
抓取动态网页
抓取动态网页(接下来如何模拟在浏览器页面中滑动鼠标获得多屏搜索结果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-02-07 08:13
让我们现在开始谈正事。第一步是在docker中连接Selenium服务器:
1library(RSelenium) # 激活包remDr "localhost" , port = 4445L , browserName = "chrome") # 设置连接参数remDr$open() # 开始连接
2
第二步,打开百度搜索首页,输入搜索关键词,点击搜索:
1remDr$navigate("https://www.baidu.com") # 打开remDr$screenshot(display = TRUE) # 截屏看一下首页xpath '//*[@id="kw"]' # 根据上面定位在界面中找到文字输入框webElem "xpath", value = xpath) # 在搜索框里输入搜索关键词‘R Cran’,然后点击回车键webElem$sendKeysToElement(list("R Cran", key = "enter")) # # 再次截屏显示搜索结果remDr$screenshot(display = TRUE)
2
这是我的两张截图的结果:
我们知道百度默认一屏显示10个搜索结果。在接下来的第三步中,我们将第一屏的 10 个结果删减:
1# 调用静态网页抓取常用包rvestlibrary(rvest)# 获取网页背后的html源代码webpage # 利用节点ID挑出10项搜索结果的内容标题result_html # 下面两行利用xpath挑出10项搜索结果的内容标题# xpath # result_html # 挑出html代码中10个标题内容result_name head(result_name,10)# 找出10个标题对应的超级链接result_link # 存成数据框result_df = data.frame(result_name=result_name, result_link=result_link)
2
10个搜索结果出来了,如果我们想模拟一个浏览器点击一个搜索结果怎么办?例如,第一个结果“综合 R 档案网络”。让我们开始吧:
1# 直接在搜索结果界面中定位10项搜索结果标题webElems 'css selector', # 把结果标题变成文本单独拎出来resHeaders function(x){x$getElementText()}))resHeaders# 准备点击第一个搜索结果webElem "The Comprehensive R Archive Network")]]# 模拟浏览器点击第一个结果超级链接,并在新窗口中打开webElem$clickElement()webElem$sendKeysToElement(list(key = "control", "w"))# 此时浏览器有两个窗口,下面几行进行窗口切换(窗口ID会动态变化)remDr$getWindowHandles()remDr$getCurrentWindowHandle()remDr$switchToWindow("CDwindow-2BA4D55F9BABCA20D3DFE2FECBA3D85A")remDr$getCurrentWindowHandle()# 获取新窗口的网址和标题,并截屏remDr$getCurrentUrl()remDr$getTitle()remDr$screenshot(display = TRUE)
2
第一个链接打开后的截图结果如下:
以上是使用RSelenium动态爬取百度搜索结果。接下来,我想展示如何在浏览器页面中模拟滑动鼠标,以获得多屏显示的所有内容。毕竟滑动鼠标后才能看到所有的网页内容,然后再抓取内容。这里以河北省的一家三级医院为例。
第一步是打开链接:
1remDr$navigate("https://m.yyk.99.com.cn/sanjia/hebei/")remDr$screenshot(display = TRUE)
2
如果不出意外,这次我们能够从 20 家医院获取信息。
1# 获取网页背后的html源代码webpage $getPageSource()[[# 找出医院名字对应的节点名称hospital_name_html 'h2')# 将医院名字从html转换为文本hospital_name # 调用stringr包把医院名字前的空格等多余符号去掉library(stringr)hospital_name "\r\n",# 看看前10家医院的名字head(hospital_name,10)# 看看总共有多少家医院length(hospital_name) # 结果为20
2
其实,在鼠标滑动几次之后,我们发现这个页面一共收录了75家医院的信息。第一次抓取只能拿到前20个,因为医院信息需要先滑动鼠标。
接下来,我们在R中运行Java代码,实现鼠标在当前网页上滑动的效果。此外,我们不想一次又一次地滑动,而是一次滑动到页面底部。
1# window.scrollTo是Java的函数,括号里跟着x和y的屏幕位置数字。比如第一个0表示屏幕最左端;# document.body.scrollHeight表示屏幕上鼠标一次滑动的最大高度,即当面页面的最底部。# 那么,下面的代码显示我们要重复地滑到页面的最底端,每次滑动中间停顿3秒,好让网页内容得以显示。# 最后,滑到不能再滑动的时候,我们就停住了。比如,第一个0表示屏幕最左端,last_height = 0 #repeat { remDr$executeScript("window.scrollTo(0,document.body.scrollHeight);") Sys.sleep(3) #delay by 3sec to give chance to load. # Updated if statement which breaks if we can't scroll further new_height = remDr$executeScript("return document.body.scrollHeight") if(unlist(last_height) == unlist(new_height)) { break } else { last_height = new_height }}
2
这样显示完这个网页的所有内容后,我们就可以按照静态网页爬取75家医院的所有数据了:
1webpage $getPageSource()[[hospital_name_html 'h2')hospital_name library(stringr)hospital_name "\r\n",head(hospital_name,10)length(hospital_name) # 结果为75
2
到目前为止,我们已经解决了动态网页抓取的两个主要问题:一是抓取搜索引擎生成的搜索结果界面的相关内容;另一种是爬取多屏显示的动态网页的相关内容。当然,这两个问题几乎没有涵盖许多其他动态网页抓取的案例。比如后者还包括点击动态网页中的方向箭头(显示其他隐藏的内容)、从同一个网页的不同栏目(框架界面)抓取不同的内容等等。
在我的探索过程中,我也发现虽然可以爬取百度搜索结果,但谷歌结果却很难实现。一位知情人士告诉我,虽然你电脑上的浏览器可以用VPN打开google,但Selenium没有VPN可以打开google,这是真的。所以,我找到了很多关于如何通过谷歌搜索使用RSelenium抓取谷歌搜索结果的方法,我想复制它,但发现同样的方法对我不起作用。
就是这样。 查看全部
抓取动态网页(接下来如何模拟在浏览器页面中滑动鼠标获得多屏搜索结果)
让我们现在开始谈正事。第一步是在docker中连接Selenium服务器:
1library(RSelenium) # 激活包remDr "localhost" , port = 4445L , browserName = "chrome") # 设置连接参数remDr$open() # 开始连接
2
第二步,打开百度搜索首页,输入搜索关键词,点击搜索:
1remDr$navigate("https://www.baidu.com";) # 打开remDr$screenshot(display = TRUE) # 截屏看一下首页xpath '//*[@id="kw"]' # 根据上面定位在界面中找到文字输入框webElem "xpath", value = xpath) # 在搜索框里输入搜索关键词‘R Cran’,然后点击回车键webElem$sendKeysToElement(list("R Cran", key = "enter")) # # 再次截屏显示搜索结果remDr$screenshot(display = TRUE)
2
这是我的两张截图的结果:


我们知道百度默认一屏显示10个搜索结果。在接下来的第三步中,我们将第一屏的 10 个结果删减:
1# 调用静态网页抓取常用包rvestlibrary(rvest)# 获取网页背后的html源代码webpage # 利用节点ID挑出10项搜索结果的内容标题result_html # 下面两行利用xpath挑出10项搜索结果的内容标题# xpath # result_html # 挑出html代码中10个标题内容result_name head(result_name,10)# 找出10个标题对应的超级链接result_link # 存成数据框result_df = data.frame(result_name=result_name, result_link=result_link)
2
10个搜索结果出来了,如果我们想模拟一个浏览器点击一个搜索结果怎么办?例如,第一个结果“综合 R 档案网络”。让我们开始吧:
1# 直接在搜索结果界面中定位10项搜索结果标题webElems 'css selector', # 把结果标题变成文本单独拎出来resHeaders function(x){x$getElementText()}))resHeaders# 准备点击第一个搜索结果webElem "The Comprehensive R Archive Network")]]# 模拟浏览器点击第一个结果超级链接,并在新窗口中打开webElem$clickElement()webElem$sendKeysToElement(list(key = "control", "w"))# 此时浏览器有两个窗口,下面几行进行窗口切换(窗口ID会动态变化)remDr$getWindowHandles()remDr$getCurrentWindowHandle()remDr$switchToWindow("CDwindow-2BA4D55F9BABCA20D3DFE2FECBA3D85A")remDr$getCurrentWindowHandle()# 获取新窗口的网址和标题,并截屏remDr$getCurrentUrl()remDr$getTitle()remDr$screenshot(display = TRUE)
2
第一个链接打开后的截图结果如下:
以上是使用RSelenium动态爬取百度搜索结果。接下来,我想展示如何在浏览器页面中模拟滑动鼠标,以获得多屏显示的所有内容。毕竟滑动鼠标后才能看到所有的网页内容,然后再抓取内容。这里以河北省的一家三级医院为例。
第一步是打开链接:
1remDr$navigate("https://m.yyk.99.com.cn/sanjia/hebei/";)remDr$screenshot(display = TRUE)
2

如果不出意外,这次我们能够从 20 家医院获取信息。
1# 获取网页背后的html源代码webpage $getPageSource()[[# 找出医院名字对应的节点名称hospital_name_html 'h2')# 将医院名字从html转换为文本hospital_name # 调用stringr包把医院名字前的空格等多余符号去掉library(stringr)hospital_name "\r\n",# 看看前10家医院的名字head(hospital_name,10)# 看看总共有多少家医院length(hospital_name) # 结果为20
2
其实,在鼠标滑动几次之后,我们发现这个页面一共收录了75家医院的信息。第一次抓取只能拿到前20个,因为医院信息需要先滑动鼠标。
接下来,我们在R中运行Java代码,实现鼠标在当前网页上滑动的效果。此外,我们不想一次又一次地滑动,而是一次滑动到页面底部。
1# window.scrollTo是Java的函数,括号里跟着x和y的屏幕位置数字。比如第一个0表示屏幕最左端;# document.body.scrollHeight表示屏幕上鼠标一次滑动的最大高度,即当面页面的最底部。# 那么,下面的代码显示我们要重复地滑到页面的最底端,每次滑动中间停顿3秒,好让网页内容得以显示。# 最后,滑到不能再滑动的时候,我们就停住了。比如,第一个0表示屏幕最左端,last_height = 0 #repeat { remDr$executeScript("window.scrollTo(0,document.body.scrollHeight);") Sys.sleep(3) #delay by 3sec to give chance to load. # Updated if statement which breaks if we can't scroll further new_height = remDr$executeScript("return document.body.scrollHeight") if(unlist(last_height) == unlist(new_height)) { break } else { last_height = new_height }}
2
这样显示完这个网页的所有内容后,我们就可以按照静态网页爬取75家医院的所有数据了:
1webpage $getPageSource()[[hospital_name_html 'h2')hospital_name library(stringr)hospital_name "\r\n",head(hospital_name,10)length(hospital_name) # 结果为75
2
到目前为止,我们已经解决了动态网页抓取的两个主要问题:一是抓取搜索引擎生成的搜索结果界面的相关内容;另一种是爬取多屏显示的动态网页的相关内容。当然,这两个问题几乎没有涵盖许多其他动态网页抓取的案例。比如后者还包括点击动态网页中的方向箭头(显示其他隐藏的内容)、从同一个网页的不同栏目(框架界面)抓取不同的内容等等。
在我的探索过程中,我也发现虽然可以爬取百度搜索结果,但谷歌结果却很难实现。一位知情人士告诉我,虽然你电脑上的浏览器可以用VPN打开google,但Selenium没有VPN可以打开google,这是真的。所以,我找到了很多关于如何通过谷歌搜索使用RSelenium抓取谷歌搜索结果的方法,我想复制它,但发现同样的方法对我不起作用。
就是这样。
抓取动态网页(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-07 00:08
我想抓取一个网页:
我需要所有商店名称、电话号码及其地址的数据
但我最多只能做10个
导致加载需要滚动页面的其他项目
我的代码:
import requests
import bs4
crawl_url = requests.get('https://www.justdial.com/Mumbai/Dairy-Product-
Retailers-in-Thane/nct-10152687', headers={'User-Agent': 'Mozilla/5.0'})
crawl_url.raise_for_status()
soup = bs4.BeautifulSoup(crawl_url.text, 'lxml')
for elems in soup.find_all('span', class_="jcn"):
select_a = elems.select('a')
for links in select_a:
href = links.get('href')
res = requests.get(href, headers={'User-Agent': 'Mozilla/5.0'})
xsoup = bs4.BeautifulSoup(res.text, 'lxml')
Name = xsoup.select('.fn')
tel = xsoup.select('.tel')
add = xsoup.select('.adrstxtr')
a = Name[0]
b = tel[0]
c = add[0]
print(a.getText())
print("--"*10)
print(b.getText())
print("--"*10)
print(c.getText())
print("=="*25)
当我们向下滚动页面时会加载其他项目
所以我想知道如何获得尽可能多的数据/项目
我试过
但是没有悄悄理解好,我也没有得到那个POST方法:/
如果您需要更多信息,请与我们联系
最佳答案
tmadam 给出的解决方案有效
这是代码
import requests
import bs4
def spider(max_pages):
page = 1
while page < max_pages:
url = "https://www.justdial.com/Mumba ... s-in-
Thane/nct-10152687/page-%s" % page
crawl_url = requests.get(url, headers={'User-Agent': 'Mozilla/5.0'})
crawl_url.raise_for_status()
soup = bs4.BeautifulSoup(crawl_url.text, 'lxml')
for elems in soup.find_all('span', class_="jcn"):
select_a = elems.select('a')
for links in select_a:
href = links.get('href')
res = requests.get(href, headers={'User-Agent':
'Mozilla/5.0'})
xsoup = bs4.BeautifulSoup(res.text, 'lxml')
Name = xsoup.select('.fn')
tel = xsoup.select('.tel')
add = xsoup.select('.adrstxtr')
a = Name[0]
b = tel[0]
c = add[0]
print(a.getText())
print("--"*10)
print(b.getText())
print("--"*10)
print(c.getText())
print("=="*25)
page += 1
spider(3)
关于 python - Beautifulsoup - 抓取网页 - 动态加载页面,我们在 Stack Overflow 上发现了一个类似的问题: 查看全部
抓取动态网页(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
我想抓取一个网页:
我需要所有商店名称、电话号码及其地址的数据
但我最多只能做10个
导致加载需要滚动页面的其他项目
我的代码:
import requests
import bs4
crawl_url = requests.get('https://www.justdial.com/Mumbai/Dairy-Product-
Retailers-in-Thane/nct-10152687', headers={'User-Agent': 'Mozilla/5.0'})
crawl_url.raise_for_status()
soup = bs4.BeautifulSoup(crawl_url.text, 'lxml')
for elems in soup.find_all('span', class_="jcn"):
select_a = elems.select('a')
for links in select_a:
href = links.get('href')
res = requests.get(href, headers={'User-Agent': 'Mozilla/5.0'})
xsoup = bs4.BeautifulSoup(res.text, 'lxml')
Name = xsoup.select('.fn')
tel = xsoup.select('.tel')
add = xsoup.select('.adrstxtr')
a = Name[0]
b = tel[0]
c = add[0]
print(a.getText())
print("--"*10)
print(b.getText())
print("--"*10)
print(c.getText())
print("=="*25)
当我们向下滚动页面时会加载其他项目
所以我想知道如何获得尽可能多的数据/项目
我试过
但是没有悄悄理解好,我也没有得到那个POST方法:/
如果您需要更多信息,请与我们联系
最佳答案
tmadam 给出的解决方案有效
这是代码
import requests
import bs4
def spider(max_pages):
page = 1
while page < max_pages:
url = "https://www.justdial.com/Mumba ... s-in-
Thane/nct-10152687/page-%s" % page
crawl_url = requests.get(url, headers={'User-Agent': 'Mozilla/5.0'})
crawl_url.raise_for_status()
soup = bs4.BeautifulSoup(crawl_url.text, 'lxml')
for elems in soup.find_all('span', class_="jcn"):
select_a = elems.select('a')
for links in select_a:
href = links.get('href')
res = requests.get(href, headers={'User-Agent':
'Mozilla/5.0'})
xsoup = bs4.BeautifulSoup(res.text, 'lxml')
Name = xsoup.select('.fn')
tel = xsoup.select('.tel')
add = xsoup.select('.adrstxtr')
a = Name[0]
b = tel[0]
c = add[0]
print(a.getText())
print("--"*10)
print(b.getText())
print("--"*10)
print(c.getText())
print("=="*25)
page += 1
spider(3)
关于 python - Beautifulsoup - 抓取网页 - 动态加载页面,我们在 Stack Overflow 上发现了一个类似的问题:
抓取动态网页(您可能感兴趣的列队申请是:+Season+J(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-06 16:18
)
在此示例中,Javascript 仅允许在网页上发送、接收和显示内容,而无需为每个请求实际重新加载网页。所以不需要解析javascript,只需要找到请求的信息,模拟那个请求,解析响应即可。为此,您可以在 Firefox 中使用 Firebug,或在 Chrome 中使用开发人员工具(在 Windows 中使用 ctrl+shift+J,在 Mac 中使用 cmd+opt+J)。在 Chrome 中,只需单击“网络”选项卡,当您单击 网站 时,您将看到请求和响应。
在这个特定的示例中,当您想要获取克利夫兰团队“2008-09”的统计数据时,javascript 会发出多个请求。您可能感兴趣的队列应用是:+Season&Season=2008-09&PaceAdjust=N&DateFrom=&sortOrder=DES&VsConference=&OpponentTeamID=0&DateTo=&GameSegment=&LastNGames=0&VsDivision=&LeagueID=00&Outcome=&GameScope=&MeasureType=Base&PerMode=Per48&sortPeriod=0N&SeasonSegment=& =0&rowsPerPage=100
下面是一个小蜘蛛的例子。你只需要定义 LineupItem 然后你就可以用 scrapy crawl stats -o output.json 来执行它。
import json
from scrapy.spider import Spider
from scrapy.http import Request
from nba.items import LineupItem
from urllib import urlencode
class StatsSpider(Spider):
name = "stats"
allowed_domains = ["stats.nba.com"]
start_urls = (
'http://stats.nba.com/',
)
def parse(self, response):
return self.get_lineup('1610612739','2008-09')
def get_lineup(self, team_id, season):
params = {
'Season': season,
'SeasonType': 'Regular Season',
'LeagueID': '00',
'TeamID': team_id,
'MeasureType': 'Base',
'PerMode': 'Per48',
'PlusMinus': 'N',
'PaceAdjust': 'N',
'Rank': 'N',
'Outcome': '',
'Location': '',
'Month': '0',
'SeasonSegment': '',
'DateFrom': '',
'DateTo': '',
'OpponentTeamID': '0',
'VsConference': '',
'VsDivision': '',
'GameSegment': '',
'Period': '0',
'LastNGames': '0',
'GroupQuantity': '5',
'GameScope': '',
'GameID': '',
'pageNo': '1',
'rowsPerPage': '100',
'sortField': 'MIN',
'sortOrder': 'DES'
}
return Request(
url="http://stats.nba.com/stats/teamdashlineups?" + urlencode(params),
dont_filter=True,
callback=self.parse_lineup
)
def parse_lineup(self,response):
data = json.loads(response.body)
for lineup in data['resultSets'][1]['rowSet']:
item = LineupItem()
item['group_set'] = lineup[0]
item['group_id'] = lineup[1]
item['group_name'] = lineup[2]
item['gp'] = lineup[3]
item['w'] = lineup[4]
item['l'] = lineup[5]
item['w_pct'] = lineup[6]
item['min'] = lineup[7]
item['fgm'] = lineup[8]
item['fga'] = lineup[9]
item['fg_pct'] = lineup[10]
item['fg3m'] = lineup[11]
item['fg3a'] = lineup[12]
item['fg3_pct'] = lineup[13]
item['ftm'] = lineup[14]
item['fta'] = lineup[15]
item['ft_pct'] = lineup[16]
item['oreb'] = lineup[17]
item['dreb'] = lineup[18]
item['reb'] = lineup[19]
item['ast'] = lineup[20]
item['tov'] = lineup[21]
item['stl'] = lineup[22]
item['blk'] = lineup[23]
item['blka'] = lineup[24]
item['pf'] = lineup[25]
item['pfd'] = lineup[26]
item['pts'] = lineup[27]
item['plus_minus'] = lineup[28]
yield item
这将产生一个json记录,例如:
{"gp": 30, "fg_pct": 0.491, "group_name": "Ilgauskas,Zydrunas - James,LeBron - Wallace,Ben - West,Delonte - Williams,Mo", "group_set": "Lineups", "w_pct": 0.833, "pts": 103.0, "min": 484.9866666666667, "tov": 13.3, "fta": 21.6, "pf": 16.0, "blk": 7.7, "reb": 44.2, "blka": 3.0, "ftm": 16.6, "ft_pct": 0.771, "fg3a": 18.7, "pfd": 17.2, "ast": 23.3, "fg3m": 7.4, "fgm": 39.5, "fg3_pct": 0.397, "dreb": 32.0, "fga": 80.4, "plus_minus": 18.4, "stl": 8.3, "l": 5, "oreb": 12.3, "w": 25, "group_id": "980 - 2544 - 1112 - 2753 - 2590"} 查看全部
抓取动态网页(您可能感兴趣的列队申请是:+Season+J(图)
)
在此示例中,Javascript 仅允许在网页上发送、接收和显示内容,而无需为每个请求实际重新加载网页。所以不需要解析javascript,只需要找到请求的信息,模拟那个请求,解析响应即可。为此,您可以在 Firefox 中使用 Firebug,或在 Chrome 中使用开发人员工具(在 Windows 中使用 ctrl+shift+J,在 Mac 中使用 cmd+opt+J)。在 Chrome 中,只需单击“网络”选项卡,当您单击 网站 时,您将看到请求和响应。
在这个特定的示例中,当您想要获取克利夫兰团队“2008-09”的统计数据时,javascript 会发出多个请求。您可能感兴趣的队列应用是:+Season&Season=2008-09&PaceAdjust=N&DateFrom=&sortOrder=DES&VsConference=&OpponentTeamID=0&DateTo=&GameSegment=&LastNGames=0&VsDivision=&LeagueID=00&Outcome=&GameScope=&MeasureType=Base&PerMode=Per48&sortPeriod=0N&SeasonSegment=& =0&rowsPerPage=100
下面是一个小蜘蛛的例子。你只需要定义 LineupItem 然后你就可以用 scrapy crawl stats -o output.json 来执行它。
import json
from scrapy.spider import Spider
from scrapy.http import Request
from nba.items import LineupItem
from urllib import urlencode
class StatsSpider(Spider):
name = "stats"
allowed_domains = ["stats.nba.com"]
start_urls = (
'http://stats.nba.com/',
)
def parse(self, response):
return self.get_lineup('1610612739','2008-09')
def get_lineup(self, team_id, season):
params = {
'Season': season,
'SeasonType': 'Regular Season',
'LeagueID': '00',
'TeamID': team_id,
'MeasureType': 'Base',
'PerMode': 'Per48',
'PlusMinus': 'N',
'PaceAdjust': 'N',
'Rank': 'N',
'Outcome': '',
'Location': '',
'Month': '0',
'SeasonSegment': '',
'DateFrom': '',
'DateTo': '',
'OpponentTeamID': '0',
'VsConference': '',
'VsDivision': '',
'GameSegment': '',
'Period': '0',
'LastNGames': '0',
'GroupQuantity': '5',
'GameScope': '',
'GameID': '',
'pageNo': '1',
'rowsPerPage': '100',
'sortField': 'MIN',
'sortOrder': 'DES'
}
return Request(
url="http://stats.nba.com/stats/teamdashlineups?" + urlencode(params),
dont_filter=True,
callback=self.parse_lineup
)
def parse_lineup(self,response):
data = json.loads(response.body)
for lineup in data['resultSets'][1]['rowSet']:
item = LineupItem()
item['group_set'] = lineup[0]
item['group_id'] = lineup[1]
item['group_name'] = lineup[2]
item['gp'] = lineup[3]
item['w'] = lineup[4]
item['l'] = lineup[5]
item['w_pct'] = lineup[6]
item['min'] = lineup[7]
item['fgm'] = lineup[8]
item['fga'] = lineup[9]
item['fg_pct'] = lineup[10]
item['fg3m'] = lineup[11]
item['fg3a'] = lineup[12]
item['fg3_pct'] = lineup[13]
item['ftm'] = lineup[14]
item['fta'] = lineup[15]
item['ft_pct'] = lineup[16]
item['oreb'] = lineup[17]
item['dreb'] = lineup[18]
item['reb'] = lineup[19]
item['ast'] = lineup[20]
item['tov'] = lineup[21]
item['stl'] = lineup[22]
item['blk'] = lineup[23]
item['blka'] = lineup[24]
item['pf'] = lineup[25]
item['pfd'] = lineup[26]
item['pts'] = lineup[27]
item['plus_minus'] = lineup[28]
yield item
这将产生一个json记录,例如:
{"gp": 30, "fg_pct": 0.491, "group_name": "Ilgauskas,Zydrunas - James,LeBron - Wallace,Ben - West,Delonte - Williams,Mo", "group_set": "Lineups", "w_pct": 0.833, "pts": 103.0, "min": 484.9866666666667, "tov": 13.3, "fta": 21.6, "pf": 16.0, "blk": 7.7, "reb": 44.2, "blka": 3.0, "ftm": 16.6, "ft_pct": 0.771, "fg3a": 18.7, "pfd": 17.2, "ast": 23.3, "fg3m": 7.4, "fgm": 39.5, "fg3_pct": 0.397, "dreb": 32.0, "fga": 80.4, "plus_minus": 18.4, "stl": 8.3, "l": 5, "oreb": 12.3, "w": 25, "group_id": "980 - 2544 - 1112 - 2753 - 2590"}
抓取动态网页(本文实例讲述Python3实现抓取javascript动态生成的html网页功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-03 05:03
本文的例子描述了Python3爬取javascript动态生成的HTML页面的功能。分享给大家,供大家参考,如下:
用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
这里介绍一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
打开火狐浏览器
在给定的url地址加载页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
【示例一】
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
希望这篇文章对你的 Python 编程有所帮助。 查看全部
抓取动态网页(本文实例讲述Python3实现抓取javascript动态生成的html网页功能)
本文的例子描述了Python3爬取javascript动态生成的HTML页面的功能。分享给大家,供大家参考,如下:
用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
这里介绍一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
打开火狐浏览器
在给定的url地址加载页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
【示例一】
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
希望这篇文章对你的 Python 编程有所帮助。
抓取动态网页(前文Ajax理论AjaxAjaxAjaxAjax)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-01 17:06
上面的爬虫都是基于静态网页的。首先通过请求网站url获取网页源代码。之后,可以提取和存储源代码。本文对动态网页采集进行数据处理。首先介绍了Ajax的理论,然后实际爬取flushflush的动态网页,获取个股的相关信息。
一、Ajax 理论
1.Ajax介绍
Ajax 的全称是“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式、快速和动态的 Web 应用程序的 Web 开发技术,可以在不重新加载整个网页的情况下更新某些网页。Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
2.Ajax 分析
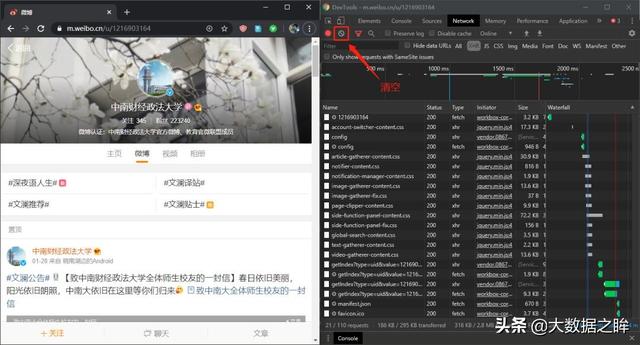
微博网站是一个比较容易识别的Ajax动态网页。首先打开Dectools工具(转到XHR专栏)和中南财经政法大学官方微博网站(),这里选择。是手机微博,然后选择清除所有内容。
接下来,滚动滚轮以下拉页面,直到一个新项目出现在空的 XHR 列中。点击项目,选择预览栏,发现这里对应的内容就是页面上的新微博。但它没有改变。至此,我们可以确定这是一个Ajax请求后的网页。
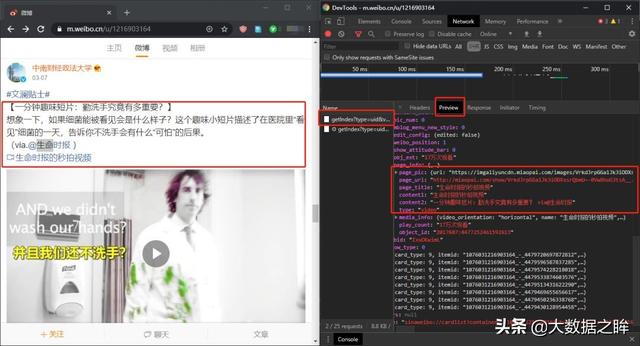
3.Ajax 提取
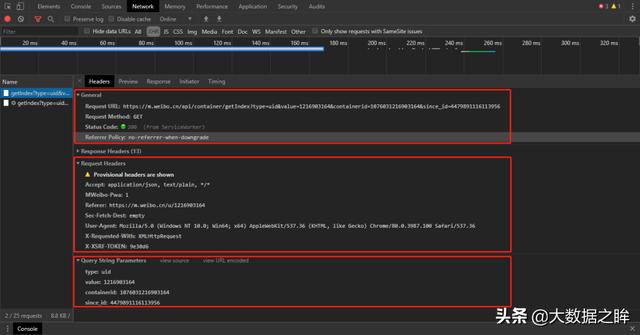
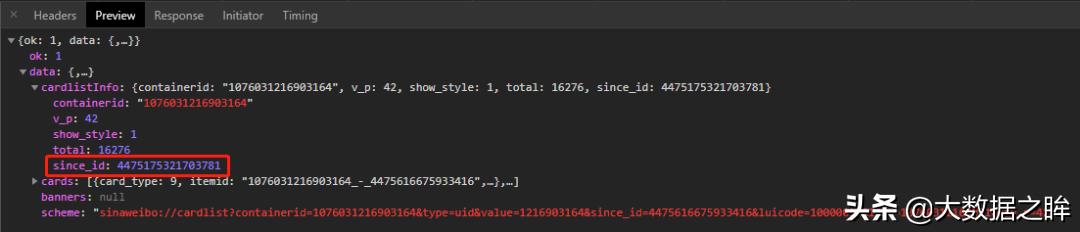
或者选择同一个条目进入Headers进一步查看信息,可以发现这是一个GET类型的请求,请求的url为:,即请求有四个参数:type、value、containerid、since_id和然后翻页发现除了since_id的变化之外,其余保持不变,这里我们可以看到since_id就是翻页方法。
接下来进一步观察since_id,发现上下请求的since_id之间没有明显的规律。进一步搜索发现,下一页的since_id在上一页的响应中的cardListInfo中,因此可以建立循环连接,进一步将动态url循环添加到爬虫中。
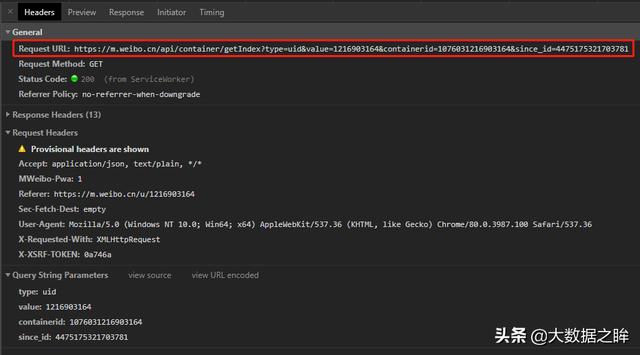
发起请求并得到响应后,可以进一步分析出响应格式是json,所以可以通过对json的进一步处理得到最终的数据!
二、网页分析
1.网站概览
经过以上分析,我们将用flush网页的数据来采集实战进行例子验证。首先打开网页:,如下图:
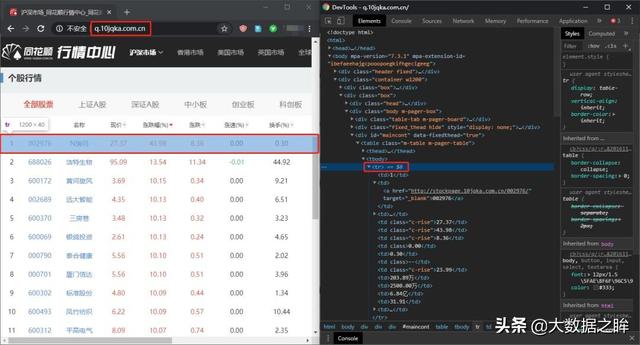
再按F12键打开Devtools后台源码,右键第一项查看源码位置。
2.阿贾克斯歧视
接下来,通过点击网页底部的下一页,我们发现网页的url并没有改变!至此,基本可以确定该网页属于Ajax动态网页。
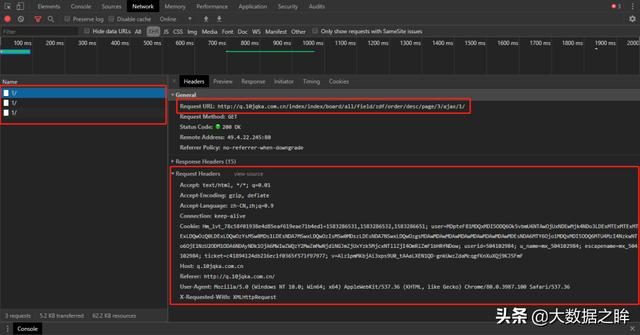
进一步,我们清空Network中的所有内容,继续点击下一页到第五页,发现连续弹出三个同名的内容,就可以得到请求的url和请求头的具体内容通过一般栏。
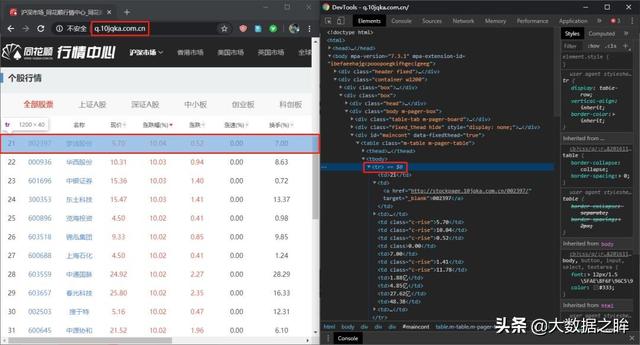
所以我们复制这个请求url,在浏览器中打开,响应内容确实是标准化的表格数据,正是我们想要的。
3.Ajax 提取
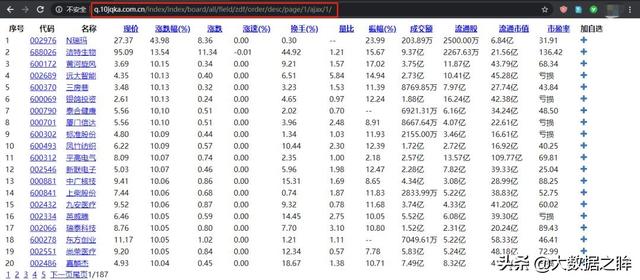
然后我们也打开源码,发现是一个html文档,说明响应内容是网页的形式,和上面微博响应的json格式不同,所以数据可以在稍后解析网页的形式。
三、爬行者战斗
1.网页访问
在第一部分的理论介绍和第二部分的网页分析之后,我们就可以开始编写爬虫代码了。首先,导入库并定义请求头。需要注意的是,这里的请求头除了User-Agent外,还需要host、Referer和X-Requested-With参数,这要和静态网页爬取区别开来。
# 导入库import timeimport jsonimport randomimport requestsimport pandas as pdfrom bs4 import BeautifulSoupheaders = { 'host':'q.10jqka.com.cn', 'Referer':'http://q.10jqka.com.cn/', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3554.0 Safari/537.36', 'X-Requested-With':'XMLHttpRequest'}url = 'http://q.10jqka.com.cn/index/i ... 39%3B % page_idres = requests.get(url,headers=headers)res.encoding = 'GBK'
2.信息提取
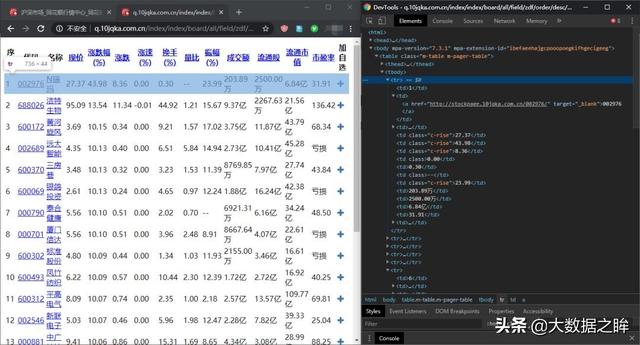
之后就是上面解析库中的内容,这里使用BaetifulSoup库,方便理解。先将上面的html转换成BeautifulSoup对象,然后通过对象的select选择器选择响应tr标签中的数据,进一步分析每个tr标签的内容,得到如下对应信息。
# 获取单页数据def get_html(page_id): headers = { 'host':'q.10jqka.com.cn', 'Referer':'http://q.10jqka.com.cn/', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3554.0 Safari/537.36', 'X-Requested-With':'XMLHttpRequest' } url = 'http://q.10jqka.com.cn/index/i ... 39%3B % page_id res = requests.get(url,headers=headers) res.encoding = 'GBK' soup = BeautifulSoup(res.text,'lxml') tr_list = soup.select('tbody tr') # print(tr_list) stocks = [] for each_tr in tr_list: td_list = each_tr.select('td') data = { '股票代码':td_list[1].text, '股票简称':td_list[2].text, '股票链接':each_tr.a['href'], '现价':td_list[3].text, '涨幅':td_list[4].text, '涨跌':td_list[5].text, '涨速':td_list[6].text, '换手':td_list[7].text, '量比':td_list[8].text, '振幅':td_list[9].text, '成交额':td_list[10].text, '流通股':td_list[11].text, '流通市值':td_list[12].text, '市盈率':td_list[13].text, } stocks.append(data) return stocks
3.保存数据
定义 write2excel 函数将数据保存到stocks.xlsx 文件中。
# 保存数据def write2excel(result): json_result = json.dumps(result) with open('stocks.json','w') as f: f.write(json_result) with open('stocks.json','r') as f: data = f.read() data = json.loads(data) df = pd.DataFrame(data,columns=['股票代码','股票简称','股票链接','现价','涨幅','涨跌','涨速','换手','量比','振幅','成交额', '流通股','流通市值','市盈率']) df.to_excel('stocks.xlsx',index=False)
4.循环结构
考虑到flushflush的多页结构和反爬的存在,这里也采用了字符串拼接和循环结构来遍历多页股票信息。同时,随机库中的randint方法和时间库中的sleep方法在爬取前会中断一定时间。
def get_pages(page_n): stocks_n = [] for page_id in range(1,page_n+1): page = get_html(page_id) stocks_n.extend(page) time.sleep(random.randint(1,10)) return stocks_n
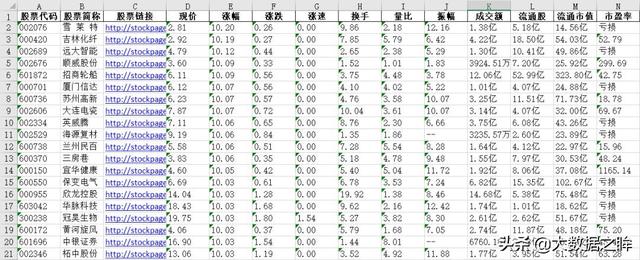
最终爬取结果如下:
四、爬虫摘要
至此,flush动态网页的爬取完成,再通过这个爬虫进行总结:首先,我们通过浏览网页结构和翻页,对比XHR bar,对页面进行Ajax判断。如果网页url没有变化,XHR会刷新内容,基本说明是动态的。这时候我们进一步检查多个页面之间url请求的异同,寻找规律。找到规则后,就可以建立多页面请求流程了。之后处理单个响应内容(详见响应内容格式),最后建立整个循环爬虫结构,自动爬取想要的信息。
爬虫的完整代码可以在今日头条私信获取。下面将进一步解释和实践浏览器模拟行为。上篇文章涉及的基础知识,请参考以下链接:
爬虫需要知道的基础知识,这一点就够了!Python网络爬虫实战系列
本文将带你深入了解和学习Python爬虫库!从现在开始,不用担心数据
Python爬虫有多简单?本文将带你实战豆瓣电影TOP250数据爬取!
一篇搞懂Python网络爬虫解析库的文章!收录多个示例 查看全部
抓取动态网页(前文Ajax理论AjaxAjaxAjaxAjax)
上面的爬虫都是基于静态网页的。首先通过请求网站url获取网页源代码。之后,可以提取和存储源代码。本文对动态网页采集进行数据处理。首先介绍了Ajax的理论,然后实际爬取flushflush的动态网页,获取个股的相关信息。

一、Ajax 理论
1.Ajax介绍
Ajax 的全称是“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式、快速和动态的 Web 应用程序的 Web 开发技术,可以在不重新加载整个网页的情况下更新某些网页。Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
2.Ajax 分析
微博网站是一个比较容易识别的Ajax动态网页。首先打开Dectools工具(转到XHR专栏)和中南财经政法大学官方微博网站(),这里选择。是手机微博,然后选择清除所有内容。
接下来,滚动滚轮以下拉页面,直到一个新项目出现在空的 XHR 列中。点击项目,选择预览栏,发现这里对应的内容就是页面上的新微博。但它没有改变。至此,我们可以确定这是一个Ajax请求后的网页。
3.Ajax 提取
或者选择同一个条目进入Headers进一步查看信息,可以发现这是一个GET类型的请求,请求的url为:,即请求有四个参数:type、value、containerid、since_id和然后翻页发现除了since_id的变化之外,其余保持不变,这里我们可以看到since_id就是翻页方法。
接下来进一步观察since_id,发现上下请求的since_id之间没有明显的规律。进一步搜索发现,下一页的since_id在上一页的响应中的cardListInfo中,因此可以建立循环连接,进一步将动态url循环添加到爬虫中。
发起请求并得到响应后,可以进一步分析出响应格式是json,所以可以通过对json的进一步处理得到最终的数据!
二、网页分析
1.网站概览
经过以上分析,我们将用flush网页的数据来采集实战进行例子验证。首先打开网页:,如下图:
再按F12键打开Devtools后台源码,右键第一项查看源码位置。
2.阿贾克斯歧视
接下来,通过点击网页底部的下一页,我们发现网页的url并没有改变!至此,基本可以确定该网页属于Ajax动态网页。

进一步,我们清空Network中的所有内容,继续点击下一页到第五页,发现连续弹出三个同名的内容,就可以得到请求的url和请求头的具体内容通过一般栏。
所以我们复制这个请求url,在浏览器中打开,响应内容确实是标准化的表格数据,正是我们想要的。
3.Ajax 提取
然后我们也打开源码,发现是一个html文档,说明响应内容是网页的形式,和上面微博响应的json格式不同,所以数据可以在稍后解析网页的形式。
三、爬行者战斗
1.网页访问
在第一部分的理论介绍和第二部分的网页分析之后,我们就可以开始编写爬虫代码了。首先,导入库并定义请求头。需要注意的是,这里的请求头除了User-Agent外,还需要host、Referer和X-Requested-With参数,这要和静态网页爬取区别开来。
# 导入库import timeimport jsonimport randomimport requestsimport pandas as pdfrom bs4 import BeautifulSoupheaders = { 'host':'q.10jqka.com.cn', 'Referer':'http://q.10jqka.com.cn/', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3554.0 Safari/537.36', 'X-Requested-With':'XMLHttpRequest'}url = 'http://q.10jqka.com.cn/index/i ... 39%3B % page_idres = requests.get(url,headers=headers)res.encoding = 'GBK'
2.信息提取
之后就是上面解析库中的内容,这里使用BaetifulSoup库,方便理解。先将上面的html转换成BeautifulSoup对象,然后通过对象的select选择器选择响应tr标签中的数据,进一步分析每个tr标签的内容,得到如下对应信息。
# 获取单页数据def get_html(page_id): headers = { 'host':'q.10jqka.com.cn', 'Referer':'http://q.10jqka.com.cn/', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3554.0 Safari/537.36', 'X-Requested-With':'XMLHttpRequest' } url = 'http://q.10jqka.com.cn/index/i ... 39%3B % page_id res = requests.get(url,headers=headers) res.encoding = 'GBK' soup = BeautifulSoup(res.text,'lxml') tr_list = soup.select('tbody tr') # print(tr_list) stocks = [] for each_tr in tr_list: td_list = each_tr.select('td') data = { '股票代码':td_list[1].text, '股票简称':td_list[2].text, '股票链接':each_tr.a['href'], '现价':td_list[3].text, '涨幅':td_list[4].text, '涨跌':td_list[5].text, '涨速':td_list[6].text, '换手':td_list[7].text, '量比':td_list[8].text, '振幅':td_list[9].text, '成交额':td_list[10].text, '流通股':td_list[11].text, '流通市值':td_list[12].text, '市盈率':td_list[13].text, } stocks.append(data) return stocks
3.保存数据
定义 write2excel 函数将数据保存到stocks.xlsx 文件中。
# 保存数据def write2excel(result): json_result = json.dumps(result) with open('stocks.json','w') as f: f.write(json_result) with open('stocks.json','r') as f: data = f.read() data = json.loads(data) df = pd.DataFrame(data,columns=['股票代码','股票简称','股票链接','现价','涨幅','涨跌','涨速','换手','量比','振幅','成交额', '流通股','流通市值','市盈率']) df.to_excel('stocks.xlsx',index=False)
4.循环结构
考虑到flushflush的多页结构和反爬的存在,这里也采用了字符串拼接和循环结构来遍历多页股票信息。同时,随机库中的randint方法和时间库中的sleep方法在爬取前会中断一定时间。
def get_pages(page_n): stocks_n = [] for page_id in range(1,page_n+1): page = get_html(page_id) stocks_n.extend(page) time.sleep(random.randint(1,10)) return stocks_n
最终爬取结果如下:
四、爬虫摘要
至此,flush动态网页的爬取完成,再通过这个爬虫进行总结:首先,我们通过浏览网页结构和翻页,对比XHR bar,对页面进行Ajax判断。如果网页url没有变化,XHR会刷新内容,基本说明是动态的。这时候我们进一步检查多个页面之间url请求的异同,寻找规律。找到规则后,就可以建立多页面请求流程了。之后处理单个响应内容(详见响应内容格式),最后建立整个循环爬虫结构,自动爬取想要的信息。
爬虫的完整代码可以在今日头条私信获取。下面将进一步解释和实践浏览器模拟行为。上篇文章涉及的基础知识,请参考以下链接:
爬虫需要知道的基础知识,这一点就够了!Python网络爬虫实战系列
本文将带你深入了解和学习Python爬虫库!从现在开始,不用担心数据
Python爬虫有多简单?本文将带你实战豆瓣电影TOP250数据爬取!
一篇搞懂Python网络爬虫解析库的文章!收录多个示例
抓取动态网页( Python爬虫请求URL分析方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-30 18:00
Python爬虫请求URL分析方法
)
请求网址分析
先打开F12控制台面板,看到照片的url都是这个格式的。
向下滚动知乎页面,找到一个带有limit、offset参数的URL请求。
检查Response面板中的内容是否收录图片的URL地址,其中图片地址的URL保存在data-original属性中。
提取图片的网址
从上图可以看出,图片的地址存放在content属性下的data-original属性中。
下面的代码会获取图片的地址并写入文件。
import re
import requests
import os
import urllib.request
import ssl
from urllib.parse import urlsplit
from os.path import basename
import json
ssl._create_default_https_context = ssl._create_unverified_context
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36",
'Accept-Encoding': 'gzip, deflate'
}
def get_image_url(qid, title):
answers_url = 'https://www.zhihu.com/api/v4/q ... 2Bstr(qid)+'/answers?include=data%5B*%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B*%5D.mark_infos%5B*%5D.url%3Bdata%5B*%5D.author.follower_count%2Cbadge%5B*%5D.topics%3Bdata%5B*%5D.settings.table_of_content.enabled&offset={}&limit=10&sort_by=default&platform=desktop'
offset = 0
session = requests.Session()
while True:
page = session.get(answers_url.format(offset), headers = headers)
json_text = json.loads(page.text)
answers = json_text['data']
offset += 10
if not answers:
print('获取图片地址完成')
return
pic_re = re.compile('data-original="(.*?)"', re.S)
for answer in answers:
tmp_list = []
pic_urls = re.findall(pic_re, answer['content'])
for item in pic_urls:
# 去掉转移字符 \
pic_url = item.replace("\\", "")
pic_url = pic_url.split('?')[0]
# 去重复
if pic_url not in tmp_list:
tmp_list.append(pic_url)
for pic_url in tmp_list:
if pic_url.endswith('r.jpg'):
print(pic_url)
write_file(title, pic_url)
def write_file(title, pic_url):
file_name = title + '.txt'
f = open(file_name, 'a')
f.write(pic_url + '\n')
f.close()
示例结果:
下载图片
以下代码会读取文件中的图片URL并下载。
def read_file(title):
file_name = title + '.txt'
pic_urls = []
# 判断文件是否存在
if not os.path.exists(file_name):
return pic_urls
with open(file_name, 'r') as f:
for line in f:
url = line.replace("\n", "")
if url not in pic_urls:
pic_urls.append(url)
print("文件中共有{}个不重复的 URL".format(len(pic_urls)))
return pic_urls
def download_pic(pic_urls, title):
# 创建文件夹
if not os.path.exists(title):
os.makedirs(title)
error_pic_urls = []
success_pic_num = 0
repeat_pic_num = 0
index = 1
for url in pic_urls:
file_name = os.sep.join((title,basename(urlsplit(url)[2])))
if os.path.exists(file_name):
print("图片{}已存在".format(file_name))
index += 1
repeat_pic_num += 1
continue
try:
urllib.request.urlretrieve(url, file_name)
success_pic_num += 1
index += 1
print("下载{}完成!({}/{})".format(file_name, index, len(pic_urls)))
except:
print("下载{}失败!({}/{})".format(file_name, index, len(pic_urls)))
error_pic_urls.append(url)
index += 1
continue
print("图片全部下载完毕!(成功:{}/重复:{}/失败:{})".format(success_pic_num, repeat_pic_num, len(error_pic_urls)))
if len(error_pic_urls) > 0:
print('下面打印失败的图片地址')
for error_url in error_pic_urls:
print(error_url)
结论
今天的文章用Python爬虫做了一个小脚本。如果大家觉得文章有趣又有用,请转发支持!
查看全部
抓取动态网页(
Python爬虫请求URL分析方法
)
请求网址分析
先打开F12控制台面板,看到照片的url都是这个格式的。
向下滚动知乎页面,找到一个带有limit、offset参数的URL请求。
检查Response面板中的内容是否收录图片的URL地址,其中图片地址的URL保存在data-original属性中。
提取图片的网址
从上图可以看出,图片的地址存放在content属性下的data-original属性中。
下面的代码会获取图片的地址并写入文件。
import re
import requests
import os
import urllib.request
import ssl
from urllib.parse import urlsplit
from os.path import basename
import json
ssl._create_default_https_context = ssl._create_unverified_context
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36",
'Accept-Encoding': 'gzip, deflate'
}
def get_image_url(qid, title):
answers_url = 'https://www.zhihu.com/api/v4/q ... 2Bstr(qid)+'/answers?include=data%5B*%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B*%5D.mark_infos%5B*%5D.url%3Bdata%5B*%5D.author.follower_count%2Cbadge%5B*%5D.topics%3Bdata%5B*%5D.settings.table_of_content.enabled&offset={}&limit=10&sort_by=default&platform=desktop'
offset = 0
session = requests.Session()
while True:
page = session.get(answers_url.format(offset), headers = headers)
json_text = json.loads(page.text)
answers = json_text['data']
offset += 10
if not answers:
print('获取图片地址完成')
return
pic_re = re.compile('data-original="(.*?)"', re.S)
for answer in answers:
tmp_list = []
pic_urls = re.findall(pic_re, answer['content'])
for item in pic_urls:
# 去掉转移字符 \
pic_url = item.replace("\\", "")
pic_url = pic_url.split('?')[0]
# 去重复
if pic_url not in tmp_list:
tmp_list.append(pic_url)
for pic_url in tmp_list:
if pic_url.endswith('r.jpg'):
print(pic_url)
write_file(title, pic_url)
def write_file(title, pic_url):
file_name = title + '.txt'
f = open(file_name, 'a')
f.write(pic_url + '\n')
f.close()
示例结果:
下载图片
以下代码会读取文件中的图片URL并下载。
def read_file(title):
file_name = title + '.txt'
pic_urls = []
# 判断文件是否存在
if not os.path.exists(file_name):
return pic_urls
with open(file_name, 'r') as f:
for line in f:
url = line.replace("\n", "")
if url not in pic_urls:
pic_urls.append(url)
print("文件中共有{}个不重复的 URL".format(len(pic_urls)))
return pic_urls
def download_pic(pic_urls, title):
# 创建文件夹
if not os.path.exists(title):
os.makedirs(title)
error_pic_urls = []
success_pic_num = 0
repeat_pic_num = 0
index = 1
for url in pic_urls:
file_name = os.sep.join((title,basename(urlsplit(url)[2])))
if os.path.exists(file_name):
print("图片{}已存在".format(file_name))
index += 1
repeat_pic_num += 1
continue
try:
urllib.request.urlretrieve(url, file_name)
success_pic_num += 1
index += 1
print("下载{}完成!({}/{})".format(file_name, index, len(pic_urls)))
except:
print("下载{}失败!({}/{})".format(file_name, index, len(pic_urls)))
error_pic_urls.append(url)
index += 1
continue
print("图片全部下载完毕!(成功:{}/重复:{}/失败:{})".format(success_pic_num, repeat_pic_num, len(error_pic_urls)))
if len(error_pic_urls) > 0:
print('下面打印失败的图片地址')
for error_url in error_pic_urls:
print(error_url)
结论
今天的文章用Python爬虫做了一个小脚本。如果大家觉得文章有趣又有用,请转发支持!
抓取动态网页()
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-30 09:12
我正在使用 VBA 和 MSXML 抓取一些 Web 内容,所以我知道基础知识。但现在我想从由 JavaScript 生成的网页中获取数据。我不能给你确切的链接,因为它是私人的,但我可以描述它 - 基本上,有带有标题和一些图像的 div 容器,下面是动态加载的表格(圆形圆圈),但不更新(所以他们只加载一次)。我不能给你确切的链接,因为它是私有的,但我可以描述它 - 基本上,有一个带有标题和一些图像的 div 容器,在它下面是动态加载的表格(圆圈),没有更新(所以它们只加载一次)。如果在浏览器中打开源代码视图,则找不到这些表,只有容器和图像的标题/src。标题/src。但是如果你点击表格并选择“检查元素”,你可以看到等的典型结构。我知道的方法:我知道的方法:
1) 保存页面然后抓取它——可能不是最好的解决方案。 1)保存页面然后抓取它 - 可能不是最好的解决方案。
如果我有所有页面的 URL 列表,有没有什么快速的方法可以保存所有页面?
2) 通过 VBA 使用 Internet Explorer 控件,等待页面加载,然后像往常一样获取元素 - 但对我来说似乎很慢(?) - 就像一页上的 25 秒,即使它是为 0.加载的@>5 秒。 2)通过 VBA 使用 Internet Explorer 控件,等待页面加载,然后像往常一样获取元素 - 但对我来说似乎很慢(?) - 就像页面上的 25 秒,即使在加载之后也是如此 0.同样适用@>5 秒。
也许我应该关闭一些会减慢加载速度的东西?也许我应该关闭一些会减慢加载速度的功能?
你能检查出什么问题吗?
这是我找到的代码:这是我找到的代码:
3) 使用 Selenium 之类的 Web 驱动程序 - 找不到合适的示例。 3)使用像 Selenium 这样的网络驱动程序 - 找不到合适的例子。如果你从头开始给我一些,比如通过类名从元素中获取数据,那就太好了。
4) 对我来说未知,但可能是最快的 - 直接从用于构建这些表的 JS 变量/数组中获取数据。 4)对我来说未知,但可能是最快的 - 直接从用于构建这些表的 JS 变量/数组中获取数据。我听说您可以将 VBA 与 JavaScript 连接,但没有找到任何适当的示例如何获取数据。
所有解决方案都应在 VBA 范围内。我想知道最快的方法是什么。 查看全部
抓取动态网页()
我正在使用 VBA 和 MSXML 抓取一些 Web 内容,所以我知道基础知识。但现在我想从由 JavaScript 生成的网页中获取数据。我不能给你确切的链接,因为它是私人的,但我可以描述它 - 基本上,有带有标题和一些图像的 div 容器,下面是动态加载的表格(圆形圆圈),但不更新(所以他们只加载一次)。我不能给你确切的链接,因为它是私有的,但我可以描述它 - 基本上,有一个带有标题和一些图像的 div 容器,在它下面是动态加载的表格(圆圈),没有更新(所以它们只加载一次)。如果在浏览器中打开源代码视图,则找不到这些表,只有容器和图像的标题/src。标题/src。但是如果你点击表格并选择“检查元素”,你可以看到等的典型结构。我知道的方法:我知道的方法:
1) 保存页面然后抓取它——可能不是最好的解决方案。 1)保存页面然后抓取它 - 可能不是最好的解决方案。
如果我有所有页面的 URL 列表,有没有什么快速的方法可以保存所有页面?
2) 通过 VBA 使用 Internet Explorer 控件,等待页面加载,然后像往常一样获取元素 - 但对我来说似乎很慢(?) - 就像一页上的 25 秒,即使它是为 0.加载的@>5 秒。 2)通过 VBA 使用 Internet Explorer 控件,等待页面加载,然后像往常一样获取元素 - 但对我来说似乎很慢(?) - 就像页面上的 25 秒,即使在加载之后也是如此 0.同样适用@>5 秒。
也许我应该关闭一些会减慢加载速度的东西?也许我应该关闭一些会减慢加载速度的功能?
你能检查出什么问题吗?
这是我找到的代码:这是我找到的代码:
3) 使用 Selenium 之类的 Web 驱动程序 - 找不到合适的示例。 3)使用像 Selenium 这样的网络驱动程序 - 找不到合适的例子。如果你从头开始给我一些,比如通过类名从元素中获取数据,那就太好了。
4) 对我来说未知,但可能是最快的 - 直接从用于构建这些表的 JS 变量/数组中获取数据。 4)对我来说未知,但可能是最快的 - 直接从用于构建这些表的 JS 变量/数组中获取数据。我听说您可以将 VBA 与 JavaScript 连接,但没有找到任何适当的示例如何获取数据。
所有解决方案都应在 VBA 范围内。我想知道最快的方法是什么。
抓取动态网页(如何用python来抓取页面中的JS动态加载的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-28 18:12
)
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,而网站的其他很多RequestURL也不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
抓取动态网页(如何用python来抓取页面中的JS动态加载的数据
)
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
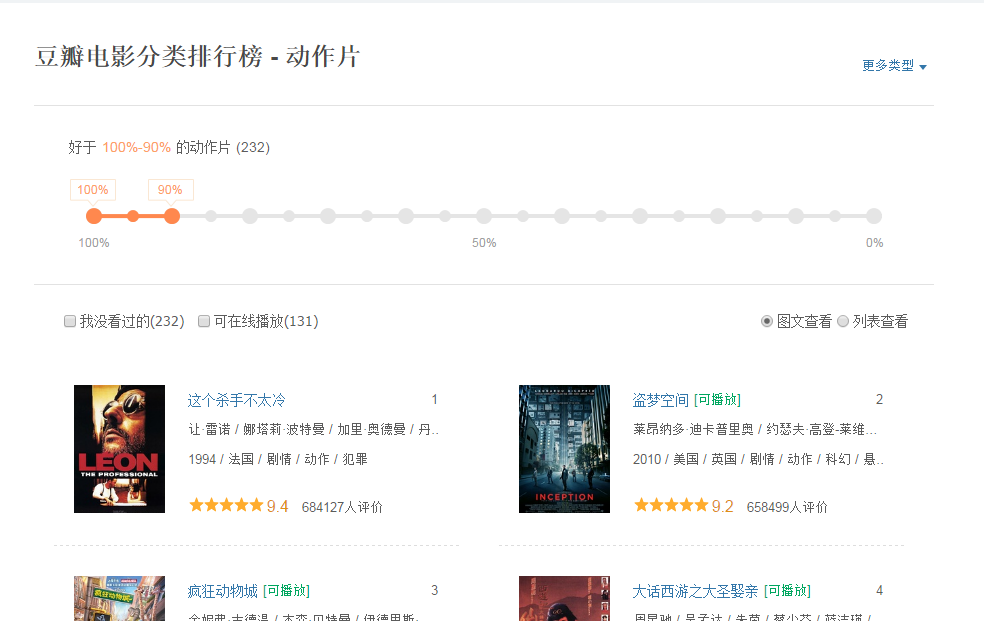
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。

我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。

查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,而网站的其他很多RequestURL也不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
抓取动态网页(搜索引擎提升静态和动态页面哪个蜘蛛抓取的快?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-28 14:11
问题:哪种蜘蛛爬取静态和动态页面的速度更快?
答:理论上,搜索引擎蜘蛛对静态页面和动态页面是一视同仁的,不会优先抓取哪个页面,但是这里有个前提,就是动态页面必须被蜘蛛识别。如果动态页面有很多复杂的参数,可能会影响蜘蛛抓取。
其实搜索引擎发展到今天已经能够很好的解决爬取的问题,不管是静态页面还是动态页面都可以爬取。不过从用户体验的角度来说,最好将URL设置为静态或伪静态,因为合理的URL可以节省用户的判断成本,对网站的优化也有帮助。
当然,不要走入死胡同,认为搜索引擎会歧视动态链接,这是错误的。
在判断页面质量和关键词排名方面,静态页面和动态页面没有严格的区别,都可以正常参与排名。不过这里也有一个需要注意的问题,就是页面的动态更新。无论页面的 URL 是什么形式,都必须保证页面是动态更新的。
比如文章页面通常会调用相关的文章,这个相关的文章的调用应该是动态的,文章在同一个标签下更新,其他的< @文章 页面也需要同步更新。这样做的好处是增加了页面的更新频率,有利于页面本身质量的提升。
关于页面ULR和蜘蛛爬取的问题,沐风SEO简单的说了这么多。总之,一般情况下,无论是静态页面还是动态页面,蜘蛛都会抓取。但是在设置网址的时候,一定要遵循一个原则,就是网址要尽量简单易懂,不能有复杂的符号! 查看全部
抓取动态网页(搜索引擎提升静态和动态页面哪个蜘蛛抓取的快?(图))
问题:哪种蜘蛛爬取静态和动态页面的速度更快?
答:理论上,搜索引擎蜘蛛对静态页面和动态页面是一视同仁的,不会优先抓取哪个页面,但是这里有个前提,就是动态页面必须被蜘蛛识别。如果动态页面有很多复杂的参数,可能会影响蜘蛛抓取。
其实搜索引擎发展到今天已经能够很好的解决爬取的问题,不管是静态页面还是动态页面都可以爬取。不过从用户体验的角度来说,最好将URL设置为静态或伪静态,因为合理的URL可以节省用户的判断成本,对网站的优化也有帮助。
当然,不要走入死胡同,认为搜索引擎会歧视动态链接,这是错误的。
在判断页面质量和关键词排名方面,静态页面和动态页面没有严格的区别,都可以正常参与排名。不过这里也有一个需要注意的问题,就是页面的动态更新。无论页面的 URL 是什么形式,都必须保证页面是动态更新的。
比如文章页面通常会调用相关的文章,这个相关的文章的调用应该是动态的,文章在同一个标签下更新,其他的< @文章 页面也需要同步更新。这样做的好处是增加了页面的更新频率,有利于页面本身质量的提升。
关于页面ULR和蜘蛛爬取的问题,沐风SEO简单的说了这么多。总之,一般情况下,无论是静态页面还是动态页面,蜘蛛都会抓取。但是在设置网址的时候,一定要遵循一个原则,就是网址要尽量简单易懂,不能有复杂的符号!
抓取动态网页(ajax横行的年代,我们的网页是残缺的吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-27 00:12
)
在ajax时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,其中包括
跳过js加载部分,表示爬虫抓取的网页不完整,不完整。您可以在下面看到博客园的主页
从首页的加载中可以看出,页面渲染完成后,会有5个异步ajax请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候,如果你想得到它,你必须调用浏览器的内核引擎来下载这些动态页面。目前内核引擎是三足的。
Trident:也就是IE内核,WebBrowser就是基于这个内核,但是加载性能比较差。
Gecko:FF的内核比Trident的性能更好。
WebKit:Safari和Chrome的核心,性能你懂的,在真实场景中还是主要的。
好的,为了简单方便,这里我们使用WebBrowser来玩,使用WebBrowser的时候要注意以下几点:
首先:因为WebBrowser是System.Windows.Forms中的winform控件,所以我们需要设置STAThread标签。
第二:winform是事件驱动的,Console不响应事件,所有事件都在windows的消息队列中等待执行,以防止程序假死,
我们需要调用DoEvents方法来传递控制权,让操作系统执行其他事件。
第三:WebBrowser内容,我们需要使用DomDocument来查看,而不是DocumentText。
判断动态网页是否加载一般有两种方式:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们这里需要这样做
记录计数值
.
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.html,看看js加载的内容有没有。
②:当然,除了通过判断最大值来判断加载是否完成,我们还可以通过设置一个Timer来判断,比如3s、4s、5s,稍后再查看
WEB浏览器是否加载。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然,效果还是一样的,就不截图了。从以上两种写法来看,我们的WebBrowser放在主线程中。让我们看看如何把它放在工作线程上。
很简单,只需将工作线程设置为STA模式即可。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 }
查看全部
抓取动态网页(ajax横行的年代,我们的网页是残缺的吗?
)
在ajax时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,其中包括
跳过js加载部分,表示爬虫抓取的网页不完整,不完整。您可以在下面看到博客园的主页

从首页的加载中可以看出,页面渲染完成后,会有5个异步ajax请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候,如果你想得到它,你必须调用浏览器的内核引擎来下载这些动态页面。目前内核引擎是三足的。
Trident:也就是IE内核,WebBrowser就是基于这个内核,但是加载性能比较差。
Gecko:FF的内核比Trident的性能更好。
WebKit:Safari和Chrome的核心,性能你懂的,在真实场景中还是主要的。
好的,为了简单方便,这里我们使用WebBrowser来玩,使用WebBrowser的时候要注意以下几点:
首先:因为WebBrowser是System.Windows.Forms中的winform控件,所以我们需要设置STAThread标签。
第二:winform是事件驱动的,Console不响应事件,所有事件都在windows的消息队列中等待执行,以防止程序假死,
我们需要调用DoEvents方法来传递控制权,让操作系统执行其他事件。
第三:WebBrowser内容,我们需要使用DomDocument来查看,而不是DocumentText。
判断动态网页是否加载一般有两种方式:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们这里需要这样做
记录计数值
.

1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.html,看看js加载的内容有没有。

②:当然,除了通过判断最大值来判断加载是否完成,我们还可以通过设置一个Timer来判断,比如3s、4s、5s,稍后再查看
WEB浏览器是否加载。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然,效果还是一样的,就不截图了。从以上两种写法来看,我们的WebBrowser放在主线程中。让我们看看如何把它放在工作线程上。
很简单,只需将工作线程设置为STA模式即可。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 }
抓取动态网页(如何抓取网页中的动态网页源码中特定的特定内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-25 21:22
背景
很多时候,很多人需要在网络上抓取一些特定的内容。
但是,除了之前介绍的内容之外,您还想从某些静态网页中提取某些内容,例如:
【教程】Python版爬网并从网页中提取需要的信息
和
【教程】C#版爬网并从网页中提取需要的信息
另外,有些人会发现自己要抓取的网页内容不在网页的源代码中。
所以,在这一点上,我不知道该怎么做。
在这里,我们来解释一下如何爬取所谓的动态网页中的特定内容。
必备知识
在阅读本文之前,您需要具备相关的基础知识:
1.爬取网页,模拟登录等相关逻辑
不熟悉的可以参考:
【组织】爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站
2.学会使用工具,比如IE9的F12,爬取对应的网页执行流程
不熟悉的可以参考:
【教程】教你如何使用工具(IE9的F12)解析模拟登录内部逻辑流程网站(百度首页))
3.对于一个普通的静态网页,如何提取想要的内容
对此不熟悉的可以参考:
(1)Python 版本:
【教程】Python版爬网并从网页中提取需要的信息
(2)C# 版本:
【教程】C#版爬网并从网页中提取需要的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指通过浏览器查看网页源代码时,你看到的网页源代码中的内容与网页上显示的内容相对应。
也就是说,当我想得到某个网页上显示的内容时,我可以通过查找网页的源代码找到对应的部分。
动态网页,相反,如果要获取动态网页中的具体内容,直接查看网页源代码是找不到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
一般来说,它是通过其他方式生成或获取的。
据我所知,有几个:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个url的过程,你会发现很可能涉及到,
在网页正常完整显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些你想抓取的内容,有时候,这些js脚本是动态执行的,最后计算出来的。
通过访问另一个url地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要抓取的动态内容
其实对于如何爬取需要的动态内容,简单来说,有一个解决方案:
根据你通过工具分析的结果,找到对应的数据并提取出来;
不过这个数据有时候可以在分析结果的过程中直接提取出来,有时候可能是通过js计算出来的。
想抓取数据,是js脚本生成的
虽然最终的动态内容是由js脚本执行生成的,但是对于你要抓取的数据:
想爬取数据是通过访问另一个url获取的
如果你要抓取的对应内容是访问另一个url地址和返回的数据,那么很简单,你也需要访问这个url,然后获取对应的返回内容,从中提取你想要的数据。
总结
同一句话,不管你访问的内容是如何生成的,最后你还是可以用工具来分析对应的内容是如何从零开始生成的。
然后用代码模拟这个过程,最后提取出你需要的内容;
具体示例演示见:
【教程】以网易博文的最新读者信息为例,教大家如何抓取动态网页的内容。 查看全部
抓取动态网页(如何抓取网页中的动态网页源码中特定的特定内容)
背景
很多时候,很多人需要在网络上抓取一些特定的内容。
但是,除了之前介绍的内容之外,您还想从某些静态网页中提取某些内容,例如:
【教程】Python版爬网并从网页中提取需要的信息
和
【教程】C#版爬网并从网页中提取需要的信息
另外,有些人会发现自己要抓取的网页内容不在网页的源代码中。
所以,在这一点上,我不知道该怎么做。
在这里,我们来解释一下如何爬取所谓的动态网页中的特定内容。
必备知识
在阅读本文之前,您需要具备相关的基础知识:
1.爬取网页,模拟登录等相关逻辑
不熟悉的可以参考:
【组织】爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站
2.学会使用工具,比如IE9的F12,爬取对应的网页执行流程
不熟悉的可以参考:
【教程】教你如何使用工具(IE9的F12)解析模拟登录内部逻辑流程网站(百度首页))
3.对于一个普通的静态网页,如何提取想要的内容
对此不熟悉的可以参考:
(1)Python 版本:
【教程】Python版爬网并从网页中提取需要的信息
(2)C# 版本:
【教程】C#版爬网并从网页中提取需要的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指通过浏览器查看网页源代码时,你看到的网页源代码中的内容与网页上显示的内容相对应。
也就是说,当我想得到某个网页上显示的内容时,我可以通过查找网页的源代码找到对应的部分。
动态网页,相反,如果要获取动态网页中的具体内容,直接查看网页源代码是找不到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
一般来说,它是通过其他方式生成或获取的。
据我所知,有几个:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个url的过程,你会发现很可能涉及到,
在网页正常完整显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些你想抓取的内容,有时候,这些js脚本是动态执行的,最后计算出来的。
通过访问另一个url地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要抓取的动态内容
其实对于如何爬取需要的动态内容,简单来说,有一个解决方案:
根据你通过工具分析的结果,找到对应的数据并提取出来;
不过这个数据有时候可以在分析结果的过程中直接提取出来,有时候可能是通过js计算出来的。
想抓取数据,是js脚本生成的
虽然最终的动态内容是由js脚本执行生成的,但是对于你要抓取的数据:
想爬取数据是通过访问另一个url获取的
如果你要抓取的对应内容是访问另一个url地址和返回的数据,那么很简单,你也需要访问这个url,然后获取对应的返回内容,从中提取你想要的数据。
总结
同一句话,不管你访问的内容是如何生成的,最后你还是可以用工具来分析对应的内容是如何从零开始生成的。
然后用代码模拟这个过程,最后提取出你需要的内容;
具体示例演示见:
【教程】以网易博文的最新读者信息为例,教大家如何抓取动态网页的内容。
抓取动态网页(如何利用Webkit从JS渲染网页中获取数据处理的任何事情)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-01-24 14:13
当我们进行网络爬取时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页收录 JavaScript 代码,我们必须渲染它以获取原创数据。在这一点上,如果我们仍然以通常的方式从中抓取数据,我们将一无所获。浏览器知道如何处理这段代码并显示出来,但是我们的程序应该如何处理这段代码呢?接下来,我将介绍一种简单粗暴的方法来抓取收录 JavaScript 代码的网页信息。
大多数人使用 lxml 和 BeautifulSoup 包来提取数据。本文不会涉及任何爬虫框架,因为我只使用最基本的lxml包来处理数据。你可能想知道为什么我更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中我要介绍一个非常有趣的案例——突然发现我的文章出现在最近的Pycoders周刊147上,所以我想爬取Pycoders周刊中所有档案的链接。
显然,这是一个带有 JavaScript 渲染的网页。我想抓取网页中的所有个人资料信息和相应的链接信息。那么我该怎么办呢?首先,我们无法通过 HTTP 方法获取任何信息。
导入请求
从 lxml 导入 html
# 存储响应
响应 = requests.get('#x27;)
# 从响应体创建 lxml 树
树 = html.fromstring(response.text)
# 查找所有的锚标签作为响应
print tree.xpath('//div[@class="campaign"]/a/@href')
当我们运行上述代码时,我们无法获得任何信息。这怎么可能?网页清楚地显示了这么多文件的信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来我将展示如何使用 Web 工具包从 JS 渲染的网页中获取数据。什么是网络套件?Web 工具包可以做任何浏览器可以处理的事情。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你安装了 QT 和 PyQT4 库,你可以直接运行它。
您可以使用命令行安装存储库:
sudo apt-get install python-qt4
现在所有的准备工作都完成了,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过 Web kit 发送请求信息,然后等待页面完全加载,然后将其分配给变量。接下来我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一点时间,但您会惊讶地看到整个页面加载完毕。
导入系统
从 PyQt4.QtGui 导入 *
从 PyQt4.Qtcore 导入 *
从 PyQt4.QtWebKit 导入 *
类渲染(QWebPage):
定义初始化(自我,网址):
self.app = QApplication(sys.argv)
QWebPage.init(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(自我,结果):
self.frame = self.mainFrame()
self.app.quit()
Render 类可用于渲染网页。当我们创建一个新的 Render 类时,它可以加载 url 中的所有信息并将其存储在一个新的框架中。
网址 = '#x27;
# 这很神奇。加载所有内容
r = 渲染(网址)
# 结果是一个QString。
结果 = r.frame.toHtml()
使用上面的代码,我们将 HTML 结果存储到变量 result 中。由于lxml不能直接处理这种特殊的字符串数据,我们需要转换数据格式。
# QString 在被 lxml 处理之前应该被转换为字符串
formatted_result = str(result.toAscii())
# 接下来从 formatted_result 构建 lxml 树
树 = html.fromstring(formatted_result)
# 现在使用正确的 Xpath 我们正在获取档案的 URL
archive_links = tree.xpath('//div[@class="campaign"]/a/@href')
打印存档链接
使用上面的代码,我们可以得到所有的文件链接信息,然后我们可以使用这些Render和这些URL链接来提取文本内容信息。Web kit 提供了一个强大的网页渲染工具,我们可以使用这个工具从 JS 渲染的网页中抓取有效的信息。
在本文中,我介绍了一种从 JS 渲染的网页中获取信息的有效方法。虽然这个工具比较慢,但是非常简单粗暴。我希望你会喜欢这个文章。现在您可以将此方法应用于您发现难以处理的任何网页。
愿你事事如意。 查看全部
抓取动态网页(如何利用Webkit从JS渲染网页中获取数据处理的任何事情)
当我们进行网络爬取时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页收录 JavaScript 代码,我们必须渲染它以获取原创数据。在这一点上,如果我们仍然以通常的方式从中抓取数据,我们将一无所获。浏览器知道如何处理这段代码并显示出来,但是我们的程序应该如何处理这段代码呢?接下来,我将介绍一种简单粗暴的方法来抓取收录 JavaScript 代码的网页信息。
大多数人使用 lxml 和 BeautifulSoup 包来提取数据。本文不会涉及任何爬虫框架,因为我只使用最基本的lxml包来处理数据。你可能想知道为什么我更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中我要介绍一个非常有趣的案例——突然发现我的文章出现在最近的Pycoders周刊147上,所以我想爬取Pycoders周刊中所有档案的链接。

显然,这是一个带有 JavaScript 渲染的网页。我想抓取网页中的所有个人资料信息和相应的链接信息。那么我该怎么办呢?首先,我们无法通过 HTTP 方法获取任何信息。
导入请求
从 lxml 导入 html
# 存储响应
响应 = requests.get('#x27;)
# 从响应体创建 lxml 树
树 = html.fromstring(response.text)
# 查找所有的锚标签作为响应
print tree.xpath('//div[@class="campaign"]/a/@href')
当我们运行上述代码时,我们无法获得任何信息。这怎么可能?网页清楚地显示了这么多文件的信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来我将展示如何使用 Web 工具包从 JS 渲染的网页中获取数据。什么是网络套件?Web 工具包可以做任何浏览器可以处理的事情。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你安装了 QT 和 PyQT4 库,你可以直接运行它。
您可以使用命令行安装存储库:
sudo apt-get install python-qt4
现在所有的准备工作都完成了,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过 Web kit 发送请求信息,然后等待页面完全加载,然后将其分配给变量。接下来我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一点时间,但您会惊讶地看到整个页面加载完毕。
导入系统
从 PyQt4.QtGui 导入 *
从 PyQt4.Qtcore 导入 *
从 PyQt4.QtWebKit 导入 *
类渲染(QWebPage):
定义初始化(自我,网址):
self.app = QApplication(sys.argv)
QWebPage.init(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(自我,结果):
self.frame = self.mainFrame()
self.app.quit()
Render 类可用于渲染网页。当我们创建一个新的 Render 类时,它可以加载 url 中的所有信息并将其存储在一个新的框架中。
网址 = '#x27;
# 这很神奇。加载所有内容
r = 渲染(网址)
# 结果是一个QString。
结果 = r.frame.toHtml()
使用上面的代码,我们将 HTML 结果存储到变量 result 中。由于lxml不能直接处理这种特殊的字符串数据,我们需要转换数据格式。
# QString 在被 lxml 处理之前应该被转换为字符串
formatted_result = str(result.toAscii())
# 接下来从 formatted_result 构建 lxml 树
树 = html.fromstring(formatted_result)
# 现在使用正确的 Xpath 我们正在获取档案的 URL
archive_links = tree.xpath('//div[@class="campaign"]/a/@href')
打印存档链接
使用上面的代码,我们可以得到所有的文件链接信息,然后我们可以使用这些Render和这些URL链接来提取文本内容信息。Web kit 提供了一个强大的网页渲染工具,我们可以使用这个工具从 JS 渲染的网页中抓取有效的信息。

在本文中,我介绍了一种从 JS 渲染的网页中获取信息的有效方法。虽然这个工具比较慢,但是非常简单粗暴。我希望你会喜欢这个文章。现在您可以将此方法应用于您发现难以处理的任何网页。
愿你事事如意。
抓取动态网页(第四章:动态网页抓取((解析真实地址+selenium) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-24 14:12
)
第 4 章:动态网页抓取(解析真实地址 + selenium)
由于网易云线程已停止,新写的第4章现已更新至此。请参考文章:
之前爬取的网页都是静态网页,这些网页在浏览器中显示的内容是在HTML源代码中。但是由于主流的网站都使用JavaScript来展示网页内容,不像静态网页,在使用JavaScript的时候,很多内容不会出现在HTML源代码中,所以爬取静态网页的技术可能不会工作正常使用。因此,我们需要使用两种动态网页抓取技术:通过浏览器检查元素解析真实网址和使用 selenium 模拟浏览器。
本章首先介绍动态网页的示例,让读者了解什么是动态网页抓取,然后利用以上两种动态网页抓取技术获取动态网页数据。
4.1 动态抓取示例
在开始爬取动态网页之前,我们还需要了解一个异步更新技术——AJAX(Asynchronous Javascript And XML)。它的价值在于可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。一方面减少了网页重复内容的下载,另一方面也节省了流量,所以AJAX被广泛使用。
与使用 AJAX 网页相比,如果传统网页需要更新内容,则必须重新加载整个网页。因此,AJAX 使 Internet 应用程序更小、更快、更友好。但是AJAX网页的爬取过程比较麻烦。
首先,我们来看一个动态网页的例子。打开作者博客的Hello World文章,文章的地址是:/2018/07/04/hello-world/。网址可能会有变化,请到作者博客官网查找Hello World文章地址。如图4-1所示,页面下方的评论是用JavaScript加载的,这些评论数据不会出现在网页的源代码中。
为了验证页面下方的评论是否加载了 JavaScript,我们可以查看该页面的网页源代码。如图 4-2 所示,放置评论的代码中没有评论数据,只有一段 JavaScript 代码。最终呈现的数据通过 JavaScript 提取并加载到源代码中进行呈现。
除了作者的博客,还可以在天猫电商网站上找到AJAX技术的例子。比如打开天猫iPhone XS Max的产品页面,点击“累计评论”,可以发现上面的url地址没有变化,整个网页也没有重新加载,网页的评论区也没有更新,如图4-3所示。
如图4-4所示,我们也可以查看这个产品网页的源码,里面没有用户评论,这段内容是空白的。
如果使用AJAX加载动态网页,如何抓取里面动态加载的内容?有两种方法:
(1)通过浏览器检查元素解析地址。
(2) 通过 Selenium 模拟浏览器抓取。
请查看第四章的其他章节
4.2 解析真实地址捕获
4.3 模拟浏览器通过selenium爬取
查看全部
抓取动态网页(第四章:动态网页抓取((解析真实地址+selenium)
)
第 4 章:动态网页抓取(解析真实地址 + selenium)
由于网易云线程已停止,新写的第4章现已更新至此。请参考文章:
之前爬取的网页都是静态网页,这些网页在浏览器中显示的内容是在HTML源代码中。但是由于主流的网站都使用JavaScript来展示网页内容,不像静态网页,在使用JavaScript的时候,很多内容不会出现在HTML源代码中,所以爬取静态网页的技术可能不会工作正常使用。因此,我们需要使用两种动态网页抓取技术:通过浏览器检查元素解析真实网址和使用 selenium 模拟浏览器。
本章首先介绍动态网页的示例,让读者了解什么是动态网页抓取,然后利用以上两种动态网页抓取技术获取动态网页数据。
4.1 动态抓取示例
在开始爬取动态网页之前,我们还需要了解一个异步更新技术——AJAX(Asynchronous Javascript And XML)。它的价值在于可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。一方面减少了网页重复内容的下载,另一方面也节省了流量,所以AJAX被广泛使用。
与使用 AJAX 网页相比,如果传统网页需要更新内容,则必须重新加载整个网页。因此,AJAX 使 Internet 应用程序更小、更快、更友好。但是AJAX网页的爬取过程比较麻烦。
首先,我们来看一个动态网页的例子。打开作者博客的Hello World文章,文章的地址是:/2018/07/04/hello-world/。网址可能会有变化,请到作者博客官网查找Hello World文章地址。如图4-1所示,页面下方的评论是用JavaScript加载的,这些评论数据不会出现在网页的源代码中。

为了验证页面下方的评论是否加载了 JavaScript,我们可以查看该页面的网页源代码。如图 4-2 所示,放置评论的代码中没有评论数据,只有一段 JavaScript 代码。最终呈现的数据通过 JavaScript 提取并加载到源代码中进行呈现。
除了作者的博客,还可以在天猫电商网站上找到AJAX技术的例子。比如打开天猫iPhone XS Max的产品页面,点击“累计评论”,可以发现上面的url地址没有变化,整个网页也没有重新加载,网页的评论区也没有更新,如图4-3所示。
如图4-4所示,我们也可以查看这个产品网页的源码,里面没有用户评论,这段内容是空白的。
如果使用AJAX加载动态网页,如何抓取里面动态加载的内容?有两种方法:
(1)通过浏览器检查元素解析地址。
(2) 通过 Selenium 模拟浏览器抓取。
请查看第四章的其他章节
4.2 解析真实地址捕获
4.3 模拟浏览器通过selenium爬取

抓取动态网页(代码中添加其他作者的不同信息(中英对照))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-24 14:10
我正在网上抓取不同作者在谷歌学术上的出版年数和数量,到目前为止,这是我只有一位作者的代码:我正在网上抓取不同作者在谷歌学术上的出版年数和出版数量,到目前为止这是我只有一位作者的代码:这是我到目前为止只有一位作者的代码:
from selenium import webdriver
mozilla_path = r"C:\Users\ivrav\Python38\geckodriver.exe"
driver = webdriver.Firefox()
driver.get("https://scholar.google.com/cit ... 6quot;)
driver.maximize_window()
years = [element.get_attribute("textContent") for element in driver.find_elements_by_xpath('//span[@class="gsc_g_t"]')]
citations = [element.get_attribute("textContent") for element in driver.find_elements_by_xpath('//span[@class="gsc_g_al"]')]
for year, citation in zip(years, citations):
print(year, citation)
但是,我的疑问取决于如何在同一代码中添加其他作者的不同信息。我应该使用循环吗?我应该使用循环吗?我不太确定如何解决这个问题。举个例子,我要刮的另一个网页只是举个例子,我要刮的另一个网页是
非常感谢,Best,Iván 查看全部
抓取动态网页(代码中添加其他作者的不同信息(中英对照))
我正在网上抓取不同作者在谷歌学术上的出版年数和数量,到目前为止,这是我只有一位作者的代码:我正在网上抓取不同作者在谷歌学术上的出版年数和出版数量,到目前为止这是我只有一位作者的代码:这是我到目前为止只有一位作者的代码:
from selenium import webdriver
mozilla_path = r"C:\Users\ivrav\Python38\geckodriver.exe"
driver = webdriver.Firefox()
driver.get("https://scholar.google.com/cit ... 6quot;)
driver.maximize_window()
years = [element.get_attribute("textContent") for element in driver.find_elements_by_xpath('//span[@class="gsc_g_t"]')]
citations = [element.get_attribute("textContent") for element in driver.find_elements_by_xpath('//span[@class="gsc_g_al"]')]
for year, citation in zip(years, citations):
print(year, citation)
但是,我的疑问取决于如何在同一代码中添加其他作者的不同信息。我应该使用循环吗?我应该使用循环吗?我不太确定如何解决这个问题。举个例子,我要刮的另一个网页只是举个例子,我要刮的另一个网页是
非常感谢,Best,Iván
抓取动态网页(python爬取js执行后输出的信息1.11.1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-01-24 00:18
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多时候,爬虫检索到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1. 两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
1 importdryscrape2 #使用dryscrape库动态抓取页面
3 defget_url_dynamic(url):4 session_req=dryscrape.Session()5 session_req.visit(url) #请求页面
6 response=session_req.body() #网页的文本
7 #打印(响应)
8 returnresponse9 get_text_line(get_url_dynamic(url)) # 会输出一个文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,因此也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
1 defget_url_dynamic2(url):2 driver=webdriver.Firefox() #调用本地火狐浏览器,Chrom甚至Ie也可以
3 driver.get(url) #请求一个页面,会打开一个浏览器窗口
4 html_text=driver.page_source5 driver.quit()6 #print html_text
7 returnhtml_text8 get_text_line(get_url_dynamic2(url)) #会输出一个文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2. selenium 的安装和使用
2.1 硒安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载 geckodriverckod 地址:
Mozilla/geckodriver
2. 解压后geckodriverckod存放在/usr/local/bin/: sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 硒的使用
1. 运行错误:
驱动程序= webdriver.chrome()
TypeError:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
1 内容 = driver.find_element_by_class_name('内容')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
1 个值 = 内容.文本 查看全部
抓取动态网页(python爬取js执行后输出的信息1.11.1)
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多时候,爬虫检索到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1. 两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
1 importdryscrape2 #使用dryscrape库动态抓取页面
3 defget_url_dynamic(url):4 session_req=dryscrape.Session()5 session_req.visit(url) #请求页面
6 response=session_req.body() #网页的文本
7 #打印(响应)
8 returnresponse9 get_text_line(get_url_dynamic(url)) # 会输出一个文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,因此也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
1 defget_url_dynamic2(url):2 driver=webdriver.Firefox() #调用本地火狐浏览器,Chrom甚至Ie也可以
3 driver.get(url) #请求一个页面,会打开一个浏览器窗口
4 html_text=driver.page_source5 driver.quit()6 #print html_text
7 returnhtml_text8 get_text_line(get_url_dynamic2(url)) #会输出一个文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2. selenium 的安装和使用
2.1 硒安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载 geckodriverckod 地址:
Mozilla/geckodriver
2. 解压后geckodriverckod存放在/usr/local/bin/: sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 硒的使用
1. 运行错误:
驱动程序= webdriver.chrome()
TypeError:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
1 内容 = driver.find_element_by_class_name('内容')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
1 个值 = 内容.文本
抓取动态网页(搜索引擎提升静态和动态页面哪个蜘蛛抓取的快?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-23 10:01
问题:哪种蜘蛛爬取静态和动态页面的速度更快?
答:理论上,搜索引擎蜘蛛把静态页面和动态页面一视同仁,不会优先抓取哪个页面,但是这里有个前提,就是动态页面必须被蜘蛛识别。如果动态页面有很多复杂的参数,可能会影响蜘蛛抓取。
其实搜索引擎发展到今天已经能够很好的解决爬取的问题,不管是静态页面还是动态页面都可以爬取。但是从用户体验的角度来说,最好将URL设置为静态或者伪静态,因为合理的URL可以节省用户的判断成本,也有利于网站的优化。
当然,不要走入死胡同,认为搜索引擎会歧视动态链接,这是错误的。
在判断页面质量和关键词排名方面,静态页面和动态页面没有严格的区别,都可以正常参与排名。不过这里也有一个需要注意的问题,就是页面的动态更新。无论页面的 URL 是什么形式,都必须保证页面是动态更新的。
比如文章页面通常会调用相关的文章,这个相关的文章的调用应该是动态的,文章在同一个标签下更新,其他的< @文章 页面也需要同步更新。这样做的好处是增加了页面的更新频率,有利于页面本身质量的提升。
关于页面ULR和蜘蛛爬取的问题,沐风SEO简单的说了这么多。总之,一般情况下,无论是静态页面还是动态页面,蜘蛛都会抓取。但是在设置网址的时候,一定要遵循一个原则,就是网址要尽量简单易懂,不能有复杂的符号! 查看全部
抓取动态网页(搜索引擎提升静态和动态页面哪个蜘蛛抓取的快?(图))
问题:哪种蜘蛛爬取静态和动态页面的速度更快?
答:理论上,搜索引擎蜘蛛把静态页面和动态页面一视同仁,不会优先抓取哪个页面,但是这里有个前提,就是动态页面必须被蜘蛛识别。如果动态页面有很多复杂的参数,可能会影响蜘蛛抓取。
其实搜索引擎发展到今天已经能够很好的解决爬取的问题,不管是静态页面还是动态页面都可以爬取。但是从用户体验的角度来说,最好将URL设置为静态或者伪静态,因为合理的URL可以节省用户的判断成本,也有利于网站的优化。
当然,不要走入死胡同,认为搜索引擎会歧视动态链接,这是错误的。
在判断页面质量和关键词排名方面,静态页面和动态页面没有严格的区别,都可以正常参与排名。不过这里也有一个需要注意的问题,就是页面的动态更新。无论页面的 URL 是什么形式,都必须保证页面是动态更新的。
比如文章页面通常会调用相关的文章,这个相关的文章的调用应该是动态的,文章在同一个标签下更新,其他的< @文章 页面也需要同步更新。这样做的好处是增加了页面的更新频率,有利于页面本身质量的提升。
关于页面ULR和蜘蛛爬取的问题,沐风SEO简单的说了这么多。总之,一般情况下,无论是静态页面还是动态页面,蜘蛛都会抓取。但是在设置网址的时候,一定要遵循一个原则,就是网址要尽量简单易懂,不能有复杂的符号!
抓取动态网页(一下企业网站建设之动态网页制作的“二点一线”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-21 05:19
目前市场上大部分的企业风站建设都会根据未来的需求来决定使用动态网页还是静态网页。继介绍了企业建设网站静态网页设计“三步曲”之后,瑞虎接下来为大家介绍建设企业动态网页制作的“两点一”。企业 网站。细绳”。
动态网页的概念
动态网页是目前常见的网页编程技术。这里的动态是指在页面代码不变的情况下,网页中显示的内容会随着时间、环境或数据库操作的变化而变化。动态网页是一种与静态网页相反的网页。动态网页结合了基本的html语法规范、Java、VB、VC等高级编程语言以及数据库编程来生成网页。在网站构建过程中实现对网站内容和样式的高效、动态、交互的管理。
动态网页的工作原理
动态网页主要是将静态网页与后台数据库进行交互,然后完成数据传输。常见的动态网页制作后缀格式有.asp、.jsp、.php、.perl等,还有一个标志性的符号“?” 在网址中。动态网页的工作原理是:基于数据库技术,实现用户注册、登录、管理等功能,当用户向服务器发送请求时,返回一个完整的网页给用户。
动态网页制作“两点一线”
动态网页制作的“一点一线”中的“两点”包括:动态网页制作的优缺点,“一根线”是指从服务器端到客户端的连接。
一、动态网页制作的优势
1、基于数据库,动静结合
动态网页的制作主要是基于数据库的网页,网站的整个操作都是通过代码调用数据库来展示和实现的。这种类型的网站交互性很强,可以大大提升用户体验。动态网站采用动静结合的原则,吸收静态网页的优点,必要时使用静态网页,让企业在网站的建设中形成动静结合的优化配置.
2、内容更新快,满足用户需求
动态网页制作技术的一大特点是网站内容更新快,这也是企业网站建设采用动态网页制作网站的原因。动态网页的更新和维护,一般是通过编辑修改网站的背景来实现的,比如企业建站常用的智盟背景。这将网站的构建和维护分开,如果业务无法自行完成网站的构建,可以外包。网站的维护只需要企业通过网站后台完成各种信息的发布。
3、灵活的开发技术和多功能操作
动态网页的技术支持不强。常用的基本网页技术包括 PHP(超文本预处理器)、ASP(Active Server Pages)、JSP(Java Server Pages)和 CGI(Common Gateway Interface)。网站开发者可以通过这四种强大的后台技术来编辑制作动态网页,并在此基础上实现对网站的多功能操作。用户注册、登录、管理等功能有助于实现网站的交互性,提高用户对网站的粘性。
二、动态网页创建的缺点
1、访问缓慢
因为动态网页是连接到服务器的数据库的,所以用户在访问网页时需要在发送请求后等待数据库的响应,然后再向用户反馈一个完整的网页。这时候如果访问的用户特征比较多,很容易导致访问速度变慢甚至崩溃。从用户的角度来看,对这个问题的直接反应就是网页加载太慢,没有响应,极大地影响了用户的访问心情,甚至让用户放弃访问。
2、对搜索引擎的亲和力低
动态网页有一个“?” URL 中的符号,并且响应必须在用户输入命令之后。根据搜索引擎的特点,蜘蛛只能识别和抓取现成的页面,所以搜索引擎对动态网页不会有很高的亲和力,不利于网站的收录 . 但是,绝大多数搜索引擎已经支持动态页面的爬取。
3、网络安全性低
动态网页在实现强大交互功能的同时,也给网站带来了很大的安全隐患。如果开发者和设计者在编写动态Web程序时没有充分考虑网站的安全性,网站很容易为攻击者留下后门,受到恶意攻击和黑客攻击的危害。
三、动态网页创建第一行
这里所说的第一行动态网页制作是指网页的服务器端和客户端,将动态网页结合起来形成一个完整的网站。下面瑞虎小编就为大家分析一下这两个。
服务终端
服务器端是指网络上的服务器。动态网页在服务器上运行程序时,主要使用的语言有ASP、ColdFusion、Perl、PHP、WebDNA等服务器端语言。动态网页是使用这些语言结合通用网关接口 (CGI) 形成的,但 JSP 除外,其网络请求被分派到共享虚拟机。动态网站的服务器端经常处于缓存状态,这样会延长动态网页的加载时间。
客户
客户端是指用户在动态网页上发出请求,服务器将响应特定网页中的鼠标或键盘操作,或指定命令。在这种情况下,动态网页会根据客户端的行为在用户本地计算机浏览器中生成相应的内容,获取用户访问的行为结果。 查看全部
抓取动态网页(一下企业网站建设之动态网页制作的“二点一线”)
目前市场上大部分的企业风站建设都会根据未来的需求来决定使用动态网页还是静态网页。继介绍了企业建设网站静态网页设计“三步曲”之后,瑞虎接下来为大家介绍建设企业动态网页制作的“两点一”。企业 网站。细绳”。
动态网页的概念
动态网页是目前常见的网页编程技术。这里的动态是指在页面代码不变的情况下,网页中显示的内容会随着时间、环境或数据库操作的变化而变化。动态网页是一种与静态网页相反的网页。动态网页结合了基本的html语法规范、Java、VB、VC等高级编程语言以及数据库编程来生成网页。在网站构建过程中实现对网站内容和样式的高效、动态、交互的管理。
动态网页的工作原理
动态网页主要是将静态网页与后台数据库进行交互,然后完成数据传输。常见的动态网页制作后缀格式有.asp、.jsp、.php、.perl等,还有一个标志性的符号“?” 在网址中。动态网页的工作原理是:基于数据库技术,实现用户注册、登录、管理等功能,当用户向服务器发送请求时,返回一个完整的网页给用户。
动态网页制作“两点一线”
动态网页制作的“一点一线”中的“两点”包括:动态网页制作的优缺点,“一根线”是指从服务器端到客户端的连接。
一、动态网页制作的优势
1、基于数据库,动静结合
动态网页的制作主要是基于数据库的网页,网站的整个操作都是通过代码调用数据库来展示和实现的。这种类型的网站交互性很强,可以大大提升用户体验。动态网站采用动静结合的原则,吸收静态网页的优点,必要时使用静态网页,让企业在网站的建设中形成动静结合的优化配置.
2、内容更新快,满足用户需求
动态网页制作技术的一大特点是网站内容更新快,这也是企业网站建设采用动态网页制作网站的原因。动态网页的更新和维护,一般是通过编辑修改网站的背景来实现的,比如企业建站常用的智盟背景。这将网站的构建和维护分开,如果业务无法自行完成网站的构建,可以外包。网站的维护只需要企业通过网站后台完成各种信息的发布。
3、灵活的开发技术和多功能操作
动态网页的技术支持不强。常用的基本网页技术包括 PHP(超文本预处理器)、ASP(Active Server Pages)、JSP(Java Server Pages)和 CGI(Common Gateway Interface)。网站开发者可以通过这四种强大的后台技术来编辑制作动态网页,并在此基础上实现对网站的多功能操作。用户注册、登录、管理等功能有助于实现网站的交互性,提高用户对网站的粘性。
二、动态网页创建的缺点
1、访问缓慢
因为动态网页是连接到服务器的数据库的,所以用户在访问网页时需要在发送请求后等待数据库的响应,然后再向用户反馈一个完整的网页。这时候如果访问的用户特征比较多,很容易导致访问速度变慢甚至崩溃。从用户的角度来看,对这个问题的直接反应就是网页加载太慢,没有响应,极大地影响了用户的访问心情,甚至让用户放弃访问。
2、对搜索引擎的亲和力低
动态网页有一个“?” URL 中的符号,并且响应必须在用户输入命令之后。根据搜索引擎的特点,蜘蛛只能识别和抓取现成的页面,所以搜索引擎对动态网页不会有很高的亲和力,不利于网站的收录 . 但是,绝大多数搜索引擎已经支持动态页面的爬取。
3、网络安全性低
动态网页在实现强大交互功能的同时,也给网站带来了很大的安全隐患。如果开发者和设计者在编写动态Web程序时没有充分考虑网站的安全性,网站很容易为攻击者留下后门,受到恶意攻击和黑客攻击的危害。
三、动态网页创建第一行
这里所说的第一行动态网页制作是指网页的服务器端和客户端,将动态网页结合起来形成一个完整的网站。下面瑞虎小编就为大家分析一下这两个。
服务终端
服务器端是指网络上的服务器。动态网页在服务器上运行程序时,主要使用的语言有ASP、ColdFusion、Perl、PHP、WebDNA等服务器端语言。动态网页是使用这些语言结合通用网关接口 (CGI) 形成的,但 JSP 除外,其网络请求被分派到共享虚拟机。动态网站的服务器端经常处于缓存状态,这样会延长动态网页的加载时间。
客户
客户端是指用户在动态网页上发出请求,服务器将响应特定网页中的鼠标或键盘操作,或指定命令。在这种情况下,动态网页会根据客户端的行为在用户本地计算机浏览器中生成相应的内容,获取用户访问的行为结果。
抓取动态网页(一个完整的网络爬虫基础框架如下图所示:整个架构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-21 03:09
一个完整的网络爬虫基础框架如下图所示:
整个架构由以下过程组成:
1)需求方提供需要爬取的种子URL列表,根据提供的URL列表和对应的优先级(先到先得)建立待爬取的URL队列;
2)网页抓取是按照要抓取的URL队列的顺序进行的;
3)将获取到的网页内容和信息下载到本地网络库,并创建爬取的URL列表(用于去重和判断爬取过程);
4)将爬取的网页放入待爬取的URL队列中,进行循环爬取操作;
2. 网络爬虫爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取URL队列中的URL排列顺序也是一个很重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面的问题。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
1)深度优先遍历策略
深度优先遍历策略很好理解,和我们有向图中的深度优先遍历一样,因为网络本身就是一个图模型。深度优先遍历的思路是从一个起始网页开始爬取,然后根据链接一个一个的爬取,直到不能再深度爬取,然后返回上一页继续关注链接。
有向图中的深度优先搜索示例如下所示:
上图左图是有向图的示意图,右图是深度优先遍历的搜索过程示意图。深度优先遍历的结果是:
2)广度优先搜索策略
广度优先搜索和深度优先搜索的工作方式完全相反。这个想法是将在新下载的网页中找到的链接直接插入到要抓取的 URL 队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。
上图是上例有向图的广度优先搜索流程图,其遍历结果为:
v1→v2→v3→v4→v5→v6→v7→v8
从树的结构来看,图的广度优先遍历就是树的层次遍历。
3)反向链接搜索策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
4)大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
5)其他搜索策略
一些比较常用的爬虫搜索侧率还包括Partial PageRank搜索策略(根据PageRank分数确定下一个抓取的URL),OPIC搜索策略(也是一种重要性)。最后必须指出的一点是,我们可以根据自己的需要来设置网页的抓取间隔,这样可以保证我们一些基本的大网站或者活跃的网站内容不会被漏掉。
3. 网络爬虫更新策略
互联网实时变化并且非常动态。网页更新策略主要决定何时更新之前已经下载的页面。常见的更新策略有以下三种:
1)历史参考政策
顾名思义,它根据页面过去的历史更新数据来预测未来页面何时会发生变化。通常,预测是通过泊松过程建模来进行的。
2)用户体验策略
尽管搜索引擎可以为某个查询返回大量结果,但用户通常只关注结果的前几页。因此,爬虫系统可以优先更新那些实际在查询结果前几页的页面,然后再更新后面的那些页面。这个更新策略也需要用到历史信息。UX 策略保留网页的多个历史版本,并根据每个过去内容更改对搜索质量的影响得出一个平均值,并以此值作为决定何时重新抓取的基础。
3)聚类抽样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页完全没有历史信息,就无法确定更新策略。
该策略认为网页具有许多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某一类别网页的更新频率,只需对该类别的网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如下:
4. 分布式抓取系统结构
一般来说,爬虫系统需要处理整个互联网上数以亿计的网页。单个爬虫不可能完成这样的任务。通常需要多个爬虫程序一起处理它们。一般来说,爬虫系统往往是分布式的三层结构。如图所示:
最底层是分布在不同地理位置的数据中心。每个数据中心有多个爬虫服务器,每个爬虫服务器可能部署多套爬虫程序。这样就构成了一个基本的分布式爬虫系统。
对于数据中心中的不同服务器,有几种方法可以协同工作:
1)主从
主从基本结构如图:
对于主从类型,有一个专门的主服务器来维护要爬取的URL队列,负责每次将URL分发给不同的从服务器,从服务器负责实际的网页下载工作。Master服务器除了维护要爬取的URL队列和分发URL外,还负责调解每个Slave服务器的负载。为了避免一些从服务器过于空闲或过度工作。
在这种模式下,Master往往会成为系统的瓶颈。
2)点对点
等价的基本结构如图所示:
在这种模式下,所有爬虫服务器之间的分工没有区别。每个爬取服务器可以从待爬取的URL队列中获取URL,然后计算该URL主域名的哈希值H,进而计算H mod m(其中m为服务器数量,上图为例如,m 对于 3),计算出来的数字是处理 URL 的主机号。
例子:假设对于URL,计算器hash值H=8,m=3,那么H mod m=2,那么编号为2的服务器会抓取该链接。假设此时服务器 0 获取了 URL,它会将 URL 传输到服务器 2,服务器 2 将获取它。
这种模式有一个问题,当一个服务器死掉或添加一个新服务器时,所有 URL 的哈希余数的结果都会改变。也就是说,这种方法不能很好地扩展。针对这种情况,提出了另一种改进方案。这种改进的方案是一致的散列以确定服务器划分。其基本结构如图所示:
一致散列对 URL 的主域名进行散列,并将其映射到 0-232 范围内的数字。这个范围平均分配给m台服务器,根据主URL域名的hash运算值的范围来确定要爬取哪个服务器。
如果某台服务器出现问题,本应负责该服务器的网页将由下一个服务器顺时针获取。在这种情况下,即使一台服务器出现问题,也不会影响其他工作。
5. 参考资料
[1] wawlian:网络爬虫基本原理(一)(二);
[2] guisu:搜索引擎——网络爬虫;
[3]《这就是搜索引擎:核心技术详解》。 查看全部
抓取动态网页(一个完整的网络爬虫基础框架如下图所示:整个架构)
一个完整的网络爬虫基础框架如下图所示:
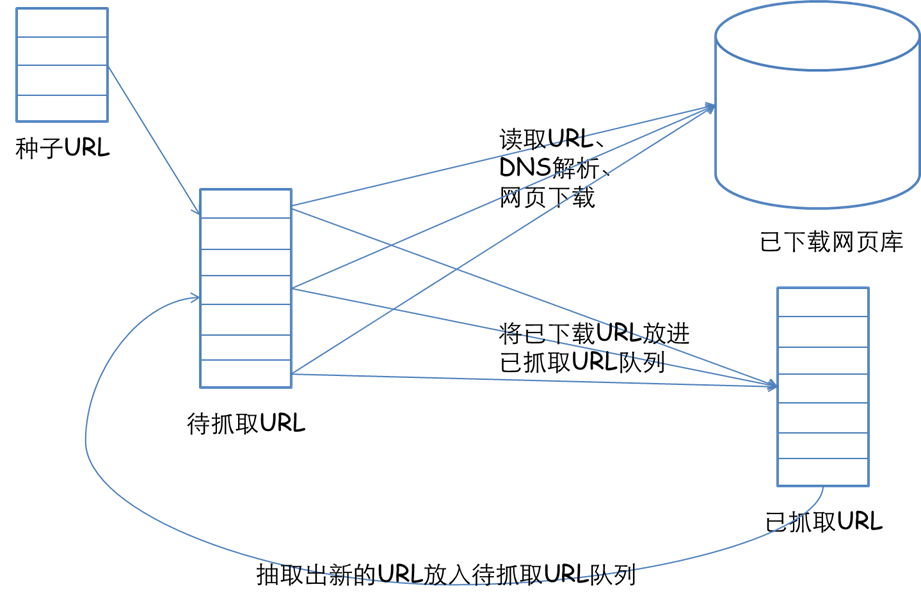
整个架构由以下过程组成:
1)需求方提供需要爬取的种子URL列表,根据提供的URL列表和对应的优先级(先到先得)建立待爬取的URL队列;
2)网页抓取是按照要抓取的URL队列的顺序进行的;
3)将获取到的网页内容和信息下载到本地网络库,并创建爬取的URL列表(用于去重和判断爬取过程);
4)将爬取的网页放入待爬取的URL队列中,进行循环爬取操作;
2. 网络爬虫爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取URL队列中的URL排列顺序也是一个很重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面的问题。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
1)深度优先遍历策略
深度优先遍历策略很好理解,和我们有向图中的深度优先遍历一样,因为网络本身就是一个图模型。深度优先遍历的思路是从一个起始网页开始爬取,然后根据链接一个一个的爬取,直到不能再深度爬取,然后返回上一页继续关注链接。
有向图中的深度优先搜索示例如下所示:
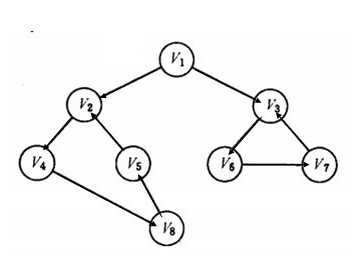

上图左图是有向图的示意图,右图是深度优先遍历的搜索过程示意图。深度优先遍历的结果是:

2)广度优先搜索策略
广度优先搜索和深度优先搜索的工作方式完全相反。这个想法是将在新下载的网页中找到的链接直接插入到要抓取的 URL 队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。
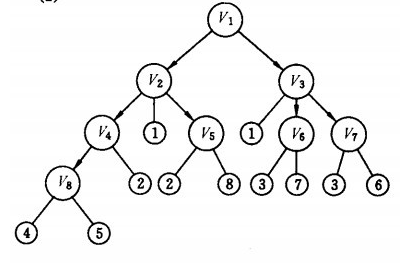
上图是上例有向图的广度优先搜索流程图,其遍历结果为:
v1→v2→v3→v4→v5→v6→v7→v8
从树的结构来看,图的广度优先遍历就是树的层次遍历。
3)反向链接搜索策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
4)大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
5)其他搜索策略
一些比较常用的爬虫搜索侧率还包括Partial PageRank搜索策略(根据PageRank分数确定下一个抓取的URL),OPIC搜索策略(也是一种重要性)。最后必须指出的一点是,我们可以根据自己的需要来设置网页的抓取间隔,这样可以保证我们一些基本的大网站或者活跃的网站内容不会被漏掉。
3. 网络爬虫更新策略
互联网实时变化并且非常动态。网页更新策略主要决定何时更新之前已经下载的页面。常见的更新策略有以下三种:
1)历史参考政策
顾名思义,它根据页面过去的历史更新数据来预测未来页面何时会发生变化。通常,预测是通过泊松过程建模来进行的。
2)用户体验策略
尽管搜索引擎可以为某个查询返回大量结果,但用户通常只关注结果的前几页。因此,爬虫系统可以优先更新那些实际在查询结果前几页的页面,然后再更新后面的那些页面。这个更新策略也需要用到历史信息。UX 策略保留网页的多个历史版本,并根据每个过去内容更改对搜索质量的影响得出一个平均值,并以此值作为决定何时重新抓取的基础。
3)聚类抽样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页完全没有历史信息,就无法确定更新策略。
该策略认为网页具有许多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某一类别网页的更新频率,只需对该类别的网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如下:
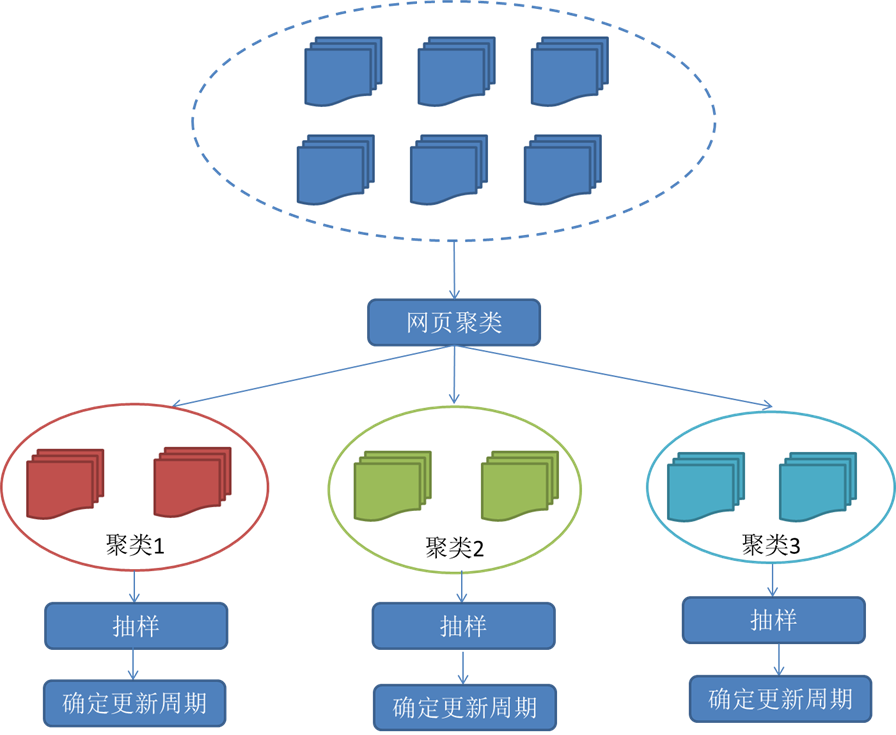
4. 分布式抓取系统结构
一般来说,爬虫系统需要处理整个互联网上数以亿计的网页。单个爬虫不可能完成这样的任务。通常需要多个爬虫程序一起处理它们。一般来说,爬虫系统往往是分布式的三层结构。如图所示:
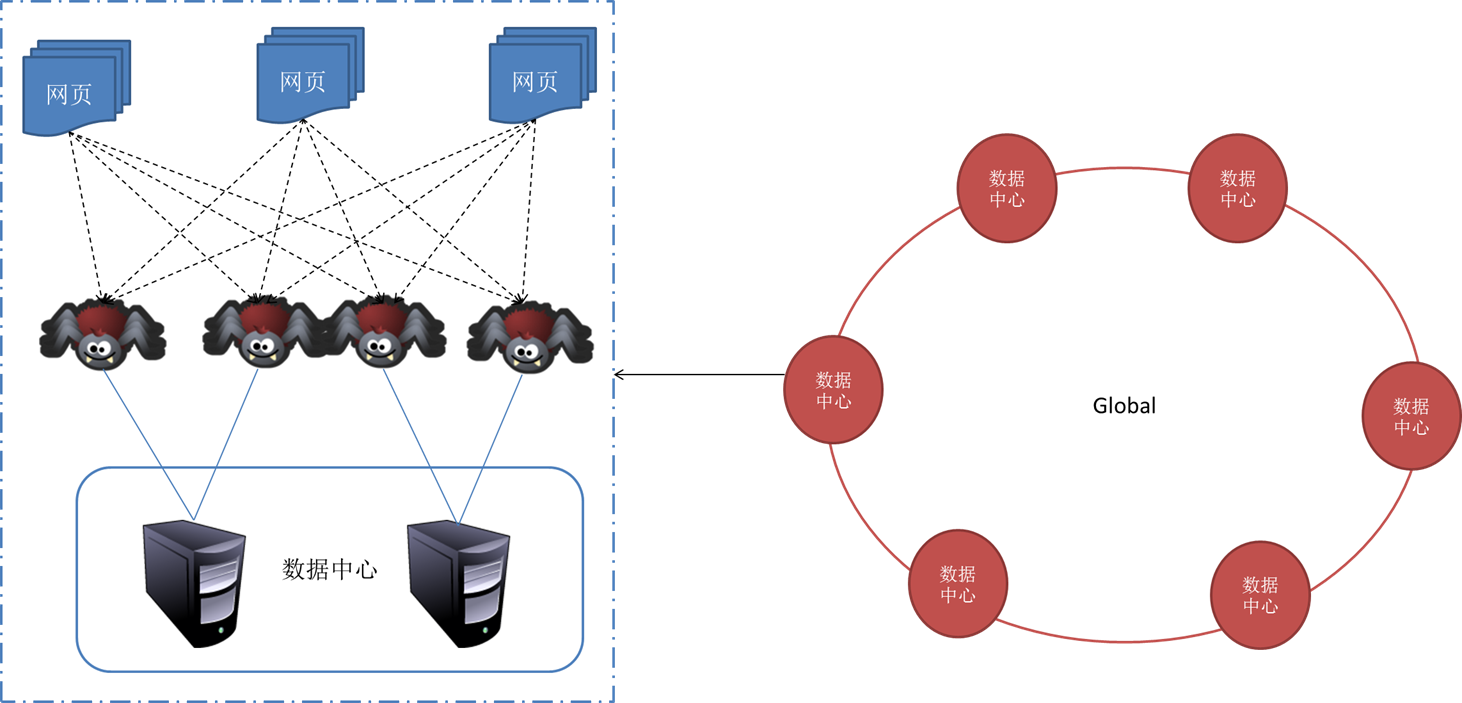
最底层是分布在不同地理位置的数据中心。每个数据中心有多个爬虫服务器,每个爬虫服务器可能部署多套爬虫程序。这样就构成了一个基本的分布式爬虫系统。
对于数据中心中的不同服务器,有几种方法可以协同工作:
1)主从
主从基本结构如图:
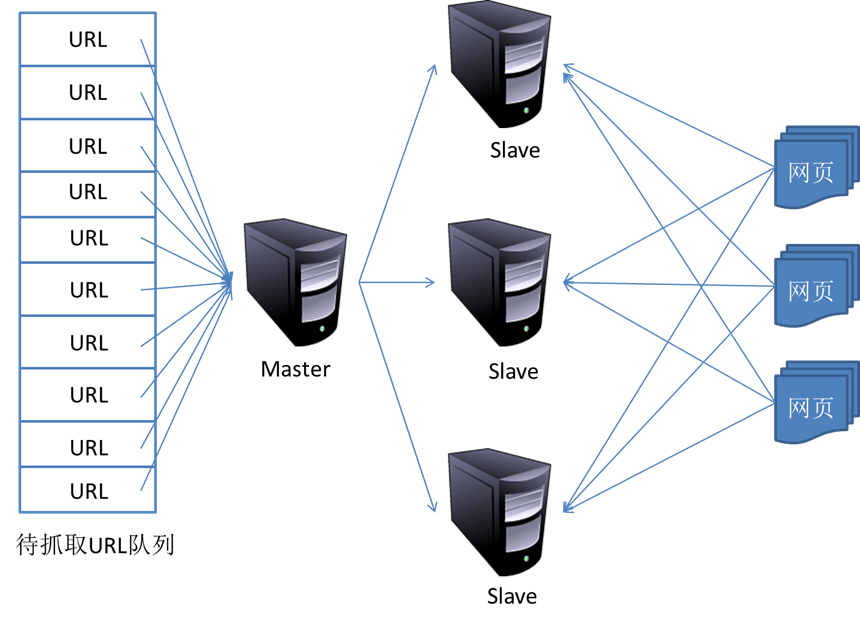
对于主从类型,有一个专门的主服务器来维护要爬取的URL队列,负责每次将URL分发给不同的从服务器,从服务器负责实际的网页下载工作。Master服务器除了维护要爬取的URL队列和分发URL外,还负责调解每个Slave服务器的负载。为了避免一些从服务器过于空闲或过度工作。
在这种模式下,Master往往会成为系统的瓶颈。
2)点对点
等价的基本结构如图所示:
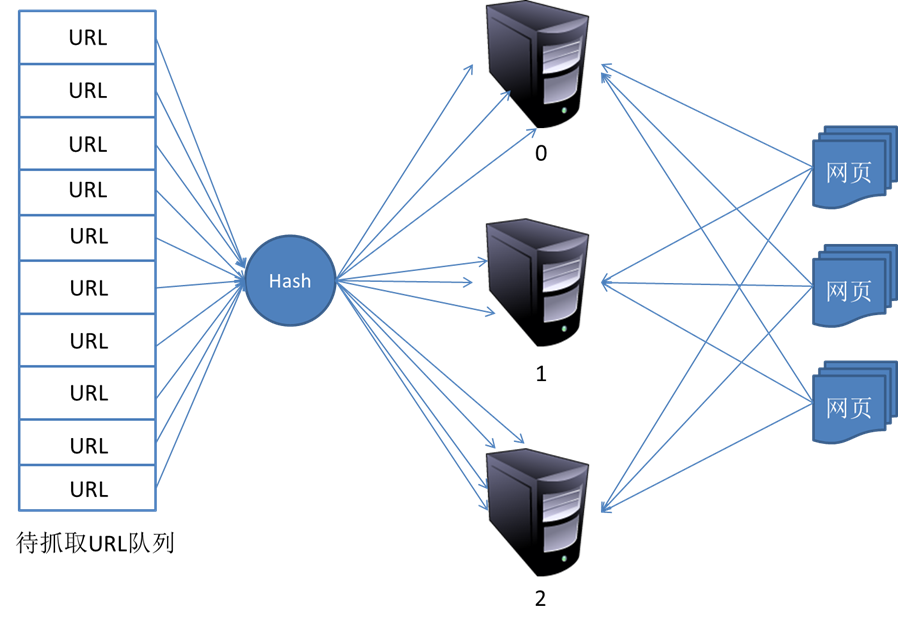
在这种模式下,所有爬虫服务器之间的分工没有区别。每个爬取服务器可以从待爬取的URL队列中获取URL,然后计算该URL主域名的哈希值H,进而计算H mod m(其中m为服务器数量,上图为例如,m 对于 3),计算出来的数字是处理 URL 的主机号。
例子:假设对于URL,计算器hash值H=8,m=3,那么H mod m=2,那么编号为2的服务器会抓取该链接。假设此时服务器 0 获取了 URL,它会将 URL 传输到服务器 2,服务器 2 将获取它。
这种模式有一个问题,当一个服务器死掉或添加一个新服务器时,所有 URL 的哈希余数的结果都会改变。也就是说,这种方法不能很好地扩展。针对这种情况,提出了另一种改进方案。这种改进的方案是一致的散列以确定服务器划分。其基本结构如图所示:
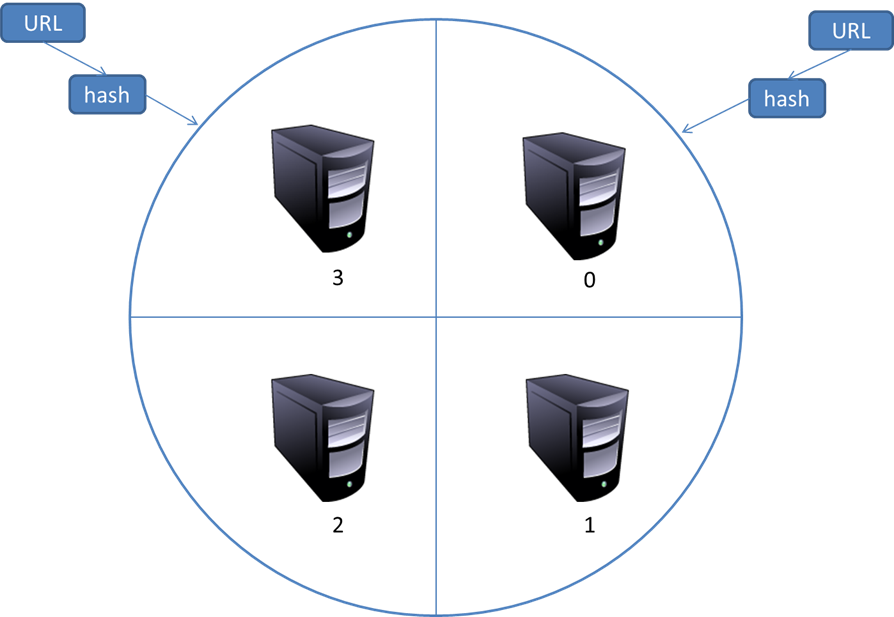
一致散列对 URL 的主域名进行散列,并将其映射到 0-232 范围内的数字。这个范围平均分配给m台服务器,根据主URL域名的hash运算值的范围来确定要爬取哪个服务器。
如果某台服务器出现问题,本应负责该服务器的网页将由下一个服务器顺时针获取。在这种情况下,即使一台服务器出现问题,也不会影响其他工作。
5. 参考资料
[1] wawlian:网络爬虫基本原理(一)(二);
[2] guisu:搜索引擎——网络爬虫;
[3]《这就是搜索引擎:核心技术详解》。
抓取动态网页( 如何用PowerBI批量爬取网页数据?PowerBI猫眼数据告诉你)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-01-20 04:11
如何用PowerBI批量爬取网页数据?PowerBI猫眼数据告诉你)
关于Power BI从网页中提取数据的技术,部分技术在之前的文章中已经分享过,大家可以看看这些内容:
如何使用PowerBI批量抓取网页数据?
Power BI 捕捉猫眼数据告诉你哪部电影更受欢迎?
提取网页上可见的规范化数据很容易,但是网页中可以再次点击的链接呢?
其实也很简单。本文以豆瓣阅读TOP250为例:
在这个网页中,不仅显示了书名、评分、作者等信息的列表,还可以点击封面或书名进入该书的详情页面。让我们看看如何提取这个链接。
在 PowerBI Desktop 中,选择 Get data with web,你会看到这个导航器,
在表格视图中看不到可以提取的数据,没关系,可以点击左下角的“使用示例添加表格”,然后就可以看到这个网页了,
在这里,只要你手动输入前两条信息,PowerBI就会确定你要提取的字段,并自动在网页中添加剩余的相似数据,比如输入前两本书的标题,
同理,还可以提取收视率、作者、出版商等信息。
URL 在此页面上不可见。您不能直接输入前两个 URL。在这种情况下,没有例子。需要手动一一复制粘贴吗?
当然不是,这里虽然看不到,但是可以打开链接,不知道网址是什么吗?
依次打开前两个链接,将 URL 复制并粘贴到示例的前两行中,
这样就得到了链接,是不是很简单。
上述步骤仅提取一页上的 25 条信息。也可以按照前面文章中介绍的方法,使用Power Query自定义函数批量提取top 250图书信息。
简单处理后,即可在PowerBI Desktop中使用。记得在点击链接前将链接的数据类型设置为“Web URL”。
PowerBI获取网页数据的技巧仅供学习交流,不得用于不正当目的。
更令人兴奋的:
学习PowerBI请采集:DAX写作格式指南
Power BI应用技巧:简单两步即可实现红绿灯效果 查看全部
抓取动态网页(
如何用PowerBI批量爬取网页数据?PowerBI猫眼数据告诉你)
关于Power BI从网页中提取数据的技术,部分技术在之前的文章中已经分享过,大家可以看看这些内容:
如何使用PowerBI批量抓取网页数据?
Power BI 捕捉猫眼数据告诉你哪部电影更受欢迎?
提取网页上可见的规范化数据很容易,但是网页中可以再次点击的链接呢?
其实也很简单。本文以豆瓣阅读TOP250为例:
在这个网页中,不仅显示了书名、评分、作者等信息的列表,还可以点击封面或书名进入该书的详情页面。让我们看看如何提取这个链接。
在 PowerBI Desktop 中,选择 Get data with web,你会看到这个导航器,
在表格视图中看不到可以提取的数据,没关系,可以点击左下角的“使用示例添加表格”,然后就可以看到这个网页了,
在这里,只要你手动输入前两条信息,PowerBI就会确定你要提取的字段,并自动在网页中添加剩余的相似数据,比如输入前两本书的标题,
同理,还可以提取收视率、作者、出版商等信息。
URL 在此页面上不可见。您不能直接输入前两个 URL。在这种情况下,没有例子。需要手动一一复制粘贴吗?
当然不是,这里虽然看不到,但是可以打开链接,不知道网址是什么吗?
依次打开前两个链接,将 URL 复制并粘贴到示例的前两行中,
这样就得到了链接,是不是很简单。
上述步骤仅提取一页上的 25 条信息。也可以按照前面文章中介绍的方法,使用Power Query自定义函数批量提取top 250图书信息。
简单处理后,即可在PowerBI Desktop中使用。记得在点击链接前将链接的数据类型设置为“Web URL”。
PowerBI获取网页数据的技巧仅供学习交流,不得用于不正当目的。
更令人兴奋的:
学习PowerBI请采集:DAX写作格式指南
Power BI应用技巧:简单两步即可实现红绿灯效果
抓取动态网页(【每日一题】今日头条街拍图片(2) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 302 次浏览 • 2022-01-20 04:10
)
大家好,本文文章主要是Python抓取今日头条街的图片数据。如果你有兴趣,请过来看看。如果对你有帮助,记得采集。
(1)今天在今日头条街拍照
(2)解析今日头条街拍结构
keyword: 街拍
pd: atlas
dvpf: pc
aid: 4916
page_num: 1
search_json: {"from_search_id":"20220104115420010212192151532E8188","origin_keyword":"街拍","image_keyword":"街拍"}
rawJSON: 1
search_id: 202201041159040101501341671A4749C4
可以找到规律,page_num从1开始累加,其他参数不变
(3)根据不同的功能编写不同的方法组织代码
获取网页json格式数据
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search% ... on%3D{%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
从json格式数据中提取街道图片
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
用 md5 代码命名街道照片并保存图像
实现方法 save_image() 来保存图像,其中 item 是前面的 get_images() 方法返回的字典。该方法首先根据item的标题创建一个文件夹,然后请求图片链接,获取图片的二进制数据,以二进制形式写入文件。图片名称可以使用其内容的MD5值,可以去除重复。相关代码如下:
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
main() 调用其他函数
(4)抢20page今日头条街拍资料
这里定义了分页的起始页和结束页,分别是 GROUP_START 和 GROUP_END。也使用了多线程线程池,调用它的map()方法实现多线程下载。
import requests
from urllib.parse import urlencode
from hashlib import md5
from multiprocessing.pool import Pool
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search% ... on%3D{%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
查看全部
抓取动态网页(【每日一题】今日头条街拍图片(2)
)
大家好,本文文章主要是Python抓取今日头条街的图片数据。如果你有兴趣,请过来看看。如果对你有帮助,记得采集。
(1)今天在今日头条街拍照
(2)解析今日头条街拍结构
keyword: 街拍
pd: atlas
dvpf: pc
aid: 4916
page_num: 1
search_json: {"from_search_id":"20220104115420010212192151532E8188","origin_keyword":"街拍","image_keyword":"街拍"}
rawJSON: 1
search_id: 202201041159040101501341671A4749C4
可以找到规律,page_num从1开始累加,其他参数不变
(3)根据不同的功能编写不同的方法组织代码
获取网页json格式数据
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search% ... on%3D{%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
从json格式数据中提取街道图片
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
用 md5 代码命名街道照片并保存图像
实现方法 save_image() 来保存图像,其中 item 是前面的 get_images() 方法返回的字典。该方法首先根据item的标题创建一个文件夹,然后请求图片链接,获取图片的二进制数据,以二进制形式写入文件。图片名称可以使用其内容的MD5值,可以去除重复。相关代码如下:
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
main() 调用其他函数
(4)抢20page今日头条街拍资料
这里定义了分页的起始页和结束页,分别是 GROUP_START 和 GROUP_END。也使用了多线程线程池,调用它的map()方法实现多线程下载。
import requests
from urllib.parse import urlencode
from hashlib import md5
from multiprocessing.pool import Pool
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search% ... on%3D{%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
抓取动态网页(接下来如何模拟在浏览器页面中滑动鼠标获得多屏搜索结果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-02-07 08:13
让我们现在开始谈正事。第一步是在docker中连接Selenium服务器:
1library(RSelenium) # 激活包remDr "localhost" , port = 4445L , browserName = "chrome") # 设置连接参数remDr$open() # 开始连接
2
第二步,打开百度搜索首页,输入搜索关键词,点击搜索:
1remDr$navigate("https://www.baidu.com") # 打开remDr$screenshot(display = TRUE) # 截屏看一下首页xpath '//*[@id="kw"]' # 根据上面定位在界面中找到文字输入框webElem "xpath", value = xpath) # 在搜索框里输入搜索关键词‘R Cran’,然后点击回车键webElem$sendKeysToElement(list("R Cran", key = "enter")) # # 再次截屏显示搜索结果remDr$screenshot(display = TRUE)
2
这是我的两张截图的结果:
我们知道百度默认一屏显示10个搜索结果。在接下来的第三步中,我们将第一屏的 10 个结果删减:
1# 调用静态网页抓取常用包rvestlibrary(rvest)# 获取网页背后的html源代码webpage # 利用节点ID挑出10项搜索结果的内容标题result_html # 下面两行利用xpath挑出10项搜索结果的内容标题# xpath # result_html # 挑出html代码中10个标题内容result_name head(result_name,10)# 找出10个标题对应的超级链接result_link # 存成数据框result_df = data.frame(result_name=result_name, result_link=result_link)
2
10个搜索结果出来了,如果我们想模拟一个浏览器点击一个搜索结果怎么办?例如,第一个结果“综合 R 档案网络”。让我们开始吧:
1# 直接在搜索结果界面中定位10项搜索结果标题webElems 'css selector', # 把结果标题变成文本单独拎出来resHeaders function(x){x$getElementText()}))resHeaders# 准备点击第一个搜索结果webElem "The Comprehensive R Archive Network")]]# 模拟浏览器点击第一个结果超级链接,并在新窗口中打开webElem$clickElement()webElem$sendKeysToElement(list(key = "control", "w"))# 此时浏览器有两个窗口,下面几行进行窗口切换(窗口ID会动态变化)remDr$getWindowHandles()remDr$getCurrentWindowHandle()remDr$switchToWindow("CDwindow-2BA4D55F9BABCA20D3DFE2FECBA3D85A")remDr$getCurrentWindowHandle()# 获取新窗口的网址和标题,并截屏remDr$getCurrentUrl()remDr$getTitle()remDr$screenshot(display = TRUE)
2
第一个链接打开后的截图结果如下:
以上是使用RSelenium动态爬取百度搜索结果。接下来,我想展示如何在浏览器页面中模拟滑动鼠标,以获得多屏显示的所有内容。毕竟滑动鼠标后才能看到所有的网页内容,然后再抓取内容。这里以河北省的一家三级医院为例。
第一步是打开链接:
1remDr$navigate("https://m.yyk.99.com.cn/sanjia/hebei/")remDr$screenshot(display = TRUE)
2
如果不出意外,这次我们能够从 20 家医院获取信息。
1# 获取网页背后的html源代码webpage $getPageSource()[[# 找出医院名字对应的节点名称hospital_name_html 'h2')# 将医院名字从html转换为文本hospital_name # 调用stringr包把医院名字前的空格等多余符号去掉library(stringr)hospital_name "\r\n",# 看看前10家医院的名字head(hospital_name,10)# 看看总共有多少家医院length(hospital_name) # 结果为20
2
其实,在鼠标滑动几次之后,我们发现这个页面一共收录了75家医院的信息。第一次抓取只能拿到前20个,因为医院信息需要先滑动鼠标。
接下来,我们在R中运行Java代码,实现鼠标在当前网页上滑动的效果。此外,我们不想一次又一次地滑动,而是一次滑动到页面底部。
1# window.scrollTo是Java的函数,括号里跟着x和y的屏幕位置数字。比如第一个0表示屏幕最左端;# document.body.scrollHeight表示屏幕上鼠标一次滑动的最大高度,即当面页面的最底部。# 那么,下面的代码显示我们要重复地滑到页面的最底端,每次滑动中间停顿3秒,好让网页内容得以显示。# 最后,滑到不能再滑动的时候,我们就停住了。比如,第一个0表示屏幕最左端,last_height = 0 #repeat { remDr$executeScript("window.scrollTo(0,document.body.scrollHeight);") Sys.sleep(3) #delay by 3sec to give chance to load. # Updated if statement which breaks if we can't scroll further new_height = remDr$executeScript("return document.body.scrollHeight") if(unlist(last_height) == unlist(new_height)) { break } else { last_height = new_height }}
2
这样显示完这个网页的所有内容后,我们就可以按照静态网页爬取75家医院的所有数据了:
1webpage $getPageSource()[[hospital_name_html 'h2')hospital_name library(stringr)hospital_name "\r\n",head(hospital_name,10)length(hospital_name) # 结果为75
2
到目前为止,我们已经解决了动态网页抓取的两个主要问题:一是抓取搜索引擎生成的搜索结果界面的相关内容;另一种是爬取多屏显示的动态网页的相关内容。当然,这两个问题几乎没有涵盖许多其他动态网页抓取的案例。比如后者还包括点击动态网页中的方向箭头(显示其他隐藏的内容)、从同一个网页的不同栏目(框架界面)抓取不同的内容等等。
在我的探索过程中,我也发现虽然可以爬取百度搜索结果,但谷歌结果却很难实现。一位知情人士告诉我,虽然你电脑上的浏览器可以用VPN打开google,但Selenium没有VPN可以打开google,这是真的。所以,我找到了很多关于如何通过谷歌搜索使用RSelenium抓取谷歌搜索结果的方法,我想复制它,但发现同样的方法对我不起作用。
就是这样。 查看全部
抓取动态网页(接下来如何模拟在浏览器页面中滑动鼠标获得多屏搜索结果)
让我们现在开始谈正事。第一步是在docker中连接Selenium服务器:
1library(RSelenium) # 激活包remDr "localhost" , port = 4445L , browserName = "chrome") # 设置连接参数remDr$open() # 开始连接
2
第二步,打开百度搜索首页,输入搜索关键词,点击搜索:
1remDr$navigate("https://www.baidu.com";) # 打开remDr$screenshot(display = TRUE) # 截屏看一下首页xpath '//*[@id="kw"]' # 根据上面定位在界面中找到文字输入框webElem "xpath", value = xpath) # 在搜索框里输入搜索关键词‘R Cran’,然后点击回车键webElem$sendKeysToElement(list("R Cran", key = "enter")) # # 再次截屏显示搜索结果remDr$screenshot(display = TRUE)
2
这是我的两张截图的结果:
我们知道百度默认一屏显示10个搜索结果。在接下来的第三步中,我们将第一屏的 10 个结果删减:
1# 调用静态网页抓取常用包rvestlibrary(rvest)# 获取网页背后的html源代码webpage # 利用节点ID挑出10项搜索结果的内容标题result_html # 下面两行利用xpath挑出10项搜索结果的内容标题# xpath # result_html # 挑出html代码中10个标题内容result_name head(result_name,10)# 找出10个标题对应的超级链接result_link # 存成数据框result_df = data.frame(result_name=result_name, result_link=result_link)
2
10个搜索结果出来了,如果我们想模拟一个浏览器点击一个搜索结果怎么办?例如,第一个结果“综合 R 档案网络”。让我们开始吧:
1# 直接在搜索结果界面中定位10项搜索结果标题webElems 'css selector', # 把结果标题变成文本单独拎出来resHeaders function(x){x$getElementText()}))resHeaders# 准备点击第一个搜索结果webElem "The Comprehensive R Archive Network")]]# 模拟浏览器点击第一个结果超级链接,并在新窗口中打开webElem$clickElement()webElem$sendKeysToElement(list(key = "control", "w"))# 此时浏览器有两个窗口,下面几行进行窗口切换(窗口ID会动态变化)remDr$getWindowHandles()remDr$getCurrentWindowHandle()remDr$switchToWindow("CDwindow-2BA4D55F9BABCA20D3DFE2FECBA3D85A")remDr$getCurrentWindowHandle()# 获取新窗口的网址和标题,并截屏remDr$getCurrentUrl()remDr$getTitle()remDr$screenshot(display = TRUE)
2
第一个链接打开后的截图结果如下:
以上是使用RSelenium动态爬取百度搜索结果。接下来,我想展示如何在浏览器页面中模拟滑动鼠标,以获得多屏显示的所有内容。毕竟滑动鼠标后才能看到所有的网页内容,然后再抓取内容。这里以河北省的一家三级医院为例。
第一步是打开链接:
1remDr$navigate("https://m.yyk.99.com.cn/sanjia/hebei/";)remDr$screenshot(display = TRUE)
2
如果不出意外,这次我们能够从 20 家医院获取信息。
1# 获取网页背后的html源代码webpage $getPageSource()[[# 找出医院名字对应的节点名称hospital_name_html 'h2')# 将医院名字从html转换为文本hospital_name # 调用stringr包把医院名字前的空格等多余符号去掉library(stringr)hospital_name "\r\n",# 看看前10家医院的名字head(hospital_name,10)# 看看总共有多少家医院length(hospital_name) # 结果为20
2
其实,在鼠标滑动几次之后,我们发现这个页面一共收录了75家医院的信息。第一次抓取只能拿到前20个,因为医院信息需要先滑动鼠标。
接下来,我们在R中运行Java代码,实现鼠标在当前网页上滑动的效果。此外,我们不想一次又一次地滑动,而是一次滑动到页面底部。
1# window.scrollTo是Java的函数,括号里跟着x和y的屏幕位置数字。比如第一个0表示屏幕最左端;# document.body.scrollHeight表示屏幕上鼠标一次滑动的最大高度,即当面页面的最底部。# 那么,下面的代码显示我们要重复地滑到页面的最底端,每次滑动中间停顿3秒,好让网页内容得以显示。# 最后,滑到不能再滑动的时候,我们就停住了。比如,第一个0表示屏幕最左端,last_height = 0 #repeat { remDr$executeScript("window.scrollTo(0,document.body.scrollHeight);") Sys.sleep(3) #delay by 3sec to give chance to load. # Updated if statement which breaks if we can't scroll further new_height = remDr$executeScript("return document.body.scrollHeight") if(unlist(last_height) == unlist(new_height)) { break } else { last_height = new_height }}
2
这样显示完这个网页的所有内容后,我们就可以按照静态网页爬取75家医院的所有数据了:
1webpage $getPageSource()[[hospital_name_html 'h2')hospital_name library(stringr)hospital_name "\r\n",head(hospital_name,10)length(hospital_name) # 结果为75
2
到目前为止,我们已经解决了动态网页抓取的两个主要问题:一是抓取搜索引擎生成的搜索结果界面的相关内容;另一种是爬取多屏显示的动态网页的相关内容。当然,这两个问题几乎没有涵盖许多其他动态网页抓取的案例。比如后者还包括点击动态网页中的方向箭头(显示其他隐藏的内容)、从同一个网页的不同栏目(框架界面)抓取不同的内容等等。
在我的探索过程中,我也发现虽然可以爬取百度搜索结果,但谷歌结果却很难实现。一位知情人士告诉我,虽然你电脑上的浏览器可以用VPN打开google,但Selenium没有VPN可以打开google,这是真的。所以,我找到了很多关于如何通过谷歌搜索使用RSelenium抓取谷歌搜索结果的方法,我想复制它,但发现同样的方法对我不起作用。
就是这样。
抓取动态网页(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-07 00:08
我想抓取一个网页:
我需要所有商店名称、电话号码及其地址的数据
但我最多只能做10个
导致加载需要滚动页面的其他项目
我的代码:
import requests
import bs4
crawl_url = requests.get('https://www.justdial.com/Mumbai/Dairy-Product-
Retailers-in-Thane/nct-10152687', headers={'User-Agent': 'Mozilla/5.0'})
crawl_url.raise_for_status()
soup = bs4.BeautifulSoup(crawl_url.text, 'lxml')
for elems in soup.find_all('span', class_="jcn"):
select_a = elems.select('a')
for links in select_a:
href = links.get('href')
res = requests.get(href, headers={'User-Agent': 'Mozilla/5.0'})
xsoup = bs4.BeautifulSoup(res.text, 'lxml')
Name = xsoup.select('.fn')
tel = xsoup.select('.tel')
add = xsoup.select('.adrstxtr')
a = Name[0]
b = tel[0]
c = add[0]
print(a.getText())
print("--"*10)
print(b.getText())
print("--"*10)
print(c.getText())
print("=="*25)
当我们向下滚动页面时会加载其他项目
所以我想知道如何获得尽可能多的数据/项目
我试过
但是没有悄悄理解好,我也没有得到那个POST方法:/
如果您需要更多信息,请与我们联系
最佳答案
tmadam 给出的解决方案有效
这是代码
import requests
import bs4
def spider(max_pages):
page = 1
while page < max_pages:
url = "https://www.justdial.com/Mumba ... s-in-
Thane/nct-10152687/page-%s" % page
crawl_url = requests.get(url, headers={'User-Agent': 'Mozilla/5.0'})
crawl_url.raise_for_status()
soup = bs4.BeautifulSoup(crawl_url.text, 'lxml')
for elems in soup.find_all('span', class_="jcn"):
select_a = elems.select('a')
for links in select_a:
href = links.get('href')
res = requests.get(href, headers={'User-Agent':
'Mozilla/5.0'})
xsoup = bs4.BeautifulSoup(res.text, 'lxml')
Name = xsoup.select('.fn')
tel = xsoup.select('.tel')
add = xsoup.select('.adrstxtr')
a = Name[0]
b = tel[0]
c = add[0]
print(a.getText())
print("--"*10)
print(b.getText())
print("--"*10)
print(c.getText())
print("=="*25)
page += 1
spider(3)
关于 python - Beautifulsoup - 抓取网页 - 动态加载页面,我们在 Stack Overflow 上发现了一个类似的问题: 查看全部
抓取动态网页(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
我想抓取一个网页:
我需要所有商店名称、电话号码及其地址的数据
但我最多只能做10个
导致加载需要滚动页面的其他项目
我的代码:
import requests
import bs4
crawl_url = requests.get('https://www.justdial.com/Mumbai/Dairy-Product-
Retailers-in-Thane/nct-10152687', headers={'User-Agent': 'Mozilla/5.0'})
crawl_url.raise_for_status()
soup = bs4.BeautifulSoup(crawl_url.text, 'lxml')
for elems in soup.find_all('span', class_="jcn"):
select_a = elems.select('a')
for links in select_a:
href = links.get('href')
res = requests.get(href, headers={'User-Agent': 'Mozilla/5.0'})
xsoup = bs4.BeautifulSoup(res.text, 'lxml')
Name = xsoup.select('.fn')
tel = xsoup.select('.tel')
add = xsoup.select('.adrstxtr')
a = Name[0]
b = tel[0]
c = add[0]
print(a.getText())
print("--"*10)
print(b.getText())
print("--"*10)
print(c.getText())
print("=="*25)
当我们向下滚动页面时会加载其他项目
所以我想知道如何获得尽可能多的数据/项目
我试过
但是没有悄悄理解好,我也没有得到那个POST方法:/
如果您需要更多信息,请与我们联系
最佳答案
tmadam 给出的解决方案有效
这是代码
import requests
import bs4
def spider(max_pages):
page = 1
while page < max_pages:
url = "https://www.justdial.com/Mumba ... s-in-
Thane/nct-10152687/page-%s" % page
crawl_url = requests.get(url, headers={'User-Agent': 'Mozilla/5.0'})
crawl_url.raise_for_status()
soup = bs4.BeautifulSoup(crawl_url.text, 'lxml')
for elems in soup.find_all('span', class_="jcn"):
select_a = elems.select('a')
for links in select_a:
href = links.get('href')
res = requests.get(href, headers={'User-Agent':
'Mozilla/5.0'})
xsoup = bs4.BeautifulSoup(res.text, 'lxml')
Name = xsoup.select('.fn')
tel = xsoup.select('.tel')
add = xsoup.select('.adrstxtr')
a = Name[0]
b = tel[0]
c = add[0]
print(a.getText())
print("--"*10)
print(b.getText())
print("--"*10)
print(c.getText())
print("=="*25)
page += 1
spider(3)
关于 python - Beautifulsoup - 抓取网页 - 动态加载页面,我们在 Stack Overflow 上发现了一个类似的问题:
抓取动态网页(您可能感兴趣的列队申请是:+Season+J(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-06 16:18
)
在此示例中,Javascript 仅允许在网页上发送、接收和显示内容,而无需为每个请求实际重新加载网页。所以不需要解析javascript,只需要找到请求的信息,模拟那个请求,解析响应即可。为此,您可以在 Firefox 中使用 Firebug,或在 Chrome 中使用开发人员工具(在 Windows 中使用 ctrl+shift+J,在 Mac 中使用 cmd+opt+J)。在 Chrome 中,只需单击“网络”选项卡,当您单击 网站 时,您将看到请求和响应。
在这个特定的示例中,当您想要获取克利夫兰团队“2008-09”的统计数据时,javascript 会发出多个请求。您可能感兴趣的队列应用是:+Season&Season=2008-09&PaceAdjust=N&DateFrom=&sortOrder=DES&VsConference=&OpponentTeamID=0&DateTo=&GameSegment=&LastNGames=0&VsDivision=&LeagueID=00&Outcome=&GameScope=&MeasureType=Base&PerMode=Per48&sortPeriod=0N&SeasonSegment=& =0&rowsPerPage=100
下面是一个小蜘蛛的例子。你只需要定义 LineupItem 然后你就可以用 scrapy crawl stats -o output.json 来执行它。
import json
from scrapy.spider import Spider
from scrapy.http import Request
from nba.items import LineupItem
from urllib import urlencode
class StatsSpider(Spider):
name = "stats"
allowed_domains = ["stats.nba.com"]
start_urls = (
'http://stats.nba.com/',
)
def parse(self, response):
return self.get_lineup('1610612739','2008-09')
def get_lineup(self, team_id, season):
params = {
'Season': season,
'SeasonType': 'Regular Season',
'LeagueID': '00',
'TeamID': team_id,
'MeasureType': 'Base',
'PerMode': 'Per48',
'PlusMinus': 'N',
'PaceAdjust': 'N',
'Rank': 'N',
'Outcome': '',
'Location': '',
'Month': '0',
'SeasonSegment': '',
'DateFrom': '',
'DateTo': '',
'OpponentTeamID': '0',
'VsConference': '',
'VsDivision': '',
'GameSegment': '',
'Period': '0',
'LastNGames': '0',
'GroupQuantity': '5',
'GameScope': '',
'GameID': '',
'pageNo': '1',
'rowsPerPage': '100',
'sortField': 'MIN',
'sortOrder': 'DES'
}
return Request(
url="http://stats.nba.com/stats/teamdashlineups?" + urlencode(params),
dont_filter=True,
callback=self.parse_lineup
)
def parse_lineup(self,response):
data = json.loads(response.body)
for lineup in data['resultSets'][1]['rowSet']:
item = LineupItem()
item['group_set'] = lineup[0]
item['group_id'] = lineup[1]
item['group_name'] = lineup[2]
item['gp'] = lineup[3]
item['w'] = lineup[4]
item['l'] = lineup[5]
item['w_pct'] = lineup[6]
item['min'] = lineup[7]
item['fgm'] = lineup[8]
item['fga'] = lineup[9]
item['fg_pct'] = lineup[10]
item['fg3m'] = lineup[11]
item['fg3a'] = lineup[12]
item['fg3_pct'] = lineup[13]
item['ftm'] = lineup[14]
item['fta'] = lineup[15]
item['ft_pct'] = lineup[16]
item['oreb'] = lineup[17]
item['dreb'] = lineup[18]
item['reb'] = lineup[19]
item['ast'] = lineup[20]
item['tov'] = lineup[21]
item['stl'] = lineup[22]
item['blk'] = lineup[23]
item['blka'] = lineup[24]
item['pf'] = lineup[25]
item['pfd'] = lineup[26]
item['pts'] = lineup[27]
item['plus_minus'] = lineup[28]
yield item
这将产生一个json记录,例如:
{"gp": 30, "fg_pct": 0.491, "group_name": "Ilgauskas,Zydrunas - James,LeBron - Wallace,Ben - West,Delonte - Williams,Mo", "group_set": "Lineups", "w_pct": 0.833, "pts": 103.0, "min": 484.9866666666667, "tov": 13.3, "fta": 21.6, "pf": 16.0, "blk": 7.7, "reb": 44.2, "blka": 3.0, "ftm": 16.6, "ft_pct": 0.771, "fg3a": 18.7, "pfd": 17.2, "ast": 23.3, "fg3m": 7.4, "fgm": 39.5, "fg3_pct": 0.397, "dreb": 32.0, "fga": 80.4, "plus_minus": 18.4, "stl": 8.3, "l": 5, "oreb": 12.3, "w": 25, "group_id": "980 - 2544 - 1112 - 2753 - 2590"} 查看全部
抓取动态网页(您可能感兴趣的列队申请是:+Season+J(图)
)
在此示例中,Javascript 仅允许在网页上发送、接收和显示内容,而无需为每个请求实际重新加载网页。所以不需要解析javascript,只需要找到请求的信息,模拟那个请求,解析响应即可。为此,您可以在 Firefox 中使用 Firebug,或在 Chrome 中使用开发人员工具(在 Windows 中使用 ctrl+shift+J,在 Mac 中使用 cmd+opt+J)。在 Chrome 中,只需单击“网络”选项卡,当您单击 网站 时,您将看到请求和响应。
在这个特定的示例中,当您想要获取克利夫兰团队“2008-09”的统计数据时,javascript 会发出多个请求。您可能感兴趣的队列应用是:+Season&Season=2008-09&PaceAdjust=N&DateFrom=&sortOrder=DES&VsConference=&OpponentTeamID=0&DateTo=&GameSegment=&LastNGames=0&VsDivision=&LeagueID=00&Outcome=&GameScope=&MeasureType=Base&PerMode=Per48&sortPeriod=0N&SeasonSegment=& =0&rowsPerPage=100
下面是一个小蜘蛛的例子。你只需要定义 LineupItem 然后你就可以用 scrapy crawl stats -o output.json 来执行它。
import json
from scrapy.spider import Spider
from scrapy.http import Request
from nba.items import LineupItem
from urllib import urlencode
class StatsSpider(Spider):
name = "stats"
allowed_domains = ["stats.nba.com"]
start_urls = (
'http://stats.nba.com/',
)
def parse(self, response):
return self.get_lineup('1610612739','2008-09')
def get_lineup(self, team_id, season):
params = {
'Season': season,
'SeasonType': 'Regular Season',
'LeagueID': '00',
'TeamID': team_id,
'MeasureType': 'Base',
'PerMode': 'Per48',
'PlusMinus': 'N',
'PaceAdjust': 'N',
'Rank': 'N',
'Outcome': '',
'Location': '',
'Month': '0',
'SeasonSegment': '',
'DateFrom': '',
'DateTo': '',
'OpponentTeamID': '0',
'VsConference': '',
'VsDivision': '',
'GameSegment': '',
'Period': '0',
'LastNGames': '0',
'GroupQuantity': '5',
'GameScope': '',
'GameID': '',
'pageNo': '1',
'rowsPerPage': '100',
'sortField': 'MIN',
'sortOrder': 'DES'
}
return Request(
url="http://stats.nba.com/stats/teamdashlineups?" + urlencode(params),
dont_filter=True,
callback=self.parse_lineup
)
def parse_lineup(self,response):
data = json.loads(response.body)
for lineup in data['resultSets'][1]['rowSet']:
item = LineupItem()
item['group_set'] = lineup[0]
item['group_id'] = lineup[1]
item['group_name'] = lineup[2]
item['gp'] = lineup[3]
item['w'] = lineup[4]
item['l'] = lineup[5]
item['w_pct'] = lineup[6]
item['min'] = lineup[7]
item['fgm'] = lineup[8]
item['fga'] = lineup[9]
item['fg_pct'] = lineup[10]
item['fg3m'] = lineup[11]
item['fg3a'] = lineup[12]
item['fg3_pct'] = lineup[13]
item['ftm'] = lineup[14]
item['fta'] = lineup[15]
item['ft_pct'] = lineup[16]
item['oreb'] = lineup[17]
item['dreb'] = lineup[18]
item['reb'] = lineup[19]
item['ast'] = lineup[20]
item['tov'] = lineup[21]
item['stl'] = lineup[22]
item['blk'] = lineup[23]
item['blka'] = lineup[24]
item['pf'] = lineup[25]
item['pfd'] = lineup[26]
item['pts'] = lineup[27]
item['plus_minus'] = lineup[28]
yield item
这将产生一个json记录,例如:
{"gp": 30, "fg_pct": 0.491, "group_name": "Ilgauskas,Zydrunas - James,LeBron - Wallace,Ben - West,Delonte - Williams,Mo", "group_set": "Lineups", "w_pct": 0.833, "pts": 103.0, "min": 484.9866666666667, "tov": 13.3, "fta": 21.6, "pf": 16.0, "blk": 7.7, "reb": 44.2, "blka": 3.0, "ftm": 16.6, "ft_pct": 0.771, "fg3a": 18.7, "pfd": 17.2, "ast": 23.3, "fg3m": 7.4, "fgm": 39.5, "fg3_pct": 0.397, "dreb": 32.0, "fga": 80.4, "plus_minus": 18.4, "stl": 8.3, "l": 5, "oreb": 12.3, "w": 25, "group_id": "980 - 2544 - 1112 - 2753 - 2590"}
抓取动态网页(本文实例讲述Python3实现抓取javascript动态生成的html网页功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-03 05:03
本文的例子描述了Python3爬取javascript动态生成的HTML页面的功能。分享给大家,供大家参考,如下:
用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
这里介绍一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
打开火狐浏览器
在给定的url地址加载页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
【示例一】
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
希望这篇文章对你的 Python 编程有所帮助。 查看全部
抓取动态网页(本文实例讲述Python3实现抓取javascript动态生成的html网页功能)
本文的例子描述了Python3爬取javascript动态生成的HTML页面的功能。分享给大家,供大家参考,如下:
用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
这里介绍一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
打开火狐浏览器
在给定的url地址加载页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
【示例一】
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
希望这篇文章对你的 Python 编程有所帮助。
抓取动态网页(前文Ajax理论AjaxAjaxAjaxAjax)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-01 17:06
上面的爬虫都是基于静态网页的。首先通过请求网站url获取网页源代码。之后,可以提取和存储源代码。本文对动态网页采集进行数据处理。首先介绍了Ajax的理论,然后实际爬取flushflush的动态网页,获取个股的相关信息。
一、Ajax 理论
1.Ajax介绍
Ajax 的全称是“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式、快速和动态的 Web 应用程序的 Web 开发技术,可以在不重新加载整个网页的情况下更新某些网页。Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
2.Ajax 分析
微博网站是一个比较容易识别的Ajax动态网页。首先打开Dectools工具(转到XHR专栏)和中南财经政法大学官方微博网站(),这里选择。是手机微博,然后选择清除所有内容。
接下来,滚动滚轮以下拉页面,直到一个新项目出现在空的 XHR 列中。点击项目,选择预览栏,发现这里对应的内容就是页面上的新微博。但它没有改变。至此,我们可以确定这是一个Ajax请求后的网页。
3.Ajax 提取
或者选择同一个条目进入Headers进一步查看信息,可以发现这是一个GET类型的请求,请求的url为:,即请求有四个参数:type、value、containerid、since_id和然后翻页发现除了since_id的变化之外,其余保持不变,这里我们可以看到since_id就是翻页方法。
接下来进一步观察since_id,发现上下请求的since_id之间没有明显的规律。进一步搜索发现,下一页的since_id在上一页的响应中的cardListInfo中,因此可以建立循环连接,进一步将动态url循环添加到爬虫中。
发起请求并得到响应后,可以进一步分析出响应格式是json,所以可以通过对json的进一步处理得到最终的数据!
二、网页分析
1.网站概览
经过以上分析,我们将用flush网页的数据来采集实战进行例子验证。首先打开网页:,如下图:
再按F12键打开Devtools后台源码,右键第一项查看源码位置。
2.阿贾克斯歧视
接下来,通过点击网页底部的下一页,我们发现网页的url并没有改变!至此,基本可以确定该网页属于Ajax动态网页。
进一步,我们清空Network中的所有内容,继续点击下一页到第五页,发现连续弹出三个同名的内容,就可以得到请求的url和请求头的具体内容通过一般栏。
所以我们复制这个请求url,在浏览器中打开,响应内容确实是标准化的表格数据,正是我们想要的。
3.Ajax 提取
然后我们也打开源码,发现是一个html文档,说明响应内容是网页的形式,和上面微博响应的json格式不同,所以数据可以在稍后解析网页的形式。
三、爬行者战斗
1.网页访问
在第一部分的理论介绍和第二部分的网页分析之后,我们就可以开始编写爬虫代码了。首先,导入库并定义请求头。需要注意的是,这里的请求头除了User-Agent外,还需要host、Referer和X-Requested-With参数,这要和静态网页爬取区别开来。
# 导入库import timeimport jsonimport randomimport requestsimport pandas as pdfrom bs4 import BeautifulSoupheaders = { 'host':'q.10jqka.com.cn', 'Referer':'http://q.10jqka.com.cn/', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3554.0 Safari/537.36', 'X-Requested-With':'XMLHttpRequest'}url = 'http://q.10jqka.com.cn/index/i ... 39%3B % page_idres = requests.get(url,headers=headers)res.encoding = 'GBK'
2.信息提取
之后就是上面解析库中的内容,这里使用BaetifulSoup库,方便理解。先将上面的html转换成BeautifulSoup对象,然后通过对象的select选择器选择响应tr标签中的数据,进一步分析每个tr标签的内容,得到如下对应信息。
# 获取单页数据def get_html(page_id): headers = { 'host':'q.10jqka.com.cn', 'Referer':'http://q.10jqka.com.cn/', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3554.0 Safari/537.36', 'X-Requested-With':'XMLHttpRequest' } url = 'http://q.10jqka.com.cn/index/i ... 39%3B % page_id res = requests.get(url,headers=headers) res.encoding = 'GBK' soup = BeautifulSoup(res.text,'lxml') tr_list = soup.select('tbody tr') # print(tr_list) stocks = [] for each_tr in tr_list: td_list = each_tr.select('td') data = { '股票代码':td_list[1].text, '股票简称':td_list[2].text, '股票链接':each_tr.a['href'], '现价':td_list[3].text, '涨幅':td_list[4].text, '涨跌':td_list[5].text, '涨速':td_list[6].text, '换手':td_list[7].text, '量比':td_list[8].text, '振幅':td_list[9].text, '成交额':td_list[10].text, '流通股':td_list[11].text, '流通市值':td_list[12].text, '市盈率':td_list[13].text, } stocks.append(data) return stocks
3.保存数据
定义 write2excel 函数将数据保存到stocks.xlsx 文件中。
# 保存数据def write2excel(result): json_result = json.dumps(result) with open('stocks.json','w') as f: f.write(json_result) with open('stocks.json','r') as f: data = f.read() data = json.loads(data) df = pd.DataFrame(data,columns=['股票代码','股票简称','股票链接','现价','涨幅','涨跌','涨速','换手','量比','振幅','成交额', '流通股','流通市值','市盈率']) df.to_excel('stocks.xlsx',index=False)
4.循环结构
考虑到flushflush的多页结构和反爬的存在,这里也采用了字符串拼接和循环结构来遍历多页股票信息。同时,随机库中的randint方法和时间库中的sleep方法在爬取前会中断一定时间。
def get_pages(page_n): stocks_n = [] for page_id in range(1,page_n+1): page = get_html(page_id) stocks_n.extend(page) time.sleep(random.randint(1,10)) return stocks_n
最终爬取结果如下:
四、爬虫摘要
至此,flush动态网页的爬取完成,再通过这个爬虫进行总结:首先,我们通过浏览网页结构和翻页,对比XHR bar,对页面进行Ajax判断。如果网页url没有变化,XHR会刷新内容,基本说明是动态的。这时候我们进一步检查多个页面之间url请求的异同,寻找规律。找到规则后,就可以建立多页面请求流程了。之后处理单个响应内容(详见响应内容格式),最后建立整个循环爬虫结构,自动爬取想要的信息。
爬虫的完整代码可以在今日头条私信获取。下面将进一步解释和实践浏览器模拟行为。上篇文章涉及的基础知识,请参考以下链接:
爬虫需要知道的基础知识,这一点就够了!Python网络爬虫实战系列
本文将带你深入了解和学习Python爬虫库!从现在开始,不用担心数据
Python爬虫有多简单?本文将带你实战豆瓣电影TOP250数据爬取!
一篇搞懂Python网络爬虫解析库的文章!收录多个示例 查看全部
抓取动态网页(前文Ajax理论AjaxAjaxAjaxAjax)
上面的爬虫都是基于静态网页的。首先通过请求网站url获取网页源代码。之后,可以提取和存储源代码。本文对动态网页采集进行数据处理。首先介绍了Ajax的理论,然后实际爬取flushflush的动态网页,获取个股的相关信息。
一、Ajax 理论
1.Ajax介绍
Ajax 的全称是“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式、快速和动态的 Web 应用程序的 Web 开发技术,可以在不重新加载整个网页的情况下更新某些网页。Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
2.Ajax 分析
微博网站是一个比较容易识别的Ajax动态网页。首先打开Dectools工具(转到XHR专栏)和中南财经政法大学官方微博网站(),这里选择。是手机微博,然后选择清除所有内容。
接下来,滚动滚轮以下拉页面,直到一个新项目出现在空的 XHR 列中。点击项目,选择预览栏,发现这里对应的内容就是页面上的新微博。但它没有改变。至此,我们可以确定这是一个Ajax请求后的网页。
3.Ajax 提取
或者选择同一个条目进入Headers进一步查看信息,可以发现这是一个GET类型的请求,请求的url为:,即请求有四个参数:type、value、containerid、since_id和然后翻页发现除了since_id的变化之外,其余保持不变,这里我们可以看到since_id就是翻页方法。
接下来进一步观察since_id,发现上下请求的since_id之间没有明显的规律。进一步搜索发现,下一页的since_id在上一页的响应中的cardListInfo中,因此可以建立循环连接,进一步将动态url循环添加到爬虫中。
发起请求并得到响应后,可以进一步分析出响应格式是json,所以可以通过对json的进一步处理得到最终的数据!
二、网页分析
1.网站概览
经过以上分析,我们将用flush网页的数据来采集实战进行例子验证。首先打开网页:,如下图:
再按F12键打开Devtools后台源码,右键第一项查看源码位置。
2.阿贾克斯歧视
接下来,通过点击网页底部的下一页,我们发现网页的url并没有改变!至此,基本可以确定该网页属于Ajax动态网页。
进一步,我们清空Network中的所有内容,继续点击下一页到第五页,发现连续弹出三个同名的内容,就可以得到请求的url和请求头的具体内容通过一般栏。
所以我们复制这个请求url,在浏览器中打开,响应内容确实是标准化的表格数据,正是我们想要的。
3.Ajax 提取
然后我们也打开源码,发现是一个html文档,说明响应内容是网页的形式,和上面微博响应的json格式不同,所以数据可以在稍后解析网页的形式。
三、爬行者战斗
1.网页访问
在第一部分的理论介绍和第二部分的网页分析之后,我们就可以开始编写爬虫代码了。首先,导入库并定义请求头。需要注意的是,这里的请求头除了User-Agent外,还需要host、Referer和X-Requested-With参数,这要和静态网页爬取区别开来。
# 导入库import timeimport jsonimport randomimport requestsimport pandas as pdfrom bs4 import BeautifulSoupheaders = { 'host':'q.10jqka.com.cn', 'Referer':'http://q.10jqka.com.cn/', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3554.0 Safari/537.36', 'X-Requested-With':'XMLHttpRequest'}url = 'http://q.10jqka.com.cn/index/i ... 39%3B % page_idres = requests.get(url,headers=headers)res.encoding = 'GBK'
2.信息提取
之后就是上面解析库中的内容,这里使用BaetifulSoup库,方便理解。先将上面的html转换成BeautifulSoup对象,然后通过对象的select选择器选择响应tr标签中的数据,进一步分析每个tr标签的内容,得到如下对应信息。
# 获取单页数据def get_html(page_id): headers = { 'host':'q.10jqka.com.cn', 'Referer':'http://q.10jqka.com.cn/', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3554.0 Safari/537.36', 'X-Requested-With':'XMLHttpRequest' } url = 'http://q.10jqka.com.cn/index/i ... 39%3B % page_id res = requests.get(url,headers=headers) res.encoding = 'GBK' soup = BeautifulSoup(res.text,'lxml') tr_list = soup.select('tbody tr') # print(tr_list) stocks = [] for each_tr in tr_list: td_list = each_tr.select('td') data = { '股票代码':td_list[1].text, '股票简称':td_list[2].text, '股票链接':each_tr.a['href'], '现价':td_list[3].text, '涨幅':td_list[4].text, '涨跌':td_list[5].text, '涨速':td_list[6].text, '换手':td_list[7].text, '量比':td_list[8].text, '振幅':td_list[9].text, '成交额':td_list[10].text, '流通股':td_list[11].text, '流通市值':td_list[12].text, '市盈率':td_list[13].text, } stocks.append(data) return stocks
3.保存数据
定义 write2excel 函数将数据保存到stocks.xlsx 文件中。
# 保存数据def write2excel(result): json_result = json.dumps(result) with open('stocks.json','w') as f: f.write(json_result) with open('stocks.json','r') as f: data = f.read() data = json.loads(data) df = pd.DataFrame(data,columns=['股票代码','股票简称','股票链接','现价','涨幅','涨跌','涨速','换手','量比','振幅','成交额', '流通股','流通市值','市盈率']) df.to_excel('stocks.xlsx',index=False)
4.循环结构
考虑到flushflush的多页结构和反爬的存在,这里也采用了字符串拼接和循环结构来遍历多页股票信息。同时,随机库中的randint方法和时间库中的sleep方法在爬取前会中断一定时间。
def get_pages(page_n): stocks_n = [] for page_id in range(1,page_n+1): page = get_html(page_id) stocks_n.extend(page) time.sleep(random.randint(1,10)) return stocks_n
最终爬取结果如下:
四、爬虫摘要
至此,flush动态网页的爬取完成,再通过这个爬虫进行总结:首先,我们通过浏览网页结构和翻页,对比XHR bar,对页面进行Ajax判断。如果网页url没有变化,XHR会刷新内容,基本说明是动态的。这时候我们进一步检查多个页面之间url请求的异同,寻找规律。找到规则后,就可以建立多页面请求流程了。之后处理单个响应内容(详见响应内容格式),最后建立整个循环爬虫结构,自动爬取想要的信息。
爬虫的完整代码可以在今日头条私信获取。下面将进一步解释和实践浏览器模拟行为。上篇文章涉及的基础知识,请参考以下链接:
爬虫需要知道的基础知识,这一点就够了!Python网络爬虫实战系列
本文将带你深入了解和学习Python爬虫库!从现在开始,不用担心数据
Python爬虫有多简单?本文将带你实战豆瓣电影TOP250数据爬取!
一篇搞懂Python网络爬虫解析库的文章!收录多个示例
抓取动态网页( Python爬虫请求URL分析方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-30 18:00
Python爬虫请求URL分析方法
)
请求网址分析
先打开F12控制台面板,看到照片的url都是这个格式的。
向下滚动知乎页面,找到一个带有limit、offset参数的URL请求。
检查Response面板中的内容是否收录图片的URL地址,其中图片地址的URL保存在data-original属性中。
提取图片的网址
从上图可以看出,图片的地址存放在content属性下的data-original属性中。
下面的代码会获取图片的地址并写入文件。
import re
import requests
import os
import urllib.request
import ssl
from urllib.parse import urlsplit
from os.path import basename
import json
ssl._create_default_https_context = ssl._create_unverified_context
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36",
'Accept-Encoding': 'gzip, deflate'
}
def get_image_url(qid, title):
answers_url = 'https://www.zhihu.com/api/v4/q ... 2Bstr(qid)+'/answers?include=data%5B*%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B*%5D.mark_infos%5B*%5D.url%3Bdata%5B*%5D.author.follower_count%2Cbadge%5B*%5D.topics%3Bdata%5B*%5D.settings.table_of_content.enabled&offset={}&limit=10&sort_by=default&platform=desktop'
offset = 0
session = requests.Session()
while True:
page = session.get(answers_url.format(offset), headers = headers)
json_text = json.loads(page.text)
answers = json_text['data']
offset += 10
if not answers:
print('获取图片地址完成')
return
pic_re = re.compile('data-original="(.*?)"', re.S)
for answer in answers:
tmp_list = []
pic_urls = re.findall(pic_re, answer['content'])
for item in pic_urls:
# 去掉转移字符 \
pic_url = item.replace("\\", "")
pic_url = pic_url.split('?')[0]
# 去重复
if pic_url not in tmp_list:
tmp_list.append(pic_url)
for pic_url in tmp_list:
if pic_url.endswith('r.jpg'):
print(pic_url)
write_file(title, pic_url)
def write_file(title, pic_url):
file_name = title + '.txt'
f = open(file_name, 'a')
f.write(pic_url + '\n')
f.close()
示例结果:
下载图片
以下代码会读取文件中的图片URL并下载。
def read_file(title):
file_name = title + '.txt'
pic_urls = []
# 判断文件是否存在
if not os.path.exists(file_name):
return pic_urls
with open(file_name, 'r') as f:
for line in f:
url = line.replace("\n", "")
if url not in pic_urls:
pic_urls.append(url)
print("文件中共有{}个不重复的 URL".format(len(pic_urls)))
return pic_urls
def download_pic(pic_urls, title):
# 创建文件夹
if not os.path.exists(title):
os.makedirs(title)
error_pic_urls = []
success_pic_num = 0
repeat_pic_num = 0
index = 1
for url in pic_urls:
file_name = os.sep.join((title,basename(urlsplit(url)[2])))
if os.path.exists(file_name):
print("图片{}已存在".format(file_name))
index += 1
repeat_pic_num += 1
continue
try:
urllib.request.urlretrieve(url, file_name)
success_pic_num += 1
index += 1
print("下载{}完成!({}/{})".format(file_name, index, len(pic_urls)))
except:
print("下载{}失败!({}/{})".format(file_name, index, len(pic_urls)))
error_pic_urls.append(url)
index += 1
continue
print("图片全部下载完毕!(成功:{}/重复:{}/失败:{})".format(success_pic_num, repeat_pic_num, len(error_pic_urls)))
if len(error_pic_urls) > 0:
print('下面打印失败的图片地址')
for error_url in error_pic_urls:
print(error_url)
结论
今天的文章用Python爬虫做了一个小脚本。如果大家觉得文章有趣又有用,请转发支持!
查看全部
抓取动态网页(
Python爬虫请求URL分析方法
)
请求网址分析
先打开F12控制台面板,看到照片的url都是这个格式的。
向下滚动知乎页面,找到一个带有limit、offset参数的URL请求。
检查Response面板中的内容是否收录图片的URL地址,其中图片地址的URL保存在data-original属性中。
提取图片的网址
从上图可以看出,图片的地址存放在content属性下的data-original属性中。
下面的代码会获取图片的地址并写入文件。
import re
import requests
import os
import urllib.request
import ssl
from urllib.parse import urlsplit
from os.path import basename
import json
ssl._create_default_https_context = ssl._create_unverified_context
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36",
'Accept-Encoding': 'gzip, deflate'
}
def get_image_url(qid, title):
answers_url = 'https://www.zhihu.com/api/v4/q ... 2Bstr(qid)+'/answers?include=data%5B*%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B*%5D.mark_infos%5B*%5D.url%3Bdata%5B*%5D.author.follower_count%2Cbadge%5B*%5D.topics%3Bdata%5B*%5D.settings.table_of_content.enabled&offset={}&limit=10&sort_by=default&platform=desktop'
offset = 0
session = requests.Session()
while True:
page = session.get(answers_url.format(offset), headers = headers)
json_text = json.loads(page.text)
answers = json_text['data']
offset += 10
if not answers:
print('获取图片地址完成')
return
pic_re = re.compile('data-original="(.*?)"', re.S)
for answer in answers:
tmp_list = []
pic_urls = re.findall(pic_re, answer['content'])
for item in pic_urls:
# 去掉转移字符 \
pic_url = item.replace("\\", "")
pic_url = pic_url.split('?')[0]
# 去重复
if pic_url not in tmp_list:
tmp_list.append(pic_url)
for pic_url in tmp_list:
if pic_url.endswith('r.jpg'):
print(pic_url)
write_file(title, pic_url)
def write_file(title, pic_url):
file_name = title + '.txt'
f = open(file_name, 'a')
f.write(pic_url + '\n')
f.close()
示例结果:
下载图片
以下代码会读取文件中的图片URL并下载。
def read_file(title):
file_name = title + '.txt'
pic_urls = []
# 判断文件是否存在
if not os.path.exists(file_name):
return pic_urls
with open(file_name, 'r') as f:
for line in f:
url = line.replace("\n", "")
if url not in pic_urls:
pic_urls.append(url)
print("文件中共有{}个不重复的 URL".format(len(pic_urls)))
return pic_urls
def download_pic(pic_urls, title):
# 创建文件夹
if not os.path.exists(title):
os.makedirs(title)
error_pic_urls = []
success_pic_num = 0
repeat_pic_num = 0
index = 1
for url in pic_urls:
file_name = os.sep.join((title,basename(urlsplit(url)[2])))
if os.path.exists(file_name):
print("图片{}已存在".format(file_name))
index += 1
repeat_pic_num += 1
continue
try:
urllib.request.urlretrieve(url, file_name)
success_pic_num += 1
index += 1
print("下载{}完成!({}/{})".format(file_name, index, len(pic_urls)))
except:
print("下载{}失败!({}/{})".format(file_name, index, len(pic_urls)))
error_pic_urls.append(url)
index += 1
continue
print("图片全部下载完毕!(成功:{}/重复:{}/失败:{})".format(success_pic_num, repeat_pic_num, len(error_pic_urls)))
if len(error_pic_urls) > 0:
print('下面打印失败的图片地址')
for error_url in error_pic_urls:
print(error_url)
结论
今天的文章用Python爬虫做了一个小脚本。如果大家觉得文章有趣又有用,请转发支持!
抓取动态网页()
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-30 09:12
我正在使用 VBA 和 MSXML 抓取一些 Web 内容,所以我知道基础知识。但现在我想从由 JavaScript 生成的网页中获取数据。我不能给你确切的链接,因为它是私人的,但我可以描述它 - 基本上,有带有标题和一些图像的 div 容器,下面是动态加载的表格(圆形圆圈),但不更新(所以他们只加载一次)。我不能给你确切的链接,因为它是私有的,但我可以描述它 - 基本上,有一个带有标题和一些图像的 div 容器,在它下面是动态加载的表格(圆圈),没有更新(所以它们只加载一次)。如果在浏览器中打开源代码视图,则找不到这些表,只有容器和图像的标题/src。标题/src。但是如果你点击表格并选择“检查元素”,你可以看到等的典型结构。我知道的方法:我知道的方法:
1) 保存页面然后抓取它——可能不是最好的解决方案。 1)保存页面然后抓取它 - 可能不是最好的解决方案。
如果我有所有页面的 URL 列表,有没有什么快速的方法可以保存所有页面?
2) 通过 VBA 使用 Internet Explorer 控件,等待页面加载,然后像往常一样获取元素 - 但对我来说似乎很慢(?) - 就像一页上的 25 秒,即使它是为 0.加载的@>5 秒。 2)通过 VBA 使用 Internet Explorer 控件,等待页面加载,然后像往常一样获取元素 - 但对我来说似乎很慢(?) - 就像页面上的 25 秒,即使在加载之后也是如此 0.同样适用@>5 秒。
也许我应该关闭一些会减慢加载速度的东西?也许我应该关闭一些会减慢加载速度的功能?
你能检查出什么问题吗?
这是我找到的代码:这是我找到的代码:
3) 使用 Selenium 之类的 Web 驱动程序 - 找不到合适的示例。 3)使用像 Selenium 这样的网络驱动程序 - 找不到合适的例子。如果你从头开始给我一些,比如通过类名从元素中获取数据,那就太好了。
4) 对我来说未知,但可能是最快的 - 直接从用于构建这些表的 JS 变量/数组中获取数据。 4)对我来说未知,但可能是最快的 - 直接从用于构建这些表的 JS 变量/数组中获取数据。我听说您可以将 VBA 与 JavaScript 连接,但没有找到任何适当的示例如何获取数据。
所有解决方案都应在 VBA 范围内。我想知道最快的方法是什么。 查看全部
抓取动态网页()
我正在使用 VBA 和 MSXML 抓取一些 Web 内容,所以我知道基础知识。但现在我想从由 JavaScript 生成的网页中获取数据。我不能给你确切的链接,因为它是私人的,但我可以描述它 - 基本上,有带有标题和一些图像的 div 容器,下面是动态加载的表格(圆形圆圈),但不更新(所以他们只加载一次)。我不能给你确切的链接,因为它是私有的,但我可以描述它 - 基本上,有一个带有标题和一些图像的 div 容器,在它下面是动态加载的表格(圆圈),没有更新(所以它们只加载一次)。如果在浏览器中打开源代码视图,则找不到这些表,只有容器和图像的标题/src。标题/src。但是如果你点击表格并选择“检查元素”,你可以看到等的典型结构。我知道的方法:我知道的方法:
1) 保存页面然后抓取它——可能不是最好的解决方案。 1)保存页面然后抓取它 - 可能不是最好的解决方案。
如果我有所有页面的 URL 列表,有没有什么快速的方法可以保存所有页面?
2) 通过 VBA 使用 Internet Explorer 控件,等待页面加载,然后像往常一样获取元素 - 但对我来说似乎很慢(?) - 就像一页上的 25 秒,即使它是为 0.加载的@>5 秒。 2)通过 VBA 使用 Internet Explorer 控件,等待页面加载,然后像往常一样获取元素 - 但对我来说似乎很慢(?) - 就像页面上的 25 秒,即使在加载之后也是如此 0.同样适用@>5 秒。
也许我应该关闭一些会减慢加载速度的东西?也许我应该关闭一些会减慢加载速度的功能?
你能检查出什么问题吗?
这是我找到的代码:这是我找到的代码:
3) 使用 Selenium 之类的 Web 驱动程序 - 找不到合适的示例。 3)使用像 Selenium 这样的网络驱动程序 - 找不到合适的例子。如果你从头开始给我一些,比如通过类名从元素中获取数据,那就太好了。
4) 对我来说未知,但可能是最快的 - 直接从用于构建这些表的 JS 变量/数组中获取数据。 4)对我来说未知,但可能是最快的 - 直接从用于构建这些表的 JS 变量/数组中获取数据。我听说您可以将 VBA 与 JavaScript 连接,但没有找到任何适当的示例如何获取数据。
所有解决方案都应在 VBA 范围内。我想知道最快的方法是什么。
抓取动态网页(如何用python来抓取页面中的JS动态加载的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-28 18:12
)
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,而网站的其他很多RequestURL也不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
抓取动态网页(如何用python来抓取页面中的JS动态加载的数据
)
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,而网站的其他很多RequestURL也不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
抓取动态网页(搜索引擎提升静态和动态页面哪个蜘蛛抓取的快?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-28 14:11
问题:哪种蜘蛛爬取静态和动态页面的速度更快?
答:理论上,搜索引擎蜘蛛对静态页面和动态页面是一视同仁的,不会优先抓取哪个页面,但是这里有个前提,就是动态页面必须被蜘蛛识别。如果动态页面有很多复杂的参数,可能会影响蜘蛛抓取。
其实搜索引擎发展到今天已经能够很好的解决爬取的问题,不管是静态页面还是动态页面都可以爬取。不过从用户体验的角度来说,最好将URL设置为静态或伪静态,因为合理的URL可以节省用户的判断成本,对网站的优化也有帮助。
当然,不要走入死胡同,认为搜索引擎会歧视动态链接,这是错误的。
在判断页面质量和关键词排名方面,静态页面和动态页面没有严格的区别,都可以正常参与排名。不过这里也有一个需要注意的问题,就是页面的动态更新。无论页面的 URL 是什么形式,都必须保证页面是动态更新的。
比如文章页面通常会调用相关的文章,这个相关的文章的调用应该是动态的,文章在同一个标签下更新,其他的< @文章 页面也需要同步更新。这样做的好处是增加了页面的更新频率,有利于页面本身质量的提升。
关于页面ULR和蜘蛛爬取的问题,沐风SEO简单的说了这么多。总之,一般情况下,无论是静态页面还是动态页面,蜘蛛都会抓取。但是在设置网址的时候,一定要遵循一个原则,就是网址要尽量简单易懂,不能有复杂的符号! 查看全部
抓取动态网页(搜索引擎提升静态和动态页面哪个蜘蛛抓取的快?(图))
问题:哪种蜘蛛爬取静态和动态页面的速度更快?
答:理论上,搜索引擎蜘蛛对静态页面和动态页面是一视同仁的,不会优先抓取哪个页面,但是这里有个前提,就是动态页面必须被蜘蛛识别。如果动态页面有很多复杂的参数,可能会影响蜘蛛抓取。
其实搜索引擎发展到今天已经能够很好的解决爬取的问题,不管是静态页面还是动态页面都可以爬取。不过从用户体验的角度来说,最好将URL设置为静态或伪静态,因为合理的URL可以节省用户的判断成本,对网站的优化也有帮助。
当然,不要走入死胡同,认为搜索引擎会歧视动态链接,这是错误的。
在判断页面质量和关键词排名方面,静态页面和动态页面没有严格的区别,都可以正常参与排名。不过这里也有一个需要注意的问题,就是页面的动态更新。无论页面的 URL 是什么形式,都必须保证页面是动态更新的。
比如文章页面通常会调用相关的文章,这个相关的文章的调用应该是动态的,文章在同一个标签下更新,其他的< @文章 页面也需要同步更新。这样做的好处是增加了页面的更新频率,有利于页面本身质量的提升。
关于页面ULR和蜘蛛爬取的问题,沐风SEO简单的说了这么多。总之,一般情况下,无论是静态页面还是动态页面,蜘蛛都会抓取。但是在设置网址的时候,一定要遵循一个原则,就是网址要尽量简单易懂,不能有复杂的符号!
抓取动态网页(ajax横行的年代,我们的网页是残缺的吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-27 00:12
)
在ajax时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,其中包括
跳过js加载部分,表示爬虫抓取的网页不完整,不完整。您可以在下面看到博客园的主页
从首页的加载中可以看出,页面渲染完成后,会有5个异步ajax请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候,如果你想得到它,你必须调用浏览器的内核引擎来下载这些动态页面。目前内核引擎是三足的。
Trident:也就是IE内核,WebBrowser就是基于这个内核,但是加载性能比较差。
Gecko:FF的内核比Trident的性能更好。
WebKit:Safari和Chrome的核心,性能你懂的,在真实场景中还是主要的。
好的,为了简单方便,这里我们使用WebBrowser来玩,使用WebBrowser的时候要注意以下几点:
首先:因为WebBrowser是System.Windows.Forms中的winform控件,所以我们需要设置STAThread标签。
第二:winform是事件驱动的,Console不响应事件,所有事件都在windows的消息队列中等待执行,以防止程序假死,
我们需要调用DoEvents方法来传递控制权,让操作系统执行其他事件。
第三:WebBrowser内容,我们需要使用DomDocument来查看,而不是DocumentText。
判断动态网页是否加载一般有两种方式:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们这里需要这样做
记录计数值
.
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.html,看看js加载的内容有没有。
②:当然,除了通过判断最大值来判断加载是否完成,我们还可以通过设置一个Timer来判断,比如3s、4s、5s,稍后再查看
WEB浏览器是否加载。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然,效果还是一样的,就不截图了。从以上两种写法来看,我们的WebBrowser放在主线程中。让我们看看如何把它放在工作线程上。
很简单,只需将工作线程设置为STA模式即可。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 }
查看全部
抓取动态网页(ajax横行的年代,我们的网页是残缺的吗?
)
在ajax时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,其中包括
跳过js加载部分,表示爬虫抓取的网页不完整,不完整。您可以在下面看到博客园的主页
从首页的加载中可以看出,页面渲染完成后,会有5个异步ajax请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候,如果你想得到它,你必须调用浏览器的内核引擎来下载这些动态页面。目前内核引擎是三足的。
Trident:也就是IE内核,WebBrowser就是基于这个内核,但是加载性能比较差。
Gecko:FF的内核比Trident的性能更好。
WebKit:Safari和Chrome的核心,性能你懂的,在真实场景中还是主要的。
好的,为了简单方便,这里我们使用WebBrowser来玩,使用WebBrowser的时候要注意以下几点:
首先:因为WebBrowser是System.Windows.Forms中的winform控件,所以我们需要设置STAThread标签。
第二:winform是事件驱动的,Console不响应事件,所有事件都在windows的消息队列中等待执行,以防止程序假死,
我们需要调用DoEvents方法来传递控制权,让操作系统执行其他事件。
第三:WebBrowser内容,我们需要使用DomDocument来查看,而不是DocumentText。
判断动态网页是否加载一般有两种方式:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们这里需要这样做
记录计数值
.
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.html,看看js加载的内容有没有。
②:当然,除了通过判断最大值来判断加载是否完成,我们还可以通过设置一个Timer来判断,比如3s、4s、5s,稍后再查看
WEB浏览器是否加载。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然,效果还是一样的,就不截图了。从以上两种写法来看,我们的WebBrowser放在主线程中。让我们看看如何把它放在工作线程上。
很简单,只需将工作线程设置为STA模式即可。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 }
抓取动态网页(如何抓取网页中的动态网页源码中特定的特定内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-25 21:22
背景
很多时候,很多人需要在网络上抓取一些特定的内容。
但是,除了之前介绍的内容之外,您还想从某些静态网页中提取某些内容,例如:
【教程】Python版爬网并从网页中提取需要的信息
和
【教程】C#版爬网并从网页中提取需要的信息
另外,有些人会发现自己要抓取的网页内容不在网页的源代码中。
所以,在这一点上,我不知道该怎么做。
在这里,我们来解释一下如何爬取所谓的动态网页中的特定内容。
必备知识
在阅读本文之前,您需要具备相关的基础知识:
1.爬取网页,模拟登录等相关逻辑
不熟悉的可以参考:
【组织】爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站
2.学会使用工具,比如IE9的F12,爬取对应的网页执行流程
不熟悉的可以参考:
【教程】教你如何使用工具(IE9的F12)解析模拟登录内部逻辑流程网站(百度首页))
3.对于一个普通的静态网页,如何提取想要的内容
对此不熟悉的可以参考:
(1)Python 版本:
【教程】Python版爬网并从网页中提取需要的信息
(2)C# 版本:
【教程】C#版爬网并从网页中提取需要的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指通过浏览器查看网页源代码时,你看到的网页源代码中的内容与网页上显示的内容相对应。
也就是说,当我想得到某个网页上显示的内容时,我可以通过查找网页的源代码找到对应的部分。
动态网页,相反,如果要获取动态网页中的具体内容,直接查看网页源代码是找不到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
一般来说,它是通过其他方式生成或获取的。
据我所知,有几个:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个url的过程,你会发现很可能涉及到,
在网页正常完整显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些你想抓取的内容,有时候,这些js脚本是动态执行的,最后计算出来的。
通过访问另一个url地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要抓取的动态内容
其实对于如何爬取需要的动态内容,简单来说,有一个解决方案:
根据你通过工具分析的结果,找到对应的数据并提取出来;
不过这个数据有时候可以在分析结果的过程中直接提取出来,有时候可能是通过js计算出来的。
想抓取数据,是js脚本生成的
虽然最终的动态内容是由js脚本执行生成的,但是对于你要抓取的数据:
想爬取数据是通过访问另一个url获取的
如果你要抓取的对应内容是访问另一个url地址和返回的数据,那么很简单,你也需要访问这个url,然后获取对应的返回内容,从中提取你想要的数据。
总结
同一句话,不管你访问的内容是如何生成的,最后你还是可以用工具来分析对应的内容是如何从零开始生成的。
然后用代码模拟这个过程,最后提取出你需要的内容;
具体示例演示见:
【教程】以网易博文的最新读者信息为例,教大家如何抓取动态网页的内容。 查看全部
抓取动态网页(如何抓取网页中的动态网页源码中特定的特定内容)
背景
很多时候,很多人需要在网络上抓取一些特定的内容。
但是,除了之前介绍的内容之外,您还想从某些静态网页中提取某些内容,例如:
【教程】Python版爬网并从网页中提取需要的信息
和
【教程】C#版爬网并从网页中提取需要的信息
另外,有些人会发现自己要抓取的网页内容不在网页的源代码中。
所以,在这一点上,我不知道该怎么做。
在这里,我们来解释一下如何爬取所谓的动态网页中的特定内容。
必备知识
在阅读本文之前,您需要具备相关的基础知识:
1.爬取网页,模拟登录等相关逻辑
不熟悉的可以参考:
【组织】爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站
2.学会使用工具,比如IE9的F12,爬取对应的网页执行流程
不熟悉的可以参考:
【教程】教你如何使用工具(IE9的F12)解析模拟登录内部逻辑流程网站(百度首页))
3.对于一个普通的静态网页,如何提取想要的内容
对此不熟悉的可以参考:
(1)Python 版本:
【教程】Python版爬网并从网页中提取需要的信息
(2)C# 版本:
【教程】C#版爬网并从网页中提取需要的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指通过浏览器查看网页源代码时,你看到的网页源代码中的内容与网页上显示的内容相对应。
也就是说,当我想得到某个网页上显示的内容时,我可以通过查找网页的源代码找到对应的部分。
动态网页,相反,如果要获取动态网页中的具体内容,直接查看网页源代码是找不到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
一般来说,它是通过其他方式生成或获取的。
据我所知,有几个:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个url的过程,你会发现很可能涉及到,
在网页正常完整显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些你想抓取的内容,有时候,这些js脚本是动态执行的,最后计算出来的。
通过访问另一个url地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要抓取的动态内容
其实对于如何爬取需要的动态内容,简单来说,有一个解决方案:
根据你通过工具分析的结果,找到对应的数据并提取出来;
不过这个数据有时候可以在分析结果的过程中直接提取出来,有时候可能是通过js计算出来的。
想抓取数据,是js脚本生成的
虽然最终的动态内容是由js脚本执行生成的,但是对于你要抓取的数据:
想爬取数据是通过访问另一个url获取的
如果你要抓取的对应内容是访问另一个url地址和返回的数据,那么很简单,你也需要访问这个url,然后获取对应的返回内容,从中提取你想要的数据。
总结
同一句话,不管你访问的内容是如何生成的,最后你还是可以用工具来分析对应的内容是如何从零开始生成的。
然后用代码模拟这个过程,最后提取出你需要的内容;
具体示例演示见:
【教程】以网易博文的最新读者信息为例,教大家如何抓取动态网页的内容。
抓取动态网页(如何利用Webkit从JS渲染网页中获取数据处理的任何事情)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-01-24 14:13
当我们进行网络爬取时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页收录 JavaScript 代码,我们必须渲染它以获取原创数据。在这一点上,如果我们仍然以通常的方式从中抓取数据,我们将一无所获。浏览器知道如何处理这段代码并显示出来,但是我们的程序应该如何处理这段代码呢?接下来,我将介绍一种简单粗暴的方法来抓取收录 JavaScript 代码的网页信息。
大多数人使用 lxml 和 BeautifulSoup 包来提取数据。本文不会涉及任何爬虫框架,因为我只使用最基本的lxml包来处理数据。你可能想知道为什么我更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中我要介绍一个非常有趣的案例——突然发现我的文章出现在最近的Pycoders周刊147上,所以我想爬取Pycoders周刊中所有档案的链接。
显然,这是一个带有 JavaScript 渲染的网页。我想抓取网页中的所有个人资料信息和相应的链接信息。那么我该怎么办呢?首先,我们无法通过 HTTP 方法获取任何信息。
导入请求
从 lxml 导入 html
# 存储响应
响应 = requests.get('#x27;)
# 从响应体创建 lxml 树
树 = html.fromstring(response.text)
# 查找所有的锚标签作为响应
print tree.xpath('//div[@class="campaign"]/a/@href')
当我们运行上述代码时,我们无法获得任何信息。这怎么可能?网页清楚地显示了这么多文件的信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来我将展示如何使用 Web 工具包从 JS 渲染的网页中获取数据。什么是网络套件?Web 工具包可以做任何浏览器可以处理的事情。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你安装了 QT 和 PyQT4 库,你可以直接运行它。
您可以使用命令行安装存储库:
sudo apt-get install python-qt4
现在所有的准备工作都完成了,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过 Web kit 发送请求信息,然后等待页面完全加载,然后将其分配给变量。接下来我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一点时间,但您会惊讶地看到整个页面加载完毕。
导入系统
从 PyQt4.QtGui 导入 *
从 PyQt4.Qtcore 导入 *
从 PyQt4.QtWebKit 导入 *
类渲染(QWebPage):
定义初始化(自我,网址):
self.app = QApplication(sys.argv)
QWebPage.init(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(自我,结果):
self.frame = self.mainFrame()
self.app.quit()
Render 类可用于渲染网页。当我们创建一个新的 Render 类时,它可以加载 url 中的所有信息并将其存储在一个新的框架中。
网址 = '#x27;
# 这很神奇。加载所有内容
r = 渲染(网址)
# 结果是一个QString。
结果 = r.frame.toHtml()
使用上面的代码,我们将 HTML 结果存储到变量 result 中。由于lxml不能直接处理这种特殊的字符串数据,我们需要转换数据格式。
# QString 在被 lxml 处理之前应该被转换为字符串
formatted_result = str(result.toAscii())
# 接下来从 formatted_result 构建 lxml 树
树 = html.fromstring(formatted_result)
# 现在使用正确的 Xpath 我们正在获取档案的 URL
archive_links = tree.xpath('//div[@class="campaign"]/a/@href')
打印存档链接
使用上面的代码,我们可以得到所有的文件链接信息,然后我们可以使用这些Render和这些URL链接来提取文本内容信息。Web kit 提供了一个强大的网页渲染工具,我们可以使用这个工具从 JS 渲染的网页中抓取有效的信息。
在本文中,我介绍了一种从 JS 渲染的网页中获取信息的有效方法。虽然这个工具比较慢,但是非常简单粗暴。我希望你会喜欢这个文章。现在您可以将此方法应用于您发现难以处理的任何网页。
愿你事事如意。 查看全部
抓取动态网页(如何利用Webkit从JS渲染网页中获取数据处理的任何事情)
当我们进行网络爬取时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页收录 JavaScript 代码,我们必须渲染它以获取原创数据。在这一点上,如果我们仍然以通常的方式从中抓取数据,我们将一无所获。浏览器知道如何处理这段代码并显示出来,但是我们的程序应该如何处理这段代码呢?接下来,我将介绍一种简单粗暴的方法来抓取收录 JavaScript 代码的网页信息。
大多数人使用 lxml 和 BeautifulSoup 包来提取数据。本文不会涉及任何爬虫框架,因为我只使用最基本的lxml包来处理数据。你可能想知道为什么我更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中我要介绍一个非常有趣的案例——突然发现我的文章出现在最近的Pycoders周刊147上,所以我想爬取Pycoders周刊中所有档案的链接。
显然,这是一个带有 JavaScript 渲染的网页。我想抓取网页中的所有个人资料信息和相应的链接信息。那么我该怎么办呢?首先,我们无法通过 HTTP 方法获取任何信息。
导入请求
从 lxml 导入 html
# 存储响应
响应 = requests.get('#x27;)
# 从响应体创建 lxml 树
树 = html.fromstring(response.text)
# 查找所有的锚标签作为响应
print tree.xpath('//div[@class="campaign"]/a/@href')
当我们运行上述代码时,我们无法获得任何信息。这怎么可能?网页清楚地显示了这么多文件的信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来我将展示如何使用 Web 工具包从 JS 渲染的网页中获取数据。什么是网络套件?Web 工具包可以做任何浏览器可以处理的事情。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你安装了 QT 和 PyQT4 库,你可以直接运行它。
您可以使用命令行安装存储库:
sudo apt-get install python-qt4
现在所有的准备工作都完成了,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过 Web kit 发送请求信息,然后等待页面完全加载,然后将其分配给变量。接下来我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一点时间,但您会惊讶地看到整个页面加载完毕。
导入系统
从 PyQt4.QtGui 导入 *
从 PyQt4.Qtcore 导入 *
从 PyQt4.QtWebKit 导入 *
类渲染(QWebPage):
定义初始化(自我,网址):
self.app = QApplication(sys.argv)
QWebPage.init(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(自我,结果):
self.frame = self.mainFrame()
self.app.quit()
Render 类可用于渲染网页。当我们创建一个新的 Render 类时,它可以加载 url 中的所有信息并将其存储在一个新的框架中。
网址 = '#x27;
# 这很神奇。加载所有内容
r = 渲染(网址)
# 结果是一个QString。
结果 = r.frame.toHtml()
使用上面的代码,我们将 HTML 结果存储到变量 result 中。由于lxml不能直接处理这种特殊的字符串数据,我们需要转换数据格式。
# QString 在被 lxml 处理之前应该被转换为字符串
formatted_result = str(result.toAscii())
# 接下来从 formatted_result 构建 lxml 树
树 = html.fromstring(formatted_result)
# 现在使用正确的 Xpath 我们正在获取档案的 URL
archive_links = tree.xpath('//div[@class="campaign"]/a/@href')
打印存档链接
使用上面的代码,我们可以得到所有的文件链接信息,然后我们可以使用这些Render和这些URL链接来提取文本内容信息。Web kit 提供了一个强大的网页渲染工具,我们可以使用这个工具从 JS 渲染的网页中抓取有效的信息。
在本文中,我介绍了一种从 JS 渲染的网页中获取信息的有效方法。虽然这个工具比较慢,但是非常简单粗暴。我希望你会喜欢这个文章。现在您可以将此方法应用于您发现难以处理的任何网页。
愿你事事如意。
抓取动态网页(第四章:动态网页抓取((解析真实地址+selenium) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-24 14:12
)
第 4 章:动态网页抓取(解析真实地址 + selenium)
由于网易云线程已停止,新写的第4章现已更新至此。请参考文章:
之前爬取的网页都是静态网页,这些网页在浏览器中显示的内容是在HTML源代码中。但是由于主流的网站都使用JavaScript来展示网页内容,不像静态网页,在使用JavaScript的时候,很多内容不会出现在HTML源代码中,所以爬取静态网页的技术可能不会工作正常使用。因此,我们需要使用两种动态网页抓取技术:通过浏览器检查元素解析真实网址和使用 selenium 模拟浏览器。
本章首先介绍动态网页的示例,让读者了解什么是动态网页抓取,然后利用以上两种动态网页抓取技术获取动态网页数据。
4.1 动态抓取示例
在开始爬取动态网页之前,我们还需要了解一个异步更新技术——AJAX(Asynchronous Javascript And XML)。它的价值在于可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。一方面减少了网页重复内容的下载,另一方面也节省了流量,所以AJAX被广泛使用。
与使用 AJAX 网页相比,如果传统网页需要更新内容,则必须重新加载整个网页。因此,AJAX 使 Internet 应用程序更小、更快、更友好。但是AJAX网页的爬取过程比较麻烦。
首先,我们来看一个动态网页的例子。打开作者博客的Hello World文章,文章的地址是:/2018/07/04/hello-world/。网址可能会有变化,请到作者博客官网查找Hello World文章地址。如图4-1所示,页面下方的评论是用JavaScript加载的,这些评论数据不会出现在网页的源代码中。
为了验证页面下方的评论是否加载了 JavaScript,我们可以查看该页面的网页源代码。如图 4-2 所示,放置评论的代码中没有评论数据,只有一段 JavaScript 代码。最终呈现的数据通过 JavaScript 提取并加载到源代码中进行呈现。
除了作者的博客,还可以在天猫电商网站上找到AJAX技术的例子。比如打开天猫iPhone XS Max的产品页面,点击“累计评论”,可以发现上面的url地址没有变化,整个网页也没有重新加载,网页的评论区也没有更新,如图4-3所示。
如图4-4所示,我们也可以查看这个产品网页的源码,里面没有用户评论,这段内容是空白的。
如果使用AJAX加载动态网页,如何抓取里面动态加载的内容?有两种方法:
(1)通过浏览器检查元素解析地址。
(2) 通过 Selenium 模拟浏览器抓取。
请查看第四章的其他章节
4.2 解析真实地址捕获
4.3 模拟浏览器通过selenium爬取
查看全部
抓取动态网页(第四章:动态网页抓取((解析真实地址+selenium)
)
第 4 章:动态网页抓取(解析真实地址 + selenium)
由于网易云线程已停止,新写的第4章现已更新至此。请参考文章:
之前爬取的网页都是静态网页,这些网页在浏览器中显示的内容是在HTML源代码中。但是由于主流的网站都使用JavaScript来展示网页内容,不像静态网页,在使用JavaScript的时候,很多内容不会出现在HTML源代码中,所以爬取静态网页的技术可能不会工作正常使用。因此,我们需要使用两种动态网页抓取技术:通过浏览器检查元素解析真实网址和使用 selenium 模拟浏览器。
本章首先介绍动态网页的示例,让读者了解什么是动态网页抓取,然后利用以上两种动态网页抓取技术获取动态网页数据。
4.1 动态抓取示例
在开始爬取动态网页之前,我们还需要了解一个异步更新技术——AJAX(Asynchronous Javascript And XML)。它的价值在于可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。一方面减少了网页重复内容的下载,另一方面也节省了流量,所以AJAX被广泛使用。
与使用 AJAX 网页相比,如果传统网页需要更新内容,则必须重新加载整个网页。因此,AJAX 使 Internet 应用程序更小、更快、更友好。但是AJAX网页的爬取过程比较麻烦。
首先,我们来看一个动态网页的例子。打开作者博客的Hello World文章,文章的地址是:/2018/07/04/hello-world/。网址可能会有变化,请到作者博客官网查找Hello World文章地址。如图4-1所示,页面下方的评论是用JavaScript加载的,这些评论数据不会出现在网页的源代码中。
为了验证页面下方的评论是否加载了 JavaScript,我们可以查看该页面的网页源代码。如图 4-2 所示,放置评论的代码中没有评论数据,只有一段 JavaScript 代码。最终呈现的数据通过 JavaScript 提取并加载到源代码中进行呈现。
除了作者的博客,还可以在天猫电商网站上找到AJAX技术的例子。比如打开天猫iPhone XS Max的产品页面,点击“累计评论”,可以发现上面的url地址没有变化,整个网页也没有重新加载,网页的评论区也没有更新,如图4-3所示。
如图4-4所示,我们也可以查看这个产品网页的源码,里面没有用户评论,这段内容是空白的。
如果使用AJAX加载动态网页,如何抓取里面动态加载的内容?有两种方法:
(1)通过浏览器检查元素解析地址。
(2) 通过 Selenium 模拟浏览器抓取。
请查看第四章的其他章节
4.2 解析真实地址捕获
4.3 模拟浏览器通过selenium爬取
抓取动态网页(代码中添加其他作者的不同信息(中英对照))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-24 14:10
我正在网上抓取不同作者在谷歌学术上的出版年数和数量,到目前为止,这是我只有一位作者的代码:我正在网上抓取不同作者在谷歌学术上的出版年数和出版数量,到目前为止这是我只有一位作者的代码:这是我到目前为止只有一位作者的代码:
from selenium import webdriver
mozilla_path = r"C:\Users\ivrav\Python38\geckodriver.exe"
driver = webdriver.Firefox()
driver.get("https://scholar.google.com/cit ... 6quot;)
driver.maximize_window()
years = [element.get_attribute("textContent") for element in driver.find_elements_by_xpath('//span[@class="gsc_g_t"]')]
citations = [element.get_attribute("textContent") for element in driver.find_elements_by_xpath('//span[@class="gsc_g_al"]')]
for year, citation in zip(years, citations):
print(year, citation)
但是,我的疑问取决于如何在同一代码中添加其他作者的不同信息。我应该使用循环吗?我应该使用循环吗?我不太确定如何解决这个问题。举个例子,我要刮的另一个网页只是举个例子,我要刮的另一个网页是
非常感谢,Best,Iván 查看全部
抓取动态网页(代码中添加其他作者的不同信息(中英对照))
我正在网上抓取不同作者在谷歌学术上的出版年数和数量,到目前为止,这是我只有一位作者的代码:我正在网上抓取不同作者在谷歌学术上的出版年数和出版数量,到目前为止这是我只有一位作者的代码:这是我到目前为止只有一位作者的代码:
from selenium import webdriver
mozilla_path = r"C:\Users\ivrav\Python38\geckodriver.exe"
driver = webdriver.Firefox()
driver.get("https://scholar.google.com/cit ... 6quot;)
driver.maximize_window()
years = [element.get_attribute("textContent") for element in driver.find_elements_by_xpath('//span[@class="gsc_g_t"]')]
citations = [element.get_attribute("textContent") for element in driver.find_elements_by_xpath('//span[@class="gsc_g_al"]')]
for year, citation in zip(years, citations):
print(year, citation)
但是,我的疑问取决于如何在同一代码中添加其他作者的不同信息。我应该使用循环吗?我应该使用循环吗?我不太确定如何解决这个问题。举个例子,我要刮的另一个网页只是举个例子,我要刮的另一个网页是
非常感谢,Best,Iván
抓取动态网页(python爬取js执行后输出的信息1.11.1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-01-24 00:18
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多时候,爬虫检索到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1. 两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
1 importdryscrape2 #使用dryscrape库动态抓取页面
3 defget_url_dynamic(url):4 session_req=dryscrape.Session()5 session_req.visit(url) #请求页面
6 response=session_req.body() #网页的文本
7 #打印(响应)
8 returnresponse9 get_text_line(get_url_dynamic(url)) # 会输出一个文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,因此也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
1 defget_url_dynamic2(url):2 driver=webdriver.Firefox() #调用本地火狐浏览器,Chrom甚至Ie也可以
3 driver.get(url) #请求一个页面,会打开一个浏览器窗口
4 html_text=driver.page_source5 driver.quit()6 #print html_text
7 returnhtml_text8 get_text_line(get_url_dynamic2(url)) #会输出一个文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2. selenium 的安装和使用
2.1 硒安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载 geckodriverckod 地址:
Mozilla/geckodriver
2. 解压后geckodriverckod存放在/usr/local/bin/: sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 硒的使用
1. 运行错误:
驱动程序= webdriver.chrome()
TypeError:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
1 内容 = driver.find_element_by_class_name('内容')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
1 个值 = 内容.文本 查看全部
抓取动态网页(python爬取js执行后输出的信息1.11.1)
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多时候,爬虫检索到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1. 两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
1 importdryscrape2 #使用dryscrape库动态抓取页面
3 defget_url_dynamic(url):4 session_req=dryscrape.Session()5 session_req.visit(url) #请求页面
6 response=session_req.body() #网页的文本
7 #打印(响应)
8 returnresponse9 get_text_line(get_url_dynamic(url)) # 会输出一个文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,因此也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
1 defget_url_dynamic2(url):2 driver=webdriver.Firefox() #调用本地火狐浏览器,Chrom甚至Ie也可以
3 driver.get(url) #请求一个页面,会打开一个浏览器窗口
4 html_text=driver.page_source5 driver.quit()6 #print html_text
7 returnhtml_text8 get_text_line(get_url_dynamic2(url)) #会输出一个文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2. selenium 的安装和使用
2.1 硒安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载 geckodriverckod 地址:
Mozilla/geckodriver
2. 解压后geckodriverckod存放在/usr/local/bin/: sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 硒的使用
1. 运行错误:
驱动程序= webdriver.chrome()
TypeError:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
1 内容 = driver.find_element_by_class_name('内容')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
1 个值 = 内容.文本
抓取动态网页(搜索引擎提升静态和动态页面哪个蜘蛛抓取的快?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-23 10:01
问题:哪种蜘蛛爬取静态和动态页面的速度更快?
答:理论上,搜索引擎蜘蛛把静态页面和动态页面一视同仁,不会优先抓取哪个页面,但是这里有个前提,就是动态页面必须被蜘蛛识别。如果动态页面有很多复杂的参数,可能会影响蜘蛛抓取。
其实搜索引擎发展到今天已经能够很好的解决爬取的问题,不管是静态页面还是动态页面都可以爬取。但是从用户体验的角度来说,最好将URL设置为静态或者伪静态,因为合理的URL可以节省用户的判断成本,也有利于网站的优化。
当然,不要走入死胡同,认为搜索引擎会歧视动态链接,这是错误的。
在判断页面质量和关键词排名方面,静态页面和动态页面没有严格的区别,都可以正常参与排名。不过这里也有一个需要注意的问题,就是页面的动态更新。无论页面的 URL 是什么形式,都必须保证页面是动态更新的。
比如文章页面通常会调用相关的文章,这个相关的文章的调用应该是动态的,文章在同一个标签下更新,其他的< @文章 页面也需要同步更新。这样做的好处是增加了页面的更新频率,有利于页面本身质量的提升。
关于页面ULR和蜘蛛爬取的问题,沐风SEO简单的说了这么多。总之,一般情况下,无论是静态页面还是动态页面,蜘蛛都会抓取。但是在设置网址的时候,一定要遵循一个原则,就是网址要尽量简单易懂,不能有复杂的符号! 查看全部
抓取动态网页(搜索引擎提升静态和动态页面哪个蜘蛛抓取的快?(图))
问题:哪种蜘蛛爬取静态和动态页面的速度更快?
答:理论上,搜索引擎蜘蛛把静态页面和动态页面一视同仁,不会优先抓取哪个页面,但是这里有个前提,就是动态页面必须被蜘蛛识别。如果动态页面有很多复杂的参数,可能会影响蜘蛛抓取。
其实搜索引擎发展到今天已经能够很好的解决爬取的问题,不管是静态页面还是动态页面都可以爬取。但是从用户体验的角度来说,最好将URL设置为静态或者伪静态,因为合理的URL可以节省用户的判断成本,也有利于网站的优化。
当然,不要走入死胡同,认为搜索引擎会歧视动态链接,这是错误的。
在判断页面质量和关键词排名方面,静态页面和动态页面没有严格的区别,都可以正常参与排名。不过这里也有一个需要注意的问题,就是页面的动态更新。无论页面的 URL 是什么形式,都必须保证页面是动态更新的。
比如文章页面通常会调用相关的文章,这个相关的文章的调用应该是动态的,文章在同一个标签下更新,其他的< @文章 页面也需要同步更新。这样做的好处是增加了页面的更新频率,有利于页面本身质量的提升。
关于页面ULR和蜘蛛爬取的问题,沐风SEO简单的说了这么多。总之,一般情况下,无论是静态页面还是动态页面,蜘蛛都会抓取。但是在设置网址的时候,一定要遵循一个原则,就是网址要尽量简单易懂,不能有复杂的符号!
抓取动态网页(一下企业网站建设之动态网页制作的“二点一线”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-21 05:19
目前市场上大部分的企业风站建设都会根据未来的需求来决定使用动态网页还是静态网页。继介绍了企业建设网站静态网页设计“三步曲”之后,瑞虎接下来为大家介绍建设企业动态网页制作的“两点一”。企业 网站。细绳”。
动态网页的概念
动态网页是目前常见的网页编程技术。这里的动态是指在页面代码不变的情况下,网页中显示的内容会随着时间、环境或数据库操作的变化而变化。动态网页是一种与静态网页相反的网页。动态网页结合了基本的html语法规范、Java、VB、VC等高级编程语言以及数据库编程来生成网页。在网站构建过程中实现对网站内容和样式的高效、动态、交互的管理。
动态网页的工作原理
动态网页主要是将静态网页与后台数据库进行交互,然后完成数据传输。常见的动态网页制作后缀格式有.asp、.jsp、.php、.perl等,还有一个标志性的符号“?” 在网址中。动态网页的工作原理是:基于数据库技术,实现用户注册、登录、管理等功能,当用户向服务器发送请求时,返回一个完整的网页给用户。
动态网页制作“两点一线”
动态网页制作的“一点一线”中的“两点”包括:动态网页制作的优缺点,“一根线”是指从服务器端到客户端的连接。
一、动态网页制作的优势
1、基于数据库,动静结合
动态网页的制作主要是基于数据库的网页,网站的整个操作都是通过代码调用数据库来展示和实现的。这种类型的网站交互性很强,可以大大提升用户体验。动态网站采用动静结合的原则,吸收静态网页的优点,必要时使用静态网页,让企业在网站的建设中形成动静结合的优化配置.
2、内容更新快,满足用户需求
动态网页制作技术的一大特点是网站内容更新快,这也是企业网站建设采用动态网页制作网站的原因。动态网页的更新和维护,一般是通过编辑修改网站的背景来实现的,比如企业建站常用的智盟背景。这将网站的构建和维护分开,如果业务无法自行完成网站的构建,可以外包。网站的维护只需要企业通过网站后台完成各种信息的发布。
3、灵活的开发技术和多功能操作
动态网页的技术支持不强。常用的基本网页技术包括 PHP(超文本预处理器)、ASP(Active Server Pages)、JSP(Java Server Pages)和 CGI(Common Gateway Interface)。网站开发者可以通过这四种强大的后台技术来编辑制作动态网页,并在此基础上实现对网站的多功能操作。用户注册、登录、管理等功能有助于实现网站的交互性,提高用户对网站的粘性。
二、动态网页创建的缺点
1、访问缓慢
因为动态网页是连接到服务器的数据库的,所以用户在访问网页时需要在发送请求后等待数据库的响应,然后再向用户反馈一个完整的网页。这时候如果访问的用户特征比较多,很容易导致访问速度变慢甚至崩溃。从用户的角度来看,对这个问题的直接反应就是网页加载太慢,没有响应,极大地影响了用户的访问心情,甚至让用户放弃访问。
2、对搜索引擎的亲和力低
动态网页有一个“?” URL 中的符号,并且响应必须在用户输入命令之后。根据搜索引擎的特点,蜘蛛只能识别和抓取现成的页面,所以搜索引擎对动态网页不会有很高的亲和力,不利于网站的收录 . 但是,绝大多数搜索引擎已经支持动态页面的爬取。
3、网络安全性低
动态网页在实现强大交互功能的同时,也给网站带来了很大的安全隐患。如果开发者和设计者在编写动态Web程序时没有充分考虑网站的安全性,网站很容易为攻击者留下后门,受到恶意攻击和黑客攻击的危害。
三、动态网页创建第一行
这里所说的第一行动态网页制作是指网页的服务器端和客户端,将动态网页结合起来形成一个完整的网站。下面瑞虎小编就为大家分析一下这两个。
服务终端
服务器端是指网络上的服务器。动态网页在服务器上运行程序时,主要使用的语言有ASP、ColdFusion、Perl、PHP、WebDNA等服务器端语言。动态网页是使用这些语言结合通用网关接口 (CGI) 形成的,但 JSP 除外,其网络请求被分派到共享虚拟机。动态网站的服务器端经常处于缓存状态,这样会延长动态网页的加载时间。
客户
客户端是指用户在动态网页上发出请求,服务器将响应特定网页中的鼠标或键盘操作,或指定命令。在这种情况下,动态网页会根据客户端的行为在用户本地计算机浏览器中生成相应的内容,获取用户访问的行为结果。 查看全部
抓取动态网页(一下企业网站建设之动态网页制作的“二点一线”)
目前市场上大部分的企业风站建设都会根据未来的需求来决定使用动态网页还是静态网页。继介绍了企业建设网站静态网页设计“三步曲”之后,瑞虎接下来为大家介绍建设企业动态网页制作的“两点一”。企业 网站。细绳”。
动态网页的概念
动态网页是目前常见的网页编程技术。这里的动态是指在页面代码不变的情况下,网页中显示的内容会随着时间、环境或数据库操作的变化而变化。动态网页是一种与静态网页相反的网页。动态网页结合了基本的html语法规范、Java、VB、VC等高级编程语言以及数据库编程来生成网页。在网站构建过程中实现对网站内容和样式的高效、动态、交互的管理。
动态网页的工作原理
动态网页主要是将静态网页与后台数据库进行交互,然后完成数据传输。常见的动态网页制作后缀格式有.asp、.jsp、.php、.perl等,还有一个标志性的符号“?” 在网址中。动态网页的工作原理是:基于数据库技术,实现用户注册、登录、管理等功能,当用户向服务器发送请求时,返回一个完整的网页给用户。
动态网页制作“两点一线”
动态网页制作的“一点一线”中的“两点”包括:动态网页制作的优缺点,“一根线”是指从服务器端到客户端的连接。
一、动态网页制作的优势
1、基于数据库,动静结合
动态网页的制作主要是基于数据库的网页,网站的整个操作都是通过代码调用数据库来展示和实现的。这种类型的网站交互性很强,可以大大提升用户体验。动态网站采用动静结合的原则,吸收静态网页的优点,必要时使用静态网页,让企业在网站的建设中形成动静结合的优化配置.
2、内容更新快,满足用户需求
动态网页制作技术的一大特点是网站内容更新快,这也是企业网站建设采用动态网页制作网站的原因。动态网页的更新和维护,一般是通过编辑修改网站的背景来实现的,比如企业建站常用的智盟背景。这将网站的构建和维护分开,如果业务无法自行完成网站的构建,可以外包。网站的维护只需要企业通过网站后台完成各种信息的发布。
3、灵活的开发技术和多功能操作
动态网页的技术支持不强。常用的基本网页技术包括 PHP(超文本预处理器)、ASP(Active Server Pages)、JSP(Java Server Pages)和 CGI(Common Gateway Interface)。网站开发者可以通过这四种强大的后台技术来编辑制作动态网页,并在此基础上实现对网站的多功能操作。用户注册、登录、管理等功能有助于实现网站的交互性,提高用户对网站的粘性。
二、动态网页创建的缺点
1、访问缓慢
因为动态网页是连接到服务器的数据库的,所以用户在访问网页时需要在发送请求后等待数据库的响应,然后再向用户反馈一个完整的网页。这时候如果访问的用户特征比较多,很容易导致访问速度变慢甚至崩溃。从用户的角度来看,对这个问题的直接反应就是网页加载太慢,没有响应,极大地影响了用户的访问心情,甚至让用户放弃访问。
2、对搜索引擎的亲和力低
动态网页有一个“?” URL 中的符号,并且响应必须在用户输入命令之后。根据搜索引擎的特点,蜘蛛只能识别和抓取现成的页面,所以搜索引擎对动态网页不会有很高的亲和力,不利于网站的收录 . 但是,绝大多数搜索引擎已经支持动态页面的爬取。
3、网络安全性低
动态网页在实现强大交互功能的同时,也给网站带来了很大的安全隐患。如果开发者和设计者在编写动态Web程序时没有充分考虑网站的安全性,网站很容易为攻击者留下后门,受到恶意攻击和黑客攻击的危害。
三、动态网页创建第一行
这里所说的第一行动态网页制作是指网页的服务器端和客户端,将动态网页结合起来形成一个完整的网站。下面瑞虎小编就为大家分析一下这两个。
服务终端
服务器端是指网络上的服务器。动态网页在服务器上运行程序时,主要使用的语言有ASP、ColdFusion、Perl、PHP、WebDNA等服务器端语言。动态网页是使用这些语言结合通用网关接口 (CGI) 形成的,但 JSP 除外,其网络请求被分派到共享虚拟机。动态网站的服务器端经常处于缓存状态,这样会延长动态网页的加载时间。
客户
客户端是指用户在动态网页上发出请求,服务器将响应特定网页中的鼠标或键盘操作,或指定命令。在这种情况下,动态网页会根据客户端的行为在用户本地计算机浏览器中生成相应的内容,获取用户访问的行为结果。
抓取动态网页(一个完整的网络爬虫基础框架如下图所示:整个架构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-21 03:09
一个完整的网络爬虫基础框架如下图所示:
整个架构由以下过程组成:
1)需求方提供需要爬取的种子URL列表,根据提供的URL列表和对应的优先级(先到先得)建立待爬取的URL队列;
2)网页抓取是按照要抓取的URL队列的顺序进行的;
3)将获取到的网页内容和信息下载到本地网络库,并创建爬取的URL列表(用于去重和判断爬取过程);
4)将爬取的网页放入待爬取的URL队列中,进行循环爬取操作;
2. 网络爬虫爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取URL队列中的URL排列顺序也是一个很重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面的问题。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
1)深度优先遍历策略
深度优先遍历策略很好理解,和我们有向图中的深度优先遍历一样,因为网络本身就是一个图模型。深度优先遍历的思路是从一个起始网页开始爬取,然后根据链接一个一个的爬取,直到不能再深度爬取,然后返回上一页继续关注链接。
有向图中的深度优先搜索示例如下所示:
上图左图是有向图的示意图,右图是深度优先遍历的搜索过程示意图。深度优先遍历的结果是:
2)广度优先搜索策略
广度优先搜索和深度优先搜索的工作方式完全相反。这个想法是将在新下载的网页中找到的链接直接插入到要抓取的 URL 队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。
上图是上例有向图的广度优先搜索流程图,其遍历结果为:
v1→v2→v3→v4→v5→v6→v7→v8
从树的结构来看,图的广度优先遍历就是树的层次遍历。
3)反向链接搜索策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
4)大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
5)其他搜索策略
一些比较常用的爬虫搜索侧率还包括Partial PageRank搜索策略(根据PageRank分数确定下一个抓取的URL),OPIC搜索策略(也是一种重要性)。最后必须指出的一点是,我们可以根据自己的需要来设置网页的抓取间隔,这样可以保证我们一些基本的大网站或者活跃的网站内容不会被漏掉。
3. 网络爬虫更新策略
互联网实时变化并且非常动态。网页更新策略主要决定何时更新之前已经下载的页面。常见的更新策略有以下三种:
1)历史参考政策
顾名思义,它根据页面过去的历史更新数据来预测未来页面何时会发生变化。通常,预测是通过泊松过程建模来进行的。
2)用户体验策略
尽管搜索引擎可以为某个查询返回大量结果,但用户通常只关注结果的前几页。因此,爬虫系统可以优先更新那些实际在查询结果前几页的页面,然后再更新后面的那些页面。这个更新策略也需要用到历史信息。UX 策略保留网页的多个历史版本,并根据每个过去内容更改对搜索质量的影响得出一个平均值,并以此值作为决定何时重新抓取的基础。
3)聚类抽样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页完全没有历史信息,就无法确定更新策略。
该策略认为网页具有许多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某一类别网页的更新频率,只需对该类别的网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如下:
4. 分布式抓取系统结构
一般来说,爬虫系统需要处理整个互联网上数以亿计的网页。单个爬虫不可能完成这样的任务。通常需要多个爬虫程序一起处理它们。一般来说,爬虫系统往往是分布式的三层结构。如图所示:
最底层是分布在不同地理位置的数据中心。每个数据中心有多个爬虫服务器,每个爬虫服务器可能部署多套爬虫程序。这样就构成了一个基本的分布式爬虫系统。
对于数据中心中的不同服务器,有几种方法可以协同工作:
1)主从
主从基本结构如图:
对于主从类型,有一个专门的主服务器来维护要爬取的URL队列,负责每次将URL分发给不同的从服务器,从服务器负责实际的网页下载工作。Master服务器除了维护要爬取的URL队列和分发URL外,还负责调解每个Slave服务器的负载。为了避免一些从服务器过于空闲或过度工作。
在这种模式下,Master往往会成为系统的瓶颈。
2)点对点
等价的基本结构如图所示:
在这种模式下,所有爬虫服务器之间的分工没有区别。每个爬取服务器可以从待爬取的URL队列中获取URL,然后计算该URL主域名的哈希值H,进而计算H mod m(其中m为服务器数量,上图为例如,m 对于 3),计算出来的数字是处理 URL 的主机号。
例子:假设对于URL,计算器hash值H=8,m=3,那么H mod m=2,那么编号为2的服务器会抓取该链接。假设此时服务器 0 获取了 URL,它会将 URL 传输到服务器 2,服务器 2 将获取它。
这种模式有一个问题,当一个服务器死掉或添加一个新服务器时,所有 URL 的哈希余数的结果都会改变。也就是说,这种方法不能很好地扩展。针对这种情况,提出了另一种改进方案。这种改进的方案是一致的散列以确定服务器划分。其基本结构如图所示:
一致散列对 URL 的主域名进行散列,并将其映射到 0-232 范围内的数字。这个范围平均分配给m台服务器,根据主URL域名的hash运算值的范围来确定要爬取哪个服务器。
如果某台服务器出现问题,本应负责该服务器的网页将由下一个服务器顺时针获取。在这种情况下,即使一台服务器出现问题,也不会影响其他工作。
5. 参考资料
[1] wawlian:网络爬虫基本原理(一)(二);
[2] guisu:搜索引擎——网络爬虫;
[3]《这就是搜索引擎:核心技术详解》。 查看全部
抓取动态网页(一个完整的网络爬虫基础框架如下图所示:整个架构)
一个完整的网络爬虫基础框架如下图所示:
整个架构由以下过程组成:
1)需求方提供需要爬取的种子URL列表,根据提供的URL列表和对应的优先级(先到先得)建立待爬取的URL队列;
2)网页抓取是按照要抓取的URL队列的顺序进行的;
3)将获取到的网页内容和信息下载到本地网络库,并创建爬取的URL列表(用于去重和判断爬取过程);
4)将爬取的网页放入待爬取的URL队列中,进行循环爬取操作;
2. 网络爬虫爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取URL队列中的URL排列顺序也是一个很重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面的问题。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
1)深度优先遍历策略
深度优先遍历策略很好理解,和我们有向图中的深度优先遍历一样,因为网络本身就是一个图模型。深度优先遍历的思路是从一个起始网页开始爬取,然后根据链接一个一个的爬取,直到不能再深度爬取,然后返回上一页继续关注链接。
有向图中的深度优先搜索示例如下所示:
上图左图是有向图的示意图,右图是深度优先遍历的搜索过程示意图。深度优先遍历的结果是:
2)广度优先搜索策略
广度优先搜索和深度优先搜索的工作方式完全相反。这个想法是将在新下载的网页中找到的链接直接插入到要抓取的 URL 队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。
上图是上例有向图的广度优先搜索流程图,其遍历结果为:
v1→v2→v3→v4→v5→v6→v7→v8
从树的结构来看,图的广度优先遍历就是树的层次遍历。
3)反向链接搜索策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
4)大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
5)其他搜索策略
一些比较常用的爬虫搜索侧率还包括Partial PageRank搜索策略(根据PageRank分数确定下一个抓取的URL),OPIC搜索策略(也是一种重要性)。最后必须指出的一点是,我们可以根据自己的需要来设置网页的抓取间隔,这样可以保证我们一些基本的大网站或者活跃的网站内容不会被漏掉。
3. 网络爬虫更新策略
互联网实时变化并且非常动态。网页更新策略主要决定何时更新之前已经下载的页面。常见的更新策略有以下三种:
1)历史参考政策
顾名思义,它根据页面过去的历史更新数据来预测未来页面何时会发生变化。通常,预测是通过泊松过程建模来进行的。
2)用户体验策略
尽管搜索引擎可以为某个查询返回大量结果,但用户通常只关注结果的前几页。因此,爬虫系统可以优先更新那些实际在查询结果前几页的页面,然后再更新后面的那些页面。这个更新策略也需要用到历史信息。UX 策略保留网页的多个历史版本,并根据每个过去内容更改对搜索质量的影响得出一个平均值,并以此值作为决定何时重新抓取的基础。
3)聚类抽样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页完全没有历史信息,就无法确定更新策略。
该策略认为网页具有许多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某一类别网页的更新频率,只需对该类别的网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如下:
4. 分布式抓取系统结构
一般来说,爬虫系统需要处理整个互联网上数以亿计的网页。单个爬虫不可能完成这样的任务。通常需要多个爬虫程序一起处理它们。一般来说,爬虫系统往往是分布式的三层结构。如图所示:
最底层是分布在不同地理位置的数据中心。每个数据中心有多个爬虫服务器,每个爬虫服务器可能部署多套爬虫程序。这样就构成了一个基本的分布式爬虫系统。
对于数据中心中的不同服务器,有几种方法可以协同工作:
1)主从
主从基本结构如图:
对于主从类型,有一个专门的主服务器来维护要爬取的URL队列,负责每次将URL分发给不同的从服务器,从服务器负责实际的网页下载工作。Master服务器除了维护要爬取的URL队列和分发URL外,还负责调解每个Slave服务器的负载。为了避免一些从服务器过于空闲或过度工作。
在这种模式下,Master往往会成为系统的瓶颈。
2)点对点
等价的基本结构如图所示:
在这种模式下,所有爬虫服务器之间的分工没有区别。每个爬取服务器可以从待爬取的URL队列中获取URL,然后计算该URL主域名的哈希值H,进而计算H mod m(其中m为服务器数量,上图为例如,m 对于 3),计算出来的数字是处理 URL 的主机号。
例子:假设对于URL,计算器hash值H=8,m=3,那么H mod m=2,那么编号为2的服务器会抓取该链接。假设此时服务器 0 获取了 URL,它会将 URL 传输到服务器 2,服务器 2 将获取它。
这种模式有一个问题,当一个服务器死掉或添加一个新服务器时,所有 URL 的哈希余数的结果都会改变。也就是说,这种方法不能很好地扩展。针对这种情况,提出了另一种改进方案。这种改进的方案是一致的散列以确定服务器划分。其基本结构如图所示:
一致散列对 URL 的主域名进行散列,并将其映射到 0-232 范围内的数字。这个范围平均分配给m台服务器,根据主URL域名的hash运算值的范围来确定要爬取哪个服务器。
如果某台服务器出现问题,本应负责该服务器的网页将由下一个服务器顺时针获取。在这种情况下,即使一台服务器出现问题,也不会影响其他工作。
5. 参考资料
[1] wawlian:网络爬虫基本原理(一)(二);
[2] guisu:搜索引擎——网络爬虫;
[3]《这就是搜索引擎:核心技术详解》。
抓取动态网页( 如何用PowerBI批量爬取网页数据?PowerBI猫眼数据告诉你)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-01-20 04:11
如何用PowerBI批量爬取网页数据?PowerBI猫眼数据告诉你)
关于Power BI从网页中提取数据的技术,部分技术在之前的文章中已经分享过,大家可以看看这些内容:
如何使用PowerBI批量抓取网页数据?
Power BI 捕捉猫眼数据告诉你哪部电影更受欢迎?
提取网页上可见的规范化数据很容易,但是网页中可以再次点击的链接呢?
其实也很简单。本文以豆瓣阅读TOP250为例:
在这个网页中,不仅显示了书名、评分、作者等信息的列表,还可以点击封面或书名进入该书的详情页面。让我们看看如何提取这个链接。
在 PowerBI Desktop 中,选择 Get data with web,你会看到这个导航器,
在表格视图中看不到可以提取的数据,没关系,可以点击左下角的“使用示例添加表格”,然后就可以看到这个网页了,
在这里,只要你手动输入前两条信息,PowerBI就会确定你要提取的字段,并自动在网页中添加剩余的相似数据,比如输入前两本书的标题,
同理,还可以提取收视率、作者、出版商等信息。
URL 在此页面上不可见。您不能直接输入前两个 URL。在这种情况下,没有例子。需要手动一一复制粘贴吗?
当然不是,这里虽然看不到,但是可以打开链接,不知道网址是什么吗?
依次打开前两个链接,将 URL 复制并粘贴到示例的前两行中,
这样就得到了链接,是不是很简单。
上述步骤仅提取一页上的 25 条信息。也可以按照前面文章中介绍的方法,使用Power Query自定义函数批量提取top 250图书信息。
简单处理后,即可在PowerBI Desktop中使用。记得在点击链接前将链接的数据类型设置为“Web URL”。
PowerBI获取网页数据的技巧仅供学习交流,不得用于不正当目的。
更令人兴奋的:
学习PowerBI请采集:DAX写作格式指南
Power BI应用技巧:简单两步即可实现红绿灯效果 查看全部
抓取动态网页(
如何用PowerBI批量爬取网页数据?PowerBI猫眼数据告诉你)
关于Power BI从网页中提取数据的技术,部分技术在之前的文章中已经分享过,大家可以看看这些内容:
如何使用PowerBI批量抓取网页数据?
Power BI 捕捉猫眼数据告诉你哪部电影更受欢迎?
提取网页上可见的规范化数据很容易,但是网页中可以再次点击的链接呢?
其实也很简单。本文以豆瓣阅读TOP250为例:
在这个网页中,不仅显示了书名、评分、作者等信息的列表,还可以点击封面或书名进入该书的详情页面。让我们看看如何提取这个链接。
在 PowerBI Desktop 中,选择 Get data with web,你会看到这个导航器,
在表格视图中看不到可以提取的数据,没关系,可以点击左下角的“使用示例添加表格”,然后就可以看到这个网页了,
在这里,只要你手动输入前两条信息,PowerBI就会确定你要提取的字段,并自动在网页中添加剩余的相似数据,比如输入前两本书的标题,
同理,还可以提取收视率、作者、出版商等信息。
URL 在此页面上不可见。您不能直接输入前两个 URL。在这种情况下,没有例子。需要手动一一复制粘贴吗?
当然不是,这里虽然看不到,但是可以打开链接,不知道网址是什么吗?
依次打开前两个链接,将 URL 复制并粘贴到示例的前两行中,
这样就得到了链接,是不是很简单。
上述步骤仅提取一页上的 25 条信息。也可以按照前面文章中介绍的方法,使用Power Query自定义函数批量提取top 250图书信息。
简单处理后,即可在PowerBI Desktop中使用。记得在点击链接前将链接的数据类型设置为“Web URL”。
PowerBI获取网页数据的技巧仅供学习交流,不得用于不正当目的。
更令人兴奋的:
学习PowerBI请采集:DAX写作格式指南
Power BI应用技巧:简单两步即可实现红绿灯效果
抓取动态网页(【每日一题】今日头条街拍图片(2) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 302 次浏览 • 2022-01-20 04:10
)
大家好,本文文章主要是Python抓取今日头条街的图片数据。如果你有兴趣,请过来看看。如果对你有帮助,记得采集。
(1)今天在今日头条街拍照
(2)解析今日头条街拍结构
keyword: 街拍
pd: atlas
dvpf: pc
aid: 4916
page_num: 1
search_json: {"from_search_id":"20220104115420010212192151532E8188","origin_keyword":"街拍","image_keyword":"街拍"}
rawJSON: 1
search_id: 202201041159040101501341671A4749C4
可以找到规律,page_num从1开始累加,其他参数不变
(3)根据不同的功能编写不同的方法组织代码
获取网页json格式数据
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search% ... on%3D{%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
从json格式数据中提取街道图片
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
用 md5 代码命名街道照片并保存图像
实现方法 save_image() 来保存图像,其中 item 是前面的 get_images() 方法返回的字典。该方法首先根据item的标题创建一个文件夹,然后请求图片链接,获取图片的二进制数据,以二进制形式写入文件。图片名称可以使用其内容的MD5值,可以去除重复。相关代码如下:
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
main() 调用其他函数
(4)抢20page今日头条街拍资料
这里定义了分页的起始页和结束页,分别是 GROUP_START 和 GROUP_END。也使用了多线程线程池,调用它的map()方法实现多线程下载。
import requests
from urllib.parse import urlencode
from hashlib import md5
from multiprocessing.pool import Pool
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search% ... on%3D{%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
查看全部
抓取动态网页(【每日一题】今日头条街拍图片(2)
)
大家好,本文文章主要是Python抓取今日头条街的图片数据。如果你有兴趣,请过来看看。如果对你有帮助,记得采集。
(1)今天在今日头条街拍照
(2)解析今日头条街拍结构
keyword: 街拍
pd: atlas
dvpf: pc
aid: 4916
page_num: 1
search_json: {"from_search_id":"20220104115420010212192151532E8188","origin_keyword":"街拍","image_keyword":"街拍"}
rawJSON: 1
search_id: 202201041159040101501341671A4749C4
可以找到规律,page_num从1开始累加,其他参数不变
(3)根据不同的功能编写不同的方法组织代码
获取网页json格式数据
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search% ... on%3D{%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
从json格式数据中提取街道图片
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
用 md5 代码命名街道照片并保存图像
实现方法 save_image() 来保存图像,其中 item 是前面的 get_images() 方法返回的字典。该方法首先根据item的标题创建一个文件夹,然后请求图片链接,获取图片的二进制数据,以二进制形式写入文件。图片名称可以使用其内容的MD5值,可以去除重复。相关代码如下:
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
main() 调用其他函数
(4)抢20page今日头条街拍资料
这里定义了分页的起始页和结束页,分别是 GROUP_START 和 GROUP_END。也使用了多线程线程池,调用它的map()方法实现多线程下载。
import requests
from urllib.parse import urlencode
from hashlib import md5
from multiprocessing.pool import Pool
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search% ... on%3D{%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()

