
文章采集内容
解读:自媒体文章采集方法,以今日头条采集为例
采集交流 • 优采云 发表了文章 • 0 个评论 • 540 次浏览 • 2020-11-10 10:02
Cloud 采集服务平台自媒体文章采集方法,以头条采集为例自媒体如今越来越流行,自媒体是基于云计算带来的社会化Internet Media,因为社交媒体更具交互性和更快性,它完全满足了每个想要发言的人的需求,并且它的及时性也非常吸引人,因此社交媒体立即拥有大量的受众。因此自媒体平台上出现了越来越多的高质量文章,并且我的许多朋友都对采集 自媒体文章有需求。让我们以今天的标题采集为例,介绍自媒体文章。如何使用本文描述优采云7.0 采集 自媒体文章采集方法的用法今天的头条新闻。 采集 网站:使用功能点:Ajax滚动加载设置列表内容提取步骤:创建采集任务1)进入主界面进行选择,选择“自定义模式”云采集服务平台自媒体文章采集步骤2)复制上述URL的URL并将其粘贴到在网站输入框中,单击“保存URL”。云采集服务平台自媒体文章采集步骤3)保存URL之后,将在优采云采集器中打开页面红框中的内容是此演示采集的内容,这是当今头条新闻所发布的最新热点新闻。 自媒体文章采集步骤2:设置ajax页面加载时间,设置打开页面的步骤的ajax滚动加载时间,找到页面翻页按钮,设置页面翻页周期,设置页面翻页步骤,ajax下拉加载时间云采集服务平台1)打开网页后,需要进行以下设置:打开流程图,单击“打开网页”步骤,在右键,检查“页面加载完成向下滚动”,设置滚动数,每个滚动间隔时间,一般设置并单击“确定”。自媒体文章采集步骤注意:网站在今天的标题中属于瀑布网站,没有翻页按钮,此处的滚动设置数量将影响采集的数据量。
云采集服务平台自媒体文章采集步骤步骤3:采集新闻内容创建数据提取列表1)如图所示,移动鼠标以选择评论列表框,右键单击,该框的背景颜色将变为绿色,然后单击“选择子元素” Cloud 采集服务平台自媒体文章采集步骤注意:单击右上角的“处理”按钮显示视觉流程图。 2)然后单击“全选”,并将页面上需要采集的信息添加到列表中。 Cloud 采集服务平台自媒体文章采集步骤注意:提示框中的字段将出现“ X”标记,单击以删除该字段。 自媒体文章采集 Step 3)单击“ 采集以下数据” 自媒体文章采集 Step cloud 采集服务平台4)修改采集字段名称,单击“保存并开始采集 自媒体文章采集框内的第10步下面的红色:;数据采集并导出1)根据采集的情况选择适当的采集方法,在此处选择“启动本地采集云采集服务平台自媒体文章采集步骤11描述:如果存在采集,则本地采集会占用采集的当前计算机资源。时间要求或当前计算机不能太长继续进行操作采集可以使用云采集功能,网络采集中可以使用云采集,如果没有当前计算机的支持,则可以关闭计算机,可以设置多个云节点以共享任务,10个节点等于10个节点计算机分配任务以帮助您采集,并且速度降低到原创速度的十分之一; 采集数据可以在云中存储三个月,并且可以随时导出。
完成2) 采集之后,选择适当的导出方法,并将采集良好数据导出到云采集服务平台自媒体文章采集步骤12相关的采集教程百度搜索结果采集新浪微博数据采集搜狗微信文章采集云采集由服务平台采集器上的70万用户选择的网页数据。1、该操作很简单,任何人都可以使用它:不需要技术背景,并且您可以浏览Internet 采集。完全可视化该过程,单击鼠标以完成操作,您可以在数分钟内快速上手。2、功能强大,可以使用任何网站:单击,登录,翻页,标识验证码,瀑布流和Ajax脚本,以通过简单的设置采集异步加载带有数据的网页。3、Cloud 采集,可以将其关闭。配置采集任务后,可以将其关闭,并可以在云中执行该任务。庞大的云采集群集不间断运行24 * 7,因此无需担心IP被阻塞和网络中断。4、可以根据需要选择免费功能和增值服务。免费版具有所有功能,可以满足用户的基本采集需求。同时,已经建立了一些增值服务(例如私有云)来满足高端付费企业用户的需求。 查看全部
自媒体文章采集方法,以今天的头条新闻采集为例
Cloud 采集服务平台自媒体文章采集方法,以头条采集为例自媒体如今越来越流行,自媒体是基于云计算带来的社会化Internet Media,因为社交媒体更具交互性和更快性,它完全满足了每个想要发言的人的需求,并且它的及时性也非常吸引人,因此社交媒体立即拥有大量的受众。因此自媒体平台上出现了越来越多的高质量文章,并且我的许多朋友都对采集 自媒体文章有需求。让我们以今天的标题采集为例,介绍自媒体文章。如何使用本文描述优采云7.0 采集 自媒体文章采集方法的用法今天的头条新闻。 采集 网站:使用功能点:Ajax滚动加载设置列表内容提取步骤:创建采集任务1)进入主界面进行选择,选择“自定义模式”云采集服务平台自媒体文章采集步骤2)复制上述URL的URL并将其粘贴到在网站输入框中,单击“保存URL”。云采集服务平台自媒体文章采集步骤3)保存URL之后,将在优采云采集器中打开页面红框中的内容是此演示采集的内容,这是当今头条新闻所发布的最新热点新闻。 自媒体文章采集步骤2:设置ajax页面加载时间,设置打开页面的步骤的ajax滚动加载时间,找到页面翻页按钮,设置页面翻页周期,设置页面翻页步骤,ajax下拉加载时间云采集服务平台1)打开网页后,需要进行以下设置:打开流程图,单击“打开网页”步骤,在右键,检查“页面加载完成向下滚动”,设置滚动数,每个滚动间隔时间,一般设置并单击“确定”。自媒体文章采集步骤注意:网站在今天的标题中属于瀑布网站,没有翻页按钮,此处的滚动设置数量将影响采集的数据量。
云采集服务平台自媒体文章采集步骤步骤3:采集新闻内容创建数据提取列表1)如图所示,移动鼠标以选择评论列表框,右键单击,该框的背景颜色将变为绿色,然后单击“选择子元素” Cloud 采集服务平台自媒体文章采集步骤注意:单击右上角的“处理”按钮显示视觉流程图。 2)然后单击“全选”,并将页面上需要采集的信息添加到列表中。 Cloud 采集服务平台自媒体文章采集步骤注意:提示框中的字段将出现“ X”标记,单击以删除该字段。 自媒体文章采集 Step 3)单击“ 采集以下数据” 自媒体文章采集 Step cloud 采集服务平台4)修改采集字段名称,单击“保存并开始采集 自媒体文章采集框内的第10步下面的红色:;数据采集并导出1)根据采集的情况选择适当的采集方法,在此处选择“启动本地采集云采集服务平台自媒体文章采集步骤11描述:如果存在采集,则本地采集会占用采集的当前计算机资源。时间要求或当前计算机不能太长继续进行操作采集可以使用云采集功能,网络采集中可以使用云采集,如果没有当前计算机的支持,则可以关闭计算机,可以设置多个云节点以共享任务,10个节点等于10个节点计算机分配任务以帮助您采集,并且速度降低到原创速度的十分之一; 采集数据可以在云中存储三个月,并且可以随时导出。
完成2) 采集之后,选择适当的导出方法,并将采集良好数据导出到云采集服务平台自媒体文章采集步骤12相关的采集教程百度搜索结果采集新浪微博数据采集搜狗微信文章采集云采集由服务平台采集器上的70万用户选择的网页数据。1、该操作很简单,任何人都可以使用它:不需要技术背景,并且您可以浏览Internet 采集。完全可视化该过程,单击鼠标以完成操作,您可以在数分钟内快速上手。2、功能强大,可以使用任何网站:单击,登录,翻页,标识验证码,瀑布流和Ajax脚本,以通过简单的设置采集异步加载带有数据的网页。3、Cloud 采集,可以将其关闭。配置采集任务后,可以将其关闭,并可以在云中执行该任务。庞大的云采集群集不间断运行24 * 7,因此无需担心IP被阻塞和网络中断。4、可以根据需要选择免费功能和增值服务。免费版具有所有功能,可以满足用户的基本采集需求。同时,已经建立了一些增值服务(例如私有云)来满足高端付费企业用户的需求。
实用文章:网站文章采集平台如何通过文章采集获取一篇高质量的网站内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-09-24 11:02
摘要:但是,内容的数量也是影响百度搜索引擎排名的一个非常重要的因素。这使我们陷入手册内容和采集之间的困境。那么,如何通过文章采集获得高质量的网站内容?那是因为编写软件时。这样,在查询过程中,替换了三篇文章文章,并添加了通用开头和通用结尾后,就实现了伪原创,不是吗?
网站文章采集平台如何通过文章采集获得高质量的网站内容
网站文章采集平台
问:现阶段,百度推出了飓风算法和轻风算法,以应对采集和低质量内容。但是,内容的数量也是影响百度搜索引擎排名的一个非常重要的因素,这使我们面临手动编写与采集之间的困境。 ...
问:在现阶段,百度已经推出了飓风算法和轻风算法,以应对采集和低质量内容。但是,内容的数量也是影响百度搜索引擎排名的一个非常重要的因素,这使我们面临手动编写与采集之间的困境。那么,如何通过文章采集获得一段高质量的网站内容?
答案:关于文章采集组合,我会告诉你我的想法:
<p>1、选择关键词,这是最重要的,并逐一挖掘出属于他的网站的关键词。不要说这很困难,如果您不能自己开发它,实际上,它就像5118思维导图。2、关键词做出选择之后,它就是对高质量内容的挖掘。您必须首先选择收录您选择的关键词的最全面的主要站点。您必须是主要站点,因为主要站点的内容很全面。然后,根据关键词至采集这个大电台的内容,当文章采集不仅是这个大电台,还必须将关键词放到百度采集]。 查看全部
网站文章采集平台如何通过文章采集获得高质量的网站内容
摘要:但是,内容的数量也是影响百度搜索引擎排名的一个非常重要的因素。这使我们陷入手册内容和采集之间的困境。那么,如何通过文章采集获得高质量的网站内容?那是因为编写软件时。这样,在查询过程中,替换了三篇文章文章,并添加了通用开头和通用结尾后,就实现了伪原创,不是吗?
网站文章采集平台如何通过文章采集获得高质量的网站内容
网站文章采集平台

问:现阶段,百度推出了飓风算法和轻风算法,以应对采集和低质量内容。但是,内容的数量也是影响百度搜索引擎排名的一个非常重要的因素,这使我们面临手动编写与采集之间的困境。 ...
问:在现阶段,百度已经推出了飓风算法和轻风算法,以应对采集和低质量内容。但是,内容的数量也是影响百度搜索引擎排名的一个非常重要的因素,这使我们面临手动编写与采集之间的困境。那么,如何通过文章采集获得一段高质量的网站内容?
答案:关于文章采集组合,我会告诉你我的想法:
<p>1、选择关键词,这是最重要的,并逐一挖掘出属于他的网站的关键词。不要说这很困难,如果您不能自己开发它,实际上,它就像5118思维导图。2、关键词做出选择之后,它就是对高质量内容的挖掘。您必须首先选择收录您选择的关键词的最全面的主要站点。您必须是主要站点,因为主要站点的内容很全面。然后,根据关键词至采集这个大电台的内容,当文章采集不仅是这个大电台,还必须将关键词放到百度采集]。
PHP 怎么使用 XPath 来采集页面数据内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 330 次浏览 • 2020-08-28 09:05
之前有说过使用 Python 使用 XPath 去采集页面数据内容,前段时间参与百度公测的一个号主页诠释插口,需要文章页面改建的application/ld+json代码
Python 具体的操作可以看一下之前的文章:Python爬虫之XPath句型和lxml库的用法以及便捷的 Chrome 网页解析工具:XPath Helper
我想过使用 QueryList 的框架去操作,但是由于他大小也算个框架,有点重,还是直接单文件吧
想到了之前写 Python 爬虫时使用的 XPath,PHP 应该也是可以搞的吧
动手就干,先找到对应的 XPath 规则,如下:
//script[@type='application/ld+json']/text()
script 节点下的 type 属性,拿到它中间的文本,也刚好是我们须要的 JSON 数据
本来也是为了递交百度便捷,所以直接做到给一个链接,然后代码去恳求百度的插口就可以了
具体代码是这样的:
$html = file_get_contents('https://qq52o.me/2530.html');
$dom = new DOMDocument();
// 从一个字符串加载HTML
@$dom->loadHTML($html);
// 使该HTML规范化
$dom->normalize();
// 用DOMXpath加载DOM,用于查询
$xpath = new DOMXPath($dom);
// 获取对应的xpath数据
$hrefs = $xpath->query("//script[@type='application/ld+json']/text()");
for ($i = 0; $i < $hrefs->length; $i++) {
$href = $hrefs->item($i);
$json = $href->nodeValue;
}
类库的用法自己可以看一下指南,使用 DOMXPath 的 query 方法,执行给定的 Xpath 规则,就酱紫~
针对百度熊掌号新插口恳求封装代码可以看一下 Github:sy-records/xzh-curl
总的来说,简单写一个页面的采集还是很简单的
沈唁志,一个PHPer的成长之路!任何个人或团体,未经准许严禁转载本文:《PHP 怎么使用 XPath 来采集页面数据内容》,谢谢合作! 查看全部
PHP 怎么使用 XPath 来采集页面数据内容

之前有说过使用 Python 使用 XPath 去采集页面数据内容,前段时间参与百度公测的一个号主页诠释插口,需要文章页面改建的application/ld+json代码
Python 具体的操作可以看一下之前的文章:Python爬虫之XPath句型和lxml库的用法以及便捷的 Chrome 网页解析工具:XPath Helper
我想过使用 QueryList 的框架去操作,但是由于他大小也算个框架,有点重,还是直接单文件吧
想到了之前写 Python 爬虫时使用的 XPath,PHP 应该也是可以搞的吧
动手就干,先找到对应的 XPath 规则,如下:
//script[@type='application/ld+json']/text()
script 节点下的 type 属性,拿到它中间的文本,也刚好是我们须要的 JSON 数据
本来也是为了递交百度便捷,所以直接做到给一个链接,然后代码去恳求百度的插口就可以了
具体代码是这样的:
$html = file_get_contents('https://qq52o.me/2530.html');
$dom = new DOMDocument();
// 从一个字符串加载HTML
@$dom->loadHTML($html);
// 使该HTML规范化
$dom->normalize();
// 用DOMXpath加载DOM,用于查询
$xpath = new DOMXPath($dom);
// 获取对应的xpath数据
$hrefs = $xpath->query("//script[@type='application/ld+json']/text()");
for ($i = 0; $i < $hrefs->length; $i++) {
$href = $hrefs->item($i);
$json = $href->nodeValue;
}
类库的用法自己可以看一下指南,使用 DOMXPath 的 query 方法,执行给定的 Xpath 规则,就酱紫~
针对百度熊掌号新插口恳求封装代码可以看一下 Github:sy-records/xzh-curl
总的来说,简单写一个页面的采集还是很简单的
沈唁志,一个PHPer的成长之路!任何个人或团体,未经准许严禁转载本文:《PHP 怎么使用 XPath 来采集页面数据内容》,谢谢合作!
PHP snoopy采集类如何采集我想要的内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 303 次浏览 • 2020-08-27 00:48
Snoopy是一个php类,用来模拟浏览器的功能,可以获取网页内容,发送表单,可以拿来开发一些采集程序和扒手程序,本文章详细介绍snoopy的使用教程。
Snoopy的一些特征:
抓取网页的内容 fetch
抓取网页的文本内容 (去除HTML标签) fetchtext
抓取网页的链接,表单 fetchlinks fetchform
支持代理主机
支持基本的用户名/密码验证
支持设置 user_agent, referer(来路), cookies 和 header content(头文件)
支持浏览器重定向,并能控制重定向深度
能把网页中的链接扩充成高质量的url(默认)
提交数据但是获取返回值
支持跟踪HTML框架
支持重定向的时侯传递cookies
要求php4以上就可以了 由于本身是php一个类 无需扩支持 服务器不支持curl时侯的最好选择,
Snoopy类方式及示例:
fetch($URI)
这是为了抓取网页的内容而使用的技巧。
$URI参数是被抓取网页的URL地址。
抓取的结果被储存在 $this->results 中。
如果你正在抓取的是一个框架,Snoopy将会将每位框架追踪后存入字段中,然后存入 $this->results。
fetchtext($URI)
本方式类似于fetch(),唯一不同的就是本方式会消除HTML标签和其他的无关数据,只返回网页中的文字内容。
fetchform($URI)
本方式类似于fetch(),唯一不同的就是本方式会消除HTML标签和其他的无关数据,只返回网页中表单内容(form)。
fetchlinks($URI)
本方式类似于fetch(),唯一不同的就是本方式会消除HTML标签和其他的无关数据,只返回网页中链接(link)。
默认情况下,相对链接将手动补全,转换成完整的URL。
submit($URI,$formvars)
本方式向$URL指定的链接地址发送确认表单。$formvars是一个储存表单参数的链表。
submittext($URI,$formvars)
本方式类似于submit(),唯一不同的就是本方式会消除HTML标签和其他的无关数据,只返回登录后网页中的文字内容。
submitlinks($URI)
本方式类似于submit(),唯一不同的就是本方式会消除HTML标签和其他的无关数据,只返回网页中链接(link)。
默认情况下,相对链接将手动补全,转换成完整的URL。 查看全部
PHP snoopy采集类如何采集我想要的内容
Snoopy是一个php类,用来模拟浏览器的功能,可以获取网页内容,发送表单,可以拿来开发一些采集程序和扒手程序,本文章详细介绍snoopy的使用教程。
Snoopy的一些特征:
抓取网页的内容 fetch
抓取网页的文本内容 (去除HTML标签) fetchtext
抓取网页的链接,表单 fetchlinks fetchform
支持代理主机
支持基本的用户名/密码验证
支持设置 user_agent, referer(来路), cookies 和 header content(头文件)
支持浏览器重定向,并能控制重定向深度
能把网页中的链接扩充成高质量的url(默认)
提交数据但是获取返回值
支持跟踪HTML框架
支持重定向的时侯传递cookies
要求php4以上就可以了 由于本身是php一个类 无需扩支持 服务器不支持curl时侯的最好选择,
Snoopy类方式及示例:
fetch($URI)
这是为了抓取网页的内容而使用的技巧。
$URI参数是被抓取网页的URL地址。
抓取的结果被储存在 $this->results 中。
如果你正在抓取的是一个框架,Snoopy将会将每位框架追踪后存入字段中,然后存入 $this->results。
fetchtext($URI)
本方式类似于fetch(),唯一不同的就是本方式会消除HTML标签和其他的无关数据,只返回网页中的文字内容。
fetchform($URI)
本方式类似于fetch(),唯一不同的就是本方式会消除HTML标签和其他的无关数据,只返回网页中表单内容(form)。
fetchlinks($URI)
本方式类似于fetch(),唯一不同的就是本方式会消除HTML标签和其他的无关数据,只返回网页中链接(link)。
默认情况下,相对链接将手动补全,转换成完整的URL。
submit($URI,$formvars)
本方式向$URL指定的链接地址发送确认表单。$formvars是一个储存表单参数的链表。
submittext($URI,$formvars)
本方式类似于submit(),唯一不同的就是本方式会消除HTML标签和其他的无关数据,只返回登录后网页中的文字内容。
submitlinks($URI)
本方式类似于submit(),唯一不同的就是本方式会消除HTML标签和其他的无关数据,只返回网页中链接(link)。
默认情况下,相对链接将手动补全,转换成完整的URL。
正确处理采集内容与原创内容的关系! - 电商宝典
采集交流 • 优采云 发表了文章 • 0 个评论 • 309 次浏览 • 2020-08-26 14:15
正确处理采集内容与原创内容的关系!采集站对你们来说是不陌生的,现在社会发展变化的速率使我们跟不上时代的步伐,我们有太多的事情要做,虽然搜索引擎优化一再的指出原创内容是多么多么的重要,但是对于真正做站的人来说,做到真正的纯原创网站是不现实的,毕竟在这个网路急速发展的世界里,复制和粘贴很容易了,所以我们要说说怎么采集内容,以及怎么将采集来的内容做大可能的帮助到你的排行,如何将你的时间和努力价值最大化:1、修改内容的标题。修改内容的标题是最直接最简单的形式,在GG上内容获取好的排行,如果你网站的权重不会很低或新站,只要更改一下内容的标题基本可以排个好名次了。如果每晚定量采集和坚持更改内容标题对网站权重积累也有帮助。2、修改或重新编撰内容摘要。很多网站的文章内容都有文章摘要,对采集内容重新编撰文章摘要也可以推动采集内容在搜索引擎中的排行。文章摘要会在网站很多地方用得上,一般情况下搜索引擎会把这种 摘要当快照说明来使用,因此对采集内容重新编撰文章摘要是十分必要的工作。3、编写内容评论。内容采集回来对整篇内容做简单的评论对内容的排行提升也太有帮助。评论通常写 在文章开始位置或结尾位置。笔者觉得写在文章开始位置比写在结尾位置疗效要好好多。4、采集内容专题化。网站专题是个挺好的东西,采集的内容通过归类筛选出内容相像的内容弄成统一专题,对采集内容在搜索引擎排名、网站权重提升有很大的帮助。采集内容专题化带来的疗效自然要比前3个方式 带来的疗效要好好多。5、对采集内容进行伪原创。伪原创的方式好多这儿介绍几个简单的伪原创的方式。|||原创很重要吧。而不是为了SEO而SEO吧。。 查看全部
正确处理采集内容与原创内容的关系! - 电商宝典
正确处理采集内容与原创内容的关系!采集站对你们来说是不陌生的,现在社会发展变化的速率使我们跟不上时代的步伐,我们有太多的事情要做,虽然搜索引擎优化一再的指出原创内容是多么多么的重要,但是对于真正做站的人来说,做到真正的纯原创网站是不现实的,毕竟在这个网路急速发展的世界里,复制和粘贴很容易了,所以我们要说说怎么采集内容,以及怎么将采集来的内容做大可能的帮助到你的排行,如何将你的时间和努力价值最大化:1、修改内容的标题。修改内容的标题是最直接最简单的形式,在GG上内容获取好的排行,如果你网站的权重不会很低或新站,只要更改一下内容的标题基本可以排个好名次了。如果每晚定量采集和坚持更改内容标题对网站权重积累也有帮助。2、修改或重新编撰内容摘要。很多网站的文章内容都有文章摘要,对采集内容重新编撰文章摘要也可以推动采集内容在搜索引擎中的排行。文章摘要会在网站很多地方用得上,一般情况下搜索引擎会把这种 摘要当快照说明来使用,因此对采集内容重新编撰文章摘要是十分必要的工作。3、编写内容评论。内容采集回来对整篇内容做简单的评论对内容的排行提升也太有帮助。评论通常写 在文章开始位置或结尾位置。笔者觉得写在文章开始位置比写在结尾位置疗效要好好多。4、采集内容专题化。网站专题是个挺好的东西,采集的内容通过归类筛选出内容相像的内容弄成统一专题,对采集内容在搜索引擎排名、网站权重提升有很大的帮助。采集内容专题化带来的疗效自然要比前3个方式 带来的疗效要好好多。5、对采集内容进行伪原创。伪原创的方式好多这儿介绍几个简单的伪原创的方式。|||原创很重要吧。而不是为了SEO而SEO吧。。
采集来的内容能被百度收录么?百度怎么收录采集的文章?
采集交流 • 优采云 发表了文章 • 0 个评论 • 357 次浏览 • 2020-08-26 00:38
内容的问题这个就复杂了,为什么说内容的问题很复杂,因为有的内容千篇一律,一旦竞争降低了排行都会增长。内容的问题似乎就是要解决采集以及内容价值的问题。你如何保证内容是不一样的。这个问题你怎么样来解决。怎么样来依据自身行业特色来制订设计内容,又能满足用户的需求,这个问题不解决你去网路采集文章,网站怎么可能会有好的收录,会有好的排行采集不是不可以,但你要保证就能提高页面附加值,在才能解决用户需求的基础上降低受众率(提升点击和阅读量,评论量)。
首先,比如一篇文章被新浪复制了,跟被通常的网站复制了,他的价值都是不一样的,而搜索引擎才能分辨下来。我们如今讲的价值问题,需求问题就是这个问题。就是受众的问题。这个受众的问题似乎是十分简单的,也就是说我们页面上面的所有的内容,我们去采集别人的内容。
其次,你采集来的文章要保证有附加值 ,就是你要保证在这篇文章放到我网站上来时,他的价值是被放大过的,而不是降低的,那我们在弄这样的文章到我们网站上面,他的价值是要降低的,比如在文章专业度上、图文结合上、解决用户须要的方式上等等,最终的目的是使用户听到你的内容后才能明晰的了解这个内容就能解决他的需求。能够解决用户需求的东西都是好东西。
最后,为什么同一篇文章到在新浪的价值会很高,而到其他的地方价值就太低呢。为什么是这样的呢!因为新浪用户多,受众也多,而且新浪他的打开速率也很快。他的资源也太稳定。当然这个是搜索引擎给他进行评估,是常年进行评估的,另外的话,他就能够引起评论,那同样的一篇文章如果到了我们的网站,如果我们的评论降低了,点击流量降低了,而且喜欢的人顶踩的人也比较多,喜欢和推荐的人比较多,那这篇文章的附加值肯定是提高的 查看全部
采集来的内容能被百度收录么?百度怎么收录采集的文章?
内容的问题这个就复杂了,为什么说内容的问题很复杂,因为有的内容千篇一律,一旦竞争降低了排行都会增长。内容的问题似乎就是要解决采集以及内容价值的问题。你如何保证内容是不一样的。这个问题你怎么样来解决。怎么样来依据自身行业特色来制订设计内容,又能满足用户的需求,这个问题不解决你去网路采集文章,网站怎么可能会有好的收录,会有好的排行采集不是不可以,但你要保证就能提高页面附加值,在才能解决用户需求的基础上降低受众率(提升点击和阅读量,评论量)。
首先,比如一篇文章被新浪复制了,跟被通常的网站复制了,他的价值都是不一样的,而搜索引擎才能分辨下来。我们如今讲的价值问题,需求问题就是这个问题。就是受众的问题。这个受众的问题似乎是十分简单的,也就是说我们页面上面的所有的内容,我们去采集别人的内容。
其次,你采集来的文章要保证有附加值 ,就是你要保证在这篇文章放到我网站上来时,他的价值是被放大过的,而不是降低的,那我们在弄这样的文章到我们网站上面,他的价值是要降低的,比如在文章专业度上、图文结合上、解决用户须要的方式上等等,最终的目的是使用户听到你的内容后才能明晰的了解这个内容就能解决他的需求。能够解决用户需求的东西都是好东西。
最后,为什么同一篇文章到在新浪的价值会很高,而到其他的地方价值就太低呢。为什么是这样的呢!因为新浪用户多,受众也多,而且新浪他的打开速率也很快。他的资源也太稳定。当然这个是搜索引擎给他进行评估,是常年进行评估的,另外的话,他就能够引起评论,那同样的一篇文章如果到了我们的网站,如果我们的评论降低了,点击流量降低了,而且喜欢的人顶踩的人也比较多,喜欢和推荐的人比较多,那这篇文章的附加值肯定是提高的
分析采集内容会给网站带来哪些弊病
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2020-08-25 22:58
“内容为王,外链为皇”这句可以成为SEO的历史了,不管是菜鸟站长还是老手,优化这两个方面早已成为习惯。但是博主听到有站长说:网站优化并不需要原创的内容,搜索引擎如今并不是太成熟,并不能判别出网站是否真的是原创内容。他说的也没错,搜索引擎似乎是难以判定,有的采集站也会被蜘蛛收录的,但是作为正规的网站来说,采集的内容吃大亏,那采集的内容对网站来说,到底是有什么样的症结。
第一:内容无法控制。很多站长为了能节约时间,采用采集的工具,采集工具也是太不健全的,采集的内容不是智能的,很多时侯采集来的文章内容中不能除去他人的信息,这样无意中也是帮他人推广,而且他人写的文章并定是符合你网站的标准。同行业的网站之间采集,很多时侯会帮着他人推广信息,这是太不值得的。
第二:采集内容容易造成误会。这种情况对于新闻门户网站很常常,新闻网站每天都要更新好多新内容,有的网站并不能找到好的新闻来源,这时都会想着要采集别人的内容,但是他人的新闻内容并没有得到你的否认,你并不能确定他人的新闻是否真实,很多时侯也会有报导错误新闻的风波,本来你不知道这个新闻,但是你采集来了,结果是假的新闻,你的网站也会遭到牵涉的,岂不是赔了夫人又折兵。
第三:不尊重他人的版权。很多时侯站长们在采集的时侯,会除去他人的链接和推广信息,如果他人的网站正处在不稳当的状态,发的原创内容并没有被正常收录,但是你采集过去了被收录了,这时面临的版权问题也会使站长们头痛的。博主的微博营销站时常会被采集,看到这样的采集器会太吃惊的,正常的人就会找到你使你删掉文章的,要不就是保留版权的。即使互联网的版权不被尊重,但是他人的辛苦找到你时,你就必须要尊重他人的版权。这岂不是又浪费了时间吗?
第四:容易被K站。内容为王,高质量的内容可以提供网站权重。站长们不得不承认这个观点,网站有高质量的内容,权重的降低就会赶快。暂且不说采集站的权重,对于正规的网站来说,经常采集别人的内容,蜘蛛来抓取的频度就会增加的,蜘蛛喜欢新鲜,数据库中放太多相同内容的时侯,它还会想着要屏蔽一些相同的内容,同时网站采集过多的内容,蜘蛛会觉得这样的网站是在作弊,特别是新站,千万不要为了快速降低网站内容,去采集内容,这样的方式是不可取的。
要想网站的权重能提升,如果不想从原创的文章出发,光靠外链的发展是不行的,内容和外链的建设缺一不可的,站长们应当要从原创的内容出发,虽然说原创的内容难了点,但是采集的内容不可取。最坏的准备也是要学会怎样写好伪原创。 查看全部
分析采集内容会给网站带来哪些弊病
“内容为王,外链为皇”这句可以成为SEO的历史了,不管是菜鸟站长还是老手,优化这两个方面早已成为习惯。但是博主听到有站长说:网站优化并不需要原创的内容,搜索引擎如今并不是太成熟,并不能判别出网站是否真的是原创内容。他说的也没错,搜索引擎似乎是难以判定,有的采集站也会被蜘蛛收录的,但是作为正规的网站来说,采集的内容吃大亏,那采集的内容对网站来说,到底是有什么样的症结。
第一:内容无法控制。很多站长为了能节约时间,采用采集的工具,采集工具也是太不健全的,采集的内容不是智能的,很多时侯采集来的文章内容中不能除去他人的信息,这样无意中也是帮他人推广,而且他人写的文章并定是符合你网站的标准。同行业的网站之间采集,很多时侯会帮着他人推广信息,这是太不值得的。
第二:采集内容容易造成误会。这种情况对于新闻门户网站很常常,新闻网站每天都要更新好多新内容,有的网站并不能找到好的新闻来源,这时都会想着要采集别人的内容,但是他人的新闻内容并没有得到你的否认,你并不能确定他人的新闻是否真实,很多时侯也会有报导错误新闻的风波,本来你不知道这个新闻,但是你采集来了,结果是假的新闻,你的网站也会遭到牵涉的,岂不是赔了夫人又折兵。
第三:不尊重他人的版权。很多时侯站长们在采集的时侯,会除去他人的链接和推广信息,如果他人的网站正处在不稳当的状态,发的原创内容并没有被正常收录,但是你采集过去了被收录了,这时面临的版权问题也会使站长们头痛的。博主的微博营销站时常会被采集,看到这样的采集器会太吃惊的,正常的人就会找到你使你删掉文章的,要不就是保留版权的。即使互联网的版权不被尊重,但是他人的辛苦找到你时,你就必须要尊重他人的版权。这岂不是又浪费了时间吗?
第四:容易被K站。内容为王,高质量的内容可以提供网站权重。站长们不得不承认这个观点,网站有高质量的内容,权重的降低就会赶快。暂且不说采集站的权重,对于正规的网站来说,经常采集别人的内容,蜘蛛来抓取的频度就会增加的,蜘蛛喜欢新鲜,数据库中放太多相同内容的时侯,它还会想着要屏蔽一些相同的内容,同时网站采集过多的内容,蜘蛛会觉得这样的网站是在作弊,特别是新站,千万不要为了快速降低网站内容,去采集内容,这样的方式是不可取的。
要想网站的权重能提升,如果不想从原创的文章出发,光靠外链的发展是不行的,内容和外链的建设缺一不可的,站长们应当要从原创的内容出发,虽然说原创的内容难了点,但是采集的内容不可取。最坏的准备也是要学会怎样写好伪原创。
用它采集内容,简直不要很轻松!
采集交流 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2020-08-25 17:13
疫情期间,很多企业不得不选择远程线上办公,互联网算是受疫情影响较小的行业之一,但是远程办公一直不及面对面工作效率高,为此优采云采集特推出智能采集工具。
相信不少营运都曾接触过采集工具,现在市面上的采集工具五花八门,很多人觉得采集工具只是作为文章热点/节日话题等信息采集的辅助工具,其实除了这么。一款成熟的采集工具除了是帮营运采集信息,还能确切剖析数据迈向,从而帮助提升产值。
一、什么是优采云采集?
优采云采集是一款自媒体素材搜索、文章原创、一键发布的营运工具,有效提高新媒体营运工作效率,降低企业成本。
二、如何使用优采云采集进行搜索?
(一) 输入关键词
优采云采集根据用户输入的关键词,通过程序自动化的步入主流自媒体数据源的搜索引擎进行搜索。
优采云采集根据先进算法匹配更精准的内容,提高搜索内容的准确率。
例如:
用户需采集有关疫情的素材,在主页面输入关键词“疫情”即可。优采云采集便会将搜索结果进行整合至一个列表里。
(二) 保存搜索素材
优采云采集具备批量保存搜索素材的功能。
点击【当前页面全选】功能,并勾选所需文章,文章将会添加至操作面板,方便用户批量保存。
(三) 精准过滤
1、搜索过滤
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使得搜索内容更精准。
2、广告过滤 查看全部
用它采集内容,简直不要很轻松!
疫情期间,很多企业不得不选择远程线上办公,互联网算是受疫情影响较小的行业之一,但是远程办公一直不及面对面工作效率高,为此优采云采集特推出智能采集工具。
相信不少营运都曾接触过采集工具,现在市面上的采集工具五花八门,很多人觉得采集工具只是作为文章热点/节日话题等信息采集的辅助工具,其实除了这么。一款成熟的采集工具除了是帮营运采集信息,还能确切剖析数据迈向,从而帮助提升产值。
一、什么是优采云采集?
优采云采集是一款自媒体素材搜索、文章原创、一键发布的营运工具,有效提高新媒体营运工作效率,降低企业成本。
二、如何使用优采云采集进行搜索?
(一) 输入关键词
优采云采集根据用户输入的关键词,通过程序自动化的步入主流自媒体数据源的搜索引擎进行搜索。
优采云采集根据先进算法匹配更精准的内容,提高搜索内容的准确率。
例如:
用户需采集有关疫情的素材,在主页面输入关键词“疫情”即可。优采云采集便会将搜索结果进行整合至一个列表里。
(二) 保存搜索素材
优采云采集具备批量保存搜索素材的功能。
点击【当前页面全选】功能,并勾选所需文章,文章将会添加至操作面板,方便用户批量保存。
(三) 精准过滤
1、搜索过滤
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使得搜索内容更精准。
2、广告过滤
网络营销的内容采集文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2020-08-24 19:06
1、网站降权问题;正常情况下,就算网站权重较低,收录还是没有问题的,如果网站文章突然之间不收录,很有可能是网站被降权了,短时间的降权,一两个月才会恢复,长时间的降权,几个月能够恢复,也有可能永远没法恢复,提醒你们不要为了眼前的利益以身犯险。
2、关键词密度不是你网站关键词出现的越多,排名就越好的,要有一个密度,一般是2%-8%,当然看文章内容的长短,总之关键词出现的要自然,不要拼凑关键词就可以了。
3、原创文章为什么没被收录原创文章不一定会收录,原创文章不收录多数是因为质量问题。原创文章只能说明“原创”而已,不能说明任何问题,原创文章未必是高质量的文章,你可以写原创文章,我可以写原创文章,他也可以写原创文章,可是你写的文章和他写的文章是两回事,你写的文章也许质量太差,他写的文章也许质量挺好,质量差的文章是不容易被收录的。
4、引导百度蛛抓抓取:去百度蜘蛛活跃度高的网站、论坛引流,获得一些导航网站链接、可换少许友链、加快网站抓取收录。
5、文章首段内容不管你是刚接触SEO,还是资深SEO,相信你都晓得一篇文章的首段是十分重要的,可以直接决定用户会不会继续往下看,搜索引擎蜘蛛在抓取的时侯也是从首段开始抓的,所以通常文章首段前60个字内一定要记得插入我们的关键词,这样愈发有利于排行。
6、轻则掉排行,重则降权。百度过来抓取到的页面结果出现好多死链,那它还会觉得这个网站质量偏低,从而不会给与高排行,甚至会增加现有网站的权重。
7、网站死链是怎样形成的?对网站的负面影响内容死链内容死链主要是由网站自身变化造成的,网页可以正常打开未发生跳转,但页面内容对爬虫来说没有收录价值,对用户来说也没有参考价值,如贴子被删除、内容已转移、空间被关掉、信息已过期、交易已关掉等。在这些没有信息价值的网页上,网站应该在显著位置直接给与提示文字,如:
8、网站内容相对质量较高这点可能有人有疑问,有的权重高的站点,直接复制别的网站的内容,也是能秒收,所以这儿我加了2个字:相对!但是我们都晓得,百度秒收后,并不代表内容一定有排行,有排行后,更不能保证能维持住。很多网站是明天查看某个关键词有排行,过几天再看就没有了,这种情况是太常见的,因为百度会再度进行算法过滤的!大家应当都晓得前段时间百度新算法升级的事情。
—————————————————————————————–
问:黑帽seo是哪些意思?
答:黑帽SEO是借助和放大搜索引擎的策略缺陷(实际上完美的系统是不存在的)获取更多用户访问量,而这种更多的访问量,是以伤害用户体验为代价的SEO行为。
问:网页标题与描述写多少字合适?
答:网站title标题搜索引擎在搜索结果中只能展示63个字节,后边都省略了;网页标题通常建议不超过32个汉字,描述Description不要超过72个汉字。
问:网站服务器空间买多大适宜?
答:根据网站规模和要提供的服务来决定选择订购何种空间(服务器),选择有实力的正规空间商,根据用户群分布选择接入商,保证用户的访问速率和稳定性。 查看全部
网络营销的内容采集文章

1、网站降权问题;正常情况下,就算网站权重较低,收录还是没有问题的,如果网站文章突然之间不收录,很有可能是网站被降权了,短时间的降权,一两个月才会恢复,长时间的降权,几个月能够恢复,也有可能永远没法恢复,提醒你们不要为了眼前的利益以身犯险。
2、关键词密度不是你网站关键词出现的越多,排名就越好的,要有一个密度,一般是2%-8%,当然看文章内容的长短,总之关键词出现的要自然,不要拼凑关键词就可以了。
3、原创文章为什么没被收录原创文章不一定会收录,原创文章不收录多数是因为质量问题。原创文章只能说明“原创”而已,不能说明任何问题,原创文章未必是高质量的文章,你可以写原创文章,我可以写原创文章,他也可以写原创文章,可是你写的文章和他写的文章是两回事,你写的文章也许质量太差,他写的文章也许质量挺好,质量差的文章是不容易被收录的。
4、引导百度蛛抓抓取:去百度蜘蛛活跃度高的网站、论坛引流,获得一些导航网站链接、可换少许友链、加快网站抓取收录。
5、文章首段内容不管你是刚接触SEO,还是资深SEO,相信你都晓得一篇文章的首段是十分重要的,可以直接决定用户会不会继续往下看,搜索引擎蜘蛛在抓取的时侯也是从首段开始抓的,所以通常文章首段前60个字内一定要记得插入我们的关键词,这样愈发有利于排行。
6、轻则掉排行,重则降权。百度过来抓取到的页面结果出现好多死链,那它还会觉得这个网站质量偏低,从而不会给与高排行,甚至会增加现有网站的权重。
7、网站死链是怎样形成的?对网站的负面影响内容死链内容死链主要是由网站自身变化造成的,网页可以正常打开未发生跳转,但页面内容对爬虫来说没有收录价值,对用户来说也没有参考价值,如贴子被删除、内容已转移、空间被关掉、信息已过期、交易已关掉等。在这些没有信息价值的网页上,网站应该在显著位置直接给与提示文字,如:
8、网站内容相对质量较高这点可能有人有疑问,有的权重高的站点,直接复制别的网站的内容,也是能秒收,所以这儿我加了2个字:相对!但是我们都晓得,百度秒收后,并不代表内容一定有排行,有排行后,更不能保证能维持住。很多网站是明天查看某个关键词有排行,过几天再看就没有了,这种情况是太常见的,因为百度会再度进行算法过滤的!大家应当都晓得前段时间百度新算法升级的事情。
—————————————————————————————–
问:黑帽seo是哪些意思?
答:黑帽SEO是借助和放大搜索引擎的策略缺陷(实际上完美的系统是不存在的)获取更多用户访问量,而这种更多的访问量,是以伤害用户体验为代价的SEO行为。
问:网页标题与描述写多少字合适?
答:网站title标题搜索引擎在搜索结果中只能展示63个字节,后边都省略了;网页标题通常建议不超过32个汉字,描述Description不要超过72个汉字。
问:网站服务器空间买多大适宜?
答:根据网站规模和要提供的服务来决定选择订购何种空间(服务器),选择有实力的正规空间商,根据用户群分布选择接入商,保证用户的访问速率和稳定性。
企业怎样提高网站内容可读性?
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2020-08-23 19:23
企业建设网站之后,就会通过后台上传内容。大部分是先上传企业信息和产品信息,接着会为了降低内容量而选择补充其它内容,都说内容是网站的核心核基础,那么企业怎样提高网站内容可读性?吸引到更多用户呢?
一、坚持文章内容原创
企业建网站有利于优化排行的形式莫过于坚持原创内容,原创主要是指企业自己编辑的,不是从哪抄来或则转换的内容,尤其是文章方面。大多数是属于自己的产品,产品图片和产品介绍多数是内部职工拍摄和编辑,原创是可以肯定的。主要在于文章方面,原创文章是可以有效地提高网站排名,加快网站内容的收录,同时可以给顾客带来可读性的内容,企业编辑原创多数是以自己或则品牌产品作为出发点,针对个别观点进行描述,能够使顾客对某方面有更深的理解。而且搜索引擎是喜欢新鲜事物,原创文章一但发布出去容易吸引搜索引擎前来抓取。因此,坚持原创对网站对企业和对顾客,都是一种质量的提高。
二、避免采集垃圾内容
企业一般会为了丰富网站内容,而到网路上进行内容采集。刚才第一点早已说到内容的原创性对网站和企业相当重要,也是优化方法的一种。那么网站内容就须要防止采集,基本上采集而来的内容都是早已发布过的,出现在其它网站里的,而且好多顾客阅读过,对她们来说阅读过的内容早已丧失了可读性。然而采集范围很广,什么文章都往里添加的话,只会适得其反。看过有的企业为了降低网站访问量,采集了与行业无关的内容,就由于标题具有吸引力而上传到自己的内容里。虽然网站访问量降低了,但跳出率同样高。客户看了文章后,发现这个网站并不是自己关注的,就会直接离开,关闭网站。对企业而言,引来的只是流量,而非潜在顾客,这些采集的文章丝毫不能为网站提升排行,也未能使企业受惠。
三、增设行业栏目
企业建网站都会上传与自己有关的内容,网站里不仅产品抢占大部分,行业文章也很重要。不同的行业都有自己的领域,涉及的知识内容不同但又有关联性。就好象服饰行业,就会与设计、色彩、时尚元素等搭边,同时与广告业、杂志业之间存在联系,所以一个行业并不能垄断整个市场。要降低网站内容可读性,可以通过收录或则转载行业文章。那么网站里可以增设行业栏目,拓展阅读量,同时也可以作为一种辅助推广,寻找适宜的合作伙伴。有合适的伙伴加入,可以使企业与不同行业之间进行合作,在各自的网站里对合作商的产品进行推广,产生1加1小于2的疗效,同时丰富网站内容。 查看全部
企业怎样提高网站内容可读性?
企业建设网站之后,就会通过后台上传内容。大部分是先上传企业信息和产品信息,接着会为了降低内容量而选择补充其它内容,都说内容是网站的核心核基础,那么企业怎样提高网站内容可读性?吸引到更多用户呢?

一、坚持文章内容原创
企业建网站有利于优化排行的形式莫过于坚持原创内容,原创主要是指企业自己编辑的,不是从哪抄来或则转换的内容,尤其是文章方面。大多数是属于自己的产品,产品图片和产品介绍多数是内部职工拍摄和编辑,原创是可以肯定的。主要在于文章方面,原创文章是可以有效地提高网站排名,加快网站内容的收录,同时可以给顾客带来可读性的内容,企业编辑原创多数是以自己或则品牌产品作为出发点,针对个别观点进行描述,能够使顾客对某方面有更深的理解。而且搜索引擎是喜欢新鲜事物,原创文章一但发布出去容易吸引搜索引擎前来抓取。因此,坚持原创对网站对企业和对顾客,都是一种质量的提高。
二、避免采集垃圾内容
企业一般会为了丰富网站内容,而到网路上进行内容采集。刚才第一点早已说到内容的原创性对网站和企业相当重要,也是优化方法的一种。那么网站内容就须要防止采集,基本上采集而来的内容都是早已发布过的,出现在其它网站里的,而且好多顾客阅读过,对她们来说阅读过的内容早已丧失了可读性。然而采集范围很广,什么文章都往里添加的话,只会适得其反。看过有的企业为了降低网站访问量,采集了与行业无关的内容,就由于标题具有吸引力而上传到自己的内容里。虽然网站访问量降低了,但跳出率同样高。客户看了文章后,发现这个网站并不是自己关注的,就会直接离开,关闭网站。对企业而言,引来的只是流量,而非潜在顾客,这些采集的文章丝毫不能为网站提升排行,也未能使企业受惠。

三、增设行业栏目
企业建网站都会上传与自己有关的内容,网站里不仅产品抢占大部分,行业文章也很重要。不同的行业都有自己的领域,涉及的知识内容不同但又有关联性。就好象服饰行业,就会与设计、色彩、时尚元素等搭边,同时与广告业、杂志业之间存在联系,所以一个行业并不能垄断整个市场。要降低网站内容可读性,可以通过收录或则转载行业文章。那么网站里可以增设行业栏目,拓展阅读量,同时也可以作为一种辅助推广,寻找适宜的合作伙伴。有合适的伙伴加入,可以使企业与不同行业之间进行合作,在各自的网站里对合作商的产品进行推广,产生1加1小于2的疗效,同时丰富网站内容。
(强文)互联网前辈教你怎么采集你想要的信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 348 次浏览 • 2020-08-20 14:01
写在上面
几个月前,团队邀我做次内部的分享,主题是怎样有效搜索信息。这是因为平常工作中,我常常会分享一些专业学习文档,而这种文档的出现常常太及时,回应一些我们自己项目的苦恼,所以你们会好奇我怎么及时找得到这么专业且对口的参考资料。
这些资料有些来自网路搜索,有些却是来自我的“个人资料库”,它分门别类,容易检索,所以太轻易就才能翻下来示人。所以后来,这次分享便从“搜索术”,扩大为怎样获取、整理各类信息的技能。
这原先我觉得是常识的东西,却在简单分享后得到好评。受到鼓励之余,我也明白了并不是所有人都明白有效的信息采集及整理有多么重要,也并不是所有人,都把握了行之有效的方式和方法。故整理成文,做抛砖引玉之用。
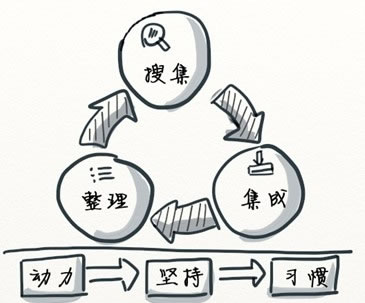
一.信息采集及整理循环图
如上图1所示,我觉得“信息采集及整理术”会收录三个关键阶段:
搜索:“找信息”——用各类搜索渠道快速找到所需的精准信息。
集成:“存信息”——简单来说,就是把你找到的信息,定制成为个人资料库,按照自定义的主题,分类储存在自己很方便访问的地方。
整理:“理信息”——信息单纯集成而不加整理,时间长了都会零乱不堪,所以才能出现很多人自己的硬碟资料库早已堆满了,每当须要哪些资料的时侯,还是须要去搜索。定期对所集成的信息进行整理(归类,去重,留精,加可供搜索的标签等等),能够明显提高信息搜索效率。
最初你须要一定的动力去尝试开始做这件事情,而一旦兴趣形成,再加以坚持, 这就早已成为习惯,和你密不可分了。
二.高效搜索术
2.1 建立你的主题关键词
建立自己关注的核心关键词是重要的一步。
如今我们遇见的信息量早已高速爆发,信息的种类和来源多种多样,信息的更新速率逐渐推进。喜欢刷微博的朋友都清楚,一旦进了微博,你就步入了无数信息和主题词的世界,通过一个消息到另一个消息,看来看去时间就消耗进去了。
如果我们不筹建一些主题,很容易深陷信息的汪洋中,而另一个极端则是两耳不闻窗前事,担心信息负载很大而刻意回避信息,导致自己和时代相悖。如果作为一个交互设计师,能够不关注最新的交互界的最新态势吗?
主题关键词有几个用处:
建立方向提醒:时刻明白对自己真正有价值的是哪些,主动保持该类信息的更新;而这些无关紧要的,则可以少看或则不看。
主动获取信息:使用各类订阅、集成工具更有目标,用这种词订阅,让信息主动找你。
减少无聊时间:无所事事比繁忙更使人疲累,若找不到想干的事,最至少可以搜索下你的主题词,找点好玩的文章或动态。
虽然靠脑部就可以产生自己的关键词,但工具可以帮助你加深记忆,比如用mindmanager等脑图工具做图,贴于自己的书房或办公桌前:
图2:Heidi的主题关键词
主题词建好以后,并不是一成不变,需要定期结合自己的工作评估及更新。比如我近一年对商务智能(Business intelligence)很感兴趣,也会定期查阅相关的资讯,但是今年此刻,我对此几乎不了解。 yixieshi
2.2 用好你的搜索引擎!
主题关键词使我们晓得自己时刻应当关注哪些,而接下来我们就要更高效去找这种信息!
搜索引擎是十分重要的信息获取入口,至于我用的方法真算不上中级,欢迎搜索达人们和我交流下省力更有效的搜索手段。
2.2.1 找准关键词,事半功倍!
很早之前,我碰巧听到两张图片。我很喜欢这两个图片,所以我希望看见更多类似的图片。 互联网的一些事
图3:用何种关键图去检索这两类图片呢?
可是,首先这些图叫哪些图呢?
先在头脑里头脑风暴下应当用的关键词,叫哪些呢?插图?图表?手绘图?插画?这些关键词搜索下来的结果真使人失望。但是,根据搜索结果的提示,一步 步更换关键词直到找到靠谱的结果。而最终,当我找到这个词后,就找到宝藏了——要找图3中右侧类型的图,请尝试用“可视化思索”,或用google搜索 “visual thinking”,要找更多图3中左侧类型的图,请尝试用“信息图”,或“infographic”。 y
图4:可视化思索的检索结果
图5:信息图的检索结果
所以,在搜索中,要不断地更换更贴切的关键词,而不是仍然打擦边球。如何找到贴切的关键词呢?从你认为可行的第一个关键词开始,不要轻言舍弃,根据每次搜索结果下来的线索跟踪,不断更换关键词,直至领到结果。
2.2.2 更换语言,别有洞天
有时更换为英文才能使你获取更精准的结果。所以这也是为何,我的主题词要中英双语版。既然好多英文的结果是从英语翻译过来的,直接查看源文章显而易见信息遗漏较少。
图6:用中文搜索“可视化思索”得到的结果
以此类推,每多一种语言就打开一扇新的了解世界的窗口。就拿家庭收纳来讲,用英文“收纳”去搜索文章,几乎只是一些零碎的图片和社区网站为了笼络用 户堆砌而成的收纳方法。而用英语“収納”去搜索,看美国的个别网站,我们就能看见好多关于收纳术的经验、文档和教程。有些教程的丰富性不亚于出版的书籍, 更好过分我们国外这些堆砌下来的家饰整理学了。如网站提供的本多先生每日 收纳教程:
图7:用英语収納检索到的专业网站
关于收纳学的网站,大家有兴趣可以用英语“収納”搜搜试试,不可以找我要。
2.2.3.更换搜索方法,殊途同归
若网页搜索不能获得所要结果,可以变换搜索类型,比如搜索图片,再通过图片链接到有价值的网站。
我常用的则是文件搜索,与普通网页相比,这些文档一般意味着更好的更系统化的组织,从而使你的信息获取愈发有效。
如何用搜索引擎搜索文档呢?
如果你使用google,在检索词前加入inurl:pdf。
如果你使用百度,在检索词前加上filetype:all,如要特定PDF格式则输入:filetype:PDF
如用百度搜商务智能的相关文档:
图8:用百度搜索文档
2.2.4.别忘掉了专业网站
专业网站让你减免在大量的垃圾信息里找所需资料的烦恼,他们的信息常常愈发聚焦。我时常用到的专业性搜索网站有:
——PPT分享网站,很多美国制做优良,内容丰富专业的PPT。我时常在这里搜索关于可视化思索的文档资料。但是很遗憾的是,目前你就须要翻墙能够够看见这个网站了。 互联网的一些事
MBA智库——专注于经管领域的资料库。你可以在这里搜到好多经管领域的各类术语解释,文档等。
维基百科——如果在墙外或则会翻墙的话。很多被国外是敏感词的,在这里才能看见特别详实的前因后果各类脉络。当然,若非敏感词的话,百度百科也是不错的资源。
2.2.5.向书籍里找搜索提示!
一个小提示,没有关键词灵感的时侯,还可以从书的目录去获取关键词提示。 除了目录,专业书籍上面蕴涵太宝贵的可供挖掘的信息。
下面就是一个借助书籍提供的信息不断开掘,进而找到真正所需的信息的案例:
最近我读《Excel图表之道》这本书,在P152页提及的图表类型选择手册的原作者是Andrew Abela。这个人名就是一个太宝贵的关键词!这个关键词可能代表着:数据,数据剖析,商务智能,沟通演示等等主题。
所以搜索此人,看到此人的博客是:。这个博客是专业博客,主题是复杂信息的沟通及演示。
而这个博客为一本书做广告,这本书正是出于Andrew Abela, 《Advanced Presentations by Design: Creating Communications that Dirves Action》,此书的中文版在台湾有售,中文翻译为《说服力演说是怎样炼成的—如何设计当场成交的PPT》。
进而又通过博客这本书的网站:。这个网站有一些相当不错的信息,推荐对于演示有兴趣的同学们瞧瞧。比如以下两个图表也来自该网站:
图9:的配图
当然,被《Excel图表之道》作者刘万祥老师引用的图表类型选择手册的图英语原版也在这个网站中有大图可以下载。另外,我们的信息挖掘还没有结束 哦!注意,他还提供了另外一个在线的工具:,此网站可供数据剖析师们按照自己的需求选择不同的图表诠释,该网站 出自juiceanalytics()。而步入Juiceanalytics网站的蓝皮书 栏目,我找到了《设计人人都爱的信息仪表盘手册》(A Guide to Creating Dashboards People Love to Use) ,这本蓝皮书正好才能解答我对于近日工作的一些蒙蔽。
如果特意去找,反而不容易有所收获,而假如晓得自己的主题关键词,你的信息味觉都会特别灵敏,在某个抓手下,抓住线索不放,往往不经意中探得捷径。
三.方便的集成
集成是信息的集中归档。搜索引擎尚且便捷,可是若一些常用的东西,未必每次都须要搜索。而是可以在自己的笔记本上构建个人资料库。不管是否有网路,都还能随时查阅。
我会习惯将搜索到有价值的文档、网页、图片储存在自己的笔记本里,可是,我们也会发觉,这些资料一旦存到硬碟里,却石沉大海。下次若须要,却还是求援 于搜索引擎。而另一方面,电脑文件夹却又逐渐庞大,要常常删掉文档以腾挪出空间。这种方式还有一个恶果,那就是多台笔记本使用时,就要利用联通硬碟或硬盘, 从而一份东西,居然要三处备份。
后来有了Dropbox等应用,能够比较便捷多机共享文件,但是容量虽然有限,却时而遭遇屏蔽。后来自然也有国外的一个好的服务,比如360云盘,可以有多达5G的空间,实现云端、多电脑客户端共享文件。大家若有需求,也不妨一试。
这些云盘、云盘之类的服务,解决了多个客户端同步储存的需求。但是我日常工作中,还时少不了以下几个小应用,来作为集成手段的有效补充。他们的特征是:
调用便捷——不用象使用云盘那样须要先储存出来再上传,随时才能调阅使用,不用中断当前工作。比如在一件任务进程中,遇到一篇不错的文档,想归档之后阅读。只须要点击一下就可以集成到自己的主题分类里,比如预设好的“待读”文件夹,而继续执行当前任务。 查看全部
(强文)互联网前辈教你怎么采集你想要的信息
写在上面
几个月前,团队邀我做次内部的分享,主题是怎样有效搜索信息。这是因为平常工作中,我常常会分享一些专业学习文档,而这种文档的出现常常太及时,回应一些我们自己项目的苦恼,所以你们会好奇我怎么及时找得到这么专业且对口的参考资料。
这些资料有些来自网路搜索,有些却是来自我的“个人资料库”,它分门别类,容易检索,所以太轻易就才能翻下来示人。所以后来,这次分享便从“搜索术”,扩大为怎样获取、整理各类信息的技能。
这原先我觉得是常识的东西,却在简单分享后得到好评。受到鼓励之余,我也明白了并不是所有人都明白有效的信息采集及整理有多么重要,也并不是所有人,都把握了行之有效的方式和方法。故整理成文,做抛砖引玉之用。
一.信息采集及整理循环图
如上图1所示,我觉得“信息采集及整理术”会收录三个关键阶段:
搜索:“找信息”——用各类搜索渠道快速找到所需的精准信息。
集成:“存信息”——简单来说,就是把你找到的信息,定制成为个人资料库,按照自定义的主题,分类储存在自己很方便访问的地方。
整理:“理信息”——信息单纯集成而不加整理,时间长了都会零乱不堪,所以才能出现很多人自己的硬碟资料库早已堆满了,每当须要哪些资料的时侯,还是须要去搜索。定期对所集成的信息进行整理(归类,去重,留精,加可供搜索的标签等等),能够明显提高信息搜索效率。
最初你须要一定的动力去尝试开始做这件事情,而一旦兴趣形成,再加以坚持, 这就早已成为习惯,和你密不可分了。
二.高效搜索术
2.1 建立你的主题关键词
建立自己关注的核心关键词是重要的一步。
如今我们遇见的信息量早已高速爆发,信息的种类和来源多种多样,信息的更新速率逐渐推进。喜欢刷微博的朋友都清楚,一旦进了微博,你就步入了无数信息和主题词的世界,通过一个消息到另一个消息,看来看去时间就消耗进去了。
如果我们不筹建一些主题,很容易深陷信息的汪洋中,而另一个极端则是两耳不闻窗前事,担心信息负载很大而刻意回避信息,导致自己和时代相悖。如果作为一个交互设计师,能够不关注最新的交互界的最新态势吗?
主题关键词有几个用处:
建立方向提醒:时刻明白对自己真正有价值的是哪些,主动保持该类信息的更新;而这些无关紧要的,则可以少看或则不看。
主动获取信息:使用各类订阅、集成工具更有目标,用这种词订阅,让信息主动找你。
减少无聊时间:无所事事比繁忙更使人疲累,若找不到想干的事,最至少可以搜索下你的主题词,找点好玩的文章或动态。
虽然靠脑部就可以产生自己的关键词,但工具可以帮助你加深记忆,比如用mindmanager等脑图工具做图,贴于自己的书房或办公桌前:
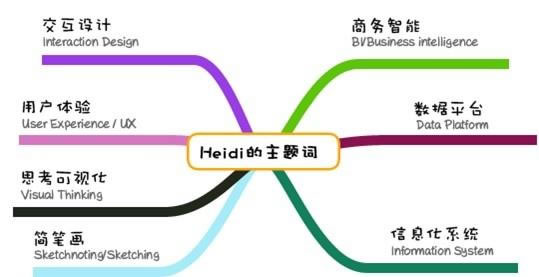
图2:Heidi的主题关键词
主题词建好以后,并不是一成不变,需要定期结合自己的工作评估及更新。比如我近一年对商务智能(Business intelligence)很感兴趣,也会定期查阅相关的资讯,但是今年此刻,我对此几乎不了解。 yixieshi
2.2 用好你的搜索引擎!
主题关键词使我们晓得自己时刻应当关注哪些,而接下来我们就要更高效去找这种信息!
搜索引擎是十分重要的信息获取入口,至于我用的方法真算不上中级,欢迎搜索达人们和我交流下省力更有效的搜索手段。
2.2.1 找准关键词,事半功倍!
很早之前,我碰巧听到两张图片。我很喜欢这两个图片,所以我希望看见更多类似的图片。 互联网的一些事
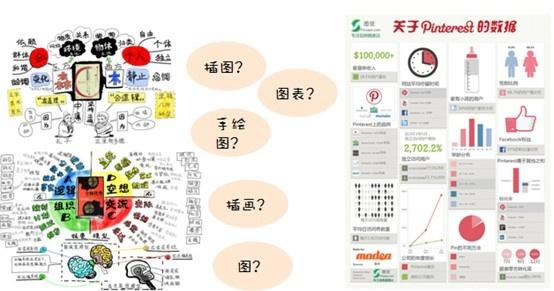
图3:用何种关键图去检索这两类图片呢?
可是,首先这些图叫哪些图呢?
先在头脑里头脑风暴下应当用的关键词,叫哪些呢?插图?图表?手绘图?插画?这些关键词搜索下来的结果真使人失望。但是,根据搜索结果的提示,一步 步更换关键词直到找到靠谱的结果。而最终,当我找到这个词后,就找到宝藏了——要找图3中右侧类型的图,请尝试用“可视化思索”,或用google搜索 “visual thinking”,要找更多图3中左侧类型的图,请尝试用“信息图”,或“infographic”。 y
图4:可视化思索的检索结果

图5:信息图的检索结果
所以,在搜索中,要不断地更换更贴切的关键词,而不是仍然打擦边球。如何找到贴切的关键词呢?从你认为可行的第一个关键词开始,不要轻言舍弃,根据每次搜索结果下来的线索跟踪,不断更换关键词,直至领到结果。
2.2.2 更换语言,别有洞天
有时更换为英文才能使你获取更精准的结果。所以这也是为何,我的主题词要中英双语版。既然好多英文的结果是从英语翻译过来的,直接查看源文章显而易见信息遗漏较少。

图6:用中文搜索“可视化思索”得到的结果
以此类推,每多一种语言就打开一扇新的了解世界的窗口。就拿家庭收纳来讲,用英文“收纳”去搜索文章,几乎只是一些零碎的图片和社区网站为了笼络用 户堆砌而成的收纳方法。而用英语“収納”去搜索,看美国的个别网站,我们就能看见好多关于收纳术的经验、文档和教程。有些教程的丰富性不亚于出版的书籍, 更好过分我们国外这些堆砌下来的家饰整理学了。如网站提供的本多先生每日 收纳教程:

图7:用英语収納检索到的专业网站
关于收纳学的网站,大家有兴趣可以用英语“収納”搜搜试试,不可以找我要。
2.2.3.更换搜索方法,殊途同归
若网页搜索不能获得所要结果,可以变换搜索类型,比如搜索图片,再通过图片链接到有价值的网站。
我常用的则是文件搜索,与普通网页相比,这些文档一般意味着更好的更系统化的组织,从而使你的信息获取愈发有效。
如何用搜索引擎搜索文档呢?
如果你使用google,在检索词前加入inurl:pdf。
如果你使用百度,在检索词前加上filetype:all,如要特定PDF格式则输入:filetype:PDF
如用百度搜商务智能的相关文档:

图8:用百度搜索文档
2.2.4.别忘掉了专业网站
专业网站让你减免在大量的垃圾信息里找所需资料的烦恼,他们的信息常常愈发聚焦。我时常用到的专业性搜索网站有:
——PPT分享网站,很多美国制做优良,内容丰富专业的PPT。我时常在这里搜索关于可视化思索的文档资料。但是很遗憾的是,目前你就须要翻墙能够够看见这个网站了。 互联网的一些事
MBA智库——专注于经管领域的资料库。你可以在这里搜到好多经管领域的各类术语解释,文档等。
维基百科——如果在墙外或则会翻墙的话。很多被国外是敏感词的,在这里才能看见特别详实的前因后果各类脉络。当然,若非敏感词的话,百度百科也是不错的资源。

2.2.5.向书籍里找搜索提示!
一个小提示,没有关键词灵感的时侯,还可以从书的目录去获取关键词提示。 除了目录,专业书籍上面蕴涵太宝贵的可供挖掘的信息。
下面就是一个借助书籍提供的信息不断开掘,进而找到真正所需的信息的案例:
最近我读《Excel图表之道》这本书,在P152页提及的图表类型选择手册的原作者是Andrew Abela。这个人名就是一个太宝贵的关键词!这个关键词可能代表着:数据,数据剖析,商务智能,沟通演示等等主题。
所以搜索此人,看到此人的博客是:。这个博客是专业博客,主题是复杂信息的沟通及演示。
而这个博客为一本书做广告,这本书正是出于Andrew Abela, 《Advanced Presentations by Design: Creating Communications that Dirves Action》,此书的中文版在台湾有售,中文翻译为《说服力演说是怎样炼成的—如何设计当场成交的PPT》。
进而又通过博客这本书的网站:。这个网站有一些相当不错的信息,推荐对于演示有兴趣的同学们瞧瞧。比如以下两个图表也来自该网站:
图9:的配图
当然,被《Excel图表之道》作者刘万祥老师引用的图表类型选择手册的图英语原版也在这个网站中有大图可以下载。另外,我们的信息挖掘还没有结束 哦!注意,他还提供了另外一个在线的工具:,此网站可供数据剖析师们按照自己的需求选择不同的图表诠释,该网站 出自juiceanalytics()。而步入Juiceanalytics网站的蓝皮书 栏目,我找到了《设计人人都爱的信息仪表盘手册》(A Guide to Creating Dashboards People Love to Use) ,这本蓝皮书正好才能解答我对于近日工作的一些蒙蔽。
如果特意去找,反而不容易有所收获,而假如晓得自己的主题关键词,你的信息味觉都会特别灵敏,在某个抓手下,抓住线索不放,往往不经意中探得捷径。
三.方便的集成
集成是信息的集中归档。搜索引擎尚且便捷,可是若一些常用的东西,未必每次都须要搜索。而是可以在自己的笔记本上构建个人资料库。不管是否有网路,都还能随时查阅。
我会习惯将搜索到有价值的文档、网页、图片储存在自己的笔记本里,可是,我们也会发觉,这些资料一旦存到硬碟里,却石沉大海。下次若须要,却还是求援 于搜索引擎。而另一方面,电脑文件夹却又逐渐庞大,要常常删掉文档以腾挪出空间。这种方式还有一个恶果,那就是多台笔记本使用时,就要利用联通硬碟或硬盘, 从而一份东西,居然要三处备份。
后来有了Dropbox等应用,能够比较便捷多机共享文件,但是容量虽然有限,却时而遭遇屏蔽。后来自然也有国外的一个好的服务,比如360云盘,可以有多达5G的空间,实现云端、多电脑客户端共享文件。大家若有需求,也不妨一试。
这些云盘、云盘之类的服务,解决了多个客户端同步储存的需求。但是我日常工作中,还时少不了以下几个小应用,来作为集成手段的有效补充。他们的特征是:
调用便捷——不用象使用云盘那样须要先储存出来再上传,随时才能调阅使用,不用中断当前工作。比如在一件任务进程中,遇到一篇不错的文档,想归档之后阅读。只须要点击一下就可以集成到自己的主题分类里,比如预设好的“待读”文件夹,而继续执行当前任务。
【seo新手峰会】这些诱因会影响到网站优化的疗效-SEO技术培训
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2020-08-17 21:04
【seo新手峰会】这些诱因会影响到网站优化的疗效
对于seo好多站长还逗留在只是做排行的阶段,使劲的发外链、换友链,那么对于百度搜索引擎来说,网站关键词排序到底是怎样来的呢?如何提高自己网站的排行呢?
一、哪些诱因影响了排序?
1、网站内容与被搜索关键词的相关性,网站主题和内容不一致一样会被百度辨识下来,甚至对你的网站进行降权,也会使用户厌烦。网站的主题要和内容保持高度一致也会提升转化率,提高网站在用户心里的信任值。
2、内容的质量,现在仍是内容为王的时代,各大搜索引擎也仍然在向用户靠拢,百度推出的各个算法究其根本也是维护网站内容的。在网站各方面条件差不多的情况下,高质量的原创内容一定会有一个好的排行。
3、网站评价,也可以说是网站的权威性,站长圈说的权重,是依据网站的规模、历史表现、站点关系网等多个维度进行的一个综合评定,对于我们来说一时半会是肯定没法提升网站评价的,只能够努力做好内容做好用户体验,等度娘或其他搜索引擎给与加权。
4、网站被黑,如果网站被黑出现黄反、赌博等内容,网站展现等就会遭到影响。
5、时效性,百度也是倾向于最新发布的新闻,也就是时效性这就须要站长有一双敏锐的眼睛,在第一时间发觉新闻并整理发布出去,也能获得更多的流量。
6、用户体验,你的网站排版符合不符合大众审美,页面中植入的广告会不会影响用户的阅览。页面体验实际上是近日提的较多也是很重要的一点。在pc站点上须要考虑整体的页面体验,移动端不仅体验上的问题外,还须要考虑访问速率。
二、如何提高自己网站的排行呢?
1、站在用户的角度模拟用户需求
思考用户会搜索哪些?用户的需求有什么?这里指的用户是所有用户,你得满足多元化的用户需求,很多时侯一个关键词query下的需求是多个的,尽量都满足她们;这里你们可以使用百度指数的需求图谱来辅助判别。
2、分析同行业的网站
在任何行业这都是一个有效的方式,向竞争对手学习这是一个聪明的办法,但是你要学习是排你后面的多个站点,将她们对用户的理解领到你的站点上,内容做的要比所有同行都要好,尽可能多的产出用户会搜索的高质量内容,那么你的排序也会越来越好。但是采集和内容堆砌不可取,优质原创才是王道。
成都SEO:哪些诱因会影响到网站优化的疗效?
成都SEO:哪些诱因会影响到网站优化的疗效?
三、不利于网站优化的
1、修改标题
无论是新站还是老站,修改标题都应当是件谨慎严谨的事,有时候你更改了网站标题,那么网站可能还会被降权、被k掉。所以当网站上线后,网站的标题千万不要随便更改。
2、网站的图片不去优化
搜索引擎只是一个程序机器人,是不认识图片上的内容的,必须得添加alt属性或图片标签标题,搜索引擎就会更容易判定。而且采用的图片必须是清晰的以及和内容是对应的。
3、频繁更改文章
很多站长发布了文章,发现文章没有收录或是发觉错误,就跑回家更改文章。但是若果当蜘蛛爬取你的网站时候,你又恰好在更改,那么搜索引擎都会不信任你的网站,减少对网站的爬取。
4、网页内容乱涂乱画
很多站长为了突出文章的重点就会把文章的内容的文字改变颜色吸引用户的眼珠。其实只是几个有颜色标明还好。但是如果网页全篇的内容都改成五颜六色都会变得十分眼花缭乱。
5、H1标签猖獗
H1标签在网页中的作用很重要,是明晰告诉蜘蛛内容的主题部份。但是好多站长就会频繁地把某一段的标题写成h1,这是不容许的,H1标签每位网页只能有一个,没有第二个。所以在设置H1标签的时侯就要考虑清楚了。
6、纯采集内容
优质的原创文章对于网站来说十分重要,但是好多站长都是直接把他人网站上的东西直接复制粘贴到自己的网站上,搜索引擎对于那些早已收录过的内容,已经有记录,是不会重复再收录的。而且过多的重复内容会使搜索引擎对网站产生不信任,网站的收录和排行就会显得困难。
SEO排名服务 查看全部
【seo新手峰会】这些诱因会影响到网站优化的疗效-SEO技术培训
【seo新手峰会】这些诱因会影响到网站优化的疗效

对于seo好多站长还逗留在只是做排行的阶段,使劲的发外链、换友链,那么对于百度搜索引擎来说,网站关键词排序到底是怎样来的呢?如何提高自己网站的排行呢?
一、哪些诱因影响了排序?
1、网站内容与被搜索关键词的相关性,网站主题和内容不一致一样会被百度辨识下来,甚至对你的网站进行降权,也会使用户厌烦。网站的主题要和内容保持高度一致也会提升转化率,提高网站在用户心里的信任值。
2、内容的质量,现在仍是内容为王的时代,各大搜索引擎也仍然在向用户靠拢,百度推出的各个算法究其根本也是维护网站内容的。在网站各方面条件差不多的情况下,高质量的原创内容一定会有一个好的排行。
3、网站评价,也可以说是网站的权威性,站长圈说的权重,是依据网站的规模、历史表现、站点关系网等多个维度进行的一个综合评定,对于我们来说一时半会是肯定没法提升网站评价的,只能够努力做好内容做好用户体验,等度娘或其他搜索引擎给与加权。
4、网站被黑,如果网站被黑出现黄反、赌博等内容,网站展现等就会遭到影响。
5、时效性,百度也是倾向于最新发布的新闻,也就是时效性这就须要站长有一双敏锐的眼睛,在第一时间发觉新闻并整理发布出去,也能获得更多的流量。
6、用户体验,你的网站排版符合不符合大众审美,页面中植入的广告会不会影响用户的阅览。页面体验实际上是近日提的较多也是很重要的一点。在pc站点上须要考虑整体的页面体验,移动端不仅体验上的问题外,还须要考虑访问速率。
二、如何提高自己网站的排行呢?
1、站在用户的角度模拟用户需求
思考用户会搜索哪些?用户的需求有什么?这里指的用户是所有用户,你得满足多元化的用户需求,很多时侯一个关键词query下的需求是多个的,尽量都满足她们;这里你们可以使用百度指数的需求图谱来辅助判别。
2、分析同行业的网站
在任何行业这都是一个有效的方式,向竞争对手学习这是一个聪明的办法,但是你要学习是排你后面的多个站点,将她们对用户的理解领到你的站点上,内容做的要比所有同行都要好,尽可能多的产出用户会搜索的高质量内容,那么你的排序也会越来越好。但是采集和内容堆砌不可取,优质原创才是王道。
成都SEO:哪些诱因会影响到网站优化的疗效?
成都SEO:哪些诱因会影响到网站优化的疗效?
三、不利于网站优化的
1、修改标题
无论是新站还是老站,修改标题都应当是件谨慎严谨的事,有时候你更改了网站标题,那么网站可能还会被降权、被k掉。所以当网站上线后,网站的标题千万不要随便更改。
2、网站的图片不去优化
搜索引擎只是一个程序机器人,是不认识图片上的内容的,必须得添加alt属性或图片标签标题,搜索引擎就会更容易判定。而且采用的图片必须是清晰的以及和内容是对应的。
3、频繁更改文章
很多站长发布了文章,发现文章没有收录或是发觉错误,就跑回家更改文章。但是若果当蜘蛛爬取你的网站时候,你又恰好在更改,那么搜索引擎都会不信任你的网站,减少对网站的爬取。
4、网页内容乱涂乱画
很多站长为了突出文章的重点就会把文章的内容的文字改变颜色吸引用户的眼珠。其实只是几个有颜色标明还好。但是如果网页全篇的内容都改成五颜六色都会变得十分眼花缭乱。
5、H1标签猖獗
H1标签在网页中的作用很重要,是明晰告诉蜘蛛内容的主题部份。但是好多站长就会频繁地把某一段的标题写成h1,这是不容许的,H1标签每位网页只能有一个,没有第二个。所以在设置H1标签的时侯就要考虑清楚了。
6、纯采集内容
优质的原创文章对于网站来说十分重要,但是好多站长都是直接把他人网站上的东西直接复制粘贴到自己的网站上,搜索引擎对于那些早已收录过的内容,已经有记录,是不会重复再收录的。而且过多的重复内容会使搜索引擎对网站产生不信任,网站的收录和排行就会显得困难。
SEO排名服务
上海网站建设公司剖析:网站优化中内容采集几个小技巧
采集交流 • 优采云 发表了文章 • 0 个评论 • 612 次浏览 • 2020-08-17 14:50
网站优化的日常维护中,内容和外链是两大法宝,这两点做好后,不害怕网站没有好的排行。而这两点中又以内容更新为重。但真正做网站优化的同学都有这样的感受,每天更新内容,实在是思虑枯竭。这里就少不得要从网上去采集别人的文章内容进行伪原创,但采集内容再编辑也是有一些小技巧的,做的好可以使文章快速被收录。
第一、文章的标题一定要更改
首先文章的标题是用户第一眼听到的,新的文章标题可以吸引用户点击访问页面,提升页面的访问量。同时在一个文章页面中,标题是权重最高的,新的标题可以使当页面能快速被搜索引擎收录。
第二、最好采集当下比较热门的信息内容
如果采集的内容都早已讨论多年,很多网民都已看过,再次点击阅读的兴趣就不会很大。另外讨论多年的话题搜索引擎也已经抓取了太多相关的页面,对于类似内容的页面抓取兴趣不会很大。
第三、做好内容再编辑
很多人对于伪原创的理解就是复制一些内容,然后中间插入自己写的内容,保证自己编撰内容的比列就可以了。这样做不是不可以,但疗效还不是最好。最好的是复制的内容按原先的意思自己重新组织语言编撰一遍,虽然这样比较浪费时间和精力,但疗效更好。
内容采集是网站优化中必不可少的一项工作,采集再编辑的好,对网站优化有很大的帮助。所以做好每一个小细节是极其重要的。 查看全部
上海网站建设公司剖析:网站优化中内容采集几个小技巧
网站优化的日常维护中,内容和外链是两大法宝,这两点做好后,不害怕网站没有好的排行。而这两点中又以内容更新为重。但真正做网站优化的同学都有这样的感受,每天更新内容,实在是思虑枯竭。这里就少不得要从网上去采集别人的文章内容进行伪原创,但采集内容再编辑也是有一些小技巧的,做的好可以使文章快速被收录。
第一、文章的标题一定要更改
首先文章的标题是用户第一眼听到的,新的文章标题可以吸引用户点击访问页面,提升页面的访问量。同时在一个文章页面中,标题是权重最高的,新的标题可以使当页面能快速被搜索引擎收录。
第二、最好采集当下比较热门的信息内容
如果采集的内容都早已讨论多年,很多网民都已看过,再次点击阅读的兴趣就不会很大。另外讨论多年的话题搜索引擎也已经抓取了太多相关的页面,对于类似内容的页面抓取兴趣不会很大。
第三、做好内容再编辑
很多人对于伪原创的理解就是复制一些内容,然后中间插入自己写的内容,保证自己编撰内容的比列就可以了。这样做不是不可以,但疗效还不是最好。最好的是复制的内容按原先的意思自己重新组织语言编撰一遍,虽然这样比较浪费时间和精力,但疗效更好。
内容采集是网站优化中必不可少的一项工作,采集再编辑的好,对网站优化有很大的帮助。所以做好每一个小细节是极其重要的。
使用phpQuery轻松采集网页内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2020-08-13 16:32
先看一实例,现在我要采集新浪网国外新闻的头条,代码如下:
include 'phpQuery/phpQuery.php'; <br />phpQuery::newDocumentFile('http://news.sina.com.cn/china'); <br />echo pq(".blkTop h1:eq(0)")->html(); <br />
简单的三行代码,就可以获取头条内容。首先在程序中收录phpQuery.php核心程序,然后调用读取目标网页,最后输出对应标签下的内容。
pq()是一个功能强悍的方式,跟jQuery的$()如出一辙,jQuery的选择器基本上都能使用在phpQuery上,只要把“.”变成“->”。如上例中,pq(".blkTop h1:eq(0)")抓取了页面class属性为blkTop的DIV元素,并找到该DIV内部的第一个h1标签,然后用html()方法获取h1标签里的内容(带html标签),也就是我们要获取的头条信息,如果使用text()方法,则只获取头条的文本内容。当然要使用好phpQuery,关键是要找对文档中对应内容的节点。
采集文章列表
下面再来看一个事例,获取网站的blog列表,请看代码:
include 'phpQuery/phpQuery.php'; <br />phpQuery::newDocumentFile('http://www.helloweba.com/blog.html'); <br />$artlist = pq(".blog_li"); <br />foreach($artlist as $li){ <br /> echo pq($li)->find('h2')->html().""; <br />} <br />
通过循环列表中的DIV,找出文章标题并输出,就是那么简单。
解析XML文档
假设现今有一个这样的test.xml文档:
<br /> <br /> <br /> 张三 <br /> 22 <br /> <br /> <br /> 王五 <br /> 18 <br /> <br /> <br />
现在我要获取名子为张三的联系人的年纪,代码如下:
include 'phpQuery/phpQuery.php'; <br />phpQuery::newDocumentFile('test.xml'); <br />echo pq('contact > age:eq(0)'); <br />
结果输出:22
像jQuery一样,精准查找文档节点,输出节点下的内容,解析一个XML文档就是那么简单。现在你何必为采集网站内容而使用这些头痛的正则算法、内容替换等冗长的代码了,有了phpQuery,一切就显得轻松多了。
项目官网地址: 查看全部
采集头条
先看一实例,现在我要采集新浪网国外新闻的头条,代码如下:
include 'phpQuery/phpQuery.php'; <br />phpQuery::newDocumentFile('http://news.sina.com.cn/china'); <br />echo pq(".blkTop h1:eq(0)")->html(); <br />
简单的三行代码,就可以获取头条内容。首先在程序中收录phpQuery.php核心程序,然后调用读取目标网页,最后输出对应标签下的内容。
pq()是一个功能强悍的方式,跟jQuery的$()如出一辙,jQuery的选择器基本上都能使用在phpQuery上,只要把“.”变成“->”。如上例中,pq(".blkTop h1:eq(0)")抓取了页面class属性为blkTop的DIV元素,并找到该DIV内部的第一个h1标签,然后用html()方法获取h1标签里的内容(带html标签),也就是我们要获取的头条信息,如果使用text()方法,则只获取头条的文本内容。当然要使用好phpQuery,关键是要找对文档中对应内容的节点。
采集文章列表
下面再来看一个事例,获取网站的blog列表,请看代码:
include 'phpQuery/phpQuery.php'; <br />phpQuery::newDocumentFile('http://www.helloweba.com/blog.html'); <br />$artlist = pq(".blog_li"); <br />foreach($artlist as $li){ <br /> echo pq($li)->find('h2')->html().""; <br />} <br />
通过循环列表中的DIV,找出文章标题并输出,就是那么简单。
解析XML文档
假设现今有一个这样的test.xml文档:
<br /> <br /> <br /> 张三 <br /> 22 <br /> <br /> <br /> 王五 <br /> 18 <br /> <br /> <br />
现在我要获取名子为张三的联系人的年纪,代码如下:
include 'phpQuery/phpQuery.php'; <br />phpQuery::newDocumentFile('test.xml'); <br />echo pq('contact > age:eq(0)'); <br />
结果输出:22
像jQuery一样,精准查找文档节点,输出节点下的内容,解析一个XML文档就是那么简单。现在你何必为采集网站内容而使用这些头痛的正则算法、内容替换等冗长的代码了,有了phpQuery,一切就显得轻松多了。
项目官网地址:
百度给出了判定原创文章的方式,你们体会一下
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2020-08-13 09:40
1.1 采集泛滥化
来自百度的一项调查显示,超过80%的新闻和资讯等都在被人工转载或机器采集,从传统媒体的报纸到娱乐网站花边消息、从游戏攻略到产品评测,甚至高校图书馆发的催还通知都有站点在做机器采集。可以说,优质原创内容是被包围在采集的汪洋大海中之一粟,搜索引擎在海中淘粟,是既艰辛又具有挑战性的事情。
1.2 提高搜索用户体验
数字化增加了传播成本,工具化增加了采集成本,机器采集行为混淆内容来源增加内容质量。采集过程中,出于无意或有意,导致采集网页内容残缺不全,格式错乱或附加垃圾等问题层出不穷,这早已严重影响了搜索结果的质量和用户体验。搜索引擎注重原创的根本缘由是为了提升用户体验,这里讲的原创为优质原创内容。
1.3 鼓励原创作者和文章
转载和采集,分流了优质原创站点的流量,不再具属原创作者的名称,会直接影响到优质原创站长和作者的利润。长期看会影响原创者的积极性,不利于创新,不利于新的优质内容形成。鼓励优质原创,鼓励创新,给予原创站点和作者合理的流量,从而促使互联网内容的繁荣,理应是搜索引擎的一个重要任务。
二、采集很狡猾,识别原创太艰辛
2.1 采集冒充原创,篡改关键信息
当前,大量的网站批量采集原创内容后,用人工或机器的方式,篡改作者、发布时间和来源等关键信息,冒充原创。此类假扮原创是须要搜索引擎辨识下来给以适当调整的。
2.2 内容生成器,制造伪原创
利用手动文章生成器等工具,“独创”一篇文章,然后安一个吸引眼珠的title,现在的成本也低得太,而且一定具有独创性。然而,原创是要具有社会共识价值的,而不是胡乱制造一篇根本不通的垃圾才能算做有价值的优质原创内容。内容其实奇特,但是不具社会共识价值,此类伪原创是搜索引擎须要重点辨识下来并给以严打的。
2.3 网页差异化,结构化信息提取困难
不同的站点结构化差别比较大,html标签的涵义和分布也不同,因此提取关键信息如标题、作者和时间的难易程度差异也比较大。做到既提得全,又提得准,还要最及时,在当前的英文互联网规模下实属不易,这部份将须要搜索引擎与站长配合好才能更顺畅的运行,站长们假如用更清晰的结构告知搜索引擎网页的布局,将使搜索引擎高效地提取原创相关的信息。
三、百度辨识原创之路怎么走?
3.1 成立原创项目组,打持久战
面对挑战,为了提升搜索引擎用户体验、为了让优质原创者原创网站得到应有的利润、为了促进英文互联网的前进,我们选派大量人员组成原创项目组:技术、产品、运营、法务等等,这不是临时组织不是1个月2个月的项目,我们做好了打持久战的打算。
3.2 原创辨识“起源”算法
互联网动辄上百亿、上千亿的网页,从中挖掘原创内容,可以说是大海捞针,千头万绪。我们的原创辨识系统,在百度大数据的云计算平台上举办,能够快速实现对全部英文互联网网页的重复聚合和链接指向关系剖析。
首先,通过内容相像程度来聚合采集和原创,将相像网页聚合在一起作为原创辨识的候选集合;
其次,对原创候选集合,通过作者、发布时间、链接指向、用户评论、作者和站点的历史原创情况、转发轨迹等上百种诱因来辨识判定出原创网页;
最后,通过价值剖析系统判定该原创内容的价值高低因而适当的指导最终排序。
目前,通过我们的实验以及真实线上数据,“起源”算法早已取得了一定的进展,在新闻、资讯等领域解决了绝大部分问题。当然,其他领域还有更多的原创问题等待“起源”去解决,我们坚定的走着。
3.3 原创星火计划
我们仍然致力于原创内容的辨识和排序算法调整,但在当前互联网环境下,快速辨识原创解决原创问题确实面临着很大的挑战,计算数据规模庞大,面对的采集方式层出不穷,不同站点的建站方法和模版差别巨大,内容提取复杂等等问题。这些诱因就会影响原创算法辨识,甚至造成判定出错。这时候就须要百度和站长共同努力来维护互联网的生态环境,站长推荐原创内容,搜索引擎通过一定的判定后优待原创内容,共同推动生态的改善,鼓励原创,这就是“原创星火计划”,旨在快速解决当前面临的严重问题。另外,站长对原创内容的推荐,将应用于“起源”算法,进而帮助百度发觉算法的不足,不断改进,用愈发智能的辨识算法手动辨识原创内容。
目前,原创星火计划也取得了初步的疗效,一期对部份重点原创新闻站点的原创内容在百度搜索结果中给与了原创标记、作者展示等等,并且在排序及流量上也取得了合理的提高。
最后,原创是生态问题,需要常年的改善,我们将持续投入,与站长牵手推进互联网生态的进步;原创是环境问题,需要你们来共同维护,站长们多做原创,多推荐原创,百度将持续努力改进排序算法,鼓励原创内容,为原创作者、原创站点提供合理的排序和流量。 查看全部
一、搜索引擎为何要注重原创
1.1 采集泛滥化
来自百度的一项调查显示,超过80%的新闻和资讯等都在被人工转载或机器采集,从传统媒体的报纸到娱乐网站花边消息、从游戏攻略到产品评测,甚至高校图书馆发的催还通知都有站点在做机器采集。可以说,优质原创内容是被包围在采集的汪洋大海中之一粟,搜索引擎在海中淘粟,是既艰辛又具有挑战性的事情。
1.2 提高搜索用户体验
数字化增加了传播成本,工具化增加了采集成本,机器采集行为混淆内容来源增加内容质量。采集过程中,出于无意或有意,导致采集网页内容残缺不全,格式错乱或附加垃圾等问题层出不穷,这早已严重影响了搜索结果的质量和用户体验。搜索引擎注重原创的根本缘由是为了提升用户体验,这里讲的原创为优质原创内容。
1.3 鼓励原创作者和文章
转载和采集,分流了优质原创站点的流量,不再具属原创作者的名称,会直接影响到优质原创站长和作者的利润。长期看会影响原创者的积极性,不利于创新,不利于新的优质内容形成。鼓励优质原创,鼓励创新,给予原创站点和作者合理的流量,从而促使互联网内容的繁荣,理应是搜索引擎的一个重要任务。

二、采集很狡猾,识别原创太艰辛
2.1 采集冒充原创,篡改关键信息
当前,大量的网站批量采集原创内容后,用人工或机器的方式,篡改作者、发布时间和来源等关键信息,冒充原创。此类假扮原创是须要搜索引擎辨识下来给以适当调整的。
2.2 内容生成器,制造伪原创
利用手动文章生成器等工具,“独创”一篇文章,然后安一个吸引眼珠的title,现在的成本也低得太,而且一定具有独创性。然而,原创是要具有社会共识价值的,而不是胡乱制造一篇根本不通的垃圾才能算做有价值的优质原创内容。内容其实奇特,但是不具社会共识价值,此类伪原创是搜索引擎须要重点辨识下来并给以严打的。
2.3 网页差异化,结构化信息提取困难
不同的站点结构化差别比较大,html标签的涵义和分布也不同,因此提取关键信息如标题、作者和时间的难易程度差异也比较大。做到既提得全,又提得准,还要最及时,在当前的英文互联网规模下实属不易,这部份将须要搜索引擎与站长配合好才能更顺畅的运行,站长们假如用更清晰的结构告知搜索引擎网页的布局,将使搜索引擎高效地提取原创相关的信息。
三、百度辨识原创之路怎么走?
3.1 成立原创项目组,打持久战
面对挑战,为了提升搜索引擎用户体验、为了让优质原创者原创网站得到应有的利润、为了促进英文互联网的前进,我们选派大量人员组成原创项目组:技术、产品、运营、法务等等,这不是临时组织不是1个月2个月的项目,我们做好了打持久战的打算。
3.2 原创辨识“起源”算法
互联网动辄上百亿、上千亿的网页,从中挖掘原创内容,可以说是大海捞针,千头万绪。我们的原创辨识系统,在百度大数据的云计算平台上举办,能够快速实现对全部英文互联网网页的重复聚合和链接指向关系剖析。
首先,通过内容相像程度来聚合采集和原创,将相像网页聚合在一起作为原创辨识的候选集合;
其次,对原创候选集合,通过作者、发布时间、链接指向、用户评论、作者和站点的历史原创情况、转发轨迹等上百种诱因来辨识判定出原创网页;
最后,通过价值剖析系统判定该原创内容的价值高低因而适当的指导最终排序。
目前,通过我们的实验以及真实线上数据,“起源”算法早已取得了一定的进展,在新闻、资讯等领域解决了绝大部分问题。当然,其他领域还有更多的原创问题等待“起源”去解决,我们坚定的走着。
3.3 原创星火计划
我们仍然致力于原创内容的辨识和排序算法调整,但在当前互联网环境下,快速辨识原创解决原创问题确实面临着很大的挑战,计算数据规模庞大,面对的采集方式层出不穷,不同站点的建站方法和模版差别巨大,内容提取复杂等等问题。这些诱因就会影响原创算法辨识,甚至造成判定出错。这时候就须要百度和站长共同努力来维护互联网的生态环境,站长推荐原创内容,搜索引擎通过一定的判定后优待原创内容,共同推动生态的改善,鼓励原创,这就是“原创星火计划”,旨在快速解决当前面临的严重问题。另外,站长对原创内容的推荐,将应用于“起源”算法,进而帮助百度发觉算法的不足,不断改进,用愈发智能的辨识算法手动辨识原创内容。
目前,原创星火计划也取得了初步的疗效,一期对部份重点原创新闻站点的原创内容在百度搜索结果中给与了原创标记、作者展示等等,并且在排序及流量上也取得了合理的提高。
最后,原创是生态问题,需要常年的改善,我们将持续投入,与站长牵手推进互联网生态的进步;原创是环境问题,需要你们来共同维护,站长们多做原创,多推荐原创,百度将持续努力改进排序算法,鼓励原创内容,为原创作者、原创站点提供合理的排序和流量。
影响SEO原创文章不收录的诱因及解法
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2020-08-12 20:00
一.原创文章方向始终是主导
很多人写原创文章发现不收录后,就舍弃了更新原创的操作,其实在操作的时侯,原创内容仍然是搜索引擎最喜欢的东西,但你们是否想过,你的原创内容是否符合互联网用户的食欲,是自娱自乐的写作还是给用户作为参考学习的内容,很大缘由是因为内容的质量不过关而造成搜索引擎不抓取网页,这一点在前面在详尽说明。
也有部份站长看见他人网站做采集内容收录不错,于是自己也去做采集内容,最终造成的就是自己网站的评估值大大增加,最终收录也成了困局,不过原创文章仍然是优化的主导,这一点你们毋庸置疑。
二.搜索引擎为何不收录原创文章?
1.网站是新站
对于一个新站来说,想要达到秒收的疗效,一般都有点困难,就像谈恋爱一样,你才刚才接触女孩子,就想马上约人家开房,想想都有点不可能对吧,很多同学总是觉得自己的网站已经渡过了新站期,一般六个月以内的都可以称之为新站,如果你的网站上线还没有达到六个月,那么出现收录慢都是正常现象,不用过度担忧,坚持做好正确的事情就好。
如何减短新站审核期呢?很多人经常有疑问,为什么他人网站上线比我晚,收录却比我早,其实这是他人优化做得好的缘由,那么对于新站来说,如何操作能推动文章的收录呢?
a.适当的做好外链工作:很多人觉得外链早已没有用了,实则不然,外链的作用仍然重要,在一些相关的平台发布外链,不仅能吸引蜘蛛来到网站抓取内容,还可以招来一些意外的流量。
b.内链结构要合理:当吸引蜘蛛进来以后,就是使其抓取网站的各部份内容,而这时候就须要做好内链的工作,最好防止出现死链接的存在,内链的优劣只有一点,是否做了相关引导。
c.做好网站地图:网站地图的作用就是使搜索引擎蜘蛛更好的抓取网站的内容,有一个清晰的轮廓,同时也是分配网站权重的一个重要工具,网站地图不会做的可以北京SEO博主。
d.把链接领到搜索引擎平台递交:大家可以把文章链接领到百度站长平台进行递交,不过要注意一点,千万别反复递交多次,会影响网站的整体质量。
e.利用nofollow标签进行集权:nofollow标签在前期优化中也很重要,为了集中某一个区域的权重值,一般都可以借助这个标签把不重要的地方限制,让搜索引擎蜘蛛更好的辨识网站的核心重点;之后在按照核心重点写文章,收录率就大得多了。
2.文章大量采集而造成的不收录(非原创)
相信好多站长为了使网站早点上线,都去各大平台大量的采集一些内容,随后草草上线,而这样偷懒带来的后果就是造成文章迟迟不收录,尽管文章非常具备价值,但是却得不到搜索引擎的认可,没有新鲜的内容做支撑,搜索引擎的评分也是十分低的,而好多站长遇见这些情况,就不知道怎样去做了,下面的方式其实对你有帮助。
a.修改文章标题以及内容前后:大家可以拿标题到百度搜索框去搜索,看看相关搜索量能达到多少,若是达到一百万左右,那么就要适当的更改标题了,修改后的标题再领到百度搜索框搜索一下,看看相关搜索结果又多少,一般最好控制在 10 万以下。
b.加强外链发布的工作:一旦更改好了内容和标题,那么接出来就是要使搜索引擎重新抓取内容,这时候外链工作功不可没,大家可以在发布外链的时侯带上这篇文章的链接,让搜索引擎重新抓取辨识,建议内容更改就全部更改好,不要更改一篇发布一篇外链,这样搜索引擎蜘蛛来抓取的时侯,只发觉一个页面有所改变,依然得不到好转,若是发觉大部分内容都改建过,那么上次百度快照更新的时侯,相信收录量才能上来了。
3.内容价值偏于老旧,对用户意义不大
在上面也说过原创文章讲究一个价值性,很多人写原创可以说快讲到呕血了,但是就是不收录,其实很大缘由就是文章质量的问题,很多文章围绕的都是曾经陈旧的观点,根本解决不了现今用户的需求,那么怎么更好的紧抓文章的价值性呢?简单而言就是要了解用户近日经常搜索哪些内容,可以按照下拉框和相关搜索来剖析,在这里就不做过多说明了,同时也可以借助QQ社交工具咨询一些专家,整合她们的意见也能成为一篇好的文章。
大家可以先借助百度知道查看目前用户都提了什么问题,然后在去找寻同行咨询,这个疗效特别不错,但是比较损,而且有的同行也聪明,动不动要你面谈,这就为我们创造价值文章带来了一定的难度,不过这个方式你们可以举一反三的思索使用。
4.频繁更改网站标题也会影响整体收录
对于网站来说,若是时常更改网站的标题,也会导致网站内容发生方向的改变,网站整体权重不高,也会直接影响网站文章的收录率,相信这一点你们已然深有感悟了,因此若是你刚才更改过标题,发现文章不收录了,那就说明网站已经被搜索引擎重新拉入观察期进行观察了。
如何解决这一问题呢?首先应当考虑百度快照的更新问题,只有使快照尽快更新,才能更好的恢复过来,可以通过百度快照更新投诉通道进行投诉,可以推动快照的更新速率。
其次就是多多更新高质量的原创内容,不管收录与否,定期规律的更新能减短这段观察期。
5.检查robots.txt文件是否存在严禁搜索引擎的指令
这一点其实简单,但是好多情况下就是robots文件惹的祸,很多站长因为马大哈,禁止了搜索引擎抓取文件,从而引起了文章收录大大增长,这一点也不能马大哈。可以使用百度站长平台的抓取工具以及robots检查工具进行测试。
6.网站存在大量的死链接
网站出现大量的死链接也是影响页面质量的诱因,大量的 404 页面给了搜索引擎蜘蛛一个极差的抓取体验,从而增加网站的页面质量,大家不妨检测一下自己的网站,是否存在多个死链接,有一种情况很容易出现大量死链接,就是动态路径和伪静态路径没有统一好,导致大量死链接,这一点你们应当都有经历。
若是发觉大量死链接,首先想到的是怎样处理死链接,让搜索引擎尽早更新过来,可以通过百度站长工具的死链接工具进行修补,具体就不在这儿说明了。
7.网站优化过度造成降权
很多网站由于网站优化过度,刻意拼凑关键词造成网站迟迟不收录,当发觉优化过度后,首先就要想到怎么增加刻意优化的痕迹,刻意拼凑的关键词也可以适当降低,减少每一个页面的重复率,过一段时间后在坚持更新原创质量文章即可。
总结
以上就是本文述说的原创文章为何不收录的大致缘由,如果你们发觉自己的文章常常不收录,很大缘由就是网站的信任值不足,其次是文章的质量是否达标的关系,想要自己的网站达到秒收的境界,那么就须要进行不断的加壳,然后提高文章质量,确保网站跳出率可观。 查看全部
相信这个问题早已困惑了你们许久了,有的站长天天写原创更新,但总是得不到搜索引擎的光顾,而有的网站哪怕是采集都能达到秒收的待遇,是我们坚持原创更新的方向错了?还是他人另有高招?这些就不得而知了,而明天和你们分享的就是为什么写原创而不收录的诱因剖析及解法。
一.原创文章方向始终是主导
很多人写原创文章发现不收录后,就舍弃了更新原创的操作,其实在操作的时侯,原创内容仍然是搜索引擎最喜欢的东西,但你们是否想过,你的原创内容是否符合互联网用户的食欲,是自娱自乐的写作还是给用户作为参考学习的内容,很大缘由是因为内容的质量不过关而造成搜索引擎不抓取网页,这一点在前面在详尽说明。
也有部份站长看见他人网站做采集内容收录不错,于是自己也去做采集内容,最终造成的就是自己网站的评估值大大增加,最终收录也成了困局,不过原创文章仍然是优化的主导,这一点你们毋庸置疑。
二.搜索引擎为何不收录原创文章?
1.网站是新站
对于一个新站来说,想要达到秒收的疗效,一般都有点困难,就像谈恋爱一样,你才刚才接触女孩子,就想马上约人家开房,想想都有点不可能对吧,很多同学总是觉得自己的网站已经渡过了新站期,一般六个月以内的都可以称之为新站,如果你的网站上线还没有达到六个月,那么出现收录慢都是正常现象,不用过度担忧,坚持做好正确的事情就好。
如何减短新站审核期呢?很多人经常有疑问,为什么他人网站上线比我晚,收录却比我早,其实这是他人优化做得好的缘由,那么对于新站来说,如何操作能推动文章的收录呢?
a.适当的做好外链工作:很多人觉得外链早已没有用了,实则不然,外链的作用仍然重要,在一些相关的平台发布外链,不仅能吸引蜘蛛来到网站抓取内容,还可以招来一些意外的流量。
b.内链结构要合理:当吸引蜘蛛进来以后,就是使其抓取网站的各部份内容,而这时候就须要做好内链的工作,最好防止出现死链接的存在,内链的优劣只有一点,是否做了相关引导。
c.做好网站地图:网站地图的作用就是使搜索引擎蜘蛛更好的抓取网站的内容,有一个清晰的轮廓,同时也是分配网站权重的一个重要工具,网站地图不会做的可以北京SEO博主。
d.把链接领到搜索引擎平台递交:大家可以把文章链接领到百度站长平台进行递交,不过要注意一点,千万别反复递交多次,会影响网站的整体质量。
e.利用nofollow标签进行集权:nofollow标签在前期优化中也很重要,为了集中某一个区域的权重值,一般都可以借助这个标签把不重要的地方限制,让搜索引擎蜘蛛更好的辨识网站的核心重点;之后在按照核心重点写文章,收录率就大得多了。
2.文章大量采集而造成的不收录(非原创)
相信好多站长为了使网站早点上线,都去各大平台大量的采集一些内容,随后草草上线,而这样偷懒带来的后果就是造成文章迟迟不收录,尽管文章非常具备价值,但是却得不到搜索引擎的认可,没有新鲜的内容做支撑,搜索引擎的评分也是十分低的,而好多站长遇见这些情况,就不知道怎样去做了,下面的方式其实对你有帮助。
a.修改文章标题以及内容前后:大家可以拿标题到百度搜索框去搜索,看看相关搜索量能达到多少,若是达到一百万左右,那么就要适当的更改标题了,修改后的标题再领到百度搜索框搜索一下,看看相关搜索结果又多少,一般最好控制在 10 万以下。
b.加强外链发布的工作:一旦更改好了内容和标题,那么接出来就是要使搜索引擎重新抓取内容,这时候外链工作功不可没,大家可以在发布外链的时侯带上这篇文章的链接,让搜索引擎重新抓取辨识,建议内容更改就全部更改好,不要更改一篇发布一篇外链,这样搜索引擎蜘蛛来抓取的时侯,只发觉一个页面有所改变,依然得不到好转,若是发觉大部分内容都改建过,那么上次百度快照更新的时侯,相信收录量才能上来了。
3.内容价值偏于老旧,对用户意义不大
在上面也说过原创文章讲究一个价值性,很多人写原创可以说快讲到呕血了,但是就是不收录,其实很大缘由就是文章质量的问题,很多文章围绕的都是曾经陈旧的观点,根本解决不了现今用户的需求,那么怎么更好的紧抓文章的价值性呢?简单而言就是要了解用户近日经常搜索哪些内容,可以按照下拉框和相关搜索来剖析,在这里就不做过多说明了,同时也可以借助QQ社交工具咨询一些专家,整合她们的意见也能成为一篇好的文章。
大家可以先借助百度知道查看目前用户都提了什么问题,然后在去找寻同行咨询,这个疗效特别不错,但是比较损,而且有的同行也聪明,动不动要你面谈,这就为我们创造价值文章带来了一定的难度,不过这个方式你们可以举一反三的思索使用。
4.频繁更改网站标题也会影响整体收录
对于网站来说,若是时常更改网站的标题,也会导致网站内容发生方向的改变,网站整体权重不高,也会直接影响网站文章的收录率,相信这一点你们已然深有感悟了,因此若是你刚才更改过标题,发现文章不收录了,那就说明网站已经被搜索引擎重新拉入观察期进行观察了。
如何解决这一问题呢?首先应当考虑百度快照的更新问题,只有使快照尽快更新,才能更好的恢复过来,可以通过百度快照更新投诉通道进行投诉,可以推动快照的更新速率。
其次就是多多更新高质量的原创内容,不管收录与否,定期规律的更新能减短这段观察期。
5.检查robots.txt文件是否存在严禁搜索引擎的指令
这一点其实简单,但是好多情况下就是robots文件惹的祸,很多站长因为马大哈,禁止了搜索引擎抓取文件,从而引起了文章收录大大增长,这一点也不能马大哈。可以使用百度站长平台的抓取工具以及robots检查工具进行测试。
6.网站存在大量的死链接
网站出现大量的死链接也是影响页面质量的诱因,大量的 404 页面给了搜索引擎蜘蛛一个极差的抓取体验,从而增加网站的页面质量,大家不妨检测一下自己的网站,是否存在多个死链接,有一种情况很容易出现大量死链接,就是动态路径和伪静态路径没有统一好,导致大量死链接,这一点你们应当都有经历。
若是发觉大量死链接,首先想到的是怎样处理死链接,让搜索引擎尽早更新过来,可以通过百度站长工具的死链接工具进行修补,具体就不在这儿说明了。
7.网站优化过度造成降权
很多网站由于网站优化过度,刻意拼凑关键词造成网站迟迟不收录,当发觉优化过度后,首先就要想到怎么增加刻意优化的痕迹,刻意拼凑的关键词也可以适当降低,减少每一个页面的重复率,过一段时间后在坚持更新原创质量文章即可。
总结
以上就是本文述说的原创文章为何不收录的大致缘由,如果你们发觉自己的文章常常不收录,很大缘由就是网站的信任值不足,其次是文章的质量是否达标的关系,想要自己的网站达到秒收的境界,那么就须要进行不断的加壳,然后提高文章质量,确保网站跳出率可观。
千万级内容类产品中台应当有什么模块?
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2020-08-12 00:51
说到内容,可以把它想像为一块羊肉。它首先是一头牛,然后这头牛被送进了加工厂,在一系列加工过后,通过货运送到商场,最后,你通过消费获得这块排骨。内容也是一样,需要经过生产、加工、审核、分发等工序最后展示在用户面前。本文说的内容中台便是这么。
一头牛(内容原料/内容生产)
和一般说的UGC/PGC的分类不一样,此处的说的中台将内容来源分为外部创作和内部创作。
外部创作
外部创作指的是爬虫采集、人工节选、渠道合作以及用户创作内容(UGC)。
(1)爬虫采集:是指对特定信息源进行机器爬虫采集、内容入库。此处说的特定的信息来源一般是公开信息网站,比如gov类的。爬虫采集要求全、快、准、稳。全,爬取的内容要全,不能把信息源的文章少爬了几篇。
(2)人工节选:主要是针对这些及时性要求比较高的内容,比如突发性重大新闻。这也侧面反映出爬虫采集存在一定缺陷,比如时效性低,很难做到秒级反应。此外部份来源也设有反爬虫机制,会促使内容有所缺位。这时候就须要人工节选进行补充。
(3)渠道合作:是指由合作商提供插口,除了常规的内容要素,还应当收录增删改信息,最好是有合适的日志以及信息同步机制。
内部创作
内部创作说的是企业原创,这类又分为两种:一种是纯人工创作,另一种是智能写稿。
纯人工创作:也就是原创内容,由强悍的编辑团队一手创作 智能写稿:这个有点象文字填充。产品总监在经过一系列的剖析之后筛选出才能满足用户需求而且能被技术支持的文章类型,再对每一类文章编写模板并规定由机器填写的数组。此后机器能够手动产出符合要求的内容了。 加工厂(内容加工)
加工厂主要有两种“机器”,一类是标签体系(内容分类),一类是内容加工。
标签体系主要服务于建立文章池并借此作为个性化推荐的基础。比如说某篇文章的标签是{A,B},某用户的标签也是{A,B},那么这篇文章便可能有很大的机率被推送到这个用户面前。而此处的标签体系便是通过对内容的剖析给它们打上各类标签便于于后续的分发和推送。值得注意的是,标签并不是越多越好,而是要遵守一定的规则,这样就能尽可能地提升匹配程度,从而提升文章的消费率。
内容加工主要有以下几步:
首先是格式的优化,对于采集过来的文章我们须要把不合适的内容去除,比如说超链、广告等。 之后是内容转存,将文章的图片和视频转入自己的服务器上(这须要取得对方许可)。 其次还有一些附加模块,这块主要作用于各前台的特色功能或则个性化需求,比如在文章中添加图片、表格、投票、附件、运营模块(主要是banner)等。 最后是盖戳环节,就像加工厂给猪肉盖戳一样,我们须要对内容的合规性、与原文的一致性等进行复核,主要是违法词屏蔽(也就是大家在王者化肥里显示不下来的馨香)、关键词替换、原文比对等。 物流分发(内容分发)
物流分发输出的就是成品猪肉——文章池,它最重要的元素有:标题、摘要、正文、时间、排序、内容标签、个性化模块。分发的逻辑比较复杂,而且也须要配合前台具体需求,这里就不展开阐述了。
最后附上逻辑图: 查看全部
文章结合猪肉加工的案例,形象地梳理了内容中台的运作机制,并对各个模块展开了剖析介绍,与你们分享。

说到内容,可以把它想像为一块羊肉。它首先是一头牛,然后这头牛被送进了加工厂,在一系列加工过后,通过货运送到商场,最后,你通过消费获得这块排骨。内容也是一样,需要经过生产、加工、审核、分发等工序最后展示在用户面前。本文说的内容中台便是这么。
一头牛(内容原料/内容生产)
和一般说的UGC/PGC的分类不一样,此处的说的中台将内容来源分为外部创作和内部创作。
外部创作
外部创作指的是爬虫采集、人工节选、渠道合作以及用户创作内容(UGC)。
(1)爬虫采集:是指对特定信息源进行机器爬虫采集、内容入库。此处说的特定的信息来源一般是公开信息网站,比如gov类的。爬虫采集要求全、快、准、稳。全,爬取的内容要全,不能把信息源的文章少爬了几篇。
(2)人工节选:主要是针对这些及时性要求比较高的内容,比如突发性重大新闻。这也侧面反映出爬虫采集存在一定缺陷,比如时效性低,很难做到秒级反应。此外部份来源也设有反爬虫机制,会促使内容有所缺位。这时候就须要人工节选进行补充。
(3)渠道合作:是指由合作商提供插口,除了常规的内容要素,还应当收录增删改信息,最好是有合适的日志以及信息同步机制。
内部创作
内部创作说的是企业原创,这类又分为两种:一种是纯人工创作,另一种是智能写稿。
纯人工创作:也就是原创内容,由强悍的编辑团队一手创作 智能写稿:这个有点象文字填充。产品总监在经过一系列的剖析之后筛选出才能满足用户需求而且能被技术支持的文章类型,再对每一类文章编写模板并规定由机器填写的数组。此后机器能够手动产出符合要求的内容了。 加工厂(内容加工)
加工厂主要有两种“机器”,一类是标签体系(内容分类),一类是内容加工。
标签体系主要服务于建立文章池并借此作为个性化推荐的基础。比如说某篇文章的标签是{A,B},某用户的标签也是{A,B},那么这篇文章便可能有很大的机率被推送到这个用户面前。而此处的标签体系便是通过对内容的剖析给它们打上各类标签便于于后续的分发和推送。值得注意的是,标签并不是越多越好,而是要遵守一定的规则,这样就能尽可能地提升匹配程度,从而提升文章的消费率。
内容加工主要有以下几步:
首先是格式的优化,对于采集过来的文章我们须要把不合适的内容去除,比如说超链、广告等。 之后是内容转存,将文章的图片和视频转入自己的服务器上(这须要取得对方许可)。 其次还有一些附加模块,这块主要作用于各前台的特色功能或则个性化需求,比如在文章中添加图片、表格、投票、附件、运营模块(主要是banner)等。 最后是盖戳环节,就像加工厂给猪肉盖戳一样,我们须要对内容的合规性、与原文的一致性等进行复核,主要是违法词屏蔽(也就是大家在王者化肥里显示不下来的馨香)、关键词替换、原文比对等。 物流分发(内容分发)
物流分发输出的就是成品猪肉——文章池,它最重要的元素有:标题、摘要、正文、时间、排序、内容标签、个性化模块。分发的逻辑比较复杂,而且也须要配合前台具体需求,这里就不展开阐述了。
最后附上逻辑图:
微信公众号文章采集的入口--历史消息页解读
采集交流 • 优采云 发表了文章 • 0 个评论 • 357 次浏览 • 2020-08-11 23:03
因为陌陌的限制,我们能复制到的链接是不完整的,在浏览器中未能打开听到内容。所以我们须要通过上一篇文章介绍的方式,使用anyproxy获取到一个完整的微信公众号历史消息页面的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
前一篇文章提到过,biz参数是公众号的ID,uin是用户的ID,目前来看uin是在所有公众号之间惟一的。其它两个重要参数key和pass_ticket是陌陌客户端补充上的参数。
所以在这个地址失效之前我们是可以通过浏览器查看原文的方式获取到历史消息的文章列表的,如果希望自动化剖析内容,也可以制做一个程序,将这个带有仍未失效的key和pass_ticket的链接地址递交进去,再通过诸如php程序来获取到文章列表。
最近有同事跟我说他的采集目标就是单一的一个公众号,我认为这样就没必要用上一篇文章写的批量采集的方式了。所以我们接下来瞧瞧历史消息页上面是如何获取到文章列表的,通过剖析文章列表,就可以得到这个公众号所有的内容链接地址,然后再采集内容就可以了。
在anyproxy的web界面中若果证书配置正确,是可以显示出https的内容的。web界面的地址是localhost:8002其中localhost可以替换成自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,点击以后两侧都会显示出这条记录的详情:
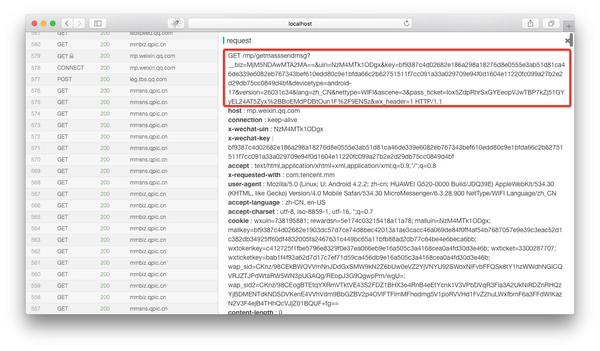
红框部份就是完整的链接地址,将微信公众平台这个域名拼接在上面以后就可以在浏览器中打开了。
然后将页面向上拉,到html内容的结尾部份,我们可以看见一个json的变量就是历史消息的文章列表:
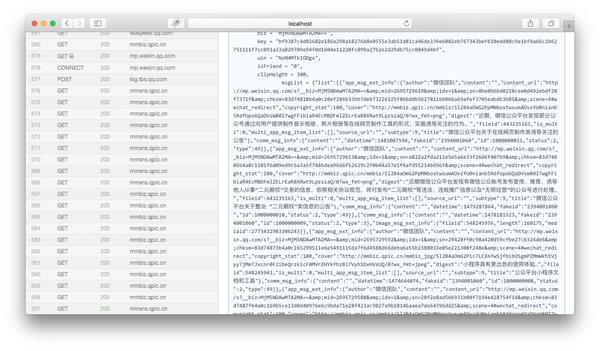
我们将msgList的变量值拷贝下来,用json低格工具剖析一下,我们就可以看见这个json是以下这个结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简要的剖析一下这个json(这里只介绍一些重要的信息,其它的被省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
在这里还要提及一点就是假如希望获取到时间更久远一些的历史消息内容,就须要在手机或模拟器上将页面向上拉,当拉到最里边的时侯,微信将手动读取下一页的内容。下一页的链接地址和历史消息页的链接地址同样是getmasssendmsg开头的地址。但是内容就是只有json了,没有html了。直接解析json就可以了。
这时可以通过上一篇文章介绍的方式,使用anyproxy将msgList变量值正则匹配下来以后,异步递交到服务器,再从服务器上使用php的json_decode解析json成为字段。然后遍历循环链表。我们就可以得到每一篇文章的标题和链接地址。
如果只须要采集单一公众号的内容,完全可以在每晚群发以后,通过anyproxy获取到完整的带有key和pass_ticket的链接地址。然后自己制做一个程序,手动将地址递交给自己的程序。使用诸如php这样的语言来正则匹配到msgList,然后解析json。这样就不用更改anyproxy的rule,也不需要制做一个采集队列和跳转页面了。
现在我们早已可以通过公众号的历史消息得到文章列表了,在下一篇文章里我将介绍怎么按照历史消息里的文章链接地址来获取文章具体内容的方式。还有一些怎样保存文章,封面图片,还有全文检索的经验。
如果你认为我那里写的不清楚,或者有不明白的地方,欢迎在下边留言。或者恐吓微信号cuijin,觉得好就点个赞。
持续更新,微信公众号文章批量采集系统的建立
微信公众号文章采集的入口--历史消息页解读
微信公众号文章页的剖析与采集
提高微信公众号文章采集效率,anyproxy进阶使用方式 查看全部
采集微信文章和采集网站内容一样,都须要从一个列表页开始。而陌陌文章的列表页就是公众号里的查看历史消息页。现在网路上的其它陌陌采集器有的是借助搜狗搜索,采集方式其实简单多了,但是内容不全。所以我们还是要从最标准最全面的公众号历史消息页来采集。
因为陌陌的限制,我们能复制到的链接是不完整的,在浏览器中未能打开听到内容。所以我们须要通过上一篇文章介绍的方式,使用anyproxy获取到一个完整的微信公众号历史消息页面的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
前一篇文章提到过,biz参数是公众号的ID,uin是用户的ID,目前来看uin是在所有公众号之间惟一的。其它两个重要参数key和pass_ticket是陌陌客户端补充上的参数。
所以在这个地址失效之前我们是可以通过浏览器查看原文的方式获取到历史消息的文章列表的,如果希望自动化剖析内容,也可以制做一个程序,将这个带有仍未失效的key和pass_ticket的链接地址递交进去,再通过诸如php程序来获取到文章列表。
最近有同事跟我说他的采集目标就是单一的一个公众号,我认为这样就没必要用上一篇文章写的批量采集的方式了。所以我们接下来瞧瞧历史消息页上面是如何获取到文章列表的,通过剖析文章列表,就可以得到这个公众号所有的内容链接地址,然后再采集内容就可以了。
在anyproxy的web界面中若果证书配置正确,是可以显示出https的内容的。web界面的地址是localhost:8002其中localhost可以替换成自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,点击以后两侧都会显示出这条记录的详情:
红框部份就是完整的链接地址,将微信公众平台这个域名拼接在上面以后就可以在浏览器中打开了。
然后将页面向上拉,到html内容的结尾部份,我们可以看见一个json的变量就是历史消息的文章列表:
我们将msgList的变量值拷贝下来,用json低格工具剖析一下,我们就可以看见这个json是以下这个结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简要的剖析一下这个json(这里只介绍一些重要的信息,其它的被省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
在这里还要提及一点就是假如希望获取到时间更久远一些的历史消息内容,就须要在手机或模拟器上将页面向上拉,当拉到最里边的时侯,微信将手动读取下一页的内容。下一页的链接地址和历史消息页的链接地址同样是getmasssendmsg开头的地址。但是内容就是只有json了,没有html了。直接解析json就可以了。
这时可以通过上一篇文章介绍的方式,使用anyproxy将msgList变量值正则匹配下来以后,异步递交到服务器,再从服务器上使用php的json_decode解析json成为字段。然后遍历循环链表。我们就可以得到每一篇文章的标题和链接地址。
如果只须要采集单一公众号的内容,完全可以在每晚群发以后,通过anyproxy获取到完整的带有key和pass_ticket的链接地址。然后自己制做一个程序,手动将地址递交给自己的程序。使用诸如php这样的语言来正则匹配到msgList,然后解析json。这样就不用更改anyproxy的rule,也不需要制做一个采集队列和跳转页面了。
现在我们早已可以通过公众号的历史消息得到文章列表了,在下一篇文章里我将介绍怎么按照历史消息里的文章链接地址来获取文章具体内容的方式。还有一些怎样保存文章,封面图片,还有全文检索的经验。
如果你认为我那里写的不清楚,或者有不明白的地方,欢迎在下边留言。或者恐吓微信号cuijin,觉得好就点个赞。
持续更新,微信公众号文章批量采集系统的建立
微信公众号文章采集的入口--历史消息页解读
微信公众号文章页的剖析与采集
提高微信公众号文章采集效率,anyproxy进阶使用方式
网站高质量内容更新注意事情
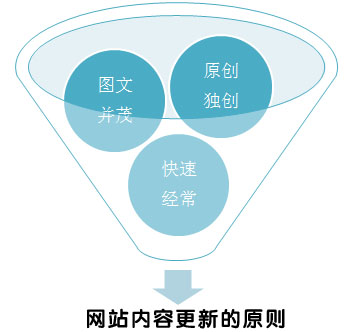
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2020-08-10 20:07
一、不可直接采集内容
要对采集的内容进行深度的加工,不能否直接借助,否则都会被搜索引擎会辨识为垃圾信息。
二、内容要怎么做不被降权
一些网站更新的内容除了不会收录,严重的还可能造成网站被降权,内容引起网站被降权也就说明搜索引擎觉得这种是垃圾信息,所以做网站内容时要想不被看做垃圾信息就要注意以下四点。
1、只需加粗文章标题和段落标题
只须要对文章两个大小标题进行加粗就可以了,这是强制指标上面涉及到H1到H2标签的运用,H1标签运用到文章标题,而H2运用到正文段落标题中。
2、正文不要放内链
不要一味地为获取关键词排行而在网站内容中倒入过多的内链,这些内链指向自己的首页但不一定会被用户点击。
3、内容中不可以放广告
内容中不要放这些包括百度网盟等在内的广告,否则会被惩罚的。如果是流量广告站点不可以在正文中和没有排行和流量的时侯加入广告,而必须在网站有排行和流量后从正文结束的位置加入广告。
4、内容中字体颜色相同
一篇文章中所有的字体颜色应当一致,因为太多的颜色会直接影响搜索引擎辨识,很多垃圾网站都是用不同颜色的字体来变幻从他人网站上采集到的内容。
总之,高质量的内容优化不是一件简单的事情,需要不断掉动头脑,不断努力,坚持不懈的进行,只有这样才有可能作出高质量的网站内容。 查看全部
网站的存在与它本身的内容有很大的关系,它对于用户和搜索引擎来讲都是很重要的,但是内容也有优劣之分。好的内容除了就能留住用户同时还可以吸引更多的用户,而质量不高的内容则是在浪费时间同时也对用户没有帮助,因此搜索引擎对质量不好的网站惩罚也是太严格的,可是我们对于好的网站内容该做何努力呢?本文广州SEO专家朗创网路营销将和你们介绍一下经验。
一、不可直接采集内容
要对采集的内容进行深度的加工,不能否直接借助,否则都会被搜索引擎会辨识为垃圾信息。
二、内容要怎么做不被降权
一些网站更新的内容除了不会收录,严重的还可能造成网站被降权,内容引起网站被降权也就说明搜索引擎觉得这种是垃圾信息,所以做网站内容时要想不被看做垃圾信息就要注意以下四点。
1、只需加粗文章标题和段落标题
只须要对文章两个大小标题进行加粗就可以了,这是强制指标上面涉及到H1到H2标签的运用,H1标签运用到文章标题,而H2运用到正文段落标题中。
2、正文不要放内链
不要一味地为获取关键词排行而在网站内容中倒入过多的内链,这些内链指向自己的首页但不一定会被用户点击。
3、内容中不可以放广告
内容中不要放这些包括百度网盟等在内的广告,否则会被惩罚的。如果是流量广告站点不可以在正文中和没有排行和流量的时侯加入广告,而必须在网站有排行和流量后从正文结束的位置加入广告。
4、内容中字体颜色相同
一篇文章中所有的字体颜色应当一致,因为太多的颜色会直接影响搜索引擎辨识,很多垃圾网站都是用不同颜色的字体来变幻从他人网站上采集到的内容。
总之,高质量的内容优化不是一件简单的事情,需要不断掉动头脑,不断努力,坚持不懈的进行,只有这样才有可能作出高质量的网站内容。
优采云采集器出现"WEB发布是否成功未知",错误缘由和解决办法
采集交流 • 优采云 发表了文章 • 0 个评论 • 374 次浏览 • 2020-08-10 00:31
一般来说发布错误缘由有两个,参见附图一:
1,模块发布中未列举所有可能发布错误的情况;
2,排除模块以外的其它缘由,如登录失败、网站主路径填写错误、网站(页面)无法访问等诱因。
解决办法:
1,发布时先只发布一条内容,然后按照软件提示打开发布时保存的错误返回代码文件“WebError.log”,查看上面的返回代码,一般的保存路径为"优采云采集器/DATA/任务名/WebError.log"。
2,如果返回代码是大篇幅的HTML代码,而你看起HTML代码来难于看天书的话,我建议你把WebError.log另存为HTML文档使用IE查看。
3,根据WebError.log中的诱因检测网站和软件的配置即可,一般的错误情况在此即可解决问题。
WebError.log出现内容为空的解决办法:
当然,WebError.log也会出现内容为空的情况,这里单独做一个说明。
这种情况通常是因为软件POST内容之后,接收不到发布页面的响应导致的。有时候优采云采集器也会把这样的情况默认为成功发布,而事实上,我们的网站却没有内容,很多站长因此呕吐不已。
其实这是一个简单的问题,你可以按照“无法接受到发布页面的响应”来找寻缘由。如:
1,你的网站是否能正常访问,特别是你的Web发布页面。
2,设置Web发布时,网站的根目录有没有填写正确,可以用刷新栏目列表是否正确来判定。
3,网站是否成功登录或则发布用户是否有权限。
4,优采云采集器-辅助工具-重新加载配置。
5,如果以上方案你都有测试过,那不妨再重启一下优采云采集器。
以下是一些图片,可以帮你愈发直观的了解:
你可以任意转摘“优采云采集器出现"WEB发布是否成功未知",错误缘由和解决办法”,但请保留本文出处和版权信息。 查看全部
这是非常典型的优采云采集器发布错误,主要缘由是因为发布时,程序获取到的返回代码中,出现了Web发布模块中未列举的代码。即,发布时,未出现成功的返回特点代码,也没有出现发布错误的特点码。
一般来说发布错误缘由有两个,参见附图一:
1,模块发布中未列举所有可能发布错误的情况;
2,排除模块以外的其它缘由,如登录失败、网站主路径填写错误、网站(页面)无法访问等诱因。
解决办法:
1,发布时先只发布一条内容,然后按照软件提示打开发布时保存的错误返回代码文件“WebError.log”,查看上面的返回代码,一般的保存路径为"优采云采集器/DATA/任务名/WebError.log"。
2,如果返回代码是大篇幅的HTML代码,而你看起HTML代码来难于看天书的话,我建议你把WebError.log另存为HTML文档使用IE查看。
3,根据WebError.log中的诱因检测网站和软件的配置即可,一般的错误情况在此即可解决问题。
WebError.log出现内容为空的解决办法:
当然,WebError.log也会出现内容为空的情况,这里单独做一个说明。
这种情况通常是因为软件POST内容之后,接收不到发布页面的响应导致的。有时候优采云采集器也会把这样的情况默认为成功发布,而事实上,我们的网站却没有内容,很多站长因此呕吐不已。
其实这是一个简单的问题,你可以按照“无法接受到发布页面的响应”来找寻缘由。如:
1,你的网站是否能正常访问,特别是你的Web发布页面。
2,设置Web发布时,网站的根目录有没有填写正确,可以用刷新栏目列表是否正确来判定。
3,网站是否成功登录或则发布用户是否有权限。
4,优采云采集器-辅助工具-重新加载配置。
5,如果以上方案你都有测试过,那不妨再重启一下优采云采集器。
以下是一些图片,可以帮你愈发直观的了解:


你可以任意转摘“优采云采集器出现"WEB发布是否成功未知",错误缘由和解决办法”,但请保留本文出处和版权信息。
解读:自媒体文章采集方法,以今日头条采集为例
采集交流 • 优采云 发表了文章 • 0 个评论 • 540 次浏览 • 2020-11-10 10:02
Cloud 采集服务平台自媒体文章采集方法,以头条采集为例自媒体如今越来越流行,自媒体是基于云计算带来的社会化Internet Media,因为社交媒体更具交互性和更快性,它完全满足了每个想要发言的人的需求,并且它的及时性也非常吸引人,因此社交媒体立即拥有大量的受众。因此自媒体平台上出现了越来越多的高质量文章,并且我的许多朋友都对采集 自媒体文章有需求。让我们以今天的标题采集为例,介绍自媒体文章。如何使用本文描述优采云7.0 采集 自媒体文章采集方法的用法今天的头条新闻。 采集 网站:使用功能点:Ajax滚动加载设置列表内容提取步骤:创建采集任务1)进入主界面进行选择,选择“自定义模式”云采集服务平台自媒体文章采集步骤2)复制上述URL的URL并将其粘贴到在网站输入框中,单击“保存URL”。云采集服务平台自媒体文章采集步骤3)保存URL之后,将在优采云采集器中打开页面红框中的内容是此演示采集的内容,这是当今头条新闻所发布的最新热点新闻。 自媒体文章采集步骤2:设置ajax页面加载时间,设置打开页面的步骤的ajax滚动加载时间,找到页面翻页按钮,设置页面翻页周期,设置页面翻页步骤,ajax下拉加载时间云采集服务平台1)打开网页后,需要进行以下设置:打开流程图,单击“打开网页”步骤,在右键,检查“页面加载完成向下滚动”,设置滚动数,每个滚动间隔时间,一般设置并单击“确定”。自媒体文章采集步骤注意:网站在今天的标题中属于瀑布网站,没有翻页按钮,此处的滚动设置数量将影响采集的数据量。
云采集服务平台自媒体文章采集步骤步骤3:采集新闻内容创建数据提取列表1)如图所示,移动鼠标以选择评论列表框,右键单击,该框的背景颜色将变为绿色,然后单击“选择子元素” Cloud 采集服务平台自媒体文章采集步骤注意:单击右上角的“处理”按钮显示视觉流程图。 2)然后单击“全选”,并将页面上需要采集的信息添加到列表中。 Cloud 采集服务平台自媒体文章采集步骤注意:提示框中的字段将出现“ X”标记,单击以删除该字段。 自媒体文章采集 Step 3)单击“ 采集以下数据” 自媒体文章采集 Step cloud 采集服务平台4)修改采集字段名称,单击“保存并开始采集 自媒体文章采集框内的第10步下面的红色:;数据采集并导出1)根据采集的情况选择适当的采集方法,在此处选择“启动本地采集云采集服务平台自媒体文章采集步骤11描述:如果存在采集,则本地采集会占用采集的当前计算机资源。时间要求或当前计算机不能太长继续进行操作采集可以使用云采集功能,网络采集中可以使用云采集,如果没有当前计算机的支持,则可以关闭计算机,可以设置多个云节点以共享任务,10个节点等于10个节点计算机分配任务以帮助您采集,并且速度降低到原创速度的十分之一; 采集数据可以在云中存储三个月,并且可以随时导出。
完成2) 采集之后,选择适当的导出方法,并将采集良好数据导出到云采集服务平台自媒体文章采集步骤12相关的采集教程百度搜索结果采集新浪微博数据采集搜狗微信文章采集云采集由服务平台采集器上的70万用户选择的网页数据。1、该操作很简单,任何人都可以使用它:不需要技术背景,并且您可以浏览Internet 采集。完全可视化该过程,单击鼠标以完成操作,您可以在数分钟内快速上手。2、功能强大,可以使用任何网站:单击,登录,翻页,标识验证码,瀑布流和Ajax脚本,以通过简单的设置采集异步加载带有数据的网页。3、Cloud 采集,可以将其关闭。配置采集任务后,可以将其关闭,并可以在云中执行该任务。庞大的云采集群集不间断运行24 * 7,因此无需担心IP被阻塞和网络中断。4、可以根据需要选择免费功能和增值服务。免费版具有所有功能,可以满足用户的基本采集需求。同时,已经建立了一些增值服务(例如私有云)来满足高端付费企业用户的需求。 查看全部
自媒体文章采集方法,以今天的头条新闻采集为例
Cloud 采集服务平台自媒体文章采集方法,以头条采集为例自媒体如今越来越流行,自媒体是基于云计算带来的社会化Internet Media,因为社交媒体更具交互性和更快性,它完全满足了每个想要发言的人的需求,并且它的及时性也非常吸引人,因此社交媒体立即拥有大量的受众。因此自媒体平台上出现了越来越多的高质量文章,并且我的许多朋友都对采集 自媒体文章有需求。让我们以今天的标题采集为例,介绍自媒体文章。如何使用本文描述优采云7.0 采集 自媒体文章采集方法的用法今天的头条新闻。 采集 网站:使用功能点:Ajax滚动加载设置列表内容提取步骤:创建采集任务1)进入主界面进行选择,选择“自定义模式”云采集服务平台自媒体文章采集步骤2)复制上述URL的URL并将其粘贴到在网站输入框中,单击“保存URL”。云采集服务平台自媒体文章采集步骤3)保存URL之后,将在优采云采集器中打开页面红框中的内容是此演示采集的内容,这是当今头条新闻所发布的最新热点新闻。 自媒体文章采集步骤2:设置ajax页面加载时间,设置打开页面的步骤的ajax滚动加载时间,找到页面翻页按钮,设置页面翻页周期,设置页面翻页步骤,ajax下拉加载时间云采集服务平台1)打开网页后,需要进行以下设置:打开流程图,单击“打开网页”步骤,在右键,检查“页面加载完成向下滚动”,设置滚动数,每个滚动间隔时间,一般设置并单击“确定”。自媒体文章采集步骤注意:网站在今天的标题中属于瀑布网站,没有翻页按钮,此处的滚动设置数量将影响采集的数据量。
云采集服务平台自媒体文章采集步骤步骤3:采集新闻内容创建数据提取列表1)如图所示,移动鼠标以选择评论列表框,右键单击,该框的背景颜色将变为绿色,然后单击“选择子元素” Cloud 采集服务平台自媒体文章采集步骤注意:单击右上角的“处理”按钮显示视觉流程图。 2)然后单击“全选”,并将页面上需要采集的信息添加到列表中。 Cloud 采集服务平台自媒体文章采集步骤注意:提示框中的字段将出现“ X”标记,单击以删除该字段。 自媒体文章采集 Step 3)单击“ 采集以下数据” 自媒体文章采集 Step cloud 采集服务平台4)修改采集字段名称,单击“保存并开始采集 自媒体文章采集框内的第10步下面的红色:;数据采集并导出1)根据采集的情况选择适当的采集方法,在此处选择“启动本地采集云采集服务平台自媒体文章采集步骤11描述:如果存在采集,则本地采集会占用采集的当前计算机资源。时间要求或当前计算机不能太长继续进行操作采集可以使用云采集功能,网络采集中可以使用云采集,如果没有当前计算机的支持,则可以关闭计算机,可以设置多个云节点以共享任务,10个节点等于10个节点计算机分配任务以帮助您采集,并且速度降低到原创速度的十分之一; 采集数据可以在云中存储三个月,并且可以随时导出。
完成2) 采集之后,选择适当的导出方法,并将采集良好数据导出到云采集服务平台自媒体文章采集步骤12相关的采集教程百度搜索结果采集新浪微博数据采集搜狗微信文章采集云采集由服务平台采集器上的70万用户选择的网页数据。1、该操作很简单,任何人都可以使用它:不需要技术背景,并且您可以浏览Internet 采集。完全可视化该过程,单击鼠标以完成操作,您可以在数分钟内快速上手。2、功能强大,可以使用任何网站:单击,登录,翻页,标识验证码,瀑布流和Ajax脚本,以通过简单的设置采集异步加载带有数据的网页。3、Cloud 采集,可以将其关闭。配置采集任务后,可以将其关闭,并可以在云中执行该任务。庞大的云采集群集不间断运行24 * 7,因此无需担心IP被阻塞和网络中断。4、可以根据需要选择免费功能和增值服务。免费版具有所有功能,可以满足用户的基本采集需求。同时,已经建立了一些增值服务(例如私有云)来满足高端付费企业用户的需求。
实用文章:网站文章采集平台如何通过文章采集获取一篇高质量的网站内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-09-24 11:02
摘要:但是,内容的数量也是影响百度搜索引擎排名的一个非常重要的因素。这使我们陷入手册内容和采集之间的困境。那么,如何通过文章采集获得高质量的网站内容?那是因为编写软件时。这样,在查询过程中,替换了三篇文章文章,并添加了通用开头和通用结尾后,就实现了伪原创,不是吗?
网站文章采集平台如何通过文章采集获得高质量的网站内容
网站文章采集平台
问:现阶段,百度推出了飓风算法和轻风算法,以应对采集和低质量内容。但是,内容的数量也是影响百度搜索引擎排名的一个非常重要的因素,这使我们面临手动编写与采集之间的困境。 ...
问:在现阶段,百度已经推出了飓风算法和轻风算法,以应对采集和低质量内容。但是,内容的数量也是影响百度搜索引擎排名的一个非常重要的因素,这使我们面临手动编写与采集之间的困境。那么,如何通过文章采集获得一段高质量的网站内容?
答案:关于文章采集组合,我会告诉你我的想法:
<p>1、选择关键词,这是最重要的,并逐一挖掘出属于他的网站的关键词。不要说这很困难,如果您不能自己开发它,实际上,它就像5118思维导图。2、关键词做出选择之后,它就是对高质量内容的挖掘。您必须首先选择收录您选择的关键词的最全面的主要站点。您必须是主要站点,因为主要站点的内容很全面。然后,根据关键词至采集这个大电台的内容,当文章采集不仅是这个大电台,还必须将关键词放到百度采集]。 查看全部
网站文章采集平台如何通过文章采集获得高质量的网站内容
摘要:但是,内容的数量也是影响百度搜索引擎排名的一个非常重要的因素。这使我们陷入手册内容和采集之间的困境。那么,如何通过文章采集获得高质量的网站内容?那是因为编写软件时。这样,在查询过程中,替换了三篇文章文章,并添加了通用开头和通用结尾后,就实现了伪原创,不是吗?
网站文章采集平台如何通过文章采集获得高质量的网站内容
网站文章采集平台
问:现阶段,百度推出了飓风算法和轻风算法,以应对采集和低质量内容。但是,内容的数量也是影响百度搜索引擎排名的一个非常重要的因素,这使我们面临手动编写与采集之间的困境。 ...
问:在现阶段,百度已经推出了飓风算法和轻风算法,以应对采集和低质量内容。但是,内容的数量也是影响百度搜索引擎排名的一个非常重要的因素,这使我们面临手动编写与采集之间的困境。那么,如何通过文章采集获得一段高质量的网站内容?
答案:关于文章采集组合,我会告诉你我的想法:
<p>1、选择关键词,这是最重要的,并逐一挖掘出属于他的网站的关键词。不要说这很困难,如果您不能自己开发它,实际上,它就像5118思维导图。2、关键词做出选择之后,它就是对高质量内容的挖掘。您必须首先选择收录您选择的关键词的最全面的主要站点。您必须是主要站点,因为主要站点的内容很全面。然后,根据关键词至采集这个大电台的内容,当文章采集不仅是这个大电台,还必须将关键词放到百度采集]。
PHP 怎么使用 XPath 来采集页面数据内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 330 次浏览 • 2020-08-28 09:05
之前有说过使用 Python 使用 XPath 去采集页面数据内容,前段时间参与百度公测的一个号主页诠释插口,需要文章页面改建的application/ld+json代码
Python 具体的操作可以看一下之前的文章:Python爬虫之XPath句型和lxml库的用法以及便捷的 Chrome 网页解析工具:XPath Helper
我想过使用 QueryList 的框架去操作,但是由于他大小也算个框架,有点重,还是直接单文件吧
想到了之前写 Python 爬虫时使用的 XPath,PHP 应该也是可以搞的吧
动手就干,先找到对应的 XPath 规则,如下:
//script[@type='application/ld+json']/text()
script 节点下的 type 属性,拿到它中间的文本,也刚好是我们须要的 JSON 数据
本来也是为了递交百度便捷,所以直接做到给一个链接,然后代码去恳求百度的插口就可以了
具体代码是这样的:
$html = file_get_contents('https://qq52o.me/2530.html');
$dom = new DOMDocument();
// 从一个字符串加载HTML
@$dom->loadHTML($html);
// 使该HTML规范化
$dom->normalize();
// 用DOMXpath加载DOM,用于查询
$xpath = new DOMXPath($dom);
// 获取对应的xpath数据
$hrefs = $xpath->query("//script[@type='application/ld+json']/text()");
for ($i = 0; $i < $hrefs->length; $i++) {
$href = $hrefs->item($i);
$json = $href->nodeValue;
}
类库的用法自己可以看一下指南,使用 DOMXPath 的 query 方法,执行给定的 Xpath 规则,就酱紫~
针对百度熊掌号新插口恳求封装代码可以看一下 Github:sy-records/xzh-curl
总的来说,简单写一个页面的采集还是很简单的
沈唁志,一个PHPer的成长之路!任何个人或团体,未经准许严禁转载本文:《PHP 怎么使用 XPath 来采集页面数据内容》,谢谢合作! 查看全部
PHP 怎么使用 XPath 来采集页面数据内容
之前有说过使用 Python 使用 XPath 去采集页面数据内容,前段时间参与百度公测的一个号主页诠释插口,需要文章页面改建的application/ld+json代码
Python 具体的操作可以看一下之前的文章:Python爬虫之XPath句型和lxml库的用法以及便捷的 Chrome 网页解析工具:XPath Helper
我想过使用 QueryList 的框架去操作,但是由于他大小也算个框架,有点重,还是直接单文件吧
想到了之前写 Python 爬虫时使用的 XPath,PHP 应该也是可以搞的吧
动手就干,先找到对应的 XPath 规则,如下:
//script[@type='application/ld+json']/text()
script 节点下的 type 属性,拿到它中间的文本,也刚好是我们须要的 JSON 数据
本来也是为了递交百度便捷,所以直接做到给一个链接,然后代码去恳求百度的插口就可以了
具体代码是这样的:
$html = file_get_contents('https://qq52o.me/2530.html');
$dom = new DOMDocument();
// 从一个字符串加载HTML
@$dom->loadHTML($html);
// 使该HTML规范化
$dom->normalize();
// 用DOMXpath加载DOM,用于查询
$xpath = new DOMXPath($dom);
// 获取对应的xpath数据
$hrefs = $xpath->query("//script[@type='application/ld+json']/text()");
for ($i = 0; $i < $hrefs->length; $i++) {
$href = $hrefs->item($i);
$json = $href->nodeValue;
}
类库的用法自己可以看一下指南,使用 DOMXPath 的 query 方法,执行给定的 Xpath 规则,就酱紫~
针对百度熊掌号新插口恳求封装代码可以看一下 Github:sy-records/xzh-curl
总的来说,简单写一个页面的采集还是很简单的
沈唁志,一个PHPer的成长之路!任何个人或团体,未经准许严禁转载本文:《PHP 怎么使用 XPath 来采集页面数据内容》,谢谢合作!
PHP snoopy采集类如何采集我想要的内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 303 次浏览 • 2020-08-27 00:48
Snoopy是一个php类,用来模拟浏览器的功能,可以获取网页内容,发送表单,可以拿来开发一些采集程序和扒手程序,本文章详细介绍snoopy的使用教程。
Snoopy的一些特征:
抓取网页的内容 fetch
抓取网页的文本内容 (去除HTML标签) fetchtext
抓取网页的链接,表单 fetchlinks fetchform
支持代理主机
支持基本的用户名/密码验证
支持设置 user_agent, referer(来路), cookies 和 header content(头文件)
支持浏览器重定向,并能控制重定向深度
能把网页中的链接扩充成高质量的url(默认)
提交数据但是获取返回值
支持跟踪HTML框架
支持重定向的时侯传递cookies
要求php4以上就可以了 由于本身是php一个类 无需扩支持 服务器不支持curl时侯的最好选择,
Snoopy类方式及示例:
fetch($URI)
这是为了抓取网页的内容而使用的技巧。
$URI参数是被抓取网页的URL地址。
抓取的结果被储存在 $this->results 中。
如果你正在抓取的是一个框架,Snoopy将会将每位框架追踪后存入字段中,然后存入 $this->results。
fetchtext($URI)
本方式类似于fetch(),唯一不同的就是本方式会消除HTML标签和其他的无关数据,只返回网页中的文字内容。
fetchform($URI)
本方式类似于fetch(),唯一不同的就是本方式会消除HTML标签和其他的无关数据,只返回网页中表单内容(form)。
fetchlinks($URI)
本方式类似于fetch(),唯一不同的就是本方式会消除HTML标签和其他的无关数据,只返回网页中链接(link)。
默认情况下,相对链接将手动补全,转换成完整的URL。
submit($URI,$formvars)
本方式向$URL指定的链接地址发送确认表单。$formvars是一个储存表单参数的链表。
submittext($URI,$formvars)
本方式类似于submit(),唯一不同的就是本方式会消除HTML标签和其他的无关数据,只返回登录后网页中的文字内容。
submitlinks($URI)
本方式类似于submit(),唯一不同的就是本方式会消除HTML标签和其他的无关数据,只返回网页中链接(link)。
默认情况下,相对链接将手动补全,转换成完整的URL。 查看全部
PHP snoopy采集类如何采集我想要的内容
Snoopy是一个php类,用来模拟浏览器的功能,可以获取网页内容,发送表单,可以拿来开发一些采集程序和扒手程序,本文章详细介绍snoopy的使用教程。
Snoopy的一些特征:
抓取网页的内容 fetch
抓取网页的文本内容 (去除HTML标签) fetchtext
抓取网页的链接,表单 fetchlinks fetchform
支持代理主机
支持基本的用户名/密码验证
支持设置 user_agent, referer(来路), cookies 和 header content(头文件)
支持浏览器重定向,并能控制重定向深度
能把网页中的链接扩充成高质量的url(默认)
提交数据但是获取返回值
支持跟踪HTML框架
支持重定向的时侯传递cookies
要求php4以上就可以了 由于本身是php一个类 无需扩支持 服务器不支持curl时侯的最好选择,
Snoopy类方式及示例:
fetch($URI)
这是为了抓取网页的内容而使用的技巧。
$URI参数是被抓取网页的URL地址。
抓取的结果被储存在 $this->results 中。
如果你正在抓取的是一个框架,Snoopy将会将每位框架追踪后存入字段中,然后存入 $this->results。
fetchtext($URI)
本方式类似于fetch(),唯一不同的就是本方式会消除HTML标签和其他的无关数据,只返回网页中的文字内容。
fetchform($URI)
本方式类似于fetch(),唯一不同的就是本方式会消除HTML标签和其他的无关数据,只返回网页中表单内容(form)。
fetchlinks($URI)
本方式类似于fetch(),唯一不同的就是本方式会消除HTML标签和其他的无关数据,只返回网页中链接(link)。
默认情况下,相对链接将手动补全,转换成完整的URL。
submit($URI,$formvars)
本方式向$URL指定的链接地址发送确认表单。$formvars是一个储存表单参数的链表。
submittext($URI,$formvars)
本方式类似于submit(),唯一不同的就是本方式会消除HTML标签和其他的无关数据,只返回登录后网页中的文字内容。
submitlinks($URI)
本方式类似于submit(),唯一不同的就是本方式会消除HTML标签和其他的无关数据,只返回网页中链接(link)。
默认情况下,相对链接将手动补全,转换成完整的URL。
正确处理采集内容与原创内容的关系! - 电商宝典
采集交流 • 优采云 发表了文章 • 0 个评论 • 309 次浏览 • 2020-08-26 14:15
正确处理采集内容与原创内容的关系!采集站对你们来说是不陌生的,现在社会发展变化的速率使我们跟不上时代的步伐,我们有太多的事情要做,虽然搜索引擎优化一再的指出原创内容是多么多么的重要,但是对于真正做站的人来说,做到真正的纯原创网站是不现实的,毕竟在这个网路急速发展的世界里,复制和粘贴很容易了,所以我们要说说怎么采集内容,以及怎么将采集来的内容做大可能的帮助到你的排行,如何将你的时间和努力价值最大化:1、修改内容的标题。修改内容的标题是最直接最简单的形式,在GG上内容获取好的排行,如果你网站的权重不会很低或新站,只要更改一下内容的标题基本可以排个好名次了。如果每晚定量采集和坚持更改内容标题对网站权重积累也有帮助。2、修改或重新编撰内容摘要。很多网站的文章内容都有文章摘要,对采集内容重新编撰文章摘要也可以推动采集内容在搜索引擎中的排行。文章摘要会在网站很多地方用得上,一般情况下搜索引擎会把这种 摘要当快照说明来使用,因此对采集内容重新编撰文章摘要是十分必要的工作。3、编写内容评论。内容采集回来对整篇内容做简单的评论对内容的排行提升也太有帮助。评论通常写 在文章开始位置或结尾位置。笔者觉得写在文章开始位置比写在结尾位置疗效要好好多。4、采集内容专题化。网站专题是个挺好的东西,采集的内容通过归类筛选出内容相像的内容弄成统一专题,对采集内容在搜索引擎排名、网站权重提升有很大的帮助。采集内容专题化带来的疗效自然要比前3个方式 带来的疗效要好好多。5、对采集内容进行伪原创。伪原创的方式好多这儿介绍几个简单的伪原创的方式。|||原创很重要吧。而不是为了SEO而SEO吧。。 查看全部
正确处理采集内容与原创内容的关系! - 电商宝典
正确处理采集内容与原创内容的关系!采集站对你们来说是不陌生的,现在社会发展变化的速率使我们跟不上时代的步伐,我们有太多的事情要做,虽然搜索引擎优化一再的指出原创内容是多么多么的重要,但是对于真正做站的人来说,做到真正的纯原创网站是不现实的,毕竟在这个网路急速发展的世界里,复制和粘贴很容易了,所以我们要说说怎么采集内容,以及怎么将采集来的内容做大可能的帮助到你的排行,如何将你的时间和努力价值最大化:1、修改内容的标题。修改内容的标题是最直接最简单的形式,在GG上内容获取好的排行,如果你网站的权重不会很低或新站,只要更改一下内容的标题基本可以排个好名次了。如果每晚定量采集和坚持更改内容标题对网站权重积累也有帮助。2、修改或重新编撰内容摘要。很多网站的文章内容都有文章摘要,对采集内容重新编撰文章摘要也可以推动采集内容在搜索引擎中的排行。文章摘要会在网站很多地方用得上,一般情况下搜索引擎会把这种 摘要当快照说明来使用,因此对采集内容重新编撰文章摘要是十分必要的工作。3、编写内容评论。内容采集回来对整篇内容做简单的评论对内容的排行提升也太有帮助。评论通常写 在文章开始位置或结尾位置。笔者觉得写在文章开始位置比写在结尾位置疗效要好好多。4、采集内容专题化。网站专题是个挺好的东西,采集的内容通过归类筛选出内容相像的内容弄成统一专题,对采集内容在搜索引擎排名、网站权重提升有很大的帮助。采集内容专题化带来的疗效自然要比前3个方式 带来的疗效要好好多。5、对采集内容进行伪原创。伪原创的方式好多这儿介绍几个简单的伪原创的方式。|||原创很重要吧。而不是为了SEO而SEO吧。。
采集来的内容能被百度收录么?百度怎么收录采集的文章?
采集交流 • 优采云 发表了文章 • 0 个评论 • 357 次浏览 • 2020-08-26 00:38
内容的问题这个就复杂了,为什么说内容的问题很复杂,因为有的内容千篇一律,一旦竞争降低了排行都会增长。内容的问题似乎就是要解决采集以及内容价值的问题。你如何保证内容是不一样的。这个问题你怎么样来解决。怎么样来依据自身行业特色来制订设计内容,又能满足用户的需求,这个问题不解决你去网路采集文章,网站怎么可能会有好的收录,会有好的排行采集不是不可以,但你要保证就能提高页面附加值,在才能解决用户需求的基础上降低受众率(提升点击和阅读量,评论量)。
首先,比如一篇文章被新浪复制了,跟被通常的网站复制了,他的价值都是不一样的,而搜索引擎才能分辨下来。我们如今讲的价值问题,需求问题就是这个问题。就是受众的问题。这个受众的问题似乎是十分简单的,也就是说我们页面上面的所有的内容,我们去采集别人的内容。
其次,你采集来的文章要保证有附加值 ,就是你要保证在这篇文章放到我网站上来时,他的价值是被放大过的,而不是降低的,那我们在弄这样的文章到我们网站上面,他的价值是要降低的,比如在文章专业度上、图文结合上、解决用户须要的方式上等等,最终的目的是使用户听到你的内容后才能明晰的了解这个内容就能解决他的需求。能够解决用户需求的东西都是好东西。
最后,为什么同一篇文章到在新浪的价值会很高,而到其他的地方价值就太低呢。为什么是这样的呢!因为新浪用户多,受众也多,而且新浪他的打开速率也很快。他的资源也太稳定。当然这个是搜索引擎给他进行评估,是常年进行评估的,另外的话,他就能够引起评论,那同样的一篇文章如果到了我们的网站,如果我们的评论降低了,点击流量降低了,而且喜欢的人顶踩的人也比较多,喜欢和推荐的人比较多,那这篇文章的附加值肯定是提高的 查看全部
采集来的内容能被百度收录么?百度怎么收录采集的文章?
内容的问题这个就复杂了,为什么说内容的问题很复杂,因为有的内容千篇一律,一旦竞争降低了排行都会增长。内容的问题似乎就是要解决采集以及内容价值的问题。你如何保证内容是不一样的。这个问题你怎么样来解决。怎么样来依据自身行业特色来制订设计内容,又能满足用户的需求,这个问题不解决你去网路采集文章,网站怎么可能会有好的收录,会有好的排行采集不是不可以,但你要保证就能提高页面附加值,在才能解决用户需求的基础上降低受众率(提升点击和阅读量,评论量)。
首先,比如一篇文章被新浪复制了,跟被通常的网站复制了,他的价值都是不一样的,而搜索引擎才能分辨下来。我们如今讲的价值问题,需求问题就是这个问题。就是受众的问题。这个受众的问题似乎是十分简单的,也就是说我们页面上面的所有的内容,我们去采集别人的内容。
其次,你采集来的文章要保证有附加值 ,就是你要保证在这篇文章放到我网站上来时,他的价值是被放大过的,而不是降低的,那我们在弄这样的文章到我们网站上面,他的价值是要降低的,比如在文章专业度上、图文结合上、解决用户须要的方式上等等,最终的目的是使用户听到你的内容后才能明晰的了解这个内容就能解决他的需求。能够解决用户需求的东西都是好东西。
最后,为什么同一篇文章到在新浪的价值会很高,而到其他的地方价值就太低呢。为什么是这样的呢!因为新浪用户多,受众也多,而且新浪他的打开速率也很快。他的资源也太稳定。当然这个是搜索引擎给他进行评估,是常年进行评估的,另外的话,他就能够引起评论,那同样的一篇文章如果到了我们的网站,如果我们的评论降低了,点击流量降低了,而且喜欢的人顶踩的人也比较多,喜欢和推荐的人比较多,那这篇文章的附加值肯定是提高的
分析采集内容会给网站带来哪些弊病
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2020-08-25 22:58
“内容为王,外链为皇”这句可以成为SEO的历史了,不管是菜鸟站长还是老手,优化这两个方面早已成为习惯。但是博主听到有站长说:网站优化并不需要原创的内容,搜索引擎如今并不是太成熟,并不能判别出网站是否真的是原创内容。他说的也没错,搜索引擎似乎是难以判定,有的采集站也会被蜘蛛收录的,但是作为正规的网站来说,采集的内容吃大亏,那采集的内容对网站来说,到底是有什么样的症结。
第一:内容无法控制。很多站长为了能节约时间,采用采集的工具,采集工具也是太不健全的,采集的内容不是智能的,很多时侯采集来的文章内容中不能除去他人的信息,这样无意中也是帮他人推广,而且他人写的文章并定是符合你网站的标准。同行业的网站之间采集,很多时侯会帮着他人推广信息,这是太不值得的。
第二:采集内容容易造成误会。这种情况对于新闻门户网站很常常,新闻网站每天都要更新好多新内容,有的网站并不能找到好的新闻来源,这时都会想着要采集别人的内容,但是他人的新闻内容并没有得到你的否认,你并不能确定他人的新闻是否真实,很多时侯也会有报导错误新闻的风波,本来你不知道这个新闻,但是你采集来了,结果是假的新闻,你的网站也会遭到牵涉的,岂不是赔了夫人又折兵。
第三:不尊重他人的版权。很多时侯站长们在采集的时侯,会除去他人的链接和推广信息,如果他人的网站正处在不稳当的状态,发的原创内容并没有被正常收录,但是你采集过去了被收录了,这时面临的版权问题也会使站长们头痛的。博主的微博营销站时常会被采集,看到这样的采集器会太吃惊的,正常的人就会找到你使你删掉文章的,要不就是保留版权的。即使互联网的版权不被尊重,但是他人的辛苦找到你时,你就必须要尊重他人的版权。这岂不是又浪费了时间吗?
第四:容易被K站。内容为王,高质量的内容可以提供网站权重。站长们不得不承认这个观点,网站有高质量的内容,权重的降低就会赶快。暂且不说采集站的权重,对于正规的网站来说,经常采集别人的内容,蜘蛛来抓取的频度就会增加的,蜘蛛喜欢新鲜,数据库中放太多相同内容的时侯,它还会想着要屏蔽一些相同的内容,同时网站采集过多的内容,蜘蛛会觉得这样的网站是在作弊,特别是新站,千万不要为了快速降低网站内容,去采集内容,这样的方式是不可取的。
要想网站的权重能提升,如果不想从原创的文章出发,光靠外链的发展是不行的,内容和外链的建设缺一不可的,站长们应当要从原创的内容出发,虽然说原创的内容难了点,但是采集的内容不可取。最坏的准备也是要学会怎样写好伪原创。 查看全部
分析采集内容会给网站带来哪些弊病
“内容为王,外链为皇”这句可以成为SEO的历史了,不管是菜鸟站长还是老手,优化这两个方面早已成为习惯。但是博主听到有站长说:网站优化并不需要原创的内容,搜索引擎如今并不是太成熟,并不能判别出网站是否真的是原创内容。他说的也没错,搜索引擎似乎是难以判定,有的采集站也会被蜘蛛收录的,但是作为正规的网站来说,采集的内容吃大亏,那采集的内容对网站来说,到底是有什么样的症结。
第一:内容无法控制。很多站长为了能节约时间,采用采集的工具,采集工具也是太不健全的,采集的内容不是智能的,很多时侯采集来的文章内容中不能除去他人的信息,这样无意中也是帮他人推广,而且他人写的文章并定是符合你网站的标准。同行业的网站之间采集,很多时侯会帮着他人推广信息,这是太不值得的。
第二:采集内容容易造成误会。这种情况对于新闻门户网站很常常,新闻网站每天都要更新好多新内容,有的网站并不能找到好的新闻来源,这时都会想着要采集别人的内容,但是他人的新闻内容并没有得到你的否认,你并不能确定他人的新闻是否真实,很多时侯也会有报导错误新闻的风波,本来你不知道这个新闻,但是你采集来了,结果是假的新闻,你的网站也会遭到牵涉的,岂不是赔了夫人又折兵。
第三:不尊重他人的版权。很多时侯站长们在采集的时侯,会除去他人的链接和推广信息,如果他人的网站正处在不稳当的状态,发的原创内容并没有被正常收录,但是你采集过去了被收录了,这时面临的版权问题也会使站长们头痛的。博主的微博营销站时常会被采集,看到这样的采集器会太吃惊的,正常的人就会找到你使你删掉文章的,要不就是保留版权的。即使互联网的版权不被尊重,但是他人的辛苦找到你时,你就必须要尊重他人的版权。这岂不是又浪费了时间吗?
第四:容易被K站。内容为王,高质量的内容可以提供网站权重。站长们不得不承认这个观点,网站有高质量的内容,权重的降低就会赶快。暂且不说采集站的权重,对于正规的网站来说,经常采集别人的内容,蜘蛛来抓取的频度就会增加的,蜘蛛喜欢新鲜,数据库中放太多相同内容的时侯,它还会想着要屏蔽一些相同的内容,同时网站采集过多的内容,蜘蛛会觉得这样的网站是在作弊,特别是新站,千万不要为了快速降低网站内容,去采集内容,这样的方式是不可取的。
要想网站的权重能提升,如果不想从原创的文章出发,光靠外链的发展是不行的,内容和外链的建设缺一不可的,站长们应当要从原创的内容出发,虽然说原创的内容难了点,但是采集的内容不可取。最坏的准备也是要学会怎样写好伪原创。
用它采集内容,简直不要很轻松!
采集交流 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2020-08-25 17:13
疫情期间,很多企业不得不选择远程线上办公,互联网算是受疫情影响较小的行业之一,但是远程办公一直不及面对面工作效率高,为此优采云采集特推出智能采集工具。
相信不少营运都曾接触过采集工具,现在市面上的采集工具五花八门,很多人觉得采集工具只是作为文章热点/节日话题等信息采集的辅助工具,其实除了这么。一款成熟的采集工具除了是帮营运采集信息,还能确切剖析数据迈向,从而帮助提升产值。
一、什么是优采云采集?
优采云采集是一款自媒体素材搜索、文章原创、一键发布的营运工具,有效提高新媒体营运工作效率,降低企业成本。
二、如何使用优采云采集进行搜索?
(一) 输入关键词
优采云采集根据用户输入的关键词,通过程序自动化的步入主流自媒体数据源的搜索引擎进行搜索。
优采云采集根据先进算法匹配更精准的内容,提高搜索内容的准确率。
例如:
用户需采集有关疫情的素材,在主页面输入关键词“疫情”即可。优采云采集便会将搜索结果进行整合至一个列表里。
(二) 保存搜索素材
优采云采集具备批量保存搜索素材的功能。
点击【当前页面全选】功能,并勾选所需文章,文章将会添加至操作面板,方便用户批量保存。
(三) 精准过滤
1、搜索过滤
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使得搜索内容更精准。
2、广告过滤 查看全部
用它采集内容,简直不要很轻松!
疫情期间,很多企业不得不选择远程线上办公,互联网算是受疫情影响较小的行业之一,但是远程办公一直不及面对面工作效率高,为此优采云采集特推出智能采集工具。
相信不少营运都曾接触过采集工具,现在市面上的采集工具五花八门,很多人觉得采集工具只是作为文章热点/节日话题等信息采集的辅助工具,其实除了这么。一款成熟的采集工具除了是帮营运采集信息,还能确切剖析数据迈向,从而帮助提升产值。
一、什么是优采云采集?
优采云采集是一款自媒体素材搜索、文章原创、一键发布的营运工具,有效提高新媒体营运工作效率,降低企业成本。
二、如何使用优采云采集进行搜索?
(一) 输入关键词
优采云采集根据用户输入的关键词,通过程序自动化的步入主流自媒体数据源的搜索引擎进行搜索。
优采云采集根据先进算法匹配更精准的内容,提高搜索内容的准确率。
例如:
用户需采集有关疫情的素材,在主页面输入关键词“疫情”即可。优采云采集便会将搜索结果进行整合至一个列表里。
(二) 保存搜索素材
优采云采集具备批量保存搜索素材的功能。
点击【当前页面全选】功能,并勾选所需文章,文章将会添加至操作面板,方便用户批量保存。
(三) 精准过滤
1、搜索过滤
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使得搜索内容更精准。
2、广告过滤
网络营销的内容采集文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2020-08-24 19:06
1、网站降权问题;正常情况下,就算网站权重较低,收录还是没有问题的,如果网站文章突然之间不收录,很有可能是网站被降权了,短时间的降权,一两个月才会恢复,长时间的降权,几个月能够恢复,也有可能永远没法恢复,提醒你们不要为了眼前的利益以身犯险。
2、关键词密度不是你网站关键词出现的越多,排名就越好的,要有一个密度,一般是2%-8%,当然看文章内容的长短,总之关键词出现的要自然,不要拼凑关键词就可以了。
3、原创文章为什么没被收录原创文章不一定会收录,原创文章不收录多数是因为质量问题。原创文章只能说明“原创”而已,不能说明任何问题,原创文章未必是高质量的文章,你可以写原创文章,我可以写原创文章,他也可以写原创文章,可是你写的文章和他写的文章是两回事,你写的文章也许质量太差,他写的文章也许质量挺好,质量差的文章是不容易被收录的。
4、引导百度蛛抓抓取:去百度蜘蛛活跃度高的网站、论坛引流,获得一些导航网站链接、可换少许友链、加快网站抓取收录。
5、文章首段内容不管你是刚接触SEO,还是资深SEO,相信你都晓得一篇文章的首段是十分重要的,可以直接决定用户会不会继续往下看,搜索引擎蜘蛛在抓取的时侯也是从首段开始抓的,所以通常文章首段前60个字内一定要记得插入我们的关键词,这样愈发有利于排行。
6、轻则掉排行,重则降权。百度过来抓取到的页面结果出现好多死链,那它还会觉得这个网站质量偏低,从而不会给与高排行,甚至会增加现有网站的权重。
7、网站死链是怎样形成的?对网站的负面影响内容死链内容死链主要是由网站自身变化造成的,网页可以正常打开未发生跳转,但页面内容对爬虫来说没有收录价值,对用户来说也没有参考价值,如贴子被删除、内容已转移、空间被关掉、信息已过期、交易已关掉等。在这些没有信息价值的网页上,网站应该在显著位置直接给与提示文字,如:
8、网站内容相对质量较高这点可能有人有疑问,有的权重高的站点,直接复制别的网站的内容,也是能秒收,所以这儿我加了2个字:相对!但是我们都晓得,百度秒收后,并不代表内容一定有排行,有排行后,更不能保证能维持住。很多网站是明天查看某个关键词有排行,过几天再看就没有了,这种情况是太常见的,因为百度会再度进行算法过滤的!大家应当都晓得前段时间百度新算法升级的事情。
—————————————————————————————–
问:黑帽seo是哪些意思?
答:黑帽SEO是借助和放大搜索引擎的策略缺陷(实际上完美的系统是不存在的)获取更多用户访问量,而这种更多的访问量,是以伤害用户体验为代价的SEO行为。
问:网页标题与描述写多少字合适?
答:网站title标题搜索引擎在搜索结果中只能展示63个字节,后边都省略了;网页标题通常建议不超过32个汉字,描述Description不要超过72个汉字。
问:网站服务器空间买多大适宜?
答:根据网站规模和要提供的服务来决定选择订购何种空间(服务器),选择有实力的正规空间商,根据用户群分布选择接入商,保证用户的访问速率和稳定性。 查看全部
网络营销的内容采集文章
1、网站降权问题;正常情况下,就算网站权重较低,收录还是没有问题的,如果网站文章突然之间不收录,很有可能是网站被降权了,短时间的降权,一两个月才会恢复,长时间的降权,几个月能够恢复,也有可能永远没法恢复,提醒你们不要为了眼前的利益以身犯险。
2、关键词密度不是你网站关键词出现的越多,排名就越好的,要有一个密度,一般是2%-8%,当然看文章内容的长短,总之关键词出现的要自然,不要拼凑关键词就可以了。
3、原创文章为什么没被收录原创文章不一定会收录,原创文章不收录多数是因为质量问题。原创文章只能说明“原创”而已,不能说明任何问题,原创文章未必是高质量的文章,你可以写原创文章,我可以写原创文章,他也可以写原创文章,可是你写的文章和他写的文章是两回事,你写的文章也许质量太差,他写的文章也许质量挺好,质量差的文章是不容易被收录的。
4、引导百度蛛抓抓取:去百度蜘蛛活跃度高的网站、论坛引流,获得一些导航网站链接、可换少许友链、加快网站抓取收录。
5、文章首段内容不管你是刚接触SEO,还是资深SEO,相信你都晓得一篇文章的首段是十分重要的,可以直接决定用户会不会继续往下看,搜索引擎蜘蛛在抓取的时侯也是从首段开始抓的,所以通常文章首段前60个字内一定要记得插入我们的关键词,这样愈发有利于排行。
6、轻则掉排行,重则降权。百度过来抓取到的页面结果出现好多死链,那它还会觉得这个网站质量偏低,从而不会给与高排行,甚至会增加现有网站的权重。
7、网站死链是怎样形成的?对网站的负面影响内容死链内容死链主要是由网站自身变化造成的,网页可以正常打开未发生跳转,但页面内容对爬虫来说没有收录价值,对用户来说也没有参考价值,如贴子被删除、内容已转移、空间被关掉、信息已过期、交易已关掉等。在这些没有信息价值的网页上,网站应该在显著位置直接给与提示文字,如:
8、网站内容相对质量较高这点可能有人有疑问,有的权重高的站点,直接复制别的网站的内容,也是能秒收,所以这儿我加了2个字:相对!但是我们都晓得,百度秒收后,并不代表内容一定有排行,有排行后,更不能保证能维持住。很多网站是明天查看某个关键词有排行,过几天再看就没有了,这种情况是太常见的,因为百度会再度进行算法过滤的!大家应当都晓得前段时间百度新算法升级的事情。
—————————————————————————————–
问:黑帽seo是哪些意思?
答:黑帽SEO是借助和放大搜索引擎的策略缺陷(实际上完美的系统是不存在的)获取更多用户访问量,而这种更多的访问量,是以伤害用户体验为代价的SEO行为。
问:网页标题与描述写多少字合适?
答:网站title标题搜索引擎在搜索结果中只能展示63个字节,后边都省略了;网页标题通常建议不超过32个汉字,描述Description不要超过72个汉字。
问:网站服务器空间买多大适宜?
答:根据网站规模和要提供的服务来决定选择订购何种空间(服务器),选择有实力的正规空间商,根据用户群分布选择接入商,保证用户的访问速率和稳定性。
企业怎样提高网站内容可读性?
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2020-08-23 19:23
企业建设网站之后,就会通过后台上传内容。大部分是先上传企业信息和产品信息,接着会为了降低内容量而选择补充其它内容,都说内容是网站的核心核基础,那么企业怎样提高网站内容可读性?吸引到更多用户呢?
一、坚持文章内容原创
企业建网站有利于优化排行的形式莫过于坚持原创内容,原创主要是指企业自己编辑的,不是从哪抄来或则转换的内容,尤其是文章方面。大多数是属于自己的产品,产品图片和产品介绍多数是内部职工拍摄和编辑,原创是可以肯定的。主要在于文章方面,原创文章是可以有效地提高网站排名,加快网站内容的收录,同时可以给顾客带来可读性的内容,企业编辑原创多数是以自己或则品牌产品作为出发点,针对个别观点进行描述,能够使顾客对某方面有更深的理解。而且搜索引擎是喜欢新鲜事物,原创文章一但发布出去容易吸引搜索引擎前来抓取。因此,坚持原创对网站对企业和对顾客,都是一种质量的提高。
二、避免采集垃圾内容
企业一般会为了丰富网站内容,而到网路上进行内容采集。刚才第一点早已说到内容的原创性对网站和企业相当重要,也是优化方法的一种。那么网站内容就须要防止采集,基本上采集而来的内容都是早已发布过的,出现在其它网站里的,而且好多顾客阅读过,对她们来说阅读过的内容早已丧失了可读性。然而采集范围很广,什么文章都往里添加的话,只会适得其反。看过有的企业为了降低网站访问量,采集了与行业无关的内容,就由于标题具有吸引力而上传到自己的内容里。虽然网站访问量降低了,但跳出率同样高。客户看了文章后,发现这个网站并不是自己关注的,就会直接离开,关闭网站。对企业而言,引来的只是流量,而非潜在顾客,这些采集的文章丝毫不能为网站提升排行,也未能使企业受惠。
三、增设行业栏目
企业建网站都会上传与自己有关的内容,网站里不仅产品抢占大部分,行业文章也很重要。不同的行业都有自己的领域,涉及的知识内容不同但又有关联性。就好象服饰行业,就会与设计、色彩、时尚元素等搭边,同时与广告业、杂志业之间存在联系,所以一个行业并不能垄断整个市场。要降低网站内容可读性,可以通过收录或则转载行业文章。那么网站里可以增设行业栏目,拓展阅读量,同时也可以作为一种辅助推广,寻找适宜的合作伙伴。有合适的伙伴加入,可以使企业与不同行业之间进行合作,在各自的网站里对合作商的产品进行推广,产生1加1小于2的疗效,同时丰富网站内容。 查看全部
企业怎样提高网站内容可读性?
企业建设网站之后,就会通过后台上传内容。大部分是先上传企业信息和产品信息,接着会为了降低内容量而选择补充其它内容,都说内容是网站的核心核基础,那么企业怎样提高网站内容可读性?吸引到更多用户呢?
一、坚持文章内容原创
企业建网站有利于优化排行的形式莫过于坚持原创内容,原创主要是指企业自己编辑的,不是从哪抄来或则转换的内容,尤其是文章方面。大多数是属于自己的产品,产品图片和产品介绍多数是内部职工拍摄和编辑,原创是可以肯定的。主要在于文章方面,原创文章是可以有效地提高网站排名,加快网站内容的收录,同时可以给顾客带来可读性的内容,企业编辑原创多数是以自己或则品牌产品作为出发点,针对个别观点进行描述,能够使顾客对某方面有更深的理解。而且搜索引擎是喜欢新鲜事物,原创文章一但发布出去容易吸引搜索引擎前来抓取。因此,坚持原创对网站对企业和对顾客,都是一种质量的提高。
二、避免采集垃圾内容
企业一般会为了丰富网站内容,而到网路上进行内容采集。刚才第一点早已说到内容的原创性对网站和企业相当重要,也是优化方法的一种。那么网站内容就须要防止采集,基本上采集而来的内容都是早已发布过的,出现在其它网站里的,而且好多顾客阅读过,对她们来说阅读过的内容早已丧失了可读性。然而采集范围很广,什么文章都往里添加的话,只会适得其反。看过有的企业为了降低网站访问量,采集了与行业无关的内容,就由于标题具有吸引力而上传到自己的内容里。虽然网站访问量降低了,但跳出率同样高。客户看了文章后,发现这个网站并不是自己关注的,就会直接离开,关闭网站。对企业而言,引来的只是流量,而非潜在顾客,这些采集的文章丝毫不能为网站提升排行,也未能使企业受惠。
三、增设行业栏目
企业建网站都会上传与自己有关的内容,网站里不仅产品抢占大部分,行业文章也很重要。不同的行业都有自己的领域,涉及的知识内容不同但又有关联性。就好象服饰行业,就会与设计、色彩、时尚元素等搭边,同时与广告业、杂志业之间存在联系,所以一个行业并不能垄断整个市场。要降低网站内容可读性,可以通过收录或则转载行业文章。那么网站里可以增设行业栏目,拓展阅读量,同时也可以作为一种辅助推广,寻找适宜的合作伙伴。有合适的伙伴加入,可以使企业与不同行业之间进行合作,在各自的网站里对合作商的产品进行推广,产生1加1小于2的疗效,同时丰富网站内容。
(强文)互联网前辈教你怎么采集你想要的信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 348 次浏览 • 2020-08-20 14:01
写在上面
几个月前,团队邀我做次内部的分享,主题是怎样有效搜索信息。这是因为平常工作中,我常常会分享一些专业学习文档,而这种文档的出现常常太及时,回应一些我们自己项目的苦恼,所以你们会好奇我怎么及时找得到这么专业且对口的参考资料。
这些资料有些来自网路搜索,有些却是来自我的“个人资料库”,它分门别类,容易检索,所以太轻易就才能翻下来示人。所以后来,这次分享便从“搜索术”,扩大为怎样获取、整理各类信息的技能。
这原先我觉得是常识的东西,却在简单分享后得到好评。受到鼓励之余,我也明白了并不是所有人都明白有效的信息采集及整理有多么重要,也并不是所有人,都把握了行之有效的方式和方法。故整理成文,做抛砖引玉之用。
一.信息采集及整理循环图
如上图1所示,我觉得“信息采集及整理术”会收录三个关键阶段:
搜索:“找信息”——用各类搜索渠道快速找到所需的精准信息。
集成:“存信息”——简单来说,就是把你找到的信息,定制成为个人资料库,按照自定义的主题,分类储存在自己很方便访问的地方。
整理:“理信息”——信息单纯集成而不加整理,时间长了都会零乱不堪,所以才能出现很多人自己的硬碟资料库早已堆满了,每当须要哪些资料的时侯,还是须要去搜索。定期对所集成的信息进行整理(归类,去重,留精,加可供搜索的标签等等),能够明显提高信息搜索效率。
最初你须要一定的动力去尝试开始做这件事情,而一旦兴趣形成,再加以坚持, 这就早已成为习惯,和你密不可分了。
二.高效搜索术
2.1 建立你的主题关键词
建立自己关注的核心关键词是重要的一步。
如今我们遇见的信息量早已高速爆发,信息的种类和来源多种多样,信息的更新速率逐渐推进。喜欢刷微博的朋友都清楚,一旦进了微博,你就步入了无数信息和主题词的世界,通过一个消息到另一个消息,看来看去时间就消耗进去了。
如果我们不筹建一些主题,很容易深陷信息的汪洋中,而另一个极端则是两耳不闻窗前事,担心信息负载很大而刻意回避信息,导致自己和时代相悖。如果作为一个交互设计师,能够不关注最新的交互界的最新态势吗?
主题关键词有几个用处:
建立方向提醒:时刻明白对自己真正有价值的是哪些,主动保持该类信息的更新;而这些无关紧要的,则可以少看或则不看。
主动获取信息:使用各类订阅、集成工具更有目标,用这种词订阅,让信息主动找你。
减少无聊时间:无所事事比繁忙更使人疲累,若找不到想干的事,最至少可以搜索下你的主题词,找点好玩的文章或动态。
虽然靠脑部就可以产生自己的关键词,但工具可以帮助你加深记忆,比如用mindmanager等脑图工具做图,贴于自己的书房或办公桌前:
图2:Heidi的主题关键词
主题词建好以后,并不是一成不变,需要定期结合自己的工作评估及更新。比如我近一年对商务智能(Business intelligence)很感兴趣,也会定期查阅相关的资讯,但是今年此刻,我对此几乎不了解。 yixieshi
2.2 用好你的搜索引擎!
主题关键词使我们晓得自己时刻应当关注哪些,而接下来我们就要更高效去找这种信息!
搜索引擎是十分重要的信息获取入口,至于我用的方法真算不上中级,欢迎搜索达人们和我交流下省力更有效的搜索手段。
2.2.1 找准关键词,事半功倍!
很早之前,我碰巧听到两张图片。我很喜欢这两个图片,所以我希望看见更多类似的图片。 互联网的一些事
图3:用何种关键图去检索这两类图片呢?
可是,首先这些图叫哪些图呢?
先在头脑里头脑风暴下应当用的关键词,叫哪些呢?插图?图表?手绘图?插画?这些关键词搜索下来的结果真使人失望。但是,根据搜索结果的提示,一步 步更换关键词直到找到靠谱的结果。而最终,当我找到这个词后,就找到宝藏了——要找图3中右侧类型的图,请尝试用“可视化思索”,或用google搜索 “visual thinking”,要找更多图3中左侧类型的图,请尝试用“信息图”,或“infographic”。 y
图4:可视化思索的检索结果
图5:信息图的检索结果
所以,在搜索中,要不断地更换更贴切的关键词,而不是仍然打擦边球。如何找到贴切的关键词呢?从你认为可行的第一个关键词开始,不要轻言舍弃,根据每次搜索结果下来的线索跟踪,不断更换关键词,直至领到结果。
2.2.2 更换语言,别有洞天
有时更换为英文才能使你获取更精准的结果。所以这也是为何,我的主题词要中英双语版。既然好多英文的结果是从英语翻译过来的,直接查看源文章显而易见信息遗漏较少。
图6:用中文搜索“可视化思索”得到的结果
以此类推,每多一种语言就打开一扇新的了解世界的窗口。就拿家庭收纳来讲,用英文“收纳”去搜索文章,几乎只是一些零碎的图片和社区网站为了笼络用 户堆砌而成的收纳方法。而用英语“収納”去搜索,看美国的个别网站,我们就能看见好多关于收纳术的经验、文档和教程。有些教程的丰富性不亚于出版的书籍, 更好过分我们国外这些堆砌下来的家饰整理学了。如网站提供的本多先生每日 收纳教程:
图7:用英语収納检索到的专业网站
关于收纳学的网站,大家有兴趣可以用英语“収納”搜搜试试,不可以找我要。
2.2.3.更换搜索方法,殊途同归
若网页搜索不能获得所要结果,可以变换搜索类型,比如搜索图片,再通过图片链接到有价值的网站。
我常用的则是文件搜索,与普通网页相比,这些文档一般意味着更好的更系统化的组织,从而使你的信息获取愈发有效。
如何用搜索引擎搜索文档呢?
如果你使用google,在检索词前加入inurl:pdf。
如果你使用百度,在检索词前加上filetype:all,如要特定PDF格式则输入:filetype:PDF
如用百度搜商务智能的相关文档:
图8:用百度搜索文档
2.2.4.别忘掉了专业网站
专业网站让你减免在大量的垃圾信息里找所需资料的烦恼,他们的信息常常愈发聚焦。我时常用到的专业性搜索网站有:
——PPT分享网站,很多美国制做优良,内容丰富专业的PPT。我时常在这里搜索关于可视化思索的文档资料。但是很遗憾的是,目前你就须要翻墙能够够看见这个网站了。 互联网的一些事
MBA智库——专注于经管领域的资料库。你可以在这里搜到好多经管领域的各类术语解释,文档等。
维基百科——如果在墙外或则会翻墙的话。很多被国外是敏感词的,在这里才能看见特别详实的前因后果各类脉络。当然,若非敏感词的话,百度百科也是不错的资源。
2.2.5.向书籍里找搜索提示!
一个小提示,没有关键词灵感的时侯,还可以从书的目录去获取关键词提示。 除了目录,专业书籍上面蕴涵太宝贵的可供挖掘的信息。
下面就是一个借助书籍提供的信息不断开掘,进而找到真正所需的信息的案例:
最近我读《Excel图表之道》这本书,在P152页提及的图表类型选择手册的原作者是Andrew Abela。这个人名就是一个太宝贵的关键词!这个关键词可能代表着:数据,数据剖析,商务智能,沟通演示等等主题。
所以搜索此人,看到此人的博客是:。这个博客是专业博客,主题是复杂信息的沟通及演示。
而这个博客为一本书做广告,这本书正是出于Andrew Abela, 《Advanced Presentations by Design: Creating Communications that Dirves Action》,此书的中文版在台湾有售,中文翻译为《说服力演说是怎样炼成的—如何设计当场成交的PPT》。
进而又通过博客这本书的网站:。这个网站有一些相当不错的信息,推荐对于演示有兴趣的同学们瞧瞧。比如以下两个图表也来自该网站:
图9:的配图
当然,被《Excel图表之道》作者刘万祥老师引用的图表类型选择手册的图英语原版也在这个网站中有大图可以下载。另外,我们的信息挖掘还没有结束 哦!注意,他还提供了另外一个在线的工具:,此网站可供数据剖析师们按照自己的需求选择不同的图表诠释,该网站 出自juiceanalytics()。而步入Juiceanalytics网站的蓝皮书 栏目,我找到了《设计人人都爱的信息仪表盘手册》(A Guide to Creating Dashboards People Love to Use) ,这本蓝皮书正好才能解答我对于近日工作的一些蒙蔽。
如果特意去找,反而不容易有所收获,而假如晓得自己的主题关键词,你的信息味觉都会特别灵敏,在某个抓手下,抓住线索不放,往往不经意中探得捷径。
三.方便的集成
集成是信息的集中归档。搜索引擎尚且便捷,可是若一些常用的东西,未必每次都须要搜索。而是可以在自己的笔记本上构建个人资料库。不管是否有网路,都还能随时查阅。
我会习惯将搜索到有价值的文档、网页、图片储存在自己的笔记本里,可是,我们也会发觉,这些资料一旦存到硬碟里,却石沉大海。下次若须要,却还是求援 于搜索引擎。而另一方面,电脑文件夹却又逐渐庞大,要常常删掉文档以腾挪出空间。这种方式还有一个恶果,那就是多台笔记本使用时,就要利用联通硬碟或硬盘, 从而一份东西,居然要三处备份。
后来有了Dropbox等应用,能够比较便捷多机共享文件,但是容量虽然有限,却时而遭遇屏蔽。后来自然也有国外的一个好的服务,比如360云盘,可以有多达5G的空间,实现云端、多电脑客户端共享文件。大家若有需求,也不妨一试。
这些云盘、云盘之类的服务,解决了多个客户端同步储存的需求。但是我日常工作中,还时少不了以下几个小应用,来作为集成手段的有效补充。他们的特征是:
调用便捷——不用象使用云盘那样须要先储存出来再上传,随时才能调阅使用,不用中断当前工作。比如在一件任务进程中,遇到一篇不错的文档,想归档之后阅读。只须要点击一下就可以集成到自己的主题分类里,比如预设好的“待读”文件夹,而继续执行当前任务。 查看全部
(强文)互联网前辈教你怎么采集你想要的信息
写在上面
几个月前,团队邀我做次内部的分享,主题是怎样有效搜索信息。这是因为平常工作中,我常常会分享一些专业学习文档,而这种文档的出现常常太及时,回应一些我们自己项目的苦恼,所以你们会好奇我怎么及时找得到这么专业且对口的参考资料。
这些资料有些来自网路搜索,有些却是来自我的“个人资料库”,它分门别类,容易检索,所以太轻易就才能翻下来示人。所以后来,这次分享便从“搜索术”,扩大为怎样获取、整理各类信息的技能。
这原先我觉得是常识的东西,却在简单分享后得到好评。受到鼓励之余,我也明白了并不是所有人都明白有效的信息采集及整理有多么重要,也并不是所有人,都把握了行之有效的方式和方法。故整理成文,做抛砖引玉之用。
一.信息采集及整理循环图
如上图1所示,我觉得“信息采集及整理术”会收录三个关键阶段:
搜索:“找信息”——用各类搜索渠道快速找到所需的精准信息。
集成:“存信息”——简单来说,就是把你找到的信息,定制成为个人资料库,按照自定义的主题,分类储存在自己很方便访问的地方。
整理:“理信息”——信息单纯集成而不加整理,时间长了都会零乱不堪,所以才能出现很多人自己的硬碟资料库早已堆满了,每当须要哪些资料的时侯,还是须要去搜索。定期对所集成的信息进行整理(归类,去重,留精,加可供搜索的标签等等),能够明显提高信息搜索效率。
最初你须要一定的动力去尝试开始做这件事情,而一旦兴趣形成,再加以坚持, 这就早已成为习惯,和你密不可分了。
二.高效搜索术
2.1 建立你的主题关键词
建立自己关注的核心关键词是重要的一步。
如今我们遇见的信息量早已高速爆发,信息的种类和来源多种多样,信息的更新速率逐渐推进。喜欢刷微博的朋友都清楚,一旦进了微博,你就步入了无数信息和主题词的世界,通过一个消息到另一个消息,看来看去时间就消耗进去了。
如果我们不筹建一些主题,很容易深陷信息的汪洋中,而另一个极端则是两耳不闻窗前事,担心信息负载很大而刻意回避信息,导致自己和时代相悖。如果作为一个交互设计师,能够不关注最新的交互界的最新态势吗?
主题关键词有几个用处:
建立方向提醒:时刻明白对自己真正有价值的是哪些,主动保持该类信息的更新;而这些无关紧要的,则可以少看或则不看。
主动获取信息:使用各类订阅、集成工具更有目标,用这种词订阅,让信息主动找你。
减少无聊时间:无所事事比繁忙更使人疲累,若找不到想干的事,最至少可以搜索下你的主题词,找点好玩的文章或动态。
虽然靠脑部就可以产生自己的关键词,但工具可以帮助你加深记忆,比如用mindmanager等脑图工具做图,贴于自己的书房或办公桌前:
图2:Heidi的主题关键词
主题词建好以后,并不是一成不变,需要定期结合自己的工作评估及更新。比如我近一年对商务智能(Business intelligence)很感兴趣,也会定期查阅相关的资讯,但是今年此刻,我对此几乎不了解。 yixieshi
2.2 用好你的搜索引擎!
主题关键词使我们晓得自己时刻应当关注哪些,而接下来我们就要更高效去找这种信息!
搜索引擎是十分重要的信息获取入口,至于我用的方法真算不上中级,欢迎搜索达人们和我交流下省力更有效的搜索手段。
2.2.1 找准关键词,事半功倍!
很早之前,我碰巧听到两张图片。我很喜欢这两个图片,所以我希望看见更多类似的图片。 互联网的一些事
图3:用何种关键图去检索这两类图片呢?
可是,首先这些图叫哪些图呢?
先在头脑里头脑风暴下应当用的关键词,叫哪些呢?插图?图表?手绘图?插画?这些关键词搜索下来的结果真使人失望。但是,根据搜索结果的提示,一步 步更换关键词直到找到靠谱的结果。而最终,当我找到这个词后,就找到宝藏了——要找图3中右侧类型的图,请尝试用“可视化思索”,或用google搜索 “visual thinking”,要找更多图3中左侧类型的图,请尝试用“信息图”,或“infographic”。 y
图4:可视化思索的检索结果
图5:信息图的检索结果
所以,在搜索中,要不断地更换更贴切的关键词,而不是仍然打擦边球。如何找到贴切的关键词呢?从你认为可行的第一个关键词开始,不要轻言舍弃,根据每次搜索结果下来的线索跟踪,不断更换关键词,直至领到结果。
2.2.2 更换语言,别有洞天
有时更换为英文才能使你获取更精准的结果。所以这也是为何,我的主题词要中英双语版。既然好多英文的结果是从英语翻译过来的,直接查看源文章显而易见信息遗漏较少。
图6:用中文搜索“可视化思索”得到的结果
以此类推,每多一种语言就打开一扇新的了解世界的窗口。就拿家庭收纳来讲,用英文“收纳”去搜索文章,几乎只是一些零碎的图片和社区网站为了笼络用 户堆砌而成的收纳方法。而用英语“収納”去搜索,看美国的个别网站,我们就能看见好多关于收纳术的经验、文档和教程。有些教程的丰富性不亚于出版的书籍, 更好过分我们国外这些堆砌下来的家饰整理学了。如网站提供的本多先生每日 收纳教程:
图7:用英语収納检索到的专业网站
关于收纳学的网站,大家有兴趣可以用英语“収納”搜搜试试,不可以找我要。
2.2.3.更换搜索方法,殊途同归
若网页搜索不能获得所要结果,可以变换搜索类型,比如搜索图片,再通过图片链接到有价值的网站。
我常用的则是文件搜索,与普通网页相比,这些文档一般意味着更好的更系统化的组织,从而使你的信息获取愈发有效。
如何用搜索引擎搜索文档呢?
如果你使用google,在检索词前加入inurl:pdf。
如果你使用百度,在检索词前加上filetype:all,如要特定PDF格式则输入:filetype:PDF
如用百度搜商务智能的相关文档:
图8:用百度搜索文档
2.2.4.别忘掉了专业网站
专业网站让你减免在大量的垃圾信息里找所需资料的烦恼,他们的信息常常愈发聚焦。我时常用到的专业性搜索网站有:
——PPT分享网站,很多美国制做优良,内容丰富专业的PPT。我时常在这里搜索关于可视化思索的文档资料。但是很遗憾的是,目前你就须要翻墙能够够看见这个网站了。 互联网的一些事
MBA智库——专注于经管领域的资料库。你可以在这里搜到好多经管领域的各类术语解释,文档等。
维基百科——如果在墙外或则会翻墙的话。很多被国外是敏感词的,在这里才能看见特别详实的前因后果各类脉络。当然,若非敏感词的话,百度百科也是不错的资源。
2.2.5.向书籍里找搜索提示!
一个小提示,没有关键词灵感的时侯,还可以从书的目录去获取关键词提示。 除了目录,专业书籍上面蕴涵太宝贵的可供挖掘的信息。
下面就是一个借助书籍提供的信息不断开掘,进而找到真正所需的信息的案例:
最近我读《Excel图表之道》这本书,在P152页提及的图表类型选择手册的原作者是Andrew Abela。这个人名就是一个太宝贵的关键词!这个关键词可能代表着:数据,数据剖析,商务智能,沟通演示等等主题。
所以搜索此人,看到此人的博客是:。这个博客是专业博客,主题是复杂信息的沟通及演示。
而这个博客为一本书做广告,这本书正是出于Andrew Abela, 《Advanced Presentations by Design: Creating Communications that Dirves Action》,此书的中文版在台湾有售,中文翻译为《说服力演说是怎样炼成的—如何设计当场成交的PPT》。
进而又通过博客这本书的网站:。这个网站有一些相当不错的信息,推荐对于演示有兴趣的同学们瞧瞧。比如以下两个图表也来自该网站:
图9:的配图
当然,被《Excel图表之道》作者刘万祥老师引用的图表类型选择手册的图英语原版也在这个网站中有大图可以下载。另外,我们的信息挖掘还没有结束 哦!注意,他还提供了另外一个在线的工具:,此网站可供数据剖析师们按照自己的需求选择不同的图表诠释,该网站 出自juiceanalytics()。而步入Juiceanalytics网站的蓝皮书 栏目,我找到了《设计人人都爱的信息仪表盘手册》(A Guide to Creating Dashboards People Love to Use) ,这本蓝皮书正好才能解答我对于近日工作的一些蒙蔽。
如果特意去找,反而不容易有所收获,而假如晓得自己的主题关键词,你的信息味觉都会特别灵敏,在某个抓手下,抓住线索不放,往往不经意中探得捷径。
三.方便的集成
集成是信息的集中归档。搜索引擎尚且便捷,可是若一些常用的东西,未必每次都须要搜索。而是可以在自己的笔记本上构建个人资料库。不管是否有网路,都还能随时查阅。
我会习惯将搜索到有价值的文档、网页、图片储存在自己的笔记本里,可是,我们也会发觉,这些资料一旦存到硬碟里,却石沉大海。下次若须要,却还是求援 于搜索引擎。而另一方面,电脑文件夹却又逐渐庞大,要常常删掉文档以腾挪出空间。这种方式还有一个恶果,那就是多台笔记本使用时,就要利用联通硬碟或硬盘, 从而一份东西,居然要三处备份。
后来有了Dropbox等应用,能够比较便捷多机共享文件,但是容量虽然有限,却时而遭遇屏蔽。后来自然也有国外的一个好的服务,比如360云盘,可以有多达5G的空间,实现云端、多电脑客户端共享文件。大家若有需求,也不妨一试。
这些云盘、云盘之类的服务,解决了多个客户端同步储存的需求。但是我日常工作中,还时少不了以下几个小应用,来作为集成手段的有效补充。他们的特征是:
调用便捷——不用象使用云盘那样须要先储存出来再上传,随时才能调阅使用,不用中断当前工作。比如在一件任务进程中,遇到一篇不错的文档,想归档之后阅读。只须要点击一下就可以集成到自己的主题分类里,比如预设好的“待读”文件夹,而继续执行当前任务。
【seo新手峰会】这些诱因会影响到网站优化的疗效-SEO技术培训
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2020-08-17 21:04
【seo新手峰会】这些诱因会影响到网站优化的疗效
对于seo好多站长还逗留在只是做排行的阶段,使劲的发外链、换友链,那么对于百度搜索引擎来说,网站关键词排序到底是怎样来的呢?如何提高自己网站的排行呢?
一、哪些诱因影响了排序?
1、网站内容与被搜索关键词的相关性,网站主题和内容不一致一样会被百度辨识下来,甚至对你的网站进行降权,也会使用户厌烦。网站的主题要和内容保持高度一致也会提升转化率,提高网站在用户心里的信任值。
2、内容的质量,现在仍是内容为王的时代,各大搜索引擎也仍然在向用户靠拢,百度推出的各个算法究其根本也是维护网站内容的。在网站各方面条件差不多的情况下,高质量的原创内容一定会有一个好的排行。
3、网站评价,也可以说是网站的权威性,站长圈说的权重,是依据网站的规模、历史表现、站点关系网等多个维度进行的一个综合评定,对于我们来说一时半会是肯定没法提升网站评价的,只能够努力做好内容做好用户体验,等度娘或其他搜索引擎给与加权。
4、网站被黑,如果网站被黑出现黄反、赌博等内容,网站展现等就会遭到影响。
5、时效性,百度也是倾向于最新发布的新闻,也就是时效性这就须要站长有一双敏锐的眼睛,在第一时间发觉新闻并整理发布出去,也能获得更多的流量。
6、用户体验,你的网站排版符合不符合大众审美,页面中植入的广告会不会影响用户的阅览。页面体验实际上是近日提的较多也是很重要的一点。在pc站点上须要考虑整体的页面体验,移动端不仅体验上的问题外,还须要考虑访问速率。
二、如何提高自己网站的排行呢?
1、站在用户的角度模拟用户需求
思考用户会搜索哪些?用户的需求有什么?这里指的用户是所有用户,你得满足多元化的用户需求,很多时侯一个关键词query下的需求是多个的,尽量都满足她们;这里你们可以使用百度指数的需求图谱来辅助判别。
2、分析同行业的网站
在任何行业这都是一个有效的方式,向竞争对手学习这是一个聪明的办法,但是你要学习是排你后面的多个站点,将她们对用户的理解领到你的站点上,内容做的要比所有同行都要好,尽可能多的产出用户会搜索的高质量内容,那么你的排序也会越来越好。但是采集和内容堆砌不可取,优质原创才是王道。
成都SEO:哪些诱因会影响到网站优化的疗效?
成都SEO:哪些诱因会影响到网站优化的疗效?
三、不利于网站优化的
1、修改标题
无论是新站还是老站,修改标题都应当是件谨慎严谨的事,有时候你更改了网站标题,那么网站可能还会被降权、被k掉。所以当网站上线后,网站的标题千万不要随便更改。
2、网站的图片不去优化
搜索引擎只是一个程序机器人,是不认识图片上的内容的,必须得添加alt属性或图片标签标题,搜索引擎就会更容易判定。而且采用的图片必须是清晰的以及和内容是对应的。
3、频繁更改文章
很多站长发布了文章,发现文章没有收录或是发觉错误,就跑回家更改文章。但是若果当蜘蛛爬取你的网站时候,你又恰好在更改,那么搜索引擎都会不信任你的网站,减少对网站的爬取。
4、网页内容乱涂乱画
很多站长为了突出文章的重点就会把文章的内容的文字改变颜色吸引用户的眼珠。其实只是几个有颜色标明还好。但是如果网页全篇的内容都改成五颜六色都会变得十分眼花缭乱。
5、H1标签猖獗
H1标签在网页中的作用很重要,是明晰告诉蜘蛛内容的主题部份。但是好多站长就会频繁地把某一段的标题写成h1,这是不容许的,H1标签每位网页只能有一个,没有第二个。所以在设置H1标签的时侯就要考虑清楚了。
6、纯采集内容
优质的原创文章对于网站来说十分重要,但是好多站长都是直接把他人网站上的东西直接复制粘贴到自己的网站上,搜索引擎对于那些早已收录过的内容,已经有记录,是不会重复再收录的。而且过多的重复内容会使搜索引擎对网站产生不信任,网站的收录和排行就会显得困难。
SEO排名服务 查看全部
【seo新手峰会】这些诱因会影响到网站优化的疗效-SEO技术培训
【seo新手峰会】这些诱因会影响到网站优化的疗效
对于seo好多站长还逗留在只是做排行的阶段,使劲的发外链、换友链,那么对于百度搜索引擎来说,网站关键词排序到底是怎样来的呢?如何提高自己网站的排行呢?
一、哪些诱因影响了排序?
1、网站内容与被搜索关键词的相关性,网站主题和内容不一致一样会被百度辨识下来,甚至对你的网站进行降权,也会使用户厌烦。网站的主题要和内容保持高度一致也会提升转化率,提高网站在用户心里的信任值。
2、内容的质量,现在仍是内容为王的时代,各大搜索引擎也仍然在向用户靠拢,百度推出的各个算法究其根本也是维护网站内容的。在网站各方面条件差不多的情况下,高质量的原创内容一定会有一个好的排行。
3、网站评价,也可以说是网站的权威性,站长圈说的权重,是依据网站的规模、历史表现、站点关系网等多个维度进行的一个综合评定,对于我们来说一时半会是肯定没法提升网站评价的,只能够努力做好内容做好用户体验,等度娘或其他搜索引擎给与加权。
4、网站被黑,如果网站被黑出现黄反、赌博等内容,网站展现等就会遭到影响。
5、时效性,百度也是倾向于最新发布的新闻,也就是时效性这就须要站长有一双敏锐的眼睛,在第一时间发觉新闻并整理发布出去,也能获得更多的流量。
6、用户体验,你的网站排版符合不符合大众审美,页面中植入的广告会不会影响用户的阅览。页面体验实际上是近日提的较多也是很重要的一点。在pc站点上须要考虑整体的页面体验,移动端不仅体验上的问题外,还须要考虑访问速率。
二、如何提高自己网站的排行呢?
1、站在用户的角度模拟用户需求
思考用户会搜索哪些?用户的需求有什么?这里指的用户是所有用户,你得满足多元化的用户需求,很多时侯一个关键词query下的需求是多个的,尽量都满足她们;这里你们可以使用百度指数的需求图谱来辅助判别。
2、分析同行业的网站
在任何行业这都是一个有效的方式,向竞争对手学习这是一个聪明的办法,但是你要学习是排你后面的多个站点,将她们对用户的理解领到你的站点上,内容做的要比所有同行都要好,尽可能多的产出用户会搜索的高质量内容,那么你的排序也会越来越好。但是采集和内容堆砌不可取,优质原创才是王道。
成都SEO:哪些诱因会影响到网站优化的疗效?
成都SEO:哪些诱因会影响到网站优化的疗效?
三、不利于网站优化的
1、修改标题
无论是新站还是老站,修改标题都应当是件谨慎严谨的事,有时候你更改了网站标题,那么网站可能还会被降权、被k掉。所以当网站上线后,网站的标题千万不要随便更改。
2、网站的图片不去优化
搜索引擎只是一个程序机器人,是不认识图片上的内容的,必须得添加alt属性或图片标签标题,搜索引擎就会更容易判定。而且采用的图片必须是清晰的以及和内容是对应的。
3、频繁更改文章
很多站长发布了文章,发现文章没有收录或是发觉错误,就跑回家更改文章。但是若果当蜘蛛爬取你的网站时候,你又恰好在更改,那么搜索引擎都会不信任你的网站,减少对网站的爬取。
4、网页内容乱涂乱画
很多站长为了突出文章的重点就会把文章的内容的文字改变颜色吸引用户的眼珠。其实只是几个有颜色标明还好。但是如果网页全篇的内容都改成五颜六色都会变得十分眼花缭乱。
5、H1标签猖獗
H1标签在网页中的作用很重要,是明晰告诉蜘蛛内容的主题部份。但是好多站长就会频繁地把某一段的标题写成h1,这是不容许的,H1标签每位网页只能有一个,没有第二个。所以在设置H1标签的时侯就要考虑清楚了。
6、纯采集内容
优质的原创文章对于网站来说十分重要,但是好多站长都是直接把他人网站上的东西直接复制粘贴到自己的网站上,搜索引擎对于那些早已收录过的内容,已经有记录,是不会重复再收录的。而且过多的重复内容会使搜索引擎对网站产生不信任,网站的收录和排行就会显得困难。
SEO排名服务
上海网站建设公司剖析:网站优化中内容采集几个小技巧
采集交流 • 优采云 发表了文章 • 0 个评论 • 612 次浏览 • 2020-08-17 14:50
网站优化的日常维护中,内容和外链是两大法宝,这两点做好后,不害怕网站没有好的排行。而这两点中又以内容更新为重。但真正做网站优化的同学都有这样的感受,每天更新内容,实在是思虑枯竭。这里就少不得要从网上去采集别人的文章内容进行伪原创,但采集内容再编辑也是有一些小技巧的,做的好可以使文章快速被收录。
第一、文章的标题一定要更改
首先文章的标题是用户第一眼听到的,新的文章标题可以吸引用户点击访问页面,提升页面的访问量。同时在一个文章页面中,标题是权重最高的,新的标题可以使当页面能快速被搜索引擎收录。
第二、最好采集当下比较热门的信息内容
如果采集的内容都早已讨论多年,很多网民都已看过,再次点击阅读的兴趣就不会很大。另外讨论多年的话题搜索引擎也已经抓取了太多相关的页面,对于类似内容的页面抓取兴趣不会很大。
第三、做好内容再编辑
很多人对于伪原创的理解就是复制一些内容,然后中间插入自己写的内容,保证自己编撰内容的比列就可以了。这样做不是不可以,但疗效还不是最好。最好的是复制的内容按原先的意思自己重新组织语言编撰一遍,虽然这样比较浪费时间和精力,但疗效更好。
内容采集是网站优化中必不可少的一项工作,采集再编辑的好,对网站优化有很大的帮助。所以做好每一个小细节是极其重要的。 查看全部
上海网站建设公司剖析:网站优化中内容采集几个小技巧
网站优化的日常维护中,内容和外链是两大法宝,这两点做好后,不害怕网站没有好的排行。而这两点中又以内容更新为重。但真正做网站优化的同学都有这样的感受,每天更新内容,实在是思虑枯竭。这里就少不得要从网上去采集别人的文章内容进行伪原创,但采集内容再编辑也是有一些小技巧的,做的好可以使文章快速被收录。
第一、文章的标题一定要更改
首先文章的标题是用户第一眼听到的,新的文章标题可以吸引用户点击访问页面,提升页面的访问量。同时在一个文章页面中,标题是权重最高的,新的标题可以使当页面能快速被搜索引擎收录。
第二、最好采集当下比较热门的信息内容
如果采集的内容都早已讨论多年,很多网民都已看过,再次点击阅读的兴趣就不会很大。另外讨论多年的话题搜索引擎也已经抓取了太多相关的页面,对于类似内容的页面抓取兴趣不会很大。
第三、做好内容再编辑
很多人对于伪原创的理解就是复制一些内容,然后中间插入自己写的内容,保证自己编撰内容的比列就可以了。这样做不是不可以,但疗效还不是最好。最好的是复制的内容按原先的意思自己重新组织语言编撰一遍,虽然这样比较浪费时间和精力,但疗效更好。
内容采集是网站优化中必不可少的一项工作,采集再编辑的好,对网站优化有很大的帮助。所以做好每一个小细节是极其重要的。
使用phpQuery轻松采集网页内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2020-08-13 16:32
先看一实例,现在我要采集新浪网国外新闻的头条,代码如下:
include 'phpQuery/phpQuery.php'; <br />phpQuery::newDocumentFile('http://news.sina.com.cn/china'); <br />echo pq(".blkTop h1:eq(0)")->html(); <br />
简单的三行代码,就可以获取头条内容。首先在程序中收录phpQuery.php核心程序,然后调用读取目标网页,最后输出对应标签下的内容。
pq()是一个功能强悍的方式,跟jQuery的$()如出一辙,jQuery的选择器基本上都能使用在phpQuery上,只要把“.”变成“->”。如上例中,pq(".blkTop h1:eq(0)")抓取了页面class属性为blkTop的DIV元素,并找到该DIV内部的第一个h1标签,然后用html()方法获取h1标签里的内容(带html标签),也就是我们要获取的头条信息,如果使用text()方法,则只获取头条的文本内容。当然要使用好phpQuery,关键是要找对文档中对应内容的节点。
采集文章列表
下面再来看一个事例,获取网站的blog列表,请看代码:
include 'phpQuery/phpQuery.php'; <br />phpQuery::newDocumentFile('http://www.helloweba.com/blog.html'); <br />$artlist = pq(".blog_li"); <br />foreach($artlist as $li){ <br /> echo pq($li)->find('h2')->html().""; <br />} <br />
通过循环列表中的DIV,找出文章标题并输出,就是那么简单。
解析XML文档
假设现今有一个这样的test.xml文档:
<br /> <br /> <br /> 张三 <br /> 22 <br /> <br /> <br /> 王五 <br /> 18 <br /> <br /> <br />
现在我要获取名子为张三的联系人的年纪,代码如下:
include 'phpQuery/phpQuery.php'; <br />phpQuery::newDocumentFile('test.xml'); <br />echo pq('contact > age:eq(0)'); <br />
结果输出:22
像jQuery一样,精准查找文档节点,输出节点下的内容,解析一个XML文档就是那么简单。现在你何必为采集网站内容而使用这些头痛的正则算法、内容替换等冗长的代码了,有了phpQuery,一切就显得轻松多了。
项目官网地址: 查看全部
采集头条
先看一实例,现在我要采集新浪网国外新闻的头条,代码如下:
include 'phpQuery/phpQuery.php'; <br />phpQuery::newDocumentFile('http://news.sina.com.cn/china'); <br />echo pq(".blkTop h1:eq(0)")->html(); <br />
简单的三行代码,就可以获取头条内容。首先在程序中收录phpQuery.php核心程序,然后调用读取目标网页,最后输出对应标签下的内容。
pq()是一个功能强悍的方式,跟jQuery的$()如出一辙,jQuery的选择器基本上都能使用在phpQuery上,只要把“.”变成“->”。如上例中,pq(".blkTop h1:eq(0)")抓取了页面class属性为blkTop的DIV元素,并找到该DIV内部的第一个h1标签,然后用html()方法获取h1标签里的内容(带html标签),也就是我们要获取的头条信息,如果使用text()方法,则只获取头条的文本内容。当然要使用好phpQuery,关键是要找对文档中对应内容的节点。
采集文章列表
下面再来看一个事例,获取网站的blog列表,请看代码:
include 'phpQuery/phpQuery.php'; <br />phpQuery::newDocumentFile('http://www.helloweba.com/blog.html'); <br />$artlist = pq(".blog_li"); <br />foreach($artlist as $li){ <br /> echo pq($li)->find('h2')->html().""; <br />} <br />
通过循环列表中的DIV,找出文章标题并输出,就是那么简单。
解析XML文档
假设现今有一个这样的test.xml文档:
<br /> <br /> <br /> 张三 <br /> 22 <br /> <br /> <br /> 王五 <br /> 18 <br /> <br /> <br />
现在我要获取名子为张三的联系人的年纪,代码如下:
include 'phpQuery/phpQuery.php'; <br />phpQuery::newDocumentFile('test.xml'); <br />echo pq('contact > age:eq(0)'); <br />
结果输出:22
像jQuery一样,精准查找文档节点,输出节点下的内容,解析一个XML文档就是那么简单。现在你何必为采集网站内容而使用这些头痛的正则算法、内容替换等冗长的代码了,有了phpQuery,一切就显得轻松多了。
项目官网地址:
百度给出了判定原创文章的方式,你们体会一下
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2020-08-13 09:40
1.1 采集泛滥化
来自百度的一项调查显示,超过80%的新闻和资讯等都在被人工转载或机器采集,从传统媒体的报纸到娱乐网站花边消息、从游戏攻略到产品评测,甚至高校图书馆发的催还通知都有站点在做机器采集。可以说,优质原创内容是被包围在采集的汪洋大海中之一粟,搜索引擎在海中淘粟,是既艰辛又具有挑战性的事情。
1.2 提高搜索用户体验
数字化增加了传播成本,工具化增加了采集成本,机器采集行为混淆内容来源增加内容质量。采集过程中,出于无意或有意,导致采集网页内容残缺不全,格式错乱或附加垃圾等问题层出不穷,这早已严重影响了搜索结果的质量和用户体验。搜索引擎注重原创的根本缘由是为了提升用户体验,这里讲的原创为优质原创内容。
1.3 鼓励原创作者和文章
转载和采集,分流了优质原创站点的流量,不再具属原创作者的名称,会直接影响到优质原创站长和作者的利润。长期看会影响原创者的积极性,不利于创新,不利于新的优质内容形成。鼓励优质原创,鼓励创新,给予原创站点和作者合理的流量,从而促使互联网内容的繁荣,理应是搜索引擎的一个重要任务。
二、采集很狡猾,识别原创太艰辛
2.1 采集冒充原创,篡改关键信息
当前,大量的网站批量采集原创内容后,用人工或机器的方式,篡改作者、发布时间和来源等关键信息,冒充原创。此类假扮原创是须要搜索引擎辨识下来给以适当调整的。
2.2 内容生成器,制造伪原创
利用手动文章生成器等工具,“独创”一篇文章,然后安一个吸引眼珠的title,现在的成本也低得太,而且一定具有独创性。然而,原创是要具有社会共识价值的,而不是胡乱制造一篇根本不通的垃圾才能算做有价值的优质原创内容。内容其实奇特,但是不具社会共识价值,此类伪原创是搜索引擎须要重点辨识下来并给以严打的。
2.3 网页差异化,结构化信息提取困难
不同的站点结构化差别比较大,html标签的涵义和分布也不同,因此提取关键信息如标题、作者和时间的难易程度差异也比较大。做到既提得全,又提得准,还要最及时,在当前的英文互联网规模下实属不易,这部份将须要搜索引擎与站长配合好才能更顺畅的运行,站长们假如用更清晰的结构告知搜索引擎网页的布局,将使搜索引擎高效地提取原创相关的信息。
三、百度辨识原创之路怎么走?
3.1 成立原创项目组,打持久战
面对挑战,为了提升搜索引擎用户体验、为了让优质原创者原创网站得到应有的利润、为了促进英文互联网的前进,我们选派大量人员组成原创项目组:技术、产品、运营、法务等等,这不是临时组织不是1个月2个月的项目,我们做好了打持久战的打算。
3.2 原创辨识“起源”算法
互联网动辄上百亿、上千亿的网页,从中挖掘原创内容,可以说是大海捞针,千头万绪。我们的原创辨识系统,在百度大数据的云计算平台上举办,能够快速实现对全部英文互联网网页的重复聚合和链接指向关系剖析。
首先,通过内容相像程度来聚合采集和原创,将相像网页聚合在一起作为原创辨识的候选集合;
其次,对原创候选集合,通过作者、发布时间、链接指向、用户评论、作者和站点的历史原创情况、转发轨迹等上百种诱因来辨识判定出原创网页;
最后,通过价值剖析系统判定该原创内容的价值高低因而适当的指导最终排序。
目前,通过我们的实验以及真实线上数据,“起源”算法早已取得了一定的进展,在新闻、资讯等领域解决了绝大部分问题。当然,其他领域还有更多的原创问题等待“起源”去解决,我们坚定的走着。
3.3 原创星火计划
我们仍然致力于原创内容的辨识和排序算法调整,但在当前互联网环境下,快速辨识原创解决原创问题确实面临着很大的挑战,计算数据规模庞大,面对的采集方式层出不穷,不同站点的建站方法和模版差别巨大,内容提取复杂等等问题。这些诱因就会影响原创算法辨识,甚至造成判定出错。这时候就须要百度和站长共同努力来维护互联网的生态环境,站长推荐原创内容,搜索引擎通过一定的判定后优待原创内容,共同推动生态的改善,鼓励原创,这就是“原创星火计划”,旨在快速解决当前面临的严重问题。另外,站长对原创内容的推荐,将应用于“起源”算法,进而帮助百度发觉算法的不足,不断改进,用愈发智能的辨识算法手动辨识原创内容。
目前,原创星火计划也取得了初步的疗效,一期对部份重点原创新闻站点的原创内容在百度搜索结果中给与了原创标记、作者展示等等,并且在排序及流量上也取得了合理的提高。
最后,原创是生态问题,需要常年的改善,我们将持续投入,与站长牵手推进互联网生态的进步;原创是环境问题,需要你们来共同维护,站长们多做原创,多推荐原创,百度将持续努力改进排序算法,鼓励原创内容,为原创作者、原创站点提供合理的排序和流量。 查看全部
一、搜索引擎为何要注重原创
1.1 采集泛滥化
来自百度的一项调查显示,超过80%的新闻和资讯等都在被人工转载或机器采集,从传统媒体的报纸到娱乐网站花边消息、从游戏攻略到产品评测,甚至高校图书馆发的催还通知都有站点在做机器采集。可以说,优质原创内容是被包围在采集的汪洋大海中之一粟,搜索引擎在海中淘粟,是既艰辛又具有挑战性的事情。
1.2 提高搜索用户体验
数字化增加了传播成本,工具化增加了采集成本,机器采集行为混淆内容来源增加内容质量。采集过程中,出于无意或有意,导致采集网页内容残缺不全,格式错乱或附加垃圾等问题层出不穷,这早已严重影响了搜索结果的质量和用户体验。搜索引擎注重原创的根本缘由是为了提升用户体验,这里讲的原创为优质原创内容。
1.3 鼓励原创作者和文章
转载和采集,分流了优质原创站点的流量,不再具属原创作者的名称,会直接影响到优质原创站长和作者的利润。长期看会影响原创者的积极性,不利于创新,不利于新的优质内容形成。鼓励优质原创,鼓励创新,给予原创站点和作者合理的流量,从而促使互联网内容的繁荣,理应是搜索引擎的一个重要任务。
二、采集很狡猾,识别原创太艰辛
2.1 采集冒充原创,篡改关键信息
当前,大量的网站批量采集原创内容后,用人工或机器的方式,篡改作者、发布时间和来源等关键信息,冒充原创。此类假扮原创是须要搜索引擎辨识下来给以适当调整的。
2.2 内容生成器,制造伪原创
利用手动文章生成器等工具,“独创”一篇文章,然后安一个吸引眼珠的title,现在的成本也低得太,而且一定具有独创性。然而,原创是要具有社会共识价值的,而不是胡乱制造一篇根本不通的垃圾才能算做有价值的优质原创内容。内容其实奇特,但是不具社会共识价值,此类伪原创是搜索引擎须要重点辨识下来并给以严打的。
2.3 网页差异化,结构化信息提取困难
不同的站点结构化差别比较大,html标签的涵义和分布也不同,因此提取关键信息如标题、作者和时间的难易程度差异也比较大。做到既提得全,又提得准,还要最及时,在当前的英文互联网规模下实属不易,这部份将须要搜索引擎与站长配合好才能更顺畅的运行,站长们假如用更清晰的结构告知搜索引擎网页的布局,将使搜索引擎高效地提取原创相关的信息。
三、百度辨识原创之路怎么走?
3.1 成立原创项目组,打持久战
面对挑战,为了提升搜索引擎用户体验、为了让优质原创者原创网站得到应有的利润、为了促进英文互联网的前进,我们选派大量人员组成原创项目组:技术、产品、运营、法务等等,这不是临时组织不是1个月2个月的项目,我们做好了打持久战的打算。
3.2 原创辨识“起源”算法
互联网动辄上百亿、上千亿的网页,从中挖掘原创内容,可以说是大海捞针,千头万绪。我们的原创辨识系统,在百度大数据的云计算平台上举办,能够快速实现对全部英文互联网网页的重复聚合和链接指向关系剖析。
首先,通过内容相像程度来聚合采集和原创,将相像网页聚合在一起作为原创辨识的候选集合;
其次,对原创候选集合,通过作者、发布时间、链接指向、用户评论、作者和站点的历史原创情况、转发轨迹等上百种诱因来辨识判定出原创网页;
最后,通过价值剖析系统判定该原创内容的价值高低因而适当的指导最终排序。
目前,通过我们的实验以及真实线上数据,“起源”算法早已取得了一定的进展,在新闻、资讯等领域解决了绝大部分问题。当然,其他领域还有更多的原创问题等待“起源”去解决,我们坚定的走着。
3.3 原创星火计划
我们仍然致力于原创内容的辨识和排序算法调整,但在当前互联网环境下,快速辨识原创解决原创问题确实面临着很大的挑战,计算数据规模庞大,面对的采集方式层出不穷,不同站点的建站方法和模版差别巨大,内容提取复杂等等问题。这些诱因就会影响原创算法辨识,甚至造成判定出错。这时候就须要百度和站长共同努力来维护互联网的生态环境,站长推荐原创内容,搜索引擎通过一定的判定后优待原创内容,共同推动生态的改善,鼓励原创,这就是“原创星火计划”,旨在快速解决当前面临的严重问题。另外,站长对原创内容的推荐,将应用于“起源”算法,进而帮助百度发觉算法的不足,不断改进,用愈发智能的辨识算法手动辨识原创内容。
目前,原创星火计划也取得了初步的疗效,一期对部份重点原创新闻站点的原创内容在百度搜索结果中给与了原创标记、作者展示等等,并且在排序及流量上也取得了合理的提高。
最后,原创是生态问题,需要常年的改善,我们将持续投入,与站长牵手推进互联网生态的进步;原创是环境问题,需要你们来共同维护,站长们多做原创,多推荐原创,百度将持续努力改进排序算法,鼓励原创内容,为原创作者、原创站点提供合理的排序和流量。
影响SEO原创文章不收录的诱因及解法
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2020-08-12 20:00
一.原创文章方向始终是主导
很多人写原创文章发现不收录后,就舍弃了更新原创的操作,其实在操作的时侯,原创内容仍然是搜索引擎最喜欢的东西,但你们是否想过,你的原创内容是否符合互联网用户的食欲,是自娱自乐的写作还是给用户作为参考学习的内容,很大缘由是因为内容的质量不过关而造成搜索引擎不抓取网页,这一点在前面在详尽说明。
也有部份站长看见他人网站做采集内容收录不错,于是自己也去做采集内容,最终造成的就是自己网站的评估值大大增加,最终收录也成了困局,不过原创文章仍然是优化的主导,这一点你们毋庸置疑。
二.搜索引擎为何不收录原创文章?
1.网站是新站
对于一个新站来说,想要达到秒收的疗效,一般都有点困难,就像谈恋爱一样,你才刚才接触女孩子,就想马上约人家开房,想想都有点不可能对吧,很多同学总是觉得自己的网站已经渡过了新站期,一般六个月以内的都可以称之为新站,如果你的网站上线还没有达到六个月,那么出现收录慢都是正常现象,不用过度担忧,坚持做好正确的事情就好。
如何减短新站审核期呢?很多人经常有疑问,为什么他人网站上线比我晚,收录却比我早,其实这是他人优化做得好的缘由,那么对于新站来说,如何操作能推动文章的收录呢?
a.适当的做好外链工作:很多人觉得外链早已没有用了,实则不然,外链的作用仍然重要,在一些相关的平台发布外链,不仅能吸引蜘蛛来到网站抓取内容,还可以招来一些意外的流量。
b.内链结构要合理:当吸引蜘蛛进来以后,就是使其抓取网站的各部份内容,而这时候就须要做好内链的工作,最好防止出现死链接的存在,内链的优劣只有一点,是否做了相关引导。
c.做好网站地图:网站地图的作用就是使搜索引擎蜘蛛更好的抓取网站的内容,有一个清晰的轮廓,同时也是分配网站权重的一个重要工具,网站地图不会做的可以北京SEO博主。
d.把链接领到搜索引擎平台递交:大家可以把文章链接领到百度站长平台进行递交,不过要注意一点,千万别反复递交多次,会影响网站的整体质量。
e.利用nofollow标签进行集权:nofollow标签在前期优化中也很重要,为了集中某一个区域的权重值,一般都可以借助这个标签把不重要的地方限制,让搜索引擎蜘蛛更好的辨识网站的核心重点;之后在按照核心重点写文章,收录率就大得多了。
2.文章大量采集而造成的不收录(非原创)
相信好多站长为了使网站早点上线,都去各大平台大量的采集一些内容,随后草草上线,而这样偷懒带来的后果就是造成文章迟迟不收录,尽管文章非常具备价值,但是却得不到搜索引擎的认可,没有新鲜的内容做支撑,搜索引擎的评分也是十分低的,而好多站长遇见这些情况,就不知道怎样去做了,下面的方式其实对你有帮助。
a.修改文章标题以及内容前后:大家可以拿标题到百度搜索框去搜索,看看相关搜索量能达到多少,若是达到一百万左右,那么就要适当的更改标题了,修改后的标题再领到百度搜索框搜索一下,看看相关搜索结果又多少,一般最好控制在 10 万以下。
b.加强外链发布的工作:一旦更改好了内容和标题,那么接出来就是要使搜索引擎重新抓取内容,这时候外链工作功不可没,大家可以在发布外链的时侯带上这篇文章的链接,让搜索引擎重新抓取辨识,建议内容更改就全部更改好,不要更改一篇发布一篇外链,这样搜索引擎蜘蛛来抓取的时侯,只发觉一个页面有所改变,依然得不到好转,若是发觉大部分内容都改建过,那么上次百度快照更新的时侯,相信收录量才能上来了。
3.内容价值偏于老旧,对用户意义不大
在上面也说过原创文章讲究一个价值性,很多人写原创可以说快讲到呕血了,但是就是不收录,其实很大缘由就是文章质量的问题,很多文章围绕的都是曾经陈旧的观点,根本解决不了现今用户的需求,那么怎么更好的紧抓文章的价值性呢?简单而言就是要了解用户近日经常搜索哪些内容,可以按照下拉框和相关搜索来剖析,在这里就不做过多说明了,同时也可以借助QQ社交工具咨询一些专家,整合她们的意见也能成为一篇好的文章。
大家可以先借助百度知道查看目前用户都提了什么问题,然后在去找寻同行咨询,这个疗效特别不错,但是比较损,而且有的同行也聪明,动不动要你面谈,这就为我们创造价值文章带来了一定的难度,不过这个方式你们可以举一反三的思索使用。
4.频繁更改网站标题也会影响整体收录
对于网站来说,若是时常更改网站的标题,也会导致网站内容发生方向的改变,网站整体权重不高,也会直接影响网站文章的收录率,相信这一点你们已然深有感悟了,因此若是你刚才更改过标题,发现文章不收录了,那就说明网站已经被搜索引擎重新拉入观察期进行观察了。
如何解决这一问题呢?首先应当考虑百度快照的更新问题,只有使快照尽快更新,才能更好的恢复过来,可以通过百度快照更新投诉通道进行投诉,可以推动快照的更新速率。
其次就是多多更新高质量的原创内容,不管收录与否,定期规律的更新能减短这段观察期。
5.检查robots.txt文件是否存在严禁搜索引擎的指令
这一点其实简单,但是好多情况下就是robots文件惹的祸,很多站长因为马大哈,禁止了搜索引擎抓取文件,从而引起了文章收录大大增长,这一点也不能马大哈。可以使用百度站长平台的抓取工具以及robots检查工具进行测试。
6.网站存在大量的死链接
网站出现大量的死链接也是影响页面质量的诱因,大量的 404 页面给了搜索引擎蜘蛛一个极差的抓取体验,从而增加网站的页面质量,大家不妨检测一下自己的网站,是否存在多个死链接,有一种情况很容易出现大量死链接,就是动态路径和伪静态路径没有统一好,导致大量死链接,这一点你们应当都有经历。
若是发觉大量死链接,首先想到的是怎样处理死链接,让搜索引擎尽早更新过来,可以通过百度站长工具的死链接工具进行修补,具体就不在这儿说明了。
7.网站优化过度造成降权
很多网站由于网站优化过度,刻意拼凑关键词造成网站迟迟不收录,当发觉优化过度后,首先就要想到怎么增加刻意优化的痕迹,刻意拼凑的关键词也可以适当降低,减少每一个页面的重复率,过一段时间后在坚持更新原创质量文章即可。
总结
以上就是本文述说的原创文章为何不收录的大致缘由,如果你们发觉自己的文章常常不收录,很大缘由就是网站的信任值不足,其次是文章的质量是否达标的关系,想要自己的网站达到秒收的境界,那么就须要进行不断的加壳,然后提高文章质量,确保网站跳出率可观。 查看全部
相信这个问题早已困惑了你们许久了,有的站长天天写原创更新,但总是得不到搜索引擎的光顾,而有的网站哪怕是采集都能达到秒收的待遇,是我们坚持原创更新的方向错了?还是他人另有高招?这些就不得而知了,而明天和你们分享的就是为什么写原创而不收录的诱因剖析及解法。
一.原创文章方向始终是主导
很多人写原创文章发现不收录后,就舍弃了更新原创的操作,其实在操作的时侯,原创内容仍然是搜索引擎最喜欢的东西,但你们是否想过,你的原创内容是否符合互联网用户的食欲,是自娱自乐的写作还是给用户作为参考学习的内容,很大缘由是因为内容的质量不过关而造成搜索引擎不抓取网页,这一点在前面在详尽说明。
也有部份站长看见他人网站做采集内容收录不错,于是自己也去做采集内容,最终造成的就是自己网站的评估值大大增加,最终收录也成了困局,不过原创文章仍然是优化的主导,这一点你们毋庸置疑。
二.搜索引擎为何不收录原创文章?
1.网站是新站
对于一个新站来说,想要达到秒收的疗效,一般都有点困难,就像谈恋爱一样,你才刚才接触女孩子,就想马上约人家开房,想想都有点不可能对吧,很多同学总是觉得自己的网站已经渡过了新站期,一般六个月以内的都可以称之为新站,如果你的网站上线还没有达到六个月,那么出现收录慢都是正常现象,不用过度担忧,坚持做好正确的事情就好。
如何减短新站审核期呢?很多人经常有疑问,为什么他人网站上线比我晚,收录却比我早,其实这是他人优化做得好的缘由,那么对于新站来说,如何操作能推动文章的收录呢?
a.适当的做好外链工作:很多人觉得外链早已没有用了,实则不然,外链的作用仍然重要,在一些相关的平台发布外链,不仅能吸引蜘蛛来到网站抓取内容,还可以招来一些意外的流量。
b.内链结构要合理:当吸引蜘蛛进来以后,就是使其抓取网站的各部份内容,而这时候就须要做好内链的工作,最好防止出现死链接的存在,内链的优劣只有一点,是否做了相关引导。
c.做好网站地图:网站地图的作用就是使搜索引擎蜘蛛更好的抓取网站的内容,有一个清晰的轮廓,同时也是分配网站权重的一个重要工具,网站地图不会做的可以北京SEO博主。
d.把链接领到搜索引擎平台递交:大家可以把文章链接领到百度站长平台进行递交,不过要注意一点,千万别反复递交多次,会影响网站的整体质量。
e.利用nofollow标签进行集权:nofollow标签在前期优化中也很重要,为了集中某一个区域的权重值,一般都可以借助这个标签把不重要的地方限制,让搜索引擎蜘蛛更好的辨识网站的核心重点;之后在按照核心重点写文章,收录率就大得多了。
2.文章大量采集而造成的不收录(非原创)
相信好多站长为了使网站早点上线,都去各大平台大量的采集一些内容,随后草草上线,而这样偷懒带来的后果就是造成文章迟迟不收录,尽管文章非常具备价值,但是却得不到搜索引擎的认可,没有新鲜的内容做支撑,搜索引擎的评分也是十分低的,而好多站长遇见这些情况,就不知道怎样去做了,下面的方式其实对你有帮助。
a.修改文章标题以及内容前后:大家可以拿标题到百度搜索框去搜索,看看相关搜索量能达到多少,若是达到一百万左右,那么就要适当的更改标题了,修改后的标题再领到百度搜索框搜索一下,看看相关搜索结果又多少,一般最好控制在 10 万以下。
b.加强外链发布的工作:一旦更改好了内容和标题,那么接出来就是要使搜索引擎重新抓取内容,这时候外链工作功不可没,大家可以在发布外链的时侯带上这篇文章的链接,让搜索引擎重新抓取辨识,建议内容更改就全部更改好,不要更改一篇发布一篇外链,这样搜索引擎蜘蛛来抓取的时侯,只发觉一个页面有所改变,依然得不到好转,若是发觉大部分内容都改建过,那么上次百度快照更新的时侯,相信收录量才能上来了。
3.内容价值偏于老旧,对用户意义不大
在上面也说过原创文章讲究一个价值性,很多人写原创可以说快讲到呕血了,但是就是不收录,其实很大缘由就是文章质量的问题,很多文章围绕的都是曾经陈旧的观点,根本解决不了现今用户的需求,那么怎么更好的紧抓文章的价值性呢?简单而言就是要了解用户近日经常搜索哪些内容,可以按照下拉框和相关搜索来剖析,在这里就不做过多说明了,同时也可以借助QQ社交工具咨询一些专家,整合她们的意见也能成为一篇好的文章。
大家可以先借助百度知道查看目前用户都提了什么问题,然后在去找寻同行咨询,这个疗效特别不错,但是比较损,而且有的同行也聪明,动不动要你面谈,这就为我们创造价值文章带来了一定的难度,不过这个方式你们可以举一反三的思索使用。
4.频繁更改网站标题也会影响整体收录
对于网站来说,若是时常更改网站的标题,也会导致网站内容发生方向的改变,网站整体权重不高,也会直接影响网站文章的收录率,相信这一点你们已然深有感悟了,因此若是你刚才更改过标题,发现文章不收录了,那就说明网站已经被搜索引擎重新拉入观察期进行观察了。
如何解决这一问题呢?首先应当考虑百度快照的更新问题,只有使快照尽快更新,才能更好的恢复过来,可以通过百度快照更新投诉通道进行投诉,可以推动快照的更新速率。
其次就是多多更新高质量的原创内容,不管收录与否,定期规律的更新能减短这段观察期。
5.检查robots.txt文件是否存在严禁搜索引擎的指令
这一点其实简单,但是好多情况下就是robots文件惹的祸,很多站长因为马大哈,禁止了搜索引擎抓取文件,从而引起了文章收录大大增长,这一点也不能马大哈。可以使用百度站长平台的抓取工具以及robots检查工具进行测试。
6.网站存在大量的死链接
网站出现大量的死链接也是影响页面质量的诱因,大量的 404 页面给了搜索引擎蜘蛛一个极差的抓取体验,从而增加网站的页面质量,大家不妨检测一下自己的网站,是否存在多个死链接,有一种情况很容易出现大量死链接,就是动态路径和伪静态路径没有统一好,导致大量死链接,这一点你们应当都有经历。
若是发觉大量死链接,首先想到的是怎样处理死链接,让搜索引擎尽早更新过来,可以通过百度站长工具的死链接工具进行修补,具体就不在这儿说明了。
7.网站优化过度造成降权
很多网站由于网站优化过度,刻意拼凑关键词造成网站迟迟不收录,当发觉优化过度后,首先就要想到怎么增加刻意优化的痕迹,刻意拼凑的关键词也可以适当降低,减少每一个页面的重复率,过一段时间后在坚持更新原创质量文章即可。
总结
以上就是本文述说的原创文章为何不收录的大致缘由,如果你们发觉自己的文章常常不收录,很大缘由就是网站的信任值不足,其次是文章的质量是否达标的关系,想要自己的网站达到秒收的境界,那么就须要进行不断的加壳,然后提高文章质量,确保网站跳出率可观。
千万级内容类产品中台应当有什么模块?
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2020-08-12 00:51
说到内容,可以把它想像为一块羊肉。它首先是一头牛,然后这头牛被送进了加工厂,在一系列加工过后,通过货运送到商场,最后,你通过消费获得这块排骨。内容也是一样,需要经过生产、加工、审核、分发等工序最后展示在用户面前。本文说的内容中台便是这么。
一头牛(内容原料/内容生产)
和一般说的UGC/PGC的分类不一样,此处的说的中台将内容来源分为外部创作和内部创作。
外部创作
外部创作指的是爬虫采集、人工节选、渠道合作以及用户创作内容(UGC)。
(1)爬虫采集:是指对特定信息源进行机器爬虫采集、内容入库。此处说的特定的信息来源一般是公开信息网站,比如gov类的。爬虫采集要求全、快、准、稳。全,爬取的内容要全,不能把信息源的文章少爬了几篇。
(2)人工节选:主要是针对这些及时性要求比较高的内容,比如突发性重大新闻。这也侧面反映出爬虫采集存在一定缺陷,比如时效性低,很难做到秒级反应。此外部份来源也设有反爬虫机制,会促使内容有所缺位。这时候就须要人工节选进行补充。
(3)渠道合作:是指由合作商提供插口,除了常规的内容要素,还应当收录增删改信息,最好是有合适的日志以及信息同步机制。
内部创作
内部创作说的是企业原创,这类又分为两种:一种是纯人工创作,另一种是智能写稿。
纯人工创作:也就是原创内容,由强悍的编辑团队一手创作 智能写稿:这个有点象文字填充。产品总监在经过一系列的剖析之后筛选出才能满足用户需求而且能被技术支持的文章类型,再对每一类文章编写模板并规定由机器填写的数组。此后机器能够手动产出符合要求的内容了。 加工厂(内容加工)
加工厂主要有两种“机器”,一类是标签体系(内容分类),一类是内容加工。
标签体系主要服务于建立文章池并借此作为个性化推荐的基础。比如说某篇文章的标签是{A,B},某用户的标签也是{A,B},那么这篇文章便可能有很大的机率被推送到这个用户面前。而此处的标签体系便是通过对内容的剖析给它们打上各类标签便于于后续的分发和推送。值得注意的是,标签并不是越多越好,而是要遵守一定的规则,这样就能尽可能地提升匹配程度,从而提升文章的消费率。
内容加工主要有以下几步:
首先是格式的优化,对于采集过来的文章我们须要把不合适的内容去除,比如说超链、广告等。 之后是内容转存,将文章的图片和视频转入自己的服务器上(这须要取得对方许可)。 其次还有一些附加模块,这块主要作用于各前台的特色功能或则个性化需求,比如在文章中添加图片、表格、投票、附件、运营模块(主要是banner)等。 最后是盖戳环节,就像加工厂给猪肉盖戳一样,我们须要对内容的合规性、与原文的一致性等进行复核,主要是违法词屏蔽(也就是大家在王者化肥里显示不下来的馨香)、关键词替换、原文比对等。 物流分发(内容分发)
物流分发输出的就是成品猪肉——文章池,它最重要的元素有:标题、摘要、正文、时间、排序、内容标签、个性化模块。分发的逻辑比较复杂,而且也须要配合前台具体需求,这里就不展开阐述了。
最后附上逻辑图: 查看全部
文章结合猪肉加工的案例,形象地梳理了内容中台的运作机制,并对各个模块展开了剖析介绍,与你们分享。
说到内容,可以把它想像为一块羊肉。它首先是一头牛,然后这头牛被送进了加工厂,在一系列加工过后,通过货运送到商场,最后,你通过消费获得这块排骨。内容也是一样,需要经过生产、加工、审核、分发等工序最后展示在用户面前。本文说的内容中台便是这么。
一头牛(内容原料/内容生产)
和一般说的UGC/PGC的分类不一样,此处的说的中台将内容来源分为外部创作和内部创作。
外部创作
外部创作指的是爬虫采集、人工节选、渠道合作以及用户创作内容(UGC)。
(1)爬虫采集:是指对特定信息源进行机器爬虫采集、内容入库。此处说的特定的信息来源一般是公开信息网站,比如gov类的。爬虫采集要求全、快、准、稳。全,爬取的内容要全,不能把信息源的文章少爬了几篇。
(2)人工节选:主要是针对这些及时性要求比较高的内容,比如突发性重大新闻。这也侧面反映出爬虫采集存在一定缺陷,比如时效性低,很难做到秒级反应。此外部份来源也设有反爬虫机制,会促使内容有所缺位。这时候就须要人工节选进行补充。
(3)渠道合作:是指由合作商提供插口,除了常规的内容要素,还应当收录增删改信息,最好是有合适的日志以及信息同步机制。
内部创作
内部创作说的是企业原创,这类又分为两种:一种是纯人工创作,另一种是智能写稿。
纯人工创作:也就是原创内容,由强悍的编辑团队一手创作 智能写稿:这个有点象文字填充。产品总监在经过一系列的剖析之后筛选出才能满足用户需求而且能被技术支持的文章类型,再对每一类文章编写模板并规定由机器填写的数组。此后机器能够手动产出符合要求的内容了。 加工厂(内容加工)
加工厂主要有两种“机器”,一类是标签体系(内容分类),一类是内容加工。
标签体系主要服务于建立文章池并借此作为个性化推荐的基础。比如说某篇文章的标签是{A,B},某用户的标签也是{A,B},那么这篇文章便可能有很大的机率被推送到这个用户面前。而此处的标签体系便是通过对内容的剖析给它们打上各类标签便于于后续的分发和推送。值得注意的是,标签并不是越多越好,而是要遵守一定的规则,这样就能尽可能地提升匹配程度,从而提升文章的消费率。
内容加工主要有以下几步:
首先是格式的优化,对于采集过来的文章我们须要把不合适的内容去除,比如说超链、广告等。 之后是内容转存,将文章的图片和视频转入自己的服务器上(这须要取得对方许可)。 其次还有一些附加模块,这块主要作用于各前台的特色功能或则个性化需求,比如在文章中添加图片、表格、投票、附件、运营模块(主要是banner)等。 最后是盖戳环节,就像加工厂给猪肉盖戳一样,我们须要对内容的合规性、与原文的一致性等进行复核,主要是违法词屏蔽(也就是大家在王者化肥里显示不下来的馨香)、关键词替换、原文比对等。 物流分发(内容分发)
物流分发输出的就是成品猪肉——文章池,它最重要的元素有:标题、摘要、正文、时间、排序、内容标签、个性化模块。分发的逻辑比较复杂,而且也须要配合前台具体需求,这里就不展开阐述了。
最后附上逻辑图:
微信公众号文章采集的入口--历史消息页解读
采集交流 • 优采云 发表了文章 • 0 个评论 • 357 次浏览 • 2020-08-11 23:03
因为陌陌的限制,我们能复制到的链接是不完整的,在浏览器中未能打开听到内容。所以我们须要通过上一篇文章介绍的方式,使用anyproxy获取到一个完整的微信公众号历史消息页面的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
前一篇文章提到过,biz参数是公众号的ID,uin是用户的ID,目前来看uin是在所有公众号之间惟一的。其它两个重要参数key和pass_ticket是陌陌客户端补充上的参数。
所以在这个地址失效之前我们是可以通过浏览器查看原文的方式获取到历史消息的文章列表的,如果希望自动化剖析内容,也可以制做一个程序,将这个带有仍未失效的key和pass_ticket的链接地址递交进去,再通过诸如php程序来获取到文章列表。
最近有同事跟我说他的采集目标就是单一的一个公众号,我认为这样就没必要用上一篇文章写的批量采集的方式了。所以我们接下来瞧瞧历史消息页上面是如何获取到文章列表的,通过剖析文章列表,就可以得到这个公众号所有的内容链接地址,然后再采集内容就可以了。
在anyproxy的web界面中若果证书配置正确,是可以显示出https的内容的。web界面的地址是localhost:8002其中localhost可以替换成自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,点击以后两侧都会显示出这条记录的详情:
红框部份就是完整的链接地址,将微信公众平台这个域名拼接在上面以后就可以在浏览器中打开了。
然后将页面向上拉,到html内容的结尾部份,我们可以看见一个json的变量就是历史消息的文章列表:
我们将msgList的变量值拷贝下来,用json低格工具剖析一下,我们就可以看见这个json是以下这个结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简要的剖析一下这个json(这里只介绍一些重要的信息,其它的被省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
在这里还要提及一点就是假如希望获取到时间更久远一些的历史消息内容,就须要在手机或模拟器上将页面向上拉,当拉到最里边的时侯,微信将手动读取下一页的内容。下一页的链接地址和历史消息页的链接地址同样是getmasssendmsg开头的地址。但是内容就是只有json了,没有html了。直接解析json就可以了。
这时可以通过上一篇文章介绍的方式,使用anyproxy将msgList变量值正则匹配下来以后,异步递交到服务器,再从服务器上使用php的json_decode解析json成为字段。然后遍历循环链表。我们就可以得到每一篇文章的标题和链接地址。
如果只须要采集单一公众号的内容,完全可以在每晚群发以后,通过anyproxy获取到完整的带有key和pass_ticket的链接地址。然后自己制做一个程序,手动将地址递交给自己的程序。使用诸如php这样的语言来正则匹配到msgList,然后解析json。这样就不用更改anyproxy的rule,也不需要制做一个采集队列和跳转页面了。
现在我们早已可以通过公众号的历史消息得到文章列表了,在下一篇文章里我将介绍怎么按照历史消息里的文章链接地址来获取文章具体内容的方式。还有一些怎样保存文章,封面图片,还有全文检索的经验。
如果你认为我那里写的不清楚,或者有不明白的地方,欢迎在下边留言。或者恐吓微信号cuijin,觉得好就点个赞。
持续更新,微信公众号文章批量采集系统的建立
微信公众号文章采集的入口--历史消息页解读
微信公众号文章页的剖析与采集
提高微信公众号文章采集效率,anyproxy进阶使用方式 查看全部
采集微信文章和采集网站内容一样,都须要从一个列表页开始。而陌陌文章的列表页就是公众号里的查看历史消息页。现在网路上的其它陌陌采集器有的是借助搜狗搜索,采集方式其实简单多了,但是内容不全。所以我们还是要从最标准最全面的公众号历史消息页来采集。
因为陌陌的限制,我们能复制到的链接是不完整的,在浏览器中未能打开听到内容。所以我们须要通过上一篇文章介绍的方式,使用anyproxy获取到一个完整的微信公众号历史消息页面的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
前一篇文章提到过,biz参数是公众号的ID,uin是用户的ID,目前来看uin是在所有公众号之间惟一的。其它两个重要参数key和pass_ticket是陌陌客户端补充上的参数。
所以在这个地址失效之前我们是可以通过浏览器查看原文的方式获取到历史消息的文章列表的,如果希望自动化剖析内容,也可以制做一个程序,将这个带有仍未失效的key和pass_ticket的链接地址递交进去,再通过诸如php程序来获取到文章列表。
最近有同事跟我说他的采集目标就是单一的一个公众号,我认为这样就没必要用上一篇文章写的批量采集的方式了。所以我们接下来瞧瞧历史消息页上面是如何获取到文章列表的,通过剖析文章列表,就可以得到这个公众号所有的内容链接地址,然后再采集内容就可以了。
在anyproxy的web界面中若果证书配置正确,是可以显示出https的内容的。web界面的地址是localhost:8002其中localhost可以替换成自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,点击以后两侧都会显示出这条记录的详情:
红框部份就是完整的链接地址,将微信公众平台这个域名拼接在上面以后就可以在浏览器中打开了。
然后将页面向上拉,到html内容的结尾部份,我们可以看见一个json的变量就是历史消息的文章列表:
我们将msgList的变量值拷贝下来,用json低格工具剖析一下,我们就可以看见这个json是以下这个结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简要的剖析一下这个json(这里只介绍一些重要的信息,其它的被省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
在这里还要提及一点就是假如希望获取到时间更久远一些的历史消息内容,就须要在手机或模拟器上将页面向上拉,当拉到最里边的时侯,微信将手动读取下一页的内容。下一页的链接地址和历史消息页的链接地址同样是getmasssendmsg开头的地址。但是内容就是只有json了,没有html了。直接解析json就可以了。
这时可以通过上一篇文章介绍的方式,使用anyproxy将msgList变量值正则匹配下来以后,异步递交到服务器,再从服务器上使用php的json_decode解析json成为字段。然后遍历循环链表。我们就可以得到每一篇文章的标题和链接地址。
如果只须要采集单一公众号的内容,完全可以在每晚群发以后,通过anyproxy获取到完整的带有key和pass_ticket的链接地址。然后自己制做一个程序,手动将地址递交给自己的程序。使用诸如php这样的语言来正则匹配到msgList,然后解析json。这样就不用更改anyproxy的rule,也不需要制做一个采集队列和跳转页面了。
现在我们早已可以通过公众号的历史消息得到文章列表了,在下一篇文章里我将介绍怎么按照历史消息里的文章链接地址来获取文章具体内容的方式。还有一些怎样保存文章,封面图片,还有全文检索的经验。
如果你认为我那里写的不清楚,或者有不明白的地方,欢迎在下边留言。或者恐吓微信号cuijin,觉得好就点个赞。
持续更新,微信公众号文章批量采集系统的建立
微信公众号文章采集的入口--历史消息页解读
微信公众号文章页的剖析与采集
提高微信公众号文章采集效率,anyproxy进阶使用方式
网站高质量内容更新注意事情
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2020-08-10 20:07
一、不可直接采集内容
要对采集的内容进行深度的加工,不能否直接借助,否则都会被搜索引擎会辨识为垃圾信息。
二、内容要怎么做不被降权
一些网站更新的内容除了不会收录,严重的还可能造成网站被降权,内容引起网站被降权也就说明搜索引擎觉得这种是垃圾信息,所以做网站内容时要想不被看做垃圾信息就要注意以下四点。
1、只需加粗文章标题和段落标题
只须要对文章两个大小标题进行加粗就可以了,这是强制指标上面涉及到H1到H2标签的运用,H1标签运用到文章标题,而H2运用到正文段落标题中。
2、正文不要放内链
不要一味地为获取关键词排行而在网站内容中倒入过多的内链,这些内链指向自己的首页但不一定会被用户点击。
3、内容中不可以放广告
内容中不要放这些包括百度网盟等在内的广告,否则会被惩罚的。如果是流量广告站点不可以在正文中和没有排行和流量的时侯加入广告,而必须在网站有排行和流量后从正文结束的位置加入广告。
4、内容中字体颜色相同
一篇文章中所有的字体颜色应当一致,因为太多的颜色会直接影响搜索引擎辨识,很多垃圾网站都是用不同颜色的字体来变幻从他人网站上采集到的内容。
总之,高质量的内容优化不是一件简单的事情,需要不断掉动头脑,不断努力,坚持不懈的进行,只有这样才有可能作出高质量的网站内容。 查看全部
网站的存在与它本身的内容有很大的关系,它对于用户和搜索引擎来讲都是很重要的,但是内容也有优劣之分。好的内容除了就能留住用户同时还可以吸引更多的用户,而质量不高的内容则是在浪费时间同时也对用户没有帮助,因此搜索引擎对质量不好的网站惩罚也是太严格的,可是我们对于好的网站内容该做何努力呢?本文广州SEO专家朗创网路营销将和你们介绍一下经验。
一、不可直接采集内容
要对采集的内容进行深度的加工,不能否直接借助,否则都会被搜索引擎会辨识为垃圾信息。
二、内容要怎么做不被降权
一些网站更新的内容除了不会收录,严重的还可能造成网站被降权,内容引起网站被降权也就说明搜索引擎觉得这种是垃圾信息,所以做网站内容时要想不被看做垃圾信息就要注意以下四点。
1、只需加粗文章标题和段落标题
只须要对文章两个大小标题进行加粗就可以了,这是强制指标上面涉及到H1到H2标签的运用,H1标签运用到文章标题,而H2运用到正文段落标题中。
2、正文不要放内链
不要一味地为获取关键词排行而在网站内容中倒入过多的内链,这些内链指向自己的首页但不一定会被用户点击。
3、内容中不可以放广告
内容中不要放这些包括百度网盟等在内的广告,否则会被惩罚的。如果是流量广告站点不可以在正文中和没有排行和流量的时侯加入广告,而必须在网站有排行和流量后从正文结束的位置加入广告。
4、内容中字体颜色相同
一篇文章中所有的字体颜色应当一致,因为太多的颜色会直接影响搜索引擎辨识,很多垃圾网站都是用不同颜色的字体来变幻从他人网站上采集到的内容。
总之,高质量的内容优化不是一件简单的事情,需要不断掉动头脑,不断努力,坚持不懈的进行,只有这样才有可能作出高质量的网站内容。
优采云采集器出现"WEB发布是否成功未知",错误缘由和解决办法
采集交流 • 优采云 发表了文章 • 0 个评论 • 374 次浏览 • 2020-08-10 00:31
一般来说发布错误缘由有两个,参见附图一:
1,模块发布中未列举所有可能发布错误的情况;
2,排除模块以外的其它缘由,如登录失败、网站主路径填写错误、网站(页面)无法访问等诱因。
解决办法:
1,发布时先只发布一条内容,然后按照软件提示打开发布时保存的错误返回代码文件“WebError.log”,查看上面的返回代码,一般的保存路径为"优采云采集器/DATA/任务名/WebError.log"。
2,如果返回代码是大篇幅的HTML代码,而你看起HTML代码来难于看天书的话,我建议你把WebError.log另存为HTML文档使用IE查看。
3,根据WebError.log中的诱因检测网站和软件的配置即可,一般的错误情况在此即可解决问题。
WebError.log出现内容为空的解决办法:
当然,WebError.log也会出现内容为空的情况,这里单独做一个说明。
这种情况通常是因为软件POST内容之后,接收不到发布页面的响应导致的。有时候优采云采集器也会把这样的情况默认为成功发布,而事实上,我们的网站却没有内容,很多站长因此呕吐不已。
其实这是一个简单的问题,你可以按照“无法接受到发布页面的响应”来找寻缘由。如:
1,你的网站是否能正常访问,特别是你的Web发布页面。
2,设置Web发布时,网站的根目录有没有填写正确,可以用刷新栏目列表是否正确来判定。
3,网站是否成功登录或则发布用户是否有权限。
4,优采云采集器-辅助工具-重新加载配置。
5,如果以上方案你都有测试过,那不妨再重启一下优采云采集器。
以下是一些图片,可以帮你愈发直观的了解:
你可以任意转摘“优采云采集器出现"WEB发布是否成功未知",错误缘由和解决办法”,但请保留本文出处和版权信息。 查看全部
这是非常典型的优采云采集器发布错误,主要缘由是因为发布时,程序获取到的返回代码中,出现了Web发布模块中未列举的代码。即,发布时,未出现成功的返回特点代码,也没有出现发布错误的特点码。
一般来说发布错误缘由有两个,参见附图一:
1,模块发布中未列举所有可能发布错误的情况;
2,排除模块以外的其它缘由,如登录失败、网站主路径填写错误、网站(页面)无法访问等诱因。
解决办法:
1,发布时先只发布一条内容,然后按照软件提示打开发布时保存的错误返回代码文件“WebError.log”,查看上面的返回代码,一般的保存路径为"优采云采集器/DATA/任务名/WebError.log"。
2,如果返回代码是大篇幅的HTML代码,而你看起HTML代码来难于看天书的话,我建议你把WebError.log另存为HTML文档使用IE查看。
3,根据WebError.log中的诱因检测网站和软件的配置即可,一般的错误情况在此即可解决问题。
WebError.log出现内容为空的解决办法:
当然,WebError.log也会出现内容为空的情况,这里单独做一个说明。
这种情况通常是因为软件POST内容之后,接收不到发布页面的响应导致的。有时候优采云采集器也会把这样的情况默认为成功发布,而事实上,我们的网站却没有内容,很多站长因此呕吐不已。
其实这是一个简单的问题,你可以按照“无法接受到发布页面的响应”来找寻缘由。如:
1,你的网站是否能正常访问,特别是你的Web发布页面。
2,设置Web发布时,网站的根目录有没有填写正确,可以用刷新栏目列表是否正确来判定。
3,网站是否成功登录或则发布用户是否有权限。
4,优采云采集器-辅助工具-重新加载配置。
5,如果以上方案你都有测试过,那不妨再重启一下优采云采集器。
以下是一些图片,可以帮你愈发直观的了解:
你可以任意转摘“优采云采集器出现"WEB发布是否成功未知",错误缘由和解决办法”,但请保留本文出处和版权信息。

