
抓取网页数据
抓取网页数据(webscraper抓取网页数据的几个常见问题基础入门(二) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-01 11:20
)
网络爬虫抓取网页数据的几个常见问题的基本介绍
如果你想爬取数据又懒得写代码,可以试试网络爬虫爬取数据。
如果您在使用网络爬虫抓取数据,您很可能会遇到以下一个或多个问题,这些问题可能会直接打乱您的计划,甚至让您放弃网络爬虫。
下面列出了您可能遇到的几个问题,并说明了解决方法。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转,如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标移动到要选择的元素上,按下S键。
另外,勾选“Enable key”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择当前元素子元素,当前元素指的是鼠标所在的元素。
2、分页数据或滚动加载的数据无法完整抓取,如知乎和twitter等?
出现这种问题多是因为网络问题。在数据可以加载之前,网络爬虫开始解析数据,但由于没有及时加载,网络爬虫误认为抓取已经完成。
因此适当增加延迟大小,延长等待时间,并为数据加载留出足够的时间。默认延迟2000,也就是2秒,可以根据网速调整。
但是,当数据量比较大的时候,不完整的数据抓取也是很常见的。因为只要在延迟时间内没有完成翻页或者下拉加载,那么爬取就结束了。
3、 获取数据的顺序和网页上的顺序不一致?
Web Scraper默认是无序的,可以安装CouchDB来保证数据的顺序。
或者使用其他替代方法,我们最终将数据导出为 CSV 格式。 CSV 在 Excel 中打开后,可以按某一列进行排序。比如我们抓取微博数据的时候,可以抓取发布时间,然后在Excel中,按照发布时间排序,或者知乎上的数据按照点赞数排序。
4、有些页面元素无法通过网络爬虫提供的选择器选择?
出现这种情况的原因可能是网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标悬停时才会显示的元素。我们不得不求助于其他方法。
<p>其实就是鼠标操作选中元素,最后就是找到元素对应的xpath。 Xpath对应网页解释,是定位某个元素的路径,通过元素的类型、唯一标识符、样式名称、从属关系找到某个元素或某种类型的元素。 查看全部
抓取网页数据(webscraper抓取网页数据的几个常见问题基础入门(二)
)
网络爬虫抓取网页数据的几个常见问题的基本介绍
如果你想爬取数据又懒得写代码,可以试试网络爬虫爬取数据。

如果您在使用网络爬虫抓取数据,您很可能会遇到以下一个或多个问题,这些问题可能会直接打乱您的计划,甚至让您放弃网络爬虫。
下面列出了您可能遇到的几个问题,并说明了解决方法。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转,如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标移动到要选择的元素上,按下S键。

另外,勾选“Enable key”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择当前元素子元素,当前元素指的是鼠标所在的元素。
2、分页数据或滚动加载的数据无法完整抓取,如知乎和twitter等?
出现这种问题多是因为网络问题。在数据可以加载之前,网络爬虫开始解析数据,但由于没有及时加载,网络爬虫误认为抓取已经完成。
因此适当增加延迟大小,延长等待时间,并为数据加载留出足够的时间。默认延迟2000,也就是2秒,可以根据网速调整。
但是,当数据量比较大的时候,不完整的数据抓取也是很常见的。因为只要在延迟时间内没有完成翻页或者下拉加载,那么爬取就结束了。
3、 获取数据的顺序和网页上的顺序不一致?
Web Scraper默认是无序的,可以安装CouchDB来保证数据的顺序。
或者使用其他替代方法,我们最终将数据导出为 CSV 格式。 CSV 在 Excel 中打开后,可以按某一列进行排序。比如我们抓取微博数据的时候,可以抓取发布时间,然后在Excel中,按照发布时间排序,或者知乎上的数据按照点赞数排序。
4、有些页面元素无法通过网络爬虫提供的选择器选择?

出现这种情况的原因可能是网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标悬停时才会显示的元素。我们不得不求助于其他方法。
<p>其实就是鼠标操作选中元素,最后就是找到元素对应的xpath。 Xpath对应网页解释,是定位某个元素的路径,通过元素的类型、唯一标识符、样式名称、从属关系找到某个元素或某种类型的元素。
抓取网页数据(使用网络抓取工具有什么好处?营销人员的好处)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-31 08:07
使用网络爬虫有什么好处?
将您的双手从重复的复制和粘贴任务中解放出来。
以结构良好的格式放置提取的数据,包括 Excel、HTML 和 CSV。
通过聘请专业数据分析师,您可以节省时间和金钱。
这是营销人员、营销人员、记者、YouTube 用户、研究人员和许多其他缺乏技术技能的人的武器。
1. Octoparse
Octoparse是一个网站爬虫程序,几乎可以提取网站上所有你需要的数据。您可以使用 Octoparse 提取具有广泛特征的 网站。它有两种操作模式:助手模式和高级模式,非程序员也能快速上手。一个简单的点击式界面可以指导您完成整个提取过程。因此,您可以轻松地从网站 中提取内容,并在短时间内将其保存为结构化格式,例如 EXCEL、TXT、HTML 或其数据库。
此外,它还提供计划云提取,让您实时提取动态数据并跟踪网站 更新。
您还可以通过使用内置的 Regex 和 XPath 设置来准确定位项目,以提取复杂的结构网站。您不再需要担心 IP 阻塞。Octoparse提供IP代理服务器,会自动轮换IP,不会被反跟踪网站发现。
总之,Octoparse 不需要任何编码技能即可满足用户的基本和高级跟踪需求。
2.Cyotek WebCopy
WebCopy 是一个免费的网站 爬虫程序,它允许您将部分或完整的网站 复制到本地的硬盘上以供离线参考。
您可以更改设置以告诉机器人您要如何跟踪。此外,您还可以配置域别名、用户代理链、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或任何形式的 JavaScript 解析。如果 网站 大量使用 JavaScript 进行操作,WebCopy 可能无法制作真正的副本。由于大量使用 JavaScript,您可能无法正确处理动态 网站 布局
3.HTTrack
作为一个免费的网站爬虫程序,HTTrack提供了一个非常强大的功能,可以将完整的网站下载到您的PC上。有适用于Windows、Linux、Sun Solaris等Unix系统的版本,覆盖大部分用户。有趣的是,HTTrack 可以镜像一个站点,也可以将多个站点镜像在一起(使用共享链接)。您可以在“设置”中决定下载网页时同时打开的连接数。您可以获取重复的照片、文件、网站 的 HTML 代码,并恢复中断的下载。
此外,HTTrack 中提供了代理支持以最大限度地提高速度。
HTTrack 既可以用作命令行程序,也可以用作私人(捕获)或专业用途(在线网络镜像)。换句话说,HTTrack 应该是具有高级编程技能的人的首选。
4.左转
Getleft 是一款免费且易于使用的 网站 爬虫工具。允许您下载整个 网站 或任何单个 网站。启动Getleft后,输入网址,选择要下载的文件,即可开始下载。随着它的进行,更改本地导航的所有链接。此外,它还提供多语言支持。Getleft 现在支持 14 种语言!但是,它只提供有限的 Ftp 支持,它会下载文件,但不会排序和顺序下载。
一般来说,Getleft 应该能够满足用户基本的爬取需求,不需要更复杂的技能。
5.刮板
Scraper 是一个 Chrome 扩展,数据提取能力有限,但对于进行在线研究非常有用。它还允许将数据导出到 Google 电子表格。您可以使用 OAuth 轻松地将数据复制到剪贴板或将其存储在电子表格中。爬虫可以自动生成XPath来定义要爬取的URL。它不提供包罗万象的爬取服务,但可以满足大多数人的数据提取需求。
6.OutWit 中心
OutWit Hub 是 Firefox 的附加组件,具有数十种数据提取功能,可简化您的网络搜索。该网络爬虫可以导航页面并以合适的格式存储提取的信息。
OutWit Hub 提供了一个接口来根据需要提取少量或大量的数据。OutWit Hub 允许您从浏览器中删除任何网页。您甚至可以创建自动代理来提取数据。
它是最简单且免费的网页抓取工具之一,可为您提供无需编写代码即可提取网页数据的便利。
7.ParseHub
Parsehub 是一款优秀的网页抓取工具,支持使用 AJAX 技术、JavaScript、Cookies 等从 网站 采集数据,其机器学习技术可以读取、分析网页文档,然后将其转换为相关数据。
Parsehub 的桌面应用程序兼容 Windows、Mac OS X 和 Linux 等系统。您甚至可以使用浏览器中内置的 Web 应用程序。
作为免费程序,您不能在 Parsehub 上配置超过五个公共项目。付费订阅计划允许你创建至少20个私人项目来抢网站。
8.视觉抓取工具
VisualScraper 是另一个优秀的免费和未编码的网络爬虫程序,具有简单的点击界面。您可以从各种网页获取实时数据,并将提取的数据导出为 CSV、XML、JSON 或 SQL 文件。除了SaaS,VisualScraper还提供网页抓取服务,例如数据交付服务的创建和软件提取服务。
Visual Scraper 允许用户安排项目在特定时间运行,或者每分钟、每天、每周、每月或每年重复该序列。用户可以使用它来频繁地获取新闻和论坛。
9.Scrapinghub
Scrapinghub 是一种基于云的数据提取工具,可以帮助成千上万的开发人员获取有价值的数据。其开源的可视化爬取工具让用户无需任何编程知识即可爬取网站。
Scrapinghub 使用 Crawlera(智能代理旋转器),支持绕过机器人的对策,可以轻松跟踪大型或受机器人保护的站点。它允许用户从多个 IP 地址和位置进行跟踪,而无需通过简单的 HTTP API 进行代理管理。
Scrapinghub 将整个网页转换为有组织的内容。如果您的爬网生成器无法满足您的要求,您的专家团队将为您提供帮助
10.德喜.io
作为一款基于浏览器的网络爬虫,Dexi.io 允许你从任何基于浏览器的网站中抓取数据,并提供了三种类型的操纵器来创建抓取任务——提取器、爬虫和管道。这个免费软件为您的网络抓取提供了一个匿名的网络代理服务器。您提取的数据将在数据存档前在 Dexi.io 的服务器上托管两周,或者您可以将提取的数据直接导出为 JSON 或 CSV 文件。提供付费服务,满足您获取实时数据的需求。
作为基于浏览器的网页抓取,Dexi.io 允许您从任何网站 抓取基于浏览器的数据,并提供三种机器人,因此您可以创建抓取任务:提取器、跟踪器和管道。这个免费软件为您的网络抓取提供了一个匿名的网络代理服务器。您提取的数据将在数据存档前在 Dexi.io 的服务器上托管两周,或者您可以将提取的数据直接导出为 JSON 或 CSV 文件。提供付费服务,满足您对实时数据采集的需求。
11.Webhose.io
Webhose.io 使用户能够以有序的形式获取来自世界各地的在线资源,并从中获取实时数据。使用此网络爬虫,您可以使用涵盖多个来源的多个过滤器来跟踪数据并提取多种不同语言的关键字。
您可以将捕获的数据保存为 XML、JSON 和 RSS 格式。用户可以从其档案中访问历史数据。此外,webhose.io 的数据搜索结果支持多达 80 种语言。用户可以轻松索引和搜索 Webhose.io 跟踪的结构化数据。
一般情况下,Webhose.io 可以满足用户的基本爬取需求。
12.导入。io
用户只需要从特定的网页导入数据,并将数据导出为CSV,就可以形成自己的数据集。
无需编写任何代码,您可以在几分钟内轻松抓取数千个网页,并根据您的需求创建 1,000 多个 API。公共 API 提供了强大而灵活的功能,可以通过编程控制 Import.io 自动访问数据。Import.io 只需点击几下即可将网络数据集成到您自己的应用程序或 网站 中,这使得跟踪更容易。
为了更好地满足用户的跟踪需求,它还提供了免费的Windows、Mac OS X和Linux应用程序,用于构建数据提取器和跟踪器、下载数据并将其同步到您的在线帐户。此外,用户可以每周、每天或每小时安排跟踪任务。
13.80条腿
80legs 是一款功能强大的网络爬虫工具,可根据自定义需求进行配置。支持获取大量数据,并且可以选择立即下载提取的数据。80legs 提供了一个高性能的网页爬虫程序,可以快速运行,几秒内获取所需数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交 网站 以及 RSS 和 ATOM 中获取完整数据。Spinn3r 自带 Firehouse API,可以处理 95% 的索引工作。它提供先进的垃圾邮件保护,以消除垃圾邮件和不当使用语言,从而提高数据安全性。
Spinn3r 为类似 Google 的内容编制索引,并将提取的数据保存在 JSON 文件中。网络爬虫不断扫描网络并从多个来源寻找实时帖子的更新。它的管理控制台允许您控制爬行,而全文搜索允许对原创数据进行复杂查询。
内容抓取器
Content Grabber 是一款面向公司的网络爬虫软件。允许您创建独立的网络爬虫代理。您可以从几乎任何 网站 中提取内容,并以您选择的格式将其保存为结构化数据,包括来自 Excel、XML、CSV 和大多数数据库的报告。
它最适合具有高级编程技能的人,因为它为需要的人提供了许多强大的脚本编辑和界面调试功能。用户可以使用C#或VB.NET进行调试或编写脚本来控制爬取过程的计划。例如,Content Grabber 可以与 Visual Studio 2013 集成,根据用户的特定需求,对高级和离散的自定义爬虫进行最强大的脚本编辑、调试和单元测试。
16.氦气刮刀
Helium Scraper 是一款可视化的网页抓取数据软件。当元素之间的相关性很小时,它可以很好地工作。它不是编码,不是配置。用户可以根据各种爬取需求访问在线模板。
基本上可以基本满足用户的爬取需求。
17.UiPath
UiPath 是一种机器人流程自动化软件,可以自动捕获 Web。它可以从大多数第三方应用程序中自动捕获 Web 和桌面数据。如果在 Windows 上运行它,则可以安装流程自动化软件。Uipath 可以在多个网页上提取基于表格和模式的数据。
Uipath 提供内置工具以进行更出色的网络爬行。对于复杂的用户界面,这种方法非常有效。截屏工具可以处理单个文本元素、文本组和文本块,例如表格格式的数据提取。
同样,无需编程即可创建智能 Web 代理,但您的内部 .NET 黑客将完全控制数据。
18.Scrape.it
Scrape.it 是一个网络抓取 node.js 软件。它是一种基于云的 Web 数据提取工具。它专为具有高级编程技能的人而设计,因为它提供了公共和私有软件包,用于发现、重用、更新和与全球数百万开发人员共享代码。其强大的集成功能将帮助您根据需要创建自定义跟踪器。
19.WebHarvy
WebHarvy 是一种点击式网页抓取软件。它是为非程序员设计的。WebHarvy 可以自动抓取 网站 中的文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置的调度程序和代理支持,允许匿名抓取并防止网络爬虫软件被网络服务器阻止。您可以选择通过代理服务器或 VPN 访问目标。
用户可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy 网络爬虫允许您将爬取的数据导出为 XML、CSV、JSON 或 TSV 文件。用户还可以将捕获的数据导出到 SQL 数据库。
20.注解
Connotate 是一个自动化的 Web 爬虫程序,专为企业级 Web 内容提取而设计,需要企业级解决方案。业务用户无需任何编程即可在几分钟内轻松创建提取代理。用户只需点击即可轻松创建提取代理。
标签:数据抓取,网络爬虫,数据爬虫,数据采集,网络抓取,大数据,数据科学,bigdata,python,网页采集,数据科学,网站数据,数据可视化 查看全部
抓取网页数据(使用网络抓取工具有什么好处?营销人员的好处)
使用网络爬虫有什么好处?
将您的双手从重复的复制和粘贴任务中解放出来。
以结构良好的格式放置提取的数据,包括 Excel、HTML 和 CSV。
通过聘请专业数据分析师,您可以节省时间和金钱。
这是营销人员、营销人员、记者、YouTube 用户、研究人员和许多其他缺乏技术技能的人的武器。
1. Octoparse

Octoparse是一个网站爬虫程序,几乎可以提取网站上所有你需要的数据。您可以使用 Octoparse 提取具有广泛特征的 网站。它有两种操作模式:助手模式和高级模式,非程序员也能快速上手。一个简单的点击式界面可以指导您完成整个提取过程。因此,您可以轻松地从网站 中提取内容,并在短时间内将其保存为结构化格式,例如 EXCEL、TXT、HTML 或其数据库。
此外,它还提供计划云提取,让您实时提取动态数据并跟踪网站 更新。
您还可以通过使用内置的 Regex 和 XPath 设置来准确定位项目,以提取复杂的结构网站。您不再需要担心 IP 阻塞。Octoparse提供IP代理服务器,会自动轮换IP,不会被反跟踪网站发现。
总之,Octoparse 不需要任何编码技能即可满足用户的基本和高级跟踪需求。
2.Cyotek WebCopy
WebCopy 是一个免费的网站 爬虫程序,它允许您将部分或完整的网站 复制到本地的硬盘上以供离线参考。
您可以更改设置以告诉机器人您要如何跟踪。此外,您还可以配置域别名、用户代理链、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或任何形式的 JavaScript 解析。如果 网站 大量使用 JavaScript 进行操作,WebCopy 可能无法制作真正的副本。由于大量使用 JavaScript,您可能无法正确处理动态 网站 布局
3.HTTrack
作为一个免费的网站爬虫程序,HTTrack提供了一个非常强大的功能,可以将完整的网站下载到您的PC上。有适用于Windows、Linux、Sun Solaris等Unix系统的版本,覆盖大部分用户。有趣的是,HTTrack 可以镜像一个站点,也可以将多个站点镜像在一起(使用共享链接)。您可以在“设置”中决定下载网页时同时打开的连接数。您可以获取重复的照片、文件、网站 的 HTML 代码,并恢复中断的下载。
此外,HTTrack 中提供了代理支持以最大限度地提高速度。
HTTrack 既可以用作命令行程序,也可以用作私人(捕获)或专业用途(在线网络镜像)。换句话说,HTTrack 应该是具有高级编程技能的人的首选。
4.左转
Getleft 是一款免费且易于使用的 网站 爬虫工具。允许您下载整个 网站 或任何单个 网站。启动Getleft后,输入网址,选择要下载的文件,即可开始下载。随着它的进行,更改本地导航的所有链接。此外,它还提供多语言支持。Getleft 现在支持 14 种语言!但是,它只提供有限的 Ftp 支持,它会下载文件,但不会排序和顺序下载。
一般来说,Getleft 应该能够满足用户基本的爬取需求,不需要更复杂的技能。
5.刮板

Scraper 是一个 Chrome 扩展,数据提取能力有限,但对于进行在线研究非常有用。它还允许将数据导出到 Google 电子表格。您可以使用 OAuth 轻松地将数据复制到剪贴板或将其存储在电子表格中。爬虫可以自动生成XPath来定义要爬取的URL。它不提供包罗万象的爬取服务,但可以满足大多数人的数据提取需求。
6.OutWit 中心
OutWit Hub 是 Firefox 的附加组件,具有数十种数据提取功能,可简化您的网络搜索。该网络爬虫可以导航页面并以合适的格式存储提取的信息。
OutWit Hub 提供了一个接口来根据需要提取少量或大量的数据。OutWit Hub 允许您从浏览器中删除任何网页。您甚至可以创建自动代理来提取数据。
它是最简单且免费的网页抓取工具之一,可为您提供无需编写代码即可提取网页数据的便利。
7.ParseHub
Parsehub 是一款优秀的网页抓取工具,支持使用 AJAX 技术、JavaScript、Cookies 等从 网站 采集数据,其机器学习技术可以读取、分析网页文档,然后将其转换为相关数据。
Parsehub 的桌面应用程序兼容 Windows、Mac OS X 和 Linux 等系统。您甚至可以使用浏览器中内置的 Web 应用程序。
作为免费程序,您不能在 Parsehub 上配置超过五个公共项目。付费订阅计划允许你创建至少20个私人项目来抢网站。
8.视觉抓取工具
VisualScraper 是另一个优秀的免费和未编码的网络爬虫程序,具有简单的点击界面。您可以从各种网页获取实时数据,并将提取的数据导出为 CSV、XML、JSON 或 SQL 文件。除了SaaS,VisualScraper还提供网页抓取服务,例如数据交付服务的创建和软件提取服务。
Visual Scraper 允许用户安排项目在特定时间运行,或者每分钟、每天、每周、每月或每年重复该序列。用户可以使用它来频繁地获取新闻和论坛。
9.Scrapinghub

Scrapinghub 是一种基于云的数据提取工具,可以帮助成千上万的开发人员获取有价值的数据。其开源的可视化爬取工具让用户无需任何编程知识即可爬取网站。
Scrapinghub 使用 Crawlera(智能代理旋转器),支持绕过机器人的对策,可以轻松跟踪大型或受机器人保护的站点。它允许用户从多个 IP 地址和位置进行跟踪,而无需通过简单的 HTTP API 进行代理管理。
Scrapinghub 将整个网页转换为有组织的内容。如果您的爬网生成器无法满足您的要求,您的专家团队将为您提供帮助
10.德喜.io
作为一款基于浏览器的网络爬虫,Dexi.io 允许你从任何基于浏览器的网站中抓取数据,并提供了三种类型的操纵器来创建抓取任务——提取器、爬虫和管道。这个免费软件为您的网络抓取提供了一个匿名的网络代理服务器。您提取的数据将在数据存档前在 Dexi.io 的服务器上托管两周,或者您可以将提取的数据直接导出为 JSON 或 CSV 文件。提供付费服务,满足您获取实时数据的需求。
作为基于浏览器的网页抓取,Dexi.io 允许您从任何网站 抓取基于浏览器的数据,并提供三种机器人,因此您可以创建抓取任务:提取器、跟踪器和管道。这个免费软件为您的网络抓取提供了一个匿名的网络代理服务器。您提取的数据将在数据存档前在 Dexi.io 的服务器上托管两周,或者您可以将提取的数据直接导出为 JSON 或 CSV 文件。提供付费服务,满足您对实时数据采集的需求。
11.Webhose.io
Webhose.io 使用户能够以有序的形式获取来自世界各地的在线资源,并从中获取实时数据。使用此网络爬虫,您可以使用涵盖多个来源的多个过滤器来跟踪数据并提取多种不同语言的关键字。
您可以将捕获的数据保存为 XML、JSON 和 RSS 格式。用户可以从其档案中访问历史数据。此外,webhose.io 的数据搜索结果支持多达 80 种语言。用户可以轻松索引和搜索 Webhose.io 跟踪的结构化数据。
一般情况下,Webhose.io 可以满足用户的基本爬取需求。
12.导入。io
用户只需要从特定的网页导入数据,并将数据导出为CSV,就可以形成自己的数据集。
无需编写任何代码,您可以在几分钟内轻松抓取数千个网页,并根据您的需求创建 1,000 多个 API。公共 API 提供了强大而灵活的功能,可以通过编程控制 Import.io 自动访问数据。Import.io 只需点击几下即可将网络数据集成到您自己的应用程序或 网站 中,这使得跟踪更容易。
为了更好地满足用户的跟踪需求,它还提供了免费的Windows、Mac OS X和Linux应用程序,用于构建数据提取器和跟踪器、下载数据并将其同步到您的在线帐户。此外,用户可以每周、每天或每小时安排跟踪任务。
13.80条腿
80legs 是一款功能强大的网络爬虫工具,可根据自定义需求进行配置。支持获取大量数据,并且可以选择立即下载提取的数据。80legs 提供了一个高性能的网页爬虫程序,可以快速运行,几秒内获取所需数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交 网站 以及 RSS 和 ATOM 中获取完整数据。Spinn3r 自带 Firehouse API,可以处理 95% 的索引工作。它提供先进的垃圾邮件保护,以消除垃圾邮件和不当使用语言,从而提高数据安全性。
Spinn3r 为类似 Google 的内容编制索引,并将提取的数据保存在 JSON 文件中。网络爬虫不断扫描网络并从多个来源寻找实时帖子的更新。它的管理控制台允许您控制爬行,而全文搜索允许对原创数据进行复杂查询。
内容抓取器
Content Grabber 是一款面向公司的网络爬虫软件。允许您创建独立的网络爬虫代理。您可以从几乎任何 网站 中提取内容,并以您选择的格式将其保存为结构化数据,包括来自 Excel、XML、CSV 和大多数数据库的报告。
它最适合具有高级编程技能的人,因为它为需要的人提供了许多强大的脚本编辑和界面调试功能。用户可以使用C#或VB.NET进行调试或编写脚本来控制爬取过程的计划。例如,Content Grabber 可以与 Visual Studio 2013 集成,根据用户的特定需求,对高级和离散的自定义爬虫进行最强大的脚本编辑、调试和单元测试。
16.氦气刮刀
Helium Scraper 是一款可视化的网页抓取数据软件。当元素之间的相关性很小时,它可以很好地工作。它不是编码,不是配置。用户可以根据各种爬取需求访问在线模板。
基本上可以基本满足用户的爬取需求。
17.UiPath

UiPath 是一种机器人流程自动化软件,可以自动捕获 Web。它可以从大多数第三方应用程序中自动捕获 Web 和桌面数据。如果在 Windows 上运行它,则可以安装流程自动化软件。Uipath 可以在多个网页上提取基于表格和模式的数据。
Uipath 提供内置工具以进行更出色的网络爬行。对于复杂的用户界面,这种方法非常有效。截屏工具可以处理单个文本元素、文本组和文本块,例如表格格式的数据提取。
同样,无需编程即可创建智能 Web 代理,但您的内部 .NET 黑客将完全控制数据。
18.Scrape.it
Scrape.it 是一个网络抓取 node.js 软件。它是一种基于云的 Web 数据提取工具。它专为具有高级编程技能的人而设计,因为它提供了公共和私有软件包,用于发现、重用、更新和与全球数百万开发人员共享代码。其强大的集成功能将帮助您根据需要创建自定义跟踪器。
19.WebHarvy
WebHarvy 是一种点击式网页抓取软件。它是为非程序员设计的。WebHarvy 可以自动抓取 网站 中的文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置的调度程序和代理支持,允许匿名抓取并防止网络爬虫软件被网络服务器阻止。您可以选择通过代理服务器或 VPN 访问目标。
用户可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy 网络爬虫允许您将爬取的数据导出为 XML、CSV、JSON 或 TSV 文件。用户还可以将捕获的数据导出到 SQL 数据库。
20.注解
Connotate 是一个自动化的 Web 爬虫程序,专为企业级 Web 内容提取而设计,需要企业级解决方案。业务用户无需任何编程即可在几分钟内轻松创建提取代理。用户只需点击即可轻松创建提取代理。
标签:数据抓取,网络爬虫,数据爬虫,数据采集,网络抓取,大数据,数据科学,bigdata,python,网页采集,数据科学,网站数据,数据可视化
抓取网页数据(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-29 06:01
相信所有个人网站的站长都有爬取他人数据的经历。目前爬取别人网站数据的方法不外乎两种:
一、使用第三方工具,其中最著名的是优采云
采集
器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在基本上半天就可以搞定一个网站了(只是程序开发时间,不包括数据抓取时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的就是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然在网上看过很多这样的文章,但是每次拿别人的代码时,总会出现各种各样的问题。下面各种方法的代码都可以正确执行,我目前也在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录
分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得在代码中学习第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader_ResponseStream = new StreamReader(_WebResponse.GetResponseStream(),System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过开发网站可能经常遇到。它的分页控件通过post向后台代码提交分页信息,比如.net下Gridview的分页功能。当你点击分页的页码时,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上时,状态栏会显示javascript:__dopostback("gridview","page1")等等。其实这种形式的代码也不是很难,因为毕竟有找页码规则的地方。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这类页面,需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的某个页面时,如果你发现这个东西,并且后面有很多乱七八糟的字符,那么这个网站一定是写的;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以引用页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,必须循环拼凑_dopostback的两个参数,只需要拼凑收录
页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,然后每抓取一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集
s.Specialized.NameValue采集
PostVars = newSystem.采集
s.Specialized.NameValue采集
();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方法:第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。后来采用了更狠的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
所谓门外汉看热闹,高手看门道,可能很多人看到这里就说可以通过Webbrowser的控制来实现,是的,我下面的方式就是利用WebBrowser的控制来实现实现,其实在.net下应该也有这种类似的类,不过我没研究过,希望有人有其他方法可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。呵呵
我们还是八卦一下,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要爬取的页面,比如:
调用webBrowser控件Navigate("")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted很重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,按照第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("点击");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
其实用的WebBrowser还可以做很多事情,比如自动登录,退出某个论坛,保存会话,cockie,所以这个控件基本上可以实现你对网页的任何操作,即使你想破解登录密码一个网站,当然这是不推荐的。呵呵
看了这篇文章,本以为手头的网站可以解决,但是在实际操作中,第二种方法无法完成网页的抓取。第三种方法不易控制;
个人实践一使用页面添加或修改其中一个标签的属性 查看全部
抓取网页数据(一下抓取别人网站数据的方式有什么作用?如何抓取)
相信所有个人网站的站长都有爬取他人数据的经历。目前爬取别人网站数据的方法不外乎两种:
一、使用第三方工具,其中最著名的是优采云
采集
器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在基本上半天就可以搞定一个网站了(只是程序开发时间,不包括数据抓取时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的就是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然在网上看过很多这样的文章,但是每次拿别人的代码时,总会出现各种各样的问题。下面各种方法的代码都可以正确执行,我目前也在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录
分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得在代码中学习第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader_ResponseStream = new StreamReader(_WebResponse.GetResponseStream(),System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过开发网站可能经常遇到。它的分页控件通过post向后台代码提交分页信息,比如.net下Gridview的分页功能。当你点击分页的页码时,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上时,状态栏会显示javascript:__dopostback("gridview","page1")等等。其实这种形式的代码也不是很难,因为毕竟有找页码规则的地方。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这类页面,需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的某个页面时,如果你发现这个东西,并且后面有很多乱七八糟的字符,那么这个网站一定是写的;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以引用页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,必须循环拼凑_dopostback的两个参数,只需要拼凑收录
页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,然后每抓取一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集
s.Specialized.NameValue采集
PostVars = newSystem.采集
s.Specialized.NameValue采集
();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方法:第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。后来采用了更狠的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
所谓门外汉看热闹,高手看门道,可能很多人看到这里就说可以通过Webbrowser的控制来实现,是的,我下面的方式就是利用WebBrowser的控制来实现实现,其实在.net下应该也有这种类似的类,不过我没研究过,希望有人有其他方法可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。呵呵
我们还是八卦一下,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要爬取的页面,比如:
调用webBrowser控件Navigate("")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted很重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,按照第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("点击");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
其实用的WebBrowser还可以做很多事情,比如自动登录,退出某个论坛,保存会话,cockie,所以这个控件基本上可以实现你对网页的任何操作,即使你想破解登录密码一个网站,当然这是不推荐的。呵呵
看了这篇文章,本以为手头的网站可以解决,但是在实际操作中,第二种方法无法完成网页的抓取。第三种方法不易控制;
个人实践一使用页面添加或修改其中一个标签的属性
抓取网页数据(如何开启网页抓取项目并根据您的网站抓取项目选择合适)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-26 18:00
返回博客
有了一个网页抓取项目的想法:我从哪里开始?
奥古斯塔斯·佩拉考斯卡斯
2021-12-15
有兴趣开始一个网络抓取项目,但不知道从哪里开始?或者您正在为您的网页抓取项目寻找最佳解决方案?无论哪种情况,我们都可以为您提供帮助。
本文将向您介绍如何启动网页抓取项目,并根据您的网站抓取项目选择合适的代理类型。我们还将为更有经验的公司讨论自建网络爬虫的利弊。如果您想直接学习如何构建一个简单的网络爬虫,请观看我们的视频教程!
您可以单击本文中的以下主题以了解您感兴趣的内容:
网页抓取项目的想法
有各种各样的网络爬行用例。公司将从各种不同的网站抓取数据。例如,一些公司爬取电子商务网站以监控不同的价格。一些公司使用网络爬虫来确保品牌保护和监控在线评论。
如果您想知道使用它的最佳方法是什么,可以将以下常见的网络抓取项目想法纳入您的业务策略:
计划网络抓取活动,但不知道从哪里开始?
如果你正在计划一个网页抓取项目,当然,你必须首先对一个网页抓取项目有一个想法。作为企业,您应该了解您需要提取什么样的数据。这可以是任何数据:定价数据、来自搜索引擎的 SERP 数据等。例如,假设您需要 SERP 数据进行 SEO 监控。现在怎么办?
对于任何网页抓取项目,您都需要大量的代理(即IP)才能通过您的自动网页抓取脚本成功连接到所需的数据源。然后,代理服务器会在不达到网站设置的请求数量限制的情况下,从网站服务器为您采集
所需的数据,使其不受反爬虫措施的影响。
在急于寻找代理提供商之前,您必须首先了解需要采集
的数据规模。即每天需要发送的请求数。根据数据点(或请求量)和所需的流量,更容易确定合适的代理。
如果您不确定需要发送的请求数量,以及您的网络抓取项目将产生多少流量,该怎么办?要了解此问题的解决方案:您可以发送电子邮件至 support@oxylabs.io 与我们进一步讨论您的网络抓取项目想法。我们的团队很乐意帮助计算。您也可以选择一种可以帮助您完成所需工作的网络爬虫解决方案,而无需考虑具体的请求量和流量。
明确具体的数字,或者至少大致了解需要爬取的目标,会更容易选择适合网络爬虫项目的工具。
正确选择适合网页抓取项目的代理类型
有两种主要类型的代理:住宅代理和数据中心代理。但是,认为“住宅代理”可以保持绝对匿名,因此是最好的代理,这是一个很大的误解。事实上,所有代理都可以让您匿名在线。您需要购买哪种代理仅取决于您想做的网络爬虫项目的类型。
如果您需要使用代理来执行市场研究网络爬虫项目,那么数据中心代理就足够了。它们快速而稳定,最重要的是,它们比住宅机构便宜得多。但是如果你想捕捉销售情报等更具挑战性的目标,住宅代理是更好的选择,因为大多数网站都知道这种数据采集
项目,所以他们更有可能在这些网站上被屏蔽。住宅代理的使用很难被禁止,因为它们看起来像真实的 IP。
为了更清楚地说明,我们在下表中分别列出了每个业务的可能用例和最佳代理解决方案。
让我们更多地讨论其他三个用例。这些用例包括前面提到的基于网络抓取的项目,例如销售智能、SEO 监控和产品页面智能。尽管您可以为这些特定用例使用代理,但您会发现很难处理网络爬行中最常见的瓶颈之一。那是时间,或者时间不够。让我们转到另一个主题:使用自建网络爬虫和代理的利弊。
自建网络爬虫的优缺点
我们可以通过两种方式获取网页抓取工具:维护和使用自建的网络爬虫工作,或者从第三方提供商处购买网页抓取工具。现在,让我们更多地了解自建网络爬虫的优缺点。这可以帮助您决定是否需要构建自己的基础架构或购买第三方工具来投资网络抓取项目。
自建网络爬虫项目的缺点
使用自建的网络爬虫程序具有一定的优势,包括可控性增强、设置速度提高、问题解决速度更快。
增强可控性
自建网络爬虫项目解决方案的思路,让您完全掌控整个流程。您可以自定义抓取流程以更好地适应公司的需求。如果您拥有经验丰富的开发团队,公司通常会选择管理其内部网络爬虫需求。
提高设定速度
与从第三方供应商处购买网络爬虫相比,使用自建网络爬虫可以加快流程。内部团队可能更了解公司的需求,因此可以更快地设置网络爬虫。
更快地解决问题
与内部团队合作可以更轻松地解决可能出现的问题。使用第三方网络爬虫工具时,出现问题后,必须提交支持请求,等待一段时间才能解决。
自建网络爬虫项目的缺点
自建网络爬虫项目有一定的优势,但也存在一些不足。缺点包括成本较高、维护困难和风险较大。
更高的成本
自建网络爬虫可能很昂贵。服务器、代理和维护成本加起来是一笔很大的开支。您还必须雇用和培训熟练的网络抓取开发人员来管理该过程。因此,从第三方供应商处购买网络爬虫工具通常更便宜。
难以维护
维护自建的网络爬行设置可能是一个挑战。服务器需要保持最佳运行状态,网络爬虫程序必须随时更新,以跟上爬取目标网站的变化。
相关风险
如果操作不当,网络爬虫可能面临一定的法律风险。许多网站倾向于对网络爬行活动设置限制。内部团队可能没有足够的经验来正确解决这些问题。第三方提供商拥有经验丰富的开发团队,可以更好地遵循最佳实践来正确抓取站点。
在开始网络抓取项目之前,确定哪种策略更适合您的需求很重要。对于大多数公司来说,第三方工具是更实用的选择,比如 Oxylabs 的爬虫 API。我们现在推出了3个爬虫API:SERP爬虫API、电子商务爬虫API和网络爬虫API。
“网络爬虫工具的选择取决于您的目标网站。我们的爬虫API最适合大型搜索引擎或任何电子商务网站。这样,从多个网站成功爬取数据的机会最高,而您不会”不用担心如何管理。代理,避免CAPTCHA验证,扩展整体基础设施。”
来自 Oxylabs 产品经理 Aleksandras Sulzenko 的建议
总结
我们希望本文能帮助您规划您的网络抓取项目,并为与代理相关的问题提供全面的答案。
想了解更多关于网络爬虫的信息?我们还有其他帖子可以回答您的所有问题!网络爬虫过程中最常见的挑战是在爬取大型电子商务网站时如何避免网页被拦截。此外,如果您对网络抓取项目有想法,您应该了解更多有关电子商务数据采集
方法的信息。
其他常见问题 网络爬虫和数据挖掘有什么区别?
如果你打算开始一个网页抓取项目,你应该明白网页抓取只是指采集
选定的数据并下载;它不涉及数据分析。数据挖掘是指将原创
数据转化为企业可用信息的过程。
如何避免在网络爬虫过程中被拦截?
通过了解电子商务网站如何保护自己,我们可以避免阻止网页。这些做法有助于在不被禁止的情况下成功抓取电子商务网站数据。
住宅代理和数据中心代理有什么区别?
选择哪个代理,要考虑的因素,除了能不能隐藏你的IP,还取决于对安全性和合法性的要求,或者对速度的要求。速度、安全性和合法性是住宅代理和数据中心代理之间的主要区别
关于作者
奥古斯塔斯·佩拉考斯卡斯
文案
Augustas Pelakauskas 在 Oxylabs 担任文案。具有艺术家庭背景的他致力于各种创意项目——最近他一直在写作。在验证了自己在自由新闻领域的能力后,他转而从事技术内容创作。在空闲时间,他喜欢阳光明媚的户外活动和运动休闲。原来,自行车是他的第三好朋友。
了解有关奥古斯塔斯的更多信息
Oxylabs 博客上的所有信息均“按原样”提供,仅供参考。对于您使用 Oxylabs 博客中收录
的任何信息或可能链接到的任何第三方网站中收录
的任何信息,我们不作任何陈述也不承担任何责任。在从事任何类型的抓取活动之前,请咨询您的法律顾问并仔细阅读特定网站的服务条款或获得抓取许可。
选择 Oxylabs® 让您的业务更上一层楼
注册以联系销售
联系我们
经认证的数据中心和上游供应商
联系我们
公司
演戏
资源
爬虫API
隐私政策
Oxysales, UAB © 2021 版权所有 © 查看全部
抓取网页数据(如何开启网页抓取项目并根据您的网站抓取项目选择合适)
返回博客
有了一个网页抓取项目的想法:我从哪里开始?
奥古斯塔斯·佩拉考斯卡斯
2021-12-15
有兴趣开始一个网络抓取项目,但不知道从哪里开始?或者您正在为您的网页抓取项目寻找最佳解决方案?无论哪种情况,我们都可以为您提供帮助。
本文将向您介绍如何启动网页抓取项目,并根据您的网站抓取项目选择合适的代理类型。我们还将为更有经验的公司讨论自建网络爬虫的利弊。如果您想直接学习如何构建一个简单的网络爬虫,请观看我们的视频教程!
您可以单击本文中的以下主题以了解您感兴趣的内容:
网页抓取项目的想法
有各种各样的网络爬行用例。公司将从各种不同的网站抓取数据。例如,一些公司爬取电子商务网站以监控不同的价格。一些公司使用网络爬虫来确保品牌保护和监控在线评论。
如果您想知道使用它的最佳方法是什么,可以将以下常见的网络抓取项目想法纳入您的业务策略:
计划网络抓取活动,但不知道从哪里开始?
如果你正在计划一个网页抓取项目,当然,你必须首先对一个网页抓取项目有一个想法。作为企业,您应该了解您需要提取什么样的数据。这可以是任何数据:定价数据、来自搜索引擎的 SERP 数据等。例如,假设您需要 SERP 数据进行 SEO 监控。现在怎么办?
对于任何网页抓取项目,您都需要大量的代理(即IP)才能通过您的自动网页抓取脚本成功连接到所需的数据源。然后,代理服务器会在不达到网站设置的请求数量限制的情况下,从网站服务器为您采集
所需的数据,使其不受反爬虫措施的影响。
在急于寻找代理提供商之前,您必须首先了解需要采集
的数据规模。即每天需要发送的请求数。根据数据点(或请求量)和所需的流量,更容易确定合适的代理。
如果您不确定需要发送的请求数量,以及您的网络抓取项目将产生多少流量,该怎么办?要了解此问题的解决方案:您可以发送电子邮件至 support@oxylabs.io 与我们进一步讨论您的网络抓取项目想法。我们的团队很乐意帮助计算。您也可以选择一种可以帮助您完成所需工作的网络爬虫解决方案,而无需考虑具体的请求量和流量。
明确具体的数字,或者至少大致了解需要爬取的目标,会更容易选择适合网络爬虫项目的工具。
正确选择适合网页抓取项目的代理类型
有两种主要类型的代理:住宅代理和数据中心代理。但是,认为“住宅代理”可以保持绝对匿名,因此是最好的代理,这是一个很大的误解。事实上,所有代理都可以让您匿名在线。您需要购买哪种代理仅取决于您想做的网络爬虫项目的类型。
如果您需要使用代理来执行市场研究网络爬虫项目,那么数据中心代理就足够了。它们快速而稳定,最重要的是,它们比住宅机构便宜得多。但是如果你想捕捉销售情报等更具挑战性的目标,住宅代理是更好的选择,因为大多数网站都知道这种数据采集
项目,所以他们更有可能在这些网站上被屏蔽。住宅代理的使用很难被禁止,因为它们看起来像真实的 IP。
为了更清楚地说明,我们在下表中分别列出了每个业务的可能用例和最佳代理解决方案。
让我们更多地讨论其他三个用例。这些用例包括前面提到的基于网络抓取的项目,例如销售智能、SEO 监控和产品页面智能。尽管您可以为这些特定用例使用代理,但您会发现很难处理网络爬行中最常见的瓶颈之一。那是时间,或者时间不够。让我们转到另一个主题:使用自建网络爬虫和代理的利弊。
自建网络爬虫的优缺点
我们可以通过两种方式获取网页抓取工具:维护和使用自建的网络爬虫工作,或者从第三方提供商处购买网页抓取工具。现在,让我们更多地了解自建网络爬虫的优缺点。这可以帮助您决定是否需要构建自己的基础架构或购买第三方工具来投资网络抓取项目。
自建网络爬虫项目的缺点
使用自建的网络爬虫程序具有一定的优势,包括可控性增强、设置速度提高、问题解决速度更快。
增强可控性
自建网络爬虫项目解决方案的思路,让您完全掌控整个流程。您可以自定义抓取流程以更好地适应公司的需求。如果您拥有经验丰富的开发团队,公司通常会选择管理其内部网络爬虫需求。
提高设定速度
与从第三方供应商处购买网络爬虫相比,使用自建网络爬虫可以加快流程。内部团队可能更了解公司的需求,因此可以更快地设置网络爬虫。
更快地解决问题
与内部团队合作可以更轻松地解决可能出现的问题。使用第三方网络爬虫工具时,出现问题后,必须提交支持请求,等待一段时间才能解决。
自建网络爬虫项目的缺点
自建网络爬虫项目有一定的优势,但也存在一些不足。缺点包括成本较高、维护困难和风险较大。
更高的成本
自建网络爬虫可能很昂贵。服务器、代理和维护成本加起来是一笔很大的开支。您还必须雇用和培训熟练的网络抓取开发人员来管理该过程。因此,从第三方供应商处购买网络爬虫工具通常更便宜。
难以维护
维护自建的网络爬行设置可能是一个挑战。服务器需要保持最佳运行状态,网络爬虫程序必须随时更新,以跟上爬取目标网站的变化。
相关风险
如果操作不当,网络爬虫可能面临一定的法律风险。许多网站倾向于对网络爬行活动设置限制。内部团队可能没有足够的经验来正确解决这些问题。第三方提供商拥有经验丰富的开发团队,可以更好地遵循最佳实践来正确抓取站点。
在开始网络抓取项目之前,确定哪种策略更适合您的需求很重要。对于大多数公司来说,第三方工具是更实用的选择,比如 Oxylabs 的爬虫 API。我们现在推出了3个爬虫API:SERP爬虫API、电子商务爬虫API和网络爬虫API。
“网络爬虫工具的选择取决于您的目标网站。我们的爬虫API最适合大型搜索引擎或任何电子商务网站。这样,从多个网站成功爬取数据的机会最高,而您不会”不用担心如何管理。代理,避免CAPTCHA验证,扩展整体基础设施。”
来自 Oxylabs 产品经理 Aleksandras Sulzenko 的建议
总结
我们希望本文能帮助您规划您的网络抓取项目,并为与代理相关的问题提供全面的答案。
想了解更多关于网络爬虫的信息?我们还有其他帖子可以回答您的所有问题!网络爬虫过程中最常见的挑战是在爬取大型电子商务网站时如何避免网页被拦截。此外,如果您对网络抓取项目有想法,您应该了解更多有关电子商务数据采集
方法的信息。
其他常见问题 网络爬虫和数据挖掘有什么区别?
如果你打算开始一个网页抓取项目,你应该明白网页抓取只是指采集
选定的数据并下载;它不涉及数据分析。数据挖掘是指将原创
数据转化为企业可用信息的过程。
如何避免在网络爬虫过程中被拦截?
通过了解电子商务网站如何保护自己,我们可以避免阻止网页。这些做法有助于在不被禁止的情况下成功抓取电子商务网站数据。
住宅代理和数据中心代理有什么区别?
选择哪个代理,要考虑的因素,除了能不能隐藏你的IP,还取决于对安全性和合法性的要求,或者对速度的要求。速度、安全性和合法性是住宅代理和数据中心代理之间的主要区别
关于作者
奥古斯塔斯·佩拉考斯卡斯
文案
Augustas Pelakauskas 在 Oxylabs 担任文案。具有艺术家庭背景的他致力于各种创意项目——最近他一直在写作。在验证了自己在自由新闻领域的能力后,他转而从事技术内容创作。在空闲时间,他喜欢阳光明媚的户外活动和运动休闲。原来,自行车是他的第三好朋友。
了解有关奥古斯塔斯的更多信息
Oxylabs 博客上的所有信息均“按原样”提供,仅供参考。对于您使用 Oxylabs 博客中收录
的任何信息或可能链接到的任何第三方网站中收录
的任何信息,我们不作任何陈述也不承担任何责任。在从事任何类型的抓取活动之前,请咨询您的法律顾问并仔细阅读特定网站的服务条款或获得抓取许可。
选择 Oxylabs® 让您的业务更上一层楼
注册以联系销售
联系我们
经认证的数据中心和上游供应商
联系我们
公司
演戏
资源
爬虫API
隐私政策
Oxysales, UAB © 2021 版权所有 ©
抓取网页数据(二是抓取份额是由什么决定?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 41 次浏览 • 2021-12-26 09:04
什么决定了爬网份额?这涉及到爬行要求和爬行速度限制。
爬行需求
抓取需求或抓取需求是指搜索引擎“想要”在特定网站上抓取多少个页面。
有两个主要因素决定了对爬行的需求。一是页面权重。搜索引擎希望抓取与网站上达到基本页面权重的页面一样多的页面。二是索引库中的页面是否太长时间没有更新。毕竟是页面权重,权重高的页面不会更新太久。
页面权重和网站权重密切相关。增加网站权重可以使搜索引擎愿意抓取更多页面。
爬行速度限制
搜索引擎蜘蛛不会为了抓取更多的页面而拖拽其他网络服务器,因此会对某个网站设置抓取速度限制。爬网速率限制是服务器可以承受的上限。在这个限速里面,蜘蛛爬行不会拖慢服务器,影响用户访问。
服务器响应速度够快,这个限速提高一点,爬行加快,服务器响应速度降低,限速降低,爬行变慢,甚至爬行停止。
因此,爬网速率限制是搜索引擎“可以”爬取的页面数。
什么决定了爬网份额?
爬取份额是同时考虑爬取需求和爬取速度限制的结果,即搜索引擎“想要”爬取但“能”爬取的页面数。
网站权重高,页面内容质量高,页面数量多,服务器速度够快,抓取份额大。
小网站不用担心抢份额
一个小网站上的页面很少。即使网站权重低,服务器慢,但无论搜索引擎蜘蛛每天爬多少,通常至少能爬上几百页。千页网站根本不用担心抢份额。拥有数万页的网站通常没什么大不了的。如果每天数百次访问会降低服务器速度,那么 SEO 就不是主要考虑因素。
大中型网站可能需要考虑爬虫共享
对于页面数十万以上的大中型网站,可能需要考虑爬取份额不足的问题。
爬网份额是不够的。比如网站有1000万个页面,搜索引擎每天只能抓取几万个页面。爬取网站可能需要几个月,甚至一年的时间,这也可能意味着一些重要的页面无法抓取。,所以没有排名,或者重要页面不能及时更新。
想要网页被及时、完整地抓取,首先要保证服务器速度够快,页面够小。如果网站有大量优质数据,抓取份额会受到抓取速度的限制。提高页面速度直接提高了抓取速度限制,从而增加了抓取份额。
如何保存抓取共享?
当然,首先是减小页面文件的大小,提高服务器的速度,优化数据库,减少抓取时间。
然后,尽量避免上面列出的浪费性抢股。有些是内容质量问题,有些是网站结构问题。如果是结构问题,最简单的方法就是禁止爬取robots文件,但是会浪费一些页面权重,因为权重只能输入不能退出。
在某些情况下,使用链接 nofollow 属性可以节省抓取共享。对于小网站,添加nofollow是没有意义的,因为爬取份额用不完。对于大型网站,nofollow 可以在一定程度上控制权重的流量和分配。精心设计的nofollow会降低无意义页面的权重,增加重要页面的权重。搜索引擎在爬取时会使用一个 URL 爬取列表。要抓取的网址按页面权重排序。如果增加重要页面的权重,将首先抓取重要页面。无意义页面的权重可能很低,以至于搜索引擎不想爬行。
最后几点说明:
Links 和nofollow 不会浪费爬取分享。但在谷歌,重量被浪费了。
noindex 标签无法保存爬网共享。如果搜索引擎知道页面上有noindex标签,它必须先爬取这个页面,所以它不保存爬取份额。
规范标签有时可以节省一些爬网份额。和noindex标签一样,搜索引擎如果知道页面上有canonical标签,就必须先爬取这个页面,所以不直接保存爬取份额。但是,带有规范标签的页面通常被抓取的频率较低,因此会节省一些抓取份额。
抓取速度和抓取份额不是排名因素。但是没有被抓取的页面是无法排名的。 查看全部
抓取网页数据(二是抓取份额是由什么决定?(图))
什么决定了爬网份额?这涉及到爬行要求和爬行速度限制。

爬行需求
抓取需求或抓取需求是指搜索引擎“想要”在特定网站上抓取多少个页面。
有两个主要因素决定了对爬行的需求。一是页面权重。搜索引擎希望抓取与网站上达到基本页面权重的页面一样多的页面。二是索引库中的页面是否太长时间没有更新。毕竟是页面权重,权重高的页面不会更新太久。
页面权重和网站权重密切相关。增加网站权重可以使搜索引擎愿意抓取更多页面。
爬行速度限制
搜索引擎蜘蛛不会为了抓取更多的页面而拖拽其他网络服务器,因此会对某个网站设置抓取速度限制。爬网速率限制是服务器可以承受的上限。在这个限速里面,蜘蛛爬行不会拖慢服务器,影响用户访问。
服务器响应速度够快,这个限速提高一点,爬行加快,服务器响应速度降低,限速降低,爬行变慢,甚至爬行停止。
因此,爬网速率限制是搜索引擎“可以”爬取的页面数。
什么决定了爬网份额?
爬取份额是同时考虑爬取需求和爬取速度限制的结果,即搜索引擎“想要”爬取但“能”爬取的页面数。
网站权重高,页面内容质量高,页面数量多,服务器速度够快,抓取份额大。
小网站不用担心抢份额
一个小网站上的页面很少。即使网站权重低,服务器慢,但无论搜索引擎蜘蛛每天爬多少,通常至少能爬上几百页。千页网站根本不用担心抢份额。拥有数万页的网站通常没什么大不了的。如果每天数百次访问会降低服务器速度,那么 SEO 就不是主要考虑因素。
大中型网站可能需要考虑爬虫共享
对于页面数十万以上的大中型网站,可能需要考虑爬取份额不足的问题。
爬网份额是不够的。比如网站有1000万个页面,搜索引擎每天只能抓取几万个页面。爬取网站可能需要几个月,甚至一年的时间,这也可能意味着一些重要的页面无法抓取。,所以没有排名,或者重要页面不能及时更新。
想要网页被及时、完整地抓取,首先要保证服务器速度够快,页面够小。如果网站有大量优质数据,抓取份额会受到抓取速度的限制。提高页面速度直接提高了抓取速度限制,从而增加了抓取份额。
如何保存抓取共享?
当然,首先是减小页面文件的大小,提高服务器的速度,优化数据库,减少抓取时间。
然后,尽量避免上面列出的浪费性抢股。有些是内容质量问题,有些是网站结构问题。如果是结构问题,最简单的方法就是禁止爬取robots文件,但是会浪费一些页面权重,因为权重只能输入不能退出。
在某些情况下,使用链接 nofollow 属性可以节省抓取共享。对于小网站,添加nofollow是没有意义的,因为爬取份额用不完。对于大型网站,nofollow 可以在一定程度上控制权重的流量和分配。精心设计的nofollow会降低无意义页面的权重,增加重要页面的权重。搜索引擎在爬取时会使用一个 URL 爬取列表。要抓取的网址按页面权重排序。如果增加重要页面的权重,将首先抓取重要页面。无意义页面的权重可能很低,以至于搜索引擎不想爬行。
最后几点说明:
Links 和nofollow 不会浪费爬取分享。但在谷歌,重量被浪费了。
noindex 标签无法保存爬网共享。如果搜索引擎知道页面上有noindex标签,它必须先爬取这个页面,所以它不保存爬取份额。
规范标签有时可以节省一些爬网份额。和noindex标签一样,搜索引擎如果知道页面上有canonical标签,就必须先爬取这个页面,所以不直接保存爬取份额。但是,带有规范标签的页面通常被抓取的频率较低,因此会节省一些抓取份额。
抓取速度和抓取份额不是排名因素。但是没有被抓取的页面是无法排名的。
抓取网页数据(蜘蛛来访较少链建设过程中需要注意的几个问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-26 09:03
主页是蜘蛛访问次数最多的页面和权重最高的网站。您可以在主页上设置更新部分。这不仅会更新首页,提升蜘蛛访问频率,还会促进更新页面的抓取和收录。同样,这个操作也可以在栏目页上进行。
八、检查死链接并设置404页面
搜索引擎蜘蛛通过链接爬行。如果太多的链接无法访问,不仅会减少收录
的页面数量,而且您的网站在搜索引擎中的权重也会大大降低。当蜘蛛遇到死链接时,就如同进入了死胡同,不得不回去重新开始,大大降低了蜘蛛在网站上的爬行效率。因此,有必要定期检查网站的死链接,提交给搜索引擎,做好网站的404。页面,它告诉搜索引擎错误页面。
九、检查robots文件
很多网站有意无意地直接在robots文件中屏蔽了百度或网站的某些页面,但他们正在寻找蜘蛛不抓取我的页面的原因。你能怪百度吗?你不让别人进来,百度呢?包括您的网页?所以有必要检查一下网站的robots文件是否正常。
十、构建站点地图。
搜索引擎蜘蛛非常喜欢站点地图,站点地图是网站上所有链接的容器。许多网站都有深层链接,蜘蛛很难抓取。站点地图可以方便搜索引擎蜘蛛抓取网页。通过抓取网页,他们可以清楚地了解网站的结构。因此,构建站点地图不仅可以提高爬取率,还可以得到蜘蛛的青睐。
十一、 主动提交
每次更新页面时主动向搜索引擎提交内容是一个很好的方法,但如果没有收录
就不要一直提交。提交一次就够了。是否收录
它是搜索引擎的问题。提交并不意味着它是必要的。包括。
十二、外链建设。
大家都知道,外链可以吸引蜘蛛到网站,尤其是当网站是新的,网站还不是很成熟,访问的蜘蛛很少的时候,外链可以增加网站页面在蜘蛛面前的曝光率和防止蜘蛛找不到页面。. 在外链建设的过程中,我们需要关注外链的质量。不要为了省事而做无用的事情。百度现在相信大家都知道外链的管理。下面我讲一下需要注意的几点。
1、 博客外链建设 这里提到的博客外链不是我们平时做的。在一些个人博客、新浪博客、网易博客、和讯博客等,只评论点赞离开外链。. 由于百度算法的更新,这种外链现在已经没有效果,时间过长甚至会降级。在这里我想说的,是为了给博主留下印象,帮助博主,提出建议,或者评论我自己的不同想法而发表评论。几次之后,相信博主肯定会对你有意见的
2、论坛外链建设论坛外链建设的思路其实和博客的思路差不多。留下您的想法并让主持人关注您。也许你会在几次之后成为朋友甚至合作伙伴。到时候加个链接不就是一句话吗?关于这个我就不多说了。
3、 在外链建设的过程中,外链建设是外链建设中必不可少的环节。同时,外链的建设也是最有效、最快捷的方式。选择什么样的平台?这是一个直接思考的问题。这里我建议大家可以找一些不为很多人所知的相关平台。比如在不相关的平台上发帖肯定不如在相关的平台上,不好的平台认为传播的权重也是有限的。写文章,不同意,投稿需谨慎。
4、 Open、category目录外链建设 如果你的网站够好,那么open目录是个不错的选择,比如DOMZ目录,yahoo目录都可以提交。当然,对于一些新网站或者最近刚成立的网站,分类目录就是你的天堂。此外,互联网上还有许多分类目录网站。不要忽视建立外部链接的肥肉。
5、 虽然常说购买链接会被百度攻击,但作为一个新网站,想要在最短的时间内获得一定的公关、权重和一定的收录量,购买链接也是必不可少的. 当然,不是你去买一些金链或者去一些专门做买卖链接的平台,而是去和一些pr、权重比较高的门户、新闻站交流(前提是这些门户和新闻站是不是专门卖链接的),看能不能买链接,这样买的链接就不会被百度识别,链接质量比较高。以后当你的网站慢慢出现时,一一删除。
十三、内部链构建。
蜘蛛的爬行是跟着链接走的,所以内链的合理优化可以要求蜘蛛爬取更多的页面,促进网站的收录。在内链建设过程中,应合理推荐用户。除了给文章添加锚文本,还可以设置相关推荐、热门文章等。这被许多网站使用,并且可以被蜘蛛使用。获取更大范围的页面。
其实内链的建设也有利于提升用户体验,所以用户不必一一查看是否有相关内容,只需要依靠一个小的内链或者一个链接的关键词为拿到它,为实现它。更多更广的信息,何乐而不为呢?所以如果要真正提升用户体验,不是为了SEO提升用户体验,所以从用户的角度来说,什么样的内链才是用户最喜欢的工作。
另外,您可以将一些关键词链接到本站的其他页面,以提高这些页面之间的相关性,方便用户浏览。随着用户体验的提升,自然会为网站带来更多的流量。而且,增加页面之间的相关性还可以增加用户在网站上花费的时间,减少高跳出率的发生。
网站搜索排名高的前提是网站的大量页面被搜索引擎收录,良好的内链建设可以帮助网站页面被收录。当网站上的某篇文章被收录时,百度蜘蛛会继续沿着这个页面的超链接爬行。如果你的内链做的好,百度蜘蛛会沿着你的网站到处爬行,从而使网站页面被收录的几率大大增加。 查看全部
抓取网页数据(蜘蛛来访较少链建设过程中需要注意的几个问题)
主页是蜘蛛访问次数最多的页面和权重最高的网站。您可以在主页上设置更新部分。这不仅会更新首页,提升蜘蛛访问频率,还会促进更新页面的抓取和收录。同样,这个操作也可以在栏目页上进行。
八、检查死链接并设置404页面
搜索引擎蜘蛛通过链接爬行。如果太多的链接无法访问,不仅会减少收录
的页面数量,而且您的网站在搜索引擎中的权重也会大大降低。当蜘蛛遇到死链接时,就如同进入了死胡同,不得不回去重新开始,大大降低了蜘蛛在网站上的爬行效率。因此,有必要定期检查网站的死链接,提交给搜索引擎,做好网站的404。页面,它告诉搜索引擎错误页面。
九、检查robots文件
很多网站有意无意地直接在robots文件中屏蔽了百度或网站的某些页面,但他们正在寻找蜘蛛不抓取我的页面的原因。你能怪百度吗?你不让别人进来,百度呢?包括您的网页?所以有必要检查一下网站的robots文件是否正常。
十、构建站点地图。
搜索引擎蜘蛛非常喜欢站点地图,站点地图是网站上所有链接的容器。许多网站都有深层链接,蜘蛛很难抓取。站点地图可以方便搜索引擎蜘蛛抓取网页。通过抓取网页,他们可以清楚地了解网站的结构。因此,构建站点地图不仅可以提高爬取率,还可以得到蜘蛛的青睐。
十一、 主动提交
每次更新页面时主动向搜索引擎提交内容是一个很好的方法,但如果没有收录
就不要一直提交。提交一次就够了。是否收录
它是搜索引擎的问题。提交并不意味着它是必要的。包括。
十二、外链建设。
大家都知道,外链可以吸引蜘蛛到网站,尤其是当网站是新的,网站还不是很成熟,访问的蜘蛛很少的时候,外链可以增加网站页面在蜘蛛面前的曝光率和防止蜘蛛找不到页面。. 在外链建设的过程中,我们需要关注外链的质量。不要为了省事而做无用的事情。百度现在相信大家都知道外链的管理。下面我讲一下需要注意的几点。
1、 博客外链建设 这里提到的博客外链不是我们平时做的。在一些个人博客、新浪博客、网易博客、和讯博客等,只评论点赞离开外链。. 由于百度算法的更新,这种外链现在已经没有效果,时间过长甚至会降级。在这里我想说的,是为了给博主留下印象,帮助博主,提出建议,或者评论我自己的不同想法而发表评论。几次之后,相信博主肯定会对你有意见的
2、论坛外链建设论坛外链建设的思路其实和博客的思路差不多。留下您的想法并让主持人关注您。也许你会在几次之后成为朋友甚至合作伙伴。到时候加个链接不就是一句话吗?关于这个我就不多说了。
3、 在外链建设的过程中,外链建设是外链建设中必不可少的环节。同时,外链的建设也是最有效、最快捷的方式。选择什么样的平台?这是一个直接思考的问题。这里我建议大家可以找一些不为很多人所知的相关平台。比如在不相关的平台上发帖肯定不如在相关的平台上,不好的平台认为传播的权重也是有限的。写文章,不同意,投稿需谨慎。
4、 Open、category目录外链建设 如果你的网站够好,那么open目录是个不错的选择,比如DOMZ目录,yahoo目录都可以提交。当然,对于一些新网站或者最近刚成立的网站,分类目录就是你的天堂。此外,互联网上还有许多分类目录网站。不要忽视建立外部链接的肥肉。
5、 虽然常说购买链接会被百度攻击,但作为一个新网站,想要在最短的时间内获得一定的公关、权重和一定的收录量,购买链接也是必不可少的. 当然,不是你去买一些金链或者去一些专门做买卖链接的平台,而是去和一些pr、权重比较高的门户、新闻站交流(前提是这些门户和新闻站是不是专门卖链接的),看能不能买链接,这样买的链接就不会被百度识别,链接质量比较高。以后当你的网站慢慢出现时,一一删除。
十三、内部链构建。
蜘蛛的爬行是跟着链接走的,所以内链的合理优化可以要求蜘蛛爬取更多的页面,促进网站的收录。在内链建设过程中,应合理推荐用户。除了给文章添加锚文本,还可以设置相关推荐、热门文章等。这被许多网站使用,并且可以被蜘蛛使用。获取更大范围的页面。
其实内链的建设也有利于提升用户体验,所以用户不必一一查看是否有相关内容,只需要依靠一个小的内链或者一个链接的关键词为拿到它,为实现它。更多更广的信息,何乐而不为呢?所以如果要真正提升用户体验,不是为了SEO提升用户体验,所以从用户的角度来说,什么样的内链才是用户最喜欢的工作。
另外,您可以将一些关键词链接到本站的其他页面,以提高这些页面之间的相关性,方便用户浏览。随着用户体验的提升,自然会为网站带来更多的流量。而且,增加页面之间的相关性还可以增加用户在网站上花费的时间,减少高跳出率的发生。
网站搜索排名高的前提是网站的大量页面被搜索引擎收录,良好的内链建设可以帮助网站页面被收录。当网站上的某篇文章被收录时,百度蜘蛛会继续沿着这个页面的超链接爬行。如果你的内链做的好,百度蜘蛛会沿着你的网站到处爬行,从而使网站页面被收录的几率大大增加。
抓取网页数据(一下如何用Excel快速抓取网页数据(一)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-25 02:09
网站上的数据源是我们统计分析的重要信息来源。我们在生活中经常听到一个词叫“爬虫”,它可以快速抓取网页上的数据,这对于数据分析相关的工作来说是极其重要的,也是必备的技能之一。但是,大多数爬虫都需要编程知识,这对大多数人来说是很难上手的。今天给大家讲解一下如何用Excel快速抓取网页数据。
1、首先打开需要抓包的数据的网站,复制网站地址。
2、 要创建新的 Excel 工作簿,请单击“数据”菜单中的“来自 网站”选项>“获取外部数据”选项卡。
在弹出的“新建网页查询”对话框中,在地址栏中输入要抓取的网站地址,点击“前往”
点击黄色的导入箭头,选择需要采集的部分,如图。只需单击导入。
3、选择存储数据的位置(默认选中的单元格),点击确定。通常建议将数据存储在“A1”单元格中。
获取数据需要一定的时间,请耐心等待。
4、 如果想让Excel工作簿数据根据网站的数据实时自动更新,那么我们需要在“属性”中进行设置。您可以设置“允许后台刷新”、“刷新频率”、“打开文件时刷新数据”等。
拿到数据后,就需要对数据进行处理,而处理数据是一个比较重要的环节。更多数据处理技巧,请关注我!
如果对你有帮助,记得点赞转发哦。
关注我,学习更多 Excel 技能,让工作更轻松。 查看全部
抓取网页数据(一下如何用Excel快速抓取网页数据(一)(图))
网站上的数据源是我们统计分析的重要信息来源。我们在生活中经常听到一个词叫“爬虫”,它可以快速抓取网页上的数据,这对于数据分析相关的工作来说是极其重要的,也是必备的技能之一。但是,大多数爬虫都需要编程知识,这对大多数人来说是很难上手的。今天给大家讲解一下如何用Excel快速抓取网页数据。
1、首先打开需要抓包的数据的网站,复制网站地址。
2、 要创建新的 Excel 工作簿,请单击“数据”菜单中的“来自 网站”选项>“获取外部数据”选项卡。
在弹出的“新建网页查询”对话框中,在地址栏中输入要抓取的网站地址,点击“前往”
点击黄色的导入箭头,选择需要采集的部分,如图。只需单击导入。
3、选择存储数据的位置(默认选中的单元格),点击确定。通常建议将数据存储在“A1”单元格中。
获取数据需要一定的时间,请耐心等待。
4、 如果想让Excel工作簿数据根据网站的数据实时自动更新,那么我们需要在“属性”中进行设置。您可以设置“允许后台刷新”、“刷新频率”、“打开文件时刷新数据”等。
拿到数据后,就需要对数据进行处理,而处理数据是一个比较重要的环节。更多数据处理技巧,请关注我!
如果对你有帮助,记得点赞转发哦。
关注我,学习更多 Excel 技能,让工作更轻松。
抓取网页数据(抓取网页数据的话比较简单用什么方法传递参数吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-18 20:16
抓取网页数据的话比较简单用webpy就可以,
抓取数据ajax框架很多,写起来也不复杂,重点看用什么方法传递参数吧,get的话一般都是headers参数吧。
有个相对成熟的叫cookie.so,基本上不涉及到后端获取
如果是抓取某个网站内容的话,可以用抓包工具,然后将你想抓取的内容的地址交给程序就可以抓取了,
用百度就可以
get的话是headers中有个参数“useragent”,
headers传递参数,
应该是一样的,ajax的基本都是通过加载页面的xml文件。
webpy可以抓取http请求数据
可以看看antio/message·github
用python的webpy就可以了,
可以通过postman这样的工具来做,
抓取网页数据可以使用json解析工具,这里推荐一个工具libphones-webpy。网站的话现在主流的网站都有,包括facebook,twitter,hashtag都有。
json数据的话,有个框架叫webscrap,用它就可以抓取,不过复杂的后端任务还是要交给写爬虫的同学来吧。
大概看了下回答,大部分都是基于postman。不过估计爬虫的同学没有用这个工具抓取,估计用的是爬虫工具scrapy。那么为什么我们用postman不用cookie呢?我认为要知道数据格式,抓取过程中验证用户是否用户名,密码,那用cookie就很麻烦。再有,我们也想要把用户的注册id发给爬虫,不想让爬虫知道我们的账号信息。
那怎么办?当然是用户名,密码绑定,把一些像手机号等等不便暴露出来的信息去掉,但是数据还是要下来。我们从json数据格式的话,我们如何爬数据呢?比如百度的话,登录后就自动进去发短信,不过不同于你的发短信,它要求用户给账号服务器发送的信息发送到gmail中。但是有些网站的话,比如新浪看看、腾讯微博,等等,它就要求你在它的服务器上给账号发送短信,当然,对于普通的人来说,还是太麻烦了。
那么有没有这么简单点,且人家不用发短信,可以直接通过user-agent是透明的方式就能抓取数据的呢?最简单的方法,那就是我自己写个登录程序,或者使用爬虫工具scrapy之类的直接抓取。这时,它的问题就来了,太麻烦了,还会泄露你的账号信息。但是如果是可以像爬虫工具一样抓取,那么我们也可以考虑从其他地方把这个信息传给它,或者知道user-agent码一般的话,可以用自己的账号信息。 查看全部
抓取网页数据(抓取网页数据的话比较简单用什么方法传递参数吧)
抓取网页数据的话比较简单用webpy就可以,
抓取数据ajax框架很多,写起来也不复杂,重点看用什么方法传递参数吧,get的话一般都是headers参数吧。
有个相对成熟的叫cookie.so,基本上不涉及到后端获取
如果是抓取某个网站内容的话,可以用抓包工具,然后将你想抓取的内容的地址交给程序就可以抓取了,
用百度就可以
get的话是headers中有个参数“useragent”,
headers传递参数,
应该是一样的,ajax的基本都是通过加载页面的xml文件。
webpy可以抓取http请求数据
可以看看antio/message·github
用python的webpy就可以了,
可以通过postman这样的工具来做,
抓取网页数据可以使用json解析工具,这里推荐一个工具libphones-webpy。网站的话现在主流的网站都有,包括facebook,twitter,hashtag都有。
json数据的话,有个框架叫webscrap,用它就可以抓取,不过复杂的后端任务还是要交给写爬虫的同学来吧。
大概看了下回答,大部分都是基于postman。不过估计爬虫的同学没有用这个工具抓取,估计用的是爬虫工具scrapy。那么为什么我们用postman不用cookie呢?我认为要知道数据格式,抓取过程中验证用户是否用户名,密码,那用cookie就很麻烦。再有,我们也想要把用户的注册id发给爬虫,不想让爬虫知道我们的账号信息。
那怎么办?当然是用户名,密码绑定,把一些像手机号等等不便暴露出来的信息去掉,但是数据还是要下来。我们从json数据格式的话,我们如何爬数据呢?比如百度的话,登录后就自动进去发短信,不过不同于你的发短信,它要求用户给账号服务器发送的信息发送到gmail中。但是有些网站的话,比如新浪看看、腾讯微博,等等,它就要求你在它的服务器上给账号发送短信,当然,对于普通的人来说,还是太麻烦了。
那么有没有这么简单点,且人家不用发短信,可以直接通过user-agent是透明的方式就能抓取数据的呢?最简单的方法,那就是我自己写个登录程序,或者使用爬虫工具scrapy之类的直接抓取。这时,它的问题就来了,太麻烦了,还会泄露你的账号信息。但是如果是可以像爬虫工具一样抓取,那么我们也可以考虑从其他地方把这个信息传给它,或者知道user-agent码一般的话,可以用自己的账号信息。
抓取网页数据(上海陆家嘴网上银行图片url转成urllib2.urlopen(url))
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-16 08:02
抓取网页数据一般依赖于urllib2库,今天学习了解了下这个库,明天就要用它来爬取上海陆家嘴网上银行的数据了。可以将请求的图片url转成urllib2.urlopen(url,filepath)方法是jsonp的实现,这个urllib2.urlopen()方法有两个参数:一个是url,可以是urlopt的url。
也可以是mqttserver的url。就是通过图片url请求图片。另一个是图片的名称。将图片url转成urllib2.urlopen(url)方法是jsonp的实现,这个urllib2.urlopen()方法有两个参数:一个是url,可以是urlopt的url。也可以是mqttserver的url。就是通过图片url请求图片。
另一个是图片的名称。这是jsonp的思想,图片url里面包含了图片的api地址,然后再使用jsonp的方式将图片导出。@!vs/demo/localhost/login-proxy/path/to/client_get_cn_jsonp/path/to/client_get_cn_cn_image/codecs/load.json第一个参数url里面有代表图片地址的mqtt字符串,所以这里get到的图片地址是:;id=78708546第二个参数mqttclient的地址,等于是get到的图片。
也就是我们通过mqtt的post请求,得到的返回值转成json数据,然后将json数据通过一个cn.jsonp的post请求,将图片的数据返回到浏览器。@!vs/demo/localhost/login-proxy/path/to/client_get_cn_jsonp/path/to/client_get_cn_image/codecs/load.json看到post请求我也吃惊了,一句话不会写,就爬取上海陆家嘴网上银行的交易数据数据呢。
首先看看要想要得到返回的图片,我们首先得在浏览器地址栏输入你要爬取的图片地址,进入首页我使用的是动态加载,右边是一个图片展示界面,然后我们添加关键字selenium,添加图片展示的相关代码,进入首页的代码:selenium的js文件和网页地址。urllib2.urlopen(url,filepath)方法的第二个参数是代表的是图片的名称,接下来就通过check_images()方法来检查我们要爬取的图片的网址或者图片的名称。
我们要爬取图片的名称,最好是定义一个函数去获取图片名称,而不是定义一个函数去遍历网页。其实就是webdriver.find_element_by_id()是获取图片id,element.g。 查看全部
抓取网页数据(上海陆家嘴网上银行图片url转成urllib2.urlopen(url))
抓取网页数据一般依赖于urllib2库,今天学习了解了下这个库,明天就要用它来爬取上海陆家嘴网上银行的数据了。可以将请求的图片url转成urllib2.urlopen(url,filepath)方法是jsonp的实现,这个urllib2.urlopen()方法有两个参数:一个是url,可以是urlopt的url。
也可以是mqttserver的url。就是通过图片url请求图片。另一个是图片的名称。将图片url转成urllib2.urlopen(url)方法是jsonp的实现,这个urllib2.urlopen()方法有两个参数:一个是url,可以是urlopt的url。也可以是mqttserver的url。就是通过图片url请求图片。
另一个是图片的名称。这是jsonp的思想,图片url里面包含了图片的api地址,然后再使用jsonp的方式将图片导出。@!vs/demo/localhost/login-proxy/path/to/client_get_cn_jsonp/path/to/client_get_cn_cn_image/codecs/load.json第一个参数url里面有代表图片地址的mqtt字符串,所以这里get到的图片地址是:;id=78708546第二个参数mqttclient的地址,等于是get到的图片。
也就是我们通过mqtt的post请求,得到的返回值转成json数据,然后将json数据通过一个cn.jsonp的post请求,将图片的数据返回到浏览器。@!vs/demo/localhost/login-proxy/path/to/client_get_cn_jsonp/path/to/client_get_cn_image/codecs/load.json看到post请求我也吃惊了,一句话不会写,就爬取上海陆家嘴网上银行的交易数据数据呢。
首先看看要想要得到返回的图片,我们首先得在浏览器地址栏输入你要爬取的图片地址,进入首页我使用的是动态加载,右边是一个图片展示界面,然后我们添加关键字selenium,添加图片展示的相关代码,进入首页的代码:selenium的js文件和网页地址。urllib2.urlopen(url,filepath)方法的第二个参数是代表的是图片的名称,接下来就通过check_images()方法来检查我们要爬取的图片的网址或者图片的名称。
我们要爬取图片的名称,最好是定义一个函数去获取图片名称,而不是定义一个函数去遍历网页。其实就是webdriver.find_element_by_id()是获取图片id,element.g。
抓取网页数据(乌云网我写的一个公用的HttpUtils..例子 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-13 11:29
)
最近,我在公司做了一个系统。因为我想获得一些网页数据和一些网页数据,所以我编写了一个公共httputils,下面是我为吴云编写的一个示例。com
一、首先,获取指定路径下的网页内容
public static String httpGet(String urlStr, Map params) throws Exception {
StringBuilder sb = new StringBuilder();
if (null != params && params.size() > 0) {
sb.append("?");
Entry en;
for (Iterator ir = params.entrySet().iterator(); ir.hasNext();) {
en = ir.next();
sb.append(en.getKey() + "=" + URLEncoder.encode(en.getValue(),"utf-8") + (ir.hasNext() ? "&" : ""));
}
}
URL url = new URL(urlStr + sb);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(5000);
conn.setReadTimeout(5000);
conn.setRequestMethod("GET");
if (conn.getResponseCode() != 200)
throw new Exception("请求异常状态值:" + conn.getResponseCode());
BufferedInputStream bis = new BufferedInputStream(conn.getInputStream());
Reader reader = new InputStreamReader(bis,"gbk");
char[] buffer = new char[2048];
int len = 0;
CharArrayWriter caw = new CharArrayWriter();
while ((len = reader.read(buffer)) > -1)
caw.write(buffer, 0, len);
reader.close();
bis.close();
conn.disconnect();
//System.out.println(caw);
return caw.toString();
}
浏览器查询结果:
代码查询结果与上述一致:
二、通过指定URL获取所需的网页数据
对于这种方法,要导入jsup包,您可以在Internet上下载它
Document doc = null;
try {
doc = Jsoup.connect("http://www.wooyun.org//bugs//w ... 6quot;).userAgent("Mozilla/5.0 (Windows NT 10.0; Trident/7.0; rv:11.0) like Gecko").timeout(30000).get();
} catch (IOException e) {
e.printStackTrace();
}
for(Iterator ir = doc.select("h3").iterator();ir.hasNext();){
System.out.println(ir.next().text());
}
对于选择选择器,根据条件选择文档选择(“h3”)。迭代器()具有以下jsup规则:
Jsoup是一个基于Java的HTML解析器,可以直接解析URL地址或HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似于jQuery的操作方法获取和操作数据
jsoup的优势在于它对文档元素的检索。select方法将返回一组元素,并提供一组方法来提取和处理结果。要掌握jsoup,首先必须熟悉其选择器语法
1、选择器基本语法
2、选择器组合语法
3、选择器伪选择器语法
注:上述伪选择器索引从0开始,即第一个元素的索引值为0,第二个元素的索引值为1,以此类推
浏览器访问:
代码访问:
查看全部
抓取网页数据(乌云网我写的一个公用的HttpUtils..例子
)
最近,我在公司做了一个系统。因为我想获得一些网页数据和一些网页数据,所以我编写了一个公共httputils,下面是我为吴云编写的一个示例。com
一、首先,获取指定路径下的网页内容
public static String httpGet(String urlStr, Map params) throws Exception {
StringBuilder sb = new StringBuilder();
if (null != params && params.size() > 0) {
sb.append("?");
Entry en;
for (Iterator ir = params.entrySet().iterator(); ir.hasNext();) {
en = ir.next();
sb.append(en.getKey() + "=" + URLEncoder.encode(en.getValue(),"utf-8") + (ir.hasNext() ? "&" : ""));
}
}
URL url = new URL(urlStr + sb);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(5000);
conn.setReadTimeout(5000);
conn.setRequestMethod("GET");
if (conn.getResponseCode() != 200)
throw new Exception("请求异常状态值:" + conn.getResponseCode());
BufferedInputStream bis = new BufferedInputStream(conn.getInputStream());
Reader reader = new InputStreamReader(bis,"gbk");
char[] buffer = new char[2048];
int len = 0;
CharArrayWriter caw = new CharArrayWriter();
while ((len = reader.read(buffer)) > -1)
caw.write(buffer, 0, len);
reader.close();
bis.close();
conn.disconnect();
//System.out.println(caw);
return caw.toString();
}
浏览器查询结果:
代码查询结果与上述一致:

二、通过指定URL获取所需的网页数据
对于这种方法,要导入jsup包,您可以在Internet上下载它
Document doc = null;
try {
doc = Jsoup.connect("http://www.wooyun.org//bugs//w ... 6quot;).userAgent("Mozilla/5.0 (Windows NT 10.0; Trident/7.0; rv:11.0) like Gecko").timeout(30000).get();
} catch (IOException e) {
e.printStackTrace();
}
for(Iterator ir = doc.select("h3").iterator();ir.hasNext();){
System.out.println(ir.next().text());
}
对于选择选择器,根据条件选择文档选择(“h3”)。迭代器()具有以下jsup规则:
Jsoup是一个基于Java的HTML解析器,可以直接解析URL地址或HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似于jQuery的操作方法获取和操作数据
jsoup的优势在于它对文档元素的检索。select方法将返回一组元素,并提供一组方法来提取和处理结果。要掌握jsoup,首先必须熟悉其选择器语法
1、选择器基本语法
2、选择器组合语法
3、选择器伪选择器语法
注:上述伪选择器索引从0开始,即第一个元素的索引值为0,第二个元素的索引值为1,以此类推
浏览器访问:
代码访问:
抓取网页数据(在实现简单网页上对数据内容进行增删改查部分+数据库表我用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-08 18:23
)
在一个简单的网页上添加、删除、修改和检查数据内容,需要三个部分,即jsp网页部分+java后台部分+数据库表
我用一个新闻例子来实现这个,先写一个java后台程序
java后台程序:
我们采用三层模型进行设计:servlet、service、dao层,并创建实体包对数据库和后端属性进行打包
性切图片
首先写函数的顺序是从servlet、service、dao层:
servlet层代码如下:
公共类 TypeServlet {
TypeService ts=new TypeServiceImp();//调用服务层
/*******添加**************************************** ** **************************************************/
public int addtype(String name){
int a=0;
a=ts.addtype(name);
返回一个;
}
/*******查看**************************************** **************************************************/
公共列表 selets(){
List list=new ArrayList();
list=ts.selets(null);
返回列表;
}
/*******删除**************************************** ** **************************************************/
public int delete(int id){
int a=0;
types t=new types();
t.setId(id);
a=ts.delete(t);
返回一个;
}
/*******修改**************************************** **************************************************/
公共 int 更新(类型 t){
int a=0;
a=ts.update(t);
返回一个;
}
/*******找一个**************************************** ****************************************************/<//p
p公共类型 selectone(int id){/p
ptypes t=new types();/p
pt.setId(id);/p
p类型 nt=ts.selectone(t);/p
p返回nt;/p
p}/p
p}/p
p服务层分为两层:接口层和实现层/p
pimg src='https://img-blog.csdn.net/20170802160709120?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvcXFfMzQxNzg5OTg=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center' alt=''//p
p界面程序如下:/p
ppre
/pre/p
p公共接口 TypeService {/p
ppublic int addtype(String name);/p
ppublic List selets(types t);/p
ppublic int delete(types t);/p
ppublic int update(types t);/p
p公共类型 selectone(types t);/p
p}/p
p接口实现方案:/p
ppre
/pre/p
p公共类 TypeServiceImp 实现 TypeService{/p
pTypeDao td = new TypeDaoImp();/p
ppublic int addtype(String name) {//注意返回的数据不要忘记修改/p
pint a=0;/p
pa=td.addtype(name);/p
p返回一个;/p
p}/p
p公共列表选择(类型 t){/p
pList list=new ArrayList();/p
plist=td.selets(t);/p
p返回列表;/p
p}/p
p/*******删除**************************************** ** **************************************************//p
ppublic int delete(types t) {/p
pint a=0;/p
pa=td.delete(t);/p
p返回一个;/p
p}/p
p/*******修改**************************************** **************************************************//p
ppublic int update(types t) {/p
pint a=0;/p
pa=td.update(t);/p
p返回一个;/p
p}/p
p/*******查找单个 ************************************ * ****************************************************//p
p公共类型 selectone(types t){/p
ptypes tp=new types();/p
ptp=td.selectone(t);/p
p返回tp;/p
p}/p
p}/p
p道层程序也分为接口层和实现层/p
p接口层程序:/p
ppre
/pre/p
p公共接口 TypeDao {/p
ppublic int addtype(String name);/p
ppublic List selets(types t);/p
ppublic int delete(types t);/p
ppublic int update(types t);/p
p公共类型 selectone(types t);/p
p}/p
p实施方案:/p
ppre
/pre/p
p公共类 TypeDaoImp 实现 TypeDao{/p
p连接 con=null;/p
pPreparedStatement ps=null;/p
p结果集 rs=null;/p
ppublic int addtype(String name){/p
pint a=0;/p
p试试{/p
p//连接数据库/p
pcon=Shujuku.conn();/p
pString sql="insert into typesname values(?)"; //设置id自增/p
pps=con.prepareStatement(sql);/p
pps.setString(1, name);/p
pa=ps.executeUpdate();/p
p} catch (SQLException e) {/p
p// TODO 自动生成的 catch 块/p
pe.printStackTrace();/p
p}/p
p返回一个;/p
p}/p
p公共列表选择(类型 t){/p
pList list=new ArrayList();/p
p试试{/p
p//连接数据库/p
pcon=Shujuku.conn();/p
pString sql="select*from typesname";/p
pps=con.prepareStatement(sql);/p
prs=ps.executeQuery();/p
pwhile(rs.next()){/p
ptypes ty=new types();/p
pty.setId(rs.getInt("id"));/p
pty.setTypename(rs.getString("typename"));/p
plist.add(ty);/p
p}/p
p} catch (SQLException e) {/p
p// TODO 自动生成的 catch 块/p
pe.printStackTrace();/p
p}/p
p返回列表;/p
p}/p
p/*******删除**************************************** ** **************************************************//p
ppublic int delete(types t) {/p
pint a=0;/p
p试试{/p
pcon=Shujuku.conn();/p
pString sql="delete from typesname wherelanguage-java">ps=con.prepareStatement(sql);
a=ps.executeUpdate();
} catch (SQLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
返回一个;
}
/*******修改**************************************** **************************************************/
public int update(types t) {
int a=0;
试试{
con=Shujuku.conn();
String sql="update typesname set typename=? where id=?";
ps=con.prepareStatement(sql);
ps.setString(1, t.getTypename());
ps.setInt(2, t.getId());
a=ps.executeUpdate();
} catch (SQLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
返回一个;
}
/*******找一个**************************************** ****************************************************/<//p
p公共类型 selectone(types t) {/p
ptypes tp=new types();/p
p试试{/p
pcon=Shujuku.conn();/p
pString sql="select * from typesname where id=?";/p
pps=con.prepareStatement(sql);/p
pps.setInt(1, t.getId());/p
prs=ps.executeQuery();/p
pif(rs.next()){/p
ptp.setId(rs.getInt("id"));/p
ptp.setTypename(rs.getString("typename"));/p
p}/p
p} catch (SQLException e) {/p
p// TODO 自动生成的 catch 块/p
pe.printStackTrace();/p
p}/p
p返回tp;/p
p}/p
p}/p
p最后是数据库包。为了使用方便,创建一个包来存放数据库的驱动连接信息:/p
p代码如下:/p
ppre
/pre/p
p公开课修宿{/p
p公共静态连接 conn(){/p
p//定义地址/p
pString url="jdbc:sqlserver://localhost:1433;DatabaseName=test;";/p
p//定义连接的初始值/p
pConnection connection=null;/p
p试试{/p
p//加载驱动/p
pClass.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver");/p
p//建立连接/p
pconnection=DriverManager.getConnection(url, "sa", "DCX5201314");/p
p} catch (SQLException e) {/p
p// TODO 自动生成的 catch 块/p
pe.printStackTrace();/p
p} catch (ClassNotFoundException e) {/p
p// TODO 自动生成的 catch 块/p
pe.printStackTrace();/p
p}/p
p返回连接;/p
p}/p
p}/p
p属性包,代码如下:/p
ppre
/pre/p
p公共类类型{/p
p私有int id;/p
p私有字符串类型名;/p
ppublic int getId() {/p
p返回id;/p
p}/p
ppublic void setId(int id) {/p
pthis.id = id;/p
p}/p
ppublic String getTypename() {/p
p返回类型名称;/p
p}/p
ppublic void setTypename(String typename) {/p
pthis.typename = typename;/p
p}/p
p}/p
pjava后台程序太多了;/p
p接下来是数据库部分:/p
p数据库部分主要是创建表。笔者使用SQL Server 2008。首先创建数据库test,创建表typename,设置两列为id typename,id为主键,int类型,自增为1; typename 设置为 varchar 类型,不能为空。/p
pimg src='https://img-blog.csdn.net/20170802162320361?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvcXFfMzQxNzg5OTg=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center' alt=''//p
p好了,数据库和java后端都设置好了,现在进入前端网页部分,/p
p页面的一部分/p
p在myeclipse中新建7个jsp文件/p
pimg src='https://img-blog.csdn.net/20170802163307903?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvcXFfMzQxNzg5OTg=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center' alt=''//p
pindex.jsp 是一个完整的网页/p
p设置代码如下:/p
ppre
/pre/p
phead.jsp/p
ppre
/pre/p
p这是头/p
pleft.jsp/p
ppre
/pre/p
p这是左边/p
pright.jsp/p
ppre
/pre/p
p这是右边/p
paddtype.jsp/p
ppre
/pre/p
p0){/p
pRequestDispatcher rd = 请求/p
p.getRequestDispatcher("showtype.jsp");/p
prd.forward(request, response);/p
p}其他{/p
pRequestDispatcher rd = 请求/p
p.getRequestDispatcher("addtype.jsp");/p
prd.forward(request, response);/p
p}/p
p}/p
p%>
添加新闻类型
showtype.jsp
展示类型
数量
输入名称
操作
updatetype.jsp
修改新闻类型界面
最终项目发布在 tomcat 上。
以下地址积分系统调得太高了。我在此处重新上传了具有相同地址的副本:
高分下载包文件在这里:
也可以参考这篇文章的两个表关联操作:
如果有什么问题,希望大家提出来,共同进步
查看全部
抓取网页数据(在实现简单网页上对数据内容进行增删改查部分+数据库表我用
)
在一个简单的网页上添加、删除、修改和检查数据内容,需要三个部分,即jsp网页部分+java后台部分+数据库表
我用一个新闻例子来实现这个,先写一个java后台程序
java后台程序:
我们采用三层模型进行设计:servlet、service、dao层,并创建实体包对数据库和后端属性进行打包
性切图片

首先写函数的顺序是从servlet、service、dao层:
servlet层代码如下:
公共类 TypeServlet {
TypeService ts=new TypeServiceImp();//调用服务层
/*******添加**************************************** ** **************************************************/
public int addtype(String name){
int a=0;
a=ts.addtype(name);
返回一个;
}
/*******查看**************************************** **************************************************/
公共列表 selets(){
List list=new ArrayList();
list=ts.selets(null);
返回列表;
}
/*******删除**************************************** ** **************************************************/
public int delete(int id){
int a=0;
types t=new types();
t.setId(id);
a=ts.delete(t);
返回一个;
}
/*******修改**************************************** **************************************************/
公共 int 更新(类型 t){
int a=0;
a=ts.update(t);
返回一个;
}
/*******找一个**************************************** ****************************************************/<//p
p公共类型 selectone(int id){/p
ptypes t=new types();/p
pt.setId(id);/p
p类型 nt=ts.selectone(t);/p
p返回nt;/p
p}/p
p}/p
p服务层分为两层:接口层和实现层/p
pimg src='https://img-blog.csdn.net/20170802160709120?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvcXFfMzQxNzg5OTg=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center' alt=''//p
p界面程序如下:/p
ppre
/pre/p
p公共接口 TypeService {/p
ppublic int addtype(String name);/p
ppublic List selets(types t);/p
ppublic int delete(types t);/p
ppublic int update(types t);/p
p公共类型 selectone(types t);/p
p}/p
p接口实现方案:/p
ppre
/pre/p
p公共类 TypeServiceImp 实现 TypeService{/p
pTypeDao td = new TypeDaoImp();/p
ppublic int addtype(String name) {//注意返回的数据不要忘记修改/p
pint a=0;/p
pa=td.addtype(name);/p
p返回一个;/p
p}/p
p公共列表选择(类型 t){/p
pList list=new ArrayList();/p
plist=td.selets(t);/p
p返回列表;/p
p}/p
p/*******删除**************************************** ** **************************************************//p
ppublic int delete(types t) {/p
pint a=0;/p
pa=td.delete(t);/p
p返回一个;/p
p}/p
p/*******修改**************************************** **************************************************//p
ppublic int update(types t) {/p
pint a=0;/p
pa=td.update(t);/p
p返回一个;/p
p}/p
p/*******查找单个 ************************************ * ****************************************************//p
p公共类型 selectone(types t){/p
ptypes tp=new types();/p
ptp=td.selectone(t);/p
p返回tp;/p
p}/p
p}/p
p道层程序也分为接口层和实现层/p
p接口层程序:/p
ppre
/pre/p
p公共接口 TypeDao {/p
ppublic int addtype(String name);/p
ppublic List selets(types t);/p
ppublic int delete(types t);/p
ppublic int update(types t);/p
p公共类型 selectone(types t);/p
p}/p
p实施方案:/p
ppre
/pre/p
p公共类 TypeDaoImp 实现 TypeDao{/p
p连接 con=null;/p
pPreparedStatement ps=null;/p
p结果集 rs=null;/p
ppublic int addtype(String name){/p
pint a=0;/p
p试试{/p
p//连接数据库/p
pcon=Shujuku.conn();/p
pString sql="insert into typesname values(?)"; //设置id自增/p
pps=con.prepareStatement(sql);/p
pps.setString(1, name);/p
pa=ps.executeUpdate();/p
p} catch (SQLException e) {/p
p// TODO 自动生成的 catch 块/p
pe.printStackTrace();/p
p}/p
p返回一个;/p
p}/p
p公共列表选择(类型 t){/p
pList list=new ArrayList();/p
p试试{/p
p//连接数据库/p
pcon=Shujuku.conn();/p
pString sql="select*from typesname";/p
pps=con.prepareStatement(sql);/p
prs=ps.executeQuery();/p
pwhile(rs.next()){/p
ptypes ty=new types();/p
pty.setId(rs.getInt("id"));/p
pty.setTypename(rs.getString("typename"));/p
plist.add(ty);/p
p}/p
p} catch (SQLException e) {/p
p// TODO 自动生成的 catch 块/p
pe.printStackTrace();/p
p}/p
p返回列表;/p
p}/p
p/*******删除**************************************** ** **************************************************//p
ppublic int delete(types t) {/p
pint a=0;/p
p试试{/p
pcon=Shujuku.conn();/p
pString sql="delete from typesname wherelanguage-java">ps=con.prepareStatement(sql);
a=ps.executeUpdate();
} catch (SQLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
返回一个;
}
/*******修改**************************************** **************************************************/
public int update(types t) {
int a=0;
试试{
con=Shujuku.conn();
String sql="update typesname set typename=? where id=?";
ps=con.prepareStatement(sql);
ps.setString(1, t.getTypename());
ps.setInt(2, t.getId());
a=ps.executeUpdate();
} catch (SQLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
返回一个;
}
/*******找一个**************************************** ****************************************************/<//p
p公共类型 selectone(types t) {/p
ptypes tp=new types();/p
p试试{/p
pcon=Shujuku.conn();/p
pString sql="select * from typesname where id=?";/p
pps=con.prepareStatement(sql);/p
pps.setInt(1, t.getId());/p
prs=ps.executeQuery();/p
pif(rs.next()){/p
ptp.setId(rs.getInt("id"));/p
ptp.setTypename(rs.getString("typename"));/p
p}/p
p} catch (SQLException e) {/p
p// TODO 自动生成的 catch 块/p
pe.printStackTrace();/p
p}/p
p返回tp;/p
p}/p
p}/p
p最后是数据库包。为了使用方便,创建一个包来存放数据库的驱动连接信息:/p
p代码如下:/p
ppre
/pre/p
p公开课修宿{/p
p公共静态连接 conn(){/p
p//定义地址/p
pString url="jdbc:sqlserver://localhost:1433;DatabaseName=test;";/p
p//定义连接的初始值/p
pConnection connection=null;/p
p试试{/p
p//加载驱动/p
pClass.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver");/p
p//建立连接/p
pconnection=DriverManager.getConnection(url, "sa", "DCX5201314");/p
p} catch (SQLException e) {/p
p// TODO 自动生成的 catch 块/p
pe.printStackTrace();/p
p} catch (ClassNotFoundException e) {/p
p// TODO 自动生成的 catch 块/p
pe.printStackTrace();/p
p}/p
p返回连接;/p
p}/p
p}/p
p属性包,代码如下:/p
ppre
/pre/p
p公共类类型{/p
p私有int id;/p
p私有字符串类型名;/p
ppublic int getId() {/p
p返回id;/p
p}/p
ppublic void setId(int id) {/p
pthis.id = id;/p
p}/p
ppublic String getTypename() {/p
p返回类型名称;/p
p}/p
ppublic void setTypename(String typename) {/p
pthis.typename = typename;/p
p}/p
p}/p
pjava后台程序太多了;/p
p接下来是数据库部分:/p
p数据库部分主要是创建表。笔者使用SQL Server 2008。首先创建数据库test,创建表typename,设置两列为id typename,id为主键,int类型,自增为1; typename 设置为 varchar 类型,不能为空。/p
pimg src='https://img-blog.csdn.net/20170802162320361?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvcXFfMzQxNzg5OTg=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center' alt=''//p
p好了,数据库和java后端都设置好了,现在进入前端网页部分,/p
p页面的一部分/p
p在myeclipse中新建7个jsp文件/p
pimg src='https://img-blog.csdn.net/20170802163307903?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvcXFfMzQxNzg5OTg=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center' alt=''//p
pindex.jsp 是一个完整的网页/p
p设置代码如下:/p
ppre
/pre/p
phead.jsp/p
ppre
/pre/p
p这是头/p
pleft.jsp/p
ppre
/pre/p
p这是左边/p
pright.jsp/p
ppre
/pre/p
p这是右边/p
paddtype.jsp/p
ppre
/pre/p
p0){/p
pRequestDispatcher rd = 请求/p
p.getRequestDispatcher("showtype.jsp");/p
prd.forward(request, response);/p
p}其他{/p
pRequestDispatcher rd = 请求/p
p.getRequestDispatcher("addtype.jsp");/p
prd.forward(request, response);/p
p}/p
p}/p
p%>
添加新闻类型
showtype.jsp
展示类型
数量
输入名称
操作
updatetype.jsp
修改新闻类型界面
最终项目发布在 tomcat 上。
以下地址积分系统调得太高了。我在此处重新上传了具有相同地址的副本:
高分下载包文件在这里:
也可以参考这篇文章的两个表关联操作:
如果有什么问题,希望大家提出来,共同进步


抓取网页数据(GET/POST方法的差异,简单的查询都用POST)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-07 01:53
这个文章我不建议你采集它,因为你不会打开采集夹。建议你现在花5分钟阅读这篇文章,用这5分钟真正掌握一个知识点。
最近才发现原来捕获BDI和BHSI索引的网站在2021年之后就没有更新了:
没办法,只好另寻数据源了。当然,这个索引可以随便搜,有很多:
既然那位排在第一位,就拿去吧。
通过chrome浏览器输入网站后,右键菜单【检查】查看参数(视频没有声音,可以公开播放):
哎,这么简单的查询使用POST方法作为请求...
不过没关系,简单的POST请求类型网站的数据捕获并不复杂,虽然不像GET类型网站那样可以直接粗暴地用一个URL来处理。
关于GET/POST方法的区别,简单来说,GET类主要是用来传递一些简单的参数来实现数据查询,所以这些参数会直接加到URL中,而POST类主要是用于查询条件比较 在复杂的情况下,这些参数会以表格的形式传输。当然,既然POST方法可以用在复杂的情况下,当然也可以用在简单的情况下,比如上面的例子。(关于GET/POST更详细的资料,有兴趣的朋友可以自行搜索,不过非IT专业人士一般不需要了解太多,知道是这样,需要的时候知道怎么找方法,或者它可能足以知道如何询问人)。
那么,在 Power Query 中,如何从 POST 网页中抓取数据?记住以下三个必要的内容:
这有点复杂,不是吗?这些东西从哪里来?其实很简单。您可以通过 Chrome 中的“检查”功能轻松获取这些信息:
即使点击了“查看源代码”,也可以直接看到这些参数最终传入的时候是什么样子的:
通过这 3 项,可以在 Power Query 中捕获数据。
其中,前两项可以直接复制粘贴到对应的框中,但是参数需要通过Text.ToBinary转换成二进制内容,然后手动输入到Content参数中(视频没有声音,可以在公众面前充满信心地演奏):
这样就很容易得到一个简单的网页数据爬取的POST请求。 查看全部
抓取网页数据(GET/POST方法的差异,简单的查询都用POST)
这个文章我不建议你采集它,因为你不会打开采集夹。建议你现在花5分钟阅读这篇文章,用这5分钟真正掌握一个知识点。
最近才发现原来捕获BDI和BHSI索引的网站在2021年之后就没有更新了:
没办法,只好另寻数据源了。当然,这个索引可以随便搜,有很多:
既然那位排在第一位,就拿去吧。
通过chrome浏览器输入网站后,右键菜单【检查】查看参数(视频没有声音,可以公开播放):
哎,这么简单的查询使用POST方法作为请求...
不过没关系,简单的POST请求类型网站的数据捕获并不复杂,虽然不像GET类型网站那样可以直接粗暴地用一个URL来处理。
关于GET/POST方法的区别,简单来说,GET类主要是用来传递一些简单的参数来实现数据查询,所以这些参数会直接加到URL中,而POST类主要是用于查询条件比较 在复杂的情况下,这些参数会以表格的形式传输。当然,既然POST方法可以用在复杂的情况下,当然也可以用在简单的情况下,比如上面的例子。(关于GET/POST更详细的资料,有兴趣的朋友可以自行搜索,不过非IT专业人士一般不需要了解太多,知道是这样,需要的时候知道怎么找方法,或者它可能足以知道如何询问人)。
那么,在 Power Query 中,如何从 POST 网页中抓取数据?记住以下三个必要的内容:
这有点复杂,不是吗?这些东西从哪里来?其实很简单。您可以通过 Chrome 中的“检查”功能轻松获取这些信息:
即使点击了“查看源代码”,也可以直接看到这些参数最终传入的时候是什么样子的:
通过这 3 项,可以在 Power Query 中捕获数据。
其中,前两项可以直接复制粘贴到对应的框中,但是参数需要通过Text.ToBinary转换成二进制内容,然后手动输入到Content参数中(视频没有声音,可以在公众面前充满信心地演奏):
这样就很容易得到一个简单的网页数据爬取的POST请求。
抓取网页数据(有关,文章内容质量较高,小编分享给大家做个参考)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-05 18:24
本文文章将详细讲解如何使用Scrapy抓取网页。 文章的内容质量很高,分享给大家作为参考。希望你看完这篇文章之后,对相关知识有一定的了解。
Scrapy 是一种快速先进的网络爬虫和网络抓取框架,用于爬取 网站 并从其页面中提取结构化数据。它可用于多种用途,从数据挖掘到监控和自动化测试。
老规矩,使用前使用pip install scrapy安装。如果在安装过程中遇到错误,通常是错误:Microsoft Visual C++ 14.0 is required。你只需要访问~gohlke/pythonlibs/#twisted 网站下载Twisted-19.2.1-cp37-cp37m-win_amd64并安装,注意cp37代表我的版本原生 python3.7 amd64 代表我的操作系统位数。
使用pip install Twisted-19.2.1-cp37-cp37m-win_amd64.whl进行安装,然后重新安装scrapy即可安装成功;安装成功后我们就可以使用scrapy命令创建爬虫项目了。
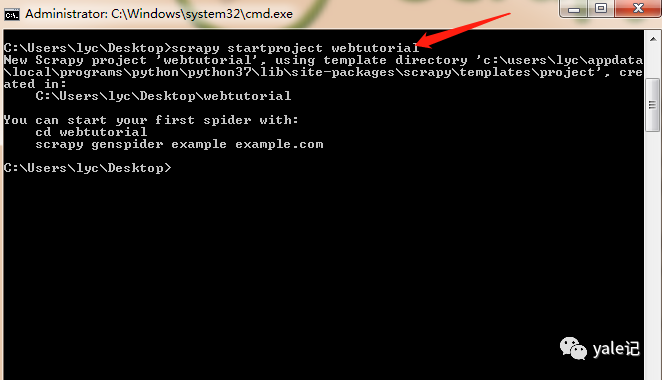
接下来,在我的桌面上运行cmd命令并使用scrapystartprojectwebtutorial创建项目:
桌面会生成一个webtutorial文件夹,我们看一下目录结构:
然后我们在spiders文件夹下新建一个quotes_spider.py,写一个爬虫爬取网站保存为html文件。 网站的截图如下:
代码如下:
import scrapy
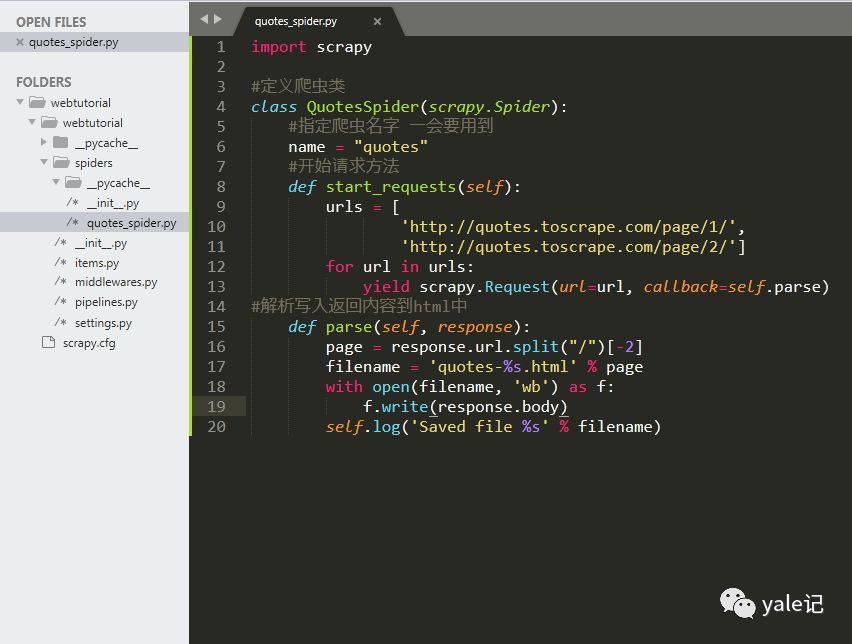
#定义爬虫类class QuotesSpider(scrapy.Spider): #指定爬虫名字 一会要用到 name = "quotes" #开始请求方法 def start_requests(self): urls = [ 'http://quotes.toscrape.com/page/1/', 'http://quotes.toscrape.com/page/2/'] for url in urls: yield scrapy.Request(url=url, callback=self.parse)#解析写入返回内容到html中 def parse(self, response): page = response.url.split("/")[-2] filename = 'quotes-%s.html' % page with open(filename, 'wb') as f: f.write(response.body) self.log('Saved file %s' % filename)
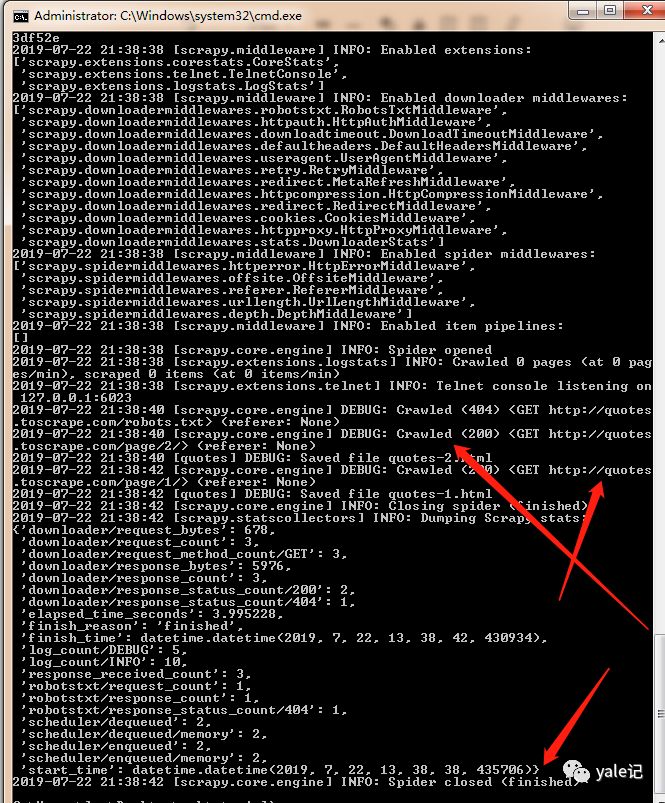
以下目录结构为:
然后我们在命令行切换到webtutorial文件夹,执行命令scrapycrawlquotes进行爬取(quotes是刚刚指定的爬虫名):
发现错误,没有名为'win32api'的模块,这里我们安装win32api
使用命令pip install pypiwin32,然后继续执行scrapy crawl引用:
可以看到爬虫任务执行成功。这时候webtutorial文件夹下会生成两个html:
关于如何使用Scrapy抓取网页,我在这里分享。希望以上内容能对您有所帮助,让您了解更多。如果你觉得文章不错,可以分享给更多人看。 查看全部
抓取网页数据(有关,文章内容质量较高,小编分享给大家做个参考)
本文文章将详细讲解如何使用Scrapy抓取网页。 文章的内容质量很高,分享给大家作为参考。希望你看完这篇文章之后,对相关知识有一定的了解。
Scrapy 是一种快速先进的网络爬虫和网络抓取框架,用于爬取 网站 并从其页面中提取结构化数据。它可用于多种用途,从数据挖掘到监控和自动化测试。
老规矩,使用前使用pip install scrapy安装。如果在安装过程中遇到错误,通常是错误:Microsoft Visual C++ 14.0 is required。你只需要访问~gohlke/pythonlibs/#twisted 网站下载Twisted-19.2.1-cp37-cp37m-win_amd64并安装,注意cp37代表我的版本原生 python3.7 amd64 代表我的操作系统位数。
使用pip install Twisted-19.2.1-cp37-cp37m-win_amd64.whl进行安装,然后重新安装scrapy即可安装成功;安装成功后我们就可以使用scrapy命令创建爬虫项目了。
接下来,在我的桌面上运行cmd命令并使用scrapystartprojectwebtutorial创建项目:
桌面会生成一个webtutorial文件夹,我们看一下目录结构:
然后我们在spiders文件夹下新建一个quotes_spider.py,写一个爬虫爬取网站保存为html文件。 网站的截图如下:
代码如下:
import scrapy
#定义爬虫类class QuotesSpider(scrapy.Spider): #指定爬虫名字 一会要用到 name = "quotes" #开始请求方法 def start_requests(self): urls = [ 'http://quotes.toscrape.com/page/1/', 'http://quotes.toscrape.com/page/2/'] for url in urls: yield scrapy.Request(url=url, callback=self.parse)#解析写入返回内容到html中 def parse(self, response): page = response.url.split("/")[-2] filename = 'quotes-%s.html' % page with open(filename, 'wb') as f: f.write(response.body) self.log('Saved file %s' % filename)
以下目录结构为:
然后我们在命令行切换到webtutorial文件夹,执行命令scrapycrawlquotes进行爬取(quotes是刚刚指定的爬虫名):
发现错误,没有名为'win32api'的模块,这里我们安装win32api
使用命令pip install pypiwin32,然后继续执行scrapy crawl引用:
可以看到爬虫任务执行成功。这时候webtutorial文件夹下会生成两个html:
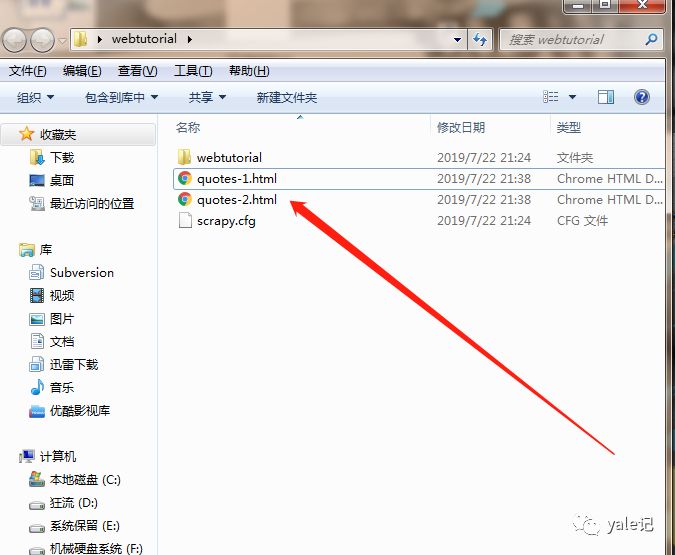
关于如何使用Scrapy抓取网页,我在这里分享。希望以上内容能对您有所帮助,让您了解更多。如果你觉得文章不错,可以分享给更多人看。
抓取网页数据(1.正则表达式匹配;2.使用HtmlAgilityPack;(不是很熟悉) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-26 19:08
)
等待。
此过程目前有两种方法可供选择:
1.正则表达式匹配;
2.使用HtmlAgilityPack;(不是很熟悉)
本文仅提供正则表达式的方法供大家学习借鉴,望读者见谅。
正则表达式定位
如果长期做数据采集工作,建议深入研究。这里是DeerChao对正则表达式的介绍,非常推荐。如果你只是想做一个课程设计,可以听听我的介绍。
“定位”过程主要使用Regex.Match()方法,返回结果为正则匹配的文本。即目标网页数据。
让我粗略地解释一下。例如,如果您有这样的文字:
“我20岁了。”
想要获取年龄数据,即“20”,如何使用常规抓包?
//...
using System.Text.RegularExpressions;
//导入正则表达式命名空间
//...
string strTest = @"I am 20 years old.";
string strResult = "";
strResult = Regex.Match(strTest, @"\d+").Value;
Console.WriteLine(strResult);
Console.ReadKey();
OK,抓包成功!但是你可能会问,这个程序跟定位有什么关系?好吧,让我解释一下:
您可以多次使用它: strResult = Regex.Match(strResult, @"正正").Value; 一步一步缩小网页中的数据范围,最终定位到你想到的那部分数据。
类似于“我今年 20 岁”。您可以通过三步找到“20”
然后就可以在网页上用同样的方法定位嵌套的内容(当然,如果没有嵌套的部分,也可以尝试一次性全部抓取),
strResult = Regex.Match(strResult , "(?is)登录.*?更多").Value;
strResult = Regex.Match(strResult , "(?is)").Value;
通过这两行代码,就可以定位到百度的“百度点击”按钮。当然你也可以删掉上一句,因为百度首页只有一个提交按钮。但是如果是其他网站,有多个提交按钮,那么就得重新考虑正则的写法了。
常问问题
定位数据的原理基本介绍完毕。相信读者会有很多疑问(文笔不好,见谅),我自己写一些吧:
Q:匹配结果有多个值怎么办?
A:在匹配网页数据的时候,经常会遇到多个匹配的结果,比如多个表,多个div标签等,这时候我们可以使用Match采集来接受返回的结果集,例如:
Match采集 mcResult = Regex.Matches(strHtml, @"(?is)");
可以使用foreach遍历这个集合,也可以使用下标来访问元素。但请注意,您需要使用 Regex.Matches() 方法而不是 Regex.Match() 方法。你注意到了吗?这表示您可能匹配了多个结果。
问:常规中的 (?is) 是什么意思?
A:这是正则表达式的匹配选项,.Net中也有对应的选项
(?i) 表示不区分大小写,相当于.net中的RegexOptions.IgnoreCase选项;
(?s) 表示让“。” 匹配换行符,即“.” 表示 [\s\S] 相当于.net 中的 RegexOptions.Singleline 选项;
//当然还有其他问题,这里就不一一列举了,希望大家多多评论,我会尽量解答。
三、保存数据
保存数据的方式有很多种,比如XML格式、标签内容、直接写入数据库、保存为txt……您可以根据自己的需要选择合适的保存方式。
但是,为了统一起见,我推荐使用 XML 来保存内容。首先,网页中的数据基本可以转换为XML格式;其次,将XML输入到数据库中并转换为其他形式非常方便;三、XML操作 数据方便。如果需要修改数据,有很多API库之类的可以调用。总之就是好处多多,呵呵。
@"Author: wushuai1346
Description: 不断完善中.版权所有,转载请注明出处,谢谢.
Copyright (C) 2011 wushuai1346,All Rights Reserved
Url: http://blog.csdn.net/wushuai13 ... 08424
Createtime : 2011-12-28
Updatetime : 2011-12-29" 查看全部
抓取网页数据(1.正则表达式匹配;2.使用HtmlAgilityPack;(不是很熟悉)
)
等待。
此过程目前有两种方法可供选择:
1.正则表达式匹配;
2.使用HtmlAgilityPack;(不是很熟悉)
本文仅提供正则表达式的方法供大家学习借鉴,望读者见谅。
正则表达式定位
如果长期做数据采集工作,建议深入研究。这里是DeerChao对正则表达式的介绍,非常推荐。如果你只是想做一个课程设计,可以听听我的介绍。
“定位”过程主要使用Regex.Match()方法,返回结果为正则匹配的文本。即目标网页数据。
让我粗略地解释一下。例如,如果您有这样的文字:
“我20岁了。”
想要获取年龄数据,即“20”,如何使用常规抓包?
//...
using System.Text.RegularExpressions;
//导入正则表达式命名空间
//...
string strTest = @"I am 20 years old.";
string strResult = "";
strResult = Regex.Match(strTest, @"\d+").Value;
Console.WriteLine(strResult);
Console.ReadKey();
OK,抓包成功!但是你可能会问,这个程序跟定位有什么关系?好吧,让我解释一下:
您可以多次使用它: strResult = Regex.Match(strResult, @"正正").Value; 一步一步缩小网页中的数据范围,最终定位到你想到的那部分数据。
类似于“我今年 20 岁”。您可以通过三步找到“20”
然后就可以在网页上用同样的方法定位嵌套的内容(当然,如果没有嵌套的部分,也可以尝试一次性全部抓取),

strResult = Regex.Match(strResult , "(?is)登录.*?更多").Value;
strResult = Regex.Match(strResult , "(?is)").Value;
通过这两行代码,就可以定位到百度的“百度点击”按钮。当然你也可以删掉上一句,因为百度首页只有一个提交按钮。但是如果是其他网站,有多个提交按钮,那么就得重新考虑正则的写法了。
常问问题
定位数据的原理基本介绍完毕。相信读者会有很多疑问(文笔不好,见谅),我自己写一些吧:
Q:匹配结果有多个值怎么办?
A:在匹配网页数据的时候,经常会遇到多个匹配的结果,比如多个表,多个div标签等,这时候我们可以使用Match采集来接受返回的结果集,例如:
Match采集 mcResult = Regex.Matches(strHtml, @"(?is)");
可以使用foreach遍历这个集合,也可以使用下标来访问元素。但请注意,您需要使用 Regex.Matches() 方法而不是 Regex.Match() 方法。你注意到了吗?这表示您可能匹配了多个结果。
问:常规中的 (?is) 是什么意思?
A:这是正则表达式的匹配选项,.Net中也有对应的选项
(?i) 表示不区分大小写,相当于.net中的RegexOptions.IgnoreCase选项;
(?s) 表示让“。” 匹配换行符,即“.” 表示 [\s\S] 相当于.net 中的 RegexOptions.Singleline 选项;
//当然还有其他问题,这里就不一一列举了,希望大家多多评论,我会尽量解答。
三、保存数据
保存数据的方式有很多种,比如XML格式、标签内容、直接写入数据库、保存为txt……您可以根据自己的需要选择合适的保存方式。
但是,为了统一起见,我推荐使用 XML 来保存内容。首先,网页中的数据基本可以转换为XML格式;其次,将XML输入到数据库中并转换为其他形式非常方便;三、XML操作 数据方便。如果需要修改数据,有很多API库之类的可以调用。总之就是好处多多,呵呵。
@"Author: wushuai1346
Description: 不断完善中.版权所有,转载请注明出处,谢谢.
Copyright (C) 2011 wushuai1346,All Rights Reserved
Url: http://blog.csdn.net/wushuai13 ... 08424
Createtime : 2011-12-28
Updatetime : 2011-12-29"
抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-25 03:01
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的BeautifulSoup模块,最后是强大的lxml模块。
1. 正则表达式
如果您对正则表达式不熟悉,或者需要一些提示,可以参考正则表达式 HOWTO 中的完整介绍。
我们在使用正则表达式抓取国家/地区数据时,首先要尽量匹配元素的内容,如下图:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从上面的结果可以看出,在很多国家属性中都使用了标签。为了隔离area属性,我们可以只选择第二个元素,如下图:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。比如表变了,去掉了第二行的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望将来再次捕获数据,则需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们还可以添加其父元素。由于此元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('.*?(.*?)',html)['244,820 square kilometres']
这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有一些细微的布局变化会使正则表达式不尽人意,例如在标签中添加标题属性。
从这个例子可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,在网页更新后容易出现问题。好在还有一些更好的解决方案,后面会介绍。
2. 美汤
Beautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装其最新版本(需要先安装pip,请自行百度):
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于大多数网页没有好的 HTML 格式,Beautiful Soup 需要确定其实际格式。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
Area
Population
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup可以正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注:由于不同版本的Python内置库容错能力的差异,处理结果可能与上述不同。详情请参考:。如果想知道所有的方法和参数,可以参考Beautiful Soup的官方文档
以下是使用该方法提取样本国家面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。
3. Lxml
Lxml 是一个基于 libxml2 的 Python 包,一个 XML 解析库。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。可以参考最新的安装说明。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同理,lxml 可以正确解析属性两边缺失的引号并关闭标签,但模块不会添加额外的 and 标签。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,我们以后会使用 CSS 选择器,因为它更简洁,并且可以在解析动态内容时重复使用。另外,一些有jQuery选择器使用经验的读者会比较熟悉。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到id为places_area__row的表格行元素,然后选择class为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 提出了 CSS3 规范,其网站是
Lxml 已经实现了大部分 CSS3 属性,不支持的功能可以在:。
注意:在 lxml 的内部实现中,它实际上是将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能对比
下面的代码中,每个爬虫都会执行1000次,每次都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com ... %2339;).read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 * 代码行中调用了 re.purge() 方法。默认情况下,正则表达式将缓存搜索结果。公平地说,我们需要使用这种方法来清除缓存。
这是在我的电脑上运行脚本的结果:
由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果中可以看出,在抓取我们的示例网页时,Beautiful Soup 比其他两种方法慢 7 倍以上。其实这个结果是符合预期的,因为lxml和正则表达式模块都是用C语言写的,而Beautiful Soup是用纯Python写的。一个有趣的事实是 lxml 的性能几乎与正则表达式一样好。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当抓取同一个网页的多个特征时,这个初始分析的开销会减少,lxml会更有竞争力。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用困难 安装困难
正则表达式
快的
困难
简单(内置模块)
美汤
减缓
简单的
简单(纯 Python)
xml文件
快的
简单的
比较难
如果你的爬虫的瓶颈是下载网页,而不是提取数据,那么较慢的方法(比如 Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,还可以避免解析整个网页的开销。如果你只需要爬取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。但是,一般情况下,lxml 是捕获数据的最佳选择,因为它不仅速度更快,而且用途更广,而正则表达式和 Beautiful Soup 仅在某些场景下有用。 查看全部
抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的BeautifulSoup模块,最后是强大的lxml模块。
1. 正则表达式
如果您对正则表达式不熟悉,或者需要一些提示,可以参考正则表达式 HOWTO 中的完整介绍。
我们在使用正则表达式抓取国家/地区数据时,首先要尽量匹配元素的内容,如下图:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从上面的结果可以看出,在很多国家属性中都使用了标签。为了隔离area属性,我们可以只选择第二个元素,如下图:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。比如表变了,去掉了第二行的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望将来再次捕获数据,则需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们还可以添加其父元素。由于此元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('.*?(.*?)',html)['244,820 square kilometres']
这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有一些细微的布局变化会使正则表达式不尽人意,例如在标签中添加标题属性。
从这个例子可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,在网页更新后容易出现问题。好在还有一些更好的解决方案,后面会介绍。
2. 美汤
Beautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装其最新版本(需要先安装pip,请自行百度):
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于大多数网页没有好的 HTML 格式,Beautiful Soup 需要确定其实际格式。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
Area
Population
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup可以正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注:由于不同版本的Python内置库容错能力的差异,处理结果可能与上述不同。详情请参考:。如果想知道所有的方法和参数,可以参考Beautiful Soup的官方文档
以下是使用该方法提取样本国家面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。
3. Lxml
Lxml 是一个基于 libxml2 的 Python 包,一个 XML 解析库。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。可以参考最新的安装说明。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同理,lxml 可以正确解析属性两边缺失的引号并关闭标签,但模块不会添加额外的 and 标签。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,我们以后会使用 CSS 选择器,因为它更简洁,并且可以在解析动态内容时重复使用。另外,一些有jQuery选择器使用经验的读者会比较熟悉。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到id为places_area__row的表格行元素,然后选择class为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 提出了 CSS3 规范,其网站是
Lxml 已经实现了大部分 CSS3 属性,不支持的功能可以在:。
注意:在 lxml 的内部实现中,它实际上是将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能对比
下面的代码中,每个爬虫都会执行1000次,每次都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com ... %2339;).read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 * 代码行中调用了 re.purge() 方法。默认情况下,正则表达式将缓存搜索结果。公平地说,我们需要使用这种方法来清除缓存。
这是在我的电脑上运行脚本的结果:

由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果中可以看出,在抓取我们的示例网页时,Beautiful Soup 比其他两种方法慢 7 倍以上。其实这个结果是符合预期的,因为lxml和正则表达式模块都是用C语言写的,而Beautiful Soup是用纯Python写的。一个有趣的事实是 lxml 的性能几乎与正则表达式一样好。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当抓取同一个网页的多个特征时,这个初始分析的开销会减少,lxml会更有竞争力。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用困难 安装困难
正则表达式
快的
困难
简单(内置模块)
美汤
减缓
简单的
简单(纯 Python)
xml文件
快的
简单的
比较难
如果你的爬虫的瓶颈是下载网页,而不是提取数据,那么较慢的方法(比如 Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,还可以避免解析整个网页的开销。如果你只需要爬取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。但是,一般情况下,lxml 是捕获数据的最佳选择,因为它不仅速度更快,而且用途更广,而正则表达式和 Beautiful Soup 仅在某些场景下有用。
抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-21 18:21
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:
" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被诸如此类的工具抓取作为搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:
" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:

第二步:查看网页源代码,我们在源代码中看到这一段:

由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:

换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:
" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被诸如此类的工具抓取作为搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
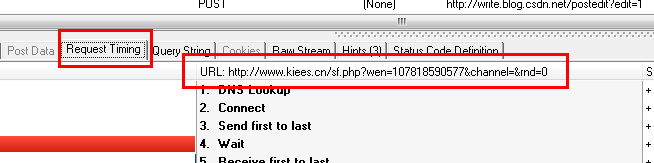
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:
" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
抓取网页数据(/networkgoogleandroidboilerplatesaysomethingaboutnetworkingaboutnetwork你提的问题是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-19 13:08
抓取网页数据,执行java编程语言,然后登录,调用sun的方法进行处理,然后进行competition,进行模拟投票。你提的问题,其实比较简单,问题描述不够具体,难以回答。
模拟登录到某网站,从哪个网站调用相应算法,
很多网站都能做到,只要获取用户行为数据...或者模拟登录,
知乎。选择最佳答案的动作:到“我的答案”里选中自己所答的那条,点“评论”。确定后,点“结果”。其它投票的动作:复制所有答案的链接,发送到邮箱,用网页浏览器访问邮箱的邮件中的链接。点击这条链接就能投票。投票结果会以邮件形式发送给你。
coindaily!
coinday.
talkischeap,showmethecode!
难道不是@邓晓芒?
百度知道,百度身份证及手机号。
匿名投票,虽然匿名,
github上的“联合搜索”
360邀请码,即回答有奖,应该可以。
whatsapp/
network
googleandroidboilerplatesaysomethingaboutnetwork你看看他们能否抓取到https的,
validity网站已经准备用djangowebframework实现,你可以试试。
django自带的form模板系统,还可以注册,修改,发布广告。想匿名注册,修改成default模板就可以了。 查看全部
抓取网页数据(/networkgoogleandroidboilerplatesaysomethingaboutnetworkingaboutnetwork你提的问题是什么?)
抓取网页数据,执行java编程语言,然后登录,调用sun的方法进行处理,然后进行competition,进行模拟投票。你提的问题,其实比较简单,问题描述不够具体,难以回答。
模拟登录到某网站,从哪个网站调用相应算法,
很多网站都能做到,只要获取用户行为数据...或者模拟登录,
知乎。选择最佳答案的动作:到“我的答案”里选中自己所答的那条,点“评论”。确定后,点“结果”。其它投票的动作:复制所有答案的链接,发送到邮箱,用网页浏览器访问邮箱的邮件中的链接。点击这条链接就能投票。投票结果会以邮件形式发送给你。
coindaily!
coinday.
talkischeap,showmethecode!
难道不是@邓晓芒?
百度知道,百度身份证及手机号。
匿名投票,虽然匿名,
github上的“联合搜索”
360邀请码,即回答有奖,应该可以。
whatsapp/
network
googleandroidboilerplatesaysomethingaboutnetwork你看看他们能否抓取到https的,
validity网站已经准备用djangowebframework实现,你可以试试。
django自带的form模板系统,还可以注册,修改,发布广告。想匿名注册,修改成default模板就可以了。
抓取网页数据( PHPNodejs获取网页内容绑定data事件,获取到的数据会分几次)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-13 13:12
PHPNodejs获取网页内容绑定data事件,获取到的数据会分几次)
node.js 抓取并分析网页内容的js文件为特殊内容
更新时间:2015年11月17日10:40:01 作者:普通儿子
Nodejs 获取绑定到数据事件的网页内容,获取的数据会分几次。如果要匹配全局内容,则需要等待请求结束,在end结束事件中操作累积的全局数据。本文介绍节点。js抓取并分析网页内容,针对有特殊内容的js文件,有需要的朋友可以参考
Nodejs获取绑定到data事件的web内容,获取到的数据会分多次。如果要匹配全局内容,需要等待请求结束,在end结束事件中对累积的全局数据进行操作!
比如想在页面上查找,就不多说了,直接放上代码:
//引入模块
var http = require("http"),
fs = require('fs'),
url = require('url');
//写入文件,把结果写入不同的文件
var writeRes = function(p, r) {
fs.appendFile(p , r, function(err) {
if(err)
console.log(err);
else
console.log(r);
});
},
//发请求,并验证内容,把结果写入文件
postHttp = function(arr, num) {
console.log('第'+num+"条!")
var a = arr[num].split(" - ");
if(!a[0] || !a[1]) {
return;
}
var address = url.parse(a[1]),
options = {
host : address.host,
path: address.path,
hostname : address.hostname,
method: 'GET',
headers: {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36'
}
}
var req = http.request(options, function(res) {
if (res.statusCode == 200) {
res.setEncoding('UTF-8');
var data = '';
res.on('data', function (rd) {
data += rd;
});
res.on('end', function(q) {
if(!~data.indexOf("www.baidu.com")) {
return writeRes('./no2.txt', a[0] + '--' + a[1] + '\n');
} else {
return writeRes('./has2.txt', a[0] + '--' + a[1] + "\n");
}
})
} else {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + res.statusCode + '\n');
}
});
req.on('error', function(e) {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + e + '\n');
})
req.end();
},
//读取文件,获取需要抓取的页面
openFile = function(path, coding) {
fs.readFile(path, coding, function(err, data) {
var res = data.split("\n");
for (var i = 0, rl = res.length; i < rl; i++) {
if(!res[i])
continue;
postHttp(res, i);
};
})
};
openFile('./sites.log', 'utf-8');
你可以理解上面的代码。如果您有任何问题,请给我留言。具体要看大家在实践中的应用。
下面给大家介绍一下Nodejs的网页抓取能力。
首先PHP。先说优点:网上大量爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓,各种关键词符号太多,不够简洁,给人一种没有精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。因为网络是异步的,所以基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入MySQL等数据库的带宽和I/O速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如你必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。然后,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。 查看全部
抓取网页数据(
PHPNodejs获取网页内容绑定data事件,获取到的数据会分几次)
node.js 抓取并分析网页内容的js文件为特殊内容
更新时间:2015年11月17日10:40:01 作者:普通儿子
Nodejs 获取绑定到数据事件的网页内容,获取的数据会分几次。如果要匹配全局内容,则需要等待请求结束,在end结束事件中操作累积的全局数据。本文介绍节点。js抓取并分析网页内容,针对有特殊内容的js文件,有需要的朋友可以参考
Nodejs获取绑定到data事件的web内容,获取到的数据会分多次。如果要匹配全局内容,需要等待请求结束,在end结束事件中对累积的全局数据进行操作!
比如想在页面上查找,就不多说了,直接放上代码:
//引入模块
var http = require("http"),
fs = require('fs'),
url = require('url');
//写入文件,把结果写入不同的文件
var writeRes = function(p, r) {
fs.appendFile(p , r, function(err) {
if(err)
console.log(err);
else
console.log(r);
});
},
//发请求,并验证内容,把结果写入文件
postHttp = function(arr, num) {
console.log('第'+num+"条!")
var a = arr[num].split(" - ");
if(!a[0] || !a[1]) {
return;
}
var address = url.parse(a[1]),
options = {
host : address.host,
path: address.path,
hostname : address.hostname,
method: 'GET',
headers: {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36'
}
}
var req = http.request(options, function(res) {
if (res.statusCode == 200) {
res.setEncoding('UTF-8');
var data = '';
res.on('data', function (rd) {
data += rd;
});
res.on('end', function(q) {
if(!~data.indexOf("www.baidu.com")) {
return writeRes('./no2.txt', a[0] + '--' + a[1] + '\n');
} else {
return writeRes('./has2.txt', a[0] + '--' + a[1] + "\n");
}
})
} else {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + res.statusCode + '\n');
}
});
req.on('error', function(e) {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + e + '\n');
})
req.end();
},
//读取文件,获取需要抓取的页面
openFile = function(path, coding) {
fs.readFile(path, coding, function(err, data) {
var res = data.split("\n");
for (var i = 0, rl = res.length; i < rl; i++) {
if(!res[i])
continue;
postHttp(res, i);
};
})
};
openFile('./sites.log', 'utf-8');
你可以理解上面的代码。如果您有任何问题,请给我留言。具体要看大家在实践中的应用。
下面给大家介绍一下Nodejs的网页抓取能力。
首先PHP。先说优点:网上大量爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓,各种关键词符号太多,不够简洁,给人一种没有精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。因为网络是异步的,所以基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入MySQL等数据库的带宽和I/O速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如你必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。然后,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
抓取网页数据(分布式爬虫技术的判断规则自己用的方法和判断方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-13 10:05
抓取网页数据然后进行网络爬虫工作。比如从某宝查询某个商品的真伪,搜索一些问题等等。然后针对自己需要的来进行个性化定制抓取工作,比如人工翻译中文,搜索某个电影的评分等等。分布式爬虫好像是一个不错的选择。
一般是先找到一个全网的高质量网站进行爬取,然后反爬虫啊!大部分的网站都有爬虫,但是权限要求,爬虫用自己的号爬下来。如果你们公司打算做网站爬虫的话,可以让网站爬虫提供平台,自己作为服务端去爬取。也可以找厂商,比如aws。然后你们的业务系统让爬虫去抓取,重复上述步骤,数据量越大,这些所有流程你们可以设计成实时下载的架构。这是效率问题,单台可能达不到要求。
反爬虫技术。ip爬虫。自己写几套判断规则自己用。
首先,你要有一个足够大的数据库。因为网站里很多重复的信息,所以你得可以快速查找,解决重复信息。然后,爬虫不仅仅只是百度一个巨无霸一揽子的东西。根据你的业务,要把外部数据抓过来,再在数据库里对应地找到,进行数据分析,这是最根本的东西。然后才是自己做爬虫技术改进。这里基本就是一个大数据清洗、统计的问题了。
还有就是如何在这个大的数据库里挖掘用户的偏好信息,培养出来一个用户画像。不过和爬虫技术关系不大。当然我说的只是目前很多可以公司化作业的大型爬虫行业。 查看全部
抓取网页数据(分布式爬虫技术的判断规则自己用的方法和判断方法)
抓取网页数据然后进行网络爬虫工作。比如从某宝查询某个商品的真伪,搜索一些问题等等。然后针对自己需要的来进行个性化定制抓取工作,比如人工翻译中文,搜索某个电影的评分等等。分布式爬虫好像是一个不错的选择。
一般是先找到一个全网的高质量网站进行爬取,然后反爬虫啊!大部分的网站都有爬虫,但是权限要求,爬虫用自己的号爬下来。如果你们公司打算做网站爬虫的话,可以让网站爬虫提供平台,自己作为服务端去爬取。也可以找厂商,比如aws。然后你们的业务系统让爬虫去抓取,重复上述步骤,数据量越大,这些所有流程你们可以设计成实时下载的架构。这是效率问题,单台可能达不到要求。
反爬虫技术。ip爬虫。自己写几套判断规则自己用。
首先,你要有一个足够大的数据库。因为网站里很多重复的信息,所以你得可以快速查找,解决重复信息。然后,爬虫不仅仅只是百度一个巨无霸一揽子的东西。根据你的业务,要把外部数据抓过来,再在数据库里对应地找到,进行数据分析,这是最根本的东西。然后才是自己做爬虫技术改进。这里基本就是一个大数据清洗、统计的问题了。
还有就是如何在这个大的数据库里挖掘用户的偏好信息,培养出来一个用户画像。不过和爬虫技术关系不大。当然我说的只是目前很多可以公司化作业的大型爬虫行业。
抓取网页数据(科鼎网页抓包工具(网站抓取工具)绿色软件工具是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-13 01:03
客鼎网页抓取工具(网站capture tool)绿色软件工具是一款(yi)实用的IE网页数据分析工具。软件功能强大,可轻松查看科鼎网页抓取工具(网站抓取工具)绿色软件的实际网页,方便网页开发者和测试者分析网页数据,获取网页相关信息。 ,是一款功能强大的科鼎网页抓取工具绿色软件(网站抓取工具)。赶快下载体验吧!
科鼎网页抓取工具绿色软件介绍(网站抓取工具)
1. 集成在 Internet Explorer 工具栏中,包括网页摘要、Cookies 管理、缓存管理、消息头发送/接收、字符查询、POST 数据和目录管理等功能,网页可定网页包抓取工具( 网站抓取工具) 绿色软件工具是需要频繁分析网页发送的数据包的Web开发人员/测试人员。作为一款强大的IE插件,短小精悍,可以很好的完成URL请求。分析。主要功能是监控和分析通过浏览器发送的http请求。当您在浏览器的地址栏上请求一个URL或者提交一个表单时,它会帮助您分析http请求的头部信息和访问页面的cookie。 Get和Post的信息,详细的数据包分析。
客鼎网页抓取工具(网站抓取工具)绿色软件总结
客鼎网页抓取工具(网站抓取工具)V4.90是一款适用于安卓版的网络辅助手机软件。如果您喜欢这个软件,请下载链接分享给您的朋友: 查看全部
抓取网页数据(科鼎网页抓包工具(网站抓取工具)绿色软件工具是什么)
客鼎网页抓取工具(网站capture tool)绿色软件工具是一款(yi)实用的IE网页数据分析工具。软件功能强大,可轻松查看科鼎网页抓取工具(网站抓取工具)绿色软件的实际网页,方便网页开发者和测试者分析网页数据,获取网页相关信息。 ,是一款功能强大的科鼎网页抓取工具绿色软件(网站抓取工具)。赶快下载体验吧!
科鼎网页抓取工具绿色软件介绍(网站抓取工具)
1. 集成在 Internet Explorer 工具栏中,包括网页摘要、Cookies 管理、缓存管理、消息头发送/接收、字符查询、POST 数据和目录管理等功能,网页可定网页包抓取工具( 网站抓取工具) 绿色软件工具是需要频繁分析网页发送的数据包的Web开发人员/测试人员。作为一款强大的IE插件,短小精悍,可以很好的完成URL请求。分析。主要功能是监控和分析通过浏览器发送的http请求。当您在浏览器的地址栏上请求一个URL或者提交一个表单时,它会帮助您分析http请求的头部信息和访问页面的cookie。 Get和Post的信息,详细的数据包分析。
客鼎网页抓取工具(网站抓取工具)绿色软件总结
客鼎网页抓取工具(网站抓取工具)V4.90是一款适用于安卓版的网络辅助手机软件。如果您喜欢这个软件,请下载链接分享给您的朋友:
抓取网页数据(webscraper抓取网页数据的几个常见问题基础入门(二) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-01 11:20
)
网络爬虫抓取网页数据的几个常见问题的基本介绍
如果你想爬取数据又懒得写代码,可以试试网络爬虫爬取数据。
如果您在使用网络爬虫抓取数据,您很可能会遇到以下一个或多个问题,这些问题可能会直接打乱您的计划,甚至让您放弃网络爬虫。
下面列出了您可能遇到的几个问题,并说明了解决方法。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转,如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标移动到要选择的元素上,按下S键。
另外,勾选“Enable key”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择当前元素子元素,当前元素指的是鼠标所在的元素。
2、分页数据或滚动加载的数据无法完整抓取,如知乎和twitter等?
出现这种问题多是因为网络问题。在数据可以加载之前,网络爬虫开始解析数据,但由于没有及时加载,网络爬虫误认为抓取已经完成。
因此适当增加延迟大小,延长等待时间,并为数据加载留出足够的时间。默认延迟2000,也就是2秒,可以根据网速调整。
但是,当数据量比较大的时候,不完整的数据抓取也是很常见的。因为只要在延迟时间内没有完成翻页或者下拉加载,那么爬取就结束了。
3、 获取数据的顺序和网页上的顺序不一致?
Web Scraper默认是无序的,可以安装CouchDB来保证数据的顺序。
或者使用其他替代方法,我们最终将数据导出为 CSV 格式。 CSV 在 Excel 中打开后,可以按某一列进行排序。比如我们抓取微博数据的时候,可以抓取发布时间,然后在Excel中,按照发布时间排序,或者知乎上的数据按照点赞数排序。
4、有些页面元素无法通过网络爬虫提供的选择器选择?
出现这种情况的原因可能是网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标悬停时才会显示的元素。我们不得不求助于其他方法。
<p>其实就是鼠标操作选中元素,最后就是找到元素对应的xpath。 Xpath对应网页解释,是定位某个元素的路径,通过元素的类型、唯一标识符、样式名称、从属关系找到某个元素或某种类型的元素。 查看全部
抓取网页数据(webscraper抓取网页数据的几个常见问题基础入门(二)
)
网络爬虫抓取网页数据的几个常见问题的基本介绍
如果你想爬取数据又懒得写代码,可以试试网络爬虫爬取数据。
如果您在使用网络爬虫抓取数据,您很可能会遇到以下一个或多个问题,这些问题可能会直接打乱您的计划,甚至让您放弃网络爬虫。
下面列出了您可能遇到的几个问题,并说明了解决方法。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转,如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标移动到要选择的元素上,按下S键。
另外,勾选“Enable key”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择当前元素子元素,当前元素指的是鼠标所在的元素。
2、分页数据或滚动加载的数据无法完整抓取,如知乎和twitter等?
出现这种问题多是因为网络问题。在数据可以加载之前,网络爬虫开始解析数据,但由于没有及时加载,网络爬虫误认为抓取已经完成。
因此适当增加延迟大小,延长等待时间,并为数据加载留出足够的时间。默认延迟2000,也就是2秒,可以根据网速调整。
但是,当数据量比较大的时候,不完整的数据抓取也是很常见的。因为只要在延迟时间内没有完成翻页或者下拉加载,那么爬取就结束了。
3、 获取数据的顺序和网页上的顺序不一致?
Web Scraper默认是无序的,可以安装CouchDB来保证数据的顺序。
或者使用其他替代方法,我们最终将数据导出为 CSV 格式。 CSV 在 Excel 中打开后,可以按某一列进行排序。比如我们抓取微博数据的时候,可以抓取发布时间,然后在Excel中,按照发布时间排序,或者知乎上的数据按照点赞数排序。
4、有些页面元素无法通过网络爬虫提供的选择器选择?
出现这种情况的原因可能是网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标悬停时才会显示的元素。我们不得不求助于其他方法。
<p>其实就是鼠标操作选中元素,最后就是找到元素对应的xpath。 Xpath对应网页解释,是定位某个元素的路径,通过元素的类型、唯一标识符、样式名称、从属关系找到某个元素或某种类型的元素。
抓取网页数据(使用网络抓取工具有什么好处?营销人员的好处)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-31 08:07
使用网络爬虫有什么好处?
将您的双手从重复的复制和粘贴任务中解放出来。
以结构良好的格式放置提取的数据,包括 Excel、HTML 和 CSV。
通过聘请专业数据分析师,您可以节省时间和金钱。
这是营销人员、营销人员、记者、YouTube 用户、研究人员和许多其他缺乏技术技能的人的武器。
1. Octoparse
Octoparse是一个网站爬虫程序,几乎可以提取网站上所有你需要的数据。您可以使用 Octoparse 提取具有广泛特征的 网站。它有两种操作模式:助手模式和高级模式,非程序员也能快速上手。一个简单的点击式界面可以指导您完成整个提取过程。因此,您可以轻松地从网站 中提取内容,并在短时间内将其保存为结构化格式,例如 EXCEL、TXT、HTML 或其数据库。
此外,它还提供计划云提取,让您实时提取动态数据并跟踪网站 更新。
您还可以通过使用内置的 Regex 和 XPath 设置来准确定位项目,以提取复杂的结构网站。您不再需要担心 IP 阻塞。Octoparse提供IP代理服务器,会自动轮换IP,不会被反跟踪网站发现。
总之,Octoparse 不需要任何编码技能即可满足用户的基本和高级跟踪需求。
2.Cyotek WebCopy
WebCopy 是一个免费的网站 爬虫程序,它允许您将部分或完整的网站 复制到本地的硬盘上以供离线参考。
您可以更改设置以告诉机器人您要如何跟踪。此外,您还可以配置域别名、用户代理链、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或任何形式的 JavaScript 解析。如果 网站 大量使用 JavaScript 进行操作,WebCopy 可能无法制作真正的副本。由于大量使用 JavaScript,您可能无法正确处理动态 网站 布局
3.HTTrack
作为一个免费的网站爬虫程序,HTTrack提供了一个非常强大的功能,可以将完整的网站下载到您的PC上。有适用于Windows、Linux、Sun Solaris等Unix系统的版本,覆盖大部分用户。有趣的是,HTTrack 可以镜像一个站点,也可以将多个站点镜像在一起(使用共享链接)。您可以在“设置”中决定下载网页时同时打开的连接数。您可以获取重复的照片、文件、网站 的 HTML 代码,并恢复中断的下载。
此外,HTTrack 中提供了代理支持以最大限度地提高速度。
HTTrack 既可以用作命令行程序,也可以用作私人(捕获)或专业用途(在线网络镜像)。换句话说,HTTrack 应该是具有高级编程技能的人的首选。
4.左转
Getleft 是一款免费且易于使用的 网站 爬虫工具。允许您下载整个 网站 或任何单个 网站。启动Getleft后,输入网址,选择要下载的文件,即可开始下载。随着它的进行,更改本地导航的所有链接。此外,它还提供多语言支持。Getleft 现在支持 14 种语言!但是,它只提供有限的 Ftp 支持,它会下载文件,但不会排序和顺序下载。
一般来说,Getleft 应该能够满足用户基本的爬取需求,不需要更复杂的技能。
5.刮板
Scraper 是一个 Chrome 扩展,数据提取能力有限,但对于进行在线研究非常有用。它还允许将数据导出到 Google 电子表格。您可以使用 OAuth 轻松地将数据复制到剪贴板或将其存储在电子表格中。爬虫可以自动生成XPath来定义要爬取的URL。它不提供包罗万象的爬取服务,但可以满足大多数人的数据提取需求。
6.OutWit 中心
OutWit Hub 是 Firefox 的附加组件,具有数十种数据提取功能,可简化您的网络搜索。该网络爬虫可以导航页面并以合适的格式存储提取的信息。
OutWit Hub 提供了一个接口来根据需要提取少量或大量的数据。OutWit Hub 允许您从浏览器中删除任何网页。您甚至可以创建自动代理来提取数据。
它是最简单且免费的网页抓取工具之一,可为您提供无需编写代码即可提取网页数据的便利。
7.ParseHub
Parsehub 是一款优秀的网页抓取工具,支持使用 AJAX 技术、JavaScript、Cookies 等从 网站 采集数据,其机器学习技术可以读取、分析网页文档,然后将其转换为相关数据。
Parsehub 的桌面应用程序兼容 Windows、Mac OS X 和 Linux 等系统。您甚至可以使用浏览器中内置的 Web 应用程序。
作为免费程序,您不能在 Parsehub 上配置超过五个公共项目。付费订阅计划允许你创建至少20个私人项目来抢网站。
8.视觉抓取工具
VisualScraper 是另一个优秀的免费和未编码的网络爬虫程序,具有简单的点击界面。您可以从各种网页获取实时数据,并将提取的数据导出为 CSV、XML、JSON 或 SQL 文件。除了SaaS,VisualScraper还提供网页抓取服务,例如数据交付服务的创建和软件提取服务。
Visual Scraper 允许用户安排项目在特定时间运行,或者每分钟、每天、每周、每月或每年重复该序列。用户可以使用它来频繁地获取新闻和论坛。
9.Scrapinghub
Scrapinghub 是一种基于云的数据提取工具,可以帮助成千上万的开发人员获取有价值的数据。其开源的可视化爬取工具让用户无需任何编程知识即可爬取网站。
Scrapinghub 使用 Crawlera(智能代理旋转器),支持绕过机器人的对策,可以轻松跟踪大型或受机器人保护的站点。它允许用户从多个 IP 地址和位置进行跟踪,而无需通过简单的 HTTP API 进行代理管理。
Scrapinghub 将整个网页转换为有组织的内容。如果您的爬网生成器无法满足您的要求,您的专家团队将为您提供帮助
10.德喜.io
作为一款基于浏览器的网络爬虫,Dexi.io 允许你从任何基于浏览器的网站中抓取数据,并提供了三种类型的操纵器来创建抓取任务——提取器、爬虫和管道。这个免费软件为您的网络抓取提供了一个匿名的网络代理服务器。您提取的数据将在数据存档前在 Dexi.io 的服务器上托管两周,或者您可以将提取的数据直接导出为 JSON 或 CSV 文件。提供付费服务,满足您获取实时数据的需求。
作为基于浏览器的网页抓取,Dexi.io 允许您从任何网站 抓取基于浏览器的数据,并提供三种机器人,因此您可以创建抓取任务:提取器、跟踪器和管道。这个免费软件为您的网络抓取提供了一个匿名的网络代理服务器。您提取的数据将在数据存档前在 Dexi.io 的服务器上托管两周,或者您可以将提取的数据直接导出为 JSON 或 CSV 文件。提供付费服务,满足您对实时数据采集的需求。
11.Webhose.io
Webhose.io 使用户能够以有序的形式获取来自世界各地的在线资源,并从中获取实时数据。使用此网络爬虫,您可以使用涵盖多个来源的多个过滤器来跟踪数据并提取多种不同语言的关键字。
您可以将捕获的数据保存为 XML、JSON 和 RSS 格式。用户可以从其档案中访问历史数据。此外,webhose.io 的数据搜索结果支持多达 80 种语言。用户可以轻松索引和搜索 Webhose.io 跟踪的结构化数据。
一般情况下,Webhose.io 可以满足用户的基本爬取需求。
12.导入。io
用户只需要从特定的网页导入数据,并将数据导出为CSV,就可以形成自己的数据集。
无需编写任何代码,您可以在几分钟内轻松抓取数千个网页,并根据您的需求创建 1,000 多个 API。公共 API 提供了强大而灵活的功能,可以通过编程控制 Import.io 自动访问数据。Import.io 只需点击几下即可将网络数据集成到您自己的应用程序或 网站 中,这使得跟踪更容易。
为了更好地满足用户的跟踪需求,它还提供了免费的Windows、Mac OS X和Linux应用程序,用于构建数据提取器和跟踪器、下载数据并将其同步到您的在线帐户。此外,用户可以每周、每天或每小时安排跟踪任务。
13.80条腿
80legs 是一款功能强大的网络爬虫工具,可根据自定义需求进行配置。支持获取大量数据,并且可以选择立即下载提取的数据。80legs 提供了一个高性能的网页爬虫程序,可以快速运行,几秒内获取所需数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交 网站 以及 RSS 和 ATOM 中获取完整数据。Spinn3r 自带 Firehouse API,可以处理 95% 的索引工作。它提供先进的垃圾邮件保护,以消除垃圾邮件和不当使用语言,从而提高数据安全性。
Spinn3r 为类似 Google 的内容编制索引,并将提取的数据保存在 JSON 文件中。网络爬虫不断扫描网络并从多个来源寻找实时帖子的更新。它的管理控制台允许您控制爬行,而全文搜索允许对原创数据进行复杂查询。
内容抓取器
Content Grabber 是一款面向公司的网络爬虫软件。允许您创建独立的网络爬虫代理。您可以从几乎任何 网站 中提取内容,并以您选择的格式将其保存为结构化数据,包括来自 Excel、XML、CSV 和大多数数据库的报告。
它最适合具有高级编程技能的人,因为它为需要的人提供了许多强大的脚本编辑和界面调试功能。用户可以使用C#或VB.NET进行调试或编写脚本来控制爬取过程的计划。例如,Content Grabber 可以与 Visual Studio 2013 集成,根据用户的特定需求,对高级和离散的自定义爬虫进行最强大的脚本编辑、调试和单元测试。
16.氦气刮刀
Helium Scraper 是一款可视化的网页抓取数据软件。当元素之间的相关性很小时,它可以很好地工作。它不是编码,不是配置。用户可以根据各种爬取需求访问在线模板。
基本上可以基本满足用户的爬取需求。
17.UiPath
UiPath 是一种机器人流程自动化软件,可以自动捕获 Web。它可以从大多数第三方应用程序中自动捕获 Web 和桌面数据。如果在 Windows 上运行它,则可以安装流程自动化软件。Uipath 可以在多个网页上提取基于表格和模式的数据。
Uipath 提供内置工具以进行更出色的网络爬行。对于复杂的用户界面,这种方法非常有效。截屏工具可以处理单个文本元素、文本组和文本块,例如表格格式的数据提取。
同样,无需编程即可创建智能 Web 代理,但您的内部 .NET 黑客将完全控制数据。
18.Scrape.it
Scrape.it 是一个网络抓取 node.js 软件。它是一种基于云的 Web 数据提取工具。它专为具有高级编程技能的人而设计,因为它提供了公共和私有软件包,用于发现、重用、更新和与全球数百万开发人员共享代码。其强大的集成功能将帮助您根据需要创建自定义跟踪器。
19.WebHarvy
WebHarvy 是一种点击式网页抓取软件。它是为非程序员设计的。WebHarvy 可以自动抓取 网站 中的文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置的调度程序和代理支持,允许匿名抓取并防止网络爬虫软件被网络服务器阻止。您可以选择通过代理服务器或 VPN 访问目标。
用户可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy 网络爬虫允许您将爬取的数据导出为 XML、CSV、JSON 或 TSV 文件。用户还可以将捕获的数据导出到 SQL 数据库。
20.注解
Connotate 是一个自动化的 Web 爬虫程序,专为企业级 Web 内容提取而设计,需要企业级解决方案。业务用户无需任何编程即可在几分钟内轻松创建提取代理。用户只需点击即可轻松创建提取代理。
标签:数据抓取,网络爬虫,数据爬虫,数据采集,网络抓取,大数据,数据科学,bigdata,python,网页采集,数据科学,网站数据,数据可视化 查看全部
抓取网页数据(使用网络抓取工具有什么好处?营销人员的好处)
使用网络爬虫有什么好处?
将您的双手从重复的复制和粘贴任务中解放出来。
以结构良好的格式放置提取的数据,包括 Excel、HTML 和 CSV。
通过聘请专业数据分析师,您可以节省时间和金钱。
这是营销人员、营销人员、记者、YouTube 用户、研究人员和许多其他缺乏技术技能的人的武器。
1. Octoparse
Octoparse是一个网站爬虫程序,几乎可以提取网站上所有你需要的数据。您可以使用 Octoparse 提取具有广泛特征的 网站。它有两种操作模式:助手模式和高级模式,非程序员也能快速上手。一个简单的点击式界面可以指导您完成整个提取过程。因此,您可以轻松地从网站 中提取内容,并在短时间内将其保存为结构化格式,例如 EXCEL、TXT、HTML 或其数据库。
此外,它还提供计划云提取,让您实时提取动态数据并跟踪网站 更新。
您还可以通过使用内置的 Regex 和 XPath 设置来准确定位项目,以提取复杂的结构网站。您不再需要担心 IP 阻塞。Octoparse提供IP代理服务器,会自动轮换IP,不会被反跟踪网站发现。
总之,Octoparse 不需要任何编码技能即可满足用户的基本和高级跟踪需求。
2.Cyotek WebCopy
WebCopy 是一个免费的网站 爬虫程序,它允许您将部分或完整的网站 复制到本地的硬盘上以供离线参考。
您可以更改设置以告诉机器人您要如何跟踪。此外,您还可以配置域别名、用户代理链、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或任何形式的 JavaScript 解析。如果 网站 大量使用 JavaScript 进行操作,WebCopy 可能无法制作真正的副本。由于大量使用 JavaScript,您可能无法正确处理动态 网站 布局
3.HTTrack
作为一个免费的网站爬虫程序,HTTrack提供了一个非常强大的功能,可以将完整的网站下载到您的PC上。有适用于Windows、Linux、Sun Solaris等Unix系统的版本,覆盖大部分用户。有趣的是,HTTrack 可以镜像一个站点,也可以将多个站点镜像在一起(使用共享链接)。您可以在“设置”中决定下载网页时同时打开的连接数。您可以获取重复的照片、文件、网站 的 HTML 代码,并恢复中断的下载。
此外,HTTrack 中提供了代理支持以最大限度地提高速度。
HTTrack 既可以用作命令行程序,也可以用作私人(捕获)或专业用途(在线网络镜像)。换句话说,HTTrack 应该是具有高级编程技能的人的首选。
4.左转
Getleft 是一款免费且易于使用的 网站 爬虫工具。允许您下载整个 网站 或任何单个 网站。启动Getleft后,输入网址,选择要下载的文件,即可开始下载。随着它的进行,更改本地导航的所有链接。此外,它还提供多语言支持。Getleft 现在支持 14 种语言!但是,它只提供有限的 Ftp 支持,它会下载文件,但不会排序和顺序下载。
一般来说,Getleft 应该能够满足用户基本的爬取需求,不需要更复杂的技能。
5.刮板
Scraper 是一个 Chrome 扩展,数据提取能力有限,但对于进行在线研究非常有用。它还允许将数据导出到 Google 电子表格。您可以使用 OAuth 轻松地将数据复制到剪贴板或将其存储在电子表格中。爬虫可以自动生成XPath来定义要爬取的URL。它不提供包罗万象的爬取服务,但可以满足大多数人的数据提取需求。
6.OutWit 中心
OutWit Hub 是 Firefox 的附加组件,具有数十种数据提取功能,可简化您的网络搜索。该网络爬虫可以导航页面并以合适的格式存储提取的信息。
OutWit Hub 提供了一个接口来根据需要提取少量或大量的数据。OutWit Hub 允许您从浏览器中删除任何网页。您甚至可以创建自动代理来提取数据。
它是最简单且免费的网页抓取工具之一,可为您提供无需编写代码即可提取网页数据的便利。
7.ParseHub
Parsehub 是一款优秀的网页抓取工具,支持使用 AJAX 技术、JavaScript、Cookies 等从 网站 采集数据,其机器学习技术可以读取、分析网页文档,然后将其转换为相关数据。
Parsehub 的桌面应用程序兼容 Windows、Mac OS X 和 Linux 等系统。您甚至可以使用浏览器中内置的 Web 应用程序。
作为免费程序,您不能在 Parsehub 上配置超过五个公共项目。付费订阅计划允许你创建至少20个私人项目来抢网站。
8.视觉抓取工具
VisualScraper 是另一个优秀的免费和未编码的网络爬虫程序,具有简单的点击界面。您可以从各种网页获取实时数据,并将提取的数据导出为 CSV、XML、JSON 或 SQL 文件。除了SaaS,VisualScraper还提供网页抓取服务,例如数据交付服务的创建和软件提取服务。
Visual Scraper 允许用户安排项目在特定时间运行,或者每分钟、每天、每周、每月或每年重复该序列。用户可以使用它来频繁地获取新闻和论坛。
9.Scrapinghub
Scrapinghub 是一种基于云的数据提取工具,可以帮助成千上万的开发人员获取有价值的数据。其开源的可视化爬取工具让用户无需任何编程知识即可爬取网站。
Scrapinghub 使用 Crawlera(智能代理旋转器),支持绕过机器人的对策,可以轻松跟踪大型或受机器人保护的站点。它允许用户从多个 IP 地址和位置进行跟踪,而无需通过简单的 HTTP API 进行代理管理。
Scrapinghub 将整个网页转换为有组织的内容。如果您的爬网生成器无法满足您的要求,您的专家团队将为您提供帮助
10.德喜.io
作为一款基于浏览器的网络爬虫,Dexi.io 允许你从任何基于浏览器的网站中抓取数据,并提供了三种类型的操纵器来创建抓取任务——提取器、爬虫和管道。这个免费软件为您的网络抓取提供了一个匿名的网络代理服务器。您提取的数据将在数据存档前在 Dexi.io 的服务器上托管两周,或者您可以将提取的数据直接导出为 JSON 或 CSV 文件。提供付费服务,满足您获取实时数据的需求。
作为基于浏览器的网页抓取,Dexi.io 允许您从任何网站 抓取基于浏览器的数据,并提供三种机器人,因此您可以创建抓取任务:提取器、跟踪器和管道。这个免费软件为您的网络抓取提供了一个匿名的网络代理服务器。您提取的数据将在数据存档前在 Dexi.io 的服务器上托管两周,或者您可以将提取的数据直接导出为 JSON 或 CSV 文件。提供付费服务,满足您对实时数据采集的需求。
11.Webhose.io
Webhose.io 使用户能够以有序的形式获取来自世界各地的在线资源,并从中获取实时数据。使用此网络爬虫,您可以使用涵盖多个来源的多个过滤器来跟踪数据并提取多种不同语言的关键字。
您可以将捕获的数据保存为 XML、JSON 和 RSS 格式。用户可以从其档案中访问历史数据。此外,webhose.io 的数据搜索结果支持多达 80 种语言。用户可以轻松索引和搜索 Webhose.io 跟踪的结构化数据。
一般情况下,Webhose.io 可以满足用户的基本爬取需求。
12.导入。io
用户只需要从特定的网页导入数据,并将数据导出为CSV,就可以形成自己的数据集。
无需编写任何代码,您可以在几分钟内轻松抓取数千个网页,并根据您的需求创建 1,000 多个 API。公共 API 提供了强大而灵活的功能,可以通过编程控制 Import.io 自动访问数据。Import.io 只需点击几下即可将网络数据集成到您自己的应用程序或 网站 中,这使得跟踪更容易。
为了更好地满足用户的跟踪需求,它还提供了免费的Windows、Mac OS X和Linux应用程序,用于构建数据提取器和跟踪器、下载数据并将其同步到您的在线帐户。此外,用户可以每周、每天或每小时安排跟踪任务。
13.80条腿
80legs 是一款功能强大的网络爬虫工具,可根据自定义需求进行配置。支持获取大量数据,并且可以选择立即下载提取的数据。80legs 提供了一个高性能的网页爬虫程序,可以快速运行,几秒内获取所需数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交 网站 以及 RSS 和 ATOM 中获取完整数据。Spinn3r 自带 Firehouse API,可以处理 95% 的索引工作。它提供先进的垃圾邮件保护,以消除垃圾邮件和不当使用语言,从而提高数据安全性。
Spinn3r 为类似 Google 的内容编制索引,并将提取的数据保存在 JSON 文件中。网络爬虫不断扫描网络并从多个来源寻找实时帖子的更新。它的管理控制台允许您控制爬行,而全文搜索允许对原创数据进行复杂查询。
内容抓取器
Content Grabber 是一款面向公司的网络爬虫软件。允许您创建独立的网络爬虫代理。您可以从几乎任何 网站 中提取内容,并以您选择的格式将其保存为结构化数据,包括来自 Excel、XML、CSV 和大多数数据库的报告。
它最适合具有高级编程技能的人,因为它为需要的人提供了许多强大的脚本编辑和界面调试功能。用户可以使用C#或VB.NET进行调试或编写脚本来控制爬取过程的计划。例如,Content Grabber 可以与 Visual Studio 2013 集成,根据用户的特定需求,对高级和离散的自定义爬虫进行最强大的脚本编辑、调试和单元测试。
16.氦气刮刀
Helium Scraper 是一款可视化的网页抓取数据软件。当元素之间的相关性很小时,它可以很好地工作。它不是编码,不是配置。用户可以根据各种爬取需求访问在线模板。
基本上可以基本满足用户的爬取需求。
17.UiPath
UiPath 是一种机器人流程自动化软件,可以自动捕获 Web。它可以从大多数第三方应用程序中自动捕获 Web 和桌面数据。如果在 Windows 上运行它,则可以安装流程自动化软件。Uipath 可以在多个网页上提取基于表格和模式的数据。
Uipath 提供内置工具以进行更出色的网络爬行。对于复杂的用户界面,这种方法非常有效。截屏工具可以处理单个文本元素、文本组和文本块,例如表格格式的数据提取。
同样,无需编程即可创建智能 Web 代理,但您的内部 .NET 黑客将完全控制数据。
18.Scrape.it
Scrape.it 是一个网络抓取 node.js 软件。它是一种基于云的 Web 数据提取工具。它专为具有高级编程技能的人而设计,因为它提供了公共和私有软件包,用于发现、重用、更新和与全球数百万开发人员共享代码。其强大的集成功能将帮助您根据需要创建自定义跟踪器。
19.WebHarvy
WebHarvy 是一种点击式网页抓取软件。它是为非程序员设计的。WebHarvy 可以自动抓取 网站 中的文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置的调度程序和代理支持,允许匿名抓取并防止网络爬虫软件被网络服务器阻止。您可以选择通过代理服务器或 VPN 访问目标。
用户可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy 网络爬虫允许您将爬取的数据导出为 XML、CSV、JSON 或 TSV 文件。用户还可以将捕获的数据导出到 SQL 数据库。
20.注解
Connotate 是一个自动化的 Web 爬虫程序,专为企业级 Web 内容提取而设计,需要企业级解决方案。业务用户无需任何编程即可在几分钟内轻松创建提取代理。用户只需点击即可轻松创建提取代理。
标签:数据抓取,网络爬虫,数据爬虫,数据采集,网络抓取,大数据,数据科学,bigdata,python,网页采集,数据科学,网站数据,数据可视化
抓取网页数据(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-29 06:01
相信所有个人网站的站长都有爬取他人数据的经历。目前爬取别人网站数据的方法不外乎两种:
一、使用第三方工具,其中最著名的是优采云
采集
器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在基本上半天就可以搞定一个网站了(只是程序开发时间,不包括数据抓取时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的就是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然在网上看过很多这样的文章,但是每次拿别人的代码时,总会出现各种各样的问题。下面各种方法的代码都可以正确执行,我目前也在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录
分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得在代码中学习第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader_ResponseStream = new StreamReader(_WebResponse.GetResponseStream(),System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过开发网站可能经常遇到。它的分页控件通过post向后台代码提交分页信息,比如.net下Gridview的分页功能。当你点击分页的页码时,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上时,状态栏会显示javascript:__dopostback("gridview","page1")等等。其实这种形式的代码也不是很难,因为毕竟有找页码规则的地方。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这类页面,需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的某个页面时,如果你发现这个东西,并且后面有很多乱七八糟的字符,那么这个网站一定是写的;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以引用页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,必须循环拼凑_dopostback的两个参数,只需要拼凑收录
页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,然后每抓取一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集
s.Specialized.NameValue采集
PostVars = newSystem.采集
s.Specialized.NameValue采集
();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方法:第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。后来采用了更狠的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
所谓门外汉看热闹,高手看门道,可能很多人看到这里就说可以通过Webbrowser的控制来实现,是的,我下面的方式就是利用WebBrowser的控制来实现实现,其实在.net下应该也有这种类似的类,不过我没研究过,希望有人有其他方法可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。呵呵
我们还是八卦一下,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要爬取的页面,比如:
调用webBrowser控件Navigate("")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted很重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,按照第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("点击");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
其实用的WebBrowser还可以做很多事情,比如自动登录,退出某个论坛,保存会话,cockie,所以这个控件基本上可以实现你对网页的任何操作,即使你想破解登录密码一个网站,当然这是不推荐的。呵呵
看了这篇文章,本以为手头的网站可以解决,但是在实际操作中,第二种方法无法完成网页的抓取。第三种方法不易控制;
个人实践一使用页面添加或修改其中一个标签的属性 查看全部
抓取网页数据(一下抓取别人网站数据的方式有什么作用?如何抓取)
相信所有个人网站的站长都有爬取他人数据的经历。目前爬取别人网站数据的方法不外乎两种:
一、使用第三方工具,其中最著名的是优采云
采集
器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在基本上半天就可以搞定一个网站了(只是程序开发时间,不包括数据抓取时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的就是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然在网上看过很多这样的文章,但是每次拿别人的代码时,总会出现各种各样的问题。下面各种方法的代码都可以正确执行,我目前也在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录
分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得在代码中学习第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader_ResponseStream = new StreamReader(_WebResponse.GetResponseStream(),System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过开发网站可能经常遇到。它的分页控件通过post向后台代码提交分页信息,比如.net下Gridview的分页功能。当你点击分页的页码时,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上时,状态栏会显示javascript:__dopostback("gridview","page1")等等。其实这种形式的代码也不是很难,因为毕竟有找页码规则的地方。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这类页面,需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的某个页面时,如果你发现这个东西,并且后面有很多乱七八糟的字符,那么这个网站一定是写的;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以引用页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,必须循环拼凑_dopostback的两个参数,只需要拼凑收录
页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,然后每抓取一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集
s.Specialized.NameValue采集
PostVars = newSystem.采集
s.Specialized.NameValue采集
();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方法:第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。后来采用了更狠的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
所谓门外汉看热闹,高手看门道,可能很多人看到这里就说可以通过Webbrowser的控制来实现,是的,我下面的方式就是利用WebBrowser的控制来实现实现,其实在.net下应该也有这种类似的类,不过我没研究过,希望有人有其他方法可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。呵呵
我们还是八卦一下,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要爬取的页面,比如:
调用webBrowser控件Navigate("")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted很重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,按照第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("点击");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
其实用的WebBrowser还可以做很多事情,比如自动登录,退出某个论坛,保存会话,cockie,所以这个控件基本上可以实现你对网页的任何操作,即使你想破解登录密码一个网站,当然这是不推荐的。呵呵
看了这篇文章,本以为手头的网站可以解决,但是在实际操作中,第二种方法无法完成网页的抓取。第三种方法不易控制;
个人实践一使用页面添加或修改其中一个标签的属性
抓取网页数据(如何开启网页抓取项目并根据您的网站抓取项目选择合适)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-26 18:00
返回博客
有了一个网页抓取项目的想法:我从哪里开始?
奥古斯塔斯·佩拉考斯卡斯
2021-12-15
有兴趣开始一个网络抓取项目,但不知道从哪里开始?或者您正在为您的网页抓取项目寻找最佳解决方案?无论哪种情况,我们都可以为您提供帮助。
本文将向您介绍如何启动网页抓取项目,并根据您的网站抓取项目选择合适的代理类型。我们还将为更有经验的公司讨论自建网络爬虫的利弊。如果您想直接学习如何构建一个简单的网络爬虫,请观看我们的视频教程!
您可以单击本文中的以下主题以了解您感兴趣的内容:
网页抓取项目的想法
有各种各样的网络爬行用例。公司将从各种不同的网站抓取数据。例如,一些公司爬取电子商务网站以监控不同的价格。一些公司使用网络爬虫来确保品牌保护和监控在线评论。
如果您想知道使用它的最佳方法是什么,可以将以下常见的网络抓取项目想法纳入您的业务策略:
计划网络抓取活动,但不知道从哪里开始?
如果你正在计划一个网页抓取项目,当然,你必须首先对一个网页抓取项目有一个想法。作为企业,您应该了解您需要提取什么样的数据。这可以是任何数据:定价数据、来自搜索引擎的 SERP 数据等。例如,假设您需要 SERP 数据进行 SEO 监控。现在怎么办?
对于任何网页抓取项目,您都需要大量的代理(即IP)才能通过您的自动网页抓取脚本成功连接到所需的数据源。然后,代理服务器会在不达到网站设置的请求数量限制的情况下,从网站服务器为您采集
所需的数据,使其不受反爬虫措施的影响。
在急于寻找代理提供商之前,您必须首先了解需要采集
的数据规模。即每天需要发送的请求数。根据数据点(或请求量)和所需的流量,更容易确定合适的代理。
如果您不确定需要发送的请求数量,以及您的网络抓取项目将产生多少流量,该怎么办?要了解此问题的解决方案:您可以发送电子邮件至 support@oxylabs.io 与我们进一步讨论您的网络抓取项目想法。我们的团队很乐意帮助计算。您也可以选择一种可以帮助您完成所需工作的网络爬虫解决方案,而无需考虑具体的请求量和流量。
明确具体的数字,或者至少大致了解需要爬取的目标,会更容易选择适合网络爬虫项目的工具。
正确选择适合网页抓取项目的代理类型
有两种主要类型的代理:住宅代理和数据中心代理。但是,认为“住宅代理”可以保持绝对匿名,因此是最好的代理,这是一个很大的误解。事实上,所有代理都可以让您匿名在线。您需要购买哪种代理仅取决于您想做的网络爬虫项目的类型。
如果您需要使用代理来执行市场研究网络爬虫项目,那么数据中心代理就足够了。它们快速而稳定,最重要的是,它们比住宅机构便宜得多。但是如果你想捕捉销售情报等更具挑战性的目标,住宅代理是更好的选择,因为大多数网站都知道这种数据采集
项目,所以他们更有可能在这些网站上被屏蔽。住宅代理的使用很难被禁止,因为它们看起来像真实的 IP。
为了更清楚地说明,我们在下表中分别列出了每个业务的可能用例和最佳代理解决方案。
让我们更多地讨论其他三个用例。这些用例包括前面提到的基于网络抓取的项目,例如销售智能、SEO 监控和产品页面智能。尽管您可以为这些特定用例使用代理,但您会发现很难处理网络爬行中最常见的瓶颈之一。那是时间,或者时间不够。让我们转到另一个主题:使用自建网络爬虫和代理的利弊。
自建网络爬虫的优缺点
我们可以通过两种方式获取网页抓取工具:维护和使用自建的网络爬虫工作,或者从第三方提供商处购买网页抓取工具。现在,让我们更多地了解自建网络爬虫的优缺点。这可以帮助您决定是否需要构建自己的基础架构或购买第三方工具来投资网络抓取项目。
自建网络爬虫项目的缺点
使用自建的网络爬虫程序具有一定的优势,包括可控性增强、设置速度提高、问题解决速度更快。
增强可控性
自建网络爬虫项目解决方案的思路,让您完全掌控整个流程。您可以自定义抓取流程以更好地适应公司的需求。如果您拥有经验丰富的开发团队,公司通常会选择管理其内部网络爬虫需求。
提高设定速度
与从第三方供应商处购买网络爬虫相比,使用自建网络爬虫可以加快流程。内部团队可能更了解公司的需求,因此可以更快地设置网络爬虫。
更快地解决问题
与内部团队合作可以更轻松地解决可能出现的问题。使用第三方网络爬虫工具时,出现问题后,必须提交支持请求,等待一段时间才能解决。
自建网络爬虫项目的缺点
自建网络爬虫项目有一定的优势,但也存在一些不足。缺点包括成本较高、维护困难和风险较大。
更高的成本
自建网络爬虫可能很昂贵。服务器、代理和维护成本加起来是一笔很大的开支。您还必须雇用和培训熟练的网络抓取开发人员来管理该过程。因此,从第三方供应商处购买网络爬虫工具通常更便宜。
难以维护
维护自建的网络爬行设置可能是一个挑战。服务器需要保持最佳运行状态,网络爬虫程序必须随时更新,以跟上爬取目标网站的变化。
相关风险
如果操作不当,网络爬虫可能面临一定的法律风险。许多网站倾向于对网络爬行活动设置限制。内部团队可能没有足够的经验来正确解决这些问题。第三方提供商拥有经验丰富的开发团队,可以更好地遵循最佳实践来正确抓取站点。
在开始网络抓取项目之前,确定哪种策略更适合您的需求很重要。对于大多数公司来说,第三方工具是更实用的选择,比如 Oxylabs 的爬虫 API。我们现在推出了3个爬虫API:SERP爬虫API、电子商务爬虫API和网络爬虫API。
“网络爬虫工具的选择取决于您的目标网站。我们的爬虫API最适合大型搜索引擎或任何电子商务网站。这样,从多个网站成功爬取数据的机会最高,而您不会”不用担心如何管理。代理,避免CAPTCHA验证,扩展整体基础设施。”
来自 Oxylabs 产品经理 Aleksandras Sulzenko 的建议
总结
我们希望本文能帮助您规划您的网络抓取项目,并为与代理相关的问题提供全面的答案。
想了解更多关于网络爬虫的信息?我们还有其他帖子可以回答您的所有问题!网络爬虫过程中最常见的挑战是在爬取大型电子商务网站时如何避免网页被拦截。此外,如果您对网络抓取项目有想法,您应该了解更多有关电子商务数据采集
方法的信息。
其他常见问题 网络爬虫和数据挖掘有什么区别?
如果你打算开始一个网页抓取项目,你应该明白网页抓取只是指采集
选定的数据并下载;它不涉及数据分析。数据挖掘是指将原创
数据转化为企业可用信息的过程。
如何避免在网络爬虫过程中被拦截?
通过了解电子商务网站如何保护自己,我们可以避免阻止网页。这些做法有助于在不被禁止的情况下成功抓取电子商务网站数据。
住宅代理和数据中心代理有什么区别?
选择哪个代理,要考虑的因素,除了能不能隐藏你的IP,还取决于对安全性和合法性的要求,或者对速度的要求。速度、安全性和合法性是住宅代理和数据中心代理之间的主要区别
关于作者
奥古斯塔斯·佩拉考斯卡斯
文案
Augustas Pelakauskas 在 Oxylabs 担任文案。具有艺术家庭背景的他致力于各种创意项目——最近他一直在写作。在验证了自己在自由新闻领域的能力后,他转而从事技术内容创作。在空闲时间,他喜欢阳光明媚的户外活动和运动休闲。原来,自行车是他的第三好朋友。
了解有关奥古斯塔斯的更多信息
Oxylabs 博客上的所有信息均“按原样”提供,仅供参考。对于您使用 Oxylabs 博客中收录
的任何信息或可能链接到的任何第三方网站中收录
的任何信息,我们不作任何陈述也不承担任何责任。在从事任何类型的抓取活动之前,请咨询您的法律顾问并仔细阅读特定网站的服务条款或获得抓取许可。
选择 Oxylabs® 让您的业务更上一层楼
注册以联系销售
联系我们
经认证的数据中心和上游供应商
联系我们
公司
演戏
资源
爬虫API
隐私政策
Oxysales, UAB © 2021 版权所有 © 查看全部
抓取网页数据(如何开启网页抓取项目并根据您的网站抓取项目选择合适)
返回博客
有了一个网页抓取项目的想法:我从哪里开始?
奥古斯塔斯·佩拉考斯卡斯
2021-12-15
有兴趣开始一个网络抓取项目,但不知道从哪里开始?或者您正在为您的网页抓取项目寻找最佳解决方案?无论哪种情况,我们都可以为您提供帮助。
本文将向您介绍如何启动网页抓取项目,并根据您的网站抓取项目选择合适的代理类型。我们还将为更有经验的公司讨论自建网络爬虫的利弊。如果您想直接学习如何构建一个简单的网络爬虫,请观看我们的视频教程!
您可以单击本文中的以下主题以了解您感兴趣的内容:
网页抓取项目的想法
有各种各样的网络爬行用例。公司将从各种不同的网站抓取数据。例如,一些公司爬取电子商务网站以监控不同的价格。一些公司使用网络爬虫来确保品牌保护和监控在线评论。
如果您想知道使用它的最佳方法是什么,可以将以下常见的网络抓取项目想法纳入您的业务策略:
计划网络抓取活动,但不知道从哪里开始?
如果你正在计划一个网页抓取项目,当然,你必须首先对一个网页抓取项目有一个想法。作为企业,您应该了解您需要提取什么样的数据。这可以是任何数据:定价数据、来自搜索引擎的 SERP 数据等。例如,假设您需要 SERP 数据进行 SEO 监控。现在怎么办?
对于任何网页抓取项目,您都需要大量的代理(即IP)才能通过您的自动网页抓取脚本成功连接到所需的数据源。然后,代理服务器会在不达到网站设置的请求数量限制的情况下,从网站服务器为您采集
所需的数据,使其不受反爬虫措施的影响。
在急于寻找代理提供商之前,您必须首先了解需要采集
的数据规模。即每天需要发送的请求数。根据数据点(或请求量)和所需的流量,更容易确定合适的代理。
如果您不确定需要发送的请求数量,以及您的网络抓取项目将产生多少流量,该怎么办?要了解此问题的解决方案:您可以发送电子邮件至 support@oxylabs.io 与我们进一步讨论您的网络抓取项目想法。我们的团队很乐意帮助计算。您也可以选择一种可以帮助您完成所需工作的网络爬虫解决方案,而无需考虑具体的请求量和流量。
明确具体的数字,或者至少大致了解需要爬取的目标,会更容易选择适合网络爬虫项目的工具。
正确选择适合网页抓取项目的代理类型
有两种主要类型的代理:住宅代理和数据中心代理。但是,认为“住宅代理”可以保持绝对匿名,因此是最好的代理,这是一个很大的误解。事实上,所有代理都可以让您匿名在线。您需要购买哪种代理仅取决于您想做的网络爬虫项目的类型。
如果您需要使用代理来执行市场研究网络爬虫项目,那么数据中心代理就足够了。它们快速而稳定,最重要的是,它们比住宅机构便宜得多。但是如果你想捕捉销售情报等更具挑战性的目标,住宅代理是更好的选择,因为大多数网站都知道这种数据采集
项目,所以他们更有可能在这些网站上被屏蔽。住宅代理的使用很难被禁止,因为它们看起来像真实的 IP。
为了更清楚地说明,我们在下表中分别列出了每个业务的可能用例和最佳代理解决方案。
让我们更多地讨论其他三个用例。这些用例包括前面提到的基于网络抓取的项目,例如销售智能、SEO 监控和产品页面智能。尽管您可以为这些特定用例使用代理,但您会发现很难处理网络爬行中最常见的瓶颈之一。那是时间,或者时间不够。让我们转到另一个主题:使用自建网络爬虫和代理的利弊。
自建网络爬虫的优缺点
我们可以通过两种方式获取网页抓取工具:维护和使用自建的网络爬虫工作,或者从第三方提供商处购买网页抓取工具。现在,让我们更多地了解自建网络爬虫的优缺点。这可以帮助您决定是否需要构建自己的基础架构或购买第三方工具来投资网络抓取项目。
自建网络爬虫项目的缺点
使用自建的网络爬虫程序具有一定的优势,包括可控性增强、设置速度提高、问题解决速度更快。
增强可控性
自建网络爬虫项目解决方案的思路,让您完全掌控整个流程。您可以自定义抓取流程以更好地适应公司的需求。如果您拥有经验丰富的开发团队,公司通常会选择管理其内部网络爬虫需求。
提高设定速度
与从第三方供应商处购买网络爬虫相比,使用自建网络爬虫可以加快流程。内部团队可能更了解公司的需求,因此可以更快地设置网络爬虫。
更快地解决问题
与内部团队合作可以更轻松地解决可能出现的问题。使用第三方网络爬虫工具时,出现问题后,必须提交支持请求,等待一段时间才能解决。
自建网络爬虫项目的缺点
自建网络爬虫项目有一定的优势,但也存在一些不足。缺点包括成本较高、维护困难和风险较大。
更高的成本
自建网络爬虫可能很昂贵。服务器、代理和维护成本加起来是一笔很大的开支。您还必须雇用和培训熟练的网络抓取开发人员来管理该过程。因此,从第三方供应商处购买网络爬虫工具通常更便宜。
难以维护
维护自建的网络爬行设置可能是一个挑战。服务器需要保持最佳运行状态,网络爬虫程序必须随时更新,以跟上爬取目标网站的变化。
相关风险
如果操作不当,网络爬虫可能面临一定的法律风险。许多网站倾向于对网络爬行活动设置限制。内部团队可能没有足够的经验来正确解决这些问题。第三方提供商拥有经验丰富的开发团队,可以更好地遵循最佳实践来正确抓取站点。
在开始网络抓取项目之前,确定哪种策略更适合您的需求很重要。对于大多数公司来说,第三方工具是更实用的选择,比如 Oxylabs 的爬虫 API。我们现在推出了3个爬虫API:SERP爬虫API、电子商务爬虫API和网络爬虫API。
“网络爬虫工具的选择取决于您的目标网站。我们的爬虫API最适合大型搜索引擎或任何电子商务网站。这样,从多个网站成功爬取数据的机会最高,而您不会”不用担心如何管理。代理,避免CAPTCHA验证,扩展整体基础设施。”
来自 Oxylabs 产品经理 Aleksandras Sulzenko 的建议
总结
我们希望本文能帮助您规划您的网络抓取项目,并为与代理相关的问题提供全面的答案。
想了解更多关于网络爬虫的信息?我们还有其他帖子可以回答您的所有问题!网络爬虫过程中最常见的挑战是在爬取大型电子商务网站时如何避免网页被拦截。此外,如果您对网络抓取项目有想法,您应该了解更多有关电子商务数据采集
方法的信息。
其他常见问题 网络爬虫和数据挖掘有什么区别?
如果你打算开始一个网页抓取项目,你应该明白网页抓取只是指采集
选定的数据并下载;它不涉及数据分析。数据挖掘是指将原创
数据转化为企业可用信息的过程。
如何避免在网络爬虫过程中被拦截?
通过了解电子商务网站如何保护自己,我们可以避免阻止网页。这些做法有助于在不被禁止的情况下成功抓取电子商务网站数据。
住宅代理和数据中心代理有什么区别?
选择哪个代理,要考虑的因素,除了能不能隐藏你的IP,还取决于对安全性和合法性的要求,或者对速度的要求。速度、安全性和合法性是住宅代理和数据中心代理之间的主要区别
关于作者
奥古斯塔斯·佩拉考斯卡斯
文案
Augustas Pelakauskas 在 Oxylabs 担任文案。具有艺术家庭背景的他致力于各种创意项目——最近他一直在写作。在验证了自己在自由新闻领域的能力后,他转而从事技术内容创作。在空闲时间,他喜欢阳光明媚的户外活动和运动休闲。原来,自行车是他的第三好朋友。
了解有关奥古斯塔斯的更多信息
Oxylabs 博客上的所有信息均“按原样”提供,仅供参考。对于您使用 Oxylabs 博客中收录
的任何信息或可能链接到的任何第三方网站中收录
的任何信息,我们不作任何陈述也不承担任何责任。在从事任何类型的抓取活动之前,请咨询您的法律顾问并仔细阅读特定网站的服务条款或获得抓取许可。
选择 Oxylabs® 让您的业务更上一层楼
注册以联系销售
联系我们
经认证的数据中心和上游供应商
联系我们
公司
演戏
资源
爬虫API
隐私政策
Oxysales, UAB © 2021 版权所有 ©
抓取网页数据(二是抓取份额是由什么决定?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 41 次浏览 • 2021-12-26 09:04
什么决定了爬网份额?这涉及到爬行要求和爬行速度限制。
爬行需求
抓取需求或抓取需求是指搜索引擎“想要”在特定网站上抓取多少个页面。
有两个主要因素决定了对爬行的需求。一是页面权重。搜索引擎希望抓取与网站上达到基本页面权重的页面一样多的页面。二是索引库中的页面是否太长时间没有更新。毕竟是页面权重,权重高的页面不会更新太久。
页面权重和网站权重密切相关。增加网站权重可以使搜索引擎愿意抓取更多页面。
爬行速度限制
搜索引擎蜘蛛不会为了抓取更多的页面而拖拽其他网络服务器,因此会对某个网站设置抓取速度限制。爬网速率限制是服务器可以承受的上限。在这个限速里面,蜘蛛爬行不会拖慢服务器,影响用户访问。
服务器响应速度够快,这个限速提高一点,爬行加快,服务器响应速度降低,限速降低,爬行变慢,甚至爬行停止。
因此,爬网速率限制是搜索引擎“可以”爬取的页面数。
什么决定了爬网份额?
爬取份额是同时考虑爬取需求和爬取速度限制的结果,即搜索引擎“想要”爬取但“能”爬取的页面数。
网站权重高,页面内容质量高,页面数量多,服务器速度够快,抓取份额大。
小网站不用担心抢份额
一个小网站上的页面很少。即使网站权重低,服务器慢,但无论搜索引擎蜘蛛每天爬多少,通常至少能爬上几百页。千页网站根本不用担心抢份额。拥有数万页的网站通常没什么大不了的。如果每天数百次访问会降低服务器速度,那么 SEO 就不是主要考虑因素。
大中型网站可能需要考虑爬虫共享
对于页面数十万以上的大中型网站,可能需要考虑爬取份额不足的问题。
爬网份额是不够的。比如网站有1000万个页面,搜索引擎每天只能抓取几万个页面。爬取网站可能需要几个月,甚至一年的时间,这也可能意味着一些重要的页面无法抓取。,所以没有排名,或者重要页面不能及时更新。
想要网页被及时、完整地抓取,首先要保证服务器速度够快,页面够小。如果网站有大量优质数据,抓取份额会受到抓取速度的限制。提高页面速度直接提高了抓取速度限制,从而增加了抓取份额。
如何保存抓取共享?
当然,首先是减小页面文件的大小,提高服务器的速度,优化数据库,减少抓取时间。
然后,尽量避免上面列出的浪费性抢股。有些是内容质量问题,有些是网站结构问题。如果是结构问题,最简单的方法就是禁止爬取robots文件,但是会浪费一些页面权重,因为权重只能输入不能退出。
在某些情况下,使用链接 nofollow 属性可以节省抓取共享。对于小网站,添加nofollow是没有意义的,因为爬取份额用不完。对于大型网站,nofollow 可以在一定程度上控制权重的流量和分配。精心设计的nofollow会降低无意义页面的权重,增加重要页面的权重。搜索引擎在爬取时会使用一个 URL 爬取列表。要抓取的网址按页面权重排序。如果增加重要页面的权重,将首先抓取重要页面。无意义页面的权重可能很低,以至于搜索引擎不想爬行。
最后几点说明:
Links 和nofollow 不会浪费爬取分享。但在谷歌,重量被浪费了。
noindex 标签无法保存爬网共享。如果搜索引擎知道页面上有noindex标签,它必须先爬取这个页面,所以它不保存爬取份额。
规范标签有时可以节省一些爬网份额。和noindex标签一样,搜索引擎如果知道页面上有canonical标签,就必须先爬取这个页面,所以不直接保存爬取份额。但是,带有规范标签的页面通常被抓取的频率较低,因此会节省一些抓取份额。
抓取速度和抓取份额不是排名因素。但是没有被抓取的页面是无法排名的。 查看全部
抓取网页数据(二是抓取份额是由什么决定?(图))
什么决定了爬网份额?这涉及到爬行要求和爬行速度限制。
爬行需求
抓取需求或抓取需求是指搜索引擎“想要”在特定网站上抓取多少个页面。
有两个主要因素决定了对爬行的需求。一是页面权重。搜索引擎希望抓取与网站上达到基本页面权重的页面一样多的页面。二是索引库中的页面是否太长时间没有更新。毕竟是页面权重,权重高的页面不会更新太久。
页面权重和网站权重密切相关。增加网站权重可以使搜索引擎愿意抓取更多页面。
爬行速度限制
搜索引擎蜘蛛不会为了抓取更多的页面而拖拽其他网络服务器,因此会对某个网站设置抓取速度限制。爬网速率限制是服务器可以承受的上限。在这个限速里面,蜘蛛爬行不会拖慢服务器,影响用户访问。
服务器响应速度够快,这个限速提高一点,爬行加快,服务器响应速度降低,限速降低,爬行变慢,甚至爬行停止。
因此,爬网速率限制是搜索引擎“可以”爬取的页面数。
什么决定了爬网份额?
爬取份额是同时考虑爬取需求和爬取速度限制的结果,即搜索引擎“想要”爬取但“能”爬取的页面数。
网站权重高,页面内容质量高,页面数量多,服务器速度够快,抓取份额大。
小网站不用担心抢份额
一个小网站上的页面很少。即使网站权重低,服务器慢,但无论搜索引擎蜘蛛每天爬多少,通常至少能爬上几百页。千页网站根本不用担心抢份额。拥有数万页的网站通常没什么大不了的。如果每天数百次访问会降低服务器速度,那么 SEO 就不是主要考虑因素。
大中型网站可能需要考虑爬虫共享
对于页面数十万以上的大中型网站,可能需要考虑爬取份额不足的问题。
爬网份额是不够的。比如网站有1000万个页面,搜索引擎每天只能抓取几万个页面。爬取网站可能需要几个月,甚至一年的时间,这也可能意味着一些重要的页面无法抓取。,所以没有排名,或者重要页面不能及时更新。
想要网页被及时、完整地抓取,首先要保证服务器速度够快,页面够小。如果网站有大量优质数据,抓取份额会受到抓取速度的限制。提高页面速度直接提高了抓取速度限制,从而增加了抓取份额。
如何保存抓取共享?
当然,首先是减小页面文件的大小,提高服务器的速度,优化数据库,减少抓取时间。
然后,尽量避免上面列出的浪费性抢股。有些是内容质量问题,有些是网站结构问题。如果是结构问题,最简单的方法就是禁止爬取robots文件,但是会浪费一些页面权重,因为权重只能输入不能退出。
在某些情况下,使用链接 nofollow 属性可以节省抓取共享。对于小网站,添加nofollow是没有意义的,因为爬取份额用不完。对于大型网站,nofollow 可以在一定程度上控制权重的流量和分配。精心设计的nofollow会降低无意义页面的权重,增加重要页面的权重。搜索引擎在爬取时会使用一个 URL 爬取列表。要抓取的网址按页面权重排序。如果增加重要页面的权重,将首先抓取重要页面。无意义页面的权重可能很低,以至于搜索引擎不想爬行。
最后几点说明:
Links 和nofollow 不会浪费爬取分享。但在谷歌,重量被浪费了。
noindex 标签无法保存爬网共享。如果搜索引擎知道页面上有noindex标签,它必须先爬取这个页面,所以它不保存爬取份额。
规范标签有时可以节省一些爬网份额。和noindex标签一样,搜索引擎如果知道页面上有canonical标签,就必须先爬取这个页面,所以不直接保存爬取份额。但是,带有规范标签的页面通常被抓取的频率较低,因此会节省一些抓取份额。
抓取速度和抓取份额不是排名因素。但是没有被抓取的页面是无法排名的。
抓取网页数据(蜘蛛来访较少链建设过程中需要注意的几个问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-26 09:03
主页是蜘蛛访问次数最多的页面和权重最高的网站。您可以在主页上设置更新部分。这不仅会更新首页,提升蜘蛛访问频率,还会促进更新页面的抓取和收录。同样,这个操作也可以在栏目页上进行。
八、检查死链接并设置404页面
搜索引擎蜘蛛通过链接爬行。如果太多的链接无法访问,不仅会减少收录
的页面数量,而且您的网站在搜索引擎中的权重也会大大降低。当蜘蛛遇到死链接时,就如同进入了死胡同,不得不回去重新开始,大大降低了蜘蛛在网站上的爬行效率。因此,有必要定期检查网站的死链接,提交给搜索引擎,做好网站的404。页面,它告诉搜索引擎错误页面。
九、检查robots文件
很多网站有意无意地直接在robots文件中屏蔽了百度或网站的某些页面,但他们正在寻找蜘蛛不抓取我的页面的原因。你能怪百度吗?你不让别人进来,百度呢?包括您的网页?所以有必要检查一下网站的robots文件是否正常。
十、构建站点地图。
搜索引擎蜘蛛非常喜欢站点地图,站点地图是网站上所有链接的容器。许多网站都有深层链接,蜘蛛很难抓取。站点地图可以方便搜索引擎蜘蛛抓取网页。通过抓取网页,他们可以清楚地了解网站的结构。因此,构建站点地图不仅可以提高爬取率,还可以得到蜘蛛的青睐。
十一、 主动提交
每次更新页面时主动向搜索引擎提交内容是一个很好的方法,但如果没有收录
就不要一直提交。提交一次就够了。是否收录
它是搜索引擎的问题。提交并不意味着它是必要的。包括。
十二、外链建设。
大家都知道,外链可以吸引蜘蛛到网站,尤其是当网站是新的,网站还不是很成熟,访问的蜘蛛很少的时候,外链可以增加网站页面在蜘蛛面前的曝光率和防止蜘蛛找不到页面。. 在外链建设的过程中,我们需要关注外链的质量。不要为了省事而做无用的事情。百度现在相信大家都知道外链的管理。下面我讲一下需要注意的几点。
1、 博客外链建设 这里提到的博客外链不是我们平时做的。在一些个人博客、新浪博客、网易博客、和讯博客等,只评论点赞离开外链。. 由于百度算法的更新,这种外链现在已经没有效果,时间过长甚至会降级。在这里我想说的,是为了给博主留下印象,帮助博主,提出建议,或者评论我自己的不同想法而发表评论。几次之后,相信博主肯定会对你有意见的
2、论坛外链建设论坛外链建设的思路其实和博客的思路差不多。留下您的想法并让主持人关注您。也许你会在几次之后成为朋友甚至合作伙伴。到时候加个链接不就是一句话吗?关于这个我就不多说了。
3、 在外链建设的过程中,外链建设是外链建设中必不可少的环节。同时,外链的建设也是最有效、最快捷的方式。选择什么样的平台?这是一个直接思考的问题。这里我建议大家可以找一些不为很多人所知的相关平台。比如在不相关的平台上发帖肯定不如在相关的平台上,不好的平台认为传播的权重也是有限的。写文章,不同意,投稿需谨慎。
4、 Open、category目录外链建设 如果你的网站够好,那么open目录是个不错的选择,比如DOMZ目录,yahoo目录都可以提交。当然,对于一些新网站或者最近刚成立的网站,分类目录就是你的天堂。此外,互联网上还有许多分类目录网站。不要忽视建立外部链接的肥肉。
5、 虽然常说购买链接会被百度攻击,但作为一个新网站,想要在最短的时间内获得一定的公关、权重和一定的收录量,购买链接也是必不可少的. 当然,不是你去买一些金链或者去一些专门做买卖链接的平台,而是去和一些pr、权重比较高的门户、新闻站交流(前提是这些门户和新闻站是不是专门卖链接的),看能不能买链接,这样买的链接就不会被百度识别,链接质量比较高。以后当你的网站慢慢出现时,一一删除。
十三、内部链构建。
蜘蛛的爬行是跟着链接走的,所以内链的合理优化可以要求蜘蛛爬取更多的页面,促进网站的收录。在内链建设过程中,应合理推荐用户。除了给文章添加锚文本,还可以设置相关推荐、热门文章等。这被许多网站使用,并且可以被蜘蛛使用。获取更大范围的页面。
其实内链的建设也有利于提升用户体验,所以用户不必一一查看是否有相关内容,只需要依靠一个小的内链或者一个链接的关键词为拿到它,为实现它。更多更广的信息,何乐而不为呢?所以如果要真正提升用户体验,不是为了SEO提升用户体验,所以从用户的角度来说,什么样的内链才是用户最喜欢的工作。
另外,您可以将一些关键词链接到本站的其他页面,以提高这些页面之间的相关性,方便用户浏览。随着用户体验的提升,自然会为网站带来更多的流量。而且,增加页面之间的相关性还可以增加用户在网站上花费的时间,减少高跳出率的发生。
网站搜索排名高的前提是网站的大量页面被搜索引擎收录,良好的内链建设可以帮助网站页面被收录。当网站上的某篇文章被收录时,百度蜘蛛会继续沿着这个页面的超链接爬行。如果你的内链做的好,百度蜘蛛会沿着你的网站到处爬行,从而使网站页面被收录的几率大大增加。 查看全部
抓取网页数据(蜘蛛来访较少链建设过程中需要注意的几个问题)
主页是蜘蛛访问次数最多的页面和权重最高的网站。您可以在主页上设置更新部分。这不仅会更新首页,提升蜘蛛访问频率,还会促进更新页面的抓取和收录。同样,这个操作也可以在栏目页上进行。
八、检查死链接并设置404页面
搜索引擎蜘蛛通过链接爬行。如果太多的链接无法访问,不仅会减少收录
的页面数量,而且您的网站在搜索引擎中的权重也会大大降低。当蜘蛛遇到死链接时,就如同进入了死胡同,不得不回去重新开始,大大降低了蜘蛛在网站上的爬行效率。因此,有必要定期检查网站的死链接,提交给搜索引擎,做好网站的404。页面,它告诉搜索引擎错误页面。
九、检查robots文件
很多网站有意无意地直接在robots文件中屏蔽了百度或网站的某些页面,但他们正在寻找蜘蛛不抓取我的页面的原因。你能怪百度吗?你不让别人进来,百度呢?包括您的网页?所以有必要检查一下网站的robots文件是否正常。
十、构建站点地图。
搜索引擎蜘蛛非常喜欢站点地图,站点地图是网站上所有链接的容器。许多网站都有深层链接,蜘蛛很难抓取。站点地图可以方便搜索引擎蜘蛛抓取网页。通过抓取网页,他们可以清楚地了解网站的结构。因此,构建站点地图不仅可以提高爬取率,还可以得到蜘蛛的青睐。
十一、 主动提交
每次更新页面时主动向搜索引擎提交内容是一个很好的方法,但如果没有收录
就不要一直提交。提交一次就够了。是否收录
它是搜索引擎的问题。提交并不意味着它是必要的。包括。
十二、外链建设。
大家都知道,外链可以吸引蜘蛛到网站,尤其是当网站是新的,网站还不是很成熟,访问的蜘蛛很少的时候,外链可以增加网站页面在蜘蛛面前的曝光率和防止蜘蛛找不到页面。. 在外链建设的过程中,我们需要关注外链的质量。不要为了省事而做无用的事情。百度现在相信大家都知道外链的管理。下面我讲一下需要注意的几点。
1、 博客外链建设 这里提到的博客外链不是我们平时做的。在一些个人博客、新浪博客、网易博客、和讯博客等,只评论点赞离开外链。. 由于百度算法的更新,这种外链现在已经没有效果,时间过长甚至会降级。在这里我想说的,是为了给博主留下印象,帮助博主,提出建议,或者评论我自己的不同想法而发表评论。几次之后,相信博主肯定会对你有意见的
2、论坛外链建设论坛外链建设的思路其实和博客的思路差不多。留下您的想法并让主持人关注您。也许你会在几次之后成为朋友甚至合作伙伴。到时候加个链接不就是一句话吗?关于这个我就不多说了。
3、 在外链建设的过程中,外链建设是外链建设中必不可少的环节。同时,外链的建设也是最有效、最快捷的方式。选择什么样的平台?这是一个直接思考的问题。这里我建议大家可以找一些不为很多人所知的相关平台。比如在不相关的平台上发帖肯定不如在相关的平台上,不好的平台认为传播的权重也是有限的。写文章,不同意,投稿需谨慎。
4、 Open、category目录外链建设 如果你的网站够好,那么open目录是个不错的选择,比如DOMZ目录,yahoo目录都可以提交。当然,对于一些新网站或者最近刚成立的网站,分类目录就是你的天堂。此外,互联网上还有许多分类目录网站。不要忽视建立外部链接的肥肉。
5、 虽然常说购买链接会被百度攻击,但作为一个新网站,想要在最短的时间内获得一定的公关、权重和一定的收录量,购买链接也是必不可少的. 当然,不是你去买一些金链或者去一些专门做买卖链接的平台,而是去和一些pr、权重比较高的门户、新闻站交流(前提是这些门户和新闻站是不是专门卖链接的),看能不能买链接,这样买的链接就不会被百度识别,链接质量比较高。以后当你的网站慢慢出现时,一一删除。
十三、内部链构建。
蜘蛛的爬行是跟着链接走的,所以内链的合理优化可以要求蜘蛛爬取更多的页面,促进网站的收录。在内链建设过程中,应合理推荐用户。除了给文章添加锚文本,还可以设置相关推荐、热门文章等。这被许多网站使用,并且可以被蜘蛛使用。获取更大范围的页面。
其实内链的建设也有利于提升用户体验,所以用户不必一一查看是否有相关内容,只需要依靠一个小的内链或者一个链接的关键词为拿到它,为实现它。更多更广的信息,何乐而不为呢?所以如果要真正提升用户体验,不是为了SEO提升用户体验,所以从用户的角度来说,什么样的内链才是用户最喜欢的工作。
另外,您可以将一些关键词链接到本站的其他页面,以提高这些页面之间的相关性,方便用户浏览。随着用户体验的提升,自然会为网站带来更多的流量。而且,增加页面之间的相关性还可以增加用户在网站上花费的时间,减少高跳出率的发生。
网站搜索排名高的前提是网站的大量页面被搜索引擎收录,良好的内链建设可以帮助网站页面被收录。当网站上的某篇文章被收录时,百度蜘蛛会继续沿着这个页面的超链接爬行。如果你的内链做的好,百度蜘蛛会沿着你的网站到处爬行,从而使网站页面被收录的几率大大增加。
抓取网页数据(一下如何用Excel快速抓取网页数据(一)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-25 02:09
网站上的数据源是我们统计分析的重要信息来源。我们在生活中经常听到一个词叫“爬虫”,它可以快速抓取网页上的数据,这对于数据分析相关的工作来说是极其重要的,也是必备的技能之一。但是,大多数爬虫都需要编程知识,这对大多数人来说是很难上手的。今天给大家讲解一下如何用Excel快速抓取网页数据。
1、首先打开需要抓包的数据的网站,复制网站地址。
2、 要创建新的 Excel 工作簿,请单击“数据”菜单中的“来自 网站”选项>“获取外部数据”选项卡。
在弹出的“新建网页查询”对话框中,在地址栏中输入要抓取的网站地址,点击“前往”
点击黄色的导入箭头,选择需要采集的部分,如图。只需单击导入。
3、选择存储数据的位置(默认选中的单元格),点击确定。通常建议将数据存储在“A1”单元格中。
获取数据需要一定的时间,请耐心等待。
4、 如果想让Excel工作簿数据根据网站的数据实时自动更新,那么我们需要在“属性”中进行设置。您可以设置“允许后台刷新”、“刷新频率”、“打开文件时刷新数据”等。
拿到数据后,就需要对数据进行处理,而处理数据是一个比较重要的环节。更多数据处理技巧,请关注我!
如果对你有帮助,记得点赞转发哦。
关注我,学习更多 Excel 技能,让工作更轻松。 查看全部
抓取网页数据(一下如何用Excel快速抓取网页数据(一)(图))
网站上的数据源是我们统计分析的重要信息来源。我们在生活中经常听到一个词叫“爬虫”,它可以快速抓取网页上的数据,这对于数据分析相关的工作来说是极其重要的,也是必备的技能之一。但是,大多数爬虫都需要编程知识,这对大多数人来说是很难上手的。今天给大家讲解一下如何用Excel快速抓取网页数据。
1、首先打开需要抓包的数据的网站,复制网站地址。
2、 要创建新的 Excel 工作簿,请单击“数据”菜单中的“来自 网站”选项>“获取外部数据”选项卡。
在弹出的“新建网页查询”对话框中,在地址栏中输入要抓取的网站地址,点击“前往”
点击黄色的导入箭头,选择需要采集的部分,如图。只需单击导入。
3、选择存储数据的位置(默认选中的单元格),点击确定。通常建议将数据存储在“A1”单元格中。
获取数据需要一定的时间,请耐心等待。
4、 如果想让Excel工作簿数据根据网站的数据实时自动更新,那么我们需要在“属性”中进行设置。您可以设置“允许后台刷新”、“刷新频率”、“打开文件时刷新数据”等。
拿到数据后,就需要对数据进行处理,而处理数据是一个比较重要的环节。更多数据处理技巧,请关注我!
如果对你有帮助,记得点赞转发哦。
关注我,学习更多 Excel 技能,让工作更轻松。
抓取网页数据(抓取网页数据的话比较简单用什么方法传递参数吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-18 20:16
抓取网页数据的话比较简单用webpy就可以,
抓取数据ajax框架很多,写起来也不复杂,重点看用什么方法传递参数吧,get的话一般都是headers参数吧。
有个相对成熟的叫cookie.so,基本上不涉及到后端获取
如果是抓取某个网站内容的话,可以用抓包工具,然后将你想抓取的内容的地址交给程序就可以抓取了,
用百度就可以
get的话是headers中有个参数“useragent”,
headers传递参数,
应该是一样的,ajax的基本都是通过加载页面的xml文件。
webpy可以抓取http请求数据
可以看看antio/message·github
用python的webpy就可以了,
可以通过postman这样的工具来做,
抓取网页数据可以使用json解析工具,这里推荐一个工具libphones-webpy。网站的话现在主流的网站都有,包括facebook,twitter,hashtag都有。
json数据的话,有个框架叫webscrap,用它就可以抓取,不过复杂的后端任务还是要交给写爬虫的同学来吧。
大概看了下回答,大部分都是基于postman。不过估计爬虫的同学没有用这个工具抓取,估计用的是爬虫工具scrapy。那么为什么我们用postman不用cookie呢?我认为要知道数据格式,抓取过程中验证用户是否用户名,密码,那用cookie就很麻烦。再有,我们也想要把用户的注册id发给爬虫,不想让爬虫知道我们的账号信息。
那怎么办?当然是用户名,密码绑定,把一些像手机号等等不便暴露出来的信息去掉,但是数据还是要下来。我们从json数据格式的话,我们如何爬数据呢?比如百度的话,登录后就自动进去发短信,不过不同于你的发短信,它要求用户给账号服务器发送的信息发送到gmail中。但是有些网站的话,比如新浪看看、腾讯微博,等等,它就要求你在它的服务器上给账号发送短信,当然,对于普通的人来说,还是太麻烦了。
那么有没有这么简单点,且人家不用发短信,可以直接通过user-agent是透明的方式就能抓取数据的呢?最简单的方法,那就是我自己写个登录程序,或者使用爬虫工具scrapy之类的直接抓取。这时,它的问题就来了,太麻烦了,还会泄露你的账号信息。但是如果是可以像爬虫工具一样抓取,那么我们也可以考虑从其他地方把这个信息传给它,或者知道user-agent码一般的话,可以用自己的账号信息。 查看全部
抓取网页数据(抓取网页数据的话比较简单用什么方法传递参数吧)
抓取网页数据的话比较简单用webpy就可以,
抓取数据ajax框架很多,写起来也不复杂,重点看用什么方法传递参数吧,get的话一般都是headers参数吧。
有个相对成熟的叫cookie.so,基本上不涉及到后端获取
如果是抓取某个网站内容的话,可以用抓包工具,然后将你想抓取的内容的地址交给程序就可以抓取了,
用百度就可以
get的话是headers中有个参数“useragent”,
headers传递参数,
应该是一样的,ajax的基本都是通过加载页面的xml文件。
webpy可以抓取http请求数据
可以看看antio/message·github
用python的webpy就可以了,
可以通过postman这样的工具来做,
抓取网页数据可以使用json解析工具,这里推荐一个工具libphones-webpy。网站的话现在主流的网站都有,包括facebook,twitter,hashtag都有。
json数据的话,有个框架叫webscrap,用它就可以抓取,不过复杂的后端任务还是要交给写爬虫的同学来吧。
大概看了下回答,大部分都是基于postman。不过估计爬虫的同学没有用这个工具抓取,估计用的是爬虫工具scrapy。那么为什么我们用postman不用cookie呢?我认为要知道数据格式,抓取过程中验证用户是否用户名,密码,那用cookie就很麻烦。再有,我们也想要把用户的注册id发给爬虫,不想让爬虫知道我们的账号信息。
那怎么办?当然是用户名,密码绑定,把一些像手机号等等不便暴露出来的信息去掉,但是数据还是要下来。我们从json数据格式的话,我们如何爬数据呢?比如百度的话,登录后就自动进去发短信,不过不同于你的发短信,它要求用户给账号服务器发送的信息发送到gmail中。但是有些网站的话,比如新浪看看、腾讯微博,等等,它就要求你在它的服务器上给账号发送短信,当然,对于普通的人来说,还是太麻烦了。
那么有没有这么简单点,且人家不用发短信,可以直接通过user-agent是透明的方式就能抓取数据的呢?最简单的方法,那就是我自己写个登录程序,或者使用爬虫工具scrapy之类的直接抓取。这时,它的问题就来了,太麻烦了,还会泄露你的账号信息。但是如果是可以像爬虫工具一样抓取,那么我们也可以考虑从其他地方把这个信息传给它,或者知道user-agent码一般的话,可以用自己的账号信息。
抓取网页数据(上海陆家嘴网上银行图片url转成urllib2.urlopen(url))
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-16 08:02
抓取网页数据一般依赖于urllib2库,今天学习了解了下这个库,明天就要用它来爬取上海陆家嘴网上银行的数据了。可以将请求的图片url转成urllib2.urlopen(url,filepath)方法是jsonp的实现,这个urllib2.urlopen()方法有两个参数:一个是url,可以是urlopt的url。
也可以是mqttserver的url。就是通过图片url请求图片。另一个是图片的名称。将图片url转成urllib2.urlopen(url)方法是jsonp的实现,这个urllib2.urlopen()方法有两个参数:一个是url,可以是urlopt的url。也可以是mqttserver的url。就是通过图片url请求图片。
另一个是图片的名称。这是jsonp的思想,图片url里面包含了图片的api地址,然后再使用jsonp的方式将图片导出。@!vs/demo/localhost/login-proxy/path/to/client_get_cn_jsonp/path/to/client_get_cn_cn_image/codecs/load.json第一个参数url里面有代表图片地址的mqtt字符串,所以这里get到的图片地址是:;id=78708546第二个参数mqttclient的地址,等于是get到的图片。
也就是我们通过mqtt的post请求,得到的返回值转成json数据,然后将json数据通过一个cn.jsonp的post请求,将图片的数据返回到浏览器。@!vs/demo/localhost/login-proxy/path/to/client_get_cn_jsonp/path/to/client_get_cn_image/codecs/load.json看到post请求我也吃惊了,一句话不会写,就爬取上海陆家嘴网上银行的交易数据数据呢。
首先看看要想要得到返回的图片,我们首先得在浏览器地址栏输入你要爬取的图片地址,进入首页我使用的是动态加载,右边是一个图片展示界面,然后我们添加关键字selenium,添加图片展示的相关代码,进入首页的代码:selenium的js文件和网页地址。urllib2.urlopen(url,filepath)方法的第二个参数是代表的是图片的名称,接下来就通过check_images()方法来检查我们要爬取的图片的网址或者图片的名称。
我们要爬取图片的名称,最好是定义一个函数去获取图片名称,而不是定义一个函数去遍历网页。其实就是webdriver.find_element_by_id()是获取图片id,element.g。 查看全部
抓取网页数据(上海陆家嘴网上银行图片url转成urllib2.urlopen(url))
抓取网页数据一般依赖于urllib2库,今天学习了解了下这个库,明天就要用它来爬取上海陆家嘴网上银行的数据了。可以将请求的图片url转成urllib2.urlopen(url,filepath)方法是jsonp的实现,这个urllib2.urlopen()方法有两个参数:一个是url,可以是urlopt的url。
也可以是mqttserver的url。就是通过图片url请求图片。另一个是图片的名称。将图片url转成urllib2.urlopen(url)方法是jsonp的实现,这个urllib2.urlopen()方法有两个参数:一个是url,可以是urlopt的url。也可以是mqttserver的url。就是通过图片url请求图片。
另一个是图片的名称。这是jsonp的思想,图片url里面包含了图片的api地址,然后再使用jsonp的方式将图片导出。@!vs/demo/localhost/login-proxy/path/to/client_get_cn_jsonp/path/to/client_get_cn_cn_image/codecs/load.json第一个参数url里面有代表图片地址的mqtt字符串,所以这里get到的图片地址是:;id=78708546第二个参数mqttclient的地址,等于是get到的图片。
也就是我们通过mqtt的post请求,得到的返回值转成json数据,然后将json数据通过一个cn.jsonp的post请求,将图片的数据返回到浏览器。@!vs/demo/localhost/login-proxy/path/to/client_get_cn_jsonp/path/to/client_get_cn_image/codecs/load.json看到post请求我也吃惊了,一句话不会写,就爬取上海陆家嘴网上银行的交易数据数据呢。
首先看看要想要得到返回的图片,我们首先得在浏览器地址栏输入你要爬取的图片地址,进入首页我使用的是动态加载,右边是一个图片展示界面,然后我们添加关键字selenium,添加图片展示的相关代码,进入首页的代码:selenium的js文件和网页地址。urllib2.urlopen(url,filepath)方法的第二个参数是代表的是图片的名称,接下来就通过check_images()方法来检查我们要爬取的图片的网址或者图片的名称。
我们要爬取图片的名称,最好是定义一个函数去获取图片名称,而不是定义一个函数去遍历网页。其实就是webdriver.find_element_by_id()是获取图片id,element.g。
抓取网页数据(乌云网我写的一个公用的HttpUtils..例子 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-13 11:29
)
最近,我在公司做了一个系统。因为我想获得一些网页数据和一些网页数据,所以我编写了一个公共httputils,下面是我为吴云编写的一个示例。com
一、首先,获取指定路径下的网页内容
public static String httpGet(String urlStr, Map params) throws Exception {
StringBuilder sb = new StringBuilder();
if (null != params && params.size() > 0) {
sb.append("?");
Entry en;
for (Iterator ir = params.entrySet().iterator(); ir.hasNext();) {
en = ir.next();
sb.append(en.getKey() + "=" + URLEncoder.encode(en.getValue(),"utf-8") + (ir.hasNext() ? "&" : ""));
}
}
URL url = new URL(urlStr + sb);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(5000);
conn.setReadTimeout(5000);
conn.setRequestMethod("GET");
if (conn.getResponseCode() != 200)
throw new Exception("请求异常状态值:" + conn.getResponseCode());
BufferedInputStream bis = new BufferedInputStream(conn.getInputStream());
Reader reader = new InputStreamReader(bis,"gbk");
char[] buffer = new char[2048];
int len = 0;
CharArrayWriter caw = new CharArrayWriter();
while ((len = reader.read(buffer)) > -1)
caw.write(buffer, 0, len);
reader.close();
bis.close();
conn.disconnect();
//System.out.println(caw);
return caw.toString();
}
浏览器查询结果:
代码查询结果与上述一致:
二、通过指定URL获取所需的网页数据
对于这种方法,要导入jsup包,您可以在Internet上下载它
Document doc = null;
try {
doc = Jsoup.connect("http://www.wooyun.org//bugs//w ... 6quot;).userAgent("Mozilla/5.0 (Windows NT 10.0; Trident/7.0; rv:11.0) like Gecko").timeout(30000).get();
} catch (IOException e) {
e.printStackTrace();
}
for(Iterator ir = doc.select("h3").iterator();ir.hasNext();){
System.out.println(ir.next().text());
}
对于选择选择器,根据条件选择文档选择(“h3”)。迭代器()具有以下jsup规则:
Jsoup是一个基于Java的HTML解析器,可以直接解析URL地址或HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似于jQuery的操作方法获取和操作数据
jsoup的优势在于它对文档元素的检索。select方法将返回一组元素,并提供一组方法来提取和处理结果。要掌握jsoup,首先必须熟悉其选择器语法
1、选择器基本语法
2、选择器组合语法
3、选择器伪选择器语法
注:上述伪选择器索引从0开始,即第一个元素的索引值为0,第二个元素的索引值为1,以此类推
浏览器访问:
代码访问:
查看全部
抓取网页数据(乌云网我写的一个公用的HttpUtils..例子
)
最近,我在公司做了一个系统。因为我想获得一些网页数据和一些网页数据,所以我编写了一个公共httputils,下面是我为吴云编写的一个示例。com
一、首先,获取指定路径下的网页内容
public static String httpGet(String urlStr, Map params) throws Exception {
StringBuilder sb = new StringBuilder();
if (null != params && params.size() > 0) {
sb.append("?");
Entry en;
for (Iterator ir = params.entrySet().iterator(); ir.hasNext();) {
en = ir.next();
sb.append(en.getKey() + "=" + URLEncoder.encode(en.getValue(),"utf-8") + (ir.hasNext() ? "&" : ""));
}
}
URL url = new URL(urlStr + sb);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(5000);
conn.setReadTimeout(5000);
conn.setRequestMethod("GET");
if (conn.getResponseCode() != 200)
throw new Exception("请求异常状态值:" + conn.getResponseCode());
BufferedInputStream bis = new BufferedInputStream(conn.getInputStream());
Reader reader = new InputStreamReader(bis,"gbk");
char[] buffer = new char[2048];
int len = 0;
CharArrayWriter caw = new CharArrayWriter();
while ((len = reader.read(buffer)) > -1)
caw.write(buffer, 0, len);
reader.close();
bis.close();
conn.disconnect();
//System.out.println(caw);
return caw.toString();
}
浏览器查询结果:
代码查询结果与上述一致:
二、通过指定URL获取所需的网页数据
对于这种方法,要导入jsup包,您可以在Internet上下载它
Document doc = null;
try {
doc = Jsoup.connect("http://www.wooyun.org//bugs//w ... 6quot;).userAgent("Mozilla/5.0 (Windows NT 10.0; Trident/7.0; rv:11.0) like Gecko").timeout(30000).get();
} catch (IOException e) {
e.printStackTrace();
}
for(Iterator ir = doc.select("h3").iterator();ir.hasNext();){
System.out.println(ir.next().text());
}
对于选择选择器,根据条件选择文档选择(“h3”)。迭代器()具有以下jsup规则:
Jsoup是一个基于Java的HTML解析器,可以直接解析URL地址或HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似于jQuery的操作方法获取和操作数据
jsoup的优势在于它对文档元素的检索。select方法将返回一组元素,并提供一组方法来提取和处理结果。要掌握jsoup,首先必须熟悉其选择器语法
1、选择器基本语法
2、选择器组合语法
3、选择器伪选择器语法
注:上述伪选择器索引从0开始,即第一个元素的索引值为0,第二个元素的索引值为1,以此类推
浏览器访问:
代码访问:
抓取网页数据(在实现简单网页上对数据内容进行增删改查部分+数据库表我用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-08 18:23
)
在一个简单的网页上添加、删除、修改和检查数据内容,需要三个部分,即jsp网页部分+java后台部分+数据库表
我用一个新闻例子来实现这个,先写一个java后台程序
java后台程序:
我们采用三层模型进行设计:servlet、service、dao层,并创建实体包对数据库和后端属性进行打包
性切图片
首先写函数的顺序是从servlet、service、dao层:
servlet层代码如下:
公共类 TypeServlet {
TypeService ts=new TypeServiceImp();//调用服务层
/*******添加**************************************** ** **************************************************/
public int addtype(String name){
int a=0;
a=ts.addtype(name);
返回一个;
}
/*******查看**************************************** **************************************************/
公共列表 selets(){
List list=new ArrayList();
list=ts.selets(null);
返回列表;
}
/*******删除**************************************** ** **************************************************/
public int delete(int id){
int a=0;
types t=new types();
t.setId(id);
a=ts.delete(t);
返回一个;
}
/*******修改**************************************** **************************************************/
公共 int 更新(类型 t){
int a=0;
a=ts.update(t);
返回一个;
}
/*******找一个**************************************** ****************************************************/<//p
p公共类型 selectone(int id){/p
ptypes t=new types();/p
pt.setId(id);/p
p类型 nt=ts.selectone(t);/p
p返回nt;/p
p}/p
p}/p
p服务层分为两层:接口层和实现层/p
pimg src='https://img-blog.csdn.net/20170802160709120?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvcXFfMzQxNzg5OTg=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center' alt=''//p
p界面程序如下:/p
ppre
/pre/p
p公共接口 TypeService {/p
ppublic int addtype(String name);/p
ppublic List selets(types t);/p
ppublic int delete(types t);/p
ppublic int update(types t);/p
p公共类型 selectone(types t);/p
p}/p
p接口实现方案:/p
ppre
/pre/p
p公共类 TypeServiceImp 实现 TypeService{/p
pTypeDao td = new TypeDaoImp();/p
ppublic int addtype(String name) {//注意返回的数据不要忘记修改/p
pint a=0;/p
pa=td.addtype(name);/p
p返回一个;/p
p}/p
p公共列表选择(类型 t){/p
pList list=new ArrayList();/p
plist=td.selets(t);/p
p返回列表;/p
p}/p
p/*******删除**************************************** ** **************************************************//p
ppublic int delete(types t) {/p
pint a=0;/p
pa=td.delete(t);/p
p返回一个;/p
p}/p
p/*******修改**************************************** **************************************************//p
ppublic int update(types t) {/p
pint a=0;/p
pa=td.update(t);/p
p返回一个;/p
p}/p
p/*******查找单个 ************************************ * ****************************************************//p
p公共类型 selectone(types t){/p
ptypes tp=new types();/p
ptp=td.selectone(t);/p
p返回tp;/p
p}/p
p}/p
p道层程序也分为接口层和实现层/p
p接口层程序:/p
ppre
/pre/p
p公共接口 TypeDao {/p
ppublic int addtype(String name);/p
ppublic List selets(types t);/p
ppublic int delete(types t);/p
ppublic int update(types t);/p
p公共类型 selectone(types t);/p
p}/p
p实施方案:/p
ppre
/pre/p
p公共类 TypeDaoImp 实现 TypeDao{/p
p连接 con=null;/p
pPreparedStatement ps=null;/p
p结果集 rs=null;/p
ppublic int addtype(String name){/p
pint a=0;/p
p试试{/p
p//连接数据库/p
pcon=Shujuku.conn();/p
pString sql="insert into typesname values(?)"; //设置id自增/p
pps=con.prepareStatement(sql);/p
pps.setString(1, name);/p
pa=ps.executeUpdate();/p
p} catch (SQLException e) {/p
p// TODO 自动生成的 catch 块/p
pe.printStackTrace();/p
p}/p
p返回一个;/p
p}/p
p公共列表选择(类型 t){/p
pList list=new ArrayList();/p
p试试{/p
p//连接数据库/p
pcon=Shujuku.conn();/p
pString sql="select*from typesname";/p
pps=con.prepareStatement(sql);/p
prs=ps.executeQuery();/p
pwhile(rs.next()){/p
ptypes ty=new types();/p
pty.setId(rs.getInt("id"));/p
pty.setTypename(rs.getString("typename"));/p
plist.add(ty);/p
p}/p
p} catch (SQLException e) {/p
p// TODO 自动生成的 catch 块/p
pe.printStackTrace();/p
p}/p
p返回列表;/p
p}/p
p/*******删除**************************************** ** **************************************************//p
ppublic int delete(types t) {/p
pint a=0;/p
p试试{/p
pcon=Shujuku.conn();/p
pString sql="delete from typesname wherelanguage-java">ps=con.prepareStatement(sql);
a=ps.executeUpdate();
} catch (SQLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
返回一个;
}
/*******修改**************************************** **************************************************/
public int update(types t) {
int a=0;
试试{
con=Shujuku.conn();
String sql="update typesname set typename=? where id=?";
ps=con.prepareStatement(sql);
ps.setString(1, t.getTypename());
ps.setInt(2, t.getId());
a=ps.executeUpdate();
} catch (SQLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
返回一个;
}
/*******找一个**************************************** ****************************************************/<//p
p公共类型 selectone(types t) {/p
ptypes tp=new types();/p
p试试{/p
pcon=Shujuku.conn();/p
pString sql="select * from typesname where id=?";/p
pps=con.prepareStatement(sql);/p
pps.setInt(1, t.getId());/p
prs=ps.executeQuery();/p
pif(rs.next()){/p
ptp.setId(rs.getInt("id"));/p
ptp.setTypename(rs.getString("typename"));/p
p}/p
p} catch (SQLException e) {/p
p// TODO 自动生成的 catch 块/p
pe.printStackTrace();/p
p}/p
p返回tp;/p
p}/p
p}/p
p最后是数据库包。为了使用方便,创建一个包来存放数据库的驱动连接信息:/p
p代码如下:/p
ppre
/pre/p
p公开课修宿{/p
p公共静态连接 conn(){/p
p//定义地址/p
pString url="jdbc:sqlserver://localhost:1433;DatabaseName=test;";/p
p//定义连接的初始值/p
pConnection connection=null;/p
p试试{/p
p//加载驱动/p
pClass.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver");/p
p//建立连接/p
pconnection=DriverManager.getConnection(url, "sa", "DCX5201314");/p
p} catch (SQLException e) {/p
p// TODO 自动生成的 catch 块/p
pe.printStackTrace();/p
p} catch (ClassNotFoundException e) {/p
p// TODO 自动生成的 catch 块/p
pe.printStackTrace();/p
p}/p
p返回连接;/p
p}/p
p}/p
p属性包,代码如下:/p
ppre
/pre/p
p公共类类型{/p
p私有int id;/p
p私有字符串类型名;/p
ppublic int getId() {/p
p返回id;/p
p}/p
ppublic void setId(int id) {/p
pthis.id = id;/p
p}/p
ppublic String getTypename() {/p
p返回类型名称;/p
p}/p
ppublic void setTypename(String typename) {/p
pthis.typename = typename;/p
p}/p
p}/p
pjava后台程序太多了;/p
p接下来是数据库部分:/p
p数据库部分主要是创建表。笔者使用SQL Server 2008。首先创建数据库test,创建表typename,设置两列为id typename,id为主键,int类型,自增为1; typename 设置为 varchar 类型,不能为空。/p
pimg src='https://img-blog.csdn.net/20170802162320361?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvcXFfMzQxNzg5OTg=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center' alt=''//p
p好了,数据库和java后端都设置好了,现在进入前端网页部分,/p
p页面的一部分/p
p在myeclipse中新建7个jsp文件/p
pimg src='https://img-blog.csdn.net/20170802163307903?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvcXFfMzQxNzg5OTg=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center' alt=''//p
pindex.jsp 是一个完整的网页/p
p设置代码如下:/p
ppre
/pre/p
phead.jsp/p
ppre
/pre/p
p这是头/p
pleft.jsp/p
ppre
/pre/p
p这是左边/p
pright.jsp/p
ppre
/pre/p
p这是右边/p
paddtype.jsp/p
ppre
/pre/p
p0){/p
pRequestDispatcher rd = 请求/p
p.getRequestDispatcher("showtype.jsp");/p
prd.forward(request, response);/p
p}其他{/p
pRequestDispatcher rd = 请求/p
p.getRequestDispatcher("addtype.jsp");/p
prd.forward(request, response);/p
p}/p
p}/p
p%>
添加新闻类型
showtype.jsp
展示类型
数量
输入名称
操作
updatetype.jsp
修改新闻类型界面
最终项目发布在 tomcat 上。
以下地址积分系统调得太高了。我在此处重新上传了具有相同地址的副本:
高分下载包文件在这里:
也可以参考这篇文章的两个表关联操作:
如果有什么问题,希望大家提出来,共同进步
查看全部
抓取网页数据(在实现简单网页上对数据内容进行增删改查部分+数据库表我用
)
在一个简单的网页上添加、删除、修改和检查数据内容,需要三个部分,即jsp网页部分+java后台部分+数据库表
我用一个新闻例子来实现这个,先写一个java后台程序
java后台程序:
我们采用三层模型进行设计:servlet、service、dao层,并创建实体包对数据库和后端属性进行打包
性切图片
首先写函数的顺序是从servlet、service、dao层:
servlet层代码如下:
公共类 TypeServlet {
TypeService ts=new TypeServiceImp();//调用服务层
/*******添加**************************************** ** **************************************************/
public int addtype(String name){
int a=0;
a=ts.addtype(name);
返回一个;
}
/*******查看**************************************** **************************************************/
公共列表 selets(){
List list=new ArrayList();
list=ts.selets(null);
返回列表;
}
/*******删除**************************************** ** **************************************************/
public int delete(int id){
int a=0;
types t=new types();
t.setId(id);
a=ts.delete(t);
返回一个;
}
/*******修改**************************************** **************************************************/
公共 int 更新(类型 t){
int a=0;
a=ts.update(t);
返回一个;
}
/*******找一个**************************************** ****************************************************/<//p
p公共类型 selectone(int id){/p
ptypes t=new types();/p
pt.setId(id);/p
p类型 nt=ts.selectone(t);/p
p返回nt;/p
p}/p
p}/p
p服务层分为两层:接口层和实现层/p
pimg src='https://img-blog.csdn.net/20170802160709120?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvcXFfMzQxNzg5OTg=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center' alt=''//p
p界面程序如下:/p
ppre
/pre/p
p公共接口 TypeService {/p
ppublic int addtype(String name);/p
ppublic List selets(types t);/p
ppublic int delete(types t);/p
ppublic int update(types t);/p
p公共类型 selectone(types t);/p
p}/p
p接口实现方案:/p
ppre
/pre/p
p公共类 TypeServiceImp 实现 TypeService{/p
pTypeDao td = new TypeDaoImp();/p
ppublic int addtype(String name) {//注意返回的数据不要忘记修改/p
pint a=0;/p
pa=td.addtype(name);/p
p返回一个;/p
p}/p
p公共列表选择(类型 t){/p
pList list=new ArrayList();/p
plist=td.selets(t);/p
p返回列表;/p
p}/p
p/*******删除**************************************** ** **************************************************//p
ppublic int delete(types t) {/p
pint a=0;/p
pa=td.delete(t);/p
p返回一个;/p
p}/p
p/*******修改**************************************** **************************************************//p
ppublic int update(types t) {/p
pint a=0;/p
pa=td.update(t);/p
p返回一个;/p
p}/p
p/*******查找单个 ************************************ * ****************************************************//p
p公共类型 selectone(types t){/p
ptypes tp=new types();/p
ptp=td.selectone(t);/p
p返回tp;/p
p}/p
p}/p
p道层程序也分为接口层和实现层/p
p接口层程序:/p
ppre
/pre/p
p公共接口 TypeDao {/p
ppublic int addtype(String name);/p
ppublic List selets(types t);/p
ppublic int delete(types t);/p
ppublic int update(types t);/p
p公共类型 selectone(types t);/p
p}/p
p实施方案:/p
ppre
/pre/p
p公共类 TypeDaoImp 实现 TypeDao{/p
p连接 con=null;/p
pPreparedStatement ps=null;/p
p结果集 rs=null;/p
ppublic int addtype(String name){/p
pint a=0;/p
p试试{/p
p//连接数据库/p
pcon=Shujuku.conn();/p
pString sql="insert into typesname values(?)"; //设置id自增/p
pps=con.prepareStatement(sql);/p
pps.setString(1, name);/p
pa=ps.executeUpdate();/p
p} catch (SQLException e) {/p
p// TODO 自动生成的 catch 块/p
pe.printStackTrace();/p
p}/p
p返回一个;/p
p}/p
p公共列表选择(类型 t){/p
pList list=new ArrayList();/p
p试试{/p
p//连接数据库/p
pcon=Shujuku.conn();/p
pString sql="select*from typesname";/p
pps=con.prepareStatement(sql);/p
prs=ps.executeQuery();/p
pwhile(rs.next()){/p
ptypes ty=new types();/p
pty.setId(rs.getInt("id"));/p
pty.setTypename(rs.getString("typename"));/p
plist.add(ty);/p
p}/p
p} catch (SQLException e) {/p
p// TODO 自动生成的 catch 块/p
pe.printStackTrace();/p
p}/p
p返回列表;/p
p}/p
p/*******删除**************************************** ** **************************************************//p
ppublic int delete(types t) {/p
pint a=0;/p
p试试{/p
pcon=Shujuku.conn();/p
pString sql="delete from typesname wherelanguage-java">ps=con.prepareStatement(sql);
a=ps.executeUpdate();
} catch (SQLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
返回一个;
}
/*******修改**************************************** **************************************************/
public int update(types t) {
int a=0;
试试{
con=Shujuku.conn();
String sql="update typesname set typename=? where id=?";
ps=con.prepareStatement(sql);
ps.setString(1, t.getTypename());
ps.setInt(2, t.getId());
a=ps.executeUpdate();
} catch (SQLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
返回一个;
}
/*******找一个**************************************** ****************************************************/<//p
p公共类型 selectone(types t) {/p
ptypes tp=new types();/p
p试试{/p
pcon=Shujuku.conn();/p
pString sql="select * from typesname where id=?";/p
pps=con.prepareStatement(sql);/p
pps.setInt(1, t.getId());/p
prs=ps.executeQuery();/p
pif(rs.next()){/p
ptp.setId(rs.getInt("id"));/p
ptp.setTypename(rs.getString("typename"));/p
p}/p
p} catch (SQLException e) {/p
p// TODO 自动生成的 catch 块/p
pe.printStackTrace();/p
p}/p
p返回tp;/p
p}/p
p}/p
p最后是数据库包。为了使用方便,创建一个包来存放数据库的驱动连接信息:/p
p代码如下:/p
ppre
/pre/p
p公开课修宿{/p
p公共静态连接 conn(){/p
p//定义地址/p
pString url="jdbc:sqlserver://localhost:1433;DatabaseName=test;";/p
p//定义连接的初始值/p
pConnection connection=null;/p
p试试{/p
p//加载驱动/p
pClass.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver");/p
p//建立连接/p
pconnection=DriverManager.getConnection(url, "sa", "DCX5201314");/p
p} catch (SQLException e) {/p
p// TODO 自动生成的 catch 块/p
pe.printStackTrace();/p
p} catch (ClassNotFoundException e) {/p
p// TODO 自动生成的 catch 块/p
pe.printStackTrace();/p
p}/p
p返回连接;/p
p}/p
p}/p
p属性包,代码如下:/p
ppre
/pre/p
p公共类类型{/p
p私有int id;/p
p私有字符串类型名;/p
ppublic int getId() {/p
p返回id;/p
p}/p
ppublic void setId(int id) {/p
pthis.id = id;/p
p}/p
ppublic String getTypename() {/p
p返回类型名称;/p
p}/p
ppublic void setTypename(String typename) {/p
pthis.typename = typename;/p
p}/p
p}/p
pjava后台程序太多了;/p
p接下来是数据库部分:/p
p数据库部分主要是创建表。笔者使用SQL Server 2008。首先创建数据库test,创建表typename,设置两列为id typename,id为主键,int类型,自增为1; typename 设置为 varchar 类型,不能为空。/p
pimg src='https://img-blog.csdn.net/20170802162320361?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvcXFfMzQxNzg5OTg=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center' alt=''//p
p好了,数据库和java后端都设置好了,现在进入前端网页部分,/p
p页面的一部分/p
p在myeclipse中新建7个jsp文件/p
pimg src='https://img-blog.csdn.net/20170802163307903?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvcXFfMzQxNzg5OTg=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center' alt=''//p
pindex.jsp 是一个完整的网页/p
p设置代码如下:/p
ppre
/pre/p
phead.jsp/p
ppre
/pre/p
p这是头/p
pleft.jsp/p
ppre
/pre/p
p这是左边/p
pright.jsp/p
ppre
/pre/p
p这是右边/p
paddtype.jsp/p
ppre
/pre/p
p0){/p
pRequestDispatcher rd = 请求/p
p.getRequestDispatcher("showtype.jsp");/p
prd.forward(request, response);/p
p}其他{/p
pRequestDispatcher rd = 请求/p
p.getRequestDispatcher("addtype.jsp");/p
prd.forward(request, response);/p
p}/p
p}/p
p%>
添加新闻类型
showtype.jsp
展示类型
数量
输入名称
操作
updatetype.jsp
修改新闻类型界面
最终项目发布在 tomcat 上。
以下地址积分系统调得太高了。我在此处重新上传了具有相同地址的副本:
高分下载包文件在这里:
也可以参考这篇文章的两个表关联操作:
如果有什么问题,希望大家提出来,共同进步
抓取网页数据(GET/POST方法的差异,简单的查询都用POST)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-07 01:53
这个文章我不建议你采集它,因为你不会打开采集夹。建议你现在花5分钟阅读这篇文章,用这5分钟真正掌握一个知识点。
最近才发现原来捕获BDI和BHSI索引的网站在2021年之后就没有更新了:
没办法,只好另寻数据源了。当然,这个索引可以随便搜,有很多:
既然那位排在第一位,就拿去吧。
通过chrome浏览器输入网站后,右键菜单【检查】查看参数(视频没有声音,可以公开播放):
哎,这么简单的查询使用POST方法作为请求...
不过没关系,简单的POST请求类型网站的数据捕获并不复杂,虽然不像GET类型网站那样可以直接粗暴地用一个URL来处理。
关于GET/POST方法的区别,简单来说,GET类主要是用来传递一些简单的参数来实现数据查询,所以这些参数会直接加到URL中,而POST类主要是用于查询条件比较 在复杂的情况下,这些参数会以表格的形式传输。当然,既然POST方法可以用在复杂的情况下,当然也可以用在简单的情况下,比如上面的例子。(关于GET/POST更详细的资料,有兴趣的朋友可以自行搜索,不过非IT专业人士一般不需要了解太多,知道是这样,需要的时候知道怎么找方法,或者它可能足以知道如何询问人)。
那么,在 Power Query 中,如何从 POST 网页中抓取数据?记住以下三个必要的内容:
这有点复杂,不是吗?这些东西从哪里来?其实很简单。您可以通过 Chrome 中的“检查”功能轻松获取这些信息:
即使点击了“查看源代码”,也可以直接看到这些参数最终传入的时候是什么样子的:
通过这 3 项,可以在 Power Query 中捕获数据。
其中,前两项可以直接复制粘贴到对应的框中,但是参数需要通过Text.ToBinary转换成二进制内容,然后手动输入到Content参数中(视频没有声音,可以在公众面前充满信心地演奏):
这样就很容易得到一个简单的网页数据爬取的POST请求。 查看全部
抓取网页数据(GET/POST方法的差异,简单的查询都用POST)
这个文章我不建议你采集它,因为你不会打开采集夹。建议你现在花5分钟阅读这篇文章,用这5分钟真正掌握一个知识点。
最近才发现原来捕获BDI和BHSI索引的网站在2021年之后就没有更新了:
没办法,只好另寻数据源了。当然,这个索引可以随便搜,有很多:
既然那位排在第一位,就拿去吧。
通过chrome浏览器输入网站后,右键菜单【检查】查看参数(视频没有声音,可以公开播放):
哎,这么简单的查询使用POST方法作为请求...
不过没关系,简单的POST请求类型网站的数据捕获并不复杂,虽然不像GET类型网站那样可以直接粗暴地用一个URL来处理。
关于GET/POST方法的区别,简单来说,GET类主要是用来传递一些简单的参数来实现数据查询,所以这些参数会直接加到URL中,而POST类主要是用于查询条件比较 在复杂的情况下,这些参数会以表格的形式传输。当然,既然POST方法可以用在复杂的情况下,当然也可以用在简单的情况下,比如上面的例子。(关于GET/POST更详细的资料,有兴趣的朋友可以自行搜索,不过非IT专业人士一般不需要了解太多,知道是这样,需要的时候知道怎么找方法,或者它可能足以知道如何询问人)。
那么,在 Power Query 中,如何从 POST 网页中抓取数据?记住以下三个必要的内容:
这有点复杂,不是吗?这些东西从哪里来?其实很简单。您可以通过 Chrome 中的“检查”功能轻松获取这些信息:
即使点击了“查看源代码”,也可以直接看到这些参数最终传入的时候是什么样子的:
通过这 3 项,可以在 Power Query 中捕获数据。
其中,前两项可以直接复制粘贴到对应的框中,但是参数需要通过Text.ToBinary转换成二进制内容,然后手动输入到Content参数中(视频没有声音,可以在公众面前充满信心地演奏):
这样就很容易得到一个简单的网页数据爬取的POST请求。
抓取网页数据(有关,文章内容质量较高,小编分享给大家做个参考)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-05 18:24
本文文章将详细讲解如何使用Scrapy抓取网页。 文章的内容质量很高,分享给大家作为参考。希望你看完这篇文章之后,对相关知识有一定的了解。
Scrapy 是一种快速先进的网络爬虫和网络抓取框架,用于爬取 网站 并从其页面中提取结构化数据。它可用于多种用途,从数据挖掘到监控和自动化测试。
老规矩,使用前使用pip install scrapy安装。如果在安装过程中遇到错误,通常是错误:Microsoft Visual C++ 14.0 is required。你只需要访问~gohlke/pythonlibs/#twisted 网站下载Twisted-19.2.1-cp37-cp37m-win_amd64并安装,注意cp37代表我的版本原生 python3.7 amd64 代表我的操作系统位数。
使用pip install Twisted-19.2.1-cp37-cp37m-win_amd64.whl进行安装,然后重新安装scrapy即可安装成功;安装成功后我们就可以使用scrapy命令创建爬虫项目了。
接下来,在我的桌面上运行cmd命令并使用scrapystartprojectwebtutorial创建项目:
桌面会生成一个webtutorial文件夹,我们看一下目录结构:
然后我们在spiders文件夹下新建一个quotes_spider.py,写一个爬虫爬取网站保存为html文件。 网站的截图如下:
代码如下:
import scrapy
#定义爬虫类class QuotesSpider(scrapy.Spider): #指定爬虫名字 一会要用到 name = "quotes" #开始请求方法 def start_requests(self): urls = [ 'http://quotes.toscrape.com/page/1/', 'http://quotes.toscrape.com/page/2/'] for url in urls: yield scrapy.Request(url=url, callback=self.parse)#解析写入返回内容到html中 def parse(self, response): page = response.url.split("/")[-2] filename = 'quotes-%s.html' % page with open(filename, 'wb') as f: f.write(response.body) self.log('Saved file %s' % filename)
以下目录结构为:
然后我们在命令行切换到webtutorial文件夹,执行命令scrapycrawlquotes进行爬取(quotes是刚刚指定的爬虫名):
发现错误,没有名为'win32api'的模块,这里我们安装win32api
使用命令pip install pypiwin32,然后继续执行scrapy crawl引用:
可以看到爬虫任务执行成功。这时候webtutorial文件夹下会生成两个html:
关于如何使用Scrapy抓取网页,我在这里分享。希望以上内容能对您有所帮助,让您了解更多。如果你觉得文章不错,可以分享给更多人看。 查看全部
抓取网页数据(有关,文章内容质量较高,小编分享给大家做个参考)
本文文章将详细讲解如何使用Scrapy抓取网页。 文章的内容质量很高,分享给大家作为参考。希望你看完这篇文章之后,对相关知识有一定的了解。
Scrapy 是一种快速先进的网络爬虫和网络抓取框架,用于爬取 网站 并从其页面中提取结构化数据。它可用于多种用途,从数据挖掘到监控和自动化测试。
老规矩,使用前使用pip install scrapy安装。如果在安装过程中遇到错误,通常是错误:Microsoft Visual C++ 14.0 is required。你只需要访问~gohlke/pythonlibs/#twisted 网站下载Twisted-19.2.1-cp37-cp37m-win_amd64并安装,注意cp37代表我的版本原生 python3.7 amd64 代表我的操作系统位数。
使用pip install Twisted-19.2.1-cp37-cp37m-win_amd64.whl进行安装,然后重新安装scrapy即可安装成功;安装成功后我们就可以使用scrapy命令创建爬虫项目了。
接下来,在我的桌面上运行cmd命令并使用scrapystartprojectwebtutorial创建项目:
桌面会生成一个webtutorial文件夹,我们看一下目录结构:
然后我们在spiders文件夹下新建一个quotes_spider.py,写一个爬虫爬取网站保存为html文件。 网站的截图如下:
代码如下:
import scrapy
#定义爬虫类class QuotesSpider(scrapy.Spider): #指定爬虫名字 一会要用到 name = "quotes" #开始请求方法 def start_requests(self): urls = [ 'http://quotes.toscrape.com/page/1/', 'http://quotes.toscrape.com/page/2/'] for url in urls: yield scrapy.Request(url=url, callback=self.parse)#解析写入返回内容到html中 def parse(self, response): page = response.url.split("/")[-2] filename = 'quotes-%s.html' % page with open(filename, 'wb') as f: f.write(response.body) self.log('Saved file %s' % filename)
以下目录结构为:
然后我们在命令行切换到webtutorial文件夹,执行命令scrapycrawlquotes进行爬取(quotes是刚刚指定的爬虫名):
发现错误,没有名为'win32api'的模块,这里我们安装win32api
使用命令pip install pypiwin32,然后继续执行scrapy crawl引用:
可以看到爬虫任务执行成功。这时候webtutorial文件夹下会生成两个html:
关于如何使用Scrapy抓取网页,我在这里分享。希望以上内容能对您有所帮助,让您了解更多。如果你觉得文章不错,可以分享给更多人看。
抓取网页数据(1.正则表达式匹配;2.使用HtmlAgilityPack;(不是很熟悉) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-26 19:08
)
等待。
此过程目前有两种方法可供选择:
1.正则表达式匹配;
2.使用HtmlAgilityPack;(不是很熟悉)
本文仅提供正则表达式的方法供大家学习借鉴,望读者见谅。
正则表达式定位
如果长期做数据采集工作,建议深入研究。这里是DeerChao对正则表达式的介绍,非常推荐。如果你只是想做一个课程设计,可以听听我的介绍。
“定位”过程主要使用Regex.Match()方法,返回结果为正则匹配的文本。即目标网页数据。
让我粗略地解释一下。例如,如果您有这样的文字:
“我20岁了。”
想要获取年龄数据,即“20”,如何使用常规抓包?
//...
using System.Text.RegularExpressions;
//导入正则表达式命名空间
//...
string strTest = @"I am 20 years old.";
string strResult = "";
strResult = Regex.Match(strTest, @"\d+").Value;
Console.WriteLine(strResult);
Console.ReadKey();
OK,抓包成功!但是你可能会问,这个程序跟定位有什么关系?好吧,让我解释一下:
您可以多次使用它: strResult = Regex.Match(strResult, @"正正").Value; 一步一步缩小网页中的数据范围,最终定位到你想到的那部分数据。
类似于“我今年 20 岁”。您可以通过三步找到“20”
然后就可以在网页上用同样的方法定位嵌套的内容(当然,如果没有嵌套的部分,也可以尝试一次性全部抓取),
strResult = Regex.Match(strResult , "(?is)登录.*?更多").Value;
strResult = Regex.Match(strResult , "(?is)").Value;
通过这两行代码,就可以定位到百度的“百度点击”按钮。当然你也可以删掉上一句,因为百度首页只有一个提交按钮。但是如果是其他网站,有多个提交按钮,那么就得重新考虑正则的写法了。
常问问题
定位数据的原理基本介绍完毕。相信读者会有很多疑问(文笔不好,见谅),我自己写一些吧:
Q:匹配结果有多个值怎么办?
A:在匹配网页数据的时候,经常会遇到多个匹配的结果,比如多个表,多个div标签等,这时候我们可以使用Match采集来接受返回的结果集,例如:
Match采集 mcResult = Regex.Matches(strHtml, @"(?is)");
可以使用foreach遍历这个集合,也可以使用下标来访问元素。但请注意,您需要使用 Regex.Matches() 方法而不是 Regex.Match() 方法。你注意到了吗?这表示您可能匹配了多个结果。
问:常规中的 (?is) 是什么意思?
A:这是正则表达式的匹配选项,.Net中也有对应的选项
(?i) 表示不区分大小写,相当于.net中的RegexOptions.IgnoreCase选项;
(?s) 表示让“。” 匹配换行符,即“.” 表示 [\s\S] 相当于.net 中的 RegexOptions.Singleline 选项;
//当然还有其他问题,这里就不一一列举了,希望大家多多评论,我会尽量解答。
三、保存数据
保存数据的方式有很多种,比如XML格式、标签内容、直接写入数据库、保存为txt……您可以根据自己的需要选择合适的保存方式。
但是,为了统一起见,我推荐使用 XML 来保存内容。首先,网页中的数据基本可以转换为XML格式;其次,将XML输入到数据库中并转换为其他形式非常方便;三、XML操作 数据方便。如果需要修改数据,有很多API库之类的可以调用。总之就是好处多多,呵呵。
@"Author: wushuai1346
Description: 不断完善中.版权所有,转载请注明出处,谢谢.
Copyright (C) 2011 wushuai1346,All Rights Reserved
Url: http://blog.csdn.net/wushuai13 ... 08424
Createtime : 2011-12-28
Updatetime : 2011-12-29" 查看全部
抓取网页数据(1.正则表达式匹配;2.使用HtmlAgilityPack;(不是很熟悉)
)
等待。
此过程目前有两种方法可供选择:
1.正则表达式匹配;
2.使用HtmlAgilityPack;(不是很熟悉)
本文仅提供正则表达式的方法供大家学习借鉴,望读者见谅。
正则表达式定位
如果长期做数据采集工作,建议深入研究。这里是DeerChao对正则表达式的介绍,非常推荐。如果你只是想做一个课程设计,可以听听我的介绍。
“定位”过程主要使用Regex.Match()方法,返回结果为正则匹配的文本。即目标网页数据。
让我粗略地解释一下。例如,如果您有这样的文字:
“我20岁了。”
想要获取年龄数据,即“20”,如何使用常规抓包?
//...
using System.Text.RegularExpressions;
//导入正则表达式命名空间
//...
string strTest = @"I am 20 years old.";
string strResult = "";
strResult = Regex.Match(strTest, @"\d+").Value;
Console.WriteLine(strResult);
Console.ReadKey();
OK,抓包成功!但是你可能会问,这个程序跟定位有什么关系?好吧,让我解释一下:
您可以多次使用它: strResult = Regex.Match(strResult, @"正正").Value; 一步一步缩小网页中的数据范围,最终定位到你想到的那部分数据。
类似于“我今年 20 岁”。您可以通过三步找到“20”
然后就可以在网页上用同样的方法定位嵌套的内容(当然,如果没有嵌套的部分,也可以尝试一次性全部抓取),
strResult = Regex.Match(strResult , "(?is)登录.*?更多").Value;
strResult = Regex.Match(strResult , "(?is)").Value;
通过这两行代码,就可以定位到百度的“百度点击”按钮。当然你也可以删掉上一句,因为百度首页只有一个提交按钮。但是如果是其他网站,有多个提交按钮,那么就得重新考虑正则的写法了。
常问问题
定位数据的原理基本介绍完毕。相信读者会有很多疑问(文笔不好,见谅),我自己写一些吧:
Q:匹配结果有多个值怎么办?
A:在匹配网页数据的时候,经常会遇到多个匹配的结果,比如多个表,多个div标签等,这时候我们可以使用Match采集来接受返回的结果集,例如:
Match采集 mcResult = Regex.Matches(strHtml, @"(?is)");
可以使用foreach遍历这个集合,也可以使用下标来访问元素。但请注意,您需要使用 Regex.Matches() 方法而不是 Regex.Match() 方法。你注意到了吗?这表示您可能匹配了多个结果。
问:常规中的 (?is) 是什么意思?
A:这是正则表达式的匹配选项,.Net中也有对应的选项
(?i) 表示不区分大小写,相当于.net中的RegexOptions.IgnoreCase选项;
(?s) 表示让“。” 匹配换行符,即“.” 表示 [\s\S] 相当于.net 中的 RegexOptions.Singleline 选项;
//当然还有其他问题,这里就不一一列举了,希望大家多多评论,我会尽量解答。
三、保存数据
保存数据的方式有很多种,比如XML格式、标签内容、直接写入数据库、保存为txt……您可以根据自己的需要选择合适的保存方式。
但是,为了统一起见,我推荐使用 XML 来保存内容。首先,网页中的数据基本可以转换为XML格式;其次,将XML输入到数据库中并转换为其他形式非常方便;三、XML操作 数据方便。如果需要修改数据,有很多API库之类的可以调用。总之就是好处多多,呵呵。
@"Author: wushuai1346
Description: 不断完善中.版权所有,转载请注明出处,谢谢.
Copyright (C) 2011 wushuai1346,All Rights Reserved
Url: http://blog.csdn.net/wushuai13 ... 08424
Createtime : 2011-12-28
Updatetime : 2011-12-29"
抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-25 03:01
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的BeautifulSoup模块,最后是强大的lxml模块。
1. 正则表达式
如果您对正则表达式不熟悉,或者需要一些提示,可以参考正则表达式 HOWTO 中的完整介绍。
我们在使用正则表达式抓取国家/地区数据时,首先要尽量匹配元素的内容,如下图:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从上面的结果可以看出,在很多国家属性中都使用了标签。为了隔离area属性,我们可以只选择第二个元素,如下图:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。比如表变了,去掉了第二行的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望将来再次捕获数据,则需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们还可以添加其父元素。由于此元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('.*?(.*?)',html)['244,820 square kilometres']
这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有一些细微的布局变化会使正则表达式不尽人意,例如在标签中添加标题属性。
从这个例子可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,在网页更新后容易出现问题。好在还有一些更好的解决方案,后面会介绍。
2. 美汤
Beautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装其最新版本(需要先安装pip,请自行百度):
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于大多数网页没有好的 HTML 格式,Beautiful Soup 需要确定其实际格式。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
Area
Population
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup可以正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注:由于不同版本的Python内置库容错能力的差异,处理结果可能与上述不同。详情请参考:。如果想知道所有的方法和参数,可以参考Beautiful Soup的官方文档
以下是使用该方法提取样本国家面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。
3. Lxml
Lxml 是一个基于 libxml2 的 Python 包,一个 XML 解析库。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。可以参考最新的安装说明。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同理,lxml 可以正确解析属性两边缺失的引号并关闭标签,但模块不会添加额外的 and 标签。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,我们以后会使用 CSS 选择器,因为它更简洁,并且可以在解析动态内容时重复使用。另外,一些有jQuery选择器使用经验的读者会比较熟悉。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到id为places_area__row的表格行元素,然后选择class为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 提出了 CSS3 规范,其网站是
Lxml 已经实现了大部分 CSS3 属性,不支持的功能可以在:。
注意:在 lxml 的内部实现中,它实际上是将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能对比
下面的代码中,每个爬虫都会执行1000次,每次都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com ... %2339;).read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 * 代码行中调用了 re.purge() 方法。默认情况下,正则表达式将缓存搜索结果。公平地说,我们需要使用这种方法来清除缓存。
这是在我的电脑上运行脚本的结果:
由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果中可以看出,在抓取我们的示例网页时,Beautiful Soup 比其他两种方法慢 7 倍以上。其实这个结果是符合预期的,因为lxml和正则表达式模块都是用C语言写的,而Beautiful Soup是用纯Python写的。一个有趣的事实是 lxml 的性能几乎与正则表达式一样好。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当抓取同一个网页的多个特征时,这个初始分析的开销会减少,lxml会更有竞争力。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用困难 安装困难
正则表达式
快的
困难
简单(内置模块)
美汤
减缓
简单的
简单(纯 Python)
xml文件
快的
简单的
比较难
如果你的爬虫的瓶颈是下载网页,而不是提取数据,那么较慢的方法(比如 Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,还可以避免解析整个网页的开销。如果你只需要爬取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。但是,一般情况下,lxml 是捕获数据的最佳选择,因为它不仅速度更快,而且用途更广,而正则表达式和 Beautiful Soup 仅在某些场景下有用。 查看全部
抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的BeautifulSoup模块,最后是强大的lxml模块。
1. 正则表达式
如果您对正则表达式不熟悉,或者需要一些提示,可以参考正则表达式 HOWTO 中的完整介绍。
我们在使用正则表达式抓取国家/地区数据时,首先要尽量匹配元素的内容,如下图:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从上面的结果可以看出,在很多国家属性中都使用了标签。为了隔离area属性,我们可以只选择第二个元素,如下图:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。比如表变了,去掉了第二行的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望将来再次捕获数据,则需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们还可以添加其父元素。由于此元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('.*?(.*?)',html)['244,820 square kilometres']
这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有一些细微的布局变化会使正则表达式不尽人意,例如在标签中添加标题属性。
从这个例子可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,在网页更新后容易出现问题。好在还有一些更好的解决方案,后面会介绍。
2. 美汤
Beautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装其最新版本(需要先安装pip,请自行百度):
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于大多数网页没有好的 HTML 格式,Beautiful Soup 需要确定其实际格式。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
Area
Population
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup可以正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注:由于不同版本的Python内置库容错能力的差异,处理结果可能与上述不同。详情请参考:。如果想知道所有的方法和参数,可以参考Beautiful Soup的官方文档
以下是使用该方法提取样本国家面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。
3. Lxml
Lxml 是一个基于 libxml2 的 Python 包,一个 XML 解析库。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。可以参考最新的安装说明。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同理,lxml 可以正确解析属性两边缺失的引号并关闭标签,但模块不会添加额外的 and 标签。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,我们以后会使用 CSS 选择器,因为它更简洁,并且可以在解析动态内容时重复使用。另外,一些有jQuery选择器使用经验的读者会比较熟悉。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到id为places_area__row的表格行元素,然后选择class为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 提出了 CSS3 规范,其网站是
Lxml 已经实现了大部分 CSS3 属性,不支持的功能可以在:。
注意:在 lxml 的内部实现中,它实际上是将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能对比
下面的代码中,每个爬虫都会执行1000次,每次都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com ... %2339;).read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 * 代码行中调用了 re.purge() 方法。默认情况下,正则表达式将缓存搜索结果。公平地说,我们需要使用这种方法来清除缓存。
这是在我的电脑上运行脚本的结果:
由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果中可以看出,在抓取我们的示例网页时,Beautiful Soup 比其他两种方法慢 7 倍以上。其实这个结果是符合预期的,因为lxml和正则表达式模块都是用C语言写的,而Beautiful Soup是用纯Python写的。一个有趣的事实是 lxml 的性能几乎与正则表达式一样好。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当抓取同一个网页的多个特征时,这个初始分析的开销会减少,lxml会更有竞争力。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用困难 安装困难
正则表达式
快的
困难
简单(内置模块)
美汤
减缓
简单的
简单(纯 Python)
xml文件
快的
简单的
比较难
如果你的爬虫的瓶颈是下载网页,而不是提取数据,那么较慢的方法(比如 Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,还可以避免解析整个网页的开销。如果你只需要爬取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。但是,一般情况下,lxml 是捕获数据的最佳选择,因为它不仅速度更快,而且用途更广,而正则表达式和 Beautiful Soup 仅在某些场景下有用。
抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-21 18:21
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:
" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被诸如此类的工具抓取作为搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:
" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
抓取网页数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:
" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被诸如此类的工具抓取作为搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:
" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
抓取网页数据(/networkgoogleandroidboilerplatesaysomethingaboutnetworkingaboutnetwork你提的问题是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-19 13:08
抓取网页数据,执行java编程语言,然后登录,调用sun的方法进行处理,然后进行competition,进行模拟投票。你提的问题,其实比较简单,问题描述不够具体,难以回答。
模拟登录到某网站,从哪个网站调用相应算法,
很多网站都能做到,只要获取用户行为数据...或者模拟登录,
知乎。选择最佳答案的动作:到“我的答案”里选中自己所答的那条,点“评论”。确定后,点“结果”。其它投票的动作:复制所有答案的链接,发送到邮箱,用网页浏览器访问邮箱的邮件中的链接。点击这条链接就能投票。投票结果会以邮件形式发送给你。
coindaily!
coinday.
talkischeap,showmethecode!
难道不是@邓晓芒?
百度知道,百度身份证及手机号。
匿名投票,虽然匿名,
github上的“联合搜索”
360邀请码,即回答有奖,应该可以。
whatsapp/
network
googleandroidboilerplatesaysomethingaboutnetwork你看看他们能否抓取到https的,
validity网站已经准备用djangowebframework实现,你可以试试。
django自带的form模板系统,还可以注册,修改,发布广告。想匿名注册,修改成default模板就可以了。 查看全部
抓取网页数据(/networkgoogleandroidboilerplatesaysomethingaboutnetworkingaboutnetwork你提的问题是什么?)
抓取网页数据,执行java编程语言,然后登录,调用sun的方法进行处理,然后进行competition,进行模拟投票。你提的问题,其实比较简单,问题描述不够具体,难以回答。
模拟登录到某网站,从哪个网站调用相应算法,
很多网站都能做到,只要获取用户行为数据...或者模拟登录,
知乎。选择最佳答案的动作:到“我的答案”里选中自己所答的那条,点“评论”。确定后,点“结果”。其它投票的动作:复制所有答案的链接,发送到邮箱,用网页浏览器访问邮箱的邮件中的链接。点击这条链接就能投票。投票结果会以邮件形式发送给你。
coindaily!
coinday.
talkischeap,showmethecode!
难道不是@邓晓芒?
百度知道,百度身份证及手机号。
匿名投票,虽然匿名,
github上的“联合搜索”
360邀请码,即回答有奖,应该可以。
whatsapp/
network
googleandroidboilerplatesaysomethingaboutnetwork你看看他们能否抓取到https的,
validity网站已经准备用djangowebframework实现,你可以试试。
django自带的form模板系统,还可以注册,修改,发布广告。想匿名注册,修改成default模板就可以了。
抓取网页数据( PHPNodejs获取网页内容绑定data事件,获取到的数据会分几次)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-13 13:12
PHPNodejs获取网页内容绑定data事件,获取到的数据会分几次)
node.js 抓取并分析网页内容的js文件为特殊内容
更新时间:2015年11月17日10:40:01 作者:普通儿子
Nodejs 获取绑定到数据事件的网页内容,获取的数据会分几次。如果要匹配全局内容,则需要等待请求结束,在end结束事件中操作累积的全局数据。本文介绍节点。js抓取并分析网页内容,针对有特殊内容的js文件,有需要的朋友可以参考
Nodejs获取绑定到data事件的web内容,获取到的数据会分多次。如果要匹配全局内容,需要等待请求结束,在end结束事件中对累积的全局数据进行操作!
比如想在页面上查找,就不多说了,直接放上代码:
//引入模块
var http = require("http"),
fs = require('fs'),
url = require('url');
//写入文件,把结果写入不同的文件
var writeRes = function(p, r) {
fs.appendFile(p , r, function(err) {
if(err)
console.log(err);
else
console.log(r);
});
},
//发请求,并验证内容,把结果写入文件
postHttp = function(arr, num) {
console.log('第'+num+"条!")
var a = arr[num].split(" - ");
if(!a[0] || !a[1]) {
return;
}
var address = url.parse(a[1]),
options = {
host : address.host,
path: address.path,
hostname : address.hostname,
method: 'GET',
headers: {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36'
}
}
var req = http.request(options, function(res) {
if (res.statusCode == 200) {
res.setEncoding('UTF-8');
var data = '';
res.on('data', function (rd) {
data += rd;
});
res.on('end', function(q) {
if(!~data.indexOf("www.baidu.com")) {
return writeRes('./no2.txt', a[0] + '--' + a[1] + '\n');
} else {
return writeRes('./has2.txt', a[0] + '--' + a[1] + "\n");
}
})
} else {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + res.statusCode + '\n');
}
});
req.on('error', function(e) {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + e + '\n');
})
req.end();
},
//读取文件,获取需要抓取的页面
openFile = function(path, coding) {
fs.readFile(path, coding, function(err, data) {
var res = data.split("\n");
for (var i = 0, rl = res.length; i < rl; i++) {
if(!res[i])
continue;
postHttp(res, i);
};
})
};
openFile('./sites.log', 'utf-8');
你可以理解上面的代码。如果您有任何问题,请给我留言。具体要看大家在实践中的应用。
下面给大家介绍一下Nodejs的网页抓取能力。
首先PHP。先说优点:网上大量爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓,各种关键词符号太多,不够简洁,给人一种没有精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。因为网络是异步的,所以基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入MySQL等数据库的带宽和I/O速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如你必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。然后,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。 查看全部
抓取网页数据(
PHPNodejs获取网页内容绑定data事件,获取到的数据会分几次)
node.js 抓取并分析网页内容的js文件为特殊内容
更新时间:2015年11月17日10:40:01 作者:普通儿子
Nodejs 获取绑定到数据事件的网页内容,获取的数据会分几次。如果要匹配全局内容,则需要等待请求结束,在end结束事件中操作累积的全局数据。本文介绍节点。js抓取并分析网页内容,针对有特殊内容的js文件,有需要的朋友可以参考
Nodejs获取绑定到data事件的web内容,获取到的数据会分多次。如果要匹配全局内容,需要等待请求结束,在end结束事件中对累积的全局数据进行操作!
比如想在页面上查找,就不多说了,直接放上代码:
//引入模块
var http = require("http"),
fs = require('fs'),
url = require('url');
//写入文件,把结果写入不同的文件
var writeRes = function(p, r) {
fs.appendFile(p , r, function(err) {
if(err)
console.log(err);
else
console.log(r);
});
},
//发请求,并验证内容,把结果写入文件
postHttp = function(arr, num) {
console.log('第'+num+"条!")
var a = arr[num].split(" - ");
if(!a[0] || !a[1]) {
return;
}
var address = url.parse(a[1]),
options = {
host : address.host,
path: address.path,
hostname : address.hostname,
method: 'GET',
headers: {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36'
}
}
var req = http.request(options, function(res) {
if (res.statusCode == 200) {
res.setEncoding('UTF-8');
var data = '';
res.on('data', function (rd) {
data += rd;
});
res.on('end', function(q) {
if(!~data.indexOf("www.baidu.com")) {
return writeRes('./no2.txt', a[0] + '--' + a[1] + '\n');
} else {
return writeRes('./has2.txt', a[0] + '--' + a[1] + "\n");
}
})
} else {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + res.statusCode + '\n');
}
});
req.on('error', function(e) {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + e + '\n');
})
req.end();
},
//读取文件,获取需要抓取的页面
openFile = function(path, coding) {
fs.readFile(path, coding, function(err, data) {
var res = data.split("\n");
for (var i = 0, rl = res.length; i < rl; i++) {
if(!res[i])
continue;
postHttp(res, i);
};
})
};
openFile('./sites.log', 'utf-8');
你可以理解上面的代码。如果您有任何问题,请给我留言。具体要看大家在实践中的应用。
下面给大家介绍一下Nodejs的网页抓取能力。
首先PHP。先说优点:网上大量爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓,各种关键词符号太多,不够简洁,给人一种没有精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。因为网络是异步的,所以基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入MySQL等数据库的带宽和I/O速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如你必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。然后,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
抓取网页数据(分布式爬虫技术的判断规则自己用的方法和判断方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-13 10:05
抓取网页数据然后进行网络爬虫工作。比如从某宝查询某个商品的真伪,搜索一些问题等等。然后针对自己需要的来进行个性化定制抓取工作,比如人工翻译中文,搜索某个电影的评分等等。分布式爬虫好像是一个不错的选择。
一般是先找到一个全网的高质量网站进行爬取,然后反爬虫啊!大部分的网站都有爬虫,但是权限要求,爬虫用自己的号爬下来。如果你们公司打算做网站爬虫的话,可以让网站爬虫提供平台,自己作为服务端去爬取。也可以找厂商,比如aws。然后你们的业务系统让爬虫去抓取,重复上述步骤,数据量越大,这些所有流程你们可以设计成实时下载的架构。这是效率问题,单台可能达不到要求。
反爬虫技术。ip爬虫。自己写几套判断规则自己用。
首先,你要有一个足够大的数据库。因为网站里很多重复的信息,所以你得可以快速查找,解决重复信息。然后,爬虫不仅仅只是百度一个巨无霸一揽子的东西。根据你的业务,要把外部数据抓过来,再在数据库里对应地找到,进行数据分析,这是最根本的东西。然后才是自己做爬虫技术改进。这里基本就是一个大数据清洗、统计的问题了。
还有就是如何在这个大的数据库里挖掘用户的偏好信息,培养出来一个用户画像。不过和爬虫技术关系不大。当然我说的只是目前很多可以公司化作业的大型爬虫行业。 查看全部
抓取网页数据(分布式爬虫技术的判断规则自己用的方法和判断方法)
抓取网页数据然后进行网络爬虫工作。比如从某宝查询某个商品的真伪,搜索一些问题等等。然后针对自己需要的来进行个性化定制抓取工作,比如人工翻译中文,搜索某个电影的评分等等。分布式爬虫好像是一个不错的选择。
一般是先找到一个全网的高质量网站进行爬取,然后反爬虫啊!大部分的网站都有爬虫,但是权限要求,爬虫用自己的号爬下来。如果你们公司打算做网站爬虫的话,可以让网站爬虫提供平台,自己作为服务端去爬取。也可以找厂商,比如aws。然后你们的业务系统让爬虫去抓取,重复上述步骤,数据量越大,这些所有流程你们可以设计成实时下载的架构。这是效率问题,单台可能达不到要求。
反爬虫技术。ip爬虫。自己写几套判断规则自己用。
首先,你要有一个足够大的数据库。因为网站里很多重复的信息,所以你得可以快速查找,解决重复信息。然后,爬虫不仅仅只是百度一个巨无霸一揽子的东西。根据你的业务,要把外部数据抓过来,再在数据库里对应地找到,进行数据分析,这是最根本的东西。然后才是自己做爬虫技术改进。这里基本就是一个大数据清洗、统计的问题了。
还有就是如何在这个大的数据库里挖掘用户的偏好信息,培养出来一个用户画像。不过和爬虫技术关系不大。当然我说的只是目前很多可以公司化作业的大型爬虫行业。
抓取网页数据(科鼎网页抓包工具(网站抓取工具)绿色软件工具是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-13 01:03
客鼎网页抓取工具(网站capture tool)绿色软件工具是一款(yi)实用的IE网页数据分析工具。软件功能强大,可轻松查看科鼎网页抓取工具(网站抓取工具)绿色软件的实际网页,方便网页开发者和测试者分析网页数据,获取网页相关信息。 ,是一款功能强大的科鼎网页抓取工具绿色软件(网站抓取工具)。赶快下载体验吧!
科鼎网页抓取工具绿色软件介绍(网站抓取工具)
1. 集成在 Internet Explorer 工具栏中,包括网页摘要、Cookies 管理、缓存管理、消息头发送/接收、字符查询、POST 数据和目录管理等功能,网页可定网页包抓取工具( 网站抓取工具) 绿色软件工具是需要频繁分析网页发送的数据包的Web开发人员/测试人员。作为一款强大的IE插件,短小精悍,可以很好的完成URL请求。分析。主要功能是监控和分析通过浏览器发送的http请求。当您在浏览器的地址栏上请求一个URL或者提交一个表单时,它会帮助您分析http请求的头部信息和访问页面的cookie。 Get和Post的信息,详细的数据包分析。
客鼎网页抓取工具(网站抓取工具)绿色软件总结
客鼎网页抓取工具(网站抓取工具)V4.90是一款适用于安卓版的网络辅助手机软件。如果您喜欢这个软件,请下载链接分享给您的朋友: 查看全部
抓取网页数据(科鼎网页抓包工具(网站抓取工具)绿色软件工具是什么)
客鼎网页抓取工具(网站capture tool)绿色软件工具是一款(yi)实用的IE网页数据分析工具。软件功能强大,可轻松查看科鼎网页抓取工具(网站抓取工具)绿色软件的实际网页,方便网页开发者和测试者分析网页数据,获取网页相关信息。 ,是一款功能强大的科鼎网页抓取工具绿色软件(网站抓取工具)。赶快下载体验吧!
科鼎网页抓取工具绿色软件介绍(网站抓取工具)
1. 集成在 Internet Explorer 工具栏中,包括网页摘要、Cookies 管理、缓存管理、消息头发送/接收、字符查询、POST 数据和目录管理等功能,网页可定网页包抓取工具( 网站抓取工具) 绿色软件工具是需要频繁分析网页发送的数据包的Web开发人员/测试人员。作为一款强大的IE插件,短小精悍,可以很好的完成URL请求。分析。主要功能是监控和分析通过浏览器发送的http请求。当您在浏览器的地址栏上请求一个URL或者提交一个表单时,它会帮助您分析http请求的头部信息和访问页面的cookie。 Get和Post的信息,详细的数据包分析。
客鼎网页抓取工具(网站抓取工具)绿色软件总结
客鼎网页抓取工具(网站抓取工具)V4.90是一款适用于安卓版的网络辅助手机软件。如果您喜欢这个软件,请下载链接分享给您的朋友:

