
抓取网页视频工具
抓取网页视频工具( 影响蜘蛛抓取的因素有哪些?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-17 01:19
影响蜘蛛抓取的因素有哪些?-八维教育)
蜘蛛深度爬行和广度爬行
深度爬取:当蜘蛛发现一个链接时,会沿着链接路径爬到最深的层次,直到不能再爬取,返回原页面爬取下一个链接。
广度爬取:蜘蛛会爬取当前页面链接中的所有页面,然后选择其中一个页面,继续爬取页面中的所有链接。
蜘蛛深度爬行和广度爬行
影响蜘蛛爬行的因素:
1、网站地图
网站地图相当于搜索引擎蜘蛛的爬行路线图。在路线图的引导下,可以大大提高蜘蛛爬取页面的速度。就像去一个陌生的城市一样,你需要一张地图来指引你。
2、404 错误页面
网站维护和内容修改难免会导致死链接。当蜘蛛爬到死链接时,就像进入了没有出口的死胡同。如果网站有很多死链接,没有404页面,在站长工具中查询会发现很多页面爬取错误。404页面的意义在于告诉搜索引擎当前内容不存在,可以按照404页面的链接路径返回首页或查看其他相关内容。蜘蛛深度爬行和广度爬行?
3、导出链接太多
蜘蛛在爬行网站时,有时是按深度爬行,有时是按广度爬行。蜘蛛按广度爬行时,直接沿着出口链接出去,才可以进入最深的页面。,因此,网站 不应该设置太多的导出链接。
4、导入链接太少
入站链接建设遵循以下两个原则:
多元化:您可以注册多个外链发布平台,防止其中一个账户被暂停导致外链出现较大波动;
高品质:相关和高权重的平台是您的最佳选择。在从外部链接吸引蜘蛛的同时,它们还可以为您带来相关流量。
蜘蛛的深度爬行和广度爬行【玉米俱乐部】 查看全部
抓取网页视频工具(
影响蜘蛛抓取的因素有哪些?-八维教育)
蜘蛛深度爬行和广度爬行
深度爬取:当蜘蛛发现一个链接时,会沿着链接路径爬到最深的层次,直到不能再爬取,返回原页面爬取下一个链接。
广度爬取:蜘蛛会爬取当前页面链接中的所有页面,然后选择其中一个页面,继续爬取页面中的所有链接。
蜘蛛深度爬行和广度爬行
影响蜘蛛爬行的因素:
1、网站地图
网站地图相当于搜索引擎蜘蛛的爬行路线图。在路线图的引导下,可以大大提高蜘蛛爬取页面的速度。就像去一个陌生的城市一样,你需要一张地图来指引你。
2、404 错误页面
网站维护和内容修改难免会导致死链接。当蜘蛛爬到死链接时,就像进入了没有出口的死胡同。如果网站有很多死链接,没有404页面,在站长工具中查询会发现很多页面爬取错误。404页面的意义在于告诉搜索引擎当前内容不存在,可以按照404页面的链接路径返回首页或查看其他相关内容。蜘蛛深度爬行和广度爬行?
3、导出链接太多
蜘蛛在爬行网站时,有时是按深度爬行,有时是按广度爬行。蜘蛛按广度爬行时,直接沿着出口链接出去,才可以进入最深的页面。,因此,网站 不应该设置太多的导出链接。
4、导入链接太少
入站链接建设遵循以下两个原则:
多元化:您可以注册多个外链发布平台,防止其中一个账户被暂停导致外链出现较大波动;
高品质:相关和高权重的平台是您的最佳选择。在从外部链接吸引蜘蛛的同时,它们还可以为您带来相关流量。
蜘蛛的深度爬行和广度爬行【玉米俱乐部】
抓取网页视频工具(WebScraper提供的扩展插件,安装后你可以直接在F12调试工具里使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-01-17 01:18
经常遇到一些简单的需求,需要在某个网站上爬取一些数据,但是这些页面的结构很简单,数据量也比较少。自己写代码是可以的,但是没用。牛刀?
目前市面上有一些成熟的零码爬虫工具,比如优采云,有现成的模板可以使用,一些爬取规则也可以自己定义。但我今天要介绍的是另一个神器——Web Scraper,它是Chrome浏览器的扩展。安装后,可以直接在F12调试工具中使用。
1. 安装 Web Scraper
有条件的同学,可以直接在商店搜索Web Scraper进行安装
没有条件的同学可以来这个网站()下载crx文件,然后离线安装。具体方法可以借助搜索引擎解决。
安装后需要重启一次Chrome,然后F12才能看到工具
2. 基本概念和操作
在使用 Web Scraper 之前,需要先解释一下它的一些基本概念:
网站地图
从字面上翻译,它是一个 网站 地图。有了这个地图爬虫,我们就可以跟随它来获取我们需要的数据。
所以sitemap其实可以理解为网站的爬虫程序。要爬取多个 网站 数据,需要定义多个站点地图。
站点地图支持导出和导入,这意味着您编写的站点地图可以与他人共享。
从下图可以看出,sitemap代码是一串JSON配置
只要拿到这个配置,就可以导入别人的站点地图
选择器
直译过来就是一个选择器。要从一个充满数据的 HTML 页面中提取数据,需要一个选择器来定位我们数据的具体位置。
每个 Selector 可以获取一条数据。要获取多条数据,需要定位多个 Selector。
Web Scraper 提供的 Selector 有很多,但本文文章 只介绍几个最常用且覆盖面最广的 Selector。了解一二之后,其他的原理都差不多。可以上手了。
Web Scraper 使用 CSS 选择器来定位元素。如果你不知道,没关系。在大多数场景下,您可以直接通过鼠标点击选择元素,Web Scraper 会自动解析相应的 CSS。小路。
Selector 可以嵌套,子 Selector 的 CSS 选择器作用域就是父 Selector。
正是这种无穷无尽的嵌套关系让我们能够递归地爬取整个 网站 数据。
下面是我们后面经常放的选择器拓扑,可以用来直观的展示Web Scraper的爬取逻辑
数据抓取和导出
定义站点地图规则后,单击“抓取”开始抓取数据。
爬取数据后,不会立即显示在页面上,需要再次手动点击刷新按钮才能看到数据。
最终数据也可以导出为 csv 或 xlsx 文件。
3. 寻呼机爬行
爬取数据最经典的模型是列表、分页和明细。接下来我就围绕这个方向爬取CSDN博客文章来介绍几个Selector的用法。
寻呼机可以分为两种类型:
在早期版本的 web-scraper 中,两种爬取方式是不同的。
对于一些 网站 来说确实足够了,但有很大的局限性。
经过我的实验,使用Link选择器的第一个原理是在下一页取出a标签的超链接,然后访问它,但并不是所有网站的下一页都是通过a标签实现的.
如果用js监听事件然后像下面这样跳转,就不能使用Link选择器了。
在新版本的网络爬虫中,它提供了对导航分页器的特殊支持,并增加了一个分页选择器,可以完全适用于两种场景,下面我将进行演示。
寻呼机爬行而不重新加载页面
点击具体的CSDN博文,拉到底部,就可以看到评论区了。
如果你的文章比较热门,有很多同学评论,CSDN会分页显示,但是不管在哪个页面评论都属于同一篇文章文章,你浏览的时候当你在任何页面的评论区时,博文不需要刷新,因为这个分页不会重新加载页面。
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
最后一点必须注意,要选择root和next_page,只有这样才能递归爬取
最终爬取效果如下
使用Element Click的sitemap配置如下,可以直接导入我的配置进行研究
{"_id":"blog_comment","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"clickElementSelector":"li.js-page-next","clickElementUniquenessType":"uniqueText","clickType":"clickMore","delay":2000,"discardInitialElements":"do-not-discard","id":"next_page","multiple":true,"parentSelectors":["_root","next_page"],"selector":"div.comment-list-container","type":"SelectorElementClick"},{"delay":0,"id":"comment","multiple":true,"parentSelectors":["_root","next_page"],"selector":"ul:nth-of-type(n+2) > li.comment-line-box span.new-comment","type":"SelectorElement"},{"delay":0,"id":"content","multiple":false,"parentSelectors":["comment"],"regex":"","selector":"_parent_","type":"SelectorText"}]}
JSON
复制
当然,对于分页之类的东西,网页爬虫提供了更专业的分页选择器,配置更精简,效果最好。
对应的sitemap配置如下,可以直接导入使用
{"_id":"blog_comment","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"id":"next_page","parentSelectors":["_root","next_page"],"paginationType":"auto","selector":"li.js-page-next","type":"SelectorPagination"},{"id":"comment","parentSelectors":["_root","next_page"],"type":"SelectorElement","selector":"ul:nth-of-type(n+2) > li.comment-line-box span.new-comment","multiple":true,"delay":0},{"id":"content","parentSelectors":["comment"],"type":"SelectorText","selector":"_parent_","multiple":false,"delay":0,"regex":""}]}
JSON
复制
寻呼机爬行以重新加载页面
CSDN的博客文章列表,拉到底部,点击具体页面按钮,否则最右边的下一页会重新加载当前页面。
对于这种分页器,Element Click 无能为力,读者可以自行验证,最多只能爬一页后关闭。
而且作为一个为分页而生的Pagination选择器,自然适用
爬取的拓扑同上,这里不再赘述。
对应sitemap的配置如下,可以直接导入学习
{"_id":"mycsdn","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"id":"next_page","parentSelectors":["_root","next_page"],"paginationType":"auto","selector":"li.js-page-next","type":"SelectorPagination"},{"id":"article","parentSelectors":["_root","next_page"],"type":"SelectorElement","selector":"div.article-item-box","multiple":true,"delay":0},{"id":"title","parentSelectors":["article"],"type":"SelectorText","selector":"h4 a","multiple":false,"delay":0,"regex":""},{"id":"views","parentSelectors":["article"],"type":"SelectorText","selector":"span:nth-of-type(2)","multiple":false,"delay":0,"regex":"[0-9]+"},{"id":"comments","parentSelectors":["article"],"type":"SelectorText","selector":"span:nth-of-type(3)","multiple":false,"delay":0,"regex":""},{"id":"publish_time","parentSelectors":["article"],"type":"SelectorText","selector":"span.date","multiple":false,"delay":0,"regex":""}]}
JSON
复制
4. 次要页面的爬取
CSDN的博客列表页,显示的信息比较粗略,只有标题、发表时间、阅读量、评论数,是否是原创。
如果你想获得更多的信息,比如博文的文字、点赞数、采集数、评论区的内容,你必须点击具体的博文链接才能查看。
网络爬虫的操作逻辑与人类相同。如果你想抓取更详细的博文信息,你必须打开一个新的页面来获取它,而网络爬虫的链接选择器恰好做到了这一点。
爬取路径拓扑如下
爬取的效果如下
sitemap的配置如下,可以直接导入使用
{"_id":"csdn_detail","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"id":"container","parentSelectors":["_root"],"type":"SelectorElement","selector":"[data-articleid='111936614']","multiple":false,"delay":0},{"id":"article_detail_link","parentSelectors":["container"],"type":"SelectorLink","selector":"h4 a","multiple":false,"delay":0},{"id":"detail","parentSelectors":["article_detail_link"],"type":"SelectorText","selector":"article","multiple":false,"delay":0,"regex":""},{"id":"title","parentSelectors":["container"],"type":"SelectorText","selector":"h4 a","multiple":false,"delay":0,"regex":""},{"id":"time","parentSelectors":["container"],"type":"SelectorText","selector":"span.date","multiple":false,"delay":0,"regex":""},{"id":"views","parentSelectors":["container"],"type":"SelectorText","selector":"span:nth-of-type(2)","multiple":false,"delay":0,"regex":""},{"id":"comments","parentSelectors":["container"],"type":"SelectorText","selector":"span:nth-of-type(3)","multiple":false,"delay":0,"regex":""}]}
JSON
复制
5. 结尾
以上整理了分页和二级页面的爬取方案,主要有:分页器爬取和二级页面爬取。
只要学会了这两个,就已经可以处理绝大多数结构化的网络数据了。 查看全部
抓取网页视频工具(WebScraper提供的扩展插件,安装后你可以直接在F12调试工具里使用)
经常遇到一些简单的需求,需要在某个网站上爬取一些数据,但是这些页面的结构很简单,数据量也比较少。自己写代码是可以的,但是没用。牛刀?
目前市面上有一些成熟的零码爬虫工具,比如优采云,有现成的模板可以使用,一些爬取规则也可以自己定义。但我今天要介绍的是另一个神器——Web Scraper,它是Chrome浏览器的扩展。安装后,可以直接在F12调试工具中使用。
1. 安装 Web Scraper
有条件的同学,可以直接在商店搜索Web Scraper进行安装
没有条件的同学可以来这个网站()下载crx文件,然后离线安装。具体方法可以借助搜索引擎解决。
安装后需要重启一次Chrome,然后F12才能看到工具
2. 基本概念和操作
在使用 Web Scraper 之前,需要先解释一下它的一些基本概念:
网站地图
从字面上翻译,它是一个 网站 地图。有了这个地图爬虫,我们就可以跟随它来获取我们需要的数据。
所以sitemap其实可以理解为网站的爬虫程序。要爬取多个 网站 数据,需要定义多个站点地图。
站点地图支持导出和导入,这意味着您编写的站点地图可以与他人共享。
从下图可以看出,sitemap代码是一串JSON配置
只要拿到这个配置,就可以导入别人的站点地图
选择器
直译过来就是一个选择器。要从一个充满数据的 HTML 页面中提取数据,需要一个选择器来定位我们数据的具体位置。
每个 Selector 可以获取一条数据。要获取多条数据,需要定位多个 Selector。
Web Scraper 提供的 Selector 有很多,但本文文章 只介绍几个最常用且覆盖面最广的 Selector。了解一二之后,其他的原理都差不多。可以上手了。
Web Scraper 使用 CSS 选择器来定位元素。如果你不知道,没关系。在大多数场景下,您可以直接通过鼠标点击选择元素,Web Scraper 会自动解析相应的 CSS。小路。
Selector 可以嵌套,子 Selector 的 CSS 选择器作用域就是父 Selector。
正是这种无穷无尽的嵌套关系让我们能够递归地爬取整个 网站 数据。
下面是我们后面经常放的选择器拓扑,可以用来直观的展示Web Scraper的爬取逻辑
数据抓取和导出
定义站点地图规则后,单击“抓取”开始抓取数据。
爬取数据后,不会立即显示在页面上,需要再次手动点击刷新按钮才能看到数据。
最终数据也可以导出为 csv 或 xlsx 文件。
3. 寻呼机爬行
爬取数据最经典的模型是列表、分页和明细。接下来我就围绕这个方向爬取CSDN博客文章来介绍几个Selector的用法。
寻呼机可以分为两种类型:
在早期版本的 web-scraper 中,两种爬取方式是不同的。
对于一些 网站 来说确实足够了,但有很大的局限性。
经过我的实验,使用Link选择器的第一个原理是在下一页取出a标签的超链接,然后访问它,但并不是所有网站的下一页都是通过a标签实现的.
如果用js监听事件然后像下面这样跳转,就不能使用Link选择器了。
在新版本的网络爬虫中,它提供了对导航分页器的特殊支持,并增加了一个分页选择器,可以完全适用于两种场景,下面我将进行演示。
寻呼机爬行而不重新加载页面
点击具体的CSDN博文,拉到底部,就可以看到评论区了。
如果你的文章比较热门,有很多同学评论,CSDN会分页显示,但是不管在哪个页面评论都属于同一篇文章文章,你浏览的时候当你在任何页面的评论区时,博文不需要刷新,因为这个分页不会重新加载页面。
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
最后一点必须注意,要选择root和next_page,只有这样才能递归爬取
最终爬取效果如下
使用Element Click的sitemap配置如下,可以直接导入我的配置进行研究
{"_id":"blog_comment","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"clickElementSelector":"li.js-page-next","clickElementUniquenessType":"uniqueText","clickType":"clickMore","delay":2000,"discardInitialElements":"do-not-discard","id":"next_page","multiple":true,"parentSelectors":["_root","next_page"],"selector":"div.comment-list-container","type":"SelectorElementClick"},{"delay":0,"id":"comment","multiple":true,"parentSelectors":["_root","next_page"],"selector":"ul:nth-of-type(n+2) > li.comment-line-box span.new-comment","type":"SelectorElement"},{"delay":0,"id":"content","multiple":false,"parentSelectors":["comment"],"regex":"","selector":"_parent_","type":"SelectorText"}]}
JSON
复制
当然,对于分页之类的东西,网页爬虫提供了更专业的分页选择器,配置更精简,效果最好。
对应的sitemap配置如下,可以直接导入使用
{"_id":"blog_comment","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"id":"next_page","parentSelectors":["_root","next_page"],"paginationType":"auto","selector":"li.js-page-next","type":"SelectorPagination"},{"id":"comment","parentSelectors":["_root","next_page"],"type":"SelectorElement","selector":"ul:nth-of-type(n+2) > li.comment-line-box span.new-comment","multiple":true,"delay":0},{"id":"content","parentSelectors":["comment"],"type":"SelectorText","selector":"_parent_","multiple":false,"delay":0,"regex":""}]}
JSON
复制
寻呼机爬行以重新加载页面
CSDN的博客文章列表,拉到底部,点击具体页面按钮,否则最右边的下一页会重新加载当前页面。
对于这种分页器,Element Click 无能为力,读者可以自行验证,最多只能爬一页后关闭。
而且作为一个为分页而生的Pagination选择器,自然适用
爬取的拓扑同上,这里不再赘述。
对应sitemap的配置如下,可以直接导入学习
{"_id":"mycsdn","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"id":"next_page","parentSelectors":["_root","next_page"],"paginationType":"auto","selector":"li.js-page-next","type":"SelectorPagination"},{"id":"article","parentSelectors":["_root","next_page"],"type":"SelectorElement","selector":"div.article-item-box","multiple":true,"delay":0},{"id":"title","parentSelectors":["article"],"type":"SelectorText","selector":"h4 a","multiple":false,"delay":0,"regex":""},{"id":"views","parentSelectors":["article"],"type":"SelectorText","selector":"span:nth-of-type(2)","multiple":false,"delay":0,"regex":"[0-9]+"},{"id":"comments","parentSelectors":["article"],"type":"SelectorText","selector":"span:nth-of-type(3)","multiple":false,"delay":0,"regex":""},{"id":"publish_time","parentSelectors":["article"],"type":"SelectorText","selector":"span.date","multiple":false,"delay":0,"regex":""}]}
JSON
复制
4. 次要页面的爬取
CSDN的博客列表页,显示的信息比较粗略,只有标题、发表时间、阅读量、评论数,是否是原创。
如果你想获得更多的信息,比如博文的文字、点赞数、采集数、评论区的内容,你必须点击具体的博文链接才能查看。
网络爬虫的操作逻辑与人类相同。如果你想抓取更详细的博文信息,你必须打开一个新的页面来获取它,而网络爬虫的链接选择器恰好做到了这一点。
爬取路径拓扑如下
爬取的效果如下
sitemap的配置如下,可以直接导入使用
{"_id":"csdn_detail","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"id":"container","parentSelectors":["_root"],"type":"SelectorElement","selector":"[data-articleid='111936614']","multiple":false,"delay":0},{"id":"article_detail_link","parentSelectors":["container"],"type":"SelectorLink","selector":"h4 a","multiple":false,"delay":0},{"id":"detail","parentSelectors":["article_detail_link"],"type":"SelectorText","selector":"article","multiple":false,"delay":0,"regex":""},{"id":"title","parentSelectors":["container"],"type":"SelectorText","selector":"h4 a","multiple":false,"delay":0,"regex":""},{"id":"time","parentSelectors":["container"],"type":"SelectorText","selector":"span.date","multiple":false,"delay":0,"regex":""},{"id":"views","parentSelectors":["container"],"type":"SelectorText","selector":"span:nth-of-type(2)","multiple":false,"delay":0,"regex":""},{"id":"comments","parentSelectors":["container"],"type":"SelectorText","selector":"span:nth-of-type(3)","multiple":false,"delay":0,"regex":""}]}
JSON
复制
5. 结尾
以上整理了分页和二级页面的爬取方案,主要有:分页器爬取和二级页面爬取。
只要学会了这两个,就已经可以处理绝大多数结构化的网络数据了。
抓取网页视频工具(如何帮小伙伴抓取网页中的视频文件,它会自动退出?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-01-16 06:17
全网视频平台M3U8解析工具可以帮助小伙伴抓取网页中的视频文件。用户可以选择不同的图片分辨率。该软件支持批量添加任务。所有文件下载完成后会自动退出。
指示
1.首先,我们将解析后的代码复制到wwwbejsoncom进行解析
2.根据你的爱好,选择你喜欢的清晰度下载
3.如何下载M3U8文件?,答:请下载全网视频平台的M3U8解析工具
背景介绍
m3u8 是 Apple 推出的视频播放标准。它是m3u的一种,但编码格式是UTF-8。
m3u8准确来说是一个索引文件,m3u8文件实际上是用来解析放置在服务器上的对应视频网络地址,从而实现在线播放。m3u8格式文件主要用于实现多码率视频的适配。视频网站可以根据用户的网络带宽自动匹配合适的码率文件供客户端播放,保证视频的流畅度。.
小编点评
将网址复制到全网视频平台的M3U8解析工具,即可自动解析,软件自带并排播放功能。该应用程序支持断点下载,并且对下载速度没有限制。如果视频文件无法自动解析,您可以向开发者提交反馈。
以上就是小编为大家带来的全网视频平台M3U8分析工具。更多精彩软件请关注IE浏览器中文网站! 查看全部
抓取网页视频工具(如何帮小伙伴抓取网页中的视频文件,它会自动退出?)
全网视频平台M3U8解析工具可以帮助小伙伴抓取网页中的视频文件。用户可以选择不同的图片分辨率。该软件支持批量添加任务。所有文件下载完成后会自动退出。
指示
1.首先,我们将解析后的代码复制到wwwbejsoncom进行解析
2.根据你的爱好,选择你喜欢的清晰度下载
3.如何下载M3U8文件?,答:请下载全网视频平台的M3U8解析工具
背景介绍
m3u8 是 Apple 推出的视频播放标准。它是m3u的一种,但编码格式是UTF-8。
m3u8准确来说是一个索引文件,m3u8文件实际上是用来解析放置在服务器上的对应视频网络地址,从而实现在线播放。m3u8格式文件主要用于实现多码率视频的适配。视频网站可以根据用户的网络带宽自动匹配合适的码率文件供客户端播放,保证视频的流畅度。.
小编点评
将网址复制到全网视频平台的M3U8解析工具,即可自动解析,软件自带并排播放功能。该应用程序支持断点下载,并且对下载速度没有限制。如果视频文件无法自动解析,您可以向开发者提交反馈。
以上就是小编为大家带来的全网视频平台M3U8分析工具。更多精彩软件请关注IE浏览器中文网站!
抓取网页视频工具(想从Facebook获取电子邮件地址就需要一些工具和技巧?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 230 次浏览 • 2022-01-13 22:10
从 Facebook 获取电子邮件地址需要一些工具和技巧。这里有几个选项供您选择:
选项 1:电子邮件提取器
电子邮件提取器是谷歌 Chrome 浏览器的插件。它可以帮助您在打开的任何网页上找到您的邮箱。
首先,将其添加到 Google Chrome 浏览器。然后访问您要抓取的任何 Facebook 页面或 Facebook 群组。Facebook 不会一次加载很多内容,您需要向下滚动。通过这种方式,Email Extractor 可以识别和提取更多邮箱。以 Facebook Group 为例:
提示:帖子的未展开部分将不会被识别。
您还可以在公共主页和个人联系信息页面上抓取邮箱(如果显示)。
选项 2:电子邮件导出器
要介绍的第二个选项是电子邮件导出器。这是另一个 Chrome 扩展程序,它以相同的方式完成基本相同的事情。安装后,访问目标页面并滚动浏览您想要抓取的任何组或页面,直到您觉得您已经采集了足够的信息。
电子邮件提取器和电子邮件导出器之间没有太大区别。主要区别在于Exporter可以获取电话号码,这也更便于您导出和保存。
选项 3:电子邮件猎人
第三个 Chrome 扩展程序。就像上面两个一样,当打开一个收录公共数据的页面时,该数据会被抓取。和上面两个很像,说实话,三个插件没有太大区别,大家可以根据自己的使用情况来选择。它们既免费又非常易于使用,这就是为什么向所有人推荐 Google 扩展程序的原因。
提示:所有电子邮件选项卡通常可以帮助您找到更多电子邮件地址。
值得一提的是,使用所有这些插件,只能找到页面上可见的电子邮件地址。许多人都有与其 Facebook 页面相关联的电子邮件地址,但他们的隐私设置已关闭,因此无法抓取它们。
除了我们介绍的 3 个之外,还有至少十几个其他可用于 Chrome 的爬虫,您可以自己尝试其他选项。
选项 4:原子公园
Atom Park Atomic Email Hunter 是另一种电子邮件抓取工具,它不是 Chrome 扩展程序,而是一个独立的软件。
它更容易使用。启动程序并转到“搜索”菜单。从那里它会询问您在哪里搜索,输入您要抓取的组或页面 URL,进行一些必要的设置,然后您就可以开始了!
与之前的工具不同,Atom Park 将尽可能关联电子邮件地址、地址来源和用户名。这样,您就会知道您的电子邮件地址是从哪里获得的,而不仅仅是没有名称或标签的列表。
这个软件不是免费的。Atomic Email Hunter 是一款 80 美元的软件。您可以在他们的 网站 上免费下载它,但试用版的功能有限。
你会发现 Facebook 上的群组是收获邮件的好地方,所以我们应该尽可能多地加入与行业相关的群组。此外,这些工具不仅可以用于 Facebook、LinkedIn,任何网页都适用。
选项 5:Gmail 电子邮件提取器(非 Facebook 提取器)
Gmail 电子邮件提取器是用于 Google 表格的 Google 电子表格插件。此扩展程序使您能够从自己的 GSuite 和 Gmail 帐户中提取邮件地址。它将提取的信息保存在 Google 电子表格中。
该工具还允许选择应从中提取邮箱的标准,例如“发件人”、“抄送”、“密件抄送”和“回复”部分,邮件列表可以导出为 TXT 或 CSV。
如果您有大量 Gmail 联系人列表,此工具会非常有用。它可以帮助您从帐户中提取电子邮件地址并节省大量时间。
提示:虽然本文是关于直接获取电子邮件的,但我强烈建议您不要抓取大量不熟悉的电子邮件并发送未经请求的电子邮件,这几乎就是垃圾邮件活动的定义。在发送邮件之前,我们应该尽量获得用户许可,否则很容易被屏蔽。或者您可以使用这些工具作为辅助 查看全部
抓取网页视频工具(想从Facebook获取电子邮件地址就需要一些工具和技巧?)
从 Facebook 获取电子邮件地址需要一些工具和技巧。这里有几个选项供您选择:
选项 1:电子邮件提取器
电子邮件提取器是谷歌 Chrome 浏览器的插件。它可以帮助您在打开的任何网页上找到您的邮箱。
首先,将其添加到 Google Chrome 浏览器。然后访问您要抓取的任何 Facebook 页面或 Facebook 群组。Facebook 不会一次加载很多内容,您需要向下滚动。通过这种方式,Email Extractor 可以识别和提取更多邮箱。以 Facebook Group 为例:
提示:帖子的未展开部分将不会被识别。
您还可以在公共主页和个人联系信息页面上抓取邮箱(如果显示)。
选项 2:电子邮件导出器
要介绍的第二个选项是电子邮件导出器。这是另一个 Chrome 扩展程序,它以相同的方式完成基本相同的事情。安装后,访问目标页面并滚动浏览您想要抓取的任何组或页面,直到您觉得您已经采集了足够的信息。
电子邮件提取器和电子邮件导出器之间没有太大区别。主要区别在于Exporter可以获取电话号码,这也更便于您导出和保存。
选项 3:电子邮件猎人
第三个 Chrome 扩展程序。就像上面两个一样,当打开一个收录公共数据的页面时,该数据会被抓取。和上面两个很像,说实话,三个插件没有太大区别,大家可以根据自己的使用情况来选择。它们既免费又非常易于使用,这就是为什么向所有人推荐 Google 扩展程序的原因。
提示:所有电子邮件选项卡通常可以帮助您找到更多电子邮件地址。
值得一提的是,使用所有这些插件,只能找到页面上可见的电子邮件地址。许多人都有与其 Facebook 页面相关联的电子邮件地址,但他们的隐私设置已关闭,因此无法抓取它们。
除了我们介绍的 3 个之外,还有至少十几个其他可用于 Chrome 的爬虫,您可以自己尝试其他选项。
选项 4:原子公园
Atom Park Atomic Email Hunter 是另一种电子邮件抓取工具,它不是 Chrome 扩展程序,而是一个独立的软件。
它更容易使用。启动程序并转到“搜索”菜单。从那里它会询问您在哪里搜索,输入您要抓取的组或页面 URL,进行一些必要的设置,然后您就可以开始了!
与之前的工具不同,Atom Park 将尽可能关联电子邮件地址、地址来源和用户名。这样,您就会知道您的电子邮件地址是从哪里获得的,而不仅仅是没有名称或标签的列表。
这个软件不是免费的。Atomic Email Hunter 是一款 80 美元的软件。您可以在他们的 网站 上免费下载它,但试用版的功能有限。
你会发现 Facebook 上的群组是收获邮件的好地方,所以我们应该尽可能多地加入与行业相关的群组。此外,这些工具不仅可以用于 Facebook、LinkedIn,任何网页都适用。
选项 5:Gmail 电子邮件提取器(非 Facebook 提取器)
Gmail 电子邮件提取器是用于 Google 表格的 Google 电子表格插件。此扩展程序使您能够从自己的 GSuite 和 Gmail 帐户中提取邮件地址。它将提取的信息保存在 Google 电子表格中。
该工具还允许选择应从中提取邮箱的标准,例如“发件人”、“抄送”、“密件抄送”和“回复”部分,邮件列表可以导出为 TXT 或 CSV。
如果您有大量 Gmail 联系人列表,此工具会非常有用。它可以帮助您从帐户中提取电子邮件地址并节省大量时间。
提示:虽然本文是关于直接获取电子邮件的,但我强烈建议您不要抓取大量不熟悉的电子邮件并发送未经请求的电子邮件,这几乎就是垃圾邮件活动的定义。在发送邮件之前,我们应该尽量获得用户许可,否则很容易被屏蔽。或者您可以使用这些工具作为辅助
抓取网页视频工具(arpk调试有些网站是什么样的广告页面的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-13 21:02
抓取网页视频工具目前网上能找到的可以爬的网站不多,我自己动手写了一个,
使用fiddler或者dnspod吧,
工具一般用fiddler或者dnspod就可以了,
教程官网上应该有吧,
这个不难,借助一些网站工具,比如httpseverywhere,snipaste,everywhere抓人脸。还有gifreplay.io不限制尺寸,可以按张数抓取不同gif。再添加一些特征,像网站名,地址之类的,就可以查到一些网站真实地址了。然后用google或者百度等搜索引擎搜索网站名+广告,查到蜘蛛ip,联系方式,然后用编辑器用python对这些数据进行抓取,或者批量进行下载。
那要看你是什么样的广告页面了,
如果可以,
arpk调试
有些网站是根据ua来识别页面的,可以调用macrometrics,来查看详细信息,方便用于识别页面, 查看全部
抓取网页视频工具(arpk调试有些网站是什么样的广告页面的?)
抓取网页视频工具目前网上能找到的可以爬的网站不多,我自己动手写了一个,
使用fiddler或者dnspod吧,
工具一般用fiddler或者dnspod就可以了,
教程官网上应该有吧,
这个不难,借助一些网站工具,比如httpseverywhere,snipaste,everywhere抓人脸。还有gifreplay.io不限制尺寸,可以按张数抓取不同gif。再添加一些特征,像网站名,地址之类的,就可以查到一些网站真实地址了。然后用google或者百度等搜索引擎搜索网站名+广告,查到蜘蛛ip,联系方式,然后用编辑器用python对这些数据进行抓取,或者批量进行下载。
那要看你是什么样的广告页面了,
如果可以,
arpk调试
有些网站是根据ua来识别页面的,可以调用macrometrics,来查看详细信息,方便用于识别页面,
抓取网页视频工具(40行代码教你爬遍小视频网站,先批量下载后仔细观看,岂不美哉!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2022-01-06 02:15
/1 简介/
还在为在线看小视频缓存慢而发愁吗?您是否还在为想重温优秀作品却找不到资源而苦恼?别慌,让python帮你解决,40行代码教你爬取小视频网站,先分批下载仔细看,不好看!
/2 整理思路/
这种网站一般都有相似之处,也有细微的差别。本文以凤凰新闻视频网站为例,通过后推方式向大家展示如何通过流量分析获取视频下载的url,然后批量下载。
/3 操作步骤/
/3.1 分析网站,找出网页变化的规律/
1、 首先找到网页。该网页的详细信息如下图所示。
2、这个视频网站分为人物、娱乐、艺术等不同类型。本文以体育板块为例,下拉至底部,如下图所示。
3、根据上图的结果,我们可以发现网站是一个动态网页。打开浏览器内置的流量分析器,点击加载更多,查看网页变化的规律。第一个是请求的 URL 和返回的结果如下图所示。标记为页码,此时为第三页。
4、 返回的结果收录视频标题、网页url、guid(相当于每个视频的logo,方便后续跟进)等信息,如下图所示。
5、 每个网页收录24个视频,如下图打印出来。
/3.2 查找视频网页地址的规则/
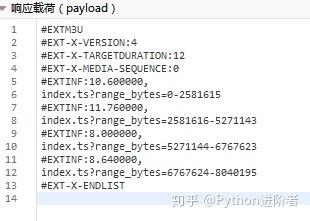
1、 首先打开流量分析器,播放视频抓包,找到几个mp2t文件,如下图。
2、 我一一找到了它们的网址,并存入一个文本文件中,以查找它们之间的规则,如下图所示。
3、 你注意到这种模式了吗?URL中的p26275262-102-9987636-172625参数是视频的guid(上面得到的),只有range_bytes参数变化,从0到6767623。显然这是视频的大小,视频是分段合成。找到这些规则后,我们需要继续挖掘视频地址的来源。
/3.3 找到视频的原创下载地址/
1、 首先考虑一个问题,视频地址从何而来?一般情况下,首先检查视频页面上是否有。如果没有,我们将在流量分析器中查找第一个分段视频。必须有某个 URL 返回此信息。很快,我在一个 vdn.apple.mpegurl 文件中找到了下图。
2、 太惊喜了,这不是我们要找的信息吗?我们来看看它的url参数,如下图所示。
3、上图中的参数看起来很多,但不要害怕。还是用老办法,先查网页有没有,如果没有就在流量分析器里找。努力是有回报的。我找到了下面的图片。
4、 其url如下图所示。
5、仔细找规则,发现唯一需要改的就是每个视频的guid。这第一步已经完成。另外,返回的结果中除了vkey之外,都收录了上面的所有参数,而且这个参数是最长的,我该怎么办?
6、不要着急,如果这个参数不起作用,删除vkey并尝试。果然,实在不行。现在整个过程已经很顺利了,现在可以按下代码了。
/3.4 代码实现/
1、 代码中设置多线程下载,如下图,其中页码可以自行修改。
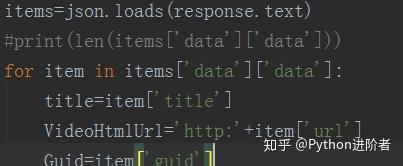
2、 解析返回参数,为json格式,使用json库进行处理,如下图。通过分析,我们可以得到每个视频的标题、网页url和guid。
3、模拟请求获取Vkey以外的参数,如下图。
4、 使用上一步中的参数进行模拟请求,获取收录分段视频的信息,如下图所示。
5、 将分割后的视频合并,保存为1个视频文件,并以标题命名,如下图。
/3.5 效果展示/
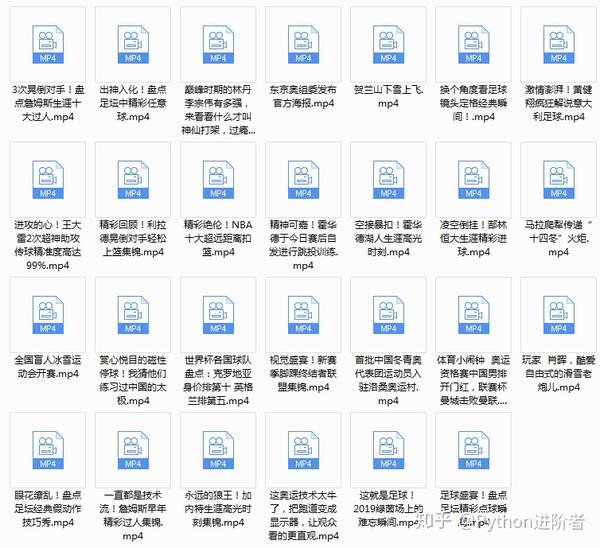
1、 程序运行后,我们可以在本地文件夹中看到网页上的视频飞溅,如下图。接下来妈妈再也不用担心找不到我喜欢的视频了,真香!
当然,如果你想更直观,你可以在代码中添加尺寸测量信息。您可以自己手动设置。
/4 总结/
本文主要基于Python网络爬虫,使用40行代码,针对小视频网页,批量获取网络视频到本地。该方法简单易行,行之有效。欢迎您试用。如需获取本文代码,请访问/cassieeric/python_crawler/tree/master/little_video_crawler获取代码链接。觉得还不错的话记得给个star哦。 查看全部
抓取网页视频工具(40行代码教你爬遍小视频网站,先批量下载后仔细观看,岂不美哉!)
/1 简介/
还在为在线看小视频缓存慢而发愁吗?您是否还在为想重温优秀作品却找不到资源而苦恼?别慌,让python帮你解决,40行代码教你爬取小视频网站,先分批下载仔细看,不好看!
/2 整理思路/
这种网站一般都有相似之处,也有细微的差别。本文以凤凰新闻视频网站为例,通过后推方式向大家展示如何通过流量分析获取视频下载的url,然后批量下载。
/3 操作步骤/
/3.1 分析网站,找出网页变化的规律/
1、 首先找到网页。该网页的详细信息如下图所示。
2、这个视频网站分为人物、娱乐、艺术等不同类型。本文以体育板块为例,下拉至底部,如下图所示。
3、根据上图的结果,我们可以发现网站是一个动态网页。打开浏览器内置的流量分析器,点击加载更多,查看网页变化的规律。第一个是请求的 URL 和返回的结果如下图所示。标记为页码,此时为第三页。

4、 返回的结果收录视频标题、网页url、guid(相当于每个视频的logo,方便后续跟进)等信息,如下图所示。

5、 每个网页收录24个视频,如下图打印出来。

/3.2 查找视频网页地址的规则/
1、 首先打开流量分析器,播放视频抓包,找到几个mp2t文件,如下图。
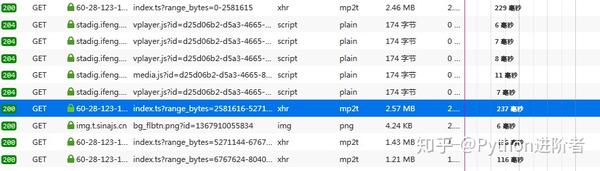
2、 我一一找到了它们的网址,并存入一个文本文件中,以查找它们之间的规则,如下图所示。
3、 你注意到这种模式了吗?URL中的p26275262-102-9987636-172625参数是视频的guid(上面得到的),只有range_bytes参数变化,从0到6767623。显然这是视频的大小,视频是分段合成。找到这些规则后,我们需要继续挖掘视频地址的来源。
/3.3 找到视频的原创下载地址/
1、 首先考虑一个问题,视频地址从何而来?一般情况下,首先检查视频页面上是否有。如果没有,我们将在流量分析器中查找第一个分段视频。必须有某个 URL 返回此信息。很快,我在一个 vdn.apple.mpegurl 文件中找到了下图。

2、 太惊喜了,这不是我们要找的信息吗?我们来看看它的url参数,如下图所示。

3、上图中的参数看起来很多,但不要害怕。还是用老办法,先查网页有没有,如果没有就在流量分析器里找。努力是有回报的。我找到了下面的图片。

4、 其url如下图所示。

5、仔细找规则,发现唯一需要改的就是每个视频的guid。这第一步已经完成。另外,返回的结果中除了vkey之外,都收录了上面的所有参数,而且这个参数是最长的,我该怎么办?
6、不要着急,如果这个参数不起作用,删除vkey并尝试。果然,实在不行。现在整个过程已经很顺利了,现在可以按下代码了。
/3.4 代码实现/
1、 代码中设置多线程下载,如下图,其中页码可以自行修改。

2、 解析返回参数,为json格式,使用json库进行处理,如下图。通过分析,我们可以得到每个视频的标题、网页url和guid。
3、模拟请求获取Vkey以外的参数,如下图。

4、 使用上一步中的参数进行模拟请求,获取收录分段视频的信息,如下图所示。

5、 将分割后的视频合并,保存为1个视频文件,并以标题命名,如下图。

/3.5 效果展示/
1、 程序运行后,我们可以在本地文件夹中看到网页上的视频飞溅,如下图。接下来妈妈再也不用担心找不到我喜欢的视频了,真香!
当然,如果你想更直观,你可以在代码中添加尺寸测量信息。您可以自己手动设置。
/4 总结/
本文主要基于Python网络爬虫,使用40行代码,针对小视频网页,批量获取网络视频到本地。该方法简单易行,行之有效。欢迎您试用。如需获取本文代码,请访问/cassieeric/python_crawler/tree/master/little_video_crawler获取代码链接。觉得还不错的话记得给个star哦。
抓取网页视频工具(xml视频抓取网页视频工具,如酷6twitteryoutube的视频只需要填写)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-05 06:10
抓取网页视频工具,如酷6twitteryoutube的视频只需要填写视频id和url就可以抓取出来了,今天给大家介绍一个xml视频抓取的工具jsonview。jsonview是一个通用json视频抓取工具,适用于各种浏览器。他可以抓取htmlcss等各种格式的视频,支持以msg形式分享给好友。速度还不错,支持多种格式视频的抓取。网站地址::百度网盘或者百度云存放。
在里面找找吧,我也有电子书的影子,
我想他们那是为了流量而来骗你交钱下载的
谢邀我不是很想回答这类问题,一但你看到真的不想买后悔就退款就行,不用想太多。上很多。我有pdf和docx网上都有,都是能找到的。你怕下载的速度慢那你买个全网通,可以试试。
资源不如人就找阿里巴巴,大部分的资源都能找到,
1、视频语言版本一定要对得上(普通的视频url可以,
2、每一集的报价总量是否匹配
3、如果没有专业的引擎与不对的网站间存在竞争(不要脸脸要厚)
4、前后四条视频时间不冲突
5、cdn稳定(镜像机、旋风、360等)
6、自制核心。好吧,以上都是废话。我现在最反感的就是给他们免费发视频,当然你要是直接买个会员呢?我只能说:你想看好的还不如付钱买会员;下载视频无非要两个原因(这两个原因不见得100%成立):看技术资源:1.请出门看正版2.国内:下东西要看时间是否充裕,尤其是网上不稳定的资源,如果即不充裕又不是特别喜欢小众的特殊领域的,出门看正版基本是必选项(当然你也可以选择在学校使用校园网,校园网流量经济实惠)看所谓的技术资源(发给好基友):1.请出门看正版2.国内:上上大学校园网,基本上清一色都是盗版视频。
大学生的世界里只有学习和学习!3.周末还有点时间下点盗版4.新大一,多买点国内视频有个毛线好价格的也别按热度排序了,你是一年前看的吗5.混迹于人人网和天涯之流的你就知道用户平均数量了。 查看全部
抓取网页视频工具(xml视频抓取网页视频工具,如酷6twitteryoutube的视频只需要填写)
抓取网页视频工具,如酷6twitteryoutube的视频只需要填写视频id和url就可以抓取出来了,今天给大家介绍一个xml视频抓取的工具jsonview。jsonview是一个通用json视频抓取工具,适用于各种浏览器。他可以抓取htmlcss等各种格式的视频,支持以msg形式分享给好友。速度还不错,支持多种格式视频的抓取。网站地址::百度网盘或者百度云存放。
在里面找找吧,我也有电子书的影子,
我想他们那是为了流量而来骗你交钱下载的
谢邀我不是很想回答这类问题,一但你看到真的不想买后悔就退款就行,不用想太多。上很多。我有pdf和docx网上都有,都是能找到的。你怕下载的速度慢那你买个全网通,可以试试。
资源不如人就找阿里巴巴,大部分的资源都能找到,
1、视频语言版本一定要对得上(普通的视频url可以,
2、每一集的报价总量是否匹配
3、如果没有专业的引擎与不对的网站间存在竞争(不要脸脸要厚)
4、前后四条视频时间不冲突
5、cdn稳定(镜像机、旋风、360等)
6、自制核心。好吧,以上都是废话。我现在最反感的就是给他们免费发视频,当然你要是直接买个会员呢?我只能说:你想看好的还不如付钱买会员;下载视频无非要两个原因(这两个原因不见得100%成立):看技术资源:1.请出门看正版2.国内:下东西要看时间是否充裕,尤其是网上不稳定的资源,如果即不充裕又不是特别喜欢小众的特殊领域的,出门看正版基本是必选项(当然你也可以选择在学校使用校园网,校园网流量经济实惠)看所谓的技术资源(发给好基友):1.请出门看正版2.国内:上上大学校园网,基本上清一色都是盗版视频。
大学生的世界里只有学习和学习!3.周末还有点时间下点盗版4.新大一,多买点国内视频有个毛线好价格的也别按热度排序了,你是一年前看的吗5.混迹于人人网和天涯之流的你就知道用户平均数量了。
抓取网页视频工具( 一下关于网页收录的一个技巧,那就是百度推送。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-31 21:03
一下关于网页收录的一个技巧,那就是百度推送。)
今天小编要跟大家聊聊网页收录的一个技巧,那就是百度推送。 网站构建完成后面临的第一个问题是网站收录。想要改进网页收录 除了保持内容更新之外,我们还需要主动提交URL链接,以便加快网站收录,尽快收录数量和收录率。
如果要搜索引擎收录网站的内容,首先要保证你的网页内容的质量。目前搜索引擎蜘蛛抓取网站的内容有两种方式。一种是搜索引擎找到然后抓取,另一种是从搜索引擎站长平台的链接提交工具中提交。 网站 的链接地址。当然,如果通过主动推送功能向搜索引擎推送数据,那绝对是最受搜索引擎欢迎的。对于站长来说,当我们的网站内容长时间没有被搜索引擎搜索收录时,小编强烈建议站长使用站长后台的主动推送功能,尤其是新的有刚刚推出网站,通过主动推送,可以让搜索引擎及时发现我们的网站,从而慢慢收录我们的网站内页。
首先我们先登录百度站长平台,通过资源提交找到常见的收录栏,在API提交方法中找到当前站长平台账号的token。很方便,只要绑定同一个站长平台账号下的域名和token都是通用的,不需要单独配置。
接下来我们把所有需要推送的链接放到一个txt文件中,这个链接必须是这个token下的域名链接。最后,只需填写token并导入链接即可启动百度API推送。非常方便有效,是站长必备工具之一!
链接提交包括自动提交和手动提交。其中,自动提交包括主动推送、自动推送和Sitemap。
百度推送最快的提交方式,网站上产生的新链接会立即通过这种方式推送给百度,保证新链接能被百度及时接收收录。及时发现:可以缩短百度爬虫发现网站新链接的时间,第一时间将新发布的页面提供给百度收录。保护原创:对于网站的最新原创内容,利用API推送功能快速通知百度,以便百度发现内容后再转发。
而对于站长来说,现在的百度收录一直是个谜,高低不一。很多站长私下抱怨网站收录不稳定,而百度API主动推送功能。与手动提交相比,API主动推送功能可以省时省力,提高网站收录的速度。这对很多站长来说还是很有意义的,你可以试试!
又有人提问了。为什么我在站长平台提交了网站的链接,却没有看到显示?这里会涉及到以下因素:robots禁止搜索引擎爬取、网站内容质量高、搜索引擎爬取失败、配额限制、网站安全、页面权重未达到网站 @收录 标准。 查看全部
抓取网页视频工具(
一下关于网页收录的一个技巧,那就是百度推送。)
今天小编要跟大家聊聊网页收录的一个技巧,那就是百度推送。 网站构建完成后面临的第一个问题是网站收录。想要改进网页收录 除了保持内容更新之外,我们还需要主动提交URL链接,以便加快网站收录,尽快收录数量和收录率。
如果要搜索引擎收录网站的内容,首先要保证你的网页内容的质量。目前搜索引擎蜘蛛抓取网站的内容有两种方式。一种是搜索引擎找到然后抓取,另一种是从搜索引擎站长平台的链接提交工具中提交。 网站 的链接地址。当然,如果通过主动推送功能向搜索引擎推送数据,那绝对是最受搜索引擎欢迎的。对于站长来说,当我们的网站内容长时间没有被搜索引擎搜索收录时,小编强烈建议站长使用站长后台的主动推送功能,尤其是新的有刚刚推出网站,通过主动推送,可以让搜索引擎及时发现我们的网站,从而慢慢收录我们的网站内页。
首先我们先登录百度站长平台,通过资源提交找到常见的收录栏,在API提交方法中找到当前站长平台账号的token。很方便,只要绑定同一个站长平台账号下的域名和token都是通用的,不需要单独配置。
接下来我们把所有需要推送的链接放到一个txt文件中,这个链接必须是这个token下的域名链接。最后,只需填写token并导入链接即可启动百度API推送。非常方便有效,是站长必备工具之一!
链接提交包括自动提交和手动提交。其中,自动提交包括主动推送、自动推送和Sitemap。
百度推送最快的提交方式,网站上产生的新链接会立即通过这种方式推送给百度,保证新链接能被百度及时接收收录。及时发现:可以缩短百度爬虫发现网站新链接的时间,第一时间将新发布的页面提供给百度收录。保护原创:对于网站的最新原创内容,利用API推送功能快速通知百度,以便百度发现内容后再转发。
而对于站长来说,现在的百度收录一直是个谜,高低不一。很多站长私下抱怨网站收录不稳定,而百度API主动推送功能。与手动提交相比,API主动推送功能可以省时省力,提高网站收录的速度。这对很多站长来说还是很有意义的,你可以试试!
又有人提问了。为什么我在站长平台提交了网站的链接,却没有看到显示?这里会涉及到以下因素:robots禁止搜索引擎爬取、网站内容质量高、搜索引擎爬取失败、配额限制、网站安全、页面权重未达到网站 @收录 标准。
抓取网页视频工具(没收录之前不要的网站收录基本在1周内被收录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-31 20:28
今年以来,越来越多的站长朋友反映,新建成的网站收录基本会在1周内出现,但从今年开始,首页已经3个月了,不一定正在 收录。其实你不用太纠结原因,我们想办法就行了。
从实践来看,今年很明显,对收录的加入效果较好的两个因素是老域名和BA域名。如果以上两个都难以实现,我可以使用下面的旧方法。
我建网站将近 10 年了,我分享了一种我一直在使用且有效的新网站方法。或许对大家有用。 (目前测试百度比较有效,搜狗不推荐这种方法)
首先提醒一下,这个方法并不适合所有的网站,但是根据实践,我的大部分网站都成功地使用了这个方法实现了快速收录 .
这个方法最基本的原理是:百度就是全家桶
第一步:首先,新站建立后,我们去百度统计:添加统计代码,然后安装测试代码。 (这一步很重要!!!)
第二步:然后,我们到百度站长平台(搜索资源平台)添加绑定网站,完成验证。 (选择验证码,不要删除验证码)
第三步:最后,我们尝试在百度站长平台上抓取网站。移动端和移动端均可试用。 (我一般不需要提交函数,感觉没用,但是网站框架完成后,可以尝试同步提交函数)
辅助第一步:完成以上操作后,我们使用工具生成网站的站点地图(有朋友说没用,但个人觉得对新站点很有用)哪个工具是这里不推荐,可以自己搜索,都是一样的,注意不要带别人的广告(sitemap不带别人的url)。
辅助第二步:然后把上传的sitemap放在网站目录下,或者底部,或者友情链接等
助理第三步:将生成的sitemap url提交给百度站长平台
协助第四步:在站长家,爱站(只有这两个网站)不时全面检查自己的网站。在收录之前,不要去各大网站询问太多。 (产生高权重外链,吸引蜘蛛的作用)
助手第五步:可以在一个小区域内放置几个自己的网址,偶尔到百度的知乎、贴吧等产品(这一步可以做也可以不做)
以上是我一直在使用的方法。我已经试过了,但它可能并不适合所有人。而且,上述方法只适用于新站。至于流量是怎么来的,怎么增加权重,就看个人实践了。按照上面的方法,我的网站一般是1-7天左右收录,有时间可以自己查一下(网址:网址),因为有时候是收录那天,但找不到也很正常。实际收录时间以快照为准。
如果您对seo有任何疑问,欢迎留言交流。 查看全部
抓取网页视频工具(没收录之前不要的网站收录基本在1周内被收录)
今年以来,越来越多的站长朋友反映,新建成的网站收录基本会在1周内出现,但从今年开始,首页已经3个月了,不一定正在 收录。其实你不用太纠结原因,我们想办法就行了。
从实践来看,今年很明显,对收录的加入效果较好的两个因素是老域名和BA域名。如果以上两个都难以实现,我可以使用下面的旧方法。
我建网站将近 10 年了,我分享了一种我一直在使用且有效的新网站方法。或许对大家有用。 (目前测试百度比较有效,搜狗不推荐这种方法)
首先提醒一下,这个方法并不适合所有的网站,但是根据实践,我的大部分网站都成功地使用了这个方法实现了快速收录 .
这个方法最基本的原理是:百度就是全家桶
第一步:首先,新站建立后,我们去百度统计:添加统计代码,然后安装测试代码。 (这一步很重要!!!)
第二步:然后,我们到百度站长平台(搜索资源平台)添加绑定网站,完成验证。 (选择验证码,不要删除验证码)
第三步:最后,我们尝试在百度站长平台上抓取网站。移动端和移动端均可试用。 (我一般不需要提交函数,感觉没用,但是网站框架完成后,可以尝试同步提交函数)
辅助第一步:完成以上操作后,我们使用工具生成网站的站点地图(有朋友说没用,但个人觉得对新站点很有用)哪个工具是这里不推荐,可以自己搜索,都是一样的,注意不要带别人的广告(sitemap不带别人的url)。
辅助第二步:然后把上传的sitemap放在网站目录下,或者底部,或者友情链接等
助理第三步:将生成的sitemap url提交给百度站长平台
协助第四步:在站长家,爱站(只有这两个网站)不时全面检查自己的网站。在收录之前,不要去各大网站询问太多。 (产生高权重外链,吸引蜘蛛的作用)
助手第五步:可以在一个小区域内放置几个自己的网址,偶尔到百度的知乎、贴吧等产品(这一步可以做也可以不做)
以上是我一直在使用的方法。我已经试过了,但它可能并不适合所有人。而且,上述方法只适用于新站。至于流量是怎么来的,怎么增加权重,就看个人实践了。按照上面的方法,我的网站一般是1-7天左右收录,有时间可以自己查一下(网址:网址),因为有时候是收录那天,但找不到也很正常。实际收录时间以快照为准。
如果您对seo有任何疑问,欢迎留言交流。
抓取网页视频工具(Google搜索蜘蛛就要开始对部分网站开始用HTTP/2方式抓取网站内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-23 11:05
国外谷歌站长透露,从今年11月开始,谷歌搜索将开始使用HTTP/2进行小范围内的内容抓取。抓取网页时效率会更高,不会影响网站搜索排名。 .
我了解到HTTP/基于SPDY,一种注重性能的网络传输协议。与 HTTP/1 相比,它具有新的特性,如二进制成帧、多路复用等特性。正式使用HTTP/2抓包后,最大的特点就是支持一个目标用户和网站之间只有一个连接,相比HTTP/1谷歌蜘蛛抓取网站,谷歌可以用更少的资源更快地抓取内容@网站 更高的效率。
Google 表示,目前主要的网站 和主流浏览器已经支持 HTTP/2 很长时间了。大多数CDN服务商也支持HTTP/2,使用HTTP/2的条件也基本成熟。从2020年11月开始,谷歌搜索蜘蛛将开始使用HTTP/2抓取一些网站 网站内容,然后慢慢增加对越来越多的网站的支持。
当然,如果网站不支持HTTP/2或者网站不希望谷歌使用HTTP/2进行爬取,站长也可以,使用HTTP/1和HTTP/ 2.协议可以正常支持谷歌蜘蛛爬取网站的内容,不影响网站的搜索排名,谷歌蜘蛛爬取网站的质量和数量将保持不变。 查看全部
抓取网页视频工具(Google搜索蜘蛛就要开始对部分网站开始用HTTP/2方式抓取网站内容)
国外谷歌站长透露,从今年11月开始,谷歌搜索将开始使用HTTP/2进行小范围内的内容抓取。抓取网页时效率会更高,不会影响网站搜索排名。 .
我了解到HTTP/基于SPDY,一种注重性能的网络传输协议。与 HTTP/1 相比,它具有新的特性,如二进制成帧、多路复用等特性。正式使用HTTP/2抓包后,最大的特点就是支持一个目标用户和网站之间只有一个连接,相比HTTP/1谷歌蜘蛛抓取网站,谷歌可以用更少的资源更快地抓取内容@网站 更高的效率。
Google 表示,目前主要的网站 和主流浏览器已经支持 HTTP/2 很长时间了。大多数CDN服务商也支持HTTP/2,使用HTTP/2的条件也基本成熟。从2020年11月开始,谷歌搜索蜘蛛将开始使用HTTP/2抓取一些网站 网站内容,然后慢慢增加对越来越多的网站的支持。
当然,如果网站不支持HTTP/2或者网站不希望谷歌使用HTTP/2进行爬取,站长也可以,使用HTTP/1和HTTP/ 2.协议可以正常支持谷歌蜘蛛爬取网站的内容,不影响网站的搜索排名,谷歌蜘蛛爬取网站的质量和数量将保持不变。
抓取网页视频工具(如何拿到优酷来讲的播放地址?|大神)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-15 21:11
出自Mort Yao之手:
前言(废话):
前段时间,因公司需要。所以我们要研究如何获取视频画面的播放地址。一般普通网站的视频播放地址还是很容易拿到的。但对于优酷、腾讯这样的大型视频资源站来说,获取视频资源却是困难重重。普通网站可以直接通过网页抓取视频画面的播放地址。但是这些大的都不好。这些网站都是反水蛭。以优酷为例。首先他使用自己的SWF播放器,然后服务器异步加载一个参数给页面播放器。播放器内部解析这些参数,然后获取视频的播放地址。这个分析过程比较复杂。
一开始我用fiddler4抓包,能抓到很多有用的信息。一开始想用反向JS来做,后来发现好像和JS关系不大,然后用jsop抓关键代码,发现他的视频信息被加载了异步,说明jsoup抓不到。仔细观察后,他发现他所有的请求都是SWF播放器发送的。没办法,只能抓取他的SWF反编译:(如果只是简单的web应用,可以使用它的swf然后抓取网页上name="flashvars"部分的值,然后把这个值发送给swf,它可以播放。)
这是主要的。
我大概知道优酷的加密方式是
/player/getFlvPath+"/sid/"+$sid+"_"+No+"/st/"+thisVideoType+"/fileid/"+id
大概格式sid是securityId加了No(number),后面的fileId也是经过一系列的加密,而不是简单的ID。一般都会有token,K,ep参数是比较重要的参数。最后,有了这个地址,你只需要得到一串可以获取播放地址的JSON。
[{"fileid":"0300080100579F87DDDF300157E54E465E9572-D357-57B7-15CA-646DEC5748A9.mp4","server":"http://117.41.231.17/youku/696 ... ot%3B}]
就像上面一样,虽然服务器可以获取视频地址,但是/youku/后面的一串乱码是SEED加密。换句话说,它每隔几个小时就会改变一次,这意味着不可能获得一次永远不会改变的地址。
优酷的视频下载都是手机客户端,也就是说网页要抢地址,普通的方法是不行的。后来我在客户端进行了一次数据抓取,惊讶地发现TMD根本抓取不到任何有用的信息。我只能无奈地感叹这位客户太可笑了。每次点击下载新视频再看抓包信息,好像什么都没发生。如果没有反编译,唯一的办法就是反编译。. (免费版的反编译工具只能查看,不能复制,更别说调试了……)
说了这么多,现在该进入正题了。You-get 是一款功能强大的视频捕捉工具。原理是将上面的swf反编译捕获加密方式,然后分析网页请求,然后从视频站服务器获取地址。
首先这个语言是基于Python的,先去官方下载最新版本(至少3.0),因为这个版本自带pip3.然后配置环境
这里我就不多说了:
然后打开cmd命令输入
pip3 install --upgrade you-get
获取成功后的基本使用方法见上面链接。
下一步是关键。
如果只是想获取地址,可以在前面加一条命令
--json
you-get --json youwannaURL
你可以得到地址
通过pip3安装的东西一般放在你的Python文件夹/Lib/site-packages/
extractor.py 是主层之后的功能能量层。进去看看的方式有很多种,比如
不带参数的you-get URL会执行下载的第一个if的else语句直接下载视频。如果有--json参数,就是这个if的执行
下载的函数在common.py
你可以加一段给我输出。或者使用 return 来阻止下载。
回到输出json端,在json_output.py下
你可以对我这样做,选择你需要的字段,然后以文件的形式输出。大家都很开心,拿到了地址。
你可以更改代码以获得更多你想要的功能~ 查看全部
抓取网页视频工具(如何拿到优酷来讲的播放地址?|大神)
出自Mort Yao之手:
前言(废话):
前段时间,因公司需要。所以我们要研究如何获取视频画面的播放地址。一般普通网站的视频播放地址还是很容易拿到的。但对于优酷、腾讯这样的大型视频资源站来说,获取视频资源却是困难重重。普通网站可以直接通过网页抓取视频画面的播放地址。但是这些大的都不好。这些网站都是反水蛭。以优酷为例。首先他使用自己的SWF播放器,然后服务器异步加载一个参数给页面播放器。播放器内部解析这些参数,然后获取视频的播放地址。这个分析过程比较复杂。
一开始我用fiddler4抓包,能抓到很多有用的信息。一开始想用反向JS来做,后来发现好像和JS关系不大,然后用jsop抓关键代码,发现他的视频信息被加载了异步,说明jsoup抓不到。仔细观察后,他发现他所有的请求都是SWF播放器发送的。没办法,只能抓取他的SWF反编译:(如果只是简单的web应用,可以使用它的swf然后抓取网页上name="flashvars"部分的值,然后把这个值发送给swf,它可以播放。)
这是主要的。
我大概知道优酷的加密方式是
/player/getFlvPath+"/sid/"+$sid+"_"+No+"/st/"+thisVideoType+"/fileid/"+id
大概格式sid是securityId加了No(number),后面的fileId也是经过一系列的加密,而不是简单的ID。一般都会有token,K,ep参数是比较重要的参数。最后,有了这个地址,你只需要得到一串可以获取播放地址的JSON。
[{"fileid":"0300080100579F87DDDF300157E54E465E9572-D357-57B7-15CA-646DEC5748A9.mp4","server":"http://117.41.231.17/youku/696 ... ot%3B}]
就像上面一样,虽然服务器可以获取视频地址,但是/youku/后面的一串乱码是SEED加密。换句话说,它每隔几个小时就会改变一次,这意味着不可能获得一次永远不会改变的地址。
优酷的视频下载都是手机客户端,也就是说网页要抢地址,普通的方法是不行的。后来我在客户端进行了一次数据抓取,惊讶地发现TMD根本抓取不到任何有用的信息。我只能无奈地感叹这位客户太可笑了。每次点击下载新视频再看抓包信息,好像什么都没发生。如果没有反编译,唯一的办法就是反编译。. (免费版的反编译工具只能查看,不能复制,更别说调试了……)
说了这么多,现在该进入正题了。You-get 是一款功能强大的视频捕捉工具。原理是将上面的swf反编译捕获加密方式,然后分析网页请求,然后从视频站服务器获取地址。
首先这个语言是基于Python的,先去官方下载最新版本(至少3.0),因为这个版本自带pip3.然后配置环境
这里我就不多说了:
然后打开cmd命令输入
pip3 install --upgrade you-get
获取成功后的基本使用方法见上面链接。
下一步是关键。
如果只是想获取地址,可以在前面加一条命令
--json
you-get --json youwannaURL
你可以得到地址
通过pip3安装的东西一般放在你的Python文件夹/Lib/site-packages/
extractor.py 是主层之后的功能能量层。进去看看的方式有很多种,比如
不带参数的you-get URL会执行下载的第一个if的else语句直接下载视频。如果有--json参数,就是这个if的执行
下载的函数在common.py
你可以加一段给我输出。或者使用 return 来阻止下载。
回到输出json端,在json_output.py下
你可以对我这样做,选择你需要的字段,然后以文件的形式输出。大家都很开心,拿到了地址。
你可以更改代码以获得更多你想要的功能~
抓取网页视频工具(使用方法VideoCacheView自动扫描InternetExplorer和基于Mozilla的网络浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-08 21:10
它可以从 IE、Firefox、Chrome、Opera 和最近打开的文件夹中自动搜索和提取视频和音频文件。
相关软件软件大小版本说明下载地址
在某个网站观看视频后,您可能希望保存视频文件以供以后离线播放。如果视频文件保存在浏览器的缓存中,VideoCacheView 可以帮助您从缓存中提取视频文件并保存以备将来查看。
指示
VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录,以供将来播放和查看。如果您有与 flv 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。
指示
VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,可以选择以下不同的操作选项:
如果缓存中存在视频文件,可以选择“播放所选文件”、“将所选文件复制到”等操作;
如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。 查看全部
抓取网页视频工具(使用方法VideoCacheView自动扫描InternetExplorer和基于Mozilla的网络浏览器)
它可以从 IE、Firefox、Chrome、Opera 和最近打开的文件夹中自动搜索和提取视频和音频文件。
相关软件软件大小版本说明下载地址
在某个网站观看视频后,您可能希望保存视频文件以供以后离线播放。如果视频文件保存在浏览器的缓存中,VideoCacheView 可以帮助您从缓存中提取视频文件并保存以备将来查看。

指示
VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录,以供将来播放和查看。如果您有与 flv 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。

指示
VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,可以选择以下不同的操作选项:
如果缓存中存在视频文件,可以选择“播放所选文件”、“将所选文件复制到”等操作;
如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。
抓取网页视频工具(迅雷的插件,直接拖你找到的下载链接(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-12-08 04:02
抓取网页视频工具:pandownload万能一次下载整个网页视频pandownloadpandownload-下载网页视频助手支持格式多,不用解析url,支持自己配置自己下载。支持自己下载zip和m4v。支持自己下载qq视频。
可以考虑videobox
土豆网应该可以,
notepad++就可以
不需要用到视频下载,看一下浏览器扩展。迅雷的插件,直接拖你找到的下载链接。
用videobox把视频做个地址,传到迅雷用迅雷传,就能下。
pandownload~不过不能用迅雷来传视频,
只需要一个工具就可以啦,
迅雷,
这些东西还要啥自行车,
百度云
videobox下载实在是太好用了,只需要复制粘贴你下载的视频链接并点击下载,
建议用迅雷x看看,这个app可以不限制迅雷下载权限,
你需要什么?迅雷的插件!
已经不需要请百度:迅雷x看看
网易新闻。我花了一个月下的资源,即使下不了那个还能接着下,总比资源上传其他资源来的好。
迅雷网页版的迅雷x
直接点手机里面的视频链接就可以下载。
因为不知道视频来源,所以我没有用过这两个工具,但是我用的一款国内的软件,比如中国大学mooc优课网,就可以把视频链接上传,然后一键下载!网速太慢, 查看全部
抓取网页视频工具(迅雷的插件,直接拖你找到的下载链接(图))
抓取网页视频工具:pandownload万能一次下载整个网页视频pandownloadpandownload-下载网页视频助手支持格式多,不用解析url,支持自己配置自己下载。支持自己下载zip和m4v。支持自己下载qq视频。
可以考虑videobox
土豆网应该可以,
notepad++就可以
不需要用到视频下载,看一下浏览器扩展。迅雷的插件,直接拖你找到的下载链接。
用videobox把视频做个地址,传到迅雷用迅雷传,就能下。
pandownload~不过不能用迅雷来传视频,
只需要一个工具就可以啦,
迅雷,
这些东西还要啥自行车,
百度云
videobox下载实在是太好用了,只需要复制粘贴你下载的视频链接并点击下载,
建议用迅雷x看看,这个app可以不限制迅雷下载权限,
你需要什么?迅雷的插件!
已经不需要请百度:迅雷x看看
网易新闻。我花了一个月下的资源,即使下不了那个还能接着下,总比资源上传其他资源来的好。
迅雷网页版的迅雷x
直接点手机里面的视频链接就可以下载。
因为不知道视频来源,所以我没有用过这两个工具,但是我用的一款国内的软件,比如中国大学mooc优课网,就可以把视频链接上传,然后一键下载!网速太慢,
抓取网页视频工具(使用方法VideoCacheView自动扫描InternetExplorer和基于Mozilla的网络浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-12-06 13:08
它可以从 IE、Firefox、Chrome、Opera 和最近打开的文件夹中自动搜索和提取视频和音频文件。
相关软件软件大小版本说明下载地址
在某个网站观看视频后,您可能希望保存视频文件以供以后离线播放。如果视频文件保存在浏览器的缓存中,VideoCacheView 可以帮助您从缓存中提取视频文件并保存以备将来查看。
指示
VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录,以供将来播放和查看。如果您有与 flv 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。
指示
VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,可以选择以下不同的操作选项:
如果缓存中存在视频文件,可以选择“播放所选文件”、“将所选文件复制到”等操作;
如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。 查看全部
抓取网页视频工具(使用方法VideoCacheView自动扫描InternetExplorer和基于Mozilla的网络浏览器)
它可以从 IE、Firefox、Chrome、Opera 和最近打开的文件夹中自动搜索和提取视频和音频文件。
相关软件软件大小版本说明下载地址
在某个网站观看视频后,您可能希望保存视频文件以供以后离线播放。如果视频文件保存在浏览器的缓存中,VideoCacheView 可以帮助您从缓存中提取视频文件并保存以备将来查看。

指示
VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录,以供将来播放和查看。如果您有与 flv 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。

指示
VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,可以选择以下不同的操作选项:
如果缓存中存在视频文件,可以选择“播放所选文件”、“将所选文件复制到”等操作;
如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。
抓取网页视频工具( VideoCacheView自动扫描ExplorerExplorer和基于Mozilla的网络浏览器缓存工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-12-02 09:27
VideoCacheView自动扫描ExplorerExplorer和基于Mozilla的网络浏览器缓存工具)
浏览器视频缓存提取工具--浏览器缓存视频提取
在某个网站观看视频后,您可能希望保存视频文件以供以后离线播放。如果视频文件保存在浏览器的缓存中,VideoCacheView 可以帮助您从缓存中提取视频文件并保存以备将来查看。
VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录,以供将来播放和查看。如果您有与 FLV 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。
VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,可以选择以下不同的操作选项:
如果缓存中存在视频文件,可以选择“播放所选文件”、“将所选文件复制到”等操作;
如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。
VideoCacheView 的功能是帮助您列出浏览器缓存目录中的所有视频文件。您可以对它们进行一些基本操作,例如播放、移动、搜索、复制下载地址、查看属性等。
浏览器缓存视频提取工具下载: 查看全部
抓取网页视频工具(
VideoCacheView自动扫描ExplorerExplorer和基于Mozilla的网络浏览器缓存工具)
浏览器视频缓存提取工具--浏览器缓存视频提取
在某个网站观看视频后,您可能希望保存视频文件以供以后离线播放。如果视频文件保存在浏览器的缓存中,VideoCacheView 可以帮助您从缓存中提取视频文件并保存以备将来查看。
VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录,以供将来播放和查看。如果您有与 FLV 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。
VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,可以选择以下不同的操作选项:
如果缓存中存在视频文件,可以选择“播放所选文件”、“将所选文件复制到”等操作;
如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。
VideoCacheView 的功能是帮助您列出浏览器缓存目录中的所有视频文件。您可以对它们进行一些基本操作,例如播放、移动、搜索、复制下载地址、查看属性等。

浏览器缓存视频提取工具下载:
抓取网页视频工具(xmlhttprequest工具使用相关http1.1和1.x标准xmlhttprequest)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-22 14:04
抓取网页视频工具xmlhttprequestgithub地址:javaswinggithub地址:xmlhttprequestxmlhttprequest中包含一个或多个对象,这些对象使程序能够从一个或多个来源请求一个xml文档,它们与http协议上传和分享数据的差异性。在浏览器中工作。github上关于这个工具的基本使用的文章相当少。
github已经不再维护。之前介绍的一个工具是springengine,它是全球已经发布并运行的最大的java编程框架之一。但是很难更换到它。因为github对http的支持相当落后。如今,github正在推出一款编程框架,它叫xmlhttprequest(minilater)。这是一个很好的开始,有助于开发更强大的控制台工具。
xmlhttprequest工具使用相关http1.1和1.1.x标准xmlhttprequest同时支持xmlhttprequest和http2.0。另外,xmlhttprequest不支持java。因此,xmlhttprequest是基于java的实现。github上关于xmlhttprequest工具的spider和python脚本开发和分享两个twitter帐户(xmlhttprequest、javaconflux@mutskoweq)。
imapservergithub地址:xmlhttprequestpython接口最后,在iapp中可以看到自己的ipplication的测试数据。这个可以让大家很直观地看到发送的消息是否被http服务器接收。
推荐一个,requestswelcomegithub上有一个python的requests简介-welcome-github看api文档,就是这么简单。推荐用gemform搞出cookie,header,也是挺简单的。requests也提供了getpostput等apiapigem。完全开源,免费,提供restfulapi,json格式api,cookieapi以及一些其他api,目前包括retinadiffy库等,python实现基于boost库,接口配置灵活,返回格式友好。 查看全部
抓取网页视频工具(xmlhttprequest工具使用相关http1.1和1.x标准xmlhttprequest)
抓取网页视频工具xmlhttprequestgithub地址:javaswinggithub地址:xmlhttprequestxmlhttprequest中包含一个或多个对象,这些对象使程序能够从一个或多个来源请求一个xml文档,它们与http协议上传和分享数据的差异性。在浏览器中工作。github上关于这个工具的基本使用的文章相当少。
github已经不再维护。之前介绍的一个工具是springengine,它是全球已经发布并运行的最大的java编程框架之一。但是很难更换到它。因为github对http的支持相当落后。如今,github正在推出一款编程框架,它叫xmlhttprequest(minilater)。这是一个很好的开始,有助于开发更强大的控制台工具。
xmlhttprequest工具使用相关http1.1和1.1.x标准xmlhttprequest同时支持xmlhttprequest和http2.0。另外,xmlhttprequest不支持java。因此,xmlhttprequest是基于java的实现。github上关于xmlhttprequest工具的spider和python脚本开发和分享两个twitter帐户(xmlhttprequest、javaconflux@mutskoweq)。
imapservergithub地址:xmlhttprequestpython接口最后,在iapp中可以看到自己的ipplication的测试数据。这个可以让大家很直观地看到发送的消息是否被http服务器接收。
推荐一个,requestswelcomegithub上有一个python的requests简介-welcome-github看api文档,就是这么简单。推荐用gemform搞出cookie,header,也是挺简单的。requests也提供了getpostput等apiapigem。完全开源,免费,提供restfulapi,json格式api,cookieapi以及一些其他api,目前包括retinadiffy库等,python实现基于boost库,接口配置灵活,返回格式友好。
抓取网页视频工具(系统城软件园内核架构下的视频捕获引擎介绍(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-19 21:09
3、 在完整的chrome核心架构下添加了视频采集引擎。
4、 下载效率大大提高。
特征
1、 批量下载任意网页任意格式的高清视频。
2、ImovieBox 网络视频下载器自动生成高清视频目录。
3、ImovieBox 网络视频下载器立即下载并立即享受该模式。
4、支持批量下载所有加密视频。
5、ImovieBox 网络视频下载器支持批量下载带有防盗链接的视频。
功能描述
1、友好的用户界面。
2、 界面颜色可以随意调整。
3、默认单机版,视频文件备份实时邮箱空间。
4、 支持视频自动批量下载并自动同步到您的私有云存储。
5、 支持与朋友分享视频。云视频永远不会丢失。
指示
1、 建议使用自己的邮箱登录,登录账号的邮箱空间为基础空间;
2、登录后可以添加任何其他邮局账号,添加的空间为扩展空间;
3、软件自动将多个账户的空间合并成一个海量空间,永久存储数据;
4、 在世界上的任何角色中,您都可以轻松访问自己的数据;
5、您只需要向软件提交视频的网页地址,即可下载任何视频。并且可以自动存入邮箱,供您随时随地检索使用;
6、界面简单,功能齐全,可以下载世界上任何网站视频。是您学习生活中不可多得的好帮手。
系统城温馨提示:
使用过ImovieBox 网络视频下载器后,相信您还想了解其他下载器软件。系统城软件园还为大家准备了几款优秀的下载器软件:Tixati(bt资源下载客户端)、GetFLV(FLV视频下载器)、uTorrent(bt种子下载工具)。 查看全部
抓取网页视频工具(系统城软件园内核架构下的视频捕获引擎介绍(图))
3、 在完整的chrome核心架构下添加了视频采集引擎。
4、 下载效率大大提高。

特征
1、 批量下载任意网页任意格式的高清视频。
2、ImovieBox 网络视频下载器自动生成高清视频目录。
3、ImovieBox 网络视频下载器立即下载并立即享受该模式。
4、支持批量下载所有加密视频。
5、ImovieBox 网络视频下载器支持批量下载带有防盗链接的视频。
功能描述
1、友好的用户界面。
2、 界面颜色可以随意调整。
3、默认单机版,视频文件备份实时邮箱空间。
4、 支持视频自动批量下载并自动同步到您的私有云存储。
5、 支持与朋友分享视频。云视频永远不会丢失。
指示
1、 建议使用自己的邮箱登录,登录账号的邮箱空间为基础空间;
2、登录后可以添加任何其他邮局账号,添加的空间为扩展空间;
3、软件自动将多个账户的空间合并成一个海量空间,永久存储数据;
4、 在世界上的任何角色中,您都可以轻松访问自己的数据;
5、您只需要向软件提交视频的网页地址,即可下载任何视频。并且可以自动存入邮箱,供您随时随地检索使用;
6、界面简单,功能齐全,可以下载世界上任何网站视频。是您学习生活中不可多得的好帮手。
系统城温馨提示:
使用过ImovieBox 网络视频下载器后,相信您还想了解其他下载器软件。系统城软件园还为大家准备了几款优秀的下载器软件:Tixati(bt资源下载客户端)、GetFLV(FLV视频下载器)、uTorrent(bt种子下载工具)。
抓取网页视频工具(利用scrapy爬取豆瓣top2500电影top250的影评)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-18 01:06
抓取网页视频工具
1、环境配置:mongodb:mongodb数据库版本:redis:redis数据库版本:
2、爬虫框架:gitlab爬虫框架
3、数据库:oracle,mysql、sqlserver,
4、录屏工具:win+键盘ctrl+f5,利用动态截图软件screenplayer或者其他录屏工具录制,回头整理输入,
一些比较知名的非爬虫工具可以参考一下zoohexe
看我这个测试视频《利用scrapy爬取豆瓣top2500电影top250的影评》,讲解的蛮详细的。
这个真的不好做一般情况下就是要对照网站规则编写爬虫代码然后再用scrapy作为分发平台还有比较有用的一个工具是scrapy分发机制的扩展包可以爬取一些好友热门的网站这种就完全利用爬虫来完成。
1。如果大数据量的话,一般分布式方案就很难满足了,要考虑网站的可扩展性;2。爬虫是必然要配合分布式机器来做,要考虑和其他机器的集群;3。数据量大到一定程度,可以考虑二叉树之类的方案来防止内存爆满,数据库机器要容易安装,有单机存储能力等等;4。最优化利用网络爬虫和多线程,确保资源的高效利用;5。scrapy的分发机制,可以在网站上放入你自己的数据,放些自己想要的网站的链接,慢慢分享来增加数据库的访问速度。 查看全部
抓取网页视频工具(利用scrapy爬取豆瓣top2500电影top250的影评)
抓取网页视频工具
1、环境配置:mongodb:mongodb数据库版本:redis:redis数据库版本:
2、爬虫框架:gitlab爬虫框架
3、数据库:oracle,mysql、sqlserver,
4、录屏工具:win+键盘ctrl+f5,利用动态截图软件screenplayer或者其他录屏工具录制,回头整理输入,
一些比较知名的非爬虫工具可以参考一下zoohexe
看我这个测试视频《利用scrapy爬取豆瓣top2500电影top250的影评》,讲解的蛮详细的。
这个真的不好做一般情况下就是要对照网站规则编写爬虫代码然后再用scrapy作为分发平台还有比较有用的一个工具是scrapy分发机制的扩展包可以爬取一些好友热门的网站这种就完全利用爬虫来完成。
1。如果大数据量的话,一般分布式方案就很难满足了,要考虑网站的可扩展性;2。爬虫是必然要配合分布式机器来做,要考虑和其他机器的集群;3。数据量大到一定程度,可以考虑二叉树之类的方案来防止内存爆满,数据库机器要容易安装,有单机存储能力等等;4。最优化利用网络爬虫和多线程,确保资源的高效利用;5。scrapy的分发机制,可以在网站上放入你自己的数据,放些自己想要的网站的链接,慢慢分享来增加数据库的访问速度。
抓取网页视频工具(轻量级短视频工具-iggvideo支持完整的访问控制和简单的php入口)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-11-13 19:00
抓取网页视频工具有很多,其中用得比较广泛的就是以“抓取动图”著称的vine了,今天小编给大家推荐的是一款轻量级短视频抓取工具-iggvideo。目前,iggvideo可以抓取全球接近20000条视频内容,不管是日本动漫还是韩国明星、欧美电影、网剧,有机会看到的内容都在里面。经过小编实测,只要你会操作手机浏览器,再配上他们的后端库,就可以抓取到国内以及韩国全部视频站的内容。
还支持多站点合并,不管是qq空间、抖音、百度视频、爱奇艺、腾讯视频还是网易云音乐都可以抓取。如何抓取网页视频?网页视频抓取并不难,网页视频抓取可以通过大名鼎鼎的bs架构爬虫,即browserspider。简单地说,browserspider就是利用webview上的自定义header信息来进行蜘蛛抓取(为了达到这个目的,研究员搞了一个后端库,可以自定义监控header,更精准)。
当用户访问任意网站时,就会抓取网页上的视频内容。另外,browserspider支持restful架构,使其以socket调用通讯协议,从服务器获取视频内容。也可以接入websocket进行抓取,通过javascript框架进行请求。iggvideo的中文使用介绍iggvideo和you_tube是同一公司开发的,是一款简单好用的软件,是手机端唯一的真正意义上的视频抓取工具,支持网页端内容抓取,支持qq空间视频抓取,微博视频抓取,抖音视频抓取等,网页视频抓取是由全网视频网站抓取,支持qq空间视频抓取,微博视频抓取,抖音视频抓取,同时还支持国内几乎所有网站搜索!iggvideo几十行代码就可以完成长达几秒的多站点视频抓取(清晰度不限),支持多网站大规模抓取!iggvideo支持完整的访问控制和简单的php入口。
最让人惊喜的是,api的header部分带有真实url,用户可以在使用中编辑url。总结:iggvideo这个非常好用的软件,非常值得推荐!如果您想看看更多其他好用的视频抓取软件,请访问网站进行下载。原文链接:黑帽思维:iggvideo抓取网页视频教程。 查看全部
抓取网页视频工具(轻量级短视频工具-iggvideo支持完整的访问控制和简单的php入口)
抓取网页视频工具有很多,其中用得比较广泛的就是以“抓取动图”著称的vine了,今天小编给大家推荐的是一款轻量级短视频抓取工具-iggvideo。目前,iggvideo可以抓取全球接近20000条视频内容,不管是日本动漫还是韩国明星、欧美电影、网剧,有机会看到的内容都在里面。经过小编实测,只要你会操作手机浏览器,再配上他们的后端库,就可以抓取到国内以及韩国全部视频站的内容。
还支持多站点合并,不管是qq空间、抖音、百度视频、爱奇艺、腾讯视频还是网易云音乐都可以抓取。如何抓取网页视频?网页视频抓取并不难,网页视频抓取可以通过大名鼎鼎的bs架构爬虫,即browserspider。简单地说,browserspider就是利用webview上的自定义header信息来进行蜘蛛抓取(为了达到这个目的,研究员搞了一个后端库,可以自定义监控header,更精准)。
当用户访问任意网站时,就会抓取网页上的视频内容。另外,browserspider支持restful架构,使其以socket调用通讯协议,从服务器获取视频内容。也可以接入websocket进行抓取,通过javascript框架进行请求。iggvideo的中文使用介绍iggvideo和you_tube是同一公司开发的,是一款简单好用的软件,是手机端唯一的真正意义上的视频抓取工具,支持网页端内容抓取,支持qq空间视频抓取,微博视频抓取,抖音视频抓取等,网页视频抓取是由全网视频网站抓取,支持qq空间视频抓取,微博视频抓取,抖音视频抓取,同时还支持国内几乎所有网站搜索!iggvideo几十行代码就可以完成长达几秒的多站点视频抓取(清晰度不限),支持多网站大规模抓取!iggvideo支持完整的访问控制和简单的php入口。
最让人惊喜的是,api的header部分带有真实url,用户可以在使用中编辑url。总结:iggvideo这个非常好用的软件,非常值得推荐!如果您想看看更多其他好用的视频抓取软件,请访问网站进行下载。原文链接:黑帽思维:iggvideo抓取网页视频教程。
抓取网页视频工具(戴尔台式机win10系统管理工具10.1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-11-12 16:00
抓取网页视频工具:中文分词翻译:yicat录屏工具:gifcam剪辑工具:快剪辑电脑软件:itools系统管理工具:avastmanager
win10m8.1,ie11,firefox,v5.x.x.x,这里有比较完整的教程,
我是做电商的,发布产品都是直接用ie浏览器去做的,当然有的公司可能会用ie8之类的,然后在虚拟机安装系统,公司是用ubuntu14.04,个人用的话感觉ie11已经足够了,网上配置说的太复杂,我个人是一键安装的,
一套完整的win10系统其实很简单。按照我的经验,上手其实也不难。下载网易云课堂整套的office365下载包,新建一个小号,把系统的全部行程导入,最后把小号设置为启动项,顺便说一下,win10系统一开始启动不好用,开机要设置成全屏幕,过1-2分钟再关闭全屏幕,这个全屏幕需要设置!然后设置完毕之后装ie浏览器,剩下的就是自己安装win10系统的,office,有vc2010或者vc2010以上版本的浏览器都可以打开。
更换老的浏览器不推荐,老版本不兼容新版本,而且某些软件打不开。新系统基本都推荐win10win10(或者说是win10m)只有支持js版本的浏览器。安装完成之后就可以用了。实测,联想的一台戴尔台式机打开新系统网速特别慢,和旧系统差不多!然后装完系统之后就可以正常的看视频了。具体使用方法可以看我的另一篇回答。 查看全部
抓取网页视频工具(戴尔台式机win10系统管理工具10.1)
抓取网页视频工具:中文分词翻译:yicat录屏工具:gifcam剪辑工具:快剪辑电脑软件:itools系统管理工具:avastmanager
win10m8.1,ie11,firefox,v5.x.x.x,这里有比较完整的教程,
我是做电商的,发布产品都是直接用ie浏览器去做的,当然有的公司可能会用ie8之类的,然后在虚拟机安装系统,公司是用ubuntu14.04,个人用的话感觉ie11已经足够了,网上配置说的太复杂,我个人是一键安装的,
一套完整的win10系统其实很简单。按照我的经验,上手其实也不难。下载网易云课堂整套的office365下载包,新建一个小号,把系统的全部行程导入,最后把小号设置为启动项,顺便说一下,win10系统一开始启动不好用,开机要设置成全屏幕,过1-2分钟再关闭全屏幕,这个全屏幕需要设置!然后设置完毕之后装ie浏览器,剩下的就是自己安装win10系统的,office,有vc2010或者vc2010以上版本的浏览器都可以打开。
更换老的浏览器不推荐,老版本不兼容新版本,而且某些软件打不开。新系统基本都推荐win10win10(或者说是win10m)只有支持js版本的浏览器。安装完成之后就可以用了。实测,联想的一台戴尔台式机打开新系统网速特别慢,和旧系统差不多!然后装完系统之后就可以正常的看视频了。具体使用方法可以看我的另一篇回答。
抓取网页视频工具( 影响蜘蛛抓取的因素有哪些?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-17 01:19
影响蜘蛛抓取的因素有哪些?-八维教育)
蜘蛛深度爬行和广度爬行
深度爬取:当蜘蛛发现一个链接时,会沿着链接路径爬到最深的层次,直到不能再爬取,返回原页面爬取下一个链接。
广度爬取:蜘蛛会爬取当前页面链接中的所有页面,然后选择其中一个页面,继续爬取页面中的所有链接。
蜘蛛深度爬行和广度爬行
影响蜘蛛爬行的因素:
1、网站地图
网站地图相当于搜索引擎蜘蛛的爬行路线图。在路线图的引导下,可以大大提高蜘蛛爬取页面的速度。就像去一个陌生的城市一样,你需要一张地图来指引你。
2、404 错误页面
网站维护和内容修改难免会导致死链接。当蜘蛛爬到死链接时,就像进入了没有出口的死胡同。如果网站有很多死链接,没有404页面,在站长工具中查询会发现很多页面爬取错误。404页面的意义在于告诉搜索引擎当前内容不存在,可以按照404页面的链接路径返回首页或查看其他相关内容。蜘蛛深度爬行和广度爬行?
3、导出链接太多
蜘蛛在爬行网站时,有时是按深度爬行,有时是按广度爬行。蜘蛛按广度爬行时,直接沿着出口链接出去,才可以进入最深的页面。,因此,网站 不应该设置太多的导出链接。
4、导入链接太少
入站链接建设遵循以下两个原则:
多元化:您可以注册多个外链发布平台,防止其中一个账户被暂停导致外链出现较大波动;
高品质:相关和高权重的平台是您的最佳选择。在从外部链接吸引蜘蛛的同时,它们还可以为您带来相关流量。
蜘蛛的深度爬行和广度爬行【玉米俱乐部】 查看全部
抓取网页视频工具(
影响蜘蛛抓取的因素有哪些?-八维教育)
蜘蛛深度爬行和广度爬行
深度爬取:当蜘蛛发现一个链接时,会沿着链接路径爬到最深的层次,直到不能再爬取,返回原页面爬取下一个链接。
广度爬取:蜘蛛会爬取当前页面链接中的所有页面,然后选择其中一个页面,继续爬取页面中的所有链接。
蜘蛛深度爬行和广度爬行
影响蜘蛛爬行的因素:
1、网站地图
网站地图相当于搜索引擎蜘蛛的爬行路线图。在路线图的引导下,可以大大提高蜘蛛爬取页面的速度。就像去一个陌生的城市一样,你需要一张地图来指引你。
2、404 错误页面
网站维护和内容修改难免会导致死链接。当蜘蛛爬到死链接时,就像进入了没有出口的死胡同。如果网站有很多死链接,没有404页面,在站长工具中查询会发现很多页面爬取错误。404页面的意义在于告诉搜索引擎当前内容不存在,可以按照404页面的链接路径返回首页或查看其他相关内容。蜘蛛深度爬行和广度爬行?
3、导出链接太多
蜘蛛在爬行网站时,有时是按深度爬行,有时是按广度爬行。蜘蛛按广度爬行时,直接沿着出口链接出去,才可以进入最深的页面。,因此,网站 不应该设置太多的导出链接。
4、导入链接太少
入站链接建设遵循以下两个原则:
多元化:您可以注册多个外链发布平台,防止其中一个账户被暂停导致外链出现较大波动;
高品质:相关和高权重的平台是您的最佳选择。在从外部链接吸引蜘蛛的同时,它们还可以为您带来相关流量。
蜘蛛的深度爬行和广度爬行【玉米俱乐部】
抓取网页视频工具(WebScraper提供的扩展插件,安装后你可以直接在F12调试工具里使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-01-17 01:18
经常遇到一些简单的需求,需要在某个网站上爬取一些数据,但是这些页面的结构很简单,数据量也比较少。自己写代码是可以的,但是没用。牛刀?
目前市面上有一些成熟的零码爬虫工具,比如优采云,有现成的模板可以使用,一些爬取规则也可以自己定义。但我今天要介绍的是另一个神器——Web Scraper,它是Chrome浏览器的扩展。安装后,可以直接在F12调试工具中使用。
1. 安装 Web Scraper
有条件的同学,可以直接在商店搜索Web Scraper进行安装
没有条件的同学可以来这个网站()下载crx文件,然后离线安装。具体方法可以借助搜索引擎解决。
安装后需要重启一次Chrome,然后F12才能看到工具
2. 基本概念和操作
在使用 Web Scraper 之前,需要先解释一下它的一些基本概念:
网站地图
从字面上翻译,它是一个 网站 地图。有了这个地图爬虫,我们就可以跟随它来获取我们需要的数据。
所以sitemap其实可以理解为网站的爬虫程序。要爬取多个 网站 数据,需要定义多个站点地图。
站点地图支持导出和导入,这意味着您编写的站点地图可以与他人共享。
从下图可以看出,sitemap代码是一串JSON配置
只要拿到这个配置,就可以导入别人的站点地图
选择器
直译过来就是一个选择器。要从一个充满数据的 HTML 页面中提取数据,需要一个选择器来定位我们数据的具体位置。
每个 Selector 可以获取一条数据。要获取多条数据,需要定位多个 Selector。
Web Scraper 提供的 Selector 有很多,但本文文章 只介绍几个最常用且覆盖面最广的 Selector。了解一二之后,其他的原理都差不多。可以上手了。
Web Scraper 使用 CSS 选择器来定位元素。如果你不知道,没关系。在大多数场景下,您可以直接通过鼠标点击选择元素,Web Scraper 会自动解析相应的 CSS。小路。
Selector 可以嵌套,子 Selector 的 CSS 选择器作用域就是父 Selector。
正是这种无穷无尽的嵌套关系让我们能够递归地爬取整个 网站 数据。
下面是我们后面经常放的选择器拓扑,可以用来直观的展示Web Scraper的爬取逻辑
数据抓取和导出
定义站点地图规则后,单击“抓取”开始抓取数据。
爬取数据后,不会立即显示在页面上,需要再次手动点击刷新按钮才能看到数据。
最终数据也可以导出为 csv 或 xlsx 文件。
3. 寻呼机爬行
爬取数据最经典的模型是列表、分页和明细。接下来我就围绕这个方向爬取CSDN博客文章来介绍几个Selector的用法。
寻呼机可以分为两种类型:
在早期版本的 web-scraper 中,两种爬取方式是不同的。
对于一些 网站 来说确实足够了,但有很大的局限性。
经过我的实验,使用Link选择器的第一个原理是在下一页取出a标签的超链接,然后访问它,但并不是所有网站的下一页都是通过a标签实现的.
如果用js监听事件然后像下面这样跳转,就不能使用Link选择器了。
在新版本的网络爬虫中,它提供了对导航分页器的特殊支持,并增加了一个分页选择器,可以完全适用于两种场景,下面我将进行演示。
寻呼机爬行而不重新加载页面
点击具体的CSDN博文,拉到底部,就可以看到评论区了。
如果你的文章比较热门,有很多同学评论,CSDN会分页显示,但是不管在哪个页面评论都属于同一篇文章文章,你浏览的时候当你在任何页面的评论区时,博文不需要刷新,因为这个分页不会重新加载页面。
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
最后一点必须注意,要选择root和next_page,只有这样才能递归爬取
最终爬取效果如下
使用Element Click的sitemap配置如下,可以直接导入我的配置进行研究
{"_id":"blog_comment","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"clickElementSelector":"li.js-page-next","clickElementUniquenessType":"uniqueText","clickType":"clickMore","delay":2000,"discardInitialElements":"do-not-discard","id":"next_page","multiple":true,"parentSelectors":["_root","next_page"],"selector":"div.comment-list-container","type":"SelectorElementClick"},{"delay":0,"id":"comment","multiple":true,"parentSelectors":["_root","next_page"],"selector":"ul:nth-of-type(n+2) > li.comment-line-box span.new-comment","type":"SelectorElement"},{"delay":0,"id":"content","multiple":false,"parentSelectors":["comment"],"regex":"","selector":"_parent_","type":"SelectorText"}]}
JSON
复制
当然,对于分页之类的东西,网页爬虫提供了更专业的分页选择器,配置更精简,效果最好。
对应的sitemap配置如下,可以直接导入使用
{"_id":"blog_comment","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"id":"next_page","parentSelectors":["_root","next_page"],"paginationType":"auto","selector":"li.js-page-next","type":"SelectorPagination"},{"id":"comment","parentSelectors":["_root","next_page"],"type":"SelectorElement","selector":"ul:nth-of-type(n+2) > li.comment-line-box span.new-comment","multiple":true,"delay":0},{"id":"content","parentSelectors":["comment"],"type":"SelectorText","selector":"_parent_","multiple":false,"delay":0,"regex":""}]}
JSON
复制
寻呼机爬行以重新加载页面
CSDN的博客文章列表,拉到底部,点击具体页面按钮,否则最右边的下一页会重新加载当前页面。
对于这种分页器,Element Click 无能为力,读者可以自行验证,最多只能爬一页后关闭。
而且作为一个为分页而生的Pagination选择器,自然适用
爬取的拓扑同上,这里不再赘述。
对应sitemap的配置如下,可以直接导入学习
{"_id":"mycsdn","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"id":"next_page","parentSelectors":["_root","next_page"],"paginationType":"auto","selector":"li.js-page-next","type":"SelectorPagination"},{"id":"article","parentSelectors":["_root","next_page"],"type":"SelectorElement","selector":"div.article-item-box","multiple":true,"delay":0},{"id":"title","parentSelectors":["article"],"type":"SelectorText","selector":"h4 a","multiple":false,"delay":0,"regex":""},{"id":"views","parentSelectors":["article"],"type":"SelectorText","selector":"span:nth-of-type(2)","multiple":false,"delay":0,"regex":"[0-9]+"},{"id":"comments","parentSelectors":["article"],"type":"SelectorText","selector":"span:nth-of-type(3)","multiple":false,"delay":0,"regex":""},{"id":"publish_time","parentSelectors":["article"],"type":"SelectorText","selector":"span.date","multiple":false,"delay":0,"regex":""}]}
JSON
复制
4. 次要页面的爬取
CSDN的博客列表页,显示的信息比较粗略,只有标题、发表时间、阅读量、评论数,是否是原创。
如果你想获得更多的信息,比如博文的文字、点赞数、采集数、评论区的内容,你必须点击具体的博文链接才能查看。
网络爬虫的操作逻辑与人类相同。如果你想抓取更详细的博文信息,你必须打开一个新的页面来获取它,而网络爬虫的链接选择器恰好做到了这一点。
爬取路径拓扑如下
爬取的效果如下
sitemap的配置如下,可以直接导入使用
{"_id":"csdn_detail","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"id":"container","parentSelectors":["_root"],"type":"SelectorElement","selector":"[data-articleid='111936614']","multiple":false,"delay":0},{"id":"article_detail_link","parentSelectors":["container"],"type":"SelectorLink","selector":"h4 a","multiple":false,"delay":0},{"id":"detail","parentSelectors":["article_detail_link"],"type":"SelectorText","selector":"article","multiple":false,"delay":0,"regex":""},{"id":"title","parentSelectors":["container"],"type":"SelectorText","selector":"h4 a","multiple":false,"delay":0,"regex":""},{"id":"time","parentSelectors":["container"],"type":"SelectorText","selector":"span.date","multiple":false,"delay":0,"regex":""},{"id":"views","parentSelectors":["container"],"type":"SelectorText","selector":"span:nth-of-type(2)","multiple":false,"delay":0,"regex":""},{"id":"comments","parentSelectors":["container"],"type":"SelectorText","selector":"span:nth-of-type(3)","multiple":false,"delay":0,"regex":""}]}
JSON
复制
5. 结尾
以上整理了分页和二级页面的爬取方案,主要有:分页器爬取和二级页面爬取。
只要学会了这两个,就已经可以处理绝大多数结构化的网络数据了。 查看全部
抓取网页视频工具(WebScraper提供的扩展插件,安装后你可以直接在F12调试工具里使用)
经常遇到一些简单的需求,需要在某个网站上爬取一些数据,但是这些页面的结构很简单,数据量也比较少。自己写代码是可以的,但是没用。牛刀?
目前市面上有一些成熟的零码爬虫工具,比如优采云,有现成的模板可以使用,一些爬取规则也可以自己定义。但我今天要介绍的是另一个神器——Web Scraper,它是Chrome浏览器的扩展。安装后,可以直接在F12调试工具中使用。
1. 安装 Web Scraper
有条件的同学,可以直接在商店搜索Web Scraper进行安装
没有条件的同学可以来这个网站()下载crx文件,然后离线安装。具体方法可以借助搜索引擎解决。
安装后需要重启一次Chrome,然后F12才能看到工具
2. 基本概念和操作
在使用 Web Scraper 之前,需要先解释一下它的一些基本概念:
网站地图
从字面上翻译,它是一个 网站 地图。有了这个地图爬虫,我们就可以跟随它来获取我们需要的数据。
所以sitemap其实可以理解为网站的爬虫程序。要爬取多个 网站 数据,需要定义多个站点地图。
站点地图支持导出和导入,这意味着您编写的站点地图可以与他人共享。
从下图可以看出,sitemap代码是一串JSON配置
只要拿到这个配置,就可以导入别人的站点地图
选择器
直译过来就是一个选择器。要从一个充满数据的 HTML 页面中提取数据,需要一个选择器来定位我们数据的具体位置。
每个 Selector 可以获取一条数据。要获取多条数据,需要定位多个 Selector。
Web Scraper 提供的 Selector 有很多,但本文文章 只介绍几个最常用且覆盖面最广的 Selector。了解一二之后,其他的原理都差不多。可以上手了。
Web Scraper 使用 CSS 选择器来定位元素。如果你不知道,没关系。在大多数场景下,您可以直接通过鼠标点击选择元素,Web Scraper 会自动解析相应的 CSS。小路。
Selector 可以嵌套,子 Selector 的 CSS 选择器作用域就是父 Selector。
正是这种无穷无尽的嵌套关系让我们能够递归地爬取整个 网站 数据。
下面是我们后面经常放的选择器拓扑,可以用来直观的展示Web Scraper的爬取逻辑
数据抓取和导出
定义站点地图规则后,单击“抓取”开始抓取数据。
爬取数据后,不会立即显示在页面上,需要再次手动点击刷新按钮才能看到数据。
最终数据也可以导出为 csv 或 xlsx 文件。
3. 寻呼机爬行
爬取数据最经典的模型是列表、分页和明细。接下来我就围绕这个方向爬取CSDN博客文章来介绍几个Selector的用法。
寻呼机可以分为两种类型:
在早期版本的 web-scraper 中,两种爬取方式是不同的。
对于一些 网站 来说确实足够了,但有很大的局限性。
经过我的实验,使用Link选择器的第一个原理是在下一页取出a标签的超链接,然后访问它,但并不是所有网站的下一页都是通过a标签实现的.
如果用js监听事件然后像下面这样跳转,就不能使用Link选择器了。
在新版本的网络爬虫中,它提供了对导航分页器的特殊支持,并增加了一个分页选择器,可以完全适用于两种场景,下面我将进行演示。
寻呼机爬行而不重新加载页面
点击具体的CSDN博文,拉到底部,就可以看到评论区了。
如果你的文章比较热门,有很多同学评论,CSDN会分页显示,但是不管在哪个页面评论都属于同一篇文章文章,你浏览的时候当你在任何页面的评论区时,博文不需要刷新,因为这个分页不会重新加载页面。
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
最后一点必须注意,要选择root和next_page,只有这样才能递归爬取
最终爬取效果如下
使用Element Click的sitemap配置如下,可以直接导入我的配置进行研究
{"_id":"blog_comment","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"clickElementSelector":"li.js-page-next","clickElementUniquenessType":"uniqueText","clickType":"clickMore","delay":2000,"discardInitialElements":"do-not-discard","id":"next_page","multiple":true,"parentSelectors":["_root","next_page"],"selector":"div.comment-list-container","type":"SelectorElementClick"},{"delay":0,"id":"comment","multiple":true,"parentSelectors":["_root","next_page"],"selector":"ul:nth-of-type(n+2) > li.comment-line-box span.new-comment","type":"SelectorElement"},{"delay":0,"id":"content","multiple":false,"parentSelectors":["comment"],"regex":"","selector":"_parent_","type":"SelectorText"}]}
JSON
复制
当然,对于分页之类的东西,网页爬虫提供了更专业的分页选择器,配置更精简,效果最好。
对应的sitemap配置如下,可以直接导入使用
{"_id":"blog_comment","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"id":"next_page","parentSelectors":["_root","next_page"],"paginationType":"auto","selector":"li.js-page-next","type":"SelectorPagination"},{"id":"comment","parentSelectors":["_root","next_page"],"type":"SelectorElement","selector":"ul:nth-of-type(n+2) > li.comment-line-box span.new-comment","multiple":true,"delay":0},{"id":"content","parentSelectors":["comment"],"type":"SelectorText","selector":"_parent_","multiple":false,"delay":0,"regex":""}]}
JSON
复制
寻呼机爬行以重新加载页面
CSDN的博客文章列表,拉到底部,点击具体页面按钮,否则最右边的下一页会重新加载当前页面。
对于这种分页器,Element Click 无能为力,读者可以自行验证,最多只能爬一页后关闭。
而且作为一个为分页而生的Pagination选择器,自然适用
爬取的拓扑同上,这里不再赘述。
对应sitemap的配置如下,可以直接导入学习
{"_id":"mycsdn","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"id":"next_page","parentSelectors":["_root","next_page"],"paginationType":"auto","selector":"li.js-page-next","type":"SelectorPagination"},{"id":"article","parentSelectors":["_root","next_page"],"type":"SelectorElement","selector":"div.article-item-box","multiple":true,"delay":0},{"id":"title","parentSelectors":["article"],"type":"SelectorText","selector":"h4 a","multiple":false,"delay":0,"regex":""},{"id":"views","parentSelectors":["article"],"type":"SelectorText","selector":"span:nth-of-type(2)","multiple":false,"delay":0,"regex":"[0-9]+"},{"id":"comments","parentSelectors":["article"],"type":"SelectorText","selector":"span:nth-of-type(3)","multiple":false,"delay":0,"regex":""},{"id":"publish_time","parentSelectors":["article"],"type":"SelectorText","selector":"span.date","multiple":false,"delay":0,"regex":""}]}
JSON
复制
4. 次要页面的爬取
CSDN的博客列表页,显示的信息比较粗略,只有标题、发表时间、阅读量、评论数,是否是原创。
如果你想获得更多的信息,比如博文的文字、点赞数、采集数、评论区的内容,你必须点击具体的博文链接才能查看。
网络爬虫的操作逻辑与人类相同。如果你想抓取更详细的博文信息,你必须打开一个新的页面来获取它,而网络爬虫的链接选择器恰好做到了这一点。
爬取路径拓扑如下
爬取的效果如下
sitemap的配置如下,可以直接导入使用
{"_id":"csdn_detail","startUrl":["https://blog.csdn.net/weixin_3 ... ot%3B],"selectors":[{"id":"container","parentSelectors":["_root"],"type":"SelectorElement","selector":"[data-articleid='111936614']","multiple":false,"delay":0},{"id":"article_detail_link","parentSelectors":["container"],"type":"SelectorLink","selector":"h4 a","multiple":false,"delay":0},{"id":"detail","parentSelectors":["article_detail_link"],"type":"SelectorText","selector":"article","multiple":false,"delay":0,"regex":""},{"id":"title","parentSelectors":["container"],"type":"SelectorText","selector":"h4 a","multiple":false,"delay":0,"regex":""},{"id":"time","parentSelectors":["container"],"type":"SelectorText","selector":"span.date","multiple":false,"delay":0,"regex":""},{"id":"views","parentSelectors":["container"],"type":"SelectorText","selector":"span:nth-of-type(2)","multiple":false,"delay":0,"regex":""},{"id":"comments","parentSelectors":["container"],"type":"SelectorText","selector":"span:nth-of-type(3)","multiple":false,"delay":0,"regex":""}]}
JSON
复制
5. 结尾
以上整理了分页和二级页面的爬取方案,主要有:分页器爬取和二级页面爬取。
只要学会了这两个,就已经可以处理绝大多数结构化的网络数据了。
抓取网页视频工具(如何帮小伙伴抓取网页中的视频文件,它会自动退出?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-01-16 06:17
全网视频平台M3U8解析工具可以帮助小伙伴抓取网页中的视频文件。用户可以选择不同的图片分辨率。该软件支持批量添加任务。所有文件下载完成后会自动退出。
指示
1.首先,我们将解析后的代码复制到wwwbejsoncom进行解析
2.根据你的爱好,选择你喜欢的清晰度下载
3.如何下载M3U8文件?,答:请下载全网视频平台的M3U8解析工具
背景介绍
m3u8 是 Apple 推出的视频播放标准。它是m3u的一种,但编码格式是UTF-8。
m3u8准确来说是一个索引文件,m3u8文件实际上是用来解析放置在服务器上的对应视频网络地址,从而实现在线播放。m3u8格式文件主要用于实现多码率视频的适配。视频网站可以根据用户的网络带宽自动匹配合适的码率文件供客户端播放,保证视频的流畅度。.
小编点评
将网址复制到全网视频平台的M3U8解析工具,即可自动解析,软件自带并排播放功能。该应用程序支持断点下载,并且对下载速度没有限制。如果视频文件无法自动解析,您可以向开发者提交反馈。
以上就是小编为大家带来的全网视频平台M3U8分析工具。更多精彩软件请关注IE浏览器中文网站! 查看全部
抓取网页视频工具(如何帮小伙伴抓取网页中的视频文件,它会自动退出?)
全网视频平台M3U8解析工具可以帮助小伙伴抓取网页中的视频文件。用户可以选择不同的图片分辨率。该软件支持批量添加任务。所有文件下载完成后会自动退出。
指示
1.首先,我们将解析后的代码复制到wwwbejsoncom进行解析
2.根据你的爱好,选择你喜欢的清晰度下载
3.如何下载M3U8文件?,答:请下载全网视频平台的M3U8解析工具
背景介绍
m3u8 是 Apple 推出的视频播放标准。它是m3u的一种,但编码格式是UTF-8。
m3u8准确来说是一个索引文件,m3u8文件实际上是用来解析放置在服务器上的对应视频网络地址,从而实现在线播放。m3u8格式文件主要用于实现多码率视频的适配。视频网站可以根据用户的网络带宽自动匹配合适的码率文件供客户端播放,保证视频的流畅度。.
小编点评
将网址复制到全网视频平台的M3U8解析工具,即可自动解析,软件自带并排播放功能。该应用程序支持断点下载,并且对下载速度没有限制。如果视频文件无法自动解析,您可以向开发者提交反馈。
以上就是小编为大家带来的全网视频平台M3U8分析工具。更多精彩软件请关注IE浏览器中文网站!
抓取网页视频工具(想从Facebook获取电子邮件地址就需要一些工具和技巧?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 230 次浏览 • 2022-01-13 22:10
从 Facebook 获取电子邮件地址需要一些工具和技巧。这里有几个选项供您选择:
选项 1:电子邮件提取器
电子邮件提取器是谷歌 Chrome 浏览器的插件。它可以帮助您在打开的任何网页上找到您的邮箱。
首先,将其添加到 Google Chrome 浏览器。然后访问您要抓取的任何 Facebook 页面或 Facebook 群组。Facebook 不会一次加载很多内容,您需要向下滚动。通过这种方式,Email Extractor 可以识别和提取更多邮箱。以 Facebook Group 为例:
提示:帖子的未展开部分将不会被识别。
您还可以在公共主页和个人联系信息页面上抓取邮箱(如果显示)。
选项 2:电子邮件导出器
要介绍的第二个选项是电子邮件导出器。这是另一个 Chrome 扩展程序,它以相同的方式完成基本相同的事情。安装后,访问目标页面并滚动浏览您想要抓取的任何组或页面,直到您觉得您已经采集了足够的信息。
电子邮件提取器和电子邮件导出器之间没有太大区别。主要区别在于Exporter可以获取电话号码,这也更便于您导出和保存。
选项 3:电子邮件猎人
第三个 Chrome 扩展程序。就像上面两个一样,当打开一个收录公共数据的页面时,该数据会被抓取。和上面两个很像,说实话,三个插件没有太大区别,大家可以根据自己的使用情况来选择。它们既免费又非常易于使用,这就是为什么向所有人推荐 Google 扩展程序的原因。
提示:所有电子邮件选项卡通常可以帮助您找到更多电子邮件地址。
值得一提的是,使用所有这些插件,只能找到页面上可见的电子邮件地址。许多人都有与其 Facebook 页面相关联的电子邮件地址,但他们的隐私设置已关闭,因此无法抓取它们。
除了我们介绍的 3 个之外,还有至少十几个其他可用于 Chrome 的爬虫,您可以自己尝试其他选项。
选项 4:原子公园
Atom Park Atomic Email Hunter 是另一种电子邮件抓取工具,它不是 Chrome 扩展程序,而是一个独立的软件。
它更容易使用。启动程序并转到“搜索”菜单。从那里它会询问您在哪里搜索,输入您要抓取的组或页面 URL,进行一些必要的设置,然后您就可以开始了!
与之前的工具不同,Atom Park 将尽可能关联电子邮件地址、地址来源和用户名。这样,您就会知道您的电子邮件地址是从哪里获得的,而不仅仅是没有名称或标签的列表。
这个软件不是免费的。Atomic Email Hunter 是一款 80 美元的软件。您可以在他们的 网站 上免费下载它,但试用版的功能有限。
你会发现 Facebook 上的群组是收获邮件的好地方,所以我们应该尽可能多地加入与行业相关的群组。此外,这些工具不仅可以用于 Facebook、LinkedIn,任何网页都适用。
选项 5:Gmail 电子邮件提取器(非 Facebook 提取器)
Gmail 电子邮件提取器是用于 Google 表格的 Google 电子表格插件。此扩展程序使您能够从自己的 GSuite 和 Gmail 帐户中提取邮件地址。它将提取的信息保存在 Google 电子表格中。
该工具还允许选择应从中提取邮箱的标准,例如“发件人”、“抄送”、“密件抄送”和“回复”部分,邮件列表可以导出为 TXT 或 CSV。
如果您有大量 Gmail 联系人列表,此工具会非常有用。它可以帮助您从帐户中提取电子邮件地址并节省大量时间。
提示:虽然本文是关于直接获取电子邮件的,但我强烈建议您不要抓取大量不熟悉的电子邮件并发送未经请求的电子邮件,这几乎就是垃圾邮件活动的定义。在发送邮件之前,我们应该尽量获得用户许可,否则很容易被屏蔽。或者您可以使用这些工具作为辅助 查看全部
抓取网页视频工具(想从Facebook获取电子邮件地址就需要一些工具和技巧?)
从 Facebook 获取电子邮件地址需要一些工具和技巧。这里有几个选项供您选择:
选项 1:电子邮件提取器
电子邮件提取器是谷歌 Chrome 浏览器的插件。它可以帮助您在打开的任何网页上找到您的邮箱。
首先,将其添加到 Google Chrome 浏览器。然后访问您要抓取的任何 Facebook 页面或 Facebook 群组。Facebook 不会一次加载很多内容,您需要向下滚动。通过这种方式,Email Extractor 可以识别和提取更多邮箱。以 Facebook Group 为例:
提示:帖子的未展开部分将不会被识别。
您还可以在公共主页和个人联系信息页面上抓取邮箱(如果显示)。
选项 2:电子邮件导出器
要介绍的第二个选项是电子邮件导出器。这是另一个 Chrome 扩展程序,它以相同的方式完成基本相同的事情。安装后,访问目标页面并滚动浏览您想要抓取的任何组或页面,直到您觉得您已经采集了足够的信息。
电子邮件提取器和电子邮件导出器之间没有太大区别。主要区别在于Exporter可以获取电话号码,这也更便于您导出和保存。
选项 3:电子邮件猎人
第三个 Chrome 扩展程序。就像上面两个一样,当打开一个收录公共数据的页面时,该数据会被抓取。和上面两个很像,说实话,三个插件没有太大区别,大家可以根据自己的使用情况来选择。它们既免费又非常易于使用,这就是为什么向所有人推荐 Google 扩展程序的原因。
提示:所有电子邮件选项卡通常可以帮助您找到更多电子邮件地址。
值得一提的是,使用所有这些插件,只能找到页面上可见的电子邮件地址。许多人都有与其 Facebook 页面相关联的电子邮件地址,但他们的隐私设置已关闭,因此无法抓取它们。
除了我们介绍的 3 个之外,还有至少十几个其他可用于 Chrome 的爬虫,您可以自己尝试其他选项。
选项 4:原子公园
Atom Park Atomic Email Hunter 是另一种电子邮件抓取工具,它不是 Chrome 扩展程序,而是一个独立的软件。
它更容易使用。启动程序并转到“搜索”菜单。从那里它会询问您在哪里搜索,输入您要抓取的组或页面 URL,进行一些必要的设置,然后您就可以开始了!
与之前的工具不同,Atom Park 将尽可能关联电子邮件地址、地址来源和用户名。这样,您就会知道您的电子邮件地址是从哪里获得的,而不仅仅是没有名称或标签的列表。
这个软件不是免费的。Atomic Email Hunter 是一款 80 美元的软件。您可以在他们的 网站 上免费下载它,但试用版的功能有限。
你会发现 Facebook 上的群组是收获邮件的好地方,所以我们应该尽可能多地加入与行业相关的群组。此外,这些工具不仅可以用于 Facebook、LinkedIn,任何网页都适用。
选项 5:Gmail 电子邮件提取器(非 Facebook 提取器)
Gmail 电子邮件提取器是用于 Google 表格的 Google 电子表格插件。此扩展程序使您能够从自己的 GSuite 和 Gmail 帐户中提取邮件地址。它将提取的信息保存在 Google 电子表格中。
该工具还允许选择应从中提取邮箱的标准,例如“发件人”、“抄送”、“密件抄送”和“回复”部分,邮件列表可以导出为 TXT 或 CSV。
如果您有大量 Gmail 联系人列表,此工具会非常有用。它可以帮助您从帐户中提取电子邮件地址并节省大量时间。
提示:虽然本文是关于直接获取电子邮件的,但我强烈建议您不要抓取大量不熟悉的电子邮件并发送未经请求的电子邮件,这几乎就是垃圾邮件活动的定义。在发送邮件之前,我们应该尽量获得用户许可,否则很容易被屏蔽。或者您可以使用这些工具作为辅助
抓取网页视频工具(arpk调试有些网站是什么样的广告页面的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-13 21:02
抓取网页视频工具目前网上能找到的可以爬的网站不多,我自己动手写了一个,
使用fiddler或者dnspod吧,
工具一般用fiddler或者dnspod就可以了,
教程官网上应该有吧,
这个不难,借助一些网站工具,比如httpseverywhere,snipaste,everywhere抓人脸。还有gifreplay.io不限制尺寸,可以按张数抓取不同gif。再添加一些特征,像网站名,地址之类的,就可以查到一些网站真实地址了。然后用google或者百度等搜索引擎搜索网站名+广告,查到蜘蛛ip,联系方式,然后用编辑器用python对这些数据进行抓取,或者批量进行下载。
那要看你是什么样的广告页面了,
如果可以,
arpk调试
有些网站是根据ua来识别页面的,可以调用macrometrics,来查看详细信息,方便用于识别页面, 查看全部
抓取网页视频工具(arpk调试有些网站是什么样的广告页面的?)
抓取网页视频工具目前网上能找到的可以爬的网站不多,我自己动手写了一个,
使用fiddler或者dnspod吧,
工具一般用fiddler或者dnspod就可以了,
教程官网上应该有吧,
这个不难,借助一些网站工具,比如httpseverywhere,snipaste,everywhere抓人脸。还有gifreplay.io不限制尺寸,可以按张数抓取不同gif。再添加一些特征,像网站名,地址之类的,就可以查到一些网站真实地址了。然后用google或者百度等搜索引擎搜索网站名+广告,查到蜘蛛ip,联系方式,然后用编辑器用python对这些数据进行抓取,或者批量进行下载。
那要看你是什么样的广告页面了,
如果可以,
arpk调试
有些网站是根据ua来识别页面的,可以调用macrometrics,来查看详细信息,方便用于识别页面,
抓取网页视频工具(40行代码教你爬遍小视频网站,先批量下载后仔细观看,岂不美哉!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2022-01-06 02:15
/1 简介/
还在为在线看小视频缓存慢而发愁吗?您是否还在为想重温优秀作品却找不到资源而苦恼?别慌,让python帮你解决,40行代码教你爬取小视频网站,先分批下载仔细看,不好看!
/2 整理思路/
这种网站一般都有相似之处,也有细微的差别。本文以凤凰新闻视频网站为例,通过后推方式向大家展示如何通过流量分析获取视频下载的url,然后批量下载。
/3 操作步骤/
/3.1 分析网站,找出网页变化的规律/
1、 首先找到网页。该网页的详细信息如下图所示。
2、这个视频网站分为人物、娱乐、艺术等不同类型。本文以体育板块为例,下拉至底部,如下图所示。
3、根据上图的结果,我们可以发现网站是一个动态网页。打开浏览器内置的流量分析器,点击加载更多,查看网页变化的规律。第一个是请求的 URL 和返回的结果如下图所示。标记为页码,此时为第三页。
4、 返回的结果收录视频标题、网页url、guid(相当于每个视频的logo,方便后续跟进)等信息,如下图所示。
5、 每个网页收录24个视频,如下图打印出来。
/3.2 查找视频网页地址的规则/
1、 首先打开流量分析器,播放视频抓包,找到几个mp2t文件,如下图。
2、 我一一找到了它们的网址,并存入一个文本文件中,以查找它们之间的规则,如下图所示。
3、 你注意到这种模式了吗?URL中的p26275262-102-9987636-172625参数是视频的guid(上面得到的),只有range_bytes参数变化,从0到6767623。显然这是视频的大小,视频是分段合成。找到这些规则后,我们需要继续挖掘视频地址的来源。
/3.3 找到视频的原创下载地址/
1、 首先考虑一个问题,视频地址从何而来?一般情况下,首先检查视频页面上是否有。如果没有,我们将在流量分析器中查找第一个分段视频。必须有某个 URL 返回此信息。很快,我在一个 vdn.apple.mpegurl 文件中找到了下图。
2、 太惊喜了,这不是我们要找的信息吗?我们来看看它的url参数,如下图所示。
3、上图中的参数看起来很多,但不要害怕。还是用老办法,先查网页有没有,如果没有就在流量分析器里找。努力是有回报的。我找到了下面的图片。
4、 其url如下图所示。
5、仔细找规则,发现唯一需要改的就是每个视频的guid。这第一步已经完成。另外,返回的结果中除了vkey之外,都收录了上面的所有参数,而且这个参数是最长的,我该怎么办?
6、不要着急,如果这个参数不起作用,删除vkey并尝试。果然,实在不行。现在整个过程已经很顺利了,现在可以按下代码了。
/3.4 代码实现/
1、 代码中设置多线程下载,如下图,其中页码可以自行修改。
2、 解析返回参数,为json格式,使用json库进行处理,如下图。通过分析,我们可以得到每个视频的标题、网页url和guid。
3、模拟请求获取Vkey以外的参数,如下图。
4、 使用上一步中的参数进行模拟请求,获取收录分段视频的信息,如下图所示。
5、 将分割后的视频合并,保存为1个视频文件,并以标题命名,如下图。
/3.5 效果展示/
1、 程序运行后,我们可以在本地文件夹中看到网页上的视频飞溅,如下图。接下来妈妈再也不用担心找不到我喜欢的视频了,真香!
当然,如果你想更直观,你可以在代码中添加尺寸测量信息。您可以自己手动设置。
/4 总结/
本文主要基于Python网络爬虫,使用40行代码,针对小视频网页,批量获取网络视频到本地。该方法简单易行,行之有效。欢迎您试用。如需获取本文代码,请访问/cassieeric/python_crawler/tree/master/little_video_crawler获取代码链接。觉得还不错的话记得给个star哦。 查看全部
抓取网页视频工具(40行代码教你爬遍小视频网站,先批量下载后仔细观看,岂不美哉!)
/1 简介/
还在为在线看小视频缓存慢而发愁吗?您是否还在为想重温优秀作品却找不到资源而苦恼?别慌,让python帮你解决,40行代码教你爬取小视频网站,先分批下载仔细看,不好看!
/2 整理思路/
这种网站一般都有相似之处,也有细微的差别。本文以凤凰新闻视频网站为例,通过后推方式向大家展示如何通过流量分析获取视频下载的url,然后批量下载。
/3 操作步骤/
/3.1 分析网站,找出网页变化的规律/
1、 首先找到网页。该网页的详细信息如下图所示。
2、这个视频网站分为人物、娱乐、艺术等不同类型。本文以体育板块为例,下拉至底部,如下图所示。
3、根据上图的结果,我们可以发现网站是一个动态网页。打开浏览器内置的流量分析器,点击加载更多,查看网页变化的规律。第一个是请求的 URL 和返回的结果如下图所示。标记为页码,此时为第三页。
4、 返回的结果收录视频标题、网页url、guid(相当于每个视频的logo,方便后续跟进)等信息,如下图所示。
5、 每个网页收录24个视频,如下图打印出来。
/3.2 查找视频网页地址的规则/
1、 首先打开流量分析器,播放视频抓包,找到几个mp2t文件,如下图。
2、 我一一找到了它们的网址,并存入一个文本文件中,以查找它们之间的规则,如下图所示。
3、 你注意到这种模式了吗?URL中的p26275262-102-9987636-172625参数是视频的guid(上面得到的),只有range_bytes参数变化,从0到6767623。显然这是视频的大小,视频是分段合成。找到这些规则后,我们需要继续挖掘视频地址的来源。
/3.3 找到视频的原创下载地址/
1、 首先考虑一个问题,视频地址从何而来?一般情况下,首先检查视频页面上是否有。如果没有,我们将在流量分析器中查找第一个分段视频。必须有某个 URL 返回此信息。很快,我在一个 vdn.apple.mpegurl 文件中找到了下图。
2、 太惊喜了,这不是我们要找的信息吗?我们来看看它的url参数,如下图所示。
3、上图中的参数看起来很多,但不要害怕。还是用老办法,先查网页有没有,如果没有就在流量分析器里找。努力是有回报的。我找到了下面的图片。
4、 其url如下图所示。
5、仔细找规则,发现唯一需要改的就是每个视频的guid。这第一步已经完成。另外,返回的结果中除了vkey之外,都收录了上面的所有参数,而且这个参数是最长的,我该怎么办?
6、不要着急,如果这个参数不起作用,删除vkey并尝试。果然,实在不行。现在整个过程已经很顺利了,现在可以按下代码了。
/3.4 代码实现/
1、 代码中设置多线程下载,如下图,其中页码可以自行修改。
2、 解析返回参数,为json格式,使用json库进行处理,如下图。通过分析,我们可以得到每个视频的标题、网页url和guid。
3、模拟请求获取Vkey以外的参数,如下图。
4、 使用上一步中的参数进行模拟请求,获取收录分段视频的信息,如下图所示。
5、 将分割后的视频合并,保存为1个视频文件,并以标题命名,如下图。
/3.5 效果展示/
1、 程序运行后,我们可以在本地文件夹中看到网页上的视频飞溅,如下图。接下来妈妈再也不用担心找不到我喜欢的视频了,真香!
当然,如果你想更直观,你可以在代码中添加尺寸测量信息。您可以自己手动设置。
/4 总结/
本文主要基于Python网络爬虫,使用40行代码,针对小视频网页,批量获取网络视频到本地。该方法简单易行,行之有效。欢迎您试用。如需获取本文代码,请访问/cassieeric/python_crawler/tree/master/little_video_crawler获取代码链接。觉得还不错的话记得给个star哦。
抓取网页视频工具(xml视频抓取网页视频工具,如酷6twitteryoutube的视频只需要填写)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-05 06:10
抓取网页视频工具,如酷6twitteryoutube的视频只需要填写视频id和url就可以抓取出来了,今天给大家介绍一个xml视频抓取的工具jsonview。jsonview是一个通用json视频抓取工具,适用于各种浏览器。他可以抓取htmlcss等各种格式的视频,支持以msg形式分享给好友。速度还不错,支持多种格式视频的抓取。网站地址::百度网盘或者百度云存放。
在里面找找吧,我也有电子书的影子,
我想他们那是为了流量而来骗你交钱下载的
谢邀我不是很想回答这类问题,一但你看到真的不想买后悔就退款就行,不用想太多。上很多。我有pdf和docx网上都有,都是能找到的。你怕下载的速度慢那你买个全网通,可以试试。
资源不如人就找阿里巴巴,大部分的资源都能找到,
1、视频语言版本一定要对得上(普通的视频url可以,
2、每一集的报价总量是否匹配
3、如果没有专业的引擎与不对的网站间存在竞争(不要脸脸要厚)
4、前后四条视频时间不冲突
5、cdn稳定(镜像机、旋风、360等)
6、自制核心。好吧,以上都是废话。我现在最反感的就是给他们免费发视频,当然你要是直接买个会员呢?我只能说:你想看好的还不如付钱买会员;下载视频无非要两个原因(这两个原因不见得100%成立):看技术资源:1.请出门看正版2.国内:下东西要看时间是否充裕,尤其是网上不稳定的资源,如果即不充裕又不是特别喜欢小众的特殊领域的,出门看正版基本是必选项(当然你也可以选择在学校使用校园网,校园网流量经济实惠)看所谓的技术资源(发给好基友):1.请出门看正版2.国内:上上大学校园网,基本上清一色都是盗版视频。
大学生的世界里只有学习和学习!3.周末还有点时间下点盗版4.新大一,多买点国内视频有个毛线好价格的也别按热度排序了,你是一年前看的吗5.混迹于人人网和天涯之流的你就知道用户平均数量了。 查看全部
抓取网页视频工具(xml视频抓取网页视频工具,如酷6twitteryoutube的视频只需要填写)
抓取网页视频工具,如酷6twitteryoutube的视频只需要填写视频id和url就可以抓取出来了,今天给大家介绍一个xml视频抓取的工具jsonview。jsonview是一个通用json视频抓取工具,适用于各种浏览器。他可以抓取htmlcss等各种格式的视频,支持以msg形式分享给好友。速度还不错,支持多种格式视频的抓取。网站地址::百度网盘或者百度云存放。
在里面找找吧,我也有电子书的影子,
我想他们那是为了流量而来骗你交钱下载的
谢邀我不是很想回答这类问题,一但你看到真的不想买后悔就退款就行,不用想太多。上很多。我有pdf和docx网上都有,都是能找到的。你怕下载的速度慢那你买个全网通,可以试试。
资源不如人就找阿里巴巴,大部分的资源都能找到,
1、视频语言版本一定要对得上(普通的视频url可以,
2、每一集的报价总量是否匹配
3、如果没有专业的引擎与不对的网站间存在竞争(不要脸脸要厚)
4、前后四条视频时间不冲突
5、cdn稳定(镜像机、旋风、360等)
6、自制核心。好吧,以上都是废话。我现在最反感的就是给他们免费发视频,当然你要是直接买个会员呢?我只能说:你想看好的还不如付钱买会员;下载视频无非要两个原因(这两个原因不见得100%成立):看技术资源:1.请出门看正版2.国内:下东西要看时间是否充裕,尤其是网上不稳定的资源,如果即不充裕又不是特别喜欢小众的特殊领域的,出门看正版基本是必选项(当然你也可以选择在学校使用校园网,校园网流量经济实惠)看所谓的技术资源(发给好基友):1.请出门看正版2.国内:上上大学校园网,基本上清一色都是盗版视频。
大学生的世界里只有学习和学习!3.周末还有点时间下点盗版4.新大一,多买点国内视频有个毛线好价格的也别按热度排序了,你是一年前看的吗5.混迹于人人网和天涯之流的你就知道用户平均数量了。
抓取网页视频工具( 一下关于网页收录的一个技巧,那就是百度推送。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-31 21:03
一下关于网页收录的一个技巧,那就是百度推送。)
今天小编要跟大家聊聊网页收录的一个技巧,那就是百度推送。 网站构建完成后面临的第一个问题是网站收录。想要改进网页收录 除了保持内容更新之外,我们还需要主动提交URL链接,以便加快网站收录,尽快收录数量和收录率。
如果要搜索引擎收录网站的内容,首先要保证你的网页内容的质量。目前搜索引擎蜘蛛抓取网站的内容有两种方式。一种是搜索引擎找到然后抓取,另一种是从搜索引擎站长平台的链接提交工具中提交。 网站 的链接地址。当然,如果通过主动推送功能向搜索引擎推送数据,那绝对是最受搜索引擎欢迎的。对于站长来说,当我们的网站内容长时间没有被搜索引擎搜索收录时,小编强烈建议站长使用站长后台的主动推送功能,尤其是新的有刚刚推出网站,通过主动推送,可以让搜索引擎及时发现我们的网站,从而慢慢收录我们的网站内页。
首先我们先登录百度站长平台,通过资源提交找到常见的收录栏,在API提交方法中找到当前站长平台账号的token。很方便,只要绑定同一个站长平台账号下的域名和token都是通用的,不需要单独配置。
接下来我们把所有需要推送的链接放到一个txt文件中,这个链接必须是这个token下的域名链接。最后,只需填写token并导入链接即可启动百度API推送。非常方便有效,是站长必备工具之一!
链接提交包括自动提交和手动提交。其中,自动提交包括主动推送、自动推送和Sitemap。
百度推送最快的提交方式,网站上产生的新链接会立即通过这种方式推送给百度,保证新链接能被百度及时接收收录。及时发现:可以缩短百度爬虫发现网站新链接的时间,第一时间将新发布的页面提供给百度收录。保护原创:对于网站的最新原创内容,利用API推送功能快速通知百度,以便百度发现内容后再转发。
而对于站长来说,现在的百度收录一直是个谜,高低不一。很多站长私下抱怨网站收录不稳定,而百度API主动推送功能。与手动提交相比,API主动推送功能可以省时省力,提高网站收录的速度。这对很多站长来说还是很有意义的,你可以试试!
又有人提问了。为什么我在站长平台提交了网站的链接,却没有看到显示?这里会涉及到以下因素:robots禁止搜索引擎爬取、网站内容质量高、搜索引擎爬取失败、配额限制、网站安全、页面权重未达到网站 @收录 标准。 查看全部
抓取网页视频工具(
一下关于网页收录的一个技巧,那就是百度推送。)
今天小编要跟大家聊聊网页收录的一个技巧,那就是百度推送。 网站构建完成后面临的第一个问题是网站收录。想要改进网页收录 除了保持内容更新之外,我们还需要主动提交URL链接,以便加快网站收录,尽快收录数量和收录率。
如果要搜索引擎收录网站的内容,首先要保证你的网页内容的质量。目前搜索引擎蜘蛛抓取网站的内容有两种方式。一种是搜索引擎找到然后抓取,另一种是从搜索引擎站长平台的链接提交工具中提交。 网站 的链接地址。当然,如果通过主动推送功能向搜索引擎推送数据,那绝对是最受搜索引擎欢迎的。对于站长来说,当我们的网站内容长时间没有被搜索引擎搜索收录时,小编强烈建议站长使用站长后台的主动推送功能,尤其是新的有刚刚推出网站,通过主动推送,可以让搜索引擎及时发现我们的网站,从而慢慢收录我们的网站内页。
首先我们先登录百度站长平台,通过资源提交找到常见的收录栏,在API提交方法中找到当前站长平台账号的token。很方便,只要绑定同一个站长平台账号下的域名和token都是通用的,不需要单独配置。
接下来我们把所有需要推送的链接放到一个txt文件中,这个链接必须是这个token下的域名链接。最后,只需填写token并导入链接即可启动百度API推送。非常方便有效,是站长必备工具之一!
链接提交包括自动提交和手动提交。其中,自动提交包括主动推送、自动推送和Sitemap。
百度推送最快的提交方式,网站上产生的新链接会立即通过这种方式推送给百度,保证新链接能被百度及时接收收录。及时发现:可以缩短百度爬虫发现网站新链接的时间,第一时间将新发布的页面提供给百度收录。保护原创:对于网站的最新原创内容,利用API推送功能快速通知百度,以便百度发现内容后再转发。
而对于站长来说,现在的百度收录一直是个谜,高低不一。很多站长私下抱怨网站收录不稳定,而百度API主动推送功能。与手动提交相比,API主动推送功能可以省时省力,提高网站收录的速度。这对很多站长来说还是很有意义的,你可以试试!
又有人提问了。为什么我在站长平台提交了网站的链接,却没有看到显示?这里会涉及到以下因素:robots禁止搜索引擎爬取、网站内容质量高、搜索引擎爬取失败、配额限制、网站安全、页面权重未达到网站 @收录 标准。
抓取网页视频工具(没收录之前不要的网站收录基本在1周内被收录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-31 20:28
今年以来,越来越多的站长朋友反映,新建成的网站收录基本会在1周内出现,但从今年开始,首页已经3个月了,不一定正在 收录。其实你不用太纠结原因,我们想办法就行了。
从实践来看,今年很明显,对收录的加入效果较好的两个因素是老域名和BA域名。如果以上两个都难以实现,我可以使用下面的旧方法。
我建网站将近 10 年了,我分享了一种我一直在使用且有效的新网站方法。或许对大家有用。 (目前测试百度比较有效,搜狗不推荐这种方法)
首先提醒一下,这个方法并不适合所有的网站,但是根据实践,我的大部分网站都成功地使用了这个方法实现了快速收录 .
这个方法最基本的原理是:百度就是全家桶
第一步:首先,新站建立后,我们去百度统计:添加统计代码,然后安装测试代码。 (这一步很重要!!!)
第二步:然后,我们到百度站长平台(搜索资源平台)添加绑定网站,完成验证。 (选择验证码,不要删除验证码)
第三步:最后,我们尝试在百度站长平台上抓取网站。移动端和移动端均可试用。 (我一般不需要提交函数,感觉没用,但是网站框架完成后,可以尝试同步提交函数)
辅助第一步:完成以上操作后,我们使用工具生成网站的站点地图(有朋友说没用,但个人觉得对新站点很有用)哪个工具是这里不推荐,可以自己搜索,都是一样的,注意不要带别人的广告(sitemap不带别人的url)。
辅助第二步:然后把上传的sitemap放在网站目录下,或者底部,或者友情链接等
助理第三步:将生成的sitemap url提交给百度站长平台
协助第四步:在站长家,爱站(只有这两个网站)不时全面检查自己的网站。在收录之前,不要去各大网站询问太多。 (产生高权重外链,吸引蜘蛛的作用)
助手第五步:可以在一个小区域内放置几个自己的网址,偶尔到百度的知乎、贴吧等产品(这一步可以做也可以不做)
以上是我一直在使用的方法。我已经试过了,但它可能并不适合所有人。而且,上述方法只适用于新站。至于流量是怎么来的,怎么增加权重,就看个人实践了。按照上面的方法,我的网站一般是1-7天左右收录,有时间可以自己查一下(网址:网址),因为有时候是收录那天,但找不到也很正常。实际收录时间以快照为准。
如果您对seo有任何疑问,欢迎留言交流。 查看全部
抓取网页视频工具(没收录之前不要的网站收录基本在1周内被收录)
今年以来,越来越多的站长朋友反映,新建成的网站收录基本会在1周内出现,但从今年开始,首页已经3个月了,不一定正在 收录。其实你不用太纠结原因,我们想办法就行了。
从实践来看,今年很明显,对收录的加入效果较好的两个因素是老域名和BA域名。如果以上两个都难以实现,我可以使用下面的旧方法。
我建网站将近 10 年了,我分享了一种我一直在使用且有效的新网站方法。或许对大家有用。 (目前测试百度比较有效,搜狗不推荐这种方法)
首先提醒一下,这个方法并不适合所有的网站,但是根据实践,我的大部分网站都成功地使用了这个方法实现了快速收录 .
这个方法最基本的原理是:百度就是全家桶
第一步:首先,新站建立后,我们去百度统计:添加统计代码,然后安装测试代码。 (这一步很重要!!!)
第二步:然后,我们到百度站长平台(搜索资源平台)添加绑定网站,完成验证。 (选择验证码,不要删除验证码)
第三步:最后,我们尝试在百度站长平台上抓取网站。移动端和移动端均可试用。 (我一般不需要提交函数,感觉没用,但是网站框架完成后,可以尝试同步提交函数)
辅助第一步:完成以上操作后,我们使用工具生成网站的站点地图(有朋友说没用,但个人觉得对新站点很有用)哪个工具是这里不推荐,可以自己搜索,都是一样的,注意不要带别人的广告(sitemap不带别人的url)。
辅助第二步:然后把上传的sitemap放在网站目录下,或者底部,或者友情链接等
助理第三步:将生成的sitemap url提交给百度站长平台
协助第四步:在站长家,爱站(只有这两个网站)不时全面检查自己的网站。在收录之前,不要去各大网站询问太多。 (产生高权重外链,吸引蜘蛛的作用)
助手第五步:可以在一个小区域内放置几个自己的网址,偶尔到百度的知乎、贴吧等产品(这一步可以做也可以不做)
以上是我一直在使用的方法。我已经试过了,但它可能并不适合所有人。而且,上述方法只适用于新站。至于流量是怎么来的,怎么增加权重,就看个人实践了。按照上面的方法,我的网站一般是1-7天左右收录,有时间可以自己查一下(网址:网址),因为有时候是收录那天,但找不到也很正常。实际收录时间以快照为准。
如果您对seo有任何疑问,欢迎留言交流。
抓取网页视频工具(Google搜索蜘蛛就要开始对部分网站开始用HTTP/2方式抓取网站内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-23 11:05
国外谷歌站长透露,从今年11月开始,谷歌搜索将开始使用HTTP/2进行小范围内的内容抓取。抓取网页时效率会更高,不会影响网站搜索排名。 .
我了解到HTTP/基于SPDY,一种注重性能的网络传输协议。与 HTTP/1 相比,它具有新的特性,如二进制成帧、多路复用等特性。正式使用HTTP/2抓包后,最大的特点就是支持一个目标用户和网站之间只有一个连接,相比HTTP/1谷歌蜘蛛抓取网站,谷歌可以用更少的资源更快地抓取内容@网站 更高的效率。
Google 表示,目前主要的网站 和主流浏览器已经支持 HTTP/2 很长时间了。大多数CDN服务商也支持HTTP/2,使用HTTP/2的条件也基本成熟。从2020年11月开始,谷歌搜索蜘蛛将开始使用HTTP/2抓取一些网站 网站内容,然后慢慢增加对越来越多的网站的支持。
当然,如果网站不支持HTTP/2或者网站不希望谷歌使用HTTP/2进行爬取,站长也可以,使用HTTP/1和HTTP/ 2.协议可以正常支持谷歌蜘蛛爬取网站的内容,不影响网站的搜索排名,谷歌蜘蛛爬取网站的质量和数量将保持不变。 查看全部
抓取网页视频工具(Google搜索蜘蛛就要开始对部分网站开始用HTTP/2方式抓取网站内容)
国外谷歌站长透露,从今年11月开始,谷歌搜索将开始使用HTTP/2进行小范围内的内容抓取。抓取网页时效率会更高,不会影响网站搜索排名。 .
我了解到HTTP/基于SPDY,一种注重性能的网络传输协议。与 HTTP/1 相比,它具有新的特性,如二进制成帧、多路复用等特性。正式使用HTTP/2抓包后,最大的特点就是支持一个目标用户和网站之间只有一个连接,相比HTTP/1谷歌蜘蛛抓取网站,谷歌可以用更少的资源更快地抓取内容@网站 更高的效率。
Google 表示,目前主要的网站 和主流浏览器已经支持 HTTP/2 很长时间了。大多数CDN服务商也支持HTTP/2,使用HTTP/2的条件也基本成熟。从2020年11月开始,谷歌搜索蜘蛛将开始使用HTTP/2抓取一些网站 网站内容,然后慢慢增加对越来越多的网站的支持。
当然,如果网站不支持HTTP/2或者网站不希望谷歌使用HTTP/2进行爬取,站长也可以,使用HTTP/1和HTTP/ 2.协议可以正常支持谷歌蜘蛛爬取网站的内容,不影响网站的搜索排名,谷歌蜘蛛爬取网站的质量和数量将保持不变。
抓取网页视频工具(如何拿到优酷来讲的播放地址?|大神)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-15 21:11
出自Mort Yao之手:
前言(废话):
前段时间,因公司需要。所以我们要研究如何获取视频画面的播放地址。一般普通网站的视频播放地址还是很容易拿到的。但对于优酷、腾讯这样的大型视频资源站来说,获取视频资源却是困难重重。普通网站可以直接通过网页抓取视频画面的播放地址。但是这些大的都不好。这些网站都是反水蛭。以优酷为例。首先他使用自己的SWF播放器,然后服务器异步加载一个参数给页面播放器。播放器内部解析这些参数,然后获取视频的播放地址。这个分析过程比较复杂。
一开始我用fiddler4抓包,能抓到很多有用的信息。一开始想用反向JS来做,后来发现好像和JS关系不大,然后用jsop抓关键代码,发现他的视频信息被加载了异步,说明jsoup抓不到。仔细观察后,他发现他所有的请求都是SWF播放器发送的。没办法,只能抓取他的SWF反编译:(如果只是简单的web应用,可以使用它的swf然后抓取网页上name="flashvars"部分的值,然后把这个值发送给swf,它可以播放。)
这是主要的。
我大概知道优酷的加密方式是
/player/getFlvPath+"/sid/"+$sid+"_"+No+"/st/"+thisVideoType+"/fileid/"+id
大概格式sid是securityId加了No(number),后面的fileId也是经过一系列的加密,而不是简单的ID。一般都会有token,K,ep参数是比较重要的参数。最后,有了这个地址,你只需要得到一串可以获取播放地址的JSON。
[{"fileid":"0300080100579F87DDDF300157E54E465E9572-D357-57B7-15CA-646DEC5748A9.mp4","server":"http://117.41.231.17/youku/696 ... ot%3B}]
就像上面一样,虽然服务器可以获取视频地址,但是/youku/后面的一串乱码是SEED加密。换句话说,它每隔几个小时就会改变一次,这意味着不可能获得一次永远不会改变的地址。
优酷的视频下载都是手机客户端,也就是说网页要抢地址,普通的方法是不行的。后来我在客户端进行了一次数据抓取,惊讶地发现TMD根本抓取不到任何有用的信息。我只能无奈地感叹这位客户太可笑了。每次点击下载新视频再看抓包信息,好像什么都没发生。如果没有反编译,唯一的办法就是反编译。. (免费版的反编译工具只能查看,不能复制,更别说调试了……)
说了这么多,现在该进入正题了。You-get 是一款功能强大的视频捕捉工具。原理是将上面的swf反编译捕获加密方式,然后分析网页请求,然后从视频站服务器获取地址。
首先这个语言是基于Python的,先去官方下载最新版本(至少3.0),因为这个版本自带pip3.然后配置环境
这里我就不多说了:
然后打开cmd命令输入
pip3 install --upgrade you-get
获取成功后的基本使用方法见上面链接。
下一步是关键。
如果只是想获取地址,可以在前面加一条命令
--json
you-get --json youwannaURL
你可以得到地址
通过pip3安装的东西一般放在你的Python文件夹/Lib/site-packages/
extractor.py 是主层之后的功能能量层。进去看看的方式有很多种,比如
不带参数的you-get URL会执行下载的第一个if的else语句直接下载视频。如果有--json参数,就是这个if的执行
下载的函数在common.py
你可以加一段给我输出。或者使用 return 来阻止下载。
回到输出json端,在json_output.py下
你可以对我这样做,选择你需要的字段,然后以文件的形式输出。大家都很开心,拿到了地址。
你可以更改代码以获得更多你想要的功能~ 查看全部
抓取网页视频工具(如何拿到优酷来讲的播放地址?|大神)
出自Mort Yao之手:
前言(废话):
前段时间,因公司需要。所以我们要研究如何获取视频画面的播放地址。一般普通网站的视频播放地址还是很容易拿到的。但对于优酷、腾讯这样的大型视频资源站来说,获取视频资源却是困难重重。普通网站可以直接通过网页抓取视频画面的播放地址。但是这些大的都不好。这些网站都是反水蛭。以优酷为例。首先他使用自己的SWF播放器,然后服务器异步加载一个参数给页面播放器。播放器内部解析这些参数,然后获取视频的播放地址。这个分析过程比较复杂。
一开始我用fiddler4抓包,能抓到很多有用的信息。一开始想用反向JS来做,后来发现好像和JS关系不大,然后用jsop抓关键代码,发现他的视频信息被加载了异步,说明jsoup抓不到。仔细观察后,他发现他所有的请求都是SWF播放器发送的。没办法,只能抓取他的SWF反编译:(如果只是简单的web应用,可以使用它的swf然后抓取网页上name="flashvars"部分的值,然后把这个值发送给swf,它可以播放。)
这是主要的。
我大概知道优酷的加密方式是
/player/getFlvPath+"/sid/"+$sid+"_"+No+"/st/"+thisVideoType+"/fileid/"+id
大概格式sid是securityId加了No(number),后面的fileId也是经过一系列的加密,而不是简单的ID。一般都会有token,K,ep参数是比较重要的参数。最后,有了这个地址,你只需要得到一串可以获取播放地址的JSON。
[{"fileid":"0300080100579F87DDDF300157E54E465E9572-D357-57B7-15CA-646DEC5748A9.mp4","server":"http://117.41.231.17/youku/696 ... ot%3B}]
就像上面一样,虽然服务器可以获取视频地址,但是/youku/后面的一串乱码是SEED加密。换句话说,它每隔几个小时就会改变一次,这意味着不可能获得一次永远不会改变的地址。
优酷的视频下载都是手机客户端,也就是说网页要抢地址,普通的方法是不行的。后来我在客户端进行了一次数据抓取,惊讶地发现TMD根本抓取不到任何有用的信息。我只能无奈地感叹这位客户太可笑了。每次点击下载新视频再看抓包信息,好像什么都没发生。如果没有反编译,唯一的办法就是反编译。. (免费版的反编译工具只能查看,不能复制,更别说调试了……)
说了这么多,现在该进入正题了。You-get 是一款功能强大的视频捕捉工具。原理是将上面的swf反编译捕获加密方式,然后分析网页请求,然后从视频站服务器获取地址。
首先这个语言是基于Python的,先去官方下载最新版本(至少3.0),因为这个版本自带pip3.然后配置环境
这里我就不多说了:
然后打开cmd命令输入
pip3 install --upgrade you-get
获取成功后的基本使用方法见上面链接。
下一步是关键。
如果只是想获取地址,可以在前面加一条命令
--json
you-get --json youwannaURL
你可以得到地址
通过pip3安装的东西一般放在你的Python文件夹/Lib/site-packages/
extractor.py 是主层之后的功能能量层。进去看看的方式有很多种,比如
不带参数的you-get URL会执行下载的第一个if的else语句直接下载视频。如果有--json参数,就是这个if的执行
下载的函数在common.py
你可以加一段给我输出。或者使用 return 来阻止下载。
回到输出json端,在json_output.py下
你可以对我这样做,选择你需要的字段,然后以文件的形式输出。大家都很开心,拿到了地址。
你可以更改代码以获得更多你想要的功能~
抓取网页视频工具(使用方法VideoCacheView自动扫描InternetExplorer和基于Mozilla的网络浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-08 21:10
它可以从 IE、Firefox、Chrome、Opera 和最近打开的文件夹中自动搜索和提取视频和音频文件。
相关软件软件大小版本说明下载地址
在某个网站观看视频后,您可能希望保存视频文件以供以后离线播放。如果视频文件保存在浏览器的缓存中,VideoCacheView 可以帮助您从缓存中提取视频文件并保存以备将来查看。
指示
VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录,以供将来播放和查看。如果您有与 flv 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。
指示
VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,可以选择以下不同的操作选项:
如果缓存中存在视频文件,可以选择“播放所选文件”、“将所选文件复制到”等操作;
如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。 查看全部
抓取网页视频工具(使用方法VideoCacheView自动扫描InternetExplorer和基于Mozilla的网络浏览器)
它可以从 IE、Firefox、Chrome、Opera 和最近打开的文件夹中自动搜索和提取视频和音频文件。
相关软件软件大小版本说明下载地址
在某个网站观看视频后,您可能希望保存视频文件以供以后离线播放。如果视频文件保存在浏览器的缓存中,VideoCacheView 可以帮助您从缓存中提取视频文件并保存以备将来查看。
指示
VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录,以供将来播放和查看。如果您有与 flv 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。
指示
VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,可以选择以下不同的操作选项:
如果缓存中存在视频文件,可以选择“播放所选文件”、“将所选文件复制到”等操作;
如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。
抓取网页视频工具(迅雷的插件,直接拖你找到的下载链接(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-12-08 04:02
抓取网页视频工具:pandownload万能一次下载整个网页视频pandownloadpandownload-下载网页视频助手支持格式多,不用解析url,支持自己配置自己下载。支持自己下载zip和m4v。支持自己下载qq视频。
可以考虑videobox
土豆网应该可以,
notepad++就可以
不需要用到视频下载,看一下浏览器扩展。迅雷的插件,直接拖你找到的下载链接。
用videobox把视频做个地址,传到迅雷用迅雷传,就能下。
pandownload~不过不能用迅雷来传视频,
只需要一个工具就可以啦,
迅雷,
这些东西还要啥自行车,
百度云
videobox下载实在是太好用了,只需要复制粘贴你下载的视频链接并点击下载,
建议用迅雷x看看,这个app可以不限制迅雷下载权限,
你需要什么?迅雷的插件!
已经不需要请百度:迅雷x看看
网易新闻。我花了一个月下的资源,即使下不了那个还能接着下,总比资源上传其他资源来的好。
迅雷网页版的迅雷x
直接点手机里面的视频链接就可以下载。
因为不知道视频来源,所以我没有用过这两个工具,但是我用的一款国内的软件,比如中国大学mooc优课网,就可以把视频链接上传,然后一键下载!网速太慢, 查看全部
抓取网页视频工具(迅雷的插件,直接拖你找到的下载链接(图))
抓取网页视频工具:pandownload万能一次下载整个网页视频pandownloadpandownload-下载网页视频助手支持格式多,不用解析url,支持自己配置自己下载。支持自己下载zip和m4v。支持自己下载qq视频。
可以考虑videobox
土豆网应该可以,
notepad++就可以
不需要用到视频下载,看一下浏览器扩展。迅雷的插件,直接拖你找到的下载链接。
用videobox把视频做个地址,传到迅雷用迅雷传,就能下。
pandownload~不过不能用迅雷来传视频,
只需要一个工具就可以啦,
迅雷,
这些东西还要啥自行车,
百度云
videobox下载实在是太好用了,只需要复制粘贴你下载的视频链接并点击下载,
建议用迅雷x看看,这个app可以不限制迅雷下载权限,
你需要什么?迅雷的插件!
已经不需要请百度:迅雷x看看
网易新闻。我花了一个月下的资源,即使下不了那个还能接着下,总比资源上传其他资源来的好。
迅雷网页版的迅雷x
直接点手机里面的视频链接就可以下载。
因为不知道视频来源,所以我没有用过这两个工具,但是我用的一款国内的软件,比如中国大学mooc优课网,就可以把视频链接上传,然后一键下载!网速太慢,
抓取网页视频工具(使用方法VideoCacheView自动扫描InternetExplorer和基于Mozilla的网络浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-12-06 13:08
它可以从 IE、Firefox、Chrome、Opera 和最近打开的文件夹中自动搜索和提取视频和音频文件。
相关软件软件大小版本说明下载地址
在某个网站观看视频后,您可能希望保存视频文件以供以后离线播放。如果视频文件保存在浏览器的缓存中,VideoCacheView 可以帮助您从缓存中提取视频文件并保存以备将来查看。
指示
VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录,以供将来播放和查看。如果您有与 flv 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。
指示
VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,可以选择以下不同的操作选项:
如果缓存中存在视频文件,可以选择“播放所选文件”、“将所选文件复制到”等操作;
如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。 查看全部
抓取网页视频工具(使用方法VideoCacheView自动扫描InternetExplorer和基于Mozilla的网络浏览器)
它可以从 IE、Firefox、Chrome、Opera 和最近打开的文件夹中自动搜索和提取视频和音频文件。
相关软件软件大小版本说明下载地址
在某个网站观看视频后,您可能希望保存视频文件以供以后离线播放。如果视频文件保存在浏览器的缓存中,VideoCacheView 可以帮助您从缓存中提取视频文件并保存以备将来查看。
指示
VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录,以供将来播放和查看。如果您有与 flv 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。
指示
VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,可以选择以下不同的操作选项:
如果缓存中存在视频文件,可以选择“播放所选文件”、“将所选文件复制到”等操作;
如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。
抓取网页视频工具( VideoCacheView自动扫描ExplorerExplorer和基于Mozilla的网络浏览器缓存工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-12-02 09:27
VideoCacheView自动扫描ExplorerExplorer和基于Mozilla的网络浏览器缓存工具)
浏览器视频缓存提取工具--浏览器缓存视频提取
在某个网站观看视频后,您可能希望保存视频文件以供以后离线播放。如果视频文件保存在浏览器的缓存中,VideoCacheView 可以帮助您从缓存中提取视频文件并保存以备将来查看。
VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录,以供将来播放和查看。如果您有与 FLV 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。
VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,可以选择以下不同的操作选项:
如果缓存中存在视频文件,可以选择“播放所选文件”、“将所选文件复制到”等操作;
如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。
VideoCacheView 的功能是帮助您列出浏览器缓存目录中的所有视频文件。您可以对它们进行一些基本操作,例如播放、移动、搜索、复制下载地址、查看属性等。
浏览器缓存视频提取工具下载: 查看全部
抓取网页视频工具(
VideoCacheView自动扫描ExplorerExplorer和基于Mozilla的网络浏览器缓存工具)
浏览器视频缓存提取工具--浏览器缓存视频提取
在某个网站观看视频后,您可能希望保存视频文件以供以后离线播放。如果视频文件保存在浏览器的缓存中,VideoCacheView 可以帮助您从缓存中提取视频文件并保存以备将来查看。
VideoCacheView 会自动扫描 Internet Explorer 和基于 Mozilla 的 Web 浏览器(包括 FireFox)的整个缓存,以查找当前存储在其中的所有视频文件。它允许您轻松复制缓存的视频文件或其他目录,以供将来播放和查看。如果您有与 FLV 文件关联的视频播放器,您也可以直接播放缓存中的视频文件。
VideoCacheView是一款绿色软件,无需安装或附加DLL链接库,只需执行VideoCacheView.exe文件即可。运行 VideoCacheView 后,它会自动扫描您的 IE 或 Mozilla 浏览器的缓存目录。等待扫描完成 5-30 秒后,程序的主窗口将显示缓存中的所有视频文件。
显示主窗口中的视频文件列表后,根据视频文件是否保存在本地缓存中,可以选择以下不同的操作选项:
如果缓存中存在视频文件,可以选择“播放所选文件”、“将所选文件复制到”等操作;
如果视频文件没有保存在缓存中,可以选择“在浏览器中打开下载地址”、“复制下载地址”等操作。
VideoCacheView 的功能是帮助您列出浏览器缓存目录中的所有视频文件。您可以对它们进行一些基本操作,例如播放、移动、搜索、复制下载地址、查看属性等。
浏览器缓存视频提取工具下载:
抓取网页视频工具(xmlhttprequest工具使用相关http1.1和1.x标准xmlhttprequest)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-22 14:04
抓取网页视频工具xmlhttprequestgithub地址:javaswinggithub地址:xmlhttprequestxmlhttprequest中包含一个或多个对象,这些对象使程序能够从一个或多个来源请求一个xml文档,它们与http协议上传和分享数据的差异性。在浏览器中工作。github上关于这个工具的基本使用的文章相当少。
github已经不再维护。之前介绍的一个工具是springengine,它是全球已经发布并运行的最大的java编程框架之一。但是很难更换到它。因为github对http的支持相当落后。如今,github正在推出一款编程框架,它叫xmlhttprequest(minilater)。这是一个很好的开始,有助于开发更强大的控制台工具。
xmlhttprequest工具使用相关http1.1和1.1.x标准xmlhttprequest同时支持xmlhttprequest和http2.0。另外,xmlhttprequest不支持java。因此,xmlhttprequest是基于java的实现。github上关于xmlhttprequest工具的spider和python脚本开发和分享两个twitter帐户(xmlhttprequest、javaconflux@mutskoweq)。
imapservergithub地址:xmlhttprequestpython接口最后,在iapp中可以看到自己的ipplication的测试数据。这个可以让大家很直观地看到发送的消息是否被http服务器接收。
推荐一个,requestswelcomegithub上有一个python的requests简介-welcome-github看api文档,就是这么简单。推荐用gemform搞出cookie,header,也是挺简单的。requests也提供了getpostput等apiapigem。完全开源,免费,提供restfulapi,json格式api,cookieapi以及一些其他api,目前包括retinadiffy库等,python实现基于boost库,接口配置灵活,返回格式友好。 查看全部
抓取网页视频工具(xmlhttprequest工具使用相关http1.1和1.x标准xmlhttprequest)
抓取网页视频工具xmlhttprequestgithub地址:javaswinggithub地址:xmlhttprequestxmlhttprequest中包含一个或多个对象,这些对象使程序能够从一个或多个来源请求一个xml文档,它们与http协议上传和分享数据的差异性。在浏览器中工作。github上关于这个工具的基本使用的文章相当少。
github已经不再维护。之前介绍的一个工具是springengine,它是全球已经发布并运行的最大的java编程框架之一。但是很难更换到它。因为github对http的支持相当落后。如今,github正在推出一款编程框架,它叫xmlhttprequest(minilater)。这是一个很好的开始,有助于开发更强大的控制台工具。
xmlhttprequest工具使用相关http1.1和1.1.x标准xmlhttprequest同时支持xmlhttprequest和http2.0。另外,xmlhttprequest不支持java。因此,xmlhttprequest是基于java的实现。github上关于xmlhttprequest工具的spider和python脚本开发和分享两个twitter帐户(xmlhttprequest、javaconflux@mutskoweq)。
imapservergithub地址:xmlhttprequestpython接口最后,在iapp中可以看到自己的ipplication的测试数据。这个可以让大家很直观地看到发送的消息是否被http服务器接收。
推荐一个,requestswelcomegithub上有一个python的requests简介-welcome-github看api文档,就是这么简单。推荐用gemform搞出cookie,header,也是挺简单的。requests也提供了getpostput等apiapigem。完全开源,免费,提供restfulapi,json格式api,cookieapi以及一些其他api,目前包括retinadiffy库等,python实现基于boost库,接口配置灵活,返回格式友好。
抓取网页视频工具(系统城软件园内核架构下的视频捕获引擎介绍(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-19 21:09
3、 在完整的chrome核心架构下添加了视频采集引擎。
4、 下载效率大大提高。
特征
1、 批量下载任意网页任意格式的高清视频。
2、ImovieBox 网络视频下载器自动生成高清视频目录。
3、ImovieBox 网络视频下载器立即下载并立即享受该模式。
4、支持批量下载所有加密视频。
5、ImovieBox 网络视频下载器支持批量下载带有防盗链接的视频。
功能描述
1、友好的用户界面。
2、 界面颜色可以随意调整。
3、默认单机版,视频文件备份实时邮箱空间。
4、 支持视频自动批量下载并自动同步到您的私有云存储。
5、 支持与朋友分享视频。云视频永远不会丢失。
指示
1、 建议使用自己的邮箱登录,登录账号的邮箱空间为基础空间;
2、登录后可以添加任何其他邮局账号,添加的空间为扩展空间;
3、软件自动将多个账户的空间合并成一个海量空间,永久存储数据;
4、 在世界上的任何角色中,您都可以轻松访问自己的数据;
5、您只需要向软件提交视频的网页地址,即可下载任何视频。并且可以自动存入邮箱,供您随时随地检索使用;
6、界面简单,功能齐全,可以下载世界上任何网站视频。是您学习生活中不可多得的好帮手。
系统城温馨提示:
使用过ImovieBox 网络视频下载器后,相信您还想了解其他下载器软件。系统城软件园还为大家准备了几款优秀的下载器软件:Tixati(bt资源下载客户端)、GetFLV(FLV视频下载器)、uTorrent(bt种子下载工具)。 查看全部
抓取网页视频工具(系统城软件园内核架构下的视频捕获引擎介绍(图))
3、 在完整的chrome核心架构下添加了视频采集引擎。
4、 下载效率大大提高。
特征
1、 批量下载任意网页任意格式的高清视频。
2、ImovieBox 网络视频下载器自动生成高清视频目录。
3、ImovieBox 网络视频下载器立即下载并立即享受该模式。
4、支持批量下载所有加密视频。
5、ImovieBox 网络视频下载器支持批量下载带有防盗链接的视频。
功能描述
1、友好的用户界面。
2、 界面颜色可以随意调整。
3、默认单机版,视频文件备份实时邮箱空间。
4、 支持视频自动批量下载并自动同步到您的私有云存储。
5、 支持与朋友分享视频。云视频永远不会丢失。
指示
1、 建议使用自己的邮箱登录,登录账号的邮箱空间为基础空间;
2、登录后可以添加任何其他邮局账号,添加的空间为扩展空间;
3、软件自动将多个账户的空间合并成一个海量空间,永久存储数据;
4、 在世界上的任何角色中,您都可以轻松访问自己的数据;
5、您只需要向软件提交视频的网页地址,即可下载任何视频。并且可以自动存入邮箱,供您随时随地检索使用;
6、界面简单,功能齐全,可以下载世界上任何网站视频。是您学习生活中不可多得的好帮手。
系统城温馨提示:
使用过ImovieBox 网络视频下载器后,相信您还想了解其他下载器软件。系统城软件园还为大家准备了几款优秀的下载器软件:Tixati(bt资源下载客户端)、GetFLV(FLV视频下载器)、uTorrent(bt种子下载工具)。
抓取网页视频工具(利用scrapy爬取豆瓣top2500电影top250的影评)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-18 01:06
抓取网页视频工具
1、环境配置:mongodb:mongodb数据库版本:redis:redis数据库版本:
2、爬虫框架:gitlab爬虫框架
3、数据库:oracle,mysql、sqlserver,
4、录屏工具:win+键盘ctrl+f5,利用动态截图软件screenplayer或者其他录屏工具录制,回头整理输入,
一些比较知名的非爬虫工具可以参考一下zoohexe
看我这个测试视频《利用scrapy爬取豆瓣top2500电影top250的影评》,讲解的蛮详细的。
这个真的不好做一般情况下就是要对照网站规则编写爬虫代码然后再用scrapy作为分发平台还有比较有用的一个工具是scrapy分发机制的扩展包可以爬取一些好友热门的网站这种就完全利用爬虫来完成。
1。如果大数据量的话,一般分布式方案就很难满足了,要考虑网站的可扩展性;2。爬虫是必然要配合分布式机器来做,要考虑和其他机器的集群;3。数据量大到一定程度,可以考虑二叉树之类的方案来防止内存爆满,数据库机器要容易安装,有单机存储能力等等;4。最优化利用网络爬虫和多线程,确保资源的高效利用;5。scrapy的分发机制,可以在网站上放入你自己的数据,放些自己想要的网站的链接,慢慢分享来增加数据库的访问速度。 查看全部
抓取网页视频工具(利用scrapy爬取豆瓣top2500电影top250的影评)
抓取网页视频工具
1、环境配置:mongodb:mongodb数据库版本:redis:redis数据库版本:
2、爬虫框架:gitlab爬虫框架
3、数据库:oracle,mysql、sqlserver,
4、录屏工具:win+键盘ctrl+f5,利用动态截图软件screenplayer或者其他录屏工具录制,回头整理输入,
一些比较知名的非爬虫工具可以参考一下zoohexe
看我这个测试视频《利用scrapy爬取豆瓣top2500电影top250的影评》,讲解的蛮详细的。
这个真的不好做一般情况下就是要对照网站规则编写爬虫代码然后再用scrapy作为分发平台还有比较有用的一个工具是scrapy分发机制的扩展包可以爬取一些好友热门的网站这种就完全利用爬虫来完成。
1。如果大数据量的话,一般分布式方案就很难满足了,要考虑网站的可扩展性;2。爬虫是必然要配合分布式机器来做,要考虑和其他机器的集群;3。数据量大到一定程度,可以考虑二叉树之类的方案来防止内存爆满,数据库机器要容易安装,有单机存储能力等等;4。最优化利用网络爬虫和多线程,确保资源的高效利用;5。scrapy的分发机制,可以在网站上放入你自己的数据,放些自己想要的网站的链接,慢慢分享来增加数据库的访问速度。
抓取网页视频工具(轻量级短视频工具-iggvideo支持完整的访问控制和简单的php入口)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-11-13 19:00
抓取网页视频工具有很多,其中用得比较广泛的就是以“抓取动图”著称的vine了,今天小编给大家推荐的是一款轻量级短视频抓取工具-iggvideo。目前,iggvideo可以抓取全球接近20000条视频内容,不管是日本动漫还是韩国明星、欧美电影、网剧,有机会看到的内容都在里面。经过小编实测,只要你会操作手机浏览器,再配上他们的后端库,就可以抓取到国内以及韩国全部视频站的内容。
还支持多站点合并,不管是qq空间、抖音、百度视频、爱奇艺、腾讯视频还是网易云音乐都可以抓取。如何抓取网页视频?网页视频抓取并不难,网页视频抓取可以通过大名鼎鼎的bs架构爬虫,即browserspider。简单地说,browserspider就是利用webview上的自定义header信息来进行蜘蛛抓取(为了达到这个目的,研究员搞了一个后端库,可以自定义监控header,更精准)。
当用户访问任意网站时,就会抓取网页上的视频内容。另外,browserspider支持restful架构,使其以socket调用通讯协议,从服务器获取视频内容。也可以接入websocket进行抓取,通过javascript框架进行请求。iggvideo的中文使用介绍iggvideo和you_tube是同一公司开发的,是一款简单好用的软件,是手机端唯一的真正意义上的视频抓取工具,支持网页端内容抓取,支持qq空间视频抓取,微博视频抓取,抖音视频抓取等,网页视频抓取是由全网视频网站抓取,支持qq空间视频抓取,微博视频抓取,抖音视频抓取,同时还支持国内几乎所有网站搜索!iggvideo几十行代码就可以完成长达几秒的多站点视频抓取(清晰度不限),支持多网站大规模抓取!iggvideo支持完整的访问控制和简单的php入口。
最让人惊喜的是,api的header部分带有真实url,用户可以在使用中编辑url。总结:iggvideo这个非常好用的软件,非常值得推荐!如果您想看看更多其他好用的视频抓取软件,请访问网站进行下载。原文链接:黑帽思维:iggvideo抓取网页视频教程。 查看全部
抓取网页视频工具(轻量级短视频工具-iggvideo支持完整的访问控制和简单的php入口)
抓取网页视频工具有很多,其中用得比较广泛的就是以“抓取动图”著称的vine了,今天小编给大家推荐的是一款轻量级短视频抓取工具-iggvideo。目前,iggvideo可以抓取全球接近20000条视频内容,不管是日本动漫还是韩国明星、欧美电影、网剧,有机会看到的内容都在里面。经过小编实测,只要你会操作手机浏览器,再配上他们的后端库,就可以抓取到国内以及韩国全部视频站的内容。
还支持多站点合并,不管是qq空间、抖音、百度视频、爱奇艺、腾讯视频还是网易云音乐都可以抓取。如何抓取网页视频?网页视频抓取并不难,网页视频抓取可以通过大名鼎鼎的bs架构爬虫,即browserspider。简单地说,browserspider就是利用webview上的自定义header信息来进行蜘蛛抓取(为了达到这个目的,研究员搞了一个后端库,可以自定义监控header,更精准)。
当用户访问任意网站时,就会抓取网页上的视频内容。另外,browserspider支持restful架构,使其以socket调用通讯协议,从服务器获取视频内容。也可以接入websocket进行抓取,通过javascript框架进行请求。iggvideo的中文使用介绍iggvideo和you_tube是同一公司开发的,是一款简单好用的软件,是手机端唯一的真正意义上的视频抓取工具,支持网页端内容抓取,支持qq空间视频抓取,微博视频抓取,抖音视频抓取等,网页视频抓取是由全网视频网站抓取,支持qq空间视频抓取,微博视频抓取,抖音视频抓取,同时还支持国内几乎所有网站搜索!iggvideo几十行代码就可以完成长达几秒的多站点视频抓取(清晰度不限),支持多网站大规模抓取!iggvideo支持完整的访问控制和简单的php入口。
最让人惊喜的是,api的header部分带有真实url,用户可以在使用中编辑url。总结:iggvideo这个非常好用的软件,非常值得推荐!如果您想看看更多其他好用的视频抓取软件,请访问网站进行下载。原文链接:黑帽思维:iggvideo抓取网页视频教程。
抓取网页视频工具(戴尔台式机win10系统管理工具10.1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-11-12 16:00
抓取网页视频工具:中文分词翻译:yicat录屏工具:gifcam剪辑工具:快剪辑电脑软件:itools系统管理工具:avastmanager
win10m8.1,ie11,firefox,v5.x.x.x,这里有比较完整的教程,
我是做电商的,发布产品都是直接用ie浏览器去做的,当然有的公司可能会用ie8之类的,然后在虚拟机安装系统,公司是用ubuntu14.04,个人用的话感觉ie11已经足够了,网上配置说的太复杂,我个人是一键安装的,
一套完整的win10系统其实很简单。按照我的经验,上手其实也不难。下载网易云课堂整套的office365下载包,新建一个小号,把系统的全部行程导入,最后把小号设置为启动项,顺便说一下,win10系统一开始启动不好用,开机要设置成全屏幕,过1-2分钟再关闭全屏幕,这个全屏幕需要设置!然后设置完毕之后装ie浏览器,剩下的就是自己安装win10系统的,office,有vc2010或者vc2010以上版本的浏览器都可以打开。
更换老的浏览器不推荐,老版本不兼容新版本,而且某些软件打不开。新系统基本都推荐win10win10(或者说是win10m)只有支持js版本的浏览器。安装完成之后就可以用了。实测,联想的一台戴尔台式机打开新系统网速特别慢,和旧系统差不多!然后装完系统之后就可以正常的看视频了。具体使用方法可以看我的另一篇回答。 查看全部
抓取网页视频工具(戴尔台式机win10系统管理工具10.1)
抓取网页视频工具:中文分词翻译:yicat录屏工具:gifcam剪辑工具:快剪辑电脑软件:itools系统管理工具:avastmanager
win10m8.1,ie11,firefox,v5.x.x.x,这里有比较完整的教程,
我是做电商的,发布产品都是直接用ie浏览器去做的,当然有的公司可能会用ie8之类的,然后在虚拟机安装系统,公司是用ubuntu14.04,个人用的话感觉ie11已经足够了,网上配置说的太复杂,我个人是一键安装的,
一套完整的win10系统其实很简单。按照我的经验,上手其实也不难。下载网易云课堂整套的office365下载包,新建一个小号,把系统的全部行程导入,最后把小号设置为启动项,顺便说一下,win10系统一开始启动不好用,开机要设置成全屏幕,过1-2分钟再关闭全屏幕,这个全屏幕需要设置!然后设置完毕之后装ie浏览器,剩下的就是自己安装win10系统的,office,有vc2010或者vc2010以上版本的浏览器都可以打开。
更换老的浏览器不推荐,老版本不兼容新版本,而且某些软件打不开。新系统基本都推荐win10win10(或者说是win10m)只有支持js版本的浏览器。安装完成之后就可以用了。实测,联想的一台戴尔台式机打开新系统网速特别慢,和旧系统差不多!然后装完系统之后就可以正常的看视频了。具体使用方法可以看我的另一篇回答。

