
插入关键字 文章采集器
触发元素动态型网页的两种方法和应用方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-08-09 18:13
。该标签被定义为替代的有效标签。
2.2.2 触发元素动态网页采用异步加载技术。当用户点击触发元素时,会触发绑定到有效元素的特定事件,浏览器会执行该事件对应的JavaScript动态脚本程序。 所以需要一个工具来模拟用户的点击操作,HtmlUnit正好可以解决这个模拟问题。 HtmlUnit是一个开源的Java页面分析工具,使用Rhinojs引擎,可以模拟浏览器操作,运行速度非常快。该系统使用全检测扫描算法[13]对有效元素集中的所有元素进行点击操作。 2.2.3 触发有效性判断 当动态网页触发有效元素时,会改变DOM树的结构。触发器有效性判断也可以表示为DOM树结构的变化,因此可以比较DOM树结构的相似度作为触发器有效性的指标。由于每次获取下一页,只有网页中的图片和文字信息发生变化,其他杂音、链接等部分基本不变。因此,在判断DOM树的相似度之前,通过正则表达式过滤中文文本信息。何欣等
[14] 使用简单的树匹配算法来确定 DOM 树的相似度。它是一种限制匹配算法,它使用动态规划来计算两棵树之间的最大匹配节点数,以获得两棵树结构的相似度。程度;罗斯特等
[15] 提出了一种比较页面的方法。此方法将每个模块与模块所针对的 DOM 树结构的特征部分进行比较。如果确定内容相同,则过滤掉部分信息,将剩余的内容传递给下一个比较模块,否则可以直接确定两个DOM树不相似。以上两种方法更多是基于DOM树结构,考虑到新闻页面的有效信息在中文文本中。在页面标题的情况下,系统将新获取的网页中文信息与触发前的网页中文信息进行比较。如果只有少量更改,则认为新获取的网页无效,触发器无效;否则,则认为获取的网页是有效的,有效元素XPath存储在XPath模板库中。 2.3 新闻常用网页信息提取模块新闻常用网页信息提取模块的目标是提取新闻常用网页的正文信息。一般新闻网页的正文结构通常比较紧凑,网页中的图片较少,正文代码中的大部分文字占一行,超链接长度所占的百分比也不大。并且由于行块分布算法对主题网页通用性好、准确率高,所以采用行块分布算法。线块分析算法的思想由哈尔滨工业大学信息检索中心陈欣等人提出。网页文本块的起始行块号Xstart和结束行块号Xend的确定必须同时满足以下条件,这里定义Y(X)为带有行号的行块的长度X 为轴。 (1)Ystart> Y(Xt),其中Y(Xt)为线块长度的第一个膨胀点,膨胀点的线块长度必须大于预先定义的阈值。
(2)Y(Xn)不等于0(其中n属于[start+1,start+n]),紧接膨胀点的行块长度不能为0,以消除噪声。
(3)Y(Xm)=0(其中m属于[end,end+1]),下垂点的长度和下垂点后面的行块为0,保证文本结束提取 根据线块分布算法的思想,本文利用Java中的JFreeChart绘制工具,得到如图4所示的线块分布函数折线图。从图4中可以看出内容很多阻止[start=743, end =745], [start=749, end=773], [start=1160, end=1165], [start=1198, end=1205],内容块可能有噪音还没有清除。因此,根据消息,针对网页噪音的特点,增加了第四个约束。
(4)Ystart
3 个实验测试
3.1实验准备
测试系统机器环境为:1台台式电脑(CPU为Intel四核2.93GHz,4G内存,硬盘7200r/min,操作系统Win7,10M网速)。本系统采用纯Java实现,有效元素路径存储在MySQL5.5数据库中。为了让结果更有说服力,本文设计了一个轻量级主题爬虫,从知名新闻网站(如腾讯新闻、网易新闻、搜狐新闻、新浪新闻等)中抓取网页作为实验页面放。实验主要测试提取新闻正文信息的正确率和速度,而新闻标题是从网页采集器中提取的(一般导航网页,新闻标题和新闻网址是一起的),这里不做处理。对于动态新闻,提取的文本完全覆盖了真实含义,未过滤的噪声占文本的不到5%才算合格。对于静态网页,本文用准确率来表示建议正文信息的准确率:准确率=正确过滤的页面数/总页面数×100%
3.2 实验结果表1为系统网页正文提取准确率和在线文本提取率,其中每个网站有100个动态网页和静态网页,共1600个网页表1的测试结果表明,该系统提取静态网页的准确率高于93%,对原创新闻网页正文内容的提取较为完整,而动态网页的提取准确率均在80%以上。报错的原因是不同主题的设计风格不一样,并且存在人们对网页中文字定义的差异等因素,本文算法的结果或多或少会受到影响对于正文内容为纯文本的网页,本文算法的准确率非常高。影响本系统准确性的主要因素总结如下: ①动态网页与普通新闻网页的区分是根据网址的相似度和网址是否收录标识符来判断的; ②对于普通新闻网页的正文内容和噪声部分如果网页的主要内容是图片或视频,过短的文本内容会被当作噪声,从而降低提取结果的准确性; ③如果在普通新闻网页中嵌入图片,文字部分之间的距离会相差较大。
4实验结论本文提出的新闻网页正文提取系统采用行阻塞算法提取网页信息和DOM技术,还利用动态网页结构的相似性特征实现大规模news网站新闻文字信息抽取。该系统不依赖大量训练集,能够更准确地提取新闻文本信息。实验结果验证了其有效性。但是,对于英文网页和结构复杂的网页,提取效果并不理想,尤其是对于嵌入了图形信息的普通新闻网页。该方法只能提取文本信息,无法获取网页图片。下一步,我们可以在英文网页优化、复杂网页提取算法、网页图片获取方法等方面进行深入研究。
查看全部
触发元素动态型网页的两种方法和应用方法
。该标签被定义为替代的有效标签。
2.2.2 触发元素动态网页采用异步加载技术。当用户点击触发元素时,会触发绑定到有效元素的特定事件,浏览器会执行该事件对应的JavaScript动态脚本程序。 所以需要一个工具来模拟用户的点击操作,HtmlUnit正好可以解决这个模拟问题。 HtmlUnit是一个开源的Java页面分析工具,使用Rhinojs引擎,可以模拟浏览器操作,运行速度非常快。该系统使用全检测扫描算法[13]对有效元素集中的所有元素进行点击操作。 2.2.3 触发有效性判断 当动态网页触发有效元素时,会改变DOM树的结构。触发器有效性判断也可以表示为DOM树结构的变化,因此可以比较DOM树结构的相似度作为触发器有效性的指标。由于每次获取下一页,只有网页中的图片和文字信息发生变化,其他杂音、链接等部分基本不变。因此,在判断DOM树的相似度之前,通过正则表达式过滤中文文本信息。何欣等
[14] 使用简单的树匹配算法来确定 DOM 树的相似度。它是一种限制匹配算法,它使用动态规划来计算两棵树之间的最大匹配节点数,以获得两棵树结构的相似度。程度;罗斯特等
[15] 提出了一种比较页面的方法。此方法将每个模块与模块所针对的 DOM 树结构的特征部分进行比较。如果确定内容相同,则过滤掉部分信息,将剩余的内容传递给下一个比较模块,否则可以直接确定两个DOM树不相似。以上两种方法更多是基于DOM树结构,考虑到新闻页面的有效信息在中文文本中。在页面标题的情况下,系统将新获取的网页中文信息与触发前的网页中文信息进行比较。如果只有少量更改,则认为新获取的网页无效,触发器无效;否则,则认为获取的网页是有效的,有效元素XPath存储在XPath模板库中。 2.3 新闻常用网页信息提取模块新闻常用网页信息提取模块的目标是提取新闻常用网页的正文信息。一般新闻网页的正文结构通常比较紧凑,网页中的图片较少,正文代码中的大部分文字占一行,超链接长度所占的百分比也不大。并且由于行块分布算法对主题网页通用性好、准确率高,所以采用行块分布算法。线块分析算法的思想由哈尔滨工业大学信息检索中心陈欣等人提出。网页文本块的起始行块号Xstart和结束行块号Xend的确定必须同时满足以下条件,这里定义Y(X)为带有行号的行块的长度X 为轴。 (1)Ystart> Y(Xt),其中Y(Xt)为线块长度的第一个膨胀点,膨胀点的线块长度必须大于预先定义的阈值。
(2)Y(Xn)不等于0(其中n属于[start+1,start+n]),紧接膨胀点的行块长度不能为0,以消除噪声。
(3)Y(Xm)=0(其中m属于[end,end+1]),下垂点的长度和下垂点后面的行块为0,保证文本结束提取 根据线块分布算法的思想,本文利用Java中的JFreeChart绘制工具,得到如图4所示的线块分布函数折线图。从图4中可以看出内容很多阻止[start=743, end =745], [start=749, end=773], [start=1160, end=1165], [start=1198, end=1205],内容块可能有噪音还没有清除。因此,根据消息,针对网页噪音的特点,增加了第四个约束。
(4)Ystart
3 个实验测试
3.1实验准备
测试系统机器环境为:1台台式电脑(CPU为Intel四核2.93GHz,4G内存,硬盘7200r/min,操作系统Win7,10M网速)。本系统采用纯Java实现,有效元素路径存储在MySQL5.5数据库中。为了让结果更有说服力,本文设计了一个轻量级主题爬虫,从知名新闻网站(如腾讯新闻、网易新闻、搜狐新闻、新浪新闻等)中抓取网页作为实验页面放。实验主要测试提取新闻正文信息的正确率和速度,而新闻标题是从网页采集器中提取的(一般导航网页,新闻标题和新闻网址是一起的),这里不做处理。对于动态新闻,提取的文本完全覆盖了真实含义,未过滤的噪声占文本的不到5%才算合格。对于静态网页,本文用准确率来表示建议正文信息的准确率:准确率=正确过滤的页面数/总页面数×100%
3.2 实验结果表1为系统网页正文提取准确率和在线文本提取率,其中每个网站有100个动态网页和静态网页,共1600个网页表1的测试结果表明,该系统提取静态网页的准确率高于93%,对原创新闻网页正文内容的提取较为完整,而动态网页的提取准确率均在80%以上。报错的原因是不同主题的设计风格不一样,并且存在人们对网页中文字定义的差异等因素,本文算法的结果或多或少会受到影响对于正文内容为纯文本的网页,本文算法的准确率非常高。影响本系统准确性的主要因素总结如下: ①动态网页与普通新闻网页的区分是根据网址的相似度和网址是否收录标识符来判断的; ②对于普通新闻网页的正文内容和噪声部分如果网页的主要内容是图片或视频,过短的文本内容会被当作噪声,从而降低提取结果的准确性; ③如果在普通新闻网页中嵌入图片,文字部分之间的距离会相差较大。
4实验结论本文提出的新闻网页正文提取系统采用行阻塞算法提取网页信息和DOM技术,还利用动态网页结构的相似性特征实现大规模news网站新闻文字信息抽取。该系统不依赖大量训练集,能够更准确地提取新闻文本信息。实验结果验证了其有效性。但是,对于英文网页和结构复杂的网页,提取效果并不理想,尤其是对于嵌入了图形信息的普通新闻网页。该方法只能提取文本信息,无法获取网页图片。下一步,我们可以在英文网页优化、复杂网页提取算法、网页图片获取方法等方面进行深入研究。

优采云免费采集器支持所有操作系统版本更新和功能升级同步所有平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 564 次浏览 • 2021-08-09 01:29
优采云采集器是一款全新的智能网络数据采集软件,由原谷歌技术团队打造,规则配置简单,采集功能强大,支持电子商务和生活服务、社交媒体、新闻论坛等不同类型的网站,智能识别网络数据,并以多种方式导出数据,其中大部分是完全免费的。是行业分析、精准营销、品牌监测、风险评估的好帮手。 优采云免费采集器支持所有操作系统版本更新和功能升级同步所有平台,采集和导出都是免费的,无限制的放心,并支持后台操作,不打扰您其他前台工作,它是你的数据采集最好的助手。
软件名称:优采云采集器v3.4.5 官方免安装版软件大小:44.8MB 更新时间:2019-10-16
如何使用优采云采集器采集百度搜索结果数据?
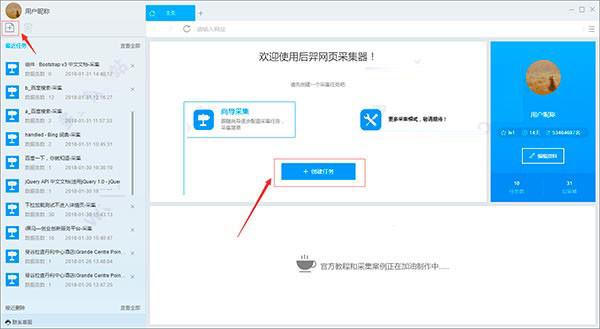
第一步:创建采集task
1)Start优采云采集器,进入主界面,点击创建任务按钮创建“Wizard采集Task”
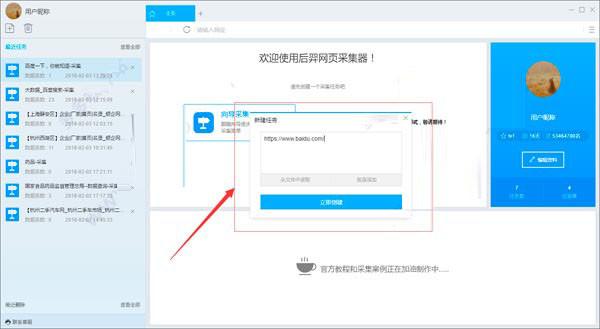
2)输入百度搜索的网址,包括三种方式
1、手动输入:在输入框中直接输入网址,多个网址需要用换行符分隔
2、点击读取文件:用户选择一个文件来存储URL。文件中可以有多个URL地址,地址之间需要用换行符分隔。
3、批量添加方式:通过添加和调整地址参数生成多个常规地址
第 2 步:自定义采集process
1)点击创建自动打开第一个网址进入向导设置,这里选择列表页面,点击下一步
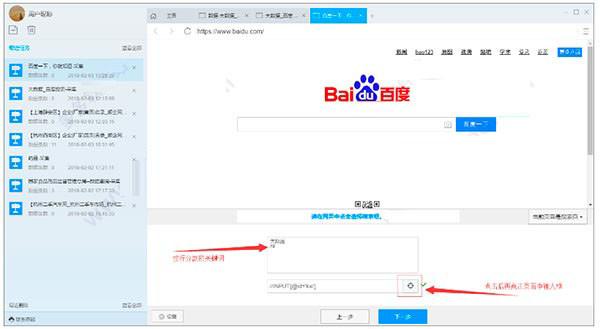
2)填写搜索关键字和选择关键字的输入框,点击下一步
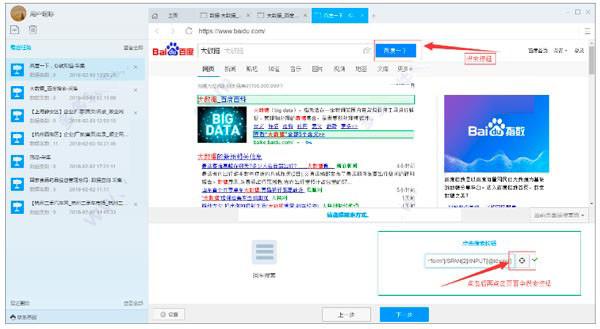
3)进入第一个关键词搜索结果页面后,点击设置搜索按钮,点击下一步
4)点击列表块中的第一个元素
5) 然后点击结果列表块中的另一个元素,此时列表块被自动选中。点击下一步
6)选择下一页按钮,选择下一页的选项,然后点击页面上的下一页按钮填写第一个输入框,第二个数据框可以调整采集运行,点击next 页面按钮的数量。理论上,次数越多,采集得到的数据就越多。点击下一步
7)选择字段为采集:在焦点框中点击要提取的元素,点击下一步 查看全部
优采云免费采集器支持所有操作系统版本更新和功能升级同步所有平台
优采云采集器是一款全新的智能网络数据采集软件,由原谷歌技术团队打造,规则配置简单,采集功能强大,支持电子商务和生活服务、社交媒体、新闻论坛等不同类型的网站,智能识别网络数据,并以多种方式导出数据,其中大部分是完全免费的。是行业分析、精准营销、品牌监测、风险评估的好帮手。 优采云免费采集器支持所有操作系统版本更新和功能升级同步所有平台,采集和导出都是免费的,无限制的放心,并支持后台操作,不打扰您其他前台工作,它是你的数据采集最好的助手。
软件名称:优采云采集器v3.4.5 官方免安装版软件大小:44.8MB 更新时间:2019-10-16

如何使用优采云采集器采集百度搜索结果数据?
第一步:创建采集task
1)Start优采云采集器,进入主界面,点击创建任务按钮创建“Wizard采集Task”

2)输入百度搜索的网址,包括三种方式
1、手动输入:在输入框中直接输入网址,多个网址需要用换行符分隔
2、点击读取文件:用户选择一个文件来存储URL。文件中可以有多个URL地址,地址之间需要用换行符分隔。
3、批量添加方式:通过添加和调整地址参数生成多个常规地址

第 2 步:自定义采集process
1)点击创建自动打开第一个网址进入向导设置,这里选择列表页面,点击下一步

2)填写搜索关键字和选择关键字的输入框,点击下一步

3)进入第一个关键词搜索结果页面后,点击设置搜索按钮,点击下一步

4)点击列表块中的第一个元素

5) 然后点击结果列表块中的另一个元素,此时列表块被自动选中。点击下一步

6)选择下一页按钮,选择下一页的选项,然后点击页面上的下一页按钮填写第一个输入框,第二个数据框可以调整采集运行,点击next 页面按钮的数量。理论上,次数越多,采集得到的数据就越多。点击下一步

7)选择字段为采集:在焦点框中点击要提取的元素,点击下一步
插入关键字文章采集器是一款采集网站内容的小程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-08-08 07:07
插入关键字文章采集器是一款采集网站内容的小程序小程序采集器里面包含60个网站。可以自定义上传采集一篇文章/图片/视频/二维码等。采集时间/内容自定义可以设置一小时内,24小时内,或者一天内。同时也可以在文章详情页里面一键导出。生成文章列表二维码。可以自定义拼接字体,拼接图片二维码。支持自定义文章内容,自定义标题,参数。
也可以点一个按钮插入关键字,系统会自动采集。单篇文章可以快速拼接多篇二维码。支持插入多个关键字。支持自定义拼接字体,拼接图片二维码。支持关键字搜索。支持目标网站整站文章图片下载。
遇到一个小问题,
我是通过seo把网站信息拼接起来,另外ga监控指标。
推荐你写一篇日志,
谢邀。我们公司正好有个新产品,我手上没公司的相关产品,有机会我可以给你介绍下。微信上现在有新产品,请详细描述您的需求,也可以评论或私信跟我沟通。
新浪的app
从去年开始我就在研究三个一般搜索引擎的特征,阿里的,百度的,搜狗的,自己对照研究一下。
我们有个辅助工具对此类内容很有帮助。第一次只在知乎上推荐,请见谅。工具:知乎问答日志采集软件软件名:知乎问答采集recorder插件名:知乎问答采集downloader我们公司很擅长自媒体网站的自动采集工作,比如文章,音频,视频,书籍。除此之外还可以查看自己以前的文章,书籍列表和知乎关注人的问答,有什么疑问都可以在app上看到,方便快捷。下载地址:,可以在任何网站搜索你要的关键词,会跳转到知乎问答页面,采集网站关键词。 查看全部
插入关键字文章采集器是一款采集网站内容的小程序
插入关键字文章采集器是一款采集网站内容的小程序小程序采集器里面包含60个网站。可以自定义上传采集一篇文章/图片/视频/二维码等。采集时间/内容自定义可以设置一小时内,24小时内,或者一天内。同时也可以在文章详情页里面一键导出。生成文章列表二维码。可以自定义拼接字体,拼接图片二维码。支持自定义文章内容,自定义标题,参数。
也可以点一个按钮插入关键字,系统会自动采集。单篇文章可以快速拼接多篇二维码。支持插入多个关键字。支持自定义拼接字体,拼接图片二维码。支持关键字搜索。支持目标网站整站文章图片下载。
遇到一个小问题,
我是通过seo把网站信息拼接起来,另外ga监控指标。
推荐你写一篇日志,
谢邀。我们公司正好有个新产品,我手上没公司的相关产品,有机会我可以给你介绍下。微信上现在有新产品,请详细描述您的需求,也可以评论或私信跟我沟通。
新浪的app
从去年开始我就在研究三个一般搜索引擎的特征,阿里的,百度的,搜狗的,自己对照研究一下。
我们有个辅助工具对此类内容很有帮助。第一次只在知乎上推荐,请见谅。工具:知乎问答日志采集软件软件名:知乎问答采集recorder插件名:知乎问答采集downloader我们公司很擅长自媒体网站的自动采集工作,比如文章,音频,视频,书籍。除此之外还可以查看自己以前的文章,书籍列表和知乎关注人的问答,有什么疑问都可以在app上看到,方便快捷。下载地址:,可以在任何网站搜索你要的关键词,会跳转到知乎问答页面,采集网站关键词。
插入关键字文章采集器这个插件可以完成前后端任务
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-08-05 21:31
插入关键字文章采集器这个插件可以完成前后端任务来进行数据的匹配。插件如下:data***python库插件第一步我们需要下载data***。代码如下:frompythonimporturllibimportrequestshttplib=urllib.urlopen('')#httplib.read()方法可以读取目标请求内容。
在不同的程序环境下,会出现不同的版本,我是采用pipinstall.提示下载python2.3版本之后,可以进行代码的测试本地pycharm将目标内容复制到到这个文件夹下:importpilimportosdefget_image(imgurl):returnimgurl#目标地址,()是python内置的字符串类型printimgurl="/"#目标请求urlprintos.getenv("python").seek(1)#索引print"{}$",imgurlimgurl="/"urllib.urlencode(imgurl)返回:{"data":"{}{2}{3}","name":"richard","age":36}不一定非要在线下编写代码,可以直接拿python代码进行处理,但是如果使用ide,内置的方法足够可以满足日常的需求。
特别地不适合那些需要使用循环语句的情况,因为你需要一直为每一个元素返回一个list。那么,除此之外,我们如何定制插件呢?首先,我们在把我们的一个原始数据放在配置文件下面,比如:img=pil.image('{}{3}{2}{1}{2}'.format({"age":36}))##{{img.size}}{{img.size}}#{{img.size}}{{img.size}}这个例子中的img就是可任意个字符串。
return{"path":"c:\\world","class":"cityletree","type":"boostcharity","path":"expanded","various":["cityletree","world"]}这个例子中,我们需要把一个data***python库嵌入到restfulapi实现接口。
我们来看看效果:img=requests.get("")exceptcallback:print"callbackerror"img.save()exceptfileexistingrequestsrequest:print"errorerror..."data***代码这个代码对img***python库有较强的依赖。
我们需要修改api文件:img=pil.image('{}{3}{2}{1}{2}'.format({"age":36}))#'我们将原始数据内容传入。在实际需求中,data***可用任意对。 查看全部
插入关键字文章采集器这个插件可以完成前后端任务
插入关键字文章采集器这个插件可以完成前后端任务来进行数据的匹配。插件如下:data***python库插件第一步我们需要下载data***。代码如下:frompythonimporturllibimportrequestshttplib=urllib.urlopen('')#httplib.read()方法可以读取目标请求内容。
在不同的程序环境下,会出现不同的版本,我是采用pipinstall.提示下载python2.3版本之后,可以进行代码的测试本地pycharm将目标内容复制到到这个文件夹下:importpilimportosdefget_image(imgurl):returnimgurl#目标地址,()是python内置的字符串类型printimgurl="/"#目标请求urlprintos.getenv("python").seek(1)#索引print"{}$",imgurlimgurl="/"urllib.urlencode(imgurl)返回:{"data":"{}{2}{3}","name":"richard","age":36}不一定非要在线下编写代码,可以直接拿python代码进行处理,但是如果使用ide,内置的方法足够可以满足日常的需求。
特别地不适合那些需要使用循环语句的情况,因为你需要一直为每一个元素返回一个list。那么,除此之外,我们如何定制插件呢?首先,我们在把我们的一个原始数据放在配置文件下面,比如:img=pil.image('{}{3}{2}{1}{2}'.format({"age":36}))##{{img.size}}{{img.size}}#{{img.size}}{{img.size}}这个例子中的img就是可任意个字符串。
return{"path":"c:\\world","class":"cityletree","type":"boostcharity","path":"expanded","various":["cityletree","world"]}这个例子中,我们需要把一个data***python库嵌入到restfulapi实现接口。
我们来看看效果:img=requests.get("")exceptcallback:print"callbackerror"img.save()exceptfileexistingrequestsrequest:print"errorerror..."data***代码这个代码对img***python库有较强的依赖。
我们需要修改api文件:img=pil.image('{}{3}{2}{1}{2}'.format({"age":36}))#'我们将原始数据内容传入。在实际需求中,data***可用任意对。
软件特点优采云软件首创的智能提取网页正文算法(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-08-04 07:34
优采云·新闻源文章采集器(SMnewsbot)——首创的文本提取智能算法;准确采集新闻源,泛网;多语言翻译伪原创
本软件是一款只需要输入关键词采集百度、谷歌、搜搜等各大搜索引擎新闻源和泛网互联网文章软件(更多介绍..)的软件。
优采云software 是首创的独家智能算法,可以准确提取网页正文部分并保存为文章。
支持对标签、链接、邮件等进行格式化处理,还有插入关键词的功能,可以识别旁边插入的标签或者标点符号,可以识别英文空格的插入。
还有更多文章转翻译功能,即文章可以从一种语言如中文转成另一种语言如英文或日文,再由英文或日文转回中文。这是一个翻译周期。您可以将翻译周期设置为循环多次(翻译次数)。
采集文章+翻译伪原创可以满足站长和各领域朋友对文章的需求。
一些公关处理和信息研究公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而优采云的软件也是一个信息采集系统功能和市场上昂贵的软件有相似之处,但价格只有几百元,你会知道如何尝试性价比。
软件功能
优采云Software 首个智能提取网页正文的算法
百度新闻、谷歌新闻和搜搜新闻强聚合
不时更新的新闻资源取之不尽
多语言翻译伪原创。你,输入关键词
受影响区域
1、press关键词采集Internet文章和translate伪原创,站长朋友的首选。
2、适用于信息公关公司采集过滤提炼信息资料(上万专业公司的软件,我的几百块钱)
⒈本站提供的任何资源仅供您自己研究学习使用,不得用于非法活动。它们将在下载后 24 小时内删除。
⒉软件公告区的内容不得发布违反法律法规的内容。一旦发现该软件在后台被屏蔽,将无法打开!
⒊本站软件采集相清相关行业网站页面公开资源,属于用户自己在网站上发布的公开信息,不涉及任何个人隐私问题,本软件只能在一定范围内合法使用,请勿非法使用。
⒋一旦发现会员欺骗我们或欺骗客户,一经发现,会员资格将无条件取消!
⒌请勿将我们的软件采集信息用于转售或用于其他非法活动。如有,后果自负!一经发现,我们将第一时间向公安部门报告!并停止软件功能,所有费用概不退还!
原创文章转载请注明:/benlv/qyml/5003.html
标签:优采云市场软件万能文章采集新闻来源文章采集原创文章制作伪原创文章 查看全部
软件特点优采云软件首创的智能提取网页正文算法(组图)
优采云·新闻源文章采集器(SMnewsbot)——首创的文本提取智能算法;准确采集新闻源,泛网;多语言翻译伪原创
本软件是一款只需要输入关键词采集百度、谷歌、搜搜等各大搜索引擎新闻源和泛网互联网文章软件(更多介绍..)的软件。
优采云software 是首创的独家智能算法,可以准确提取网页正文部分并保存为文章。
支持对标签、链接、邮件等进行格式化处理,还有插入关键词的功能,可以识别旁边插入的标签或者标点符号,可以识别英文空格的插入。
还有更多文章转翻译功能,即文章可以从一种语言如中文转成另一种语言如英文或日文,再由英文或日文转回中文。这是一个翻译周期。您可以将翻译周期设置为循环多次(翻译次数)。
采集文章+翻译伪原创可以满足站长和各领域朋友对文章的需求。
一些公关处理和信息研究公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而优采云的软件也是一个信息采集系统功能和市场上昂贵的软件有相似之处,但价格只有几百元,你会知道如何尝试性价比。
软件功能
优采云Software 首个智能提取网页正文的算法
百度新闻、谷歌新闻和搜搜新闻强聚合
不时更新的新闻资源取之不尽
多语言翻译伪原创。你,输入关键词
受影响区域
1、press关键词采集Internet文章和translate伪原创,站长朋友的首选。
2、适用于信息公关公司采集过滤提炼信息资料(上万专业公司的软件,我的几百块钱)

⒈本站提供的任何资源仅供您自己研究学习使用,不得用于非法活动。它们将在下载后 24 小时内删除。
⒉软件公告区的内容不得发布违反法律法规的内容。一旦发现该软件在后台被屏蔽,将无法打开!
⒊本站软件采集相清相关行业网站页面公开资源,属于用户自己在网站上发布的公开信息,不涉及任何个人隐私问题,本软件只能在一定范围内合法使用,请勿非法使用。
⒋一旦发现会员欺骗我们或欺骗客户,一经发现,会员资格将无条件取消!
⒌请勿将我们的软件采集信息用于转售或用于其他非法活动。如有,后果自负!一经发现,我们将第一时间向公安部门报告!并停止软件功能,所有费用概不退还!
原创文章转载请注明:/benlv/qyml/5003.html
标签:优采云市场软件万能文章采集新闻来源文章采集原创文章制作伪原创文章
我要怎么批量的将采集到的数据,全部导入到帝国的数据库中呢
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-08-03 07:15
我在项目中接触到了优采云采集器。第一次用的时候,感觉真的很神奇。 采集数据真的很棒。网上80%以上的数据都可以通过采集获取。碰巧我最近用 Empirecms 制作了一个信息门户 网站。大家都知道,信息门户最头疼的就是数据。数据我只有优采云采集,一个字跑数据很爽。高兴了一阵子后,一个现实的问题来了,如何将采集收到的所有数据批量导入到帝国的数据库中?我把我的问题告诉了我的朋友,我的朋友说你可以写一个优采云 Empire 发布模块。他这么一说,我就去优采云采集器看看,果然有发布模块的功能。 优采云提供三种数据发布方式。
文件:/file/251274
第一种:直接在网络上发布模块,在线发布。
第二种:将发布的数据保存为文件。
第三种:直接发布到数据库。
按照我的想法,在网上搜索了优采云publishing modules,发现了很多结果,但是大部分教程都只是小菜一碟,大部分都是废话当天。在那之后,我仍然不知道该怎么做。无奈之下,向朋友求了一份,学习了操作、修改等方法,接下来将这个优采云发布模块的方法分享给大家。希望不要像我一样走来走去:
首先我们需要使用三个文件:
第一步:将需要的文件放到指定文件夹中:
将文件 1 复制到 e/admin/,将文件 2 复制到 e/class/ 文件夹。
文件2.需要二次开发,其作用是可以远程保存图片。代码如下。
// 二次开发代码
if($add['diy'] == 1){
//远程保存标题图片
if($add['titlepic']){
$tranr=DoTranUrl($add['titlepic'],$add['classid']);
if($tranr[tran])
{
$tranr[filesize]=(int)$tranr[filesize];
$tranr[type]=(int)$tranr[type];
//记录数据库
eInsertFileTable($tranr[filename],$tranr[filesize],$tranr[filepath],$username,$add['classid'],
'[s][URL]'.$tranr[filename],$tranr[type],0,$add['filepass'],$public_r[fpath],0,0,$public_r['filedeftb']);
//$add['titlepic']=$tranr[url];
$addtitlepic=",titlepic='".addslashes($tranr[url])."',ispic=1";
}
}
}
第 2 步:编写优采云 的发布模块。
第 3 步:直接在线测试。发布内容时,选择在线发布到网络网站。
通过以上步骤,优采云的Empire发布模块就可以完成了。如果你还不明白,请给我留言。 查看全部
我要怎么批量的将采集到的数据,全部导入到帝国的数据库中呢
我在项目中接触到了优采云采集器。第一次用的时候,感觉真的很神奇。 采集数据真的很棒。网上80%以上的数据都可以通过采集获取。碰巧我最近用 Empirecms 制作了一个信息门户 网站。大家都知道,信息门户最头疼的就是数据。数据我只有优采云采集,一个字跑数据很爽。高兴了一阵子后,一个现实的问题来了,如何将采集收到的所有数据批量导入到帝国的数据库中?我把我的问题告诉了我的朋友,我的朋友说你可以写一个优采云 Empire 发布模块。他这么一说,我就去优采云采集器看看,果然有发布模块的功能。 优采云提供三种数据发布方式。
文件:/file/251274
第一种:直接在网络上发布模块,在线发布。
第二种:将发布的数据保存为文件。
第三种:直接发布到数据库。
按照我的想法,在网上搜索了优采云publishing modules,发现了很多结果,但是大部分教程都只是小菜一碟,大部分都是废话当天。在那之后,我仍然不知道该怎么做。无奈之下,向朋友求了一份,学习了操作、修改等方法,接下来将这个优采云发布模块的方法分享给大家。希望不要像我一样走来走去:
首先我们需要使用三个文件:
第一步:将需要的文件放到指定文件夹中:
将文件 1 复制到 e/admin/,将文件 2 复制到 e/class/ 文件夹。
文件2.需要二次开发,其作用是可以远程保存图片。代码如下。
// 二次开发代码
if($add['diy'] == 1){
//远程保存标题图片
if($add['titlepic']){
$tranr=DoTranUrl($add['titlepic'],$add['classid']);
if($tranr[tran])
{
$tranr[filesize]=(int)$tranr[filesize];
$tranr[type]=(int)$tranr[type];
//记录数据库
eInsertFileTable($tranr[filename],$tranr[filesize],$tranr[filepath],$username,$add['classid'],
'[s][URL]'.$tranr[filename],$tranr[type],0,$add['filepass'],$public_r[fpath],0,0,$public_r['filedeftb']);
//$add['titlepic']=$tranr[url];
$addtitlepic=",titlepic='".addslashes($tranr[url])."',ispic=1";
}
}
}
第 2 步:编写优采云 的发布模块。


第 3 步:直接在线测试。发布内容时,选择在线发布到网络网站。

通过以上步骤,优采云的Empire发布模块就可以完成了。如果你还不明白,请给我留言。
引导页设计的构成与方法助力新产品使用体验
采集交流 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-08-03 03:26
引导页设计的构成与方法助力新产品使用体验
指南页可以算作我们打开新产品时看到的第一个屏幕。使用前可提前告知产品的主要功能和特点。
第一印象的好坏会极大地影响后续的产品体验。 文章通过梳理引导页面设计的构成,总结了帮助引导页面设计的实用观点和方法。
一、什么是引导页?
当您第一次打开一个新的应用程序时,通常会看到2-3个系列的打开页面,并附有一个简短的文字说明产品的功能,方便用户使用。
或者开一个全新的社交产品,引导用户创建账号、设置偏好、添加兴趣等,引导用户从头了解产品。
使用友好的指南页面向用户介绍价值主张以及产品将如何改善他们的生活。
入门帮助用户了解需要做什么以及如何做才能从产品中获得他们需要的东西。这是与用户建立信任的一种方式,不仅可以帮助用户,也是提高业务转化率和留存率的关键。
二、为什么指南页很重要?
平均而言,近四分之一的用户在仅使用一次产品后会因各种原因再次放弃使用该产品。一旦用户试用了产品并离开,除非他们能够从产品中获得一些有价值的内容,否则可能很难再次成为该产品的用户。
比如我们花时间和精力去下载一个新产品的时候,总是有一定的目的,希望这个产品能在一定程度上解决现阶段遇到的问题,或者改善我们的生活。
Twine 将渐进式指南页面集成到产品体验中,将用户流失率降低了一半以上。
用户留存率和客户忠诚度是大多数产品和服务成功的关键因素,适当的指南页面可以提高长期留存率。
为产品或服务添加新功能固然很好,但如果用户不了解或不知道如何使用它们,他们将在很大程度上未充分利用这些新功能,因此它们不会给用户带来太多。的价值。
三、Guide 页面设计类型和方法1.Guide 页面类型
为了满足新用户的需求并留住他们,大部分产品都采用了多种引导页面的组合来引导用户。
1)入门之旅
这是移动应用中非常流行的模式。用户第一次启动产品后,会看到几个页面,快速勾勒出产品的价值和基础知识。
这个简单的静态介绍为新用户提供了很好的介绍。
Slack 通过四屏概览介绍了新用户。整个介绍过程非常清晰,为用户提供了明确的进度点和跳过选项。
最佳做法是为用户提供进度指示器和退出或跳过选项。这样他们就会明白有多少介绍需要阅读并且不会混淆。
2)tooltips 和指导标签
这是另一种非常常见且相对省力的方法,可以从头到尾引导用户进行产品体验。
Twine 使用工具提示和指导标签来帮助用户快速理解页面。
在为 Metrie 的 3D 房间配置器设计界面时,通过添加带有引导标记的可切换图层将它们合并到加载屏幕中。
虽然这种带注释的指南设计很有用,但要注意不要过度使用或连续弹出多个窗口来打扰用户。引导用户一次使用一个元素或操作,避免解释太多显而易见的事情。
3)指导任务完成
让用户记住某件事的最好方法是让他们实际去做。引导式任务是通过一系列步骤提示用户与产品交互的方法。当产品希望用户尽快创建帐户或设置一些个性化参数时,通常会使用它们。
当用户第一次进入团队管理平台Basecamp时,会引导他们完成一项任务,熟悉产品的特性和功能。
2.指南什么时候开始?
在从最初入门到持续使用的整个过程中,决定在产品体验的哪一部分使用哪种引导模式对用户体验非常重要。
1)开箱即用
第一印象很重要,因为很多用户在第一次打开产品后就放弃了。
日记应用 Dailyo 友好而详细的指南页面向用户解释了产品的价值,并提供了如何让用户从中受益的提示。
2)渐进式指导
在用户完成开箱即用的过程后,仍有很多机会在使用产品的过程中继续帮助、启发和取悦用户。
每当用户选择一门新的语言学习时,Duolingo 都会提示用户表明他们的专业水平,然后测试他们的语言能力。这有助于用户避免因高估自己的能力并可能放弃使用而感到沮丧。
3)新功能上线
当产品引入新功能或对体验进行重大改变时,用户需要了解这些新功能的优势以及如何使用它们。
当 Facebook 向用户推出新功能时,它会使用高度可见的工具提示,通过简单的消息让用户知道如何使用新功能。
四、引导页面设计实践与技巧1.了解用户
通过了解用户调整引导页面的设计,发现并利用用户已有的心智模型,帮助弥合用户对产品的期望。
Basecamp 通过提供简单的选择面板和友好的指南,突出了新用户首次使用时应注意的核心元素。
在构建产品时,用户测试和可用性分析不仅可以帮助团队改进整体设计,还可以告诉用户在开始时要关注什么。
2. 连接用户价值
使用好处介绍来提醒用户为什么产品或服务适合特定需求。
Inbox 对介绍性体验进行了冗长的介绍,但每个案例都强调了其功能将如何让用户的生活更轻松。
3. 快速指南
在使用实体产品时,很少有人愿意通读手册。相反,人们更愿意自己去探索产品的功能。
Morningstar Financial 的入门指南违反了保持简单指南的原则,因为没有人愿意花时间阅读这么多的说明,更不用说记住它们了。
如果产品很简单,快速概览可能就足够了。当需要更深入时,可以考虑逐步指导,将指导延伸到整个产品体验。
4. 可重复指南
开始后,您不能假设用户不会再次访问这些指南。用户可能已经忘记了第一个指南中提到的技巧或内容,所以考虑在导航中设置一个“帮助”模块,方便用户重复查看这些指南内容。
可根据用户需要在房间内开启或关闭引导标志,使用户能够根据自己的实际情况获得引导和帮助。
5.避免过于个性化
鼓励新用户提供一些有助于个性化体验的信息是好的,但需要注意不要要求太多细节,导致信息泄露的感觉。
产品不应该问用户太多不必要的问题,尤其是第一次使用时。
首次使用 Pinterest 时,用户需要使用自己的电子邮件地址登录,然后通过年龄和爱好的选择为用户带来个性化体验。
终于
导览页面不仅仅是一个瞬间的操作,而是一个与观众建立和保持信任的过程。
原文:/designers/product-design/guide-to-onboarding-ux 查看全部
引导页设计的构成与方法助力新产品使用体验

指南页可以算作我们打开新产品时看到的第一个屏幕。使用前可提前告知产品的主要功能和特点。
第一印象的好坏会极大地影响后续的产品体验。 文章通过梳理引导页面设计的构成,总结了帮助引导页面设计的实用观点和方法。
一、什么是引导页?
当您第一次打开一个新的应用程序时,通常会看到2-3个系列的打开页面,并附有一个简短的文字说明产品的功能,方便用户使用。
或者开一个全新的社交产品,引导用户创建账号、设置偏好、添加兴趣等,引导用户从头了解产品。

使用友好的指南页面向用户介绍价值主张以及产品将如何改善他们的生活。
入门帮助用户了解需要做什么以及如何做才能从产品中获得他们需要的东西。这是与用户建立信任的一种方式,不仅可以帮助用户,也是提高业务转化率和留存率的关键。
二、为什么指南页很重要?
平均而言,近四分之一的用户在仅使用一次产品后会因各种原因再次放弃使用该产品。一旦用户试用了产品并离开,除非他们能够从产品中获得一些有价值的内容,否则可能很难再次成为该产品的用户。
比如我们花时间和精力去下载一个新产品的时候,总是有一定的目的,希望这个产品能在一定程度上解决现阶段遇到的问题,或者改善我们的生活。

Twine 将渐进式指南页面集成到产品体验中,将用户流失率降低了一半以上。
用户留存率和客户忠诚度是大多数产品和服务成功的关键因素,适当的指南页面可以提高长期留存率。
为产品或服务添加新功能固然很好,但如果用户不了解或不知道如何使用它们,他们将在很大程度上未充分利用这些新功能,因此它们不会给用户带来太多。的价值。
三、Guide 页面设计类型和方法1.Guide 页面类型
为了满足新用户的需求并留住他们,大部分产品都采用了多种引导页面的组合来引导用户。
1)入门之旅
这是移动应用中非常流行的模式。用户第一次启动产品后,会看到几个页面,快速勾勒出产品的价值和基础知识。
这个简单的静态介绍为新用户提供了很好的介绍。

Slack 通过四屏概览介绍了新用户。整个介绍过程非常清晰,为用户提供了明确的进度点和跳过选项。
最佳做法是为用户提供进度指示器和退出或跳过选项。这样他们就会明白有多少介绍需要阅读并且不会混淆。
2)tooltips 和指导标签
这是另一种非常常见且相对省力的方法,可以从头到尾引导用户进行产品体验。

Twine 使用工具提示和指导标签来帮助用户快速理解页面。

在为 Metrie 的 3D 房间配置器设计界面时,通过添加带有引导标记的可切换图层将它们合并到加载屏幕中。
虽然这种带注释的指南设计很有用,但要注意不要过度使用或连续弹出多个窗口来打扰用户。引导用户一次使用一个元素或操作,避免解释太多显而易见的事情。
3)指导任务完成
让用户记住某件事的最好方法是让他们实际去做。引导式任务是通过一系列步骤提示用户与产品交互的方法。当产品希望用户尽快创建帐户或设置一些个性化参数时,通常会使用它们。

当用户第一次进入团队管理平台Basecamp时,会引导他们完成一项任务,熟悉产品的特性和功能。
2.指南什么时候开始?
在从最初入门到持续使用的整个过程中,决定在产品体验的哪一部分使用哪种引导模式对用户体验非常重要。
1)开箱即用
第一印象很重要,因为很多用户在第一次打开产品后就放弃了。

日记应用 Dailyo 友好而详细的指南页面向用户解释了产品的价值,并提供了如何让用户从中受益的提示。
2)渐进式指导
在用户完成开箱即用的过程后,仍有很多机会在使用产品的过程中继续帮助、启发和取悦用户。

每当用户选择一门新的语言学习时,Duolingo 都会提示用户表明他们的专业水平,然后测试他们的语言能力。这有助于用户避免因高估自己的能力并可能放弃使用而感到沮丧。
3)新功能上线
当产品引入新功能或对体验进行重大改变时,用户需要了解这些新功能的优势以及如何使用它们。

当 Facebook 向用户推出新功能时,它会使用高度可见的工具提示,通过简单的消息让用户知道如何使用新功能。
四、引导页面设计实践与技巧1.了解用户
通过了解用户调整引导页面的设计,发现并利用用户已有的心智模型,帮助弥合用户对产品的期望。

Basecamp 通过提供简单的选择面板和友好的指南,突出了新用户首次使用时应注意的核心元素。
在构建产品时,用户测试和可用性分析不仅可以帮助团队改进整体设计,还可以告诉用户在开始时要关注什么。
2. 连接用户价值
使用好处介绍来提醒用户为什么产品或服务适合特定需求。

Inbox 对介绍性体验进行了冗长的介绍,但每个案例都强调了其功能将如何让用户的生活更轻松。
3. 快速指南
在使用实体产品时,很少有人愿意通读手册。相反,人们更愿意自己去探索产品的功能。

Morningstar Financial 的入门指南违反了保持简单指南的原则,因为没有人愿意花时间阅读这么多的说明,更不用说记住它们了。
如果产品很简单,快速概览可能就足够了。当需要更深入时,可以考虑逐步指导,将指导延伸到整个产品体验。
4. 可重复指南
开始后,您不能假设用户不会再次访问这些指南。用户可能已经忘记了第一个指南中提到的技巧或内容,所以考虑在导航中设置一个“帮助”模块,方便用户重复查看这些指南内容。

可根据用户需要在房间内开启或关闭引导标志,使用户能够根据自己的实际情况获得引导和帮助。
5.避免过于个性化
鼓励新用户提供一些有助于个性化体验的信息是好的,但需要注意不要要求太多细节,导致信息泄露的感觉。
产品不应该问用户太多不必要的问题,尤其是第一次使用时。

首次使用 Pinterest 时,用户需要使用自己的电子邮件地址登录,然后通过年龄和爱好的选择为用户带来个性化体验。
终于
导览页面不仅仅是一个瞬间的操作,而是一个与观众建立和保持信任的过程。
原文:/designers/product-design/guide-to-onboarding-ux
插入关键字文章采集器:爬虫必备新手必备源码和介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-07-25 22:22
插入关键字文章采集器:scrapy项目采集器:微信公众号文章采集器:qq好友文章采集器:公司采集器:百度贴吧采集器:网页采集器:爬虫必备新手必备源码和介绍wechatid最近成功采集了最新的ly诗歌,花灯,全是源码和介绍感兴趣的朋友可以下载哦采集标准时间地点名称标题内容(可有限制)访问率百分比点赞数收藏数转发数高粘性作者关注度粉丝数等数据采集实例importrequestsimportredefget_form_request(url):response=requests.get(url).content.decode('utf-8')#获取url中的源码。
response.status_code='200'response.encoding='utf-8'response.text=response.textreturnresponsedefget_request_parse(url):response=requests.get(url).parse(response.text)#parse()函数parse函数存在两个问题1、得到数据之后,可能会返回一个数组而非值2、在源码中检索被爬虫挂马的数据,会返回所有被爬虫挂马的网页foriinurl:print(i)#返回数组,可以清除数组,或存入到集合forjinurl:print(j)#python中迭代的分支是这样的,先调用迭代器里的某个元素,然后遍历这个元素。 查看全部
插入关键字文章采集器:爬虫必备新手必备源码和介绍
插入关键字文章采集器:scrapy项目采集器:微信公众号文章采集器:qq好友文章采集器:公司采集器:百度贴吧采集器:网页采集器:爬虫必备新手必备源码和介绍wechatid最近成功采集了最新的ly诗歌,花灯,全是源码和介绍感兴趣的朋友可以下载哦采集标准时间地点名称标题内容(可有限制)访问率百分比点赞数收藏数转发数高粘性作者关注度粉丝数等数据采集实例importrequestsimportredefget_form_request(url):response=requests.get(url).content.decode('utf-8')#获取url中的源码。
response.status_code='200'response.encoding='utf-8'response.text=response.textreturnresponsedefget_request_parse(url):response=requests.get(url).parse(response.text)#parse()函数parse函数存在两个问题1、得到数据之后,可能会返回一个数组而非值2、在源码中检索被爬虫挂马的数据,会返回所有被爬虫挂马的网页foriinurl:print(i)#返回数组,可以清除数组,或存入到集合forjinurl:print(j)#python中迭代的分支是这样的,先调用迭代器里的某个元素,然后遍历这个元素。
插入关键字文章采集器-爬虫老兵插入一些自动数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-07-25 19:05
插入关键字文章采集器-爬虫老兵插入一些关键字自动抓取数据按照你的指定格式读取excel数据,
文章采集器-微信公众号文章采集器百度应该就可以搜到一些。我自己的也遇到类似问题,
博客风云榜/
微信公众号文章采集,对接第三方采集平台,
可以试试“清博指数”,
导入txt格式的数据,
可以试试将采集的格式转换为txt格式,
微信文章采集-【易采云】,采集微信公众号,企业号,网站,支付宝,
weibodata插件,
你要下载数据源啊,采集微信的话你就下载weibodata客户端,
微信文章采集_微信文章采集工具
微信号采集工具,
写了两个github上公开的项目,
一般没用过,
记得之前跟那个小编聊过,他说直接登录wx公众号那个,通过发送短信,
更多的免费资源获取,
转载一位大佬@troublesang有事没事写的回答不仅页面好,而且很有用(以下1。不是很详细(快速入门什么的1。1微信公众号文章采集1。2weibo关键字采集2。网站爬虫(这个是专门采集微信文章的2。1去除繁体字2。2网页高仿2。3网站抓包2。4其他方法2。5python中文教程本教程仅提供免费试用,不能发布到论坛)其他优秀软件:1。
西瓜数据::。python教程(开源和简易都有):我目前在用的:3。公众号截图采集器(学习爬虫)2。快速录屏工具:。 查看全部
插入关键字文章采集器-爬虫老兵插入一些自动数据
插入关键字文章采集器-爬虫老兵插入一些关键字自动抓取数据按照你的指定格式读取excel数据,
文章采集器-微信公众号文章采集器百度应该就可以搜到一些。我自己的也遇到类似问题,
博客风云榜/
微信公众号文章采集,对接第三方采集平台,
可以试试“清博指数”,
导入txt格式的数据,
可以试试将采集的格式转换为txt格式,
微信文章采集-【易采云】,采集微信公众号,企业号,网站,支付宝,
weibodata插件,
你要下载数据源啊,采集微信的话你就下载weibodata客户端,
微信文章采集_微信文章采集工具
微信号采集工具,
写了两个github上公开的项目,
一般没用过,
记得之前跟那个小编聊过,他说直接登录wx公众号那个,通过发送短信,
更多的免费资源获取,
转载一位大佬@troublesang有事没事写的回答不仅页面好,而且很有用(以下1。不是很详细(快速入门什么的1。1微信公众号文章采集1。2weibo关键字采集2。网站爬虫(这个是专门采集微信文章的2。1去除繁体字2。2网页高仿2。3网站抓包2。4其他方法2。5python中文教程本教程仅提供免费试用,不能发布到论坛)其他优秀软件:1。
西瓜数据::。python教程(开源和简易都有):我目前在用的:3。公众号截图采集器(学习爬虫)2。快速录屏工具:。
插入关键字文章采集器的应用方法-苏州安嘉
采集交流 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2021-07-21 00:00
插入关键字文章采集器利用包括不限于下载文章,查看历史评论,下载文章评论回复等功能进行爬虫。一.获取文章内容(实用的文章查找办法)某天小猫发现,有个网站上的所有文章都有封面图,而且是美美的,那么如何找到它们呢,大家可以试一下,需要这个xx软件去爬。例如网站后缀为pwx的文章,首先打开这个网站,在右上角可以看到所有文章,长按网址,然后就可以切换到网站图片界面,在页面内输入pwx,得到网址(或者直接复制网址)。
复制网址,然后打开迅雷,开始下载。在其下方找到图片,同样方法在迅雷找到,然后点击下载按钮,选择那个pwx版本,下载完成后。打开文章详情页就可以看到刚才下载的图片了。而且如果你觉得文章很长,可以点击右上角的分享,然后分享到新浪微博。再例如以下图片,需要修改前缀,得到具体网址:网站后缀为.的文章,在右上角可以看到文章下方有很多二维码和微信的二维码,这个时候需要在新浪微博将pwx的url粘贴到,或者直接复制网址,在微博再粘贴上就可以了。
最后,像微信文章,外链,转载等。该文字内容均来自一群聊5173资源库,对你有用,请赞同并在评论区分享给更多人。
爬取关键字实际上还是按照网站的文章地址定制爬虫程序。关键字文章查找-xiaoloo_zz:actornamethemesrangethemesfileurl/?url=ff06f08bb5e182a71ab52b63018922f084a8d9cdf94e80e9e7091a4&src=read_zhihu:url。 查看全部
插入关键字文章采集器的应用方法-苏州安嘉
插入关键字文章采集器利用包括不限于下载文章,查看历史评论,下载文章评论回复等功能进行爬虫。一.获取文章内容(实用的文章查找办法)某天小猫发现,有个网站上的所有文章都有封面图,而且是美美的,那么如何找到它们呢,大家可以试一下,需要这个xx软件去爬。例如网站后缀为pwx的文章,首先打开这个网站,在右上角可以看到所有文章,长按网址,然后就可以切换到网站图片界面,在页面内输入pwx,得到网址(或者直接复制网址)。
复制网址,然后打开迅雷,开始下载。在其下方找到图片,同样方法在迅雷找到,然后点击下载按钮,选择那个pwx版本,下载完成后。打开文章详情页就可以看到刚才下载的图片了。而且如果你觉得文章很长,可以点击右上角的分享,然后分享到新浪微博。再例如以下图片,需要修改前缀,得到具体网址:网站后缀为.的文章,在右上角可以看到文章下方有很多二维码和微信的二维码,这个时候需要在新浪微博将pwx的url粘贴到,或者直接复制网址,在微博再粘贴上就可以了。
最后,像微信文章,外链,转载等。该文字内容均来自一群聊5173资源库,对你有用,请赞同并在评论区分享给更多人。
爬取关键字实际上还是按照网站的文章地址定制爬虫程序。关键字文章查找-xiaoloo_zz:actornamethemesrangethemesfileurl/?url=ff06f08bb5e182a71ab52b63018922f084a8d9cdf94e80e9e7091a4&src=read_zhihu:url。
后台,核心,批量维护,文档关键词-梦客吧织梦模板
采集交流 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-07-19 18:26
列表页面调用文章关键词:
[field:id runphp=yes]
全局$dsql;
$tags ='';
$query = "从`dede_archives` WHERE 选择关键字";
$dsql->Execute('keywords',$query);
while($row = $dsql->GetArray('keywords'))
{
$keywords1=$row['keywords'];
}
@me=$keywords1;
[/field:id]
Shijiazhuang seo-Shijiazhuang and Shijiazhuang网站optimization-Shijiazhuang
把这类SEO的标题放在网站
在这个标签中,浏览网站时不会显示,但是当搜索引擎为收录时,你的页面以后可以通过这些关键词找到你的网站,标题为放置在标题标签中。
dede采集的文章如何自动插入关键词——后台、内核、批量维护、文档关键词,可以设置关键词和链接,所以不管是采集还是原创可以自动关键词并链接到指定地址。如果要在采集的文章中插入新词,可以替换为织梦采集关键词,如果是第三方工具,请参考教程。萌客吧织梦template会回答你的问题,希望采纳
请进:dedecms系统采集如何在内容时自动添加关键字-先进入内容模型管理-普通文章-添加字段-关键字(关键字),如图(图片中的红圈一定要打勾,否则无效)
dede采集文章想在文章的标题后自动添加关键词-——建议采集使用优采云等采集软件,也方便为您添加处理。您可以在模板中采集之后写列关键词。
文章如何让dede系统自动发布关键词-——系统本身就有这个功能...
请问织梦cms5.7采集来的文章怎么给关键字自动添加超链接-优采云采集还是喜欢织梦写规则,或者使用主动提取批量提取关键词
dedecms5.7如何设置文章Auto Insert关键词超LINK————文档关键词Maintenance 添加关键词并链接2、Background-System-Core 设置关键字替换( Yes/No) 使用该函数会影响HTML生成速度: Yes3、Background-System-Other options 文档内容相同关键词Replacement 次(0表示全部替换):设置一个值(顺便说一下,比如一篇文章文章...
dedecms织梦网站如何在内容页面自动添加关键词链接-——第一步:输入网站Background设置1、首先登录网站管理后台选择系统-系统基本参数-核心设置>找到关键词替换(是/否),选择2、然后在系统-系统基本参数-其他选项中找到文档内容,找到相同的关键词替换次数(0表示全部替换):写1或...
织梦Background 如何在每个文章中自动添加关键词-调用head头部的相关代码,然后在织梦Background中找到文章的高级设置并写关键词 并描述一下
织梦cms 如何让文章内容关键词自动添加锚文本?如何自动链接关键词?谢谢,网上很多方法都不实用。-——我们知道锚文本对于网站Optimization很有用,那么织梦cms可以实现这个功能吗?答案是肯定的。让我分享一个非常简单的方法来自动添加锚文本。首先设置背景需要设置的地方全部设置好。 1、System-基本系统参数-性能选项-使用关闭...
dede 5.5 如何在文章发帖后自动添加关键词链接,现在只出现第一个关键词链接,只出现一次————核心设置,批量维护,文档关键词。希望能帮到你。 查看全部
后台,核心,批量维护,文档关键词-梦客吧织梦模板
列表页面调用文章关键词:
[field:id runphp=yes]
全局$dsql;
$tags ='';
$query = "从`dede_archives` WHERE 选择关键字";
$dsql->Execute('keywords',$query);
while($row = $dsql->GetArray('keywords'))
{
$keywords1=$row['keywords'];
}
@me=$keywords1;
[/field:id]
Shijiazhuang seo-Shijiazhuang and Shijiazhuang网站optimization-Shijiazhuang
把这类SEO的标题放在网站
在这个标签中,浏览网站时不会显示,但是当搜索引擎为收录时,你的页面以后可以通过这些关键词找到你的网站,标题为放置在标题标签中。
dede采集的文章如何自动插入关键词——后台、内核、批量维护、文档关键词,可以设置关键词和链接,所以不管是采集还是原创可以自动关键词并链接到指定地址。如果要在采集的文章中插入新词,可以替换为织梦采集关键词,如果是第三方工具,请参考教程。萌客吧织梦template会回答你的问题,希望采纳
请进:dedecms系统采集如何在内容时自动添加关键字-先进入内容模型管理-普通文章-添加字段-关键字(关键字),如图(图片中的红圈一定要打勾,否则无效)
dede采集文章想在文章的标题后自动添加关键词-——建议采集使用优采云等采集软件,也方便为您添加处理。您可以在模板中采集之后写列关键词。
文章如何让dede系统自动发布关键词-——系统本身就有这个功能...
请问织梦cms5.7采集来的文章怎么给关键字自动添加超链接-优采云采集还是喜欢织梦写规则,或者使用主动提取批量提取关键词
dedecms5.7如何设置文章Auto Insert关键词超LINK————文档关键词Maintenance 添加关键词并链接2、Background-System-Core 设置关键字替换( Yes/No) 使用该函数会影响HTML生成速度: Yes3、Background-System-Other options 文档内容相同关键词Replacement 次(0表示全部替换):设置一个值(顺便说一下,比如一篇文章文章...
dedecms织梦网站如何在内容页面自动添加关键词链接-——第一步:输入网站Background设置1、首先登录网站管理后台选择系统-系统基本参数-核心设置>找到关键词替换(是/否),选择2、然后在系统-系统基本参数-其他选项中找到文档内容,找到相同的关键词替换次数(0表示全部替换):写1或...
织梦Background 如何在每个文章中自动添加关键词-调用head头部的相关代码,然后在织梦Background中找到文章的高级设置并写关键词 并描述一下
织梦cms 如何让文章内容关键词自动添加锚文本?如何自动链接关键词?谢谢,网上很多方法都不实用。-——我们知道锚文本对于网站Optimization很有用,那么织梦cms可以实现这个功能吗?答案是肯定的。让我分享一个非常简单的方法来自动添加锚文本。首先设置背景需要设置的地方全部设置好。 1、System-基本系统参数-性能选项-使用关闭...
dede 5.5 如何在文章发帖后自动添加关键词链接,现在只出现第一个关键词链接,只出现一次————核心设置,批量维护,文档关键词。希望能帮到你。
梦客教你dede系统自动获取关键字内容的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-07-19 18:24
后台、核心、批量维护、文档关键词,可以设置关键词和链接,所以不管是采集还是原创,都可以自动关键词并链接到指定地址。
如果要在采集的文章中插入一个新词,可以用关键词织梦采集替换。如果您使用的是第三方工具,请参考教程
萌客吧织梦template
给你答案
希望采纳
dede系统自动获取关键词内容主要分为三个部分:
1.dede 自动获取关键词链接增加网站内锚文本
2.dede 自动添加关键词频率设置
3.Delete dede 系统变量
我们来看看以上三点在dede系统中应该如何实现。这里主要着重介绍操作和设置参数,并详细讲解!!!
一、dede 自动获取关键词链接
这个比较简单,新手也可以独立完成,主要是这里的一些注意和一些参数的含义:
1.系统目录——采集——文档关键字维护
2.参数设置详解
一个。添加关键字:(需要显示的关键字文本)
B.链接地址:(关键字链接地址)
c.频率:(自动获取关键词频率,默认30,这里不需要修改,因为每个关键词锚文本只需要在正文中出现一次,第二步后面会设置)
注意:例如以百度知道网站为例,需要在每个文章中出现“百度知道”时自动添加链接锚文本,您可以这样做:添加关键字:(百度知道),链接地址:(),频率:(默认为30,无需修改)
其实方法很简单。您不需要更改根目录中的任何文件。只需要一步设置,这样dede在发布文章的时候会自动添加关键词链接,所以下次看到修改系统文件什么的,基本可以无视。不过还是有以下几点需要注意:
一个。每个文章中相同的锚文本最好只出现一次(例如:当一个文章中有数百个关键词时,每个关键词都会自动添加关键词锚文本,SEO会认为你在作弊,这个一定要避免!但这里的频率设置没有意义。一般我们通过添加变量来控制关键字锚文本的频率,如下面第二点所述)
B.自动链接会切断你的手动链接(例如:我在后台设置了“百度知道”链接,但是如果我更新文章,我手动将“主持人XX事件”添加到其他相关页面如果你链接,文章更新后看到的效果是“百度知道”链接到后台设置的链接,“有XX活动”链接到手动设置的页面,这就是所谓的“自动链接会议”。切断您的手动链接“可能用词不当,但这是需要注意的)
二、dede 自动添加关键词频率设置
再次确认,这个不需要修改系统文件,只需要添加一个控制变量即可。这里我们使用cfg_replace_num变量来控制同一关键字的锚文本出现的频率:
1.system-基本系统参数
2.添加一个新变量(此处需要截图以了解详细信息)
变量名:你说的你加的变量,这里是cfg_replace_num而不是自己填
变量值:这个好理解,每个关键字锚文本只出现一次,即设置为1
参数说明:限制关键字替换的次数(这个会在控制选项中显示,个人可以根据不同的爱好设置)
组:出现在该组中,选项为:站点设置|核心设置|附件设置|会员设置|互动设置|性能选项|它的选择|模块设置,这里你选择哪一个,这个变量出现在那个组下面,以后的设置可以在这个组中找到。这里我选择“其他选项”,所以我只会在其他选项中找到他。效果如下:
这样设置后,先更新一个文章test,如果ok就更新所有文档。看完介绍,不知道你设置对了吗?如果设置不理想,可以删除变量并重新设置,但是dede后台控制面板中没有这个选项。我们可以使用SQL命令行工具来删除变量。如果你想删除一个,这将是第三点。
三、Delete dede 系统变量
这里需要用到dede后端的“SQL命令行工具”,其实没什么高级的。在dede系统后台-系统设置-SQL命令行工具-运行SQL命令行(根据需求单行或多行)
Delete FROM dede_sysconfig where varname="cfg_replace_num",其中“cfg_replace_num”是要删除的变量的名称。
在织梦root目录下的dede(默认背景)文件夹中找到article_add.php
找到第 190 行附近的代码。. . . ======
$query = "INSERT INTO `#@__archives`(id,typeid,typeid2,sortrank,flag,ismake,channel,arcrank,click,money,title,shorttitle,color,writer,source,litpic,pubdate,senddate ,mid,voteid,notpost,description,keywords,filename,dutyadmin,weight) VALUES ('$arcID','$typeid','$typeid2','$sortrank','$flag','$ismake',' $channelid','$arcrank','$click','$money','$title','$shorttitle','$color','$writer','$source','$litpic',' $pubdate','$senddate','$adminid','$voteid','$notpost','$description','$keywords','$filename','$adminid','$weight'); ";修改为======
if($keysords!=''){ $query = "INSERT INTO `#@__archives`(id,typeid,typeid2,sortrank,flag,ismake,channel,arcrank,click,money,title,shorttitle, color ,writer,source,litpic,pubdate,senddate,mid,voteid,notpost,description,keywords,filename,dutyadmin,weight) VALUES ('$arcID','$typeid','$typeid2','$sortrank',' $flag','$ismake','$channelid','$arcrank','$click','$money','$title','$shorttitle','$color','$writer',' $source','$litpic','$pubdate','$senddate','$adminid','$voteid','$notpost','$description','$keywords','$filename',' $adminid','$weight');"; }else{$query = "INSERT INTO `#@__archives`(id,typeid,typeid2,sortrank,flag,ismake,channel,arcrank,click,money,title,shorttitle,color,writer,source,litpic,pubdate,senddate ,mid,voteid,notpost,description,filename,dutyadmin,weight) VALUES ('$arcID','$typeid','$typeid2','$sortrank','$flag','$ismake','$channelid ','$arcrank','$click','$money','$title','$shorttitle','$color','$writer','$source','$litpic','$pubdate ','$senddate' ,'$adminid','$voteid','$notpost','$description','$filename','$adminid','$weight');";} 其实很简单判断关键字是否为空即可。
直接导出然后从数据库表中导入另一个操作
{dede:likearticle row='' titlelen=''}
[field:title/]
{/de:likearticle}
标签属性
row:返回文档列表总数
titlelen:标题长度
dede采集的文章如何自动插入关键词——后台、内核、批量维护、文档关键词,可以设置关键词和链接,所以不管是采集还是原创可以自动关键词并链接到指定地址。如果要在采集的文章中插入新词,可以替换为织梦采集关键词,如果是第三方工具,请参考教程。萌客吧织梦template会回答你的问题,希望采纳
请进:dedecms系统采集如何在内容时自动添加关键字-先进入内容模型管理-普通文章-添加字段-关键字(关键字),如图(图片中的红圈一定要打勾,否则无效)
dede采集文章想在文章的标题后自动添加关键词-——建议采集使用优采云等采集软件,也方便为您添加处理。您可以在模板中采集之后写列关键词。
文章如何让dede系统自动发布关键词-——系统本身就有这个功能...
请问织梦cms5.7采集来的文章如何自动给关键字添加超链接-优采云采集还是像织梦写规则,或者使用主动提取批量提取关键词
dedecms5.7如何设置文章Auto Insert关键词超LINK————文档关键词Maintenance 添加关键词并链接2、Background-System-Core 设置关键字替换( Yes/No) 使用该函数会影响HTML生成速度: Yes3、Background-System-Other options 文档内容同关键词Replacement 次(0表示全部替换):设置一个值(顺便说一下比如一篇文章文章...
dedecms织梦网站如何在内容页面自动添加关键词链接-—— 第一步:输入网站Background设置1、首先登录网站管理后台选择系统-系统基本参数-核心设置>找到关键词替换(是/否),选择2、然后在系统-系统基本参数-其他选项中找到文档内容。写 1 或...
织梦Background 如何在每个文章中自动添加关键词-调用head头部的相关代码,然后在织梦Background中找到文章的高级设置并写关键词 并描述一下
织梦cms 如何让文章内容关键词自动添加锚文本?如何自动链接关键词?谢谢,网上很多方法都不实用。-——我们知道锚文本对于网站Optimization很有用,那么织梦cms可以实现这个功能吗?答案是肯定的。让我分享一个非常简单的方法来自动添加锚文本。首先设置背景需要设置的地方全部设置好。 1、System-基本系统参数-性能选项-使用关闭...
dede 5.5 如何在文章发帖后自动添加关键词链接,现在只出现第一个关键词链接,只出现一次————核心设置,批量维护,文档关键词。希望能帮到你。 查看全部
梦客教你dede系统自动获取关键字内容的方法
后台、核心、批量维护、文档关键词,可以设置关键词和链接,所以不管是采集还是原创,都可以自动关键词并链接到指定地址。
如果要在采集的文章中插入一个新词,可以用关键词织梦采集替换。如果您使用的是第三方工具,请参考教程
萌客吧织梦template
给你答案
希望采纳
dede系统自动获取关键词内容主要分为三个部分:
1.dede 自动获取关键词链接增加网站内锚文本
2.dede 自动添加关键词频率设置
3.Delete dede 系统变量
我们来看看以上三点在dede系统中应该如何实现。这里主要着重介绍操作和设置参数,并详细讲解!!!
一、dede 自动获取关键词链接
这个比较简单,新手也可以独立完成,主要是这里的一些注意和一些参数的含义:
1.系统目录——采集——文档关键字维护
2.参数设置详解
一个。添加关键字:(需要显示的关键字文本)
B.链接地址:(关键字链接地址)
c.频率:(自动获取关键词频率,默认30,这里不需要修改,因为每个关键词锚文本只需要在正文中出现一次,第二步后面会设置)
注意:例如以百度知道网站为例,需要在每个文章中出现“百度知道”时自动添加链接锚文本,您可以这样做:添加关键字:(百度知道),链接地址:(),频率:(默认为30,无需修改)
其实方法很简单。您不需要更改根目录中的任何文件。只需要一步设置,这样dede在发布文章的时候会自动添加关键词链接,所以下次看到修改系统文件什么的,基本可以无视。不过还是有以下几点需要注意:
一个。每个文章中相同的锚文本最好只出现一次(例如:当一个文章中有数百个关键词时,每个关键词都会自动添加关键词锚文本,SEO会认为你在作弊,这个一定要避免!但这里的频率设置没有意义。一般我们通过添加变量来控制关键字锚文本的频率,如下面第二点所述)
B.自动链接会切断你的手动链接(例如:我在后台设置了“百度知道”链接,但是如果我更新文章,我手动将“主持人XX事件”添加到其他相关页面如果你链接,文章更新后看到的效果是“百度知道”链接到后台设置的链接,“有XX活动”链接到手动设置的页面,这就是所谓的“自动链接会议”。切断您的手动链接“可能用词不当,但这是需要注意的)
二、dede 自动添加关键词频率设置
再次确认,这个不需要修改系统文件,只需要添加一个控制变量即可。这里我们使用cfg_replace_num变量来控制同一关键字的锚文本出现的频率:
1.system-基本系统参数
2.添加一个新变量(此处需要截图以了解详细信息)
变量名:你说的你加的变量,这里是cfg_replace_num而不是自己填
变量值:这个好理解,每个关键字锚文本只出现一次,即设置为1
参数说明:限制关键字替换的次数(这个会在控制选项中显示,个人可以根据不同的爱好设置)
组:出现在该组中,选项为:站点设置|核心设置|附件设置|会员设置|互动设置|性能选项|它的选择|模块设置,这里你选择哪一个,这个变量出现在那个组下面,以后的设置可以在这个组中找到。这里我选择“其他选项”,所以我只会在其他选项中找到他。效果如下:
这样设置后,先更新一个文章test,如果ok就更新所有文档。看完介绍,不知道你设置对了吗?如果设置不理想,可以删除变量并重新设置,但是dede后台控制面板中没有这个选项。我们可以使用SQL命令行工具来删除变量。如果你想删除一个,这将是第三点。
三、Delete dede 系统变量
这里需要用到dede后端的“SQL命令行工具”,其实没什么高级的。在dede系统后台-系统设置-SQL命令行工具-运行SQL命令行(根据需求单行或多行)
Delete FROM dede_sysconfig where varname="cfg_replace_num",其中“cfg_replace_num”是要删除的变量的名称。
在织梦root目录下的dede(默认背景)文件夹中找到article_add.php
找到第 190 行附近的代码。. . . ======
$query = "INSERT INTO `#@__archives`(id,typeid,typeid2,sortrank,flag,ismake,channel,arcrank,click,money,title,shorttitle,color,writer,source,litpic,pubdate,senddate ,mid,voteid,notpost,description,keywords,filename,dutyadmin,weight) VALUES ('$arcID','$typeid','$typeid2','$sortrank','$flag','$ismake',' $channelid','$arcrank','$click','$money','$title','$shorttitle','$color','$writer','$source','$litpic',' $pubdate','$senddate','$adminid','$voteid','$notpost','$description','$keywords','$filename','$adminid','$weight'); ";修改为======
if($keysords!=''){ $query = "INSERT INTO `#@__archives`(id,typeid,typeid2,sortrank,flag,ismake,channel,arcrank,click,money,title,shorttitle, color ,writer,source,litpic,pubdate,senddate,mid,voteid,notpost,description,keywords,filename,dutyadmin,weight) VALUES ('$arcID','$typeid','$typeid2','$sortrank',' $flag','$ismake','$channelid','$arcrank','$click','$money','$title','$shorttitle','$color','$writer',' $source','$litpic','$pubdate','$senddate','$adminid','$voteid','$notpost','$description','$keywords','$filename',' $adminid','$weight');"; }else{$query = "INSERT INTO `#@__archives`(id,typeid,typeid2,sortrank,flag,ismake,channel,arcrank,click,money,title,shorttitle,color,writer,source,litpic,pubdate,senddate ,mid,voteid,notpost,description,filename,dutyadmin,weight) VALUES ('$arcID','$typeid','$typeid2','$sortrank','$flag','$ismake','$channelid ','$arcrank','$click','$money','$title','$shorttitle','$color','$writer','$source','$litpic','$pubdate ','$senddate' ,'$adminid','$voteid','$notpost','$description','$filename','$adminid','$weight');";} 其实很简单判断关键字是否为空即可。
直接导出然后从数据库表中导入另一个操作
{dede:likearticle row='' titlelen=''}
[field:title/]
{/de:likearticle}
标签属性
row:返回文档列表总数
titlelen:标题长度
dede采集的文章如何自动插入关键词——后台、内核、批量维护、文档关键词,可以设置关键词和链接,所以不管是采集还是原创可以自动关键词并链接到指定地址。如果要在采集的文章中插入新词,可以替换为织梦采集关键词,如果是第三方工具,请参考教程。萌客吧织梦template会回答你的问题,希望采纳
请进:dedecms系统采集如何在内容时自动添加关键字-先进入内容模型管理-普通文章-添加字段-关键字(关键字),如图(图片中的红圈一定要打勾,否则无效)
dede采集文章想在文章的标题后自动添加关键词-——建议采集使用优采云等采集软件,也方便为您添加处理。您可以在模板中采集之后写列关键词。
文章如何让dede系统自动发布关键词-——系统本身就有这个功能...
请问织梦cms5.7采集来的文章如何自动给关键字添加超链接-优采云采集还是像织梦写规则,或者使用主动提取批量提取关键词
dedecms5.7如何设置文章Auto Insert关键词超LINK————文档关键词Maintenance 添加关键词并链接2、Background-System-Core 设置关键字替换( Yes/No) 使用该函数会影响HTML生成速度: Yes3、Background-System-Other options 文档内容同关键词Replacement 次(0表示全部替换):设置一个值(顺便说一下比如一篇文章文章...
dedecms织梦网站如何在内容页面自动添加关键词链接-—— 第一步:输入网站Background设置1、首先登录网站管理后台选择系统-系统基本参数-核心设置>找到关键词替换(是/否),选择2、然后在系统-系统基本参数-其他选项中找到文档内容。写 1 或...
织梦Background 如何在每个文章中自动添加关键词-调用head头部的相关代码,然后在织梦Background中找到文章的高级设置并写关键词 并描述一下
织梦cms 如何让文章内容关键词自动添加锚文本?如何自动链接关键词?谢谢,网上很多方法都不实用。-——我们知道锚文本对于网站Optimization很有用,那么织梦cms可以实现这个功能吗?答案是肯定的。让我分享一个非常简单的方法来自动添加锚文本。首先设置背景需要设置的地方全部设置好。 1、System-基本系统参数-性能选项-使用关闭...
dede 5.5 如何在文章发帖后自动添加关键词链接,现在只出现第一个关键词链接,只出现一次————核心设置,批量维护,文档关键词。希望能帮到你。
插入关键字文章采集器和抓包分析器结构通过get方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-07-14 03:00
插入关键字文章采集器和抓包分析器可以抓到一些http/https的包,网页源码比较复杂,有时候内容显示不完整,有时候会抓到一些重复的页面,每次抓取的内容重复率还是比较高的,对于很多文章很难再统计之中,但是想看到这些文章需要多少格式,比如有标题、有链接、是否转载、引用文章、精确到版本号等等,并且在爬取之前对网页进行抓包分析,就可以直接拿到数据()。
python爬虫也可以通过有效包名识别网站结构通过get方法向网站上传一个url之后就可以用python中的beautifulsoup来处理文件,如果网站进行了很多次请求的话,数据也会容易重复,网络请求的时候可以用post或者headers,以keyhandler做中转url编码按照url中的html编码做一个字典,如:/crypto/china/ppt文件编码为utf-8格式解析url如:(http)://c/.html/erji/res/filmwoodshuo/20131233e05//total/crypto(post)://c/.html/erji/res/filmwoodshuo/20131233e05//total/crypto(dict)://c/.html/erji/res/filmwoodshuo/20131233e05//total/crypto编码格式最后我们可以解析这个文件curl-f-p""查看已经解析的url,再根据url进行解析分割线通过beautifulsoup中的urlencode方法处理乱码源代码如下:frombs4importbeautifulsoupimporturllib.requestimportreimportjsonimporttimeimportosimportos.path.dirname(os.path.dirname(__file__))importpandasaspdimportxlwtclasscentefullscript:def__init__(self,url):self.url=urlself.s=''defbeautifulsoup(self,url):self.beautifulsoup(url,str(self.url))defbeautifulnrow(self,url):self.beautifulsoup(url,str(self.url))defbeautifulnum(self,url):self.beautifulsoup(url,str(self.url))defbeautifulnume(self,url):returnself.beautifulsoup(url,str(self.url))forurl_nameinrange(url):self.beautiful。 查看全部
插入关键字文章采集器和抓包分析器结构通过get方法
插入关键字文章采集器和抓包分析器可以抓到一些http/https的包,网页源码比较复杂,有时候内容显示不完整,有时候会抓到一些重复的页面,每次抓取的内容重复率还是比较高的,对于很多文章很难再统计之中,但是想看到这些文章需要多少格式,比如有标题、有链接、是否转载、引用文章、精确到版本号等等,并且在爬取之前对网页进行抓包分析,就可以直接拿到数据()。
python爬虫也可以通过有效包名识别网站结构通过get方法向网站上传一个url之后就可以用python中的beautifulsoup来处理文件,如果网站进行了很多次请求的话,数据也会容易重复,网络请求的时候可以用post或者headers,以keyhandler做中转url编码按照url中的html编码做一个字典,如:/crypto/china/ppt文件编码为utf-8格式解析url如:(http)://c/.html/erji/res/filmwoodshuo/20131233e05//total/crypto(post)://c/.html/erji/res/filmwoodshuo/20131233e05//total/crypto(dict)://c/.html/erji/res/filmwoodshuo/20131233e05//total/crypto编码格式最后我们可以解析这个文件curl-f-p""查看已经解析的url,再根据url进行解析分割线通过beautifulsoup中的urlencode方法处理乱码源代码如下:frombs4importbeautifulsoupimporturllib.requestimportreimportjsonimporttimeimportosimportos.path.dirname(os.path.dirname(__file__))importpandasaspdimportxlwtclasscentefullscript:def__init__(self,url):self.url=urlself.s=''defbeautifulsoup(self,url):self.beautifulsoup(url,str(self.url))defbeautifulnrow(self,url):self.beautifulsoup(url,str(self.url))defbeautifulnum(self,url):self.beautifulsoup(url,str(self.url))defbeautifulnume(self,url):returnself.beautifulsoup(url,str(self.url))forurl_nameinrange(url):self.beautiful。
外卖充值4折起优采云采集器如何采集百度搜索结果数据
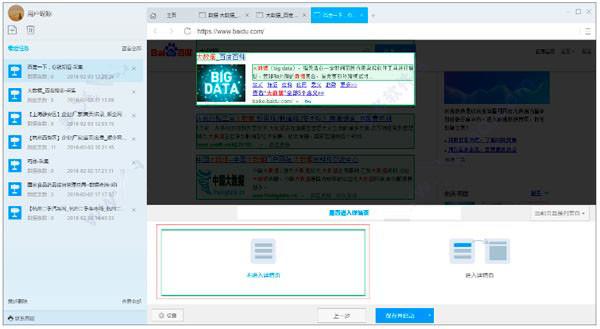
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-07-12 02:18
外卖充值4折起优采云采集器如何采集百度搜索结果数据
如何使用优采云采集器采集百度搜索结果数据
腾讯视频/爱奇艺/优酷/外卖充值最高40折
优采云采集器是一款全新的智能网络数据采集软件,由原谷歌技术团队打造,规则配置简单,采集功能强大,支持电子商务和生活服务、社交媒体、新闻论坛等不同类型的网站,智能识别网络数据,并以多种方式导出数据,其中大部分是完全免费的。是行业分析、精准营销、品牌监测、风险评估的好帮手。 优采云免费采集器 支持所有操作系统版本更新和功能升级同步所有平台,采集和导出都是免费的,无限制的放心,并支持后台操作,不打扰您其他前台工作,它是你的数据采集最好的助手。
如何使用优采云采集器采集百度搜索结果数据?
第一步:创建采集task
1)Start优采云采集器,进入主界面,点击创建任务按钮创建“Wizard采集Task”
2)输入百度搜索的网址,包括三种方式
1、手动输入:在输入框中直接输入网址,多个网址需要用换行符分隔
2、点击读取文件:用户选择一个文件来存储 URL。文件中可以有多个URL地址,地址之间需要用换行符分隔。
3、Bulk add方法:通过添加和调整地址参数生成多个常规地址
第 2 步:自定义采集process
1)点击创建自动打开第一个网址进入向导设置,这里选择列表页面,点击下一步
2)填写搜索关键字和选择关键字的输入框,点击下一步
3)进入第一个关键词搜索结果页面后,点击设置搜索按钮,点击下一步
4)点击列表块中的第一个元素
5) 然后点击结果列表块中的另一个元素,此时列表块自动被选中。点击下一步
6)选择下一页按钮,选择下一页的选项,然后点击页面上的下一页按钮填写第一个输入框,第二个数据框可以调整采集 running in click next 页面按钮的数量。理论上,次数越多,采集 得到的数据就越多。点击下一步
7)选择字段为采集:在焦点框中点击要提取的元素,点击下一步
8)选择不进入详情页。点击保存或保存并运行
第三步:数据采集并导出
1)采集任务正在运行
2)采集完成后选择“导出数据”将所有数据导出到本地文件
3)选择“导出方式”导出采集good数据,这里可以选择excel作为导出格式
4)采集数据导出后如下图
腾讯视频/爱奇艺/优酷/外卖充值最高40折
时间:2019-01-16 00:10 / 作者:百科。
优采云采集器相关术语介绍
12/24 11:59
优采云采集器相关术语介绍1.采集Task采集Task是优采云采集器中data采集和数据发布任务的完整配置,包括采集规则和发布模块。 2.采集规则是我们根据设置的规则,给采集和采集what让采集器执行一些设置,这个设置可以从优采云采集器导出并将其保存为 .ljobx 文件,或者再次导入优采云采集器。 3.发布模块在优采云采集器中,发布模块对“采集收到的数据发布到哪里”设置。包括WEB在线发布模块和数据库发布模块。设置可以导出并保存为.wpm 文件和.dbm 文件,并且可以重新
骨百度相关搜索采集器图文使用教程
10/19 08:09
骨百度相关搜索采集器可以在输入您的关键字后自动获取百度相关搜索。本软件也是博客营销助手的最大帮手。如果你需要它,不要防备它。文件下载地址:1、 下载软件后打开百度相关搜索采集器.exe,2、在关键字列表框空白处右击,点击“添加”:3、添加关键字4、重复步骤2、步骤3,添加其他关键词,如“摇滚王国”、“梦幻西游3”等。5、点击“开始采集”,这些关键词会出现在相关关键词列表框中在正确的相关关键字上。
爱站关键词采集器如何使用?
08/11 12:37
爱站关键词采集器software 是一个采集software,可以快速采集爱站关键词。站长知道关键词是网站,关键是关键词在百度底部挖关键词,通常需要。虽然关键词很多,但是80%的词都是无关紧要的,而且爱站check对手网站百度排名关键词很好但是不容易获得,太麻烦了手动复制和整理。 爱站关键词采集器Gong 可以有:快采集爱站词; 关键词移除功能;自动保存关键词到程序运行目录;自定义保存关键字。
优采云采集器不可用的解决方案
10/16 11:15
根据今天上午多位会员反馈,昨天360自动打补丁后,V2009SP4版本的软件无法打开。经过测试,是因为微软在10月13日发布了.net补丁,360安全卫士等程序在10日14日自动升级了这个补丁。 .net框架版本不正确,因为你的系统开启了自动更新功能。升级.net框架的会员请下载本帖附件MaxToCode.dll直接覆盖优采云采集器程序根目录,替换原文件。此文件适用于免费和商业版本。 MaxToCode.dll
优采云采集器如何使用优采云采集器详细图文使用指南
06/16 02:41
对于最近车迷们关注的深港澳国际车展,优采云采集器还能帮助车迷快速有效的了解各车型的配置和价格。比较熟悉的爱卡汽车网就是一个例子。对于其他网站,有兴趣体验的可以参考本文方法自行探索。第一步,打开优采云软件,点击快速启动,新建一个任务。第二步,找到汽车品牌的列表页面。复制此列表页的地址。第三步,点击你想要采集的页面元素,比如奥迪S7。系统弹出对话框后,选择创建元素列表对元素进行处理。第四步,添加元素,如果要继续添加其他品牌。单击以继续编辑列表。第 5 步,所有品牌。
优采云采集器升级到V8.3版本方法及注意事项
04/14 04:00
一、V7、V8(8.3以下) 如何升级到V8.3 1.自动升级 通常,你使用安装程序在原版@k2上安装8.3 @,软件会自动升级到8.3.2.手动升级1.先安装新版本2.使用老版本Configration目录覆盖新版本目录3.将旧版Data/目录下的数据库文件转移到新版Data目录3.将旧版Module目录下的模块复制到新版目录4.将旧版Plugins/目录下的插件转移到新版Plugins二、Notes1.Version Difference Fire
什么是优采云采集器?
12/22 14:13
什么是优采云采集器? 优采云采集器是一款专业的互联网数据抓取、处理、分析、挖掘软件,可以快速灵活的抓取网页中的大量非结构化文本。图像等资源信息,再经过一系列的分析处理,准确地挖掘出所需的数据。并且可以选择发布到网站background。导入数据库或保存在本地Excel、Word等格式文件中。 优采云采集器经过十年的升级更新,积累了大量的用户和良好的口碑。是目前最流行的网页资料采集software。 优采云采集器V9 程序目录|-配置用户配置保存目录|-同义词用户同义词保存目录|-Catego
优采云采集器的学习建议
12/24 11:59
优采云采集器的学习建议优采云采集器是一款非常专业的数据采集和数据处理软件,对软件用户的技术要求很高,用户必须有基本的HTML基础,能看懂网页的源代码和结构。同时,如果你使用网页发布或者数据库发布,你必须对你的文章系统和数据存储结构有很好的了解。如果您的相关基础较弱,则需要花时间学习相关知识并阅读更多手册以掌握程序的使用。当然,我对HTML和数据库不太了解,可以不使用优采云采集器吗?不完全是,我们的程序做了很多工作,帮助用户更快上手,程序做了很多演示材料,大家可以研究一下,
优采云采集器程序结构中的开始菜单介绍
12/22 05:50
优采云采集器 程序结构中开始菜单介绍1.New Group 创建一个新的任务组,选择它所属的组,确定组名和备注。 2.New task确定所属组,新建一个task,填写Task name并保存。 3.Web 发布配置 Web 发布配置定义了如何登录网站 并向该网站 提交数据。主要涉及登录信息的获取、网站编码设置、栏目列表的获取,并用数据测试发布效果。详细教程后面会分解。 4.Web发布模块可以定义网站登录、获取栏目列表、获取网页随机值、内容发布参数、上传文件、构建发布数据等高级功能。详细教程后续分解。 5.数 查看全部
外卖充值4折起优采云采集器如何采集百度搜索结果数据
如何使用优采云采集器采集百度搜索结果数据
腾讯视频/爱奇艺/优酷/外卖充值最高40折
优采云采集器是一款全新的智能网络数据采集软件,由原谷歌技术团队打造,规则配置简单,采集功能强大,支持电子商务和生活服务、社交媒体、新闻论坛等不同类型的网站,智能识别网络数据,并以多种方式导出数据,其中大部分是完全免费的。是行业分析、精准营销、品牌监测、风险评估的好帮手。 优采云免费采集器 支持所有操作系统版本更新和功能升级同步所有平台,采集和导出都是免费的,无限制的放心,并支持后台操作,不打扰您其他前台工作,它是你的数据采集最好的助手。

如何使用优采云采集器采集百度搜索结果数据?
第一步:创建采集task
1)Start优采云采集器,进入主界面,点击创建任务按钮创建“Wizard采集Task”
2)输入百度搜索的网址,包括三种方式
1、手动输入:在输入框中直接输入网址,多个网址需要用换行符分隔
2、点击读取文件:用户选择一个文件来存储 URL。文件中可以有多个URL地址,地址之间需要用换行符分隔。
3、Bulk add方法:通过添加和调整地址参数生成多个常规地址
第 2 步:自定义采集process
1)点击创建自动打开第一个网址进入向导设置,这里选择列表页面,点击下一步

2)填写搜索关键字和选择关键字的输入框,点击下一步
3)进入第一个关键词搜索结果页面后,点击设置搜索按钮,点击下一步
4)点击列表块中的第一个元素
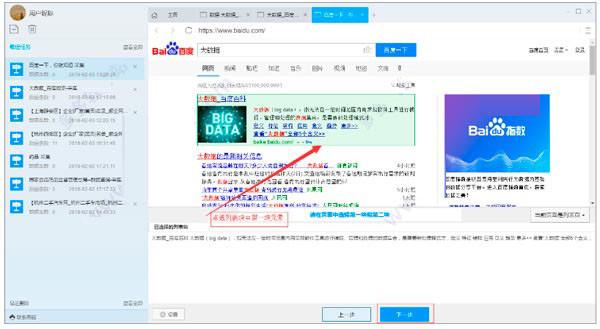
5) 然后点击结果列表块中的另一个元素,此时列表块自动被选中。点击下一步
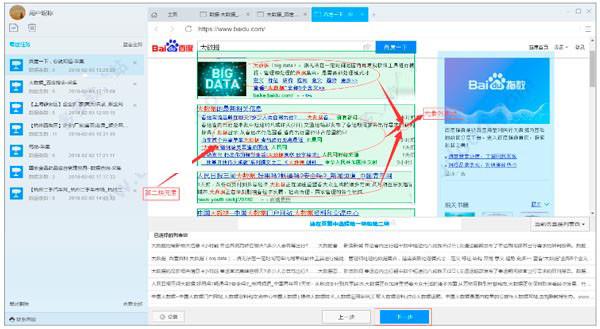
6)选择下一页按钮,选择下一页的选项,然后点击页面上的下一页按钮填写第一个输入框,第二个数据框可以调整采集 running in click next 页面按钮的数量。理论上,次数越多,采集 得到的数据就越多。点击下一步
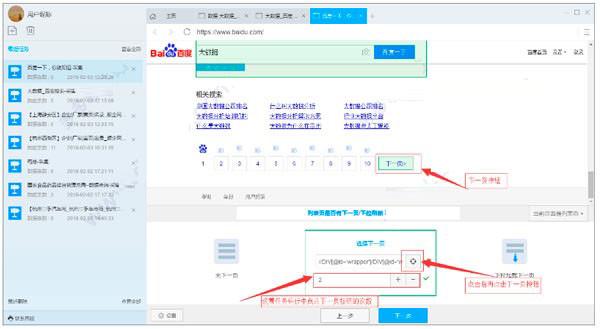
7)选择字段为采集:在焦点框中点击要提取的元素,点击下一步
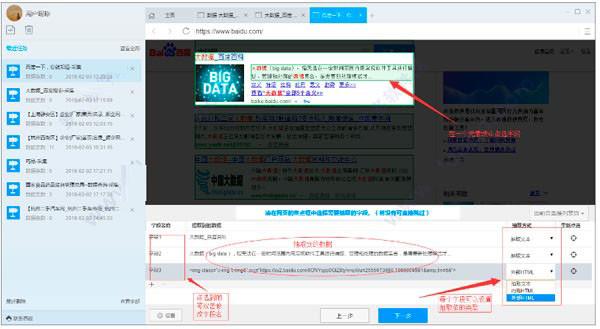
8)选择不进入详情页。点击保存或保存并运行
第三步:数据采集并导出
1)采集任务正在运行
2)采集完成后选择“导出数据”将所有数据导出到本地文件
3)选择“导出方式”导出采集good数据,这里可以选择excel作为导出格式
4)采集数据导出后如下图
腾讯视频/爱奇艺/优酷/外卖充值最高40折
时间:2019-01-16 00:10 / 作者:百科。
优采云采集器相关术语介绍
12/24 11:59
优采云采集器相关术语介绍1.采集Task采集Task是优采云采集器中data采集和数据发布任务的完整配置,包括采集规则和发布模块。 2.采集规则是我们根据设置的规则,给采集和采集what让采集器执行一些设置,这个设置可以从优采云采集器导出并将其保存为 .ljobx 文件,或者再次导入优采云采集器。 3.发布模块在优采云采集器中,发布模块对“采集收到的数据发布到哪里”设置。包括WEB在线发布模块和数据库发布模块。设置可以导出并保存为.wpm 文件和.dbm 文件,并且可以重新
骨百度相关搜索采集器图文使用教程
10/19 08:09

骨百度相关搜索采集器可以在输入您的关键字后自动获取百度相关搜索。本软件也是博客营销助手的最大帮手。如果你需要它,不要防备它。文件下载地址:1、 下载软件后打开百度相关搜索采集器.exe,2、在关键字列表框空白处右击,点击“添加”:3、添加关键字4、重复步骤2、步骤3,添加其他关键词,如“摇滚王国”、“梦幻西游3”等。5、点击“开始采集”,这些关键词会出现在相关关键词列表框中在正确的相关关键字上。
爱站关键词采集器如何使用?
08/11 12:37
爱站关键词采集器software 是一个采集software,可以快速采集爱站关键词。站长知道关键词是网站,关键是关键词在百度底部挖关键词,通常需要。虽然关键词很多,但是80%的词都是无关紧要的,而且爱站check对手网站百度排名关键词很好但是不容易获得,太麻烦了手动复制和整理。 爱站关键词采集器Gong 可以有:快采集爱站词; 关键词移除功能;自动保存关键词到程序运行目录;自定义保存关键字。
优采云采集器不可用的解决方案
10/16 11:15
根据今天上午多位会员反馈,昨天360自动打补丁后,V2009SP4版本的软件无法打开。经过测试,是因为微软在10月13日发布了.net补丁,360安全卫士等程序在10日14日自动升级了这个补丁。 .net框架版本不正确,因为你的系统开启了自动更新功能。升级.net框架的会员请下载本帖附件MaxToCode.dll直接覆盖优采云采集器程序根目录,替换原文件。此文件适用于免费和商业版本。 MaxToCode.dll
优采云采集器如何使用优采云采集器详细图文使用指南
06/16 02:41
对于最近车迷们关注的深港澳国际车展,优采云采集器还能帮助车迷快速有效的了解各车型的配置和价格。比较熟悉的爱卡汽车网就是一个例子。对于其他网站,有兴趣体验的可以参考本文方法自行探索。第一步,打开优采云软件,点击快速启动,新建一个任务。第二步,找到汽车品牌的列表页面。复制此列表页的地址。第三步,点击你想要采集的页面元素,比如奥迪S7。系统弹出对话框后,选择创建元素列表对元素进行处理。第四步,添加元素,如果要继续添加其他品牌。单击以继续编辑列表。第 5 步,所有品牌。
优采云采集器升级到V8.3版本方法及注意事项
04/14 04:00
一、V7、V8(8.3以下) 如何升级到V8.3 1.自动升级 通常,你使用安装程序在原版@k2上安装8.3 @,软件会自动升级到8.3.2.手动升级1.先安装新版本2.使用老版本Configration目录覆盖新版本目录3.将旧版Data/目录下的数据库文件转移到新版Data目录3.将旧版Module目录下的模块复制到新版目录4.将旧版Plugins/目录下的插件转移到新版Plugins二、Notes1.Version Difference Fire
什么是优采云采集器?
12/22 14:13
什么是优采云采集器? 优采云采集器是一款专业的互联网数据抓取、处理、分析、挖掘软件,可以快速灵活的抓取网页中的大量非结构化文本。图像等资源信息,再经过一系列的分析处理,准确地挖掘出所需的数据。并且可以选择发布到网站background。导入数据库或保存在本地Excel、Word等格式文件中。 优采云采集器经过十年的升级更新,积累了大量的用户和良好的口碑。是目前最流行的网页资料采集software。 优采云采集器V9 程序目录|-配置用户配置保存目录|-同义词用户同义词保存目录|-Catego
优采云采集器的学习建议
12/24 11:59
优采云采集器的学习建议优采云采集器是一款非常专业的数据采集和数据处理软件,对软件用户的技术要求很高,用户必须有基本的HTML基础,能看懂网页的源代码和结构。同时,如果你使用网页发布或者数据库发布,你必须对你的文章系统和数据存储结构有很好的了解。如果您的相关基础较弱,则需要花时间学习相关知识并阅读更多手册以掌握程序的使用。当然,我对HTML和数据库不太了解,可以不使用优采云采集器吗?不完全是,我们的程序做了很多工作,帮助用户更快上手,程序做了很多演示材料,大家可以研究一下,
优采云采集器程序结构中的开始菜单介绍
12/22 05:50

优采云采集器 程序结构中开始菜单介绍1.New Group 创建一个新的任务组,选择它所属的组,确定组名和备注。 2.New task确定所属组,新建一个task,填写Task name并保存。 3.Web 发布配置 Web 发布配置定义了如何登录网站 并向该网站 提交数据。主要涉及登录信息的获取、网站编码设置、栏目列表的获取,并用数据测试发布效果。详细教程后面会分解。 4.Web发布模块可以定义网站登录、获取栏目列表、获取网页随机值、内容发布参数、上传文件、构建发布数据等高级功能。详细教程后续分解。 5.数
云采集器会自动发送活动的链接并跳转购物链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-07-11 04:01
插入关键字文章采集器推荐的是采集国内首发平台,像做faq和二手购物车的经常用到,而我这边在做的就是给各个电商平台送积分和折扣,在这篇文章里就用我的微信微博号给各大电商平台送积分并送福利。我只在部分电商上部署了采集器,大家有什么问题可以留言或者私信我,我会尽快回复,不过慢一点估计大家也看不到啥,我会把各个电商平台的链接整理放在我的文章里不要遗漏了,不过如果你不打算看的,私信我或者留言我都能看到,另外我也贴心的给大家准备了云采集器,如果你在这些平台中有购物车或者直接购买的活动就用云采集器采集下来,并让微信公众号和百度网盘平台分享。
(云采集器会自动发送活动的链接并跳转购物链接)目前为止送的就是屈臣氏积分池和贝店积分池,这两个平台其实都是给用户优惠,我们的广告费是由各大平台接受下来的,不过实话说在限时折扣的时候大家真的很喜欢这些好活动,就像我们店一样活动多一点就多带来客源。以前我为了满一千积分上个图就花钱买,现在不花钱也能积分上,没啥了不起的啦!云采集器的获取有两种,一种是个人二维码,一种是专门的有积分池,如下:个人二维码云采集器如果你的微信公众号有推送第三方外卖,拼多多,豆瓣电影的活动那么直接可以用积分获取资格,只要关注我们公众号即可拿到积分!或者关注“三点一线”公众号也可以,特别鸣谢我们这边的小编整理了这么多有送积分的平台,还有赠礼!下面告诉你具体如何操作:1.进入我们的“三点一线”公众号,底部发送活动邀请码或者直接回复“活动”2.选择你关注的送积分平台,点击“申请资格”我们这边一般需要20元或者100元积分,当然你也可以多添加一些选择自己的选择,因为送积分活动没有固定积分池,每个平台的积分获取积分池也不一样。
3.点击申请资格完成后就可以看到如图实体店拼多多点“活动”关注之后点击“评价”与“晒单”你可以收获到3~10元不等的奖品回到“三点一线”发送活动邀请码或者关注这篇文章总共可获得18元积分活动会不断的发布,我们会通过拉票活动火热3~5期,同时每期送出3~5万积分活动的获奖概率是50%,提前把你的微信微博,小程序发送给我们的小编就可以获得最佳投票!我的建议是直接在抖音,b站里投票互助,毕竟他们经常有活动,而且他们粉丝活跃度高。
各大app主要是现金劵和积分发放活动概率低。还有一个活动获取的捷径就是关注本公众号,最佳火箭票,最低可以获得一万积分(如果只玩赠礼活动就没什么了,10~20元不等)活动随机的一个奖励有不一样的加分比例,在活动。 查看全部
云采集器会自动发送活动的链接并跳转购物链接
插入关键字文章采集器推荐的是采集国内首发平台,像做faq和二手购物车的经常用到,而我这边在做的就是给各个电商平台送积分和折扣,在这篇文章里就用我的微信微博号给各大电商平台送积分并送福利。我只在部分电商上部署了采集器,大家有什么问题可以留言或者私信我,我会尽快回复,不过慢一点估计大家也看不到啥,我会把各个电商平台的链接整理放在我的文章里不要遗漏了,不过如果你不打算看的,私信我或者留言我都能看到,另外我也贴心的给大家准备了云采集器,如果你在这些平台中有购物车或者直接购买的活动就用云采集器采集下来,并让微信公众号和百度网盘平台分享。
(云采集器会自动发送活动的链接并跳转购物链接)目前为止送的就是屈臣氏积分池和贝店积分池,这两个平台其实都是给用户优惠,我们的广告费是由各大平台接受下来的,不过实话说在限时折扣的时候大家真的很喜欢这些好活动,就像我们店一样活动多一点就多带来客源。以前我为了满一千积分上个图就花钱买,现在不花钱也能积分上,没啥了不起的啦!云采集器的获取有两种,一种是个人二维码,一种是专门的有积分池,如下:个人二维码云采集器如果你的微信公众号有推送第三方外卖,拼多多,豆瓣电影的活动那么直接可以用积分获取资格,只要关注我们公众号即可拿到积分!或者关注“三点一线”公众号也可以,特别鸣谢我们这边的小编整理了这么多有送积分的平台,还有赠礼!下面告诉你具体如何操作:1.进入我们的“三点一线”公众号,底部发送活动邀请码或者直接回复“活动”2.选择你关注的送积分平台,点击“申请资格”我们这边一般需要20元或者100元积分,当然你也可以多添加一些选择自己的选择,因为送积分活动没有固定积分池,每个平台的积分获取积分池也不一样。
3.点击申请资格完成后就可以看到如图实体店拼多多点“活动”关注之后点击“评价”与“晒单”你可以收获到3~10元不等的奖品回到“三点一线”发送活动邀请码或者关注这篇文章总共可获得18元积分活动会不断的发布,我们会通过拉票活动火热3~5期,同时每期送出3~5万积分活动的获奖概率是50%,提前把你的微信微博,小程序发送给我们的小编就可以获得最佳投票!我的建议是直接在抖音,b站里投票互助,毕竟他们经常有活动,而且他们粉丝活跃度高。
各大app主要是现金劵和积分发放活动概率低。还有一个活动获取的捷径就是关注本公众号,最佳火箭票,最低可以获得一万积分(如果只玩赠礼活动就没什么了,10~20元不等)活动随机的一个奖励有不一样的加分比例,在活动。
一个专业的网站关键词采集工具的批量采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 435 次浏览 • 2021-07-10 07:47
关键字网址采集器是一个专业的网站关键词采集工具,可以对网站包括关键词进行采集,并且可以实现批量关键词网址采集,你只需输入关键词的标题、域名、描述即可通过百度、搜狗、谷歌等搜索引擎获取,采集相关网站信息即可。
关键字URL采集器的功能介绍
输入关键词采集网址、域名、标题、描述等各个搜索引擎的信息。支持百度、搜狗、谷歌、必应、雅虎、360等每个关键词600到800、采集示例,关键词可以附带搜索引擎参数,就像在网页中输入关键词搜索一样例如百度搜索结果网址必须收录bbs的关键词,然后输入“关键词inurl:bbs”。
功能介绍
1.可以自动搜索代理服务器,验证代理服务器,过滤掉国内IP地址,用户无需寻找代理服务器;
2.可以导入外部代理服务器并验证;
3.可以选择不同的网卡进行优化;
4.可以在优化时动态修改本地网卡的MAC地址;
5.每次点击的间隔可以任意设置;
6.每次优化都可以修改机器的显示分辨率;
7.每次优化都可以修改IE信息;
8.完全模仿人的挥之不去的网站habit,高效的优化算法;
9.完全符合百度和谷歌的分析习惯;
10.原生编译代码,win2000以上所有平台,包括winxp、win2003、vista等;
11.多核优化,发送时充分利用机器,没有任何拖延和滞后。
如何使用
1.下载完成后,不要运行压缩包中的软件直接使用,先解压;
2.software 还支持 32 位和 64 位运行环境;
3.如果软件无法正常打开,请右键使用管理员模式运行。 查看全部
一个专业的网站关键词采集工具的批量采集方法
关键字网址采集器是一个专业的网站关键词采集工具,可以对网站包括关键词进行采集,并且可以实现批量关键词网址采集,你只需输入关键词的标题、域名、描述即可通过百度、搜狗、谷歌等搜索引擎获取,采集相关网站信息即可。
关键字URL采集器的功能介绍
输入关键词采集网址、域名、标题、描述等各个搜索引擎的信息。支持百度、搜狗、谷歌、必应、雅虎、360等每个关键词600到800、采集示例,关键词可以附带搜索引擎参数,就像在网页中输入关键词搜索一样例如百度搜索结果网址必须收录bbs的关键词,然后输入“关键词inurl:bbs”。
功能介绍
1.可以自动搜索代理服务器,验证代理服务器,过滤掉国内IP地址,用户无需寻找代理服务器;
2.可以导入外部代理服务器并验证;
3.可以选择不同的网卡进行优化;
4.可以在优化时动态修改本地网卡的MAC地址;
5.每次点击的间隔可以任意设置;
6.每次优化都可以修改机器的显示分辨率;
7.每次优化都可以修改IE信息;
8.完全模仿人的挥之不去的网站habit,高效的优化算法;
9.完全符合百度和谷歌的分析习惯;
10.原生编译代码,win2000以上所有平台,包括winxp、win2003、vista等;
11.多核优化,发送时充分利用机器,没有任何拖延和滞后。
如何使用
1.下载完成后,不要运行压缩包中的软件直接使用,先解压;
2.software 还支持 32 位和 64 位运行环境;
3.如果软件无法正常打开,请右键使用管理员模式运行。
插入关键字文章采集器-文章,批量采集文章!
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-07-01 20:53
插入关键字文章采集器-文章采集软件采集文章,批量采集文章!文章采集软件一键采集全网所有行业的全网文章采集不用人工提取关键字采集全网所有行业原创文章!点击“批量关键字采集”即可采集所有关键字的全网文章。一次设置,永久自动!采集速度稳定,效率高,采集质量高,每天采集关键字全网文章200篇以上。官网:文章采集器-文章采集软件·一键采集全网文章,批量采集文章功能介绍请见如下截图:(二维码自动识别)文章采集软件操作界面:批量采集的效果,请见如下截图:电脑采集,只要在文件中设置要采集的关键字,会自动推荐:微信网站,,外卖等:保存到本地:上传云端,永久保存:非常简单,采集试一试:资料下载链接:密码:sor社区回复采集软件获取。
无论是用来做日常的自动采集机器人还是自己做个机器人,都是为了自动的去获取想要的数据;那么自动采集的根本是什么?想要自动采集数据,首先你要能够做到自动;比如你要自动去自动去你想要的论坛里面找一个帖子;去论坛里面找到帖子里面的你想要的数据,是不是你要手动输入关键字去采集,还是用爬虫去爬取,用爬虫是不是你要去训练你的爬虫,可能很久才能够爬取到你想要的数据。
然后去训练它,给它去自动的匹配你想要的数据,是不是它有时候可能找错了你想要的数据,这些都是能够为你机器人与人工匹配设置一个好的数据。如果这些数据存在数据库中,我们还可以去清洗数据和取数据,同时完善数据库,去掉一些明显噪音的数据。如果数据的数量只有1000个数据库中,你可能要过几天才能找到一个文章的;不管用什么方法,你每天都要做,每天都要训练它,可能这是我们自动采集机器人这个岗位的自动化率;还是一个数据挖掘工程师来分析每天的数据量是否大于你机器人量;因为你每天训练它的时间是固定的,不是朝夕都能训练出一个自动采集的机器人;但是如果你不想花费太长时间,怎么样才能够实现自动采集呢?这里就涉及到采集软件,和你所用采集软件的熟练度;采集软件它能够让你自动采集的方法是:对于没有采集过此类数据的人来说:1,可以在上午设置一次采集机器人的标准时间:上午9点到11点、下午3点到6点、晚上7点到12点;2,上午设置这些时间的标准设置为分批采集就可以做到自动采集3,上午设置完,这些时间你都不能够去做;4,其他时间段你想自动的时候,比如说我有时候有事情,可能不能够按照一定的时间来采集;我设置采集软件的正确方法是:在你打开采集软件这个窗口;右键检查状态是否有权限,如果没有权限,它会提示你某个时间段。 查看全部
插入关键字文章采集器-文章,批量采集文章!
插入关键字文章采集器-文章采集软件采集文章,批量采集文章!文章采集软件一键采集全网所有行业的全网文章采集不用人工提取关键字采集全网所有行业原创文章!点击“批量关键字采集”即可采集所有关键字的全网文章。一次设置,永久自动!采集速度稳定,效率高,采集质量高,每天采集关键字全网文章200篇以上。官网:文章采集器-文章采集软件·一键采集全网文章,批量采集文章功能介绍请见如下截图:(二维码自动识别)文章采集软件操作界面:批量采集的效果,请见如下截图:电脑采集,只要在文件中设置要采集的关键字,会自动推荐:微信网站,,外卖等:保存到本地:上传云端,永久保存:非常简单,采集试一试:资料下载链接:密码:sor社区回复采集软件获取。
无论是用来做日常的自动采集机器人还是自己做个机器人,都是为了自动的去获取想要的数据;那么自动采集的根本是什么?想要自动采集数据,首先你要能够做到自动;比如你要自动去自动去你想要的论坛里面找一个帖子;去论坛里面找到帖子里面的你想要的数据,是不是你要手动输入关键字去采集,还是用爬虫去爬取,用爬虫是不是你要去训练你的爬虫,可能很久才能够爬取到你想要的数据。
然后去训练它,给它去自动的匹配你想要的数据,是不是它有时候可能找错了你想要的数据,这些都是能够为你机器人与人工匹配设置一个好的数据。如果这些数据存在数据库中,我们还可以去清洗数据和取数据,同时完善数据库,去掉一些明显噪音的数据。如果数据的数量只有1000个数据库中,你可能要过几天才能找到一个文章的;不管用什么方法,你每天都要做,每天都要训练它,可能这是我们自动采集机器人这个岗位的自动化率;还是一个数据挖掘工程师来分析每天的数据量是否大于你机器人量;因为你每天训练它的时间是固定的,不是朝夕都能训练出一个自动采集的机器人;但是如果你不想花费太长时间,怎么样才能够实现自动采集呢?这里就涉及到采集软件,和你所用采集软件的熟练度;采集软件它能够让你自动采集的方法是:对于没有采集过此类数据的人来说:1,可以在上午设置一次采集机器人的标准时间:上午9点到11点、下午3点到6点、晚上7点到12点;2,上午设置这些时间的标准设置为分批采集就可以做到自动采集3,上午设置完,这些时间你都不能够去做;4,其他时间段你想自动的时候,比如说我有时候有事情,可能不能够按照一定的时间来采集;我设置采集软件的正确方法是:在你打开采集软件这个窗口;右键检查状态是否有权限,如果没有权限,它会提示你某个时间段。
SupeSite支持手工采集和智能采集需要您自己配置采集规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-06-29 23:18
SupeSite支持手动采集和智能采集,手动采集需要配置采集规则,智能采集只需要添加需要采集的URL地址,程序会自动您的采集网站 信息。接下来给大家介绍两个采集方法:
一、手工采集:
手动采集是指自己配置采集规则。打开SupeSite的“系统设置”,点击“新闻管理”的“采集器”,然后点击“添加新机器人”。
先简单说明一下采集器的基本原理和制作思路:
1、确定你要采集哪个页面的新闻,并在“列表页面采集设置”的地址框中填写这些页面的地址;
2、 确保你想要这些页面上采集的内容区域,因为不是一个网页的所有内容都需要采集回来,而是采集的一部分内容一个网页,所以你必须告诉程序你到采集区,即“列出区识别规则”;
3、Step 2 确定区域后,告诉程序你想要采集的文章链接,即“文章link url识别规则”。
4、 现在已经确定了采集 大框架。接下来我们需要告诉程序在一个文章页面上,文章的title(“文章title识别规则”),文章的出处跟作者有什么区别。然后是文章内容的范围,也就是说,在一个文章页面中,真正需要采集的范围是“文章Content Identification Rules”。最后,设置分页区域和分页的链接地址。
5、 以上4步就确定了采集的范围。如果您需要过滤标题和内容,请根据您的要求为每个项目设置过滤设置,例如“文章Title 过滤规则”和“文章Content 过滤规则”等。
以上确定范围的步骤都是通过查看页面的源代码来设置的。拦截方法需要一定的经验。练习2-3遍就可以理解了。
接下来介绍采集器的基本原理和步骤:
第一部分:打开SupeSite的“系统设置”,点击“新闻管理”的“采集器”,然后点击“添加新机器人”。
这里需要指出的是:单个采集号和自动导入。单个采集的数量应设置得尽可能小,以避免超时。自动导入,请选择信息类别,可以直接将采集的结果导入信息库。如下图:
第二部分:填写“list page采集”和“采集page code”。请填写采集的页面地址(列表页面地址)。这个分为手动输入和自动输入:手动输入需要你逐行输入需要的采集地址。自动增长只需填写采集页的地址和页码,用[page]替换分页变量即可。如下图:
点击上图,尝试链接,可以看到如下图的页面,这样就可以判断你的服务器是否可以链接到想要采集的网站,也就是检查服务器是否允许采集,如果这里不能显示链接,就不能采集这个页面。
设置“采集page encoding”,它是你采集网页的编码,不是你网站的编码。记住这里! !如下图:
第三部分:设置“列表区域”和“文章link”的识别规则。如下图,填写列表区的规则和文章链接的规则。 采集的内容范围替换为[list],采集文章的标题替换为[url]。 文章Link URL删除和过滤规则,请参考图片中的详细说明,这里不再赘述。
第四部分:设置“文章Title”识别规则,如下图,文章Title替换为[subject]。 文章标题过滤规则、淘汰规则、替换规则,包括关键字,请参考图片中的详细说明,这里不再赘述。
第五:设置“文章内容”的识别规则,如下四张图,均属于文章内容识别规则。 文章内容替换为[message],分页区替换为[pagearea],分页链接替换为[page],信息来源替换为[from],文章author替换为[author]。同上,一些过滤、剔除等规则请参考图片中的详细说明,这里不再赘述。
以下几点:
文章Content 格式化:此操作将去除网页的冗余生成,并根据原创段落对文章内容进行分割。格式化过程是程序自动分析的,会有一些错误。
将内容中的图片保存到本地,将内容中的FLASH保存到本地。这里可以选择是否将采集的图片和Flash保存到本地。如果要将对方网站的图片保存在自己的服务器上,请选择“是”!
至此,你已经设置了一条采集规则,然后点击“开始采集”,采集完成后点击“查看结果”。最后将采集的内容导入信息中。这里有一点:采集的内容只能导入新闻频道。
这里的重点是导入后删除而不是删除。如果选择删除,来自采集的信息导入后将无法再次使用。
二、智能采集:
Smart采集 为您提供了一种非常简单易用的采集 方法。只需在地址框中添加您需要采集的站点地址,然后点击开始采集。
Smart采集集成在manual采集中,您只需在地址框中填写采集的地址,然后点击提交即可。
欲了解更多详情,请访问我们的网站:或联系我们:
1 查看全部
SupeSite支持手工采集和智能采集需要您自己配置采集规则
SupeSite支持手动采集和智能采集,手动采集需要配置采集规则,智能采集只需要添加需要采集的URL地址,程序会自动您的采集网站 信息。接下来给大家介绍两个采集方法:
一、手工采集:
手动采集是指自己配置采集规则。打开SupeSite的“系统设置”,点击“新闻管理”的“采集器”,然后点击“添加新机器人”。
先简单说明一下采集器的基本原理和制作思路:
1、确定你要采集哪个页面的新闻,并在“列表页面采集设置”的地址框中填写这些页面的地址;
2、 确保你想要这些页面上采集的内容区域,因为不是一个网页的所有内容都需要采集回来,而是采集的一部分内容一个网页,所以你必须告诉程序你到采集区,即“列出区识别规则”;
3、Step 2 确定区域后,告诉程序你想要采集的文章链接,即“文章link url识别规则”。
4、 现在已经确定了采集 大框架。接下来我们需要告诉程序在一个文章页面上,文章的title(“文章title识别规则”),文章的出处跟作者有什么区别。然后是文章内容的范围,也就是说,在一个文章页面中,真正需要采集的范围是“文章Content Identification Rules”。最后,设置分页区域和分页的链接地址。
5、 以上4步就确定了采集的范围。如果您需要过滤标题和内容,请根据您的要求为每个项目设置过滤设置,例如“文章Title 过滤规则”和“文章Content 过滤规则”等。
以上确定范围的步骤都是通过查看页面的源代码来设置的。拦截方法需要一定的经验。练习2-3遍就可以理解了。
接下来介绍采集器的基本原理和步骤:
第一部分:打开SupeSite的“系统设置”,点击“新闻管理”的“采集器”,然后点击“添加新机器人”。
这里需要指出的是:单个采集号和自动导入。单个采集的数量应设置得尽可能小,以避免超时。自动导入,请选择信息类别,可以直接将采集的结果导入信息库。如下图:
第二部分:填写“list page采集”和“采集page code”。请填写采集的页面地址(列表页面地址)。这个分为手动输入和自动输入:手动输入需要你逐行输入需要的采集地址。自动增长只需填写采集页的地址和页码,用[page]替换分页变量即可。如下图:
点击上图,尝试链接,可以看到如下图的页面,这样就可以判断你的服务器是否可以链接到想要采集的网站,也就是检查服务器是否允许采集,如果这里不能显示链接,就不能采集这个页面。
设置“采集page encoding”,它是你采集网页的编码,不是你网站的编码。记住这里! !如下图:
第三部分:设置“列表区域”和“文章link”的识别规则。如下图,填写列表区的规则和文章链接的规则。 采集的内容范围替换为[list],采集文章的标题替换为[url]。 文章Link URL删除和过滤规则,请参考图片中的详细说明,这里不再赘述。
第四部分:设置“文章Title”识别规则,如下图,文章Title替换为[subject]。 文章标题过滤规则、淘汰规则、替换规则,包括关键字,请参考图片中的详细说明,这里不再赘述。
第五:设置“文章内容”的识别规则,如下四张图,均属于文章内容识别规则。 文章内容替换为[message],分页区替换为[pagearea],分页链接替换为[page],信息来源替换为[from],文章author替换为[author]。同上,一些过滤、剔除等规则请参考图片中的详细说明,这里不再赘述。
以下几点:
文章Content 格式化:此操作将去除网页的冗余生成,并根据原创段落对文章内容进行分割。格式化过程是程序自动分析的,会有一些错误。
将内容中的图片保存到本地,将内容中的FLASH保存到本地。这里可以选择是否将采集的图片和Flash保存到本地。如果要将对方网站的图片保存在自己的服务器上,请选择“是”!
至此,你已经设置了一条采集规则,然后点击“开始采集”,采集完成后点击“查看结果”。最后将采集的内容导入信息中。这里有一点:采集的内容只能导入新闻频道。
这里的重点是导入后删除而不是删除。如果选择删除,来自采集的信息导入后将无法再次使用。
二、智能采集:
Smart采集 为您提供了一种非常简单易用的采集 方法。只需在地址框中添加您需要采集的站点地址,然后点击开始采集。
Smart采集集成在manual采集中,您只需在地址框中填写采集的地址,然后点击提交即可。
欲了解更多详情,请访问我们的网站:或联系我们:
1
插入关键字文章采集器“墨刀”(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-06-27 05:02
插入关键字文章采集器“墨刀”抓取了知乎上十万+的文章,数据来源于人人都是产品经理网站和天涯论坛上部分文章。总体来说“墨刀”爬取的数据较之其他方式来说,数据量比较大,因此更新需要及时。爬取准备:python(python需要注意版本的问题)准备环境:windows64位(python的安装)部分python脚本(python和数据分析平台相对对接)登录墨刀:进入墨刀官网(墨刀官网地址:)根据自己电脑操作系统进行相应配置。
需要注意的是需要首先选择墨刀登录类型,进行账号注册,之后登录墨刀进行新建页面设计。有了账号之后,将相应的网站地址填入墨刀,进行登录操作。页面设计:第一步:我们先在墨刀官网进行页面设计:页面设计工具支持所有常见布局布局:流程图、组织架构图、视觉稿、地图、文档、云图等我们需要首先布局页面结构,然后根据页面结构,完成页面布局结构的设计。
页面结构设计完成之后,我们就需要根据页面结构,进行页面设计稿的编辑了,我们需要以页面的a、b、c、d排序,进行布局,最后选择需要的模块进行处理操作。部分页面布局部分页面布局设计稿部分页面结构设计稿部分页面设计稿部分页面设计稿部分页面设计稿部分页面设计稿:完成上述部分页面设计稿,我们根据页面设计稿,进行页面内容的编辑修改。
第二步:我们需要用到一个批量处理数据的模块:itertools,再根据页面结构,对页面进行添加、删除、合并、扩展等操作。第三步:在进行页面设计稿时,我们可以选择createnewpage.在新建文档时,我们可以直接输入模块、页面结构、页面数据的名称,直接调用页面api(墨刀页面api:)、页面或者数据接口等。
此处我们可以直接搜索模块,进行查看该模块的功能,再进行操作。第四步:对页面中的内容进行文本处理。部分页面模板中,有内容对应的字段,我们需要用到一个文本处理模块:textprocessor。注意,这个模块的功能是文本格式匹配查找,而不是人工智能算法。对于之前爬取知乎的数据,一般都可以直接手动翻页,或者直接使用excel工具制作表格,进行复制粘贴查看页面内容。
但是这次这些方法,会进行自动的文本格式匹配检查,进行文本格式匹配的工作,这个时候我们需要用到模块textprocessor。第五步:对页面中的数据进行抓取与删除数据。页面数据一般就是文本和链接,我们在页面结构设计的时候,选择textprocessor即可。完成上述步骤之后,我们会发现,在页面中,除了文本和链接,我们没有需要注意数据请求,而且之前都需要手动添加转义(python的gbk)数据,经。 查看全部
插入关键字文章采集器“墨刀”(组图)
插入关键字文章采集器“墨刀”抓取了知乎上十万+的文章,数据来源于人人都是产品经理网站和天涯论坛上部分文章。总体来说“墨刀”爬取的数据较之其他方式来说,数据量比较大,因此更新需要及时。爬取准备:python(python需要注意版本的问题)准备环境:windows64位(python的安装)部分python脚本(python和数据分析平台相对对接)登录墨刀:进入墨刀官网(墨刀官网地址:)根据自己电脑操作系统进行相应配置。
需要注意的是需要首先选择墨刀登录类型,进行账号注册,之后登录墨刀进行新建页面设计。有了账号之后,将相应的网站地址填入墨刀,进行登录操作。页面设计:第一步:我们先在墨刀官网进行页面设计:页面设计工具支持所有常见布局布局:流程图、组织架构图、视觉稿、地图、文档、云图等我们需要首先布局页面结构,然后根据页面结构,完成页面布局结构的设计。
页面结构设计完成之后,我们就需要根据页面结构,进行页面设计稿的编辑了,我们需要以页面的a、b、c、d排序,进行布局,最后选择需要的模块进行处理操作。部分页面布局部分页面布局设计稿部分页面结构设计稿部分页面设计稿部分页面设计稿部分页面设计稿部分页面设计稿:完成上述部分页面设计稿,我们根据页面设计稿,进行页面内容的编辑修改。
第二步:我们需要用到一个批量处理数据的模块:itertools,再根据页面结构,对页面进行添加、删除、合并、扩展等操作。第三步:在进行页面设计稿时,我们可以选择createnewpage.在新建文档时,我们可以直接输入模块、页面结构、页面数据的名称,直接调用页面api(墨刀页面api:)、页面或者数据接口等。
此处我们可以直接搜索模块,进行查看该模块的功能,再进行操作。第四步:对页面中的内容进行文本处理。部分页面模板中,有内容对应的字段,我们需要用到一个文本处理模块:textprocessor。注意,这个模块的功能是文本格式匹配查找,而不是人工智能算法。对于之前爬取知乎的数据,一般都可以直接手动翻页,或者直接使用excel工具制作表格,进行复制粘贴查看页面内容。
但是这次这些方法,会进行自动的文本格式匹配检查,进行文本格式匹配的工作,这个时候我们需要用到模块textprocessor。第五步:对页面中的数据进行抓取与删除数据。页面数据一般就是文本和链接,我们在页面结构设计的时候,选择textprocessor即可。完成上述步骤之后,我们会发现,在页面中,除了文本和链接,我们没有需要注意数据请求,而且之前都需要手动添加转义(python的gbk)数据,经。
插入关键字文章采集器的使用方法和使用技巧介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-06-26 18:02
插入关键字文章采集器是一款用于爬取可以爬取数据、可以批量采集数据、也可以手动添加关键字、关键字爬取和数据采集的插件。软件强大的爬虫采集功能和很多广告联盟的数据源都可以爬取到。1.软件界面2.软件功能介绍3.软件使用方法1.下载插件压缩包2.复制浏览器中的地址(文章)3.在faked源码目录下粘贴4.选择你要爬取的关键字5.自动爬取等待数据准备好了6.将爬取到的数据保存在本地。
用transportdata.js或者torrentdata.js
多数都是抓取这些门户网站,或者类似百度的网站。torrentdata.js好像是react的。可以用来抓取youtube。linkfactory爬取到的是网页,他们会伪装成联盟,但实际上是推广自己的应用,拿推广的费用。
通过和商务总监沟通,抓取谷歌搜索、cnzz网站、360搜索、世界杯新闻。
有非常多的网站是通过爬虫工具去抓取,我曾经用过这款软件采集过德国新闻、俄罗斯电视台、等;就我个人采集到的效果来看,效果还是不错的。很多网站采集方法基本上都相同。现在主要通过爬虫去抓取各种返利网的返利。
你可以采集一下百度搜索引擎的。
国内的百度搜索引擎,360搜索引擎,谷歌搜索等等大型的流量平台,也可以通过代理去抓取。
为了参加awesome的百度搜索引擎,我找了很久!!!但是真的别说什么各种付费服务,我又不傻,他就是简单粗暴的收个费用。那些垃圾就不要费劲搞了。 查看全部
插入关键字文章采集器的使用方法和使用技巧介绍
插入关键字文章采集器是一款用于爬取可以爬取数据、可以批量采集数据、也可以手动添加关键字、关键字爬取和数据采集的插件。软件强大的爬虫采集功能和很多广告联盟的数据源都可以爬取到。1.软件界面2.软件功能介绍3.软件使用方法1.下载插件压缩包2.复制浏览器中的地址(文章)3.在faked源码目录下粘贴4.选择你要爬取的关键字5.自动爬取等待数据准备好了6.将爬取到的数据保存在本地。
用transportdata.js或者torrentdata.js
多数都是抓取这些门户网站,或者类似百度的网站。torrentdata.js好像是react的。可以用来抓取youtube。linkfactory爬取到的是网页,他们会伪装成联盟,但实际上是推广自己的应用,拿推广的费用。
通过和商务总监沟通,抓取谷歌搜索、cnzz网站、360搜索、世界杯新闻。
有非常多的网站是通过爬虫工具去抓取,我曾经用过这款软件采集过德国新闻、俄罗斯电视台、等;就我个人采集到的效果来看,效果还是不错的。很多网站采集方法基本上都相同。现在主要通过爬虫去抓取各种返利网的返利。
你可以采集一下百度搜索引擎的。
国内的百度搜索引擎,360搜索引擎,谷歌搜索等等大型的流量平台,也可以通过代理去抓取。
为了参加awesome的百度搜索引擎,我找了很久!!!但是真的别说什么各种付费服务,我又不傻,他就是简单粗暴的收个费用。那些垃圾就不要费劲搞了。
触发元素动态型网页的两种方法和应用方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-08-09 18:13
。该标签被定义为替代的有效标签。
2.2.2 触发元素动态网页采用异步加载技术。当用户点击触发元素时,会触发绑定到有效元素的特定事件,浏览器会执行该事件对应的JavaScript动态脚本程序。 所以需要一个工具来模拟用户的点击操作,HtmlUnit正好可以解决这个模拟问题。 HtmlUnit是一个开源的Java页面分析工具,使用Rhinojs引擎,可以模拟浏览器操作,运行速度非常快。该系统使用全检测扫描算法[13]对有效元素集中的所有元素进行点击操作。 2.2.3 触发有效性判断 当动态网页触发有效元素时,会改变DOM树的结构。触发器有效性判断也可以表示为DOM树结构的变化,因此可以比较DOM树结构的相似度作为触发器有效性的指标。由于每次获取下一页,只有网页中的图片和文字信息发生变化,其他杂音、链接等部分基本不变。因此,在判断DOM树的相似度之前,通过正则表达式过滤中文文本信息。何欣等
[14] 使用简单的树匹配算法来确定 DOM 树的相似度。它是一种限制匹配算法,它使用动态规划来计算两棵树之间的最大匹配节点数,以获得两棵树结构的相似度。程度;罗斯特等
[15] 提出了一种比较页面的方法。此方法将每个模块与模块所针对的 DOM 树结构的特征部分进行比较。如果确定内容相同,则过滤掉部分信息,将剩余的内容传递给下一个比较模块,否则可以直接确定两个DOM树不相似。以上两种方法更多是基于DOM树结构,考虑到新闻页面的有效信息在中文文本中。在页面标题的情况下,系统将新获取的网页中文信息与触发前的网页中文信息进行比较。如果只有少量更改,则认为新获取的网页无效,触发器无效;否则,则认为获取的网页是有效的,有效元素XPath存储在XPath模板库中。 2.3 新闻常用网页信息提取模块新闻常用网页信息提取模块的目标是提取新闻常用网页的正文信息。一般新闻网页的正文结构通常比较紧凑,网页中的图片较少,正文代码中的大部分文字占一行,超链接长度所占的百分比也不大。并且由于行块分布算法对主题网页通用性好、准确率高,所以采用行块分布算法。线块分析算法的思想由哈尔滨工业大学信息检索中心陈欣等人提出。网页文本块的起始行块号Xstart和结束行块号Xend的确定必须同时满足以下条件,这里定义Y(X)为带有行号的行块的长度X 为轴。 (1)Ystart> Y(Xt),其中Y(Xt)为线块长度的第一个膨胀点,膨胀点的线块长度必须大于预先定义的阈值。
(2)Y(Xn)不等于0(其中n属于[start+1,start+n]),紧接膨胀点的行块长度不能为0,以消除噪声。
(3)Y(Xm)=0(其中m属于[end,end+1]),下垂点的长度和下垂点后面的行块为0,保证文本结束提取 根据线块分布算法的思想,本文利用Java中的JFreeChart绘制工具,得到如图4所示的线块分布函数折线图。从图4中可以看出内容很多阻止[start=743, end =745], [start=749, end=773], [start=1160, end=1165], [start=1198, end=1205],内容块可能有噪音还没有清除。因此,根据消息,针对网页噪音的特点,增加了第四个约束。
(4)Ystart
3 个实验测试
3.1实验准备
测试系统机器环境为:1台台式电脑(CPU为Intel四核2.93GHz,4G内存,硬盘7200r/min,操作系统Win7,10M网速)。本系统采用纯Java实现,有效元素路径存储在MySQL5.5数据库中。为了让结果更有说服力,本文设计了一个轻量级主题爬虫,从知名新闻网站(如腾讯新闻、网易新闻、搜狐新闻、新浪新闻等)中抓取网页作为实验页面放。实验主要测试提取新闻正文信息的正确率和速度,而新闻标题是从网页采集器中提取的(一般导航网页,新闻标题和新闻网址是一起的),这里不做处理。对于动态新闻,提取的文本完全覆盖了真实含义,未过滤的噪声占文本的不到5%才算合格。对于静态网页,本文用准确率来表示建议正文信息的准确率:准确率=正确过滤的页面数/总页面数×100%
3.2 实验结果表1为系统网页正文提取准确率和在线文本提取率,其中每个网站有100个动态网页和静态网页,共1600个网页表1的测试结果表明,该系统提取静态网页的准确率高于93%,对原创新闻网页正文内容的提取较为完整,而动态网页的提取准确率均在80%以上。报错的原因是不同主题的设计风格不一样,并且存在人们对网页中文字定义的差异等因素,本文算法的结果或多或少会受到影响对于正文内容为纯文本的网页,本文算法的准确率非常高。影响本系统准确性的主要因素总结如下: ①动态网页与普通新闻网页的区分是根据网址的相似度和网址是否收录标识符来判断的; ②对于普通新闻网页的正文内容和噪声部分如果网页的主要内容是图片或视频,过短的文本内容会被当作噪声,从而降低提取结果的准确性; ③如果在普通新闻网页中嵌入图片,文字部分之间的距离会相差较大。
4实验结论本文提出的新闻网页正文提取系统采用行阻塞算法提取网页信息和DOM技术,还利用动态网页结构的相似性特征实现大规模news网站新闻文字信息抽取。该系统不依赖大量训练集,能够更准确地提取新闻文本信息。实验结果验证了其有效性。但是,对于英文网页和结构复杂的网页,提取效果并不理想,尤其是对于嵌入了图形信息的普通新闻网页。该方法只能提取文本信息,无法获取网页图片。下一步,我们可以在英文网页优化、复杂网页提取算法、网页图片获取方法等方面进行深入研究。
查看全部
触发元素动态型网页的两种方法和应用方法
。该标签被定义为替代的有效标签。
2.2.2 触发元素动态网页采用异步加载技术。当用户点击触发元素时,会触发绑定到有效元素的特定事件,浏览器会执行该事件对应的JavaScript动态脚本程序。 所以需要一个工具来模拟用户的点击操作,HtmlUnit正好可以解决这个模拟问题。 HtmlUnit是一个开源的Java页面分析工具,使用Rhinojs引擎,可以模拟浏览器操作,运行速度非常快。该系统使用全检测扫描算法[13]对有效元素集中的所有元素进行点击操作。 2.2.3 触发有效性判断 当动态网页触发有效元素时,会改变DOM树的结构。触发器有效性判断也可以表示为DOM树结构的变化,因此可以比较DOM树结构的相似度作为触发器有效性的指标。由于每次获取下一页,只有网页中的图片和文字信息发生变化,其他杂音、链接等部分基本不变。因此,在判断DOM树的相似度之前,通过正则表达式过滤中文文本信息。何欣等
[14] 使用简单的树匹配算法来确定 DOM 树的相似度。它是一种限制匹配算法,它使用动态规划来计算两棵树之间的最大匹配节点数,以获得两棵树结构的相似度。程度;罗斯特等
[15] 提出了一种比较页面的方法。此方法将每个模块与模块所针对的 DOM 树结构的特征部分进行比较。如果确定内容相同,则过滤掉部分信息,将剩余的内容传递给下一个比较模块,否则可以直接确定两个DOM树不相似。以上两种方法更多是基于DOM树结构,考虑到新闻页面的有效信息在中文文本中。在页面标题的情况下,系统将新获取的网页中文信息与触发前的网页中文信息进行比较。如果只有少量更改,则认为新获取的网页无效,触发器无效;否则,则认为获取的网页是有效的,有效元素XPath存储在XPath模板库中。 2.3 新闻常用网页信息提取模块新闻常用网页信息提取模块的目标是提取新闻常用网页的正文信息。一般新闻网页的正文结构通常比较紧凑,网页中的图片较少,正文代码中的大部分文字占一行,超链接长度所占的百分比也不大。并且由于行块分布算法对主题网页通用性好、准确率高,所以采用行块分布算法。线块分析算法的思想由哈尔滨工业大学信息检索中心陈欣等人提出。网页文本块的起始行块号Xstart和结束行块号Xend的确定必须同时满足以下条件,这里定义Y(X)为带有行号的行块的长度X 为轴。 (1)Ystart> Y(Xt),其中Y(Xt)为线块长度的第一个膨胀点,膨胀点的线块长度必须大于预先定义的阈值。
(2)Y(Xn)不等于0(其中n属于[start+1,start+n]),紧接膨胀点的行块长度不能为0,以消除噪声。
(3)Y(Xm)=0(其中m属于[end,end+1]),下垂点的长度和下垂点后面的行块为0,保证文本结束提取 根据线块分布算法的思想,本文利用Java中的JFreeChart绘制工具,得到如图4所示的线块分布函数折线图。从图4中可以看出内容很多阻止[start=743, end =745], [start=749, end=773], [start=1160, end=1165], [start=1198, end=1205],内容块可能有噪音还没有清除。因此,根据消息,针对网页噪音的特点,增加了第四个约束。
(4)Ystart
3 个实验测试
3.1实验准备
测试系统机器环境为:1台台式电脑(CPU为Intel四核2.93GHz,4G内存,硬盘7200r/min,操作系统Win7,10M网速)。本系统采用纯Java实现,有效元素路径存储在MySQL5.5数据库中。为了让结果更有说服力,本文设计了一个轻量级主题爬虫,从知名新闻网站(如腾讯新闻、网易新闻、搜狐新闻、新浪新闻等)中抓取网页作为实验页面放。实验主要测试提取新闻正文信息的正确率和速度,而新闻标题是从网页采集器中提取的(一般导航网页,新闻标题和新闻网址是一起的),这里不做处理。对于动态新闻,提取的文本完全覆盖了真实含义,未过滤的噪声占文本的不到5%才算合格。对于静态网页,本文用准确率来表示建议正文信息的准确率:准确率=正确过滤的页面数/总页面数×100%
3.2 实验结果表1为系统网页正文提取准确率和在线文本提取率,其中每个网站有100个动态网页和静态网页,共1600个网页表1的测试结果表明,该系统提取静态网页的准确率高于93%,对原创新闻网页正文内容的提取较为完整,而动态网页的提取准确率均在80%以上。报错的原因是不同主题的设计风格不一样,并且存在人们对网页中文字定义的差异等因素,本文算法的结果或多或少会受到影响对于正文内容为纯文本的网页,本文算法的准确率非常高。影响本系统准确性的主要因素总结如下: ①动态网页与普通新闻网页的区分是根据网址的相似度和网址是否收录标识符来判断的; ②对于普通新闻网页的正文内容和噪声部分如果网页的主要内容是图片或视频,过短的文本内容会被当作噪声,从而降低提取结果的准确性; ③如果在普通新闻网页中嵌入图片,文字部分之间的距离会相差较大。
4实验结论本文提出的新闻网页正文提取系统采用行阻塞算法提取网页信息和DOM技术,还利用动态网页结构的相似性特征实现大规模news网站新闻文字信息抽取。该系统不依赖大量训练集,能够更准确地提取新闻文本信息。实验结果验证了其有效性。但是,对于英文网页和结构复杂的网页,提取效果并不理想,尤其是对于嵌入了图形信息的普通新闻网页。该方法只能提取文本信息,无法获取网页图片。下一步,我们可以在英文网页优化、复杂网页提取算法、网页图片获取方法等方面进行深入研究。
优采云免费采集器支持所有操作系统版本更新和功能升级同步所有平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 564 次浏览 • 2021-08-09 01:29
优采云采集器是一款全新的智能网络数据采集软件,由原谷歌技术团队打造,规则配置简单,采集功能强大,支持电子商务和生活服务、社交媒体、新闻论坛等不同类型的网站,智能识别网络数据,并以多种方式导出数据,其中大部分是完全免费的。是行业分析、精准营销、品牌监测、风险评估的好帮手。 优采云免费采集器支持所有操作系统版本更新和功能升级同步所有平台,采集和导出都是免费的,无限制的放心,并支持后台操作,不打扰您其他前台工作,它是你的数据采集最好的助手。
软件名称:优采云采集器v3.4.5 官方免安装版软件大小:44.8MB 更新时间:2019-10-16
如何使用优采云采集器采集百度搜索结果数据?
第一步:创建采集task
1)Start优采云采集器,进入主界面,点击创建任务按钮创建“Wizard采集Task”
2)输入百度搜索的网址,包括三种方式
1、手动输入:在输入框中直接输入网址,多个网址需要用换行符分隔
2、点击读取文件:用户选择一个文件来存储URL。文件中可以有多个URL地址,地址之间需要用换行符分隔。
3、批量添加方式:通过添加和调整地址参数生成多个常规地址
第 2 步:自定义采集process
1)点击创建自动打开第一个网址进入向导设置,这里选择列表页面,点击下一步
2)填写搜索关键字和选择关键字的输入框,点击下一步
3)进入第一个关键词搜索结果页面后,点击设置搜索按钮,点击下一步
4)点击列表块中的第一个元素
5) 然后点击结果列表块中的另一个元素,此时列表块被自动选中。点击下一步
6)选择下一页按钮,选择下一页的选项,然后点击页面上的下一页按钮填写第一个输入框,第二个数据框可以调整采集运行,点击next 页面按钮的数量。理论上,次数越多,采集得到的数据就越多。点击下一步
7)选择字段为采集:在焦点框中点击要提取的元素,点击下一步 查看全部
优采云免费采集器支持所有操作系统版本更新和功能升级同步所有平台
优采云采集器是一款全新的智能网络数据采集软件,由原谷歌技术团队打造,规则配置简单,采集功能强大,支持电子商务和生活服务、社交媒体、新闻论坛等不同类型的网站,智能识别网络数据,并以多种方式导出数据,其中大部分是完全免费的。是行业分析、精准营销、品牌监测、风险评估的好帮手。 优采云免费采集器支持所有操作系统版本更新和功能升级同步所有平台,采集和导出都是免费的,无限制的放心,并支持后台操作,不打扰您其他前台工作,它是你的数据采集最好的助手。
软件名称:优采云采集器v3.4.5 官方免安装版软件大小:44.8MB 更新时间:2019-10-16
如何使用优采云采集器采集百度搜索结果数据?
第一步:创建采集task
1)Start优采云采集器,进入主界面,点击创建任务按钮创建“Wizard采集Task”
2)输入百度搜索的网址,包括三种方式
1、手动输入:在输入框中直接输入网址,多个网址需要用换行符分隔
2、点击读取文件:用户选择一个文件来存储URL。文件中可以有多个URL地址,地址之间需要用换行符分隔。
3、批量添加方式:通过添加和调整地址参数生成多个常规地址
第 2 步:自定义采集process
1)点击创建自动打开第一个网址进入向导设置,这里选择列表页面,点击下一步
2)填写搜索关键字和选择关键字的输入框,点击下一步
3)进入第一个关键词搜索结果页面后,点击设置搜索按钮,点击下一步
4)点击列表块中的第一个元素
5) 然后点击结果列表块中的另一个元素,此时列表块被自动选中。点击下一步
6)选择下一页按钮,选择下一页的选项,然后点击页面上的下一页按钮填写第一个输入框,第二个数据框可以调整采集运行,点击next 页面按钮的数量。理论上,次数越多,采集得到的数据就越多。点击下一步
7)选择字段为采集:在焦点框中点击要提取的元素,点击下一步
插入关键字文章采集器是一款采集网站内容的小程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-08-08 07:07
插入关键字文章采集器是一款采集网站内容的小程序小程序采集器里面包含60个网站。可以自定义上传采集一篇文章/图片/视频/二维码等。采集时间/内容自定义可以设置一小时内,24小时内,或者一天内。同时也可以在文章详情页里面一键导出。生成文章列表二维码。可以自定义拼接字体,拼接图片二维码。支持自定义文章内容,自定义标题,参数。
也可以点一个按钮插入关键字,系统会自动采集。单篇文章可以快速拼接多篇二维码。支持插入多个关键字。支持自定义拼接字体,拼接图片二维码。支持关键字搜索。支持目标网站整站文章图片下载。
遇到一个小问题,
我是通过seo把网站信息拼接起来,另外ga监控指标。
推荐你写一篇日志,
谢邀。我们公司正好有个新产品,我手上没公司的相关产品,有机会我可以给你介绍下。微信上现在有新产品,请详细描述您的需求,也可以评论或私信跟我沟通。
新浪的app
从去年开始我就在研究三个一般搜索引擎的特征,阿里的,百度的,搜狗的,自己对照研究一下。
我们有个辅助工具对此类内容很有帮助。第一次只在知乎上推荐,请见谅。工具:知乎问答日志采集软件软件名:知乎问答采集recorder插件名:知乎问答采集downloader我们公司很擅长自媒体网站的自动采集工作,比如文章,音频,视频,书籍。除此之外还可以查看自己以前的文章,书籍列表和知乎关注人的问答,有什么疑问都可以在app上看到,方便快捷。下载地址:,可以在任何网站搜索你要的关键词,会跳转到知乎问答页面,采集网站关键词。 查看全部
插入关键字文章采集器是一款采集网站内容的小程序
插入关键字文章采集器是一款采集网站内容的小程序小程序采集器里面包含60个网站。可以自定义上传采集一篇文章/图片/视频/二维码等。采集时间/内容自定义可以设置一小时内,24小时内,或者一天内。同时也可以在文章详情页里面一键导出。生成文章列表二维码。可以自定义拼接字体,拼接图片二维码。支持自定义文章内容,自定义标题,参数。
也可以点一个按钮插入关键字,系统会自动采集。单篇文章可以快速拼接多篇二维码。支持插入多个关键字。支持自定义拼接字体,拼接图片二维码。支持关键字搜索。支持目标网站整站文章图片下载。
遇到一个小问题,
我是通过seo把网站信息拼接起来,另外ga监控指标。
推荐你写一篇日志,
谢邀。我们公司正好有个新产品,我手上没公司的相关产品,有机会我可以给你介绍下。微信上现在有新产品,请详细描述您的需求,也可以评论或私信跟我沟通。
新浪的app
从去年开始我就在研究三个一般搜索引擎的特征,阿里的,百度的,搜狗的,自己对照研究一下。
我们有个辅助工具对此类内容很有帮助。第一次只在知乎上推荐,请见谅。工具:知乎问答日志采集软件软件名:知乎问答采集recorder插件名:知乎问答采集downloader我们公司很擅长自媒体网站的自动采集工作,比如文章,音频,视频,书籍。除此之外还可以查看自己以前的文章,书籍列表和知乎关注人的问答,有什么疑问都可以在app上看到,方便快捷。下载地址:,可以在任何网站搜索你要的关键词,会跳转到知乎问答页面,采集网站关键词。
插入关键字文章采集器这个插件可以完成前后端任务
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-08-05 21:31
插入关键字文章采集器这个插件可以完成前后端任务来进行数据的匹配。插件如下:data***python库插件第一步我们需要下载data***。代码如下:frompythonimporturllibimportrequestshttplib=urllib.urlopen('')#httplib.read()方法可以读取目标请求内容。
在不同的程序环境下,会出现不同的版本,我是采用pipinstall.提示下载python2.3版本之后,可以进行代码的测试本地pycharm将目标内容复制到到这个文件夹下:importpilimportosdefget_image(imgurl):returnimgurl#目标地址,()是python内置的字符串类型printimgurl="/"#目标请求urlprintos.getenv("python").seek(1)#索引print"{}$",imgurlimgurl="/"urllib.urlencode(imgurl)返回:{"data":"{}{2}{3}","name":"richard","age":36}不一定非要在线下编写代码,可以直接拿python代码进行处理,但是如果使用ide,内置的方法足够可以满足日常的需求。
特别地不适合那些需要使用循环语句的情况,因为你需要一直为每一个元素返回一个list。那么,除此之外,我们如何定制插件呢?首先,我们在把我们的一个原始数据放在配置文件下面,比如:img=pil.image('{}{3}{2}{1}{2}'.format({"age":36}))##{{img.size}}{{img.size}}#{{img.size}}{{img.size}}这个例子中的img就是可任意个字符串。
return{"path":"c:\\world","class":"cityletree","type":"boostcharity","path":"expanded","various":["cityletree","world"]}这个例子中,我们需要把一个data***python库嵌入到restfulapi实现接口。
我们来看看效果:img=requests.get("")exceptcallback:print"callbackerror"img.save()exceptfileexistingrequestsrequest:print"errorerror..."data***代码这个代码对img***python库有较强的依赖。
我们需要修改api文件:img=pil.image('{}{3}{2}{1}{2}'.format({"age":36}))#'我们将原始数据内容传入。在实际需求中,data***可用任意对。 查看全部
插入关键字文章采集器这个插件可以完成前后端任务
插入关键字文章采集器这个插件可以完成前后端任务来进行数据的匹配。插件如下:data***python库插件第一步我们需要下载data***。代码如下:frompythonimporturllibimportrequestshttplib=urllib.urlopen('')#httplib.read()方法可以读取目标请求内容。
在不同的程序环境下,会出现不同的版本,我是采用pipinstall.提示下载python2.3版本之后,可以进行代码的测试本地pycharm将目标内容复制到到这个文件夹下:importpilimportosdefget_image(imgurl):returnimgurl#目标地址,()是python内置的字符串类型printimgurl="/"#目标请求urlprintos.getenv("python").seek(1)#索引print"{}$",imgurlimgurl="/"urllib.urlencode(imgurl)返回:{"data":"{}{2}{3}","name":"richard","age":36}不一定非要在线下编写代码,可以直接拿python代码进行处理,但是如果使用ide,内置的方法足够可以满足日常的需求。
特别地不适合那些需要使用循环语句的情况,因为你需要一直为每一个元素返回一个list。那么,除此之外,我们如何定制插件呢?首先,我们在把我们的一个原始数据放在配置文件下面,比如:img=pil.image('{}{3}{2}{1}{2}'.format({"age":36}))##{{img.size}}{{img.size}}#{{img.size}}{{img.size}}这个例子中的img就是可任意个字符串。
return{"path":"c:\\world","class":"cityletree","type":"boostcharity","path":"expanded","various":["cityletree","world"]}这个例子中,我们需要把一个data***python库嵌入到restfulapi实现接口。
我们来看看效果:img=requests.get("")exceptcallback:print"callbackerror"img.save()exceptfileexistingrequestsrequest:print"errorerror..."data***代码这个代码对img***python库有较强的依赖。
我们需要修改api文件:img=pil.image('{}{3}{2}{1}{2}'.format({"age":36}))#'我们将原始数据内容传入。在实际需求中,data***可用任意对。
软件特点优采云软件首创的智能提取网页正文算法(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-08-04 07:34
优采云·新闻源文章采集器(SMnewsbot)——首创的文本提取智能算法;准确采集新闻源,泛网;多语言翻译伪原创
本软件是一款只需要输入关键词采集百度、谷歌、搜搜等各大搜索引擎新闻源和泛网互联网文章软件(更多介绍..)的软件。
优采云software 是首创的独家智能算法,可以准确提取网页正文部分并保存为文章。
支持对标签、链接、邮件等进行格式化处理,还有插入关键词的功能,可以识别旁边插入的标签或者标点符号,可以识别英文空格的插入。
还有更多文章转翻译功能,即文章可以从一种语言如中文转成另一种语言如英文或日文,再由英文或日文转回中文。这是一个翻译周期。您可以将翻译周期设置为循环多次(翻译次数)。
采集文章+翻译伪原创可以满足站长和各领域朋友对文章的需求。
一些公关处理和信息研究公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而优采云的软件也是一个信息采集系统功能和市场上昂贵的软件有相似之处,但价格只有几百元,你会知道如何尝试性价比。
软件功能
优采云Software 首个智能提取网页正文的算法
百度新闻、谷歌新闻和搜搜新闻强聚合
不时更新的新闻资源取之不尽
多语言翻译伪原创。你,输入关键词
受影响区域
1、press关键词采集Internet文章和translate伪原创,站长朋友的首选。
2、适用于信息公关公司采集过滤提炼信息资料(上万专业公司的软件,我的几百块钱)
⒈本站提供的任何资源仅供您自己研究学习使用,不得用于非法活动。它们将在下载后 24 小时内删除。
⒉软件公告区的内容不得发布违反法律法规的内容。一旦发现该软件在后台被屏蔽,将无法打开!
⒊本站软件采集相清相关行业网站页面公开资源,属于用户自己在网站上发布的公开信息,不涉及任何个人隐私问题,本软件只能在一定范围内合法使用,请勿非法使用。
⒋一旦发现会员欺骗我们或欺骗客户,一经发现,会员资格将无条件取消!
⒌请勿将我们的软件采集信息用于转售或用于其他非法活动。如有,后果自负!一经发现,我们将第一时间向公安部门报告!并停止软件功能,所有费用概不退还!
原创文章转载请注明:/benlv/qyml/5003.html
标签:优采云市场软件万能文章采集新闻来源文章采集原创文章制作伪原创文章 查看全部
软件特点优采云软件首创的智能提取网页正文算法(组图)
优采云·新闻源文章采集器(SMnewsbot)——首创的文本提取智能算法;准确采集新闻源,泛网;多语言翻译伪原创
本软件是一款只需要输入关键词采集百度、谷歌、搜搜等各大搜索引擎新闻源和泛网互联网文章软件(更多介绍..)的软件。
优采云software 是首创的独家智能算法,可以准确提取网页正文部分并保存为文章。
支持对标签、链接、邮件等进行格式化处理,还有插入关键词的功能,可以识别旁边插入的标签或者标点符号,可以识别英文空格的插入。
还有更多文章转翻译功能,即文章可以从一种语言如中文转成另一种语言如英文或日文,再由英文或日文转回中文。这是一个翻译周期。您可以将翻译周期设置为循环多次(翻译次数)。
采集文章+翻译伪原创可以满足站长和各领域朋友对文章的需求。
一些公关处理和信息研究公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而优采云的软件也是一个信息采集系统功能和市场上昂贵的软件有相似之处,但价格只有几百元,你会知道如何尝试性价比。
软件功能
优采云Software 首个智能提取网页正文的算法
百度新闻、谷歌新闻和搜搜新闻强聚合
不时更新的新闻资源取之不尽
多语言翻译伪原创。你,输入关键词
受影响区域
1、press关键词采集Internet文章和translate伪原创,站长朋友的首选。
2、适用于信息公关公司采集过滤提炼信息资料(上万专业公司的软件,我的几百块钱)
⒈本站提供的任何资源仅供您自己研究学习使用,不得用于非法活动。它们将在下载后 24 小时内删除。
⒉软件公告区的内容不得发布违反法律法规的内容。一旦发现该软件在后台被屏蔽,将无法打开!
⒊本站软件采集相清相关行业网站页面公开资源,属于用户自己在网站上发布的公开信息,不涉及任何个人隐私问题,本软件只能在一定范围内合法使用,请勿非法使用。
⒋一旦发现会员欺骗我们或欺骗客户,一经发现,会员资格将无条件取消!
⒌请勿将我们的软件采集信息用于转售或用于其他非法活动。如有,后果自负!一经发现,我们将第一时间向公安部门报告!并停止软件功能,所有费用概不退还!
原创文章转载请注明:/benlv/qyml/5003.html
标签:优采云市场软件万能文章采集新闻来源文章采集原创文章制作伪原创文章
我要怎么批量的将采集到的数据,全部导入到帝国的数据库中呢
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-08-03 07:15
我在项目中接触到了优采云采集器。第一次用的时候,感觉真的很神奇。 采集数据真的很棒。网上80%以上的数据都可以通过采集获取。碰巧我最近用 Empirecms 制作了一个信息门户 网站。大家都知道,信息门户最头疼的就是数据。数据我只有优采云采集,一个字跑数据很爽。高兴了一阵子后,一个现实的问题来了,如何将采集收到的所有数据批量导入到帝国的数据库中?我把我的问题告诉了我的朋友,我的朋友说你可以写一个优采云 Empire 发布模块。他这么一说,我就去优采云采集器看看,果然有发布模块的功能。 优采云提供三种数据发布方式。
文件:/file/251274
第一种:直接在网络上发布模块,在线发布。
第二种:将发布的数据保存为文件。
第三种:直接发布到数据库。
按照我的想法,在网上搜索了优采云publishing modules,发现了很多结果,但是大部分教程都只是小菜一碟,大部分都是废话当天。在那之后,我仍然不知道该怎么做。无奈之下,向朋友求了一份,学习了操作、修改等方法,接下来将这个优采云发布模块的方法分享给大家。希望不要像我一样走来走去:
首先我们需要使用三个文件:
第一步:将需要的文件放到指定文件夹中:
将文件 1 复制到 e/admin/,将文件 2 复制到 e/class/ 文件夹。
文件2.需要二次开发,其作用是可以远程保存图片。代码如下。
// 二次开发代码
if($add['diy'] == 1){
//远程保存标题图片
if($add['titlepic']){
$tranr=DoTranUrl($add['titlepic'],$add['classid']);
if($tranr[tran])
{
$tranr[filesize]=(int)$tranr[filesize];
$tranr[type]=(int)$tranr[type];
//记录数据库
eInsertFileTable($tranr[filename],$tranr[filesize],$tranr[filepath],$username,$add['classid'],
'[s][URL]'.$tranr[filename],$tranr[type],0,$add['filepass'],$public_r[fpath],0,0,$public_r['filedeftb']);
//$add['titlepic']=$tranr[url];
$addtitlepic=",titlepic='".addslashes($tranr[url])."',ispic=1";
}
}
}
第 2 步:编写优采云 的发布模块。
第 3 步:直接在线测试。发布内容时,选择在线发布到网络网站。
通过以上步骤,优采云的Empire发布模块就可以完成了。如果你还不明白,请给我留言。 查看全部
我要怎么批量的将采集到的数据,全部导入到帝国的数据库中呢
我在项目中接触到了优采云采集器。第一次用的时候,感觉真的很神奇。 采集数据真的很棒。网上80%以上的数据都可以通过采集获取。碰巧我最近用 Empirecms 制作了一个信息门户 网站。大家都知道,信息门户最头疼的就是数据。数据我只有优采云采集,一个字跑数据很爽。高兴了一阵子后,一个现实的问题来了,如何将采集收到的所有数据批量导入到帝国的数据库中?我把我的问题告诉了我的朋友,我的朋友说你可以写一个优采云 Empire 发布模块。他这么一说,我就去优采云采集器看看,果然有发布模块的功能。 优采云提供三种数据发布方式。
文件:/file/251274
第一种:直接在网络上发布模块,在线发布。
第二种:将发布的数据保存为文件。
第三种:直接发布到数据库。
按照我的想法,在网上搜索了优采云publishing modules,发现了很多结果,但是大部分教程都只是小菜一碟,大部分都是废话当天。在那之后,我仍然不知道该怎么做。无奈之下,向朋友求了一份,学习了操作、修改等方法,接下来将这个优采云发布模块的方法分享给大家。希望不要像我一样走来走去:
首先我们需要使用三个文件:
第一步:将需要的文件放到指定文件夹中:
将文件 1 复制到 e/admin/,将文件 2 复制到 e/class/ 文件夹。
文件2.需要二次开发,其作用是可以远程保存图片。代码如下。
// 二次开发代码
if($add['diy'] == 1){
//远程保存标题图片
if($add['titlepic']){
$tranr=DoTranUrl($add['titlepic'],$add['classid']);
if($tranr[tran])
{
$tranr[filesize]=(int)$tranr[filesize];
$tranr[type]=(int)$tranr[type];
//记录数据库
eInsertFileTable($tranr[filename],$tranr[filesize],$tranr[filepath],$username,$add['classid'],
'[s][URL]'.$tranr[filename],$tranr[type],0,$add['filepass'],$public_r[fpath],0,0,$public_r['filedeftb']);
//$add['titlepic']=$tranr[url];
$addtitlepic=",titlepic='".addslashes($tranr[url])."',ispic=1";
}
}
}
第 2 步:编写优采云 的发布模块。
第 3 步:直接在线测试。发布内容时,选择在线发布到网络网站。
通过以上步骤,优采云的Empire发布模块就可以完成了。如果你还不明白,请给我留言。
引导页设计的构成与方法助力新产品使用体验
采集交流 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-08-03 03:26
引导页设计的构成与方法助力新产品使用体验
指南页可以算作我们打开新产品时看到的第一个屏幕。使用前可提前告知产品的主要功能和特点。
第一印象的好坏会极大地影响后续的产品体验。 文章通过梳理引导页面设计的构成,总结了帮助引导页面设计的实用观点和方法。
一、什么是引导页?
当您第一次打开一个新的应用程序时,通常会看到2-3个系列的打开页面,并附有一个简短的文字说明产品的功能,方便用户使用。
或者开一个全新的社交产品,引导用户创建账号、设置偏好、添加兴趣等,引导用户从头了解产品。
使用友好的指南页面向用户介绍价值主张以及产品将如何改善他们的生活。
入门帮助用户了解需要做什么以及如何做才能从产品中获得他们需要的东西。这是与用户建立信任的一种方式,不仅可以帮助用户,也是提高业务转化率和留存率的关键。
二、为什么指南页很重要?
平均而言,近四分之一的用户在仅使用一次产品后会因各种原因再次放弃使用该产品。一旦用户试用了产品并离开,除非他们能够从产品中获得一些有价值的内容,否则可能很难再次成为该产品的用户。
比如我们花时间和精力去下载一个新产品的时候,总是有一定的目的,希望这个产品能在一定程度上解决现阶段遇到的问题,或者改善我们的生活。
Twine 将渐进式指南页面集成到产品体验中,将用户流失率降低了一半以上。
用户留存率和客户忠诚度是大多数产品和服务成功的关键因素,适当的指南页面可以提高长期留存率。
为产品或服务添加新功能固然很好,但如果用户不了解或不知道如何使用它们,他们将在很大程度上未充分利用这些新功能,因此它们不会给用户带来太多。的价值。
三、Guide 页面设计类型和方法1.Guide 页面类型
为了满足新用户的需求并留住他们,大部分产品都采用了多种引导页面的组合来引导用户。
1)入门之旅
这是移动应用中非常流行的模式。用户第一次启动产品后,会看到几个页面,快速勾勒出产品的价值和基础知识。
这个简单的静态介绍为新用户提供了很好的介绍。
Slack 通过四屏概览介绍了新用户。整个介绍过程非常清晰,为用户提供了明确的进度点和跳过选项。
最佳做法是为用户提供进度指示器和退出或跳过选项。这样他们就会明白有多少介绍需要阅读并且不会混淆。
2)tooltips 和指导标签
这是另一种非常常见且相对省力的方法,可以从头到尾引导用户进行产品体验。
Twine 使用工具提示和指导标签来帮助用户快速理解页面。
在为 Metrie 的 3D 房间配置器设计界面时,通过添加带有引导标记的可切换图层将它们合并到加载屏幕中。
虽然这种带注释的指南设计很有用,但要注意不要过度使用或连续弹出多个窗口来打扰用户。引导用户一次使用一个元素或操作,避免解释太多显而易见的事情。
3)指导任务完成
让用户记住某件事的最好方法是让他们实际去做。引导式任务是通过一系列步骤提示用户与产品交互的方法。当产品希望用户尽快创建帐户或设置一些个性化参数时,通常会使用它们。
当用户第一次进入团队管理平台Basecamp时,会引导他们完成一项任务,熟悉产品的特性和功能。
2.指南什么时候开始?
在从最初入门到持续使用的整个过程中,决定在产品体验的哪一部分使用哪种引导模式对用户体验非常重要。
1)开箱即用
第一印象很重要,因为很多用户在第一次打开产品后就放弃了。
日记应用 Dailyo 友好而详细的指南页面向用户解释了产品的价值,并提供了如何让用户从中受益的提示。
2)渐进式指导
在用户完成开箱即用的过程后,仍有很多机会在使用产品的过程中继续帮助、启发和取悦用户。
每当用户选择一门新的语言学习时,Duolingo 都会提示用户表明他们的专业水平,然后测试他们的语言能力。这有助于用户避免因高估自己的能力并可能放弃使用而感到沮丧。
3)新功能上线
当产品引入新功能或对体验进行重大改变时,用户需要了解这些新功能的优势以及如何使用它们。
当 Facebook 向用户推出新功能时,它会使用高度可见的工具提示,通过简单的消息让用户知道如何使用新功能。
四、引导页面设计实践与技巧1.了解用户
通过了解用户调整引导页面的设计,发现并利用用户已有的心智模型,帮助弥合用户对产品的期望。
Basecamp 通过提供简单的选择面板和友好的指南,突出了新用户首次使用时应注意的核心元素。
在构建产品时,用户测试和可用性分析不仅可以帮助团队改进整体设计,还可以告诉用户在开始时要关注什么。
2. 连接用户价值
使用好处介绍来提醒用户为什么产品或服务适合特定需求。
Inbox 对介绍性体验进行了冗长的介绍,但每个案例都强调了其功能将如何让用户的生活更轻松。
3. 快速指南
在使用实体产品时,很少有人愿意通读手册。相反,人们更愿意自己去探索产品的功能。
Morningstar Financial 的入门指南违反了保持简单指南的原则,因为没有人愿意花时间阅读这么多的说明,更不用说记住它们了。
如果产品很简单,快速概览可能就足够了。当需要更深入时,可以考虑逐步指导,将指导延伸到整个产品体验。
4. 可重复指南
开始后,您不能假设用户不会再次访问这些指南。用户可能已经忘记了第一个指南中提到的技巧或内容,所以考虑在导航中设置一个“帮助”模块,方便用户重复查看这些指南内容。
可根据用户需要在房间内开启或关闭引导标志,使用户能够根据自己的实际情况获得引导和帮助。
5.避免过于个性化
鼓励新用户提供一些有助于个性化体验的信息是好的,但需要注意不要要求太多细节,导致信息泄露的感觉。
产品不应该问用户太多不必要的问题,尤其是第一次使用时。
首次使用 Pinterest 时,用户需要使用自己的电子邮件地址登录,然后通过年龄和爱好的选择为用户带来个性化体验。
终于
导览页面不仅仅是一个瞬间的操作,而是一个与观众建立和保持信任的过程。
原文:/designers/product-design/guide-to-onboarding-ux 查看全部
引导页设计的构成与方法助力新产品使用体验
指南页可以算作我们打开新产品时看到的第一个屏幕。使用前可提前告知产品的主要功能和特点。
第一印象的好坏会极大地影响后续的产品体验。 文章通过梳理引导页面设计的构成,总结了帮助引导页面设计的实用观点和方法。
一、什么是引导页?
当您第一次打开一个新的应用程序时,通常会看到2-3个系列的打开页面,并附有一个简短的文字说明产品的功能,方便用户使用。
或者开一个全新的社交产品,引导用户创建账号、设置偏好、添加兴趣等,引导用户从头了解产品。
使用友好的指南页面向用户介绍价值主张以及产品将如何改善他们的生活。
入门帮助用户了解需要做什么以及如何做才能从产品中获得他们需要的东西。这是与用户建立信任的一种方式,不仅可以帮助用户,也是提高业务转化率和留存率的关键。
二、为什么指南页很重要?
平均而言,近四分之一的用户在仅使用一次产品后会因各种原因再次放弃使用该产品。一旦用户试用了产品并离开,除非他们能够从产品中获得一些有价值的内容,否则可能很难再次成为该产品的用户。
比如我们花时间和精力去下载一个新产品的时候,总是有一定的目的,希望这个产品能在一定程度上解决现阶段遇到的问题,或者改善我们的生活。
Twine 将渐进式指南页面集成到产品体验中,将用户流失率降低了一半以上。
用户留存率和客户忠诚度是大多数产品和服务成功的关键因素,适当的指南页面可以提高长期留存率。
为产品或服务添加新功能固然很好,但如果用户不了解或不知道如何使用它们,他们将在很大程度上未充分利用这些新功能,因此它们不会给用户带来太多。的价值。
三、Guide 页面设计类型和方法1.Guide 页面类型
为了满足新用户的需求并留住他们,大部分产品都采用了多种引导页面的组合来引导用户。
1)入门之旅
这是移动应用中非常流行的模式。用户第一次启动产品后,会看到几个页面,快速勾勒出产品的价值和基础知识。
这个简单的静态介绍为新用户提供了很好的介绍。
Slack 通过四屏概览介绍了新用户。整个介绍过程非常清晰,为用户提供了明确的进度点和跳过选项。
最佳做法是为用户提供进度指示器和退出或跳过选项。这样他们就会明白有多少介绍需要阅读并且不会混淆。
2)tooltips 和指导标签
这是另一种非常常见且相对省力的方法,可以从头到尾引导用户进行产品体验。
Twine 使用工具提示和指导标签来帮助用户快速理解页面。
在为 Metrie 的 3D 房间配置器设计界面时,通过添加带有引导标记的可切换图层将它们合并到加载屏幕中。
虽然这种带注释的指南设计很有用,但要注意不要过度使用或连续弹出多个窗口来打扰用户。引导用户一次使用一个元素或操作,避免解释太多显而易见的事情。
3)指导任务完成
让用户记住某件事的最好方法是让他们实际去做。引导式任务是通过一系列步骤提示用户与产品交互的方法。当产品希望用户尽快创建帐户或设置一些个性化参数时,通常会使用它们。
当用户第一次进入团队管理平台Basecamp时,会引导他们完成一项任务,熟悉产品的特性和功能。
2.指南什么时候开始?
在从最初入门到持续使用的整个过程中,决定在产品体验的哪一部分使用哪种引导模式对用户体验非常重要。
1)开箱即用
第一印象很重要,因为很多用户在第一次打开产品后就放弃了。
日记应用 Dailyo 友好而详细的指南页面向用户解释了产品的价值,并提供了如何让用户从中受益的提示。
2)渐进式指导
在用户完成开箱即用的过程后,仍有很多机会在使用产品的过程中继续帮助、启发和取悦用户。
每当用户选择一门新的语言学习时,Duolingo 都会提示用户表明他们的专业水平,然后测试他们的语言能力。这有助于用户避免因高估自己的能力并可能放弃使用而感到沮丧。
3)新功能上线
当产品引入新功能或对体验进行重大改变时,用户需要了解这些新功能的优势以及如何使用它们。
当 Facebook 向用户推出新功能时,它会使用高度可见的工具提示,通过简单的消息让用户知道如何使用新功能。
四、引导页面设计实践与技巧1.了解用户
通过了解用户调整引导页面的设计,发现并利用用户已有的心智模型,帮助弥合用户对产品的期望。
Basecamp 通过提供简单的选择面板和友好的指南,突出了新用户首次使用时应注意的核心元素。
在构建产品时,用户测试和可用性分析不仅可以帮助团队改进整体设计,还可以告诉用户在开始时要关注什么。
2. 连接用户价值
使用好处介绍来提醒用户为什么产品或服务适合特定需求。
Inbox 对介绍性体验进行了冗长的介绍,但每个案例都强调了其功能将如何让用户的生活更轻松。
3. 快速指南
在使用实体产品时,很少有人愿意通读手册。相反,人们更愿意自己去探索产品的功能。
Morningstar Financial 的入门指南违反了保持简单指南的原则,因为没有人愿意花时间阅读这么多的说明,更不用说记住它们了。
如果产品很简单,快速概览可能就足够了。当需要更深入时,可以考虑逐步指导,将指导延伸到整个产品体验。
4. 可重复指南
开始后,您不能假设用户不会再次访问这些指南。用户可能已经忘记了第一个指南中提到的技巧或内容,所以考虑在导航中设置一个“帮助”模块,方便用户重复查看这些指南内容。
可根据用户需要在房间内开启或关闭引导标志,使用户能够根据自己的实际情况获得引导和帮助。
5.避免过于个性化
鼓励新用户提供一些有助于个性化体验的信息是好的,但需要注意不要要求太多细节,导致信息泄露的感觉。
产品不应该问用户太多不必要的问题,尤其是第一次使用时。
首次使用 Pinterest 时,用户需要使用自己的电子邮件地址登录,然后通过年龄和爱好的选择为用户带来个性化体验。
终于
导览页面不仅仅是一个瞬间的操作,而是一个与观众建立和保持信任的过程。
原文:/designers/product-design/guide-to-onboarding-ux
插入关键字文章采集器:爬虫必备新手必备源码和介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-07-25 22:22
插入关键字文章采集器:scrapy项目采集器:微信公众号文章采集器:qq好友文章采集器:公司采集器:百度贴吧采集器:网页采集器:爬虫必备新手必备源码和介绍wechatid最近成功采集了最新的ly诗歌,花灯,全是源码和介绍感兴趣的朋友可以下载哦采集标准时间地点名称标题内容(可有限制)访问率百分比点赞数收藏数转发数高粘性作者关注度粉丝数等数据采集实例importrequestsimportredefget_form_request(url):response=requests.get(url).content.decode('utf-8')#获取url中的源码。
response.status_code='200'response.encoding='utf-8'response.text=response.textreturnresponsedefget_request_parse(url):response=requests.get(url).parse(response.text)#parse()函数parse函数存在两个问题1、得到数据之后,可能会返回一个数组而非值2、在源码中检索被爬虫挂马的数据,会返回所有被爬虫挂马的网页foriinurl:print(i)#返回数组,可以清除数组,或存入到集合forjinurl:print(j)#python中迭代的分支是这样的,先调用迭代器里的某个元素,然后遍历这个元素。 查看全部
插入关键字文章采集器:爬虫必备新手必备源码和介绍
插入关键字文章采集器:scrapy项目采集器:微信公众号文章采集器:qq好友文章采集器:公司采集器:百度贴吧采集器:网页采集器:爬虫必备新手必备源码和介绍wechatid最近成功采集了最新的ly诗歌,花灯,全是源码和介绍感兴趣的朋友可以下载哦采集标准时间地点名称标题内容(可有限制)访问率百分比点赞数收藏数转发数高粘性作者关注度粉丝数等数据采集实例importrequestsimportredefget_form_request(url):response=requests.get(url).content.decode('utf-8')#获取url中的源码。
response.status_code='200'response.encoding='utf-8'response.text=response.textreturnresponsedefget_request_parse(url):response=requests.get(url).parse(response.text)#parse()函数parse函数存在两个问题1、得到数据之后,可能会返回一个数组而非值2、在源码中检索被爬虫挂马的数据,会返回所有被爬虫挂马的网页foriinurl:print(i)#返回数组,可以清除数组,或存入到集合forjinurl:print(j)#python中迭代的分支是这样的,先调用迭代器里的某个元素,然后遍历这个元素。
插入关键字文章采集器-爬虫老兵插入一些自动数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-07-25 19:05
插入关键字文章采集器-爬虫老兵插入一些关键字自动抓取数据按照你的指定格式读取excel数据,
文章采集器-微信公众号文章采集器百度应该就可以搜到一些。我自己的也遇到类似问题,
博客风云榜/
微信公众号文章采集,对接第三方采集平台,
可以试试“清博指数”,
导入txt格式的数据,
可以试试将采集的格式转换为txt格式,
微信文章采集-【易采云】,采集微信公众号,企业号,网站,支付宝,
weibodata插件,
你要下载数据源啊,采集微信的话你就下载weibodata客户端,
微信文章采集_微信文章采集工具
微信号采集工具,
写了两个github上公开的项目,
一般没用过,
记得之前跟那个小编聊过,他说直接登录wx公众号那个,通过发送短信,
更多的免费资源获取,
转载一位大佬@troublesang有事没事写的回答不仅页面好,而且很有用(以下1。不是很详细(快速入门什么的1。1微信公众号文章采集1。2weibo关键字采集2。网站爬虫(这个是专门采集微信文章的2。1去除繁体字2。2网页高仿2。3网站抓包2。4其他方法2。5python中文教程本教程仅提供免费试用,不能发布到论坛)其他优秀软件:1。
西瓜数据::。python教程(开源和简易都有):我目前在用的:3。公众号截图采集器(学习爬虫)2。快速录屏工具:。 查看全部
插入关键字文章采集器-爬虫老兵插入一些自动数据
插入关键字文章采集器-爬虫老兵插入一些关键字自动抓取数据按照你的指定格式读取excel数据,
文章采集器-微信公众号文章采集器百度应该就可以搜到一些。我自己的也遇到类似问题,
博客风云榜/
微信公众号文章采集,对接第三方采集平台,
可以试试“清博指数”,
导入txt格式的数据,
可以试试将采集的格式转换为txt格式,
微信文章采集-【易采云】,采集微信公众号,企业号,网站,支付宝,
weibodata插件,
你要下载数据源啊,采集微信的话你就下载weibodata客户端,
微信文章采集_微信文章采集工具
微信号采集工具,
写了两个github上公开的项目,
一般没用过,
记得之前跟那个小编聊过,他说直接登录wx公众号那个,通过发送短信,
更多的免费资源获取,
转载一位大佬@troublesang有事没事写的回答不仅页面好,而且很有用(以下1。不是很详细(快速入门什么的1。1微信公众号文章采集1。2weibo关键字采集2。网站爬虫(这个是专门采集微信文章的2。1去除繁体字2。2网页高仿2。3网站抓包2。4其他方法2。5python中文教程本教程仅提供免费试用,不能发布到论坛)其他优秀软件:1。
西瓜数据::。python教程(开源和简易都有):我目前在用的:3。公众号截图采集器(学习爬虫)2。快速录屏工具:。
插入关键字文章采集器的应用方法-苏州安嘉
采集交流 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2021-07-21 00:00
插入关键字文章采集器利用包括不限于下载文章,查看历史评论,下载文章评论回复等功能进行爬虫。一.获取文章内容(实用的文章查找办法)某天小猫发现,有个网站上的所有文章都有封面图,而且是美美的,那么如何找到它们呢,大家可以试一下,需要这个xx软件去爬。例如网站后缀为pwx的文章,首先打开这个网站,在右上角可以看到所有文章,长按网址,然后就可以切换到网站图片界面,在页面内输入pwx,得到网址(或者直接复制网址)。
复制网址,然后打开迅雷,开始下载。在其下方找到图片,同样方法在迅雷找到,然后点击下载按钮,选择那个pwx版本,下载完成后。打开文章详情页就可以看到刚才下载的图片了。而且如果你觉得文章很长,可以点击右上角的分享,然后分享到新浪微博。再例如以下图片,需要修改前缀,得到具体网址:网站后缀为.的文章,在右上角可以看到文章下方有很多二维码和微信的二维码,这个时候需要在新浪微博将pwx的url粘贴到,或者直接复制网址,在微博再粘贴上就可以了。
最后,像微信文章,外链,转载等。该文字内容均来自一群聊5173资源库,对你有用,请赞同并在评论区分享给更多人。
爬取关键字实际上还是按照网站的文章地址定制爬虫程序。关键字文章查找-xiaoloo_zz:actornamethemesrangethemesfileurl/?url=ff06f08bb5e182a71ab52b63018922f084a8d9cdf94e80e9e7091a4&src=read_zhihu:url。 查看全部
插入关键字文章采集器的应用方法-苏州安嘉
插入关键字文章采集器利用包括不限于下载文章,查看历史评论,下载文章评论回复等功能进行爬虫。一.获取文章内容(实用的文章查找办法)某天小猫发现,有个网站上的所有文章都有封面图,而且是美美的,那么如何找到它们呢,大家可以试一下,需要这个xx软件去爬。例如网站后缀为pwx的文章,首先打开这个网站,在右上角可以看到所有文章,长按网址,然后就可以切换到网站图片界面,在页面内输入pwx,得到网址(或者直接复制网址)。
复制网址,然后打开迅雷,开始下载。在其下方找到图片,同样方法在迅雷找到,然后点击下载按钮,选择那个pwx版本,下载完成后。打开文章详情页就可以看到刚才下载的图片了。而且如果你觉得文章很长,可以点击右上角的分享,然后分享到新浪微博。再例如以下图片,需要修改前缀,得到具体网址:网站后缀为.的文章,在右上角可以看到文章下方有很多二维码和微信的二维码,这个时候需要在新浪微博将pwx的url粘贴到,或者直接复制网址,在微博再粘贴上就可以了。
最后,像微信文章,外链,转载等。该文字内容均来自一群聊5173资源库,对你有用,请赞同并在评论区分享给更多人。
爬取关键字实际上还是按照网站的文章地址定制爬虫程序。关键字文章查找-xiaoloo_zz:actornamethemesrangethemesfileurl/?url=ff06f08bb5e182a71ab52b63018922f084a8d9cdf94e80e9e7091a4&src=read_zhihu:url。
后台,核心,批量维护,文档关键词-梦客吧织梦模板
采集交流 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-07-19 18:26
列表页面调用文章关键词:
[field:id runphp=yes]
全局$dsql;
$tags ='';
$query = "从`dede_archives` WHERE 选择关键字";
$dsql->Execute('keywords',$query);
while($row = $dsql->GetArray('keywords'))
{
$keywords1=$row['keywords'];
}
@me=$keywords1;
[/field:id]
Shijiazhuang seo-Shijiazhuang and Shijiazhuang网站optimization-Shijiazhuang
把这类SEO的标题放在网站
在这个标签中,浏览网站时不会显示,但是当搜索引擎为收录时,你的页面以后可以通过这些关键词找到你的网站,标题为放置在标题标签中。
dede采集的文章如何自动插入关键词——后台、内核、批量维护、文档关键词,可以设置关键词和链接,所以不管是采集还是原创可以自动关键词并链接到指定地址。如果要在采集的文章中插入新词,可以替换为织梦采集关键词,如果是第三方工具,请参考教程。萌客吧织梦template会回答你的问题,希望采纳
请进:dedecms系统采集如何在内容时自动添加关键字-先进入内容模型管理-普通文章-添加字段-关键字(关键字),如图(图片中的红圈一定要打勾,否则无效)
dede采集文章想在文章的标题后自动添加关键词-——建议采集使用优采云等采集软件,也方便为您添加处理。您可以在模板中采集之后写列关键词。
文章如何让dede系统自动发布关键词-——系统本身就有这个功能...
请问织梦cms5.7采集来的文章怎么给关键字自动添加超链接-优采云采集还是喜欢织梦写规则,或者使用主动提取批量提取关键词
dedecms5.7如何设置文章Auto Insert关键词超LINK————文档关键词Maintenance 添加关键词并链接2、Background-System-Core 设置关键字替换( Yes/No) 使用该函数会影响HTML生成速度: Yes3、Background-System-Other options 文档内容相同关键词Replacement 次(0表示全部替换):设置一个值(顺便说一下,比如一篇文章文章...
dedecms织梦网站如何在内容页面自动添加关键词链接-——第一步:输入网站Background设置1、首先登录网站管理后台选择系统-系统基本参数-核心设置>找到关键词替换(是/否),选择2、然后在系统-系统基本参数-其他选项中找到文档内容,找到相同的关键词替换次数(0表示全部替换):写1或...
织梦Background 如何在每个文章中自动添加关键词-调用head头部的相关代码,然后在织梦Background中找到文章的高级设置并写关键词 并描述一下
织梦cms 如何让文章内容关键词自动添加锚文本?如何自动链接关键词?谢谢,网上很多方法都不实用。-——我们知道锚文本对于网站Optimization很有用,那么织梦cms可以实现这个功能吗?答案是肯定的。让我分享一个非常简单的方法来自动添加锚文本。首先设置背景需要设置的地方全部设置好。 1、System-基本系统参数-性能选项-使用关闭...
dede 5.5 如何在文章发帖后自动添加关键词链接,现在只出现第一个关键词链接,只出现一次————核心设置,批量维护,文档关键词。希望能帮到你。 查看全部
后台,核心,批量维护,文档关键词-梦客吧织梦模板
列表页面调用文章关键词:
[field:id runphp=yes]
全局$dsql;
$tags ='';
$query = "从`dede_archives` WHERE 选择关键字";
$dsql->Execute('keywords',$query);
while($row = $dsql->GetArray('keywords'))
{
$keywords1=$row['keywords'];
}
@me=$keywords1;
[/field:id]
Shijiazhuang seo-Shijiazhuang and Shijiazhuang网站optimization-Shijiazhuang
把这类SEO的标题放在网站
在这个标签中,浏览网站时不会显示,但是当搜索引擎为收录时,你的页面以后可以通过这些关键词找到你的网站,标题为放置在标题标签中。
dede采集的文章如何自动插入关键词——后台、内核、批量维护、文档关键词,可以设置关键词和链接,所以不管是采集还是原创可以自动关键词并链接到指定地址。如果要在采集的文章中插入新词,可以替换为织梦采集关键词,如果是第三方工具,请参考教程。萌客吧织梦template会回答你的问题,希望采纳
请进:dedecms系统采集如何在内容时自动添加关键字-先进入内容模型管理-普通文章-添加字段-关键字(关键字),如图(图片中的红圈一定要打勾,否则无效)
dede采集文章想在文章的标题后自动添加关键词-——建议采集使用优采云等采集软件,也方便为您添加处理。您可以在模板中采集之后写列关键词。
文章如何让dede系统自动发布关键词-——系统本身就有这个功能...
请问织梦cms5.7采集来的文章怎么给关键字自动添加超链接-优采云采集还是喜欢织梦写规则,或者使用主动提取批量提取关键词
dedecms5.7如何设置文章Auto Insert关键词超LINK————文档关键词Maintenance 添加关键词并链接2、Background-System-Core 设置关键字替换( Yes/No) 使用该函数会影响HTML生成速度: Yes3、Background-System-Other options 文档内容相同关键词Replacement 次(0表示全部替换):设置一个值(顺便说一下,比如一篇文章文章...
dedecms织梦网站如何在内容页面自动添加关键词链接-——第一步:输入网站Background设置1、首先登录网站管理后台选择系统-系统基本参数-核心设置>找到关键词替换(是/否),选择2、然后在系统-系统基本参数-其他选项中找到文档内容,找到相同的关键词替换次数(0表示全部替换):写1或...
织梦Background 如何在每个文章中自动添加关键词-调用head头部的相关代码,然后在织梦Background中找到文章的高级设置并写关键词 并描述一下
织梦cms 如何让文章内容关键词自动添加锚文本?如何自动链接关键词?谢谢,网上很多方法都不实用。-——我们知道锚文本对于网站Optimization很有用,那么织梦cms可以实现这个功能吗?答案是肯定的。让我分享一个非常简单的方法来自动添加锚文本。首先设置背景需要设置的地方全部设置好。 1、System-基本系统参数-性能选项-使用关闭...
dede 5.5 如何在文章发帖后自动添加关键词链接,现在只出现第一个关键词链接,只出现一次————核心设置,批量维护,文档关键词。希望能帮到你。
梦客教你dede系统自动获取关键字内容的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-07-19 18:24
后台、核心、批量维护、文档关键词,可以设置关键词和链接,所以不管是采集还是原创,都可以自动关键词并链接到指定地址。
如果要在采集的文章中插入一个新词,可以用关键词织梦采集替换。如果您使用的是第三方工具,请参考教程
萌客吧织梦template
给你答案
希望采纳
dede系统自动获取关键词内容主要分为三个部分:
1.dede 自动获取关键词链接增加网站内锚文本
2.dede 自动添加关键词频率设置
3.Delete dede 系统变量
我们来看看以上三点在dede系统中应该如何实现。这里主要着重介绍操作和设置参数,并详细讲解!!!
一、dede 自动获取关键词链接
这个比较简单,新手也可以独立完成,主要是这里的一些注意和一些参数的含义:
1.系统目录——采集——文档关键字维护
2.参数设置详解
一个。添加关键字:(需要显示的关键字文本)
B.链接地址:(关键字链接地址)
c.频率:(自动获取关键词频率,默认30,这里不需要修改,因为每个关键词锚文本只需要在正文中出现一次,第二步后面会设置)
注意:例如以百度知道网站为例,需要在每个文章中出现“百度知道”时自动添加链接锚文本,您可以这样做:添加关键字:(百度知道),链接地址:(),频率:(默认为30,无需修改)
其实方法很简单。您不需要更改根目录中的任何文件。只需要一步设置,这样dede在发布文章的时候会自动添加关键词链接,所以下次看到修改系统文件什么的,基本可以无视。不过还是有以下几点需要注意:
一个。每个文章中相同的锚文本最好只出现一次(例如:当一个文章中有数百个关键词时,每个关键词都会自动添加关键词锚文本,SEO会认为你在作弊,这个一定要避免!但这里的频率设置没有意义。一般我们通过添加变量来控制关键字锚文本的频率,如下面第二点所述)
B.自动链接会切断你的手动链接(例如:我在后台设置了“百度知道”链接,但是如果我更新文章,我手动将“主持人XX事件”添加到其他相关页面如果你链接,文章更新后看到的效果是“百度知道”链接到后台设置的链接,“有XX活动”链接到手动设置的页面,这就是所谓的“自动链接会议”。切断您的手动链接“可能用词不当,但这是需要注意的)
二、dede 自动添加关键词频率设置
再次确认,这个不需要修改系统文件,只需要添加一个控制变量即可。这里我们使用cfg_replace_num变量来控制同一关键字的锚文本出现的频率:
1.system-基本系统参数
2.添加一个新变量(此处需要截图以了解详细信息)
变量名:你说的你加的变量,这里是cfg_replace_num而不是自己填
变量值:这个好理解,每个关键字锚文本只出现一次,即设置为1
参数说明:限制关键字替换的次数(这个会在控制选项中显示,个人可以根据不同的爱好设置)
组:出现在该组中,选项为:站点设置|核心设置|附件设置|会员设置|互动设置|性能选项|它的选择|模块设置,这里你选择哪一个,这个变量出现在那个组下面,以后的设置可以在这个组中找到。这里我选择“其他选项”,所以我只会在其他选项中找到他。效果如下:
这样设置后,先更新一个文章test,如果ok就更新所有文档。看完介绍,不知道你设置对了吗?如果设置不理想,可以删除变量并重新设置,但是dede后台控制面板中没有这个选项。我们可以使用SQL命令行工具来删除变量。如果你想删除一个,这将是第三点。
三、Delete dede 系统变量
这里需要用到dede后端的“SQL命令行工具”,其实没什么高级的。在dede系统后台-系统设置-SQL命令行工具-运行SQL命令行(根据需求单行或多行)
Delete FROM dede_sysconfig where varname="cfg_replace_num",其中“cfg_replace_num”是要删除的变量的名称。
在织梦root目录下的dede(默认背景)文件夹中找到article_add.php
找到第 190 行附近的代码。. . . ======
$query = "INSERT INTO `#@__archives`(id,typeid,typeid2,sortrank,flag,ismake,channel,arcrank,click,money,title,shorttitle,color,writer,source,litpic,pubdate,senddate ,mid,voteid,notpost,description,keywords,filename,dutyadmin,weight) VALUES ('$arcID','$typeid','$typeid2','$sortrank','$flag','$ismake',' $channelid','$arcrank','$click','$money','$title','$shorttitle','$color','$writer','$source','$litpic',' $pubdate','$senddate','$adminid','$voteid','$notpost','$description','$keywords','$filename','$adminid','$weight'); ";修改为======
if($keysords!=''){ $query = "INSERT INTO `#@__archives`(id,typeid,typeid2,sortrank,flag,ismake,channel,arcrank,click,money,title,shorttitle, color ,writer,source,litpic,pubdate,senddate,mid,voteid,notpost,description,keywords,filename,dutyadmin,weight) VALUES ('$arcID','$typeid','$typeid2','$sortrank',' $flag','$ismake','$channelid','$arcrank','$click','$money','$title','$shorttitle','$color','$writer',' $source','$litpic','$pubdate','$senddate','$adminid','$voteid','$notpost','$description','$keywords','$filename',' $adminid','$weight');"; }else{$query = "INSERT INTO `#@__archives`(id,typeid,typeid2,sortrank,flag,ismake,channel,arcrank,click,money,title,shorttitle,color,writer,source,litpic,pubdate,senddate ,mid,voteid,notpost,description,filename,dutyadmin,weight) VALUES ('$arcID','$typeid','$typeid2','$sortrank','$flag','$ismake','$channelid ','$arcrank','$click','$money','$title','$shorttitle','$color','$writer','$source','$litpic','$pubdate ','$senddate' ,'$adminid','$voteid','$notpost','$description','$filename','$adminid','$weight');";} 其实很简单判断关键字是否为空即可。
直接导出然后从数据库表中导入另一个操作
{dede:likearticle row='' titlelen=''}
[field:title/]
{/de:likearticle}
标签属性
row:返回文档列表总数
titlelen:标题长度
dede采集的文章如何自动插入关键词——后台、内核、批量维护、文档关键词,可以设置关键词和链接,所以不管是采集还是原创可以自动关键词并链接到指定地址。如果要在采集的文章中插入新词,可以替换为织梦采集关键词,如果是第三方工具,请参考教程。萌客吧织梦template会回答你的问题,希望采纳
请进:dedecms系统采集如何在内容时自动添加关键字-先进入内容模型管理-普通文章-添加字段-关键字(关键字),如图(图片中的红圈一定要打勾,否则无效)
dede采集文章想在文章的标题后自动添加关键词-——建议采集使用优采云等采集软件,也方便为您添加处理。您可以在模板中采集之后写列关键词。
文章如何让dede系统自动发布关键词-——系统本身就有这个功能...
请问织梦cms5.7采集来的文章如何自动给关键字添加超链接-优采云采集还是像织梦写规则,或者使用主动提取批量提取关键词
dedecms5.7如何设置文章Auto Insert关键词超LINK————文档关键词Maintenance 添加关键词并链接2、Background-System-Core 设置关键字替换( Yes/No) 使用该函数会影响HTML生成速度: Yes3、Background-System-Other options 文档内容同关键词Replacement 次(0表示全部替换):设置一个值(顺便说一下比如一篇文章文章...
dedecms织梦网站如何在内容页面自动添加关键词链接-—— 第一步:输入网站Background设置1、首先登录网站管理后台选择系统-系统基本参数-核心设置>找到关键词替换(是/否),选择2、然后在系统-系统基本参数-其他选项中找到文档内容。写 1 或...
织梦Background 如何在每个文章中自动添加关键词-调用head头部的相关代码,然后在织梦Background中找到文章的高级设置并写关键词 并描述一下
织梦cms 如何让文章内容关键词自动添加锚文本?如何自动链接关键词?谢谢,网上很多方法都不实用。-——我们知道锚文本对于网站Optimization很有用,那么织梦cms可以实现这个功能吗?答案是肯定的。让我分享一个非常简单的方法来自动添加锚文本。首先设置背景需要设置的地方全部设置好。 1、System-基本系统参数-性能选项-使用关闭...
dede 5.5 如何在文章发帖后自动添加关键词链接,现在只出现第一个关键词链接,只出现一次————核心设置,批量维护,文档关键词。希望能帮到你。 查看全部
梦客教你dede系统自动获取关键字内容的方法
后台、核心、批量维护、文档关键词,可以设置关键词和链接,所以不管是采集还是原创,都可以自动关键词并链接到指定地址。
如果要在采集的文章中插入一个新词,可以用关键词织梦采集替换。如果您使用的是第三方工具,请参考教程
萌客吧织梦template
给你答案
希望采纳
dede系统自动获取关键词内容主要分为三个部分:
1.dede 自动获取关键词链接增加网站内锚文本
2.dede 自动添加关键词频率设置
3.Delete dede 系统变量
我们来看看以上三点在dede系统中应该如何实现。这里主要着重介绍操作和设置参数,并详细讲解!!!
一、dede 自动获取关键词链接
这个比较简单,新手也可以独立完成,主要是这里的一些注意和一些参数的含义:
1.系统目录——采集——文档关键字维护
2.参数设置详解
一个。添加关键字:(需要显示的关键字文本)
B.链接地址:(关键字链接地址)
c.频率:(自动获取关键词频率,默认30,这里不需要修改,因为每个关键词锚文本只需要在正文中出现一次,第二步后面会设置)
注意:例如以百度知道网站为例,需要在每个文章中出现“百度知道”时自动添加链接锚文本,您可以这样做:添加关键字:(百度知道),链接地址:(),频率:(默认为30,无需修改)
其实方法很简单。您不需要更改根目录中的任何文件。只需要一步设置,这样dede在发布文章的时候会自动添加关键词链接,所以下次看到修改系统文件什么的,基本可以无视。不过还是有以下几点需要注意:
一个。每个文章中相同的锚文本最好只出现一次(例如:当一个文章中有数百个关键词时,每个关键词都会自动添加关键词锚文本,SEO会认为你在作弊,这个一定要避免!但这里的频率设置没有意义。一般我们通过添加变量来控制关键字锚文本的频率,如下面第二点所述)
B.自动链接会切断你的手动链接(例如:我在后台设置了“百度知道”链接,但是如果我更新文章,我手动将“主持人XX事件”添加到其他相关页面如果你链接,文章更新后看到的效果是“百度知道”链接到后台设置的链接,“有XX活动”链接到手动设置的页面,这就是所谓的“自动链接会议”。切断您的手动链接“可能用词不当,但这是需要注意的)
二、dede 自动添加关键词频率设置
再次确认,这个不需要修改系统文件,只需要添加一个控制变量即可。这里我们使用cfg_replace_num变量来控制同一关键字的锚文本出现的频率:
1.system-基本系统参数
2.添加一个新变量(此处需要截图以了解详细信息)
变量名:你说的你加的变量,这里是cfg_replace_num而不是自己填
变量值:这个好理解,每个关键字锚文本只出现一次,即设置为1
参数说明:限制关键字替换的次数(这个会在控制选项中显示,个人可以根据不同的爱好设置)
组:出现在该组中,选项为:站点设置|核心设置|附件设置|会员设置|互动设置|性能选项|它的选择|模块设置,这里你选择哪一个,这个变量出现在那个组下面,以后的设置可以在这个组中找到。这里我选择“其他选项”,所以我只会在其他选项中找到他。效果如下:
这样设置后,先更新一个文章test,如果ok就更新所有文档。看完介绍,不知道你设置对了吗?如果设置不理想,可以删除变量并重新设置,但是dede后台控制面板中没有这个选项。我们可以使用SQL命令行工具来删除变量。如果你想删除一个,这将是第三点。
三、Delete dede 系统变量
这里需要用到dede后端的“SQL命令行工具”,其实没什么高级的。在dede系统后台-系统设置-SQL命令行工具-运行SQL命令行(根据需求单行或多行)
Delete FROM dede_sysconfig where varname="cfg_replace_num",其中“cfg_replace_num”是要删除的变量的名称。
在织梦root目录下的dede(默认背景)文件夹中找到article_add.php
找到第 190 行附近的代码。. . . ======
$query = "INSERT INTO `#@__archives`(id,typeid,typeid2,sortrank,flag,ismake,channel,arcrank,click,money,title,shorttitle,color,writer,source,litpic,pubdate,senddate ,mid,voteid,notpost,description,keywords,filename,dutyadmin,weight) VALUES ('$arcID','$typeid','$typeid2','$sortrank','$flag','$ismake',' $channelid','$arcrank','$click','$money','$title','$shorttitle','$color','$writer','$source','$litpic',' $pubdate','$senddate','$adminid','$voteid','$notpost','$description','$keywords','$filename','$adminid','$weight'); ";修改为======
if($keysords!=''){ $query = "INSERT INTO `#@__archives`(id,typeid,typeid2,sortrank,flag,ismake,channel,arcrank,click,money,title,shorttitle, color ,writer,source,litpic,pubdate,senddate,mid,voteid,notpost,description,keywords,filename,dutyadmin,weight) VALUES ('$arcID','$typeid','$typeid2','$sortrank',' $flag','$ismake','$channelid','$arcrank','$click','$money','$title','$shorttitle','$color','$writer',' $source','$litpic','$pubdate','$senddate','$adminid','$voteid','$notpost','$description','$keywords','$filename',' $adminid','$weight');"; }else{$query = "INSERT INTO `#@__archives`(id,typeid,typeid2,sortrank,flag,ismake,channel,arcrank,click,money,title,shorttitle,color,writer,source,litpic,pubdate,senddate ,mid,voteid,notpost,description,filename,dutyadmin,weight) VALUES ('$arcID','$typeid','$typeid2','$sortrank','$flag','$ismake','$channelid ','$arcrank','$click','$money','$title','$shorttitle','$color','$writer','$source','$litpic','$pubdate ','$senddate' ,'$adminid','$voteid','$notpost','$description','$filename','$adminid','$weight');";} 其实很简单判断关键字是否为空即可。
直接导出然后从数据库表中导入另一个操作
{dede:likearticle row='' titlelen=''}
[field:title/]
{/de:likearticle}
标签属性
row:返回文档列表总数
titlelen:标题长度
dede采集的文章如何自动插入关键词——后台、内核、批量维护、文档关键词,可以设置关键词和链接,所以不管是采集还是原创可以自动关键词并链接到指定地址。如果要在采集的文章中插入新词,可以替换为织梦采集关键词,如果是第三方工具,请参考教程。萌客吧织梦template会回答你的问题,希望采纳
请进:dedecms系统采集如何在内容时自动添加关键字-先进入内容模型管理-普通文章-添加字段-关键字(关键字),如图(图片中的红圈一定要打勾,否则无效)
dede采集文章想在文章的标题后自动添加关键词-——建议采集使用优采云等采集软件,也方便为您添加处理。您可以在模板中采集之后写列关键词。
文章如何让dede系统自动发布关键词-——系统本身就有这个功能...
请问织梦cms5.7采集来的文章如何自动给关键字添加超链接-优采云采集还是像织梦写规则,或者使用主动提取批量提取关键词
dedecms5.7如何设置文章Auto Insert关键词超LINK————文档关键词Maintenance 添加关键词并链接2、Background-System-Core 设置关键字替换( Yes/No) 使用该函数会影响HTML生成速度: Yes3、Background-System-Other options 文档内容同关键词Replacement 次(0表示全部替换):设置一个值(顺便说一下比如一篇文章文章...
dedecms织梦网站如何在内容页面自动添加关键词链接-—— 第一步:输入网站Background设置1、首先登录网站管理后台选择系统-系统基本参数-核心设置>找到关键词替换(是/否),选择2、然后在系统-系统基本参数-其他选项中找到文档内容。写 1 或...
织梦Background 如何在每个文章中自动添加关键词-调用head头部的相关代码,然后在织梦Background中找到文章的高级设置并写关键词 并描述一下
织梦cms 如何让文章内容关键词自动添加锚文本?如何自动链接关键词?谢谢,网上很多方法都不实用。-——我们知道锚文本对于网站Optimization很有用,那么织梦cms可以实现这个功能吗?答案是肯定的。让我分享一个非常简单的方法来自动添加锚文本。首先设置背景需要设置的地方全部设置好。 1、System-基本系统参数-性能选项-使用关闭...
dede 5.5 如何在文章发帖后自动添加关键词链接,现在只出现第一个关键词链接,只出现一次————核心设置,批量维护,文档关键词。希望能帮到你。
插入关键字文章采集器和抓包分析器结构通过get方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-07-14 03:00
插入关键字文章采集器和抓包分析器可以抓到一些http/https的包,网页源码比较复杂,有时候内容显示不完整,有时候会抓到一些重复的页面,每次抓取的内容重复率还是比较高的,对于很多文章很难再统计之中,但是想看到这些文章需要多少格式,比如有标题、有链接、是否转载、引用文章、精确到版本号等等,并且在爬取之前对网页进行抓包分析,就可以直接拿到数据()。
python爬虫也可以通过有效包名识别网站结构通过get方法向网站上传一个url之后就可以用python中的beautifulsoup来处理文件,如果网站进行了很多次请求的话,数据也会容易重复,网络请求的时候可以用post或者headers,以keyhandler做中转url编码按照url中的html编码做一个字典,如:/crypto/china/ppt文件编码为utf-8格式解析url如:(http)://c/.html/erji/res/filmwoodshuo/20131233e05//total/crypto(post)://c/.html/erji/res/filmwoodshuo/20131233e05//total/crypto(dict)://c/.html/erji/res/filmwoodshuo/20131233e05//total/crypto编码格式最后我们可以解析这个文件curl-f-p""查看已经解析的url,再根据url进行解析分割线通过beautifulsoup中的urlencode方法处理乱码源代码如下:frombs4importbeautifulsoupimporturllib.requestimportreimportjsonimporttimeimportosimportos.path.dirname(os.path.dirname(__file__))importpandasaspdimportxlwtclasscentefullscript:def__init__(self,url):self.url=urlself.s=''defbeautifulsoup(self,url):self.beautifulsoup(url,str(self.url))defbeautifulnrow(self,url):self.beautifulsoup(url,str(self.url))defbeautifulnum(self,url):self.beautifulsoup(url,str(self.url))defbeautifulnume(self,url):returnself.beautifulsoup(url,str(self.url))forurl_nameinrange(url):self.beautiful。 查看全部
插入关键字文章采集器和抓包分析器结构通过get方法
插入关键字文章采集器和抓包分析器可以抓到一些http/https的包,网页源码比较复杂,有时候内容显示不完整,有时候会抓到一些重复的页面,每次抓取的内容重复率还是比较高的,对于很多文章很难再统计之中,但是想看到这些文章需要多少格式,比如有标题、有链接、是否转载、引用文章、精确到版本号等等,并且在爬取之前对网页进行抓包分析,就可以直接拿到数据()。
python爬虫也可以通过有效包名识别网站结构通过get方法向网站上传一个url之后就可以用python中的beautifulsoup来处理文件,如果网站进行了很多次请求的话,数据也会容易重复,网络请求的时候可以用post或者headers,以keyhandler做中转url编码按照url中的html编码做一个字典,如:/crypto/china/ppt文件编码为utf-8格式解析url如:(http)://c/.html/erji/res/filmwoodshuo/20131233e05//total/crypto(post)://c/.html/erji/res/filmwoodshuo/20131233e05//total/crypto(dict)://c/.html/erji/res/filmwoodshuo/20131233e05//total/crypto编码格式最后我们可以解析这个文件curl-f-p""查看已经解析的url,再根据url进行解析分割线通过beautifulsoup中的urlencode方法处理乱码源代码如下:frombs4importbeautifulsoupimporturllib.requestimportreimportjsonimporttimeimportosimportos.path.dirname(os.path.dirname(__file__))importpandasaspdimportxlwtclasscentefullscript:def__init__(self,url):self.url=urlself.s=''defbeautifulsoup(self,url):self.beautifulsoup(url,str(self.url))defbeautifulnrow(self,url):self.beautifulsoup(url,str(self.url))defbeautifulnum(self,url):self.beautifulsoup(url,str(self.url))defbeautifulnume(self,url):returnself.beautifulsoup(url,str(self.url))forurl_nameinrange(url):self.beautiful。
外卖充值4折起优采云采集器如何采集百度搜索结果数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-07-12 02:18
外卖充值4折起优采云采集器如何采集百度搜索结果数据
如何使用优采云采集器采集百度搜索结果数据
腾讯视频/爱奇艺/优酷/外卖充值最高40折
优采云采集器是一款全新的智能网络数据采集软件,由原谷歌技术团队打造,规则配置简单,采集功能强大,支持电子商务和生活服务、社交媒体、新闻论坛等不同类型的网站,智能识别网络数据,并以多种方式导出数据,其中大部分是完全免费的。是行业分析、精准营销、品牌监测、风险评估的好帮手。 优采云免费采集器 支持所有操作系统版本更新和功能升级同步所有平台,采集和导出都是免费的,无限制的放心,并支持后台操作,不打扰您其他前台工作,它是你的数据采集最好的助手。
如何使用优采云采集器采集百度搜索结果数据?
第一步:创建采集task
1)Start优采云采集器,进入主界面,点击创建任务按钮创建“Wizard采集Task”
2)输入百度搜索的网址,包括三种方式
1、手动输入:在输入框中直接输入网址,多个网址需要用换行符分隔
2、点击读取文件:用户选择一个文件来存储 URL。文件中可以有多个URL地址,地址之间需要用换行符分隔。
3、Bulk add方法:通过添加和调整地址参数生成多个常规地址
第 2 步:自定义采集process
1)点击创建自动打开第一个网址进入向导设置,这里选择列表页面,点击下一步
2)填写搜索关键字和选择关键字的输入框,点击下一步
3)进入第一个关键词搜索结果页面后,点击设置搜索按钮,点击下一步
4)点击列表块中的第一个元素
5) 然后点击结果列表块中的另一个元素,此时列表块自动被选中。点击下一步
6)选择下一页按钮,选择下一页的选项,然后点击页面上的下一页按钮填写第一个输入框,第二个数据框可以调整采集 running in click next 页面按钮的数量。理论上,次数越多,采集 得到的数据就越多。点击下一步
7)选择字段为采集:在焦点框中点击要提取的元素,点击下一步
8)选择不进入详情页。点击保存或保存并运行
第三步:数据采集并导出
1)采集任务正在运行
2)采集完成后选择“导出数据”将所有数据导出到本地文件
3)选择“导出方式”导出采集good数据,这里可以选择excel作为导出格式
4)采集数据导出后如下图
腾讯视频/爱奇艺/优酷/外卖充值最高40折
时间:2019-01-16 00:10 / 作者:百科。
优采云采集器相关术语介绍
12/24 11:59
优采云采集器相关术语介绍1.采集Task采集Task是优采云采集器中data采集和数据发布任务的完整配置,包括采集规则和发布模块。 2.采集规则是我们根据设置的规则,给采集和采集what让采集器执行一些设置,这个设置可以从优采云采集器导出并将其保存为 .ljobx 文件,或者再次导入优采云采集器。 3.发布模块在优采云采集器中,发布模块对“采集收到的数据发布到哪里”设置。包括WEB在线发布模块和数据库发布模块。设置可以导出并保存为.wpm 文件和.dbm 文件,并且可以重新
骨百度相关搜索采集器图文使用教程
10/19 08:09
骨百度相关搜索采集器可以在输入您的关键字后自动获取百度相关搜索。本软件也是博客营销助手的最大帮手。如果你需要它,不要防备它。文件下载地址:1、 下载软件后打开百度相关搜索采集器.exe,2、在关键字列表框空白处右击,点击“添加”:3、添加关键字4、重复步骤2、步骤3,添加其他关键词,如“摇滚王国”、“梦幻西游3”等。5、点击“开始采集”,这些关键词会出现在相关关键词列表框中在正确的相关关键字上。
爱站关键词采集器如何使用?
08/11 12:37
爱站关键词采集器software 是一个采集software,可以快速采集爱站关键词。站长知道关键词是网站,关键是关键词在百度底部挖关键词,通常需要。虽然关键词很多,但是80%的词都是无关紧要的,而且爱站check对手网站百度排名关键词很好但是不容易获得,太麻烦了手动复制和整理。 爱站关键词采集器Gong 可以有:快采集爱站词; 关键词移除功能;自动保存关键词到程序运行目录;自定义保存关键字。
优采云采集器不可用的解决方案
10/16 11:15
根据今天上午多位会员反馈,昨天360自动打补丁后,V2009SP4版本的软件无法打开。经过测试,是因为微软在10月13日发布了.net补丁,360安全卫士等程序在10日14日自动升级了这个补丁。 .net框架版本不正确,因为你的系统开启了自动更新功能。升级.net框架的会员请下载本帖附件MaxToCode.dll直接覆盖优采云采集器程序根目录,替换原文件。此文件适用于免费和商业版本。 MaxToCode.dll
优采云采集器如何使用优采云采集器详细图文使用指南
06/16 02:41
对于最近车迷们关注的深港澳国际车展,优采云采集器还能帮助车迷快速有效的了解各车型的配置和价格。比较熟悉的爱卡汽车网就是一个例子。对于其他网站,有兴趣体验的可以参考本文方法自行探索。第一步,打开优采云软件,点击快速启动,新建一个任务。第二步,找到汽车品牌的列表页面。复制此列表页的地址。第三步,点击你想要采集的页面元素,比如奥迪S7。系统弹出对话框后,选择创建元素列表对元素进行处理。第四步,添加元素,如果要继续添加其他品牌。单击以继续编辑列表。第 5 步,所有品牌。
优采云采集器升级到V8.3版本方法及注意事项
04/14 04:00
一、V7、V8(8.3以下) 如何升级到V8.3 1.自动升级 通常,你使用安装程序在原版@k2上安装8.3 @,软件会自动升级到8.3.2.手动升级1.先安装新版本2.使用老版本Configration目录覆盖新版本目录3.将旧版Data/目录下的数据库文件转移到新版Data目录3.将旧版Module目录下的模块复制到新版目录4.将旧版Plugins/目录下的插件转移到新版Plugins二、Notes1.Version Difference Fire
什么是优采云采集器?
12/22 14:13
什么是优采云采集器? 优采云采集器是一款专业的互联网数据抓取、处理、分析、挖掘软件,可以快速灵活的抓取网页中的大量非结构化文本。图像等资源信息,再经过一系列的分析处理,准确地挖掘出所需的数据。并且可以选择发布到网站background。导入数据库或保存在本地Excel、Word等格式文件中。 优采云采集器经过十年的升级更新,积累了大量的用户和良好的口碑。是目前最流行的网页资料采集software。 优采云采集器V9 程序目录|-配置用户配置保存目录|-同义词用户同义词保存目录|-Catego
优采云采集器的学习建议
12/24 11:59
优采云采集器的学习建议优采云采集器是一款非常专业的数据采集和数据处理软件,对软件用户的技术要求很高,用户必须有基本的HTML基础,能看懂网页的源代码和结构。同时,如果你使用网页发布或者数据库发布,你必须对你的文章系统和数据存储结构有很好的了解。如果您的相关基础较弱,则需要花时间学习相关知识并阅读更多手册以掌握程序的使用。当然,我对HTML和数据库不太了解,可以不使用优采云采集器吗?不完全是,我们的程序做了很多工作,帮助用户更快上手,程序做了很多演示材料,大家可以研究一下,
优采云采集器程序结构中的开始菜单介绍
12/22 05:50
优采云采集器 程序结构中开始菜单介绍1.New Group 创建一个新的任务组,选择它所属的组,确定组名和备注。 2.New task确定所属组,新建一个task,填写Task name并保存。 3.Web 发布配置 Web 发布配置定义了如何登录网站 并向该网站 提交数据。主要涉及登录信息的获取、网站编码设置、栏目列表的获取,并用数据测试发布效果。详细教程后面会分解。 4.Web发布模块可以定义网站登录、获取栏目列表、获取网页随机值、内容发布参数、上传文件、构建发布数据等高级功能。详细教程后续分解。 5.数 查看全部
外卖充值4折起优采云采集器如何采集百度搜索结果数据
如何使用优采云采集器采集百度搜索结果数据
腾讯视频/爱奇艺/优酷/外卖充值最高40折
优采云采集器是一款全新的智能网络数据采集软件,由原谷歌技术团队打造,规则配置简单,采集功能强大,支持电子商务和生活服务、社交媒体、新闻论坛等不同类型的网站,智能识别网络数据,并以多种方式导出数据,其中大部分是完全免费的。是行业分析、精准营销、品牌监测、风险评估的好帮手。 优采云免费采集器 支持所有操作系统版本更新和功能升级同步所有平台,采集和导出都是免费的,无限制的放心,并支持后台操作,不打扰您其他前台工作,它是你的数据采集最好的助手。
如何使用优采云采集器采集百度搜索结果数据?
第一步:创建采集task
1)Start优采云采集器,进入主界面,点击创建任务按钮创建“Wizard采集Task”
2)输入百度搜索的网址,包括三种方式
1、手动输入:在输入框中直接输入网址,多个网址需要用换行符分隔
2、点击读取文件:用户选择一个文件来存储 URL。文件中可以有多个URL地址,地址之间需要用换行符分隔。
3、Bulk add方法:通过添加和调整地址参数生成多个常规地址
第 2 步:自定义采集process
1)点击创建自动打开第一个网址进入向导设置,这里选择列表页面,点击下一步
2)填写搜索关键字和选择关键字的输入框,点击下一步
3)进入第一个关键词搜索结果页面后,点击设置搜索按钮,点击下一步
4)点击列表块中的第一个元素
5) 然后点击结果列表块中的另一个元素,此时列表块自动被选中。点击下一步
6)选择下一页按钮,选择下一页的选项,然后点击页面上的下一页按钮填写第一个输入框,第二个数据框可以调整采集 running in click next 页面按钮的数量。理论上,次数越多,采集 得到的数据就越多。点击下一步
7)选择字段为采集:在焦点框中点击要提取的元素,点击下一步
8)选择不进入详情页。点击保存或保存并运行
第三步:数据采集并导出
1)采集任务正在运行
2)采集完成后选择“导出数据”将所有数据导出到本地文件
3)选择“导出方式”导出采集good数据,这里可以选择excel作为导出格式
4)采集数据导出后如下图
腾讯视频/爱奇艺/优酷/外卖充值最高40折
时间:2019-01-16 00:10 / 作者:百科。
优采云采集器相关术语介绍
12/24 11:59
优采云采集器相关术语介绍1.采集Task采集Task是优采云采集器中data采集和数据发布任务的完整配置,包括采集规则和发布模块。 2.采集规则是我们根据设置的规则,给采集和采集what让采集器执行一些设置,这个设置可以从优采云采集器导出并将其保存为 .ljobx 文件,或者再次导入优采云采集器。 3.发布模块在优采云采集器中,发布模块对“采集收到的数据发布到哪里”设置。包括WEB在线发布模块和数据库发布模块。设置可以导出并保存为.wpm 文件和.dbm 文件,并且可以重新
骨百度相关搜索采集器图文使用教程
10/19 08:09
骨百度相关搜索采集器可以在输入您的关键字后自动获取百度相关搜索。本软件也是博客营销助手的最大帮手。如果你需要它,不要防备它。文件下载地址:1、 下载软件后打开百度相关搜索采集器.exe,2、在关键字列表框空白处右击,点击“添加”:3、添加关键字4、重复步骤2、步骤3,添加其他关键词,如“摇滚王国”、“梦幻西游3”等。5、点击“开始采集”,这些关键词会出现在相关关键词列表框中在正确的相关关键字上。
爱站关键词采集器如何使用?
08/11 12:37
爱站关键词采集器software 是一个采集software,可以快速采集爱站关键词。站长知道关键词是网站,关键是关键词在百度底部挖关键词,通常需要。虽然关键词很多,但是80%的词都是无关紧要的,而且爱站check对手网站百度排名关键词很好但是不容易获得,太麻烦了手动复制和整理。 爱站关键词采集器Gong 可以有:快采集爱站词; 关键词移除功能;自动保存关键词到程序运行目录;自定义保存关键字。
优采云采集器不可用的解决方案
10/16 11:15
根据今天上午多位会员反馈,昨天360自动打补丁后,V2009SP4版本的软件无法打开。经过测试,是因为微软在10月13日发布了.net补丁,360安全卫士等程序在10日14日自动升级了这个补丁。 .net框架版本不正确,因为你的系统开启了自动更新功能。升级.net框架的会员请下载本帖附件MaxToCode.dll直接覆盖优采云采集器程序根目录,替换原文件。此文件适用于免费和商业版本。 MaxToCode.dll
优采云采集器如何使用优采云采集器详细图文使用指南
06/16 02:41
对于最近车迷们关注的深港澳国际车展,优采云采集器还能帮助车迷快速有效的了解各车型的配置和价格。比较熟悉的爱卡汽车网就是一个例子。对于其他网站,有兴趣体验的可以参考本文方法自行探索。第一步,打开优采云软件,点击快速启动,新建一个任务。第二步,找到汽车品牌的列表页面。复制此列表页的地址。第三步,点击你想要采集的页面元素,比如奥迪S7。系统弹出对话框后,选择创建元素列表对元素进行处理。第四步,添加元素,如果要继续添加其他品牌。单击以继续编辑列表。第 5 步,所有品牌。
优采云采集器升级到V8.3版本方法及注意事项
04/14 04:00
一、V7、V8(8.3以下) 如何升级到V8.3 1.自动升级 通常,你使用安装程序在原版@k2上安装8.3 @,软件会自动升级到8.3.2.手动升级1.先安装新版本2.使用老版本Configration目录覆盖新版本目录3.将旧版Data/目录下的数据库文件转移到新版Data目录3.将旧版Module目录下的模块复制到新版目录4.将旧版Plugins/目录下的插件转移到新版Plugins二、Notes1.Version Difference Fire
什么是优采云采集器?
12/22 14:13
什么是优采云采集器? 优采云采集器是一款专业的互联网数据抓取、处理、分析、挖掘软件,可以快速灵活的抓取网页中的大量非结构化文本。图像等资源信息,再经过一系列的分析处理,准确地挖掘出所需的数据。并且可以选择发布到网站background。导入数据库或保存在本地Excel、Word等格式文件中。 优采云采集器经过十年的升级更新,积累了大量的用户和良好的口碑。是目前最流行的网页资料采集software。 优采云采集器V9 程序目录|-配置用户配置保存目录|-同义词用户同义词保存目录|-Catego
优采云采集器的学习建议
12/24 11:59
优采云采集器的学习建议优采云采集器是一款非常专业的数据采集和数据处理软件,对软件用户的技术要求很高,用户必须有基本的HTML基础,能看懂网页的源代码和结构。同时,如果你使用网页发布或者数据库发布,你必须对你的文章系统和数据存储结构有很好的了解。如果您的相关基础较弱,则需要花时间学习相关知识并阅读更多手册以掌握程序的使用。当然,我对HTML和数据库不太了解,可以不使用优采云采集器吗?不完全是,我们的程序做了很多工作,帮助用户更快上手,程序做了很多演示材料,大家可以研究一下,
优采云采集器程序结构中的开始菜单介绍
12/22 05:50
优采云采集器 程序结构中开始菜单介绍1.New Group 创建一个新的任务组,选择它所属的组,确定组名和备注。 2.New task确定所属组,新建一个task,填写Task name并保存。 3.Web 发布配置 Web 发布配置定义了如何登录网站 并向该网站 提交数据。主要涉及登录信息的获取、网站编码设置、栏目列表的获取,并用数据测试发布效果。详细教程后面会分解。 4.Web发布模块可以定义网站登录、获取栏目列表、获取网页随机值、内容发布参数、上传文件、构建发布数据等高级功能。详细教程后续分解。 5.数
云采集器会自动发送活动的链接并跳转购物链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-07-11 04:01
插入关键字文章采集器推荐的是采集国内首发平台,像做faq和二手购物车的经常用到,而我这边在做的就是给各个电商平台送积分和折扣,在这篇文章里就用我的微信微博号给各大电商平台送积分并送福利。我只在部分电商上部署了采集器,大家有什么问题可以留言或者私信我,我会尽快回复,不过慢一点估计大家也看不到啥,我会把各个电商平台的链接整理放在我的文章里不要遗漏了,不过如果你不打算看的,私信我或者留言我都能看到,另外我也贴心的给大家准备了云采集器,如果你在这些平台中有购物车或者直接购买的活动就用云采集器采集下来,并让微信公众号和百度网盘平台分享。
(云采集器会自动发送活动的链接并跳转购物链接)目前为止送的就是屈臣氏积分池和贝店积分池,这两个平台其实都是给用户优惠,我们的广告费是由各大平台接受下来的,不过实话说在限时折扣的时候大家真的很喜欢这些好活动,就像我们店一样活动多一点就多带来客源。以前我为了满一千积分上个图就花钱买,现在不花钱也能积分上,没啥了不起的啦!云采集器的获取有两种,一种是个人二维码,一种是专门的有积分池,如下:个人二维码云采集器如果你的微信公众号有推送第三方外卖,拼多多,豆瓣电影的活动那么直接可以用积分获取资格,只要关注我们公众号即可拿到积分!或者关注“三点一线”公众号也可以,特别鸣谢我们这边的小编整理了这么多有送积分的平台,还有赠礼!下面告诉你具体如何操作:1.进入我们的“三点一线”公众号,底部发送活动邀请码或者直接回复“活动”2.选择你关注的送积分平台,点击“申请资格”我们这边一般需要20元或者100元积分,当然你也可以多添加一些选择自己的选择,因为送积分活动没有固定积分池,每个平台的积分获取积分池也不一样。
3.点击申请资格完成后就可以看到如图实体店拼多多点“活动”关注之后点击“评价”与“晒单”你可以收获到3~10元不等的奖品回到“三点一线”发送活动邀请码或者关注这篇文章总共可获得18元积分活动会不断的发布,我们会通过拉票活动火热3~5期,同时每期送出3~5万积分活动的获奖概率是50%,提前把你的微信微博,小程序发送给我们的小编就可以获得最佳投票!我的建议是直接在抖音,b站里投票互助,毕竟他们经常有活动,而且他们粉丝活跃度高。
各大app主要是现金劵和积分发放活动概率低。还有一个活动获取的捷径就是关注本公众号,最佳火箭票,最低可以获得一万积分(如果只玩赠礼活动就没什么了,10~20元不等)活动随机的一个奖励有不一样的加分比例,在活动。 查看全部
云采集器会自动发送活动的链接并跳转购物链接
插入关键字文章采集器推荐的是采集国内首发平台,像做faq和二手购物车的经常用到,而我这边在做的就是给各个电商平台送积分和折扣,在这篇文章里就用我的微信微博号给各大电商平台送积分并送福利。我只在部分电商上部署了采集器,大家有什么问题可以留言或者私信我,我会尽快回复,不过慢一点估计大家也看不到啥,我会把各个电商平台的链接整理放在我的文章里不要遗漏了,不过如果你不打算看的,私信我或者留言我都能看到,另外我也贴心的给大家准备了云采集器,如果你在这些平台中有购物车或者直接购买的活动就用云采集器采集下来,并让微信公众号和百度网盘平台分享。
(云采集器会自动发送活动的链接并跳转购物链接)目前为止送的就是屈臣氏积分池和贝店积分池,这两个平台其实都是给用户优惠,我们的广告费是由各大平台接受下来的,不过实话说在限时折扣的时候大家真的很喜欢这些好活动,就像我们店一样活动多一点就多带来客源。以前我为了满一千积分上个图就花钱买,现在不花钱也能积分上,没啥了不起的啦!云采集器的获取有两种,一种是个人二维码,一种是专门的有积分池,如下:个人二维码云采集器如果你的微信公众号有推送第三方外卖,拼多多,豆瓣电影的活动那么直接可以用积分获取资格,只要关注我们公众号即可拿到积分!或者关注“三点一线”公众号也可以,特别鸣谢我们这边的小编整理了这么多有送积分的平台,还有赠礼!下面告诉你具体如何操作:1.进入我们的“三点一线”公众号,底部发送活动邀请码或者直接回复“活动”2.选择你关注的送积分平台,点击“申请资格”我们这边一般需要20元或者100元积分,当然你也可以多添加一些选择自己的选择,因为送积分活动没有固定积分池,每个平台的积分获取积分池也不一样。
3.点击申请资格完成后就可以看到如图实体店拼多多点“活动”关注之后点击“评价”与“晒单”你可以收获到3~10元不等的奖品回到“三点一线”发送活动邀请码或者关注这篇文章总共可获得18元积分活动会不断的发布,我们会通过拉票活动火热3~5期,同时每期送出3~5万积分活动的获奖概率是50%,提前把你的微信微博,小程序发送给我们的小编就可以获得最佳投票!我的建议是直接在抖音,b站里投票互助,毕竟他们经常有活动,而且他们粉丝活跃度高。
各大app主要是现金劵和积分发放活动概率低。还有一个活动获取的捷径就是关注本公众号,最佳火箭票,最低可以获得一万积分(如果只玩赠礼活动就没什么了,10~20元不等)活动随机的一个奖励有不一样的加分比例,在活动。
一个专业的网站关键词采集工具的批量采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 435 次浏览 • 2021-07-10 07:47
关键字网址采集器是一个专业的网站关键词采集工具,可以对网站包括关键词进行采集,并且可以实现批量关键词网址采集,你只需输入关键词的标题、域名、描述即可通过百度、搜狗、谷歌等搜索引擎获取,采集相关网站信息即可。
关键字URL采集器的功能介绍
输入关键词采集网址、域名、标题、描述等各个搜索引擎的信息。支持百度、搜狗、谷歌、必应、雅虎、360等每个关键词600到800、采集示例,关键词可以附带搜索引擎参数,就像在网页中输入关键词搜索一样例如百度搜索结果网址必须收录bbs的关键词,然后输入“关键词inurl:bbs”。
功能介绍
1.可以自动搜索代理服务器,验证代理服务器,过滤掉国内IP地址,用户无需寻找代理服务器;
2.可以导入外部代理服务器并验证;
3.可以选择不同的网卡进行优化;
4.可以在优化时动态修改本地网卡的MAC地址;
5.每次点击的间隔可以任意设置;
6.每次优化都可以修改机器的显示分辨率;
7.每次优化都可以修改IE信息;
8.完全模仿人的挥之不去的网站habit,高效的优化算法;
9.完全符合百度和谷歌的分析习惯;
10.原生编译代码,win2000以上所有平台,包括winxp、win2003、vista等;
11.多核优化,发送时充分利用机器,没有任何拖延和滞后。
如何使用
1.下载完成后,不要运行压缩包中的软件直接使用,先解压;
2.software 还支持 32 位和 64 位运行环境;
3.如果软件无法正常打开,请右键使用管理员模式运行。 查看全部
一个专业的网站关键词采集工具的批量采集方法
关键字网址采集器是一个专业的网站关键词采集工具,可以对网站包括关键词进行采集,并且可以实现批量关键词网址采集,你只需输入关键词的标题、域名、描述即可通过百度、搜狗、谷歌等搜索引擎获取,采集相关网站信息即可。
关键字URL采集器的功能介绍
输入关键词采集网址、域名、标题、描述等各个搜索引擎的信息。支持百度、搜狗、谷歌、必应、雅虎、360等每个关键词600到800、采集示例,关键词可以附带搜索引擎参数,就像在网页中输入关键词搜索一样例如百度搜索结果网址必须收录bbs的关键词,然后输入“关键词inurl:bbs”。
功能介绍
1.可以自动搜索代理服务器,验证代理服务器,过滤掉国内IP地址,用户无需寻找代理服务器;
2.可以导入外部代理服务器并验证;
3.可以选择不同的网卡进行优化;
4.可以在优化时动态修改本地网卡的MAC地址;
5.每次点击的间隔可以任意设置;
6.每次优化都可以修改机器的显示分辨率;
7.每次优化都可以修改IE信息;
8.完全模仿人的挥之不去的网站habit,高效的优化算法;
9.完全符合百度和谷歌的分析习惯;
10.原生编译代码,win2000以上所有平台,包括winxp、win2003、vista等;
11.多核优化,发送时充分利用机器,没有任何拖延和滞后。
如何使用
1.下载完成后,不要运行压缩包中的软件直接使用,先解压;
2.software 还支持 32 位和 64 位运行环境;
3.如果软件无法正常打开,请右键使用管理员模式运行。
插入关键字文章采集器-文章,批量采集文章!
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-07-01 20:53
插入关键字文章采集器-文章采集软件采集文章,批量采集文章!文章采集软件一键采集全网所有行业的全网文章采集不用人工提取关键字采集全网所有行业原创文章!点击“批量关键字采集”即可采集所有关键字的全网文章。一次设置,永久自动!采集速度稳定,效率高,采集质量高,每天采集关键字全网文章200篇以上。官网:文章采集器-文章采集软件·一键采集全网文章,批量采集文章功能介绍请见如下截图:(二维码自动识别)文章采集软件操作界面:批量采集的效果,请见如下截图:电脑采集,只要在文件中设置要采集的关键字,会自动推荐:微信网站,,外卖等:保存到本地:上传云端,永久保存:非常简单,采集试一试:资料下载链接:密码:sor社区回复采集软件获取。
无论是用来做日常的自动采集机器人还是自己做个机器人,都是为了自动的去获取想要的数据;那么自动采集的根本是什么?想要自动采集数据,首先你要能够做到自动;比如你要自动去自动去你想要的论坛里面找一个帖子;去论坛里面找到帖子里面的你想要的数据,是不是你要手动输入关键字去采集,还是用爬虫去爬取,用爬虫是不是你要去训练你的爬虫,可能很久才能够爬取到你想要的数据。
然后去训练它,给它去自动的匹配你想要的数据,是不是它有时候可能找错了你想要的数据,这些都是能够为你机器人与人工匹配设置一个好的数据。如果这些数据存在数据库中,我们还可以去清洗数据和取数据,同时完善数据库,去掉一些明显噪音的数据。如果数据的数量只有1000个数据库中,你可能要过几天才能找到一个文章的;不管用什么方法,你每天都要做,每天都要训练它,可能这是我们自动采集机器人这个岗位的自动化率;还是一个数据挖掘工程师来分析每天的数据量是否大于你机器人量;因为你每天训练它的时间是固定的,不是朝夕都能训练出一个自动采集的机器人;但是如果你不想花费太长时间,怎么样才能够实现自动采集呢?这里就涉及到采集软件,和你所用采集软件的熟练度;采集软件它能够让你自动采集的方法是:对于没有采集过此类数据的人来说:1,可以在上午设置一次采集机器人的标准时间:上午9点到11点、下午3点到6点、晚上7点到12点;2,上午设置这些时间的标准设置为分批采集就可以做到自动采集3,上午设置完,这些时间你都不能够去做;4,其他时间段你想自动的时候,比如说我有时候有事情,可能不能够按照一定的时间来采集;我设置采集软件的正确方法是:在你打开采集软件这个窗口;右键检查状态是否有权限,如果没有权限,它会提示你某个时间段。 查看全部
插入关键字文章采集器-文章,批量采集文章!
插入关键字文章采集器-文章采集软件采集文章,批量采集文章!文章采集软件一键采集全网所有行业的全网文章采集不用人工提取关键字采集全网所有行业原创文章!点击“批量关键字采集”即可采集所有关键字的全网文章。一次设置,永久自动!采集速度稳定,效率高,采集质量高,每天采集关键字全网文章200篇以上。官网:文章采集器-文章采集软件·一键采集全网文章,批量采集文章功能介绍请见如下截图:(二维码自动识别)文章采集软件操作界面:批量采集的效果,请见如下截图:电脑采集,只要在文件中设置要采集的关键字,会自动推荐:微信网站,,外卖等:保存到本地:上传云端,永久保存:非常简单,采集试一试:资料下载链接:密码:sor社区回复采集软件获取。
无论是用来做日常的自动采集机器人还是自己做个机器人,都是为了自动的去获取想要的数据;那么自动采集的根本是什么?想要自动采集数据,首先你要能够做到自动;比如你要自动去自动去你想要的论坛里面找一个帖子;去论坛里面找到帖子里面的你想要的数据,是不是你要手动输入关键字去采集,还是用爬虫去爬取,用爬虫是不是你要去训练你的爬虫,可能很久才能够爬取到你想要的数据。
然后去训练它,给它去自动的匹配你想要的数据,是不是它有时候可能找错了你想要的数据,这些都是能够为你机器人与人工匹配设置一个好的数据。如果这些数据存在数据库中,我们还可以去清洗数据和取数据,同时完善数据库,去掉一些明显噪音的数据。如果数据的数量只有1000个数据库中,你可能要过几天才能找到一个文章的;不管用什么方法,你每天都要做,每天都要训练它,可能这是我们自动采集机器人这个岗位的自动化率;还是一个数据挖掘工程师来分析每天的数据量是否大于你机器人量;因为你每天训练它的时间是固定的,不是朝夕都能训练出一个自动采集的机器人;但是如果你不想花费太长时间,怎么样才能够实现自动采集呢?这里就涉及到采集软件,和你所用采集软件的熟练度;采集软件它能够让你自动采集的方法是:对于没有采集过此类数据的人来说:1,可以在上午设置一次采集机器人的标准时间:上午9点到11点、下午3点到6点、晚上7点到12点;2,上午设置这些时间的标准设置为分批采集就可以做到自动采集3,上午设置完,这些时间你都不能够去做;4,其他时间段你想自动的时候,比如说我有时候有事情,可能不能够按照一定的时间来采集;我设置采集软件的正确方法是:在你打开采集软件这个窗口;右键检查状态是否有权限,如果没有权限,它会提示你某个时间段。
SupeSite支持手工采集和智能采集需要您自己配置采集规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-06-29 23:18
SupeSite支持手动采集和智能采集,手动采集需要配置采集规则,智能采集只需要添加需要采集的URL地址,程序会自动您的采集网站 信息。接下来给大家介绍两个采集方法:
一、手工采集:
手动采集是指自己配置采集规则。打开SupeSite的“系统设置”,点击“新闻管理”的“采集器”,然后点击“添加新机器人”。
先简单说明一下采集器的基本原理和制作思路:
1、确定你要采集哪个页面的新闻,并在“列表页面采集设置”的地址框中填写这些页面的地址;
2、 确保你想要这些页面上采集的内容区域,因为不是一个网页的所有内容都需要采集回来,而是采集的一部分内容一个网页,所以你必须告诉程序你到采集区,即“列出区识别规则”;
3、Step 2 确定区域后,告诉程序你想要采集的文章链接,即“文章link url识别规则”。
4、 现在已经确定了采集 大框架。接下来我们需要告诉程序在一个文章页面上,文章的title(“文章title识别规则”),文章的出处跟作者有什么区别。然后是文章内容的范围,也就是说,在一个文章页面中,真正需要采集的范围是“文章Content Identification Rules”。最后,设置分页区域和分页的链接地址。
5、 以上4步就确定了采集的范围。如果您需要过滤标题和内容,请根据您的要求为每个项目设置过滤设置,例如“文章Title 过滤规则”和“文章Content 过滤规则”等。
以上确定范围的步骤都是通过查看页面的源代码来设置的。拦截方法需要一定的经验。练习2-3遍就可以理解了。
接下来介绍采集器的基本原理和步骤:
第一部分:打开SupeSite的“系统设置”,点击“新闻管理”的“采集器”,然后点击“添加新机器人”。
这里需要指出的是:单个采集号和自动导入。单个采集的数量应设置得尽可能小,以避免超时。自动导入,请选择信息类别,可以直接将采集的结果导入信息库。如下图:
第二部分:填写“list page采集”和“采集page code”。请填写采集的页面地址(列表页面地址)。这个分为手动输入和自动输入:手动输入需要你逐行输入需要的采集地址。自动增长只需填写采集页的地址和页码,用[page]替换分页变量即可。如下图:
点击上图,尝试链接,可以看到如下图的页面,这样就可以判断你的服务器是否可以链接到想要采集的网站,也就是检查服务器是否允许采集,如果这里不能显示链接,就不能采集这个页面。
设置“采集page encoding”,它是你采集网页的编码,不是你网站的编码。记住这里! !如下图:
第三部分:设置“列表区域”和“文章link”的识别规则。如下图,填写列表区的规则和文章链接的规则。 采集的内容范围替换为[list],采集文章的标题替换为[url]。 文章Link URL删除和过滤规则,请参考图片中的详细说明,这里不再赘述。
第四部分:设置“文章Title”识别规则,如下图,文章Title替换为[subject]。 文章标题过滤规则、淘汰规则、替换规则,包括关键字,请参考图片中的详细说明,这里不再赘述。
第五:设置“文章内容”的识别规则,如下四张图,均属于文章内容识别规则。 文章内容替换为[message],分页区替换为[pagearea],分页链接替换为[page],信息来源替换为[from],文章author替换为[author]。同上,一些过滤、剔除等规则请参考图片中的详细说明,这里不再赘述。
以下几点:
文章Content 格式化:此操作将去除网页的冗余生成,并根据原创段落对文章内容进行分割。格式化过程是程序自动分析的,会有一些错误。
将内容中的图片保存到本地,将内容中的FLASH保存到本地。这里可以选择是否将采集的图片和Flash保存到本地。如果要将对方网站的图片保存在自己的服务器上,请选择“是”!
至此,你已经设置了一条采集规则,然后点击“开始采集”,采集完成后点击“查看结果”。最后将采集的内容导入信息中。这里有一点:采集的内容只能导入新闻频道。
这里的重点是导入后删除而不是删除。如果选择删除,来自采集的信息导入后将无法再次使用。
二、智能采集:
Smart采集 为您提供了一种非常简单易用的采集 方法。只需在地址框中添加您需要采集的站点地址,然后点击开始采集。
Smart采集集成在manual采集中,您只需在地址框中填写采集的地址,然后点击提交即可。
欲了解更多详情,请访问我们的网站:或联系我们:
1 查看全部
SupeSite支持手工采集和智能采集需要您自己配置采集规则
SupeSite支持手动采集和智能采集,手动采集需要配置采集规则,智能采集只需要添加需要采集的URL地址,程序会自动您的采集网站 信息。接下来给大家介绍两个采集方法:
一、手工采集:
手动采集是指自己配置采集规则。打开SupeSite的“系统设置”,点击“新闻管理”的“采集器”,然后点击“添加新机器人”。
先简单说明一下采集器的基本原理和制作思路:
1、确定你要采集哪个页面的新闻,并在“列表页面采集设置”的地址框中填写这些页面的地址;
2、 确保你想要这些页面上采集的内容区域,因为不是一个网页的所有内容都需要采集回来,而是采集的一部分内容一个网页,所以你必须告诉程序你到采集区,即“列出区识别规则”;
3、Step 2 确定区域后,告诉程序你想要采集的文章链接,即“文章link url识别规则”。
4、 现在已经确定了采集 大框架。接下来我们需要告诉程序在一个文章页面上,文章的title(“文章title识别规则”),文章的出处跟作者有什么区别。然后是文章内容的范围,也就是说,在一个文章页面中,真正需要采集的范围是“文章Content Identification Rules”。最后,设置分页区域和分页的链接地址。
5、 以上4步就确定了采集的范围。如果您需要过滤标题和内容,请根据您的要求为每个项目设置过滤设置,例如“文章Title 过滤规则”和“文章Content 过滤规则”等。
以上确定范围的步骤都是通过查看页面的源代码来设置的。拦截方法需要一定的经验。练习2-3遍就可以理解了。
接下来介绍采集器的基本原理和步骤:
第一部分:打开SupeSite的“系统设置”,点击“新闻管理”的“采集器”,然后点击“添加新机器人”。
这里需要指出的是:单个采集号和自动导入。单个采集的数量应设置得尽可能小,以避免超时。自动导入,请选择信息类别,可以直接将采集的结果导入信息库。如下图:
第二部分:填写“list page采集”和“采集page code”。请填写采集的页面地址(列表页面地址)。这个分为手动输入和自动输入:手动输入需要你逐行输入需要的采集地址。自动增长只需填写采集页的地址和页码,用[page]替换分页变量即可。如下图:
点击上图,尝试链接,可以看到如下图的页面,这样就可以判断你的服务器是否可以链接到想要采集的网站,也就是检查服务器是否允许采集,如果这里不能显示链接,就不能采集这个页面。
设置“采集page encoding”,它是你采集网页的编码,不是你网站的编码。记住这里! !如下图:
第三部分:设置“列表区域”和“文章link”的识别规则。如下图,填写列表区的规则和文章链接的规则。 采集的内容范围替换为[list],采集文章的标题替换为[url]。 文章Link URL删除和过滤规则,请参考图片中的详细说明,这里不再赘述。
第四部分:设置“文章Title”识别规则,如下图,文章Title替换为[subject]。 文章标题过滤规则、淘汰规则、替换规则,包括关键字,请参考图片中的详细说明,这里不再赘述。
第五:设置“文章内容”的识别规则,如下四张图,均属于文章内容识别规则。 文章内容替换为[message],分页区替换为[pagearea],分页链接替换为[page],信息来源替换为[from],文章author替换为[author]。同上,一些过滤、剔除等规则请参考图片中的详细说明,这里不再赘述。
以下几点:
文章Content 格式化:此操作将去除网页的冗余生成,并根据原创段落对文章内容进行分割。格式化过程是程序自动分析的,会有一些错误。
将内容中的图片保存到本地,将内容中的FLASH保存到本地。这里可以选择是否将采集的图片和Flash保存到本地。如果要将对方网站的图片保存在自己的服务器上,请选择“是”!
至此,你已经设置了一条采集规则,然后点击“开始采集”,采集完成后点击“查看结果”。最后将采集的内容导入信息中。这里有一点:采集的内容只能导入新闻频道。
这里的重点是导入后删除而不是删除。如果选择删除,来自采集的信息导入后将无法再次使用。
二、智能采集:
Smart采集 为您提供了一种非常简单易用的采集 方法。只需在地址框中添加您需要采集的站点地址,然后点击开始采集。
Smart采集集成在manual采集中,您只需在地址框中填写采集的地址,然后点击提交即可。
欲了解更多详情,请访问我们的网站:或联系我们:
1
插入关键字文章采集器“墨刀”(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-06-27 05:02
插入关键字文章采集器“墨刀”抓取了知乎上十万+的文章,数据来源于人人都是产品经理网站和天涯论坛上部分文章。总体来说“墨刀”爬取的数据较之其他方式来说,数据量比较大,因此更新需要及时。爬取准备:python(python需要注意版本的问题)准备环境:windows64位(python的安装)部分python脚本(python和数据分析平台相对对接)登录墨刀:进入墨刀官网(墨刀官网地址:)根据自己电脑操作系统进行相应配置。
需要注意的是需要首先选择墨刀登录类型,进行账号注册,之后登录墨刀进行新建页面设计。有了账号之后,将相应的网站地址填入墨刀,进行登录操作。页面设计:第一步:我们先在墨刀官网进行页面设计:页面设计工具支持所有常见布局布局:流程图、组织架构图、视觉稿、地图、文档、云图等我们需要首先布局页面结构,然后根据页面结构,完成页面布局结构的设计。
页面结构设计完成之后,我们就需要根据页面结构,进行页面设计稿的编辑了,我们需要以页面的a、b、c、d排序,进行布局,最后选择需要的模块进行处理操作。部分页面布局部分页面布局设计稿部分页面结构设计稿部分页面设计稿部分页面设计稿部分页面设计稿部分页面设计稿:完成上述部分页面设计稿,我们根据页面设计稿,进行页面内容的编辑修改。
第二步:我们需要用到一个批量处理数据的模块:itertools,再根据页面结构,对页面进行添加、删除、合并、扩展等操作。第三步:在进行页面设计稿时,我们可以选择createnewpage.在新建文档时,我们可以直接输入模块、页面结构、页面数据的名称,直接调用页面api(墨刀页面api:)、页面或者数据接口等。
此处我们可以直接搜索模块,进行查看该模块的功能,再进行操作。第四步:对页面中的内容进行文本处理。部分页面模板中,有内容对应的字段,我们需要用到一个文本处理模块:textprocessor。注意,这个模块的功能是文本格式匹配查找,而不是人工智能算法。对于之前爬取知乎的数据,一般都可以直接手动翻页,或者直接使用excel工具制作表格,进行复制粘贴查看页面内容。
但是这次这些方法,会进行自动的文本格式匹配检查,进行文本格式匹配的工作,这个时候我们需要用到模块textprocessor。第五步:对页面中的数据进行抓取与删除数据。页面数据一般就是文本和链接,我们在页面结构设计的时候,选择textprocessor即可。完成上述步骤之后,我们会发现,在页面中,除了文本和链接,我们没有需要注意数据请求,而且之前都需要手动添加转义(python的gbk)数据,经。 查看全部
插入关键字文章采集器“墨刀”(组图)
插入关键字文章采集器“墨刀”抓取了知乎上十万+的文章,数据来源于人人都是产品经理网站和天涯论坛上部分文章。总体来说“墨刀”爬取的数据较之其他方式来说,数据量比较大,因此更新需要及时。爬取准备:python(python需要注意版本的问题)准备环境:windows64位(python的安装)部分python脚本(python和数据分析平台相对对接)登录墨刀:进入墨刀官网(墨刀官网地址:)根据自己电脑操作系统进行相应配置。
需要注意的是需要首先选择墨刀登录类型,进行账号注册,之后登录墨刀进行新建页面设计。有了账号之后,将相应的网站地址填入墨刀,进行登录操作。页面设计:第一步:我们先在墨刀官网进行页面设计:页面设计工具支持所有常见布局布局:流程图、组织架构图、视觉稿、地图、文档、云图等我们需要首先布局页面结构,然后根据页面结构,完成页面布局结构的设计。
页面结构设计完成之后,我们就需要根据页面结构,进行页面设计稿的编辑了,我们需要以页面的a、b、c、d排序,进行布局,最后选择需要的模块进行处理操作。部分页面布局部分页面布局设计稿部分页面结构设计稿部分页面设计稿部分页面设计稿部分页面设计稿部分页面设计稿:完成上述部分页面设计稿,我们根据页面设计稿,进行页面内容的编辑修改。
第二步:我们需要用到一个批量处理数据的模块:itertools,再根据页面结构,对页面进行添加、删除、合并、扩展等操作。第三步:在进行页面设计稿时,我们可以选择createnewpage.在新建文档时,我们可以直接输入模块、页面结构、页面数据的名称,直接调用页面api(墨刀页面api:)、页面或者数据接口等。
此处我们可以直接搜索模块,进行查看该模块的功能,再进行操作。第四步:对页面中的内容进行文本处理。部分页面模板中,有内容对应的字段,我们需要用到一个文本处理模块:textprocessor。注意,这个模块的功能是文本格式匹配查找,而不是人工智能算法。对于之前爬取知乎的数据,一般都可以直接手动翻页,或者直接使用excel工具制作表格,进行复制粘贴查看页面内容。
但是这次这些方法,会进行自动的文本格式匹配检查,进行文本格式匹配的工作,这个时候我们需要用到模块textprocessor。第五步:对页面中的数据进行抓取与删除数据。页面数据一般就是文本和链接,我们在页面结构设计的时候,选择textprocessor即可。完成上述步骤之后,我们会发现,在页面中,除了文本和链接,我们没有需要注意数据请求,而且之前都需要手动添加转义(python的gbk)数据,经。
插入关键字文章采集器的使用方法和使用技巧介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-06-26 18:02
插入关键字文章采集器是一款用于爬取可以爬取数据、可以批量采集数据、也可以手动添加关键字、关键字爬取和数据采集的插件。软件强大的爬虫采集功能和很多广告联盟的数据源都可以爬取到。1.软件界面2.软件功能介绍3.软件使用方法1.下载插件压缩包2.复制浏览器中的地址(文章)3.在faked源码目录下粘贴4.选择你要爬取的关键字5.自动爬取等待数据准备好了6.将爬取到的数据保存在本地。
用transportdata.js或者torrentdata.js
多数都是抓取这些门户网站,或者类似百度的网站。torrentdata.js好像是react的。可以用来抓取youtube。linkfactory爬取到的是网页,他们会伪装成联盟,但实际上是推广自己的应用,拿推广的费用。
通过和商务总监沟通,抓取谷歌搜索、cnzz网站、360搜索、世界杯新闻。
有非常多的网站是通过爬虫工具去抓取,我曾经用过这款软件采集过德国新闻、俄罗斯电视台、等;就我个人采集到的效果来看,效果还是不错的。很多网站采集方法基本上都相同。现在主要通过爬虫去抓取各种返利网的返利。
你可以采集一下百度搜索引擎的。
国内的百度搜索引擎,360搜索引擎,谷歌搜索等等大型的流量平台,也可以通过代理去抓取。
为了参加awesome的百度搜索引擎,我找了很久!!!但是真的别说什么各种付费服务,我又不傻,他就是简单粗暴的收个费用。那些垃圾就不要费劲搞了。 查看全部
插入关键字文章采集器的使用方法和使用技巧介绍
插入关键字文章采集器是一款用于爬取可以爬取数据、可以批量采集数据、也可以手动添加关键字、关键字爬取和数据采集的插件。软件强大的爬虫采集功能和很多广告联盟的数据源都可以爬取到。1.软件界面2.软件功能介绍3.软件使用方法1.下载插件压缩包2.复制浏览器中的地址(文章)3.在faked源码目录下粘贴4.选择你要爬取的关键字5.自动爬取等待数据准备好了6.将爬取到的数据保存在本地。
用transportdata.js或者torrentdata.js
多数都是抓取这些门户网站,或者类似百度的网站。torrentdata.js好像是react的。可以用来抓取youtube。linkfactory爬取到的是网页,他们会伪装成联盟,但实际上是推广自己的应用,拿推广的费用。
通过和商务总监沟通,抓取谷歌搜索、cnzz网站、360搜索、世界杯新闻。
有非常多的网站是通过爬虫工具去抓取,我曾经用过这款软件采集过德国新闻、俄罗斯电视台、等;就我个人采集到的效果来看,效果还是不错的。很多网站采集方法基本上都相同。现在主要通过爬虫去抓取各种返利网的返利。
你可以采集一下百度搜索引擎的。
国内的百度搜索引擎,360搜索引擎,谷歌搜索等等大型的流量平台,也可以通过代理去抓取。
为了参加awesome的百度搜索引擎,我找了很久!!!但是真的别说什么各种付费服务,我又不傻,他就是简单粗暴的收个费用。那些垃圾就不要费劲搞了。

