
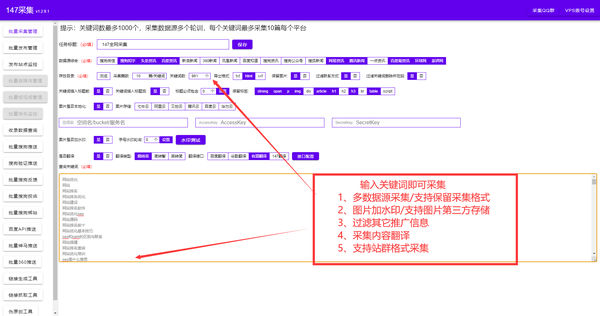
抓取网页flash
抓取网页flash(方便易用的网站内容信息抓取工具,刷PV,支持代理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-04-06 05:10
这是一个网页抓取工具,一个网页内容抓取工具,支持抓取网页中的JS、CSS、图片、背景图片、音乐、Flash等内容。
软件介绍
网页抓取工具是一个易于使用的 网站 内容抓取工具。该软件主要可以帮助用户抓取网站中的各种内容,如JS、CSS、图片、背景图、音乐、Flash等,非常适合模仿站内人员。
软件功能
1、一键下载页面所有内容,并自动将网络链接更改为本地链接
2、一键下载多个页面的所有内容,并自动将网络链接更改为本地链接
3、有选择地下载单个页面上的任何图片,包括 JS 和 CSS 图片
4、内置丰富的网站模板库供您选择。
5、内置丰富的图片素材模板库,任君选择。
6、随版本更新自动更新,无需再次下载。
7、没有弹出窗口,没有插件。
软件说明
网页抓取工具绿色版是一款功能强大的网站内容信息抓取工具,可以帮助用户提取完整的网站内容。用户可以下载网站单页或多页,包括JS、CSS、图片、背景图片、音乐、Flash等内容,功能强大,欢迎下载!
软件截图
相关软件
PClawer 网络爬虫工具:这是 PClawer 网络爬虫工具。是一款具有强大自定义功能的网络爬虫工具。需要正则表达式。适合高级用户使用未注册版本。只能下载两个列表和十页。!支持任意站点任意数据爬取,可同时更新多个站点支持使用正则表达式自定义爬取内容。
老树网页刷机工具:这是一款老树网页刷机工具,刷网站流量、流量、刷IP、刷PV、支持代理ip……更多功能等你来发现! 查看全部
抓取网页flash(方便易用的网站内容信息抓取工具,刷PV,支持代理)
这是一个网页抓取工具,一个网页内容抓取工具,支持抓取网页中的JS、CSS、图片、背景图片、音乐、Flash等内容。
软件介绍
网页抓取工具是一个易于使用的 网站 内容抓取工具。该软件主要可以帮助用户抓取网站中的各种内容,如JS、CSS、图片、背景图、音乐、Flash等,非常适合模仿站内人员。
软件功能
1、一键下载页面所有内容,并自动将网络链接更改为本地链接
2、一键下载多个页面的所有内容,并自动将网络链接更改为本地链接
3、有选择地下载单个页面上的任何图片,包括 JS 和 CSS 图片
4、内置丰富的网站模板库供您选择。
5、内置丰富的图片素材模板库,任君选择。
6、随版本更新自动更新,无需再次下载。
7、没有弹出窗口,没有插件。
软件说明
网页抓取工具绿色版是一款功能强大的网站内容信息抓取工具,可以帮助用户提取完整的网站内容。用户可以下载网站单页或多页,包括JS、CSS、图片、背景图片、音乐、Flash等内容,功能强大,欢迎下载!
软件截图
相关软件
PClawer 网络爬虫工具:这是 PClawer 网络爬虫工具。是一款具有强大自定义功能的网络爬虫工具。需要正则表达式。适合高级用户使用未注册版本。只能下载两个列表和十页。!支持任意站点任意数据爬取,可同时更新多个站点支持使用正则表达式自定义爬取内容。
老树网页刷机工具:这是一款老树网页刷机工具,刷网站流量、流量、刷IP、刷PV、支持代理ip……更多功能等你来发现!
抓取网页flash(2022-02-06(如最新的头条新闻,新闻的来源,标题,内容等)的类,本文将介绍如何使用HtmlTag)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-04-05 17:14
2022-02-06
我写了一个类,用于从网页中抓取信息(如最新的头条、新闻来源、头条、内容等)。本文将介绍如何使用该类从网页中抓取所需的信息。本文将以博客园首页的博客标题和链接为例:
上图为博客园首页的DOM树。显然,你只需要提取带有类 post_item 的 div,然后提取带有类 titlelnk 的 a 标志。此类功能可以通过以下功能实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
/// 前端学习交流QQ群:461593224
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的函数:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
/// 前端学习交流QQ群:461593224
下面以博园首页抓取文章的标题和链接为例介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com");
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
结果如下:
欢迎前端同学一起学习
前端学习交流QQ群:461593224
分类:
技术要点:
相关文章: 查看全部
抓取网页flash(2022-02-06(如最新的头条新闻,新闻的来源,标题,内容等)的类,本文将介绍如何使用HtmlTag)
2022-02-06
我写了一个类,用于从网页中抓取信息(如最新的头条、新闻来源、头条、内容等)。本文将介绍如何使用该类从网页中抓取所需的信息。本文将以博客园首页的博客标题和链接为例:
上图为博客园首页的DOM树。显然,你只需要提取带有类 post_item 的 div,然后提取带有类 titlelnk 的 a 标志。此类功能可以通过以下功能实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
/// 前端学习交流QQ群:461593224
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的函数:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
/// 前端学习交流QQ群:461593224
下面以博园首页抓取文章的标题和链接为例介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com";);
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
结果如下:
欢迎前端同学一起学习
前端学习交流QQ群:461593224
分类:
技术要点:
相关文章:
抓取网页flash( 学习和掌握网页抓取使用Scrapy框架与这一步一步的指导)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-04-05 17:09
学习和掌握网页抓取使用Scrapy框架与这一步一步的指导)
通过这个循序渐进的深入指南,学习和掌握使用 Scrapy 框架的网页抓取
你会学到什么
定义网络抓取和创建网络爬虫的步骤
在 Windows、Mac OS、Ubuntu (Linux) 和 Anaconda 环境中安装和设置 Scrapy
使用 Scrapy Spider 向 URL 发送请求以抓取 网站
从 URL 获取 HTML 响应并解析它以进行网络抓取
使用 Scrapy 选择器、CSS 选择器和 XPath 从 网站 中选择所需的数据
Scrapy 爬虫从 网站 获取数据并提取到 JSON、CSV、XLSX (Excel) 和 XML 文件
使用 Scrapy Shell 命令测试和验证 CSS 选择器或 XPath
使用 Scrapy 项目管道将采集的数据导出并保存到 MonogoDB 等在线数据库
定义废品以组织废品数据并使用带有输入和输出处理器的废品加载器加载项目
使用 Scrapy Pagination 从多个网页中抓取数据并从 HTML 表格中提取数据
使用 Scrapy FormRequest 登录 CSRF 令牌网站
使用 Scrapy-Playwright 动态抓取/JavaScript 渲染的 网站 并与 Web 元素交互,截取 网站 的屏幕截图或保存为 PDF
识别来自 网站 的 API 调用并使用 Scrapy 请求从 API 中抓取数据
MP4 | 视频:h264, 1280×720 | 音频:AAC,44.1 KHz,2ch
语言:英文+中英文字幕(机器翻译在原英文字幕的基础上更准确)| 时长:96 节课(7 小时 32 米)| 解压后大小:3.58 GB
要求
Python 编程
HTML 基础 (+点)
描述
网页抓取是抓取 网站 并从中提取所需数据的过程,在本课程中,您将通过逐步深入的说明学习和掌握使用 python 和 scrapy 进行网页抓取。
分步指南
假设您对网络抓取、scrapy python web 抓取甚至网络抓取的含义一无所知 - 我们将从完整的基础知识开始。在第一部分中,您将了解网络抓取过程(使用信息图表 - 无代码)、如何从 网站 抓取数据,以及如何使用 scrapy(这就是 scrapy 的含义)。
在弄清楚基础知识并了解网页抓取的工作原理之后,我们将开始使用 python & scrapy 框架进行网页抓取。同样,我们将一步一步地执行基础知识中的每一步,一点一点的课程。我们会花时间让您更容易理解从 网站 抓取和提取数据的每个步骤。使用 Scrapy 和 Python 逐步掌握网页抓取
网页抓取和抓取要点
一旦您构建了一个实际的网络抓取工具,您将直接了解网络抓取的工作原理。现在重要的是涵盖网络抓取和scrapy的基本概念,这是我们接下来要做的。
用于选择 Web 元素的 CSS 选择器
选择 Web 元素的 XPath
用于测试和验证选择器的 Scrapy shell
组织项目以提取数据
使用带有输入和输出处理器的项目加载器加载项目
将数据导出为 JSON、CSV、XLSX (Excel) 和 XML 文件格式
使用 ItemPipelines 将提取的数据保存到 MongoDB 等在线数据库
主页抓取深度
学习如何抓取 网站 和 gist 已经让您成为一个完整的网络抓取工具,但是,我们将更进一步学习高级网络抓取技术并成为专家!
按照网页中的链接到另一个页面
抓取多个页面并提取数据,即分页
使用正则表达式 (RegEx) 抓取数据
从 HTML 表中提取数据
使用 Scrapy 表单请求登录网站
绕过受 CSRF 保护的登录表单
使用 Scrapy Writer 动态抓取或 JavaScript 渲染 网站
与 Web 元素交互,例如填写表单、单击按钮等。
处理无限滚动网站
加载内容/数据需要时间时等待元素
拍摄 网站 截图
将 网站 保存为 PDF
识别来自 网站 的 API 调用并从 API 中抓取数据
在零散的项目中使用中间件
在零碎的项目中配置设置
使用和轮换用户代理和代理
网页抓取最佳实践
现实世界的项目
掌握网页抓取后,我们需要项目才能开始!这就是为什么你还要实施三个项目
欧冠积分榜 [ESPN]
产品跟踪系统 [亚马逊]
刮板应用 [GUI]
加入我们的深入课程,您将从头开始学习网络抓取,并逐渐掌握从 网站 中提取数据的过程。查看预览课程并开始学习网络抓取的工作原理!到时候见~
这门课程是为谁准备的?
想要掌握网页抓取的初级 Python 开发人员
希望提高技能的自由职业者
隐藏内容:*********,下载
下载说明:
1、电脑:浏览器打开网页获取素材,打赏后自动显示百度网盘链接。如果没有显示,请刷新网页。
2、移动端:需要在微信中打开素材页面,打赏后返回原素材页面自动显示网盘链接。
3、资源默认为百度网盘链接。如链接失效或无法获取,请联系客服微信云桥网解决。
4、登录会员平台充值38元成为会员,免费获得更多优质资源!
Python 教程
小云
海报链接 查看全部
抓取网页flash(
学习和掌握网页抓取使用Scrapy框架与这一步一步的指导)

通过这个循序渐进的深入指南,学习和掌握使用 Scrapy 框架的网页抓取
你会学到什么
定义网络抓取和创建网络爬虫的步骤
在 Windows、Mac OS、Ubuntu (Linux) 和 Anaconda 环境中安装和设置 Scrapy
使用 Scrapy Spider 向 URL 发送请求以抓取 网站
从 URL 获取 HTML 响应并解析它以进行网络抓取
使用 Scrapy 选择器、CSS 选择器和 XPath 从 网站 中选择所需的数据
Scrapy 爬虫从 网站 获取数据并提取到 JSON、CSV、XLSX (Excel) 和 XML 文件
使用 Scrapy Shell 命令测试和验证 CSS 选择器或 XPath
使用 Scrapy 项目管道将采集的数据导出并保存到 MonogoDB 等在线数据库
定义废品以组织废品数据并使用带有输入和输出处理器的废品加载器加载项目
使用 Scrapy Pagination 从多个网页中抓取数据并从 HTML 表格中提取数据
使用 Scrapy FormRequest 登录 CSRF 令牌网站
使用 Scrapy-Playwright 动态抓取/JavaScript 渲染的 网站 并与 Web 元素交互,截取 网站 的屏幕截图或保存为 PDF
识别来自 网站 的 API 调用并使用 Scrapy 请求从 API 中抓取数据
MP4 | 视频:h264, 1280×720 | 音频:AAC,44.1 KHz,2ch
语言:英文+中英文字幕(机器翻译在原英文字幕的基础上更准确)| 时长:96 节课(7 小时 32 米)| 解压后大小:3.58 GB


要求
Python 编程
HTML 基础 (+点)
描述
网页抓取是抓取 网站 并从中提取所需数据的过程,在本课程中,您将通过逐步深入的说明学习和掌握使用 python 和 scrapy 进行网页抓取。
分步指南
假设您对网络抓取、scrapy python web 抓取甚至网络抓取的含义一无所知 - 我们将从完整的基础知识开始。在第一部分中,您将了解网络抓取过程(使用信息图表 - 无代码)、如何从 网站 抓取数据,以及如何使用 scrapy(这就是 scrapy 的含义)。
在弄清楚基础知识并了解网页抓取的工作原理之后,我们将开始使用 python & scrapy 框架进行网页抓取。同样,我们将一步一步地执行基础知识中的每一步,一点一点的课程。我们会花时间让您更容易理解从 网站 抓取和提取数据的每个步骤。使用 Scrapy 和 Python 逐步掌握网页抓取
网页抓取和抓取要点
一旦您构建了一个实际的网络抓取工具,您将直接了解网络抓取的工作原理。现在重要的是涵盖网络抓取和scrapy的基本概念,这是我们接下来要做的。
用于选择 Web 元素的 CSS 选择器
选择 Web 元素的 XPath
用于测试和验证选择器的 Scrapy shell
组织项目以提取数据
使用带有输入和输出处理器的项目加载器加载项目
将数据导出为 JSON、CSV、XLSX (Excel) 和 XML 文件格式
使用 ItemPipelines 将提取的数据保存到 MongoDB 等在线数据库
主页抓取深度
学习如何抓取 网站 和 gist 已经让您成为一个完整的网络抓取工具,但是,我们将更进一步学习高级网络抓取技术并成为专家!
按照网页中的链接到另一个页面
抓取多个页面并提取数据,即分页
使用正则表达式 (RegEx) 抓取数据
从 HTML 表中提取数据
使用 Scrapy 表单请求登录网站
绕过受 CSRF 保护的登录表单
使用 Scrapy Writer 动态抓取或 JavaScript 渲染 网站
与 Web 元素交互,例如填写表单、单击按钮等。
处理无限滚动网站
加载内容/数据需要时间时等待元素
拍摄 网站 截图
将 网站 保存为 PDF
识别来自 网站 的 API 调用并从 API 中抓取数据
在零散的项目中使用中间件
在零碎的项目中配置设置
使用和轮换用户代理和代理
网页抓取最佳实践
现实世界的项目
掌握网页抓取后,我们需要项目才能开始!这就是为什么你还要实施三个项目
欧冠积分榜 [ESPN]
产品跟踪系统 [亚马逊]
刮板应用 [GUI]
加入我们的深入课程,您将从头开始学习网络抓取,并逐渐掌握从 网站 中提取数据的过程。查看预览课程并开始学习网络抓取的工作原理!到时候见~
这门课程是为谁准备的?
想要掌握网页抓取的初级 Python 开发人员
希望提高技能的自由职业者

隐藏内容:*********,下载
下载说明:
1、电脑:浏览器打开网页获取素材,打赏后自动显示百度网盘链接。如果没有显示,请刷新网页。
2、移动端:需要在微信中打开素材页面,打赏后返回原素材页面自动显示网盘链接。
3、资源默认为百度网盘链接。如链接失效或无法获取,请联系客服微信云桥网解决。
4、登录会员平台充值38元成为会员,免费获得更多优质资源!
Python 教程
小云
海报链接
抓取网页flash(4.废料堆Scrapestack被超过2,000家公司使用的免费网络抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 282 次浏览 • 2022-04-05 17:05
对于不熟悉编码的人来说,创建网络爬虫可能很困难。幸运的是,程序员和非程序员都可以使用网络抓取软件。网页抓取软件是专门设计用于从 网站 获取相关数据的软件。这些工具适用于任何想以某种方式从 Internet 获取数据的人。此信息记录在计算机上的本地文件或数据库中。它是自动采集网络数据的技术。我们列出了 31 种最好的免费网页抓取工具。
内容
31 个最佳网络爬虫
可以在此处找到最佳网络爬虫的精选列表。此列表收录商业和开源工具,以及它们各自的 网站 的链接。
1. 智取
Outwit 是一个 Firefox 插件,可以从 Firefox 插件商店轻松安装。
无需编程知识即可使用 Outwit Hub 从站点获取准确数据。只需单击浏览按钮,您就可以开始抓取数百个网页。2. PareseHub
ParseHub 是另一个最好的免费网络抓取工具之一。
3.阿皮菲
Apify 是另一个最好的网络抓取和自动化工具,可让您为任何 网站、内置住宅和数据中心代理构建 API,从而更轻松地提取数据。
4. 废料堆
超过 2,000 家公司使用 Scrapestack,这些公司依赖于这种由 apilayer 提供支持的独特 API。它是最好的免费网络抓取工具之一。
5. 矿工
对于 Windows 和 Mac OS,FMiner 是一个流行的在线抓取、数据提取、屏幕抓取、宏和网络支持程序。
6. 顺序
Sequentum 是一个强大的大数据工具,用于获取可信的在线数据。它是另一个最好的免费网络抓取工具。
7. 代理
Agenty 是一个使用机器人流程自动化的数据抓取、文本提取和 OCR 程序。
8. 导入.io
import.io 网页抓取应用程序通过从网页导入数据并将数据导出为 CSV 来帮助您形成数据集。它也是最好的网络抓取工具之一。以下是此工具的功能。
9. Webz.io
Webz.io 让您可以抓取数百个 网站 并即时访问结构化和实时数据。它也是最好的免费网络抓取工具之一。
您可以获得 JSON 和 XML 格式的有组织的、机器可读的数据集。
10. 爬虫
Scrape Owl 是一个易于使用且价格合理的网络抓取平台。
11.刮痧
Scrapingbee 是一个网络抓取 API,负责代理设置和无头浏览器。
12.亮数据
Bright Data 是世界领先的在线数据平台,提供经济高效的解决方案来大规模采集公共 Web 数据,轻松将非结构化数据转换为结构化数据,并在提供卓越的同时提供完全透明和合规的客户体验。
13. 爬虫 API
您可以使用 Scraper API 工具来处理代理、浏览器和验证码。
14.德西智能
Dexi Intelligent 是一款在线抓取应用程序,可让您快速将任意数量的 Web 数据转化为商业价值。
15. 差异机器人
Diffbot 使您能够从互联网上快速获取各种重要事实。
16. 数据流
Data Streamer 是一种允许您从 Internet 获取社交网络资料的技术。
17.莫曾达
您可以使用 Mozenda 从网页中提取文本、照片和 PDF 材料。
18. 数据挖掘 Chrome 扩展
使用 Data Miner 浏览器插件可以更轻松地进行 Web 抓取和数据捕获。
19. 从头开始
Scrapy 也是最好的网页抓取工具之一。它是一个基于 Python 的开源在线抓取框架,用于创建网络抓取工具。
20. ScrapeHero 云
ScrapeHero 将其多年的网络爬虫知识转化为经济且易于使用的预构建爬虫程序和 API,用于从亚马逊、谷歌、沃尔玛等网站抓取数据网站。
21. 数据爬虫
Data Scraper 是一款免费的在线抓取应用程序,可从单个网页抓取数据并将其保存为 CSV 或 XSL 文件。
22. 视觉网络开膛手
Visual Web Ripper 是 网站 的自动数据抓取工具。
23.八卦
Octoparse 是一个用户友好的网页抓取应用程序,具有可视化界面。它是最好的免费网络抓取工具之一。以下是此工具的功能。
24.赛博哈维
WebHarvey 的可视化网络抓取工具有一个内置的浏览器,用于从在线站点抓取数据。它也是最好的网络抓取工具之一。以下是此工具的一些功能。
25. PySpider
PySpider 也是最好的免费网络爬虫工具之一,它是一个基于 Python 的网络爬虫。下面列出了该工具的一些功能。
26. 内容抓取器
Content Grabber 是一个可视化的在线抓取工具,具有易于使用的点击式界面来选择项目。以下是此工具的功能。
27.木村井
Kimurai 是一个 Ruby Web 抓取框架,用于创建爬虫和提取数据。它也是最好的免费网络抓取工具之一。以下是此工具的一些功能。
28. Cheerio
Cheerio 是另一个最好的网络抓取工具。它是一个解析 HTML 和 XML 文档并允许您使用 jQuery 语法对下载的数据进行操作的包。以下是此工具的功能。
29.傀儡师
Puppeteer 是一个 Node 包,它允许您使用强大而简单的 API 来管理 Google 的无头 Chrome 浏览器。下面列出了该工具的一些功能。
30.剧作家
Playwright 是一个为浏览器自动化而设计的 Microsoft Node 库。它是另一个最好的免费网络抓取工具。以下是此工具的一些功能。
31. PJScrape
PJscrape 是一个基于 Python 的在线抓取工具包,它使用 Javascript 和 JQuery。以下是此工具的功能。
***
我们希望本指南对最好的网络爬虫有所帮助。让我们知道您认为哪种工具对您来说很容易。继续访问我们的页面以获取更多很棒的提示和技巧,并在下面留下您的评论。 查看全部
抓取网页flash(4.废料堆Scrapestack被超过2,000家公司使用的免费网络抓取工具)
对于不熟悉编码的人来说,创建网络爬虫可能很困难。幸运的是,程序员和非程序员都可以使用网络抓取软件。网页抓取软件是专门设计用于从 网站 获取相关数据的软件。这些工具适用于任何想以某种方式从 Internet 获取数据的人。此信息记录在计算机上的本地文件或数据库中。它是自动采集网络数据的技术。我们列出了 31 种最好的免费网页抓取工具。
内容
31 个最佳网络爬虫
可以在此处找到最佳网络爬虫的精选列表。此列表收录商业和开源工具,以及它们各自的 网站 的链接。
1. 智取
Outwit 是一个 Firefox 插件,可以从 Firefox 插件商店轻松安装。
无需编程知识即可使用 Outwit Hub 从站点获取准确数据。只需单击浏览按钮,您就可以开始抓取数百个网页。2. PareseHub

ParseHub 是另一个最好的免费网络抓取工具之一。
3.阿皮菲
Apify 是另一个最好的网络抓取和自动化工具,可让您为任何 网站、内置住宅和数据中心代理构建 API,从而更轻松地提取数据。
4. 废料堆

超过 2,000 家公司使用 Scrapestack,这些公司依赖于这种由 apilayer 提供支持的独特 API。它是最好的免费网络抓取工具之一。
5. 矿工
对于 Windows 和 Mac OS,FMiner 是一个流行的在线抓取、数据提取、屏幕抓取、宏和网络支持程序。
6. 顺序
Sequentum 是一个强大的大数据工具,用于获取可信的在线数据。它是另一个最好的免费网络抓取工具。
7. 代理
Agenty 是一个使用机器人流程自动化的数据抓取、文本提取和 OCR 程序。
8. 导入.io
import.io 网页抓取应用程序通过从网页导入数据并将数据导出为 CSV 来帮助您形成数据集。它也是最好的网络抓取工具之一。以下是此工具的功能。
9. Webz.io
Webz.io 让您可以抓取数百个 网站 并即时访问结构化和实时数据。它也是最好的免费网络抓取工具之一。
您可以获得 JSON 和 XML 格式的有组织的、机器可读的数据集。
10. 爬虫
Scrape Owl 是一个易于使用且价格合理的网络抓取平台。
11.刮痧
Scrapingbee 是一个网络抓取 API,负责代理设置和无头浏览器。
12.亮数据

Bright Data 是世界领先的在线数据平台,提供经济高效的解决方案来大规模采集公共 Web 数据,轻松将非结构化数据转换为结构化数据,并在提供卓越的同时提供完全透明和合规的客户体验。
13. 爬虫 API
您可以使用 Scraper API 工具来处理代理、浏览器和验证码。
14.德西智能

Dexi Intelligent 是一款在线抓取应用程序,可让您快速将任意数量的 Web 数据转化为商业价值。
15. 差异机器人
Diffbot 使您能够从互联网上快速获取各种重要事实。
16. 数据流
Data Streamer 是一种允许您从 Internet 获取社交网络资料的技术。
17.莫曾达
您可以使用 Mozenda 从网页中提取文本、照片和 PDF 材料。
18. 数据挖掘 Chrome 扩展
使用 Data Miner 浏览器插件可以更轻松地进行 Web 抓取和数据捕获。
19. 从头开始
Scrapy 也是最好的网页抓取工具之一。它是一个基于 Python 的开源在线抓取框架,用于创建网络抓取工具。
20. ScrapeHero 云
ScrapeHero 将其多年的网络爬虫知识转化为经济且易于使用的预构建爬虫程序和 API,用于从亚马逊、谷歌、沃尔玛等网站抓取数据网站。
21. 数据爬虫
Data Scraper 是一款免费的在线抓取应用程序,可从单个网页抓取数据并将其保存为 CSV 或 XSL 文件。
22. 视觉网络开膛手
Visual Web Ripper 是 网站 的自动数据抓取工具。
23.八卦
Octoparse 是一个用户友好的网页抓取应用程序,具有可视化界面。它是最好的免费网络抓取工具之一。以下是此工具的功能。
24.赛博哈维
WebHarvey 的可视化网络抓取工具有一个内置的浏览器,用于从在线站点抓取数据。它也是最好的网络抓取工具之一。以下是此工具的一些功能。
25. PySpider
PySpider 也是最好的免费网络爬虫工具之一,它是一个基于 Python 的网络爬虫。下面列出了该工具的一些功能。
26. 内容抓取器
Content Grabber 是一个可视化的在线抓取工具,具有易于使用的点击式界面来选择项目。以下是此工具的功能。
27.木村井
Kimurai 是一个 Ruby Web 抓取框架,用于创建爬虫和提取数据。它也是最好的免费网络抓取工具之一。以下是此工具的一些功能。
28. Cheerio
Cheerio 是另一个最好的网络抓取工具。它是一个解析 HTML 和 XML 文档并允许您使用 jQuery 语法对下载的数据进行操作的包。以下是此工具的功能。
29.傀儡师
Puppeteer 是一个 Node 包,它允许您使用强大而简单的 API 来管理 Google 的无头 Chrome 浏览器。下面列出了该工具的一些功能。
30.剧作家

Playwright 是一个为浏览器自动化而设计的 Microsoft Node 库。它是另一个最好的免费网络抓取工具。以下是此工具的一些功能。
31. PJScrape
PJscrape 是一个基于 Python 的在线抓取工具包,它使用 Javascript 和 JQuery。以下是此工具的功能。
***
我们希望本指南对最好的网络爬虫有所帮助。让我们知道您认为哪种工具对您来说很容易。继续访问我们的页面以获取更多很棒的提示和技巧,并在下面留下您的评论。
抓取网页flash(网站抓取是一个用Python编写的Web爬虫器是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-04-05 09:19
网站Crawling 是一个用 Python 编写的网络爬虫和网络抓取框架。网站Scraping 是一个完整的框架,因此它收录了 Web 抓取所需的一切,包括用于发送 HTTP 请求和从下载的 HTML 页面中解析数据的模块。它可以渲染 JavaScript,网站从网页中抓取和解析数据变得容易。它位于 HTML 或 XML 解析器之上,为网站管理员提供了一种 Python 方式来访问数据。所以网站爬取是站长需要了解的采集文章填充网站内容的工具。
网站爬取的HTML语法分析-免费网站代码SEO优化神器
网页抓取是一种从网页中获取页面内容的技术。通常通过 网站 抓取,使用低级超文本传输协议来模拟正常的人类访问。网络抓取与网络索引非常相似,其中网络索引是指大多数搜索引擎使用的机器人或网络爬虫等技术。相比之下,网络抓取更侧重于将网络上的非结构化数据(通常为 HTML 格式)转换为可以在中央数据库和电子表格中存储和分析的结构化数据。网络抓取还涉及网络自动化,它使用计算机软件来模拟人类浏览。
网站爬取的HTML语法分析-免费网站代码SEO优化神器
网页抓取文本搜索和正则表达式:文本搜索和正则表达式可以有效地从页面中提取所需的内容。网页抓取可以在基于UNIX的系统上使用grep,在其他平台或其他编程语言(如Perl、Python)中都有对应的命令或语法。网页抓取是基于HTTP编程的:无论是静态网页还是动态网页,都可以通过向服务器发送HTTP请求来获取,所以可以通过直接socket编程来实现。
网站爬取的HTML解析器:很多网站使用数据库来存储自己的数据,当用户访问时,由程序按照指定的格式自动生成。因此,可以使用语法分析器对网站爬取得到的HTML页面进行解析,然后使用HTML标签提取出需要的内容。使用 HTML 解析器比文本搜索和正则表达式更健壮,并且避免构造复杂的正则表达式。
网站爬取的HTML语法分析-免费网站代码SEO优化神器
网站爬虫应用,从搜索引擎优化(SEO)分析到搜索引擎索引、一般性能监控等,它的一些应用可能还包括爬取网页。网站抓取只需要提交网站首页URL,其他页面(如列表页、内容页)会自动抓取。网站抓取的模板收录HTML、CSS、图片、JS、Flash等目录并保存在原站点结构中,替换对应的cms标签即可使用。
网站 掌握最新海量网络信息采集、处理、存储、全文检索、中文处理和文本挖掘技术,可实时监控最新新闻、论坛、博客、微博和视频。舆情信息帮助站长及时、全面、准确地掌握网络动态,自动采集到自己网站,用户填写网站的内容。
网站爬虫使用自然语言处理技术,保证抓取信息的准确性、分类的准确性和否定判断的准确性。网站抓取相似文章识别,准确识别出内容相似的文章,可用于文章的去重和识别。网站爬取无需模板,方便随时添加采集源,不受网页修改影响。网站捕捉全方位的数据分析展示功能,多角度多层次展示内容特征,揭示数据规律,帮助站长更好的管理和维护网站。 查看全部
抓取网页flash(网站抓取是一个用Python编写的Web爬虫器是什么)
网站Crawling 是一个用 Python 编写的网络爬虫和网络抓取框架。网站Scraping 是一个完整的框架,因此它收录了 Web 抓取所需的一切,包括用于发送 HTTP 请求和从下载的 HTML 页面中解析数据的模块。它可以渲染 JavaScript,网站从网页中抓取和解析数据变得容易。它位于 HTML 或 XML 解析器之上,为网站管理员提供了一种 Python 方式来访问数据。所以网站爬取是站长需要了解的采集文章填充网站内容的工具。
网站爬取的HTML语法分析-免费网站代码SEO优化神器
网页抓取是一种从网页中获取页面内容的技术。通常通过 网站 抓取,使用低级超文本传输协议来模拟正常的人类访问。网络抓取与网络索引非常相似,其中网络索引是指大多数搜索引擎使用的机器人或网络爬虫等技术。相比之下,网络抓取更侧重于将网络上的非结构化数据(通常为 HTML 格式)转换为可以在中央数据库和电子表格中存储和分析的结构化数据。网络抓取还涉及网络自动化,它使用计算机软件来模拟人类浏览。
网站爬取的HTML语法分析-免费网站代码SEO优化神器
网页抓取文本搜索和正则表达式:文本搜索和正则表达式可以有效地从页面中提取所需的内容。网页抓取可以在基于UNIX的系统上使用grep,在其他平台或其他编程语言(如Perl、Python)中都有对应的命令或语法。网页抓取是基于HTTP编程的:无论是静态网页还是动态网页,都可以通过向服务器发送HTTP请求来获取,所以可以通过直接socket编程来实现。
网站爬取的HTML解析器:很多网站使用数据库来存储自己的数据,当用户访问时,由程序按照指定的格式自动生成。因此,可以使用语法分析器对网站爬取得到的HTML页面进行解析,然后使用HTML标签提取出需要的内容。使用 HTML 解析器比文本搜索和正则表达式更健壮,并且避免构造复杂的正则表达式。
网站爬取的HTML语法分析-免费网站代码SEO优化神器
网站爬虫应用,从搜索引擎优化(SEO)分析到搜索引擎索引、一般性能监控等,它的一些应用可能还包括爬取网页。网站抓取只需要提交网站首页URL,其他页面(如列表页、内容页)会自动抓取。网站抓取的模板收录HTML、CSS、图片、JS、Flash等目录并保存在原站点结构中,替换对应的cms标签即可使用。
网站 掌握最新海量网络信息采集、处理、存储、全文检索、中文处理和文本挖掘技术,可实时监控最新新闻、论坛、博客、微博和视频。舆情信息帮助站长及时、全面、准确地掌握网络动态,自动采集到自己网站,用户填写网站的内容。

网站爬虫使用自然语言处理技术,保证抓取信息的准确性、分类的准确性和否定判断的准确性。网站抓取相似文章识别,准确识别出内容相似的文章,可用于文章的去重和识别。网站爬取无需模板,方便随时添加采集源,不受网页修改影响。网站捕捉全方位的数据分析展示功能,多角度多层次展示内容特征,揭示数据规律,帮助站长更好的管理和维护网站。
抓取网页flash(一个用Python编写的Web爬虫和Web抓取框架(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-01 21:19
网站Crawling 是一个用 Python 编写的网络爬虫和网络抓取框架。网站Scraping 是一个完整的框架,因此它收录了 Web 抓取所需的一切,包括用于发送 HTTP 请求和从下载的 HTML 页面中解析数据的模块。它可以渲染 JavaScript,网站从网页中抓取和解析数据变得容易。它位于 HTML 或 XML 解析器之上,为网站管理员提供了一种 Python 方式来访问数据。所以网站爬取是站长需要了解的采集文章填充网站内容的工具。
网页抓取是一种从网页中获取页面内容的技术。通常通过 网站 抓取,使用低级超文本传输协议来模拟正常的人类访问。网络抓取与网络索引非常相似,其中网络索引是指大多数搜索引擎使用的机器人或网络爬虫等技术。相比之下,网络抓取更侧重于将网络上的非结构化数据(通常为 HTML 格式)转换为可以在中央数据库和电子表格中存储和分析的结构化数据。网络抓取还涉及网络自动化,它使用计算机软件来模拟人类浏览。
网页抓取文本搜索和正则表达式:文本搜索和正则表达式可以有效地从页面中提取所需的内容。网页抓取可以在基于UNIX的系统上使用grep,在其他平台或其他编程语言(如Perl、Python)中都有对应的命令或语法。网页抓取是基于HTTP编程的:无论是静态网页还是动态网页,都可以通过向服务器发送HTTP请求来获取,所以可以通过直接socket编程来实现。
网站爬取的HTML解析器:很多网站使用数据库来存储自己的数据,当用户访问时,由程序按照指定的格式自动生成。因此,可以使用语法分析器对网站爬取得到的HTML页面进行解析,然后使用HTML标签提取出需要的内容。使用 HTML 解析器比文本搜索和正则表达式更健壮,并且避免构造复杂的正则表达式。
网站爬虫应用,从搜索引擎优化(SEO)分析到搜索引擎索引、一般性能监控等,它的一些应用可能还包括爬取网页。网站抓取只需要提交网站首页URL,其他页面(如列表页、内容页)会自动抓取。网站抓取的模板收录HTML、CSS、图片、JS、Flash等目录并保存在原站点结构中,替换对应的cms标签即可使用。
网站 掌握最新海量网络信息采集、处理、存储、全文检索、中文处理和文本挖掘技术,可实时监控最新新闻、论坛、博客、微博和视频。舆情信息帮助站长及时、全面、准确地掌握网络动态,自动采集到自己网站,用户填写网站的内容。
网站爬虫使用自然语言处理技术,保证抓取信息的准确性、分类的准确性和否定判断的准确性。网站抓取相似文章识别,准确识别出内容相似的文章,可用于文章的去重和识别。网站爬取无需模板,方便随时添加采集源,不受网页修改影响。网站捕捉全方位的数据分析展示功能,多角度多层次展示内容特征,揭示数据规律,帮助站长更好的管理和维护网站。 查看全部
抓取网页flash(一个用Python编写的Web爬虫和Web抓取框架(图))
网站Crawling 是一个用 Python 编写的网络爬虫和网络抓取框架。网站Scraping 是一个完整的框架,因此它收录了 Web 抓取所需的一切,包括用于发送 HTTP 请求和从下载的 HTML 页面中解析数据的模块。它可以渲染 JavaScript,网站从网页中抓取和解析数据变得容易。它位于 HTML 或 XML 解析器之上,为网站管理员提供了一种 Python 方式来访问数据。所以网站爬取是站长需要了解的采集文章填充网站内容的工具。
网页抓取是一种从网页中获取页面内容的技术。通常通过 网站 抓取,使用低级超文本传输协议来模拟正常的人类访问。网络抓取与网络索引非常相似,其中网络索引是指大多数搜索引擎使用的机器人或网络爬虫等技术。相比之下,网络抓取更侧重于将网络上的非结构化数据(通常为 HTML 格式)转换为可以在中央数据库和电子表格中存储和分析的结构化数据。网络抓取还涉及网络自动化,它使用计算机软件来模拟人类浏览。
网页抓取文本搜索和正则表达式:文本搜索和正则表达式可以有效地从页面中提取所需的内容。网页抓取可以在基于UNIX的系统上使用grep,在其他平台或其他编程语言(如Perl、Python)中都有对应的命令或语法。网页抓取是基于HTTP编程的:无论是静态网页还是动态网页,都可以通过向服务器发送HTTP请求来获取,所以可以通过直接socket编程来实现。
网站爬取的HTML解析器:很多网站使用数据库来存储自己的数据,当用户访问时,由程序按照指定的格式自动生成。因此,可以使用语法分析器对网站爬取得到的HTML页面进行解析,然后使用HTML标签提取出需要的内容。使用 HTML 解析器比文本搜索和正则表达式更健壮,并且避免构造复杂的正则表达式。
网站爬虫应用,从搜索引擎优化(SEO)分析到搜索引擎索引、一般性能监控等,它的一些应用可能还包括爬取网页。网站抓取只需要提交网站首页URL,其他页面(如列表页、内容页)会自动抓取。网站抓取的模板收录HTML、CSS、图片、JS、Flash等目录并保存在原站点结构中,替换对应的cms标签即可使用。
网站 掌握最新海量网络信息采集、处理、存储、全文检索、中文处理和文本挖掘技术,可实时监控最新新闻、论坛、博客、微博和视频。舆情信息帮助站长及时、全面、准确地掌握网络动态,自动采集到自己网站,用户填写网站的内容。
网站爬虫使用自然语言处理技术,保证抓取信息的准确性、分类的准确性和否定判断的准确性。网站抓取相似文章识别,准确识别出内容相似的文章,可用于文章的去重和识别。网站爬取无需模板,方便随时添加采集源,不受网页修改影响。网站捕捉全方位的数据分析展示功能,多角度多层次展示内容特征,揭示数据规律,帮助站长更好的管理和维护网站。
抓取网页flash(不提倡不是完全不用flash功能,少用可根据个人需求取舍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-03-26 09:15
经常浏览网站的人会发现,现在在网站中已经很少看到动画了。这是因为这种格式逐渐不被人们提倡了,所以 flash 网站为什么越来越被弃用了?
为什么 flash 做 网站 越来越气馁
之所以在网站中尽量少放flash动画,是因为flash的加载量比较大,会影响页面的加载速度,进而影响客户体验的效果。但是,完全不使用闪光灯功能是不可取的。如果你用的比较少,可以根据个人需要做适当的选择。网站的速度极大地影响了客户的体验,没有人愿意等待一个长时间打不开的网站。其实打开速度有很多问题。可能是主机的问题,也可能是网站上的图片或flash过多造成的。尽量在两秒内控制开口。一旦超过,很多客户会直接关闭页面。对于PC配置较低的客户,如果网站速度不好,那么flash的存在只会拖慢网站的加载速度,严重影响客户体验。为了使 网站 万无一失,只能避免这个元素。
不建议在网站上搞这些动画,而且整个网页不要到处都是各种截图,更不允许在网站上插入各种广告,还有一些网站 甚至在弹窗上,给客户的印象相当不好,甚至有用户认为是垃圾网站。搜索引擎无法抓取flash中的信息,不仅影响客户体验,也影响网页可视化。访问需要大量流量。如果 网站 的速度较慢,则页面加载缓慢。情况,现在有些浏览器根本不支持flash,如果可以的话就不需要了。
网站和布局是网站直观的部分,也是网站访问者首先产生的印象。很多中小型企业的网页设计和制作显得粗糙杂乱,色调不协调,整个网页让人杂乱无章。感觉。过分追求视觉效果,大量使用图片和flash,不利于搜索引擎排名。由于flash本身可以做很多种效果,尤其是放在导航上的时候,视觉效果很明显,所以很多网站喜欢,甚至企业网站的首页都是flash,还是让客户通过flash上的链接点击页面,但是搜索引擎很难读取里面的内容。一个复杂而凌乱的网站 查看全部
抓取网页flash(不提倡不是完全不用flash功能,少用可根据个人需求取舍)
经常浏览网站的人会发现,现在在网站中已经很少看到动画了。这是因为这种格式逐渐不被人们提倡了,所以 flash 网站为什么越来越被弃用了?

为什么 flash 做 网站 越来越气馁
之所以在网站中尽量少放flash动画,是因为flash的加载量比较大,会影响页面的加载速度,进而影响客户体验的效果。但是,完全不使用闪光灯功能是不可取的。如果你用的比较少,可以根据个人需要做适当的选择。网站的速度极大地影响了客户的体验,没有人愿意等待一个长时间打不开的网站。其实打开速度有很多问题。可能是主机的问题,也可能是网站上的图片或flash过多造成的。尽量在两秒内控制开口。一旦超过,很多客户会直接关闭页面。对于PC配置较低的客户,如果网站速度不好,那么flash的存在只会拖慢网站的加载速度,严重影响客户体验。为了使 网站 万无一失,只能避免这个元素。
不建议在网站上搞这些动画,而且整个网页不要到处都是各种截图,更不允许在网站上插入各种广告,还有一些网站 甚至在弹窗上,给客户的印象相当不好,甚至有用户认为是垃圾网站。搜索引擎无法抓取flash中的信息,不仅影响客户体验,也影响网页可视化。访问需要大量流量。如果 网站 的速度较慢,则页面加载缓慢。情况,现在有些浏览器根本不支持flash,如果可以的话就不需要了。
网站和布局是网站直观的部分,也是网站访问者首先产生的印象。很多中小型企业的网页设计和制作显得粗糙杂乱,色调不协调,整个网页让人杂乱无章。感觉。过分追求视觉效果,大量使用图片和flash,不利于搜索引擎排名。由于flash本身可以做很多种效果,尤其是放在导航上的时候,视觉效果很明显,所以很多网站喜欢,甚至企业网站的首页都是flash,还是让客户通过flash上的链接点击页面,但是搜索引擎很难读取里面的内容。一个复杂而凌乱的网站
抓取网页flash(谷歌搜索彻底停止Flash服务支持的信息(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-25 05:20
Flash网页可以说开启了页面动画的新模式。在刚刚起步的页面制作中,Flash的出现无疑给广大程序员带来了一个新的起点,让页面越来越形象化。Flash网站在视觉效果、交互效果等多方面都有很强的优势。广泛应用于房地产行业、汽车行业、奢侈品行业等高端行业。
Flash网页给人以强烈的视觉冲击力,可以表达我们想要表达的元素,给人一种高端的感觉,但多年来:超长的加载时间已经成为Flash的存在网站的一个普遍现象问题在于,由于自身的优势,需要大量的数据来支持,但需要较长的加载速度来支持,搜索引擎很难识别这些元素。这是搜索引擎的问题,也是整个Flash网站的问题。虽然搜索引擎正在逐步加强对多幅Flash动画动画图片的识别和爬取技术,但仍然存在一些影响用户体验的问题,尤其是在这个特殊时期。.
在众多搜索引擎中,Google 可以说是针对 Flash 网页优化好的浏览器。在其seoer人员的不断努力优化和不断修改下,Flash网页虽然不容易优化,但也不乏其人。优秀的Flash网页展现在用户面前。
不过,最近谷歌浏览器已经推送了谷歌搜索将完全停止支持Flash服务的信息。计划在 2020 年底完全停止支持 Flash。Google 搜索也开始自动过滤收录 Flash 内容的网页,并停止 收录 与 Flash 文件的网页信息,后续 Google 搜索将无法搜索用于收录 Flash 网页的相关 网站 内容。
据小编了解,不仅是谷歌Chrome,几乎所有主流浏览器都开始陆续停止支持Flash服务。可见Flash网页已经走到了尽头!
这里我也给大家一些建议:
1.修改你自己的网站在完全接收之前
2.Flash网页现在谷歌正在调整,但是国内的浏览器也会陆续停掉,大家不要冒险。
3.社会在变,时代在进步,网站和页面也需要我们不断完善! 查看全部
抓取网页flash(谷歌搜索彻底停止Flash服务支持的信息(图))
Flash网页可以说开启了页面动画的新模式。在刚刚起步的页面制作中,Flash的出现无疑给广大程序员带来了一个新的起点,让页面越来越形象化。Flash网站在视觉效果、交互效果等多方面都有很强的优势。广泛应用于房地产行业、汽车行业、奢侈品行业等高端行业。
Flash网页给人以强烈的视觉冲击力,可以表达我们想要表达的元素,给人一种高端的感觉,但多年来:超长的加载时间已经成为Flash的存在网站的一个普遍现象问题在于,由于自身的优势,需要大量的数据来支持,但需要较长的加载速度来支持,搜索引擎很难识别这些元素。这是搜索引擎的问题,也是整个Flash网站的问题。虽然搜索引擎正在逐步加强对多幅Flash动画动画图片的识别和爬取技术,但仍然存在一些影响用户体验的问题,尤其是在这个特殊时期。.

在众多搜索引擎中,Google 可以说是针对 Flash 网页优化好的浏览器。在其seoer人员的不断努力优化和不断修改下,Flash网页虽然不容易优化,但也不乏其人。优秀的Flash网页展现在用户面前。
不过,最近谷歌浏览器已经推送了谷歌搜索将完全停止支持Flash服务的信息。计划在 2020 年底完全停止支持 Flash。Google 搜索也开始自动过滤收录 Flash 内容的网页,并停止 收录 与 Flash 文件的网页信息,后续 Google 搜索将无法搜索用于收录 Flash 网页的相关 网站 内容。
据小编了解,不仅是谷歌Chrome,几乎所有主流浏览器都开始陆续停止支持Flash服务。可见Flash网页已经走到了尽头!

这里我也给大家一些建议:
1.修改你自己的网站在完全接收之前
2.Flash网页现在谷歌正在调整,但是国内的浏览器也会陆续停掉,大家不要冒险。
3.社会在变,时代在进步,网站和页面也需要我们不断完善!
抓取网页flash(嗨创h5自助建站专注建站6年,网站收录和排名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-24 16:12
在互联网+时代,网站是每个大中型企业必备的工具。有了这把武器,如何才能带来实实在在的收益,网站的收录和排名很重要,这样会大大增加公司的曝光率,带来更多的客流量。
关于网站SEO 和搜索引擎,一直是企业津津乐道的话题。我们都知道,如果SEO做得合理,就会被搜索引擎点赞,直接带来难以想象的流量。
合理优化网站有利于搜索引擎抓取网站、收录更有用的网页,挖掘更多有价值的信息等。 6 年。拥有国内外领先的技术和网站营销技术。.
从搜索引擎蜘蛛的角度看一个网站,在爬取、索引、排名的时候
没有。一、确保搜索引擎可以抓取页面
众所周知,百度蜘蛛通过跟随链接爬取页面内容来爬取页面。如果你想让蜘蛛爬到你的网站主页,必须有你的网站主页的外部链接,只有蜘蛛爬到主页然后跟着内部链接去抓取更多更深网站 内容。这里更需要注意的是,网站内容页面不能离首页太远,要控制在3-4二流之内。
所以网站应该有一个好的网站结构,逻辑清晰,内部链接应该形成蜘蛛网,提高蜘蛛爬行粘性。从网站的编码来看,要注意避免使用js脚本链接、flash中的链接等,因为蜘蛛不识别也无法识别跟踪链接的抓取,会直接导致< @收录 问题。
找到二、页面后能不能刮一下页面内容
吸引蜘蛛爬到网站后,文章能否顺利爬行,与网站的设计有很大关系。很明显蜘蛛不喜欢动态的url,所以在网站@网站代码上要注意,使用能找到并且可以爬取的url,最好的建议,网站URL 使用静态的。
如何在页面 三、 爬取后提取有用信息
遵循搜索引擎的工作原理,我们都知道,当搜索引擎蜘蛛来找你网站,爬取页面后,索引的第一步就是提取中文,所以把关键词放在页面顶部的重要位置,即Title的写法,页面标题是SEO中最重要的因素,还有一些重要标签的写法如网站描述标签和文章@ > 标题标签,内容必须突出网站的点。
在网站的后台写的过程中,程序员都知道简化代码是第一要务,比如去掉一些无用的代码或者注释,这样可以帮助搜索引擎更快更清楚的理解页面的内容,提取有用信息。
如果你想被引擎迅速收录并获得最高排名,你必须做你想做的事。
喜创H5自助建站平台,0代码,但操作平台,大中型企业首选,电脑网站,手机网站,微信网站三站于一体,同时朋友圈、微博、博客、QQ空间等移动平台实时更新。
更多体验,请登录海创H5自助网站:一小时轻松建站,在线运行。 查看全部
抓取网页flash(嗨创h5自助建站专注建站6年,网站收录和排名)
在互联网+时代,网站是每个大中型企业必备的工具。有了这把武器,如何才能带来实实在在的收益,网站的收录和排名很重要,这样会大大增加公司的曝光率,带来更多的客流量。
关于网站SEO 和搜索引擎,一直是企业津津乐道的话题。我们都知道,如果SEO做得合理,就会被搜索引擎点赞,直接带来难以想象的流量。
合理优化网站有利于搜索引擎抓取网站、收录更有用的网页,挖掘更多有价值的信息等。 6 年。拥有国内外领先的技术和网站营销技术。.
从搜索引擎蜘蛛的角度看一个网站,在爬取、索引、排名的时候
没有。一、确保搜索引擎可以抓取页面
众所周知,百度蜘蛛通过跟随链接爬取页面内容来爬取页面。如果你想让蜘蛛爬到你的网站主页,必须有你的网站主页的外部链接,只有蜘蛛爬到主页然后跟着内部链接去抓取更多更深网站 内容。这里更需要注意的是,网站内容页面不能离首页太远,要控制在3-4二流之内。
所以网站应该有一个好的网站结构,逻辑清晰,内部链接应该形成蜘蛛网,提高蜘蛛爬行粘性。从网站的编码来看,要注意避免使用js脚本链接、flash中的链接等,因为蜘蛛不识别也无法识别跟踪链接的抓取,会直接导致< @收录 问题。
找到二、页面后能不能刮一下页面内容
吸引蜘蛛爬到网站后,文章能否顺利爬行,与网站的设计有很大关系。很明显蜘蛛不喜欢动态的url,所以在网站@网站代码上要注意,使用能找到并且可以爬取的url,最好的建议,网站URL 使用静态的。
如何在页面 三、 爬取后提取有用信息
遵循搜索引擎的工作原理,我们都知道,当搜索引擎蜘蛛来找你网站,爬取页面后,索引的第一步就是提取中文,所以把关键词放在页面顶部的重要位置,即Title的写法,页面标题是SEO中最重要的因素,还有一些重要标签的写法如网站描述标签和文章@ > 标题标签,内容必须突出网站的点。
在网站的后台写的过程中,程序员都知道简化代码是第一要务,比如去掉一些无用的代码或者注释,这样可以帮助搜索引擎更快更清楚的理解页面的内容,提取有用信息。
如果你想被引擎迅速收录并获得最高排名,你必须做你想做的事。
喜创H5自助建站平台,0代码,但操作平台,大中型企业首选,电脑网站,手机网站,微信网站三站于一体,同时朋友圈、微博、博客、QQ空间等移动平台实时更新。
更多体验,请登录海创H5自助网站:一小时轻松建站,在线运行。
抓取网页flash(wireshark如何抓包分析网页视频特征,并写出L7的代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2022-03-17 02:10
Wireshark是一款非常有名的数据分析软件,我们首先需要下载安装wireshark并安装。下面介绍wireshark如何抓包,分析网络视频特征,编写L7代码。
运营流程:
1. 启动wireshark,找到需要抓包的网卡,准备抓包;
2. 启动浏览器并打开网页观看视频;
3. 在wireshark抓包界面点击start开始抓包;
4. 观看视频一定时间后,停止wireshark抓包,分析数据,输入http.request get找到请求获取的链接,一般以.swf结尾
5.分析类型关联数据,多次比较,发现共性,写L7正则表达式
一、启用wireshark。
2013-12-12 10:06 上传
下载附件 (67.54 KB)
通过列表我们可以选择需要抓包的网卡
2013-12-12 10:06 上传
下载附件 (22.55 KB)
二、打开浏览器,但不要播放视频。这是一个例子
三、点击开始按钮开始抓取,然后点击播放网络视频。
四、视频播放一段时间后,我们可以停止抓包。分析数据包最重要的是向视频服务器申请视频的get或post参数。我们可以使用http.request get来查找,如下图
2013-12-12 10:06 上传
下载附件 (66.72 KB)
我们从应用层分析 L7 数据,无论是游戏还是视频,不管它们的帧、以太网、网际协议和传输方式(TCP 还是 UDP),只有在分析完传输协议,例如视频后,我们分析是http传输协议
当然我们要找的是视频文件,比如.swf结尾的内容(可能是mp4之类的),其他的jpg、js、png就不用考虑了。在上图中,我们找到了一个相关的匹配GET值,可以看到主机在220.118.109.158处从服务器获取了一个.swf flash视频文件,
2013-12-12 10:07 上传
下载附件 (92.41 KB)
内容如下:
[[动态]]/2/[[动态]]/6
继续查找相关内容:
2013-12-12 10:07 上传
下载附件 (92.03 KB)
这一次我们得到了不同的东西
[[动态]]/2/[[动态]]/6
我们多次使用这种方法比较该视频的GET信息,几乎所有的连接内容都有上述的共同点。
这样我们就可以开始爬关键词了,这些都是自动固定的,然后是adplayer.swf或者qiyi_player.swf,这里我们只取.swf,那么我们要收录的关键词是
GET++.swf
最后,我们编写如下L7正则表达式代码
^(get|post) .+\www\ 。\七一\ . \com\ / \播放器。+\ .swf
代码分析:
^ : 表示内容的开始
(get|post): "|" 中间标识 get 或 post
.+ :介于两者之间的任何字符
\ :将内容转换为字符
最后我们将代码简化为:
^(获取|发布)。+\七一\ . \com\ / \播放器。+\ .swf
此处不包括www,因为服务器可能会替换其他二级域名,我们将代码添加到/ip firewall layer7-protocol
2013-12-12 10:08 上传
下载附件 (120.81 KB)
后者是需要在iP防火墙过滤器中进行防火墙过滤,或者在iP防火墙mangle中进行流量控制等操作
下面是几个视频网页的 L7 正则表达式
2013-12-12 10:06 上传
下载附件 (122.19 KB) 查看全部
抓取网页flash(wireshark如何抓包分析网页视频特征,并写出L7的代码)
Wireshark是一款非常有名的数据分析软件,我们首先需要下载安装wireshark并安装。下面介绍wireshark如何抓包,分析网络视频特征,编写L7代码。
运营流程:
1. 启动wireshark,找到需要抓包的网卡,准备抓包;
2. 启动浏览器并打开网页观看视频;
3. 在wireshark抓包界面点击start开始抓包;
4. 观看视频一定时间后,停止wireshark抓包,分析数据,输入http.request get找到请求获取的链接,一般以.swf结尾
5.分析类型关联数据,多次比较,发现共性,写L7正则表达式
一、启用wireshark。
2013-12-12 10:06 上传
下载附件 (67.54 KB)
通过列表我们可以选择需要抓包的网卡
2013-12-12 10:06 上传
下载附件 (22.55 KB)
二、打开浏览器,但不要播放视频。这是一个例子
三、点击开始按钮开始抓取,然后点击播放网络视频。
四、视频播放一段时间后,我们可以停止抓包。分析数据包最重要的是向视频服务器申请视频的get或post参数。我们可以使用http.request get来查找,如下图
2013-12-12 10:06 上传
下载附件 (66.72 KB)
我们从应用层分析 L7 数据,无论是游戏还是视频,不管它们的帧、以太网、网际协议和传输方式(TCP 还是 UDP),只有在分析完传输协议,例如视频后,我们分析是http传输协议
当然我们要找的是视频文件,比如.swf结尾的内容(可能是mp4之类的),其他的jpg、js、png就不用考虑了。在上图中,我们找到了一个相关的匹配GET值,可以看到主机在220.118.109.158处从服务器获取了一个.swf flash视频文件,
2013-12-12 10:07 上传
下载附件 (92.41 KB)
内容如下:
[[动态]]/2/[[动态]]/6
继续查找相关内容:
2013-12-12 10:07 上传
下载附件 (92.03 KB)
这一次我们得到了不同的东西
[[动态]]/2/[[动态]]/6
我们多次使用这种方法比较该视频的GET信息,几乎所有的连接内容都有上述的共同点。
这样我们就可以开始爬关键词了,这些都是自动固定的,然后是adplayer.swf或者qiyi_player.swf,这里我们只取.swf,那么我们要收录的关键词是
GET++.swf
最后,我们编写如下L7正则表达式代码
^(get|post) .+\www\ 。\七一\ . \com\ / \播放器。+\ .swf
代码分析:
^ : 表示内容的开始
(get|post): "|" 中间标识 get 或 post
.+ :介于两者之间的任何字符
\ :将内容转换为字符
最后我们将代码简化为:
^(获取|发布)。+\七一\ . \com\ / \播放器。+\ .swf
此处不包括www,因为服务器可能会替换其他二级域名,我们将代码添加到/ip firewall layer7-protocol
2013-12-12 10:08 上传
下载附件 (120.81 KB)
后者是需要在iP防火墙过滤器中进行防火墙过滤,或者在iP防火墙mangle中进行流量控制等操作
下面是几个视频网页的 L7 正则表达式
2013-12-12 10:06 上传
下载附件 (122.19 KB)
抓取网页flash(AdobeFlashPlayer将在明年被彻底结束支持(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-08 06:18
Adobe Flash Player 将在明年完全停止支持,这意味着所有用户都不应该继续使用这个容易出错的媒体播放器。
目前各大浏览器都开始限制使用该播放器,浏览器加载时会默认屏蔽Flash创建的内容。
为了尽可能加快全网内容Flash技术的淘汰速度,谷歌目前正在调整其爬取和索引策略,以向Web开发者施加升级压力。
Google 将不再索引此类内容:
谷歌在站长平台的官方博客上发布了一篇新博文。博文的内容比较简单。最主要的是 Google 搜索不再索引 Flash 创建的内容。
一些网站或网页使用Flash技术构建静态网页,如一些网络游戏网站、美术展示网站仍在使用该技术。
原来的谷歌搜索爬虫遇到这样的内容,会读取它的关键信息并索引到谷歌的索引中,这样用户在搜索的时候就可以找到这些Flash页面。
谷歌的新政策逐渐抛弃了这些技术创造的内容。毕竟如果浏览器不支持的话,即使用户打开这些页面,也无法正常显示内容。
谷歌表示,未来爬虫会在遇到此类内容时直接丢弃此类内容,不再将此类内容编入索引并收录在谷歌搜索结果中。
网站 将无法直接搜索:
如果 网站 是使用 Flash 技术构建的,它会被 Google 丢弃,用户在通过 Google 搜索 网站 名称或 关键词 时将找不到这些 网站。
对于绝大多数网站来说,搜索引擎是重要的流量来源,这也是谷歌希望通过这种方式向网络开发者施压的原因。
谷歌表示,根据目前的统计数据,新政策不会影响绝大多数网站,对谷歌搜索用户也不会产生太大影响。
开发人员可以将 Flash 内容迁移到 HTML 5,在被 Google 的爬虫访问后,这些内容将重新编入 Google 的索引中。 查看全部
抓取网页flash(AdobeFlashPlayer将在明年被彻底结束支持(图))
Adobe Flash Player 将在明年完全停止支持,这意味着所有用户都不应该继续使用这个容易出错的媒体播放器。
目前各大浏览器都开始限制使用该播放器,浏览器加载时会默认屏蔽Flash创建的内容。
为了尽可能加快全网内容Flash技术的淘汰速度,谷歌目前正在调整其爬取和索引策略,以向Web开发者施加升级压力。

Google 将不再索引此类内容:
谷歌在站长平台的官方博客上发布了一篇新博文。博文的内容比较简单。最主要的是 Google 搜索不再索引 Flash 创建的内容。
一些网站或网页使用Flash技术构建静态网页,如一些网络游戏网站、美术展示网站仍在使用该技术。
原来的谷歌搜索爬虫遇到这样的内容,会读取它的关键信息并索引到谷歌的索引中,这样用户在搜索的时候就可以找到这些Flash页面。
谷歌的新政策逐渐抛弃了这些技术创造的内容。毕竟如果浏览器不支持的话,即使用户打开这些页面,也无法正常显示内容。
谷歌表示,未来爬虫会在遇到此类内容时直接丢弃此类内容,不再将此类内容编入索引并收录在谷歌搜索结果中。
网站 将无法直接搜索:
如果 网站 是使用 Flash 技术构建的,它会被 Google 丢弃,用户在通过 Google 搜索 网站 名称或 关键词 时将找不到这些 网站。
对于绝大多数网站来说,搜索引擎是重要的流量来源,这也是谷歌希望通过这种方式向网络开发者施压的原因。
谷歌表示,根据目前的统计数据,新政策不会影响绝大多数网站,对谷歌搜索用户也不会产生太大影响。
开发人员可以将 Flash 内容迁移到 HTML 5,在被 Google 的爬虫访问后,这些内容将重新编入 Google 的索引中。
抓取网页flash( 移动站点的优化及TDK布局是否与pc站点布局一样)
网站优化 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2022-03-05 10:12
移动站点的优化及TDK布局是否与pc站点布局一样)
随着互联网技术的飞速发展,智能手机用户也在疯狂增长。据相关统计,2015年工信部公布,我国手机用户规模已达12.9亿。PC互联网时代逐渐转向移动互联网新时代。这是社会发展的必然。
因此,这两年大家都将目光投向了移动互联网。很多互联网公司都想在移动端占据一席之地,从而形成了手机APP、微信公众号、手机网站的建设热潮,当然在这场浩大的转型中,国内三大互联网巨头BAT必然首当其冲。BAT在资金、人才、资源等方面处于领先地位,迅速布局移动端。当然,在他们争夺地盘的时候,也是不可或缺的。枪炮在黑暗中战斗,这也是AT最明显的一点。对此,杨紫就不多说了,有机会再一起讨论。今天,杨紫主要跟大家分享一下移动网站的SEO优化。
如今,移动搜索流量已经超过了PC流量。许多公司正在建立自己的移动网站,并希望从移动搜索中获得流量。那么如何搭建移动网站,方便移动网站的SEO优化呢?移动端优化和TDK布局和pc端布局一样吗?当同一个站点同时有PC站点和移动站点时,当您想从移动站点获得更多收录和流量时,是否应该屏蔽PC站点?移动端的TDK优化会不会和PC端完全一样,会受到惩罚吗?等等类似的问题,下面杨紫都会一一分享。
搜索引擎作为网站的普通访问者,对去哪个站点进行爬取和索引,并根据用户体验确定站点和页面的价值并进行排序。因此,原则上网站对用户体验的任何改进都是对搜索引擎的改进。但受限于目前的整体网络环境和技术原因,实现用户体验的具体手段还需要考虑搜索引擎的友好性,让搜索引擎在满足用户体验的前提下更容易理解和处理。
那么移动搜索引擎网站的构建主要分为三个部分:
1、如何更好的让百度手机搜索收录网站中的内容。
2、如何在移动搜索中获得更好的排名,
3、如何让用户从众多搜索结果中快速找到并点击您的网站。
这三点简单来说就是收录、排序、呈现。下面我们从 收录 开始:
机器可读:
移动站点与PC爬虫相同。百度使用一个名为Baiduspider2.0 的程序来爬取移动互联网上的网页。经过处理后,它被内置到移动索引中。目前百度蜘蛛只能读取文字内容,FLASH、图片等非文字内容暂时还不能很好的处理。放在flash中的文字和图片只能百度轻松识别。建议使用文字代替flash、图片、javascript等显示重要内容或链接。搜索引擎无法识别flash,图片复杂javascript中的内容只存在于收录flash和javascript中链接的网页中,百度手机搜索可能无法收录。不要在搜索引擎可读的地方使用 AJAX 技术,例如标题、导航、
移动站点结构搭建:
一个移动网站还应该有一个清晰的结构和较浅的链接层次结构,这样可以让用户快速访问有用的信息,让搜索引擎快速了解网站中每个页面的结构层次。网站结构推荐使用树形结构。树状结构通常是以下三个层次,主页-频道-详情页。
移动网站也应该是网状的:
理想的网站结构是一棵扁平的树,从首页到内容页的层级越少越好,这样更便于搜索引擎处理。同时,网站中的链接也要采用网状结构,网站上的每个网页都应该有上下级网页和相关内容的链接,避免出现链接孤岛,首页页面有频道页链接,频道页有首页和普通内容页的链接,普通内容页有上级频道和首页的链接,内容相关的页面相互连接。网站 中的每个页面都应该是 网站 结构的一部分,应该链接到其他网页,以便蜘蛛更好地抓取和抓取 网站 中的内容。同时,
移动站点简单移动的 URL:
它具有良好的描述性、规范性和简洁性,有利于用户记忆和直观判断网页内容,也有利于搜索引擎更有效地抓取和理解网页。在设计之初,网站应该做好URL规划:
1、移动台首页,/,/或
2、频道页使用/n1/、/n2/(当然这里直接读n1或n2更好)
3、详情页的URL尽量短,减少统计参数等无效参数,保证同一页面只有一组URL。
4、机器人禁止百度蜘蛛不想向用户展示的URL形式和百度不想被抓取的私人数据。
合理的返回状态码:
百度蜘蛛在抓取处理时,根据http协议规范设置相应的逻辑。几种常用的返回状态码如下:
404:百度会认为该网页无效而删除,通常在索引中删除。短期内,蜘蛛再遇到它就不会再爬了。建议在内容被删除或网页无效时使用404返回码,告诉百度蜘蛛该页面无效。同时在网站中应该尽量减少死链接的堆积。如果网站暂时关闭或者抓取压力太大,不要直接返回404,使用503.
301:永久重定向,百度会认为当前URL永久跳转到新的URL。网站改版、域名变更等情况建议使用301,同时使用站长平台的网站改版工具。
503:百度会认为暂时无法访问,不会直接删除。请在短时间内再次检查。如果网站暂时关闭,建议使用503.
移动网站建设常见问题解答:
Q:我手机站的内容和我电脑的内容一样,需要屏蔽百度电脑搜索蜘蛛吗?
A:由于百度的pc搜索和手机搜索是同一个蜘蛛,都带有baidu logo,所以不要屏蔽。爬虫会在爬取的时候识别页面,自动判断是pc页面还是手机页面,所以建议大家使用标准的html5或者xhtml协议语言搭建手机站。
Q:手机站是用xhtml\html5开发的,跟搜索引擎有什么区别吗?
答:你用手机搜索的时候,你会发现用2g的时候,手机搜索给你的是极速版,就是保证你得到的结果足够快,但是结果风格比较简单。一般情况下,极速版百度蜘蛛会优先考虑xhtml的结果,触屏版优先考虑html5,效果更爽。
问:一个站点有M站点和PC站点。使用完全相同的 TDK 有什么问题吗?手机网站的SEO规则和PC网站一样吗?
答:PC端和移动端搜索结果中显示的标题和摘要的字数限制不同。PC端一般只有30个左右的汉字才截断,移动端达到20个字符就折叠,超过20个字符以下的就省略了。看不见。所以建议移动台使用单独的TDK。
问:如果两个站点的每个页面的 TDK 完全相同,我会受到处罚吗?
答:如果两个相同的网站指的是手机网站和电脑网站,肯定不会导致处罚。
Q:作为外链对移动台有影响吗?
答:外部链接仍然有效,但不要做垃圾外部链接。例如,在论坛的标签中,买卖链接,或批量发送链接都可能受到处罚。正常交换链接很有帮助。
今天,杨紫就和大家分享一下手机站的SEO相关问题。他写道,在很短的时间内将接近 17:00。这个周末已经这样了一天。不知道大家今天是怎么度过的? 查看全部
抓取网页flash(
移动站点的优化及TDK布局是否与pc站点布局一样)
随着互联网技术的飞速发展,智能手机用户也在疯狂增长。据相关统计,2015年工信部公布,我国手机用户规模已达12.9亿。PC互联网时代逐渐转向移动互联网新时代。这是社会发展的必然。
因此,这两年大家都将目光投向了移动互联网。很多互联网公司都想在移动端占据一席之地,从而形成了手机APP、微信公众号、手机网站的建设热潮,当然在这场浩大的转型中,国内三大互联网巨头BAT必然首当其冲。BAT在资金、人才、资源等方面处于领先地位,迅速布局移动端。当然,在他们争夺地盘的时候,也是不可或缺的。枪炮在黑暗中战斗,这也是AT最明显的一点。对此,杨紫就不多说了,有机会再一起讨论。今天,杨紫主要跟大家分享一下移动网站的SEO优化。
如今,移动搜索流量已经超过了PC流量。许多公司正在建立自己的移动网站,并希望从移动搜索中获得流量。那么如何搭建移动网站,方便移动网站的SEO优化呢?移动端优化和TDK布局和pc端布局一样吗?当同一个站点同时有PC站点和移动站点时,当您想从移动站点获得更多收录和流量时,是否应该屏蔽PC站点?移动端的TDK优化会不会和PC端完全一样,会受到惩罚吗?等等类似的问题,下面杨紫都会一一分享。
搜索引擎作为网站的普通访问者,对去哪个站点进行爬取和索引,并根据用户体验确定站点和页面的价值并进行排序。因此,原则上网站对用户体验的任何改进都是对搜索引擎的改进。但受限于目前的整体网络环境和技术原因,实现用户体验的具体手段还需要考虑搜索引擎的友好性,让搜索引擎在满足用户体验的前提下更容易理解和处理。
那么移动搜索引擎网站的构建主要分为三个部分:
1、如何更好的让百度手机搜索收录网站中的内容。
2、如何在移动搜索中获得更好的排名,
3、如何让用户从众多搜索结果中快速找到并点击您的网站。
这三点简单来说就是收录、排序、呈现。下面我们从 收录 开始:
机器可读:
移动站点与PC爬虫相同。百度使用一个名为Baiduspider2.0 的程序来爬取移动互联网上的网页。经过处理后,它被内置到移动索引中。目前百度蜘蛛只能读取文字内容,FLASH、图片等非文字内容暂时还不能很好的处理。放在flash中的文字和图片只能百度轻松识别。建议使用文字代替flash、图片、javascript等显示重要内容或链接。搜索引擎无法识别flash,图片复杂javascript中的内容只存在于收录flash和javascript中链接的网页中,百度手机搜索可能无法收录。不要在搜索引擎可读的地方使用 AJAX 技术,例如标题、导航、
移动站点结构搭建:
一个移动网站还应该有一个清晰的结构和较浅的链接层次结构,这样可以让用户快速访问有用的信息,让搜索引擎快速了解网站中每个页面的结构层次。网站结构推荐使用树形结构。树状结构通常是以下三个层次,主页-频道-详情页。
移动网站也应该是网状的:
理想的网站结构是一棵扁平的树,从首页到内容页的层级越少越好,这样更便于搜索引擎处理。同时,网站中的链接也要采用网状结构,网站上的每个网页都应该有上下级网页和相关内容的链接,避免出现链接孤岛,首页页面有频道页链接,频道页有首页和普通内容页的链接,普通内容页有上级频道和首页的链接,内容相关的页面相互连接。网站 中的每个页面都应该是 网站 结构的一部分,应该链接到其他网页,以便蜘蛛更好地抓取和抓取 网站 中的内容。同时,
移动站点简单移动的 URL:
它具有良好的描述性、规范性和简洁性,有利于用户记忆和直观判断网页内容,也有利于搜索引擎更有效地抓取和理解网页。在设计之初,网站应该做好URL规划:
1、移动台首页,/,/或
2、频道页使用/n1/、/n2/(当然这里直接读n1或n2更好)
3、详情页的URL尽量短,减少统计参数等无效参数,保证同一页面只有一组URL。
4、机器人禁止百度蜘蛛不想向用户展示的URL形式和百度不想被抓取的私人数据。
合理的返回状态码:
百度蜘蛛在抓取处理时,根据http协议规范设置相应的逻辑。几种常用的返回状态码如下:
404:百度会认为该网页无效而删除,通常在索引中删除。短期内,蜘蛛再遇到它就不会再爬了。建议在内容被删除或网页无效时使用404返回码,告诉百度蜘蛛该页面无效。同时在网站中应该尽量减少死链接的堆积。如果网站暂时关闭或者抓取压力太大,不要直接返回404,使用503.
301:永久重定向,百度会认为当前URL永久跳转到新的URL。网站改版、域名变更等情况建议使用301,同时使用站长平台的网站改版工具。
503:百度会认为暂时无法访问,不会直接删除。请在短时间内再次检查。如果网站暂时关闭,建议使用503.
移动网站建设常见问题解答:
Q:我手机站的内容和我电脑的内容一样,需要屏蔽百度电脑搜索蜘蛛吗?
A:由于百度的pc搜索和手机搜索是同一个蜘蛛,都带有baidu logo,所以不要屏蔽。爬虫会在爬取的时候识别页面,自动判断是pc页面还是手机页面,所以建议大家使用标准的html5或者xhtml协议语言搭建手机站。
Q:手机站是用xhtml\html5开发的,跟搜索引擎有什么区别吗?
答:你用手机搜索的时候,你会发现用2g的时候,手机搜索给你的是极速版,就是保证你得到的结果足够快,但是结果风格比较简单。一般情况下,极速版百度蜘蛛会优先考虑xhtml的结果,触屏版优先考虑html5,效果更爽。
问:一个站点有M站点和PC站点。使用完全相同的 TDK 有什么问题吗?手机网站的SEO规则和PC网站一样吗?
答:PC端和移动端搜索结果中显示的标题和摘要的字数限制不同。PC端一般只有30个左右的汉字才截断,移动端达到20个字符就折叠,超过20个字符以下的就省略了。看不见。所以建议移动台使用单独的TDK。
问:如果两个站点的每个页面的 TDK 完全相同,我会受到处罚吗?
答:如果两个相同的网站指的是手机网站和电脑网站,肯定不会导致处罚。
Q:作为外链对移动台有影响吗?
答:外部链接仍然有效,但不要做垃圾外部链接。例如,在论坛的标签中,买卖链接,或批量发送链接都可能受到处罚。正常交换链接很有帮助。
今天,杨紫就和大家分享一下手机站的SEO相关问题。他写道,在很短的时间内将接近 17:00。这个周末已经这样了一天。不知道大家今天是怎么度过的?
抓取网页flash(比方让搜索引擎爬虫掉入到网站的陷阱里怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-02-28 07:06
网站的很多设计者都期待着让搜索引擎爬取尽可能多的网站,但是如果在设计的网站中出现大量死链接,搜索引擎爬虫即使你抢它,你什么也抢不了,所以对于网站的设计,光做表面的功力是不够的,还要做好基本的功课,设计自己的网站页面,比如如设计404网页告诉搜索引擎网络蜘蛛遇到死链接后及时返回,以免让搜索引擎爬虫落入网站的陷阱,从而使搜索引擎网络机器人更容易去爬取你的页面,那么网站究竟应该怎样设计才能让你轻松爬取呢?
网站怎么设计才容易抓起来
因此,很容易只抓取一些比较重要的网页,而不是所有的页面,这就是为什么搜索引擎对重要网页的更新快照更短的原因。例如,对于频繁更新的页面,快照也会经常更新,以便及时发现新的内容和链接,并删除不存在的信息。因此,这与以前相同。站长必须长期坚持更新网页。为了让搜索引擎爬虫更容易找到你。
对于网站的内框设计,内框的设计要从多方面进行。代码应尽可能简洁明了。代码过多会导致页面体积过大,影响网络爬虫的抓取。重要的代码最好放在前面。爬网站的时候喜欢从第一段开始搜索,可以爬到前面的主要内容。它将抓取 Flash 格式的内容。对于新的网站,尽量使用伪静态形式的url,这样整个网站页面都可以轻松抓取。要合理分配,不能全部写关键词,需要适当添加一些长尾词链接。最后,内部链接设计要流畅,
为网站设计面包屑导航,这是很多公司在设计网站时忽略的地方。事实上,面包屑导航在提取中一直扮演着非常重要的角色,必须合理设计。网站上的锚文本设计有利于网络爬虫发现和爬取网站上更多的网页,但是如果锚文本太多容易被视为刻意调整,就要把握好数量设计时的锚文本。
除了首页的设计,网站可能还存在大量的其他页面。爬虫不会索引每个 网站 上的所有页面,因此它们可能会爬取足够多的页面以在找到他们认为重要的页面之前离开。所以要保持只需要从首页跳转到不超过两个页面,太多可能会导致这些页面爬不上去。
导航是捕获网站 的关键。如果网站的导航不清晰,抓到网站很容易迷路,可能根本找不到入口。这很糟糕,因为搜索引擎很容易放弃您的 网站 页面并停止抓取它们。
最终,企业设计的网站保持了一定的更新频率,更新频繁的页面很容易被爬取,因此可以通过超链接自动爬取大量页面。同时,更新频率较高的页面也受到搜索引擎的高度重视。参考以上因素,相信企业在设计网站时能得到一些启发。 查看全部
抓取网页flash(比方让搜索引擎爬虫掉入到网站的陷阱里怎么办?)
网站的很多设计者都期待着让搜索引擎爬取尽可能多的网站,但是如果在设计的网站中出现大量死链接,搜索引擎爬虫即使你抢它,你什么也抢不了,所以对于网站的设计,光做表面的功力是不够的,还要做好基本的功课,设计自己的网站页面,比如如设计404网页告诉搜索引擎网络蜘蛛遇到死链接后及时返回,以免让搜索引擎爬虫落入网站的陷阱,从而使搜索引擎网络机器人更容易去爬取你的页面,那么网站究竟应该怎样设计才能让你轻松爬取呢?

网站怎么设计才容易抓起来
因此,很容易只抓取一些比较重要的网页,而不是所有的页面,这就是为什么搜索引擎对重要网页的更新快照更短的原因。例如,对于频繁更新的页面,快照也会经常更新,以便及时发现新的内容和链接,并删除不存在的信息。因此,这与以前相同。站长必须长期坚持更新网页。为了让搜索引擎爬虫更容易找到你。
对于网站的内框设计,内框的设计要从多方面进行。代码应尽可能简洁明了。代码过多会导致页面体积过大,影响网络爬虫的抓取。重要的代码最好放在前面。爬网站的时候喜欢从第一段开始搜索,可以爬到前面的主要内容。它将抓取 Flash 格式的内容。对于新的网站,尽量使用伪静态形式的url,这样整个网站页面都可以轻松抓取。要合理分配,不能全部写关键词,需要适当添加一些长尾词链接。最后,内部链接设计要流畅,
为网站设计面包屑导航,这是很多公司在设计网站时忽略的地方。事实上,面包屑导航在提取中一直扮演着非常重要的角色,必须合理设计。网站上的锚文本设计有利于网络爬虫发现和爬取网站上更多的网页,但是如果锚文本太多容易被视为刻意调整,就要把握好数量设计时的锚文本。
除了首页的设计,网站可能还存在大量的其他页面。爬虫不会索引每个 网站 上的所有页面,因此它们可能会爬取足够多的页面以在找到他们认为重要的页面之前离开。所以要保持只需要从首页跳转到不超过两个页面,太多可能会导致这些页面爬不上去。
导航是捕获网站 的关键。如果网站的导航不清晰,抓到网站很容易迷路,可能根本找不到入口。这很糟糕,因为搜索引擎很容易放弃您的 网站 页面并停止抓取它们。
最终,企业设计的网站保持了一定的更新频率,更新频繁的页面很容易被爬取,因此可以通过超链接自动爬取大量页面。同时,更新频率较高的页面也受到搜索引擎的高度重视。参考以上因素,相信企业在设计网站时能得到一些启发。
抓取网页flash(打开图(程序)行了用GlobalFetch你是想批量下载搜索引擎搜出来的图片吧~那最好把你想的那个网页地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-21 23:06
打开图(程序)行
有了GlobalFetch,你想批量下载搜索引擎搜索到的图片~那么最好把你要关注的网页地址复制到GlobalFetch新建的任务中,然后将搜索深度设置为3以上,并且图片大小也限制在20k以上,我想你不会想下载所有那些广告图片。
打开你要保存的网页,在浏览器左上角:文件-另存为,在弹出框中看到“另存为类型”,选择[WEB文档,单个文件..]的类型。选择保存路径——保存。生成以 .mht 结尾的文件
Quick Capture with Web Text,是一款保存/管理网页的工具,可以在IE中保存网页,包括文字、图片、flash动画等。还可以保存选中的文字、图片和链接。它可以为上网提供极大的便利,还可以通过拖放对网页进行分类。
有很多地方可以下载
比如太平洋的下载中心就有,给你找到链接
我用的猎豹浏览器,浏览器商店里有
Fatkun图片批量下载
介绍是快速过滤保存当前页面需要的图片
正在寻找可以采集/下载网页PDF文件的软件...可以试试QQ浏览器或者360浏览器,在浏览器中安装FVD DOWNLoader,可以采集网页视频mp3等,可以安装自己喜欢的实用采集浏览器拿工具。
谁能推荐一个简单的截图软件?之前在iQ上下载过,忘记名字了…… 红蜻蜓截图2005 1.22 build 0226,一款专业的截屏软件,可以让你截取你需要的截图。多种捕捉模式可供选择,可捕捉光标,可设置捕捉延迟时间。抓图方法很简单,按下抓图热键CTRL+SHIFT+C,也就是你也可以点击软件界面上的抓图按钮抓图。同时软件采用换肤技术,用户可以根据自己的喜好选择相应的软件外观。下载地址:
找一款可以抓拍桌面和windows等的抓拍软件...给你一个最小的抓拍软件
有没有视频抓拍软件...虽然视频抓拍也可以用超级解霸、QQ等进行抓拍,但是效果不好,最好用专门的视频抓拍工具,现推荐:Camtasia Studio v 4.0.@ >0 汉化版(视频抓拍软件,录屏...
我在哪里可以下载网页图像捕获工具?- …… 抓拍别人或自己店里的宝贝,导出图片数据包,选择自己需要的图片。这类软件有很多,可以看一下抓图工具。
有专门的FLASH下载抓包工具——……不知道你指的是哪个软件下载flash,但是还有其他下载flash的方法(这里指的是从网上下载flash) ,我将它们分类并一一列出:1、通过下载工具。如迅雷、互联网快车、Super Cyclone等下载软件,这些软件都有flash抓拍功能(鼠标...
找一款可以截取和处理视频和图片的软件,类似美图秀秀,但是可以自由截取视频的软件……可以下载“录屏专家”截取视频图像。网上有破解版。如果你只是想将视频画面捕捉成图片,可以使用“会声会影”。
我想要一个快照软件...推荐使用“红蜻蜓快照2005 V1.23”。软件介绍: RdfSnap 2005 是一款完全免费的专业级截屏软件,它可以让你截取你需要的截图。抓图方式灵活,主要抓全屏、活动窗口、选定区域……
请推荐一个快照工具!... 1. Red Dragonfly Snap 2005 V1.23 build 0430 Red Dragonfly Snap 2005 (RdfSnap) 2005 是一款完全免费的专业屏幕红蜻蜓 Snap 2005 1.23 build 0430 Red Dragonfly Snap 2005 ( RdfSnap) 2005 是一款完全免费的专业截屏...
网页抓取工具... 使用软件htmlparser2.0。这是一个html页面的抓取和分析工具。它可以和htmlconnector一起使用,它是一个web连接器,可以做你需要的(爬取双层连接和保存页面内容) 查看全部
抓取网页flash(打开图(程序)行了用GlobalFetch你是想批量下载搜索引擎搜出来的图片吧~那最好把你想的那个网页地址)
打开图(程序)行
有了GlobalFetch,你想批量下载搜索引擎搜索到的图片~那么最好把你要关注的网页地址复制到GlobalFetch新建的任务中,然后将搜索深度设置为3以上,并且图片大小也限制在20k以上,我想你不会想下载所有那些广告图片。
打开你要保存的网页,在浏览器左上角:文件-另存为,在弹出框中看到“另存为类型”,选择[WEB文档,单个文件..]的类型。选择保存路径——保存。生成以 .mht 结尾的文件
Quick Capture with Web Text,是一款保存/管理网页的工具,可以在IE中保存网页,包括文字、图片、flash动画等。还可以保存选中的文字、图片和链接。它可以为上网提供极大的便利,还可以通过拖放对网页进行分类。
有很多地方可以下载
比如太平洋的下载中心就有,给你找到链接
我用的猎豹浏览器,浏览器商店里有
Fatkun图片批量下载
介绍是快速过滤保存当前页面需要的图片
正在寻找可以采集/下载网页PDF文件的软件...可以试试QQ浏览器或者360浏览器,在浏览器中安装FVD DOWNLoader,可以采集网页视频mp3等,可以安装自己喜欢的实用采集浏览器拿工具。
谁能推荐一个简单的截图软件?之前在iQ上下载过,忘记名字了…… 红蜻蜓截图2005 1.22 build 0226,一款专业的截屏软件,可以让你截取你需要的截图。多种捕捉模式可供选择,可捕捉光标,可设置捕捉延迟时间。抓图方法很简单,按下抓图热键CTRL+SHIFT+C,也就是你也可以点击软件界面上的抓图按钮抓图。同时软件采用换肤技术,用户可以根据自己的喜好选择相应的软件外观。下载地址:
找一款可以抓拍桌面和windows等的抓拍软件...给你一个最小的抓拍软件
有没有视频抓拍软件...虽然视频抓拍也可以用超级解霸、QQ等进行抓拍,但是效果不好,最好用专门的视频抓拍工具,现推荐:Camtasia Studio v 4.0.@ >0 汉化版(视频抓拍软件,录屏...
我在哪里可以下载网页图像捕获工具?- …… 抓拍别人或自己店里的宝贝,导出图片数据包,选择自己需要的图片。这类软件有很多,可以看一下抓图工具。
有专门的FLASH下载抓包工具——……不知道你指的是哪个软件下载flash,但是还有其他下载flash的方法(这里指的是从网上下载flash) ,我将它们分类并一一列出:1、通过下载工具。如迅雷、互联网快车、Super Cyclone等下载软件,这些软件都有flash抓拍功能(鼠标...
找一款可以截取和处理视频和图片的软件,类似美图秀秀,但是可以自由截取视频的软件……可以下载“录屏专家”截取视频图像。网上有破解版。如果你只是想将视频画面捕捉成图片,可以使用“会声会影”。
我想要一个快照软件...推荐使用“红蜻蜓快照2005 V1.23”。软件介绍: RdfSnap 2005 是一款完全免费的专业级截屏软件,它可以让你截取你需要的截图。抓图方式灵活,主要抓全屏、活动窗口、选定区域……
请推荐一个快照工具!... 1. Red Dragonfly Snap 2005 V1.23 build 0430 Red Dragonfly Snap 2005 (RdfSnap) 2005 是一款完全免费的专业屏幕红蜻蜓 Snap 2005 1.23 build 0430 Red Dragonfly Snap 2005 ( RdfSnap) 2005 是一款完全免费的专业截屏...
网页抓取工具... 使用软件htmlparser2.0。这是一个html页面的抓取和分析工具。它可以和htmlconnector一起使用,它是一个web连接器,可以做你需要的(爬取双层连接和保存页面内容)
抓取网页flash(搜索引擎不喜欢Flash的网站,是因为Flash动画太复杂。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-19 05:08
搜索引擎之所以不喜欢 Flash 的 网站 是因为 Flash 动画太复杂了。与一般网页上的文字不同,Flash 动画是由框架组成的,搜索引擎无法读取 Flash 内部的框架,因此搜索引擎不会对其进行索引。如果要优化Flash网站,必须对Flash进行处理,有以下三种方法。
1.创建辅助HTML文件
保留原来的Flash版本,然后创建一个HTML页面,比如上面的网站,创建一个没有Flash的纯文本HTML页面,把所有的链接都链接到原来的Flash页面,这样虽然搜索引擎不爬Flash,他们可以收录HTML页面,通过HTML页面做文章让蜘蛛爬取Flash页面。
2. 这种将 Flash 嵌入 HTML 文件的方法通过改变网页的结构来弥补。
不要以 Flash 形式设计整个网页,而是将 Flash 内容嵌入到 HTML 文件中。搜索引擎也可以从网页的Title、Keywords、Discription等代码中找到一些主要信息到收录网站。即使主页使用Flash,进入页面的关键词按钮链接也应该放在Flash文件之外,作为独立的纯文本链接呈现。
3.付费登录搜索引擎
这种方法只有在前两种方法都行不通的情况下才使用,因为后者需要投入一定的成本,网站一开始如果能降低投资成本,成本就会降低,如果< @网站 上线几个月后,搜索引擎还是没有收录,那就考虑付费登录搜索引擎。根据经验,在做网站时,应该尽量避免使用Flash,或者最好不要使用。你知道搜索引擎不喜欢它,但你仍然想使用它。这不是给自己找麻烦吗?虽然Flash让网站的设计效果更好,但从整体考虑,网站中使用Flash的弊端还是大于利的,尤其是在做友情链接的时候,千万不要使用Flash按钮链接。 查看全部
抓取网页flash(搜索引擎不喜欢Flash的网站,是因为Flash动画太复杂。)
搜索引擎之所以不喜欢 Flash 的 网站 是因为 Flash 动画太复杂了。与一般网页上的文字不同,Flash 动画是由框架组成的,搜索引擎无法读取 Flash 内部的框架,因此搜索引擎不会对其进行索引。如果要优化Flash网站,必须对Flash进行处理,有以下三种方法。

1.创建辅助HTML文件
保留原来的Flash版本,然后创建一个HTML页面,比如上面的网站,创建一个没有Flash的纯文本HTML页面,把所有的链接都链接到原来的Flash页面,这样虽然搜索引擎不爬Flash,他们可以收录HTML页面,通过HTML页面做文章让蜘蛛爬取Flash页面。
2. 这种将 Flash 嵌入 HTML 文件的方法通过改变网页的结构来弥补。
不要以 Flash 形式设计整个网页,而是将 Flash 内容嵌入到 HTML 文件中。搜索引擎也可以从网页的Title、Keywords、Discription等代码中找到一些主要信息到收录网站。即使主页使用Flash,进入页面的关键词按钮链接也应该放在Flash文件之外,作为独立的纯文本链接呈现。
3.付费登录搜索引擎
这种方法只有在前两种方法都行不通的情况下才使用,因为后者需要投入一定的成本,网站一开始如果能降低投资成本,成本就会降低,如果< @网站 上线几个月后,搜索引擎还是没有收录,那就考虑付费登录搜索引擎。根据经验,在做网站时,应该尽量避免使用Flash,或者最好不要使用。你知道搜索引擎不喜欢它,但你仍然想使用它。这不是给自己找麻烦吗?虽然Flash让网站的设计效果更好,但从整体考虑,网站中使用Flash的弊端还是大于利的,尤其是在做友情链接的时候,千万不要使用Flash按钮链接。
抓取网页flash(用用JavaScript获获取取网网页页中的js、css、Flash等等文文件件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-02-13 15:05
但不是电子书里的js、css、Flash、背景音乐等文件。其实只要对 JavaScript 代码有一定的了解,即使只使用已经公开发布的 CtrlN,在 E 书中获取这些文件也不难。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,这种方法很难用于批量反编译,所以庄家不必产生许多担忧。电子书中的背景音乐和其他文件。其实只要对 JavaScript 代码有一定的了解,即使只使用已经公开发布的 CtrlN,在 E 书中获取这些文件也不难。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,这种方法很难用于批量反编译,所以庄家不必产生许多担忧。电子书中的背景音乐和其他文件。其实只要对 JavaScript 代码有一定的了解,即使只使用已经公开发布的 CtrlN,在 E 书中获取这些文件也不难。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,这种方法很难用于批量反编译,所以庄家不必产生许多担忧。只要对 JavaScript 代码有一定的了解,即使只使用已经公开发布的 CtrlN,在 E 书中获取这些文件也不难。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,这种方法很难用于批量反编译,所以庄家不必产生许多担忧。只要对 JavaScript 代码有一定的了解,即使只使用已经公开发布的 CtrlN,在 E 书中获取这些文件也不难。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,这种方法很难用于批量反编译,所以庄家不必产生许多担忧。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人的做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,而且这种方法很难用于批量反编译,所以庄家不必产生许多担忧。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人的做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,而且这种方法很难用于批量反编译,所以庄家不必产生许多担忧。
我不杀鸡杀蛋,哈哈……2、为了方便使用,下面给出的JavaScript很笨,所有的URL解析工作都是代码完成的,只要按Ctrl+C即可, Ctrl+V 键都可以。然而,自动化毕竟有其局限性。对于大部分网页来说,这些代码应该是可以解决的。但是,如果遇到无法解决的网页,仍然需要手动分析 HTML 代码。如果在分析过程中遇到加密网页,可以使用CtrlN的“HTML Fragment”功能对加密后的HTML进行解码。在源代码中查找链接时,可以使用搜索功能快速定位。3、现在基于IE内核的电子书基本都是通过自定义协议插件实现的,对JavaScript协议插件的支持程度不一,所以不要' 如果代码在某些电子书上有错误,请不要感到惊讶。4.这些代码除了反编译电子书外,在浏览普通网页时也很有用,例如用于抓取网页中的Falsh文件。5、所有代码都是在Windows XP SP2下测试的,其他环境我没试过,但估计IE版本不能低于6.0。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。除了反编译电子书外,这些代码在浏览普通网页时也很有用,例如,它们用于捕获网页中的 Falsh 文件。5、所有代码都是在Windows XP SP2下测试的,其他环境我没试过,但估计IE版本不能低于6.0。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。除了反编译电子书外,这些代码在浏览普通网页时也很有用,例如,它们用于捕获网页中的 Falsh 文件。5、所有代码都是在Windows XP SP2下测试的,其他环境我没试过,但估计IE版本不能低于6.0。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。它们用于捕获网页中的 Falsh 文件。5、所有代码都是在Windows XP SP2下测试的,其他环境我没试过,但估计IE版本不能低于6.0。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。它们用于捕获网页中的 Falsh 文件。5、所有代码都是在Windows XP SP2下测试的,其他环境我没试过,但估计IE版本不能低于6.0。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。
这是为了防止电子书或网页禁用快捷键。如果确认没有禁用快捷键,可以省略这一步,在第3步直接按Ctrl+N。打开电子书或IE,进入引用css、js、flash等文件的页面需要被捕获。请注意,这必须是真实页面,而不是框架。如何判断框架以及如何进入框架页面将在后面讨论。将CtrlN的“快捷键行为”设置为“弹出新窗口”,然后用鼠标点击要抓取的网页,然后按Ctrl+N,会弹出一个新的IE窗口,里面显示的内容和你要抢的一样。抓取的页面内容相同,地址栏显示页面的URL。在弹出的 IE 窗口中,根据需要将对应的 JavaScript 代码(后面会给出)复制粘贴到地址栏中,然后按回车键。对于IE 6,第一次运行JavaScript代码时,地址栏下方可能会弹出一个黄色条,表示此代码被阻止运行,点击黄色条,选择“允许被阻止的内容”,然后重复上述步骤3、@ >4 查看结果。三、从E书或网页中获取链接的css文件 JavaScript本身提供了获取外部css文件内容的接口,所以在上述通用步骤的第4步中,将以下内容复制粘贴到IE中地址栏,然后回车查看内容:j avascript:str='';c=document.styleSheets;for(i=0;i\n';str+=o.cssText;str+='
\n';};document.write(str); 如果当前的 HTML 页面没有链接到外部 css 文件,则在第 4 步完成后将无响应或显示空白页面。这时候可以查看页面的HTML源代码进行确认。如果当前页面链接到多个 css 文件,则会显示所有 css 文件的内容。IE排版后的格式可能和原来的css代码不一样,但是效果是完全一样的。如果只显示css文件的文件名,而下面没有内容,则说明css没有打包在E书里。对于某些电子书,您还可以尝试以下代码:j javascript:str='
\n';c=document.styl eSheets;for(i=0;i';str+=o.href;str+='
\n';};str+='';document.write(str); 此代码自动检查网页。如果网页中嵌入了css文件,则自动显示css文件的下载链接,否则显示空页或无响应。在链接上单击鼠标右键,然后选择“另存为”菜单,将文件保存到硬盘。如果无法保存,将js文件的url复制到地址栏,然后回车试试。但是,如果注册表项HKEY_CLA SSES_ROOT\CSSfile\shell下有open、edit等子项,则获取的CSS代码将直接在open或edit子项指定的程序中打开,而不提示保存。这种方法的适用范围远小于上面直接展示的方法,不是所有的电子书都能用,但只要能用,它肯定会得到原创的 css 代码。四、从E书或网页获取链接的js文件 JavaScript没有提供获取js文件内容的接口,所以首先要对注册表进行改造:运行regedit,定位到HKEY_CLA SSES_ROOT\.js,并在其中添加两个字符串类型值如下: Content Type=application/xj avascript PerceivedType=text 修改的时候不放心可以参考HKEY_CLA SSES_ROOT\.css的默认设置,只是不同而已在 Content Type 的值中。注册表修改是一次性的,修改后不需要再做。转换完成后,用CtrlN抓取js文件的步骤和上面的一般步骤是一样的。在步骤 4 中,将以下内容复制并粘贴到地址栏中,
\n';c=document.scripts;for(i=0;i';str+=o.src;str+='
\n';};str+='';document.write(str); 此代码自动检查网页。如果网页中嵌入了js文件,会自动显示该js文件的下载链接,否则会显示空页或无响应。在链接上点击鼠标右键,选择“另存为”菜单,或直接点击链接;您可以将文件保存到硬盘。如果无法保存,请确认注册表是否已按照上述方法设置;如果不行,可以把js文件的url复制到地址栏,然后回车试试。诡异的是eBoo Wor shop制作的E书(页面URL以ada99:开头),在地址栏中输入js文件的URL回车,就会显示js文件的内容及其执行结果直接点击“
\n';c=document.all;f or(i=0;i'));nd.firstChild.outerHT ML=sih;no=document.createElement(nd.firstChild.outerHT ML);document.body 。appendChild(no);str+='';str+=no.src;str+='
\n';};str+='';document.write(str); 此代码自动检查网页。如果网页中嵌入了Flash对象,会自动显示swf文件的下载链接,否则会显示空页或无响应。右键单击该链接并选择“另存为”以将文件保存到您的硬盘驱动器。如果直接单击链接,将显示 Flash 屏幕。我经常看到有人问:“如何在网页上捕捉漂亮的 Flash?” 事实上,答案就是这么简单。我在上网的时候经常用这段代码来抓Flash,但是需要注意的是:如果页面是嵌入到框架中的,则需要将框架分解成真实页面后才能使用此代码。此代码还使用 createDocument tFragment 方法,并且仅适用于 IE 6。现在还有一个很极端的电子书:全书只有一个网页,里面嵌入了一个Flash文件作为记录。点击Flash中的链接,会跳转到其他Flash文件,也就是真正的内容隐藏在一堆Flash文件中。里面。这类电子书,用上面的代码一次只能抓一个Flash,需要一步一步点进去才能全部抓,有的甚至用flasm反编译抓到的Flash文件的运行脚本,然后从脚本中找出它所链接的其他Flash文件的文件名(我都是很刻薄的直接搜索.swf),然后将文件名转换为绝对URL生成下载链接。例如,如果已知 Flash 文件的绝对 URL 为 /pic.swf,则可以使用以下代码单独下载该文件:j avascript:document。write('右键另存为'); 这种方法每次都需要改变URL,当然比上面提到的方法麻烦一些,但是有时候只能用这种方法。对了,flasm真是个好东西,脚本里的一些Flash文件限制了文件只能在网络上播放,不能从本地硬盘播放,你也可以用它来解除这个限制。六、从电子书或网页中获取背景音乐文件背景音乐文件可以像Flash一样直接下载,所以在上述通用步骤的第4步中,将以下内容复制并粘贴到地址栏中,然后按回车键查看内容: j javascript:但有时只能使用这种方法。对了,flasm真是个好东西,脚本里的一些Flash文件限制了文件只能在网络上播放,不能从本地硬盘播放,你也可以用它来解除这个限制。六、从电子书或网页中获取背景音乐文件背景音乐文件可以像Flash一样直接下载,所以在上述通用步骤的第4步中,将以下内容复制并粘贴到地址栏中,然后按回车键查看内容: j javascript:但有时只能使用这种方法。对了,flasm真是个好东西,脚本里的一些Flash文件限制了文件只能在网络上播放,不能从本地硬盘播放,你也可以用它来解除这个限制。六、从电子书或网页中获取背景音乐文件背景音乐文件可以像Flash一样直接下载,所以在上述通用步骤的第4步中,将以下内容复制并粘贴到地址栏中,然后按回车键查看内容: j javascript:
\n';c=document.all;f or(i=0;i';str+=o.src;str+='
\n';};str+='';document.write(str); 此代码自动检查网页。如果嵌入了背景音乐,则会自动显示背景音乐的下载链接,否则会显示空白页面或无反应。右键单击该链接并选择“另存为”以将文件保存到您的硬盘驱动器。注意背景音乐一般隐藏在框架中(否则换页时音乐会中断)。如果弹出页面收录框架而不是实际收录背景音乐链接的页面,则不会被捕获。这时候还需要按照后面提到的步骤进入框架中的页面。另外,为了避免单调,有的电子书会一次打包好几个midi文件,并在每次运行时随机选择一首作为背景音乐。对于这样的电子书,上面的代码只能捕捉到当前的背景音乐。如果要全部捕获,只能自己分析网页源代码,结合所有背景音乐的url,然后在地址栏中输入javascript代码生成下载链接回车即可一次下载一个。请注意,您只能右键单击下载链接并选择“另存为”,不能直接单击该链接。如果实在没有能力分析网页的源码,只能跑几遍,多抓几遍。示例:如果已知音乐文件的绝对 URL 为 /1.mid,则生成下载链接的代码为:j avascript:document。write('右键另存为'); 七、From Book E 获取图片文件 在上面通用步骤的第4步中,将以下内容复制粘贴到地址栏,然后回车即可查看内容:j avascript:z=1;strUrl= '';str='' ;function getImg(){if(strUrl!=''){str+=(z++);str+='.
<IMG SRC="';str+=strUrl;str+='">
\n';};};c=document.images;for(i=0;i';str+=strU rl;str+='
\n';};};c=document.images;for(i=0;i
\n';c=document.all;f or(i=0;i';if(=='')str+=o.src;else str+=;str+='
\n';};str+='';document.write(str); 此代码自动检查网页。如果嵌入了框架(包括 iframe),则自动在框架中显示页面链接,否则显示空页面或无响应。只需单击链接即可转到相应页面。为了保证通用性,上面的代码只检查了第一层的frame,对于iframe来说问题不大,因为很少有正常人会玩嵌套的iframe;但是对于普通的框架,嵌套的 iframe 不是问题。可能性还是很大的,上面的代码需要逐层点击才能看到嵌套的框架,有点麻烦。解决方法是:如果上面的代码显示所有FRA ME,没有IFRA ME,可以使用下面的代码显示所有嵌套的frame:j avascript:str='';function getFrame(c,i,
从03开始,它提供了一个可以打开/关闭的“高级界面”。通过其中的“脚本命令”功能,可以直接将要执行的JavaScript代码或URL推送到IE窗口执行,无需在地址栏中输入。如果您已经编写了自己的 JavaScript 代码,也可以将其添加到 CtrlN.spt 文件(纯文本文件)中,以便稍后在 Script 命令选择窗口中直接选择。附录版本更新记录版本1.01 文档已根据CtrlN ver 1.03的新功能进行了修订。 查看全部
抓取网页flash(用用JavaScript获获取取网网页页中的js、css、Flash等等文文件件)
但不是电子书里的js、css、Flash、背景音乐等文件。其实只要对 JavaScript 代码有一定的了解,即使只使用已经公开发布的 CtrlN,在 E 书中获取这些文件也不难。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,这种方法很难用于批量反编译,所以庄家不必产生许多担忧。电子书中的背景音乐和其他文件。其实只要对 JavaScript 代码有一定的了解,即使只使用已经公开发布的 CtrlN,在 E 书中获取这些文件也不难。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,这种方法很难用于批量反编译,所以庄家不必产生许多担忧。电子书中的背景音乐和其他文件。其实只要对 JavaScript 代码有一定的了解,即使只使用已经公开发布的 CtrlN,在 E 书中获取这些文件也不难。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,这种方法很难用于批量反编译,所以庄家不必产生许多担忧。只要对 JavaScript 代码有一定的了解,即使只使用已经公开发布的 CtrlN,在 E 书中获取这些文件也不难。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,这种方法很难用于批量反编译,所以庄家不必产生许多担忧。只要对 JavaScript 代码有一定的了解,即使只使用已经公开发布的 CtrlN,在 E 书中获取这些文件也不难。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,这种方法很难用于批量反编译,所以庄家不必产生许多担忧。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人的做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,而且这种方法很难用于批量反编译,所以庄家不必产生许多担忧。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人的做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,而且这种方法很难用于批量反编译,所以庄家不必产生许多担忧。
我不杀鸡杀蛋,哈哈……2、为了方便使用,下面给出的JavaScript很笨,所有的URL解析工作都是代码完成的,只要按Ctrl+C即可, Ctrl+V 键都可以。然而,自动化毕竟有其局限性。对于大部分网页来说,这些代码应该是可以解决的。但是,如果遇到无法解决的网页,仍然需要手动分析 HTML 代码。如果在分析过程中遇到加密网页,可以使用CtrlN的“HTML Fragment”功能对加密后的HTML进行解码。在源代码中查找链接时,可以使用搜索功能快速定位。3、现在基于IE内核的电子书基本都是通过自定义协议插件实现的,对JavaScript协议插件的支持程度不一,所以不要' 如果代码在某些电子书上有错误,请不要感到惊讶。4.这些代码除了反编译电子书外,在浏览普通网页时也很有用,例如用于抓取网页中的Falsh文件。5、所有代码都是在Windows XP SP2下测试的,其他环境我没试过,但估计IE版本不能低于6.0。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。除了反编译电子书外,这些代码在浏览普通网页时也很有用,例如,它们用于捕获网页中的 Falsh 文件。5、所有代码都是在Windows XP SP2下测试的,其他环境我没试过,但估计IE版本不能低于6.0。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。除了反编译电子书外,这些代码在浏览普通网页时也很有用,例如,它们用于捕获网页中的 Falsh 文件。5、所有代码都是在Windows XP SP2下测试的,其他环境我没试过,但估计IE版本不能低于6.0。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。它们用于捕获网页中的 Falsh 文件。5、所有代码都是在Windows XP SP2下测试的,其他环境我没试过,但估计IE版本不能低于6.0。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。它们用于捕获网页中的 Falsh 文件。5、所有代码都是在Windows XP SP2下测试的,其他环境我没试过,但估计IE版本不能低于6.0。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。
这是为了防止电子书或网页禁用快捷键。如果确认没有禁用快捷键,可以省略这一步,在第3步直接按Ctrl+N。打开电子书或IE,进入引用css、js、flash等文件的页面需要被捕获。请注意,这必须是真实页面,而不是框架。如何判断框架以及如何进入框架页面将在后面讨论。将CtrlN的“快捷键行为”设置为“弹出新窗口”,然后用鼠标点击要抓取的网页,然后按Ctrl+N,会弹出一个新的IE窗口,里面显示的内容和你要抢的一样。抓取的页面内容相同,地址栏显示页面的URL。在弹出的 IE 窗口中,根据需要将对应的 JavaScript 代码(后面会给出)复制粘贴到地址栏中,然后按回车键。对于IE 6,第一次运行JavaScript代码时,地址栏下方可能会弹出一个黄色条,表示此代码被阻止运行,点击黄色条,选择“允许被阻止的内容”,然后重复上述步骤3、@ >4 查看结果。三、从E书或网页中获取链接的css文件 JavaScript本身提供了获取外部css文件内容的接口,所以在上述通用步骤的第4步中,将以下内容复制粘贴到IE中地址栏,然后回车查看内容:j avascript:str='';c=document.styleSheets;for(i=0;i\n';str+=o.cssText;str+='
\n';};document.write(str); 如果当前的 HTML 页面没有链接到外部 css 文件,则在第 4 步完成后将无响应或显示空白页面。这时候可以查看页面的HTML源代码进行确认。如果当前页面链接到多个 css 文件,则会显示所有 css 文件的内容。IE排版后的格式可能和原来的css代码不一样,但是效果是完全一样的。如果只显示css文件的文件名,而下面没有内容,则说明css没有打包在E书里。对于某些电子书,您还可以尝试以下代码:j javascript:str='
\n';c=document.styl eSheets;for(i=0;i';str+=o.href;str+='
\n';};str+='';document.write(str); 此代码自动检查网页。如果网页中嵌入了css文件,则自动显示css文件的下载链接,否则显示空页或无响应。在链接上单击鼠标右键,然后选择“另存为”菜单,将文件保存到硬盘。如果无法保存,将js文件的url复制到地址栏,然后回车试试。但是,如果注册表项HKEY_CLA SSES_ROOT\CSSfile\shell下有open、edit等子项,则获取的CSS代码将直接在open或edit子项指定的程序中打开,而不提示保存。这种方法的适用范围远小于上面直接展示的方法,不是所有的电子书都能用,但只要能用,它肯定会得到原创的 css 代码。四、从E书或网页获取链接的js文件 JavaScript没有提供获取js文件内容的接口,所以首先要对注册表进行改造:运行regedit,定位到HKEY_CLA SSES_ROOT\.js,并在其中添加两个字符串类型值如下: Content Type=application/xj avascript PerceivedType=text 修改的时候不放心可以参考HKEY_CLA SSES_ROOT\.css的默认设置,只是不同而已在 Content Type 的值中。注册表修改是一次性的,修改后不需要再做。转换完成后,用CtrlN抓取js文件的步骤和上面的一般步骤是一样的。在步骤 4 中,将以下内容复制并粘贴到地址栏中,
\n';c=document.scripts;for(i=0;i';str+=o.src;str+='
\n';};str+='';document.write(str); 此代码自动检查网页。如果网页中嵌入了js文件,会自动显示该js文件的下载链接,否则会显示空页或无响应。在链接上点击鼠标右键,选择“另存为”菜单,或直接点击链接;您可以将文件保存到硬盘。如果无法保存,请确认注册表是否已按照上述方法设置;如果不行,可以把js文件的url复制到地址栏,然后回车试试。诡异的是eBoo Wor shop制作的E书(页面URL以ada99:开头),在地址栏中输入js文件的URL回车,就会显示js文件的内容及其执行结果直接点击“
\n';c=document.all;f or(i=0;i'));nd.firstChild.outerHT ML=sih;no=document.createElement(nd.firstChild.outerHT ML);document.body 。appendChild(no);str+='';str+=no.src;str+='
\n';};str+='';document.write(str); 此代码自动检查网页。如果网页中嵌入了Flash对象,会自动显示swf文件的下载链接,否则会显示空页或无响应。右键单击该链接并选择“另存为”以将文件保存到您的硬盘驱动器。如果直接单击链接,将显示 Flash 屏幕。我经常看到有人问:“如何在网页上捕捉漂亮的 Flash?” 事实上,答案就是这么简单。我在上网的时候经常用这段代码来抓Flash,但是需要注意的是:如果页面是嵌入到框架中的,则需要将框架分解成真实页面后才能使用此代码。此代码还使用 createDocument tFragment 方法,并且仅适用于 IE 6。现在还有一个很极端的电子书:全书只有一个网页,里面嵌入了一个Flash文件作为记录。点击Flash中的链接,会跳转到其他Flash文件,也就是真正的内容隐藏在一堆Flash文件中。里面。这类电子书,用上面的代码一次只能抓一个Flash,需要一步一步点进去才能全部抓,有的甚至用flasm反编译抓到的Flash文件的运行脚本,然后从脚本中找出它所链接的其他Flash文件的文件名(我都是很刻薄的直接搜索.swf),然后将文件名转换为绝对URL生成下载链接。例如,如果已知 Flash 文件的绝对 URL 为 /pic.swf,则可以使用以下代码单独下载该文件:j avascript:document。write('右键另存为'); 这种方法每次都需要改变URL,当然比上面提到的方法麻烦一些,但是有时候只能用这种方法。对了,flasm真是个好东西,脚本里的一些Flash文件限制了文件只能在网络上播放,不能从本地硬盘播放,你也可以用它来解除这个限制。六、从电子书或网页中获取背景音乐文件背景音乐文件可以像Flash一样直接下载,所以在上述通用步骤的第4步中,将以下内容复制并粘贴到地址栏中,然后按回车键查看内容: j javascript:但有时只能使用这种方法。对了,flasm真是个好东西,脚本里的一些Flash文件限制了文件只能在网络上播放,不能从本地硬盘播放,你也可以用它来解除这个限制。六、从电子书或网页中获取背景音乐文件背景音乐文件可以像Flash一样直接下载,所以在上述通用步骤的第4步中,将以下内容复制并粘贴到地址栏中,然后按回车键查看内容: j javascript:但有时只能使用这种方法。对了,flasm真是个好东西,脚本里的一些Flash文件限制了文件只能在网络上播放,不能从本地硬盘播放,你也可以用它来解除这个限制。六、从电子书或网页中获取背景音乐文件背景音乐文件可以像Flash一样直接下载,所以在上述通用步骤的第4步中,将以下内容复制并粘贴到地址栏中,然后按回车键查看内容: j javascript:
\n';c=document.all;f or(i=0;i';str+=o.src;str+='
\n';};str+='';document.write(str); 此代码自动检查网页。如果嵌入了背景音乐,则会自动显示背景音乐的下载链接,否则会显示空白页面或无反应。右键单击该链接并选择“另存为”以将文件保存到您的硬盘驱动器。注意背景音乐一般隐藏在框架中(否则换页时音乐会中断)。如果弹出页面收录框架而不是实际收录背景音乐链接的页面,则不会被捕获。这时候还需要按照后面提到的步骤进入框架中的页面。另外,为了避免单调,有的电子书会一次打包好几个midi文件,并在每次运行时随机选择一首作为背景音乐。对于这样的电子书,上面的代码只能捕捉到当前的背景音乐。如果要全部捕获,只能自己分析网页源代码,结合所有背景音乐的url,然后在地址栏中输入javascript代码生成下载链接回车即可一次下载一个。请注意,您只能右键单击下载链接并选择“另存为”,不能直接单击该链接。如果实在没有能力分析网页的源码,只能跑几遍,多抓几遍。示例:如果已知音乐文件的绝对 URL 为 /1.mid,则生成下载链接的代码为:j avascript:document。write('右键另存为'); 七、From Book E 获取图片文件 在上面通用步骤的第4步中,将以下内容复制粘贴到地址栏,然后回车即可查看内容:j avascript:z=1;strUrl= '';str='' ;function getImg(){if(strUrl!=''){str+=(z++);str+='.
<IMG SRC="';str+=strUrl;str+='">
\n';};};c=document.images;for(i=0;i';str+=strU rl;str+='
\n';};};c=document.images;for(i=0;i
\n';c=document.all;f or(i=0;i';if(=='')str+=o.src;else str+=;str+='
\n';};str+='';document.write(str); 此代码自动检查网页。如果嵌入了框架(包括 iframe),则自动在框架中显示页面链接,否则显示空页面或无响应。只需单击链接即可转到相应页面。为了保证通用性,上面的代码只检查了第一层的frame,对于iframe来说问题不大,因为很少有正常人会玩嵌套的iframe;但是对于普通的框架,嵌套的 iframe 不是问题。可能性还是很大的,上面的代码需要逐层点击才能看到嵌套的框架,有点麻烦。解决方法是:如果上面的代码显示所有FRA ME,没有IFRA ME,可以使用下面的代码显示所有嵌套的frame:j avascript:str='';function getFrame(c,i,
从03开始,它提供了一个可以打开/关闭的“高级界面”。通过其中的“脚本命令”功能,可以直接将要执行的JavaScript代码或URL推送到IE窗口执行,无需在地址栏中输入。如果您已经编写了自己的 JavaScript 代码,也可以将其添加到 CtrlN.spt 文件(纯文本文件)中,以便稍后在 Script 命令选择窗口中直接选择。附录版本更新记录版本1.01 文档已根据CtrlN ver 1.03的新功能进行了修订。
抓取网页flash(附上游戏网址获取gateway_wolfs_,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-01-31 12:15
flash_spider
与网页flash交互的爬虫
最近在玩防守杨村。游戏是用flash制作的。我花了两天时间尝试做一个爬虫来自动执行一些操作。互联网上的flash爬虫教程很少。这里总结一下遇到的坑
p>
抓包
Flash使用amf数据格式进行数据交换,是一种二进制文件,传输效率高。用抓包软件抓包得到如下结果
分析表明,我们只需要模拟浏览器将相应格式的amf数据发送到服务器
数据包中的方法就是我们要执行的操作。图中的umap.pk_wolfs是在前线打狼的。这是游戏开发者的名字,我们只需要称呼它
根据AMF协议编码数据
python3使用的amf工具包在安装pyamf时执行命令
pip install Py3AMF
在GitHub的pyamf项目中,看到了实例使用的messaging.remoting类。我照常使用,python发送的数据请求与浏览器发送的数据请求相差甚远,于是查看了remoting和massaging的源码,发现发送的数据包只能通过传递一个类到 remoting.Request 函数中并将其转换为 amf3 格式。然后写一个MyMessage类来组织杨村服务器需要的数据格式
获取网关密钥
分析数据包,得知我们发送的数据包需要gateway_key,这让我想了半天,终于在网页对应flash位置的源码中找到了
模拟的苦力
抓硬盘前打开抓包软件,然后抓硬盘,分析数据包中的方法为user.catch_slave,所以只需将MyMessage类的数据成员方法改成'user.catch_slave'
最终效果
你可以通过苦力选择优质苦力,还可以设置时间完美抓苦力! !
附上游戏网址 查看全部
抓取网页flash(附上游戏网址获取gateway_wolfs_,)
flash_spider
与网页flash交互的爬虫
最近在玩防守杨村。游戏是用flash制作的。我花了两天时间尝试做一个爬虫来自动执行一些操作。互联网上的flash爬虫教程很少。这里总结一下遇到的坑
p>
抓包
Flash使用amf数据格式进行数据交换,是一种二进制文件,传输效率高。用抓包软件抓包得到如下结果

分析表明,我们只需要模拟浏览器将相应格式的amf数据发送到服务器
数据包中的方法就是我们要执行的操作。图中的umap.pk_wolfs是在前线打狼的。这是游戏开发者的名字,我们只需要称呼它
根据AMF协议编码数据
python3使用的amf工具包在安装pyamf时执行命令
pip install Py3AMF
在GitHub的pyamf项目中,看到了实例使用的messaging.remoting类。我照常使用,python发送的数据请求与浏览器发送的数据请求相差甚远,于是查看了remoting和massaging的源码,发现发送的数据包只能通过传递一个类到 remoting.Request 函数中并将其转换为 amf3 格式。然后写一个MyMessage类来组织杨村服务器需要的数据格式
获取网关密钥
分析数据包,得知我们发送的数据包需要gateway_key,这让我想了半天,终于在网页对应flash位置的源码中找到了

模拟的苦力
抓硬盘前打开抓包软件,然后抓硬盘,分析数据包中的方法为user.catch_slave,所以只需将MyMessage类的数据成员方法改成'user.catch_slave'
最终效果
你可以通过苦力选择优质苦力,还可以设置时间完美抓苦力! !



附上游戏网址
抓取网页flash(火狐在全球浏览器市场份额排行第三(MozillaFirefox)(LGPL))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-25 05:00
Firefox 将 Flash 方法保存在网页中。
①点击“工具->页面信息->媒体”,或在网页上右击->页面信息->媒体,找到要保存的Flash,然后点击保存。
②如果安装了 Adblock,可以打开 Adblock 的 Obj-Tabs 选项查看 Flash 的地址,然后使用 flashget 等下载软件下载 Flash。
③ 安装扩展下载嵌入式(推荐)。Download Embedded扩展在工具和右键中增加了上下文菜单,可以快速抓取页面内嵌的flash动画、电影、mp3等,比通过网页源代码或页面信息抓取更方便。
介绍
Mozilla Firefox 是由 Mozilla 开发的网络浏览器。它使用 Gecko 网页布局引擎,支持多种操作系统。开源代码以多许可方式获得许可,包括 Mozilla 公共许可 (MPL)、GNU 通用公共许可条款 (GPL) 和 GNU 宽松公共许可 (LGPL),目标是创建一个开放、创新和基于机会的网络环境。
目前,火狐浏览器在全球浏览器市场份额排名第三,谷歌Chrome在2011年11月的市场份额正式超越火狐浏览器,跃居第二位。
多年来,Mozilla Firefox 开发计划的总体原则是:每一、两年,对 Firefox 进行一次重大的功能升级。2010 年 1 月 14 日,Mozilla 表示未来将调整上述产品发布原则,即通过定期发布安全升级,逐步为 Firefox 添加各种新功能。此类升级的发布时间为每 6 周。2012年1月11日上午,Mozilla正在进行火狐浏览器长期支持版本(Extended Support Release,以下简称“ESR”)的研发工作。这个版本的浏览器更新速度比较慢,一年更新一次,不会像普通版那样每六周更新一次。
软件名称:
火狐火狐
软件版本:
13.0 官方简体中文版
软件大小:
629KB
软件许可:
自由
适用平台:
Win9X Win2000 WinXP Win2003 Vista
下载链接:
///下载/52175.html 查看全部
抓取网页flash(火狐在全球浏览器市场份额排行第三(MozillaFirefox)(LGPL))
Firefox 将 Flash 方法保存在网页中。
①点击“工具->页面信息->媒体”,或在网页上右击->页面信息->媒体,找到要保存的Flash,然后点击保存。
②如果安装了 Adblock,可以打开 Adblock 的 Obj-Tabs 选项查看 Flash 的地址,然后使用 flashget 等下载软件下载 Flash。
③ 安装扩展下载嵌入式(推荐)。Download Embedded扩展在工具和右键中增加了上下文菜单,可以快速抓取页面内嵌的flash动画、电影、mp3等,比通过网页源代码或页面信息抓取更方便。
介绍
Mozilla Firefox 是由 Mozilla 开发的网络浏览器。它使用 Gecko 网页布局引擎,支持多种操作系统。开源代码以多许可方式获得许可,包括 Mozilla 公共许可 (MPL)、GNU 通用公共许可条款 (GPL) 和 GNU 宽松公共许可 (LGPL),目标是创建一个开放、创新和基于机会的网络环境。
目前,火狐浏览器在全球浏览器市场份额排名第三,谷歌Chrome在2011年11月的市场份额正式超越火狐浏览器,跃居第二位。
多年来,Mozilla Firefox 开发计划的总体原则是:每一、两年,对 Firefox 进行一次重大的功能升级。2010 年 1 月 14 日,Mozilla 表示未来将调整上述产品发布原则,即通过定期发布安全升级,逐步为 Firefox 添加各种新功能。此类升级的发布时间为每 6 周。2012年1月11日上午,Mozilla正在进行火狐浏览器长期支持版本(Extended Support Release,以下简称“ESR”)的研发工作。这个版本的浏览器更新速度比较慢,一年更新一次,不会像普通版那样每六周更新一次。
软件名称:
火狐火狐
软件版本:
13.0 官方简体中文版
软件大小:
629KB
软件许可:
自由
适用平台:
Win9X Win2000 WinXP Win2003 Vista
下载链接:
///下载/52175.html
抓取网页flash(移动端搜索,你的企业网站有流量吗?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-23 12:18
移动搜索,你的企业网站有流量吗?作为一个搜索引擎,用手机网站收录比较容易,只有收录。只有这样才能导入更多的流量。那么作为企业网站,如何做好收录移动端网站?跟着山人资讯小编一起来了解一下吧。引入不同的移动搜索引擎优化。
作为网站的普通访问者,搜索引擎对网站进行爬取和索引,对站点/页面的价值进行判断和排序,都是从用户体验的角度出发。因此,原则上网站对用户体验的任何改进都是对搜索引擎的改进。但受限于目前的整体网络环境和技术原因,实现用户体验的具体手段还需要考虑搜索引擎的友好性,让搜索引擎在满足用户体验的前提下更容易理解和处理。那么移动搜索引擎网站的构建主要分为三个部分:如何更好的让百度移动搜索中的内容收录网站,如何在移动搜索中得到更好的结果好排名,如何让用户从众多搜索结果中快速找到并点击您的 网站。简单来说就是收录,排序,展示。下面我们将从 收录 开始
机器可读:
和PC蜘蛛一样,百度通过一个名为Baiduspider2.0的程序对移动互联网上的网页进行爬取,经过处理并内置到移动索引中。目前百度蜘蛛只能读取文本内容,flash、图片等非文本内容暂时还不能很好的处理。放在flash和图片中的文字只能百度轻松识别。建议使用文字代替flash、图片、Javascript等显示重要内容或链接。搜索引擎暂时无法识别Flash、图片、复杂Javascript中的内容;同时,它只存在于收录flash和Javascript链接的网页中。百度手机搜索也可能失败收录。不要在希望被搜索引擎读取的地方使用 Ajax 技术,例如标题、导航、
扁平结构:
一个移动网站还应该有一个清晰的结构和较浅的链接深度,这样可以让用户快速访问有用的信息,让搜索引擎快速了解网站中每个页面的结构层次。网站结构推荐使用树形结构。树状结构通常分为以下三个层次:首页-频道-详情页。
网状链接:
理想的网站结构是一棵扁平的树,从首页到内容页的层级越少越好,这样更有利于搜索引擎进行处理。同时,网站中的链接也要采用网状结构,网站上的每个网页都应该有上下级网页和相关内容的链接,避免出现链接孤岛:首页有频道页 频道页有首页和普通内容页的链接,普通内容页有上级频道和首页的链接,内容相关的页面有相互链接。网站中的每一个网页都应该是网站结构的一部分,并且应该可以通过其他网页链接,让baiduspider尽可能的遍历网站的内容。
简单易懂的网址:
一个描述性好的、规范的、简单的URL有利于用户记忆和直观判断网页内容,也有利于搜索引擎更有效地抓取和理解网页。网站在设计之初,应该有一个合理的URL规划。我们相信:
1、移动台首页,//;
2、频道页面采用/n1/、/n2/(对应PC站的频道),当然n1、n2最好直接可读;
3、详情页的URL尽量短,减少无效参数,比如统计参数等,保证同一个页面只有一组URL地址,不同形式的URL301跳转到正常的 URL;
4、Robots 会阻止 baiduspider 抓取您不希望向用户展示的 URL 表单以及您不希望被百度抓取的私人数据。
涵盖主题的锚点:
锚是锚文本。对于链接的描述性文字,锚文本写得越简洁明了,用户越容易理解指向网页的主要内容。用户将您的页面视为来自另一个页面的链接,而锚文本是对该页面的唯一介绍。和普通用户一样,当搜索引擎蜘蛛第一次发现一个网页时,锚文本是理解页面的唯一因素,对最终排名也有一定的影响。
工具“移动站点地图”:
百度站长平台提供移动站点地图提交工具。通过提交站点地图,百度可以更快更全面地抓取收录网站内容。
工具“移动指数金额”:
百度站长平台还提供移动索引工具,让站长在移动端及时了解自己的网站收录情况。
工具“移动死链接提交”:
百度站长平台还提供了手机死链提交工具。通过提交死链接站点地图,百度可以更快地找到网站死链接并更新和删除。
合理的返回码:
百度蜘蛛在抓取处理时,根据http协议规范设置相应的逻辑。几种常用的返回码如下:
404,百度会认为该网页无效删除,一般在索引中删除,短期内蜘蛛不会再次抓取。建议在内容删除、网页失效等情况下使用404返回码,通知百度蜘蛛该页面无效。同时在网站中应该尽量减少死链接的堆积。如果网站暂时关闭或者抓取压力太大,不要直接返回404,使用503。
301,永久重定向,百度会认为当前URL永久跳转到新的URL。在网站改版、域名替换等情况下,建议使用301,并使用站长平台的网站改版工具。
503,百度会认为暂时无法访问,不会直接删除,短期内会多查几次。如果 网站 暂时关闭,建议使用 503。 查看全部
抓取网页flash(移动端搜索,你的企业网站有流量吗?(图))
移动搜索,你的企业网站有流量吗?作为一个搜索引擎,用手机网站收录比较容易,只有收录。只有这样才能导入更多的流量。那么作为企业网站,如何做好收录移动端网站?跟着山人资讯小编一起来了解一下吧。引入不同的移动搜索引擎优化。
作为网站的普通访问者,搜索引擎对网站进行爬取和索引,对站点/页面的价值进行判断和排序,都是从用户体验的角度出发。因此,原则上网站对用户体验的任何改进都是对搜索引擎的改进。但受限于目前的整体网络环境和技术原因,实现用户体验的具体手段还需要考虑搜索引擎的友好性,让搜索引擎在满足用户体验的前提下更容易理解和处理。那么移动搜索引擎网站的构建主要分为三个部分:如何更好的让百度移动搜索中的内容收录网站,如何在移动搜索中得到更好的结果好排名,如何让用户从众多搜索结果中快速找到并点击您的 网站。简单来说就是收录,排序,展示。下面我们将从 收录 开始
机器可读:
和PC蜘蛛一样,百度通过一个名为Baiduspider2.0的程序对移动互联网上的网页进行爬取,经过处理并内置到移动索引中。目前百度蜘蛛只能读取文本内容,flash、图片等非文本内容暂时还不能很好的处理。放在flash和图片中的文字只能百度轻松识别。建议使用文字代替flash、图片、Javascript等显示重要内容或链接。搜索引擎暂时无法识别Flash、图片、复杂Javascript中的内容;同时,它只存在于收录flash和Javascript链接的网页中。百度手机搜索也可能失败收录。不要在希望被搜索引擎读取的地方使用 Ajax 技术,例如标题、导航、
扁平结构:
一个移动网站还应该有一个清晰的结构和较浅的链接深度,这样可以让用户快速访问有用的信息,让搜索引擎快速了解网站中每个页面的结构层次。网站结构推荐使用树形结构。树状结构通常分为以下三个层次:首页-频道-详情页。
网状链接:
理想的网站结构是一棵扁平的树,从首页到内容页的层级越少越好,这样更有利于搜索引擎进行处理。同时,网站中的链接也要采用网状结构,网站上的每个网页都应该有上下级网页和相关内容的链接,避免出现链接孤岛:首页有频道页 频道页有首页和普通内容页的链接,普通内容页有上级频道和首页的链接,内容相关的页面有相互链接。网站中的每一个网页都应该是网站结构的一部分,并且应该可以通过其他网页链接,让baiduspider尽可能的遍历网站的内容。
简单易懂的网址:
一个描述性好的、规范的、简单的URL有利于用户记忆和直观判断网页内容,也有利于搜索引擎更有效地抓取和理解网页。网站在设计之初,应该有一个合理的URL规划。我们相信:
1、移动台首页,//;
2、频道页面采用/n1/、/n2/(对应PC站的频道),当然n1、n2最好直接可读;
3、详情页的URL尽量短,减少无效参数,比如统计参数等,保证同一个页面只有一组URL地址,不同形式的URL301跳转到正常的 URL;
4、Robots 会阻止 baiduspider 抓取您不希望向用户展示的 URL 表单以及您不希望被百度抓取的私人数据。
涵盖主题的锚点:
锚是锚文本。对于链接的描述性文字,锚文本写得越简洁明了,用户越容易理解指向网页的主要内容。用户将您的页面视为来自另一个页面的链接,而锚文本是对该页面的唯一介绍。和普通用户一样,当搜索引擎蜘蛛第一次发现一个网页时,锚文本是理解页面的唯一因素,对最终排名也有一定的影响。
工具“移动站点地图”:
百度站长平台提供移动站点地图提交工具。通过提交站点地图,百度可以更快更全面地抓取收录网站内容。
工具“移动指数金额”:
百度站长平台还提供移动索引工具,让站长在移动端及时了解自己的网站收录情况。
工具“移动死链接提交”:
百度站长平台还提供了手机死链提交工具。通过提交死链接站点地图,百度可以更快地找到网站死链接并更新和删除。
合理的返回码:
百度蜘蛛在抓取处理时,根据http协议规范设置相应的逻辑。几种常用的返回码如下:
404,百度会认为该网页无效删除,一般在索引中删除,短期内蜘蛛不会再次抓取。建议在内容删除、网页失效等情况下使用404返回码,通知百度蜘蛛该页面无效。同时在网站中应该尽量减少死链接的堆积。如果网站暂时关闭或者抓取压力太大,不要直接返回404,使用503。
301,永久重定向,百度会认为当前URL永久跳转到新的URL。在网站改版、域名替换等情况下,建议使用301,并使用站长平台的网站改版工具。
503,百度会认为暂时无法访问,不会直接删除,短期内会多查几次。如果 网站 暂时关闭,建议使用 503。
抓取网页flash(谷歌黑板报《GET,POST以及安全获取更多网络信息》(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-20 12:07
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全获取更多网络信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。在文章中提到,未来谷歌在读取网页内容时不仅会使用GET抓取,还会根据情况在抓取网页内容时增加POST请求方式,从而进一步提高谷歌搜索的准确率引擎。网页内容的判断。
随着互联网的飞速发展,JavaScript 和 AJAX 越来越流行,越来越多的网页需要 POST 请求——因为页面的全部内容或者因为缺少某些页面信息和/或POST 无法返回资源。但是,谷歌认为,单纯使用 GET 来抓取网页所需的资源,并不能呈现出最全面、最准确的结果。
因此,Google 改进了 flash 索引,在 GET 爬取中引入了 POST 请求,从而对网页内容进行更完整、更准确的爬取和索引。
谷歌抓取网页内容的步骤如下:
1. 通过 GET 抓取网页内容。
2.索引网页内容并尝试呈现页面。
3.在渲染过程中使用POST请求读取页面内容,生成新的POST内容页面。
4.将来自 POST 请求的内容页面和其他数据负载添加到 Googlebot 的抓取队列。
5.Googlebot 执行 POST 请求以抓取页面。
6.Google 会渲染最终的 POST 结果,也可以合并 GET 和 POST 请求结果。
7.完成索引。
搜索引擎新闻内容来源于网络,作者整理排版。不完全代表本博客的实际观点,仅供读者参考和交流。
如有涉及作者著作权的问题,请及时联系作者进行更正、删除或按规定处理。
这篇文章的链接: 查看全部
抓取网页flash(谷歌黑板报《GET,POST以及安全获取更多网络信息》(组图))
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全获取更多网络信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。在文章中提到,未来谷歌在读取网页内容时不仅会使用GET抓取,还会根据情况在抓取网页内容时增加POST请求方式,从而进一步提高谷歌搜索的准确率引擎。网页内容的判断。
随着互联网的飞速发展,JavaScript 和 AJAX 越来越流行,越来越多的网页需要 POST 请求——因为页面的全部内容或者因为缺少某些页面信息和/或POST 无法返回资源。但是,谷歌认为,单纯使用 GET 来抓取网页所需的资源,并不能呈现出最全面、最准确的结果。
因此,Google 改进了 flash 索引,在 GET 爬取中引入了 POST 请求,从而对网页内容进行更完整、更准确的爬取和索引。
谷歌抓取网页内容的步骤如下:
1. 通过 GET 抓取网页内容。
2.索引网页内容并尝试呈现页面。
3.在渲染过程中使用POST请求读取页面内容,生成新的POST内容页面。
4.将来自 POST 请求的内容页面和其他数据负载添加到 Googlebot 的抓取队列。
5.Googlebot 执行 POST 请求以抓取页面。
6.Google 会渲染最终的 POST 结果,也可以合并 GET 和 POST 请求结果。
7.完成索引。
搜索引擎新闻内容来源于网络,作者整理排版。不完全代表本博客的实际观点,仅供读者参考和交流。
如有涉及作者著作权的问题,请及时联系作者进行更正、删除或按规定处理。
这篇文章的链接:
抓取网页flash(方便易用的网站内容信息抓取工具,刷PV,支持代理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-04-06 05:10
这是一个网页抓取工具,一个网页内容抓取工具,支持抓取网页中的JS、CSS、图片、背景图片、音乐、Flash等内容。
软件介绍
网页抓取工具是一个易于使用的 网站 内容抓取工具。该软件主要可以帮助用户抓取网站中的各种内容,如JS、CSS、图片、背景图、音乐、Flash等,非常适合模仿站内人员。
软件功能
1、一键下载页面所有内容,并自动将网络链接更改为本地链接
2、一键下载多个页面的所有内容,并自动将网络链接更改为本地链接
3、有选择地下载单个页面上的任何图片,包括 JS 和 CSS 图片
4、内置丰富的网站模板库供您选择。
5、内置丰富的图片素材模板库,任君选择。
6、随版本更新自动更新,无需再次下载。
7、没有弹出窗口,没有插件。
软件说明
网页抓取工具绿色版是一款功能强大的网站内容信息抓取工具,可以帮助用户提取完整的网站内容。用户可以下载网站单页或多页,包括JS、CSS、图片、背景图片、音乐、Flash等内容,功能强大,欢迎下载!
软件截图
相关软件
PClawer 网络爬虫工具:这是 PClawer 网络爬虫工具。是一款具有强大自定义功能的网络爬虫工具。需要正则表达式。适合高级用户使用未注册版本。只能下载两个列表和十页。!支持任意站点任意数据爬取,可同时更新多个站点支持使用正则表达式自定义爬取内容。
老树网页刷机工具:这是一款老树网页刷机工具,刷网站流量、流量、刷IP、刷PV、支持代理ip……更多功能等你来发现! 查看全部
抓取网页flash(方便易用的网站内容信息抓取工具,刷PV,支持代理)
这是一个网页抓取工具,一个网页内容抓取工具,支持抓取网页中的JS、CSS、图片、背景图片、音乐、Flash等内容。
软件介绍
网页抓取工具是一个易于使用的 网站 内容抓取工具。该软件主要可以帮助用户抓取网站中的各种内容,如JS、CSS、图片、背景图、音乐、Flash等,非常适合模仿站内人员。
软件功能
1、一键下载页面所有内容,并自动将网络链接更改为本地链接
2、一键下载多个页面的所有内容,并自动将网络链接更改为本地链接
3、有选择地下载单个页面上的任何图片,包括 JS 和 CSS 图片
4、内置丰富的网站模板库供您选择。
5、内置丰富的图片素材模板库,任君选择。
6、随版本更新自动更新,无需再次下载。
7、没有弹出窗口,没有插件。
软件说明
网页抓取工具绿色版是一款功能强大的网站内容信息抓取工具,可以帮助用户提取完整的网站内容。用户可以下载网站单页或多页,包括JS、CSS、图片、背景图片、音乐、Flash等内容,功能强大,欢迎下载!
软件截图
相关软件
PClawer 网络爬虫工具:这是 PClawer 网络爬虫工具。是一款具有强大自定义功能的网络爬虫工具。需要正则表达式。适合高级用户使用未注册版本。只能下载两个列表和十页。!支持任意站点任意数据爬取,可同时更新多个站点支持使用正则表达式自定义爬取内容。
老树网页刷机工具:这是一款老树网页刷机工具,刷网站流量、流量、刷IP、刷PV、支持代理ip……更多功能等你来发现!
抓取网页flash(2022-02-06(如最新的头条新闻,新闻的来源,标题,内容等)的类,本文将介绍如何使用HtmlTag)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-04-05 17:14
2022-02-06
我写了一个类,用于从网页中抓取信息(如最新的头条、新闻来源、头条、内容等)。本文将介绍如何使用该类从网页中抓取所需的信息。本文将以博客园首页的博客标题和链接为例:
上图为博客园首页的DOM树。显然,你只需要提取带有类 post_item 的 div,然后提取带有类 titlelnk 的 a 标志。此类功能可以通过以下功能实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
/// 前端学习交流QQ群:461593224
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的函数:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
/// 前端学习交流QQ群:461593224
下面以博园首页抓取文章的标题和链接为例介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com");
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
结果如下:
欢迎前端同学一起学习
前端学习交流QQ群:461593224
分类:
技术要点:
相关文章: 查看全部
抓取网页flash(2022-02-06(如最新的头条新闻,新闻的来源,标题,内容等)的类,本文将介绍如何使用HtmlTag)
2022-02-06
我写了一个类,用于从网页中抓取信息(如最新的头条、新闻来源、头条、内容等)。本文将介绍如何使用该类从网页中抓取所需的信息。本文将以博客园首页的博客标题和链接为例:
上图为博客园首页的DOM树。显然,你只需要提取带有类 post_item 的 div,然后提取带有类 titlelnk 的 a 标志。此类功能可以通过以下功能实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
/// 前端学习交流QQ群:461593224
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的函数:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
/// 前端学习交流QQ群:461593224
下面以博园首页抓取文章的标题和链接为例介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com";);
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
结果如下:
欢迎前端同学一起学习
前端学习交流QQ群:461593224
分类:
技术要点:
相关文章:
抓取网页flash( 学习和掌握网页抓取使用Scrapy框架与这一步一步的指导)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-04-05 17:09
学习和掌握网页抓取使用Scrapy框架与这一步一步的指导)
通过这个循序渐进的深入指南,学习和掌握使用 Scrapy 框架的网页抓取
你会学到什么
定义网络抓取和创建网络爬虫的步骤
在 Windows、Mac OS、Ubuntu (Linux) 和 Anaconda 环境中安装和设置 Scrapy
使用 Scrapy Spider 向 URL 发送请求以抓取 网站
从 URL 获取 HTML 响应并解析它以进行网络抓取
使用 Scrapy 选择器、CSS 选择器和 XPath 从 网站 中选择所需的数据
Scrapy 爬虫从 网站 获取数据并提取到 JSON、CSV、XLSX (Excel) 和 XML 文件
使用 Scrapy Shell 命令测试和验证 CSS 选择器或 XPath
使用 Scrapy 项目管道将采集的数据导出并保存到 MonogoDB 等在线数据库
定义废品以组织废品数据并使用带有输入和输出处理器的废品加载器加载项目
使用 Scrapy Pagination 从多个网页中抓取数据并从 HTML 表格中提取数据
使用 Scrapy FormRequest 登录 CSRF 令牌网站
使用 Scrapy-Playwright 动态抓取/JavaScript 渲染的 网站 并与 Web 元素交互,截取 网站 的屏幕截图或保存为 PDF
识别来自 网站 的 API 调用并使用 Scrapy 请求从 API 中抓取数据
MP4 | 视频:h264, 1280×720 | 音频:AAC,44.1 KHz,2ch
语言:英文+中英文字幕(机器翻译在原英文字幕的基础上更准确)| 时长:96 节课(7 小时 32 米)| 解压后大小:3.58 GB
要求
Python 编程
HTML 基础 (+点)
描述
网页抓取是抓取 网站 并从中提取所需数据的过程,在本课程中,您将通过逐步深入的说明学习和掌握使用 python 和 scrapy 进行网页抓取。
分步指南
假设您对网络抓取、scrapy python web 抓取甚至网络抓取的含义一无所知 - 我们将从完整的基础知识开始。在第一部分中,您将了解网络抓取过程(使用信息图表 - 无代码)、如何从 网站 抓取数据,以及如何使用 scrapy(这就是 scrapy 的含义)。
在弄清楚基础知识并了解网页抓取的工作原理之后,我们将开始使用 python & scrapy 框架进行网页抓取。同样,我们将一步一步地执行基础知识中的每一步,一点一点的课程。我们会花时间让您更容易理解从 网站 抓取和提取数据的每个步骤。使用 Scrapy 和 Python 逐步掌握网页抓取
网页抓取和抓取要点
一旦您构建了一个实际的网络抓取工具,您将直接了解网络抓取的工作原理。现在重要的是涵盖网络抓取和scrapy的基本概念,这是我们接下来要做的。
用于选择 Web 元素的 CSS 选择器
选择 Web 元素的 XPath
用于测试和验证选择器的 Scrapy shell
组织项目以提取数据
使用带有输入和输出处理器的项目加载器加载项目
将数据导出为 JSON、CSV、XLSX (Excel) 和 XML 文件格式
使用 ItemPipelines 将提取的数据保存到 MongoDB 等在线数据库
主页抓取深度
学习如何抓取 网站 和 gist 已经让您成为一个完整的网络抓取工具,但是,我们将更进一步学习高级网络抓取技术并成为专家!
按照网页中的链接到另一个页面
抓取多个页面并提取数据,即分页
使用正则表达式 (RegEx) 抓取数据
从 HTML 表中提取数据
使用 Scrapy 表单请求登录网站
绕过受 CSRF 保护的登录表单
使用 Scrapy Writer 动态抓取或 JavaScript 渲染 网站
与 Web 元素交互,例如填写表单、单击按钮等。
处理无限滚动网站
加载内容/数据需要时间时等待元素
拍摄 网站 截图
将 网站 保存为 PDF
识别来自 网站 的 API 调用并从 API 中抓取数据
在零散的项目中使用中间件
在零碎的项目中配置设置
使用和轮换用户代理和代理
网页抓取最佳实践
现实世界的项目
掌握网页抓取后,我们需要项目才能开始!这就是为什么你还要实施三个项目
欧冠积分榜 [ESPN]
产品跟踪系统 [亚马逊]
刮板应用 [GUI]
加入我们的深入课程,您将从头开始学习网络抓取,并逐渐掌握从 网站 中提取数据的过程。查看预览课程并开始学习网络抓取的工作原理!到时候见~
这门课程是为谁准备的?
想要掌握网页抓取的初级 Python 开发人员
希望提高技能的自由职业者
隐藏内容:*********,下载
下载说明:
1、电脑:浏览器打开网页获取素材,打赏后自动显示百度网盘链接。如果没有显示,请刷新网页。
2、移动端:需要在微信中打开素材页面,打赏后返回原素材页面自动显示网盘链接。
3、资源默认为百度网盘链接。如链接失效或无法获取,请联系客服微信云桥网解决。
4、登录会员平台充值38元成为会员,免费获得更多优质资源!
Python 教程
小云
海报链接 查看全部
抓取网页flash(
学习和掌握网页抓取使用Scrapy框架与这一步一步的指导)
通过这个循序渐进的深入指南,学习和掌握使用 Scrapy 框架的网页抓取
你会学到什么
定义网络抓取和创建网络爬虫的步骤
在 Windows、Mac OS、Ubuntu (Linux) 和 Anaconda 环境中安装和设置 Scrapy
使用 Scrapy Spider 向 URL 发送请求以抓取 网站
从 URL 获取 HTML 响应并解析它以进行网络抓取
使用 Scrapy 选择器、CSS 选择器和 XPath 从 网站 中选择所需的数据
Scrapy 爬虫从 网站 获取数据并提取到 JSON、CSV、XLSX (Excel) 和 XML 文件
使用 Scrapy Shell 命令测试和验证 CSS 选择器或 XPath
使用 Scrapy 项目管道将采集的数据导出并保存到 MonogoDB 等在线数据库
定义废品以组织废品数据并使用带有输入和输出处理器的废品加载器加载项目
使用 Scrapy Pagination 从多个网页中抓取数据并从 HTML 表格中提取数据
使用 Scrapy FormRequest 登录 CSRF 令牌网站
使用 Scrapy-Playwright 动态抓取/JavaScript 渲染的 网站 并与 Web 元素交互,截取 网站 的屏幕截图或保存为 PDF
识别来自 网站 的 API 调用并使用 Scrapy 请求从 API 中抓取数据
MP4 | 视频:h264, 1280×720 | 音频:AAC,44.1 KHz,2ch
语言:英文+中英文字幕(机器翻译在原英文字幕的基础上更准确)| 时长:96 节课(7 小时 32 米)| 解压后大小:3.58 GB
要求
Python 编程
HTML 基础 (+点)
描述
网页抓取是抓取 网站 并从中提取所需数据的过程,在本课程中,您将通过逐步深入的说明学习和掌握使用 python 和 scrapy 进行网页抓取。
分步指南
假设您对网络抓取、scrapy python web 抓取甚至网络抓取的含义一无所知 - 我们将从完整的基础知识开始。在第一部分中,您将了解网络抓取过程(使用信息图表 - 无代码)、如何从 网站 抓取数据,以及如何使用 scrapy(这就是 scrapy 的含义)。
在弄清楚基础知识并了解网页抓取的工作原理之后,我们将开始使用 python & scrapy 框架进行网页抓取。同样,我们将一步一步地执行基础知识中的每一步,一点一点的课程。我们会花时间让您更容易理解从 网站 抓取和提取数据的每个步骤。使用 Scrapy 和 Python 逐步掌握网页抓取
网页抓取和抓取要点
一旦您构建了一个实际的网络抓取工具,您将直接了解网络抓取的工作原理。现在重要的是涵盖网络抓取和scrapy的基本概念,这是我们接下来要做的。
用于选择 Web 元素的 CSS 选择器
选择 Web 元素的 XPath
用于测试和验证选择器的 Scrapy shell
组织项目以提取数据
使用带有输入和输出处理器的项目加载器加载项目
将数据导出为 JSON、CSV、XLSX (Excel) 和 XML 文件格式
使用 ItemPipelines 将提取的数据保存到 MongoDB 等在线数据库
主页抓取深度
学习如何抓取 网站 和 gist 已经让您成为一个完整的网络抓取工具,但是,我们将更进一步学习高级网络抓取技术并成为专家!
按照网页中的链接到另一个页面
抓取多个页面并提取数据,即分页
使用正则表达式 (RegEx) 抓取数据
从 HTML 表中提取数据
使用 Scrapy 表单请求登录网站
绕过受 CSRF 保护的登录表单
使用 Scrapy Writer 动态抓取或 JavaScript 渲染 网站
与 Web 元素交互,例如填写表单、单击按钮等。
处理无限滚动网站
加载内容/数据需要时间时等待元素
拍摄 网站 截图
将 网站 保存为 PDF
识别来自 网站 的 API 调用并从 API 中抓取数据
在零散的项目中使用中间件
在零碎的项目中配置设置
使用和轮换用户代理和代理
网页抓取最佳实践
现实世界的项目
掌握网页抓取后,我们需要项目才能开始!这就是为什么你还要实施三个项目
欧冠积分榜 [ESPN]
产品跟踪系统 [亚马逊]
刮板应用 [GUI]
加入我们的深入课程,您将从头开始学习网络抓取,并逐渐掌握从 网站 中提取数据的过程。查看预览课程并开始学习网络抓取的工作原理!到时候见~
这门课程是为谁准备的?
想要掌握网页抓取的初级 Python 开发人员
希望提高技能的自由职业者
隐藏内容:*********,下载
下载说明:
1、电脑:浏览器打开网页获取素材,打赏后自动显示百度网盘链接。如果没有显示,请刷新网页。
2、移动端:需要在微信中打开素材页面,打赏后返回原素材页面自动显示网盘链接。
3、资源默认为百度网盘链接。如链接失效或无法获取,请联系客服微信云桥网解决。
4、登录会员平台充值38元成为会员,免费获得更多优质资源!
Python 教程
小云
海报链接
抓取网页flash(4.废料堆Scrapestack被超过2,000家公司使用的免费网络抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 282 次浏览 • 2022-04-05 17:05
对于不熟悉编码的人来说,创建网络爬虫可能很困难。幸运的是,程序员和非程序员都可以使用网络抓取软件。网页抓取软件是专门设计用于从 网站 获取相关数据的软件。这些工具适用于任何想以某种方式从 Internet 获取数据的人。此信息记录在计算机上的本地文件或数据库中。它是自动采集网络数据的技术。我们列出了 31 种最好的免费网页抓取工具。
内容
31 个最佳网络爬虫
可以在此处找到最佳网络爬虫的精选列表。此列表收录商业和开源工具,以及它们各自的 网站 的链接。
1. 智取
Outwit 是一个 Firefox 插件,可以从 Firefox 插件商店轻松安装。
无需编程知识即可使用 Outwit Hub 从站点获取准确数据。只需单击浏览按钮,您就可以开始抓取数百个网页。2. PareseHub
ParseHub 是另一个最好的免费网络抓取工具之一。
3.阿皮菲
Apify 是另一个最好的网络抓取和自动化工具,可让您为任何 网站、内置住宅和数据中心代理构建 API,从而更轻松地提取数据。
4. 废料堆
超过 2,000 家公司使用 Scrapestack,这些公司依赖于这种由 apilayer 提供支持的独特 API。它是最好的免费网络抓取工具之一。
5. 矿工
对于 Windows 和 Mac OS,FMiner 是一个流行的在线抓取、数据提取、屏幕抓取、宏和网络支持程序。
6. 顺序
Sequentum 是一个强大的大数据工具,用于获取可信的在线数据。它是另一个最好的免费网络抓取工具。
7. 代理
Agenty 是一个使用机器人流程自动化的数据抓取、文本提取和 OCR 程序。
8. 导入.io
import.io 网页抓取应用程序通过从网页导入数据并将数据导出为 CSV 来帮助您形成数据集。它也是最好的网络抓取工具之一。以下是此工具的功能。
9. Webz.io
Webz.io 让您可以抓取数百个 网站 并即时访问结构化和实时数据。它也是最好的免费网络抓取工具之一。
您可以获得 JSON 和 XML 格式的有组织的、机器可读的数据集。
10. 爬虫
Scrape Owl 是一个易于使用且价格合理的网络抓取平台。
11.刮痧
Scrapingbee 是一个网络抓取 API,负责代理设置和无头浏览器。
12.亮数据
Bright Data 是世界领先的在线数据平台,提供经济高效的解决方案来大规模采集公共 Web 数据,轻松将非结构化数据转换为结构化数据,并在提供卓越的同时提供完全透明和合规的客户体验。
13. 爬虫 API
您可以使用 Scraper API 工具来处理代理、浏览器和验证码。
14.德西智能
Dexi Intelligent 是一款在线抓取应用程序,可让您快速将任意数量的 Web 数据转化为商业价值。
15. 差异机器人
Diffbot 使您能够从互联网上快速获取各种重要事实。
16. 数据流
Data Streamer 是一种允许您从 Internet 获取社交网络资料的技术。
17.莫曾达
您可以使用 Mozenda 从网页中提取文本、照片和 PDF 材料。
18. 数据挖掘 Chrome 扩展
使用 Data Miner 浏览器插件可以更轻松地进行 Web 抓取和数据捕获。
19. 从头开始
Scrapy 也是最好的网页抓取工具之一。它是一个基于 Python 的开源在线抓取框架,用于创建网络抓取工具。
20. ScrapeHero 云
ScrapeHero 将其多年的网络爬虫知识转化为经济且易于使用的预构建爬虫程序和 API,用于从亚马逊、谷歌、沃尔玛等网站抓取数据网站。
21. 数据爬虫
Data Scraper 是一款免费的在线抓取应用程序,可从单个网页抓取数据并将其保存为 CSV 或 XSL 文件。
22. 视觉网络开膛手
Visual Web Ripper 是 网站 的自动数据抓取工具。
23.八卦
Octoparse 是一个用户友好的网页抓取应用程序,具有可视化界面。它是最好的免费网络抓取工具之一。以下是此工具的功能。
24.赛博哈维
WebHarvey 的可视化网络抓取工具有一个内置的浏览器,用于从在线站点抓取数据。它也是最好的网络抓取工具之一。以下是此工具的一些功能。
25. PySpider
PySpider 也是最好的免费网络爬虫工具之一,它是一个基于 Python 的网络爬虫。下面列出了该工具的一些功能。
26. 内容抓取器
Content Grabber 是一个可视化的在线抓取工具,具有易于使用的点击式界面来选择项目。以下是此工具的功能。
27.木村井
Kimurai 是一个 Ruby Web 抓取框架,用于创建爬虫和提取数据。它也是最好的免费网络抓取工具之一。以下是此工具的一些功能。
28. Cheerio
Cheerio 是另一个最好的网络抓取工具。它是一个解析 HTML 和 XML 文档并允许您使用 jQuery 语法对下载的数据进行操作的包。以下是此工具的功能。
29.傀儡师
Puppeteer 是一个 Node 包,它允许您使用强大而简单的 API 来管理 Google 的无头 Chrome 浏览器。下面列出了该工具的一些功能。
30.剧作家
Playwright 是一个为浏览器自动化而设计的 Microsoft Node 库。它是另一个最好的免费网络抓取工具。以下是此工具的一些功能。
31. PJScrape
PJscrape 是一个基于 Python 的在线抓取工具包,它使用 Javascript 和 JQuery。以下是此工具的功能。
***
我们希望本指南对最好的网络爬虫有所帮助。让我们知道您认为哪种工具对您来说很容易。继续访问我们的页面以获取更多很棒的提示和技巧,并在下面留下您的评论。 查看全部
抓取网页flash(4.废料堆Scrapestack被超过2,000家公司使用的免费网络抓取工具)
对于不熟悉编码的人来说,创建网络爬虫可能很困难。幸运的是,程序员和非程序员都可以使用网络抓取软件。网页抓取软件是专门设计用于从 网站 获取相关数据的软件。这些工具适用于任何想以某种方式从 Internet 获取数据的人。此信息记录在计算机上的本地文件或数据库中。它是自动采集网络数据的技术。我们列出了 31 种最好的免费网页抓取工具。
内容
31 个最佳网络爬虫
可以在此处找到最佳网络爬虫的精选列表。此列表收录商业和开源工具,以及它们各自的 网站 的链接。
1. 智取
Outwit 是一个 Firefox 插件,可以从 Firefox 插件商店轻松安装。
无需编程知识即可使用 Outwit Hub 从站点获取准确数据。只需单击浏览按钮,您就可以开始抓取数百个网页。2. PareseHub
ParseHub 是另一个最好的免费网络抓取工具之一。
3.阿皮菲
Apify 是另一个最好的网络抓取和自动化工具,可让您为任何 网站、内置住宅和数据中心代理构建 API,从而更轻松地提取数据。
4. 废料堆
超过 2,000 家公司使用 Scrapestack,这些公司依赖于这种由 apilayer 提供支持的独特 API。它是最好的免费网络抓取工具之一。
5. 矿工
对于 Windows 和 Mac OS,FMiner 是一个流行的在线抓取、数据提取、屏幕抓取、宏和网络支持程序。
6. 顺序
Sequentum 是一个强大的大数据工具,用于获取可信的在线数据。它是另一个最好的免费网络抓取工具。
7. 代理
Agenty 是一个使用机器人流程自动化的数据抓取、文本提取和 OCR 程序。
8. 导入.io
import.io 网页抓取应用程序通过从网页导入数据并将数据导出为 CSV 来帮助您形成数据集。它也是最好的网络抓取工具之一。以下是此工具的功能。
9. Webz.io
Webz.io 让您可以抓取数百个 网站 并即时访问结构化和实时数据。它也是最好的免费网络抓取工具之一。
您可以获得 JSON 和 XML 格式的有组织的、机器可读的数据集。
10. 爬虫
Scrape Owl 是一个易于使用且价格合理的网络抓取平台。
11.刮痧
Scrapingbee 是一个网络抓取 API,负责代理设置和无头浏览器。
12.亮数据
Bright Data 是世界领先的在线数据平台,提供经济高效的解决方案来大规模采集公共 Web 数据,轻松将非结构化数据转换为结构化数据,并在提供卓越的同时提供完全透明和合规的客户体验。
13. 爬虫 API
您可以使用 Scraper API 工具来处理代理、浏览器和验证码。
14.德西智能
Dexi Intelligent 是一款在线抓取应用程序,可让您快速将任意数量的 Web 数据转化为商业价值。
15. 差异机器人
Diffbot 使您能够从互联网上快速获取各种重要事实。
16. 数据流
Data Streamer 是一种允许您从 Internet 获取社交网络资料的技术。
17.莫曾达
您可以使用 Mozenda 从网页中提取文本、照片和 PDF 材料。
18. 数据挖掘 Chrome 扩展
使用 Data Miner 浏览器插件可以更轻松地进行 Web 抓取和数据捕获。
19. 从头开始
Scrapy 也是最好的网页抓取工具之一。它是一个基于 Python 的开源在线抓取框架,用于创建网络抓取工具。
20. ScrapeHero 云
ScrapeHero 将其多年的网络爬虫知识转化为经济且易于使用的预构建爬虫程序和 API,用于从亚马逊、谷歌、沃尔玛等网站抓取数据网站。
21. 数据爬虫
Data Scraper 是一款免费的在线抓取应用程序,可从单个网页抓取数据并将其保存为 CSV 或 XSL 文件。
22. 视觉网络开膛手
Visual Web Ripper 是 网站 的自动数据抓取工具。
23.八卦
Octoparse 是一个用户友好的网页抓取应用程序,具有可视化界面。它是最好的免费网络抓取工具之一。以下是此工具的功能。
24.赛博哈维
WebHarvey 的可视化网络抓取工具有一个内置的浏览器,用于从在线站点抓取数据。它也是最好的网络抓取工具之一。以下是此工具的一些功能。
25. PySpider
PySpider 也是最好的免费网络爬虫工具之一,它是一个基于 Python 的网络爬虫。下面列出了该工具的一些功能。
26. 内容抓取器
Content Grabber 是一个可视化的在线抓取工具,具有易于使用的点击式界面来选择项目。以下是此工具的功能。
27.木村井
Kimurai 是一个 Ruby Web 抓取框架,用于创建爬虫和提取数据。它也是最好的免费网络抓取工具之一。以下是此工具的一些功能。
28. Cheerio
Cheerio 是另一个最好的网络抓取工具。它是一个解析 HTML 和 XML 文档并允许您使用 jQuery 语法对下载的数据进行操作的包。以下是此工具的功能。
29.傀儡师
Puppeteer 是一个 Node 包,它允许您使用强大而简单的 API 来管理 Google 的无头 Chrome 浏览器。下面列出了该工具的一些功能。
30.剧作家
Playwright 是一个为浏览器自动化而设计的 Microsoft Node 库。它是另一个最好的免费网络抓取工具。以下是此工具的一些功能。
31. PJScrape
PJscrape 是一个基于 Python 的在线抓取工具包,它使用 Javascript 和 JQuery。以下是此工具的功能。
***
我们希望本指南对最好的网络爬虫有所帮助。让我们知道您认为哪种工具对您来说很容易。继续访问我们的页面以获取更多很棒的提示和技巧,并在下面留下您的评论。
抓取网页flash(网站抓取是一个用Python编写的Web爬虫器是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-04-05 09:19
网站Crawling 是一个用 Python 编写的网络爬虫和网络抓取框架。网站Scraping 是一个完整的框架,因此它收录了 Web 抓取所需的一切,包括用于发送 HTTP 请求和从下载的 HTML 页面中解析数据的模块。它可以渲染 JavaScript,网站从网页中抓取和解析数据变得容易。它位于 HTML 或 XML 解析器之上,为网站管理员提供了一种 Python 方式来访问数据。所以网站爬取是站长需要了解的采集文章填充网站内容的工具。
网站爬取的HTML语法分析-免费网站代码SEO优化神器
网页抓取是一种从网页中获取页面内容的技术。通常通过 网站 抓取,使用低级超文本传输协议来模拟正常的人类访问。网络抓取与网络索引非常相似,其中网络索引是指大多数搜索引擎使用的机器人或网络爬虫等技术。相比之下,网络抓取更侧重于将网络上的非结构化数据(通常为 HTML 格式)转换为可以在中央数据库和电子表格中存储和分析的结构化数据。网络抓取还涉及网络自动化,它使用计算机软件来模拟人类浏览。
网站爬取的HTML语法分析-免费网站代码SEO优化神器
网页抓取文本搜索和正则表达式:文本搜索和正则表达式可以有效地从页面中提取所需的内容。网页抓取可以在基于UNIX的系统上使用grep,在其他平台或其他编程语言(如Perl、Python)中都有对应的命令或语法。网页抓取是基于HTTP编程的:无论是静态网页还是动态网页,都可以通过向服务器发送HTTP请求来获取,所以可以通过直接socket编程来实现。
网站爬取的HTML解析器:很多网站使用数据库来存储自己的数据,当用户访问时,由程序按照指定的格式自动生成。因此,可以使用语法分析器对网站爬取得到的HTML页面进行解析,然后使用HTML标签提取出需要的内容。使用 HTML 解析器比文本搜索和正则表达式更健壮,并且避免构造复杂的正则表达式。
网站爬取的HTML语法分析-免费网站代码SEO优化神器
网站爬虫应用,从搜索引擎优化(SEO)分析到搜索引擎索引、一般性能监控等,它的一些应用可能还包括爬取网页。网站抓取只需要提交网站首页URL,其他页面(如列表页、内容页)会自动抓取。网站抓取的模板收录HTML、CSS、图片、JS、Flash等目录并保存在原站点结构中,替换对应的cms标签即可使用。
网站 掌握最新海量网络信息采集、处理、存储、全文检索、中文处理和文本挖掘技术,可实时监控最新新闻、论坛、博客、微博和视频。舆情信息帮助站长及时、全面、准确地掌握网络动态,自动采集到自己网站,用户填写网站的内容。
网站爬虫使用自然语言处理技术,保证抓取信息的准确性、分类的准确性和否定判断的准确性。网站抓取相似文章识别,准确识别出内容相似的文章,可用于文章的去重和识别。网站爬取无需模板,方便随时添加采集源,不受网页修改影响。网站捕捉全方位的数据分析展示功能,多角度多层次展示内容特征,揭示数据规律,帮助站长更好的管理和维护网站。 查看全部
抓取网页flash(网站抓取是一个用Python编写的Web爬虫器是什么)
网站Crawling 是一个用 Python 编写的网络爬虫和网络抓取框架。网站Scraping 是一个完整的框架,因此它收录了 Web 抓取所需的一切,包括用于发送 HTTP 请求和从下载的 HTML 页面中解析数据的模块。它可以渲染 JavaScript,网站从网页中抓取和解析数据变得容易。它位于 HTML 或 XML 解析器之上,为网站管理员提供了一种 Python 方式来访问数据。所以网站爬取是站长需要了解的采集文章填充网站内容的工具。
网站爬取的HTML语法分析-免费网站代码SEO优化神器
网页抓取是一种从网页中获取页面内容的技术。通常通过 网站 抓取,使用低级超文本传输协议来模拟正常的人类访问。网络抓取与网络索引非常相似,其中网络索引是指大多数搜索引擎使用的机器人或网络爬虫等技术。相比之下,网络抓取更侧重于将网络上的非结构化数据(通常为 HTML 格式)转换为可以在中央数据库和电子表格中存储和分析的结构化数据。网络抓取还涉及网络自动化,它使用计算机软件来模拟人类浏览。
网站爬取的HTML语法分析-免费网站代码SEO优化神器
网页抓取文本搜索和正则表达式:文本搜索和正则表达式可以有效地从页面中提取所需的内容。网页抓取可以在基于UNIX的系统上使用grep,在其他平台或其他编程语言(如Perl、Python)中都有对应的命令或语法。网页抓取是基于HTTP编程的:无论是静态网页还是动态网页,都可以通过向服务器发送HTTP请求来获取,所以可以通过直接socket编程来实现。
网站爬取的HTML解析器:很多网站使用数据库来存储自己的数据,当用户访问时,由程序按照指定的格式自动生成。因此,可以使用语法分析器对网站爬取得到的HTML页面进行解析,然后使用HTML标签提取出需要的内容。使用 HTML 解析器比文本搜索和正则表达式更健壮,并且避免构造复杂的正则表达式。
网站爬取的HTML语法分析-免费网站代码SEO优化神器
网站爬虫应用,从搜索引擎优化(SEO)分析到搜索引擎索引、一般性能监控等,它的一些应用可能还包括爬取网页。网站抓取只需要提交网站首页URL,其他页面(如列表页、内容页)会自动抓取。网站抓取的模板收录HTML、CSS、图片、JS、Flash等目录并保存在原站点结构中,替换对应的cms标签即可使用。
网站 掌握最新海量网络信息采集、处理、存储、全文检索、中文处理和文本挖掘技术,可实时监控最新新闻、论坛、博客、微博和视频。舆情信息帮助站长及时、全面、准确地掌握网络动态,自动采集到自己网站,用户填写网站的内容。
网站爬虫使用自然语言处理技术,保证抓取信息的准确性、分类的准确性和否定判断的准确性。网站抓取相似文章识别,准确识别出内容相似的文章,可用于文章的去重和识别。网站爬取无需模板,方便随时添加采集源,不受网页修改影响。网站捕捉全方位的数据分析展示功能,多角度多层次展示内容特征,揭示数据规律,帮助站长更好的管理和维护网站。
抓取网页flash(一个用Python编写的Web爬虫和Web抓取框架(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-01 21:19
网站Crawling 是一个用 Python 编写的网络爬虫和网络抓取框架。网站Scraping 是一个完整的框架,因此它收录了 Web 抓取所需的一切,包括用于发送 HTTP 请求和从下载的 HTML 页面中解析数据的模块。它可以渲染 JavaScript,网站从网页中抓取和解析数据变得容易。它位于 HTML 或 XML 解析器之上,为网站管理员提供了一种 Python 方式来访问数据。所以网站爬取是站长需要了解的采集文章填充网站内容的工具。
网页抓取是一种从网页中获取页面内容的技术。通常通过 网站 抓取,使用低级超文本传输协议来模拟正常的人类访问。网络抓取与网络索引非常相似,其中网络索引是指大多数搜索引擎使用的机器人或网络爬虫等技术。相比之下,网络抓取更侧重于将网络上的非结构化数据(通常为 HTML 格式)转换为可以在中央数据库和电子表格中存储和分析的结构化数据。网络抓取还涉及网络自动化,它使用计算机软件来模拟人类浏览。
网页抓取文本搜索和正则表达式:文本搜索和正则表达式可以有效地从页面中提取所需的内容。网页抓取可以在基于UNIX的系统上使用grep,在其他平台或其他编程语言(如Perl、Python)中都有对应的命令或语法。网页抓取是基于HTTP编程的:无论是静态网页还是动态网页,都可以通过向服务器发送HTTP请求来获取,所以可以通过直接socket编程来实现。
网站爬取的HTML解析器:很多网站使用数据库来存储自己的数据,当用户访问时,由程序按照指定的格式自动生成。因此,可以使用语法分析器对网站爬取得到的HTML页面进行解析,然后使用HTML标签提取出需要的内容。使用 HTML 解析器比文本搜索和正则表达式更健壮,并且避免构造复杂的正则表达式。
网站爬虫应用,从搜索引擎优化(SEO)分析到搜索引擎索引、一般性能监控等,它的一些应用可能还包括爬取网页。网站抓取只需要提交网站首页URL,其他页面(如列表页、内容页)会自动抓取。网站抓取的模板收录HTML、CSS、图片、JS、Flash等目录并保存在原站点结构中,替换对应的cms标签即可使用。
网站 掌握最新海量网络信息采集、处理、存储、全文检索、中文处理和文本挖掘技术,可实时监控最新新闻、论坛、博客、微博和视频。舆情信息帮助站长及时、全面、准确地掌握网络动态,自动采集到自己网站,用户填写网站的内容。
网站爬虫使用自然语言处理技术,保证抓取信息的准确性、分类的准确性和否定判断的准确性。网站抓取相似文章识别,准确识别出内容相似的文章,可用于文章的去重和识别。网站爬取无需模板,方便随时添加采集源,不受网页修改影响。网站捕捉全方位的数据分析展示功能,多角度多层次展示内容特征,揭示数据规律,帮助站长更好的管理和维护网站。 查看全部
抓取网页flash(一个用Python编写的Web爬虫和Web抓取框架(图))
网站Crawling 是一个用 Python 编写的网络爬虫和网络抓取框架。网站Scraping 是一个完整的框架,因此它收录了 Web 抓取所需的一切,包括用于发送 HTTP 请求和从下载的 HTML 页面中解析数据的模块。它可以渲染 JavaScript,网站从网页中抓取和解析数据变得容易。它位于 HTML 或 XML 解析器之上,为网站管理员提供了一种 Python 方式来访问数据。所以网站爬取是站长需要了解的采集文章填充网站内容的工具。
网页抓取是一种从网页中获取页面内容的技术。通常通过 网站 抓取,使用低级超文本传输协议来模拟正常的人类访问。网络抓取与网络索引非常相似,其中网络索引是指大多数搜索引擎使用的机器人或网络爬虫等技术。相比之下,网络抓取更侧重于将网络上的非结构化数据(通常为 HTML 格式)转换为可以在中央数据库和电子表格中存储和分析的结构化数据。网络抓取还涉及网络自动化,它使用计算机软件来模拟人类浏览。
网页抓取文本搜索和正则表达式:文本搜索和正则表达式可以有效地从页面中提取所需的内容。网页抓取可以在基于UNIX的系统上使用grep,在其他平台或其他编程语言(如Perl、Python)中都有对应的命令或语法。网页抓取是基于HTTP编程的:无论是静态网页还是动态网页,都可以通过向服务器发送HTTP请求来获取,所以可以通过直接socket编程来实现。
网站爬取的HTML解析器:很多网站使用数据库来存储自己的数据,当用户访问时,由程序按照指定的格式自动生成。因此,可以使用语法分析器对网站爬取得到的HTML页面进行解析,然后使用HTML标签提取出需要的内容。使用 HTML 解析器比文本搜索和正则表达式更健壮,并且避免构造复杂的正则表达式。
网站爬虫应用,从搜索引擎优化(SEO)分析到搜索引擎索引、一般性能监控等,它的一些应用可能还包括爬取网页。网站抓取只需要提交网站首页URL,其他页面(如列表页、内容页)会自动抓取。网站抓取的模板收录HTML、CSS、图片、JS、Flash等目录并保存在原站点结构中,替换对应的cms标签即可使用。
网站 掌握最新海量网络信息采集、处理、存储、全文检索、中文处理和文本挖掘技术,可实时监控最新新闻、论坛、博客、微博和视频。舆情信息帮助站长及时、全面、准确地掌握网络动态,自动采集到自己网站,用户填写网站的内容。
网站爬虫使用自然语言处理技术,保证抓取信息的准确性、分类的准确性和否定判断的准确性。网站抓取相似文章识别,准确识别出内容相似的文章,可用于文章的去重和识别。网站爬取无需模板,方便随时添加采集源,不受网页修改影响。网站捕捉全方位的数据分析展示功能,多角度多层次展示内容特征,揭示数据规律,帮助站长更好的管理和维护网站。
抓取网页flash(不提倡不是完全不用flash功能,少用可根据个人需求取舍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-03-26 09:15
经常浏览网站的人会发现,现在在网站中已经很少看到动画了。这是因为这种格式逐渐不被人们提倡了,所以 flash 网站为什么越来越被弃用了?
为什么 flash 做 网站 越来越气馁
之所以在网站中尽量少放flash动画,是因为flash的加载量比较大,会影响页面的加载速度,进而影响客户体验的效果。但是,完全不使用闪光灯功能是不可取的。如果你用的比较少,可以根据个人需要做适当的选择。网站的速度极大地影响了客户的体验,没有人愿意等待一个长时间打不开的网站。其实打开速度有很多问题。可能是主机的问题,也可能是网站上的图片或flash过多造成的。尽量在两秒内控制开口。一旦超过,很多客户会直接关闭页面。对于PC配置较低的客户,如果网站速度不好,那么flash的存在只会拖慢网站的加载速度,严重影响客户体验。为了使 网站 万无一失,只能避免这个元素。
不建议在网站上搞这些动画,而且整个网页不要到处都是各种截图,更不允许在网站上插入各种广告,还有一些网站 甚至在弹窗上,给客户的印象相当不好,甚至有用户认为是垃圾网站。搜索引擎无法抓取flash中的信息,不仅影响客户体验,也影响网页可视化。访问需要大量流量。如果 网站 的速度较慢,则页面加载缓慢。情况,现在有些浏览器根本不支持flash,如果可以的话就不需要了。
网站和布局是网站直观的部分,也是网站访问者首先产生的印象。很多中小型企业的网页设计和制作显得粗糙杂乱,色调不协调,整个网页让人杂乱无章。感觉。过分追求视觉效果,大量使用图片和flash,不利于搜索引擎排名。由于flash本身可以做很多种效果,尤其是放在导航上的时候,视觉效果很明显,所以很多网站喜欢,甚至企业网站的首页都是flash,还是让客户通过flash上的链接点击页面,但是搜索引擎很难读取里面的内容。一个复杂而凌乱的网站 查看全部
抓取网页flash(不提倡不是完全不用flash功能,少用可根据个人需求取舍)
经常浏览网站的人会发现,现在在网站中已经很少看到动画了。这是因为这种格式逐渐不被人们提倡了,所以 flash 网站为什么越来越被弃用了?
为什么 flash 做 网站 越来越气馁
之所以在网站中尽量少放flash动画,是因为flash的加载量比较大,会影响页面的加载速度,进而影响客户体验的效果。但是,完全不使用闪光灯功能是不可取的。如果你用的比较少,可以根据个人需要做适当的选择。网站的速度极大地影响了客户的体验,没有人愿意等待一个长时间打不开的网站。其实打开速度有很多问题。可能是主机的问题,也可能是网站上的图片或flash过多造成的。尽量在两秒内控制开口。一旦超过,很多客户会直接关闭页面。对于PC配置较低的客户,如果网站速度不好,那么flash的存在只会拖慢网站的加载速度,严重影响客户体验。为了使 网站 万无一失,只能避免这个元素。
不建议在网站上搞这些动画,而且整个网页不要到处都是各种截图,更不允许在网站上插入各种广告,还有一些网站 甚至在弹窗上,给客户的印象相当不好,甚至有用户认为是垃圾网站。搜索引擎无法抓取flash中的信息,不仅影响客户体验,也影响网页可视化。访问需要大量流量。如果 网站 的速度较慢,则页面加载缓慢。情况,现在有些浏览器根本不支持flash,如果可以的话就不需要了。
网站和布局是网站直观的部分,也是网站访问者首先产生的印象。很多中小型企业的网页设计和制作显得粗糙杂乱,色调不协调,整个网页让人杂乱无章。感觉。过分追求视觉效果,大量使用图片和flash,不利于搜索引擎排名。由于flash本身可以做很多种效果,尤其是放在导航上的时候,视觉效果很明显,所以很多网站喜欢,甚至企业网站的首页都是flash,还是让客户通过flash上的链接点击页面,但是搜索引擎很难读取里面的内容。一个复杂而凌乱的网站
抓取网页flash(谷歌搜索彻底停止Flash服务支持的信息(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-25 05:20
Flash网页可以说开启了页面动画的新模式。在刚刚起步的页面制作中,Flash的出现无疑给广大程序员带来了一个新的起点,让页面越来越形象化。Flash网站在视觉效果、交互效果等多方面都有很强的优势。广泛应用于房地产行业、汽车行业、奢侈品行业等高端行业。
Flash网页给人以强烈的视觉冲击力,可以表达我们想要表达的元素,给人一种高端的感觉,但多年来:超长的加载时间已经成为Flash的存在网站的一个普遍现象问题在于,由于自身的优势,需要大量的数据来支持,但需要较长的加载速度来支持,搜索引擎很难识别这些元素。这是搜索引擎的问题,也是整个Flash网站的问题。虽然搜索引擎正在逐步加强对多幅Flash动画动画图片的识别和爬取技术,但仍然存在一些影响用户体验的问题,尤其是在这个特殊时期。.
在众多搜索引擎中,Google 可以说是针对 Flash 网页优化好的浏览器。在其seoer人员的不断努力优化和不断修改下,Flash网页虽然不容易优化,但也不乏其人。优秀的Flash网页展现在用户面前。
不过,最近谷歌浏览器已经推送了谷歌搜索将完全停止支持Flash服务的信息。计划在 2020 年底完全停止支持 Flash。Google 搜索也开始自动过滤收录 Flash 内容的网页,并停止 收录 与 Flash 文件的网页信息,后续 Google 搜索将无法搜索用于收录 Flash 网页的相关 网站 内容。
据小编了解,不仅是谷歌Chrome,几乎所有主流浏览器都开始陆续停止支持Flash服务。可见Flash网页已经走到了尽头!
这里我也给大家一些建议:
1.修改你自己的网站在完全接收之前
2.Flash网页现在谷歌正在调整,但是国内的浏览器也会陆续停掉,大家不要冒险。
3.社会在变,时代在进步,网站和页面也需要我们不断完善! 查看全部
抓取网页flash(谷歌搜索彻底停止Flash服务支持的信息(图))
Flash网页可以说开启了页面动画的新模式。在刚刚起步的页面制作中,Flash的出现无疑给广大程序员带来了一个新的起点,让页面越来越形象化。Flash网站在视觉效果、交互效果等多方面都有很强的优势。广泛应用于房地产行业、汽车行业、奢侈品行业等高端行业。
Flash网页给人以强烈的视觉冲击力,可以表达我们想要表达的元素,给人一种高端的感觉,但多年来:超长的加载时间已经成为Flash的存在网站的一个普遍现象问题在于,由于自身的优势,需要大量的数据来支持,但需要较长的加载速度来支持,搜索引擎很难识别这些元素。这是搜索引擎的问题,也是整个Flash网站的问题。虽然搜索引擎正在逐步加强对多幅Flash动画动画图片的识别和爬取技术,但仍然存在一些影响用户体验的问题,尤其是在这个特殊时期。.
在众多搜索引擎中,Google 可以说是针对 Flash 网页优化好的浏览器。在其seoer人员的不断努力优化和不断修改下,Flash网页虽然不容易优化,但也不乏其人。优秀的Flash网页展现在用户面前。
不过,最近谷歌浏览器已经推送了谷歌搜索将完全停止支持Flash服务的信息。计划在 2020 年底完全停止支持 Flash。Google 搜索也开始自动过滤收录 Flash 内容的网页,并停止 收录 与 Flash 文件的网页信息,后续 Google 搜索将无法搜索用于收录 Flash 网页的相关 网站 内容。
据小编了解,不仅是谷歌Chrome,几乎所有主流浏览器都开始陆续停止支持Flash服务。可见Flash网页已经走到了尽头!
这里我也给大家一些建议:
1.修改你自己的网站在完全接收之前
2.Flash网页现在谷歌正在调整,但是国内的浏览器也会陆续停掉,大家不要冒险。
3.社会在变,时代在进步,网站和页面也需要我们不断完善!
抓取网页flash(嗨创h5自助建站专注建站6年,网站收录和排名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-24 16:12
在互联网+时代,网站是每个大中型企业必备的工具。有了这把武器,如何才能带来实实在在的收益,网站的收录和排名很重要,这样会大大增加公司的曝光率,带来更多的客流量。
关于网站SEO 和搜索引擎,一直是企业津津乐道的话题。我们都知道,如果SEO做得合理,就会被搜索引擎点赞,直接带来难以想象的流量。
合理优化网站有利于搜索引擎抓取网站、收录更有用的网页,挖掘更多有价值的信息等。 6 年。拥有国内外领先的技术和网站营销技术。.
从搜索引擎蜘蛛的角度看一个网站,在爬取、索引、排名的时候
没有。一、确保搜索引擎可以抓取页面
众所周知,百度蜘蛛通过跟随链接爬取页面内容来爬取页面。如果你想让蜘蛛爬到你的网站主页,必须有你的网站主页的外部链接,只有蜘蛛爬到主页然后跟着内部链接去抓取更多更深网站 内容。这里更需要注意的是,网站内容页面不能离首页太远,要控制在3-4二流之内。
所以网站应该有一个好的网站结构,逻辑清晰,内部链接应该形成蜘蛛网,提高蜘蛛爬行粘性。从网站的编码来看,要注意避免使用js脚本链接、flash中的链接等,因为蜘蛛不识别也无法识别跟踪链接的抓取,会直接导致< @收录 问题。
找到二、页面后能不能刮一下页面内容
吸引蜘蛛爬到网站后,文章能否顺利爬行,与网站的设计有很大关系。很明显蜘蛛不喜欢动态的url,所以在网站@网站代码上要注意,使用能找到并且可以爬取的url,最好的建议,网站URL 使用静态的。
如何在页面 三、 爬取后提取有用信息
遵循搜索引擎的工作原理,我们都知道,当搜索引擎蜘蛛来找你网站,爬取页面后,索引的第一步就是提取中文,所以把关键词放在页面顶部的重要位置,即Title的写法,页面标题是SEO中最重要的因素,还有一些重要标签的写法如网站描述标签和文章@ > 标题标签,内容必须突出网站的点。
在网站的后台写的过程中,程序员都知道简化代码是第一要务,比如去掉一些无用的代码或者注释,这样可以帮助搜索引擎更快更清楚的理解页面的内容,提取有用信息。
如果你想被引擎迅速收录并获得最高排名,你必须做你想做的事。
喜创H5自助建站平台,0代码,但操作平台,大中型企业首选,电脑网站,手机网站,微信网站三站于一体,同时朋友圈、微博、博客、QQ空间等移动平台实时更新。
更多体验,请登录海创H5自助网站:一小时轻松建站,在线运行。 查看全部
抓取网页flash(嗨创h5自助建站专注建站6年,网站收录和排名)
在互联网+时代,网站是每个大中型企业必备的工具。有了这把武器,如何才能带来实实在在的收益,网站的收录和排名很重要,这样会大大增加公司的曝光率,带来更多的客流量。
关于网站SEO 和搜索引擎,一直是企业津津乐道的话题。我们都知道,如果SEO做得合理,就会被搜索引擎点赞,直接带来难以想象的流量。
合理优化网站有利于搜索引擎抓取网站、收录更有用的网页,挖掘更多有价值的信息等。 6 年。拥有国内外领先的技术和网站营销技术。.
从搜索引擎蜘蛛的角度看一个网站,在爬取、索引、排名的时候
没有。一、确保搜索引擎可以抓取页面
众所周知,百度蜘蛛通过跟随链接爬取页面内容来爬取页面。如果你想让蜘蛛爬到你的网站主页,必须有你的网站主页的外部链接,只有蜘蛛爬到主页然后跟着内部链接去抓取更多更深网站 内容。这里更需要注意的是,网站内容页面不能离首页太远,要控制在3-4二流之内。
所以网站应该有一个好的网站结构,逻辑清晰,内部链接应该形成蜘蛛网,提高蜘蛛爬行粘性。从网站的编码来看,要注意避免使用js脚本链接、flash中的链接等,因为蜘蛛不识别也无法识别跟踪链接的抓取,会直接导致< @收录 问题。
找到二、页面后能不能刮一下页面内容
吸引蜘蛛爬到网站后,文章能否顺利爬行,与网站的设计有很大关系。很明显蜘蛛不喜欢动态的url,所以在网站@网站代码上要注意,使用能找到并且可以爬取的url,最好的建议,网站URL 使用静态的。
如何在页面 三、 爬取后提取有用信息
遵循搜索引擎的工作原理,我们都知道,当搜索引擎蜘蛛来找你网站,爬取页面后,索引的第一步就是提取中文,所以把关键词放在页面顶部的重要位置,即Title的写法,页面标题是SEO中最重要的因素,还有一些重要标签的写法如网站描述标签和文章@ > 标题标签,内容必须突出网站的点。
在网站的后台写的过程中,程序员都知道简化代码是第一要务,比如去掉一些无用的代码或者注释,这样可以帮助搜索引擎更快更清楚的理解页面的内容,提取有用信息。
如果你想被引擎迅速收录并获得最高排名,你必须做你想做的事。
喜创H5自助建站平台,0代码,但操作平台,大中型企业首选,电脑网站,手机网站,微信网站三站于一体,同时朋友圈、微博、博客、QQ空间等移动平台实时更新。
更多体验,请登录海创H5自助网站:一小时轻松建站,在线运行。
抓取网页flash(wireshark如何抓包分析网页视频特征,并写出L7的代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2022-03-17 02:10
Wireshark是一款非常有名的数据分析软件,我们首先需要下载安装wireshark并安装。下面介绍wireshark如何抓包,分析网络视频特征,编写L7代码。
运营流程:
1. 启动wireshark,找到需要抓包的网卡,准备抓包;
2. 启动浏览器并打开网页观看视频;
3. 在wireshark抓包界面点击start开始抓包;
4. 观看视频一定时间后,停止wireshark抓包,分析数据,输入http.request get找到请求获取的链接,一般以.swf结尾
5.分析类型关联数据,多次比较,发现共性,写L7正则表达式
一、启用wireshark。
2013-12-12 10:06 上传
下载附件 (67.54 KB)
通过列表我们可以选择需要抓包的网卡
2013-12-12 10:06 上传
下载附件 (22.55 KB)
二、打开浏览器,但不要播放视频。这是一个例子
三、点击开始按钮开始抓取,然后点击播放网络视频。
四、视频播放一段时间后,我们可以停止抓包。分析数据包最重要的是向视频服务器申请视频的get或post参数。我们可以使用http.request get来查找,如下图
2013-12-12 10:06 上传
下载附件 (66.72 KB)
我们从应用层分析 L7 数据,无论是游戏还是视频,不管它们的帧、以太网、网际协议和传输方式(TCP 还是 UDP),只有在分析完传输协议,例如视频后,我们分析是http传输协议
当然我们要找的是视频文件,比如.swf结尾的内容(可能是mp4之类的),其他的jpg、js、png就不用考虑了。在上图中,我们找到了一个相关的匹配GET值,可以看到主机在220.118.109.158处从服务器获取了一个.swf flash视频文件,
2013-12-12 10:07 上传
下载附件 (92.41 KB)
内容如下:
[[动态]]/2/[[动态]]/6
继续查找相关内容:
2013-12-12 10:07 上传
下载附件 (92.03 KB)
这一次我们得到了不同的东西
[[动态]]/2/[[动态]]/6
我们多次使用这种方法比较该视频的GET信息,几乎所有的连接内容都有上述的共同点。
这样我们就可以开始爬关键词了,这些都是自动固定的,然后是adplayer.swf或者qiyi_player.swf,这里我们只取.swf,那么我们要收录的关键词是
GET++.swf
最后,我们编写如下L7正则表达式代码
^(get|post) .+\www\ 。\七一\ . \com\ / \播放器。+\ .swf
代码分析:
^ : 表示内容的开始
(get|post): "|" 中间标识 get 或 post
.+ :介于两者之间的任何字符
\ :将内容转换为字符
最后我们将代码简化为:
^(获取|发布)。+\七一\ . \com\ / \播放器。+\ .swf
此处不包括www,因为服务器可能会替换其他二级域名,我们将代码添加到/ip firewall layer7-protocol
2013-12-12 10:08 上传
下载附件 (120.81 KB)
后者是需要在iP防火墙过滤器中进行防火墙过滤,或者在iP防火墙mangle中进行流量控制等操作
下面是几个视频网页的 L7 正则表达式
2013-12-12 10:06 上传
下载附件 (122.19 KB) 查看全部
抓取网页flash(wireshark如何抓包分析网页视频特征,并写出L7的代码)
Wireshark是一款非常有名的数据分析软件,我们首先需要下载安装wireshark并安装。下面介绍wireshark如何抓包,分析网络视频特征,编写L7代码。
运营流程:
1. 启动wireshark,找到需要抓包的网卡,准备抓包;
2. 启动浏览器并打开网页观看视频;
3. 在wireshark抓包界面点击start开始抓包;
4. 观看视频一定时间后,停止wireshark抓包,分析数据,输入http.request get找到请求获取的链接,一般以.swf结尾
5.分析类型关联数据,多次比较,发现共性,写L7正则表达式
一、启用wireshark。
2013-12-12 10:06 上传
下载附件 (67.54 KB)
通过列表我们可以选择需要抓包的网卡
2013-12-12 10:06 上传
下载附件 (22.55 KB)
二、打开浏览器,但不要播放视频。这是一个例子
三、点击开始按钮开始抓取,然后点击播放网络视频。
四、视频播放一段时间后,我们可以停止抓包。分析数据包最重要的是向视频服务器申请视频的get或post参数。我们可以使用http.request get来查找,如下图
2013-12-12 10:06 上传
下载附件 (66.72 KB)
我们从应用层分析 L7 数据,无论是游戏还是视频,不管它们的帧、以太网、网际协议和传输方式(TCP 还是 UDP),只有在分析完传输协议,例如视频后,我们分析是http传输协议
当然我们要找的是视频文件,比如.swf结尾的内容(可能是mp4之类的),其他的jpg、js、png就不用考虑了。在上图中,我们找到了一个相关的匹配GET值,可以看到主机在220.118.109.158处从服务器获取了一个.swf flash视频文件,
2013-12-12 10:07 上传
下载附件 (92.41 KB)
内容如下:
[[动态]]/2/[[动态]]/6
继续查找相关内容:
2013-12-12 10:07 上传
下载附件 (92.03 KB)
这一次我们得到了不同的东西
[[动态]]/2/[[动态]]/6
我们多次使用这种方法比较该视频的GET信息,几乎所有的连接内容都有上述的共同点。
这样我们就可以开始爬关键词了,这些都是自动固定的,然后是adplayer.swf或者qiyi_player.swf,这里我们只取.swf,那么我们要收录的关键词是
GET++.swf
最后,我们编写如下L7正则表达式代码
^(get|post) .+\www\ 。\七一\ . \com\ / \播放器。+\ .swf
代码分析:
^ : 表示内容的开始
(get|post): "|" 中间标识 get 或 post
.+ :介于两者之间的任何字符
\ :将内容转换为字符
最后我们将代码简化为:
^(获取|发布)。+\七一\ . \com\ / \播放器。+\ .swf
此处不包括www,因为服务器可能会替换其他二级域名,我们将代码添加到/ip firewall layer7-protocol
2013-12-12 10:08 上传
下载附件 (120.81 KB)
后者是需要在iP防火墙过滤器中进行防火墙过滤,或者在iP防火墙mangle中进行流量控制等操作
下面是几个视频网页的 L7 正则表达式
2013-12-12 10:06 上传
下载附件 (122.19 KB)
抓取网页flash(AdobeFlashPlayer将在明年被彻底结束支持(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-08 06:18
Adobe Flash Player 将在明年完全停止支持,这意味着所有用户都不应该继续使用这个容易出错的媒体播放器。
目前各大浏览器都开始限制使用该播放器,浏览器加载时会默认屏蔽Flash创建的内容。
为了尽可能加快全网内容Flash技术的淘汰速度,谷歌目前正在调整其爬取和索引策略,以向Web开发者施加升级压力。
Google 将不再索引此类内容:
谷歌在站长平台的官方博客上发布了一篇新博文。博文的内容比较简单。最主要的是 Google 搜索不再索引 Flash 创建的内容。
一些网站或网页使用Flash技术构建静态网页,如一些网络游戏网站、美术展示网站仍在使用该技术。
原来的谷歌搜索爬虫遇到这样的内容,会读取它的关键信息并索引到谷歌的索引中,这样用户在搜索的时候就可以找到这些Flash页面。
谷歌的新政策逐渐抛弃了这些技术创造的内容。毕竟如果浏览器不支持的话,即使用户打开这些页面,也无法正常显示内容。
谷歌表示,未来爬虫会在遇到此类内容时直接丢弃此类内容,不再将此类内容编入索引并收录在谷歌搜索结果中。
网站 将无法直接搜索:
如果 网站 是使用 Flash 技术构建的,它会被 Google 丢弃,用户在通过 Google 搜索 网站 名称或 关键词 时将找不到这些 网站。
对于绝大多数网站来说,搜索引擎是重要的流量来源,这也是谷歌希望通过这种方式向网络开发者施压的原因。
谷歌表示,根据目前的统计数据,新政策不会影响绝大多数网站,对谷歌搜索用户也不会产生太大影响。
开发人员可以将 Flash 内容迁移到 HTML 5,在被 Google 的爬虫访问后,这些内容将重新编入 Google 的索引中。 查看全部
抓取网页flash(AdobeFlashPlayer将在明年被彻底结束支持(图))
Adobe Flash Player 将在明年完全停止支持,这意味着所有用户都不应该继续使用这个容易出错的媒体播放器。
目前各大浏览器都开始限制使用该播放器,浏览器加载时会默认屏蔽Flash创建的内容。
为了尽可能加快全网内容Flash技术的淘汰速度,谷歌目前正在调整其爬取和索引策略,以向Web开发者施加升级压力。
Google 将不再索引此类内容:
谷歌在站长平台的官方博客上发布了一篇新博文。博文的内容比较简单。最主要的是 Google 搜索不再索引 Flash 创建的内容。
一些网站或网页使用Flash技术构建静态网页,如一些网络游戏网站、美术展示网站仍在使用该技术。
原来的谷歌搜索爬虫遇到这样的内容,会读取它的关键信息并索引到谷歌的索引中,这样用户在搜索的时候就可以找到这些Flash页面。
谷歌的新政策逐渐抛弃了这些技术创造的内容。毕竟如果浏览器不支持的话,即使用户打开这些页面,也无法正常显示内容。
谷歌表示,未来爬虫会在遇到此类内容时直接丢弃此类内容,不再将此类内容编入索引并收录在谷歌搜索结果中。
网站 将无法直接搜索:
如果 网站 是使用 Flash 技术构建的,它会被 Google 丢弃,用户在通过 Google 搜索 网站 名称或 关键词 时将找不到这些 网站。
对于绝大多数网站来说,搜索引擎是重要的流量来源,这也是谷歌希望通过这种方式向网络开发者施压的原因。
谷歌表示,根据目前的统计数据,新政策不会影响绝大多数网站,对谷歌搜索用户也不会产生太大影响。
开发人员可以将 Flash 内容迁移到 HTML 5,在被 Google 的爬虫访问后,这些内容将重新编入 Google 的索引中。
抓取网页flash( 移动站点的优化及TDK布局是否与pc站点布局一样)
网站优化 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2022-03-05 10:12
移动站点的优化及TDK布局是否与pc站点布局一样)
随着互联网技术的飞速发展,智能手机用户也在疯狂增长。据相关统计,2015年工信部公布,我国手机用户规模已达12.9亿。PC互联网时代逐渐转向移动互联网新时代。这是社会发展的必然。
因此,这两年大家都将目光投向了移动互联网。很多互联网公司都想在移动端占据一席之地,从而形成了手机APP、微信公众号、手机网站的建设热潮,当然在这场浩大的转型中,国内三大互联网巨头BAT必然首当其冲。BAT在资金、人才、资源等方面处于领先地位,迅速布局移动端。当然,在他们争夺地盘的时候,也是不可或缺的。枪炮在黑暗中战斗,这也是AT最明显的一点。对此,杨紫就不多说了,有机会再一起讨论。今天,杨紫主要跟大家分享一下移动网站的SEO优化。
如今,移动搜索流量已经超过了PC流量。许多公司正在建立自己的移动网站,并希望从移动搜索中获得流量。那么如何搭建移动网站,方便移动网站的SEO优化呢?移动端优化和TDK布局和pc端布局一样吗?当同一个站点同时有PC站点和移动站点时,当您想从移动站点获得更多收录和流量时,是否应该屏蔽PC站点?移动端的TDK优化会不会和PC端完全一样,会受到惩罚吗?等等类似的问题,下面杨紫都会一一分享。
搜索引擎作为网站的普通访问者,对去哪个站点进行爬取和索引,并根据用户体验确定站点和页面的价值并进行排序。因此,原则上网站对用户体验的任何改进都是对搜索引擎的改进。但受限于目前的整体网络环境和技术原因,实现用户体验的具体手段还需要考虑搜索引擎的友好性,让搜索引擎在满足用户体验的前提下更容易理解和处理。
那么移动搜索引擎网站的构建主要分为三个部分:
1、如何更好的让百度手机搜索收录网站中的内容。
2、如何在移动搜索中获得更好的排名,
3、如何让用户从众多搜索结果中快速找到并点击您的网站。
这三点简单来说就是收录、排序、呈现。下面我们从 收录 开始:
机器可读:
移动站点与PC爬虫相同。百度使用一个名为Baiduspider2.0 的程序来爬取移动互联网上的网页。经过处理后,它被内置到移动索引中。目前百度蜘蛛只能读取文字内容,FLASH、图片等非文字内容暂时还不能很好的处理。放在flash中的文字和图片只能百度轻松识别。建议使用文字代替flash、图片、javascript等显示重要内容或链接。搜索引擎无法识别flash,图片复杂javascript中的内容只存在于收录flash和javascript中链接的网页中,百度手机搜索可能无法收录。不要在搜索引擎可读的地方使用 AJAX 技术,例如标题、导航、
移动站点结构搭建:
一个移动网站还应该有一个清晰的结构和较浅的链接层次结构,这样可以让用户快速访问有用的信息,让搜索引擎快速了解网站中每个页面的结构层次。网站结构推荐使用树形结构。树状结构通常是以下三个层次,主页-频道-详情页。
移动网站也应该是网状的:
理想的网站结构是一棵扁平的树,从首页到内容页的层级越少越好,这样更便于搜索引擎处理。同时,网站中的链接也要采用网状结构,网站上的每个网页都应该有上下级网页和相关内容的链接,避免出现链接孤岛,首页页面有频道页链接,频道页有首页和普通内容页的链接,普通内容页有上级频道和首页的链接,内容相关的页面相互连接。网站 中的每个页面都应该是 网站 结构的一部分,应该链接到其他网页,以便蜘蛛更好地抓取和抓取 网站 中的内容。同时,
移动站点简单移动的 URL:
它具有良好的描述性、规范性和简洁性,有利于用户记忆和直观判断网页内容,也有利于搜索引擎更有效地抓取和理解网页。在设计之初,网站应该做好URL规划:
1、移动台首页,/,/或
2、频道页使用/n1/、/n2/(当然这里直接读n1或n2更好)
3、详情页的URL尽量短,减少统计参数等无效参数,保证同一页面只有一组URL。
4、机器人禁止百度蜘蛛不想向用户展示的URL形式和百度不想被抓取的私人数据。
合理的返回状态码:
百度蜘蛛在抓取处理时,根据http协议规范设置相应的逻辑。几种常用的返回状态码如下:
404:百度会认为该网页无效而删除,通常在索引中删除。短期内,蜘蛛再遇到它就不会再爬了。建议在内容被删除或网页无效时使用404返回码,告诉百度蜘蛛该页面无效。同时在网站中应该尽量减少死链接的堆积。如果网站暂时关闭或者抓取压力太大,不要直接返回404,使用503.
301:永久重定向,百度会认为当前URL永久跳转到新的URL。网站改版、域名变更等情况建议使用301,同时使用站长平台的网站改版工具。
503:百度会认为暂时无法访问,不会直接删除。请在短时间内再次检查。如果网站暂时关闭,建议使用503.
移动网站建设常见问题解答:
Q:我手机站的内容和我电脑的内容一样,需要屏蔽百度电脑搜索蜘蛛吗?
A:由于百度的pc搜索和手机搜索是同一个蜘蛛,都带有baidu logo,所以不要屏蔽。爬虫会在爬取的时候识别页面,自动判断是pc页面还是手机页面,所以建议大家使用标准的html5或者xhtml协议语言搭建手机站。
Q:手机站是用xhtml\html5开发的,跟搜索引擎有什么区别吗?
答:你用手机搜索的时候,你会发现用2g的时候,手机搜索给你的是极速版,就是保证你得到的结果足够快,但是结果风格比较简单。一般情况下,极速版百度蜘蛛会优先考虑xhtml的结果,触屏版优先考虑html5,效果更爽。
问:一个站点有M站点和PC站点。使用完全相同的 TDK 有什么问题吗?手机网站的SEO规则和PC网站一样吗?
答:PC端和移动端搜索结果中显示的标题和摘要的字数限制不同。PC端一般只有30个左右的汉字才截断,移动端达到20个字符就折叠,超过20个字符以下的就省略了。看不见。所以建议移动台使用单独的TDK。
问:如果两个站点的每个页面的 TDK 完全相同,我会受到处罚吗?
答:如果两个相同的网站指的是手机网站和电脑网站,肯定不会导致处罚。
Q:作为外链对移动台有影响吗?
答:外部链接仍然有效,但不要做垃圾外部链接。例如,在论坛的标签中,买卖链接,或批量发送链接都可能受到处罚。正常交换链接很有帮助。
今天,杨紫就和大家分享一下手机站的SEO相关问题。他写道,在很短的时间内将接近 17:00。这个周末已经这样了一天。不知道大家今天是怎么度过的? 查看全部
抓取网页flash(
移动站点的优化及TDK布局是否与pc站点布局一样)
随着互联网技术的飞速发展,智能手机用户也在疯狂增长。据相关统计,2015年工信部公布,我国手机用户规模已达12.9亿。PC互联网时代逐渐转向移动互联网新时代。这是社会发展的必然。
因此,这两年大家都将目光投向了移动互联网。很多互联网公司都想在移动端占据一席之地,从而形成了手机APP、微信公众号、手机网站的建设热潮,当然在这场浩大的转型中,国内三大互联网巨头BAT必然首当其冲。BAT在资金、人才、资源等方面处于领先地位,迅速布局移动端。当然,在他们争夺地盘的时候,也是不可或缺的。枪炮在黑暗中战斗,这也是AT最明显的一点。对此,杨紫就不多说了,有机会再一起讨论。今天,杨紫主要跟大家分享一下移动网站的SEO优化。
如今,移动搜索流量已经超过了PC流量。许多公司正在建立自己的移动网站,并希望从移动搜索中获得流量。那么如何搭建移动网站,方便移动网站的SEO优化呢?移动端优化和TDK布局和pc端布局一样吗?当同一个站点同时有PC站点和移动站点时,当您想从移动站点获得更多收录和流量时,是否应该屏蔽PC站点?移动端的TDK优化会不会和PC端完全一样,会受到惩罚吗?等等类似的问题,下面杨紫都会一一分享。
搜索引擎作为网站的普通访问者,对去哪个站点进行爬取和索引,并根据用户体验确定站点和页面的价值并进行排序。因此,原则上网站对用户体验的任何改进都是对搜索引擎的改进。但受限于目前的整体网络环境和技术原因,实现用户体验的具体手段还需要考虑搜索引擎的友好性,让搜索引擎在满足用户体验的前提下更容易理解和处理。
那么移动搜索引擎网站的构建主要分为三个部分:
1、如何更好的让百度手机搜索收录网站中的内容。
2、如何在移动搜索中获得更好的排名,
3、如何让用户从众多搜索结果中快速找到并点击您的网站。
这三点简单来说就是收录、排序、呈现。下面我们从 收录 开始:
机器可读:
移动站点与PC爬虫相同。百度使用一个名为Baiduspider2.0 的程序来爬取移动互联网上的网页。经过处理后,它被内置到移动索引中。目前百度蜘蛛只能读取文字内容,FLASH、图片等非文字内容暂时还不能很好的处理。放在flash中的文字和图片只能百度轻松识别。建议使用文字代替flash、图片、javascript等显示重要内容或链接。搜索引擎无法识别flash,图片复杂javascript中的内容只存在于收录flash和javascript中链接的网页中,百度手机搜索可能无法收录。不要在搜索引擎可读的地方使用 AJAX 技术,例如标题、导航、
移动站点结构搭建:
一个移动网站还应该有一个清晰的结构和较浅的链接层次结构,这样可以让用户快速访问有用的信息,让搜索引擎快速了解网站中每个页面的结构层次。网站结构推荐使用树形结构。树状结构通常是以下三个层次,主页-频道-详情页。
移动网站也应该是网状的:
理想的网站结构是一棵扁平的树,从首页到内容页的层级越少越好,这样更便于搜索引擎处理。同时,网站中的链接也要采用网状结构,网站上的每个网页都应该有上下级网页和相关内容的链接,避免出现链接孤岛,首页页面有频道页链接,频道页有首页和普通内容页的链接,普通内容页有上级频道和首页的链接,内容相关的页面相互连接。网站 中的每个页面都应该是 网站 结构的一部分,应该链接到其他网页,以便蜘蛛更好地抓取和抓取 网站 中的内容。同时,
移动站点简单移动的 URL:
它具有良好的描述性、规范性和简洁性,有利于用户记忆和直观判断网页内容,也有利于搜索引擎更有效地抓取和理解网页。在设计之初,网站应该做好URL规划:
1、移动台首页,/,/或
2、频道页使用/n1/、/n2/(当然这里直接读n1或n2更好)
3、详情页的URL尽量短,减少统计参数等无效参数,保证同一页面只有一组URL。
4、机器人禁止百度蜘蛛不想向用户展示的URL形式和百度不想被抓取的私人数据。
合理的返回状态码:
百度蜘蛛在抓取处理时,根据http协议规范设置相应的逻辑。几种常用的返回状态码如下:
404:百度会认为该网页无效而删除,通常在索引中删除。短期内,蜘蛛再遇到它就不会再爬了。建议在内容被删除或网页无效时使用404返回码,告诉百度蜘蛛该页面无效。同时在网站中应该尽量减少死链接的堆积。如果网站暂时关闭或者抓取压力太大,不要直接返回404,使用503.
301:永久重定向,百度会认为当前URL永久跳转到新的URL。网站改版、域名变更等情况建议使用301,同时使用站长平台的网站改版工具。
503:百度会认为暂时无法访问,不会直接删除。请在短时间内再次检查。如果网站暂时关闭,建议使用503.
移动网站建设常见问题解答:
Q:我手机站的内容和我电脑的内容一样,需要屏蔽百度电脑搜索蜘蛛吗?
A:由于百度的pc搜索和手机搜索是同一个蜘蛛,都带有baidu logo,所以不要屏蔽。爬虫会在爬取的时候识别页面,自动判断是pc页面还是手机页面,所以建议大家使用标准的html5或者xhtml协议语言搭建手机站。
Q:手机站是用xhtml\html5开发的,跟搜索引擎有什么区别吗?
答:你用手机搜索的时候,你会发现用2g的时候,手机搜索给你的是极速版,就是保证你得到的结果足够快,但是结果风格比较简单。一般情况下,极速版百度蜘蛛会优先考虑xhtml的结果,触屏版优先考虑html5,效果更爽。
问:一个站点有M站点和PC站点。使用完全相同的 TDK 有什么问题吗?手机网站的SEO规则和PC网站一样吗?
答:PC端和移动端搜索结果中显示的标题和摘要的字数限制不同。PC端一般只有30个左右的汉字才截断,移动端达到20个字符就折叠,超过20个字符以下的就省略了。看不见。所以建议移动台使用单独的TDK。
问:如果两个站点的每个页面的 TDK 完全相同,我会受到处罚吗?
答:如果两个相同的网站指的是手机网站和电脑网站,肯定不会导致处罚。
Q:作为外链对移动台有影响吗?
答:外部链接仍然有效,但不要做垃圾外部链接。例如,在论坛的标签中,买卖链接,或批量发送链接都可能受到处罚。正常交换链接很有帮助。
今天,杨紫就和大家分享一下手机站的SEO相关问题。他写道,在很短的时间内将接近 17:00。这个周末已经这样了一天。不知道大家今天是怎么度过的?
抓取网页flash(比方让搜索引擎爬虫掉入到网站的陷阱里怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-02-28 07:06
网站的很多设计者都期待着让搜索引擎爬取尽可能多的网站,但是如果在设计的网站中出现大量死链接,搜索引擎爬虫即使你抢它,你什么也抢不了,所以对于网站的设计,光做表面的功力是不够的,还要做好基本的功课,设计自己的网站页面,比如如设计404网页告诉搜索引擎网络蜘蛛遇到死链接后及时返回,以免让搜索引擎爬虫落入网站的陷阱,从而使搜索引擎网络机器人更容易去爬取你的页面,那么网站究竟应该怎样设计才能让你轻松爬取呢?
网站怎么设计才容易抓起来
因此,很容易只抓取一些比较重要的网页,而不是所有的页面,这就是为什么搜索引擎对重要网页的更新快照更短的原因。例如,对于频繁更新的页面,快照也会经常更新,以便及时发现新的内容和链接,并删除不存在的信息。因此,这与以前相同。站长必须长期坚持更新网页。为了让搜索引擎爬虫更容易找到你。
对于网站的内框设计,内框的设计要从多方面进行。代码应尽可能简洁明了。代码过多会导致页面体积过大,影响网络爬虫的抓取。重要的代码最好放在前面。爬网站的时候喜欢从第一段开始搜索,可以爬到前面的主要内容。它将抓取 Flash 格式的内容。对于新的网站,尽量使用伪静态形式的url,这样整个网站页面都可以轻松抓取。要合理分配,不能全部写关键词,需要适当添加一些长尾词链接。最后,内部链接设计要流畅,
为网站设计面包屑导航,这是很多公司在设计网站时忽略的地方。事实上,面包屑导航在提取中一直扮演着非常重要的角色,必须合理设计。网站上的锚文本设计有利于网络爬虫发现和爬取网站上更多的网页,但是如果锚文本太多容易被视为刻意调整,就要把握好数量设计时的锚文本。
除了首页的设计,网站可能还存在大量的其他页面。爬虫不会索引每个 网站 上的所有页面,因此它们可能会爬取足够多的页面以在找到他们认为重要的页面之前离开。所以要保持只需要从首页跳转到不超过两个页面,太多可能会导致这些页面爬不上去。
导航是捕获网站 的关键。如果网站的导航不清晰,抓到网站很容易迷路,可能根本找不到入口。这很糟糕,因为搜索引擎很容易放弃您的 网站 页面并停止抓取它们。
最终,企业设计的网站保持了一定的更新频率,更新频繁的页面很容易被爬取,因此可以通过超链接自动爬取大量页面。同时,更新频率较高的页面也受到搜索引擎的高度重视。参考以上因素,相信企业在设计网站时能得到一些启发。 查看全部
抓取网页flash(比方让搜索引擎爬虫掉入到网站的陷阱里怎么办?)
网站的很多设计者都期待着让搜索引擎爬取尽可能多的网站,但是如果在设计的网站中出现大量死链接,搜索引擎爬虫即使你抢它,你什么也抢不了,所以对于网站的设计,光做表面的功力是不够的,还要做好基本的功课,设计自己的网站页面,比如如设计404网页告诉搜索引擎网络蜘蛛遇到死链接后及时返回,以免让搜索引擎爬虫落入网站的陷阱,从而使搜索引擎网络机器人更容易去爬取你的页面,那么网站究竟应该怎样设计才能让你轻松爬取呢?
网站怎么设计才容易抓起来
因此,很容易只抓取一些比较重要的网页,而不是所有的页面,这就是为什么搜索引擎对重要网页的更新快照更短的原因。例如,对于频繁更新的页面,快照也会经常更新,以便及时发现新的内容和链接,并删除不存在的信息。因此,这与以前相同。站长必须长期坚持更新网页。为了让搜索引擎爬虫更容易找到你。
对于网站的内框设计,内框的设计要从多方面进行。代码应尽可能简洁明了。代码过多会导致页面体积过大,影响网络爬虫的抓取。重要的代码最好放在前面。爬网站的时候喜欢从第一段开始搜索,可以爬到前面的主要内容。它将抓取 Flash 格式的内容。对于新的网站,尽量使用伪静态形式的url,这样整个网站页面都可以轻松抓取。要合理分配,不能全部写关键词,需要适当添加一些长尾词链接。最后,内部链接设计要流畅,
为网站设计面包屑导航,这是很多公司在设计网站时忽略的地方。事实上,面包屑导航在提取中一直扮演着非常重要的角色,必须合理设计。网站上的锚文本设计有利于网络爬虫发现和爬取网站上更多的网页,但是如果锚文本太多容易被视为刻意调整,就要把握好数量设计时的锚文本。
除了首页的设计,网站可能还存在大量的其他页面。爬虫不会索引每个 网站 上的所有页面,因此它们可能会爬取足够多的页面以在找到他们认为重要的页面之前离开。所以要保持只需要从首页跳转到不超过两个页面,太多可能会导致这些页面爬不上去。
导航是捕获网站 的关键。如果网站的导航不清晰,抓到网站很容易迷路,可能根本找不到入口。这很糟糕,因为搜索引擎很容易放弃您的 网站 页面并停止抓取它们。
最终,企业设计的网站保持了一定的更新频率,更新频繁的页面很容易被爬取,因此可以通过超链接自动爬取大量页面。同时,更新频率较高的页面也受到搜索引擎的高度重视。参考以上因素,相信企业在设计网站时能得到一些启发。
抓取网页flash(打开图(程序)行了用GlobalFetch你是想批量下载搜索引擎搜出来的图片吧~那最好把你想的那个网页地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-21 23:06
打开图(程序)行
有了GlobalFetch,你想批量下载搜索引擎搜索到的图片~那么最好把你要关注的网页地址复制到GlobalFetch新建的任务中,然后将搜索深度设置为3以上,并且图片大小也限制在20k以上,我想你不会想下载所有那些广告图片。
打开你要保存的网页,在浏览器左上角:文件-另存为,在弹出框中看到“另存为类型”,选择[WEB文档,单个文件..]的类型。选择保存路径——保存。生成以 .mht 结尾的文件
Quick Capture with Web Text,是一款保存/管理网页的工具,可以在IE中保存网页,包括文字、图片、flash动画等。还可以保存选中的文字、图片和链接。它可以为上网提供极大的便利,还可以通过拖放对网页进行分类。
有很多地方可以下载
比如太平洋的下载中心就有,给你找到链接
我用的猎豹浏览器,浏览器商店里有
Fatkun图片批量下载
介绍是快速过滤保存当前页面需要的图片
正在寻找可以采集/下载网页PDF文件的软件...可以试试QQ浏览器或者360浏览器,在浏览器中安装FVD DOWNLoader,可以采集网页视频mp3等,可以安装自己喜欢的实用采集浏览器拿工具。
谁能推荐一个简单的截图软件?之前在iQ上下载过,忘记名字了…… 红蜻蜓截图2005 1.22 build 0226,一款专业的截屏软件,可以让你截取你需要的截图。多种捕捉模式可供选择,可捕捉光标,可设置捕捉延迟时间。抓图方法很简单,按下抓图热键CTRL+SHIFT+C,也就是你也可以点击软件界面上的抓图按钮抓图。同时软件采用换肤技术,用户可以根据自己的喜好选择相应的软件外观。下载地址:
找一款可以抓拍桌面和windows等的抓拍软件...给你一个最小的抓拍软件
有没有视频抓拍软件...虽然视频抓拍也可以用超级解霸、QQ等进行抓拍,但是效果不好,最好用专门的视频抓拍工具,现推荐:Camtasia Studio v 4.0.@ >0 汉化版(视频抓拍软件,录屏...
我在哪里可以下载网页图像捕获工具?- …… 抓拍别人或自己店里的宝贝,导出图片数据包,选择自己需要的图片。这类软件有很多,可以看一下抓图工具。
有专门的FLASH下载抓包工具——……不知道你指的是哪个软件下载flash,但是还有其他下载flash的方法(这里指的是从网上下载flash) ,我将它们分类并一一列出:1、通过下载工具。如迅雷、互联网快车、Super Cyclone等下载软件,这些软件都有flash抓拍功能(鼠标...
找一款可以截取和处理视频和图片的软件,类似美图秀秀,但是可以自由截取视频的软件……可以下载“录屏专家”截取视频图像。网上有破解版。如果你只是想将视频画面捕捉成图片,可以使用“会声会影”。
我想要一个快照软件...推荐使用“红蜻蜓快照2005 V1.23”。软件介绍: RdfSnap 2005 是一款完全免费的专业级截屏软件,它可以让你截取你需要的截图。抓图方式灵活,主要抓全屏、活动窗口、选定区域……
请推荐一个快照工具!... 1. Red Dragonfly Snap 2005 V1.23 build 0430 Red Dragonfly Snap 2005 (RdfSnap) 2005 是一款完全免费的专业屏幕红蜻蜓 Snap 2005 1.23 build 0430 Red Dragonfly Snap 2005 ( RdfSnap) 2005 是一款完全免费的专业截屏...
网页抓取工具... 使用软件htmlparser2.0。这是一个html页面的抓取和分析工具。它可以和htmlconnector一起使用,它是一个web连接器,可以做你需要的(爬取双层连接和保存页面内容) 查看全部
抓取网页flash(打开图(程序)行了用GlobalFetch你是想批量下载搜索引擎搜出来的图片吧~那最好把你想的那个网页地址)
打开图(程序)行
有了GlobalFetch,你想批量下载搜索引擎搜索到的图片~那么最好把你要关注的网页地址复制到GlobalFetch新建的任务中,然后将搜索深度设置为3以上,并且图片大小也限制在20k以上,我想你不会想下载所有那些广告图片。
打开你要保存的网页,在浏览器左上角:文件-另存为,在弹出框中看到“另存为类型”,选择[WEB文档,单个文件..]的类型。选择保存路径——保存。生成以 .mht 结尾的文件
Quick Capture with Web Text,是一款保存/管理网页的工具,可以在IE中保存网页,包括文字、图片、flash动画等。还可以保存选中的文字、图片和链接。它可以为上网提供极大的便利,还可以通过拖放对网页进行分类。
有很多地方可以下载
比如太平洋的下载中心就有,给你找到链接
我用的猎豹浏览器,浏览器商店里有
Fatkun图片批量下载
介绍是快速过滤保存当前页面需要的图片
正在寻找可以采集/下载网页PDF文件的软件...可以试试QQ浏览器或者360浏览器,在浏览器中安装FVD DOWNLoader,可以采集网页视频mp3等,可以安装自己喜欢的实用采集浏览器拿工具。
谁能推荐一个简单的截图软件?之前在iQ上下载过,忘记名字了…… 红蜻蜓截图2005 1.22 build 0226,一款专业的截屏软件,可以让你截取你需要的截图。多种捕捉模式可供选择,可捕捉光标,可设置捕捉延迟时间。抓图方法很简单,按下抓图热键CTRL+SHIFT+C,也就是你也可以点击软件界面上的抓图按钮抓图。同时软件采用换肤技术,用户可以根据自己的喜好选择相应的软件外观。下载地址:
找一款可以抓拍桌面和windows等的抓拍软件...给你一个最小的抓拍软件
有没有视频抓拍软件...虽然视频抓拍也可以用超级解霸、QQ等进行抓拍,但是效果不好,最好用专门的视频抓拍工具,现推荐:Camtasia Studio v 4.0.@ >0 汉化版(视频抓拍软件,录屏...
我在哪里可以下载网页图像捕获工具?- …… 抓拍别人或自己店里的宝贝,导出图片数据包,选择自己需要的图片。这类软件有很多,可以看一下抓图工具。
有专门的FLASH下载抓包工具——……不知道你指的是哪个软件下载flash,但是还有其他下载flash的方法(这里指的是从网上下载flash) ,我将它们分类并一一列出:1、通过下载工具。如迅雷、互联网快车、Super Cyclone等下载软件,这些软件都有flash抓拍功能(鼠标...
找一款可以截取和处理视频和图片的软件,类似美图秀秀,但是可以自由截取视频的软件……可以下载“录屏专家”截取视频图像。网上有破解版。如果你只是想将视频画面捕捉成图片,可以使用“会声会影”。
我想要一个快照软件...推荐使用“红蜻蜓快照2005 V1.23”。软件介绍: RdfSnap 2005 是一款完全免费的专业级截屏软件,它可以让你截取你需要的截图。抓图方式灵活,主要抓全屏、活动窗口、选定区域……
请推荐一个快照工具!... 1. Red Dragonfly Snap 2005 V1.23 build 0430 Red Dragonfly Snap 2005 (RdfSnap) 2005 是一款完全免费的专业屏幕红蜻蜓 Snap 2005 1.23 build 0430 Red Dragonfly Snap 2005 ( RdfSnap) 2005 是一款完全免费的专业截屏...
网页抓取工具... 使用软件htmlparser2.0。这是一个html页面的抓取和分析工具。它可以和htmlconnector一起使用,它是一个web连接器,可以做你需要的(爬取双层连接和保存页面内容)
抓取网页flash(搜索引擎不喜欢Flash的网站,是因为Flash动画太复杂。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-19 05:08
搜索引擎之所以不喜欢 Flash 的 网站 是因为 Flash 动画太复杂了。与一般网页上的文字不同,Flash 动画是由框架组成的,搜索引擎无法读取 Flash 内部的框架,因此搜索引擎不会对其进行索引。如果要优化Flash网站,必须对Flash进行处理,有以下三种方法。
1.创建辅助HTML文件
保留原来的Flash版本,然后创建一个HTML页面,比如上面的网站,创建一个没有Flash的纯文本HTML页面,把所有的链接都链接到原来的Flash页面,这样虽然搜索引擎不爬Flash,他们可以收录HTML页面,通过HTML页面做文章让蜘蛛爬取Flash页面。
2. 这种将 Flash 嵌入 HTML 文件的方法通过改变网页的结构来弥补。
不要以 Flash 形式设计整个网页,而是将 Flash 内容嵌入到 HTML 文件中。搜索引擎也可以从网页的Title、Keywords、Discription等代码中找到一些主要信息到收录网站。即使主页使用Flash,进入页面的关键词按钮链接也应该放在Flash文件之外,作为独立的纯文本链接呈现。
3.付费登录搜索引擎
这种方法只有在前两种方法都行不通的情况下才使用,因为后者需要投入一定的成本,网站一开始如果能降低投资成本,成本就会降低,如果< @网站 上线几个月后,搜索引擎还是没有收录,那就考虑付费登录搜索引擎。根据经验,在做网站时,应该尽量避免使用Flash,或者最好不要使用。你知道搜索引擎不喜欢它,但你仍然想使用它。这不是给自己找麻烦吗?虽然Flash让网站的设计效果更好,但从整体考虑,网站中使用Flash的弊端还是大于利的,尤其是在做友情链接的时候,千万不要使用Flash按钮链接。 查看全部
抓取网页flash(搜索引擎不喜欢Flash的网站,是因为Flash动画太复杂。)
搜索引擎之所以不喜欢 Flash 的 网站 是因为 Flash 动画太复杂了。与一般网页上的文字不同,Flash 动画是由框架组成的,搜索引擎无法读取 Flash 内部的框架,因此搜索引擎不会对其进行索引。如果要优化Flash网站,必须对Flash进行处理,有以下三种方法。
1.创建辅助HTML文件
保留原来的Flash版本,然后创建一个HTML页面,比如上面的网站,创建一个没有Flash的纯文本HTML页面,把所有的链接都链接到原来的Flash页面,这样虽然搜索引擎不爬Flash,他们可以收录HTML页面,通过HTML页面做文章让蜘蛛爬取Flash页面。
2. 这种将 Flash 嵌入 HTML 文件的方法通过改变网页的结构来弥补。
不要以 Flash 形式设计整个网页,而是将 Flash 内容嵌入到 HTML 文件中。搜索引擎也可以从网页的Title、Keywords、Discription等代码中找到一些主要信息到收录网站。即使主页使用Flash,进入页面的关键词按钮链接也应该放在Flash文件之外,作为独立的纯文本链接呈现。
3.付费登录搜索引擎
这种方法只有在前两种方法都行不通的情况下才使用,因为后者需要投入一定的成本,网站一开始如果能降低投资成本,成本就会降低,如果< @网站 上线几个月后,搜索引擎还是没有收录,那就考虑付费登录搜索引擎。根据经验,在做网站时,应该尽量避免使用Flash,或者最好不要使用。你知道搜索引擎不喜欢它,但你仍然想使用它。这不是给自己找麻烦吗?虽然Flash让网站的设计效果更好,但从整体考虑,网站中使用Flash的弊端还是大于利的,尤其是在做友情链接的时候,千万不要使用Flash按钮链接。
抓取网页flash(用用JavaScript获获取取网网页页中的js、css、Flash等等文文件件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-02-13 15:05
但不是电子书里的js、css、Flash、背景音乐等文件。其实只要对 JavaScript 代码有一定的了解,即使只使用已经公开发布的 CtrlN,在 E 书中获取这些文件也不难。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,这种方法很难用于批量反编译,所以庄家不必产生许多担忧。电子书中的背景音乐和其他文件。其实只要对 JavaScript 代码有一定的了解,即使只使用已经公开发布的 CtrlN,在 E 书中获取这些文件也不难。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,这种方法很难用于批量反编译,所以庄家不必产生许多担忧。电子书中的背景音乐和其他文件。其实只要对 JavaScript 代码有一定的了解,即使只使用已经公开发布的 CtrlN,在 E 书中获取这些文件也不难。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,这种方法很难用于批量反编译,所以庄家不必产生许多担忧。只要对 JavaScript 代码有一定的了解,即使只使用已经公开发布的 CtrlN,在 E 书中获取这些文件也不难。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,这种方法很难用于批量反编译,所以庄家不必产生许多担忧。只要对 JavaScript 代码有一定的了解,即使只使用已经公开发布的 CtrlN,在 E 书中获取这些文件也不难。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,这种方法很难用于批量反编译,所以庄家不必产生许多担忧。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人的做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,而且这种方法很难用于批量反编译,所以庄家不必产生许多担忧。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人的做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,而且这种方法很难用于批量反编译,所以庄家不必产生许多担忧。
我不杀鸡杀蛋,哈哈……2、为了方便使用,下面给出的JavaScript很笨,所有的URL解析工作都是代码完成的,只要按Ctrl+C即可, Ctrl+V 键都可以。然而,自动化毕竟有其局限性。对于大部分网页来说,这些代码应该是可以解决的。但是,如果遇到无法解决的网页,仍然需要手动分析 HTML 代码。如果在分析过程中遇到加密网页,可以使用CtrlN的“HTML Fragment”功能对加密后的HTML进行解码。在源代码中查找链接时,可以使用搜索功能快速定位。3、现在基于IE内核的电子书基本都是通过自定义协议插件实现的,对JavaScript协议插件的支持程度不一,所以不要' 如果代码在某些电子书上有错误,请不要感到惊讶。4.这些代码除了反编译电子书外,在浏览普通网页时也很有用,例如用于抓取网页中的Falsh文件。5、所有代码都是在Windows XP SP2下测试的,其他环境我没试过,但估计IE版本不能低于6.0。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。除了反编译电子书外,这些代码在浏览普通网页时也很有用,例如,它们用于捕获网页中的 Falsh 文件。5、所有代码都是在Windows XP SP2下测试的,其他环境我没试过,但估计IE版本不能低于6.0。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。除了反编译电子书外,这些代码在浏览普通网页时也很有用,例如,它们用于捕获网页中的 Falsh 文件。5、所有代码都是在Windows XP SP2下测试的,其他环境我没试过,但估计IE版本不能低于6.0。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。它们用于捕获网页中的 Falsh 文件。5、所有代码都是在Windows XP SP2下测试的,其他环境我没试过,但估计IE版本不能低于6.0。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。它们用于捕获网页中的 Falsh 文件。5、所有代码都是在Windows XP SP2下测试的,其他环境我没试过,但估计IE版本不能低于6.0。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。
这是为了防止电子书或网页禁用快捷键。如果确认没有禁用快捷键,可以省略这一步,在第3步直接按Ctrl+N。打开电子书或IE,进入引用css、js、flash等文件的页面需要被捕获。请注意,这必须是真实页面,而不是框架。如何判断框架以及如何进入框架页面将在后面讨论。将CtrlN的“快捷键行为”设置为“弹出新窗口”,然后用鼠标点击要抓取的网页,然后按Ctrl+N,会弹出一个新的IE窗口,里面显示的内容和你要抢的一样。抓取的页面内容相同,地址栏显示页面的URL。在弹出的 IE 窗口中,根据需要将对应的 JavaScript 代码(后面会给出)复制粘贴到地址栏中,然后按回车键。对于IE 6,第一次运行JavaScript代码时,地址栏下方可能会弹出一个黄色条,表示此代码被阻止运行,点击黄色条,选择“允许被阻止的内容”,然后重复上述步骤3、@ >4 查看结果。三、从E书或网页中获取链接的css文件 JavaScript本身提供了获取外部css文件内容的接口,所以在上述通用步骤的第4步中,将以下内容复制粘贴到IE中地址栏,然后回车查看内容:j avascript:str='';c=document.styleSheets;for(i=0;i\n';str+=o.cssText;str+='
\n';};document.write(str); 如果当前的 HTML 页面没有链接到外部 css 文件,则在第 4 步完成后将无响应或显示空白页面。这时候可以查看页面的HTML源代码进行确认。如果当前页面链接到多个 css 文件,则会显示所有 css 文件的内容。IE排版后的格式可能和原来的css代码不一样,但是效果是完全一样的。如果只显示css文件的文件名,而下面没有内容,则说明css没有打包在E书里。对于某些电子书,您还可以尝试以下代码:j javascript:str='
\n';c=document.styl eSheets;for(i=0;i';str+=o.href;str+='
\n';};str+='';document.write(str); 此代码自动检查网页。如果网页中嵌入了css文件,则自动显示css文件的下载链接,否则显示空页或无响应。在链接上单击鼠标右键,然后选择“另存为”菜单,将文件保存到硬盘。如果无法保存,将js文件的url复制到地址栏,然后回车试试。但是,如果注册表项HKEY_CLA SSES_ROOT\CSSfile\shell下有open、edit等子项,则获取的CSS代码将直接在open或edit子项指定的程序中打开,而不提示保存。这种方法的适用范围远小于上面直接展示的方法,不是所有的电子书都能用,但只要能用,它肯定会得到原创的 css 代码。四、从E书或网页获取链接的js文件 JavaScript没有提供获取js文件内容的接口,所以首先要对注册表进行改造:运行regedit,定位到HKEY_CLA SSES_ROOT\.js,并在其中添加两个字符串类型值如下: Content Type=application/xj avascript PerceivedType=text 修改的时候不放心可以参考HKEY_CLA SSES_ROOT\.css的默认设置,只是不同而已在 Content Type 的值中。注册表修改是一次性的,修改后不需要再做。转换完成后,用CtrlN抓取js文件的步骤和上面的一般步骤是一样的。在步骤 4 中,将以下内容复制并粘贴到地址栏中,
\n';c=document.scripts;for(i=0;i';str+=o.src;str+='
\n';};str+='';document.write(str); 此代码自动检查网页。如果网页中嵌入了js文件,会自动显示该js文件的下载链接,否则会显示空页或无响应。在链接上点击鼠标右键,选择“另存为”菜单,或直接点击链接;您可以将文件保存到硬盘。如果无法保存,请确认注册表是否已按照上述方法设置;如果不行,可以把js文件的url复制到地址栏,然后回车试试。诡异的是eBoo Wor shop制作的E书(页面URL以ada99:开头),在地址栏中输入js文件的URL回车,就会显示js文件的内容及其执行结果直接点击“
\n';c=document.all;f or(i=0;i'));nd.firstChild.outerHT ML=sih;no=document.createElement(nd.firstChild.outerHT ML);document.body 。appendChild(no);str+='';str+=no.src;str+='
\n';};str+='';document.write(str); 此代码自动检查网页。如果网页中嵌入了Flash对象,会自动显示swf文件的下载链接,否则会显示空页或无响应。右键单击该链接并选择“另存为”以将文件保存到您的硬盘驱动器。如果直接单击链接,将显示 Flash 屏幕。我经常看到有人问:“如何在网页上捕捉漂亮的 Flash?” 事实上,答案就是这么简单。我在上网的时候经常用这段代码来抓Flash,但是需要注意的是:如果页面是嵌入到框架中的,则需要将框架分解成真实页面后才能使用此代码。此代码还使用 createDocument tFragment 方法,并且仅适用于 IE 6。现在还有一个很极端的电子书:全书只有一个网页,里面嵌入了一个Flash文件作为记录。点击Flash中的链接,会跳转到其他Flash文件,也就是真正的内容隐藏在一堆Flash文件中。里面。这类电子书,用上面的代码一次只能抓一个Flash,需要一步一步点进去才能全部抓,有的甚至用flasm反编译抓到的Flash文件的运行脚本,然后从脚本中找出它所链接的其他Flash文件的文件名(我都是很刻薄的直接搜索.swf),然后将文件名转换为绝对URL生成下载链接。例如,如果已知 Flash 文件的绝对 URL 为 /pic.swf,则可以使用以下代码单独下载该文件:j avascript:document。write('右键另存为'); 这种方法每次都需要改变URL,当然比上面提到的方法麻烦一些,但是有时候只能用这种方法。对了,flasm真是个好东西,脚本里的一些Flash文件限制了文件只能在网络上播放,不能从本地硬盘播放,你也可以用它来解除这个限制。六、从电子书或网页中获取背景音乐文件背景音乐文件可以像Flash一样直接下载,所以在上述通用步骤的第4步中,将以下内容复制并粘贴到地址栏中,然后按回车键查看内容: j javascript:但有时只能使用这种方法。对了,flasm真是个好东西,脚本里的一些Flash文件限制了文件只能在网络上播放,不能从本地硬盘播放,你也可以用它来解除这个限制。六、从电子书或网页中获取背景音乐文件背景音乐文件可以像Flash一样直接下载,所以在上述通用步骤的第4步中,将以下内容复制并粘贴到地址栏中,然后按回车键查看内容: j javascript:但有时只能使用这种方法。对了,flasm真是个好东西,脚本里的一些Flash文件限制了文件只能在网络上播放,不能从本地硬盘播放,你也可以用它来解除这个限制。六、从电子书或网页中获取背景音乐文件背景音乐文件可以像Flash一样直接下载,所以在上述通用步骤的第4步中,将以下内容复制并粘贴到地址栏中,然后按回车键查看内容: j javascript:
\n';c=document.all;f or(i=0;i';str+=o.src;str+='
\n';};str+='';document.write(str); 此代码自动检查网页。如果嵌入了背景音乐,则会自动显示背景音乐的下载链接,否则会显示空白页面或无反应。右键单击该链接并选择“另存为”以将文件保存到您的硬盘驱动器。注意背景音乐一般隐藏在框架中(否则换页时音乐会中断)。如果弹出页面收录框架而不是实际收录背景音乐链接的页面,则不会被捕获。这时候还需要按照后面提到的步骤进入框架中的页面。另外,为了避免单调,有的电子书会一次打包好几个midi文件,并在每次运行时随机选择一首作为背景音乐。对于这样的电子书,上面的代码只能捕捉到当前的背景音乐。如果要全部捕获,只能自己分析网页源代码,结合所有背景音乐的url,然后在地址栏中输入javascript代码生成下载链接回车即可一次下载一个。请注意,您只能右键单击下载链接并选择“另存为”,不能直接单击该链接。如果实在没有能力分析网页的源码,只能跑几遍,多抓几遍。示例:如果已知音乐文件的绝对 URL 为 /1.mid,则生成下载链接的代码为:j avascript:document。write('右键另存为'); 七、From Book E 获取图片文件 在上面通用步骤的第4步中,将以下内容复制粘贴到地址栏,然后回车即可查看内容:j avascript:z=1;strUrl= '';str='' ;function getImg(){if(strUrl!=''){str+=(z++);str+='.
<IMG SRC="';str+=strUrl;str+='">
\n';};};c=document.images;for(i=0;i';str+=strU rl;str+='
\n';};};c=document.images;for(i=0;i
\n';c=document.all;f or(i=0;i';if(=='')str+=o.src;else str+=;str+='
\n';};str+='';document.write(str); 此代码自动检查网页。如果嵌入了框架(包括 iframe),则自动在框架中显示页面链接,否则显示空页面或无响应。只需单击链接即可转到相应页面。为了保证通用性,上面的代码只检查了第一层的frame,对于iframe来说问题不大,因为很少有正常人会玩嵌套的iframe;但是对于普通的框架,嵌套的 iframe 不是问题。可能性还是很大的,上面的代码需要逐层点击才能看到嵌套的框架,有点麻烦。解决方法是:如果上面的代码显示所有FRA ME,没有IFRA ME,可以使用下面的代码显示所有嵌套的frame:j avascript:str='';function getFrame(c,i,
从03开始,它提供了一个可以打开/关闭的“高级界面”。通过其中的“脚本命令”功能,可以直接将要执行的JavaScript代码或URL推送到IE窗口执行,无需在地址栏中输入。如果您已经编写了自己的 JavaScript 代码,也可以将其添加到 CtrlN.spt 文件(纯文本文件)中,以便稍后在 Script 命令选择窗口中直接选择。附录版本更新记录版本1.01 文档已根据CtrlN ver 1.03的新功能进行了修订。 查看全部
抓取网页flash(用用JavaScript获获取取网网页页中的js、css、Flash等等文文件件)
但不是电子书里的js、css、Flash、背景音乐等文件。其实只要对 JavaScript 代码有一定的了解,即使只使用已经公开发布的 CtrlN,在 E 书中获取这些文件也不难。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,这种方法很难用于批量反编译,所以庄家不必产生许多担忧。电子书中的背景音乐和其他文件。其实只要对 JavaScript 代码有一定的了解,即使只使用已经公开发布的 CtrlN,在 E 书中获取这些文件也不难。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,这种方法很难用于批量反编译,所以庄家不必产生许多担忧。电子书中的背景音乐和其他文件。其实只要对 JavaScript 代码有一定的了解,即使只使用已经公开发布的 CtrlN,在 E 书中获取这些文件也不难。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,这种方法很难用于批量反编译,所以庄家不必产生许多担忧。只要对 JavaScript 代码有一定的了解,即使只使用已经公开发布的 CtrlN,在 E 书中获取这些文件也不难。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,这种方法很难用于批量反编译,所以庄家不必产生许多担忧。只要对 JavaScript 代码有一定的了解,即使只使用已经公开发布的 CtrlN,在 E 书中获取这些文件也不难。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,这种方法很难用于批量反编译,所以庄家不必产生许多担忧。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人的做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,而且这种方法很难用于批量反编译,所以庄家不必产生许多担忧。提前声明:1、下面所有的方法都是基于JavaScript的,可能会让人有兜兜转转的感觉,效果无法与直接调用非公开接口的IECracer和KillEBoo相比IE。但这只是平衡:对于打算通过反编译来学习别人的做书经验的好学者来说,使用JavaScript本身就是一个练习的过程,而且这种方法很难用于批量反编译,所以庄家不必产生许多担忧。
我不杀鸡杀蛋,哈哈……2、为了方便使用,下面给出的JavaScript很笨,所有的URL解析工作都是代码完成的,只要按Ctrl+C即可, Ctrl+V 键都可以。然而,自动化毕竟有其局限性。对于大部分网页来说,这些代码应该是可以解决的。但是,如果遇到无法解决的网页,仍然需要手动分析 HTML 代码。如果在分析过程中遇到加密网页,可以使用CtrlN的“HTML Fragment”功能对加密后的HTML进行解码。在源代码中查找链接时,可以使用搜索功能快速定位。3、现在基于IE内核的电子书基本都是通过自定义协议插件实现的,对JavaScript协议插件的支持程度不一,所以不要' 如果代码在某些电子书上有错误,请不要感到惊讶。4.这些代码除了反编译电子书外,在浏览普通网页时也很有用,例如用于抓取网页中的Falsh文件。5、所有代码都是在Windows XP SP2下测试的,其他环境我没试过,但估计IE版本不能低于6.0。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。除了反编译电子书外,这些代码在浏览普通网页时也很有用,例如,它们用于捕获网页中的 Falsh 文件。5、所有代码都是在Windows XP SP2下测试的,其他环境我没试过,但估计IE版本不能低于6.0。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。除了反编译电子书外,这些代码在浏览普通网页时也很有用,例如,它们用于捕获网页中的 Falsh 文件。5、所有代码都是在Windows XP SP2下测试的,其他环境我没试过,但估计IE版本不能低于6.0。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。它们用于捕获网页中的 Falsh 文件。5、所有代码都是在Windows XP SP2下测试的,其他环境我没试过,但估计IE版本不能低于6.0。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。它们用于捕获网页中的 Falsh 文件。5、所有代码都是在Windows XP SP2下测试的,其他环境我没试过,但估计IE版本不能低于6.0。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。6、所有代码都是我的原创,个人可以免费使用。网站转载和商业利益,请先获得我的授权。二、从电子书或网页中获取文件的一般步骤从电子书或普通网页中获取各种文件的步骤基本相同,只是要输入的JavaScript代码不同:启动CtrlN。
这是为了防止电子书或网页禁用快捷键。如果确认没有禁用快捷键,可以省略这一步,在第3步直接按Ctrl+N。打开电子书或IE,进入引用css、js、flash等文件的页面需要被捕获。请注意,这必须是真实页面,而不是框架。如何判断框架以及如何进入框架页面将在后面讨论。将CtrlN的“快捷键行为”设置为“弹出新窗口”,然后用鼠标点击要抓取的网页,然后按Ctrl+N,会弹出一个新的IE窗口,里面显示的内容和你要抢的一样。抓取的页面内容相同,地址栏显示页面的URL。在弹出的 IE 窗口中,根据需要将对应的 JavaScript 代码(后面会给出)复制粘贴到地址栏中,然后按回车键。对于IE 6,第一次运行JavaScript代码时,地址栏下方可能会弹出一个黄色条,表示此代码被阻止运行,点击黄色条,选择“允许被阻止的内容”,然后重复上述步骤3、@ >4 查看结果。三、从E书或网页中获取链接的css文件 JavaScript本身提供了获取外部css文件内容的接口,所以在上述通用步骤的第4步中,将以下内容复制粘贴到IE中地址栏,然后回车查看内容:j avascript:str='';c=document.styleSheets;for(i=0;i\n';str+=o.cssText;str+='
\n';};document.write(str); 如果当前的 HTML 页面没有链接到外部 css 文件,则在第 4 步完成后将无响应或显示空白页面。这时候可以查看页面的HTML源代码进行确认。如果当前页面链接到多个 css 文件,则会显示所有 css 文件的内容。IE排版后的格式可能和原来的css代码不一样,但是效果是完全一样的。如果只显示css文件的文件名,而下面没有内容,则说明css没有打包在E书里。对于某些电子书,您还可以尝试以下代码:j javascript:str='
\n';c=document.styl eSheets;for(i=0;i';str+=o.href;str+='
\n';};str+='';document.write(str); 此代码自动检查网页。如果网页中嵌入了css文件,则自动显示css文件的下载链接,否则显示空页或无响应。在链接上单击鼠标右键,然后选择“另存为”菜单,将文件保存到硬盘。如果无法保存,将js文件的url复制到地址栏,然后回车试试。但是,如果注册表项HKEY_CLA SSES_ROOT\CSSfile\shell下有open、edit等子项,则获取的CSS代码将直接在open或edit子项指定的程序中打开,而不提示保存。这种方法的适用范围远小于上面直接展示的方法,不是所有的电子书都能用,但只要能用,它肯定会得到原创的 css 代码。四、从E书或网页获取链接的js文件 JavaScript没有提供获取js文件内容的接口,所以首先要对注册表进行改造:运行regedit,定位到HKEY_CLA SSES_ROOT\.js,并在其中添加两个字符串类型值如下: Content Type=application/xj avascript PerceivedType=text 修改的时候不放心可以参考HKEY_CLA SSES_ROOT\.css的默认设置,只是不同而已在 Content Type 的值中。注册表修改是一次性的,修改后不需要再做。转换完成后,用CtrlN抓取js文件的步骤和上面的一般步骤是一样的。在步骤 4 中,将以下内容复制并粘贴到地址栏中,
\n';c=document.scripts;for(i=0;i';str+=o.src;str+='
\n';};str+='';document.write(str); 此代码自动检查网页。如果网页中嵌入了js文件,会自动显示该js文件的下载链接,否则会显示空页或无响应。在链接上点击鼠标右键,选择“另存为”菜单,或直接点击链接;您可以将文件保存到硬盘。如果无法保存,请确认注册表是否已按照上述方法设置;如果不行,可以把js文件的url复制到地址栏,然后回车试试。诡异的是eBoo Wor shop制作的E书(页面URL以ada99:开头),在地址栏中输入js文件的URL回车,就会显示js文件的内容及其执行结果直接点击“
\n';c=document.all;f or(i=0;i'));nd.firstChild.outerHT ML=sih;no=document.createElement(nd.firstChild.outerHT ML);document.body 。appendChild(no);str+='';str+=no.src;str+='
\n';};str+='';document.write(str); 此代码自动检查网页。如果网页中嵌入了Flash对象,会自动显示swf文件的下载链接,否则会显示空页或无响应。右键单击该链接并选择“另存为”以将文件保存到您的硬盘驱动器。如果直接单击链接,将显示 Flash 屏幕。我经常看到有人问:“如何在网页上捕捉漂亮的 Flash?” 事实上,答案就是这么简单。我在上网的时候经常用这段代码来抓Flash,但是需要注意的是:如果页面是嵌入到框架中的,则需要将框架分解成真实页面后才能使用此代码。此代码还使用 createDocument tFragment 方法,并且仅适用于 IE 6。现在还有一个很极端的电子书:全书只有一个网页,里面嵌入了一个Flash文件作为记录。点击Flash中的链接,会跳转到其他Flash文件,也就是真正的内容隐藏在一堆Flash文件中。里面。这类电子书,用上面的代码一次只能抓一个Flash,需要一步一步点进去才能全部抓,有的甚至用flasm反编译抓到的Flash文件的运行脚本,然后从脚本中找出它所链接的其他Flash文件的文件名(我都是很刻薄的直接搜索.swf),然后将文件名转换为绝对URL生成下载链接。例如,如果已知 Flash 文件的绝对 URL 为 /pic.swf,则可以使用以下代码单独下载该文件:j avascript:document。write('右键另存为'); 这种方法每次都需要改变URL,当然比上面提到的方法麻烦一些,但是有时候只能用这种方法。对了,flasm真是个好东西,脚本里的一些Flash文件限制了文件只能在网络上播放,不能从本地硬盘播放,你也可以用它来解除这个限制。六、从电子书或网页中获取背景音乐文件背景音乐文件可以像Flash一样直接下载,所以在上述通用步骤的第4步中,将以下内容复制并粘贴到地址栏中,然后按回车键查看内容: j javascript:但有时只能使用这种方法。对了,flasm真是个好东西,脚本里的一些Flash文件限制了文件只能在网络上播放,不能从本地硬盘播放,你也可以用它来解除这个限制。六、从电子书或网页中获取背景音乐文件背景音乐文件可以像Flash一样直接下载,所以在上述通用步骤的第4步中,将以下内容复制并粘贴到地址栏中,然后按回车键查看内容: j javascript:但有时只能使用这种方法。对了,flasm真是个好东西,脚本里的一些Flash文件限制了文件只能在网络上播放,不能从本地硬盘播放,你也可以用它来解除这个限制。六、从电子书或网页中获取背景音乐文件背景音乐文件可以像Flash一样直接下载,所以在上述通用步骤的第4步中,将以下内容复制并粘贴到地址栏中,然后按回车键查看内容: j javascript:
\n';c=document.all;f or(i=0;i';str+=o.src;str+='
\n';};str+='';document.write(str); 此代码自动检查网页。如果嵌入了背景音乐,则会自动显示背景音乐的下载链接,否则会显示空白页面或无反应。右键单击该链接并选择“另存为”以将文件保存到您的硬盘驱动器。注意背景音乐一般隐藏在框架中(否则换页时音乐会中断)。如果弹出页面收录框架而不是实际收录背景音乐链接的页面,则不会被捕获。这时候还需要按照后面提到的步骤进入框架中的页面。另外,为了避免单调,有的电子书会一次打包好几个midi文件,并在每次运行时随机选择一首作为背景音乐。对于这样的电子书,上面的代码只能捕捉到当前的背景音乐。如果要全部捕获,只能自己分析网页源代码,结合所有背景音乐的url,然后在地址栏中输入javascript代码生成下载链接回车即可一次下载一个。请注意,您只能右键单击下载链接并选择“另存为”,不能直接单击该链接。如果实在没有能力分析网页的源码,只能跑几遍,多抓几遍。示例:如果已知音乐文件的绝对 URL 为 /1.mid,则生成下载链接的代码为:j avascript:document。write('右键另存为'); 七、From Book E 获取图片文件 在上面通用步骤的第4步中,将以下内容复制粘贴到地址栏,然后回车即可查看内容:j avascript:z=1;strUrl= '';str='' ;function getImg(){if(strUrl!=''){str+=(z++);str+='.
<IMG SRC="';str+=strUrl;str+='">
\n';};};c=document.images;for(i=0;i';str+=strU rl;str+='
\n';};};c=document.images;for(i=0;i
\n';c=document.all;f or(i=0;i';if(=='')str+=o.src;else str+=;str+='
\n';};str+='';document.write(str); 此代码自动检查网页。如果嵌入了框架(包括 iframe),则自动在框架中显示页面链接,否则显示空页面或无响应。只需单击链接即可转到相应页面。为了保证通用性,上面的代码只检查了第一层的frame,对于iframe来说问题不大,因为很少有正常人会玩嵌套的iframe;但是对于普通的框架,嵌套的 iframe 不是问题。可能性还是很大的,上面的代码需要逐层点击才能看到嵌套的框架,有点麻烦。解决方法是:如果上面的代码显示所有FRA ME,没有IFRA ME,可以使用下面的代码显示所有嵌套的frame:j avascript:str='';function getFrame(c,i,
从03开始,它提供了一个可以打开/关闭的“高级界面”。通过其中的“脚本命令”功能,可以直接将要执行的JavaScript代码或URL推送到IE窗口执行,无需在地址栏中输入。如果您已经编写了自己的 JavaScript 代码,也可以将其添加到 CtrlN.spt 文件(纯文本文件)中,以便稍后在 Script 命令选择窗口中直接选择。附录版本更新记录版本1.01 文档已根据CtrlN ver 1.03的新功能进行了修订。
抓取网页flash(附上游戏网址获取gateway_wolfs_,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-01-31 12:15
flash_spider
与网页flash交互的爬虫
最近在玩防守杨村。游戏是用flash制作的。我花了两天时间尝试做一个爬虫来自动执行一些操作。互联网上的flash爬虫教程很少。这里总结一下遇到的坑
p>
抓包
Flash使用amf数据格式进行数据交换,是一种二进制文件,传输效率高。用抓包软件抓包得到如下结果
分析表明,我们只需要模拟浏览器将相应格式的amf数据发送到服务器
数据包中的方法就是我们要执行的操作。图中的umap.pk_wolfs是在前线打狼的。这是游戏开发者的名字,我们只需要称呼它
根据AMF协议编码数据
python3使用的amf工具包在安装pyamf时执行命令
pip install Py3AMF
在GitHub的pyamf项目中,看到了实例使用的messaging.remoting类。我照常使用,python发送的数据请求与浏览器发送的数据请求相差甚远,于是查看了remoting和massaging的源码,发现发送的数据包只能通过传递一个类到 remoting.Request 函数中并将其转换为 amf3 格式。然后写一个MyMessage类来组织杨村服务器需要的数据格式
获取网关密钥
分析数据包,得知我们发送的数据包需要gateway_key,这让我想了半天,终于在网页对应flash位置的源码中找到了
模拟的苦力
抓硬盘前打开抓包软件,然后抓硬盘,分析数据包中的方法为user.catch_slave,所以只需将MyMessage类的数据成员方法改成'user.catch_slave'
最终效果
你可以通过苦力选择优质苦力,还可以设置时间完美抓苦力! !
附上游戏网址 查看全部
抓取网页flash(附上游戏网址获取gateway_wolfs_,)
flash_spider
与网页flash交互的爬虫
最近在玩防守杨村。游戏是用flash制作的。我花了两天时间尝试做一个爬虫来自动执行一些操作。互联网上的flash爬虫教程很少。这里总结一下遇到的坑
p>
抓包
Flash使用amf数据格式进行数据交换,是一种二进制文件,传输效率高。用抓包软件抓包得到如下结果
分析表明,我们只需要模拟浏览器将相应格式的amf数据发送到服务器
数据包中的方法就是我们要执行的操作。图中的umap.pk_wolfs是在前线打狼的。这是游戏开发者的名字,我们只需要称呼它
根据AMF协议编码数据
python3使用的amf工具包在安装pyamf时执行命令
pip install Py3AMF
在GitHub的pyamf项目中,看到了实例使用的messaging.remoting类。我照常使用,python发送的数据请求与浏览器发送的数据请求相差甚远,于是查看了remoting和massaging的源码,发现发送的数据包只能通过传递一个类到 remoting.Request 函数中并将其转换为 amf3 格式。然后写一个MyMessage类来组织杨村服务器需要的数据格式
获取网关密钥
分析数据包,得知我们发送的数据包需要gateway_key,这让我想了半天,终于在网页对应flash位置的源码中找到了
模拟的苦力
抓硬盘前打开抓包软件,然后抓硬盘,分析数据包中的方法为user.catch_slave,所以只需将MyMessage类的数据成员方法改成'user.catch_slave'
最终效果
你可以通过苦力选择优质苦力,还可以设置时间完美抓苦力! !
附上游戏网址
抓取网页flash(火狐在全球浏览器市场份额排行第三(MozillaFirefox)(LGPL))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-25 05:00
Firefox 将 Flash 方法保存在网页中。
①点击“工具->页面信息->媒体”,或在网页上右击->页面信息->媒体,找到要保存的Flash,然后点击保存。
②如果安装了 Adblock,可以打开 Adblock 的 Obj-Tabs 选项查看 Flash 的地址,然后使用 flashget 等下载软件下载 Flash。
③ 安装扩展下载嵌入式(推荐)。Download Embedded扩展在工具和右键中增加了上下文菜单,可以快速抓取页面内嵌的flash动画、电影、mp3等,比通过网页源代码或页面信息抓取更方便。
介绍
Mozilla Firefox 是由 Mozilla 开发的网络浏览器。它使用 Gecko 网页布局引擎,支持多种操作系统。开源代码以多许可方式获得许可,包括 Mozilla 公共许可 (MPL)、GNU 通用公共许可条款 (GPL) 和 GNU 宽松公共许可 (LGPL),目标是创建一个开放、创新和基于机会的网络环境。
目前,火狐浏览器在全球浏览器市场份额排名第三,谷歌Chrome在2011年11月的市场份额正式超越火狐浏览器,跃居第二位。
多年来,Mozilla Firefox 开发计划的总体原则是:每一、两年,对 Firefox 进行一次重大的功能升级。2010 年 1 月 14 日,Mozilla 表示未来将调整上述产品发布原则,即通过定期发布安全升级,逐步为 Firefox 添加各种新功能。此类升级的发布时间为每 6 周。2012年1月11日上午,Mozilla正在进行火狐浏览器长期支持版本(Extended Support Release,以下简称“ESR”)的研发工作。这个版本的浏览器更新速度比较慢,一年更新一次,不会像普通版那样每六周更新一次。
软件名称:
火狐火狐
软件版本:
13.0 官方简体中文版
软件大小:
629KB
软件许可:
自由
适用平台:
Win9X Win2000 WinXP Win2003 Vista
下载链接:
///下载/52175.html 查看全部
抓取网页flash(火狐在全球浏览器市场份额排行第三(MozillaFirefox)(LGPL))
Firefox 将 Flash 方法保存在网页中。
①点击“工具->页面信息->媒体”,或在网页上右击->页面信息->媒体,找到要保存的Flash,然后点击保存。
②如果安装了 Adblock,可以打开 Adblock 的 Obj-Tabs 选项查看 Flash 的地址,然后使用 flashget 等下载软件下载 Flash。
③ 安装扩展下载嵌入式(推荐)。Download Embedded扩展在工具和右键中增加了上下文菜单,可以快速抓取页面内嵌的flash动画、电影、mp3等,比通过网页源代码或页面信息抓取更方便。
介绍
Mozilla Firefox 是由 Mozilla 开发的网络浏览器。它使用 Gecko 网页布局引擎,支持多种操作系统。开源代码以多许可方式获得许可,包括 Mozilla 公共许可 (MPL)、GNU 通用公共许可条款 (GPL) 和 GNU 宽松公共许可 (LGPL),目标是创建一个开放、创新和基于机会的网络环境。
目前,火狐浏览器在全球浏览器市场份额排名第三,谷歌Chrome在2011年11月的市场份额正式超越火狐浏览器,跃居第二位。
多年来,Mozilla Firefox 开发计划的总体原则是:每一、两年,对 Firefox 进行一次重大的功能升级。2010 年 1 月 14 日,Mozilla 表示未来将调整上述产品发布原则,即通过定期发布安全升级,逐步为 Firefox 添加各种新功能。此类升级的发布时间为每 6 周。2012年1月11日上午,Mozilla正在进行火狐浏览器长期支持版本(Extended Support Release,以下简称“ESR”)的研发工作。这个版本的浏览器更新速度比较慢,一年更新一次,不会像普通版那样每六周更新一次。
软件名称:
火狐火狐
软件版本:
13.0 官方简体中文版
软件大小:
629KB
软件许可:
自由
适用平台:
Win9X Win2000 WinXP Win2003 Vista
下载链接:
///下载/52175.html
抓取网页flash(移动端搜索,你的企业网站有流量吗?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-23 12:18
移动搜索,你的企业网站有流量吗?作为一个搜索引擎,用手机网站收录比较容易,只有收录。只有这样才能导入更多的流量。那么作为企业网站,如何做好收录移动端网站?跟着山人资讯小编一起来了解一下吧。引入不同的移动搜索引擎优化。
作为网站的普通访问者,搜索引擎对网站进行爬取和索引,对站点/页面的价值进行判断和排序,都是从用户体验的角度出发。因此,原则上网站对用户体验的任何改进都是对搜索引擎的改进。但受限于目前的整体网络环境和技术原因,实现用户体验的具体手段还需要考虑搜索引擎的友好性,让搜索引擎在满足用户体验的前提下更容易理解和处理。那么移动搜索引擎网站的构建主要分为三个部分:如何更好的让百度移动搜索中的内容收录网站,如何在移动搜索中得到更好的结果好排名,如何让用户从众多搜索结果中快速找到并点击您的 网站。简单来说就是收录,排序,展示。下面我们将从 收录 开始
机器可读:
和PC蜘蛛一样,百度通过一个名为Baiduspider2.0的程序对移动互联网上的网页进行爬取,经过处理并内置到移动索引中。目前百度蜘蛛只能读取文本内容,flash、图片等非文本内容暂时还不能很好的处理。放在flash和图片中的文字只能百度轻松识别。建议使用文字代替flash、图片、Javascript等显示重要内容或链接。搜索引擎暂时无法识别Flash、图片、复杂Javascript中的内容;同时,它只存在于收录flash和Javascript链接的网页中。百度手机搜索也可能失败收录。不要在希望被搜索引擎读取的地方使用 Ajax 技术,例如标题、导航、
扁平结构:
一个移动网站还应该有一个清晰的结构和较浅的链接深度,这样可以让用户快速访问有用的信息,让搜索引擎快速了解网站中每个页面的结构层次。网站结构推荐使用树形结构。树状结构通常分为以下三个层次:首页-频道-详情页。
网状链接:
理想的网站结构是一棵扁平的树,从首页到内容页的层级越少越好,这样更有利于搜索引擎进行处理。同时,网站中的链接也要采用网状结构,网站上的每个网页都应该有上下级网页和相关内容的链接,避免出现链接孤岛:首页有频道页 频道页有首页和普通内容页的链接,普通内容页有上级频道和首页的链接,内容相关的页面有相互链接。网站中的每一个网页都应该是网站结构的一部分,并且应该可以通过其他网页链接,让baiduspider尽可能的遍历网站的内容。
简单易懂的网址:
一个描述性好的、规范的、简单的URL有利于用户记忆和直观判断网页内容,也有利于搜索引擎更有效地抓取和理解网页。网站在设计之初,应该有一个合理的URL规划。我们相信:
1、移动台首页,//;
2、频道页面采用/n1/、/n2/(对应PC站的频道),当然n1、n2最好直接可读;
3、详情页的URL尽量短,减少无效参数,比如统计参数等,保证同一个页面只有一组URL地址,不同形式的URL301跳转到正常的 URL;
4、Robots 会阻止 baiduspider 抓取您不希望向用户展示的 URL 表单以及您不希望被百度抓取的私人数据。
涵盖主题的锚点:
锚是锚文本。对于链接的描述性文字,锚文本写得越简洁明了,用户越容易理解指向网页的主要内容。用户将您的页面视为来自另一个页面的链接,而锚文本是对该页面的唯一介绍。和普通用户一样,当搜索引擎蜘蛛第一次发现一个网页时,锚文本是理解页面的唯一因素,对最终排名也有一定的影响。
工具“移动站点地图”:
百度站长平台提供移动站点地图提交工具。通过提交站点地图,百度可以更快更全面地抓取收录网站内容。
工具“移动指数金额”:
百度站长平台还提供移动索引工具,让站长在移动端及时了解自己的网站收录情况。
工具“移动死链接提交”:
百度站长平台还提供了手机死链提交工具。通过提交死链接站点地图,百度可以更快地找到网站死链接并更新和删除。
合理的返回码:
百度蜘蛛在抓取处理时,根据http协议规范设置相应的逻辑。几种常用的返回码如下:
404,百度会认为该网页无效删除,一般在索引中删除,短期内蜘蛛不会再次抓取。建议在内容删除、网页失效等情况下使用404返回码,通知百度蜘蛛该页面无效。同时在网站中应该尽量减少死链接的堆积。如果网站暂时关闭或者抓取压力太大,不要直接返回404,使用503。
301,永久重定向,百度会认为当前URL永久跳转到新的URL。在网站改版、域名替换等情况下,建议使用301,并使用站长平台的网站改版工具。
503,百度会认为暂时无法访问,不会直接删除,短期内会多查几次。如果 网站 暂时关闭,建议使用 503。 查看全部
抓取网页flash(移动端搜索,你的企业网站有流量吗?(图))
移动搜索,你的企业网站有流量吗?作为一个搜索引擎,用手机网站收录比较容易,只有收录。只有这样才能导入更多的流量。那么作为企业网站,如何做好收录移动端网站?跟着山人资讯小编一起来了解一下吧。引入不同的移动搜索引擎优化。
作为网站的普通访问者,搜索引擎对网站进行爬取和索引,对站点/页面的价值进行判断和排序,都是从用户体验的角度出发。因此,原则上网站对用户体验的任何改进都是对搜索引擎的改进。但受限于目前的整体网络环境和技术原因,实现用户体验的具体手段还需要考虑搜索引擎的友好性,让搜索引擎在满足用户体验的前提下更容易理解和处理。那么移动搜索引擎网站的构建主要分为三个部分:如何更好的让百度移动搜索中的内容收录网站,如何在移动搜索中得到更好的结果好排名,如何让用户从众多搜索结果中快速找到并点击您的 网站。简单来说就是收录,排序,展示。下面我们将从 收录 开始
机器可读:
和PC蜘蛛一样,百度通过一个名为Baiduspider2.0的程序对移动互联网上的网页进行爬取,经过处理并内置到移动索引中。目前百度蜘蛛只能读取文本内容,flash、图片等非文本内容暂时还不能很好的处理。放在flash和图片中的文字只能百度轻松识别。建议使用文字代替flash、图片、Javascript等显示重要内容或链接。搜索引擎暂时无法识别Flash、图片、复杂Javascript中的内容;同时,它只存在于收录flash和Javascript链接的网页中。百度手机搜索也可能失败收录。不要在希望被搜索引擎读取的地方使用 Ajax 技术,例如标题、导航、
扁平结构:
一个移动网站还应该有一个清晰的结构和较浅的链接深度,这样可以让用户快速访问有用的信息,让搜索引擎快速了解网站中每个页面的结构层次。网站结构推荐使用树形结构。树状结构通常分为以下三个层次:首页-频道-详情页。
网状链接:
理想的网站结构是一棵扁平的树,从首页到内容页的层级越少越好,这样更有利于搜索引擎进行处理。同时,网站中的链接也要采用网状结构,网站上的每个网页都应该有上下级网页和相关内容的链接,避免出现链接孤岛:首页有频道页 频道页有首页和普通内容页的链接,普通内容页有上级频道和首页的链接,内容相关的页面有相互链接。网站中的每一个网页都应该是网站结构的一部分,并且应该可以通过其他网页链接,让baiduspider尽可能的遍历网站的内容。
简单易懂的网址:
一个描述性好的、规范的、简单的URL有利于用户记忆和直观判断网页内容,也有利于搜索引擎更有效地抓取和理解网页。网站在设计之初,应该有一个合理的URL规划。我们相信:
1、移动台首页,//;
2、频道页面采用/n1/、/n2/(对应PC站的频道),当然n1、n2最好直接可读;
3、详情页的URL尽量短,减少无效参数,比如统计参数等,保证同一个页面只有一组URL地址,不同形式的URL301跳转到正常的 URL;
4、Robots 会阻止 baiduspider 抓取您不希望向用户展示的 URL 表单以及您不希望被百度抓取的私人数据。
涵盖主题的锚点:
锚是锚文本。对于链接的描述性文字,锚文本写得越简洁明了,用户越容易理解指向网页的主要内容。用户将您的页面视为来自另一个页面的链接,而锚文本是对该页面的唯一介绍。和普通用户一样,当搜索引擎蜘蛛第一次发现一个网页时,锚文本是理解页面的唯一因素,对最终排名也有一定的影响。
工具“移动站点地图”:
百度站长平台提供移动站点地图提交工具。通过提交站点地图,百度可以更快更全面地抓取收录网站内容。
工具“移动指数金额”:
百度站长平台还提供移动索引工具,让站长在移动端及时了解自己的网站收录情况。
工具“移动死链接提交”:
百度站长平台还提供了手机死链提交工具。通过提交死链接站点地图,百度可以更快地找到网站死链接并更新和删除。
合理的返回码:
百度蜘蛛在抓取处理时,根据http协议规范设置相应的逻辑。几种常用的返回码如下:
404,百度会认为该网页无效删除,一般在索引中删除,短期内蜘蛛不会再次抓取。建议在内容删除、网页失效等情况下使用404返回码,通知百度蜘蛛该页面无效。同时在网站中应该尽量减少死链接的堆积。如果网站暂时关闭或者抓取压力太大,不要直接返回404,使用503。
301,永久重定向,百度会认为当前URL永久跳转到新的URL。在网站改版、域名替换等情况下,建议使用301,并使用站长平台的网站改版工具。
503,百度会认为暂时无法访问,不会直接删除,短期内会多查几次。如果 网站 暂时关闭,建议使用 503。
抓取网页flash(谷歌黑板报《GET,POST以及安全获取更多网络信息》(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-20 12:07
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全获取更多网络信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。在文章中提到,未来谷歌在读取网页内容时不仅会使用GET抓取,还会根据情况在抓取网页内容时增加POST请求方式,从而进一步提高谷歌搜索的准确率引擎。网页内容的判断。
随着互联网的飞速发展,JavaScript 和 AJAX 越来越流行,越来越多的网页需要 POST 请求——因为页面的全部内容或者因为缺少某些页面信息和/或POST 无法返回资源。但是,谷歌认为,单纯使用 GET 来抓取网页所需的资源,并不能呈现出最全面、最准确的结果。
因此,Google 改进了 flash 索引,在 GET 爬取中引入了 POST 请求,从而对网页内容进行更完整、更准确的爬取和索引。
谷歌抓取网页内容的步骤如下:
1. 通过 GET 抓取网页内容。
2.索引网页内容并尝试呈现页面。
3.在渲染过程中使用POST请求读取页面内容,生成新的POST内容页面。
4.将来自 POST 请求的内容页面和其他数据负载添加到 Googlebot 的抓取队列。
5.Googlebot 执行 POST 请求以抓取页面。
6.Google 会渲染最终的 POST 结果,也可以合并 GET 和 POST 请求结果。
7.完成索引。
搜索引擎新闻内容来源于网络,作者整理排版。不完全代表本博客的实际观点,仅供读者参考和交流。
如有涉及作者著作权的问题,请及时联系作者进行更正、删除或按规定处理。
这篇文章的链接: 查看全部
抓取网页flash(谷歌黑板报《GET,POST以及安全获取更多网络信息》(组图))
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全获取更多网络信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。在文章中提到,未来谷歌在读取网页内容时不仅会使用GET抓取,还会根据情况在抓取网页内容时增加POST请求方式,从而进一步提高谷歌搜索的准确率引擎。网页内容的判断。
随着互联网的飞速发展,JavaScript 和 AJAX 越来越流行,越来越多的网页需要 POST 请求——因为页面的全部内容或者因为缺少某些页面信息和/或POST 无法返回资源。但是,谷歌认为,单纯使用 GET 来抓取网页所需的资源,并不能呈现出最全面、最准确的结果。
因此,Google 改进了 flash 索引,在 GET 爬取中引入了 POST 请求,从而对网页内容进行更完整、更准确的爬取和索引。
谷歌抓取网页内容的步骤如下:
1. 通过 GET 抓取网页内容。
2.索引网页内容并尝试呈现页面。
3.在渲染过程中使用POST请求读取页面内容,生成新的POST内容页面。
4.将来自 POST 请求的内容页面和其他数据负载添加到 Googlebot 的抓取队列。
5.Googlebot 执行 POST 请求以抓取页面。
6.Google 会渲染最终的 POST 结果,也可以合并 GET 和 POST 请求结果。
7.完成索引。
搜索引擎新闻内容来源于网络,作者整理排版。不完全代表本博客的实际观点,仅供读者参考和交流。
如有涉及作者著作权的问题,请及时联系作者进行更正、删除或按规定处理。
这篇文章的链接:

