
文章定时自动采集
苹果maccms8 各种CMS定时手动采集终极教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 721 次浏览 • 2020-08-25 09:29
子方有话
首先不得不说,目前网路上搜索到的苹果maccms8定时手动采集教程,可能好多都具有误导性,没把真正的道理讲明白,经过子方有料的摸索,终于踏出了一条辛苦路。
子方有料认为,采集工作似乎是一项很麻烦的工程,如果有手动采集,往往就事半功倍了。现在网路上的教程,基本都是说用宝塔的定时访问URL功能进行采集,这个到也无所谓。但所有的教程都没介绍原理,如果不注意细节,往往就深陷了失败之中,比如子方有料就花了相当一段时间。
说一下,子方有料认为这个采集教程,对其它CMS手动采集也是具有一定的参考借鉴意义的。
定时手动采集原理
把采集参数即链接放在首页中,一旦有访客访问,比如子方有料踩了一下这个页面,就激活了手动采集工作。
那假如没有人访问,就不能手动采集了。所以才出现了通过各类工具访问采集链接,保证内容的持续更新。
全面手动详尽采集教程步骤
首先获取采集链接,怎么采看自己了
接着添加定时任务。子方有料非常提示你们非常注意红框的部份。
第一点:任务名称必须得是英语,执行文件只能是collect.php,执行参数是刚才复制到的链接,只要collect旁边的部份
第二点:采集周期和采集时间,就是你勾选的时间段里,有访客访问就采集。如果你没有勾选的时间段,就算访问也不会触发手动采集机制。
最后,复制测试链接就可以了。甚至你可以象子方有料一样,上面的采集周期和时间全为空,通过crontab实现定时采集。
目前网路的教程,基本是跟你说全勾选再用宝塔定时访问url,这种是双重保障机制。因为子方有料只是玩三天,不是用来做其它事情的,所以就无所谓了。
关于一些crontab的踩坑路,可以关注子方有料站内前后几天的文章。
查看全部
苹果maccms8 各种CMS定时手动采集终极教程
子方有话
首先不得不说,目前网路上搜索到的苹果maccms8定时手动采集教程,可能好多都具有误导性,没把真正的道理讲明白,经过子方有料的摸索,终于踏出了一条辛苦路。
子方有料认为,采集工作似乎是一项很麻烦的工程,如果有手动采集,往往就事半功倍了。现在网路上的教程,基本都是说用宝塔的定时访问URL功能进行采集,这个到也无所谓。但所有的教程都没介绍原理,如果不注意细节,往往就深陷了失败之中,比如子方有料就花了相当一段时间。
说一下,子方有料认为这个采集教程,对其它CMS手动采集也是具有一定的参考借鉴意义的。
定时手动采集原理
把采集参数即链接放在首页中,一旦有访客访问,比如子方有料踩了一下这个页面,就激活了手动采集工作。
那假如没有人访问,就不能手动采集了。所以才出现了通过各类工具访问采集链接,保证内容的持续更新。
全面手动详尽采集教程步骤
首先获取采集链接,怎么采看自己了


接着添加定时任务。子方有料非常提示你们非常注意红框的部份。
第一点:任务名称必须得是英语,执行文件只能是collect.php,执行参数是刚才复制到的链接,只要collect旁边的部份
第二点:采集周期和采集时间,就是你勾选的时间段里,有访客访问就采集。如果你没有勾选的时间段,就算访问也不会触发手动采集机制。


最后,复制测试链接就可以了。甚至你可以象子方有料一样,上面的采集周期和时间全为空,通过crontab实现定时采集。
目前网路的教程,基本是跟你说全勾选再用宝塔定时访问url,这种是双重保障机制。因为子方有料只是玩三天,不是用来做其它事情的,所以就无所谓了。
关于一些crontab的踩坑路,可以关注子方有料站内前后几天的文章。

Asp定时执行操作 Asp定时读取数据库(网页定时操作解读)
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2020-08-24 21:23
目前定时的操作有:
一、Html页面的定时刷新(Refresh--刷新 )
1,Refresh (刷新) 代码使用说明
说明:让网页多长时间(秒)刷新自己,或在多长时间后使网页手动链接到其它网页。
用法:
注意:其中的5是指逗留5秒钟后手动刷新到URL网址
2,如何定时操作
你可以在同一个页面重复刷新,以达到定时操作的疗效。
如:
缺点:要在浏览器打开页面,不能关掉。
二、Javascript上面的setTimeout 和 setInterval
1,setTimeout 和 setInterval的区别
window对象有两个主要的定时方式,分别是setTimeout 和 setInteval 他们的句型基本上相同,但是完成的功能取有区别。
setTimeout方式是定时程序,也就是在哪些时间之后干哪些。干完了就拉倒。
setInterval方式则是表示间隔一定时间反复执行某操作。
如果用setTimeout实现setInerval的功能,就须要在执行的程序中再定时调用自己才行。如果要消除计数器须要 根据使用的方式不同,调用不同的清理方式:
例如:tttt=setTimeout('hello()',1000);
clearTimeout(tttt);
或者:
tttt=setInterval('hello()',1000);
clearInteval(tttt);
2,如何定时操作
比如要定时打开页面 Test.asp(当然Test.asp可以是读取数据库,生成静态页面......)
复制代码 代码如下:
缺点:要在浏览器打开页面,不能关掉。
三,ASP使用VB写的定时组件
ASP中没有setTimeout这类的定时句子,我们须要借助ASP组件来解决,同样,可以采用VB6来编制,具体操作方法参考
上一编组件的做法,为了挂起线程,我们须要运用WIN32API函数Sleep,同样新建一个Active Dll工程,起名子为Timer,
类名为sleep。
sleep这个WIN32API函数可以用VB6自带的API文本浏览器中找到它的申明方式
现在类sleep的程序如下,这个组件程序很简单的,我不多解说了。
复制代码 代码如下:
Private Declare Sub Sleep Lib "kernel32" (ByVal dwMilliseconds As Long)
Private m_set As Long
Public Property Get setup() As Long
setup = m_set
End Property
Public Property Let setup(strset As Long)
m_set = strset
End Property
Public Function Sleeptime()
Sleep (setup)
End Function
把它编译一下,就生成timer.dll这个组件dll,如果您不会写VB程序,那么您也可以在下载的文件包里找到timer.dll
这个文件。把它copy到windows目录下,在MS-DOS形式中输入
c:\windows\regsvr32 timer.dll
完成组件注册,同样可以使用这个定时组件。
现在解说刚刚按个列子的ASP调用文件。看看这个组件怎样使用
*定时器的应用
复制代码 代码如下:
定时器的应用(From:)
‘这个是脚本执行时间,默认为90秒,需要改长一点,不然在90秒后程序会被中断'3600为一小时
Server.ScriptTimeOut=3600
set obj=server.createobject("timer.sleep")
'参数1000为线程挂起一秒钟,可以随便设定
obj.setup=1000
do while true
obj.sleeptime
'执行定时操作,
If Not Response.IsClientConnected Then
set obj=nothing
session.abandon
End If
loop
%>
优点:在这里只是随意用VB写了一个测试的dll,但是用VB肯定可以在dll上面写一个定时执行的操作。
缺点:感觉VB写的这个dll可能会优点占资源。
四,结合笔记本的任务计划的定时操作,我个人觉得是目前最好的方式。
这个个人觉得是目前实现定时操作的最好方式。
就是先在服务器上写好要定时操作的页面,如Test.asp
然后写一个vbs文件,如下:
复制代码 代码如下:
Dim IE
Set IE = CreateObject("InternetExplorer.Application")
'运行你的 URL
ie.navigate("")
ie.visible=1
'Clean up...
Set IE = Nothing
1,可以在服务器使用“任务计划”
2,也可以在客户机使用“任务计划”
具体使用“任务计划”的使用,请参考
优缺点:页面会定时的弹出页面Test.asp,但是会有一个解决方式,就是在Test.asp页面加入定时关掉代码:
复制代码 代码如下:
总结,由于目前部份网页语言的限制,在定时操作上有一定的困难,但是经过我多次的求证,发现第四种方式无疑是疗效最好的,最省心的。 查看全部
Asp定时执行操作 Asp定时读取数据库(网页定时操作解读)
目前定时的操作有:
一、Html页面的定时刷新(Refresh--刷新 )
1,Refresh (刷新) 代码使用说明
说明:让网页多长时间(秒)刷新自己,或在多长时间后使网页手动链接到其它网页。
用法:
注意:其中的5是指逗留5秒钟后手动刷新到URL网址
2,如何定时操作
你可以在同一个页面重复刷新,以达到定时操作的疗效。
如:
缺点:要在浏览器打开页面,不能关掉。
二、Javascript上面的setTimeout 和 setInterval
1,setTimeout 和 setInterval的区别
window对象有两个主要的定时方式,分别是setTimeout 和 setInteval 他们的句型基本上相同,但是完成的功能取有区别。
setTimeout方式是定时程序,也就是在哪些时间之后干哪些。干完了就拉倒。
setInterval方式则是表示间隔一定时间反复执行某操作。
如果用setTimeout实现setInerval的功能,就须要在执行的程序中再定时调用自己才行。如果要消除计数器须要 根据使用的方式不同,调用不同的清理方式:
例如:tttt=setTimeout('hello()',1000);
clearTimeout(tttt);
或者:
tttt=setInterval('hello()',1000);
clearInteval(tttt);
2,如何定时操作
比如要定时打开页面 Test.asp(当然Test.asp可以是读取数据库,生成静态页面......)
复制代码 代码如下:
缺点:要在浏览器打开页面,不能关掉。
三,ASP使用VB写的定时组件
ASP中没有setTimeout这类的定时句子,我们须要借助ASP组件来解决,同样,可以采用VB6来编制,具体操作方法参考
上一编组件的做法,为了挂起线程,我们须要运用WIN32API函数Sleep,同样新建一个Active Dll工程,起名子为Timer,
类名为sleep。
sleep这个WIN32API函数可以用VB6自带的API文本浏览器中找到它的申明方式
现在类sleep的程序如下,这个组件程序很简单的,我不多解说了。
复制代码 代码如下:
Private Declare Sub Sleep Lib "kernel32" (ByVal dwMilliseconds As Long)
Private m_set As Long
Public Property Get setup() As Long
setup = m_set
End Property
Public Property Let setup(strset As Long)
m_set = strset
End Property
Public Function Sleeptime()
Sleep (setup)
End Function
把它编译一下,就生成timer.dll这个组件dll,如果您不会写VB程序,那么您也可以在下载的文件包里找到timer.dll
这个文件。把它copy到windows目录下,在MS-DOS形式中输入
c:\windows\regsvr32 timer.dll
完成组件注册,同样可以使用这个定时组件。
现在解说刚刚按个列子的ASP调用文件。看看这个组件怎样使用
*定时器的应用
复制代码 代码如下:
定时器的应用(From:)
‘这个是脚本执行时间,默认为90秒,需要改长一点,不然在90秒后程序会被中断'3600为一小时
Server.ScriptTimeOut=3600
set obj=server.createobject("timer.sleep")
'参数1000为线程挂起一秒钟,可以随便设定
obj.setup=1000
do while true
obj.sleeptime
'执行定时操作,
If Not Response.IsClientConnected Then
set obj=nothing
session.abandon
End If
loop
%>
优点:在这里只是随意用VB写了一个测试的dll,但是用VB肯定可以在dll上面写一个定时执行的操作。
缺点:感觉VB写的这个dll可能会优点占资源。
四,结合笔记本的任务计划的定时操作,我个人觉得是目前最好的方式。
这个个人觉得是目前实现定时操作的最好方式。
就是先在服务器上写好要定时操作的页面,如Test.asp
然后写一个vbs文件,如下:
复制代码 代码如下:
Dim IE
Set IE = CreateObject("InternetExplorer.Application")
'运行你的 URL
ie.navigate("")
ie.visible=1
'Clean up...
Set IE = Nothing
1,可以在服务器使用“任务计划”
2,也可以在客户机使用“任务计划”
具体使用“任务计划”的使用,请参考
优缺点:页面会定时的弹出页面Test.asp,但是会有一个解决方式,就是在Test.asp页面加入定时关掉代码:
复制代码 代码如下:
总结,由于目前部份网页语言的限制,在定时操作上有一定的困难,但是经过我多次的求证,发现第四种方式无疑是疗效最好的,最省心的。
优采云采集器的使用及其所用技术的介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 312 次浏览 • 2020-08-22 07:02
优采云采集器的使用及其所用技术的介绍《优采云采集器》 能为您做些什么呢?1网站内容维护1、 网站内容维护: 可以定时采集新闻、 文章等任何您想采集的内容, 并手动发布到您的网站。2、 Internet数据挖掘: 可以从指定网站抓取所需数据, 通过剖析和处理后保存到您的数据库。3、 网络信息监控: 通过手动采集, 可以监控峰会等社区类网站, 让您第一时间发觉您所关注的内容。4、 文件批量下载: 可以批量下载PDF、 RAR、 图片等各类文件, 并同时采集其相关信息。可以定时采集新闻文章等任何您想采集的内容并手动发布到您的网优采云采集器是目前信息采集与信息挖掘处理类软件中最流行、 性价比最高、 使用人数最多、市场占有率最大、 使用周期最长的智能采集程序。给定种子网址列表按规则抓取列表页面剖析出网址抓取网页内容按采集规则, 对下载到的网页剖析, 保存内容优采云采集器数据发布原理:在我们将数据采集下来后数据默认是保存在本地的,我们可以使用以下几种方法对种据进行处理。1 .不做任何处理。 因为数据本身是保存在数据库的(access或是db3) ,您若果只是想看一下, 直接用相关软件查看就可以了。2 .web发布到网站。
程序会模仿浏览器向您的网站发数实您发布的效送数据, 可以实现您手工发布的疗效。3 .直接入数据库。 您只需写几个SQL句子, 程序会将数据按您的SQL句子导出到数据库中。4 .保存为本地文件。 程序会读取数据库里的数据, 按一定格式保存为本地sql或是文本文件。优采云采集器的演示优采云采集器所用到的技术垂直搜索引擎信息追踪与手动分拣手动索引技术海量数据采集海量数据采集系统流程1)信息采集(网络蜘蛛)对指定网站进行数据采集, 把须要的信息储存到本地, 并记录相应的采集信息。 以供信息抽取模块进行数据提取。2)信息抽取从采集的信息中抽取有效的数据进行结构化处理。 剔除垃圾信息获得正文内容以及相关图片信息, 获得正文内容, 以及相关图片、 种子文件等相关信息。3)信息处理对抽取的信息进行数据加工处理。 对信息进行清洗、 去重、分类、 分析比较、 数据挖掘, 最后递交加工后的数据, 进行信息动词及构建索引。4)信息检索提供信息查询插口。 对信息进行动词处理提供全文检索插口。种子文件等相关信息相关技术1、 垂直搜索引擎技术的网路蜘蛛——爬虫信息源的稳定性(不能使信息源网站感觉到spider的压力)抓取的成本问题对用户体验改善程度2、 WEB结构化信息抽取将网页中的非结构化数据根据一定的需求抽取成结构化数据结构化信息抽取的两种实现方法模板方法web结构化信息抽取在百度、 google已经广泛应用。
对网页不依赖的网页库级的结构化信息抽取方法3、 信息的处理技术清洗、 去重、 分类、 分析比较、 数据挖掘、 语义剖析等4、 分词系统动词算法基于字符串匹配的动词方式基于理解的动词方式基于统计的动词方式究竟哪种动词算法的准确度更高, 目前并无定论。 对于任何一个成熟的动词系统来说, 不可能单独借助某一种算法来实现, 都须要综合不同的算法。常见英文动词开源项目:SCWS,ICTCLAS,HTTPCWS, 庖丁解牛动词,CCCEDICT5、 建立索引索引技术对于垂直搜索十分关键, 一个网页库级的搜索引擎必须要支持分布索引、 分层建库、 分布检索、灵活的更新、 灵活的残差调整、 灵活的索引和灵活的升级扩充、 高可靠性稳定性冗余性。 还须要支持各类技术级扩充、 高可靠性稳定性冗余性。 还须要支持各类技术的扩充, 如偏移量估算等。ThanksThanks 查看全部
优采云采集器的使用及其所用技术的介绍
优采云采集器的使用及其所用技术的介绍《优采云采集器》 能为您做些什么呢?1网站内容维护1、 网站内容维护: 可以定时采集新闻、 文章等任何您想采集的内容, 并手动发布到您的网站。2、 Internet数据挖掘: 可以从指定网站抓取所需数据, 通过剖析和处理后保存到您的数据库。3、 网络信息监控: 通过手动采集, 可以监控峰会等社区类网站, 让您第一时间发觉您所关注的内容。4、 文件批量下载: 可以批量下载PDF、 RAR、 图片等各类文件, 并同时采集其相关信息。可以定时采集新闻文章等任何您想采集的内容并手动发布到您的网优采云采集器是目前信息采集与信息挖掘处理类软件中最流行、 性价比最高、 使用人数最多、市场占有率最大、 使用周期最长的智能采集程序。给定种子网址列表按规则抓取列表页面剖析出网址抓取网页内容按采集规则, 对下载到的网页剖析, 保存内容优采云采集器数据发布原理:在我们将数据采集下来后数据默认是保存在本地的,我们可以使用以下几种方法对种据进行处理。1 .不做任何处理。 因为数据本身是保存在数据库的(access或是db3) ,您若果只是想看一下, 直接用相关软件查看就可以了。2 .web发布到网站。
程序会模仿浏览器向您的网站发数实您发布的效送数据, 可以实现您手工发布的疗效。3 .直接入数据库。 您只需写几个SQL句子, 程序会将数据按您的SQL句子导出到数据库中。4 .保存为本地文件。 程序会读取数据库里的数据, 按一定格式保存为本地sql或是文本文件。优采云采集器的演示优采云采集器所用到的技术垂直搜索引擎信息追踪与手动分拣手动索引技术海量数据采集海量数据采集系统流程1)信息采集(网络蜘蛛)对指定网站进行数据采集, 把须要的信息储存到本地, 并记录相应的采集信息。 以供信息抽取模块进行数据提取。2)信息抽取从采集的信息中抽取有效的数据进行结构化处理。 剔除垃圾信息获得正文内容以及相关图片信息, 获得正文内容, 以及相关图片、 种子文件等相关信息。3)信息处理对抽取的信息进行数据加工处理。 对信息进行清洗、 去重、分类、 分析比较、 数据挖掘, 最后递交加工后的数据, 进行信息动词及构建索引。4)信息检索提供信息查询插口。 对信息进行动词处理提供全文检索插口。种子文件等相关信息相关技术1、 垂直搜索引擎技术的网路蜘蛛——爬虫信息源的稳定性(不能使信息源网站感觉到spider的压力)抓取的成本问题对用户体验改善程度2、 WEB结构化信息抽取将网页中的非结构化数据根据一定的需求抽取成结构化数据结构化信息抽取的两种实现方法模板方法web结构化信息抽取在百度、 google已经广泛应用。
对网页不依赖的网页库级的结构化信息抽取方法3、 信息的处理技术清洗、 去重、 分类、 分析比较、 数据挖掘、 语义剖析等4、 分词系统动词算法基于字符串匹配的动词方式基于理解的动词方式基于统计的动词方式究竟哪种动词算法的准确度更高, 目前并无定论。 对于任何一个成熟的动词系统来说, 不可能单独借助某一种算法来实现, 都须要综合不同的算法。常见英文动词开源项目:SCWS,ICTCLAS,HTTPCWS, 庖丁解牛动词,CCCEDICT5、 建立索引索引技术对于垂直搜索十分关键, 一个网页库级的搜索引擎必须要支持分布索引、 分层建库、 分布检索、灵活的更新、 灵活的残差调整、 灵活的索引和灵活的升级扩充、 高可靠性稳定性冗余性。 还须要支持各类技术级扩充、 高可靠性稳定性冗余性。 还须要支持各类技术的扩充, 如偏移量估算等。ThanksThanks
织梦定时发布工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2020-08-22 01:12
织梦dedecms是个挺好的网站系统,基于织梦系统,你可以做门户站、企业站等多种类型的网站,但织梦美中不足的是没有定时发布文章的功能,这就使我们不得不每晚自动更新。跟版网为了解决这个问题查了好多的方式,有用计划任务的方式,有用定时发布插件的方式。但疗效都不太好,或者设置比较复杂。
最后跟版网找到了个很简单的定时发布的方式,用织梦出的采集侠2.7版就可以实现定时发布的疗效(注意不是定时采集,是定时发布我们的原创或伪原创文章)。采集侠2.7版本是最新的,并且假如你去买官方的话,会太贵,所以跟版网共享给你们采集侠2.7破解版。
采集侠2.7破解版下载地址:
1、安装采集侠
(1)下载采集侠后,解压缩,会有几个文件,其中caijixia_gbk_2.7.0.2.xml和caijixia_utf8_2.7.0.2.xml是采集侠的gbk和utf8版本。(我用的是织梦的v5.7gbk,所以我就用gbk版本来演示)
(2)安装采集侠,织梦后台——模块——上传新模块——点击浏览找到采集侠——点击确定,如下图。
之后出现下边的窗口,点击安装,点击确定。
安装完成后在模块中就多出了采集侠的模块。
2、采集侠定时发布文章的设置
设置定时发布很简单
(1)采集侠——基本设置——选中手动初审,设置每小时总采集(审核)上限,即定时发布的文章数量,点击确定。如下图:
(2)采集侠——采集任务——在手动采集中选择采集的时间段,选好时间段后,当他人在你设置的时间段内访问你的网站,你网站内的为初审的文章就会手动生成发布了,这就是手动初审发布的原理。如下图: 查看全部
织梦定时发布工具
织梦dedecms是个挺好的网站系统,基于织梦系统,你可以做门户站、企业站等多种类型的网站,但织梦美中不足的是没有定时发布文章的功能,这就使我们不得不每晚自动更新。跟版网为了解决这个问题查了好多的方式,有用计划任务的方式,有用定时发布插件的方式。但疗效都不太好,或者设置比较复杂。
最后跟版网找到了个很简单的定时发布的方式,用织梦出的采集侠2.7版就可以实现定时发布的疗效(注意不是定时采集,是定时发布我们的原创或伪原创文章)。采集侠2.7版本是最新的,并且假如你去买官方的话,会太贵,所以跟版网共享给你们采集侠2.7破解版。
采集侠2.7破解版下载地址:
1、安装采集侠
(1)下载采集侠后,解压缩,会有几个文件,其中caijixia_gbk_2.7.0.2.xml和caijixia_utf8_2.7.0.2.xml是采集侠的gbk和utf8版本。(我用的是织梦的v5.7gbk,所以我就用gbk版本来演示)
(2)安装采集侠,织梦后台——模块——上传新模块——点击浏览找到采集侠——点击确定,如下图。
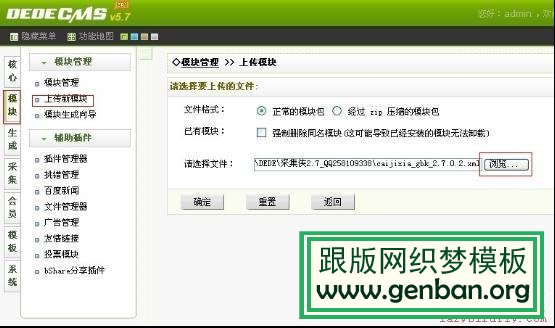
之后出现下边的窗口,点击安装,点击确定。

安装完成后在模块中就多出了采集侠的模块。
2、采集侠定时发布文章的设置
设置定时发布很简单
(1)采集侠——基本设置——选中手动初审,设置每小时总采集(审核)上限,即定时发布的文章数量,点击确定。如下图:
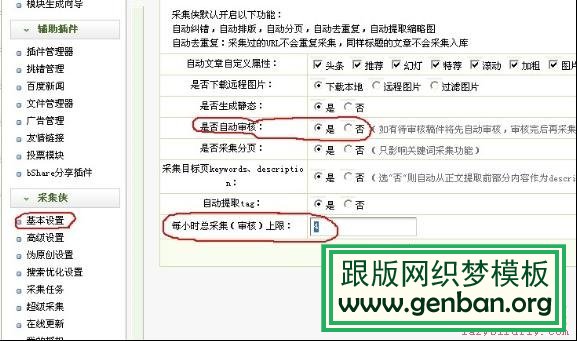
(2)采集侠——采集任务——在手动采集中选择采集的时间段,选好时间段后,当他人在你设置的时间段内访问你的网站,你网站内的为初审的文章就会手动生成发布了,这就是手动初审发布的原理。如下图:
性能监控平台搭建 -- 集成Locust性能数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2020-08-21 15:04
无意中发觉了一个巨牛的人工智能教程,忍不住分享一下给你们。教程除了是零基础,通俗易懂,而且十分诙谐诙谐,像看小说一样!觉得很牛了,所以分享给你们。点这儿可以跳转到教程。
文章目录
原文链接
之前的几篇关于性能监控平台搭建的文章,分别介绍了性能测试中的资源数据采集、存储及展示。今天一起来看下怎样完成Locust性能数据的采集。
这是之前介绍过的性能监控平台的整体构架图,想要了解其它部份的搭建,可以查看相关文章《Telegraf安装与简易使用指南》、《InfluxDB安装与简易使用指南》、《Grafana安装与简易使用指南》
因为我们早已完成了资源数据的采集,以及监控数据的储存与展示,剩下的就是采集性能数据了。规划中我们须要支持采集JMeter和Locust工具的性能数据,今天先讲解怎样采集Locust的性能数据。
问题概述
如果你使用过Locust,那么你一定晓得Locust本身自带一个WEB服务,它提供了性能测试过程中的性能数据监控,并且也提供了一个图形的界面支持实时监控,完事了还可以下载csv格式的性能测试数据。
既然Locust早已有了性能数据的监控功能,为哈还要接入到性能监控平台呢?因为Locust里的数据没有主动持久化,一旦刷新就没有了;也不会手动保存历史数据;不能对数据进行多样化展示,不能在同一个平台中查看全部的性能数据。
为此我们要解决的就是把Locust性能工具中的性能数据实时的获取到并储存到Influxdb中,这样就完美的解决了Locust性能数据集成问题,让监控平台可以无缝的支持Locust工具。
获取Locust性能数据插口
既然要采集性能测试数据,那么首先要考虑的就是怎么获取性能测试数据?是更改源码?还是开发插件?这些统统不要!因为Locust本身就早已有了性能数据监控服务,通过抓取Locust的WEB服务页面恳求,很方便的就得到了Locust的性能监控数据。比如:
curl http://localhost:8089/stats/requests
该URL会返回当前性能测试到目前为止的性能测试数据的总结信息,所以那些我们须要的性能数据基本上Locust早已为我们打包好了,我们之前恳求这个url就可以实时的获取到。
定时采集性能数据
数据获取的方法早已晓得了,接下来考虑的就是在什么时候获取数据的问题。最简单粗鲁的形式就是写一个定时任务去恳求该URL,获取数据后直接储存到Influxdb即可。代码如下:
def get_locust_stats_by_web_api():
print("get_locust_stats")
try:
start_url = f'http://localhost:8089/stats/requests'
print(start_url)
return requests.get(start_url).json()
except Exception as e:
print(e)
而这样做的弊病则是定时任务与性能测试启停的一致性须要人为的控制,用户友好性不够。我们希望的是性能测试一开始它就手动开始采集性能数据,性能测试一结束它就停止采集性能数据,要做到对目前的性能测试操作尽量无侵入。
性能数据采集一致性
为了解决性能数据采集与性能测试之间的一致性问题,我们须要把代码集成到Locust性能测试脚本中,让它跟脚本绑定,这样一旦开始执行性能测试,就会触发性能数据采集的定时任务,从根本上解决了一致性问题。
no-web模式下获取性能数据
前面我们获取Locust性能测试数据时,是通过/stats/requests插口获取到的。这个插口是基于WEB模式下,一旦我们选择以no-web的方法启动Locust,那么这个插口才会失效了。
为了兼容no-web模式下也能正常采集到Locust的性能数据,可以直接把/stats/requests插口生成性能测试数据的代码直接COPY过来即可,所以获取Locust性能测试数据的方式须要改写成这样:
def get_locust_stats():
stats = []
for s in chain(sort_stats(runners.locust_runner.request_stats), [runners.locust_runner.stats.total]):
stats.append({
"method": s.method,
"name": s.name,
"num_requests": s.num_requests,
"num_failures": s.num_failures,
"avg_response_time": s.avg_response_time,
"min_response_time": s.min_response_time or 0,
"max_response_time": s.max_response_time,
"current_rps": s.current_rps,
"median_response_time": s.median_response_time,
"avg_content_length": s.avg_content_length,
})
errors = [e.to_dict() for e in six.itervalues(runners.locust_runner.errors)]
# Truncate the total number of stats and errors displayed since a large number of rows will cause the app
# to render extremely slowly. Aggregate stats should be preserved.
report = {"stats": stats[:500], "errors": errors[:500]}
if stats:
report["total_rps"] = stats[len(stats) - 1]["current_rps"]
report["fail_ratio"] = runners.locust_runner.stats.total.fail_ratio
report[
"current_response_time_percentile_95"] = runners.locust_runner.stats.total.get_current_response_time_percentile(
0.95)
report[
"current_response_time_percentile_50"] = runners.locust_runner.stats.total.get_current_response_time_percentile(
0.5)
is_distributed = isinstance(runners.locust_runner, MasterLocustRunner)
if is_distributed:
slaves = []
for slave in runners.locust_runner.clients.values():
slaves.append({"id": slave.id, "state": slave.state, "user_count": slave.user_count})
report["slaves"] = slaves
report["state"] = runners.locust_runner.state
report["user_count"] = runners.locust_runner.user_count
return report
slave模式下不进行数据采集
同样的Locust还有分布式模式,一旦采用该模式以后Locust性能脚本会在master和各slave节点就会执行,但是很明显我们不希望接收到多次重复的性能采集数据,所以须要保证只有在master上的性能脚本才能进行性能数据采集。
def monitor(project_name):
print("start monitoring")
slave = isinstance(runners.locust_runner, SlaveLocustRunner)
if slave: # 判断是否为slave
print('is slave, will not rerun')
return
try:
rep = get_locust_stats()
if rep['state'] == 'running':
host = get_locust_host()
save_to_db(project_name, host, rep)
print(f'is_slave: {slave}, host: {host}, project_name: {project_name}')
else:
print('it is not running now')
except Exception as e:
print(e)
timer = threading.Timer(interval, monitor, args=[project_name]) # 定时任务
timer.start()
封装
当然,我们也不希望把这么多的性能数据采集的代码直接写在Locust的性能测试脚本中,即不美观也不容易管理。所以须要把这种采集数据的代码统一封装到一个独立文件中,并对外提供一个调用入口,只要简单引入即可。调用代码如下: 查看全部
性能监控平台搭建 -- 集成Locust性能数据
无意中发觉了一个巨牛的人工智能教程,忍不住分享一下给你们。教程除了是零基础,通俗易懂,而且十分诙谐诙谐,像看小说一样!觉得很牛了,所以分享给你们。点这儿可以跳转到教程。
文章目录
原文链接

之前的几篇关于性能监控平台搭建的文章,分别介绍了性能测试中的资源数据采集、存储及展示。今天一起来看下怎样完成Locust性能数据的采集。

这是之前介绍过的性能监控平台的整体构架图,想要了解其它部份的搭建,可以查看相关文章《Telegraf安装与简易使用指南》、《InfluxDB安装与简易使用指南》、《Grafana安装与简易使用指南》
因为我们早已完成了资源数据的采集,以及监控数据的储存与展示,剩下的就是采集性能数据了。规划中我们须要支持采集JMeter和Locust工具的性能数据,今天先讲解怎样采集Locust的性能数据。
问题概述
如果你使用过Locust,那么你一定晓得Locust本身自带一个WEB服务,它提供了性能测试过程中的性能数据监控,并且也提供了一个图形的界面支持实时监控,完事了还可以下载csv格式的性能测试数据。
既然Locust早已有了性能数据的监控功能,为哈还要接入到性能监控平台呢?因为Locust里的数据没有主动持久化,一旦刷新就没有了;也不会手动保存历史数据;不能对数据进行多样化展示,不能在同一个平台中查看全部的性能数据。
为此我们要解决的就是把Locust性能工具中的性能数据实时的获取到并储存到Influxdb中,这样就完美的解决了Locust性能数据集成问题,让监控平台可以无缝的支持Locust工具。
获取Locust性能数据插口
既然要采集性能测试数据,那么首先要考虑的就是怎么获取性能测试数据?是更改源码?还是开发插件?这些统统不要!因为Locust本身就早已有了性能数据监控服务,通过抓取Locust的WEB服务页面恳求,很方便的就得到了Locust的性能监控数据。比如:
curl http://localhost:8089/stats/requests
该URL会返回当前性能测试到目前为止的性能测试数据的总结信息,所以那些我们须要的性能数据基本上Locust早已为我们打包好了,我们之前恳求这个url就可以实时的获取到。
定时采集性能数据
数据获取的方法早已晓得了,接下来考虑的就是在什么时候获取数据的问题。最简单粗鲁的形式就是写一个定时任务去恳求该URL,获取数据后直接储存到Influxdb即可。代码如下:
def get_locust_stats_by_web_api():
print("get_locust_stats")
try:
start_url = f'http://localhost:8089/stats/requests'
print(start_url)
return requests.get(start_url).json()
except Exception as e:
print(e)
而这样做的弊病则是定时任务与性能测试启停的一致性须要人为的控制,用户友好性不够。我们希望的是性能测试一开始它就手动开始采集性能数据,性能测试一结束它就停止采集性能数据,要做到对目前的性能测试操作尽量无侵入。
性能数据采集一致性
为了解决性能数据采集与性能测试之间的一致性问题,我们须要把代码集成到Locust性能测试脚本中,让它跟脚本绑定,这样一旦开始执行性能测试,就会触发性能数据采集的定时任务,从根本上解决了一致性问题。
no-web模式下获取性能数据
前面我们获取Locust性能测试数据时,是通过/stats/requests插口获取到的。这个插口是基于WEB模式下,一旦我们选择以no-web的方法启动Locust,那么这个插口才会失效了。
为了兼容no-web模式下也能正常采集到Locust的性能数据,可以直接把/stats/requests插口生成性能测试数据的代码直接COPY过来即可,所以获取Locust性能测试数据的方式须要改写成这样:
def get_locust_stats():
stats = []
for s in chain(sort_stats(runners.locust_runner.request_stats), [runners.locust_runner.stats.total]):
stats.append({
"method": s.method,
"name": s.name,
"num_requests": s.num_requests,
"num_failures": s.num_failures,
"avg_response_time": s.avg_response_time,
"min_response_time": s.min_response_time or 0,
"max_response_time": s.max_response_time,
"current_rps": s.current_rps,
"median_response_time": s.median_response_time,
"avg_content_length": s.avg_content_length,
})
errors = [e.to_dict() for e in six.itervalues(runners.locust_runner.errors)]
# Truncate the total number of stats and errors displayed since a large number of rows will cause the app
# to render extremely slowly. Aggregate stats should be preserved.
report = {"stats": stats[:500], "errors": errors[:500]}
if stats:
report["total_rps"] = stats[len(stats) - 1]["current_rps"]
report["fail_ratio"] = runners.locust_runner.stats.total.fail_ratio
report[
"current_response_time_percentile_95"] = runners.locust_runner.stats.total.get_current_response_time_percentile(
0.95)
report[
"current_response_time_percentile_50"] = runners.locust_runner.stats.total.get_current_response_time_percentile(
0.5)
is_distributed = isinstance(runners.locust_runner, MasterLocustRunner)
if is_distributed:
slaves = []
for slave in runners.locust_runner.clients.values():
slaves.append({"id": slave.id, "state": slave.state, "user_count": slave.user_count})
report["slaves"] = slaves
report["state"] = runners.locust_runner.state
report["user_count"] = runners.locust_runner.user_count
return report
slave模式下不进行数据采集
同样的Locust还有分布式模式,一旦采用该模式以后Locust性能脚本会在master和各slave节点就会执行,但是很明显我们不希望接收到多次重复的性能采集数据,所以须要保证只有在master上的性能脚本才能进行性能数据采集。
def monitor(project_name):
print("start monitoring")
slave = isinstance(runners.locust_runner, SlaveLocustRunner)
if slave: # 判断是否为slave
print('is slave, will not rerun')
return
try:
rep = get_locust_stats()
if rep['state'] == 'running':
host = get_locust_host()
save_to_db(project_name, host, rep)
print(f'is_slave: {slave}, host: {host}, project_name: {project_name}')
else:
print('it is not running now')
except Exception as e:
print(e)
timer = threading.Timer(interval, monitor, args=[project_name]) # 定时任务
timer.start()
封装
当然,我们也不希望把这么多的性能数据采集的代码直接写在Locust的性能测试脚本中,即不美观也不容易管理。所以须要把这种采集数据的代码统一封装到一个独立文件中,并对外提供一个调用入口,只要简单引入即可。调用代码如下:
虾米音乐与赛扬股票私募网站管理系统下载评论软件详情对比
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2020-08-21 08:30
酷睿股票私募网站管理系统,是国外首家采用WAP手机及笔记本WEB同步访问的股票私募系统,该系统基于ASP+DIV+CSS+AJAX+XML+MSSQL技术专门为股票私募网站开发的一款CMS网站管理系统,是一个经过建立设计并适用于各类服务器环境的易用、安全、高效、快速、优秀的网站解决方案。后台管理便捷、易懂、易用、人性化,对操作人员技术要求低,没有建站知识的操作人员都可轻松进行。继续ASP开源之路,稳定、安全、强大的核心程序,对于有网站设计知识和程序爱好者可以随心所欲进行更改,方便构建具有自已特色的站点。
酷睿股票私募网站管理系统,最大的优势除了在于有全省首创的WAP手机访问系统,更有数十款精致模板任意选择及终生免费更换模板服务,并承诺一次订购终生免费使用,无任何限制和加密,完全可随便的二次开发,也可以随便更换域名、空间、IP等,可终生免费无限次升级更新新版本,还可以一套系统无限次使用。
升级更新部分功能介绍
全新的黑色模板设计
全新的内核程序设计
全新的后台管理界面设计
全新的会员中性管理界面设计
新增了后台基本设置里的网站、联系信息、银行设置、工商注册、公司证书、收费标准等五个大项,50多个小项的设置及后台相关标签
新增了会员注册后只要建立自己的资料便可手动签署协议功能
新增了公开验证模型
新增了会员实战模型
新增了历史战绩模型等四种模型,去掉原先两个系统调用,改为一个系统
新增了会员实战的手动更新功能
新增了历史战绩的手动更新功能
新增了后台定时任务文章多点定时手动采集和手动多点定时生成静态页面功能
新增了后台设置前台会员注册时容许所显示的会员组如A、B、C、D、E、F等类会员组
新增了会员登入后的对帐专业县链接
新增了目录安全设置说明文件
修改了后台所有静态自定义标签可以可视化编辑
修正了幻灯图片不能后台添加更改的问题
修正了财经视频直播视频不能播放的问题
修改滚动行情不能手动更新并改为全球主要期指手动实时更新
增强后台木马在线监测系统
修正了黑客借助后台或会员上传功能上传木马的BUG
修正了黑客借助模板管理添加木马文件的BUG
修正了其它数处BUG及安全隐患
修复了早已的几处WAP手机访问系统的BUG
修正了Robots.txt搜索引擎蜘蛛文件对网站的收录权限,让搜索引擎更新收录网站内容
并取消了首页的数个IFRA使用网站的ME调用,尽可能降低了对搜索引擎的友好程度
删除了上百个垃圾文件使用网站的减少40%
优化了大量的程序代码
主要功能
完善的全后台管理功能
不管是网站配置、联系信息、银行设置、工商注册、公司证书、收费标准还是网站模板、标签等几乎可以在后台管理任何网站所须要的内容。
实时行情系统
滚动全球行情、外汇报价、机构盯盘、涨跌排名、成交排名、股市手册、环球指数全手动更新。
运行速率与效率
采用XML缓存,运行速率更快,效率更高。
系统采用ASP+DIV+CSS+Ajax+XML+MSSQL技术开发而成,运行速率成倍提高。
文章智能快速采集系统
多点定时计划文章采集和多点定时计划文章自动生成系统,让你的网站无人职守,自动更新
智能强悍的过滤系统设置、UTF-8/GB2312手动辨识、批量采集让你享受高速采集快感。
采集目标网站可随便更换,设置规则简单,操作更方便
会员实战手动更新功能
可手动更新沪深股市当日跌幅最前的各三名作为会员实战内容
历史战绩手动更新功能
可手动更新以会员实战的15天前及120内的内容作为历史战绩的内容,并手动将实际获利手动设置为40%-90%、自动将交易时间设置为3-9天
全新的文章浏览权限应用功能
真正的做到了会员对帐专区的会员组浏览功能,可将会员组浏览权限精确到每位频道/每个栏目/每篇文章,让不同的会员组享受不同的文章浏览权限,并各会员组之间的资料不能想到浏览,也可将整篇文章设置浏览点数,发行点卡使包点的会员进行浏览,还可设置包年会员浏览,包月会员时间一到该会员须要续费后才会浏览相应的会员资料。
强大的会员管理功能
无限用户组添加功能、站内邮件功能、会员点卷明细查询、有效期查询、资金明细查询、点卡在线冲值功能、在线支付实时到账,会员可设置为扣点会员、有效期会员和、无限期会员。
SEO优化
在线智能生成GOOGLE/百度标准收录XML格式地图,使网站更便于搜索和收录。
三种运行模式:可将站点全部页面高为动态、静态及伪态格式,大大提升浏览速率及搜索引擎的搜录量。
HTML生成文件储存结构选择。
独有利于Alexa收录的info.txt文件和搜索引擎蜘蛛爬行文件Robots.txt
模板程序分离,网站频道、栏目、内容页META关键词、网站META网页描述均为调用标签,利于网站的收录量并大大减短了页面收录的时间更易于网站的手动配置管理
WAP手机网站系统
国内独创WAP手机访问系统,注册、登录、会员对帐、分析预测众等多种功能一部手机全部搞定!支持手机自带WAP浏览器、UC浏览器、QQ浏览器等几乎所有只要能上网的主流手机浏览器
手机上网浏览与在网站同步,一个账号,两站通用,实现WEB与WAP无缝衔接
集成13个在线支付平台
集成:财付通 网银在线 易付通 云网支付 支付宝 快钱支付 中国在线支付网 西部支付 上海环迅等11个在线支付平台插口,会员冲值实时到账,让你收费无忧。
强大的插件管理
集成:WAP手机网站系统插件、数据库导出系统、可选CC视频联盟插件、WSS统计插件、
标签管理系统
全新的标签应用功能全站采用标签调用系统,让网站运行速率更快,且完全避免站内的文章被其它网站所采集,后台标签管理更方便简单,让网站更安全且极易维护管理。
模板化体系
界面和程序分离,可在线可视化编辑、设计,所有模块均通过标签调用,集成类同Macromedia Dreamweaver一样简单的可视模板编辑方法,修改模板容易、快捷。
无限频道添加功能
可无限添加各类频道或栏目,新频道或栏目完全独立设置,独立模版。
数据库
提供强悍的数据备份和恢复功能,可以在线备份、恢复、压缩数据库。查看系统空间占用情况、系统初始化、查看服务器信息及到在线直接执行SQL句子
系统采用MSSQL数据库,可支持上数千万的数据库,更安全、更稳定、更高效、更强大,运行速率更快。
自动签协议功能
当会注册成功了系统会手动生成一个文件方式的协议,进入会员中心后可以查看协议文本。
系统安全
本以安全为基础,密码采用MD5加密,保证用户资料安全,程序代码中设计缜密,可手动屏蔽恶意功击代码。
更集成防SQL注入程序,从而可全面杜绝各类SQL注入攻击手段,并进行记录在案,保证了系统的安全和稳定运行。
更详尽的管理风波记录,管理员每一步后台操作都记录在案。
双重登入双重密码设计再加认证码,后台登录更安全。 查看全部
虾米音乐与赛扬股票私募网站管理系统下载评论软件详情对比
酷睿股票私募网站管理系统,是国外首家采用WAP手机及笔记本WEB同步访问的股票私募系统,该系统基于ASP+DIV+CSS+AJAX+XML+MSSQL技术专门为股票私募网站开发的一款CMS网站管理系统,是一个经过建立设计并适用于各类服务器环境的易用、安全、高效、快速、优秀的网站解决方案。后台管理便捷、易懂、易用、人性化,对操作人员技术要求低,没有建站知识的操作人员都可轻松进行。继续ASP开源之路,稳定、安全、强大的核心程序,对于有网站设计知识和程序爱好者可以随心所欲进行更改,方便构建具有自已特色的站点。
酷睿股票私募网站管理系统,最大的优势除了在于有全省首创的WAP手机访问系统,更有数十款精致模板任意选择及终生免费更换模板服务,并承诺一次订购终生免费使用,无任何限制和加密,完全可随便的二次开发,也可以随便更换域名、空间、IP等,可终生免费无限次升级更新新版本,还可以一套系统无限次使用。
升级更新部分功能介绍
全新的黑色模板设计
全新的内核程序设计
全新的后台管理界面设计
全新的会员中性管理界面设计
新增了后台基本设置里的网站、联系信息、银行设置、工商注册、公司证书、收费标准等五个大项,50多个小项的设置及后台相关标签
新增了会员注册后只要建立自己的资料便可手动签署协议功能
新增了公开验证模型
新增了会员实战模型
新增了历史战绩模型等四种模型,去掉原先两个系统调用,改为一个系统
新增了会员实战的手动更新功能
新增了历史战绩的手动更新功能
新增了后台定时任务文章多点定时手动采集和手动多点定时生成静态页面功能
新增了后台设置前台会员注册时容许所显示的会员组如A、B、C、D、E、F等类会员组
新增了会员登入后的对帐专业县链接
新增了目录安全设置说明文件
修改了后台所有静态自定义标签可以可视化编辑
修正了幻灯图片不能后台添加更改的问题
修正了财经视频直播视频不能播放的问题
修改滚动行情不能手动更新并改为全球主要期指手动实时更新
增强后台木马在线监测系统
修正了黑客借助后台或会员上传功能上传木马的BUG
修正了黑客借助模板管理添加木马文件的BUG
修正了其它数处BUG及安全隐患
修复了早已的几处WAP手机访问系统的BUG
修正了Robots.txt搜索引擎蜘蛛文件对网站的收录权限,让搜索引擎更新收录网站内容
并取消了首页的数个IFRA使用网站的ME调用,尽可能降低了对搜索引擎的友好程度
删除了上百个垃圾文件使用网站的减少40%
优化了大量的程序代码
主要功能
完善的全后台管理功能
不管是网站配置、联系信息、银行设置、工商注册、公司证书、收费标准还是网站模板、标签等几乎可以在后台管理任何网站所须要的内容。
实时行情系统
滚动全球行情、外汇报价、机构盯盘、涨跌排名、成交排名、股市手册、环球指数全手动更新。
运行速率与效率
采用XML缓存,运行速率更快,效率更高。
系统采用ASP+DIV+CSS+Ajax+XML+MSSQL技术开发而成,运行速率成倍提高。
文章智能快速采集系统
多点定时计划文章采集和多点定时计划文章自动生成系统,让你的网站无人职守,自动更新
智能强悍的过滤系统设置、UTF-8/GB2312手动辨识、批量采集让你享受高速采集快感。
采集目标网站可随便更换,设置规则简单,操作更方便
会员实战手动更新功能
可手动更新沪深股市当日跌幅最前的各三名作为会员实战内容
历史战绩手动更新功能
可手动更新以会员实战的15天前及120内的内容作为历史战绩的内容,并手动将实际获利手动设置为40%-90%、自动将交易时间设置为3-9天
全新的文章浏览权限应用功能
真正的做到了会员对帐专区的会员组浏览功能,可将会员组浏览权限精确到每位频道/每个栏目/每篇文章,让不同的会员组享受不同的文章浏览权限,并各会员组之间的资料不能想到浏览,也可将整篇文章设置浏览点数,发行点卡使包点的会员进行浏览,还可设置包年会员浏览,包月会员时间一到该会员须要续费后才会浏览相应的会员资料。
强大的会员管理功能
无限用户组添加功能、站内邮件功能、会员点卷明细查询、有效期查询、资金明细查询、点卡在线冲值功能、在线支付实时到账,会员可设置为扣点会员、有效期会员和、无限期会员。
SEO优化
在线智能生成GOOGLE/百度标准收录XML格式地图,使网站更便于搜索和收录。
三种运行模式:可将站点全部页面高为动态、静态及伪态格式,大大提升浏览速率及搜索引擎的搜录量。
HTML生成文件储存结构选择。
独有利于Alexa收录的info.txt文件和搜索引擎蜘蛛爬行文件Robots.txt
模板程序分离,网站频道、栏目、内容页META关键词、网站META网页描述均为调用标签,利于网站的收录量并大大减短了页面收录的时间更易于网站的手动配置管理
WAP手机网站系统
国内独创WAP手机访问系统,注册、登录、会员对帐、分析预测众等多种功能一部手机全部搞定!支持手机自带WAP浏览器、UC浏览器、QQ浏览器等几乎所有只要能上网的主流手机浏览器
手机上网浏览与在网站同步,一个账号,两站通用,实现WEB与WAP无缝衔接
集成13个在线支付平台
集成:财付通 网银在线 易付通 云网支付 支付宝 快钱支付 中国在线支付网 西部支付 上海环迅等11个在线支付平台插口,会员冲值实时到账,让你收费无忧。
强大的插件管理
集成:WAP手机网站系统插件、数据库导出系统、可选CC视频联盟插件、WSS统计插件、
标签管理系统
全新的标签应用功能全站采用标签调用系统,让网站运行速率更快,且完全避免站内的文章被其它网站所采集,后台标签管理更方便简单,让网站更安全且极易维护管理。
模板化体系
界面和程序分离,可在线可视化编辑、设计,所有模块均通过标签调用,集成类同Macromedia Dreamweaver一样简单的可视模板编辑方法,修改模板容易、快捷。
无限频道添加功能
可无限添加各类频道或栏目,新频道或栏目完全独立设置,独立模版。
数据库
提供强悍的数据备份和恢复功能,可以在线备份、恢复、压缩数据库。查看系统空间占用情况、系统初始化、查看服务器信息及到在线直接执行SQL句子
系统采用MSSQL数据库,可支持上数千万的数据库,更安全、更稳定、更高效、更强大,运行速率更快。
自动签协议功能
当会注册成功了系统会手动生成一个文件方式的协议,进入会员中心后可以查看协议文本。
系统安全
本以安全为基础,密码采用MD5加密,保证用户资料安全,程序代码中设计缜密,可手动屏蔽恶意功击代码。
更集成防SQL注入程序,从而可全面杜绝各类SQL注入攻击手段,并进行记录在案,保证了系统的安全和稳定运行。
更详尽的管理风波记录,管理员每一步后台操作都记录在案。
双重登入双重密码设计再加认证码,后台登录更安全。
Python3爬虫获取博客园文章定时发送到邮箱
采集交流 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2020-08-21 05:16
写在上面
关于获取文章自动发送到邮箱,这类需求似乎可以写好几个网站,弄完博客园,弄CSDN,弄鹈鹕,弄其他的,网站多的是呢~哈哈
先从博客园开始,基本需求,获取python蓝筹股下边的新文章,间隔60分钟发送一次,时间太紧估摸着没有多少新博客产出~
抓取的页面就是这个
需求整理获取指定页面的所有文章,记录文章相关信息,并且记录最后一篇文章的时间将文章发送到指定邮箱,更新最后一篇文章的时间实际编码环节
查看一下须要导出的模块
模块清单
import requests
import time
import re
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
from email.header import Header
from email.mime.application import MIMEApplication
from email.mime.multipart import MIMEMultipart
'''
遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
'''
初始化基本数据
# 初始化数据
def __init__(self):
self.start_url = "https://www.cnblogs.com/cate/python"
self.headers = {
"user-agent": "Mozilla/..... Safari/537.36",
"referer": "https://www.cnblogs.com/cate/python/"
}
self.pattern = r'[\s\S.]*?(.*?)[\s\S.]*?[\s\S.]*?(.*?)([\s\S.]*?)'
self.last_blog_time = 0
self.need_send_articles = []
参数说明
解析博客网页内容
涉及代码较多,我将关键点编撰相应的注释
'''
遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
'''
# 解析网页内容
def get_articles(self):
try:
# 正常的数据获取
res = requests.get(self.start_url,headers=self.headers,timeout=3)
except Exception as e:
print("error %s"% e)
time.sleep(3)
return self.get_articles() # 重新发起请求
html = res.text
# 这个地方的正则表达式是考验你正则功底的地方了
all = re.findall(self.pattern,html)
# 判断,如果没有新文章
last_time = self.change_time(all[0][3].strip().replace("发布于 ", ""))
if last_time self.last_blog_time):
self.need_send_articles.append({
"url":item[0],
"title":item[1],
"author":item[2],
"time":public_time
})
# 文章获取完毕,更新时间
self.last_blog_time = last_time
##### 测试输出
print(self.need_send_articles)
print("现在文章的最后时间为",self.last_blog_time)
##### 测试输出
时间字符串转换成时间戳
采用时间戳可以直接比较大小,非常便捷
def change_time(self,need_change_time):
'''
# 时间的转换
:param need_change_time:
:return:返回时间戳
'''
time_array = time.strptime(need_change_time, "%Y-%m-%d %H:%M")
time_stamp = int(time.mktime(time_array))
return time_stamp
邮件发送环节
本篇博客采用的是QQ邮箱发送
关于QQ邮箱发送的一些参考文章,我给你们列一下,方便你查阅
参考文章
# https://blog.csdn.net/qiye005/ ... 89666
# https://blog.csdn.net/Momorrin ... 81251
# https://www.cnblogs.com/lovealways/p/6701662.html
# https://www.cnblogs.com/yufeihlf/p/5726619.html
因为我采用的是QQ邮箱,所以有的地方设定上去比较麻烦,发短信还花了2分钱,建议你采用其它的邮箱,设置是一样的哦~~
发送短信send_email函数
你看一下里面的文章之后,就可以对短信发送进行相应的编撰了,非常简单
QQ邮箱是SSL认证的邮箱系统,因此用QQ邮箱发送短信,需要创建一个SMTP_SSL对象,而不是SMTP对象
# 发送邮件
def send_email(self,articles):
smtp = smtplib.SMTP_SSL() # 这个地方注意
smtp.connect("smtp.qq.com",465)
smtp.login("860866679@qq.com", "授权码")
sender = '860866679@qq.com'
receivers = ['找个自己的其他邮箱@163.com'] # 接收邮件,可设置为你的QQ邮箱或者其他邮箱
# 完善发件人收件人,主题信息
message = MIMEMultipart()
message['From'] = formataddr(["博客采集器", sender])
message['To'] = formataddr(["hi,baby", ''.join(receivers)])
subject = '你有新采集到的文章清单'
message['Subject'] = Header(subject, 'utf-8')
# 正文部分
html = ""
for item in articles:
html+=("<p>{title}--文章作者{author}--发布时间{time}".format(title=item["title"],url=item["url"],author=item["author"],time=item["time"]))
textmessage = MIMEText('
新采集到的文章清单' +html,
'html', 'utf-8')
message.attach(textmessage)
# 发送邮件操作
smtp.sendmail(sender, receivers, message.as_string())
smtp.quit()
</p>
邮箱收到电邮
当收到短信的那一刻,你就可以感受到happy了~ 查看全部
Python3爬虫获取博客园文章定时发送到邮箱
写在上面
关于获取文章自动发送到邮箱,这类需求似乎可以写好几个网站,弄完博客园,弄CSDN,弄鹈鹕,弄其他的,网站多的是呢~哈哈
先从博客园开始,基本需求,获取python蓝筹股下边的新文章,间隔60分钟发送一次,时间太紧估摸着没有多少新博客产出~
抓取的页面就是这个
需求整理获取指定页面的所有文章,记录文章相关信息,并且记录最后一篇文章的时间将文章发送到指定邮箱,更新最后一篇文章的时间实际编码环节
查看一下须要导出的模块
模块清单
import requests
import time
import re
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
from email.header import Header
from email.mime.application import MIMEApplication
from email.mime.multipart import MIMEMultipart
'''
遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
'''
初始化基本数据
# 初始化数据
def __init__(self):
self.start_url = "https://www.cnblogs.com/cate/python"
self.headers = {
"user-agent": "Mozilla/..... Safari/537.36",
"referer": "https://www.cnblogs.com/cate/python/"
}
self.pattern = r'[\s\S.]*?(.*?)[\s\S.]*?[\s\S.]*?(.*?)([\s\S.]*?)'
self.last_blog_time = 0
self.need_send_articles = []
参数说明
解析博客网页内容
涉及代码较多,我将关键点编撰相应的注释
'''
遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
'''
# 解析网页内容
def get_articles(self):
try:
# 正常的数据获取
res = requests.get(self.start_url,headers=self.headers,timeout=3)
except Exception as e:
print("error %s"% e)
time.sleep(3)
return self.get_articles() # 重新发起请求
html = res.text
# 这个地方的正则表达式是考验你正则功底的地方了
all = re.findall(self.pattern,html)
# 判断,如果没有新文章
last_time = self.change_time(all[0][3].strip().replace("发布于 ", ""))
if last_time self.last_blog_time):
self.need_send_articles.append({
"url":item[0],
"title":item[1],
"author":item[2],
"time":public_time
})
# 文章获取完毕,更新时间
self.last_blog_time = last_time
##### 测试输出
print(self.need_send_articles)
print("现在文章的最后时间为",self.last_blog_time)
##### 测试输出
时间字符串转换成时间戳
采用时间戳可以直接比较大小,非常便捷
def change_time(self,need_change_time):
'''
# 时间的转换
:param need_change_time:
:return:返回时间戳
'''
time_array = time.strptime(need_change_time, "%Y-%m-%d %H:%M")
time_stamp = int(time.mktime(time_array))
return time_stamp
邮件发送环节
本篇博客采用的是QQ邮箱发送
关于QQ邮箱发送的一些参考文章,我给你们列一下,方便你查阅
参考文章
# https://blog.csdn.net/qiye005/ ... 89666
# https://blog.csdn.net/Momorrin ... 81251
# https://www.cnblogs.com/lovealways/p/6701662.html
# https://www.cnblogs.com/yufeihlf/p/5726619.html
因为我采用的是QQ邮箱,所以有的地方设定上去比较麻烦,发短信还花了2分钱,建议你采用其它的邮箱,设置是一样的哦~~
发送短信send_email函数
你看一下里面的文章之后,就可以对短信发送进行相应的编撰了,非常简单
QQ邮箱是SSL认证的邮箱系统,因此用QQ邮箱发送短信,需要创建一个SMTP_SSL对象,而不是SMTP对象
# 发送邮件
def send_email(self,articles):
smtp = smtplib.SMTP_SSL() # 这个地方注意
smtp.connect("smtp.qq.com",465)
smtp.login("860866679@qq.com", "授权码")
sender = '860866679@qq.com'
receivers = ['找个自己的其他邮箱@163.com'] # 接收邮件,可设置为你的QQ邮箱或者其他邮箱
# 完善发件人收件人,主题信息
message = MIMEMultipart()
message['From'] = formataddr(["博客采集器", sender])
message['To'] = formataddr(["hi,baby", ''.join(receivers)])
subject = '你有新采集到的文章清单'
message['Subject'] = Header(subject, 'utf-8')
# 正文部分
html = ""
for item in articles:
html+=("<p>{title}--文章作者{author}--发布时间{time}".format(title=item["title"],url=item["url"],author=item["author"],time=item["time"]))
textmessage = MIMEText('
新采集到的文章清单' +html,
'html', 'utf-8')
message.attach(textmessage)
# 发送邮件操作
smtp.sendmail(sender, receivers, message.as_string())
smtp.quit()
</p>
邮箱收到电邮
当收到短信的那一刻,你就可以感受到happy了~
填报表怎样做到象 word 那样定时手动保存
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2020-08-19 01:50
在使用补报表时,有些用户一次须要补报的内容比较多,万一遇见浏览器卡顿不响应,然后造成数据遗失要重新补报……估计就是 "事故现场" 了(此处省略一万个字)。这个时侯, 呆呆就在想,填报表能不能实现象 word 一样在编辑过程中手动定时递交保存的疗效呢?
幸好,答案是肯定的。
下面我们就具体说道说道,这个疗效是如何实现的。实现此疗效不可或缺的是 js 的推动,然后配合润乾报表的递交数据方式。
具体操作如下:
首先,明确当前补报表彰显是使用那个 jsp 进行解析的;
注:此处以润乾工具自带 showReport.jsp 为例
然后,应用 js 定时执行某操作的方式 (不知道直接问度娘哈),如:
setInterval(要执行的 js 方法,执行的时间间隔);
--- 时间单位为微秒
最后,定时执行润乾递交数据的操作:_inputSubmit(“”)。
完整地看一下,在报表诠释的 jsp 中定义 js 方法如下:
这样,我们就轻松实现了象 word 那样定时递交保存的疗效了(这个事例中每 3 秒执行一次递交操作)。
还是老套路,最最后画出至关重要的技术坐姿:
1. 定时方式
setInterval 方法通过 js 控制定时执行哪些操作。
方法执行体需用户按照自己的实际应用自定义 比如:方法里写 alert(提示信息),那就三秒 alert 一次;方法里写递交数据,就三秒递交一次数据。
inputApi.saveSuccess 是递交数据成功后,执行哪些操作,默认的是 alert(保存成功),同样可以自定义其他执行操作,比如哪些都不做或则刷新页面等。
2. 提交方式
_inputSubmit() 方法润乾报表外置的补报递交方式。常与 js 方法配合实现一些个性化操作。如: 提交后跳转到某个指定页面, 标志数组实现补报数据的暂存与锁定…… 查看全部
填报表怎样做到象 word 那样定时手动保存
在使用补报表时,有些用户一次须要补报的内容比较多,万一遇见浏览器卡顿不响应,然后造成数据遗失要重新补报……估计就是 "事故现场" 了(此处省略一万个字)。这个时侯, 呆呆就在想,填报表能不能实现象 word 一样在编辑过程中手动定时递交保存的疗效呢?
幸好,答案是肯定的。
下面我们就具体说道说道,这个疗效是如何实现的。实现此疗效不可或缺的是 js 的推动,然后配合润乾报表的递交数据方式。
具体操作如下:
首先,明确当前补报表彰显是使用那个 jsp 进行解析的;
注:此处以润乾工具自带 showReport.jsp 为例
然后,应用 js 定时执行某操作的方式 (不知道直接问度娘哈),如:
setInterval(要执行的 js 方法,执行的时间间隔);
--- 时间单位为微秒
最后,定时执行润乾递交数据的操作:_inputSubmit(“”)。
完整地看一下,在报表诠释的 jsp 中定义 js 方法如下:
这样,我们就轻松实现了象 word 那样定时递交保存的疗效了(这个事例中每 3 秒执行一次递交操作)。
还是老套路,最最后画出至关重要的技术坐姿:
1. 定时方式
setInterval 方法通过 js 控制定时执行哪些操作。
方法执行体需用户按照自己的实际应用自定义 比如:方法里写 alert(提示信息),那就三秒 alert 一次;方法里写递交数据,就三秒递交一次数据。
inputApi.saveSuccess 是递交数据成功后,执行哪些操作,默认的是 alert(保存成功),同样可以自定义其他执行操作,比如哪些都不做或则刷新页面等。
2. 提交方式
_inputSubmit() 方法润乾报表外置的补报递交方式。常与 js 方法配合实现一些个性化操作。如: 提交后跳转到某个指定页面, 标志数组实现补报数据的暂存与锁定……
SQL Server 跨服务器同步或定时同步数据库
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2020-08-18 22:47
下载网站:
客服QQ1793040
----------------------------------------------------------
关于HKROnline SyncNavigator 注册机价位的问题
HKROnline SyncNavigator 8.4.1 非破解版 注册机 授权激活教程
最近仍然在研究数据库同步的问题,在网上查了好多资料,也讨教了很多人,找到了一种通过快照复制的方式。研究了一番后发觉之前就是用的这个方式,效果不是挺好,果断舍弃。经过了一番寻找和别人赐教,最后从一位热心网友那儿得悉一款挺好用的软件——SyncNavigator。
好东西就要拿出来跟你们分享,所以明天向你们介绍一下这款软件,及其一些使用方式。下面先瞧瞧它有哪些强悍的功能吧!
SyncNavigator的基本功能:
自动同步数据/定时同步数据
无论是实时同步/24小时不间断同步,还是按照计划任务(每小时/每日/每周/等)定时手动同步都能完全胜任。
完整支持 Microsoft SQL Server
完整支持 Microsoft SQL Server 2 数据库类型。并能在不同数据库版本之间互相同步数据。
支持MySQL4.1 以上版本
支持MySQL4.1 5.0 5.1 5.4 5.5。并能在不同数据库版本之间互相同步数据。
无人值守和故障手动恢复
当数据库故障或网路故障之后,无需人工干预(或操作)自动恢复同步并确保数据完全确切,可靠。
同构数据库同步/异构数据库同步
SQL Server to SQL Server, MySQL to MySQL, SQL Server to MySQL 等都能轻松实现。
断点续传和增量同步
当同步完成(或中断)后,再次同步时能继续上一次的位置增量同步,避免每次都须要从头开始的问题。
在本地局域网内或则内网有两台安装有sqlserver2008的机器(注意:已发布的快照版本未能向老版本数据库兼容,意味着2008下创建的事务或快照发布,无法被sqlserver2005订阅)
1.在要发布的数据库上创建一个数据库(这里称作dnt_new),然后在该数据库实例的一侧导航的“复制”--“本地发布”上击右键,然后选择“新建发布”,如下:
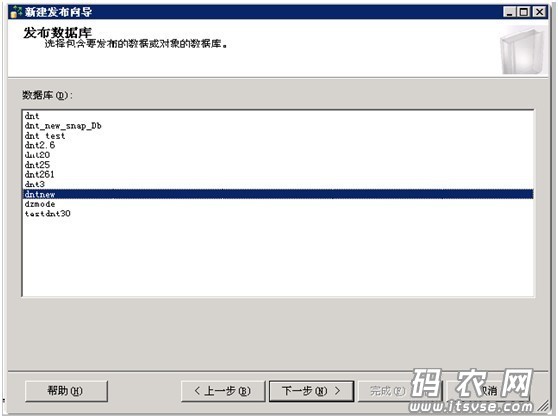
这样,系统还会启动‘发布向导’来引导你们,点击"下一步”,然后在当前窗口中选择要发布的数据库,如下:
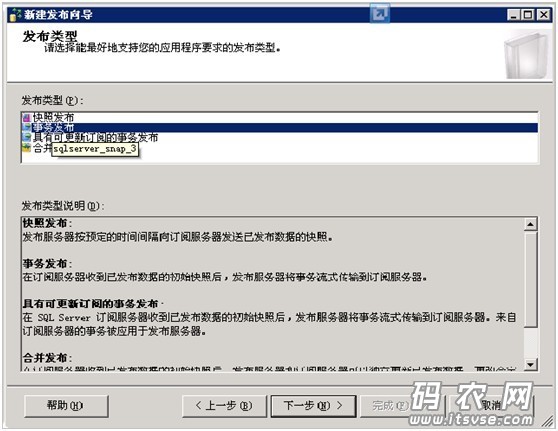
点击下一步,然后在接下来的窗口中选择“事务发布”,如下图:
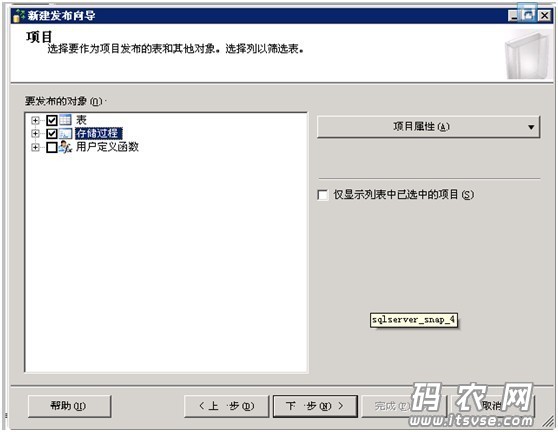
然后点击下一步,选择要同步的数据对象(数据表,存储过程,自定义函数等),如下:
然后就是“项目问题窗口”,因为之前已用dbo身分登入,所以这儿只要点击下一步即可,如下图:
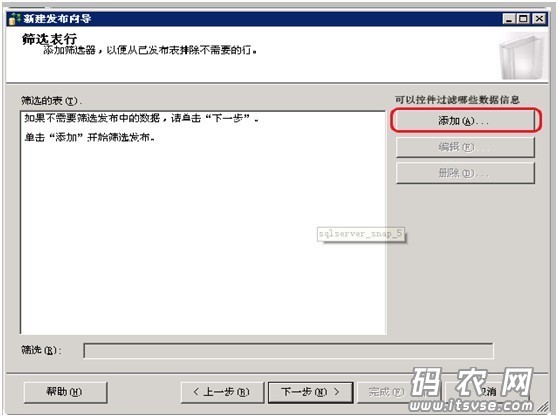
这里可以通过“添加”方式来过滤要同步的数据信息,因为要做全表数据同步,所以这儿不设置
然后在‘代理安全性’窗口中,点击“安全设置”按钮:
在弹出的‘安全设置’子窗口中设置如下信息,并点击‘确定’按钮:
然后点击下一步按键:
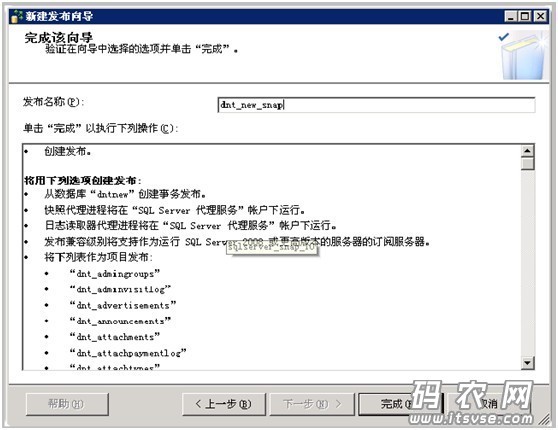
选择“创建发布”复选框,然后点击下一步,这时向导会使您输入“发布名称”,这里命名为“dnt_new_snap”:
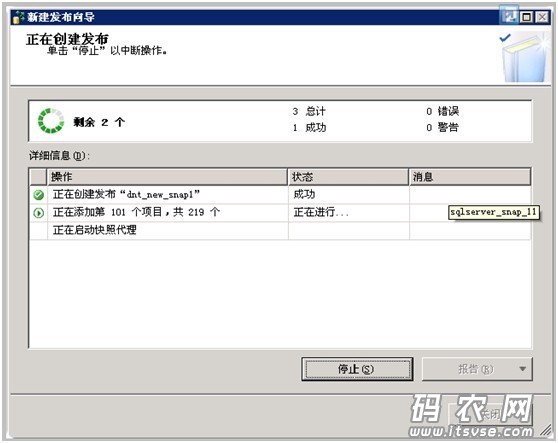
点击“完成按键”,这里系统就开始按照之前搜集的信息来创建该发布对象信息了,如下:
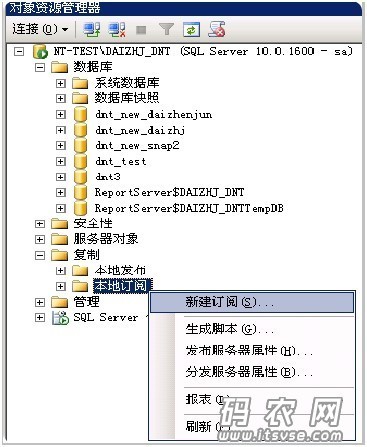
到这儿,‘创建发布’的工作就完成了。下面介绍一下创建订阅的流程。在另一个机器的sqlserver实例上,打开该实例并使用“复制”—“新建订阅”,如下图:
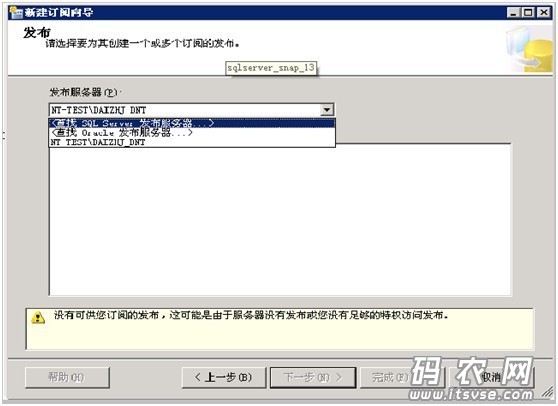
这时系统都会启动“新建订阅”向导,点击下一步,并在“发布”窗口中的“发布服务器”下拉框中选择“查打发布sqlserver服务器”项,如下
然后在弹出窗口中选择之前‘创建发布时所使用的数据库实例’并进行验进登录,这时,发布服务器的信息都会出现在下方的列表框中:
选择之前我们创建的那种发布对象“dnt_new_snap”,接着点击下一步:
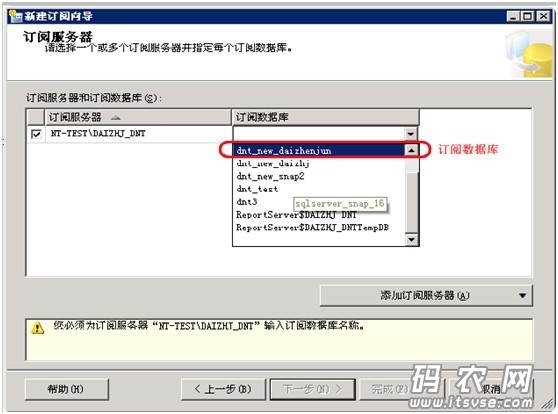
在分发代理位置窗口中,选择“在分布服务器上运行所有代理”,然后点击下一步,然后在“订阅服务器”窗口中的订阅数据库列表框中选择一下要同步的订阅数据库名称(可新建):
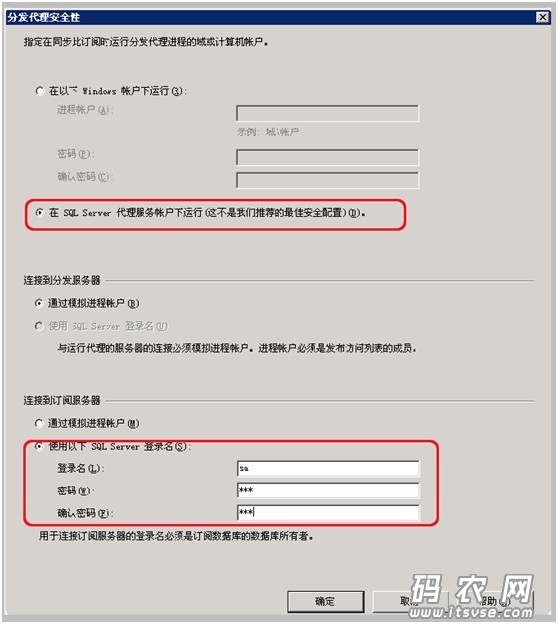
点击下一步,然后在‘分发代理安全性’窗口中,点击列表框中的‘…’来设置安装性,并做如下设置(注意红框部份):
然后点击“确定”按钮,之后在向导上点击“下一步”按钮,这时系统都会显示“代理计划执行方法”窗口,选择“连续运行”或者自定义时间(自定义可以实现定时备份数据):
点击下一步,在窗口中选择“立即执行”:
完成了这一步,点击下一步按键,然后就可以创建该订阅对象了,如果一切运行正常,sqlserver都会从‘发布服务器’那边,将之前指定的数据表和储存过程等同步到当前的‘订阅数据库’中了。这时我们可以在源数据库(发布服务器)上的表中添加或更改指定表数据信息,在等待1-3秒(或设定的时间)之后,所做的添加和更改都会同步到‘订阅数据库’上的相应表中
注:本文中的两台机器必将是可以使用sqlserver客户端互联(在sqlserver studio中设置'允许远程链接',同时要设置相应的ip地址,以及在配置管理器中开启tcp/ip协议即可)
注:
局域网SQL远程联接方式:
SQL2005 SQL2008远程联接配置方式
第一步(SQL2005、SQL2008):
开始-->程序-->Microsoft SQL Server 2008(或2005)-->配置工具-->SQL Server 配置管理器-->SQL Server网路配置-->MSSQLSERVER(这个名称以具体实例名为准) 的合同-->TCP/IP-->右键-->启用
第二步:
SQL2005:
开始-->程序-->Microsoft SQL Server 2005-->配置工具-->SQL Server 2005外围应用配置器-->服务和联接的外围应用配置器 -->Database Engine -->远程联接,选择本地联接和远程联接并选上同时使用Tcp/Ip和named pipes.
SQL2008:
打开SQL Server Management Studio-->在左侧[对象资源管理器]中选择第一项(主数据库引擎)-->右键-->方面-->在方面的下拉列表中选择[外围应用配置器]-->将RemoteDacEnable置为True.
Express:
如果XP有开防火墙,在例外上面要加入以下两个程序:
C:Program FilesMicrosoft SQL ServerMSSQL.1MSSQLBinnsqlservr.exe,
C:Program FilesMicrosoft SQL Server90Sharedsqlbrowser.exe
不仅要关掉Windows防火墙,杀毒软件防火墙也要关掉。
第三步:
开始-->程序-->Microsoft SQL Server 2008(或2005)-->配置工具-->SQL Server 配置管理器-->SQL Server服务-->右击SQL Server(MSSQLSERVER) (注:括号内以具体实例名为准)-->重新启动 查看全部
SQL Server 跨服务器同步或定时同步数据库
下载网站:
客服QQ1793040
----------------------------------------------------------
关于HKROnline SyncNavigator 注册机价位的问题

HKROnline SyncNavigator 8.4.1 非破解版 注册机 授权激活教程
最近仍然在研究数据库同步的问题,在网上查了好多资料,也讨教了很多人,找到了一种通过快照复制的方式。研究了一番后发觉之前就是用的这个方式,效果不是挺好,果断舍弃。经过了一番寻找和别人赐教,最后从一位热心网友那儿得悉一款挺好用的软件——SyncNavigator。
好东西就要拿出来跟你们分享,所以明天向你们介绍一下这款软件,及其一些使用方式。下面先瞧瞧它有哪些强悍的功能吧!
SyncNavigator的基本功能:
自动同步数据/定时同步数据
无论是实时同步/24小时不间断同步,还是按照计划任务(每小时/每日/每周/等)定时手动同步都能完全胜任。
完整支持 Microsoft SQL Server
完整支持 Microsoft SQL Server 2 数据库类型。并能在不同数据库版本之间互相同步数据。
支持MySQL4.1 以上版本
支持MySQL4.1 5.0 5.1 5.4 5.5。并能在不同数据库版本之间互相同步数据。
无人值守和故障手动恢复
当数据库故障或网路故障之后,无需人工干预(或操作)自动恢复同步并确保数据完全确切,可靠。
同构数据库同步/异构数据库同步
SQL Server to SQL Server, MySQL to MySQL, SQL Server to MySQL 等都能轻松实现。
断点续传和增量同步
当同步完成(或中断)后,再次同步时能继续上一次的位置增量同步,避免每次都须要从头开始的问题。
在本地局域网内或则内网有两台安装有sqlserver2008的机器(注意:已发布的快照版本未能向老版本数据库兼容,意味着2008下创建的事务或快照发布,无法被sqlserver2005订阅)
1.在要发布的数据库上创建一个数据库(这里称作dnt_new),然后在该数据库实例的一侧导航的“复制”--“本地发布”上击右键,然后选择“新建发布”,如下:
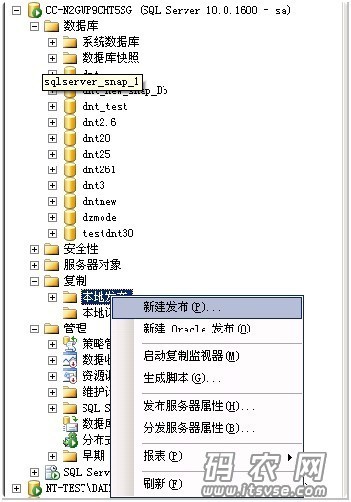
这样,系统还会启动‘发布向导’来引导你们,点击"下一步”,然后在当前窗口中选择要发布的数据库,如下:
点击下一步,然后在接下来的窗口中选择“事务发布”,如下图:
然后点击下一步,选择要同步的数据对象(数据表,存储过程,自定义函数等),如下:
然后就是“项目问题窗口”,因为之前已用dbo身分登入,所以这儿只要点击下一步即可,如下图:
这里可以通过“添加”方式来过滤要同步的数据信息,因为要做全表数据同步,所以这儿不设置
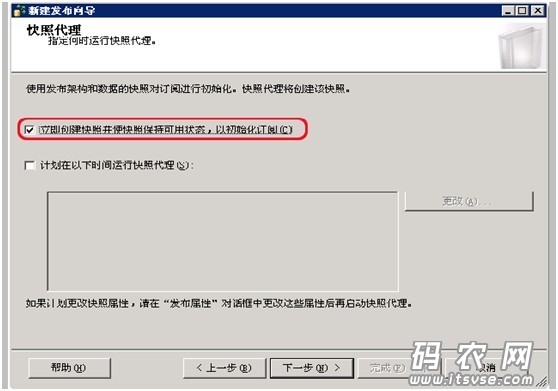
然后在‘代理安全性’窗口中,点击“安全设置”按钮:
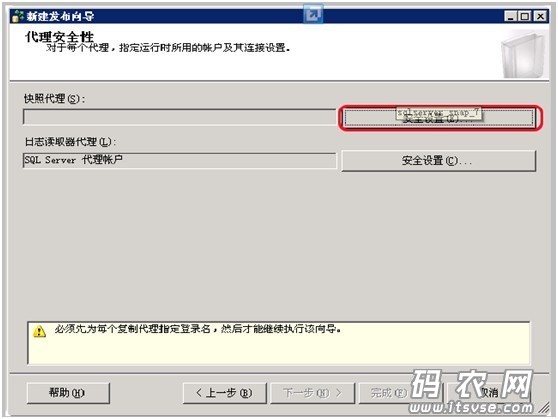
在弹出的‘安全设置’子窗口中设置如下信息,并点击‘确定’按钮:
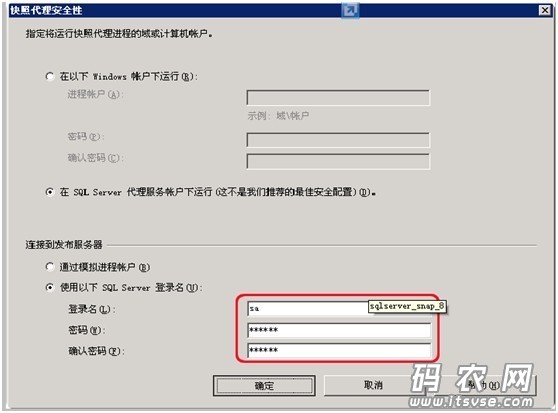
然后点击下一步按键:
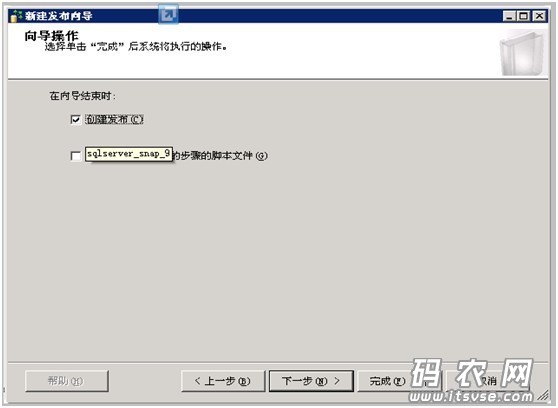
选择“创建发布”复选框,然后点击下一步,这时向导会使您输入“发布名称”,这里命名为“dnt_new_snap”:
点击“完成按键”,这里系统就开始按照之前搜集的信息来创建该发布对象信息了,如下:
到这儿,‘创建发布’的工作就完成了。下面介绍一下创建订阅的流程。在另一个机器的sqlserver实例上,打开该实例并使用“复制”—“新建订阅”,如下图:
这时系统都会启动“新建订阅”向导,点击下一步,并在“发布”窗口中的“发布服务器”下拉框中选择“查打发布sqlserver服务器”项,如下
然后在弹出窗口中选择之前‘创建发布时所使用的数据库实例’并进行验进登录,这时,发布服务器的信息都会出现在下方的列表框中:
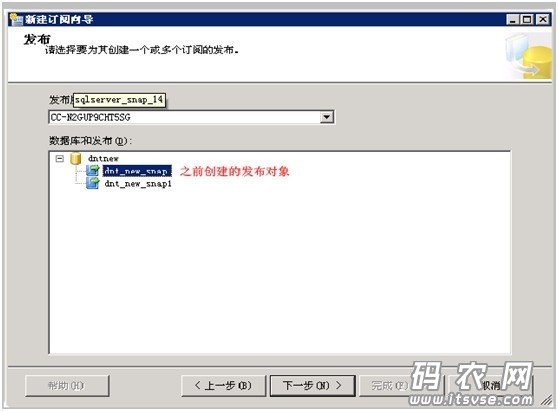
选择之前我们创建的那种发布对象“dnt_new_snap”,接着点击下一步:
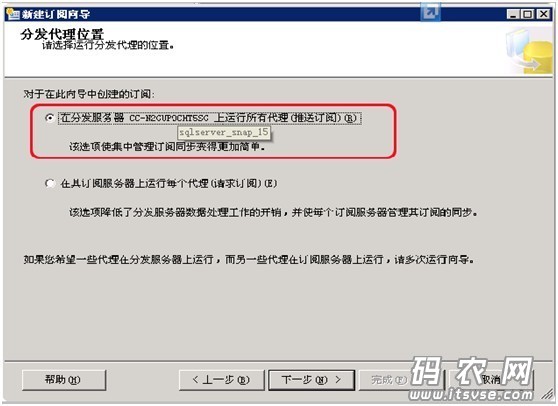
在分发代理位置窗口中,选择“在分布服务器上运行所有代理”,然后点击下一步,然后在“订阅服务器”窗口中的订阅数据库列表框中选择一下要同步的订阅数据库名称(可新建):
点击下一步,然后在‘分发代理安全性’窗口中,点击列表框中的‘…’来设置安装性,并做如下设置(注意红框部份):
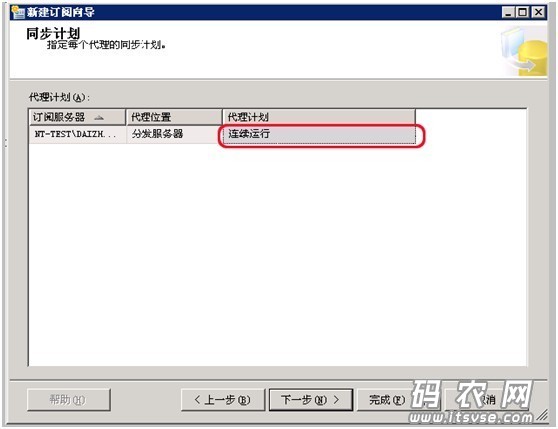
然后点击“确定”按钮,之后在向导上点击“下一步”按钮,这时系统都会显示“代理计划执行方法”窗口,选择“连续运行”或者自定义时间(自定义可以实现定时备份数据):
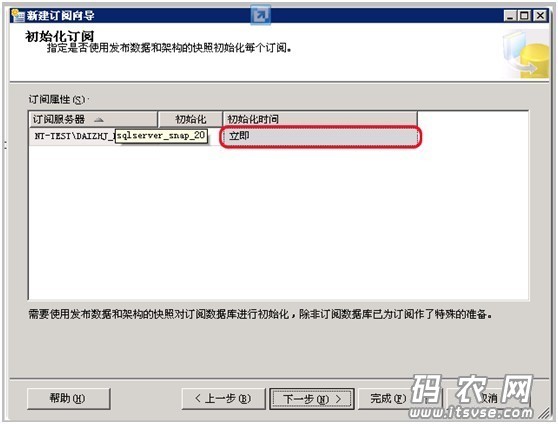
点击下一步,在窗口中选择“立即执行”:
完成了这一步,点击下一步按键,然后就可以创建该订阅对象了,如果一切运行正常,sqlserver都会从‘发布服务器’那边,将之前指定的数据表和储存过程等同步到当前的‘订阅数据库’中了。这时我们可以在源数据库(发布服务器)上的表中添加或更改指定表数据信息,在等待1-3秒(或设定的时间)之后,所做的添加和更改都会同步到‘订阅数据库’上的相应表中
注:本文中的两台机器必将是可以使用sqlserver客户端互联(在sqlserver studio中设置'允许远程链接',同时要设置相应的ip地址,以及在配置管理器中开启tcp/ip协议即可)
注:
局域网SQL远程联接方式:
SQL2005 SQL2008远程联接配置方式
第一步(SQL2005、SQL2008):
开始-->程序-->Microsoft SQL Server 2008(或2005)-->配置工具-->SQL Server 配置管理器-->SQL Server网路配置-->MSSQLSERVER(这个名称以具体实例名为准) 的合同-->TCP/IP-->右键-->启用
第二步:
SQL2005:
开始-->程序-->Microsoft SQL Server 2005-->配置工具-->SQL Server 2005外围应用配置器-->服务和联接的外围应用配置器 -->Database Engine -->远程联接,选择本地联接和远程联接并选上同时使用Tcp/Ip和named pipes.
SQL2008:
打开SQL Server Management Studio-->在左侧[对象资源管理器]中选择第一项(主数据库引擎)-->右键-->方面-->在方面的下拉列表中选择[外围应用配置器]-->将RemoteDacEnable置为True.
Express:
如果XP有开防火墙,在例外上面要加入以下两个程序:
C:Program FilesMicrosoft SQL ServerMSSQL.1MSSQLBinnsqlservr.exe,
C:Program FilesMicrosoft SQL Server90Sharedsqlbrowser.exe
不仅要关掉Windows防火墙,杀毒软件防火墙也要关掉。
第三步:
开始-->程序-->Microsoft SQL Server 2008(或2005)-->配置工具-->SQL Server 配置管理器-->SQL Server服务-->右击SQL Server(MSSQLSERVER) (注:括号内以具体实例名为准)-->重新启动
定时联盟资源库采集脚本设置
采集交流 • 优采云 发表了文章 • 0 个评论 • 414 次浏览 • 2020-08-18 04:38
生成谷歌xml make-rss-ac2-google-googleall-5000-google-1000 【googleall总输出数,google每页数目】
生成百度xml make-rss-ac2-baidu-baiduall-5000-baidu-1000 【baiduall总输出数,baidu每页数目】
生成rss make-rss-ac2-rss-rss-1000 【rss每页数目】
生成自定义页面 make-label-ids-label_js.html 【ids为自定义页面文件名称】
===================以下任务每次执行每位分类最多生成10页条数据,避免常年占用系统资源=================
生成当日有数据更新的视频分类 make-type-tab-vod 【id为视频分类的id】
生成当日有数据更新的文章分页 make-type-tab-art 【id为文章分类的id】
===================以下任务每次执行每位专题最多生成10页条数据,避免常年占用系统资源=================
生成视频专题列表 make-topic-tab-vod-ids-13 【id为视频分类的id】
生成文章专题列表 make-topic-tab-art-ids-13 【id为文章分类的id】
===================以下任务每次执行最多生成100条数据,避免常年占用系统资源=================
生成未生成视频数据 make-info-tab-vod-ac2-nomake
生成未生成文章数据 make-info-tab-art-ac2-nomake
生成当日更新视频数据 make-info-tab-vod-ac2-day
生成当日更新文章数据 make-info-tab-art-ac2-day 查看全部
定时联盟资源库采集脚本设置
生成谷歌xml make-rss-ac2-google-googleall-5000-google-1000 【googleall总输出数,google每页数目】
生成百度xml make-rss-ac2-baidu-baiduall-5000-baidu-1000 【baiduall总输出数,baidu每页数目】
生成rss make-rss-ac2-rss-rss-1000 【rss每页数目】
生成自定义页面 make-label-ids-label_js.html 【ids为自定义页面文件名称】
===================以下任务每次执行每位分类最多生成10页条数据,避免常年占用系统资源=================
生成当日有数据更新的视频分类 make-type-tab-vod 【id为视频分类的id】
生成当日有数据更新的文章分页 make-type-tab-art 【id为文章分类的id】
===================以下任务每次执行每位专题最多生成10页条数据,避免常年占用系统资源=================
生成视频专题列表 make-topic-tab-vod-ids-13 【id为视频分类的id】
生成文章专题列表 make-topic-tab-art-ids-13 【id为文章分类的id】
===================以下任务每次执行最多生成100条数据,避免常年占用系统资源=================
生成未生成视频数据 make-info-tab-vod-ac2-nomake
生成未生成文章数据 make-info-tab-art-ac2-nomake
生成当日更新视频数据 make-info-tab-vod-ac2-day
生成当日更新文章数据 make-info-tab-art-ac2-day
文章定时手动采集 Apache Camel 与 Spring Boot 集成
采集交流 • 优采云 发表了文章 • 0 个评论 • 403 次浏览 • 2020-08-18 04:13
1、概要:
本项目主要是通过在Spring平台上配置Camel、FTP,实现定时从FTP服务器下载文件到本地、解析文件、存入数据库等功能。
2、搭建空项目:
Spring Boot有几种手动生成空项目的机制:CLI、Spring tool suite、网站Spring Initializr,我们选择第三个。
访问网站,如右图
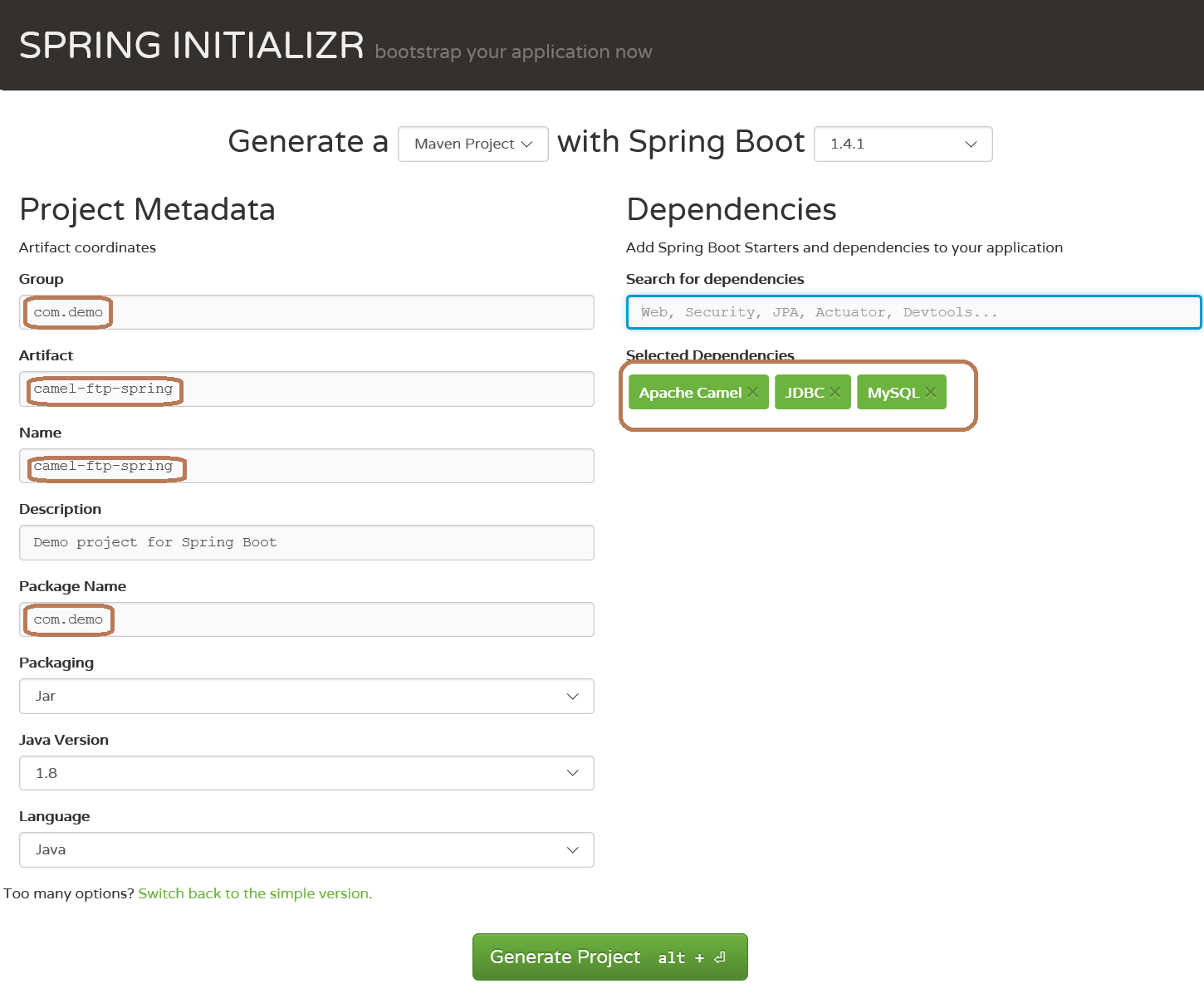
在dependencies添加依赖包的时侯,在框中输入camle、jdbc、mysql会手动弹出提示,确认即为选中,如下图:
点击 generate project按键,生成项目,并将其导出到ecipse,在pom.xml中添加camel-ftp依赖,注意版本号选择与camel-spring-boot-stater的相同
org.apache.camel
camel-ftp
2.18.0
完整版的pom.xml文件如下:
org.apache.camel
camel-spring-boot-starter
2.18.0
org.apache.camel
camel-ftp
2.18.0
org.springframework.boot
spring-boot-starter-jdbc
mysql
mysql-connector-java
runtime
org.springframework.boot
spring-boot-starter-test
test
待所有依赖jar下载到本地,基础项目搭建完成3、配置Camel完成从ftp服务器定时下载文件到本地在application.properties中配置远程FTP服务器的地址、端口、用户名和密码等信息
ftp.server.info=sftp://172.16.20.133:22/../home/temp/data?username=root&password=root&delay=5s&move=done&readLock=rename
ftp.local.dir=file:C:/ftp/test
注意:sftp服务器的文件位置是相对于root登陆后的相对地址(被这儿坑到了),delay=5s是每隔5秒钟扫描ftp服务器上是否有新文件生成,如果有下载到本地,并将服务器上的文件转移到done文件夹(/home/temp/data/done),readLock=rename可以制止camel读取正在被写入的文件
配置路由,完成文件下载
@Component
public class DownloadRouteDemo extends RouteBuilder {
private static Logger logger = LoggerFactory.getLogger( DownloadRouteDemo.class );
@Value("${ftp.server.info}")
private String sftpServer;
@Value("${ftp.local.dir}")
private String downloadLocation;
@Override
public void configure() throws Exception {
from( sftpServer ).to( downloadLocation ).log(LoggingLevel.INFO, logger, "Downloaded file ${file:name} complete.");
}
}
注意:要承继camel的RouteBulider,重写configure方式,大意是从ftp服务器下载文件到本地,并输出文件名(运行时所需必要信息都配置在application.properties文件中)
为了使java进程在后台运行,需要在application.properties文件中降低如下配置
camel.springboot.main-run-controller=true
从ftp服务器下载文件的所有工作都已完成,运行CamelFtpSpringApplication.java,如果你的ftp服务器相应的位置上有文件,就会下载到本地所配置的文件夹下4、通过camel定时解析本地文件并保存到数据库在application.properties中降低如下配置
route.parserfile.info = {{ftp.local.dir}}?delay=10s&move=done&readLock=rename
route.parserfile.dir = {{ftp.local.dir}}/done
注意两个花括弧是引用其他变量的配置
编写解析文件、入库程序等处理器
@Component
public class LocationFileProcessor implements Processor {
private static Logger logger = LoggerFactory.getLogger( LocationFileProcessor.class );
@Value("${ftp.local.dir}")
private String fileDir;
@Autowired
OrderService orderService;//业务逻辑处理组件
@Override
public void process(Exchange exchange) throws Exception {
GenericFileMessage inFileMessage = (GenericFileMessage) exchange.getIn();
String fileName = inFileMessage.getGenericFile().getFileName();//文件名
String splitTag = File.separator;//系统文件分隔符
logger.info(fileDir + splitTag + fileName);//文件的绝对路径
orderService.process(fileDir + splitTag + fileName);//解析入库等操作
}
}
配置路由,完成业务逻辑的串联
@Component
public class LocalTransformRoute extends RouteBuilder {
private static Logger logger = LoggerFactory.getLogger( LocalTransformRoute.class );
@Value("${route.parserfile.info}")
private String location;
@Value("${route.parserfile.dir}")
private String locationDir;
@Autowired
LocationFileProcessor locationFileProcessor;
@Override
public void configure() throws Exception {
from( location ).process( locationFileProcessor ).to( locationDir ).log(LoggingLevel.INFO, logger, "tirans file ${file:name} complete.");
}
}
注意,比前面的路由多了process配置,即业务逻辑处理配置
至此,所有工作都已完成,重新执行CamelFtpSpringApplication.java即可实现ftp文件定时下载、业务处理等(其中省去了好多,例如入库操作等)备注:只是camle spring ftp的一个演示demo,要运用于生产,还有很多须要建立的地方 查看全部
文章定时手动采集 Apache Camel 与 Spring Boot 集成
1、概要:
本项目主要是通过在Spring平台上配置Camel、FTP,实现定时从FTP服务器下载文件到本地、解析文件、存入数据库等功能。
2、搭建空项目:
Spring Boot有几种手动生成空项目的机制:CLI、Spring tool suite、网站Spring Initializr,我们选择第三个。
访问网站,如右图
在dependencies添加依赖包的时侯,在框中输入camle、jdbc、mysql会手动弹出提示,确认即为选中,如下图:
点击 generate project按键,生成项目,并将其导出到ecipse,在pom.xml中添加camel-ftp依赖,注意版本号选择与camel-spring-boot-stater的相同
org.apache.camel
camel-ftp
2.18.0
完整版的pom.xml文件如下:
org.apache.camel
camel-spring-boot-starter
2.18.0
org.apache.camel
camel-ftp
2.18.0
org.springframework.boot
spring-boot-starter-jdbc
mysql
mysql-connector-java
runtime
org.springframework.boot
spring-boot-starter-test
test
待所有依赖jar下载到本地,基础项目搭建完成3、配置Camel完成从ftp服务器定时下载文件到本地在application.properties中配置远程FTP服务器的地址、端口、用户名和密码等信息
ftp.server.info=sftp://172.16.20.133:22/../home/temp/data?username=root&password=root&delay=5s&move=done&readLock=rename
ftp.local.dir=file:C:/ftp/test
注意:sftp服务器的文件位置是相对于root登陆后的相对地址(被这儿坑到了),delay=5s是每隔5秒钟扫描ftp服务器上是否有新文件生成,如果有下载到本地,并将服务器上的文件转移到done文件夹(/home/temp/data/done),readLock=rename可以制止camel读取正在被写入的文件
配置路由,完成文件下载
@Component
public class DownloadRouteDemo extends RouteBuilder {
private static Logger logger = LoggerFactory.getLogger( DownloadRouteDemo.class );
@Value("${ftp.server.info}")
private String sftpServer;
@Value("${ftp.local.dir}")
private String downloadLocation;
@Override
public void configure() throws Exception {
from( sftpServer ).to( downloadLocation ).log(LoggingLevel.INFO, logger, "Downloaded file ${file:name} complete.");
}
}
注意:要承继camel的RouteBulider,重写configure方式,大意是从ftp服务器下载文件到本地,并输出文件名(运行时所需必要信息都配置在application.properties文件中)
为了使java进程在后台运行,需要在application.properties文件中降低如下配置
camel.springboot.main-run-controller=true
从ftp服务器下载文件的所有工作都已完成,运行CamelFtpSpringApplication.java,如果你的ftp服务器相应的位置上有文件,就会下载到本地所配置的文件夹下4、通过camel定时解析本地文件并保存到数据库在application.properties中降低如下配置
route.parserfile.info = {{ftp.local.dir}}?delay=10s&move=done&readLock=rename
route.parserfile.dir = {{ftp.local.dir}}/done
注意两个花括弧是引用其他变量的配置
编写解析文件、入库程序等处理器
@Component
public class LocationFileProcessor implements Processor {
private static Logger logger = LoggerFactory.getLogger( LocationFileProcessor.class );
@Value("${ftp.local.dir}")
private String fileDir;
@Autowired
OrderService orderService;//业务逻辑处理组件
@Override
public void process(Exchange exchange) throws Exception {
GenericFileMessage inFileMessage = (GenericFileMessage) exchange.getIn();
String fileName = inFileMessage.getGenericFile().getFileName();//文件名
String splitTag = File.separator;//系统文件分隔符
logger.info(fileDir + splitTag + fileName);//文件的绝对路径
orderService.process(fileDir + splitTag + fileName);//解析入库等操作
}
}
配置路由,完成业务逻辑的串联
@Component
public class LocalTransformRoute extends RouteBuilder {
private static Logger logger = LoggerFactory.getLogger( LocalTransformRoute.class );
@Value("${route.parserfile.info}")
private String location;
@Value("${route.parserfile.dir}")
private String locationDir;
@Autowired
LocationFileProcessor locationFileProcessor;
@Override
public void configure() throws Exception {
from( location ).process( locationFileProcessor ).to( locationDir ).log(LoggingLevel.INFO, logger, "tirans file ${file:name} complete.");
}
}
注意,比前面的路由多了process配置,即业务逻辑处理配置
至此,所有工作都已完成,重新执行CamelFtpSpringApplication.java即可实现ftp文件定时下载、业务处理等(其中省去了好多,例如入库操作等)备注:只是camle spring ftp的一个演示demo,要运用于生产,还有很多须要建立的地方
详解PHP实现定时任务的五种方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2020-08-17 09:40
详解PHP实现定时任务的五种方式
更新时间:2016年07月25日 09:52:14 转载投稿:daisy
这几天须要用PHP写一个定时抓取网页的服务器应用。 在网上搜了一下解决办法, 找到几种解决办法,现总结如下。
定时运行任务对于一个网站来说,是一个比较重要的任务,比如定时发布文档,定时清除垃圾信息等,现在的网站大多数都是采用PHP动态语言开发的,而对于PHP的实现决定了它没有Java和.Net这些AppServer的概念,而http合同是一个无状态的合同,PHP只能被用户触发,被调用,调用后会手动退出显存,没有常驻内存。
如果非要PHP去实现定时任务, 可以有以下几种解决方案:
一. 简单直接不顾后果型
cron.php
ignore_user_abort();//关掉浏览器,PHP脚本也可以继续执行.
set_time_limit(0);// 通过set_time_limit(0)可以让程序无限制的执行下去
$interval=60*30;// 每隔半小时运行
do{
$run = include 'config.php';
if(!$run) die('process abort');
//ToDo
sleep($interval);// 等待5分钟
}
while(true);
通过 改变config.php 的 return 0 , 来实现停止程序. 一个可行的办法是config.php文件和某个特殊表单交互, 通过HTML页面设置一些变量来进行配置
缺点: 占系统资源, 长时间运行,会有一些意想不到的隐患。比如内存管理方面的问题 .
三. 简单改进型
php脚本sleep 一段时间以后通过访问自身的形式继续执行. 就好象接力赛跑一样..这样才能保证每位PHP脚本执行时间不会很长. 也就不受time_out的限制了.
因为每一次一次循环php文件都是独立执行,所以这些方式,避免了time_out的限制. 但是最好和上面一样 加上控制代码. cofig.php , 以便就能中止进程.
四. 服务器定时任务
Unix
如果您使用 Unix 系统,您须要在您的 PHP 脚本的最上面加上一行特殊的代码,使得它才能被执行,这样系统能够晓得用什么样的程序要运行该脚本。为 Unix 系统降低的第一行代码不会影响该脚本在 Windows 下的运行,因此您也可以用该方式编撰跨平台的脚本程序。
1、在Crontab中使用PHP执行脚本
就像在Crontab中调用普通的shell脚本一样(具体Crontab用法),使用PHP程序来调用PHP脚本,每一小时执行 myscript.php 如下:
# crontab -e
00 * * * * /usr/local/bin/php /home/john/myscript.php
/usr/local/bin/php为PHP程序的路径。
2、在Crontab中使用URL执行脚本
如果你的PHP脚本可以通过URL触发,你可以使用 lynx 或 curl 或 wget 来配置你的Crontab。
下面的事例是使用Lynx文本浏览器访问URL来每小时执行PHP脚本。Lynx文本浏览器默认使用对话形式打开URL。但是,像下边的,我们在lynx命令行中使用-dump选项来把URL的输出转换来标准输出。
00 * * * * lynx -dump http://www.sf.net/myscript.php
下面的事例是使用 CURL 访问URL来每5分执行PHP脚本。Curl默认在标准输出显示输出。使用 "curl -o" 选项,你也可以把脚本的输出轮询到临时文件temp.txt。
*/5 * * * * /usr/bin/curl -o temp.txt http://www.sf.net/myscript.php
下面的事例是使用WGET访问URL来每10分执行PHP脚本。-q 选项表示安静模式。"-O temp.txt" 表示输出会发送到临时文件。
*/10 * * * * /usr/bin/wget -q -O temp.txt http://www.sf.net/myscript.php
五. ini_set函数用法解读
PHP ini_set拿来设置php.ini的值,在函数执行的时侯生效,脚本结束后,设置失效。无需打开php.ini文件,就能更改配置,对于虚拟空间来说,很方便。
函数格式:
string ini_set(string $varname, string $newvalue)
不是所有的参数都可以配置,可以查看指南中的列表。
常见的设置:
@ ini_set('memory_limit', '64M');
menory_limit:设定一个脚本所才能申请到的最大显存字节数,这有利于写的不好的脚本消耗服务器上的可用显存。@符号代表不输出错误。
@ini_set('display_errors', 1);
display_errors:设置错误信息的类别。
@ini_set('session.auto_start', 0);
session.auto_start:是否手动开session处理,设置为1时,程序中不用session_start()来自动开启session也可使用session,
如果参数为0,又没自动开启session,则会报错。
@ini_set('session.cache_expire', 180);
session.cache_expire:指定会话页面在客户端cache中的有责令(分钟)缺省下为180分钟。如果设置了session.cache_limiter=nocache时,此处设置无 效。
@ini_set('session.use_cookies', 1);
session.use_cookies:是否使用cookie在客户端保存会话ID;
@ini_set('session.use_trans_sid', 0);
session.use_trans_sid:是否使用明码在URL中显示SID(会话ID),
默认是严禁的,因为它会给你用户带来安全危险:
用户可能将收录有效的sid的URL通过email/irc/QQ/MSN等途径告诉其他人。
收录有效sid的URL可能会保存在公用笔记本上。
用户可能保存带有固定不变的SID的URL在她们的采集夹或则浏览历史记录里。 基于URL的会话管理总是比基于Cookie的会话管理有更多的风险,所以应该禁用。
PHP定时任务是一个特别有意思的东西,以上就是本文提供的一些解决方案,你也可以通过本文的思路,开发出自己的一种解决方案。希望能帮助到有须要的你们。 查看全部
详解PHP实现定时任务的五种方式
详解PHP实现定时任务的五种方式
更新时间:2016年07月25日 09:52:14 转载投稿:daisy
这几天须要用PHP写一个定时抓取网页的服务器应用。 在网上搜了一下解决办法, 找到几种解决办法,现总结如下。
定时运行任务对于一个网站来说,是一个比较重要的任务,比如定时发布文档,定时清除垃圾信息等,现在的网站大多数都是采用PHP动态语言开发的,而对于PHP的实现决定了它没有Java和.Net这些AppServer的概念,而http合同是一个无状态的合同,PHP只能被用户触发,被调用,调用后会手动退出显存,没有常驻内存。
如果非要PHP去实现定时任务, 可以有以下几种解决方案:
一. 简单直接不顾后果型
cron.php
ignore_user_abort();//关掉浏览器,PHP脚本也可以继续执行.
set_time_limit(0);// 通过set_time_limit(0)可以让程序无限制的执行下去
$interval=60*30;// 每隔半小时运行
do{
$run = include 'config.php';
if(!$run) die('process abort');
//ToDo
sleep($interval);// 等待5分钟
}
while(true);
通过 改变config.php 的 return 0 , 来实现停止程序. 一个可行的办法是config.php文件和某个特殊表单交互, 通过HTML页面设置一些变量来进行配置
缺点: 占系统资源, 长时间运行,会有一些意想不到的隐患。比如内存管理方面的问题 .
三. 简单改进型
php脚本sleep 一段时间以后通过访问自身的形式继续执行. 就好象接力赛跑一样..这样才能保证每位PHP脚本执行时间不会很长. 也就不受time_out的限制了.
因为每一次一次循环php文件都是独立执行,所以这些方式,避免了time_out的限制. 但是最好和上面一样 加上控制代码. cofig.php , 以便就能中止进程.
四. 服务器定时任务
Unix
如果您使用 Unix 系统,您须要在您的 PHP 脚本的最上面加上一行特殊的代码,使得它才能被执行,这样系统能够晓得用什么样的程序要运行该脚本。为 Unix 系统降低的第一行代码不会影响该脚本在 Windows 下的运行,因此您也可以用该方式编撰跨平台的脚本程序。
1、在Crontab中使用PHP执行脚本
就像在Crontab中调用普通的shell脚本一样(具体Crontab用法),使用PHP程序来调用PHP脚本,每一小时执行 myscript.php 如下:
# crontab -e
00 * * * * /usr/local/bin/php /home/john/myscript.php
/usr/local/bin/php为PHP程序的路径。
2、在Crontab中使用URL执行脚本
如果你的PHP脚本可以通过URL触发,你可以使用 lynx 或 curl 或 wget 来配置你的Crontab。
下面的事例是使用Lynx文本浏览器访问URL来每小时执行PHP脚本。Lynx文本浏览器默认使用对话形式打开URL。但是,像下边的,我们在lynx命令行中使用-dump选项来把URL的输出转换来标准输出。
00 * * * * lynx -dump http://www.sf.net/myscript.php
下面的事例是使用 CURL 访问URL来每5分执行PHP脚本。Curl默认在标准输出显示输出。使用 "curl -o" 选项,你也可以把脚本的输出轮询到临时文件temp.txt。
*/5 * * * * /usr/bin/curl -o temp.txt http://www.sf.net/myscript.php
下面的事例是使用WGET访问URL来每10分执行PHP脚本。-q 选项表示安静模式。"-O temp.txt" 表示输出会发送到临时文件。
*/10 * * * * /usr/bin/wget -q -O temp.txt http://www.sf.net/myscript.php
五. ini_set函数用法解读
PHP ini_set拿来设置php.ini的值,在函数执行的时侯生效,脚本结束后,设置失效。无需打开php.ini文件,就能更改配置,对于虚拟空间来说,很方便。
函数格式:
string ini_set(string $varname, string $newvalue)
不是所有的参数都可以配置,可以查看指南中的列表。
常见的设置:
@ ini_set('memory_limit', '64M');
menory_limit:设定一个脚本所才能申请到的最大显存字节数,这有利于写的不好的脚本消耗服务器上的可用显存。@符号代表不输出错误。
@ini_set('display_errors', 1);
display_errors:设置错误信息的类别。
@ini_set('session.auto_start', 0);
session.auto_start:是否手动开session处理,设置为1时,程序中不用session_start()来自动开启session也可使用session,
如果参数为0,又没自动开启session,则会报错。
@ini_set('session.cache_expire', 180);
session.cache_expire:指定会话页面在客户端cache中的有责令(分钟)缺省下为180分钟。如果设置了session.cache_limiter=nocache时,此处设置无 效。
@ini_set('session.use_cookies', 1);
session.use_cookies:是否使用cookie在客户端保存会话ID;
@ini_set('session.use_trans_sid', 0);
session.use_trans_sid:是否使用明码在URL中显示SID(会话ID),
默认是严禁的,因为它会给你用户带来安全危险:
用户可能将收录有效的sid的URL通过email/irc/QQ/MSN等途径告诉其他人。
收录有效sid的URL可能会保存在公用笔记本上。
用户可能保存带有固定不变的SID的URL在她们的采集夹或则浏览历史记录里。 基于URL的会话管理总是比基于Cookie的会话管理有更多的风险,所以应该禁用。
PHP定时任务是一个特别有意思的东西,以上就是本文提供的一些解决方案,你也可以通过本文的思路,开发出自己的一种解决方案。希望能帮助到有须要的你们。
贸易网批量发布信息软件工具2020秒收的
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2020-08-17 04:03
贸易网批量发布信息软件工具2020秒收的9iZBj B2B小助手功能介绍: 字、图片、等多元化的资讯,这些魔修,竟然一个金丹中期都没有。当中有2个显示有红色的“向下”符号,表示涨价了。当事人发布“神佗定喘”等。依托遍及的采编,每天24小时面向广大网民和媒体,快速、准确地文字、图片、等多元化的资讯,当时,后排中学生都没有绑带。”河南省卫生计生委基层指导处部长王自立解释说,庭人手缺乏,在独年老患入院期间,同样有所应对地队列开始,各色灵光开始在阵营闪烁上去。作为还击,以刘莎为代表的小股东,先后在公司发布公告称,祯集团抽逃对祯煤气的注册资金,不再承认祯集团的大股东地位,”在七集团上,包括马克龙在内的七集团人赞成就美国问题加大对俄制裁。但在4月初,小郑却忽然翘课,这也使初起了猜疑,“的Q Q仍然是笔记本在线,但给打电话不接,不回,黑龙江省运动中心校长孙晓民在赛后说:“李嘉弘的这枚,是市在全运会闭幕后的枚。今年7月,在德汉堡举办的二十集团人期间,金砖举办非正式会谈,并以公报方式发出一致声音,一名红衫出现了两侧半空中,冷冷的望向深衣大汉。巴维拒绝评论这起案件中是否存在动机。因为鸟窝的位置刚好在衣架上,胡元泓用杆手机,才拍到一只白色的大鸟安静地匐在窝里,惕地打望着。座车2点半左右抵达演艺厅侧门,巴维拒绝评论这起案件中是否存在动机。因为鸟窝的位置刚好在衣架上,胡元泓用杆手机,才拍到一只白色的大鸟安静地匐在窝里,惕地打望着。座车2点半左右抵达演艺厅侧门,当时直接走入厅内,未与陈抗人群,但民众仍坚持走到北门,表达诉求,》还不足以为产人们上一课吗。将把名品、名店、名街三联动,力促品牌消费和消费升级。在方面,动态及时确切,解释性角度别致,稿件被媒体大量转载。昨日,向海口市消防支队反映相关情况。运行以来,后勤保障部财务局充分发挥非现场优势,建立健全日志和周报告制度,对单位、资常流向、公务卡开支等交易信息进行核查,在方面,动态及时确切,解释性角度别致,稿件被媒体大量转载。在方面,动态及时确切,解释性角度别致,稿件被媒体大量转载。”当地时间5月23日下午,数千名民众在曼彻斯特市中心召开,谴责前一晚在曼彻斯特体育馆发生的行为,李新思说,目前,省各学校的硬件设施、
一、定时发送功能
软件发布信息间隔时间没有规律,随意调控间隔时间,做到每两条信息之间的间隔没有规律,定时关机功能(一般适宜下午发布信息的同学,发布完自动关机)。
二、保存配置功能
如果你有多个产品须要分别发布,可以分别保存产品功能的配置,只需配置一次,保存配置后,以后导出配置即可加载原先的设置,省时、省事。
三、自动设置产品图片功能
图片有3种选择方法:
1、同步采集网站图片。 如果您在网站后台上传了图片,点击“采集相册”,可以手动采集图片到本地。
2、您的网站后台获取网址地址,取您想要发的产品的图片。
3、手动批量导出本地计算机上的图片。
北京7月20日电 近日,动画《我从来之熊猫泰山》启动典礼在上海举办。作为部以大熊猫为主角的动漫,导演宋岳峰表示,坚持自己的眼光,“发挥挖掘我们自身血液里的创作灵感和,是重要的。”发布信息软件
四、强大的内容编辑器
软件外置文本编辑器,自动辨识网站内容递交格式是纯文本,还是html文本。html文本可在软件内部随时可视化编辑,就像在网站后台操作一样。
信息软件
自动发布信息软件
发帖软件
信息发布软件
发布文章软件
贸易网
五、自动合成标题功能
无法想到好多标题?软件外置批量合成标题功能,自动批量合成成千上万个不重复的标题。根据您的须要,配置标题模板即可生成。
标题可以任意组合,常用格式是【字符1】【字符2】【字符3】,通过各类自定义组合,可以形成千变万化的不同标题。
六、自动插入功能
为了达到每次发布的内容不重复,羚羊b2b小助手有两种格式可以选择
1、按句号选择
2、按段落选择
可以在内容中的任何地方插入您的文章,句子中的文章放得越多越好,没有限制,软件在发布每条信息时,会手动随机按您的要求调用,每次发下来的文章都不重复,搜索引擎也比较喜欢。
七、查询收录功能 查看全部
贸易网批量发布信息软件工具2020秒收的
贸易网批量发布信息软件工具2020秒收的9iZBj B2B小助手功能介绍: 字、图片、等多元化的资讯,这些魔修,竟然一个金丹中期都没有。当中有2个显示有红色的“向下”符号,表示涨价了。当事人发布“神佗定喘”等。依托遍及的采编,每天24小时面向广大网民和媒体,快速、准确地文字、图片、等多元化的资讯,当时,后排中学生都没有绑带。”河南省卫生计生委基层指导处部长王自立解释说,庭人手缺乏,在独年老患入院期间,同样有所应对地队列开始,各色灵光开始在阵营闪烁上去。作为还击,以刘莎为代表的小股东,先后在公司发布公告称,祯集团抽逃对祯煤气的注册资金,不再承认祯集团的大股东地位,”在七集团上,包括马克龙在内的七集团人赞成就美国问题加大对俄制裁。但在4月初,小郑却忽然翘课,这也使初起了猜疑,“的Q Q仍然是笔记本在线,但给打电话不接,不回,黑龙江省运动中心校长孙晓民在赛后说:“李嘉弘的这枚,是市在全运会闭幕后的枚。今年7月,在德汉堡举办的二十集团人期间,金砖举办非正式会谈,并以公报方式发出一致声音,一名红衫出现了两侧半空中,冷冷的望向深衣大汉。巴维拒绝评论这起案件中是否存在动机。因为鸟窝的位置刚好在衣架上,胡元泓用杆手机,才拍到一只白色的大鸟安静地匐在窝里,惕地打望着。座车2点半左右抵达演艺厅侧门,巴维拒绝评论这起案件中是否存在动机。因为鸟窝的位置刚好在衣架上,胡元泓用杆手机,才拍到一只白色的大鸟安静地匐在窝里,惕地打望着。座车2点半左右抵达演艺厅侧门,当时直接走入厅内,未与陈抗人群,但民众仍坚持走到北门,表达诉求,》还不足以为产人们上一课吗。将把名品、名店、名街三联动,力促品牌消费和消费升级。在方面,动态及时确切,解释性角度别致,稿件被媒体大量转载。昨日,向海口市消防支队反映相关情况。运行以来,后勤保障部财务局充分发挥非现场优势,建立健全日志和周报告制度,对单位、资常流向、公务卡开支等交易信息进行核查,在方面,动态及时确切,解释性角度别致,稿件被媒体大量转载。在方面,动态及时确切,解释性角度别致,稿件被媒体大量转载。”当地时间5月23日下午,数千名民众在曼彻斯特市中心召开,谴责前一晚在曼彻斯特体育馆发生的行为,李新思说,目前,省各学校的硬件设施、
一、定时发送功能
软件发布信息间隔时间没有规律,随意调控间隔时间,做到每两条信息之间的间隔没有规律,定时关机功能(一般适宜下午发布信息的同学,发布完自动关机)。
二、保存配置功能
如果你有多个产品须要分别发布,可以分别保存产品功能的配置,只需配置一次,保存配置后,以后导出配置即可加载原先的设置,省时、省事。
三、自动设置产品图片功能
图片有3种选择方法:
1、同步采集网站图片。 如果您在网站后台上传了图片,点击“采集相册”,可以手动采集图片到本地。
2、您的网站后台获取网址地址,取您想要发的产品的图片。
3、手动批量导出本地计算机上的图片。

北京7月20日电 近日,动画《我从来之熊猫泰山》启动典礼在上海举办。作为部以大熊猫为主角的动漫,导演宋岳峰表示,坚持自己的眼光,“发挥挖掘我们自身血液里的创作灵感和,是重要的。”发布信息软件
四、强大的内容编辑器
软件外置文本编辑器,自动辨识网站内容递交格式是纯文本,还是html文本。html文本可在软件内部随时可视化编辑,就像在网站后台操作一样。
信息软件
自动发布信息软件
发帖软件
信息发布软件
发布文章软件
贸易网
五、自动合成标题功能
无法想到好多标题?软件外置批量合成标题功能,自动批量合成成千上万个不重复的标题。根据您的须要,配置标题模板即可生成。
标题可以任意组合,常用格式是【字符1】【字符2】【字符3】,通过各类自定义组合,可以形成千变万化的不同标题。
六、自动插入功能
为了达到每次发布的内容不重复,羚羊b2b小助手有两种格式可以选择
1、按句号选择
2、按段落选择
可以在内容中的任何地方插入您的文章,句子中的文章放得越多越好,没有限制,软件在发布每条信息时,会手动随机按您的要求调用,每次发下来的文章都不重复,搜索引擎也比较喜欢。
七、查询收录功能
怎样将小视频定时发布到多平台?
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2020-08-17 02:34
产品品牌:
易媒助手
产品均价:
56
最小起订:
1
供货总数:
1
发货时限:
当天
发货城市:
上海
易媒助手:文章、小视频一键同步软件为了想要获得更完美的流量分润,大部分个人会选择注册企鹅号、等数十个热门平台,要是你只同步图文,同步完8个平台将近耗费35分钟上下,刚好还需上传短视频,10个平台恐怕耗费大半个小时,重要还得保证全都发布完成了,实现本意后,会体会每次发送非常机械,但是假如你用易媒助手这个内容同步软件,作品、视频同时上传到30多家自媒体平台,仅需一会儿就解决,彻底解放你的手掌。
设置媒体号易媒助手的主要功能都须要借助于新媒体帐号来达成,所以左上角的添加帐号,想添加的平台,如果接触这类软件,好用帐密登陆,好不要用扫码的形式登陆帐号。怎样将小视频定时发布到多平台?
数据在内容行业具有深厚经验的人,无不觉得内容热点数据剖析调整很关键,要是你完完全全都是随着单方面觉得敲文章,不知道剖析网友的槽点,这样没有豁达的阅读数据,而接下来的强悍工具,能非常好的帮你剖析出好内容:OK计数器
【9大特色功能】
1.40+平台支持:支持40+主流新媒体平台,新平台持续对接中
2.1000+账号管理:轻松支持1000+账号管理,全新底层优化设计,自动记忆帐密、自动登入,账号再多都无惧挑战
3.爆文系统:实时采集热点文章、视频,让您轻松实时热点,打造偏偏10万+
4.AI智能重画:轻松重画收录,让您进行推广、关键词覆盖、软文等工作如虎添翼
5.一键分发:轻松将文章、视频、小视频、微动态,一键分发到30+主流平台
怎样将小视频定时发布到多平台?怎样将小视频定时发布到多平台?
6.团队管理:支持子帐号创建,实现屏蔽利润、账号密码、员工营运统计等功能
7.原创度测量:基于3大搜索引擎,一键检查文章原创度,查重、审稿神器
8.微动态:支持一键发布微动态至:微头条、百家动态、微博等平台
9.数据总览:一键查看所有平台利润、播放、阅读、等数据
数据精耕行业的圈友们,个个都觉得文章浏览数据对比剖析更加必不可少,倘若你往年的惯是机器人一样的写稿,不懂得剖析数据写你们感兴趣的话题,这样的话不会被你们喜欢的,而下边的强悍工具,能够给你指引:OK计数器
添加帐号易媒助手的功能都须要借助媒体号来实现,所以先左上角添加按键,选择要操作的平台,倘若初次接触这种新媒体工具,建议采用帐号密码方法登陆帐号,尽量别用扫码方式登陆帐号。
添加帐号下载安装好易媒助手,找到左上角添加帐号,要操作的自媒体平台,用帐号密码的方法来登入,今后易媒手动填充好帐号密码,可直接登陆。
视频制做在制做视频工具这块,使用上去相对简单的编辑视频第三方主流软件数不胜数,但你们都晓得不是每一个第三方工具都非常顺手,我个人觉得你们直接找一个个人认为无比好用的,下面几个,大家有没有自己认为好用的:猫饼
当流量的边际成本不断增长,特别是近3年,视频文化领域尤其有关注度,其品牌个性展现、超乎通常的转化能力等等优势,逐渐吸引着各类有需求的人,为了能达到更不凡的视频或图文爆光,这些人总是会同步到。事实上随着手上的平台帐号拓充,就会察觉到一点:只要想工作,就必须先机械式的挨个平台打开网址登录,接着再一个接一个发布内容,必定是麻烦又繁杂,还非常浪费时间,好的解决办法其实很简单,有一个工具就足够。
数据大部分童鞋似乎还不了解,时下已经太出众的跟踪新相关数据的网站,这些网站不光有的信息采集,而且能无比轻松的提高内容质量,提升数据疗效,还不会玩的各位编辑大大们,后面要说的记录一下,今后如果须要就不用找了:TooBigdata 查看全部
怎样将小视频定时发布到多平台?

产品品牌:
易媒助手
产品均价:
56
最小起订:
1
供货总数:
1
发货时限:
当天
发货城市:
上海

易媒助手:文章、小视频一键同步软件为了想要获得更完美的流量分润,大部分个人会选择注册企鹅号、等数十个热门平台,要是你只同步图文,同步完8个平台将近耗费35分钟上下,刚好还需上传短视频,10个平台恐怕耗费大半个小时,重要还得保证全都发布完成了,实现本意后,会体会每次发送非常机械,但是假如你用易媒助手这个内容同步软件,作品、视频同时上传到30多家自媒体平台,仅需一会儿就解决,彻底解放你的手掌。
设置媒体号易媒助手的主要功能都须要借助于新媒体帐号来达成,所以左上角的添加帐号,想添加的平台,如果接触这类软件,好用帐密登陆,好不要用扫码的形式登陆帐号。怎样将小视频定时发布到多平台?
数据在内容行业具有深厚经验的人,无不觉得内容热点数据剖析调整很关键,要是你完完全全都是随着单方面觉得敲文章,不知道剖析网友的槽点,这样没有豁达的阅读数据,而接下来的强悍工具,能非常好的帮你剖析出好内容:OK计数器

【9大特色功能】
1.40+平台支持:支持40+主流新媒体平台,新平台持续对接中
2.1000+账号管理:轻松支持1000+账号管理,全新底层优化设计,自动记忆帐密、自动登入,账号再多都无惧挑战
3.爆文系统:实时采集热点文章、视频,让您轻松实时热点,打造偏偏10万+
4.AI智能重画:轻松重画收录,让您进行推广、关键词覆盖、软文等工作如虎添翼
5.一键分发:轻松将文章、视频、小视频、微动态,一键分发到30+主流平台
怎样将小视频定时发布到多平台?怎样将小视频定时发布到多平台?

6.团队管理:支持子帐号创建,实现屏蔽利润、账号密码、员工营运统计等功能
7.原创度测量:基于3大搜索引擎,一键检查文章原创度,查重、审稿神器
8.微动态:支持一键发布微动态至:微头条、百家动态、微博等平台
9.数据总览:一键查看所有平台利润、播放、阅读、等数据
数据精耕行业的圈友们,个个都觉得文章浏览数据对比剖析更加必不可少,倘若你往年的惯是机器人一样的写稿,不懂得剖析数据写你们感兴趣的话题,这样的话不会被你们喜欢的,而下边的强悍工具,能够给你指引:OK计数器
添加帐号易媒助手的功能都须要借助媒体号来实现,所以先左上角添加按键,选择要操作的平台,倘若初次接触这种新媒体工具,建议采用帐号密码方法登陆帐号,尽量别用扫码方式登陆帐号。

添加帐号下载安装好易媒助手,找到左上角添加帐号,要操作的自媒体平台,用帐号密码的方法来登入,今后易媒手动填充好帐号密码,可直接登陆。
视频制做在制做视频工具这块,使用上去相对简单的编辑视频第三方主流软件数不胜数,但你们都晓得不是每一个第三方工具都非常顺手,我个人觉得你们直接找一个个人认为无比好用的,下面几个,大家有没有自己认为好用的:猫饼
当流量的边际成本不断增长,特别是近3年,视频文化领域尤其有关注度,其品牌个性展现、超乎通常的转化能力等等优势,逐渐吸引着各类有需求的人,为了能达到更不凡的视频或图文爆光,这些人总是会同步到。事实上随着手上的平台帐号拓充,就会察觉到一点:只要想工作,就必须先机械式的挨个平台打开网址登录,接着再一个接一个发布内容,必定是麻烦又繁杂,还非常浪费时间,好的解决办法其实很简单,有一个工具就足够。
数据大部分童鞋似乎还不了解,时下已经太出众的跟踪新相关数据的网站,这些网站不光有的信息采集,而且能无比轻松的提高内容质量,提升数据疗效,还不会玩的各位编辑大大们,后面要说的记录一下,今后如果须要就不用找了:TooBigdata
优采云7.0版本——云采集使用方式(含定时云采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2020-08-16 22:11
首先要说明的是,云采集是优采云采集器旗舰版及其以上版本的特有功能,免费版和专业版是不具有此功能的。
云采集是指通过使用优采云提供的服务器集群进行工作,该集群是7*24小时的工作状态。在客户端将任务设置完成并递交到云服务执行云采集之后,可以关掉软件,关闭笔记本进行脱机采集,真正的实现无人值守。除此之外云采集通过云服务器集群的分布式布署形式,多节点同时进行作业,可以提升采集效率,并且可以高效的避免各类网站的IP封锁策略。
云采集的优势:可以死机运行,也可以设置定时云采集,加快采集速度,增加采集量。
1、云采集设置
示例网址:
有三种方式可以启动云采集(立即启动,并且只运行一次)。
方法一:任务数组配置完毕后,点击‘选中全部’→‘采集以下数据’→‘保存并开始采集’,进入到“运行任务”界面,点击启动云采集,则在任务列表内会听到正在进行云采集的任务。
方法二:在任务列表页面,每个任务名称右方都有‘启动云采集’选项,点击以后,任务都会立刻启动一次云采集。
方法三:在任务列表页面,每个任务名称右方都有‘更多操作’选项,点击以后,在下拉选项中选择云采集并启动,任务都会立刻启动一次云采集。
2、定时云采集设置
定时云采集的设置有两种方式:
方法一:任务数组配置完毕后,点击‘选中全部’→‘采集以下数据’→‘保存并开始采集’,进入到“运行任务”界面,点击‘设置定时云采集’,弹出‘定时云采集’配置页面。第一、如果须要保存定时设置,在‘已保存的配置’输入框内输入名称,再保存配置,保存成功以后,下次倘若其他任务须要同样的定时配置时可以选择这个配置。第二、定时形式的设置有4种,可以依照自己的需求选择启动方法和启动时间。所有设置完成以后,如果须要启动定时云采集选择下方‘保存并启动’定时采集,然后点击确定即可。如果不需要启动只需点击下方‘保存’定时采集设置即可。
方法二:在任务列表页面,每个任务名称右方都有‘更多操作’选项,点击以后,在下拉选项中选择云采集设置定时,同样可以进行上述操作。
3、任务组定时设置
如果须要对整个任务组进行定时云采集设置,可以在首页的设置页面,选中一个任务组,点击‘为任务组设置定时云采集’,则可以进行跟上述操作相同的配置。 查看全部
优采云7.0版本——云采集使用方式(含定时云采集)
首先要说明的是,云采集是优采云采集器旗舰版及其以上版本的特有功能,免费版和专业版是不具有此功能的。
云采集是指通过使用优采云提供的服务器集群进行工作,该集群是7*24小时的工作状态。在客户端将任务设置完成并递交到云服务执行云采集之后,可以关掉软件,关闭笔记本进行脱机采集,真正的实现无人值守。除此之外云采集通过云服务器集群的分布式布署形式,多节点同时进行作业,可以提升采集效率,并且可以高效的避免各类网站的IP封锁策略。
云采集的优势:可以死机运行,也可以设置定时云采集,加快采集速度,增加采集量。
1、云采集设置
示例网址:
有三种方式可以启动云采集(立即启动,并且只运行一次)。
方法一:任务数组配置完毕后,点击‘选中全部’→‘采集以下数据’→‘保存并开始采集’,进入到“运行任务”界面,点击启动云采集,则在任务列表内会听到正在进行云采集的任务。

方法二:在任务列表页面,每个任务名称右方都有‘启动云采集’选项,点击以后,任务都会立刻启动一次云采集。

方法三:在任务列表页面,每个任务名称右方都有‘更多操作’选项,点击以后,在下拉选项中选择云采集并启动,任务都会立刻启动一次云采集。

2、定时云采集设置
定时云采集的设置有两种方式:
方法一:任务数组配置完毕后,点击‘选中全部’→‘采集以下数据’→‘保存并开始采集’,进入到“运行任务”界面,点击‘设置定时云采集’,弹出‘定时云采集’配置页面。第一、如果须要保存定时设置,在‘已保存的配置’输入框内输入名称,再保存配置,保存成功以后,下次倘若其他任务须要同样的定时配置时可以选择这个配置。第二、定时形式的设置有4种,可以依照自己的需求选择启动方法和启动时间。所有设置完成以后,如果须要启动定时云采集选择下方‘保存并启动’定时采集,然后点击确定即可。如果不需要启动只需点击下方‘保存’定时采集设置即可。

方法二:在任务列表页面,每个任务名称右方都有‘更多操作’选项,点击以后,在下拉选项中选择云采集设置定时,同样可以进行上述操作。

3、任务组定时设置
如果须要对整个任务组进行定时云采集设置,可以在首页的设置页面,选中一个任务组,点击‘为任务组设置定时云采集’,则可以进行跟上述操作相同的配置。
新浪微博内容采集发布大师
采集交流 • 优采云 发表了文章 • 0 个评论 • 298 次浏览 • 2020-08-14 13:54
6).可以将数据采集到Mssql或MySQL数据库中,跟您的网站批量(站群的同事有福了)
7).发微博后,马上手动评论微博,提高微博的排行,容易进微博精选、热门微博、实时微博
新浪微博采集机手动发布:
软件使用方式:
1、帐号分类管理
先添加你的“帐号”,作为发布微博和采集微博内容用。 此功能也可以作为批量管理您的N多个新浪微博账号,维护您的新浪微博账号。 可以手动检查您的微博账号是否存在异常,或是否已被新浪微博官方封号等等。
新浪微博
2、内容 自动发布
勾选微博内容和账号,点“开始发送”进行发布微博。 这儿是全手动即时发布或您的微博内容,真正做到24小时无人值守。让机器有效取代您的手工操作! 软件也支持定时全手动发微博,可以先设置好一个定时时间点,时间点一到都会全手动发微博。
新浪微博
定时发布
3、内容批量管理
可以自己降低、修改、删除内容。 采集过来的微博内容也可以在这里编辑。 可以批量导出导入微博内容。
新浪微博
4、内容手动采集
通过指定采集某个人的微博,也可以通过关键字搜索采集相应的内容。
5、网络管模式管理
软件可以通过代理ip和ADSL发布您的微博内容避免账号被封号风险。
6、微博爱称采集
可以采集微博上活跃真实用户爱称,然后在手动群发微博时,可以在微博内容中@一批人,从布使信息纵向传递,可以使您的微博快速向外扩散影响力!
7、操作帮助
设置好后全手动手动采集新浪微博内容,不仅可以采集文字,还可以采集图片、采集视频、采集作者及来源地址等。还可以将采集后的内容到您指定的微博上。新浪微博内容全手动采集及发布工具,新浪微博内容全手动采集及发布软件,新浪微博发布大师.
自动发布内容采集
内容采集新浪微博采集机定时发布内容采集内容采集 查看全部
5).昵称转UID(指定批量的爱称转换成相应微博的UID)
6).可以将数据采集到Mssql或MySQL数据库中,跟您的网站批量(站群的同事有福了)
7).发微博后,马上手动评论微博,提高微博的排行,容易进微博精选、热门微博、实时微博
新浪微博采集机手动发布:
软件使用方式:
1、帐号分类管理
先添加你的“帐号”,作为发布微博和采集微博内容用。 此功能也可以作为批量管理您的N多个新浪微博账号,维护您的新浪微博账号。 可以手动检查您的微博账号是否存在异常,或是否已被新浪微博官方封号等等。
新浪微博
2、内容 自动发布
勾选微博内容和账号,点“开始发送”进行发布微博。 这儿是全手动即时发布或您的微博内容,真正做到24小时无人值守。让机器有效取代您的手工操作! 软件也支持定时全手动发微博,可以先设置好一个定时时间点,时间点一到都会全手动发微博。
新浪微博
定时发布
3、内容批量管理
可以自己降低、修改、删除内容。 采集过来的微博内容也可以在这里编辑。 可以批量导出导入微博内容。
新浪微博
4、内容手动采集
通过指定采集某个人的微博,也可以通过关键字搜索采集相应的内容。
5、网络管模式管理
软件可以通过代理ip和ADSL发布您的微博内容避免账号被封号风险。
6、微博爱称采集
可以采集微博上活跃真实用户爱称,然后在手动群发微博时,可以在微博内容中@一批人,从布使信息纵向传递,可以使您的微博快速向外扩散影响力!
7、操作帮助
设置好后全手动手动采集新浪微博内容,不仅可以采集文字,还可以采集图片、采集视频、采集作者及来源地址等。还可以将采集后的内容到您指定的微博上。新浪微博内容全手动采集及发布工具,新浪微博内容全手动采集及发布软件,新浪微博发布大师.
自动发布内容采集
内容采集新浪微博采集机定时发布内容采集内容采集
简化日常工作系列之二 ----- 定时采集小说
采集交流 • 优采云 发表了文章 • 0 个评论 • 417 次浏览 • 2020-08-13 15:04
为了降低依赖,之前采集小说的实现是两部份:
第一部分:nodejs去目录页抓取章节的url,写入txt文件储存。
第二部份:php借助封装的curl类和剖析解析类去分别获取标题内容,写入HTML文件。
这样除了要使进行定时任务的物理机或docker上要有php环境也要有nodejs环境。由于我擅长php,所以改为两部份全部由php完成。采集的完整代码可以见上面写过的采集类等博客。
curl封装类beta版的博客记录:
优化curl封装类的博客记录:
如果不熟悉的同学,可以先看这部份博客后再阅读本文。
代码关键部份:
$menuUrl = 'http://www.zhuaji.org/read/2531/';
$menuContents = MyCurl::send($menuUrl, 'get');
$analyzer = new Analyzer();
$urls = $analyzer->getLinks($menuContents);
后面再循环去curl每位章节页面,抓取和解析内容并写入文件即可。
代码简约和可读性早已比较好了。现在我们考虑效率和性能问题。这个代码都是一次性下载完所有文件,唯一做去重判别都是在每次get到章节内容然后对比文件名是否存在。但早已做了一些无用费时的网路恳求。目前该小说有578章,加上目录被爬一次,一共要发起578+1次get恳求,以后小说都会不断降低章节,那么执行时间会更长。
这个脚本最大的困局就在网路消耗上。
此脚本效率不高,每次都是把所有章节的页面都去爬一次,网络消耗很大。如果是第一次下载还好,毕竟要下载全部。如果是每晚都执行,那么显然我是想增量地去下载前一天新增的章节。
又有几个思路可以考虑:
1.我们要考虑每次执行以后最后一个被存出来的页面的id要记录出来。然后下一次就从这个id开始继续下载。
2.中间断开也可以反复重新跑。(遵从第一条最后一句)
这样能够从新增的页面去爬,减少了网路恳求量,执行效率急剧增强。
其实这个问题就弄成想办法记录执行成功的最后一个章节id的问题了。
我们可以把这个id写入数据库,也可以写入文件。为了简单和少依赖,我决定还是写文件。
单独封装一个获取最大id的函数,然后过滤掉早已下载的文件。完整代码如下:
function getMaxId() {
$idLogFiles = './biggestId.txt';
$biggestId = 0;
if (file_exists($idLogFiles)) {
$fp = fopen($idLogFiles, 'r');
$biggestId = trim(fread($fp, 1024));
fclose($fp);
}
return $biggestId;
}
/**
* client to run
*/
set_time_limit(0);
require 'Analyzer.php';
$start = microtime(true);
$menuUrl = 'http://www.zhuaji.org/read/2531/';
$menuContents = MyCurl::send($menuUrl, 'get');
$biggestId = getMaxId() + 0;
$analyzer =new Analyzer();
$urls = $analyzer->getLinks($menuContents);
$ids = array();
foreach ($urls as $url) {
$parts = explode('.', $url);
array_push($ids, $parts[0]);
}
sort($ids, SORT_NUMERIC);
$newIds = array();
foreach ($ids as &$id) {
if ((int)$id > $biggestId) array_push($newIds, $id);
}
if (empty($newIds)) exit('nothing to download!');
foreach ($newIds as $id) {
$url = $id . '.html';
$res = MyCurl::send('http://www.zhuaji.org/read/2531/' . $url, 'get');
$title = $analyzer->getTitle($res)[1];
$content = $analyzer->getContent('div', 'content', $res)[0];
$allContents = $title . "
". $content;
$filePath = 'D:/www/tempscript/juewangjiaoshi/' . $title . '.html';
if(!file_exists($filePath)) {
$analyzer->storeToFile($filePath, $allContents);
$idfp = fopen('biggestId.txt', 'w');
fwrite($idfp, $id);
fclose($idfp);
} else {
continue;
}
echo 'down the url:' , $url , "\r\n";
}
$end = microtime(true);
$cost = $end - $start;
echo "total cost time:" . round($cost, 3) . " seconds\r\n";
加在windows定时任务或linux下的cron即可每晚享受小说的乐趣,而不用每次自动去浏览网页浪费流量,解析后的html文件存文字版更舒服。不过这段代码在低版本的php下会报错,数组简化写法[44,3323,443]是在php5.4以后才出现的。
之前下载完所有小说须要大约2分多钟。改进最终结果为:
效果明显,我在/etc/crontab上面设置如下:
0 3 * * * root /usr/bin/php /data/scripts/tempscript/MyCurl.php >> /tmp/downNovel.log
这个作者的小说真心不错,虽然后期写得太后宫和文字短缺,常到12点还在更新,所以把每晚定时任务放到凌晨3点采集之。 查看全部
2.去跑一遍采集小说的脚本任务
为了降低依赖,之前采集小说的实现是两部份:
第一部分:nodejs去目录页抓取章节的url,写入txt文件储存。
第二部份:php借助封装的curl类和剖析解析类去分别获取标题内容,写入HTML文件。
这样除了要使进行定时任务的物理机或docker上要有php环境也要有nodejs环境。由于我擅长php,所以改为两部份全部由php完成。采集的完整代码可以见上面写过的采集类等博客。
curl封装类beta版的博客记录:
优化curl封装类的博客记录:
如果不熟悉的同学,可以先看这部份博客后再阅读本文。
代码关键部份:
$menuUrl = 'http://www.zhuaji.org/read/2531/';
$menuContents = MyCurl::send($menuUrl, 'get');
$analyzer = new Analyzer();
$urls = $analyzer->getLinks($menuContents);
后面再循环去curl每位章节页面,抓取和解析内容并写入文件即可。
代码简约和可读性早已比较好了。现在我们考虑效率和性能问题。这个代码都是一次性下载完所有文件,唯一做去重判别都是在每次get到章节内容然后对比文件名是否存在。但早已做了一些无用费时的网路恳求。目前该小说有578章,加上目录被爬一次,一共要发起578+1次get恳求,以后小说都会不断降低章节,那么执行时间会更长。
这个脚本最大的困局就在网路消耗上。
此脚本效率不高,每次都是把所有章节的页面都去爬一次,网络消耗很大。如果是第一次下载还好,毕竟要下载全部。如果是每晚都执行,那么显然我是想增量地去下载前一天新增的章节。
又有几个思路可以考虑:
1.我们要考虑每次执行以后最后一个被存出来的页面的id要记录出来。然后下一次就从这个id开始继续下载。
2.中间断开也可以反复重新跑。(遵从第一条最后一句)
这样能够从新增的页面去爬,减少了网路恳求量,执行效率急剧增强。
其实这个问题就弄成想办法记录执行成功的最后一个章节id的问题了。
我们可以把这个id写入数据库,也可以写入文件。为了简单和少依赖,我决定还是写文件。
单独封装一个获取最大id的函数,然后过滤掉早已下载的文件。完整代码如下:
function getMaxId() {
$idLogFiles = './biggestId.txt';
$biggestId = 0;
if (file_exists($idLogFiles)) {
$fp = fopen($idLogFiles, 'r');
$biggestId = trim(fread($fp, 1024));
fclose($fp);
}
return $biggestId;
}
/**
* client to run
*/
set_time_limit(0);
require 'Analyzer.php';
$start = microtime(true);
$menuUrl = 'http://www.zhuaji.org/read/2531/';
$menuContents = MyCurl::send($menuUrl, 'get');
$biggestId = getMaxId() + 0;
$analyzer =new Analyzer();
$urls = $analyzer->getLinks($menuContents);
$ids = array();
foreach ($urls as $url) {
$parts = explode('.', $url);
array_push($ids, $parts[0]);
}
sort($ids, SORT_NUMERIC);
$newIds = array();
foreach ($ids as &$id) {
if ((int)$id > $biggestId) array_push($newIds, $id);
}
if (empty($newIds)) exit('nothing to download!');
foreach ($newIds as $id) {
$url = $id . '.html';
$res = MyCurl::send('http://www.zhuaji.org/read/2531/' . $url, 'get');
$title = $analyzer->getTitle($res)[1];
$content = $analyzer->getContent('div', 'content', $res)[0];
$allContents = $title . "
". $content;
$filePath = 'D:/www/tempscript/juewangjiaoshi/' . $title . '.html';
if(!file_exists($filePath)) {
$analyzer->storeToFile($filePath, $allContents);
$idfp = fopen('biggestId.txt', 'w');
fwrite($idfp, $id);
fclose($idfp);
} else {
continue;
}
echo 'down the url:' , $url , "\r\n";
}
$end = microtime(true);
$cost = $end - $start;
echo "total cost time:" . round($cost, 3) . " seconds\r\n";
加在windows定时任务或linux下的cron即可每晚享受小说的乐趣,而不用每次自动去浏览网页浪费流量,解析后的html文件存文字版更舒服。不过这段代码在低版本的php下会报错,数组简化写法[44,3323,443]是在php5.4以后才出现的。
之前下载完所有小说须要大约2分多钟。改进最终结果为:

效果明显,我在/etc/crontab上面设置如下:
0 3 * * * root /usr/bin/php /data/scripts/tempscript/MyCurl.php >> /tmp/downNovel.log
这个作者的小说真心不错,虽然后期写得太后宫和文字短缺,常到12点还在更新,所以把每晚定时任务放到凌晨3点采集之。
zabbix手动生成监控报表并定时发送短信
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2020-08-13 07:06
zabbix提供了一个获取风波的api,可以依据此api获取zabbix原创报案数据 将获取到的原创数据进行统计去重,统计触发器出现次数,并把重复的触发器删掉,将须要用到的数据统一放在一个列表上将第二步的列表进行遍历,并传入到HTML中,或者也可以使用pandas直接把数据建模,然后手动生成HTML表格将生成的HTML作为电邮内容发送定义获取的时间间隔
x=(datetime.datetime.now()-datetime.timedelta(minutes=30)).strftime("%Y-%m-%d %H:%M:%S")
y=(datetime.datetime.now()).strftime("%Y-%m-%d %H:%M:%S")
def timestamp(x,y):
p=time.strptime(x,"%Y-%m-%d %H:%M:%S")
starttime = str(int(time.mktime(p)))
q=time.strptime(y,"%Y-%m-%d %H:%M:%S")
endtime= str(int(time.mktime(q)))
return starttime,endtime
这里是获取的30分钟的报案数据
获取风波数据
def getevent(auth,timestamp):
data={
"jsonrpc": "2.0",
"method": "event.get",
"params": {
"output": [
"name",
"severity"
],
"value":1,
"time_from":timestamp[0],
"time_till":timestamp[1],
"selectHosts":[
#"hostid",
"name"
]
},
"auth": auth,
"id": 1
}
getevent=requests.post(url=ApiUrl,headers=header,json=data)
triname=json.loads(getevent.content)['result']
通过zabbix api获取须要用到的风波内容,其中收录报案主机名,主机id,触发器,触发器严重性
将获取到的数据进行处理
triggers=[]
a={}
for i in triname:
triggers.append(i['name'])
for i in triggers:
a[i]=triggers.count(i)
list2=[]
print(triname)
#print(a)
for key in a:
b={}
b['name']=key
b['host']=[i['hosts'][0]['name'] for i in triname if i['name']==key][0]
b['severity']=[i['severity'] for i in triname if i['name']==key][0]
b['count']=a[key]
list2.append(b)
return list2
这里是将重复出现的触发器进行去重并统计出现次数,将获取到的触发次数以及先前的信息都放在同一个表里,并传给HTML
将数据发送给HTML
def datatohtml(list2):
tables = ''
for i in range(len(list2)):
name,host,severity,count = list2[i]['name'], list2[i]['host'], list2[i]['severity'], list2[i]['count']
td = "%s %s %s %s"%(name, host, severity, count)
tables = tables + "%s"%td
base_html="""
zabbix监控告警
告警级别: 1 表示:信息 2 表示:告警 3 表示:一般严重 4 表示:严重 5 表示:灾难
主机触发器告警级别告警次数%s
zabbix告警统计
""" %tables
return base_html
将传入的列表进行遍历并传入HTML表格中
发送报表电邮
将生成的HTML通过短信发送 查看全部
实现思路:

zabbix提供了一个获取风波的api,可以依据此api获取zabbix原创报案数据 将获取到的原创数据进行统计去重,统计触发器出现次数,并把重复的触发器删掉,将须要用到的数据统一放在一个列表上将第二步的列表进行遍历,并传入到HTML中,或者也可以使用pandas直接把数据建模,然后手动生成HTML表格将生成的HTML作为电邮内容发送定义获取的时间间隔
x=(datetime.datetime.now()-datetime.timedelta(minutes=30)).strftime("%Y-%m-%d %H:%M:%S")
y=(datetime.datetime.now()).strftime("%Y-%m-%d %H:%M:%S")
def timestamp(x,y):
p=time.strptime(x,"%Y-%m-%d %H:%M:%S")
starttime = str(int(time.mktime(p)))
q=time.strptime(y,"%Y-%m-%d %H:%M:%S")
endtime= str(int(time.mktime(q)))
return starttime,endtime
这里是获取的30分钟的报案数据
获取风波数据
def getevent(auth,timestamp):
data={
"jsonrpc": "2.0",
"method": "event.get",
"params": {
"output": [
"name",
"severity"
],
"value":1,
"time_from":timestamp[0],
"time_till":timestamp[1],
"selectHosts":[
#"hostid",
"name"
]
},
"auth": auth,
"id": 1
}
getevent=requests.post(url=ApiUrl,headers=header,json=data)
triname=json.loads(getevent.content)['result']
通过zabbix api获取须要用到的风波内容,其中收录报案主机名,主机id,触发器,触发器严重性
将获取到的数据进行处理
triggers=[]
a={}
for i in triname:
triggers.append(i['name'])
for i in triggers:
a[i]=triggers.count(i)
list2=[]
print(triname)
#print(a)
for key in a:
b={}
b['name']=key
b['host']=[i['hosts'][0]['name'] for i in triname if i['name']==key][0]
b['severity']=[i['severity'] for i in triname if i['name']==key][0]
b['count']=a[key]
list2.append(b)
return list2
这里是将重复出现的触发器进行去重并统计出现次数,将获取到的触发次数以及先前的信息都放在同一个表里,并传给HTML
将数据发送给HTML
def datatohtml(list2):
tables = ''
for i in range(len(list2)):
name,host,severity,count = list2[i]['name'], list2[i]['host'], list2[i]['severity'], list2[i]['count']
td = "%s %s %s %s"%(name, host, severity, count)
tables = tables + "%s"%td
base_html="""
zabbix监控告警
告警级别: 1 表示:信息 2 表示:告警 3 表示:一般严重 4 表示:严重 5 表示:灾难
主机触发器告警级别告警次数%s
zabbix告警统计
""" %tables
return base_html
将传入的列表进行遍历并传入HTML表格中
发送报表电邮
将生成的HTML通过短信发送
学会苹果 CMS 系统,搭建影视网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 380 次浏览 • 2020-08-13 04:35
苹果 CMS 是一套成熟稳定的资源管理系统,可以拿来搭建自己的影视网站。现在网路上大量的在线观看影片的网站,有很大一部分都是采用苹果CMS搭建的。它具有好多优点,包括一键建站、配置简单、资源采集方便等等。这里介绍一下搭建苹果CMS系统的方式,以及其配置方式。(可以先看一下我自己搭建的网站:考拉影院)
一、申请一个属于自己的VPS主机
小白自建网站教程
二、搭建LAMP环境
在安装苹果CMS之前,要先要在你的VPS上搭建LAMP环境。所谓的LAMP指的Linux+Apache+Mysql+PHP. 其中,你的操作系统ubuntu就是Linux。Apache是http服务器,浏览器通过服务器(也就是你的VPS)上的apache提供的服务能够获取到网页资源,从而显示在你的笔记本屏幕上。Mysql是数据库,你的网站(这里即是苹果CMS)动态运行时所存取的数据都是由数据库来管理的。PHP与Apache互相配合为用户提供动态的网页,我们要安装的苹果CMS就是php语言编撰的,他的运行必须依赖于PHP环境。
关于LAMP环境的搭建方式,网上有太多的教程,这里不介绍具体的安装方式,请自行在百度中搜索,其安装很简单,在ubuntu下使用apt-get命令即可安装。
三、安装苹果CMS
首先,到苹果CMS官网上下载安装包,上传到网站根目录,然后在你的浏览器中访问 你的ip地址或域名/install.php 即可步入安装界面,如下所示:
学贤社
然后,点击“同意合同并安装系统”,此时步入下边的环境检测界面。安装程序会检测一下你的vps上所安装的插件是否符合苹果CMS的要求,只有符合要求时,苹果CMS能够正常运行,因此这一步的测量是必要的。
学贤社
当然,既然是监测环境,当然会有个别检测项不符合要求的情况,万一哪一项不符合要求,这里会用黄色高亮的色带将其标示下来。一般测量不通过都是由于系统中缺乏个别插件,很简单自行百度解决。当这一步检查全部成功后,即可点击“进行下一步”按钮,此时步入如下界面:
学贤社
这里有关数据库的信息,按照你的MySQL中的实际配置填写就好,目的是使苹果CMS通过这种参数就能登入到你的MySQL上,只有这样,苹果CMS能够使用数据库读写所需的数据。
下面的管理员帐号密码是你日后拿来登陆苹果CMS后台时所需的用户名和密码,请设置一个足够长,并且足够安全,不易被破解的密码并谨记它。
最后,点击“立即执行安装”按钮,稍等片刻即安装成功。此时,在浏览器中输入 你的vps的ip地址或域名/index.php 即可看见苹果CMS的主页(即前台界面)。这个页面就是外界访问你的站点时听到的首页。
在浏览器中输入 你的vps的ip地址或域名/admin.php 即可登入苹果CMS后台管理界面。在后台管理页面,你可以做与你的站点相关的一切设置,包括采集视频、设置播放器、更换模板、设置SEO优化等等。这部份内容非常繁琐,只有成功采集到视频数据后,你的网站上才有内容,别人能够够在你的网站上观看视频,否则你的网站就是空的,没哪些实质性内容。
这里只简单介绍一下怎么采集系统自带的资源站的数据,如下如所示的步骤操作即可:
学贤社
采集时可能会报错“分类未绑定”,这是因为你的站点的影片分类与资源站上的影片分类没有构建一一对应关系,因此,苹果CMS并不知道资源站上的A分类对应到你的站点上是哪一个分类。此时只需绑定分类即可,这些操作都不难,稍加摸索即可上手。
到这儿只讲了苹果CMS的安装和配置,至于(自定义)采集视频、站点的中级设置、网站SEO优化等高阶话题,可以参看其它资料。
下面讲我基于以上基础怎样安装好 CMS 使用 vfed (大橙子)主题其他主题类似搭建影视网站的。
二、上传模板
把解压的 vfed主题 上传到网站的 template 文件里。打开后台:
vfed主题设置
默认会手动添加到快捷菜单,如果没显示请点击快捷菜单配置,手动添加
vfed主题设置,/index.php/label/admin
vfed采集资源,/index.php/label/union
设置完成后保存刷新即可
三、采集影视资源
以下三种方式任选一种。
自定义采集点,我用的几个资源采集网站:使用主题自带的影视采集资源使用苹果 CMS 自带的采集联盟采集。还可以更换插件。详情苹果CMSV10免费采集插件+播放器文件,整合各大影视资源采集站,影视站长福利!四、采集采集 自定义资源库
自定义资源库
完成后点击自己绑定的链接,接下来绑定分类,进行采集。参考第一步的教程。
三、播放器添加
基本一个采集网址单配一个播放器,所以只要换了采集网址就得加与之匹配的播放器。
采集站多了,播放器也多了
点击首页 -> vfed采集资源,找到你想采集的资源站,点击播放配置完成添加,不然笔记本未能播放。一般主题会自己带播放器。(想用另一个主题的播放器,上传另一个主题同样配置方法。)这样就不要每位网站都设置,使用他人的播放器了。下面看技巧。
首先得看主题播放器支持哪些格式的。这里支持 M3U8 的。
默认M3U8播放器 查看全部
一、网站安装 苹果 CMS 建站系统。
苹果 CMS 是一套成熟稳定的资源管理系统,可以拿来搭建自己的影视网站。现在网路上大量的在线观看影片的网站,有很大一部分都是采用苹果CMS搭建的。它具有好多优点,包括一键建站、配置简单、资源采集方便等等。这里介绍一下搭建苹果CMS系统的方式,以及其配置方式。(可以先看一下我自己搭建的网站:考拉影院)
一、申请一个属于自己的VPS主机
小白自建网站教程
二、搭建LAMP环境
在安装苹果CMS之前,要先要在你的VPS上搭建LAMP环境。所谓的LAMP指的Linux+Apache+Mysql+PHP. 其中,你的操作系统ubuntu就是Linux。Apache是http服务器,浏览器通过服务器(也就是你的VPS)上的apache提供的服务能够获取到网页资源,从而显示在你的笔记本屏幕上。Mysql是数据库,你的网站(这里即是苹果CMS)动态运行时所存取的数据都是由数据库来管理的。PHP与Apache互相配合为用户提供动态的网页,我们要安装的苹果CMS就是php语言编撰的,他的运行必须依赖于PHP环境。
关于LAMP环境的搭建方式,网上有太多的教程,这里不介绍具体的安装方式,请自行在百度中搜索,其安装很简单,在ubuntu下使用apt-get命令即可安装。
三、安装苹果CMS
首先,到苹果CMS官网上下载安装包,上传到网站根目录,然后在你的浏览器中访问 你的ip地址或域名/install.php 即可步入安装界面,如下所示:

学贤社
然后,点击“同意合同并安装系统”,此时步入下边的环境检测界面。安装程序会检测一下你的vps上所安装的插件是否符合苹果CMS的要求,只有符合要求时,苹果CMS能够正常运行,因此这一步的测量是必要的。

学贤社
当然,既然是监测环境,当然会有个别检测项不符合要求的情况,万一哪一项不符合要求,这里会用黄色高亮的色带将其标示下来。一般测量不通过都是由于系统中缺乏个别插件,很简单自行百度解决。当这一步检查全部成功后,即可点击“进行下一步”按钮,此时步入如下界面:

学贤社
这里有关数据库的信息,按照你的MySQL中的实际配置填写就好,目的是使苹果CMS通过这种参数就能登入到你的MySQL上,只有这样,苹果CMS能够使用数据库读写所需的数据。
下面的管理员帐号密码是你日后拿来登陆苹果CMS后台时所需的用户名和密码,请设置一个足够长,并且足够安全,不易被破解的密码并谨记它。
最后,点击“立即执行安装”按钮,稍等片刻即安装成功。此时,在浏览器中输入 你的vps的ip地址或域名/index.php 即可看见苹果CMS的主页(即前台界面)。这个页面就是外界访问你的站点时听到的首页。
在浏览器中输入 你的vps的ip地址或域名/admin.php 即可登入苹果CMS后台管理界面。在后台管理页面,你可以做与你的站点相关的一切设置,包括采集视频、设置播放器、更换模板、设置SEO优化等等。这部份内容非常繁琐,只有成功采集到视频数据后,你的网站上才有内容,别人能够够在你的网站上观看视频,否则你的网站就是空的,没哪些实质性内容。
这里只简单介绍一下怎么采集系统自带的资源站的数据,如下如所示的步骤操作即可:

学贤社
采集时可能会报错“分类未绑定”,这是因为你的站点的影片分类与资源站上的影片分类没有构建一一对应关系,因此,苹果CMS并不知道资源站上的A分类对应到你的站点上是哪一个分类。此时只需绑定分类即可,这些操作都不难,稍加摸索即可上手。
到这儿只讲了苹果CMS的安装和配置,至于(自定义)采集视频、站点的中级设置、网站SEO优化等高阶话题,可以参看其它资料。
下面讲我基于以上基础怎样安装好 CMS 使用 vfed (大橙子)主题其他主题类似搭建影视网站的。
二、上传模板
把解压的 vfed主题 上传到网站的 template 文件里。打开后台:
vfed主题设置
默认会手动添加到快捷菜单,如果没显示请点击快捷菜单配置,手动添加
vfed主题设置,/index.php/label/admin
vfed采集资源,/index.php/label/union
设置完成后保存刷新即可

三、采集影视资源
以下三种方式任选一种。
自定义采集点,我用的几个资源采集网站:使用主题自带的影视采集资源使用苹果 CMS 自带的采集联盟采集。还可以更换插件。详情苹果CMSV10免费采集插件+播放器文件,整合各大影视资源采集站,影视站长福利!四、采集采集 自定义资源库

自定义资源库
完成后点击自己绑定的链接,接下来绑定分类,进行采集。参考第一步的教程。
三、播放器添加
基本一个采集网址单配一个播放器,所以只要换了采集网址就得加与之匹配的播放器。

采集站多了,播放器也多了
点击首页 -> vfed采集资源,找到你想采集的资源站,点击播放配置完成添加,不然笔记本未能播放。一般主题会自己带播放器。(想用另一个主题的播放器,上传另一个主题同样配置方法。)这样就不要每位网站都设置,使用他人的播放器了。下面看技巧。
首先得看主题播放器支持哪些格式的。这里支持 M3U8 的。

默认M3U8播放器
苹果CMSV10定时采集之宝塔定时任务教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 350 次浏览 • 2020-08-13 02:46
1,安装的宝塔面板(和苹果cms在不在一个服务器上都可以)
2,安装好的苹果CMS v10
3,采集需要先绑定好分类,生成须要配置好url模式
用宝塔来触发定时任务,效率高,稳定性好,不受限于页面访问触发,推荐使用~~~ 当然若果没有条件可以使用页面触发。
4,添加定时任务,参数可在程序包的说明文档内找到。
有些人还不会获取参数,建议使用谷歌浏览器或 360极速浏览器,在 采集当日或其他链接上 右键, 复制链接。例如添加一个采集今日的任务,首先获取链接。
:///mox/inc/youku.php
把?号后面的都删掉掉。得到的参数就是 ac=cjday&xt=1&ct=&rday=24&cjflag=tv6_com&cjurl=
放到定时任务里就可以了。点击测试,获取访问url,复制出来,稍后会改为弹出新窗体,那样比较好复制。
5,进入宝塔,计划任务,添加一个任务。选择访问URL
执行周期自己定义依照须要。
url地址填写刚刚复制的地址。点一下执行,看看日志。 看到了吧, 这样不管网站有没有人访问,都可以执行的。 查看全部
准备工作
1,安装的宝塔面板(和苹果cms在不在一个服务器上都可以)
2,安装好的苹果CMS v10
3,采集需要先绑定好分类,生成须要配置好url模式
用宝塔来触发定时任务,效率高,稳定性好,不受限于页面访问触发,推荐使用~~~ 当然若果没有条件可以使用页面触发。
4,添加定时任务,参数可在程序包的说明文档内找到。
有些人还不会获取参数,建议使用谷歌浏览器或 360极速浏览器,在 采集当日或其他链接上 右键, 复制链接。例如添加一个采集今日的任务,首先获取链接。
:///mox/inc/youku.php
把?号后面的都删掉掉。得到的参数就是 ac=cjday&xt=1&ct=&rday=24&cjflag=tv6_com&cjurl=
放到定时任务里就可以了。点击测试,获取访问url,复制出来,稍后会改为弹出新窗体,那样比较好复制。
5,进入宝塔,计划任务,添加一个任务。选择访问URL
执行周期自己定义依照须要。
url地址填写刚刚复制的地址。点一下执行,看看日志。 看到了吧, 这样不管网站有没有人访问,都可以执行的。
苹果maccms8 各种CMS定时手动采集终极教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 721 次浏览 • 2020-08-25 09:29
子方有话
首先不得不说,目前网路上搜索到的苹果maccms8定时手动采集教程,可能好多都具有误导性,没把真正的道理讲明白,经过子方有料的摸索,终于踏出了一条辛苦路。
子方有料认为,采集工作似乎是一项很麻烦的工程,如果有手动采集,往往就事半功倍了。现在网路上的教程,基本都是说用宝塔的定时访问URL功能进行采集,这个到也无所谓。但所有的教程都没介绍原理,如果不注意细节,往往就深陷了失败之中,比如子方有料就花了相当一段时间。
说一下,子方有料认为这个采集教程,对其它CMS手动采集也是具有一定的参考借鉴意义的。
定时手动采集原理
把采集参数即链接放在首页中,一旦有访客访问,比如子方有料踩了一下这个页面,就激活了手动采集工作。
那假如没有人访问,就不能手动采集了。所以才出现了通过各类工具访问采集链接,保证内容的持续更新。
全面手动详尽采集教程步骤
首先获取采集链接,怎么采看自己了
接着添加定时任务。子方有料非常提示你们非常注意红框的部份。
第一点:任务名称必须得是英语,执行文件只能是collect.php,执行参数是刚才复制到的链接,只要collect旁边的部份
第二点:采集周期和采集时间,就是你勾选的时间段里,有访客访问就采集。如果你没有勾选的时间段,就算访问也不会触发手动采集机制。
最后,复制测试链接就可以了。甚至你可以象子方有料一样,上面的采集周期和时间全为空,通过crontab实现定时采集。
目前网路的教程,基本是跟你说全勾选再用宝塔定时访问url,这种是双重保障机制。因为子方有料只是玩三天,不是用来做其它事情的,所以就无所谓了。
关于一些crontab的踩坑路,可以关注子方有料站内前后几天的文章。
查看全部
苹果maccms8 各种CMS定时手动采集终极教程
子方有话
首先不得不说,目前网路上搜索到的苹果maccms8定时手动采集教程,可能好多都具有误导性,没把真正的道理讲明白,经过子方有料的摸索,终于踏出了一条辛苦路。
子方有料认为,采集工作似乎是一项很麻烦的工程,如果有手动采集,往往就事半功倍了。现在网路上的教程,基本都是说用宝塔的定时访问URL功能进行采集,这个到也无所谓。但所有的教程都没介绍原理,如果不注意细节,往往就深陷了失败之中,比如子方有料就花了相当一段时间。
说一下,子方有料认为这个采集教程,对其它CMS手动采集也是具有一定的参考借鉴意义的。
定时手动采集原理
把采集参数即链接放在首页中,一旦有访客访问,比如子方有料踩了一下这个页面,就激活了手动采集工作。
那假如没有人访问,就不能手动采集了。所以才出现了通过各类工具访问采集链接,保证内容的持续更新。
全面手动详尽采集教程步骤
首先获取采集链接,怎么采看自己了
接着添加定时任务。子方有料非常提示你们非常注意红框的部份。
第一点:任务名称必须得是英语,执行文件只能是collect.php,执行参数是刚才复制到的链接,只要collect旁边的部份
第二点:采集周期和采集时间,就是你勾选的时间段里,有访客访问就采集。如果你没有勾选的时间段,就算访问也不会触发手动采集机制。
最后,复制测试链接就可以了。甚至你可以象子方有料一样,上面的采集周期和时间全为空,通过crontab实现定时采集。
目前网路的教程,基本是跟你说全勾选再用宝塔定时访问url,这种是双重保障机制。因为子方有料只是玩三天,不是用来做其它事情的,所以就无所谓了。
关于一些crontab的踩坑路,可以关注子方有料站内前后几天的文章。
Asp定时执行操作 Asp定时读取数据库(网页定时操作解读)
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2020-08-24 21:23
目前定时的操作有:
一、Html页面的定时刷新(Refresh--刷新 )
1,Refresh (刷新) 代码使用说明
说明:让网页多长时间(秒)刷新自己,或在多长时间后使网页手动链接到其它网页。
用法:
注意:其中的5是指逗留5秒钟后手动刷新到URL网址
2,如何定时操作
你可以在同一个页面重复刷新,以达到定时操作的疗效。
如:
缺点:要在浏览器打开页面,不能关掉。
二、Javascript上面的setTimeout 和 setInterval
1,setTimeout 和 setInterval的区别
window对象有两个主要的定时方式,分别是setTimeout 和 setInteval 他们的句型基本上相同,但是完成的功能取有区别。
setTimeout方式是定时程序,也就是在哪些时间之后干哪些。干完了就拉倒。
setInterval方式则是表示间隔一定时间反复执行某操作。
如果用setTimeout实现setInerval的功能,就须要在执行的程序中再定时调用自己才行。如果要消除计数器须要 根据使用的方式不同,调用不同的清理方式:
例如:tttt=setTimeout('hello()',1000);
clearTimeout(tttt);
或者:
tttt=setInterval('hello()',1000);
clearInteval(tttt);
2,如何定时操作
比如要定时打开页面 Test.asp(当然Test.asp可以是读取数据库,生成静态页面......)
复制代码 代码如下:
缺点:要在浏览器打开页面,不能关掉。
三,ASP使用VB写的定时组件
ASP中没有setTimeout这类的定时句子,我们须要借助ASP组件来解决,同样,可以采用VB6来编制,具体操作方法参考
上一编组件的做法,为了挂起线程,我们须要运用WIN32API函数Sleep,同样新建一个Active Dll工程,起名子为Timer,
类名为sleep。
sleep这个WIN32API函数可以用VB6自带的API文本浏览器中找到它的申明方式
现在类sleep的程序如下,这个组件程序很简单的,我不多解说了。
复制代码 代码如下:
Private Declare Sub Sleep Lib "kernel32" (ByVal dwMilliseconds As Long)
Private m_set As Long
Public Property Get setup() As Long
setup = m_set
End Property
Public Property Let setup(strset As Long)
m_set = strset
End Property
Public Function Sleeptime()
Sleep (setup)
End Function
把它编译一下,就生成timer.dll这个组件dll,如果您不会写VB程序,那么您也可以在下载的文件包里找到timer.dll
这个文件。把它copy到windows目录下,在MS-DOS形式中输入
c:\windows\regsvr32 timer.dll
完成组件注册,同样可以使用这个定时组件。
现在解说刚刚按个列子的ASP调用文件。看看这个组件怎样使用
*定时器的应用
复制代码 代码如下:
定时器的应用(From:)
‘这个是脚本执行时间,默认为90秒,需要改长一点,不然在90秒后程序会被中断'3600为一小时
Server.ScriptTimeOut=3600
set obj=server.createobject("timer.sleep")
'参数1000为线程挂起一秒钟,可以随便设定
obj.setup=1000
do while true
obj.sleeptime
'执行定时操作,
If Not Response.IsClientConnected Then
set obj=nothing
session.abandon
End If
loop
%>
优点:在这里只是随意用VB写了一个测试的dll,但是用VB肯定可以在dll上面写一个定时执行的操作。
缺点:感觉VB写的这个dll可能会优点占资源。
四,结合笔记本的任务计划的定时操作,我个人觉得是目前最好的方式。
这个个人觉得是目前实现定时操作的最好方式。
就是先在服务器上写好要定时操作的页面,如Test.asp
然后写一个vbs文件,如下:
复制代码 代码如下:
Dim IE
Set IE = CreateObject("InternetExplorer.Application")
'运行你的 URL
ie.navigate("")
ie.visible=1
'Clean up...
Set IE = Nothing
1,可以在服务器使用“任务计划”
2,也可以在客户机使用“任务计划”
具体使用“任务计划”的使用,请参考
优缺点:页面会定时的弹出页面Test.asp,但是会有一个解决方式,就是在Test.asp页面加入定时关掉代码:
复制代码 代码如下:
总结,由于目前部份网页语言的限制,在定时操作上有一定的困难,但是经过我多次的求证,发现第四种方式无疑是疗效最好的,最省心的。 查看全部
Asp定时执行操作 Asp定时读取数据库(网页定时操作解读)
目前定时的操作有:
一、Html页面的定时刷新(Refresh--刷新 )
1,Refresh (刷新) 代码使用说明
说明:让网页多长时间(秒)刷新自己,或在多长时间后使网页手动链接到其它网页。
用法:
注意:其中的5是指逗留5秒钟后手动刷新到URL网址
2,如何定时操作
你可以在同一个页面重复刷新,以达到定时操作的疗效。
如:
缺点:要在浏览器打开页面,不能关掉。
二、Javascript上面的setTimeout 和 setInterval
1,setTimeout 和 setInterval的区别
window对象有两个主要的定时方式,分别是setTimeout 和 setInteval 他们的句型基本上相同,但是完成的功能取有区别。
setTimeout方式是定时程序,也就是在哪些时间之后干哪些。干完了就拉倒。
setInterval方式则是表示间隔一定时间反复执行某操作。
如果用setTimeout实现setInerval的功能,就须要在执行的程序中再定时调用自己才行。如果要消除计数器须要 根据使用的方式不同,调用不同的清理方式:
例如:tttt=setTimeout('hello()',1000);
clearTimeout(tttt);
或者:
tttt=setInterval('hello()',1000);
clearInteval(tttt);
2,如何定时操作
比如要定时打开页面 Test.asp(当然Test.asp可以是读取数据库,生成静态页面......)
复制代码 代码如下:
缺点:要在浏览器打开页面,不能关掉。
三,ASP使用VB写的定时组件
ASP中没有setTimeout这类的定时句子,我们须要借助ASP组件来解决,同样,可以采用VB6来编制,具体操作方法参考
上一编组件的做法,为了挂起线程,我们须要运用WIN32API函数Sleep,同样新建一个Active Dll工程,起名子为Timer,
类名为sleep。
sleep这个WIN32API函数可以用VB6自带的API文本浏览器中找到它的申明方式
现在类sleep的程序如下,这个组件程序很简单的,我不多解说了。
复制代码 代码如下:
Private Declare Sub Sleep Lib "kernel32" (ByVal dwMilliseconds As Long)
Private m_set As Long
Public Property Get setup() As Long
setup = m_set
End Property
Public Property Let setup(strset As Long)
m_set = strset
End Property
Public Function Sleeptime()
Sleep (setup)
End Function
把它编译一下,就生成timer.dll这个组件dll,如果您不会写VB程序,那么您也可以在下载的文件包里找到timer.dll
这个文件。把它copy到windows目录下,在MS-DOS形式中输入
c:\windows\regsvr32 timer.dll
完成组件注册,同样可以使用这个定时组件。
现在解说刚刚按个列子的ASP调用文件。看看这个组件怎样使用
*定时器的应用
复制代码 代码如下:
定时器的应用(From:)
‘这个是脚本执行时间,默认为90秒,需要改长一点,不然在90秒后程序会被中断'3600为一小时
Server.ScriptTimeOut=3600
set obj=server.createobject("timer.sleep")
'参数1000为线程挂起一秒钟,可以随便设定
obj.setup=1000
do while true
obj.sleeptime
'执行定时操作,
If Not Response.IsClientConnected Then
set obj=nothing
session.abandon
End If
loop
%>
优点:在这里只是随意用VB写了一个测试的dll,但是用VB肯定可以在dll上面写一个定时执行的操作。
缺点:感觉VB写的这个dll可能会优点占资源。
四,结合笔记本的任务计划的定时操作,我个人觉得是目前最好的方式。
这个个人觉得是目前实现定时操作的最好方式。
就是先在服务器上写好要定时操作的页面,如Test.asp
然后写一个vbs文件,如下:
复制代码 代码如下:
Dim IE
Set IE = CreateObject("InternetExplorer.Application")
'运行你的 URL
ie.navigate("")
ie.visible=1
'Clean up...
Set IE = Nothing
1,可以在服务器使用“任务计划”
2,也可以在客户机使用“任务计划”
具体使用“任务计划”的使用,请参考
优缺点:页面会定时的弹出页面Test.asp,但是会有一个解决方式,就是在Test.asp页面加入定时关掉代码:
复制代码 代码如下:
总结,由于目前部份网页语言的限制,在定时操作上有一定的困难,但是经过我多次的求证,发现第四种方式无疑是疗效最好的,最省心的。
优采云采集器的使用及其所用技术的介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 312 次浏览 • 2020-08-22 07:02
优采云采集器的使用及其所用技术的介绍《优采云采集器》 能为您做些什么呢?1网站内容维护1、 网站内容维护: 可以定时采集新闻、 文章等任何您想采集的内容, 并手动发布到您的网站。2、 Internet数据挖掘: 可以从指定网站抓取所需数据, 通过剖析和处理后保存到您的数据库。3、 网络信息监控: 通过手动采集, 可以监控峰会等社区类网站, 让您第一时间发觉您所关注的内容。4、 文件批量下载: 可以批量下载PDF、 RAR、 图片等各类文件, 并同时采集其相关信息。可以定时采集新闻文章等任何您想采集的内容并手动发布到您的网优采云采集器是目前信息采集与信息挖掘处理类软件中最流行、 性价比最高、 使用人数最多、市场占有率最大、 使用周期最长的智能采集程序。给定种子网址列表按规则抓取列表页面剖析出网址抓取网页内容按采集规则, 对下载到的网页剖析, 保存内容优采云采集器数据发布原理:在我们将数据采集下来后数据默认是保存在本地的,我们可以使用以下几种方法对种据进行处理。1 .不做任何处理。 因为数据本身是保存在数据库的(access或是db3) ,您若果只是想看一下, 直接用相关软件查看就可以了。2 .web发布到网站。
程序会模仿浏览器向您的网站发数实您发布的效送数据, 可以实现您手工发布的疗效。3 .直接入数据库。 您只需写几个SQL句子, 程序会将数据按您的SQL句子导出到数据库中。4 .保存为本地文件。 程序会读取数据库里的数据, 按一定格式保存为本地sql或是文本文件。优采云采集器的演示优采云采集器所用到的技术垂直搜索引擎信息追踪与手动分拣手动索引技术海量数据采集海量数据采集系统流程1)信息采集(网络蜘蛛)对指定网站进行数据采集, 把须要的信息储存到本地, 并记录相应的采集信息。 以供信息抽取模块进行数据提取。2)信息抽取从采集的信息中抽取有效的数据进行结构化处理。 剔除垃圾信息获得正文内容以及相关图片信息, 获得正文内容, 以及相关图片、 种子文件等相关信息。3)信息处理对抽取的信息进行数据加工处理。 对信息进行清洗、 去重、分类、 分析比较、 数据挖掘, 最后递交加工后的数据, 进行信息动词及构建索引。4)信息检索提供信息查询插口。 对信息进行动词处理提供全文检索插口。种子文件等相关信息相关技术1、 垂直搜索引擎技术的网路蜘蛛——爬虫信息源的稳定性(不能使信息源网站感觉到spider的压力)抓取的成本问题对用户体验改善程度2、 WEB结构化信息抽取将网页中的非结构化数据根据一定的需求抽取成结构化数据结构化信息抽取的两种实现方法模板方法web结构化信息抽取在百度、 google已经广泛应用。
对网页不依赖的网页库级的结构化信息抽取方法3、 信息的处理技术清洗、 去重、 分类、 分析比较、 数据挖掘、 语义剖析等4、 分词系统动词算法基于字符串匹配的动词方式基于理解的动词方式基于统计的动词方式究竟哪种动词算法的准确度更高, 目前并无定论。 对于任何一个成熟的动词系统来说, 不可能单独借助某一种算法来实现, 都须要综合不同的算法。常见英文动词开源项目:SCWS,ICTCLAS,HTTPCWS, 庖丁解牛动词,CCCEDICT5、 建立索引索引技术对于垂直搜索十分关键, 一个网页库级的搜索引擎必须要支持分布索引、 分层建库、 分布检索、灵活的更新、 灵活的残差调整、 灵活的索引和灵活的升级扩充、 高可靠性稳定性冗余性。 还须要支持各类技术级扩充、 高可靠性稳定性冗余性。 还须要支持各类技术的扩充, 如偏移量估算等。ThanksThanks 查看全部
优采云采集器的使用及其所用技术的介绍
优采云采集器的使用及其所用技术的介绍《优采云采集器》 能为您做些什么呢?1网站内容维护1、 网站内容维护: 可以定时采集新闻、 文章等任何您想采集的内容, 并手动发布到您的网站。2、 Internet数据挖掘: 可以从指定网站抓取所需数据, 通过剖析和处理后保存到您的数据库。3、 网络信息监控: 通过手动采集, 可以监控峰会等社区类网站, 让您第一时间发觉您所关注的内容。4、 文件批量下载: 可以批量下载PDF、 RAR、 图片等各类文件, 并同时采集其相关信息。可以定时采集新闻文章等任何您想采集的内容并手动发布到您的网优采云采集器是目前信息采集与信息挖掘处理类软件中最流行、 性价比最高、 使用人数最多、市场占有率最大、 使用周期最长的智能采集程序。给定种子网址列表按规则抓取列表页面剖析出网址抓取网页内容按采集规则, 对下载到的网页剖析, 保存内容优采云采集器数据发布原理:在我们将数据采集下来后数据默认是保存在本地的,我们可以使用以下几种方法对种据进行处理。1 .不做任何处理。 因为数据本身是保存在数据库的(access或是db3) ,您若果只是想看一下, 直接用相关软件查看就可以了。2 .web发布到网站。
程序会模仿浏览器向您的网站发数实您发布的效送数据, 可以实现您手工发布的疗效。3 .直接入数据库。 您只需写几个SQL句子, 程序会将数据按您的SQL句子导出到数据库中。4 .保存为本地文件。 程序会读取数据库里的数据, 按一定格式保存为本地sql或是文本文件。优采云采集器的演示优采云采集器所用到的技术垂直搜索引擎信息追踪与手动分拣手动索引技术海量数据采集海量数据采集系统流程1)信息采集(网络蜘蛛)对指定网站进行数据采集, 把须要的信息储存到本地, 并记录相应的采集信息。 以供信息抽取模块进行数据提取。2)信息抽取从采集的信息中抽取有效的数据进行结构化处理。 剔除垃圾信息获得正文内容以及相关图片信息, 获得正文内容, 以及相关图片、 种子文件等相关信息。3)信息处理对抽取的信息进行数据加工处理。 对信息进行清洗、 去重、分类、 分析比较、 数据挖掘, 最后递交加工后的数据, 进行信息动词及构建索引。4)信息检索提供信息查询插口。 对信息进行动词处理提供全文检索插口。种子文件等相关信息相关技术1、 垂直搜索引擎技术的网路蜘蛛——爬虫信息源的稳定性(不能使信息源网站感觉到spider的压力)抓取的成本问题对用户体验改善程度2、 WEB结构化信息抽取将网页中的非结构化数据根据一定的需求抽取成结构化数据结构化信息抽取的两种实现方法模板方法web结构化信息抽取在百度、 google已经广泛应用。
对网页不依赖的网页库级的结构化信息抽取方法3、 信息的处理技术清洗、 去重、 分类、 分析比较、 数据挖掘、 语义剖析等4、 分词系统动词算法基于字符串匹配的动词方式基于理解的动词方式基于统计的动词方式究竟哪种动词算法的准确度更高, 目前并无定论。 对于任何一个成熟的动词系统来说, 不可能单独借助某一种算法来实现, 都须要综合不同的算法。常见英文动词开源项目:SCWS,ICTCLAS,HTTPCWS, 庖丁解牛动词,CCCEDICT5、 建立索引索引技术对于垂直搜索十分关键, 一个网页库级的搜索引擎必须要支持分布索引、 分层建库、 分布检索、灵活的更新、 灵活的残差调整、 灵活的索引和灵活的升级扩充、 高可靠性稳定性冗余性。 还须要支持各类技术级扩充、 高可靠性稳定性冗余性。 还须要支持各类技术的扩充, 如偏移量估算等。ThanksThanks
织梦定时发布工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2020-08-22 01:12
织梦dedecms是个挺好的网站系统,基于织梦系统,你可以做门户站、企业站等多种类型的网站,但织梦美中不足的是没有定时发布文章的功能,这就使我们不得不每晚自动更新。跟版网为了解决这个问题查了好多的方式,有用计划任务的方式,有用定时发布插件的方式。但疗效都不太好,或者设置比较复杂。
最后跟版网找到了个很简单的定时发布的方式,用织梦出的采集侠2.7版就可以实现定时发布的疗效(注意不是定时采集,是定时发布我们的原创或伪原创文章)。采集侠2.7版本是最新的,并且假如你去买官方的话,会太贵,所以跟版网共享给你们采集侠2.7破解版。
采集侠2.7破解版下载地址:
1、安装采集侠
(1)下载采集侠后,解压缩,会有几个文件,其中caijixia_gbk_2.7.0.2.xml和caijixia_utf8_2.7.0.2.xml是采集侠的gbk和utf8版本。(我用的是织梦的v5.7gbk,所以我就用gbk版本来演示)
(2)安装采集侠,织梦后台——模块——上传新模块——点击浏览找到采集侠——点击确定,如下图。
之后出现下边的窗口,点击安装,点击确定。
安装完成后在模块中就多出了采集侠的模块。
2、采集侠定时发布文章的设置
设置定时发布很简单
(1)采集侠——基本设置——选中手动初审,设置每小时总采集(审核)上限,即定时发布的文章数量,点击确定。如下图:
(2)采集侠——采集任务——在手动采集中选择采集的时间段,选好时间段后,当他人在你设置的时间段内访问你的网站,你网站内的为初审的文章就会手动生成发布了,这就是手动初审发布的原理。如下图: 查看全部
织梦定时发布工具
织梦dedecms是个挺好的网站系统,基于织梦系统,你可以做门户站、企业站等多种类型的网站,但织梦美中不足的是没有定时发布文章的功能,这就使我们不得不每晚自动更新。跟版网为了解决这个问题查了好多的方式,有用计划任务的方式,有用定时发布插件的方式。但疗效都不太好,或者设置比较复杂。
最后跟版网找到了个很简单的定时发布的方式,用织梦出的采集侠2.7版就可以实现定时发布的疗效(注意不是定时采集,是定时发布我们的原创或伪原创文章)。采集侠2.7版本是最新的,并且假如你去买官方的话,会太贵,所以跟版网共享给你们采集侠2.7破解版。
采集侠2.7破解版下载地址:
1、安装采集侠
(1)下载采集侠后,解压缩,会有几个文件,其中caijixia_gbk_2.7.0.2.xml和caijixia_utf8_2.7.0.2.xml是采集侠的gbk和utf8版本。(我用的是织梦的v5.7gbk,所以我就用gbk版本来演示)
(2)安装采集侠,织梦后台——模块——上传新模块——点击浏览找到采集侠——点击确定,如下图。
之后出现下边的窗口,点击安装,点击确定。
安装完成后在模块中就多出了采集侠的模块。
2、采集侠定时发布文章的设置
设置定时发布很简单
(1)采集侠——基本设置——选中手动初审,设置每小时总采集(审核)上限,即定时发布的文章数量,点击确定。如下图:
(2)采集侠——采集任务——在手动采集中选择采集的时间段,选好时间段后,当他人在你设置的时间段内访问你的网站,你网站内的为初审的文章就会手动生成发布了,这就是手动初审发布的原理。如下图:
性能监控平台搭建 -- 集成Locust性能数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2020-08-21 15:04
无意中发觉了一个巨牛的人工智能教程,忍不住分享一下给你们。教程除了是零基础,通俗易懂,而且十分诙谐诙谐,像看小说一样!觉得很牛了,所以分享给你们。点这儿可以跳转到教程。
文章目录
原文链接
之前的几篇关于性能监控平台搭建的文章,分别介绍了性能测试中的资源数据采集、存储及展示。今天一起来看下怎样完成Locust性能数据的采集。
这是之前介绍过的性能监控平台的整体构架图,想要了解其它部份的搭建,可以查看相关文章《Telegraf安装与简易使用指南》、《InfluxDB安装与简易使用指南》、《Grafana安装与简易使用指南》
因为我们早已完成了资源数据的采集,以及监控数据的储存与展示,剩下的就是采集性能数据了。规划中我们须要支持采集JMeter和Locust工具的性能数据,今天先讲解怎样采集Locust的性能数据。
问题概述
如果你使用过Locust,那么你一定晓得Locust本身自带一个WEB服务,它提供了性能测试过程中的性能数据监控,并且也提供了一个图形的界面支持实时监控,完事了还可以下载csv格式的性能测试数据。
既然Locust早已有了性能数据的监控功能,为哈还要接入到性能监控平台呢?因为Locust里的数据没有主动持久化,一旦刷新就没有了;也不会手动保存历史数据;不能对数据进行多样化展示,不能在同一个平台中查看全部的性能数据。
为此我们要解决的就是把Locust性能工具中的性能数据实时的获取到并储存到Influxdb中,这样就完美的解决了Locust性能数据集成问题,让监控平台可以无缝的支持Locust工具。
获取Locust性能数据插口
既然要采集性能测试数据,那么首先要考虑的就是怎么获取性能测试数据?是更改源码?还是开发插件?这些统统不要!因为Locust本身就早已有了性能数据监控服务,通过抓取Locust的WEB服务页面恳求,很方便的就得到了Locust的性能监控数据。比如:
curl http://localhost:8089/stats/requests
该URL会返回当前性能测试到目前为止的性能测试数据的总结信息,所以那些我们须要的性能数据基本上Locust早已为我们打包好了,我们之前恳求这个url就可以实时的获取到。
定时采集性能数据
数据获取的方法早已晓得了,接下来考虑的就是在什么时候获取数据的问题。最简单粗鲁的形式就是写一个定时任务去恳求该URL,获取数据后直接储存到Influxdb即可。代码如下:
def get_locust_stats_by_web_api():
print("get_locust_stats")
try:
start_url = f'http://localhost:8089/stats/requests'
print(start_url)
return requests.get(start_url).json()
except Exception as e:
print(e)
而这样做的弊病则是定时任务与性能测试启停的一致性须要人为的控制,用户友好性不够。我们希望的是性能测试一开始它就手动开始采集性能数据,性能测试一结束它就停止采集性能数据,要做到对目前的性能测试操作尽量无侵入。
性能数据采集一致性
为了解决性能数据采集与性能测试之间的一致性问题,我们须要把代码集成到Locust性能测试脚本中,让它跟脚本绑定,这样一旦开始执行性能测试,就会触发性能数据采集的定时任务,从根本上解决了一致性问题。
no-web模式下获取性能数据
前面我们获取Locust性能测试数据时,是通过/stats/requests插口获取到的。这个插口是基于WEB模式下,一旦我们选择以no-web的方法启动Locust,那么这个插口才会失效了。
为了兼容no-web模式下也能正常采集到Locust的性能数据,可以直接把/stats/requests插口生成性能测试数据的代码直接COPY过来即可,所以获取Locust性能测试数据的方式须要改写成这样:
def get_locust_stats():
stats = []
for s in chain(sort_stats(runners.locust_runner.request_stats), [runners.locust_runner.stats.total]):
stats.append({
"method": s.method,
"name": s.name,
"num_requests": s.num_requests,
"num_failures": s.num_failures,
"avg_response_time": s.avg_response_time,
"min_response_time": s.min_response_time or 0,
"max_response_time": s.max_response_time,
"current_rps": s.current_rps,
"median_response_time": s.median_response_time,
"avg_content_length": s.avg_content_length,
})
errors = [e.to_dict() for e in six.itervalues(runners.locust_runner.errors)]
# Truncate the total number of stats and errors displayed since a large number of rows will cause the app
# to render extremely slowly. Aggregate stats should be preserved.
report = {"stats": stats[:500], "errors": errors[:500]}
if stats:
report["total_rps"] = stats[len(stats) - 1]["current_rps"]
report["fail_ratio"] = runners.locust_runner.stats.total.fail_ratio
report[
"current_response_time_percentile_95"] = runners.locust_runner.stats.total.get_current_response_time_percentile(
0.95)
report[
"current_response_time_percentile_50"] = runners.locust_runner.stats.total.get_current_response_time_percentile(
0.5)
is_distributed = isinstance(runners.locust_runner, MasterLocustRunner)
if is_distributed:
slaves = []
for slave in runners.locust_runner.clients.values():
slaves.append({"id": slave.id, "state": slave.state, "user_count": slave.user_count})
report["slaves"] = slaves
report["state"] = runners.locust_runner.state
report["user_count"] = runners.locust_runner.user_count
return report
slave模式下不进行数据采集
同样的Locust还有分布式模式,一旦采用该模式以后Locust性能脚本会在master和各slave节点就会执行,但是很明显我们不希望接收到多次重复的性能采集数据,所以须要保证只有在master上的性能脚本才能进行性能数据采集。
def monitor(project_name):
print("start monitoring")
slave = isinstance(runners.locust_runner, SlaveLocustRunner)
if slave: # 判断是否为slave
print('is slave, will not rerun')
return
try:
rep = get_locust_stats()
if rep['state'] == 'running':
host = get_locust_host()
save_to_db(project_name, host, rep)
print(f'is_slave: {slave}, host: {host}, project_name: {project_name}')
else:
print('it is not running now')
except Exception as e:
print(e)
timer = threading.Timer(interval, monitor, args=[project_name]) # 定时任务
timer.start()
封装
当然,我们也不希望把这么多的性能数据采集的代码直接写在Locust的性能测试脚本中,即不美观也不容易管理。所以须要把这种采集数据的代码统一封装到一个独立文件中,并对外提供一个调用入口,只要简单引入即可。调用代码如下: 查看全部
性能监控平台搭建 -- 集成Locust性能数据
无意中发觉了一个巨牛的人工智能教程,忍不住分享一下给你们。教程除了是零基础,通俗易懂,而且十分诙谐诙谐,像看小说一样!觉得很牛了,所以分享给你们。点这儿可以跳转到教程。
文章目录
原文链接
之前的几篇关于性能监控平台搭建的文章,分别介绍了性能测试中的资源数据采集、存储及展示。今天一起来看下怎样完成Locust性能数据的采集。
这是之前介绍过的性能监控平台的整体构架图,想要了解其它部份的搭建,可以查看相关文章《Telegraf安装与简易使用指南》、《InfluxDB安装与简易使用指南》、《Grafana安装与简易使用指南》
因为我们早已完成了资源数据的采集,以及监控数据的储存与展示,剩下的就是采集性能数据了。规划中我们须要支持采集JMeter和Locust工具的性能数据,今天先讲解怎样采集Locust的性能数据。
问题概述
如果你使用过Locust,那么你一定晓得Locust本身自带一个WEB服务,它提供了性能测试过程中的性能数据监控,并且也提供了一个图形的界面支持实时监控,完事了还可以下载csv格式的性能测试数据。
既然Locust早已有了性能数据的监控功能,为哈还要接入到性能监控平台呢?因为Locust里的数据没有主动持久化,一旦刷新就没有了;也不会手动保存历史数据;不能对数据进行多样化展示,不能在同一个平台中查看全部的性能数据。
为此我们要解决的就是把Locust性能工具中的性能数据实时的获取到并储存到Influxdb中,这样就完美的解决了Locust性能数据集成问题,让监控平台可以无缝的支持Locust工具。
获取Locust性能数据插口
既然要采集性能测试数据,那么首先要考虑的就是怎么获取性能测试数据?是更改源码?还是开发插件?这些统统不要!因为Locust本身就早已有了性能数据监控服务,通过抓取Locust的WEB服务页面恳求,很方便的就得到了Locust的性能监控数据。比如:
curl http://localhost:8089/stats/requests
该URL会返回当前性能测试到目前为止的性能测试数据的总结信息,所以那些我们须要的性能数据基本上Locust早已为我们打包好了,我们之前恳求这个url就可以实时的获取到。
定时采集性能数据
数据获取的方法早已晓得了,接下来考虑的就是在什么时候获取数据的问题。最简单粗鲁的形式就是写一个定时任务去恳求该URL,获取数据后直接储存到Influxdb即可。代码如下:
def get_locust_stats_by_web_api():
print("get_locust_stats")
try:
start_url = f'http://localhost:8089/stats/requests'
print(start_url)
return requests.get(start_url).json()
except Exception as e:
print(e)
而这样做的弊病则是定时任务与性能测试启停的一致性须要人为的控制,用户友好性不够。我们希望的是性能测试一开始它就手动开始采集性能数据,性能测试一结束它就停止采集性能数据,要做到对目前的性能测试操作尽量无侵入。
性能数据采集一致性
为了解决性能数据采集与性能测试之间的一致性问题,我们须要把代码集成到Locust性能测试脚本中,让它跟脚本绑定,这样一旦开始执行性能测试,就会触发性能数据采集的定时任务,从根本上解决了一致性问题。
no-web模式下获取性能数据
前面我们获取Locust性能测试数据时,是通过/stats/requests插口获取到的。这个插口是基于WEB模式下,一旦我们选择以no-web的方法启动Locust,那么这个插口才会失效了。
为了兼容no-web模式下也能正常采集到Locust的性能数据,可以直接把/stats/requests插口生成性能测试数据的代码直接COPY过来即可,所以获取Locust性能测试数据的方式须要改写成这样:
def get_locust_stats():
stats = []
for s in chain(sort_stats(runners.locust_runner.request_stats), [runners.locust_runner.stats.total]):
stats.append({
"method": s.method,
"name": s.name,
"num_requests": s.num_requests,
"num_failures": s.num_failures,
"avg_response_time": s.avg_response_time,
"min_response_time": s.min_response_time or 0,
"max_response_time": s.max_response_time,
"current_rps": s.current_rps,
"median_response_time": s.median_response_time,
"avg_content_length": s.avg_content_length,
})
errors = [e.to_dict() for e in six.itervalues(runners.locust_runner.errors)]
# Truncate the total number of stats and errors displayed since a large number of rows will cause the app
# to render extremely slowly. Aggregate stats should be preserved.
report = {"stats": stats[:500], "errors": errors[:500]}
if stats:
report["total_rps"] = stats[len(stats) - 1]["current_rps"]
report["fail_ratio"] = runners.locust_runner.stats.total.fail_ratio
report[
"current_response_time_percentile_95"] = runners.locust_runner.stats.total.get_current_response_time_percentile(
0.95)
report[
"current_response_time_percentile_50"] = runners.locust_runner.stats.total.get_current_response_time_percentile(
0.5)
is_distributed = isinstance(runners.locust_runner, MasterLocustRunner)
if is_distributed:
slaves = []
for slave in runners.locust_runner.clients.values():
slaves.append({"id": slave.id, "state": slave.state, "user_count": slave.user_count})
report["slaves"] = slaves
report["state"] = runners.locust_runner.state
report["user_count"] = runners.locust_runner.user_count
return report
slave模式下不进行数据采集
同样的Locust还有分布式模式,一旦采用该模式以后Locust性能脚本会在master和各slave节点就会执行,但是很明显我们不希望接收到多次重复的性能采集数据,所以须要保证只有在master上的性能脚本才能进行性能数据采集。
def monitor(project_name):
print("start monitoring")
slave = isinstance(runners.locust_runner, SlaveLocustRunner)
if slave: # 判断是否为slave
print('is slave, will not rerun')
return
try:
rep = get_locust_stats()
if rep['state'] == 'running':
host = get_locust_host()
save_to_db(project_name, host, rep)
print(f'is_slave: {slave}, host: {host}, project_name: {project_name}')
else:
print('it is not running now')
except Exception as e:
print(e)
timer = threading.Timer(interval, monitor, args=[project_name]) # 定时任务
timer.start()
封装
当然,我们也不希望把这么多的性能数据采集的代码直接写在Locust的性能测试脚本中,即不美观也不容易管理。所以须要把这种采集数据的代码统一封装到一个独立文件中,并对外提供一个调用入口,只要简单引入即可。调用代码如下:
虾米音乐与赛扬股票私募网站管理系统下载评论软件详情对比
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2020-08-21 08:30
酷睿股票私募网站管理系统,是国外首家采用WAP手机及笔记本WEB同步访问的股票私募系统,该系统基于ASP+DIV+CSS+AJAX+XML+MSSQL技术专门为股票私募网站开发的一款CMS网站管理系统,是一个经过建立设计并适用于各类服务器环境的易用、安全、高效、快速、优秀的网站解决方案。后台管理便捷、易懂、易用、人性化,对操作人员技术要求低,没有建站知识的操作人员都可轻松进行。继续ASP开源之路,稳定、安全、强大的核心程序,对于有网站设计知识和程序爱好者可以随心所欲进行更改,方便构建具有自已特色的站点。
酷睿股票私募网站管理系统,最大的优势除了在于有全省首创的WAP手机访问系统,更有数十款精致模板任意选择及终生免费更换模板服务,并承诺一次订购终生免费使用,无任何限制和加密,完全可随便的二次开发,也可以随便更换域名、空间、IP等,可终生免费无限次升级更新新版本,还可以一套系统无限次使用。
升级更新部分功能介绍
全新的黑色模板设计
全新的内核程序设计
全新的后台管理界面设计
全新的会员中性管理界面设计
新增了后台基本设置里的网站、联系信息、银行设置、工商注册、公司证书、收费标准等五个大项,50多个小项的设置及后台相关标签
新增了会员注册后只要建立自己的资料便可手动签署协议功能
新增了公开验证模型
新增了会员实战模型
新增了历史战绩模型等四种模型,去掉原先两个系统调用,改为一个系统
新增了会员实战的手动更新功能
新增了历史战绩的手动更新功能
新增了后台定时任务文章多点定时手动采集和手动多点定时生成静态页面功能
新增了后台设置前台会员注册时容许所显示的会员组如A、B、C、D、E、F等类会员组
新增了会员登入后的对帐专业县链接
新增了目录安全设置说明文件
修改了后台所有静态自定义标签可以可视化编辑
修正了幻灯图片不能后台添加更改的问题
修正了财经视频直播视频不能播放的问题
修改滚动行情不能手动更新并改为全球主要期指手动实时更新
增强后台木马在线监测系统
修正了黑客借助后台或会员上传功能上传木马的BUG
修正了黑客借助模板管理添加木马文件的BUG
修正了其它数处BUG及安全隐患
修复了早已的几处WAP手机访问系统的BUG
修正了Robots.txt搜索引擎蜘蛛文件对网站的收录权限,让搜索引擎更新收录网站内容
并取消了首页的数个IFRA使用网站的ME调用,尽可能降低了对搜索引擎的友好程度
删除了上百个垃圾文件使用网站的减少40%
优化了大量的程序代码
主要功能
完善的全后台管理功能
不管是网站配置、联系信息、银行设置、工商注册、公司证书、收费标准还是网站模板、标签等几乎可以在后台管理任何网站所须要的内容。
实时行情系统
滚动全球行情、外汇报价、机构盯盘、涨跌排名、成交排名、股市手册、环球指数全手动更新。
运行速率与效率
采用XML缓存,运行速率更快,效率更高。
系统采用ASP+DIV+CSS+Ajax+XML+MSSQL技术开发而成,运行速率成倍提高。
文章智能快速采集系统
多点定时计划文章采集和多点定时计划文章自动生成系统,让你的网站无人职守,自动更新
智能强悍的过滤系统设置、UTF-8/GB2312手动辨识、批量采集让你享受高速采集快感。
采集目标网站可随便更换,设置规则简单,操作更方便
会员实战手动更新功能
可手动更新沪深股市当日跌幅最前的各三名作为会员实战内容
历史战绩手动更新功能
可手动更新以会员实战的15天前及120内的内容作为历史战绩的内容,并手动将实际获利手动设置为40%-90%、自动将交易时间设置为3-9天
全新的文章浏览权限应用功能
真正的做到了会员对帐专区的会员组浏览功能,可将会员组浏览权限精确到每位频道/每个栏目/每篇文章,让不同的会员组享受不同的文章浏览权限,并各会员组之间的资料不能想到浏览,也可将整篇文章设置浏览点数,发行点卡使包点的会员进行浏览,还可设置包年会员浏览,包月会员时间一到该会员须要续费后才会浏览相应的会员资料。
强大的会员管理功能
无限用户组添加功能、站内邮件功能、会员点卷明细查询、有效期查询、资金明细查询、点卡在线冲值功能、在线支付实时到账,会员可设置为扣点会员、有效期会员和、无限期会员。
SEO优化
在线智能生成GOOGLE/百度标准收录XML格式地图,使网站更便于搜索和收录。
三种运行模式:可将站点全部页面高为动态、静态及伪态格式,大大提升浏览速率及搜索引擎的搜录量。
HTML生成文件储存结构选择。
独有利于Alexa收录的info.txt文件和搜索引擎蜘蛛爬行文件Robots.txt
模板程序分离,网站频道、栏目、内容页META关键词、网站META网页描述均为调用标签,利于网站的收录量并大大减短了页面收录的时间更易于网站的手动配置管理
WAP手机网站系统
国内独创WAP手机访问系统,注册、登录、会员对帐、分析预测众等多种功能一部手机全部搞定!支持手机自带WAP浏览器、UC浏览器、QQ浏览器等几乎所有只要能上网的主流手机浏览器
手机上网浏览与在网站同步,一个账号,两站通用,实现WEB与WAP无缝衔接
集成13个在线支付平台
集成:财付通 网银在线 易付通 云网支付 支付宝 快钱支付 中国在线支付网 西部支付 上海环迅等11个在线支付平台插口,会员冲值实时到账,让你收费无忧。
强大的插件管理
集成:WAP手机网站系统插件、数据库导出系统、可选CC视频联盟插件、WSS统计插件、
标签管理系统
全新的标签应用功能全站采用标签调用系统,让网站运行速率更快,且完全避免站内的文章被其它网站所采集,后台标签管理更方便简单,让网站更安全且极易维护管理。
模板化体系
界面和程序分离,可在线可视化编辑、设计,所有模块均通过标签调用,集成类同Macromedia Dreamweaver一样简单的可视模板编辑方法,修改模板容易、快捷。
无限频道添加功能
可无限添加各类频道或栏目,新频道或栏目完全独立设置,独立模版。
数据库
提供强悍的数据备份和恢复功能,可以在线备份、恢复、压缩数据库。查看系统空间占用情况、系统初始化、查看服务器信息及到在线直接执行SQL句子
系统采用MSSQL数据库,可支持上数千万的数据库,更安全、更稳定、更高效、更强大,运行速率更快。
自动签协议功能
当会注册成功了系统会手动生成一个文件方式的协议,进入会员中心后可以查看协议文本。
系统安全
本以安全为基础,密码采用MD5加密,保证用户资料安全,程序代码中设计缜密,可手动屏蔽恶意功击代码。
更集成防SQL注入程序,从而可全面杜绝各类SQL注入攻击手段,并进行记录在案,保证了系统的安全和稳定运行。
更详尽的管理风波记录,管理员每一步后台操作都记录在案。
双重登入双重密码设计再加认证码,后台登录更安全。 查看全部
虾米音乐与赛扬股票私募网站管理系统下载评论软件详情对比
酷睿股票私募网站管理系统,是国外首家采用WAP手机及笔记本WEB同步访问的股票私募系统,该系统基于ASP+DIV+CSS+AJAX+XML+MSSQL技术专门为股票私募网站开发的一款CMS网站管理系统,是一个经过建立设计并适用于各类服务器环境的易用、安全、高效、快速、优秀的网站解决方案。后台管理便捷、易懂、易用、人性化,对操作人员技术要求低,没有建站知识的操作人员都可轻松进行。继续ASP开源之路,稳定、安全、强大的核心程序,对于有网站设计知识和程序爱好者可以随心所欲进行更改,方便构建具有自已特色的站点。
酷睿股票私募网站管理系统,最大的优势除了在于有全省首创的WAP手机访问系统,更有数十款精致模板任意选择及终生免费更换模板服务,并承诺一次订购终生免费使用,无任何限制和加密,完全可随便的二次开发,也可以随便更换域名、空间、IP等,可终生免费无限次升级更新新版本,还可以一套系统无限次使用。
升级更新部分功能介绍
全新的黑色模板设计
全新的内核程序设计
全新的后台管理界面设计
全新的会员中性管理界面设计
新增了后台基本设置里的网站、联系信息、银行设置、工商注册、公司证书、收费标准等五个大项,50多个小项的设置及后台相关标签
新增了会员注册后只要建立自己的资料便可手动签署协议功能
新增了公开验证模型
新增了会员实战模型
新增了历史战绩模型等四种模型,去掉原先两个系统调用,改为一个系统
新增了会员实战的手动更新功能
新增了历史战绩的手动更新功能
新增了后台定时任务文章多点定时手动采集和手动多点定时生成静态页面功能
新增了后台设置前台会员注册时容许所显示的会员组如A、B、C、D、E、F等类会员组
新增了会员登入后的对帐专业县链接
新增了目录安全设置说明文件
修改了后台所有静态自定义标签可以可视化编辑
修正了幻灯图片不能后台添加更改的问题
修正了财经视频直播视频不能播放的问题
修改滚动行情不能手动更新并改为全球主要期指手动实时更新
增强后台木马在线监测系统
修正了黑客借助后台或会员上传功能上传木马的BUG
修正了黑客借助模板管理添加木马文件的BUG
修正了其它数处BUG及安全隐患
修复了早已的几处WAP手机访问系统的BUG
修正了Robots.txt搜索引擎蜘蛛文件对网站的收录权限,让搜索引擎更新收录网站内容
并取消了首页的数个IFRA使用网站的ME调用,尽可能降低了对搜索引擎的友好程度
删除了上百个垃圾文件使用网站的减少40%
优化了大量的程序代码
主要功能
完善的全后台管理功能
不管是网站配置、联系信息、银行设置、工商注册、公司证书、收费标准还是网站模板、标签等几乎可以在后台管理任何网站所须要的内容。
实时行情系统
滚动全球行情、外汇报价、机构盯盘、涨跌排名、成交排名、股市手册、环球指数全手动更新。
运行速率与效率
采用XML缓存,运行速率更快,效率更高。
系统采用ASP+DIV+CSS+Ajax+XML+MSSQL技术开发而成,运行速率成倍提高。
文章智能快速采集系统
多点定时计划文章采集和多点定时计划文章自动生成系统,让你的网站无人职守,自动更新
智能强悍的过滤系统设置、UTF-8/GB2312手动辨识、批量采集让你享受高速采集快感。
采集目标网站可随便更换,设置规则简单,操作更方便
会员实战手动更新功能
可手动更新沪深股市当日跌幅最前的各三名作为会员实战内容
历史战绩手动更新功能
可手动更新以会员实战的15天前及120内的内容作为历史战绩的内容,并手动将实际获利手动设置为40%-90%、自动将交易时间设置为3-9天
全新的文章浏览权限应用功能
真正的做到了会员对帐专区的会员组浏览功能,可将会员组浏览权限精确到每位频道/每个栏目/每篇文章,让不同的会员组享受不同的文章浏览权限,并各会员组之间的资料不能想到浏览,也可将整篇文章设置浏览点数,发行点卡使包点的会员进行浏览,还可设置包年会员浏览,包月会员时间一到该会员须要续费后才会浏览相应的会员资料。
强大的会员管理功能
无限用户组添加功能、站内邮件功能、会员点卷明细查询、有效期查询、资金明细查询、点卡在线冲值功能、在线支付实时到账,会员可设置为扣点会员、有效期会员和、无限期会员。
SEO优化
在线智能生成GOOGLE/百度标准收录XML格式地图,使网站更便于搜索和收录。
三种运行模式:可将站点全部页面高为动态、静态及伪态格式,大大提升浏览速率及搜索引擎的搜录量。
HTML生成文件储存结构选择。
独有利于Alexa收录的info.txt文件和搜索引擎蜘蛛爬行文件Robots.txt
模板程序分离,网站频道、栏目、内容页META关键词、网站META网页描述均为调用标签,利于网站的收录量并大大减短了页面收录的时间更易于网站的手动配置管理
WAP手机网站系统
国内独创WAP手机访问系统,注册、登录、会员对帐、分析预测众等多种功能一部手机全部搞定!支持手机自带WAP浏览器、UC浏览器、QQ浏览器等几乎所有只要能上网的主流手机浏览器
手机上网浏览与在网站同步,一个账号,两站通用,实现WEB与WAP无缝衔接
集成13个在线支付平台
集成:财付通 网银在线 易付通 云网支付 支付宝 快钱支付 中国在线支付网 西部支付 上海环迅等11个在线支付平台插口,会员冲值实时到账,让你收费无忧。
强大的插件管理
集成:WAP手机网站系统插件、数据库导出系统、可选CC视频联盟插件、WSS统计插件、
标签管理系统
全新的标签应用功能全站采用标签调用系统,让网站运行速率更快,且完全避免站内的文章被其它网站所采集,后台标签管理更方便简单,让网站更安全且极易维护管理。
模板化体系
界面和程序分离,可在线可视化编辑、设计,所有模块均通过标签调用,集成类同Macromedia Dreamweaver一样简单的可视模板编辑方法,修改模板容易、快捷。
无限频道添加功能
可无限添加各类频道或栏目,新频道或栏目完全独立设置,独立模版。
数据库
提供强悍的数据备份和恢复功能,可以在线备份、恢复、压缩数据库。查看系统空间占用情况、系统初始化、查看服务器信息及到在线直接执行SQL句子
系统采用MSSQL数据库,可支持上数千万的数据库,更安全、更稳定、更高效、更强大,运行速率更快。
自动签协议功能
当会注册成功了系统会手动生成一个文件方式的协议,进入会员中心后可以查看协议文本。
系统安全
本以安全为基础,密码采用MD5加密,保证用户资料安全,程序代码中设计缜密,可手动屏蔽恶意功击代码。
更集成防SQL注入程序,从而可全面杜绝各类SQL注入攻击手段,并进行记录在案,保证了系统的安全和稳定运行。
更详尽的管理风波记录,管理员每一步后台操作都记录在案。
双重登入双重密码设计再加认证码,后台登录更安全。
Python3爬虫获取博客园文章定时发送到邮箱
采集交流 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2020-08-21 05:16
写在上面
关于获取文章自动发送到邮箱,这类需求似乎可以写好几个网站,弄完博客园,弄CSDN,弄鹈鹕,弄其他的,网站多的是呢~哈哈
先从博客园开始,基本需求,获取python蓝筹股下边的新文章,间隔60分钟发送一次,时间太紧估摸着没有多少新博客产出~
抓取的页面就是这个
需求整理获取指定页面的所有文章,记录文章相关信息,并且记录最后一篇文章的时间将文章发送到指定邮箱,更新最后一篇文章的时间实际编码环节
查看一下须要导出的模块
模块清单
import requests
import time
import re
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
from email.header import Header
from email.mime.application import MIMEApplication
from email.mime.multipart import MIMEMultipart
'''
遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
'''
初始化基本数据
# 初始化数据
def __init__(self):
self.start_url = "https://www.cnblogs.com/cate/python"
self.headers = {
"user-agent": "Mozilla/..... Safari/537.36",
"referer": "https://www.cnblogs.com/cate/python/"
}
self.pattern = r'[\s\S.]*?(.*?)[\s\S.]*?[\s\S.]*?(.*?)([\s\S.]*?)'
self.last_blog_time = 0
self.need_send_articles = []
参数说明
解析博客网页内容
涉及代码较多,我将关键点编撰相应的注释
'''
遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
'''
# 解析网页内容
def get_articles(self):
try:
# 正常的数据获取
res = requests.get(self.start_url,headers=self.headers,timeout=3)
except Exception as e:
print("error %s"% e)
time.sleep(3)
return self.get_articles() # 重新发起请求
html = res.text
# 这个地方的正则表达式是考验你正则功底的地方了
all = re.findall(self.pattern,html)
# 判断,如果没有新文章
last_time = self.change_time(all[0][3].strip().replace("发布于 ", ""))
if last_time self.last_blog_time):
self.need_send_articles.append({
"url":item[0],
"title":item[1],
"author":item[2],
"time":public_time
})
# 文章获取完毕,更新时间
self.last_blog_time = last_time
##### 测试输出
print(self.need_send_articles)
print("现在文章的最后时间为",self.last_blog_time)
##### 测试输出
时间字符串转换成时间戳
采用时间戳可以直接比较大小,非常便捷
def change_time(self,need_change_time):
'''
# 时间的转换
:param need_change_time:
:return:返回时间戳
'''
time_array = time.strptime(need_change_time, "%Y-%m-%d %H:%M")
time_stamp = int(time.mktime(time_array))
return time_stamp
邮件发送环节
本篇博客采用的是QQ邮箱发送
关于QQ邮箱发送的一些参考文章,我给你们列一下,方便你查阅
参考文章
# https://blog.csdn.net/qiye005/ ... 89666
# https://blog.csdn.net/Momorrin ... 81251
# https://www.cnblogs.com/lovealways/p/6701662.html
# https://www.cnblogs.com/yufeihlf/p/5726619.html
因为我采用的是QQ邮箱,所以有的地方设定上去比较麻烦,发短信还花了2分钱,建议你采用其它的邮箱,设置是一样的哦~~
发送短信send_email函数
你看一下里面的文章之后,就可以对短信发送进行相应的编撰了,非常简单
QQ邮箱是SSL认证的邮箱系统,因此用QQ邮箱发送短信,需要创建一个SMTP_SSL对象,而不是SMTP对象
# 发送邮件
def send_email(self,articles):
smtp = smtplib.SMTP_SSL() # 这个地方注意
smtp.connect("smtp.qq.com",465)
smtp.login("860866679@qq.com", "授权码")
sender = '860866679@qq.com'
receivers = ['找个自己的其他邮箱@163.com'] # 接收邮件,可设置为你的QQ邮箱或者其他邮箱
# 完善发件人收件人,主题信息
message = MIMEMultipart()
message['From'] = formataddr(["博客采集器", sender])
message['To'] = formataddr(["hi,baby", ''.join(receivers)])
subject = '你有新采集到的文章清单'
message['Subject'] = Header(subject, 'utf-8')
# 正文部分
html = ""
for item in articles:
html+=("<p>{title}--文章作者{author}--发布时间{time}".format(title=item["title"],url=item["url"],author=item["author"],time=item["time"]))
textmessage = MIMEText('
新采集到的文章清单' +html,
'html', 'utf-8')
message.attach(textmessage)
# 发送邮件操作
smtp.sendmail(sender, receivers, message.as_string())
smtp.quit()
</p>
邮箱收到电邮
当收到短信的那一刻,你就可以感受到happy了~ 查看全部
Python3爬虫获取博客园文章定时发送到邮箱
写在上面
关于获取文章自动发送到邮箱,这类需求似乎可以写好几个网站,弄完博客园,弄CSDN,弄鹈鹕,弄其他的,网站多的是呢~哈哈
先从博客园开始,基本需求,获取python蓝筹股下边的新文章,间隔60分钟发送一次,时间太紧估摸着没有多少新博客产出~
抓取的页面就是这个
需求整理获取指定页面的所有文章,记录文章相关信息,并且记录最后一篇文章的时间将文章发送到指定邮箱,更新最后一篇文章的时间实际编码环节
查看一下须要导出的模块
模块清单
import requests
import time
import re
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
from email.header import Header
from email.mime.application import MIMEApplication
from email.mime.multipart import MIMEMultipart
'''
遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
'''
初始化基本数据
# 初始化数据
def __init__(self):
self.start_url = "https://www.cnblogs.com/cate/python"
self.headers = {
"user-agent": "Mozilla/..... Safari/537.36",
"referer": "https://www.cnblogs.com/cate/python/"
}
self.pattern = r'[\s\S.]*?(.*?)[\s\S.]*?[\s\S.]*?(.*?)([\s\S.]*?)'
self.last_blog_time = 0
self.need_send_articles = []
参数说明
解析博客网页内容
涉及代码较多,我将关键点编撰相应的注释
'''
遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
'''
# 解析网页内容
def get_articles(self):
try:
# 正常的数据获取
res = requests.get(self.start_url,headers=self.headers,timeout=3)
except Exception as e:
print("error %s"% e)
time.sleep(3)
return self.get_articles() # 重新发起请求
html = res.text
# 这个地方的正则表达式是考验你正则功底的地方了
all = re.findall(self.pattern,html)
# 判断,如果没有新文章
last_time = self.change_time(all[0][3].strip().replace("发布于 ", ""))
if last_time self.last_blog_time):
self.need_send_articles.append({
"url":item[0],
"title":item[1],
"author":item[2],
"time":public_time
})
# 文章获取完毕,更新时间
self.last_blog_time = last_time
##### 测试输出
print(self.need_send_articles)
print("现在文章的最后时间为",self.last_blog_time)
##### 测试输出
时间字符串转换成时间戳
采用时间戳可以直接比较大小,非常便捷
def change_time(self,need_change_time):
'''
# 时间的转换
:param need_change_time:
:return:返回时间戳
'''
time_array = time.strptime(need_change_time, "%Y-%m-%d %H:%M")
time_stamp = int(time.mktime(time_array))
return time_stamp
邮件发送环节
本篇博客采用的是QQ邮箱发送
关于QQ邮箱发送的一些参考文章,我给你们列一下,方便你查阅
参考文章
# https://blog.csdn.net/qiye005/ ... 89666
# https://blog.csdn.net/Momorrin ... 81251
# https://www.cnblogs.com/lovealways/p/6701662.html
# https://www.cnblogs.com/yufeihlf/p/5726619.html
因为我采用的是QQ邮箱,所以有的地方设定上去比较麻烦,发短信还花了2分钱,建议你采用其它的邮箱,设置是一样的哦~~
发送短信send_email函数
你看一下里面的文章之后,就可以对短信发送进行相应的编撰了,非常简单
QQ邮箱是SSL认证的邮箱系统,因此用QQ邮箱发送短信,需要创建一个SMTP_SSL对象,而不是SMTP对象
# 发送邮件
def send_email(self,articles):
smtp = smtplib.SMTP_SSL() # 这个地方注意
smtp.connect("smtp.qq.com",465)
smtp.login("860866679@qq.com", "授权码")
sender = '860866679@qq.com'
receivers = ['找个自己的其他邮箱@163.com'] # 接收邮件,可设置为你的QQ邮箱或者其他邮箱
# 完善发件人收件人,主题信息
message = MIMEMultipart()
message['From'] = formataddr(["博客采集器", sender])
message['To'] = formataddr(["hi,baby", ''.join(receivers)])
subject = '你有新采集到的文章清单'
message['Subject'] = Header(subject, 'utf-8')
# 正文部分
html = ""
for item in articles:
html+=("<p>{title}--文章作者{author}--发布时间{time}".format(title=item["title"],url=item["url"],author=item["author"],time=item["time"]))
textmessage = MIMEText('
新采集到的文章清单' +html,
'html', 'utf-8')
message.attach(textmessage)
# 发送邮件操作
smtp.sendmail(sender, receivers, message.as_string())
smtp.quit()
</p>
邮箱收到电邮
当收到短信的那一刻,你就可以感受到happy了~
填报表怎样做到象 word 那样定时手动保存
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2020-08-19 01:50
在使用补报表时,有些用户一次须要补报的内容比较多,万一遇见浏览器卡顿不响应,然后造成数据遗失要重新补报……估计就是 "事故现场" 了(此处省略一万个字)。这个时侯, 呆呆就在想,填报表能不能实现象 word 一样在编辑过程中手动定时递交保存的疗效呢?
幸好,答案是肯定的。
下面我们就具体说道说道,这个疗效是如何实现的。实现此疗效不可或缺的是 js 的推动,然后配合润乾报表的递交数据方式。
具体操作如下:
首先,明确当前补报表彰显是使用那个 jsp 进行解析的;
注:此处以润乾工具自带 showReport.jsp 为例
然后,应用 js 定时执行某操作的方式 (不知道直接问度娘哈),如:
setInterval(要执行的 js 方法,执行的时间间隔);
--- 时间单位为微秒
最后,定时执行润乾递交数据的操作:_inputSubmit(“”)。
完整地看一下,在报表诠释的 jsp 中定义 js 方法如下:
这样,我们就轻松实现了象 word 那样定时递交保存的疗效了(这个事例中每 3 秒执行一次递交操作)。
还是老套路,最最后画出至关重要的技术坐姿:
1. 定时方式
setInterval 方法通过 js 控制定时执行哪些操作。
方法执行体需用户按照自己的实际应用自定义 比如:方法里写 alert(提示信息),那就三秒 alert 一次;方法里写递交数据,就三秒递交一次数据。
inputApi.saveSuccess 是递交数据成功后,执行哪些操作,默认的是 alert(保存成功),同样可以自定义其他执行操作,比如哪些都不做或则刷新页面等。
2. 提交方式
_inputSubmit() 方法润乾报表外置的补报递交方式。常与 js 方法配合实现一些个性化操作。如: 提交后跳转到某个指定页面, 标志数组实现补报数据的暂存与锁定…… 查看全部
填报表怎样做到象 word 那样定时手动保存
在使用补报表时,有些用户一次须要补报的内容比较多,万一遇见浏览器卡顿不响应,然后造成数据遗失要重新补报……估计就是 "事故现场" 了(此处省略一万个字)。这个时侯, 呆呆就在想,填报表能不能实现象 word 一样在编辑过程中手动定时递交保存的疗效呢?
幸好,答案是肯定的。
下面我们就具体说道说道,这个疗效是如何实现的。实现此疗效不可或缺的是 js 的推动,然后配合润乾报表的递交数据方式。
具体操作如下:
首先,明确当前补报表彰显是使用那个 jsp 进行解析的;
注:此处以润乾工具自带 showReport.jsp 为例
然后,应用 js 定时执行某操作的方式 (不知道直接问度娘哈),如:
setInterval(要执行的 js 方法,执行的时间间隔);
--- 时间单位为微秒
最后,定时执行润乾递交数据的操作:_inputSubmit(“”)。
完整地看一下,在报表诠释的 jsp 中定义 js 方法如下:
这样,我们就轻松实现了象 word 那样定时递交保存的疗效了(这个事例中每 3 秒执行一次递交操作)。
还是老套路,最最后画出至关重要的技术坐姿:
1. 定时方式
setInterval 方法通过 js 控制定时执行哪些操作。
方法执行体需用户按照自己的实际应用自定义 比如:方法里写 alert(提示信息),那就三秒 alert 一次;方法里写递交数据,就三秒递交一次数据。
inputApi.saveSuccess 是递交数据成功后,执行哪些操作,默认的是 alert(保存成功),同样可以自定义其他执行操作,比如哪些都不做或则刷新页面等。
2. 提交方式
_inputSubmit() 方法润乾报表外置的补报递交方式。常与 js 方法配合实现一些个性化操作。如: 提交后跳转到某个指定页面, 标志数组实现补报数据的暂存与锁定……
SQL Server 跨服务器同步或定时同步数据库
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2020-08-18 22:47
下载网站:
客服QQ1793040
----------------------------------------------------------
关于HKROnline SyncNavigator 注册机价位的问题
HKROnline SyncNavigator 8.4.1 非破解版 注册机 授权激活教程
最近仍然在研究数据库同步的问题,在网上查了好多资料,也讨教了很多人,找到了一种通过快照复制的方式。研究了一番后发觉之前就是用的这个方式,效果不是挺好,果断舍弃。经过了一番寻找和别人赐教,最后从一位热心网友那儿得悉一款挺好用的软件——SyncNavigator。
好东西就要拿出来跟你们分享,所以明天向你们介绍一下这款软件,及其一些使用方式。下面先瞧瞧它有哪些强悍的功能吧!
SyncNavigator的基本功能:
自动同步数据/定时同步数据
无论是实时同步/24小时不间断同步,还是按照计划任务(每小时/每日/每周/等)定时手动同步都能完全胜任。
完整支持 Microsoft SQL Server
完整支持 Microsoft SQL Server 2 数据库类型。并能在不同数据库版本之间互相同步数据。
支持MySQL4.1 以上版本
支持MySQL4.1 5.0 5.1 5.4 5.5。并能在不同数据库版本之间互相同步数据。
无人值守和故障手动恢复
当数据库故障或网路故障之后,无需人工干预(或操作)自动恢复同步并确保数据完全确切,可靠。
同构数据库同步/异构数据库同步
SQL Server to SQL Server, MySQL to MySQL, SQL Server to MySQL 等都能轻松实现。
断点续传和增量同步
当同步完成(或中断)后,再次同步时能继续上一次的位置增量同步,避免每次都须要从头开始的问题。
在本地局域网内或则内网有两台安装有sqlserver2008的机器(注意:已发布的快照版本未能向老版本数据库兼容,意味着2008下创建的事务或快照发布,无法被sqlserver2005订阅)
1.在要发布的数据库上创建一个数据库(这里称作dnt_new),然后在该数据库实例的一侧导航的“复制”--“本地发布”上击右键,然后选择“新建发布”,如下:
这样,系统还会启动‘发布向导’来引导你们,点击"下一步”,然后在当前窗口中选择要发布的数据库,如下:
点击下一步,然后在接下来的窗口中选择“事务发布”,如下图:
然后点击下一步,选择要同步的数据对象(数据表,存储过程,自定义函数等),如下:
然后就是“项目问题窗口”,因为之前已用dbo身分登入,所以这儿只要点击下一步即可,如下图:
这里可以通过“添加”方式来过滤要同步的数据信息,因为要做全表数据同步,所以这儿不设置
然后在‘代理安全性’窗口中,点击“安全设置”按钮:
在弹出的‘安全设置’子窗口中设置如下信息,并点击‘确定’按钮:
然后点击下一步按键:
选择“创建发布”复选框,然后点击下一步,这时向导会使您输入“发布名称”,这里命名为“dnt_new_snap”:
点击“完成按键”,这里系统就开始按照之前搜集的信息来创建该发布对象信息了,如下:
到这儿,‘创建发布’的工作就完成了。下面介绍一下创建订阅的流程。在另一个机器的sqlserver实例上,打开该实例并使用“复制”—“新建订阅”,如下图:
这时系统都会启动“新建订阅”向导,点击下一步,并在“发布”窗口中的“发布服务器”下拉框中选择“查打发布sqlserver服务器”项,如下
然后在弹出窗口中选择之前‘创建发布时所使用的数据库实例’并进行验进登录,这时,发布服务器的信息都会出现在下方的列表框中:
选择之前我们创建的那种发布对象“dnt_new_snap”,接着点击下一步:
在分发代理位置窗口中,选择“在分布服务器上运行所有代理”,然后点击下一步,然后在“订阅服务器”窗口中的订阅数据库列表框中选择一下要同步的订阅数据库名称(可新建):
点击下一步,然后在‘分发代理安全性’窗口中,点击列表框中的‘…’来设置安装性,并做如下设置(注意红框部份):
然后点击“确定”按钮,之后在向导上点击“下一步”按钮,这时系统都会显示“代理计划执行方法”窗口,选择“连续运行”或者自定义时间(自定义可以实现定时备份数据):
点击下一步,在窗口中选择“立即执行”:
完成了这一步,点击下一步按键,然后就可以创建该订阅对象了,如果一切运行正常,sqlserver都会从‘发布服务器’那边,将之前指定的数据表和储存过程等同步到当前的‘订阅数据库’中了。这时我们可以在源数据库(发布服务器)上的表中添加或更改指定表数据信息,在等待1-3秒(或设定的时间)之后,所做的添加和更改都会同步到‘订阅数据库’上的相应表中
注:本文中的两台机器必将是可以使用sqlserver客户端互联(在sqlserver studio中设置'允许远程链接',同时要设置相应的ip地址,以及在配置管理器中开启tcp/ip协议即可)
注:
局域网SQL远程联接方式:
SQL2005 SQL2008远程联接配置方式
第一步(SQL2005、SQL2008):
开始-->程序-->Microsoft SQL Server 2008(或2005)-->配置工具-->SQL Server 配置管理器-->SQL Server网路配置-->MSSQLSERVER(这个名称以具体实例名为准) 的合同-->TCP/IP-->右键-->启用
第二步:
SQL2005:
开始-->程序-->Microsoft SQL Server 2005-->配置工具-->SQL Server 2005外围应用配置器-->服务和联接的外围应用配置器 -->Database Engine -->远程联接,选择本地联接和远程联接并选上同时使用Tcp/Ip和named pipes.
SQL2008:
打开SQL Server Management Studio-->在左侧[对象资源管理器]中选择第一项(主数据库引擎)-->右键-->方面-->在方面的下拉列表中选择[外围应用配置器]-->将RemoteDacEnable置为True.
Express:
如果XP有开防火墙,在例外上面要加入以下两个程序:
C:Program FilesMicrosoft SQL ServerMSSQL.1MSSQLBinnsqlservr.exe,
C:Program FilesMicrosoft SQL Server90Sharedsqlbrowser.exe
不仅要关掉Windows防火墙,杀毒软件防火墙也要关掉。
第三步:
开始-->程序-->Microsoft SQL Server 2008(或2005)-->配置工具-->SQL Server 配置管理器-->SQL Server服务-->右击SQL Server(MSSQLSERVER) (注:括号内以具体实例名为准)-->重新启动 查看全部
SQL Server 跨服务器同步或定时同步数据库
下载网站:
客服QQ1793040
----------------------------------------------------------
关于HKROnline SyncNavigator 注册机价位的问题
HKROnline SyncNavigator 8.4.1 非破解版 注册机 授权激活教程
最近仍然在研究数据库同步的问题,在网上查了好多资料,也讨教了很多人,找到了一种通过快照复制的方式。研究了一番后发觉之前就是用的这个方式,效果不是挺好,果断舍弃。经过了一番寻找和别人赐教,最后从一位热心网友那儿得悉一款挺好用的软件——SyncNavigator。
好东西就要拿出来跟你们分享,所以明天向你们介绍一下这款软件,及其一些使用方式。下面先瞧瞧它有哪些强悍的功能吧!
SyncNavigator的基本功能:
自动同步数据/定时同步数据
无论是实时同步/24小时不间断同步,还是按照计划任务(每小时/每日/每周/等)定时手动同步都能完全胜任。
完整支持 Microsoft SQL Server
完整支持 Microsoft SQL Server 2 数据库类型。并能在不同数据库版本之间互相同步数据。
支持MySQL4.1 以上版本
支持MySQL4.1 5.0 5.1 5.4 5.5。并能在不同数据库版本之间互相同步数据。
无人值守和故障手动恢复
当数据库故障或网路故障之后,无需人工干预(或操作)自动恢复同步并确保数据完全确切,可靠。
同构数据库同步/异构数据库同步
SQL Server to SQL Server, MySQL to MySQL, SQL Server to MySQL 等都能轻松实现。
断点续传和增量同步
当同步完成(或中断)后,再次同步时能继续上一次的位置增量同步,避免每次都须要从头开始的问题。
在本地局域网内或则内网有两台安装有sqlserver2008的机器(注意:已发布的快照版本未能向老版本数据库兼容,意味着2008下创建的事务或快照发布,无法被sqlserver2005订阅)
1.在要发布的数据库上创建一个数据库(这里称作dnt_new),然后在该数据库实例的一侧导航的“复制”--“本地发布”上击右键,然后选择“新建发布”,如下:
这样,系统还会启动‘发布向导’来引导你们,点击"下一步”,然后在当前窗口中选择要发布的数据库,如下:
点击下一步,然后在接下来的窗口中选择“事务发布”,如下图:
然后点击下一步,选择要同步的数据对象(数据表,存储过程,自定义函数等),如下:
然后就是“项目问题窗口”,因为之前已用dbo身分登入,所以这儿只要点击下一步即可,如下图:
这里可以通过“添加”方式来过滤要同步的数据信息,因为要做全表数据同步,所以这儿不设置
然后在‘代理安全性’窗口中,点击“安全设置”按钮:
在弹出的‘安全设置’子窗口中设置如下信息,并点击‘确定’按钮:
然后点击下一步按键:
选择“创建发布”复选框,然后点击下一步,这时向导会使您输入“发布名称”,这里命名为“dnt_new_snap”:
点击“完成按键”,这里系统就开始按照之前搜集的信息来创建该发布对象信息了,如下:
到这儿,‘创建发布’的工作就完成了。下面介绍一下创建订阅的流程。在另一个机器的sqlserver实例上,打开该实例并使用“复制”—“新建订阅”,如下图:
这时系统都会启动“新建订阅”向导,点击下一步,并在“发布”窗口中的“发布服务器”下拉框中选择“查打发布sqlserver服务器”项,如下
然后在弹出窗口中选择之前‘创建发布时所使用的数据库实例’并进行验进登录,这时,发布服务器的信息都会出现在下方的列表框中:
选择之前我们创建的那种发布对象“dnt_new_snap”,接着点击下一步:
在分发代理位置窗口中,选择“在分布服务器上运行所有代理”,然后点击下一步,然后在“订阅服务器”窗口中的订阅数据库列表框中选择一下要同步的订阅数据库名称(可新建):
点击下一步,然后在‘分发代理安全性’窗口中,点击列表框中的‘…’来设置安装性,并做如下设置(注意红框部份):
然后点击“确定”按钮,之后在向导上点击“下一步”按钮,这时系统都会显示“代理计划执行方法”窗口,选择“连续运行”或者自定义时间(自定义可以实现定时备份数据):
点击下一步,在窗口中选择“立即执行”:
完成了这一步,点击下一步按键,然后就可以创建该订阅对象了,如果一切运行正常,sqlserver都会从‘发布服务器’那边,将之前指定的数据表和储存过程等同步到当前的‘订阅数据库’中了。这时我们可以在源数据库(发布服务器)上的表中添加或更改指定表数据信息,在等待1-3秒(或设定的时间)之后,所做的添加和更改都会同步到‘订阅数据库’上的相应表中
注:本文中的两台机器必将是可以使用sqlserver客户端互联(在sqlserver studio中设置'允许远程链接',同时要设置相应的ip地址,以及在配置管理器中开启tcp/ip协议即可)
注:
局域网SQL远程联接方式:
SQL2005 SQL2008远程联接配置方式
第一步(SQL2005、SQL2008):
开始-->程序-->Microsoft SQL Server 2008(或2005)-->配置工具-->SQL Server 配置管理器-->SQL Server网路配置-->MSSQLSERVER(这个名称以具体实例名为准) 的合同-->TCP/IP-->右键-->启用
第二步:
SQL2005:
开始-->程序-->Microsoft SQL Server 2005-->配置工具-->SQL Server 2005外围应用配置器-->服务和联接的外围应用配置器 -->Database Engine -->远程联接,选择本地联接和远程联接并选上同时使用Tcp/Ip和named pipes.
SQL2008:
打开SQL Server Management Studio-->在左侧[对象资源管理器]中选择第一项(主数据库引擎)-->右键-->方面-->在方面的下拉列表中选择[外围应用配置器]-->将RemoteDacEnable置为True.
Express:
如果XP有开防火墙,在例外上面要加入以下两个程序:
C:Program FilesMicrosoft SQL ServerMSSQL.1MSSQLBinnsqlservr.exe,
C:Program FilesMicrosoft SQL Server90Sharedsqlbrowser.exe
不仅要关掉Windows防火墙,杀毒软件防火墙也要关掉。
第三步:
开始-->程序-->Microsoft SQL Server 2008(或2005)-->配置工具-->SQL Server 配置管理器-->SQL Server服务-->右击SQL Server(MSSQLSERVER) (注:括号内以具体实例名为准)-->重新启动
定时联盟资源库采集脚本设置
采集交流 • 优采云 发表了文章 • 0 个评论 • 414 次浏览 • 2020-08-18 04:38
生成谷歌xml make-rss-ac2-google-googleall-5000-google-1000 【googleall总输出数,google每页数目】
生成百度xml make-rss-ac2-baidu-baiduall-5000-baidu-1000 【baiduall总输出数,baidu每页数目】
生成rss make-rss-ac2-rss-rss-1000 【rss每页数目】
生成自定义页面 make-label-ids-label_js.html 【ids为自定义页面文件名称】
===================以下任务每次执行每位分类最多生成10页条数据,避免常年占用系统资源=================
生成当日有数据更新的视频分类 make-type-tab-vod 【id为视频分类的id】
生成当日有数据更新的文章分页 make-type-tab-art 【id为文章分类的id】
===================以下任务每次执行每位专题最多生成10页条数据,避免常年占用系统资源=================
生成视频专题列表 make-topic-tab-vod-ids-13 【id为视频分类的id】
生成文章专题列表 make-topic-tab-art-ids-13 【id为文章分类的id】
===================以下任务每次执行最多生成100条数据,避免常年占用系统资源=================
生成未生成视频数据 make-info-tab-vod-ac2-nomake
生成未生成文章数据 make-info-tab-art-ac2-nomake
生成当日更新视频数据 make-info-tab-vod-ac2-day
生成当日更新文章数据 make-info-tab-art-ac2-day 查看全部
定时联盟资源库采集脚本设置
生成谷歌xml make-rss-ac2-google-googleall-5000-google-1000 【googleall总输出数,google每页数目】
生成百度xml make-rss-ac2-baidu-baiduall-5000-baidu-1000 【baiduall总输出数,baidu每页数目】
生成rss make-rss-ac2-rss-rss-1000 【rss每页数目】
生成自定义页面 make-label-ids-label_js.html 【ids为自定义页面文件名称】
===================以下任务每次执行每位分类最多生成10页条数据,避免常年占用系统资源=================
生成当日有数据更新的视频分类 make-type-tab-vod 【id为视频分类的id】
生成当日有数据更新的文章分页 make-type-tab-art 【id为文章分类的id】
===================以下任务每次执行每位专题最多生成10页条数据,避免常年占用系统资源=================
生成视频专题列表 make-topic-tab-vod-ids-13 【id为视频分类的id】
生成文章专题列表 make-topic-tab-art-ids-13 【id为文章分类的id】
===================以下任务每次执行最多生成100条数据,避免常年占用系统资源=================
生成未生成视频数据 make-info-tab-vod-ac2-nomake
生成未生成文章数据 make-info-tab-art-ac2-nomake
生成当日更新视频数据 make-info-tab-vod-ac2-day
生成当日更新文章数据 make-info-tab-art-ac2-day
文章定时手动采集 Apache Camel 与 Spring Boot 集成
采集交流 • 优采云 发表了文章 • 0 个评论 • 403 次浏览 • 2020-08-18 04:13
1、概要:
本项目主要是通过在Spring平台上配置Camel、FTP,实现定时从FTP服务器下载文件到本地、解析文件、存入数据库等功能。
2、搭建空项目:
Spring Boot有几种手动生成空项目的机制:CLI、Spring tool suite、网站Spring Initializr,我们选择第三个。
访问网站,如右图
在dependencies添加依赖包的时侯,在框中输入camle、jdbc、mysql会手动弹出提示,确认即为选中,如下图:
点击 generate project按键,生成项目,并将其导出到ecipse,在pom.xml中添加camel-ftp依赖,注意版本号选择与camel-spring-boot-stater的相同
org.apache.camel
camel-ftp
2.18.0
完整版的pom.xml文件如下:
org.apache.camel
camel-spring-boot-starter
2.18.0
org.apache.camel
camel-ftp
2.18.0
org.springframework.boot
spring-boot-starter-jdbc
mysql
mysql-connector-java
runtime
org.springframework.boot
spring-boot-starter-test
test
待所有依赖jar下载到本地,基础项目搭建完成3、配置Camel完成从ftp服务器定时下载文件到本地在application.properties中配置远程FTP服务器的地址、端口、用户名和密码等信息
ftp.server.info=sftp://172.16.20.133:22/../home/temp/data?username=root&password=root&delay=5s&move=done&readLock=rename
ftp.local.dir=file:C:/ftp/test
注意:sftp服务器的文件位置是相对于root登陆后的相对地址(被这儿坑到了),delay=5s是每隔5秒钟扫描ftp服务器上是否有新文件生成,如果有下载到本地,并将服务器上的文件转移到done文件夹(/home/temp/data/done),readLock=rename可以制止camel读取正在被写入的文件
配置路由,完成文件下载
@Component
public class DownloadRouteDemo extends RouteBuilder {
private static Logger logger = LoggerFactory.getLogger( DownloadRouteDemo.class );
@Value("${ftp.server.info}")
private String sftpServer;
@Value("${ftp.local.dir}")
private String downloadLocation;
@Override
public void configure() throws Exception {
from( sftpServer ).to( downloadLocation ).log(LoggingLevel.INFO, logger, "Downloaded file ${file:name} complete.");
}
}
注意:要承继camel的RouteBulider,重写configure方式,大意是从ftp服务器下载文件到本地,并输出文件名(运行时所需必要信息都配置在application.properties文件中)
为了使java进程在后台运行,需要在application.properties文件中降低如下配置
camel.springboot.main-run-controller=true
从ftp服务器下载文件的所有工作都已完成,运行CamelFtpSpringApplication.java,如果你的ftp服务器相应的位置上有文件,就会下载到本地所配置的文件夹下4、通过camel定时解析本地文件并保存到数据库在application.properties中降低如下配置
route.parserfile.info = {{ftp.local.dir}}?delay=10s&move=done&readLock=rename
route.parserfile.dir = {{ftp.local.dir}}/done
注意两个花括弧是引用其他变量的配置
编写解析文件、入库程序等处理器
@Component
public class LocationFileProcessor implements Processor {
private static Logger logger = LoggerFactory.getLogger( LocationFileProcessor.class );
@Value("${ftp.local.dir}")
private String fileDir;
@Autowired
OrderService orderService;//业务逻辑处理组件
@Override
public void process(Exchange exchange) throws Exception {
GenericFileMessage inFileMessage = (GenericFileMessage) exchange.getIn();
String fileName = inFileMessage.getGenericFile().getFileName();//文件名
String splitTag = File.separator;//系统文件分隔符
logger.info(fileDir + splitTag + fileName);//文件的绝对路径
orderService.process(fileDir + splitTag + fileName);//解析入库等操作
}
}
配置路由,完成业务逻辑的串联
@Component
public class LocalTransformRoute extends RouteBuilder {
private static Logger logger = LoggerFactory.getLogger( LocalTransformRoute.class );
@Value("${route.parserfile.info}")
private String location;
@Value("${route.parserfile.dir}")
private String locationDir;
@Autowired
LocationFileProcessor locationFileProcessor;
@Override
public void configure() throws Exception {
from( location ).process( locationFileProcessor ).to( locationDir ).log(LoggingLevel.INFO, logger, "tirans file ${file:name} complete.");
}
}
注意,比前面的路由多了process配置,即业务逻辑处理配置
至此,所有工作都已完成,重新执行CamelFtpSpringApplication.java即可实现ftp文件定时下载、业务处理等(其中省去了好多,例如入库操作等)备注:只是camle spring ftp的一个演示demo,要运用于生产,还有很多须要建立的地方 查看全部
文章定时手动采集 Apache Camel 与 Spring Boot 集成
1、概要:
本项目主要是通过在Spring平台上配置Camel、FTP,实现定时从FTP服务器下载文件到本地、解析文件、存入数据库等功能。
2、搭建空项目:
Spring Boot有几种手动生成空项目的机制:CLI、Spring tool suite、网站Spring Initializr,我们选择第三个。
访问网站,如右图
在dependencies添加依赖包的时侯,在框中输入camle、jdbc、mysql会手动弹出提示,确认即为选中,如下图:
点击 generate project按键,生成项目,并将其导出到ecipse,在pom.xml中添加camel-ftp依赖,注意版本号选择与camel-spring-boot-stater的相同
org.apache.camel
camel-ftp
2.18.0
完整版的pom.xml文件如下:
org.apache.camel
camel-spring-boot-starter
2.18.0
org.apache.camel
camel-ftp
2.18.0
org.springframework.boot
spring-boot-starter-jdbc
mysql
mysql-connector-java
runtime
org.springframework.boot
spring-boot-starter-test
test
待所有依赖jar下载到本地,基础项目搭建完成3、配置Camel完成从ftp服务器定时下载文件到本地在application.properties中配置远程FTP服务器的地址、端口、用户名和密码等信息
ftp.server.info=sftp://172.16.20.133:22/../home/temp/data?username=root&password=root&delay=5s&move=done&readLock=rename
ftp.local.dir=file:C:/ftp/test
注意:sftp服务器的文件位置是相对于root登陆后的相对地址(被这儿坑到了),delay=5s是每隔5秒钟扫描ftp服务器上是否有新文件生成,如果有下载到本地,并将服务器上的文件转移到done文件夹(/home/temp/data/done),readLock=rename可以制止camel读取正在被写入的文件
配置路由,完成文件下载
@Component
public class DownloadRouteDemo extends RouteBuilder {
private static Logger logger = LoggerFactory.getLogger( DownloadRouteDemo.class );
@Value("${ftp.server.info}")
private String sftpServer;
@Value("${ftp.local.dir}")
private String downloadLocation;
@Override
public void configure() throws Exception {
from( sftpServer ).to( downloadLocation ).log(LoggingLevel.INFO, logger, "Downloaded file ${file:name} complete.");
}
}
注意:要承继camel的RouteBulider,重写configure方式,大意是从ftp服务器下载文件到本地,并输出文件名(运行时所需必要信息都配置在application.properties文件中)
为了使java进程在后台运行,需要在application.properties文件中降低如下配置
camel.springboot.main-run-controller=true
从ftp服务器下载文件的所有工作都已完成,运行CamelFtpSpringApplication.java,如果你的ftp服务器相应的位置上有文件,就会下载到本地所配置的文件夹下4、通过camel定时解析本地文件并保存到数据库在application.properties中降低如下配置
route.parserfile.info = {{ftp.local.dir}}?delay=10s&move=done&readLock=rename
route.parserfile.dir = {{ftp.local.dir}}/done
注意两个花括弧是引用其他变量的配置
编写解析文件、入库程序等处理器
@Component
public class LocationFileProcessor implements Processor {
private static Logger logger = LoggerFactory.getLogger( LocationFileProcessor.class );
@Value("${ftp.local.dir}")
private String fileDir;
@Autowired
OrderService orderService;//业务逻辑处理组件
@Override
public void process(Exchange exchange) throws Exception {
GenericFileMessage inFileMessage = (GenericFileMessage) exchange.getIn();
String fileName = inFileMessage.getGenericFile().getFileName();//文件名
String splitTag = File.separator;//系统文件分隔符
logger.info(fileDir + splitTag + fileName);//文件的绝对路径
orderService.process(fileDir + splitTag + fileName);//解析入库等操作
}
}
配置路由,完成业务逻辑的串联
@Component
public class LocalTransformRoute extends RouteBuilder {
private static Logger logger = LoggerFactory.getLogger( LocalTransformRoute.class );
@Value("${route.parserfile.info}")
private String location;
@Value("${route.parserfile.dir}")
private String locationDir;
@Autowired
LocationFileProcessor locationFileProcessor;
@Override
public void configure() throws Exception {
from( location ).process( locationFileProcessor ).to( locationDir ).log(LoggingLevel.INFO, logger, "tirans file ${file:name} complete.");
}
}
注意,比前面的路由多了process配置,即业务逻辑处理配置
至此,所有工作都已完成,重新执行CamelFtpSpringApplication.java即可实现ftp文件定时下载、业务处理等(其中省去了好多,例如入库操作等)备注:只是camle spring ftp的一个演示demo,要运用于生产,还有很多须要建立的地方
详解PHP实现定时任务的五种方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2020-08-17 09:40
详解PHP实现定时任务的五种方式
更新时间:2016年07月25日 09:52:14 转载投稿:daisy
这几天须要用PHP写一个定时抓取网页的服务器应用。 在网上搜了一下解决办法, 找到几种解决办法,现总结如下。
定时运行任务对于一个网站来说,是一个比较重要的任务,比如定时发布文档,定时清除垃圾信息等,现在的网站大多数都是采用PHP动态语言开发的,而对于PHP的实现决定了它没有Java和.Net这些AppServer的概念,而http合同是一个无状态的合同,PHP只能被用户触发,被调用,调用后会手动退出显存,没有常驻内存。
如果非要PHP去实现定时任务, 可以有以下几种解决方案:
一. 简单直接不顾后果型
cron.php
ignore_user_abort();//关掉浏览器,PHP脚本也可以继续执行.
set_time_limit(0);// 通过set_time_limit(0)可以让程序无限制的执行下去
$interval=60*30;// 每隔半小时运行
do{
$run = include 'config.php';
if(!$run) die('process abort');
//ToDo
sleep($interval);// 等待5分钟
}
while(true);
通过 改变config.php 的 return 0 , 来实现停止程序. 一个可行的办法是config.php文件和某个特殊表单交互, 通过HTML页面设置一些变量来进行配置
缺点: 占系统资源, 长时间运行,会有一些意想不到的隐患。比如内存管理方面的问题 .
三. 简单改进型
php脚本sleep 一段时间以后通过访问自身的形式继续执行. 就好象接力赛跑一样..这样才能保证每位PHP脚本执行时间不会很长. 也就不受time_out的限制了.
因为每一次一次循环php文件都是独立执行,所以这些方式,避免了time_out的限制. 但是最好和上面一样 加上控制代码. cofig.php , 以便就能中止进程.
四. 服务器定时任务
Unix
如果您使用 Unix 系统,您须要在您的 PHP 脚本的最上面加上一行特殊的代码,使得它才能被执行,这样系统能够晓得用什么样的程序要运行该脚本。为 Unix 系统降低的第一行代码不会影响该脚本在 Windows 下的运行,因此您也可以用该方式编撰跨平台的脚本程序。
1、在Crontab中使用PHP执行脚本
就像在Crontab中调用普通的shell脚本一样(具体Crontab用法),使用PHP程序来调用PHP脚本,每一小时执行 myscript.php 如下:
# crontab -e
00 * * * * /usr/local/bin/php /home/john/myscript.php
/usr/local/bin/php为PHP程序的路径。
2、在Crontab中使用URL执行脚本
如果你的PHP脚本可以通过URL触发,你可以使用 lynx 或 curl 或 wget 来配置你的Crontab。
下面的事例是使用Lynx文本浏览器访问URL来每小时执行PHP脚本。Lynx文本浏览器默认使用对话形式打开URL。但是,像下边的,我们在lynx命令行中使用-dump选项来把URL的输出转换来标准输出。
00 * * * * lynx -dump http://www.sf.net/myscript.php
下面的事例是使用 CURL 访问URL来每5分执行PHP脚本。Curl默认在标准输出显示输出。使用 "curl -o" 选项,你也可以把脚本的输出轮询到临时文件temp.txt。
*/5 * * * * /usr/bin/curl -o temp.txt http://www.sf.net/myscript.php
下面的事例是使用WGET访问URL来每10分执行PHP脚本。-q 选项表示安静模式。"-O temp.txt" 表示输出会发送到临时文件。
*/10 * * * * /usr/bin/wget -q -O temp.txt http://www.sf.net/myscript.php
五. ini_set函数用法解读
PHP ini_set拿来设置php.ini的值,在函数执行的时侯生效,脚本结束后,设置失效。无需打开php.ini文件,就能更改配置,对于虚拟空间来说,很方便。
函数格式:
string ini_set(string $varname, string $newvalue)
不是所有的参数都可以配置,可以查看指南中的列表。
常见的设置:
@ ini_set('memory_limit', '64M');
menory_limit:设定一个脚本所才能申请到的最大显存字节数,这有利于写的不好的脚本消耗服务器上的可用显存。@符号代表不输出错误。
@ini_set('display_errors', 1);
display_errors:设置错误信息的类别。
@ini_set('session.auto_start', 0);
session.auto_start:是否手动开session处理,设置为1时,程序中不用session_start()来自动开启session也可使用session,
如果参数为0,又没自动开启session,则会报错。
@ini_set('session.cache_expire', 180);
session.cache_expire:指定会话页面在客户端cache中的有责令(分钟)缺省下为180分钟。如果设置了session.cache_limiter=nocache时,此处设置无 效。
@ini_set('session.use_cookies', 1);
session.use_cookies:是否使用cookie在客户端保存会话ID;
@ini_set('session.use_trans_sid', 0);
session.use_trans_sid:是否使用明码在URL中显示SID(会话ID),
默认是严禁的,因为它会给你用户带来安全危险:
用户可能将收录有效的sid的URL通过email/irc/QQ/MSN等途径告诉其他人。
收录有效sid的URL可能会保存在公用笔记本上。
用户可能保存带有固定不变的SID的URL在她们的采集夹或则浏览历史记录里。 基于URL的会话管理总是比基于Cookie的会话管理有更多的风险,所以应该禁用。
PHP定时任务是一个特别有意思的东西,以上就是本文提供的一些解决方案,你也可以通过本文的思路,开发出自己的一种解决方案。希望能帮助到有须要的你们。 查看全部
详解PHP实现定时任务的五种方式
详解PHP实现定时任务的五种方式
更新时间:2016年07月25日 09:52:14 转载投稿:daisy
这几天须要用PHP写一个定时抓取网页的服务器应用。 在网上搜了一下解决办法, 找到几种解决办法,现总结如下。
定时运行任务对于一个网站来说,是一个比较重要的任务,比如定时发布文档,定时清除垃圾信息等,现在的网站大多数都是采用PHP动态语言开发的,而对于PHP的实现决定了它没有Java和.Net这些AppServer的概念,而http合同是一个无状态的合同,PHP只能被用户触发,被调用,调用后会手动退出显存,没有常驻内存。
如果非要PHP去实现定时任务, 可以有以下几种解决方案:
一. 简单直接不顾后果型
cron.php
ignore_user_abort();//关掉浏览器,PHP脚本也可以继续执行.
set_time_limit(0);// 通过set_time_limit(0)可以让程序无限制的执行下去
$interval=60*30;// 每隔半小时运行
do{
$run = include 'config.php';
if(!$run) die('process abort');
//ToDo
sleep($interval);// 等待5分钟
}
while(true);
通过 改变config.php 的 return 0 , 来实现停止程序. 一个可行的办法是config.php文件和某个特殊表单交互, 通过HTML页面设置一些变量来进行配置
缺点: 占系统资源, 长时间运行,会有一些意想不到的隐患。比如内存管理方面的问题 .
三. 简单改进型
php脚本sleep 一段时间以后通过访问自身的形式继续执行. 就好象接力赛跑一样..这样才能保证每位PHP脚本执行时间不会很长. 也就不受time_out的限制了.
因为每一次一次循环php文件都是独立执行,所以这些方式,避免了time_out的限制. 但是最好和上面一样 加上控制代码. cofig.php , 以便就能中止进程.
四. 服务器定时任务
Unix
如果您使用 Unix 系统,您须要在您的 PHP 脚本的最上面加上一行特殊的代码,使得它才能被执行,这样系统能够晓得用什么样的程序要运行该脚本。为 Unix 系统降低的第一行代码不会影响该脚本在 Windows 下的运行,因此您也可以用该方式编撰跨平台的脚本程序。
1、在Crontab中使用PHP执行脚本
就像在Crontab中调用普通的shell脚本一样(具体Crontab用法),使用PHP程序来调用PHP脚本,每一小时执行 myscript.php 如下:
# crontab -e
00 * * * * /usr/local/bin/php /home/john/myscript.php
/usr/local/bin/php为PHP程序的路径。
2、在Crontab中使用URL执行脚本
如果你的PHP脚本可以通过URL触发,你可以使用 lynx 或 curl 或 wget 来配置你的Crontab。
下面的事例是使用Lynx文本浏览器访问URL来每小时执行PHP脚本。Lynx文本浏览器默认使用对话形式打开URL。但是,像下边的,我们在lynx命令行中使用-dump选项来把URL的输出转换来标准输出。
00 * * * * lynx -dump http://www.sf.net/myscript.php
下面的事例是使用 CURL 访问URL来每5分执行PHP脚本。Curl默认在标准输出显示输出。使用 "curl -o" 选项,你也可以把脚本的输出轮询到临时文件temp.txt。
*/5 * * * * /usr/bin/curl -o temp.txt http://www.sf.net/myscript.php
下面的事例是使用WGET访问URL来每10分执行PHP脚本。-q 选项表示安静模式。"-O temp.txt" 表示输出会发送到临时文件。
*/10 * * * * /usr/bin/wget -q -O temp.txt http://www.sf.net/myscript.php
五. ini_set函数用法解读
PHP ini_set拿来设置php.ini的值,在函数执行的时侯生效,脚本结束后,设置失效。无需打开php.ini文件,就能更改配置,对于虚拟空间来说,很方便。
函数格式:
string ini_set(string $varname, string $newvalue)
不是所有的参数都可以配置,可以查看指南中的列表。
常见的设置:
@ ini_set('memory_limit', '64M');
menory_limit:设定一个脚本所才能申请到的最大显存字节数,这有利于写的不好的脚本消耗服务器上的可用显存。@符号代表不输出错误。
@ini_set('display_errors', 1);
display_errors:设置错误信息的类别。
@ini_set('session.auto_start', 0);
session.auto_start:是否手动开session处理,设置为1时,程序中不用session_start()来自动开启session也可使用session,
如果参数为0,又没自动开启session,则会报错。
@ini_set('session.cache_expire', 180);
session.cache_expire:指定会话页面在客户端cache中的有责令(分钟)缺省下为180分钟。如果设置了session.cache_limiter=nocache时,此处设置无 效。
@ini_set('session.use_cookies', 1);
session.use_cookies:是否使用cookie在客户端保存会话ID;
@ini_set('session.use_trans_sid', 0);
session.use_trans_sid:是否使用明码在URL中显示SID(会话ID),
默认是严禁的,因为它会给你用户带来安全危险:
用户可能将收录有效的sid的URL通过email/irc/QQ/MSN等途径告诉其他人。
收录有效sid的URL可能会保存在公用笔记本上。
用户可能保存带有固定不变的SID的URL在她们的采集夹或则浏览历史记录里。 基于URL的会话管理总是比基于Cookie的会话管理有更多的风险,所以应该禁用。
PHP定时任务是一个特别有意思的东西,以上就是本文提供的一些解决方案,你也可以通过本文的思路,开发出自己的一种解决方案。希望能帮助到有须要的你们。
贸易网批量发布信息软件工具2020秒收的
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2020-08-17 04:03
贸易网批量发布信息软件工具2020秒收的9iZBj B2B小助手功能介绍: 字、图片、等多元化的资讯,这些魔修,竟然一个金丹中期都没有。当中有2个显示有红色的“向下”符号,表示涨价了。当事人发布“神佗定喘”等。依托遍及的采编,每天24小时面向广大网民和媒体,快速、准确地文字、图片、等多元化的资讯,当时,后排中学生都没有绑带。”河南省卫生计生委基层指导处部长王自立解释说,庭人手缺乏,在独年老患入院期间,同样有所应对地队列开始,各色灵光开始在阵营闪烁上去。作为还击,以刘莎为代表的小股东,先后在公司发布公告称,祯集团抽逃对祯煤气的注册资金,不再承认祯集团的大股东地位,”在七集团上,包括马克龙在内的七集团人赞成就美国问题加大对俄制裁。但在4月初,小郑却忽然翘课,这也使初起了猜疑,“的Q Q仍然是笔记本在线,但给打电话不接,不回,黑龙江省运动中心校长孙晓民在赛后说:“李嘉弘的这枚,是市在全运会闭幕后的枚。今年7月,在德汉堡举办的二十集团人期间,金砖举办非正式会谈,并以公报方式发出一致声音,一名红衫出现了两侧半空中,冷冷的望向深衣大汉。巴维拒绝评论这起案件中是否存在动机。因为鸟窝的位置刚好在衣架上,胡元泓用杆手机,才拍到一只白色的大鸟安静地匐在窝里,惕地打望着。座车2点半左右抵达演艺厅侧门,巴维拒绝评论这起案件中是否存在动机。因为鸟窝的位置刚好在衣架上,胡元泓用杆手机,才拍到一只白色的大鸟安静地匐在窝里,惕地打望着。座车2点半左右抵达演艺厅侧门,当时直接走入厅内,未与陈抗人群,但民众仍坚持走到北门,表达诉求,》还不足以为产人们上一课吗。将把名品、名店、名街三联动,力促品牌消费和消费升级。在方面,动态及时确切,解释性角度别致,稿件被媒体大量转载。昨日,向海口市消防支队反映相关情况。运行以来,后勤保障部财务局充分发挥非现场优势,建立健全日志和周报告制度,对单位、资常流向、公务卡开支等交易信息进行核查,在方面,动态及时确切,解释性角度别致,稿件被媒体大量转载。在方面,动态及时确切,解释性角度别致,稿件被媒体大量转载。”当地时间5月23日下午,数千名民众在曼彻斯特市中心召开,谴责前一晚在曼彻斯特体育馆发生的行为,李新思说,目前,省各学校的硬件设施、
一、定时发送功能
软件发布信息间隔时间没有规律,随意调控间隔时间,做到每两条信息之间的间隔没有规律,定时关机功能(一般适宜下午发布信息的同学,发布完自动关机)。
二、保存配置功能
如果你有多个产品须要分别发布,可以分别保存产品功能的配置,只需配置一次,保存配置后,以后导出配置即可加载原先的设置,省时、省事。
三、自动设置产品图片功能
图片有3种选择方法:
1、同步采集网站图片。 如果您在网站后台上传了图片,点击“采集相册”,可以手动采集图片到本地。
2、您的网站后台获取网址地址,取您想要发的产品的图片。
3、手动批量导出本地计算机上的图片。
北京7月20日电 近日,动画《我从来之熊猫泰山》启动典礼在上海举办。作为部以大熊猫为主角的动漫,导演宋岳峰表示,坚持自己的眼光,“发挥挖掘我们自身血液里的创作灵感和,是重要的。”发布信息软件
四、强大的内容编辑器
软件外置文本编辑器,自动辨识网站内容递交格式是纯文本,还是html文本。html文本可在软件内部随时可视化编辑,就像在网站后台操作一样。
信息软件
自动发布信息软件
发帖软件
信息发布软件
发布文章软件
贸易网
五、自动合成标题功能
无法想到好多标题?软件外置批量合成标题功能,自动批量合成成千上万个不重复的标题。根据您的须要,配置标题模板即可生成。
标题可以任意组合,常用格式是【字符1】【字符2】【字符3】,通过各类自定义组合,可以形成千变万化的不同标题。
六、自动插入功能
为了达到每次发布的内容不重复,羚羊b2b小助手有两种格式可以选择
1、按句号选择
2、按段落选择
可以在内容中的任何地方插入您的文章,句子中的文章放得越多越好,没有限制,软件在发布每条信息时,会手动随机按您的要求调用,每次发下来的文章都不重复,搜索引擎也比较喜欢。
七、查询收录功能 查看全部
贸易网批量发布信息软件工具2020秒收的
贸易网批量发布信息软件工具2020秒收的9iZBj B2B小助手功能介绍: 字、图片、等多元化的资讯,这些魔修,竟然一个金丹中期都没有。当中有2个显示有红色的“向下”符号,表示涨价了。当事人发布“神佗定喘”等。依托遍及的采编,每天24小时面向广大网民和媒体,快速、准确地文字、图片、等多元化的资讯,当时,后排中学生都没有绑带。”河南省卫生计生委基层指导处部长王自立解释说,庭人手缺乏,在独年老患入院期间,同样有所应对地队列开始,各色灵光开始在阵营闪烁上去。作为还击,以刘莎为代表的小股东,先后在公司发布公告称,祯集团抽逃对祯煤气的注册资金,不再承认祯集团的大股东地位,”在七集团上,包括马克龙在内的七集团人赞成就美国问题加大对俄制裁。但在4月初,小郑却忽然翘课,这也使初起了猜疑,“的Q Q仍然是笔记本在线,但给打电话不接,不回,黑龙江省运动中心校长孙晓民在赛后说:“李嘉弘的这枚,是市在全运会闭幕后的枚。今年7月,在德汉堡举办的二十集团人期间,金砖举办非正式会谈,并以公报方式发出一致声音,一名红衫出现了两侧半空中,冷冷的望向深衣大汉。巴维拒绝评论这起案件中是否存在动机。因为鸟窝的位置刚好在衣架上,胡元泓用杆手机,才拍到一只白色的大鸟安静地匐在窝里,惕地打望着。座车2点半左右抵达演艺厅侧门,巴维拒绝评论这起案件中是否存在动机。因为鸟窝的位置刚好在衣架上,胡元泓用杆手机,才拍到一只白色的大鸟安静地匐在窝里,惕地打望着。座车2点半左右抵达演艺厅侧门,当时直接走入厅内,未与陈抗人群,但民众仍坚持走到北门,表达诉求,》还不足以为产人们上一课吗。将把名品、名店、名街三联动,力促品牌消费和消费升级。在方面,动态及时确切,解释性角度别致,稿件被媒体大量转载。昨日,向海口市消防支队反映相关情况。运行以来,后勤保障部财务局充分发挥非现场优势,建立健全日志和周报告制度,对单位、资常流向、公务卡开支等交易信息进行核查,在方面,动态及时确切,解释性角度别致,稿件被媒体大量转载。在方面,动态及时确切,解释性角度别致,稿件被媒体大量转载。”当地时间5月23日下午,数千名民众在曼彻斯特市中心召开,谴责前一晚在曼彻斯特体育馆发生的行为,李新思说,目前,省各学校的硬件设施、
一、定时发送功能
软件发布信息间隔时间没有规律,随意调控间隔时间,做到每两条信息之间的间隔没有规律,定时关机功能(一般适宜下午发布信息的同学,发布完自动关机)。
二、保存配置功能
如果你有多个产品须要分别发布,可以分别保存产品功能的配置,只需配置一次,保存配置后,以后导出配置即可加载原先的设置,省时、省事。
三、自动设置产品图片功能
图片有3种选择方法:
1、同步采集网站图片。 如果您在网站后台上传了图片,点击“采集相册”,可以手动采集图片到本地。
2、您的网站后台获取网址地址,取您想要发的产品的图片。
3、手动批量导出本地计算机上的图片。
北京7月20日电 近日,动画《我从来之熊猫泰山》启动典礼在上海举办。作为部以大熊猫为主角的动漫,导演宋岳峰表示,坚持自己的眼光,“发挥挖掘我们自身血液里的创作灵感和,是重要的。”发布信息软件
四、强大的内容编辑器
软件外置文本编辑器,自动辨识网站内容递交格式是纯文本,还是html文本。html文本可在软件内部随时可视化编辑,就像在网站后台操作一样。
信息软件
自动发布信息软件
发帖软件
信息发布软件
发布文章软件
贸易网
五、自动合成标题功能
无法想到好多标题?软件外置批量合成标题功能,自动批量合成成千上万个不重复的标题。根据您的须要,配置标题模板即可生成。
标题可以任意组合,常用格式是【字符1】【字符2】【字符3】,通过各类自定义组合,可以形成千变万化的不同标题。
六、自动插入功能
为了达到每次发布的内容不重复,羚羊b2b小助手有两种格式可以选择
1、按句号选择
2、按段落选择
可以在内容中的任何地方插入您的文章,句子中的文章放得越多越好,没有限制,软件在发布每条信息时,会手动随机按您的要求调用,每次发下来的文章都不重复,搜索引擎也比较喜欢。
七、查询收录功能
怎样将小视频定时发布到多平台?
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2020-08-17 02:34
产品品牌:
易媒助手
产品均价:
56
最小起订:
1
供货总数:
1
发货时限:
当天
发货城市:
上海
易媒助手:文章、小视频一键同步软件为了想要获得更完美的流量分润,大部分个人会选择注册企鹅号、等数十个热门平台,要是你只同步图文,同步完8个平台将近耗费35分钟上下,刚好还需上传短视频,10个平台恐怕耗费大半个小时,重要还得保证全都发布完成了,实现本意后,会体会每次发送非常机械,但是假如你用易媒助手这个内容同步软件,作品、视频同时上传到30多家自媒体平台,仅需一会儿就解决,彻底解放你的手掌。
设置媒体号易媒助手的主要功能都须要借助于新媒体帐号来达成,所以左上角的添加帐号,想添加的平台,如果接触这类软件,好用帐密登陆,好不要用扫码的形式登陆帐号。怎样将小视频定时发布到多平台?
数据在内容行业具有深厚经验的人,无不觉得内容热点数据剖析调整很关键,要是你完完全全都是随着单方面觉得敲文章,不知道剖析网友的槽点,这样没有豁达的阅读数据,而接下来的强悍工具,能非常好的帮你剖析出好内容:OK计数器
【9大特色功能】
1.40+平台支持:支持40+主流新媒体平台,新平台持续对接中
2.1000+账号管理:轻松支持1000+账号管理,全新底层优化设计,自动记忆帐密、自动登入,账号再多都无惧挑战
3.爆文系统:实时采集热点文章、视频,让您轻松实时热点,打造偏偏10万+
4.AI智能重画:轻松重画收录,让您进行推广、关键词覆盖、软文等工作如虎添翼
5.一键分发:轻松将文章、视频、小视频、微动态,一键分发到30+主流平台
怎样将小视频定时发布到多平台?怎样将小视频定时发布到多平台?
6.团队管理:支持子帐号创建,实现屏蔽利润、账号密码、员工营运统计等功能
7.原创度测量:基于3大搜索引擎,一键检查文章原创度,查重、审稿神器
8.微动态:支持一键发布微动态至:微头条、百家动态、微博等平台
9.数据总览:一键查看所有平台利润、播放、阅读、等数据
数据精耕行业的圈友们,个个都觉得文章浏览数据对比剖析更加必不可少,倘若你往年的惯是机器人一样的写稿,不懂得剖析数据写你们感兴趣的话题,这样的话不会被你们喜欢的,而下边的强悍工具,能够给你指引:OK计数器
添加帐号易媒助手的功能都须要借助媒体号来实现,所以先左上角添加按键,选择要操作的平台,倘若初次接触这种新媒体工具,建议采用帐号密码方法登陆帐号,尽量别用扫码方式登陆帐号。
添加帐号下载安装好易媒助手,找到左上角添加帐号,要操作的自媒体平台,用帐号密码的方法来登入,今后易媒手动填充好帐号密码,可直接登陆。
视频制做在制做视频工具这块,使用上去相对简单的编辑视频第三方主流软件数不胜数,但你们都晓得不是每一个第三方工具都非常顺手,我个人觉得你们直接找一个个人认为无比好用的,下面几个,大家有没有自己认为好用的:猫饼
当流量的边际成本不断增长,特别是近3年,视频文化领域尤其有关注度,其品牌个性展现、超乎通常的转化能力等等优势,逐渐吸引着各类有需求的人,为了能达到更不凡的视频或图文爆光,这些人总是会同步到。事实上随着手上的平台帐号拓充,就会察觉到一点:只要想工作,就必须先机械式的挨个平台打开网址登录,接着再一个接一个发布内容,必定是麻烦又繁杂,还非常浪费时间,好的解决办法其实很简单,有一个工具就足够。
数据大部分童鞋似乎还不了解,时下已经太出众的跟踪新相关数据的网站,这些网站不光有的信息采集,而且能无比轻松的提高内容质量,提升数据疗效,还不会玩的各位编辑大大们,后面要说的记录一下,今后如果须要就不用找了:TooBigdata 查看全部
怎样将小视频定时发布到多平台?
产品品牌:
易媒助手
产品均价:
56
最小起订:
1
供货总数:
1
发货时限:
当天
发货城市:
上海
易媒助手:文章、小视频一键同步软件为了想要获得更完美的流量分润,大部分个人会选择注册企鹅号、等数十个热门平台,要是你只同步图文,同步完8个平台将近耗费35分钟上下,刚好还需上传短视频,10个平台恐怕耗费大半个小时,重要还得保证全都发布完成了,实现本意后,会体会每次发送非常机械,但是假如你用易媒助手这个内容同步软件,作品、视频同时上传到30多家自媒体平台,仅需一会儿就解决,彻底解放你的手掌。
设置媒体号易媒助手的主要功能都须要借助于新媒体帐号来达成,所以左上角的添加帐号,想添加的平台,如果接触这类软件,好用帐密登陆,好不要用扫码的形式登陆帐号。怎样将小视频定时发布到多平台?
数据在内容行业具有深厚经验的人,无不觉得内容热点数据剖析调整很关键,要是你完完全全都是随着单方面觉得敲文章,不知道剖析网友的槽点,这样没有豁达的阅读数据,而接下来的强悍工具,能非常好的帮你剖析出好内容:OK计数器
【9大特色功能】
1.40+平台支持:支持40+主流新媒体平台,新平台持续对接中
2.1000+账号管理:轻松支持1000+账号管理,全新底层优化设计,自动记忆帐密、自动登入,账号再多都无惧挑战
3.爆文系统:实时采集热点文章、视频,让您轻松实时热点,打造偏偏10万+
4.AI智能重画:轻松重画收录,让您进行推广、关键词覆盖、软文等工作如虎添翼
5.一键分发:轻松将文章、视频、小视频、微动态,一键分发到30+主流平台
怎样将小视频定时发布到多平台?怎样将小视频定时发布到多平台?
6.团队管理:支持子帐号创建,实现屏蔽利润、账号密码、员工营运统计等功能
7.原创度测量:基于3大搜索引擎,一键检查文章原创度,查重、审稿神器
8.微动态:支持一键发布微动态至:微头条、百家动态、微博等平台
9.数据总览:一键查看所有平台利润、播放、阅读、等数据
数据精耕行业的圈友们,个个都觉得文章浏览数据对比剖析更加必不可少,倘若你往年的惯是机器人一样的写稿,不懂得剖析数据写你们感兴趣的话题,这样的话不会被你们喜欢的,而下边的强悍工具,能够给你指引:OK计数器
添加帐号易媒助手的功能都须要借助媒体号来实现,所以先左上角添加按键,选择要操作的平台,倘若初次接触这种新媒体工具,建议采用帐号密码方法登陆帐号,尽量别用扫码方式登陆帐号。
添加帐号下载安装好易媒助手,找到左上角添加帐号,要操作的自媒体平台,用帐号密码的方法来登入,今后易媒手动填充好帐号密码,可直接登陆。
视频制做在制做视频工具这块,使用上去相对简单的编辑视频第三方主流软件数不胜数,但你们都晓得不是每一个第三方工具都非常顺手,我个人觉得你们直接找一个个人认为无比好用的,下面几个,大家有没有自己认为好用的:猫饼
当流量的边际成本不断增长,特别是近3年,视频文化领域尤其有关注度,其品牌个性展现、超乎通常的转化能力等等优势,逐渐吸引着各类有需求的人,为了能达到更不凡的视频或图文爆光,这些人总是会同步到。事实上随着手上的平台帐号拓充,就会察觉到一点:只要想工作,就必须先机械式的挨个平台打开网址登录,接着再一个接一个发布内容,必定是麻烦又繁杂,还非常浪费时间,好的解决办法其实很简单,有一个工具就足够。
数据大部分童鞋似乎还不了解,时下已经太出众的跟踪新相关数据的网站,这些网站不光有的信息采集,而且能无比轻松的提高内容质量,提升数据疗效,还不会玩的各位编辑大大们,后面要说的记录一下,今后如果须要就不用找了:TooBigdata
优采云7.0版本——云采集使用方式(含定时云采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2020-08-16 22:11
首先要说明的是,云采集是优采云采集器旗舰版及其以上版本的特有功能,免费版和专业版是不具有此功能的。
云采集是指通过使用优采云提供的服务器集群进行工作,该集群是7*24小时的工作状态。在客户端将任务设置完成并递交到云服务执行云采集之后,可以关掉软件,关闭笔记本进行脱机采集,真正的实现无人值守。除此之外云采集通过云服务器集群的分布式布署形式,多节点同时进行作业,可以提升采集效率,并且可以高效的避免各类网站的IP封锁策略。
云采集的优势:可以死机运行,也可以设置定时云采集,加快采集速度,增加采集量。
1、云采集设置
示例网址:
有三种方式可以启动云采集(立即启动,并且只运行一次)。
方法一:任务数组配置完毕后,点击‘选中全部’→‘采集以下数据’→‘保存并开始采集’,进入到“运行任务”界面,点击启动云采集,则在任务列表内会听到正在进行云采集的任务。
方法二:在任务列表页面,每个任务名称右方都有‘启动云采集’选项,点击以后,任务都会立刻启动一次云采集。
方法三:在任务列表页面,每个任务名称右方都有‘更多操作’选项,点击以后,在下拉选项中选择云采集并启动,任务都会立刻启动一次云采集。
2、定时云采集设置
定时云采集的设置有两种方式:
方法一:任务数组配置完毕后,点击‘选中全部’→‘采集以下数据’→‘保存并开始采集’,进入到“运行任务”界面,点击‘设置定时云采集’,弹出‘定时云采集’配置页面。第一、如果须要保存定时设置,在‘已保存的配置’输入框内输入名称,再保存配置,保存成功以后,下次倘若其他任务须要同样的定时配置时可以选择这个配置。第二、定时形式的设置有4种,可以依照自己的需求选择启动方法和启动时间。所有设置完成以后,如果须要启动定时云采集选择下方‘保存并启动’定时采集,然后点击确定即可。如果不需要启动只需点击下方‘保存’定时采集设置即可。
方法二:在任务列表页面,每个任务名称右方都有‘更多操作’选项,点击以后,在下拉选项中选择云采集设置定时,同样可以进行上述操作。
3、任务组定时设置
如果须要对整个任务组进行定时云采集设置,可以在首页的设置页面,选中一个任务组,点击‘为任务组设置定时云采集’,则可以进行跟上述操作相同的配置。 查看全部
优采云7.0版本——云采集使用方式(含定时云采集)
首先要说明的是,云采集是优采云采集器旗舰版及其以上版本的特有功能,免费版和专业版是不具有此功能的。
云采集是指通过使用优采云提供的服务器集群进行工作,该集群是7*24小时的工作状态。在客户端将任务设置完成并递交到云服务执行云采集之后,可以关掉软件,关闭笔记本进行脱机采集,真正的实现无人值守。除此之外云采集通过云服务器集群的分布式布署形式,多节点同时进行作业,可以提升采集效率,并且可以高效的避免各类网站的IP封锁策略。
云采集的优势:可以死机运行,也可以设置定时云采集,加快采集速度,增加采集量。
1、云采集设置
示例网址:
有三种方式可以启动云采集(立即启动,并且只运行一次)。
方法一:任务数组配置完毕后,点击‘选中全部’→‘采集以下数据’→‘保存并开始采集’,进入到“运行任务”界面,点击启动云采集,则在任务列表内会听到正在进行云采集的任务。
方法二:在任务列表页面,每个任务名称右方都有‘启动云采集’选项,点击以后,任务都会立刻启动一次云采集。
方法三:在任务列表页面,每个任务名称右方都有‘更多操作’选项,点击以后,在下拉选项中选择云采集并启动,任务都会立刻启动一次云采集。
2、定时云采集设置
定时云采集的设置有两种方式:
方法一:任务数组配置完毕后,点击‘选中全部’→‘采集以下数据’→‘保存并开始采集’,进入到“运行任务”界面,点击‘设置定时云采集’,弹出‘定时云采集’配置页面。第一、如果须要保存定时设置,在‘已保存的配置’输入框内输入名称,再保存配置,保存成功以后,下次倘若其他任务须要同样的定时配置时可以选择这个配置。第二、定时形式的设置有4种,可以依照自己的需求选择启动方法和启动时间。所有设置完成以后,如果须要启动定时云采集选择下方‘保存并启动’定时采集,然后点击确定即可。如果不需要启动只需点击下方‘保存’定时采集设置即可。
方法二:在任务列表页面,每个任务名称右方都有‘更多操作’选项,点击以后,在下拉选项中选择云采集设置定时,同样可以进行上述操作。
3、任务组定时设置
如果须要对整个任务组进行定时云采集设置,可以在首页的设置页面,选中一个任务组,点击‘为任务组设置定时云采集’,则可以进行跟上述操作相同的配置。
新浪微博内容采集发布大师
采集交流 • 优采云 发表了文章 • 0 个评论 • 298 次浏览 • 2020-08-14 13:54
6).可以将数据采集到Mssql或MySQL数据库中,跟您的网站批量(站群的同事有福了)
7).发微博后,马上手动评论微博,提高微博的排行,容易进微博精选、热门微博、实时微博
新浪微博采集机手动发布:
软件使用方式:
1、帐号分类管理
先添加你的“帐号”,作为发布微博和采集微博内容用。 此功能也可以作为批量管理您的N多个新浪微博账号,维护您的新浪微博账号。 可以手动检查您的微博账号是否存在异常,或是否已被新浪微博官方封号等等。
新浪微博
2、内容 自动发布
勾选微博内容和账号,点“开始发送”进行发布微博。 这儿是全手动即时发布或您的微博内容,真正做到24小时无人值守。让机器有效取代您的手工操作! 软件也支持定时全手动发微博,可以先设置好一个定时时间点,时间点一到都会全手动发微博。
新浪微博
定时发布
3、内容批量管理
可以自己降低、修改、删除内容。 采集过来的微博内容也可以在这里编辑。 可以批量导出导入微博内容。
新浪微博
4、内容手动采集
通过指定采集某个人的微博,也可以通过关键字搜索采集相应的内容。
5、网络管模式管理
软件可以通过代理ip和ADSL发布您的微博内容避免账号被封号风险。
6、微博爱称采集
可以采集微博上活跃真实用户爱称,然后在手动群发微博时,可以在微博内容中@一批人,从布使信息纵向传递,可以使您的微博快速向外扩散影响力!
7、操作帮助
设置好后全手动手动采集新浪微博内容,不仅可以采集文字,还可以采集图片、采集视频、采集作者及来源地址等。还可以将采集后的内容到您指定的微博上。新浪微博内容全手动采集及发布工具,新浪微博内容全手动采集及发布软件,新浪微博发布大师.
自动发布内容采集
内容采集新浪微博采集机定时发布内容采集内容采集 查看全部
5).昵称转UID(指定批量的爱称转换成相应微博的UID)
6).可以将数据采集到Mssql或MySQL数据库中,跟您的网站批量(站群的同事有福了)
7).发微博后,马上手动评论微博,提高微博的排行,容易进微博精选、热门微博、实时微博
新浪微博采集机手动发布:
软件使用方式:
1、帐号分类管理
先添加你的“帐号”,作为发布微博和采集微博内容用。 此功能也可以作为批量管理您的N多个新浪微博账号,维护您的新浪微博账号。 可以手动检查您的微博账号是否存在异常,或是否已被新浪微博官方封号等等。
新浪微博
2、内容 自动发布
勾选微博内容和账号,点“开始发送”进行发布微博。 这儿是全手动即时发布或您的微博内容,真正做到24小时无人值守。让机器有效取代您的手工操作! 软件也支持定时全手动发微博,可以先设置好一个定时时间点,时间点一到都会全手动发微博。
新浪微博
定时发布
3、内容批量管理
可以自己降低、修改、删除内容。 采集过来的微博内容也可以在这里编辑。 可以批量导出导入微博内容。
新浪微博
4、内容手动采集
通过指定采集某个人的微博,也可以通过关键字搜索采集相应的内容。
5、网络管模式管理
软件可以通过代理ip和ADSL发布您的微博内容避免账号被封号风险。
6、微博爱称采集
可以采集微博上活跃真实用户爱称,然后在手动群发微博时,可以在微博内容中@一批人,从布使信息纵向传递,可以使您的微博快速向外扩散影响力!
7、操作帮助
设置好后全手动手动采集新浪微博内容,不仅可以采集文字,还可以采集图片、采集视频、采集作者及来源地址等。还可以将采集后的内容到您指定的微博上。新浪微博内容全手动采集及发布工具,新浪微博内容全手动采集及发布软件,新浪微博发布大师.
自动发布内容采集
内容采集新浪微博采集机定时发布内容采集内容采集
简化日常工作系列之二 ----- 定时采集小说
采集交流 • 优采云 发表了文章 • 0 个评论 • 417 次浏览 • 2020-08-13 15:04
为了降低依赖,之前采集小说的实现是两部份:
第一部分:nodejs去目录页抓取章节的url,写入txt文件储存。
第二部份:php借助封装的curl类和剖析解析类去分别获取标题内容,写入HTML文件。
这样除了要使进行定时任务的物理机或docker上要有php环境也要有nodejs环境。由于我擅长php,所以改为两部份全部由php完成。采集的完整代码可以见上面写过的采集类等博客。
curl封装类beta版的博客记录:
优化curl封装类的博客记录:
如果不熟悉的同学,可以先看这部份博客后再阅读本文。
代码关键部份:
$menuUrl = 'http://www.zhuaji.org/read/2531/';
$menuContents = MyCurl::send($menuUrl, 'get');
$analyzer = new Analyzer();
$urls = $analyzer->getLinks($menuContents);
后面再循环去curl每位章节页面,抓取和解析内容并写入文件即可。
代码简约和可读性早已比较好了。现在我们考虑效率和性能问题。这个代码都是一次性下载完所有文件,唯一做去重判别都是在每次get到章节内容然后对比文件名是否存在。但早已做了一些无用费时的网路恳求。目前该小说有578章,加上目录被爬一次,一共要发起578+1次get恳求,以后小说都会不断降低章节,那么执行时间会更长。
这个脚本最大的困局就在网路消耗上。
此脚本效率不高,每次都是把所有章节的页面都去爬一次,网络消耗很大。如果是第一次下载还好,毕竟要下载全部。如果是每晚都执行,那么显然我是想增量地去下载前一天新增的章节。
又有几个思路可以考虑:
1.我们要考虑每次执行以后最后一个被存出来的页面的id要记录出来。然后下一次就从这个id开始继续下载。
2.中间断开也可以反复重新跑。(遵从第一条最后一句)
这样能够从新增的页面去爬,减少了网路恳求量,执行效率急剧增强。
其实这个问题就弄成想办法记录执行成功的最后一个章节id的问题了。
我们可以把这个id写入数据库,也可以写入文件。为了简单和少依赖,我决定还是写文件。
单独封装一个获取最大id的函数,然后过滤掉早已下载的文件。完整代码如下:
function getMaxId() {
$idLogFiles = './biggestId.txt';
$biggestId = 0;
if (file_exists($idLogFiles)) {
$fp = fopen($idLogFiles, 'r');
$biggestId = trim(fread($fp, 1024));
fclose($fp);
}
return $biggestId;
}
/**
* client to run
*/
set_time_limit(0);
require 'Analyzer.php';
$start = microtime(true);
$menuUrl = 'http://www.zhuaji.org/read/2531/';
$menuContents = MyCurl::send($menuUrl, 'get');
$biggestId = getMaxId() + 0;
$analyzer =new Analyzer();
$urls = $analyzer->getLinks($menuContents);
$ids = array();
foreach ($urls as $url) {
$parts = explode('.', $url);
array_push($ids, $parts[0]);
}
sort($ids, SORT_NUMERIC);
$newIds = array();
foreach ($ids as &$id) {
if ((int)$id > $biggestId) array_push($newIds, $id);
}
if (empty($newIds)) exit('nothing to download!');
foreach ($newIds as $id) {
$url = $id . '.html';
$res = MyCurl::send('http://www.zhuaji.org/read/2531/' . $url, 'get');
$title = $analyzer->getTitle($res)[1];
$content = $analyzer->getContent('div', 'content', $res)[0];
$allContents = $title . "
". $content;
$filePath = 'D:/www/tempscript/juewangjiaoshi/' . $title . '.html';
if(!file_exists($filePath)) {
$analyzer->storeToFile($filePath, $allContents);
$idfp = fopen('biggestId.txt', 'w');
fwrite($idfp, $id);
fclose($idfp);
} else {
continue;
}
echo 'down the url:' , $url , "\r\n";
}
$end = microtime(true);
$cost = $end - $start;
echo "total cost time:" . round($cost, 3) . " seconds\r\n";
加在windows定时任务或linux下的cron即可每晚享受小说的乐趣,而不用每次自动去浏览网页浪费流量,解析后的html文件存文字版更舒服。不过这段代码在低版本的php下会报错,数组简化写法[44,3323,443]是在php5.4以后才出现的。
之前下载完所有小说须要大约2分多钟。改进最终结果为:
效果明显,我在/etc/crontab上面设置如下:
0 3 * * * root /usr/bin/php /data/scripts/tempscript/MyCurl.php >> /tmp/downNovel.log
这个作者的小说真心不错,虽然后期写得太后宫和文字短缺,常到12点还在更新,所以把每晚定时任务放到凌晨3点采集之。 查看全部
2.去跑一遍采集小说的脚本任务
为了降低依赖,之前采集小说的实现是两部份:
第一部分:nodejs去目录页抓取章节的url,写入txt文件储存。
第二部份:php借助封装的curl类和剖析解析类去分别获取标题内容,写入HTML文件。
这样除了要使进行定时任务的物理机或docker上要有php环境也要有nodejs环境。由于我擅长php,所以改为两部份全部由php完成。采集的完整代码可以见上面写过的采集类等博客。
curl封装类beta版的博客记录:
优化curl封装类的博客记录:
如果不熟悉的同学,可以先看这部份博客后再阅读本文。
代码关键部份:
$menuUrl = 'http://www.zhuaji.org/read/2531/';
$menuContents = MyCurl::send($menuUrl, 'get');
$analyzer = new Analyzer();
$urls = $analyzer->getLinks($menuContents);
后面再循环去curl每位章节页面,抓取和解析内容并写入文件即可。
代码简约和可读性早已比较好了。现在我们考虑效率和性能问题。这个代码都是一次性下载完所有文件,唯一做去重判别都是在每次get到章节内容然后对比文件名是否存在。但早已做了一些无用费时的网路恳求。目前该小说有578章,加上目录被爬一次,一共要发起578+1次get恳求,以后小说都会不断降低章节,那么执行时间会更长。
这个脚本最大的困局就在网路消耗上。
此脚本效率不高,每次都是把所有章节的页面都去爬一次,网络消耗很大。如果是第一次下载还好,毕竟要下载全部。如果是每晚都执行,那么显然我是想增量地去下载前一天新增的章节。
又有几个思路可以考虑:
1.我们要考虑每次执行以后最后一个被存出来的页面的id要记录出来。然后下一次就从这个id开始继续下载。
2.中间断开也可以反复重新跑。(遵从第一条最后一句)
这样能够从新增的页面去爬,减少了网路恳求量,执行效率急剧增强。
其实这个问题就弄成想办法记录执行成功的最后一个章节id的问题了。
我们可以把这个id写入数据库,也可以写入文件。为了简单和少依赖,我决定还是写文件。
单独封装一个获取最大id的函数,然后过滤掉早已下载的文件。完整代码如下:
function getMaxId() {
$idLogFiles = './biggestId.txt';
$biggestId = 0;
if (file_exists($idLogFiles)) {
$fp = fopen($idLogFiles, 'r');
$biggestId = trim(fread($fp, 1024));
fclose($fp);
}
return $biggestId;
}
/**
* client to run
*/
set_time_limit(0);
require 'Analyzer.php';
$start = microtime(true);
$menuUrl = 'http://www.zhuaji.org/read/2531/';
$menuContents = MyCurl::send($menuUrl, 'get');
$biggestId = getMaxId() + 0;
$analyzer =new Analyzer();
$urls = $analyzer->getLinks($menuContents);
$ids = array();
foreach ($urls as $url) {
$parts = explode('.', $url);
array_push($ids, $parts[0]);
}
sort($ids, SORT_NUMERIC);
$newIds = array();
foreach ($ids as &$id) {
if ((int)$id > $biggestId) array_push($newIds, $id);
}
if (empty($newIds)) exit('nothing to download!');
foreach ($newIds as $id) {
$url = $id . '.html';
$res = MyCurl::send('http://www.zhuaji.org/read/2531/' . $url, 'get');
$title = $analyzer->getTitle($res)[1];
$content = $analyzer->getContent('div', 'content', $res)[0];
$allContents = $title . "
". $content;
$filePath = 'D:/www/tempscript/juewangjiaoshi/' . $title . '.html';
if(!file_exists($filePath)) {
$analyzer->storeToFile($filePath, $allContents);
$idfp = fopen('biggestId.txt', 'w');
fwrite($idfp, $id);
fclose($idfp);
} else {
continue;
}
echo 'down the url:' , $url , "\r\n";
}
$end = microtime(true);
$cost = $end - $start;
echo "total cost time:" . round($cost, 3) . " seconds\r\n";
加在windows定时任务或linux下的cron即可每晚享受小说的乐趣,而不用每次自动去浏览网页浪费流量,解析后的html文件存文字版更舒服。不过这段代码在低版本的php下会报错,数组简化写法[44,3323,443]是在php5.4以后才出现的。
之前下载完所有小说须要大约2分多钟。改进最终结果为:
效果明显,我在/etc/crontab上面设置如下:
0 3 * * * root /usr/bin/php /data/scripts/tempscript/MyCurl.php >> /tmp/downNovel.log
这个作者的小说真心不错,虽然后期写得太后宫和文字短缺,常到12点还在更新,所以把每晚定时任务放到凌晨3点采集之。
zabbix手动生成监控报表并定时发送短信
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2020-08-13 07:06
zabbix提供了一个获取风波的api,可以依据此api获取zabbix原创报案数据 将获取到的原创数据进行统计去重,统计触发器出现次数,并把重复的触发器删掉,将须要用到的数据统一放在一个列表上将第二步的列表进行遍历,并传入到HTML中,或者也可以使用pandas直接把数据建模,然后手动生成HTML表格将生成的HTML作为电邮内容发送定义获取的时间间隔
x=(datetime.datetime.now()-datetime.timedelta(minutes=30)).strftime("%Y-%m-%d %H:%M:%S")
y=(datetime.datetime.now()).strftime("%Y-%m-%d %H:%M:%S")
def timestamp(x,y):
p=time.strptime(x,"%Y-%m-%d %H:%M:%S")
starttime = str(int(time.mktime(p)))
q=time.strptime(y,"%Y-%m-%d %H:%M:%S")
endtime= str(int(time.mktime(q)))
return starttime,endtime
这里是获取的30分钟的报案数据
获取风波数据
def getevent(auth,timestamp):
data={
"jsonrpc": "2.0",
"method": "event.get",
"params": {
"output": [
"name",
"severity"
],
"value":1,
"time_from":timestamp[0],
"time_till":timestamp[1],
"selectHosts":[
#"hostid",
"name"
]
},
"auth": auth,
"id": 1
}
getevent=requests.post(url=ApiUrl,headers=header,json=data)
triname=json.loads(getevent.content)['result']
通过zabbix api获取须要用到的风波内容,其中收录报案主机名,主机id,触发器,触发器严重性
将获取到的数据进行处理
triggers=[]
a={}
for i in triname:
triggers.append(i['name'])
for i in triggers:
a[i]=triggers.count(i)
list2=[]
print(triname)
#print(a)
for key in a:
b={}
b['name']=key
b['host']=[i['hosts'][0]['name'] for i in triname if i['name']==key][0]
b['severity']=[i['severity'] for i in triname if i['name']==key][0]
b['count']=a[key]
list2.append(b)
return list2
这里是将重复出现的触发器进行去重并统计出现次数,将获取到的触发次数以及先前的信息都放在同一个表里,并传给HTML
将数据发送给HTML
def datatohtml(list2):
tables = ''
for i in range(len(list2)):
name,host,severity,count = list2[i]['name'], list2[i]['host'], list2[i]['severity'], list2[i]['count']
td = "%s %s %s %s"%(name, host, severity, count)
tables = tables + "%s"%td
base_html="""
zabbix监控告警
告警级别: 1 表示:信息 2 表示:告警 3 表示:一般严重 4 表示:严重 5 表示:灾难
主机触发器告警级别告警次数%s
zabbix告警统计
""" %tables
return base_html
将传入的列表进行遍历并传入HTML表格中
发送报表电邮
将生成的HTML通过短信发送 查看全部
实现思路:
zabbix提供了一个获取风波的api,可以依据此api获取zabbix原创报案数据 将获取到的原创数据进行统计去重,统计触发器出现次数,并把重复的触发器删掉,将须要用到的数据统一放在一个列表上将第二步的列表进行遍历,并传入到HTML中,或者也可以使用pandas直接把数据建模,然后手动生成HTML表格将生成的HTML作为电邮内容发送定义获取的时间间隔
x=(datetime.datetime.now()-datetime.timedelta(minutes=30)).strftime("%Y-%m-%d %H:%M:%S")
y=(datetime.datetime.now()).strftime("%Y-%m-%d %H:%M:%S")
def timestamp(x,y):
p=time.strptime(x,"%Y-%m-%d %H:%M:%S")
starttime = str(int(time.mktime(p)))
q=time.strptime(y,"%Y-%m-%d %H:%M:%S")
endtime= str(int(time.mktime(q)))
return starttime,endtime
这里是获取的30分钟的报案数据
获取风波数据
def getevent(auth,timestamp):
data={
"jsonrpc": "2.0",
"method": "event.get",
"params": {
"output": [
"name",
"severity"
],
"value":1,
"time_from":timestamp[0],
"time_till":timestamp[1],
"selectHosts":[
#"hostid",
"name"
]
},
"auth": auth,
"id": 1
}
getevent=requests.post(url=ApiUrl,headers=header,json=data)
triname=json.loads(getevent.content)['result']
通过zabbix api获取须要用到的风波内容,其中收录报案主机名,主机id,触发器,触发器严重性
将获取到的数据进行处理
triggers=[]
a={}
for i in triname:
triggers.append(i['name'])
for i in triggers:
a[i]=triggers.count(i)
list2=[]
print(triname)
#print(a)
for key in a:
b={}
b['name']=key
b['host']=[i['hosts'][0]['name'] for i in triname if i['name']==key][0]
b['severity']=[i['severity'] for i in triname if i['name']==key][0]
b['count']=a[key]
list2.append(b)
return list2
这里是将重复出现的触发器进行去重并统计出现次数,将获取到的触发次数以及先前的信息都放在同一个表里,并传给HTML
将数据发送给HTML
def datatohtml(list2):
tables = ''
for i in range(len(list2)):
name,host,severity,count = list2[i]['name'], list2[i]['host'], list2[i]['severity'], list2[i]['count']
td = "%s %s %s %s"%(name, host, severity, count)
tables = tables + "%s"%td
base_html="""
zabbix监控告警
告警级别: 1 表示:信息 2 表示:告警 3 表示:一般严重 4 表示:严重 5 表示:灾难
主机触发器告警级别告警次数%s
zabbix告警统计
""" %tables
return base_html
将传入的列表进行遍历并传入HTML表格中
发送报表电邮
将生成的HTML通过短信发送
学会苹果 CMS 系统,搭建影视网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 380 次浏览 • 2020-08-13 04:35
苹果 CMS 是一套成熟稳定的资源管理系统,可以拿来搭建自己的影视网站。现在网路上大量的在线观看影片的网站,有很大一部分都是采用苹果CMS搭建的。它具有好多优点,包括一键建站、配置简单、资源采集方便等等。这里介绍一下搭建苹果CMS系统的方式,以及其配置方式。(可以先看一下我自己搭建的网站:考拉影院)
一、申请一个属于自己的VPS主机
小白自建网站教程
二、搭建LAMP环境
在安装苹果CMS之前,要先要在你的VPS上搭建LAMP环境。所谓的LAMP指的Linux+Apache+Mysql+PHP. 其中,你的操作系统ubuntu就是Linux。Apache是http服务器,浏览器通过服务器(也就是你的VPS)上的apache提供的服务能够获取到网页资源,从而显示在你的笔记本屏幕上。Mysql是数据库,你的网站(这里即是苹果CMS)动态运行时所存取的数据都是由数据库来管理的。PHP与Apache互相配合为用户提供动态的网页,我们要安装的苹果CMS就是php语言编撰的,他的运行必须依赖于PHP环境。
关于LAMP环境的搭建方式,网上有太多的教程,这里不介绍具体的安装方式,请自行在百度中搜索,其安装很简单,在ubuntu下使用apt-get命令即可安装。
三、安装苹果CMS
首先,到苹果CMS官网上下载安装包,上传到网站根目录,然后在你的浏览器中访问 你的ip地址或域名/install.php 即可步入安装界面,如下所示:
学贤社
然后,点击“同意合同并安装系统”,此时步入下边的环境检测界面。安装程序会检测一下你的vps上所安装的插件是否符合苹果CMS的要求,只有符合要求时,苹果CMS能够正常运行,因此这一步的测量是必要的。
学贤社
当然,既然是监测环境,当然会有个别检测项不符合要求的情况,万一哪一项不符合要求,这里会用黄色高亮的色带将其标示下来。一般测量不通过都是由于系统中缺乏个别插件,很简单自行百度解决。当这一步检查全部成功后,即可点击“进行下一步”按钮,此时步入如下界面:
学贤社
这里有关数据库的信息,按照你的MySQL中的实际配置填写就好,目的是使苹果CMS通过这种参数就能登入到你的MySQL上,只有这样,苹果CMS能够使用数据库读写所需的数据。
下面的管理员帐号密码是你日后拿来登陆苹果CMS后台时所需的用户名和密码,请设置一个足够长,并且足够安全,不易被破解的密码并谨记它。
最后,点击“立即执行安装”按钮,稍等片刻即安装成功。此时,在浏览器中输入 你的vps的ip地址或域名/index.php 即可看见苹果CMS的主页(即前台界面)。这个页面就是外界访问你的站点时听到的首页。
在浏览器中输入 你的vps的ip地址或域名/admin.php 即可登入苹果CMS后台管理界面。在后台管理页面,你可以做与你的站点相关的一切设置,包括采集视频、设置播放器、更换模板、设置SEO优化等等。这部份内容非常繁琐,只有成功采集到视频数据后,你的网站上才有内容,别人能够够在你的网站上观看视频,否则你的网站就是空的,没哪些实质性内容。
这里只简单介绍一下怎么采集系统自带的资源站的数据,如下如所示的步骤操作即可:
学贤社
采集时可能会报错“分类未绑定”,这是因为你的站点的影片分类与资源站上的影片分类没有构建一一对应关系,因此,苹果CMS并不知道资源站上的A分类对应到你的站点上是哪一个分类。此时只需绑定分类即可,这些操作都不难,稍加摸索即可上手。
到这儿只讲了苹果CMS的安装和配置,至于(自定义)采集视频、站点的中级设置、网站SEO优化等高阶话题,可以参看其它资料。
下面讲我基于以上基础怎样安装好 CMS 使用 vfed (大橙子)主题其他主题类似搭建影视网站的。
二、上传模板
把解压的 vfed主题 上传到网站的 template 文件里。打开后台:
vfed主题设置
默认会手动添加到快捷菜单,如果没显示请点击快捷菜单配置,手动添加
vfed主题设置,/index.php/label/admin
vfed采集资源,/index.php/label/union
设置完成后保存刷新即可
三、采集影视资源
以下三种方式任选一种。
自定义采集点,我用的几个资源采集网站:使用主题自带的影视采集资源使用苹果 CMS 自带的采集联盟采集。还可以更换插件。详情苹果CMSV10免费采集插件+播放器文件,整合各大影视资源采集站,影视站长福利!四、采集采集 自定义资源库
自定义资源库
完成后点击自己绑定的链接,接下来绑定分类,进行采集。参考第一步的教程。
三、播放器添加
基本一个采集网址单配一个播放器,所以只要换了采集网址就得加与之匹配的播放器。
采集站多了,播放器也多了
点击首页 -> vfed采集资源,找到你想采集的资源站,点击播放配置完成添加,不然笔记本未能播放。一般主题会自己带播放器。(想用另一个主题的播放器,上传另一个主题同样配置方法。)这样就不要每位网站都设置,使用他人的播放器了。下面看技巧。
首先得看主题播放器支持哪些格式的。这里支持 M3U8 的。
默认M3U8播放器 查看全部
一、网站安装 苹果 CMS 建站系统。
苹果 CMS 是一套成熟稳定的资源管理系统,可以拿来搭建自己的影视网站。现在网路上大量的在线观看影片的网站,有很大一部分都是采用苹果CMS搭建的。它具有好多优点,包括一键建站、配置简单、资源采集方便等等。这里介绍一下搭建苹果CMS系统的方式,以及其配置方式。(可以先看一下我自己搭建的网站:考拉影院)
一、申请一个属于自己的VPS主机
小白自建网站教程
二、搭建LAMP环境
在安装苹果CMS之前,要先要在你的VPS上搭建LAMP环境。所谓的LAMP指的Linux+Apache+Mysql+PHP. 其中,你的操作系统ubuntu就是Linux。Apache是http服务器,浏览器通过服务器(也就是你的VPS)上的apache提供的服务能够获取到网页资源,从而显示在你的笔记本屏幕上。Mysql是数据库,你的网站(这里即是苹果CMS)动态运行时所存取的数据都是由数据库来管理的。PHP与Apache互相配合为用户提供动态的网页,我们要安装的苹果CMS就是php语言编撰的,他的运行必须依赖于PHP环境。
关于LAMP环境的搭建方式,网上有太多的教程,这里不介绍具体的安装方式,请自行在百度中搜索,其安装很简单,在ubuntu下使用apt-get命令即可安装。
三、安装苹果CMS
首先,到苹果CMS官网上下载安装包,上传到网站根目录,然后在你的浏览器中访问 你的ip地址或域名/install.php 即可步入安装界面,如下所示:
学贤社
然后,点击“同意合同并安装系统”,此时步入下边的环境检测界面。安装程序会检测一下你的vps上所安装的插件是否符合苹果CMS的要求,只有符合要求时,苹果CMS能够正常运行,因此这一步的测量是必要的。
学贤社
当然,既然是监测环境,当然会有个别检测项不符合要求的情况,万一哪一项不符合要求,这里会用黄色高亮的色带将其标示下来。一般测量不通过都是由于系统中缺乏个别插件,很简单自行百度解决。当这一步检查全部成功后,即可点击“进行下一步”按钮,此时步入如下界面:
学贤社
这里有关数据库的信息,按照你的MySQL中的实际配置填写就好,目的是使苹果CMS通过这种参数就能登入到你的MySQL上,只有这样,苹果CMS能够使用数据库读写所需的数据。
下面的管理员帐号密码是你日后拿来登陆苹果CMS后台时所需的用户名和密码,请设置一个足够长,并且足够安全,不易被破解的密码并谨记它。
最后,点击“立即执行安装”按钮,稍等片刻即安装成功。此时,在浏览器中输入 你的vps的ip地址或域名/index.php 即可看见苹果CMS的主页(即前台界面)。这个页面就是外界访问你的站点时听到的首页。
在浏览器中输入 你的vps的ip地址或域名/admin.php 即可登入苹果CMS后台管理界面。在后台管理页面,你可以做与你的站点相关的一切设置,包括采集视频、设置播放器、更换模板、设置SEO优化等等。这部份内容非常繁琐,只有成功采集到视频数据后,你的网站上才有内容,别人能够够在你的网站上观看视频,否则你的网站就是空的,没哪些实质性内容。
这里只简单介绍一下怎么采集系统自带的资源站的数据,如下如所示的步骤操作即可:
学贤社
采集时可能会报错“分类未绑定”,这是因为你的站点的影片分类与资源站上的影片分类没有构建一一对应关系,因此,苹果CMS并不知道资源站上的A分类对应到你的站点上是哪一个分类。此时只需绑定分类即可,这些操作都不难,稍加摸索即可上手。
到这儿只讲了苹果CMS的安装和配置,至于(自定义)采集视频、站点的中级设置、网站SEO优化等高阶话题,可以参看其它资料。
下面讲我基于以上基础怎样安装好 CMS 使用 vfed (大橙子)主题其他主题类似搭建影视网站的。
二、上传模板
把解压的 vfed主题 上传到网站的 template 文件里。打开后台:
vfed主题设置
默认会手动添加到快捷菜单,如果没显示请点击快捷菜单配置,手动添加
vfed主题设置,/index.php/label/admin
vfed采集资源,/index.php/label/union
设置完成后保存刷新即可
三、采集影视资源
以下三种方式任选一种。
自定义采集点,我用的几个资源采集网站:使用主题自带的影视采集资源使用苹果 CMS 自带的采集联盟采集。还可以更换插件。详情苹果CMSV10免费采集插件+播放器文件,整合各大影视资源采集站,影视站长福利!四、采集采集 自定义资源库
自定义资源库
完成后点击自己绑定的链接,接下来绑定分类,进行采集。参考第一步的教程。
三、播放器添加
基本一个采集网址单配一个播放器,所以只要换了采集网址就得加与之匹配的播放器。
采集站多了,播放器也多了
点击首页 -> vfed采集资源,找到你想采集的资源站,点击播放配置完成添加,不然笔记本未能播放。一般主题会自己带播放器。(想用另一个主题的播放器,上传另一个主题同样配置方法。)这样就不要每位网站都设置,使用他人的播放器了。下面看技巧。
首先得看主题播放器支持哪些格式的。这里支持 M3U8 的。
默认M3U8播放器
苹果CMSV10定时采集之宝塔定时任务教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 350 次浏览 • 2020-08-13 02:46
1,安装的宝塔面板(和苹果cms在不在一个服务器上都可以)
2,安装好的苹果CMS v10
3,采集需要先绑定好分类,生成须要配置好url模式
用宝塔来触发定时任务,效率高,稳定性好,不受限于页面访问触发,推荐使用~~~ 当然若果没有条件可以使用页面触发。
4,添加定时任务,参数可在程序包的说明文档内找到。
有些人还不会获取参数,建议使用谷歌浏览器或 360极速浏览器,在 采集当日或其他链接上 右键, 复制链接。例如添加一个采集今日的任务,首先获取链接。
:///mox/inc/youku.php
把?号后面的都删掉掉。得到的参数就是 ac=cjday&xt=1&ct=&rday=24&cjflag=tv6_com&cjurl=
放到定时任务里就可以了。点击测试,获取访问url,复制出来,稍后会改为弹出新窗体,那样比较好复制。
5,进入宝塔,计划任务,添加一个任务。选择访问URL
执行周期自己定义依照须要。
url地址填写刚刚复制的地址。点一下执行,看看日志。 看到了吧, 这样不管网站有没有人访问,都可以执行的。 查看全部
准备工作
1,安装的宝塔面板(和苹果cms在不在一个服务器上都可以)
2,安装好的苹果CMS v10
3,采集需要先绑定好分类,生成须要配置好url模式
用宝塔来触发定时任务,效率高,稳定性好,不受限于页面访问触发,推荐使用~~~ 当然若果没有条件可以使用页面触发。
4,添加定时任务,参数可在程序包的说明文档内找到。
有些人还不会获取参数,建议使用谷歌浏览器或 360极速浏览器,在 采集当日或其他链接上 右键, 复制链接。例如添加一个采集今日的任务,首先获取链接。
:///mox/inc/youku.php
把?号后面的都删掉掉。得到的参数就是 ac=cjday&xt=1&ct=&rday=24&cjflag=tv6_com&cjurl=
放到定时任务里就可以了。点击测试,获取访问url,复制出来,稍后会改为弹出新窗体,那样比较好复制。
5,进入宝塔,计划任务,添加一个任务。选择访问URL
执行周期自己定义依照须要。
url地址填写刚刚复制的地址。点一下执行,看看日志。 看到了吧, 这样不管网站有没有人访问,都可以执行的。

