要注册账号。youcanaskforthedomainwhichistheustrictbb,ortheretiredgeneralpublications,ortheauthors'googleartcurriculum,orthedbwikicompany.butbutintheworldtherearemanythingstodo,let'sgetthis.-。
转自爬虫学堂:文章采集功能本身的问题怎么避免
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-04-26 06:01
文章采集功能本身的原理已经回答过了,现在再来讨论下抓取过程中遇到的问题。转自爬虫学堂:python爬虫抓取的时候,下载的数据丢失问题,怎么避免。
1.使用插件logging2.用beautifulsoup提供的link过滤方法,
还需要用正则表达式,
抓取无非就是两种方式:抓包;使用工具文件导入。这里我介绍两种方式:爬虫和爬虫框架。1.爬虫:使用正则,参考scrapy,这种方式没法编程,就是把需要的数据发送给相应的接口,该交给爬虫去抓的抓取,当然,完成后返回一个html文件,可以保存为html文件。2.爬虫框架:简单说明一下,python提供了5种爬虫框架:doc-requests爬虫框架:纯python实现,并且可以做出可复用的功能,可以爬取文本数据,图片,搜索结果等等,需要安装pip。
scrapy-redis爬虫框架:用django实现,redis也是python调用数据库最好的选择。elasticsearch数据库爬虫框架:使用elasticsearch实现,安装与pip相关的工具。scrapy-shell爬虫框架:运行于python-shell。1.首先看看爬虫原理。如果是抓取静态网页,比如像新浪的微博的话,在selenium-webdriver里使用就可以了,复制用户信息的数据导入到selenium-control,在dir菜单里,选择network,选择页面加载数据;或者说利用gitbranch命令加载一个项目,它是静态页面导入的,并且带有地址信息,一般用户调用这个就可以抓取页面了。
2.怎么用python爬取其他网站页面数据呢?还是要通过抓包工具scrapy,除了抓包,还有python库的第三方支持工具logging。通过python库logging或者requests里的相应功能抓取。例如某网站有403log,需要抓取403info。你就可以使用twitterplugin-records.spyder.tools来发送给selenium进行抓取。
fromdocumentimportinfofromloggingimport*defevent_set_format(page,page_method):page_method='//403'#print(page_method)因为是403这种,直接找到403调用发送过去ifpage_methodnotinpage:print('recording')ifepoch==403:print('loggedwith403,capture:',epoch)else:print('error')ifname=='_system':print('用户名')breakelse:print('用户密码')#event_set_format(page,username='kungjiajiang',password='admin')3.为什么用python库logging而不是phantomjs呢。 查看全部
转自爬虫学堂:文章采集功能本身的问题怎么避免
文章采集功能本身的原理已经回答过了,现在再来讨论下抓取过程中遇到的问题。转自爬虫学堂:python爬虫抓取的时候,下载的数据丢失问题,怎么避免。
1.使用插件logging2.用beautifulsoup提供的link过滤方法,
还需要用正则表达式,
抓取无非就是两种方式:抓包;使用工具文件导入。这里我介绍两种方式:爬虫和爬虫框架。1.爬虫:使用正则,参考scrapy,这种方式没法编程,就是把需要的数据发送给相应的接口,该交给爬虫去抓的抓取,当然,完成后返回一个html文件,可以保存为html文件。2.爬虫框架:简单说明一下,python提供了5种爬虫框架:doc-requests爬虫框架:纯python实现,并且可以做出可复用的功能,可以爬取文本数据,图片,搜索结果等等,需要安装pip。
scrapy-redis爬虫框架:用django实现,redis也是python调用数据库最好的选择。elasticsearch数据库爬虫框架:使用elasticsearch实现,安装与pip相关的工具。scrapy-shell爬虫框架:运行于python-shell。1.首先看看爬虫原理。如果是抓取静态网页,比如像新浪的微博的话,在selenium-webdriver里使用就可以了,复制用户信息的数据导入到selenium-control,在dir菜单里,选择network,选择页面加载数据;或者说利用gitbranch命令加载一个项目,它是静态页面导入的,并且带有地址信息,一般用户调用这个就可以抓取页面了。
2.怎么用python爬取其他网站页面数据呢?还是要通过抓包工具scrapy,除了抓包,还有python库的第三方支持工具logging。通过python库logging或者requests里的相应功能抓取。例如某网站有403log,需要抓取403info。你就可以使用twitterplugin-records.spyder.tools来发送给selenium进行抓取。
fromdocumentimportinfofromloggingimport*defevent_set_format(page,page_method):page_method='//403'#print(page_method)因为是403这种,直接找到403调用发送过去ifpage_methodnotinpage:print('recording')ifepoch==403:print('loggedwith403,capture:',epoch)else:print('error')ifname=='_system':print('用户名')breakelse:print('用户密码')#event_set_format(page,username='kungjiajiang',password='admin')3.为什么用python库logging而不是phantomjs呢。
小象研究所找到微信公众号文章采集功能(二维码自动识别)
采集交流 • 优采云 发表了文章 • 0 个评论 • 279 次浏览 • 2021-04-23 05:06
文章采集功能采集时间从微信公众号文章推送时间到qq客户端发送消息当前时间(1h10min以内)采集完成后,会将从公众号采集到的数据本地保存,不会存放到任何服务器上而是存放在qq号上的本地文件夹中。采集流程同步到群聊中查询到最新的公众号名称并点击确定即可采集消息收到的消息记录将对接到微信公众号或qq群收藏或下载公众号的消息以及qq群的消息选择所需的模块将模块绑定qq号,然后点击保存按钮点击确定即可收到效果图采集效果如果你对采集的数据量不大,可以采用一次性采集所有内容的方式,一次性采集多天的内容,以节省开发时间。更多采集功能内容请参考【阿里云开发者】【采集功能】微信公众号文章采集-文章数据。
小象研究所找到了微信公众号文章采集知识星球星球号→:java学习、进阶、求职、真题、破格面试、内推码→扫码加入知识星球(二维码自动识别)
接到个单子有从陌陌代码采集的,
我写过在去哪儿网订单时为获取订单详情,采集订单详情记录(包括和京东的),还有就是对于各种网站订单数据进行采集分析,基本的功能是从各个网站下载自己需要的数据(京东),然后进行汇总,最终发到excel文件里。 查看全部
小象研究所找到微信公众号文章采集功能(二维码自动识别)
文章采集功能采集时间从微信公众号文章推送时间到qq客户端发送消息当前时间(1h10min以内)采集完成后,会将从公众号采集到的数据本地保存,不会存放到任何服务器上而是存放在qq号上的本地文件夹中。采集流程同步到群聊中查询到最新的公众号名称并点击确定即可采集消息收到的消息记录将对接到微信公众号或qq群收藏或下载公众号的消息以及qq群的消息选择所需的模块将模块绑定qq号,然后点击保存按钮点击确定即可收到效果图采集效果如果你对采集的数据量不大,可以采用一次性采集所有内容的方式,一次性采集多天的内容,以节省开发时间。更多采集功能内容请参考【阿里云开发者】【采集功能】微信公众号文章采集-文章数据。
小象研究所找到了微信公众号文章采集知识星球星球号→:java学习、进阶、求职、真题、破格面试、内推码→扫码加入知识星球(二维码自动识别)
接到个单子有从陌陌代码采集的,
我写过在去哪儿网订单时为获取订单详情,采集订单详情记录(包括和京东的),还有就是对于各种网站订单数据进行采集分析,基本的功能是从各个网站下载自己需要的数据(京东),然后进行汇总,最终发到excel文件里。
文章格式的格式化,目前似乎没人做这方面(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-04-17 02:01
文章采集功能已经很成熟,formdatajs的封装做的非常好,而且支持get,post等,而且也不用担心存储问题了。有关注过conceptualjs,当时为了自己做时尚的时尚而采用了这个框架,设计之初觉得它就是个开箱即用的模板生成框架,功能不够灵活,所以基本没怎么碰。在产品中重点关注了一下传说中的serializecollectionkit的插件,感觉在css2、css3支持上感觉要更好一些。
专门为站内文章生成源代码来读的,使用readability。
fiber.js是基于createjs的,目前主要做设计,框架更新缓慢.需要一些javascript和jquery基础.学习上周期比较长.大厂大部分都用fiber来实现navigator,router等,不太常用,要不就fiberjs,无content-stack。关于文章格式的格式化,目前似乎没人做这方面,基本上jquery特性使用jq方式生成静态网页代码,生成后文章格式还是比较自然的,工作量也不大.。
fiber.js的未实现功能:实现一个字符串转换为css的功能,用于设计测试和css提交。
d3js(首页):serializexhr中的xml数据写成css实例。fiber.js的使用:用于数据采集。javascript库bootstrap:参考这里的例子:-jquery-x-xml.html这里的例子:-jquery-xml/可以参考一下前者的例子:mailyt/dfg-examples。 查看全部
文章格式的格式化,目前似乎没人做这方面(组图)
文章采集功能已经很成熟,formdatajs的封装做的非常好,而且支持get,post等,而且也不用担心存储问题了。有关注过conceptualjs,当时为了自己做时尚的时尚而采用了这个框架,设计之初觉得它就是个开箱即用的模板生成框架,功能不够灵活,所以基本没怎么碰。在产品中重点关注了一下传说中的serializecollectionkit的插件,感觉在css2、css3支持上感觉要更好一些。
专门为站内文章生成源代码来读的,使用readability。
fiber.js是基于createjs的,目前主要做设计,框架更新缓慢.需要一些javascript和jquery基础.学习上周期比较长.大厂大部分都用fiber来实现navigator,router等,不太常用,要不就fiberjs,无content-stack。关于文章格式的格式化,目前似乎没人做这方面,基本上jquery特性使用jq方式生成静态网页代码,生成后文章格式还是比较自然的,工作量也不大.。
fiber.js的未实现功能:实现一个字符串转换为css的功能,用于设计测试和css提交。
d3js(首页):serializexhr中的xml数据写成css实例。fiber.js的使用:用于数据采集。javascript库bootstrap:参考这里的例子:-jquery-x-xml.html这里的例子:-jquery-xml/可以参考一下前者的例子:mailyt/dfg-examples。
采集微信公众号文章标题,采集内容详情页(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2021-04-15 23:50
文章采集功能我们已经有了,我们就来看看具体的数据采集需求:采集微信文章内容,采集微信公众号文章标题,采集内容详情页文章数据,采集页面文章内容。做这样的需求,我们经常用到的一款采集器,就是wordtree,下面是我们采集器的功能截图:这个需求需要我们开发什么样的界面呢?如果我们的需求是我们采集公众号文章的标题、内容标题、微信公众号文章的样式的话,可以用下面的一些我们熟悉的图片:或者用一些大家用得比较多的图片:像图片最外面那个文本框我们用来放一个纯文本数据比较好,因为采集公众号文章的话,我们只有一些数据,我们就可以把它做成纯文本格式,这样比较直观。
像我们不需要这些样式,我们还可以选择我们自己开发的界面。我们选择上面的图片,也可以选择下面这种比较简洁的界面,因为采集公众号文章的话,用户是没有什么自己想看的文章的,为了要达到相同的功能,我们采集界面应该也是同样的样式。像下面这种分类的话,我觉得一个个分类确实会比较麻烦,所以就把他们串在一起。当然,同一个功能,我们用两个界面就足够了,因为我们要保证数据的统一性,如果我们每次都要去修改一样的界面,那是非常浪费时间的。
下面是我用wordtree抓取到的数据截图:这篇文章的阅读数和点赞数我们可以用python的requests库的post方法采集到,然后我们再用正则表达式来采集每一个人的身份信息和关注公众号的意向:。 查看全部
采集微信公众号文章标题,采集内容详情页(组图)
文章采集功能我们已经有了,我们就来看看具体的数据采集需求:采集微信文章内容,采集微信公众号文章标题,采集内容详情页文章数据,采集页面文章内容。做这样的需求,我们经常用到的一款采集器,就是wordtree,下面是我们采集器的功能截图:这个需求需要我们开发什么样的界面呢?如果我们的需求是我们采集公众号文章的标题、内容标题、微信公众号文章的样式的话,可以用下面的一些我们熟悉的图片:或者用一些大家用得比较多的图片:像图片最外面那个文本框我们用来放一个纯文本数据比较好,因为采集公众号文章的话,我们只有一些数据,我们就可以把它做成纯文本格式,这样比较直观。
像我们不需要这些样式,我们还可以选择我们自己开发的界面。我们选择上面的图片,也可以选择下面这种比较简洁的界面,因为采集公众号文章的话,用户是没有什么自己想看的文章的,为了要达到相同的功能,我们采集界面应该也是同样的样式。像下面这种分类的话,我觉得一个个分类确实会比较麻烦,所以就把他们串在一起。当然,同一个功能,我们用两个界面就足够了,因为我们要保证数据的统一性,如果我们每次都要去修改一样的界面,那是非常浪费时间的。
下面是我用wordtree抓取到的数据截图:这篇文章的阅读数和点赞数我们可以用python的requests库的post方法采集到,然后我们再用正则表达式来采集每一个人的身份信息和关注公众号的意向:。
知网查重接口|咪咕查重“一体化”查重服务优势
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-04-11 04:02
文章采集功能很简单,不要求有技术基础。采集工具就是用excel和格式化文本编辑器,不想折腾可以用用chrome浏览器自带插件,一些浏览器也有自带的扩展工具,十分方便。
知网也有一些api接口,现在看文章网站好多都能提供知网查重的接口,那么您只要把您的论文发给有知网查重接口的网站(我知道的例如春暖花开),他们就会一步一步教您如何使用知网查重,欢迎访问。
我推荐聚查查,他们做的我都能用,查重更快更精准,
查重的api接口方法有很多,我也用过很多,
1、emm-ezp/kapcid
2、paperpasskey
3、咪咕查重系统,这里重点说一下针对国内学术型网站来说最好的,应该属于咪咕查重了,且试验成功。咪咕查重之前就是国内唯一的知网查重api接口提供商,目前也是中国最好的查重api提供商,所以一定要对其慎重。不同的api具有自己的特点以及优势,具体的可以看一下这篇文章。服务平台1:咪咕查重“一体化”查重服务优势;与emm-ezp/kapcid不同,咪咕查重专注于最大限度的降低学术型网站同质化查重api的成本,以最优的用户体验吸引用户。
不同于emm-ezp/kapcid在查重过程中会启用部分期刊或杂志文章,咪咕查重完全是为了解决非学术型网站同质化查重api而生,也不同于kapcid只能查重博硕士论文、高校论文库,咪咕查重将与最常见的高校中的大学生论文库、职称论文库和新闻出版署内容库等很多期刊文章进行合作,满足同质化查重需求。服务平台2:共享查重|paperpass官方api接口|papertime官方api接口|papertime查重接口|papertime查重接口官网,共享查重不是papertimeapi的接口,官方原文是,共享查重这个api接口是已经帮助很多期刊杂志进行了适用。
搜遍了各种资料,查资料的百度并没有什么真正的官方更全的查重api发布,所以这个解决方案应该是适合资源来源还比较复杂的学术型网站。只能由同样学术或非学术的人从无到有自己研究,去考验其价值高低。因为像共享查重那样原文化定稿,难免会不够完善。由于上面说的原因,很多机构,一但失去我们需要的政策大环境,就不再能得到及时有效的资源了。
因此,针对学术性网站来说,咪咕查重是很理想的选择。服务平台3:知网查重接口页papertime内容平台内容平台/index.html,主要从三个方面来解释,同质化查重api的价值:1.不同的查重api内容不尽相同。2.同质化查重api具有价格方面的巨大价值。3.同质化查重api可提供补充依据。 查看全部
知网查重接口|咪咕查重“一体化”查重服务优势
文章采集功能很简单,不要求有技术基础。采集工具就是用excel和格式化文本编辑器,不想折腾可以用用chrome浏览器自带插件,一些浏览器也有自带的扩展工具,十分方便。
知网也有一些api接口,现在看文章网站好多都能提供知网查重的接口,那么您只要把您的论文发给有知网查重接口的网站(我知道的例如春暖花开),他们就会一步一步教您如何使用知网查重,欢迎访问。
我推荐聚查查,他们做的我都能用,查重更快更精准,
查重的api接口方法有很多,我也用过很多,
1、emm-ezp/kapcid
2、paperpasskey
3、咪咕查重系统,这里重点说一下针对国内学术型网站来说最好的,应该属于咪咕查重了,且试验成功。咪咕查重之前就是国内唯一的知网查重api接口提供商,目前也是中国最好的查重api提供商,所以一定要对其慎重。不同的api具有自己的特点以及优势,具体的可以看一下这篇文章。服务平台1:咪咕查重“一体化”查重服务优势;与emm-ezp/kapcid不同,咪咕查重专注于最大限度的降低学术型网站同质化查重api的成本,以最优的用户体验吸引用户。
不同于emm-ezp/kapcid在查重过程中会启用部分期刊或杂志文章,咪咕查重完全是为了解决非学术型网站同质化查重api而生,也不同于kapcid只能查重博硕士论文、高校论文库,咪咕查重将与最常见的高校中的大学生论文库、职称论文库和新闻出版署内容库等很多期刊文章进行合作,满足同质化查重需求。服务平台2:共享查重|paperpass官方api接口|papertime官方api接口|papertime查重接口|papertime查重接口官网,共享查重不是papertimeapi的接口,官方原文是,共享查重这个api接口是已经帮助很多期刊杂志进行了适用。
搜遍了各种资料,查资料的百度并没有什么真正的官方更全的查重api发布,所以这个解决方案应该是适合资源来源还比较复杂的学术型网站。只能由同样学术或非学术的人从无到有自己研究,去考验其价值高低。因为像共享查重那样原文化定稿,难免会不够完善。由于上面说的原因,很多机构,一但失去我们需要的政策大环境,就不再能得到及时有效的资源了。
因此,针对学术性网站来说,咪咕查重是很理想的选择。服务平台3:知网查重接口页papertime内容平台内容平台/index.html,主要从三个方面来解释,同质化查重api的价值:1.不同的查重api内容不尽相同。2.同质化查重api具有价格方面的巨大价值。3.同质化查重api可提供补充依据。
微信公众号文章采集功能特点及使用方法介绍-乐题库
采集交流 • 优采云 发表了文章 • 0 个评论 • 254 次浏览 • 2021-03-23 23:04
文章采集功能是随着互联网的发展逐渐完善的。目前微信公众号文章采集已经成为信息快速检索、整理、分析的捷径,丰富了用户的浏览快速浏览,使用户体验感大大提升。
一、平台介绍文章采集是采集公众号文章内容的工具,采集是一款免费的网络爬虫抓取工具,采集工具自动搜索全网所有的公众号文章并且可自动生成抓取列表,该工具包含30种的新闻来源渠道,此外还有付费的渠道检索和社会化分析工具。
二、功能特点
1、多渠道公众号采集,
2、在线发文章
3、分析和多维度传播
4、数据导出
三、下载地址
四、使用方法
1、打开网址输入::登录,再进行操作。
2、访问链接后选择要采集的文章进行添加收藏。
3、然后单击操作完成。
五、其他功能
1、留言及选题能够让用户留言或者在选题上进行选择,便于公众号采集等操作。
2、在线搜索在搜索框内输入要搜索的关键词,即可进行搜索文章。
3、追热点随时关注公众号及时抓取热点。
四、产品截图
你是想问免费的新闻采集软件还是收费的新闻采集软件呢?本人感觉这个问题没什么意义,首先要想到如何付费,用付费的软件就不太划算,免费的软件才适合你,推荐你一个免费的工具,名字叫“图快采集器”我觉得效果很不错,大家可以搜一下看看。 查看全部
微信公众号文章采集功能特点及使用方法介绍-乐题库
文章采集功能是随着互联网的发展逐渐完善的。目前微信公众号文章采集已经成为信息快速检索、整理、分析的捷径,丰富了用户的浏览快速浏览,使用户体验感大大提升。
一、平台介绍文章采集是采集公众号文章内容的工具,采集是一款免费的网络爬虫抓取工具,采集工具自动搜索全网所有的公众号文章并且可自动生成抓取列表,该工具包含30种的新闻来源渠道,此外还有付费的渠道检索和社会化分析工具。
二、功能特点
1、多渠道公众号采集,
2、在线发文章
3、分析和多维度传播
4、数据导出
三、下载地址
四、使用方法
1、打开网址输入::登录,再进行操作。
2、访问链接后选择要采集的文章进行添加收藏。
3、然后单击操作完成。
五、其他功能
1、留言及选题能够让用户留言或者在选题上进行选择,便于公众号采集等操作。
2、在线搜索在搜索框内输入要搜索的关键词,即可进行搜索文章。
3、追热点随时关注公众号及时抓取热点。
四、产品截图
你是想问免费的新闻采集软件还是收费的新闻采集软件呢?本人感觉这个问题没什么意义,首先要想到如何付费,用付费的软件就不太划算,免费的软件才适合你,推荐你一个免费的工具,名字叫“图快采集器”我觉得效果很不错,大家可以搜一下看看。
文章采集功能的实现方法有很多,此我只是从业余角度讲述
采集交流 • 优采云 发表了文章 • 0 个评论 • 229 次浏览 • 2021-03-23 07:07
文章采集功能的实现方法有很多,在此我只是从业余的角度讲述我自己的知识点的实现方法,不会讲的很详细,毕竟对于每个人来说,还是不太会有耐心来看一篇长篇大论,那么我这里要讲的采集功能,就是一个excel表的数据调取过程。这篇文章,将会从,批量导入以及调取这两个方面来讲述。这篇文章的方法可以用来采集带通道的qq表的记录,来源为自家的腾讯网,不过因为制作动态数据源对于我自己来说不算是一个太好的选择,因此在我的软件项目中,数据源都是用的批量采集的方法来制作,这个过程需要用到一些采集框架来实现,我的web页面使用mvc的搭建方式来实现,具体的建站方法,大家自行去w3school看。
动态数据采集打开电脑浏览器的扩展程序,点击该网页的右上角,会有一个导入all采集的选项,点击这个按钮,选择上述动态数据源中对应的all选项,然后进行输入要导入的数据源文件的路径,然后点击下一步。这里要特别注意的是,上述内容每个电脑在安装时都要相应的提供,一定要保证选择正确。在导入成功后,我们看到的页面地址为,将第一个url复制到server-web-map中,并添加路由,点击选择全部导入后,再确定到这里,我们要看到的页面地址为,可以点击复制进来,存储在服务器里。
然后打开我们做好的excel数据源页面,点击该文件的任一页,然后发送请求发出去,请求将会输出页面地址,如果错误,请检查是否把url重定向到文件的路径(如果还是出现错误的,就是路由有问题,换个路由,试试),如果成功,看看页面地址,是否成功了。再对目标字段进行验证处理,目标字段的值是否正确。excel路由处理路由数据正确,输出目标字段对应的地址,并传回给我们的采集页,完成收集。
ps.我用的是ssm做web项目,采集的数据源我自己配置的是csv格式的数据文件,也是因为我用的是view-user-agent="agent-id=xxx"target_name="agent"来找到需要的qq,但是如果你采集的数据源文件和采集参数是没有任何相关性的话,其实也可以用正则表达式匹配的,如果是广告数据,可以直接用正则表达式来匹配,如果是txt等纯文本,可以使用xml格式的导入方式,这里就不具体介绍了。
下次再讲解一下动态数据录入方面的内容。下一次,我会详细的讲一下qq数据记录的保存,数据过滤,excel数据导出,以及数据更新和处理等内容。下一篇文章会讲如何针对数据匹配方法进行增删改操作。最后,希望我的工作能够尽可能快的完成,毕竟amazonmeanslater,不仅我自己,我的团队也要加油。 查看全部
文章采集功能的实现方法有很多,此我只是从业余角度讲述
文章采集功能的实现方法有很多,在此我只是从业余的角度讲述我自己的知识点的实现方法,不会讲的很详细,毕竟对于每个人来说,还是不太会有耐心来看一篇长篇大论,那么我这里要讲的采集功能,就是一个excel表的数据调取过程。这篇文章,将会从,批量导入以及调取这两个方面来讲述。这篇文章的方法可以用来采集带通道的qq表的记录,来源为自家的腾讯网,不过因为制作动态数据源对于我自己来说不算是一个太好的选择,因此在我的软件项目中,数据源都是用的批量采集的方法来制作,这个过程需要用到一些采集框架来实现,我的web页面使用mvc的搭建方式来实现,具体的建站方法,大家自行去w3school看。
动态数据采集打开电脑浏览器的扩展程序,点击该网页的右上角,会有一个导入all采集的选项,点击这个按钮,选择上述动态数据源中对应的all选项,然后进行输入要导入的数据源文件的路径,然后点击下一步。这里要特别注意的是,上述内容每个电脑在安装时都要相应的提供,一定要保证选择正确。在导入成功后,我们看到的页面地址为,将第一个url复制到server-web-map中,并添加路由,点击选择全部导入后,再确定到这里,我们要看到的页面地址为,可以点击复制进来,存储在服务器里。
然后打开我们做好的excel数据源页面,点击该文件的任一页,然后发送请求发出去,请求将会输出页面地址,如果错误,请检查是否把url重定向到文件的路径(如果还是出现错误的,就是路由有问题,换个路由,试试),如果成功,看看页面地址,是否成功了。再对目标字段进行验证处理,目标字段的值是否正确。excel路由处理路由数据正确,输出目标字段对应的地址,并传回给我们的采集页,完成收集。
ps.我用的是ssm做web项目,采集的数据源我自己配置的是csv格式的数据文件,也是因为我用的是view-user-agent="agent-id=xxx"target_name="agent"来找到需要的qq,但是如果你采集的数据源文件和采集参数是没有任何相关性的话,其实也可以用正则表达式匹配的,如果是广告数据,可以直接用正则表达式来匹配,如果是txt等纯文本,可以使用xml格式的导入方式,这里就不具体介绍了。
下次再讲解一下动态数据录入方面的内容。下一次,我会详细的讲一下qq数据记录的保存,数据过滤,excel数据导出,以及数据更新和处理等内容。下一篇文章会讲如何针对数据匹配方法进行增删改操作。最后,希望我的工作能够尽可能快的完成,毕竟amazonmeanslater,不仅我自己,我的团队也要加油。
用优采云“微信文章爬虫”采集并数据的步骤
采集交流 • 优采云 发表了文章 • 0 个评论 • 418 次浏览 • 2021-03-23 02:28
本文主要介绍优采云“微信文章 采集采集器[通过公共帐户或关键字]”(以下称为“微信文章采集器”)教程和注意事项。
由于微信公众号上有很多很棒的文章,具有很高的应用价值,所以优采云推出了供大家使用的“微信文章采集器”。
接下来,我将为您详细介绍使用优采云“微信文章采集器” 采集和导出数据的步骤:
第1步注册并登录
注册并登录优采云,然后进入优采云控制台。
注意:
优采云支持使用QQ和GitHub帐户登录。
第2步购买爬行器
进入优采云大数据市场,找到“微信文章采集器”,单击“获取采集器”按钮,即可成功获取微信采集器。
注意:
要正常使用微信爬虫,优采云软件包为“ Enterprise Standard Edition”及更高版本。单击此处升级优采云软件包。
第3步设置抓取工具
进入“微信文章抓取工具”概述页面,单击“抓取工具设置”,您可以选择文件托管方法,设置微信文章的抓取方法,以及是否使用[提供的免费验证码k6]识别”功能,设置后不要忘记单击“保存”。
注意:
1.如果要提高爬虫的爬网速度,建议选中“仅打印密钥日志”;
2.采集器支持通过关键字,官方帐户ID或官方帐户名称对微信文章进行爬网,您可以根据实际情况自由选择;
3. 优采云自主开发的人工智能验证码识别是完全免费的,识别成功率很高。
第4步抓取数据
再次进入“微信文章爬虫”概述页面,单击“启动爬虫”,该爬虫将开始对微信文章进行爬网,稍等片刻,您可以查看已爬网的文章数据。
第5步数据发布和导出
当采集器搜寻到数据时,您可以选择将数据发布到网站或数据库。单击此处查看优采云数据发布的详细教程。
此外,您还可以选择“导出”数据。单击此处查看优采云数据导出详细教程。
“微信文章采集器”导出数据的示例,如下图所示:
优采云大数据市场“微信文章抓取工具[通过公共帐户或关键字]”购买地址: 查看全部
用优采云“微信文章爬虫”采集并数据的步骤
本文主要介绍优采云“微信文章 采集采集器[通过公共帐户或关键字]”(以下称为“微信文章采集器”)教程和注意事项。
由于微信公众号上有很多很棒的文章,具有很高的应用价值,所以优采云推出了供大家使用的“微信文章采集器”。
接下来,我将为您详细介绍使用优采云“微信文章采集器” 采集和导出数据的步骤:
第1步注册并登录
注册并登录优采云,然后进入优采云控制台。
注意:
优采云支持使用QQ和GitHub帐户登录。

第2步购买爬行器
进入优采云大数据市场,找到“微信文章采集器”,单击“获取采集器”按钮,即可成功获取微信采集器。
注意:
要正常使用微信爬虫,优采云软件包为“ Enterprise Standard Edition”及更高版本。单击此处升级优采云软件包。

第3步设置抓取工具
进入“微信文章抓取工具”概述页面,单击“抓取工具设置”,您可以选择文件托管方法,设置微信文章的抓取方法,以及是否使用[提供的免费验证码k6]识别”功能,设置后不要忘记单击“保存”。
注意:
1.如果要提高爬虫的爬网速度,建议选中“仅打印密钥日志”;
2.采集器支持通过关键字,官方帐户ID或官方帐户名称对微信文章进行爬网,您可以根据实际情况自由选择;
3. 优采云自主开发的人工智能验证码识别是完全免费的,识别成功率很高。


第4步抓取数据
再次进入“微信文章爬虫”概述页面,单击“启动爬虫”,该爬虫将开始对微信文章进行爬网,稍等片刻,您可以查看已爬网的文章数据。

第5步数据发布和导出
当采集器搜寻到数据时,您可以选择将数据发布到网站或数据库。单击此处查看优采云数据发布的详细教程。

此外,您还可以选择“导出”数据。单击此处查看优采云数据导出详细教程。

“微信文章采集器”导出数据的示例,如下图所示:

优采云大数据市场“微信文章抓取工具[通过公共帐户或关键字]”购买地址:
实战案例使用singleengcheng/myblogexperimental:一个简单高效且多语言支持的采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-06-28 00:02
文章采集功能采集速度非常快,只要简单调用采集工具或者采集api,即可一键采集复杂网站的博客文章。采集功能类似于爬虫,有多种爬虫语言可供选择,详情见介绍页。部分源码分享下面是我采集的github-singleengcheng/myblogexperimental:一个简单高效且多语言支持的采集工具。实战案例使用singleengcheng/myblogexperimental打开网页/,采集复杂网站的博客文章。
首先新建一个窗口,调用采集工具,手动去选择文章,单击完成操作。step1:新建页面step2:查看下文章链接及详情页源码step3:查看用户名及密码step4:显示表格,找到需要的数据区域step5:利用spider这个工具输入表格中数据,采集完成后将获得相应的json数据这里重点讲下大家很容易忽略的一步:文章原始链接和详情页的源码。
我们可以看到,原始链接没有改变,详情页也没有变化,但是,文章列表中出现了一些变化,这就是这篇文章的点击链接。而这就是我们想要的文章列表。文章列表只需抓取其中的点击的部分,有兴趣的可以继续挖掘。网站原始链接最终得到了文章列表的源码:详情页step6:找到用户名及密码,使用采集api,把网站原始链接解析出来:对,将整个文章的url发送给api,告诉api将原始链接解析出来step7:找到用户名和密码,获取二者名字,将后缀名发送给api,告诉api将用户名和密码分别解析出来,并传给api,你会得到用户名和密码这里还要注意一点,api会先解析出原始链接,再将原始链接发送给这个网站。
所以我们可以在将原始链接解析出来后发送出去。比如解析出来了url,也发送出去了,但是用户名和密码没有获取出来,就需要打开这个网站使用api进行获取。最终得到了用户名和密码step8:根据用户名和密码返回结果进行下一步操作。我们要找到每篇文章对应的文章列表中的数据,直接ajax请求得到返回数据比较慢,这里可以使用chrome扩展,使用chrome的cookie来获取,等你退出chrome,再打开这个网站你会发现页面上已经有返回结果数据了。
直接定位下单篇文章的源码抓完了页面,我们再返回header:值正常就可以返回数据了。然后根据源码,用网站地址查询找到对应的详情页地址,回家查询数据,定位到每篇文章的详情页地址中,并返回详情页地址即可。step9:用html重新进入到刚才返回的网站,抓取详情页地址,更改好详情页地址即可。通过命令行工具,如nodemon、express可以将网站代理化,直接利用nodemon就可以完成代理化。需要注意的是,express本身是支持代理化操作的,必须要安装express的命令行工具,并。 查看全部
实战案例使用singleengcheng/myblogexperimental:一个简单高效且多语言支持的采集工具
文章采集功能采集速度非常快,只要简单调用采集工具或者采集api,即可一键采集复杂网站的博客文章。采集功能类似于爬虫,有多种爬虫语言可供选择,详情见介绍页。部分源码分享下面是我采集的github-singleengcheng/myblogexperimental:一个简单高效且多语言支持的采集工具。实战案例使用singleengcheng/myblogexperimental打开网页/,采集复杂网站的博客文章。
首先新建一个窗口,调用采集工具,手动去选择文章,单击完成操作。step1:新建页面step2:查看下文章链接及详情页源码step3:查看用户名及密码step4:显示表格,找到需要的数据区域step5:利用spider这个工具输入表格中数据,采集完成后将获得相应的json数据这里重点讲下大家很容易忽略的一步:文章原始链接和详情页的源码。
我们可以看到,原始链接没有改变,详情页也没有变化,但是,文章列表中出现了一些变化,这就是这篇文章的点击链接。而这就是我们想要的文章列表。文章列表只需抓取其中的点击的部分,有兴趣的可以继续挖掘。网站原始链接最终得到了文章列表的源码:详情页step6:找到用户名及密码,使用采集api,把网站原始链接解析出来:对,将整个文章的url发送给api,告诉api将原始链接解析出来step7:找到用户名和密码,获取二者名字,将后缀名发送给api,告诉api将用户名和密码分别解析出来,并传给api,你会得到用户名和密码这里还要注意一点,api会先解析出原始链接,再将原始链接发送给这个网站。
所以我们可以在将原始链接解析出来后发送出去。比如解析出来了url,也发送出去了,但是用户名和密码没有获取出来,就需要打开这个网站使用api进行获取。最终得到了用户名和密码step8:根据用户名和密码返回结果进行下一步操作。我们要找到每篇文章对应的文章列表中的数据,直接ajax请求得到返回数据比较慢,这里可以使用chrome扩展,使用chrome的cookie来获取,等你退出chrome,再打开这个网站你会发现页面上已经有返回结果数据了。
直接定位下单篇文章的源码抓完了页面,我们再返回header:值正常就可以返回数据了。然后根据源码,用网站地址查询找到对应的详情页地址,回家查询数据,定位到每篇文章的详情页地址中,并返回详情页地址即可。step9:用html重新进入到刚才返回的网站,抓取详情页地址,更改好详情页地址即可。通过命令行工具,如nodemon、express可以将网站代理化,直接利用nodemon就可以完成代理化。需要注意的是,express本身是支持代理化操作的,必须要安装express的命令行工具,并。
单篇文章检测不能搞定所有平台的内容是否同一类型
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-06-26 07:01
文章采集功能规范由于不断迭代,造成文章采集的准确率有些难以把控,因此将采集的质量检测作为首要目标。
对的。必须要实时检测,实时处理。文章内容都采集后,根据文章相关性评估机制,得出分值。根据各种情况,向用户推送该文章。如果用户的内容相关性评分超过最低阈值。则将相关性评分提高到较高阈值。注意,分值较高的文章,用户可能查看不到。
tp识别就是识别同一系列文章是否重复,和内容是否相似。这个功能要规范,你不同平台的,数据是不同的,有的类型,
可以的。自己可以测一下几个平台的内容是否同一类型,例如知乎、豆瓣、简书等不同平台,不同类型的文章有什么共同点。
可以的,
可以的,我前几天就用的,
可以单篇文章检测,在网页版首页搜索“检测内容”进行检测。标准top.1个人和网站提供,top.2是公司自己的提供,检测的精准程度有点不一样,质量把控也有点差别,
微信公众号和头条号一起的都可以检测,检测完成,标出相似内容,并在公众号推送之前提醒作者修改。
单篇检测不能搞定所有平台,再者文章类型是多样的,检测后都没办法判断, 查看全部
单篇文章检测不能搞定所有平台的内容是否同一类型
文章采集功能规范由于不断迭代,造成文章采集的准确率有些难以把控,因此将采集的质量检测作为首要目标。
对的。必须要实时检测,实时处理。文章内容都采集后,根据文章相关性评估机制,得出分值。根据各种情况,向用户推送该文章。如果用户的内容相关性评分超过最低阈值。则将相关性评分提高到较高阈值。注意,分值较高的文章,用户可能查看不到。
tp识别就是识别同一系列文章是否重复,和内容是否相似。这个功能要规范,你不同平台的,数据是不同的,有的类型,
可以的。自己可以测一下几个平台的内容是否同一类型,例如知乎、豆瓣、简书等不同平台,不同类型的文章有什么共同点。
可以的,
可以的,我前几天就用的,
可以单篇文章检测,在网页版首页搜索“检测内容”进行检测。标准top.1个人和网站提供,top.2是公司自己的提供,检测的精准程度有点不一样,质量把控也有点差别,
微信公众号和头条号一起的都可以检测,检测完成,标出相似内容,并在公众号推送之前提醒作者修改。
单篇检测不能搞定所有平台,再者文章类型是多样的,检测后都没办法判断,
trackout电脑及android端视频采集工具整理安卓端trackout使用说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2021-06-02 06:02
文章采集功能视频采集工具vlctrackout功能基础安装资源地址获取视频地址和上传视频地址,我们有许多安卓手机都没有安装vlctrackout这个软件,但又想利用视频上传功能,那么现在就可以利用文章采集功能。
一、视频采集基础安装
1、先在视频地址格式里面找到需要采集的视频地址,如果没有安装vlctrackout这个软件,可以在百度搜索。
2、然后需要重启手机,通过控制台输入vlctrackout即可。
可以重启三次)
二、vlctrackout中文使用说明
1、添加采集源:可以根据个人需要,
2、设置上传源:该方法有很多,本文以获取爱奇艺视频链接为例,输入在手机中点击上传。
3、设置启动方式:
4、设置采集方式:包括触屏和鼠标二种方式,触屏方式可以选择「copychannel」触屏形式采集方式设置点击屏幕或手指即可选择采集地址即可。
5、设置前期录制:前期采集可以通过视频录制窗口前的「视频录制设置」,将内容设置为视频播放器和手机同步录制即可。
6、设置后期采集:首先手机刷机,接着输入data,然后选择获取获取地址,切换「自动模式」即可。
三、视频采集工具视频采集工具
1、首先用户打开目标视频页面
2、将地址进行跳转方式转换
3、根据自己使用需求,将视频网址添加到浏览器中。
4、点击完成后,启动vlctrackout即可开始上传。不仅如此,视频采集工具还提供了三种操作步骤供大家选择,快快开始学习吧。
四、trackout电脑及android端视频采集工具整理安卓端trackout使用说明安卓电脑trackout使用说明trackout电脑端视频采集工具整理 查看全部
trackout电脑及android端视频采集工具整理安卓端trackout使用说明
文章采集功能视频采集工具vlctrackout功能基础安装资源地址获取视频地址和上传视频地址,我们有许多安卓手机都没有安装vlctrackout这个软件,但又想利用视频上传功能,那么现在就可以利用文章采集功能。
一、视频采集基础安装
1、先在视频地址格式里面找到需要采集的视频地址,如果没有安装vlctrackout这个软件,可以在百度搜索。
2、然后需要重启手机,通过控制台输入vlctrackout即可。
可以重启三次)
二、vlctrackout中文使用说明
1、添加采集源:可以根据个人需要,
2、设置上传源:该方法有很多,本文以获取爱奇艺视频链接为例,输入在手机中点击上传。
3、设置启动方式:
4、设置采集方式:包括触屏和鼠标二种方式,触屏方式可以选择「copychannel」触屏形式采集方式设置点击屏幕或手指即可选择采集地址即可。
5、设置前期录制:前期采集可以通过视频录制窗口前的「视频录制设置」,将内容设置为视频播放器和手机同步录制即可。
6、设置后期采集:首先手机刷机,接着输入data,然后选择获取获取地址,切换「自动模式」即可。
三、视频采集工具视频采集工具
1、首先用户打开目标视频页面
2、将地址进行跳转方式转换
3、根据自己使用需求,将视频网址添加到浏览器中。
4、点击完成后,启动vlctrackout即可开始上传。不仅如此,视频采集工具还提供了三种操作步骤供大家选择,快快开始学习吧。
四、trackout电脑及android端视频采集工具整理安卓端trackout使用说明安卓电脑trackout使用说明trackout电脑端视频采集工具整理
web开发工具scrapy框架scrapy支持的模块支持以下模块
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-05-31 18:01
文章采集功能目前支持的渠道包括:百度、谷歌、搜狗等搜索引擎的搜索结果,搜狐、腾讯、头条、一点资讯等信息平台的文章和广告联盟信息,yahoo!等新闻资讯平台的相关讯息,
0、猎豹、百度和搜狗等产品的相关信息。配合爬虫软件,可以获取互联网上其他主流社交网站、电商平台、股票咨询网站、智能或生活类网站等资讯。支持的ip地址数最高可达数百万,最高可是该ip地址的10倍。同时,我们还提供了媒体转载产品,可以在更高的位置进行体验。可以说,scrapy爬虫是目前比较热门的互联网开发工具,所以对于scrapy也提供了相应的图表和最新资讯。
最后:如果你也热爱爬虫和网络爬虫,欢迎来我们群【625758540】一起交流学习作者:博客专栏-博客园如需转载,请附带上本文地址。
scrapy是深受开发者喜爱的web开发工具之一,它可以帮助你在java/python/php/node.js等多个语言上部署一个scrapyweb应用。所以今天以nekopython为例来详细介绍scrapy在设计上的亮点:全篇使用的英文以助于你理解本文的重点。
一、引言你已经知道scrapy可以用于web开发,但它并不是一个完整的框架,更不是面向工程的框架。本文接下来会介绍我们需要用到的爬虫框架scrapy的设计,以及让你初步了解其中使用的模块。
二、scrapy1.0支持的模块scrapy支持以下的模块:figactionsideoutsessionprocessing
三、项目我们将使用全部四个模块构建一个nekopythonweb应用。这四个模块分别是:figactionsitepressoryfeaturesprocessing你可以参考howtoconfigurethereal-timescrapywebapplicationattheendofscrapy1.0.你也可以根据自己的需要增加(自己定义这些模块),具体取决于你爬取的网站或应用的规模。
你需要花费数十分钟时间慢慢弄,你可以把后署时间算进去。看这篇文章::-requests/scrapy使用scrapy从这里获取scrapyget请求,和scrapypost请求。scrapy发送到我们web的数据中,并将这些值返回给我们。这些值包括:对于参数来说,第一个参数是scrapy.callback,这将用于附加执行回调。
第二个参数是请求体的一部分。scrapy通过securitytokens来验证其真实性,真实性满足条件时会被调用。请求体会被传输到httpserver去,之后转发到scrapyweb应用上。你还可以通过特定http访问协议,以确保scrapy应用使用同一http请求对待你。在特定情况下,你的请求需要额外的工作。如果你在scrapyweb应用上有任何爬虫的开发经验,你可能会为你。 查看全部
web开发工具scrapy框架scrapy支持的模块支持以下模块
文章采集功能目前支持的渠道包括:百度、谷歌、搜狗等搜索引擎的搜索结果,搜狐、腾讯、头条、一点资讯等信息平台的文章和广告联盟信息,yahoo!等新闻资讯平台的相关讯息,
0、猎豹、百度和搜狗等产品的相关信息。配合爬虫软件,可以获取互联网上其他主流社交网站、电商平台、股票咨询网站、智能或生活类网站等资讯。支持的ip地址数最高可达数百万,最高可是该ip地址的10倍。同时,我们还提供了媒体转载产品,可以在更高的位置进行体验。可以说,scrapy爬虫是目前比较热门的互联网开发工具,所以对于scrapy也提供了相应的图表和最新资讯。
最后:如果你也热爱爬虫和网络爬虫,欢迎来我们群【625758540】一起交流学习作者:博客专栏-博客园如需转载,请附带上本文地址。
scrapy是深受开发者喜爱的web开发工具之一,它可以帮助你在java/python/php/node.js等多个语言上部署一个scrapyweb应用。所以今天以nekopython为例来详细介绍scrapy在设计上的亮点:全篇使用的英文以助于你理解本文的重点。
一、引言你已经知道scrapy可以用于web开发,但它并不是一个完整的框架,更不是面向工程的框架。本文接下来会介绍我们需要用到的爬虫框架scrapy的设计,以及让你初步了解其中使用的模块。
二、scrapy1.0支持的模块scrapy支持以下的模块:figactionsideoutsessionprocessing
三、项目我们将使用全部四个模块构建一个nekopythonweb应用。这四个模块分别是:figactionsitepressoryfeaturesprocessing你可以参考howtoconfigurethereal-timescrapywebapplicationattheendofscrapy1.0.你也可以根据自己的需要增加(自己定义这些模块),具体取决于你爬取的网站或应用的规模。
你需要花费数十分钟时间慢慢弄,你可以把后署时间算进去。看这篇文章::-requests/scrapy使用scrapy从这里获取scrapyget请求,和scrapypost请求。scrapy发送到我们web的数据中,并将这些值返回给我们。这些值包括:对于参数来说,第一个参数是scrapy.callback,这将用于附加执行回调。
第二个参数是请求体的一部分。scrapy通过securitytokens来验证其真实性,真实性满足条件时会被调用。请求体会被传输到httpserver去,之后转发到scrapyweb应用上。你还可以通过特定http访问协议,以确保scrapy应用使用同一http请求对待你。在特定情况下,你的请求需要额外的工作。如果你在scrapyweb应用上有任何爬虫的开发经验,你可能会为你。
怎样借用工具一天编写数万篇原创的搜索文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-05-26 21:16
Koala SEO [批处理SEO 原创 文章]平台支持本文。借助考拉,一天之内就可以制作成千上万的高质量SEO文章文章!
我很抱歉。现在,当我们单击此页面时,也许对Web文本采集器没有任何响应,因为该内容是批处理书写工具站AI生成的排水内容。如果您对该AI 原创 文章的内容感兴趣,则最好将Internet文本采集器放在一旁。我建议每个人都应体验如何使用该工具每天进行成千上万的原创搜索文章!许多看过Koala SEO的网站的网民都认为这是一个伪原创系统,这是非常错误的!实际上,这是一个原创工具。内容和模板都是自己编写的。在Internet上碰到接近本文的作品绝对是不可能的。我们是如何创建的?接下来,编辑器将为您提供全面的解释!
说实话,想要了解网络文本采集器的朋友,您最关心的是上面讨论的内容。最初,编写一些高质量的优化文案非常方便,但是可以由一个文章生成的搜索量确实微不足道。为了追求文章积累以获取长尾单词流量的目的,绝对关键的方法是批量!如果某个网页文章每天可以获取紫外线,我认为它可以产生10,000页,并且每天的访问者数量可以增加10,000倍。但这很容易说。实际上,写作时,一个人只能在24小时内撰写40篇以上的文章,而在最高处,他们只能撰写约60篇文章。即使我们使用某些伪原创系统,也只会持续一百篇文章!阅读本文之后,我们应该撇开网络文本采集器的话题,并深入研究如何实现批处理生成文章!
搜索引擎识别什么原创?内容原创绝不会一个字一个字地写原创!在搜索到的系统词典中,原创不收录邮政重复性文本。换句话说,只要我们的副本不与其他网站内容重叠,就会大大提高被捕获的可能性。 1份高质量的副本,充满了干货,保留了相同的核心思想,只要确认没有相同的大段落,那么此文章仍然很有可能被捕获,甚至成为爆文 。例如,在我的文章中,您可能已经通过搜索引擎搜索了网络文本采集器,最后单击以对其进行浏览。实际上,在下一篇文章文章中,将使用koala平台的批量编写文章软件来快速导出该软件!
准确地说,此站点的伪原创平台应为自动文章软件,该软件可以在5个小时内产生数以万计的强大网站 文章,并且您的网站重量应足够大,索引率至少可以达到66%。有关详细的操作方法,个人中心有一个视频显示屏和一个初学者指南。您可能希望免费测试!我很抱歉无法为您带来网络文本的最终解释采集器,可能让我们浏览了许多系统语言。但是,如果每个人都对智能书写工具文章感兴趣,则可以单击导航栏,使我们的优化结果每天达到数以万计的UV。是不是很酷? 查看全部
怎样借用工具一天编写数万篇原创的搜索文章
Koala SEO [批处理SEO 原创 文章]平台支持本文。借助考拉,一天之内就可以制作成千上万的高质量SEO文章文章!
我很抱歉。现在,当我们单击此页面时,也许对Web文本采集器没有任何响应,因为该内容是批处理书写工具站AI生成的排水内容。如果您对该AI 原创 文章的内容感兴趣,则最好将Internet文本采集器放在一旁。我建议每个人都应体验如何使用该工具每天进行成千上万的原创搜索文章!许多看过Koala SEO的网站的网民都认为这是一个伪原创系统,这是非常错误的!实际上,这是一个原创工具。内容和模板都是自己编写的。在Internet上碰到接近本文的作品绝对是不可能的。我们是如何创建的?接下来,编辑器将为您提供全面的解释!
说实话,想要了解网络文本采集器的朋友,您最关心的是上面讨论的内容。最初,编写一些高质量的优化文案非常方便,但是可以由一个文章生成的搜索量确实微不足道。为了追求文章积累以获取长尾单词流量的目的,绝对关键的方法是批量!如果某个网页文章每天可以获取紫外线,我认为它可以产生10,000页,并且每天的访问者数量可以增加10,000倍。但这很容易说。实际上,写作时,一个人只能在24小时内撰写40篇以上的文章,而在最高处,他们只能撰写约60篇文章。即使我们使用某些伪原创系统,也只会持续一百篇文章!阅读本文之后,我们应该撇开网络文本采集器的话题,并深入研究如何实现批处理生成文章!
搜索引擎识别什么原创?内容原创绝不会一个字一个字地写原创!在搜索到的系统词典中,原创不收录邮政重复性文本。换句话说,只要我们的副本不与其他网站内容重叠,就会大大提高被捕获的可能性。 1份高质量的副本,充满了干货,保留了相同的核心思想,只要确认没有相同的大段落,那么此文章仍然很有可能被捕获,甚至成为爆文 。例如,在我的文章中,您可能已经通过搜索引擎搜索了网络文本采集器,最后单击以对其进行浏览。实际上,在下一篇文章文章中,将使用koala平台的批量编写文章软件来快速导出该软件!
准确地说,此站点的伪原创平台应为自动文章软件,该软件可以在5个小时内产生数以万计的强大网站 文章,并且您的网站重量应足够大,索引率至少可以达到66%。有关详细的操作方法,个人中心有一个视频显示屏和一个初学者指南。您可能希望免费测试!我很抱歉无法为您带来网络文本的最终解释采集器,可能让我们浏览了许多系统语言。但是,如果每个人都对智能书写工具文章感兴趣,则可以单击导航栏,使我们的优化结果每天达到数以万计的UV。是不是很酷?
android的标准的通讯协议-帧驱动(上图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-05-22 04:02
文章采集功能现在很普遍,在android平台是采用的channel机制,无非是扩展采集的数据粒度,缩小采集的范围,拿本文说说android的标准的通讯协议-帧驱动。ssl协议本文要介绍的是标准的格式,具体是:通讯帧(pre-message):通讯帧的具体封装格式是gzip,通讯帧封装格式可以参考下面这个清单(参考:pre-messagesuites/implementation.html)。
现有的udp协议是使用udp协议客户端向服务器建立tcp连接,如果选择ftp协议建立tcp连接,服务器需要输入正确的二进制数据传输到客户端。gap(availableframe):是由多个可用的数据帧组成的封装格式,数据帧具体封装格式可以参考下面这个清单(参考:httputility.html),下面的封装格式可以获取最新的数据帧格式。
帧/区块连接(frame/block/transition):帧/区块的规则是ftp协议服务器规则,是ftp协议规则、上图里的规则以及一些以前有用到过的协议。帧/区块跳板(frame/blocktrap):帧/区块跳板是更简单的规则,只需要1秒的时间就可以建立跨tcp连接。android采用帧,而不是以太网帧,是因为android的框架和内核的关系。
android的帧协议是从udp转化出来的。udp协议只能传递文本数据,而帧协议支持文本和数据相结合。一个简单的文本帧/帧连接方式如下:{"available_sides":3,"data":[{"pre-message":"available_pre-message","response":"udp"},{"pre-message":"available_pre-message","response":"tcp"}]}跳板帧在传输时必须用跳板连接转发。
如果某跳板区域传输的数据被堵塞,则跳板帧就会被阻塞,直到有数据到达,也就是速度会延迟(大于5ms)。这样实现的好处是,在传输时消除延迟。帧协议在传输过程中不会经常“重传”——每条数据在传输过程中都会被重传。第一跳就是以太网帧。udp协议用的一个传输方法是跳板连接转发——跳板连接的概念我们以后再介绍。总结ftp的帧协议由udp转化出来的,与channel机制有关。
android的帧协议是从udp转化出来的,不了解客户端以及服务器层,所以单独拿出来谈谈这个帧。im圈子里的相关服务器开发已经介绍过,这里不再累述。两种帧:跳板帧和帧协议ftp协议协议不是以太网帧,而是跳板帧,和我们前面介绍的跳板帧封装格式是一样的。它的核心概念是xlen帧和每个帧封装在floattenablebits空间里,把帧封装到floattenablebits空间中就可以一次只传送一个字节的数据,节省服务器空间和客户端空间。用跳板帧转发的接收一条数据只需要一次传送一。 查看全部
android的标准的通讯协议-帧驱动(上图)
文章采集功能现在很普遍,在android平台是采用的channel机制,无非是扩展采集的数据粒度,缩小采集的范围,拿本文说说android的标准的通讯协议-帧驱动。ssl协议本文要介绍的是标准的格式,具体是:通讯帧(pre-message):通讯帧的具体封装格式是gzip,通讯帧封装格式可以参考下面这个清单(参考:pre-messagesuites/implementation.html)。
现有的udp协议是使用udp协议客户端向服务器建立tcp连接,如果选择ftp协议建立tcp连接,服务器需要输入正确的二进制数据传输到客户端。gap(availableframe):是由多个可用的数据帧组成的封装格式,数据帧具体封装格式可以参考下面这个清单(参考:httputility.html),下面的封装格式可以获取最新的数据帧格式。
帧/区块连接(frame/block/transition):帧/区块的规则是ftp协议服务器规则,是ftp协议规则、上图里的规则以及一些以前有用到过的协议。帧/区块跳板(frame/blocktrap):帧/区块跳板是更简单的规则,只需要1秒的时间就可以建立跨tcp连接。android采用帧,而不是以太网帧,是因为android的框架和内核的关系。
android的帧协议是从udp转化出来的。udp协议只能传递文本数据,而帧协议支持文本和数据相结合。一个简单的文本帧/帧连接方式如下:{"available_sides":3,"data":[{"pre-message":"available_pre-message","response":"udp"},{"pre-message":"available_pre-message","response":"tcp"}]}跳板帧在传输时必须用跳板连接转发。
如果某跳板区域传输的数据被堵塞,则跳板帧就会被阻塞,直到有数据到达,也就是速度会延迟(大于5ms)。这样实现的好处是,在传输时消除延迟。帧协议在传输过程中不会经常“重传”——每条数据在传输过程中都会被重传。第一跳就是以太网帧。udp协议用的一个传输方法是跳板连接转发——跳板连接的概念我们以后再介绍。总结ftp的帧协议由udp转化出来的,与channel机制有关。
android的帧协议是从udp转化出来的,不了解客户端以及服务器层,所以单独拿出来谈谈这个帧。im圈子里的相关服务器开发已经介绍过,这里不再累述。两种帧:跳板帧和帧协议ftp协议协议不是以太网帧,而是跳板帧,和我们前面介绍的跳板帧封装格式是一样的。它的核心概念是xlen帧和每个帧封装在floattenablebits空间里,把帧封装到floattenablebits空间中就可以一次只传送一个字节的数据,节省服务器空间和客户端空间。用跳板帧转发的接收一条数据只需要一次传送一。
公众号文章采集器的特点和功能有哪些吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-05-18 02:16
正式帐户文章 采集器的特征和功能是什么?如何采集官方帐户文章? 关键词:如何采集正式帐户文章说明:现在,许多人会在正式帐户平台上采集一些美国论文,然后将其发表在他们的正式帐户上。您知道官方帐户文章 采集器的特征和功能吗?另外,如何采集官方帐户文章?让我们看一下Tuotu数据编辑器。现在,许多人在官方帐户平台上发表了一些美国论文,然后将其发表在他们的官方帐户上。您知道官方帐户文章 采集器的特征和功能是什么?另外,如何采集官方帐户?让我们用Tuotu数据编辑器了解一下。官方帐户文章 采集器 Cloud 采集 5000台24 * 7高效稳定的云服务器采集的特征和功能,结合API,可以无缝连接到内部系统,并定期同步数据。智能采集提供了多个网页采集策略和支持资源,以帮助整个采集流程实现数据完整性和稳定性。如何采集官方帐户文章适用于整个网络。无论是文字图片还是贴吧论坛,都可以看到。它支持所有业务渠道的采集器,并满足各种采集需求。大量的模板。内置了数百个网站数据源,涵盖了多个行业。通过简单的设置,您可以快速而准确地获取数据。简单易用无需学习爬虫编程技术,您可以通过三个简单的步骤轻松获取网页数据,支持多种格式,一键导出,并快速导入数据库。稳定高效借助分布式云集群服务器和多用户协作管理平台的支持,可以灵活地调度任务,并可以平滑地抓取大量数据。
微信公众号文章如何使用小程序转移流量? 1.该小程序具有较大的搜索流量入口,方便用户浏览。 2.微信公众号文章自动生成小程序界面,如下图所示,文章自动采集由您自己的官方帐户文章批量发布,页面浏览量,喜欢和评论都与官方帐户文章同步,自动分类,您可以更好地显示您过去发布的微信文章,并便于统一显示。 3.对于自媒体和流量拥有者,更容易通过频繁发布高质量的文章来保留客户,并且可以扩展广告并再次赚钱。 4.您可以转到官方帐户。如何通过其他微信公众号的采集 文章 一、获取文章链接计算机用户可以直接在浏览器地址栏中选择所有文章链接。移动用户可以单击右上角的菜单按钮,选择复制链接,然后将链接发送到计算机。 二、单击编辑菜单右上角的采集 文章按钮1. 采集 文章按钮。 2.右侧功能按钮底部的采集 文章按钮。 三、粘贴文章链接,然后单击采集 采集以编辑和修改文章。如何采集官方帐户文章在上述文章中,Tuotu Data的编辑向您介绍了官方帐户文章 采集器的功能和特点以及如何采集官方的相关内容帐户文章,希望对大家有帮助。拓图数据网络提供官方帐户数据恢复,官方帐户统计工具等软件。有需要的朋友可以咨询一下。更多信息和知识点将继续受到关注,后续活动将成为官方账户分析工具,湖南分析官方账户的最佳工具,官方账户分析数据工具,如何采集官方帐户文章,自媒体如何获得公共帐户文章采集和其他知识点。 查看全部
公众号文章采集器的特点和功能有哪些吗?
正式帐户文章 采集器的特征和功能是什么?如何采集官方帐户文章? 关键词:如何采集正式帐户文章说明:现在,许多人会在正式帐户平台上采集一些美国论文,然后将其发表在他们的正式帐户上。您知道官方帐户文章 采集器的特征和功能吗?另外,如何采集官方帐户文章?让我们看一下Tuotu数据编辑器。现在,许多人在官方帐户平台上发表了一些美国论文,然后将其发表在他们的官方帐户上。您知道官方帐户文章 采集器的特征和功能是什么?另外,如何采集官方帐户?让我们用Tuotu数据编辑器了解一下。官方帐户文章 采集器 Cloud 采集 5000台24 * 7高效稳定的云服务器采集的特征和功能,结合API,可以无缝连接到内部系统,并定期同步数据。智能采集提供了多个网页采集策略和支持资源,以帮助整个采集流程实现数据完整性和稳定性。如何采集官方帐户文章适用于整个网络。无论是文字图片还是贴吧论坛,都可以看到。它支持所有业务渠道的采集器,并满足各种采集需求。大量的模板。内置了数百个网站数据源,涵盖了多个行业。通过简单的设置,您可以快速而准确地获取数据。简单易用无需学习爬虫编程技术,您可以通过三个简单的步骤轻松获取网页数据,支持多种格式,一键导出,并快速导入数据库。稳定高效借助分布式云集群服务器和多用户协作管理平台的支持,可以灵活地调度任务,并可以平滑地抓取大量数据。
微信公众号文章如何使用小程序转移流量? 1.该小程序具有较大的搜索流量入口,方便用户浏览。 2.微信公众号文章自动生成小程序界面,如下图所示,文章自动采集由您自己的官方帐户文章批量发布,页面浏览量,喜欢和评论都与官方帐户文章同步,自动分类,您可以更好地显示您过去发布的微信文章,并便于统一显示。 3.对于自媒体和流量拥有者,更容易通过频繁发布高质量的文章来保留客户,并且可以扩展广告并再次赚钱。 4.您可以转到官方帐户。如何通过其他微信公众号的采集 文章 一、获取文章链接计算机用户可以直接在浏览器地址栏中选择所有文章链接。移动用户可以单击右上角的菜单按钮,选择复制链接,然后将链接发送到计算机。 二、单击编辑菜单右上角的采集 文章按钮1. 采集 文章按钮。 2.右侧功能按钮底部的采集 文章按钮。 三、粘贴文章链接,然后单击采集 采集以编辑和修改文章。如何采集官方帐户文章在上述文章中,Tuotu Data的编辑向您介绍了官方帐户文章 采集器的功能和特点以及如何采集官方的相关内容帐户文章,希望对大家有帮助。拓图数据网络提供官方帐户数据恢复,官方帐户统计工具等软件。有需要的朋友可以咨询一下。更多信息和知识点将继续受到关注,后续活动将成为官方账户分析工具,湖南分析官方账户的最佳工具,官方账户分析数据工具,如何采集官方帐户文章,自媒体如何获得公共帐户文章采集和其他知识点。
「赛马助手」ai解析商品大数据解析方式重新研发
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-05-17 23:03
文章采集功能已上线,点击「赛马助手」即可使用。经过1个月的打磨,我们终于将ai解析商品的功能,同步到了「京东精选」和「饿了么外卖」两个产品上。写这篇文章,我真不想让这个产品成为我们的短板,也是我最近工作的打算。我们使用了一种新的数据解析方式,即通过视觉来解析商品。同时,结合「数据运营」的大数据解析方式,重新研发「关联商品」,会对用户更加有价值。
也是应@潘菲瑶的要求,「爱不爱我」在这个版本是1.0。希望能够尽快完善它,共同打造一个完整的ai解析商品的工具。
具体技术实现请参考深圳湾产品线负责人@谢怀宇的技术分享
有可能需要用到mongoose,但基本不用怕,mongoose在几千万的商品数据库中查询并没有问题,至于可用性,目前还没有听说mongoose在大范围故障情况下仍能正常使用的情况。
这种不是很重要的东西,也无非就是要用到大量的运营经验。代码能写清楚不难,容易写清楚也不难,难在读懂这些代码。要是相关的运营都分不清多少人点击,多少次浏览,有没有购买。就算公司有钱,有牛人做大量的积累,只要没啥积累,天天加班还依然是写不出的。再好的技术,人做不出来,也是没用。
主要是一些图像处理算法,主要是通过将图像训练好的网络变换、卷积、降采样等网络结构,输入到最基本的分类算法,对图像分类。现在最基本的是逻辑多分类问题。 查看全部
「赛马助手」ai解析商品大数据解析方式重新研发
文章采集功能已上线,点击「赛马助手」即可使用。经过1个月的打磨,我们终于将ai解析商品的功能,同步到了「京东精选」和「饿了么外卖」两个产品上。写这篇文章,我真不想让这个产品成为我们的短板,也是我最近工作的打算。我们使用了一种新的数据解析方式,即通过视觉来解析商品。同时,结合「数据运营」的大数据解析方式,重新研发「关联商品」,会对用户更加有价值。
也是应@潘菲瑶的要求,「爱不爱我」在这个版本是1.0。希望能够尽快完善它,共同打造一个完整的ai解析商品的工具。
具体技术实现请参考深圳湾产品线负责人@谢怀宇的技术分享
有可能需要用到mongoose,但基本不用怕,mongoose在几千万的商品数据库中查询并没有问题,至于可用性,目前还没有听说mongoose在大范围故障情况下仍能正常使用的情况。
这种不是很重要的东西,也无非就是要用到大量的运营经验。代码能写清楚不难,容易写清楚也不难,难在读懂这些代码。要是相关的运营都分不清多少人点击,多少次浏览,有没有购买。就算公司有钱,有牛人做大量的积累,只要没啥积累,天天加班还依然是写不出的。再好的技术,人做不出来,也是没用。
主要是一些图像处理算法,主要是通过将图像训练好的网络变换、卷积、降采样等网络结构,输入到最基本的分类算法,对图像分类。现在最基本的是逻辑多分类问题。
如何借用软件半天撰写1万篇原创的引流文案页
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-05-17 01:33
Koala SEO [批处理SEO 原创 文章]平台支持本文。借助考拉,一天之内就可以制作成千上万的高质量SEO文章文章!
超级抱歉,现在大家伙输入了这个内容,可以浏览的文章并不是对网络采集器功能的分析,这是因为这个文章是我们工具站批量生产的网页文章。如果您需要此自动编辑内容的内容,则可以先搁置网络采集器功能,然后让您体验一下:如何借用半天的时间来编写10,000 原创排水副本页面!许多朋友看到了我们的广告,并认为这是一个伪原创系统,这是一个很大的错误!从本质上讲,我们是一个AI系统。广告文案和模板是独立编写的,几乎无法在Internet上找到和生成它们。 文章具有高度相似性。究竟是如何创建的?我将在下面给大家做详细的分析!
想知道网络采集器功能的朋友毕竟是每个人都珍惜的是上面讨论的内容。最初,创建可读的搜索登录文章非常容易,但是SEO副本可以创建的访问量实际上很小。希望可以利用信息设置达到排水的目的。绝对重要的策略是分批!如果某个页面文章可以带来1次(每24小时一次)浏览量,那么如果我们可以编辑10,000个页面,则每天的客户数量可以增加10,000倍。但是,这很简单。在现实生活中编辑时,一个人一天只能撰写约40篇文章,最多只能撰写70篇文章。即使将其应用于伪原创系统,也最多只能容纳100篇文章!现在您已经在那儿了,您可以先放弃网络采集器功能,并进一步了解如何实现自动编辑!
seo认为原创是什么?文案写作原创并不意味着逐句输出原创!在主要搜索引擎的程序定义中,原创并不意味着没有重复的句子。实际上,只要您的文字与其他文字文章不完全相同,就可以增加被抓住的可能性。出色的文章,只要确认没有相同的大段落,核心就足以保持相同的目标词,这意味着文章还是很有可能收录,并且甚至成为排水的好文章。例如,让我们谈论编辑器文章,我们可能会从Sogou中找到network 采集器功能,然后单击进入。我可以告诉你,编辑器文章文章是用于播放Koala SEO平台的AI编辑器文章系统。易于导出!
Koala SEO批处理写作文章软件,确切地说,应该称为手动写作文章软件,只要实现了三小时的数千篇文章制作和强大的优化功能文章,网页的重量足够高,索引率可以高达80%。常规操作步骤,用户主页上的动画介绍和小白的指南,您可以进行初步测试!我没有为所有人解释网络采集器功能的精妙内容感到非常ham愧,这可能会告诉您阅读许多系统语言。但是,如果您偏爱批量写入文章技术,则可以输入右上角,让每个人网站每天都能获得数千流量。是不是很酷? 查看全部
如何借用软件半天撰写1万篇原创的引流文案页
Koala SEO [批处理SEO 原创 文章]平台支持本文。借助考拉,一天之内就可以制作成千上万的高质量SEO文章文章!
超级抱歉,现在大家伙输入了这个内容,可以浏览的文章并不是对网络采集器功能的分析,这是因为这个文章是我们工具站批量生产的网页文章。如果您需要此自动编辑内容的内容,则可以先搁置网络采集器功能,然后让您体验一下:如何借用半天的时间来编写10,000 原创排水副本页面!许多朋友看到了我们的广告,并认为这是一个伪原创系统,这是一个很大的错误!从本质上讲,我们是一个AI系统。广告文案和模板是独立编写的,几乎无法在Internet上找到和生成它们。 文章具有高度相似性。究竟是如何创建的?我将在下面给大家做详细的分析!
想知道网络采集器功能的朋友毕竟是每个人都珍惜的是上面讨论的内容。最初,创建可读的搜索登录文章非常容易,但是SEO副本可以创建的访问量实际上很小。希望可以利用信息设置达到排水的目的。绝对重要的策略是分批!如果某个页面文章可以带来1次(每24小时一次)浏览量,那么如果我们可以编辑10,000个页面,则每天的客户数量可以增加10,000倍。但是,这很简单。在现实生活中编辑时,一个人一天只能撰写约40篇文章,最多只能撰写70篇文章。即使将其应用于伪原创系统,也最多只能容纳100篇文章!现在您已经在那儿了,您可以先放弃网络采集器功能,并进一步了解如何实现自动编辑!
seo认为原创是什么?文案写作原创并不意味着逐句输出原创!在主要搜索引擎的程序定义中,原创并不意味着没有重复的句子。实际上,只要您的文字与其他文字文章不完全相同,就可以增加被抓住的可能性。出色的文章,只要确认没有相同的大段落,核心就足以保持相同的目标词,这意味着文章还是很有可能收录,并且甚至成为排水的好文章。例如,让我们谈论编辑器文章,我们可能会从Sogou中找到network 采集器功能,然后单击进入。我可以告诉你,编辑器文章文章是用于播放Koala SEO平台的AI编辑器文章系统。易于导出!
Koala SEO批处理写作文章软件,确切地说,应该称为手动写作文章软件,只要实现了三小时的数千篇文章制作和强大的优化功能文章,网页的重量足够高,索引率可以高达80%。常规操作步骤,用户主页上的动画介绍和小白的指南,您可以进行初步测试!我没有为所有人解释网络采集器功能的精妙内容感到非常ham愧,这可能会告诉您阅读许多系统语言。但是,如果您偏爱批量写入文章技术,则可以输入右上角,让每个人网站每天都能获得数千流量。是不是很酷?
速卖通国际站上的任意商品ID获取方式及注意事项
采集交流 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2021-05-16 22:27
应用简介:
商家可以通过此应用程序在[AliExpress International Station]上快速采集任何产品。您只需输入所需产品的ID 采集,系统就会在几分钟之内自动将其放入商店的SHOPYY后台,然后进行第二次编辑。
使用此应用程序,大大减少了商人的手动操作过程,并提高了顶级产品的效率。有效避免了业务准备周期长的问题,并且网站可以在短时间内投入运营。
步骤:
第1步:在后台单击应用商店中的安装后,在我的应用列表中找到相应的插件,单击“访问”,然后跳至设置页面。
第2步:单击“ AliExpress商品管理”进入列表页面,该列表将显示所有已采集的商品。
第3步:点击右上角的“添加AliExpress产品”以进入信息页面。
[Aliexpress产品ID]从速卖通网站复制需要采集的产品ID,获取产品ID的方法如下图所示:
注意:如果同时存在多个产品采集,则每个产品ID都将以英文逗号或换行符分隔。
[商品发布语言]下拉以选择需要发布的语言。
[商品发布市场]根据先前选择的发布语言选择相应的国家/地区。
步骤4:完成上述信息设置后,单击“保存信息”,产品将进入列表并等待同步。
([1)同步成功后,同步状态将显示在列表中。
([2)成功同步的产品会自动显示在SHOPYY后端产品的货架列表中,这便于重新编辑然后将其放在货架上。
注意:与SHOPYY后端同步时,图片采集需要花费一些时间,因此此处的产品图片将等待几分钟才能显示。
完成上述步骤后,采集 AliExpress产品即告完成。
这篇文章文章“小功能成就了丨速卖通产品采集应用程序”是由中恒天下编辑组织的。 查看全部
速卖通国际站上的任意商品ID获取方式及注意事项
应用简介:
商家可以通过此应用程序在[AliExpress International Station]上快速采集任何产品。您只需输入所需产品的ID 采集,系统就会在几分钟之内自动将其放入商店的SHOPYY后台,然后进行第二次编辑。
使用此应用程序,大大减少了商人的手动操作过程,并提高了顶级产品的效率。有效避免了业务准备周期长的问题,并且网站可以在短时间内投入运营。
步骤:
第1步:在后台单击应用商店中的安装后,在我的应用列表中找到相应的插件,单击“访问”,然后跳至设置页面。
第2步:单击“ AliExpress商品管理”进入列表页面,该列表将显示所有已采集的商品。
第3步:点击右上角的“添加AliExpress产品”以进入信息页面。
[Aliexpress产品ID]从速卖通网站复制需要采集的产品ID,获取产品ID的方法如下图所示:
注意:如果同时存在多个产品采集,则每个产品ID都将以英文逗号或换行符分隔。
[商品发布语言]下拉以选择需要发布的语言。
[商品发布市场]根据先前选择的发布语言选择相应的国家/地区。
步骤4:完成上述信息设置后,单击“保存信息”,产品将进入列表并等待同步。
([1)同步成功后,同步状态将显示在列表中。
([2)成功同步的产品会自动显示在SHOPYY后端产品的货架列表中,这便于重新编辑然后将其放在货架上。
注意:与SHOPYY后端同步时,图片采集需要花费一些时间,因此此处的产品图片将等待几分钟才能显示。
完成上述步骤后,采集 AliExpress产品即告完成。
这篇文章文章“小功能成就了丨速卖通产品采集应用程序”是由中恒天下编辑组织的。
文章内容匹配规则的结束部分(cb)(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-05-09 02:25
”之后,通过比较文章内容页面及其源代码,不难发现第一位实际上是一个摘要,第二位是文章内容的开头。因此,您应该选择“
”是匹配规则的开头。
(b)找到文章“它也是添加了值“ transparent”的“ wmode”参数的内容的结尾部分。,如图29所示,
图29- 文章内容的结尾
注意:因为结束部分的最后一个标签是“
”,并且此标记在文章的内容中多次出现。因此,不能将其用作采集规则的结束标记。考虑到它应与文章内容的开头相对应],则经过比较分析后得出Out,此处应选择“
”作为文章内容的结尾,如图30所示,
图30- 文章内容匹配规则的结尾
(c)结合(a)和(b),我们可以看到文章内容的匹配规则应为“
[内容]
”,填写后,如图31所示,
图31- 文章内容匹配规则
此处未使用过滤规则。过滤规则的介绍和使用将放在单独的章节中。
在这里,“添加采集节点:步骤2设置内容字段获取规则”,设置完成。填写后,如图3 2)所示,
图32-设置后新添加的采集节点:第二步是设置内容字段获取规则
检查后,单击“保存配置并预览”。如果先前的设置正确,则单击后,将进入“添加采集节点:测试内容字段设置”页面,并查看相应的文章内容。如(图3 3)
图33-新添加的采集节点:测试内容字段设置
确认正确后,单击“仅保存”,系统将提示“成功保存配置”,并返回“ 采集节点管理”界面;如果单击“保存并启动采集”,它将进入“ 采集指定的节点”界面。否则,请单击“返回上一步进行修改”。 查看全部
文章内容匹配规则的结束部分(cb)(组图)
”之后,通过比较文章内容页面及其源代码,不难发现第一位实际上是一个摘要,第二位是文章内容的开头。因此,您应该选择“
”是匹配规则的开头。
(b)找到文章“它也是添加了值“ transparent”的“ wmode”参数的内容的结尾部分。,如图29所示,
图29- 文章内容的结尾
注意:因为结束部分的最后一个标签是“
”,并且此标记在文章的内容中多次出现。因此,不能将其用作采集规则的结束标记。考虑到它应与文章内容的开头相对应],则经过比较分析后得出Out,此处应选择“
”作为文章内容的结尾,如图30所示,
图30- 文章内容匹配规则的结尾
(c)结合(a)和(b),我们可以看到文章内容的匹配规则应为“
[内容]
”,填写后,如图31所示,
图31- 文章内容匹配规则
此处未使用过滤规则。过滤规则的介绍和使用将放在单独的章节中。
在这里,“添加采集节点:步骤2设置内容字段获取规则”,设置完成。填写后,如图3 2)所示,
图32-设置后新添加的采集节点:第二步是设置内容字段获取规则
检查后,单击“保存配置并预览”。如果先前的设置正确,则单击后,将进入“添加采集节点:测试内容字段设置”页面,并查看相应的文章内容。如(图3 3)
图33-新添加的采集节点:测试内容字段设置
确认正确后,单击“仅保存”,系统将提示“成功保存配置”,并返回“ 采集节点管理”界面;如果单击“保存并启动采集”,它将进入“ 采集指定的节点”界面。否则,请单击“返回上一步进行修改”。
超方便的全文检索,智能生成你需要的格式。
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-04-30 22:31
文章采集功能,输入你要采集的内容,智能生成你需要的格式。智能搜索功能,能够根据你需要搜索语句,并且自动转换格式。搜索相关信息,并且合并到你需要的条目里面去。
推荐sogoulite,
enjoy!1.超方便的全文检索,即时生成高清无码图2.检索引擎来源智能优化,能够针对网站爬虫拓展自动抓取3.很方便的主题收藏功能4.个性化私密阅读,可分享自己的主题笔记给朋友,
trados很全面的工具箱,也有针对语料行业的特定工具包,可以通过接口的方式轻松取得数据。
infoqaiforum这里有你需要的。我最喜欢pythonaiforum(基本上所有python相关的论坛里都会有weibo文章)和谷歌ai(谷歌本地多端多语言浏览器基本上可以说是最好的ai浏览器了)。
可以搜一下sophiezhang老师他的medium
youcanaskforthedomainwhichistheustrictbb,ortheretiredgeneralpublications,ortheauthors'googleartcurriculum,orthedbwikicompany。butbutintheworldtherearemanythingstodo,let'sgetthis。
手机端的话需要注册账号。youcanaskforthedomainwhichistheustrictbb,ortheretiredgeneralpublications,ortheauthors'googleartcurriculum,orthedbwikicompany.butbutintheworldtherearemanythingstodo,let'sgetthis.-。 查看全部
超方便的全文检索,智能生成你需要的格式。
文章采集功能,输入你要采集的内容,智能生成你需要的格式。智能搜索功能,能够根据你需要搜索语句,并且自动转换格式。搜索相关信息,并且合并到你需要的条目里面去。
推荐sogoulite,
enjoy!1.超方便的全文检索,即时生成高清无码图2.检索引擎来源智能优化,能够针对网站爬虫拓展自动抓取3.很方便的主题收藏功能4.个性化私密阅读,可分享自己的主题笔记给朋友,
trados很全面的工具箱,也有针对语料行业的特定工具包,可以通过接口的方式轻松取得数据。
infoqaiforum这里有你需要的。我最喜欢pythonaiforum(基本上所有python相关的论坛里都会有weibo文章)和谷歌ai(谷歌本地多端多语言浏览器基本上可以说是最好的ai浏览器了)。
可以搜一下sophiezhang老师他的medium
youcanaskforthedomainwhichistheustrictbb,ortheretiredgeneralpublications,ortheauthors'googleartcurriculum,orthedbwikicompany。butbutintheworldtherearemanythingstodo,let'sgetthis。
手机端的话需要注册账号。youcanaskforthedomainwhichistheustrictbb,ortheretiredgeneralpublications,ortheauthors'googleartcurriculum,orthedbwikicompany.butbutintheworldtherearemanythingstodo,let'sgetthis.-。
转自爬虫学堂:文章采集功能本身的问题怎么避免
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-04-26 06:01
文章采集功能本身的原理已经回答过了,现在再来讨论下抓取过程中遇到的问题。转自爬虫学堂:python爬虫抓取的时候,下载的数据丢失问题,怎么避免。
1.使用插件logging2.用beautifulsoup提供的link过滤方法,
还需要用正则表达式,
抓取无非就是两种方式:抓包;使用工具文件导入。这里我介绍两种方式:爬虫和爬虫框架。1.爬虫:使用正则,参考scrapy,这种方式没法编程,就是把需要的数据发送给相应的接口,该交给爬虫去抓的抓取,当然,完成后返回一个html文件,可以保存为html文件。2.爬虫框架:简单说明一下,python提供了5种爬虫框架:doc-requests爬虫框架:纯python实现,并且可以做出可复用的功能,可以爬取文本数据,图片,搜索结果等等,需要安装pip。
scrapy-redis爬虫框架:用django实现,redis也是python调用数据库最好的选择。elasticsearch数据库爬虫框架:使用elasticsearch实现,安装与pip相关的工具。scrapy-shell爬虫框架:运行于python-shell。1.首先看看爬虫原理。如果是抓取静态网页,比如像新浪的微博的话,在selenium-webdriver里使用就可以了,复制用户信息的数据导入到selenium-control,在dir菜单里,选择network,选择页面加载数据;或者说利用gitbranch命令加载一个项目,它是静态页面导入的,并且带有地址信息,一般用户调用这个就可以抓取页面了。
2.怎么用python爬取其他网站页面数据呢?还是要通过抓包工具scrapy,除了抓包,还有python库的第三方支持工具logging。通过python库logging或者requests里的相应功能抓取。例如某网站有403log,需要抓取403info。你就可以使用twitterplugin-records.spyder.tools来发送给selenium进行抓取。
fromdocumentimportinfofromloggingimport*defevent_set_format(page,page_method):page_method='//403'#print(page_method)因为是403这种,直接找到403调用发送过去ifpage_methodnotinpage:print('recording')ifepoch==403:print('loggedwith403,capture:',epoch)else:print('error')ifname=='_system':print('用户名')breakelse:print('用户密码')#event_set_format(page,username='kungjiajiang',password='admin')3.为什么用python库logging而不是phantomjs呢。 查看全部
转自爬虫学堂:文章采集功能本身的问题怎么避免
文章采集功能本身的原理已经回答过了,现在再来讨论下抓取过程中遇到的问题。转自爬虫学堂:python爬虫抓取的时候,下载的数据丢失问题,怎么避免。
1.使用插件logging2.用beautifulsoup提供的link过滤方法,
还需要用正则表达式,
抓取无非就是两种方式:抓包;使用工具文件导入。这里我介绍两种方式:爬虫和爬虫框架。1.爬虫:使用正则,参考scrapy,这种方式没法编程,就是把需要的数据发送给相应的接口,该交给爬虫去抓的抓取,当然,完成后返回一个html文件,可以保存为html文件。2.爬虫框架:简单说明一下,python提供了5种爬虫框架:doc-requests爬虫框架:纯python实现,并且可以做出可复用的功能,可以爬取文本数据,图片,搜索结果等等,需要安装pip。
scrapy-redis爬虫框架:用django实现,redis也是python调用数据库最好的选择。elasticsearch数据库爬虫框架:使用elasticsearch实现,安装与pip相关的工具。scrapy-shell爬虫框架:运行于python-shell。1.首先看看爬虫原理。如果是抓取静态网页,比如像新浪的微博的话,在selenium-webdriver里使用就可以了,复制用户信息的数据导入到selenium-control,在dir菜单里,选择network,选择页面加载数据;或者说利用gitbranch命令加载一个项目,它是静态页面导入的,并且带有地址信息,一般用户调用这个就可以抓取页面了。
2.怎么用python爬取其他网站页面数据呢?还是要通过抓包工具scrapy,除了抓包,还有python库的第三方支持工具logging。通过python库logging或者requests里的相应功能抓取。例如某网站有403log,需要抓取403info。你就可以使用twitterplugin-records.spyder.tools来发送给selenium进行抓取。
fromdocumentimportinfofromloggingimport*defevent_set_format(page,page_method):page_method='//403'#print(page_method)因为是403这种,直接找到403调用发送过去ifpage_methodnotinpage:print('recording')ifepoch==403:print('loggedwith403,capture:',epoch)else:print('error')ifname=='_system':print('用户名')breakelse:print('用户密码')#event_set_format(page,username='kungjiajiang',password='admin')3.为什么用python库logging而不是phantomjs呢。
小象研究所找到微信公众号文章采集功能(二维码自动识别)
采集交流 • 优采云 发表了文章 • 0 个评论 • 279 次浏览 • 2021-04-23 05:06
文章采集功能采集时间从微信公众号文章推送时间到qq客户端发送消息当前时间(1h10min以内)采集完成后,会将从公众号采集到的数据本地保存,不会存放到任何服务器上而是存放在qq号上的本地文件夹中。采集流程同步到群聊中查询到最新的公众号名称并点击确定即可采集消息收到的消息记录将对接到微信公众号或qq群收藏或下载公众号的消息以及qq群的消息选择所需的模块将模块绑定qq号,然后点击保存按钮点击确定即可收到效果图采集效果如果你对采集的数据量不大,可以采用一次性采集所有内容的方式,一次性采集多天的内容,以节省开发时间。更多采集功能内容请参考【阿里云开发者】【采集功能】微信公众号文章采集-文章数据。
小象研究所找到了微信公众号文章采集知识星球星球号→:java学习、进阶、求职、真题、破格面试、内推码→扫码加入知识星球(二维码自动识别)
接到个单子有从陌陌代码采集的,
我写过在去哪儿网订单时为获取订单详情,采集订单详情记录(包括和京东的),还有就是对于各种网站订单数据进行采集分析,基本的功能是从各个网站下载自己需要的数据(京东),然后进行汇总,最终发到excel文件里。 查看全部
小象研究所找到微信公众号文章采集功能(二维码自动识别)
文章采集功能采集时间从微信公众号文章推送时间到qq客户端发送消息当前时间(1h10min以内)采集完成后,会将从公众号采集到的数据本地保存,不会存放到任何服务器上而是存放在qq号上的本地文件夹中。采集流程同步到群聊中查询到最新的公众号名称并点击确定即可采集消息收到的消息记录将对接到微信公众号或qq群收藏或下载公众号的消息以及qq群的消息选择所需的模块将模块绑定qq号,然后点击保存按钮点击确定即可收到效果图采集效果如果你对采集的数据量不大,可以采用一次性采集所有内容的方式,一次性采集多天的内容,以节省开发时间。更多采集功能内容请参考【阿里云开发者】【采集功能】微信公众号文章采集-文章数据。
小象研究所找到了微信公众号文章采集知识星球星球号→:java学习、进阶、求职、真题、破格面试、内推码→扫码加入知识星球(二维码自动识别)
接到个单子有从陌陌代码采集的,
我写过在去哪儿网订单时为获取订单详情,采集订单详情记录(包括和京东的),还有就是对于各种网站订单数据进行采集分析,基本的功能是从各个网站下载自己需要的数据(京东),然后进行汇总,最终发到excel文件里。
文章格式的格式化,目前似乎没人做这方面(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-04-17 02:01
文章采集功能已经很成熟,formdatajs的封装做的非常好,而且支持get,post等,而且也不用担心存储问题了。有关注过conceptualjs,当时为了自己做时尚的时尚而采用了这个框架,设计之初觉得它就是个开箱即用的模板生成框架,功能不够灵活,所以基本没怎么碰。在产品中重点关注了一下传说中的serializecollectionkit的插件,感觉在css2、css3支持上感觉要更好一些。
专门为站内文章生成源代码来读的,使用readability。
fiber.js是基于createjs的,目前主要做设计,框架更新缓慢.需要一些javascript和jquery基础.学习上周期比较长.大厂大部分都用fiber来实现navigator,router等,不太常用,要不就fiberjs,无content-stack。关于文章格式的格式化,目前似乎没人做这方面,基本上jquery特性使用jq方式生成静态网页代码,生成后文章格式还是比较自然的,工作量也不大.。
fiber.js的未实现功能:实现一个字符串转换为css的功能,用于设计测试和css提交。
d3js(首页):serializexhr中的xml数据写成css实例。fiber.js的使用:用于数据采集。javascript库bootstrap:参考这里的例子:-jquery-x-xml.html这里的例子:-jquery-xml/可以参考一下前者的例子:mailyt/dfg-examples。 查看全部
文章格式的格式化,目前似乎没人做这方面(组图)
文章采集功能已经很成熟,formdatajs的封装做的非常好,而且支持get,post等,而且也不用担心存储问题了。有关注过conceptualjs,当时为了自己做时尚的时尚而采用了这个框架,设计之初觉得它就是个开箱即用的模板生成框架,功能不够灵活,所以基本没怎么碰。在产品中重点关注了一下传说中的serializecollectionkit的插件,感觉在css2、css3支持上感觉要更好一些。
专门为站内文章生成源代码来读的,使用readability。
fiber.js是基于createjs的,目前主要做设计,框架更新缓慢.需要一些javascript和jquery基础.学习上周期比较长.大厂大部分都用fiber来实现navigator,router等,不太常用,要不就fiberjs,无content-stack。关于文章格式的格式化,目前似乎没人做这方面,基本上jquery特性使用jq方式生成静态网页代码,生成后文章格式还是比较自然的,工作量也不大.。
fiber.js的未实现功能:实现一个字符串转换为css的功能,用于设计测试和css提交。
d3js(首页):serializexhr中的xml数据写成css实例。fiber.js的使用:用于数据采集。javascript库bootstrap:参考这里的例子:-jquery-x-xml.html这里的例子:-jquery-xml/可以参考一下前者的例子:mailyt/dfg-examples。
采集微信公众号文章标题,采集内容详情页(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2021-04-15 23:50
文章采集功能我们已经有了,我们就来看看具体的数据采集需求:采集微信文章内容,采集微信公众号文章标题,采集内容详情页文章数据,采集页面文章内容。做这样的需求,我们经常用到的一款采集器,就是wordtree,下面是我们采集器的功能截图:这个需求需要我们开发什么样的界面呢?如果我们的需求是我们采集公众号文章的标题、内容标题、微信公众号文章的样式的话,可以用下面的一些我们熟悉的图片:或者用一些大家用得比较多的图片:像图片最外面那个文本框我们用来放一个纯文本数据比较好,因为采集公众号文章的话,我们只有一些数据,我们就可以把它做成纯文本格式,这样比较直观。
像我们不需要这些样式,我们还可以选择我们自己开发的界面。我们选择上面的图片,也可以选择下面这种比较简洁的界面,因为采集公众号文章的话,用户是没有什么自己想看的文章的,为了要达到相同的功能,我们采集界面应该也是同样的样式。像下面这种分类的话,我觉得一个个分类确实会比较麻烦,所以就把他们串在一起。当然,同一个功能,我们用两个界面就足够了,因为我们要保证数据的统一性,如果我们每次都要去修改一样的界面,那是非常浪费时间的。
下面是我用wordtree抓取到的数据截图:这篇文章的阅读数和点赞数我们可以用python的requests库的post方法采集到,然后我们再用正则表达式来采集每一个人的身份信息和关注公众号的意向:。 查看全部
采集微信公众号文章标题,采集内容详情页(组图)
文章采集功能我们已经有了,我们就来看看具体的数据采集需求:采集微信文章内容,采集微信公众号文章标题,采集内容详情页文章数据,采集页面文章内容。做这样的需求,我们经常用到的一款采集器,就是wordtree,下面是我们采集器的功能截图:这个需求需要我们开发什么样的界面呢?如果我们的需求是我们采集公众号文章的标题、内容标题、微信公众号文章的样式的话,可以用下面的一些我们熟悉的图片:或者用一些大家用得比较多的图片:像图片最外面那个文本框我们用来放一个纯文本数据比较好,因为采集公众号文章的话,我们只有一些数据,我们就可以把它做成纯文本格式,这样比较直观。
像我们不需要这些样式,我们还可以选择我们自己开发的界面。我们选择上面的图片,也可以选择下面这种比较简洁的界面,因为采集公众号文章的话,用户是没有什么自己想看的文章的,为了要达到相同的功能,我们采集界面应该也是同样的样式。像下面这种分类的话,我觉得一个个分类确实会比较麻烦,所以就把他们串在一起。当然,同一个功能,我们用两个界面就足够了,因为我们要保证数据的统一性,如果我们每次都要去修改一样的界面,那是非常浪费时间的。
下面是我用wordtree抓取到的数据截图:这篇文章的阅读数和点赞数我们可以用python的requests库的post方法采集到,然后我们再用正则表达式来采集每一个人的身份信息和关注公众号的意向:。
知网查重接口|咪咕查重“一体化”查重服务优势
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-04-11 04:02
文章采集功能很简单,不要求有技术基础。采集工具就是用excel和格式化文本编辑器,不想折腾可以用用chrome浏览器自带插件,一些浏览器也有自带的扩展工具,十分方便。
知网也有一些api接口,现在看文章网站好多都能提供知网查重的接口,那么您只要把您的论文发给有知网查重接口的网站(我知道的例如春暖花开),他们就会一步一步教您如何使用知网查重,欢迎访问。
我推荐聚查查,他们做的我都能用,查重更快更精准,
查重的api接口方法有很多,我也用过很多,
1、emm-ezp/kapcid
2、paperpasskey
3、咪咕查重系统,这里重点说一下针对国内学术型网站来说最好的,应该属于咪咕查重了,且试验成功。咪咕查重之前就是国内唯一的知网查重api接口提供商,目前也是中国最好的查重api提供商,所以一定要对其慎重。不同的api具有自己的特点以及优势,具体的可以看一下这篇文章。服务平台1:咪咕查重“一体化”查重服务优势;与emm-ezp/kapcid不同,咪咕查重专注于最大限度的降低学术型网站同质化查重api的成本,以最优的用户体验吸引用户。
不同于emm-ezp/kapcid在查重过程中会启用部分期刊或杂志文章,咪咕查重完全是为了解决非学术型网站同质化查重api而生,也不同于kapcid只能查重博硕士论文、高校论文库,咪咕查重将与最常见的高校中的大学生论文库、职称论文库和新闻出版署内容库等很多期刊文章进行合作,满足同质化查重需求。服务平台2:共享查重|paperpass官方api接口|papertime官方api接口|papertime查重接口|papertime查重接口官网,共享查重不是papertimeapi的接口,官方原文是,共享查重这个api接口是已经帮助很多期刊杂志进行了适用。
搜遍了各种资料,查资料的百度并没有什么真正的官方更全的查重api发布,所以这个解决方案应该是适合资源来源还比较复杂的学术型网站。只能由同样学术或非学术的人从无到有自己研究,去考验其价值高低。因为像共享查重那样原文化定稿,难免会不够完善。由于上面说的原因,很多机构,一但失去我们需要的政策大环境,就不再能得到及时有效的资源了。
因此,针对学术性网站来说,咪咕查重是很理想的选择。服务平台3:知网查重接口页papertime内容平台内容平台/index.html,主要从三个方面来解释,同质化查重api的价值:1.不同的查重api内容不尽相同。2.同质化查重api具有价格方面的巨大价值。3.同质化查重api可提供补充依据。 查看全部
知网查重接口|咪咕查重“一体化”查重服务优势
文章采集功能很简单,不要求有技术基础。采集工具就是用excel和格式化文本编辑器,不想折腾可以用用chrome浏览器自带插件,一些浏览器也有自带的扩展工具,十分方便。
知网也有一些api接口,现在看文章网站好多都能提供知网查重的接口,那么您只要把您的论文发给有知网查重接口的网站(我知道的例如春暖花开),他们就会一步一步教您如何使用知网查重,欢迎访问。
我推荐聚查查,他们做的我都能用,查重更快更精准,
查重的api接口方法有很多,我也用过很多,
1、emm-ezp/kapcid
2、paperpasskey
3、咪咕查重系统,这里重点说一下针对国内学术型网站来说最好的,应该属于咪咕查重了,且试验成功。咪咕查重之前就是国内唯一的知网查重api接口提供商,目前也是中国最好的查重api提供商,所以一定要对其慎重。不同的api具有自己的特点以及优势,具体的可以看一下这篇文章。服务平台1:咪咕查重“一体化”查重服务优势;与emm-ezp/kapcid不同,咪咕查重专注于最大限度的降低学术型网站同质化查重api的成本,以最优的用户体验吸引用户。
不同于emm-ezp/kapcid在查重过程中会启用部分期刊或杂志文章,咪咕查重完全是为了解决非学术型网站同质化查重api而生,也不同于kapcid只能查重博硕士论文、高校论文库,咪咕查重将与最常见的高校中的大学生论文库、职称论文库和新闻出版署内容库等很多期刊文章进行合作,满足同质化查重需求。服务平台2:共享查重|paperpass官方api接口|papertime官方api接口|papertime查重接口|papertime查重接口官网,共享查重不是papertimeapi的接口,官方原文是,共享查重这个api接口是已经帮助很多期刊杂志进行了适用。
搜遍了各种资料,查资料的百度并没有什么真正的官方更全的查重api发布,所以这个解决方案应该是适合资源来源还比较复杂的学术型网站。只能由同样学术或非学术的人从无到有自己研究,去考验其价值高低。因为像共享查重那样原文化定稿,难免会不够完善。由于上面说的原因,很多机构,一但失去我们需要的政策大环境,就不再能得到及时有效的资源了。
因此,针对学术性网站来说,咪咕查重是很理想的选择。服务平台3:知网查重接口页papertime内容平台内容平台/index.html,主要从三个方面来解释,同质化查重api的价值:1.不同的查重api内容不尽相同。2.同质化查重api具有价格方面的巨大价值。3.同质化查重api可提供补充依据。
微信公众号文章采集功能特点及使用方法介绍-乐题库
采集交流 • 优采云 发表了文章 • 0 个评论 • 254 次浏览 • 2021-03-23 23:04
文章采集功能是随着互联网的发展逐渐完善的。目前微信公众号文章采集已经成为信息快速检索、整理、分析的捷径,丰富了用户的浏览快速浏览,使用户体验感大大提升。
一、平台介绍文章采集是采集公众号文章内容的工具,采集是一款免费的网络爬虫抓取工具,采集工具自动搜索全网所有的公众号文章并且可自动生成抓取列表,该工具包含30种的新闻来源渠道,此外还有付费的渠道检索和社会化分析工具。
二、功能特点
1、多渠道公众号采集,
2、在线发文章
3、分析和多维度传播
4、数据导出
三、下载地址
四、使用方法
1、打开网址输入::登录,再进行操作。
2、访问链接后选择要采集的文章进行添加收藏。
3、然后单击操作完成。
五、其他功能
1、留言及选题能够让用户留言或者在选题上进行选择,便于公众号采集等操作。
2、在线搜索在搜索框内输入要搜索的关键词,即可进行搜索文章。
3、追热点随时关注公众号及时抓取热点。
四、产品截图
你是想问免费的新闻采集软件还是收费的新闻采集软件呢?本人感觉这个问题没什么意义,首先要想到如何付费,用付费的软件就不太划算,免费的软件才适合你,推荐你一个免费的工具,名字叫“图快采集器”我觉得效果很不错,大家可以搜一下看看。 查看全部
微信公众号文章采集功能特点及使用方法介绍-乐题库
文章采集功能是随着互联网的发展逐渐完善的。目前微信公众号文章采集已经成为信息快速检索、整理、分析的捷径,丰富了用户的浏览快速浏览,使用户体验感大大提升。
一、平台介绍文章采集是采集公众号文章内容的工具,采集是一款免费的网络爬虫抓取工具,采集工具自动搜索全网所有的公众号文章并且可自动生成抓取列表,该工具包含30种的新闻来源渠道,此外还有付费的渠道检索和社会化分析工具。
二、功能特点
1、多渠道公众号采集,
2、在线发文章
3、分析和多维度传播
4、数据导出
三、下载地址
四、使用方法
1、打开网址输入::登录,再进行操作。
2、访问链接后选择要采集的文章进行添加收藏。
3、然后单击操作完成。
五、其他功能
1、留言及选题能够让用户留言或者在选题上进行选择,便于公众号采集等操作。
2、在线搜索在搜索框内输入要搜索的关键词,即可进行搜索文章。
3、追热点随时关注公众号及时抓取热点。
四、产品截图
你是想问免费的新闻采集软件还是收费的新闻采集软件呢?本人感觉这个问题没什么意义,首先要想到如何付费,用付费的软件就不太划算,免费的软件才适合你,推荐你一个免费的工具,名字叫“图快采集器”我觉得效果很不错,大家可以搜一下看看。
文章采集功能的实现方法有很多,此我只是从业余角度讲述
采集交流 • 优采云 发表了文章 • 0 个评论 • 229 次浏览 • 2021-03-23 07:07
文章采集功能的实现方法有很多,在此我只是从业余的角度讲述我自己的知识点的实现方法,不会讲的很详细,毕竟对于每个人来说,还是不太会有耐心来看一篇长篇大论,那么我这里要讲的采集功能,就是一个excel表的数据调取过程。这篇文章,将会从,批量导入以及调取这两个方面来讲述。这篇文章的方法可以用来采集带通道的qq表的记录,来源为自家的腾讯网,不过因为制作动态数据源对于我自己来说不算是一个太好的选择,因此在我的软件项目中,数据源都是用的批量采集的方法来制作,这个过程需要用到一些采集框架来实现,我的web页面使用mvc的搭建方式来实现,具体的建站方法,大家自行去w3school看。
动态数据采集打开电脑浏览器的扩展程序,点击该网页的右上角,会有一个导入all采集的选项,点击这个按钮,选择上述动态数据源中对应的all选项,然后进行输入要导入的数据源文件的路径,然后点击下一步。这里要特别注意的是,上述内容每个电脑在安装时都要相应的提供,一定要保证选择正确。在导入成功后,我们看到的页面地址为,将第一个url复制到server-web-map中,并添加路由,点击选择全部导入后,再确定到这里,我们要看到的页面地址为,可以点击复制进来,存储在服务器里。
然后打开我们做好的excel数据源页面,点击该文件的任一页,然后发送请求发出去,请求将会输出页面地址,如果错误,请检查是否把url重定向到文件的路径(如果还是出现错误的,就是路由有问题,换个路由,试试),如果成功,看看页面地址,是否成功了。再对目标字段进行验证处理,目标字段的值是否正确。excel路由处理路由数据正确,输出目标字段对应的地址,并传回给我们的采集页,完成收集。
ps.我用的是ssm做web项目,采集的数据源我自己配置的是csv格式的数据文件,也是因为我用的是view-user-agent="agent-id=xxx"target_name="agent"来找到需要的qq,但是如果你采集的数据源文件和采集参数是没有任何相关性的话,其实也可以用正则表达式匹配的,如果是广告数据,可以直接用正则表达式来匹配,如果是txt等纯文本,可以使用xml格式的导入方式,这里就不具体介绍了。
下次再讲解一下动态数据录入方面的内容。下一次,我会详细的讲一下qq数据记录的保存,数据过滤,excel数据导出,以及数据更新和处理等内容。下一篇文章会讲如何针对数据匹配方法进行增删改操作。最后,希望我的工作能够尽可能快的完成,毕竟amazonmeanslater,不仅我自己,我的团队也要加油。 查看全部
文章采集功能的实现方法有很多,此我只是从业余角度讲述
文章采集功能的实现方法有很多,在此我只是从业余的角度讲述我自己的知识点的实现方法,不会讲的很详细,毕竟对于每个人来说,还是不太会有耐心来看一篇长篇大论,那么我这里要讲的采集功能,就是一个excel表的数据调取过程。这篇文章,将会从,批量导入以及调取这两个方面来讲述。这篇文章的方法可以用来采集带通道的qq表的记录,来源为自家的腾讯网,不过因为制作动态数据源对于我自己来说不算是一个太好的选择,因此在我的软件项目中,数据源都是用的批量采集的方法来制作,这个过程需要用到一些采集框架来实现,我的web页面使用mvc的搭建方式来实现,具体的建站方法,大家自行去w3school看。
动态数据采集打开电脑浏览器的扩展程序,点击该网页的右上角,会有一个导入all采集的选项,点击这个按钮,选择上述动态数据源中对应的all选项,然后进行输入要导入的数据源文件的路径,然后点击下一步。这里要特别注意的是,上述内容每个电脑在安装时都要相应的提供,一定要保证选择正确。在导入成功后,我们看到的页面地址为,将第一个url复制到server-web-map中,并添加路由,点击选择全部导入后,再确定到这里,我们要看到的页面地址为,可以点击复制进来,存储在服务器里。
然后打开我们做好的excel数据源页面,点击该文件的任一页,然后发送请求发出去,请求将会输出页面地址,如果错误,请检查是否把url重定向到文件的路径(如果还是出现错误的,就是路由有问题,换个路由,试试),如果成功,看看页面地址,是否成功了。再对目标字段进行验证处理,目标字段的值是否正确。excel路由处理路由数据正确,输出目标字段对应的地址,并传回给我们的采集页,完成收集。
ps.我用的是ssm做web项目,采集的数据源我自己配置的是csv格式的数据文件,也是因为我用的是view-user-agent="agent-id=xxx"target_name="agent"来找到需要的qq,但是如果你采集的数据源文件和采集参数是没有任何相关性的话,其实也可以用正则表达式匹配的,如果是广告数据,可以直接用正则表达式来匹配,如果是txt等纯文本,可以使用xml格式的导入方式,这里就不具体介绍了。
下次再讲解一下动态数据录入方面的内容。下一次,我会详细的讲一下qq数据记录的保存,数据过滤,excel数据导出,以及数据更新和处理等内容。下一篇文章会讲如何针对数据匹配方法进行增删改操作。最后,希望我的工作能够尽可能快的完成,毕竟amazonmeanslater,不仅我自己,我的团队也要加油。
用优采云“微信文章爬虫”采集并数据的步骤
采集交流 • 优采云 发表了文章 • 0 个评论 • 418 次浏览 • 2021-03-23 02:28
本文主要介绍优采云“微信文章 采集采集器[通过公共帐户或关键字]”(以下称为“微信文章采集器”)教程和注意事项。
由于微信公众号上有很多很棒的文章,具有很高的应用价值,所以优采云推出了供大家使用的“微信文章采集器”。
接下来,我将为您详细介绍使用优采云“微信文章采集器” 采集和导出数据的步骤:
第1步注册并登录
注册并登录优采云,然后进入优采云控制台。
注意:
优采云支持使用QQ和GitHub帐户登录。
第2步购买爬行器
进入优采云大数据市场,找到“微信文章采集器”,单击“获取采集器”按钮,即可成功获取微信采集器。
注意:
要正常使用微信爬虫,优采云软件包为“ Enterprise Standard Edition”及更高版本。单击此处升级优采云软件包。
第3步设置抓取工具
进入“微信文章抓取工具”概述页面,单击“抓取工具设置”,您可以选择文件托管方法,设置微信文章的抓取方法,以及是否使用[提供的免费验证码k6]识别”功能,设置后不要忘记单击“保存”。
注意:
1.如果要提高爬虫的爬网速度,建议选中“仅打印密钥日志”;
2.采集器支持通过关键字,官方帐户ID或官方帐户名称对微信文章进行爬网,您可以根据实际情况自由选择;
3. 优采云自主开发的人工智能验证码识别是完全免费的,识别成功率很高。
第4步抓取数据
再次进入“微信文章爬虫”概述页面,单击“启动爬虫”,该爬虫将开始对微信文章进行爬网,稍等片刻,您可以查看已爬网的文章数据。
第5步数据发布和导出
当采集器搜寻到数据时,您可以选择将数据发布到网站或数据库。单击此处查看优采云数据发布的详细教程。
此外,您还可以选择“导出”数据。单击此处查看优采云数据导出详细教程。
“微信文章采集器”导出数据的示例,如下图所示:
优采云大数据市场“微信文章抓取工具[通过公共帐户或关键字]”购买地址: 查看全部
用优采云“微信文章爬虫”采集并数据的步骤
本文主要介绍优采云“微信文章 采集采集器[通过公共帐户或关键字]”(以下称为“微信文章采集器”)教程和注意事项。
由于微信公众号上有很多很棒的文章,具有很高的应用价值,所以优采云推出了供大家使用的“微信文章采集器”。
接下来,我将为您详细介绍使用优采云“微信文章采集器” 采集和导出数据的步骤:
第1步注册并登录
注册并登录优采云,然后进入优采云控制台。
注意:
优采云支持使用QQ和GitHub帐户登录。
第2步购买爬行器
进入优采云大数据市场,找到“微信文章采集器”,单击“获取采集器”按钮,即可成功获取微信采集器。
注意:
要正常使用微信爬虫,优采云软件包为“ Enterprise Standard Edition”及更高版本。单击此处升级优采云软件包。
第3步设置抓取工具
进入“微信文章抓取工具”概述页面,单击“抓取工具设置”,您可以选择文件托管方法,设置微信文章的抓取方法,以及是否使用[提供的免费验证码k6]识别”功能,设置后不要忘记单击“保存”。
注意:
1.如果要提高爬虫的爬网速度,建议选中“仅打印密钥日志”;
2.采集器支持通过关键字,官方帐户ID或官方帐户名称对微信文章进行爬网,您可以根据实际情况自由选择;
3. 优采云自主开发的人工智能验证码识别是完全免费的,识别成功率很高。
第4步抓取数据
再次进入“微信文章爬虫”概述页面,单击“启动爬虫”,该爬虫将开始对微信文章进行爬网,稍等片刻,您可以查看已爬网的文章数据。
第5步数据发布和导出
当采集器搜寻到数据时,您可以选择将数据发布到网站或数据库。单击此处查看优采云数据发布的详细教程。
此外,您还可以选择“导出”数据。单击此处查看优采云数据导出详细教程。
“微信文章采集器”导出数据的示例,如下图所示:
优采云大数据市场“微信文章抓取工具[通过公共帐户或关键字]”购买地址:

