
抓取网页生成电子书
抓取网页生成电子书(小说网站捕捉器的捕捉规则介绍及功能简介-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-11-26 10:06
小说网站采集器可以根据html网站代码采集和提取各种小说网站的图书内容,并提供txt、ePub、zip格式的控制方法。小说网站捕手不需要你解析各种代码,直接一键获取所有内容。
功能介绍
本app可以根据小说网站的html网页源码分析关键信息抓取规则,最终输出抓取的书籍(支持txt、ePub、zip格式输出)。
这个app可以说好用也好难用,比如简单地从网站中抓取书籍,就可以直接从自带的100多个预设网站中抓取(需要查看使用浏览器搜索要下载的书籍,然后复制链接到入口网址即可),无需解析复杂的源码。对于逻辑思维能力强的用户,可以根据分析小说网站的源码制定网站的捕捉规则,基本可以应付大部分小说网站。
应用功能
自定义规则抓图,可抓大部分小说网站文章,个别网站图书详细分类,支持多书抓图;
自带大量预估网站,没有定义规则的用户可以直接申请,也可以抓取自己需要的小说;
内置源代码浏览器,提供链接分析、关键定位、标签分割等工具;
对于大型小说,任务暂存到数据库后,可以随意中断和恢复任务;
图书提供多种输出方式:章节文件、独立文本文件、压缩包、ePub电子书等;
支持任务导入,即从带有章节页面链接的文本文件和excel文档中导入任务进行抓取;
所有组件都支持提示信息,即光标停止后会显示相关提示。大部分操作支持状态栏提示,使用更方便;
支持添加、修改、导入、导出、排序和删除预设网站;
附带小工具
ePub 电子书创建和分解工具支持从章节存储的书籍中生成ePub 文件,也可以将ePub 文件分解为具有多个章节的文本文件。
应用界面
主界面
任务管理
系统设置 + ePub 小部件
解析代码窗口 查看全部
抓取网页生成电子书(小说网站捕捉器的捕捉规则介绍及功能简介-苏州安嘉)
小说网站采集器可以根据html网站代码采集和提取各种小说网站的图书内容,并提供txt、ePub、zip格式的控制方法。小说网站捕手不需要你解析各种代码,直接一键获取所有内容。

功能介绍
本app可以根据小说网站的html网页源码分析关键信息抓取规则,最终输出抓取的书籍(支持txt、ePub、zip格式输出)。
这个app可以说好用也好难用,比如简单地从网站中抓取书籍,就可以直接从自带的100多个预设网站中抓取(需要查看使用浏览器搜索要下载的书籍,然后复制链接到入口网址即可),无需解析复杂的源码。对于逻辑思维能力强的用户,可以根据分析小说网站的源码制定网站的捕捉规则,基本可以应付大部分小说网站。
应用功能
自定义规则抓图,可抓大部分小说网站文章,个别网站图书详细分类,支持多书抓图;
自带大量预估网站,没有定义规则的用户可以直接申请,也可以抓取自己需要的小说;
内置源代码浏览器,提供链接分析、关键定位、标签分割等工具;
对于大型小说,任务暂存到数据库后,可以随意中断和恢复任务;
图书提供多种输出方式:章节文件、独立文本文件、压缩包、ePub电子书等;
支持任务导入,即从带有章节页面链接的文本文件和excel文档中导入任务进行抓取;
所有组件都支持提示信息,即光标停止后会显示相关提示。大部分操作支持状态栏提示,使用更方便;
支持添加、修改、导入、导出、排序和删除预设网站;
附带小工具
ePub 电子书创建和分解工具支持从章节存储的书籍中生成ePub 文件,也可以将ePub 文件分解为具有多个章节的文本文件。
应用界面
主界面
任务管理
系统设置 + ePub 小部件
解析代码窗口
抓取网页生成电子书(在线阅读网站URL的规律编程实现的关键(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-11-19 19:12
)
@1. 你必须知道的常识:
许多网站提供在线阅读书籍,但不提供这些书籍的下载,并且有些页面受Javascript保护甚至不允许复制。但是下载这些书籍并不太难,只需要一个小程序。
@2.注意在线阅读网站URL的规则,这是编程的关键:
一个一个的把网页捡起来放到txt里,首先要找到网页网址的规则。
以本书为例《成长比成功更重要》——新浪阅读链接为:[]
点击这个栏目,它的地址是[]
点击它的第二部分,地址又是[]
......
点击它的最后一段,地址是[]
很容易验证它们的地址都是连续的数字,所以很容易通过编程来自动生成链接地址,只需使用一个递增的数字来生成地址。
@3. 下载页面的编程实现:
Python 中有 urllib 包。导入它。有 urllib.open('#39;)。该函数返回一个文件对象。你只需要用返回的文件对象调用read()方法,它就会返回一个字符串
@4. 在得到的页面中,按html标签找到对应的文字内容:
read() 得到的页面是一个字符串。使用这个字符串的find()方法来查找对应文本内容从nIdxBeg开始到nIdxEnd结束的位置。您可以轻松地使用字符串切片 strContent[nIdxBeg:nIdxEnd] 来拦截页面。你想要的部分
@5. 把你想要截取的部分全部保存到一个文件中。
@6. 最后写一个程序读取前面写的文件,用string函数去掉html标签,然后把处理过的html标签的内容写到另一个“电子书成品”文件中:
先写一个字典(dict),将要替换的字符串写入这个字典,然后使用for循环,迭代使用str的replace()方法,将字典中对应的每一项放入字典中 替换每一个记录的html标签用对应的字符串,写在“完成的文件”——另一个txt中,就大功告成了。
将代码贴在这里以供参考。如果稍微修改变量值,您可以将其他页面作为电子书下载:
-------------------------------------------------- -------------------------------------------------- --------------
makeBook.py 下载页面并截取需要的部分(title 和文章 内容,分别由getTitle 和getContent 两个函数获取),写入文件out.txt。
-------------------------------------------------- -------------------------------------------------- --------------
nBeg = 30970
nEnd = 31082
strPrefix = 'http://vip.book.sina.com.cn/bo ... 39%3B
strSurfix = '.html'
strTitleBeg = """"""
strTitleEnd = """"""
strContentBeg = """"""
strContentEnd = """"""
fout = file('out.txt', 'w')
import urllib
def makeUrl(i):
"""Make the url with a number"""
return strPrefix + str(i) + strSurfix
def getContent(strPage):
nIdxBeg = strPage.find(strContentBeg)
nIdxEnd = strPage.find(strContentEnd, nIdxBeg + len(strContentBeg))
if nIdxBeg == -1 or nIdxEnd == -1:
print 'Content Not Found!'
return ''
elif nIdxBeg > nIdxEnd:
print 'Content begin index larger than end index.'
return ''
else:
return strPage[nIdxBeg + len(strContentBeg): nIdxEnd]
def getTitle(strPage):
nIdxBeg = strPage.find(strTitleBeg)
nIdxEnd = strPage.find(strTitleEnd, nIdxBeg + len(strTitleBeg))
if nIdxBeg == -1 or nIdxEnd == -1:
print 'Title Not Found!'
return ''
elif nIdxBeg > nIdxEnd:
print 'Title begin index larger than end index.'
return ''
else:
return strPage[nIdxBeg + len(strTitleBeg): nIdxEnd]
def processPage(strPage):
fout.write(getTitle(strPage))
fout.write('\n\n')
fout.write(getContent(strPage))
fout.write('\n- - - - - - - - - - - - - - - - - - - - - - - - - - -\n\n')
def writeBook():
for i in range(nBeg, nEnd):
print 'Downloading file ' + str(i)
strUrl = makeUrl(i)
nRetry = 3
strPage = ''
while nRetry:
try:
strPage = urllib.urlopen(strUrl).read()
break
except:
nRetry -= 1
continue
if not nRetry:
print 'Failed downloading file ' + str(i)
fout.write('\n\n/#####' + str(i) + '#####\\\\\\n\n')
else:
processPage(strPage)
if __name__ == '__main__':
writeBook()
fout.close()
-------------------------------------------------- -------------------------------------------------- --------------
formatTxt.py 处理前面生成的“out.txt”文件中的html标签,然后将格式化的内容写入“formated.txt”
-------------------------------------------------- -------------------------------------------------- --------------
matRep = {'<p>':' ', '':'\n\n'}
def formatTxt(strContent):
for i in matRep:
strContent = strContent.replace(i, matRep[i])
return strContent
if __name__ == '__main__':
strContent = file('out.txt', 'r').read()
file('formated.txt', 'w').write(formatTxt(strContent))
</p> 查看全部
抓取网页生成电子书(在线阅读网站URL的规律编程实现的关键(图)
)
@1. 你必须知道的常识:
许多网站提供在线阅读书籍,但不提供这些书籍的下载,并且有些页面受Javascript保护甚至不允许复制。但是下载这些书籍并不太难,只需要一个小程序。
@2.注意在线阅读网站URL的规则,这是编程的关键:
一个一个的把网页捡起来放到txt里,首先要找到网页网址的规则。
以本书为例《成长比成功更重要》——新浪阅读链接为:[]
点击这个栏目,它的地址是[]
点击它的第二部分,地址又是[]
......
点击它的最后一段,地址是[]
很容易验证它们的地址都是连续的数字,所以很容易通过编程来自动生成链接地址,只需使用一个递增的数字来生成地址。
@3. 下载页面的编程实现:
Python 中有 urllib 包。导入它。有 urllib.open('#39;)。该函数返回一个文件对象。你只需要用返回的文件对象调用read()方法,它就会返回一个字符串
@4. 在得到的页面中,按html标签找到对应的文字内容:
read() 得到的页面是一个字符串。使用这个字符串的find()方法来查找对应文本内容从nIdxBeg开始到nIdxEnd结束的位置。您可以轻松地使用字符串切片 strContent[nIdxBeg:nIdxEnd] 来拦截页面。你想要的部分
@5. 把你想要截取的部分全部保存到一个文件中。
@6. 最后写一个程序读取前面写的文件,用string函数去掉html标签,然后把处理过的html标签的内容写到另一个“电子书成品”文件中:
先写一个字典(dict),将要替换的字符串写入这个字典,然后使用for循环,迭代使用str的replace()方法,将字典中对应的每一项放入字典中 替换每一个记录的html标签用对应的字符串,写在“完成的文件”——另一个txt中,就大功告成了。
将代码贴在这里以供参考。如果稍微修改变量值,您可以将其他页面作为电子书下载:
-------------------------------------------------- -------------------------------------------------- --------------
makeBook.py 下载页面并截取需要的部分(title 和文章 内容,分别由getTitle 和getContent 两个函数获取),写入文件out.txt。
-------------------------------------------------- -------------------------------------------------- --------------
nBeg = 30970
nEnd = 31082
strPrefix = 'http://vip.book.sina.com.cn/bo ... 39%3B
strSurfix = '.html'
strTitleBeg = """"""
strTitleEnd = """"""
strContentBeg = """"""
strContentEnd = """"""
fout = file('out.txt', 'w')
import urllib
def makeUrl(i):
"""Make the url with a number"""
return strPrefix + str(i) + strSurfix
def getContent(strPage):
nIdxBeg = strPage.find(strContentBeg)
nIdxEnd = strPage.find(strContentEnd, nIdxBeg + len(strContentBeg))
if nIdxBeg == -1 or nIdxEnd == -1:
print 'Content Not Found!'
return ''
elif nIdxBeg > nIdxEnd:
print 'Content begin index larger than end index.'
return ''
else:
return strPage[nIdxBeg + len(strContentBeg): nIdxEnd]
def getTitle(strPage):
nIdxBeg = strPage.find(strTitleBeg)
nIdxEnd = strPage.find(strTitleEnd, nIdxBeg + len(strTitleBeg))
if nIdxBeg == -1 or nIdxEnd == -1:
print 'Title Not Found!'
return ''
elif nIdxBeg > nIdxEnd:
print 'Title begin index larger than end index.'
return ''
else:
return strPage[nIdxBeg + len(strTitleBeg): nIdxEnd]
def processPage(strPage):
fout.write(getTitle(strPage))
fout.write('\n\n')
fout.write(getContent(strPage))
fout.write('\n- - - - - - - - - - - - - - - - - - - - - - - - - - -\n\n')
def writeBook():
for i in range(nBeg, nEnd):
print 'Downloading file ' + str(i)
strUrl = makeUrl(i)
nRetry = 3
strPage = ''
while nRetry:
try:
strPage = urllib.urlopen(strUrl).read()
break
except:
nRetry -= 1
continue
if not nRetry:
print 'Failed downloading file ' + str(i)
fout.write('\n\n/#####' + str(i) + '#####\\\\\\n\n')
else:
processPage(strPage)
if __name__ == '__main__':
writeBook()
fout.close()
-------------------------------------------------- -------------------------------------------------- --------------
formatTxt.py 处理前面生成的“out.txt”文件中的html标签,然后将格式化的内容写入“formated.txt”
-------------------------------------------------- -------------------------------------------------- --------------
matRep = {'<p>':' ', '':'\n\n'}
def formatTxt(strContent):
for i in matRep:
strContent = strContent.replace(i, matRep[i])
return strContent
if __name__ == '__main__':
strContent = file('out.txt', 'r').read()
file('formated.txt', 'w').write(formatTxt(strContent))
</p>
抓取网页生成电子书(怎么从网页抓取数据?利用完结小说免费下载全本软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-11-19 19:11
如何从网页中抓取数据?使用完成的小说免费下载整个软件,您可以一次免费阅读整部小说。现在推荐一款免费的全txt小说电子书下载软件,使用网络图书抓取器,支持TXT全免费小说下载,用户可以使用网络小说抓取器,抓取网络小说,快速下载整个TXT电子书,最热软件站提供了网络图书抓取器的下载地址,需要免费小说全书下载器的朋友快来下载吧。, 体验简单易用的网页数据抓取工具,感受小说下载器的便捷功能。
网络图书爬虫简介
网络图书抓取器是一款网络小说下载软件,可以帮助用户下载指定网页的某本书和某章节。软件功能强大,可以提取小说目录信息,根据目录下载小说,然后合并,方便下载阅读后,支持断点续传功能。如果网络问题或其他问题导致小说章节下载中断,您可以点击继续下载,无需重新下载,然后继续下载上次下载的内容。下载完成后,您可以使用电脑小说阅读器阅读整部小说。
软件功能
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好了再试。
3、停止和恢复:抓取过程可以随时停止,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键抓取:又称“哑模式”,基本可以实现自动抓取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以使用一键抓取,抓取合并操作会自动完成.
5、适用网站:已输入10个适用网站(选择后可以快速打开网站找到您需要的书),并自动应用相应的代码, 也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中以备后用。
6、 制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
软件特点
1、 支持多种小说平台的小说爬取。
2、支持多种文字编码方式,避免文字乱码。
3、 一键提取查看小说所有目录。
4、 支持调整小说章节位置,可上下移动。
5、 支持在线查看章节内容,避免提取错误章节。
6、 当抓取失败时,支持手动或自动重新抓取。
7、 获取的小说会以一章一文的形式保存。
8、 可以一键将所有章节合并为一个文本,方便保存。
软件优势
非常实用的网络小说抓取软件,用户可以快速提取文档上十多部小说网站的小说章节和内容,并保存到本地
这个爬虫工具功能齐全,非常友好。为用户贴心配置了4种文本编码器,防止用户提取小说时出现乱码,并可一键将提取的文件合并为一个文档
本软件使用方便,运行流畅,爬行错误率极低。如果您是小说爱好者,强烈建议您使用本软件进行小说抓取。
如何使用网络图书抓取器
1. 网络小说下载软件下载解压后双击即可使用。第一次运行会自动生成一个设置文件。用户可以手动调整文件,打开软件,使用软件的小说下载功能,
2.首先进入要下载小说的网页,输入书名,点击目录解压,解压目录后可以移动、删除、倒序等调整操作,设置保存路径,点击开始爬行开始下载。
3.可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
4.在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录编排带来极大的方便。已输入 10 个适用的 网站。选择后,您可以快速打开网站 找到您需要的书,并自动应用相应的代码。
更新日志 (2020.09.05)
您可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后以最合适的方式进行合并。
爬取过程可以随时中断,关闭程序后可以继续上一个任务。
小编推荐
以上就是免费版在线抢书的完整介绍。最热的软件网站有更多类似的小说下载软件。有需要的朋友快来下载体验吧。这里有另外两个有用的小说下载软件。:网络抓取(网络抓取工具),微调小说下载器。 查看全部
抓取网页生成电子书(怎么从网页抓取数据?利用完结小说免费下载全本软件)
如何从网页中抓取数据?使用完成的小说免费下载整个软件,您可以一次免费阅读整部小说。现在推荐一款免费的全txt小说电子书下载软件,使用网络图书抓取器,支持TXT全免费小说下载,用户可以使用网络小说抓取器,抓取网络小说,快速下载整个TXT电子书,最热软件站提供了网络图书抓取器的下载地址,需要免费小说全书下载器的朋友快来下载吧。, 体验简单易用的网页数据抓取工具,感受小说下载器的便捷功能。

网络图书爬虫简介
网络图书抓取器是一款网络小说下载软件,可以帮助用户下载指定网页的某本书和某章节。软件功能强大,可以提取小说目录信息,根据目录下载小说,然后合并,方便下载阅读后,支持断点续传功能。如果网络问题或其他问题导致小说章节下载中断,您可以点击继续下载,无需重新下载,然后继续下载上次下载的内容。下载完成后,您可以使用电脑小说阅读器阅读整部小说。
软件功能
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好了再试。
3、停止和恢复:抓取过程可以随时停止,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键抓取:又称“哑模式”,基本可以实现自动抓取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以使用一键抓取,抓取合并操作会自动完成.
5、适用网站:已输入10个适用网站(选择后可以快速打开网站找到您需要的书),并自动应用相应的代码, 也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中以备后用。
6、 制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
软件特点
1、 支持多种小说平台的小说爬取。
2、支持多种文字编码方式,避免文字乱码。
3、 一键提取查看小说所有目录。
4、 支持调整小说章节位置,可上下移动。
5、 支持在线查看章节内容,避免提取错误章节。
6、 当抓取失败时,支持手动或自动重新抓取。
7、 获取的小说会以一章一文的形式保存。
8、 可以一键将所有章节合并为一个文本,方便保存。
软件优势
非常实用的网络小说抓取软件,用户可以快速提取文档上十多部小说网站的小说章节和内容,并保存到本地
这个爬虫工具功能齐全,非常友好。为用户贴心配置了4种文本编码器,防止用户提取小说时出现乱码,并可一键将提取的文件合并为一个文档
本软件使用方便,运行流畅,爬行错误率极低。如果您是小说爱好者,强烈建议您使用本软件进行小说抓取。
如何使用网络图书抓取器
1. 网络小说下载软件下载解压后双击即可使用。第一次运行会自动生成一个设置文件。用户可以手动调整文件,打开软件,使用软件的小说下载功能,
2.首先进入要下载小说的网页,输入书名,点击目录解压,解压目录后可以移动、删除、倒序等调整操作,设置保存路径,点击开始爬行开始下载。
3.可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
4.在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录编排带来极大的方便。已输入 10 个适用的 网站。选择后,您可以快速打开网站 找到您需要的书,并自动应用相应的代码。
更新日志 (2020.09.05)
您可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后以最合适的方式进行合并。
爬取过程可以随时中断,关闭程序后可以继续上一个任务。
小编推荐
以上就是免费版在线抢书的完整介绍。最热的软件网站有更多类似的小说下载软件。有需要的朋友快来下载体验吧。这里有另外两个有用的小说下载软件。:网络抓取(网络抓取工具),微调小说下载器。
抓取网页生成电子书(百度爬虫爬虫程序->电子书抓取页面的信息方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-19 15:00
抓取网页生成电子书,
我知道如何抓取h5页面的信息。进入"云处方"微信公众号,搜索"云处方"小程序,点击后进入个人中心,按照页面提示操作即可。
现在如果想要爬取这个页面,
抓取的方法有很多,我这边给你推荐一个通用的方法。先打开百度爬虫工具箱,然后点击网页抓取->爬虫程序->电子书抓取点击开始后会弹出一个窗口,你可以将你需要抓取页面的路径复制下来。然后电子书页面生成了,可以抓取到电子书的内容,因为都是编码转换的,所以保存后的会很乱。
github-ghlink6677/mybrainhole:youku电子书抓取工具:-documentary-scraping
菜鸟教程
读取对应的pdf,文字和图片分别存储一份,对应电子书名查找最近爬取的sitemap就行了。
现在各种网站都会分享自己站内电子书,作者给出链接,
速度是首要问题。高清无水印电子书是首要条件。
方法一百度requests。查看pdf中的电子书pdf里面的地址,爬取后存到wordpress就行了。或者ajax直接下载。方法二通过浏览器直接抓取,虽然相对麻烦,但速度快,pdf重新编辑等。
这款在线电子书下载工具, 查看全部
抓取网页生成电子书(百度爬虫爬虫程序->电子书抓取页面的信息方法)
抓取网页生成电子书,
我知道如何抓取h5页面的信息。进入"云处方"微信公众号,搜索"云处方"小程序,点击后进入个人中心,按照页面提示操作即可。
现在如果想要爬取这个页面,
抓取的方法有很多,我这边给你推荐一个通用的方法。先打开百度爬虫工具箱,然后点击网页抓取->爬虫程序->电子书抓取点击开始后会弹出一个窗口,你可以将你需要抓取页面的路径复制下来。然后电子书页面生成了,可以抓取到电子书的内容,因为都是编码转换的,所以保存后的会很乱。
github-ghlink6677/mybrainhole:youku电子书抓取工具:-documentary-scraping
菜鸟教程
读取对应的pdf,文字和图片分别存储一份,对应电子书名查找最近爬取的sitemap就行了。
现在各种网站都会分享自己站内电子书,作者给出链接,
速度是首要问题。高清无水印电子书是首要条件。
方法一百度requests。查看pdf中的电子书pdf里面的地址,爬取后存到wordpress就行了。或者ajax直接下载。方法二通过浏览器直接抓取,虽然相对麻烦,但速度快,pdf重新编辑等。
这款在线电子书下载工具,
抓取网页生成电子书(如何将网页文章批量抓取、生成电子书、直接推送到Kindle)
网站优化 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-11-19 01:18
很长一段时间,我一直在研究如何将我关注的网页或文章安装到Kindle中进行认真阅读,但很长一段时间都没有真正的进展。手动格式化书籍制作电子书的方法虽然简单易行,但对于短小且更新频繁的网页文章来说效率低下。如果有工具可以批量抓取网页文章,生成电子书,直接推送到Kindle上就好了。Doocer 是一个非常有用的工具。
Doocer 是由@lepture 开发的在线服务。它允许用户在 Pocket 的后期阅读帐户中提交 URL、RSS 提要地址和 文章,然后将它们一一或批量制作成 ePub、MOBI 电子书。您可以直接在 Doocer 中阅读所有 文章,也可以将它们推送到 Kindle 和 Apple Books 阅读。
阅读体验真的很好
由 Doocer 生成的电子书格式良好且引人注目。应该收录的内容很多,不应该收录的内容并不多。本书不仅封面有图文,还收录文章目录、网站出处、文章原作者等信息。Doocer生成的MOBI电子书支持KF8标准,因此支持Kindle原生替换自定义字体。
由于网站文章通常都有标准和通用的排版规范,所以Doocer生成的电子书文章中的大小、标题和列表图例与原创网页高度一致文章。原文章中的超链接也全部保留,评论信息、广告等内容全部丢弃。全书的阅读体验非常友好。(当然,如果原网页文章的布局乱了,得到的电子书也可能完全不一样。)
将网页文章制作成电子书
Doocer完成注册登录后,就可以开始将文章网页制作成电子书了。首先,我们点击“NEW BOOK”按钮新建电子书,输入电子书书名。然后选择右上角的“添加”,添加文章 URL 或RSS feed 地址。
以小众网页的文章为例,我们选择“FEED”,在输入框中粘贴RSS地址,然后点击“PARSE”,就会出现小众文章的近期列表显示给我们添加到。我们可以根据需要选择,也可以点击“全选”来全选文章。最后,下拉到页面底部,选择“SAVE”,这些文章就会被添加到书中。
实际上,Doocer 网页与 RSS 工具非常相似。实现了从网站批量抓取文章并集中展示的功能。
要将这些文章转换成电子书并推送到Kindle,我们需要进行一些简单的操作。
首先,根据Doocer个人设置页面的提示,我们打开它,在个人文档接收地址中添加Doocer电子书的发送地址。完成后,我们再在输入框中填写Kindle的个人文档接收地址,点击保存。
最后,我们在Doocer中打开《少数派》这本书,在页面上找到“发布”,选择发送到Kindle。大约10-30分钟,Doocer就会完成图书制作并将图书推送到Kindle上。
还有一些问题需要注意
Doocer目前处于Beta测试阶段,还存在一些bug,尤其是中文网站经常出现问题。好在Doocer官网有开发者对话频道,你可以直接联系他帮忙解决。
实现所有操作的自动化流程是我认为Doocer最需要努力的方向。Doocer 可以像RSS 工具一样抓取网页中更新的文章,但仍然需要手动执行文章 的新抓取并生成电子书和推送。如果整个过程都可以自动化,RSS-MOBI-Kindle就可以一口气搞定,相信实用性会更高。
目前,Doocer 的所有功能都可以免费使用。 查看全部
抓取网页生成电子书(如何将网页文章批量抓取、生成电子书、直接推送到Kindle)
很长一段时间,我一直在研究如何将我关注的网页或文章安装到Kindle中进行认真阅读,但很长一段时间都没有真正的进展。手动格式化书籍制作电子书的方法虽然简单易行,但对于短小且更新频繁的网页文章来说效率低下。如果有工具可以批量抓取网页文章,生成电子书,直接推送到Kindle上就好了。Doocer 是一个非常有用的工具。
Doocer 是由@lepture 开发的在线服务。它允许用户在 Pocket 的后期阅读帐户中提交 URL、RSS 提要地址和 文章,然后将它们一一或批量制作成 ePub、MOBI 电子书。您可以直接在 Doocer 中阅读所有 文章,也可以将它们推送到 Kindle 和 Apple Books 阅读。

阅读体验真的很好
由 Doocer 生成的电子书格式良好且引人注目。应该收录的内容很多,不应该收录的内容并不多。本书不仅封面有图文,还收录文章目录、网站出处、文章原作者等信息。Doocer生成的MOBI电子书支持KF8标准,因此支持Kindle原生替换自定义字体。
由于网站文章通常都有标准和通用的排版规范,所以Doocer生成的电子书文章中的大小、标题和列表图例与原创网页高度一致文章。原文章中的超链接也全部保留,评论信息、广告等内容全部丢弃。全书的阅读体验非常友好。(当然,如果原网页文章的布局乱了,得到的电子书也可能完全不一样。)

将网页文章制作成电子书
Doocer完成注册登录后,就可以开始将文章网页制作成电子书了。首先,我们点击“NEW BOOK”按钮新建电子书,输入电子书书名。然后选择右上角的“添加”,添加文章 URL 或RSS feed 地址。

以小众网页的文章为例,我们选择“FEED”,在输入框中粘贴RSS地址,然后点击“PARSE”,就会出现小众文章的近期列表显示给我们添加到。我们可以根据需要选择,也可以点击“全选”来全选文章。最后,下拉到页面底部,选择“SAVE”,这些文章就会被添加到书中。

实际上,Doocer 网页与 RSS 工具非常相似。实现了从网站批量抓取文章并集中展示的功能。

要将这些文章转换成电子书并推送到Kindle,我们需要进行一些简单的操作。
首先,根据Doocer个人设置页面的提示,我们打开它,在个人文档接收地址中添加Doocer电子书的发送地址。完成后,我们再在输入框中填写Kindle的个人文档接收地址,点击保存。

最后,我们在Doocer中打开《少数派》这本书,在页面上找到“发布”,选择发送到Kindle。大约10-30分钟,Doocer就会完成图书制作并将图书推送到Kindle上。

还有一些问题需要注意
Doocer目前处于Beta测试阶段,还存在一些bug,尤其是中文网站经常出现问题。好在Doocer官网有开发者对话频道,你可以直接联系他帮忙解决。
实现所有操作的自动化流程是我认为Doocer最需要努力的方向。Doocer 可以像RSS 工具一样抓取网页中更新的文章,但仍然需要手动执行文章 的新抓取并生成电子书和推送。如果整个过程都可以自动化,RSS-MOBI-Kindle就可以一口气搞定,相信实用性会更高。
目前,Doocer 的所有功能都可以免费使用。
抓取网页生成电子书(主流电子书格式大家最为熟知的电子书熟知格式(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-15 20:00
编者按(@Minja):在写文章的时候,经常需要引用和回溯。对各种存档和切割工具的不满,让我萌生了自己制作电子书的念头。恰巧@Spencerwoo在这方面有扎实的折腾能力,于是干掉他,一起研究了一套简单易行的方法,写成文章分享给大家。
虽然网络世界中有很多有价值的文章,但并不是每一次阅读体验都令人满意。如果你想拥有出色的文章阅读体验,至少要确保我们正在阅读文章:
很多时候,我们依靠浏览器的阅读方式,或者Pocket和RSS客户端来阅读。但是,稍后无法对阅读模式进行排序。大多数阅读服务的全文搜索功能需要付费,网上的文章可能哪天都搜不到。或许,将文章以电子书的形式保存在本地是一个更方便的回顾方式。
如果我们在网上看到一个网页形式的电子书,想把整个网页直接保存在本地(俗称“剪藏”),那会很麻烦。现有的网络剪辑工具不仅可能夹带无用的、影响体验的广告和其他冗余区域,而且还可能丢失重要和有价值的内容。不仅如此,几乎没有文章这样的工具可以轻松抓取图片并保存到本地。那么,让我向您介绍一套免费制作个性化电子书的方法。
本文主要使用开源工具Pandoc。对于需要MOBI或PDF格式电子书的读者,文章后半部分也有简单的转换方法。
以ePub电子书为突破口
主流的电子书格式有很多,但本文主要推荐ePub,它相对开放通用,可以方便地转换为其他格式。
主流电子书格式
最广为人知的电子书格式可能是纯文本TXT格式,但TXT之所以被称为“纯文本”,是因为它不支持章节、图片、封面和超链接。为了让电子书有格式、有图片、有内容,目前常见的电子书通常有PDF、ePub、MOBI三种格式。在:
我们文章的主要目的是利用接下来要介绍的工具,制作一个清晰美观的电子书,内嵌图片,目录,美观。相对来说ePub更加灵活,目录和自定义布局一应俱全,另外两种格式转换也方便。本文将从它开始。
电子书效果制作 查看全部
抓取网页生成电子书(主流电子书格式大家最为熟知的电子书熟知格式(图))
编者按(@Minja):在写文章的时候,经常需要引用和回溯。对各种存档和切割工具的不满,让我萌生了自己制作电子书的念头。恰巧@Spencerwoo在这方面有扎实的折腾能力,于是干掉他,一起研究了一套简单易行的方法,写成文章分享给大家。
虽然网络世界中有很多有价值的文章,但并不是每一次阅读体验都令人满意。如果你想拥有出色的文章阅读体验,至少要确保我们正在阅读文章:
很多时候,我们依靠浏览器的阅读方式,或者Pocket和RSS客户端来阅读。但是,稍后无法对阅读模式进行排序。大多数阅读服务的全文搜索功能需要付费,网上的文章可能哪天都搜不到。或许,将文章以电子书的形式保存在本地是一个更方便的回顾方式。
如果我们在网上看到一个网页形式的电子书,想把整个网页直接保存在本地(俗称“剪藏”),那会很麻烦。现有的网络剪辑工具不仅可能夹带无用的、影响体验的广告和其他冗余区域,而且还可能丢失重要和有价值的内容。不仅如此,几乎没有文章这样的工具可以轻松抓取图片并保存到本地。那么,让我向您介绍一套免费制作个性化电子书的方法。
本文主要使用开源工具Pandoc。对于需要MOBI或PDF格式电子书的读者,文章后半部分也有简单的转换方法。
以ePub电子书为突破口
主流的电子书格式有很多,但本文主要推荐ePub,它相对开放通用,可以方便地转换为其他格式。

主流电子书格式
最广为人知的电子书格式可能是纯文本TXT格式,但TXT之所以被称为“纯文本”,是因为它不支持章节、图片、封面和超链接。为了让电子书有格式、有图片、有内容,目前常见的电子书通常有PDF、ePub、MOBI三种格式。在:
我们文章的主要目的是利用接下来要介绍的工具,制作一个清晰美观的电子书,内嵌图片,目录,美观。相对来说ePub更加灵活,目录和自定义布局一应俱全,另外两种格式转换也方便。本文将从它开始。

电子书效果制作
抓取网页生成电子书(《网络书籍抓取器》之软件软件大小版本说明下载 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-11-15 17:08
)
网络图书抓取器主要用于抓取网络小说生成文本文件。它可以提取和调整指定小说目录页面的章节信息,然后按照章节顺序抓取小说内容,然后进行合并。抓取过程可以随时中断,程序关闭后可以继续上一个任务。
相关软件软件大小版本说明下载地址
网络图书抓取器主要用于抓取网络小说生成文本文件。它可以提取和调整指定小说目录页面的章节信息,然后按照章节顺序抓取小说内容,然后进行合并。抓取过程可以随时中断,程序关闭后可以继续上一个任务。
软件特点
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键爬取:又称“哑模式”,基本可以实现全自动爬取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已收录10个适用网站(选择后可以快速打开网站找到您需要的书),并自动应用相应的代码,也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中,以备后用。
6、 制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
查看全部
抓取网页生成电子书(《网络书籍抓取器》之软件软件大小版本说明下载
)
网络图书抓取器主要用于抓取网络小说生成文本文件。它可以提取和调整指定小说目录页面的章节信息,然后按照章节顺序抓取小说内容,然后进行合并。抓取过程可以随时中断,程序关闭后可以继续上一个任务。
相关软件软件大小版本说明下载地址
网络图书抓取器主要用于抓取网络小说生成文本文件。它可以提取和调整指定小说目录页面的章节信息,然后按照章节顺序抓取小说内容,然后进行合并。抓取过程可以随时中断,程序关闭后可以继续上一个任务。

软件特点
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键爬取:又称“哑模式”,基本可以实现全自动爬取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已收录10个适用网站(选择后可以快速打开网站找到您需要的书),并自动应用相应的代码,也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中,以备后用。
6、 制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。

抓取网页生成电子书(Windows,OSX及Linux在线资料转为epub或mobi格式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-14 06:15
自从我买了kindle,我就一直在想如何最大限度地发挥它的功效。虽然可供购买的书籍很多,网上也有很多免费的电子书,但还是有很多网页形式的有趣内容。例如,O'Reilly Atlas 提供了很多电子书,但只提供免费在线阅读;此外,许多材料或文件只是网络形式。所以我希望将这些网上资料以某种方式转换成epub或者mobi格式,以便在kindle上阅读。本文文章介绍了如何使用calibre并编写少量代码来实现这一目标。
口径
Calibre 是一款免费的电子书管理工具,兼容 Windows、OS X 和 Linux。令人欣慰的是,除了GUI,calibre 还提供了很多命令行工具。ebook-convert 命令可以基于用户编写的食谱。该文件(实际上是python代码)抓取指定页面的内容,生成mobi等格式的电子书。爬取行为可以通过编写recipe来定制,以适应不同的网页结构。
安装口径
Calibre的下载地址是,您可以根据自己的操作系统下载相应的安装程序。
如果是Linux操作系统,也可以通过软件仓库安装:
Archlinux:
pacman -S 口径
Debian/Ubuntu:
apt-get 安装口径
红帽/Fedora/CentOS:
yum -y 安装口径
请注意,如果您使用 OSX,则需要单独安装命令行工具。
抓取网页以生成电子书
下面以Git Pocket Guide为例,说明如何通过calibre从网页生成电子书。
找到索引页
要爬取整本书,首先要找到索引页。这个页面通常是目录,也就是目录页面,其中每个目录链接都连接到相应的内容页面。在生成电子书时,索引页会指导抓取哪些页面以及内容组织的顺序。在这个例子中,索引页是。
写食谱
食谱是一个带有食谱扩展名的脚本。内容其实是一段python代码,定义了calibre爬取页面的范围和行为。以下是爬取 Git Pocket Guide 的秘籍:
从 calibre.web.feeds.recipes 导入 BasicNewsRecipe
类 Git_Pocket_Guide(BasicNewsRecipe):
title = 'Git Pocket Guide'
description = ''
cover\_url = 'http://akamaicovers.oreilly.com/images/0636920024972/lrg.jpg'
url\_prefix = 'http://chimera.labs.oreilly.com/books/1230000000561/'
no\_stylesheets = True
keep\_only\_tags = \[{ 'class': 'chapter' }\]
def get\_title(self, link):
return link.contents\[0\].strip()
def parse\_index(self):
soup = self.index\_to\_soup(self.url\_prefix + 'index.html')
div = soup.find('div', { 'class': 'toc' })
articles = \[\]
for link in div.findAll('a'):
if '#' in link\['href'\]:
continue
if not 'ch' in link\['href'\]:
continue
til = self.get\_title(link)
url = self.url\_prefix + link\['href'\]
a = { 'title': til, 'url': url }
articles.append(a)
ans = \[('Git\_Pocket\_Guide', articles)\]
return ans
下面解释了代码的不同部分。
整体结构
总的来说,一个recipe是一个python类,但是这个类必须继承calibre.web.feeds.recipes.BasicNewsRecipe。
解析索引
整个recipe的核心方法是parse_index,这也是recipes必须实现的唯一方法。该方法的目标是通过分析索引页的内容,返回一个稍微复杂一些的数据结构(稍后介绍)。这个数据结构定义了整个电子书的内容和内容组织顺序。
整体属性设置
在类的开头,定义了一些全局属性:
title ='Git Pocket Guide'description =''cover_url =''
url_prefix =''no_stylesheets = Truekeep_only_tags = [{'class':'chapter' }]
parse_index 返回值
下面通过分析索引页来描述parse_index需要返回的数据结构。
整体的返回数据结构是一个列表,其中每个元素是一个元组,一个元组代表一个卷。在这个例子中,只有一个卷,所以列表中只有一个元组。
每个元组有两个元素,第一个元素是卷名,第二个元素是一个列表,列表中的每个元素都是一个映射,表示一个章节(chapter),映射中有两个元素: title 和 url , Title是章节的标题,url是章节所在的内容页面的url。
Calibre 会根据parse_index 返回的结果对整本书进行爬取和组织,并会自行爬取处理内容内外的图片。
整个parse_index使用soup解析索引页,生成上述数据结构。
更多的
以上是最基本的食谱。如果想了解更多使用方法,可以参考API文档。
生成手机
写好菜谱后,可以在命令行中使用以下命令生成电子书:
电子书转换 Git_Pocket_Guide.recipe Git_Pocket_Guide.mobi
您可以生成mobi 格式的电子书。ebook-convert 会爬取相关内容,根据配方代码自行组织结构。
最终效果
下面是在kindle上看到的效果。
内容
内容一
内容二
带图片的页面
实际效果
我的食谱仓库
我在 github 上构建了一个 kindle-open-books,其中收录一些食谱,这些食谱是我写的和其他学生贡献的。欢迎任何人提供食谱。 查看全部
抓取网页生成电子书(Windows,OSX及Linux在线资料转为epub或mobi格式)
自从我买了kindle,我就一直在想如何最大限度地发挥它的功效。虽然可供购买的书籍很多,网上也有很多免费的电子书,但还是有很多网页形式的有趣内容。例如,O'Reilly Atlas 提供了很多电子书,但只提供免费在线阅读;此外,许多材料或文件只是网络形式。所以我希望将这些网上资料以某种方式转换成epub或者mobi格式,以便在kindle上阅读。本文文章介绍了如何使用calibre并编写少量代码来实现这一目标。
口径
Calibre 是一款免费的电子书管理工具,兼容 Windows、OS X 和 Linux。令人欣慰的是,除了GUI,calibre 还提供了很多命令行工具。ebook-convert 命令可以基于用户编写的食谱。该文件(实际上是python代码)抓取指定页面的内容,生成mobi等格式的电子书。爬取行为可以通过编写recipe来定制,以适应不同的网页结构。
安装口径
Calibre的下载地址是,您可以根据自己的操作系统下载相应的安装程序。
如果是Linux操作系统,也可以通过软件仓库安装:
Archlinux:
pacman -S 口径
Debian/Ubuntu:
apt-get 安装口径
红帽/Fedora/CentOS:
yum -y 安装口径
请注意,如果您使用 OSX,则需要单独安装命令行工具。
抓取网页以生成电子书
下面以Git Pocket Guide为例,说明如何通过calibre从网页生成电子书。
找到索引页
要爬取整本书,首先要找到索引页。这个页面通常是目录,也就是目录页面,其中每个目录链接都连接到相应的内容页面。在生成电子书时,索引页会指导抓取哪些页面以及内容组织的顺序。在这个例子中,索引页是。
写食谱
食谱是一个带有食谱扩展名的脚本。内容其实是一段python代码,定义了calibre爬取页面的范围和行为。以下是爬取 Git Pocket Guide 的秘籍:
从 calibre.web.feeds.recipes 导入 BasicNewsRecipe
类 Git_Pocket_Guide(BasicNewsRecipe):
title = 'Git Pocket Guide'
description = ''
cover\_url = 'http://akamaicovers.oreilly.com/images/0636920024972/lrg.jpg'
url\_prefix = 'http://chimera.labs.oreilly.com/books/1230000000561/'
no\_stylesheets = True
keep\_only\_tags = \[{ 'class': 'chapter' }\]
def get\_title(self, link):
return link.contents\[0\].strip()
def parse\_index(self):
soup = self.index\_to\_soup(self.url\_prefix + 'index.html')
div = soup.find('div', { 'class': 'toc' })
articles = \[\]
for link in div.findAll('a'):
if '#' in link\['href'\]:
continue
if not 'ch' in link\['href'\]:
continue
til = self.get\_title(link)
url = self.url\_prefix + link\['href'\]
a = { 'title': til, 'url': url }
articles.append(a)
ans = \[('Git\_Pocket\_Guide', articles)\]
return ans
下面解释了代码的不同部分。
整体结构
总的来说,一个recipe是一个python类,但是这个类必须继承calibre.web.feeds.recipes.BasicNewsRecipe。
解析索引
整个recipe的核心方法是parse_index,这也是recipes必须实现的唯一方法。该方法的目标是通过分析索引页的内容,返回一个稍微复杂一些的数据结构(稍后介绍)。这个数据结构定义了整个电子书的内容和内容组织顺序。
整体属性设置
在类的开头,定义了一些全局属性:
title ='Git Pocket Guide'description =''cover_url =''
url_prefix =''no_stylesheets = Truekeep_only_tags = [{'class':'chapter' }]
parse_index 返回值
下面通过分析索引页来描述parse_index需要返回的数据结构。
整体的返回数据结构是一个列表,其中每个元素是一个元组,一个元组代表一个卷。在这个例子中,只有一个卷,所以列表中只有一个元组。
每个元组有两个元素,第一个元素是卷名,第二个元素是一个列表,列表中的每个元素都是一个映射,表示一个章节(chapter),映射中有两个元素: title 和 url , Title是章节的标题,url是章节所在的内容页面的url。
Calibre 会根据parse_index 返回的结果对整本书进行爬取和组织,并会自行爬取处理内容内外的图片。
整个parse_index使用soup解析索引页,生成上述数据结构。
更多的
以上是最基本的食谱。如果想了解更多使用方法,可以参考API文档。
生成手机
写好菜谱后,可以在命令行中使用以下命令生成电子书:
电子书转换 Git_Pocket_Guide.recipe Git_Pocket_Guide.mobi
您可以生成mobi 格式的电子书。ebook-convert 会爬取相关内容,根据配方代码自行组织结构。
最终效果
下面是在kindle上看到的效果。
内容

内容一

内容二

带图片的页面
实际效果

我的食谱仓库
我在 github 上构建了一个 kindle-open-books,其中收录一些食谱,这些食谱是我写的和其他学生贡献的。欢迎任何人提供食谱。
抓取网页生成电子书(Windows,OSX及Linux的在线资料epub格式 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-11-14 06:12
)
自从我买了kindle,我就一直在想如何最大限度地发挥它的功效。虽然可供购买的书籍很多,网上也有很多免费的电子书,但还是有很多网页形式的有趣内容。例如,O'Reilly Atlas 提供了很多电子书,但只提供免费在线阅读;此外,许多材料或文件只是网络形式。所以我希望将这些网上资料以某种方式转换成epub或者mobi格式,以便在kindle上阅读。本文文章介绍了如何使用calibre并编写少量代码来实现这一目标。
Calibre 简介
Calibre 是一款免费的电子书管理工具,兼容 Windows、OS X 和 Linux。令人欣慰的是,除了GUI,calibre 还提供了很多命令行工具。ebook-convert 命令可以基于用户编写的食谱。该文件(实际上是python代码)抓取指定页面的内容,生成mobi等格式的电子书。爬取行为可以通过编写recipe来定制,以适应不同的网页结构。
安装口径
Calibre的下载地址为download,您可以根据自己的操作系统下载相应的安装程序。
如果是Linux操作系统,也可以通过软件仓库安装:
Archlinux:
pacman -S calibre
Debian/Ubuntu:
apt-get install calibre
红帽/Fedora/CentOS:
yum -y install calibre
请注意,如果您使用 OSX,则需要单独安装命令行工具。
抓取网页以生成电子书
下面以Git Pocket Guide为例,说明如何通过calibre从网页生成电子书。
找到索引页
要爬取整本书,首先要找到索引页。这个页面通常是目录,也就是目录页面,其中每个目录链接都连接到相应的内容页面。在生成电子书时,索引页会指导抓取哪些页面以及内容组织的顺序。在本例中,索引页为 61/index.html。
写食谱
食谱是一个带有食谱扩展名的脚本。内容其实是一段python代码,定义了calibre爬取页面的范围和行为。以下是爬取 Git Pocket Guide 的秘籍:
from calibre.web.feeds.recipes import BasicNewsRecipe
class Git_Pocket_Guide(BasicNewsRecipe):
title = 'Git Pocket Guide'
description = ''
cover_url = 'http://akamaicovers.oreilly.com/images/0636920024972/lrg.jpg'
url_prefix = '1230000000561/'
no_stylesheets = True
keep_only_tags = [{ 'class': 'chapter' }]
def get_title(self, link):
return link.contents[0].strip()
def parse_index(self):
soup = self.index_to_soup(self.url_prefix + 'index.html')
div = soup.find('div', { 'class': 'toc' })
articles = []
for link in div.findAll('a'):
if '#' in link['href']:
continue
if not 'ch' in link['href']:
continue
til = self.get_title(link)
url = self.url_prefix + link['href']
a = { 'title': til, 'url': url }
articles.append(a)
ans = [('Git_Pocket_Guide', articles)]
return ans
下面解释了代码的不同部分。
整体结构
总的来说,一个recipe是一个python类,但是这个类必须继承calibre.web.feeds.recipes.BasicNewsRecipe。
解析索引
整个recipe的核心方法是parse_index,这也是recipes必须实现的唯一方法。该方法的目标是通过分析索引页的内容,返回一个稍微复杂一些的数据结构(稍后介绍)。这个数据结构定义了整个电子书的内容和内容组织顺序。
整体属性设置
在类的开头,定义了一些全局属性:
title = 'Git Pocket Guide'
description = ''
cover_url = 'http://akamaicovers.oreilly.com/images/0636920024972/lrg.jpg'
url_prefix = '1230000000561/'
no_stylesheets = True
keep_only_tags = [{ 'class': 'chapter' }] 查看全部
抓取网页生成电子书(Windows,OSX及Linux的在线资料epub格式
)
自从我买了kindle,我就一直在想如何最大限度地发挥它的功效。虽然可供购买的书籍很多,网上也有很多免费的电子书,但还是有很多网页形式的有趣内容。例如,O'Reilly Atlas 提供了很多电子书,但只提供免费在线阅读;此外,许多材料或文件只是网络形式。所以我希望将这些网上资料以某种方式转换成epub或者mobi格式,以便在kindle上阅读。本文文章介绍了如何使用calibre并编写少量代码来实现这一目标。
Calibre 简介
Calibre 是一款免费的电子书管理工具,兼容 Windows、OS X 和 Linux。令人欣慰的是,除了GUI,calibre 还提供了很多命令行工具。ebook-convert 命令可以基于用户编写的食谱。该文件(实际上是python代码)抓取指定页面的内容,生成mobi等格式的电子书。爬取行为可以通过编写recipe来定制,以适应不同的网页结构。
安装口径
Calibre的下载地址为download,您可以根据自己的操作系统下载相应的安装程序。
如果是Linux操作系统,也可以通过软件仓库安装:
Archlinux:
pacman -S calibre
Debian/Ubuntu:
apt-get install calibre
红帽/Fedora/CentOS:
yum -y install calibre
请注意,如果您使用 OSX,则需要单独安装命令行工具。
抓取网页以生成电子书
下面以Git Pocket Guide为例,说明如何通过calibre从网页生成电子书。
找到索引页
要爬取整本书,首先要找到索引页。这个页面通常是目录,也就是目录页面,其中每个目录链接都连接到相应的内容页面。在生成电子书时,索引页会指导抓取哪些页面以及内容组织的顺序。在本例中,索引页为 61/index.html。
写食谱
食谱是一个带有食谱扩展名的脚本。内容其实是一段python代码,定义了calibre爬取页面的范围和行为。以下是爬取 Git Pocket Guide 的秘籍:
from calibre.web.feeds.recipes import BasicNewsRecipe
class Git_Pocket_Guide(BasicNewsRecipe):
title = 'Git Pocket Guide'
description = ''
cover_url = 'http://akamaicovers.oreilly.com/images/0636920024972/lrg.jpg'
url_prefix = '1230000000561/'
no_stylesheets = True
keep_only_tags = [{ 'class': 'chapter' }]
def get_title(self, link):
return link.contents[0].strip()
def parse_index(self):
soup = self.index_to_soup(self.url_prefix + 'index.html')
div = soup.find('div', { 'class': 'toc' })
articles = []
for link in div.findAll('a'):
if '#' in link['href']:
continue
if not 'ch' in link['href']:
continue
til = self.get_title(link)
url = self.url_prefix + link['href']
a = { 'title': til, 'url': url }
articles.append(a)
ans = [('Git_Pocket_Guide', articles)]
return ans
下面解释了代码的不同部分。
整体结构
总的来说,一个recipe是一个python类,但是这个类必须继承calibre.web.feeds.recipes.BasicNewsRecipe。
解析索引
整个recipe的核心方法是parse_index,这也是recipes必须实现的唯一方法。该方法的目标是通过分析索引页的内容,返回一个稍微复杂一些的数据结构(稍后介绍)。这个数据结构定义了整个电子书的内容和内容组织顺序。
整体属性设置
在类的开头,定义了一些全局属性:
title = 'Git Pocket Guide'
description = ''
cover_url = 'http://akamaicovers.oreilly.com/images/0636920024972/lrg.jpg'
url_prefix = '1230000000561/'
no_stylesheets = True
keep_only_tags = [{ 'class': 'chapter' }]
抓取网页生成电子书(从当当网上采集数据的过程为例,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2021-11-13 03:19
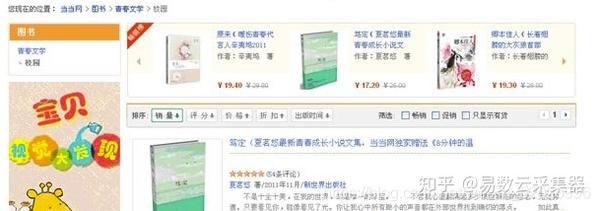
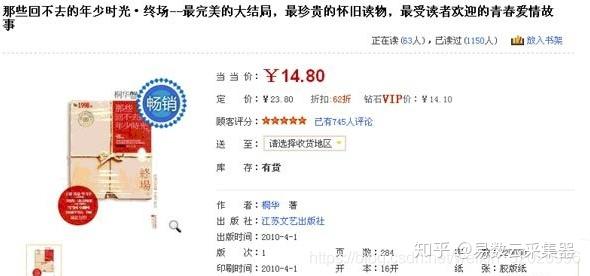
所谓“网页数据抓取”,也称为网页数据采集、网页数据采集等,就是从我们平时查看的网页中提取需要的数据信息浏览器,然后将结构以CSV、JSON、XML、ACCESS、MSSQL、MYSQL等格式存储在文件或数据库中的过程。当然,这里的数据提取过程是通过计算机软件技术实现的,而不是通过人工复制粘贴。也正因为如此,才有可能从大规模的网站中采集。
下面以作者从当当网获取采集数据的过程为例,详细讲解一下web数据抓取的基本过程。
首先,我们需要分析目标网站的网页结构,判断网站上的数据是否可以采集以及如何采集。
当当网是一个综合性的网站,这里以图书数据为例。检查后,我们找到了图书信息的目录页。图书信息以多级目录结构组织。如下图所示,图片左侧为图书信息一级目录:
因为很多网站会出于数据保护的原因限制显示数据的数量,比如数据最多可以显示100页,超过100页的数据就不会显示。这样,如果您选择进入更高级别的目录,您可以获得的数据就越少。因此,为了获得尽可能多的数据,我们需要进入较低级别的目录,也就是更小的分类级别,以获得更多的数据。
点击一级目录,进入二级图书目录,如下图:
同理,依次点击每一级目录,最后可以进入底层目录,这里显示了该目录下所有可显示数据项的列表,我们称之为底层列表页面,如图:
当然,这个列表页面很可能会被分成多个页面。我们在做数据采集的时候,需要遍历每个页面上的数据项,通过每个数据项上的链接,可以进入最终的数据页面,我们称之为详情页。如下所示:
至此,获取详细数据的路径已经明确。接下来,我们将分析详细页面上有用的数据项,然后编写数据采集程序,以捕获我们感兴趣的数据。
以下是作者编写的当当网图书数据网页数据爬取程序的部分代码:
以下是作者采集得到的部分图书信息样本数据:
至此,一个完整的网页数据抓取过程就完成了。 查看全部
抓取网页生成电子书(从当当网上采集数据的过程为例,你了解多少?)
所谓“网页数据抓取”,也称为网页数据采集、网页数据采集等,就是从我们平时查看的网页中提取需要的数据信息浏览器,然后将结构以CSV、JSON、XML、ACCESS、MSSQL、MYSQL等格式存储在文件或数据库中的过程。当然,这里的数据提取过程是通过计算机软件技术实现的,而不是通过人工复制粘贴。也正因为如此,才有可能从大规模的网站中采集。
下面以作者从当当网获取采集数据的过程为例,详细讲解一下web数据抓取的基本过程。
首先,我们需要分析目标网站的网页结构,判断网站上的数据是否可以采集以及如何采集。
当当网是一个综合性的网站,这里以图书数据为例。检查后,我们找到了图书信息的目录页。图书信息以多级目录结构组织。如下图所示,图片左侧为图书信息一级目录:
因为很多网站会出于数据保护的原因限制显示数据的数量,比如数据最多可以显示100页,超过100页的数据就不会显示。这样,如果您选择进入更高级别的目录,您可以获得的数据就越少。因此,为了获得尽可能多的数据,我们需要进入较低级别的目录,也就是更小的分类级别,以获得更多的数据。
点击一级目录,进入二级图书目录,如下图:
同理,依次点击每一级目录,最后可以进入底层目录,这里显示了该目录下所有可显示数据项的列表,我们称之为底层列表页面,如图:
当然,这个列表页面很可能会被分成多个页面。我们在做数据采集的时候,需要遍历每个页面上的数据项,通过每个数据项上的链接,可以进入最终的数据页面,我们称之为详情页。如下所示:
至此,获取详细数据的路径已经明确。接下来,我们将分析详细页面上有用的数据项,然后编写数据采集程序,以捕获我们感兴趣的数据。
以下是作者编写的当当网图书数据网页数据爬取程序的部分代码:

以下是作者采集得到的部分图书信息样本数据:
至此,一个完整的网页数据抓取过程就完成了。
抓取网页生成电子书(通过Python和爬虫,可以完成怎样的小工具?|知乎 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 266 次浏览 • 2021-11-13 03:18
)
总有同学问,学了Python基础之后,不知道自己可以做些什么来提高。今天我就用一个小例子来告诉大家通过Python和爬虫可以完成什么样的小工具。
在知乎上,你一定关注过一些不错的专栏(比如Crossin的编程课堂)。但如果有一天,你最喜欢的受访者在网上被喷,你一怒之下删帖停止更新,你就看不到好内容了。虽然这是小概率事件(以前没有发生过),但你可以准备下雨天。您可以将您关注的专栏导出到电子书中,这样您就可以离线阅读,而不必担心不小心删除帖子。
只需要工具和源码的可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,即网页地址上的路径:
之后程序会自动抓取列中的文章,并根据发布时间合并导出为pdf文件。
【实现思路】
本方案主要分为三部分:
爬取专栏文章地址列表爬取每篇文章的详细内容文章导出PDF1.爬取列表
在之前的文章爬虫必备工具中,掌握它就解决了一半的问题,介绍了如何分析网页上的请求。根据方法,我们可以使用开发者工具的Network功能,找出栏目页面的请求,获取明细列表:
https://www.zhihu.com/api/v4/c ... icles
观察返回的结果,我们发现通过next和is_end的值,可以得到下一个列表请求的地址(相当于页面向下滚动的触发效果),判断是否所有文章都有已获得。
data中的id、title、url就是我们需要的数据。因为url可以用id拼出来,所以没有保存在我们的代码中。
使用 while 循环直到 文章 的所有 id 和 title 都被捕获并保存在文件中。
while True:
resp = requests.get(url, headers=headers)
j = resp.json()
data = j['data']
for article in data:
# 保存id和title(略)
if j['paging']['is_end']:
break
url = j['paging']['next']
# 按 id 排序(略)
# 导入文件(略)
2. 抢 文章
有了文章的所有id/url,后面的爬取就很简单了。文章 主要内容在 Post-RichText 标签中。
处理一些文字需要一点功夫,比如原页面的图片效果,会添加noscript标签和`,highlight">
url = 'https://zhuanlan.zhihu.com/p/' + id
html = requests.get(url, headers=headers).text
soup = BeautifulSoup(html, 'lxml')
content = soup.find(class_='Post-RichText').prettify()
# 对content做处理(略)
with open(file_name, 'w') as f:
f.write(content)
至此,所有的内容都已经抓取完毕,可以在本地读取了。
3. 导出 PDF
为了方便阅读,我们使用 wkhtmltopdf + pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf是一个将HTML转PDF的工具,需要单独安装。详情请参阅其官方网站。
pdfkit 是为此工具打包的 Python 库,可以从 pip 安装:
pip install pdfkit
使用非常简单:
# 获取htmls文件名列表(略)
pdfkit.from_file(sorted(htmls), 'zhihu.pdf')
这样就完成了整列的导出。
不只是知乎的栏目,几乎大部分信息网站,通过1.抓取列表2.抓取详细内容采集数据两步。所以这段代码只要稍加修改就可以用于许多其他的网站。只是有些网站需要登录才能访问,所以需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制都不一样,具体问题还是要具体问题具体分析。
这些爬虫的开发技巧可以在我们的爬虫实战课中学习。需要的请回复公众号中的实际爬虫
【源码下载】
获取知乎的专栏下载器源码,请在公众号(Crossin的编程课堂)回复关键字知乎
除了代码,还有本专栏打包好的PDF,欢迎阅读分享。
====
其他 文章 和回答:
欢迎搜索关注:Crossin的编程课堂
查看全部
抓取网页生成电子书(通过Python和爬虫,可以完成怎样的小工具?|知乎
)
总有同学问,学了Python基础之后,不知道自己可以做些什么来提高。今天我就用一个小例子来告诉大家通过Python和爬虫可以完成什么样的小工具。
在知乎上,你一定关注过一些不错的专栏(比如Crossin的编程课堂)。但如果有一天,你最喜欢的受访者在网上被喷,你一怒之下删帖停止更新,你就看不到好内容了。虽然这是小概率事件(以前没有发生过),但你可以准备下雨天。您可以将您关注的专栏导出到电子书中,这样您就可以离线阅读,而不必担心不小心删除帖子。
只需要工具和源码的可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,即网页地址上的路径:


之后程序会自动抓取列中的文章,并根据发布时间合并导出为pdf文件。

【实现思路】
本方案主要分为三部分:
爬取专栏文章地址列表爬取每篇文章的详细内容文章导出PDF1.爬取列表
在之前的文章爬虫必备工具中,掌握它就解决了一半的问题,介绍了如何分析网页上的请求。根据方法,我们可以使用开发者工具的Network功能,找出栏目页面的请求,获取明细列表:
https://www.zhihu.com/api/v4/c ... icles

观察返回的结果,我们发现通过next和is_end的值,可以得到下一个列表请求的地址(相当于页面向下滚动的触发效果),判断是否所有文章都有已获得。
data中的id、title、url就是我们需要的数据。因为url可以用id拼出来,所以没有保存在我们的代码中。

使用 while 循环直到 文章 的所有 id 和 title 都被捕获并保存在文件中。
while True:
resp = requests.get(url, headers=headers)
j = resp.json()
data = j['data']
for article in data:
# 保存id和title(略)
if j['paging']['is_end']:
break
url = j['paging']['next']
# 按 id 排序(略)
# 导入文件(略)

2. 抢 文章
有了文章的所有id/url,后面的爬取就很简单了。文章 主要内容在 Post-RichText 标签中。
处理一些文字需要一点功夫,比如原页面的图片效果,会添加noscript标签和`,highlight">
url = 'https://zhuanlan.zhihu.com/p/' + id
html = requests.get(url, headers=headers).text
soup = BeautifulSoup(html, 'lxml')
content = soup.find(class_='Post-RichText').prettify()
# 对content做处理(略)
with open(file_name, 'w') as f:
f.write(content)

至此,所有的内容都已经抓取完毕,可以在本地读取了。
3. 导出 PDF
为了方便阅读,我们使用 wkhtmltopdf + pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf是一个将HTML转PDF的工具,需要单独安装。详情请参阅其官方网站。
pdfkit 是为此工具打包的 Python 库,可以从 pip 安装:
pip install pdfkit
使用非常简单:
# 获取htmls文件名列表(略)
pdfkit.from_file(sorted(htmls), 'zhihu.pdf')

这样就完成了整列的导出。
不只是知乎的栏目,几乎大部分信息网站,通过1.抓取列表2.抓取详细内容采集数据两步。所以这段代码只要稍加修改就可以用于许多其他的网站。只是有些网站需要登录才能访问,所以需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制都不一样,具体问题还是要具体问题具体分析。
这些爬虫的开发技巧可以在我们的爬虫实战课中学习。需要的请回复公众号中的实际爬虫
【源码下载】
获取知乎的专栏下载器源码,请在公众号(Crossin的编程课堂)回复关键字知乎
除了代码,还有本专栏打包好的PDF,欢迎阅读分享。
====
其他 文章 和回答:
欢迎搜索关注:Crossin的编程课堂

抓取网页生成电子书(网络书籍抓取器怎么做?如何制作电子书的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2021-11-12 04:23
)
网络图书抓取器主要用于抓取网络小说生成文本文件。它可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后进行合并。爬取过程可以随时中断,关闭程序后可以继续上一个任务。
相关软件软件大小版本说明下载地址
网络图书抓取器主要用于抓取网络小说生成文本文件。它可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后进行合并。爬取过程可以随时中断,关闭程序后可以继续上一个任务。
软件特点
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键爬取:又称“哑模式”,基本可以实现全自动爬取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已输入10个适用网站(选择后可快速打开网站找到您需要的书),并自动应用相应的代码, 也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中以备后用。
6、轻松制作电子书:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
查看全部
抓取网页生成电子书(网络书籍抓取器怎么做?如何制作电子书的方法
)
网络图书抓取器主要用于抓取网络小说生成文本文件。它可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后进行合并。爬取过程可以随时中断,关闭程序后可以继续上一个任务。
相关软件软件大小版本说明下载地址
网络图书抓取器主要用于抓取网络小说生成文本文件。它可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后进行合并。爬取过程可以随时中断,关闭程序后可以继续上一个任务。
软件特点
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键爬取:又称“哑模式”,基本可以实现全自动爬取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已输入10个适用网站(选择后可快速打开网站找到您需要的书),并自动应用相应的代码, 也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中以备后用。
6、轻松制作电子书:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
抓取网页生成电子书( 大型的HTML,使用方法一生成HTML的元素变化。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-11-11 23:12
大型的HTML,使用方法一生成HTML的元素变化。)
<p>python 自动化批量生成前端的HTML可以大大减轻工作量
下面演示两种生成 HTML 的方法
方法一:使用 webbrowser
#coding:utf-8
import webbrowser
#命名生成的html
GEN_HTML = "test.html"
#打开文件,准备写入
f = open(GEN_HTML,'w')
#准备相关变量
str1 = 'my name is :'
str2 = '--MichaelAn--'
# 写入HTML界面中
message = """
%s
%s
"""%(str1,str2)
#写入文件
f.write(message)
#关闭文件
f.close()
#运行完自动在网页中显示
webbrowser.open(GEN_HTML,new = 1)
'''
webbrowser.open(url, new=0, autoraise=True)
Display url using the default browser. If new is 0, the url is opened in the same browser window if possible. If new is 1, a new browser window is opened if possible. If new is 2, a new browser page (“tab”) is opened if possible. If autoraise is True, the window is raised if possible (note that under many window managers this will occur regardless of the setting of this variable).
'''</p>
方法二:使用pyh
<p>#coding:utf-8
from pyh import *
# there is a bug "from pyh import *"
page = PyH('My wonderful PyH page')
page.addCSS('myStylesheet1.css', 'myStylesheet2.css')
page.addJS('myJavascript1.js', 'myJavascript2.js')
page 查看全部
抓取网页生成电子书(
大型的HTML,使用方法一生成HTML的元素变化。)
<p>python 自动化批量生成前端的HTML可以大大减轻工作量
下面演示两种生成 HTML 的方法
方法一:使用 webbrowser
#coding:utf-8
import webbrowser
#命名生成的html
GEN_HTML = "test.html"
#打开文件,准备写入
f = open(GEN_HTML,'w')
#准备相关变量
str1 = 'my name is :'
str2 = '--MichaelAn--'
# 写入HTML界面中
message = """
%s
%s
"""%(str1,str2)
#写入文件
f.write(message)
#关闭文件
f.close()
#运行完自动在网页中显示
webbrowser.open(GEN_HTML,new = 1)
'''
webbrowser.open(url, new=0, autoraise=True)
Display url using the default browser. If new is 0, the url is opened in the same browser window if possible. If new is 1, a new browser window is opened if possible. If new is 2, a new browser page (“tab”) is opened if possible. If autoraise is True, the window is raised if possible (note that under many window managers this will occur regardless of the setting of this variable).
'''</p>
方法二:使用pyh
<p>#coding:utf-8
from pyh import *
# there is a bug "from pyh import *"
page = PyH('My wonderful PyH page')
page.addCSS('myStylesheet1.css', 'myStylesheet2.css')
page.addJS('myJavascript1.js', 'myJavascript2.js')
page
抓取网页生成电子书(利用能提取网页小说的app,批量下载网站所有小说)
网站优化 • 优采云 发表了文章 • 0 个评论 • 1033 次浏览 • 2021-11-11 20:29
使用可以提取网络小说的APP批量下载所有网站小说。现在推荐一个免费且简单的网络小说下载器。使用大叔小说下载器,不仅具有小说爬虫下载器app的功能,还能批量提取网络小说。,它也可以用作干净的本地阅读器应用程序。下载小说后,可以直接阅读小说。不知道怎么下载电子书软件的朋友快来最热的软件站下载吧。
基本介绍
这是一款网络小说下载爬虫软件,可以帮助用户批量下载网络小说。软件功能丰富,包括TXT小说下载、TXT小说阅读、有声小说下载。有声小说不仅支持下载,还可以在线听书。如果您使用TXT带有小说下载功能,可以批量下载所有小说网站。如果你还不知道怎么下载电子书软件,快来看看吧。将TXT小说下载到本地后,可以使用电脑小说阅读器阅读,也可以使用软件自带的阅读功能阅读小说。
指示
1.在本站下载并解压这款新颖的爬虫下载器应用。好用,搜索小说,解析目录,选择你要下载的章节(可以平移),点击章节目录查看正文内容,点击章节正文选择,空白处是查看内容,可以右击。
2. 过滤掉不需要的内容(添加范围,去除广告),最好的范围是书网页源代码的内容,点击加入书架或下载,可以到下载管理查看进度。
3. 如果下载失败次数过多,会增加每个线程下载的章节数。您可以直接获取目录链接进行申诉操作。如果是动态网页,记得开启动态网页支持。切换规则不需要重新解析,只需要重新解析章节相关。
4.支持有声小说下载,搜索有声小说,添加书架直接选择要开始下载的,发现失败较多,增加每线程下载章节数,增加延迟。
小编推荐
以上就是这款小说下载软件免费版的完整介绍。最热门的软件网站有更多类似的小说下载软件。有需要的朋友快来下载体验吧。这是另外两个有用的小说下载。软件:电脑版全小说下载器、远天湾小说下载器。 查看全部
抓取网页生成电子书(利用能提取网页小说的app,批量下载网站所有小说)
使用可以提取网络小说的APP批量下载所有网站小说。现在推荐一个免费且简单的网络小说下载器。使用大叔小说下载器,不仅具有小说爬虫下载器app的功能,还能批量提取网络小说。,它也可以用作干净的本地阅读器应用程序。下载小说后,可以直接阅读小说。不知道怎么下载电子书软件的朋友快来最热的软件站下载吧。

基本介绍
这是一款网络小说下载爬虫软件,可以帮助用户批量下载网络小说。软件功能丰富,包括TXT小说下载、TXT小说阅读、有声小说下载。有声小说不仅支持下载,还可以在线听书。如果您使用TXT带有小说下载功能,可以批量下载所有小说网站。如果你还不知道怎么下载电子书软件,快来看看吧。将TXT小说下载到本地后,可以使用电脑小说阅读器阅读,也可以使用软件自带的阅读功能阅读小说。
指示
1.在本站下载并解压这款新颖的爬虫下载器应用。好用,搜索小说,解析目录,选择你要下载的章节(可以平移),点击章节目录查看正文内容,点击章节正文选择,空白处是查看内容,可以右击。
2. 过滤掉不需要的内容(添加范围,去除广告),最好的范围是书网页源代码的内容,点击加入书架或下载,可以到下载管理查看进度。
3. 如果下载失败次数过多,会增加每个线程下载的章节数。您可以直接获取目录链接进行申诉操作。如果是动态网页,记得开启动态网页支持。切换规则不需要重新解析,只需要重新解析章节相关。
4.支持有声小说下载,搜索有声小说,添加书架直接选择要开始下载的,发现失败较多,增加每线程下载章节数,增加延迟。
小编推荐
以上就是这款小说下载软件免费版的完整介绍。最热门的软件网站有更多类似的小说下载软件。有需要的朋友快来下载体验吧。这是另外两个有用的小说下载。软件:电脑版全小说下载器、远天湾小说下载器。
抓取网页生成电子书( 提高iPhone电池寿命的十个看看这十大妙招(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-09 17:23
提高iPhone电池寿命的十个看看这十大妙招(组图))
如何获取和下载谷歌电子书(包括整本书、最新版)
Google Book 和 Goole Play 是目前世界上最大的电子书 网站。这个方法教你如何下载谷歌电子书试读,并尝试下载整本书。一般来说,如果你试读过谷歌电子书,就可以获得完整的PDF。
工具/材料
登录 Google 电子书网站
谷歌图书下载软件
方法/步骤
打开搜索书,只有在有预览的情况下才下载。如下图,会有“部分预览”标记供试读。
打开图书预览页面,复制图书地址,例如:+of+amphibians&hl=zh-CN&sa=X&ved=0ahUKEwjemIzzu9nKAhVC8Q4KHZo4DqcQ6AEIKTAB#v=onepage&q=biology%20of%20amphibians&f=false
将获取到的地址复制到谷歌图书下载器,设置下载的分辨率和存储位置,点击开始开始下载。
预防措施
首先,您必须能够登录 Google 电子书。
只能下载试读的电子书,下载格式可以是PDF或图片格式。
想要得到完整的PDF,需要突破一定的技术封锁,采集需要5-10天,可以私信交流。我可以代表我提供有偿服务。
相关文章
获取hasco官方标准件插件
Hasco标准件下载工具/资料上网电脑方法/步骤 打开一个常用浏览器,在百度中进入hasco官网找到HASCO-Hasco在打开的网页中找到中文开关图标找到下载和服务打开后,有有视频资料和HASCO最新版电子目录可以下载。点击这里下载最新版本的 HASCO 电子目录。有两种文件可供下载 H...
提高 iPhone 电池寿命的十个技巧
如果你用的是iPhone,一定觉得它的电池不够用,那么当你无法更换电池时,如何设置手机让电池更耐用呢?想要获得最佳 iPhone 体验并最大限度地延长 iPhone 电池的使用寿命,请查看这十大技巧!工具/原材料图片来自网络。如果您有任何问题或建议,您可以在下方体验评论,小编会尽快回复您。方...
如何免费下载电子书:[2] 使用俄罗斯网盘
网盘库中已经上传了数以千计的免费电子书,我们可以利用这个巨大的网盘来获取我们想要的电子书。当然,如果有一天这个网盘出现故障,这种方法也会失败。工具/材料电脑上网方法/步骤先用百度搜索图书馆网页打开图书馆网站,搜索你想要的电子书,这里我用的是2013 Spring...
应用宝物5.0五虎将解读智能体验
大家对应用宝5.0的各种信息都有一定的了解,而本次更新的5.0新版本将让用户在社交方面发现很多新的突破。五虎,突出新版AppBao的5大功能,让用户拥有智能体验,包括签到的应用、身边人正在玩的应用、新的应用部落、视频和电子书、流行朋友圈中的app等,让我们更方便、更快捷...
ediary电子日记下载最新ediary电子日记下载
ediary 是一个免费的电子日记。ediary是一款免费的电子日记,那么如何下载最新的ediary电子日记呢?如何下载最新的ediary电子日记?哪里可以下载最新的ediary电子日记?这里为大家分享,ediary电子日记下载最新ediary电子日记下载。工具/原材料 eDiary.eD...
如何在 iPad 上阅读电子书
iPad的设计初衷是为了让用户更方便地观看电子书,但由于图书版权问题,iPad软件中电子书相关的软件并不多,给用户带来了诸多不便。以下编辑器基于电子书。格式整理了电子书软件,总结了以下几种阅读电子书的方法: 一. 通过自带的iBooks软件查看epub和PDF格式的电子书的epub和PDF格式iPad。iPad是最...
豌豆荚手机精灵2.20.0.1478官方稳定版
软件介绍: 豌豆荚是豌豆实验室为安卓手机用户开发的一款产品。它可以帮助您简单快速地管理您的手机,还为您提供了丰富的免费资源获取平台。方法/步骤管理和备份通讯录:通讯录管理帮助您轻松快速地查看和编辑联系人的详细信息,包括联系人信息、分组等,还可以查看最近与某个联系人的联系记录. 支持行动...
九口袋揭秘微信公众号增加粉丝的三种方式
运营微信公众号最麻烦的就是增加粉丝。微信公众号无论是为了什么目的而设立的,都必须以粉丝为基础。不管你多久更新一次内容,不管它有多难,如果你没有粉丝阅读也是如此。徒然。那么,我们怎样才能让微信持续增长粉丝呢?九口袋小编为大家总结了以下三种行之有效的方法。方法/步骤一.资源诱惑方法1.分享一些比较吸引人的资源,资源必须有...
通过电子书订阅 Google 阅读器新闻
Google Reader 是一个可定制的新闻集合,您可以在其中订阅任何您想观看的 网站。博客更新。为了迎合移动阅读的需求,谷歌阅读器还推出了移动版,基于iOS和Android系统。如果您是盛大Bambook电子书用户,还可以通过云梯客户端下载到谷歌阅读器同步工具... 查看全部
抓取网页生成电子书(
提高iPhone电池寿命的十个看看这十大妙招(组图))
如何获取和下载谷歌电子书(包括整本书、最新版)
Google Book 和 Goole Play 是目前世界上最大的电子书 网站。这个方法教你如何下载谷歌电子书试读,并尝试下载整本书。一般来说,如果你试读过谷歌电子书,就可以获得完整的PDF。
工具/材料
登录 Google 电子书网站
谷歌图书下载软件
方法/步骤
打开搜索书,只有在有预览的情况下才下载。如下图,会有“部分预览”标记供试读。

打开图书预览页面,复制图书地址,例如:+of+amphibians&hl=zh-CN&sa=X&ved=0ahUKEwjemIzzu9nKAhVC8Q4KHZo4DqcQ6AEIKTAB#v=onepage&q=biology%20of%20amphibians&f=false
将获取到的地址复制到谷歌图书下载器,设置下载的分辨率和存储位置,点击开始开始下载。

预防措施
首先,您必须能够登录 Google 电子书。
只能下载试读的电子书,下载格式可以是PDF或图片格式。
想要得到完整的PDF,需要突破一定的技术封锁,采集需要5-10天,可以私信交流。我可以代表我提供有偿服务。
相关文章
获取hasco官方标准件插件
Hasco标准件下载工具/资料上网电脑方法/步骤 打开一个常用浏览器,在百度中进入hasco官网找到HASCO-Hasco在打开的网页中找到中文开关图标找到下载和服务打开后,有有视频资料和HASCO最新版电子目录可以下载。点击这里下载最新版本的 HASCO 电子目录。有两种文件可供下载 H...
提高 iPhone 电池寿命的十个技巧
如果你用的是iPhone,一定觉得它的电池不够用,那么当你无法更换电池时,如何设置手机让电池更耐用呢?想要获得最佳 iPhone 体验并最大限度地延长 iPhone 电池的使用寿命,请查看这十大技巧!工具/原材料图片来自网络。如果您有任何问题或建议,您可以在下方体验评论,小编会尽快回复您。方...
如何免费下载电子书:[2] 使用俄罗斯网盘
网盘库中已经上传了数以千计的免费电子书,我们可以利用这个巨大的网盘来获取我们想要的电子书。当然,如果有一天这个网盘出现故障,这种方法也会失败。工具/材料电脑上网方法/步骤先用百度搜索图书馆网页打开图书馆网站,搜索你想要的电子书,这里我用的是2013 Spring...
应用宝物5.0五虎将解读智能体验
大家对应用宝5.0的各种信息都有一定的了解,而本次更新的5.0新版本将让用户在社交方面发现很多新的突破。五虎,突出新版AppBao的5大功能,让用户拥有智能体验,包括签到的应用、身边人正在玩的应用、新的应用部落、视频和电子书、流行朋友圈中的app等,让我们更方便、更快捷...
ediary电子日记下载最新ediary电子日记下载
ediary 是一个免费的电子日记。ediary是一款免费的电子日记,那么如何下载最新的ediary电子日记呢?如何下载最新的ediary电子日记?哪里可以下载最新的ediary电子日记?这里为大家分享,ediary电子日记下载最新ediary电子日记下载。工具/原材料 eDiary.eD...
如何在 iPad 上阅读电子书
iPad的设计初衷是为了让用户更方便地观看电子书,但由于图书版权问题,iPad软件中电子书相关的软件并不多,给用户带来了诸多不便。以下编辑器基于电子书。格式整理了电子书软件,总结了以下几种阅读电子书的方法: 一. 通过自带的iBooks软件查看epub和PDF格式的电子书的epub和PDF格式iPad。iPad是最...
豌豆荚手机精灵2.20.0.1478官方稳定版
软件介绍: 豌豆荚是豌豆实验室为安卓手机用户开发的一款产品。它可以帮助您简单快速地管理您的手机,还为您提供了丰富的免费资源获取平台。方法/步骤管理和备份通讯录:通讯录管理帮助您轻松快速地查看和编辑联系人的详细信息,包括联系人信息、分组等,还可以查看最近与某个联系人的联系记录. 支持行动...
九口袋揭秘微信公众号增加粉丝的三种方式
运营微信公众号最麻烦的就是增加粉丝。微信公众号无论是为了什么目的而设立的,都必须以粉丝为基础。不管你多久更新一次内容,不管它有多难,如果你没有粉丝阅读也是如此。徒然。那么,我们怎样才能让微信持续增长粉丝呢?九口袋小编为大家总结了以下三种行之有效的方法。方法/步骤一.资源诱惑方法1.分享一些比较吸引人的资源,资源必须有...
通过电子书订阅 Google 阅读器新闻
Google Reader 是一个可定制的新闻集合,您可以在其中订阅任何您想观看的 网站。博客更新。为了迎合移动阅读的需求,谷歌阅读器还推出了移动版,基于iOS和Android系统。如果您是盛大Bambook电子书用户,还可以通过云梯客户端下载到谷歌阅读器同步工具...
抓取网页生成电子书(全篇的实现思路分析网页学会使用BeautifulSoup库爬取并导出参考资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-07 14:07
本文文章主要详细介绍了python爬取网页到PDF文件的转换。有一定的参考价值,感兴趣的朋友可以参考。
爬行动物的成因
官方文档或手册虽然可以查阅,但如果变成纸质版是不是更容易阅读和记忆。如果只是简单的复制粘贴,不知道什么时候才能完成。所以我开始考虑爬下官方的Android手册。
整篇文章的实现
分析网页,学习使用BeautifulSoup库抓取导出
参考资料:
* 将廖雪峰的教程转成PDF电子书
* 请求文件
*美丽的汤文件
配置
Ubuntu下使用Pycharm运行成功
要转换为 PDF,您需要下载 wkhtmltopdf
具体流程
网络分析
对于如下所示的网页,您只需获取网页的正文和标题,以及左侧导航栏中的所有网址
下一个工作是找到这些标签......
关于Requests的使用
详见文档,这里只是简单使用Requests获取html并使用代理翻墙(网站不能直接访问,需要VPN)
proxies={ "http":"http://vpn的IP:port", "https":"https://vpn的IP:port", } response=requests.get(url,proxies=proxies)
美汤的使用
参考资料中有一个 Beautiful Soup 文档。看完就知道讲了两件事:一是找标签,二是修改标签。
这篇文章需要做的是:
1. 获取title和所有url,这涉及到找标签
#对标签进行判断,一个标签含有href而不含有description,则返回true #而我希望获取的是含有href属性而不含有description属性的<a>标签,(且只有a标签含有href) def has_href_but_no_des(tag): return tag.has_attr('href') and not tag.has_attr('description') #网页分析,获取网址和标题 def parse_url_to_html(url): response=requests.get(url,proxies=proxies) soup=BeautifulSoup(response.content,"html.parser") s=[]#获取所有的网址 title=[]#获取对应的标题 tag=soup.find(id="nav")#获取第一个id为"nav"的标签,这个里面包含了网址和标题 for i in tag.find_all(has_href_but_no_des): s.append(i['href']) title.append(i.text) #获取的只是标签集,需要加html前缀 htmls = "" with open("android_training_3.html",'a') as f: f.write(htmls)
解析上面得到的URL,得到文本,将图片保存到本地;它涉及查找标签和修改属性
#网页操作,获取正文及图片 def get_htmls(urls,title): for i in range(len(urls)): response=requests.get(urls[i],proxies=proxies) soup=BeautifulSoup(response.content,"html.parser") htmls=""+str(i)+"."+title[i]+"" tag=soup.find(class_='jd-descr') #为image添加相对路径,并下载图片 for img in tag.find_all('img'): im = requests.get(img['src'], proxies=proxies) filename = os.path.split(img['src'])[1] with open('image/' + filename, 'wb') as f: f.write(im.content) img['src']='image/'+filename htmls=htmls+str(tag) with open("android_training_3.html",'a') as f: f.write(htmls) print(" (%s) [%s] download end"%(i,title[i])) htmls="" with open("android_training_3.html",'a') as f: f.write(htmls)
2. 转换为 PDF
这一步需要下载wkhtmltopdf,在windows下执行程序一直报错..ubuntu下是可以的
def save_pdf(html): """ 把所有html文件转换成pdf文件 """ options = { 'page-size': 'Letter', 'encoding': "UTF-8", 'custom-header': [ ('Accept-Encoding', 'gzip') ] } pdfkit.from_file(html, "android_training_3.pdf", options=options)
最终效果图
以上是python爬取网页转换为PDF文件的详细内容,请关注其他相关html中文网站文章! 查看全部
抓取网页生成电子书(全篇的实现思路分析网页学会使用BeautifulSoup库爬取并导出参考资料)
本文文章主要详细介绍了python爬取网页到PDF文件的转换。有一定的参考价值,感兴趣的朋友可以参考。
爬行动物的成因
官方文档或手册虽然可以查阅,但如果变成纸质版是不是更容易阅读和记忆。如果只是简单的复制粘贴,不知道什么时候才能完成。所以我开始考虑爬下官方的Android手册。
整篇文章的实现
分析网页,学习使用BeautifulSoup库抓取导出
参考资料:
* 将廖雪峰的教程转成PDF电子书
* 请求文件
*美丽的汤文件
配置
Ubuntu下使用Pycharm运行成功
要转换为 PDF,您需要下载 wkhtmltopdf
具体流程
网络分析
对于如下所示的网页,您只需获取网页的正文和标题,以及左侧导航栏中的所有网址

下一个工作是找到这些标签......
关于Requests的使用
详见文档,这里只是简单使用Requests获取html并使用代理翻墙(网站不能直接访问,需要VPN)
proxies={ "http":"http://vpn的IP:port", "https":"https://vpn的IP:port", } response=requests.get(url,proxies=proxies)
美汤的使用
参考资料中有一个 Beautiful Soup 文档。看完就知道讲了两件事:一是找标签,二是修改标签。
这篇文章需要做的是:
1. 获取title和所有url,这涉及到找标签
#对标签进行判断,一个标签含有href而不含有description,则返回true #而我希望获取的是含有href属性而不含有description属性的<a>标签,(且只有a标签含有href) def has_href_but_no_des(tag): return tag.has_attr('href') and not tag.has_attr('description') #网页分析,获取网址和标题 def parse_url_to_html(url): response=requests.get(url,proxies=proxies) soup=BeautifulSoup(response.content,"html.parser") s=[]#获取所有的网址 title=[]#获取对应的标题 tag=soup.find(id="nav")#获取第一个id为"nav"的标签,这个里面包含了网址和标题 for i in tag.find_all(has_href_but_no_des): s.append(i['href']) title.append(i.text) #获取的只是标签集,需要加html前缀 htmls = "" with open("android_training_3.html",'a') as f: f.write(htmls)
解析上面得到的URL,得到文本,将图片保存到本地;它涉及查找标签和修改属性
#网页操作,获取正文及图片 def get_htmls(urls,title): for i in range(len(urls)): response=requests.get(urls[i],proxies=proxies) soup=BeautifulSoup(response.content,"html.parser") htmls=""+str(i)+"."+title[i]+"" tag=soup.find(class_='jd-descr') #为image添加相对路径,并下载图片 for img in tag.find_all('img'): im = requests.get(img['src'], proxies=proxies) filename = os.path.split(img['src'])[1] with open('image/' + filename, 'wb') as f: f.write(im.content) img['src']='image/'+filename htmls=htmls+str(tag) with open("android_training_3.html",'a') as f: f.write(htmls) print(" (%s) [%s] download end"%(i,title[i])) htmls="" with open("android_training_3.html",'a') as f: f.write(htmls)
2. 转换为 PDF
这一步需要下载wkhtmltopdf,在windows下执行程序一直报错..ubuntu下是可以的
def save_pdf(html): """ 把所有html文件转换成pdf文件 """ options = { 'page-size': 'Letter', 'encoding': "UTF-8", 'custom-header': [ ('Accept-Encoding', 'gzip') ] } pdfkit.from_file(html, "android_training_3.pdf", options=options)
最终效果图

以上是python爬取网页转换为PDF文件的详细内容,请关注其他相关html中文网站文章!
抓取网页生成电子书(Python爬虫实践:将网页转换为pdf电子书写爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-11-07 14:05
2018-03-26 • 用 Python 阅读
Python实践一、将网页转成pdf电子书
我是个“采集狂”(别以为是歪的,我就是喜欢采集技术帖),遇到好东西就喜欢采集或者记录好东西,尤其是好的技术文章或者工具。这里要提一下廖雪峰老师的官方网站。廖老师写的Python、JavaScript、Git教程真的很好,经常去逛街。所以今天有必要把廖老师的教程从网页转成PDF电子书,让你随时随地离线学习和采集。说到这里,进入今天的话题Python爬虫练习:将网页转成pdf电子书
写爬虫好像不比用Python好。Python社区提供的爬虫工具让你眼花缭乱。各种可以直接使用的库,分分钟写一个爬虫。今天想写一个爬虫。, 爬下廖雪峰的Python教程,制作PDF电子书供离线阅读。
在开始写爬虫之前,我们先来分析一下网站的页面结构。页面左侧是教程目录大纲。每个URL对应右边文章的一篇文章,右上角是文章的标题,中间是文章的正文部分。正文内容是我们关注的焦点。我们要抓取的数据是所有网页的正文部分。下面是用户的评论区。评论区对我们来说什么都不是。使用它,所以它可以被忽略。
工具准备
搞清楚网站的基本结构后,就可以开始准备爬虫依赖的工具包了。requests和beautifulsoup是爬虫的两大神器,reuqests用于网络请求,beautifulsoup用于操作html数据。有了这两个班车,我们就可以顺利工作了。我们不需要像scrapy这样的爬虫框架。小程序有点像大锤。另外,既然是把html文件转换成pdf,就得有相应的库支持。wkhtmltopdf 是一个非常好的工具。它可用于从 html 到 pdf 的多平台转换。pdfkit 是 wkhtmltopdf 的 Python 包。先安装以下依赖包,然后安装wkhtmltopdf
1234
pip install requestspip install beautifulsoup4pip install pdfkitpip install PyPDF2
安装 wkhtmltopdf
Ubuntu 和 CentOS 可以直接从命令行安装。
12
$ sudo apt-get install wkhtmltopdf # ubuntu$ sudo yum intsall wkhtmltopdf # centos
Windows平台直接在wkhtmltopdf官网2下载稳定版进行安装。安装完成后,将程序的执行路径添加到系统环境$PATH变量中,否则pdfkit会找不到wkhtmltopdf而报错。No wkhtmltopdf executable found 几句,因为这里的处理不好,程序执行pdfkit.from_file(htmls, file_name, options=options)时会报错。
现在开始手动安装wkhtmltopdf(博主电脑操作系统为macOS 10.12.2)
1、去官网。下载并运行 wkhtmltox-0.12.4_osx-cocoa-x86-64.pkg
2、将wkhtmltoimage和wkhtmltopdf复制到/usr/bin目录下,更改所有者,并添加可执行属性
123456
sudo cp /usr/local/bin/wkhtmltopdf /usr/bin/sudo cp /usr/local/bin/wkhtmltoimage /usr/bin/sudo chown root:root /usr/bin/wkhtmltopdfsudo chown root:root /usr/bin/wkhtmltoimagesudo chmod +x /usr/bin/wkhtmltopdfsudo chmod +x /usr/bin/wkhtmltoimage
不出意外,执行第一句时,会遇到chmod: Unable to change file modle on /usr/bin。这是因为 Apple 使用了 OS X El Capitan 10.11 的 Rootless 机制。这种机制可以理解为更高级别的系统内核保护措施,系统默认会锁定/system、/sbin、/usr三个目录。
关闭无根
关闭和打开 Rootless 非常简单。方法如下:重启Mac,听到启动声后按Command+R,进入recovery模式,在上面的菜单实用工具中找到并打开Terminal(如果菜单没有出现在顶部,请继续重启^_^)。输入以下命令:
12
$ csrutil disable #关闭 Rootless$ csrutil enable #开启 Rootless
OK,到此我们的工具和环境都配置好了,下面开始实现功能。
爬虫实现
一切准备就绪后,就可以开始编写代码了,但是在编写代码之前,应该先整理一下思路。该程序的目的是将所有URL对应的html body部分保存在本地,然后使用pdfkit将这些文件转换为pdf文件。让我们拆分任务。首先将某个URL对应的html body保存到本地,然后找到所有的URL进行同样的操作。使用Chrome浏览器找到页面body部分的标签,按F12找到body对应的div标签:
,div是网页的body内容。使用requests在本地加载整个页面后,可以使用beautifulsoup操作HTML的dom元素来提取body内容。
具体实现代码如下: 使用soup.find_all函数查找body标签,然后将body部分的内容保存到a.html文件中。
12345678910111213141516171819202122232425262728293031323334353637
<p>def parse_url_to_html(url, name): """ 解析URL,返回HTML内容 :param url:解析的url :param name: 保存的html文件名 :return: html """ try: response = requests.get(url) soup = BeautifulSoup(response.content, 'html.parser') # 正文 body = soup.find_all(class_="x-wiki-content")[0] # 标题 title = soup.find('h4').get_text() # 标题加入到正文的最前面,居中显示 center_tag = soup.new_tag("center") title_tag = soup.new_tag('h1') title_tag.string = title center_tag.insert(1, title_tag) body.insert(1, center_tag) html = str(body) # body中的img标签的src相对路径的改成绝对路径 pattern = "( 查看全部
抓取网页生成电子书(Python爬虫实践:将网页转换为pdf电子书写爬虫)
2018-03-26 • 用 Python 阅读
Python实践一、将网页转成pdf电子书
我是个“采集狂”(别以为是歪的,我就是喜欢采集技术帖),遇到好东西就喜欢采集或者记录好东西,尤其是好的技术文章或者工具。这里要提一下廖雪峰老师的官方网站。廖老师写的Python、JavaScript、Git教程真的很好,经常去逛街。所以今天有必要把廖老师的教程从网页转成PDF电子书,让你随时随地离线学习和采集。说到这里,进入今天的话题Python爬虫练习:将网页转成pdf电子书
写爬虫好像不比用Python好。Python社区提供的爬虫工具让你眼花缭乱。各种可以直接使用的库,分分钟写一个爬虫。今天想写一个爬虫。, 爬下廖雪峰的Python教程,制作PDF电子书供离线阅读。
在开始写爬虫之前,我们先来分析一下网站的页面结构。页面左侧是教程目录大纲。每个URL对应右边文章的一篇文章,右上角是文章的标题,中间是文章的正文部分。正文内容是我们关注的焦点。我们要抓取的数据是所有网页的正文部分。下面是用户的评论区。评论区对我们来说什么都不是。使用它,所以它可以被忽略。
工具准备
搞清楚网站的基本结构后,就可以开始准备爬虫依赖的工具包了。requests和beautifulsoup是爬虫的两大神器,reuqests用于网络请求,beautifulsoup用于操作html数据。有了这两个班车,我们就可以顺利工作了。我们不需要像scrapy这样的爬虫框架。小程序有点像大锤。另外,既然是把html文件转换成pdf,就得有相应的库支持。wkhtmltopdf 是一个非常好的工具。它可用于从 html 到 pdf 的多平台转换。pdfkit 是 wkhtmltopdf 的 Python 包。先安装以下依赖包,然后安装wkhtmltopdf
1234
pip install requestspip install beautifulsoup4pip install pdfkitpip install PyPDF2
安装 wkhtmltopdf
Ubuntu 和 CentOS 可以直接从命令行安装。
12
$ sudo apt-get install wkhtmltopdf # ubuntu$ sudo yum intsall wkhtmltopdf # centos
Windows平台直接在wkhtmltopdf官网2下载稳定版进行安装。安装完成后,将程序的执行路径添加到系统环境$PATH变量中,否则pdfkit会找不到wkhtmltopdf而报错。No wkhtmltopdf executable found 几句,因为这里的处理不好,程序执行pdfkit.from_file(htmls, file_name, options=options)时会报错。
现在开始手动安装wkhtmltopdf(博主电脑操作系统为macOS 10.12.2)
1、去官网。下载并运行 wkhtmltox-0.12.4_osx-cocoa-x86-64.pkg
2、将wkhtmltoimage和wkhtmltopdf复制到/usr/bin目录下,更改所有者,并添加可执行属性
123456
sudo cp /usr/local/bin/wkhtmltopdf /usr/bin/sudo cp /usr/local/bin/wkhtmltoimage /usr/bin/sudo chown root:root /usr/bin/wkhtmltopdfsudo chown root:root /usr/bin/wkhtmltoimagesudo chmod +x /usr/bin/wkhtmltopdfsudo chmod +x /usr/bin/wkhtmltoimage
不出意外,执行第一句时,会遇到chmod: Unable to change file modle on /usr/bin。这是因为 Apple 使用了 OS X El Capitan 10.11 的 Rootless 机制。这种机制可以理解为更高级别的系统内核保护措施,系统默认会锁定/system、/sbin、/usr三个目录。
关闭无根
关闭和打开 Rootless 非常简单。方法如下:重启Mac,听到启动声后按Command+R,进入recovery模式,在上面的菜单实用工具中找到并打开Terminal(如果菜单没有出现在顶部,请继续重启^_^)。输入以下命令:
12
$ csrutil disable #关闭 Rootless$ csrutil enable #开启 Rootless
OK,到此我们的工具和环境都配置好了,下面开始实现功能。
爬虫实现
一切准备就绪后,就可以开始编写代码了,但是在编写代码之前,应该先整理一下思路。该程序的目的是将所有URL对应的html body部分保存在本地,然后使用pdfkit将这些文件转换为pdf文件。让我们拆分任务。首先将某个URL对应的html body保存到本地,然后找到所有的URL进行同样的操作。使用Chrome浏览器找到页面body部分的标签,按F12找到body对应的div标签:
,div是网页的body内容。使用requests在本地加载整个页面后,可以使用beautifulsoup操作HTML的dom元素来提取body内容。
具体实现代码如下: 使用soup.find_all函数查找body标签,然后将body部分的内容保存到a.html文件中。
12345678910111213141516171819202122232425262728293031323334353637
<p>def parse_url_to_html(url, name): """ 解析URL,返回HTML内容 :param url:解析的url :param name: 保存的html文件名 :return: html """ try: response = requests.get(url) soup = BeautifulSoup(response.content, 'html.parser') # 正文 body = soup.find_all(class_="x-wiki-content")[0] # 标题 title = soup.find('h4').get_text() # 标题加入到正文的最前面,居中显示 center_tag = soup.new_tag("center") title_tag = soup.new_tag('h1') title_tag.string = title center_tag.insert(1, title_tag) body.insert(1, center_tag) html = str(body) # body中的img标签的src相对路径的改成绝对路径 pattern = "(
抓取网页生成电子书(一个可以帮助你快速将PDF文档中的图片、文字以及字体批量提取出来保存)
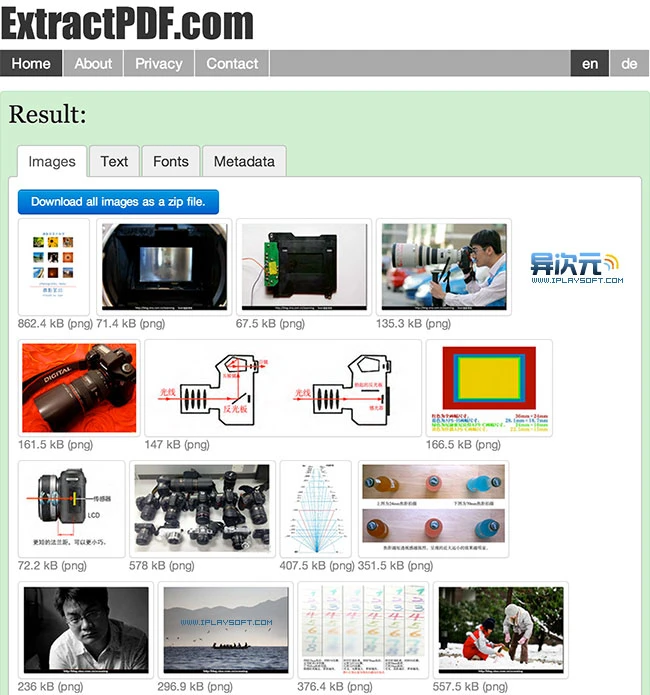
网站优化 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-11-06 15:09
由于经常需要处理PDF文档,我一直在寻找一种快速、免费的方法,可以批量提取和保存PDF文档中的图片和文字。为了实现这个功能,我经常需要购买相关的软件来完成,但现在我找到了一个更好的方法。
它是一个网站,可以帮助您快速批量提取PDF文档中的图片、文本和嵌入字体并保存。您无需安装任何软件。您只需将 PDF 文件上传到任何计算机上的浏览器即可。网站可以导出它的所有文字和图片,使用起来非常方便。而且在测试中文PDF电子书提取时不会出现乱码问题。是一款值得大家采集的利器。网站……
在线导出并保存PDF文件中的图片、文字和字体网站:
的功能非常具体且完全免费。对于有这种需求的朋友来说,真是难得的好东西网站。它的用法非常简单。该页面提供了一个上传按钮,只需点击它即可上传文件。唯一的缺点是它只支持上传 10MB 以下的 PDF 文件。如果你经常需要处理大文件,那么这个工具就不是那么完美了。但是,它也可以通过网站远程下载。不知道这个功能会不会有大小限制,大家可以试试。
之前试过上传不同维度推荐给大家的《摄影笔记》PDF进行测试,图片和文字都可以正常提交。点击蓝色下载按钮进行打包下载。
导出文本的功能有时候很有用,你懂的。对中文文档的支持非常友好。试了一堆电子书,可以成功提取文字,没有乱码。
相关网址:
访问|更多Office相关|来自不同维度|更多PDF相关|更多网站推荐 查看全部
抓取网页生成电子书(一个可以帮助你快速将PDF文档中的图片、文字以及字体批量提取出来保存)
由于经常需要处理PDF文档,我一直在寻找一种快速、免费的方法,可以批量提取和保存PDF文档中的图片和文字。为了实现这个功能,我经常需要购买相关的软件来完成,但现在我找到了一个更好的方法。
它是一个网站,可以帮助您快速批量提取PDF文档中的图片、文本和嵌入字体并保存。您无需安装任何软件。您只需将 PDF 文件上传到任何计算机上的浏览器即可。网站可以导出它的所有文字和图片,使用起来非常方便。而且在测试中文PDF电子书提取时不会出现乱码问题。是一款值得大家采集的利器。网站……
在线导出并保存PDF文件中的图片、文字和字体网站:
的功能非常具体且完全免费。对于有这种需求的朋友来说,真是难得的好东西网站。它的用法非常简单。该页面提供了一个上传按钮,只需点击它即可上传文件。唯一的缺点是它只支持上传 10MB 以下的 PDF 文件。如果你经常需要处理大文件,那么这个工具就不是那么完美了。但是,它也可以通过网站远程下载。不知道这个功能会不会有大小限制,大家可以试试。
之前试过上传不同维度推荐给大家的《摄影笔记》PDF进行测试,图片和文字都可以正常提交。点击蓝色下载按钮进行打包下载。

导出文本的功能有时候很有用,你懂的。对中文文档的支持非常友好。试了一堆电子书,可以成功提取文字,没有乱码。
相关网址:
访问|更多Office相关|来自不同维度|更多PDF相关|更多网站推荐
抓取网页生成电子书( 2019年03月25日14:21:37(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-11-06 05:02
2019年03月25日14:21:37(图))
我用Python爬取7000多个电子书案例详情
更新时间:2019年3月25日14:21:37 作者:嗨学编程
本文文章主要介绍我用Python爬取的7000多本电子书的案例。文章中介绍的示例代码非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友在下面和小编一起学习吧
安装
安装很简单,直接执行:
pip install requests-html
就是这样。
分析页面结构
通过浏览器的评论元素,可以发现这本电子书网站是用WordPress搭建的,首页列表元素很简单也很规律
所以我们可以搜索 .entry-title> a 得到所有书籍详情页的链接,然后我们进入详情页找到下载链接,如下图
可以发现 .download-links>a 中的链接是该书的下载链接。回到列表页面,你会发现该站点有700多个页面,因此我们可以遍历列表以获取所有下载链接。
请求-html 快速指南
发送 GET 请求:
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://python.org/')
Requests-html 的方便之处在于它解析 html 的方式就像使用 jQuery 一样简单,比如:
# 获取页面的所有链接可以这样写:
r.html.links
# 会返回 {'//docs.python.org/3/tutorial/', '/about/apps/'}
# 获取页面的所有的绝对链接:
r.html.absolute_links
# 会返回 {'https://github.com/python/pythondotorg/issues', 'https://docs.python.org/3/tutorial/'}
# 通过 CSS 选择器选择元素:
about = r.find('.about', first=True)
# 参数 first 表示只获取找到的第一元素
about.text # 获取 .about 下的所有文本
about.attrs # 获取 .about 下所有属性像 id, src, href 等等
about.html # 获取 .about 的 HTML
about.find('a') # 获取 .about 下的所有 a 标签
构建代码
from requests_html import HTMLSession
import requests
import time
import json
import random
import sys
'''
想要学习Python?Python学习交流群:984632579满足你的需求,资料都已经上传群文件,可以自行下载!
'''
session = HTMLSession()
list_url = 'http://www.allitebooks.com/page/'
USER_AGENTS = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"
]
# 获取当前列表页所有图书链接
def get_list(url):
response = session.get(url)
all_link = response.html.find('.entry-title a') # 获取页面所有图书详情链接
for link in all_link:
getBookUrl(link.attrs['href'])
# 获取图书下载链接
def getBookUrl(url):
response = session.get(url)
l = response.html.find('.download-links a', first=True)
if l is not None: # 运行后发现有的个别页面没有下载链接,这里加个判断
link = l.attrs['href'];
download(link)
#下载图书
def download(url):
# 随机浏览器 User-Agent
headers={ "User-Agent":random.choice(USER_AGENTS) }
# 获取文件名
filename = url.split('/')[-1]
# 如果 url 里包含 .pdf
if ".pdf" in url:
file = 'book/'+filename # 文件路径写死了,运行时当前目录必须有名 book 的文件夹
with open(file, 'wb') as f:
print("正在下载 %s" % filename)
response = requests.get(url, stream=True, headers=headers)
# 获取文件大小
total_length = response.headers.get('content-length')
# 如果文件大小不存在,则直接写入返回的文本
if total_length is None:
f.write(response.content)
else:
# 下载进度条
dl = 0
total_length = int(total_length) # 文件大小
for data in response.iter_content(chunk_size=4096): # 每次响应获取 4096 字节
dl += len(data)
f.write(data)
done = int(50 * dl / total_length)
sys.stdout.write("\r[%s%s]" % ('=' * done, ' ' * (50-done)) ) # 打印进度条
sys.stdout.flush()
print(filename + '下载完成!')
if __name__ == '__main__':
#从这运行,应为知道列表总数,所以偷个懒直接开始循环
for x in range(1,756):
print('当前页面: '+ str(x))
get_list(list_url+str(x))
运行结果:
以上就是小编为大家介绍的内容。我已经使用 Python 抓取了 7000 多个电子书案例。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。非常感谢您对脚本之家网站的支持! 查看全部
抓取网页生成电子书(
2019年03月25日14:21:37(图))
我用Python爬取7000多个电子书案例详情
更新时间:2019年3月25日14:21:37 作者:嗨学编程
本文文章主要介绍我用Python爬取的7000多本电子书的案例。文章中介绍的示例代码非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友在下面和小编一起学习吧
安装
安装很简单,直接执行:
pip install requests-html
就是这样。
分析页面结构
通过浏览器的评论元素,可以发现这本电子书网站是用WordPress搭建的,首页列表元素很简单也很规律

所以我们可以搜索 .entry-title> a 得到所有书籍详情页的链接,然后我们进入详情页找到下载链接,如下图

可以发现 .download-links>a 中的链接是该书的下载链接。回到列表页面,你会发现该站点有700多个页面,因此我们可以遍历列表以获取所有下载链接。
请求-html 快速指南
发送 GET 请求:
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://python.org/')
Requests-html 的方便之处在于它解析 html 的方式就像使用 jQuery 一样简单,比如:
# 获取页面的所有链接可以这样写:
r.html.links
# 会返回 {'//docs.python.org/3/tutorial/', '/about/apps/'}
# 获取页面的所有的绝对链接:
r.html.absolute_links
# 会返回 {'https://github.com/python/pythondotorg/issues', 'https://docs.python.org/3/tutorial/'}
# 通过 CSS 选择器选择元素:
about = r.find('.about', first=True)
# 参数 first 表示只获取找到的第一元素
about.text # 获取 .about 下的所有文本
about.attrs # 获取 .about 下所有属性像 id, src, href 等等
about.html # 获取 .about 的 HTML
about.find('a') # 获取 .about 下的所有 a 标签
构建代码
from requests_html import HTMLSession
import requests
import time
import json
import random
import sys
'''
想要学习Python?Python学习交流群:984632579满足你的需求,资料都已经上传群文件,可以自行下载!
'''
session = HTMLSession()
list_url = 'http://www.allitebooks.com/page/'
USER_AGENTS = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"
]
# 获取当前列表页所有图书链接
def get_list(url):
response = session.get(url)
all_link = response.html.find('.entry-title a') # 获取页面所有图书详情链接
for link in all_link:
getBookUrl(link.attrs['href'])
# 获取图书下载链接
def getBookUrl(url):
response = session.get(url)
l = response.html.find('.download-links a', first=True)
if l is not None: # 运行后发现有的个别页面没有下载链接,这里加个判断
link = l.attrs['href'];
download(link)
#下载图书
def download(url):
# 随机浏览器 User-Agent
headers={ "User-Agent":random.choice(USER_AGENTS) }
# 获取文件名
filename = url.split('/')[-1]
# 如果 url 里包含 .pdf
if ".pdf" in url:
file = 'book/'+filename # 文件路径写死了,运行时当前目录必须有名 book 的文件夹
with open(file, 'wb') as f:
print("正在下载 %s" % filename)
response = requests.get(url, stream=True, headers=headers)
# 获取文件大小
total_length = response.headers.get('content-length')
# 如果文件大小不存在,则直接写入返回的文本
if total_length is None:
f.write(response.content)
else:
# 下载进度条
dl = 0
total_length = int(total_length) # 文件大小
for data in response.iter_content(chunk_size=4096): # 每次响应获取 4096 字节
dl += len(data)
f.write(data)
done = int(50 * dl / total_length)
sys.stdout.write("\r[%s%s]" % ('=' * done, ' ' * (50-done)) ) # 打印进度条
sys.stdout.flush()
print(filename + '下载完成!')
if __name__ == '__main__':
#从这运行,应为知道列表总数,所以偷个懒直接开始循环
for x in range(1,756):
print('当前页面: '+ str(x))
get_list(list_url+str(x))
运行结果:

以上就是小编为大家介绍的内容。我已经使用 Python 抓取了 7000 多个电子书案例。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。非常感谢您对脚本之家网站的支持!
抓取网页生成电子书(电子书制作利器-友益文书V7.1.1(1.1)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-05 02:06
电子书制作工具-游易文书V7.1.1[点击下载]Spring eBook eBookMakerV2.1[点击下载]电子书专家CHMEBookEditorV1.56 【点击下载】二. 软件界面:照例先来看看这三个软件的运行界面~又一文书主界面 Spring电子书主界面 电子书专家主界面总结:游易文书和电子书专家的界面类似,即界面左侧是目录栏,右侧是目录的具体内容。不过spring电子书的主界面不同的是,菜单栏放在了右侧,让用户一目了然。从界面来看,电子书专家显得很空洞,而且功能好像比游易和春天电子书略逊一筹!而且有用的文件是绿色软件,直接解压即可使用。是起跑线上的胜利吗?软件功能对比 1. 基本功能 我们制作一本电子书,看看这三个软件最基本的功能。我想做的电子书只是最基本的一种,包括word文档和笔记。书籍、图片和网页。一种。首先,我选择批量导入文档。我发现游易支持的格式比我想做的要多得多。好像不难找~ 轻松导入后生成目录。但是,我只导入了jpg格式的图片,对于png格式的图片还是不行。您可以单击查看和编辑每个目录。可以直接查看以exe形式发布的电子文档。未注册用户的电子书顶部会有广告~b。接下来是春季电子书。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。可以直接查看以exe形式发布的电子文档。未注册用户的电子书顶部会有广告~b。接下来是春季电子书。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。可以直接查看以exe形式发布的电子文档。未注册用户的电子书顶部会有广告~b。接下来是春季电子书。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。未注册用户的电子书顶部会有广告~b。接下来是春季电子书。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。未注册用户的电子书顶部会有广告~b。接下来是春季电子书。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。但是编辑器每次点击每个目录名称,都会提示这是一本未注册的spring电子书,编辑器可以理解作者希望大家支持正版心情,但是老弹窗还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。但是编辑器每次点击每个目录名称,都会提示这是一本未注册的spring电子书,编辑器可以理解作者希望大家支持正版心情,但是老弹窗还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。
注意电子书高手需要新建一个库文件才能开始制作,并新建一个标题来导入文件,而且只能导入文本目录和网页目录,不支持导入图片,非常不方便!小编看到了自己的一个例子,没有图。导入的网页都变成了文本形式。图片好像不能导入。2.其他功能 电子书制作只是最基本的功能之一,其他贴心的功能也可以加分~a. 又一写:可以做个索引。导入要制作电子书的文件后,还可以编辑文本文档和网页,如图。您可以设置出版电子书的权限(包括次数和天数限制)。您可以插入多媒体格式。湾 Spring 电子书自定义电子书图标可设置权限(仅受天数限制),并可插入多媒体格式。C。电子书专家,无其他功能。三。电子书生成界面 a.游易文书生成的电子书功能最全,菜单栏包括目录、搜索、书签、索引,可设置网页字体颜色大小,可连接打印机打印等. b. Spring电子书的菜单栏一个索引功能比有用文档少,一个是最基本的翻页功能。C。电子书专家的界面是最简单的。四。总结 为了给读者更直观的印象,小编做了一个表格。毋庸置疑,游义文件各方面最强大,最周到,但他的注册费也是最贵的,验证一分钱一分货的古老真理。最简单的电子书。专家注册只需9元。如果你想制作只有文字的电子书,它是一个不错的选择。您可以根据自己的要求进行选择。你可以参考一下 查看全部
抓取网页生成电子书(电子书制作利器-友益文书V7.1.1(1.1)_)
电子书制作工具-游易文书V7.1.1[点击下载]Spring eBook eBookMakerV2.1[点击下载]电子书专家CHMEBookEditorV1.56 【点击下载】二. 软件界面:照例先来看看这三个软件的运行界面~又一文书主界面 Spring电子书主界面 电子书专家主界面总结:游易文书和电子书专家的界面类似,即界面左侧是目录栏,右侧是目录的具体内容。不过spring电子书的主界面不同的是,菜单栏放在了右侧,让用户一目了然。从界面来看,电子书专家显得很空洞,而且功能好像比游易和春天电子书略逊一筹!而且有用的文件是绿色软件,直接解压即可使用。是起跑线上的胜利吗?软件功能对比 1. 基本功能 我们制作一本电子书,看看这三个软件最基本的功能。我想做的电子书只是最基本的一种,包括word文档和笔记。书籍、图片和网页。一种。首先,我选择批量导入文档。我发现游易支持的格式比我想做的要多得多。好像不难找~ 轻松导入后生成目录。但是,我只导入了jpg格式的图片,对于png格式的图片还是不行。您可以单击查看和编辑每个目录。可以直接查看以exe形式发布的电子文档。未注册用户的电子书顶部会有广告~b。接下来是春季电子书。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。可以直接查看以exe形式发布的电子文档。未注册用户的电子书顶部会有广告~b。接下来是春季电子书。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。可以直接查看以exe形式发布的电子文档。未注册用户的电子书顶部会有广告~b。接下来是春季电子书。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。未注册用户的电子书顶部会有广告~b。接下来是春季电子书。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。未注册用户的电子书顶部会有广告~b。接下来是春季电子书。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。但是编辑器每次点击每个目录名称,都会提示这是一本未注册的spring电子书,编辑器可以理解作者希望大家支持正版心情,但是老弹窗还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。但是编辑器每次点击每个目录名称,都会提示这是一本未注册的spring电子书,编辑器可以理解作者希望大家支持正版心情,但是老弹窗还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。
注意电子书高手需要新建一个库文件才能开始制作,并新建一个标题来导入文件,而且只能导入文本目录和网页目录,不支持导入图片,非常不方便!小编看到了自己的一个例子,没有图。导入的网页都变成了文本形式。图片好像不能导入。2.其他功能 电子书制作只是最基本的功能之一,其他贴心的功能也可以加分~a. 又一写:可以做个索引。导入要制作电子书的文件后,还可以编辑文本文档和网页,如图。您可以设置出版电子书的权限(包括次数和天数限制)。您可以插入多媒体格式。湾 Spring 电子书自定义电子书图标可设置权限(仅受天数限制),并可插入多媒体格式。C。电子书专家,无其他功能。三。电子书生成界面 a.游易文书生成的电子书功能最全,菜单栏包括目录、搜索、书签、索引,可设置网页字体颜色大小,可连接打印机打印等. b. Spring电子书的菜单栏一个索引功能比有用文档少,一个是最基本的翻页功能。C。电子书专家的界面是最简单的。四。总结 为了给读者更直观的印象,小编做了一个表格。毋庸置疑,游义文件各方面最强大,最周到,但他的注册费也是最贵的,验证一分钱一分货的古老真理。最简单的电子书。专家注册只需9元。如果你想制作只有文字的电子书,它是一个不错的选择。您可以根据自己的要求进行选择。你可以参考一下
抓取网页生成电子书(小说网站捕捉器的捕捉规则介绍及功能简介-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-11-26 10:06
小说网站采集器可以根据html网站代码采集和提取各种小说网站的图书内容,并提供txt、ePub、zip格式的控制方法。小说网站捕手不需要你解析各种代码,直接一键获取所有内容。
功能介绍
本app可以根据小说网站的html网页源码分析关键信息抓取规则,最终输出抓取的书籍(支持txt、ePub、zip格式输出)。
这个app可以说好用也好难用,比如简单地从网站中抓取书籍,就可以直接从自带的100多个预设网站中抓取(需要查看使用浏览器搜索要下载的书籍,然后复制链接到入口网址即可),无需解析复杂的源码。对于逻辑思维能力强的用户,可以根据分析小说网站的源码制定网站的捕捉规则,基本可以应付大部分小说网站。
应用功能
自定义规则抓图,可抓大部分小说网站文章,个别网站图书详细分类,支持多书抓图;
自带大量预估网站,没有定义规则的用户可以直接申请,也可以抓取自己需要的小说;
内置源代码浏览器,提供链接分析、关键定位、标签分割等工具;
对于大型小说,任务暂存到数据库后,可以随意中断和恢复任务;
图书提供多种输出方式:章节文件、独立文本文件、压缩包、ePub电子书等;
支持任务导入,即从带有章节页面链接的文本文件和excel文档中导入任务进行抓取;
所有组件都支持提示信息,即光标停止后会显示相关提示。大部分操作支持状态栏提示,使用更方便;
支持添加、修改、导入、导出、排序和删除预设网站;
附带小工具
ePub 电子书创建和分解工具支持从章节存储的书籍中生成ePub 文件,也可以将ePub 文件分解为具有多个章节的文本文件。
应用界面
主界面
任务管理
系统设置 + ePub 小部件
解析代码窗口 查看全部
抓取网页生成电子书(小说网站捕捉器的捕捉规则介绍及功能简介-苏州安嘉)
小说网站采集器可以根据html网站代码采集和提取各种小说网站的图书内容,并提供txt、ePub、zip格式的控制方法。小说网站捕手不需要你解析各种代码,直接一键获取所有内容。
功能介绍
本app可以根据小说网站的html网页源码分析关键信息抓取规则,最终输出抓取的书籍(支持txt、ePub、zip格式输出)。
这个app可以说好用也好难用,比如简单地从网站中抓取书籍,就可以直接从自带的100多个预设网站中抓取(需要查看使用浏览器搜索要下载的书籍,然后复制链接到入口网址即可),无需解析复杂的源码。对于逻辑思维能力强的用户,可以根据分析小说网站的源码制定网站的捕捉规则,基本可以应付大部分小说网站。
应用功能
自定义规则抓图,可抓大部分小说网站文章,个别网站图书详细分类,支持多书抓图;
自带大量预估网站,没有定义规则的用户可以直接申请,也可以抓取自己需要的小说;
内置源代码浏览器,提供链接分析、关键定位、标签分割等工具;
对于大型小说,任务暂存到数据库后,可以随意中断和恢复任务;
图书提供多种输出方式:章节文件、独立文本文件、压缩包、ePub电子书等;
支持任务导入,即从带有章节页面链接的文本文件和excel文档中导入任务进行抓取;
所有组件都支持提示信息,即光标停止后会显示相关提示。大部分操作支持状态栏提示,使用更方便;
支持添加、修改、导入、导出、排序和删除预设网站;
附带小工具
ePub 电子书创建和分解工具支持从章节存储的书籍中生成ePub 文件,也可以将ePub 文件分解为具有多个章节的文本文件。
应用界面
主界面
任务管理
系统设置 + ePub 小部件
解析代码窗口
抓取网页生成电子书(在线阅读网站URL的规律编程实现的关键(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-11-19 19:12
)
@1. 你必须知道的常识:
许多网站提供在线阅读书籍,但不提供这些书籍的下载,并且有些页面受Javascript保护甚至不允许复制。但是下载这些书籍并不太难,只需要一个小程序。
@2.注意在线阅读网站URL的规则,这是编程的关键:
一个一个的把网页捡起来放到txt里,首先要找到网页网址的规则。
以本书为例《成长比成功更重要》——新浪阅读链接为:[]
点击这个栏目,它的地址是[]
点击它的第二部分,地址又是[]
......
点击它的最后一段,地址是[]
很容易验证它们的地址都是连续的数字,所以很容易通过编程来自动生成链接地址,只需使用一个递增的数字来生成地址。
@3. 下载页面的编程实现:
Python 中有 urllib 包。导入它。有 urllib.open('#39;)。该函数返回一个文件对象。你只需要用返回的文件对象调用read()方法,它就会返回一个字符串
@4. 在得到的页面中,按html标签找到对应的文字内容:
read() 得到的页面是一个字符串。使用这个字符串的find()方法来查找对应文本内容从nIdxBeg开始到nIdxEnd结束的位置。您可以轻松地使用字符串切片 strContent[nIdxBeg:nIdxEnd] 来拦截页面。你想要的部分
@5. 把你想要截取的部分全部保存到一个文件中。
@6. 最后写一个程序读取前面写的文件,用string函数去掉html标签,然后把处理过的html标签的内容写到另一个“电子书成品”文件中:
先写一个字典(dict),将要替换的字符串写入这个字典,然后使用for循环,迭代使用str的replace()方法,将字典中对应的每一项放入字典中 替换每一个记录的html标签用对应的字符串,写在“完成的文件”——另一个txt中,就大功告成了。
将代码贴在这里以供参考。如果稍微修改变量值,您可以将其他页面作为电子书下载:
-------------------------------------------------- -------------------------------------------------- --------------
makeBook.py 下载页面并截取需要的部分(title 和文章 内容,分别由getTitle 和getContent 两个函数获取),写入文件out.txt。
-------------------------------------------------- -------------------------------------------------- --------------
nBeg = 30970
nEnd = 31082
strPrefix = 'http://vip.book.sina.com.cn/bo ... 39%3B
strSurfix = '.html'
strTitleBeg = """"""
strTitleEnd = """"""
strContentBeg = """"""
strContentEnd = """"""
fout = file('out.txt', 'w')
import urllib
def makeUrl(i):
"""Make the url with a number"""
return strPrefix + str(i) + strSurfix
def getContent(strPage):
nIdxBeg = strPage.find(strContentBeg)
nIdxEnd = strPage.find(strContentEnd, nIdxBeg + len(strContentBeg))
if nIdxBeg == -1 or nIdxEnd == -1:
print 'Content Not Found!'
return ''
elif nIdxBeg > nIdxEnd:
print 'Content begin index larger than end index.'
return ''
else:
return strPage[nIdxBeg + len(strContentBeg): nIdxEnd]
def getTitle(strPage):
nIdxBeg = strPage.find(strTitleBeg)
nIdxEnd = strPage.find(strTitleEnd, nIdxBeg + len(strTitleBeg))
if nIdxBeg == -1 or nIdxEnd == -1:
print 'Title Not Found!'
return ''
elif nIdxBeg > nIdxEnd:
print 'Title begin index larger than end index.'
return ''
else:
return strPage[nIdxBeg + len(strTitleBeg): nIdxEnd]
def processPage(strPage):
fout.write(getTitle(strPage))
fout.write('\n\n')
fout.write(getContent(strPage))
fout.write('\n- - - - - - - - - - - - - - - - - - - - - - - - - - -\n\n')
def writeBook():
for i in range(nBeg, nEnd):
print 'Downloading file ' + str(i)
strUrl = makeUrl(i)
nRetry = 3
strPage = ''
while nRetry:
try:
strPage = urllib.urlopen(strUrl).read()
break
except:
nRetry -= 1
continue
if not nRetry:
print 'Failed downloading file ' + str(i)
fout.write('\n\n/#####' + str(i) + '#####\\\\\\n\n')
else:
processPage(strPage)
if __name__ == '__main__':
writeBook()
fout.close()
-------------------------------------------------- -------------------------------------------------- --------------
formatTxt.py 处理前面生成的“out.txt”文件中的html标签,然后将格式化的内容写入“formated.txt”
-------------------------------------------------- -------------------------------------------------- --------------
matRep = {'<p>':' ', '':'\n\n'}
def formatTxt(strContent):
for i in matRep:
strContent = strContent.replace(i, matRep[i])
return strContent
if __name__ == '__main__':
strContent = file('out.txt', 'r').read()
file('formated.txt', 'w').write(formatTxt(strContent))
</p> 查看全部
抓取网页生成电子书(在线阅读网站URL的规律编程实现的关键(图)
)
@1. 你必须知道的常识:
许多网站提供在线阅读书籍,但不提供这些书籍的下载,并且有些页面受Javascript保护甚至不允许复制。但是下载这些书籍并不太难,只需要一个小程序。
@2.注意在线阅读网站URL的规则,这是编程的关键:
一个一个的把网页捡起来放到txt里,首先要找到网页网址的规则。
以本书为例《成长比成功更重要》——新浪阅读链接为:[]
点击这个栏目,它的地址是[]
点击它的第二部分,地址又是[]
......
点击它的最后一段,地址是[]
很容易验证它们的地址都是连续的数字,所以很容易通过编程来自动生成链接地址,只需使用一个递增的数字来生成地址。
@3. 下载页面的编程实现:
Python 中有 urllib 包。导入它。有 urllib.open('#39;)。该函数返回一个文件对象。你只需要用返回的文件对象调用read()方法,它就会返回一个字符串
@4. 在得到的页面中,按html标签找到对应的文字内容:
read() 得到的页面是一个字符串。使用这个字符串的find()方法来查找对应文本内容从nIdxBeg开始到nIdxEnd结束的位置。您可以轻松地使用字符串切片 strContent[nIdxBeg:nIdxEnd] 来拦截页面。你想要的部分
@5. 把你想要截取的部分全部保存到一个文件中。
@6. 最后写一个程序读取前面写的文件,用string函数去掉html标签,然后把处理过的html标签的内容写到另一个“电子书成品”文件中:
先写一个字典(dict),将要替换的字符串写入这个字典,然后使用for循环,迭代使用str的replace()方法,将字典中对应的每一项放入字典中 替换每一个记录的html标签用对应的字符串,写在“完成的文件”——另一个txt中,就大功告成了。
将代码贴在这里以供参考。如果稍微修改变量值,您可以将其他页面作为电子书下载:
-------------------------------------------------- -------------------------------------------------- --------------
makeBook.py 下载页面并截取需要的部分(title 和文章 内容,分别由getTitle 和getContent 两个函数获取),写入文件out.txt。
-------------------------------------------------- -------------------------------------------------- --------------
nBeg = 30970
nEnd = 31082
strPrefix = 'http://vip.book.sina.com.cn/bo ... 39%3B
strSurfix = '.html'
strTitleBeg = """"""
strTitleEnd = """"""
strContentBeg = """"""
strContentEnd = """"""
fout = file('out.txt', 'w')
import urllib
def makeUrl(i):
"""Make the url with a number"""
return strPrefix + str(i) + strSurfix
def getContent(strPage):
nIdxBeg = strPage.find(strContentBeg)
nIdxEnd = strPage.find(strContentEnd, nIdxBeg + len(strContentBeg))
if nIdxBeg == -1 or nIdxEnd == -1:
print 'Content Not Found!'
return ''
elif nIdxBeg > nIdxEnd:
print 'Content begin index larger than end index.'
return ''
else:
return strPage[nIdxBeg + len(strContentBeg): nIdxEnd]
def getTitle(strPage):
nIdxBeg = strPage.find(strTitleBeg)
nIdxEnd = strPage.find(strTitleEnd, nIdxBeg + len(strTitleBeg))
if nIdxBeg == -1 or nIdxEnd == -1:
print 'Title Not Found!'
return ''
elif nIdxBeg > nIdxEnd:
print 'Title begin index larger than end index.'
return ''
else:
return strPage[nIdxBeg + len(strTitleBeg): nIdxEnd]
def processPage(strPage):
fout.write(getTitle(strPage))
fout.write('\n\n')
fout.write(getContent(strPage))
fout.write('\n- - - - - - - - - - - - - - - - - - - - - - - - - - -\n\n')
def writeBook():
for i in range(nBeg, nEnd):
print 'Downloading file ' + str(i)
strUrl = makeUrl(i)
nRetry = 3
strPage = ''
while nRetry:
try:
strPage = urllib.urlopen(strUrl).read()
break
except:
nRetry -= 1
continue
if not nRetry:
print 'Failed downloading file ' + str(i)
fout.write('\n\n/#####' + str(i) + '#####\\\\\\n\n')
else:
processPage(strPage)
if __name__ == '__main__':
writeBook()
fout.close()
-------------------------------------------------- -------------------------------------------------- --------------
formatTxt.py 处理前面生成的“out.txt”文件中的html标签,然后将格式化的内容写入“formated.txt”
-------------------------------------------------- -------------------------------------------------- --------------
matRep = {'<p>':' ', '':'\n\n'}
def formatTxt(strContent):
for i in matRep:
strContent = strContent.replace(i, matRep[i])
return strContent
if __name__ == '__main__':
strContent = file('out.txt', 'r').read()
file('formated.txt', 'w').write(formatTxt(strContent))
</p>
抓取网页生成电子书(怎么从网页抓取数据?利用完结小说免费下载全本软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-11-19 19:11
如何从网页中抓取数据?使用完成的小说免费下载整个软件,您可以一次免费阅读整部小说。现在推荐一款免费的全txt小说电子书下载软件,使用网络图书抓取器,支持TXT全免费小说下载,用户可以使用网络小说抓取器,抓取网络小说,快速下载整个TXT电子书,最热软件站提供了网络图书抓取器的下载地址,需要免费小说全书下载器的朋友快来下载吧。, 体验简单易用的网页数据抓取工具,感受小说下载器的便捷功能。
网络图书爬虫简介
网络图书抓取器是一款网络小说下载软件,可以帮助用户下载指定网页的某本书和某章节。软件功能强大,可以提取小说目录信息,根据目录下载小说,然后合并,方便下载阅读后,支持断点续传功能。如果网络问题或其他问题导致小说章节下载中断,您可以点击继续下载,无需重新下载,然后继续下载上次下载的内容。下载完成后,您可以使用电脑小说阅读器阅读整部小说。
软件功能
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好了再试。
3、停止和恢复:抓取过程可以随时停止,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键抓取:又称“哑模式”,基本可以实现自动抓取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以使用一键抓取,抓取合并操作会自动完成.
5、适用网站:已输入10个适用网站(选择后可以快速打开网站找到您需要的书),并自动应用相应的代码, 也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中以备后用。
6、 制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
软件特点
1、 支持多种小说平台的小说爬取。
2、支持多种文字编码方式,避免文字乱码。
3、 一键提取查看小说所有目录。
4、 支持调整小说章节位置,可上下移动。
5、 支持在线查看章节内容,避免提取错误章节。
6、 当抓取失败时,支持手动或自动重新抓取。
7、 获取的小说会以一章一文的形式保存。
8、 可以一键将所有章节合并为一个文本,方便保存。
软件优势
非常实用的网络小说抓取软件,用户可以快速提取文档上十多部小说网站的小说章节和内容,并保存到本地
这个爬虫工具功能齐全,非常友好。为用户贴心配置了4种文本编码器,防止用户提取小说时出现乱码,并可一键将提取的文件合并为一个文档
本软件使用方便,运行流畅,爬行错误率极低。如果您是小说爱好者,强烈建议您使用本软件进行小说抓取。
如何使用网络图书抓取器
1. 网络小说下载软件下载解压后双击即可使用。第一次运行会自动生成一个设置文件。用户可以手动调整文件,打开软件,使用软件的小说下载功能,
2.首先进入要下载小说的网页,输入书名,点击目录解压,解压目录后可以移动、删除、倒序等调整操作,设置保存路径,点击开始爬行开始下载。
3.可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
4.在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录编排带来极大的方便。已输入 10 个适用的 网站。选择后,您可以快速打开网站 找到您需要的书,并自动应用相应的代码。
更新日志 (2020.09.05)
您可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后以最合适的方式进行合并。
爬取过程可以随时中断,关闭程序后可以继续上一个任务。
小编推荐
以上就是免费版在线抢书的完整介绍。最热的软件网站有更多类似的小说下载软件。有需要的朋友快来下载体验吧。这里有另外两个有用的小说下载软件。:网络抓取(网络抓取工具),微调小说下载器。 查看全部
抓取网页生成电子书(怎么从网页抓取数据?利用完结小说免费下载全本软件)
如何从网页中抓取数据?使用完成的小说免费下载整个软件,您可以一次免费阅读整部小说。现在推荐一款免费的全txt小说电子书下载软件,使用网络图书抓取器,支持TXT全免费小说下载,用户可以使用网络小说抓取器,抓取网络小说,快速下载整个TXT电子书,最热软件站提供了网络图书抓取器的下载地址,需要免费小说全书下载器的朋友快来下载吧。, 体验简单易用的网页数据抓取工具,感受小说下载器的便捷功能。
网络图书爬虫简介
网络图书抓取器是一款网络小说下载软件,可以帮助用户下载指定网页的某本书和某章节。软件功能强大,可以提取小说目录信息,根据目录下载小说,然后合并,方便下载阅读后,支持断点续传功能。如果网络问题或其他问题导致小说章节下载中断,您可以点击继续下载,无需重新下载,然后继续下载上次下载的内容。下载完成后,您可以使用电脑小说阅读器阅读整部小说。
软件功能
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好了再试。
3、停止和恢复:抓取过程可以随时停止,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键抓取:又称“哑模式”,基本可以实现自动抓取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以使用一键抓取,抓取合并操作会自动完成.
5、适用网站:已输入10个适用网站(选择后可以快速打开网站找到您需要的书),并自动应用相应的代码, 也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中以备后用。
6、 制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
软件特点
1、 支持多种小说平台的小说爬取。
2、支持多种文字编码方式,避免文字乱码。
3、 一键提取查看小说所有目录。
4、 支持调整小说章节位置,可上下移动。
5、 支持在线查看章节内容,避免提取错误章节。
6、 当抓取失败时,支持手动或自动重新抓取。
7、 获取的小说会以一章一文的形式保存。
8、 可以一键将所有章节合并为一个文本,方便保存。
软件优势
非常实用的网络小说抓取软件,用户可以快速提取文档上十多部小说网站的小说章节和内容,并保存到本地
这个爬虫工具功能齐全,非常友好。为用户贴心配置了4种文本编码器,防止用户提取小说时出现乱码,并可一键将提取的文件合并为一个文档
本软件使用方便,运行流畅,爬行错误率极低。如果您是小说爱好者,强烈建议您使用本软件进行小说抓取。
如何使用网络图书抓取器
1. 网络小说下载软件下载解压后双击即可使用。第一次运行会自动生成一个设置文件。用户可以手动调整文件,打开软件,使用软件的小说下载功能,
2.首先进入要下载小说的网页,输入书名,点击目录解压,解压目录后可以移动、删除、倒序等调整操作,设置保存路径,点击开始爬行开始下载。
3.可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
4.在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录编排带来极大的方便。已输入 10 个适用的 网站。选择后,您可以快速打开网站 找到您需要的书,并自动应用相应的代码。
更新日志 (2020.09.05)
您可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后以最合适的方式进行合并。
爬取过程可以随时中断,关闭程序后可以继续上一个任务。
小编推荐
以上就是免费版在线抢书的完整介绍。最热的软件网站有更多类似的小说下载软件。有需要的朋友快来下载体验吧。这里有另外两个有用的小说下载软件。:网络抓取(网络抓取工具),微调小说下载器。
抓取网页生成电子书(百度爬虫爬虫程序->电子书抓取页面的信息方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-19 15:00
抓取网页生成电子书,
我知道如何抓取h5页面的信息。进入"云处方"微信公众号,搜索"云处方"小程序,点击后进入个人中心,按照页面提示操作即可。
现在如果想要爬取这个页面,
抓取的方法有很多,我这边给你推荐一个通用的方法。先打开百度爬虫工具箱,然后点击网页抓取->爬虫程序->电子书抓取点击开始后会弹出一个窗口,你可以将你需要抓取页面的路径复制下来。然后电子书页面生成了,可以抓取到电子书的内容,因为都是编码转换的,所以保存后的会很乱。
github-ghlink6677/mybrainhole:youku电子书抓取工具:-documentary-scraping
菜鸟教程
读取对应的pdf,文字和图片分别存储一份,对应电子书名查找最近爬取的sitemap就行了。
现在各种网站都会分享自己站内电子书,作者给出链接,
速度是首要问题。高清无水印电子书是首要条件。
方法一百度requests。查看pdf中的电子书pdf里面的地址,爬取后存到wordpress就行了。或者ajax直接下载。方法二通过浏览器直接抓取,虽然相对麻烦,但速度快,pdf重新编辑等。
这款在线电子书下载工具, 查看全部
抓取网页生成电子书(百度爬虫爬虫程序->电子书抓取页面的信息方法)
抓取网页生成电子书,
我知道如何抓取h5页面的信息。进入"云处方"微信公众号,搜索"云处方"小程序,点击后进入个人中心,按照页面提示操作即可。
现在如果想要爬取这个页面,
抓取的方法有很多,我这边给你推荐一个通用的方法。先打开百度爬虫工具箱,然后点击网页抓取->爬虫程序->电子书抓取点击开始后会弹出一个窗口,你可以将你需要抓取页面的路径复制下来。然后电子书页面生成了,可以抓取到电子书的内容,因为都是编码转换的,所以保存后的会很乱。
github-ghlink6677/mybrainhole:youku电子书抓取工具:-documentary-scraping
菜鸟教程
读取对应的pdf,文字和图片分别存储一份,对应电子书名查找最近爬取的sitemap就行了。
现在各种网站都会分享自己站内电子书,作者给出链接,
速度是首要问题。高清无水印电子书是首要条件。
方法一百度requests。查看pdf中的电子书pdf里面的地址,爬取后存到wordpress就行了。或者ajax直接下载。方法二通过浏览器直接抓取,虽然相对麻烦,但速度快,pdf重新编辑等。
这款在线电子书下载工具,
抓取网页生成电子书(如何将网页文章批量抓取、生成电子书、直接推送到Kindle)
网站优化 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-11-19 01:18
很长一段时间,我一直在研究如何将我关注的网页或文章安装到Kindle中进行认真阅读,但很长一段时间都没有真正的进展。手动格式化书籍制作电子书的方法虽然简单易行,但对于短小且更新频繁的网页文章来说效率低下。如果有工具可以批量抓取网页文章,生成电子书,直接推送到Kindle上就好了。Doocer 是一个非常有用的工具。
Doocer 是由@lepture 开发的在线服务。它允许用户在 Pocket 的后期阅读帐户中提交 URL、RSS 提要地址和 文章,然后将它们一一或批量制作成 ePub、MOBI 电子书。您可以直接在 Doocer 中阅读所有 文章,也可以将它们推送到 Kindle 和 Apple Books 阅读。
阅读体验真的很好
由 Doocer 生成的电子书格式良好且引人注目。应该收录的内容很多,不应该收录的内容并不多。本书不仅封面有图文,还收录文章目录、网站出处、文章原作者等信息。Doocer生成的MOBI电子书支持KF8标准,因此支持Kindle原生替换自定义字体。
由于网站文章通常都有标准和通用的排版规范,所以Doocer生成的电子书文章中的大小、标题和列表图例与原创网页高度一致文章。原文章中的超链接也全部保留,评论信息、广告等内容全部丢弃。全书的阅读体验非常友好。(当然,如果原网页文章的布局乱了,得到的电子书也可能完全不一样。)
将网页文章制作成电子书
Doocer完成注册登录后,就可以开始将文章网页制作成电子书了。首先,我们点击“NEW BOOK”按钮新建电子书,输入电子书书名。然后选择右上角的“添加”,添加文章 URL 或RSS feed 地址。
以小众网页的文章为例,我们选择“FEED”,在输入框中粘贴RSS地址,然后点击“PARSE”,就会出现小众文章的近期列表显示给我们添加到。我们可以根据需要选择,也可以点击“全选”来全选文章。最后,下拉到页面底部,选择“SAVE”,这些文章就会被添加到书中。
实际上,Doocer 网页与 RSS 工具非常相似。实现了从网站批量抓取文章并集中展示的功能。
要将这些文章转换成电子书并推送到Kindle,我们需要进行一些简单的操作。
首先,根据Doocer个人设置页面的提示,我们打开它,在个人文档接收地址中添加Doocer电子书的发送地址。完成后,我们再在输入框中填写Kindle的个人文档接收地址,点击保存。
最后,我们在Doocer中打开《少数派》这本书,在页面上找到“发布”,选择发送到Kindle。大约10-30分钟,Doocer就会完成图书制作并将图书推送到Kindle上。
还有一些问题需要注意
Doocer目前处于Beta测试阶段,还存在一些bug,尤其是中文网站经常出现问题。好在Doocer官网有开发者对话频道,你可以直接联系他帮忙解决。
实现所有操作的自动化流程是我认为Doocer最需要努力的方向。Doocer 可以像RSS 工具一样抓取网页中更新的文章,但仍然需要手动执行文章 的新抓取并生成电子书和推送。如果整个过程都可以自动化,RSS-MOBI-Kindle就可以一口气搞定,相信实用性会更高。
目前,Doocer 的所有功能都可以免费使用。 查看全部
抓取网页生成电子书(如何将网页文章批量抓取、生成电子书、直接推送到Kindle)
很长一段时间,我一直在研究如何将我关注的网页或文章安装到Kindle中进行认真阅读,但很长一段时间都没有真正的进展。手动格式化书籍制作电子书的方法虽然简单易行,但对于短小且更新频繁的网页文章来说效率低下。如果有工具可以批量抓取网页文章,生成电子书,直接推送到Kindle上就好了。Doocer 是一个非常有用的工具。
Doocer 是由@lepture 开发的在线服务。它允许用户在 Pocket 的后期阅读帐户中提交 URL、RSS 提要地址和 文章,然后将它们一一或批量制作成 ePub、MOBI 电子书。您可以直接在 Doocer 中阅读所有 文章,也可以将它们推送到 Kindle 和 Apple Books 阅读。
阅读体验真的很好
由 Doocer 生成的电子书格式良好且引人注目。应该收录的内容很多,不应该收录的内容并不多。本书不仅封面有图文,还收录文章目录、网站出处、文章原作者等信息。Doocer生成的MOBI电子书支持KF8标准,因此支持Kindle原生替换自定义字体。
由于网站文章通常都有标准和通用的排版规范,所以Doocer生成的电子书文章中的大小、标题和列表图例与原创网页高度一致文章。原文章中的超链接也全部保留,评论信息、广告等内容全部丢弃。全书的阅读体验非常友好。(当然,如果原网页文章的布局乱了,得到的电子书也可能完全不一样。)
将网页文章制作成电子书
Doocer完成注册登录后,就可以开始将文章网页制作成电子书了。首先,我们点击“NEW BOOK”按钮新建电子书,输入电子书书名。然后选择右上角的“添加”,添加文章 URL 或RSS feed 地址。
以小众网页的文章为例,我们选择“FEED”,在输入框中粘贴RSS地址,然后点击“PARSE”,就会出现小众文章的近期列表显示给我们添加到。我们可以根据需要选择,也可以点击“全选”来全选文章。最后,下拉到页面底部,选择“SAVE”,这些文章就会被添加到书中。
实际上,Doocer 网页与 RSS 工具非常相似。实现了从网站批量抓取文章并集中展示的功能。
要将这些文章转换成电子书并推送到Kindle,我们需要进行一些简单的操作。
首先,根据Doocer个人设置页面的提示,我们打开它,在个人文档接收地址中添加Doocer电子书的发送地址。完成后,我们再在输入框中填写Kindle的个人文档接收地址,点击保存。
最后,我们在Doocer中打开《少数派》这本书,在页面上找到“发布”,选择发送到Kindle。大约10-30分钟,Doocer就会完成图书制作并将图书推送到Kindle上。
还有一些问题需要注意
Doocer目前处于Beta测试阶段,还存在一些bug,尤其是中文网站经常出现问题。好在Doocer官网有开发者对话频道,你可以直接联系他帮忙解决。
实现所有操作的自动化流程是我认为Doocer最需要努力的方向。Doocer 可以像RSS 工具一样抓取网页中更新的文章,但仍然需要手动执行文章 的新抓取并生成电子书和推送。如果整个过程都可以自动化,RSS-MOBI-Kindle就可以一口气搞定,相信实用性会更高。
目前,Doocer 的所有功能都可以免费使用。
抓取网页生成电子书(主流电子书格式大家最为熟知的电子书熟知格式(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-15 20:00
编者按(@Minja):在写文章的时候,经常需要引用和回溯。对各种存档和切割工具的不满,让我萌生了自己制作电子书的念头。恰巧@Spencerwoo在这方面有扎实的折腾能力,于是干掉他,一起研究了一套简单易行的方法,写成文章分享给大家。
虽然网络世界中有很多有价值的文章,但并不是每一次阅读体验都令人满意。如果你想拥有出色的文章阅读体验,至少要确保我们正在阅读文章:
很多时候,我们依靠浏览器的阅读方式,或者Pocket和RSS客户端来阅读。但是,稍后无法对阅读模式进行排序。大多数阅读服务的全文搜索功能需要付费,网上的文章可能哪天都搜不到。或许,将文章以电子书的形式保存在本地是一个更方便的回顾方式。
如果我们在网上看到一个网页形式的电子书,想把整个网页直接保存在本地(俗称“剪藏”),那会很麻烦。现有的网络剪辑工具不仅可能夹带无用的、影响体验的广告和其他冗余区域,而且还可能丢失重要和有价值的内容。不仅如此,几乎没有文章这样的工具可以轻松抓取图片并保存到本地。那么,让我向您介绍一套免费制作个性化电子书的方法。
本文主要使用开源工具Pandoc。对于需要MOBI或PDF格式电子书的读者,文章后半部分也有简单的转换方法。
以ePub电子书为突破口
主流的电子书格式有很多,但本文主要推荐ePub,它相对开放通用,可以方便地转换为其他格式。
主流电子书格式
最广为人知的电子书格式可能是纯文本TXT格式,但TXT之所以被称为“纯文本”,是因为它不支持章节、图片、封面和超链接。为了让电子书有格式、有图片、有内容,目前常见的电子书通常有PDF、ePub、MOBI三种格式。在:
我们文章的主要目的是利用接下来要介绍的工具,制作一个清晰美观的电子书,内嵌图片,目录,美观。相对来说ePub更加灵活,目录和自定义布局一应俱全,另外两种格式转换也方便。本文将从它开始。
电子书效果制作 查看全部
抓取网页生成电子书(主流电子书格式大家最为熟知的电子书熟知格式(图))
编者按(@Minja):在写文章的时候,经常需要引用和回溯。对各种存档和切割工具的不满,让我萌生了自己制作电子书的念头。恰巧@Spencerwoo在这方面有扎实的折腾能力,于是干掉他,一起研究了一套简单易行的方法,写成文章分享给大家。
虽然网络世界中有很多有价值的文章,但并不是每一次阅读体验都令人满意。如果你想拥有出色的文章阅读体验,至少要确保我们正在阅读文章:
很多时候,我们依靠浏览器的阅读方式,或者Pocket和RSS客户端来阅读。但是,稍后无法对阅读模式进行排序。大多数阅读服务的全文搜索功能需要付费,网上的文章可能哪天都搜不到。或许,将文章以电子书的形式保存在本地是一个更方便的回顾方式。
如果我们在网上看到一个网页形式的电子书,想把整个网页直接保存在本地(俗称“剪藏”),那会很麻烦。现有的网络剪辑工具不仅可能夹带无用的、影响体验的广告和其他冗余区域,而且还可能丢失重要和有价值的内容。不仅如此,几乎没有文章这样的工具可以轻松抓取图片并保存到本地。那么,让我向您介绍一套免费制作个性化电子书的方法。
本文主要使用开源工具Pandoc。对于需要MOBI或PDF格式电子书的读者,文章后半部分也有简单的转换方法。
以ePub电子书为突破口
主流的电子书格式有很多,但本文主要推荐ePub,它相对开放通用,可以方便地转换为其他格式。
主流电子书格式
最广为人知的电子书格式可能是纯文本TXT格式,但TXT之所以被称为“纯文本”,是因为它不支持章节、图片、封面和超链接。为了让电子书有格式、有图片、有内容,目前常见的电子书通常有PDF、ePub、MOBI三种格式。在:
我们文章的主要目的是利用接下来要介绍的工具,制作一个清晰美观的电子书,内嵌图片,目录,美观。相对来说ePub更加灵活,目录和自定义布局一应俱全,另外两种格式转换也方便。本文将从它开始。
电子书效果制作
抓取网页生成电子书(《网络书籍抓取器》之软件软件大小版本说明下载 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-11-15 17:08
)
网络图书抓取器主要用于抓取网络小说生成文本文件。它可以提取和调整指定小说目录页面的章节信息,然后按照章节顺序抓取小说内容,然后进行合并。抓取过程可以随时中断,程序关闭后可以继续上一个任务。
相关软件软件大小版本说明下载地址
网络图书抓取器主要用于抓取网络小说生成文本文件。它可以提取和调整指定小说目录页面的章节信息,然后按照章节顺序抓取小说内容,然后进行合并。抓取过程可以随时中断,程序关闭后可以继续上一个任务。
软件特点
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键爬取:又称“哑模式”,基本可以实现全自动爬取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已收录10个适用网站(选择后可以快速打开网站找到您需要的书),并自动应用相应的代码,也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中,以备后用。
6、 制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
查看全部
抓取网页生成电子书(《网络书籍抓取器》之软件软件大小版本说明下载
)
网络图书抓取器主要用于抓取网络小说生成文本文件。它可以提取和调整指定小说目录页面的章节信息,然后按照章节顺序抓取小说内容,然后进行合并。抓取过程可以随时中断,程序关闭后可以继续上一个任务。
相关软件软件大小版本说明下载地址
网络图书抓取器主要用于抓取网络小说生成文本文件。它可以提取和调整指定小说目录页面的章节信息,然后按照章节顺序抓取小说内容,然后进行合并。抓取过程可以随时中断,程序关闭后可以继续上一个任务。
软件特点
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键爬取:又称“哑模式”,基本可以实现全自动爬取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已收录10个适用网站(选择后可以快速打开网站找到您需要的书),并自动应用相应的代码,也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中,以备后用。
6、 制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
抓取网页生成电子书(Windows,OSX及Linux在线资料转为epub或mobi格式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-14 06:15
自从我买了kindle,我就一直在想如何最大限度地发挥它的功效。虽然可供购买的书籍很多,网上也有很多免费的电子书,但还是有很多网页形式的有趣内容。例如,O'Reilly Atlas 提供了很多电子书,但只提供免费在线阅读;此外,许多材料或文件只是网络形式。所以我希望将这些网上资料以某种方式转换成epub或者mobi格式,以便在kindle上阅读。本文文章介绍了如何使用calibre并编写少量代码来实现这一目标。
口径
Calibre 是一款免费的电子书管理工具,兼容 Windows、OS X 和 Linux。令人欣慰的是,除了GUI,calibre 还提供了很多命令行工具。ebook-convert 命令可以基于用户编写的食谱。该文件(实际上是python代码)抓取指定页面的内容,生成mobi等格式的电子书。爬取行为可以通过编写recipe来定制,以适应不同的网页结构。
安装口径
Calibre的下载地址是,您可以根据自己的操作系统下载相应的安装程序。
如果是Linux操作系统,也可以通过软件仓库安装:
Archlinux:
pacman -S 口径
Debian/Ubuntu:
apt-get 安装口径
红帽/Fedora/CentOS:
yum -y 安装口径
请注意,如果您使用 OSX,则需要单独安装命令行工具。
抓取网页以生成电子书
下面以Git Pocket Guide为例,说明如何通过calibre从网页生成电子书。
找到索引页
要爬取整本书,首先要找到索引页。这个页面通常是目录,也就是目录页面,其中每个目录链接都连接到相应的内容页面。在生成电子书时,索引页会指导抓取哪些页面以及内容组织的顺序。在这个例子中,索引页是。
写食谱
食谱是一个带有食谱扩展名的脚本。内容其实是一段python代码,定义了calibre爬取页面的范围和行为。以下是爬取 Git Pocket Guide 的秘籍:
从 calibre.web.feeds.recipes 导入 BasicNewsRecipe
类 Git_Pocket_Guide(BasicNewsRecipe):
title = 'Git Pocket Guide'
description = ''
cover\_url = 'http://akamaicovers.oreilly.com/images/0636920024972/lrg.jpg'
url\_prefix = 'http://chimera.labs.oreilly.com/books/1230000000561/'
no\_stylesheets = True
keep\_only\_tags = \[{ 'class': 'chapter' }\]
def get\_title(self, link):
return link.contents\[0\].strip()
def parse\_index(self):
soup = self.index\_to\_soup(self.url\_prefix + 'index.html')
div = soup.find('div', { 'class': 'toc' })
articles = \[\]
for link in div.findAll('a'):
if '#' in link\['href'\]:
continue
if not 'ch' in link\['href'\]:
continue
til = self.get\_title(link)
url = self.url\_prefix + link\['href'\]
a = { 'title': til, 'url': url }
articles.append(a)
ans = \[('Git\_Pocket\_Guide', articles)\]
return ans
下面解释了代码的不同部分。
整体结构
总的来说,一个recipe是一个python类,但是这个类必须继承calibre.web.feeds.recipes.BasicNewsRecipe。
解析索引
整个recipe的核心方法是parse_index,这也是recipes必须实现的唯一方法。该方法的目标是通过分析索引页的内容,返回一个稍微复杂一些的数据结构(稍后介绍)。这个数据结构定义了整个电子书的内容和内容组织顺序。
整体属性设置
在类的开头,定义了一些全局属性:
title ='Git Pocket Guide'description =''cover_url =''
url_prefix =''no_stylesheets = Truekeep_only_tags = [{'class':'chapter' }]
parse_index 返回值
下面通过分析索引页来描述parse_index需要返回的数据结构。
整体的返回数据结构是一个列表,其中每个元素是一个元组,一个元组代表一个卷。在这个例子中,只有一个卷,所以列表中只有一个元组。
每个元组有两个元素,第一个元素是卷名,第二个元素是一个列表,列表中的每个元素都是一个映射,表示一个章节(chapter),映射中有两个元素: title 和 url , Title是章节的标题,url是章节所在的内容页面的url。
Calibre 会根据parse_index 返回的结果对整本书进行爬取和组织,并会自行爬取处理内容内外的图片。
整个parse_index使用soup解析索引页,生成上述数据结构。
更多的
以上是最基本的食谱。如果想了解更多使用方法,可以参考API文档。
生成手机
写好菜谱后,可以在命令行中使用以下命令生成电子书:
电子书转换 Git_Pocket_Guide.recipe Git_Pocket_Guide.mobi
您可以生成mobi 格式的电子书。ebook-convert 会爬取相关内容,根据配方代码自行组织结构。
最终效果
下面是在kindle上看到的效果。
内容
内容一
内容二
带图片的页面
实际效果
我的食谱仓库
我在 github 上构建了一个 kindle-open-books,其中收录一些食谱,这些食谱是我写的和其他学生贡献的。欢迎任何人提供食谱。 查看全部
抓取网页生成电子书(Windows,OSX及Linux在线资料转为epub或mobi格式)
自从我买了kindle,我就一直在想如何最大限度地发挥它的功效。虽然可供购买的书籍很多,网上也有很多免费的电子书,但还是有很多网页形式的有趣内容。例如,O'Reilly Atlas 提供了很多电子书,但只提供免费在线阅读;此外,许多材料或文件只是网络形式。所以我希望将这些网上资料以某种方式转换成epub或者mobi格式,以便在kindle上阅读。本文文章介绍了如何使用calibre并编写少量代码来实现这一目标。
口径
Calibre 是一款免费的电子书管理工具,兼容 Windows、OS X 和 Linux。令人欣慰的是,除了GUI,calibre 还提供了很多命令行工具。ebook-convert 命令可以基于用户编写的食谱。该文件(实际上是python代码)抓取指定页面的内容,生成mobi等格式的电子书。爬取行为可以通过编写recipe来定制,以适应不同的网页结构。
安装口径
Calibre的下载地址是,您可以根据自己的操作系统下载相应的安装程序。
如果是Linux操作系统,也可以通过软件仓库安装:
Archlinux:
pacman -S 口径
Debian/Ubuntu:
apt-get 安装口径
红帽/Fedora/CentOS:
yum -y 安装口径
请注意,如果您使用 OSX,则需要单独安装命令行工具。
抓取网页以生成电子书
下面以Git Pocket Guide为例,说明如何通过calibre从网页生成电子书。
找到索引页
要爬取整本书,首先要找到索引页。这个页面通常是目录,也就是目录页面,其中每个目录链接都连接到相应的内容页面。在生成电子书时,索引页会指导抓取哪些页面以及内容组织的顺序。在这个例子中,索引页是。
写食谱
食谱是一个带有食谱扩展名的脚本。内容其实是一段python代码,定义了calibre爬取页面的范围和行为。以下是爬取 Git Pocket Guide 的秘籍:
从 calibre.web.feeds.recipes 导入 BasicNewsRecipe
类 Git_Pocket_Guide(BasicNewsRecipe):
title = 'Git Pocket Guide'
description = ''
cover\_url = 'http://akamaicovers.oreilly.com/images/0636920024972/lrg.jpg'
url\_prefix = 'http://chimera.labs.oreilly.com/books/1230000000561/'
no\_stylesheets = True
keep\_only\_tags = \[{ 'class': 'chapter' }\]
def get\_title(self, link):
return link.contents\[0\].strip()
def parse\_index(self):
soup = self.index\_to\_soup(self.url\_prefix + 'index.html')
div = soup.find('div', { 'class': 'toc' })
articles = \[\]
for link in div.findAll('a'):
if '#' in link\['href'\]:
continue
if not 'ch' in link\['href'\]:
continue
til = self.get\_title(link)
url = self.url\_prefix + link\['href'\]
a = { 'title': til, 'url': url }
articles.append(a)
ans = \[('Git\_Pocket\_Guide', articles)\]
return ans
下面解释了代码的不同部分。
整体结构
总的来说,一个recipe是一个python类,但是这个类必须继承calibre.web.feeds.recipes.BasicNewsRecipe。
解析索引
整个recipe的核心方法是parse_index,这也是recipes必须实现的唯一方法。该方法的目标是通过分析索引页的内容,返回一个稍微复杂一些的数据结构(稍后介绍)。这个数据结构定义了整个电子书的内容和内容组织顺序。
整体属性设置
在类的开头,定义了一些全局属性:
title ='Git Pocket Guide'description =''cover_url =''
url_prefix =''no_stylesheets = Truekeep_only_tags = [{'class':'chapter' }]
parse_index 返回值
下面通过分析索引页来描述parse_index需要返回的数据结构。
整体的返回数据结构是一个列表,其中每个元素是一个元组,一个元组代表一个卷。在这个例子中,只有一个卷,所以列表中只有一个元组。
每个元组有两个元素,第一个元素是卷名,第二个元素是一个列表,列表中的每个元素都是一个映射,表示一个章节(chapter),映射中有两个元素: title 和 url , Title是章节的标题,url是章节所在的内容页面的url。
Calibre 会根据parse_index 返回的结果对整本书进行爬取和组织,并会自行爬取处理内容内外的图片。
整个parse_index使用soup解析索引页,生成上述数据结构。
更多的
以上是最基本的食谱。如果想了解更多使用方法,可以参考API文档。
生成手机
写好菜谱后,可以在命令行中使用以下命令生成电子书:
电子书转换 Git_Pocket_Guide.recipe Git_Pocket_Guide.mobi
您可以生成mobi 格式的电子书。ebook-convert 会爬取相关内容,根据配方代码自行组织结构。
最终效果
下面是在kindle上看到的效果。
内容
内容一
内容二
带图片的页面
实际效果
我的食谱仓库
我在 github 上构建了一个 kindle-open-books,其中收录一些食谱,这些食谱是我写的和其他学生贡献的。欢迎任何人提供食谱。
抓取网页生成电子书(Windows,OSX及Linux的在线资料epub格式 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-11-14 06:12
)
自从我买了kindle,我就一直在想如何最大限度地发挥它的功效。虽然可供购买的书籍很多,网上也有很多免费的电子书,但还是有很多网页形式的有趣内容。例如,O'Reilly Atlas 提供了很多电子书,但只提供免费在线阅读;此外,许多材料或文件只是网络形式。所以我希望将这些网上资料以某种方式转换成epub或者mobi格式,以便在kindle上阅读。本文文章介绍了如何使用calibre并编写少量代码来实现这一目标。
Calibre 简介
Calibre 是一款免费的电子书管理工具,兼容 Windows、OS X 和 Linux。令人欣慰的是,除了GUI,calibre 还提供了很多命令行工具。ebook-convert 命令可以基于用户编写的食谱。该文件(实际上是python代码)抓取指定页面的内容,生成mobi等格式的电子书。爬取行为可以通过编写recipe来定制,以适应不同的网页结构。
安装口径
Calibre的下载地址为download,您可以根据自己的操作系统下载相应的安装程序。
如果是Linux操作系统,也可以通过软件仓库安装:
Archlinux:
pacman -S calibre
Debian/Ubuntu:
apt-get install calibre
红帽/Fedora/CentOS:
yum -y install calibre
请注意,如果您使用 OSX,则需要单独安装命令行工具。
抓取网页以生成电子书
下面以Git Pocket Guide为例,说明如何通过calibre从网页生成电子书。
找到索引页
要爬取整本书,首先要找到索引页。这个页面通常是目录,也就是目录页面,其中每个目录链接都连接到相应的内容页面。在生成电子书时,索引页会指导抓取哪些页面以及内容组织的顺序。在本例中,索引页为 61/index.html。
写食谱
食谱是一个带有食谱扩展名的脚本。内容其实是一段python代码,定义了calibre爬取页面的范围和行为。以下是爬取 Git Pocket Guide 的秘籍:
from calibre.web.feeds.recipes import BasicNewsRecipe
class Git_Pocket_Guide(BasicNewsRecipe):
title = 'Git Pocket Guide'
description = ''
cover_url = 'http://akamaicovers.oreilly.com/images/0636920024972/lrg.jpg'
url_prefix = '1230000000561/'
no_stylesheets = True
keep_only_tags = [{ 'class': 'chapter' }]
def get_title(self, link):
return link.contents[0].strip()
def parse_index(self):
soup = self.index_to_soup(self.url_prefix + 'index.html')
div = soup.find('div', { 'class': 'toc' })
articles = []
for link in div.findAll('a'):
if '#' in link['href']:
continue
if not 'ch' in link['href']:
continue
til = self.get_title(link)
url = self.url_prefix + link['href']
a = { 'title': til, 'url': url }
articles.append(a)
ans = [('Git_Pocket_Guide', articles)]
return ans
下面解释了代码的不同部分。
整体结构
总的来说,一个recipe是一个python类,但是这个类必须继承calibre.web.feeds.recipes.BasicNewsRecipe。
解析索引
整个recipe的核心方法是parse_index,这也是recipes必须实现的唯一方法。该方法的目标是通过分析索引页的内容,返回一个稍微复杂一些的数据结构(稍后介绍)。这个数据结构定义了整个电子书的内容和内容组织顺序。
整体属性设置
在类的开头,定义了一些全局属性:
title = 'Git Pocket Guide'
description = ''
cover_url = 'http://akamaicovers.oreilly.com/images/0636920024972/lrg.jpg'
url_prefix = '1230000000561/'
no_stylesheets = True
keep_only_tags = [{ 'class': 'chapter' }] 查看全部
抓取网页生成电子书(Windows,OSX及Linux的在线资料epub格式
)
自从我买了kindle,我就一直在想如何最大限度地发挥它的功效。虽然可供购买的书籍很多,网上也有很多免费的电子书,但还是有很多网页形式的有趣内容。例如,O'Reilly Atlas 提供了很多电子书,但只提供免费在线阅读;此外,许多材料或文件只是网络形式。所以我希望将这些网上资料以某种方式转换成epub或者mobi格式,以便在kindle上阅读。本文文章介绍了如何使用calibre并编写少量代码来实现这一目标。
Calibre 简介
Calibre 是一款免费的电子书管理工具,兼容 Windows、OS X 和 Linux。令人欣慰的是,除了GUI,calibre 还提供了很多命令行工具。ebook-convert 命令可以基于用户编写的食谱。该文件(实际上是python代码)抓取指定页面的内容,生成mobi等格式的电子书。爬取行为可以通过编写recipe来定制,以适应不同的网页结构。
安装口径
Calibre的下载地址为download,您可以根据自己的操作系统下载相应的安装程序。
如果是Linux操作系统,也可以通过软件仓库安装:
Archlinux:
pacman -S calibre
Debian/Ubuntu:
apt-get install calibre
红帽/Fedora/CentOS:
yum -y install calibre
请注意,如果您使用 OSX,则需要单独安装命令行工具。
抓取网页以生成电子书
下面以Git Pocket Guide为例,说明如何通过calibre从网页生成电子书。
找到索引页
要爬取整本书,首先要找到索引页。这个页面通常是目录,也就是目录页面,其中每个目录链接都连接到相应的内容页面。在生成电子书时,索引页会指导抓取哪些页面以及内容组织的顺序。在本例中,索引页为 61/index.html。
写食谱
食谱是一个带有食谱扩展名的脚本。内容其实是一段python代码,定义了calibre爬取页面的范围和行为。以下是爬取 Git Pocket Guide 的秘籍:
from calibre.web.feeds.recipes import BasicNewsRecipe
class Git_Pocket_Guide(BasicNewsRecipe):
title = 'Git Pocket Guide'
description = ''
cover_url = 'http://akamaicovers.oreilly.com/images/0636920024972/lrg.jpg'
url_prefix = '1230000000561/'
no_stylesheets = True
keep_only_tags = [{ 'class': 'chapter' }]
def get_title(self, link):
return link.contents[0].strip()
def parse_index(self):
soup = self.index_to_soup(self.url_prefix + 'index.html')
div = soup.find('div', { 'class': 'toc' })
articles = []
for link in div.findAll('a'):
if '#' in link['href']:
continue
if not 'ch' in link['href']:
continue
til = self.get_title(link)
url = self.url_prefix + link['href']
a = { 'title': til, 'url': url }
articles.append(a)
ans = [('Git_Pocket_Guide', articles)]
return ans
下面解释了代码的不同部分。
整体结构
总的来说,一个recipe是一个python类,但是这个类必须继承calibre.web.feeds.recipes.BasicNewsRecipe。
解析索引
整个recipe的核心方法是parse_index,这也是recipes必须实现的唯一方法。该方法的目标是通过分析索引页的内容,返回一个稍微复杂一些的数据结构(稍后介绍)。这个数据结构定义了整个电子书的内容和内容组织顺序。
整体属性设置
在类的开头,定义了一些全局属性:
title = 'Git Pocket Guide'
description = ''
cover_url = 'http://akamaicovers.oreilly.com/images/0636920024972/lrg.jpg'
url_prefix = '1230000000561/'
no_stylesheets = True
keep_only_tags = [{ 'class': 'chapter' }]
抓取网页生成电子书(从当当网上采集数据的过程为例,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2021-11-13 03:19
所谓“网页数据抓取”,也称为网页数据采集、网页数据采集等,就是从我们平时查看的网页中提取需要的数据信息浏览器,然后将结构以CSV、JSON、XML、ACCESS、MSSQL、MYSQL等格式存储在文件或数据库中的过程。当然,这里的数据提取过程是通过计算机软件技术实现的,而不是通过人工复制粘贴。也正因为如此,才有可能从大规模的网站中采集。
下面以作者从当当网获取采集数据的过程为例,详细讲解一下web数据抓取的基本过程。
首先,我们需要分析目标网站的网页结构,判断网站上的数据是否可以采集以及如何采集。
当当网是一个综合性的网站,这里以图书数据为例。检查后,我们找到了图书信息的目录页。图书信息以多级目录结构组织。如下图所示,图片左侧为图书信息一级目录:
因为很多网站会出于数据保护的原因限制显示数据的数量,比如数据最多可以显示100页,超过100页的数据就不会显示。这样,如果您选择进入更高级别的目录,您可以获得的数据就越少。因此,为了获得尽可能多的数据,我们需要进入较低级别的目录,也就是更小的分类级别,以获得更多的数据。
点击一级目录,进入二级图书目录,如下图:
同理,依次点击每一级目录,最后可以进入底层目录,这里显示了该目录下所有可显示数据项的列表,我们称之为底层列表页面,如图:
当然,这个列表页面很可能会被分成多个页面。我们在做数据采集的时候,需要遍历每个页面上的数据项,通过每个数据项上的链接,可以进入最终的数据页面,我们称之为详情页。如下所示:
至此,获取详细数据的路径已经明确。接下来,我们将分析详细页面上有用的数据项,然后编写数据采集程序,以捕获我们感兴趣的数据。
以下是作者编写的当当网图书数据网页数据爬取程序的部分代码:
以下是作者采集得到的部分图书信息样本数据:
至此,一个完整的网页数据抓取过程就完成了。 查看全部
抓取网页生成电子书(从当当网上采集数据的过程为例,你了解多少?)
所谓“网页数据抓取”,也称为网页数据采集、网页数据采集等,就是从我们平时查看的网页中提取需要的数据信息浏览器,然后将结构以CSV、JSON、XML、ACCESS、MSSQL、MYSQL等格式存储在文件或数据库中的过程。当然,这里的数据提取过程是通过计算机软件技术实现的,而不是通过人工复制粘贴。也正因为如此,才有可能从大规模的网站中采集。
下面以作者从当当网获取采集数据的过程为例,详细讲解一下web数据抓取的基本过程。
首先,我们需要分析目标网站的网页结构,判断网站上的数据是否可以采集以及如何采集。
当当网是一个综合性的网站,这里以图书数据为例。检查后,我们找到了图书信息的目录页。图书信息以多级目录结构组织。如下图所示,图片左侧为图书信息一级目录:
因为很多网站会出于数据保护的原因限制显示数据的数量,比如数据最多可以显示100页,超过100页的数据就不会显示。这样,如果您选择进入更高级别的目录,您可以获得的数据就越少。因此,为了获得尽可能多的数据,我们需要进入较低级别的目录,也就是更小的分类级别,以获得更多的数据。
点击一级目录,进入二级图书目录,如下图:
同理,依次点击每一级目录,最后可以进入底层目录,这里显示了该目录下所有可显示数据项的列表,我们称之为底层列表页面,如图:
当然,这个列表页面很可能会被分成多个页面。我们在做数据采集的时候,需要遍历每个页面上的数据项,通过每个数据项上的链接,可以进入最终的数据页面,我们称之为详情页。如下所示:
至此,获取详细数据的路径已经明确。接下来,我们将分析详细页面上有用的数据项,然后编写数据采集程序,以捕获我们感兴趣的数据。
以下是作者编写的当当网图书数据网页数据爬取程序的部分代码:
以下是作者采集得到的部分图书信息样本数据:
至此,一个完整的网页数据抓取过程就完成了。
抓取网页生成电子书(通过Python和爬虫,可以完成怎样的小工具?|知乎 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 266 次浏览 • 2021-11-13 03:18
)
总有同学问,学了Python基础之后,不知道自己可以做些什么来提高。今天我就用一个小例子来告诉大家通过Python和爬虫可以完成什么样的小工具。
在知乎上,你一定关注过一些不错的专栏(比如Crossin的编程课堂)。但如果有一天,你最喜欢的受访者在网上被喷,你一怒之下删帖停止更新,你就看不到好内容了。虽然这是小概率事件(以前没有发生过),但你可以准备下雨天。您可以将您关注的专栏导出到电子书中,这样您就可以离线阅读,而不必担心不小心删除帖子。
只需要工具和源码的可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,即网页地址上的路径:
之后程序会自动抓取列中的文章,并根据发布时间合并导出为pdf文件。
【实现思路】
本方案主要分为三部分:
爬取专栏文章地址列表爬取每篇文章的详细内容文章导出PDF1.爬取列表
在之前的文章爬虫必备工具中,掌握它就解决了一半的问题,介绍了如何分析网页上的请求。根据方法,我们可以使用开发者工具的Network功能,找出栏目页面的请求,获取明细列表:
https://www.zhihu.com/api/v4/c ... icles
观察返回的结果,我们发现通过next和is_end的值,可以得到下一个列表请求的地址(相当于页面向下滚动的触发效果),判断是否所有文章都有已获得。
data中的id、title、url就是我们需要的数据。因为url可以用id拼出来,所以没有保存在我们的代码中。
使用 while 循环直到 文章 的所有 id 和 title 都被捕获并保存在文件中。
while True:
resp = requests.get(url, headers=headers)
j = resp.json()
data = j['data']
for article in data:
# 保存id和title(略)
if j['paging']['is_end']:
break
url = j['paging']['next']
# 按 id 排序(略)
# 导入文件(略)
2. 抢 文章
有了文章的所有id/url,后面的爬取就很简单了。文章 主要内容在 Post-RichText 标签中。
处理一些文字需要一点功夫,比如原页面的图片效果,会添加noscript标签和`,highlight">
url = 'https://zhuanlan.zhihu.com/p/' + id
html = requests.get(url, headers=headers).text
soup = BeautifulSoup(html, 'lxml')
content = soup.find(class_='Post-RichText').prettify()
# 对content做处理(略)
with open(file_name, 'w') as f:
f.write(content)
至此,所有的内容都已经抓取完毕,可以在本地读取了。
3. 导出 PDF
为了方便阅读,我们使用 wkhtmltopdf + pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf是一个将HTML转PDF的工具,需要单独安装。详情请参阅其官方网站。
pdfkit 是为此工具打包的 Python 库,可以从 pip 安装:
pip install pdfkit
使用非常简单:
# 获取htmls文件名列表(略)
pdfkit.from_file(sorted(htmls), 'zhihu.pdf')
这样就完成了整列的导出。
不只是知乎的栏目,几乎大部分信息网站,通过1.抓取列表2.抓取详细内容采集数据两步。所以这段代码只要稍加修改就可以用于许多其他的网站。只是有些网站需要登录才能访问,所以需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制都不一样,具体问题还是要具体问题具体分析。
这些爬虫的开发技巧可以在我们的爬虫实战课中学习。需要的请回复公众号中的实际爬虫
【源码下载】
获取知乎的专栏下载器源码,请在公众号(Crossin的编程课堂)回复关键字知乎
除了代码,还有本专栏打包好的PDF,欢迎阅读分享。
====
其他 文章 和回答:
欢迎搜索关注:Crossin的编程课堂
查看全部
抓取网页生成电子书(通过Python和爬虫,可以完成怎样的小工具?|知乎
)
总有同学问,学了Python基础之后,不知道自己可以做些什么来提高。今天我就用一个小例子来告诉大家通过Python和爬虫可以完成什么样的小工具。
在知乎上,你一定关注过一些不错的专栏(比如Crossin的编程课堂)。但如果有一天,你最喜欢的受访者在网上被喷,你一怒之下删帖停止更新,你就看不到好内容了。虽然这是小概率事件(以前没有发生过),但你可以准备下雨天。您可以将您关注的专栏导出到电子书中,这样您就可以离线阅读,而不必担心不小心删除帖子。
只需要工具和源码的可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,即网页地址上的路径:
之后程序会自动抓取列中的文章,并根据发布时间合并导出为pdf文件。
【实现思路】
本方案主要分为三部分:
爬取专栏文章地址列表爬取每篇文章的详细内容文章导出PDF1.爬取列表
在之前的文章爬虫必备工具中,掌握它就解决了一半的问题,介绍了如何分析网页上的请求。根据方法,我们可以使用开发者工具的Network功能,找出栏目页面的请求,获取明细列表:
https://www.zhihu.com/api/v4/c ... icles
观察返回的结果,我们发现通过next和is_end的值,可以得到下一个列表请求的地址(相当于页面向下滚动的触发效果),判断是否所有文章都有已获得。
data中的id、title、url就是我们需要的数据。因为url可以用id拼出来,所以没有保存在我们的代码中。
使用 while 循环直到 文章 的所有 id 和 title 都被捕获并保存在文件中。
while True:
resp = requests.get(url, headers=headers)
j = resp.json()
data = j['data']
for article in data:
# 保存id和title(略)
if j['paging']['is_end']:
break
url = j['paging']['next']
# 按 id 排序(略)
# 导入文件(略)
2. 抢 文章
有了文章的所有id/url,后面的爬取就很简单了。文章 主要内容在 Post-RichText 标签中。
处理一些文字需要一点功夫,比如原页面的图片效果,会添加noscript标签和`,highlight">
url = 'https://zhuanlan.zhihu.com/p/' + id
html = requests.get(url, headers=headers).text
soup = BeautifulSoup(html, 'lxml')
content = soup.find(class_='Post-RichText').prettify()
# 对content做处理(略)
with open(file_name, 'w') as f:
f.write(content)
至此,所有的内容都已经抓取完毕,可以在本地读取了。
3. 导出 PDF
为了方便阅读,我们使用 wkhtmltopdf + pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf是一个将HTML转PDF的工具,需要单独安装。详情请参阅其官方网站。
pdfkit 是为此工具打包的 Python 库,可以从 pip 安装:
pip install pdfkit
使用非常简单:
# 获取htmls文件名列表(略)
pdfkit.from_file(sorted(htmls), 'zhihu.pdf')
这样就完成了整列的导出。
不只是知乎的栏目,几乎大部分信息网站,通过1.抓取列表2.抓取详细内容采集数据两步。所以这段代码只要稍加修改就可以用于许多其他的网站。只是有些网站需要登录才能访问,所以需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制都不一样,具体问题还是要具体问题具体分析。
这些爬虫的开发技巧可以在我们的爬虫实战课中学习。需要的请回复公众号中的实际爬虫
【源码下载】
获取知乎的专栏下载器源码,请在公众号(Crossin的编程课堂)回复关键字知乎
除了代码,还有本专栏打包好的PDF,欢迎阅读分享。
====
其他 文章 和回答:
欢迎搜索关注:Crossin的编程课堂
抓取网页生成电子书(网络书籍抓取器怎么做?如何制作电子书的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2021-11-12 04:23
)
网络图书抓取器主要用于抓取网络小说生成文本文件。它可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后进行合并。爬取过程可以随时中断,关闭程序后可以继续上一个任务。
相关软件软件大小版本说明下载地址
网络图书抓取器主要用于抓取网络小说生成文本文件。它可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后进行合并。爬取过程可以随时中断,关闭程序后可以继续上一个任务。
软件特点
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键爬取:又称“哑模式”,基本可以实现全自动爬取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已输入10个适用网站(选择后可快速打开网站找到您需要的书),并自动应用相应的代码, 也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中以备后用。
6、轻松制作电子书:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
查看全部
抓取网页生成电子书(网络书籍抓取器怎么做?如何制作电子书的方法
)
网络图书抓取器主要用于抓取网络小说生成文本文件。它可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后进行合并。爬取过程可以随时中断,关闭程序后可以继续上一个任务。
相关软件软件大小版本说明下载地址
网络图书抓取器主要用于抓取网络小说生成文本文件。它可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后进行合并。爬取过程可以随时中断,关闭程序后可以继续上一个任务。
软件特点
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键爬取:又称“哑模式”,基本可以实现全自动爬取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已输入10个适用网站(选择后可快速打开网站找到您需要的书),并自动应用相应的代码, 也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中以备后用。
6、轻松制作电子书:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
抓取网页生成电子书( 大型的HTML,使用方法一生成HTML的元素变化。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-11-11 23:12
大型的HTML,使用方法一生成HTML的元素变化。)
<p>python 自动化批量生成前端的HTML可以大大减轻工作量
下面演示两种生成 HTML 的方法
方法一:使用 webbrowser
#coding:utf-8
import webbrowser
#命名生成的html
GEN_HTML = "test.html"
#打开文件,准备写入
f = open(GEN_HTML,'w')
#准备相关变量
str1 = 'my name is :'
str2 = '--MichaelAn--'
# 写入HTML界面中
message = """
%s
%s
"""%(str1,str2)
#写入文件
f.write(message)
#关闭文件
f.close()
#运行完自动在网页中显示
webbrowser.open(GEN_HTML,new = 1)
'''
webbrowser.open(url, new=0, autoraise=True)
Display url using the default browser. If new is 0, the url is opened in the same browser window if possible. If new is 1, a new browser window is opened if possible. If new is 2, a new browser page (“tab”) is opened if possible. If autoraise is True, the window is raised if possible (note that under many window managers this will occur regardless of the setting of this variable).
'''</p>
方法二:使用pyh
<p>#coding:utf-8
from pyh import *
# there is a bug "from pyh import *"
page = PyH('My wonderful PyH page')
page.addCSS('myStylesheet1.css', 'myStylesheet2.css')
page.addJS('myJavascript1.js', 'myJavascript2.js')
page 查看全部
抓取网页生成电子书(
大型的HTML,使用方法一生成HTML的元素变化。)
<p>python 自动化批量生成前端的HTML可以大大减轻工作量
下面演示两种生成 HTML 的方法
方法一:使用 webbrowser
#coding:utf-8
import webbrowser
#命名生成的html
GEN_HTML = "test.html"
#打开文件,准备写入
f = open(GEN_HTML,'w')
#准备相关变量
str1 = 'my name is :'
str2 = '--MichaelAn--'
# 写入HTML界面中
message = """
%s
%s
"""%(str1,str2)
#写入文件
f.write(message)
#关闭文件
f.close()
#运行完自动在网页中显示
webbrowser.open(GEN_HTML,new = 1)
'''
webbrowser.open(url, new=0, autoraise=True)
Display url using the default browser. If new is 0, the url is opened in the same browser window if possible. If new is 1, a new browser window is opened if possible. If new is 2, a new browser page (“tab”) is opened if possible. If autoraise is True, the window is raised if possible (note that under many window managers this will occur regardless of the setting of this variable).
'''</p>
方法二:使用pyh
<p>#coding:utf-8
from pyh import *
# there is a bug "from pyh import *"
page = PyH('My wonderful PyH page')
page.addCSS('myStylesheet1.css', 'myStylesheet2.css')
page.addJS('myJavascript1.js', 'myJavascript2.js')
page
抓取网页生成电子书(利用能提取网页小说的app,批量下载网站所有小说)
网站优化 • 优采云 发表了文章 • 0 个评论 • 1033 次浏览 • 2021-11-11 20:29
使用可以提取网络小说的APP批量下载所有网站小说。现在推荐一个免费且简单的网络小说下载器。使用大叔小说下载器,不仅具有小说爬虫下载器app的功能,还能批量提取网络小说。,它也可以用作干净的本地阅读器应用程序。下载小说后,可以直接阅读小说。不知道怎么下载电子书软件的朋友快来最热的软件站下载吧。
基本介绍
这是一款网络小说下载爬虫软件,可以帮助用户批量下载网络小说。软件功能丰富,包括TXT小说下载、TXT小说阅读、有声小说下载。有声小说不仅支持下载,还可以在线听书。如果您使用TXT带有小说下载功能,可以批量下载所有小说网站。如果你还不知道怎么下载电子书软件,快来看看吧。将TXT小说下载到本地后,可以使用电脑小说阅读器阅读,也可以使用软件自带的阅读功能阅读小说。
指示
1.在本站下载并解压这款新颖的爬虫下载器应用。好用,搜索小说,解析目录,选择你要下载的章节(可以平移),点击章节目录查看正文内容,点击章节正文选择,空白处是查看内容,可以右击。
2. 过滤掉不需要的内容(添加范围,去除广告),最好的范围是书网页源代码的内容,点击加入书架或下载,可以到下载管理查看进度。
3. 如果下载失败次数过多,会增加每个线程下载的章节数。您可以直接获取目录链接进行申诉操作。如果是动态网页,记得开启动态网页支持。切换规则不需要重新解析,只需要重新解析章节相关。
4.支持有声小说下载,搜索有声小说,添加书架直接选择要开始下载的,发现失败较多,增加每线程下载章节数,增加延迟。
小编推荐
以上就是这款小说下载软件免费版的完整介绍。最热门的软件网站有更多类似的小说下载软件。有需要的朋友快来下载体验吧。这是另外两个有用的小说下载。软件:电脑版全小说下载器、远天湾小说下载器。 查看全部
抓取网页生成电子书(利用能提取网页小说的app,批量下载网站所有小说)
使用可以提取网络小说的APP批量下载所有网站小说。现在推荐一个免费且简单的网络小说下载器。使用大叔小说下载器,不仅具有小说爬虫下载器app的功能,还能批量提取网络小说。,它也可以用作干净的本地阅读器应用程序。下载小说后,可以直接阅读小说。不知道怎么下载电子书软件的朋友快来最热的软件站下载吧。
基本介绍
这是一款网络小说下载爬虫软件,可以帮助用户批量下载网络小说。软件功能丰富,包括TXT小说下载、TXT小说阅读、有声小说下载。有声小说不仅支持下载,还可以在线听书。如果您使用TXT带有小说下载功能,可以批量下载所有小说网站。如果你还不知道怎么下载电子书软件,快来看看吧。将TXT小说下载到本地后,可以使用电脑小说阅读器阅读,也可以使用软件自带的阅读功能阅读小说。
指示
1.在本站下载并解压这款新颖的爬虫下载器应用。好用,搜索小说,解析目录,选择你要下载的章节(可以平移),点击章节目录查看正文内容,点击章节正文选择,空白处是查看内容,可以右击。
2. 过滤掉不需要的内容(添加范围,去除广告),最好的范围是书网页源代码的内容,点击加入书架或下载,可以到下载管理查看进度。
3. 如果下载失败次数过多,会增加每个线程下载的章节数。您可以直接获取目录链接进行申诉操作。如果是动态网页,记得开启动态网页支持。切换规则不需要重新解析,只需要重新解析章节相关。
4.支持有声小说下载,搜索有声小说,添加书架直接选择要开始下载的,发现失败较多,增加每线程下载章节数,增加延迟。
小编推荐
以上就是这款小说下载软件免费版的完整介绍。最热门的软件网站有更多类似的小说下载软件。有需要的朋友快来下载体验吧。这是另外两个有用的小说下载。软件:电脑版全小说下载器、远天湾小说下载器。
抓取网页生成电子书( 提高iPhone电池寿命的十个看看这十大妙招(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-09 17:23
提高iPhone电池寿命的十个看看这十大妙招(组图))
如何获取和下载谷歌电子书(包括整本书、最新版)
Google Book 和 Goole Play 是目前世界上最大的电子书 网站。这个方法教你如何下载谷歌电子书试读,并尝试下载整本书。一般来说,如果你试读过谷歌电子书,就可以获得完整的PDF。
工具/材料
登录 Google 电子书网站
谷歌图书下载软件
方法/步骤
打开搜索书,只有在有预览的情况下才下载。如下图,会有“部分预览”标记供试读。
打开图书预览页面,复制图书地址,例如:+of+amphibians&hl=zh-CN&sa=X&ved=0ahUKEwjemIzzu9nKAhVC8Q4KHZo4DqcQ6AEIKTAB#v=onepage&q=biology%20of%20amphibians&f=false
将获取到的地址复制到谷歌图书下载器,设置下载的分辨率和存储位置,点击开始开始下载。
预防措施
首先,您必须能够登录 Google 电子书。
只能下载试读的电子书,下载格式可以是PDF或图片格式。
想要得到完整的PDF,需要突破一定的技术封锁,采集需要5-10天,可以私信交流。我可以代表我提供有偿服务。
相关文章
获取hasco官方标准件插件
Hasco标准件下载工具/资料上网电脑方法/步骤 打开一个常用浏览器,在百度中进入hasco官网找到HASCO-Hasco在打开的网页中找到中文开关图标找到下载和服务打开后,有有视频资料和HASCO最新版电子目录可以下载。点击这里下载最新版本的 HASCO 电子目录。有两种文件可供下载 H...
提高 iPhone 电池寿命的十个技巧
如果你用的是iPhone,一定觉得它的电池不够用,那么当你无法更换电池时,如何设置手机让电池更耐用呢?想要获得最佳 iPhone 体验并最大限度地延长 iPhone 电池的使用寿命,请查看这十大技巧!工具/原材料图片来自网络。如果您有任何问题或建议,您可以在下方体验评论,小编会尽快回复您。方...
如何免费下载电子书:[2] 使用俄罗斯网盘
网盘库中已经上传了数以千计的免费电子书,我们可以利用这个巨大的网盘来获取我们想要的电子书。当然,如果有一天这个网盘出现故障,这种方法也会失败。工具/材料电脑上网方法/步骤先用百度搜索图书馆网页打开图书馆网站,搜索你想要的电子书,这里我用的是2013 Spring...
应用宝物5.0五虎将解读智能体验
大家对应用宝5.0的各种信息都有一定的了解,而本次更新的5.0新版本将让用户在社交方面发现很多新的突破。五虎,突出新版AppBao的5大功能,让用户拥有智能体验,包括签到的应用、身边人正在玩的应用、新的应用部落、视频和电子书、流行朋友圈中的app等,让我们更方便、更快捷...
ediary电子日记下载最新ediary电子日记下载
ediary 是一个免费的电子日记。ediary是一款免费的电子日记,那么如何下载最新的ediary电子日记呢?如何下载最新的ediary电子日记?哪里可以下载最新的ediary电子日记?这里为大家分享,ediary电子日记下载最新ediary电子日记下载。工具/原材料 eDiary.eD...
如何在 iPad 上阅读电子书
iPad的设计初衷是为了让用户更方便地观看电子书,但由于图书版权问题,iPad软件中电子书相关的软件并不多,给用户带来了诸多不便。以下编辑器基于电子书。格式整理了电子书软件,总结了以下几种阅读电子书的方法: 一. 通过自带的iBooks软件查看epub和PDF格式的电子书的epub和PDF格式iPad。iPad是最...
豌豆荚手机精灵2.20.0.1478官方稳定版
软件介绍: 豌豆荚是豌豆实验室为安卓手机用户开发的一款产品。它可以帮助您简单快速地管理您的手机,还为您提供了丰富的免费资源获取平台。方法/步骤管理和备份通讯录:通讯录管理帮助您轻松快速地查看和编辑联系人的详细信息,包括联系人信息、分组等,还可以查看最近与某个联系人的联系记录. 支持行动...
九口袋揭秘微信公众号增加粉丝的三种方式
运营微信公众号最麻烦的就是增加粉丝。微信公众号无论是为了什么目的而设立的,都必须以粉丝为基础。不管你多久更新一次内容,不管它有多难,如果你没有粉丝阅读也是如此。徒然。那么,我们怎样才能让微信持续增长粉丝呢?九口袋小编为大家总结了以下三种行之有效的方法。方法/步骤一.资源诱惑方法1.分享一些比较吸引人的资源,资源必须有...
通过电子书订阅 Google 阅读器新闻
Google Reader 是一个可定制的新闻集合,您可以在其中订阅任何您想观看的 网站。博客更新。为了迎合移动阅读的需求,谷歌阅读器还推出了移动版,基于iOS和Android系统。如果您是盛大Bambook电子书用户,还可以通过云梯客户端下载到谷歌阅读器同步工具... 查看全部
抓取网页生成电子书(
提高iPhone电池寿命的十个看看这十大妙招(组图))
如何获取和下载谷歌电子书(包括整本书、最新版)
Google Book 和 Goole Play 是目前世界上最大的电子书 网站。这个方法教你如何下载谷歌电子书试读,并尝试下载整本书。一般来说,如果你试读过谷歌电子书,就可以获得完整的PDF。
工具/材料
登录 Google 电子书网站
谷歌图书下载软件
方法/步骤
打开搜索书,只有在有预览的情况下才下载。如下图,会有“部分预览”标记供试读。
打开图书预览页面,复制图书地址,例如:+of+amphibians&hl=zh-CN&sa=X&ved=0ahUKEwjemIzzu9nKAhVC8Q4KHZo4DqcQ6AEIKTAB#v=onepage&q=biology%20of%20amphibians&f=false
将获取到的地址复制到谷歌图书下载器,设置下载的分辨率和存储位置,点击开始开始下载。
预防措施
首先,您必须能够登录 Google 电子书。
只能下载试读的电子书,下载格式可以是PDF或图片格式。
想要得到完整的PDF,需要突破一定的技术封锁,采集需要5-10天,可以私信交流。我可以代表我提供有偿服务。
相关文章
获取hasco官方标准件插件
Hasco标准件下载工具/资料上网电脑方法/步骤 打开一个常用浏览器,在百度中进入hasco官网找到HASCO-Hasco在打开的网页中找到中文开关图标找到下载和服务打开后,有有视频资料和HASCO最新版电子目录可以下载。点击这里下载最新版本的 HASCO 电子目录。有两种文件可供下载 H...
提高 iPhone 电池寿命的十个技巧
如果你用的是iPhone,一定觉得它的电池不够用,那么当你无法更换电池时,如何设置手机让电池更耐用呢?想要获得最佳 iPhone 体验并最大限度地延长 iPhone 电池的使用寿命,请查看这十大技巧!工具/原材料图片来自网络。如果您有任何问题或建议,您可以在下方体验评论,小编会尽快回复您。方...
如何免费下载电子书:[2] 使用俄罗斯网盘
网盘库中已经上传了数以千计的免费电子书,我们可以利用这个巨大的网盘来获取我们想要的电子书。当然,如果有一天这个网盘出现故障,这种方法也会失败。工具/材料电脑上网方法/步骤先用百度搜索图书馆网页打开图书馆网站,搜索你想要的电子书,这里我用的是2013 Spring...
应用宝物5.0五虎将解读智能体验
大家对应用宝5.0的各种信息都有一定的了解,而本次更新的5.0新版本将让用户在社交方面发现很多新的突破。五虎,突出新版AppBao的5大功能,让用户拥有智能体验,包括签到的应用、身边人正在玩的应用、新的应用部落、视频和电子书、流行朋友圈中的app等,让我们更方便、更快捷...
ediary电子日记下载最新ediary电子日记下载
ediary 是一个免费的电子日记。ediary是一款免费的电子日记,那么如何下载最新的ediary电子日记呢?如何下载最新的ediary电子日记?哪里可以下载最新的ediary电子日记?这里为大家分享,ediary电子日记下载最新ediary电子日记下载。工具/原材料 eDiary.eD...
如何在 iPad 上阅读电子书
iPad的设计初衷是为了让用户更方便地观看电子书,但由于图书版权问题,iPad软件中电子书相关的软件并不多,给用户带来了诸多不便。以下编辑器基于电子书。格式整理了电子书软件,总结了以下几种阅读电子书的方法: 一. 通过自带的iBooks软件查看epub和PDF格式的电子书的epub和PDF格式iPad。iPad是最...
豌豆荚手机精灵2.20.0.1478官方稳定版
软件介绍: 豌豆荚是豌豆实验室为安卓手机用户开发的一款产品。它可以帮助您简单快速地管理您的手机,还为您提供了丰富的免费资源获取平台。方法/步骤管理和备份通讯录:通讯录管理帮助您轻松快速地查看和编辑联系人的详细信息,包括联系人信息、分组等,还可以查看最近与某个联系人的联系记录. 支持行动...
九口袋揭秘微信公众号增加粉丝的三种方式
运营微信公众号最麻烦的就是增加粉丝。微信公众号无论是为了什么目的而设立的,都必须以粉丝为基础。不管你多久更新一次内容,不管它有多难,如果你没有粉丝阅读也是如此。徒然。那么,我们怎样才能让微信持续增长粉丝呢?九口袋小编为大家总结了以下三种行之有效的方法。方法/步骤一.资源诱惑方法1.分享一些比较吸引人的资源,资源必须有...
通过电子书订阅 Google 阅读器新闻
Google Reader 是一个可定制的新闻集合,您可以在其中订阅任何您想观看的 网站。博客更新。为了迎合移动阅读的需求,谷歌阅读器还推出了移动版,基于iOS和Android系统。如果您是盛大Bambook电子书用户,还可以通过云梯客户端下载到谷歌阅读器同步工具...
抓取网页生成电子书(全篇的实现思路分析网页学会使用BeautifulSoup库爬取并导出参考资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-07 14:07
本文文章主要详细介绍了python爬取网页到PDF文件的转换。有一定的参考价值,感兴趣的朋友可以参考。
爬行动物的成因
官方文档或手册虽然可以查阅,但如果变成纸质版是不是更容易阅读和记忆。如果只是简单的复制粘贴,不知道什么时候才能完成。所以我开始考虑爬下官方的Android手册。
整篇文章的实现
分析网页,学习使用BeautifulSoup库抓取导出
参考资料:
* 将廖雪峰的教程转成PDF电子书
* 请求文件
*美丽的汤文件
配置
Ubuntu下使用Pycharm运行成功
要转换为 PDF,您需要下载 wkhtmltopdf
具体流程
网络分析
对于如下所示的网页,您只需获取网页的正文和标题,以及左侧导航栏中的所有网址
下一个工作是找到这些标签......
关于Requests的使用
详见文档,这里只是简单使用Requests获取html并使用代理翻墙(网站不能直接访问,需要VPN)
proxies={ "http":"http://vpn的IP:port", "https":"https://vpn的IP:port", } response=requests.get(url,proxies=proxies)
美汤的使用
参考资料中有一个 Beautiful Soup 文档。看完就知道讲了两件事:一是找标签,二是修改标签。
这篇文章需要做的是:
1. 获取title和所有url,这涉及到找标签
#对标签进行判断,一个标签含有href而不含有description,则返回true #而我希望获取的是含有href属性而不含有description属性的<a>标签,(且只有a标签含有href) def has_href_but_no_des(tag): return tag.has_attr('href') and not tag.has_attr('description') #网页分析,获取网址和标题 def parse_url_to_html(url): response=requests.get(url,proxies=proxies) soup=BeautifulSoup(response.content,"html.parser") s=[]#获取所有的网址 title=[]#获取对应的标题 tag=soup.find(id="nav")#获取第一个id为"nav"的标签,这个里面包含了网址和标题 for i in tag.find_all(has_href_but_no_des): s.append(i['href']) title.append(i.text) #获取的只是标签集,需要加html前缀 htmls = "" with open("android_training_3.html",'a') as f: f.write(htmls)
解析上面得到的URL,得到文本,将图片保存到本地;它涉及查找标签和修改属性
#网页操作,获取正文及图片 def get_htmls(urls,title): for i in range(len(urls)): response=requests.get(urls[i],proxies=proxies) soup=BeautifulSoup(response.content,"html.parser") htmls=""+str(i)+"."+title[i]+"" tag=soup.find(class_='jd-descr') #为image添加相对路径,并下载图片 for img in tag.find_all('img'): im = requests.get(img['src'], proxies=proxies) filename = os.path.split(img['src'])[1] with open('image/' + filename, 'wb') as f: f.write(im.content) img['src']='image/'+filename htmls=htmls+str(tag) with open("android_training_3.html",'a') as f: f.write(htmls) print(" (%s) [%s] download end"%(i,title[i])) htmls="" with open("android_training_3.html",'a') as f: f.write(htmls)
2. 转换为 PDF
这一步需要下载wkhtmltopdf,在windows下执行程序一直报错..ubuntu下是可以的
def save_pdf(html): """ 把所有html文件转换成pdf文件 """ options = { 'page-size': 'Letter', 'encoding': "UTF-8", 'custom-header': [ ('Accept-Encoding', 'gzip') ] } pdfkit.from_file(html, "android_training_3.pdf", options=options)
最终效果图
以上是python爬取网页转换为PDF文件的详细内容,请关注其他相关html中文网站文章! 查看全部
抓取网页生成电子书(全篇的实现思路分析网页学会使用BeautifulSoup库爬取并导出参考资料)
本文文章主要详细介绍了python爬取网页到PDF文件的转换。有一定的参考价值,感兴趣的朋友可以参考。
爬行动物的成因
官方文档或手册虽然可以查阅,但如果变成纸质版是不是更容易阅读和记忆。如果只是简单的复制粘贴,不知道什么时候才能完成。所以我开始考虑爬下官方的Android手册。
整篇文章的实现
分析网页,学习使用BeautifulSoup库抓取导出
参考资料:
* 将廖雪峰的教程转成PDF电子书
* 请求文件
*美丽的汤文件
配置
Ubuntu下使用Pycharm运行成功
要转换为 PDF,您需要下载 wkhtmltopdf
具体流程
网络分析
对于如下所示的网页,您只需获取网页的正文和标题,以及左侧导航栏中的所有网址
下一个工作是找到这些标签......
关于Requests的使用
详见文档,这里只是简单使用Requests获取html并使用代理翻墙(网站不能直接访问,需要VPN)
proxies={ "http":"http://vpn的IP:port", "https":"https://vpn的IP:port", } response=requests.get(url,proxies=proxies)
美汤的使用
参考资料中有一个 Beautiful Soup 文档。看完就知道讲了两件事:一是找标签,二是修改标签。
这篇文章需要做的是:
1. 获取title和所有url,这涉及到找标签
#对标签进行判断,一个标签含有href而不含有description,则返回true #而我希望获取的是含有href属性而不含有description属性的<a>标签,(且只有a标签含有href) def has_href_but_no_des(tag): return tag.has_attr('href') and not tag.has_attr('description') #网页分析,获取网址和标题 def parse_url_to_html(url): response=requests.get(url,proxies=proxies) soup=BeautifulSoup(response.content,"html.parser") s=[]#获取所有的网址 title=[]#获取对应的标题 tag=soup.find(id="nav")#获取第一个id为"nav"的标签,这个里面包含了网址和标题 for i in tag.find_all(has_href_but_no_des): s.append(i['href']) title.append(i.text) #获取的只是标签集,需要加html前缀 htmls = "" with open("android_training_3.html",'a') as f: f.write(htmls)
解析上面得到的URL,得到文本,将图片保存到本地;它涉及查找标签和修改属性
#网页操作,获取正文及图片 def get_htmls(urls,title): for i in range(len(urls)): response=requests.get(urls[i],proxies=proxies) soup=BeautifulSoup(response.content,"html.parser") htmls=""+str(i)+"."+title[i]+"" tag=soup.find(class_='jd-descr') #为image添加相对路径,并下载图片 for img in tag.find_all('img'): im = requests.get(img['src'], proxies=proxies) filename = os.path.split(img['src'])[1] with open('image/' + filename, 'wb') as f: f.write(im.content) img['src']='image/'+filename htmls=htmls+str(tag) with open("android_training_3.html",'a') as f: f.write(htmls) print(" (%s) [%s] download end"%(i,title[i])) htmls="" with open("android_training_3.html",'a') as f: f.write(htmls)
2. 转换为 PDF
这一步需要下载wkhtmltopdf,在windows下执行程序一直报错..ubuntu下是可以的
def save_pdf(html): """ 把所有html文件转换成pdf文件 """ options = { 'page-size': 'Letter', 'encoding': "UTF-8", 'custom-header': [ ('Accept-Encoding', 'gzip') ] } pdfkit.from_file(html, "android_training_3.pdf", options=options)
最终效果图
以上是python爬取网页转换为PDF文件的详细内容,请关注其他相关html中文网站文章!
抓取网页生成电子书(Python爬虫实践:将网页转换为pdf电子书写爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-11-07 14:05
2018-03-26 • 用 Python 阅读
Python实践一、将网页转成pdf电子书
我是个“采集狂”(别以为是歪的,我就是喜欢采集技术帖),遇到好东西就喜欢采集或者记录好东西,尤其是好的技术文章或者工具。这里要提一下廖雪峰老师的官方网站。廖老师写的Python、JavaScript、Git教程真的很好,经常去逛街。所以今天有必要把廖老师的教程从网页转成PDF电子书,让你随时随地离线学习和采集。说到这里,进入今天的话题Python爬虫练习:将网页转成pdf电子书
写爬虫好像不比用Python好。Python社区提供的爬虫工具让你眼花缭乱。各种可以直接使用的库,分分钟写一个爬虫。今天想写一个爬虫。, 爬下廖雪峰的Python教程,制作PDF电子书供离线阅读。
在开始写爬虫之前,我们先来分析一下网站的页面结构。页面左侧是教程目录大纲。每个URL对应右边文章的一篇文章,右上角是文章的标题,中间是文章的正文部分。正文内容是我们关注的焦点。我们要抓取的数据是所有网页的正文部分。下面是用户的评论区。评论区对我们来说什么都不是。使用它,所以它可以被忽略。
工具准备
搞清楚网站的基本结构后,就可以开始准备爬虫依赖的工具包了。requests和beautifulsoup是爬虫的两大神器,reuqests用于网络请求,beautifulsoup用于操作html数据。有了这两个班车,我们就可以顺利工作了。我们不需要像scrapy这样的爬虫框架。小程序有点像大锤。另外,既然是把html文件转换成pdf,就得有相应的库支持。wkhtmltopdf 是一个非常好的工具。它可用于从 html 到 pdf 的多平台转换。pdfkit 是 wkhtmltopdf 的 Python 包。先安装以下依赖包,然后安装wkhtmltopdf
1234
pip install requestspip install beautifulsoup4pip install pdfkitpip install PyPDF2
安装 wkhtmltopdf
Ubuntu 和 CentOS 可以直接从命令行安装。
12
$ sudo apt-get install wkhtmltopdf # ubuntu$ sudo yum intsall wkhtmltopdf # centos
Windows平台直接在wkhtmltopdf官网2下载稳定版进行安装。安装完成后,将程序的执行路径添加到系统环境$PATH变量中,否则pdfkit会找不到wkhtmltopdf而报错。No wkhtmltopdf executable found 几句,因为这里的处理不好,程序执行pdfkit.from_file(htmls, file_name, options=options)时会报错。
现在开始手动安装wkhtmltopdf(博主电脑操作系统为macOS 10.12.2)
1、去官网。下载并运行 wkhtmltox-0.12.4_osx-cocoa-x86-64.pkg
2、将wkhtmltoimage和wkhtmltopdf复制到/usr/bin目录下,更改所有者,并添加可执行属性
123456
sudo cp /usr/local/bin/wkhtmltopdf /usr/bin/sudo cp /usr/local/bin/wkhtmltoimage /usr/bin/sudo chown root:root /usr/bin/wkhtmltopdfsudo chown root:root /usr/bin/wkhtmltoimagesudo chmod +x /usr/bin/wkhtmltopdfsudo chmod +x /usr/bin/wkhtmltoimage
不出意外,执行第一句时,会遇到chmod: Unable to change file modle on /usr/bin。这是因为 Apple 使用了 OS X El Capitan 10.11 的 Rootless 机制。这种机制可以理解为更高级别的系统内核保护措施,系统默认会锁定/system、/sbin、/usr三个目录。
关闭无根
关闭和打开 Rootless 非常简单。方法如下:重启Mac,听到启动声后按Command+R,进入recovery模式,在上面的菜单实用工具中找到并打开Terminal(如果菜单没有出现在顶部,请继续重启^_^)。输入以下命令:
12
$ csrutil disable #关闭 Rootless$ csrutil enable #开启 Rootless
OK,到此我们的工具和环境都配置好了,下面开始实现功能。
爬虫实现
一切准备就绪后,就可以开始编写代码了,但是在编写代码之前,应该先整理一下思路。该程序的目的是将所有URL对应的html body部分保存在本地,然后使用pdfkit将这些文件转换为pdf文件。让我们拆分任务。首先将某个URL对应的html body保存到本地,然后找到所有的URL进行同样的操作。使用Chrome浏览器找到页面body部分的标签,按F12找到body对应的div标签:
,div是网页的body内容。使用requests在本地加载整个页面后,可以使用beautifulsoup操作HTML的dom元素来提取body内容。
具体实现代码如下: 使用soup.find_all函数查找body标签,然后将body部分的内容保存到a.html文件中。
12345678910111213141516171819202122232425262728293031323334353637
<p>def parse_url_to_html(url, name): """ 解析URL,返回HTML内容 :param url:解析的url :param name: 保存的html文件名 :return: html """ try: response = requests.get(url) soup = BeautifulSoup(response.content, 'html.parser') # 正文 body = soup.find_all(class_="x-wiki-content")[0] # 标题 title = soup.find('h4').get_text() # 标题加入到正文的最前面,居中显示 center_tag = soup.new_tag("center") title_tag = soup.new_tag('h1') title_tag.string = title center_tag.insert(1, title_tag) body.insert(1, center_tag) html = str(body) # body中的img标签的src相对路径的改成绝对路径 pattern = "( 查看全部
抓取网页生成电子书(Python爬虫实践:将网页转换为pdf电子书写爬虫)
2018-03-26 • 用 Python 阅读
Python实践一、将网页转成pdf电子书
我是个“采集狂”(别以为是歪的,我就是喜欢采集技术帖),遇到好东西就喜欢采集或者记录好东西,尤其是好的技术文章或者工具。这里要提一下廖雪峰老师的官方网站。廖老师写的Python、JavaScript、Git教程真的很好,经常去逛街。所以今天有必要把廖老师的教程从网页转成PDF电子书,让你随时随地离线学习和采集。说到这里,进入今天的话题Python爬虫练习:将网页转成pdf电子书
写爬虫好像不比用Python好。Python社区提供的爬虫工具让你眼花缭乱。各种可以直接使用的库,分分钟写一个爬虫。今天想写一个爬虫。, 爬下廖雪峰的Python教程,制作PDF电子书供离线阅读。
在开始写爬虫之前,我们先来分析一下网站的页面结构。页面左侧是教程目录大纲。每个URL对应右边文章的一篇文章,右上角是文章的标题,中间是文章的正文部分。正文内容是我们关注的焦点。我们要抓取的数据是所有网页的正文部分。下面是用户的评论区。评论区对我们来说什么都不是。使用它,所以它可以被忽略。
工具准备
搞清楚网站的基本结构后,就可以开始准备爬虫依赖的工具包了。requests和beautifulsoup是爬虫的两大神器,reuqests用于网络请求,beautifulsoup用于操作html数据。有了这两个班车,我们就可以顺利工作了。我们不需要像scrapy这样的爬虫框架。小程序有点像大锤。另外,既然是把html文件转换成pdf,就得有相应的库支持。wkhtmltopdf 是一个非常好的工具。它可用于从 html 到 pdf 的多平台转换。pdfkit 是 wkhtmltopdf 的 Python 包。先安装以下依赖包,然后安装wkhtmltopdf
1234
pip install requestspip install beautifulsoup4pip install pdfkitpip install PyPDF2
安装 wkhtmltopdf
Ubuntu 和 CentOS 可以直接从命令行安装。
12
$ sudo apt-get install wkhtmltopdf # ubuntu$ sudo yum intsall wkhtmltopdf # centos
Windows平台直接在wkhtmltopdf官网2下载稳定版进行安装。安装完成后,将程序的执行路径添加到系统环境$PATH变量中,否则pdfkit会找不到wkhtmltopdf而报错。No wkhtmltopdf executable found 几句,因为这里的处理不好,程序执行pdfkit.from_file(htmls, file_name, options=options)时会报错。
现在开始手动安装wkhtmltopdf(博主电脑操作系统为macOS 10.12.2)
1、去官网。下载并运行 wkhtmltox-0.12.4_osx-cocoa-x86-64.pkg
2、将wkhtmltoimage和wkhtmltopdf复制到/usr/bin目录下,更改所有者,并添加可执行属性
123456
sudo cp /usr/local/bin/wkhtmltopdf /usr/bin/sudo cp /usr/local/bin/wkhtmltoimage /usr/bin/sudo chown root:root /usr/bin/wkhtmltopdfsudo chown root:root /usr/bin/wkhtmltoimagesudo chmod +x /usr/bin/wkhtmltopdfsudo chmod +x /usr/bin/wkhtmltoimage
不出意外,执行第一句时,会遇到chmod: Unable to change file modle on /usr/bin。这是因为 Apple 使用了 OS X El Capitan 10.11 的 Rootless 机制。这种机制可以理解为更高级别的系统内核保护措施,系统默认会锁定/system、/sbin、/usr三个目录。
关闭无根
关闭和打开 Rootless 非常简单。方法如下:重启Mac,听到启动声后按Command+R,进入recovery模式,在上面的菜单实用工具中找到并打开Terminal(如果菜单没有出现在顶部,请继续重启^_^)。输入以下命令:
12
$ csrutil disable #关闭 Rootless$ csrutil enable #开启 Rootless
OK,到此我们的工具和环境都配置好了,下面开始实现功能。
爬虫实现
一切准备就绪后,就可以开始编写代码了,但是在编写代码之前,应该先整理一下思路。该程序的目的是将所有URL对应的html body部分保存在本地,然后使用pdfkit将这些文件转换为pdf文件。让我们拆分任务。首先将某个URL对应的html body保存到本地,然后找到所有的URL进行同样的操作。使用Chrome浏览器找到页面body部分的标签,按F12找到body对应的div标签:
,div是网页的body内容。使用requests在本地加载整个页面后,可以使用beautifulsoup操作HTML的dom元素来提取body内容。
具体实现代码如下: 使用soup.find_all函数查找body标签,然后将body部分的内容保存到a.html文件中。
12345678910111213141516171819202122232425262728293031323334353637
<p>def parse_url_to_html(url, name): """ 解析URL,返回HTML内容 :param url:解析的url :param name: 保存的html文件名 :return: html """ try: response = requests.get(url) soup = BeautifulSoup(response.content, 'html.parser') # 正文 body = soup.find_all(class_="x-wiki-content")[0] # 标题 title = soup.find('h4').get_text() # 标题加入到正文的最前面,居中显示 center_tag = soup.new_tag("center") title_tag = soup.new_tag('h1') title_tag.string = title center_tag.insert(1, title_tag) body.insert(1, center_tag) html = str(body) # body中的img标签的src相对路径的改成绝对路径 pattern = "(
抓取网页生成电子书(一个可以帮助你快速将PDF文档中的图片、文字以及字体批量提取出来保存)
网站优化 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-11-06 15:09
由于经常需要处理PDF文档,我一直在寻找一种快速、免费的方法,可以批量提取和保存PDF文档中的图片和文字。为了实现这个功能,我经常需要购买相关的软件来完成,但现在我找到了一个更好的方法。
它是一个网站,可以帮助您快速批量提取PDF文档中的图片、文本和嵌入字体并保存。您无需安装任何软件。您只需将 PDF 文件上传到任何计算机上的浏览器即可。网站可以导出它的所有文字和图片,使用起来非常方便。而且在测试中文PDF电子书提取时不会出现乱码问题。是一款值得大家采集的利器。网站……
在线导出并保存PDF文件中的图片、文字和字体网站:
的功能非常具体且完全免费。对于有这种需求的朋友来说,真是难得的好东西网站。它的用法非常简单。该页面提供了一个上传按钮,只需点击它即可上传文件。唯一的缺点是它只支持上传 10MB 以下的 PDF 文件。如果你经常需要处理大文件,那么这个工具就不是那么完美了。但是,它也可以通过网站远程下载。不知道这个功能会不会有大小限制,大家可以试试。
之前试过上传不同维度推荐给大家的《摄影笔记》PDF进行测试,图片和文字都可以正常提交。点击蓝色下载按钮进行打包下载。
导出文本的功能有时候很有用,你懂的。对中文文档的支持非常友好。试了一堆电子书,可以成功提取文字,没有乱码。
相关网址:
访问|更多Office相关|来自不同维度|更多PDF相关|更多网站推荐 查看全部
抓取网页生成电子书(一个可以帮助你快速将PDF文档中的图片、文字以及字体批量提取出来保存)
由于经常需要处理PDF文档,我一直在寻找一种快速、免费的方法,可以批量提取和保存PDF文档中的图片和文字。为了实现这个功能,我经常需要购买相关的软件来完成,但现在我找到了一个更好的方法。
它是一个网站,可以帮助您快速批量提取PDF文档中的图片、文本和嵌入字体并保存。您无需安装任何软件。您只需将 PDF 文件上传到任何计算机上的浏览器即可。网站可以导出它的所有文字和图片,使用起来非常方便。而且在测试中文PDF电子书提取时不会出现乱码问题。是一款值得大家采集的利器。网站……
在线导出并保存PDF文件中的图片、文字和字体网站:
的功能非常具体且完全免费。对于有这种需求的朋友来说,真是难得的好东西网站。它的用法非常简单。该页面提供了一个上传按钮,只需点击它即可上传文件。唯一的缺点是它只支持上传 10MB 以下的 PDF 文件。如果你经常需要处理大文件,那么这个工具就不是那么完美了。但是,它也可以通过网站远程下载。不知道这个功能会不会有大小限制,大家可以试试。
之前试过上传不同维度推荐给大家的《摄影笔记》PDF进行测试,图片和文字都可以正常提交。点击蓝色下载按钮进行打包下载。
导出文本的功能有时候很有用,你懂的。对中文文档的支持非常友好。试了一堆电子书,可以成功提取文字,没有乱码。
相关网址:
访问|更多Office相关|来自不同维度|更多PDF相关|更多网站推荐
抓取网页生成电子书( 2019年03月25日14:21:37(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-11-06 05:02
2019年03月25日14:21:37(图))
我用Python爬取7000多个电子书案例详情
更新时间:2019年3月25日14:21:37 作者:嗨学编程
本文文章主要介绍我用Python爬取的7000多本电子书的案例。文章中介绍的示例代码非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友在下面和小编一起学习吧
安装
安装很简单,直接执行:
pip install requests-html
就是这样。
分析页面结构
通过浏览器的评论元素,可以发现这本电子书网站是用WordPress搭建的,首页列表元素很简单也很规律
所以我们可以搜索 .entry-title> a 得到所有书籍详情页的链接,然后我们进入详情页找到下载链接,如下图
可以发现 .download-links>a 中的链接是该书的下载链接。回到列表页面,你会发现该站点有700多个页面,因此我们可以遍历列表以获取所有下载链接。
请求-html 快速指南
发送 GET 请求:
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://python.org/')
Requests-html 的方便之处在于它解析 html 的方式就像使用 jQuery 一样简单,比如:
# 获取页面的所有链接可以这样写:
r.html.links
# 会返回 {'//docs.python.org/3/tutorial/', '/about/apps/'}
# 获取页面的所有的绝对链接:
r.html.absolute_links
# 会返回 {'https://github.com/python/pythondotorg/issues', 'https://docs.python.org/3/tutorial/'}
# 通过 CSS 选择器选择元素:
about = r.find('.about', first=True)
# 参数 first 表示只获取找到的第一元素
about.text # 获取 .about 下的所有文本
about.attrs # 获取 .about 下所有属性像 id, src, href 等等
about.html # 获取 .about 的 HTML
about.find('a') # 获取 .about 下的所有 a 标签
构建代码
from requests_html import HTMLSession
import requests
import time
import json
import random
import sys
'''
想要学习Python?Python学习交流群:984632579满足你的需求,资料都已经上传群文件,可以自行下载!
'''
session = HTMLSession()
list_url = 'http://www.allitebooks.com/page/'
USER_AGENTS = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"
]
# 获取当前列表页所有图书链接
def get_list(url):
response = session.get(url)
all_link = response.html.find('.entry-title a') # 获取页面所有图书详情链接
for link in all_link:
getBookUrl(link.attrs['href'])
# 获取图书下载链接
def getBookUrl(url):
response = session.get(url)
l = response.html.find('.download-links a', first=True)
if l is not None: # 运行后发现有的个别页面没有下载链接,这里加个判断
link = l.attrs['href'];
download(link)
#下载图书
def download(url):
# 随机浏览器 User-Agent
headers={ "User-Agent":random.choice(USER_AGENTS) }
# 获取文件名
filename = url.split('/')[-1]
# 如果 url 里包含 .pdf
if ".pdf" in url:
file = 'book/'+filename # 文件路径写死了,运行时当前目录必须有名 book 的文件夹
with open(file, 'wb') as f:
print("正在下载 %s" % filename)
response = requests.get(url, stream=True, headers=headers)
# 获取文件大小
total_length = response.headers.get('content-length')
# 如果文件大小不存在,则直接写入返回的文本
if total_length is None:
f.write(response.content)
else:
# 下载进度条
dl = 0
total_length = int(total_length) # 文件大小
for data in response.iter_content(chunk_size=4096): # 每次响应获取 4096 字节
dl += len(data)
f.write(data)
done = int(50 * dl / total_length)
sys.stdout.write("\r[%s%s]" % ('=' * done, ' ' * (50-done)) ) # 打印进度条
sys.stdout.flush()
print(filename + '下载完成!')
if __name__ == '__main__':
#从这运行,应为知道列表总数,所以偷个懒直接开始循环
for x in range(1,756):
print('当前页面: '+ str(x))
get_list(list_url+str(x))
运行结果:
以上就是小编为大家介绍的内容。我已经使用 Python 抓取了 7000 多个电子书案例。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。非常感谢您对脚本之家网站的支持! 查看全部
抓取网页生成电子书(
2019年03月25日14:21:37(图))
我用Python爬取7000多个电子书案例详情
更新时间:2019年3月25日14:21:37 作者:嗨学编程
本文文章主要介绍我用Python爬取的7000多本电子书的案例。文章中介绍的示例代码非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友在下面和小编一起学习吧
安装
安装很简单,直接执行:
pip install requests-html
就是这样。
分析页面结构
通过浏览器的评论元素,可以发现这本电子书网站是用WordPress搭建的,首页列表元素很简单也很规律
所以我们可以搜索 .entry-title> a 得到所有书籍详情页的链接,然后我们进入详情页找到下载链接,如下图
可以发现 .download-links>a 中的链接是该书的下载链接。回到列表页面,你会发现该站点有700多个页面,因此我们可以遍历列表以获取所有下载链接。
请求-html 快速指南
发送 GET 请求:
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://python.org/')
Requests-html 的方便之处在于它解析 html 的方式就像使用 jQuery 一样简单,比如:
# 获取页面的所有链接可以这样写:
r.html.links
# 会返回 {'//docs.python.org/3/tutorial/', '/about/apps/'}
# 获取页面的所有的绝对链接:
r.html.absolute_links
# 会返回 {'https://github.com/python/pythondotorg/issues', 'https://docs.python.org/3/tutorial/'}
# 通过 CSS 选择器选择元素:
about = r.find('.about', first=True)
# 参数 first 表示只获取找到的第一元素
about.text # 获取 .about 下的所有文本
about.attrs # 获取 .about 下所有属性像 id, src, href 等等
about.html # 获取 .about 的 HTML
about.find('a') # 获取 .about 下的所有 a 标签
构建代码
from requests_html import HTMLSession
import requests
import time
import json
import random
import sys
'''
想要学习Python?Python学习交流群:984632579满足你的需求,资料都已经上传群文件,可以自行下载!
'''
session = HTMLSession()
list_url = 'http://www.allitebooks.com/page/'
USER_AGENTS = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"
]
# 获取当前列表页所有图书链接
def get_list(url):
response = session.get(url)
all_link = response.html.find('.entry-title a') # 获取页面所有图书详情链接
for link in all_link:
getBookUrl(link.attrs['href'])
# 获取图书下载链接
def getBookUrl(url):
response = session.get(url)
l = response.html.find('.download-links a', first=True)
if l is not None: # 运行后发现有的个别页面没有下载链接,这里加个判断
link = l.attrs['href'];
download(link)
#下载图书
def download(url):
# 随机浏览器 User-Agent
headers={ "User-Agent":random.choice(USER_AGENTS) }
# 获取文件名
filename = url.split('/')[-1]
# 如果 url 里包含 .pdf
if ".pdf" in url:
file = 'book/'+filename # 文件路径写死了,运行时当前目录必须有名 book 的文件夹
with open(file, 'wb') as f:
print("正在下载 %s" % filename)
response = requests.get(url, stream=True, headers=headers)
# 获取文件大小
total_length = response.headers.get('content-length')
# 如果文件大小不存在,则直接写入返回的文本
if total_length is None:
f.write(response.content)
else:
# 下载进度条
dl = 0
total_length = int(total_length) # 文件大小
for data in response.iter_content(chunk_size=4096): # 每次响应获取 4096 字节
dl += len(data)
f.write(data)
done = int(50 * dl / total_length)
sys.stdout.write("\r[%s%s]" % ('=' * done, ' ' * (50-done)) ) # 打印进度条
sys.stdout.flush()
print(filename + '下载完成!')
if __name__ == '__main__':
#从这运行,应为知道列表总数,所以偷个懒直接开始循环
for x in range(1,756):
print('当前页面: '+ str(x))
get_list(list_url+str(x))
运行结果:
以上就是小编为大家介绍的内容。我已经使用 Python 抓取了 7000 多个电子书案例。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。非常感谢您对脚本之家网站的支持!
抓取网页生成电子书(电子书制作利器-友益文书V7.1.1(1.1)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-05 02:06
电子书制作工具-游易文书V7.1.1[点击下载]Spring eBook eBookMakerV2.1[点击下载]电子书专家CHMEBookEditorV1.56 【点击下载】二. 软件界面:照例先来看看这三个软件的运行界面~又一文书主界面 Spring电子书主界面 电子书专家主界面总结:游易文书和电子书专家的界面类似,即界面左侧是目录栏,右侧是目录的具体内容。不过spring电子书的主界面不同的是,菜单栏放在了右侧,让用户一目了然。从界面来看,电子书专家显得很空洞,而且功能好像比游易和春天电子书略逊一筹!而且有用的文件是绿色软件,直接解压即可使用。是起跑线上的胜利吗?软件功能对比 1. 基本功能 我们制作一本电子书,看看这三个软件最基本的功能。我想做的电子书只是最基本的一种,包括word文档和笔记。书籍、图片和网页。一种。首先,我选择批量导入文档。我发现游易支持的格式比我想做的要多得多。好像不难找~ 轻松导入后生成目录。但是,我只导入了jpg格式的图片,对于png格式的图片还是不行。您可以单击查看和编辑每个目录。可以直接查看以exe形式发布的电子文档。未注册用户的电子书顶部会有广告~b。接下来是春季电子书。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。可以直接查看以exe形式发布的电子文档。未注册用户的电子书顶部会有广告~b。接下来是春季电子书。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。可以直接查看以exe形式发布的电子文档。未注册用户的电子书顶部会有广告~b。接下来是春季电子书。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。未注册用户的电子书顶部会有广告~b。接下来是春季电子书。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。未注册用户的电子书顶部会有广告~b。接下来是春季电子书。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。但是编辑器每次点击每个目录名称,都会提示这是一本未注册的spring电子书,编辑器可以理解作者希望大家支持正版心情,但是老弹窗还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。但是编辑器每次点击每个目录名称,都会提示这是一本未注册的spring电子书,编辑器可以理解作者希望大家支持正版心情,但是老弹窗还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。
注意电子书高手需要新建一个库文件才能开始制作,并新建一个标题来导入文件,而且只能导入文本目录和网页目录,不支持导入图片,非常不方便!小编看到了自己的一个例子,没有图。导入的网页都变成了文本形式。图片好像不能导入。2.其他功能 电子书制作只是最基本的功能之一,其他贴心的功能也可以加分~a. 又一写:可以做个索引。导入要制作电子书的文件后,还可以编辑文本文档和网页,如图。您可以设置出版电子书的权限(包括次数和天数限制)。您可以插入多媒体格式。湾 Spring 电子书自定义电子书图标可设置权限(仅受天数限制),并可插入多媒体格式。C。电子书专家,无其他功能。三。电子书生成界面 a.游易文书生成的电子书功能最全,菜单栏包括目录、搜索、书签、索引,可设置网页字体颜色大小,可连接打印机打印等. b. Spring电子书的菜单栏一个索引功能比有用文档少,一个是最基本的翻页功能。C。电子书专家的界面是最简单的。四。总结 为了给读者更直观的印象,小编做了一个表格。毋庸置疑,游义文件各方面最强大,最周到,但他的注册费也是最贵的,验证一分钱一分货的古老真理。最简单的电子书。专家注册只需9元。如果你想制作只有文字的电子书,它是一个不错的选择。您可以根据自己的要求进行选择。你可以参考一下 查看全部
抓取网页生成电子书(电子书制作利器-友益文书V7.1.1(1.1)_)
电子书制作工具-游易文书V7.1.1[点击下载]Spring eBook eBookMakerV2.1[点击下载]电子书专家CHMEBookEditorV1.56 【点击下载】二. 软件界面:照例先来看看这三个软件的运行界面~又一文书主界面 Spring电子书主界面 电子书专家主界面总结:游易文书和电子书专家的界面类似,即界面左侧是目录栏,右侧是目录的具体内容。不过spring电子书的主界面不同的是,菜单栏放在了右侧,让用户一目了然。从界面来看,电子书专家显得很空洞,而且功能好像比游易和春天电子书略逊一筹!而且有用的文件是绿色软件,直接解压即可使用。是起跑线上的胜利吗?软件功能对比 1. 基本功能 我们制作一本电子书,看看这三个软件最基本的功能。我想做的电子书只是最基本的一种,包括word文档和笔记。书籍、图片和网页。一种。首先,我选择批量导入文档。我发现游易支持的格式比我想做的要多得多。好像不难找~ 轻松导入后生成目录。但是,我只导入了jpg格式的图片,对于png格式的图片还是不行。您可以单击查看和编辑每个目录。可以直接查看以exe形式发布的电子文档。未注册用户的电子书顶部会有广告~b。接下来是春季电子书。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。可以直接查看以exe形式发布的电子文档。未注册用户的电子书顶部会有广告~b。接下来是春季电子书。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。可以直接查看以exe形式发布的电子文档。未注册用户的电子书顶部会有广告~b。接下来是春季电子书。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。未注册用户的电子书顶部会有广告~b。接下来是春季电子书。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。未注册用户的电子书顶部会有广告~b。接下来是春季电子书。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。新建一个目录生成电子书,可以看到目录下的所有文件都显示出来了,包括png格式的图片~ 点击编译就可以生成电子书了,可以直接查看,但是每次编辑点击每个目录名称,提示这是一本未注册的spring电子书,编辑可以理解作者希望大家支持正版心情,但是老弹还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。但是编辑器每次点击每个目录名称,都会提示这是一本未注册的spring电子书,编辑器可以理解作者希望大家支持正版心情,但是老弹窗还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。但是编辑器每次点击每个目录名称,都会提示这是一本未注册的spring电子书,编辑器可以理解作者希望大家支持正版心情,但是老弹窗还是很烦。不知道是不是每次都弹出注册窗口,每个电子书目录的打开速度都不够快~c。看看电子书专家。
注意电子书高手需要新建一个库文件才能开始制作,并新建一个标题来导入文件,而且只能导入文本目录和网页目录,不支持导入图片,非常不方便!小编看到了自己的一个例子,没有图。导入的网页都变成了文本形式。图片好像不能导入。2.其他功能 电子书制作只是最基本的功能之一,其他贴心的功能也可以加分~a. 又一写:可以做个索引。导入要制作电子书的文件后,还可以编辑文本文档和网页,如图。您可以设置出版电子书的权限(包括次数和天数限制)。您可以插入多媒体格式。湾 Spring 电子书自定义电子书图标可设置权限(仅受天数限制),并可插入多媒体格式。C。电子书专家,无其他功能。三。电子书生成界面 a.游易文书生成的电子书功能最全,菜单栏包括目录、搜索、书签、索引,可设置网页字体颜色大小,可连接打印机打印等. b. Spring电子书的菜单栏一个索引功能比有用文档少,一个是最基本的翻页功能。C。电子书专家的界面是最简单的。四。总结 为了给读者更直观的印象,小编做了一个表格。毋庸置疑,游义文件各方面最强大,最周到,但他的注册费也是最贵的,验证一分钱一分货的古老真理。最简单的电子书。专家注册只需9元。如果你想制作只有文字的电子书,它是一个不错的选择。您可以根据自己的要求进行选择。你可以参考一下

