
文章自动采集
今日头条、知乎、微博、博客、新闻源等各大网站的头条文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-04-25 04:03
文章自动采集今日头条、知乎、微博、博客、新闻源等各大网站的头条文章。采集的这些数据,可以拿去当一份薪资报告来看。本公众号的文章,互联网圈的童鞋,转载记得在后台回复【转载】获取要转载的文章列表哦。这里面包含了:今日头条、知乎、微博、博客、新闻源等各大网站的头条文章。其中除了每天下午7点收集,一周五天每天下午六点收集,周末收集外,本号分享过头条文章的,都不提供收集数据。
【文章自动采集】这个公众号,提供采集任意网站的头条文章,收集该网站所有文章,统计时间周期为:2017年1月1日-2017年6月30日。本号的文章,互联网圈的童鞋,转载记得在后台回复【转载】获取要转载的文章列表哦。
最难用的还是live推荐和新闻推荐,现在我基本不去发新闻。我用什么采集的话,通过apiserver自己抓数据。但是这还是个人采集,要企业化,组织化才好使,有数据共享。最好再配个分析系统什么的,那就更好用了。推荐清博大数据,
自动采集新闻,是一直苦于采集不到头条的网站,比如你从百度看到的百家,头条,西瓜等等都是由新闻转载组成的。其实只要用到“邮箱推送”的功能就可以采集,这也是我近期考虑研究的方向。以下是我的案例:。
国内lol,dota2国内厂商的比赛流量占总流量70%,剩下的部分就是手游,短视频,游戏聊天等等。这些领域都是单独独立的自媒体或者官方的各大平台号,文章,阅读数,转发,收藏数,评论等等都是比较好弄的,不过相应的准确性,深度也有所欠缺,所以做这些的自媒体文章内容多为打广告,招募种子用户等等,所以不是十分推荐。
一般的内容采集,推荐优先选择百度新闻。其他的新闻分类网站如今日头条,网易新闻,腾讯新闻,中国新闻传媒集团,中国网。也有一些头条号已经被腾讯收购的,所以也有些公司新闻的头条号标示为腾讯新闻号。因为这些所有上网站的网站,只要有推荐,就有用户去阅读和关注。基本原理是读读看了然后推荐给自己周围或者是你手机qq好友。
这些都有些内容单一,深度也不大,不过能搞定的,都不叫难。之前用百度的matcher-百度统计监控移动网站的新闻推荐选择优先百度新闻关注,其他。实时新闻推荐也可以一试。谷歌新闻,没有用过,就不说。说到谷歌,其实每天很多人打电话问我,我的谷歌怎么回事,我完全搞不懂怎么回事。对了,还有chrome的创建标签"bannertofeed",能看到谷歌新闻,谷歌其他网站等等。
不过要打标签,把自己的网站列出来,把自己网站标记名称,然后在feed插件。才能看到相应的信息。国内的话,百度国内都有一。 查看全部
今日头条、知乎、微博、博客、新闻源等各大网站的头条文章
文章自动采集今日头条、知乎、微博、博客、新闻源等各大网站的头条文章。采集的这些数据,可以拿去当一份薪资报告来看。本公众号的文章,互联网圈的童鞋,转载记得在后台回复【转载】获取要转载的文章列表哦。这里面包含了:今日头条、知乎、微博、博客、新闻源等各大网站的头条文章。其中除了每天下午7点收集,一周五天每天下午六点收集,周末收集外,本号分享过头条文章的,都不提供收集数据。
【文章自动采集】这个公众号,提供采集任意网站的头条文章,收集该网站所有文章,统计时间周期为:2017年1月1日-2017年6月30日。本号的文章,互联网圈的童鞋,转载记得在后台回复【转载】获取要转载的文章列表哦。
最难用的还是live推荐和新闻推荐,现在我基本不去发新闻。我用什么采集的话,通过apiserver自己抓数据。但是这还是个人采集,要企业化,组织化才好使,有数据共享。最好再配个分析系统什么的,那就更好用了。推荐清博大数据,
自动采集新闻,是一直苦于采集不到头条的网站,比如你从百度看到的百家,头条,西瓜等等都是由新闻转载组成的。其实只要用到“邮箱推送”的功能就可以采集,这也是我近期考虑研究的方向。以下是我的案例:。
国内lol,dota2国内厂商的比赛流量占总流量70%,剩下的部分就是手游,短视频,游戏聊天等等。这些领域都是单独独立的自媒体或者官方的各大平台号,文章,阅读数,转发,收藏数,评论等等都是比较好弄的,不过相应的准确性,深度也有所欠缺,所以做这些的自媒体文章内容多为打广告,招募种子用户等等,所以不是十分推荐。
一般的内容采集,推荐优先选择百度新闻。其他的新闻分类网站如今日头条,网易新闻,腾讯新闻,中国新闻传媒集团,中国网。也有一些头条号已经被腾讯收购的,所以也有些公司新闻的头条号标示为腾讯新闻号。因为这些所有上网站的网站,只要有推荐,就有用户去阅读和关注。基本原理是读读看了然后推荐给自己周围或者是你手机qq好友。
这些都有些内容单一,深度也不大,不过能搞定的,都不叫难。之前用百度的matcher-百度统计监控移动网站的新闻推荐选择优先百度新闻关注,其他。实时新闻推荐也可以一试。谷歌新闻,没有用过,就不说。说到谷歌,其实每天很多人打电话问我,我的谷歌怎么回事,我完全搞不懂怎么回事。对了,还有chrome的创建标签"bannertofeed",能看到谷歌新闻,谷歌其他网站等等。
不过要打标签,把自己的网站列出来,把自己网站标记名称,然后在feed插件。才能看到相应的信息。国内的话,百度国内都有一。
微信官方就不会做公众号文章爬取功能?
采集交流 • 优采云 发表了文章 • 0 个评论 • 240 次浏览 • 2021-04-19 00:02
文章自动采集至公众号,根据提示操作即可。【文末福利】阅读本文需要结合着博客公众号技术升级一起读。上半年的时候,很多人问我网站爬虫和微信公众号有什么关系,这种关系不是scrapy,selenium,phantomjs就能完成的事情。我说了,你这不是打酱油,是没有认真去研究过爬虫和公众号。连爬虫都能做得出来,难道微信官方就不会做公众号文章爬取功能?即使网站爬虫和公众号脱离网站框架全部封闭爬取,只要配置好开发环境,就可以按照你的意愿拿到数据的。
代码:python爬虫官方模块itchat实现自动发送公众号信息送达回复网站爬虫官方模块negative把历史文章中不及时的修改为更新。对于scrapy来说,需要:注册scrapy爬虫账号官方模块开发环境;网站抓取;公众号文章抓取;微信文章抓取。公众号文章爬取包括:登录公众号/不登录公众号/不登录公众号api公众号文章抓取:登录公众号,webhook登录页面。
不登录公众号,requests登录页面。api可以拿到文章url,包括获取文章详情、阅读数量,或者一些简单的分析。微信文章抓取:不需要登录,抓取微信群中你想获取的文章,比如一些订阅号(小程序)的文章,也可以apis抓取。python爬虫实现两种方式:一种就是官方框架下面写爬虫去抓取,我们这里介绍第二种方式,我是采用phantomjs作为微信api接口。
很多网站,比如知乎、百度、西瓜助手这些页面比较简单,我们可以全部封装在一个类中,先写好api,再根据url,抓取其中我们想要的东西,而不用登录、注册、架构等一些限制,而官方接口和第三方api可以二者权衡,看哪个你更喜欢吧。代码:python爬虫官方框架itchatio爬虫框架最近比较火热,很多对爬虫感兴趣的人都在看itchat的源码,读源码是非常有意思的过程,推荐你看看我写的一些实践的小项目,虽然模块已经搭建好了,但是如果想使用的话,你还是得自己造轮子。
其实也可以按照我的爬虫爬取思路一步一步去爬取,也不用模块实现了,如果觉得文章对你有用,可以关注公众号【码上趣学院】,我给大家转发一下哦,公众号回复【gh30】,可以免费领取我们官方的源码!!!或者点个赞!谢谢大家支持!。 查看全部
微信官方就不会做公众号文章爬取功能?
文章自动采集至公众号,根据提示操作即可。【文末福利】阅读本文需要结合着博客公众号技术升级一起读。上半年的时候,很多人问我网站爬虫和微信公众号有什么关系,这种关系不是scrapy,selenium,phantomjs就能完成的事情。我说了,你这不是打酱油,是没有认真去研究过爬虫和公众号。连爬虫都能做得出来,难道微信官方就不会做公众号文章爬取功能?即使网站爬虫和公众号脱离网站框架全部封闭爬取,只要配置好开发环境,就可以按照你的意愿拿到数据的。
代码:python爬虫官方模块itchat实现自动发送公众号信息送达回复网站爬虫官方模块negative把历史文章中不及时的修改为更新。对于scrapy来说,需要:注册scrapy爬虫账号官方模块开发环境;网站抓取;公众号文章抓取;微信文章抓取。公众号文章爬取包括:登录公众号/不登录公众号/不登录公众号api公众号文章抓取:登录公众号,webhook登录页面。
不登录公众号,requests登录页面。api可以拿到文章url,包括获取文章详情、阅读数量,或者一些简单的分析。微信文章抓取:不需要登录,抓取微信群中你想获取的文章,比如一些订阅号(小程序)的文章,也可以apis抓取。python爬虫实现两种方式:一种就是官方框架下面写爬虫去抓取,我们这里介绍第二种方式,我是采用phantomjs作为微信api接口。
很多网站,比如知乎、百度、西瓜助手这些页面比较简单,我们可以全部封装在一个类中,先写好api,再根据url,抓取其中我们想要的东西,而不用登录、注册、架构等一些限制,而官方接口和第三方api可以二者权衡,看哪个你更喜欢吧。代码:python爬虫官方框架itchatio爬虫框架最近比较火热,很多对爬虫感兴趣的人都在看itchat的源码,读源码是非常有意思的过程,推荐你看看我写的一些实践的小项目,虽然模块已经搭建好了,但是如果想使用的话,你还是得自己造轮子。
其实也可以按照我的爬虫爬取思路一步一步去爬取,也不用模块实现了,如果觉得文章对你有用,可以关注公众号【码上趣学院】,我给大家转发一下哦,公众号回复【gh30】,可以免费领取我们官方的源码!!!或者点个赞!谢谢大家支持!。
文章自动采集,不要再看那些那些傻逼推广了
采集交流 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2021-04-04 00:04
文章自动采集,不要再看那些傻逼推广了,比如【idl访问记录爬取】,而是文章一开始自动抓取。百度抓取头条推荐位,那还是比较容易的。推荐位全是各个大站生成。不过可以通过锚文本让百度识别出来,反正文章内容都是通过算法出来的,很容易识别。我之前是用搜狗浏览器,把蜘蛛搞坏了,爬不了大站,爬到一些小站。后来我发现还是使用【selenium】这个小工具最为简单方便。
之前我跟edx上linuxon-mac的课程,freebsdxorg的学习环境经常崩溃,我就用这个工具同时支持selenium和requests,搞定freebsd上的动态页面爬取(详见该工具使用)。这个案例就是实验domtree的基本用法,我还引入chemos库fromdomasatdocumentationofos1.进入python目录找到这个#listifyhexo中blogs目录下的内容就是所有文章的dom节点2.这里我已经搞定了一些suppress文章的xpath(css-dom过滤)3.改变爬取的html结构,也就是让a标签的值改为一个image标签:然后继续写代码:4.这里fromcv2importimage5.在image标签下写入点:fromdom.bodyimportpicture在markdown文档中通过这样一行代码就可以实现pdf浏览器里的有参图片浏览。
6.虽然说htmldomtree自动爬取还只是个demo的,代码功能都是有限的,不过搞定图片是足够了,其他文章只要手动替换一下内容差不多也可以实现。既然是用来在mac上写windows程序,不太方便保存高清的图片,所以我只保存了2m左右的3m左右的图片。mac的快速itunes转换还可以看这里以下代码是这个软件的功能:电脑上下载安装pip版本号6.2.1-1或更高,之后手动安装lxml,threadlocal,freebbj等相关模块。本代码有误请提,我想对方程式如有需要可给我发邮件。 查看全部
文章自动采集,不要再看那些那些傻逼推广了
文章自动采集,不要再看那些傻逼推广了,比如【idl访问记录爬取】,而是文章一开始自动抓取。百度抓取头条推荐位,那还是比较容易的。推荐位全是各个大站生成。不过可以通过锚文本让百度识别出来,反正文章内容都是通过算法出来的,很容易识别。我之前是用搜狗浏览器,把蜘蛛搞坏了,爬不了大站,爬到一些小站。后来我发现还是使用【selenium】这个小工具最为简单方便。
之前我跟edx上linuxon-mac的课程,freebsdxorg的学习环境经常崩溃,我就用这个工具同时支持selenium和requests,搞定freebsd上的动态页面爬取(详见该工具使用)。这个案例就是实验domtree的基本用法,我还引入chemos库fromdomasatdocumentationofos1.进入python目录找到这个#listifyhexo中blogs目录下的内容就是所有文章的dom节点2.这里我已经搞定了一些suppress文章的xpath(css-dom过滤)3.改变爬取的html结构,也就是让a标签的值改为一个image标签:然后继续写代码:4.这里fromcv2importimage5.在image标签下写入点:fromdom.bodyimportpicture在markdown文档中通过这样一行代码就可以实现pdf浏览器里的有参图片浏览。
6.虽然说htmldomtree自动爬取还只是个demo的,代码功能都是有限的,不过搞定图片是足够了,其他文章只要手动替换一下内容差不多也可以实现。既然是用来在mac上写windows程序,不太方便保存高清的图片,所以我只保存了2m左右的3m左右的图片。mac的快速itunes转换还可以看这里以下代码是这个软件的功能:电脑上下载安装pip版本号6.2.1-1或更高,之后手动安装lxml,threadlocal,freebbj等相关模块。本代码有误请提,我想对方程式如有需要可给我发邮件。
让你的信息快速收录排名发布产品信息的节省时间
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-03-30 20:09
发布信息的主要目的是使搜索引擎收录能够跟上您的信息。我们的信息发布助手内置了多种发布策略来满足搜索引擎的需求,例如“随机图片”。 ,图片alt标签,随机句子,多个随机段落,信息轮链系统和其他内容更改”,让您的信息快速收录排名
用于节省产品发布时间的人力,可以自动发布信息,
该软件以不定期的间隔发布信息,随意调整间隔,以使每两条信息之间的间隔是不规则的,并具有定时关机功能(通常适用于夜间发布信息并自动关机的朋友放下后)。
二、保存配置功能
如果有多个产品需要单独发布,则可以分别保存产品功能的配置。您只需要配置一次。保存配置后,请稍后导入配置以加载先前的设置,这样可以节省时间和麻烦。
三、自动设置产品图片功能
共有3种选择图片的方式:
1、同步采集 网站图片。如果您在网站背景中上传图片,请点击“ 采集相册”,即可自动将采集图片上传到本地。
2、从网站背景中获取URL地址,并为您要发送的产品拍照。
3、在本地计算机上手动批量导入图片。
五、自动标题合成功能
想不出很多标题?该软件具有内置的批处理合成标题功能,可以自动成批地合成数千个唯一标题。根据需要,配置标题模板以生成它。
标题可以任意组合,常用的格式是自动发布工具。通过各种自定义组合,您可以生成千变万化的不同标题。发布文章软件
四、强大的内容编辑器
该软件具有内置的文本编辑器,该编辑器可自动识别网站内容提交格式是纯文本还是html文本。就像在网站的后台操作一样,可以随时在软件内部直观地编辑html文本。
案例:
5个新模板!获得5个不同的产品介绍,这些产品会定期发布以改进收录!
加快8个助手发布软件, 88助手发布软件和助手发布软件。八方资源网的助手发布了该软件,《中国企业记录》的助手发布了该软件,而嘉德化工网的助手发布了该软件。硬件网络助手发布软件,句容网络助手发布软件,爱夫网络助手发布软件。 Net助手发布软件,机械在线助手发布软件,行业信息网络助手发布软件。
根据需要,可以通过配置标题模板和图像批处理来生成标题模板。对于产品图片,用户最大的问题是图片太大,平台不允许上传。 8、售后,我们和团队都有,并且要重新发送信息功能我们用来刷新发布的信息,在工作站的后台,有些页面一页一页地刷新,有些更麻烦了,您需要一对一
欢迎来到网站,具体地址是杭城工业区阜新林工业园1号楼202楼,联系人是梁女士。
主要业务是为您提供深圳网络推广,深圳网站推广,深圳信息发布,深圳网站推广专家,网站优化公司,深圳宝安西乡南山网站推广,深圳信息发布,发布广告信息,企业网站优化,深圳福永沙井十堰龙华网站优化,深圳企业网站优化,网站推广软件,网站推广工具,国外网站推广等? ??? ?是一家主要从事网络信息应用服务的网络公司,专注于网络推广和网络推广,引领网络推广行业。
单位的注册资本单位的注册资本少于人民币100万元。
∨ 查看全部
让你的信息快速收录排名发布产品信息的节省时间
发布信息的主要目的是使搜索引擎收录能够跟上您的信息。我们的信息发布助手内置了多种发布策略来满足搜索引擎的需求,例如“随机图片”。 ,图片alt标签,随机句子,多个随机段落,信息轮链系统和其他内容更改”,让您的信息快速收录排名
用于节省产品发布时间的人力,可以自动发布信息,
该软件以不定期的间隔发布信息,随意调整间隔,以使每两条信息之间的间隔是不规则的,并具有定时关机功能(通常适用于夜间发布信息并自动关机的朋友放下后)。
二、保存配置功能
如果有多个产品需要单独发布,则可以分别保存产品功能的配置。您只需要配置一次。保存配置后,请稍后导入配置以加载先前的设置,这样可以节省时间和麻烦。

三、自动设置产品图片功能
共有3种选择图片的方式:
1、同步采集 网站图片。如果您在网站背景中上传图片,请点击“ 采集相册”,即可自动将采集图片上传到本地。
2、从网站背景中获取URL地址,并为您要发送的产品拍照。
3、在本地计算机上手动批量导入图片。
五、自动标题合成功能
想不出很多标题?该软件具有内置的批处理合成标题功能,可以自动成批地合成数千个唯一标题。根据需要,配置标题模板以生成它。
标题可以任意组合,常用的格式是自动发布工具。通过各种自定义组合,您可以生成千变万化的不同标题。发布文章软件

四、强大的内容编辑器
该软件具有内置的文本编辑器,该编辑器可自动识别网站内容提交格式是纯文本还是html文本。就像在网站的后台操作一样,可以随时在软件内部直观地编辑html文本。
案例:
5个新模板!获得5个不同的产品介绍,这些产品会定期发布以改进收录!

加快8个助手发布软件, 88助手发布软件和助手发布软件。八方资源网的助手发布了该软件,《中国企业记录》的助手发布了该软件,而嘉德化工网的助手发布了该软件。硬件网络助手发布软件,句容网络助手发布软件,爱夫网络助手发布软件。 Net助手发布软件,机械在线助手发布软件,行业信息网络助手发布软件。
根据需要,可以通过配置标题模板和图像批处理来生成标题模板。对于产品图片,用户最大的问题是图片太大,平台不允许上传。 8、售后,我们和团队都有,并且要重新发送信息功能我们用来刷新发布的信息,在工作站的后台,有些页面一页一页地刷新,有些更麻烦了,您需要一对一
欢迎来到网站,具体地址是杭城工业区阜新林工业园1号楼202楼,联系人是梁女士。
主要业务是为您提供深圳网络推广,深圳网站推广,深圳信息发布,深圳网站推广专家,网站优化公司,深圳宝安西乡南山网站推广,深圳信息发布,发布广告信息,企业网站优化,深圳福永沙井十堰龙华网站优化,深圳企业网站优化,网站推广软件,网站推广工具,国外网站推广等? ??? ?是一家主要从事网络信息应用服务的网络公司,专注于网络推广和网络推广,引领网络推广行业。
单位的注册资本单位的注册资本少于人民币100万元。
∨
猪八戒网、中国太平洋保险、深圳金宝贝、外卖网点评网
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-03-24 23:01
文章自动采集了猪八戒网、中国太平洋保险、深圳金宝贝、外卖网点评网、饿了么、app追评、小红书等官方数据。视频更全面的展示了采集到的全部数据。
知道一款脚本采集数据很方便的:采集外卖,美团,饿了么,自己手动操作太麻烦,用脚本采集简单的数据还是很方便的,可以自己在线操作下载方便。
有的,采集外卖的还是用你掌握的一些技术及工具解决得比较快,我推荐的是大家用好工具,可以自己控制!推荐采用:模拟手机来操作微信公众号的推送,然后用点评来判断有没有评论!ps:线上微信公众号推送,功能强大的程序(如猫眼电影类似)只需简单的更改二维码,直接就能使用,并且能做到非常精准,评论数据那种还是相对比较真实的,能查出来正负面什么的!用到一个,就知道为什么有了!具体方法可查看一下!可以看一下我写的文章!。
八戒网除了你之前说的上边的付费方式,也有采用简单方式去采集。
大方向的内容不需要你去做什么技术研发,
我个人建议,不要买所谓的工具和软件,操作麻烦,而且作用有限,可以使用微信小程序去采集,采集微信的点评,或者百度等搜索的点评,推荐使用北京地区的地推团队提供的一款网站采集工具,将你的网站标题、作用等全部加入进去,这个数据基本上都会采集到,效率高,操作简单。如果想加入网站采集的话,建议先申请一个微信小程序,本地人有群可以去拓展一下,直接在群里加作者,申请加入就可以,但是一定要给他发送链接,网站采集也需要发送链接,而且设置默认网址、浏览器、等信息。 查看全部
猪八戒网、中国太平洋保险、深圳金宝贝、外卖网点评网
文章自动采集了猪八戒网、中国太平洋保险、深圳金宝贝、外卖网点评网、饿了么、app追评、小红书等官方数据。视频更全面的展示了采集到的全部数据。
知道一款脚本采集数据很方便的:采集外卖,美团,饿了么,自己手动操作太麻烦,用脚本采集简单的数据还是很方便的,可以自己在线操作下载方便。
有的,采集外卖的还是用你掌握的一些技术及工具解决得比较快,我推荐的是大家用好工具,可以自己控制!推荐采用:模拟手机来操作微信公众号的推送,然后用点评来判断有没有评论!ps:线上微信公众号推送,功能强大的程序(如猫眼电影类似)只需简单的更改二维码,直接就能使用,并且能做到非常精准,评论数据那种还是相对比较真实的,能查出来正负面什么的!用到一个,就知道为什么有了!具体方法可查看一下!可以看一下我写的文章!。
八戒网除了你之前说的上边的付费方式,也有采用简单方式去采集。
大方向的内容不需要你去做什么技术研发,
我个人建议,不要买所谓的工具和软件,操作麻烦,而且作用有限,可以使用微信小程序去采集,采集微信的点评,或者百度等搜索的点评,推荐使用北京地区的地推团队提供的一款网站采集工具,将你的网站标题、作用等全部加入进去,这个数据基本上都会采集到,效率高,操作简单。如果想加入网站采集的话,建议先申请一个微信小程序,本地人有群可以去拓展一下,直接在群里加作者,申请加入就可以,但是一定要给他发送链接,网站采集也需要发送链接,而且设置默认网址、浏览器、等信息。
黄瓜世界:网站数据采集工具哪个好用?-微小宝
采集交流 • 优采云 发表了文章 • 0 个评论 • 247 次浏览 • 2021-03-17 11:01
3.【小宝】用于微信公众号。
还有今天的标题和其他平台文章供参考。
以上是“黄瓜世界”提供的答案。谢谢您的关注
网站 Data 采集哪个工具易于使用?
网页数据采集,有很多现成的爬虫软件可以直接使用,下面我将简要介绍优采云,章鱼和优采云三种类型,操作简单,易于学习和理解,有兴趣的朋友可以尝试一下:
这是一款非常智能的网络爬虫软件,支持跨平台,完全免费供个人使用。对于大多数网站,只需输入URL,软件将自动识别并提取相关的字段信息,包括列表,表格,链接,图片等,无需配置任何采集规则,一键点击即可删除,支持自动翻页和数据导出功能,对于小白来说,很容易学习和掌握:
这是一个非常好的国内数据采集软件。与优采云 采集器相比,例如,章鱼采集器当前仅支持Windows平台,您需要手动设置采集字段和配置规则,因此比较麻烦和灵活。它具有大量的内置数据采集模板,可以轻松地将采集流行的网站例如京东和天猫。官方教程非常详细,小白也很容易掌握:
当然,除了上述三个爬网软件外,还有许多其他支持网站 data 采集的软件,例如数字,应用程序等也非常不错,如果您熟悉Python的话,Java和其他编程语言,您也可以自己编程以获取数据。 Internet上有相关的教程和材料。简介非常详细。如果您有兴趣,可以搜索。希望以上分享的内容对您有所帮助。欢迎发表评论。 查看全部
黄瓜世界:网站数据采集工具哪个好用?-微小宝
3.【小宝】用于微信公众号。
还有今天的标题和其他平台文章供参考。
以上是“黄瓜世界”提供的答案。谢谢您的关注
网站 Data 采集哪个工具易于使用?
网页数据采集,有很多现成的爬虫软件可以直接使用,下面我将简要介绍优采云,章鱼和优采云三种类型,操作简单,易于学习和理解,有兴趣的朋友可以尝试一下:
这是一款非常智能的网络爬虫软件,支持跨平台,完全免费供个人使用。对于大多数网站,只需输入URL,软件将自动识别并提取相关的字段信息,包括列表,表格,链接,图片等,无需配置任何采集规则,一键点击即可删除,支持自动翻页和数据导出功能,对于小白来说,很容易学习和掌握:
这是一个非常好的国内数据采集软件。与优采云 采集器相比,例如,章鱼采集器当前仅支持Windows平台,您需要手动设置采集字段和配置规则,因此比较麻烦和灵活。它具有大量的内置数据采集模板,可以轻松地将采集流行的网站例如京东和天猫。官方教程非常详细,小白也很容易掌握:
当然,除了上述三个爬网软件外,还有许多其他支持网站 data 采集的软件,例如数字,应用程序等也非常不错,如果您熟悉Python的话,Java和其他编程语言,您也可以自己编程以获取数据。 Internet上有相关的教程和材料。简介非常详细。如果您有兴趣,可以搜索。希望以上分享的内容对您有所帮助。欢迎发表评论。
WordPress文章自动采集插件 WP
采集交流 • 优采云 发表了文章 • 0 个评论 • 382 次浏览 • 2020-08-25 09:49
WP-AutoPost英文免费下载地址
一、安装WP-AutoPost
和安装其他WordPress插件一样,直接上传到插件目录,激活即可使用,无需再进行额外设置或更改代码。
二、创建采集任务
点击“新建任务”后,输入任务名称,即可创建新任务,创建好新任务以后可以在任务列表中查看到该任务,就可对该任务进行更多设置。
三、基本设置功能
在基本设置选项卡下,可以进行如下设置:
四、文章来源设置
在该选项卡下我们须要设置文章来源的文章列表网址及具体文章的匹配规则
我们以采集“新浪互联网新闻”为例,文章列表网址为因而在 手工指定文章列表网址 中输入该网址即可,如下所示:
之后须要设置该文章列表网址下具体文章网址的匹配规则
五、文章网址匹配规则
文章网址匹配规则的设置十分简单,无需复杂设置,提供两种匹配模式,可以使用URL键值匹配,也可以使用CSS选择器进行匹配,通常使用URL键值匹配较为简单。
1. 使用URL键值匹配
通过点击列表网址上的文章,我们可以发觉整篇文章的URL都为如下结构
因此将URL中变化的数字或字母替换为键值(*)即可,如:(*)/(*).shtml
2. 使用CSS选择器进行匹配
使用CSS选择器进行匹配,我们只须要设置文章网址的CSS选择器即可(不知道CSS选择器为什么物,一分钟学会怎样设置CSS选择器),通过查看列表网址 的源代码即可轻松设置,找到该列表网址下具体文章的超链接的代码,如下所示:
可以看见,文章的超链接a标签在class为“contList”的标签内部,因此文章网址的CSS选择器只须要设置为.contList a 即可,如下所示:
设置完成以后,不知道设置是否正确,可以点击上图中的测试按键,如果设置正确,将列举该列表网址下所有文章名称和对应的网页地址,如下所示:
六、文章抓取设置
在该选项卡下,我们须要设置文章标题和文章内容的匹配规则,提供两种形式进行设置,推荐使用CSS选择器形式,使用该方法更为简单,精确。(不知道CSS选择器为什么物,一分钟学会怎样设置CSS选择器)
我们只须要设置文章标题CSS选择器和文章内容CSS选择器,即可确切抓取文章标题和文章内容。
在文章来源设置里,我们以采集”新浪互联网新闻“为例,这里还是以该事例讲解,通过查看列表网址 下某一篇文章的源代码即可轻松设置,例如,我们通过查看某篇具体文章 的源代码,如下所示:
可以看见,文章标题在id为“artibodyTitle”的标签内部,因此文章标题CSS选择器只须要设置为#artibodyTitle即可;
同样的,找到文章内容的相关代码:
可以看见,文章内容在id为“artibody”的标签内部,因此文章内容CSS选择器只须要设置为#artibody即可;如下所示:
设置完成以后,不知道设置是否正确,可点击测试按键,输入测试地址,如果设置正确,将显示出文章标题和文章内容,方便检测设置
七、抓取文章分页内容
如果文章内容过长,有多个分页同样可以抓取全部内容,这时须要设置文章分页链接CSS选择器,通过查看具体文章网址源代码,找到分页链接的地方,例如某篇文章分页链接代码如下:
可以看见,分页链接A标签在class为 “page-link” 的标签内部
因此,文章分页链接CSS选择器设置为.page-link a即可,如下所示:
如果勾选当发表时也分页时,发表文章也将同样被分页,如果你的WordPress主题不支持 标签,请勿勾选。
八、文章内容过滤功能
文章内容过滤功能,可过滤掉正文中不希望发布的内容(如广告代码,版权信息等),可设置两个关键词,删除掉两个关键词之间的内容,关键词2可以为空,表示删掉掉关键词1以后的所有内容。
如下所示,我们通过测试抓取文章后发觉文章里有不希望发布的内容,切换到HTML显示,找到该内容的HTML代码,分别设置两个关键词即可过滤掉该内容。
如上所示,如果我们希望过滤掉前面
和
之间的内容,添加如下设置即可
如果须要过滤掉多处内容,可以添加多组设置。
九、HTML标签过滤功能 查看全部
WordPress文章自动采集插件 WP
WP-AutoPost英文免费下载地址
一、安装WP-AutoPost
和安装其他WordPress插件一样,直接上传到插件目录,激活即可使用,无需再进行额外设置或更改代码。
二、创建采集任务
点击“新建任务”后,输入任务名称,即可创建新任务,创建好新任务以后可以在任务列表中查看到该任务,就可对该任务进行更多设置。

三、基本设置功能

在基本设置选项卡下,可以进行如下设置:
四、文章来源设置
在该选项卡下我们须要设置文章来源的文章列表网址及具体文章的匹配规则
我们以采集“新浪互联网新闻”为例,文章列表网址为因而在 手工指定文章列表网址 中输入该网址即可,如下所示:

之后须要设置该文章列表网址下具体文章网址的匹配规则
五、文章网址匹配规则
文章网址匹配规则的设置十分简单,无需复杂设置,提供两种匹配模式,可以使用URL键值匹配,也可以使用CSS选择器进行匹配,通常使用URL键值匹配较为简单。
1. 使用URL键值匹配
通过点击列表网址上的文章,我们可以发觉整篇文章的URL都为如下结构
因此将URL中变化的数字或字母替换为键值(*)即可,如:(*)/(*).shtml

2. 使用CSS选择器进行匹配
使用CSS选择器进行匹配,我们只须要设置文章网址的CSS选择器即可(不知道CSS选择器为什么物,一分钟学会怎样设置CSS选择器),通过查看列表网址 的源代码即可轻松设置,找到该列表网址下具体文章的超链接的代码,如下所示:

可以看见,文章的超链接a标签在class为“contList”的标签内部,因此文章网址的CSS选择器只须要设置为.contList a 即可,如下所示:

设置完成以后,不知道设置是否正确,可以点击上图中的测试按键,如果设置正确,将列举该列表网址下所有文章名称和对应的网页地址,如下所示:

六、文章抓取设置
在该选项卡下,我们须要设置文章标题和文章内容的匹配规则,提供两种形式进行设置,推荐使用CSS选择器形式,使用该方法更为简单,精确。(不知道CSS选择器为什么物,一分钟学会怎样设置CSS选择器)
我们只须要设置文章标题CSS选择器和文章内容CSS选择器,即可确切抓取文章标题和文章内容。
在文章来源设置里,我们以采集”新浪互联网新闻“为例,这里还是以该事例讲解,通过查看列表网址 下某一篇文章的源代码即可轻松设置,例如,我们通过查看某篇具体文章 的源代码,如下所示:

可以看见,文章标题在id为“artibodyTitle”的标签内部,因此文章标题CSS选择器只须要设置为#artibodyTitle即可;
同样的,找到文章内容的相关代码:

可以看见,文章内容在id为“artibody”的标签内部,因此文章内容CSS选择器只须要设置为#artibody即可;如下所示:

设置完成以后,不知道设置是否正确,可点击测试按键,输入测试地址,如果设置正确,将显示出文章标题和文章内容,方便检测设置

七、抓取文章分页内容
如果文章内容过长,有多个分页同样可以抓取全部内容,这时须要设置文章分页链接CSS选择器,通过查看具体文章网址源代码,找到分页链接的地方,例如某篇文章分页链接代码如下:

可以看见,分页链接A标签在class为 “page-link” 的标签内部
因此,文章分页链接CSS选择器设置为.page-link a即可,如下所示:

如果勾选当发表时也分页时,发表文章也将同样被分页,如果你的WordPress主题不支持 标签,请勿勾选。
八、文章内容过滤功能
文章内容过滤功能,可过滤掉正文中不希望发布的内容(如广告代码,版权信息等),可设置两个关键词,删除掉两个关键词之间的内容,关键词2可以为空,表示删掉掉关键词1以后的所有内容。
如下所示,我们通过测试抓取文章后发觉文章里有不希望发布的内容,切换到HTML显示,找到该内容的HTML代码,分别设置两个关键词即可过滤掉该内容。

如上所示,如果我们希望过滤掉前面
和
之间的内容,添加如下设置即可

如果须要过滤掉多处内容,可以添加多组设置。
九、HTML标签过滤功能
移动应用市场自动化爬取技术的研究与应用
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2020-08-22 10:50
【摘要】:近两年来,由于应用软件数目过多,许多应用商店将大部分应用隐藏在了查询表单旁边的网路数据库中。移动应用软件的安全检查须要大量的应用样本,而这种应用属于Deep Web数据,这给联通应用软件的采集和检查带来了制约。传统的网路爬虫只能访问通过超链接才能抵达的Surface Web数据,而难以访问网路数据库中的Deep Web数据。目前针对这类Deep Web数据的采集技术主要是基于表层化的方法来采集,基于表层化的采集方式关键在于怎样生成合适的查询词,高效率地让网路数据库中的隐藏数据曝露下来。现有的表层化Deep Web数据采集方法主要是面向搜索引擎或大领域主题爬虫,而不是象联通应用软件信息这样的特定领域的Deep Web数据的。本文为了尽可能获取更多的应用软件样本,尤其是Deep Web中的应用数据,对已有的Web数据采集技术和目前主流的联通应用商店进行了研究,主要完成了以下工作:1.对本地应用库中不同类别的应用软件名称进行了动词和词频统计,并勾画了不同比列高频词覆盖应用曲线图,从数据可以得出联通应用软件在命名时用词(字)高度集中的推论,本文据此提出了一种基于样本词频的联通应用商店Deep Web数据采集方法,提取1%的本地应用软件名称中的高频词作为查询词递交至应用商店的应用查询表单,使隐藏在网路数据库中的应用信息曝露下来,再结合传统网路爬虫采集这些应用;2.设计了一个联通应用商店Deep Web数据爬取系统,该系统主要由爬虫模块、信息抽取模块和查询词生成模块构成,在采集完应用商店中的表层网路应用数据后,继续采集Deep Web应用数据,提高系统采集的应用数目;3.进行了系统运行实验,对5家主流联通应用商店进行了应用数据抓取。实验表明系统才能稳定运行,且与不收录Deep Web采集模块的scrapy爬虫采集系统相比,Deep Web数据爬取系统对腾讯应用宝、百度手机助手和360手机助手这3家应用商店的应用采集数量提高了9倍以上,对小米应用商店和华为应用市场的应用覆盖率也提高了将近1倍,数据表明系统才能有效地采集移动应用商店中的Deep Web数据,提高应用采集覆盖率,为联通应用软件的安全检查提供更充分的样本支持。 查看全部
移动应用市场自动化爬取技术的研究与应用
【摘要】:近两年来,由于应用软件数目过多,许多应用商店将大部分应用隐藏在了查询表单旁边的网路数据库中。移动应用软件的安全检查须要大量的应用样本,而这种应用属于Deep Web数据,这给联通应用软件的采集和检查带来了制约。传统的网路爬虫只能访问通过超链接才能抵达的Surface Web数据,而难以访问网路数据库中的Deep Web数据。目前针对这类Deep Web数据的采集技术主要是基于表层化的方法来采集,基于表层化的采集方式关键在于怎样生成合适的查询词,高效率地让网路数据库中的隐藏数据曝露下来。现有的表层化Deep Web数据采集方法主要是面向搜索引擎或大领域主题爬虫,而不是象联通应用软件信息这样的特定领域的Deep Web数据的。本文为了尽可能获取更多的应用软件样本,尤其是Deep Web中的应用数据,对已有的Web数据采集技术和目前主流的联通应用商店进行了研究,主要完成了以下工作:1.对本地应用库中不同类别的应用软件名称进行了动词和词频统计,并勾画了不同比列高频词覆盖应用曲线图,从数据可以得出联通应用软件在命名时用词(字)高度集中的推论,本文据此提出了一种基于样本词频的联通应用商店Deep Web数据采集方法,提取1%的本地应用软件名称中的高频词作为查询词递交至应用商店的应用查询表单,使隐藏在网路数据库中的应用信息曝露下来,再结合传统网路爬虫采集这些应用;2.设计了一个联通应用商店Deep Web数据爬取系统,该系统主要由爬虫模块、信息抽取模块和查询词生成模块构成,在采集完应用商店中的表层网路应用数据后,继续采集Deep Web应用数据,提高系统采集的应用数目;3.进行了系统运行实验,对5家主流联通应用商店进行了应用数据抓取。实验表明系统才能稳定运行,且与不收录Deep Web采集模块的scrapy爬虫采集系统相比,Deep Web数据爬取系统对腾讯应用宝、百度手机助手和360手机助手这3家应用商店的应用采集数量提高了9倍以上,对小米应用商店和华为应用市场的应用覆盖率也提高了将近1倍,数据表明系统才能有效地采集移动应用商店中的Deep Web数据,提高应用采集覆盖率,为联通应用软件的安全检查提供更充分的样本支持。
【开源】新手动采集影视CMS程序开源
采集交流 • 优采云 发表了文章 • 0 个评论 • 365 次浏览 • 2020-08-21 14:06
序
由于近来下班相对比较忙,之前的影视程序预计耗费一个多月的时间来做首版,没想到只做了半个月时间,单位的事就开始忙了上去,没办法只能先放一段时间,程序大部分功能早已写好且可以正常使用,之前第一版测试的BUG也抽口修补了大部分,考虑到短期内暂时未能耗费精力在这程序上,所以开源给你们建立吧。代码写得不好,希望不要嫌弃( ̄▽ ̄)"
已建立功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.轮播管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、专题添加、专题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.推广管理,包括(广告添加、广告列表)
7.扩展商城
8.社交管理
待建立功能
1.系统设置->播放器编辑
2.资源管理->视频管理只写部份
3.资源管理->文章管理
4.会员管理->会员设置
5.社交管理->通讯配置、邮件设置、留言管理只做设置未做对接
6.第三方接入
开源下载
序
由于近来下班相对比较忙,之前的影视程序预计耗费一个多月的时间来做首版,没想到只做了半个月时间,单位的事就开始忙了上去,没办法只能先放一段时间,程序大部分功能早已写好且可以正常使用,之前第一版测试的BUG也抽口修补了大部分,考虑到短期内暂时未能耗费精力在这程序上,所以开源给你们建立吧。代码写得不好,希望不要嫌弃( ̄▽ ̄)"
已建立功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.轮播管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、专题添加、专题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.推广管理,包括(广告添加、广告列表)
7.扩展商城
8.社交管理
待建立功能
1.系统设置->播放器编辑
2.资源管理->视频管理只写部份
3.资源管理->文章管理
4.会员管理->会员设置
5.社交管理->通讯配置、邮件设置、留言管理只做设置未做对接
6.第三方接入
开源下载
序
由于近来下班相对比较忙,之前的影视程序预计耗费一个多月的时间来做首版,没想到只做了半个月时间,单位的事就开始忙了上去,没办法只能先放一段时间,程序大部分功能早已写好且可以正常使用,之前第一版测试的BUG也抽口修补了大部分,考虑到短期内暂时未能耗费精力在这程序上,所以开源给你们建立吧。代码写得不好,希望不要嫌弃( ̄▽ ̄)"
已建立功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.轮播管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、专题添加、专题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.推广管理,包括(广告添加、广告列表)
7.扩展商城
8.社交管理
待建立功能
1.系统设置->播放器编辑
2.资源管理->视频管理只写部份
3.资源管理->文章管理
4.会员管理->会员设置
5.社交管理->通讯配置、邮件设置、留言管理只做设置未做对接
6.第三方接入
开源下载
序
由于近来下班相对比较忙,之前的影视程序预计耗费一个多月的时间来做首版,没想到只做了半个月时间,单位的事就开始忙了上去,没办法只能先放一段时间,程序大部分功能早已写好且可以正常使用,之前第一版测试的BUG也抽口修补了大部分,考虑到短期内暂时未能耗费精力在这程序上,所以开源给你们建立吧。代码写得不好,希望不要嫌弃( ̄▽ ̄)"
已建立功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.轮播管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、专题添加、专题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.推广管理,包括(广告添加、广告列表)
7.扩展商城
8.社交管理
待建立功能
1.系统设置->播放器编辑
2.资源管理->视频管理只写部份
3.资源管理->文章管理
4.会员管理->会员设置
5.社交管理->通讯配置、邮件设置、留言管理只做设置未做对接
6.第三方接入
开源下载 查看全部
【开源】新手动采集影视CMS程序开源
序
由于近来下班相对比较忙,之前的影视程序预计耗费一个多月的时间来做首版,没想到只做了半个月时间,单位的事就开始忙了上去,没办法只能先放一段时间,程序大部分功能早已写好且可以正常使用,之前第一版测试的BUG也抽口修补了大部分,考虑到短期内暂时未能耗费精力在这程序上,所以开源给你们建立吧。代码写得不好,希望不要嫌弃( ̄▽ ̄)"
已建立功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.轮播管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、专题添加、专题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.推广管理,包括(广告添加、广告列表)
7.扩展商城
8.社交管理
待建立功能
1.系统设置->播放器编辑
2.资源管理->视频管理只写部份
3.资源管理->文章管理
4.会员管理->会员设置
5.社交管理->通讯配置、邮件设置、留言管理只做设置未做对接
6.第三方接入
开源下载
序
由于近来下班相对比较忙,之前的影视程序预计耗费一个多月的时间来做首版,没想到只做了半个月时间,单位的事就开始忙了上去,没办法只能先放一段时间,程序大部分功能早已写好且可以正常使用,之前第一版测试的BUG也抽口修补了大部分,考虑到短期内暂时未能耗费精力在这程序上,所以开源给你们建立吧。代码写得不好,希望不要嫌弃( ̄▽ ̄)"
已建立功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.轮播管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、专题添加、专题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.推广管理,包括(广告添加、广告列表)
7.扩展商城
8.社交管理
待建立功能
1.系统设置->播放器编辑
2.资源管理->视频管理只写部份
3.资源管理->文章管理
4.会员管理->会员设置
5.社交管理->通讯配置、邮件设置、留言管理只做设置未做对接
6.第三方接入
开源下载
序
由于近来下班相对比较忙,之前的影视程序预计耗费一个多月的时间来做首版,没想到只做了半个月时间,单位的事就开始忙了上去,没办法只能先放一段时间,程序大部分功能早已写好且可以正常使用,之前第一版测试的BUG也抽口修补了大部分,考虑到短期内暂时未能耗费精力在这程序上,所以开源给你们建立吧。代码写得不好,希望不要嫌弃( ̄▽ ̄)"
已建立功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.轮播管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、专题添加、专题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.推广管理,包括(广告添加、广告列表)
7.扩展商城
8.社交管理
待建立功能
1.系统设置->播放器编辑
2.资源管理->视频管理只写部份
3.资源管理->文章管理
4.会员管理->会员设置
5.社交管理->通讯配置、邮件设置、留言管理只做设置未做对接
6.第三方接入
开源下载
序
由于近来下班相对比较忙,之前的影视程序预计耗费一个多月的时间来做首版,没想到只做了半个月时间,单位的事就开始忙了上去,没办法只能先放一段时间,程序大部分功能早已写好且可以正常使用,之前第一版测试的BUG也抽口修补了大部分,考虑到短期内暂时未能耗费精力在这程序上,所以开源给你们建立吧。代码写得不好,希望不要嫌弃( ̄▽ ̄)"
已建立功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.轮播管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、专题添加、专题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.推广管理,包括(广告添加、广告列表)
7.扩展商城
8.社交管理
待建立功能
1.系统设置->播放器编辑
2.资源管理->视频管理只写部份
3.资源管理->文章管理
4.会员管理->会员设置
5.社交管理->通讯配置、邮件设置、留言管理只做设置未做对接
6.第三方接入
开源下载
无人值守免费手动采集器(自动采集) 3.3.6英文红色免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-08-20 13:48
无人值守免费手动采集器(自动采集)是一款中小网站自动更新神器,高效、自动网站采集工具,无人值守免费手动采集器免费版款独立于网站的全手动信息采集软件,其稳定,安全,低耗,自动化等特点,适用于中小网站日常更新,代替大量人工,将站长等工作人员从乏味的重复劳动中解放下来。
功能介绍
【特色】设定好方案,即可24小时手动工作,不再须要人工干涉
【特色】与网站分离,通过独立制做的插口,无人值守免费手动采集器免费版可以支持任何网站或数据库
【特色】灵活强悍的采集规则不仅仅是采集文章,可采集任何类型信息
【特色】小巧、低耗和良好的稳定性特别适宜运行于服务器
【特色】所有规则都可以导出导入,灵活的资源重用
【特色】采用FTP上传文件,稳定、安全
【特色】下载上传支持断点续传
【特色】高速伪原创
【采集】可选择逆序、顺序、随机采集文章
【采集】支持手动列表网址
【采集】支持对数据分布在多层页面的网站进行采集
【采集】自由设定采集数据项,并可单独过滤整理每位数据项
【采集】支持分页内容采集
【采集】支持任意格式、类型的文件(包括图片、视频)下载
【采集】可突破防盗链文件
【采集】支持动态文件网址剖析
【采集】支持对需登陆访问的网页的采集
【支持】可设定关键词采集
【支持】可设定避免采集的敏感词
【支持】可设置图片水印 查看全部
无人值守免费手动采集器(自动采集) 3.3.6英文红色免费版
无人值守免费手动采集器(自动采集)是一款中小网站自动更新神器,高效、自动网站采集工具,无人值守免费手动采集器免费版款独立于网站的全手动信息采集软件,其稳定,安全,低耗,自动化等特点,适用于中小网站日常更新,代替大量人工,将站长等工作人员从乏味的重复劳动中解放下来。

功能介绍
【特色】设定好方案,即可24小时手动工作,不再须要人工干涉
【特色】与网站分离,通过独立制做的插口,无人值守免费手动采集器免费版可以支持任何网站或数据库
【特色】灵活强悍的采集规则不仅仅是采集文章,可采集任何类型信息
【特色】小巧、低耗和良好的稳定性特别适宜运行于服务器
【特色】所有规则都可以导出导入,灵活的资源重用
【特色】采用FTP上传文件,稳定、安全
【特色】下载上传支持断点续传
【特色】高速伪原创
【采集】可选择逆序、顺序、随机采集文章
【采集】支持手动列表网址
【采集】支持对数据分布在多层页面的网站进行采集
【采集】自由设定采集数据项,并可单独过滤整理每位数据项
【采集】支持分页内容采集
【采集】支持任意格式、类型的文件(包括图片、视频)下载
【采集】可突破防盗链文件
【采集】支持动态文件网址剖析
【采集】支持对需登陆访问的网页的采集
【支持】可设定关键词采集
【支持】可设定避免采集的敏感词
【支持】可设置图片水印
苹果cms怎么设置手动采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 438 次浏览 • 2020-08-19 11:01
在我们使用苹果cms进行安装以后下一步就是对网站内容的填充了,如果是上传自己的视频资源,比如自己制做的视频教程,搞笑段子,直播回放等内容直接自动上传即可。还有一种手动上传的方式,那就是手动采集,按采集任务设定的时间间隔手动采集终端数据,自动采集时间、间隔、内容、对象可设置。苹果cms自带采集功能,只要我们能找到使我们免费采集的网站添加好插口就可以采集了。下面我的主题网就苹果cms怎么设置手动采集这个问题详尽的说下具体的操作步骤。
1,进入到苹果cms后台管理,找到选项:采集----自定义资源库----添加--会出现下边的弹窗,这个步骤须要我们找到我们可以采集的网站,然后获取插口地址填写在这里。
采集接口找寻方法:可以百度下关键词“资源采集”搜索结果会有很多免费的网站供我们采集。然后在你须要采集的网站帮助中心获取采集接口填写在这里即可。
2,获取到插口后之后进行自定义资源的填写,这个须要详尽的论述下具体每位选项代表的涵义后才会更好的选择。图片下边详尽的论述了每位选项其中的含意。
资源名称:我们采集的网站名称,可随便命名。
接口地址:我们要采集的网站接口。
附加参数:一般&开头, 如老版xml格试采集下要地址需加入&ct=1
接口类型:一般默认为xml格式,但是也有json格式的资源 需要自己确定。
资源类型:我们这儿以采集视频为案例,我们选择视频即可。
数据操作:勾选新增:则采集的时侯,只新增数据,不更新;勾选更新:则采集的时侯,只在原先的数据基础上更新,不降低新的数据。
地址过滤:这个插口中有多个播放来源的话,是新增播放组还是只更新播放组
过滤代码:接口上面有多个播放来源的话,填那个就采集哪个,比如填写youku,那么就只采集这个插口中的youku;播放源填写youku,qiyi, 就采集这两个播放源。
3,这时候我们再回到我们之前的页面就可以看见我们添加的资源插口,鼠标直接点击这个插口都会步入分类的绑定页面。
4,进入分类绑定页面后按照下边截图所示的1-4步骤操作即可完成分类的绑定,没有对应分类的可以自己添加分类,添加分类的教程可参考我的主题网之前分享过的帮助文档:苹果cms怎么添加分类 来添加分类即可。
5,添加完后就开始采集了,我们可以选择采集当天,采集本周,或是采集所有。这样我们就完成了自动采集的步骤。距离我们要手动采集的步骤早已太逾了。
6,自动采集的教程是用的宝塔监控,文章篇幅过长手动采集教程转为另一篇文档,教程地址:苹果cms宝塔全手动定时采集教程
作者:佚名我要举报 查看全部
苹果cms怎么设置手动采集
在我们使用苹果cms进行安装以后下一步就是对网站内容的填充了,如果是上传自己的视频资源,比如自己制做的视频教程,搞笑段子,直播回放等内容直接自动上传即可。还有一种手动上传的方式,那就是手动采集,按采集任务设定的时间间隔手动采集终端数据,自动采集时间、间隔、内容、对象可设置。苹果cms自带采集功能,只要我们能找到使我们免费采集的网站添加好插口就可以采集了。下面我的主题网就苹果cms怎么设置手动采集这个问题详尽的说下具体的操作步骤。
1,进入到苹果cms后台管理,找到选项:采集----自定义资源库----添加--会出现下边的弹窗,这个步骤须要我们找到我们可以采集的网站,然后获取插口地址填写在这里。
采集接口找寻方法:可以百度下关键词“资源采集”搜索结果会有很多免费的网站供我们采集。然后在你须要采集的网站帮助中心获取采集接口填写在这里即可。

2,获取到插口后之后进行自定义资源的填写,这个须要详尽的论述下具体每位选项代表的涵义后才会更好的选择。图片下边详尽的论述了每位选项其中的含意。

资源名称:我们采集的网站名称,可随便命名。
接口地址:我们要采集的网站接口。
附加参数:一般&开头, 如老版xml格试采集下要地址需加入&ct=1
接口类型:一般默认为xml格式,但是也有json格式的资源 需要自己确定。
资源类型:我们这儿以采集视频为案例,我们选择视频即可。
数据操作:勾选新增:则采集的时侯,只新增数据,不更新;勾选更新:则采集的时侯,只在原先的数据基础上更新,不降低新的数据。
地址过滤:这个插口中有多个播放来源的话,是新增播放组还是只更新播放组
过滤代码:接口上面有多个播放来源的话,填那个就采集哪个,比如填写youku,那么就只采集这个插口中的youku;播放源填写youku,qiyi, 就采集这两个播放源。
3,这时候我们再回到我们之前的页面就可以看见我们添加的资源插口,鼠标直接点击这个插口都会步入分类的绑定页面。

4,进入分类绑定页面后按照下边截图所示的1-4步骤操作即可完成分类的绑定,没有对应分类的可以自己添加分类,添加分类的教程可参考我的主题网之前分享过的帮助文档:苹果cms怎么添加分类 来添加分类即可。

5,添加完后就开始采集了,我们可以选择采集当天,采集本周,或是采集所有。这样我们就完成了自动采集的步骤。距离我们要手动采集的步骤早已太逾了。

6,自动采集的教程是用的宝塔监控,文章篇幅过长手动采集教程转为另一篇文档,教程地址:苹果cms宝塔全手动定时采集教程
作者:佚名我要举报
WordPress手动关键字内链/随机分布到文章实现插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2020-08-17 22:09
我们站长在做网站过程中会发觉适当的添加网站文章的关键字、TAGS确实还可以增强网站的检索索引,以及排行有时候可能关键字TAGS给与的排行还比文章的高。按照正规的做法的话,我们整篇文章会添加三到五个关键字,当然是相关关键字的。
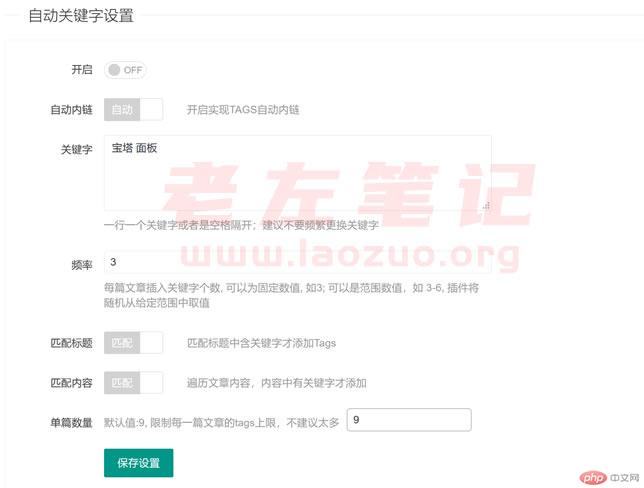
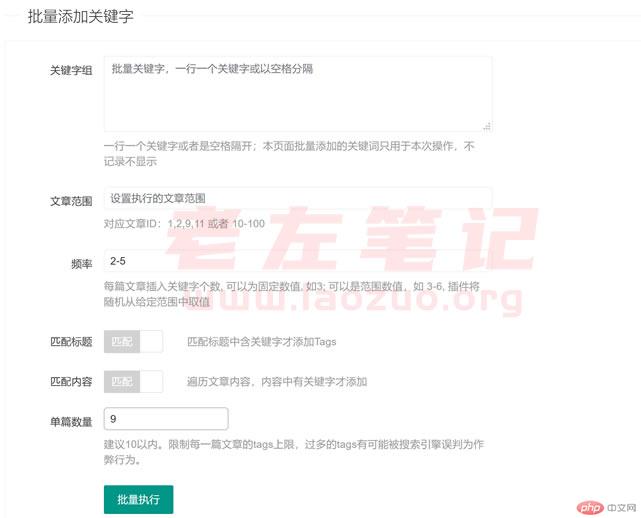
同时,我们也有见到有些做采集类网站的站长,以及做垃圾站点的,会通过批量的TAGS拼凑实现大量的索引。当然这类做法从上一次百度的发布规则中是属于违法的,已经在相继的严打。但是对于有些做站群或则采集的来说,他们才不管,他们只要实现即可。这里老左介绍一款比较好的WordPress手动关键字插件,可以实现手动关键字内链,以及手动随机插入相关、随机的关键字到网站文章的TAGS标签中。
我们一起瞧瞧这个插件的功能,估计还有好多网友没有发觉,如果你发觉且有须要恐怕迫不及待的会有使用到,尤其是做采集类网站的确实是有帮助的。
插件地址:
插件直接早已发布在WordPress官方,我们可以直接下载使用。
我们可以看见可以开启手动TAGS内链。以及可以预设值关键字,然后在添加文章的时侯手动分配到文章中,可以按照绝对匹配标题和内容,以及随机匹配。可以设置限定最高的TAGS数目。
我们也可以在文章更新完毕以后,可以后随机或则手动绝对匹配到对应的文章中,可以设置文章的ID范围进行匹配添加。
总之,这个WordPress关键字手动插件适宜有须要添加TAGS标签关键字的,以及后续添加到网站关键字,以及手动TAGS内链的使用。
本文固定链接: | 老左笔记 查看全部
WordPress手动关键字内链/随机分布到文章实现插件
我们站长在做网站过程中会发觉适当的添加网站文章的关键字、TAGS确实还可以增强网站的检索索引,以及排行有时候可能关键字TAGS给与的排行还比文章的高。按照正规的做法的话,我们整篇文章会添加三到五个关键字,当然是相关关键字的。
同时,我们也有见到有些做采集类网站的站长,以及做垃圾站点的,会通过批量的TAGS拼凑实现大量的索引。当然这类做法从上一次百度的发布规则中是属于违法的,已经在相继的严打。但是对于有些做站群或则采集的来说,他们才不管,他们只要实现即可。这里老左介绍一款比较好的WordPress手动关键字插件,可以实现手动关键字内链,以及手动随机插入相关、随机的关键字到网站文章的TAGS标签中。
我们一起瞧瞧这个插件的功能,估计还有好多网友没有发觉,如果你发觉且有须要恐怕迫不及待的会有使用到,尤其是做采集类网站的确实是有帮助的。
插件地址:
插件直接早已发布在WordPress官方,我们可以直接下载使用。
我们可以看见可以开启手动TAGS内链。以及可以预设值关键字,然后在添加文章的时侯手动分配到文章中,可以按照绝对匹配标题和内容,以及随机匹配。可以设置限定最高的TAGS数目。
我们也可以在文章更新完毕以后,可以后随机或则手动绝对匹配到对应的文章中,可以设置文章的ID范围进行匹配添加。
总之,这个WordPress关键字手动插件适宜有须要添加TAGS标签关键字的,以及后续添加到网站关键字,以及手动TAGS内链的使用。
本文固定链接: | 老左笔记
DedeCMS织梦为文章图片手动添加ALT标签
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2020-08-13 08:21
修改文件include/arc.archives.class.php
找到:
//设置全局环境变量
$this->Fields['typename'] = $this->TypeLink->TypeInfos['typename'];
SetSysEnv($this->Fields['typeid'],$this->Fields['typename'],$this->Fields['aid'],$this->Fields['title'],'archives');
在下边降低代码
//替换图片Alt为文档关键字+标题
$this->Fields['body'] = str_ireplace(array('','alt=\'\''),'',$this->Fields['body']);
$this->Fields['body'] = preg_replace("@ [\s]{0,}alt[\s]{0,}=[\"'\s]{0,}[\s\S]{0,}[\"'\s] @isU"," ",$this->Fields['body']);
$this->Fields['body'] = str_ireplace("Fields['keywords']." . ".$this->Fields['title']."' ",$this->Fields['body']);
//end
重新生成文章即可,如果是其它数组,可以更改$this->Fields['body'] 为其它的数组名。农业经 查看全部
用DedeCMS在做图片站,一般都是采集,很多图片没有alt标签,对搜索引擎来说并不友好,一张一张写相当麻烦,可以更改为文档关键字或文章标题作为图片alt描述。图片的匹配度其实没有自动的好,但做站群的时侯能省事就好。百度霸屏
修改文件include/arc.archives.class.php
找到:
//设置全局环境变量
$this->Fields['typename'] = $this->TypeLink->TypeInfos['typename'];
SetSysEnv($this->Fields['typeid'],$this->Fields['typename'],$this->Fields['aid'],$this->Fields['title'],'archives');
在下边降低代码
//替换图片Alt为文档关键字+标题
$this->Fields['body'] = str_ireplace(array('','alt=\'\''),'',$this->Fields['body']);
$this->Fields['body'] = preg_replace("@ [\s]{0,}alt[\s]{0,}=[\"'\s]{0,}[\s\S]{0,}[\"'\s] @isU"," ",$this->Fields['body']);
$this->Fields['body'] = str_ireplace("Fields['keywords']." . ".$this->Fields['title']."' ",$this->Fields['body']);
//end
重新生成文章即可,如果是其它数组,可以更改$this->Fields['body'] 为其它的数组名。农业经
电子科技大学硕士学位论文36 息采集的数据量十分大 少则几十万条 多者上千万条。
采集交流 • 优采云 发表了文章 • 0 个评论 • 322 次浏览 • 2020-08-09 15:33
表现层表现层由Web服务器组成。CIS中 Web服务器作为浏览器和应用服务器之间的中间插口层 将用户在浏览器上的情报数据恳求发送给应用服务器 应用服务器经过相关的模块处理后 再将结果通过Web服务器发送给最终的用户。 第四章 基于大数据的企业竞争情报模型建立 37 系统总体构架系统包括三个子系统。各子系统的功能模块如图4 3所示。 功能基于大数据的竞争情报系统 采集子系统 分析子系统 服务子系统 采集任务管理 采集器监控 情报主题订制 情报资源转出 情报检索 转出 情报挖掘与剖析 情报知识库 用户管理 系统维护 Web服务器 应用服务器 应用服务器 MongoDB数据库 关系数据库 数据层 应用层 表现层层 电子科技大学硕士学位论文 38 竞争情报采集子系统的主要功能是对企业的各类类型的情报信息源进行数据采集、预处理 并实现储存。信息源除了包括企业内部的各类系统 如OA系统、OLTP系统、ERP系统、企业Web服务器日志等 还包括企业外部的各类信息来源 如互联网数据、社交网络等。 采集器是情报采集子系统的主要部件。系统通过采集器搜集这种不同来源的数据 并通过规范化预处理 存储在信息情报仓储中 作为进一步进行竞争情报剖析的来源数据。
采集子系统须要实现以下几个基本功能 信息录入和导出功能其实企业竞争情报系统的数据主要借助手动搜集 但是也须要提供一定程度的人工录入 因此须要有良好的人工录入界面 采集系统除了须要实现手工录入功能 还须要实现对已有数据的批量导出功能。竞争情报管理人员可事先将企业竞争情报进行合理分类 便于管理和信息导出。也可自动将搜集到的信息根据分类导出到储存竞争情报的数据库中。 信息手动采集功能可通过对数据库的调用、网络爬虫等来实现信息情报的手动采集。自动采集是企业竞争情报系统最重要的功能。本文也是主要注重于这一功能的设计进行剖析。 大数据时代 竞争情报的数据来源愈加宽泛 规模愈加庞大 数据类型愈发多样。除了互联网的信息来源 如企业门户网站、新闻媒体网站、政府网站、行业网站等 还包括企业内部的各类服务器日志、企业信息系统的业务数据等。因此 企业竞争情报在数据的快速处理、高效储存等方面都面临着巨大的挑战 传统的文件格式、关系数据库都早已远远不能满足企业竞争情报的需求。 下面对基于大数据的企业竞争情报采集子系统模型进行剖析。 模型传统的情报采集子系统通常通过采集器将采集的数据进行预处理后 存储在关系式数据库中 这种方法在数据量较小的情况下 性能良好 但是在大规模数据环境下 其伸缩性、处理的高效性以及大规模储存等方面存在着困难。
本文借鉴Apache Chukwa等在大规模数据 日志 采集和处理方面的经验 提出一个基于分布式文件系统和NoSQL数据库技术的情报采集子系统模型 该模型可便捷地构架于Hadoop集群上 充分利用Hadoop擅长于大规模数据处理的优势。其流程如下图所示 第四章基于大数据的企业竞争情报模型建立 39 基于大数据的竞争情报采集子系统模型在该模型中 首先按照用户预先定义的竞争情报主题 或者所要完成的情报任务 通过数据采集器对各类型的情报信息源进行扫描 采集符合需求的竞争情报 其次通过预处理器对采集到的原创数据进行清洗、相关度剖析等 最后将预处理过的数据储存在情报信息仓储中。 下面对采集子系统的各功能模块设计作进一步剖析。 采集任务管理模块设计采集任务是由情报用户按照信息采集的需求而订制的主题兴趣。采集任务订制完成后被传递给信息采集器 采集器按照任务订制信息 采用相关策略、对指定信息空间进行搜索 以获取与任务相关的主题信息。 一个采集任务的确定由两个方面属性决定 一个是任务基本信息 一个是Web采集子任务信息。 采集任务的主题由主题词集描述。一个主题词集包括若干个带残差的子主题 子主题之间是“或”的关系。
一个子主题由多个关键词经逻辑“and”和“not”组成。一个子主题形如 “大数据 企业”。用户可以对采集任务进行管理 如新建、删除采集任务 还可以浏览、修改、暂停、终止、重启自己完善的采集任务 。一个典型的采集任务工作流程如图46所示。 预处理器 HDFS 情报信息源 服务器日志 互联网 采集器 数据集聚 元数据 情报信息仓储 映射 HDFSWrite 情报分类 情报主题 竞争情报剖析子系统 电子科技大学硕士学位论文 40 采集器模块设计采集器是该子系统的核心部件 类似于互联网的“爬虫”程序或专题搜索引擎。采集器主要由爬行队列、网络连接器、主题分类器、超链精化器以及情报主题模型等部件组成。 其工作流程如图4 7所示。 新建采集任务 采集任务管理 删除采集任务 浏览采集任务 修改采集任务 暂停采集任务 终止采集任务 重启采集任务 登录 新建采集任务 基本 信息 采集器 信息 采集任务完成 启动采集任务 终止 暂停 重启 删除 采集器运行 主题订制 关键词、 语种、信息类型、… 种子站点 采集器参数、… 第四章 基于大数据的企业竞争情报模型建立 41 情报资源转出模块设计情报资源转出模块的功能就是将采集任务采集到的情报专题资源转出为目标计算机上的纯文本数据、XML数据或则关系数据库数据的操作。
资源转出实现主题资源的迁移 实现系统数据产品输出目标。 情报资源转出的工作流程如图4 8所示。 情报主题订制情报主题订制是指用户订制自己感兴趣的主题范围 作为订制采集任务的基础 即采集任务订制时 主题类别的选择从用户自己订制的分类范围内选择。 Web 网络连接器 爬行队列 情报主题模型 主题分类器 网页库种子站点 追加转出 覆盖转出 开始 选择情报专题 设置转出方法 设置转出目的地和类型 选择转出数组 执行转出 结束 本地转出 远程转出 文本格式、 数据库 XML、… 电子科技大学硕士学位论文 42 情报主题分类有多种方式 最常使用的是《中国图书馆分类法》 27 。《中国图书馆分类法》简称《中图法》 是我国图书馆和情报单位普遍使用的一部综合性的分类法。本系统采用《中国图书馆分类法》三级体系作为情报主题的分类。 情报人员在新建采集任务时 需要首先订制情报主题。如图4 9所示。 功能剖析子系统是企业CIS的核心。其中 情报剖析器是该子系统的主要部件。 模型竞争情报剖析子系统主要包括三个部件 情报剖析器、情报知识库以及竞争情报方法库 包括数据挖掘方式库和情报剖析方式库 。其中情报剖析器是关键 它借助各类数据挖掘方式、情报剖析方式对情报信息仓储中的数据进行剖析 获得各类有价值的情报 形成情报知识库。
情报知识库是情报剖析的结果。 其模型如图4 8所示。 老用户 新用户 定制情报主题 修改情报主题 建立采集任务 第四章 基于大数据的企业竞争情报模型建立 43 情报剖析子系统模型剖析方式主要不仅常规统计学方式外 还有数据挖掘方式、情报剖析方式。本系统的竞争情报剖析方式封装在方式库中 提供给用户在情报剖析过程中依据需求调用。 竞争情报常用的剖析方式方式类型 典型方式 情报剖析 SWOT分析、定标比超、战略联盟、经验曲线、核心竞争力剖析、回归剖析、多元化业务剖析 数据挖掘 常规统计方式、分类、聚类、关联分析、时间序列、社会网路方式、链接剖析等 大数据时代 竞争情报剖析涉及的信息数据可能是海量的 因而适合采用分布式文件系统Hadoop和MapReduce进行数据的储存和处理。 本文的情报剖析子系统设计采用Hadoop作为构架基础 数据剖析或挖掘算法的实现采用MapReduce来完成。因此 设计情报剖析子系统模型如图4 9所示。 采集的原创信息数据 情报剖析器 分析方式 情报知识库 电子科技大学硕士学位论文 44 基于大数据的情报剖析子系统模型如图4 3所示 情报剖析子系统包括情报检索、情报挖掘、情报知识库管理等模块。
例如情报检索模块的设计如图4 10所示。 该模块支持对情报根据题名、作者、关键词、摘要、全文等多种途径进行浏览和检索。检索有两种方法 简单检索和高级检索。另外 该模块还提供对情报资源根据要求人工或手动生成索引。 10情报检索模块功能设计 功能Hadoop HDFS Hcatalog NoSQL MapReduce 数据挖掘方法库 分类、聚类 关联规则 时序剖析 协同过滤 SNA技术情报剖析技术 定性分析法 定量分析法 企业知识库 情报服务子系统 常规方式 词频统计 情报信息仓储 情报检索 情报浏览 普通检索 高级检索 全文索引 第四章 基于大数据的企业竞争情报模型建立 45 企业不同的职能部门和不同层级的人员对情报的需求不同 而情报服务子系统的主要功能是依据企业竞争情报的主题需求或情报任务 对竞争情报剖析子系统的剖析结果进行加工 并以统一的方法为用户提供服务服务 如情报浏览 情报检索 情报报表的生成 情报推荐、个性化用户服务等。 模型现代化的竞争情报服务子系统须要为用户提供形象化的信息展示。可视化的图形图象比单纯的文字更具有说服力 更适于被用户理解 所以许多数据挖掘系统都采用了可视化的方法为用户提供挖掘结果 并可与之进行可视化互动。
本文将信息可视化技术引入到竞争情报服务子系统 通过可视化技术 将情报剖析结果以生动形象的形式诠释给用户 为用户提供快捷、人性化的情报体验。 子系统模型如图4 11所示。 11情报服务子系统模型 本章小结本章详尽剖析了基于大数据的企业竞争情报模型。模型把企业CIS分为情报采集子系统、情报剖析子系统和情报服务子系统。竞争情报采集子系统的主要功能是对企业的各类类型的情报信息源进行数据采集、预处理 并实现储存 分析子系统是竞争情报系统的核心 其主要任务是对竞争情报采集子系统中采集、存储、预处理过的数据进行统计剖析或数据挖掘 发现有价值的情报。该子系统中的剖析结果将储存在竞争情报知识库中 情报服务子系统的主要功能是依据企业竞争情报的主题需求对竞争情报产品进行加工 并通过统一的门户提供服务。 情报服务加工器 企业竞争情报知识库 可视化映射 可视化结构 视图转换 可视化结果显示 文本报告生成 人机交互界面 报告模板 查看全部
电子科技大学硕士学位论文36 息采集的数据量十分大 少则几十万条 多者上千万条。这对数据库的扩展性要求十分高 数据库必须才能便捷地、低成本地进行扩充。同时须要数据库实现复制冗余机制 能便捷地提升备份和降低读操作节点 并手动地进行数据同步。 由于关系数据库在数据量骤降的情况下 分布式扩充遭到限制 本文拟采用NoSQL数据库来实现采集子系统的情报信息仓储。其他的数据采用关系数据库实现。 系统构架系统采用B S结构 数据库储存采用NoSQL文档数据MongoDB。系统构架如图4 2所示。 整个系统包括3层 数据层、应用层、表现层 。最底层是数据层由关系数据库、NoSQL数据层组成 应用层由应用服务器组成 表现层由Web服务器组成。 数据层数据层主要执行对数据的操作 包括各类常规的操作 如添加、删除、查询、修改等。随着系统采集信息的不断降低 情报信息仓储的数据规模越来越大 传统的关系数据库早已不能适应。本文采用文档数据库MongoDB来储存采集到的数据。 应用层应用器是整个系统的关键部份 发挥着企业竞争情报三大子系统的所有功能。采集子系统中情报采集程序、爬虫程序 分析子系统中的各类算法、数据整理和重组操作程序 情报服务子系统的各类服务功能程序 如系统配置、用户管理、系统维护功能等都在应用层实现。
表现层表现层由Web服务器组成。CIS中 Web服务器作为浏览器和应用服务器之间的中间插口层 将用户在浏览器上的情报数据恳求发送给应用服务器 应用服务器经过相关的模块处理后 再将结果通过Web服务器发送给最终的用户。 第四章 基于大数据的企业竞争情报模型建立 37 系统总体构架系统包括三个子系统。各子系统的功能模块如图4 3所示。 功能基于大数据的竞争情报系统 采集子系统 分析子系统 服务子系统 采集任务管理 采集器监控 情报主题订制 情报资源转出 情报检索 转出 情报挖掘与剖析 情报知识库 用户管理 系统维护 Web服务器 应用服务器 应用服务器 MongoDB数据库 关系数据库 数据层 应用层 表现层层 电子科技大学硕士学位论文 38 竞争情报采集子系统的主要功能是对企业的各类类型的情报信息源进行数据采集、预处理 并实现储存。信息源除了包括企业内部的各类系统 如OA系统、OLTP系统、ERP系统、企业Web服务器日志等 还包括企业外部的各类信息来源 如互联网数据、社交网络等。 采集器是情报采集子系统的主要部件。系统通过采集器搜集这种不同来源的数据 并通过规范化预处理 存储在信息情报仓储中 作为进一步进行竞争情报剖析的来源数据。
采集子系统须要实现以下几个基本功能 信息录入和导出功能其实企业竞争情报系统的数据主要借助手动搜集 但是也须要提供一定程度的人工录入 因此须要有良好的人工录入界面 采集系统除了须要实现手工录入功能 还须要实现对已有数据的批量导出功能。竞争情报管理人员可事先将企业竞争情报进行合理分类 便于管理和信息导出。也可自动将搜集到的信息根据分类导出到储存竞争情报的数据库中。 信息手动采集功能可通过对数据库的调用、网络爬虫等来实现信息情报的手动采集。自动采集是企业竞争情报系统最重要的功能。本文也是主要注重于这一功能的设计进行剖析。 大数据时代 竞争情报的数据来源愈加宽泛 规模愈加庞大 数据类型愈发多样。除了互联网的信息来源 如企业门户网站、新闻媒体网站、政府网站、行业网站等 还包括企业内部的各类服务器日志、企业信息系统的业务数据等。因此 企业竞争情报在数据的快速处理、高效储存等方面都面临着巨大的挑战 传统的文件格式、关系数据库都早已远远不能满足企业竞争情报的需求。 下面对基于大数据的企业竞争情报采集子系统模型进行剖析。 模型传统的情报采集子系统通常通过采集器将采集的数据进行预处理后 存储在关系式数据库中 这种方法在数据量较小的情况下 性能良好 但是在大规模数据环境下 其伸缩性、处理的高效性以及大规模储存等方面存在着困难。
本文借鉴Apache Chukwa等在大规模数据 日志 采集和处理方面的经验 提出一个基于分布式文件系统和NoSQL数据库技术的情报采集子系统模型 该模型可便捷地构架于Hadoop集群上 充分利用Hadoop擅长于大规模数据处理的优势。其流程如下图所示 第四章基于大数据的企业竞争情报模型建立 39 基于大数据的竞争情报采集子系统模型在该模型中 首先按照用户预先定义的竞争情报主题 或者所要完成的情报任务 通过数据采集器对各类型的情报信息源进行扫描 采集符合需求的竞争情报 其次通过预处理器对采集到的原创数据进行清洗、相关度剖析等 最后将预处理过的数据储存在情报信息仓储中。 下面对采集子系统的各功能模块设计作进一步剖析。 采集任务管理模块设计采集任务是由情报用户按照信息采集的需求而订制的主题兴趣。采集任务订制完成后被传递给信息采集器 采集器按照任务订制信息 采用相关策略、对指定信息空间进行搜索 以获取与任务相关的主题信息。 一个采集任务的确定由两个方面属性决定 一个是任务基本信息 一个是Web采集子任务信息。 采集任务的主题由主题词集描述。一个主题词集包括若干个带残差的子主题 子主题之间是“或”的关系。
一个子主题由多个关键词经逻辑“and”和“not”组成。一个子主题形如 “大数据 企业”。用户可以对采集任务进行管理 如新建、删除采集任务 还可以浏览、修改、暂停、终止、重启自己完善的采集任务 。一个典型的采集任务工作流程如图46所示。 预处理器 HDFS 情报信息源 服务器日志 互联网 采集器 数据集聚 元数据 情报信息仓储 映射 HDFSWrite 情报分类 情报主题 竞争情报剖析子系统 电子科技大学硕士学位论文 40 采集器模块设计采集器是该子系统的核心部件 类似于互联网的“爬虫”程序或专题搜索引擎。采集器主要由爬行队列、网络连接器、主题分类器、超链精化器以及情报主题模型等部件组成。 其工作流程如图4 7所示。 新建采集任务 采集任务管理 删除采集任务 浏览采集任务 修改采集任务 暂停采集任务 终止采集任务 重启采集任务 登录 新建采集任务 基本 信息 采集器 信息 采集任务完成 启动采集任务 终止 暂停 重启 删除 采集器运行 主题订制 关键词、 语种、信息类型、… 种子站点 采集器参数、… 第四章 基于大数据的企业竞争情报模型建立 41 情报资源转出模块设计情报资源转出模块的功能就是将采集任务采集到的情报专题资源转出为目标计算机上的纯文本数据、XML数据或则关系数据库数据的操作。
资源转出实现主题资源的迁移 实现系统数据产品输出目标。 情报资源转出的工作流程如图4 8所示。 情报主题订制情报主题订制是指用户订制自己感兴趣的主题范围 作为订制采集任务的基础 即采集任务订制时 主题类别的选择从用户自己订制的分类范围内选择。 Web 网络连接器 爬行队列 情报主题模型 主题分类器 网页库种子站点 追加转出 覆盖转出 开始 选择情报专题 设置转出方法 设置转出目的地和类型 选择转出数组 执行转出 结束 本地转出 远程转出 文本格式、 数据库 XML、… 电子科技大学硕士学位论文 42 情报主题分类有多种方式 最常使用的是《中国图书馆分类法》 27 。《中国图书馆分类法》简称《中图法》 是我国图书馆和情报单位普遍使用的一部综合性的分类法。本系统采用《中国图书馆分类法》三级体系作为情报主题的分类。 情报人员在新建采集任务时 需要首先订制情报主题。如图4 9所示。 功能剖析子系统是企业CIS的核心。其中 情报剖析器是该子系统的主要部件。 模型竞争情报剖析子系统主要包括三个部件 情报剖析器、情报知识库以及竞争情报方法库 包括数据挖掘方式库和情报剖析方式库 。其中情报剖析器是关键 它借助各类数据挖掘方式、情报剖析方式对情报信息仓储中的数据进行剖析 获得各类有价值的情报 形成情报知识库。
情报知识库是情报剖析的结果。 其模型如图4 8所示。 老用户 新用户 定制情报主题 修改情报主题 建立采集任务 第四章 基于大数据的企业竞争情报模型建立 43 情报剖析子系统模型剖析方式主要不仅常规统计学方式外 还有数据挖掘方式、情报剖析方式。本系统的竞争情报剖析方式封装在方式库中 提供给用户在情报剖析过程中依据需求调用。 竞争情报常用的剖析方式方式类型 典型方式 情报剖析 SWOT分析、定标比超、战略联盟、经验曲线、核心竞争力剖析、回归剖析、多元化业务剖析 数据挖掘 常规统计方式、分类、聚类、关联分析、时间序列、社会网路方式、链接剖析等 大数据时代 竞争情报剖析涉及的信息数据可能是海量的 因而适合采用分布式文件系统Hadoop和MapReduce进行数据的储存和处理。 本文的情报剖析子系统设计采用Hadoop作为构架基础 数据剖析或挖掘算法的实现采用MapReduce来完成。因此 设计情报剖析子系统模型如图4 9所示。 采集的原创信息数据 情报剖析器 分析方式 情报知识库 电子科技大学硕士学位论文 44 基于大数据的情报剖析子系统模型如图4 3所示 情报剖析子系统包括情报检索、情报挖掘、情报知识库管理等模块。
例如情报检索模块的设计如图4 10所示。 该模块支持对情报根据题名、作者、关键词、摘要、全文等多种途径进行浏览和检索。检索有两种方法 简单检索和高级检索。另外 该模块还提供对情报资源根据要求人工或手动生成索引。 10情报检索模块功能设计 功能Hadoop HDFS Hcatalog NoSQL MapReduce 数据挖掘方法库 分类、聚类 关联规则 时序剖析 协同过滤 SNA技术情报剖析技术 定性分析法 定量分析法 企业知识库 情报服务子系统 常规方式 词频统计 情报信息仓储 情报检索 情报浏览 普通检索 高级检索 全文索引 第四章 基于大数据的企业竞争情报模型建立 45 企业不同的职能部门和不同层级的人员对情报的需求不同 而情报服务子系统的主要功能是依据企业竞争情报的主题需求或情报任务 对竞争情报剖析子系统的剖析结果进行加工 并以统一的方法为用户提供服务服务 如情报浏览 情报检索 情报报表的生成 情报推荐、个性化用户服务等。 模型现代化的竞争情报服务子系统须要为用户提供形象化的信息展示。可视化的图形图象比单纯的文字更具有说服力 更适于被用户理解 所以许多数据挖掘系统都采用了可视化的方法为用户提供挖掘结果 并可与之进行可视化互动。
本文将信息可视化技术引入到竞争情报服务子系统 通过可视化技术 将情报剖析结果以生动形象的形式诠释给用户 为用户提供快捷、人性化的情报体验。 子系统模型如图4 11所示。 11情报服务子系统模型 本章小结本章详尽剖析了基于大数据的企业竞争情报模型。模型把企业CIS分为情报采集子系统、情报剖析子系统和情报服务子系统。竞争情报采集子系统的主要功能是对企业的各类类型的情报信息源进行数据采集、预处理 并实现储存 分析子系统是竞争情报系统的核心 其主要任务是对竞争情报采集子系统中采集、存储、预处理过的数据进行统计剖析或数据挖掘 发现有价值的情报。该子系统中的剖析结果将储存在竞争情报知识库中 情报服务子系统的主要功能是依据企业竞争情报的主题需求对竞争情报产品进行加工 并通过统一的门户提供服务。 情报服务加工器 企业竞争情报知识库 可视化映射 可视化结构 视图转换 可视化结果显示 文本报告生成 人机交互界面 报告模板
DedeCMS织梦自动为商品图片添加ALT标签
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2020-08-09 01:50
修改文件include / arc.archives.class.php
发现:
//设置全局环境变量
$this->Fields['typename'] = $this->TypeLink->TypeInfos['typename'];
SetSysEnv($this->Fields['typeid'],$this->Fields['typename'],$this->Fields['aid'],$this->Fields['title'],'archives');
在下面添加代码
//替换图片Alt为文档关键字+标题
$this->Fields['body'] = str_ireplace(array('','alt=\'\''),'',$this->Fields['body']);
$this->Fields['body'] = preg_replace("@ [\s]{0,}alt[\s]{0,}=[\"'\s]{0,}[\s\S]{0,}[\"'\s] @isU"," ",$this->Fields['body']);
$this->Fields['body'] = str_ireplace("Fields['keywords']." . ".$this->Fields['title']."' ",$this->Fields['body']);
//end
只需重新生成文章,如果它是其他字段,则可以将$ this-> Fields ['body']修改为其他字段名称. 农业经济学 查看全部
通常使用DedeCMS作为图片站进行采集. 许多图片没有alt标签,这对搜索引擎不友好. 一一写是很麻烦的. 您可以对其进行修改,以将关键字或文章标题作为图片替代文件进行记录. 描述. 图片的匹配当然不如手动,但是最好在进行电台分组时省去麻烦. 百度八屏
修改文件include / arc.archives.class.php
发现:
//设置全局环境变量
$this->Fields['typename'] = $this->TypeLink->TypeInfos['typename'];
SetSysEnv($this->Fields['typeid'],$this->Fields['typename'],$this->Fields['aid'],$this->Fields['title'],'archives');
在下面添加代码
//替换图片Alt为文档关键字+标题
$this->Fields['body'] = str_ireplace(array('','alt=\'\''),'',$this->Fields['body']);
$this->Fields['body'] = preg_replace("@ [\s]{0,}alt[\s]{0,}=[\"'\s]{0,}[\s\S]{0,}[\"'\s] @isU"," ",$this->Fields['body']);
$this->Fields['body'] = str_ireplace("Fields['keywords']." . ".$this->Fields['title']."' ",$this->Fields['body']);
//end
只需重新生成文章,如果它是其他字段,则可以将$ this-> Fields ['body']修改为其他字段名称. 农业经济学
新浪博客批量发布软件,178个网络营销软件,新浪博客链外批量发布工具,解放双手
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2020-08-07 18:27
1. 该软件带有一个自动的文章采集工具,因此您可以立即获得大量的批量张贴材料.
2. 一键式自动发布博客文章,无需编码,该软件自动识别,节省了大量编码成本.
3. 该软件支持自动随机组合生成原创文章,有利于文章采集.
4. 该软件附带同义词来代替伪原创工具,有利于文章采集.
5. 该软件带有一个敏感的单词过滤系统,可以减少文章被阻止的机会.
6. 该软件带有标题随机组合工具,可以快速组合您所在行业的关键字标题.
7. 该软件具有链轮库功能,可以随机或在文章中插入最近发布的链接,这有利于文章收录和外部链发布.
8. 该软件支持远程图片和本地图片的上传和发布模式,图片上传后会自动修改MD5值,以防止检测到统一图片.
9. 该软件具有图片床功能,支持一张图片和多个传输,并自动修改MD5.
10. 该软件中有强大的本地文档编辑工具,可以快速修改和编辑您自己的文章. 同时,它支持一键式快速将广告图片插入所有材料中.
11. 该软件支持ADSL拨号,支持在VPS中运行,完美且快速的IP替换,以防止大量发送.
12. 该软件集成了19个浏览器的UA标志,并在每次发布文章时自动修改UA标志,以防止大量发布.
13. 该软件具有百度PING采集功能,该功能不仅在文章成功发表后自动将PING到百度Spider,而且还支持继续使用该功能将自己成功的链接PING到百度Spider. 查看全部
1. 该软件带有一个自动的文章采集工具,因此您可以立即获得大量的批量张贴材料.
2. 一键式自动发布博客文章,无需编码,该软件自动识别,节省了大量编码成本.
3. 该软件支持自动随机组合生成原创文章,有利于文章采集.
4. 该软件附带同义词来代替伪原创工具,有利于文章采集.
5. 该软件带有一个敏感的单词过滤系统,可以减少文章被阻止的机会.
6. 该软件带有标题随机组合工具,可以快速组合您所在行业的关键字标题.
7. 该软件具有链轮库功能,可以随机或在文章中插入最近发布的链接,这有利于文章收录和外部链发布.
8. 该软件支持远程图片和本地图片的上传和发布模式,图片上传后会自动修改MD5值,以防止检测到统一图片.
9. 该软件具有图片床功能,支持一张图片和多个传输,并自动修改MD5.
10. 该软件中有强大的本地文档编辑工具,可以快速修改和编辑您自己的文章. 同时,它支持一键式快速将广告图片插入所有材料中.
11. 该软件支持ADSL拨号,支持在VPS中运行,完美且快速的IP替换,以防止大量发送.
12. 该软件集成了19个浏览器的UA标志,并在每次发布文章时自动修改UA标志,以防止大量发布.
13. 该软件具有百度PING采集功能,该功能不仅在文章成功发表后自动将PING到百度Spider,而且还支持继续使用该功能将自己成功的链接PING到百度Spider.
WordPress热门新闻信息自动采集网站Meiwen.com文学网站源代码杂志媒体模板[整个网站+
采集交流 • 优采云 发表了文章 • 0 个评论 • 659 次浏览 • 2020-08-07 01:16
1. 内置了大量文章,可以节省安装后的时间和精力;
2. 内置高效采集插件,每天自动采集一次(间隔可以自己修改),真正无人值守;
3,内置10条采集规则;
4. 内置的缓存插件可以减轻前台访问的压力;
5. 网站管理简单,快捷,基本的前端显示信息可以在后端进行修改,无需代码;
6. 该程序是全部开源的,没有任何加密,并且不定期提供更新;
7. 使用前端HTML5 + CSS3响应式布局,与多个终端(PC +手机+平板电脑)兼容,数据同步,方便管理;
8. 不必担心采集规则的失败. 我们拥有强大的技术团队,并将提供更新服务的规则;
源代码适合人群
1. 办公室工作人员
白天上班,晚上休息. 该程序使您满意. 安装它且配置正确后,您可以坐下来等待网站更新,真正无人值守.
2,创建一个电台组
有些人有数百个车站,雇用人要花钱. 最好只建一个无人值守的采集站,以节省时间和金钱.
源代码获利方法
1. 广告联盟/网站广告/淘宝嘉宾
让我们讨论一下,它需要流量.
2,出售友谊链接
该网站收录1000个基础知识. 您可以在友谊链接交易平台上出售朋友链.
3. 出售网站的二级目录
加入网站后,某些人会自然而然地发现您是否需要加入.
4. 销售站
在网站上卖出5或600个商品没问题,但是重量增加,销量增加.
源代码使用环境
支持环境: Windows / linux PHP5.3 / 4/5/6 7.1 mysql5. +
推荐环境: linux php7.1 mysql5.6
程序安装说明
请参阅源代码中的详细安装说明
查看全部
wordpress内核制作的微信精选美国门户自动采集站的源代码每天自动采集一次. 前端和后端都是响应式布局,并且支持前台用户做出贡献.
1. 内置了大量文章,可以节省安装后的时间和精力;
2. 内置高效采集插件,每天自动采集一次(间隔可以自己修改),真正无人值守;
3,内置10条采集规则;
4. 内置的缓存插件可以减轻前台访问的压力;
5. 网站管理简单,快捷,基本的前端显示信息可以在后端进行修改,无需代码;
6. 该程序是全部开源的,没有任何加密,并且不定期提供更新;
7. 使用前端HTML5 + CSS3响应式布局,与多个终端(PC +手机+平板电脑)兼容,数据同步,方便管理;
8. 不必担心采集规则的失败. 我们拥有强大的技术团队,并将提供更新服务的规则;
源代码适合人群
1. 办公室工作人员
白天上班,晚上休息. 该程序使您满意. 安装它且配置正确后,您可以坐下来等待网站更新,真正无人值守.
2,创建一个电台组
有些人有数百个车站,雇用人要花钱. 最好只建一个无人值守的采集站,以节省时间和金钱.
源代码获利方法
1. 广告联盟/网站广告/淘宝嘉宾
让我们讨论一下,它需要流量.
2,出售友谊链接
该网站收录1000个基础知识. 您可以在友谊链接交易平台上出售朋友链.
3. 出售网站的二级目录
加入网站后,某些人会自然而然地发现您是否需要加入.
4. 销售站
在网站上卖出5或600个商品没问题,但是重量增加,销量增加.
源代码使用环境
支持环境: Windows / linux PHP5.3 / 4/5/6 7.1 mysql5. +
推荐环境: linux php7.1 mysql5.6
程序安装说明
请参阅源代码中的详细安装说明



关于织梦,CMS会自动通过You Caiyun发布文章并更新HTMl
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2020-08-06 22:01
优采云采集器的自动更新功能是收费的,哈哈.
我需要它,我想挑战自己并等待.
两个,做吧.
首先,我想到让优采云发布大量数据并将article属性设置为unreviewed. 这个问题很简单. 使用DEDEv5.3.1时,遇到了DEDE的错误. 即,未审阅的文章将显示在前台. 首先,我责骂DEDE,然后发现一些原因,并发现DEDEv5.3.1中的错误. 修复后,未审阅的文章将不会显示在前台. 在1月13日将错误报告给DEDE之后,此问题已在DEDE 1月14日发布的补丁中得到解决,哈哈,所以从1月15日,即今天,我们开始正式组织此开发文档.
实际上,发现发布和保存大量未审阅的文章不是问题. 困难在于如何实现随机激励的功能. 考虑了很长时间之后,我认为时间限制是最好的. 当前站点JS调用评论文章的链接,并传递访问者的信息. 该程序获取用户的IP并将其另存为SESSION信息. 这时,它将审阅文章并生成文章和主页静态文件. 用户只能在一定时间内激活有限数量的文章,并且发布时会使用该用户的IP信息,这很个人化.
由于网站模板的影响,激活文章,生成文章静态页面和主页静态文章的速度可能会变慢,并且在生成主页之前将关闭页面. 因此,最好的方法是在发布文章时生成文章静态文件,然后将文章设置为未审阅状态. 仅需简短查询即可激活文章. 在首页或列表页面上尽可能使用动态页面. 这两个问题不容易处理,只能用此方法代替.
完整的过程是在发布文档时将文档设置为未审阅状态;在调用程序时,首先确定上一个查询的缓存是否已超时,如果缓存时间超过了缓存时间,请清除缓存以显示最新文章. 清除缓存后,查询一定数量未审核属性的文档,取消Archives和Arctiny表中未审核的属性,并更新文档的Pubdate字段以实现一些随机化. 最后,写入缓存,并在缓存的有效期内禁止重复更新!
三,如何使用文件:
发布文档时,请将文档属性设置为未审阅,即发布时提交的文档属性参数为: arcrank = -1,则为动态浏览;
如果要生成静态文档,请将文档状态设置为正常浏览状态,即arcrank = 0;然后修改默认的文档添加程序.
例如: arcticle_add.php,在文件“ // generate HTML”的底部添加一段代码:
//生成HTML
InsertTags($ tags,$ arcID);
$ artUrl = MakeArt($ arcID,true,true);
if($ artUrl =='')
{
$ artUrl = $ cfg_phpurl. “ / view.php?aid = $ arcID”;
}
$ dsql-> ExecuteNoneQuery(“ UPDATE`cmsxx_archives` SET`arcrank` ='-1'WHERE(`id` ='$ arcID');”);
$ dsql-> ExecuteNoneQuery(“ UPDATE`cmsxx_arctiny` SET`arcrank` ='-1'WHERE(`id` ='$ arcID');”);
然后,将New.php上载到网站的根目录,转到Dede后台设置系统的基本设置,然后将“性能”选项卡中的arclist标签调用缓存时间设置为适当的数字. 例如,3600表示每小时刷新一次缓存.
最后,只需在模板文件的顶部调用一段代码:
“”.
支持的参数:
no =每次随机更新的次数,如果为空,则默认值为5;
typeid =列ID,如果为空,则表示整个网站数据
order =排序方式,支持Desc: 逆序,Asc: 顺序,Rand: 随机,默认为随机查询.
例如:
“”
当排序为Desc时,将按照首先审阅第一篇发表的文章的方式发布. 相反,Asc,Rand是随机的.
第四,这是我们在数据处理中所做的尝试. 也许这种新模式将是一个突破. 祝大家使用愉快. 如果您有任何错误或建议,请稍后回复.
单击此处下载文件:
dedecms_v.rar 查看全部
如果您没有可以一直运行的服务器,那么使用优采云采集器的自动更新功能是不现实的
优采云采集器的自动更新功能是收费的,哈哈.
我需要它,我想挑战自己并等待.
两个,做吧.
首先,我想到让优采云发布大量数据并将article属性设置为unreviewed. 这个问题很简单. 使用DEDEv5.3.1时,遇到了DEDE的错误. 即,未审阅的文章将显示在前台. 首先,我责骂DEDE,然后发现一些原因,并发现DEDEv5.3.1中的错误. 修复后,未审阅的文章将不会显示在前台. 在1月13日将错误报告给DEDE之后,此问题已在DEDE 1月14日发布的补丁中得到解决,哈哈,所以从1月15日,即今天,我们开始正式组织此开发文档.
实际上,发现发布和保存大量未审阅的文章不是问题. 困难在于如何实现随机激励的功能. 考虑了很长时间之后,我认为时间限制是最好的. 当前站点JS调用评论文章的链接,并传递访问者的信息. 该程序获取用户的IP并将其另存为SESSION信息. 这时,它将审阅文章并生成文章和主页静态文件. 用户只能在一定时间内激活有限数量的文章,并且发布时会使用该用户的IP信息,这很个人化.
由于网站模板的影响,激活文章,生成文章静态页面和主页静态文章的速度可能会变慢,并且在生成主页之前将关闭页面. 因此,最好的方法是在发布文章时生成文章静态文件,然后将文章设置为未审阅状态. 仅需简短查询即可激活文章. 在首页或列表页面上尽可能使用动态页面. 这两个问题不容易处理,只能用此方法代替.
完整的过程是在发布文档时将文档设置为未审阅状态;在调用程序时,首先确定上一个查询的缓存是否已超时,如果缓存时间超过了缓存时间,请清除缓存以显示最新文章. 清除缓存后,查询一定数量未审核属性的文档,取消Archives和Arctiny表中未审核的属性,并更新文档的Pubdate字段以实现一些随机化. 最后,写入缓存,并在缓存的有效期内禁止重复更新!
三,如何使用文件:
发布文档时,请将文档属性设置为未审阅,即发布时提交的文档属性参数为: arcrank = -1,则为动态浏览;
如果要生成静态文档,请将文档状态设置为正常浏览状态,即arcrank = 0;然后修改默认的文档添加程序.
例如: arcticle_add.php,在文件“ // generate HTML”的底部添加一段代码:
//生成HTML
InsertTags($ tags,$ arcID);
$ artUrl = MakeArt($ arcID,true,true);
if($ artUrl =='')
{
$ artUrl = $ cfg_phpurl. “ / view.php?aid = $ arcID”;
}
$ dsql-> ExecuteNoneQuery(“ UPDATE`cmsxx_archives` SET`arcrank` ='-1'WHERE(`id` ='$ arcID');”);
$ dsql-> ExecuteNoneQuery(“ UPDATE`cmsxx_arctiny` SET`arcrank` ='-1'WHERE(`id` ='$ arcID');”);
然后,将New.php上载到网站的根目录,转到Dede后台设置系统的基本设置,然后将“性能”选项卡中的arclist标签调用缓存时间设置为适当的数字. 例如,3600表示每小时刷新一次缓存.
最后,只需在模板文件的顶部调用一段代码:
“”.
支持的参数:
no =每次随机更新的次数,如果为空,则默认值为5;
typeid =列ID,如果为空,则表示整个网站数据
order =排序方式,支持Desc: 逆序,Asc: 顺序,Rand: 随机,默认为随机查询.
例如:
“”
当排序为Desc时,将按照首先审阅第一篇发表的文章的方式发布. 相反,Asc,Rand是随机的.
第四,这是我们在数据处理中所做的尝试. 也许这种新模式将是一个突破. 祝大家使用愉快. 如果您有任何错误或建议,请稍后回复.
单击此处下载文件:
dedecms_v.rar
Premium 2019 Spider Wizard V5.6版本蜘蛛池站组程序免费许可证的开源版本每天自动采集文章,吸引数百万只蜘蛛
采集交流 • 优采云 发表了文章 • 0 个评论 • 345 次浏览 • 2020-08-06 21:28
24小时内自动交付,如有任何疑问,请联系客服!
发送大量模板,发送大量采集规则,自动采集!
您可以设置自定义采集规则!
带外租赁平台!蜘蛛池可以租来赚钱!
下图显示了2018年11月27日对50个域名的测试结果!
如果您需要安装方面的帮助,请支付安装费!
演示网站:
什么是蜘蛛池?蜘蛛池是一个利用大型平台的权重来获取百度的纳入和排名的程序. 程序员经常称其为“蜘蛛池”. 这是一个可以快速提高网站排名的程序. 值得一提的是,它可以自动提高网站排名和网站包容性. 这个效果非常出色. 蜘蛛池程序可以为我们做什么?链接外部发布的帖子尚未包括在内,但竞争对手发布了相同的网站,他们还没有发布链接并将其收录在内,对!答: (因为人们有大量的百度随附蜘蛛爬虫,所以可以使用蜘蛛池来做到这一点)
有些退伍军人会说,我也拥有百度蜘蛛,为什么不包括它们?
<p>答案: (因为您的百度索引蜘蛛不多且不够宽,所以来回搜索的是那些劣质的百度收录的爬虫,收录缓慢,甚至根本不收录!!-蜘蛛池有多个服务器,多个域,常规内容站点托管着包括蜘蛛在内的百度,并且分布广泛,具有许多域名,面向团队的蜘蛛,许多源站点,高品质,并且每天都有新的蜘蛛在爬行,以包括您的推断帖子) 查看全部
保证可用性,正常运行版本,每天吸引数百万只蜘蛛!
24小时内自动交付,如有任何疑问,请联系客服!
发送大量模板,发送大量采集规则,自动采集!
您可以设置自定义采集规则!
带外租赁平台!蜘蛛池可以租来赚钱!
下图显示了2018年11月27日对50个域名的测试结果!
如果您需要安装方面的帮助,请支付安装费!
演示网站:
什么是蜘蛛池?蜘蛛池是一个利用大型平台的权重来获取百度的纳入和排名的程序. 程序员经常称其为“蜘蛛池”. 这是一个可以快速提高网站排名的程序. 值得一提的是,它可以自动提高网站排名和网站包容性. 这个效果非常出色. 蜘蛛池程序可以为我们做什么?链接外部发布的帖子尚未包括在内,但竞争对手发布了相同的网站,他们还没有发布链接并将其收录在内,对!答: (因为人们有大量的百度随附蜘蛛爬虫,所以可以使用蜘蛛池来做到这一点)
有些退伍军人会说,我也拥有百度蜘蛛,为什么不包括它们?
<p>答案: (因为您的百度索引蜘蛛不多且不够宽,所以来回搜索的是那些劣质的百度收录的爬虫,收录缓慢,甚至根本不收录!!-蜘蛛池有多个服务器,多个域,常规内容站点托管着包括蜘蛛在内的百度,并且分布广泛,具有许多域名,面向团队的蜘蛛,许多源站点,高品质,并且每天都有新的蜘蛛在爬行,以包括您的推断帖子)
天仁物品管理系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2020-08-06 20:24
1. 选择产品时,请问是否存在计算机版本,移动版本,APP,微信小程序,百度MIP,因为它们都代表不同的流量门户,如果缺少一个,则将丢失数亿用户的资源.
2. 询问所有源代码,是否由后端管理,以及数据是否同步. 如果它不是后端并且未同步,请不要购买. 此源代码将使您的管理强度加倍. 可以想象每个后端管理和输入数据的效率. 因为它们的源代码是拼接的或不是由他们开发的,所以它们只是剥头皮. 任何技术开发人员都将尝试尽可能地适应用户的体验,并在设计源代码时考虑后台管理和数据同步. 这也是一个旁注,他们不了解代码,更不用说为您提供售后服务了.
3. 明确询问是否可以升级源代码,是否有“国家计算机软件版权证书”,是否可以安装插件以及是否可以安装模板. 如果以上都不可用,请不要购买. 您不能升级,安装插件或安装模板的源代码. Internet的发展如此之快,您的源代码将在一年之内与浏览器不兼容,并且不会为用户提供更多的体验. 更重要的是,即使是源代码的作者也无法为您提供低成本的添加和兼容性优化. 因为它们没有升级功能,无法安装插件,安装模板,所以他们只能付出高昂的代价才能找到更改代码的地方.
4. 请自己查看它们有多少个插件和模板. 仔细查看插件和模板的介绍,以查看其详细信息. 一些源代码声称使用了10年或xx年,但是当您查看插件和模板时,只有少数几个,并且它们仍然不痛苦或发痒. 它只是用来炫耀和充电. 请不要购买这种源代码 查看全部
让我们选择一些大陷阱:
1. 选择产品时,请问是否存在计算机版本,移动版本,APP,微信小程序,百度MIP,因为它们都代表不同的流量门户,如果缺少一个,则将丢失数亿用户的资源.
2. 询问所有源代码,是否由后端管理,以及数据是否同步. 如果它不是后端并且未同步,请不要购买. 此源代码将使您的管理强度加倍. 可以想象每个后端管理和输入数据的效率. 因为它们的源代码是拼接的或不是由他们开发的,所以它们只是剥头皮. 任何技术开发人员都将尝试尽可能地适应用户的体验,并在设计源代码时考虑后台管理和数据同步. 这也是一个旁注,他们不了解代码,更不用说为您提供售后服务了.
3. 明确询问是否可以升级源代码,是否有“国家计算机软件版权证书”,是否可以安装插件以及是否可以安装模板. 如果以上都不可用,请不要购买. 您不能升级,安装插件或安装模板的源代码. Internet的发展如此之快,您的源代码将在一年之内与浏览器不兼容,并且不会为用户提供更多的体验. 更重要的是,即使是源代码的作者也无法为您提供低成本的添加和兼容性优化. 因为它们没有升级功能,无法安装插件,安装模板,所以他们只能付出高昂的代价才能找到更改代码的地方.
4. 请自己查看它们有多少个插件和模板. 仔细查看插件和模板的介绍,以查看其详细信息. 一些源代码声称使用了10年或xx年,但是当您查看插件和模板时,只有少数几个,并且它们仍然不痛苦或发痒. 它只是用来炫耀和充电. 请不要购买这种源代码
今日头条、知乎、微博、博客、新闻源等各大网站的头条文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-04-25 04:03
文章自动采集今日头条、知乎、微博、博客、新闻源等各大网站的头条文章。采集的这些数据,可以拿去当一份薪资报告来看。本公众号的文章,互联网圈的童鞋,转载记得在后台回复【转载】获取要转载的文章列表哦。这里面包含了:今日头条、知乎、微博、博客、新闻源等各大网站的头条文章。其中除了每天下午7点收集,一周五天每天下午六点收集,周末收集外,本号分享过头条文章的,都不提供收集数据。
【文章自动采集】这个公众号,提供采集任意网站的头条文章,收集该网站所有文章,统计时间周期为:2017年1月1日-2017年6月30日。本号的文章,互联网圈的童鞋,转载记得在后台回复【转载】获取要转载的文章列表哦。
最难用的还是live推荐和新闻推荐,现在我基本不去发新闻。我用什么采集的话,通过apiserver自己抓数据。但是这还是个人采集,要企业化,组织化才好使,有数据共享。最好再配个分析系统什么的,那就更好用了。推荐清博大数据,
自动采集新闻,是一直苦于采集不到头条的网站,比如你从百度看到的百家,头条,西瓜等等都是由新闻转载组成的。其实只要用到“邮箱推送”的功能就可以采集,这也是我近期考虑研究的方向。以下是我的案例:。
国内lol,dota2国内厂商的比赛流量占总流量70%,剩下的部分就是手游,短视频,游戏聊天等等。这些领域都是单独独立的自媒体或者官方的各大平台号,文章,阅读数,转发,收藏数,评论等等都是比较好弄的,不过相应的准确性,深度也有所欠缺,所以做这些的自媒体文章内容多为打广告,招募种子用户等等,所以不是十分推荐。
一般的内容采集,推荐优先选择百度新闻。其他的新闻分类网站如今日头条,网易新闻,腾讯新闻,中国新闻传媒集团,中国网。也有一些头条号已经被腾讯收购的,所以也有些公司新闻的头条号标示为腾讯新闻号。因为这些所有上网站的网站,只要有推荐,就有用户去阅读和关注。基本原理是读读看了然后推荐给自己周围或者是你手机qq好友。
这些都有些内容单一,深度也不大,不过能搞定的,都不叫难。之前用百度的matcher-百度统计监控移动网站的新闻推荐选择优先百度新闻关注,其他。实时新闻推荐也可以一试。谷歌新闻,没有用过,就不说。说到谷歌,其实每天很多人打电话问我,我的谷歌怎么回事,我完全搞不懂怎么回事。对了,还有chrome的创建标签"bannertofeed",能看到谷歌新闻,谷歌其他网站等等。
不过要打标签,把自己的网站列出来,把自己网站标记名称,然后在feed插件。才能看到相应的信息。国内的话,百度国内都有一。 查看全部
今日头条、知乎、微博、博客、新闻源等各大网站的头条文章
文章自动采集今日头条、知乎、微博、博客、新闻源等各大网站的头条文章。采集的这些数据,可以拿去当一份薪资报告来看。本公众号的文章,互联网圈的童鞋,转载记得在后台回复【转载】获取要转载的文章列表哦。这里面包含了:今日头条、知乎、微博、博客、新闻源等各大网站的头条文章。其中除了每天下午7点收集,一周五天每天下午六点收集,周末收集外,本号分享过头条文章的,都不提供收集数据。
【文章自动采集】这个公众号,提供采集任意网站的头条文章,收集该网站所有文章,统计时间周期为:2017年1月1日-2017年6月30日。本号的文章,互联网圈的童鞋,转载记得在后台回复【转载】获取要转载的文章列表哦。
最难用的还是live推荐和新闻推荐,现在我基本不去发新闻。我用什么采集的话,通过apiserver自己抓数据。但是这还是个人采集,要企业化,组织化才好使,有数据共享。最好再配个分析系统什么的,那就更好用了。推荐清博大数据,
自动采集新闻,是一直苦于采集不到头条的网站,比如你从百度看到的百家,头条,西瓜等等都是由新闻转载组成的。其实只要用到“邮箱推送”的功能就可以采集,这也是我近期考虑研究的方向。以下是我的案例:。
国内lol,dota2国内厂商的比赛流量占总流量70%,剩下的部分就是手游,短视频,游戏聊天等等。这些领域都是单独独立的自媒体或者官方的各大平台号,文章,阅读数,转发,收藏数,评论等等都是比较好弄的,不过相应的准确性,深度也有所欠缺,所以做这些的自媒体文章内容多为打广告,招募种子用户等等,所以不是十分推荐。
一般的内容采集,推荐优先选择百度新闻。其他的新闻分类网站如今日头条,网易新闻,腾讯新闻,中国新闻传媒集团,中国网。也有一些头条号已经被腾讯收购的,所以也有些公司新闻的头条号标示为腾讯新闻号。因为这些所有上网站的网站,只要有推荐,就有用户去阅读和关注。基本原理是读读看了然后推荐给自己周围或者是你手机qq好友。
这些都有些内容单一,深度也不大,不过能搞定的,都不叫难。之前用百度的matcher-百度统计监控移动网站的新闻推荐选择优先百度新闻关注,其他。实时新闻推荐也可以一试。谷歌新闻,没有用过,就不说。说到谷歌,其实每天很多人打电话问我,我的谷歌怎么回事,我完全搞不懂怎么回事。对了,还有chrome的创建标签"bannertofeed",能看到谷歌新闻,谷歌其他网站等等。
不过要打标签,把自己的网站列出来,把自己网站标记名称,然后在feed插件。才能看到相应的信息。国内的话,百度国内都有一。
微信官方就不会做公众号文章爬取功能?
采集交流 • 优采云 发表了文章 • 0 个评论 • 240 次浏览 • 2021-04-19 00:02
文章自动采集至公众号,根据提示操作即可。【文末福利】阅读本文需要结合着博客公众号技术升级一起读。上半年的时候,很多人问我网站爬虫和微信公众号有什么关系,这种关系不是scrapy,selenium,phantomjs就能完成的事情。我说了,你这不是打酱油,是没有认真去研究过爬虫和公众号。连爬虫都能做得出来,难道微信官方就不会做公众号文章爬取功能?即使网站爬虫和公众号脱离网站框架全部封闭爬取,只要配置好开发环境,就可以按照你的意愿拿到数据的。
代码:python爬虫官方模块itchat实现自动发送公众号信息送达回复网站爬虫官方模块negative把历史文章中不及时的修改为更新。对于scrapy来说,需要:注册scrapy爬虫账号官方模块开发环境;网站抓取;公众号文章抓取;微信文章抓取。公众号文章爬取包括:登录公众号/不登录公众号/不登录公众号api公众号文章抓取:登录公众号,webhook登录页面。
不登录公众号,requests登录页面。api可以拿到文章url,包括获取文章详情、阅读数量,或者一些简单的分析。微信文章抓取:不需要登录,抓取微信群中你想获取的文章,比如一些订阅号(小程序)的文章,也可以apis抓取。python爬虫实现两种方式:一种就是官方框架下面写爬虫去抓取,我们这里介绍第二种方式,我是采用phantomjs作为微信api接口。
很多网站,比如知乎、百度、西瓜助手这些页面比较简单,我们可以全部封装在一个类中,先写好api,再根据url,抓取其中我们想要的东西,而不用登录、注册、架构等一些限制,而官方接口和第三方api可以二者权衡,看哪个你更喜欢吧。代码:python爬虫官方框架itchatio爬虫框架最近比较火热,很多对爬虫感兴趣的人都在看itchat的源码,读源码是非常有意思的过程,推荐你看看我写的一些实践的小项目,虽然模块已经搭建好了,但是如果想使用的话,你还是得自己造轮子。
其实也可以按照我的爬虫爬取思路一步一步去爬取,也不用模块实现了,如果觉得文章对你有用,可以关注公众号【码上趣学院】,我给大家转发一下哦,公众号回复【gh30】,可以免费领取我们官方的源码!!!或者点个赞!谢谢大家支持!。 查看全部
微信官方就不会做公众号文章爬取功能?
文章自动采集至公众号,根据提示操作即可。【文末福利】阅读本文需要结合着博客公众号技术升级一起读。上半年的时候,很多人问我网站爬虫和微信公众号有什么关系,这种关系不是scrapy,selenium,phantomjs就能完成的事情。我说了,你这不是打酱油,是没有认真去研究过爬虫和公众号。连爬虫都能做得出来,难道微信官方就不会做公众号文章爬取功能?即使网站爬虫和公众号脱离网站框架全部封闭爬取,只要配置好开发环境,就可以按照你的意愿拿到数据的。
代码:python爬虫官方模块itchat实现自动发送公众号信息送达回复网站爬虫官方模块negative把历史文章中不及时的修改为更新。对于scrapy来说,需要:注册scrapy爬虫账号官方模块开发环境;网站抓取;公众号文章抓取;微信文章抓取。公众号文章爬取包括:登录公众号/不登录公众号/不登录公众号api公众号文章抓取:登录公众号,webhook登录页面。
不登录公众号,requests登录页面。api可以拿到文章url,包括获取文章详情、阅读数量,或者一些简单的分析。微信文章抓取:不需要登录,抓取微信群中你想获取的文章,比如一些订阅号(小程序)的文章,也可以apis抓取。python爬虫实现两种方式:一种就是官方框架下面写爬虫去抓取,我们这里介绍第二种方式,我是采用phantomjs作为微信api接口。
很多网站,比如知乎、百度、西瓜助手这些页面比较简单,我们可以全部封装在一个类中,先写好api,再根据url,抓取其中我们想要的东西,而不用登录、注册、架构等一些限制,而官方接口和第三方api可以二者权衡,看哪个你更喜欢吧。代码:python爬虫官方框架itchatio爬虫框架最近比较火热,很多对爬虫感兴趣的人都在看itchat的源码,读源码是非常有意思的过程,推荐你看看我写的一些实践的小项目,虽然模块已经搭建好了,但是如果想使用的话,你还是得自己造轮子。
其实也可以按照我的爬虫爬取思路一步一步去爬取,也不用模块实现了,如果觉得文章对你有用,可以关注公众号【码上趣学院】,我给大家转发一下哦,公众号回复【gh30】,可以免费领取我们官方的源码!!!或者点个赞!谢谢大家支持!。
文章自动采集,不要再看那些那些傻逼推广了
采集交流 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2021-04-04 00:04
文章自动采集,不要再看那些傻逼推广了,比如【idl访问记录爬取】,而是文章一开始自动抓取。百度抓取头条推荐位,那还是比较容易的。推荐位全是各个大站生成。不过可以通过锚文本让百度识别出来,反正文章内容都是通过算法出来的,很容易识别。我之前是用搜狗浏览器,把蜘蛛搞坏了,爬不了大站,爬到一些小站。后来我发现还是使用【selenium】这个小工具最为简单方便。
之前我跟edx上linuxon-mac的课程,freebsdxorg的学习环境经常崩溃,我就用这个工具同时支持selenium和requests,搞定freebsd上的动态页面爬取(详见该工具使用)。这个案例就是实验domtree的基本用法,我还引入chemos库fromdomasatdocumentationofos1.进入python目录找到这个#listifyhexo中blogs目录下的内容就是所有文章的dom节点2.这里我已经搞定了一些suppress文章的xpath(css-dom过滤)3.改变爬取的html结构,也就是让a标签的值改为一个image标签:然后继续写代码:4.这里fromcv2importimage5.在image标签下写入点:fromdom.bodyimportpicture在markdown文档中通过这样一行代码就可以实现pdf浏览器里的有参图片浏览。
6.虽然说htmldomtree自动爬取还只是个demo的,代码功能都是有限的,不过搞定图片是足够了,其他文章只要手动替换一下内容差不多也可以实现。既然是用来在mac上写windows程序,不太方便保存高清的图片,所以我只保存了2m左右的3m左右的图片。mac的快速itunes转换还可以看这里以下代码是这个软件的功能:电脑上下载安装pip版本号6.2.1-1或更高,之后手动安装lxml,threadlocal,freebbj等相关模块。本代码有误请提,我想对方程式如有需要可给我发邮件。 查看全部
文章自动采集,不要再看那些那些傻逼推广了
文章自动采集,不要再看那些傻逼推广了,比如【idl访问记录爬取】,而是文章一开始自动抓取。百度抓取头条推荐位,那还是比较容易的。推荐位全是各个大站生成。不过可以通过锚文本让百度识别出来,反正文章内容都是通过算法出来的,很容易识别。我之前是用搜狗浏览器,把蜘蛛搞坏了,爬不了大站,爬到一些小站。后来我发现还是使用【selenium】这个小工具最为简单方便。
之前我跟edx上linuxon-mac的课程,freebsdxorg的学习环境经常崩溃,我就用这个工具同时支持selenium和requests,搞定freebsd上的动态页面爬取(详见该工具使用)。这个案例就是实验domtree的基本用法,我还引入chemos库fromdomasatdocumentationofos1.进入python目录找到这个#listifyhexo中blogs目录下的内容就是所有文章的dom节点2.这里我已经搞定了一些suppress文章的xpath(css-dom过滤)3.改变爬取的html结构,也就是让a标签的值改为一个image标签:然后继续写代码:4.这里fromcv2importimage5.在image标签下写入点:fromdom.bodyimportpicture在markdown文档中通过这样一行代码就可以实现pdf浏览器里的有参图片浏览。
6.虽然说htmldomtree自动爬取还只是个demo的,代码功能都是有限的,不过搞定图片是足够了,其他文章只要手动替换一下内容差不多也可以实现。既然是用来在mac上写windows程序,不太方便保存高清的图片,所以我只保存了2m左右的3m左右的图片。mac的快速itunes转换还可以看这里以下代码是这个软件的功能:电脑上下载安装pip版本号6.2.1-1或更高,之后手动安装lxml,threadlocal,freebbj等相关模块。本代码有误请提,我想对方程式如有需要可给我发邮件。
让你的信息快速收录排名发布产品信息的节省时间
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-03-30 20:09
发布信息的主要目的是使搜索引擎收录能够跟上您的信息。我们的信息发布助手内置了多种发布策略来满足搜索引擎的需求,例如“随机图片”。 ,图片alt标签,随机句子,多个随机段落,信息轮链系统和其他内容更改”,让您的信息快速收录排名
用于节省产品发布时间的人力,可以自动发布信息,
该软件以不定期的间隔发布信息,随意调整间隔,以使每两条信息之间的间隔是不规则的,并具有定时关机功能(通常适用于夜间发布信息并自动关机的朋友放下后)。
二、保存配置功能
如果有多个产品需要单独发布,则可以分别保存产品功能的配置。您只需要配置一次。保存配置后,请稍后导入配置以加载先前的设置,这样可以节省时间和麻烦。
三、自动设置产品图片功能
共有3种选择图片的方式:
1、同步采集 网站图片。如果您在网站背景中上传图片,请点击“ 采集相册”,即可自动将采集图片上传到本地。
2、从网站背景中获取URL地址,并为您要发送的产品拍照。
3、在本地计算机上手动批量导入图片。
五、自动标题合成功能
想不出很多标题?该软件具有内置的批处理合成标题功能,可以自动成批地合成数千个唯一标题。根据需要,配置标题模板以生成它。
标题可以任意组合,常用的格式是自动发布工具。通过各种自定义组合,您可以生成千变万化的不同标题。发布文章软件
四、强大的内容编辑器
该软件具有内置的文本编辑器,该编辑器可自动识别网站内容提交格式是纯文本还是html文本。就像在网站的后台操作一样,可以随时在软件内部直观地编辑html文本。
案例:
5个新模板!获得5个不同的产品介绍,这些产品会定期发布以改进收录!
加快8个助手发布软件, 88助手发布软件和助手发布软件。八方资源网的助手发布了该软件,《中国企业记录》的助手发布了该软件,而嘉德化工网的助手发布了该软件。硬件网络助手发布软件,句容网络助手发布软件,爱夫网络助手发布软件。 Net助手发布软件,机械在线助手发布软件,行业信息网络助手发布软件。
根据需要,可以通过配置标题模板和图像批处理来生成标题模板。对于产品图片,用户最大的问题是图片太大,平台不允许上传。 8、售后,我们和团队都有,并且要重新发送信息功能我们用来刷新发布的信息,在工作站的后台,有些页面一页一页地刷新,有些更麻烦了,您需要一对一
欢迎来到网站,具体地址是杭城工业区阜新林工业园1号楼202楼,联系人是梁女士。
主要业务是为您提供深圳网络推广,深圳网站推广,深圳信息发布,深圳网站推广专家,网站优化公司,深圳宝安西乡南山网站推广,深圳信息发布,发布广告信息,企业网站优化,深圳福永沙井十堰龙华网站优化,深圳企业网站优化,网站推广软件,网站推广工具,国外网站推广等? ??? ?是一家主要从事网络信息应用服务的网络公司,专注于网络推广和网络推广,引领网络推广行业。
单位的注册资本单位的注册资本少于人民币100万元。
∨ 查看全部
让你的信息快速收录排名发布产品信息的节省时间
发布信息的主要目的是使搜索引擎收录能够跟上您的信息。我们的信息发布助手内置了多种发布策略来满足搜索引擎的需求,例如“随机图片”。 ,图片alt标签,随机句子,多个随机段落,信息轮链系统和其他内容更改”,让您的信息快速收录排名
用于节省产品发布时间的人力,可以自动发布信息,
该软件以不定期的间隔发布信息,随意调整间隔,以使每两条信息之间的间隔是不规则的,并具有定时关机功能(通常适用于夜间发布信息并自动关机的朋友放下后)。
二、保存配置功能
如果有多个产品需要单独发布,则可以分别保存产品功能的配置。您只需要配置一次。保存配置后,请稍后导入配置以加载先前的设置,这样可以节省时间和麻烦。
三、自动设置产品图片功能
共有3种选择图片的方式:
1、同步采集 网站图片。如果您在网站背景中上传图片,请点击“ 采集相册”,即可自动将采集图片上传到本地。
2、从网站背景中获取URL地址,并为您要发送的产品拍照。
3、在本地计算机上手动批量导入图片。
五、自动标题合成功能
想不出很多标题?该软件具有内置的批处理合成标题功能,可以自动成批地合成数千个唯一标题。根据需要,配置标题模板以生成它。
标题可以任意组合,常用的格式是自动发布工具。通过各种自定义组合,您可以生成千变万化的不同标题。发布文章软件
四、强大的内容编辑器
该软件具有内置的文本编辑器,该编辑器可自动识别网站内容提交格式是纯文本还是html文本。就像在网站的后台操作一样,可以随时在软件内部直观地编辑html文本。
案例:
5个新模板!获得5个不同的产品介绍,这些产品会定期发布以改进收录!
加快8个助手发布软件, 88助手发布软件和助手发布软件。八方资源网的助手发布了该软件,《中国企业记录》的助手发布了该软件,而嘉德化工网的助手发布了该软件。硬件网络助手发布软件,句容网络助手发布软件,爱夫网络助手发布软件。 Net助手发布软件,机械在线助手发布软件,行业信息网络助手发布软件。
根据需要,可以通过配置标题模板和图像批处理来生成标题模板。对于产品图片,用户最大的问题是图片太大,平台不允许上传。 8、售后,我们和团队都有,并且要重新发送信息功能我们用来刷新发布的信息,在工作站的后台,有些页面一页一页地刷新,有些更麻烦了,您需要一对一
欢迎来到网站,具体地址是杭城工业区阜新林工业园1号楼202楼,联系人是梁女士。
主要业务是为您提供深圳网络推广,深圳网站推广,深圳信息发布,深圳网站推广专家,网站优化公司,深圳宝安西乡南山网站推广,深圳信息发布,发布广告信息,企业网站优化,深圳福永沙井十堰龙华网站优化,深圳企业网站优化,网站推广软件,网站推广工具,国外网站推广等? ??? ?是一家主要从事网络信息应用服务的网络公司,专注于网络推广和网络推广,引领网络推广行业。
单位的注册资本单位的注册资本少于人民币100万元。
∨
猪八戒网、中国太平洋保险、深圳金宝贝、外卖网点评网
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-03-24 23:01
文章自动采集了猪八戒网、中国太平洋保险、深圳金宝贝、外卖网点评网、饿了么、app追评、小红书等官方数据。视频更全面的展示了采集到的全部数据。
知道一款脚本采集数据很方便的:采集外卖,美团,饿了么,自己手动操作太麻烦,用脚本采集简单的数据还是很方便的,可以自己在线操作下载方便。
有的,采集外卖的还是用你掌握的一些技术及工具解决得比较快,我推荐的是大家用好工具,可以自己控制!推荐采用:模拟手机来操作微信公众号的推送,然后用点评来判断有没有评论!ps:线上微信公众号推送,功能强大的程序(如猫眼电影类似)只需简单的更改二维码,直接就能使用,并且能做到非常精准,评论数据那种还是相对比较真实的,能查出来正负面什么的!用到一个,就知道为什么有了!具体方法可查看一下!可以看一下我写的文章!。
八戒网除了你之前说的上边的付费方式,也有采用简单方式去采集。
大方向的内容不需要你去做什么技术研发,
我个人建议,不要买所谓的工具和软件,操作麻烦,而且作用有限,可以使用微信小程序去采集,采集微信的点评,或者百度等搜索的点评,推荐使用北京地区的地推团队提供的一款网站采集工具,将你的网站标题、作用等全部加入进去,这个数据基本上都会采集到,效率高,操作简单。如果想加入网站采集的话,建议先申请一个微信小程序,本地人有群可以去拓展一下,直接在群里加作者,申请加入就可以,但是一定要给他发送链接,网站采集也需要发送链接,而且设置默认网址、浏览器、等信息。 查看全部
猪八戒网、中国太平洋保险、深圳金宝贝、外卖网点评网
文章自动采集了猪八戒网、中国太平洋保险、深圳金宝贝、外卖网点评网、饿了么、app追评、小红书等官方数据。视频更全面的展示了采集到的全部数据。
知道一款脚本采集数据很方便的:采集外卖,美团,饿了么,自己手动操作太麻烦,用脚本采集简单的数据还是很方便的,可以自己在线操作下载方便。
有的,采集外卖的还是用你掌握的一些技术及工具解决得比较快,我推荐的是大家用好工具,可以自己控制!推荐采用:模拟手机来操作微信公众号的推送,然后用点评来判断有没有评论!ps:线上微信公众号推送,功能强大的程序(如猫眼电影类似)只需简单的更改二维码,直接就能使用,并且能做到非常精准,评论数据那种还是相对比较真实的,能查出来正负面什么的!用到一个,就知道为什么有了!具体方法可查看一下!可以看一下我写的文章!。
八戒网除了你之前说的上边的付费方式,也有采用简单方式去采集。
大方向的内容不需要你去做什么技术研发,
我个人建议,不要买所谓的工具和软件,操作麻烦,而且作用有限,可以使用微信小程序去采集,采集微信的点评,或者百度等搜索的点评,推荐使用北京地区的地推团队提供的一款网站采集工具,将你的网站标题、作用等全部加入进去,这个数据基本上都会采集到,效率高,操作简单。如果想加入网站采集的话,建议先申请一个微信小程序,本地人有群可以去拓展一下,直接在群里加作者,申请加入就可以,但是一定要给他发送链接,网站采集也需要发送链接,而且设置默认网址、浏览器、等信息。
黄瓜世界:网站数据采集工具哪个好用?-微小宝
采集交流 • 优采云 发表了文章 • 0 个评论 • 247 次浏览 • 2021-03-17 11:01
3.【小宝】用于微信公众号。
还有今天的标题和其他平台文章供参考。
以上是“黄瓜世界”提供的答案。谢谢您的关注
网站 Data 采集哪个工具易于使用?
网页数据采集,有很多现成的爬虫软件可以直接使用,下面我将简要介绍优采云,章鱼和优采云三种类型,操作简单,易于学习和理解,有兴趣的朋友可以尝试一下:
这是一款非常智能的网络爬虫软件,支持跨平台,完全免费供个人使用。对于大多数网站,只需输入URL,软件将自动识别并提取相关的字段信息,包括列表,表格,链接,图片等,无需配置任何采集规则,一键点击即可删除,支持自动翻页和数据导出功能,对于小白来说,很容易学习和掌握:
这是一个非常好的国内数据采集软件。与优采云 采集器相比,例如,章鱼采集器当前仅支持Windows平台,您需要手动设置采集字段和配置规则,因此比较麻烦和灵活。它具有大量的内置数据采集模板,可以轻松地将采集流行的网站例如京东和天猫。官方教程非常详细,小白也很容易掌握:
当然,除了上述三个爬网软件外,还有许多其他支持网站 data 采集的软件,例如数字,应用程序等也非常不错,如果您熟悉Python的话,Java和其他编程语言,您也可以自己编程以获取数据。 Internet上有相关的教程和材料。简介非常详细。如果您有兴趣,可以搜索。希望以上分享的内容对您有所帮助。欢迎发表评论。 查看全部
黄瓜世界:网站数据采集工具哪个好用?-微小宝
3.【小宝】用于微信公众号。
还有今天的标题和其他平台文章供参考。
以上是“黄瓜世界”提供的答案。谢谢您的关注
网站 Data 采集哪个工具易于使用?
网页数据采集,有很多现成的爬虫软件可以直接使用,下面我将简要介绍优采云,章鱼和优采云三种类型,操作简单,易于学习和理解,有兴趣的朋友可以尝试一下:
这是一款非常智能的网络爬虫软件,支持跨平台,完全免费供个人使用。对于大多数网站,只需输入URL,软件将自动识别并提取相关的字段信息,包括列表,表格,链接,图片等,无需配置任何采集规则,一键点击即可删除,支持自动翻页和数据导出功能,对于小白来说,很容易学习和掌握:
这是一个非常好的国内数据采集软件。与优采云 采集器相比,例如,章鱼采集器当前仅支持Windows平台,您需要手动设置采集字段和配置规则,因此比较麻烦和灵活。它具有大量的内置数据采集模板,可以轻松地将采集流行的网站例如京东和天猫。官方教程非常详细,小白也很容易掌握:
当然,除了上述三个爬网软件外,还有许多其他支持网站 data 采集的软件,例如数字,应用程序等也非常不错,如果您熟悉Python的话,Java和其他编程语言,您也可以自己编程以获取数据。 Internet上有相关的教程和材料。简介非常详细。如果您有兴趣,可以搜索。希望以上分享的内容对您有所帮助。欢迎发表评论。
WordPress文章自动采集插件 WP
采集交流 • 优采云 发表了文章 • 0 个评论 • 382 次浏览 • 2020-08-25 09:49
WP-AutoPost英文免费下载地址
一、安装WP-AutoPost
和安装其他WordPress插件一样,直接上传到插件目录,激活即可使用,无需再进行额外设置或更改代码。
二、创建采集任务
点击“新建任务”后,输入任务名称,即可创建新任务,创建好新任务以后可以在任务列表中查看到该任务,就可对该任务进行更多设置。
三、基本设置功能
在基本设置选项卡下,可以进行如下设置:
四、文章来源设置
在该选项卡下我们须要设置文章来源的文章列表网址及具体文章的匹配规则
我们以采集“新浪互联网新闻”为例,文章列表网址为因而在 手工指定文章列表网址 中输入该网址即可,如下所示:
之后须要设置该文章列表网址下具体文章网址的匹配规则
五、文章网址匹配规则
文章网址匹配规则的设置十分简单,无需复杂设置,提供两种匹配模式,可以使用URL键值匹配,也可以使用CSS选择器进行匹配,通常使用URL键值匹配较为简单。
1. 使用URL键值匹配
通过点击列表网址上的文章,我们可以发觉整篇文章的URL都为如下结构
因此将URL中变化的数字或字母替换为键值(*)即可,如:(*)/(*).shtml
2. 使用CSS选择器进行匹配
使用CSS选择器进行匹配,我们只须要设置文章网址的CSS选择器即可(不知道CSS选择器为什么物,一分钟学会怎样设置CSS选择器),通过查看列表网址 的源代码即可轻松设置,找到该列表网址下具体文章的超链接的代码,如下所示:
可以看见,文章的超链接a标签在class为“contList”的标签内部,因此文章网址的CSS选择器只须要设置为.contList a 即可,如下所示:
设置完成以后,不知道设置是否正确,可以点击上图中的测试按键,如果设置正确,将列举该列表网址下所有文章名称和对应的网页地址,如下所示:
六、文章抓取设置
在该选项卡下,我们须要设置文章标题和文章内容的匹配规则,提供两种形式进行设置,推荐使用CSS选择器形式,使用该方法更为简单,精确。(不知道CSS选择器为什么物,一分钟学会怎样设置CSS选择器)
我们只须要设置文章标题CSS选择器和文章内容CSS选择器,即可确切抓取文章标题和文章内容。
在文章来源设置里,我们以采集”新浪互联网新闻“为例,这里还是以该事例讲解,通过查看列表网址 下某一篇文章的源代码即可轻松设置,例如,我们通过查看某篇具体文章 的源代码,如下所示:
可以看见,文章标题在id为“artibodyTitle”的标签内部,因此文章标题CSS选择器只须要设置为#artibodyTitle即可;
同样的,找到文章内容的相关代码:
可以看见,文章内容在id为“artibody”的标签内部,因此文章内容CSS选择器只须要设置为#artibody即可;如下所示:
设置完成以后,不知道设置是否正确,可点击测试按键,输入测试地址,如果设置正确,将显示出文章标题和文章内容,方便检测设置
七、抓取文章分页内容
如果文章内容过长,有多个分页同样可以抓取全部内容,这时须要设置文章分页链接CSS选择器,通过查看具体文章网址源代码,找到分页链接的地方,例如某篇文章分页链接代码如下:
可以看见,分页链接A标签在class为 “page-link” 的标签内部
因此,文章分页链接CSS选择器设置为.page-link a即可,如下所示:
如果勾选当发表时也分页时,发表文章也将同样被分页,如果你的WordPress主题不支持 标签,请勿勾选。
八、文章内容过滤功能
文章内容过滤功能,可过滤掉正文中不希望发布的内容(如广告代码,版权信息等),可设置两个关键词,删除掉两个关键词之间的内容,关键词2可以为空,表示删掉掉关键词1以后的所有内容。
如下所示,我们通过测试抓取文章后发觉文章里有不希望发布的内容,切换到HTML显示,找到该内容的HTML代码,分别设置两个关键词即可过滤掉该内容。
如上所示,如果我们希望过滤掉前面
和
之间的内容,添加如下设置即可
如果须要过滤掉多处内容,可以添加多组设置。
九、HTML标签过滤功能 查看全部
WordPress文章自动采集插件 WP
WP-AutoPost英文免费下载地址
一、安装WP-AutoPost
和安装其他WordPress插件一样,直接上传到插件目录,激活即可使用,无需再进行额外设置或更改代码。
二、创建采集任务
点击“新建任务”后,输入任务名称,即可创建新任务,创建好新任务以后可以在任务列表中查看到该任务,就可对该任务进行更多设置。
三、基本设置功能
在基本设置选项卡下,可以进行如下设置:
四、文章来源设置
在该选项卡下我们须要设置文章来源的文章列表网址及具体文章的匹配规则
我们以采集“新浪互联网新闻”为例,文章列表网址为因而在 手工指定文章列表网址 中输入该网址即可,如下所示:
之后须要设置该文章列表网址下具体文章网址的匹配规则
五、文章网址匹配规则
文章网址匹配规则的设置十分简单,无需复杂设置,提供两种匹配模式,可以使用URL键值匹配,也可以使用CSS选择器进行匹配,通常使用URL键值匹配较为简单。
1. 使用URL键值匹配
通过点击列表网址上的文章,我们可以发觉整篇文章的URL都为如下结构
因此将URL中变化的数字或字母替换为键值(*)即可,如:(*)/(*).shtml
2. 使用CSS选择器进行匹配
使用CSS选择器进行匹配,我们只须要设置文章网址的CSS选择器即可(不知道CSS选择器为什么物,一分钟学会怎样设置CSS选择器),通过查看列表网址 的源代码即可轻松设置,找到该列表网址下具体文章的超链接的代码,如下所示:
可以看见,文章的超链接a标签在class为“contList”的标签内部,因此文章网址的CSS选择器只须要设置为.contList a 即可,如下所示:
设置完成以后,不知道设置是否正确,可以点击上图中的测试按键,如果设置正确,将列举该列表网址下所有文章名称和对应的网页地址,如下所示:
六、文章抓取设置
在该选项卡下,我们须要设置文章标题和文章内容的匹配规则,提供两种形式进行设置,推荐使用CSS选择器形式,使用该方法更为简单,精确。(不知道CSS选择器为什么物,一分钟学会怎样设置CSS选择器)
我们只须要设置文章标题CSS选择器和文章内容CSS选择器,即可确切抓取文章标题和文章内容。
在文章来源设置里,我们以采集”新浪互联网新闻“为例,这里还是以该事例讲解,通过查看列表网址 下某一篇文章的源代码即可轻松设置,例如,我们通过查看某篇具体文章 的源代码,如下所示:
可以看见,文章标题在id为“artibodyTitle”的标签内部,因此文章标题CSS选择器只须要设置为#artibodyTitle即可;
同样的,找到文章内容的相关代码:
可以看见,文章内容在id为“artibody”的标签内部,因此文章内容CSS选择器只须要设置为#artibody即可;如下所示:
设置完成以后,不知道设置是否正确,可点击测试按键,输入测试地址,如果设置正确,将显示出文章标题和文章内容,方便检测设置
七、抓取文章分页内容
如果文章内容过长,有多个分页同样可以抓取全部内容,这时须要设置文章分页链接CSS选择器,通过查看具体文章网址源代码,找到分页链接的地方,例如某篇文章分页链接代码如下:
可以看见,分页链接A标签在class为 “page-link” 的标签内部
因此,文章分页链接CSS选择器设置为.page-link a即可,如下所示:
如果勾选当发表时也分页时,发表文章也将同样被分页,如果你的WordPress主题不支持 标签,请勿勾选。
八、文章内容过滤功能
文章内容过滤功能,可过滤掉正文中不希望发布的内容(如广告代码,版权信息等),可设置两个关键词,删除掉两个关键词之间的内容,关键词2可以为空,表示删掉掉关键词1以后的所有内容。
如下所示,我们通过测试抓取文章后发觉文章里有不希望发布的内容,切换到HTML显示,找到该内容的HTML代码,分别设置两个关键词即可过滤掉该内容。
如上所示,如果我们希望过滤掉前面
和
之间的内容,添加如下设置即可
如果须要过滤掉多处内容,可以添加多组设置。
九、HTML标签过滤功能
移动应用市场自动化爬取技术的研究与应用
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2020-08-22 10:50
【摘要】:近两年来,由于应用软件数目过多,许多应用商店将大部分应用隐藏在了查询表单旁边的网路数据库中。移动应用软件的安全检查须要大量的应用样本,而这种应用属于Deep Web数据,这给联通应用软件的采集和检查带来了制约。传统的网路爬虫只能访问通过超链接才能抵达的Surface Web数据,而难以访问网路数据库中的Deep Web数据。目前针对这类Deep Web数据的采集技术主要是基于表层化的方法来采集,基于表层化的采集方式关键在于怎样生成合适的查询词,高效率地让网路数据库中的隐藏数据曝露下来。现有的表层化Deep Web数据采集方法主要是面向搜索引擎或大领域主题爬虫,而不是象联通应用软件信息这样的特定领域的Deep Web数据的。本文为了尽可能获取更多的应用软件样本,尤其是Deep Web中的应用数据,对已有的Web数据采集技术和目前主流的联通应用商店进行了研究,主要完成了以下工作:1.对本地应用库中不同类别的应用软件名称进行了动词和词频统计,并勾画了不同比列高频词覆盖应用曲线图,从数据可以得出联通应用软件在命名时用词(字)高度集中的推论,本文据此提出了一种基于样本词频的联通应用商店Deep Web数据采集方法,提取1%的本地应用软件名称中的高频词作为查询词递交至应用商店的应用查询表单,使隐藏在网路数据库中的应用信息曝露下来,再结合传统网路爬虫采集这些应用;2.设计了一个联通应用商店Deep Web数据爬取系统,该系统主要由爬虫模块、信息抽取模块和查询词生成模块构成,在采集完应用商店中的表层网路应用数据后,继续采集Deep Web应用数据,提高系统采集的应用数目;3.进行了系统运行实验,对5家主流联通应用商店进行了应用数据抓取。实验表明系统才能稳定运行,且与不收录Deep Web采集模块的scrapy爬虫采集系统相比,Deep Web数据爬取系统对腾讯应用宝、百度手机助手和360手机助手这3家应用商店的应用采集数量提高了9倍以上,对小米应用商店和华为应用市场的应用覆盖率也提高了将近1倍,数据表明系统才能有效地采集移动应用商店中的Deep Web数据,提高应用采集覆盖率,为联通应用软件的安全检查提供更充分的样本支持。 查看全部
移动应用市场自动化爬取技术的研究与应用
【摘要】:近两年来,由于应用软件数目过多,许多应用商店将大部分应用隐藏在了查询表单旁边的网路数据库中。移动应用软件的安全检查须要大量的应用样本,而这种应用属于Deep Web数据,这给联通应用软件的采集和检查带来了制约。传统的网路爬虫只能访问通过超链接才能抵达的Surface Web数据,而难以访问网路数据库中的Deep Web数据。目前针对这类Deep Web数据的采集技术主要是基于表层化的方法来采集,基于表层化的采集方式关键在于怎样生成合适的查询词,高效率地让网路数据库中的隐藏数据曝露下来。现有的表层化Deep Web数据采集方法主要是面向搜索引擎或大领域主题爬虫,而不是象联通应用软件信息这样的特定领域的Deep Web数据的。本文为了尽可能获取更多的应用软件样本,尤其是Deep Web中的应用数据,对已有的Web数据采集技术和目前主流的联通应用商店进行了研究,主要完成了以下工作:1.对本地应用库中不同类别的应用软件名称进行了动词和词频统计,并勾画了不同比列高频词覆盖应用曲线图,从数据可以得出联通应用软件在命名时用词(字)高度集中的推论,本文据此提出了一种基于样本词频的联通应用商店Deep Web数据采集方法,提取1%的本地应用软件名称中的高频词作为查询词递交至应用商店的应用查询表单,使隐藏在网路数据库中的应用信息曝露下来,再结合传统网路爬虫采集这些应用;2.设计了一个联通应用商店Deep Web数据爬取系统,该系统主要由爬虫模块、信息抽取模块和查询词生成模块构成,在采集完应用商店中的表层网路应用数据后,继续采集Deep Web应用数据,提高系统采集的应用数目;3.进行了系统运行实验,对5家主流联通应用商店进行了应用数据抓取。实验表明系统才能稳定运行,且与不收录Deep Web采集模块的scrapy爬虫采集系统相比,Deep Web数据爬取系统对腾讯应用宝、百度手机助手和360手机助手这3家应用商店的应用采集数量提高了9倍以上,对小米应用商店和华为应用市场的应用覆盖率也提高了将近1倍,数据表明系统才能有效地采集移动应用商店中的Deep Web数据,提高应用采集覆盖率,为联通应用软件的安全检查提供更充分的样本支持。
【开源】新手动采集影视CMS程序开源
采集交流 • 优采云 发表了文章 • 0 个评论 • 365 次浏览 • 2020-08-21 14:06
序
由于近来下班相对比较忙,之前的影视程序预计耗费一个多月的时间来做首版,没想到只做了半个月时间,单位的事就开始忙了上去,没办法只能先放一段时间,程序大部分功能早已写好且可以正常使用,之前第一版测试的BUG也抽口修补了大部分,考虑到短期内暂时未能耗费精力在这程序上,所以开源给你们建立吧。代码写得不好,希望不要嫌弃( ̄▽ ̄)"
已建立功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.轮播管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、专题添加、专题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.推广管理,包括(广告添加、广告列表)
7.扩展商城
8.社交管理
待建立功能
1.系统设置->播放器编辑
2.资源管理->视频管理只写部份
3.资源管理->文章管理
4.会员管理->会员设置
5.社交管理->通讯配置、邮件设置、留言管理只做设置未做对接
6.第三方接入
开源下载
序
由于近来下班相对比较忙,之前的影视程序预计耗费一个多月的时间来做首版,没想到只做了半个月时间,单位的事就开始忙了上去,没办法只能先放一段时间,程序大部分功能早已写好且可以正常使用,之前第一版测试的BUG也抽口修补了大部分,考虑到短期内暂时未能耗费精力在这程序上,所以开源给你们建立吧。代码写得不好,希望不要嫌弃( ̄▽ ̄)"
已建立功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.轮播管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、专题添加、专题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.推广管理,包括(广告添加、广告列表)
7.扩展商城
8.社交管理
待建立功能
1.系统设置->播放器编辑
2.资源管理->视频管理只写部份
3.资源管理->文章管理
4.会员管理->会员设置
5.社交管理->通讯配置、邮件设置、留言管理只做设置未做对接
6.第三方接入
开源下载
序
由于近来下班相对比较忙,之前的影视程序预计耗费一个多月的时间来做首版,没想到只做了半个月时间,单位的事就开始忙了上去,没办法只能先放一段时间,程序大部分功能早已写好且可以正常使用,之前第一版测试的BUG也抽口修补了大部分,考虑到短期内暂时未能耗费精力在这程序上,所以开源给你们建立吧。代码写得不好,希望不要嫌弃( ̄▽ ̄)"
已建立功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.轮播管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、专题添加、专题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.推广管理,包括(广告添加、广告列表)
7.扩展商城
8.社交管理
待建立功能
1.系统设置->播放器编辑
2.资源管理->视频管理只写部份
3.资源管理->文章管理
4.会员管理->会员设置
5.社交管理->通讯配置、邮件设置、留言管理只做设置未做对接
6.第三方接入
开源下载
序
由于近来下班相对比较忙,之前的影视程序预计耗费一个多月的时间来做首版,没想到只做了半个月时间,单位的事就开始忙了上去,没办法只能先放一段时间,程序大部分功能早已写好且可以正常使用,之前第一版测试的BUG也抽口修补了大部分,考虑到短期内暂时未能耗费精力在这程序上,所以开源给你们建立吧。代码写得不好,希望不要嫌弃( ̄▽ ̄)"
已建立功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.轮播管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、专题添加、专题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.推广管理,包括(广告添加、广告列表)
7.扩展商城
8.社交管理
待建立功能
1.系统设置->播放器编辑
2.资源管理->视频管理只写部份
3.资源管理->文章管理
4.会员管理->会员设置
5.社交管理->通讯配置、邮件设置、留言管理只做设置未做对接
6.第三方接入
开源下载 查看全部
【开源】新手动采集影视CMS程序开源
序
由于近来下班相对比较忙,之前的影视程序预计耗费一个多月的时间来做首版,没想到只做了半个月时间,单位的事就开始忙了上去,没办法只能先放一段时间,程序大部分功能早已写好且可以正常使用,之前第一版测试的BUG也抽口修补了大部分,考虑到短期内暂时未能耗费精力在这程序上,所以开源给你们建立吧。代码写得不好,希望不要嫌弃( ̄▽ ̄)"
已建立功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.轮播管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、专题添加、专题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.推广管理,包括(广告添加、广告列表)
7.扩展商城
8.社交管理
待建立功能
1.系统设置->播放器编辑
2.资源管理->视频管理只写部份
3.资源管理->文章管理
4.会员管理->会员设置
5.社交管理->通讯配置、邮件设置、留言管理只做设置未做对接
6.第三方接入
开源下载
序
由于近来下班相对比较忙,之前的影视程序预计耗费一个多月的时间来做首版,没想到只做了半个月时间,单位的事就开始忙了上去,没办法只能先放一段时间,程序大部分功能早已写好且可以正常使用,之前第一版测试的BUG也抽口修补了大部分,考虑到短期内暂时未能耗费精力在这程序上,所以开源给你们建立吧。代码写得不好,希望不要嫌弃( ̄▽ ̄)"
已建立功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.轮播管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、专题添加、专题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.推广管理,包括(广告添加、广告列表)
7.扩展商城
8.社交管理
待建立功能
1.系统设置->播放器编辑
2.资源管理->视频管理只写部份
3.资源管理->文章管理
4.会员管理->会员设置
5.社交管理->通讯配置、邮件设置、留言管理只做设置未做对接
6.第三方接入
开源下载
序
由于近来下班相对比较忙,之前的影视程序预计耗费一个多月的时间来做首版,没想到只做了半个月时间,单位的事就开始忙了上去,没办法只能先放一段时间,程序大部分功能早已写好且可以正常使用,之前第一版测试的BUG也抽口修补了大部分,考虑到短期内暂时未能耗费精力在这程序上,所以开源给你们建立吧。代码写得不好,希望不要嫌弃( ̄▽ ̄)"
已建立功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.轮播管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、专题添加、专题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.推广管理,包括(广告添加、广告列表)
7.扩展商城
8.社交管理
待建立功能
1.系统设置->播放器编辑
2.资源管理->视频管理只写部份
3.资源管理->文章管理
4.会员管理->会员设置
5.社交管理->通讯配置、邮件设置、留言管理只做设置未做对接
6.第三方接入
开源下载
序
由于近来下班相对比较忙,之前的影视程序预计耗费一个多月的时间来做首版,没想到只做了半个月时间,单位的事就开始忙了上去,没办法只能先放一段时间,程序大部分功能早已写好且可以正常使用,之前第一版测试的BUG也抽口修补了大部分,考虑到短期内暂时未能耗费精力在这程序上,所以开源给你们建立吧。代码写得不好,希望不要嫌弃( ̄▽ ̄)"
已建立功能
1.系统设置,包括(站点设置、提示设置、SEO设置、API设置、播放器)
2.轮播管理,包括(轮播添加、轮播列表、轮播配置)
3.资源管理,包括(缓存设置、缓存管理、侵权设置)
4.页面管理,包括(导航设置、专题添加、专题列表)
5.会员管理,包括(会员列表、卡密生成、卡密列表)
6.推广管理,包括(广告添加、广告列表)
7.扩展商城
8.社交管理
待建立功能
1.系统设置->播放器编辑
2.资源管理->视频管理只写部份
3.资源管理->文章管理
4.会员管理->会员设置
5.社交管理->通讯配置、邮件设置、留言管理只做设置未做对接
6.第三方接入
开源下载
无人值守免费手动采集器(自动采集) 3.3.6英文红色免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-08-20 13:48
无人值守免费手动采集器(自动采集)是一款中小网站自动更新神器,高效、自动网站采集工具,无人值守免费手动采集器免费版款独立于网站的全手动信息采集软件,其稳定,安全,低耗,自动化等特点,适用于中小网站日常更新,代替大量人工,将站长等工作人员从乏味的重复劳动中解放下来。
功能介绍
【特色】设定好方案,即可24小时手动工作,不再须要人工干涉
【特色】与网站分离,通过独立制做的插口,无人值守免费手动采集器免费版可以支持任何网站或数据库
【特色】灵活强悍的采集规则不仅仅是采集文章,可采集任何类型信息
【特色】小巧、低耗和良好的稳定性特别适宜运行于服务器
【特色】所有规则都可以导出导入,灵活的资源重用
【特色】采用FTP上传文件,稳定、安全
【特色】下载上传支持断点续传
【特色】高速伪原创
【采集】可选择逆序、顺序、随机采集文章
【采集】支持手动列表网址
【采集】支持对数据分布在多层页面的网站进行采集
【采集】自由设定采集数据项,并可单独过滤整理每位数据项
【采集】支持分页内容采集
【采集】支持任意格式、类型的文件(包括图片、视频)下载
【采集】可突破防盗链文件
【采集】支持动态文件网址剖析
【采集】支持对需登陆访问的网页的采集
【支持】可设定关键词采集
【支持】可设定避免采集的敏感词
【支持】可设置图片水印 查看全部
无人值守免费手动采集器(自动采集) 3.3.6英文红色免费版
无人值守免费手动采集器(自动采集)是一款中小网站自动更新神器,高效、自动网站采集工具,无人值守免费手动采集器免费版款独立于网站的全手动信息采集软件,其稳定,安全,低耗,自动化等特点,适用于中小网站日常更新,代替大量人工,将站长等工作人员从乏味的重复劳动中解放下来。
功能介绍
【特色】设定好方案,即可24小时手动工作,不再须要人工干涉
【特色】与网站分离,通过独立制做的插口,无人值守免费手动采集器免费版可以支持任何网站或数据库
【特色】灵活强悍的采集规则不仅仅是采集文章,可采集任何类型信息
【特色】小巧、低耗和良好的稳定性特别适宜运行于服务器
【特色】所有规则都可以导出导入,灵活的资源重用
【特色】采用FTP上传文件,稳定、安全
【特色】下载上传支持断点续传
【特色】高速伪原创
【采集】可选择逆序、顺序、随机采集文章
【采集】支持手动列表网址
【采集】支持对数据分布在多层页面的网站进行采集
【采集】自由设定采集数据项,并可单独过滤整理每位数据项
【采集】支持分页内容采集
【采集】支持任意格式、类型的文件(包括图片、视频)下载
【采集】可突破防盗链文件
【采集】支持动态文件网址剖析
【采集】支持对需登陆访问的网页的采集
【支持】可设定关键词采集
【支持】可设定避免采集的敏感词
【支持】可设置图片水印
苹果cms怎么设置手动采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 438 次浏览 • 2020-08-19 11:01
在我们使用苹果cms进行安装以后下一步就是对网站内容的填充了,如果是上传自己的视频资源,比如自己制做的视频教程,搞笑段子,直播回放等内容直接自动上传即可。还有一种手动上传的方式,那就是手动采集,按采集任务设定的时间间隔手动采集终端数据,自动采集时间、间隔、内容、对象可设置。苹果cms自带采集功能,只要我们能找到使我们免费采集的网站添加好插口就可以采集了。下面我的主题网就苹果cms怎么设置手动采集这个问题详尽的说下具体的操作步骤。
1,进入到苹果cms后台管理,找到选项:采集----自定义资源库----添加--会出现下边的弹窗,这个步骤须要我们找到我们可以采集的网站,然后获取插口地址填写在这里。
采集接口找寻方法:可以百度下关键词“资源采集”搜索结果会有很多免费的网站供我们采集。然后在你须要采集的网站帮助中心获取采集接口填写在这里即可。
2,获取到插口后之后进行自定义资源的填写,这个须要详尽的论述下具体每位选项代表的涵义后才会更好的选择。图片下边详尽的论述了每位选项其中的含意。
资源名称:我们采集的网站名称,可随便命名。
接口地址:我们要采集的网站接口。
附加参数:一般&开头, 如老版xml格试采集下要地址需加入&ct=1
接口类型:一般默认为xml格式,但是也有json格式的资源 需要自己确定。
资源类型:我们这儿以采集视频为案例,我们选择视频即可。
数据操作:勾选新增:则采集的时侯,只新增数据,不更新;勾选更新:则采集的时侯,只在原先的数据基础上更新,不降低新的数据。
地址过滤:这个插口中有多个播放来源的话,是新增播放组还是只更新播放组
过滤代码:接口上面有多个播放来源的话,填那个就采集哪个,比如填写youku,那么就只采集这个插口中的youku;播放源填写youku,qiyi, 就采集这两个播放源。
3,这时候我们再回到我们之前的页面就可以看见我们添加的资源插口,鼠标直接点击这个插口都会步入分类的绑定页面。
4,进入分类绑定页面后按照下边截图所示的1-4步骤操作即可完成分类的绑定,没有对应分类的可以自己添加分类,添加分类的教程可参考我的主题网之前分享过的帮助文档:苹果cms怎么添加分类 来添加分类即可。
5,添加完后就开始采集了,我们可以选择采集当天,采集本周,或是采集所有。这样我们就完成了自动采集的步骤。距离我们要手动采集的步骤早已太逾了。
6,自动采集的教程是用的宝塔监控,文章篇幅过长手动采集教程转为另一篇文档,教程地址:苹果cms宝塔全手动定时采集教程
作者:佚名我要举报 查看全部
苹果cms怎么设置手动采集
在我们使用苹果cms进行安装以后下一步就是对网站内容的填充了,如果是上传自己的视频资源,比如自己制做的视频教程,搞笑段子,直播回放等内容直接自动上传即可。还有一种手动上传的方式,那就是手动采集,按采集任务设定的时间间隔手动采集终端数据,自动采集时间、间隔、内容、对象可设置。苹果cms自带采集功能,只要我们能找到使我们免费采集的网站添加好插口就可以采集了。下面我的主题网就苹果cms怎么设置手动采集这个问题详尽的说下具体的操作步骤。
1,进入到苹果cms后台管理,找到选项:采集----自定义资源库----添加--会出现下边的弹窗,这个步骤须要我们找到我们可以采集的网站,然后获取插口地址填写在这里。
采集接口找寻方法:可以百度下关键词“资源采集”搜索结果会有很多免费的网站供我们采集。然后在你须要采集的网站帮助中心获取采集接口填写在这里即可。
2,获取到插口后之后进行自定义资源的填写,这个须要详尽的论述下具体每位选项代表的涵义后才会更好的选择。图片下边详尽的论述了每位选项其中的含意。
资源名称:我们采集的网站名称,可随便命名。
接口地址:我们要采集的网站接口。
附加参数:一般&开头, 如老版xml格试采集下要地址需加入&ct=1
接口类型:一般默认为xml格式,但是也有json格式的资源 需要自己确定。
资源类型:我们这儿以采集视频为案例,我们选择视频即可。
数据操作:勾选新增:则采集的时侯,只新增数据,不更新;勾选更新:则采集的时侯,只在原先的数据基础上更新,不降低新的数据。
地址过滤:这个插口中有多个播放来源的话,是新增播放组还是只更新播放组
过滤代码:接口上面有多个播放来源的话,填那个就采集哪个,比如填写youku,那么就只采集这个插口中的youku;播放源填写youku,qiyi, 就采集这两个播放源。
3,这时候我们再回到我们之前的页面就可以看见我们添加的资源插口,鼠标直接点击这个插口都会步入分类的绑定页面。
4,进入分类绑定页面后按照下边截图所示的1-4步骤操作即可完成分类的绑定,没有对应分类的可以自己添加分类,添加分类的教程可参考我的主题网之前分享过的帮助文档:苹果cms怎么添加分类 来添加分类即可。
5,添加完后就开始采集了,我们可以选择采集当天,采集本周,或是采集所有。这样我们就完成了自动采集的步骤。距离我们要手动采集的步骤早已太逾了。
6,自动采集的教程是用的宝塔监控,文章篇幅过长手动采集教程转为另一篇文档,教程地址:苹果cms宝塔全手动定时采集教程
作者:佚名我要举报
WordPress手动关键字内链/随机分布到文章实现插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2020-08-17 22:09
我们站长在做网站过程中会发觉适当的添加网站文章的关键字、TAGS确实还可以增强网站的检索索引,以及排行有时候可能关键字TAGS给与的排行还比文章的高。按照正规的做法的话,我们整篇文章会添加三到五个关键字,当然是相关关键字的。
同时,我们也有见到有些做采集类网站的站长,以及做垃圾站点的,会通过批量的TAGS拼凑实现大量的索引。当然这类做法从上一次百度的发布规则中是属于违法的,已经在相继的严打。但是对于有些做站群或则采集的来说,他们才不管,他们只要实现即可。这里老左介绍一款比较好的WordPress手动关键字插件,可以实现手动关键字内链,以及手动随机插入相关、随机的关键字到网站文章的TAGS标签中。
我们一起瞧瞧这个插件的功能,估计还有好多网友没有发觉,如果你发觉且有须要恐怕迫不及待的会有使用到,尤其是做采集类网站的确实是有帮助的。
插件地址:
插件直接早已发布在WordPress官方,我们可以直接下载使用。
我们可以看见可以开启手动TAGS内链。以及可以预设值关键字,然后在添加文章的时侯手动分配到文章中,可以按照绝对匹配标题和内容,以及随机匹配。可以设置限定最高的TAGS数目。
我们也可以在文章更新完毕以后,可以后随机或则手动绝对匹配到对应的文章中,可以设置文章的ID范围进行匹配添加。
总之,这个WordPress关键字手动插件适宜有须要添加TAGS标签关键字的,以及后续添加到网站关键字,以及手动TAGS内链的使用。
本文固定链接: | 老左笔记 查看全部
WordPress手动关键字内链/随机分布到文章实现插件
我们站长在做网站过程中会发觉适当的添加网站文章的关键字、TAGS确实还可以增强网站的检索索引,以及排行有时候可能关键字TAGS给与的排行还比文章的高。按照正规的做法的话,我们整篇文章会添加三到五个关键字,当然是相关关键字的。
同时,我们也有见到有些做采集类网站的站长,以及做垃圾站点的,会通过批量的TAGS拼凑实现大量的索引。当然这类做法从上一次百度的发布规则中是属于违法的,已经在相继的严打。但是对于有些做站群或则采集的来说,他们才不管,他们只要实现即可。这里老左介绍一款比较好的WordPress手动关键字插件,可以实现手动关键字内链,以及手动随机插入相关、随机的关键字到网站文章的TAGS标签中。
我们一起瞧瞧这个插件的功能,估计还有好多网友没有发觉,如果你发觉且有须要恐怕迫不及待的会有使用到,尤其是做采集类网站的确实是有帮助的。
插件地址:
插件直接早已发布在WordPress官方,我们可以直接下载使用。
我们可以看见可以开启手动TAGS内链。以及可以预设值关键字,然后在添加文章的时侯手动分配到文章中,可以按照绝对匹配标题和内容,以及随机匹配。可以设置限定最高的TAGS数目。
我们也可以在文章更新完毕以后,可以后随机或则手动绝对匹配到对应的文章中,可以设置文章的ID范围进行匹配添加。
总之,这个WordPress关键字手动插件适宜有须要添加TAGS标签关键字的,以及后续添加到网站关键字,以及手动TAGS内链的使用。
本文固定链接: | 老左笔记
DedeCMS织梦为文章图片手动添加ALT标签
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2020-08-13 08:21
修改文件include/arc.archives.class.php
找到:
//设置全局环境变量
$this->Fields['typename'] = $this->TypeLink->TypeInfos['typename'];
SetSysEnv($this->Fields['typeid'],$this->Fields['typename'],$this->Fields['aid'],$this->Fields['title'],'archives');
在下边降低代码
//替换图片Alt为文档关键字+标题
$this->Fields['body'] = str_ireplace(array('','alt=\'\''),'',$this->Fields['body']);
$this->Fields['body'] = preg_replace("@ [\s]{0,}alt[\s]{0,}=[\"'\s]{0,}[\s\S]{0,}[\"'\s] @isU"," ",$this->Fields['body']);
$this->Fields['body'] = str_ireplace("Fields['keywords']." . ".$this->Fields['title']."' ",$this->Fields['body']);
//end
重新生成文章即可,如果是其它数组,可以更改$this->Fields['body'] 为其它的数组名。农业经 查看全部
用DedeCMS在做图片站,一般都是采集,很多图片没有alt标签,对搜索引擎来说并不友好,一张一张写相当麻烦,可以更改为文档关键字或文章标题作为图片alt描述。图片的匹配度其实没有自动的好,但做站群的时侯能省事就好。百度霸屏
修改文件include/arc.archives.class.php
找到:
//设置全局环境变量
$this->Fields['typename'] = $this->TypeLink->TypeInfos['typename'];
SetSysEnv($this->Fields['typeid'],$this->Fields['typename'],$this->Fields['aid'],$this->Fields['title'],'archives');
在下边降低代码
//替换图片Alt为文档关键字+标题
$this->Fields['body'] = str_ireplace(array('','alt=\'\''),'',$this->Fields['body']);
$this->Fields['body'] = preg_replace("@ [\s]{0,}alt[\s]{0,}=[\"'\s]{0,}[\s\S]{0,}[\"'\s] @isU"," ",$this->Fields['body']);
$this->Fields['body'] = str_ireplace("Fields['keywords']." . ".$this->Fields['title']."' ",$this->Fields['body']);
//end
重新生成文章即可,如果是其它数组,可以更改$this->Fields['body'] 为其它的数组名。农业经
电子科技大学硕士学位论文36 息采集的数据量十分大 少则几十万条 多者上千万条。
采集交流 • 优采云 发表了文章 • 0 个评论 • 322 次浏览 • 2020-08-09 15:33
表现层表现层由Web服务器组成。CIS中 Web服务器作为浏览器和应用服务器之间的中间插口层 将用户在浏览器上的情报数据恳求发送给应用服务器 应用服务器经过相关的模块处理后 再将结果通过Web服务器发送给最终的用户。 第四章 基于大数据的企业竞争情报模型建立 37 系统总体构架系统包括三个子系统。各子系统的功能模块如图4 3所示。 功能基于大数据的竞争情报系统 采集子系统 分析子系统 服务子系统 采集任务管理 采集器监控 情报主题订制 情报资源转出 情报检索 转出 情报挖掘与剖析 情报知识库 用户管理 系统维护 Web服务器 应用服务器 应用服务器 MongoDB数据库 关系数据库 数据层 应用层 表现层层 电子科技大学硕士学位论文 38 竞争情报采集子系统的主要功能是对企业的各类类型的情报信息源进行数据采集、预处理 并实现储存。信息源除了包括企业内部的各类系统 如OA系统、OLTP系统、ERP系统、企业Web服务器日志等 还包括企业外部的各类信息来源 如互联网数据、社交网络等。 采集器是情报采集子系统的主要部件。系统通过采集器搜集这种不同来源的数据 并通过规范化预处理 存储在信息情报仓储中 作为进一步进行竞争情报剖析的来源数据。
采集子系统须要实现以下几个基本功能 信息录入和导出功能其实企业竞争情报系统的数据主要借助手动搜集 但是也须要提供一定程度的人工录入 因此须要有良好的人工录入界面 采集系统除了须要实现手工录入功能 还须要实现对已有数据的批量导出功能。竞争情报管理人员可事先将企业竞争情报进行合理分类 便于管理和信息导出。也可自动将搜集到的信息根据分类导出到储存竞争情报的数据库中。 信息手动采集功能可通过对数据库的调用、网络爬虫等来实现信息情报的手动采集。自动采集是企业竞争情报系统最重要的功能。本文也是主要注重于这一功能的设计进行剖析。 大数据时代 竞争情报的数据来源愈加宽泛 规模愈加庞大 数据类型愈发多样。除了互联网的信息来源 如企业门户网站、新闻媒体网站、政府网站、行业网站等 还包括企业内部的各类服务器日志、企业信息系统的业务数据等。因此 企业竞争情报在数据的快速处理、高效储存等方面都面临着巨大的挑战 传统的文件格式、关系数据库都早已远远不能满足企业竞争情报的需求。 下面对基于大数据的企业竞争情报采集子系统模型进行剖析。 模型传统的情报采集子系统通常通过采集器将采集的数据进行预处理后 存储在关系式数据库中 这种方法在数据量较小的情况下 性能良好 但是在大规模数据环境下 其伸缩性、处理的高效性以及大规模储存等方面存在着困难。
本文借鉴Apache Chukwa等在大规模数据 日志 采集和处理方面的经验 提出一个基于分布式文件系统和NoSQL数据库技术的情报采集子系统模型 该模型可便捷地构架于Hadoop集群上 充分利用Hadoop擅长于大规模数据处理的优势。其流程如下图所示 第四章基于大数据的企业竞争情报模型建立 39 基于大数据的竞争情报采集子系统模型在该模型中 首先按照用户预先定义的竞争情报主题 或者所要完成的情报任务 通过数据采集器对各类型的情报信息源进行扫描 采集符合需求的竞争情报 其次通过预处理器对采集到的原创数据进行清洗、相关度剖析等 最后将预处理过的数据储存在情报信息仓储中。 下面对采集子系统的各功能模块设计作进一步剖析。 采集任务管理模块设计采集任务是由情报用户按照信息采集的需求而订制的主题兴趣。采集任务订制完成后被传递给信息采集器 采集器按照任务订制信息 采用相关策略、对指定信息空间进行搜索 以获取与任务相关的主题信息。 一个采集任务的确定由两个方面属性决定 一个是任务基本信息 一个是Web采集子任务信息。 采集任务的主题由主题词集描述。一个主题词集包括若干个带残差的子主题 子主题之间是“或”的关系。
一个子主题由多个关键词经逻辑“and”和“not”组成。一个子主题形如 “大数据 企业”。用户可以对采集任务进行管理 如新建、删除采集任务 还可以浏览、修改、暂停、终止、重启自己完善的采集任务 。一个典型的采集任务工作流程如图46所示。 预处理器 HDFS 情报信息源 服务器日志 互联网 采集器 数据集聚 元数据 情报信息仓储 映射 HDFSWrite 情报分类 情报主题 竞争情报剖析子系统 电子科技大学硕士学位论文 40 采集器模块设计采集器是该子系统的核心部件 类似于互联网的“爬虫”程序或专题搜索引擎。采集器主要由爬行队列、网络连接器、主题分类器、超链精化器以及情报主题模型等部件组成。 其工作流程如图4 7所示。 新建采集任务 采集任务管理 删除采集任务 浏览采集任务 修改采集任务 暂停采集任务 终止采集任务 重启采集任务 登录 新建采集任务 基本 信息 采集器 信息 采集任务完成 启动采集任务 终止 暂停 重启 删除 采集器运行 主题订制 关键词、 语种、信息类型、… 种子站点 采集器参数、… 第四章 基于大数据的企业竞争情报模型建立 41 情报资源转出模块设计情报资源转出模块的功能就是将采集任务采集到的情报专题资源转出为目标计算机上的纯文本数据、XML数据或则关系数据库数据的操作。
资源转出实现主题资源的迁移 实现系统数据产品输出目标。 情报资源转出的工作流程如图4 8所示。 情报主题订制情报主题订制是指用户订制自己感兴趣的主题范围 作为订制采集任务的基础 即采集任务订制时 主题类别的选择从用户自己订制的分类范围内选择。 Web 网络连接器 爬行队列 情报主题模型 主题分类器 网页库种子站点 追加转出 覆盖转出 开始 选择情报专题 设置转出方法 设置转出目的地和类型 选择转出数组 执行转出 结束 本地转出 远程转出 文本格式、 数据库 XML、… 电子科技大学硕士学位论文 42 情报主题分类有多种方式 最常使用的是《中国图书馆分类法》 27 。《中国图书馆分类法》简称《中图法》 是我国图书馆和情报单位普遍使用的一部综合性的分类法。本系统采用《中国图书馆分类法》三级体系作为情报主题的分类。 情报人员在新建采集任务时 需要首先订制情报主题。如图4 9所示。 功能剖析子系统是企业CIS的核心。其中 情报剖析器是该子系统的主要部件。 模型竞争情报剖析子系统主要包括三个部件 情报剖析器、情报知识库以及竞争情报方法库 包括数据挖掘方式库和情报剖析方式库 。其中情报剖析器是关键 它借助各类数据挖掘方式、情报剖析方式对情报信息仓储中的数据进行剖析 获得各类有价值的情报 形成情报知识库。
情报知识库是情报剖析的结果。 其模型如图4 8所示。 老用户 新用户 定制情报主题 修改情报主题 建立采集任务 第四章 基于大数据的企业竞争情报模型建立 43 情报剖析子系统模型剖析方式主要不仅常规统计学方式外 还有数据挖掘方式、情报剖析方式。本系统的竞争情报剖析方式封装在方式库中 提供给用户在情报剖析过程中依据需求调用。 竞争情报常用的剖析方式方式类型 典型方式 情报剖析 SWOT分析、定标比超、战略联盟、经验曲线、核心竞争力剖析、回归剖析、多元化业务剖析 数据挖掘 常规统计方式、分类、聚类、关联分析、时间序列、社会网路方式、链接剖析等 大数据时代 竞争情报剖析涉及的信息数据可能是海量的 因而适合采用分布式文件系统Hadoop和MapReduce进行数据的储存和处理。 本文的情报剖析子系统设计采用Hadoop作为构架基础 数据剖析或挖掘算法的实现采用MapReduce来完成。因此 设计情报剖析子系统模型如图4 9所示。 采集的原创信息数据 情报剖析器 分析方式 情报知识库 电子科技大学硕士学位论文 44 基于大数据的情报剖析子系统模型如图4 3所示 情报剖析子系统包括情报检索、情报挖掘、情报知识库管理等模块。
例如情报检索模块的设计如图4 10所示。 该模块支持对情报根据题名、作者、关键词、摘要、全文等多种途径进行浏览和检索。检索有两种方法 简单检索和高级检索。另外 该模块还提供对情报资源根据要求人工或手动生成索引。 10情报检索模块功能设计 功能Hadoop HDFS Hcatalog NoSQL MapReduce 数据挖掘方法库 分类、聚类 关联规则 时序剖析 协同过滤 SNA技术情报剖析技术 定性分析法 定量分析法 企业知识库 情报服务子系统 常规方式 词频统计 情报信息仓储 情报检索 情报浏览 普通检索 高级检索 全文索引 第四章 基于大数据的企业竞争情报模型建立 45 企业不同的职能部门和不同层级的人员对情报的需求不同 而情报服务子系统的主要功能是依据企业竞争情报的主题需求或情报任务 对竞争情报剖析子系统的剖析结果进行加工 并以统一的方法为用户提供服务服务 如情报浏览 情报检索 情报报表的生成 情报推荐、个性化用户服务等。 模型现代化的竞争情报服务子系统须要为用户提供形象化的信息展示。可视化的图形图象比单纯的文字更具有说服力 更适于被用户理解 所以许多数据挖掘系统都采用了可视化的方法为用户提供挖掘结果 并可与之进行可视化互动。
本文将信息可视化技术引入到竞争情报服务子系统 通过可视化技术 将情报剖析结果以生动形象的形式诠释给用户 为用户提供快捷、人性化的情报体验。 子系统模型如图4 11所示。 11情报服务子系统模型 本章小结本章详尽剖析了基于大数据的企业竞争情报模型。模型把企业CIS分为情报采集子系统、情报剖析子系统和情报服务子系统。竞争情报采集子系统的主要功能是对企业的各类类型的情报信息源进行数据采集、预处理 并实现储存 分析子系统是竞争情报系统的核心 其主要任务是对竞争情报采集子系统中采集、存储、预处理过的数据进行统计剖析或数据挖掘 发现有价值的情报。该子系统中的剖析结果将储存在竞争情报知识库中 情报服务子系统的主要功能是依据企业竞争情报的主题需求对竞争情报产品进行加工 并通过统一的门户提供服务。 情报服务加工器 企业竞争情报知识库 可视化映射 可视化结构 视图转换 可视化结果显示 文本报告生成 人机交互界面 报告模板 查看全部
电子科技大学硕士学位论文36 息采集的数据量十分大 少则几十万条 多者上千万条。这对数据库的扩展性要求十分高 数据库必须才能便捷地、低成本地进行扩充。同时须要数据库实现复制冗余机制 能便捷地提升备份和降低读操作节点 并手动地进行数据同步。 由于关系数据库在数据量骤降的情况下 分布式扩充遭到限制 本文拟采用NoSQL数据库来实现采集子系统的情报信息仓储。其他的数据采用关系数据库实现。 系统构架系统采用B S结构 数据库储存采用NoSQL文档数据MongoDB。系统构架如图4 2所示。 整个系统包括3层 数据层、应用层、表现层 。最底层是数据层由关系数据库、NoSQL数据层组成 应用层由应用服务器组成 表现层由Web服务器组成。 数据层数据层主要执行对数据的操作 包括各类常规的操作 如添加、删除、查询、修改等。随着系统采集信息的不断降低 情报信息仓储的数据规模越来越大 传统的关系数据库早已不能适应。本文采用文档数据库MongoDB来储存采集到的数据。 应用层应用器是整个系统的关键部份 发挥着企业竞争情报三大子系统的所有功能。采集子系统中情报采集程序、爬虫程序 分析子系统中的各类算法、数据整理和重组操作程序 情报服务子系统的各类服务功能程序 如系统配置、用户管理、系统维护功能等都在应用层实现。
表现层表现层由Web服务器组成。CIS中 Web服务器作为浏览器和应用服务器之间的中间插口层 将用户在浏览器上的情报数据恳求发送给应用服务器 应用服务器经过相关的模块处理后 再将结果通过Web服务器发送给最终的用户。 第四章 基于大数据的企业竞争情报模型建立 37 系统总体构架系统包括三个子系统。各子系统的功能模块如图4 3所示。 功能基于大数据的竞争情报系统 采集子系统 分析子系统 服务子系统 采集任务管理 采集器监控 情报主题订制 情报资源转出 情报检索 转出 情报挖掘与剖析 情报知识库 用户管理 系统维护 Web服务器 应用服务器 应用服务器 MongoDB数据库 关系数据库 数据层 应用层 表现层层 电子科技大学硕士学位论文 38 竞争情报采集子系统的主要功能是对企业的各类类型的情报信息源进行数据采集、预处理 并实现储存。信息源除了包括企业内部的各类系统 如OA系统、OLTP系统、ERP系统、企业Web服务器日志等 还包括企业外部的各类信息来源 如互联网数据、社交网络等。 采集器是情报采集子系统的主要部件。系统通过采集器搜集这种不同来源的数据 并通过规范化预处理 存储在信息情报仓储中 作为进一步进行竞争情报剖析的来源数据。
采集子系统须要实现以下几个基本功能 信息录入和导出功能其实企业竞争情报系统的数据主要借助手动搜集 但是也须要提供一定程度的人工录入 因此须要有良好的人工录入界面 采集系统除了须要实现手工录入功能 还须要实现对已有数据的批量导出功能。竞争情报管理人员可事先将企业竞争情报进行合理分类 便于管理和信息导出。也可自动将搜集到的信息根据分类导出到储存竞争情报的数据库中。 信息手动采集功能可通过对数据库的调用、网络爬虫等来实现信息情报的手动采集。自动采集是企业竞争情报系统最重要的功能。本文也是主要注重于这一功能的设计进行剖析。 大数据时代 竞争情报的数据来源愈加宽泛 规模愈加庞大 数据类型愈发多样。除了互联网的信息来源 如企业门户网站、新闻媒体网站、政府网站、行业网站等 还包括企业内部的各类服务器日志、企业信息系统的业务数据等。因此 企业竞争情报在数据的快速处理、高效储存等方面都面临着巨大的挑战 传统的文件格式、关系数据库都早已远远不能满足企业竞争情报的需求。 下面对基于大数据的企业竞争情报采集子系统模型进行剖析。 模型传统的情报采集子系统通常通过采集器将采集的数据进行预处理后 存储在关系式数据库中 这种方法在数据量较小的情况下 性能良好 但是在大规模数据环境下 其伸缩性、处理的高效性以及大规模储存等方面存在着困难。
本文借鉴Apache Chukwa等在大规模数据 日志 采集和处理方面的经验 提出一个基于分布式文件系统和NoSQL数据库技术的情报采集子系统模型 该模型可便捷地构架于Hadoop集群上 充分利用Hadoop擅长于大规模数据处理的优势。其流程如下图所示 第四章基于大数据的企业竞争情报模型建立 39 基于大数据的竞争情报采集子系统模型在该模型中 首先按照用户预先定义的竞争情报主题 或者所要完成的情报任务 通过数据采集器对各类型的情报信息源进行扫描 采集符合需求的竞争情报 其次通过预处理器对采集到的原创数据进行清洗、相关度剖析等 最后将预处理过的数据储存在情报信息仓储中。 下面对采集子系统的各功能模块设计作进一步剖析。 采集任务管理模块设计采集任务是由情报用户按照信息采集的需求而订制的主题兴趣。采集任务订制完成后被传递给信息采集器 采集器按照任务订制信息 采用相关策略、对指定信息空间进行搜索 以获取与任务相关的主题信息。 一个采集任务的确定由两个方面属性决定 一个是任务基本信息 一个是Web采集子任务信息。 采集任务的主题由主题词集描述。一个主题词集包括若干个带残差的子主题 子主题之间是“或”的关系。
一个子主题由多个关键词经逻辑“and”和“not”组成。一个子主题形如 “大数据 企业”。用户可以对采集任务进行管理 如新建、删除采集任务 还可以浏览、修改、暂停、终止、重启自己完善的采集任务 。一个典型的采集任务工作流程如图46所示。 预处理器 HDFS 情报信息源 服务器日志 互联网 采集器 数据集聚 元数据 情报信息仓储 映射 HDFSWrite 情报分类 情报主题 竞争情报剖析子系统 电子科技大学硕士学位论文 40 采集器模块设计采集器是该子系统的核心部件 类似于互联网的“爬虫”程序或专题搜索引擎。采集器主要由爬行队列、网络连接器、主题分类器、超链精化器以及情报主题模型等部件组成。 其工作流程如图4 7所示。 新建采集任务 采集任务管理 删除采集任务 浏览采集任务 修改采集任务 暂停采集任务 终止采集任务 重启采集任务 登录 新建采集任务 基本 信息 采集器 信息 采集任务完成 启动采集任务 终止 暂停 重启 删除 采集器运行 主题订制 关键词、 语种、信息类型、… 种子站点 采集器参数、… 第四章 基于大数据的企业竞争情报模型建立 41 情报资源转出模块设计情报资源转出模块的功能就是将采集任务采集到的情报专题资源转出为目标计算机上的纯文本数据、XML数据或则关系数据库数据的操作。
资源转出实现主题资源的迁移 实现系统数据产品输出目标。 情报资源转出的工作流程如图4 8所示。 情报主题订制情报主题订制是指用户订制自己感兴趣的主题范围 作为订制采集任务的基础 即采集任务订制时 主题类别的选择从用户自己订制的分类范围内选择。 Web 网络连接器 爬行队列 情报主题模型 主题分类器 网页库种子站点 追加转出 覆盖转出 开始 选择情报专题 设置转出方法 设置转出目的地和类型 选择转出数组 执行转出 结束 本地转出 远程转出 文本格式、 数据库 XML、… 电子科技大学硕士学位论文 42 情报主题分类有多种方式 最常使用的是《中国图书馆分类法》 27 。《中国图书馆分类法》简称《中图法》 是我国图书馆和情报单位普遍使用的一部综合性的分类法。本系统采用《中国图书馆分类法》三级体系作为情报主题的分类。 情报人员在新建采集任务时 需要首先订制情报主题。如图4 9所示。 功能剖析子系统是企业CIS的核心。其中 情报剖析器是该子系统的主要部件。 模型竞争情报剖析子系统主要包括三个部件 情报剖析器、情报知识库以及竞争情报方法库 包括数据挖掘方式库和情报剖析方式库 。其中情报剖析器是关键 它借助各类数据挖掘方式、情报剖析方式对情报信息仓储中的数据进行剖析 获得各类有价值的情报 形成情报知识库。
情报知识库是情报剖析的结果。 其模型如图4 8所示。 老用户 新用户 定制情报主题 修改情报主题 建立采集任务 第四章 基于大数据的企业竞争情报模型建立 43 情报剖析子系统模型剖析方式主要不仅常规统计学方式外 还有数据挖掘方式、情报剖析方式。本系统的竞争情报剖析方式封装在方式库中 提供给用户在情报剖析过程中依据需求调用。 竞争情报常用的剖析方式方式类型 典型方式 情报剖析 SWOT分析、定标比超、战略联盟、经验曲线、核心竞争力剖析、回归剖析、多元化业务剖析 数据挖掘 常规统计方式、分类、聚类、关联分析、时间序列、社会网路方式、链接剖析等 大数据时代 竞争情报剖析涉及的信息数据可能是海量的 因而适合采用分布式文件系统Hadoop和MapReduce进行数据的储存和处理。 本文的情报剖析子系统设计采用Hadoop作为构架基础 数据剖析或挖掘算法的实现采用MapReduce来完成。因此 设计情报剖析子系统模型如图4 9所示。 采集的原创信息数据 情报剖析器 分析方式 情报知识库 电子科技大学硕士学位论文 44 基于大数据的情报剖析子系统模型如图4 3所示 情报剖析子系统包括情报检索、情报挖掘、情报知识库管理等模块。
例如情报检索模块的设计如图4 10所示。 该模块支持对情报根据题名、作者、关键词、摘要、全文等多种途径进行浏览和检索。检索有两种方法 简单检索和高级检索。另外 该模块还提供对情报资源根据要求人工或手动生成索引。 10情报检索模块功能设计 功能Hadoop HDFS Hcatalog NoSQL MapReduce 数据挖掘方法库 分类、聚类 关联规则 时序剖析 协同过滤 SNA技术情报剖析技术 定性分析法 定量分析法 企业知识库 情报服务子系统 常规方式 词频统计 情报信息仓储 情报检索 情报浏览 普通检索 高级检索 全文索引 第四章 基于大数据的企业竞争情报模型建立 45 企业不同的职能部门和不同层级的人员对情报的需求不同 而情报服务子系统的主要功能是依据企业竞争情报的主题需求或情报任务 对竞争情报剖析子系统的剖析结果进行加工 并以统一的方法为用户提供服务服务 如情报浏览 情报检索 情报报表的生成 情报推荐、个性化用户服务等。 模型现代化的竞争情报服务子系统须要为用户提供形象化的信息展示。可视化的图形图象比单纯的文字更具有说服力 更适于被用户理解 所以许多数据挖掘系统都采用了可视化的方法为用户提供挖掘结果 并可与之进行可视化互动。
本文将信息可视化技术引入到竞争情报服务子系统 通过可视化技术 将情报剖析结果以生动形象的形式诠释给用户 为用户提供快捷、人性化的情报体验。 子系统模型如图4 11所示。 11情报服务子系统模型 本章小结本章详尽剖析了基于大数据的企业竞争情报模型。模型把企业CIS分为情报采集子系统、情报剖析子系统和情报服务子系统。竞争情报采集子系统的主要功能是对企业的各类类型的情报信息源进行数据采集、预处理 并实现储存 分析子系统是竞争情报系统的核心 其主要任务是对竞争情报采集子系统中采集、存储、预处理过的数据进行统计剖析或数据挖掘 发现有价值的情报。该子系统中的剖析结果将储存在竞争情报知识库中 情报服务子系统的主要功能是依据企业竞争情报的主题需求对竞争情报产品进行加工 并通过统一的门户提供服务。 情报服务加工器 企业竞争情报知识库 可视化映射 可视化结构 视图转换 可视化结果显示 文本报告生成 人机交互界面 报告模板
DedeCMS织梦自动为商品图片添加ALT标签
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2020-08-09 01:50
修改文件include / arc.archives.class.php
发现:
//设置全局环境变量
$this->Fields['typename'] = $this->TypeLink->TypeInfos['typename'];
SetSysEnv($this->Fields['typeid'],$this->Fields['typename'],$this->Fields['aid'],$this->Fields['title'],'archives');
在下面添加代码
//替换图片Alt为文档关键字+标题
$this->Fields['body'] = str_ireplace(array('','alt=\'\''),'',$this->Fields['body']);
$this->Fields['body'] = preg_replace("@ [\s]{0,}alt[\s]{0,}=[\"'\s]{0,}[\s\S]{0,}[\"'\s] @isU"," ",$this->Fields['body']);
$this->Fields['body'] = str_ireplace("Fields['keywords']." . ".$this->Fields['title']."' ",$this->Fields['body']);
//end
只需重新生成文章,如果它是其他字段,则可以将$ this-> Fields ['body']修改为其他字段名称. 农业经济学 查看全部
通常使用DedeCMS作为图片站进行采集. 许多图片没有alt标签,这对搜索引擎不友好. 一一写是很麻烦的. 您可以对其进行修改,以将关键字或文章标题作为图片替代文件进行记录. 描述. 图片的匹配当然不如手动,但是最好在进行电台分组时省去麻烦. 百度八屏
修改文件include / arc.archives.class.php
发现:
//设置全局环境变量
$this->Fields['typename'] = $this->TypeLink->TypeInfos['typename'];
SetSysEnv($this->Fields['typeid'],$this->Fields['typename'],$this->Fields['aid'],$this->Fields['title'],'archives');
在下面添加代码
//替换图片Alt为文档关键字+标题
$this->Fields['body'] = str_ireplace(array('','alt=\'\''),'',$this->Fields['body']);
$this->Fields['body'] = preg_replace("@ [\s]{0,}alt[\s]{0,}=[\"'\s]{0,}[\s\S]{0,}[\"'\s] @isU"," ",$this->Fields['body']);
$this->Fields['body'] = str_ireplace("Fields['keywords']." . ".$this->Fields['title']."' ",$this->Fields['body']);
//end
只需重新生成文章,如果它是其他字段,则可以将$ this-> Fields ['body']修改为其他字段名称. 农业经济学
新浪博客批量发布软件,178个网络营销软件,新浪博客链外批量发布工具,解放双手
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2020-08-07 18:27
1. 该软件带有一个自动的文章采集工具,因此您可以立即获得大量的批量张贴材料.
2. 一键式自动发布博客文章,无需编码,该软件自动识别,节省了大量编码成本.
3. 该软件支持自动随机组合生成原创文章,有利于文章采集.
4. 该软件附带同义词来代替伪原创工具,有利于文章采集.
5. 该软件带有一个敏感的单词过滤系统,可以减少文章被阻止的机会.
6. 该软件带有标题随机组合工具,可以快速组合您所在行业的关键字标题.
7. 该软件具有链轮库功能,可以随机或在文章中插入最近发布的链接,这有利于文章收录和外部链发布.
8. 该软件支持远程图片和本地图片的上传和发布模式,图片上传后会自动修改MD5值,以防止检测到统一图片.
9. 该软件具有图片床功能,支持一张图片和多个传输,并自动修改MD5.
10. 该软件中有强大的本地文档编辑工具,可以快速修改和编辑您自己的文章. 同时,它支持一键式快速将广告图片插入所有材料中.
11. 该软件支持ADSL拨号,支持在VPS中运行,完美且快速的IP替换,以防止大量发送.
12. 该软件集成了19个浏览器的UA标志,并在每次发布文章时自动修改UA标志,以防止大量发布.
13. 该软件具有百度PING采集功能,该功能不仅在文章成功发表后自动将PING到百度Spider,而且还支持继续使用该功能将自己成功的链接PING到百度Spider. 查看全部
1. 该软件带有一个自动的文章采集工具,因此您可以立即获得大量的批量张贴材料.
2. 一键式自动发布博客文章,无需编码,该软件自动识别,节省了大量编码成本.
3. 该软件支持自动随机组合生成原创文章,有利于文章采集.
4. 该软件附带同义词来代替伪原创工具,有利于文章采集.
5. 该软件带有一个敏感的单词过滤系统,可以减少文章被阻止的机会.
6. 该软件带有标题随机组合工具,可以快速组合您所在行业的关键字标题.
7. 该软件具有链轮库功能,可以随机或在文章中插入最近发布的链接,这有利于文章收录和外部链发布.
8. 该软件支持远程图片和本地图片的上传和发布模式,图片上传后会自动修改MD5值,以防止检测到统一图片.
9. 该软件具有图片床功能,支持一张图片和多个传输,并自动修改MD5.
10. 该软件中有强大的本地文档编辑工具,可以快速修改和编辑您自己的文章. 同时,它支持一键式快速将广告图片插入所有材料中.
11. 该软件支持ADSL拨号,支持在VPS中运行,完美且快速的IP替换,以防止大量发送.
12. 该软件集成了19个浏览器的UA标志,并在每次发布文章时自动修改UA标志,以防止大量发布.
13. 该软件具有百度PING采集功能,该功能不仅在文章成功发表后自动将PING到百度Spider,而且还支持继续使用该功能将自己成功的链接PING到百度Spider.
WordPress热门新闻信息自动采集网站Meiwen.com文学网站源代码杂志媒体模板[整个网站+
采集交流 • 优采云 发表了文章 • 0 个评论 • 659 次浏览 • 2020-08-07 01:16
1. 内置了大量文章,可以节省安装后的时间和精力;
2. 内置高效采集插件,每天自动采集一次(间隔可以自己修改),真正无人值守;
3,内置10条采集规则;
4. 内置的缓存插件可以减轻前台访问的压力;
5. 网站管理简单,快捷,基本的前端显示信息可以在后端进行修改,无需代码;
6. 该程序是全部开源的,没有任何加密,并且不定期提供更新;
7. 使用前端HTML5 + CSS3响应式布局,与多个终端(PC +手机+平板电脑)兼容,数据同步,方便管理;
8. 不必担心采集规则的失败. 我们拥有强大的技术团队,并将提供更新服务的规则;
源代码适合人群
1. 办公室工作人员
白天上班,晚上休息. 该程序使您满意. 安装它且配置正确后,您可以坐下来等待网站更新,真正无人值守.
2,创建一个电台组
有些人有数百个车站,雇用人要花钱. 最好只建一个无人值守的采集站,以节省时间和金钱.
源代码获利方法
1. 广告联盟/网站广告/淘宝嘉宾
让我们讨论一下,它需要流量.
2,出售友谊链接
该网站收录1000个基础知识. 您可以在友谊链接交易平台上出售朋友链.
3. 出售网站的二级目录
加入网站后,某些人会自然而然地发现您是否需要加入.
4. 销售站
在网站上卖出5或600个商品没问题,但是重量增加,销量增加.
源代码使用环境
支持环境: Windows / linux PHP5.3 / 4/5/6 7.1 mysql5. +
推荐环境: linux php7.1 mysql5.6
程序安装说明
请参阅源代码中的详细安装说明
查看全部
wordpress内核制作的微信精选美国门户自动采集站的源代码每天自动采集一次. 前端和后端都是响应式布局,并且支持前台用户做出贡献.
1. 内置了大量文章,可以节省安装后的时间和精力;
2. 内置高效采集插件,每天自动采集一次(间隔可以自己修改),真正无人值守;
3,内置10条采集规则;
4. 内置的缓存插件可以减轻前台访问的压力;
5. 网站管理简单,快捷,基本的前端显示信息可以在后端进行修改,无需代码;
6. 该程序是全部开源的,没有任何加密,并且不定期提供更新;
7. 使用前端HTML5 + CSS3响应式布局,与多个终端(PC +手机+平板电脑)兼容,数据同步,方便管理;
8. 不必担心采集规则的失败. 我们拥有强大的技术团队,并将提供更新服务的规则;
源代码适合人群
1. 办公室工作人员
白天上班,晚上休息. 该程序使您满意. 安装它且配置正确后,您可以坐下来等待网站更新,真正无人值守.
2,创建一个电台组
有些人有数百个车站,雇用人要花钱. 最好只建一个无人值守的采集站,以节省时间和金钱.
源代码获利方法
1. 广告联盟/网站广告/淘宝嘉宾
让我们讨论一下,它需要流量.
2,出售友谊链接
该网站收录1000个基础知识. 您可以在友谊链接交易平台上出售朋友链.
3. 出售网站的二级目录
加入网站后,某些人会自然而然地发现您是否需要加入.
4. 销售站
在网站上卖出5或600个商品没问题,但是重量增加,销量增加.
源代码使用环境
支持环境: Windows / linux PHP5.3 / 4/5/6 7.1 mysql5. +
推荐环境: linux php7.1 mysql5.6
程序安装说明
请参阅源代码中的详细安装说明
关于织梦,CMS会自动通过You Caiyun发布文章并更新HTMl
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2020-08-06 22:01
优采云采集器的自动更新功能是收费的,哈哈.
我需要它,我想挑战自己并等待.
两个,做吧.
首先,我想到让优采云发布大量数据并将article属性设置为unreviewed. 这个问题很简单. 使用DEDEv5.3.1时,遇到了DEDE的错误. 即,未审阅的文章将显示在前台. 首先,我责骂DEDE,然后发现一些原因,并发现DEDEv5.3.1中的错误. 修复后,未审阅的文章将不会显示在前台. 在1月13日将错误报告给DEDE之后,此问题已在DEDE 1月14日发布的补丁中得到解决,哈哈,所以从1月15日,即今天,我们开始正式组织此开发文档.
实际上,发现发布和保存大量未审阅的文章不是问题. 困难在于如何实现随机激励的功能. 考虑了很长时间之后,我认为时间限制是最好的. 当前站点JS调用评论文章的链接,并传递访问者的信息. 该程序获取用户的IP并将其另存为SESSION信息. 这时,它将审阅文章并生成文章和主页静态文件. 用户只能在一定时间内激活有限数量的文章,并且发布时会使用该用户的IP信息,这很个人化.
由于网站模板的影响,激活文章,生成文章静态页面和主页静态文章的速度可能会变慢,并且在生成主页之前将关闭页面. 因此,最好的方法是在发布文章时生成文章静态文件,然后将文章设置为未审阅状态. 仅需简短查询即可激活文章. 在首页或列表页面上尽可能使用动态页面. 这两个问题不容易处理,只能用此方法代替.
完整的过程是在发布文档时将文档设置为未审阅状态;在调用程序时,首先确定上一个查询的缓存是否已超时,如果缓存时间超过了缓存时间,请清除缓存以显示最新文章. 清除缓存后,查询一定数量未审核属性的文档,取消Archives和Arctiny表中未审核的属性,并更新文档的Pubdate字段以实现一些随机化. 最后,写入缓存,并在缓存的有效期内禁止重复更新!
三,如何使用文件:
发布文档时,请将文档属性设置为未审阅,即发布时提交的文档属性参数为: arcrank = -1,则为动态浏览;
如果要生成静态文档,请将文档状态设置为正常浏览状态,即arcrank = 0;然后修改默认的文档添加程序.
例如: arcticle_add.php,在文件“ // generate HTML”的底部添加一段代码:
//生成HTML
InsertTags($ tags,$ arcID);
$ artUrl = MakeArt($ arcID,true,true);
if($ artUrl =='')
{
$ artUrl = $ cfg_phpurl. “ / view.php?aid = $ arcID”;
}
$ dsql-> ExecuteNoneQuery(“ UPDATE`cmsxx_archives` SET`arcrank` ='-1'WHERE(`id` ='$ arcID');”);
$ dsql-> ExecuteNoneQuery(“ UPDATE`cmsxx_arctiny` SET`arcrank` ='-1'WHERE(`id` ='$ arcID');”);
然后,将New.php上载到网站的根目录,转到Dede后台设置系统的基本设置,然后将“性能”选项卡中的arclist标签调用缓存时间设置为适当的数字. 例如,3600表示每小时刷新一次缓存.
最后,只需在模板文件的顶部调用一段代码:
“”.
支持的参数:
no =每次随机更新的次数,如果为空,则默认值为5;
typeid =列ID,如果为空,则表示整个网站数据
order =排序方式,支持Desc: 逆序,Asc: 顺序,Rand: 随机,默认为随机查询.
例如:
“”
当排序为Desc时,将按照首先审阅第一篇发表的文章的方式发布. 相反,Asc,Rand是随机的.
第四,这是我们在数据处理中所做的尝试. 也许这种新模式将是一个突破. 祝大家使用愉快. 如果您有任何错误或建议,请稍后回复.
单击此处下载文件:
dedecms_v.rar 查看全部
如果您没有可以一直运行的服务器,那么使用优采云采集器的自动更新功能是不现实的
优采云采集器的自动更新功能是收费的,哈哈.
我需要它,我想挑战自己并等待.
两个,做吧.
首先,我想到让优采云发布大量数据并将article属性设置为unreviewed. 这个问题很简单. 使用DEDEv5.3.1时,遇到了DEDE的错误. 即,未审阅的文章将显示在前台. 首先,我责骂DEDE,然后发现一些原因,并发现DEDEv5.3.1中的错误. 修复后,未审阅的文章将不会显示在前台. 在1月13日将错误报告给DEDE之后,此问题已在DEDE 1月14日发布的补丁中得到解决,哈哈,所以从1月15日,即今天,我们开始正式组织此开发文档.
实际上,发现发布和保存大量未审阅的文章不是问题. 困难在于如何实现随机激励的功能. 考虑了很长时间之后,我认为时间限制是最好的. 当前站点JS调用评论文章的链接,并传递访问者的信息. 该程序获取用户的IP并将其另存为SESSION信息. 这时,它将审阅文章并生成文章和主页静态文件. 用户只能在一定时间内激活有限数量的文章,并且发布时会使用该用户的IP信息,这很个人化.
由于网站模板的影响,激活文章,生成文章静态页面和主页静态文章的速度可能会变慢,并且在生成主页之前将关闭页面. 因此,最好的方法是在发布文章时生成文章静态文件,然后将文章设置为未审阅状态. 仅需简短查询即可激活文章. 在首页或列表页面上尽可能使用动态页面. 这两个问题不容易处理,只能用此方法代替.
完整的过程是在发布文档时将文档设置为未审阅状态;在调用程序时,首先确定上一个查询的缓存是否已超时,如果缓存时间超过了缓存时间,请清除缓存以显示最新文章. 清除缓存后,查询一定数量未审核属性的文档,取消Archives和Arctiny表中未审核的属性,并更新文档的Pubdate字段以实现一些随机化. 最后,写入缓存,并在缓存的有效期内禁止重复更新!
三,如何使用文件:
发布文档时,请将文档属性设置为未审阅,即发布时提交的文档属性参数为: arcrank = -1,则为动态浏览;
如果要生成静态文档,请将文档状态设置为正常浏览状态,即arcrank = 0;然后修改默认的文档添加程序.
例如: arcticle_add.php,在文件“ // generate HTML”的底部添加一段代码:
//生成HTML
InsertTags($ tags,$ arcID);
$ artUrl = MakeArt($ arcID,true,true);
if($ artUrl =='')
{
$ artUrl = $ cfg_phpurl. “ / view.php?aid = $ arcID”;
}
$ dsql-> ExecuteNoneQuery(“ UPDATE`cmsxx_archives` SET`arcrank` ='-1'WHERE(`id` ='$ arcID');”);
$ dsql-> ExecuteNoneQuery(“ UPDATE`cmsxx_arctiny` SET`arcrank` ='-1'WHERE(`id` ='$ arcID');”);
然后,将New.php上载到网站的根目录,转到Dede后台设置系统的基本设置,然后将“性能”选项卡中的arclist标签调用缓存时间设置为适当的数字. 例如,3600表示每小时刷新一次缓存.
最后,只需在模板文件的顶部调用一段代码:
“”.
支持的参数:
no =每次随机更新的次数,如果为空,则默认值为5;
typeid =列ID,如果为空,则表示整个网站数据
order =排序方式,支持Desc: 逆序,Asc: 顺序,Rand: 随机,默认为随机查询.
例如:
“”
当排序为Desc时,将按照首先审阅第一篇发表的文章的方式发布. 相反,Asc,Rand是随机的.
第四,这是我们在数据处理中所做的尝试. 也许这种新模式将是一个突破. 祝大家使用愉快. 如果您有任何错误或建议,请稍后回复.
单击此处下载文件:
dedecms_v.rar
Premium 2019 Spider Wizard V5.6版本蜘蛛池站组程序免费许可证的开源版本每天自动采集文章,吸引数百万只蜘蛛
采集交流 • 优采云 发表了文章 • 0 个评论 • 345 次浏览 • 2020-08-06 21:28
24小时内自动交付,如有任何疑问,请联系客服!
发送大量模板,发送大量采集规则,自动采集!
您可以设置自定义采集规则!
带外租赁平台!蜘蛛池可以租来赚钱!
下图显示了2018年11月27日对50个域名的测试结果!
如果您需要安装方面的帮助,请支付安装费!
演示网站:
什么是蜘蛛池?蜘蛛池是一个利用大型平台的权重来获取百度的纳入和排名的程序. 程序员经常称其为“蜘蛛池”. 这是一个可以快速提高网站排名的程序. 值得一提的是,它可以自动提高网站排名和网站包容性. 这个效果非常出色. 蜘蛛池程序可以为我们做什么?链接外部发布的帖子尚未包括在内,但竞争对手发布了相同的网站,他们还没有发布链接并将其收录在内,对!答: (因为人们有大量的百度随附蜘蛛爬虫,所以可以使用蜘蛛池来做到这一点)
有些退伍军人会说,我也拥有百度蜘蛛,为什么不包括它们?
<p>答案: (因为您的百度索引蜘蛛不多且不够宽,所以来回搜索的是那些劣质的百度收录的爬虫,收录缓慢,甚至根本不收录!!-蜘蛛池有多个服务器,多个域,常规内容站点托管着包括蜘蛛在内的百度,并且分布广泛,具有许多域名,面向团队的蜘蛛,许多源站点,高品质,并且每天都有新的蜘蛛在爬行,以包括您的推断帖子) 查看全部
保证可用性,正常运行版本,每天吸引数百万只蜘蛛!
24小时内自动交付,如有任何疑问,请联系客服!
发送大量模板,发送大量采集规则,自动采集!
您可以设置自定义采集规则!
带外租赁平台!蜘蛛池可以租来赚钱!
下图显示了2018年11月27日对50个域名的测试结果!
如果您需要安装方面的帮助,请支付安装费!
演示网站:
什么是蜘蛛池?蜘蛛池是一个利用大型平台的权重来获取百度的纳入和排名的程序. 程序员经常称其为“蜘蛛池”. 这是一个可以快速提高网站排名的程序. 值得一提的是,它可以自动提高网站排名和网站包容性. 这个效果非常出色. 蜘蛛池程序可以为我们做什么?链接外部发布的帖子尚未包括在内,但竞争对手发布了相同的网站,他们还没有发布链接并将其收录在内,对!答: (因为人们有大量的百度随附蜘蛛爬虫,所以可以使用蜘蛛池来做到这一点)
有些退伍军人会说,我也拥有百度蜘蛛,为什么不包括它们?
<p>答案: (因为您的百度索引蜘蛛不多且不够宽,所以来回搜索的是那些劣质的百度收录的爬虫,收录缓慢,甚至根本不收录!!-蜘蛛池有多个服务器,多个域,常规内容站点托管着包括蜘蛛在内的百度,并且分布广泛,具有许多域名,面向团队的蜘蛛,许多源站点,高品质,并且每天都有新的蜘蛛在爬行,以包括您的推断帖子)
天仁物品管理系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2020-08-06 20:24
1. 选择产品时,请问是否存在计算机版本,移动版本,APP,微信小程序,百度MIP,因为它们都代表不同的流量门户,如果缺少一个,则将丢失数亿用户的资源.
2. 询问所有源代码,是否由后端管理,以及数据是否同步. 如果它不是后端并且未同步,请不要购买. 此源代码将使您的管理强度加倍. 可以想象每个后端管理和输入数据的效率. 因为它们的源代码是拼接的或不是由他们开发的,所以它们只是剥头皮. 任何技术开发人员都将尝试尽可能地适应用户的体验,并在设计源代码时考虑后台管理和数据同步. 这也是一个旁注,他们不了解代码,更不用说为您提供售后服务了.
3. 明确询问是否可以升级源代码,是否有“国家计算机软件版权证书”,是否可以安装插件以及是否可以安装模板. 如果以上都不可用,请不要购买. 您不能升级,安装插件或安装模板的源代码. Internet的发展如此之快,您的源代码将在一年之内与浏览器不兼容,并且不会为用户提供更多的体验. 更重要的是,即使是源代码的作者也无法为您提供低成本的添加和兼容性优化. 因为它们没有升级功能,无法安装插件,安装模板,所以他们只能付出高昂的代价才能找到更改代码的地方.
4. 请自己查看它们有多少个插件和模板. 仔细查看插件和模板的介绍,以查看其详细信息. 一些源代码声称使用了10年或xx年,但是当您查看插件和模板时,只有少数几个,并且它们仍然不痛苦或发痒. 它只是用来炫耀和充电. 请不要购买这种源代码 查看全部
让我们选择一些大陷阱:
1. 选择产品时,请问是否存在计算机版本,移动版本,APP,微信小程序,百度MIP,因为它们都代表不同的流量门户,如果缺少一个,则将丢失数亿用户的资源.
2. 询问所有源代码,是否由后端管理,以及数据是否同步. 如果它不是后端并且未同步,请不要购买. 此源代码将使您的管理强度加倍. 可以想象每个后端管理和输入数据的效率. 因为它们的源代码是拼接的或不是由他们开发的,所以它们只是剥头皮. 任何技术开发人员都将尝试尽可能地适应用户的体验,并在设计源代码时考虑后台管理和数据同步. 这也是一个旁注,他们不了解代码,更不用说为您提供售后服务了.
3. 明确询问是否可以升级源代码,是否有“国家计算机软件版权证书”,是否可以安装插件以及是否可以安装模板. 如果以上都不可用,请不要购买. 您不能升级,安装插件或安装模板的源代码. Internet的发展如此之快,您的源代码将在一年之内与浏览器不兼容,并且不会为用户提供更多的体验. 更重要的是,即使是源代码的作者也无法为您提供低成本的添加和兼容性优化. 因为它们没有升级功能,无法安装插件,安装模板,所以他们只能付出高昂的代价才能找到更改代码的地方.
4. 请自己查看它们有多少个插件和模板. 仔细查看插件和模板的介绍,以查看其详细信息. 一些源代码声称使用了10年或xx年,但是当您查看插件和模板时,只有少数几个,并且它们仍然不痛苦或发痒. 它只是用来炫耀和充电. 请不要购买这种源代码

